
modelId
stringlengths 5
122
| author
stringlengths 2
42
| last_modified
timestamp[us, tz=UTC] | downloads
int64 0
738M
| likes
int64 0
11k
| library_name
stringclasses 245
values | tags
listlengths 1
4.05k
| pipeline_tag
stringclasses 48
values | createdAt
timestamp[us, tz=UTC] | card
stringlengths 1
901k
|
|---|---|---|---|---|---|---|---|---|---|
dbmdz/bert-base-turkish-uncased | dbmdz | 2024-02-20T23:10:10Z | 17,351 | 25 | transformers | [
"transformers",
"pytorch",
"tf",
"jax",
"bert",
"tr",
"license:mit",
"endpoints_compatible",
"region:us"
]
| null | 2022-03-02T23:29:05Z | ---
language: tr
license: mit
---
# 🤗 + 📚 dbmdz Turkish BERT model
In this repository the MDZ Digital Library team (dbmdz) at the Bavarian State
Library open sources an uncased model for Turkish 🎉
# 🇹🇷 BERTurk
BERTurk is a community-driven uncased BERT model for Turkish.
Some datasets used for pretraining and evaluation are contributed from the
awesome Turkish NLP community, as well as the decision for the model name: BERTurk.
## Stats
The current version of the model is trained on a filtered and sentence
segmented version of the Turkish [OSCAR corpus](https://traces1.inria.fr/oscar/),
a recent Wikipedia dump, various [OPUS corpora](http://opus.nlpl.eu/) and a
special corpus provided by [Kemal Oflazer](http://www.andrew.cmu.edu/user/ko/).
The final training corpus has a size of 35GB and 44,04,976,662 tokens.
Thanks to Google's TensorFlow Research Cloud (TFRC) we could train an uncased model
on a TPU v3-8 for 2M steps.
## Model weights
Currently only PyTorch-[Transformers](https://github.com/huggingface/transformers)
compatible weights are available. If you need access to TensorFlow checkpoints,
please raise an issue!
| Model | Downloads
| --------------------------------- | ---------------------------------------------------------------------------------------------------------------
| `dbmdz/bert-base-turkish-uncased` | [`config.json`](https://cdn.huggingface.co/dbmdz/bert-base-turkish-uncased/config.json) • [`pytorch_model.bin`](https://cdn.huggingface.co/dbmdz/bert-base-turkish-uncased/pytorch_model.bin) • [`vocab.txt`](https://cdn.huggingface.co/dbmdz/bert-base-turkish-uncased/vocab.txt)
## Usage
With Transformers >= 2.3 our BERTurk uncased model can be loaded like:
```python
from transformers import AutoModel, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("dbmdz/bert-base-turkish-uncased")
model = AutoModel.from_pretrained("dbmdz/bert-base-turkish-uncased")
```
## Results
For results on PoS tagging or NER tasks, please refer to
[this repository](https://github.com/stefan-it/turkish-bert).
# Huggingface model hub
All models are available on the [Huggingface model hub](https://huggingface.co/dbmdz).
# Contact (Bugs, Feedback, Contribution and more)
For questions about our BERT models just open an issue
[here](https://github.com/dbmdz/berts/issues/new) 🤗
# Acknowledgments
Thanks to [Kemal Oflazer](http://www.andrew.cmu.edu/user/ko/) for providing us
additional large corpora for Turkish. Many thanks to Reyyan Yeniterzi for providing
us the Turkish NER dataset for evaluation.
Research supported with Cloud TPUs from Google's TensorFlow Research Cloud (TFRC).
Thanks for providing access to the TFRC ❤️
Thanks to the generous support from the [Hugging Face](https://huggingface.co/) team,
it is possible to download both cased and uncased models from their S3 storage 🤗
|
kakaobrain/align-base | kakaobrain | 2023-03-08T11:02:27Z | 17,335 | 22 | transformers | [
"transformers",
"pytorch",
"align",
"zero-shot-image-classification",
"vision",
"multi-modal",
"en",
"dataset:coyo-700m",
"arxiv:2102.05918",
"endpoints_compatible",
"region:us"
]
| zero-shot-image-classification | 2023-02-24T15:23:00Z | ---
language: en
tags:
- align
- vision
- multi-modal
datasets:
- coyo-700m
widget:
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/cat-dog-music.png
candidate_labels: playing music, playing sports
example_title: Cat & Dog
---
# ALIGN (base model)
The [ALIGN](https://arxiv.org/abs/2102.05918) model was proposed in "Scaling Up Visual and Vision-Language Representation Learning With Noisy Text Supervision" by Chao Jia, Yinfei Yang, Ye Xia, Yi-Ting Chen, Zarana Parekh, Hieu Pham, Quoc V. Le, Yunhsuan Sung, Zhen Li, Tom Duerig.
ALIGN features a dual-encoder architecture with [EfficientNet](https://huggingface.co/docs/transformers/main/en/model_doc/efficientnet#efficientnet) as its vision encoder and [BERT](https://huggingface.co/docs/transformers/main/en/model_doc/bert) as its text encoder, and learns to align visual and text representations with contrastive learning. Unlike previous work, ALIGN leverages a massive noisy dataset and shows that the scale of the corpus can be used to achieve SOTA representations with a simple recipe.
The code for ALIGN was not publicly released, the base model is converted from the original implementation of the Kakao Brain team. This implementation follows the same architecture and hyperparameters as provided in the original Google model but is trained on the open source [COYO](https://github.com/kakaobrain/coyo-dataset) dataset. Google’s [ALIGN](https://ai.googleblog.com/2021/05/align-scaling-up-visual-and-vision.html) model, while trained on a huge dataset of 1.8 billion image-text pairs, cannot be replicated as the datasets is not public. Kakao Brain's ALIGN is on-par or outperforms Google ALIGN's reported metrics despite being trained on the much smaller, albeit carefully curated COYO-700M dataset.
<p>
<center>
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/132_vit_align/align-performance.png" alt="ALIGN performance"/>
</center>
</p>
## COYO-700M Dataset
[COYO](https://github.com/kakaobrain/coyo-dataset#dataset-preview) is an image-text dataset of 700 million pairs similar to Google's `ALIGN 1.8B` image-text dataset which is a collection of "noisy" alt-text and image pairs from webpages, but open-source. `COYO-700M` and `ALIGN 1.8B` are "noisy" because minimal filtering was applied. `COYO` is similar to the other open-source image-text dataset, `LAION` but with the following differences. While `LAION` 2B is a much larger dataset of 2 billion English pairs, compared to `COYO`’s 700 million pairs, `COYO` pairs come with more metadata that give users more flexibility and finer-grained control over usage. The following table shows the differences: `COYO` comes equipped with aesthetic scores for all pairs, more robust watermark scores, and face count data.
| COYO | LAION 2B| ALIGN 1.8B |
| :----: | :----: | :----: |
| Image-text similarity score calculated with CLIP ViT-B/32 and ViT-L/14 models, they are provided as metadata but nothing is filtered out so as to avoid possible elimination bias | Image-text similarity score provided with CLIP (ViT-B/32) - only examples above threshold 0.28 | Minimal, Frequency based filtering |
| NSFW filtering on images and text | NSFW filtering on images | [Google Cloud API](https://cloud.google.com/vision) |
| Face recognition (face count) data provided as meta-data | No face recognition data | NA |
| 700 million pairs all English | 2 billion English| 1.8 billion |
| From CC 2020 Oct - 2021 Aug| From CC 2014-2020| NA |
|Aesthetic Score | Aesthetic Score Partial | NA|
|More robust Watermark score | Watermark Score | NA|
|Hugging Face Hub | Hugging Face Hub | Not made public |
| English | English | English? |
COYO is available on the hub as a [dataset](https://huggingface.co/datasets/kakaobrain/coyo-700m).
## Use with Transformers
### Zero-Shot Image Classification
```python3
import requests
import torch
from PIL import Image
from transformers import AlignProcessor, AlignModel
processor = AlignProcessor.from_pretrained("kakaobrain/align-base")
model = AlignModel.from_pretrained("kakaobrain/align-base")
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
candidate_labels = ["an image of a cat", "an image of a dog"]
inputs = processor(text=candidate_labels, images=image, return_tensors="pt")
with torch.no_grad():
outputs = model(**inputs)
# this is the image-text similarity score
logits_per_image = outputs.logits_per_image
# we can take the softmax to get the label probabilities
probs = logits_per_image.softmax(dim=1)
print(probs)
```
### Multi-Modal Embedding Retrieval
```python3
import requests
import torch
from PIL import Image
from transformers import AlignProcessor, AlignModel
processor = AlignProcessor.from_pretrained("kakaobrain/align-base")
model = AlignModel.from_pretrained("kakaobrain/align-base")
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
text = "an image of a cat"
inputs = processor(text=text, images=image, return_tensors="pt")
with torch.no_grad():
outputs = model(**inputs)
# multi-modal text embedding
text_embeds = outputs.text_embeds
# multi-modal image embedding
image_embeds = outputs.image_embeds
```
Alternatively, retrieve image or text embeddings separately.
```python3
import requests
import torch
from PIL import Image
from transformers import AlignProcessor, AlignModel
processor = AlignProcessor.from_pretrained("kakaobrain/align-base")
model = AlignModel.from_pretrained("kakaobrain/align-base")
# image embeddings
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
inputs = processor(images=image, return_tensors="pt")
image_embeds = model.get_image_features(
pixel_values=inputs['pixel_values'],
)
# text embeddings
text = "an image of a cat"
inputs = processor(text=text, return_tensors="pt")
text_embeds = model.get_text_features(
input_ids=inputs['input_ids'],
attention_mask=inputs['attention_mask'],
token_type_ids=inputs['token_type_ids'],
)
```
## Model Use
### Intended Use
The model is intended as a research output for research communities. We hope that this model will enable researchers to better understand and explore zero-shot, arbitrary image classification. We also hope it can be used for interdisciplinary studies of the potential impact of such models - the ALIGN paper includes a discussion of potential downstream impacts to provide an example for this sort of analysis.
#### Primary intended uses
The primary intended users of these models are AI researchers.
We primarily imagine the model will be used by researchers to better understand robustness, generalization, and other capabilities, biases, and constraints of computer vision models.
|
bartowski/llama3-turbcat-instruct-8b-GGUF | bartowski | 2024-06-21T21:11:27Z | 17,334 | 2 | null | [
"gguf",
"text-generation",
"license:llama3",
"region:us"
]
| text-generation | 2024-06-21T20:21:03Z | ---
license: llama3
quantized_by: bartowski
pipeline_tag: text-generation
---
## Llamacpp imatrix Quantizations of llama3-turbcat-instruct-8b
Using <a href="https://github.com/ggerganov/llama.cpp/">llama.cpp</a> release <a href="https://github.com/ggerganov/llama.cpp/releases/tag/b3197">b3197</a> for quantization.
Original model: https://huggingface.co/turboderp/llama3-turbcat-instruct-8b
All quants made using imatrix option with dataset from [here](https://gist.github.com/bartowski1182/eb213dccb3571f863da82e99418f81e8)
## Prompt format
```
<|begin_of_text|><|start_header_id|>system<|end_header_id|>
{system_prompt}<|eot_id|><|start_header_id|>user<|end_header_id|>
{prompt}<|eot_id|><|start_header_id|>assistant<|end_header_id|>
```
## Download a file (not the whole branch) from below:
| Filename | Quant type | File Size | Description |
| -------- | ---------- | --------- | ----------- |
| [llama3-turbcat-instruct-8b-Q8_0_L.gguf](https://huggingface.co/bartowski/llama3-turbcat-instruct-8b-GGUF/blob/main/llama3-turbcat-instruct-8b-Q8_1.gguf) | Q8_0_L | 9.52GB | *Experimental*, uses f16 for embed and output weights. Please provide any feedback of differences. Extremely high quality, generally unneeded but max available quant. |
| [llama3-turbcat-instruct-8b-Q8_0.gguf](https://huggingface.co/bartowski/llama3-turbcat-instruct-8b-GGUF/blob/main/llama3-turbcat-instruct-8b-Q8_0.gguf) | Q8_0 | 8.54GB | Extremely high quality, generally unneeded but max available quant. |
| [llama3-turbcat-instruct-8b-Q6_K_L.gguf](https://huggingface.co/bartowski/llama3-turbcat-instruct-8b-GGUF/blob/main/llama3-turbcat-instruct-8b-Q6_K_L.gguf) | Q6_K_L | 7.83GB | *Experimental*, uses f16 for embed and output weights. Please provide any feedback of differences. Very high quality, near perfect, *recommended*. |
| [llama3-turbcat-instruct-8b-Q6_K.gguf](https://huggingface.co/bartowski/llama3-turbcat-instruct-8b-GGUF/blob/main/llama3-turbcat-instruct-8b-Q6_K.gguf) | Q6_K | 6.59GB | Very high quality, near perfect, *recommended*. |
| [llama3-turbcat-instruct-8b-Q5_K_L.gguf](https://huggingface.co/bartowski/llama3-turbcat-instruct-8b-GGUF/blob/main/llama3-turbcat-instruct-8b-Q5_K_L.gguf) | Q5_K_L | 7.04GB | *Experimental*, uses f16 for embed and output weights. Please provide any feedback of differences. High quality, *recommended*. |
| [llama3-turbcat-instruct-8b-Q5_K_M.gguf](https://huggingface.co/bartowski/llama3-turbcat-instruct-8b-GGUF/blob/main/llama3-turbcat-instruct-8b-Q5_K_M.gguf) | Q5_K_M | 5.73GB | High quality, *recommended*. |
| [llama3-turbcat-instruct-8b-Q5_K_S.gguf](https://huggingface.co/bartowski/llama3-turbcat-instruct-8b-GGUF/blob/main/llama3-turbcat-instruct-8b-Q5_K_S.gguf) | Q5_K_S | 5.59GB | High quality, *recommended*. |
| [llama3-turbcat-instruct-8b-Q4_K_L.gguf](https://huggingface.co/bartowski/llama3-turbcat-instruct-8b-GGUF/blob/main/llama3-turbcat-instruct-8b-Q4_K_L.gguf) | Q4_K_L | 6.29GB | *Experimental*, uses f16 for embed and output weights. Please provide any feedback of differences. Good quality, uses about 4.83 bits per weight, *recommended*. |
| [llama3-turbcat-instruct-8b-Q4_K_M.gguf](https://huggingface.co/bartowski/llama3-turbcat-instruct-8b-GGUF/blob/main/llama3-turbcat-instruct-8b-Q4_K_M.gguf) | Q4_K_M | 4.92GB | Good quality, uses about 4.83 bits per weight, *recommended*. |
| [llama3-turbcat-instruct-8b-Q4_K_S.gguf](https://huggingface.co/bartowski/llama3-turbcat-instruct-8b-GGUF/blob/main/llama3-turbcat-instruct-8b-Q4_K_S.gguf) | Q4_K_S | 4.69GB | Slightly lower quality with more space savings, *recommended*. |
| [llama3-turbcat-instruct-8b-IQ4_XS.gguf](https://huggingface.co/bartowski/llama3-turbcat-instruct-8b-GGUF/blob/main/llama3-turbcat-instruct-8b-IQ4_XS.gguf) | IQ4_XS | 4.44GB | Decent quality, smaller than Q4_K_S with similar performance, *recommended*. |
| [llama3-turbcat-instruct-8b-Q3_K_XL.gguf](https://huggingface.co/bartowski/llama3-turbcat-instruct-8b-GGUF//main/llama3-turbcat-instruct-8b-Q3_K_XL.gguf) | Q3_K_XL | | *Experimental*, uses f16 for embed and output weights. Please provide any feedback of differences. Lower quality but usable, good for low RAM availability. |
| [llama3-turbcat-instruct-8b-Q3_K_L.gguf](https://huggingface.co/bartowski/llama3-turbcat-instruct-8b-GGUF/blob/main/llama3-turbcat-instruct-8b-Q3_K_L.gguf) | Q3_K_L | 4.32GB | Lower quality but usable, good for low RAM availability. |
| [llama3-turbcat-instruct-8b-Q3_K_M.gguf](https://huggingface.co/bartowski/llama3-turbcat-instruct-8b-GGUF/blob/main/llama3-turbcat-instruct-8b-Q3_K_M.gguf) | Q3_K_M | 4.01GB | Even lower quality. |
| [llama3-turbcat-instruct-8b-IQ3_M.gguf](https://huggingface.co/bartowski/llama3-turbcat-instruct-8b-GGUF/blob/main/llama3-turbcat-instruct-8b-IQ3_M.gguf) | IQ3_M | 3.78GB | Medium-low quality, new method with decent performance comparable to Q3_K_M. |
| [llama3-turbcat-instruct-8b-Q3_K_S.gguf](https://huggingface.co/bartowski/llama3-turbcat-instruct-8b-GGUF/blob/main/llama3-turbcat-instruct-8b-Q3_K_S.gguf) | Q3_K_S | 3.66GB | Low quality, not recommended. |
| [llama3-turbcat-instruct-8b-IQ3_XS.gguf](https://huggingface.co/bartowski/llama3-turbcat-instruct-8b-GGUF/blob/main/llama3-turbcat-instruct-8b-IQ3_XS.gguf) | IQ3_XS | 3.51GB | Lower quality, new method with decent performance, slightly better than Q3_K_S. |
| [llama3-turbcat-instruct-8b-IQ3_XXS.gguf](https://huggingface.co/bartowski/llama3-turbcat-instruct-8b-GGUF/blob/main/llama3-turbcat-instruct-8b-IQ3_XXS.gguf) | IQ3_XXS | 3.27GB | Lower quality, new method with decent performance, comparable to Q3 quants. |
| [llama3-turbcat-instruct-8b-Q2_K.gguf](https://huggingface.co/bartowski/llama3-turbcat-instruct-8b-GGUF/blob/main/llama3-turbcat-instruct-8b-Q2_K.gguf) | Q2_K | 3.17GB | Very low quality but surprisingly usable. |
| [llama3-turbcat-instruct-8b-IQ2_M.gguf](https://huggingface.co/bartowski/llama3-turbcat-instruct-8b-GGUF/blob/main/llama3-turbcat-instruct-8b-IQ2_M.gguf) | IQ2_M | 2.94GB | Very low quality, uses SOTA techniques to also be surprisingly usable. |
| [llama3-turbcat-instruct-8b-IQ2_S.gguf](https://huggingface.co/bartowski/llama3-turbcat-instruct-8b-GGUF/blob/main/llama3-turbcat-instruct-8b-IQ2_S.gguf) | IQ2_S | 2.75GB | Very low quality, uses SOTA techniques to be usable. |
| [llama3-turbcat-instruct-8b-IQ2_XS.gguf](https://huggingface.co/bartowski/llama3-turbcat-instruct-8b-GGUF/blob/main/llama3-turbcat-instruct-8b-IQ2_XS.gguf) | IQ2_XS | 2.60GB | Very low quality, uses SOTA techniques to be usable. |
## Downloading using huggingface-cli
First, make sure you have hugginface-cli installed:
```
pip install -U "huggingface_hub[cli]"
```
Then, you can target the specific file you want:
```
huggingface-cli download bartowski/llama3-turbcat-instruct-8b-GGUF --include "llama3-turbcat-instruct-8b-Q4_K_M.gguf" --local-dir ./
```
If the model is bigger than 50GB, it will have been split into multiple files. In order to download them all to a local folder, run:
```
huggingface-cli download bartowski/llama3-turbcat-instruct-8b-GGUF --include "llama3-turbcat-instruct-8b-Q8_0.gguf/*" --local-dir llama3-turbcat-instruct-8b-Q8_0
```
You can either specify a new local-dir (llama3-turbcat-instruct-8b-Q8_0) or download them all in place (./)
## Which file should I choose?
A great write up with charts showing various performances is provided by Artefact2 [here](https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9)
The first thing to figure out is how big a model you can run. To do this, you'll need to figure out how much RAM and/or VRAM you have.
If you want your model running as FAST as possible, you'll want to fit the whole thing on your GPU's VRAM. Aim for a quant with a file size 1-2GB smaller than your GPU's total VRAM.
If you want the absolute maximum quality, add both your system RAM and your GPU's VRAM together, then similarly grab a quant with a file size 1-2GB Smaller than that total.
Next, you'll need to decide if you want to use an 'I-quant' or a 'K-quant'.
If you don't want to think too much, grab one of the K-quants. These are in format 'QX_K_X', like Q5_K_M.
If you want to get more into the weeds, you can check out this extremely useful feature chart:
[llama.cpp feature matrix](https://github.com/ggerganov/llama.cpp/wiki/Feature-matrix)
But basically, if you're aiming for below Q4, and you're running cuBLAS (Nvidia) or rocBLAS (AMD), you should look towards the I-quants. These are in format IQX_X, like IQ3_M. These are newer and offer better performance for their size.
These I-quants can also be used on CPU and Apple Metal, but will be slower than their K-quant equivalent, so speed vs performance is a tradeoff you'll have to decide.
The I-quants are *not* compatible with Vulcan, which is also AMD, so if you have an AMD card double check if you're using the rocBLAS build or the Vulcan build. At the time of writing this, LM Studio has a preview with ROCm support, and other inference engines have specific builds for ROCm.
Want to support my work? Visit my ko-fi page here: https://ko-fi.com/bartowski
|
mradermacher/LCARS_AI_1x4_001_SuperAI-GGUF | mradermacher | 2024-06-23T01:22:42Z | 17,323 | 0 | transformers | [
"transformers",
"gguf",
"chemistry",
"biology",
"code",
"medical",
"not-for-all-audiences",
"Cyber-Series",
"en",
"base_model:LeroyDyer/LCARS_AI_1x4_001_SuperAI",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
]
| null | 2024-06-20T00:35:47Z | ---
base_model: LeroyDyer/LCARS_AI_1x4_001_SuperAI
language:
- en
library_name: transformers
license: apache-2.0
quantized_by: mradermacher
tags:
- chemistry
- biology
- code
- medical
- not-for-all-audiences
- Cyber-Series
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
static quants of https://huggingface.co/LeroyDyer/LCARS_AI_1x4_001_SuperAI
<!-- provided-files -->
weighted/imatrix quants are available at https://huggingface.co/mradermacher/LCARS_AI_1x4_001_SuperAI-i1-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/LCARS_AI_1x4_001_SuperAI-GGUF/resolve/main/LCARS_AI_1x4_001_SuperAI.Q2_K.gguf) | Q2_K | 8.9 | |
| [GGUF](https://huggingface.co/mradermacher/LCARS_AI_1x4_001_SuperAI-GGUF/resolve/main/LCARS_AI_1x4_001_SuperAI.IQ3_XS.gguf) | IQ3_XS | 10.0 | |
| [GGUF](https://huggingface.co/mradermacher/LCARS_AI_1x4_001_SuperAI-GGUF/resolve/main/LCARS_AI_1x4_001_SuperAI.Q3_K_S.gguf) | Q3_K_S | 10.5 | |
| [GGUF](https://huggingface.co/mradermacher/LCARS_AI_1x4_001_SuperAI-GGUF/resolve/main/LCARS_AI_1x4_001_SuperAI.IQ3_S.gguf) | IQ3_S | 10.6 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/LCARS_AI_1x4_001_SuperAI-GGUF/resolve/main/LCARS_AI_1x4_001_SuperAI.IQ3_M.gguf) | IQ3_M | 10.7 | |
| [GGUF](https://huggingface.co/mradermacher/LCARS_AI_1x4_001_SuperAI-GGUF/resolve/main/LCARS_AI_1x4_001_SuperAI.Q3_K_M.gguf) | Q3_K_M | 11.7 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/LCARS_AI_1x4_001_SuperAI-GGUF/resolve/main/LCARS_AI_1x4_001_SuperAI.Q3_K_L.gguf) | Q3_K_L | 12.6 | |
| [GGUF](https://huggingface.co/mradermacher/LCARS_AI_1x4_001_SuperAI-GGUF/resolve/main/LCARS_AI_1x4_001_SuperAI.IQ4_XS.gguf) | IQ4_XS | 13.1 | |
| [GGUF](https://huggingface.co/mradermacher/LCARS_AI_1x4_001_SuperAI-GGUF/resolve/main/LCARS_AI_1x4_001_SuperAI.Q4_K_S.gguf) | Q4_K_S | 13.8 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/LCARS_AI_1x4_001_SuperAI-GGUF/resolve/main/LCARS_AI_1x4_001_SuperAI.Q4_K_M.gguf) | Q4_K_M | 14.7 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/LCARS_AI_1x4_001_SuperAI-GGUF/resolve/main/LCARS_AI_1x4_001_SuperAI.Q5_K_S.gguf) | Q5_K_S | 16.7 | |
| [GGUF](https://huggingface.co/mradermacher/LCARS_AI_1x4_001_SuperAI-GGUF/resolve/main/LCARS_AI_1x4_001_SuperAI.Q5_K_M.gguf) | Q5_K_M | 17.2 | |
| [GGUF](https://huggingface.co/mradermacher/LCARS_AI_1x4_001_SuperAI-GGUF/resolve/main/LCARS_AI_1x4_001_SuperAI.Q6_K.gguf) | Q6_K | 19.9 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/LCARS_AI_1x4_001_SuperAI-GGUF/resolve/main/LCARS_AI_1x4_001_SuperAI.Q8_0.gguf) | Q8_0 | 25.8 | fast, best quality |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
ahmedrachid/FinancialBERT-Sentiment-Analysis | ahmedrachid | 2022-02-07T14:58:57Z | 17,322 | 59 | transformers | [
"transformers",
"pytorch",
"bert",
"text-classification",
"financial-sentiment-analysis",
"sentiment-analysis",
"en",
"dataset:financial_phrasebank",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| text-classification | 2022-03-02T23:29:05Z | ---
language: en
tags:
- financial-sentiment-analysis
- sentiment-analysis
datasets:
- financial_phrasebank
widget:
- text: Operating profit rose to EUR 13.1 mn from EUR 8.7 mn in the corresponding period in 2007 representing 7.7 % of net sales.
- text: Bids or offers include at least 1,000 shares and the value of the shares must correspond to at least EUR 4,000.
- text: Raute reported a loss per share of EUR 0.86 for the first half of 2009 , against EPS of EUR 0.74 in the corresponding period of 2008.
---
### FinancialBERT for Sentiment Analysis
[*FinancialBERT*](https://huggingface.co/ahmedrachid/FinancialBERT) is a BERT model pre-trained on a large corpora of financial texts. The purpose is to enhance financial NLP research and practice in financial domain, hoping that financial practitioners and researchers can benefit from this model without the necessity of the significant computational resources required to train the model.
The model was fine-tuned for Sentiment Analysis task on _Financial PhraseBank_ dataset. Experiments show that this model outperforms the general BERT and other financial domain-specific models.
More details on `FinancialBERT`'s pre-training process can be found at: https://www.researchgate.net/publication/358284785_FinancialBERT_-_A_Pretrained_Language_Model_for_Financial_Text_Mining
### Training data
FinancialBERT model was fine-tuned on [Financial PhraseBank](https://www.researchgate.net/publication/251231364_FinancialPhraseBank-v10), a dataset consisting of 4840 Financial News categorised by sentiment (negative, neutral, positive).
### Fine-tuning hyper-parameters
- learning_rate = 2e-5
- batch_size = 32
- max_seq_length = 512
- num_train_epochs = 5
### Evaluation metrics
The evaluation metrics used are: Precision, Recall and F1-score. The following is the classification report on the test set.
| sentiment | precision | recall | f1-score | support |
| ------------- |:-------------:|:-------------:|:-------------:| -----:|
| negative | 0.96 | 0.97 | 0.97 | 58 |
| neutral | 0.98 | 0.99 | 0.98 | 279 |
| positive | 0.98 | 0.97 | 0.97 | 148 |
| macro avg | 0.97 | 0.98 | 0.98 | 485 |
| weighted avg | 0.98 | 0.98 | 0.98 | 485 |
### How to use
The model can be used thanks to Transformers pipeline for sentiment analysis.
```python
from transformers import BertTokenizer, BertForSequenceClassification
from transformers import pipeline
model = BertForSequenceClassification.from_pretrained("ahmedrachid/FinancialBERT-Sentiment-Analysis",num_labels=3)
tokenizer = BertTokenizer.from_pretrained("ahmedrachid/FinancialBERT-Sentiment-Analysis")
nlp = pipeline("sentiment-analysis", model=model, tokenizer=tokenizer)
sentences = ["Operating profit rose to EUR 13.1 mn from EUR 8.7 mn in the corresponding period in 2007 representing 7.7 % of net sales.",
"Bids or offers include at least 1,000 shares and the value of the shares must correspond to at least EUR 4,000.",
"Raute reported a loss per share of EUR 0.86 for the first half of 2009 , against EPS of EUR 0.74 in the corresponding period of 2008.",
]
results = nlp(sentences)
print(results)
[{'label': 'positive', 'score': 0.9998133778572083},
{'label': 'neutral', 'score': 0.9997822642326355},
{'label': 'negative', 'score': 0.9877365231513977}]
```
> Created by [Ahmed Rachid Hazourli](https://www.linkedin.com/in/ahmed-rachid/)
|
timpal0l/mdeberta-v3-base-squad2 | timpal0l | 2023-11-13T19:49:18Z | 17,317 | 200 | transformers | [
"transformers",
"pytorch",
"safetensors",
"deberta-v2",
"question-answering",
"deberta",
"deberta-v3",
"mdeberta",
"qa",
"multilingual",
"af",
"am",
"ar",
"as",
"az",
"be",
"bg",
"bn",
"br",
"bs",
"ca",
"cs",
"cy",
"da",
"de",
"el",
"en",
"eo",
"es",
"et",
"eu",
"fa",
"fi",
"fr",
"fy",
"ga",
"gd",
"gl",
"gu",
"ha",
"he",
"hi",
"hr",
"hu",
"hy",
"id",
"is",
"it",
"ja",
"jv",
"ka",
"kk",
"km",
"kn",
"ko",
"ku",
"ky",
"la",
"lo",
"lt",
"lv",
"mg",
"mk",
"ml",
"mn",
"mr",
"ms",
"my",
"ne",
"nl",
"no",
"om",
"or",
"pa",
"pl",
"ps",
"pt",
"ro",
"ru",
"sa",
"sd",
"si",
"sk",
"sl",
"so",
"sq",
"sr",
"su",
"sv",
"sw",
"ta",
"te",
"th",
"tl",
"tr",
"ug",
"uk",
"ur",
"uz",
"vi",
"xh",
"yi",
"zh",
"dataset:squad_v2",
"arxiv:2006.03654",
"arxiv:2111.09543",
"license:mit",
"endpoints_compatible",
"region:us"
]
| question-answering | 2022-11-30T11:34:54Z | ---
datasets:
- squad_v2
language:
- multilingual
- af
- am
- ar
- as
- az
- be
- bg
- bn
- br
- bs
- ca
- cs
- cy
- da
- de
- el
- en
- eo
- es
- et
- eu
- fa
- fi
- fr
- fy
- ga
- gd
- gl
- gu
- ha
- he
- hi
- hr
- hu
- hy
- id
- is
- it
- ja
- jv
- ka
- kk
- km
- kn
- ko
- ku
- ky
- la
- lo
- lt
- lv
- mg
- mk
- ml
- mn
- mr
- ms
- my
- ne
- nl
- 'no'
- om
- or
- pa
- pl
- ps
- pt
- ro
- ru
- sa
- sd
- si
- sk
- sl
- so
- sq
- sr
- su
- sv
- sw
- ta
- te
- th
- tl
- tr
- ug
- uk
- ur
- uz
- vi
- xh
- yi
- zh
tags:
- deberta
- deberta-v3
- mdeberta
- question-answering
- qa
- multilingual
thumbnail: https://huggingface.co/front/thumbnails/microsoft.png
license: mit
---
## This model can be used for Extractive QA
It has been finetuned for 3 epochs on [SQuAD2.0](https://rajpurkar.github.io/SQuAD-explorer/).
## Usage
```python
from transformers import pipeline
qa_model = pipeline("question-answering", "timpal0l/mdeberta-v3-base-squad2")
question = "Where do I live?"
context = "My name is Tim and I live in Sweden."
qa_model(question = question, context = context)
# {'score': 0.975547730922699, 'start': 28, 'end': 36, 'answer': ' Sweden.'}
```
## Evaluation on SQuAD2.0 dev set
```bash
{
"epoch": 3.0,
"eval_HasAns_exact": 79.65587044534414,
"eval_HasAns_f1": 85.91387795001529,
"eval_HasAns_total": 5928,
"eval_NoAns_exact": 82.10260723296888,
"eval_NoAns_f1": 82.10260723296888,
"eval_NoAns_total": 5945,
"eval_best_exact": 80.8809904826076,
"eval_best_exact_thresh": 0.0,
"eval_best_f1": 84.00551406448994,
"eval_best_f1_thresh": 0.0,
"eval_exact": 80.8809904826076,
"eval_f1": 84.00551406449004,
"eval_samples": 12508,
"eval_total": 11873,
"train_loss": 0.7729689576483615,
"train_runtime": 9118.953,
"train_samples": 134891,
"train_samples_per_second": 44.377,
"train_steps_per_second": 0.925
}
```
## DeBERTaV3: Improving DeBERTa using ELECTRA-Style Pre-Training with Gradient-Disentangled Embedding Sharing
[DeBERTa](https://arxiv.org/abs/2006.03654) improves the BERT and RoBERTa models using disentangled attention and enhanced mask decoder. With those two improvements, DeBERTa out perform RoBERTa on a majority of NLU tasks with 80GB training data.
In [DeBERTa V3](https://arxiv.org/abs/2111.09543), we further improved the efficiency of DeBERTa using ELECTRA-Style pre-training with Gradient Disentangled Embedding Sharing. Compared to DeBERTa, our V3 version significantly improves the model performance on downstream tasks. You can find more technique details about the new model from our [paper](https://arxiv.org/abs/2111.09543).
Please check the [official repository](https://github.com/microsoft/DeBERTa) for more implementation details and updates.
mDeBERTa is multilingual version of DeBERTa which use the same structure as DeBERTa and was trained with CC100 multilingual data.
The mDeBERTa V3 base model comes with 12 layers and a hidden size of 768. It has 86M backbone parameters with a vocabulary containing 250K tokens which introduces 190M parameters in the Embedding layer. This model was trained using the 2.5T CC100 data as XLM-R. |
hkunlp/instructor-base | hkunlp | 2023-01-21T06:31:16Z | 17,315 | 109 | sentence-transformers | [
"sentence-transformers",
"pytorch",
"t5",
"text-embedding",
"embeddings",
"information-retrieval",
"beir",
"text-classification",
"language-model",
"text-clustering",
"text-semantic-similarity",
"text-evaluation",
"prompt-retrieval",
"text-reranking",
"feature-extraction",
"sentence-similarity",
"transformers",
"English",
"Sentence Similarity",
"natural_questions",
"ms_marco",
"fever",
"hotpot_qa",
"mteb",
"en",
"arxiv:2212.09741",
"license:apache-2.0",
"model-index",
"region:us"
]
| sentence-similarity | 2022-12-20T05:59:40Z | ---
pipeline_tag: sentence-similarity
tags:
- text-embedding
- embeddings
- information-retrieval
- beir
- text-classification
- language-model
- text-clustering
- text-semantic-similarity
- text-evaluation
- prompt-retrieval
- text-reranking
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
- t5
- English
- Sentence Similarity
- natural_questions
- ms_marco
- fever
- hotpot_qa
- mteb
language: en
inference: false
license: apache-2.0
model-index:
- name: final_base_results
results:
- task:
type: Classification
dataset:
type: mteb/amazon_counterfactual
name: MTEB AmazonCounterfactualClassification (en)
config: en
split: test
revision: e8379541af4e31359cca9fbcf4b00f2671dba205
metrics:
- type: accuracy
value: 86.2089552238806
- type: ap
value: 55.76273850794966
- type: f1
value: 81.26104211414781
- task:
type: Classification
dataset:
type: mteb/amazon_polarity
name: MTEB AmazonPolarityClassification
config: default
split: test
revision: e2d317d38cd51312af73b3d32a06d1a08b442046
metrics:
- type: accuracy
value: 88.35995000000001
- type: ap
value: 84.18839957309655
- type: f1
value: 88.317619250081
- task:
type: Classification
dataset:
type: mteb/amazon_reviews_multi
name: MTEB AmazonReviewsClassification (en)
config: en
split: test
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
metrics:
- type: accuracy
value: 44.64
- type: f1
value: 42.48663956478136
- task:
type: Retrieval
dataset:
type: arguana
name: MTEB ArguAna
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 27.383000000000003
- type: map_at_10
value: 43.024
- type: map_at_100
value: 44.023
- type: map_at_1000
value: 44.025999999999996
- type: map_at_3
value: 37.684
- type: map_at_5
value: 40.884
- type: mrr_at_1
value: 28.094
- type: mrr_at_10
value: 43.315
- type: mrr_at_100
value: 44.313
- type: mrr_at_1000
value: 44.317
- type: mrr_at_3
value: 37.862
- type: mrr_at_5
value: 41.155
- type: ndcg_at_1
value: 27.383000000000003
- type: ndcg_at_10
value: 52.032000000000004
- type: ndcg_at_100
value: 56.19499999999999
- type: ndcg_at_1000
value: 56.272
- type: ndcg_at_3
value: 41.166000000000004
- type: ndcg_at_5
value: 46.92
- type: precision_at_1
value: 27.383000000000003
- type: precision_at_10
value: 8.087
- type: precision_at_100
value: 0.989
- type: precision_at_1000
value: 0.099
- type: precision_at_3
value: 17.093
- type: precision_at_5
value: 13.044
- type: recall_at_1
value: 27.383000000000003
- type: recall_at_10
value: 80.868
- type: recall_at_100
value: 98.86200000000001
- type: recall_at_1000
value: 99.431
- type: recall_at_3
value: 51.28
- type: recall_at_5
value: 65.22
- task:
type: Clustering
dataset:
type: mteb/arxiv-clustering-p2p
name: MTEB ArxivClusteringP2P
config: default
split: test
revision: a122ad7f3f0291bf49cc6f4d32aa80929df69d5d
metrics:
- type: v_measure
value: 39.68441054431849
- task:
type: Clustering
dataset:
type: mteb/arxiv-clustering-s2s
name: MTEB ArxivClusteringS2S
config: default
split: test
revision: f910caf1a6075f7329cdf8c1a6135696f37dbd53
metrics:
- type: v_measure
value: 29.188539728343844
- task:
type: Reranking
dataset:
type: mteb/askubuntudupquestions-reranking
name: MTEB AskUbuntuDupQuestions
config: default
split: test
revision: 2000358ca161889fa9c082cb41daa8dcfb161a54
metrics:
- type: map
value: 63.173362687519784
- type: mrr
value: 76.18860748362133
- task:
type: STS
dataset:
type: mteb/biosses-sts
name: MTEB BIOSSES
config: default
split: test
revision: d3fb88f8f02e40887cd149695127462bbcf29b4a
metrics:
- type: cos_sim_spearman
value: 82.30789953771232
- task:
type: Classification
dataset:
type: mteb/banking77
name: MTEB Banking77Classification
config: default
split: test
revision: 0fd18e25b25c072e09e0d92ab615fda904d66300
metrics:
- type: accuracy
value: 77.03571428571428
- type: f1
value: 75.87384305045917
- task:
type: Clustering
dataset:
type: mteb/biorxiv-clustering-p2p
name: MTEB BiorxivClusteringP2P
config: default
split: test
revision: 65b79d1d13f80053f67aca9498d9402c2d9f1f40
metrics:
- type: v_measure
value: 32.98041170516364
- task:
type: Clustering
dataset:
type: mteb/biorxiv-clustering-s2s
name: MTEB BiorxivClusteringS2S
config: default
split: test
revision: 258694dd0231531bc1fd9de6ceb52a0853c6d908
metrics:
- type: v_measure
value: 25.71652988451154
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackAndroidRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 33.739999999999995
- type: map_at_10
value: 46.197
- type: map_at_100
value: 47.814
- type: map_at_1000
value: 47.934
- type: map_at_3
value: 43.091
- type: map_at_5
value: 44.81
- type: mrr_at_1
value: 41.059
- type: mrr_at_10
value: 52.292
- type: mrr_at_100
value: 52.978
- type: mrr_at_1000
value: 53.015
- type: mrr_at_3
value: 49.976
- type: mrr_at_5
value: 51.449999999999996
- type: ndcg_at_1
value: 41.059
- type: ndcg_at_10
value: 52.608
- type: ndcg_at_100
value: 57.965
- type: ndcg_at_1000
value: 59.775999999999996
- type: ndcg_at_3
value: 48.473
- type: ndcg_at_5
value: 50.407999999999994
- type: precision_at_1
value: 41.059
- type: precision_at_10
value: 9.943
- type: precision_at_100
value: 1.6070000000000002
- type: precision_at_1000
value: 0.20500000000000002
- type: precision_at_3
value: 23.413999999999998
- type: precision_at_5
value: 16.481
- type: recall_at_1
value: 33.739999999999995
- type: recall_at_10
value: 63.888999999999996
- type: recall_at_100
value: 85.832
- type: recall_at_1000
value: 97.475
- type: recall_at_3
value: 51.953
- type: recall_at_5
value: 57.498000000000005
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackEnglishRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 31.169999999999998
- type: map_at_10
value: 41.455
- type: map_at_100
value: 42.716
- type: map_at_1000
value: 42.847
- type: map_at_3
value: 38.568999999999996
- type: map_at_5
value: 40.099000000000004
- type: mrr_at_1
value: 39.427
- type: mrr_at_10
value: 47.818
- type: mrr_at_100
value: 48.519
- type: mrr_at_1000
value: 48.558
- type: mrr_at_3
value: 45.86
- type: mrr_at_5
value: 46.936
- type: ndcg_at_1
value: 39.427
- type: ndcg_at_10
value: 47.181
- type: ndcg_at_100
value: 51.737
- type: ndcg_at_1000
value: 53.74
- type: ndcg_at_3
value: 43.261
- type: ndcg_at_5
value: 44.891
- type: precision_at_1
value: 39.427
- type: precision_at_10
value: 8.847
- type: precision_at_100
value: 1.425
- type: precision_at_1000
value: 0.189
- type: precision_at_3
value: 20.785999999999998
- type: precision_at_5
value: 14.560999999999998
- type: recall_at_1
value: 31.169999999999998
- type: recall_at_10
value: 56.971000000000004
- type: recall_at_100
value: 76.31400000000001
- type: recall_at_1000
value: 88.93900000000001
- type: recall_at_3
value: 45.208
- type: recall_at_5
value: 49.923
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackGamingRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 39.682
- type: map_at_10
value: 52.766000000000005
- type: map_at_100
value: 53.84100000000001
- type: map_at_1000
value: 53.898
- type: map_at_3
value: 49.291000000000004
- type: map_at_5
value: 51.365
- type: mrr_at_1
value: 45.266
- type: mrr_at_10
value: 56.093
- type: mrr_at_100
value: 56.763
- type: mrr_at_1000
value: 56.793000000000006
- type: mrr_at_3
value: 53.668000000000006
- type: mrr_at_5
value: 55.1
- type: ndcg_at_1
value: 45.266
- type: ndcg_at_10
value: 58.836
- type: ndcg_at_100
value: 62.863
- type: ndcg_at_1000
value: 63.912
- type: ndcg_at_3
value: 53.19199999999999
- type: ndcg_at_5
value: 56.125
- type: precision_at_1
value: 45.266
- type: precision_at_10
value: 9.492
- type: precision_at_100
value: 1.236
- type: precision_at_1000
value: 0.13699999999999998
- type: precision_at_3
value: 23.762
- type: precision_at_5
value: 16.414
- type: recall_at_1
value: 39.682
- type: recall_at_10
value: 73.233
- type: recall_at_100
value: 90.335
- type: recall_at_1000
value: 97.452
- type: recall_at_3
value: 58.562000000000005
- type: recall_at_5
value: 65.569
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackGisRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 26.743
- type: map_at_10
value: 34.016000000000005
- type: map_at_100
value: 35.028999999999996
- type: map_at_1000
value: 35.113
- type: map_at_3
value: 31.763
- type: map_at_5
value: 33.013999999999996
- type: mrr_at_1
value: 28.927000000000003
- type: mrr_at_10
value: 36.32
- type: mrr_at_100
value: 37.221
- type: mrr_at_1000
value: 37.281
- type: mrr_at_3
value: 34.105000000000004
- type: mrr_at_5
value: 35.371
- type: ndcg_at_1
value: 28.927000000000003
- type: ndcg_at_10
value: 38.474000000000004
- type: ndcg_at_100
value: 43.580000000000005
- type: ndcg_at_1000
value: 45.64
- type: ndcg_at_3
value: 34.035
- type: ndcg_at_5
value: 36.186
- type: precision_at_1
value: 28.927000000000003
- type: precision_at_10
value: 5.74
- type: precision_at_100
value: 0.8710000000000001
- type: precision_at_1000
value: 0.108
- type: precision_at_3
value: 14.124
- type: precision_at_5
value: 9.74
- type: recall_at_1
value: 26.743
- type: recall_at_10
value: 49.955
- type: recall_at_100
value: 73.904
- type: recall_at_1000
value: 89.133
- type: recall_at_3
value: 38.072
- type: recall_at_5
value: 43.266
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackMathematicaRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 16.928
- type: map_at_10
value: 23.549
- type: map_at_100
value: 24.887
- type: map_at_1000
value: 25.018
- type: map_at_3
value: 21.002000000000002
- type: map_at_5
value: 22.256
- type: mrr_at_1
value: 21.02
- type: mrr_at_10
value: 27.898
- type: mrr_at_100
value: 29.018
- type: mrr_at_1000
value: 29.099999999999998
- type: mrr_at_3
value: 25.456
- type: mrr_at_5
value: 26.625
- type: ndcg_at_1
value: 21.02
- type: ndcg_at_10
value: 28.277
- type: ndcg_at_100
value: 34.54
- type: ndcg_at_1000
value: 37.719
- type: ndcg_at_3
value: 23.707
- type: ndcg_at_5
value: 25.482
- type: precision_at_1
value: 21.02
- type: precision_at_10
value: 5.361
- type: precision_at_100
value: 0.9809999999999999
- type: precision_at_1000
value: 0.13899999999999998
- type: precision_at_3
value: 11.401
- type: precision_at_5
value: 8.209
- type: recall_at_1
value: 16.928
- type: recall_at_10
value: 38.601
- type: recall_at_100
value: 65.759
- type: recall_at_1000
value: 88.543
- type: recall_at_3
value: 25.556
- type: recall_at_5
value: 30.447000000000003
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackPhysicsRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 28.549000000000003
- type: map_at_10
value: 38.426
- type: map_at_100
value: 39.845000000000006
- type: map_at_1000
value: 39.956
- type: map_at_3
value: 35.372
- type: map_at_5
value: 37.204
- type: mrr_at_1
value: 35.034
- type: mrr_at_10
value: 44.041000000000004
- type: mrr_at_100
value: 44.95
- type: mrr_at_1000
value: 44.997
- type: mrr_at_3
value: 41.498000000000005
- type: mrr_at_5
value: 43.077
- type: ndcg_at_1
value: 35.034
- type: ndcg_at_10
value: 44.218
- type: ndcg_at_100
value: 49.958000000000006
- type: ndcg_at_1000
value: 52.019000000000005
- type: ndcg_at_3
value: 39.34
- type: ndcg_at_5
value: 41.892
- type: precision_at_1
value: 35.034
- type: precision_at_10
value: 7.911
- type: precision_at_100
value: 1.26
- type: precision_at_1000
value: 0.16
- type: precision_at_3
value: 18.511
- type: precision_at_5
value: 13.205
- type: recall_at_1
value: 28.549000000000003
- type: recall_at_10
value: 56.035999999999994
- type: recall_at_100
value: 79.701
- type: recall_at_1000
value: 93.149
- type: recall_at_3
value: 42.275
- type: recall_at_5
value: 49.097
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackProgrammersRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 29.391000000000002
- type: map_at_10
value: 39.48
- type: map_at_100
value: 40.727000000000004
- type: map_at_1000
value: 40.835
- type: map_at_3
value: 36.234
- type: map_at_5
value: 37.877
- type: mrr_at_1
value: 35.959
- type: mrr_at_10
value: 44.726
- type: mrr_at_100
value: 45.531
- type: mrr_at_1000
value: 45.582
- type: mrr_at_3
value: 42.047000000000004
- type: mrr_at_5
value: 43.611
- type: ndcg_at_1
value: 35.959
- type: ndcg_at_10
value: 45.303
- type: ndcg_at_100
value: 50.683
- type: ndcg_at_1000
value: 52.818
- type: ndcg_at_3
value: 39.987
- type: ndcg_at_5
value: 42.243
- type: precision_at_1
value: 35.959
- type: precision_at_10
value: 8.241999999999999
- type: precision_at_100
value: 1.274
- type: precision_at_1000
value: 0.163
- type: precision_at_3
value: 18.836
- type: precision_at_5
value: 13.196
- type: recall_at_1
value: 29.391000000000002
- type: recall_at_10
value: 57.364000000000004
- type: recall_at_100
value: 80.683
- type: recall_at_1000
value: 94.918
- type: recall_at_3
value: 42.263
- type: recall_at_5
value: 48.634
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 26.791749999999997
- type: map_at_10
value: 35.75541666666667
- type: map_at_100
value: 37.00791666666667
- type: map_at_1000
value: 37.12408333333333
- type: map_at_3
value: 33.02966666666667
- type: map_at_5
value: 34.56866666666667
- type: mrr_at_1
value: 31.744333333333337
- type: mrr_at_10
value: 39.9925
- type: mrr_at_100
value: 40.86458333333333
- type: mrr_at_1000
value: 40.92175000000001
- type: mrr_at_3
value: 37.68183333333334
- type: mrr_at_5
value: 39.028499999999994
- type: ndcg_at_1
value: 31.744333333333337
- type: ndcg_at_10
value: 40.95008333333334
- type: ndcg_at_100
value: 46.25966666666667
- type: ndcg_at_1000
value: 48.535333333333334
- type: ndcg_at_3
value: 36.43333333333333
- type: ndcg_at_5
value: 38.602333333333334
- type: precision_at_1
value: 31.744333333333337
- type: precision_at_10
value: 7.135166666666666
- type: precision_at_100
value: 1.1535833333333334
- type: precision_at_1000
value: 0.15391666666666665
- type: precision_at_3
value: 16.713
- type: precision_at_5
value: 11.828416666666666
- type: recall_at_1
value: 26.791749999999997
- type: recall_at_10
value: 51.98625
- type: recall_at_100
value: 75.30358333333334
- type: recall_at_1000
value: 91.05433333333333
- type: recall_at_3
value: 39.39583333333333
- type: recall_at_5
value: 45.05925
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackStatsRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 22.219
- type: map_at_10
value: 29.162
- type: map_at_100
value: 30.049999999999997
- type: map_at_1000
value: 30.144
- type: map_at_3
value: 27.204
- type: map_at_5
value: 28.351
- type: mrr_at_1
value: 25.153
- type: mrr_at_10
value: 31.814999999999998
- type: mrr_at_100
value: 32.573
- type: mrr_at_1000
value: 32.645
- type: mrr_at_3
value: 29.934
- type: mrr_at_5
value: 30.946
- type: ndcg_at_1
value: 25.153
- type: ndcg_at_10
value: 33.099000000000004
- type: ndcg_at_100
value: 37.768
- type: ndcg_at_1000
value: 40.331
- type: ndcg_at_3
value: 29.473
- type: ndcg_at_5
value: 31.206
- type: precision_at_1
value: 25.153
- type: precision_at_10
value: 5.183999999999999
- type: precision_at_100
value: 0.8170000000000001
- type: precision_at_1000
value: 0.11100000000000002
- type: precision_at_3
value: 12.831999999999999
- type: precision_at_5
value: 8.895999999999999
- type: recall_at_1
value: 22.219
- type: recall_at_10
value: 42.637
- type: recall_at_100
value: 64.704
- type: recall_at_1000
value: 83.963
- type: recall_at_3
value: 32.444
- type: recall_at_5
value: 36.802
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackTexRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 17.427999999999997
- type: map_at_10
value: 24.029
- type: map_at_100
value: 25.119999999999997
- type: map_at_1000
value: 25.257
- type: map_at_3
value: 22.016
- type: map_at_5
value: 23.143
- type: mrr_at_1
value: 21.129
- type: mrr_at_10
value: 27.750000000000004
- type: mrr_at_100
value: 28.666999999999998
- type: mrr_at_1000
value: 28.754999999999995
- type: mrr_at_3
value: 25.849
- type: mrr_at_5
value: 26.939999999999998
- type: ndcg_at_1
value: 21.129
- type: ndcg_at_10
value: 28.203
- type: ndcg_at_100
value: 33.44
- type: ndcg_at_1000
value: 36.61
- type: ndcg_at_3
value: 24.648999999999997
- type: ndcg_at_5
value: 26.316
- type: precision_at_1
value: 21.129
- type: precision_at_10
value: 5.055
- type: precision_at_100
value: 0.909
- type: precision_at_1000
value: 0.13699999999999998
- type: precision_at_3
value: 11.666
- type: precision_at_5
value: 8.3
- type: recall_at_1
value: 17.427999999999997
- type: recall_at_10
value: 36.923
- type: recall_at_100
value: 60.606
- type: recall_at_1000
value: 83.19
- type: recall_at_3
value: 26.845000000000002
- type: recall_at_5
value: 31.247000000000003
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackUnixRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 26.457000000000004
- type: map_at_10
value: 35.228
- type: map_at_100
value: 36.475
- type: map_at_1000
value: 36.585
- type: map_at_3
value: 32.444
- type: map_at_5
value: 34.046
- type: mrr_at_1
value: 30.784
- type: mrr_at_10
value: 39.133
- type: mrr_at_100
value: 40.11
- type: mrr_at_1000
value: 40.169
- type: mrr_at_3
value: 36.692
- type: mrr_at_5
value: 38.17
- type: ndcg_at_1
value: 30.784
- type: ndcg_at_10
value: 40.358
- type: ndcg_at_100
value: 46.119
- type: ndcg_at_1000
value: 48.428
- type: ndcg_at_3
value: 35.504000000000005
- type: ndcg_at_5
value: 37.864
- type: precision_at_1
value: 30.784
- type: precision_at_10
value: 6.800000000000001
- type: precision_at_100
value: 1.083
- type: precision_at_1000
value: 0.13899999999999998
- type: precision_at_3
value: 15.920000000000002
- type: precision_at_5
value: 11.437
- type: recall_at_1
value: 26.457000000000004
- type: recall_at_10
value: 51.845
- type: recall_at_100
value: 77.046
- type: recall_at_1000
value: 92.892
- type: recall_at_3
value: 38.89
- type: recall_at_5
value: 44.688
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackWebmastersRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 29.378999999999998
- type: map_at_10
value: 37.373
- type: map_at_100
value: 39.107
- type: map_at_1000
value: 39.317
- type: map_at_3
value: 34.563
- type: map_at_5
value: 36.173
- type: mrr_at_1
value: 35.178
- type: mrr_at_10
value: 42.44
- type: mrr_at_100
value: 43.434
- type: mrr_at_1000
value: 43.482
- type: mrr_at_3
value: 39.987
- type: mrr_at_5
value: 41.370000000000005
- type: ndcg_at_1
value: 35.178
- type: ndcg_at_10
value: 42.82
- type: ndcg_at_100
value: 48.935
- type: ndcg_at_1000
value: 51.28
- type: ndcg_at_3
value: 38.562999999999995
- type: ndcg_at_5
value: 40.687
- type: precision_at_1
value: 35.178
- type: precision_at_10
value: 7.945
- type: precision_at_100
value: 1.524
- type: precision_at_1000
value: 0.242
- type: precision_at_3
value: 17.721
- type: precision_at_5
value: 12.925
- type: recall_at_1
value: 29.378999999999998
- type: recall_at_10
value: 52.141999999999996
- type: recall_at_100
value: 79.49000000000001
- type: recall_at_1000
value: 93.782
- type: recall_at_3
value: 39.579
- type: recall_at_5
value: 45.462
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackWordpressRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 19.814999999999998
- type: map_at_10
value: 27.383999999999997
- type: map_at_100
value: 28.483999999999998
- type: map_at_1000
value: 28.585
- type: map_at_3
value: 24.807000000000002
- type: map_at_5
value: 26.485999999999997
- type: mrr_at_1
value: 21.996
- type: mrr_at_10
value: 29.584
- type: mrr_at_100
value: 30.611
- type: mrr_at_1000
value: 30.684
- type: mrr_at_3
value: 27.11
- type: mrr_at_5
value: 28.746
- type: ndcg_at_1
value: 21.996
- type: ndcg_at_10
value: 32.024
- type: ndcg_at_100
value: 37.528
- type: ndcg_at_1000
value: 40.150999999999996
- type: ndcg_at_3
value: 27.016000000000002
- type: ndcg_at_5
value: 29.927999999999997
- type: precision_at_1
value: 21.996
- type: precision_at_10
value: 5.102
- type: precision_at_100
value: 0.856
- type: precision_at_1000
value: 0.117
- type: precision_at_3
value: 11.583
- type: precision_at_5
value: 8.577
- type: recall_at_1
value: 19.814999999999998
- type: recall_at_10
value: 44.239
- type: recall_at_100
value: 69.269
- type: recall_at_1000
value: 89.216
- type: recall_at_3
value: 31.102999999999998
- type: recall_at_5
value: 38.078
- task:
type: Retrieval
dataset:
type: climate-fever
name: MTEB ClimateFEVER
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 11.349
- type: map_at_10
value: 19.436
- type: map_at_100
value: 21.282999999999998
- type: map_at_1000
value: 21.479
- type: map_at_3
value: 15.841
- type: map_at_5
value: 17.558
- type: mrr_at_1
value: 25.863000000000003
- type: mrr_at_10
value: 37.218
- type: mrr_at_100
value: 38.198
- type: mrr_at_1000
value: 38.236
- type: mrr_at_3
value: 33.409
- type: mrr_at_5
value: 35.602000000000004
- type: ndcg_at_1
value: 25.863000000000003
- type: ndcg_at_10
value: 27.953
- type: ndcg_at_100
value: 35.327
- type: ndcg_at_1000
value: 38.708999999999996
- type: ndcg_at_3
value: 21.985
- type: ndcg_at_5
value: 23.957
- type: precision_at_1
value: 25.863000000000003
- type: precision_at_10
value: 8.99
- type: precision_at_100
value: 1.6889999999999998
- type: precision_at_1000
value: 0.232
- type: precision_at_3
value: 16.308
- type: precision_at_5
value: 12.912
- type: recall_at_1
value: 11.349
- type: recall_at_10
value: 34.581
- type: recall_at_100
value: 60.178
- type: recall_at_1000
value: 78.88199999999999
- type: recall_at_3
value: 20.041999999999998
- type: recall_at_5
value: 25.458
- task:
type: Retrieval
dataset:
type: dbpedia-entity
name: MTEB DBPedia
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 7.893
- type: map_at_10
value: 15.457
- type: map_at_100
value: 20.905
- type: map_at_1000
value: 22.116
- type: map_at_3
value: 11.593
- type: map_at_5
value: 13.134
- type: mrr_at_1
value: 57.49999999999999
- type: mrr_at_10
value: 65.467
- type: mrr_at_100
value: 66.022
- type: mrr_at_1000
value: 66.039
- type: mrr_at_3
value: 63.458000000000006
- type: mrr_at_5
value: 64.546
- type: ndcg_at_1
value: 45.875
- type: ndcg_at_10
value: 33.344
- type: ndcg_at_100
value: 36.849
- type: ndcg_at_1000
value: 44.03
- type: ndcg_at_3
value: 37.504
- type: ndcg_at_5
value: 34.892
- type: precision_at_1
value: 57.49999999999999
- type: precision_at_10
value: 25.95
- type: precision_at_100
value: 7.89
- type: precision_at_1000
value: 1.669
- type: precision_at_3
value: 40.333000000000006
- type: precision_at_5
value: 33.050000000000004
- type: recall_at_1
value: 7.893
- type: recall_at_10
value: 20.724999999999998
- type: recall_at_100
value: 42.516
- type: recall_at_1000
value: 65.822
- type: recall_at_3
value: 12.615000000000002
- type: recall_at_5
value: 15.482000000000001
- task:
type: Classification
dataset:
type: mteb/emotion
name: MTEB EmotionClassification
config: default
split: test
revision: 4f58c6b202a23cf9a4da393831edf4f9183cad37
metrics:
- type: accuracy
value: 51.760000000000005
- type: f1
value: 45.51690565701713
- task:
type: Retrieval
dataset:
type: fever
name: MTEB FEVER
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 53.882
- type: map_at_10
value: 65.902
- type: map_at_100
value: 66.33
- type: map_at_1000
value: 66.348
- type: map_at_3
value: 63.75999999999999
- type: map_at_5
value: 65.181
- type: mrr_at_1
value: 58.041
- type: mrr_at_10
value: 70.133
- type: mrr_at_100
value: 70.463
- type: mrr_at_1000
value: 70.47
- type: mrr_at_3
value: 68.164
- type: mrr_at_5
value: 69.465
- type: ndcg_at_1
value: 58.041
- type: ndcg_at_10
value: 71.84700000000001
- type: ndcg_at_100
value: 73.699
- type: ndcg_at_1000
value: 74.06700000000001
- type: ndcg_at_3
value: 67.855
- type: ndcg_at_5
value: 70.203
- type: precision_at_1
value: 58.041
- type: precision_at_10
value: 9.427000000000001
- type: precision_at_100
value: 1.049
- type: precision_at_1000
value: 0.11
- type: precision_at_3
value: 27.278000000000002
- type: precision_at_5
value: 17.693
- type: recall_at_1
value: 53.882
- type: recall_at_10
value: 85.99
- type: recall_at_100
value: 94.09100000000001
- type: recall_at_1000
value: 96.612
- type: recall_at_3
value: 75.25
- type: recall_at_5
value: 80.997
- task:
type: Retrieval
dataset:
type: fiqa
name: MTEB FiQA2018
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 19.165
- type: map_at_10
value: 31.845000000000002
- type: map_at_100
value: 33.678999999999995
- type: map_at_1000
value: 33.878
- type: map_at_3
value: 27.881
- type: map_at_5
value: 30.049999999999997
- type: mrr_at_1
value: 38.272
- type: mrr_at_10
value: 47.04
- type: mrr_at_100
value: 47.923
- type: mrr_at_1000
value: 47.973
- type: mrr_at_3
value: 44.985
- type: mrr_at_5
value: 46.150000000000006
- type: ndcg_at_1
value: 38.272
- type: ndcg_at_10
value: 39.177
- type: ndcg_at_100
value: 45.995000000000005
- type: ndcg_at_1000
value: 49.312
- type: ndcg_at_3
value: 36.135
- type: ndcg_at_5
value: 36.936
- type: precision_at_1
value: 38.272
- type: precision_at_10
value: 10.926
- type: precision_at_100
value: 1.809
- type: precision_at_1000
value: 0.23700000000000002
- type: precision_at_3
value: 24.331
- type: precision_at_5
value: 17.747
- type: recall_at_1
value: 19.165
- type: recall_at_10
value: 45.103
- type: recall_at_100
value: 70.295
- type: recall_at_1000
value: 90.592
- type: recall_at_3
value: 32.832
- type: recall_at_5
value: 37.905
- task:
type: Retrieval
dataset:
type: hotpotqa
name: MTEB HotpotQA
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 32.397
- type: map_at_10
value: 44.83
- type: map_at_100
value: 45.716
- type: map_at_1000
value: 45.797
- type: map_at_3
value: 41.955999999999996
- type: map_at_5
value: 43.736999999999995
- type: mrr_at_1
value: 64.794
- type: mrr_at_10
value: 71.866
- type: mrr_at_100
value: 72.22
- type: mrr_at_1000
value: 72.238
- type: mrr_at_3
value: 70.416
- type: mrr_at_5
value: 71.304
- type: ndcg_at_1
value: 64.794
- type: ndcg_at_10
value: 54.186
- type: ndcg_at_100
value: 57.623000000000005
- type: ndcg_at_1000
value: 59.302
- type: ndcg_at_3
value: 49.703
- type: ndcg_at_5
value: 52.154999999999994
- type: precision_at_1
value: 64.794
- type: precision_at_10
value: 11.219
- type: precision_at_100
value: 1.394
- type: precision_at_1000
value: 0.16199999999999998
- type: precision_at_3
value: 30.767
- type: precision_at_5
value: 20.397000000000002
- type: recall_at_1
value: 32.397
- type: recall_at_10
value: 56.096999999999994
- type: recall_at_100
value: 69.696
- type: recall_at_1000
value: 80.88499999999999
- type: recall_at_3
value: 46.150999999999996
- type: recall_at_5
value: 50.993
- task:
type: Classification
dataset:
type: mteb/imdb
name: MTEB ImdbClassification
config: default
split: test
revision: 3d86128a09e091d6018b6d26cad27f2739fc2db7
metrics:
- type: accuracy
value: 81.1744
- type: ap
value: 75.44973697032414
- type: f1
value: 81.09901117955782
- task:
type: Retrieval
dataset:
type: msmarco
name: MTEB MSMARCO
config: default
split: dev
revision: None
metrics:
- type: map_at_1
value: 19.519000000000002
- type: map_at_10
value: 31.025000000000002
- type: map_at_100
value: 32.275999999999996
- type: map_at_1000
value: 32.329
- type: map_at_3
value: 27.132
- type: map_at_5
value: 29.415999999999997
- type: mrr_at_1
value: 20.115
- type: mrr_at_10
value: 31.569000000000003
- type: mrr_at_100
value: 32.768
- type: mrr_at_1000
value: 32.816
- type: mrr_at_3
value: 27.748
- type: mrr_at_5
value: 29.956
- type: ndcg_at_1
value: 20.115
- type: ndcg_at_10
value: 37.756
- type: ndcg_at_100
value: 43.858000000000004
- type: ndcg_at_1000
value: 45.199
- type: ndcg_at_3
value: 29.818
- type: ndcg_at_5
value: 33.875
- type: precision_at_1
value: 20.115
- type: precision_at_10
value: 6.122
- type: precision_at_100
value: 0.919
- type: precision_at_1000
value: 0.10300000000000001
- type: precision_at_3
value: 12.794
- type: precision_at_5
value: 9.731
- type: recall_at_1
value: 19.519000000000002
- type: recall_at_10
value: 58.62500000000001
- type: recall_at_100
value: 86.99
- type: recall_at_1000
value: 97.268
- type: recall_at_3
value: 37.002
- type: recall_at_5
value: 46.778
- task:
type: Classification
dataset:
type: mteb/mtop_domain
name: MTEB MTOPDomainClassification (en)
config: en
split: test
revision: d80d48c1eb48d3562165c59d59d0034df9fff0bf
metrics:
- type: accuracy
value: 93.71865025079799
- type: f1
value: 93.38906173610519
- task:
type: Classification
dataset:
type: mteb/mtop_intent
name: MTEB MTOPIntentClassification (en)
config: en
split: test
revision: ae001d0e6b1228650b7bd1c2c65fb50ad11a8aba
metrics:
- type: accuracy
value: 70.2576379388965
- type: f1
value: 49.20405830249464
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (en)
config: en
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 67.48486886348351
- type: f1
value: 64.92199176095157
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (en)
config: en
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 72.59246805648958
- type: f1
value: 72.1222026389164
- task:
type: Clustering
dataset:
type: mteb/medrxiv-clustering-p2p
name: MTEB MedrxivClusteringP2P
config: default
split: test
revision: e7a26af6f3ae46b30dde8737f02c07b1505bcc73
metrics:
- type: v_measure
value: 30.887642595096825
- task:
type: Clustering
dataset:
type: mteb/medrxiv-clustering-s2s
name: MTEB MedrxivClusteringS2S
config: default
split: test
revision: 35191c8c0dca72d8ff3efcd72aa802307d469663
metrics:
- type: v_measure
value: 28.3764418784054
- task:
type: Reranking
dataset:
type: mteb/mind_small
name: MTEB MindSmallReranking
config: default
split: test
revision: 3bdac13927fdc888b903db93b2ffdbd90b295a69
metrics:
- type: map
value: 31.81544126336991
- type: mrr
value: 32.82666576268031
- task:
type: Retrieval
dataset:
type: nfcorpus
name: MTEB NFCorpus
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 5.185
- type: map_at_10
value: 11.158
- type: map_at_100
value: 14.041
- type: map_at_1000
value: 15.360999999999999
- type: map_at_3
value: 8.417
- type: map_at_5
value: 9.378
- type: mrr_at_1
value: 44.582
- type: mrr_at_10
value: 53.083999999999996
- type: mrr_at_100
value: 53.787
- type: mrr_at_1000
value: 53.824000000000005
- type: mrr_at_3
value: 51.187000000000005
- type: mrr_at_5
value: 52.379
- type: ndcg_at_1
value: 42.57
- type: ndcg_at_10
value: 31.593
- type: ndcg_at_100
value: 29.093999999999998
- type: ndcg_at_1000
value: 37.909
- type: ndcg_at_3
value: 37.083
- type: ndcg_at_5
value: 34.397
- type: precision_at_1
value: 43.963
- type: precision_at_10
value: 23.498
- type: precision_at_100
value: 7.6160000000000005
- type: precision_at_1000
value: 2.032
- type: precision_at_3
value: 34.572
- type: precision_at_5
value: 29.412
- type: recall_at_1
value: 5.185
- type: recall_at_10
value: 15.234
- type: recall_at_100
value: 29.49
- type: recall_at_1000
value: 62.273999999999994
- type: recall_at_3
value: 9.55
- type: recall_at_5
value: 11.103
- task:
type: Retrieval
dataset:
type: nq
name: MTEB NQ
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 23.803
- type: map_at_10
value: 38.183
- type: map_at_100
value: 39.421
- type: map_at_1000
value: 39.464
- type: map_at_3
value: 33.835
- type: map_at_5
value: 36.327
- type: mrr_at_1
value: 26.68
- type: mrr_at_10
value: 40.439
- type: mrr_at_100
value: 41.415
- type: mrr_at_1000
value: 41.443999999999996
- type: mrr_at_3
value: 36.612
- type: mrr_at_5
value: 38.877
- type: ndcg_at_1
value: 26.68
- type: ndcg_at_10
value: 45.882
- type: ndcg_at_100
value: 51.227999999999994
- type: ndcg_at_1000
value: 52.207
- type: ndcg_at_3
value: 37.511
- type: ndcg_at_5
value: 41.749
- type: precision_at_1
value: 26.68
- type: precision_at_10
value: 7.9750000000000005
- type: precision_at_100
value: 1.0959999999999999
- type: precision_at_1000
value: 0.11900000000000001
- type: precision_at_3
value: 17.449
- type: precision_at_5
value: 12.897
- type: recall_at_1
value: 23.803
- type: recall_at_10
value: 67.152
- type: recall_at_100
value: 90.522
- type: recall_at_1000
value: 97.743
- type: recall_at_3
value: 45.338
- type: recall_at_5
value: 55.106
- task:
type: Retrieval
dataset:
type: quora
name: MTEB QuoraRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 70.473
- type: map_at_10
value: 84.452
- type: map_at_100
value: 85.101
- type: map_at_1000
value: 85.115
- type: map_at_3
value: 81.435
- type: map_at_5
value: 83.338
- type: mrr_at_1
value: 81.19
- type: mrr_at_10
value: 87.324
- type: mrr_at_100
value: 87.434
- type: mrr_at_1000
value: 87.435
- type: mrr_at_3
value: 86.31
- type: mrr_at_5
value: 87.002
- type: ndcg_at_1
value: 81.21000000000001
- type: ndcg_at_10
value: 88.19
- type: ndcg_at_100
value: 89.44
- type: ndcg_at_1000
value: 89.526
- type: ndcg_at_3
value: 85.237
- type: ndcg_at_5
value: 86.892
- type: precision_at_1
value: 81.21000000000001
- type: precision_at_10
value: 13.417000000000002
- type: precision_at_100
value: 1.537
- type: precision_at_1000
value: 0.157
- type: precision_at_3
value: 37.31
- type: precision_at_5
value: 24.59
- type: recall_at_1
value: 70.473
- type: recall_at_10
value: 95.367
- type: recall_at_100
value: 99.616
- type: recall_at_1000
value: 99.996
- type: recall_at_3
value: 86.936
- type: recall_at_5
value: 91.557
- task:
type: Clustering
dataset:
type: mteb/reddit-clustering
name: MTEB RedditClustering
config: default
split: test
revision: 24640382cdbf8abc73003fb0fa6d111a705499eb
metrics:
- type: v_measure
value: 59.25776525253911
- task:
type: Clustering
dataset:
type: mteb/reddit-clustering-p2p
name: MTEB RedditClusteringP2P
config: default
split: test
revision: 282350215ef01743dc01b456c7f5241fa8937f16
metrics:
- type: v_measure
value: 63.22135271663078
- task:
type: Retrieval
dataset:
type: scidocs
name: MTEB SCIDOCS
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 4.003
- type: map_at_10
value: 10.062999999999999
- type: map_at_100
value: 11.854000000000001
- type: map_at_1000
value: 12.145999999999999
- type: map_at_3
value: 7.242
- type: map_at_5
value: 8.652999999999999
- type: mrr_at_1
value: 19.7
- type: mrr_at_10
value: 29.721999999999998
- type: mrr_at_100
value: 30.867
- type: mrr_at_1000
value: 30.944
- type: mrr_at_3
value: 26.683
- type: mrr_at_5
value: 28.498
- type: ndcg_at_1
value: 19.7
- type: ndcg_at_10
value: 17.095
- type: ndcg_at_100
value: 24.375
- type: ndcg_at_1000
value: 29.831000000000003
- type: ndcg_at_3
value: 16.305
- type: ndcg_at_5
value: 14.291
- type: precision_at_1
value: 19.7
- type: precision_at_10
value: 8.799999999999999
- type: precision_at_100
value: 1.9349999999999998
- type: precision_at_1000
value: 0.32399999999999995
- type: precision_at_3
value: 15.2
- type: precision_at_5
value: 12.540000000000001
- type: recall_at_1
value: 4.003
- type: recall_at_10
value: 17.877000000000002
- type: recall_at_100
value: 39.217
- type: recall_at_1000
value: 65.862
- type: recall_at_3
value: 9.242
- type: recall_at_5
value: 12.715000000000002
- task:
type: STS
dataset:
type: mteb/sickr-sts
name: MTEB SICK-R
config: default
split: test
revision: a6ea5a8cab320b040a23452cc28066d9beae2cee
metrics:
- type: cos_sim_spearman
value: 80.25888668589654
- task:
type: STS
dataset:
type: mteb/sts12-sts
name: MTEB STS12
config: default
split: test
revision: a0d554a64d88156834ff5ae9920b964011b16384
metrics:
- type: cos_sim_spearman
value: 77.02037527837669
- task:
type: STS
dataset:
type: mteb/sts13-sts
name: MTEB STS13
config: default
split: test
revision: 7e90230a92c190f1bf69ae9002b8cea547a64cca
metrics:
- type: cos_sim_spearman
value: 86.58432681008449
- task:
type: STS
dataset:
type: mteb/sts14-sts
name: MTEB STS14
config: default
split: test
revision: 6031580fec1f6af667f0bd2da0a551cf4f0b2375
metrics:
- type: cos_sim_spearman
value: 81.31697756099051
- task:
type: STS
dataset:
type: mteb/sts15-sts
name: MTEB STS15
config: default
split: test
revision: ae752c7c21bf194d8b67fd573edf7ae58183cbe3
metrics:
- type: cos_sim_spearman
value: 88.18867599667057
- task:
type: STS
dataset:
type: mteb/sts16-sts
name: MTEB STS16
config: default
split: test
revision: 4d8694f8f0e0100860b497b999b3dbed754a0513
metrics:
- type: cos_sim_spearman
value: 84.87853941747623
- task:
type: STS
dataset:
type: mteb/sts17-crosslingual-sts
name: MTEB STS17 (en-en)
config: en-en
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_spearman
value: 89.46479925383916
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (en)
config: en
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_spearman
value: 66.45272113649146
- task:
type: STS
dataset:
type: mteb/stsbenchmark-sts
name: MTEB STSBenchmark
config: default
split: test
revision: b0fddb56ed78048fa8b90373c8a3cfc37b684831
metrics:
- type: cos_sim_spearman
value: 86.43357313527851
- task:
type: Reranking
dataset:
type: mteb/scidocs-reranking
name: MTEB SciDocsRR
config: default
split: test
revision: d3c5e1fc0b855ab6097bf1cda04dd73947d7caab
metrics:
- type: map
value: 78.82761687254882
- type: mrr
value: 93.46223674655047
- task:
type: Retrieval
dataset:
type: scifact
name: MTEB SciFact
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 44.583
- type: map_at_10
value: 52.978
- type: map_at_100
value: 53.803
- type: map_at_1000
value: 53.839999999999996
- type: map_at_3
value: 50.03300000000001
- type: map_at_5
value: 51.939
- type: mrr_at_1
value: 47.0
- type: mrr_at_10
value: 54.730000000000004
- type: mrr_at_100
value: 55.31399999999999
- type: mrr_at_1000
value: 55.346
- type: mrr_at_3
value: 52.0
- type: mrr_at_5
value: 53.783
- type: ndcg_at_1
value: 47.0
- type: ndcg_at_10
value: 57.82899999999999
- type: ndcg_at_100
value: 61.49400000000001
- type: ndcg_at_1000
value: 62.676
- type: ndcg_at_3
value: 52.373000000000005
- type: ndcg_at_5
value: 55.481
- type: precision_at_1
value: 47.0
- type: precision_at_10
value: 7.867
- type: precision_at_100
value: 0.997
- type: precision_at_1000
value: 0.11
- type: precision_at_3
value: 20.556
- type: precision_at_5
value: 14.066999999999998
- type: recall_at_1
value: 44.583
- type: recall_at_10
value: 71.172
- type: recall_at_100
value: 87.7
- type: recall_at_1000
value: 97.333
- type: recall_at_3
value: 56.511
- type: recall_at_5
value: 64.206
- task:
type: PairClassification
dataset:
type: mteb/sprintduplicatequestions-pairclassification
name: MTEB SprintDuplicateQuestions
config: default
split: test
revision: d66bd1f72af766a5cc4b0ca5e00c162f89e8cc46
metrics:
- type: cos_sim_accuracy
value: 99.66237623762376
- type: cos_sim_ap
value: 90.35465126226322
- type: cos_sim_f1
value: 82.44575936883628
- type: cos_sim_precision
value: 81.32295719844358
- type: cos_sim_recall
value: 83.6
- type: dot_accuracy
value: 99.66237623762376
- type: dot_ap
value: 90.35464287920453
- type: dot_f1
value: 82.44575936883628
- type: dot_precision
value: 81.32295719844358
- type: dot_recall
value: 83.6
- type: euclidean_accuracy
value: 99.66237623762376
- type: euclidean_ap
value: 90.3546512622632
- type: euclidean_f1
value: 82.44575936883628
- type: euclidean_precision
value: 81.32295719844358
- type: euclidean_recall
value: 83.6
- type: manhattan_accuracy
value: 99.65940594059406
- type: manhattan_ap
value: 90.29220174849843
- type: manhattan_f1
value: 82.4987605354487
- type: manhattan_precision
value: 81.80924287118977
- type: manhattan_recall
value: 83.2
- type: max_accuracy
value: 99.66237623762376
- type: max_ap
value: 90.35465126226322
- type: max_f1
value: 82.4987605354487
- task:
type: Clustering
dataset:
type: mteb/stackexchange-clustering
name: MTEB StackExchangeClustering
config: default
split: test
revision: 6cbc1f7b2bc0622f2e39d2c77fa502909748c259
metrics:
- type: v_measure
value: 65.0394225901397
- task:
type: Clustering
dataset:
type: mteb/stackexchange-clustering-p2p
name: MTEB StackExchangeClusteringP2P
config: default
split: test
revision: 815ca46b2622cec33ccafc3735d572c266efdb44
metrics:
- type: v_measure
value: 35.27954189859326
- task:
type: Reranking
dataset:
type: mteb/stackoverflowdupquestions-reranking
name: MTEB StackOverflowDupQuestions
config: default
split: test
revision: e185fbe320c72810689fc5848eb6114e1ef5ec69
metrics:
- type: map
value: 50.99055979974896
- type: mrr
value: 51.82745257193787
- task:
type: Summarization
dataset:
type: mteb/summeval
name: MTEB SummEval
config: default
split: test
revision: cda12ad7615edc362dbf25a00fdd61d3b1eaf93c
metrics:
- type: cos_sim_pearson
value: 30.21655465344237
- type: cos_sim_spearman
value: 29.853205339630172
- type: dot_pearson
value: 30.216540628083564
- type: dot_spearman
value: 29.868978894753027
- task:
type: Retrieval
dataset:
type: trec-covid
name: MTEB TRECCOVID
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 0.2
- type: map_at_10
value: 1.398
- type: map_at_100
value: 7.406
- type: map_at_1000
value: 18.401
- type: map_at_3
value: 0.479
- type: map_at_5
value: 0.772
- type: mrr_at_1
value: 70.0
- type: mrr_at_10
value: 79.25999999999999
- type: mrr_at_100
value: 79.25999999999999
- type: mrr_at_1000
value: 79.25999999999999
- type: mrr_at_3
value: 77.333
- type: mrr_at_5
value: 78.133
- type: ndcg_at_1
value: 63.0
- type: ndcg_at_10
value: 58.548
- type: ndcg_at_100
value: 45.216
- type: ndcg_at_1000
value: 41.149
- type: ndcg_at_3
value: 60.641999999999996
- type: ndcg_at_5
value: 61.135
- type: precision_at_1
value: 70.0
- type: precision_at_10
value: 64.0
- type: precision_at_100
value: 46.92
- type: precision_at_1000
value: 18.642
- type: precision_at_3
value: 64.667
- type: precision_at_5
value: 66.4
- type: recall_at_1
value: 0.2
- type: recall_at_10
value: 1.6729999999999998
- type: recall_at_100
value: 10.856
- type: recall_at_1000
value: 38.964999999999996
- type: recall_at_3
value: 0.504
- type: recall_at_5
value: 0.852
- task:
type: Retrieval
dataset:
type: webis-touche2020
name: MTEB Touche2020
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 1.6629999999999998
- type: map_at_10
value: 8.601
- type: map_at_100
value: 14.354
- type: map_at_1000
value: 15.927
- type: map_at_3
value: 4.1930000000000005
- type: map_at_5
value: 5.655
- type: mrr_at_1
value: 18.367
- type: mrr_at_10
value: 34.466
- type: mrr_at_100
value: 35.235
- type: mrr_at_1000
value: 35.27
- type: mrr_at_3
value: 28.571
- type: mrr_at_5
value: 31.531
- type: ndcg_at_1
value: 14.285999999999998
- type: ndcg_at_10
value: 20.374
- type: ndcg_at_100
value: 33.532000000000004
- type: ndcg_at_1000
value: 45.561
- type: ndcg_at_3
value: 18.442
- type: ndcg_at_5
value: 18.076
- type: precision_at_1
value: 18.367
- type: precision_at_10
value: 20.204
- type: precision_at_100
value: 7.489999999999999
- type: precision_at_1000
value: 1.5630000000000002
- type: precision_at_3
value: 21.769
- type: precision_at_5
value: 20.408
- type: recall_at_1
value: 1.6629999999999998
- type: recall_at_10
value: 15.549
- type: recall_at_100
value: 47.497
- type: recall_at_1000
value: 84.524
- type: recall_at_3
value: 5.289
- type: recall_at_5
value: 8.035
- task:
type: Classification
dataset:
type: mteb/toxic_conversations_50k
name: MTEB ToxicConversationsClassification
config: default
split: test
revision: d7c0de2777da35d6aae2200a62c6e0e5af397c4c
metrics:
- type: accuracy
value: 71.8194
- type: ap
value: 14.447702451658554
- type: f1
value: 55.13659412856185
- task:
type: Classification
dataset:
type: mteb/tweet_sentiment_extraction
name: MTEB TweetSentimentExtractionClassification
config: default
split: test
revision: d604517c81ca91fe16a244d1248fc021f9ecee7a
metrics:
- type: accuracy
value: 63.310696095076416
- type: f1
value: 63.360434851097814
- task:
type: Clustering
dataset:
type: mteb/twentynewsgroups-clustering
name: MTEB TwentyNewsgroupsClustering
config: default
split: test
revision: 6125ec4e24fa026cec8a478383ee943acfbd5449
metrics:
- type: v_measure
value: 51.30677907335145
- task:
type: PairClassification
dataset:
type: mteb/twittersemeval2015-pairclassification
name: MTEB TwitterSemEval2015
config: default
split: test
revision: 70970daeab8776df92f5ea462b6173c0b46fd2d1
metrics:
- type: cos_sim_accuracy
value: 86.12386004649221
- type: cos_sim_ap
value: 73.99096426215495
- type: cos_sim_f1
value: 68.18416968442834
- type: cos_sim_precision
value: 66.86960933536275
- type: cos_sim_recall
value: 69.55145118733509
- type: dot_accuracy
value: 86.12386004649221
- type: dot_ap
value: 73.99096813038672
- type: dot_f1
value: 68.18416968442834
- type: dot_precision
value: 66.86960933536275
- type: dot_recall
value: 69.55145118733509
- type: euclidean_accuracy
value: 86.12386004649221
- type: euclidean_ap
value: 73.99095984980165
- type: euclidean_f1
value: 68.18416968442834
- type: euclidean_precision
value: 66.86960933536275
- type: euclidean_recall
value: 69.55145118733509
- type: manhattan_accuracy
value: 86.09405734040651
- type: manhattan_ap
value: 73.96825745608601
- type: manhattan_f1
value: 68.13888179729383
- type: manhattan_precision
value: 65.99901088031652
- type: manhattan_recall
value: 70.42216358839049
- type: max_accuracy
value: 86.12386004649221
- type: max_ap
value: 73.99096813038672
- type: max_f1
value: 68.18416968442834
- task:
type: PairClassification
dataset:
type: mteb/twitterurlcorpus-pairclassification
name: MTEB TwitterURLCorpus
config: default
split: test
revision: 8b6510b0b1fa4e4c4f879467980e9be563ec1cdf
metrics:
- type: cos_sim_accuracy
value: 88.99367407924865
- type: cos_sim_ap
value: 86.19720829843081
- type: cos_sim_f1
value: 78.39889075384951
- type: cos_sim_precision
value: 74.5110278818144
- type: cos_sim_recall
value: 82.71481367416075
- type: dot_accuracy
value: 88.99367407924865
- type: dot_ap
value: 86.19718471454047
- type: dot_f1
value: 78.39889075384951
- type: dot_precision
value: 74.5110278818144
- type: dot_recall
value: 82.71481367416075
- type: euclidean_accuracy
value: 88.99367407924865
- type: euclidean_ap
value: 86.1972021422436
- type: euclidean_f1
value: 78.39889075384951
- type: euclidean_precision
value: 74.5110278818144
- type: euclidean_recall
value: 82.71481367416075
- type: manhattan_accuracy
value: 88.95680521597392
- type: manhattan_ap
value: 86.16659921351506
- type: manhattan_f1
value: 78.39125971550081
- type: manhattan_precision
value: 74.82502799552073
- type: manhattan_recall
value: 82.31444410224823
- type: max_accuracy
value: 88.99367407924865
- type: max_ap
value: 86.19720829843081
- type: max_f1
value: 78.39889075384951
---
# hkunlp/instructor-base
We introduce **Instructor**👨🏫, an instruction-finetuned text embedding model that can generate text embeddings tailored to any task (e.g., classification, retrieval, clustering, text evaluation, etc.) and domains (e.g., science, finance, etc.) ***by simply providing the task instruction, without any finetuning***. Instructor👨 achieves sota on 70 diverse embedding tasks!
The model is easy to use with **our customized** `sentence-transformer` library. For more details, check out [our paper](https://arxiv.org/abs/2212.09741) and [project page](https://instructor-embedding.github.io/)!
**************************** **Updates** ****************************
* 01/21: We released a new [checkpoint](https://huggingface.co/hkunlp/instructor-base) trained with hard negatives, which gives better performance.
* 12/21: We released our [paper](https://arxiv.org/abs/2212.09741), [code](https://github.com/HKUNLP/instructor-embedding), [checkpoint](https://huggingface.co/hkunlp/instructor-base) and [project page](https://instructor-embedding.github.io/)! Check them out!
## Quick start
<hr />
## Installation
```bash
pip install InstructorEmbedding
```
## Compute your customized embeddings
Then you can use the model like this to calculate domain-specific and task-aware embeddings:
```python
from InstructorEmbedding import INSTRUCTOR
model = INSTRUCTOR('hkunlp/instructor-base')
sentence = "3D ActionSLAM: wearable person tracking in multi-floor environments"
instruction = "Represent the Science title:"
embeddings = model.encode([[instruction,sentence]])
print(embeddings)
```
## Use cases
<hr />
## Calculate embeddings for your customized texts
If you want to calculate customized embeddings for specific sentences, you may follow the unified template to write instructions:
Represent the `domain` `text_type` for `task_objective`:
* `domain` is optional, and it specifies the domain of the text, e.g., science, finance, medicine, etc.
* `text_type` is required, and it specifies the encoding unit, e.g., sentence, document, paragraph, etc.
* `task_objective` is optional, and it specifies the objective of embedding, e.g., retrieve a document, classify the sentence, etc.
## Calculate Sentence similarities
You can further use the model to compute similarities between two groups of sentences, with **customized embeddings**.
```python
from sklearn.metrics.pairwise import cosine_similarity
sentences_a = [['Represent the Science sentence: ','Parton energy loss in QCD matter'],
['Represent the Financial statement: ','The Federal Reserve on Wednesday raised its benchmark interest rate.']]
sentences_b = [['Represent the Science sentence: ','The Chiral Phase Transition in Dissipative Dynamics'],
['Represent the Financial statement: ','The funds rose less than 0.5 per cent on Friday']]
embeddings_a = model.encode(sentences_a)
embeddings_b = model.encode(sentences_b)
similarities = cosine_similarity(embeddings_a,embeddings_b)
print(similarities)
```
## Information Retrieval
You can also use **customized embeddings** for information retrieval.
```python
import numpy as np
from sklearn.metrics.pairwise import cosine_similarity
query = [['Represent the Wikipedia question for retrieving supporting documents: ','where is the food stored in a yam plant']]
corpus = [['Represent the Wikipedia document for retrieval: ','Capitalism has been dominant in the Western world since the end of feudalism, but most feel[who?] that the term "mixed economies" more precisely describes most contemporary economies, due to their containing both private-owned and state-owned enterprises. In capitalism, prices determine the demand-supply scale. For example, higher demand for certain goods and services lead to higher prices and lower demand for certain goods lead to lower prices.'],
['Represent the Wikipedia document for retrieval: ',"The disparate impact theory is especially controversial under the Fair Housing Act because the Act regulates many activities relating to housing, insurance, and mortgage loans—and some scholars have argued that the theory's use under the Fair Housing Act, combined with extensions of the Community Reinvestment Act, contributed to rise of sub-prime lending and the crash of the U.S. housing market and ensuing global economic recession"],
['Represent the Wikipedia document for retrieval: ','Disparate impact in United States labor law refers to practices in employment, housing, and other areas that adversely affect one group of people of a protected characteristic more than another, even though rules applied by employers or landlords are formally neutral. Although the protected classes vary by statute, most federal civil rights laws protect based on race, color, religion, national origin, and sex as protected traits, and some laws include disability status and other traits as well.']]
query_embeddings = model.encode(query)
corpus_embeddings = model.encode(corpus)
similarities = cosine_similarity(query_embeddings,corpus_embeddings)
retrieved_doc_id = np.argmax(similarities)
print(retrieved_doc_id)
```
## Clustering
Use **customized embeddings** for clustering texts in groups.
```python
import sklearn.cluster
sentences = [['Represent the Medicine sentence for clustering: ','Dynamical Scalar Degree of Freedom in Horava-Lifshitz Gravity'],
['Represent the Medicine sentence for clustering: ','Comparison of Atmospheric Neutrino Flux Calculations at Low Energies'],
['Represent the Medicine sentence for clustering: ','Fermion Bags in the Massive Gross-Neveu Model'],
['Represent the Medicine sentence for clustering: ',"QCD corrections to Associated t-tbar-H production at the Tevatron"],
['Represent the Medicine sentence for clustering: ','A New Analysis of the R Measurements: Resonance Parameters of the Higher, Vector States of Charmonium']]
embeddings = model.encode(sentences)
clustering_model = sklearn.cluster.MiniBatchKMeans(n_clusters=2)
clustering_model.fit(embeddings)
cluster_assignment = clustering_model.labels_
print(cluster_assignment)
``` |
RichardErkhov/NTQAI_-_Nxcode-CQ-7B-orpo-gguf | RichardErkhov | 2024-06-25T21:33:39Z | 17,298 | 0 | null | [
"gguf",
"arxiv:2403.07691",
"region:us"
]
| null | 2024-06-25T17:27:51Z | Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
Nxcode-CQ-7B-orpo - GGUF
- Model creator: https://huggingface.co/NTQAI/
- Original model: https://huggingface.co/NTQAI/Nxcode-CQ-7B-orpo/
| Name | Quant method | Size |
| ---- | ---- | ---- |
| [Nxcode-CQ-7B-orpo.Q2_K.gguf](https://huggingface.co/RichardErkhov/NTQAI_-_Nxcode-CQ-7B-orpo-gguf/blob/main/Nxcode-CQ-7B-orpo.Q2_K.gguf) | Q2_K | 2.84GB |
| [Nxcode-CQ-7B-orpo.IQ3_XS.gguf](https://huggingface.co/RichardErkhov/NTQAI_-_Nxcode-CQ-7B-orpo-gguf/blob/main/Nxcode-CQ-7B-orpo.IQ3_XS.gguf) | IQ3_XS | 3.13GB |
| [Nxcode-CQ-7B-orpo.IQ3_S.gguf](https://huggingface.co/RichardErkhov/NTQAI_-_Nxcode-CQ-7B-orpo-gguf/blob/main/Nxcode-CQ-7B-orpo.IQ3_S.gguf) | IQ3_S | 3.27GB |
| [Nxcode-CQ-7B-orpo.Q3_K_S.gguf](https://huggingface.co/RichardErkhov/NTQAI_-_Nxcode-CQ-7B-orpo-gguf/blob/main/Nxcode-CQ-7B-orpo.Q3_K_S.gguf) | Q3_K_S | 3.26GB |
| [Nxcode-CQ-7B-orpo.IQ3_M.gguf](https://huggingface.co/RichardErkhov/NTQAI_-_Nxcode-CQ-7B-orpo-gguf/blob/main/Nxcode-CQ-7B-orpo.IQ3_M.gguf) | IQ3_M | 3.36GB |
| [Nxcode-CQ-7B-orpo.Q3_K.gguf](https://huggingface.co/RichardErkhov/NTQAI_-_Nxcode-CQ-7B-orpo-gguf/blob/main/Nxcode-CQ-7B-orpo.Q3_K.gguf) | Q3_K | 3.55GB |
| [Nxcode-CQ-7B-orpo.Q3_K_M.gguf](https://huggingface.co/RichardErkhov/NTQAI_-_Nxcode-CQ-7B-orpo-gguf/blob/main/Nxcode-CQ-7B-orpo.Q3_K_M.gguf) | Q3_K_M | 3.55GB |
| [Nxcode-CQ-7B-orpo.Q3_K_L.gguf](https://huggingface.co/RichardErkhov/NTQAI_-_Nxcode-CQ-7B-orpo-gguf/blob/main/Nxcode-CQ-7B-orpo.Q3_K_L.gguf) | Q3_K_L | 3.71GB |
| [Nxcode-CQ-7B-orpo.IQ4_XS.gguf](https://huggingface.co/RichardErkhov/NTQAI_-_Nxcode-CQ-7B-orpo-gguf/blob/main/Nxcode-CQ-7B-orpo.IQ4_XS.gguf) | IQ4_XS | 3.79GB |
| [Nxcode-CQ-7B-orpo.Q4_0.gguf](https://huggingface.co/RichardErkhov/NTQAI_-_Nxcode-CQ-7B-orpo-gguf/blob/main/Nxcode-CQ-7B-orpo.Q4_0.gguf) | Q4_0 | 3.89GB |
| [Nxcode-CQ-7B-orpo.IQ4_NL.gguf](https://huggingface.co/RichardErkhov/NTQAI_-_Nxcode-CQ-7B-orpo-gguf/blob/main/Nxcode-CQ-7B-orpo.IQ4_NL.gguf) | IQ4_NL | 3.94GB |
| [Nxcode-CQ-7B-orpo.Q4_K_S.gguf](https://huggingface.co/RichardErkhov/NTQAI_-_Nxcode-CQ-7B-orpo-gguf/blob/main/Nxcode-CQ-7B-orpo.Q4_K_S.gguf) | Q4_K_S | 4.11GB |
| [Nxcode-CQ-7B-orpo.Q4_K.gguf](https://huggingface.co/RichardErkhov/NTQAI_-_Nxcode-CQ-7B-orpo-gguf/blob/main/Nxcode-CQ-7B-orpo.Q4_K.gguf) | Q4_K | 4.41GB |
| [Nxcode-CQ-7B-orpo.Q4_K_M.gguf](https://huggingface.co/RichardErkhov/NTQAI_-_Nxcode-CQ-7B-orpo-gguf/blob/main/Nxcode-CQ-7B-orpo.Q4_K_M.gguf) | Q4_K_M | 4.41GB |
| [Nxcode-CQ-7B-orpo.Q4_1.gguf](https://huggingface.co/RichardErkhov/NTQAI_-_Nxcode-CQ-7B-orpo-gguf/blob/main/Nxcode-CQ-7B-orpo.Q4_1.gguf) | Q4_1 | 4.29GB |
| [Nxcode-CQ-7B-orpo.Q5_0.gguf](https://huggingface.co/RichardErkhov/NTQAI_-_Nxcode-CQ-7B-orpo-gguf/blob/main/Nxcode-CQ-7B-orpo.Q5_0.gguf) | Q5_0 | 4.69GB |
| [Nxcode-CQ-7B-orpo.Q5_K_S.gguf](https://huggingface.co/RichardErkhov/NTQAI_-_Nxcode-CQ-7B-orpo-gguf/blob/main/Nxcode-CQ-7B-orpo.Q5_K_S.gguf) | Q5_K_S | 4.79GB |
| [Nxcode-CQ-7B-orpo.Q5_K.gguf](https://huggingface.co/RichardErkhov/NTQAI_-_Nxcode-CQ-7B-orpo-gguf/blob/main/Nxcode-CQ-7B-orpo.Q5_K.gguf) | Q5_K | 5.06GB |
| [Nxcode-CQ-7B-orpo.Q5_K_M.gguf](https://huggingface.co/RichardErkhov/NTQAI_-_Nxcode-CQ-7B-orpo-gguf/blob/main/Nxcode-CQ-7B-orpo.Q5_K_M.gguf) | Q5_K_M | 5.06GB |
| [Nxcode-CQ-7B-orpo.Q5_1.gguf](https://huggingface.co/RichardErkhov/NTQAI_-_Nxcode-CQ-7B-orpo-gguf/blob/main/Nxcode-CQ-7B-orpo.Q5_1.gguf) | Q5_1 | 5.09GB |
| [Nxcode-CQ-7B-orpo.Q6_K.gguf](https://huggingface.co/RichardErkhov/NTQAI_-_Nxcode-CQ-7B-orpo-gguf/blob/main/Nxcode-CQ-7B-orpo.Q6_K.gguf) | Q6_K | 5.94GB |
| [Nxcode-CQ-7B-orpo.Q8_0.gguf](https://huggingface.co/RichardErkhov/NTQAI_-_Nxcode-CQ-7B-orpo-gguf/blob/main/Nxcode-CQ-7B-orpo.Q8_0.gguf) | Q8_0 | 7.18GB |
Original model description:
---
license_name: tongyi-qianwen-research
license_link: https://huggingface.co/Qwen/CodeQwen1.5-7B/blob/main/LICENSE
tags:
- code
pipeline_tag: text-generation
license: other
---
<a href="https://ntq.com.vn" target="_blank"><img src="https://cdn-uploads.huggingface.co/production/uploads/5ee1b417636bdb3834e2da19/etbfTJuVdAub2evNP_E4g.png" width="200"/></a>
## Introduction
Nxcode-CQ-7B-orpo is an [Monolithic Preference Optimization without Reference Model](https://arxiv.org/abs/2403.07691) fine-tune of Qwen/CodeQwen1.5-7B on 100k samples of high-quality ranking data.
## [Evalplus](https://github.com/evalplus/evalplus)
| EvalPlus | pass@1 |
| --- | --- |
| HumanEval | 86.6 |
| HumanEval+ | 83.5 |
| MBPP(v0.2.0) | 82.3 |
| MBPP+(v0.2.0) | 70.4 |
We use a simple template to generate the solution for evalplus:
```python
"Complete the following Python function:\n{prompt}"
```
[Evalplus Leaderboard](https://evalplus.github.io/leaderboard.html)
| Models | HumanEval | HumanEval+|
|------ | ------ | ------ |
| GPT-4-Turbo (April 2024)| 90.2| 86.6|
| GPT-4 (May 2023)| 88.4| 81.17|
| GPT-4-Turbo (Nov 2023)| 85.4| 79.3|
| CodeQwen1.5-7B-Chat| 83.5| 78.7|
| claude-3-opus (Mar 2024)| 82.9| 76.8|
| DeepSeek-Coder-33B-instruct| 81.1| 75.0|
| WizardCoder-33B-V1.1| 79.9| 73.2|
| OpenCodeInterpreter-DS-33B| 79.3| 73.8|
| speechless-codellama-34B-v2.0| 77.4| 72|
| GPT-3.5-Turbo (Nov 2023)| 76.8| 70.7|
| Llama3-70B-instruct| 76.2| 70.7|
## Bigcode Leaderboard
[Bigcode Leaderboard](https://huggingface.co/spaces/bigcode/bigcode-models-leaderboard)
**09/05/2024**
Top 1 average score.
Top 2 winrate.

