
modelId
stringlengths 5
122
| author
stringlengths 2
42
| last_modified
timestamp[us, tz=UTC] | downloads
int64 0
738M
| likes
int64 0
11k
| library_name
stringclasses 245
values | tags
sequencelengths 1
4.05k
| pipeline_tag
stringclasses 48
values | createdAt
timestamp[us, tz=UTC] | card
stringlengths 1
901k
|
|---|---|---|---|---|---|---|---|---|---|
uer/sbert-base-chinese-nli | uer | 2023-10-17T15:29:59Z | 6,995 | 104 | sentence-transformers | [
"sentence-transformers",
"pytorch",
"bert",
"feature-extraction",
"sentence-similarity",
"transformers",
"zh",
"arxiv:1909.05658",
"arxiv:2212.06385",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-embeddings-inference",
"region:us"
] | sentence-similarity | 2022-03-02T23:29:05Z | ---
language: zh
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
license: apache-2.0
widget:
- source_sentence: "那个人很开心"
sentences:
- "那个人非常开心"
- "那只猫很开心"
- "那个人在吃东西"
---
# Chinese Sentence BERT
## Model description
This is the sentence embedding model pre-trained by [UER-py](https://github.com/dbiir/UER-py/), which is introduced in [this paper](https://arxiv.org/abs/1909.05658). Besides, the model could also be pre-trained by [TencentPretrain](https://github.com/Tencent/TencentPretrain) introduced in [this paper](https://arxiv.org/abs/2212.06385), which inherits UER-py to support models with parameters above one billion, and extends it to a multimodal pre-training framework.
## How to use
You can use this model to extract sentence embeddings for sentence similarity task. We use cosine distance to calculate the embedding similarity here:
```python
>>> from sentence_transformers import SentenceTransformer
>>> model = SentenceTransformer('uer/sbert-base-chinese-nli')
>>> sentences = ['那个人很开心', '那个人非常开心']
>>> sentence_embeddings = model.encode(sentences)
>>> from sklearn.metrics.pairwise import paired_cosine_distances
>>> cosine_score = 1 - paired_cosine_distances([sentence_embeddings[0]],[sentence_embeddings[1]])
```
## Training data
[ChineseTextualInference](https://github.com/liuhuanyong/ChineseTextualInference/) is used as training data.
## Training procedure
The model is fine-tuned by [UER-py](https://github.com/dbiir/UER-py/) on [Tencent Cloud](https://cloud.tencent.com/). We fine-tune five epochs with a sequence length of 128 on the basis of the pre-trained model [chinese_roberta_L-12_H-768](https://huggingface.co/uer/chinese_roberta_L-12_H-768). At the end of each epoch, the model is saved when the best performance on development set is achieved.
```
python3 finetune/run_classifier_siamese.py --pretrained_model_path models/cluecorpussmall_roberta_base_seq512_model.bin-250000 \
--vocab_path models/google_zh_vocab.txt \
--config_path models/sbert/base_config.json \
--train_path datasets/ChineseTextualInference/train.tsv \
--dev_path datasets/ChineseTextualInference/dev.tsv \
--learning_rate 5e-5 --epochs_num 5 --batch_size 64
```
Finally, we convert the pre-trained model into Huggingface's format:
```
python3 scripts/convert_sbert_from_uer_to_huggingface.py --input_model_path models/finetuned_model.bin \
--output_model_path pytorch_model.bin \
--layers_num 12
```
### BibTeX entry and citation info
```
@article{reimers2019sentence,
title={Sentence-bert: Sentence embeddings using siamese bert-networks},
author={Reimers, Nils and Gurevych, Iryna},
journal={arXiv preprint arXiv:1908.10084},
year={2019}
}
@article{zhao2019uer,
title={UER: An Open-Source Toolkit for Pre-training Models},
author={Zhao, Zhe and Chen, Hui and Zhang, Jinbin and Zhao, Xin and Liu, Tao and Lu, Wei and Chen, Xi and Deng, Haotang and Ju, Qi and Du, Xiaoyong},
journal={EMNLP-IJCNLP 2019},
pages={241},
year={2019}
}
@article{zhao2023tencentpretrain,
title={TencentPretrain: A Scalable and Flexible Toolkit for Pre-training Models of Different Modalities},
author={Zhao, Zhe and Li, Yudong and Hou, Cheng and Zhao, Jing and others},
journal={ACL 2023},
pages={217},
year={2023}
``` |
RichardErkhov/gemmathon_-_gemma-2b-ko-dev-pbmt192-gguf | RichardErkhov | 2024-06-24T18:25:36Z | 6,995 | 0 | null | [
"gguf",
"arxiv:1910.09700",
"region:us"
] | null | 2024-06-24T11:23:30Z | Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
gemma-2b-ko-dev-pbmt192 - GGUF
- Model creator: https://huggingface.co/gemmathon/
- Original model: https://huggingface.co/gemmathon/gemma-2b-ko-dev-pbmt192/
| Name | Quant method | Size |
| ---- | ---- | ---- |
| [gemma-2b-ko-dev-pbmt192.Q2_K.gguf](https://huggingface.co/RichardErkhov/gemmathon_-_gemma-2b-ko-dev-pbmt192-gguf/blob/main/gemma-2b-ko-dev-pbmt192.Q2_K.gguf) | Q2_K | 1.08GB |
| [gemma-2b-ko-dev-pbmt192.IQ3_XS.gguf](https://huggingface.co/RichardErkhov/gemmathon_-_gemma-2b-ko-dev-pbmt192-gguf/blob/main/gemma-2b-ko-dev-pbmt192.IQ3_XS.gguf) | IQ3_XS | 1.16GB |
| [gemma-2b-ko-dev-pbmt192.IQ3_S.gguf](https://huggingface.co/RichardErkhov/gemmathon_-_gemma-2b-ko-dev-pbmt192-gguf/blob/main/gemma-2b-ko-dev-pbmt192.IQ3_S.gguf) | IQ3_S | 1.2GB |
| [gemma-2b-ko-dev-pbmt192.Q3_K_S.gguf](https://huggingface.co/RichardErkhov/gemmathon_-_gemma-2b-ko-dev-pbmt192-gguf/blob/main/gemma-2b-ko-dev-pbmt192.Q3_K_S.gguf) | Q3_K_S | 1.2GB |
| [gemma-2b-ko-dev-pbmt192.IQ3_M.gguf](https://huggingface.co/RichardErkhov/gemmathon_-_gemma-2b-ko-dev-pbmt192-gguf/blob/main/gemma-2b-ko-dev-pbmt192.IQ3_M.gguf) | IQ3_M | 1.22GB |
| [gemma-2b-ko-dev-pbmt192.Q3_K.gguf](https://huggingface.co/RichardErkhov/gemmathon_-_gemma-2b-ko-dev-pbmt192-gguf/blob/main/gemma-2b-ko-dev-pbmt192.Q3_K.gguf) | Q3_K | 1.29GB |
| [gemma-2b-ko-dev-pbmt192.Q3_K_M.gguf](https://huggingface.co/RichardErkhov/gemmathon_-_gemma-2b-ko-dev-pbmt192-gguf/blob/main/gemma-2b-ko-dev-pbmt192.Q3_K_M.gguf) | Q3_K_M | 1.29GB |
| [gemma-2b-ko-dev-pbmt192.Q3_K_L.gguf](https://huggingface.co/RichardErkhov/gemmathon_-_gemma-2b-ko-dev-pbmt192-gguf/blob/main/gemma-2b-ko-dev-pbmt192.Q3_K_L.gguf) | Q3_K_L | 1.36GB |
| [gemma-2b-ko-dev-pbmt192.IQ4_XS.gguf](https://huggingface.co/RichardErkhov/gemmathon_-_gemma-2b-ko-dev-pbmt192-gguf/blob/main/gemma-2b-ko-dev-pbmt192.IQ4_XS.gguf) | IQ4_XS | 1.4GB |
| [gemma-2b-ko-dev-pbmt192.Q4_0.gguf](https://huggingface.co/RichardErkhov/gemmathon_-_gemma-2b-ko-dev-pbmt192-gguf/blob/main/gemma-2b-ko-dev-pbmt192.Q4_0.gguf) | Q4_0 | 1.44GB |
| [gemma-2b-ko-dev-pbmt192.IQ4_NL.gguf](https://huggingface.co/RichardErkhov/gemmathon_-_gemma-2b-ko-dev-pbmt192-gguf/blob/main/gemma-2b-ko-dev-pbmt192.IQ4_NL.gguf) | IQ4_NL | 1.45GB |
| [gemma-2b-ko-dev-pbmt192.Q4_K_S.gguf](https://huggingface.co/RichardErkhov/gemmathon_-_gemma-2b-ko-dev-pbmt192-gguf/blob/main/gemma-2b-ko-dev-pbmt192.Q4_K_S.gguf) | Q4_K_S | 1.45GB |
| [gemma-2b-ko-dev-pbmt192.Q4_K.gguf](https://huggingface.co/RichardErkhov/gemmathon_-_gemma-2b-ko-dev-pbmt192-gguf/blob/main/gemma-2b-ko-dev-pbmt192.Q4_K.gguf) | Q4_K | 1.52GB |
| [gemma-2b-ko-dev-pbmt192.Q4_K_M.gguf](https://huggingface.co/RichardErkhov/gemmathon_-_gemma-2b-ko-dev-pbmt192-gguf/blob/main/gemma-2b-ko-dev-pbmt192.Q4_K_M.gguf) | Q4_K_M | 1.52GB |
| [gemma-2b-ko-dev-pbmt192.Q4_1.gguf](https://huggingface.co/RichardErkhov/gemmathon_-_gemma-2b-ko-dev-pbmt192-gguf/blob/main/gemma-2b-ko-dev-pbmt192.Q4_1.gguf) | Q4_1 | 1.56GB |
| [gemma-2b-ko-dev-pbmt192.Q5_0.gguf](https://huggingface.co/RichardErkhov/gemmathon_-_gemma-2b-ko-dev-pbmt192-gguf/blob/main/gemma-2b-ko-dev-pbmt192.Q5_0.gguf) | Q5_0 | 1.68GB |
| [gemma-2b-ko-dev-pbmt192.Q5_K_S.gguf](https://huggingface.co/RichardErkhov/gemmathon_-_gemma-2b-ko-dev-pbmt192-gguf/blob/main/gemma-2b-ko-dev-pbmt192.Q5_K_S.gguf) | Q5_K_S | 1.68GB |
| [gemma-2b-ko-dev-pbmt192.Q5_K.gguf](https://huggingface.co/RichardErkhov/gemmathon_-_gemma-2b-ko-dev-pbmt192-gguf/blob/main/gemma-2b-ko-dev-pbmt192.Q5_K.gguf) | Q5_K | 1.71GB |
| [gemma-2b-ko-dev-pbmt192.Q5_K_M.gguf](https://huggingface.co/RichardErkhov/gemmathon_-_gemma-2b-ko-dev-pbmt192-gguf/blob/main/gemma-2b-ko-dev-pbmt192.Q5_K_M.gguf) | Q5_K_M | 1.71GB |
| [gemma-2b-ko-dev-pbmt192.Q5_1.gguf](https://huggingface.co/RichardErkhov/gemmathon_-_gemma-2b-ko-dev-pbmt192-gguf/blob/main/gemma-2b-ko-dev-pbmt192.Q5_1.gguf) | Q5_1 | 1.79GB |
| [gemma-2b-ko-dev-pbmt192.Q6_K.gguf](https://huggingface.co/RichardErkhov/gemmathon_-_gemma-2b-ko-dev-pbmt192-gguf/blob/main/gemma-2b-ko-dev-pbmt192.Q6_K.gguf) | Q6_K | 1.92GB |
| [gemma-2b-ko-dev-pbmt192.Q8_0.gguf](https://huggingface.co/RichardErkhov/gemmathon_-_gemma-2b-ko-dev-pbmt192-gguf/blob/main/gemma-2b-ko-dev-pbmt192.Q8_0.gguf) | Q8_0 | 2.49GB |
Original model description:
---
license: other
library_name: transformers
license_name: gemma-terms-of-use
license_link: https://ai.google.dev/gemma/terms
pipeline_tag: text-generation
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
RichardErkhov/AI-B_-_UTENA-7B-V3-gguf | RichardErkhov | 2024-06-26T21:29:05Z | 6,994 | 0 | null | [
"gguf",
"region:us"
] | null | 2024-06-26T17:29:35Z | Entry not found |
abeja/gpt-neox-japanese-2.7b | abeja | 2023-04-10T05:12:30Z | 6,988 | 55 | transformers | [
"transformers",
"pytorch",
"gpt_neox_japanese",
"text-generation",
"ja",
"japanese",
"gpt_neox",
"gpt",
"lm",
"nlp",
"dataset:cc100",
"dataset:wikipedia",
"dataset:oscar",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-generation | 2022-08-29T02:15:44Z | ---
language: ja
tags:
- ja
- japanese
- gpt_neox
- gpt
- text-generation
- lm
- nlp
license: mit
datasets:
- cc100
- wikipedia
- oscar
widget:
- text: "人とAIが協調するためには、"
---
# gpt-neox-japanese-2.7b
**The [open PR](https://github.com/huggingface/transformers/pull/18814) is merged on 2022/9/14.**
You can use this model with v4.23 and higher versions of transformers as follows,
```
pip install transformers
```
This repository provides a 2.7B-parameter Japanese [GPT-NeoX](https://github.com/EleutherAI/gpt-neox)-based model. The model was trained by [ABEJA, Inc](https://www.abejainc.com/)
# How to use
When using pipeline for text generation.
``` python
from transformers import pipeline
generator = pipeline("text-generation", model="abeja/gpt-neox-japanese-2.7b")
generated = generator(
"人とAIが協調するためには、",
max_length=300,
do_sample=True,
num_return_sequences=3,
top_p=0.95,
top_k=50
)
print(*generated, sep="\n")
"""
[out]
{"generated_text": "人とAIが協調するためには、「人が持っている優れた能力とAIの得意とする分野を掛け合わせる」ことが不可欠になります。"}
{"generated_text": "人とAIが協調するためには、双方の長所を活かしていくことが不可欠だと考えています。"}
{"generated_text": "人とAIが協調するためには、人間がAIを理解する、ということが重要です。人間には「AIに対してAIが何をするべきか」ということを明確に教えないと、AIはある程度の知識はあっても何をすべきかがわかりません。だから、コンピューターが考えたり、決めたりすることはAIではなく、人間が解釈して理解できるようにしなくて"}
"""
```
When using PyTorch.