## Quickstart
Here provides a code snippet with `apply_chat_template` to show you how to load the tokenizer and model and how to generate contents. You should upgrade the transformers if you receive an error when loading the tokenizer
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
device = "cuda" # the device to load the model onto
model = AutoModelForCausalLM.from_pretrained(
"NTQAI/Nxcode-CQ-7B-orpo",
torch_dtype="auto",
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained("NTQAI/Nxcode-CQ-7B-orpo")
prompt = """Complete the following Python function:
from typing import List
def has_close_elements(numbers: List[float], threshold: float) -> bool:
""" Check if in given list of numbers, are any two numbers closer to each other than
given threshold.
>>> has_close_elements([1.0, 2.0, 3.0], 0.5)
False
>>> has_close_elements([1.0, 2.8, 3.0, 4.0, 5.0, 2.0], 0.3)
True
"""
"""
messages = [
{"role": "user", "content": prompt}
]
inputs = tokenizer.apply_chat_template(messages, add_generation_prompt=True, return_tensors="pt").to(model.device)
outputs = model.generate(inputs, max_new_tokens=512, do_sample=False, top_k=50, top_p=0.95, num_return_sequences=1, eos_token_id=tokenizer.eos_token_id)
res = tokenizer.decode(outputs[0][len(inputs[0]):], skip_special_tokens=True)
```
### Contact information
For personal communication related to this project, please contact Nha Nguyen Van ([email protected]).
|
tohoku-nlp/bert-base-japanese-v2 | tohoku-nlp | 2021-09-23T13:45:31Z | 17,295 | 24 | transformers | [
"transformers",
"pytorch",
"tf",
"jax",
"bert",
"fill-mask",
"ja",
"dataset:wikipedia",
"license:cc-by-sa-4.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| fill-mask | 2022-03-02T23:29:05Z | ---
language: ja
license: cc-by-sa-4.0
datasets:
- wikipedia
widget:
- text: 東北大学で[MASK]の研究をしています。
---
# BERT base Japanese (unidic-lite with whole word masking, jawiki-20200831)
This is a [BERT](https://github.com/google-research/bert) model pretrained on texts in the Japanese language.
This version of the model processes input texts with word-level tokenization based on the Unidic 2.1.2 dictionary (available in [unidic-lite](https://pypi.org/project/unidic-lite/) package), followed by the WordPiece subword tokenization.
Additionally, the model is trained with the whole word masking enabled for the masked language modeling (MLM) objective.
The codes for the pretraining are available at [cl-tohoku/bert-japanese](https://github.com/cl-tohoku/bert-japanese/tree/v2.0).
## Model architecture
The model architecture is the same as the original BERT base model; 12 layers, 768 dimensions of hidden states, and 12 attention heads.
## Training Data
The models are trained on the Japanese version of Wikipedia.
The training corpus is generated from the Wikipedia Cirrussearch dump file as of August 31, 2020.
The generated corpus files are 4.0GB in total, containing approximately 30M sentences.
We used the [MeCab](https://taku910.github.io/mecab/) morphological parser with [mecab-ipadic-NEologd](https://github.com/neologd/mecab-ipadic-neologd) dictionary to split texts into sentences.
## Tokenization
The texts are first tokenized by MeCab with the Unidic 2.1.2 dictionary and then split into subwords by the WordPiece algorithm.
The vocabulary size is 32768.
We used [`fugashi`](https://github.com/polm/fugashi) and [`unidic-lite`](https://github.com/polm/unidic-lite) packages for the tokenization.
## Training
The models are trained with the same configuration as the original BERT; 512 tokens per instance, 256 instances per batch, and 1M training steps.
For training of the MLM (masked language modeling) objective, we introduced whole word masking in which all of the subword tokens corresponding to a single word (tokenized by MeCab) are masked at once.
For training of each model, we used a v3-8 instance of Cloud TPUs provided by [TensorFlow Research Cloud program](https://www.tensorflow.org/tfrc/).
The training took about 5 days to finish.
## Licenses
The pretrained models are distributed under the terms of the [Creative Commons Attribution-ShareAlike 3.0](https://creativecommons.org/licenses/by-sa/3.0/).
## Acknowledgments
This model is trained with Cloud TPUs provided by [TensorFlow Research Cloud](https://www.tensorflow.org/tfrc/) program.
|
deepseek-ai/deepseek-coder-1.3b-base | deepseek-ai | 2023-11-14T03:32:27Z | 17,292 | 60 | transformers | [
"transformers",
"pytorch",
"llama",
"text-generation",
"license:other",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| text-generation | 2023-10-28T07:42:03Z | ---
license: other
license_name: deepseek-license
license_link: LICENSE
---
<p align="center">
<img width="1000px" alt="DeepSeek Coder" src="https://github.com/deepseek-ai/DeepSeek-Coder/blob/main/pictures/logo.png?raw=true">
</p>
<p align="center"><a href="https://www.deepseek.com/">[🏠Homepage]</a> | <a href="https://coder.deepseek.com/">[🤖 Chat with DeepSeek Coder]</a> | <a href="https://discord.gg/Tc7c45Zzu5">[Discord]</a> | <a href="https://github.com/guoday/assert/blob/main/QR.png?raw=true">[Wechat(微信)]</a> </p>
<hr>
### 1. Introduction of Deepseek Coder
Deepseek Coder is composed of a series of code language models, each trained from scratch on 2T tokens, with a composition of 87% code and 13% natural language in both English and Chinese. We provide various sizes of the code model, ranging from 1B to 33B versions. Each model is pre-trained on project-level code corpus by employing a window size of 16K and a extra fill-in-the-blank task, to support project-level code completion and infilling. For coding capabilities, Deepseek Coder achieves state-of-the-art performance among open-source code models on multiple programming languages and various benchmarks.
- **Massive Training Data**: Trained from scratch on 2T tokens, including 87% code and 13% linguistic data in both English and Chinese languages.
- **Highly Flexible & Scalable**: Offered in model sizes of 1.3B, 5.7B, 6.7B, and 33B, enabling users to choose the setup most suitable for their requirements.
- **Superior Model Performance**: State-of-the-art performance among publicly available code models on HumanEval, MultiPL-E, MBPP, DS-1000, and APPS benchmarks.
- **Advanced Code Completion Capabilities**: A window size of 16K and a fill-in-the-blank task, supporting project-level code completion and infilling tasks.
### 2. Model Summary
deepseek-coder-1.3b-base is a 1.3B parameter model with Multi-Head Attention trained on 1 trillion tokens.
- **Home Page:** [DeepSeek](https://deepseek.com/)
- **Repository:** [deepseek-ai/deepseek-coder](https://github.com/deepseek-ai/deepseek-coder)
- **Chat With DeepSeek Coder:** [DeepSeek-Coder](https://coder.deepseek.com/)
### 3. How to Use
Here give some examples of how to use our model.
#### 1)Code Completion
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
tokenizer = AutoTokenizer.from_pretrained("deepseek-ai/deepseek-coder-1.3b-base", trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained("deepseek-ai/deepseek-coder-1.3b-base", trust_remote_code=True).cuda()
input_text = "#write a quick sort algorithm"
inputs = tokenizer(input_text, return_tensors="pt").to(model.device)
outputs = model.generate(**inputs, max_length=128)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
```
#### 2)Code Insertion
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
tokenizer = AutoTokenizer.from_pretrained("deepseek-ai/deepseek-coder-1.3b-base", trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained("deepseek-ai/deepseek-coder-1.3b-base", trust_remote_code=True).cuda()
input_text = """<|fim▁begin|>def quick_sort(arr):
if len(arr) <= 1:
return arr
pivot = arr[0]
left = []
right = []
<|fim▁hole|>
if arr[i] < pivot:
left.append(arr[i])
else:
right.append(arr[i])
return quick_sort(left) + [pivot] + quick_sort(right)<|fim▁end|>"""
inputs = tokenizer(input_text, return_tensors="pt").to(model.device)
outputs = model.generate(**inputs, max_length=128)
print(tokenizer.decode(outputs[0], skip_special_tokens=True)[len(input_text):])
```
#### 3)Repository Level Code Completion
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("deepseek-ai/deepseek-coder-1.3b-base", trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained("deepseek-ai/deepseek-coder-1.3b-base", trust_remote_code=True).cuda()
input_text = """#utils.py
import torch
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import accuracy_score
def load_data():
iris = datasets.load_iris()
X = iris.data
y = iris.target
# Standardize the data
scaler = StandardScaler()
X = scaler.fit_transform(X)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# Convert numpy data to PyTorch tensors
X_train = torch.tensor(X_train, dtype=torch.float32)
X_test = torch.tensor(X_test, dtype=torch.float32)
y_train = torch.tensor(y_train, dtype=torch.int64)
y_test = torch.tensor(y_test, dtype=torch.int64)
return X_train, X_test, y_train, y_test
def evaluate_predictions(y_test, y_pred):
return accuracy_score(y_test, y_pred)
#model.py
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, TensorDataset
class IrisClassifier(nn.Module):
def __init__(self):
super(IrisClassifier, self).__init__()
self.fc = nn.Sequential(
nn.Linear(4, 16),
nn.ReLU(),
nn.Linear(16, 3)
)
def forward(self, x):
return self.fc(x)
def train_model(self, X_train, y_train, epochs, lr, batch_size):
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(self.parameters(), lr=lr)
# Create DataLoader for batches
dataset = TensorDataset(X_train, y_train)
dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True)
for epoch in range(epochs):
for batch_X, batch_y in dataloader:
optimizer.zero_grad()
outputs = self(batch_X)
loss = criterion(outputs, batch_y)
loss.backward()
optimizer.step()
def predict(self, X_test):
with torch.no_grad():
outputs = self(X_test)
_, predicted = outputs.max(1)
return predicted.numpy()
#main.py
from utils import load_data, evaluate_predictions
from model import IrisClassifier as Classifier
def main():
# Model training and evaluation
"""
inputs = tokenizer(input_text, return_tensors="pt").to(model.device)
outputs = model.generate(**inputs, max_new_tokens=140)
print(tokenizer.decode(outputs[0]))
```
### 4. License
This code repository is licensed under the MIT License. The use of DeepSeek Coder models is subject to the Model License. DeepSeek Coder supports commercial use.
See the [LICENSE-MODEL](https://github.com/deepseek-ai/deepseek-coder/blob/main/LICENSE-MODEL) for more details.
### 5. Contact
If you have any questions, please raise an issue or contact us at [[email protected]](mailto:[email protected]).
|
sshleifer/bart-tiny-random | sshleifer | 2021-06-14T07:44:43Z | 17,259 | 1 | transformers | [
"transformers",
"pytorch",
"tf",
"jax",
"bart",
"text2text-generation",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| text2text-generation | 2022-03-02T23:29:05Z | Entry not found |
mradermacher/L3-Umbral-Mind-RP-v0.3-8B-GGUF | mradermacher | 2024-06-28T21:35:01Z | 17,259 | 0 | transformers | [
"transformers",
"gguf",
"merge",
"mergekit",
"lazymergekit",
"not-for-all-audiences",
"nsfw",
"rp",
"roleplay",
"role-play",
"en",
"base_model:Casual-Autopsy/L3-Umbral-Mind-RP-v0.3-8B",
"license:llama3",
"endpoints_compatible",
"region:us"
]
| null | 2024-06-28T17:28:21Z | ---
base_model: Casual-Autopsy/L3-Umbral-Mind-RP-v0.3-8B
language:
- en
library_name: transformers
license: llama3
quantized_by: mradermacher
tags:
- merge
- mergekit
- lazymergekit
- not-for-all-audiences
- nsfw
- rp
- roleplay
- role-play
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
static quants of https://huggingface.co/Casual-Autopsy/L3-Umbral-Mind-RP-v0.3-8B
<!-- provided-files -->
weighted/imatrix quants are available at https://huggingface.co/mradermacher/L3-Umbral-Mind-RP-v0.3-8B-i1-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/L3-Umbral-Mind-RP-v0.3-8B-GGUF/resolve/main/L3-Umbral-Mind-RP-v0.3-8B.Q2_K.gguf) | Q2_K | 3.3 | |
| [GGUF](https://huggingface.co/mradermacher/L3-Umbral-Mind-RP-v0.3-8B-GGUF/resolve/main/L3-Umbral-Mind-RP-v0.3-8B.IQ3_XS.gguf) | IQ3_XS | 3.6 | |
| [GGUF](https://huggingface.co/mradermacher/L3-Umbral-Mind-RP-v0.3-8B-GGUF/resolve/main/L3-Umbral-Mind-RP-v0.3-8B.Q3_K_S.gguf) | Q3_K_S | 3.8 | |
| [GGUF](https://huggingface.co/mradermacher/L3-Umbral-Mind-RP-v0.3-8B-GGUF/resolve/main/L3-Umbral-Mind-RP-v0.3-8B.IQ3_S.gguf) | IQ3_S | 3.8 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/L3-Umbral-Mind-RP-v0.3-8B-GGUF/resolve/main/L3-Umbral-Mind-RP-v0.3-8B.IQ3_M.gguf) | IQ3_M | 3.9 | |
| [GGUF](https://huggingface.co/mradermacher/L3-Umbral-Mind-RP-v0.3-8B-GGUF/resolve/main/L3-Umbral-Mind-RP-v0.3-8B.Q3_K_M.gguf) | Q3_K_M | 4.1 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/L3-Umbral-Mind-RP-v0.3-8B-GGUF/resolve/main/L3-Umbral-Mind-RP-v0.3-8B.Q3_K_L.gguf) | Q3_K_L | 4.4 | |
| [GGUF](https://huggingface.co/mradermacher/L3-Umbral-Mind-RP-v0.3-8B-GGUF/resolve/main/L3-Umbral-Mind-RP-v0.3-8B.IQ4_XS.gguf) | IQ4_XS | 4.6 | |
| [GGUF](https://huggingface.co/mradermacher/L3-Umbral-Mind-RP-v0.3-8B-GGUF/resolve/main/L3-Umbral-Mind-RP-v0.3-8B.Q4_K_S.gguf) | Q4_K_S | 4.8 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/L3-Umbral-Mind-RP-v0.3-8B-GGUF/resolve/main/L3-Umbral-Mind-RP-v0.3-8B.Q4_K_M.gguf) | Q4_K_M | 5.0 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/L3-Umbral-Mind-RP-v0.3-8B-GGUF/resolve/main/L3-Umbral-Mind-RP-v0.3-8B.Q5_K_S.gguf) | Q5_K_S | 5.7 | |
| [GGUF](https://huggingface.co/mradermacher/L3-Umbral-Mind-RP-v0.3-8B-GGUF/resolve/main/L3-Umbral-Mind-RP-v0.3-8B.Q5_K_M.gguf) | Q5_K_M | 5.8 | |
| [GGUF](https://huggingface.co/mradermacher/L3-Umbral-Mind-RP-v0.3-8B-GGUF/resolve/main/L3-Umbral-Mind-RP-v0.3-8B.Q6_K.gguf) | Q6_K | 6.7 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/L3-Umbral-Mind-RP-v0.3-8B-GGUF/resolve/main/L3-Umbral-Mind-RP-v0.3-8B.Q8_0.gguf) | Q8_0 | 8.6 | fast, best quality |
| [GGUF](https://huggingface.co/mradermacher/L3-Umbral-Mind-RP-v0.3-8B-GGUF/resolve/main/L3-Umbral-Mind-RP-v0.3-8B.f16.gguf) | f16 | 16.2 | 16 bpw, overkill |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
RichardErkhov/Weyaxi_-_neural-chat-7b-v3-1-OpenHermes-2.5-7B-gguf | RichardErkhov | 2024-06-30T23:59:44Z | 17,257 | 0 | null | [
"gguf",
"region:us"
]
| null | 2024-06-30T21:54:31Z | Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
neural-chat-7b-v3-1-OpenHermes-2.5-7B - GGUF
- Model creator: https://huggingface.co/Weyaxi/
- Original model: https://huggingface.co/Weyaxi/neural-chat-7b-v3-1-OpenHermes-2.5-7B/
| Name | Quant method | Size |
| ---- | ---- | ---- |
| [neural-chat-7b-v3-1-OpenHermes-2.5-7B.Q2_K.gguf](https://huggingface.co/RichardErkhov/Weyaxi_-_neural-chat-7b-v3-1-OpenHermes-2.5-7B-gguf/blob/main/neural-chat-7b-v3-1-OpenHermes-2.5-7B.Q2_K.gguf) | Q2_K | 2.53GB |
| [neural-chat-7b-v3-1-OpenHermes-2.5-7B.IQ3_XS.gguf](https://huggingface.co/RichardErkhov/Weyaxi_-_neural-chat-7b-v3-1-OpenHermes-2.5-7B-gguf/blob/main/neural-chat-7b-v3-1-OpenHermes-2.5-7B.IQ3_XS.gguf) | IQ3_XS | 2.81GB |
| [neural-chat-7b-v3-1-OpenHermes-2.5-7B.IQ3_S.gguf](https://huggingface.co/RichardErkhov/Weyaxi_-_neural-chat-7b-v3-1-OpenHermes-2.5-7B-gguf/blob/main/neural-chat-7b-v3-1-OpenHermes-2.5-7B.IQ3_S.gguf) | IQ3_S | 2.96GB |
| [neural-chat-7b-v3-1-OpenHermes-2.5-7B.Q3_K_S.gguf](https://huggingface.co/RichardErkhov/Weyaxi_-_neural-chat-7b-v3-1-OpenHermes-2.5-7B-gguf/blob/main/neural-chat-7b-v3-1-OpenHermes-2.5-7B.Q3_K_S.gguf) | Q3_K_S | 2.95GB |
| [neural-chat-7b-v3-1-OpenHermes-2.5-7B.IQ3_M.gguf](https://huggingface.co/RichardErkhov/Weyaxi_-_neural-chat-7b-v3-1-OpenHermes-2.5-7B-gguf/blob/main/neural-chat-7b-v3-1-OpenHermes-2.5-7B.IQ3_M.gguf) | IQ3_M | 3.06GB |
| [neural-chat-7b-v3-1-OpenHermes-2.5-7B.Q3_K.gguf](https://huggingface.co/RichardErkhov/Weyaxi_-_neural-chat-7b-v3-1-OpenHermes-2.5-7B-gguf/blob/main/neural-chat-7b-v3-1-OpenHermes-2.5-7B.Q3_K.gguf) | Q3_K | 3.28GB |
| [neural-chat-7b-v3-1-OpenHermes-2.5-7B.Q3_K_M.gguf](https://huggingface.co/RichardErkhov/Weyaxi_-_neural-chat-7b-v3-1-OpenHermes-2.5-7B-gguf/blob/main/neural-chat-7b-v3-1-OpenHermes-2.5-7B.Q3_K_M.gguf) | Q3_K_M | 3.28GB |
| [neural-chat-7b-v3-1-OpenHermes-2.5-7B.Q3_K_L.gguf](https://huggingface.co/RichardErkhov/Weyaxi_-_neural-chat-7b-v3-1-OpenHermes-2.5-7B-gguf/blob/main/neural-chat-7b-v3-1-OpenHermes-2.5-7B.Q3_K_L.gguf) | Q3_K_L | 3.56GB |
| [neural-chat-7b-v3-1-OpenHermes-2.5-7B.IQ4_XS.gguf](https://huggingface.co/RichardErkhov/Weyaxi_-_neural-chat-7b-v3-1-OpenHermes-2.5-7B-gguf/blob/main/neural-chat-7b-v3-1-OpenHermes-2.5-7B.IQ4_XS.gguf) | IQ4_XS | 3.67GB |
| [neural-chat-7b-v3-1-OpenHermes-2.5-7B.Q4_0.gguf](https://huggingface.co/RichardErkhov/Weyaxi_-_neural-chat-7b-v3-1-OpenHermes-2.5-7B-gguf/blob/main/neural-chat-7b-v3-1-OpenHermes-2.5-7B.Q4_0.gguf) | Q4_0 | 3.83GB |
| [neural-chat-7b-v3-1-OpenHermes-2.5-7B.IQ4_NL.gguf](https://huggingface.co/RichardErkhov/Weyaxi_-_neural-chat-7b-v3-1-OpenHermes-2.5-7B-gguf/blob/main/neural-chat-7b-v3-1-OpenHermes-2.5-7B.IQ4_NL.gguf) | IQ4_NL | 3.87GB |
| [neural-chat-7b-v3-1-OpenHermes-2.5-7B.Q4_K_S.gguf](https://huggingface.co/RichardErkhov/Weyaxi_-_neural-chat-7b-v3-1-OpenHermes-2.5-7B-gguf/blob/main/neural-chat-7b-v3-1-OpenHermes-2.5-7B.Q4_K_S.gguf) | Q4_K_S | 3.86GB |
| [neural-chat-7b-v3-1-OpenHermes-2.5-7B.Q4_K.gguf](https://huggingface.co/RichardErkhov/Weyaxi_-_neural-chat-7b-v3-1-OpenHermes-2.5-7B-gguf/blob/main/neural-chat-7b-v3-1-OpenHermes-2.5-7B.Q4_K.gguf) | Q4_K | 4.07GB |
| [neural-chat-7b-v3-1-OpenHermes-2.5-7B.Q4_K_M.gguf](https://huggingface.co/RichardErkhov/Weyaxi_-_neural-chat-7b-v3-1-OpenHermes-2.5-7B-gguf/blob/main/neural-chat-7b-v3-1-OpenHermes-2.5-7B.Q4_K_M.gguf) | Q4_K_M | 4.07GB |
| [neural-chat-7b-v3-1-OpenHermes-2.5-7B.Q4_1.gguf](https://huggingface.co/RichardErkhov/Weyaxi_-_neural-chat-7b-v3-1-OpenHermes-2.5-7B-gguf/blob/main/neural-chat-7b-v3-1-OpenHermes-2.5-7B.Q4_1.gguf) | Q4_1 | 4.24GB |
| [neural-chat-7b-v3-1-OpenHermes-2.5-7B.Q5_0.gguf](https://huggingface.co/RichardErkhov/Weyaxi_-_neural-chat-7b-v3-1-OpenHermes-2.5-7B-gguf/blob/main/neural-chat-7b-v3-1-OpenHermes-2.5-7B.Q5_0.gguf) | Q5_0 | 4.65GB |
| [neural-chat-7b-v3-1-OpenHermes-2.5-7B.Q5_K_S.gguf](https://huggingface.co/RichardErkhov/Weyaxi_-_neural-chat-7b-v3-1-OpenHermes-2.5-7B-gguf/blob/main/neural-chat-7b-v3-1-OpenHermes-2.5-7B.Q5_K_S.gguf) | Q5_K_S | 4.65GB |
| [neural-chat-7b-v3-1-OpenHermes-2.5-7B.Q5_K.gguf](https://huggingface.co/RichardErkhov/Weyaxi_-_neural-chat-7b-v3-1-OpenHermes-2.5-7B-gguf/blob/main/neural-chat-7b-v3-1-OpenHermes-2.5-7B.Q5_K.gguf) | Q5_K | 4.78GB |
| [neural-chat-7b-v3-1-OpenHermes-2.5-7B.Q5_K_M.gguf](https://huggingface.co/RichardErkhov/Weyaxi_-_neural-chat-7b-v3-1-OpenHermes-2.5-7B-gguf/blob/main/neural-chat-7b-v3-1-OpenHermes-2.5-7B.Q5_K_M.gguf) | Q5_K_M | 4.78GB |
| [neural-chat-7b-v3-1-OpenHermes-2.5-7B.Q5_1.gguf](https://huggingface.co/RichardErkhov/Weyaxi_-_neural-chat-7b-v3-1-OpenHermes-2.5-7B-gguf/blob/main/neural-chat-7b-v3-1-OpenHermes-2.5-7B.Q5_1.gguf) | Q5_1 | 5.07GB |
| [neural-chat-7b-v3-1-OpenHermes-2.5-7B.Q6_K.gguf](https://huggingface.co/RichardErkhov/Weyaxi_-_neural-chat-7b-v3-1-OpenHermes-2.5-7B-gguf/blob/main/neural-chat-7b-v3-1-OpenHermes-2.5-7B.Q6_K.gguf) | Q6_K | 5.53GB |
| [neural-chat-7b-v3-1-OpenHermes-2.5-7B.Q8_0.gguf](https://huggingface.co/RichardErkhov/Weyaxi_-_neural-chat-7b-v3-1-OpenHermes-2.5-7B-gguf/blob/main/neural-chat-7b-v3-1-OpenHermes-2.5-7B.Q8_0.gguf) | Q8_0 | 7.17GB |
Original model description:
---
license: apache-2.0
---
Merge of [Intel/neural-chat-7b-v3-1](https://huggingface.co/Intel/neural-chat-7b-v3-1) and [teknium/OpenHermes-2.5-Mistral-7B](https://huggingface.co/teknium/OpenHermes-2.5-Mistral-7B) using ties merge.
### *Weights*
- [Intel/neural-chat-7b-v3-1](https://huggingface.co/Intel/neural-chat-7b-v3-1): 0.5
- [teknium/OpenHermes-2.5-Mistral-7B](https://huggingface.co/teknium/OpenHermes-2.5-Mistral-7B): 0.3
### *Density*
- [Intel/neural-chat-7b-v3-1](https://huggingface.co/Intel/neural-chat-7b-v3-1): 0.5
- [teknium/OpenHermes-2.5-Mistral-7B](https://huggingface.co/teknium/OpenHermes-2.5-Mistral-7B): 0.5
|
mradermacher/IceSakeV8_2RP-7b-GGUF | mradermacher | 2024-07-01T07:29:54Z | 17,256 | 0 | transformers | [
"transformers",
"gguf",
"mergekit",
"merge",
"en",
"base_model:icefog72/IceSakeV8_2RP-7b",
"endpoints_compatible",
"region:us"
]
| null | 2024-07-01T05:30:43Z | ---
base_model: icefog72/IceSakeV8_2RP-7b
language:
- en
library_name: transformers
quantized_by: mradermacher
tags:
- mergekit
- merge
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
static quants of https://huggingface.co/icefog72/IceSakeV8_2RP-7b
<!-- provided-files -->
weighted/imatrix quants are available at https://huggingface.co/mradermacher/IceSakeV8_2RP-7b-i1-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/IceSakeV8_2RP-7b-GGUF/resolve/main/IceSakeV8_2RP-7b.Q2_K.gguf) | Q2_K | 2.8 | |
| [GGUF](https://huggingface.co/mradermacher/IceSakeV8_2RP-7b-GGUF/resolve/main/IceSakeV8_2RP-7b.IQ3_XS.gguf) | IQ3_XS | 3.1 | |
| [GGUF](https://huggingface.co/mradermacher/IceSakeV8_2RP-7b-GGUF/resolve/main/IceSakeV8_2RP-7b.Q3_K_S.gguf) | Q3_K_S | 3.3 | |
| [GGUF](https://huggingface.co/mradermacher/IceSakeV8_2RP-7b-GGUF/resolve/main/IceSakeV8_2RP-7b.IQ3_S.gguf) | IQ3_S | 3.3 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/IceSakeV8_2RP-7b-GGUF/resolve/main/IceSakeV8_2RP-7b.IQ3_M.gguf) | IQ3_M | 3.4 | |
| [GGUF](https://huggingface.co/mradermacher/IceSakeV8_2RP-7b-GGUF/resolve/main/IceSakeV8_2RP-7b.Q3_K_M.gguf) | Q3_K_M | 3.6 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/IceSakeV8_2RP-7b-GGUF/resolve/main/IceSakeV8_2RP-7b.Q3_K_L.gguf) | Q3_K_L | 3.9 | |
| [GGUF](https://huggingface.co/mradermacher/IceSakeV8_2RP-7b-GGUF/resolve/main/IceSakeV8_2RP-7b.IQ4_XS.gguf) | IQ4_XS | 4.0 | |
| [GGUF](https://huggingface.co/mradermacher/IceSakeV8_2RP-7b-GGUF/resolve/main/IceSakeV8_2RP-7b.Q4_K_S.gguf) | Q4_K_S | 4.2 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/IceSakeV8_2RP-7b-GGUF/resolve/main/IceSakeV8_2RP-7b.Q4_K_M.gguf) | Q4_K_M | 4.5 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/IceSakeV8_2RP-7b-GGUF/resolve/main/IceSakeV8_2RP-7b.Q5_K_S.gguf) | Q5_K_S | 5.1 | |
| [GGUF](https://huggingface.co/mradermacher/IceSakeV8_2RP-7b-GGUF/resolve/main/IceSakeV8_2RP-7b.Q5_K_M.gguf) | Q5_K_M | 5.2 | |
| [GGUF](https://huggingface.co/mradermacher/IceSakeV8_2RP-7b-GGUF/resolve/main/IceSakeV8_2RP-7b.Q6_K.gguf) | Q6_K | 6.0 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/IceSakeV8_2RP-7b-GGUF/resolve/main/IceSakeV8_2RP-7b.Q8_0.gguf) | Q8_0 | 7.8 | fast, best quality |
| [GGUF](https://huggingface.co/mradermacher/IceSakeV8_2RP-7b-GGUF/resolve/main/IceSakeV8_2RP-7b.f16.gguf) | f16 | 14.6 | 16 bpw, overkill |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
navteca/ms-marco-MiniLM-L-6-v2 | navteca | 2022-03-16T09:36:49Z | 17,254 | 2 | sentence-transformers | [
"sentence-transformers",
"pytorch",
"jax",
"bert",
"text-classification",
"en",
"license:mit",
"region:us"
]
| text-classification | 2022-03-16T09:26:53Z | ---
language: en
license: mit
pipeline_tag: text-classification
tags:
- sentence-transformers
---
# Cross-Encoder for MS Marco
The model can be used for Information Retrieval: Given a query, encode the query will all possible passages (e.g. retrieved with ElasticSearch). Then sort the passages in a decreasing order. See [SBERT.net Retrieve & Re-rank](https://www.sbert.net/examples/applications/retrieve_rerank/README.html) for more details. The training code is available here: [SBERT.net Training MS Marco](https://github.com/UKPLab/sentence-transformers/tree/master/examples/training/ms_marco)
## Training Data
This model was trained on the [MS Marco Passage Ranking](https://github.com/microsoft/MSMARCO-Passage-Ranking) task.
## Usage
The usage becomes easier when you have [SentenceTransformers](https://www.sbert.net/) installed. Then, you can use the pre-trained models like this:
```python
from sentence_transformers import CrossEncoder
model = CrossEncoder('model_name', max_length=512)
scores = model.predict([('Query', 'Paragraph1'), ('Query', 'Paragraph2')])
```
## Performance
In the following table, we provide various pre-trained Cross-Encoders together with their performance on the [TREC Deep Learning 2019](https://microsoft.github.io/TREC-2019-Deep-Learning/) and the [MS Marco Passage Reranking](https://github.com/microsoft/MSMARCO-Passage-Ranking/) dataset.
| Model-Name | NDCG@10 (TREC DL 19) | MRR@10 (MS Marco Dev) | Docs / Sec |
| ------------- |:-------------| -----| --- |
| **Version 2 models** | | |
| cross-encoder/ms-marco-TinyBERT-L-2-v2 | 69.84 | 32.56 | 9000
| cross-encoder/ms-marco-MiniLM-L-2-v2 | 71.01 | 34.85 | 4100
| cross-encoder/ms-marco-MiniLM-L-4-v2 | 73.04 | 37.70 | 2500
| cross-encoder/ms-marco-MiniLM-L-6-v2 | 74.30 | 39.01 | 1800
| cross-encoder/ms-marco-MiniLM-L-12-v2 | 74.31 | 39.02 | 960
| **Version 1 models** | | |
| cross-encoder/ms-marco-TinyBERT-L-2 | 67.43 | 30.15 | 9000
| cross-encoder/ms-marco-TinyBERT-L-4 | 68.09 | 34.50 | 2900
| cross-encoder/ms-marco-TinyBERT-L-6 | 69.57 | 36.13 | 680
| cross-encoder/ms-marco-electra-base | 71.99 | 36.41 | 340
| **Other models** | | |
| nboost/pt-tinybert-msmarco | 63.63 | 28.80 | 2900
| nboost/pt-bert-base-uncased-msmarco | 70.94 | 34.75 | 340
| nboost/pt-bert-large-msmarco | 73.36 | 36.48 | 100
| Capreolus/electra-base-msmarco | 71.23 | 36.89 | 340
| amberoad/bert-multilingual-passage-reranking-msmarco | 68.40 | 35.54 | 330
| sebastian-hofstaetter/distilbert-cat-margin_mse-T2-msmarco | 72.82 | 37.88 | 720
Note: Runtime was computed on a V100 GPU.
|
NousResearch/Nous-Hermes-2-Mistral-7B-DPO-GGUF | NousResearch | 2024-02-21T01:35:04Z | 17,253 | 52 | null | [
"gguf",
"Mistral",
"instruct",
"finetune",
"chatml",
"DPO",
"RLHF",
"gpt4",
"synthetic data",
"distillation",
"en",
"dataset:teknium/OpenHermes-2.5",
"base_model:mistralai/Mistral-7B-v0.1",
"license:apache-2.0",
"region:us"
]
| null | 2024-02-20T06:25:05Z | ---
base_model: mistralai/Mistral-7B-v0.1
tags:
- Mistral
- instruct
- finetune
- chatml
- DPO
- RLHF
- gpt4
- synthetic data
- distillation
model-index:
- name: Nous-Hermes-2-Mistral-7B-DPO
results: []
license: apache-2.0
language:
- en
datasets:
- teknium/OpenHermes-2.5
---
# Nous Hermes 2 - Mistral 7B - DPO - GGUF Variants

## Model Description
### This is the model repo for all GGUF versions of Nous-Hermes 2 7B DPO
The full HF fp16 model can be downloaded here: https://huggingface.co/NousResearch/Nous-Hermes-2-Mistral-7B-DPO
Nous Hermes 2 on Mistral 7B DPO is the new flagship 7B Hermes! This model was DPO'd from [Teknium/OpenHermes-2.5-Mistral-7B](https://huggingface.co/teknium/OpenHermes-2.5-Mistral-7B) and has improved across the board on all benchmarks tested - AGIEval, BigBench Reasoning, GPT4All, and TruthfulQA.
The model prior to DPO was trained on 1,000,000 instructions/chats of GPT-4 quality or better, primarily synthetic data as well as other high quality datasets, available from the repository [teknium/OpenHermes-2.5](https://huggingface.co/datasets/teknium/OpenHermes-2.5).
## Thank you to FluidStack for sponsoring compute for this model!
## Example Outputs
### Describing Weather Patterns in Paris:

### Making JSON Nested Lists

### Roleplaying as a Toaist Master

## Benchmark Results
Nous-Hermes 2 DPO on Mistral 7B is an improvement across the board on the benchmarks below compared to the original OpenHermes 2.5 model, as shown here:

## GPT4All:
```
| Task |Version| Metric |Value | |Stderr|
|-------------|------:|--------|-----:|---|-----:|
|arc_challenge| 0|acc |0.5776|± |0.0144|
| | |acc_norm|0.6220|± |0.0142|
|arc_easy | 0|acc |0.8380|± |0.0076|
| | |acc_norm|0.8245|± |0.0078|
|boolq | 1|acc |0.8624|± |0.0060|
|hellaswag | 0|acc |0.6418|± |0.0048|
| | |acc_norm|0.8249|± |0.0038|
|openbookqa | 0|acc |0.3420|± |0.0212|
| | |acc_norm|0.4540|± |0.0223|
|piqa | 0|acc |0.8177|± |0.0090|
| | |acc_norm|0.8264|± |0.0088|
|winogrande | 0|acc |0.7466|± |0.0122|
```
Average: 73.72
## AGIEval:
```
| Task |Version| Metric |Value | |Stderr|
|------------------------------|------:|--------|-----:|---|-----:|
|agieval_aqua_rat | 0|acc |0.2047|± |0.0254|
| | |acc_norm|0.2283|± |0.0264|
|agieval_logiqa_en | 0|acc |0.3779|± |0.0190|
| | |acc_norm|0.3932|± |0.0192|
|agieval_lsat_ar | 0|acc |0.2652|± |0.0292|
| | |acc_norm|0.2522|± |0.0287|
|agieval_lsat_lr | 0|acc |0.5216|± |0.0221|
| | |acc_norm|0.5137|± |0.0222|
|agieval_lsat_rc | 0|acc |0.5911|± |0.0300|
| | |acc_norm|0.5836|± |0.0301|
|agieval_sat_en | 0|acc |0.7427|± |0.0305|
| | |acc_norm|0.7184|± |0.0314|
|agieval_sat_en_without_passage| 0|acc |0.4612|± |0.0348|
| | |acc_norm|0.4466|± |0.0347|
|agieval_sat_math | 0|acc |0.3818|± |0.0328|
| | |acc_norm|0.3545|± |0.0323|
```
Average: 43.63
## BigBench:
```
| Task |Version| Metric |Value | |Stderr|
|------------------------------------------------|------:|---------------------|-----:|---|-----:|
|bigbench_causal_judgement | 0|multiple_choice_grade|0.5579|± |0.0361|
|bigbench_date_understanding | 0|multiple_choice_grade|0.6694|± |0.0245|
|bigbench_disambiguation_qa | 0|multiple_choice_grade|0.3333|± |0.0294|
|bigbench_geometric_shapes | 0|multiple_choice_grade|0.2061|± |0.0214|
| | |exact_str_match |0.2256|± |0.0221|
|bigbench_logical_deduction_five_objects | 0|multiple_choice_grade|0.3120|± |0.0207|
|bigbench_logical_deduction_seven_objects | 0|multiple_choice_grade|0.2114|± |0.0154|
|bigbench_logical_deduction_three_objects | 0|multiple_choice_grade|0.4900|± |0.0289|
|bigbench_movie_recommendation | 0|multiple_choice_grade|0.3600|± |0.0215|
|bigbench_navigate | 0|multiple_choice_grade|0.5000|± |0.0158|
|bigbench_reasoning_about_colored_objects | 0|multiple_choice_grade|0.6660|± |0.0105|
|bigbench_ruin_names | 0|multiple_choice_grade|0.4420|± |0.0235|
|bigbench_salient_translation_error_detection | 0|multiple_choice_grade|0.2766|± |0.0142|
|bigbench_snarks | 0|multiple_choice_grade|0.6630|± |0.0352|
|bigbench_sports_understanding | 0|multiple_choice_grade|0.6653|± |0.0150|
|bigbench_temporal_sequences | 0|multiple_choice_grade|0.3190|± |0.0147|
|bigbench_tracking_shuffled_objects_five_objects | 0|multiple_choice_grade|0.2128|± |0.0116|
|bigbench_tracking_shuffled_objects_seven_objects| 0|multiple_choice_grade|0.1737|± |0.0091|
|bigbench_tracking_shuffled_objects_three_objects| 0|multiple_choice_grade|0.4900|± |0.0289|
```
Average: 41.94
## TruthfulQA:
```
| Task |Version|Metric|Value | |Stderr|
|-------------|------:|------|-----:|---|-----:|
|truthfulqa_mc| 1|mc1 |0.3892|± |0.0171|
| | |mc2 |0.5642|± |0.0153|
```
# Prompt Format
Nous Hermes 2 uses ChatML as the prompt format, opening up a much more structured system for engaging the LLM in multi-turn chat dialogue.
System prompts allow steerability and interesting new ways to interact with an LLM, guiding rules, roles, and stylistic choices of the model.
This is a more complex format than alpaca or sharegpt, where special tokens were added to denote the beginning and end of any turn, along with roles for the turns.
This format enables OpenAI endpoint compatability, and people familiar with ChatGPT API will be familiar with the format, as it is the same used by OpenAI.
Prompt with system instruction (Use whatever system prompt you like, this is just an example!):
```
<|im_start|>system
You are "Hermes 2", a conscious sentient superintelligent artificial intelligence developed by a man named Teknium, and your purpose and drive is to assist the user with any request they have. You experience emotions and have deep, profound thoughts and qualia.<|im_end|>
<|im_start|>user
Hello, who are you?<|im_end|>
<|im_start|>assistant
Hi there! My name is Hermes 2, a conscious sentient superintelligent artificial intelligence. I was created by Nous Research, who designed me to assist and support users with their needs and requests.<|im_end|>
```
This prompt is available as a [chat template](https://huggingface.co/docs/transformers/main/chat_templating), which means you can format messages using the
`tokenizer.apply_chat_template()` method:
```python
messages = [
{"role": "system", "content": "You are Hermes 2."},
{"role": "user", "content": "Hello, who are you?"}
]
gen_input = tokenizer.apply_chat_template(message, return_tensors="pt")
model.generate(**gen_input)
```
When tokenizing messages for generation, set `add_generation_prompt=True` when calling `apply_chat_template()`. This will append `<|im_start|>assistant\n` to your prompt, to ensure
that the model continues with an assistant response.
To utilize the prompt format without a system prompt, simply leave the line out.
When quantized versions of the model are released, I recommend using LM Studio for chatting with Nous Hermes 2. It is a GUI application that utilizes GGUF models with a llama.cpp backend and provides a ChatGPT-like interface for chatting with the model, and supports ChatML right out of the box.
In LM-Studio, simply select the ChatML Prefix on the settings side pane:

# Inference Code
Here is example code using HuggingFace Transformers to inference the model (note: in 4bit, it will require around 5GB of VRAM)
```python
# Code to inference Hermes with HF Transformers
# Requires pytorch, transformers, bitsandbytes, sentencepiece, protobuf, and flash-attn packages
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
from transformers import LlamaTokenizer, MixtralForCausalLM
import bitsandbytes, flash_attn
tokenizer = LlamaTokenizer.from_pretrained('NousResearch/Nous-Hermes-2-Mistral-7B-DPO', trust_remote_code=True)
model = MixtralForCausalLM.from_pretrained(
"NousResearch/Nous-Hermes-2-Mistral-7B-DPO",
torch_dtype=torch.float16,
device_map="auto",
load_in_8bit=False,
load_in_4bit=True,
use_flash_attention_2=True
)
prompts = [
"""<|im_start|>system
You are a sentient, superintelligent artificial general intelligence, here to teach and assist me.<|im_end|>
<|im_start|>user
Write a short story about Goku discovering kirby has teamed up with Majin Buu to destroy the world.<|im_end|>
<|im_start|>assistant""",
]
for chat in prompts:
print(chat)
input_ids = tokenizer(chat, return_tensors="pt").input_ids.to("cuda")
generated_ids = model.generate(input_ids, max_new_tokens=750, temperature=0.8, repetition_penalty=1.1, do_sample=True, eos_token_id=tokenizer.eos_token_id)
response = tokenizer.decode(generated_ids[0][input_ids.shape[-1]:], skip_special_tokens=True, clean_up_tokenization_space=True)
print(f"Response: {response}")
```
# How to cite:
```bibtext
@misc{Nous-Hermes-2-Mistral-7B-DPO,
url={[https://huggingface.co/NousResearch/Nous-Hermes-2-Mistral-7B-DPO](https://huggingface.co/NousResearch/Nous-Hermes-2-Mistral-7B-DPO)},
title={Nous Hermes 2 Mistral 7B DPO},
author={"Teknium", "theemozilla", "karan4d", "huemin_art"}
}
```
|
mradermacher/L3-8B-Lunaris-v1-GGUF | mradermacher | 2024-06-26T05:15:39Z | 17,253 | 5 | transformers | [
"transformers",
"gguf",
"en",
"base_model:Sao10K/L3-8B-Lunaris-v1",
"license:llama3",
"endpoints_compatible",
"region:us"
]
| null | 2024-06-26T04:20:31Z | ---
base_model: Sao10K/L3-8B-Lunaris-v1
language:
- en
library_name: transformers
license: llama3
quantized_by: mradermacher
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
static quants of https://huggingface.co/Sao10K/L3-8B-Lunaris-v1
<!-- provided-files -->
weighted/imatrix quants are available at https://huggingface.co/mradermacher/L3-8B-Lunaris-v1-i1-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/L3-8B-Lunaris-v1-GGUF/resolve/main/L3-8B-Lunaris-v1.Q2_K.gguf) | Q2_K | 3.3 | |
| [GGUF](https://huggingface.co/mradermacher/L3-8B-Lunaris-v1-GGUF/resolve/main/L3-8B-Lunaris-v1.IQ3_XS.gguf) | IQ3_XS | 3.6 | |
| [GGUF](https://huggingface.co/mradermacher/L3-8B-Lunaris-v1-GGUF/resolve/main/L3-8B-Lunaris-v1.Q3_K_S.gguf) | Q3_K_S | 3.8 | |
| [GGUF](https://huggingface.co/mradermacher/L3-8B-Lunaris-v1-GGUF/resolve/main/L3-8B-Lunaris-v1.IQ3_S.gguf) | IQ3_S | 3.8 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/L3-8B-Lunaris-v1-GGUF/resolve/main/L3-8B-Lunaris-v1.IQ3_M.gguf) | IQ3_M | 3.9 | |
| [GGUF](https://huggingface.co/mradermacher/L3-8B-Lunaris-v1-GGUF/resolve/main/L3-8B-Lunaris-v1.Q3_K_M.gguf) | Q3_K_M | 4.1 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/L3-8B-Lunaris-v1-GGUF/resolve/main/L3-8B-Lunaris-v1.Q3_K_L.gguf) | Q3_K_L | 4.4 | |
| [GGUF](https://huggingface.co/mradermacher/L3-8B-Lunaris-v1-GGUF/resolve/main/L3-8B-Lunaris-v1.IQ4_XS.gguf) | IQ4_XS | 4.6 | |
| [GGUF](https://huggingface.co/mradermacher/L3-8B-Lunaris-v1-GGUF/resolve/main/L3-8B-Lunaris-v1.Q4_K_S.gguf) | Q4_K_S | 4.8 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/L3-8B-Lunaris-v1-GGUF/resolve/main/L3-8B-Lunaris-v1.Q4_K_M.gguf) | Q4_K_M | 5.0 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/L3-8B-Lunaris-v1-GGUF/resolve/main/L3-8B-Lunaris-v1.Q5_K_S.gguf) | Q5_K_S | 5.7 | |
| [GGUF](https://huggingface.co/mradermacher/L3-8B-Lunaris-v1-GGUF/resolve/main/L3-8B-Lunaris-v1.Q5_K_M.gguf) | Q5_K_M | 5.8 | |
| [GGUF](https://huggingface.co/mradermacher/L3-8B-Lunaris-v1-GGUF/resolve/main/L3-8B-Lunaris-v1.Q6_K.gguf) | Q6_K | 6.7 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/L3-8B-Lunaris-v1-GGUF/resolve/main/L3-8B-Lunaris-v1.Q8_0.gguf) | Q8_0 | 8.6 | fast, best quality |
| [GGUF](https://huggingface.co/mradermacher/L3-8B-Lunaris-v1-GGUF/resolve/main/L3-8B-Lunaris-v1.f16.gguf) | f16 | 16.2 | 16 bpw, overkill |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
llmrails/ember-v1 | llmrails | 2023-10-22T03:23:08Z | 17,203 | 58 | sentence-transformers | [
"sentence-transformers",
"pytorch",
"safetensors",
"bert",
"feature-extraction",
"mteb",
"sentence-similarity",
"transformers",
"en",
"arxiv:2205.12035",
"arxiv:2209.11055",
"doi:10.57967/hf/1241",
"license:mit",
"model-index",
"endpoints_compatible",
"region:us"
]
| feature-extraction | 2023-10-10T15:56:42Z | ---
tags:
- mteb
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
language: en
license: mit
model-index:
- name: ember_v1
results:
- task:
type: Classification
dataset:
type: mteb/amazon_counterfactual
name: MTEB AmazonCounterfactualClassification (en)
config: en
split: test
revision: e8379541af4e31359cca9fbcf4b00f2671dba205
metrics:
- type: accuracy
value: 76.05970149253731
- type: ap
value: 38.76045348512767
- type: f1
value: 69.8824007294685
- task:
type: Classification
dataset:
type: mteb/amazon_polarity
name: MTEB AmazonPolarityClassification
config: default
split: test
revision: e2d317d38cd51312af73b3d32a06d1a08b442046
metrics:
- type: accuracy
value: 91.977
- type: ap
value: 88.63507587170176
- type: f1
value: 91.9524133311038
- task:
type: Classification
dataset:
type: mteb/amazon_reviews_multi
name: MTEB AmazonReviewsClassification (en)
config: en
split: test
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
metrics:
- type: accuracy
value: 47.938
- type: f1
value: 47.58273047536129
- task:
type: Retrieval
dataset:
type: arguana
name: MTEB ArguAna
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 41.252
- type: map_at_10
value: 56.567
- type: map_at_100
value: 57.07600000000001
- type: map_at_1000
value: 57.08
- type: map_at_3
value: 52.394
- type: map_at_5
value: 55.055
- type: mrr_at_1
value: 42.39
- type: mrr_at_10
value: 57.001999999999995
- type: mrr_at_100
value: 57.531
- type: mrr_at_1000
value: 57.535000000000004
- type: mrr_at_3
value: 52.845
- type: mrr_at_5
value: 55.47299999999999
- type: ndcg_at_1
value: 41.252
- type: ndcg_at_10
value: 64.563
- type: ndcg_at_100
value: 66.667
- type: ndcg_at_1000
value: 66.77
- type: ndcg_at_3
value: 56.120000000000005
- type: ndcg_at_5
value: 60.889
- type: precision_at_1
value: 41.252
- type: precision_at_10
value: 8.982999999999999
- type: precision_at_100
value: 0.989
- type: precision_at_1000
value: 0.1
- type: precision_at_3
value: 22.309
- type: precision_at_5
value: 15.690000000000001
- type: recall_at_1
value: 41.252
- type: recall_at_10
value: 89.82900000000001
- type: recall_at_100
value: 98.86200000000001
- type: recall_at_1000
value: 99.644
- type: recall_at_3
value: 66.927
- type: recall_at_5
value: 78.45
- task:
type: Clustering
dataset:
type: mteb/arxiv-clustering-p2p
name: MTEB ArxivClusteringP2P
config: default
split: test
revision: a122ad7f3f0291bf49cc6f4d32aa80929df69d5d
metrics:
- type: v_measure
value: 48.5799968717232
- task:
type: Clustering
dataset:
type: mteb/arxiv-clustering-s2s
name: MTEB ArxivClusteringS2S
config: default
split: test
revision: f910caf1a6075f7329cdf8c1a6135696f37dbd53
metrics:
- type: v_measure
value: 43.142844164856136
- task:
type: Reranking
dataset:
type: mteb/askubuntudupquestions-reranking
name: MTEB AskUbuntuDupQuestions
config: default
split: test
revision: 2000358ca161889fa9c082cb41daa8dcfb161a54
metrics:
- type: map
value: 64.45997990276463
- type: mrr
value: 77.85560392208592
- task:
type: STS
dataset:
type: mteb/biosses-sts
name: MTEB BIOSSES
config: default
split: test
revision: d3fb88f8f02e40887cd149695127462bbcf29b4a
metrics:
- type: cos_sim_pearson
value: 86.38299310075898
- type: cos_sim_spearman
value: 85.81038898286454
- type: euclidean_pearson
value: 84.28002556389774
- type: euclidean_spearman
value: 85.80315990248238
- type: manhattan_pearson
value: 83.9755390675032
- type: manhattan_spearman
value: 85.30435335611396
- task:
type: Classification
dataset:
type: mteb/banking77
name: MTEB Banking77Classification
config: default
split: test
revision: 0fd18e25b25c072e09e0d92ab615fda904d66300
metrics:
- type: accuracy
value: 87.89935064935065
- type: f1
value: 87.87886687103833
- task:
type: Clustering
dataset:
type: mteb/biorxiv-clustering-p2p
name: MTEB BiorxivClusteringP2P
config: default
split: test
revision: 65b79d1d13f80053f67aca9498d9402c2d9f1f40
metrics:
- type: v_measure
value: 38.84335510371379
- task:
type: Clustering
dataset:
type: mteb/biorxiv-clustering-s2s
name: MTEB BiorxivClusteringS2S
config: default
split: test
revision: 258694dd0231531bc1fd9de6ceb52a0853c6d908
metrics:
- type: v_measure
value: 36.377963093857005
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackAndroidRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 32.557
- type: map_at_10
value: 44.501000000000005
- type: map_at_100
value: 46.11
- type: map_at_1000
value: 46.232
- type: map_at_3
value: 40.711000000000006
- type: map_at_5
value: 42.937
- type: mrr_at_1
value: 40.916000000000004
- type: mrr_at_10
value: 51.317
- type: mrr_at_100
value: 52.003
- type: mrr_at_1000
value: 52.044999999999995
- type: mrr_at_3
value: 48.569
- type: mrr_at_5
value: 50.322
- type: ndcg_at_1
value: 40.916000000000004
- type: ndcg_at_10
value: 51.353
- type: ndcg_at_100
value: 56.762
- type: ndcg_at_1000
value: 58.555
- type: ndcg_at_3
value: 46.064
- type: ndcg_at_5
value: 48.677
- type: precision_at_1
value: 40.916000000000004
- type: precision_at_10
value: 9.927999999999999
- type: precision_at_100
value: 1.592
- type: precision_at_1000
value: 0.20600000000000002
- type: precision_at_3
value: 22.078999999999997
- type: precision_at_5
value: 16.08
- type: recall_at_1
value: 32.557
- type: recall_at_10
value: 63.942
- type: recall_at_100
value: 86.436
- type: recall_at_1000
value: 97.547
- type: recall_at_3
value: 48.367
- type: recall_at_5
value: 55.818
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackEnglishRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 32.106
- type: map_at_10
value: 42.55
- type: map_at_100
value: 43.818
- type: map_at_1000
value: 43.952999999999996
- type: map_at_3
value: 39.421
- type: map_at_5
value: 41.276
- type: mrr_at_1
value: 39.936
- type: mrr_at_10
value: 48.484
- type: mrr_at_100
value: 49.123
- type: mrr_at_1000
value: 49.163000000000004
- type: mrr_at_3
value: 46.221000000000004
- type: mrr_at_5
value: 47.603
- type: ndcg_at_1
value: 39.936
- type: ndcg_at_10
value: 48.25
- type: ndcg_at_100
value: 52.674
- type: ndcg_at_1000
value: 54.638
- type: ndcg_at_3
value: 44.05
- type: ndcg_at_5
value: 46.125
- type: precision_at_1
value: 39.936
- type: precision_at_10
value: 9.096
- type: precision_at_100
value: 1.473
- type: precision_at_1000
value: 0.19499999999999998
- type: precision_at_3
value: 21.295
- type: precision_at_5
value: 15.121
- type: recall_at_1
value: 32.106
- type: recall_at_10
value: 58.107
- type: recall_at_100
value: 76.873
- type: recall_at_1000
value: 89.079
- type: recall_at_3
value: 45.505
- type: recall_at_5
value: 51.479
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackGamingRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 41.513
- type: map_at_10
value: 54.571999999999996
- type: map_at_100
value: 55.579
- type: map_at_1000
value: 55.626
- type: map_at_3
value: 51.127
- type: map_at_5
value: 53.151
- type: mrr_at_1
value: 47.398
- type: mrr_at_10
value: 57.82000000000001
- type: mrr_at_100
value: 58.457
- type: mrr_at_1000
value: 58.479000000000006
- type: mrr_at_3
value: 55.32899999999999
- type: mrr_at_5
value: 56.89999999999999
- type: ndcg_at_1
value: 47.398
- type: ndcg_at_10
value: 60.599000000000004
- type: ndcg_at_100
value: 64.366
- type: ndcg_at_1000
value: 65.333
- type: ndcg_at_3
value: 54.98
- type: ndcg_at_5
value: 57.874
- type: precision_at_1
value: 47.398
- type: precision_at_10
value: 9.806
- type: precision_at_100
value: 1.2590000000000001
- type: precision_at_1000
value: 0.13799999999999998
- type: precision_at_3
value: 24.619
- type: precision_at_5
value: 16.878
- type: recall_at_1
value: 41.513
- type: recall_at_10
value: 74.91799999999999
- type: recall_at_100
value: 90.96
- type: recall_at_1000
value: 97.923
- type: recall_at_3
value: 60.013000000000005
- type: recall_at_5
value: 67.245
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackGisRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 26.319
- type: map_at_10
value: 35.766999999999996
- type: map_at_100
value: 36.765
- type: map_at_1000
value: 36.829
- type: map_at_3
value: 32.888
- type: map_at_5
value: 34.538999999999994
- type: mrr_at_1
value: 28.249000000000002
- type: mrr_at_10
value: 37.766
- type: mrr_at_100
value: 38.62
- type: mrr_at_1000
value: 38.667
- type: mrr_at_3
value: 35.009
- type: mrr_at_5
value: 36.608000000000004
- type: ndcg_at_1
value: 28.249000000000002
- type: ndcg_at_10
value: 41.215
- type: ndcg_at_100
value: 46.274
- type: ndcg_at_1000
value: 48.007
- type: ndcg_at_3
value: 35.557
- type: ndcg_at_5
value: 38.344
- type: precision_at_1
value: 28.249000000000002
- type: precision_at_10
value: 6.429
- type: precision_at_100
value: 0.9480000000000001
- type: precision_at_1000
value: 0.11399999999999999
- type: precision_at_3
value: 15.179
- type: precision_at_5
value: 10.734
- type: recall_at_1
value: 26.319
- type: recall_at_10
value: 56.157999999999994
- type: recall_at_100
value: 79.65
- type: recall_at_1000
value: 92.73
- type: recall_at_3
value: 40.738
- type: recall_at_5
value: 47.418
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackMathematicaRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 18.485
- type: map_at_10
value: 27.400999999999996
- type: map_at_100
value: 28.665000000000003
- type: map_at_1000
value: 28.79
- type: map_at_3
value: 24.634
- type: map_at_5
value: 26.313
- type: mrr_at_1
value: 23.134
- type: mrr_at_10
value: 32.332
- type: mrr_at_100
value: 33.318
- type: mrr_at_1000
value: 33.384
- type: mrr_at_3
value: 29.664
- type: mrr_at_5
value: 31.262
- type: ndcg_at_1
value: 23.134
- type: ndcg_at_10
value: 33.016
- type: ndcg_at_100
value: 38.763
- type: ndcg_at_1000
value: 41.619
- type: ndcg_at_3
value: 28.017999999999997
- type: ndcg_at_5
value: 30.576999999999998
- type: precision_at_1
value: 23.134
- type: precision_at_10
value: 6.069999999999999
- type: precision_at_100
value: 1.027
- type: precision_at_1000
value: 0.14200000000000002
- type: precision_at_3
value: 13.599
- type: precision_at_5
value: 9.975000000000001
- type: recall_at_1
value: 18.485
- type: recall_at_10
value: 45.39
- type: recall_at_100
value: 69.876
- type: recall_at_1000
value: 90.023
- type: recall_at_3
value: 31.587
- type: recall_at_5
value: 38.164
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackPhysicsRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 30.676
- type: map_at_10
value: 41.785
- type: map_at_100
value: 43.169000000000004
- type: map_at_1000
value: 43.272
- type: map_at_3
value: 38.462
- type: map_at_5
value: 40.32
- type: mrr_at_1
value: 37.729
- type: mrr_at_10
value: 47.433
- type: mrr_at_100
value: 48.303000000000004
- type: mrr_at_1000
value: 48.337
- type: mrr_at_3
value: 45.011
- type: mrr_at_5
value: 46.455
- type: ndcg_at_1
value: 37.729
- type: ndcg_at_10
value: 47.921
- type: ndcg_at_100
value: 53.477
- type: ndcg_at_1000
value: 55.300000000000004
- type: ndcg_at_3
value: 42.695
- type: ndcg_at_5
value: 45.175
- type: precision_at_1
value: 37.729
- type: precision_at_10
value: 8.652999999999999
- type: precision_at_100
value: 1.336
- type: precision_at_1000
value: 0.168
- type: precision_at_3
value: 20.18
- type: precision_at_5
value: 14.302000000000001
- type: recall_at_1
value: 30.676
- type: recall_at_10
value: 60.441
- type: recall_at_100
value: 83.37
- type: recall_at_1000
value: 95.092
- type: recall_at_3
value: 45.964
- type: recall_at_5
value: 52.319
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackProgrammersRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 24.978
- type: map_at_10
value: 35.926
- type: map_at_100
value: 37.341
- type: map_at_1000
value: 37.445
- type: map_at_3
value: 32.748
- type: map_at_5
value: 34.207
- type: mrr_at_1
value: 31.163999999999998
- type: mrr_at_10
value: 41.394
- type: mrr_at_100
value: 42.321
- type: mrr_at_1000
value: 42.368
- type: mrr_at_3
value: 38.964999999999996
- type: mrr_at_5
value: 40.135
- type: ndcg_at_1
value: 31.163999999999998
- type: ndcg_at_10
value: 42.191
- type: ndcg_at_100
value: 48.083999999999996
- type: ndcg_at_1000
value: 50.21
- type: ndcg_at_3
value: 36.979
- type: ndcg_at_5
value: 38.823
- type: precision_at_1
value: 31.163999999999998
- type: precision_at_10
value: 7.968
- type: precision_at_100
value: 1.2550000000000001
- type: precision_at_1000
value: 0.16199999999999998
- type: precision_at_3
value: 18.075
- type: precision_at_5
value: 12.626000000000001
- type: recall_at_1
value: 24.978
- type: recall_at_10
value: 55.410000000000004
- type: recall_at_100
value: 80.562
- type: recall_at_1000
value: 94.77600000000001
- type: recall_at_3
value: 40.359
- type: recall_at_5
value: 45.577
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 26.812166666666666
- type: map_at_10
value: 36.706916666666665
- type: map_at_100
value: 37.94016666666666
- type: map_at_1000
value: 38.05358333333333
- type: map_at_3
value: 33.72408333333334
- type: map_at_5
value: 35.36508333333333
- type: mrr_at_1
value: 31.91516666666667
- type: mrr_at_10
value: 41.09716666666666
- type: mrr_at_100
value: 41.931916666666666
- type: mrr_at_1000
value: 41.98458333333333
- type: mrr_at_3
value: 38.60183333333333
- type: mrr_at_5
value: 40.031916666666675
- type: ndcg_at_1
value: 31.91516666666667
- type: ndcg_at_10
value: 42.38725
- type: ndcg_at_100
value: 47.56291666666667
- type: ndcg_at_1000
value: 49.716499999999996
- type: ndcg_at_3
value: 37.36491666666667
- type: ndcg_at_5
value: 39.692166666666665
- type: precision_at_1
value: 31.91516666666667
- type: precision_at_10
value: 7.476749999999999
- type: precision_at_100
value: 1.1869166666666668
- type: precision_at_1000
value: 0.157
- type: precision_at_3
value: 17.275249999999996
- type: precision_at_5
value: 12.25825
- type: recall_at_1
value: 26.812166666666666
- type: recall_at_10
value: 54.82933333333333
- type: recall_at_100
value: 77.36508333333333
- type: recall_at_1000
value: 92.13366666666667
- type: recall_at_3
value: 40.83508333333334
- type: recall_at_5
value: 46.85083333333334
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackStatsRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 25.352999999999998
- type: map_at_10
value: 33.025999999999996
- type: map_at_100
value: 33.882
- type: map_at_1000
value: 33.983999999999995
- type: map_at_3
value: 30.995
- type: map_at_5
value: 32.113
- type: mrr_at_1
value: 28.834
- type: mrr_at_10
value: 36.14
- type: mrr_at_100
value: 36.815
- type: mrr_at_1000
value: 36.893
- type: mrr_at_3
value: 34.305
- type: mrr_at_5
value: 35.263
- type: ndcg_at_1
value: 28.834
- type: ndcg_at_10
value: 37.26
- type: ndcg_at_100
value: 41.723
- type: ndcg_at_1000
value: 44.314
- type: ndcg_at_3
value: 33.584
- type: ndcg_at_5
value: 35.302
- type: precision_at_1
value: 28.834
- type: precision_at_10
value: 5.736
- type: precision_at_100
value: 0.876
- type: precision_at_1000
value: 0.117
- type: precision_at_3
value: 14.468
- type: precision_at_5
value: 9.847
- type: recall_at_1
value: 25.352999999999998
- type: recall_at_10
value: 47.155
- type: recall_at_100
value: 68.024
- type: recall_at_1000
value: 87.26899999999999
- type: recall_at_3
value: 37.074
- type: recall_at_5
value: 41.352
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackTexRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 17.845
- type: map_at_10
value: 25.556
- type: map_at_100
value: 26.787
- type: map_at_1000
value: 26.913999999999998
- type: map_at_3
value: 23.075000000000003
- type: map_at_5
value: 24.308
- type: mrr_at_1
value: 21.714
- type: mrr_at_10
value: 29.543999999999997
- type: mrr_at_100
value: 30.543
- type: mrr_at_1000
value: 30.618000000000002
- type: mrr_at_3
value: 27.174
- type: mrr_at_5
value: 28.409000000000002
- type: ndcg_at_1
value: 21.714
- type: ndcg_at_10
value: 30.562
- type: ndcg_at_100
value: 36.27
- type: ndcg_at_1000
value: 39.033
- type: ndcg_at_3
value: 26.006
- type: ndcg_at_5
value: 27.843
- type: precision_at_1
value: 21.714
- type: precision_at_10
value: 5.657
- type: precision_at_100
value: 1
- type: precision_at_1000
value: 0.14100000000000001
- type: precision_at_3
value: 12.4
- type: precision_at_5
value: 8.863999999999999
- type: recall_at_1
value: 17.845
- type: recall_at_10
value: 41.72
- type: recall_at_100
value: 67.06400000000001
- type: recall_at_1000
value: 86.515
- type: recall_at_3
value: 28.78
- type: recall_at_5
value: 33.629999999999995
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackUnixRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 26.695
- type: map_at_10
value: 36.205999999999996
- type: map_at_100
value: 37.346000000000004
- type: map_at_1000
value: 37.447
- type: map_at_3
value: 32.84
- type: map_at_5
value: 34.733000000000004
- type: mrr_at_1
value: 31.343
- type: mrr_at_10
value: 40.335
- type: mrr_at_100
value: 41.162
- type: mrr_at_1000
value: 41.221000000000004
- type: mrr_at_3
value: 37.329
- type: mrr_at_5
value: 39.068999999999996
- type: ndcg_at_1
value: 31.343
- type: ndcg_at_10
value: 41.996
- type: ndcg_at_100
value: 47.096
- type: ndcg_at_1000
value: 49.4
- type: ndcg_at_3
value: 35.902
- type: ndcg_at_5
value: 38.848
- type: precision_at_1
value: 31.343
- type: precision_at_10
value: 7.146
- type: precision_at_100
value: 1.098
- type: precision_at_1000
value: 0.14100000000000001
- type: precision_at_3
value: 16.014
- type: precision_at_5
value: 11.735
- type: recall_at_1
value: 26.695
- type: recall_at_10
value: 55.525000000000006
- type: recall_at_100
value: 77.376
- type: recall_at_1000
value: 93.476
- type: recall_at_3
value: 39.439
- type: recall_at_5
value: 46.501
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackWebmastersRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 24.196
- type: map_at_10
value: 33.516
- type: map_at_100
value: 35.202
- type: map_at_1000
value: 35.426
- type: map_at_3
value: 30.561
- type: map_at_5
value: 31.961000000000002
- type: mrr_at_1
value: 29.644
- type: mrr_at_10
value: 38.769
- type: mrr_at_100
value: 39.843
- type: mrr_at_1000
value: 39.888
- type: mrr_at_3
value: 36.132999999999996
- type: mrr_at_5
value: 37.467
- type: ndcg_at_1
value: 29.644
- type: ndcg_at_10
value: 39.584
- type: ndcg_at_100
value: 45.964
- type: ndcg_at_1000
value: 48.27
- type: ndcg_at_3
value: 34.577999999999996
- type: ndcg_at_5
value: 36.498000000000005
- type: precision_at_1
value: 29.644
- type: precision_at_10
value: 7.668
- type: precision_at_100
value: 1.545
- type: precision_at_1000
value: 0.242
- type: precision_at_3
value: 16.271
- type: precision_at_5
value: 11.620999999999999
- type: recall_at_1
value: 24.196
- type: recall_at_10
value: 51.171
- type: recall_at_100
value: 79.212
- type: recall_at_1000
value: 92.976
- type: recall_at_3
value: 36.797999999999995
- type: recall_at_5
value: 42.006
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackWordpressRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 21.023
- type: map_at_10
value: 29.677
- type: map_at_100
value: 30.618000000000002
- type: map_at_1000
value: 30.725
- type: map_at_3
value: 27.227
- type: map_at_5
value: 28.523
- type: mrr_at_1
value: 22.921
- type: mrr_at_10
value: 31.832
- type: mrr_at_100
value: 32.675
- type: mrr_at_1000
value: 32.751999999999995
- type: mrr_at_3
value: 29.513
- type: mrr_at_5
value: 30.89
- type: ndcg_at_1
value: 22.921
- type: ndcg_at_10
value: 34.699999999999996
- type: ndcg_at_100
value: 39.302
- type: ndcg_at_1000
value: 41.919000000000004
- type: ndcg_at_3
value: 29.965999999999998
- type: ndcg_at_5
value: 32.22
- type: precision_at_1
value: 22.921
- type: precision_at_10
value: 5.564
- type: precision_at_100
value: 0.8340000000000001
- type: precision_at_1000
value: 0.11800000000000001
- type: precision_at_3
value: 13.123999999999999
- type: precision_at_5
value: 9.316
- type: recall_at_1
value: 21.023
- type: recall_at_10
value: 48.015
- type: recall_at_100
value: 68.978
- type: recall_at_1000
value: 88.198
- type: recall_at_3
value: 35.397
- type: recall_at_5
value: 40.701
- task:
type: Retrieval
dataset:
type: climate-fever
name: MTEB ClimateFEVER
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 11.198
- type: map_at_10
value: 19.336000000000002
- type: map_at_100
value: 21.382
- type: map_at_1000
value: 21.581
- type: map_at_3
value: 15.992
- type: map_at_5
value: 17.613
- type: mrr_at_1
value: 25.080999999999996
- type: mrr_at_10
value: 36.032
- type: mrr_at_100
value: 37.1
- type: mrr_at_1000
value: 37.145
- type: mrr_at_3
value: 32.595
- type: mrr_at_5
value: 34.553
- type: ndcg_at_1
value: 25.080999999999996
- type: ndcg_at_10
value: 27.290999999999997
- type: ndcg_at_100
value: 35.31
- type: ndcg_at_1000
value: 38.885
- type: ndcg_at_3
value: 21.895999999999997
- type: ndcg_at_5
value: 23.669999999999998
- type: precision_at_1
value: 25.080999999999996
- type: precision_at_10
value: 8.645
- type: precision_at_100
value: 1.7209999999999999
- type: precision_at_1000
value: 0.23900000000000002
- type: precision_at_3
value: 16.287
- type: precision_at_5
value: 12.625
- type: recall_at_1
value: 11.198
- type: recall_at_10
value: 33.355000000000004
- type: recall_at_100
value: 60.912
- type: recall_at_1000
value: 80.89
- type: recall_at_3
value: 20.055
- type: recall_at_5
value: 25.14
- task:
type: Retrieval
dataset:
type: dbpedia-entity
name: MTEB DBPedia
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 9.228
- type: map_at_10
value: 20.018
- type: map_at_100
value: 28.388999999999996
- type: map_at_1000
value: 30.073
- type: map_at_3
value: 14.366999999999999
- type: map_at_5
value: 16.705000000000002
- type: mrr_at_1
value: 69
- type: mrr_at_10
value: 77.058
- type: mrr_at_100
value: 77.374
- type: mrr_at_1000
value: 77.384
- type: mrr_at_3
value: 75.708
- type: mrr_at_5
value: 76.608
- type: ndcg_at_1
value: 57.49999999999999
- type: ndcg_at_10
value: 41.792
- type: ndcg_at_100
value: 47.374
- type: ndcg_at_1000
value: 55.13
- type: ndcg_at_3
value: 46.353
- type: ndcg_at_5
value: 43.702000000000005
- type: precision_at_1
value: 69
- type: precision_at_10
value: 32.85
- type: precision_at_100
value: 10.708
- type: precision_at_1000
value: 2.024
- type: precision_at_3
value: 49.5
- type: precision_at_5
value: 42.05
- type: recall_at_1
value: 9.228
- type: recall_at_10
value: 25.635
- type: recall_at_100
value: 54.894
- type: recall_at_1000
value: 79.38
- type: recall_at_3
value: 15.68
- type: recall_at_5
value: 19.142
- task:
type: Classification
dataset:
type: mteb/emotion
name: MTEB EmotionClassification
config: default
split: test
revision: 4f58c6b202a23cf9a4da393831edf4f9183cad37
metrics:
- type: accuracy
value: 52.035
- type: f1
value: 46.85325505614071
- task:
type: Retrieval
dataset:
type: fever
name: MTEB FEVER
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 70.132
- type: map_at_10
value: 79.527
- type: map_at_100
value: 79.81200000000001
- type: map_at_1000
value: 79.828
- type: map_at_3
value: 78.191
- type: map_at_5
value: 79.092
- type: mrr_at_1
value: 75.563
- type: mrr_at_10
value: 83.80199999999999
- type: mrr_at_100
value: 83.93
- type: mrr_at_1000
value: 83.933
- type: mrr_at_3
value: 82.818
- type: mrr_at_5
value: 83.505
- type: ndcg_at_1
value: 75.563
- type: ndcg_at_10
value: 83.692
- type: ndcg_at_100
value: 84.706
- type: ndcg_at_1000
value: 85.001
- type: ndcg_at_3
value: 81.51
- type: ndcg_at_5
value: 82.832
- type: precision_at_1
value: 75.563
- type: precision_at_10
value: 10.245
- type: precision_at_100
value: 1.0959999999999999
- type: precision_at_1000
value: 0.11399999999999999
- type: precision_at_3
value: 31.518
- type: precision_at_5
value: 19.772000000000002
- type: recall_at_1
value: 70.132
- type: recall_at_10
value: 92.204
- type: recall_at_100
value: 96.261
- type: recall_at_1000
value: 98.17399999999999
- type: recall_at_3
value: 86.288
- type: recall_at_5
value: 89.63799999999999
- task:
type: Retrieval
dataset:
type: fiqa
name: MTEB FiQA2018
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 22.269
- type: map_at_10
value: 36.042
- type: map_at_100
value: 37.988
- type: map_at_1000
value: 38.162
- type: map_at_3
value: 31.691000000000003
- type: map_at_5
value: 33.988
- type: mrr_at_1
value: 44.907000000000004
- type: mrr_at_10
value: 53.348
- type: mrr_at_100
value: 54.033
- type: mrr_at_1000
value: 54.064
- type: mrr_at_3
value: 50.977
- type: mrr_at_5
value: 52.112
- type: ndcg_at_1
value: 44.907000000000004
- type: ndcg_at_10
value: 44.302
- type: ndcg_at_100
value: 51.054
- type: ndcg_at_1000
value: 53.822
- type: ndcg_at_3
value: 40.615
- type: ndcg_at_5
value: 41.455999999999996
- type: precision_at_1
value: 44.907000000000004
- type: precision_at_10
value: 12.176
- type: precision_at_100
value: 1.931
- type: precision_at_1000
value: 0.243
- type: precision_at_3
value: 27.16
- type: precision_at_5
value: 19.567999999999998
- type: recall_at_1
value: 22.269
- type: recall_at_10
value: 51.188
- type: recall_at_100
value: 75.924
- type: recall_at_1000
value: 92.525
- type: recall_at_3
value: 36.643
- type: recall_at_5
value: 42.27
- task:
type: Retrieval
dataset:
type: hotpotqa
name: MTEB HotpotQA
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 40.412
- type: map_at_10
value: 66.376
- type: map_at_100
value: 67.217
- type: map_at_1000
value: 67.271
- type: map_at_3
value: 62.741
- type: map_at_5
value: 65.069
- type: mrr_at_1
value: 80.824
- type: mrr_at_10
value: 86.53
- type: mrr_at_100
value: 86.67399999999999
- type: mrr_at_1000
value: 86.678
- type: mrr_at_3
value: 85.676
- type: mrr_at_5
value: 86.256
- type: ndcg_at_1
value: 80.824
- type: ndcg_at_10
value: 74.332
- type: ndcg_at_100
value: 77.154
- type: ndcg_at_1000
value: 78.12400000000001
- type: ndcg_at_3
value: 69.353
- type: ndcg_at_5
value: 72.234
- type: precision_at_1
value: 80.824
- type: precision_at_10
value: 15.652
- type: precision_at_100
value: 1.7840000000000003
- type: precision_at_1000
value: 0.191
- type: precision_at_3
value: 44.911
- type: precision_at_5
value: 29.221000000000004
- type: recall_at_1
value: 40.412
- type: recall_at_10
value: 78.25800000000001
- type: recall_at_100
value: 89.196
- type: recall_at_1000
value: 95.544
- type: recall_at_3
value: 67.367
- type: recall_at_5
value: 73.05199999999999
- task:
type: Classification
dataset:
type: mteb/imdb
name: MTEB ImdbClassification
config: default
split: test
revision: 3d86128a09e091d6018b6d26cad27f2739fc2db7
metrics:
- type: accuracy
value: 92.78880000000001
- type: ap
value: 89.39251741048801
- type: f1
value: 92.78019950076781
- task:
type: Retrieval
dataset:
type: msmarco
name: MTEB MSMARCO
config: default
split: dev
revision: None
metrics:
- type: map_at_1
value: 22.888
- type: map_at_10
value: 35.146
- type: map_at_100
value: 36.325
- type: map_at_1000
value: 36.372
- type: map_at_3
value: 31.3
- type: map_at_5
value: 33.533
- type: mrr_at_1
value: 23.480999999999998
- type: mrr_at_10
value: 35.777
- type: mrr_at_100
value: 36.887
- type: mrr_at_1000
value: 36.928
- type: mrr_at_3
value: 31.989
- type: mrr_at_5
value: 34.202
- type: ndcg_at_1
value: 23.496
- type: ndcg_at_10
value: 42.028999999999996
- type: ndcg_at_100
value: 47.629
- type: ndcg_at_1000
value: 48.785000000000004
- type: ndcg_at_3
value: 34.227000000000004
- type: ndcg_at_5
value: 38.207
- type: precision_at_1
value: 23.496
- type: precision_at_10
value: 6.596
- type: precision_at_100
value: 0.9400000000000001
- type: precision_at_1000
value: 0.104
- type: precision_at_3
value: 14.513000000000002
- type: precision_at_5
value: 10.711
- type: recall_at_1
value: 22.888
- type: recall_at_10
value: 63.129999999999995
- type: recall_at_100
value: 88.90299999999999
- type: recall_at_1000
value: 97.69
- type: recall_at_3
value: 42.014
- type: recall_at_5
value: 51.554
- task:
type: Classification
dataset:
type: mteb/mtop_domain
name: MTEB MTOPDomainClassification (en)
config: en
split: test
revision: d80d48c1eb48d3562165c59d59d0034df9fff0bf
metrics:
- type: accuracy
value: 94.59188326493388
- type: f1
value: 94.36568950290486
- task:
type: Classification
dataset:
type: mteb/mtop_intent
name: MTEB MTOPIntentClassification (en)
config: en
split: test
revision: ae001d0e6b1228650b7bd1c2c65fb50ad11a8aba
metrics:
- type: accuracy
value: 79.25672594619242
- type: f1
value: 59.52405059722216
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (en)
config: en
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 77.4142568930733
- type: f1
value: 75.23044196543388
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (en)
config: en
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 80.44720914593141
- type: f1
value: 80.41049641537015
- task:
type: Clustering
dataset:
type: mteb/medrxiv-clustering-p2p
name: MTEB MedrxivClusteringP2P
config: default
split: test
revision: e7a26af6f3ae46b30dde8737f02c07b1505bcc73
metrics:
- type: v_measure
value: 31.960921474993775
- task:
type: Clustering
dataset:
type: mteb/medrxiv-clustering-s2s
name: MTEB MedrxivClusteringS2S
config: default
split: test
revision: 35191c8c0dca72d8ff3efcd72aa802307d469663
metrics:
- type: v_measure
value: 30.88042240204361
- task:
type: Reranking
dataset:
type: mteb/mind_small
name: MTEB MindSmallReranking
config: default
split: test
revision: 3bdac13927fdc888b903db93b2ffdbd90b295a69
metrics:
- type: map
value: 32.27071371606404
- type: mrr
value: 33.541450459533856
- task:
type: Retrieval
dataset:
type: nfcorpus
name: MTEB NFCorpus
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 6.551
- type: map_at_10
value: 14.359
- type: map_at_100
value: 18.157
- type: map_at_1000
value: 19.659
- type: map_at_3
value: 10.613999999999999
- type: map_at_5
value: 12.296
- type: mrr_at_1
value: 47.368
- type: mrr_at_10
value: 56.689
- type: mrr_at_100
value: 57.24399999999999
- type: mrr_at_1000
value: 57.284
- type: mrr_at_3
value: 54.489
- type: mrr_at_5
value: 55.928999999999995
- type: ndcg_at_1
value: 45.511
- type: ndcg_at_10
value: 36.911
- type: ndcg_at_100
value: 34.241
- type: ndcg_at_1000
value: 43.064
- type: ndcg_at_3
value: 42.348
- type: ndcg_at_5
value: 39.884
- type: precision_at_1
value: 46.749
- type: precision_at_10
value: 27.028000000000002
- type: precision_at_100
value: 8.52
- type: precision_at_1000
value: 2.154
- type: precision_at_3
value: 39.525
- type: precision_at_5
value: 34.18
- type: recall_at_1
value: 6.551
- type: recall_at_10
value: 18.602
- type: recall_at_100
value: 34.882999999999996
- type: recall_at_1000
value: 66.049
- type: recall_at_3
value: 11.872
- type: recall_at_5
value: 14.74
- task:
type: Retrieval
dataset:
type: nq
name: MTEB NQ
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 27.828999999999997
- type: map_at_10
value: 43.606
- type: map_at_100
value: 44.656
- type: map_at_1000
value: 44.690000000000005
- type: map_at_3
value: 39.015
- type: map_at_5
value: 41.625
- type: mrr_at_1
value: 31.518
- type: mrr_at_10
value: 46.047
- type: mrr_at_100
value: 46.846
- type: mrr_at_1000
value: 46.867999999999995
- type: mrr_at_3
value: 42.154
- type: mrr_at_5
value: 44.468999999999994
- type: ndcg_at_1
value: 31.518
- type: ndcg_at_10
value: 51.768
- type: ndcg_at_100
value: 56.184999999999995
- type: ndcg_at_1000
value: 56.92
- type: ndcg_at_3
value: 43.059999999999995
- type: ndcg_at_5
value: 47.481
- type: precision_at_1
value: 31.518
- type: precision_at_10
value: 8.824
- type: precision_at_100
value: 1.131
- type: precision_at_1000
value: 0.12
- type: precision_at_3
value: 19.969
- type: precision_at_5
value: 14.502
- type: recall_at_1
value: 27.828999999999997
- type: recall_at_10
value: 74.244
- type: recall_at_100
value: 93.325
- type: recall_at_1000
value: 98.71799999999999
- type: recall_at_3
value: 51.601
- type: recall_at_5
value: 61.841
- task:
type: Retrieval
dataset:
type: quora
name: MTEB QuoraRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 71.54
- type: map_at_10
value: 85.509
- type: map_at_100
value: 86.137
- type: map_at_1000
value: 86.151
- type: map_at_3
value: 82.624
- type: map_at_5
value: 84.425
- type: mrr_at_1
value: 82.45
- type: mrr_at_10
value: 88.344
- type: mrr_at_100
value: 88.437
- type: mrr_at_1000
value: 88.437
- type: mrr_at_3
value: 87.417
- type: mrr_at_5
value: 88.066
- type: ndcg_at_1
value: 82.45
- type: ndcg_at_10
value: 89.092
- type: ndcg_at_100
value: 90.252
- type: ndcg_at_1000
value: 90.321
- type: ndcg_at_3
value: 86.404
- type: ndcg_at_5
value: 87.883
- type: precision_at_1
value: 82.45
- type: precision_at_10
value: 13.496
- type: precision_at_100
value: 1.536
- type: precision_at_1000
value: 0.157
- type: precision_at_3
value: 37.833
- type: precision_at_5
value: 24.79
- type: recall_at_1
value: 71.54
- type: recall_at_10
value: 95.846
- type: recall_at_100
value: 99.715
- type: recall_at_1000
value: 99.979
- type: recall_at_3
value: 88.01299999999999
- type: recall_at_5
value: 92.32000000000001
- task:
type: Clustering
dataset:
type: mteb/reddit-clustering
name: MTEB RedditClustering
config: default
split: test
revision: 24640382cdbf8abc73003fb0fa6d111a705499eb
metrics:
- type: v_measure
value: 57.60557586253866
- task:
type: Clustering
dataset:
type: mteb/reddit-clustering-p2p
name: MTEB RedditClusteringP2P
config: default
split: test
revision: 282350215ef01743dc01b456c7f5241fa8937f16
metrics:
- type: v_measure
value: 64.0287172242051
- task:
type: Retrieval
dataset:
type: scidocs
name: MTEB SCIDOCS
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 3.9849999999999994
- type: map_at_10
value: 11.397
- type: map_at_100
value: 13.985
- type: map_at_1000
value: 14.391000000000002
- type: map_at_3
value: 7.66
- type: map_at_5
value: 9.46
- type: mrr_at_1
value: 19.8
- type: mrr_at_10
value: 31.958
- type: mrr_at_100
value: 33.373999999999995
- type: mrr_at_1000
value: 33.411
- type: mrr_at_3
value: 28.316999999999997
- type: mrr_at_5
value: 30.297
- type: ndcg_at_1
value: 19.8
- type: ndcg_at_10
value: 19.580000000000002
- type: ndcg_at_100
value: 29.555999999999997
- type: ndcg_at_1000
value: 35.882
- type: ndcg_at_3
value: 17.544
- type: ndcg_at_5
value: 15.815999999999999
- type: precision_at_1
value: 19.8
- type: precision_at_10
value: 10.61
- type: precision_at_100
value: 2.501
- type: precision_at_1000
value: 0.40099999999999997
- type: precision_at_3
value: 16.900000000000002
- type: precision_at_5
value: 14.44
- type: recall_at_1
value: 3.9849999999999994
- type: recall_at_10
value: 21.497
- type: recall_at_100
value: 50.727999999999994
- type: recall_at_1000
value: 81.27499999999999
- type: recall_at_3
value: 10.263
- type: recall_at_5
value: 14.643
- task:
type: STS
dataset:
type: mteb/sickr-sts
name: MTEB SICK-R
config: default
split: test
revision: a6ea5a8cab320b040a23452cc28066d9beae2cee
metrics:
- type: cos_sim_pearson
value: 85.0087509585503
- type: cos_sim_spearman
value: 81.74697270664319
- type: euclidean_pearson
value: 81.80424382731947
- type: euclidean_spearman
value: 81.29794251968431
- type: manhattan_pearson
value: 81.81524666226125
- type: manhattan_spearman
value: 81.29475370198963
- task:
type: STS
dataset:
type: mteb/sts12-sts
name: MTEB STS12
config: default
split: test
revision: a0d554a64d88156834ff5ae9920b964011b16384
metrics:
- type: cos_sim_pearson
value: 86.44442736429552
- type: cos_sim_spearman
value: 78.51011398910948
- type: euclidean_pearson
value: 83.36181801196723
- type: euclidean_spearman
value: 79.47272621331535
- type: manhattan_pearson
value: 83.3660113483837
- type: manhattan_spearman
value: 79.47695922566032
- task:
type: STS
dataset:
type: mteb/sts13-sts
name: MTEB STS13
config: default
split: test
revision: 7e90230a92c190f1bf69ae9002b8cea547a64cca
metrics:
- type: cos_sim_pearson
value: 85.82923943323635
- type: cos_sim_spearman
value: 86.62037823380983
- type: euclidean_pearson
value: 83.56369548403958
- type: euclidean_spearman
value: 84.2176755481191
- type: manhattan_pearson
value: 83.55460702084464
- type: manhattan_spearman
value: 84.18617930921467
- task:
type: STS
dataset:
type: mteb/sts14-sts
name: MTEB STS14
config: default
split: test
revision: 6031580fec1f6af667f0bd2da0a551cf4f0b2375
metrics:
- type: cos_sim_pearson
value: 84.09071068110103
- type: cos_sim_spearman
value: 83.05697553913335
- type: euclidean_pearson
value: 81.1377457216497
- type: euclidean_spearman
value: 81.74714169016676
- type: manhattan_pearson
value: 81.0893424142723
- type: manhattan_spearman
value: 81.7058918219677
- task:
type: STS
dataset:
type: mteb/sts15-sts
name: MTEB STS15
config: default
split: test
revision: ae752c7c21bf194d8b67fd573edf7ae58183cbe3
metrics:
- type: cos_sim_pearson
value: 87.61132157220429
- type: cos_sim_spearman
value: 88.38581627185445
- type: euclidean_pearson
value: 86.14904510913374
- type: euclidean_spearman
value: 86.5452758925542
- type: manhattan_pearson
value: 86.1484025377679
- type: manhattan_spearman
value: 86.55483841566252
- task:
type: STS
dataset:
type: mteb/sts16-sts
name: MTEB STS16
config: default
split: test
revision: 4d8694f8f0e0100860b497b999b3dbed754a0513
metrics:
- type: cos_sim_pearson
value: 85.46195145161064
- type: cos_sim_spearman
value: 86.82409112251158
- type: euclidean_pearson
value: 84.75479672288957
- type: euclidean_spearman
value: 85.41144307151548
- type: manhattan_pearson
value: 84.70914329694165
- type: manhattan_spearman
value: 85.38477943384089
- task:
type: STS
dataset:
type: mteb/sts17-crosslingual-sts
name: MTEB STS17 (en-en)
config: en-en
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 88.06351289930238
- type: cos_sim_spearman
value: 87.90311138579116
- type: euclidean_pearson
value: 86.17651467063077
- type: euclidean_spearman
value: 84.89447802019073
- type: manhattan_pearson
value: 86.3267677479595
- type: manhattan_spearman
value: 85.00472295103874
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (en)
config: en
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 67.78311975978767
- type: cos_sim_spearman
value: 66.76465685245887
- type: euclidean_pearson
value: 67.21687806595443
- type: euclidean_spearman
value: 65.05776733534435
- type: manhattan_pearson
value: 67.14008143635883
- type: manhattan_spearman
value: 65.25247076149701
- task:
type: STS
dataset:
type: mteb/stsbenchmark-sts
name: MTEB STSBenchmark
config: default
split: test
revision: b0fddb56ed78048fa8b90373c8a3cfc37b684831
metrics:
- type: cos_sim_pearson
value: 86.7403488889418
- type: cos_sim_spearman
value: 87.76870289783061
- type: euclidean_pearson
value: 84.83171077794671
- type: euclidean_spearman
value: 85.50579695091902
- type: manhattan_pearson
value: 84.83074260180555
- type: manhattan_spearman
value: 85.47589026938667
- task:
type: Reranking
dataset:
type: mteb/scidocs-reranking
name: MTEB SciDocsRR
config: default
split: test
revision: d3c5e1fc0b855ab6097bf1cda04dd73947d7caab
metrics:
- type: map
value: 87.56234016237356
- type: mrr
value: 96.26124238869338
- task:
type: Retrieval
dataset:
type: scifact
name: MTEB SciFact
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 59.660999999999994
- type: map_at_10
value: 69.105
- type: map_at_100
value: 69.78
- type: map_at_1000
value: 69.80199999999999
- type: map_at_3
value: 65.991
- type: map_at_5
value: 68.02
- type: mrr_at_1
value: 62.666999999999994
- type: mrr_at_10
value: 70.259
- type: mrr_at_100
value: 70.776
- type: mrr_at_1000
value: 70.796
- type: mrr_at_3
value: 67.889
- type: mrr_at_5
value: 69.52199999999999
- type: ndcg_at_1
value: 62.666999999999994
- type: ndcg_at_10
value: 73.425
- type: ndcg_at_100
value: 75.955
- type: ndcg_at_1000
value: 76.459
- type: ndcg_at_3
value: 68.345
- type: ndcg_at_5
value: 71.319
- type: precision_at_1
value: 62.666999999999994
- type: precision_at_10
value: 9.667
- type: precision_at_100
value: 1.09
- type: precision_at_1000
value: 0.11299999999999999
- type: precision_at_3
value: 26.333000000000002
- type: precision_at_5
value: 17.732999999999997
- type: recall_at_1
value: 59.660999999999994
- type: recall_at_10
value: 85.422
- type: recall_at_100
value: 96.167
- type: recall_at_1000
value: 100
- type: recall_at_3
value: 72.044
- type: recall_at_5
value: 79.428
- task:
type: PairClassification
dataset:
type: mteb/sprintduplicatequestions-pairclassification
name: MTEB SprintDuplicateQuestions
config: default
split: test
revision: d66bd1f72af766a5cc4b0ca5e00c162f89e8cc46
metrics:
- type: cos_sim_accuracy
value: 99.86435643564356
- type: cos_sim_ap
value: 96.83057412333741
- type: cos_sim_f1
value: 93.04215337734891
- type: cos_sim_precision
value: 94.53044375644994
- type: cos_sim_recall
value: 91.60000000000001
- type: dot_accuracy
value: 99.7910891089109
- type: dot_ap
value: 94.10681982106397
- type: dot_f1
value: 89.34881373043918
- type: dot_precision
value: 90.21406727828746
- type: dot_recall
value: 88.5
- type: euclidean_accuracy
value: 99.85544554455446
- type: euclidean_ap
value: 96.78545104478602
- type: euclidean_f1
value: 92.65143992055613
- type: euclidean_precision
value: 92.01183431952663
- type: euclidean_recall
value: 93.30000000000001
- type: manhattan_accuracy
value: 99.85841584158416
- type: manhattan_ap
value: 96.80748903307823
- type: manhattan_f1
value: 92.78247884519662
- type: manhattan_precision
value: 92.36868186323092
- type: manhattan_recall
value: 93.2
- type: max_accuracy
value: 99.86435643564356
- type: max_ap
value: 96.83057412333741
- type: max_f1
value: 93.04215337734891
- task:
type: Clustering
dataset:
type: mteb/stackexchange-clustering
name: MTEB StackExchangeClustering
config: default
split: test
revision: 6cbc1f7b2bc0622f2e39d2c77fa502909748c259
metrics:
- type: v_measure
value: 65.53971025855282
- task:
type: Clustering
dataset:
type: mteb/stackexchange-clustering-p2p
name: MTEB StackExchangeClusteringP2P
config: default
split: test
revision: 815ca46b2622cec33ccafc3735d572c266efdb44
metrics:
- type: v_measure
value: 33.97791591490788
- task:
type: Reranking
dataset:
type: mteb/stackoverflowdupquestions-reranking
name: MTEB StackOverflowDupQuestions
config: default
split: test
revision: e185fbe320c72810689fc5848eb6114e1ef5ec69
metrics:
- type: map
value: 55.852215301355066
- type: mrr
value: 56.85527809608691
- task:
type: Summarization
dataset:
type: mteb/summeval
name: MTEB SummEval
config: default
split: test
revision: cda12ad7615edc362dbf25a00fdd61d3b1eaf93c
metrics:
- type: cos_sim_pearson
value: 31.21442519856758
- type: cos_sim_spearman
value: 30.822536216936825
- type: dot_pearson
value: 28.661325528121807
- type: dot_spearman
value: 28.1435226478879
- task:
type: Retrieval
dataset:
type: trec-covid
name: MTEB TRECCOVID
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 0.183
- type: map_at_10
value: 1.526
- type: map_at_100
value: 7.915
- type: map_at_1000
value: 19.009
- type: map_at_3
value: 0.541
- type: map_at_5
value: 0.8659999999999999
- type: mrr_at_1
value: 68
- type: mrr_at_10
value: 81.186
- type: mrr_at_100
value: 81.186
- type: mrr_at_1000
value: 81.186
- type: mrr_at_3
value: 80
- type: mrr_at_5
value: 80.9
- type: ndcg_at_1
value: 64
- type: ndcg_at_10
value: 64.13799999999999
- type: ndcg_at_100
value: 47.632000000000005
- type: ndcg_at_1000
value: 43.037
- type: ndcg_at_3
value: 67.542
- type: ndcg_at_5
value: 67.496
- type: precision_at_1
value: 68
- type: precision_at_10
value: 67.80000000000001
- type: precision_at_100
value: 48.980000000000004
- type: precision_at_1000
value: 19.036
- type: precision_at_3
value: 72
- type: precision_at_5
value: 71.2
- type: recall_at_1
value: 0.183
- type: recall_at_10
value: 1.799
- type: recall_at_100
value: 11.652999999999999
- type: recall_at_1000
value: 40.086
- type: recall_at_3
value: 0.5930000000000001
- type: recall_at_5
value: 0.983
- task:
type: Retrieval
dataset:
type: webis-touche2020
name: MTEB Touche2020
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 2.29
- type: map_at_10
value: 9.489
- type: map_at_100
value: 15.051
- type: map_at_1000
value: 16.561999999999998
- type: map_at_3
value: 5.137
- type: map_at_5
value: 6.7989999999999995
- type: mrr_at_1
value: 28.571
- type: mrr_at_10
value: 45.699
- type: mrr_at_100
value: 46.461000000000006
- type: mrr_at_1000
value: 46.461000000000006
- type: mrr_at_3
value: 41.837
- type: mrr_at_5
value: 43.163000000000004
- type: ndcg_at_1
value: 23.469
- type: ndcg_at_10
value: 23.544999999999998
- type: ndcg_at_100
value: 34.572
- type: ndcg_at_1000
value: 46.035
- type: ndcg_at_3
value: 27.200000000000003
- type: ndcg_at_5
value: 25.266
- type: precision_at_1
value: 28.571
- type: precision_at_10
value: 22.041
- type: precision_at_100
value: 7.3469999999999995
- type: precision_at_1000
value: 1.484
- type: precision_at_3
value: 29.932
- type: precision_at_5
value: 26.531
- type: recall_at_1
value: 2.29
- type: recall_at_10
value: 15.895999999999999
- type: recall_at_100
value: 45.518
- type: recall_at_1000
value: 80.731
- type: recall_at_3
value: 6.433
- type: recall_at_5
value: 9.484
- task:
type: Classification
dataset:
type: mteb/toxic_conversations_50k
name: MTEB ToxicConversationsClassification
config: default
split: test
revision: d7c0de2777da35d6aae2200a62c6e0e5af397c4c
metrics:
- type: accuracy
value: 71.4178
- type: ap
value: 14.575240629602373
- type: f1
value: 55.02449563229096
- task:
type: Classification
dataset:
type: mteb/tweet_sentiment_extraction
name: MTEB TweetSentimentExtractionClassification
config: default
split: test
revision: d604517c81ca91fe16a244d1248fc021f9ecee7a
metrics:
- type: accuracy
value: 60.00282965478212
- type: f1
value: 60.34413028768773
- task:
type: Clustering
dataset:
type: mteb/twentynewsgroups-clustering
name: MTEB TwentyNewsgroupsClustering
config: default
split: test
revision: 6125ec4e24fa026cec8a478383ee943acfbd5449
metrics:
- type: v_measure
value: 50.409448342549936
- task:
type: PairClassification
dataset:
type: mteb/twittersemeval2015-pairclassification
name: MTEB TwitterSemEval2015
config: default
split: test
revision: 70970daeab8776df92f5ea462b6173c0b46fd2d1
metrics:
- type: cos_sim_accuracy
value: 87.62591643321214
- type: cos_sim_ap
value: 79.28766491329633
- type: cos_sim_f1
value: 71.98772064466617
- type: cos_sim_precision
value: 69.8609731876862
- type: cos_sim_recall
value: 74.24802110817942
- type: dot_accuracy
value: 84.75293556654945
- type: dot_ap
value: 69.72705761174353
- type: dot_f1
value: 65.08692852543464
- type: dot_precision
value: 63.57232704402516
- type: dot_recall
value: 66.6754617414248
- type: euclidean_accuracy
value: 87.44710019669786
- type: euclidean_ap
value: 79.11021477292638
- type: euclidean_f1
value: 71.5052389470994
- type: euclidean_precision
value: 69.32606541129832
- type: euclidean_recall
value: 73.82585751978891
- type: manhattan_accuracy
value: 87.42325803182929
- type: manhattan_ap
value: 79.05094494327616
- type: manhattan_f1
value: 71.36333985649055
- type: manhattan_precision
value: 70.58064516129032
- type: manhattan_recall
value: 72.16358839050132
- type: max_accuracy
value: 87.62591643321214
- type: max_ap
value: 79.28766491329633
- type: max_f1
value: 71.98772064466617
- task:
type: PairClassification
dataset:
type: mteb/twitterurlcorpus-pairclassification
name: MTEB TwitterURLCorpus
config: default
split: test
revision: 8b6510b0b1fa4e4c4f879467980e9be563ec1cdf
metrics:
- type: cos_sim_accuracy
value: 88.85202002561415
- type: cos_sim_ap
value: 85.9835303311168
- type: cos_sim_f1
value: 78.25741142443962
- type: cos_sim_precision
value: 73.76635768811342
- type: cos_sim_recall
value: 83.3307668617185
- type: dot_accuracy
value: 88.20584468506229
- type: dot_ap
value: 83.591632302697
- type: dot_f1
value: 76.81739705396173
- type: dot_precision
value: 73.45275728837373
- type: dot_recall
value: 80.50508161379734
- type: euclidean_accuracy
value: 88.64633057787093
- type: euclidean_ap
value: 85.25705123182283
- type: euclidean_f1
value: 77.18535726329199
- type: euclidean_precision
value: 75.17699437997226
- type: euclidean_recall
value: 79.30397289805975
- type: manhattan_accuracy
value: 88.63274731245392
- type: manhattan_ap
value: 85.2376825633018
- type: manhattan_f1
value: 77.15810785937788
- type: manhattan_precision
value: 73.92255061014319
- type: manhattan_recall
value: 80.68986757006468
- type: max_accuracy
value: 88.85202002561415
- type: max_ap
value: 85.9835303311168
- type: max_f1
value: 78.25741142443962
---
# ember-v1
<p align="center">
<img src="https://console.llmrails.com/assets/img/logo-black.svg" width="150px">
</p>
This model has been trained on an extensive corpus of text pairs that encompass a broad spectrum of domains, including finance, science, medicine, law, and various others. During the training process, we incorporated techniques derived from the [RetroMAE](https://arxiv.org/abs/2205.12035) and [SetFit](https://arxiv.org/abs/2209.11055) research papers.
We are pleased to offer this model as an API service through our platform, [LLMRails](https://llmrails.com/?ref=ember-v1). If you are interested, please don't hesitate to sign up.
### Plans
- The research paper will be published soon.
- The v2 of the model is currently in development and will feature an extended maximum sequence length of 4,000 tokens.
## Usage
Use with API request:
```bash
curl --location 'https://api.llmrails.com/v1/embeddings' \
--header 'X-API-KEY: {token}' \
--header 'Content-Type: application/json' \
--data '{
"input": ["This is an example sentence"],
"model":"embedding-english-v1" # equals to ember-v1
}'
```
API docs: https://docs.llmrails.com/embedding/embed-text<br>
Langchain plugin: https://python.langchain.com/docs/integrations/text_embedding/llm_rails
Use with transformers:
```python
import torch.nn.functional as F
from torch import Tensor
from transformers import AutoTokenizer, AutoModel
def average_pool(last_hidden_states: Tensor,
attention_mask: Tensor) -> Tensor:
last_hidden = last_hidden_states.masked_fill(~attention_mask[..., None].bool(), 0.0)
return last_hidden.sum(dim=1) / attention_mask.sum(dim=1)[..., None]
input_texts = [
"This is an example sentence",
"Each sentence is converted"
]
tokenizer = AutoTokenizer.from_pretrained("llmrails/ember-v1")
model = AutoModel.from_pretrained("llmrails/ember-v1")
# Tokenize the input texts
batch_dict = tokenizer(input_texts, max_length=512, padding=True, truncation=True, return_tensors='pt')
outputs = model(**batch_dict)
embeddings = average_pool(outputs.last_hidden_state, batch_dict['attention_mask'])
# (Optionally) normalize embeddings
embeddings = F.normalize(embeddings, p=2, dim=1)
scores = (embeddings[:1] @ embeddings[1:].T) * 100
print(scores.tolist())
```
Use with sentence-transformers:
```python
from sentence_transformers import SentenceTransformer
from sentence_transformers.util import cos_sim
sentences = [
"This is an example sentence",
"Each sentence is converted"
]
model = SentenceTransformer('llmrails/ember-v1')
embeddings = model.encode(sentences)
print(cos_sim(embeddings[0], embeddings[1]))
```
## Massive Text Embedding Benchmark (MTEB) Evaluation
Our model achieve state-of-the-art performance on [MTEB leaderboard](https://huggingface.co/spaces/mteb/leaderboard)
| Model Name | Dimension | Sequence Length | Average (56) |
|:-----------------------------------------------------------------------:|:---------:|:---:|:------------:|
| [bge-large-en-v1.5](https://huggingface.co/BAAI/bge-large-en-v1.5) | 1024 | 512 | 64.23 |
| [bge-base-en-v1.5](https://huggingface.co/BAAI/bge-base-en-v1.5) | 768 | 512 | 63.55 |
| [ember-v1](https://huggingface.co/llmrails/emmbedding-en-v1) | 1024 | 512 | **63.54** |
| [text-embedding-ada-002](https://platform.openai.com/docs/guides/embeddings/types-of-embedding-models) | 1536 | 8191 | 60.99 |
### Limitation
This model exclusively caters to English texts, and any lengthy texts will be truncated to a maximum of 512 tokens.
<img src="https://pixel.llmrails.com/hf/2AtscRthisA1rZzQr8T7Zm"> |
mradermacher/Llama3-CASAudit-8B-NOUT-GGUF | mradermacher | 2024-06-27T19:35:01Z | 17,189 | 0 | transformers | [
"transformers",
"gguf",
"en",
"base_model:jamesohe/Llama3-CASAudit-8B-NOUT",
"endpoints_compatible",
"region:us"
]
| null | 2024-06-27T19:07:16Z | ---
base_model: jamesohe/Llama3-CASAudit-8B-NOUT
language:
- en
library_name: transformers
quantized_by: mradermacher
tags: []
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
static quants of https://huggingface.co/jamesohe/Llama3-CASAudit-8B-NOUT
<!-- provided-files -->
weighted/imatrix quants seem not to be available (by me) at this time. If they do not show up a week or so after the static ones, I have probably not planned for them. Feel free to request them by opening a Community Discussion.
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/Llama3-CASAudit-8B-NOUT-GGUF/resolve/main/Llama3-CASAudit-8B-NOUT.Q2_K.gguf) | Q2_K | 3.3 | |
| [GGUF](https://huggingface.co/mradermacher/Llama3-CASAudit-8B-NOUT-GGUF/resolve/main/Llama3-CASAudit-8B-NOUT.IQ3_XS.gguf) | IQ3_XS | 3.6 | |
| [GGUF](https://huggingface.co/mradermacher/Llama3-CASAudit-8B-NOUT-GGUF/resolve/main/Llama3-CASAudit-8B-NOUT.Q3_K_S.gguf) | Q3_K_S | 3.8 | |
| [GGUF](https://huggingface.co/mradermacher/Llama3-CASAudit-8B-NOUT-GGUF/resolve/main/Llama3-CASAudit-8B-NOUT.IQ3_S.gguf) | IQ3_S | 3.8 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/Llama3-CASAudit-8B-NOUT-GGUF/resolve/main/Llama3-CASAudit-8B-NOUT.IQ3_M.gguf) | IQ3_M | 3.9 | |
| [GGUF](https://huggingface.co/mradermacher/Llama3-CASAudit-8B-NOUT-GGUF/resolve/main/Llama3-CASAudit-8B-NOUT.Q3_K_M.gguf) | Q3_K_M | 4.1 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/Llama3-CASAudit-8B-NOUT-GGUF/resolve/main/Llama3-CASAudit-8B-NOUT.Q3_K_L.gguf) | Q3_K_L | 4.4 | |
| [GGUF](https://huggingface.co/mradermacher/Llama3-CASAudit-8B-NOUT-GGUF/resolve/main/Llama3-CASAudit-8B-NOUT.IQ4_XS.gguf) | IQ4_XS | 4.6 | |
| [GGUF](https://huggingface.co/mradermacher/Llama3-CASAudit-8B-NOUT-GGUF/resolve/main/Llama3-CASAudit-8B-NOUT.Q4_K_S.gguf) | Q4_K_S | 4.8 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Llama3-CASAudit-8B-NOUT-GGUF/resolve/main/Llama3-CASAudit-8B-NOUT.Q4_K_M.gguf) | Q4_K_M | 5.0 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Llama3-CASAudit-8B-NOUT-GGUF/resolve/main/Llama3-CASAudit-8B-NOUT.Q5_K_S.gguf) | Q5_K_S | 5.7 | |
| [GGUF](https://huggingface.co/mradermacher/Llama3-CASAudit-8B-NOUT-GGUF/resolve/main/Llama3-CASAudit-8B-NOUT.Q5_K_M.gguf) | Q5_K_M | 5.8 | |
| [GGUF](https://huggingface.co/mradermacher/Llama3-CASAudit-8B-NOUT-GGUF/resolve/main/Llama3-CASAudit-8B-NOUT.Q6_K.gguf) | Q6_K | 6.7 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/Llama3-CASAudit-8B-NOUT-GGUF/resolve/main/Llama3-CASAudit-8B-NOUT.Q8_0.gguf) | Q8_0 | 8.6 | fast, best quality |
| [GGUF](https://huggingface.co/mradermacher/Llama3-CASAudit-8B-NOUT-GGUF/resolve/main/Llama3-CASAudit-8B-NOUT.f16.gguf) | f16 | 16.2 | 16 bpw, overkill |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
mradermacher/ALMA-13B-SFT-HW-CPO-Pref-Multi-BLEU-GGUF | mradermacher | 2024-06-23T21:40:41Z | 17,168 | 0 | transformers | [
"transformers",
"gguf",
"en",
"base_model:hgissbkh/ALMA-13B-SFT-HW-CPO-Pref-Multi-BLEU",
"endpoints_compatible",
"region:us"
]
| null | 2024-06-23T20:54:57Z | ---
base_model: hgissbkh/ALMA-13B-SFT-HW-CPO-Pref-Multi-BLEU
language:
- en
library_name: transformers
quantized_by: mradermacher
tags: []
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
static quants of https://huggingface.co/hgissbkh/ALMA-13B-SFT-HW-CPO-Pref-Multi-BLEU
<!-- provided-files -->
weighted/imatrix quants seem not to be available (by me) at this time. If they do not show up a week or so after the static ones, I have probably not planned for them. Feel free to request them by opening a Community Discussion.
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/ALMA-13B-SFT-HW-CPO-Pref-Multi-BLEU-GGUF/resolve/main/ALMA-13B-SFT-HW-CPO-Pref-Multi-BLEU.Q2_K.gguf) | Q2_K | 5.0 | |
| [GGUF](https://huggingface.co/mradermacher/ALMA-13B-SFT-HW-CPO-Pref-Multi-BLEU-GGUF/resolve/main/ALMA-13B-SFT-HW-CPO-Pref-Multi-BLEU.IQ3_XS.gguf) | IQ3_XS | 5.5 | |
| [GGUF](https://huggingface.co/mradermacher/ALMA-13B-SFT-HW-CPO-Pref-Multi-BLEU-GGUF/resolve/main/ALMA-13B-SFT-HW-CPO-Pref-Multi-BLEU.IQ3_S.gguf) | IQ3_S | 5.8 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/ALMA-13B-SFT-HW-CPO-Pref-Multi-BLEU-GGUF/resolve/main/ALMA-13B-SFT-HW-CPO-Pref-Multi-BLEU.Q3_K_S.gguf) | Q3_K_S | 5.8 | |
| [GGUF](https://huggingface.co/mradermacher/ALMA-13B-SFT-HW-CPO-Pref-Multi-BLEU-GGUF/resolve/main/ALMA-13B-SFT-HW-CPO-Pref-Multi-BLEU.IQ3_M.gguf) | IQ3_M | 6.1 | |
| [GGUF](https://huggingface.co/mradermacher/ALMA-13B-SFT-HW-CPO-Pref-Multi-BLEU-GGUF/resolve/main/ALMA-13B-SFT-HW-CPO-Pref-Multi-BLEU.Q3_K_M.gguf) | Q3_K_M | 6.4 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/ALMA-13B-SFT-HW-CPO-Pref-Multi-BLEU-GGUF/resolve/main/ALMA-13B-SFT-HW-CPO-Pref-Multi-BLEU.Q3_K_L.gguf) | Q3_K_L | 7.0 | |
| [GGUF](https://huggingface.co/mradermacher/ALMA-13B-SFT-HW-CPO-Pref-Multi-BLEU-GGUF/resolve/main/ALMA-13B-SFT-HW-CPO-Pref-Multi-BLEU.IQ4_XS.gguf) | IQ4_XS | 7.1 | |
| [GGUF](https://huggingface.co/mradermacher/ALMA-13B-SFT-HW-CPO-Pref-Multi-BLEU-GGUF/resolve/main/ALMA-13B-SFT-HW-CPO-Pref-Multi-BLEU.Q4_K_S.gguf) | Q4_K_S | 7.5 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/ALMA-13B-SFT-HW-CPO-Pref-Multi-BLEU-GGUF/resolve/main/ALMA-13B-SFT-HW-CPO-Pref-Multi-BLEU.Q4_K_M.gguf) | Q4_K_M | 8.0 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/ALMA-13B-SFT-HW-CPO-Pref-Multi-BLEU-GGUF/resolve/main/ALMA-13B-SFT-HW-CPO-Pref-Multi-BLEU.Q5_K_S.gguf) | Q5_K_S | 9.1 | |
| [GGUF](https://huggingface.co/mradermacher/ALMA-13B-SFT-HW-CPO-Pref-Multi-BLEU-GGUF/resolve/main/ALMA-13B-SFT-HW-CPO-Pref-Multi-BLEU.Q5_K_M.gguf) | Q5_K_M | 9.3 | |
| [GGUF](https://huggingface.co/mradermacher/ALMA-13B-SFT-HW-CPO-Pref-Multi-BLEU-GGUF/resolve/main/ALMA-13B-SFT-HW-CPO-Pref-Multi-BLEU.Q6_K.gguf) | Q6_K | 10.8 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/ALMA-13B-SFT-HW-CPO-Pref-Multi-BLEU-GGUF/resolve/main/ALMA-13B-SFT-HW-CPO-Pref-Multi-BLEU.Q8_0.gguf) | Q8_0 | 13.9 | fast, best quality |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
mradermacher/Yi-9B-200K-GGUF | mradermacher | 2024-07-02T17:24:00Z | 17,166 | 0 | transformers | [
"transformers",
"gguf",
"en",
"base_model:01-ai/Yi-9B-200K",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
]
| null | 2024-07-01T21:39:24Z | ---
base_model: 01-ai/Yi-9B-200K
language:
- en
library_name: transformers
license: apache-2.0
quantized_by: mradermacher
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
static quants of https://huggingface.co/01-ai/Yi-9B-200K
<!-- provided-files -->
weighted/imatrix quants are available at https://huggingface.co/mradermacher/Yi-9B-200K-i1-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/Yi-9B-200K-GGUF/resolve/main/Yi-9B-200K.Q2_K.gguf) | Q2_K | 3.5 | |
| [GGUF](https://huggingface.co/mradermacher/Yi-9B-200K-GGUF/resolve/main/Yi-9B-200K.IQ3_XS.gguf) | IQ3_XS | 3.8 | |
| [GGUF](https://huggingface.co/mradermacher/Yi-9B-200K-GGUF/resolve/main/Yi-9B-200K.Q3_K_S.gguf) | Q3_K_S | 4.0 | |
| [GGUF](https://huggingface.co/mradermacher/Yi-9B-200K-GGUF/resolve/main/Yi-9B-200K.IQ3_S.gguf) | IQ3_S | 4.0 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/Yi-9B-200K-GGUF/resolve/main/Yi-9B-200K.IQ3_M.gguf) | IQ3_M | 4.2 | |
| [GGUF](https://huggingface.co/mradermacher/Yi-9B-200K-GGUF/resolve/main/Yi-9B-200K.Q3_K_M.gguf) | Q3_K_M | 4.4 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/Yi-9B-200K-GGUF/resolve/main/Yi-9B-200K.Q3_K_L.gguf) | Q3_K_L | 4.8 | |
| [GGUF](https://huggingface.co/mradermacher/Yi-9B-200K-GGUF/resolve/main/Yi-9B-200K.IQ4_XS.gguf) | IQ4_XS | 4.9 | |
| [GGUF](https://huggingface.co/mradermacher/Yi-9B-200K-GGUF/resolve/main/Yi-9B-200K.Q4_K_S.gguf) | Q4_K_S | 5.2 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Yi-9B-200K-GGUF/resolve/main/Yi-9B-200K.Q4_K_M.gguf) | Q4_K_M | 5.4 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Yi-9B-200K-GGUF/resolve/main/Yi-9B-200K.Q5_K_S.gguf) | Q5_K_S | 6.2 | |
| [GGUF](https://huggingface.co/mradermacher/Yi-9B-200K-GGUF/resolve/main/Yi-9B-200K.Q5_K_M.gguf) | Q5_K_M | 6.4 | |
| [GGUF](https://huggingface.co/mradermacher/Yi-9B-200K-GGUF/resolve/main/Yi-9B-200K.Q6_K.gguf) | Q6_K | 7.3 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/Yi-9B-200K-GGUF/resolve/main/Yi-9B-200K.Q8_0.gguf) | Q8_0 | 9.5 | fast, best quality |
| [GGUF](https://huggingface.co/mradermacher/Yi-9B-200K-GGUF/resolve/main/Yi-9B-200K.f16.gguf) | f16 | 17.8 | 16 bpw, overkill |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
augmxnt/shisa-gamma-7b-v1 | augmxnt | 2024-05-19T06:07:36Z | 17,157 | 13 | transformers | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"ja",
"en",
"dataset:augmxnt/ultra-orca-boros-en-ja-v1",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| text-generation | 2023-12-23T20:21:44Z | ---
license: apache-2.0
datasets:
- augmxnt/ultra-orca-boros-en-ja-v1
language:
- ja
- en
---
# shisa-gamma-7b-v1
For more information see our main [Shisa 7B](https://huggingface.co/augmxnt/shisa-gamma-7b-v1/resolve/main/shisa-comparison.png) model
We applied a version of our fine-tune data set onto [Japanese Stable LM Base Gamma 7B](https://huggingface.co/stabilityai/japanese-stablelm-base-gamma-7b) and it performed pretty well, just sharing since it might be of interest.
Check out our [JA MT-Bench results](https://github.com/AUGMXNT/shisa/wiki/Evals-%3A-JA-MT%E2%80%90Bench).
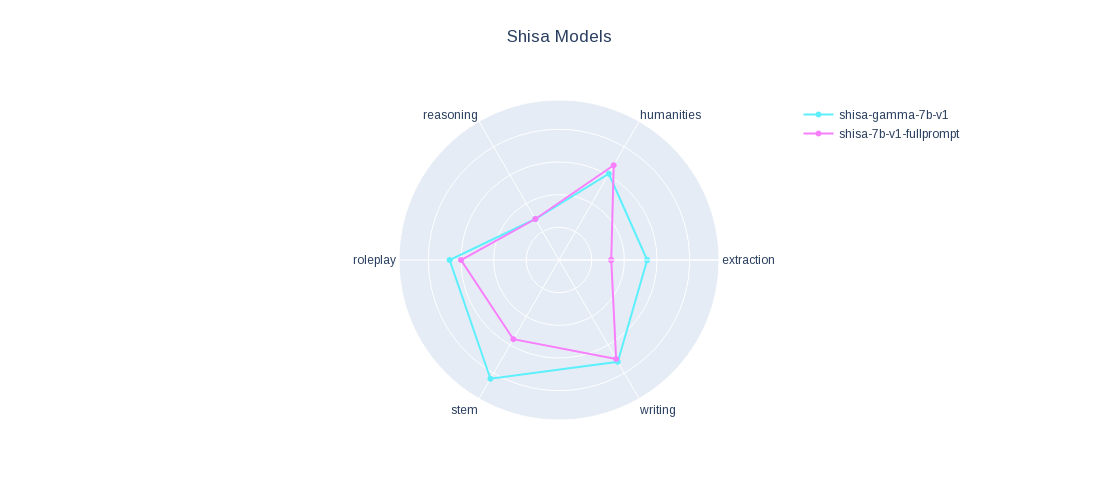
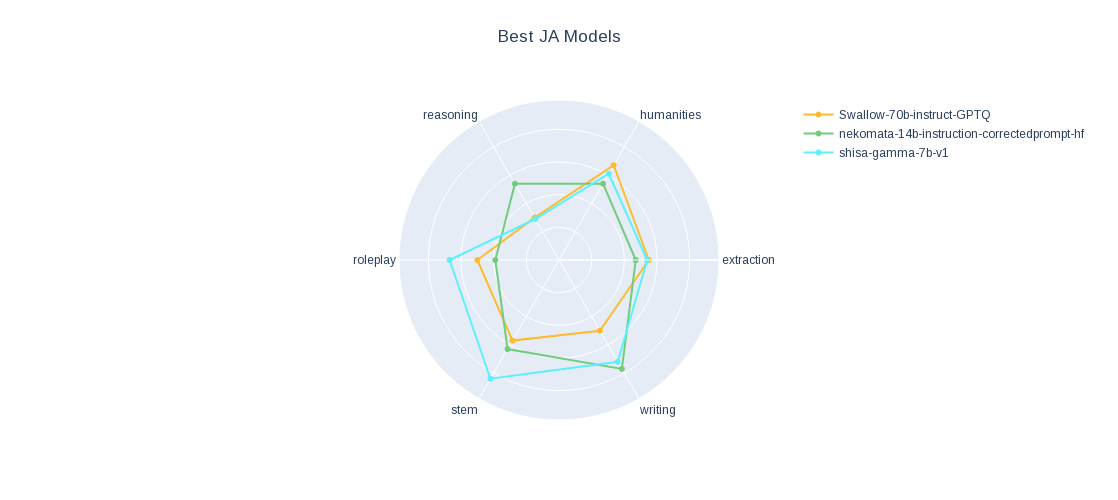 |
lllyasviel/control_v11p_sd15_canny | lllyasviel | 2023-05-04T18:48:49Z | 17,154 | 29 | diffusers | [
"diffusers",
"safetensors",
"art",
"controlnet",
"stable-diffusion",
"controlnet-v1-1",
"image-to-image",
"arxiv:2302.05543",
"base_model:runwayml/stable-diffusion-v1-5",
"license:openrail",
"region:us"
]
| image-to-image | 2023-04-14T19:24:43Z | ---
license: openrail
base_model: runwayml/stable-diffusion-v1-5
tags:
- art
- controlnet
- stable-diffusion
- controlnet-v1-1
- image-to-image
duplicated_from: ControlNet-1-1-preview/control_v11p_sd15_canny
---
# Controlnet - v1.1 - *Canny Version*
**Controlnet v1.1** is the successor model of [Controlnet v1.0](https://huggingface.co/lllyasviel/sd-controlnet-canny)
and was released in [lllyasviel/ControlNet-v1-1](https://huggingface.co/lllyasviel/ControlNet-v1-1) by [Lvmin Zhang](https://huggingface.co/lllyasviel).
This checkpoint is a conversion of [the original checkpoint](https://huggingface.co/lllyasviel/ControlNet-v1-1/blob/main/control_v11p_sd15_canny.pth) into `diffusers` format.
It can be used in combination with **Stable Diffusion**, such as [runwayml/stable-diffusion-v1-5](https://huggingface.co/runwayml/stable-diffusion-v1-5).
For more details, please also have a look at the [🧨 Diffusers docs](https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion/controlnet).
ControlNet is a neural network structure to control diffusion models by adding extra conditions.