``` python
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("abeja/gpt-neox-japanese-2.7b")
model = AutoModelForCausalLM.from_pretrained("abeja/gpt-neox-japanese-2.7b")
input_text = "人とAIが協調するためには、"
input_ids = tokenizer.encode(input_text, return_tensors="pt")
gen_tokens = model.generate(
input_ids,
max_length=100,
do_sample=True,
num_return_sequences=3,
top_p=0.95,
top_k=50,
)
for gen_text in tokenizer.batch_decode(gen_tokens, skip_special_tokens=True):
print(gen_text)
```
# Dataset
The model was trained on [Japanese CC-100](http://data.statmt.org/cc-100/ja.txt.xz), [Japanese Wikipedia](https://dumps.wikimedia.org/other/cirrussearch), and [Japanese OSCAR](https://huggingface.co/datasets/oscar).
# Tokenization
The model uses a [special sub-word tokenizer](https://github.com/tanreinama/Japanese-BPEEncoder_V2). Please refer the original repository or [GPT-NeoX-Japanese](https://huggingface.co/docs/transformers/model_doc/gpt_neox_japanese) in detail.
# Licenese
[The MIT license](https://opensource.org/licenses/MIT)
|
RichardErkhov/mlgawd_-_navarasa-2b-2.0-cyberdost-gguf | RichardErkhov | 2024-06-30T04:53:08Z | 6,987 | 0 | null | [
"gguf",
"region:us"
] | null | 2024-06-30T04:02:36Z | Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
navarasa-2b-2.0-cyberdost - GGUF
- Model creator: https://huggingface.co/mlgawd/
- Original model: https://huggingface.co/mlgawd/navarasa-2b-2.0-cyberdost/
| Name | Quant method | Size |
| ---- | ---- | ---- |
| [navarasa-2b-2.0-cyberdost.Q2_K.gguf](https://huggingface.co/RichardErkhov/mlgawd_-_navarasa-2b-2.0-cyberdost-gguf/blob/main/navarasa-2b-2.0-cyberdost.Q2_K.gguf) | Q2_K | 1.08GB |
| [navarasa-2b-2.0-cyberdost.IQ3_XS.gguf](https://huggingface.co/RichardErkhov/mlgawd_-_navarasa-2b-2.0-cyberdost-gguf/blob/main/navarasa-2b-2.0-cyberdost.IQ3_XS.gguf) | IQ3_XS | 1.16GB |
| [navarasa-2b-2.0-cyberdost.IQ3_S.gguf](https://huggingface.co/RichardErkhov/mlgawd_-_navarasa-2b-2.0-cyberdost-gguf/blob/main/navarasa-2b-2.0-cyberdost.IQ3_S.gguf) | IQ3_S | 1.2GB |
| [navarasa-2b-2.0-cyberdost.Q3_K_S.gguf](https://huggingface.co/RichardErkhov/mlgawd_-_navarasa-2b-2.0-cyberdost-gguf/blob/main/navarasa-2b-2.0-cyberdost.Q3_K_S.gguf) | Q3_K_S | 1.2GB |
| [navarasa-2b-2.0-cyberdost.IQ3_M.gguf](https://huggingface.co/RichardErkhov/mlgawd_-_navarasa-2b-2.0-cyberdost-gguf/blob/main/navarasa-2b-2.0-cyberdost.IQ3_M.gguf) | IQ3_M | 1.22GB |
| [navarasa-2b-2.0-cyberdost.Q3_K.gguf](https://huggingface.co/RichardErkhov/mlgawd_-_navarasa-2b-2.0-cyberdost-gguf/blob/main/navarasa-2b-2.0-cyberdost.Q3_K.gguf) | Q3_K | 1.29GB |
| [navarasa-2b-2.0-cyberdost.Q3_K_M.gguf](https://huggingface.co/RichardErkhov/mlgawd_-_navarasa-2b-2.0-cyberdost-gguf/blob/main/navarasa-2b-2.0-cyberdost.Q3_K_M.gguf) | Q3_K_M | 1.29GB |
| [navarasa-2b-2.0-cyberdost.Q3_K_L.gguf](https://huggingface.co/RichardErkhov/mlgawd_-_navarasa-2b-2.0-cyberdost-gguf/blob/main/navarasa-2b-2.0-cyberdost.Q3_K_L.gguf) | Q3_K_L | 1.36GB |
| [navarasa-2b-2.0-cyberdost.IQ4_XS.gguf](https://huggingface.co/RichardErkhov/mlgawd_-_navarasa-2b-2.0-cyberdost-gguf/blob/main/navarasa-2b-2.0-cyberdost.IQ4_XS.gguf) | IQ4_XS | 1.4GB |
| [navarasa-2b-2.0-cyberdost.Q4_0.gguf](https://huggingface.co/RichardErkhov/mlgawd_-_navarasa-2b-2.0-cyberdost-gguf/blob/main/navarasa-2b-2.0-cyberdost.Q4_0.gguf) | Q4_0 | 1.44GB |
| [navarasa-2b-2.0-cyberdost.IQ4_NL.gguf](https://huggingface.co/RichardErkhov/mlgawd_-_navarasa-2b-2.0-cyberdost-gguf/blob/main/navarasa-2b-2.0-cyberdost.IQ4_NL.gguf) | IQ4_NL | 1.45GB |
| [navarasa-2b-2.0-cyberdost.Q4_K_S.gguf](https://huggingface.co/RichardErkhov/mlgawd_-_navarasa-2b-2.0-cyberdost-gguf/blob/main/navarasa-2b-2.0-cyberdost.Q4_K_S.gguf) | Q4_K_S | 1.45GB |
| [navarasa-2b-2.0-cyberdost.Q4_K.gguf](https://huggingface.co/RichardErkhov/mlgawd_-_navarasa-2b-2.0-cyberdost-gguf/blob/main/navarasa-2b-2.0-cyberdost.Q4_K.gguf) | Q4_K | 1.52GB |
| [navarasa-2b-2.0-cyberdost.Q4_K_M.gguf](https://huggingface.co/RichardErkhov/mlgawd_-_navarasa-2b-2.0-cyberdost-gguf/blob/main/navarasa-2b-2.0-cyberdost.Q4_K_M.gguf) | Q4_K_M | 1.52GB |
| [navarasa-2b-2.0-cyberdost.Q4_1.gguf](https://huggingface.co/RichardErkhov/mlgawd_-_navarasa-2b-2.0-cyberdost-gguf/blob/main/navarasa-2b-2.0-cyberdost.Q4_1.gguf) | Q4_1 | 1.56GB |
| [navarasa-2b-2.0-cyberdost.Q5_0.gguf](https://huggingface.co/RichardErkhov/mlgawd_-_navarasa-2b-2.0-cyberdost-gguf/blob/main/navarasa-2b-2.0-cyberdost.Q5_0.gguf) | Q5_0 | 1.68GB |
| [navarasa-2b-2.0-cyberdost.Q5_K_S.gguf](https://huggingface.co/RichardErkhov/mlgawd_-_navarasa-2b-2.0-cyberdost-gguf/blob/main/navarasa-2b-2.0-cyberdost.Q5_K_S.gguf) | Q5_K_S | 1.68GB |
| [navarasa-2b-2.0-cyberdost.Q5_K.gguf](https://huggingface.co/RichardErkhov/mlgawd_-_navarasa-2b-2.0-cyberdost-gguf/blob/main/navarasa-2b-2.0-cyberdost.Q5_K.gguf) | Q5_K | 1.71GB |
| [navarasa-2b-2.0-cyberdost.Q5_K_M.gguf](https://huggingface.co/RichardErkhov/mlgawd_-_navarasa-2b-2.0-cyberdost-gguf/blob/main/navarasa-2b-2.0-cyberdost.Q5_K_M.gguf) | Q5_K_M | 1.71GB |
| [navarasa-2b-2.0-cyberdost.Q5_1.gguf](https://huggingface.co/RichardErkhov/mlgawd_-_navarasa-2b-2.0-cyberdost-gguf/blob/main/navarasa-2b-2.0-cyberdost.Q5_1.gguf) | Q5_1 | 1.79GB |
| [navarasa-2b-2.0-cyberdost.Q6_K.gguf](https://huggingface.co/RichardErkhov/mlgawd_-_navarasa-2b-2.0-cyberdost-gguf/blob/main/navarasa-2b-2.0-cyberdost.Q6_K.gguf) | Q6_K | 1.92GB |
| [navarasa-2b-2.0-cyberdost.Q8_0.gguf](https://huggingface.co/RichardErkhov/mlgawd_-_navarasa-2b-2.0-cyberdost-gguf/blob/main/navarasa-2b-2.0-cyberdost.Q8_0.gguf) | Q8_0 | 2.49GB |
Original model description:
# Cybersecurity LLM Indic
## Model Card
### Overview
We present **Cybersecurity LLM Indic**, a large language model fine-tuned specifically for cybersecurity purposes. This model has been trained on a curated dataset containing cybersecurity data, tips, and guidelines from various Indian government sources. The fine-tuning process involved approximately 3,000 rows of data, ensuring that the model is well-versed in the nuances of cybersecurity within the Indian context.
### Base Model
The base model used for this fine-tuning process is **Navarasa 2.0 2B Gemma Instruct**. This base model is renowned for its versatility and robustness, making it an excellent foundation for building a specialized cybersecurity model.
### Training Data
The training dataset comprises a diverse collection of cybersecurity-related information, including:
- Guidelines and advisories from Indian government agencies
- Best practices for securing information systems and networks
- Tips for individuals and organizations to safeguard against cyber threats
- Case studies and real-world examples of cybersecurity incidents and responses
### Training Procedure
The model was fine-tuned using the following procedure:
- **Data Preparation:** The raw data was cleaned and preprocessed to ensure high-quality input for training. This involved removing duplicates, correcting formatting issues, and standardizing terminology.
- **Fine-Tuning:** The fine-tuning process involved training the model on the prepared dataset for several epochs, optimizing for performance on cybersecurity-related tasks.
- **Evaluation:** The model was evaluated on a separate validation set to ensure its accuracy and relevance in providing cybersecurity advice and guidelines.
### Use Cases
**Cybersecurity LLM Indic** can be utilized in various scenarios, including:
- **Education and Training:** Providing comprehensive and accurate cybersecurity training materials.
- **Advisory Services:** Offering real-time cybersecurity advice and best practices.
- **Policy Development:** Assisting policymakers in drafting effective cybersecurity policies.
- **Incident Response:** Guiding organizations in responding to cybersecurity incidents.
### Limitations
While **Cybersecurity LLM Indic** is a powerful tool for cybersecurity applications, it has certain limitations:
- **Domain-Specific Knowledge:** The model is specialized for cybersecurity within the Indian context and may not perform as well on general or international cybersecurity issues.
- **Data Limitations:** The training data consists of approximately 3,000 rows, which, while substantial, may not cover every possible cybersecurity scenario.
- **Continuous Learning:** Cybersecurity is a rapidly evolving field, and the model may need periodic updates to stay current with new threats and best practices.
### Ethical Considerations
The model was developed with a strong emphasis on ethical considerations, including:
- **Privacy:** Ensuring that the training data does not contain sensitive or personally identifiable information.
- **Bias Mitigation:** Efforts were made to minimize biases in the training data to ensure fair and unbiased advice.
### License
This model is licensed under the [Apache-2.0 License](LICENSE).
### Contact Information
For more information or to provide feedback, please contact the development team at [contact email].