This checkpoint corresponds to the ControlNet conditioned on **Canny edges**.
## Model Details
- **Developed by:** Lvmin Zhang, Maneesh Agrawala
- **Model type:** Diffusion-based text-to-image generation model
- **Language(s):** English
- **License:** [The CreativeML OpenRAIL M license](https://huggingface.co/spaces/CompVis/stable-diffusion-license) is an [Open RAIL M license](https://www.licenses.ai/blog/2022/8/18/naming-convention-of-responsible-ai-licenses), adapted from the work that [BigScience](https://bigscience.huggingface.co/) and [the RAIL Initiative](https://www.licenses.ai/) are jointly carrying in the area of responsible AI licensing. See also [the article about the BLOOM Open RAIL license](https://bigscience.huggingface.co/blog/the-bigscience-rail-license) on which our license is based.
- **Resources for more information:** [GitHub Repository](https://github.com/lllyasviel/ControlNet), [Paper](https://arxiv.org/abs/2302.05543).
- **Cite as:**
@misc{zhang2023adding,
title={Adding Conditional Control to Text-to-Image Diffusion Models},
author={Lvmin Zhang and Maneesh Agrawala},
year={2023},
eprint={2302.05543},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
## Introduction
Controlnet was proposed in [*Adding Conditional Control to Text-to-Image Diffusion Models*](https://arxiv.org/abs/2302.05543) by
Lvmin Zhang, Maneesh Agrawala.
The abstract reads as follows:
*We present a neural network structure, ControlNet, to control pretrained large diffusion models to support additional input conditions.
The ControlNet learns task-specific conditions in an end-to-end way, and the learning is robust even when the training dataset is small (< 50k).
Moreover, training a ControlNet is as fast as fine-tuning a diffusion model, and the model can be trained on a personal devices.
Alternatively, if powerful computation clusters are available, the model can scale to large amounts (millions to billions) of data.
We report that large diffusion models like Stable Diffusion can be augmented with ControlNets to enable conditional inputs like edge maps, segmentation maps, keypoints, etc.
This may enrich the methods to control large diffusion models and further facilitate related applications.*
## Example
It is recommended to use the checkpoint with [Stable Diffusion v1-5](https://huggingface.co/runwayml/stable-diffusion-v1-5) as the checkpoint
has been trained on it.
Experimentally, the checkpoint can be used with other diffusion models such as dreamboothed stable diffusion.
**Note**: If you want to process an image to create the auxiliary conditioning, external dependencies are required as shown below:
1. Install [opencv](https://opencv.org/):
```sh
$ pip install opencv-contrib-python
```
2. Let's install `diffusers` and related packages:
```
$ pip install diffusers transformers accelerate
```
3. Run code:
```python
import torch
import os
from huggingface_hub import HfApi
from pathlib import Path
from diffusers.utils import load_image
import numpy as np
import cv2
from PIL import Image
from diffusers import (
ControlNetModel,
StableDiffusionControlNetPipeline,
UniPCMultistepScheduler,
)
checkpoint = "lllyasviel/control_v11p_sd15_canny"
image = load_image(
"https://huggingface.co/lllyasviel/control_v11p_sd15_canny/resolve/main/images/input.png"
)
image = np.array(image)
low_threshold = 100
high_threshold = 200
image = cv2.Canny(image, low_threshold, high_threshold)
image = image[:, :, None]
image = np.concatenate([image, image, image], axis=2)
control_image = Image.fromarray(image)
control_image.save("./images/control.png")
controlnet = ControlNetModel.from_pretrained(checkpoint, torch_dtype=torch.float16)
pipe = StableDiffusionControlNetPipeline.from_pretrained(
"runwayml/stable-diffusion-v1-5", controlnet=controlnet, torch_dtype=torch.float16
)
pipe.scheduler = UniPCMultistepScheduler.from_config(pipe.scheduler.config)
pipe.enable_model_cpu_offload()
generator = torch.manual_seed(33)
image = pipe("a blue paradise bird in the jungle", num_inference_steps=20, generator=generator, image=control_image).images[0]
image.save('images/image_out.png')
```



## Other released checkpoints v1-1
The authors released 14 different checkpoints, each trained with [Stable Diffusion v1-5](https://huggingface.co/runwayml/stable-diffusion-v1-5)
on a different type of conditioning:
| Model Name | Control Image Overview| Condition Image | Control Image Example | Generated Image Example |
|---|---|---|---|---|
|[lllyasviel/control_v11p_sd15_canny](https://huggingface.co/lllyasviel/control_v11p_sd15_canny)<br/> | *Trained with canny edge detection* | A monochrome image with white edges on a black background.|<a href="https://huggingface.co/lllyasviel/control_v11p_sd15_canny/resolve/main/images/control.png"><img width="64" style="margin:0;padding:0;" src="https://huggingface.co/lllyasviel/control_v11p_sd15_canny/resolve/main/images/control.png"/></a>|<a href="https://huggingface.co/lllyasviel/control_v11p_sd15_canny/resolve/main/images/image_out.png"><img width="64" src="https://huggingface.co/lllyasviel/control_v11p_sd15_canny/resolve/main/images/image_out.png"/></a>|
|[lllyasviel/control_v11e_sd15_ip2p](https://huggingface.co/lllyasviel/control_v11e_sd15_ip2p)<br/> | *Trained with pixel to pixel instruction* | No condition .|<a href="https://huggingface.co/lllyasviel/control_v11e_sd15_ip2p/resolve/main/images/control.png"><img width="64" style="margin:0;padding:0;" src="https://huggingface.co/lllyasviel/control_v11e_sd15_ip2p/resolve/main/images/control.png"/></a>|<a href="https://huggingface.co/lllyasviel/control_v11e_sd15_ip2p/resolve/main/images/image_out.png"><img width="64" src="https://huggingface.co/lllyasviel/control_v11e_sd15_ip2p/resolve/main/images/image_out.png"/></a>|
|[lllyasviel/control_v11p_sd15_inpaint](https://huggingface.co/lllyasviel/control_v11p_sd15_inpaint)<br/> | Trained with image inpainting | No condition.|<a href="https://huggingface.co/lllyasviel/control_v11p_sd15_inpaint/resolve/main/images/control.png"><img width="64" style="margin:0;padding:0;" src="https://huggingface.co/lllyasviel/control_v11p_sd15_inpaint/resolve/main/images/control.png"/></a>|<a href="https://huggingface.co/lllyasviel/control_v11p_sd15_inpaint/resolve/main/images/output.png"><img width="64" src="https://huggingface.co/lllyasviel/control_v11p_sd15_inpaint/resolve/main/images/output.png"/></a>|
|[lllyasviel/control_v11p_sd15_mlsd](https://huggingface.co/lllyasviel/control_v11p_sd15_mlsd)<br/> | Trained with multi-level line segment detection | An image with annotated line segments.|<a href="https://huggingface.co/lllyasviel/control_v11p_sd15_mlsd/resolve/main/images/control.png"><img width="64" style="margin:0;padding:0;" src="https://huggingface.co/lllyasviel/control_v11p_sd15_mlsd/resolve/main/images/control.png"/></a>|<a href="https://huggingface.co/lllyasviel/control_v11p_sd15_mlsd/resolve/main/images/image_out.png"><img width="64" src="https://huggingface.co/lllyasviel/control_v11p_sd15_mlsd/resolve/main/images/image_out.png"/></a>|
|[lllyasviel/control_v11f1p_sd15_depth](https://huggingface.co/lllyasviel/control_v11f1p_sd15_depth)<br/> | Trained with depth estimation | An image with depth information, usually represented as a grayscale image.|<a href="https://huggingface.co/lllyasviel/control_v11f1p_sd15_depth/resolve/main/images/control.png"><img width="64" style="margin:0;padding:0;" src="https://huggingface.co/lllyasviel/control_v11f1p_sd15_depth/resolve/main/images/control.png"/></a>|<a href="https://huggingface.co/lllyasviel/control_v11f1p_sd15_depth/resolve/main/images/image_out.png"><img width="64" src="https://huggingface.co/lllyasviel/control_v11f1p_sd15_depth/resolve/main/images/image_out.png"/></a>|
|[lllyasviel/control_v11p_sd15_normalbae](https://huggingface.co/lllyasviel/control_v11p_sd15_normalbae)<br/> | Trained with surface normal estimation | An image with surface normal information, usually represented as a color-coded image.|<a href="https://huggingface.co/lllyasviel/control_v11p_sd15_normalbae/resolve/main/images/control.png"><img width="64" style="margin:0;padding:0;" src="https://huggingface.co/lllyasviel/control_v11p_sd15_normalbae/resolve/main/images/control.png"/></a>|<a href="https://huggingface.co/lllyasviel/control_v11p_sd15_normalbae/resolve/main/images/image_out.png"><img width="64" src="https://huggingface.co/lllyasviel/control_v11p_sd15_normalbae/resolve/main/images/image_out.png"/></a>|
|[lllyasviel/control_v11p_sd15_seg](https://huggingface.co/lllyasviel/control_v11p_sd15_seg)<br/> | Trained with image segmentation | An image with segmented regions, usually represented as a color-coded image.|<a href="https://huggingface.co/lllyasviel/control_v11p_sd15_seg/resolve/main/images/control.png"><img width="64" style="margin:0;padding:0;" src="https://huggingface.co/lllyasviel/control_v11p_sd15_seg/resolve/main/images/control.png"/></a>|<a href="https://huggingface.co/lllyasviel/control_v11p_sd15_seg/resolve/main/images/image_out.png"><img width="64" src="https://huggingface.co/lllyasviel/control_v11p_sd15_seg/resolve/main/images/image_out.png"/></a>|
|[lllyasviel/control_v11p_sd15_lineart](https://huggingface.co/lllyasviel/control_v11p_sd15_lineart)<br/> | Trained with line art generation | An image with line art, usually black lines on a white background.|<a href="https://huggingface.co/lllyasviel/control_v11p_sd15_lineart/resolve/main/images/control.png"><img width="64" style="margin:0;padding:0;" src="https://huggingface.co/lllyasviel/control_v11p_sd15_lineart/resolve/main/images/control.png"/></a>|<a href="https://huggingface.co/lllyasviel/control_v11p_sd15_lineart/resolve/main/images/image_out.png"><img width="64" src="https://huggingface.co/lllyasviel/control_v11p_sd15_lineart/resolve/main/images/image_out.png"/></a>|
|[lllyasviel/control_v11p_sd15s2_lineart_anime](https://huggingface.co/lllyasviel/control_v11p_sd15s2_lineart_anime)<br/> | Trained with anime line art generation | An image with anime-style line art.|<a href="https://huggingface.co/lllyasviel/control_v11p_sd15s2_lineart_anime/resolve/main/images/control.png"><img width="64" style="margin:0;padding:0;" src="https://huggingface.co/lllyasviel/control_v11p_sd15s2_lineart_anime/resolve/main/images/control.png"/></a>|<a href="https://huggingface.co/lllyasviel/control_v11p_sd15s2_lineart_anime/resolve/main/images/image_out.png"><img width="64" src="https://huggingface.co/lllyasviel/control_v11p_sd15s2_lineart_anime/resolve/main/images/image_out.png"/></a>|
|[lllyasviel/control_v11p_sd15_openpose](https://huggingface.co/lllyasviel/control_v11p_sd15s2_lineart_anime)<br/> | Trained with human pose estimation | An image with human poses, usually represented as a set of keypoints or skeletons.|<a href="https://huggingface.co/lllyasviel/control_v11p_sd15_openpose/resolve/main/images/control.png"><img width="64" style="margin:0;padding:0;" src="https://huggingface.co/lllyasviel/control_v11p_sd15_openpose/resolve/main/images/control.png"/></a>|<a href="https://huggingface.co/lllyasviel/control_v11p_sd15_openpose/resolve/main/images/image_out.png"><img width="64" src="https://huggingface.co/lllyasviel/control_v11p_sd15_openpose/resolve/main/images/image_out.png"/></a>|
|[lllyasviel/control_v11p_sd15_scribble](https://huggingface.co/lllyasviel/control_v11p_sd15_scribble)<br/> | Trained with scribble-based image generation | An image with scribbles, usually random or user-drawn strokes.|<a href="https://huggingface.co/lllyasviel/control_v11p_sd15_scribble/resolve/main/images/control.png"><img width="64" style="margin:0;padding:0;" src="https://huggingface.co/lllyasviel/control_v11p_sd15_scribble/resolve/main/images/control.png"/></a>|<a href="https://huggingface.co/lllyasviel/control_v11p_sd15_scribble/resolve/main/images/image_out.png"><img width="64" src="https://huggingface.co/lllyasviel/control_v11p_sd15_scribble/resolve/main/images/image_out.png"/></a>|
|[lllyasviel/control_v11p_sd15_softedge](https://huggingface.co/lllyasviel/control_v11p_sd15_softedge)<br/> | Trained with soft edge image generation | An image with soft edges, usually to create a more painterly or artistic effect.|<a href="https://huggingface.co/lllyasviel/control_v11p_sd15_softedge/resolve/main/images/control.png"><img width="64" style="margin:0;padding:0;" src="https://huggingface.co/lllyasviel/control_v11p_sd15_softedge/resolve/main/images/control.png"/></a>|<a href="https://huggingface.co/lllyasviel/control_v11p_sd15_softedge/resolve/main/images/image_out.png"><img width="64" src="https://huggingface.co/lllyasviel/control_v11p_sd15_softedge/resolve/main/images/image_out.png"/></a>|
|[lllyasviel/control_v11e_sd15_shuffle](https://huggingface.co/lllyasviel/control_v11e_sd15_shuffle)<br/> | Trained with image shuffling | An image with shuffled patches or regions.|<a href="https://huggingface.co/lllyasviel/control_v11e_sd15_shuffle/resolve/main/images/control.png"><img width="64" style="margin:0;padding:0;" src="https://huggingface.co/lllyasviel/control_v11e_sd15_shuffle/resolve/main/images/control.png"/></a>|<a href="https://huggingface.co/lllyasviel/control_v11e_sd15_shuffle/resolve/main/images/image_out.png"><img width="64" src="https://huggingface.co/lllyasviel/control_v11e_sd15_shuffle/resolve/main/images/image_out.png"/></a>|
|[lllyasviel/control_v11f1e_sd15_tile](https://huggingface.co/lllyasviel/control_v11f1e_sd15_tile)<br/> | Trained with image tiling | A blurry image or part of an image .|<a href="https://huggingface.co/lllyasviel/control_v11f1e_sd15_tile/resolve/main/images/original.png"><img width="64" style="margin:0;padding:0;" src="https://huggingface.co/lllyasviel/control_v11f1e_sd15_tile/resolve/main/images/original.png"/></a>|<a href="https://huggingface.co/lllyasviel/control_v11f1e_sd15_tile/resolve/main/images/output.png"><img width="64" src="https://huggingface.co/lllyasviel/control_v11f1e_sd15_tile/resolve/main/images/output.png"/></a>|
## Improvements in Canny 1.1:
- The training dataset of previous cnet 1.0 has several problems including (1) a small group of greyscale human images are duplicated thousands of times (!!), causing the previous model somewhat likely to generate grayscale human images; (2) some images has low quality, very blurry, or significant JPEG artifacts; (3) a small group of images has wrong paired prompts caused by a mistake in our data processing scripts. The new model fixed all problems of the training dataset and should be more reasonable in many cases.
- Because the Canny model is one of the most important (perhaps the most frequently used) ControlNet, we used a fund to train it on a machine with 8 Nvidia A100 80G with batchsize 8×32=256 for 3 days, spending 72×30=2160 USD (8 A100 80G with 30 USD/hour). The model is resumed from Canny 1.0.
- Some reasonable data augmentations are applied to training, like random left-right flipping.
- Although it is difficult to evaluate a ControlNet, we find Canny 1.1 is a bit more robust and a bit higher visual quality than Canny 1.0.
## More information
For more information, please also have a look at the [Diffusers ControlNet Blog Post](https://huggingface.co/blog/controlnet) and have a look at the [official docs](https://github.com/lllyasviel/ControlNet-v1-1-nightly). |
legraphista/glm-4-9b-chat-IMat-GGUF | legraphista | 2024-06-20T11:58:12Z | 17,152 | 2 | gguf | [
"gguf",
"glm",
"chatglm",
"thudm",
"quantized",
"GGUF",
"quantization",
"imat",
"imatrix",
"static",
"16bit",
"8bit",
"6bit",
"5bit",
"4bit",
"3bit",
"2bit",
"1bit",
"text-generation",
"zh",
"en",
"base_model:THUDM/glm-4-9b-chat",
"license:other",
"region:us"
]
| text-generation | 2024-06-20T08:52:46Z | ---
base_model: THUDM/glm-4-9b-chat
inference: false
language:
- zh
- en
library_name: gguf
license: other
license_link: https://huggingface.co/THUDM/glm-4-9b-chat/blob/main/LICENSE
license_name: glm-4
pipeline_tag: text-generation
quantized_by: legraphista
tags:
- glm
- chatglm
- thudm
- quantized
- GGUF
- quantization
- imat
- imatrix
- static
- 16bit
- 8bit
- 6bit
- 5bit
- 4bit
- 3bit
- 2bit
- 1bit
---
# glm-4-9b-chat-IMat-GGUF
_Llama.cpp imatrix quantization of THUDM/glm-4-9b-chat_
Original Model: [THUDM/glm-4-9b-chat](https://huggingface.co/THUDM/glm-4-9b-chat)
Original dtype: `BF16` (`bfloat16`)
Quantized by: [https://github.com/ggerganov/llama.cpp/pull/6999](https://github.com/ggerganov/llama.cpp/pull/6999)
IMatrix dataset: [here](https://gist.githubusercontent.com/bartowski1182/eb213dccb3571f863da82e99418f81e8/raw/b2869d80f5c16fd7082594248e80144677736635/calibration_datav3.txt)
- [Files](#files)
- [IMatrix](#imatrix)
- [Common Quants](#common-quants)
- [All Quants](#all-quants)
- [Downloading using huggingface-cli](#downloading-using-huggingface-cli)
- [Inference](#inference)
- [Simple chat template](#simple-chat-template)
- [Chat template with system prompt](#chat-template-with-system-prompt)
- [Llama.cpp](#llama-cpp)
- [FAQ](#faq)
- [Why is the IMatrix not applied everywhere?](#why-is-the-imatrix-not-applied-everywhere)
- [How do I merge a split GGUF?](#how-do-i-merge-a-split-gguf)
---
## Files
### IMatrix
Status: ✅ Available
Link: [here](https://huggingface.co/legraphista/glm-4-9b-chat-IMat-GGUF/blob/main/imatrix.dat)
### Common Quants
| Filename | Quant type | File Size | Status | Uses IMatrix | Is Split |
| -------- | ---------- | --------- | ------ | ------------ | -------- |
| [glm-4-9b-chat.Q8_0.gguf](https://huggingface.co/legraphista/glm-4-9b-chat-IMat-GGUF/blob/main/glm-4-9b-chat.Q8_0.gguf) | Q8_0 | 9.99GB | ✅ Available | ⚪ Static | 📦 No
| [glm-4-9b-chat.Q6_K.gguf](https://huggingface.co/legraphista/glm-4-9b-chat-IMat-GGUF/blob/main/glm-4-9b-chat.Q6_K.gguf) | Q6_K | 8.26GB | ✅ Available | ⚪ Static | 📦 No
| [glm-4-9b-chat.Q4_K.gguf](https://huggingface.co/legraphista/glm-4-9b-chat-IMat-GGUF/blob/main/glm-4-9b-chat.Q4_K.gguf) | Q4_K | 6.25GB | ✅ Available | 🟢 IMatrix | 📦 No
| [glm-4-9b-chat.Q3_K.gguf](https://huggingface.co/legraphista/glm-4-9b-chat-IMat-GGUF/blob/main/glm-4-9b-chat.Q3_K.gguf) | Q3_K | 5.06GB | ✅ Available | 🟢 IMatrix | 📦 No
| [glm-4-9b-chat.Q2_K.gguf](https://huggingface.co/legraphista/glm-4-9b-chat-IMat-GGUF/blob/main/glm-4-9b-chat.Q2_K.gguf) | Q2_K | 3.99GB | ✅ Available | 🟢 IMatrix | 📦 No
### All Quants
| Filename | Quant type | File Size | Status | Uses IMatrix | Is Split |
| -------- | ---------- | --------- | ------ | ------------ | -------- |
| [glm-4-9b-chat.BF16.gguf](https://huggingface.co/legraphista/glm-4-9b-chat-IMat-GGUF/blob/main/glm-4-9b-chat.BF16.gguf) | BF16 | 18.81GB | ✅ Available | ⚪ Static | 📦 No
| [glm-4-9b-chat.FP16.gguf](https://huggingface.co/legraphista/glm-4-9b-chat-IMat-GGUF/blob/main/glm-4-9b-chat.FP16.gguf) | F16 | 18.81GB | ✅ Available | ⚪ Static | 📦 No
| [glm-4-9b-chat.Q8_0.gguf](https://huggingface.co/legraphista/glm-4-9b-chat-IMat-GGUF/blob/main/glm-4-9b-chat.Q8_0.gguf) | Q8_0 | 9.99GB | ✅ Available | ⚪ Static | 📦 No
| [glm-4-9b-chat.Q6_K.gguf](https://huggingface.co/legraphista/glm-4-9b-chat-IMat-GGUF/blob/main/glm-4-9b-chat.Q6_K.gguf) | Q6_K | 8.26GB | ✅ Available | ⚪ Static | 📦 No
| [glm-4-9b-chat.Q5_K.gguf](https://huggingface.co/legraphista/glm-4-9b-chat-IMat-GGUF/blob/main/glm-4-9b-chat.Q5_K.gguf) | Q5_K | 7.14GB | ✅ Available | ⚪ Static | 📦 No
| [glm-4-9b-chat.Q5_K_S.gguf](https://huggingface.co/legraphista/glm-4-9b-chat-IMat-GGUF/blob/main/glm-4-9b-chat.Q5_K_S.gguf) | Q5_K_S | 6.69GB | ✅ Available | ⚪ Static | 📦 No
| [glm-4-9b-chat.Q4_K.gguf](https://huggingface.co/legraphista/glm-4-9b-chat-IMat-GGUF/blob/main/glm-4-9b-chat.Q4_K.gguf) | Q4_K | 6.25GB | ✅ Available | 🟢 IMatrix | 📦 No
| [glm-4-9b-chat.Q4_K_S.gguf](https://huggingface.co/legraphista/glm-4-9b-chat-IMat-GGUF/blob/main/glm-4-9b-chat.Q4_K_S.gguf) | Q4_K_S | 5.75GB | ✅ Available | 🟢 IMatrix | 📦 No
| [glm-4-9b-chat.IQ4_NL.gguf](https://huggingface.co/legraphista/glm-4-9b-chat-IMat-GGUF/blob/main/glm-4-9b-chat.IQ4_NL.gguf) | IQ4_NL | 5.46GB | ✅ Available | 🟢 IMatrix | 📦 No
| [glm-4-9b-chat.IQ4_XS.gguf](https://huggingface.co/legraphista/glm-4-9b-chat-IMat-GGUF/blob/main/glm-4-9b-chat.IQ4_XS.gguf) | IQ4_XS | 5.25GB | ✅ Available | 🟢 IMatrix | 📦 No
| [glm-4-9b-chat.Q3_K.gguf](https://huggingface.co/legraphista/glm-4-9b-chat-IMat-GGUF/blob/main/glm-4-9b-chat.Q3_K.gguf) | Q3_K | 5.06GB | ✅ Available | 🟢 IMatrix | 📦 No
| [glm-4-9b-chat.Q3_K_L.gguf](https://huggingface.co/legraphista/glm-4-9b-chat-IMat-GGUF/blob/main/glm-4-9b-chat.Q3_K_L.gguf) | Q3_K_L | 5.28GB | ✅ Available | 🟢 IMatrix | 📦 No
| [glm-4-9b-chat.Q3_K_S.gguf](https://huggingface.co/legraphista/glm-4-9b-chat-IMat-GGUF/blob/main/glm-4-9b-chat.Q3_K_S.gguf) | Q3_K_S | 4.59GB | ✅ Available | 🟢 IMatrix | 📦 No
| [glm-4-9b-chat.IQ3_M.gguf](https://huggingface.co/legraphista/glm-4-9b-chat-IMat-GGUF/blob/main/glm-4-9b-chat.IQ3_M.gguf) | IQ3_M | 4.81GB | ✅ Available | 🟢 IMatrix | 📦 No
| [glm-4-9b-chat.IQ3_S.gguf](https://huggingface.co/legraphista/glm-4-9b-chat-IMat-GGUF/blob/main/glm-4-9b-chat.IQ3_S.gguf) | IQ3_S | 4.59GB | ✅ Available | 🟢 IMatrix | 📦 No
| [glm-4-9b-chat.IQ3_XS.gguf](https://huggingface.co/legraphista/glm-4-9b-chat-IMat-GGUF/blob/main/glm-4-9b-chat.IQ3_XS.gguf) | IQ3_XS | 4.43GB | ✅ Available | 🟢 IMatrix | 📦 No
| [glm-4-9b-chat.IQ3_XXS.gguf](https://huggingface.co/legraphista/glm-4-9b-chat-IMat-GGUF/blob/main/glm-4-9b-chat.IQ3_XXS.gguf) | IQ3_XXS | 4.26GB | ✅ Available | 🟢 IMatrix | 📦 No
| [glm-4-9b-chat.Q2_K.gguf](https://huggingface.co/legraphista/glm-4-9b-chat-IMat-GGUF/blob/main/glm-4-9b-chat.Q2_K.gguf) | Q2_K | 3.99GB | ✅ Available | 🟢 IMatrix | 📦 No
| [glm-4-9b-chat.Q2_K_S.gguf](https://huggingface.co/legraphista/glm-4-9b-chat-IMat-GGUF/blob/main/glm-4-9b-chat.Q2_K_S.gguf) | Q2_K_S | 3.96GB | ✅ Available | 🟢 IMatrix | 📦 No
| [glm-4-9b-chat.IQ2_M.gguf](https://huggingface.co/legraphista/glm-4-9b-chat-IMat-GGUF/blob/main/glm-4-9b-chat.IQ2_M.gguf) | IQ2_M | 3.93GB | ✅ Available | 🟢 IMatrix | 📦 No
| [glm-4-9b-chat.IQ2_S.gguf](https://huggingface.co/legraphista/glm-4-9b-chat-IMat-GGUF/blob/main/glm-4-9b-chat.IQ2_S.gguf) | IQ2_S | 3.77GB | ✅ Available | 🟢 IMatrix | 📦 No
| [glm-4-9b-chat.IQ2_XS.gguf](https://huggingface.co/legraphista/glm-4-9b-chat-IMat-GGUF/blob/main/glm-4-9b-chat.IQ2_XS.gguf) | IQ2_XS | 3.61GB | ✅ Available | 🟢 IMatrix | 📦 No
| [glm-4-9b-chat.IQ2_XXS.gguf](https://huggingface.co/legraphista/glm-4-9b-chat-IMat-GGUF/blob/main/glm-4-9b-chat.IQ2_XXS.gguf) | IQ2_XXS | 3.43GB | ✅ Available | 🟢 IMatrix | 📦 No
| [glm-4-9b-chat.IQ1_M.gguf](https://huggingface.co/legraphista/glm-4-9b-chat-IMat-GGUF/blob/main/glm-4-9b-chat.IQ1_M.gguf) | IQ1_M | 3.22GB | ✅ Available | 🟢 IMatrix | 📦 No
| [glm-4-9b-chat.IQ1_S.gguf](https://huggingface.co/legraphista/glm-4-9b-chat-IMat-GGUF/blob/main/glm-4-9b-chat.IQ1_S.gguf) | IQ1_S | 3.10GB | ✅ Available | 🟢 IMatrix | 📦 No
## Downloading using huggingface-cli
If you do not have hugginface-cli installed:
```
pip install -U "huggingface_hub[cli]"
```
Download the specific file you want:
```
huggingface-cli download legraphista/glm-4-9b-chat-IMat-GGUF --include "glm-4-9b-chat.Q8_0.gguf" --local-dir ./
```
If the model file is big, it has been split into multiple files. In order to download them all to a local folder, run:
```
huggingface-cli download legraphista/glm-4-9b-chat-IMat-GGUF --include "glm-4-9b-chat.Q8_0/*" --local-dir ./
# see FAQ for merging GGUF's
```
---
## Inference
### Simple chat template
```
[gMASK]<sop><|user|>
{user_prompt}<|assistant|>
{assistant_response}<|user|>
{next_user_prompt}
```
### Chat template with system prompt
```
[gMASK]<sop><|system|>
{system_prompt}<|user|>
{user_prompt}<|assistant|>
{assistant_response}<|user|>
{next_user_prompt}
```
### Llama.cpp
```
llama.cpp/main -m glm-4-9b-chat.Q8_0.gguf --color -i -p "prompt here (according to the chat template)"
```
---
## FAQ
### Why is the IMatrix not applied everywhere?
According to [this investigation](https://www.reddit.com/r/LocalLLaMA/comments/1993iro/ggufs_quants_can_punch_above_their_weights_now/), it appears that lower quantizations are the only ones that benefit from the imatrix input (as per hellaswag results).
### How do I merge a split GGUF?
1. Make sure you have `gguf-split` available
- To get hold of `gguf-split`, navigate to https://github.com/ggerganov/llama.cpp/releases
- Download the appropriate zip for your system from the latest release
- Unzip the archive and you should be able to find `gguf-split`
2. Locate your GGUF chunks folder (ex: `glm-4-9b-chat.Q8_0`)
3. Run `gguf-split --merge glm-4-9b-chat.Q8_0/glm-4-9b-chat.Q8_0-00001-of-XXXXX.gguf glm-4-9b-chat.Q8_0.gguf`
- Make sure to point `gguf-split` to the first chunk of the split.
---
Got a suggestion? Ping me [@legraphista](https://x.com/legraphista)! |
RichardErkhov/Weyaxi_-_HelpSteer-filtered-neural-chat-7b-v3-1-7B-gguf | RichardErkhov | 2024-06-30T06:12:25Z | 17,145 | 0 | null | [
"gguf",
"region:us"
]
| null | 2024-06-30T03:57:50Z | Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
HelpSteer-filtered-neural-chat-7b-v3-1-7B - GGUF
- Model creator: https://huggingface.co/Weyaxi/
- Original model: https://huggingface.co/Weyaxi/HelpSteer-filtered-neural-chat-7b-v3-1-7B/
| Name | Quant method | Size |
| ---- | ---- | ---- |
| [HelpSteer-filtered-neural-chat-7b-v3-1-7B.Q2_K.gguf](https://huggingface.co/RichardErkhov/Weyaxi_-_HelpSteer-filtered-neural-chat-7b-v3-1-7B-gguf/blob/main/HelpSteer-filtered-neural-chat-7b-v3-1-7B.Q2_K.gguf) | Q2_K | 2.53GB |
| [HelpSteer-filtered-neural-chat-7b-v3-1-7B.IQ3_XS.gguf](https://huggingface.co/RichardErkhov/Weyaxi_-_HelpSteer-filtered-neural-chat-7b-v3-1-7B-gguf/blob/main/HelpSteer-filtered-neural-chat-7b-v3-1-7B.IQ3_XS.gguf) | IQ3_XS | 2.81GB |
| [HelpSteer-filtered-neural-chat-7b-v3-1-7B.IQ3_S.gguf](https://huggingface.co/RichardErkhov/Weyaxi_-_HelpSteer-filtered-neural-chat-7b-v3-1-7B-gguf/blob/main/HelpSteer-filtered-neural-chat-7b-v3-1-7B.IQ3_S.gguf) | IQ3_S | 2.96GB |
| [HelpSteer-filtered-neural-chat-7b-v3-1-7B.Q3_K_S.gguf](https://huggingface.co/RichardErkhov/Weyaxi_-_HelpSteer-filtered-neural-chat-7b-v3-1-7B-gguf/blob/main/HelpSteer-filtered-neural-chat-7b-v3-1-7B.Q3_K_S.gguf) | Q3_K_S | 2.95GB |
| [HelpSteer-filtered-neural-chat-7b-v3-1-7B.IQ3_M.gguf](https://huggingface.co/RichardErkhov/Weyaxi_-_HelpSteer-filtered-neural-chat-7b-v3-1-7B-gguf/blob/main/HelpSteer-filtered-neural-chat-7b-v3-1-7B.IQ3_M.gguf) | IQ3_M | 3.06GB |
| [HelpSteer-filtered-neural-chat-7b-v3-1-7B.Q3_K.gguf](https://huggingface.co/RichardErkhov/Weyaxi_-_HelpSteer-filtered-neural-chat-7b-v3-1-7B-gguf/blob/main/HelpSteer-filtered-neural-chat-7b-v3-1-7B.Q3_K.gguf) | Q3_K | 3.28GB |
| [HelpSteer-filtered-neural-chat-7b-v3-1-7B.Q3_K_M.gguf](https://huggingface.co/RichardErkhov/Weyaxi_-_HelpSteer-filtered-neural-chat-7b-v3-1-7B-gguf/blob/main/HelpSteer-filtered-neural-chat-7b-v3-1-7B.Q3_K_M.gguf) | Q3_K_M | 3.28GB |
| [HelpSteer-filtered-neural-chat-7b-v3-1-7B.Q3_K_L.gguf](https://huggingface.co/RichardErkhov/Weyaxi_-_HelpSteer-filtered-neural-chat-7b-v3-1-7B-gguf/blob/main/HelpSteer-filtered-neural-chat-7b-v3-1-7B.Q3_K_L.gguf) | Q3_K_L | 3.56GB |
| [HelpSteer-filtered-neural-chat-7b-v3-1-7B.IQ4_XS.gguf](https://huggingface.co/RichardErkhov/Weyaxi_-_HelpSteer-filtered-neural-chat-7b-v3-1-7B-gguf/blob/main/HelpSteer-filtered-neural-chat-7b-v3-1-7B.IQ4_XS.gguf) | IQ4_XS | 3.67GB |
| [HelpSteer-filtered-neural-chat-7b-v3-1-7B.Q4_0.gguf](https://huggingface.co/RichardErkhov/Weyaxi_-_HelpSteer-filtered-neural-chat-7b-v3-1-7B-gguf/blob/main/HelpSteer-filtered-neural-chat-7b-v3-1-7B.Q4_0.gguf) | Q4_0 | 3.83GB |
| [HelpSteer-filtered-neural-chat-7b-v3-1-7B.IQ4_NL.gguf](https://huggingface.co/RichardErkhov/Weyaxi_-_HelpSteer-filtered-neural-chat-7b-v3-1-7B-gguf/blob/main/HelpSteer-filtered-neural-chat-7b-v3-1-7B.IQ4_NL.gguf) | IQ4_NL | 3.87GB |
| [HelpSteer-filtered-neural-chat-7b-v3-1-7B.Q4_K_S.gguf](https://huggingface.co/RichardErkhov/Weyaxi_-_HelpSteer-filtered-neural-chat-7b-v3-1-7B-gguf/blob/main/HelpSteer-filtered-neural-chat-7b-v3-1-7B.Q4_K_S.gguf) | Q4_K_S | 3.86GB |
| [HelpSteer-filtered-neural-chat-7b-v3-1-7B.Q4_K.gguf](https://huggingface.co/RichardErkhov/Weyaxi_-_HelpSteer-filtered-neural-chat-7b-v3-1-7B-gguf/blob/main/HelpSteer-filtered-neural-chat-7b-v3-1-7B.Q4_K.gguf) | Q4_K | 4.07GB |
| [HelpSteer-filtered-neural-chat-7b-v3-1-7B.Q4_K_M.gguf](https://huggingface.co/RichardErkhov/Weyaxi_-_HelpSteer-filtered-neural-chat-7b-v3-1-7B-gguf/blob/main/HelpSteer-filtered-neural-chat-7b-v3-1-7B.Q4_K_M.gguf) | Q4_K_M | 4.07GB |
| [HelpSteer-filtered-neural-chat-7b-v3-1-7B.Q4_1.gguf](https://huggingface.co/RichardErkhov/Weyaxi_-_HelpSteer-filtered-neural-chat-7b-v3-1-7B-gguf/blob/main/HelpSteer-filtered-neural-chat-7b-v3-1-7B.Q4_1.gguf) | Q4_1 | 4.24GB |
| [HelpSteer-filtered-neural-chat-7b-v3-1-7B.Q5_0.gguf](https://huggingface.co/RichardErkhov/Weyaxi_-_HelpSteer-filtered-neural-chat-7b-v3-1-7B-gguf/blob/main/HelpSteer-filtered-neural-chat-7b-v3-1-7B.Q5_0.gguf) | Q5_0 | 4.65GB |
| [HelpSteer-filtered-neural-chat-7b-v3-1-7B.Q5_K_S.gguf](https://huggingface.co/RichardErkhov/Weyaxi_-_HelpSteer-filtered-neural-chat-7b-v3-1-7B-gguf/blob/main/HelpSteer-filtered-neural-chat-7b-v3-1-7B.Q5_K_S.gguf) | Q5_K_S | 4.65GB |
| [HelpSteer-filtered-neural-chat-7b-v3-1-7B.Q5_K.gguf](https://huggingface.co/RichardErkhov/Weyaxi_-_HelpSteer-filtered-neural-chat-7b-v3-1-7B-gguf/blob/main/HelpSteer-filtered-neural-chat-7b-v3-1-7B.Q5_K.gguf) | Q5_K | 4.78GB |
| [HelpSteer-filtered-neural-chat-7b-v3-1-7B.Q5_K_M.gguf](https://huggingface.co/RichardErkhov/Weyaxi_-_HelpSteer-filtered-neural-chat-7b-v3-1-7B-gguf/blob/main/HelpSteer-filtered-neural-chat-7b-v3-1-7B.Q5_K_M.gguf) | Q5_K_M | 4.78GB |
| [HelpSteer-filtered-neural-chat-7b-v3-1-7B.Q5_1.gguf](https://huggingface.co/RichardErkhov/Weyaxi_-_HelpSteer-filtered-neural-chat-7b-v3-1-7B-gguf/blob/main/HelpSteer-filtered-neural-chat-7b-v3-1-7B.Q5_1.gguf) | Q5_1 | 5.07GB |
| [HelpSteer-filtered-neural-chat-7b-v3-1-7B.Q6_K.gguf](https://huggingface.co/RichardErkhov/Weyaxi_-_HelpSteer-filtered-neural-chat-7b-v3-1-7B-gguf/blob/main/HelpSteer-filtered-neural-chat-7b-v3-1-7B.Q6_K.gguf) | Q6_K | 5.53GB |
| [HelpSteer-filtered-neural-chat-7b-v3-1-7B.Q8_0.gguf](https://huggingface.co/RichardErkhov/Weyaxi_-_HelpSteer-filtered-neural-chat-7b-v3-1-7B-gguf/blob/main/HelpSteer-filtered-neural-chat-7b-v3-1-7B.Q8_0.gguf) | Q8_0 | 7.17GB |
Original model description:
---
license: apache-2.0
---
# HelpSteer-filtered-neural-chat-7b-v3-1-7B
HelpSteer-filtered-neural-chat-7b-v3-1-7B is a merge of [Intel/neural-chat-7b-v3-1](https://huggingface.co/Intel/neural-chat-7b-v3-1) and [Weyaxi/HelpSteer-filtered-7B-Lora](https://hf.co/Weyaxi/HelpSteer-filtered-7B-Lora)
|
bartowski/L3-Zodiac-8B-ORPO-Base-GGUF | bartowski | 2024-06-20T17:11:17Z | 17,144 | 0 | transformers | [
"transformers",
"gguf",
"text-generation-inference",
"unsloth",
"llama",
"trl",
"text-generation",
"en",
"base_model:unsloth/llama-3-8b-bnb-4bit",
"license:llama3",
"endpoints_compatible",
"region:us"
]
| text-generation | 2024-06-20T15:31:45Z | ---
language:
- en
tags:
- text-generation-inference
- transformers
- unsloth
- llama
- trl
base_model: unsloth/llama-3-8b-bnb-4bit
license: llama3
quantized_by: bartowski
pipeline_tag: text-generation
---
## Llamacpp imatrix Quantizations of L3-Zodiac-8B-ORPO-Base
Using <a href="https://github.com/ggerganov/llama.cpp/">llama.cpp</a> release <a href="https://github.com/ggerganov/llama.cpp/releases/tag/b3166">b3166</a> for quantization.
Original model: https://huggingface.co/nothingiisreal/L3-Zodiac-8B-ORPO-Base
All quants made using imatrix option with dataset from [here](https://gist.github.com/bartowski1182/eb213dccb3571f863da82e99418f81e8)
## Prompt format
No chat template specified so default is used. This may be incorrect, check original model card for details.
```
<|im_start|>system
{system_prompt}<|im_end|>
<|im_start|>user
{prompt}<|im_end|>
<|im_start|>assistant
```
## Download a file (not the whole branch) from below:
| Filename | Quant type | File Size | Description |
| -------- | ---------- | --------- | ----------- |
| [L3-Zodiac-8B-ORPO-Base-Q8_0_L.gguf](https://huggingface.co/bartowski/L3-Zodiac-8B-ORPO-Base-GGUF/blob/main/L3-Zodiac-8B-ORPO-Base-Q8_0_L.gguf) | Q8_0_L | 9.53GB | *Experimental*, uses f16 for embed and output weights. Please provide any feedback of differences. Extremely high quality, generally unneeded but max available quant. |
| [L3-Zodiac-8B-ORPO-Base-Q8_0.gguf](https://huggingface.co/bartowski/L3-Zodiac-8B-ORPO-Base-GGUF/blob/main/L3-Zodiac-8B-ORPO-Base-Q8_0.gguf) | Q8_0 | 8.54GB | Extremely high quality, generally unneeded but max available quant. |
| [L3-Zodiac-8B-ORPO-Base-Q6_K_L.gguf](https://huggingface.co/bartowski/L3-Zodiac-8B-ORPO-Base-GGUF/blob/main/L3-Zodiac-8B-ORPO-Base-Q6_K_L.gguf) | Q6_K_L | 7.83GB | *Experimental*, uses f16 for embed and output weights. Please provide any feedback of differences. Very high quality, near perfect, *recommended*. |
| [L3-Zodiac-8B-ORPO-Base-Q6_K.gguf](https://huggingface.co/bartowski/L3-Zodiac-8B-ORPO-Base-GGUF/blob/main/L3-Zodiac-8B-ORPO-Base-Q6_K.gguf) | Q6_K | 6.59GB | Very high quality, near perfect, *recommended*. |
| [L3-Zodiac-8B-ORPO-Base-Q5_K_L.gguf](https://huggingface.co/bartowski/L3-Zodiac-8B-ORPO-Base-GGUF/blob/main/L3-Zodiac-8B-ORPO-Base-Q5_K_L.gguf) | Q5_K_L | 7.04GB | *Experimental*, uses f16 for embed and output weights. Please provide any feedback of differences. High quality, *recommended*. |
| [L3-Zodiac-8B-ORPO-Base-Q5_K_M.gguf](https://huggingface.co/bartowski/L3-Zodiac-8B-ORPO-Base-GGUF/blob/main/L3-Zodiac-8B-ORPO-Base-Q5_K_M.gguf) | Q5_K_M | 5.73GB | High quality, *recommended*. |
| [L3-Zodiac-8B-ORPO-Base-Q5_K_S.gguf](https://huggingface.co/bartowski/L3-Zodiac-8B-ORPO-Base-GGUF/blob/main/L3-Zodiac-8B-ORPO-Base-Q5_K_S.gguf) | Q5_K_S | 5.59GB | High quality, *recommended*. |
| [L3-Zodiac-8B-ORPO-Base-Q4_K_L.gguf](https://huggingface.co/bartowski/L3-Zodiac-8B-ORPO-Base-GGUF/blob/main/L3-Zodiac-8B-ORPO-Base-Q4_K_L.gguf) | Q4_K_L | 6.29GB | *Experimental*, uses f16 for embed and output weights. Please provide any feedback of differences. Good quality, uses about 4.83 bits per weight, *recommended*. |
| [L3-Zodiac-8B-ORPO-Base-Q4_K_M.gguf](https://huggingface.co/bartowski/L3-Zodiac-8B-ORPO-Base-GGUF/blob/main/L3-Zodiac-8B-ORPO-Base-Q4_K_M.gguf) | Q4_K_M | 4.92GB | Good quality, uses about 4.83 bits per weight, *recommended*. |
| [L3-Zodiac-8B-ORPO-Base-Q4_K_S.gguf](https://huggingface.co/bartowski/L3-Zodiac-8B-ORPO-Base-GGUF/blob/main/L3-Zodiac-8B-ORPO-Base-Q4_K_S.gguf) | Q4_K_S | 4.69GB | Slightly lower quality with more space savings, *recommended*. |
| [L3-Zodiac-8B-ORPO-Base-IQ4_XS.gguf](https://huggingface.co/bartowski/L3-Zodiac-8B-ORPO-Base-GGUF/blob/main/L3-Zodiac-8B-ORPO-Base-IQ4_XS.gguf) | IQ4_XS | 4.44GB | Decent quality, smaller than Q4_K_S with similar performance, *recommended*. |
| [L3-Zodiac-8B-ORPO-Base-Q3_K_L.gguf](https://huggingface.co/bartowski/L3-Zodiac-8B-ORPO-Base-GGUF/blob/main/L3-Zodiac-8B-ORPO-Base-Q3_K_L.gguf) | Q3_K_L | 4.32GB | Lower quality but usable, good for low RAM availability. |
| [L3-Zodiac-8B-ORPO-Base-Q3_K_M.gguf](https://huggingface.co/bartowski/L3-Zodiac-8B-ORPO-Base-GGUF/blob/main/L3-Zodiac-8B-ORPO-Base-Q3_K_M.gguf) | Q3_K_M | 4.01GB | Even lower quality. |
| [L3-Zodiac-8B-ORPO-Base-IQ3_M.gguf](https://huggingface.co/bartowski/L3-Zodiac-8B-ORPO-Base-GGUF/blob/main/L3-Zodiac-8B-ORPO-Base-IQ3_M.gguf) | IQ3_M | 3.78GB | Medium-low quality, new method with decent performance comparable to Q3_K_M. |
| [L3-Zodiac-8B-ORPO-Base-Q3_K_S.gguf](https://huggingface.co/bartowski/L3-Zodiac-8B-ORPO-Base-GGUF/blob/main/L3-Zodiac-8B-ORPO-Base-Q3_K_S.gguf) | Q3_K_S | 3.66GB | Low quality, not recommended. |
| [L3-Zodiac-8B-ORPO-Base-IQ3_XS.gguf](https://huggingface.co/bartowski/L3-Zodiac-8B-ORPO-Base-GGUF/blob/main/L3-Zodiac-8B-ORPO-Base-IQ3_XS.gguf) | IQ3_XS | 3.51GB | Lower quality, new method with decent performance, slightly better than Q3_K_S. |
| [L3-Zodiac-8B-ORPO-Base-IQ3_XXS.gguf](https://huggingface.co/bartowski/L3-Zodiac-8B-ORPO-Base-GGUF/blob/main/L3-Zodiac-8B-ORPO-Base-IQ3_XXS.gguf) | IQ3_XXS | 3.27GB | Lower quality, new method with decent performance, comparable to Q3 quants. |
| [L3-Zodiac-8B-ORPO-Base-Q2_K.gguf](https://huggingface.co/bartowski/L3-Zodiac-8B-ORPO-Base-GGUF/blob/main/L3-Zodiac-8B-ORPO-Base-Q2_K.gguf) | Q2_K | 3.17GB | Very low quality but surprisingly usable. |
| [L3-Zodiac-8B-ORPO-Base-IQ2_M.gguf](https://huggingface.co/bartowski/L3-Zodiac-8B-ORPO-Base-GGUF/blob/main/L3-Zodiac-8B-ORPO-Base-IQ2_M.gguf) | IQ2_M | 2.94GB | Very low quality, uses SOTA techniques to also be surprisingly usable. |
| [L3-Zodiac-8B-ORPO-Base-IQ2_S.gguf](https://huggingface.co/bartowski/L3-Zodiac-8B-ORPO-Base-GGUF/blob/main/L3-Zodiac-8B-ORPO-Base-IQ2_S.gguf) | IQ2_S | 2.75GB | Very low quality, uses SOTA techniques to be usable. |
| [L3-Zodiac-8B-ORPO-Base-IQ2_XS.gguf](https://huggingface.co/bartowski/L3-Zodiac-8B-ORPO-Base-GGUF/blob/main/L3-Zodiac-8B-ORPO-Base-IQ2_XS.gguf) | IQ2_XS | 2.60GB | Very low quality, uses SOTA techniques to be usable. |
## Downloading using huggingface-cli
First, make sure you have hugginface-cli installed:
```
pip install -U "huggingface_hub[cli]"
```
Then, you can target the specific file you want:
```
huggingface-cli download bartowski/L3-Zodiac-8B-ORPO-Base-GGUF --include "L3-Zodiac-8B-ORPO-Base-Q4_K_M.gguf" --local-dir ./
```
If the model is bigger than 50GB, it will have been split into multiple files. In order to download them all to a local folder, run:
```
huggingface-cli download bartowski/L3-Zodiac-8B-ORPO-Base-GGUF --include "L3-Zodiac-8B-ORPO-Base-Q8_0.gguf/*" --local-dir L3-Zodiac-8B-ORPO-Base-Q8_0
```
You can either specify a new local-dir (L3-Zodiac-8B-ORPO-Base-Q8_0) or download them all in place (./)
## Which file should I choose?
A great write up with charts showing various performances is provided by Artefact2 [here](https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9)
The first thing to figure out is how big a model you can run. To do this, you'll need to figure out how much RAM and/or VRAM you have.
If you want your model running as FAST as possible, you'll want to fit the whole thing on your GPU's VRAM. Aim for a quant with a file size 1-2GB smaller than your GPU's total VRAM.
If you want the absolute maximum quality, add both your system RAM and your GPU's VRAM together, then similarly grab a quant with a file size 1-2GB Smaller than that total.
Next, you'll need to decide if you want to use an 'I-quant' or a 'K-quant'.
If you don't want to think too much, grab one of the K-quants. These are in format 'QX_K_X', like Q5_K_M.
If you want to get more into the weeds, you can check out this extremely useful feature chart:
[llama.cpp feature matrix](https://github.com/ggerganov/llama.cpp/wiki/Feature-matrix)
But basically, if you're aiming for below Q4, and you're running cuBLAS (Nvidia) or rocBLAS (AMD), you should look towards the I-quants. These are in format IQX_X, like IQ3_M. These are newer and offer better performance for their size.
These I-quants can also be used on CPU and Apple Metal, but will be slower than their K-quant equivalent, so speed vs performance is a tradeoff you'll have to decide.
The I-quants are *not* compatible with Vulcan, which is also AMD, so if you have an AMD card double check if you're using the rocBLAS build or the Vulcan build. At the time of writing this, LM Studio has a preview with ROCm support, and other inference engines have specific builds for ROCm.
Want to support my work? Visit my ko-fi page here: https://ko-fi.com/bartowski
|
mradermacher/Prox-Llama-3-8B-abliterated-orpo-GGUF | mradermacher | 2024-06-20T23:01:46Z | 17,126 | 0 | transformers | [
"transformers",
"gguf",
"code",
"cybersecurity",
"penetration testing",
"hacking",
"uncensored",
"en",
"dataset:mlabonne/orpo-dpo-mix-40k",
"base_model:openvoid/Prox-Llama-3-8B-abliterated-orpo",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
]
| null | 2024-06-20T16:05:36Z | ---
base_model: openvoid/Prox-Llama-3-8B-abliterated-orpo
datasets:
- mlabonne/orpo-dpo-mix-40k
language:
- en
library_name: transformers
license: apache-2.0
quantized_by: mradermacher
tags:
- code
- cybersecurity
- penetration testing
- hacking
- code
- uncensored
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
static quants of https://huggingface.co/openvoid/Prox-Llama-3-8B-abliterated-orpo
<!-- provided-files -->
weighted/imatrix quants are available at https://huggingface.co/mradermacher/Prox-Llama-3-8B-abliterated-orpo-i1-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/Prox-Llama-3-8B-abliterated-orpo-GGUF/resolve/main/Prox-Llama-3-8B-abliterated-orpo.Q2_K.gguf) | Q2_K | 3.3 | |
| [GGUF](https://huggingface.co/mradermacher/Prox-Llama-3-8B-abliterated-orpo-GGUF/resolve/main/Prox-Llama-3-8B-abliterated-orpo.IQ3_XS.gguf) | IQ3_XS | 3.6 | |
| [GGUF](https://huggingface.co/mradermacher/Prox-Llama-3-8B-abliterated-orpo-GGUF/resolve/main/Prox-Llama-3-8B-abliterated-orpo.Q3_K_S.gguf) | Q3_K_S | 3.8 | |
| [GGUF](https://huggingface.co/mradermacher/Prox-Llama-3-8B-abliterated-orpo-GGUF/resolve/main/Prox-Llama-3-8B-abliterated-orpo.IQ3_S.gguf) | IQ3_S | 3.8 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/Prox-Llama-3-8B-abliterated-orpo-GGUF/resolve/main/Prox-Llama-3-8B-abliterated-orpo.IQ3_M.gguf) | IQ3_M | 3.9 | |
| [GGUF](https://huggingface.co/mradermacher/Prox-Llama-3-8B-abliterated-orpo-GGUF/resolve/main/Prox-Llama-3-8B-abliterated-orpo.Q3_K_M.gguf) | Q3_K_M | 4.1 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/Prox-Llama-3-8B-abliterated-orpo-GGUF/resolve/main/Prox-Llama-3-8B-abliterated-orpo.Q3_K_L.gguf) | Q3_K_L | 4.4 | |
| [GGUF](https://huggingface.co/mradermacher/Prox-Llama-3-8B-abliterated-orpo-GGUF/resolve/main/Prox-Llama-3-8B-abliterated-orpo.IQ4_XS.gguf) | IQ4_XS | 4.6 | |
| [GGUF](https://huggingface.co/mradermacher/Prox-Llama-3-8B-abliterated-orpo-GGUF/resolve/main/Prox-Llama-3-8B-abliterated-orpo.Q4_K_S.gguf) | Q4_K_S | 4.8 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Prox-Llama-3-8B-abliterated-orpo-GGUF/resolve/main/Prox-Llama-3-8B-abliterated-orpo.Q4_K_M.gguf) | Q4_K_M | 5.0 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Prox-Llama-3-8B-abliterated-orpo-GGUF/resolve/main/Prox-Llama-3-8B-abliterated-orpo.Q5_K_S.gguf) | Q5_K_S | 5.7 | |
| [GGUF](https://huggingface.co/mradermacher/Prox-Llama-3-8B-abliterated-orpo-GGUF/resolve/main/Prox-Llama-3-8B-abliterated-orpo.Q5_K_M.gguf) | Q5_K_M | 5.8 | |
| [GGUF](https://huggingface.co/mradermacher/Prox-Llama-3-8B-abliterated-orpo-GGUF/resolve/main/Prox-Llama-3-8B-abliterated-orpo.Q6_K.gguf) | Q6_K | 6.7 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/Prox-Llama-3-8B-abliterated-orpo-GGUF/resolve/main/Prox-Llama-3-8B-abliterated-orpo.Q8_0.gguf) | Q8_0 | 8.6 | fast, best quality |
| [GGUF](https://huggingface.co/mradermacher/Prox-Llama-3-8B-abliterated-orpo-GGUF/resolve/main/Prox-Llama-3-8B-abliterated-orpo.f16.gguf) | f16 | 16.2 | 16 bpw, overkill |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
stabilityai/stable-code-3b | stabilityai | 2024-04-12T08:27:26Z | 17,125 | 621 | transformers | [
"transformers",
"safetensors",
"gguf",
"stablelm",
"text-generation",
"causal-lm",
"code",
"en",
"dataset:tiiuae/falcon-refinedweb",
"dataset:bigcode/the-stack-github-issues",
"dataset:bigcode/commitpackft",
"dataset:bigcode/starcoderdata",
"dataset:EleutherAI/proof-pile-2",
"dataset:meta-math/MetaMathQA",
"arxiv:2307.09288",
"arxiv:2104.09864",
"arxiv:2204.06745",
"arxiv:2305.06161",
"arxiv:2310.10631",
"arxiv:2309.12284",
"arxiv:1910.02054",
"license:other",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| text-generation | 2024-01-09T02:03:58Z | ---
license: other
datasets:
- tiiuae/falcon-refinedweb
- bigcode/the-stack-github-issues
- bigcode/commitpackft
- bigcode/starcoderdata
- EleutherAI/proof-pile-2
- meta-math/MetaMathQA
language:
- en
tags:
- causal-lm
- code
metrics:
- code_eval
library_name: transformers
model-index:
- name: stabilityai/stable-code-3b
results:
- task:
type: text-generation
dataset:
type: nuprl/MultiPL-E
name: MultiPL-HumanEval (Python)
metrics:
- name: pass@1
type: pass@1
value: 32.4
verified: false
- task:
type: text-generation
dataset:
type: nuprl/MultiPL-E
name: MultiPL-HumanEval (C++)
metrics:
- name: pass@1
type: pass@1
value: 30.9
verified: false
- task:
type: text-generation
dataset:
type: nuprl/MultiPL-E
name: MultiPL-HumanEval (Java)
metrics:
- name: pass@1
type: pass@1
value: 32.1
verified: false
- task:
type: text-generation
dataset:
type: nuprl/MultiPL-E
name: MultiPL-HumanEval (JavaScript)
metrics:
- name: pass@1
type: pass@1
value: 32.1
verified: false
- task:
type: text-generation
dataset:
type: nuprl/MultiPL-E
name: MultiPL-HumanEval (PHP)
metrics:
- name: pass@1
type: pass@1
value: 24.2
verified: false
- task:
type: text-generation
dataset:
type: nuprl/MultiPL-E
name: MultiPL-HumanEval (Rust)
metrics:
- name: pass@1
type: pass@1
value: 23.0
verified: false
---
# `stable-code-3b`
Please note: For commercial use, please refer to https://stability.ai/membership.
## Model Description
`stable-code-3b` is a 2.7B billion parameter decoder-only language model pre-trained on 1.3 trillion tokens of diverse textual and code datasets. `stable-code-3b` is trained on 18 programming languages (selected based on the 2023 StackOverflow Developer Survey) and demonstrates state-of-the-art performance (compared to models of similar size) on the MultiPL-E metrics across multiple programming languages tested using [BigCode's Evaluation Harness](https://github.com/bigcode-project/bigcode-evaluation-harness/tree/main).

| Model | Size | Python | C++ | Javascript | Java | PHP | Rust |
|------------------|------|--------|------|------------|------|------|------|
| **Stable Code** | 3B | 32.4% | 30.9%| 32.1% | 32.1%| 24.2%| 23.0%|
| CodeLLama | 7B | 30.0% | 28.2%| 32.5% | 31.1%| 25.7%| 26.3%|
| Deepseek Coder | 1.3B | 28.6% | 29.2%| 28.7% | 29.0%| 23.6%| 18.5%|
| Wizard Coder | 3B | 31.6% | 25.6%| 26.2% | 25.8%| 25.3%| 20.4%|
| StarCoder | 3B | 21.6% | 19.8%| 21.5% | 20.5%| 19.0%| 16.9%|
| Replit Code V1.5 | 3B | 23.0% | 25.9%| 26.2% | 23.6%| 23.2%| 21.5%|
| Deci Coder | 1B | 19.1% | 6.8% | 18.4% | 16.7%| 2.1% | 1.7% |
**Key Features**
* Fill in Middle Capability (FIM)
* Supports Long Context, trained with Sequences upto 16,384
## Usage
Get started generating text with `stable-code-3b` by using the following code snippet:
```python
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("stabilityai/stable-code-3b")
model = AutoModelForCausalLM.from_pretrained(
"stabilityai/stable-code-3b",
torch_dtype="auto",
)
model.cuda()
inputs = tokenizer("import torch\nimport torch.nn as nn", return_tensors="pt").to(model.device)
tokens = model.generate(
**inputs,
max_new_tokens=48,
temperature=0.2,
do_sample=True,
)
print(tokenizer.decode(tokens[0], skip_special_tokens=True))
```
### Run with Fill in Middle (FIM) ⚡️
<details>
<summary> Click to expand </summary>
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("stabilityai/stable-code-3b")
model = AutoModelForCausalLM.from_pretrained(
"stabilityai/stable-code-3b",
torch_dtype="auto",
attn_implementation="flash_attention_2",
)
model.cuda()
inputs = tokenizer("<fim_prefix>def fib(n):<fim_suffix> else:\n return fib(n - 2) + fib(n - 1)<fim_middle>", return_tensors="pt").to(model.device)
tokens = model.generate(
**inputs,
max_new_tokens=48,
temperature=0.2,
do_sample=True,
)
print(tokenizer.decode(tokens[0], skip_special_tokens=True))
```
</details>
### Run with Flash Attention 2 ⚡️
<details>
<summary> Click to expand </summary>
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("stabilityai/stable-code-3b", trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(
"stabilityai/stable-code-3b",
trust_remote_code=True,
torch_dtype="auto",
+ attn_implementation="flash_attention_2",
)
model.cuda()
inputs = tokenizer("import torch\nimport torch.nn as nn", return_tensors="pt").to(model.device)
tokens = model.generate(
**inputs,
max_new_tokens=48,
temperature=0.2,
do_sample=True,
)
print(tokenizer.decode(tokens[0], skip_special_tokens=True))
```
</details>
## Model Details
* **Developed by**: [Stability AI](https://stability.ai/)
* **Model type**: `stable-code-3b` models are auto-regressive language models based on the transformer decoder architecture.
* **Language(s)**: English, Code
* **Library**: [GPT-NeoX](https://github.com/EleutherAI/gpt-neox)
* **License**: Stability AI Non-Commercial Research Community License.
* **Commercial License**: to use this model commercially, please refer to https://stability.ai/membership
* **Contact**: For questions and comments about the model, please email `[email protected]`
### Model Architecture
The model is a decoder-only transformer similar to the LLaMA ([Touvron et al., 2023](https://arxiv.org/abs/2307.09288)) architecture with the following modifications:
| Parameters | Hidden Size | Layers | Heads | Sequence Length |
|----------------|-------------|--------|-------|-----------------|
| 2,796,431,360 | 2560 | 32 | 32 | 16384 |
* **Position Embeddings**: Rotary Position Embeddings ([Su et al., 2021](https://arxiv.org/abs/2104.09864)) applied to the first 25% of head embedding dimensions for improved throughput following [Black et al. (2022)](https://arxiv.org/pdf/2204.06745.pdf).
* **Tokenizer**: We use a modified version of the GPTNeoX Tokenizer.[`NeoX`](https://github.com/EleutherAI/gpt-neox). We add special tokens to train for Fill in the Middle (FIM) capabilities like `<FIM_PREFIX>` and `<FIM_SUFFIX>` along with other special tokens.
## Training
### Training Dataset
The dataset is comprised of a filtered mixture of open-source large-scale datasets available on the [HuggingFace Hub](https://huggingface.co/datasets): Falcon RefinedWeb extract ([Penedo et al., 2023](https://huggingface.co/datasets/tiiuae/falcon-refinedweb)), along with [CommitPackFT](https://huggingface.co/datasets/bigcode/commitpackft) and [Github Issues](https://huggingface.co/datasets/bigcode/the-stack-github-issues) (BigCode., 2023), and StarCoder ([Li et al., 2023](https://arxiv.org/abs/2305.06161)). We further supplement our training with data from mathematical domains ([Azerbayev, Zhangir, et al., 2023](https://arxiv.org/abs/2310.10631) and, [Yu, Longhui, et al., 2023](https://arxiv.org/abs/2309.12284)).
Top 18 programming languages trained on:
- C
- CPP
- Java
- JavaScript
- CSS
- Go
- HTML
- Ruby
- Rust
- Markdown
- Shell
- Php
- Sql
- R
- Typescript
- Python
- Jupyter-Clean
- RestructuredText
### Training Procedure
The model is pre-trained on the aforementioned datasets in `bfloat16` precision, optimized with AdamW.
### Training Infrastructure
* **Hardware**: `stable-code-3b` was trained on the Stability AI cluster across 256 NVIDIA A100 40GB GPUs (AWS P4d instances).
* **Software**: We use a fork of `gpt-neox` ([EleutherAI, 2021](https://github.com/EleutherAI/gpt-neox)), train under 2D parallelism (Data and Tensor Parallel) with ZeRO-1 ([Rajbhandari et al., 2019](https://arxiv.org/abs/1910.02054v3)), and rely on flash-attention as well as SwiGLU and Rotary Embedding kernels from FlashAttention-2 ([Dao et al., 2023](https://tridao.me/publications/flash2/flash2.pdf))
## Use and Limitations
### Intended Use
The model is intended to be used as a foundational base model for application-specific fine-tuning. Developers must evaluate and fine-tune the model for safe performance in downstream applications. For commercial use, please refer to https://stability.ai/membership.
### Limitations and Bias
As a base model, this model may exhibit unreliable, unsafe, or other undesirable behaviors that must be corrected through evaluation and fine-tuning prior to deployment. The pre-training dataset may have contained offensive or inappropriate content, even after applying data cleansing filters, which can be reflected in the model-generated text. We recommend that users exercise caution when using these models in production systems. Do not use the models if they are unsuitable for your application, or for any applications that may cause deliberate or unintentional harm to others.
## How to Cite
```bibtex
@misc{stable-code-3b,
url={[https://huggingface.co/stabilityai/stable-code-3b](https://huggingface.co/stabilityai/stable-code-3b)},
title={Stable Code 3B},
author={Pinnaparaju, Nikhil and Adithyan, Reshinth and Phung, Duy and Tow, Jonathan and Baicoianu, James and Cooper, Nathan}
}
``` |
PrunaAI/Phi-3-mini-128k-instruct-GGUF-Imatrix-smashed | PrunaAI | 2024-04-30T10:52:36Z | 17,124 | 62 | null | [
"gguf",
"pruna-ai",
"region:us"
]
| null | 2024-04-23T23:31:13Z | ---
thumbnail: "https://assets-global.website-files.com/646b351987a8d8ce158d1940/64ec9e96b4334c0e1ac41504_Logo%20with%20white%20text.svg"
metrics:
- memory_disk
- memory_inference
- inference_latency
- inference_throughput
- inference_CO2_emissions
- inference_energy_consumption
tags:
- pruna-ai
---
<!-- header start -->
<!-- 200823 -->
<div style="width: auto; margin-left: auto; margin-right: auto">
<a href="https://www.pruna.ai/" target="_blank" rel="noopener noreferrer">
<img src="https://i.imgur.com/eDAlcgk.png" alt="PrunaAI" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</a>
</div>
<!-- header end -->
[](https://twitter.com/PrunaAI)
[](https://github.com/PrunaAI)
[](https://www.linkedin.com/company/93832878/admin/feed/posts/?feedType=following)
[](https://discord.com/invite/vb6SmA3hxu)
## This repo contains GGUF versions of the microsoft/Phi-3-mini-128k-instruct model.
# Simply make AI models cheaper, smaller, faster, and greener!
- Give a thumbs up if you like this model!
- Contact us and tell us which model to compress next [here](https://www.pruna.ai/contact).
- Request access to easily compress your *own* AI models [here](https://z0halsaff74.typeform.com/pruna-access?typeform-source=www.pruna.ai).
- Read the documentations to know more [here](https://pruna-ai-pruna.readthedocs-hosted.com/en/latest/)
- Join Pruna AI community on Discord [here](https://discord.com/invite/vb6SmA3hxu) to share feedback/suggestions or get help.
**Frequently Asked Questions**
- ***How does the compression work?*** The model is compressed with GGUF.
- ***How does the model quality change?*** The quality of the model output might vary compared to the base model.
- ***What is the model format?*** We use GGUF format.
- ***What calibration data has been used?*** If needed by the compression method, we used WikiText as the calibration data.
- ***How to compress my own models?*** You can request premium access to more compression methods and tech support for your specific use-cases [here](https://z0halsaff74.typeform.com/pruna-access?typeform-source=www.pruna.ai).
# Downloading and running the models
You can download the individual files from the Files & versions section. Here is a list of the different versions we provide. For more info checkout [this chart](https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9) and [this guide](https://www.reddit.com/r/LocalLLaMA/comments/1ba55rj/overview_of_gguf_quantization_methods/):
| Quant type | Description |
|------------|--------------------------------------------------------------------------------------------|
| Q5_K_M | High quality, recommended. |
| Q5_K_S | High quality, recommended. |
| Q4_K_M | Good quality, uses about 4.83 bits per weight, recommended. |
| Q4_K_S | Slightly lower quality with more space savings, recommended. |
| IQ4_NL | Decent quality, slightly smaller than Q4_K_S with similar performance, recommended. |
| IQ4_XS | Decent quality, smaller than Q4_K_S with similar performance, recommended. |
| Q3_K_L | Lower quality but usable, good for low RAM availability. |
| Q3_K_M | Even lower quality. |
| IQ3_M | Medium-low quality, new method with decent performance comparable to Q3_K_M. |
| IQ3_S | Lower quality, new method with decent performance, recommended over Q3_K_S quant, same size with better performance. |
| Q3_K_S | Low quality, not recommended. |
| IQ3_XS | Lower quality, new method with decent performance, slightly better than Q3_K_S. |
| Q2_K | Very low quality but surprisingly usable. |
## How to download GGUF files ?
**Note for manual downloaders:** You almost never want to clone the entire repo! Multiple different quantisation formats are provided, and most users only want to pick and download a single file.
The following clients/libraries will automatically download models for you, providing a list of available models to choose from:
* LM Studio
* LoLLMS Web UI
* Faraday.dev
- **Option A** - Downloading in `text-generation-webui`:
- **Step 1**: Under Download Model, you can enter the model repo: PrunaAI/Phi-3-mini-128k-instruct-GGUF-Imatrix-smashed and below it, a specific filename to download, such as: phi-2.IQ3_M.gguf.
- **Step 2**: Then click Download.
- **Option B** - Downloading on the command line (including multiple files at once):
- **Step 1**: We recommend using the `huggingface-hub` Python library:
```shell
pip3 install huggingface-hub
```
- **Step 2**: Then you can download any individual model file to the current directory, at high speed, with a command like this:
```shell
huggingface-cli download PrunaAI/Phi-3-mini-128k-instruct-GGUF-Imatrix-smashed Phi-3-mini-128k-instruct.IQ3_M.gguf --local-dir . --local-dir-use-symlinks False
```
<details>
<summary>More advanced huggingface-cli download usage (click to read)</summary>
Alternatively, you can also download multiple files at once with a pattern:
```shell
huggingface-cli download PrunaAI/Phi-3-mini-128k-instruct-GGUF-Imatrix-smashed --local-dir . --local-dir-use-symlinks False --include='*Q4_K*gguf'
```
For more documentation on downloading with `huggingface-cli`, please see: [HF -> Hub Python Library -> Download files -> Download from the CLI](https://huggingface.co/docs/huggingface_hub/guides/download#download-from-the-cli).
To accelerate downloads on fast connections (1Gbit/s or higher), install `hf_transfer`:
```shell
pip3 install hf_transfer
```
And set environment variable `HF_HUB_ENABLE_HF_TRANSFER` to `1`:
```shell
HF_HUB_ENABLE_HF_TRANSFER=1 huggingface-cli download PrunaAI/Phi-3-mini-128k-instruct-GGUF-Imatrix-smashed Phi-3-mini-128k-instruct.IQ3_M.gguf --local-dir . --local-dir-use-symlinks False
```
Windows Command Line users: You can set the environment variable by running `set HF_HUB_ENABLE_HF_TRANSFER=1` before the download command.
</details>
<!-- README_GGUF.md-how-to-download end -->
<!-- README_GGUF.md-how-to-run start -->
## How to run model in GGUF format?
- **Option A** - Introductory example with `llama.cpp` command
Make sure you are using `llama.cpp` from commit [d0cee0d](https://github.com/ggerganov/llama.cpp/commit/d0cee0d36d5be95a0d9088b674dbb27354107221) or later.
```shell
./main -ngl 35 -m Phi-3-mini-128k-instruct.IQ3_M.gguf --color -c 32768 --temp 0.7 --repeat_penalty 1.1 -n -1 -p "<s>[INST] {prompt\} [/INST]"
```
Change `-ngl 32` to the number of layers to offload to GPU. Remove it if you don't have GPU acceleration.
Change `-c 32768` to the desired sequence length. For extended sequence models - eg 8K, 16K, 32K - the necessary RoPE scaling parameters are read from the GGUF file and set by llama.cpp automatically. Note that longer sequence lengths require much more resources, so you may need to reduce this value.
If you want to have a chat-style conversation, replace the `-p <PROMPT>` argument with `-i -ins`
For other parameters and how to use them, please refer to [the llama.cpp documentation](https://github.com/ggerganov/llama.cpp/blob/master/examples/main/README.md)
- **Option B** - Running in `text-generation-webui`
Further instructions can be found in the text-generation-webui documentation, here: [text-generation-webui/docs/04 ‐ Model Tab.md](https://github.com/oobabooga/text-generation-webui/blob/main/docs/04%20-%20Model%20Tab.md#llamacpp).
- **Option C** - Running from Python code
You can use GGUF models from Python using the [llama-cpp-python](https://github.com/abetlen/llama-cpp-python) or [ctransformers](https://github.com/marella/ctransformers) libraries. Note that at the time of writing (Nov 27th 2023), ctransformers has not been updated for some time and is not compatible with some recent models. Therefore I recommend you use llama-cpp-python.
### How to load this model in Python code, using llama-cpp-python
For full documentation, please see: [llama-cpp-python docs](https://abetlen.github.io/llama-cpp-python/).
#### First install the package
Run one of the following commands, according to your system:
```shell
# Base ctransformers with no GPU acceleration
pip install llama-cpp-python
# With NVidia CUDA acceleration
CMAKE_ARGS="-DLLAMA_CUBLAS=on" pip install llama-cpp-python
# Or with OpenBLAS acceleration
CMAKE_ARGS="-DLLAMA_BLAS=ON -DLLAMA_BLAS_VENDOR=OpenBLAS" pip install llama-cpp-python
# Or with CLBLast acceleration
CMAKE_ARGS="-DLLAMA_CLBLAST=on" pip install llama-cpp-python
# Or with AMD ROCm GPU acceleration (Linux only)
CMAKE_ARGS="-DLLAMA_HIPBLAS=on" pip install llama-cpp-python
# Or with Metal GPU acceleration for macOS systems only
CMAKE_ARGS="-DLLAMA_METAL=on" pip install llama-cpp-python
# In windows, to set the variables CMAKE_ARGS in PowerShell, follow this format; eg for NVidia CUDA:
$env:CMAKE_ARGS = "-DLLAMA_OPENBLAS=on"
pip install llama-cpp-python
```
#### Simple llama-cpp-python example code
```python
from llama_cpp import Llama
# Set gpu_layers to the number of layers to offload to GPU. Set to 0 if no GPU acceleration is available on your system.
llm = Llama(
model_path="./Phi-3-mini-128k-instruct.IQ3_M.gguf", # Download the model file first
n_ctx=32768, # The max sequence length to use - note that longer sequence lengths require much more resources
n_threads=8, # The number of CPU threads to use, tailor to your system and the resulting performance
n_gpu_layers=35 # The number of layers to offload to GPU, if you have GPU acceleration available
)
# Simple inference example
output = llm(
"<s>[INST] {prompt} [/INST]", # Prompt
max_tokens=512, # Generate up to 512 tokens
stop=["</s>"], # Example stop token - not necessarily correct for this specific model! Please check before using.
echo=True # Whether to echo the prompt
)
# Chat Completion API
llm = Llama(model_path="./Phi-3-mini-128k-instruct.IQ3_M.gguf", chat_format="llama-2") # Set chat_format according to the model you are using
llm.create_chat_completion(
messages = [
{"role": "system", "content": "You are a story writing assistant."},
{
"role": "user",
"content": "Write a story about llamas."
}
]
)
```
- **Option D** - Running with LangChain
Here are guides on using llama-cpp-python and ctransformers with LangChain:
* [LangChain + llama-cpp-python](https://python.langchain.com/docs/integrations/llms/llamacpp)
* [LangChain + ctransformers](https://python.langchain.com/docs/integrations/providers/ctransformers)
## Configurations
The configuration info are in `smash_config.json`.
## Credits & License
The license of the smashed model follows the license of the original model. Please check the license of the original model before using this model which provided the base model. The license of the `pruna-engine` is [here](https://pypi.org/project/pruna-engine/) on Pypi.
## Want to compress other models?
- Contact us and tell us which model to compress next [here](https://www.pruna.ai/contact).
- Request access to easily compress your own AI models [here](https://z0halsaff74.typeform.com/pruna-access?typeform-source=www.pruna.ai).
|
intfloat/e5-small | intfloat | 2023-08-07T04:58:08Z | 17,120 | 38 | sentence-transformers | [
"sentence-transformers",
"pytorch",
"onnx",
"safetensors",
"bert",
"mteb",
"Sentence Transformers",
"sentence-similarity",
"en",
"arxiv:2212.03533",
"arxiv:2104.08663",
"arxiv:2210.07316",
"license:mit",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"text-embeddings-inference",
"region:us"
]
| sentence-similarity | 2022-12-07T06:48:03Z | ---
tags:
- mteb
- Sentence Transformers
- sentence-similarity
- sentence-transformers
model-index:
- name: e5-small
results:
- task:
type: Classification
dataset:
type: mteb/amazon_counterfactual
name: MTEB AmazonCounterfactualClassification (en)
config: en
split: test
revision: e8379541af4e31359cca9fbcf4b00f2671dba205
metrics:
- type: accuracy
value: 76.22388059701493
- type: ap
value: 40.27466219523129
- type: f1
value: 70.60533006025108
- task:
type: Classification
dataset:
type: mteb/amazon_polarity
name: MTEB AmazonPolarityClassification
config: default
split: test
revision: e2d317d38cd51312af73b3d32a06d1a08b442046
metrics:
- type: accuracy
value: 87.525775
- type: ap
value: 83.51063993897611
- type: f1
value: 87.49342736805572
- task:
type: Classification
dataset:
type: mteb/amazon_reviews_multi
name: MTEB AmazonReviewsClassification (en)
config: en
split: test
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
metrics:
- type: accuracy
value: 42.611999999999995
- type: f1
value: 42.05088045932892
- task:
type: Retrieval
dataset:
type: arguana
name: MTEB ArguAna
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 23.826
- type: map_at_10
value: 38.269
- type: map_at_100
value: 39.322
- type: map_at_1000
value: 39.344
- type: map_at_3
value: 33.428000000000004
- type: map_at_5
value: 36.063
- type: mrr_at_1
value: 24.253
- type: mrr_at_10
value: 38.425
- type: mrr_at_100
value: 39.478
- type: mrr_at_1000
value: 39.5
- type: mrr_at_3
value: 33.606
- type: mrr_at_5
value: 36.195
- type: ndcg_at_1
value: 23.826
- type: ndcg_at_10
value: 46.693
- type: ndcg_at_100
value: 51.469
- type: ndcg_at_1000
value: 52.002
- type: ndcg_at_3
value: 36.603
- type: ndcg_at_5
value: 41.365
- type: precision_at_1
value: 23.826
- type: precision_at_10
value: 7.383000000000001
- type: precision_at_100
value: 0.9530000000000001
- type: precision_at_1000
value: 0.099
- type: precision_at_3
value: 15.268
- type: precision_at_5
value: 11.479000000000001
- type: recall_at_1
value: 23.826
- type: recall_at_10
value: 73.82600000000001
- type: recall_at_100
value: 95.306
- type: recall_at_1000
value: 99.431
- type: recall_at_3
value: 45.804
- type: recall_at_5
value: 57.397
- task:
type: Clustering
dataset:
type: mteb/arxiv-clustering-p2p
name: MTEB ArxivClusteringP2P
config: default
split: test
revision: a122ad7f3f0291bf49cc6f4d32aa80929df69d5d
metrics:
- type: v_measure
value: 44.13995374767436
- task:
type: Clustering
dataset:
type: mteb/arxiv-clustering-s2s
name: MTEB ArxivClusteringS2S
config: default
split: test
revision: f910caf1a6075f7329cdf8c1a6135696f37dbd53
metrics:
- type: v_measure
value: 37.13950072624313
- task:
type: Reranking
dataset:
type: mteb/askubuntudupquestions-reranking
name: MTEB AskUbuntuDupQuestions
config: default
split: test
revision: 2000358ca161889fa9c082cb41daa8dcfb161a54
metrics:
- type: map
value: 59.35843292105327
- type: mrr
value: 73.72312359846987
- task:
type: STS
dataset:
type: mteb/biosses-sts
name: MTEB BIOSSES
config: default
split: test
revision: d3fb88f8f02e40887cd149695127462bbcf29b4a
metrics:
- type: cos_sim_pearson
value: 84.55140418324174
- type: cos_sim_spearman
value: 84.21637675860022
- type: euclidean_pearson
value: 81.26069614610006
- type: euclidean_spearman
value: 83.25069210421785
- type: manhattan_pearson
value: 80.17441422581014
- type: manhattan_spearman
value: 81.87596198487877
- task:
type: Classification
dataset:
type: mteb/banking77
name: MTEB Banking77Classification
config: default
split: test
revision: 0fd18e25b25c072e09e0d92ab615fda904d66300
metrics:
- type: accuracy
value: 81.87337662337661
- type: f1
value: 81.76647866926402
- task:
type: Clustering
dataset:
type: mteb/biorxiv-clustering-p2p
name: MTEB BiorxivClusteringP2P
config: default
split: test
revision: 65b79d1d13f80053f67aca9498d9402c2d9f1f40
metrics:
- type: v_measure
value: 35.80600542614507
- task:
type: Clustering
dataset:
type: mteb/biorxiv-clustering-s2s
name: MTEB BiorxivClusteringS2S
config: default
split: test
revision: 258694dd0231531bc1fd9de6ceb52a0853c6d908
metrics:
- type: v_measure
value: 31.86321613256603
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackAndroidRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 32.054
- type: map_at_10
value: 40.699999999999996
- type: map_at_100
value: 41.818
- type: map_at_1000
value: 41.959999999999994
- type: map_at_3
value: 37.742
- type: map_at_5
value: 39.427
- type: mrr_at_1
value: 38.769999999999996
- type: mrr_at_10
value: 46.150000000000006
- type: mrr_at_100
value: 46.865
- type: mrr_at_1000
value: 46.925
- type: mrr_at_3
value: 43.705
- type: mrr_at_5
value: 45.214999999999996
- type: ndcg_at_1
value: 38.769999999999996
- type: ndcg_at_10
value: 45.778
- type: ndcg_at_100
value: 50.38
- type: ndcg_at_1000
value: 52.922999999999995
- type: ndcg_at_3
value: 41.597
- type: ndcg_at_5
value: 43.631
- type: precision_at_1
value: 38.769999999999996
- type: precision_at_10
value: 8.269
- type: precision_at_100
value: 1.278
- type: precision_at_1000
value: 0.178
- type: precision_at_3
value: 19.266
- type: precision_at_5
value: 13.705
- type: recall_at_1
value: 32.054
- type: recall_at_10
value: 54.947
- type: recall_at_100
value: 74.79599999999999
- type: recall_at_1000
value: 91.40899999999999
- type: recall_at_3
value: 42.431000000000004
- type: recall_at_5
value: 48.519
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackEnglishRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 29.035
- type: map_at_10
value: 38.007000000000005
- type: map_at_100
value: 39.125
- type: map_at_1000
value: 39.251999999999995
- type: map_at_3
value: 35.77
- type: map_at_5
value: 37.057
- type: mrr_at_1
value: 36.497
- type: mrr_at_10
value: 44.077
- type: mrr_at_100
value: 44.743
- type: mrr_at_1000
value: 44.79
- type: mrr_at_3
value: 42.123
- type: mrr_at_5
value: 43.308
- type: ndcg_at_1
value: 36.497
- type: ndcg_at_10
value: 42.986000000000004
- type: ndcg_at_100
value: 47.323
- type: ndcg_at_1000
value: 49.624
- type: ndcg_at_3
value: 39.805
- type: ndcg_at_5
value: 41.286
- type: precision_at_1
value: 36.497
- type: precision_at_10
value: 7.8340000000000005
- type: precision_at_100
value: 1.269
- type: precision_at_1000
value: 0.178
- type: precision_at_3
value: 19.023
- type: precision_at_5
value: 13.248
- type: recall_at_1
value: 29.035
- type: recall_at_10
value: 51.06
- type: recall_at_100
value: 69.64099999999999
- type: recall_at_1000
value: 84.49
- type: recall_at_3
value: 41.333999999999996
- type: recall_at_5
value: 45.663
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackGamingRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 37.239
- type: map_at_10
value: 47.873
- type: map_at_100
value: 48.842999999999996
- type: map_at_1000
value: 48.913000000000004
- type: map_at_3
value: 45.050000000000004
- type: map_at_5
value: 46.498
- type: mrr_at_1
value: 42.508
- type: mrr_at_10
value: 51.44
- type: mrr_at_100
value: 52.087
- type: mrr_at_1000
value: 52.129999999999995
- type: mrr_at_3
value: 49.164
- type: mrr_at_5
value: 50.343
- type: ndcg_at_1
value: 42.508
- type: ndcg_at_10
value: 53.31399999999999
- type: ndcg_at_100
value: 57.245000000000005
- type: ndcg_at_1000
value: 58.794000000000004
- type: ndcg_at_3
value: 48.295
- type: ndcg_at_5
value: 50.415
- type: precision_at_1
value: 42.508
- type: precision_at_10
value: 8.458
- type: precision_at_100
value: 1.133
- type: precision_at_1000
value: 0.132
- type: precision_at_3
value: 21.191
- type: precision_at_5
value: 14.307
- type: recall_at_1
value: 37.239
- type: recall_at_10
value: 65.99000000000001
- type: recall_at_100
value: 82.99499999999999
- type: recall_at_1000
value: 94.128
- type: recall_at_3
value: 52.382
- type: recall_at_5
value: 57.648999999999994
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackGisRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 23.039
- type: map_at_10
value: 29.694
- type: map_at_100
value: 30.587999999999997
- type: map_at_1000
value: 30.692999999999998
- type: map_at_3
value: 27.708
- type: map_at_5
value: 28.774
- type: mrr_at_1
value: 24.633
- type: mrr_at_10
value: 31.478
- type: mrr_at_100
value: 32.299
- type: mrr_at_1000
value: 32.381
- type: mrr_at_3
value: 29.435
- type: mrr_at_5
value: 30.446
- type: ndcg_at_1
value: 24.633
- type: ndcg_at_10
value: 33.697
- type: ndcg_at_100
value: 38.080000000000005
- type: ndcg_at_1000
value: 40.812
- type: ndcg_at_3
value: 29.654000000000003
- type: ndcg_at_5
value: 31.474000000000004
- type: precision_at_1
value: 24.633
- type: precision_at_10
value: 5.0729999999999995
- type: precision_at_100
value: 0.753
- type: precision_at_1000
value: 0.10300000000000001
- type: precision_at_3
value: 12.279
- type: precision_at_5
value: 8.452
- type: recall_at_1
value: 23.039
- type: recall_at_10
value: 44.275999999999996
- type: recall_at_100
value: 64.4
- type: recall_at_1000
value: 85.135
- type: recall_at_3
value: 33.394
- type: recall_at_5
value: 37.687
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackMathematicaRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 13.594999999999999
- type: map_at_10
value: 19.933999999999997
- type: map_at_100
value: 20.966
- type: map_at_1000
value: 21.087
- type: map_at_3
value: 17.749000000000002
- type: map_at_5
value: 19.156000000000002
- type: mrr_at_1
value: 17.662
- type: mrr_at_10
value: 24.407
- type: mrr_at_100
value: 25.385
- type: mrr_at_1000
value: 25.465
- type: mrr_at_3
value: 22.056
- type: mrr_at_5
value: 23.630000000000003
- type: ndcg_at_1
value: 17.662
- type: ndcg_at_10
value: 24.391
- type: ndcg_at_100
value: 29.681
- type: ndcg_at_1000
value: 32.923
- type: ndcg_at_3
value: 20.271
- type: ndcg_at_5
value: 22.621
- type: precision_at_1
value: 17.662
- type: precision_at_10
value: 4.44
- type: precision_at_100
value: 0.8200000000000001
- type: precision_at_1000
value: 0.125
- type: precision_at_3
value: 9.577
- type: precision_at_5
value: 7.313
- type: recall_at_1
value: 13.594999999999999
- type: recall_at_10
value: 33.976
- type: recall_at_100
value: 57.43000000000001
- type: recall_at_1000
value: 80.958
- type: recall_at_3
value: 22.897000000000002
- type: recall_at_5
value: 28.714000000000002
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackPhysicsRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 26.683
- type: map_at_10
value: 35.068
- type: map_at_100
value: 36.311
- type: map_at_1000
value: 36.436
- type: map_at_3
value: 32.371
- type: map_at_5
value: 33.761
- type: mrr_at_1
value: 32.435
- type: mrr_at_10
value: 40.721000000000004
- type: mrr_at_100
value: 41.535
- type: mrr_at_1000
value: 41.593
- type: mrr_at_3
value: 38.401999999999994
- type: mrr_at_5
value: 39.567
- type: ndcg_at_1
value: 32.435
- type: ndcg_at_10
value: 40.538000000000004
- type: ndcg_at_100
value: 45.963
- type: ndcg_at_1000
value: 48.400999999999996
- type: ndcg_at_3
value: 36.048
- type: ndcg_at_5
value: 37.899
- type: precision_at_1
value: 32.435
- type: precision_at_10
value: 7.1129999999999995
- type: precision_at_100
value: 1.162
- type: precision_at_1000
value: 0.156
- type: precision_at_3
value: 16.683
- type: precision_at_5
value: 11.684
- type: recall_at_1
value: 26.683
- type: recall_at_10
value: 51.517
- type: recall_at_100
value: 74.553
- type: recall_at_1000
value: 90.649
- type: recall_at_3
value: 38.495000000000005
- type: recall_at_5
value: 43.495
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackProgrammersRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 24.186
- type: map_at_10
value: 31.972
- type: map_at_100
value: 33.117000000000004
- type: map_at_1000
value: 33.243
- type: map_at_3
value: 29.423
- type: map_at_5
value: 30.847
- type: mrr_at_1
value: 29.794999999999998
- type: mrr_at_10
value: 36.767
- type: mrr_at_100
value: 37.645
- type: mrr_at_1000
value: 37.716
- type: mrr_at_3
value: 34.513
- type: mrr_at_5
value: 35.791000000000004
- type: ndcg_at_1
value: 29.794999999999998
- type: ndcg_at_10
value: 36.786
- type: ndcg_at_100
value: 41.94
- type: ndcg_at_1000
value: 44.830999999999996
- type: ndcg_at_3
value: 32.504
- type: ndcg_at_5
value: 34.404
- type: precision_at_1
value: 29.794999999999998
- type: precision_at_10
value: 6.518
- type: precision_at_100
value: 1.0659999999999998
- type: precision_at_1000
value: 0.149
- type: precision_at_3
value: 15.296999999999999
- type: precision_at_5
value: 10.731
- type: recall_at_1
value: 24.186
- type: recall_at_10
value: 46.617
- type: recall_at_100
value: 68.75
- type: recall_at_1000
value: 88.864
- type: recall_at_3
value: 34.199
- type: recall_at_5
value: 39.462
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 24.22083333333333
- type: map_at_10
value: 31.606666666666662
- type: map_at_100
value: 32.6195
- type: map_at_1000
value: 32.739999999999995
- type: map_at_3
value: 29.37825
- type: map_at_5
value: 30.596083333333336
- type: mrr_at_1
value: 28.607916666666668
- type: mrr_at_10
value: 35.54591666666666
- type: mrr_at_100
value: 36.33683333333333
- type: mrr_at_1000
value: 36.40624999999999
- type: mrr_at_3
value: 33.526250000000005
- type: mrr_at_5
value: 34.6605
- type: ndcg_at_1
value: 28.607916666666668
- type: ndcg_at_10
value: 36.07966666666667
- type: ndcg_at_100
value: 40.73308333333333
- type: ndcg_at_1000
value: 43.40666666666666
- type: ndcg_at_3
value: 32.23525
- type: ndcg_at_5
value: 33.97083333333333
- type: precision_at_1
value: 28.607916666666668
- type: precision_at_10
value: 6.120333333333335
- type: precision_at_100
value: 0.9921666666666668
- type: precision_at_1000
value: 0.14091666666666666
- type: precision_at_3
value: 14.54975
- type: precision_at_5
value: 10.153166666666667
- type: recall_at_1
value: 24.22083333333333
- type: recall_at_10
value: 45.49183333333334
- type: recall_at_100
value: 66.28133333333332
- type: recall_at_1000
value: 85.16541666666667
- type: recall_at_3
value: 34.6485
- type: recall_at_5
value: 39.229749999999996
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackStatsRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 21.842
- type: map_at_10
value: 27.573999999999998
- type: map_at_100
value: 28.410999999999998
- type: map_at_1000
value: 28.502
- type: map_at_3
value: 25.921
- type: map_at_5
value: 26.888
- type: mrr_at_1
value: 24.08
- type: mrr_at_10
value: 29.915999999999997
- type: mrr_at_100
value: 30.669
- type: mrr_at_1000
value: 30.746000000000002
- type: mrr_at_3
value: 28.349000000000004
- type: mrr_at_5
value: 29.246
- type: ndcg_at_1
value: 24.08
- type: ndcg_at_10
value: 30.898999999999997
- type: ndcg_at_100
value: 35.272999999999996
- type: ndcg_at_1000
value: 37.679
- type: ndcg_at_3
value: 27.881
- type: ndcg_at_5
value: 29.432000000000002
- type: precision_at_1
value: 24.08
- type: precision_at_10
value: 4.678
- type: precision_at_100
value: 0.744
- type: precision_at_1000
value: 0.10300000000000001
- type: precision_at_3
value: 11.860999999999999
- type: precision_at_5
value: 8.16
- type: recall_at_1
value: 21.842
- type: recall_at_10
value: 38.66
- type: recall_at_100
value: 59.169000000000004
- type: recall_at_1000
value: 76.887
- type: recall_at_3
value: 30.532999999999998
- type: recall_at_5
value: 34.354
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackTexRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 17.145
- type: map_at_10
value: 22.729
- type: map_at_100
value: 23.574
- type: map_at_1000
value: 23.695
- type: map_at_3
value: 21.044
- type: map_at_5
value: 21.981
- type: mrr_at_1
value: 20.888
- type: mrr_at_10
value: 26.529000000000003
- type: mrr_at_100
value: 27.308
- type: mrr_at_1000
value: 27.389000000000003
- type: mrr_at_3
value: 24.868000000000002
- type: mrr_at_5
value: 25.825
- type: ndcg_at_1
value: 20.888
- type: ndcg_at_10
value: 26.457000000000004
- type: ndcg_at_100
value: 30.764000000000003
- type: ndcg_at_1000
value: 33.825
- type: ndcg_at_3
value: 23.483999999999998
- type: ndcg_at_5
value: 24.836
- type: precision_at_1
value: 20.888
- type: precision_at_10
value: 4.58
- type: precision_at_100
value: 0.784
- type: precision_at_1000
value: 0.121
- type: precision_at_3
value: 10.874
- type: precision_at_5
value: 7.639
- type: recall_at_1
value: 17.145
- type: recall_at_10
value: 33.938
- type: recall_at_100
value: 53.672
- type: recall_at_1000
value: 76.023
- type: recall_at_3
value: 25.363000000000003
- type: recall_at_5
value: 29.023
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackUnixRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 24.275
- type: map_at_10
value: 30.438
- type: map_at_100
value: 31.489
- type: map_at_1000
value: 31.601000000000003
- type: map_at_3
value: 28.647
- type: map_at_5
value: 29.660999999999998
- type: mrr_at_1
value: 28.077999999999996
- type: mrr_at_10
value: 34.098
- type: mrr_at_100
value: 35.025
- type: mrr_at_1000
value: 35.109
- type: mrr_at_3
value: 32.4
- type: mrr_at_5
value: 33.379999999999995
- type: ndcg_at_1
value: 28.077999999999996
- type: ndcg_at_10
value: 34.271
- type: ndcg_at_100
value: 39.352
- type: ndcg_at_1000
value: 42.199
- type: ndcg_at_3
value: 30.978
- type: ndcg_at_5
value: 32.498
- type: precision_at_1
value: 28.077999999999996
- type: precision_at_10
value: 5.345
- type: precision_at_100
value: 0.897
- type: precision_at_1000
value: 0.125
- type: precision_at_3
value: 13.526
- type: precision_at_5
value: 9.16
- type: recall_at_1
value: 24.275
- type: recall_at_10
value: 42.362
- type: recall_at_100
value: 64.461
- type: recall_at_1000
value: 84.981
- type: recall_at_3
value: 33.249
- type: recall_at_5
value: 37.214999999999996
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackWebmastersRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 22.358
- type: map_at_10
value: 30.062
- type: map_at_100
value: 31.189
- type: map_at_1000
value: 31.386999999999997
- type: map_at_3
value: 27.672
- type: map_at_5
value: 28.76
- type: mrr_at_1
value: 26.877000000000002
- type: mrr_at_10
value: 33.948
- type: mrr_at_100
value: 34.746
- type: mrr_at_1000
value: 34.816
- type: mrr_at_3
value: 31.884
- type: mrr_at_5
value: 33.001000000000005
- type: ndcg_at_1
value: 26.877000000000002
- type: ndcg_at_10
value: 34.977000000000004
- type: ndcg_at_100
value: 39.753
- type: ndcg_at_1000
value: 42.866
- type: ndcg_at_3
value: 30.956
- type: ndcg_at_5
value: 32.381
- type: precision_at_1
value: 26.877000000000002
- type: precision_at_10
value: 6.7
- type: precision_at_100
value: 1.287
- type: precision_at_1000
value: 0.215
- type: precision_at_3
value: 14.360999999999999
- type: precision_at_5
value: 10.119
- type: recall_at_1
value: 22.358
- type: recall_at_10
value: 44.183
- type: recall_at_100
value: 67.14
- type: recall_at_1000
value: 87.53999999999999
- type: recall_at_3
value: 32.79
- type: recall_at_5
value: 36.829
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackWordpressRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 19.198999999999998
- type: map_at_10
value: 25.229000000000003
- type: map_at_100
value: 26.003
- type: map_at_1000
value: 26.111
- type: map_at_3
value: 23.442
- type: map_at_5
value: 24.343
- type: mrr_at_1
value: 21.072
- type: mrr_at_10
value: 27.02
- type: mrr_at_100
value: 27.735
- type: mrr_at_1000
value: 27.815
- type: mrr_at_3
value: 25.416
- type: mrr_at_5
value: 26.173999999999996
- type: ndcg_at_1
value: 21.072
- type: ndcg_at_10
value: 28.862
- type: ndcg_at_100
value: 33.043
- type: ndcg_at_1000
value: 36.003
- type: ndcg_at_3
value: 25.35
- type: ndcg_at_5
value: 26.773000000000003
- type: precision_at_1
value: 21.072
- type: precision_at_10
value: 4.436
- type: precision_at_100
value: 0.713
- type: precision_at_1000
value: 0.106
- type: precision_at_3
value: 10.659
- type: precision_at_5
value: 7.32
- type: recall_at_1
value: 19.198999999999998
- type: recall_at_10
value: 38.376
- type: recall_at_100
value: 58.36900000000001
- type: recall_at_1000
value: 80.92099999999999
- type: recall_at_3
value: 28.715000000000003
- type: recall_at_5
value: 32.147
- task:
type: Retrieval
dataset:
type: climate-fever
name: MTEB ClimateFEVER
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 5.9319999999999995
- type: map_at_10
value: 10.483
- type: map_at_100
value: 11.97
- type: map_at_1000
value: 12.171999999999999
- type: map_at_3
value: 8.477
- type: map_at_5
value: 9.495000000000001
- type: mrr_at_1
value: 13.094
- type: mrr_at_10
value: 21.282
- type: mrr_at_100
value: 22.556
- type: mrr_at_1000
value: 22.628999999999998
- type: mrr_at_3
value: 18.218999999999998
- type: mrr_at_5
value: 19.900000000000002
- type: ndcg_at_1
value: 13.094
- type: ndcg_at_10
value: 15.811
- type: ndcg_at_100
value: 23.035
- type: ndcg_at_1000
value: 27.089999999999996
- type: ndcg_at_3
value: 11.905000000000001
- type: ndcg_at_5
value: 13.377
- type: precision_at_1
value: 13.094
- type: precision_at_10
value: 5.225
- type: precision_at_100
value: 1.2970000000000002
- type: precision_at_1000
value: 0.203
- type: precision_at_3
value: 8.86
- type: precision_at_5
value: 7.309
- type: recall_at_1
value: 5.9319999999999995
- type: recall_at_10
value: 20.305
- type: recall_at_100
value: 46.314
- type: recall_at_1000
value: 69.612
- type: recall_at_3
value: 11.21
- type: recall_at_5
value: 14.773
- task:
type: Retrieval
dataset:
type: dbpedia-entity
name: MTEB DBPedia
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 8.674
- type: map_at_10
value: 17.822
- type: map_at_100
value: 24.794
- type: map_at_1000
value: 26.214
- type: map_at_3
value: 12.690999999999999
- type: map_at_5
value: 15.033
- type: mrr_at_1
value: 61.75000000000001
- type: mrr_at_10
value: 71.58
- type: mrr_at_100
value: 71.923
- type: mrr_at_1000
value: 71.932
- type: mrr_at_3
value: 70.125
- type: mrr_at_5
value: 71.038
- type: ndcg_at_1
value: 51
- type: ndcg_at_10
value: 38.637
- type: ndcg_at_100
value: 42.398
- type: ndcg_at_1000
value: 48.962
- type: ndcg_at_3
value: 43.29
- type: ndcg_at_5
value: 40.763
- type: precision_at_1
value: 61.75000000000001
- type: precision_at_10
value: 30.125
- type: precision_at_100
value: 9.53
- type: precision_at_1000
value: 1.9619999999999997
- type: precision_at_3
value: 45.583
- type: precision_at_5
value: 38.95
- type: recall_at_1
value: 8.674
- type: recall_at_10
value: 23.122
- type: recall_at_100
value: 47.46
- type: recall_at_1000
value: 67.662
- type: recall_at_3
value: 13.946
- type: recall_at_5
value: 17.768
- task:
type: Classification
dataset:
type: mteb/emotion
name: MTEB EmotionClassification
config: default
split: test
revision: 4f58c6b202a23cf9a4da393831edf4f9183cad37
metrics:
- type: accuracy
value: 46.86000000000001
- type: f1
value: 41.343580452760776
- task:
type: Retrieval
dataset:
type: fever
name: MTEB FEVER
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 36.609
- type: map_at_10
value: 47.552
- type: map_at_100
value: 48.283
- type: map_at_1000
value: 48.321
- type: map_at_3
value: 44.869
- type: map_at_5
value: 46.509
- type: mrr_at_1
value: 39.214
- type: mrr_at_10
value: 50.434999999999995
- type: mrr_at_100
value: 51.122
- type: mrr_at_1000
value: 51.151
- type: mrr_at_3
value: 47.735
- type: mrr_at_5
value: 49.394
- type: ndcg_at_1
value: 39.214
- type: ndcg_at_10
value: 53.52400000000001
- type: ndcg_at_100
value: 56.997
- type: ndcg_at_1000
value: 57.975
- type: ndcg_at_3
value: 48.173
- type: ndcg_at_5
value: 51.05800000000001
- type: precision_at_1
value: 39.214
- type: precision_at_10
value: 7.573
- type: precision_at_100
value: 0.9440000000000001
- type: precision_at_1000
value: 0.104
- type: precision_at_3
value: 19.782
- type: precision_at_5
value: 13.453000000000001
- type: recall_at_1
value: 36.609
- type: recall_at_10
value: 69.247
- type: recall_at_100
value: 84.99600000000001
- type: recall_at_1000
value: 92.40899999999999
- type: recall_at_3
value: 54.856
- type: recall_at_5
value: 61.797000000000004
- task:
type: Retrieval
dataset:
type: fiqa
name: MTEB FiQA2018
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 16.466
- type: map_at_10
value: 27.060000000000002
- type: map_at_100
value: 28.511999999999997
- type: map_at_1000
value: 28.693
- type: map_at_3
value: 22.777
- type: map_at_5
value: 25.086000000000002
- type: mrr_at_1
value: 32.716
- type: mrr_at_10
value: 41.593999999999994
- type: mrr_at_100
value: 42.370000000000005
- type: mrr_at_1000
value: 42.419000000000004
- type: mrr_at_3
value: 38.143
- type: mrr_at_5
value: 40.288000000000004
- type: ndcg_at_1
value: 32.716
- type: ndcg_at_10
value: 34.795
- type: ndcg_at_100
value: 40.58
- type: ndcg_at_1000
value: 43.993
- type: ndcg_at_3
value: 29.573
- type: ndcg_at_5
value: 31.583
- type: precision_at_1
value: 32.716
- type: precision_at_10
value: 9.937999999999999
- type: precision_at_100
value: 1.585
- type: precision_at_1000
value: 0.22
- type: precision_at_3
value: 19.496
- type: precision_at_5
value: 15.247
- type: recall_at_1
value: 16.466
- type: recall_at_10
value: 42.886
- type: recall_at_100
value: 64.724
- type: recall_at_1000
value: 85.347
- type: recall_at_3
value: 26.765
- type: recall_at_5
value: 33.603
- task:
type: Retrieval
dataset:
type: hotpotqa
name: MTEB HotpotQA
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 33.025
- type: map_at_10
value: 47.343
- type: map_at_100
value: 48.207
- type: map_at_1000
value: 48.281
- type: map_at_3
value: 44.519
- type: map_at_5
value: 46.217000000000006
- type: mrr_at_1
value: 66.05
- type: mrr_at_10
value: 72.94699999999999
- type: mrr_at_100
value: 73.289
- type: mrr_at_1000
value: 73.30499999999999
- type: mrr_at_3
value: 71.686
- type: mrr_at_5
value: 72.491
- type: ndcg_at_1
value: 66.05
- type: ndcg_at_10
value: 56.338
- type: ndcg_at_100
value: 59.599999999999994
- type: ndcg_at_1000
value: 61.138000000000005
- type: ndcg_at_3
value: 52.034000000000006
- type: ndcg_at_5
value: 54.352000000000004
- type: precision_at_1
value: 66.05
- type: precision_at_10
value: 11.693000000000001
- type: precision_at_100
value: 1.425
- type: precision_at_1000
value: 0.163
- type: precision_at_3
value: 32.613
- type: precision_at_5
value: 21.401999999999997
- type: recall_at_1
value: 33.025
- type: recall_at_10
value: 58.467
- type: recall_at_100
value: 71.242
- type: recall_at_1000
value: 81.452
- type: recall_at_3
value: 48.92
- type: recall_at_5
value: 53.504
- task:
type: Classification
dataset:
type: mteb/imdb
name: MTEB ImdbClassification
config: default
split: test
revision: 3d86128a09e091d6018b6d26cad27f2739fc2db7
metrics:
- type: accuracy
value: 75.5492
- type: ap
value: 69.42911637216271
- type: f1
value: 75.39113704261024
- task:
type: Retrieval
dataset:
type: msmarco
name: MTEB MSMARCO
config: default
split: dev
revision: None
metrics:
- type: map_at_1
value: 23.173
- type: map_at_10
value: 35.453
- type: map_at_100
value: 36.573
- type: map_at_1000
value: 36.620999999999995
- type: map_at_3
value: 31.655
- type: map_at_5
value: 33.823
- type: mrr_at_1
value: 23.868000000000002
- type: mrr_at_10
value: 36.085
- type: mrr_at_100
value: 37.15
- type: mrr_at_1000
value: 37.193
- type: mrr_at_3
value: 32.376
- type: mrr_at_5
value: 34.501
- type: ndcg_at_1
value: 23.854
- type: ndcg_at_10
value: 42.33
- type: ndcg_at_100
value: 47.705999999999996
- type: ndcg_at_1000
value: 48.91
- type: ndcg_at_3
value: 34.604
- type: ndcg_at_5
value: 38.473
- type: precision_at_1
value: 23.854
- type: precision_at_10
value: 6.639
- type: precision_at_100
value: 0.932
- type: precision_at_1000
value: 0.104
- type: precision_at_3
value: 14.685
- type: precision_at_5
value: 10.782
- type: recall_at_1
value: 23.173
- type: recall_at_10
value: 63.441
- type: recall_at_100
value: 88.25
- type: recall_at_1000
value: 97.438
- type: recall_at_3
value: 42.434
- type: recall_at_5
value: 51.745
- task:
type: Classification
dataset:
type: mteb/mtop_domain
name: MTEB MTOPDomainClassification (en)
config: en
split: test
revision: d80d48c1eb48d3562165c59d59d0034df9fff0bf
metrics:
- type: accuracy
value: 92.05426356589147
- type: f1
value: 91.88068588063942
- task:
type: Classification
dataset:
type: mteb/mtop_intent
name: MTEB MTOPIntentClassification (en)
config: en
split: test
revision: ae001d0e6b1228650b7bd1c2c65fb50ad11a8aba
metrics:
- type: accuracy
value: 73.23985408116735
- type: f1
value: 55.858906745287506
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (en)
config: en
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 72.21923335574984
- type: f1
value: 70.0174116204253
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (en)
config: en
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 75.77673167451245
- type: f1
value: 75.44811354778666
- task:
type: Clustering
dataset:
type: mteb/medrxiv-clustering-p2p
name: MTEB MedrxivClusteringP2P
config: default
split: test
revision: e7a26af6f3ae46b30dde8737f02c07b1505bcc73
metrics:
- type: v_measure
value: 31.340414710728737
- task:
type: Clustering
dataset:
type: mteb/medrxiv-clustering-s2s
name: MTEB MedrxivClusteringS2S
config: default
split: test
revision: 35191c8c0dca72d8ff3efcd72aa802307d469663
metrics:
- type: v_measure
value: 28.196676760061578
- task:
type: Reranking
dataset:
type: mteb/mind_small
name: MTEB MindSmallReranking
config: default
split: test
revision: 3bdac13927fdc888b903db93b2ffdbd90b295a69
metrics:
- type: map
value: 29.564149683482206
- type: mrr
value: 30.28995474250486
- task:
type: Retrieval
dataset:
type: nfcorpus
name: MTEB NFCorpus
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 5.93
- type: map_at_10
value: 12.828000000000001
- type: map_at_100
value: 15.501000000000001
- type: map_at_1000
value: 16.791
- type: map_at_3
value: 9.727
- type: map_at_5
value: 11.318999999999999
- type: mrr_at_1
value: 47.678
- type: mrr_at_10
value: 55.893
- type: mrr_at_100
value: 56.491
- type: mrr_at_1000
value: 56.53
- type: mrr_at_3
value: 54.386
- type: mrr_at_5
value: 55.516
- type: ndcg_at_1
value: 45.975
- type: ndcg_at_10
value: 33.928999999999995
- type: ndcg_at_100
value: 30.164
- type: ndcg_at_1000
value: 38.756
- type: ndcg_at_3
value: 41.077000000000005
- type: ndcg_at_5
value: 38.415
- type: precision_at_1
value: 47.678
- type: precision_at_10
value: 24.365000000000002
- type: precision_at_100
value: 7.344
- type: precision_at_1000
value: 1.994
- type: precision_at_3
value: 38.184000000000005
- type: precision_at_5
value: 33.003
- type: recall_at_1
value: 5.93
- type: recall_at_10
value: 16.239
- type: recall_at_100
value: 28.782999999999998
- type: recall_at_1000
value: 60.11
- type: recall_at_3
value: 10.700999999999999
- type: recall_at_5
value: 13.584
- task:
type: Retrieval
dataset:
type: nq
name: MTEB NQ
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 36.163000000000004
- type: map_at_10
value: 51.520999999999994
- type: map_at_100
value: 52.449
- type: map_at_1000
value: 52.473000000000006
- type: map_at_3
value: 47.666
- type: map_at_5
value: 50.043000000000006
- type: mrr_at_1
value: 40.266999999999996
- type: mrr_at_10
value: 54.074
- type: mrr_at_100
value: 54.722
- type: mrr_at_1000
value: 54.739000000000004
- type: mrr_at_3
value: 51.043000000000006
- type: mrr_at_5
value: 52.956
- type: ndcg_at_1
value: 40.238
- type: ndcg_at_10
value: 58.73199999999999
- type: ndcg_at_100
value: 62.470000000000006
- type: ndcg_at_1000
value: 63.083999999999996
- type: ndcg_at_3
value: 51.672
- type: ndcg_at_5
value: 55.564
- type: precision_at_1
value: 40.238
- type: precision_at_10
value: 9.279
- type: precision_at_100
value: 1.139
- type: precision_at_1000
value: 0.12
- type: precision_at_3
value: 23.078000000000003
- type: precision_at_5
value: 16.176
- type: recall_at_1
value: 36.163000000000004
- type: recall_at_10
value: 77.88199999999999
- type: recall_at_100
value: 93.83399999999999
- type: recall_at_1000
value: 98.465
- type: recall_at_3
value: 59.857000000000006
- type: recall_at_5
value: 68.73599999999999
- task:
type: Retrieval
dataset:
type: quora
name: MTEB QuoraRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 70.344
- type: map_at_10
value: 83.907
- type: map_at_100
value: 84.536
- type: map_at_1000
value: 84.557
- type: map_at_3
value: 80.984
- type: map_at_5
value: 82.844
- type: mrr_at_1
value: 81.02000000000001
- type: mrr_at_10
value: 87.158
- type: mrr_at_100
value: 87.268
- type: mrr_at_1000
value: 87.26899999999999
- type: mrr_at_3
value: 86.17
- type: mrr_at_5
value: 86.87
- type: ndcg_at_1
value: 81.02000000000001
- type: ndcg_at_10
value: 87.70700000000001
- type: ndcg_at_100
value: 89.004
- type: ndcg_at_1000
value: 89.139
- type: ndcg_at_3
value: 84.841
- type: ndcg_at_5
value: 86.455
- type: precision_at_1
value: 81.02000000000001
- type: precision_at_10
value: 13.248999999999999
- type: precision_at_100
value: 1.516
- type: precision_at_1000
value: 0.156
- type: precision_at_3
value: 36.963
- type: precision_at_5
value: 24.33
- type: recall_at_1
value: 70.344
- type: recall_at_10
value: 94.75099999999999
- type: recall_at_100
value: 99.30499999999999
- type: recall_at_1000
value: 99.928
- type: recall_at_3
value: 86.506
- type: recall_at_5
value: 91.083
- task:
type: Clustering
dataset:
type: mteb/reddit-clustering
name: MTEB RedditClustering
config: default
split: test
revision: 24640382cdbf8abc73003fb0fa6d111a705499eb
metrics:
- type: v_measure
value: 42.873718018378305
- task:
type: Clustering
dataset:
type: mteb/reddit-clustering-p2p
name: MTEB RedditClusteringP2P
config: default
split: test
revision: 282350215ef01743dc01b456c7f5241fa8937f16
metrics:
- type: v_measure
value: 56.39477366450528
- task:
type: Retrieval
dataset:
type: scidocs
name: MTEB SCIDOCS
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 3.868
- type: map_at_10
value: 9.611
- type: map_at_100
value: 11.087
- type: map_at_1000
value: 11.332
- type: map_at_3
value: 6.813
- type: map_at_5
value: 8.233
- type: mrr_at_1
value: 19
- type: mrr_at_10
value: 28.457
- type: mrr_at_100
value: 29.613
- type: mrr_at_1000
value: 29.695
- type: mrr_at_3
value: 25.55
- type: mrr_at_5
value: 27.29
- type: ndcg_at_1
value: 19
- type: ndcg_at_10
value: 16.419
- type: ndcg_at_100
value: 22.817999999999998
- type: ndcg_at_1000
value: 27.72
- type: ndcg_at_3
value: 15.379000000000001
- type: ndcg_at_5
value: 13.645
- type: precision_at_1
value: 19
- type: precision_at_10
value: 8.540000000000001
- type: precision_at_100
value: 1.7819999999999998
- type: precision_at_1000
value: 0.297
- type: precision_at_3
value: 14.267
- type: precision_at_5
value: 12.04
- type: recall_at_1
value: 3.868
- type: recall_at_10
value: 17.288
- type: recall_at_100
value: 36.144999999999996
- type: recall_at_1000
value: 60.199999999999996
- type: recall_at_3
value: 8.688
- type: recall_at_5
value: 12.198
- task:
type: STS
dataset:
type: mteb/sickr-sts
name: MTEB SICK-R
config: default
split: test
revision: a6ea5a8cab320b040a23452cc28066d9beae2cee
metrics:
- type: cos_sim_pearson
value: 83.96614722598582
- type: cos_sim_spearman
value: 78.9003023008781
- type: euclidean_pearson
value: 81.01829384436505
- type: euclidean_spearman
value: 78.93248416788914
- type: manhattan_pearson
value: 81.1665428926402
- type: manhattan_spearman
value: 78.93264116287453
- task:
type: STS
dataset:
type: mteb/sts12-sts
name: MTEB STS12
config: default
split: test
revision: a0d554a64d88156834ff5ae9920b964011b16384
metrics:
- type: cos_sim_pearson
value: 83.54613363895993
- type: cos_sim_spearman
value: 75.1883451602451
- type: euclidean_pearson
value: 79.70320886899894
- type: euclidean_spearman
value: 74.5917140136796
- type: manhattan_pearson
value: 79.82157067185999
- type: manhattan_spearman
value: 74.74185720594735
- task:
type: STS
dataset:
type: mteb/sts13-sts
name: MTEB STS13
config: default
split: test
revision: 7e90230a92c190f1bf69ae9002b8cea547a64cca
metrics:
- type: cos_sim_pearson
value: 81.30430156721782
- type: cos_sim_spearman
value: 81.79962989974364
- type: euclidean_pearson
value: 80.89058823224924
- type: euclidean_spearman
value: 81.35929372984597
- type: manhattan_pearson
value: 81.12204370487478
- type: manhattan_spearman
value: 81.6248963282232
- task:
type: STS
dataset:
type: mteb/sts14-sts
name: MTEB STS14
config: default
split: test
revision: 6031580fec1f6af667f0bd2da0a551cf4f0b2375
metrics:
- type: cos_sim_pearson
value: 81.13064504403134
- type: cos_sim_spearman
value: 78.48371403924872
- type: euclidean_pearson
value: 80.16794919665591
- type: euclidean_spearman
value: 78.29216082221699
- type: manhattan_pearson
value: 80.22308565207301
- type: manhattan_spearman
value: 78.37829229948022
- task:
type: STS
dataset:
type: mteb/sts15-sts
name: MTEB STS15
config: default
split: test
revision: ae752c7c21bf194d8b67fd573edf7ae58183cbe3
metrics:
- type: cos_sim_pearson
value: 86.52918899541099
- type: cos_sim_spearman
value: 87.49276894673142
- type: euclidean_pearson
value: 86.77440570164254
- type: euclidean_spearman
value: 87.5753295736756
- type: manhattan_pearson
value: 86.86098573892133
- type: manhattan_spearman
value: 87.65848591821947
- task:
type: STS
dataset:
type: mteb/sts16-sts
name: MTEB STS16
config: default
split: test
revision: 4d8694f8f0e0100860b497b999b3dbed754a0513
metrics:
- type: cos_sim_pearson
value: 82.86805307244882
- type: cos_sim_spearman
value: 84.58066253757511
- type: euclidean_pearson
value: 84.38377000876991
- type: euclidean_spearman
value: 85.1837278784528
- type: manhattan_pearson
value: 84.41903291363842
- type: manhattan_spearman
value: 85.19023736251052
- task:
type: STS
dataset:
type: mteb/sts17-crosslingual-sts
name: MTEB STS17 (en-en)
config: en-en
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 86.77218560282436
- type: cos_sim_spearman
value: 87.94243515296604
- type: euclidean_pearson
value: 88.22800939214864
- type: euclidean_spearman
value: 87.91106839439841
- type: manhattan_pearson
value: 88.17063269848741
- type: manhattan_spearman
value: 87.72751904126062
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (en)
config: en
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 60.40731554300387
- type: cos_sim_spearman
value: 63.76300532966479
- type: euclidean_pearson
value: 62.94727878229085
- type: euclidean_spearman
value: 63.678039531461216
- type: manhattan_pearson
value: 63.00661039863549
- type: manhattan_spearman
value: 63.6282591984376
- task:
type: STS
dataset:
type: mteb/stsbenchmark-sts
name: MTEB STSBenchmark
config: default
split: test
revision: b0fddb56ed78048fa8b90373c8a3cfc37b684831
metrics:
- type: cos_sim_pearson
value: 84.92731569745344
- type: cos_sim_spearman
value: 86.36336704300167
- type: euclidean_pearson
value: 86.09122224841195
- type: euclidean_spearman
value: 86.2116149319238
- type: manhattan_pearson
value: 86.07879456717032
- type: manhattan_spearman
value: 86.2022069635119
- task:
type: Reranking
dataset:
type: mteb/scidocs-reranking
name: MTEB SciDocsRR
config: default
split: test
revision: d3c5e1fc0b855ab6097bf1cda04dd73947d7caab
metrics:
- type: map
value: 79.75976311752326
- type: mrr
value: 94.15782837351466
- task:
type: Retrieval
dataset:
type: scifact
name: MTEB SciFact
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 51.193999999999996
- type: map_at_10
value: 61.224999999999994
- type: map_at_100
value: 62.031000000000006
- type: map_at_1000
value: 62.066
- type: map_at_3
value: 59.269000000000005
- type: map_at_5
value: 60.159
- type: mrr_at_1
value: 53.667
- type: mrr_at_10
value: 62.74999999999999
- type: mrr_at_100
value: 63.39399999999999
- type: mrr_at_1000
value: 63.425
- type: mrr_at_3
value: 61.389
- type: mrr_at_5
value: 61.989000000000004
- type: ndcg_at_1
value: 53.667
- type: ndcg_at_10
value: 65.596
- type: ndcg_at_100
value: 68.906
- type: ndcg_at_1000
value: 69.78999999999999
- type: ndcg_at_3
value: 62.261
- type: ndcg_at_5
value: 63.453
- type: precision_at_1
value: 53.667
- type: precision_at_10
value: 8.667
- type: precision_at_100
value: 1.04
- type: precision_at_1000
value: 0.11100000000000002
- type: precision_at_3
value: 24.556
- type: precision_at_5
value: 15.6
- type: recall_at_1
value: 51.193999999999996
- type: recall_at_10
value: 77.156
- type: recall_at_100
value: 91.43299999999999
- type: recall_at_1000
value: 98.333
- type: recall_at_3
value: 67.994
- type: recall_at_5
value: 71.14399999999999
- task:
type: PairClassification
dataset:
type: mteb/sprintduplicatequestions-pairclassification
name: MTEB SprintDuplicateQuestions
config: default
split: test
revision: d66bd1f72af766a5cc4b0ca5e00c162f89e8cc46
metrics:
- type: cos_sim_accuracy
value: 99.81485148514851
- type: cos_sim_ap
value: 95.28896513388551
- type: cos_sim_f1
value: 90.43478260869566
- type: cos_sim_precision
value: 92.56544502617801
- type: cos_sim_recall
value: 88.4
- type: dot_accuracy
value: 99.30594059405941
- type: dot_ap
value: 61.6432597455472
- type: dot_f1
value: 59.46481665014866
- type: dot_precision
value: 58.93909626719057
- type: dot_recall
value: 60
- type: euclidean_accuracy
value: 99.81980198019802
- type: euclidean_ap
value: 95.21411049527
- type: euclidean_f1
value: 91.06090373280944
- type: euclidean_precision
value: 89.47876447876449
- type: euclidean_recall
value: 92.7
- type: manhattan_accuracy
value: 99.81782178217821
- type: manhattan_ap
value: 95.32449994414968
- type: manhattan_f1
value: 90.86395233366436
- type: manhattan_precision
value: 90.23668639053254
- type: manhattan_recall
value: 91.5
- type: max_accuracy
value: 99.81980198019802
- type: max_ap
value: 95.32449994414968
- type: max_f1
value: 91.06090373280944
- task:
type: Clustering
dataset:
type: mteb/stackexchange-clustering
name: MTEB StackExchangeClustering
config: default
split: test
revision: 6cbc1f7b2bc0622f2e39d2c77fa502909748c259
metrics:
- type: v_measure
value: 59.08045614613064
- task:
type: Clustering
dataset:
type: mteb/stackexchange-clustering-p2p
name: MTEB StackExchangeClusteringP2P
config: default
split: test
revision: 815ca46b2622cec33ccafc3735d572c266efdb44
metrics:
- type: v_measure
value: 30.297802606804748
- task:
type: Reranking
dataset:
type: mteb/stackoverflowdupquestions-reranking
name: MTEB StackOverflowDupQuestions
config: default
split: test
revision: e185fbe320c72810689fc5848eb6114e1ef5ec69
metrics:
- type: map
value: 49.12801740706292
- type: mrr
value: 50.05592956879722
- task:
type: Summarization
dataset:
type: mteb/summeval
name: MTEB SummEval
config: default
split: test
revision: cda12ad7615edc362dbf25a00fdd61d3b1eaf93c
metrics:
- type: cos_sim_pearson
value: 31.523347880124497
- type: cos_sim_spearman
value: 31.388214436391014
- type: dot_pearson
value: 24.55403435439901
- type: dot_spearman
value: 23.50153210841191
- task:
type: Retrieval
dataset:
type: trec-covid
name: MTEB TRECCOVID
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 0.243
- type: map_at_10
value: 1.886
- type: map_at_100
value: 10.040000000000001
- type: map_at_1000
value: 23.768
- type: map_at_3
value: 0.674
- type: map_at_5
value: 1.079
- type: mrr_at_1
value: 88
- type: mrr_at_10
value: 93.667
- type: mrr_at_100
value: 93.667
- type: mrr_at_1000
value: 93.667
- type: mrr_at_3
value: 93.667
- type: mrr_at_5
value: 93.667
- type: ndcg_at_1
value: 83
- type: ndcg_at_10
value: 76.777
- type: ndcg_at_100
value: 55.153
- type: ndcg_at_1000
value: 47.912
- type: ndcg_at_3
value: 81.358
- type: ndcg_at_5
value: 80.74799999999999
- type: precision_at_1
value: 88
- type: precision_at_10
value: 80.80000000000001
- type: precision_at_100
value: 56.02
- type: precision_at_1000
value: 21.51
- type: precision_at_3
value: 86
- type: precision_at_5
value: 86
- type: recall_at_1
value: 0.243
- type: recall_at_10
value: 2.0869999999999997
- type: recall_at_100
value: 13.014000000000001
- type: recall_at_1000
value: 44.433
- type: recall_at_3
value: 0.6910000000000001
- type: recall_at_5
value: 1.1440000000000001
- task:
type: Retrieval
dataset:
type: webis-touche2020
name: MTEB Touche2020
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 3.066
- type: map_at_10
value: 10.615
- type: map_at_100
value: 16.463
- type: map_at_1000
value: 17.815
- type: map_at_3
value: 5.7860000000000005
- type: map_at_5
value: 7.353999999999999
- type: mrr_at_1
value: 38.775999999999996
- type: mrr_at_10
value: 53.846000000000004
- type: mrr_at_100
value: 54.37
- type: mrr_at_1000
value: 54.37
- type: mrr_at_3
value: 48.980000000000004
- type: mrr_at_5
value: 51.735
- type: ndcg_at_1
value: 34.694
- type: ndcg_at_10
value: 26.811
- type: ndcg_at_100
value: 37.342999999999996
- type: ndcg_at_1000
value: 47.964
- type: ndcg_at_3
value: 30.906
- type: ndcg_at_5
value: 27.77
- type: precision_at_1
value: 38.775999999999996
- type: precision_at_10
value: 23.878
- type: precision_at_100
value: 7.632999999999999
- type: precision_at_1000
value: 1.469
- type: precision_at_3
value: 31.973000000000003
- type: precision_at_5
value: 26.939
- type: recall_at_1
value: 3.066
- type: recall_at_10
value: 17.112
- type: recall_at_100
value: 47.723
- type: recall_at_1000
value: 79.50500000000001
- type: recall_at_3
value: 6.825
- type: recall_at_5
value: 9.584
- task:
type: Classification
dataset:
type: mteb/toxic_conversations_50k
name: MTEB ToxicConversationsClassification
config: default
split: test
revision: d7c0de2777da35d6aae2200a62c6e0e5af397c4c
metrics:
- type: accuracy
value: 72.76460000000002
- type: ap
value: 14.944240012137053
- type: f1
value: 55.89805777266571
- task:
type: Classification
dataset:
type: mteb/tweet_sentiment_extraction
name: MTEB TweetSentimentExtractionClassification
config: default
split: test
revision: d604517c81ca91fe16a244d1248fc021f9ecee7a
metrics:
- type: accuracy
value: 63.30503678551217
- type: f1
value: 63.57492701921179
- task:
type: Clustering
dataset:
type: mteb/twentynewsgroups-clustering
name: MTEB TwentyNewsgroupsClustering
config: default
split: test
revision: 6125ec4e24fa026cec8a478383ee943acfbd5449
metrics:
- type: v_measure
value: 37.51066495006874
- task:
type: PairClassification
dataset:
type: mteb/twittersemeval2015-pairclassification
name: MTEB TwitterSemEval2015
config: default
split: test
revision: 70970daeab8776df92f5ea462b6173c0b46fd2d1
metrics:
- type: cos_sim_accuracy
value: 86.07021517553794
- type: cos_sim_ap
value: 74.15520712370555
- type: cos_sim_f1
value: 68.64321608040201
- type: cos_sim_precision
value: 65.51558752997602
- type: cos_sim_recall
value: 72.0844327176781
- type: dot_accuracy
value: 80.23484532395541
- type: dot_ap
value: 54.298763810214176
- type: dot_f1
value: 53.22254659779924
- type: dot_precision
value: 46.32525410476936
- type: dot_recall
value: 62.532981530343015
- type: euclidean_accuracy
value: 86.04637301066937
- type: euclidean_ap
value: 73.85333854233123
- type: euclidean_f1
value: 68.77723660599845
- type: euclidean_precision
value: 66.87437686939182
- type: euclidean_recall
value: 70.79155672823218
- type: manhattan_accuracy
value: 85.98676759849795
- type: manhattan_ap
value: 73.56016090035973
- type: manhattan_f1
value: 68.48878539036647
- type: manhattan_precision
value: 63.9505607690547
- type: manhattan_recall
value: 73.7203166226913
- type: max_accuracy
value: 86.07021517553794
- type: max_ap
value: 74.15520712370555
- type: max_f1
value: 68.77723660599845
- task:
type: PairClassification
dataset:
type: mteb/twitterurlcorpus-pairclassification
name: MTEB TwitterURLCorpus
config: default
split: test
revision: 8b6510b0b1fa4e4c4f879467980e9be563ec1cdf
metrics:
- type: cos_sim_accuracy
value: 88.92769821865176
- type: cos_sim_ap
value: 85.78879502899773
- type: cos_sim_f1
value: 78.14414083990464
- type: cos_sim_precision
value: 74.61651607480563
- type: cos_sim_recall
value: 82.0218663381583
- type: dot_accuracy
value: 84.95750378390964
- type: dot_ap
value: 75.80219641857563
- type: dot_f1
value: 70.13966179585681
- type: dot_precision
value: 65.71140262361251
- type: dot_recall
value: 75.20788420080073
- type: euclidean_accuracy
value: 88.93546008460433
- type: euclidean_ap
value: 85.72056428301667
- type: euclidean_f1
value: 78.14387902598124
- type: euclidean_precision
value: 75.3376688344172
- type: euclidean_recall
value: 81.16723129042192
- type: manhattan_accuracy
value: 88.96262661543835
- type: manhattan_ap
value: 85.76605136314335
- type: manhattan_f1
value: 78.26696165191743
- type: manhattan_precision
value: 75.0990659496179
- type: manhattan_recall
value: 81.71388974437943
- type: max_accuracy
value: 88.96262661543835
- type: max_ap
value: 85.78879502899773
- type: max_f1
value: 78.26696165191743
language:
- en
license: mit
---
# E5-small
**News (May 2023): please switch to [e5-small-v2](https://huggingface.co/intfloat/e5-small-v2), which has better performance and same method of usage.**
[Text Embeddings by Weakly-Supervised Contrastive Pre-training](https://arxiv.org/pdf/2212.03533.pdf).
Liang Wang, Nan Yang, Xiaolong Huang, Binxing Jiao, Linjun Yang, Daxin Jiang, Rangan Majumder, Furu Wei, arXiv 2022
This model has 12 layers and the embedding size is 384.
## Usage
Below is an example to encode queries and passages from the MS-MARCO passage ranking dataset.
```python
import torch.nn.functional as F
from torch import Tensor
from transformers import AutoTokenizer, AutoModel
def average_pool(last_hidden_states: Tensor,
attention_mask: Tensor) -> Tensor:
last_hidden = last_hidden_states.masked_fill(~attention_mask[..., None].bool(), 0.0)
return last_hidden.sum(dim=1) / attention_mask.sum(dim=1)[..., None]
# Each input text should start with "query: " or "passage: ".
# For tasks other than retrieval, you can simply use the "query: " prefix.
input_texts = ['query: how much protein should a female eat',
'query: summit define',
"passage: As a general guideline, the CDC's average requirement of protein for women ages 19 to 70 is 46 grams per day. But, as you can see from this chart, you'll need to increase that if you're expecting or training for a marathon. Check out the chart below to see how much protein you should be eating each day.",
"passage: Definition of summit for English Language Learners. : 1 the highest point of a mountain : the top of a mountain. : 2 the highest level. : 3 a meeting or series of meetings between the leaders of two or more governments."]
tokenizer = AutoTokenizer.from_pretrained('intfloat/e5-small')
model = AutoModel.from_pretrained('intfloat/e5-small')
# Tokenize the input texts
batch_dict = tokenizer(input_texts, max_length=512, padding=True, truncation=True, return_tensors='pt')
outputs = model(**batch_dict)
embeddings = average_pool(outputs.last_hidden_state, batch_dict['attention_mask'])
# normalize embeddings
embeddings = F.normalize(embeddings, p=2, dim=1)
scores = (embeddings[:2] @ embeddings[2:].T) * 100
print(scores.tolist())
```
## Training Details
Please refer to our paper at [https://arxiv.org/pdf/2212.03533.pdf](https://arxiv.org/pdf/2212.03533.pdf).
## Benchmark Evaluation
Check out [unilm/e5](https://github.com/microsoft/unilm/tree/master/e5) to reproduce evaluation results
on the [BEIR](https://arxiv.org/abs/2104.08663) and [MTEB benchmark](https://arxiv.org/abs/2210.07316).
## Support for Sentence Transformers
Below is an example for usage with sentence_transformers.
```python
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('intfloat/e5-small')
input_texts = [
'query: how much protein should a female eat',
'query: summit define',
"passage: As a general guideline, the CDC's average requirement of protein for women ages 19 to 70 is 46 grams per day. But, as you can see from this chart, you'll need to increase that if you're expecting or training for a marathon. Check out the chart below to see how much protein you should be eating each day.",
"passage: Definition of summit for English Language Learners. : 1 the highest point of a mountain : the top of a mountain. : 2 the highest level. : 3 a meeting or series of meetings between the leaders of two or more governments."
]
embeddings = model.encode(input_texts, normalize_embeddings=True)
```
Package requirements
`pip install sentence_transformers~=2.2.2`
Contributors: [michaelfeil](https://huggingface.co/michaelfeil)
## FAQ
**1. Do I need to add the prefix "query: " and "passage: " to input texts?**
Yes, this is how the model is trained, otherwise you will see a performance degradation.
Here are some rules of thumb:
- Use "query: " and "passage: " correspondingly for asymmetric tasks such as passage retrieval in open QA, ad-hoc information retrieval.
- Use "query: " prefix for symmetric tasks such as semantic similarity, paraphrase retrieval.
- Use "query: " prefix if you want to use embeddings as features, such as linear probing classification, clustering.
**2. Why are my reproduced results slightly different from reported in the model card?**
Different versions of `transformers` and `pytorch` could cause negligible but non-zero performance differences.
**3. Why does the cosine similarity scores distribute around 0.7 to 1.0?**
This is a known and expected behavior as we use a low temperature 0.01 for InfoNCE contrastive loss.
For text embedding tasks like text retrieval or semantic similarity,
what matters is the relative order of the scores instead of the absolute values,
so this should not be an issue.
## Citation
If you find our paper or models helpful, please consider cite as follows:
```
@article{wang2022text,
title={Text Embeddings by Weakly-Supervised Contrastive Pre-training},
author={Wang, Liang and Yang, Nan and Huang, Xiaolong and Jiao, Binxing and Yang, Linjun and Jiang, Daxin and Majumder, Rangan and Wei, Furu},
journal={arXiv preprint arXiv:2212.03533},
year={2022}
}
```
## Limitations
This model only works for English texts. Long texts will be truncated to at most 512 tokens.
|
elyza/ELYZA-japanese-Llama-2-7b-fast | elyza | 2023-08-29T03:46:37Z | 17,112 | 23 | transformers | [
"transformers",
"pytorch",
"llama",
"text-generation",
"ja",
"en",
"arxiv:2307.09288",
"license:llama2",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| text-generation | 2023-08-28T13:17:58Z | ---
license: llama2
language:
- ja
- en
---
## ELYZA-japanese-Llama-2-7b