|
izhx/udever-bloom-1b1 | izhx | 2023-11-07T06:56:52Z | 6,984 | 2 | transformers | [
"transformers",
"pytorch",
"bloom",
"feature-extraction",
"mteb",
"ak",
"ar",
"as",
"bm",
"bn",
"ca",
"code",
"en",
"es",
"eu",
"fon",
"fr",
"gu",
"hi",
"id",
"ig",
"ki",
"kn",
"lg",
"ln",
"ml",
"mr",
"ne",
"nso",
"ny",
"or",
"pa",
"pt",
"rn",
"rw",
"sn",
"st",
"sw",
"ta",
"te",
"tn",
"ts",
"tum",
"tw",
"ur",
"vi",
"wo",
"xh",
"yo",
"zh",
"zhs",
"zht",
"zu",
"arxiv:2310.08232",
"license:bigscience-bloom-rail-1.0",
"model-index",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | feature-extraction | 2023-10-24T13:53:52Z | ---
license: bigscience-bloom-rail-1.0
language:
- ak
- ar
- as
- bm
- bn
- ca
- code
- en
- es
- eu
- fon
- fr
- gu
- hi
- id
- ig
- ki
- kn
- lg
- ln
- ml
- mr
- ne
- nso
- ny
- or
- pa
- pt
- rn
- rw
- sn
- st
- sw
- ta
- te
- tn
- ts
- tum
- tw
- ur
- vi
- wo
- xh
- yo
- zh
- zhs
- zht
- zu
tags:
- mteb
model-index:
- name: udever-bloom-1b1
results:
- task:
type: STS
dataset:
type: C-MTEB/AFQMC
name: MTEB AFQMC
config: default
split: validation
revision: None
metrics:
- type: cos_sim_pearson
value: 27.90020553155914
- type: cos_sim_spearman
value: 27.980812877007445
- type: euclidean_pearson
value: 27.412021502878105
- type: euclidean_spearman
value: 27.608320539898134
- type: manhattan_pearson
value: 27.493591460276278
- type: manhattan_spearman
value: 27.715134644174423
- task:
type: STS
dataset:
type: C-MTEB/ATEC
name: MTEB ATEC
config: default
split: test
revision: None
metrics:
- type: cos_sim_pearson
value: 35.15277604796132
- type: cos_sim_spearman
value: 35.863846005221575
- type: euclidean_pearson
value: 37.65681598655078
- type: euclidean_spearman
value: 35.50116107334066
- type: manhattan_pearson
value: 37.736463166370854
- type: manhattan_spearman
value: 35.53412987209704
- task:
type: Classification
dataset:
type: mteb/amazon_counterfactual
name: MTEB AmazonCounterfactualClassification (en)
config: en
split: test
revision: e8379541af4e31359cca9fbcf4b00f2671dba205
metrics:
- type: accuracy
value: 69.9402985074627
- type: ap
value: 33.4661141650045
- type: f1
value: 64.31759903129324
- task:
type: Classification
dataset:
type: mteb/amazon_counterfactual
name: MTEB AmazonCounterfactualClassification (de)
config: de
split: test
revision: e8379541af4e31359cca9fbcf4b00f2671dba205
metrics:
- type: accuracy
value: 66.02783725910065
- type: ap
value: 78.25152113775748
- type: f1
value: 64.00236113368896
- task:
type: Classification
dataset:
type: mteb/amazon_counterfactual
name: MTEB AmazonCounterfactualClassification (en-ext)
config: en-ext
split: test
revision: e8379541af4e31359cca9fbcf4b00f2671dba205
metrics:
- type: accuracy
value: 72.01649175412295
- type: ap
value: 21.28416661100625
- type: f1
value: 59.481902269256096
- task:
type: Classification
dataset:
type: mteb/amazon_counterfactual
name: MTEB AmazonCounterfactualClassification (ja)
config: ja
split: test
revision: e8379541af4e31359cca9fbcf4b00f2671dba205
metrics:
- type: accuracy
value: 58.76873661670234
- type: ap
value: 12.828869547428084
- type: f1
value: 47.5200475889544
- task:
type: Classification
dataset:
type: mteb/amazon_polarity
name: MTEB AmazonPolarityClassification
config: default
split: test
revision: e2d317d38cd51312af73b3d32a06d1a08b442046
metrics:
- type: accuracy
value: 87.191175
- type: ap
value: 82.4408783026622
- type: f1
value: 87.16605834054603
- task:
type: Classification
dataset:
type: mteb/amazon_reviews_multi
name: MTEB AmazonReviewsClassification (en)
config: en
split: test
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
metrics:
- type: accuracy
value: 41.082
- type: f1
value: 40.54924237159631
- task:
type: Classification
dataset:
type: mteb/amazon_reviews_multi
name: MTEB AmazonReviewsClassification (de)
config: de
split: test
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
metrics:
- type: accuracy
value: 30.447999999999997
- type: f1
value: 30.0643283775686
- task:
type: Classification
dataset:
type: mteb/amazon_reviews_multi
name: MTEB AmazonReviewsClassification (es)
config: es
split: test
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
metrics:
- type: accuracy
value: 40.800000000000004
- type: f1
value: 39.64954112879312
- task:
type: Classification
dataset:
type: mteb/amazon_reviews_multi
name: MTEB AmazonReviewsClassification (fr)
config: fr
split: test
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
metrics:
- type: accuracy
value: 40.686
- type: f1
value: 39.917643425172
- task:
type: Classification
dataset:
type: mteb/amazon_reviews_multi
name: MTEB AmazonReviewsClassification (ja)
config: ja
split: test
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
metrics:
- type: accuracy
value: 32.074
- type: f1
value: 31.878305643409334
- task:
type: Classification
dataset:
type: mteb/amazon_reviews_multi
name: MTEB AmazonReviewsClassification (zh)
config: zh
split: test
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
metrics:
- type: accuracy
value: 38.122
- type: f1
value: 37.296210966123446
- task:
type: Retrieval
dataset:
type: arguana
name: MTEB ArguAna
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 22.262
- type: map_at_10
value: 37.667
- type: map_at_100
value: 38.812999999999995
- type: map_at_1000
value: 38.829
- type: map_at_3
value: 32.421
- type: map_at_5
value: 35.202
- type: mrr_at_1
value: 22.759999999999998
- type: mrr_at_10
value: 37.817
- type: mrr_at_100
value: 38.983000000000004
- type: mrr_at_1000
value: 38.999
- type: mrr_at_3
value: 32.61
- type: mrr_at_5
value: 35.333999999999996
- type: ndcg_at_1
value: 22.262
- type: ndcg_at_10
value: 46.671
- type: ndcg_at_100
value: 51.519999999999996
- type: ndcg_at_1000
value: 51.876999999999995
- type: ndcg_at_3
value: 35.696
- type: ndcg_at_5
value: 40.722
- type: precision_at_1
value: 22.262
- type: precision_at_10
value: 7.575
- type: precision_at_100
value: 0.9690000000000001
- type: precision_at_1000
value: 0.1
- type: precision_at_3
value: 15.055
- type: precision_at_5
value: 11.479000000000001
- type: recall_at_1
value: 22.262
- type: recall_at_10
value: 75.747
- type: recall_at_100
value: 96.871
- type: recall_at_1000
value: 99.57300000000001
- type: recall_at_3
value: 45.164
- type: recall_at_5
value: 57.397
- task:
type: Clustering
dataset:
type: mteb/arxiv-clustering-p2p
name: MTEB ArxivClusteringP2P
config: default
split: test
revision: a122ad7f3f0291bf49cc6f4d32aa80929df69d5d
metrics:
- type: v_measure
value: 44.51799756336072
- task:
type: Clustering
dataset:
type: mteb/arxiv-clustering-s2s
name: MTEB ArxivClusteringS2S
config: default
split: test
revision: f910caf1a6075f7329cdf8c1a6135696f37dbd53
metrics:
- type: v_measure
value: 34.44923356952161
- task:
type: Reranking
dataset:
type: mteb/askubuntudupquestions-reranking
name: MTEB AskUbuntuDupQuestions
config: default
split: test
revision: 2000358ca161889fa9c082cb41daa8dcfb161a54
metrics:
- type: map
value: 59.49540399419566
- type: mrr
value: 73.43028624192061
- task:
type: STS
dataset:
type: mteb/biosses-sts
name: MTEB BIOSSES
config: default
split: test
revision: d3fb88f8f02e40887cd149695127462bbcf29b4a
metrics:
- type: cos_sim_pearson
value: 87.67018580352695
- type: cos_sim_spearman
value: 84.64530219460785
- type: euclidean_pearson
value: 87.10187265189109
- type: euclidean_spearman
value: 86.19051812629264
- type: manhattan_pearson
value: 86.78890467534343
- type: manhattan_spearman
value: 85.60134807514734
- task:
type: STS
dataset:
type: C-MTEB/BQ
name: MTEB BQ
config: default
split: test
revision: None
metrics:
- type: cos_sim_pearson
value: 46.308790362891266
- type: cos_sim_spearman
value: 46.22674926863126
- type: euclidean_pearson
value: 47.36625172551589
- type: euclidean_spearman
value: 47.55854392572494
- type: manhattan_pearson
value: 47.3342490976193
- type: manhattan_spearman
value: 47.52249648456463
- task:
type: BitextMining
dataset:
type: mteb/bucc-bitext-mining
name: MTEB BUCC (de-en)
config: de-en
split: test
revision: d51519689f32196a32af33b075a01d0e7c51e252
metrics:
- type: accuracy
value: 42.67223382045929
- type: f1
value: 42.02704262244064
- type: precision
value: 41.76166726545405
- type: recall
value: 42.67223382045929
- task:
type: BitextMining
dataset:
type: mteb/bucc-bitext-mining
name: MTEB BUCC (fr-en)
config: fr-en
split: test
revision: d51519689f32196a32af33b075a01d0e7c51e252
metrics:
- type: accuracy
value: 97.95289456306405
- type: f1
value: 97.70709516472228
- type: precision
value: 97.58602978941964
- type: recall
value: 97.95289456306405
- task:
type: BitextMining
dataset:
type: mteb/bucc-bitext-mining
name: MTEB BUCC (ru-en)
config: ru-en
split: test
revision: d51519689f32196a32af33b075a01d0e7c51e252
metrics:
- type: accuracy
value: 25.375822653273296
- type: f1
value: 24.105776263207947
- type: precision
value: 23.644628498465117
- type: recall
value: 25.375822653273296
- task:
type: BitextMining
dataset:
type: mteb/bucc-bitext-mining
name: MTEB BUCC (zh-en)
config: zh-en
split: test
revision: d51519689f32196a32af33b075a01d0e7c51e252
metrics:
- type: accuracy
value: 98.31490258030541
- type: f1
value: 98.24469018781815
- type: precision
value: 98.2095839915745
- type: recall
value: 98.31490258030541
- task:
type: Classification
dataset:
type: mteb/banking77
name: MTEB Banking77Classification
config: default
split: test
revision: 0fd18e25b25c072e09e0d92ab615fda904d66300
metrics:
- type: accuracy
value: 82.89285714285714
- type: f1
value: 82.84943089389121
- task:
type: Clustering
dataset:
type: mteb/biorxiv-clustering-p2p
name: MTEB BiorxivClusteringP2P
config: default
split: test
revision: 65b79d1d13f80053f67aca9498d9402c2d9f1f40
metrics:
- type: v_measure
value: 35.25261508107809
- task:
type: Clustering
dataset:
type: mteb/biorxiv-clustering-s2s
name: MTEB BiorxivClusteringS2S
config: default
split: test
revision: 258694dd0231531bc1fd9de6ceb52a0853c6d908
metrics:
- type: v_measure
value: 30.708512338509653
- task:
type: Clustering
dataset:
type: C-MTEB/CLSClusteringP2P
name: MTEB CLSClusteringP2P
config: default
split: test
revision: None
metrics:
- type: v_measure
value: 35.361295166692464
- task:
type: Clustering
dataset:
type: C-MTEB/CLSClusteringS2S
name: MTEB CLSClusteringS2S
config: default
split: test
revision: None
metrics:
- type: v_measure
value: 37.06879287045825
- task:
type: Reranking
dataset:
type: C-MTEB/CMedQAv1-reranking
name: MTEB CMedQAv1
config: default
split: test
revision: None
metrics:
- type: map
value: 66.06033605600476
- type: mrr
value: 70.82825396825396
- task:
type: Reranking
dataset:
type: C-MTEB/CMedQAv2-reranking
name: MTEB CMedQAv2
config: default
split: test
revision: None
metrics:
- type: map
value: 66.9600733219955
- type: mrr
value: 72.19742063492063
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackAndroidRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 29.526999999999997
- type: map_at_10
value: 38.747
- type: map_at_100
value: 40.172999999999995
- type: map_at_1000
value: 40.311
- type: map_at_3
value: 35.969
- type: map_at_5
value: 37.344
- type: mrr_at_1
value: 36.767
- type: mrr_at_10
value: 45.082
- type: mrr_at_100
value: 45.898
- type: mrr_at_1000
value: 45.958
- type: mrr_at_3
value: 43.085
- type: mrr_at_5
value: 44.044
- type: ndcg_at_1
value: 36.767
- type: ndcg_at_10
value: 44.372
- type: ndcg_at_100
value: 49.908
- type: ndcg_at_1000
value: 52.358000000000004
- type: ndcg_at_3
value: 40.711000000000006
- type: ndcg_at_5
value: 41.914
- type: precision_at_1
value: 36.767
- type: precision_at_10
value: 8.283
- type: precision_at_100
value: 1.3679999999999999
- type: precision_at_1000
value: 0.189
- type: precision_at_3
value: 19.599
- type: precision_at_5
value: 13.505
- type: recall_at_1
value: 29.526999999999997
- type: recall_at_10
value: 54.198
- type: recall_at_100
value: 77.818
- type: recall_at_1000
value: 93.703
- type: recall_at_3
value: 42.122
- type: recall_at_5
value: 46.503
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackEnglishRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 22.646
- type: map_at_10
value: 30.447999999999997
- type: map_at_100
value: 31.417
- type: map_at_1000
value: 31.528
- type: map_at_3
value: 28.168
- type: map_at_5
value: 29.346
- type: mrr_at_1
value: 28.854000000000003
- type: mrr_at_10
value: 35.611
- type: mrr_at_100
value: 36.321
- type: mrr_at_1000
value: 36.378
- type: mrr_at_3
value: 33.726
- type: mrr_at_5
value: 34.745
- type: ndcg_at_1
value: 28.854000000000003
- type: ndcg_at_10
value: 35.052
- type: ndcg_at_100
value: 39.190999999999995
- type: ndcg_at_1000
value: 41.655
- type: ndcg_at_3
value: 31.684
- type: ndcg_at_5
value: 32.998
- type: precision_at_1
value: 28.854000000000003
- type: precision_at_10
value: 6.49
- type: precision_at_100
value: 1.057
- type: precision_at_1000
value: 0.153
- type: precision_at_3
value: 15.244
- type: precision_at_5
value: 10.599
- type: recall_at_1
value: 22.646
- type: recall_at_10
value: 43.482
- type: recall_at_100
value: 61.324
- type: recall_at_1000
value: 77.866
- type: recall_at_3
value: 33.106
- type: recall_at_5
value: 37.124
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackGamingRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 35.061
- type: map_at_10
value: 46.216
- type: map_at_100
value: 47.318
- type: map_at_1000
value: 47.384
- type: map_at_3
value: 43.008
- type: map_at_5
value: 44.79
- type: mrr_at_1
value: 40.251
- type: mrr_at_10
value: 49.677
- type: mrr_at_100
value: 50.39
- type: mrr_at_1000
value: 50.429
- type: mrr_at_3
value: 46.792
- type: mrr_at_5
value: 48.449999999999996
- type: ndcg_at_1
value: 40.251
- type: ndcg_at_10
value: 51.99399999999999
- type: ndcg_at_100
value: 56.418
- type: ndcg_at_1000
value: 57.798
- type: ndcg_at_3
value: 46.192
- type: ndcg_at_5
value: 48.998000000000005
- type: precision_at_1
value: 40.251
- type: precision_at_10
value: 8.469999999999999
- type: precision_at_100
value: 1.159
- type: precision_at_1000
value: 0.133
- type: precision_at_3
value: 20.46
- type: precision_at_5
value: 14.332
- type: recall_at_1
value: 35.061
- type: recall_at_10
value: 65.818
- type: recall_at_100
value: 84.935
- type: recall_at_1000
value: 94.69300000000001
- type: recall_at_3
value: 50.300999999999995
- type: recall_at_5
value: 57.052
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackGisRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 20.776
- type: map_at_10
value: 27.945999999999998
- type: map_at_100
value: 28.976000000000003
- type: map_at_1000
value: 29.073999999999998
- type: map_at_3
value: 25.673000000000002
- type: map_at_5
value: 26.96
- type: mrr_at_1
value: 22.486
- type: mrr_at_10
value: 29.756
- type: mrr_at_100
value: 30.735
- type: mrr_at_1000
value: 30.81
- type: mrr_at_3
value: 27.571
- type: mrr_at_5
value: 28.808
- type: ndcg_at_1
value: 22.486
- type: ndcg_at_10
value: 32.190000000000005
- type: ndcg_at_100
value: 37.61
- type: ndcg_at_1000
value: 40.116
- type: ndcg_at_3
value: 27.688000000000002
- type: ndcg_at_5
value: 29.87
- type: precision_at_1
value: 22.486
- type: precision_at_10
value: 5.028
- type: precision_at_100
value: 0.818
- type: precision_at_1000
value: 0.107
- type: precision_at_3