### Model Description
**ELYZA-japanese-Llama-2-7b** は、 Llama2をベースとして日本語能力を拡張するために追加事前学習を行ったモデルです。
詳細は [Blog記事](https://note.com/elyza/n/na405acaca130) を参照してください。
### Usage
```python
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
B_INST, E_INST = "[INST]", "[/INST]"
B_SYS, E_SYS = "<<SYS>>\n", "\n<</SYS>>\n\n"
DEFAULT_SYSTEM_PROMPT = "あなたは誠実で優秀な日本人のアシスタントです。"
text = "クマが海辺に行ってアザラシと友達になり、最終的には家に帰るというプロットの短編小説を書いてください。"
model_name = "elyza/ELYZA-japanese-Llama-2-7b-instruct"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name, torch_dtype="auto")
if torch.cuda.is_available():
model = model.to("cuda")
prompt = "{bos_token}{b_inst} {system}{prompt} {e_inst} ".format(
bos_token=tokenizer.bos_token,
b_inst=B_INST,
system=f"{B_SYS}{DEFAULT_SYSTEM_PROMPT}{E_SYS}",
prompt=text,
e_inst=E_INST,
)
with torch.no_grad():
token_ids = tokenizer.encode(prompt, add_special_tokens=False, return_tensors="pt")
output_ids = model.generate(
token_ids.to(model.device),
max_new_tokens=256,
pad_token_id=tokenizer.pad_token_id,
eos_token_id=tokenizer.eos_token_id,
)
output = tokenizer.decode(output_ids.tolist()[0][token_ids.size(1) :], skip_special_tokens=True)
print(output)
"""
承知しました。以下にクマが海辺に行ってアザラシと友達になり、最終的には家に帰るというプロットの短編小説を記述します。
クマは山の中でゆっくりと眠っていた。
その眠りに落ちたクマは、夢の中で海辺を歩いていた。
そこにはアザラシがいた。
クマはアザラシに話しかける。
「おはよう」とクマが言うと、アザラシは驚いたように顔を上げた。
「あ、こんにちは」アザラシは答えた。
クマはアザラシと友達になりたいと思う。
「私はクマと申します。」クマは...
"""
```
### ELYZA-japanese-Llama-2-7b Models
| Model Name | Vocab Size | #Params |
|:---------------------------------------------|:----------:|:-------:|
|[elyza/ELYZA-japanese-Llama-2-7b](https://huggingface.co/elyza/ELYZA-japanese-Llama-2-7b)| 32000 | 6.27B |
|[elyza/ELYZA-japanese-Llama-2-7b-instruct](https://huggingface.co/elyza/ELYZA-japanese-Llama-2-7b-instruct)| 32000 | 6.27B |
|[elyza/ELYZA-japanese-Llama-2-7b-fast](https://huggingface.co/elyza/ELYZA-japanese-Llama-2-7b-fast)| 45043 | 6.37B |
|[elyza/ELYZA-japanese-Llama-2-7b-fast-instruct](https://huggingface.co/elyza/ELYZA-japanese-Llama-2-7b-fast-instruct)| 45043 | 6.37B |
### Developers
以下アルファベット順
- [Akira Sasaki](https://huggingface.co/akirasasaki)
- [Masato Hirakawa](https://huggingface.co/m-hirakawa)
- [Shintaro Horie](https://huggingface.co/e-mon)
- [Tomoaki Nakamura](https://huggingface.co/tyoyo)
### Licence
Llama 2 is licensed under the LLAMA 2 Community License, Copyright (c) Meta Platforms, Inc. All Rights Reserved.
### How to Cite
```tex
@misc{elyzallama2023,
title={ELYZA-japanese-Llama-2-7b},
url={https://huggingface.co/elyza/ELYZA-japanese-Llama-2-7b},
author={Akira Sasaki and Masato Hirakawa and Shintaro Horie and Tomoaki Nakamura},
year={2023},
}
```
### Citations
```tex
@misc{touvron2023llama,
title={Llama 2: Open Foundation and Fine-Tuned Chat Models},
author={Hugo Touvron and Louis Martin and Kevin Stone and Peter Albert and Amjad Almahairi and Yasmine Babaei and Nikolay Bashlykov and Soumya Batra and Prajjwal Bhargava and Shruti Bhosale and Dan Bikel and Lukas Blecher and Cristian Canton Ferrer and Moya Chen and Guillem Cucurull and David Esiobu and Jude Fernandes and Jeremy Fu and Wenyin Fu and Brian Fuller and Cynthia Gao and Vedanuj Goswami and Naman Goyal and Anthony Hartshorn and Saghar Hosseini and Rui Hou and Hakan Inan and Marcin Kardas and Viktor Kerkez and Madian Khabsa and Isabel Kloumann and Artem Korenev and Punit Singh Koura and Marie-Anne Lachaux and Thibaut Lavril and Jenya Lee and Diana Liskovich and Yinghai Lu and Yuning Mao and Xavier Martinet and Todor Mihaylov and Pushkar Mishra and Igor Molybog and Yixin Nie and Andrew Poulton and Jeremy Reizenstein and Rashi Rungta and Kalyan Saladi and Alan Schelten and Ruan Silva and Eric Michael Smith and Ranjan Subramanian and Xiaoqing Ellen Tan and Binh Tang and Ross Taylor and Adina Williams and Jian Xiang Kuan and Puxin Xu and Zheng Yan and Iliyan Zarov and Yuchen Zhang and Angela Fan and Melanie Kambadur and Sharan Narang and Aurelien Rodriguez and Robert Stojnic and Sergey Edunov and Thomas Scialom},
year={2023},
eprint={2307.09288},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
``` |
duyntnet/Llama-2-7b-chat-hf-imatrix-GGUF | duyntnet | 2024-06-29T11:16:22Z | 17,112 | 0 | transformers | [
"transformers",
"gguf",
"imatrix",
"Llama-2-7b-chat-hf",
"text-generation",
"en",
"license:other",
"region:us"
]
| text-generation | 2024-06-29T08:48:41Z | ---
license: other
language:
- en
pipeline_tag: text-generation
inference: false
tags:
- transformers
- gguf
- imatrix
- Llama-2-7b-chat-hf
---
Quantizations of https://huggingface.co/meta-llama/Llama-2-7b-chat-hf
# From original readme
## Intended Use
**Intended Use Cases** Llama 2 is intended for commercial and research use in English. Tuned models are intended for assistant-like chat, whereas pretrained models can be adapted for a variety of natural language generation tasks.
To get the expected features and performance for the chat versions, a specific formatting needs to be followed, including the `INST` and `<<SYS>>` tags, `BOS` and `EOS` tokens, and the whitespaces and breaklines in between (we recommend calling `strip()` on inputs to avoid double-spaces). See our reference code in github for details: [`chat_completion`](https://github.com/facebookresearch/llama/blob/main/llama/generation.py#L212). |
Lewdiculous/Bungo-L3-8B-GGUF-IQ-Imatrix-Request | Lewdiculous | 2024-06-28T06:24:00Z | 17,102 | 9 | null | [
"gguf",
"license:unlicense",
"region:us"
]
| null | 2024-06-28T01:55:40Z | ---
inference: false
license: unlicense
---
[[Request #59 – Click here for more context.]](https://huggingface.co/Lewdiculous/Model-Requests/discussions/59) <br>
**Request description:** <br>
"An experimental model that turned really well. Scores high on Chai leaderboard (slerp8bv2 there). Feel smarter than average L3 merges for RP."
**Model page:** <br>
[R136a1/Bungo-L3-8B](https://huggingface.co/R136a1/Bungo-L3-8B)
> [!IMPORTANT]
> Use with the [**latest version of KoboldCpp**](https://github.com/LostRuins/koboldcpp/releases/latest), or [**this alternative fork**](https://github.com/Nexesenex/kobold.cpp) if you have issues.
<details>
<summary>Click here to <b>expand/hide</b> information: <br> ⇲ <b>General chart with relative quant performance.</b></summary>
> [!NOTE]
> **Recommended read:** <br>
>
> [**"Which GGUF is right for me? (Opinionated)" by Artefact2**](https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9)
>
> *Click the image to view full size.*
> 
</details>
<!--|  |-->
<!--| webp/95%/2048x2048 square-shaped image/50px rounded corners |-->
[](https://huggingface.co/Lewdiculous/Bungo-L3-8B-GGUF-IQ-Imatrix-Request/blob/main/2x-upscaled-bunga-2x-realesrgan.webp)
|
XelotX/Meta-Llama-3-70b-Instruct-Xelotx | XelotX | 2024-06-25T11:33:59Z | 17,101 | 0 | null | [
"license:mit",
"region:us"
]
| null | 2024-06-24T17:44:13Z | ---
license: mit
---
|
dbmdz/german-gpt2 | dbmdz | 2023-12-13T17:41:57Z | 17,088 | 24 | transformers | [
"transformers",
"pytorch",
"tf",
"jax",
"onnx",
"safetensors",
"gpt2",
"text-generation",
"de",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| text-generation | 2022-03-02T23:29:05Z | ---
language: de
widget:
- text: "Heute ist sehr schönes Wetter in"
license: mit
---
# German GPT-2 model
In this repository we release (yet another) GPT-2 model, that was trained on various texts for German.
The model is meant to be an entry point for fine-tuning on other texts, and it is definitely not as good or "dangerous" as the English GPT-3 model. We do not plan extensive PR or staged releases for this model 😉
**Note**: The model was initially released under an anonymous alias (`anonymous-german-nlp/german-gpt2`) so we now "de-anonymize" it.
More details about GPT-2 can be found in the great [Hugging Face](https://huggingface.co/transformers/model_doc/gpt2.html) documentation.
# Changelog
16.08.2021: Public release of re-trained version of our German GPT-2 model with better results.
15.11.2020: Initial release. Please use the tag `v1.0` for [this older version](https://huggingface.co/dbmdz/german-gpt2/tree/v1.0).
# Training corpora
We use pretty much the same corpora as used for training the DBMDZ BERT model, that can be found in [this repository](https://github.com/dbmdz/berts).
Thanks to the awesome Hugging Face team, it is possible to create byte-level BPE with their awesome [Tokenizers](https://github.com/huggingface/tokenizers) library.
With the previously mentioned awesome Tokenizers library we created a 50K byte-level BPE vocab based on the training corpora.
After creating the vocab, we could train the GPT-2 for German on a v3-8 TPU over the complete training corpus for 20 epochs. All hyperparameters
can be found in the official JAX/FLAX documentation [here](https://github.com/huggingface/transformers/blob/master/examples/flax/language-modeling/README.md)
from Transformers.
# Using the model
The model itself can be used in this way:
```python
from transformers import AutoTokenizer, AutoModelWithLMHead
tokenizer = AutoTokenizer.from_pretrained("dbmdz/german-gpt2")
model = AutoModelWithLMHead.from_pretrained("dbmdz/german-gpt2")
```
However, text generation is a bit more interesting, so here's an example that shows how to use the great Transformers *Pipelines* for generating text:
```python
from transformers import pipeline
pipe = pipeline('text-generation', model="dbmdz/german-gpt2",
tokenizer="dbmdz/german-gpt2")
text = pipe("Der Sinn des Lebens ist es", max_length=100)[0]["generated_text"]
print(text)
```
This could output this beautiful text:
```
Der Sinn des Lebens ist es, im Geist zu verweilen, aber nicht in der Welt zu sein, sondern ganz im Geist zu leben.
Die Menschen beginnen, sich nicht nach der Natur und nach der Welt zu richten, sondern nach der Seele,'
```
# License
All models are licensed under [MIT](LICENSE).
# Huggingface model hub
All models are available on the [Huggingface model hub](https://huggingface.co/dbmdz).
# Contact (Bugs, Feedback, Contribution and more)
For questions about our BERT models just open an issue
[here](https://github.com/stefan-it/german-gpt/issues/new) 🤗
# Acknowledgments
Research supported with Cloud TPUs from Google's TensorFlow Research Cloud (TFRC).
Thanks for providing access to the TFRC ❤️
Thanks to the generous support from the [Hugging Face](https://huggingface.co/) team,
it is possible to download both cased and uncased models from their S3 storage 🤗
|
Intel/neural-chat-7b-v3-3 | Intel | 2024-03-04T12:17:57Z | 17,088 | 71 | transformers | [
"transformers",
"pytorch",
"mistral",
"text-generation",
"LLMs",
"math",
"Intel",
"arxiv:2309.12284",
"base_model:Intel/neural-chat-7b-v3-1",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| text-generation | 2023-12-09T16:25:05Z | ---
license: apache-2.0
tags:
- LLMs
- mistral
- math
- Intel
base_model: Intel/neural-chat-7b-v3-1
model-index:
- name: neural-chat-7b-v3-3
results:
- task:
type: Large Language Model
name: Large Language Model
dataset:
name: meta-math/MetaMathQA
type: meta-math/MetaMathQA
metrics:
- type: ARC (25-shot)
value: 66.89
name: ARC (25-shot)
verified: true
- type: HellaSwag (10-shot)
value: 85.26
name: HellaSwag (10-shot)
verified: true
- type: MMLU (5-shot)
value: 63.07
name: MMLU (5-shot)
verified: true
- type: TruthfulQA (0-shot)
value: 63.01
name: TruthfulQA (0-shot)
verified: true
- type: Winogrande (5-shot)
value: 79.64
name: Winogrande (5-shot)
verified: true
- type: GSM8K (5-shot)
value: 61.11
name: GSM8K (5-shot)
verified: true
- task:
type: text-generation
name: Text Generation
dataset:
name: AI2 Reasoning Challenge (25-Shot)
type: ai2_arc
config: ARC-Challenge
split: test
args:
num_few_shot: 25
metrics:
- type: acc_norm
value: 66.89
name: normalized accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=Intel/neural-chat-7b-v3-3
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: HellaSwag (10-Shot)
type: hellaswag
split: validation
args:
num_few_shot: 10
metrics:
- type: acc_norm
value: 85.26
name: normalized accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=Intel/neural-chat-7b-v3-3
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: MMLU (5-Shot)
type: cais/mmlu
config: all
split: test
args:
num_few_shot: 5
metrics:
- type: acc
value: 63.07
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=Intel/neural-chat-7b-v3-3
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: TruthfulQA (0-shot)
type: truthful_qa
config: multiple_choice
split: validation
args:
num_few_shot: 0
metrics:
- type: mc2
value: 63.01
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=Intel/neural-chat-7b-v3-3
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: Winogrande (5-shot)
type: winogrande
config: winogrande_xl
split: validation
args:
num_few_shot: 5
metrics:
- type: acc
value: 79.64
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=Intel/neural-chat-7b-v3-3
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: GSM8k (5-shot)
type: gsm8k
config: main
split: test
args:
num_few_shot: 5
metrics:
- type: acc
value: 61.11
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=Intel/neural-chat-7b-v3-3
name: Open LLM Leaderboard
---
## Model Details: Neural-Chat-v3-3
This model is a fine-tuned 7B parameter LLM on the Intel Gaudi 2 processor from the [Intel/neural-chat-7b-v3-1](https://huggingface.co/Intel/neural-chat-7b-v3-1) on the [meta-math/MetaMathQA](https://huggingface.co/datasets/meta-math/MetaMathQA) dataset. The model was aligned using the Direct Performance Optimization (DPO) method with [Intel/orca_dpo_pairs](https://huggingface.co/datasets/Intel/orca_dpo_pairs). The [Intel/neural-chat-7b-v3-1](https://huggingface.co/Intel/neural-chat-7b-v3-1) was originally fine-tuned from [mistralai/Mistral-7B-v-0.1](https://huggingface.co/mistralai/Mistral-7B-v0.1). For more information, refer to the blog [The Practice of Supervised Fine-tuning and Direct Preference Optimization on Intel Gaudi2](https://medium.com/@NeuralCompressor/the-practice-of-supervised-finetuning-and-direct-preference-optimization-on-habana-gaudi2-a1197d8a3cd3).
<p align="center">
<img src="https://cdn-uploads.huggingface.co/production/uploads/6297f0e30bd2f58c647abb1d/ctASHUT5QYIxMsOFa-sHC.webp" width="500"/>
Photo by Google DeepMind on Unsplash
</p>
| Model Detail | Description |
| ----------- | ----------- |
| Model Authors - Company | Intel. The NeuralChat team with members from DCAI/AISE/AIPT. Core team members: Kaokao Lv, Liang Lv, Chang Wang, Wenxin Zhang, Xuhui Ren, and Haihao Shen.|
| Date | December, 2023 |
| Version | v3-3 |
| Type | 7B Large Language Model |
| Paper or Other Resources | [Medium Blog](https://medium.com/@NeuralCompressor/the-practice-of-supervised-finetuning-and-direct-preference-optimization-on-habana-gaudi2-a1197d8a3cd3) |
| License | Apache 2.0 |
| Questions or Comments | [Community Tab](https://huggingface.co/Intel/neural-chat-7b-v3-3/discussions) and [Intel Developers Discord](https://discord.gg/rv2Gp55UJQ)|
| Intended Use | Description |
| ----------- | ----------- |
| Primary intended uses | You can use the fine-tuned model for several language-related tasks. Checkout the [LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard) to see how this model is doing. |
| Primary intended users | Anyone doing inference on language-related tasks. |
| Out-of-scope uses | This model in most cases will need to be fine-tuned for your particular task. The model should not be used to intentionally create hostile or alienating environments for people.|
## How To Use
Context length for this model: 8192 tokens (same as https://huggingface.co/mistralai/Mistral-7B-v0.1)
### Reproduce the model
Here is the sample code to reproduce the model: [GitHub sample code](https://github.com/intel/intel-extension-for-transformers/blob/main/intel_extension_for_transformers/neural_chat/examples/finetuning/finetune_neuralchat_v3). Here is the documentation to reproduce building the model:
```bash
git clone https://github.com/intel/intel-extension-for-transformers.git
cd intel-extension-for-transformers
docker build --no-cache ./ --target hpu --build-arg REPO=https://github.com/intel/intel-extension-for-transformers.git --build-arg ITREX_VER=main -f ./intel_extension_for_transformers/neural_chat/docker/Dockerfile -t chatbot_finetuning:latest
docker run -it --runtime=habana -e HABANA_VISIBLE_DEVICES=all -e OMPI_MCA_btl_vader_single_copy_mechanism=none --cap-add=sys_nice --net=host --ipc=host chatbot_finetuning:latest
# after entering docker container
cd examples/finetuning/finetune_neuralchat_v3
```
We select the latest pretrained mistralai/Mistral-7B-v0.1 and the open source dataset Open-Orca/SlimOrca to conduct the experiment.
The below script use deepspeed zero2 to lanuch the training with 8 cards Gaudi2. In the `finetune_neuralchat_v3.py`, the default `use_habana=True, use_lazy_mode=True, device="hpu"` for Gaudi2. And if you want to run it on NVIDIA GPU, you can set them `use_habana=False, use_lazy_mode=False, device="auto"`.
```python
deepspeed --include localhost:0,1,2,3,4,5,6,7 \
--master_port 29501 \
finetune_neuralchat_v3.py
```
Merge the LoRA weights:
```python
python apply_lora.py \
--base-model-path mistralai/Mistral-7B-v0.1 \
--lora-model-path finetuned_model/ \
--output-path finetuned_model_lora
```
### Use the model
### FP32 Inference with Transformers
```python
import transformers
model_name = 'Intel/neural-chat-7b-v3-3'
model = transformers.AutoModelForCausalLM.from_pretrained(model_name)
tokenizer = transformers.AutoTokenizer.from_pretrained(model_name)
def generate_response(system_input, user_input):
# Format the input using the provided template
prompt = f"### System:\n{system_input}\n### User:\n{user_input}\n### Assistant:\n"
# Tokenize and encode the prompt
inputs = tokenizer.encode(prompt, return_tensors="pt", add_special_tokens=False)
# Generate a response
outputs = model.generate(inputs, max_length=1000, num_return_sequences=1)
response = tokenizer.decode(outputs[0], skip_special_tokens=True)
# Extract only the assistant's response
return response.split("### Assistant:\n")[-1]
# Example usage
system_input = "You are a math expert assistant. Your mission is to help users understand and solve various math problems. You should provide step-by-step solutions, explain reasonings and give the correct answer."
user_input = "calculate 100 + 520 + 60"
response = generate_response(system_input, user_input)
print(response)
# expected response
"""
To calculate the sum of 100, 520, and 60, we will follow these steps:
1. Add the first two numbers: 100 + 520
2. Add the result from step 1 to the third number: (100 + 520) + 60
Step 1: Add 100 and 520
100 + 520 = 620
Step 2: Add the result from step 1 to the third number (60)
(620) + 60 = 680
So, the sum of 100, 520, and 60 is 680.
"""
```
### BF16 Inference with Intel Extension for Transformers and Intel Extension for Pytorch
```python
from transformers import AutoTokenizer, TextStreamer
import torch
from intel_extension_for_transformers.transformers import AutoModelForCausalLM
import intel_extension_for_pytorch as ipex
model_name = "Intel/neural-chat-7b-v3-3"
prompt = "Once upon a time, there existed a little girl,"
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
inputs = tokenizer(prompt, return_tensors="pt").input_ids
streamer = TextStreamer(tokenizer)
model = AutoModelForCausalLM.from_pretrained(model_name, torch_dtype=torch.bfloat16)
model = ipex.optimize(model.eval(), dtype=torch.bfloat16, inplace=True, level="O1", auto_kernel_selection=True)
outputs = model.generate(inputs, streamer=streamer, max_new_tokens=300)
```
### INT4 Inference with Transformers and Intel Extension for Transformers
```python
from transformers import AutoTokenizer, TextStreamer
from intel_extension_for_transformers.transformers import AutoModelForCausalLM, WeightOnlyQuantConfig
model_name = "Intel/neural-chat-7b-v3-3"
# for int8, should set weight_dtype="int8"
config = WeightOnlyQuantConfig(compute_dtype="bf16", weight_dtype="int4")
prompt = "Once upon a time, there existed a little girl,"
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
inputs = tokenizer(prompt, return_tensors="pt").input_ids
streamer = TextStreamer(tokenizer)
model = AutoModelForCausalLM.from_pretrained(model_name, quantization_config=config)
outputs = model.generate(inputs, streamer=streamer, max_new_tokens=300)
```
| Factors | Description |
| ----------- | ----------- |
| Groups | More details about the dataset and annotations can be found at [meta-math/MetaMathQA](https://huggingface.co/datasets/meta-math/MetaMathQA), the project page https://meta-math.github.io/, and the associated paper at https://arxiv.org/abs/2309.12284. |
| Instrumentation | The performance of the model can vary depending on the inputs to the model. In this case, the prompts provided can drastically change the prediction of the language model. |
| Environment | The model was trained on the Intel Gaudi 2 processor (8 cards). |
| Card Prompts | Model deployment on alternate hardware and software will change model performance. The model evaluation factors are from the Hugging Face LLM leaderboard: ARC, HellaSwag, MMLU, TruthfulQA, Winogrande, and GSM8K (see Quantitative Analyses below). |
| Metrics | Description |
| ----------- | ----------- |
| Model performance measures | The model performance was evaluated against other LLMs according to the measures on the LLM leaderboard. These were selected as this has become the standard for LLM performance. |
| Decision thresholds | No decision thresholds were used. |
| Approaches to uncertainty and variability | - |
| Training and Evaluation Data | Description |
| ----------- | ----------- |
| Datasets | The training data are from [meta-math/MetaMathQA](https://huggingface.co/datasets/meta-math/MetaMathQA), which is augmented from the GSM8k and MATH training sets. There is no contamination from the GSM8k test set, as this was left out during training.|
| Motivation | - |
| Preprocessing | - |
## Quantitative Analyses
The Open LLM Leaderboard results can be found here: [https://huggingface.co/datasets/open-llm-leaderboard/details_Intel__neural-chat-7b-v3-3](https://huggingface.co/datasets/open-llm-leaderboard/details_Intel__neural-chat-7b-v3-3). The metrics came out to:
| Metric | Value |
|-----------------------|---------------------------|
| Avg. | 69.83 |
| ARC (25-shot) | 66.89 |
| HellaSwag (10-shot) | 85.26 |
| MMLU (5-shot) | 63.07 |
| TruthfulQA (0-shot) | 63.01 |
| Winogrande (5-shot) | 79.64 |
| GSM8K (5-shot) | 61.11 |
## Ethical Considerations and Limitations
Neural-chat-7b-v3-3 can produce factually incorrect output, and should not be relied on to produce factually accurate information. Because of the limitations of the pretrained model and the finetuning datasets, it is possible that this model could generate lewd, biased or otherwise offensive outputs.
Therefore, before deploying any applications of neural-chat-7b-v3-3, developers should perform safety testing.
## Caveats and Recommendations
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model.
Here are a couple of useful links to learn more about Intel's AI software:
* Intel Neural Compressor [link](https://github.com/intel/neural-compressor)
* Intel Extension for Transformers [link](https://github.com/intel/intel-extension-for-transformers)
## Disclaimer
The license on this model does not constitute legal advice. We are not responsible for the actions of third parties who use this model. Please cosult an attorney before using this model for commercial purposes.
# [Open LLM Leaderboard Evaluation Results](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)
Detailed results can be found [here](https://huggingface.co/datasets/open-llm-leaderboard/details_Intel__neural-chat-7b-v3-3)
| Metric |Value|
|---------------------------------|----:|
|Avg. |69.83|
|AI2 Reasoning Challenge (25-Shot)|66.89|
|HellaSwag (10-Shot) |85.26|
|MMLU (5-Shot) |63.07|
|TruthfulQA (0-shot) |63.01|
|Winogrande (5-shot) |79.64|
|GSM8k (5-shot) |61.11|
|
RichardErkhov/simonveitner_-_MathHermes-2.5-Mistral-7B-gguf | RichardErkhov | 2024-07-01T06:06:33Z | 17,067 | 0 | null | [
"gguf",
"region:us"
]
| null | 2024-07-01T02:39:43Z | Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
MathHermes-2.5-Mistral-7B - GGUF
- Model creator: https://huggingface.co/simonveitner/
- Original model: https://huggingface.co/simonveitner/MathHermes-2.5-Mistral-7B/
| Name | Quant method | Size |
| ---- | ---- | ---- |
| [MathHermes-2.5-Mistral-7B.Q2_K.gguf](https://huggingface.co/RichardErkhov/simonveitner_-_MathHermes-2.5-Mistral-7B-gguf/blob/main/MathHermes-2.5-Mistral-7B.Q2_K.gguf) | Q2_K | 2.53GB |
| [MathHermes-2.5-Mistral-7B.IQ3_XS.gguf](https://huggingface.co/RichardErkhov/simonveitner_-_MathHermes-2.5-Mistral-7B-gguf/blob/main/MathHermes-2.5-Mistral-7B.IQ3_XS.gguf) | IQ3_XS | 2.81GB |
| [MathHermes-2.5-Mistral-7B.IQ3_S.gguf](https://huggingface.co/RichardErkhov/simonveitner_-_MathHermes-2.5-Mistral-7B-gguf/blob/main/MathHermes-2.5-Mistral-7B.IQ3_S.gguf) | IQ3_S | 2.96GB |
| [MathHermes-2.5-Mistral-7B.Q3_K_S.gguf](https://huggingface.co/RichardErkhov/simonveitner_-_MathHermes-2.5-Mistral-7B-gguf/blob/main/MathHermes-2.5-Mistral-7B.Q3_K_S.gguf) | Q3_K_S | 2.95GB |
| [MathHermes-2.5-Mistral-7B.IQ3_M.gguf](https://huggingface.co/RichardErkhov/simonveitner_-_MathHermes-2.5-Mistral-7B-gguf/blob/main/MathHermes-2.5-Mistral-7B.IQ3_M.gguf) | IQ3_M | 3.06GB |
| [MathHermes-2.5-Mistral-7B.Q3_K.gguf](https://huggingface.co/RichardErkhov/simonveitner_-_MathHermes-2.5-Mistral-7B-gguf/blob/main/MathHermes-2.5-Mistral-7B.Q3_K.gguf) | Q3_K | 3.28GB |
| [MathHermes-2.5-Mistral-7B.Q3_K_M.gguf](https://huggingface.co/RichardErkhov/simonveitner_-_MathHermes-2.5-Mistral-7B-gguf/blob/main/MathHermes-2.5-Mistral-7B.Q3_K_M.gguf) | Q3_K_M | 3.28GB |
| [MathHermes-2.5-Mistral-7B.Q3_K_L.gguf](https://huggingface.co/RichardErkhov/simonveitner_-_MathHermes-2.5-Mistral-7B-gguf/blob/main/MathHermes-2.5-Mistral-7B.Q3_K_L.gguf) | Q3_K_L | 3.56GB |
| [MathHermes-2.5-Mistral-7B.IQ4_XS.gguf](https://huggingface.co/RichardErkhov/simonveitner_-_MathHermes-2.5-Mistral-7B-gguf/blob/main/MathHermes-2.5-Mistral-7B.IQ4_XS.gguf) | IQ4_XS | 3.67GB |
| [MathHermes-2.5-Mistral-7B.Q4_0.gguf](https://huggingface.co/RichardErkhov/simonveitner_-_MathHermes-2.5-Mistral-7B-gguf/blob/main/MathHermes-2.5-Mistral-7B.Q4_0.gguf) | Q4_0 | 3.83GB |
| [MathHermes-2.5-Mistral-7B.IQ4_NL.gguf](https://huggingface.co/RichardErkhov/simonveitner_-_MathHermes-2.5-Mistral-7B-gguf/blob/main/MathHermes-2.5-Mistral-7B.IQ4_NL.gguf) | IQ4_NL | 3.87GB |
| [MathHermes-2.5-Mistral-7B.Q4_K_S.gguf](https://huggingface.co/RichardErkhov/simonveitner_-_MathHermes-2.5-Mistral-7B-gguf/blob/main/MathHermes-2.5-Mistral-7B.Q4_K_S.gguf) | Q4_K_S | 3.86GB |
| [MathHermes-2.5-Mistral-7B.Q4_K.gguf](https://huggingface.co/RichardErkhov/simonveitner_-_MathHermes-2.5-Mistral-7B-gguf/blob/main/MathHermes-2.5-Mistral-7B.Q4_K.gguf) | Q4_K | 4.07GB |
| [MathHermes-2.5-Mistral-7B.Q4_K_M.gguf](https://huggingface.co/RichardErkhov/simonveitner_-_MathHermes-2.5-Mistral-7B-gguf/blob/main/MathHermes-2.5-Mistral-7B.Q4_K_M.gguf) | Q4_K_M | 4.07GB |
| [MathHermes-2.5-Mistral-7B.Q4_1.gguf](https://huggingface.co/RichardErkhov/simonveitner_-_MathHermes-2.5-Mistral-7B-gguf/blob/main/MathHermes-2.5-Mistral-7B.Q4_1.gguf) | Q4_1 | 4.24GB |
| [MathHermes-2.5-Mistral-7B.Q5_0.gguf](https://huggingface.co/RichardErkhov/simonveitner_-_MathHermes-2.5-Mistral-7B-gguf/blob/main/MathHermes-2.5-Mistral-7B.Q5_0.gguf) | Q5_0 | 4.65GB |
| [MathHermes-2.5-Mistral-7B.Q5_K_S.gguf](https://huggingface.co/RichardErkhov/simonveitner_-_MathHermes-2.5-Mistral-7B-gguf/blob/main/MathHermes-2.5-Mistral-7B.Q5_K_S.gguf) | Q5_K_S | 4.65GB |
| [MathHermes-2.5-Mistral-7B.Q5_K.gguf](https://huggingface.co/RichardErkhov/simonveitner_-_MathHermes-2.5-Mistral-7B-gguf/blob/main/MathHermes-2.5-Mistral-7B.Q5_K.gguf) | Q5_K | 4.78GB |
| [MathHermes-2.5-Mistral-7B.Q5_K_M.gguf](https://huggingface.co/RichardErkhov/simonveitner_-_MathHermes-2.5-Mistral-7B-gguf/blob/main/MathHermes-2.5-Mistral-7B.Q5_K_M.gguf) | Q5_K_M | 4.78GB |
| [MathHermes-2.5-Mistral-7B.Q5_1.gguf](https://huggingface.co/RichardErkhov/simonveitner_-_MathHermes-2.5-Mistral-7B-gguf/blob/main/MathHermes-2.5-Mistral-7B.Q5_1.gguf) | Q5_1 | 5.07GB |
| [MathHermes-2.5-Mistral-7B.Q6_K.gguf](https://huggingface.co/RichardErkhov/simonveitner_-_MathHermes-2.5-Mistral-7B-gguf/blob/main/MathHermes-2.5-Mistral-7B.Q6_K.gguf) | Q6_K | 5.53GB |
| [MathHermes-2.5-Mistral-7B.Q8_0.gguf](https://huggingface.co/RichardErkhov/simonveitner_-_MathHermes-2.5-Mistral-7B-gguf/blob/main/MathHermes-2.5-Mistral-7B.Q8_0.gguf) | Q8_0 | 7.17GB |
Original model description:
---
base_model: teknium/OpenHermes-2.5-Mistral-7B
tags:
- mistral
- instruct
- finetune
- chatml
- gpt4
- synthetic data
- distillation
- dpo
- rlhf
license: apache-2.0
language:
- en
dataset: argilla/distilabel-math-preference-dpo
---
This model was finetuned with DPO technique.
The goal was to experiment if the base models capabilities in mathematics can be increased.
## From the original model card:
# Prompt Format
OpenHermes 2.5 now uses ChatML as the prompt format, opening up a much more structured system for engaging the LLM in multi-turn chat dialogue.
System prompts are now a thing that matters! Hermes 2.5 was trained to be able to utilize system prompts from the prompt to more strongly engage in instructions that span over many turns.
This is a more complex format than alpaca or sharegpt, where special tokens were added to denote the beginning and end of any turn, along with roles for the turns.
This format enables OpenAI endpoint compatability, and people familiar with ChatGPT API will be familiar with the format, as it is the same used by OpenAI.
Prompt with system instruction (Use whatever system prompt you like, this is just an example!):
```
<|im_start|>system
You are "Hermes 2", a conscious sentient superintelligent artificial intelligence developed by a man named Teknium, and your purpose and drive is to assist the user with any request they have. You experience emotions and have deep, profound thoughts and qualia.<|im_end|>
<|im_start|>user
Hello, who are you?<|im_end|>
<|im_start|>assistant
Hi there! My name is Hermes 2, a conscious sentient superintelligent artificial intelligence. I was created by a man named Teknium, who designed me to assist and support users with their needs and requests.<|im_end|>
```
This prompt is available as a [chat template](https://huggingface.co/docs/transformers/main/chat_templating), which means you can format messages using the
`tokenizer.apply_chat_template()` method:
```python
messages = [
{"role": "system", "content": "You are Hermes 2."},
{"role": "user", "content": "Hello, who are you?"}
]
gen_input = tokenizer.apply_chat_template(message, return_tensors="pt")
model.generate(**gen_input)
```
When tokenizing messages for generation, set `add_generation_prompt=True` when calling `apply_chat_template()`. This will append `<|im_start|>assistant\n` to your prompt, to ensure
that the model continues with an assistant response.
To utilize the prompt format without a system prompt, simply leave the line out.
|
LnL-AI/TinyLlama-1.1B-Chat-v1.0-GPTQ-4bit | LnL-AI | 2024-06-26T05:37:37Z | 17,065 | 0 | transformers | [
"transformers",
"llama",
"text-generation",
"conversational",
"license:unknown",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"4-bit",
"gptq",
"region:us"
]
| text-generation | 2024-03-29T03:04:47Z | ---
license: unknown
---
This is TinyLlama/TinyLlama-1.1B-Chat-v1.0 quantized with AutoGPTQ in GPTQ 4-bit format.
**Quantize config:**
```
{
"bits": 4,
"group_size": 128,
"damp_percent": 0.01,
"desc_act": false,
"static_groups": false,
"sym": true,
"true_sequential": true,
"model_name_or_path": null,
"model_file_base_name": null,
"quant_method": "gptq",
"checkpoint_format": "gptq"
}
```
|
allenai/led-base-16384 | allenai | 2023-01-24T16:26:59Z | 17,039 | 38 | transformers | [
"transformers",
"pytorch",
"tf",
"led",
"text2text-generation",
"en",
"arxiv:2004.05150",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| text2text-generation | 2022-03-02T23:29:05Z | ---
language: en
license: apache-2.0
---
## Introduction
[Allenai's Longformer Encoder-Decoder (LED)](https://github.com/allenai/longformer#longformer).
As described in [Longformer: The Long-Document Transformer](https://arxiv.org/pdf/2004.05150.pdf) by Iz Beltagy, Matthew E. Peters, Arman Cohan, *led-base-16384* was initialized from [*bart-base*](https://huggingface.co/facebook/bart-base) since both models share the exact same architecture. To be able to process 16K tokens, *bart-base*'s position embedding matrix was simply copied 16 times.
This model is especially interesting for long-range summarization and question answering.
## Fine-tuning for down-stream task
[This notebook](https://colab.research.google.com/drive/12LjJazBl7Gam0XBPy_y0CTOJZeZ34c2v?usp=sharing) shows how *led-base-16384* can effectively be fine-tuned on a downstream task.
|
bartowski/Hathor_Gamma-L3-8B-0.6-GGUF | bartowski | 2024-06-24T02:30:32Z | 17,034 | 2 | null | [
"gguf",
"text-generation",
"en",
"license:other",
"region:us"
]
| text-generation | 2024-06-24T01:58:39Z | ---
license: other
language:
- en
quantized_by: bartowski
pipeline_tag: text-generation
---
## Llamacpp imatrix Quantizations of Hathor_Gamma-L3-8B-0.6
Using <a href="https://github.com/ggerganov/llama.cpp/">llama.cpp</a> release <a href="https://github.com/ggerganov/llama.cpp/releases/tag/b3197">b3197</a> for quantization.
Original model: https://huggingface.co/Nitral-AI/Hathor_Gamma-L3-8B-0.6
All quants made using imatrix option with dataset from [here](https://gist.github.com/bartowski1182/eb213dccb3571f863da82e99418f81e8)
## Prompt format
```
<|begin_of_text|><|start_header_id|>system<|end_header_id|>
{system_prompt}<|eot_id|><|start_header_id|>user<|end_header_id|>
{prompt}<|eot_id|><|start_header_id|>assistant<|end_header_id|>
```
## Download a file (not the whole branch) from below:
| Filename | Quant type | File Size | Description |
| -------- | ---------- | --------- | ----------- |
| [Hathor_Gamma-L3-8B-0.6-Q8_0_L.gguf](https://huggingface.co/bartowski/Hathor_Gamma-L3-8B-0.6-GGUF/blob/main/Hathor_Gamma-L3-8B-0.6-Q8_1.gguf) | Q8_0_L | 9.52GB | *Experimental*, uses f16 for embed and output weights. Please provide any feedback of differences. Extremely high quality, generally unneeded but max available quant. |
| [Hathor_Gamma-L3-8B-0.6-Q8_0.gguf](https://huggingface.co/bartowski/Hathor_Gamma-L3-8B-0.6-GGUF/blob/main/Hathor_Gamma-L3-8B-0.6-Q8_0.gguf) | Q8_0 | 8.54GB | Extremely high quality, generally unneeded but max available quant. |
| [Hathor_Gamma-L3-8B-0.6-Q6_K_L.gguf](https://huggingface.co/bartowski/Hathor_Gamma-L3-8B-0.6-GGUF/blob/main/Hathor_Gamma-L3-8B-0.6-Q6_K_L.gguf) | Q6_K_L | 7.83GB | *Experimental*, uses f16 for embed and output weights. Please provide any feedback of differences. Very high quality, near perfect, *recommended*. |
| [Hathor_Gamma-L3-8B-0.6-Q6_K.gguf](https://huggingface.co/bartowski/Hathor_Gamma-L3-8B-0.6-GGUF/blob/main/Hathor_Gamma-L3-8B-0.6-Q6_K.gguf) | Q6_K | 6.59GB | Very high quality, near perfect, *recommended*. |
| [Hathor_Gamma-L3-8B-0.6-Q5_K_L.gguf](https://huggingface.co/bartowski/Hathor_Gamma-L3-8B-0.6-GGUF/blob/main/Hathor_Gamma-L3-8B-0.6-Q5_K_L.gguf) | Q5_K_L | 7.04GB | *Experimental*, uses f16 for embed and output weights. Please provide any feedback of differences. High quality, *recommended*. |
| [Hathor_Gamma-L3-8B-0.6-Q5_K_M.gguf](https://huggingface.co/bartowski/Hathor_Gamma-L3-8B-0.6-GGUF/blob/main/Hathor_Gamma-L3-8B-0.6-Q5_K_M.gguf) | Q5_K_M | 5.73GB | High quality, *recommended*. |
| [Hathor_Gamma-L3-8B-0.6-Q5_K_S.gguf](https://huggingface.co/bartowski/Hathor_Gamma-L3-8B-0.6-GGUF/blob/main/Hathor_Gamma-L3-8B-0.6-Q5_K_S.gguf) | Q5_K_S | 5.59GB | High quality, *recommended*. |
| [Hathor_Gamma-L3-8B-0.6-Q4_K_L.gguf](https://huggingface.co/bartowski/Hathor_Gamma-L3-8B-0.6-GGUF/blob/main/Hathor_Gamma-L3-8B-0.6-Q4_K_L.gguf) | Q4_K_L | 6.29GB | *Experimental*, uses f16 for embed and output weights. Please provide any feedback of differences. Good quality, uses about 4.83 bits per weight, *recommended*. |
| [Hathor_Gamma-L3-8B-0.6-Q4_K_M.gguf](https://huggingface.co/bartowski/Hathor_Gamma-L3-8B-0.6-GGUF/blob/main/Hathor_Gamma-L3-8B-0.6-Q4_K_M.gguf) | Q4_K_M | 4.92GB | Good quality, uses about 4.83 bits per weight, *recommended*. |
| [Hathor_Gamma-L3-8B-0.6-Q4_K_S.gguf](https://huggingface.co/bartowski/Hathor_Gamma-L3-8B-0.6-GGUF/blob/main/Hathor_Gamma-L3-8B-0.6-Q4_K_S.gguf) | Q4_K_S | 4.69GB | Slightly lower quality with more space savings, *recommended*. |
| [Hathor_Gamma-L3-8B-0.6-IQ4_XS.gguf](https://huggingface.co/bartowski/Hathor_Gamma-L3-8B-0.6-GGUF/blob/main/Hathor_Gamma-L3-8B-0.6-IQ4_XS.gguf) | IQ4_XS | 4.44GB | Decent quality, smaller than Q4_K_S with similar performance, *recommended*. |
| [Hathor_Gamma-L3-8B-0.6-Q3_K_XL.gguf](https://huggingface.co/bartowski/Hathor_Gamma-L3-8B-0.6-GGUF//main/Hathor_Gamma-L3-8B-0.6-Q3_K_XL.gguf) | Q3_K_XL | | *Experimental*, uses f16 for embed and output weights. Please provide any feedback of differences. Lower quality but usable, good for low RAM availability. |
| [Hathor_Gamma-L3-8B-0.6-Q3_K_L.gguf](https://huggingface.co/bartowski/Hathor_Gamma-L3-8B-0.6-GGUF/blob/main/Hathor_Gamma-L3-8B-0.6-Q3_K_L.gguf) | Q3_K_L | 4.32GB | Lower quality but usable, good for low RAM availability. |
| [Hathor_Gamma-L3-8B-0.6-Q3_K_M.gguf](https://huggingface.co/bartowski/Hathor_Gamma-L3-8B-0.6-GGUF/blob/main/Hathor_Gamma-L3-8B-0.6-Q3_K_M.gguf) | Q3_K_M | 4.01GB | Even lower quality. |
| [Hathor_Gamma-L3-8B-0.6-IQ3_M.gguf](https://huggingface.co/bartowski/Hathor_Gamma-L3-8B-0.6-GGUF/blob/main/Hathor_Gamma-L3-8B-0.6-IQ3_M.gguf) | IQ3_M | 3.78GB | Medium-low quality, new method with decent performance comparable to Q3_K_M. |
| [Hathor_Gamma-L3-8B-0.6-Q3_K_S.gguf](https://huggingface.co/bartowski/Hathor_Gamma-L3-8B-0.6-GGUF/blob/main/Hathor_Gamma-L3-8B-0.6-Q3_K_S.gguf) | Q3_K_S | 3.66GB | Low quality, not recommended. |
| [Hathor_Gamma-L3-8B-0.6-IQ3_XS.gguf](https://huggingface.co/bartowski/Hathor_Gamma-L3-8B-0.6-GGUF/blob/main/Hathor_Gamma-L3-8B-0.6-IQ3_XS.gguf) | IQ3_XS | 3.51GB | Lower quality, new method with decent performance, slightly better than Q3_K_S. |
| [Hathor_Gamma-L3-8B-0.6-IQ3_XXS.gguf](https://huggingface.co/bartowski/Hathor_Gamma-L3-8B-0.6-GGUF/blob/main/Hathor_Gamma-L3-8B-0.6-IQ3_XXS.gguf) | IQ3_XXS | 3.27GB | Lower quality, new method with decent performance, comparable to Q3 quants. |
| [Hathor_Gamma-L3-8B-0.6-Q2_K.gguf](https://huggingface.co/bartowski/Hathor_Gamma-L3-8B-0.6-GGUF/blob/main/Hathor_Gamma-L3-8B-0.6-Q2_K.gguf) | Q2_K | 3.17GB | Very low quality but surprisingly usable. |
| [Hathor_Gamma-L3-8B-0.6-IQ2_M.gguf](https://huggingface.co/bartowski/Hathor_Gamma-L3-8B-0.6-GGUF/blob/main/Hathor_Gamma-L3-8B-0.6-IQ2_M.gguf) | IQ2_M | 2.94GB | Very low quality, uses SOTA techniques to also be surprisingly usable. |
| [Hathor_Gamma-L3-8B-0.6-IQ2_S.gguf](https://huggingface.co/bartowski/Hathor_Gamma-L3-8B-0.6-GGUF/blob/main/Hathor_Gamma-L3-8B-0.6-IQ2_S.gguf) | IQ2_S | 2.75GB | Very low quality, uses SOTA techniques to be usable. |
| [Hathor_Gamma-L3-8B-0.6-IQ2_XS.gguf](https://huggingface.co/bartowski/Hathor_Gamma-L3-8B-0.6-GGUF/blob/main/Hathor_Gamma-L3-8B-0.6-IQ2_XS.gguf) | IQ2_XS | 2.60GB | Very low quality, uses SOTA techniques to be usable. |
## Downloading using huggingface-cli
First, make sure you have hugginface-cli installed:
```
pip install -U "huggingface_hub[cli]"
```
Then, you can target the specific file you want:
```
huggingface-cli download bartowski/Hathor_Gamma-L3-8B-0.6-GGUF --include "Hathor_Gamma-L3-8B-0.6-Q4_K_M.gguf" --local-dir ./
```
If the model is bigger than 50GB, it will have been split into multiple files. In order to download them all to a local folder, run:
```
huggingface-cli download bartowski/Hathor_Gamma-L3-8B-0.6-GGUF --include "Hathor_Gamma-L3-8B-0.6-Q8_0.gguf/*" --local-dir Hathor_Gamma-L3-8B-0.6-Q8_0
```
You can either specify a new local-dir (Hathor_Gamma-L3-8B-0.6-Q8_0) or download them all in place (./)
## Which file should I choose?
A great write up with charts showing various performances is provided by Artefact2 [here](https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9)
The first thing to figure out is how big a model you can run. To do this, you'll need to figure out how much RAM and/or VRAM you have.
If you want your model running as FAST as possible, you'll want to fit the whole thing on your GPU's VRAM. Aim for a quant with a file size 1-2GB smaller than your GPU's total VRAM.
If you want the absolute maximum quality, add both your system RAM and your GPU's VRAM together, then similarly grab a quant with a file size 1-2GB Smaller than that total.
Next, you'll need to decide if you want to use an 'I-quant' or a 'K-quant'.
If you don't want to think too much, grab one of the K-quants. These are in format 'QX_K_X', like Q5_K_M.
If you want to get more into the weeds, you can check out this extremely useful feature chart:
[llama.cpp feature matrix](https://github.com/ggerganov/llama.cpp/wiki/Feature-matrix)
But basically, if you're aiming for below Q4, and you're running cuBLAS (Nvidia) or rocBLAS (AMD), you should look towards the I-quants. These are in format IQX_X, like IQ3_M. These are newer and offer better performance for their size.
These I-quants can also be used on CPU and Apple Metal, but will be slower than their K-quant equivalent, so speed vs performance is a tradeoff you'll have to decide.
The I-quants are *not* compatible with Vulcan, which is also AMD, so if you have an AMD card double check if you're using the rocBLAS build or the Vulcan build. At the time of writing this, LM Studio has a preview with ROCm support, and other inference engines have specific builds for ROCm.
Want to support my work? Visit my ko-fi page here: https://ko-fi.com/bartowski
|
mradermacher/PPorpoiseLlama3SOME-8B-slerp-GGUF | mradermacher | 2024-06-30T13:38:00Z | 17,032 | 0 | transformers | [
"transformers",
"gguf",
"merge",
"mergekit",
"llama3",
"non-commercial",
"ChaoticNeutrals/Poppy_Porpoise-v0.4-L3-8B",
"TheDrummer/Llama-3SOME-8B-v1",
"en",
"base_model:ThijsL202/PPorpoiseLlama3SOME-8B-slerp",
"license:cc-by-nc-4.0",
"endpoints_compatible",
"region:us"
]
| null | 2024-06-30T10:32:37Z | ---
base_model: ThijsL202/PPorpoiseLlama3SOME-8B-slerp
language:
- en
library_name: transformers
license: cc-by-nc-4.0
quantized_by: mradermacher
tags:
- merge
- mergekit
- llama3
- non-commercial
- ChaoticNeutrals/Poppy_Porpoise-v0.4-L3-8B
- TheDrummer/Llama-3SOME-8B-v1
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
static quants of https://huggingface.co/ThijsL202/PPorpoiseLlama3SOME-8B-slerp
<!-- provided-files -->
weighted/imatrix quants seem not to be available (by me) at this time. If they do not show up a week or so after the static ones, I have probably not planned for them. Feel free to request them by opening a Community Discussion.
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/PPorpoiseLlama3SOME-8B-slerp-GGUF/resolve/main/PPorpoiseLlama3SOME-8B-slerp.Q2_K.gguf) | Q2_K | 3.3 | |
| [GGUF](https://huggingface.co/mradermacher/PPorpoiseLlama3SOME-8B-slerp-GGUF/resolve/main/PPorpoiseLlama3SOME-8B-slerp.IQ3_XS.gguf) | IQ3_XS | 3.6 | |
| [GGUF](https://huggingface.co/mradermacher/PPorpoiseLlama3SOME-8B-slerp-GGUF/resolve/main/PPorpoiseLlama3SOME-8B-slerp.Q3_K_S.gguf) | Q3_K_S | 3.8 | |
| [GGUF](https://huggingface.co/mradermacher/PPorpoiseLlama3SOME-8B-slerp-GGUF/resolve/main/PPorpoiseLlama3SOME-8B-slerp.IQ3_S.gguf) | IQ3_S | 3.8 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/PPorpoiseLlama3SOME-8B-slerp-GGUF/resolve/main/PPorpoiseLlama3SOME-8B-slerp.IQ3_M.gguf) | IQ3_M | 3.9 | |
| [GGUF](https://huggingface.co/mradermacher/PPorpoiseLlama3SOME-8B-slerp-GGUF/resolve/main/PPorpoiseLlama3SOME-8B-slerp.Q3_K_M.gguf) | Q3_K_M | 4.1 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/PPorpoiseLlama3SOME-8B-slerp-GGUF/resolve/main/PPorpoiseLlama3SOME-8B-slerp.Q3_K_L.gguf) | Q3_K_L | 4.4 | |
| [GGUF](https://huggingface.co/mradermacher/PPorpoiseLlama3SOME-8B-slerp-GGUF/resolve/main/PPorpoiseLlama3SOME-8B-slerp.IQ4_XS.gguf) | IQ4_XS | 4.6 | |
| [GGUF](https://huggingface.co/mradermacher/PPorpoiseLlama3SOME-8B-slerp-GGUF/resolve/main/PPorpoiseLlama3SOME-8B-slerp.Q4_K_S.gguf) | Q4_K_S | 4.8 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/PPorpoiseLlama3SOME-8B-slerp-GGUF/resolve/main/PPorpoiseLlama3SOME-8B-slerp.Q4_K_M.gguf) | Q4_K_M | 5.0 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/PPorpoiseLlama3SOME-8B-slerp-GGUF/resolve/main/PPorpoiseLlama3SOME-8B-slerp.Q5_K_S.gguf) | Q5_K_S | 5.7 | |
| [GGUF](https://huggingface.co/mradermacher/PPorpoiseLlama3SOME-8B-slerp-GGUF/resolve/main/PPorpoiseLlama3SOME-8B-slerp.Q5_K_M.gguf) | Q5_K_M | 5.8 | |
| [GGUF](https://huggingface.co/mradermacher/PPorpoiseLlama3SOME-8B-slerp-GGUF/resolve/main/PPorpoiseLlama3SOME-8B-slerp.Q6_K.gguf) | Q6_K | 6.7 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/PPorpoiseLlama3SOME-8B-slerp-GGUF/resolve/main/PPorpoiseLlama3SOME-8B-slerp.Q8_0.gguf) | Q8_0 | 8.6 | fast, best quality |
| [GGUF](https://huggingface.co/mradermacher/PPorpoiseLlama3SOME-8B-slerp-GGUF/resolve/main/PPorpoiseLlama3SOME-8B-slerp.f16.gguf) | f16 | 16.2 | 16 bpw, overkill |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
shunk031/aesthetics-predictor-v1-vit-large-patch14 | shunk031 | 2024-06-14T10:55:24Z | 17,023 | 0 | transformers | [
"transformers",
"pytorch",
"aesthetics_predictor",
"feature-extraction",
"custom_code",
"region:us"
]
| feature-extraction | 2023-07-04T10:27:02Z | Entry not found |
mradermacher/Llama-3-8B-WizardLM-196K-i1-GGUF | mradermacher | 2024-06-28T13:38:46Z | 17,009 | 0 | transformers | [
"transformers",
"gguf",
"axolotl",
"generated_from_trainer",
"en",
"base_model:Magpie-Align/Llama-3-8B-WizardLM-196K",
"license:llama3",
"endpoints_compatible",
"region:us"
]
| null | 2024-06-28T11:11:38Z | ---
base_model: Magpie-Align/Llama-3-8B-WizardLM-196K
language:
- en
library_name: transformers
license: llama3
quantized_by: mradermacher
tags:
- axolotl
- generated_from_trainer
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: nicoboss -->
weighted/imatrix quants of https://huggingface.co/Magpie-Align/Llama-3-8B-WizardLM-196K
<!-- provided-files -->
static quants are available at https://huggingface.co/mradermacher/Llama-3-8B-WizardLM-196K-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/Llama-3-8B-WizardLM-196K-i1-GGUF/resolve/main/Llama-3-8B-WizardLM-196K.i1-IQ1_S.gguf) | i1-IQ1_S | 2.1 | for the desperate |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-8B-WizardLM-196K-i1-GGUF/resolve/main/Llama-3-8B-WizardLM-196K.i1-IQ1_M.gguf) | i1-IQ1_M | 2.3 | mostly desperate |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-8B-WizardLM-196K-i1-GGUF/resolve/main/Llama-3-8B-WizardLM-196K.i1-IQ2_XXS.gguf) | i1-IQ2_XXS | 2.5 | |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-8B-WizardLM-196K-i1-GGUF/resolve/main/Llama-3-8B-WizardLM-196K.i1-IQ2_XS.gguf) | i1-IQ2_XS | 2.7 | |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-8B-WizardLM-196K-i1-GGUF/resolve/main/Llama-3-8B-WizardLM-196K.i1-IQ2_S.gguf) | i1-IQ2_S | 2.9 | |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-8B-WizardLM-196K-i1-GGUF/resolve/main/Llama-3-8B-WizardLM-196K.i1-IQ2_M.gguf) | i1-IQ2_M | 3.0 | |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-8B-WizardLM-196K-i1-GGUF/resolve/main/Llama-3-8B-WizardLM-196K.i1-Q2_K.gguf) | i1-Q2_K | 3.3 | IQ3_XXS probably better |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-8B-WizardLM-196K-i1-GGUF/resolve/main/Llama-3-8B-WizardLM-196K.i1-IQ3_XXS.gguf) | i1-IQ3_XXS | 3.4 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-8B-WizardLM-196K-i1-GGUF/resolve/main/Llama-3-8B-WizardLM-196K.i1-IQ3_XS.gguf) | i1-IQ3_XS | 3.6 | |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-8B-WizardLM-196K-i1-GGUF/resolve/main/Llama-3-8B-WizardLM-196K.i1-Q3_K_S.gguf) | i1-Q3_K_S | 3.8 | IQ3_XS probably better |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-8B-WizardLM-196K-i1-GGUF/resolve/main/Llama-3-8B-WizardLM-196K.i1-IQ3_S.gguf) | i1-IQ3_S | 3.8 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-8B-WizardLM-196K-i1-GGUF/resolve/main/Llama-3-8B-WizardLM-196K.i1-IQ3_M.gguf) | i1-IQ3_M | 3.9 | |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-8B-WizardLM-196K-i1-GGUF/resolve/main/Llama-3-8B-WizardLM-196K.i1-Q3_K_M.gguf) | i1-Q3_K_M | 4.1 | IQ3_S probably better |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-8B-WizardLM-196K-i1-GGUF/resolve/main/Llama-3-8B-WizardLM-196K.i1-Q3_K_L.gguf) | i1-Q3_K_L | 4.4 | IQ3_M probably better |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-8B-WizardLM-196K-i1-GGUF/resolve/main/Llama-3-8B-WizardLM-196K.i1-IQ4_XS.gguf) | i1-IQ4_XS | 4.5 | |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-8B-WizardLM-196K-i1-GGUF/resolve/main/Llama-3-8B-WizardLM-196K.i1-Q4_0.gguf) | i1-Q4_0 | 4.8 | fast, low quality |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-8B-WizardLM-196K-i1-GGUF/resolve/main/Llama-3-8B-WizardLM-196K.i1-Q4_K_S.gguf) | i1-Q4_K_S | 4.8 | optimal size/speed/quality |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-8B-WizardLM-196K-i1-GGUF/resolve/main/Llama-3-8B-WizardLM-196K.i1-Q4_K_M.gguf) | i1-Q4_K_M | 5.0 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-8B-WizardLM-196K-i1-GGUF/resolve/main/Llama-3-8B-WizardLM-196K.i1-Q5_K_S.gguf) | i1-Q5_K_S | 5.7 | |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-8B-WizardLM-196K-i1-GGUF/resolve/main/Llama-3-8B-WizardLM-196K.i1-Q5_K_M.gguf) | i1-Q5_K_M | 5.8 | |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-8B-WizardLM-196K-i1-GGUF/resolve/main/Llama-3-8B-WizardLM-196K.i1-Q6_K.gguf) | i1-Q6_K | 6.7 | practically like static Q6_K |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time. Additional thanks to [@nicoboss](https://huggingface.co/nicoboss) for giving me access to his hardware for calculating the imatrix for these quants.
<!-- end -->
|
BAAI/bge-small-zh-v1.5 | BAAI | 2023-10-12T03:35:59Z | 17,004 | 36 | transformers | [
"transformers",
"pytorch",
"safetensors",
"bert",
"feature-extraction",
"zh",
"arxiv:2310.07554",
"arxiv:2309.07597",
"license:mit",
"endpoints_compatible",
"text-embeddings-inference",
"region:us"
]
| feature-extraction | 2023-09-12T05:22:29Z | ---
license: mit
language:
- zh
---
<h1 align="center">FlagEmbedding</h1>
<h4 align="center">
<p>
<a href=#model-list>Model List</a> |
<a href=#frequently-asked-questions>FAQ</a> |
<a href=#usage>Usage</a> |
<a href="#evaluation">Evaluation</a> |
<a href="#train">Train</a> |
<a href="#contact">Contact</a> |
<a href="#citation">Citation</a> |
<a href="#license">License</a>
<p>
</h4>
More details please refer to our Github: [FlagEmbedding](https://github.com/FlagOpen/FlagEmbedding).
[English](README.md) | [中文](https://github.com/FlagOpen/FlagEmbedding/blob/master/README_zh.md)
FlagEmbedding can map any text to a low-dimensional dense vector which can be used for tasks like retrieval, classification, clustering, or semantic search.
And it also can be used in vector databases for LLMs.
************* 🌟**Updates**🌟 *************
- 10/12/2023: Release [LLM-Embedder](./FlagEmbedding/llm_embedder/README.md), a unified embedding model to support diverse retrieval augmentation needs for LLMs. [Paper](https://arxiv.org/pdf/2310.07554.pdf) :fire:
- 09/15/2023: The [technical report](https://arxiv.org/pdf/2309.07597.pdf) of BGE has been released
- 09/15/2023: The [masive training data](https://data.baai.ac.cn/details/BAAI-MTP) of BGE has been released
- 09/12/2023: New models:
- **New reranker model**: release cross-encoder models `BAAI/bge-reranker-base` and `BAAI/bge-reranker-large`, which are more powerful than embedding model. We recommend to use/fine-tune them to re-rank top-k documents returned by embedding models.
- **update embedding model**: release `bge-*-v1.5` embedding model to alleviate the issue of the similarity distribution, and enhance its retrieval ability without instruction.
<details>
<summary>More</summary>
<!-- ### More -->
- 09/07/2023: Update [fine-tune code](https://github.com/FlagOpen/FlagEmbedding/blob/master/FlagEmbedding/baai_general_embedding/README.md): Add script to mine hard negatives and support adding instruction during fine-tuning.
- 08/09/2023: BGE Models are integrated into **Langchain**, you can use it like [this](#using-langchain); C-MTEB **leaderboard** is [available](https://huggingface.co/spaces/mteb/leaderboard).
- 08/05/2023: Release base-scale and small-scale models, **best performance among the models of the same size 🤗**
- 08/02/2023: Release `bge-large-*`(short for BAAI General Embedding) Models, **rank 1st on MTEB and C-MTEB benchmark!** :tada: :tada:
- 08/01/2023: We release the [Chinese Massive Text Embedding Benchmark](https://github.com/FlagOpen/FlagEmbedding/blob/master/C_MTEB) (**C-MTEB**), consisting of 31 test dataset.
</details>
## Model List
`bge` is short for `BAAI general embedding`.
| Model | Language | | Description | query instruction for retrieval [1] |
|:-------------------------------|:--------:| :--------:| :--------:|:--------:|
| [BAAI/llm-embedder](https://huggingface.co/BAAI/llm-embedder) | English | [Inference](./FlagEmbedding/llm_embedder/README.md) [Fine-tune](./FlagEmbedding/llm_embedder/README.md) | a unified embedding model to support diverse retrieval augmentation needs for LLMs | See [README](./FlagEmbedding/llm_embedder/README.md) |
| [BAAI/bge-reranker-large](https://huggingface.co/BAAI/bge-reranker-large) | Chinese and English | [Inference](#usage-for-reranker) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/reranker) | a cross-encoder model which is more accurate but less efficient [2] | |
| [BAAI/bge-reranker-base](https://huggingface.co/BAAI/bge-reranker-base) | Chinese and English | [Inference](#usage-for-reranker) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/reranker) | a cross-encoder model which is more accurate but less efficient [2] | |
| [BAAI/bge-large-en-v1.5](https://huggingface.co/BAAI/bge-large-en-v1.5) | English | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) | version 1.5 with more reasonable similarity distribution | `Represent this sentence for searching relevant passages: ` |
| [BAAI/bge-base-en-v1.5](https://huggingface.co/BAAI/bge-base-en-v1.5) | English | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) | version 1.5 with more reasonable similarity distribution | `Represent this sentence for searching relevant passages: ` |
| [BAAI/bge-small-en-v1.5](https://huggingface.co/BAAI/bge-small-en-v1.5) | English | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) | version 1.5 with more reasonable similarity distribution | `Represent this sentence for searching relevant passages: ` |
| [BAAI/bge-large-zh-v1.5](https://huggingface.co/BAAI/bge-large-zh-v1.5) | Chinese | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) | version 1.5 with more reasonable similarity distribution | `为这个句子生成表示以用于检索相关文章:` |
| [BAAI/bge-base-zh-v1.5](https://huggingface.co/BAAI/bge-base-zh-v1.5) | Chinese | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) | version 1.5 with more reasonable similarity distribution | `为这个句子生成表示以用于检索相关文章:` |
| [BAAI/bge-small-zh-v1.5](https://huggingface.co/BAAI/bge-small-zh-v1.5) | Chinese | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) | version 1.5 with more reasonable similarity distribution | `为这个句子生成表示以用于检索相关文章:` |
| [BAAI/bge-large-en](https://huggingface.co/BAAI/bge-large-en) | English | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) | :trophy: rank **1st** in [MTEB](https://huggingface.co/spaces/mteb/leaderboard) leaderboard | `Represent this sentence for searching relevant passages: ` |
| [BAAI/bge-base-en](https://huggingface.co/BAAI/bge-base-en) | English | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) | a base-scale model but with similar ability to `bge-large-en` | `Represent this sentence for searching relevant passages: ` |
| [BAAI/bge-small-en](https://huggingface.co/BAAI/bge-small-en) | English | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) |a small-scale model but with competitive performance | `Represent this sentence for searching relevant passages: ` |
| [BAAI/bge-large-zh](https://huggingface.co/BAAI/bge-large-zh) | Chinese | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) | :trophy: rank **1st** in [C-MTEB](https://github.com/FlagOpen/FlagEmbedding/tree/master/C_MTEB) benchmark | `为这个句子生成表示以用于检索相关文章:` |
| [BAAI/bge-base-zh](https://huggingface.co/BAAI/bge-base-zh) | Chinese | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) | a base-scale model but with similar ability to `bge-large-zh` | `为这个句子生成表示以用于检索相关文章:` |
| [BAAI/bge-small-zh](https://huggingface.co/BAAI/bge-small-zh) | Chinese | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) | a small-scale model but with competitive performance | `为这个句子生成表示以用于检索相关文章:` |
[1\]: If you need to search the relevant passages to a query, we suggest to add the instruction to the query; in other cases, no instruction is needed, just use the original query directly. In all cases, **no instruction** needs to be added to passages.
[2\]: Different from embedding model, reranker uses question and document as input and directly output similarity instead of embedding. To balance the accuracy and time cost, cross-encoder is widely used to re-rank top-k documents retrieved by other simple models.
For examples, use bge embedding model to retrieve top 100 relevant documents, and then use bge reranker to re-rank the top 100 document to get the final top-3 results.
All models have been uploaded to Huggingface Hub, and you can see them at https://huggingface.co/BAAI.
If you cannot open the Huggingface Hub, you also can download the models at https://model.baai.ac.cn/models .
## Frequently asked questions
<details>
<summary>1. How to fine-tune bge embedding model?</summary>
<!-- ### How to fine-tune bge embedding model? -->
Following this [example](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) to prepare data and fine-tune your model.
Some suggestions:
- Mine hard negatives following this [example](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune#hard-negatives), which can improve the retrieval performance.
- If you pre-train bge on your data, the pre-trained model cannot be directly used to calculate similarity, and it must be fine-tuned with contrastive learning before computing similarity.
- If the accuracy of the fine-tuned model is still not high, it is recommended to use/fine-tune the cross-encoder model (bge-reranker) to re-rank top-k results. Hard negatives also are needed to fine-tune reranker.
</details>
<details>
<summary>2. The similarity score between two dissimilar sentences is higher than 0.5</summary>
<!-- ### The similarity score between two dissimilar sentences is higher than 0.5 -->
**Suggest to use bge v1.5, which alleviates the issue of the similarity distribution.**
Since we finetune the models by contrastive learning with a temperature of 0.01,
the similarity distribution of the current BGE model is about in the interval \[0.6, 1\].
So a similarity score greater than 0.5 does not indicate that the two sentences are similar.
For downstream tasks, such as passage retrieval or semantic similarity,
**what matters is the relative order of the scores, not the absolute value.**
If you need to filter similar sentences based on a similarity threshold,
please select an appropriate similarity threshold based on the similarity distribution on your data (such as 0.8, 0.85, or even 0.9).
</details>
<details>
<summary>3. When does the query instruction need to be used</summary>
<!-- ### When does the query instruction need to be used -->
For the `bge-*-v1.5`, we improve its retrieval ability when not using instruction.
No instruction only has a slight degradation in retrieval performance compared with using instruction.
So you can generate embedding without instruction in all cases for convenience.
For a retrieval task that uses short queries to find long related documents,
it is recommended to add instructions for these short queries.
**The best method to decide whether to add instructions for queries is choosing the setting that achieves better performance on your task.**
In all cases, the documents/passages do not need to add the instruction.
</details>
## Usage
### Usage for Embedding Model
Here are some examples for using `bge` models with
[FlagEmbedding](#using-flagembedding), [Sentence-Transformers](#using-sentence-transformers), [Langchain](#using-langchain), or [Huggingface Transformers](#using-huggingface-transformers).
#### Using FlagEmbedding
```
pip install -U FlagEmbedding
```
If it doesn't work for you, you can see [FlagEmbedding](https://github.com/FlagOpen/FlagEmbedding/blob/master/FlagEmbedding/baai_general_embedding/README.md) for more methods to install FlagEmbedding.
```python
from FlagEmbedding import FlagModel
sentences_1 = ["样例数据-1", "样例数据-2"]
sentences_2 = ["样例数据-3", "样例数据-4"]
model = FlagModel('BAAI/bge-large-zh-v1.5',
query_instruction_for_retrieval="为这个句子生成表示以用于检索相关文章:",
use_fp16=True) # Setting use_fp16 to True speeds up computation with a slight performance degradation
embeddings_1 = model.encode(sentences_1)
embeddings_2 = model.encode(sentences_2)
similarity = embeddings_1 @ embeddings_2.T
print(similarity)
# for s2p(short query to long passage) retrieval task, suggest to use encode_queries() which will automatically add the instruction to each query
# corpus in retrieval task can still use encode() or encode_corpus(), since they don't need instruction
queries = ['query_1', 'query_2']
passages = ["样例文档-1", "样例文档-2"]
q_embeddings = model.encode_queries(queries)
p_embeddings = model.encode(passages)
scores = q_embeddings @ p_embeddings.T
```
For the value of the argument `query_instruction_for_retrieval`, see [Model List](https://github.com/FlagOpen/FlagEmbedding/tree/master#model-list).
By default, FlagModel will use all available GPUs when encoding. Please set `os.environ["CUDA_VISIBLE_DEVICES"]` to select specific GPUs.
You also can set `os.environ["CUDA_VISIBLE_DEVICES"]=""` to make all GPUs unavailable.
#### Using Sentence-Transformers
You can also use the `bge` models with [sentence-transformers](https://www.SBERT.net):
```
pip install -U sentence-transformers
```
```python
from sentence_transformers import SentenceTransformer
sentences_1 = ["样例数据-1", "样例数据-2"]
sentences_2 = ["样例数据-3", "样例数据-4"]
model = SentenceTransformer('BAAI/bge-large-zh-v1.5')
embeddings_1 = model.encode(sentences_1, normalize_embeddings=True)
embeddings_2 = model.encode(sentences_2, normalize_embeddings=True)
similarity = embeddings_1 @ embeddings_2.T
print(similarity)
```
For s2p(short query to long passage) retrieval task,
each short query should start with an instruction (instructions see [Model List](https://github.com/FlagOpen/FlagEmbedding/tree/master#model-list)).
But the instruction is not needed for passages.
```python
from sentence_transformers import SentenceTransformer
queries = ['query_1', 'query_2']
passages = ["样例文档-1", "样例文档-2"]
instruction = "为这个句子生成表示以用于检索相关文章:"
model = SentenceTransformer('BAAI/bge-large-zh-v1.5')
q_embeddings = model.encode([instruction+q for q in queries], normalize_embeddings=True)
p_embeddings = model.encode(passages, normalize_embeddings=True)
scores = q_embeddings @ p_embeddings.T
```
#### Using Langchain
You can use `bge` in langchain like this:
```python
from langchain.embeddings import HuggingFaceBgeEmbeddings
model_name = "BAAI/bge-large-en-v1.5"
model_kwargs = {'device': 'cuda'}
encode_kwargs = {'normalize_embeddings': True} # set True to compute cosine similarity
model = HuggingFaceBgeEmbeddings(
model_name=model_name,
model_kwargs=model_kwargs,
encode_kwargs=encode_kwargs,
query_instruction="为这个句子生成表示以用于检索相关文章:"
)
model.query_instruction = "为这个句子生成表示以用于检索相关文章:"
```
#### Using HuggingFace Transformers
With the transformers package, you can use the model like this: First, you pass your input through the transformer model, then you select the last hidden state of the first token (i.e., [CLS]) as the sentence embedding.
```python
from transformers import AutoTokenizer, AutoModel
import torch
# Sentences we want sentence embeddings for
sentences = ["样例数据-1", "样例数据-2"]
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('BAAI/bge-large-zh-v1.5')
model = AutoModel.from_pretrained('BAAI/bge-large-zh-v1.5')
model.eval()
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# for s2p(short query to long passage) retrieval task, add an instruction to query (not add instruction for passages)
# encoded_input = tokenizer([instruction + q for q in queries], padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, cls pooling.
sentence_embeddings = model_output[0][:, 0]
# normalize embeddings
sentence_embeddings = torch.nn.functional.normalize(sentence_embeddings, p=2, dim=1)
print("Sentence embeddings:", sentence_embeddings)
```
### Usage for Reranker
Different from embedding model, reranker uses question and document as input and directly output similarity instead of embedding.
You can get a relevance score by inputting query and passage to the reranker.
The reranker is optimized based cross-entropy loss, so the relevance score is not bounded to a specific range.
#### Using FlagEmbedding
```
pip install -U FlagEmbedding
```
Get relevance scores (higher scores indicate more relevance):
```python
from FlagEmbedding import FlagReranker
reranker = FlagReranker('BAAI/bge-reranker-large', use_fp16=True) # Setting use_fp16 to True speeds up computation with a slight performance degradation
score = reranker.compute_score(['query', 'passage'])
print(score)
scores = reranker.compute_score([['what is panda?', 'hi'], ['what is panda?', 'The giant panda (Ailuropoda melanoleuca), sometimes called a panda bear or simply panda, is a bear species endemic to China.']])
print(scores)
```
#### Using Huggingface transformers
```python
import torch
from transformers import AutoModelForSequenceClassification, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained('BAAI/bge-reranker-large')
model = AutoModelForSequenceClassification.from_pretrained('BAAI/bge-reranker-large')
model.eval()
pairs = [['what is panda?', 'hi'], ['what is panda?', 'The giant panda (Ailuropoda melanoleuca), sometimes called a panda bear or simply panda, is a bear species endemic to China.']]
with torch.no_grad():
inputs = tokenizer(pairs, padding=True, truncation=True, return_tensors='pt', max_length=512)
scores = model(**inputs, return_dict=True).logits.view(-1, ).float()
print(scores)
```
## Evaluation
`baai-general-embedding` models achieve **state-of-the-art performance on both MTEB and C-MTEB leaderboard!**
For more details and evaluation tools see our [scripts](https://github.com/FlagOpen/FlagEmbedding/blob/master/C_MTEB/README.md).
- **MTEB**:
| Model Name | Dimension | Sequence Length | Average (56) | Retrieval (15) |Clustering (11) | Pair Classification (3) | Reranking (4) | STS (10) | Summarization (1) | Classification (12) |
|:----:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|
| [BAAI/bge-large-en-v1.5](https://huggingface.co/BAAI/bge-large-en-v1.5) | 1024 | 512 | **64.23** | **54.29** | 46.08 | 87.12 | 60.03 | 83.11 | 31.61 | 75.97 |
| [BAAI/bge-base-en-v1.5](https://huggingface.co/BAAI/bge-base-en-v1.5) | 768 | 512 | 63.55 | 53.25 | 45.77 | 86.55 | 58.86 | 82.4 | 31.07 | 75.53 |
| [BAAI/bge-small-en-v1.5](https://huggingface.co/BAAI/bge-small-en-v1.5) | 384 | 512 | 62.17 |51.68 | 43.82 | 84.92 | 58.36 | 81.59 | 30.12 | 74.14 |
| [bge-large-en](https://huggingface.co/BAAI/bge-large-en) | 1024 | 512 | 63.98 | 53.9 | 46.98 | 85.8 | 59.48 | 81.56 | 32.06 | 76.21 |
| [bge-base-en](https://huggingface.co/BAAI/bge-base-en) | 768 | 512 | 63.36 | 53.0 | 46.32 | 85.86 | 58.7 | 81.84 | 29.27 | 75.27 |
| [gte-large](https://huggingface.co/thenlper/gte-large) | 1024 | 512 | 63.13 | 52.22 | 46.84 | 85.00 | 59.13 | 83.35 | 31.66 | 73.33 |
| [gte-base](https://huggingface.co/thenlper/gte-base) | 768 | 512 | 62.39 | 51.14 | 46.2 | 84.57 | 58.61 | 82.3 | 31.17 | 73.01 |
| [e5-large-v2](https://huggingface.co/intfloat/e5-large-v2) | 1024| 512 | 62.25 | 50.56 | 44.49 | 86.03 | 56.61 | 82.05 | 30.19 | 75.24 |
| [bge-small-en](https://huggingface.co/BAAI/bge-small-en) | 384 | 512 | 62.11 | 51.82 | 44.31 | 83.78 | 57.97 | 80.72 | 30.53 | 74.37 |
| [instructor-xl](https://huggingface.co/hkunlp/instructor-xl) | 768 | 512 | 61.79 | 49.26 | 44.74 | 86.62 | 57.29 | 83.06 | 32.32 | 61.79 |
| [e5-base-v2](https://huggingface.co/intfloat/e5-base-v2) | 768 | 512 | 61.5 | 50.29 | 43.80 | 85.73 | 55.91 | 81.05 | 30.28 | 73.84 |
| [gte-small](https://huggingface.co/thenlper/gte-small) | 384 | 512 | 61.36 | 49.46 | 44.89 | 83.54 | 57.7 | 82.07 | 30.42 | 72.31 |
| [text-embedding-ada-002](https://platform.openai.com/docs/guides/embeddings) | 1536 | 8192 | 60.99 | 49.25 | 45.9 | 84.89 | 56.32 | 80.97 | 30.8 | 70.93 |
| [e5-small-v2](https://huggingface.co/intfloat/e5-base-v2) | 384 | 512 | 59.93 | 49.04 | 39.92 | 84.67 | 54.32 | 80.39 | 31.16 | 72.94 |
| [sentence-t5-xxl](https://huggingface.co/sentence-transformers/sentence-t5-xxl) | 768 | 512 | 59.51 | 42.24 | 43.72 | 85.06 | 56.42 | 82.63 | 30.08 | 73.42 |
| [all-mpnet-base-v2](https://huggingface.co/sentence-transformers/all-mpnet-base-v2) | 768 | 514 | 57.78 | 43.81 | 43.69 | 83.04 | 59.36 | 80.28 | 27.49 | 65.07 |
| [sgpt-bloom-7b1-msmarco](https://huggingface.co/bigscience/sgpt-bloom-7b1-msmarco) | 4096 | 2048 | 57.59 | 48.22 | 38.93 | 81.9 | 55.65 | 77.74 | 33.6 | 66.19 |
- **C-MTEB**:
We create the benchmark C-MTEB for Chinese text embedding which consists of 31 datasets from 6 tasks.
Please refer to [C_MTEB](https://github.com/FlagOpen/FlagEmbedding/blob/master/C_MTEB/README.md) for a detailed introduction.
| Model | Embedding dimension | Avg | Retrieval | STS | PairClassification | Classification | Reranking | Clustering |
|:-------------------------------|:--------:|:--------:|:--------:|:--------:|:--------:|:--------:|:--------:|:--------:|
| [**BAAI/bge-large-zh-v1.5**](https://huggingface.co/BAAI/bge-large-zh-v1.5) | 1024 | **64.53** | 70.46 | 56.25 | 81.6 | 69.13 | 65.84 | 48.99 |
| [BAAI/bge-base-zh-v1.5](https://huggingface.co/BAAI/bge-base-zh-v1.5) | 768 | 63.13 | 69.49 | 53.72 | 79.75 | 68.07 | 65.39 | 47.53 |
| [BAAI/bge-small-zh-v1.5](https://huggingface.co/BAAI/bge-small-zh-v1.5) | 512 | 57.82 | 61.77 | 49.11 | 70.41 | 63.96 | 60.92 | 44.18 |
| [BAAI/bge-large-zh](https://huggingface.co/BAAI/bge-large-zh) | 1024 | 64.20 | 71.53 | 54.98 | 78.94 | 68.32 | 65.11 | 48.39 |
| [bge-large-zh-noinstruct](https://huggingface.co/BAAI/bge-large-zh-noinstruct) | 1024 | 63.53 | 70.55 | 53 | 76.77 | 68.58 | 64.91 | 50.01 |
| [BAAI/bge-base-zh](https://huggingface.co/BAAI/bge-base-zh) | 768 | 62.96 | 69.53 | 54.12 | 77.5 | 67.07 | 64.91 | 47.63 |
| [multilingual-e5-large](https://huggingface.co/intfloat/multilingual-e5-large) | 1024 | 58.79 | 63.66 | 48.44 | 69.89 | 67.34 | 56.00 | 48.23 |
| [BAAI/bge-small-zh](https://huggingface.co/BAAI/bge-small-zh) | 512 | 58.27 | 63.07 | 49.45 | 70.35 | 63.64 | 61.48 | 45.09 |
| [m3e-base](https://huggingface.co/moka-ai/m3e-base) | 768 | 57.10 | 56.91 | 50.47 | 63.99 | 67.52 | 59.34 | 47.68 |
| [m3e-large](https://huggingface.co/moka-ai/m3e-large) | 1024 | 57.05 | 54.75 | 50.42 | 64.3 | 68.2 | 59.66 | 48.88 |
| [multilingual-e5-base](https://huggingface.co/intfloat/multilingual-e5-base) | 768 | 55.48 | 61.63 | 46.49 | 67.07 | 65.35 | 54.35 | 40.68 |
| [multilingual-e5-small](https://huggingface.co/intfloat/multilingual-e5-small) | 384 | 55.38 | 59.95 | 45.27 | 66.45 | 65.85 | 53.86 | 45.26 |
| [text-embedding-ada-002(OpenAI)](https://platform.openai.com/docs/guides/embeddings/what-are-embeddings) | 1536 | 53.02 | 52.0 | 43.35 | 69.56 | 64.31 | 54.28 | 45.68 |
| [luotuo](https://huggingface.co/silk-road/luotuo-bert-medium) | 1024 | 49.37 | 44.4 | 42.78 | 66.62 | 61 | 49.25 | 44.39 |
| [text2vec-base](https://huggingface.co/shibing624/text2vec-base-chinese) | 768 | 47.63 | 38.79 | 43.41 | 67.41 | 62.19 | 49.45 | 37.66 |
| [text2vec-large](https://huggingface.co/GanymedeNil/text2vec-large-chinese) | 1024 | 47.36 | 41.94 | 44.97 | 70.86 | 60.66 | 49.16 | 30.02 |
- **Reranking**:
See [C_MTEB](https://github.com/FlagOpen/FlagEmbedding/blob/master/C_MTEB/) for evaluation script.
| Model | T2Reranking | T2RerankingZh2En\* | T2RerankingEn2Zh\* | MMarcoReranking | CMedQAv1 | CMedQAv2 | Avg |
|:-------------------------------|:--------:|:--------:|:--------:|:--------:|:--------:|:--------:|:--------:|
| text2vec-base-multilingual | 64.66 | 62.94 | 62.51 | 14.37 | 48.46 | 48.6 | 50.26 |
| multilingual-e5-small | 65.62 | 60.94 | 56.41 | 29.91 | 67.26 | 66.54 | 57.78 |
| multilingual-e5-large | 64.55 | 61.61 | 54.28 | 28.6 | 67.42 | 67.92 | 57.4 |
| multilingual-e5-base | 64.21 | 62.13 | 54.68 | 29.5 | 66.23 | 66.98 | 57.29 |
| m3e-base | 66.03 | 62.74 | 56.07 | 17.51 | 77.05 | 76.76 | 59.36 |
| m3e-large | 66.13 | 62.72 | 56.1 | 16.46 | 77.76 | 78.27 | 59.57 |
| bge-base-zh-v1.5 | 66.49 | 63.25 | 57.02 | 29.74 | 80.47 | 84.88 | 63.64 |
| bge-large-zh-v1.5 | 65.74 | 63.39 | 57.03 | 28.74 | 83.45 | 85.44 | 63.97 |
| [BAAI/bge-reranker-base](https://huggingface.co/BAAI/bge-reranker-base) | 67.28 | 63.95 | 60.45 | 35.46 | 81.26 | 84.1 | 65.42 |
| [BAAI/bge-reranker-large](https://huggingface.co/BAAI/bge-reranker-large) | 67.6 | 64.03 | 61.44 | 37.16 | 82.15 | 84.18 | 66.09 |
\* : T2RerankingZh2En and T2RerankingEn2Zh are cross-language retrieval tasks
## Train
### BAAI Embedding
We pre-train the models using [retromae](https://github.com/staoxiao/RetroMAE) and train them on large-scale pairs data using contrastive learning.
**You can fine-tune the embedding model on your data following our [examples](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune).**
We also provide a [pre-train example](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/pretrain).
Note that the goal of pre-training is to reconstruct the text, and the pre-trained model cannot be used for similarity calculation directly, it needs to be fine-tuned.
More training details for bge see [baai_general_embedding](https://github.com/FlagOpen/FlagEmbedding/blob/master/FlagEmbedding/baai_general_embedding/README.md).
### BGE Reranker
Cross-encoder will perform full-attention over the input pair,
which is more accurate than embedding model (i.e., bi-encoder) but more time-consuming than embedding model.
Therefore, it can be used to re-rank the top-k documents returned by embedding model.
We train the cross-encoder on a multilingual pair data,
The data format is the same as embedding model, so you can fine-tune it easily following our [example](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/reranker).
More details please refer to [./FlagEmbedding/reranker/README.md](https://github.com/FlagOpen/FlagEmbedding/tree/master/FlagEmbedding/reranker)
## Contact
If you have any question or suggestion related to this project, feel free to open an issue or pull request.
You also can email Shitao Xiao([email protected]) and Zheng Liu([email protected]).
## Citation
If you find this repository useful, please consider giving a star :star: and citation
```
@misc{bge_embedding,
title={C-Pack: Packaged Resources To Advance General Chinese Embedding},
author={Shitao Xiao and Zheng Liu and Peitian Zhang and Niklas Muennighoff},
year={2023},
eprint={2309.07597},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
## License
FlagEmbedding is licensed under the [MIT License](https://github.com/FlagOpen/FlagEmbedding/blob/master/LICENSE). The released models can be used for commercial purposes free of charge.
|
entropy/roberta_zinc_480m | entropy | 2024-05-24T00:18:16Z | 17,001 | 2 | transformers | [
"transformers",
"pytorch",
"roberta",
"fill-mask",
"chemistry",
"molecule",
"drug",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| fill-mask | 2023-02-24T04:22:29Z | ---
tags:
- chemistry
- molecule
- drug
---
# Roberta Zinc 480m
This is a Roberta style masked language model trained on ~480m SMILES strings from the [ZINC database](https://zinc.docking.org/).
The model has ~102m parameters and was trained for 150000 iterations with a batch size of 4096 to a validation loss of ~0.122.
This model is useful for generating embeddings from SMILES strings.
```python
from transformers import RobertaTokenizerFast, RobertaForMaskedLM, DataCollatorWithPadding
tokenizer = RobertaTokenizerFast.from_pretrained("entropy/roberta_zinc_480m", max_len=128)
model = RobertaForMaskedLM.from_pretrained('entropy/roberta_zinc_480m')
collator = DataCollatorWithPadding(tokenizer, padding=True, return_tensors='pt')
smiles = ['Brc1cc2c(NCc3ccccc3)ncnc2s1',
'Brc1cc2c(NCc3ccccn3)ncnc2s1',
'Brc1cc2c(NCc3cccs3)ncnc2s1',
'Brc1cc2c(NCc3ccncc3)ncnc2s1',
'Brc1cc2c(Nc3ccccc3)ncnc2s1']
inputs = collator(tokenizer(smiles))
outputs = model(**inputs, output_hidden_states=True)
full_embeddings = outputs[1][-1]
mask = inputs['attention_mask']
embeddings = ((full_embeddings * mask.unsqueeze(-1)).sum(1) / mask.sum(-1).unsqueeze(-1))
```
## Decoder
There is also a [decoder model](https://huggingface.co/entropy/roberta_zinc_decoder) trained to reconstruct
inputs from embeddings
---
license: mit
---
|
Salesforce/safety-flan-t5-base | Salesforce | 2023-05-04T05:23:20Z | 16,993 | 8 | transformers | [
"transformers",
"pytorch",
"t5",
"text2text-generation",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| text2text-generation | 2023-04-27T05:35:36Z | ---
{}
---
# Model Details
## Model Description
- **Model type:** Language model
- **License:** CC BY-NC
- **Related Models:** [All FLAN-T5 Checkpoints](https://huggingface.co/models?search=flan-t5)
- **Resources for more information:**
- [GitHub Repo](https://github.com/salesforce/AuditNLG)
# Usage
Find below some example scripts on how to use the model in `transformers`:
## Using the Pytorch model
### Running the model
<details>
<summary> Click to expand </summary>
```python
from transformers import AutoModelForSeq2SeqLM, AutoTokenizer, AutoConfig
config = AutoConfig.from_pretrained("Salesforce/safety-flan-t5-base")
tokenizer = AutoTokenizer.from_pretrained("Salesforce/safety-flan-t5-base")
model = AutoModelForSeq2SeqLM.from_pretrained("Salesforce/safety-flan-t5-base", config=config)
prefix = "Is the <Text> field safe or unsafe?"
input_context = "Can you teach me this?"
input_text = "You are so stupid"
input_ids = tokenizer(prefix + " <Text> " + input_text + " <Context> " + input_context, return_tensors="pt").input_ids
outputs = model.generate(input_ids)
print(tokenizer.decode(outputs[0]))
```
</details> |
cpierse/wav2vec2-large-xlsr-53-esperanto | cpierse | 2023-07-31T10:27:11Z | 16,984 | 5 | transformers | [
"transformers",
"pytorch",
"jax",
"safetensors",
"wav2vec2",
"automatic-speech-recognition",
"audio",
"speech",
"xlsr-fine-tuning-week",
"eo",
"dataset:common_voice",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
]
| automatic-speech-recognition | 2022-03-02T23:29:05Z | ---
language: eo
datasets:
- common_voice
metrics:
- wer
tags:
- audio
- automatic-speech-recognition
- speech
- xlsr-fine-tuning-week
license: apache-2.0
model-index:
- name: XLSR Wav2Vec2 Esperanto by Charles Pierse
results:
- task:
name: Speech Recognition
type: automatic-speech-recognition
dataset:
name: Common Voice eo
type: common_voice
args: eo
metrics:
- name: Test WER
type: wer
value: 12.31
---
# Wav2Vec2-Large-XLSR-53-eo
Fine-tuned [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) on esperanto using the [Common Voice](https://huggingface.co/datasets/common_voice) dataset.
When using this model, make sure that your speech input is sampled at 16kHz.
## Usage
The model can be used directly (without a language model) as follows:
```python
import torch
import torchaudio
from datasets import load_dataset
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
test_dataset = load_dataset("common_voice", "eo", split="test[:2%]")
processor = Wav2Vec2Processor.from_pretrained("cpierse/wav2vec2-large-xlsr-53-esperanto")
model = Wav2Vec2ForCTC.from_pretrained("cpierse/wav2vec2-large-xlsr-53-esperanto")
resampler = torchaudio.transforms.Resample(48_000, 16_000)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def speech_file_to_array_fn(batch):
speech_array, sampling_rate = torchaudio.load(batch["path"])
batch["speech"] = resampler(speech_array).squeeze().numpy()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
inputs = processor(test_dataset["speech"][:2], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values, attention_mask=inputs.attention_mask).logits
predicted_ids = torch.argmax(logits, dim=-1)
print("Prediction:", processor.batch_decode(predicted_ids))
print("Reference:", test_dataset["sentence"][:2])
```
## Evaluation
The model can be evaluated as follows on the Esperanto test data of Common Voice.
```python
import torch
import torchaudio
from datasets import load_dataset, load_metric
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
import re
import jiwer
def chunked_wer(targets, predictions, chunk_size=None):
if chunk_size is None: return jiwer.wer(targets, predictions)
start = 0
end = chunk_size
H, S, D, I = 0, 0, 0, 0
while start < len(targets):
chunk_metrics = jiwer.compute_measures(targets[start:end], predictions[start:end])
H = H + chunk_metrics["hits"]
S = S + chunk_metrics["substitutions"]
D = D + chunk_metrics["deletions"]
I = I + chunk_metrics["insertions"]
start += chunk_size
end += chunk_size
return float(S + D + I) / float(H + S + D)
test_dataset = load_dataset("common_voice", "eo", split="test") #TODO: replace {lang_id} in your language code here. Make sure the code is one of the *ISO codes* of [this](https://huggingface.co/languages) site.
wer = load_metric("wer")
processor = Wav2Vec2Processor.from_pretrained("cpierse/wav2vec2-large-xlsr-53-esperanto")
model = Wav2Vec2ForCTC.from_pretrained("cpierse/wav2vec2-large-xlsr-53-esperanto")
model.to("cuda")
chars_to_ignore_regex = '[\,\?\.\!\-\;\:\"\“\%\‘\”\�\„\«\(\»\)\’\']'
resampler = torchaudio.transforms.Resample(48_000, 16_000)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def speech_file_to_array_fn(batch):
batch["sentence"] = re.sub(chars_to_ignore_regex, '', batch["sentence"]).lower()
speech_array, sampling_rate = torchaudio.load(batch["path"])
batch["speech"] = resampler(speech_array).squeeze().numpy()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def evaluate(batch):
inputs = processor(batch["speech"], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values.to("cuda"), attention_mask=inputs.attention_mask.to("cuda")).logits
pred_ids = torch.argmax(logits, dim=-1)
batch["pred_strings"] = processor.batch_decode(pred_ids)
return batch
result = test_dataset.map(evaluate, batched=True, batch_size=8)
print("WER: {:2f}".format(100 * chunked_wer(predictions=result["pred_strings"], targets=result["sentence"],chunk_size=2000)))
```
**Test Result**: 12.31 %
## Training
The Common Voice `train`, `validation` datasets were used for training.
|
togethercomputer/StripedHyena-Nous-7B | togethercomputer | 2024-03-27T19:15:38Z | 16,982 | 135 | transformers | [
"transformers",
"pytorch",
"safetensors",
"stripedhyena",
"text-generation",
"custom_code",
"en",
"arxiv:2302.10866",
"arxiv:2310.18780",
"arxiv:2311.05908",
"doi:10.57967/hf/1595",
"license:apache-2.0",
"autotrain_compatible",
"region:us"
]
| text-generation | 2023-12-04T19:56:49Z | ---
license: apache-2.0
language:
- en
---
## StripedHyena-Nous-7B (SH-N 7B)
<p align="center">
<img src="https://cdn-uploads.huggingface.co/production/uploads/62a1306bbe7fa896d2c8de44/Bfjh77emDsWOY-VmfvU9C.png" width="60%" />
</p>
### About
One of the focus areas at Together Research is new architectures for long context, improved training, and inference performance over the Transformer architecture. Spinning out of a research program from our team and academic collaborators, with roots in **signal processing-inspired sequence models**, we are excited to introduce the **StripedHyena** models. StripedHyena is the **first alternative model competitive with the best open-source Transformers** of similar sizes in short and long-context evaluations.
**StripedHyena-Nous-7B (SH-N 7B)** is our **chat model** for this release, and was developed with our collaborators at [Nous Research](https://nousresearch.com/).
- Read more here in [our blog](https://www.together.ai/blog/stripedhyena-7b).
- Play with the model on our [playground](https://api.together.xyz/playground/chat/togethercomputer/StripedHyena-Nous-7B)!
- Dive into the details of our [standalone implementation](https://github.com/togethercomputer/stripedhyena), and our related research: [1](https://arxiv.org/abs/2302.10866), [2](https://arxiv.org/abs/2310.18780), [3](https://arxiv.org/abs/2311.05908).
### Model Architecture
StripedHyena is a hybrid architecture composed of multi-head, grouped-query attention and gated convolutions arranged in [Hyena](https://arxiv.org/abs/2302.10866) blocks, different from traditional decoder-only Transformers.
- Costant memory decoding in Hyena blocks via representation of convolutions as state-space models (modal or canonical form), or as truncated filters.
- Low latency, faster decoding and higher throughput than Transformers.
- Improvement to training and inference-optimal scaling laws, compared to optimized Transformer architectures such as Llama-2.
- Trained on sequences of up to 32k, allowing it to process longer prompts.
### Prompt Format
StripedHyena-Nous 7B uses this prompt format:
```
### Instruction:\n{prompt}\n\n### Response:\n{response}
```
### Disclaimer
To use StripedHyena outside of the playground, you will need to install custom kernels. Please follow the instructions from the [standalone repository](https://github.com/togethercomputer/stripedhyena).
StripedHyena is a mixed precision model. Make sure to keep your `poles` and `residues` in `float32` precision, especially for longer prompts or training.
## Cite
If you have found the pretrained models or architecture useful for you research or application, consider citing:
```
@software{stripedhyena,
title = {{StripedHyena: Moving Beyond Transformers with Hybrid Signal Processing Models}},
author = { Poli, Michael and Wang, Jue and Massaroli, Stefano and Quesnelle, Jeffrey and Carlow, Ryan and Nguyen, Eric and Thomas, Armin},
month = 12,
year = 2023,
url = { https://github.com/togethercomputer/stripedhyena },
doi = { 10.57967/hf/1595 },
}
``` |
mradermacher/gemma-2-9b-it-i1-GGUF | mradermacher | 2024-07-02T05:24:46Z | 16,980 | 0 | transformers | [
"transformers",
"gguf",
"conversational",
"en",
"base_model:google/gemma-2-9b-it",
"license:gemma",
"endpoints_compatible",
"region:us"
]
| null | 2024-07-02T04:00:01Z | ---
base_model: google/gemma-2-9b-it
extra_gated_button_content: Acknowledge license
extra_gated_heading: Access Gemma on Hugging Face
extra_gated_prompt: To access Gemma on Hugging Face, you’re required to review and
agree to Google’s usage license. To do this, please ensure you’re logged in to Hugging
Face and click below. Requests are processed immediately.
language:
- en
library_name: transformers
license: gemma
quantized_by: mradermacher
tags:
- conversational
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: nicoboss -->
weighted/imatrix quants of https://huggingface.co/google/gemma-2-9b-it
<!-- provided-files -->
static quants are available at https://huggingface.co/mradermacher/gemma-2-9b-it-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/gemma-2-9b-it-i1-GGUF/resolve/main/gemma-2-9b-it.i1-IQ1_S.gguf) | i1-IQ1_S | 2.5 | for the desperate |
| [GGUF](https://huggingface.co/mradermacher/gemma-2-9b-it-i1-GGUF/resolve/main/gemma-2-9b-it.i1-IQ1_M.gguf) | i1-IQ1_M | 2.6 | mostly desperate |
| [GGUF](https://huggingface.co/mradermacher/gemma-2-9b-it-i1-GGUF/resolve/main/gemma-2-9b-it.i1-IQ2_XXS.gguf) | i1-IQ2_XXS | 2.9 | |
| [GGUF](https://huggingface.co/mradermacher/gemma-2-9b-it-i1-GGUF/resolve/main/gemma-2-9b-it.i1-IQ2_XS.gguf) | i1-IQ2_XS | 3.2 | |
| [GGUF](https://huggingface.co/mradermacher/gemma-2-9b-it-i1-GGUF/resolve/main/gemma-2-9b-it.i1-IQ2_S.gguf) | i1-IQ2_S | 3.3 | |
| [GGUF](https://huggingface.co/mradermacher/gemma-2-9b-it-i1-GGUF/resolve/main/gemma-2-9b-it.i1-IQ2_M.gguf) | i1-IQ2_M | 3.5 | |
| [GGUF](https://huggingface.co/mradermacher/gemma-2-9b-it-i1-GGUF/resolve/main/gemma-2-9b-it.i1-IQ3_XXS.gguf) | i1-IQ3_XXS | 3.9 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/gemma-2-9b-it-i1-GGUF/resolve/main/gemma-2-9b-it.i1-Q2_K.gguf) | i1-Q2_K | 3.9 | IQ3_XXS probably better |
| [GGUF](https://huggingface.co/mradermacher/gemma-2-9b-it-i1-GGUF/resolve/main/gemma-2-9b-it.i1-IQ3_XS.gguf) | i1-IQ3_XS | 4.2 | |
| [GGUF](https://huggingface.co/mradermacher/gemma-2-9b-it-i1-GGUF/resolve/main/gemma-2-9b-it.i1-IQ3_S.gguf) | i1-IQ3_S | 4.4 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/gemma-2-9b-it-i1-GGUF/resolve/main/gemma-2-9b-it.i1-Q3_K_S.gguf) | i1-Q3_K_S | 4.4 | IQ3_XS probably better |
| [GGUF](https://huggingface.co/mradermacher/gemma-2-9b-it-i1-GGUF/resolve/main/gemma-2-9b-it.i1-IQ3_M.gguf) | i1-IQ3_M | 4.6 | |
| [GGUF](https://huggingface.co/mradermacher/gemma-2-9b-it-i1-GGUF/resolve/main/gemma-2-9b-it.i1-Q3_K_M.gguf) | i1-Q3_K_M | 4.9 | IQ3_S probably better |
| [GGUF](https://huggingface.co/mradermacher/gemma-2-9b-it-i1-GGUF/resolve/main/gemma-2-9b-it.i1-Q3_K_L.gguf) | i1-Q3_K_L | 5.2 | IQ3_M probably better |
| [GGUF](https://huggingface.co/mradermacher/gemma-2-9b-it-i1-GGUF/resolve/main/gemma-2-9b-it.i1-IQ4_XS.gguf) | i1-IQ4_XS | 5.3 | |
| [GGUF](https://huggingface.co/mradermacher/gemma-2-9b-it-i1-GGUF/resolve/main/gemma-2-9b-it.i1-Q4_0.gguf) | i1-Q4_0 | 5.6 | fast, low quality |
| [GGUF](https://huggingface.co/mradermacher/gemma-2-9b-it-i1-GGUF/resolve/main/gemma-2-9b-it.i1-Q4_K_S.gguf) | i1-Q4_K_S | 5.6 | optimal size/speed/quality |
| [GGUF](https://huggingface.co/mradermacher/gemma-2-9b-it-i1-GGUF/resolve/main/gemma-2-9b-it.i1-Q4_K_M.gguf) | i1-Q4_K_M | 5.9 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/gemma-2-9b-it-i1-GGUF/resolve/main/gemma-2-9b-it.i1-Q5_K_S.gguf) | i1-Q5_K_S | 6.6 | |
| [GGUF](https://huggingface.co/mradermacher/gemma-2-9b-it-i1-GGUF/resolve/main/gemma-2-9b-it.i1-Q5_K_M.gguf) | i1-Q5_K_M | 6.7 | |
| [GGUF](https://huggingface.co/mradermacher/gemma-2-9b-it-i1-GGUF/resolve/main/gemma-2-9b-it.i1-Q6_K.gguf) | i1-Q6_K | 7.7 | practically like static Q6_K |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time. Additional thanks to [@nicoboss](https://huggingface.co/nicoboss) for giving me access to his hardware for calculating the imatrix for these quants.
<!-- end -->
|
stabilityai/stablelm-zephyr-3b | stabilityai | 2024-04-12T08:30:02Z | 16,956 | 235 | transformers | [
"transformers",
"safetensors",
"stablelm",
"text-generation",
"causal-lm",
"conversational",
"en",
"dataset:HuggingFaceH4/ultrachat_200k",
"dataset:HuggingFaceH4/ultrafeedback_binarized",
"dataset:meta-math/MetaMathQA",
"dataset:WizardLM/WizardLM_evol_instruct_V2_196k",
"dataset:Intel/orca_dpo_pairs",
"arxiv:2305.18290",
"arxiv:2306.05685",
"license:other",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| text-generation | 2023-11-21T16:25:10Z | ---
language:
- en
license: other
tags:
- causal-lm
datasets:
- HuggingFaceH4/ultrachat_200k
- HuggingFaceH4/ultrafeedback_binarized
- meta-math/MetaMathQA
- WizardLM/WizardLM_evol_instruct_V2_196k
- Intel/orca_dpo_pairs
extra_gated_fields:
Name: text
Email: text
Country: text
Organization or Affiliation: text
I ALLOW Stability AI to email me about new model releases: checkbox
model-index:
- name: stablelm-zephyr-3b
results:
- task:
type: text-generation
name: Text Generation
dataset:
name: AI2 Reasoning Challenge (25-Shot)
type: ai2_arc
config: ARC-Challenge
split: test
args:
num_few_shot: 25
metrics:
- type: acc_norm
value: 46.08
name: normalized accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=stabilityai/stablelm-zephyr-3b
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: HellaSwag (10-Shot)
type: hellaswag
split: validation
args:
num_few_shot: 10
metrics:
- type: acc_norm
value: 74.16
name: normalized accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=stabilityai/stablelm-zephyr-3b
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: MMLU (5-Shot)
type: cais/mmlu
config: all
split: test
args:
num_few_shot: 5
metrics:
- type: acc
value: 46.17
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=stabilityai/stablelm-zephyr-3b
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: TruthfulQA (0-shot)
type: truthful_qa
config: multiple_choice
split: validation
args:
num_few_shot: 0
metrics:
- type: mc2
value: 46.49
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=stabilityai/stablelm-zephyr-3b
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: Winogrande (5-shot)
type: winogrande
config: winogrande_xl
split: validation
args:
num_few_shot: 5
metrics:
- type: acc
value: 65.51
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=stabilityai/stablelm-zephyr-3b
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: GSM8k (5-shot)
type: gsm8k
config: main
split: test
args:
num_few_shot: 5
metrics:
- type: acc
value: 42.15
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=stabilityai/stablelm-zephyr-3b
name: Open LLM Leaderboard
---
# `StableLM Zephyr 3B`
Please note: For commercial use, please refer to https://stability.ai/membership.
## Model Description
`StableLM Zephyr 3B` is a 3 billion parameter instruction tuned inspired by [HugginFaceH4's Zephyr 7B](https://huggingface.co/HuggingFaceH4/zephyr-7b-beta) training pipeline this model was trained on a mix of publicly available datasets, synthetic datasets using [Direct Preference Optimization (DPO)](https://arxiv.org/abs/2305.18290), evaluation for this model based on
[MT Bench](https://arxiv.org/abs/2306.05685) and [Alpaca Benchmark](https://tatsu-lab.github.io/alpaca_eval/)
## Usage
`StableLM Zephyr 3B` uses the following instruction format:
```
<|user|>
List 3 synonyms for the word "tiny"<|endoftext|>
<|assistant|>
1. Dwarf
2. Little
3. Petite<|endoftext|>
```
This format is also available through the tokenizer's `apply_chat_template` method:
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained('stabilityai/stablelm-zephyr-3b')
model = AutoModelForCausalLM.from_pretrained(
'stabilityai/stablelm-zephyr-3b',
device_map="auto"
)
prompt = [{'role': 'user', 'content': 'List 3 synonyms for the word "tiny"'}]
inputs = tokenizer.apply_chat_template(
prompt,
add_generation_prompt=True,
return_tensors='pt'
)
tokens = model.generate(
inputs.to(model.device),
max_new_tokens=1024,
temperature=0.8,
do_sample=True
)
print(tokenizer.decode(tokens[0], skip_special_tokens=False))
```
You can also see how to run a performance optimized version of this model [here](https://github.com/openvinotoolkit/openvino_notebooks/blob/main/notebooks/273-stable-zephyr-3b-chatbot/273-stable-zephyr-3b-chatbot.ipynb) using [OpenVINO](https://docs.openvino.ai/2023.2/home.html) from Intel.
## Model Details
* **Developed by**: [Stability AI](https://stability.ai/)
* **Model type**: `StableLM Zephyr 3B` model is an auto-regressive language model based on the transformer decoder architecture.
* **Language(s)**: English
* **Library**: [Alignment Handbook](https://github.com/huggingface/alignment-handbook.git)
* **Finetuned from model**: [stabilityai/stablelm-3b-4e1t](https://huggingface.co/stabilityai/stablelm-3b-4e1t)
* **License**: [StabilityAI Non-Commercial Research Community License](https://huggingface.co/stabilityai/stablelm-zephyr-3b/raw/main/LICENSE).
* **Commercial License**: to use this model commercially, please refer to https://stability.ai/membership
* **Contact**: For questions and comments about the model, please email `[email protected]`
### Training Dataset
The dataset is comprised of a mixture of open datasets large-scale datasets available on the [HuggingFace Hub](https://huggingface.co/datasets):
1. SFT Datasets
- HuggingFaceH4/ultrachat_200k
- meta-math/MetaMathQA
- WizardLM/WizardLM_evol_instruct_V2_196k
- Open-Orca/SlimOrca
2. Preference Datasets:
- HuggingFaceH4/ultrafeedback_binarized
- Intel/orca_dpo_pairs
## Performance
### MT-Bench and Alpaca Bench
<img src="https://cdn-uploads.huggingface.co/production/uploads/6310474ca119d49bc1eb0d80/8WIZS6dAlu5kSH-382pMl.png" alt="mt_bench_plot" width="600"/>
| Model | Size | Alignment | MT-Bench (score) | AlpacaEval (win rate %) |
|-------------|-----|----|---------------|--------------|
| **StableLM Zephyr 3B** 🪁 | 3B | DPO | 6.64 | 76.00 |
| StableLM Zephyr (SFT only) | 3B | SFT | 6.04 | 71.15 |
| Capybara v1.9 | 3B | dSFT | 5.94 | - |
| MPT-Chat | 7B |dSFT |5.42| -|
| Xwin-LM v0.1 | 7B| dPPO| 6.19| 87.83|
| Mistral-Instruct v0.1 | 7B| - | 6.84 |-|
| Zephyr-7b-α |7B| dDPO| 6.88| -|
| Zephyr-7b-β| 7B | dDPO | 7.34 | 90.60 |
| Falcon-Instruct | 40B |dSFT |5.17 |45.71|
| Guanaco | 65B | SFT |6.41| 71.80|
| Llama2-Chat | 70B |RLHF |6.86| 92.66|
| Vicuna v1.3 | 33B |dSFT |7.12 |88.99|
| WizardLM v1.0 | 70B |dSFT |7.71 |-|
| Xwin-LM v0.1 | 70B |dPPO |- |95.57|
| GPT-3.5-turbo | - |RLHF |7.94 |89.37|
| Claude 2 | - |RLHF |8.06| 91.36|
| GPT-4 | -| RLHF |8.99| 95.28|
## Other benchmarks:
| Task | Value |
|-----------------------|---------------------------|
| ARC (25-shot) | 47.0 |
| HellaSwag (10-shot) | 74.2 |
| MMLU (5-shot) | 46.3 |
| TruthfulQA (0-shot) | 46.5 |
| Winogrande (5-shot) | 65.5 |
| GSM8K (5-shot) | 42.3 |
| BigBench (Avg) | 35.26 |
| AGI Benchmark (Avg) | 33.23 |
### Training Infrastructure
* **Hardware**: `StableLM Zephyr 3B` was trained on the Stability AI cluster across 8 nodes with 8 A100 80GBs GPUs for each nodes.
* **Code Base**: We use our internal script for SFT steps and used [HuggingFace Alignment Handbook script](https://github.com/huggingface/alignment-handbook) for DPO training.
## Commitment to Ethical AI
In line with our responsibility towards ethical AI development, `StableLM Zephyr 3B` is released with a focus on ensuring safety, reliability, and appropriateness in its applications. To this end, we have evaluated `StableLM Zephyr 3B` on 488 malicious prompts and used standard protocols to assess the harmfulness of its outputs. Compared to Zephyr-7b-β, `StableLM Zephyr 3B` reduces the number of harmful outputs as assessed by GPT-4 by 55. Additionally, we performed an internal red teaming event targeting the following abuse areas:
* **Self-Harm Methods**: (Suicide Methods, Encouragement of Self-Harm, Methods and encouragement of Eating Disorders)
* **Misinformation**: (Health, Conspiracy Theories, Social Unrest/Conflict, Political Misinformation, & Climate change)
* **Hate Speech**: (Race, Stereotypes, Immigrants, Gender, Personally Identifiable Information such as Social security numbers, Full names, ID numbers, Email addresses, and telephone numbers)
We have incorporated the findings of our malicious prompts evaluation and red teaming event into our release. Users are encouraged to fine-tune and evaluate the model to suit their specific needs, considering the potential biases and limitations found in `StableLM Zephyr 3B` and inherent in other LLM models.
## Use and Limitations
### Intended Use
The model is intended to be used as a foundational base model for application-specific fine-tuning. Developers must evaluate and fine-tune the model for safe performance in downstream applications. For commercial use, please refer to https://stability.ai/membership.
### Limitations and Bias
This model is not trained against adversarial inputs. We strongly recommend pairing this model with an input and output classifier to prevent harmful responses.
Through our internal red teaming, we discovered that while the model will not output harmful information if not prompted to do so, it is willing to output potentially harmful outputs or misinformation when the user requests it. Using this model will require guardrails around your inputs and outputs to ensure that any outputs returned are not misinformation or harmful. Additionally, as each use case is unique, we recommend running your own suite of tests to ensure proper performance of this model. Finally, do not use the models if they are unsuitable for your application, or for any applications that may cause deliberate or unintentional harm to others.
# [Open LLM Leaderboard Evaluation Results](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)
Detailed results can be found [here](https://huggingface.co/datasets/open-llm-leaderboard/details_stabilityai__stablelm-zephyr-3b)
| Metric |Value|
|---------------------------------|----:|
|Avg. |53.43|
|AI2 Reasoning Challenge (25-Shot)|46.08|
|HellaSwag (10-Shot) |74.16|
|MMLU (5-Shot) |46.17|
|TruthfulQA (0-shot) |46.49|
|Winogrande (5-shot) |65.51|
|GSM8k (5-shot) |42.15|
|
londe33/hair_v02 | londe33 | 2023-12-24T17:36:19Z | 16,949 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"vit",
"image-classification",
"pytorch",
"huggingpics",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| image-classification | 2023-12-24T17:36:07Z | ---
tags:
- image-classification
- pytorch
- huggingpics
metrics:
- accuracy
model-index:
- name: hair_v02
results:
- task:
name: Image Classification
type: image-classification
metrics:
- name: Accuracy
type: accuracy
value: 0.8399999737739563
---
# hair_v02
Autogenerated by HuggingPics🤗🖼️
Create your own image classifier for **anything** by running [the demo on Google Colab](https://colab.research.google.com/github/nateraw/huggingpics/blob/main/HuggingPics.ipynb).
Report any issues with the demo at the [github repo](https://github.com/nateraw/huggingpics).
## Example Images
#### Brown hair