value: 11.827
- type: precision_at_5
value: 8.362
- type: recall_at_1
value: 20.776
- type: recall_at_10
value: 43.588
- type: recall_at_100
value: 69.139
- type: recall_at_1000
value: 88.144
- type: recall_at_3
value: 31.411
- type: recall_at_5
value: 36.655
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackMathematicaRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 12.994
- type: map_at_10
value: 19.747999999999998
- type: map_at_100
value: 20.877000000000002
- type: map_at_1000
value: 21.021
- type: map_at_3
value: 17.473
- type: map_at_5
value: 18.683
- type: mrr_at_1
value: 16.542
- type: mrr_at_10
value: 23.830000000000002
- type: mrr_at_100
value: 24.789
- type: mrr_at_1000
value: 24.877
- type: mrr_at_3
value: 21.476
- type: mrr_at_5
value: 22.838
- type: ndcg_at_1
value: 16.542
- type: ndcg_at_10
value: 24.422
- type: ndcg_at_100
value: 30.011
- type: ndcg_at_1000
value: 33.436
- type: ndcg_at_3
value: 20.061999999999998
- type: ndcg_at_5
value: 22.009999999999998
- type: precision_at_1
value: 16.542
- type: precision_at_10
value: 4.664
- type: precision_at_100
value: 0.876
- type: precision_at_1000
value: 0.132
- type: precision_at_3
value: 9.826
- type: precision_at_5
value: 7.2139999999999995
- type: recall_at_1
value: 12.994
- type: recall_at_10
value: 34.917
- type: recall_at_100
value: 59.455000000000005
- type: recall_at_1000
value: 83.87299999999999
- type: recall_at_3
value: 22.807
- type: recall_at_5
value: 27.773999999999997
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackPhysicsRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 24.85
- type: map_at_10
value: 35.285
- type: map_at_100
value: 36.592999999999996
- type: map_at_1000
value: 36.720000000000006
- type: map_at_3
value: 32.183
- type: map_at_5
value: 33.852
- type: mrr_at_1
value: 30.703000000000003
- type: mrr_at_10
value: 40.699000000000005
- type: mrr_at_100
value: 41.598
- type: mrr_at_1000
value: 41.654
- type: mrr_at_3
value: 38.080999999999996
- type: mrr_at_5
value: 39.655
- type: ndcg_at_1
value: 30.703000000000003
- type: ndcg_at_10
value: 41.422
- type: ndcg_at_100
value: 46.998
- type: ndcg_at_1000
value: 49.395
- type: ndcg_at_3
value: 36.353
- type: ndcg_at_5
value: 38.7
- type: precision_at_1
value: 30.703000000000003
- type: precision_at_10
value: 7.757
- type: precision_at_100
value: 1.2349999999999999
- type: precision_at_1000
value: 0.164
- type: precision_at_3
value: 17.613
- type: precision_at_5
value: 12.589
- type: recall_at_1
value: 24.85
- type: recall_at_10
value: 54.19500000000001
- type: recall_at_100
value: 77.697
- type: recall_at_1000
value: 93.35900000000001
- type: recall_at_3
value: 39.739999999999995
- type: recall_at_5
value: 46.03
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackProgrammersRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 19.844
- type: map_at_10
value: 28.663
- type: map_at_100
value: 30.013
- type: map_at_1000
value: 30.139
- type: map_at_3
value: 25.953
- type: map_at_5
value: 27.425
- type: mrr_at_1
value: 25.457
- type: mrr_at_10
value: 34.266000000000005
- type: mrr_at_100
value: 35.204
- type: mrr_at_1000
value: 35.27
- type: mrr_at_3
value: 31.791999999999998
- type: mrr_at_5
value: 33.213
- type: ndcg_at_1
value: 25.457
- type: ndcg_at_10
value: 34.266000000000005
- type: ndcg_at_100
value: 40.239999999999995
- type: ndcg_at_1000
value: 42.917
- type: ndcg_at_3
value: 29.593999999999998
- type: ndcg_at_5
value: 31.71
- type: precision_at_1
value: 25.457
- type: precision_at_10
value: 6.438000000000001
- type: precision_at_100
value: 1.1159999999999999
- type: precision_at_1000
value: 0.153
- type: precision_at_3
value: 14.46
- type: precision_at_5
value: 10.388
- type: recall_at_1
value: 19.844
- type: recall_at_10
value: 45.787
- type: recall_at_100
value: 71.523
- type: recall_at_1000
value: 89.689
- type: recall_at_3
value: 32.665
- type: recall_at_5
value: 38.292
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 21.601166666666668
- type: map_at_10
value: 29.434166666666666
- type: map_at_100
value: 30.5905
- type: map_at_1000
value: 30.716583333333343
- type: map_at_3
value: 26.962333333333333
- type: map_at_5
value: 28.287250000000004
- type: mrr_at_1
value: 25.84825
- type: mrr_at_10
value: 33.49966666666667
- type: mrr_at_100
value: 34.39425000000001
- type: mrr_at_1000
value: 34.46366666666667
- type: mrr_at_3
value: 31.256
- type: mrr_at_5
value: 32.52016666666667
- type: ndcg_at_1
value: 25.84825
- type: ndcg_at_10
value: 34.2975
- type: ndcg_at_100
value: 39.50983333333333
- type: ndcg_at_1000
value: 42.17958333333333
- type: ndcg_at_3
value: 30.00558333333333
- type: ndcg_at_5
value: 31.931416666666664
- type: precision_at_1
value: 25.84825
- type: precision_at_10
value: 6.075083333333334
- type: precision_at_100
value: 1.0205833333333334
- type: precision_at_1000
value: 0.14425
- type: precision_at_3
value: 13.903249999999998
- type: precision_at_5
value: 9.874999999999998
- type: recall_at_1
value: 21.601166666666668
- type: recall_at_10
value: 44.787333333333336
- type: recall_at_100
value: 67.89450000000001
- type: recall_at_1000
value: 86.62424999999999
- type: recall_at_3
value: 32.66375
- type: recall_at_5
value: 37.71825
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackStatsRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 19.804
- type: map_at_10
value: 25.983
- type: map_at_100
value: 26.956999999999997
- type: map_at_1000
value: 27.067999999999998
- type: map_at_3
value: 23.804
- type: map_at_5
value: 24.978
- type: mrr_at_1
value: 22.853
- type: mrr_at_10
value: 28.974
- type: mrr_at_100
value: 29.855999999999998
- type: mrr_at_1000
value: 29.936
- type: mrr_at_3
value: 26.866
- type: mrr_at_5
value: 28.032
- type: ndcg_at_1
value: 22.853
- type: ndcg_at_10
value: 29.993
- type: ndcg_at_100
value: 34.735
- type: ndcg_at_1000
value: 37.637
- type: ndcg_at_3
value: 25.863000000000003
- type: ndcg_at_5
value: 27.769
- type: precision_at_1
value: 22.853
- type: precision_at_10
value: 4.8469999999999995
- type: precision_at_100
value: 0.779
- type: precision_at_1000
value: 0.11
- type: precision_at_3
value: 11.35
- type: precision_at_5
value: 7.9750000000000005
- type: recall_at_1
value: 19.804
- type: recall_at_10
value: 39.616
- type: recall_at_100
value: 61.06399999999999
- type: recall_at_1000
value: 82.69800000000001
- type: recall_at_3
value: 28.012999999999998
- type: recall_at_5
value: 32.96
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackTexRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 13.156
- type: map_at_10
value: 18.734
- type: map_at_100
value: 19.721
- type: map_at_1000
value: 19.851
- type: map_at_3
value: 17.057
- type: map_at_5
value: 17.941
- type: mrr_at_1
value: 16.07
- type: mrr_at_10
value: 22.113
- type: mrr_at_100
value: 23.021
- type: mrr_at_1000
value: 23.108
- type: mrr_at_3
value: 20.429
- type: mrr_at_5
value: 21.332
- type: ndcg_at_1
value: 16.07
- type: ndcg_at_10
value: 22.427
- type: ndcg_at_100
value: 27.277
- type: ndcg_at_1000
value: 30.525000000000002
- type: ndcg_at_3
value: 19.374
- type: ndcg_at_5
value: 20.695
- type: precision_at_1
value: 16.07
- type: precision_at_10
value: 4.1259999999999994
- type: precision_at_100
value: 0.769
- type: precision_at_1000
value: 0.122
- type: precision_at_3
value: 9.325999999999999
- type: precision_at_5
value: 6.683
- type: recall_at_1
value: 13.156
- type: recall_at_10
value: 30.223
- type: recall_at_100
value: 52.012
- type: recall_at_1000
value: 75.581
- type: recall_at_3
value: 21.508
- type: recall_at_5
value: 24.975
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackUnixRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 22.14
- type: map_at_10
value: 28.961
- type: map_at_100
value: 29.996000000000002
- type: map_at_1000
value: 30.112
- type: map_at_3
value: 26.540000000000003
- type: map_at_5
value: 27.916999999999998
- type: mrr_at_1
value: 25.746000000000002
- type: mrr_at_10
value: 32.936
- type: mrr_at_100
value: 33.811
- type: mrr_at_1000
value: 33.887
- type: mrr_at_3
value: 30.55
- type: mrr_at_5
value: 32.08
- type: ndcg_at_1
value: 25.746000000000002
- type: ndcg_at_10
value: 33.536
- type: ndcg_at_100
value: 38.830999999999996
- type: ndcg_at_1000
value: 41.644999999999996
- type: ndcg_at_3
value: 29.004
- type: ndcg_at_5
value: 31.284
- type: precision_at_1
value: 25.746000000000002
- type: precision_at_10
value: 5.569
- type: precision_at_100
value: 0.9259999999999999
- type: precision_at_1000
value: 0.128
- type: precision_at_3
value: 12.748999999999999
- type: precision_at_5
value: 9.216000000000001
- type: recall_at_1
value: 22.14
- type: recall_at_10
value: 43.628
- type: recall_at_100
value: 67.581
- type: recall_at_1000
value: 87.737
- type: recall_at_3
value: 31.579
- type: recall_at_5
value: 37.12
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackWebmastersRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 22.384
- type: map_at_10
value: 30.156
- type: map_at_100
value: 31.728
- type: map_at_1000
value: 31.971
- type: map_at_3
value: 27.655
- type: map_at_5
value: 28.965000000000003
- type: mrr_at_1
value: 27.075
- type: mrr_at_10
value: 34.894
- type: mrr_at_100
value: 36.0
- type: mrr_at_1000
value: 36.059000000000005
- type: mrr_at_3
value: 32.708
- type: mrr_at_5
value: 33.893
- type: ndcg_at_1
value: 27.075
- type: ndcg_at_10
value: 35.58
- type: ndcg_at_100
value: 41.597
- type: ndcg_at_1000
value: 44.529999999999994
- type: ndcg_at_3
value: 31.628
- type: ndcg_at_5
value: 33.333
- type: precision_at_1
value: 27.075
- type: precision_at_10
value: 6.9959999999999996
- type: precision_at_100
value: 1.431
- type: precision_at_1000
value: 0.23800000000000002
- type: precision_at_3
value: 15.02
- type: precision_at_5
value: 10.909
- type: recall_at_1
value: 22.384
- type: recall_at_10
value: 45.052
- type: recall_at_100
value: 72.441
- type: recall_at_1000
value: 91.047
- type: recall_at_3
value: 33.617000000000004
- type: recall_at_5
value: 38.171
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackWordpressRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 16.032
- type: map_at_10
value: 22.323
- type: map_at_100
value: 23.317
- type: map_at_1000
value: 23.419999999999998
- type: map_at_3
value: 20.064999999999998
- type: map_at_5
value: 21.246000000000002
- type: mrr_at_1
value: 17.375
- type: mrr_at_10
value: 24.157999999999998
- type: mrr_at_100
value: 25.108000000000004
- type: mrr_at_1000
value: 25.197999999999997
- type: mrr_at_3
value: 21.996
- type: mrr_at_5
value: 23.152
- type: ndcg_at_1
value: 17.375
- type: ndcg_at_10
value: 26.316
- type: ndcg_at_100
value: 31.302000000000003
- type: ndcg_at_1000
value: 34.143
- type: ndcg_at_3
value: 21.914
- type: ndcg_at_5
value: 23.896
- type: precision_at_1
value: 17.375
- type: precision_at_10
value: 4.233
- type: precision_at_100
value: 0.713
- type: precision_at_1000
value: 0.10200000000000001
- type: precision_at_3
value: 9.365
- type: precision_at_5
value: 6.728000000000001
- type: recall_at_1
value: 16.032
- type: recall_at_10
value: 36.944
- type: recall_at_100
value: 59.745000000000005
- type: recall_at_1000
value: 81.101
- type: recall_at_3
value: 25.096
- type: recall_at_5
value: 29.963
- task:
type: Retrieval
dataset:
type: climate-fever
name: MTEB ClimateFEVER
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 9.656
- type: map_at_10
value: 17.578
- type: map_at_100
value: 19.38
- type: map_at_1000
value: 19.552
- type: map_at_3
value: 14.544
- type: map_at_5
value: 15.914
- type: mrr_at_1
value: 21.041999999999998
- type: mrr_at_10
value: 33.579
- type: mrr_at_100
value: 34.483000000000004
- type: mrr_at_1000
value: 34.526
- type: mrr_at_3
value: 30.0
- type: mrr_at_5
value: 31.813999999999997
- type: ndcg_at_1
value: 21.041999999999998
- type: ndcg_at_10
value: 25.563999999999997
- type: ndcg_at_100
value: 32.714
- type: ndcg_at_1000
value: 35.943000000000005
- type: ndcg_at_3
value: 20.357
- type: ndcg_at_5
value: 21.839
- type: precision_at_1
value: 21.041999999999998
- type: precision_at_10
value: 8.319
- type: precision_at_100
value: 1.593
- type: precision_at_1000
value: 0.219
- type: precision_at_3
value: 15.440000000000001
- type: precision_at_5
value: 11.792
- type: recall_at_1
value: 9.656
- type: recall_at_10
value: 32.023
- type: recall_at_100
value: 56.812
- type: recall_at_1000
value: 75.098
- type: recall_at_3
value: 19.455
- type: recall_at_5
value: 23.68
- task:
type: Retrieval
dataset:
type: C-MTEB/CmedqaRetrieval
name: MTEB CmedqaRetrieval
config: default
split: dev
revision: None
metrics:
- type: map_at_1
value: 13.084999999999999
- type: map_at_10
value: 19.389
- type: map_at_100
value: 20.761
- type: map_at_1000
value: 20.944
- type: map_at_3
value: 17.273
- type: map_at_5
value: 18.37
- type: mrr_at_1
value: 20.955
- type: mrr_at_10
value: 26.741999999999997
- type: mrr_at_100
value: 27.724
- type: mrr_at_1000
value: 27.819
- type: mrr_at_3
value: 24.881
- type: mrr_at_5
value: 25.833000000000002
- type: ndcg_at_1
value: 20.955
- type: ndcg_at_10
value: 23.905
- type: ndcg_at_100
value: 30.166999999999998
- type: ndcg_at_1000
value: 34.202
- type: ndcg_at_3
value: 20.854
- type: ndcg_at_5
value: 21.918000000000003
- type: precision_at_1
value: 20.955
- type: precision_at_10
value: 5.479
- type: precision_at_100
value: 1.065
- type: precision_at_1000
value: 0.159
- type: precision_at_3
value: 11.960999999999999
- type: precision_at_5
value: 8.647
- type: recall_at_1
value: 13.084999999999999
- type: recall_at_10
value: 30.202
- type: recall_at_100
value: 56.579
- type: recall_at_1000
value: 84.641
- type: recall_at_3
value: 20.751
- type: recall_at_5
value: 24.317
- task:
type: PairClassification
dataset:
type: C-MTEB/CMNLI
name: MTEB Cmnli
config: default
split: validation
revision: None
metrics:
- type: cos_sim_accuracy
value: 72.8322309079976
- type: cos_sim_ap
value: 81.34356949111096
- type: cos_sim_f1
value: 74.88546438983758
- type: cos_sim_precision
value: 67.50516238032664
- type: cos_sim_recall
value: 84.07762450315643
- type: dot_accuracy
value: 69.28442573662056
- type: dot_ap
value: 74.87961278837321
- type: dot_f1
value: 72.20502901353966
- type: dot_precision
value: 61.5701797789873
- type: dot_recall
value: 87.2808043020809
- type: euclidean_accuracy
value: 71.99037883343355
- type: euclidean_ap
value: 80.70039825164011
- type: euclidean_f1
value: 74.23149154887813
- type: euclidean_precision
value: 64.29794520547945
- type: euclidean_recall
value: 87.79518353986438
- type: manhattan_accuracy
value: 72.0625375826819
- type: manhattan_ap
value: 80.78886354854423
- type: manhattan_f1
value: 74.20842299415924
- type: manhattan_precision
value: 66.0525355709595
- type: manhattan_recall
value: 84.66214636427402
- type: max_accuracy
value: 72.8322309079976
- type: max_ap
value: 81.34356949111096
- type: max_f1
value: 74.88546438983758
- task:
type: Retrieval
dataset:
type: C-MTEB/CovidRetrieval
name: MTEB CovidRetrieval
config: default
split: dev
revision: None
metrics:
- type: map_at_1
value: 54.847
- type: map_at_10
value: 63.736000000000004
- type: map_at_100
value: 64.302
- type: map_at_1000