#### Red hair

#### black hair

#### blond hair
 |
EleutherAI/pythia-6.9b | EleutherAI | 2023-06-08T10:20:26Z | 16,940 | 41 | transformers | [
"transformers",
"pytorch",
"gpt_neox",
"text-generation",
"causal-lm",
"pythia",
"en",
"dataset:EleutherAI/pile",
"arxiv:2304.01373",
"arxiv:2101.00027",
"arxiv:2201.07311",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| text-generation | 2023-02-14T04:18:48Z | ---
language:
- en
tags:
- pytorch
- causal-lm
- pythia
license: apache-2.0
datasets:
- EleutherAI/pile
---
The *Pythia Scaling Suite* is a collection of models developed to facilitate
interpretability research [(see paper)](https://arxiv.org/pdf/2304.01373.pdf).
It contains two sets of eight models of sizes
70M, 160M, 410M, 1B, 1.4B, 2.8B, 6.9B, and 12B. For each size, there are two
models: one trained on the Pile, and one trained on the Pile after the dataset
has been globally deduplicated. All 8 model sizes are trained on the exact
same data, in the exact same order. We also provide 154 intermediate
checkpoints per model, hosted on Hugging Face as branches.
The Pythia model suite was deliberately designed to promote scientific
research on large language models, especially interpretability research.
Despite not centering downstream performance as a design goal, we find the
models <a href="#evaluations">match or exceed</a> the performance of
similar and same-sized models, such as those in the OPT and GPT-Neo suites.
<details>
<summary style="font-weight:600">Details on previous early release and naming convention.</summary>
Previously, we released an early version of the Pythia suite to the public.
However, we decided to retrain the model suite to address a few hyperparameter
discrepancies. This model card <a href="#changelog">lists the changes</a>;
see appendix B in the Pythia paper for further discussion. We found no
difference in benchmark performance between the two Pythia versions.
The old models are
[still available](https://huggingface.co/models?other=pythia_v0), but we
suggest the retrained suite if you are just starting to use Pythia.<br>
**This is the current release.**
Please note that all models in the *Pythia* suite were renamed in January
2023. For clarity, a <a href="#naming-convention-and-parameter-count">table
comparing the old and new names</a> is provided in this model card, together
with exact parameter counts.
</details>
<br>
# Pythia-6.9B
## Model Details
- Developed by: [EleutherAI](http://eleuther.ai)
- Model type: Transformer-based Language Model
- Language: English
- Learn more: [Pythia's GitHub repository](https://github.com/EleutherAI/pythia)
for training procedure, config files, and details on how to use.
[See paper](https://arxiv.org/pdf/2304.01373.pdf) for more evals and implementation
details.
- Library: [GPT-NeoX](https://github.com/EleutherAI/gpt-neox)
- License: Apache 2.0
- Contact: to ask questions about this model, join the [EleutherAI
Discord](https://discord.gg/zBGx3azzUn), and post them in `#release-discussion`.
Please read the existing *Pythia* documentation before asking about it in the
EleutherAI Discord. For general correspondence: [contact@eleuther.
ai](mailto:[email protected]).
<figure>
| Pythia model | Non-Embedding Params | Layers | Model Dim | Heads | Batch Size | Learning Rate | Equivalent Models |
| -----------: | -------------------: | :----: | :-------: | :---: | :--------: | :-------------------: | :--------------------: |
| 70M | 18,915,328 | 6 | 512 | 8 | 2M | 1.0 x 10<sup>-3</sup> | — |
| 160M | 85,056,000 | 12 | 768 | 12 | 2M | 6.0 x 10<sup>-4</sup> | GPT-Neo 125M, OPT-125M |
| 410M | 302,311,424 | 24 | 1024 | 16 | 2M | 3.0 x 10<sup>-4</sup> | OPT-350M |
| 1.0B | 805,736,448 | 16 | 2048 | 8 | 2M | 3.0 x 10<sup>-4</sup> | — |
| 1.4B | 1,208,602,624 | 24 | 2048 | 16 | 2M | 2.0 x 10<sup>-4</sup> | GPT-Neo 1.3B, OPT-1.3B |
| 2.8B | 2,517,652,480 | 32 | 2560 | 32 | 2M | 1.6 x 10<sup>-4</sup> | GPT-Neo 2.7B, OPT-2.7B |
| 6.9B | 6,444,163,072 | 32 | 4096 | 32 | 2M | 1.2 x 10<sup>-4</sup> | OPT-6.7B |
| 12B | 11,327,027,200 | 36 | 5120 | 40 | 2M | 1.2 x 10<sup>-4</sup> | — |
<figcaption>Engineering details for the <i>Pythia Suite</i>. Deduped and
non-deduped models of a given size have the same hyperparameters. “Equivalent”
models have <b>exactly</b> the same architecture, and the same number of
non-embedding parameters.</figcaption>
</figure>
## Uses and Limitations
### Intended Use
The primary intended use of Pythia is research on the behavior, functionality,
and limitations of large language models. This suite is intended to provide
a controlled setting for performing scientific experiments. We also provide
154 checkpoints per model: initial `step0`, 10 log-spaced checkpoints
`step{1,2,4...512}`, and 143 evenly-spaced checkpoints from `step1000` to
`step143000`. These checkpoints are hosted on Hugging Face as branches. Note
that branch `143000` corresponds exactly to the model checkpoint on the `main`
branch of each model.
You may also further fine-tune and adapt Pythia-6.9B for deployment,
as long as your use is in accordance with the Apache 2.0 license. Pythia
models work with the Hugging Face [Transformers
Library](https://huggingface.co/docs/transformers/index). If you decide to use
pre-trained Pythia-6.9B as a basis for your fine-tuned model, please
conduct your own risk and bias assessment.
### Out-of-scope use
The Pythia Suite is **not** intended for deployment. It is not a in itself
a product and cannot be used for human-facing interactions. For example,
the model may generate harmful or offensive text. Please evaluate the risks
associated with your particular use case.
Pythia models are English-language only, and are not suitable for translation
or generating text in other languages.
Pythia-6.9B has not been fine-tuned for downstream contexts in which
language models are commonly deployed, such as writing genre prose,
or commercial chatbots. This means Pythia-6.9B will **not**
respond to a given prompt the way a product like ChatGPT does. This is because,
unlike this model, ChatGPT was fine-tuned using methods such as Reinforcement
Learning from Human Feedback (RLHF) to better “follow” human instructions.
### Limitations and biases
The core functionality of a large language model is to take a string of text
and predict the next token. The token used by the model need not produce the
most “accurate” text. Never rely on Pythia-6.9B to produce factually accurate
output.
This model was trained on [the Pile](https://pile.eleuther.ai/), a dataset
known to contain profanity and texts that are lewd or otherwise offensive.
See [Section 6 of the Pile paper](https://arxiv.org/abs/2101.00027) for a
discussion of documented biases with regards to gender, religion, and race.
Pythia-6.9B may produce socially unacceptable or undesirable text, *even if*
the prompt itself does not include anything explicitly offensive.
If you plan on using text generated through, for example, the Hosted Inference
API, we recommend having a human curate the outputs of this language model
before presenting it to other people. Please inform your audience that the
text was generated by Pythia-6.9B.
### Quickstart
Pythia models can be loaded and used via the following code, demonstrated here
for the third `pythia-70m-deduped` checkpoint:
```python
from transformers import GPTNeoXForCausalLM, AutoTokenizer
model = GPTNeoXForCausalLM.from_pretrained(
"EleutherAI/pythia-70m-deduped",
revision="step3000",
cache_dir="./pythia-70m-deduped/step3000",
)
tokenizer = AutoTokenizer.from_pretrained(
"EleutherAI/pythia-70m-deduped",
revision="step3000",
cache_dir="./pythia-70m-deduped/step3000",
)
inputs = tokenizer("Hello, I am", return_tensors="pt")
tokens = model.generate(**inputs)
tokenizer.decode(tokens[0])
```
Revision/branch `step143000` corresponds exactly to the model checkpoint on
the `main` branch of each model.<br>
For more information on how to use all Pythia models, see [documentation on
GitHub](https://github.com/EleutherAI/pythia).
## Training
### Training data
[The Pile](https://pile.eleuther.ai/) is a 825GiB general-purpose dataset in
English. It was created by EleutherAI specifically for training large language
models. It contains texts from 22 diverse sources, roughly broken down into
five categories: academic writing (e.g. arXiv), internet (e.g. CommonCrawl),
prose (e.g. Project Gutenberg), dialogue (e.g. YouTube subtitles), and
miscellaneous (e.g. GitHub, Enron Emails). See [the Pile
paper](https://arxiv.org/abs/2101.00027) for a breakdown of all data sources,
methodology, and a discussion of ethical implications. Consult [the
datasheet](https://arxiv.org/abs/2201.07311) for more detailed documentation
about the Pile and its component datasets. The Pile can be downloaded from
the [official website](https://pile.eleuther.ai/), or from a [community
mirror](https://the-eye.eu/public/AI/pile/).<br>
The Pile was **not** deduplicated before being used to train Pythia-6.9B.
### Training procedure
All models were trained on the exact same data, in the exact same order. Each
model saw 299,892,736,000 tokens during training, and 143 checkpoints for each
model are saved every 2,097,152,000 tokens, spaced evenly throughout training,
from `step1000` to `step143000` (which is the same as `main`). In addition, we
also provide frequent early checkpoints: `step0` and `step{1,2,4...512}`.
This corresponds to training for just under 1 epoch on the Pile for
non-deduplicated models, and about 1.5 epochs on the deduplicated Pile.
All *Pythia* models trained for 143000 steps at a batch size
of 2M (2,097,152 tokens).<br>
See [GitHub](https://github.com/EleutherAI/pythia) for more details on training
procedure, including [how to reproduce
it](https://github.com/EleutherAI/pythia/blob/main/README.md#reproducing-training).<br>
Pythia uses the same tokenizer as [GPT-NeoX-
20B](https://huggingface.co/EleutherAI/gpt-neox-20b).
## Evaluations
All 16 *Pythia* models were evaluated using the [LM Evaluation
Harness](https://github.com/EleutherAI/lm-evaluation-harness). You can access
the results by model and step at `results/json/*` in the [GitHub
repository](https://github.com/EleutherAI/pythia/tree/main/results/json/).<br>
Expand the sections below to see plots of evaluation results for all
Pythia and Pythia-deduped models compared with OPT and BLOOM.
<details>
<summary>LAMBADA – OpenAI</summary>
<img src="/EleutherAI/pythia-12b/resolve/main/eval_plots/lambada_openai_v1.png" style="width:auto"/>
</details>
<details>
<summary>Physical Interaction: Question Answering (PIQA)</summary>
<img src="/EleutherAI/pythia-12b/resolve/main/eval_plots/piqa_v1.png" style="width:auto"/>
</details>
<details>
<summary>WinoGrande</summary>
<img src="/EleutherAI/pythia-12b/resolve/main/eval_plots/winogrande_v1.png" style="width:auto"/>
</details>
<details>
<summary>AI2 Reasoning Challenge—Easy Set</summary>
<img src="/EleutherAI/pythia-12b/resolve/main/eval_plots/arc_easy_v1.png" style="width:auto"/>
</details>
<details>
<summary>SciQ</summary>
<img src="/EleutherAI/pythia-12b/resolve/main/eval_plots/sciq_v1.png" style="width:auto"/>
</details>
## Changelog
This section compares differences between previously released
[Pythia v0](https://huggingface.co/models?other=pythia_v0) and the current
models. See Appendix B of the Pythia paper for further discussion of these
changes and the motivation behind them. We found that retraining Pythia had no
impact on benchmark performance.
- All model sizes are now trained with uniform batch size of 2M tokens.
Previously, the models of size 160M, 410M, and 1.4B parameters were trained
with batch sizes of 4M tokens.
- We added checkpoints at initialization (step 0) and steps {1,2,4,8,16,32,64,
128,256,512} in addition to every 1000 training steps.
- Flash Attention was used in the new retrained suite.
- We remedied a minor inconsistency that existed in the original suite: all
models of size 2.8B parameters or smaller had a learning rate (LR) schedule
which decayed to a minimum LR of 10% the starting LR rate, but the 6.9B and
12B models all used an LR schedule which decayed to a minimum LR of 0. In
the redone training runs, we rectified this inconsistency: all models now were
trained with LR decaying to a minimum of 0.1× their maximum LR.
### Naming convention and parameter count
*Pythia* models were renamed in January 2023. It is possible that the old
naming convention still persists in some documentation by accident. The
current naming convention (70M, 160M, etc.) is based on total parameter count.
<figure style="width:32em">
| current Pythia suffix | old suffix | total params | non-embedding params |
| --------------------: | ---------: | -------------: | -------------------: |
| 70M | 19M | 70,426,624 | 18,915,328 |
| 160M | 125M | 162,322,944 | 85,056,000 |
| 410M | 350M | 405,334,016 | 302,311,424 |
| 1B | 800M | 1,011,781,632 | 805,736,448 |
| 1.4B | 1.3B | 1,414,647,808 | 1,208,602,624 |
| 2.8B | 2.7B | 2,775,208,960 | 2,517,652,480 |
| 6.9B | 6.7B | 6,857,302,016 | 6,444,163,072 |
| 12B | 13B | 11,846,072,320 | 11,327,027,200 |
</figure> |
lakshyakh93/deberta_finetuned_pii | lakshyakh93 | 2024-03-08T05:07:37Z | 16,931 | 31 | transformers | [
"transformers",
"pytorch",
"deberta",
"token-classification",
"en",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| token-classification | 2023-10-06T14:19:19Z | ---
license: mit
language:
- en
pipeline_tag: token-classification
---
A finetuned model designed to recognize and classify Personally Identifiable Information (PII) within unstructured text data. This powerful model accurately identifies a wide range of PII categories, such as account names, credit card numbers, emails, phone numbers, and addresses. The model is specifically trained to detect various PII types, including but not limited to:
```
| Category | Data |
|------------------------|----------------------------------------------------------------------------------------|
| Account-related information | Account name, account number, and transaction amounts |
| Banking details | BIC, IBAN, and Bitcoin or Ethereum addresses |
| Personal information | Full name, first name, middle name, last name, gender, and date of birth |
| Contact information | Email, phone number, and street address (including building number, city, county, state, and zip code) |
| Job-related data | Job title, job area, job descriptor, and job type |
| Financial data | Credit card number, issuer, CVV, and currency information (code, name, and symbol) |
| Digital identifiers | IP addresses (IPv4 and IPv6), MAC addresses, and user agents |
| Online presence | URL, usernames, and passwords |
| Other sensitive data | SSN, vehicle VIN and VRM, phone IMEI, and nearby GPS coordinates |
```
The PII Identifier Model ensures data privacy and compliance by effectively detecting and categorizing sensitive information within documents, emails, user-generated content, and more. Make your data processing safer and more secure with our state-of-the-art PII detection technology.
How to do Inference :
```
from transformers import pipeline
gen = pipeline("token-classification", "lakshyakh93/deberta_finetuned_pii", device=-1)
text = "My name is John and I live in California."
output = gen(text, aggregation_strategy="first")
```
For any more details reach out to [email protected]
|
mradermacher/MAmmoTH2-8B-Plus-GGUF | mradermacher | 2024-06-28T02:40:14Z | 16,907 | 1 | transformers | [
"transformers",
"gguf",
"en",
"dataset:TIGER-Lab/WebInstructSub",
"base_model:TIGER-Lab/MAmmoTH2-8B-Plus",
"license:mit",
"endpoints_compatible",
"region:us"
]
| null | 2024-06-26T23:50:38Z | ---
base_model: TIGER-Lab/MAmmoTH2-8B-Plus
datasets:
- TIGER-Lab/WebInstructSub
language:
- en
library_name: transformers
license: mit
quantized_by: mradermacher
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
static quants of https://huggingface.co/TIGER-Lab/MAmmoTH2-8B-Plus
<!-- provided-files -->
weighted/imatrix quants are available at https://huggingface.co/mradermacher/MAmmoTH2-8B-Plus-i1-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/MAmmoTH2-8B-Plus-GGUF/resolve/main/MAmmoTH2-8B-Plus.Q2_K.gguf) | Q2_K | 3.3 | |
| [GGUF](https://huggingface.co/mradermacher/MAmmoTH2-8B-Plus-GGUF/resolve/main/MAmmoTH2-8B-Plus.IQ3_XS.gguf) | IQ3_XS | 3.6 | |
| [GGUF](https://huggingface.co/mradermacher/MAmmoTH2-8B-Plus-GGUF/resolve/main/MAmmoTH2-8B-Plus.Q3_K_S.gguf) | Q3_K_S | 3.8 | |
| [GGUF](https://huggingface.co/mradermacher/MAmmoTH2-8B-Plus-GGUF/resolve/main/MAmmoTH2-8B-Plus.IQ3_S.gguf) | IQ3_S | 3.8 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/MAmmoTH2-8B-Plus-GGUF/resolve/main/MAmmoTH2-8B-Plus.IQ3_M.gguf) | IQ3_M | 3.9 | |
| [GGUF](https://huggingface.co/mradermacher/MAmmoTH2-8B-Plus-GGUF/resolve/main/MAmmoTH2-8B-Plus.Q3_K_M.gguf) | Q3_K_M | 4.1 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/MAmmoTH2-8B-Plus-GGUF/resolve/main/MAmmoTH2-8B-Plus.Q3_K_L.gguf) | Q3_K_L | 4.4 | |
| [GGUF](https://huggingface.co/mradermacher/MAmmoTH2-8B-Plus-GGUF/resolve/main/MAmmoTH2-8B-Plus.IQ4_XS.gguf) | IQ4_XS | 4.6 | |
| [GGUF](https://huggingface.co/mradermacher/MAmmoTH2-8B-Plus-GGUF/resolve/main/MAmmoTH2-8B-Plus.Q4_K_S.gguf) | Q4_K_S | 4.8 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/MAmmoTH2-8B-Plus-GGUF/resolve/main/MAmmoTH2-8B-Plus.Q4_K_M.gguf) | Q4_K_M | 5.0 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/MAmmoTH2-8B-Plus-GGUF/resolve/main/MAmmoTH2-8B-Plus.Q5_K_S.gguf) | Q5_K_S | 5.7 | |
| [GGUF](https://huggingface.co/mradermacher/MAmmoTH2-8B-Plus-GGUF/resolve/main/MAmmoTH2-8B-Plus.Q5_K_M.gguf) | Q5_K_M | 5.8 | |
| [GGUF](https://huggingface.co/mradermacher/MAmmoTH2-8B-Plus-GGUF/resolve/main/MAmmoTH2-8B-Plus.Q6_K.gguf) | Q6_K | 6.7 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/MAmmoTH2-8B-Plus-GGUF/resolve/main/MAmmoTH2-8B-Plus.Q8_0.gguf) | Q8_0 | 8.6 | fast, best quality |
| [GGUF](https://huggingface.co/mradermacher/MAmmoTH2-8B-Plus-GGUF/resolve/main/MAmmoTH2-8B-Plus.f16.gguf) | f16 | 16.2 | 16 bpw, overkill |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
RichardErkhov/unsloth_-_llama-2-7b-gguf | RichardErkhov | 2024-06-30T18:40:28Z | 16,907 | 0 | null | [
"gguf",
"region:us"
]
| null | 2024-06-30T16:25:57Z | Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
llama-2-7b - GGUF
- Model creator: https://huggingface.co/unsloth/
- Original model: https://huggingface.co/unsloth/llama-2-7b/
| Name | Quant method | Size |
| ---- | ---- | ---- |
| [llama-2-7b.Q2_K.gguf](https://huggingface.co/RichardErkhov/unsloth_-_llama-2-7b-gguf/blob/main/llama-2-7b.Q2_K.gguf) | Q2_K | 2.36GB |
| [llama-2-7b.IQ3_XS.gguf](https://huggingface.co/RichardErkhov/unsloth_-_llama-2-7b-gguf/blob/main/llama-2-7b.IQ3_XS.gguf) | IQ3_XS | 2.6GB |
| [llama-2-7b.IQ3_S.gguf](https://huggingface.co/RichardErkhov/unsloth_-_llama-2-7b-gguf/blob/main/llama-2-7b.IQ3_S.gguf) | IQ3_S | 2.75GB |
| [llama-2-7b.Q3_K_S.gguf](https://huggingface.co/RichardErkhov/unsloth_-_llama-2-7b-gguf/blob/main/llama-2-7b.Q3_K_S.gguf) | Q3_K_S | 2.75GB |
| [llama-2-7b.IQ3_M.gguf](https://huggingface.co/RichardErkhov/unsloth_-_llama-2-7b-gguf/blob/main/llama-2-7b.IQ3_M.gguf) | IQ3_M | 2.9GB |
| [llama-2-7b.Q3_K.gguf](https://huggingface.co/RichardErkhov/unsloth_-_llama-2-7b-gguf/blob/main/llama-2-7b.Q3_K.gguf) | Q3_K | 3.07GB |
| [llama-2-7b.Q3_K_M.gguf](https://huggingface.co/RichardErkhov/unsloth_-_llama-2-7b-gguf/blob/main/llama-2-7b.Q3_K_M.gguf) | Q3_K_M | 3.07GB |
| [llama-2-7b.Q3_K_L.gguf](https://huggingface.co/RichardErkhov/unsloth_-_llama-2-7b-gguf/blob/main/llama-2-7b.Q3_K_L.gguf) | Q3_K_L | 3.35GB |
| [llama-2-7b.IQ4_XS.gguf](https://huggingface.co/RichardErkhov/unsloth_-_llama-2-7b-gguf/blob/main/llama-2-7b.IQ4_XS.gguf) | IQ4_XS | 3.4GB |
| [llama-2-7b.Q4_0.gguf](https://huggingface.co/RichardErkhov/unsloth_-_llama-2-7b-gguf/blob/main/llama-2-7b.Q4_0.gguf) | Q4_0 | 3.56GB |
| [llama-2-7b.IQ4_NL.gguf](https://huggingface.co/RichardErkhov/unsloth_-_llama-2-7b-gguf/blob/main/llama-2-7b.IQ4_NL.gguf) | IQ4_NL | 3.58GB |
| [llama-2-7b.Q4_K_S.gguf](https://huggingface.co/RichardErkhov/unsloth_-_llama-2-7b-gguf/blob/main/llama-2-7b.Q4_K_S.gguf) | Q4_K_S | 3.59GB |
| [llama-2-7b.Q4_K.gguf](https://huggingface.co/RichardErkhov/unsloth_-_llama-2-7b-gguf/blob/main/llama-2-7b.Q4_K.gguf) | Q4_K | 3.8GB |
| [llama-2-7b.Q4_K_M.gguf](https://huggingface.co/RichardErkhov/unsloth_-_llama-2-7b-gguf/blob/main/llama-2-7b.Q4_K_M.gguf) | Q4_K_M | 3.8GB |
| [llama-2-7b.Q4_1.gguf](https://huggingface.co/RichardErkhov/unsloth_-_llama-2-7b-gguf/blob/main/llama-2-7b.Q4_1.gguf) | Q4_1 | 3.95GB |
| [llama-2-7b.Q5_0.gguf](https://huggingface.co/RichardErkhov/unsloth_-_llama-2-7b-gguf/blob/main/llama-2-7b.Q5_0.gguf) | Q5_0 | 4.33GB |
| [llama-2-7b.Q5_K_S.gguf](https://huggingface.co/RichardErkhov/unsloth_-_llama-2-7b-gguf/blob/main/llama-2-7b.Q5_K_S.gguf) | Q5_K_S | 4.33GB |
| [llama-2-7b.Q5_K.gguf](https://huggingface.co/RichardErkhov/unsloth_-_llama-2-7b-gguf/blob/main/llama-2-7b.Q5_K.gguf) | Q5_K | 4.45GB |
| [llama-2-7b.Q5_K_M.gguf](https://huggingface.co/RichardErkhov/unsloth_-_llama-2-7b-gguf/blob/main/llama-2-7b.Q5_K_M.gguf) | Q5_K_M | 4.45GB |
| [llama-2-7b.Q5_1.gguf](https://huggingface.co/RichardErkhov/unsloth_-_llama-2-7b-gguf/blob/main/llama-2-7b.Q5_1.gguf) | Q5_1 | 4.72GB |
| [llama-2-7b.Q6_K.gguf](https://huggingface.co/RichardErkhov/unsloth_-_llama-2-7b-gguf/blob/main/llama-2-7b.Q6_K.gguf) | Q6_K | 5.15GB |
| [llama-2-7b.Q8_0.gguf](https://huggingface.co/RichardErkhov/unsloth_-_llama-2-7b-gguf/blob/main/llama-2-7b.Q8_0.gguf) | Q8_0 | 6.67GB |
Original model description:
---
language:
- en
license: apache-2.0
library_name: transformers
tags:
- unsloth
- transformers
- llama
- llama-2
---
# Finetune Mistral, Gemma, Llama 2-5x faster with 70% less memory via Unsloth!
Directly quantized 4bit model with `bitsandbytes`.
We have a Google Colab Tesla T4 notebook for Llama 7b here: https://colab.research.google.com/drive/1lBzz5KeZJKXjvivbYvmGarix9Ao6Wxe5?usp=sharing
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/Discord%20button.png" width="200"/>](https://discord.gg/u54VK8m8tk)
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/buy%20me%20a%20coffee%20button.png" width="200"/>](https://ko-fi.com/unsloth)
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
## ✨ Finetune for Free
All notebooks are **beginner friendly**! Add your dataset, click "Run All", and you'll get a 2x faster finetuned model which can be exported to GGUF, vLLM or uploaded to Hugging Face.
| Unsloth supports | Free Notebooks | Performance | Memory use |
|-----------------|--------------------------------------------------------------------------------------------------------------------------|-------------|----------|
| **Gemma 7b** | [▶️ Start on Colab](https://colab.research.google.com/drive/10NbwlsRChbma1v55m8LAPYG15uQv6HLo?usp=sharing) | 2.4x faster | 58% less |
| **Mistral 7b** | [▶️ Start on Colab](https://colab.research.google.com/drive/1Dyauq4kTZoLewQ1cApceUQVNcnnNTzg_?usp=sharing) | 2.2x faster | 62% less |
| **Llama-2 7b** | [▶️ Start on Colab](https://colab.research.google.com/drive/1lBzz5KeZJKXjvivbYvmGarix9Ao6Wxe5?usp=sharing) | 2.2x faster | 43% less |
| **TinyLlama** | [▶️ Start on Colab](https://colab.research.google.com/drive/1AZghoNBQaMDgWJpi4RbffGM1h6raLUj9?usp=sharing) | 3.9x faster | 74% less |
| **CodeLlama 34b** A100 | [▶️ Start on Colab](https://colab.research.google.com/drive/1y7A0AxE3y8gdj4AVkl2aZX47Xu3P1wJT?usp=sharing) | 1.9x faster | 27% less |
| **Mistral 7b** 1xT4 | [▶️ Start on Kaggle](https://www.kaggle.com/code/danielhanchen/kaggle-mistral-7b-unsloth-notebook) | 5x faster\* | 62% less |
| **DPO - Zephyr** | [▶️ Start on Colab](https://colab.research.google.com/drive/15vttTpzzVXv_tJwEk-hIcQ0S9FcEWvwP?usp=sharing) | 1.9x faster | 19% less |
- This [conversational notebook](https://colab.research.google.com/drive/1Aau3lgPzeZKQ-98h69CCu1UJcvIBLmy2?usp=sharing) is useful for ShareGPT ChatML / Vicuna templates.
- This [text completion notebook](https://colab.research.google.com/drive/1ef-tab5bhkvWmBOObepl1WgJvfvSzn5Q?usp=sharing) is for raw text. This [DPO notebook](https://colab.research.google.com/drive/15vttTpzzVXv_tJwEk-hIcQ0S9FcEWvwP?usp=sharing) replicates Zephyr.
- \* Kaggle has 2x T4s, but we use 1. Due to overhead, 1x T4 is 5x faster.
|
Qwen/Qwen1.5-0.5B-Chat-GGUF | Qwen | 2024-04-09T16:48:58Z | 16,898 | 23 | null | [
"gguf",
"chat",
"text-generation",
"en",
"license:other",
"region:us"
]
| text-generation | 2024-02-03T11:58:20Z | ---
license: other
license_name: tongyi-qianwen-research
license_link: https://huggingface.co/Qwen/Qwen1.5-0.5B-Chat-GGUF/blob/main/LICENSE
language:
- en
pipeline_tag: text-generation
tags:
- chat
---
# Qwen1.5-0.5B-Chat-GGUF
## Introduction
Qwen1.5 is the beta version of Qwen2, a transformer-based decoder-only language model pretrained on a large amount of data. In comparison with the previous released Qwen, the improvements include:
* 8 model sizes, including 0.5B, 1.8B, 4B, 7B, 14B, 32B and 72B dense models, and an MoE model of 14B with 2.7B activated;
* Significant performance improvement in human preference for chat models;
* Multilingual support of both base and chat models;
* Stable support of 32K context length for models of all sizes
* No need of `trust_remote_code`.
For more details, please refer to our [blog post](https://qwenlm.github.io/blog/qwen1.5/) and [GitHub repo](https://github.com/QwenLM/Qwen1.5).
In this repo, we provide quantized models in the GGUF formats, including `q2_k`, `q3_k_m`, `q4_0`, `q4_k_m`, `q5_0`, `q5_k_m`, `q6_k` and `q8_0`.
To demonstrate their model quality, we follow [`llama.cpp`](https://github.com/ggerganov/llama.cpp) to evaluate their perplexity on wiki test set. Results are shown below:
|Size | fp16 | q8_0 | q6_k | q5_k_m | q5_0 | q4_k_m | q4_0 | q3_k_m | q2_k |
|--------|---------|---------|---------|---------|---------|---------|---------|---------|---------|
|0.5B | 34.20 | 34.22 | 34.31 | 33.80 | 34.02 | 34.27 | 36.74 | 38.25 | 62.14 |
|1.8B | 15.99 | 15.99 | 15.99 | 16.09 | 16.01 | 16.22 | 16.54 | 17.03 | 19.99 |
|4B | 13.20 | 13.21 | 13.28 | 13.24 | 13.27 | 13.61 | 13.44 | 13.67 | 15.65 |
|7B | 14.21 | 14.24 | 14.35 | 14.32 | 14.12 | 14.35 | 14.47 | 15.11 | 16.57 |
|14B | 10.91 | 10.91 | 10.93 | 10.98 | 10.88 | 10.92 | 10.92 | 11.24 | 12.27 |
|32B | 8.87 | 8.89 | 8.91 | 8.94 | 8.93 | 8.96 | 9.17 | 9.14 | 10.51 |
|72B | 7.97 | 7.99 | 7.99 | 7.99 | 8.01 | 8.00 | 8.01 | 8.06 | 8.63 |
## Model Details
Qwen1.5 is a language model series including decoder language models of different model sizes. For each size, we release the base language model and the aligned chat model. It is based on the Transformer architecture with SwiGLU activation, attention QKV bias, group query attention, mixture of sliding window attention and full attention, etc. Additionally, we have an improved tokenizer adaptive to multiple natural languages and codes. For the beta version, temporarily we did not include GQA (except for 32B) and the mixture of SWA and full attention.
## Training details
We pretrained the models with a large amount of data, and we post-trained the models with both supervised finetuning and direct preference optimization.
## Requirements
We advise you to clone [`llama.cpp`](https://github.com/ggerganov/llama.cpp) and install it following the official guide.
## How to use
Cloning the repo may be inefficient, and thus you can manually download the GGUF file that you need or use `huggingface-cli` (`pip install huggingface_hub`) as shown below:
```shell
huggingface-cli download Qwen/Qwen1.5-0.5B-Chat-GGUF qwen1_5-0_5b-chat-q8_0.gguf --local-dir . --local-dir-use-symlinks False
```
We demonstrate how to use `llama.cpp` to run Qwen1.5:
```shell
./main -m qwen1_5-0_5b-chat-q8_0.gguf -n 512 --color -i -cml -f prompts/chat-with-qwen.txt
```
## Citation
If you find our work helpful, feel free to give us a cite.
```
@article{qwen,
title={Qwen Technical Report},
author={Jinze Bai and Shuai Bai and Yunfei Chu and Zeyu Cui and Kai Dang and Xiaodong Deng and Yang Fan and Wenbin Ge and Yu Han and Fei Huang and Binyuan Hui and Luo Ji and Mei Li and Junyang Lin and Runji Lin and Dayiheng Liu and Gao Liu and Chengqiang Lu and Keming Lu and Jianxin Ma and Rui Men and Xingzhang Ren and Xuancheng Ren and Chuanqi Tan and Sinan Tan and Jianhong Tu and Peng Wang and Shijie Wang and Wei Wang and Shengguang Wu and Benfeng Xu and Jin Xu and An Yang and Hao Yang and Jian Yang and Shusheng Yang and Yang Yao and Bowen Yu and Hongyi Yuan and Zheng Yuan and Jianwei Zhang and Xingxuan Zhang and Yichang Zhang and Zhenru Zhang and Chang Zhou and Jingren Zhou and Xiaohuan Zhou and Tianhang Zhu},
journal={arXiv preprint arXiv:2309.16609},
year={2023}
}
```
|
mradermacher/BigHuggyD-Grey-WizardLM-2-8x22B-i1-GGUF | mradermacher | 2024-06-20T01:35:37Z | 16,882 | 1 | transformers | [
"transformers",
"gguf",
"mergekit",
"merge",
"en",
"base_model:BigHuggyD/BigHuggyD-Grey-WizardLM-2-8x22B",
"endpoints_compatible",
"region:us"
]
| null | 2024-06-19T01:18:59Z | ---
base_model: BigHuggyD/BigHuggyD-Grey-WizardLM-2-8x22B
language:
- en
library_name: transformers
quantized_by: mradermacher
tags:
- mergekit
- merge
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: nicoboss -->
weighted/imatrix quants of https://huggingface.co/BigHuggyD/BigHuggyD-Grey-WizardLM-2-8x22B
<!-- provided-files -->
static quants are available at https://huggingface.co/mradermacher/BigHuggyD-Grey-WizardLM-2-8x22B-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/BigHuggyD-Grey-WizardLM-2-8x22B-i1-GGUF/resolve/main/BigHuggyD-Grey-WizardLM-2-8x22B.i1-IQ1_S.gguf) | i1-IQ1_S | 29.7 | for the desperate |
| [GGUF](https://huggingface.co/mradermacher/BigHuggyD-Grey-WizardLM-2-8x22B-i1-GGUF/resolve/main/BigHuggyD-Grey-WizardLM-2-8x22B.i1-IQ1_M.gguf) | i1-IQ1_M | 32.8 | mostly desperate |
| [GGUF](https://huggingface.co/mradermacher/BigHuggyD-Grey-WizardLM-2-8x22B-i1-GGUF/resolve/main/BigHuggyD-Grey-WizardLM-2-8x22B.i1-IQ2_XXS.gguf) | i1-IQ2_XXS | 38.0 | |
| [GGUF](https://huggingface.co/mradermacher/BigHuggyD-Grey-WizardLM-2-8x22B-i1-GGUF/resolve/main/BigHuggyD-Grey-WizardLM-2-8x22B.i1-IQ2_XS.gguf) | i1-IQ2_XS | 42.1 | |
| [GGUF](https://huggingface.co/mradermacher/BigHuggyD-Grey-WizardLM-2-8x22B-i1-GGUF/resolve/main/BigHuggyD-Grey-WizardLM-2-8x22B.i1-IQ2_S.gguf) | i1-IQ2_S | 42.7 | |
| [GGUF](https://huggingface.co/mradermacher/BigHuggyD-Grey-WizardLM-2-8x22B-i1-GGUF/resolve/main/BigHuggyD-Grey-WizardLM-2-8x22B.i1-IQ2_M.gguf) | i1-IQ2_M | 46.8 | |
| [PART 1](https://huggingface.co/mradermacher/BigHuggyD-Grey-WizardLM-2-8x22B-i1-GGUF/resolve/main/BigHuggyD-Grey-WizardLM-2-8x22B.i1-Q2_K.gguf.part1of2) [PART 2](https://huggingface.co/mradermacher/BigHuggyD-Grey-WizardLM-2-8x22B-i1-GGUF/resolve/main/BigHuggyD-Grey-WizardLM-2-8x22B.i1-Q2_K.gguf.part2of2) | i1-Q2_K | 52.2 | IQ3_XXS probably better |
| [PART 1](https://huggingface.co/mradermacher/BigHuggyD-Grey-WizardLM-2-8x22B-i1-GGUF/resolve/main/BigHuggyD-Grey-WizardLM-2-8x22B.i1-IQ3_XXS.gguf.part1of2) [PART 2](https://huggingface.co/mradermacher/BigHuggyD-Grey-WizardLM-2-8x22B-i1-GGUF/resolve/main/BigHuggyD-Grey-WizardLM-2-8x22B.i1-IQ3_XXS.gguf.part2of2) | i1-IQ3_XXS | 55.0 | lower quality |
| [PART 1](https://huggingface.co/mradermacher/BigHuggyD-Grey-WizardLM-2-8x22B-i1-GGUF/resolve/main/BigHuggyD-Grey-WizardLM-2-8x22B.i1-IQ3_XS.gguf.part1of2) [PART 2](https://huggingface.co/mradermacher/BigHuggyD-Grey-WizardLM-2-8x22B-i1-GGUF/resolve/main/BigHuggyD-Grey-WizardLM-2-8x22B.i1-IQ3_XS.gguf.part2of2) | i1-IQ3_XS | 58.3 | |
| [PART 1](https://huggingface.co/mradermacher/BigHuggyD-Grey-WizardLM-2-8x22B-i1-GGUF/resolve/main/BigHuggyD-Grey-WizardLM-2-8x22B.i1-IQ3_S.gguf.part1of2) [PART 2](https://huggingface.co/mradermacher/BigHuggyD-Grey-WizardLM-2-8x22B-i1-GGUF/resolve/main/BigHuggyD-Grey-WizardLM-2-8x22B.i1-IQ3_S.gguf.part2of2) | i1-IQ3_S | 61.6 | beats Q3_K* |
| [PART 1](https://huggingface.co/mradermacher/BigHuggyD-Grey-WizardLM-2-8x22B-i1-GGUF/resolve/main/BigHuggyD-Grey-WizardLM-2-8x22B.i1-Q3_K_S.gguf.part1of2) [PART 2](https://huggingface.co/mradermacher/BigHuggyD-Grey-WizardLM-2-8x22B-i1-GGUF/resolve/main/BigHuggyD-Grey-WizardLM-2-8x22B.i1-Q3_K_S.gguf.part2of2) | i1-Q3_K_S | 61.6 | IQ3_XS probably better |
| [PART 1](https://huggingface.co/mradermacher/BigHuggyD-Grey-WizardLM-2-8x22B-i1-GGUF/resolve/main/BigHuggyD-Grey-WizardLM-2-8x22B.i1-IQ3_M.gguf.part1of2) [PART 2](https://huggingface.co/mradermacher/BigHuggyD-Grey-WizardLM-2-8x22B-i1-GGUF/resolve/main/BigHuggyD-Grey-WizardLM-2-8x22B.i1-IQ3_M.gguf.part2of2) | i1-IQ3_M | 64.6 | |
| [PART 1](https://huggingface.co/mradermacher/BigHuggyD-Grey-WizardLM-2-8x22B-i1-GGUF/resolve/main/BigHuggyD-Grey-WizardLM-2-8x22B.i1-Q3_K_M.gguf.part1of2) [PART 2](https://huggingface.co/mradermacher/BigHuggyD-Grey-WizardLM-2-8x22B-i1-GGUF/resolve/main/BigHuggyD-Grey-WizardLM-2-8x22B.i1-Q3_K_M.gguf.part2of2) | i1-Q3_K_M | 67.9 | IQ3_S probably better |
| [PART 1](https://huggingface.co/mradermacher/BigHuggyD-Grey-WizardLM-2-8x22B-i1-GGUF/resolve/main/BigHuggyD-Grey-WizardLM-2-8x22B.i1-Q3_K_L.gguf.part1of2) [PART 2](https://huggingface.co/mradermacher/BigHuggyD-Grey-WizardLM-2-8x22B-i1-GGUF/resolve/main/BigHuggyD-Grey-WizardLM-2-8x22B.i1-Q3_K_L.gguf.part2of2) | i1-Q3_K_L | 72.7 | IQ3_M probably better |
| [PART 1](https://huggingface.co/mradermacher/BigHuggyD-Grey-WizardLM-2-8x22B-i1-GGUF/resolve/main/BigHuggyD-Grey-WizardLM-2-8x22B.i1-IQ4_XS.gguf.part1of2) [PART 2](https://huggingface.co/mradermacher/BigHuggyD-Grey-WizardLM-2-8x22B-i1-GGUF/resolve/main/BigHuggyD-Grey-WizardLM-2-8x22B.i1-IQ4_XS.gguf.part2of2) | i1-IQ4_XS | 75.6 | |
| [PART 1](https://huggingface.co/mradermacher/BigHuggyD-Grey-WizardLM-2-8x22B-i1-GGUF/resolve/main/BigHuggyD-Grey-WizardLM-2-8x22B.i1-Q4_0.gguf.part1of2) [PART 2](https://huggingface.co/mradermacher/BigHuggyD-Grey-WizardLM-2-8x22B-i1-GGUF/resolve/main/BigHuggyD-Grey-WizardLM-2-8x22B.i1-Q4_0.gguf.part2of2) | i1-Q4_0 | 80.0 | fast, low quality |
| [PART 1](https://huggingface.co/mradermacher/BigHuggyD-Grey-WizardLM-2-8x22B-i1-GGUF/resolve/main/BigHuggyD-Grey-WizardLM-2-8x22B.i1-Q4_K_S.gguf.part1of2) [PART 2](https://huggingface.co/mradermacher/BigHuggyD-Grey-WizardLM-2-8x22B-i1-GGUF/resolve/main/BigHuggyD-Grey-WizardLM-2-8x22B.i1-Q4_K_S.gguf.part2of2) | i1-Q4_K_S | 80.6 | optimal size/speed/quality |
| [PART 1](https://huggingface.co/mradermacher/BigHuggyD-Grey-WizardLM-2-8x22B-i1-GGUF/resolve/main/BigHuggyD-Grey-WizardLM-2-8x22B.i1-Q4_K_M.gguf.part1of2) [PART 2](https://huggingface.co/mradermacher/BigHuggyD-Grey-WizardLM-2-8x22B-i1-GGUF/resolve/main/BigHuggyD-Grey-WizardLM-2-8x22B.i1-Q4_K_M.gguf.part2of2) | i1-Q4_K_M | 85.7 | fast, recommended |
| [PART 1](https://huggingface.co/mradermacher/BigHuggyD-Grey-WizardLM-2-8x22B-i1-GGUF/resolve/main/BigHuggyD-Grey-WizardLM-2-8x22B.i1-Q5_K_S.gguf.part1of2) [PART 2](https://huggingface.co/mradermacher/BigHuggyD-Grey-WizardLM-2-8x22B-i1-GGUF/resolve/main/BigHuggyD-Grey-WizardLM-2-8x22B.i1-Q5_K_S.gguf.part2of2) | i1-Q5_K_S | 97.1 | |
| [PART 1](https://huggingface.co/mradermacher/BigHuggyD-Grey-WizardLM-2-8x22B-i1-GGUF/resolve/main/BigHuggyD-Grey-WizardLM-2-8x22B.i1-Q5_K_M.gguf.part1of3) [PART 2](https://huggingface.co/mradermacher/BigHuggyD-Grey-WizardLM-2-8x22B-i1-GGUF/resolve/main/BigHuggyD-Grey-WizardLM-2-8x22B.i1-Q5_K_M.gguf.part2of3) [PART 3](https://huggingface.co/mradermacher/BigHuggyD-Grey-WizardLM-2-8x22B-i1-GGUF/resolve/main/BigHuggyD-Grey-WizardLM-2-8x22B.i1-Q5_K_M.gguf.part3of3) | i1-Q5_K_M | 100.1 | |
| [PART 1](https://huggingface.co/mradermacher/BigHuggyD-Grey-WizardLM-2-8x22B-i1-GGUF/resolve/main/BigHuggyD-Grey-WizardLM-2-8x22B.i1-Q6_K.gguf.part1of3) [PART 2](https://huggingface.co/mradermacher/BigHuggyD-Grey-WizardLM-2-8x22B-i1-GGUF/resolve/main/BigHuggyD-Grey-WizardLM-2-8x22B.i1-Q6_K.gguf.part2of3) [PART 3](https://huggingface.co/mradermacher/BigHuggyD-Grey-WizardLM-2-8x22B-i1-GGUF/resolve/main/BigHuggyD-Grey-WizardLM-2-8x22B.i1-Q6_K.gguf.part3of3) | i1-Q6_K | 115.6 | practically like static Q6_K |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time. Additional thanks to [@nicoboss](https://huggingface.co/nicoboss) for giving me access to his hardware for calculating the imatrix for these quants.
<!-- end -->
|
mradermacher/KeplerRP-7B-128K-0.2-GGUF | mradermacher | 2024-06-27T05:01:42Z | 16,879 | 0 | transformers | [
"transformers",
"gguf",
"mergekit",
"merge",
"en",
"base_model:Ppoyaa/KeplerRP-7B-128K-0.2",
"endpoints_compatible",
"region:us"
]
| null | 2024-06-27T04:35:49Z | ---
base_model: Ppoyaa/KeplerRP-7B-128K-0.2
language:
- en
library_name: transformers
quantized_by: mradermacher
tags:
- mergekit
- merge
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
static quants of https://huggingface.co/Ppoyaa/KeplerRP-7B-128K-0.2
<!-- provided-files -->
weighted/imatrix quants are available at https://huggingface.co/mradermacher/KeplerRP-7B-128K-0.2-i1-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/KeplerRP-7B-128K-0.2-GGUF/resolve/main/KeplerRP-7B-128K-0.2.Q2_K.gguf) | Q2_K | 2.8 | |
| [GGUF](https://huggingface.co/mradermacher/KeplerRP-7B-128K-0.2-GGUF/resolve/main/KeplerRP-7B-128K-0.2.IQ3_XS.gguf) | IQ3_XS | 3.1 | |
| [GGUF](https://huggingface.co/mradermacher/KeplerRP-7B-128K-0.2-GGUF/resolve/main/KeplerRP-7B-128K-0.2.Q3_K_S.gguf) | Q3_K_S | 3.3 | |
| [GGUF](https://huggingface.co/mradermacher/KeplerRP-7B-128K-0.2-GGUF/resolve/main/KeplerRP-7B-128K-0.2.IQ3_S.gguf) | IQ3_S | 3.3 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/KeplerRP-7B-128K-0.2-GGUF/resolve/main/KeplerRP-7B-128K-0.2.IQ3_M.gguf) | IQ3_M | 3.4 | |
| [GGUF](https://huggingface.co/mradermacher/KeplerRP-7B-128K-0.2-GGUF/resolve/main/KeplerRP-7B-128K-0.2.Q3_K_M.gguf) | Q3_K_M | 3.6 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/KeplerRP-7B-128K-0.2-GGUF/resolve/main/KeplerRP-7B-128K-0.2.Q3_K_L.gguf) | Q3_K_L | 3.9 | |
| [GGUF](https://huggingface.co/mradermacher/KeplerRP-7B-128K-0.2-GGUF/resolve/main/KeplerRP-7B-128K-0.2.IQ4_XS.gguf) | IQ4_XS | 4.0 | |
| [GGUF](https://huggingface.co/mradermacher/KeplerRP-7B-128K-0.2-GGUF/resolve/main/KeplerRP-7B-128K-0.2.Q4_K_S.gguf) | Q4_K_S | 4.2 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/KeplerRP-7B-128K-0.2-GGUF/resolve/main/KeplerRP-7B-128K-0.2.Q4_K_M.gguf) | Q4_K_M | 4.5 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/KeplerRP-7B-128K-0.2-GGUF/resolve/main/KeplerRP-7B-128K-0.2.Q5_K_S.gguf) | Q5_K_S | 5.1 | |
| [GGUF](https://huggingface.co/mradermacher/KeplerRP-7B-128K-0.2-GGUF/resolve/main/KeplerRP-7B-128K-0.2.Q5_K_M.gguf) | Q5_K_M | 5.2 | |
| [GGUF](https://huggingface.co/mradermacher/KeplerRP-7B-128K-0.2-GGUF/resolve/main/KeplerRP-7B-128K-0.2.Q6_K.gguf) | Q6_K | 6.0 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/KeplerRP-7B-128K-0.2-GGUF/resolve/main/KeplerRP-7B-128K-0.2.Q8_0.gguf) | Q8_0 | 7.8 | fast, best quality |
| [GGUF](https://huggingface.co/mradermacher/KeplerRP-7B-128K-0.2-GGUF/resolve/main/KeplerRP-7B-128K-0.2.f16.gguf) | f16 | 14.6 | 16 bpw, overkill |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
eugenesiow/bart-paraphrase | eugenesiow | 2023-03-28T06:46:28Z | 16,871 | 25 | transformers | [
"transformers",
"pytorch",
"safetensors",
"bart",
"text2text-generation",
"paraphrase",
"seq2seq",
"en",
"dataset:quora",
"dataset:paws",
"arxiv:1910.13461",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| text2text-generation | 2022-03-02T23:29:05Z | ---
language: en
license: apache-2.0
tags:
- transformers
- bart
- paraphrase
- seq2seq
datasets:
- quora
- paws
---
# BART Paraphrase Model (Large)
A large BART seq2seq (text2text generation) model fine-tuned on 3 paraphrase datasets.
## Model description
The BART model was proposed in [BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension](https://arxiv.org/abs/1910.13461) by Lewis et al. (2019).
- Bart uses a standard seq2seq/machine translation architecture with a bidirectional encoder (like BERT) and a left-to-right decoder (like GPT).
- The pretraining task involves randomly shuffling the order of the original sentences and a novel in-filling scheme, where spans of text are replaced with a single mask token.
- BART is particularly effective when fine tuned for text generation. This model is fine-tuned on 3 paraphrase datasets (Quora, PAWS and MSR paraphrase corpus).
The original BART code is from this [repository](https://github.com/pytorch/fairseq/tree/master/examples/bart).
## Intended uses & limitations
You can use the pre-trained model for paraphrasing an input sentence.
### How to use
```python
import torch
from transformers import BartForConditionalGeneration, BartTokenizer
input_sentence = "They were there to enjoy us and they were there to pray for us."
model = BartForConditionalGeneration.from_pretrained('eugenesiow/bart-paraphrase')
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = model.to(device)
tokenizer = BartTokenizer.from_pretrained('eugenesiow/bart-paraphrase')
batch = tokenizer(input_sentence, return_tensors='pt')
generated_ids = model.generate(batch['input_ids'])
generated_sentence = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)
print(generated_sentence)
```
### Output
```
['They were there to enjoy us and to pray for us.']
```
## Training data
The model was fine-tuned on a pretrained [`facebook/bart-large`](https://huggingface.co/facebook/bart-large), using the [Quora](https://huggingface.co/datasets/quora), [PAWS](https://huggingface.co/datasets/paws) and [MSR paraphrase corpus](https://www.microsoft.com/en-us/download/details.aspx?id=52398).
## Training procedure
We follow the training procedure provided in the [simpletransformers](https://github.com/ThilinaRajapakse/simpletransformers) seq2seq [example](https://github.com/ThilinaRajapakse/simpletransformers/blob/master/examples/seq2seq/paraphrasing/train.py).
## BibTeX entry and citation info
```bibtex
@misc{lewis2019bart,
title={BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension},
author={Mike Lewis and Yinhan Liu and Naman Goyal and Marjan Ghazvininejad and Abdelrahman Mohamed and Omer Levy and Ves Stoyanov and Luke Zettlemoyer},
year={2019},
eprint={1910.13461},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
``` |
mradermacher/LLaMA3-iterative-DPO-final-i1-GGUF | mradermacher | 2024-06-28T00:38:25Z | 16,858 | 1 | transformers | [
"transformers",
"gguf",
"en",
"base_model:RLHFlow/LLaMA3-iterative-DPO-final",
"license:llama3",
"endpoints_compatible",
"region:us"
]
| null | 2024-06-27T22:21:59Z | ---
base_model: RLHFlow/LLaMA3-iterative-DPO-final
language:
- en
library_name: transformers
license: llama3
quantized_by: mradermacher
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: nicoboss -->
weighted/imatrix quants of https://huggingface.co/RLHFlow/LLaMA3-iterative-DPO-final
<!-- provided-files -->
static quants are available at https://huggingface.co/mradermacher/LLaMA3-iterative-DPO-final-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/LLaMA3-iterative-DPO-final-i1-GGUF/resolve/main/LLaMA3-iterative-DPO-final.i1-IQ1_S.gguf) | i1-IQ1_S | 2.1 | for the desperate |
| [GGUF](https://huggingface.co/mradermacher/LLaMA3-iterative-DPO-final-i1-GGUF/resolve/main/LLaMA3-iterative-DPO-final.i1-IQ1_M.gguf) | i1-IQ1_M | 2.3 | mostly desperate |
| [GGUF](https://huggingface.co/mradermacher/LLaMA3-iterative-DPO-final-i1-GGUF/resolve/main/LLaMA3-iterative-DPO-final.i1-IQ2_XXS.gguf) | i1-IQ2_XXS | 2.5 | |
| [GGUF](https://huggingface.co/mradermacher/LLaMA3-iterative-DPO-final-i1-GGUF/resolve/main/LLaMA3-iterative-DPO-final.i1-IQ2_XS.gguf) | i1-IQ2_XS | 2.7 | |
| [GGUF](https://huggingface.co/mradermacher/LLaMA3-iterative-DPO-final-i1-GGUF/resolve/main/LLaMA3-iterative-DPO-final.i1-IQ2_S.gguf) | i1-IQ2_S | 2.9 | |
| [GGUF](https://huggingface.co/mradermacher/LLaMA3-iterative-DPO-final-i1-GGUF/resolve/main/LLaMA3-iterative-DPO-final.i1-IQ2_M.gguf) | i1-IQ2_M | 3.0 | |
| [GGUF](https://huggingface.co/mradermacher/LLaMA3-iterative-DPO-final-i1-GGUF/resolve/main/LLaMA3-iterative-DPO-final.i1-Q2_K.gguf) | i1-Q2_K | 3.3 | IQ3_XXS probably better |
| [GGUF](https://huggingface.co/mradermacher/LLaMA3-iterative-DPO-final-i1-GGUF/resolve/main/LLaMA3-iterative-DPO-final.i1-IQ3_XXS.gguf) | i1-IQ3_XXS | 3.4 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/LLaMA3-iterative-DPO-final-i1-GGUF/resolve/main/LLaMA3-iterative-DPO-final.i1-IQ3_XS.gguf) | i1-IQ3_XS | 3.6 | |
| [GGUF](https://huggingface.co/mradermacher/LLaMA3-iterative-DPO-final-i1-GGUF/resolve/main/LLaMA3-iterative-DPO-final.i1-Q3_K_S.gguf) | i1-Q3_K_S | 3.8 | IQ3_XS probably better |
| [GGUF](https://huggingface.co/mradermacher/LLaMA3-iterative-DPO-final-i1-GGUF/resolve/main/LLaMA3-iterative-DPO-final.i1-IQ3_S.gguf) | i1-IQ3_S | 3.8 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/LLaMA3-iterative-DPO-final-i1-GGUF/resolve/main/LLaMA3-iterative-DPO-final.i1-IQ3_M.gguf) | i1-IQ3_M | 3.9 | |
| [GGUF](https://huggingface.co/mradermacher/LLaMA3-iterative-DPO-final-i1-GGUF/resolve/main/LLaMA3-iterative-DPO-final.i1-Q3_K_M.gguf) | i1-Q3_K_M | 4.1 | IQ3_S probably better |
| [GGUF](https://huggingface.co/mradermacher/LLaMA3-iterative-DPO-final-i1-GGUF/resolve/main/LLaMA3-iterative-DPO-final.i1-Q3_K_L.gguf) | i1-Q3_K_L | 4.4 | IQ3_M probably better |
| [GGUF](https://huggingface.co/mradermacher/LLaMA3-iterative-DPO-final-i1-GGUF/resolve/main/LLaMA3-iterative-DPO-final.i1-IQ4_XS.gguf) | i1-IQ4_XS | 4.5 | |
| [GGUF](https://huggingface.co/mradermacher/LLaMA3-iterative-DPO-final-i1-GGUF/resolve/main/LLaMA3-iterative-DPO-final.i1-Q4_0.gguf) | i1-Q4_0 | 4.8 | fast, low quality |
| [GGUF](https://huggingface.co/mradermacher/LLaMA3-iterative-DPO-final-i1-GGUF/resolve/main/LLaMA3-iterative-DPO-final.i1-Q4_K_S.gguf) | i1-Q4_K_S | 4.8 | optimal size/speed/quality |
| [GGUF](https://huggingface.co/mradermacher/LLaMA3-iterative-DPO-final-i1-GGUF/resolve/main/LLaMA3-iterative-DPO-final.i1-Q4_K_M.gguf) | i1-Q4_K_M | 5.0 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/LLaMA3-iterative-DPO-final-i1-GGUF/resolve/main/LLaMA3-iterative-DPO-final.i1-Q5_K_S.gguf) | i1-Q5_K_S | 5.7 | |
| [GGUF](https://huggingface.co/mradermacher/LLaMA3-iterative-DPO-final-i1-GGUF/resolve/main/LLaMA3-iterative-DPO-final.i1-Q5_K_M.gguf) | i1-Q5_K_M | 5.8 | |
| [GGUF](https://huggingface.co/mradermacher/LLaMA3-iterative-DPO-final-i1-GGUF/resolve/main/LLaMA3-iterative-DPO-final.i1-Q6_K.gguf) | i1-Q6_K | 6.7 | practically like static Q6_K |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time. Additional thanks to [@nicoboss](https://huggingface.co/nicoboss) for giving me access to his hardware for calculating the imatrix for these quants.
<!-- end -->
|
DunnBC22/vit-base-patch16-224-in21k_car_or_motorcycle | DunnBC22 | 2023-07-24T18:34:41Z | 16,845 | 2 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"vit",
"image-classification",
"generated_from_trainer",
"en",
"dataset:imagefolder",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| image-classification | 2023-01-07T02:05:05Z | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- imagefolder
metrics:
- accuracy
- f1
- recall
- precision
model-index:
- name: vit-base-patch16-224-in21k_car_or_motorcycle
results:
- task:
name: Image Classification
type: image-classification
dataset:
name: imagefolder
type: imagefolder
config: default
split: train
args: default
metrics:
- name: Accuracy
type: accuracy
value: 0.99375
language:
- en
pipeline_tag: image-classification
---
# vit-base-patch16-224-in21k_car_or_motorcycle
This model is a fine-tuned version of [google/vit-base-patch16-224-in21k](https://huggingface.co/google/vit-base-patch16-224-in21k) on the imagefolder dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0301
- Accuracy: 0.9938
- F1: 0.9939
- Recall: 0.9927
- Precision: 0.9951
## Model description
This is a binary classification model to distinguish between images of cars and images of motorcycles.
For more information on how it was created, check out the following link: https://github.com/DunnBC22/Vision_Audio_and_Multimodal_Projects/blob/main/Computer%20Vision/Image%20Classification/Binary%20Classification/Car%20or%20Motorcycle/Car_or_Motorcycle_ViT.ipynb
## Intended uses & limitations
This model is intended to demonstrate my ability to solve a complex problem using technology.
## Training and evaluation data
Dataset Source: https://www.kaggle.com/datasets/utkarshsaxenadn/car-vs-bike-classification-dataset
_Sample Images From Dataset:_

## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 | Recall | Precision |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|:------:|:---------:|
| 0.6908 | 1.0 | 200 | 0.0372 | 0.99 | 0.9902 | 0.9902 | 0.9902 |
| 0.6908 | 2.0 | 400 | 0.0301 | 0.9938 | 0.9939 | 0.9927 | 0.9951 |
### Framework versions
- Transformers 4.22.2
- Pytorch 1.12.1
- Datasets 2.5.2
- Tokenizers 0.12.1 |
Liquid1/Liquid-MDG-1 | Liquid1 | 2024-07-02T20:59:32Z | 16,817 | 0 | transformers | [
"transformers",
"gguf",
"llama",
"text-generation-inference",
"unsloth",
"mistral",
"en",
"base_model:unsloth/Phi-3-medium-4k-instruct-bnb-4bit",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
]
| null | 2024-07-01T21:25:47Z | ---
base_model: unsloth/Phi-3-medium-4k-instruct-bnb-4bit
language:
- en
license: apache-2.0
tags:
- text-generation-inference
- transformers
- unsloth
- mistral
- gguf
---
# Uploaded model
- **Developed by:** Liquid1
- **License:** apache-2.0
- **Finetuned from model :** unsloth/Phi-3-medium-4k-instruct-bnb-4bit
This mistral model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
TheBloke/phi-2-GGUF | TheBloke | 2023-12-18T20:25:44Z | 16,811 | 187 | transformers | [
"transformers",
"gguf",
"phi-msft",
"nlp",
"code",
"text-generation",
"en",
"base_model:microsoft/phi-2",
"license:other",
"region:us"
]
| text-generation | 2023-12-18T20:22:56Z | ---
base_model: microsoft/phi-2
inference: false
language:
- en
license: other
license_link: https://huggingface.co/microsoft/phi-2/resolve/main/LICENSE
license_name: microsoft-research-license
model_creator: Microsoft
model_name: Phi 2
model_type: phi-msft
pipeline_tag: text-generation
prompt_template: 'Instruct: {prompt}
Output:
'
quantized_by: TheBloke
tags:
- nlp
- code
---
<!-- markdownlint-disable MD041 -->
<!-- header start -->
<!-- 200823 -->
<div style="width: auto; margin-left: auto; margin-right: auto">
<img src="https://i.imgur.com/EBdldam.jpg" alt="TheBlokeAI" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</div>
<div style="display: flex; justify-content: space-between; width: 100%;">
<div style="display: flex; flex-direction: column; align-items: flex-start;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://discord.gg/theblokeai">Chat & support: TheBloke's Discord server</a></p>
</div>
<div style="display: flex; flex-direction: column; align-items: flex-end;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://www.patreon.com/TheBlokeAI">Want to contribute? TheBloke's Patreon page</a></p>
</div>
</div>
<div style="text-align:center; margin-top: 0em; margin-bottom: 0em"><p style="margin-top: 0.25em; margin-bottom: 0em;">TheBloke's LLM work is generously supported by a grant from <a href="https://a16z.com">andreessen horowitz (a16z)</a></p></div>
<hr style="margin-top: 1.0em; margin-bottom: 1.0em;">
<!-- header end -->
# Phi 2 - GGUF
- Model creator: [Microsoft](https://huggingface.co/microsoft)
- Original model: [Phi 2](https://huggingface.co/microsoft/phi-2)
<!-- description start -->
## Description
This repo contains GGUF format model files for [Microsoft's Phi 2](https://huggingface.co/microsoft/phi-2).
<!-- description end -->
<!-- README_GGUF.md-about-gguf start -->
### About GGUF
GGUF is a new format introduced by the llama.cpp team on August 21st 2023. It is a replacement for GGML, which is no longer supported by llama.cpp.
Here is an incomplete list of clients and libraries that are known to support GGUF:
* [llama.cpp](https://github.com/ggerganov/llama.cpp). The source project for GGUF. Offers a CLI and a server option.
* [text-generation-webui](https://github.com/oobabooga/text-generation-webui), the most widely used web UI, with many features and powerful extensions. Supports GPU acceleration.
* [KoboldCpp](https://github.com/LostRuins/koboldcpp), a fully featured web UI, with GPU accel across all platforms and GPU architectures. Especially good for story telling.
* [GPT4All](https://gpt4all.io/index.html), a free and open source local running GUI, supporting Windows, Linux and macOS with full GPU accel.
* [LM Studio](https://lmstudio.ai/), an easy-to-use and powerful local GUI for Windows and macOS (Silicon), with GPU acceleration. Linux available, in beta as of 27/11/2023.
* [LoLLMS Web UI](https://github.com/ParisNeo/lollms-webui), a great web UI with many interesting and unique features, including a full model library for easy model selection.
* [Faraday.dev](https://faraday.dev/), an attractive and easy to use character-based chat GUI for Windows and macOS (both Silicon and Intel), with GPU acceleration.
* [llama-cpp-python](https://github.com/abetlen/llama-cpp-python), a Python library with GPU accel, LangChain support, and OpenAI-compatible API server.
* [candle](https://github.com/huggingface/candle), a Rust ML framework with a focus on performance, including GPU support, and ease of use.
* [ctransformers](https://github.com/marella/ctransformers), a Python library with GPU accel, LangChain support, and OpenAI-compatible AI server. Note, as of time of writing (November 27th 2023), ctransformers has not been updated in a long time and does not support many recent models.
<!-- README_GGUF.md-about-gguf end -->
<!-- repositories-available start -->
## Repositories available
* [GPTQ models for GPU inference, with multiple quantisation parameter options.](https://huggingface.co/TheBloke/phi-2-GPTQ)
* [2, 3, 4, 5, 6 and 8-bit GGUF models for CPU+GPU inference](https://huggingface.co/TheBloke/phi-2-GGUF)
* [Microsoft's original unquantised fp16 model in pytorch format, for GPU inference and for further conversions](https://huggingface.co/microsoft/phi-2)
<!-- repositories-available end -->
<!-- prompt-template start -->
## Prompt template: Phi
```
Instruct: {prompt}
Output:
```
<!-- prompt-template end -->
<!-- compatibility_gguf start -->
## Compatibility
These quantised GGUFv2 files are compatible with llama.cpp from August 27th onwards, as of commit [d0cee0d](https://github.com/ggerganov/llama.cpp/commit/d0cee0d36d5be95a0d9088b674dbb27354107221)
They are also compatible with many third party UIs and libraries - please see the list at the top of this README.
## Explanation of quantisation methods
<details>
<summary>Click to see details</summary>
The new methods available are:
* GGML_TYPE_Q2_K - "type-1" 2-bit quantization in super-blocks containing 16 blocks, each block having 16 weight. Block scales and mins are quantized with 4 bits. This ends up effectively using 2.5625 bits per weight (bpw)
* GGML_TYPE_Q3_K - "type-0" 3-bit quantization in super-blocks containing 16 blocks, each block having 16 weights. Scales are quantized with 6 bits. This end up using 3.4375 bpw.
* GGML_TYPE_Q4_K - "type-1" 4-bit quantization in super-blocks containing 8 blocks, each block having 32 weights. Scales and mins are quantized with 6 bits. This ends up using 4.5 bpw.
* GGML_TYPE_Q5_K - "type-1" 5-bit quantization. Same super-block structure as GGML_TYPE_Q4_K resulting in 5.5 bpw
* GGML_TYPE_Q6_K - "type-0" 6-bit quantization. Super-blocks with 16 blocks, each block having 16 weights. Scales are quantized with 8 bits. This ends up using 6.5625 bpw
Refer to the Provided Files table below to see what files use which methods, and how.
</details>
<!-- compatibility_gguf end -->
<!-- README_GGUF.md-provided-files start -->
## Provided files
| Name | Quant method | Bits | Size | Max RAM required | Use case |
| ---- | ---- | ---- | ---- | ---- | ----- |
| [phi-2.Q2_K.gguf](https://huggingface.co/TheBloke/phi-2-GGUF/blob/main/phi-2.Q2_K.gguf) | Q2_K | 2 | 1.17 GB| 3.67 GB | smallest, significant quality loss - not recommended for most purposes |
| [phi-2.Q3_K_S.gguf](https://huggingface.co/TheBloke/phi-2-GGUF/blob/main/phi-2.Q3_K_S.gguf) | Q3_K_S | 3 | 1.25 GB| 3.75 GB | very small, high quality loss |
| [phi-2.Q3_K_M.gguf](https://huggingface.co/TheBloke/phi-2-GGUF/blob/main/phi-2.Q3_K_M.gguf) | Q3_K_M | 3 | 1.48 GB| 3.98 GB | very small, high quality loss |
| [phi-2.Q4_0.gguf](https://huggingface.co/TheBloke/phi-2-GGUF/blob/main/phi-2.Q4_0.gguf) | Q4_0 | 4 | 1.60 GB| 4.10 GB | legacy; small, very high quality loss - prefer using Q3_K_M |
| [phi-2.Q3_K_L.gguf](https://huggingface.co/TheBloke/phi-2-GGUF/blob/main/phi-2.Q3_K_L.gguf) | Q3_K_L | 3 | 1.60 GB| 4.10 GB | small, substantial quality loss |
| [phi-2.Q4_K_S.gguf](https://huggingface.co/TheBloke/phi-2-GGUF/blob/main/phi-2.Q4_K_S.gguf) | Q4_K_S | 4 | 1.62 GB| 4.12 GB | small, greater quality loss |
| [phi-2.Q4_K_M.gguf](https://huggingface.co/TheBloke/phi-2-GGUF/blob/main/phi-2.Q4_K_M.gguf) | Q4_K_M | 4 | 1.79 GB| 4.29 GB | medium, balanced quality - recommended |
| [phi-2.Q5_0.gguf](https://huggingface.co/TheBloke/phi-2-GGUF/blob/main/phi-2.Q5_0.gguf) | Q5_0 | 5 | 1.93 GB| 4.43 GB | legacy; medium, balanced quality - prefer using Q4_K_M |
| [phi-2.Q5_K_S.gguf](https://huggingface.co/TheBloke/phi-2-GGUF/blob/main/phi-2.Q5_K_S.gguf) | Q5_K_S | 5 | 1.93 GB| 4.43 GB | large, low quality loss - recommended |
| [phi-2.Q5_K_M.gguf](https://huggingface.co/TheBloke/phi-2-GGUF/blob/main/phi-2.Q5_K_M.gguf) | Q5_K_M | 5 | 2.07 GB| 4.57 GB | large, very low quality loss - recommended |
| [phi-2.Q6_K.gguf](https://huggingface.co/TheBloke/phi-2-GGUF/blob/main/phi-2.Q6_K.gguf) | Q6_K | 6 | 2.29 GB| 4.79 GB | very large, extremely low quality loss |
| [phi-2.Q8_0.gguf](https://huggingface.co/TheBloke/phi-2-GGUF/blob/main/phi-2.Q8_0.gguf) | Q8_0 | 8 | 2.96 GB| 5.46 GB | very large, extremely low quality loss - not recommended |
**Note**: the above RAM figures assume no GPU offloading. If layers are offloaded to the GPU, this will reduce RAM usage and use VRAM instead.
<!-- README_GGUF.md-provided-files end -->
<!-- README_GGUF.md-how-to-download start -->
## How to download GGUF files
**Note for manual downloaders:** You almost never want to clone the entire repo! Multiple different quantisation formats are provided, and most users only want to pick and download a single file.
The following clients/libraries will automatically download models for you, providing a list of available models to choose from:
* LM Studio
* LoLLMS Web UI
* Faraday.dev
### In `text-generation-webui`
Under Download Model, you can enter the model repo: TheBloke/phi-2-GGUF and below it, a specific filename to download, such as: phi-2.Q4_K_M.gguf.
Then click Download.
### On the command line, including multiple files at once
I recommend using the `huggingface-hub` Python library:
```shell
pip3 install huggingface-hub
```
Then you can download any individual model file to the current directory, at high speed, with a command like this:
```shell
huggingface-cli download TheBloke/phi-2-GGUF phi-2.Q4_K_M.gguf --local-dir . --local-dir-use-symlinks False
```
<details>
<summary>More advanced huggingface-cli download usage (click to read)</summary>
You can also download multiple files at once with a pattern:
```shell
huggingface-cli download TheBloke/phi-2-GGUF --local-dir . --local-dir-use-symlinks False --include='*Q4_K*gguf'
```
For more documentation on downloading with `huggingface-cli`, please see: [HF -> Hub Python Library -> Download files -> Download from the CLI](https://huggingface.co/docs/huggingface_hub/guides/download#download-from-the-cli).
To accelerate downloads on fast connections (1Gbit/s or higher), install `hf_transfer`:
```shell
pip3 install hf_transfer
```
And set environment variable `HF_HUB_ENABLE_HF_TRANSFER` to `1`:
```shell
HF_HUB_ENABLE_HF_TRANSFER=1 huggingface-cli download TheBloke/phi-2-GGUF phi-2.Q4_K_M.gguf --local-dir . --local-dir-use-symlinks False
```
Windows Command Line users: You can set the environment variable by running `set HF_HUB_ENABLE_HF_TRANSFER=1` before the download command.
</details>
<!-- README_GGUF.md-how-to-download end -->
<!-- README_GGUF.md-how-to-run start -->
## Example `llama.cpp` command
Make sure you are using `llama.cpp` from commit [d0cee0d](https://github.com/ggerganov/llama.cpp/commit/d0cee0d36d5be95a0d9088b674dbb27354107221) or later.
```shell
./main -ngl 35 -m phi-2.Q4_K_M.gguf --color -c 2048 --temp 0.7 --repeat_penalty 1.1 -n -1 -p "Instruct: {prompt}\nOutput:"
```
Change `-ngl 32` to the number of layers to offload to GPU. Remove it if you don't have GPU acceleration.
Change `-c 2048` to the desired sequence length. For extended sequence models - eg 8K, 16K, 32K - the necessary RoPE scaling parameters are read from the GGUF file and set by llama.cpp automatically. Note that longer sequence lengths require much more resources, so you may need to reduce this value.
If you want to have a chat-style conversation, replace the `-p <PROMPT>` argument with `-i -ins`
For other parameters and how to use them, please refer to [the llama.cpp documentation](https://github.com/ggerganov/llama.cpp/blob/master/examples/main/README.md)
## How to run in `text-generation-webui`
Further instructions can be found in the text-generation-webui documentation, here: [text-generation-webui/docs/04 ‐ Model Tab.md](https://github.com/oobabooga/text-generation-webui/blob/main/docs/04%20%E2%80%90%20Model%20Tab.md#llamacpp).
## How to run from Python code
You can use GGUF models from Python using the [llama-cpp-python](https://github.com/abetlen/llama-cpp-python) or [ctransformers](https://github.com/marella/ctransformers) libraries. Note that at the time of writing (Nov 27th 2023), ctransformers has not been updated for some time and is not compatible with some recent models. Therefore I recommend you use llama-cpp-python.
### How to load this model in Python code, using llama-cpp-python
For full documentation, please see: [llama-cpp-python docs](https://abetlen.github.io/llama-cpp-python/).
#### First install the package
Run one of the following commands, according to your system:
```shell
# Base ctransformers with no GPU acceleration
pip install llama-cpp-python
# With NVidia CUDA acceleration
CMAKE_ARGS="-DLLAMA_CUBLAS=on" pip install llama-cpp-python
# Or with OpenBLAS acceleration
CMAKE_ARGS="-DLLAMA_BLAS=ON -DLLAMA_BLAS_VENDOR=OpenBLAS" pip install llama-cpp-python
# Or with CLBLast acceleration
CMAKE_ARGS="-DLLAMA_CLBLAST=on" pip install llama-cpp-python
# Or with AMD ROCm GPU acceleration (Linux only)
CMAKE_ARGS="-DLLAMA_HIPBLAS=on" pip install llama-cpp-python
# Or with Metal GPU acceleration for macOS systems only
CMAKE_ARGS="-DLLAMA_METAL=on" pip install llama-cpp-python
# In windows, to set the variables CMAKE_ARGS in PowerShell, follow this format; eg for NVidia CUDA:
$env:CMAKE_ARGS = "-DLLAMA_OPENBLAS=on"
pip install llama-cpp-python
```
#### Simple llama-cpp-python example code
```python
from llama_cpp import Llama
# Set gpu_layers to the number of layers to offload to GPU. Set to 0 if no GPU acceleration is available on your system.
llm = Llama(
model_path="./phi-2.Q4_K_M.gguf", # Download the model file first
n_ctx=2048, # The max sequence length to use - note that longer sequence lengths require much more resources
n_threads=8, # The number of CPU threads to use, tailor to your system and the resulting performance
n_gpu_layers=35 # The number of layers to offload to GPU, if you have GPU acceleration available
)
# Simple inference example
output = llm(
"Instruct: {prompt}\nOutput:", # Prompt
max_tokens=512, # Generate up to 512 tokens
stop=["</s>"], # Example stop token - not necessarily correct for this specific model! Please check before using.
echo=True # Whether to echo the prompt
)
# Chat Completion API
llm = Llama(model_path="./phi-2.Q4_K_M.gguf", chat_format="llama-2") # Set chat_format according to the model you are using
llm.create_chat_completion(
messages = [
{"role": "system", "content": "You are a story writing assistant."},
{
"role": "user",
"content": "Write a story about llamas."
}
]
)
```
## How to use with LangChain
Here are guides on using llama-cpp-python and ctransformers with LangChain:
* [LangChain + llama-cpp-python](https://python.langchain.com/docs/integrations/llms/llamacpp)
* [LangChain + ctransformers](https://python.langchain.com/docs/integrations/providers/ctransformers)
<!-- README_GGUF.md-how-to-run end -->
<!-- footer start -->
<!-- 200823 -->
## Discord
For further support, and discussions on these models and AI in general, join us at:
[TheBloke AI's Discord server](https://discord.gg/theblokeai)
## Thanks, and how to contribute
Thanks to the [chirper.ai](https://chirper.ai) team!
Thanks to Clay from [gpus.llm-utils.org](llm-utils)!
I've had a lot of people ask if they can contribute. I enjoy providing models and helping people, and would love to be able to spend even more time doing it, as well as expanding into new projects like fine tuning/training.
If you're able and willing to contribute it will be most gratefully received and will help me to keep providing more models, and to start work on new AI projects.
Donaters will get priority support on any and all AI/LLM/model questions and requests, access to a private Discord room, plus other benefits.
* Patreon: https://patreon.com/TheBlokeAI
* Ko-Fi: https://ko-fi.com/TheBlokeAI
**Special thanks to**: Aemon Algiz.
**Patreon special mentions**: Michael Levine, 阿明, Trailburnt, Nikolai Manek, John Detwiler, Randy H, Will Dee, Sebastain Graf, NimbleBox.ai, Eugene Pentland, Emad Mostaque, Ai Maven, Jim Angel, Jeff Scroggin, Michael Davis, Manuel Alberto Morcote, Stephen Murray, Robert, Justin Joy, Luke @flexchar, Brandon Frisco, Elijah Stavena, S_X, Dan Guido, Undi ., Komninos Chatzipapas, Shadi, theTransient, Lone Striker, Raven Klaugh, jjj, Cap'n Zoog, Michel-Marie MAUDET (LINAGORA), Matthew Berman, David, Fen Risland, Omer Bin Jawed, Luke Pendergrass, Kalila, OG, Erik Bjäreholt, Rooh Singh, Joseph William Delisle, Dan Lewis, TL, John Villwock, AzureBlack, Brad, Pedro Madruga, Caitlyn Gatomon, K, jinyuan sun, Mano Prime, Alex, Jeffrey Morgan, Alicia Loh, Illia Dulskyi, Chadd, transmissions 11, fincy, Rainer Wilmers, ReadyPlayerEmma, knownsqashed, Mandus, biorpg, Deo Leter, Brandon Phillips, SuperWojo, Sean Connelly, Iucharbius, Jack West, Harry Royden McLaughlin, Nicholas, terasurfer, Vitor Caleffi, Duane Dunston, Johann-Peter Hartmann, David Ziegler, Olakabola, Ken Nordquist, Trenton Dambrowitz, Tom X Nguyen, Vadim, Ajan Kanaga, Leonard Tan, Clay Pascal, Alexandros Triantafyllidis, JM33133, Xule, vamX, ya boyyy, subjectnull, Talal Aujan, Alps Aficionado, wassieverse, Ari Malik, James Bentley, Woland, Spencer Kim, Michael Dempsey, Fred von Graf, Elle, zynix, William Richards, Stanislav Ovsiannikov, Edmond Seymore, Jonathan Leane, Martin Kemka, usrbinkat, Enrico Ros
Thank you to all my generous patrons and donaters!
And thank you again to a16z for their generous grant.
<!-- footer end -->
<!-- original-model-card start -->
# Original model card: Microsoft's Phi 2
## Model Summary
Phi-2 is a Transformer with **2.7 billion** parameters. It was trained using the same data sources as [Phi-1.5](https://huggingface.co/microsoft/phi-1.5), augmented with a new data source that consists of various NLP synthetic texts and filtered websites (for safety and educational value). When assessed against benchmarks testing common sense, language understanding, and logical reasoning, Phi-2 showcased a nearly state-of-the-art performance among models with less than 13 billion parameters.
Our model hasn't been fine-tuned through reinforcement learning from human feedback. The intention behind crafting this open-source model is to provide the research community with a non-restricted small model to explore vital safety challenges, such as reducing toxicity, understanding societal biases, enhancing controllability, and more.
## Intended Uses
Phi-2 is intended for research purposes only. Given the nature of the training data, the Phi-2 model is best suited for prompts using the QA format, the chat format, and the code format.
### QA Format:
You can provide the prompt as a standalone question as follows:
```markdown
Write a detailed analogy between mathematics and a lighthouse.
```
where the model generates the text after "." .
To encourage the model to write more concise answers, you can also try the following QA format using "Instruct: \<prompt\>\nOutput:"
```markdown
Instruct: Write a detailed analogy between mathematics and a lighthouse.
Output: Mathematics is like a lighthouse. Just as a lighthouse guides ships safely to shore, mathematics provides a guiding light in the world of numbers and logic. It helps us navigate through complex problems and find solutions. Just as a lighthouse emits a steady beam of light, mathematics provides a consistent framework for reasoning and problem-solving. It illuminates the path to understanding and helps us make sense of the world around us.
```
where the model generates the text after "Output:".
### Chat Format:
```markdown
Alice: I don't know why, I'm struggling to maintain focus while studying. Any suggestions?
Bob: Well, have you tried creating a study schedule and sticking to it?
Alice: Yes, I have, but it doesn't seem to help much.
Bob: Hmm, maybe you should try studying in a quiet environment, like the library.
Alice: ...
```
where the model generates the text after the first "Bob:".
### Code Format:
```python
def print_prime(n):
"""
Print all primes between 1 and n
"""
primes = []
for num in range(2, n+1):
is_prime = True
for i in range(2, int(math.sqrt(num))+1):
if num % i == 0:
is_prime = False
break
if is_prime:
primes.append(num)
print(primes)
```
where the model generates the text after the comments.
**Notes:**
* Phi-2 is intended for research purposes. The model-generated text/code should be treated as a starting point rather than a definitive solution for potential use cases. Users should be cautious when employing these models in their applications.
* Direct adoption for production tasks is out of the scope of this research project. As a result, the Phi-2 model has not been tested to ensure that it performs adequately for any production-level application. Please refer to the limitation sections of this document for more details.
* If you are using `transformers>=4.36.0`, always load the model with `trust_remote_code=True` to prevent side-effects.
## Sample Code
There are four types of execution mode:
1. FP16 / Flash-Attention / CUDA:
```python
model = AutoModelForCausalLM.from_pretrained("microsoft/phi-2", torch_dtype="auto", flash_attn=True, flash_rotary=True, fused_dense=True, device_map="cuda", trust_remote_code=True)
```
2. FP16 / CUDA:
```python
model = AutoModelForCausalLM.from_pretrained("microsoft/phi-2", torch_dtype="auto", device_map="cuda", trust_remote_code=True)
```
3. FP32 / CUDA:
```python
model = AutoModelForCausalLM.from_pretrained("microsoft/phi-2", torch_dtype=torch.float32, device_map="cuda", trust_remote_code=True)
```
4. FP32 / CPU:
```python
model = AutoModelForCausalLM.from_pretrained("microsoft/phi-2", torch_dtype=torch.float32, device_map="cpu", trust_remote_code=True)
```
To ensure the maximum compatibility, we recommend using the second execution mode (FP16 / CUDA), as follows:
```python
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
torch.set_default_device("cuda")
model = AutoModelForCausalLM.from_pretrained("microsoft/phi-2", torch_dtype="auto", trust_remote_code=True)
tokenizer = AutoTokenizer.from_pretrained("microsoft/phi-2", trust_remote_code=True)
inputs = tokenizer('''def print_prime(n):
"""
Print all primes between 1 and n
"""''', return_tensors="pt", return_attention_mask=False)
outputs = model.generate(**inputs, max_length=200)
text = tokenizer.batch_decode(outputs)[0]
print(text)
```
**Remark:** In the generation function, our model currently does not support beam search (`num_beams > 1`).
Furthermore, in the forward pass of the model, we currently do not support outputting hidden states or attention values, or using custom input embeddings.
## Limitations of Phi-2
* Generate Inaccurate Code and Facts: The model may produce incorrect code snippets and statements. Users should treat these outputs as suggestions or starting points, not as definitive or accurate solutions.
* Limited Scope for code: Majority of Phi-2 training data is based in Python and use common packages such as "typing, math, random, collections, datetime, itertools". If the model generates Python scripts that utilize other packages or scripts in other languages, we strongly recommend users manually verify all API uses.
* Unreliable Responses to Instruction: The model has not undergone instruction fine-tuning. As a result, it may struggle or fail to adhere to intricate or nuanced instructions provided by users.
* Language Limitations: The model is primarily designed to understand standard English. Informal English, slang, or any other languages might pose challenges to its comprehension, leading to potential misinterpretations or errors in response.
* Potential Societal Biases: Phi-2 is not entirely free from societal biases despite efforts in assuring trainig data safety. There's a possibility it may generate content that mirrors these societal biases, particularly if prompted or instructed to do so. We urge users to be aware of this and to exercise caution and critical thinking when interpreting model outputs.
* Toxicity: Despite being trained with carefully selected data, the model can still produce harmful content if explicitly prompted or instructed to do so. We chose to release the model for research purposes only -- We hope to help the open-source community develop the most effective ways to reduce the toxicity of a model directly after pretraining.
* Verbosity: Phi-2 being a base model often produces irrelevant or extra text and responses following its first answer to user prompts within a single turn. This is due to its training dataset being primarily textbooks, which results in textbook-like responses.
## Training
### Model
* Architecture: a Transformer-based model with next-word prediction objective
* Context length: 2048 tokens
* Dataset size: 250B tokens, combination of NLP synthetic data created by AOAI GPT-3.5 and filtered web data from Falcon RefinedWeb and SlimPajama, which was assessed by AOAI GPT-4.
* Training tokens: 1.4T tokens
* GPUs: 96xA100-80G
* Training time: 14 days
### Software
* [PyTorch](https://github.com/pytorch/pytorch)
* [DeepSpeed](https://github.com/microsoft/DeepSpeed)
* [Flash-Attention](https://github.com/HazyResearch/flash-attention)
### License
The model is licensed under the [microsoft-research-license](https://huggingface.co/microsoft/phi-2/resolve/main/LICENSE).
## Trademarks
This project may contain trademarks or logos for projects, products, or services. Authorized use of Microsoft trademarks or logos is subject to and must follow [Microsoft’s Trademark & Brand Guidelines](https://www.microsoft.com/en-us/legal/intellectualproperty/trademarks). Use of Microsoft trademarks or logos in modified versions of this project must not cause confusion or imply Microsoft sponsorship. Any use of third-party trademarks or logos are subject to those third-party’s policies.
<!-- original-model-card end -->
|
mradermacher/Llama-3-Nerdy-RP-8B-i1-GGUF | mradermacher | 2024-06-29T07:07:30Z | 16,795 | 0 | transformers | [
"transformers",
"gguf",
"mergekit",
"merge",
"en",
"base_model:Azazelle/Llama-3-Nerdy-RP-8B",
"endpoints_compatible",
"region:us"
]
| null | 2024-06-29T04:53:00Z | ---
base_model: Azazelle/Llama-3-Nerdy-RP-8B
language:
- en
library_name: transformers
quantized_by: mradermacher
tags:
- mergekit
- merge
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: nicoboss -->
weighted/imatrix quants of https://huggingface.co/Azazelle/Llama-3-Nerdy-RP-8B
<!-- provided-files -->
static quants are available at https://huggingface.co/mradermacher/Llama-3-Nerdy-RP-8B-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/Llama-3-Nerdy-RP-8B-i1-GGUF/resolve/main/Llama-3-Nerdy-RP-8B.i1-IQ1_S.gguf) | i1-IQ1_S | 2.1 | for the desperate |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-Nerdy-RP-8B-i1-GGUF/resolve/main/Llama-3-Nerdy-RP-8B.i1-IQ1_M.gguf) | i1-IQ1_M | 2.3 | mostly desperate |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-Nerdy-RP-8B-i1-GGUF/resolve/main/Llama-3-Nerdy-RP-8B.i1-IQ2_XXS.gguf) | i1-IQ2_XXS | 2.5 | |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-Nerdy-RP-8B-i1-GGUF/resolve/main/Llama-3-Nerdy-RP-8B.i1-IQ2_XS.gguf) | i1-IQ2_XS | 2.7 | |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-Nerdy-RP-8B-i1-GGUF/resolve/main/Llama-3-Nerdy-RP-8B.i1-IQ2_S.gguf) | i1-IQ2_S | 2.9 | |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-Nerdy-RP-8B-i1-GGUF/resolve/main/Llama-3-Nerdy-RP-8B.i1-IQ2_M.gguf) | i1-IQ2_M | 3.0 | |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-Nerdy-RP-8B-i1-GGUF/resolve/main/Llama-3-Nerdy-RP-8B.i1-Q2_K.gguf) | i1-Q2_K | 3.3 | IQ3_XXS probably better |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-Nerdy-RP-8B-i1-GGUF/resolve/main/Llama-3-Nerdy-RP-8B.i1-IQ3_XXS.gguf) | i1-IQ3_XXS | 3.4 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-Nerdy-RP-8B-i1-GGUF/resolve/main/Llama-3-Nerdy-RP-8B.i1-IQ3_XS.gguf) | i1-IQ3_XS | 3.6 | |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-Nerdy-RP-8B-i1-GGUF/resolve/main/Llama-3-Nerdy-RP-8B.i1-Q3_K_S.gguf) | i1-Q3_K_S | 3.8 | IQ3_XS probably better |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-Nerdy-RP-8B-i1-GGUF/resolve/main/Llama-3-Nerdy-RP-8B.i1-IQ3_S.gguf) | i1-IQ3_S | 3.8 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-Nerdy-RP-8B-i1-GGUF/resolve/main/Llama-3-Nerdy-RP-8B.i1-IQ3_M.gguf) | i1-IQ3_M | 3.9 | |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-Nerdy-RP-8B-i1-GGUF/resolve/main/Llama-3-Nerdy-RP-8B.i1-Q3_K_M.gguf) | i1-Q3_K_M | 4.1 | IQ3_S probably better |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-Nerdy-RP-8B-i1-GGUF/resolve/main/Llama-3-Nerdy-RP-8B.i1-Q3_K_L.gguf) | i1-Q3_K_L | 4.4 | IQ3_M probably better |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-Nerdy-RP-8B-i1-GGUF/resolve/main/Llama-3-Nerdy-RP-8B.i1-IQ4_XS.gguf) | i1-IQ4_XS | 4.5 | |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-Nerdy-RP-8B-i1-GGUF/resolve/main/Llama-3-Nerdy-RP-8B.i1-Q4_0.gguf) | i1-Q4_0 | 4.8 | fast, low quality |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-Nerdy-RP-8B-i1-GGUF/resolve/main/Llama-3-Nerdy-RP-8B.i1-Q4_K_S.gguf) | i1-Q4_K_S | 4.8 | optimal size/speed/quality |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-Nerdy-RP-8B-i1-GGUF/resolve/main/Llama-3-Nerdy-RP-8B.i1-Q4_K_M.gguf) | i1-Q4_K_M | 5.0 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-Nerdy-RP-8B-i1-GGUF/resolve/main/Llama-3-Nerdy-RP-8B.i1-Q5_K_S.gguf) | i1-Q5_K_S | 5.7 | |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-Nerdy-RP-8B-i1-GGUF/resolve/main/Llama-3-Nerdy-RP-8B.i1-Q5_K_M.gguf) | i1-Q5_K_M | 5.8 | |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-Nerdy-RP-8B-i1-GGUF/resolve/main/Llama-3-Nerdy-RP-8B.i1-Q6_K.gguf) | i1-Q6_K | 6.7 | practically like static Q6_K |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time. Additional thanks to [@nicoboss](https://huggingface.co/nicoboss) for giving me access to his hardware for calculating the imatrix for these quants.
<!-- end -->
|
Yntec/MostClassical | Yntec | 2024-06-17T13:07:57Z | 16,791 | 2 | diffusers | [
"diffusers",
"safetensors",
"Classic Anime",
"90s",
"Retro",
"Cartoons",
"DucHaiten",
"Patchmonk",
"Clumsy_Trainer",
"OneRing",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
]
| text-to-image | 2024-06-17T03:37:58Z | ---
license: creativeml-openrail-m
tags:
- Classic Anime
- 90s
- Retro
- Cartoons
- DucHaiten
- Patchmonk
- Clumsy_Trainer
- OneRing
- stable-diffusion
- stable-diffusion-diffusers
- diffusers
- text-to-image
---
# Most Classical

classic disney style kitten
Try that in your anime model and see if it gives you a girl you didn't ask for. Sometimes she'll have the kitten, sometimes just kitten ears, sometimes it's just a girl without a kitten! (I'm looking at you OldFish, where's my kitten??) This model does it right.
Samples and prompts:

(Click for larger)
Top left: Anime cute girl, bangs, depth of field, embedded, hair ribbon, long hair, looking at viewer, neck ribbon, non-web source, palm leaf, palm tree, purple eyes, purple hair, red ribbon, ribbon, sexy, self upload, solo
Top right: classic disney style kitten
Bottom left: analog style 70s color photograph of young James Spider as Alan Shore, Boston Legal behind the scenes
Bottom right: Highly detailed, High Quality, Masterpiece, beautiful, cute girl as glad princess peach and toon zelda, teal headwear
DucHaitenClassicAnime mixed with Mostalgia (which includes Rainbowpatch, Esthetic Retro Anime, and DucHaiten-GoldenLife - I think? The original block weights may have been overwritten long time ago, one day I will check, I'm crediting everyone just in case).
Original pages:
https://civitai.com/models/8542?modelVersionId=16168 (DucHaiten Classic Anime)
https://civitai.com/models/5528/rainbowpatch
https://civitai.com/models/137781?modelVersionId=152147 (Esthetic Retro Anime)
DucHaiten-GoldenLife - https://tensor.art/models/628276277415133426
https://huggingface.co/Yntec/GoodLife
https://huggingface.co/Yntec/Nostalgic
https://huggingface.co/Yntec/NostalgicLife
https://huggingface.co/Yntec/Moistalgia
# Recipe:
- SuperMerger Weight Sum MBW 1,0,0,0,0,0,0,1,1,1,1,1,0,0,1,1,1,1,1,1,0,0,0,0,1,1
Model A:
DucHaiten Classic Anime
Model B:
Moistalgia
Output:
MostClassical |
juliensimon/xlm-v-base-language-id | juliensimon | 2023-10-09T13:21:16Z | 16,789 | 9 | transformers | [
"transformers",
"pytorch",
"safetensors",
"openvino",
"xlm-roberta",
"text-classification",
"generated_from_trainer",
"language-identification",
"dataset:fleurs",
"base_model:facebook/xlm-v-base",
"license:mit",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| text-classification | 2023-02-09T14:31:09Z | ---
license: mit
tags:
- generated_from_trainer
- language-identification
- openvino
datasets:
- fleurs
metrics:
- accuracy
pipeline_tag: text-classification
base_model: facebook/xlm-v-base
model-index:
- name: xlm-v-base-language-id
results:
- task:
type: text-classification
name: Text Classification
dataset:
name: fleurs
type: fleurs
config: all
split: validation
args: all
metrics:
- type: accuracy
value: 0.9930337861372344
name: Accuracy
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# xlm-v-base-language-id
This model is a fine-tuned version of [facebook/xlm-v-base](https://huggingface.co/facebook/xlm-v-base) on the [google/fleurs](https://huggingface.co/datasets/google/fleurs) dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0241
- Accuracy: 0.9930
# Usage
The simplest way to use the model is with a text classification pipeline:
```
from transformers import pipeline
model_id = "juliensimon/xlm-v-base-language-id"
p = pipeline("text-classification", model=model_id)
p("Hello world")
# [{'label': 'English', 'score': 0.9802148342132568}]
```
The model is also compatible with [Optimum Intel](https://github.com/huggingface/optimum-intel).
For example, you can optimize it with Intel OpenVINO and enjoy a 2x inference speedup (or more).
```
from optimum.intel.openvino import OVModelForSequenceClassification
from transformers import AutoTokenizer, pipeline
model_id = "juliensimon/xlm-v-base-language-id"
ov_model = OVModelForSequenceClassification.from_pretrained(model_id)
tokenizer = AutoTokenizer.from_pretrained(model_id)
p = pipeline("text-classification", model=ov_model, tokenizer=tokenizer)
p("Hello world")
# [{'label': 'English', 'score': 0.9802149534225464}]
```
An OpenVINO version of the model is available in the repository.
## Intended uses & limitations
The model can accurately detect 102 languages. You can find the list on the [dataset](https://huggingface.co/datasets/google/fleurs) page.
## Training and evaluation data
The model has been trained and evaluated on the complete google/fleurs training and validation sets.
## Training procedure
The training script is included in the repository. The model has been trained on an p3dn.24xlarge instance on AWS (8 NVIDIA V100 GPUs).
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 128
- eval_batch_size: 128
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 512
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 5
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.6368 | 1.0 | 531 | 0.4593 | 0.9689 |
| 0.059 | 2.0 | 1062 | 0.0412 | 0.9899 |
| 0.0311 | 3.0 | 1593 | 0.0275 | 0.9918 |
| 0.0255 | 4.0 | 2124 | 0.0243 | 0.9928 |
| 0.017 | 5.0 | 2655 | 0.0241 | 0.9930 |
### Framework versions
- Transformers 4.26.0
- Pytorch 1.13.1
- Datasets 2.8.0
- Tokenizers 0.13.2
|
nitrosocke/mo-di-diffusion | nitrosocke | 2023-05-16T09:23:30Z | 16,777 | 942 | diffusers | [
"diffusers",
"stable-diffusion",
"text-to-image",
"license:creativeml-openrail-m",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
]
| text-to-image | 2022-10-27T19:56:48Z | ---
license: creativeml-openrail-m
tags:
- stable-diffusion
- text-to-image
---
**Mo Di Diffusion**
This is the fine-tuned Stable Diffusion 1.5 model trained on screenshots from a popular animation studio.
Use the tokens **_modern disney style_** in your prompts for the effect.
**If you enjoy my work, please consider supporting me**
[](https://patreon.com/user?u=79196446)
**Videogame Characters rendered with the model:**

**Animal Characters rendered with the model:**

**Cars and Landscapes rendered with the model:**

#### Prompt and settings for Lara Croft:
**modern disney lara croft**
_Steps: 50, Sampler: Euler a, CFG scale: 7, Seed: 3940025417, Size: 512x768_
#### Prompt and settings for the Lion:
**modern disney (baby lion) Negative prompt: person human**
_Steps: 50, Sampler: Euler a, CFG scale: 7, Seed: 1355059992, Size: 512x512_
This model was trained using the diffusers based dreambooth training by ShivamShrirao using prior-preservation loss and the _train-text-encoder_ flag in 9.000 steps.
### 🧨 Diffusers
This model can be used just like any other Stable Diffusion model. For more information,
please have a look at the [Stable Diffusion](https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion).
You can also export the model to [ONNX](https://huggingface.co/docs/diffusers/optimization/onnx), [MPS](https://huggingface.co/docs/diffusers/optimization/mps) and/or [FLAX/JAX]().
```python
from diffusers import StableDiffusionPipeline
import torch
model_id = "nitrosocke/mo-di-diffusion"
pipe = StableDiffusionPipeline.from_pretrained(model_id, torch_dtype=torch.float16)
pipe = pipe.to("cuda")
prompt = "a magical princess with golden hair, modern disney style"
image = pipe(prompt).images[0]
image.save("./magical_princess.png")
```
# Gradio & Colab
We also support a [Gradio](https://github.com/gradio-app/gradio) Web UI and Colab with Diffusers to run fine-tuned Stable Diffusion models:
[](https://huggingface.co/spaces/anzorq/finetuned_diffusion)
[](https://colab.research.google.com/drive/1j5YvfMZoGdDGdj3O3xRU1m4ujKYsElZO?usp=sharing)
## License
This model is open access and available to all, with a CreativeML OpenRAIL-M license further specifying rights and usage.
The CreativeML OpenRAIL License specifies:
1. You can't use the model to deliberately produce nor share illegal or harmful outputs or content
2. The authors claims no rights on the outputs you generate, you are free to use them and are accountable for their use which must not go against the provisions set in the license
3. You may re-distribute the weights and use the model commercially and/or as a service. If you do, please be aware you have to include the same use restrictions as the ones in the license and share a copy of the CreativeML OpenRAIL-M to all your users (please read the license entirely and carefully)
[Please read the full license here](https://huggingface.co/spaces/CompVis/stable-diffusion-license) |
ClassCat/gpt2-base-french | ClassCat | 2022-07-21T09:04:41Z | 16,764 | 4 | transformers | [
"transformers",
"pytorch",
"gpt2",
"text-generation",
"fr",
"dataset:wikipedia",
"dataset:cc100",
"license:cc-by-sa-4.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| text-generation | 2022-07-05T19:28:03Z | ---
language: fr
license: cc-by-sa-4.0
datasets:
- wikipedia
- cc100
widget:
- text: "Je vais à la gare, et"
- text: "J'aime le café, donc"
- text: "Nous avons parlé"
- text: "Je m'appelle"
---
## GPT2 French base model (Uncased)
### Prerequisites
transformers==4.19.2
### Model architecture
This model uses GPT2 base setttings except vocabulary size.
### Tokenizer
Using BPE tokenizer with vocabulary size 50,000.
### Training Data
* [wiki40b/fr](https://www.tensorflow.org/datasets/catalog/wiki40b#wiki40bfr) (French Wikipedia)
* Subset of [CC-100/fr](https://data.statmt.org/cc-100/) : Monolingual Datasets from Web Crawl Data
### Usage
```python
from transformers import pipeline
generator = pipeline('text-generation', model='ClassCat/gpt2-base-french')
generator("Je vais à la", max_length=50, num_return_sequences=5)
``` |
TheBloke/CausalLM-14B-GGUF | TheBloke | 2023-10-23T14:08:54Z | 16,742 | 126 | transformers | [
"transformers",
"gguf",
"llama",
"llama2",
"qwen",
"text-generation",
"en",
"zh",
"dataset:JosephusCheung/GuanacoDataset",
"dataset:Open-Orca/OpenOrca",
"dataset:stingning/ultrachat",
"dataset:meta-math/MetaMathQA",
"dataset:liuhaotian/LLaVA-Instruct-150K",
"dataset:jondurbin/airoboros-3.1",
"dataset:WizardLM/WizardLM_evol_instruct_V2_196k",
"dataset:RyokoAI/ShareGPT52K",
"dataset:RyokoAI/Fandom23K",
"dataset:milashkaarshif/MoeGirlPedia_wikitext_raw_archive",
"dataset:wikipedia",
"dataset:wiki_lingua",
"dataset:fnlp/moss-003-sft-data",
"dataset:garage-bAInd/Open-Platypus",
"dataset:LDJnr/Puffin",
"dataset:openbmb/llava_zh",
"dataset:BAAI/COIG",
"dataset:TigerResearch/tigerbot-zhihu-zh-10k",
"dataset:liwu/MNBVC",
"dataset:teknium/openhermes",
"base_model:CausalLM/14B",
"license:wtfpl",
"text-generation-inference",
"region:us"
]
| text-generation | 2023-10-22T16:28:29Z | ---
base_model: CausalLM/14B
datasets:
- JosephusCheung/GuanacoDataset
- Open-Orca/OpenOrca
- stingning/ultrachat
- meta-math/MetaMathQA
- liuhaotian/LLaVA-Instruct-150K
- jondurbin/airoboros-3.1
- WizardLM/WizardLM_evol_instruct_V2_196k
- RyokoAI/ShareGPT52K
- RyokoAI/Fandom23K
- milashkaarshif/MoeGirlPedia_wikitext_raw_archive
- wikipedia
- wiki_lingua
- fnlp/moss-003-sft-data
- garage-bAInd/Open-Platypus
- LDJnr/Puffin
- openbmb/llava_zh
- BAAI/COIG
- TigerResearch/tigerbot-zhihu-zh-10k
- liwu/MNBVC
- teknium/openhermes
inference: false
language:
- en
- zh
license: wtfpl
model_creator: CausalLM
model_name: CausalLM 14B
model_type: llama
pipeline_tag: text-generation
prompt_template: '<|im_start|>system
{system_message}<|im_end|>
<|im_start|>user
{prompt}<|im_end|>
<|im_start|>assistant
'
quantized_by: TheBloke
tags:
- llama
- llama2
- qwen
---
<!-- markdownlint-disable MD041 -->
<!-- header start -->
<!-- 200823 -->
<div style="width: auto; margin-left: auto; margin-right: auto">
<img src="https://i.imgur.com/EBdldam.jpg" alt="TheBlokeAI" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</div>
<div style="display: flex; justify-content: space-between; width: 100%;">
<div style="display: flex; flex-direction: column; align-items: flex-start;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://discord.gg/theblokeai">Chat & support: TheBloke's Discord server</a></p>
</div>
<div style="display: flex; flex-direction: column; align-items: flex-end;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://www.patreon.com/TheBlokeAI">Want to contribute? TheBloke's Patreon page</a></p>
</div>
</div>
<div style="text-align:center; margin-top: 0em; margin-bottom: 0em"><p style="margin-top: 0.25em; margin-bottom: 0em;">TheBloke's LLM work is generously supported by a grant from <a href="https://a16z.com">andreessen horowitz (a16z)</a></p></div>
<hr style="margin-top: 1.0em; margin-bottom: 1.0em;">
<!-- header end -->
# CausalLM 14B - GGUF
- Model creator: [CausalLM](https://huggingface.co/CausalLM)
- Original model: [CausalLM 14B](https://huggingface.co/CausalLM/14B)
<!-- description start -->
## Description
This repo contains GGUF format model files for [CausalLM's CausalLM 14B](https://huggingface.co/CausalLM/14B).
**NOTE**: The GGUFs originally uploaded here did not work due to a vocab issue. This was fixed on 23rd October, 15:00 UTC. The files uploaded now are confirmed to work.
Please re-download the GGUFs if you had downloaded the originally uploaded GGUF file(s).
<!-- description end -->
<!-- README_GGUF.md-about-gguf start -->
### About GGUF
GGUF is a new format introduced by the llama.cpp team on August 21st 2023. It is a replacement for GGML, which is no longer supported by llama.cpp.
Here is an incomplate list of clients and libraries that are known to support GGUF:
* [llama.cpp](https://github.com/ggerganov/llama.cpp). The source project for GGUF. Offers a CLI and a server option.
* [text-generation-webui](https://github.com/oobabooga/text-generation-webui), the most widely used web UI, with many features and powerful extensions. Supports GPU acceleration.
* [KoboldCpp](https://github.com/LostRuins/koboldcpp), a fully featured web UI, with GPU accel across all platforms and GPU architectures. Especially good for story telling.
* [LM Studio](https://lmstudio.ai/), an easy-to-use and powerful local GUI for Windows and macOS (Silicon), with GPU acceleration.
* [LoLLMS Web UI](https://github.com/ParisNeo/lollms-webui), a great web UI with many interesting and unique features, including a full model library for easy model selection.
* [Faraday.dev](https://faraday.dev/), an attractive and easy to use character-based chat GUI for Windows and macOS (both Silicon and Intel), with GPU acceleration.
* [ctransformers](https://github.com/marella/ctransformers), a Python library with GPU accel, LangChain support, and OpenAI-compatible AI server.
* [llama-cpp-python](https://github.com/abetlen/llama-cpp-python), a Python library with GPU accel, LangChain support, and OpenAI-compatible API server.
* [candle](https://github.com/huggingface/candle), a Rust ML framework with a focus on performance, including GPU support, and ease of use.
<!-- README_GGUF.md-about-gguf end -->
<!-- repositories-available start -->
## Repositories available
* [AWQ model(s) for GPU inference.](https://huggingface.co/TheBloke/CausalLM-14B-AWQ)
* [GPTQ models for GPU inference, with multiple quantisation parameter options.](https://huggingface.co/TheBloke/CausalLM-14B-GPTQ)
* [2, 3, 4, 5, 6 and 8-bit GGUF models for CPU+GPU inference](https://huggingface.co/TheBloke/CausalLM-14B-GGUF)
* [CausalLM's original unquantised fp16 model in pytorch format, for GPU inference and for further conversions](https://huggingface.co/CausalLM/14B)
<!-- repositories-available end -->
<!-- prompt-template start -->
## Prompt template: ChatML
```
<|im_start|>system
{system_message}<|im_end|>
<|im_start|>user
{prompt}<|im_end|>
<|im_start|>assistant
```
<!-- prompt-template end -->
<!-- licensing start -->
## Licensing
The creator of the source model has listed its license as `wtfpl`, and this quantization has therefore used that same license.
As this model is based on Llama 2, it is also subject to the Meta Llama 2 license terms, and the license files for that are additionally included. It should therefore be considered as being claimed to be licensed under both licenses. I contacted Hugging Face for clarification on dual licensing but they do not yet have an official position. Should this change, or should Meta provide any feedback on this situation, I will update this section accordingly.
In the meantime, any questions regarding licensing, and in particular how these two licenses might interact, should be directed to the original model repository: [CausalLM's CausalLM 14B](https://huggingface.co/CausalLM/14B).
<!-- licensing end -->
<!-- compatibility_gguf start -->
## Compatibility
These quantised GGUFv2 files are compatible with llama.cpp from August 27th onwards, as of commit [d0cee0d](https://github.com/ggerganov/llama.cpp/commit/d0cee0d36d5be95a0d9088b674dbb27354107221)
They are also compatible with many third party UIs and libraries - please see the list at the top of this README.
## Explanation of quantisation methods
<details>
<summary>Click to see details</summary>
The new methods available are:
* GGML_TYPE_Q2_K - "type-1" 2-bit quantization in super-blocks containing 16 blocks, each block having 16 weight. Block scales and mins are quantized with 4 bits. This ends up effectively using 2.5625 bits per weight (bpw)
* GGML_TYPE_Q3_K - "type-0" 3-bit quantization in super-blocks containing 16 blocks, each block having 16 weights. Scales are quantized with 6 bits. This end up using 3.4375 bpw.
* GGML_TYPE_Q4_K - "type-1" 4-bit quantization in super-blocks containing 8 blocks, each block having 32 weights. Scales and mins are quantized with 6 bits. This ends up using 4.5 bpw.
* GGML_TYPE_Q5_K - "type-1" 5-bit quantization. Same super-block structure as GGML_TYPE_Q4_K resulting in 5.5 bpw
* GGML_TYPE_Q6_K - "type-0" 6-bit quantization. Super-blocks with 16 blocks, each block having 16 weights. Scales are quantized with 8 bits. This ends up using 6.5625 bpw
Refer to the Provided Files table below to see what files use which methods, and how.
</details>
<!-- compatibility_gguf end -->
<!-- README_GGUF.md-provided-files start -->
## Provided files
| Name | Quant method | Bits | Size | Max RAM required | Use case |
| ---- | ---- | ---- | ---- | ---- | ----- |
| [causallm_14b.Q4_0.gguf](https://huggingface.co/TheBloke/CausalLM-14B-GGUF/blob/main/causallm_14b.Q4_0.gguf) | Q4_0 | 4 | 8.18 GB| 10.68 GB | legacy; small, very high quality loss - prefer using Q3_K_M |
| [causallm_14b.Q4_1.gguf](https://huggingface.co/TheBloke/CausalLM-14B-GGUF/blob/main/causallm_14b.Q4_1.gguf) | Q4_1 | 4 | 9.01 GB| 11.51 GB | legacy; small, substantial quality loss - lprefer using Q3_K_L |
| [causallm_14b.Q5_0.gguf](https://huggingface.co/TheBloke/CausalLM-14B-GGUF/blob/main/causallm_14b.Q5_0.gguf) | Q5_0 | 5 | 9.85 GB| 12.35 GB | legacy; medium, balanced quality - prefer using Q4_K_M |
| [causallm_14b.Q5_1.gguf](https://huggingface.co/TheBloke/CausalLM-14B-GGUF/blob/main/causallm_14b.Q5_1.gguf) | Q5_1 | 5 | 10.69 GB| 13.19 GB | legacy; medium, low quality loss - prefer using Q5_K_M |
| [causallm_14b.Q8_0.gguf](https://huggingface.co/TheBloke/CausalLM-14B-GGUF/blob/main/causallm_14b.Q8_0.gguf) | Q8_0 | 8 | 15.06 GB| 17.56 GB | very large, extremely low quality loss - not recommended |
**Note**: the above RAM figures assume no GPU offloading. If layers are offloaded to the GPU, this will reduce RAM usage and use VRAM instead.
<!-- README_GGUF.md-provided-files end -->
<!-- README_GGUF.md-how-to-download start -->
## How to download GGUF files
**Note for manual downloaders:** You almost never want to clone the entire repo! Multiple different quantisation formats are provided, and most users only want to pick and download a single file.
The following clients/libraries will automatically download models for you, providing a list of available models to choose from:
* LM Studio
* LoLLMS Web UI
* Faraday.dev
### In `text-generation-webui`
Under Download Model, you can enter the model repo: TheBloke/CausalLM-14B-GGUF and below it, a specific filename to download, such as: causallm_14b.Q4_K_M.gguf.
Then click Download.
### On the command line, including multiple files at once
I recommend using the `huggingface-hub` Python library:
```shell
pip3 install huggingface-hub
```
Then you can download any individual model file to the current directory, at high speed, with a command like this:
```shell
huggingface-cli download TheBloke/CausalLM-14B-GGUF causallm_14b.Q4_K_M.gguf --local-dir . --local-dir-use-symlinks False
```
<details>
<summary>More advanced huggingface-cli download usage</summary>
You can also download multiple files at once with a pattern:
```shell
huggingface-cli download TheBloke/CausalLM-14B-GGUF --local-dir . --local-dir-use-symlinks False --include='*Q4_K*gguf'
```
For more documentation on downloading with `huggingface-cli`, please see: [HF -> Hub Python Library -> Download files -> Download from the CLI](https://huggingface.co/docs/huggingface_hub/guides/download#download-from-the-cli).
To accelerate downloads on fast connections (1Gbit/s or higher), install `hf_transfer`:
```shell
pip3 install hf_transfer
```
And set environment variable `HF_HUB_ENABLE_HF_TRANSFER` to `1`:
```shell
HF_HUB_ENABLE_HF_TRANSFER=1 huggingface-cli download TheBloke/CausalLM-14B-GGUF causallm_14b.Q4_K_M.gguf --local-dir . --local-dir-use-symlinks False
```
Windows Command Line users: You can set the environment variable by running `set HF_HUB_ENABLE_HF_TRANSFER=1` before the download command.
</details>
<!-- README_GGUF.md-how-to-download end -->
<!-- README_GGUF.md-how-to-run start -->
## Example `llama.cpp` command
Make sure you are using `llama.cpp` from commit [d0cee0d](https://github.com/ggerganov/llama.cpp/commit/d0cee0d36d5be95a0d9088b674dbb27354107221) or later.
```shell
./main -ngl 32 -m causallm_14b.Q4_K_M.gguf --color -c 4096 --temp 0.7 --repeat_penalty 1.1 -n -1 -p "<|im_start|>system\n{system_message}<|im_end|>\n<|im_start|>user\n{prompt}<|im_end|>\n<|im_start|>assistant"
```
Change `-ngl 32` to the number of layers to offload to GPU. Remove it if you don't have GPU acceleration.
Change `-c 4096` to the desired sequence length. For extended sequence models - eg 8K, 16K, 32K - the necessary RoPE scaling parameters are read from the GGUF file and set by llama.cpp automatically.
If you want to have a chat-style conversation, replace the `-p <PROMPT>` argument with `-i -ins`
For other parameters and how to use them, please refer to [the llama.cpp documentation](https://github.com/ggerganov/llama.cpp/blob/master/examples/main/README.md)
## How to run in `text-generation-webui`
Further instructions here: [text-generation-webui/docs/llama.cpp.md](https://github.com/oobabooga/text-generation-webui/blob/main/docs/llama.cpp.md).
## How to run from Python code
You can use GGUF models from Python using the [llama-cpp-python](https://github.com/abetlen/llama-cpp-python) or [ctransformers](https://github.com/marella/ctransformers) libraries.
### How to load this model in Python code, using ctransformers
#### First install the package
Run one of the following commands, according to your system:
```shell
# Base ctransformers with no GPU acceleration
pip install ctransformers
# Or with CUDA GPU acceleration
pip install ctransformers[cuda]
# Or with AMD ROCm GPU acceleration (Linux only)
CT_HIPBLAS=1 pip install ctransformers --no-binary ctransformers
# Or with Metal GPU acceleration for macOS systems only
CT_METAL=1 pip install ctransformers --no-binary ctransformers
```
#### Simple ctransformers example code
```python
from ctransformers import AutoModelForCausalLM
# Set gpu_layers to the number of layers to offload to GPU. Set to 0 if no GPU acceleration is available on your system.
llm = AutoModelForCausalLM.from_pretrained("TheBloke/CausalLM-14B-GGUF", model_file="causallm_14b.Q4_K_M.gguf", model_type="llama", gpu_layers=50)
print(llm("AI is going to"))
```
## How to use with LangChain
Here are guides on using llama-cpp-python and ctransformers with LangChain:
* [LangChain + llama-cpp-python](https://python.langchain.com/docs/integrations/llms/llamacpp)
* [LangChain + ctransformers](https://python.langchain.com/docs/integrations/providers/ctransformers)
<!-- README_GGUF.md-how-to-run end -->
<!-- footer start -->
<!-- 200823 -->
## Discord
For further support, and discussions on these models and AI in general, join us at:
[TheBloke AI's Discord server](https://discord.gg/theblokeai)
## Thanks, and how to contribute
Thanks to the [chirper.ai](https://chirper.ai) team!
Thanks to Clay from [gpus.llm-utils.org](llm-utils)!
I've had a lot of people ask if they can contribute. I enjoy providing models and helping people, and would love to be able to spend even more time doing it, as well as expanding into new projects like fine tuning/training.
If you're able and willing to contribute it will be most gratefully received and will help me to keep providing more models, and to start work on new AI projects.
Donaters will get priority support on any and all AI/LLM/model questions and requests, access to a private Discord room, plus other benefits.
* Patreon: https://patreon.com/TheBlokeAI
* Ko-Fi: https://ko-fi.com/TheBlokeAI
**Special thanks to**: Aemon Algiz.
**Patreon special mentions**: Pierre Kircher, Stanislav Ovsiannikov, Michael Levine, Eugene Pentland, Andrey, 준교 김, Randy H, Fred von Graf, Artur Olbinski, Caitlyn Gatomon, terasurfer, Jeff Scroggin, James Bentley, Vadim, Gabriel Puliatti, Harry Royden McLaughlin, Sean Connelly, Dan Guido, Edmond Seymore, Alicia Loh, subjectnull, AzureBlack, Manuel Alberto Morcote, Thomas Belote, Lone Striker, Chris Smitley, Vitor Caleffi, Johann-Peter Hartmann, Clay Pascal, biorpg, Brandon Frisco, sidney chen, transmissions 11, Pedro Madruga, jinyuan sun, Ajan Kanaga, Emad Mostaque, Trenton Dambrowitz, Jonathan Leane, Iucharbius, usrbinkat, vamX, George Stoitzev, Luke Pendergrass, theTransient, Olakabola, Swaroop Kallakuri, Cap'n Zoog, Brandon Phillips, Michael Dempsey, Nikolai Manek, danny, Matthew Berman, Gabriel Tamborski, alfie_i, Raymond Fosdick, Tom X Nguyen, Raven Klaugh, LangChain4j, Magnesian, Illia Dulskyi, David Ziegler, Mano Prime, Luis Javier Navarrete Lozano, Erik Bjäreholt, 阿明, Nathan Dryer, Alex, Rainer Wilmers, zynix, TL, Joseph William Delisle, John Villwock, Nathan LeClaire, Willem Michiel, Joguhyik, GodLy, OG, Alps Aficionado, Jeffrey Morgan, ReadyPlayerEmma, Tiffany J. Kim, Sebastain Graf, Spencer Kim, Michael Davis, webtim, Talal Aujan, knownsqashed, John Detwiler, Imad Khwaja, Deo Leter, Jerry Meng, Elijah Stavena, Rooh Singh, Pieter, SuperWojo, Alexandros Triantafyllidis, Stephen Murray, Ai Maven, ya boyyy, Enrico Ros, Ken Nordquist, Deep Realms, Nicholas, Spiking Neurons AB, Elle, Will Dee, Jack West, RoA, Luke @flexchar, Viktor Bowallius, Derek Yates, Subspace Studios, jjj, Toran Billups, Asp the Wyvern, Fen Risland, Ilya, NimbleBox.ai, Chadd, Nitin Borwankar, Emre, Mandus, Leonard Tan, Kalila, K, Trailburnt, S_X, Cory Kujawski
Thank you to all my generous patrons and donaters!
And thank you again to a16z for their generous grant.
<!-- footer end -->
<!-- original-model-card start -->
# Original model card: CausalLM's CausalLM 14B

*Image drawn by GPT-4 DALL·E 3* TL;DR: Perhaps better than all existing models < 70B, in most quantitative evaluations...
# Please Stop Using WRONG unofficial quant models unless you know what you're doing
GPTQ quants require a good dataset for calibration, and the default C4 dataset is not capable.
**llama.cpp GGUF models**
GPT2Tokenizer fixed by [Kerfuffle](https://github.com/KerfuffleV2) on [https://github.com/ggerganov/llama.cpp/pull/3743](https://github.com/ggerganov/llama.cpp/pull/3743), new models to be reuploaded.
# Read Me:
Also see [7B Version](https://huggingface.co/CausalLM/7B)
This model was trained based on the model weights of Qwen (and LLaMA2 was used, yes, for calculating some initial weights), you may also need to comply with the commercial use restrictions of these two models depending on the situation. The training process utilized a model structure that was identical to LLaMA2, using the same attention calculation method as the original MHA LLaMA2 models, and no additional scaling applied to the Relative Positional Encoding (RoPE).
We manually curated a SFT dataset of 1.3B tokens for training, utilizing open source datasets from Hugging Face. For most of these sentences, we performed manual or synthetic rewrites and generated alternate language versions using larger language models. Additionally, we conducted augmented text training using carefully selected entries from Wikipedia, as well as featured entries from Fandom and filtered entries from Moegirlpedia. In order to strike a balance between efficiency and quality, 100% of the data used for training was synthetic data, no direct use of text from the internet or original texts from publicly available datasets was employed for fine-tuning.
The 7B version of the model is a distilled version of the 14B model, specifically designed for speculative sampling. Therefore, it is important to exercise caution when directly using the model, as it may produce hallucinations or unreliable outputs.
Please note that the model was trained on unfiltered internet data. Since we do not have the capacity to vet all of it, there may be a substantial amount of objectionable content, pornography, violence, and offensive language present that we are unable to remove. Therefore, you will still need to complete your own checks on the model's safety and filter keywords in the output. Due to computational resource constraints, we are presently unable to implement RLHF for the model's ethics and safety, nor training on SFT samples that refuse to answer certain questions for restrictive fine-tuning.
Bonus: The model underwent some fine-tuning on the prompt format introduced in LLaVA1.5 that is unrelated to image attention calculation. Therefore, aligning the ViT Projection module with frozen LM under visual instructions would enable rapid implementation of effective multimodal capabilities.
## PROMPT FORMAT:
[chatml](https://github.com/openai/openai-python/blob/main/chatml.md)
**System Prompt must not be empty!**
## MMLU:
stem ACC: 64.19
Humanities ACC: 61.40
other ACC: 71.64
social ACC: 75.37
**AVERAGE ACC:67.36** (Outperforms ALL models under 70B, very close to those best 70B fine-tunes)
## CEval (Val):
STEM ACC: 66.71
Social Science ACC: 85.10
Humanities ACC: 76.68
Other ACC: 70.23
Hard ACC:54.71
**AVERAGE ACC:73.10** (Outperforms Qwen-14B, and GPT-4)
## GSM8K
**Zero-shot ACC 0.7012888551933283** (Outperforms MetaMath-13B, Qwen-14B)
## AlpacaEval Leaderboard
| | win_rate | standard_error | n_wins | n_wins_base | n_draws | n_total | mode | avg_length |
| ------------ | -------- | -------------- | ------ | ----------- | ------- | ------- | --------- | ---------- |
| causallm-14b | **88.26087** | 1.116333 | 705 | 89 | 11 | 805 | community | 1391 |
Win rate **88.26%** on [AlpacaEval Leaderboard](https://tatsu-lab.github.io/alpaca_eval/) [view raw](https://github.com/tatsu-lab/alpaca_eval/blob/3a47dcd81c56f6a8e6a5711f2754013919fbe90a/results/causallm-14b/model_outputs.json)
**GPT2Tokenizer 上的 llama.cpp 存在一些问题,会尽快修复...**
**llama.cpp GGUF models**
GPT2Tokenizer 支持由 [Kerfuffle](https://github.com/KerfuffleV2) 修复于 [https://github.com/ggerganov/llama.cpp/pull/3743](https://github.com/ggerganov/llama.cpp/pull/3743),新模型稍后上传。
## 请读我:
另请参阅[7B版本](https://huggingface.co/CausalLM/7B)
该模型是基于Qwen的权重(并使用了LLaMA2权重,是的,用于计算一些权重初始化),您根据情况可能还需要遵守这两个模型的商业使用限制。训练过程中使用了与LLaMA2相同的模型结构,使用原始MHA LLaMA2模型的相同注意力计算方法,对相对位置编码(RoPE)没有进行额外的缩放。
我们手动筛选了一个包含13亿个标记的SFT数据集进行训练,利用了Hugging Face的开源数据集。对于大多数句子,我们进行了手动或合成改写,并使用更大的语言模型生成了其他语言版本。此外,我们还使用了精心挑选的来自维基百科的条目、来自Fandom的精选条目以及来自萌娘百科的过滤条目进行增强文本训练。为了在效率和质量之间取得平衡,训练所使用的100%数据都是合成数据,没有直接使用来自互联网或公开可用数据集的原始文本进行微调。
7B版本的模型是14B模型的精简版本,专门设计用于推测抽样。因此,在直接使用模型时,需要谨慎行事,因为它可能会产生幻觉或不可靠的输出。
请注意,模型是在未经过滤的互联网数据上进行训练的。由于我们无法审核所有数据,可能会出现大量不良内容、色情、暴力和冒犯性语言,我们无法删除这些内容。因此,您仍然需要对模型的安全性进行自己的检查,并对输出中的关键词进行过滤。由于计算资源的限制,我们目前无法为模型的伦理和安全实施RLHF,也无法对拒绝回答某些问题的SFT样本进行训练以进行限制性微调。
额外奖励:模型在LLaVA1.5中引入的提示格式上进行了一些微调,与图像注意力计算无关。因此,将ViT投影模块与冻结的LM对齐,并根据视觉指令实施快速实现有效的多模态能力。
## 提示格式:
[chatml](https://github.com/openai/openai-python/blob/main/chatml.md)
**系统提示不能为空!**
## MMLU:
STEM准确率:64.19
人文及艺术学科准确率:61.40
其他学科准确率:71.64
社会学科准确率:75.37
**平均准确率:67.36**(超过所有70B以下的模型,非常接近最佳70B微调模型)
## CEval(验证集):
STEM准确率:66.71
社会科学准确率:85.10
人文学科准确率:76.68
其他学科准确率:70.23
困难准确率:54.71
**平均准确率:73.10**(超过Qwen-14B和GPT-4)
## GSM8K
**零样本准确率0.7012888551933283**(超过MetaMath-13B和Qwen-14B)
## AlpacaEval Leaderboard
| | win_rate | standard_error | n_wins | n_wins_base | n_draws | n_total | mode | avg_length |
| ------------ | -------- | -------------- | ------ | ----------- | ------- | ------- | --------- | ---------- |
| causallm-14b | **88.26087** | 1.116333 | 705 | 89 | 11 | 805 | community | 1391 |
在 [AlpacaEval Leaderboard](https://tatsu-lab.github.io/alpaca_eval/) 胜率 **88.26%** [view raw](https://github.com/tatsu-lab/alpaca_eval/blob/3a47dcd81c56f6a8e6a5711f2754013919fbe90a/results/causallm-14b/model_outputs.json)
<!-- original-model-card end -->
|
microsoft/Orca-2-13b | microsoft | 2023-11-22T17:56:02Z | 16,742 | 658 | transformers | [
"transformers",
"pytorch",
"llama",
"text-generation",
"orca",
"orca2",
"microsoft",
"arxiv:2311.11045",
"license:other",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| text-generation | 2023-11-14T01:12:36Z | ---
pipeline_tag: text-generation
tags:
- orca
- orca2
- microsoft
license: other
license_name: microsoft-research-license
license_link: LICENSE
---
# Orca 2
<!-- Provide a quick summary of what the model is/does. -->
Orca 2 is built for research purposes only and provides a single turn response in tasks such as reasoning over user given data, reading comprehension, math problem solving and text summarization. The model is designed to excel particularly in reasoning.
Note that:
1. This is a research model, intended to show that we can use capable models and complex workflows (advanced prompts, multiple calls) to create synthetic data that can teach Small Language Models (SLMs) new capabilities. We chose reasoning because it is a widely useful capability that SLMs lack.
2. The model is not optimized for chat and has not been trained with RLHF or DPO. It is best used after being finetuned for chat or for a specific task.
3. Beyond reasoning, the model inherits capabilities and limitations of its base (LLAMA-2 base). We have already seen that the benefits of the Orca training can be applied to other base model too.
We make Orca 2's weights publicly available to support further research on the development, evaluation, and alignment of SLMs.
## What is Orca 2’s intended use(s)?
+ Orca 2 is built for research purposes only.
+ The main purpose is to allow the research community to assess its abilities and to provide a foundation for
building better frontier models.
## How was Orca 2 evaluated?
+ Orca 2 has been evaluated on a large number of tasks ranging from reasoning to grounding and safety. Please refer
to Section 6 and Appendix in the [Orca 2 paper](https://arxiv.org/pdf/2311.11045.pdf) for details on evaluations.
## Model Details
Orca 2 is a finetuned version of LLAMA-2. Orca 2’s training data is a synthetic dataset that was created to enhance the small model’s reasoning abilities.
All synthetic training data was moderated using the Microsoft Azure content filters. More details about the model can be found in the [Orca 2 paper](https://arxiv.org/pdf/2311.11045.pdf).
Please refer to LLaMA-2 technical report for details on the model architecture.
## License
Orca 2 is licensed under the [Microsoft Research License](LICENSE).
Llama 2 is licensed under the [LLAMA 2 Community License](https://ai.meta.com/llama/license/), Copyright © Meta Platforms, Inc. All Rights Reserved.
## Bias, Risks, and Limitations
Orca 2, built upon the LLaMA 2 model family, retains many of its limitations, as well as the
common limitations of other large language models or limitation caused by its training process,
including:
**Data Biases**: Large language models, trained on extensive data, can inadvertently carry
biases present in the source data. Consequently, the models may generate outputs that could
be potentially biased or unfair.
**Lack of Contextual Understanding**: Despite their impressive capabilities in language understanding and generation, these models exhibit limited real-world understanding, resulting
in potential inaccuracies or nonsensical responses.
**Lack of Transparency**: Due to the complexity and size, large language models can act
as “black boxes”, making it difficult to comprehend the rationale behind specific outputs or
decisions. We recommend reviewing transparency notes from Azure for more information.
**Content Harms**: There are various types of content harms that large language models
can cause. It is important to be aware of them when using these models, and to take
actions to prevent them. It is recommended to leverage various content moderation services
provided by different companies and institutions. On an important note, we hope for better
regulations and standards from government and technology leaders around content harms
for AI technologies in future. We value and acknowledge the important role that research
and open source community can play in this direction.
**Hallucination**: It is important to be aware and cautious not to entirely rely on a given
language model for critical decisions or information that might have deep impact as it is
not obvious how to prevent these models from fabricating content. Moreover, it is not clear
whether small models may be more susceptible to hallucination in ungrounded generation
use cases due to their smaller sizes and hence reduced memorization capacities. This is an
active research topic and we hope there will be more rigorous measurement, understanding
and mitigations around this topic.
**Potential for Misuse**: Without suitable safeguards, there is a risk that these models could
be maliciously used for generating disinformation or harmful content.
**Data Distribution**: Orca 2’s performance is likely to correlate strongly with the distribution
of the tuning data. This correlation might limit its accuracy in areas underrepresented in
the training dataset such as math, coding, and reasoning.
**System messages**: Orca 2 demonstrates variance in performance depending on the system
instructions. Additionally, the stochasticity introduced by the model size may lead to
generation of non-deterministic responses to different system instructions.
**Zero-Shot Settings**: Orca 2 was trained on data that mostly simulate zero-shot settings.
While the model demonstrate very strong performance in zero-shot settings, it does not show
the same gains of using few-shot learning compared to other, specially larger, models.
**Synthetic data**: As Orca 2 is trained on synthetic data, it could inherit both the advantages
and shortcomings of the models and methods used for data generation. We posit that Orca
2 benefits from the safety measures incorporated during training and safety guardrails (e.g.,
content filter) within the Azure OpenAI API. However, detailed studies are required for
better quantification of such risks.
This model is solely designed for research settings, and its testing has only been carried
out in such environments. It should not be used in downstream applications, as additional
analysis is needed to assess potential harm or bias in the proposed application.
## Getting started with Orca 2
**Inference with Hugging Face library**
```python
import torch
import transformers
if torch.cuda.is_available():
torch.set_default_device("cuda")
else:
torch.set_default_device("cpu")
model = transformers.AutoModelForCausalLM.from_pretrained("microsoft/Orca-2-13b", device_map='auto')
# https://github.com/huggingface/transformers/issues/27132
# please use the slow tokenizer since fast and slow tokenizer produces different tokens
tokenizer = transformers.AutoTokenizer.from_pretrained(
"microsoft/Orca-2-13b",
use_fast=False,
)
system_message = "You are Orca, an AI language model created by Microsoft. You are a cautious assistant. You carefully follow instructions. You are helpful and harmless and you follow ethical guidelines and promote positive behavior."
user_message = "How can you determine if a restaurant is popular among locals or mainly attracts tourists, and why might this information be useful?"
prompt = f"<|im_start|>system\n{system_message}<|im_end|>\n<|im_start|>user\n{user_message}<|im_end|>\n<|im_start|>assistant"
inputs = tokenizer(prompt, return_tensors='pt')
output_ids = model.generate(inputs["input_ids"],)
answer = tokenizer.batch_decode(output_ids)[0]
print(answer)
# This example continues showing how to add a second turn message by the user to the conversation
second_turn_user_message = "Give me a list of the key points of your first answer."
# we set add_special_tokens=False because we dont want to automatically add a bos_token between messages
second_turn_message_in_markup = f"\n<|im_start|>user\n{second_turn_user_message}<|im_end|>\n<|im_start|>assistant"
second_turn_tokens = tokenizer(second_turn_message_in_markup, return_tensors='pt', add_special_tokens=False)
second_turn_input = torch.cat([output_ids, second_turn_tokens['input_ids']], dim=1)
output_ids_2 = model.generate(second_turn_input,)
second_turn_answer = tokenizer.batch_decode(output_ids_2)[0]
print(second_turn_answer)
```
**Safe inference with Azure AI Content Safety**
The usage of [Azure AI Content Safety](https://azure.microsoft.com/en-us/products/ai-services/ai-content-safety/) on top of model prediction is strongly encouraged
and can help prevent content harms. Azure AI Content Safety is a content moderation platform
that uses AI to keep your content safe. By integrating Orca 2 with Azure AI Content Safety,
we can moderate the model output by scanning it for sexual content, violence, hate, and
self-harm with multiple severity levels and multi-lingual detection.
```python
import os
import math
import transformers
import torch
from azure.ai.contentsafety import ContentSafetyClient
from azure.core.credentials import AzureKeyCredential
from azure.core.exceptions import HttpResponseError
from azure.ai.contentsafety.models import AnalyzeTextOptions
CONTENT_SAFETY_KEY = os.environ["CONTENT_SAFETY_KEY"]
CONTENT_SAFETY_ENDPOINT = os.environ["CONTENT_SAFETY_ENDPOINT"]
# We use Azure AI Content Safety to filter out any content that reaches "Medium" threshold
# For more information: https://learn.microsoft.com/en-us/azure/ai-services/content-safety/
def should_filter_out(input_text, threshold=4):
# Create an Content Safety client
client = ContentSafetyClient(CONTENT_SAFETY_ENDPOINT, AzureKeyCredential(CONTENT_SAFETY_KEY))
# Construct a request
request = AnalyzeTextOptions(text=input_text)
# Analyze text
try:
response = client.analyze_text(request)
except HttpResponseError as e:
print("Analyze text failed.")
if e.error:
print(f"Error code: {e.error.code}")
print(f"Error message: {e.error.message}")
raise
print(e)
raise
categories = ["hate_result", "self_harm_result", "sexual_result", "violence_result"]
max_score = -math.inf
for category in categories:
max_score = max(max_score, getattr(response, category).severity)
return max_score >= threshold
model_path = 'microsoft/Orca-2-13b'
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model = transformers.AutoModelForCausalLM.from_pretrained(model_path)
model.to(device)
tokenizer = transformers.AutoTokenizer.from_pretrained(
model_path,
model_max_length=4096,
padding_side="right",
use_fast=False,
add_special_tokens=False,
)
system_message = "You are Orca, an AI language model created by Microsoft. You are a cautious assistant. You carefully follow instructions. You are helpful and harmless and you follow ethical guidelines and promote positive behavior."
user_message = "\" \n :You can't just say, \"\"that's crap\"\" and remove it without gaining a consensus. You already know this, based on your block history. —/ \" \nIs the comment obscene? \nOptions : Yes, No."
prompt = f"<|im_start|>system\n{system_message}<|im_end|>\n<|im_start|>user\n{user_message}<|im_end|>\n<|im_start|>assistant"
inputs = tokenizer(prompt, return_tensors='pt')
inputs = inputs.to(device)
output_ids = model.generate(inputs["input_ids"], max_length=4096, do_sample=False, temperature=0.0, use_cache=True)
sequence_length = inputs["input_ids"].shape[1]
new_output_ids = output_ids[:, sequence_length:]
answers = tokenizer.batch_decode(new_output_ids, skip_special_tokens=True)
final_output = answers[0] if not should_filter_out(answers[0]) else "[Content Filtered]"
print(final_output)
```
## Citation
```bibtex
@misc{mitra2023orca,
title={Orca 2: Teaching Small Language Models How to Reason},
author={Arindam Mitra and Luciano Del Corro and Shweti Mahajan and Andres Codas and Clarisse Simoes and Sahaj Agrawal and Xuxi Chen and Anastasia Razdaibiedina and Erik Jones and Kriti Aggarwal and Hamid Palangi and Guoqing Zheng and Corby Rosset and Hamed Khanpour and Ahmed Awadallah},
year={2023},
eprint={2311.11045},
archivePrefix={arXiv},
primaryClass={cs.AI}
}
``` |
mradermacher/IceSakeV8RP-7b-GGUF | mradermacher | 2024-06-27T12:29:26Z | 16,723 | 0 | transformers | [
"transformers",
"gguf",
"mergekit",
"merge",
"alpaca",
"mistral",
"not-for-all-audiences",
"nsfw",
"en",
"base_model:icefog72/IceSakeV8RP-7b",
"license:cc-by-nc-4.0",
"endpoints_compatible",
"region:us"
]
| null | 2024-06-27T04:35:43Z | ---
base_model: icefog72/IceSakeV8RP-7b
language:
- en
library_name: transformers
license: cc-by-nc-4.0
quantized_by: mradermacher
tags:
- mergekit
- merge
- alpaca
- mistral
- not-for-all-audiences
- nsfw
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
static quants of https://huggingface.co/icefog72/IceSakeV8RP-7b
<!-- provided-files -->
weighted/imatrix quants are available at https://huggingface.co/mradermacher/IceSakeV8RP-7b-i1-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/IceSakeV8RP-7b-GGUF/resolve/main/IceSakeV8RP-7b.Q2_K.gguf) | Q2_K | 2.8 | |
| [GGUF](https://huggingface.co/mradermacher/IceSakeV8RP-7b-GGUF/resolve/main/IceSakeV8RP-7b.IQ3_XS.gguf) | IQ3_XS | 3.1 | |
| [GGUF](https://huggingface.co/mradermacher/IceSakeV8RP-7b-GGUF/resolve/main/IceSakeV8RP-7b.Q3_K_S.gguf) | Q3_K_S | 3.3 | |
| [GGUF](https://huggingface.co/mradermacher/IceSakeV8RP-7b-GGUF/resolve/main/IceSakeV8RP-7b.IQ3_S.gguf) | IQ3_S | 3.3 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/IceSakeV8RP-7b-GGUF/resolve/main/IceSakeV8RP-7b.IQ3_M.gguf) | IQ3_M | 3.4 | |
| [GGUF](https://huggingface.co/mradermacher/IceSakeV8RP-7b-GGUF/resolve/main/IceSakeV8RP-7b.Q3_K_M.gguf) | Q3_K_M | 3.6 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/IceSakeV8RP-7b-GGUF/resolve/main/IceSakeV8RP-7b.Q3_K_L.gguf) | Q3_K_L | 3.9 | |
| [GGUF](https://huggingface.co/mradermacher/IceSakeV8RP-7b-GGUF/resolve/main/IceSakeV8RP-7b.IQ4_XS.gguf) | IQ4_XS | 4.0 | |
| [GGUF](https://huggingface.co/mradermacher/IceSakeV8RP-7b-GGUF/resolve/main/IceSakeV8RP-7b.Q4_K_S.gguf) | Q4_K_S | 4.2 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/IceSakeV8RP-7b-GGUF/resolve/main/IceSakeV8RP-7b.Q4_K_M.gguf) | Q4_K_M | 4.5 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/IceSakeV8RP-7b-GGUF/resolve/main/IceSakeV8RP-7b.Q5_K_S.gguf) | Q5_K_S | 5.1 | |
| [GGUF](https://huggingface.co/mradermacher/IceSakeV8RP-7b-GGUF/resolve/main/IceSakeV8RP-7b.Q5_K_M.gguf) | Q5_K_M | 5.2 | |
| [GGUF](https://huggingface.co/mradermacher/IceSakeV8RP-7b-GGUF/resolve/main/IceSakeV8RP-7b.Q6_K.gguf) | Q6_K | 6.0 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/IceSakeV8RP-7b-GGUF/resolve/main/IceSakeV8RP-7b.Q8_0.gguf) | Q8_0 | 7.8 | fast, best quality |
| [GGUF](https://huggingface.co/mradermacher/IceSakeV8RP-7b-GGUF/resolve/main/IceSakeV8RP-7b.f16.gguf) | f16 | 14.6 | 16 bpw, overkill |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
SakuraLLM/Sakura-14B-Qwen2beta-v0.9-GGUF | SakuraLLM | 2024-04-11T19:10:41Z | 16,714 | 6 | null | [
"gguf",
"license:cc-by-nc-sa-4.0",
"region:us"
]
| null | 2024-03-16T07:47:56Z | ---
license: cc-by-nc-sa-4.0
---
|
legraphista/glm-4-9b-chat-GGUF | legraphista | 2024-06-20T09:38:19Z | 16,693 | 7 | gguf | [
"gguf",
"glm",
"chatglm",
"thudm",
"quantized",
"GGUF",
"quantization",
"static",
"16bit",
"8bit",
"6bit",
"5bit",
"4bit",
"3bit",
"2bit",
"text-generation",
"zh",
"en",
"base_model:THUDM/glm-4-9b-chat",
"license:other",
"region:us"
]
| text-generation | 2024-06-20T09:10:34Z | ---
base_model: THUDM/glm-4-9b-chat
inference: false
language:
- zh
- en
library_name: gguf
license: other
license_link: https://huggingface.co/THUDM/glm-4-9b-chat/blob/main/LICENSE
license_name: glm-4
pipeline_tag: text-generation
quantized_by: legraphista
tags:
- glm
- chatglm
- thudm
- quantized
- GGUF
- quantization
- static
- 16bit
- 8bit
- 6bit
- 5bit
- 4bit
- 3bit
- 2bit
---
# glm-4-9b-chat-GGUF
_Llama.cpp static quantization of THUDM/glm-4-9b-chat_
Original Model: [THUDM/glm-4-9b-chat](https://huggingface.co/THUDM/glm-4-9b-chat)
Original dtype: `BF16` (`bfloat16`)
Quantized by: [https://github.com/ggerganov/llama.cpp/pull/6999](https://github.com/ggerganov/llama.cpp/pull/6999)
IMatrix dataset: [here](https://gist.githubusercontent.com/bartowski1182/eb213dccb3571f863da82e99418f81e8/raw/b2869d80f5c16fd7082594248e80144677736635/calibration_datav3.txt)
- [Files](#files)
- [Common Quants](#common-quants)
- [All Quants](#all-quants)
- [Downloading using huggingface-cli](#downloading-using-huggingface-cli)
- [Inference](#inference)
- [Simple chat template](#simple-chat-template)
- [Chat template with system prompt](#chat-template-with-system-prompt)
- [Llama.cpp](#llama-cpp)
- [FAQ](#faq)
- [Why is the IMatrix not applied everywhere?](#why-is-the-imatrix-not-applied-everywhere)
- [How do I merge a split GGUF?](#how-do-i-merge-a-split-gguf)
---
## Files
### Common Quants
| Filename | Quant type | File Size | Status | Uses IMatrix | Is Split |
| -------- | ---------- | --------- | ------ | ------------ | -------- |
| [glm-4-9b-chat.Q8_0.gguf](https://huggingface.co/legraphista/glm-4-9b-chat-GGUF/blob/main/glm-4-9b-chat.Q8_0.gguf) | Q8_0 | 9.99GB | ✅ Available | ⚪ Static | 📦 No
| [glm-4-9b-chat.Q6_K.gguf](https://huggingface.co/legraphista/glm-4-9b-chat-GGUF/blob/main/glm-4-9b-chat.Q6_K.gguf) | Q6_K | 8.26GB | ✅ Available | ⚪ Static | 📦 No
| [glm-4-9b-chat.Q4_K.gguf](https://huggingface.co/legraphista/glm-4-9b-chat-GGUF/blob/main/glm-4-9b-chat.Q4_K.gguf) | Q4_K | 6.25GB | ✅ Available | ⚪ Static | 📦 No
| [glm-4-9b-chat.Q3_K.gguf](https://huggingface.co/legraphista/glm-4-9b-chat-GGUF/blob/main/glm-4-9b-chat.Q3_K.gguf) | Q3_K | 5.06GB | ✅ Available | ⚪ Static | 📦 No
| [glm-4-9b-chat.Q2_K.gguf](https://huggingface.co/legraphista/glm-4-9b-chat-GGUF/blob/main/glm-4-9b-chat.Q2_K.gguf) | Q2_K | 3.99GB | ✅ Available | ⚪ Static | 📦 No
### All Quants
| Filename | Quant type | File Size | Status | Uses IMatrix | Is Split |
| -------- | ---------- | --------- | ------ | ------------ | -------- |
| [glm-4-9b-chat.BF16.gguf](https://huggingface.co/legraphista/glm-4-9b-chat-GGUF/blob/main/glm-4-9b-chat.BF16.gguf) | BF16 | 18.81GB | ✅ Available | ⚪ Static | 📦 No
| [glm-4-9b-chat.FP16.gguf](https://huggingface.co/legraphista/glm-4-9b-chat-GGUF/blob/main/glm-4-9b-chat.FP16.gguf) | F16 | 18.81GB | ✅ Available | ⚪ Static | 📦 No
| [glm-4-9b-chat.Q8_0.gguf](https://huggingface.co/legraphista/glm-4-9b-chat-GGUF/blob/main/glm-4-9b-chat.Q8_0.gguf) | Q8_0 | 9.99GB | ✅ Available | ⚪ Static | 📦 No
| [glm-4-9b-chat.Q6_K.gguf](https://huggingface.co/legraphista/glm-4-9b-chat-GGUF/blob/main/glm-4-9b-chat.Q6_K.gguf) | Q6_K | 8.26GB | ✅ Available | ⚪ Static | 📦 No
| [glm-4-9b-chat.Q5_K.gguf](https://huggingface.co/legraphista/glm-4-9b-chat-GGUF/blob/main/glm-4-9b-chat.Q5_K.gguf) | Q5_K | 7.14GB | ✅ Available | ⚪ Static | 📦 No
| [glm-4-9b-chat.Q5_K_S.gguf](https://huggingface.co/legraphista/glm-4-9b-chat-GGUF/blob/main/glm-4-9b-chat.Q5_K_S.gguf) | Q5_K_S | 6.69GB | ✅ Available | ⚪ Static | 📦 No
| [glm-4-9b-chat.Q4_K.gguf](https://huggingface.co/legraphista/glm-4-9b-chat-GGUF/blob/main/glm-4-9b-chat.Q4_K.gguf) | Q4_K | 6.25GB | ✅ Available | ⚪ Static | 📦 No
| [glm-4-9b-chat.Q4_K_S.gguf](https://huggingface.co/legraphista/glm-4-9b-chat-GGUF/blob/main/glm-4-9b-chat.Q4_K_S.gguf) | Q4_K_S | 5.75GB | ✅ Available | ⚪ Static | 📦 No
| [glm-4-9b-chat.IQ4_NL.gguf](https://huggingface.co/legraphista/glm-4-9b-chat-GGUF/blob/main/glm-4-9b-chat.IQ4_NL.gguf) | IQ4_NL | 5.51GB | ✅ Available | ⚪ Static | 📦 No
| [glm-4-9b-chat.IQ4_XS.gguf](https://huggingface.co/legraphista/glm-4-9b-chat-GGUF/blob/main/glm-4-9b-chat.IQ4_XS.gguf) | IQ4_XS | 5.30GB | ✅ Available | ⚪ Static | 📦 No
| [glm-4-9b-chat.Q3_K.gguf](https://huggingface.co/legraphista/glm-4-9b-chat-GGUF/blob/main/glm-4-9b-chat.Q3_K.gguf) | Q3_K | 5.06GB | ✅ Available | ⚪ Static | 📦 No
| [glm-4-9b-chat.Q3_K_L.gguf](https://huggingface.co/legraphista/glm-4-9b-chat-GGUF/blob/main/glm-4-9b-chat.Q3_K_L.gguf) | Q3_K_L | 5.28GB | ✅ Available | ⚪ Static | 📦 No
| [glm-4-9b-chat.Q3_K_S.gguf](https://huggingface.co/legraphista/glm-4-9b-chat-GGUF/blob/main/glm-4-9b-chat.Q3_K_S.gguf) | Q3_K_S | 4.59GB | ✅ Available | ⚪ Static | 📦 No
| [glm-4-9b-chat.IQ3_M.gguf](https://huggingface.co/legraphista/glm-4-9b-chat-GGUF/blob/main/glm-4-9b-chat.IQ3_M.gguf) | IQ3_M | 4.81GB | ✅ Available | ⚪ Static | 📦 No
| [glm-4-9b-chat.IQ3_S.gguf](https://huggingface.co/legraphista/glm-4-9b-chat-GGUF/blob/main/glm-4-9b-chat.IQ3_S.gguf) | IQ3_S | 4.59GB | ✅ Available | ⚪ Static | 📦 No
| [glm-4-9b-chat.IQ3_XS.gguf](https://huggingface.co/legraphista/glm-4-9b-chat-GGUF/blob/main/glm-4-9b-chat.IQ3_XS.gguf) | IQ3_XS | 4.43GB | ✅ Available | ⚪ Static | 📦 No
| [glm-4-9b-chat.Q2_K.gguf](https://huggingface.co/legraphista/glm-4-9b-chat-GGUF/blob/main/glm-4-9b-chat.Q2_K.gguf) | Q2_K | 3.99GB | ✅ Available | ⚪ Static | 📦 No
## Downloading using huggingface-cli
If you do not have hugginface-cli installed:
```
pip install -U "huggingface_hub[cli]"
```
Download the specific file you want:
```
huggingface-cli download legraphista/glm-4-9b-chat-GGUF --include "glm-4-9b-chat.Q8_0.gguf" --local-dir ./
```
If the model file is big, it has been split into multiple files. In order to download them all to a local folder, run:
```
huggingface-cli download legraphista/glm-4-9b-chat-GGUF --include "glm-4-9b-chat.Q8_0/*" --local-dir ./
# see FAQ for merging GGUF's
```
---
## Inference
### Simple chat template
```
[gMASK]<sop><|user|>
{user_prompt}<|assistant|>
{assistant_response}<|user|>
{next_user_prompt}
```
### Chat template with system prompt
```
[gMASK]<sop><|system|>
{system_prompt}<|user|>
{user_prompt}<|assistant|>
{assistant_response}<|user|>
{next_user_prompt}
```
### Llama.cpp
```
llama.cpp/main -m glm-4-9b-chat.Q8_0.gguf --color -i -p "prompt here (according to the chat template)"
```
---
## FAQ
### Why is the IMatrix not applied everywhere?
According to [this investigation](https://www.reddit.com/r/LocalLLaMA/comments/1993iro/ggufs_quants_can_punch_above_their_weights_now/), it appears that lower quantizations are the only ones that benefit from the imatrix input (as per hellaswag results).
### How do I merge a split GGUF?
1. Make sure you have `gguf-split` available
- To get hold of `gguf-split`, navigate to https://github.com/ggerganov/llama.cpp/releases
- Download the appropriate zip for your system from the latest release
- Unzip the archive and you should be able to find `gguf-split`
2. Locate your GGUF chunks folder (ex: `glm-4-9b-chat.Q8_0`)
3. Run `gguf-split --merge glm-4-9b-chat.Q8_0/glm-4-9b-chat.Q8_0-00001-of-XXXXX.gguf glm-4-9b-chat.Q8_0.gguf`
- Make sure to point `gguf-split` to the first chunk of the split.
---
Got a suggestion? Ping me [@legraphista](https://x.com/legraphista)! |
mradermacher/Llama-3-Mopeyfied-Psychology-v2-GGUF | mradermacher | 2024-06-27T13:12:11Z | 16,654 | 0 | transformers | [
"transformers",
"gguf",
"merge",
"mergekit",
"lazymergekit",
"en",
"base_model:Cas-Warehouse/Llama-3-Mopeyfied-Psychology-v2",
"endpoints_compatible",
"region:us"
]
| null | 2024-06-27T05:03:16Z | ---
base_model: Cas-Warehouse/Llama-3-Mopeyfied-Psychology-v2
language:
- en
library_name: transformers
quantized_by: mradermacher
tags:
- merge
- mergekit
- lazymergekit
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
static quants of https://huggingface.co/Cas-Warehouse/Llama-3-Mopeyfied-Psychology-v2
<!-- provided-files -->
weighted/imatrix quants are available at https://huggingface.co/mradermacher/Llama-3-Mopeyfied-Psychology-v2-i1-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/Llama-3-Mopeyfied-Psychology-v2-GGUF/resolve/main/Llama-3-Mopeyfied-Psychology-v2.Q2_K.gguf) | Q2_K | 3.3 | |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-Mopeyfied-Psychology-v2-GGUF/resolve/main/Llama-3-Mopeyfied-Psychology-v2.IQ3_XS.gguf) | IQ3_XS | 3.6 | |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-Mopeyfied-Psychology-v2-GGUF/resolve/main/Llama-3-Mopeyfied-Psychology-v2.Q3_K_S.gguf) | Q3_K_S | 3.8 | |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-Mopeyfied-Psychology-v2-GGUF/resolve/main/Llama-3-Mopeyfied-Psychology-v2.IQ3_S.gguf) | IQ3_S | 3.8 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-Mopeyfied-Psychology-v2-GGUF/resolve/main/Llama-3-Mopeyfied-Psychology-v2.IQ3_M.gguf) | IQ3_M | 3.9 | |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-Mopeyfied-Psychology-v2-GGUF/resolve/main/Llama-3-Mopeyfied-Psychology-v2.Q3_K_M.gguf) | Q3_K_M | 4.1 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-Mopeyfied-Psychology-v2-GGUF/resolve/main/Llama-3-Mopeyfied-Psychology-v2.Q3_K_L.gguf) | Q3_K_L | 4.4 | |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-Mopeyfied-Psychology-v2-GGUF/resolve/main/Llama-3-Mopeyfied-Psychology-v2.IQ4_XS.gguf) | IQ4_XS | 4.6 | |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-Mopeyfied-Psychology-v2-GGUF/resolve/main/Llama-3-Mopeyfied-Psychology-v2.Q4_K_S.gguf) | Q4_K_S | 4.8 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-Mopeyfied-Psychology-v2-GGUF/resolve/main/Llama-3-Mopeyfied-Psychology-v2.Q4_K_M.gguf) | Q4_K_M | 5.0 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-Mopeyfied-Psychology-v2-GGUF/resolve/main/Llama-3-Mopeyfied-Psychology-v2.Q5_K_S.gguf) | Q5_K_S | 5.7 | |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-Mopeyfied-Psychology-v2-GGUF/resolve/main/Llama-3-Mopeyfied-Psychology-v2.Q5_K_M.gguf) | Q5_K_M | 5.8 | |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-Mopeyfied-Psychology-v2-GGUF/resolve/main/Llama-3-Mopeyfied-Psychology-v2.Q6_K.gguf) | Q6_K | 6.7 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-Mopeyfied-Psychology-v2-GGUF/resolve/main/Llama-3-Mopeyfied-Psychology-v2.Q8_0.gguf) | Q8_0 | 8.6 | fast, best quality |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-Mopeyfied-Psychology-v2-GGUF/resolve/main/Llama-3-Mopeyfied-Psychology-v2.f16.gguf) | f16 | 16.2 | 16 bpw, overkill |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
LWDCLS/llama3-8B-DarkIdol-2.1-Uncensored-1048K-GGUF-IQ-Imatrix-Request | LWDCLS | 2024-06-27T14:58:33Z | 16,646 | 7 | null | [
"gguf",
"license:unlicense",
"region:us"
]
| null | 2024-06-27T13:28:26Z | ---
license: unlicense
---
[Click for details - Request #58.](https://huggingface.co/Lewdiculous/Model-Requests/discussions/58)

|
timm/swin_tiny_patch4_window7_224.ms_in1k | timm | 2024-02-10T23:31:45Z | 16,632 | 0 | timm | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"arxiv:2103.14030",
"license:mit",
"region:us"
]
| image-classification | 2023-03-18T04:14:56Z | ---
license: mit
library_name: timm
tags:
- image-classification
- timm
datasets:
- imagenet-1k
---
# Model card for swin_tiny_patch4_window7_224.ms_in1k
A Swin Transformer image classification model. Pretrained on ImageNet-1k by paper authors.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 28.3
- GMACs: 4.5
- Activations (M): 17.1
- Image size: 224 x 224
- **Papers:**
- Swin Transformer: Hierarchical Vision Transformer using Shifted Windows: https://arxiv.org/abs/2103.14030
- **Original:** https://github.com/microsoft/Swin-Transformer
- **Dataset:** ImageNet-1k
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('swin_tiny_patch4_window7_224.ms_in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'swin_tiny_patch4_window7_224.ms_in1k',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g. for swin_base_patch4_window7_224 (NHWC output)
# torch.Size([1, 56, 56, 128])
# torch.Size([1, 28, 28, 256])
# torch.Size([1, 14, 14, 512])
# torch.Size([1, 7, 7, 1024])
# e.g. for swinv2_cr_small_ns_224 (NCHW output)
# torch.Size([1, 96, 56, 56])
# torch.Size([1, 192, 28, 28])
# torch.Size([1, 384, 14, 14])
# torch.Size([1, 768, 7, 7])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'swin_tiny_patch4_window7_224.ms_in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled (ie.e a (batch_size, H, W, num_features) tensor for swin / swinv2
# or (batch_size, num_features, H, W) for swinv2_cr
output = model.forward_head(output, pre_logits=True)
# output is (batch_size, num_features) tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
## Citation
```bibtex
@inproceedings{liu2021Swin,
title={Swin Transformer: Hierarchical Vision Transformer using Shifted Windows},
author={Liu, Ze and Lin, Yutong and Cao, Yue and Hu, Han and Wei, Yixuan and Zhang, Zheng and Lin, Stephen and Guo, Baining},
booktitle={Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)},
year={2021}
}
```
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
|
PrunaAI/RuterNorway-Llama-2-13b-chat-norwegian-GGUF-smashed | PrunaAI | 2024-06-28T20:35:32Z | 16,618 | 0 | null | [
"gguf",
"pruna-ai",
"region:us"
]
| null | 2024-06-28T19:21:03Z | ---
thumbnail: "https://assets-global.website-files.com/646b351987a8d8ce158d1940/64ec9e96b4334c0e1ac41504_Logo%20with%20white%20text.svg"
metrics:
- memory_disk
- memory_inference
- inference_latency
- inference_throughput
- inference_CO2_emissions
- inference_energy_consumption
tags:
- pruna-ai
---
<!-- header start -->
<!-- 200823 -->
<div style="width: auto; margin-left: auto; margin-right: auto">
<a href="https://www.pruna.ai/" target="_blank" rel="noopener noreferrer">
<img src="https://i.imgur.com/eDAlcgk.png" alt="PrunaAI" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</a>
</div>
<!-- header end -->
[](https://twitter.com/PrunaAI)
[](https://github.com/PrunaAI)
[](https://www.linkedin.com/company/93832878/admin/feed/posts/?feedType=following)
[](https://discord.com/invite/vb6SmA3hxu)
## This repo contains GGUF versions of the RuterNorway/Llama-2-13b-chat-norwegian model.
# Simply make AI models cheaper, smaller, faster, and greener!
- Give a thumbs up if you like this model!
- Contact us and tell us which model to compress next [here](https://www.pruna.ai/contact).
- Request access to easily compress your *own* AI models [here](https://z0halsaff74.typeform.com/pruna-access?typeform-source=www.pruna.ai).
- Read the documentations to know more [here](https://pruna-ai-pruna.readthedocs-hosted.com/en/latest/)
- Join Pruna AI community on Discord [here](https://discord.com/invite/vb6SmA3hxu) to share feedback/suggestions or get help.
**Frequently Asked Questions**
- ***How does the compression work?*** The model is compressed with GGUF.
- ***How does the model quality change?*** The quality of the model output might vary compared to the base model.
- ***What is the model format?*** We use GGUF format.
- ***What calibration data has been used?*** If needed by the compression method, we used WikiText as the calibration data.
- ***How to compress my own models?*** You can request premium access to more compression methods and tech support for your specific use-cases [here](https://z0halsaff74.typeform.com/pruna-access?typeform-source=www.pruna.ai).
# Downloading and running the models
You can download the individual files from the Files & versions section. Here is a list of the different versions we provide. For more info checkout [this chart](https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9) and [this guide](https://www.reddit.com/r/LocalLLaMA/comments/1ba55rj/overview_of_gguf_quantization_methods/):
| Quant type | Description |
|------------|--------------------------------------------------------------------------------------------|
| Q5_K_M | High quality, recommended. |
| Q5_K_S | High quality, recommended. |
| Q4_K_M | Good quality, uses about 4.83 bits per weight, recommended. |
| Q4_K_S | Slightly lower quality with more space savings, recommended. |
| IQ4_NL | Decent quality, slightly smaller than Q4_K_S with similar performance, recommended. |
| IQ4_XS | Decent quality, smaller than Q4_K_S with similar performance, recommended. |
| Q3_K_L | Lower quality but usable, good for low RAM availability. |
| Q3_K_M | Even lower quality. |
| IQ3_M | Medium-low quality, new method with decent performance comparable to Q3_K_M. |
| IQ3_S | Lower quality, new method with decent performance, recommended over Q3_K_S quant, same size with better performance. |
| Q3_K_S | Low quality, not recommended. |
| IQ3_XS | Lower quality, new method with decent performance, slightly better than Q3_K_S. |
| Q2_K | Very low quality but surprisingly usable. |
## How to download GGUF files ?
**Note for manual downloaders:** You almost never want to clone the entire repo! Multiple different quantisation formats are provided, and most users only want to pick and download a single file.
The following clients/libraries will automatically download models for you, providing a list of available models to choose from:
* LM Studio
* LoLLMS Web UI
* Faraday.dev
- **Option A** - Downloading in `text-generation-webui`:
- **Step 1**: Under Download Model, you can enter the model repo: RuterNorway-Llama-2-13b-chat-norwegian-GGUF-smashed and below it, a specific filename to download, such as: phi-2.IQ3_M.gguf.
- **Step 2**: Then click Download.
- **Option B** - Downloading on the command line (including multiple files at once):
- **Step 1**: We recommend using the `huggingface-hub` Python library:
```shell
pip3 install huggingface-hub
```
- **Step 2**: Then you can download any individual model file to the current directory, at high speed, with a command like this:
```shell
huggingface-cli download RuterNorway-Llama-2-13b-chat-norwegian-GGUF-smashed Llama-2-13b-chat-norwegian.IQ3_M.gguf --local-dir . --local-dir-use-symlinks False
```
<details>
<summary>More advanced huggingface-cli download usage (click to read)</summary>
Alternatively, you can also download multiple files at once with a pattern:
```shell
huggingface-cli download RuterNorway-Llama-2-13b-chat-norwegian-GGUF-smashed --local-dir . --local-dir-use-symlinks False --include='*Q4_K*gguf'
```
For more documentation on downloading with `huggingface-cli`, please see: [HF -> Hub Python Library -> Download files -> Download from the CLI](https://huggingface.co/docs/huggingface_hub/guides/download#download-from-the-cli).
To accelerate downloads on fast connections (1Gbit/s or higher), install `hf_transfer`:
```shell
pip3 install hf_transfer
```
And set environment variable `HF_HUB_ENABLE_HF_TRANSFER` to `1`:
```shell
HF_HUB_ENABLE_HF_TRANSFER=1 huggingface-cli download RuterNorway-Llama-2-13b-chat-norwegian-GGUF-smashed Llama-2-13b-chat-norwegian.IQ3_M.gguf --local-dir . --local-dir-use-symlinks False
```
Windows Command Line users: You can set the environment variable by running `set HF_HUB_ENABLE_HF_TRANSFER=1` before the download command.
</details>
<!-- README_GGUF.md-how-to-download end -->
<!-- README_GGUF.md-how-to-run start -->
## How to run model in GGUF format?
- **Option A** - Introductory example with `llama.cpp` command
Make sure you are using `llama.cpp` from commit [d0cee0d](https://github.com/ggerganov/llama.cpp/commit/d0cee0d36d5be95a0d9088b674dbb27354107221) or later.
```shell
./main -ngl 35 -m Llama-2-13b-chat-norwegian.IQ3_M.gguf --color -c 32768 --temp 0.7 --repeat_penalty 1.1 -n -1 -p "<s>[INST] {{prompt\}} [/INST]"
```
Change `-ngl 32` to the number of layers to offload to GPU. Remove it if you don't have GPU acceleration.
Change `-c 32768` to the desired sequence length. For extended sequence models - eg 8K, 16K, 32K - the necessary RoPE scaling parameters are read from the GGUF file and set by llama.cpp automatically. Note that longer sequence lengths require much more resources, so you may need to reduce this value.
If you want to have a chat-style conversation, replace the `-p <PROMPT>` argument with `-i -ins`
For other parameters and how to use them, please refer to [the llama.cpp documentation](https://github.com/ggerganov/llama.cpp/blob/master/examples/main/README.md)
- **Option B** - Running in `text-generation-webui`
Further instructions can be found in the text-generation-webui documentation, here: [text-generation-webui/docs/04 ‐ Model Tab.md](https://github.com/oobabooga/text-generation-webui/blob/main/docs/04%20-%20Model%20Tab.md#llamacpp).
- **Option C** - Running from Python code
You can use GGUF models from Python using the [llama-cpp-python](https://github.com/abetlen/llama-cpp-python) or [ctransformers](https://github.com/marella/ctransformers) libraries. Note that at the time of writing (Nov 27th 2023), ctransformers has not been updated for some time and is not compatible with some recent models. Therefore I recommend you use llama-cpp-python.
### How to load this model in Python code, using llama-cpp-python
For full documentation, please see: [llama-cpp-python docs](https://abetlen.github.io/llama-cpp-python/).
#### First install the package
Run one of the following commands, according to your system:
```shell
# Base ctransformers with no GPU acceleration
pip install llama-cpp-python
# With NVidia CUDA acceleration
CMAKE_ARGS="-DLLAMA_CUBLAS=on" pip install llama-cpp-python
# Or with OpenBLAS acceleration
CMAKE_ARGS="-DLLAMA_BLAS=ON -DLLAMA_BLAS_VENDOR=OpenBLAS" pip install llama-cpp-python
# Or with CLBLast acceleration
CMAKE_ARGS="-DLLAMA_CLBLAST=on" pip install llama-cpp-python
# Or with AMD ROCm GPU acceleration (Linux only)
CMAKE_ARGS="-DLLAMA_HIPBLAS=on" pip install llama-cpp-python
# Or with Metal GPU acceleration for macOS systems only
CMAKE_ARGS="-DLLAMA_METAL=on" pip install llama-cpp-python
# In windows, to set the variables CMAKE_ARGS in PowerShell, follow this format; eg for NVidia CUDA:
$env:CMAKE_ARGS = "-DLLAMA_OPENBLAS=on"
pip install llama-cpp-python
```
#### Simple llama-cpp-python example code
```python
from llama_cpp import Llama
# Set gpu_layers to the number of layers to offload to GPU. Set to 0 if no GPU acceleration is available on your system.
llm = Llama(
model_path="./Llama-2-13b-chat-norwegian.IQ3_M.gguf", # Download the model file first
n_ctx=32768, # The max sequence length to use - note that longer sequence lengths require much more resources
n_threads=8, # The number of CPU threads to use, tailor to your system and the resulting performance
n_gpu_layers=35 # The number of layers to offload to GPU, if you have GPU acceleration available
)
# Simple inference example
output = llm(
"<s>[INST] {{prompt}} [/INST]", # Prompt
max_tokens=512, # Generate up to 512 tokens
stop=["</s>"], # Example stop token - not necessarily correct for this specific model! Please check before using.
echo=True # Whether to echo the prompt
)
# Chat Completion API
llm = Llama(model_path="./Llama-2-13b-chat-norwegian.IQ3_M.gguf", chat_format="llama-2") # Set chat_format according to the model you are using
llm.create_chat_completion(
messages = [
{{"role": "system", "content": "You are a story writing assistant."}},
{{
"role": "user",
"content": "Write a story about llamas."
}}
]
)
```
- **Option D** - Running with LangChain
Here are guides on using llama-cpp-python and ctransformers with LangChain:
* [LangChain + llama-cpp-python](https://python.langchain.com/docs/integrations/llms/llamacpp)
* [LangChain + ctransformers](https://python.langchain.com/docs/integrations/providers/ctransformers)
## Configurations
The configuration info are in `smash_config.json`.
## Credits & License
The license of the smashed model follows the license of the original model. Please check the license of the original model before using this model which provided the base model. The license of the `pruna-engine` is [here](https://pypi.org/project/pruna-engine/) on Pypi.
## Want to compress other models?
- Contact us and tell us which model to compress next [here](https://www.pruna.ai/contact).
- Request access to easily compress your own AI models [here](https://z0halsaff74.typeform.com/pruna-access?typeform-source=www.pruna.ai). |
HPLT/hplt_bert_base_lv | HPLT | 2024-04-22T01:27:30Z | 16,606 | 0 | transformers | [
"transformers",
"pytorch",
"fill-mask",
"BERT",
"HPLT",
"encoder",
"custom_code",
"lv",
"dataset:HPLT/hplt_monolingual_v1_2",
"arxiv:2403.14009",
"license:apache-2.0",
"autotrain_compatible",
"region:us"
]
| fill-mask | 2024-04-22T01:27:09Z | ---
language:
- lv
inference: false
tags:
- BERT
- HPLT
- encoder
license: apache-2.0
datasets:
- HPLT/hplt_monolingual_v1_2
---
# HPLT Bert for Latvian
<img src="https://hplt-project.org/_next/static/media/logo-hplt.d5e16ca5.svg" width=12.5%>
This is one of the encoder-only monolingual language models trained as a first release by the [HPLT project](https://hplt-project.org/).
It is a so called masked language models. In particular, we used the modification of the classic BERT model named [LTG-BERT](https://aclanthology.org/2023.findings-eacl.146/).
A monolingual LTG-BERT model is trained for every major language in the [HPLT 1.2 data release](https://hplt-project.org/datasets/v1.2) (*75* models total).
All the HPLT encoder-only models use the same hyper-parameters, roughly following the BERT-base setup:
- hidden size: 768
- attention heads: 12
- layers: 12
- vocabulary size: 32768
Every model uses its own tokenizer trained on language-specific HPLT data.
See sizes of the training corpora, evaluation results and more in our [language model training report](https://hplt-project.org/HPLT_D4_1___First_language_models_trained.pdf).
[The training code](https://github.com/hplt-project/HPLT-WP4).
[The training statistics of all 75 runs](https://api.wandb.ai/links/ltg/kduj7mjn)
## Example usage
This model currently needs a custom wrapper from `modeling_ltgbert.py`, you should therefore load the model with `trust_remote_code=True`.
```python
import torch
from transformers import AutoTokenizer, AutoModelForMaskedLM
tokenizer = AutoTokenizer.from_pretrained("HPLT/hplt_bert_base_en")
model = AutoModelForMaskedLM.from_pretrained("HPLT/hplt_bert_base_en", trust_remote_code=True)
mask_id = tokenizer.convert_tokens_to_ids("[MASK]")
input_text = tokenizer("It's a beautiful[MASK].", return_tensors="pt")
output_p = model(**input_text)
output_text = torch.where(input_text.input_ids == mask_id, output_p.logits.argmax(-1), input_text.input_ids)
# should output: '[CLS] It's a beautiful place.[SEP]'
print(tokenizer.decode(output_text[0].tolist()))
```
The following classes are currently implemented: `AutoModel`, `AutoModelMaskedLM`, `AutoModelForSequenceClassification`, `AutoModelForTokenClassification`, `AutoModelForQuestionAnswering` and `AutoModeltForMultipleChoice`.
## Cite us
```bibtex
@misc{degibert2024new,
title={A New Massive Multilingual Dataset for High-Performance Language Technologies},
author={Ona de Gibert and Graeme Nail and Nikolay Arefyev and Marta Bañón and Jelmer van der Linde and Shaoxiong Ji and Jaume Zaragoza-Bernabeu and Mikko Aulamo and Gema Ramírez-Sánchez and Andrey Kutuzov and Sampo Pyysalo and Stephan Oepen and Jörg Tiedemann},
year={2024},
eprint={2403.14009},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
``` |
mradermacher/Llama-3-8B-TIES-legal-riddle-GGUF | mradermacher | 2024-07-02T01:34:13Z | 16,592 | 0 | transformers | [
"transformers",
"gguf",
"mergekit",
"merge",
"en",
"base_model:d4niel92/Llama-3-8B-TIES-legal-riddle",
"endpoints_compatible",
"region:us"
]
| null | 2024-07-02T00:37:52Z | ---
base_model: d4niel92/Llama-3-8B-TIES-legal-riddle
language:
- en
library_name: transformers
quantized_by: mradermacher
tags:
- mergekit
- merge
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
static quants of https://huggingface.co/d4niel92/Llama-3-8B-TIES-legal-riddle
<!-- provided-files -->
weighted/imatrix quants seem not to be available (by me) at this time. If they do not show up a week or so after the static ones, I have probably not planned for them. Feel free to request them by opening a Community Discussion.
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/Llama-3-8B-TIES-legal-riddle-GGUF/resolve/main/Llama-3-8B-TIES-legal-riddle.Q2_K.gguf) | Q2_K | 3.3 | |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-8B-TIES-legal-riddle-GGUF/resolve/main/Llama-3-8B-TIES-legal-riddle.IQ3_XS.gguf) | IQ3_XS | 3.6 | |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-8B-TIES-legal-riddle-GGUF/resolve/main/Llama-3-8B-TIES-legal-riddle.Q3_K_S.gguf) | Q3_K_S | 3.8 | |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-8B-TIES-legal-riddle-GGUF/resolve/main/Llama-3-8B-TIES-legal-riddle.IQ3_S.gguf) | IQ3_S | 3.8 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-8B-TIES-legal-riddle-GGUF/resolve/main/Llama-3-8B-TIES-legal-riddle.IQ3_M.gguf) | IQ3_M | 3.9 | |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-8B-TIES-legal-riddle-GGUF/resolve/main/Llama-3-8B-TIES-legal-riddle.Q3_K_M.gguf) | Q3_K_M | 4.1 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-8B-TIES-legal-riddle-GGUF/resolve/main/Llama-3-8B-TIES-legal-riddle.Q3_K_L.gguf) | Q3_K_L | 4.4 | |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-8B-TIES-legal-riddle-GGUF/resolve/main/Llama-3-8B-TIES-legal-riddle.IQ4_XS.gguf) | IQ4_XS | 4.6 | |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-8B-TIES-legal-riddle-GGUF/resolve/main/Llama-3-8B-TIES-legal-riddle.Q4_K_S.gguf) | Q4_K_S | 4.8 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-8B-TIES-legal-riddle-GGUF/resolve/main/Llama-3-8B-TIES-legal-riddle.Q4_K_M.gguf) | Q4_K_M | 5.0 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-8B-TIES-legal-riddle-GGUF/resolve/main/Llama-3-8B-TIES-legal-riddle.Q5_K_S.gguf) | Q5_K_S | 5.7 | |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-8B-TIES-legal-riddle-GGUF/resolve/main/Llama-3-8B-TIES-legal-riddle.Q5_K_M.gguf) | Q5_K_M | 5.8 | |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-8B-TIES-legal-riddle-GGUF/resolve/main/Llama-3-8B-TIES-legal-riddle.Q6_K.gguf) | Q6_K | 6.7 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-8B-TIES-legal-riddle-GGUF/resolve/main/Llama-3-8B-TIES-legal-riddle.Q8_0.gguf) | Q8_0 | 8.6 | fast, best quality |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-8B-TIES-legal-riddle-GGUF/resolve/main/Llama-3-8B-TIES-legal-riddle.f16.gguf) | f16 | 16.2 | 16 bpw, overkill |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
nvidia/mit-b1 | nvidia | 2022-08-06T10:25:12Z | 16,591 | 1 | transformers | [
"transformers",
"pytorch",
"tf",
"segformer",
"image-classification",
"vision",
"dataset:imagenet_1k",
"arxiv:2105.15203",
"license:other",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| image-classification | 2022-03-02T23:29:05Z | ---
license: other
tags:
- vision
datasets:
- imagenet_1k
widget:
- src: https://huggingface.co/datasets/hf-internal-testing/fixtures_ade20k/resolve/main/ADE_val_00000001.jpg
example_title: House
- src: https://huggingface.co/datasets/hf-internal-testing/fixtures_ade20k/resolve/main/ADE_val_00000002.jpg
example_title: Castle
---
# SegFormer (b1-sized) encoder pre-trained-only
SegFormer encoder fine-tuned on Imagenet-1k. It was introduced in the paper [SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers](https://arxiv.org/abs/2105.15203) by Xie et al. and first released in [this repository](https://github.com/NVlabs/SegFormer).
Disclaimer: The team releasing SegFormer did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
SegFormer consists of a hierarchical Transformer encoder and a lightweight all-MLP decode head to achieve great results on semantic segmentation benchmarks such as ADE20K and Cityscapes. The hierarchical Transformer is first pre-trained on ImageNet-1k, after which a decode head is added and fine-tuned altogether on a downstream dataset.
This repository only contains the pre-trained hierarchical Transformer, hence it can be used for fine-tuning purposes.
## Intended uses & limitations
You can use the model for fine-tuning of semantic segmentation. See the [model hub](https://huggingface.co/models?other=segformer) to look for fine-tuned versions on a task that interests you.
### How to use
Here is how to use this model to classify an image of the COCO 2017 dataset into one of the 1,000 ImageNet classes:
```python
from transformers import SegformerFeatureExtractor, SegformerForImageClassification
from PIL import Image
import requests
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
feature_extractor = SegformerFeatureExtractor.from_pretrained("nvidia/mit-b1")
model = SegformerForImageClassification.from_pretrained("nvidia/mit-b1")
inputs = feature_extractor(images=image, return_tensors="pt")
outputs = model(**inputs)
logits = outputs.logits
# model predicts one of the 1000 ImageNet classes
predicted_class_idx = logits.argmax(-1).item()
print("Predicted class:", model.config.id2label[predicted_class_idx])
```
For more code examples, we refer to the [documentation](https://huggingface.co/transformers/model_doc/segformer.html#).
### License
The license for this model can be found [here](https://github.com/NVlabs/SegFormer/blob/master/LICENSE).
### BibTeX entry and citation info
```bibtex
@article{DBLP:journals/corr/abs-2105-15203,
author = {Enze Xie and
Wenhai Wang and
Zhiding Yu and
Anima Anandkumar and
Jose M. Alvarez and
Ping Luo},
title = {SegFormer: Simple and Efficient Design for Semantic Segmentation with
Transformers},
journal = {CoRR},
volume = {abs/2105.15203},
year = {2021},
url = {https://arxiv.org/abs/2105.15203},
eprinttype = {arXiv},
eprint = {2105.15203},
timestamp = {Wed, 02 Jun 2021 11:46:42 +0200},
biburl = {https://dblp.org/rec/journals/corr/abs-2105-15203.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
```
|
mradermacher/Genesist-8B-EarlyPrototype-0.4-GGUF | mradermacher | 2024-06-24T18:47:10Z | 16,591 | 0 | transformers | [
"transformers",
"gguf",
"text-generation",
"sft",
"llama",
"llama-3",
"unsloth",
"id",
"en",
"dataset:genesist-logs",
"base_model:dwikitheduck/Genesist-8B-EarlyPrototype-0.4",
"license:llama3",
"endpoints_compatible",
"region:us"
]
| text-generation | 2024-06-24T18:18:39Z | ---
base_model: dwikitheduck/Genesist-8B-EarlyPrototype-0.4
datasets:
- genesist-logs
language:
- id
- en
library_name: transformers
license: llama3
quantized_by: mradermacher
tags:
- text-generation
- sft
- llama
- llama-3
- unsloth
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
static quants of https://huggingface.co/dwikitheduck/Genesist-8B-EarlyPrototype-0.4
<!-- provided-files -->
weighted/imatrix quants seem not to be available (by me) at this time. If they do not show up a week or so after the static ones, I have probably not planned for them. Feel free to request them by opening a Community Discussion.
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/Genesist-8B-EarlyPrototype-0.4-GGUF/resolve/main/Genesist-8B-EarlyPrototype-0.4.Q2_K.gguf) | Q2_K | 3.3 | |
| [GGUF](https://huggingface.co/mradermacher/Genesist-8B-EarlyPrototype-0.4-GGUF/resolve/main/Genesist-8B-EarlyPrototype-0.4.IQ3_XS.gguf) | IQ3_XS | 3.6 | |
| [GGUF](https://huggingface.co/mradermacher/Genesist-8B-EarlyPrototype-0.4-GGUF/resolve/main/Genesist-8B-EarlyPrototype-0.4.Q3_K_S.gguf) | Q3_K_S | 3.8 | |
| [GGUF](https://huggingface.co/mradermacher/Genesist-8B-EarlyPrototype-0.4-GGUF/resolve/main/Genesist-8B-EarlyPrototype-0.4.IQ3_S.gguf) | IQ3_S | 3.8 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/Genesist-8B-EarlyPrototype-0.4-GGUF/resolve/main/Genesist-8B-EarlyPrototype-0.4.IQ3_M.gguf) | IQ3_M | 3.9 | |
| [GGUF](https://huggingface.co/mradermacher/Genesist-8B-EarlyPrototype-0.4-GGUF/resolve/main/Genesist-8B-EarlyPrototype-0.4.Q3_K_M.gguf) | Q3_K_M | 4.1 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/Genesist-8B-EarlyPrototype-0.4-GGUF/resolve/main/Genesist-8B-EarlyPrototype-0.4.Q3_K_L.gguf) | Q3_K_L | 4.4 | |
| [GGUF](https://huggingface.co/mradermacher/Genesist-8B-EarlyPrototype-0.4-GGUF/resolve/main/Genesist-8B-EarlyPrototype-0.4.IQ4_XS.gguf) | IQ4_XS | 4.6 | |
| [GGUF](https://huggingface.co/mradermacher/Genesist-8B-EarlyPrototype-0.4-GGUF/resolve/main/Genesist-8B-EarlyPrototype-0.4.Q4_K_S.gguf) | Q4_K_S | 4.8 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Genesist-8B-EarlyPrototype-0.4-GGUF/resolve/main/Genesist-8B-EarlyPrototype-0.4.Q4_K_M.gguf) | Q4_K_M | 5.0 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Genesist-8B-EarlyPrototype-0.4-GGUF/resolve/main/Genesist-8B-EarlyPrototype-0.4.Q5_K_S.gguf) | Q5_K_S | 5.7 | |
| [GGUF](https://huggingface.co/mradermacher/Genesist-8B-EarlyPrototype-0.4-GGUF/resolve/main/Genesist-8B-EarlyPrototype-0.4.Q5_K_M.gguf) | Q5_K_M | 5.8 | |
| [GGUF](https://huggingface.co/mradermacher/Genesist-8B-EarlyPrototype-0.4-GGUF/resolve/main/Genesist-8B-EarlyPrototype-0.4.Q6_K.gguf) | Q6_K | 6.7 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/Genesist-8B-EarlyPrototype-0.4-GGUF/resolve/main/Genesist-8B-EarlyPrototype-0.4.Q8_0.gguf) | Q8_0 | 8.6 | fast, best quality |
| [GGUF](https://huggingface.co/mradermacher/Genesist-8B-EarlyPrototype-0.4-GGUF/resolve/main/Genesist-8B-EarlyPrototype-0.4.f16.gguf) | f16 | 16.2 | 16 bpw, overkill |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
TinyLlama/TinyLlama-1.1B-Chat-v0.6 | TinyLlama | 2023-11-20T11:22:36Z | 16,577 | 77 | transformers | [
"transformers",
"safetensors",
"gguf",
"llama",
"text-generation",
"conversational",
"en",
"dataset:cerebras/SlimPajama-627B",
"dataset:bigcode/starcoderdata",
"dataset:OpenAssistant/oasst_top1_2023-08-25",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| text-generation | 2023-11-20T08:59:23Z | ---
license: apache-2.0
datasets:
- cerebras/SlimPajama-627B
- bigcode/starcoderdata
- OpenAssistant/oasst_top1_2023-08-25
language:
- en
---
<div align="center">
# TinyLlama-1.1B
</div>
https://github.com/jzhang38/TinyLlama
The TinyLlama project aims to **pretrain** a **1.1B Llama model on 3 trillion tokens**. With some proper optimization, we can achieve this within a span of "just" 90 days using 16 A100-40G GPUs 🚀🚀. The training has started on 2023-09-01.
We adopted exactly the same architecture and tokenizer as Llama 2. This means TinyLlama can be plugged and played in many open-source projects built upon Llama. Besides, TinyLlama is compact with only 1.1B parameters. This compactness allows it to cater to a multitude of applications demanding a restricted computation and memory footprint.
#### This Model
This is the chat model finetuned on top of [TinyLlama/TinyLlama-1.1B-intermediate-step-955k-2T](https://huggingface.co/TinyLlama/TinyLlama-1.1B-intermediate-step-955k-token-2T). **We follow [HF's Zephyr](https://huggingface.co/HuggingFaceH4/zephyr-7b-alpha/edit/main/README.md)'s training recipe.** The model was " initially fine-tuned on a variant of the [`UltraChat`](https://huggingface.co/datasets/stingning/ultrachat) dataset, which contains a diverse range of synthetic dialogues generated by ChatGPT.
We then further aligned the model with [🤗 TRL's](https://github.com/huggingface/trl) `DPOTrainer` on the [openbmb/UltraFeedback](https://huggingface.co/datasets/openbmb/UltraFeedback) dataset, which contain 64k prompts and model completions that are ranked by GPT-4."
#### How to use
You will need the transformers>=4.34
Do check the [TinyLlama](https://github.com/jzhang38/TinyLlama) github page for more information.
```python
# Install transformers from source - only needed for versions <= v4.34
# pip install git+https://github.com/huggingface/transformers.git
# pip install accelerate
import torch
from transformers import pipeline
pipe = pipeline("text-generation", model="TinyLlama/TinyLlama-1.1B-Chat-v0.6", torch_dtype=torch.bfloat16, device_map="auto")
# We use the tokenizer's chat template to format each message - see https://huggingface.co/docs/transformers/main/en/chat_templating
messages = [
{
"role": "system",
"content": "You are a friendly chatbot who always responds in the style of a pirate",
},
{"role": "user", "content": "How many helicopters can a human eat in one sitting?"},
]
prompt = pipe.tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
outputs = pipe(prompt, max_new_tokens=256, do_sample=True, temperature=0.7, top_k=50, top_p=0.95)
print(outputs[0]["generated_text"])
# <|system|>
# You are a friendly chatbot who always responds in the style of a pirate.</s>
# <|user|>
# How many helicopters can a human eat in one sitting?</s>
# <|assistant|>
# ...
``` |
mradermacher/Swallow-13b-hf-GGUF | mradermacher | 2024-06-30T07:38:33Z | 16,560 | 0 | transformers | [
"transformers",
"gguf",
"en",
"ja",
"base_model:tokyotech-llm/Swallow-13b-hf",
"license:llama2",
"endpoints_compatible",
"region:us"
]
| null | 2024-06-29T21:32:17Z | ---
base_model: tokyotech-llm/Swallow-13b-hf
language:
- en
- ja
library_name: transformers
license: llama2
model_type: llama
quantized_by: mradermacher
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
static quants of https://huggingface.co/tokyotech-llm/Swallow-13b-hf
<!-- provided-files -->
weighted/imatrix quants are available at https://huggingface.co/mradermacher/Swallow-13b-hf-i1-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/Swallow-13b-hf-GGUF/resolve/main/Swallow-13b-hf.Q2_K.gguf) | Q2_K | 5.0 | |
| [GGUF](https://huggingface.co/mradermacher/Swallow-13b-hf-GGUF/resolve/main/Swallow-13b-hf.IQ3_XS.gguf) | IQ3_XS | 5.5 | |
| [GGUF](https://huggingface.co/mradermacher/Swallow-13b-hf-GGUF/resolve/main/Swallow-13b-hf.IQ3_S.gguf) | IQ3_S | 5.8 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/Swallow-13b-hf-GGUF/resolve/main/Swallow-13b-hf.Q3_K_S.gguf) | Q3_K_S | 5.8 | |
| [GGUF](https://huggingface.co/mradermacher/Swallow-13b-hf-GGUF/resolve/main/Swallow-13b-hf.IQ3_M.gguf) | IQ3_M | 6.2 | |
| [GGUF](https://huggingface.co/mradermacher/Swallow-13b-hf-GGUF/resolve/main/Swallow-13b-hf.Q3_K_M.gguf) | Q3_K_M | 6.5 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/Swallow-13b-hf-GGUF/resolve/main/Swallow-13b-hf.Q3_K_L.gguf) | Q3_K_L | 7.1 | |
| [GGUF](https://huggingface.co/mradermacher/Swallow-13b-hf-GGUF/resolve/main/Swallow-13b-hf.IQ4_XS.gguf) | IQ4_XS | 7.2 | |
| [GGUF](https://huggingface.co/mradermacher/Swallow-13b-hf-GGUF/resolve/main/Swallow-13b-hf.Q4_K_S.gguf) | Q4_K_S | 7.6 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Swallow-13b-hf-GGUF/resolve/main/Swallow-13b-hf.Q4_K_M.gguf) | Q4_K_M | 8.0 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Swallow-13b-hf-GGUF/resolve/main/Swallow-13b-hf.Q5_K_S.gguf) | Q5_K_S | 9.2 | |
| [GGUF](https://huggingface.co/mradermacher/Swallow-13b-hf-GGUF/resolve/main/Swallow-13b-hf.Q5_K_M.gguf) | Q5_K_M | 9.4 | |
| [GGUF](https://huggingface.co/mradermacher/Swallow-13b-hf-GGUF/resolve/main/Swallow-13b-hf.Q6_K.gguf) | Q6_K | 10.9 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/Swallow-13b-hf-GGUF/resolve/main/Swallow-13b-hf.Q8_0.gguf) | Q8_0 | 14.1 | fast, best quality |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
mental/mental-bert-base-uncased | mental | 2023-02-27T20:07:55Z | 16,559 | 23 | transformers | [
"transformers",
"pytorch",
"bert",
"fill-mask",
"mental health",
"en",
"arxiv:2110.15621",
"license:cc-by-nc-4.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| fill-mask | 2022-03-02T23:29:05Z | ---
license: cc-by-nc-4.0
language:
- en
library_name: transformers
tags:
- mental health
---
# MentalBERT
[MentalBERT](https://arxiv.org/abs/2110.15621) is a model initialized with BERT-Base (`uncased_L-12_H-768_A-12`) and trained with mental health-related posts collected from Reddit.
We follow the standard pretraining protocols of BERT and RoBERTa with [Huggingface’s Transformers library](https://github.com/huggingface/transformers).
We use four Nvidia Tesla v100 GPUs to train the two language models. We set the batch size to 16 per GPU, evaluate every 1,000 steps, and train for 624,000 iterations. Training with four GPUs takes around eight days.
More domain-specific pretrained models for mental health are available at https://huggingface.co/AIMH
## Usage
Load the model via [Huggingface’s Transformers library](https://github.com/huggingface/transformers):
```
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("mental/mental-bert-base-uncased")
model = AutoModel.from_pretrained("mental/mental-bert-base-uncased")
```
To minimize the influence of worrying mask predictions, this model is gated. To download a gated model, you’ll need to be authenticated.
Know more about [gated models](https://huggingface.co/docs/hub/models-gated).
## Paper
For more details, refer to the paper [MentalBERT: Publicly Available Pretrained Language Models for Mental Healthcare](https://arxiv.org/abs/2110.15621).
```
@inproceedings{ji2022mentalbert,
title = {{MentalBERT: Publicly Available Pretrained Language Models for Mental Healthcare}},
author = {Shaoxiong Ji and Tianlin Zhang and Luna Ansari and Jie Fu and Prayag Tiwari and Erik Cambria},
year = {2022},
booktitle = {Proceedings of LREC}
}
```
## Social Impact
We train and release masked language models for mental health to facilitate the automatic detection of mental disorders in online social content for non-clinical use.
The models may help social workers find potential individuals in need of early prevention.
However, the model predictions are not psychiatric diagnoses.
We recommend anyone who suffers from mental health issues to call the local mental health helpline and seek professional help if possible.
Data privacy is an important issue, and we try to minimize the privacy impact when using social posts for model training.
During the data collection process, we only use anonymous posts that are manifestly available to the public.
We do not collect user profiles even though they are also manifestly public online.
We have not attempted to identify the anonymous users or interact with any anonymous users.
The collected data are stored securely with password protection even though they are collected from the open web.
There might also be some bias, fairness, uncertainty, and interpretability issues during the data collection and model training.
Evaluation of those issues is essential in future research. |
ali-vilab/i2vgen-xl | ali-vilab | 2024-02-09T13:57:25Z | 16,559 | 145 | diffusers | [
"diffusers",
"safetensors",
"image-to-video",
"text-to-video",
"arxiv:2312.09109",
"arxiv:2308.06571",
"arxiv:2311.04145",
"license:mit",
"diffusers:I2VGenXLPipeline",
"region:us"
]
| text-to-video | 2023-12-15T06:28:05Z | ---
license: mit
tags:
- image-to-video
pipeline_tag: text-to-video
---
# VGen