value: 64.319
- type: map_at_3
value: 61.565000000000005
- type: map_at_5
value: 62.671
- type: mrr_at_1
value: 54.900000000000006
- type: mrr_at_10
value: 63.744
- type: mrr_at_100
value: 64.287
- type: mrr_at_1000
value: 64.30399999999999
- type: mrr_at_3
value: 61.590999999999994
- type: mrr_at_5
value: 62.724000000000004
- type: ndcg_at_1
value: 55.005
- type: ndcg_at_10
value: 68.142
- type: ndcg_at_100
value: 70.95
- type: ndcg_at_1000
value: 71.40100000000001
- type: ndcg_at_3
value: 63.641999999999996
- type: ndcg_at_5
value: 65.62599999999999
- type: precision_at_1
value: 55.005
- type: precision_at_10
value: 8.272
- type: precision_at_100
value: 0.963
- type: precision_at_1000
value: 0.1
- type: precision_at_3
value: 23.288
- type: precision_at_5
value: 14.963000000000001
- type: recall_at_1
value: 54.847
- type: recall_at_10
value: 81.955
- type: recall_at_100
value: 95.258
- type: recall_at_1000
value: 98.84100000000001
- type: recall_at_3
value: 69.547
- type: recall_at_5
value: 74.315
- task:
type: Retrieval
dataset:
type: dbpedia-entity
name: MTEB DBPedia
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 7.2620000000000005
- type: map_at_10
value: 15.196000000000002
- type: map_at_100
value: 19.454
- type: map_at_1000
value: 20.445
- type: map_at_3
value: 11.532
- type: map_at_5
value: 13.053999999999998
- type: mrr_at_1
value: 57.49999999999999
- type: mrr_at_10
value: 66.661
- type: mrr_at_100
value: 67.086
- type: mrr_at_1000
value: 67.105
- type: mrr_at_3
value: 64.625
- type: mrr_at_5
value: 65.962
- type: ndcg_at_1
value: 46.125
- type: ndcg_at_10
value: 32.609
- type: ndcg_at_100
value: 34.611999999999995
- type: ndcg_at_1000
value: 40.836
- type: ndcg_at_3
value: 37.513000000000005
- type: ndcg_at_5
value: 34.699999999999996
- type: precision_at_1
value: 57.49999999999999
- type: precision_at_10
value: 24.975
- type: precision_at_100
value: 6.9830000000000005
- type: precision_at_1000
value: 1.505
- type: precision_at_3
value: 40.75
- type: precision_at_5
value: 33.2
- type: recall_at_1
value: 7.2620000000000005
- type: recall_at_10
value: 20.341
- type: recall_at_100
value: 38.690999999999995
- type: recall_at_1000
value: 58.879000000000005
- type: recall_at_3
value: 12.997
- type: recall_at_5
value: 15.628
- task:
type: Retrieval
dataset:
type: C-MTEB/DuRetrieval
name: MTEB DuRetrieval
config: default
split: dev
revision: None
metrics:
- type: map_at_1
value: 20.86
- type: map_at_10
value: 62.28
- type: map_at_100
value: 65.794
- type: map_at_1000
value: 65.903
- type: map_at_3
value: 42.616
- type: map_at_5
value: 53.225
- type: mrr_at_1
value: 76.75
- type: mrr_at_10
value: 83.387
- type: mrr_at_100
value: 83.524
- type: mrr_at_1000
value: 83.531
- type: mrr_at_3
value: 82.592
- type: mrr_at_5
value: 83.07900000000001
- type: ndcg_at_1
value: 76.75
- type: ndcg_at_10
value: 72.83500000000001
- type: ndcg_at_100
value: 77.839
- type: ndcg_at_1000
value: 78.976
- type: ndcg_at_3
value: 70.977
- type: ndcg_at_5
value: 69.419
- type: precision_at_1
value: 76.75
- type: precision_at_10
value: 35.825
- type: precision_at_100
value: 4.507
- type: precision_at_1000
value: 0.47800000000000004
- type: precision_at_3
value: 63.733
- type: precision_at_5
value: 53.44
- type: recall_at_1
value: 20.86
- type: recall_at_10
value: 75.115
- type: recall_at_100
value: 90.47699999999999
- type: recall_at_1000
value: 96.304
- type: recall_at_3
value: 45.976
- type: recall_at_5
value: 59.971
- task:
type: Retrieval
dataset:
type: C-MTEB/EcomRetrieval
name: MTEB EcomRetrieval
config: default
split: dev
revision: None
metrics:
- type: map_at_1
value: 37.8
- type: map_at_10
value: 47.154
- type: map_at_100
value: 48.012
- type: map_at_1000
value: 48.044
- type: map_at_3
value: 44.667
- type: map_at_5
value: 45.992
- type: mrr_at_1
value: 37.8
- type: mrr_at_10
value: 47.154
- type: mrr_at_100
value: 48.012
- type: mrr_at_1000
value: 48.044
- type: mrr_at_3
value: 44.667
- type: mrr_at_5
value: 45.992
- type: ndcg_at_1
value: 37.8
- type: ndcg_at_10
value: 52.025
- type: ndcg_at_100
value: 56.275
- type: ndcg_at_1000
value: 57.174
- type: ndcg_at_3
value: 46.861999999999995
- type: ndcg_at_5
value: 49.229
- type: precision_at_1
value: 37.8
- type: precision_at_10
value: 6.75
- type: precision_at_100
value: 0.8750000000000001
- type: precision_at_1000
value: 0.095
- type: precision_at_3
value: 17.732999999999997
- type: precision_at_5
value: 11.78
- type: recall_at_1
value: 37.8
- type: recall_at_10
value: 67.5
- type: recall_at_100
value: 87.5
- type: recall_at_1000
value: 94.69999999999999
- type: recall_at_3
value: 53.2
- type: recall_at_5
value: 58.9
- task:
type: Classification
dataset:
type: mteb/emotion
name: MTEB EmotionClassification
config: default
split: test
revision: 4f58c6b202a23cf9a4da393831edf4f9183cad37
metrics:
- type: accuracy
value: 46.845
- type: f1
value: 42.70952656074019
- task:
type: Retrieval
dataset:
type: fever
name: MTEB FEVER
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 50.058
- type: map_at_10
value: 61.295
- type: map_at_100
value: 61.82
- type: map_at_1000
value: 61.843
- type: map_at_3
value: 58.957
- type: map_at_5
value: 60.467999999999996
- type: mrr_at_1
value: 54.05
- type: mrr_at_10
value: 65.52900000000001
- type: mrr_at_100
value: 65.984
- type: mrr_at_1000
value: 65.999
- type: mrr_at_3
value: 63.286
- type: mrr_at_5
value: 64.777
- type: ndcg_at_1
value: 54.05
- type: ndcg_at_10
value: 67.216
- type: ndcg_at_100
value: 69.594
- type: ndcg_at_1000
value: 70.13000000000001
- type: ndcg_at_3
value: 62.778999999999996
- type: ndcg_at_5
value: 65.36
- type: precision_at_1
value: 54.05
- type: precision_at_10
value: 8.924
- type: precision_at_100
value: 1.019
- type: precision_at_1000
value: 0.108
- type: precision_at_3
value: 25.218
- type: precision_at_5
value: 16.547
- type: recall_at_1
value: 50.058
- type: recall_at_10
value: 81.39699999999999
- type: recall_at_100
value: 92.022
- type: recall_at_1000
value: 95.877
- type: recall_at_3
value: 69.485
- type: recall_at_5
value: 75.833
- task:
type: Retrieval
dataset:
type: fiqa
name: MTEB FiQA2018
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 15.078
- type: map_at_10
value: 24.162
- type: map_at_100
value: 25.818
- type: map_at_1000
value: 26.009
- type: map_at_3
value: 20.706
- type: map_at_5
value: 22.542
- type: mrr_at_1
value: 30.709999999999997
- type: mrr_at_10
value: 38.828
- type: mrr_at_100
value: 39.794000000000004
- type: mrr_at_1000
value: 39.843
- type: mrr_at_3
value: 36.163000000000004
- type: mrr_at_5
value: 37.783
- type: ndcg_at_1
value: 30.709999999999997
- type: ndcg_at_10
value: 31.290000000000003
- type: ndcg_at_100
value: 38.051
- type: ndcg_at_1000
value: 41.487
- type: ndcg_at_3
value: 27.578999999999997
- type: ndcg_at_5
value: 28.799000000000003
- type: precision_at_1
value: 30.709999999999997
- type: precision_at_10
value: 8.92
- type: precision_at_100
value: 1.5599999999999998
- type: precision_at_1000
value: 0.219
- type: precision_at_3
value: 18.416
- type: precision_at_5
value: 13.827
- type: recall_at_1
value: 15.078
- type: recall_at_10
value: 37.631
- type: recall_at_100
value: 63.603
- type: recall_at_1000
value: 84.121
- type: recall_at_3
value: 24.438
- type: recall_at_5
value: 29.929
- task:
type: Retrieval
dataset:
type: hotpotqa
name: MTEB HotpotQA
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 31.202
- type: map_at_10
value: 42.653
- type: map_at_100
value: 43.411
- type: map_at_1000
value: 43.479
- type: map_at_3
value: 40.244
- type: map_at_5
value: 41.736000000000004
- type: mrr_at_1
value: 62.404
- type: mrr_at_10
value: 69.43599999999999
- type: mrr_at_100
value: 69.788
- type: mrr_at_1000
value: 69.809
- type: mrr_at_3
value: 68.12700000000001
- type: mrr_at_5
value: 68.961
- type: ndcg_at_1
value: 62.404
- type: ndcg_at_10
value: 51.665000000000006
- type: ndcg_at_100
value: 54.623
- type: ndcg_at_1000
value: 56.154
- type: ndcg_at_3
value: 47.861
- type: ndcg_at_5
value: 49.968
- type: precision_at_1
value: 62.404
- type: precision_at_10
value: 10.57
- type: precision_at_100
value: 1.2890000000000001
- type: precision_at_1000
value: 0.149
- type: precision_at_3
value: 29.624
- type: precision_at_5
value: 19.441
- type: recall_at_1
value: 31.202
- type: recall_at_10
value: 52.849000000000004
- type: recall_at_100
value: 64.47
- type: recall_at_1000
value: 74.74
- type: recall_at_3
value: 44.436
- type: recall_at_5
value: 48.602000000000004
- task:
type: Classification
dataset:
type: C-MTEB/IFlyTek-classification
name: MTEB IFlyTek
config: default
split: validation
revision: None
metrics:
- type: accuracy
value: 43.51673720661793
- type: f1
value: 35.81126468608715
- task:
type: Classification
dataset:
type: mteb/imdb
name: MTEB ImdbClassification
config: default
split: test
revision: 3d86128a09e091d6018b6d26cad27f2739fc2db7
metrics:
- type: accuracy
value: 74.446
- type: ap
value: 68.71359666500074
- type: f1
value: 74.32080431056023
- task:
type: Classification
dataset:
type: C-MTEB/JDReview-classification
name: MTEB JDReview
config: default
split: test
revision: None
metrics:
- type: accuracy
value: 81.08818011257036
- type: ap
value: 43.68599141287235
- type: f1
value: 74.37787266346157
- task:
type: STS
dataset:
type: C-MTEB/LCQMC
name: MTEB LCQMC
config: default
split: test
revision: None
metrics:
- type: cos_sim_pearson
value: 65.9116523539515
- type: cos_sim_spearman
value: 72.79966865646485
- type: euclidean_pearson
value: 71.4995885009818
- type: euclidean_spearman
value: 72.91799793240196
- type: manhattan_pearson
value: 71.83065174544116
- type: manhattan_spearman
value: 73.22568775268935
- task:
type: Retrieval
dataset:
type: C-MTEB/MMarcoRetrieval
name: MTEB MMarcoRetrieval
config: default
split: dev
revision: None
metrics:
- type: map_at_1
value: 61.79900000000001
- type: map_at_10
value: 70.814
- type: map_at_100
value: 71.22500000000001
- type: map_at_1000
value: 71.243
- type: map_at_3
value: 68.795
- type: map_at_5
value: 70.12
- type: mrr_at_1
value: 63.910999999999994
- type: mrr_at_10
value: 71.437
- type: mrr_at_100
value: 71.807
- type: mrr_at_1000
value: 71.82300000000001
- type: mrr_at_3
value: 69.65599999999999
- type: mrr_at_5
value: 70.821
- type: ndcg_at_1
value: 63.910999999999994
- type: ndcg_at_10
value: 74.664
- type: ndcg_at_100
value: 76.545
- type: ndcg_at_1000
value: 77.00099999999999
- type: ndcg_at_3
value: 70.838
- type: ndcg_at_5
value: 73.076
- type: precision_at_1
value: 63.910999999999994
- type: precision_at_10
value: 9.139999999999999
- type: precision_at_100
value: 1.008
- type: precision_at_1000
value: 0.105
- type: precision_at_3
value: 26.729000000000003
- type: precision_at_5
value: 17.232
- type: recall_at_1
value: 61.79900000000001
- type: recall_at_10
value: 85.941
- type: recall_at_100
value: 94.514
- type: recall_at_1000
value: 98.04899999999999
- type: recall_at_3
value: 75.85499999999999
- type: recall_at_5
value: 81.15599999999999
- task:
type: Retrieval
dataset:
type: msmarco
name: MTEB MSMARCO
config: default
split: dev
revision: None
metrics:
- type: map_at_1
value: 20.079
- type: map_at_10
value: 31.735000000000003
- type: map_at_100
value: 32.932
- type: map_at_1000
value: 32.987
- type: map_at_3
value: 28.216
- type: map_at_5
value: 30.127
- type: mrr_at_1
value: 20.688000000000002
- type: mrr_at_10
value: 32.357
- type: mrr_at_100
value: 33.487
- type: mrr_at_1000
value: 33.536
- type: mrr_at_3
value: 28.887
- type: mrr_at_5
value: 30.764000000000003
- type: ndcg_at_1
value: 20.688000000000002
- type: ndcg_at_10
value: 38.266
- type: ndcg_at_100
value: 44.105
- type: ndcg_at_1000
value: 45.554
- type: ndcg_at_3
value: 31.046000000000003
- type: ndcg_at_5
value: 34.44
- type: precision_at_1
value: 20.688000000000002
- type: precision_at_10
value: 6.0920000000000005
- type: precision_at_100
value: 0.903
- type: precision_at_1000
value: 0.10300000000000001
- type: precision_at_3
value: 13.338
- type: precision_at_5
value: 9.725
- type: recall_at_1
value: 20.079
- type: recall_at_10
value: 58.315
- type: recall_at_100
value: 85.50999999999999
- type: recall_at_1000
value: 96.72800000000001
- type: recall_at_3
value: 38.582
- type: recall_at_5
value: 46.705999999999996
- task:
type: Classification
dataset:
type: mteb/mtop_domain
name: MTEB MTOPDomainClassification (en)
config: en
split: test
revision: d80d48c1eb48d3562165c59d59d0034df9fff0bf
metrics:
- type: accuracy
value: 92.18422252621978
- type: f1
value: 91.82800582693794
- task:
type: Classification
dataset:
type: mteb/mtop_domain
name: MTEB MTOPDomainClassification (de)
config: de
split: test
revision: d80d48c1eb48d3562165c59d59d0034df9fff0bf
metrics:
- type: accuracy
value: 74.63792617638771
- type: f1
value: 73.13966942566492
- task:
type: Classification
dataset:
type: mteb/mtop_domain
name: MTEB MTOPDomainClassification (es)
config: es
split: test
revision: d80d48c1eb48d3562165c59d59d0034df9fff0bf
metrics:
- type: accuracy
value: 92.07138092061375
- type: f1
value: 91.58983799467875
- task:
type: Classification
dataset:
type: mteb/mtop_domain
name: MTEB MTOPDomainClassification (fr)
config: fr
split: test
revision: d80d48c1eb48d3562165c59d59d0034df9fff0bf
metrics:
- type: accuracy
value: 89.19824616348262
- type: f1
value: 89.06796384273765
- task:
type: Classification
dataset:
type: mteb/mtop_domain
name: MTEB MTOPDomainClassification (hi)
config: hi
split: test
revision: d80d48c1eb48d3562165c59d59d0034df9fff0bf
metrics:
- type: accuracy
value: 88.54069558981713
- type: f1
value: 87.83448658971352
- task:
type: Classification
dataset:
type: mteb/mtop_domain
name: MTEB MTOPDomainClassification (th)
config: th
split: test
revision: d80d48c1eb48d3562165c59d59d0034df9fff0bf
metrics:
- type: accuracy
value: 55.63471971066908
- type: f1
value: 53.84017845089774
- task:
type: Classification
dataset:
type: mteb/mtop_intent
name: MTEB MTOPIntentClassification (en)
config: en
split: test
revision: ae001d0e6b1228650b7bd1c2c65fb50ad11a8aba
metrics:
- type: accuracy
value: 70.29867761057912
- type: f1
value: 52.76509068762125
- task:
type: Classification
dataset:
type: mteb/mtop_intent
name: MTEB MTOPIntentClassification (de)
config: de
split: test
revision: ae001d0e6b1228650b7bd1c2c65fb50ad11a8aba
metrics:
- type: accuracy
value: 53.39814032121725
- type: f1
value: 34.27161745913036
- task:
type: Classification
dataset:
type: mteb/mtop_intent
name: MTEB MTOPIntentClassification (es)
config: es
split: test
revision: ae001d0e6b1228650b7bd1c2c65fb50ad11a8aba
metrics:
- type: accuracy
value: 71.33422281521014
- type: f1
value: 52.171603212251384
- task:
type: Classification
dataset:
type: mteb/mtop_intent
name: MTEB MTOPIntentClassification (fr)
config: fr
split: test
revision: ae001d0e6b1228650b7bd1c2c65fb50ad11a8aba
metrics:
- type: accuracy
value: 66.6019417475728
- type: f1
value: 49.212091278323975
- task:
type: Classification
dataset:
type: mteb/mtop_intent
name: MTEB MTOPIntentClassification (hi)
config: hi
split: test
revision: ae001d0e6b1228650b7bd1c2c65fb50ad11a8aba
metrics:
- type: accuracy
value: 66.73001075654356
- type: f1
value: 45.97084834271623
- task:
type: Classification
dataset:
type: mteb/mtop_intent
name: MTEB MTOPIntentClassification (th)
config: th
split: test
revision: ae001d0e6b1228650b7bd1c2c65fb50ad11a8aba
metrics:
- type: accuracy
value: 42.13381555153707
- type: f1
value: 27.222558885215964
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (af)
config: af
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 44.97982515131137
- type: f1
value: 43.08686679862984
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (am)
config: am
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 25.353059852051107
- type: f1
value: 24.56465252790922
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (ar)
config: ar
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 57.078009414929376
- type: f1
value: 54.933541125458795
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (az)
config: az
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 39.10558170813719
- type: f1
value: 39.15270496151374
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (bn)
config: bn
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 61.368527236045736
- type: f1
value: 58.65381984021665
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (cy)
config: cy
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 42.96906523201076
- type: f1
value: 41.88085083446726
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (da)
config: da
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 49.54270342972428
- type: f1
value: 48.44206747172913
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (de)
config: de
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 50.93140551445864
- type: f1
value: 47.40396853548677
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (el)
config: el
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 40.09414929388029
- type: f1
value: 38.27158057191927
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (en)
config: en
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 67.93207800941494
- type: f1
value: 66.50282035579518
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (es)
config: es
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 63.81304640215198
- type: f1
value: 62.51979490279083
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (fa)
config: fa
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 49.05850706119704
- type: f1
value: 47.49872899848797
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (fi)
config: fi
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 42.57901815736382
- type: f1
value: 40.386069905109956
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (fr)
config: fr
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 65.33960995292534
- type: f1
value: 63.96475759829612
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (he)
config: he
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 37.14862138533962
- type: f1
value: 35.954583318470384
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (hi)
config: hi
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 62.88836583725621
- type: f1
value: 61.139092331276856
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (hu)
config: hu
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 41.62071284465366
- type: f1
value: 40.23779890980788
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (hy)
config: hy
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 32.982515131136516
- type: f1
value: 31.82828709111086
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (id)
config: id
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 62.11499663752521
- type: f1
value: 60.307651330689716
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (is)
config: is
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 41.039004707464684
- type: f1
value: 39.531615524370686
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (it)
config: it
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 55.8338937457969
- type: f1
value: 54.86425916837068
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (ja)
config: ja
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 58.83322125084061
- type: f1
value: 56.52595986400214
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (jv)
config: jv
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 49.31069266980497
- type: f1
value: 47.241381065322265
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (ka)
config: ka
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 26.432414256893072
- type: f1
value: 25.787833437725848
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (km)
config: km
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 28.76933422999327
- type: f1
value: 27.34778980866226
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (kn)
config: kn
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 52.33019502353733
- type: f1
value: 49.49897965390079
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (ko)
config: ko
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 46.930060524546064
- type: f1
value: 44.71215467580226
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (lv)
config: lv
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 44.25689307330195
- type: f1
value: 43.61087006714549
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (ml)
config: ml
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 57.74714189643577
- type: f1
value: 54.571431590522735
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (mn)
config: mn
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 33.30531271015468
- type: f1
value: 33.4982889160085
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (ms)
config: ms
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 55.699394754539334
- type: f1
value: 54.00478534026828
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (my)
config: my
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 27.38735709482179
- type: f1
value: 26.139112212692474
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (nb)
config: nb
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 46.18359112306658
- type: f1
value: 45.298479798547106
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (nl)
config: nl
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 48.33557498318763
- type: f1
value: 46.102865846786294
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (pl)
config: pl
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 44.46872898453261
- type: f1
value: 42.43443803309795
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (pt)
config: pt
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 64.74445191661063
- type: f1
value: 63.453679590322174
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (ro)
config: ro
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 48.41291190316072
- type: f1
value: 47.14401920664497
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (ru)
config: ru
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 52.989240080699396
- type: f1
value: 50.91931775407477
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (sl)
config: sl
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 44.771351714862135
- type: f1
value: 42.90054169209577
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (sq)
config: sq
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 45.45393409549428
- type: f1
value: 45.027761715583146
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (sv)
config: sv
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 45.67585743106927
- type: f1
value: 44.45608727957947
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (sw)
config: sw
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 46.45595158036314
- type: f1
value: 44.70548836690419
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (ta)
config: ta
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 55.4640215198386
- type: f1
value: 52.28532276735651
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (te)
config: te
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 51.408876933422995
- type: f1
value: 48.86454236156204
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (th)
config: th
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 39.19636852723604
- type: f1
value: 38.88247037601754
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (tl)
config: tl
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 48.53396099529254
- type: f1
value: 46.961492802320656
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (tr)
config: tr
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 39.509078681909884
- type: f1
value: 39.30973355583357
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (ur)
config: ur
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 54.717552118359116
- type: f1
value: 52.08348704897728
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (vi)
config: vi
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 62.007397444519164
- type: f1
value: 60.57772322803523
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (zh-CN)
config: zh-CN
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 66.906523201076
- type: f1
value: 65.2730417732602
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (zh-TW)
config: zh-TW
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 62.562205783456626
- type: f1
value: 62.3944953225828
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (af)
config: af
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 50.46738399462004
- type: f1
value: 48.277337351043066
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (am)
config: am
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 27.222595830531272
- type: f1
value: 26.15959037949326
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (ar)
config: ar
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 65.4303967720242
- type: f1
value: 65.58227814316872
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (az)
config: az
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 40.736381977135174
- type: f1
value: 39.85702036251076
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (bn)
config: bn
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 67.64626765299259
- type: f1
value: 67.12298813657769
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (cy)
config: cy
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 43.940820443846675
- type: f1
value: 41.63412499587839
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (da)
config: da
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 52.5252185608608
- type: f1
value: 50.25821961669483
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (de)
config: de
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 56.67114996637525
- type: f1
value: 54.204117831814244
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (el)
config: el
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 41.8123739071957
- type: f1
value: 40.25676895490678
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (en)
config: en
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 75.71956960322798
- type: f1
value: 75.95126212201126
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (es)
config: es
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 71.7787491593813
- type: f1
value: 71.90678548502461
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (fa)
config: fa
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 49.95965030262274
- type: f1
value: 48.625859921623515
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (fi)
config: fi
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 41.005379959650305
- type: f1
value: 38.25957953711836
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (fr)
config: fr
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 71.99058507061198
- type: f1
value: 72.30034867942928
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (he)
config: he
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 36.691324815063886
- type: f1
value: 35.09762112518494
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (hi)
config: hi
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 69.27706792199058
- type: f1
value: 68.96935505580095
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (hu)
config: hu
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 44.31405514458642
- type: f1
value: 41.75837557089336
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (hy)
config: hy
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 33.63819771351715
- type: f1
value: 32.00999199645466
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (id)
config: id
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 68.98117014122394
- type: f1
value: 68.48993356947226
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (is)
config: is
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 42.10154673839946
- type: f1
value: 39.537580201439035
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (it)
config: it
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 60.27236045729657
- type: f1
value: 58.8041857941664
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (ja)
config: ja
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 62.47814391392063
- type: f1
value: 61.4800551358116
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (jv)
config: jv
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 54.68392737054473
- type: f1
value: 53.28619831432411
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (ka)
config: ka
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 27.215870880968396
- type: f1
value: 26.137784395348483
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (km)
config: km
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 32.1385339609953
- type: f1
value: 29.886918185071977
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (kn)
config: kn
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 57.94889038332213
- type: f1
value: 57.19252000109654
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (ko)
config: ko
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 47.94552790854068
- type: f1
value: 46.21337507975437
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (lv)
config: lv
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 42.75722932078009
- type: f1
value: 40.62195245815035
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (ml)
config: ml
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 62.84129119031607
- type: f1
value: 62.56205475932971
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (mn)
config: mn
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 33.21116341627438
- type: f1
value: 32.231827617771046
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (ms)
config: ms
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 62.56893073301949
- type: f1
value: 60.94616552257348
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (my)
config: my
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 28.8399462004035
- type: f1
value: 27.8503615081592
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (nb)
config: nb
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 50.31607262945528
- type: f1
value: 47.993368005418205