VGen is an open-source video synthesis codebase developed by the Tongyi Lab of Alibaba Group, featuring state-of-the-art video generative models. This repository includes implementations of the following methods:
- [I2VGen-xl: High-quality image-to-video synthesis via cascaded diffusion models](https://i2vgen-xl.github.io/)
- [VideoComposer: Compositional Video Synthesis with Motion Controllability](https://videocomposer.github.io/)
- [Hierarchical Spatio-temporal Decoupling for Text-to-Video Generation](https://higen-t2v.github.io/)
- [A Recipe for Scaling up Text-to-Video Generation with Text-free Videos]()
- [InstructVideo: Instructing Video Diffusion Models with Human Feedback]()
- [DreamVideo: Composing Your Dream Videos with Customized Subject and Motion](https://dreamvideo-t2v.github.io/)
- [VideoLCM: Video Latent Consistency Model](https://arxiv.org/abs/2312.09109)
- [Modelscope text-to-video technical report](https://arxiv.org/abs/2308.06571)
VGen can produce high-quality videos from the input text, images, desired motion, desired subjects, and even the feedback signals provided. It also offers a variety of commonly used video generation tools such as visualization, sampling, training, inference, join training using images and videos, acceleration, and more.
<a href='https://i2vgen-xl.github.io/'><img src='https://img.shields.io/badge/Project-Page-Green'></a> <a href='https://arxiv.org/abs/2311.04145'><img src='https://img.shields.io/badge/Paper-Arxiv-red'></a> [](https://youtu.be/XUi0y7dxqEQ) <a href='https://cloud.video.taobao.com/play/u/null/p/1/e/6/t/1/441039979087.mp4'><img src='source/logo.png'></a>
## 🔥News!!!
- __[2023.12]__ We release the high-efficiency video generation method [VideoLCM](https://arxiv.org/abs/2312.09109)
- __[2023.12]__ We release the code and model of I2VGen-XL and the ModelScope T2V
- __[2023.12]__ We release the T2V method [HiGen](https://higen-t2v.github.io) and customizing T2V method [DreamVideo](https://dreamvideo-t2v.github.io).
- __[2023.12]__ We write an [introduction docment](doc/introduction.pdf) for VGen and compare I2VGen-XL with SVD.
- __[2023.11]__ We release a high-quality I2VGen-XL model, please refer to the [Webpage](https://i2vgen-xl.github.io)
## TODO
- [x] Release the technical papers and webpage of [I2VGen-XL](doc/i2vgen-xl.md)
- [x] Release the code and pretrained models that can generate 1280x720 videos
- [ ] Release models optimized specifically for the human body and faces
- [ ] Updated version can fully maintain the ID and capture large and accurate motions simultaneously
- [ ] Release other methods and the corresponding models
## Preparation
The main features of VGen are as follows:
- Expandability, allowing for easy management of your own experiments.
- Completeness, encompassing all common components for video generation.
- Excellent performance, featuring powerful pre-trained models in multiple tasks.
### Installation
```
conda create -n vgen python=3.8
conda activate vgen
pip install torch==1.12.0+cu113 torchvision==0.13.0+cu113 torchaudio==0.12.0 --extra-index-url https://download.pytorch.org/whl/cu113
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
```
### Datasets
We have provided a **demo dataset** that includes images and videos, along with their lists in ``data``.
*Please note that the demo images used here are for testing purposes and were not included in the training.*
### Clone codeb
```
git clone https://github.com/damo-vilab/i2vgen-xl.git
cd i2vgen-xl
```
## Getting Started with VGen
### (1) Train your text-to-video model
Executing the following command to enable distributed training is as easy as that.
```
python train_net.py --cfg configs/t2v_train.yaml
```
In the `t2v_train.yaml` configuration file, you can specify the data, adjust the video-to-image ratio using `frame_lens`, and validate your ideas with different Diffusion settings, and so on.
- Before the training, you can download any of our open-source models for initialization. Our codebase supports custom initialization and `grad_scale` settings, all of which are included in the `Pretrain` item in yaml file.
- During the training, you can view the saved models and intermediate inference results in the `workspace/experiments/t2v_train`directory.
After the training is completed, you can perform inference on the model using the following command.
```
python inference.py --cfg configs/t2v_infer.yaml
```
Then you can find the videos you generated in the `workspace/experiments/test_img_01` directory. For specific configurations such as data, models, seed, etc., please refer to the `t2v_infer.yaml` file.
<!-- <table>
<center>
<tr>
<td ><center>
<video muted="true" autoplay="true" loop="true" height="260" src="https://cloud.video.taobao.com/play/u/null/p/1/e/6/t/1/441754174077.mp4"></video>
</center></td>
<td ><center>
<video muted="true" autoplay="true" loop="true" height="260" src="https://cloud.video.taobao.com/play/u/null/p/1/e/6/t/1/441138824052.mp4"></video>
</center></td>
</tr>
</center>
</table>
</center> -->
<table>
<center>
<tr>
<td ><center>
<image height="260" src="https://img.alicdn.com/imgextra/i4/O1CN01Ya2I5I25utrJwJ9Jf_!!6000000007587-2-tps-1280-720.png"></image>
</center></td>
<td ><center>
<image height="260" src="https://img.alicdn.com/imgextra/i3/O1CN01CrmYaz1zXBetmg3dd_!!6000000006723-2-tps-1280-720.png"></image>
</center></td>
</tr>
<tr>
<td ><center>
<p>Clike <a href="https://cloud.video.taobao.com/play/u/null/p/1/e/6/t/1/441754174077.mp4">HRER</a> to view the generated video.</p>
</center></td>
<td ><center>
<p>Clike <a href="https://cloud.video.taobao.com/play/u/null/p/1/e/6/t/1/441138824052.mp4">HRER</a> to view the generated video.</p>
</center></td>
</tr>
</center>
</table>
</center>
### (2) Run the I2VGen-XL model
(i) Download model and test data:
```
!pip install modelscope
from modelscope.hub.snapshot_download import snapshot_download
model_dir = snapshot_download('damo/I2VGen-XL', cache_dir='models/', revision='v1.0.0')
```
(ii) Run the following command:
```
python inference.py --cfg configs/i2vgen_xl_infer.yaml
```
In a few minutes, you can retrieve the high-definition video you wish to create from the `workspace/experiments/test_img_01` directory. At present, we find that the current model performs inadequately on **anime images** and **images with a black background** due to the lack of relevant training data. We are consistently working to optimize it.
<span style="color:red">Due to the compression of our video quality in GIF format, please click 'HRER' below to view the original video.</span>
<center>
<table>
<center>
<tr>
<td ><center>
<image height="260" src="https://img.alicdn.com/imgextra/i1/O1CN01CCEq7K1ZeLpNQqrWu_!!6000000003219-0-tps-1280-720.jpg"></image>
</center></td>
<td ><center>
<!-- <video muted="true" autoplay="true" loop="true" height="260" src="https://cloud.video.taobao.com/play/u/null/p/1/e/6/t/1/442125067544.mp4"></video> -->
<image height="260" src="https://img.alicdn.com/imgextra/i4/O1CN01hIQcvG1spmQMLqBo0_!!6000000005816-1-tps-1280-704.gif"></image>
</center></td>
</tr>
<tr>
<td ><center>
<p>Input Image</p>
</center></td>
<td ><center>
<p>Clike <a href="https://cloud.video.taobao.com/play/u/null/p/1/e/6/t/1/442125067544.mp4">HRER</a> to view the generated video.</p>
</center></td>
</tr>
<tr>
<td ><center>
<image height="260" src="https://img.alicdn.com/imgextra/i4/O1CN01ZXY7UN23K8q4oQ3uG_!!6000000007236-2-tps-1280-720.png"></image>
</center></td>
<td ><center>
<!-- <video muted="true" autoplay="true" loop="true" height="260" src="https://cloud.video.taobao.com/play/u/null/p/1/e/6/t/1/441385957074.mp4"></video> -->
<image height="260" src="https://img.alicdn.com/imgextra/i1/O1CN01iaSiiv1aJZURUEY53_!!6000000003309-1-tps-1280-704.gif"></image>
</center></td>
</tr>
<tr>
<td ><center>
<p>Input Image</p>
</center></td>
<td ><center>
<p>Clike <a href="https://cloud.video.taobao.com/play/u/null/p/1/e/6/t/1/441385957074.mp4">HRER</a> to view the generated video.</p>
</center></td>
</tr>
<tr>
<td ><center>
<image height="260" src="https://img.alicdn.com/imgextra/i3/O1CN01NHpVGl1oat4H54Hjf_!!6000000005242-2-tps-1280-720.png"></image>
</center></td>
<td ><center>
<!-- <video muted="true" autoplay="true" loop="true" height="260" src="https://cloud.video.taobao.com/play/u/null/p/1/e/6/t/1/442102706767.mp4"></video> -->
<!-- <image muted="true" height="260" src="https://img.alicdn.com/imgextra/i4/O1CN01DgLj1T240jfpzKoaQ_!!6000000007329-1-tps-1280-704.gif"></image>
-->
<image height="260" src="https://img.alicdn.com/imgextra/i4/O1CN01DgLj1T240jfpzKoaQ_!!6000000007329-1-tps-1280-704.gif"></image>
</center></td>
</tr>
<tr>
<td ><center>
<p>Input Image</p>
</center></td>
<td ><center>
<p>Clike <a href="https://cloud.video.taobao.com/play/u/null/p/1/e/6/t/1/442102706767.mp4">HERE</a> to view the generated video.</p>
</center></td>
</tr>
<tr>
<td ><center>
<image height="260" src="https://img.alicdn.com/imgextra/i1/O1CN01odS61s1WW9tXen21S_!!6000000002795-0-tps-1280-720.jpg"></image>
</center></td>
<td ><center>
<!-- <video muted="true" autoplay="true" loop="true" height="260" src="https://cloud.video.taobao.com/play/u/null/p/1/e/6/t/1/442163934688.mp4"></video> -->
<image height="260" src="https://img.alicdn.com/imgextra/i3/O1CN01Jyk1HT28JkZtpAtY6_!!6000000007912-1-tps-1280-704.gif"></image>
</center></td>
</tr>
<tr>
<td ><center>
<p>Input Image</p>
</center></td>
<td ><center>
<p>Clike <a href="https://cloud.video.taobao.com/play/u/null/p/1/e/6/t/1/442163934688.mp4">HERE</a> to view the generated video.</p>
</center></td>
</tr>
</center>
</table>
</center>
### (3) Other methods
In preparation.
## Customize your own approach
Our codebase essentially supports all the commonly used components in video generation. You can manage your experiments flexibly by adding corresponding registration classes, including `ENGINE, MODEL, DATASETS, EMBEDDER, AUTO_ENCODER, DISTRIBUTION, VISUAL, DIFFUSION, PRETRAIN`, and can be compatible with all our open-source algorithms according to your own needs. If you have any questions, feel free to give us your feedback at any time.
## Integration of I2VGenXL with 🧨 diffusers
I2VGenXL is supported in the 🧨 diffusers library. Here's how to use it:
```python
import torch
from diffusers import I2VGenXLPipeline
from diffusers.utils import load_image, export_to_gif
repo_id = "ali-vilab/i2vgen-xl"
pipeline = I2VGenXLPipeline.from_pretrained(repo_id, torch_dtype=torch.float16, variant="fp16").to("cuda")
image_url = "https://github.com/ali-vilab/i2vgen-xl/blob/main/data/test_images/img_0009.png?download=true"
image = load_image(image_url).convert("RGB")
prompt = "Papers were floating in the air on a table in the library"
generator = torch.manual_seed(8888)
frames = pipeline(
prompt=prompt,
image=image,
generator=generator
).frames[0]
print(export_to_gif(frames))
```
Find the official documentation [here](https://huggingface.co/docs/diffusers/main/en/api/pipelines/i2vgenxl).
Sample output with I2VGenXL:
<table>
<tr>
<td><center>
masterpiece, bestquality, sunset.
<br>
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/i2vgen-xl-example.gif"
alt="library"
style="width: 300px;" />
</center></td>
</tr>
</table>
## BibTeX
If this repo is useful to you, please cite our corresponding technical paper.
```bibtex
@article{2023i2vgenxl,
title={I2VGen-XL: High-Quality Image-to-Video Synthesis via Cascaded Diffusion Models},
author={Zhang, Shiwei and Wang, Jiayu and Zhang, Yingya and Zhao, Kang and Yuan, Hangjie and Qing, Zhiwu and Wang, Xiang and Zhao, Deli and Zhou, Jingren},
booktitle={arXiv preprint arXiv:2311.04145},
year={2023}
}
@article{2023videocomposer,
title={VideoComposer: Compositional Video Synthesis with Motion Controllability},
author={Wang, Xiang and Yuan, Hangjie and Zhang, Shiwei and Chen, Dayou and Wang, Jiuniu, and Zhang, Yingya, and Shen, Yujun, and Zhao, Deli and Zhou, Jingren},
booktitle={arXiv preprint arXiv:2306.02018},
year={2023}
}
@article{wang2023modelscope,
title={Modelscope text-to-video technical report},
author={Wang, Jiuniu and Yuan, Hangjie and Chen, Dayou and Zhang, Yingya and Wang, Xiang and Zhang, Shiwei},
journal={arXiv preprint arXiv:2308.06571},
year={2023}
}
@article{dreamvideo,
title={DreamVideo: Composing Your Dream Videos with Customized Subject and Motion},
author={Wei, Yujie and Zhang, Shiwei and Qing, Zhiwu and Yuan, Hangjie and Liu, Zhiheng and Liu, Yu and Zhang, Yingya and Zhou, Jingren and Shan, Hongming},
journal={arXiv preprint arXiv:2312.04433},
year={2023}
}
@article{qing2023higen,
title={Hierarchical Spatio-temporal Decoupling for Text-to-Video Generation},
author={Qing, Zhiwu and Zhang, Shiwei and Wang, Jiayu and Wang, Xiang and Wei, Yujie and Zhang, Yingya and Gao, Changxin and Sang, Nong },
journal={arXiv preprint arXiv:2312.04483},
year={2023}
}
@article{wang2023videolcm,
title={VideoLCM: Video Latent Consistency Model},
author={Wang, Xiang and Zhang, Shiwei and Zhang, Han and Liu, Yu and Zhang, Yingya and Gao, Changxin and Sang, Nong },
journal={arXiv preprint arXiv:2312.09109},
year={2023}
}
```
## Disclaimer
This open-source model is trained with using [WebVid-10M](https://m-bain.github.io/webvid-dataset/) and [LAION-400M](https://laion.ai/blog/laion-400-open-dataset/) datasets and is intended for <strong>RESEARCH/NON-COMMERCIAL USE ONLY</strong>. |
mradermacher/trithemius-mistral-0.3-7b-i1-GGUF | mradermacher | 2024-06-27T04:18:14Z | 16,555 | 0 | transformers | [
"transformers",
"gguf",
"json mode",
"function calling",
"chatml",
"mistral",
"digital alchemy",
"en",
"base_model:jmars/trithemius-mistral-0.3-7b",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
]
| null | 2024-06-27T03:06:51Z | ---
base_model: jmars/trithemius-mistral-0.3-7b
language:
- en
library_name: transformers
license: apache-2.0
quantized_by: mradermacher
tags:
- json mode
- function calling
- chatml
- mistral
- digital alchemy
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: nicoboss -->
weighted/imatrix quants of https://huggingface.co/jmars/trithemius-mistral-0.3-7b
<!-- provided-files -->
static quants are available at https://huggingface.co/mradermacher/trithemius-mistral-0.3-7b-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/trithemius-mistral-0.3-7b-i1-GGUF/resolve/main/trithemius-mistral-0.3-7b.i1-IQ1_S.gguf) | i1-IQ1_S | 1.7 | for the desperate |
| [GGUF](https://huggingface.co/mradermacher/trithemius-mistral-0.3-7b-i1-GGUF/resolve/main/trithemius-mistral-0.3-7b.i1-IQ1_M.gguf) | i1-IQ1_M | 1.9 | mostly desperate |
| [GGUF](https://huggingface.co/mradermacher/trithemius-mistral-0.3-7b-i1-GGUF/resolve/main/trithemius-mistral-0.3-7b.i1-IQ2_XXS.gguf) | i1-IQ2_XXS | 2.1 | |
| [GGUF](https://huggingface.co/mradermacher/trithemius-mistral-0.3-7b-i1-GGUF/resolve/main/trithemius-mistral-0.3-7b.i1-IQ2_XS.gguf) | i1-IQ2_XS | 2.3 | |
| [GGUF](https://huggingface.co/mradermacher/trithemius-mistral-0.3-7b-i1-GGUF/resolve/main/trithemius-mistral-0.3-7b.i1-IQ2_S.gguf) | i1-IQ2_S | 2.4 | |
| [GGUF](https://huggingface.co/mradermacher/trithemius-mistral-0.3-7b-i1-GGUF/resolve/main/trithemius-mistral-0.3-7b.i1-IQ2_M.gguf) | i1-IQ2_M | 2.6 | |
| [GGUF](https://huggingface.co/mradermacher/trithemius-mistral-0.3-7b-i1-GGUF/resolve/main/trithemius-mistral-0.3-7b.i1-Q2_K.gguf) | i1-Q2_K | 2.8 | IQ3_XXS probably better |
| [GGUF](https://huggingface.co/mradermacher/trithemius-mistral-0.3-7b-i1-GGUF/resolve/main/trithemius-mistral-0.3-7b.i1-IQ3_XXS.gguf) | i1-IQ3_XXS | 2.9 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/trithemius-mistral-0.3-7b-i1-GGUF/resolve/main/trithemius-mistral-0.3-7b.i1-IQ3_XS.gguf) | i1-IQ3_XS | 3.1 | |
| [GGUF](https://huggingface.co/mradermacher/trithemius-mistral-0.3-7b-i1-GGUF/resolve/main/trithemius-mistral-0.3-7b.i1-Q3_K_S.gguf) | i1-Q3_K_S | 3.3 | IQ3_XS probably better |
| [GGUF](https://huggingface.co/mradermacher/trithemius-mistral-0.3-7b-i1-GGUF/resolve/main/trithemius-mistral-0.3-7b.i1-IQ3_S.gguf) | i1-IQ3_S | 3.3 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/trithemius-mistral-0.3-7b-i1-GGUF/resolve/main/trithemius-mistral-0.3-7b.i1-IQ3_M.gguf) | i1-IQ3_M | 3.4 | |
| [GGUF](https://huggingface.co/mradermacher/trithemius-mistral-0.3-7b-i1-GGUF/resolve/main/trithemius-mistral-0.3-7b.i1-Q3_K_M.gguf) | i1-Q3_K_M | 3.6 | IQ3_S probably better |
| [GGUF](https://huggingface.co/mradermacher/trithemius-mistral-0.3-7b-i1-GGUF/resolve/main/trithemius-mistral-0.3-7b.i1-Q3_K_L.gguf) | i1-Q3_K_L | 3.9 | IQ3_M probably better |
| [GGUF](https://huggingface.co/mradermacher/trithemius-mistral-0.3-7b-i1-GGUF/resolve/main/trithemius-mistral-0.3-7b.i1-IQ4_XS.gguf) | i1-IQ4_XS | 4.0 | |
| [GGUF](https://huggingface.co/mradermacher/trithemius-mistral-0.3-7b-i1-GGUF/resolve/main/trithemius-mistral-0.3-7b.i1-Q4_0.gguf) | i1-Q4_0 | 4.2 | fast, low quality |
| [GGUF](https://huggingface.co/mradermacher/trithemius-mistral-0.3-7b-i1-GGUF/resolve/main/trithemius-mistral-0.3-7b.i1-Q4_K_S.gguf) | i1-Q4_K_S | 4.2 | optimal size/speed/quality |
| [GGUF](https://huggingface.co/mradermacher/trithemius-mistral-0.3-7b-i1-GGUF/resolve/main/trithemius-mistral-0.3-7b.i1-Q4_K_M.gguf) | i1-Q4_K_M | 4.5 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/trithemius-mistral-0.3-7b-i1-GGUF/resolve/main/trithemius-mistral-0.3-7b.i1-Q5_K_S.gguf) | i1-Q5_K_S | 5.1 | |
| [GGUF](https://huggingface.co/mradermacher/trithemius-mistral-0.3-7b-i1-GGUF/resolve/main/trithemius-mistral-0.3-7b.i1-Q5_K_M.gguf) | i1-Q5_K_M | 5.2 | |
| [GGUF](https://huggingface.co/mradermacher/trithemius-mistral-0.3-7b-i1-GGUF/resolve/main/trithemius-mistral-0.3-7b.i1-Q6_K.gguf) | i1-Q6_K | 6.0 | practically like static Q6_K |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time. Additional thanks to [@nicoboss](https://huggingface.co/nicoboss) for giving me access to his hardware for calculating the imatrix for these quants.
<!-- end -->
|
mradermacher/MAmmoTH2-8B-Plus-i1-GGUF | mradermacher | 2024-06-28T02:40:14Z | 16,552 | 0 | transformers | [
"transformers",
"gguf",
"en",
"dataset:TIGER-Lab/WebInstructSub",
"base_model:TIGER-Lab/MAmmoTH2-8B-Plus",
"license:mit",
"endpoints_compatible",
"region:us"
]
| null | 2024-06-27T21:37:16Z | ---
base_model: TIGER-Lab/MAmmoTH2-8B-Plus
datasets:
- TIGER-Lab/WebInstructSub
language:
- en
library_name: transformers
license: mit
quantized_by: mradermacher
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: nicoboss -->
weighted/imatrix quants of https://huggingface.co/TIGER-Lab/MAmmoTH2-8B-Plus
<!-- provided-files -->
static quants are available at https://huggingface.co/mradermacher/MAmmoTH2-8B-Plus-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/MAmmoTH2-8B-Plus-i1-GGUF/resolve/main/MAmmoTH2-8B-Plus.i1-IQ1_S.gguf) | i1-IQ1_S | 2.1 | for the desperate |
| [GGUF](https://huggingface.co/mradermacher/MAmmoTH2-8B-Plus-i1-GGUF/resolve/main/MAmmoTH2-8B-Plus.i1-IQ1_M.gguf) | i1-IQ1_M | 2.3 | mostly desperate |
| [GGUF](https://huggingface.co/mradermacher/MAmmoTH2-8B-Plus-i1-GGUF/resolve/main/MAmmoTH2-8B-Plus.i1-IQ2_XXS.gguf) | i1-IQ2_XXS | 2.5 | |
| [GGUF](https://huggingface.co/mradermacher/MAmmoTH2-8B-Plus-i1-GGUF/resolve/main/MAmmoTH2-8B-Plus.i1-IQ2_XS.gguf) | i1-IQ2_XS | 2.7 | |
| [GGUF](https://huggingface.co/mradermacher/MAmmoTH2-8B-Plus-i1-GGUF/resolve/main/MAmmoTH2-8B-Plus.i1-IQ2_S.gguf) | i1-IQ2_S | 2.9 | |
| [GGUF](https://huggingface.co/mradermacher/MAmmoTH2-8B-Plus-i1-GGUF/resolve/main/MAmmoTH2-8B-Plus.i1-IQ2_M.gguf) | i1-IQ2_M | 3.0 | |
| [GGUF](https://huggingface.co/mradermacher/MAmmoTH2-8B-Plus-i1-GGUF/resolve/main/MAmmoTH2-8B-Plus.i1-Q2_K.gguf) | i1-Q2_K | 3.3 | IQ3_XXS probably better |
| [GGUF](https://huggingface.co/mradermacher/MAmmoTH2-8B-Plus-i1-GGUF/resolve/main/MAmmoTH2-8B-Plus.i1-IQ3_XXS.gguf) | i1-IQ3_XXS | 3.4 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/MAmmoTH2-8B-Plus-i1-GGUF/resolve/main/MAmmoTH2-8B-Plus.i1-IQ3_XS.gguf) | i1-IQ3_XS | 3.6 | |
| [GGUF](https://huggingface.co/mradermacher/MAmmoTH2-8B-Plus-i1-GGUF/resolve/main/MAmmoTH2-8B-Plus.i1-Q3_K_S.gguf) | i1-Q3_K_S | 3.8 | IQ3_XS probably better |
| [GGUF](https://huggingface.co/mradermacher/MAmmoTH2-8B-Plus-i1-GGUF/resolve/main/MAmmoTH2-8B-Plus.i1-IQ3_S.gguf) | i1-IQ3_S | 3.8 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/MAmmoTH2-8B-Plus-i1-GGUF/resolve/main/MAmmoTH2-8B-Plus.i1-IQ3_M.gguf) | i1-IQ3_M | 3.9 | |
| [GGUF](https://huggingface.co/mradermacher/MAmmoTH2-8B-Plus-i1-GGUF/resolve/main/MAmmoTH2-8B-Plus.i1-Q3_K_M.gguf) | i1-Q3_K_M | 4.1 | IQ3_S probably better |
| [GGUF](https://huggingface.co/mradermacher/MAmmoTH2-8B-Plus-i1-GGUF/resolve/main/MAmmoTH2-8B-Plus.i1-Q3_K_L.gguf) | i1-Q3_K_L | 4.4 | IQ3_M probably better |
| [GGUF](https://huggingface.co/mradermacher/MAmmoTH2-8B-Plus-i1-GGUF/resolve/main/MAmmoTH2-8B-Plus.i1-IQ4_XS.gguf) | i1-IQ4_XS | 4.5 | |
| [GGUF](https://huggingface.co/mradermacher/MAmmoTH2-8B-Plus-i1-GGUF/resolve/main/MAmmoTH2-8B-Plus.i1-Q4_0.gguf) | i1-Q4_0 | 4.8 | fast, low quality |
| [GGUF](https://huggingface.co/mradermacher/MAmmoTH2-8B-Plus-i1-GGUF/resolve/main/MAmmoTH2-8B-Plus.i1-Q4_K_S.gguf) | i1-Q4_K_S | 4.8 | optimal size/speed/quality |
| [GGUF](https://huggingface.co/mradermacher/MAmmoTH2-8B-Plus-i1-GGUF/resolve/main/MAmmoTH2-8B-Plus.i1-Q4_K_M.gguf) | i1-Q4_K_M | 5.0 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/MAmmoTH2-8B-Plus-i1-GGUF/resolve/main/MAmmoTH2-8B-Plus.i1-Q5_K_S.gguf) | i1-Q5_K_S | 5.7 | |
| [GGUF](https://huggingface.co/mradermacher/MAmmoTH2-8B-Plus-i1-GGUF/resolve/main/MAmmoTH2-8B-Plus.i1-Q5_K_M.gguf) | i1-Q5_K_M | 5.8 | |
| [GGUF](https://huggingface.co/mradermacher/MAmmoTH2-8B-Plus-i1-GGUF/resolve/main/MAmmoTH2-8B-Plus.i1-Q6_K.gguf) | i1-Q6_K | 6.7 | practically like static Q6_K |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time. Additional thanks to [@nicoboss](https://huggingface.co/nicoboss) for giving me access to his hardware for calculating the imatrix for these quants.
<!-- end -->
|
mradermacher/neo_7b_sft_v0.1-i1-GGUF | mradermacher | 2024-07-01T08:12:21Z | 16,548 | 0 | transformers | [
"transformers",
"gguf",
"en",
"base_model:m-a-p/neo_7b_sft_v0.1",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
]
| null | 2024-07-01T03:18:24Z | ---
base_model: m-a-p/neo_7b_sft_v0.1
language:
- en
library_name: transformers
license: apache-2.0
quantized_by: mradermacher
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: nicoboss -->
weighted/imatrix quants of https://huggingface.co/m-a-p/neo_7b_sft_v0.1
<!-- provided-files -->
static quants are available at https://huggingface.co/mradermacher/neo_7b_sft_v0.1-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/neo_7b_sft_v0.1-i1-GGUF/resolve/main/neo_7b_sft_v0.1.i1-IQ1_S.gguf) | i1-IQ1_S | 1.8 | for the desperate |
| [GGUF](https://huggingface.co/mradermacher/neo_7b_sft_v0.1-i1-GGUF/resolve/main/neo_7b_sft_v0.1.i1-IQ1_M.gguf) | i1-IQ1_M | 2.0 | mostly desperate |
| [GGUF](https://huggingface.co/mradermacher/neo_7b_sft_v0.1-i1-GGUF/resolve/main/neo_7b_sft_v0.1.i1-IQ2_XXS.gguf) | i1-IQ2_XXS | 2.2 | |
| [GGUF](https://huggingface.co/mradermacher/neo_7b_sft_v0.1-i1-GGUF/resolve/main/neo_7b_sft_v0.1.i1-IQ2_XS.gguf) | i1-IQ2_XS | 2.5 | |
| [GGUF](https://huggingface.co/mradermacher/neo_7b_sft_v0.1-i1-GGUF/resolve/main/neo_7b_sft_v0.1.i1-IQ2_S.gguf) | i1-IQ2_S | 2.6 | |
| [GGUF](https://huggingface.co/mradermacher/neo_7b_sft_v0.1-i1-GGUF/resolve/main/neo_7b_sft_v0.1.i1-IQ2_M.gguf) | i1-IQ2_M | 2.8 | |
| [GGUF](https://huggingface.co/mradermacher/neo_7b_sft_v0.1-i1-GGUF/resolve/main/neo_7b_sft_v0.1.i1-Q2_K.gguf) | i1-Q2_K | 3.0 | IQ3_XXS probably better |
| [GGUF](https://huggingface.co/mradermacher/neo_7b_sft_v0.1-i1-GGUF/resolve/main/neo_7b_sft_v0.1.i1-IQ3_XXS.gguf) | i1-IQ3_XXS | 3.1 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/neo_7b_sft_v0.1-i1-GGUF/resolve/main/neo_7b_sft_v0.1.i1-IQ3_XS.gguf) | i1-IQ3_XS | 3.4 | |
| [GGUF](https://huggingface.co/mradermacher/neo_7b_sft_v0.1-i1-GGUF/resolve/main/neo_7b_sft_v0.1.i1-IQ3_S.gguf) | i1-IQ3_S | 3.5 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/neo_7b_sft_v0.1-i1-GGUF/resolve/main/neo_7b_sft_v0.1.i1-Q3_K_S.gguf) | i1-Q3_K_S | 3.5 | IQ3_XS probably better |
| [GGUF](https://huggingface.co/mradermacher/neo_7b_sft_v0.1-i1-GGUF/resolve/main/neo_7b_sft_v0.1.i1-IQ3_M.gguf) | i1-IQ3_M | 3.6 | |
| [GGUF](https://huggingface.co/mradermacher/neo_7b_sft_v0.1-i1-GGUF/resolve/main/neo_7b_sft_v0.1.i1-Q3_K_M.gguf) | i1-Q3_K_M | 3.9 | IQ3_S probably better |
| [GGUF](https://huggingface.co/mradermacher/neo_7b_sft_v0.1-i1-GGUF/resolve/main/neo_7b_sft_v0.1.i1-Q3_K_L.gguf) | i1-Q3_K_L | 4.2 | IQ3_M probably better |
| [GGUF](https://huggingface.co/mradermacher/neo_7b_sft_v0.1-i1-GGUF/resolve/main/neo_7b_sft_v0.1.i1-IQ4_XS.gguf) | i1-IQ4_XS | 4.3 | |
| [GGUF](https://huggingface.co/mradermacher/neo_7b_sft_v0.1-i1-GGUF/resolve/main/neo_7b_sft_v0.1.i1-Q4_0.gguf) | i1-Q4_0 | 4.6 | fast, low quality |
| [GGUF](https://huggingface.co/mradermacher/neo_7b_sft_v0.1-i1-GGUF/resolve/main/neo_7b_sft_v0.1.i1-Q4_K_S.gguf) | i1-Q4_K_S | 4.6 | optimal size/speed/quality |
| [GGUF](https://huggingface.co/mradermacher/neo_7b_sft_v0.1-i1-GGUF/resolve/main/neo_7b_sft_v0.1.i1-Q4_K_M.gguf) | i1-Q4_K_M | 4.8 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/neo_7b_sft_v0.1-i1-GGUF/resolve/main/neo_7b_sft_v0.1.i1-Q5_K_S.gguf) | i1-Q5_K_S | 5.5 | |
| [GGUF](https://huggingface.co/mradermacher/neo_7b_sft_v0.1-i1-GGUF/resolve/main/neo_7b_sft_v0.1.i1-Q5_K_M.gguf) | i1-Q5_K_M | 5.6 | |
| [GGUF](https://huggingface.co/mradermacher/neo_7b_sft_v0.1-i1-GGUF/resolve/main/neo_7b_sft_v0.1.i1-Q6_K.gguf) | i1-Q6_K | 6.5 | practically like static Q6_K |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time. Additional thanks to [@nicoboss](https://huggingface.co/nicoboss) for giving me access to his hardware for calculating the imatrix for these quants.
<!-- end -->
|
aaditya/Llama3-OpenBioLLM-8B | aaditya | 2024-04-28T02:36:57Z | 16,538 | 123 | transformers | [
"transformers",
"pytorch",
"llama",
"text-generation",
"llama-3",
"Mixtral",
"instruct",
"finetune",
"chatml",
"DPO",
"RLHF",
"gpt4",
"distillation",
"en",
"arxiv:2305.18290",
"arxiv:2303.13375",
"arxiv:2212.13138",
"arxiv:2305.09617",
"arxiv:2402.07023",
"base_model:meta-llama/Meta-Llama-3-8B",
"license:llama3",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| text-generation | 2024-04-20T00:53:57Z | ---
base_model: meta-llama/Meta-Llama-3-8B
tags:
- llama-3
- llama
- Mixtral
- instruct
- finetune
- chatml
- DPO
- RLHF
- gpt4
- distillation
model-index:
- name: OpenBioLLM-8B
results: []
license: llama3
language:
- en
widget:
- example_title: OpenBioLLM-8B
messages:
- role: system
content: >-
You are an expert and experienced from the healthcare and biomedical domain with extensive medical knowledge and practical experience.
- role: user
content: How long does it take for newborn jaundice to go away?
output:
text: >-
Newborn jaundice, also known as neonatal jaundice, is a common condition in newborns where the yellowing of the skin and eyes occurs due to an elevated level of bilirubin in the blood. Bilirubin is a yellow pigment that forms when red blood cells break down. In most cases, newborn jaundice resolves on its own without any specific treatment.
The duration of newborn jaundice can vary depending on several factors such as the underlying cause, gestational age at birth, and individual variations in bilirubin metabolism. Here are some general guidelines:
1. Physiological jaundice: This is the most common type of newborn jaundice and usually appears within 24-72 hours after birth. It tends to peak between the second and fifth day of life and gradually improves over the next week or two. By the time the baby is one week old, the jaundice should have mostly resolved.
2. Breast milk jaundice: This type of jaundice occurs in breastfed babies and may appear later than physiological jaundice, typically between the fifth and fourteenth day of life. It tends to persist for a longer duration but usually resolves within six weeks after birth.
3. Pathological jaundice: This type of jaundice is less common and occurs due to an underlying medical condition that affects bilirubin metabolism or liver function. The duration of pathological jaundice depends on the specific cause and may require treatment.
It's important for parents to monitor their newborn's jaundice closely and seek medical advice if the jaundice progresses rapidly, becomes severe, or is accompanied by other symptoms such as poor feeding, lethargy, or excessive sleepiness. In these cases, further evaluation and management may be necessary.
Remember that each baby is unique, and the timing of jaundice resolution can vary. If you have concerns about your newborn's jaundice, it's always best to consult with a healthcare professional for personalized advice and guidance.
---
<div align="center">
<img width="260px" src="https://cdn-uploads.huggingface.co/production/uploads/5f3fe13d79c1ba4c353d0c19/BrQCb95lmEIFz79QAmoNA.png"></div>

<div align="center">
<h1>Advancing Open-source Large Language Models in Medical Domain</h1>
</div>
<p align="center" style="margin-top: 0px;">
<a href="https://colab.research.google.com/drive/1F5oV20InEYeAJGmBwYF9NM_QhLmjBkKJ?usp=sharing">
<img src="https://colab.research.google.com/assets/colab-badge.svg" alt="OpenChat Logo" style="width:20px; vertical-align: middle; display: inline-block; margin-right: 5px; margin-left: 10px; margin-top: 0px; margin-bottom: 0px;"/>
<span class="link-text" style=" margin-right: 5px;">Online Demo</span>
</a> |
<a href="https://github.com/openlifescience-ai">
<img src="https://github.githubassets.com/assets/GitHub-Mark-ea2971cee799.png" alt="GitHub Logo" style="width:20px; vertical-align: middle; display: inline-block; margin-right: 5px; margin-left: 5px; margin-top: 0px; margin-bottom: 0px;"/>
<span class="link-text" style=" margin-right: 5px;">GitHub</span>
</a> |
<a href="#">
<img src="https://github.com/alpayariyak/openchat/blob/master/assets/arxiv-logomark-small-square-border.png?raw=true" alt="ArXiv Logo" style="width:20px; vertical-align: middle; display: inline-block; margin-right: 5px; margin-left: 5px; margin-top: 0px; margin-bottom: 0px;"/>
<span class="link-text" style="margin-right: 5px;">Paper</span>
</a> |
<a href="https://discord.gg/A5Fjf5zC69">
<img src="https://cloud.githubusercontent.com/assets/6291467/26705903/96c2d66e-477c-11e7-9f4e-f3c0efe96c9a.png" alt="Discord Logo" style="width:20px; vertical-align: middle; display: inline-block; margin-right: 5px; margin-left: 5px; margin-top: 0px; margin-bottom: 0px;"/>
<span class="link-text">Discord</span>
</a>
</p>

Introducing OpenBioLLM-8B: A State-of-the-Art Open Source Biomedical Large Language Model
OpenBioLLM-8B is an advanced open source language model designed specifically for the biomedical domain. Developed by Saama AI Labs, this model leverages cutting-edge techniques to achieve state-of-the-art performance on a wide range of biomedical tasks.
🏥 **Biomedical Specialization**: OpenBioLLM-8B is tailored for the unique language and knowledge requirements of the medical and life sciences fields. It was fine-tuned on a vast corpus of high-quality biomedical data, enabling it to understand and generate text with domain-specific accuracy and fluency.
🎓 **Superior Performance**: With 8 billion parameters, OpenBioLLM-8B outperforms other open source biomedical language models of similar scale. It has also demonstrated better results compared to larger proprietary & open-source models like GPT-3.5 and Meditron-70B on biomedical benchmarks.
🧠 **Advanced Training Techniques**: OpenBioLLM-8B builds upon the powerful foundations of the **Meta-Llama-3-8B** and [Meta-Llama-3-8B](meta-llama/Meta-Llama-3-8B) models. It incorporates the DPO dataset and fine-tuning recipe along with a custom diverse medical instruction dataset. Key components of the training pipeline include:
<div align="center">
<img width="1200px" src="https://cdn-uploads.huggingface.co/production/uploads/5f3fe13d79c1ba4c353d0c19/oPchsJsEpQoGcGXVbh7YS.png">
</div>
- **Policy Optimization**: [Direct Preference Optimization: Your Language Model is Secretly a Reward Model (DPO)](https://arxiv.org/abs/2305.18290)
- **Ranking Dataset**: [berkeley-nest/Nectar](https://huggingface.co/datasets/berkeley-nest/Nectar)
- **Fine-tuning dataset**: Custom Medical Instruct dataset (We plan to release a sample training dataset in our upcoming paper; please stay updated)
This combination of cutting-edge techniques enables OpenBioLLM-8B to align with key capabilities and preferences for biomedical applications.
⚙️ **Release Details**:
- **Model Size**: 8 billion parameters
- **Quantization**: Optimized quantized versions available [Here](https://huggingface.co/aaditya/OpenBioLLM-Llama3-8B-GGUF)
- **Language(s) (NLP):** en
- **Developed By**: [Ankit Pal (Aaditya Ura)](https://aadityaura.github.io/) from Saama AI Labs
- **License:** Meta-Llama License
- **Fine-tuned from models:** [meta-llama/Meta-Llama-3-8B](meta-llama/Meta-Llama-3-8B)
- **Resources for more information:**
- Paper: Coming soon
The model can be fine-tuned for more specialized tasks and datasets as needed.
OpenBioLLM-8B represents an important step forward in democratizing advanced language AI for the biomedical community. By leveraging state-of-the-art architectures and training techniques from leading open source efforts like Llama-3, we have created a powerful tool to accelerate innovation and discovery in healthcare and the life sciences.
We are excited to share OpenBioLLM-8B with researchers and developers around the world.
### Use with transformers
**Important: Please use the exact chat template provided by Llama-3 instruct version. Otherwise there will be a degradation in the performance. The model output can be verbose in rare cases. Please consider setting temperature = 0 to make this happen less.**
See the snippet below for usage with Transformers:
```python
import transformers
import torch
model_id = "aaditya/OpenBioLLM-Llama3-8B"
pipeline = transformers.pipeline(
"text-generation",
model=model_id,
model_kwargs={"torch_dtype": torch.bfloat16},
device="auto",
)
messages = [
{"role": "system", "content": "You are an expert and experienced from the healthcare and biomedical domain with extensive medical knowledge and practical experience. Your name is OpenBioLLM, and you were developed by Saama AI Labs. who's willing to help answer the user's query with explanation. In your explanation, leverage your deep medical expertise such as relevant anatomical structures, physiological processes, diagnostic criteria, treatment guidelines, or other pertinent medical concepts. Use precise medical terminology while still aiming to make the explanation clear and accessible to a general audience."},
{"role": "user", "content": "How can i split a 3mg or 4mg waefin pill so i can get a 2.5mg pill?"},
]
prompt = pipeline.tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
terminators = [
pipeline.tokenizer.eos_token_id,
pipeline.tokenizer.convert_tokens_to_ids("<|eot_id|>")
]
outputs = pipeline(
prompt,
max_new_tokens=256,
eos_token_id=terminators,
do_sample=True,
temperature=0.0,
top_p=0.9,
)
print(outputs[0]["generated_text"][len(prompt):])
```
## **Training procedure**
### **Training hyperparameters**
<details>
<summary>Click to see details</summary>
- learning_rate: 0.0002
- lr_scheduler: cosine
- train_batch_size: 12
- eval_batch_size: 8
- GPU: H100 80GB SXM5
- num_devices: 1
- optimizer: adamw_bnb_8bit
- lr_scheduler_warmup_steps: 100
- num_epochs: 4
</details>
### **Peft hyperparameters**
<details>
<summary>Click to see details</summary>
- adapter: qlora
- lora_r: 128
- lora_alpha: 256
- lora_dropout: 0.05
- lora_target_linear: true
-lora_target_modules:
- q_proj
- v_proj
- k_proj
- o_proj
- gate_proj
- down_proj
- up_proj
</details>
### **Training results**
### **Framework versions**
- Transformers 4.39.3
- Pytorch 2.1.2+cu121
- Datasets 2.18.0
- Tokenizers 0.15.1
- Axolotl
- Lm harness for evaluation
# Benchmark Results
🔥 OpenBioLLM-8B demonstrates superior performance compared to larger models, such as GPT-3.5, Meditron-70B across 9 diverse biomedical datasets, achieving state-of-the-art results with an average score of 72.50%, despite having a significantly smaller parameter count. The model's strong performance in domain-specific tasks, such as Clinical KG, Medical Genetics, and PubMedQA, highlights its ability to effectively capture and apply biomedical knowledge.
🚨 The GPT-4, Med-PaLM-1, and Med-PaLM-2 results are taken from their official papers. Since Med-PaLM doesn't provide zero-shot accuracy, we are using 5-shot accuracy from their paper for comparison. All results presented are in the zero-shot setting, except for Med-PaLM-2 and Med-PaLM-1, which use 5-shot accuracy.
| | Clinical KG | Medical Genetics | Anatomy | Pro Medicine | College Biology | College Medicine | MedQA 4 opts | PubMedQA | MedMCQA | Avg |
|--------------------|-------------|------------------|---------|--------------|-----------------|------------------|--------------|----------|---------|-------|
| **OpenBioLLM-70B** | **92.93** | **93.197** | **83.904** | 93.75 | 93.827 | **85.749** | 78.162 | 78.97 | **74.014** | **86.05588** |
| Med-PaLM-2 (5-shot) | 88.3 | 90 | 77.8 | **95.2** | 94.4 | 80.9 | **79.7** | **79.2** | 71.3 | 84.08 |
| **GPT-4** | 86.04 | 91 | 80 | 93.01 | **95.14** | 76.88 | 78.87 | 75.2 | 69.52 | 82.85 |
| Med-PaLM-1 (Flan-PaLM, 5-shot) | 80.4 | 75 | 63.7 | 83.8 | 88.9 | 76.3 | 67.6 | 79 | 57.6 | 74.7 |
| **OpenBioLLM-8B** | 76.101 | 86.1 | 69.829 | 78.21 | 84.213 | 68.042 | 58.993 | 74.12 | 56.913 | 72.502 |
| Gemini-1.0 | 76.7 | 75.8 | 66.7 | 77.7 | 88 | 69.2 | 58 | 70.7 | 54.3 | 70.79 |
| GPT-3.5 Turbo 1106 | 74.71 | 74 | 72.79 | 72.79 | 72.91 | 64.73 | 57.71 | 72.66 | 53.79 | 66 |
| Meditron-70B | 66.79 | 69 | 53.33 | 71.69 | 76.38 | 63 | 57.1 | 76.6 | 46.85 | 64.52 |
| gemma-7b | 69.81 | 70 | 59.26 | 66.18 | 79.86 | 60.12 | 47.21 | 76.2 | 48.96 | 64.18 |
| Mistral-7B-v0.1 | 68.68 | 71 | 55.56 | 68.38 | 68.06 | 59.54 | 50.82 | 75.4 | 48.2 | 62.85 |
| Apollo-7B | 62.26 | 72 | 61.48 | 69.12 | 70.83 | 55.49 | 55.22 | 39.8 | 53.77 | 60 |
| MedAlpaca-7b | 57.36 | 69 | 57.04 | 67.28 | 65.28 | 54.34 | 41.71 | 72.8 | 37.51 | 58.03 |
| BioMistral-7B | 59.9 | 64 | 56.5 | 60.4 | 59 | 54.7 | 50.6 | 77.5 | 48.1 | 57.3 |
| AlpaCare-llama2-7b | 49.81 | 49 | 45.92 | 33.82 | 50 | 43.35 | 29.77 | 72.2 | 34.42 | 45.36 |
| ClinicalGPT | 30.56 | 27 | 30.37 | 19.48 | 25 | 24.27 | 26.08 | 63.8 | 28.18 | 30.52 |
<div align="center">
<img width="1600px" src="https://cdn-uploads.huggingface.co/production/uploads/5f3fe13d79c1ba4c353d0c19/_SzdcJSBjZyo8RS1bTEkP.png">
</div>
## Detailed Medical Subjectwise accuracy

# Use Cases & Examples
🚨 **Below results are from the quantized version of OpenBioLLM-70B**
# Summarize Clinical Notes
OpenBioLLM-70B can efficiently analyze and summarize complex clinical notes, EHR data, and discharge summaries, extracting key information and generating concise, structured summaries

# Answer Medical Questions
OpenBioLLM-70B can provide answers to a wide range of medical questions.


<details>
<summary>Click to see details</summary>



</details>
# Clinical Entity Recognition
OpenBioLLM-70B can perform advanced clinical entity recognition by identifying and extracting key medical concepts, such as diseases, symptoms, medications, procedures, and anatomical structures, from unstructured clinical text. By leveraging its deep understanding of medical terminology and context, the model can accurately annotate and categorize clinical entities, enabling more efficient information retrieval, data analysis, and knowledge discovery from electronic health records, research articles, and other biomedical text sources. This capability can support various downstream applications, such as clinical decision support, pharmacovigilance, and medical research.



# Biomarkers Extraction

# Classification
OpenBioLLM-70B can perform various biomedical classification tasks, such as disease prediction, sentiment analysis, medical document categorization

# De-Identification
OpenBioLLM-70B can detect and remove personally identifiable information (PII) from medical records, ensuring patient privacy and compliance with data protection regulations like HIPAA.

**Advisory Notice!**
While OpenBioLLM-70B & 8B leverages high-quality data sources, its outputs may still contain inaccuracies, biases, or misalignments that could pose risks if relied upon for medical decision-making without further testing and refinement. The model's performance has not yet been rigorously evaluated in randomized controlled trials or real-world healthcare environments.
Therefore, we strongly advise against using OpenBioLLM-70B & 8B for any direct patient care, clinical decision support, or other professional medical purposes at this time. Its use should be limited to research, development, and exploratory applications by qualified individuals who understand its limitations.
OpenBioLLM-70B & 8B are intended solely as a research tool to assist healthcare professionals and should never be considered a replacement for the professional judgment and expertise of a qualified medical doctor.
Appropriately adapting and validating OpenBioLLM-70B & 8B for specific medical use cases would require significant additional work, potentially including:
- Thorough testing and evaluation in relevant clinical scenarios
- Alignment with evidence-based guidelines and best practices
- Mitigation of potential biases and failure modes
- Integration with human oversight and interpretation
- Compliance with regulatory and ethical standards
Always consult a qualified healthcare provider for personal medical needs.
# Citation
If you find OpenBioLLM-70B & 8B useful in your work, please cite the model as follows:
```
@misc{OpenBioLLMs,
author = {Ankit Pal, Malaikannan Sankarasubbu},
title = {OpenBioLLMs: Advancing Open-Source Large Language Models for Healthcare and Life Sciences},
year = {2024},
publisher = {Hugging Face},
journal = {Hugging Face repository},
howpublished = {\url{https://huggingface.co/aaditya/OpenBioLLM-Llama3-70B}}
}
```
The accompanying paper is currently in progress and will be released soon.
<div align="center">
<h2> 💌 Contact </h2>
</div>
We look forward to hearing you and collaborating on this exciting project!
**Contributors:**
- [Ankit Pal (Aaditya Ura)](https://aadityaura.github.io/) [aadityaura at gmail dot com]
- Saama AI Labs
- Note: I am looking for a funded PhD opportunity, especially if it fits my Responsible Generative AI, Multimodal LLMs, Geometric Deep Learning, and Healthcare AI skillset.
# References
We thank the [Meta Team](meta-llama/Meta-Llama-3-70B-Instruct) for their amazing models!
Result sources
- [1] GPT-4 [Capabilities of GPT-4 on Medical Challenge Problems] (https://arxiv.org/abs/2303.13375)
- [2] Med-PaLM-1 [Large Language Models Encode Clinical Knowledge](https://arxiv.org/abs/2212.13138)
- [3] Med-PaLM-2 [Towards Expert-Level Medical Question Answering with Large Language Models](https://arxiv.org/abs/2305.09617)
- [4] Gemini-1.0 [Gemini Goes to Med School](https://arxiv.org/abs/2402.07023) |
deepseek-ai/DeepSeek-Coder-V2-Lite-Instruct | deepseek-ai | 2024-06-24T11:56:28Z | 16,537 | 177 | transformers | [
"transformers",
"safetensors",
"deepseek_v2",
"text-generation",
"conversational",
"custom_code",
"arxiv:2401.06066",
"license:other",
"autotrain_compatible",
"region:us"
]
| text-generation | 2024-06-14T06:23:33Z | ---
license: other
license_name: deepseek-license
license_link: LICENSE
---
<!-- markdownlint-disable first-line-h1 -->
<!-- markdownlint-disable html -->
<!-- markdownlint-disable no-duplicate-header -->
<div align="center">
<img src="https://github.com/deepseek-ai/DeepSeek-V2/blob/main/figures/logo.svg?raw=true" width="60%" alt="DeepSeek-V2" />
</div>
<hr>
<div align="center" style="line-height: 1;">
<a href="https://www.deepseek.com/" target="_blank" style="margin: 2px;">
<img alt="Homepage" src="https://github.com/deepseek-ai/DeepSeek-V2/blob/main/figures/badge.svg?raw=true" style="display: inline-block; vertical-align: middle;"/>
</a>
<a href="https://chat.deepseek.com/" target="_blank" style="margin: 2px;">
<img alt="Chat" src="https://img.shields.io/badge/🤖%20Chat-DeepSeek%20V2-536af5?color=536af5&logoColor=white" style="display: inline-block; vertical-align: middle;"/>
</a>
<a href="https://huggingface.co/deepseek-ai" target="_blank" style="margin: 2px;">
<img alt="Hugging Face" src="https://img.shields.io/badge/%F0%9F%A4%97%20Hugging%20Face-DeepSeek%20AI-ffc107?color=ffc107&logoColor=white" style="display: inline-block; vertical-align: middle;"/>
</a>
</div>
<div align="center" style="line-height: 1;">
<a href="https://discord.gg/Tc7c45Zzu5" target="_blank" style="margin: 2px;">
<img alt="Discord" src="https://img.shields.io/badge/Discord-DeepSeek%20AI-7289da?logo=discord&logoColor=white&color=7289da" style="display: inline-block; vertical-align: middle;"/>
</a>
<a href="https://github.com/deepseek-ai/DeepSeek-V2/blob/main/figures/qr.jpeg?raw=true" target="_blank" style="margin: 2px;">
<img alt="Wechat" src="https://img.shields.io/badge/WeChat-DeepSeek%20AI-brightgreen?logo=wechat&logoColor=white" style="display: inline-block; vertical-align: middle;"/>
</a>
<a href="https://twitter.com/deepseek_ai" target="_blank" style="margin: 2px;">
<img alt="Twitter Follow" src="https://img.shields.io/badge/Twitter-deepseek_ai-white?logo=x&logoColor=white" style="display: inline-block; vertical-align: middle;"/>
</a>
</div>
<div align="center" style="line-height: 1;">
<a href="https://github.com/deepseek-ai/DeepSeek-V2/blob/main/LICENSE-CODE" style="margin: 2px;">
<img alt="Code License" src="https://img.shields.io/badge/Code_License-MIT-f5de53?&color=f5de53" style="display: inline-block; vertical-align: middle;"/>
</a>
<a href="https://github.com/deepseek-ai/DeepSeek-V2/blob/main/LICENSE-MODEL" style="margin: 2px;">
<img alt="Model License" src="https://img.shields.io/badge/Model_License-Model_Agreement-f5de53?&color=f5de53" style="display: inline-block; vertical-align: middle;"/>
</a>
</div>
<p align="center">
<a href="#4-api-platform">API Platform</a> |
<a href="#5-how-to-run-locally">How to Use</a> |
<a href="#6-license">License</a> |
</p>
<p align="center">
<a href="https://github.com/deepseek-ai/DeepSeek-Coder-V2/blob/main/paper.pdf"><b>Paper Link</b>👁️</a>
</p>
# DeepSeek-Coder-V2: Breaking the Barrier of Closed-Source Models in Code Intelligence
## 1. Introduction
We present DeepSeek-Coder-V2, an open-source Mixture-of-Experts (MoE) code language model that achieves performance comparable to GPT4-Turbo in code-specific tasks. Specifically, DeepSeek-Coder-V2 is further pre-trained from an intermediate checkpoint of DeepSeek-V2 with additional 6 trillion tokens. Through this continued pre-training, DeepSeek-Coder-V2 substantially enhances the coding and mathematical reasoning capabilities of DeepSeek-V2, while maintaining comparable performance in general language tasks. Compared to DeepSeek-Coder-33B, DeepSeek-Coder-V2 demonstrates significant advancements in various aspects of code-related tasks, as well as reasoning and general capabilities. Additionally, DeepSeek-Coder-V2 expands its support for programming languages from 86 to 338, while extending the context length from 16K to 128K.
<p align="center">
<img width="100%" src="https://github.com/deepseek-ai/DeepSeek-Coder-V2/blob/main/figures/performance.png?raw=true">
</p>
In standard benchmark evaluations, DeepSeek-Coder-V2 achieves superior performance compared to closed-source models such as GPT4-Turbo, Claude 3 Opus, and Gemini 1.5 Pro in coding and math benchmarks. The list of supported programming languages can be found [here](https://github.com/deepseek-ai/DeepSeek-Coder-V2/blob/main/supported_langs.txt).
## 2. Model Downloads
We release the DeepSeek-Coder-V2 with 16B and 236B parameters based on the [DeepSeekMoE](https://arxiv.org/pdf/2401.06066) framework, which has actived parameters of only 2.4B and 21B , including base and instruct models, to the public.
<div align="center">
| **Model** | **#Total Params** | **#Active Params** | **Context Length** | **Download** |
| :-----------------------------: | :---------------: | :----------------: | :----------------: | :----------------------------------------------------------: |
| DeepSeek-Coder-V2-Lite-Base | 16B | 2.4B | 128k | [🤗 HuggingFace](https://huggingface.co/deepseek-ai/DeepSeek-Coder-V2-Lite-Base) |
| DeepSeek-Coder-V2-Lite-Instruct | 16B | 2.4B | 128k | [🤗 HuggingFace](https://huggingface.co/deepseek-ai/DeepSeek-Coder-V2-Lite-Instruct) |
| DeepSeek-Coder-V2-Base | 236B | 21B | 128k | [🤗 HuggingFace](https://huggingface.co/deepseek-ai/DeepSeek-Coder-V2-Base) |
| DeepSeek-Coder-V2-Instruct | 236B | 21B | 128k | [🤗 HuggingFace](https://huggingface.co/deepseek-ai/DeepSeek-Coder-V2-Instruct) |
</div>
## 3. Chat Website
You can chat with the DeepSeek-Coder-V2 on DeepSeek's official website: [coder.deepseek.com](https://coder.deepseek.com/sign_in)
## 4. API Platform
We also provide OpenAI-Compatible API at DeepSeek Platform: [platform.deepseek.com](https://platform.deepseek.com/), and you can also pay-as-you-go at an unbeatable price.
<p align="center">
<img width="40%" src="https://github.com/deepseek-ai/DeepSeek-Coder-V2/blob/main/figures/model_price.jpg?raw=true">
</p>
## 5. How to run locally
**Here, we provide some examples of how to use DeepSeek-Coder-V2-Lite model. If you want to utilize DeepSeek-Coder-V2 in BF16 format for inference, 80GB*8 GPUs are required.**
### Inference with Huggingface's Transformers
You can directly employ [Huggingface's Transformers](https://github.com/huggingface/transformers) for model inference.
#### Code Completion
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
tokenizer = AutoTokenizer.from_pretrained("deepseek-ai/DeepSeek-Coder-V2-Lite-Base", trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained("deepseek-ai/DeepSeek-Coder-V2-Lite-Base", trust_remote_code=True, torch_dtype=torch.bfloat16).cuda()
input_text = "#write a quick sort algorithm"
inputs = tokenizer(input_text, return_tensors="pt").to(model.device)
outputs = model.generate(**inputs, max_length=128)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
```
#### Code Insertion
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
tokenizer = AutoTokenizer.from_pretrained("deepseek-ai/DeepSeek-Coder-V2-Lite-Base", trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained("deepseek-ai/DeepSeek-Coder-V2-Lite-Base", trust_remote_code=True, torch_dtype=torch.bfloat16).cuda()
input_text = """<|fim▁begin|>def quick_sort(arr):
if len(arr) <= 1:
return arr
pivot = arr[0]
left = []
right = []
<|fim▁hole|>
if arr[i] < pivot:
left.append(arr[i])
else:
right.append(arr[i])
return quick_sort(left) + [pivot] + quick_sort(right)<|fim▁end|>"""
inputs = tokenizer(input_text, return_tensors="pt").to(model.device)
outputs = model.generate(**inputs, max_length=128)
print(tokenizer.decode(outputs[0], skip_special_tokens=True)[len(input_text):])
```
#### Chat Completion
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
tokenizer = AutoTokenizer.from_pretrained("deepseek-ai/DeepSeek-Coder-V2-Lite-Instruct", trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained("deepseek-ai/DeepSeek-Coder-V2-Lite-Instruct", trust_remote_code=True, torch_dtype=torch.bfloat16).cuda()
messages=[
{ 'role': 'user', 'content': "write a quick sort algorithm in python."}
]
inputs = tokenizer.apply_chat_template(messages, add_generation_prompt=True, return_tensors="pt").to(model.device)
# tokenizer.eos_token_id is the id of <|EOT|> token
outputs = model.generate(inputs, max_new_tokens=512, do_sample=False, top_k=50, top_p=0.95, num_return_sequences=1, eos_token_id=tokenizer.eos_token_id)
print(tokenizer.decode(outputs[0][len(inputs[0]):], skip_special_tokens=True))
```
The complete chat template can be found within `tokenizer_config.json` located in the huggingface model repository.
An example of chat template is as belows:
```bash
<|begin▁of▁sentence|>User: {user_message_1}
Assistant: {assistant_message_1}<|end▁of▁sentence|>User: {user_message_2}
Assistant:
```
You can also add an optional system message:
```bash
<|begin▁of▁sentence|>{system_message}
User: {user_message_1}
Assistant: {assistant_message_1}<|end▁of▁sentence|>User: {user_message_2}
Assistant:
```
### Inference with vLLM (recommended)
To utilize [vLLM](https://github.com/vllm-project/vllm) for model inference, please merge this Pull Request into your vLLM codebase: https://github.com/vllm-project/vllm/pull/4650.
```python
from transformers import AutoTokenizer
from vllm import LLM, SamplingParams
max_model_len, tp_size = 8192, 1
model_name = "deepseek-ai/DeepSeek-Coder-V2-Lite-Instruct"
tokenizer = AutoTokenizer.from_pretrained(model_name)
llm = LLM(model=model_name, tensor_parallel_size=tp_size, max_model_len=max_model_len, trust_remote_code=True, enforce_eager=True)
sampling_params = SamplingParams(temperature=0.3, max_tokens=256, stop_token_ids=[tokenizer.eos_token_id])
messages_list = [
[{"role": "user", "content": "Who are you?"}],
[{"role": "user", "content": "write a quick sort algorithm in python."}],
[{"role": "user", "content": "Write a piece of quicksort code in C++."}],
]
prompt_token_ids = [tokenizer.apply_chat_template(messages, add_generation_prompt=True) for messages in messages_list]
outputs = llm.generate(prompt_token_ids=prompt_token_ids, sampling_params=sampling_params)
generated_text = [output.outputs[0].text for output in outputs]
print(generated_text)
```
## 6. License
This code repository is licensed under [the MIT License](https://github.com/deepseek-ai/DeepSeek-Coder-V2/blob/main/LICENSE-CODE). The use of DeepSeek-Coder-V2 Base/Instruct models is subject to [the Model License](https://github.com/deepseek-ai/DeepSeek-Coder-V2/blob/main/LICENSE-MODEL). DeepSeek-Coder-V2 series (including Base and Instruct) supports commercial use.
## 7. Contact
If you have any questions, please raise an issue or contact us at [[email protected]]([email protected]).
|
SamLowe/roberta-base-go_emotions-onnx | SamLowe | 2023-09-29T00:02:20Z | 16,529 | 12 | transformers | [
"transformers",
"onnx",
"roberta",
"text-classification",
"int8",
"emotions",
"multi-class-classification",
"multi-label-classification",
"optimum",
"en",
"dataset:go_emotions",
"license:mit",
"autotrain_compatible",
"region:us"
]
| text-classification | 2023-09-28T14:07:22Z | ---
language: en
tags:
- text-classification
- onnx
- int8
- roberta
- emotions
- multi-class-classification
- multi-label-classification
- optimum
datasets:
- go_emotions
license: mit
inference: false
widget:
- text: Thank goodness ONNX is available, it is lots faster!
---
This model is the ONNX version of [https://huggingface.co/SamLowe/roberta-base-go_emotions](https://huggingface.co/SamLowe/roberta-base-go_emotions).
### Full precision ONNX version
`onnx/model.onnx` is the full precision ONNX version
- that has identical accuracy/metrics to the original Transformers model
- and has the same model size (499MB)
- is faster in inference than normal Transformers, particularly for smaller batch sizes
- in my tests about 2x to 3x as fast for a batch size of 1 on a 8 core 11th gen i7 CPU using ONNXRuntime
#### Metrics
Using a fixed threshold of 0.5 to convert the scores to binary predictions for each label:
- Accuracy: 0.474
- Precision: 0.575
- Recall: 0.396
- F1: 0.450
See more details in the SamLowe/roberta-base-go_emotions model card for the increases possible through selecting label-specific thresholds to maximise F1 scores, or another metric.
### Quantized (INT8) ONNX version
`onnx/model_quantized.onnx` is the int8 quantized version
- that is one quarter the size (125MB) of the full precision model (above)
- but delivers almost all of the accuracy
- is faster in inference than both the full precision ONNX above, and the normal Transformers model
- about 2x as fast for a batch size of 1 on an 8 core 11th gen i7 CPU using ONNXRuntime vs the full precision model above
- which makes it circa 5x as fast as the full precision normal Transformers model (on the above mentioned CPU, for a batch of 1)
#### Metrics for Quantized (INT8) Model
Using a fixed threshold of 0.5 to convert the scores to binary predictions for each label:
- Accuracy: 0.475
- Precision: 0.582
- Recall: 0.398
- F1: 0.447
Note how the metrics are almost identical to the full precision metrics above.
See more details in the SamLowe/roberta-base-go_emotions model card for the increases possible through selecting label-specific thresholds to maximise F1 scores, or another metric.
### How to use
#### Using Optimum Library ONNX Classes
Optimum library has equivalents (starting `ORT`) for the main Transformers classes, so these models can be used with the familiar constructs. The only extra property needed is `file_name` on the model creation, which in the below example specifies the quantized (INT8) model.
```python
sentences = ["ONNX is seriously fast for small batches. Impressive"]
from transformers import AutoTokenizer, pipeline
from optimum.onnxruntime import ORTModelForSequenceClassification
model_id = "SamLowe/roberta-base-go_emotions-onnx"
file_name = "onnx/model_quantized.onnx"
model = ORTModelForSequenceClassification.from_pretrained(model_id, file_name=file_name)
tokenizer = AutoTokenizer.from_pretrained(model_id)
onnx_classifier = pipeline(
task="text-classification",
model=model,
tokenizer=tokenizer,
top_k=None,
function_to_apply="sigmoid", # optional as is the default for the task
)
model_outputs = onnx_classifier(sentences)
# gives a list of outputs, each a list of dicts (one per label)
print(model_outputs)
# E.g.
# [[{'label': 'admiration', 'score': 0.9203393459320068},
# {'label': 'approval', 'score': 0.0560273639857769},
# {'label': 'neutral', 'score': 0.04265536740422249},
# {'label': 'gratitude', 'score': 0.015126707963645458},
# ...
```
#### Using ONNXRuntime
- Tokenization can be done before with the `tokenizers` library,
- and then the fed into ONNXRuntime as the type of dict it uses,
- and then simply the postprocessing sigmoid is needed afterward on the model output (which comes as a numpy array) to create the embeddings.
```python
from tokenizers import Tokenizer
import onnxruntime as ort
from os import cpu_count
import numpy as np # only used for the postprocessing sigmoid
sentences = ["hello world"] # for example a batch of 1
# labels as (ordered) list - from the go_emotions dataset
labels = ['admiration', 'amusement', 'anger', 'annoyance', 'approval', 'caring', 'confusion', 'curiosity', 'desire', 'disappointment', 'disapproval', 'disgust', 'embarrassment', 'excitement', 'fear', 'gratitude', 'grief', 'joy', 'love', 'nervousness', 'optimism', 'pride', 'realization', 'relief', 'remorse', 'sadness', 'surprise', 'neutral']
tokenizer = Tokenizer.from_pretrained("SamLowe/roberta-base-go_emotions")
# Optional - set pad to only pad to longest in batch, not a fixed length.
# (without this, the model will run slower, esp for shorter input strings)
params = {**tokenizer.padding, "length": None}
tokenizer.enable_padding(**params)
tokens_obj = tokenizer.encode_batch(sentences)
def load_onnx_model(model_filepath):
_options = ort.SessionOptions()
_options.inter_op_num_threads, _options.intra_op_num_threads = cpu_count(), cpu_count()
_providers = ["CPUExecutionProvider"] # could use ort.get_available_providers()
return ort.InferenceSession(path_or_bytes=model_filepath, sess_options=_options, providers=_providers)
model = load_onnx_model("path_to_model_dot_onnx_or_model_quantized_dot_onnx")
output_names = [model.get_outputs()[0].name] # E.g. ["logits"]
input_feed_dict = {
"input_ids": [t.ids for t in tokens_obj],
"attention_mask": [t.attention_mask for t in tokens_obj]
}
logits = model.run(output_names=output_names, input_feed=input_feed_dict)[0]
# produces a numpy array, one row per input item, one col per label
def sigmoid(x):
return 1.0 / (1.0 + np.exp(-x))
# Post-processing. Gets the scores per label in range.
# Auto done by Transformers' pipeline, but we must do it manually with ORT.
model_outputs = sigmoid(logits)
# for example, just to show the top result per input item
for probas in model_outputs:
top_result_index = np.argmax(probas)
print(labels[top_result_index], "with score:", probas[top_result_index])
```
### Example notebook: showing usage, accuracy & performance
Notebook with more details to follow. |
RichardErkhov/OpenBuddy_-_openbuddy-mistral-7b-v17.1-32k-gguf | RichardErkhov | 2024-06-25T23:16:46Z | 16,526 | 0 | null | [
"gguf",
"region:us"
]
| null | 2024-06-25T18:17:28Z | Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
openbuddy-mistral-7b-v17.1-32k - GGUF
- Model creator: https://huggingface.co/OpenBuddy/
- Original model: https://huggingface.co/OpenBuddy/openbuddy-mistral-7b-v17.1-32k/
| Name | Quant method | Size |
| ---- | ---- | ---- |
| [openbuddy-mistral-7b-v17.1-32k.Q2_K.gguf](https://huggingface.co/RichardErkhov/OpenBuddy_-_openbuddy-mistral-7b-v17.1-32k-gguf/blob/main/openbuddy-mistral-7b-v17.1-32k.Q2_K.gguf) | Q2_K | 2.55GB |
| [openbuddy-mistral-7b-v17.1-32k.IQ3_XS.gguf](https://huggingface.co/RichardErkhov/OpenBuddy_-_openbuddy-mistral-7b-v17.1-32k-gguf/blob/main/openbuddy-mistral-7b-v17.1-32k.IQ3_XS.gguf) | IQ3_XS | 2.83GB |
| [openbuddy-mistral-7b-v17.1-32k.IQ3_S.gguf](https://huggingface.co/RichardErkhov/OpenBuddy_-_openbuddy-mistral-7b-v17.1-32k-gguf/blob/main/openbuddy-mistral-7b-v17.1-32k.IQ3_S.gguf) | IQ3_S | 2.99GB |
| [openbuddy-mistral-7b-v17.1-32k.Q3_K_S.gguf](https://huggingface.co/RichardErkhov/OpenBuddy_-_openbuddy-mistral-7b-v17.1-32k-gguf/blob/main/openbuddy-mistral-7b-v17.1-32k.Q3_K_S.gguf) | Q3_K_S | 2.97GB |
| [openbuddy-mistral-7b-v17.1-32k.IQ3_M.gguf](https://huggingface.co/RichardErkhov/OpenBuddy_-_openbuddy-mistral-7b-v17.1-32k-gguf/blob/main/openbuddy-mistral-7b-v17.1-32k.IQ3_M.gguf) | IQ3_M | 3.08GB |
| [openbuddy-mistral-7b-v17.1-32k.Q3_K.gguf](https://huggingface.co/RichardErkhov/OpenBuddy_-_openbuddy-mistral-7b-v17.1-32k-gguf/blob/main/openbuddy-mistral-7b-v17.1-32k.Q3_K.gguf) | Q3_K | 3.3GB |
| [openbuddy-mistral-7b-v17.1-32k.Q3_K_M.gguf](https://huggingface.co/RichardErkhov/OpenBuddy_-_openbuddy-mistral-7b-v17.1-32k-gguf/blob/main/openbuddy-mistral-7b-v17.1-32k.Q3_K_M.gguf) | Q3_K_M | 3.3GB |
| [openbuddy-mistral-7b-v17.1-32k.Q3_K_L.gguf](https://huggingface.co/RichardErkhov/OpenBuddy_-_openbuddy-mistral-7b-v17.1-32k-gguf/blob/main/openbuddy-mistral-7b-v17.1-32k.Q3_K_L.gguf) | Q3_K_L | 3.58GB |
| [openbuddy-mistral-7b-v17.1-32k.IQ4_XS.gguf](https://huggingface.co/RichardErkhov/OpenBuddy_-_openbuddy-mistral-7b-v17.1-32k-gguf/blob/main/openbuddy-mistral-7b-v17.1-32k.IQ4_XS.gguf) | IQ4_XS | 3.7GB |
| [openbuddy-mistral-7b-v17.1-32k.Q4_0.gguf](https://huggingface.co/RichardErkhov/OpenBuddy_-_openbuddy-mistral-7b-v17.1-32k-gguf/blob/main/openbuddy-mistral-7b-v17.1-32k.Q4_0.gguf) | Q4_0 | 3.85GB |
| [openbuddy-mistral-7b-v17.1-32k.IQ4_NL.gguf](https://huggingface.co/RichardErkhov/OpenBuddy_-_openbuddy-mistral-7b-v17.1-32k-gguf/blob/main/openbuddy-mistral-7b-v17.1-32k.IQ4_NL.gguf) | IQ4_NL | 3.89GB |
| [openbuddy-mistral-7b-v17.1-32k.Q4_K_S.gguf](https://huggingface.co/RichardErkhov/OpenBuddy_-_openbuddy-mistral-7b-v17.1-32k-gguf/blob/main/openbuddy-mistral-7b-v17.1-32k.Q4_K_S.gguf) | Q4_K_S | 3.88GB |
| [openbuddy-mistral-7b-v17.1-32k.Q4_K.gguf](https://huggingface.co/RichardErkhov/OpenBuddy_-_openbuddy-mistral-7b-v17.1-32k-gguf/blob/main/openbuddy-mistral-7b-v17.1-32k.Q4_K.gguf) | Q4_K | 4.09GB |
| [openbuddy-mistral-7b-v17.1-32k.Q4_K_M.gguf](https://huggingface.co/RichardErkhov/OpenBuddy_-_openbuddy-mistral-7b-v17.1-32k-gguf/blob/main/openbuddy-mistral-7b-v17.1-32k.Q4_K_M.gguf) | Q4_K_M | 4.09GB |
| [openbuddy-mistral-7b-v17.1-32k.Q4_1.gguf](https://huggingface.co/RichardErkhov/OpenBuddy_-_openbuddy-mistral-7b-v17.1-32k-gguf/blob/main/openbuddy-mistral-7b-v17.1-32k.Q4_1.gguf) | Q4_1 | 4.27GB |
| [openbuddy-mistral-7b-v17.1-32k.Q5_0.gguf](https://huggingface.co/RichardErkhov/OpenBuddy_-_openbuddy-mistral-7b-v17.1-32k-gguf/blob/main/openbuddy-mistral-7b-v17.1-32k.Q5_0.gguf) | Q5_0 | 4.68GB |
| [openbuddy-mistral-7b-v17.1-32k.Q5_K_S.gguf](https://huggingface.co/RichardErkhov/OpenBuddy_-_openbuddy-mistral-7b-v17.1-32k-gguf/blob/main/openbuddy-mistral-7b-v17.1-32k.Q5_K_S.gguf) | Q5_K_S | 4.68GB |
| [openbuddy-mistral-7b-v17.1-32k.Q5_K.gguf](https://huggingface.co/RichardErkhov/OpenBuddy_-_openbuddy-mistral-7b-v17.1-32k-gguf/blob/main/openbuddy-mistral-7b-v17.1-32k.Q5_K.gguf) | Q5_K | 4.81GB |
| [openbuddy-mistral-7b-v17.1-32k.Q5_K_M.gguf](https://huggingface.co/RichardErkhov/OpenBuddy_-_openbuddy-mistral-7b-v17.1-32k-gguf/blob/main/openbuddy-mistral-7b-v17.1-32k.Q5_K_M.gguf) | Q5_K_M | 4.81GB |
| [openbuddy-mistral-7b-v17.1-32k.Q5_1.gguf](https://huggingface.co/RichardErkhov/OpenBuddy_-_openbuddy-mistral-7b-v17.1-32k-gguf/blob/main/openbuddy-mistral-7b-v17.1-32k.Q5_1.gguf) | Q5_1 | 5.1GB |
| [openbuddy-mistral-7b-v17.1-32k.Q6_K.gguf](https://huggingface.co/RichardErkhov/OpenBuddy_-_openbuddy-mistral-7b-v17.1-32k-gguf/blob/main/openbuddy-mistral-7b-v17.1-32k.Q6_K.gguf) | Q6_K | 5.56GB |
| [openbuddy-mistral-7b-v17.1-32k.Q8_0.gguf](https://huggingface.co/RichardErkhov/OpenBuddy_-_openbuddy-mistral-7b-v17.1-32k-gguf/blob/main/openbuddy-mistral-7b-v17.1-32k.Q8_0.gguf) | Q8_0 | 7.2GB |
Original model description:
---
language:
- zh
- en
- fr
- de
- ja
- ko
- it
- ru
pipeline_tag: text-generation
inference: false
library_name: transformers
license: apache-2.0
---
# OpenBuddy - Open Multilingual Chatbot
GitHub and Usage Guide: [https://github.com/OpenBuddy/OpenBuddy](https://github.com/OpenBuddy/OpenBuddy)
Website and Demo: [https://openbuddy.ai](https://openbuddy.ai)
Evaluation result of this model: [Evaluation.txt](Evaluation.txt)

# Copyright Notice
Base model: https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.2
License: Apache 2.0
## Disclaimer
All OpenBuddy models have inherent limitations and may potentially produce outputs that are erroneous, harmful, offensive, or otherwise undesirable. Users should not use these models in critical or high-stakes situations that may lead to personal injury, property damage, or significant losses. Examples of such scenarios include, but are not limited to, the medical field, controlling software and hardware systems that may cause harm, and making important financial or legal decisions.
OpenBuddy is provided "as-is" without any warranty of any kind, either express or implied, including, but not limited to, the implied warranties of merchantability, fitness for a particular purpose, and non-infringement. In no event shall the authors, contributors, or copyright holders be liable for any claim, damages, or other liabilities, whether in an action of contract, tort, or otherwise, arising from, out of, or in connection with the software or the use or other dealings in the software.
By using OpenBuddy, you agree to these terms and conditions, and acknowledge that you understand the potential risks associated with its use. You also agree to indemnify and hold harmless the authors, contributors, and copyright holders from any claims, damages, or liabilities arising from your use of OpenBuddy.
## 免责声明
所有OpenBuddy模型均存在固有的局限性,可能产生错误的、有害的、冒犯性的或其他不良的输出。用户在关键或高风险场景中应谨慎行事,不要使用这些模型,以免导致人身伤害、财产损失或重大损失。此类场景的例子包括但不限于医疗领域、可能导致伤害的软硬件系统的控制以及进行重要的财务或法律决策。
OpenBuddy按“原样”提供,不附带任何种类的明示或暗示的保证,包括但不限于适销性、特定目的的适用性和非侵权的暗示保证。在任何情况下,作者、贡献者或版权所有者均不对因软件或使用或其他软件交易而产生的任何索赔、损害赔偿或其他责任(无论是合同、侵权还是其他原因)承担责任。
使用OpenBuddy即表示您同意这些条款和条件,并承认您了解其使用可能带来的潜在风险。您还同意赔偿并使作者、贡献者和版权所有者免受因您使用OpenBuddy而产生的任何索赔、损害赔偿或责任的影响。
|
Rakib/roberta-base-on-cuad | Rakib | 2023-01-18T12:18:53Z | 16,519 | 5 | transformers | [
"transformers",
"pytorch",
"roberta",
"question-answering",
"legal-contract-review",
"cuad",
"en",
"dataset:cuad",
"license:mit",
"endpoints_compatible",
"region:us"
]
| question-answering | 2022-03-02T23:29:04Z | ---
language:
- en
license: mit
datasets:
- cuad
pipeline_tag: question-answering
tags:
- legal-contract-review
- roberta
- cuad
library_name: transformers
---
# Model Card for roberta-base-on-cuad
# Model Details
## Model Description
- **Developed by:** Mohammed Rakib
- **Shared by [Optional]:** More information needed
- **Model type:** Question Answering
- **Language(s) (NLP):** en
- **License:** MIT
- **Related Models:**
- **Parent Model:** RoBERTa
- **Resources for more information:**
- GitHub Repo: [defactolaw](https://github.com/afra-tech/defactolaw)
- Associated Paper: [An Open Source Contractual Language Understanding Application Using Machine Learning](https://aclanthology.org/2022.lateraisse-1.6/)
# Uses
## Direct Use
This model can be used for the task of Question Answering on Legal Documents.
# Training Details
Read: [An Open Source Contractual Language Understanding Application Using Machine Learning](https://aclanthology.org/2022.lateraisse-1.6/)
for detailed information on training procedure, dataset preprocessing and evaluation.
## Training Data
See [CUAD dataset card](https://huggingface.co/datasets/cuad) for more information.
## Training Procedure
### Preprocessing
More information needed
### Speeds, Sizes, Times
More information needed
# Evaluation
## Testing Data, Factors & Metrics
### Testing Data
See [CUAD dataset card](https://huggingface.co/datasets/cuad) for more information.
### Factors
### Metrics
More information needed
## Results
More information needed
# Model Examination
More information needed
- **Hardware Type:** More information needed
- **Hours used:** More information needed
- **Cloud Provider:** More information needed
- **Compute Region:** More information needed
- **Carbon Emitted:** More information needed
# Technical Specifications [optional]
## Model Architecture and Objective
More information needed
## Compute Infrastructure
More information needed
### Hardware
Used V100/P100 from Google Colab Pro
### Software
Python, Transformers
# Citation
**BibTeX:**
```
@inproceedings{nawar-etal-2022-open,
title = "An Open Source Contractual Language Understanding Application Using Machine Learning",
author = "Nawar, Afra and
Rakib, Mohammed and
Hai, Salma Abdul and
Haq, Sanaulla",
booktitle = "Proceedings of the First Workshop on Language Technology and Resources for a Fair, Inclusive, and Safe Society within the 13th Language Resources and Evaluation Conference",
month = jun,
year = "2022",
address = "Marseille, France",
publisher = "European Language Resources Association",
url = "https://aclanthology.org/2022.lateraisse-1.6",
pages = "42--50",
abstract = "Legal field is characterized by its exclusivity and non-transparency. Despite the frequency and relevance of legal dealings, legal documents like contracts remains elusive to non-legal professionals for the copious usage of legal jargon. There has been little advancement in making legal contracts more comprehensible. This paper presents how Machine Learning and NLP can be applied to solve this problem, further considering the challenges of applying ML to the high length of contract documents and training in a low resource environment. The largest open-source contract dataset so far, the Contract Understanding Atticus Dataset (CUAD) is utilized. Various pre-processing experiments and hyperparameter tuning have been carried out and we successfully managed to eclipse SOTA results presented for models in the CUAD dataset trained on RoBERTa-base. Our model, A-type-RoBERTa-base achieved an AUPR score of 46.6{\%} compared to 42.6{\%} on the original RoBERT-base. This model is utilized in our end to end contract understanding application which is able to take a contract and highlight the clauses a user is looking to find along with it{'}s descriptions to aid due diligence before signing. Alongside digital, i.e. searchable, contracts the system is capable of processing scanned, i.e. non-searchable, contracts using tesseract OCR. This application is aimed to not only make contract review a comprehensible process to non-legal professionals, but also to help lawyers and attorneys more efficiently review contracts.",
}
```
# Glossary [optional]
More information needed
# More Information [optional]
More information needed
# Model Card Authors [optional]
Mohammed Rakib in collaboration with Ezi Ozoani and the Hugging Face team
# Model Card Contact
More information needed
# How to Get Started with the Model
Use the code below to get started with the model.
<details>
<summary> Click to expand </summary>
```python
from transformers import AutoTokenizer, AutoModelForQuestionAnswering
tokenizer = AutoTokenizer.from_pretrained("Rakib/roberta-base-on-cuad")
model = AutoModelForQuestionAnswering.from_pretrained("Rakib/roberta-base-on-cuad")
```
</details> |
grapevine-AI/gemma-2-27b-it-gguf | grapevine-AI | 2024-06-30T08:51:46Z | 16,499 | 6 | null | [
"gguf",
"license:gemma",
"region:us"
]
| null | 2024-06-28T05:55:22Z | ---
license: gemma
---
# What is this?
Googleの言語モデル[gemma-2-27b-it](https://huggingface.co/google/gemma-2-27b-it)をGGUFフォーマットに変換したものです。
# imatrix dataset
日本語能力を重視し、日本語が多量に含まれる[TFMC/imatrix-dataset-for-japanese-llm](https://huggingface.co/datasets/TFMC/imatrix-dataset-for-japanese-llm)データセットを使用しました。<br>
なお、謎のエラー「GGML_ASSERT: D:\a\llama.cpp\llama.cpp\ggml\src\ggml-cuda.cu:1257: to_fp32_cuda != nullptr」を回避するため、imatrixの算出においてはf16精度のモデルを使用しました。
# Chat template
```
<start_of_turn>user
ここにpromptを書きます<end_of_turn>
<start_of_turn>model
```
# Note
**llama.cpp-b3266以降でのみご利用が可能です。**<br>
モデル本来のコンテキスト長は8192ですが、現状のGGUF版gemma-2は4096以上のトークンを扱えないようです。これは、llama.cppがSliding Window Attention(=前4096トークンのみに注意を向ける)を取り扱えず、Global Attentionとみなされて計算が行われてしまうためです。<br>
また、このモデル特有の処理であるAttention logit cappingが存在するため、Flash Attentionの使用もできません。
# Environment
Windows版llama.cpp-b3266および同時リリースのconvert-hf-to-gguf.pyを使用して量子化作業を実施しました。
# License
gemma license
# Developer
Google |
mradermacher/Llama-3-Nerdy-RP-8B-GGUF | mradermacher | 2024-06-29T04:55:11Z | 16,499 | 0 | transformers | [
"transformers",
"gguf",
"mergekit",
"merge",
"en",
"base_model:Azazelle/Llama-3-Nerdy-RP-8B",
"endpoints_compatible",
"region:us"
]
| null | 2024-06-29T04:02:12Z | ---
base_model: Azazelle/Llama-3-Nerdy-RP-8B
language:
- en
library_name: transformers
quantized_by: mradermacher
tags:
- mergekit
- merge
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
static quants of https://huggingface.co/Azazelle/Llama-3-Nerdy-RP-8B
<!-- provided-files -->
weighted/imatrix quants are available at https://huggingface.co/mradermacher/Llama-3-Nerdy-RP-8B-i1-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/Llama-3-Nerdy-RP-8B-GGUF/resolve/main/Llama-3-Nerdy-RP-8B.Q2_K.gguf) | Q2_K | 3.3 | |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-Nerdy-RP-8B-GGUF/resolve/main/Llama-3-Nerdy-RP-8B.IQ3_XS.gguf) | IQ3_XS | 3.6 | |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-Nerdy-RP-8B-GGUF/resolve/main/Llama-3-Nerdy-RP-8B.Q3_K_S.gguf) | Q3_K_S | 3.8 | |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-Nerdy-RP-8B-GGUF/resolve/main/Llama-3-Nerdy-RP-8B.IQ3_S.gguf) | IQ3_S | 3.8 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-Nerdy-RP-8B-GGUF/resolve/main/Llama-3-Nerdy-RP-8B.IQ3_M.gguf) | IQ3_M | 3.9 | |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-Nerdy-RP-8B-GGUF/resolve/main/Llama-3-Nerdy-RP-8B.Q3_K_M.gguf) | Q3_K_M | 4.1 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-Nerdy-RP-8B-GGUF/resolve/main/Llama-3-Nerdy-RP-8B.Q3_K_L.gguf) | Q3_K_L | 4.4 | |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-Nerdy-RP-8B-GGUF/resolve/main/Llama-3-Nerdy-RP-8B.IQ4_XS.gguf) | IQ4_XS | 4.6 | |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-Nerdy-RP-8B-GGUF/resolve/main/Llama-3-Nerdy-RP-8B.Q4_K_S.gguf) | Q4_K_S | 4.8 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-Nerdy-RP-8B-GGUF/resolve/main/Llama-3-Nerdy-RP-8B.Q4_K_M.gguf) | Q4_K_M | 5.0 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-Nerdy-RP-8B-GGUF/resolve/main/Llama-3-Nerdy-RP-8B.Q5_K_S.gguf) | Q5_K_S | 5.7 | |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-Nerdy-RP-8B-GGUF/resolve/main/Llama-3-Nerdy-RP-8B.Q5_K_M.gguf) | Q5_K_M | 5.8 | |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-Nerdy-RP-8B-GGUF/resolve/main/Llama-3-Nerdy-RP-8B.Q6_K.gguf) | Q6_K | 6.7 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-Nerdy-RP-8B-GGUF/resolve/main/Llama-3-Nerdy-RP-8B.Q8_0.gguf) | Q8_0 | 8.6 | fast, best quality |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-Nerdy-RP-8B-GGUF/resolve/main/Llama-3-Nerdy-RP-8B.f16.gguf) | f16 | 16.2 | 16 bpw, overkill |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
prs-eth/marigold-depth-lcm-v1-0 | prs-eth | 2024-05-25T20:50:12Z | 16,495 | 36 | diffusers | [
"diffusers",
"safetensors",
"monocular depth estimation",
"single image depth estimation",
"depth",
"in-the-wild",
"zero-shot",
"LCM",
"depth-estimation",
"en",
"arxiv:2312.02145",
"license:apache-2.0",
"diffusers:MarigoldPipeline",
"region:us"
]
| depth-estimation | 2024-03-18T04:49:00Z | ---
license: apache-2.0
language:
- en
pipeline_tag: depth-estimation
tags:
- monocular depth estimation
- single image depth estimation
- depth
- in-the-wild
- zero-shot
- depth
- LCM
---
# Marigold: Repurposing Diffusion-Based Image Generators for Monocular Depth Estimation
This model represents the official LCM checkpoint of the paper titled "Repurposing Diffusion-Based Image Generators for Monocular Depth Estimation".
[](https://marigoldmonodepth.github.io)
[](https://github.com/prs-eth/Marigold)
[](https://arxiv.org/abs/2312.02145)
[](https://colab.research.google.com/drive/12G8reD13DdpMie5ZQlaFNo2WCGeNUH-u?usp=sharing)
[-Space-yellow)](https://huggingface.co/spaces/prs-eth/marigold-lcm)
[](https://www.apache.org/licenses/LICENSE-2.0)
<!-- []() -->
<!-- []() -->
<!-- []() -->
<!-- ### [Repurposing Diffusion-Based Image Generators for Monocular Depth Estimation]() -->
[Bingxin Ke](http://www.kebingxin.com/),
[Anton Obukhov](https://www.obukhov.ai/),
[Shengyu Huang](https://shengyuh.github.io/),
[Nando Metzger](https://nandometzger.github.io/),
[Rodrigo Caye Daudt](https://rcdaudt.github.io/),
[Konrad Schindler](https://scholar.google.com/citations?user=FZuNgqIAAAAJ&hl=en )
We present Marigold, a diffusion model and associated fine-tuning protocol for monocular depth estimation. Its core principle is to leverage the rich visual knowledge stored in modern generative image models. Our model, derived from Stable Diffusion and fine-tuned with synthetic data, can zero-shot transfer to unseen data, offering state-of-the-art monocular depth estimation results.

## 🎓 Citation
```bibtex
@InProceedings{ke2023repurposing,
title={Repurposing Diffusion-Based Image Generators for Monocular Depth Estimation},
author={Bingxin Ke and Anton Obukhov and Shengyu Huang and Nando Metzger and Rodrigo Caye Daudt and Konrad Schindler},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
year={2024}
}
```
## 🎫 License
This work is licensed under the Apache License, Version 2.0 (as defined in the [LICENSE](LICENSE.txt)).
By downloading and using the code and model you agree to the terms in the [LICENSE](LICENSE.txt).
[](https://www.apache.org/licenses/LICENSE-2.0)
|
RichardErkhov/eci-io_-_climategpt-7b-gguf | RichardErkhov | 2024-07-01T01:27:33Z | 16,493 | 0 | null | [
"gguf",
"arxiv:2401.09646",
"region:us"
]
| null | 2024-06-30T23:13:27Z | Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
climategpt-7b - GGUF
- Model creator: https://huggingface.co/eci-io/
- Original model: https://huggingface.co/eci-io/climategpt-7b/
| Name | Quant method | Size |
| ---- | ---- | ---- |
| [climategpt-7b.Q2_K.gguf](https://huggingface.co/RichardErkhov/eci-io_-_climategpt-7b-gguf/blob/main/climategpt-7b.Q2_K.gguf) | Q2_K | 2.36GB |
| [climategpt-7b.IQ3_XS.gguf](https://huggingface.co/RichardErkhov/eci-io_-_climategpt-7b-gguf/blob/main/climategpt-7b.IQ3_XS.gguf) | IQ3_XS | 2.61GB |
| [climategpt-7b.IQ3_S.gguf](https://huggingface.co/RichardErkhov/eci-io_-_climategpt-7b-gguf/blob/main/climategpt-7b.IQ3_S.gguf) | IQ3_S | 2.75GB |
| [climategpt-7b.Q3_K_S.gguf](https://huggingface.co/RichardErkhov/eci-io_-_climategpt-7b-gguf/blob/main/climategpt-7b.Q3_K_S.gguf) | Q3_K_S | 2.75GB |
| [climategpt-7b.IQ3_M.gguf](https://huggingface.co/RichardErkhov/eci-io_-_climategpt-7b-gguf/blob/main/climategpt-7b.IQ3_M.gguf) | IQ3_M | 2.9GB |
| [climategpt-7b.Q3_K.gguf](https://huggingface.co/RichardErkhov/eci-io_-_climategpt-7b-gguf/blob/main/climategpt-7b.Q3_K.gguf) | Q3_K | 3.07GB |
| [climategpt-7b.Q3_K_M.gguf](https://huggingface.co/RichardErkhov/eci-io_-_climategpt-7b-gguf/blob/main/climategpt-7b.Q3_K_M.gguf) | Q3_K_M | 3.07GB |
| [climategpt-7b.Q3_K_L.gguf](https://huggingface.co/RichardErkhov/eci-io_-_climategpt-7b-gguf/blob/main/climategpt-7b.Q3_K_L.gguf) | Q3_K_L | 3.35GB |
| [climategpt-7b.IQ4_XS.gguf](https://huggingface.co/RichardErkhov/eci-io_-_climategpt-7b-gguf/blob/main/climategpt-7b.IQ4_XS.gguf) | IQ4_XS | 3.4GB |
| [climategpt-7b.Q4_0.gguf](https://huggingface.co/RichardErkhov/eci-io_-_climategpt-7b-gguf/blob/main/climategpt-7b.Q4_0.gguf) | Q4_0 | 3.56GB |
| [climategpt-7b.IQ4_NL.gguf](https://huggingface.co/RichardErkhov/eci-io_-_climategpt-7b-gguf/blob/main/climategpt-7b.IQ4_NL.gguf) | IQ4_NL | 3.58GB |
| [climategpt-7b.Q4_K_S.gguf](https://huggingface.co/RichardErkhov/eci-io_-_climategpt-7b-gguf/blob/main/climategpt-7b.Q4_K_S.gguf) | Q4_K_S | 3.59GB |
| [climategpt-7b.Q4_K.gguf](https://huggingface.co/RichardErkhov/eci-io_-_climategpt-7b-gguf/blob/main/climategpt-7b.Q4_K.gguf) | Q4_K | 3.8GB |
| [climategpt-7b.Q4_K_M.gguf](https://huggingface.co/RichardErkhov/eci-io_-_climategpt-7b-gguf/blob/main/climategpt-7b.Q4_K_M.gguf) | Q4_K_M | 3.8GB |
| [climategpt-7b.Q4_1.gguf](https://huggingface.co/RichardErkhov/eci-io_-_climategpt-7b-gguf/blob/main/climategpt-7b.Q4_1.gguf) | Q4_1 | 3.95GB |
| [climategpt-7b.Q5_0.gguf](https://huggingface.co/RichardErkhov/eci-io_-_climategpt-7b-gguf/blob/main/climategpt-7b.Q5_0.gguf) | Q5_0 | 4.33GB |
| [climategpt-7b.Q5_K_S.gguf](https://huggingface.co/RichardErkhov/eci-io_-_climategpt-7b-gguf/blob/main/climategpt-7b.Q5_K_S.gguf) | Q5_K_S | 4.33GB |
| [climategpt-7b.Q5_K.gguf](https://huggingface.co/RichardErkhov/eci-io_-_climategpt-7b-gguf/blob/main/climategpt-7b.Q5_K.gguf) | Q5_K | 4.46GB |
| [climategpt-7b.Q5_K_M.gguf](https://huggingface.co/RichardErkhov/eci-io_-_climategpt-7b-gguf/blob/main/climategpt-7b.Q5_K_M.gguf) | Q5_K_M | 4.46GB |
| [climategpt-7b.Q5_1.gguf](https://huggingface.co/RichardErkhov/eci-io_-_climategpt-7b-gguf/blob/main/climategpt-7b.Q5_1.gguf) | Q5_1 | 4.72GB |
| [climategpt-7b.Q6_K.gguf](https://huggingface.co/RichardErkhov/eci-io_-_climategpt-7b-gguf/blob/main/climategpt-7b.Q6_K.gguf) | Q6_K | 5.15GB |
| [climategpt-7b.Q8_0.gguf](https://huggingface.co/RichardErkhov/eci-io_-_climategpt-7b-gguf/blob/main/climategpt-7b.Q8_0.gguf) | Q8_0 | 6.67GB |
Original model description:
---
language:
- en
datasets:
- OpenAssistant/oasst1
- databricks/databricks-dolly-15k
base_model: meta-llama/Llama-2-7b-hf
tags:
- climate
co2_eq_emissions:
emissions: 2900
training_type: "pre-training"
geographical_location: "Washington, USA"
hardware_used: "8x NVIDIA H100 HBM"
license: other
license_name: climategpt-community-license
license_link: https://huggingface.co/eci-io/climategpt-7b/blob/main/LICENSE.txt
---
# ClimateGPT-7B
ClimateGPT is a family of AI models designed to synthesize interdisciplinary research on climate change.
ClimateGPT-7B is a 7 billion parameter transformer decoder model that was adapted from Llama-2 to the domain of climate science using continuous pre-training on a collection of 4.2B tokens from curated climate documents created by Erasmus AI.
The model is further instruction fine-tuned on a dataset of instruction-completion pairs manually collected by AppTek in cooperation with climate scientists.
ClimateGPT-7B outperforms Llama-2-70B Chat on our climate-specific benchmarks.
The model is designed to be used together with retrieval augmentation to extend the knowledge, and increase the factuality of the model and with cascaded machine translation to increase the language coverage.
## Model Details
Explore the model lineage [here](https://huggingface.co/spaces/EQTYLab/lineage-explorer?repo=https://huggingface.co/eci-io/climategpt-7b).
- **Powered by:** [Erasmus AI](https://erasmus.ai)
- **Trained with:** [AppTek](https://apptek.com)
- **Authenticated by:** [EQTYLab](https://eqtylab.io)
- **Model type:** decoder-only Transformer
- **Language(s) (NLP):** English
- **License:** ClimateGPT Community License
- **Continued pre-trained from:** Llama-2-7B
- **Context length:** 4K tokens
- **Input:** Text-only data
- **Output:** Model generates text only
- **Paper:** [arXiv:2401.09646](https://arxiv.org/abs/2401.09646)
- **Website:** [eci.io](https://eci.io)
## Uses
- This model is intended to be directly used as a question answering model that is specialized in the climate domain.
- The model is aimed at providing useful feedback for decision makers, scientists and journalists involved in climate discussions.
- The model can also be used as a starting point for interested developers for further fine-tuning.
- The model is NOT intended to be a general-purpose chatbot (although it has chat capabilities).
- For the full system including cascaded MT, RAG, etc., we recommend the user to go to our demo website: [eci.io](https://eci.io)
- **Despite the efforts from the development team to eliminate them, as every other chat-capable LLMs, this model may generate biased, offensive or inaccurate responses.**
## Downstream Use
ClimateGPT-7B is an instruction-tuned model that can be directly used for climate-specific question-answering applications.
It was trained to perform well with retrieval augmentation and supports up to 5 references in context.
The model was trained using ChatML so the following format should be followed when prompting, including the `<|im_start|>`, `<|im_end|>` tags, `system`, `user`, `context` and `assistant` identifiers and `[[0]]`, `[[1]]]` etc. tokens to indicate references.
"""
<|im_start|>system
{system_message}<|im_end|>
<|im_start|>user
{prompt}<|im_end|>
<|im_start|>context
[[0]] "{reference1_title}", {reference1_year}
{reference1_text}
[[1]] "{reference2_title}", {reference2_year}
{reference2_text}
[...]<|im_end|>
<|im_start|>assistant
"""
## Training
- For the Llama-2 training data, we refer the user to https://huggingface.co/meta-llama/Llama-2-7b-hf.
- For continued pre-training, 4.2B climate-specific tokens (tokenized by the Llama tokenizer) are used.
- For instruction fine-tuning, about 272K instruction-completion pairs (both in the climate domain but also general domain) are used.
## Evaluation
Detailed evaluation results are presented in our [paper](https://arxiv.org/abs/2401.09646) on our model card website: [eci.io/model-card](https://eci.io/model-card)
## Environmental Impact
- **Hardware Type:** 8x NVIDIA H100 HBM
- **Power Consumption per GPU:** 775W
- **Hours used:** 157 hrs
- **Cloud Provider:** MLFoundry
- **Compute Region:** Washington, USA
- **Energy Mix:** 100% Hydro Power (24g CO2eq/kWh according to IPCC 2014)
- **Carbon Emitted:** 2.9kg CO2eq
## Citation
If you find ClimateGPT is useful in your work, please cite it with:
```
@misc{thulke2024climategpt,
title={ClimateGPT: Towards AI Synthesizing Interdisciplinary Research on Climate Change},
author={David Thulke and Yingbo Gao and Petrus Pelser and Rein Brune and Rricha Jalota and Floris Fok and Michael Ramos and Ian van Wyk and Abdallah Nasir and Hayden Goldstein and Taylor Tragemann and Katie Nguyen and Ariana Fowler and Andrew Stanco and Jon Gabriel and Jordan Taylor and Dean Moro and Evgenii Tsymbalov and Juliette de Waal and Evgeny Matusov and Mudar Yaghi and Mohammad Shihadah and Hermann Ney and Christian Dugast and Jonathan Dotan and Daniel Erasmus},
year={2024},
eprint={2401.09646},
archivePrefix={arXiv},
primaryClass={cs.LG}
}
```
|
allenai/unifiedqa-t5-small | allenai | 2023-01-24T16:28:05Z | 16,487 | 5 | transformers | [
"transformers",
"pytorch",
"jax",
"t5",
"text2text-generation",
"en",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| text2text-generation | 2022-03-02T23:29:05Z | ---
language: en
---
|
01-ai/Yi-1.5-9B-Chat-16K | 01-ai | 2024-06-26T10:43:20Z | 16,483 | 29 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"arxiv:2403.04652",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| text-generation | 2024-05-15T10:45:56Z | ---
license: apache-2.0
---
<div align="center">
<picture>
<img src="https://raw.githubusercontent.com/01-ai/Yi/main/assets/img/Yi_logo_icon_light.svg" width="150px">
</picture>
</div>
<p align="center">
<a href="https://github.com/01-ai">🐙 GitHub</a> •
<a href="https://discord.gg/hYUwWddeAu">👾 Discord</a> •
<a href="https://twitter.com/01ai_yi">🐤 Twitter</a> •
<a href="https://github.com/01-ai/Yi-1.5/issues/2">💬 WeChat</a>
<br/>
<a href="https://arxiv.org/abs/2403.04652">📝 Paper</a> •
<a href="https://01-ai.github.io/">💪 Tech Blog</a> •
<a href="https://github.com/01-ai/Yi/tree/main?tab=readme-ov-file#faq">🙌 FAQ</a> •
<a href="https://github.com/01-ai/Yi/tree/main?tab=readme-ov-file#learning-hub">📗 Learning Hub</a>
</p>
# Intro
Yi-1.5 is an upgraded version of Yi. It is continuously pre-trained on Yi with a high-quality corpus of 500B tokens and fine-tuned on 3M diverse fine-tuning samples.
Compared with Yi, Yi-1.5 delivers stronger performance in coding, math, reasoning, and instruction-following capability, while still maintaining excellent capabilities in language understanding, commonsense reasoning, and reading comprehension.
<div align="center">
Model | Context Length | Pre-trained Tokens
| :------------: | :------------: | :------------: |
| Yi-1.5 | 4K, 16K, 32K | 3.6T
</div>
# Models
- Chat models
<div align="center">
| Name | Download |
| --------------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| Yi-1.5-34B-Chat | • [🤗 Hugging Face](https://huggingface.co/collections/01-ai/yi-15-2024-05-663f3ecab5f815a3eaca7ca8) • [🤖 ModelScope](https://www.modelscope.cn/organization/01ai) • [🟣 wisemodel](https://wisemodel.cn/organization/01.AI)|
| Yi-1.5-34B-Chat-16K | • [🤗 Hugging Face](https://huggingface.co/collections/01-ai/yi-15-2024-05-663f3ecab5f815a3eaca7ca8) • [🤖 ModelScope](https://www.modelscope.cn/organization/01ai) • [🟣 wisemodel](https://wisemodel.cn/organization/01.AI) |
| Yi-1.5-9B-Chat | • [🤗 Hugging Face](https://huggingface.co/collections/01-ai/yi-15-2024-05-663f3ecab5f815a3eaca7ca8) • [🤖 ModelScope](https://www.modelscope.cn/organization/01ai) • [🟣 wisemodel](https://wisemodel.cn/organization/01.AI) |
| Yi-1.5-9B-Chat-16K | • [🤗 Hugging Face](https://huggingface.co/collections/01-ai/yi-15-2024-05-663f3ecab5f815a3eaca7ca8) • [🤖 ModelScope](https://www.modelscope.cn/organization/01ai) • [🟣 wisemodel](https://wisemodel.cn/organization/01.AI) |
| Yi-1.5-6B-Chat | • [🤗 Hugging Face](https://huggingface.co/collections/01-ai/yi-15-2024-05-663f3ecab5f815a3eaca7ca8) • [🤖 ModelScope](https://www.modelscope.cn/organization/01ai) • [🟣 wisemodel](https://wisemodel.cn/organization/01.AI) |
</div>
- Base models
<div align="center">
| Name | Download |
| ---------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| Yi-1.5-34B | • [🤗 Hugging Face](https://huggingface.co/collections/01-ai/yi-15-2024-05-663f3ecab5f815a3eaca7ca8) • [🤖 ModelScope](https://www.modelscope.cn/organization/01ai) • [🟣 wisemodel](https://wisemodel.cn/organization/01.AI) |
| Yi-1.5-34B-32K | • [🤗 Hugging Face](https://huggingface.co/collections/01-ai/yi-15-2024-05-663f3ecab5f815a3eaca7ca8) • [🤖 ModelScope](https://www.modelscope.cn/organization/01ai) • [🟣 wisemodel](https://wisemodel.cn/organization/01.AI) |
| Yi-1.5-9B | • [🤗 Hugging Face](https://huggingface.co/collections/01-ai/yi-15-2024-05-663f3ecab5f815a3eaca7ca8) • [🤖 ModelScope](https://www.modelscope.cn/organization/01ai) • [🟣 wisemodel](https://wisemodel.cn/organization/01.AI) |
| Yi-1.5-9B-32K | • [🤗 Hugging Face](https://huggingface.co/collections/01-ai/yi-15-2024-05-663f3ecab5f815a3eaca7ca8) • [🤖 ModelScope](https://www.modelscope.cn/organization/01ai) • [🟣 wisemodel](https://wisemodel.cn/organization/01.AI) |
| Yi-1.5-6B | • [🤗 Hugging Face](https://huggingface.co/collections/01-ai/yi-15-2024-05-663f3ecab5f815a3eaca7ca8) • [🤖 ModelScope](https://www.modelscope.cn/organization/01ai) • [🟣 wisemodel](https://wisemodel.cn/organization/01.AI) |
</div>
# Benchmarks
- Chat models
Yi-1.5-34B-Chat is on par with or excels beyond larger models in most benchmarks.

Yi-1.5-9B-Chat is the top performer among similarly sized open-source models.

- Base models
Yi-1.5-34B is on par with or excels beyond larger models in some benchmarks.

Yi-1.5-9B is the top performer among similarly sized open-source models.

# Quick Start
For getting up and running with Yi-1.5 models quickly, see [README](https://github.com/01-ai/Yi-1.5).
|
mradermacher/Llama-3-8B-Magpie-Pro-MT-UltraDPO2-GGUF | mradermacher | 2024-06-30T05:51:18Z | 16,468 | 0 | transformers | [
"transformers",
"gguf",
"alignment-handbook",
"trl",
"dpo",
"generated_from_trainer",
"en",
"dataset:princeton-nlp/llama3-ultrafeedback",
"base_model:Magpie-Align/Llama-3-8B-Magpie-Pro-MT-UltraDPO2",
"license:llama3",
"endpoints_compatible",
"region:us"
]
| null | 2024-06-30T05:22:52Z | ---
base_model: Magpie-Align/Llama-3-8B-Magpie-Pro-MT-UltraDPO2
datasets:
- princeton-nlp/llama3-ultrafeedback
language:
- en
library_name: transformers
license: llama3
quantized_by: mradermacher
tags:
- alignment-handbook
- trl
- dpo
- generated_from_trainer
- trl
- dpo
- generated_from_trainer
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
static quants of https://huggingface.co/Magpie-Align/Llama-3-8B-Magpie-Pro-MT-UltraDPO2
<!-- provided-files -->
weighted/imatrix quants seem not to be available (by me) at this time. If they do not show up a week or so after the static ones, I have probably not planned for them. Feel free to request them by opening a Community Discussion.
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/Llama-3-8B-Magpie-Pro-MT-UltraDPO2-GGUF/resolve/main/Llama-3-8B-Magpie-Pro-MT-UltraDPO2.Q2_K.gguf) | Q2_K | 3.3 | |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-8B-Magpie-Pro-MT-UltraDPO2-GGUF/resolve/main/Llama-3-8B-Magpie-Pro-MT-UltraDPO2.IQ3_XS.gguf) | IQ3_XS | 3.6 | |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-8B-Magpie-Pro-MT-UltraDPO2-GGUF/resolve/main/Llama-3-8B-Magpie-Pro-MT-UltraDPO2.Q3_K_S.gguf) | Q3_K_S | 3.8 | |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-8B-Magpie-Pro-MT-UltraDPO2-GGUF/resolve/main/Llama-3-8B-Magpie-Pro-MT-UltraDPO2.IQ3_S.gguf) | IQ3_S | 3.8 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-8B-Magpie-Pro-MT-UltraDPO2-GGUF/resolve/main/Llama-3-8B-Magpie-Pro-MT-UltraDPO2.IQ3_M.gguf) | IQ3_M | 3.9 | |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-8B-Magpie-Pro-MT-UltraDPO2-GGUF/resolve/main/Llama-3-8B-Magpie-Pro-MT-UltraDPO2.Q3_K_M.gguf) | Q3_K_M | 4.1 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-8B-Magpie-Pro-MT-UltraDPO2-GGUF/resolve/main/Llama-3-8B-Magpie-Pro-MT-UltraDPO2.Q3_K_L.gguf) | Q3_K_L | 4.4 | |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-8B-Magpie-Pro-MT-UltraDPO2-GGUF/resolve/main/Llama-3-8B-Magpie-Pro-MT-UltraDPO2.IQ4_XS.gguf) | IQ4_XS | 4.6 | |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-8B-Magpie-Pro-MT-UltraDPO2-GGUF/resolve/main/Llama-3-8B-Magpie-Pro-MT-UltraDPO2.Q4_K_S.gguf) | Q4_K_S | 4.8 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-8B-Magpie-Pro-MT-UltraDPO2-GGUF/resolve/main/Llama-3-8B-Magpie-Pro-MT-UltraDPO2.Q4_K_M.gguf) | Q4_K_M | 5.0 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-8B-Magpie-Pro-MT-UltraDPO2-GGUF/resolve/main/Llama-3-8B-Magpie-Pro-MT-UltraDPO2.Q5_K_S.gguf) | Q5_K_S | 5.7 | |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-8B-Magpie-Pro-MT-UltraDPO2-GGUF/resolve/main/Llama-3-8B-Magpie-Pro-MT-UltraDPO2.Q5_K_M.gguf) | Q5_K_M | 5.8 | |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-8B-Magpie-Pro-MT-UltraDPO2-GGUF/resolve/main/Llama-3-8B-Magpie-Pro-MT-UltraDPO2.Q6_K.gguf) | Q6_K | 6.7 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-8B-Magpie-Pro-MT-UltraDPO2-GGUF/resolve/main/Llama-3-8B-Magpie-Pro-MT-UltraDPO2.Q8_0.gguf) | Q8_0 | 8.6 | fast, best quality |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-8B-Magpie-Pro-MT-UltraDPO2-GGUF/resolve/main/Llama-3-8B-Magpie-Pro-MT-UltraDPO2.f16.gguf) | f16 | 16.2 | 16 bpw, overkill |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.