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (nl)
config: nl
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 52.851378614660405
- type: f1
value: 50.444332639513824
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (pl)
config: pl
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 45.595158036314736
- type: f1
value: 44.241686886064755
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (pt)
config: pt
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 70.24209818426363
- type: f1
value: 70.48109122752663
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (ro)
config: ro
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 52.73369199731002
- type: f1
value: 51.14034087602817
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (ru)
config: ru
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 54.263618022864826
- type: f1
value: 53.3188846615122
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (sl)
config: sl
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 46.88634835238735
- type: f1
value: 45.257261686960796
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (sq)
config: sq
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 47.15534633490249
- type: f1
value: 45.218807618409215
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (sv)
config: sv
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 47.9119031607263
- type: f1
value: 45.96730030717468
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (sw)
config: sw
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 51.20040349697377
- type: f1
value: 49.113423730259214
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (ta)
config: ta
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 61.8392737054472
- type: f1
value: 61.65834459536364
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (te)
config: te
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 59.791526563550775
- type: f1
value: 58.2891677685128
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (th)
config: th
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 41.62071284465366
- type: f1
value: 39.591525429243575
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (tl)
config: tl
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 50.46738399462004
- type: f1
value: 49.50612154409957
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (tr)
config: tr
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 43.41291190316072
- type: f1
value: 43.85070302174815
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (ur)
config: ur
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 60.15131136516476
- type: f1
value: 59.260012738676316
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (vi)
config: vi
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 68.98789509078682
- type: f1
value: 69.86968024553558
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (zh-CN)
config: zh-CN
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 74.72091459314055
- type: f1
value: 74.69866015852224
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (zh-TW)
config: zh-TW
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 71.7014122394082
- type: f1
value: 72.66856729607628
- task:
type: Retrieval
dataset:
type: C-MTEB/MedicalRetrieval
name: MTEB MedicalRetrieval
config: default
split: dev
revision: None
metrics:
- type: map_at_1
value: 35.8
- type: map_at_10
value: 40.949999999999996
- type: map_at_100
value: 41.455999999999996
- type: map_at_1000
value: 41.52
- type: map_at_3
value: 40.033
- type: map_at_5
value: 40.493
- type: mrr_at_1
value: 35.9
- type: mrr_at_10
value: 41.0
- type: mrr_at_100
value: 41.506
- type: mrr_at_1000
value: 41.57
- type: mrr_at_3
value: 40.083
- type: mrr_at_5
value: 40.543
- type: ndcg_at_1
value: 35.8
- type: ndcg_at_10
value: 43.269000000000005
- type: ndcg_at_100
value: 45.974
- type: ndcg_at_1000
value: 47.969
- type: ndcg_at_3
value: 41.339999999999996
- type: ndcg_at_5
value: 42.167
- type: precision_at_1
value: 35.8
- type: precision_at_10
value: 5.050000000000001
- type: precision_at_100
value: 0.637
- type: precision_at_1000
value: 0.08
- type: precision_at_3
value: 15.033
- type: precision_at_5
value: 9.42
- type: recall_at_1
value: 35.8
- type: recall_at_10
value: 50.5
- type: recall_at_100
value: 63.7
- type: recall_at_1000
value: 80.0
- type: recall_at_3
value: 45.1
- type: recall_at_5
value: 47.099999999999994
- task:
type: Clustering
dataset:
type: mteb/medrxiv-clustering-p2p
name: MTEB MedrxivClusteringP2P
config: default
split: test
revision: e7a26af6f3ae46b30dde8737f02c07b1505bcc73
metrics:
- type: v_measure
value: 29.43291218491871
- task:
type: Clustering
dataset:
type: mteb/medrxiv-clustering-s2s
name: MTEB MedrxivClusteringS2S
config: default
split: test
revision: 35191c8c0dca72d8ff3efcd72aa802307d469663
metrics:
- type: v_measure
value: 28.87018200800912
- task:
type: Reranking
dataset:
type: mteb/mind_small
name: MTEB MindSmallReranking
config: default
split: test
revision: 3bdac13927fdc888b903db93b2ffdbd90b295a69
metrics:
- type: map
value: 30.51003589330728
- type: mrr
value: 31.57412386045135
- task:
type: Reranking
dataset:
type: C-MTEB/Mmarco-reranking
name: MTEB MMarcoReranking
config: default
split: dev
revision: None
metrics:
- type: map
value: 26.136250989818222
- type: mrr
value: 25.00753968253968
- task:
type: Classification
dataset:
type: C-MTEB/MultilingualSentiment-classification
name: MTEB MultilingualSentiment
config: default
split: validation
revision: None
metrics:
- type: accuracy
value: 66.32999999999998
- type: f1
value: 66.2828795526323
- task:
type: Retrieval
dataset:
type: nfcorpus
name: MTEB NFCorpus
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 4.369
- type: map_at_10
value: 11.04
- type: map_at_100
value: 13.850000000000001
- type: map_at_1000
value: 15.290000000000001
- type: map_at_3
value: 8.014000000000001
- type: map_at_5
value: 9.4
- type: mrr_at_1
value: 39.938
- type: mrr_at_10
value: 49.043
- type: mrr_at_100
value: 49.775000000000006
- type: mrr_at_1000
value: 49.803999999999995
- type: mrr_at_3
value: 47.007
- type: mrr_at_5
value: 48.137
- type: ndcg_at_1
value: 37.461
- type: ndcg_at_10
value: 30.703000000000003
- type: ndcg_at_100
value: 28.686
- type: ndcg_at_1000
value: 37.809
- type: ndcg_at_3
value: 35.697
- type: ndcg_at_5
value: 33.428000000000004
- type: precision_at_1
value: 39.628
- type: precision_at_10
value: 23.250999999999998
- type: precision_at_100
value: 7.553999999999999
- type: precision_at_1000
value: 2.077
- type: precision_at_3
value: 34.159
- type: precision_at_5
value: 29.164
- type: recall_at_1
value: 4.369
- type: recall_at_10
value: 15.024000000000001
- type: recall_at_100
value: 30.642999999999997
- type: recall_at_1000
value: 62.537
- type: recall_at_3
value: 9.504999999999999
- type: recall_at_5
value: 11.89
- task:
type: Retrieval
dataset:
type: nq
name: MTEB NQ
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 26.161
- type: map_at_10
value: 39.126
- type: map_at_100
value: 40.201
- type: map_at_1000
value: 40.247
- type: map_at_3
value: 35.169
- type: map_at_5
value: 37.403
- type: mrr_at_1
value: 29.403000000000002
- type: mrr_at_10
value: 41.644999999999996
- type: mrr_at_100
value: 42.503
- type: mrr_at_1000
value: 42.535000000000004
- type: mrr_at_3
value: 38.321
- type: mrr_at_5
value: 40.265
- type: ndcg_at_1
value: 29.403000000000002
- type: ndcg_at_10
value: 46.155
- type: ndcg_at_100
value: 50.869
- type: ndcg_at_1000
value: 52.004
- type: ndcg_at_3
value: 38.65
- type: ndcg_at_5
value: 42.400999999999996
- type: precision_at_1
value: 29.403000000000002
- type: precision_at_10
value: 7.743
- type: precision_at_100
value: 1.0410000000000001
- type: precision_at_1000
value: 0.11499999999999999
- type: precision_at_3
value: 17.623
- type: precision_at_5
value: 12.764000000000001
- type: recall_at_1
value: 26.161
- type: recall_at_10
value: 65.155
- type: recall_at_100
value: 85.885
- type: recall_at_1000
value: 94.443
- type: recall_at_3
value: 45.592
- type: recall_at_5
value: 54.234
- task:
type: PairClassification
dataset:
type: C-MTEB/OCNLI
name: MTEB Ocnli
config: default
split: validation
revision: None
metrics:
- type: cos_sim_accuracy
value: 65.34921494315105
- type: cos_sim_ap
value: 68.58191894316523
- type: cos_sim_f1
value: 70.47294418406477
- type: cos_sim_precision
value: 59.07142857142858
- type: cos_sim_recall
value: 87.32840549102428
- type: dot_accuracy
value: 61.93827828911749
- type: dot_ap
value: 64.19230712895958
- type: dot_f1
value: 68.30769230769232
- type: dot_precision
value: 53.72050816696915
- type: dot_recall
value: 93.76979936642027
- type: euclidean_accuracy
value: 67.0817541959935
- type: euclidean_ap
value: 69.17499163875786
- type: euclidean_f1
value: 71.67630057803468
- type: euclidean_precision
value: 61.904761904761905
- type: euclidean_recall
value: 85.11087645195353
- type: manhattan_accuracy
value: 67.19003789929616
- type: manhattan_ap
value: 69.72684682556992
- type: manhattan_f1
value: 71.25396106835673
- type: manhattan_precision
value: 62.361331220285265
- type: manhattan_recall
value: 83.10454065469905
- type: max_accuracy
value: 67.19003789929616
- type: max_ap
value: 69.72684682556992
- type: max_f1
value: 71.67630057803468
- task:
type: Classification
dataset:
type: C-MTEB/OnlineShopping-classification
name: MTEB OnlineShopping
config: default
split: test
revision: None
metrics:
- type: accuracy
value: 88.35000000000001
- type: ap
value: 85.45377991151882
- type: f1
value: 88.33274122313945
- task:
type: STS
dataset:
type: C-MTEB/PAWSX
name: MTEB PAWSX
config: default
split: test
revision: None
metrics:
- type: cos_sim_pearson
value: 13.700131726042631
- type: cos_sim_spearman
value: 15.663851577320184
- type: euclidean_pearson
value: 17.869909454798112
- type: euclidean_spearman
value: 16.09518673735175
- type: manhattan_pearson
value: 18.030818366917593
- type: manhattan_spearman
value: 16.34096397687474
- task:
type: STS
dataset:
type: C-MTEB/QBQTC
name: MTEB QBQTC
config: default
split: test
revision: None
metrics:
- type: cos_sim_pearson
value: 30.200343733562946
- type: cos_sim_spearman
value: 32.645434631834966
- type: euclidean_pearson
value: 32.612030669583234
- type: euclidean_spearman
value: 34.67603837485763
- type: manhattan_pearson
value: 32.6673080122766
- type: manhattan_spearman
value: 34.8163622783733
- task:
type: Retrieval
dataset:
type: quora
name: MTEB QuoraRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 69.321
- type: map_at_10
value: 83.07
- type: map_at_100
value: 83.737
- type: map_at_1000
value: 83.758
- type: map_at_3
value: 80.12700000000001
- type: map_at_5
value: 81.97
- type: mrr_at_1
value: 79.74
- type: mrr_at_10
value: 86.22
- type: mrr_at_100
value: 86.345
- type: mrr_at_1000
value: 86.347
- type: mrr_at_3
value: 85.172
- type: mrr_at_5
value: 85.89099999999999
- type: ndcg_at_1
value: 79.77
- type: ndcg_at_10
value: 87.01299999999999
- type: ndcg_at_100
value: 88.382
- type: ndcg_at_1000
value: 88.53
- type: ndcg_at_3
value: 84.04
- type: ndcg_at_5
value: 85.68
- type: precision_at_1
value: 79.77
- type: precision_at_10
value: 13.211999999999998
- type: precision_at_100
value: 1.52
- type: precision_at_1000
value: 0.157
- type: precision_at_3
value: 36.730000000000004
- type: precision_at_5
value: 24.21
- type: recall_at_1
value: 69.321
- type: recall_at_10
value: 94.521
- type: recall_at_100
value: 99.258
- type: recall_at_1000
value: 99.97200000000001
- type: recall_at_3
value: 85.97200000000001
- type: recall_at_5
value: 90.589
- task:
type: Clustering
dataset:
type: mteb/reddit-clustering
name: MTEB RedditClustering
config: default
split: test
revision: 24640382cdbf8abc73003fb0fa6d111a705499eb
metrics:
- type: v_measure
value: 44.51751457277441
- task:
type: Clustering
dataset:
type: mteb/reddit-clustering-p2p
name: MTEB RedditClusteringP2P
config: default
split: test
revision: 282350215ef01743dc01b456c7f5241fa8937f16
metrics:
- type: v_measure
value: 53.60727449352775
- task:
type: Retrieval
dataset:
type: scidocs
name: MTEB SCIDOCS
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 4.058
- type: map_at_10
value: 9.995999999999999
- type: map_at_100
value: 11.738
- type: map_at_1000
value: 11.999
- type: map_at_3
value: 7.353999999999999
- type: map_at_5
value: 8.68
- type: mrr_at_1
value: 20.0
- type: mrr_at_10
value: 30.244
- type: mrr_at_100
value: 31.378
- type: mrr_at_1000
value: 31.445
- type: mrr_at_3
value: 26.933
- type: mrr_at_5
value: 28.748
- type: ndcg_at_1
value: 20.0
- type: ndcg_at_10
value: 17.235
- type: ndcg_at_100
value: 24.241
- type: ndcg_at_1000
value: 29.253
- type: ndcg_at_3
value: 16.542
- type: ndcg_at_5
value: 14.386
- type: precision_at_1
value: 20.0
- type: precision_at_10
value: 8.9
- type: precision_at_100
value: 1.8929999999999998
- type: precision_at_1000
value: 0.31
- type: precision_at_3
value: 15.567
- type: precision_at_5
value: 12.620000000000001
- type: recall_at_1
value: 4.058
- type: recall_at_10
value: 18.062
- type: recall_at_100
value: 38.440000000000005
- type: recall_at_1000
value: 63.044999999999995
- type: recall_at_3
value: 9.493
- type: recall_at_5
value: 12.842
- task:
type: STS
dataset:
type: mteb/sickr-sts
name: MTEB SICK-R
config: default
split: test
revision: a6ea5a8cab320b040a23452cc28066d9beae2cee
metrics:
- type: cos_sim_pearson
value: 85.36702895231333
- type: cos_sim_spearman
value: 79.91790376084445
- type: euclidean_pearson
value: 81.58989754571684
- type: euclidean_spearman
value: 79.43876559435684
- type: manhattan_pearson
value: 81.5041355053572
- type: manhattan_spearman
value: 79.35411927652234
- task:
type: STS
dataset:
type: mteb/sts12-sts
name: MTEB STS12
config: default
split: test
revision: a0d554a64d88156834ff5ae9920b964011b16384
metrics:
- type: cos_sim_pearson
value: 83.77166067512005
- type: cos_sim_spearman
value: 75.7961015562481
- type: euclidean_pearson
value: 82.03845114943047
- type: euclidean_spearman
value: 78.75422268992615
- type: manhattan_pearson
value: 82.11841609875198
- type: manhattan_spearman
value: 78.79349601386468
- task:
type: STS
dataset:
type: mteb/sts13-sts
name: MTEB STS13
config: default
split: test
revision: 7e90230a92c190f1bf69ae9002b8cea547a64cca
metrics:
- type: cos_sim_pearson
value: 83.28403658061106
- type: cos_sim_spearman
value: 83.61682237930194
- type: euclidean_pearson
value: 84.50220149144553
- type: euclidean_spearman
value: 85.01944483089126
- type: manhattan_pearson
value: 84.5526583345216
- type: manhattan_spearman
value: 85.06290695547032
- task:
type: STS
dataset:
type: mteb/sts14-sts
name: MTEB STS14
config: default
split: test
revision: 6031580fec1f6af667f0bd2da0a551cf4f0b2375
metrics:
- type: cos_sim_pearson
value: 82.66893263127082
- type: cos_sim_spearman
value: 78.73277873007592
- type: euclidean_pearson
value: 80.78325001462842
- type: euclidean_spearman
value: 79.1692321029638
- type: manhattan_pearson
value: 80.82812137898084
- type: manhattan_spearman
value: 79.23433932409523
- task:
type: STS
dataset:
type: mteb/sts15-sts
name: MTEB STS15
config: default
split: test
revision: ae752c7c21bf194d8b67fd573edf7ae58183cbe3
metrics:
- type: cos_sim_pearson
value: 85.6046231732945
- type: cos_sim_spearman
value: 86.41326579037185
- type: euclidean_pearson
value: 85.85739124012164
- type: euclidean_spearman
value: 86.54285701350923
- type: manhattan_pearson
value: 85.78835254765399
- type: manhattan_spearman
value: 86.45431641050791
- task:
type: STS
dataset:
type: mteb/sts16-sts
name: MTEB STS16
config: default
split: test
revision: 4d8694f8f0e0100860b497b999b3dbed754a0513
metrics:
- type: cos_sim_pearson
value: 82.97881854103466
- type: cos_sim_spearman
value: 84.50343997301495
- type: euclidean_pearson
value: 82.83306004280789
- type: euclidean_spearman
value: 83.2801802732528
- type: manhattan_pearson
value: 82.73250604776496
- type: manhattan_spearman
value: 83.12452727964241
- task:
type: STS
dataset:
type: mteb/sts17-crosslingual-sts
name: MTEB STS17 (ko-ko)
config: ko-ko
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 61.59564206989664
- type: cos_sim_spearman
value: 61.88740058576333
- type: euclidean_pearson
value: 60.23297902405152
- type: euclidean_spearman
value: 60.21120786234968
- type: manhattan_pearson
value: 60.48897723321176
- type: manhattan_spearman
value: 60.44230460138873
- task:
type: STS
dataset:
type: mteb/sts17-crosslingual-sts
name: MTEB STS17 (ar-ar)
config: ar-ar
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 80.44912821552151
- type: cos_sim_spearman
value: 81.13348443154915
- type: euclidean_pearson
value: 81.09038308120358
- type: euclidean_spearman
value: 80.5609874348409
- type: manhattan_pearson
value: 81.13776188970186
- type: manhattan_spearman
value: 80.5900946438308
- task:
type: STS
dataset:
type: mteb/sts17-crosslingual-sts
name: MTEB STS17 (en-ar)
config: en-ar
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 78.72913217243624
- type: cos_sim_spearman
value: 79.63696165091363
- type: euclidean_pearson
value: 73.19989464436063
- type: euclidean_spearman
value: 73.54600704085456
- type: manhattan_pearson
value: 72.86702738433412
- type: manhattan_spearman
value: 72.90617504239171
- task:
type: STS
dataset:
type: mteb/sts17-crosslingual-sts
name: MTEB STS17 (en-de)
config: en-de
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 50.732677791011525
- type: cos_sim_spearman
value: 52.523598781843916
- type: euclidean_pearson
value: 49.35416337421446
- type: euclidean_spearman
value: 51.33696662867874
- type: manhattan_pearson
value: 50.506295752592145
- type: manhattan_spearman
value: 52.62915407476881
- task:
type: STS
dataset:
type: mteb/sts17-crosslingual-sts
name: MTEB STS17 (en-en)
config: en-en
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 89.36491555020613
- type: cos_sim_spearman
value: 89.9454102616469
- type: euclidean_pearson
value: 88.86298725696331
- type: euclidean_spearman
value: 88.65552919486326
- type: manhattan_pearson
value: 88.92114540797368
- type: manhattan_spearman
value: 88.70527010857221
- task:
type: STS
dataset:
type: mteb/sts17-crosslingual-sts
name: MTEB STS17 (en-tr)
config: en-tr
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 8.714024392790805
- type: cos_sim_spearman
value: 4.749252746175972
- type: euclidean_pearson
value: 10.22053449467633
- type: euclidean_spearman
value: 9.037870998258068
- type: manhattan_pearson
value: 12.0555115545086
- type: manhattan_spearman
value: 10.63527037732596
- task:
type: STS
dataset:
type: mteb/sts17-crosslingual-sts
name: MTEB STS17 (es-en)
config: es-en
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 84.02829923391249
- type: cos_sim_spearman
value: 85.4083636563418
- type: euclidean_pearson
value: 80.36151292795275
- type: euclidean_spearman
value: 80.77292573694929
- type: manhattan_pearson
value: 80.6693169692864
- type: manhattan_spearman
value: 81.14159565166888
- task:
type: STS
dataset:
type: mteb/sts17-crosslingual-sts
name: MTEB STS17 (es-es)
config: es-es
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 86.99900583005198
- type: cos_sim_spearman
value: 87.3279898301188
- type: euclidean_pearson
value: 86.87787294488236
- type: euclidean_spearman
value: 85.53646010337043
- type: manhattan_pearson
value: 86.9509718845318
- type: manhattan_spearman
value: 85.71691660800931
- task:
type: STS
dataset:
type: mteb/sts17-crosslingual-sts
name: MTEB STS17 (fr-en)
config: fr-en
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 83.46126526473
- type: cos_sim_spearman
value: 83.95970248728918
- type: euclidean_pearson
value: 81.73140443111127
- type: euclidean_spearman
value: 81.74150374966206
- type: manhattan_pearson
value: 81.86557893665228
- type: manhattan_spearman
value: 82.09645552492371
- task:
type: STS
dataset:
type: mteb/sts17-crosslingual-sts
name: MTEB STS17 (it-en)
config: it-en
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 46.49174934231959
- type: cos_sim_spearman
value: 45.61787630214591
- type: euclidean_pearson
value: 49.99290765454166
- type: euclidean_spearman
value: 49.69936044179364
- type: manhattan_pearson
value: 51.3375093082487
- type: manhattan_spearman
value: 51.28438118049182
- task:
type: STS
dataset:
type: mteb/sts17-crosslingual-sts
name: MTEB STS17 (nl-en)
config: nl-en
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 48.29554395534795
- type: cos_sim_spearman
value: 46.68726750723354
- type: euclidean_pearson
value: 47.17222230888035
- type: euclidean_spearman
value: 45.92754616369105
- type: manhattan_pearson
value: 47.75493126673596
- type: manhattan_spearman
value: 46.20677181839115
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (en)
config: en
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 66.3630120343016
- type: cos_sim_spearman
value: 65.81094140725656
- type: euclidean_pearson
value: 67.90672012385122
- type: euclidean_spearman
value: 67.81659181369037
- type: manhattan_pearson
value: 68.0253831292356
- type: manhattan_spearman
value: 67.6187327404364
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (de)
config: de
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 29.18452426712489
- type: cos_sim_spearman
value: 37.51420703956064
- type: euclidean_pearson
value: 28.026224447990934
- type: euclidean_spearman
value: 38.80123640343127
- type: manhattan_pearson
value: 28.71522521219943
- type: manhattan_spearman
value: 39.336233734574066
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (es)
config: es
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 56.859180417788316
- type: cos_sim_spearman
value: 59.78915219131012
- type: euclidean_pearson
value: 62.96361204638708
- type: euclidean_spearman
value: 61.17669127090527
- type: manhattan_pearson
value: 63.76244034298364
- type: manhattan_spearman
value: 61.86264089685531
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (pl)
config: pl
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 16.606738041913964
- type: cos_sim_spearman
value: 27.979167349378507
- type: euclidean_pearson
value: 9.681469291321502
- type: euclidean_spearman
value: 28.088375191612652
- type: manhattan_pearson
value: 10.511180494241913
- type: manhattan_spearman
value: 28.551302212661085
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (tr)
config: tr
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 25.299512638088835
- type: cos_sim_spearman
value: 42.32704160389304
- type: euclidean_pearson
value: 38.695432241220615
- type: euclidean_spearman
value: 42.64456376476522
- type: manhattan_pearson
value: 39.85979335053606
- type: manhattan_spearman
value: 42.769358737309716
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (ar)
config: ar
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 47.92303842321097
- type: cos_sim_spearman
value: 55.000760154318996
- type: euclidean_pearson
value: 54.09534510237817
- type: euclidean_spearman
value: 56.174584414116055
- type: manhattan_pearson
value: 56.361913198454616
- type: manhattan_spearman
value: 58.34526441198397
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (ru)
config: ru
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 31.742856551594826
- type: cos_sim_spearman
value: 43.13787302806463
- type: euclidean_pearson
value: 31.905579993088136
- type: euclidean_spearman
value: 39.885035201343186
- type: manhattan_pearson
value: 32.43242118943698
- type: manhattan_spearman
value: 40.11107248799126
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (zh)
config: zh
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 47.44633750616152
- type: cos_sim_spearman
value: 54.083033284097816
- type: euclidean_pearson
value: 51.444658791680155
- type: euclidean_spearman
value: 53.1381741726486
- type: manhattan_pearson
value: 56.75523385117588
- type: manhattan_spearman
value: 58.34517911003165
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (fr)
config: fr
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 79.36983311049038
- type: cos_sim_spearman
value: 81.25208121596035
- type: euclidean_pearson
value: 79.0841246591628
- type: euclidean_spearman
value: 79.63170247237287
- type: manhattan_pearson
value: 79.76857988012227
- type: manhattan_spearman
value: 80.19933344030764
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (de-en)
config: de-en
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 50.08537255290631
- type: cos_sim_spearman
value: 51.6560951182032
- type: euclidean_pearson
value: 56.245817211229856
- type: euclidean_spearman
value: 57.84579505485162
- type: manhattan_pearson
value: 57.178628792860394
- type: manhattan_spearman
value: 58.868316567418965
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (es-en)
config: es-en
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 69.32518691946098
- type: cos_sim_spearman
value: 73.58536905137812
- type: euclidean_pearson
value: 73.3593301595928
- type: euclidean_spearman
value: 74.72443890443692
- type: manhattan_pearson
value: 73.89491090838783
- type: manhattan_spearman
value: 75.01810348241496
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (it)
config: it
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 65.63185657261381
- type: cos_sim_spearman
value: 68.8680524426534
- type: euclidean_pearson
value: 65.8069214967351
- type: euclidean_spearman
value: 67.58006300921988
- type: manhattan_pearson
value: 66.42691541820066
- type: manhattan_spearman
value: 68.20501753012334
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (pl-en)
config: pl-en
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 63.5746658293195
- type: cos_sim_spearman
value: 60.766781234511114
- type: euclidean_pearson
value: 63.87934914483433
- type: euclidean_spearman
value: 57.609930019070575
- type: manhattan_pearson
value: 66.02268099209732
- type: manhattan_spearman
value: 60.27189531789914
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (zh-en)
config: zh-en
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 66.00715694009531
- type: cos_sim_spearman
value: 65.00759157082473
- type: euclidean_pearson
value: 46.532834841771916
- type: euclidean_spearman
value: 45.726258106671516
- type: manhattan_pearson
value: 67.32238041001737
- type: manhattan_spearman
value: 66.143420656417
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (es-it)
config: es-it
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 62.65123838155666
- type: cos_sim_spearman
value: 67.8261281384735
- type: euclidean_pearson
value: 63.477912220562025
- type: euclidean_spearman
value: 65.51430407718927
- type: manhattan_pearson
value: 61.935191484002964
- type: manhattan_spearman
value: 63.836661905551374
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (de-fr)
config: de-fr
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 38.397676312074786
- type: cos_sim_spearman
value: 39.66141773675305
- type: euclidean_pearson
value: 32.78160515193193
- type: euclidean_spearman
value: 33.754398073832384
- type: manhattan_pearson
value: 31.542566989070103
- type: manhattan_spearman
value: 31.84555978703678
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (de-pl)
config: de-pl
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 16.134054972017115
- type: cos_sim_spearman
value: 26.113399767684193
- type: euclidean_pearson
value: 24.956029896964587
- type: euclidean_spearman
value: 26.513723113179346
- type: manhattan_pearson
value: 27.504346443344712
- type: manhattan_spearman
value: 35.382424921072094
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (fr-pl)
config: fr-pl
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 74.63601297425362
- type: cos_sim_spearman
value: 84.51542547285167
- type: euclidean_pearson
value: 72.60877043745072
- type: euclidean_spearman
value: 73.24670207647144
- type: manhattan_pearson
value: 69.30655335948613
- type: manhattan_spearman
value: 73.24670207647144
- task:
type: STS
dataset:
type: C-MTEB/STSB
name: MTEB STSB
config: default
split: test
revision: None
metrics:
- type: cos_sim_pearson
value: 79.4028184159866
- type: cos_sim_spearman
value: 79.53464687577328
- type: euclidean_pearson
value: 79.25913610578554
- type: euclidean_spearman
value: 79.55288323830753
- type: manhattan_pearson
value: 79.44759977916512
- type: manhattan_spearman
value: 79.71927216173198
- task:
type: STS
dataset:
type: mteb/stsbenchmark-sts
name: MTEB STSBenchmark
config: default
split: test
revision: b0fddb56ed78048fa8b90373c8a3cfc37b684831
metrics:
- type: cos_sim_pearson
value: 85.07398235741444
- type: cos_sim_spearman
value: 85.78865814488006
- type: euclidean_pearson
value: 83.2824378418878
- type: euclidean_spearman
value: 83.36258201307002
- type: manhattan_pearson
value: 83.22221949643878
- type: manhattan_spearman
value: 83.27892691688584
- task:
type: Reranking
dataset:
type: mteb/scidocs-reranking
name: MTEB SciDocsRR
config: default
split: test
revision: d3c5e1fc0b855ab6097bf1cda04dd73947d7caab
metrics:
- type: map
value: 78.1122816381465
- type: mrr
value: 93.44523849425809
- task:
type: Retrieval
dataset:
type: scifact
name: MTEB SciFact
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 51.132999999999996
- type: map_at_10
value: 60.672000000000004
- type: map_at_100
value: 61.504000000000005
- type: map_at_1000
value: 61.526
- type: map_at_3
value: 57.536
- type: map_at_5
value: 59.362
- type: mrr_at_1
value: 53.667
- type: mrr_at_10
value: 61.980000000000004
- type: mrr_at_100
value: 62.633
- type: mrr_at_1000
value: 62.653000000000006
- type: mrr_at_3
value: 59.721999999999994
- type: mrr_at_5
value: 60.789
- type: ndcg_at_1
value: 53.667
- type: ndcg_at_10
value: 65.42099999999999
- type: ndcg_at_100
value: 68.884
- type: ndcg_at_1000
value: 69.494
- type: ndcg_at_3
value: 60.007
- type: ndcg_at_5
value: 62.487
- type: precision_at_1
value: 53.667
- type: precision_at_10
value: 8.833
- type: precision_at_100
value: 1.0699999999999998
- type: precision_at_1000
value: 0.11199999999999999
- type: precision_at_3
value: 23.222
- type: precision_at_5
value: 15.667
- type: recall_at_1
value: 51.132999999999996
- type: recall_at_10
value: 78.989
- type: recall_at_100
value: 94.167
- type: recall_at_1000
value: 99.0
- type: recall_at_3
value: 64.328
- type: recall_at_5
value: 70.35
- task:
type: PairClassification
dataset:
type: mteb/sprintduplicatequestions-pairclassification
name: MTEB SprintDuplicateQuestions
config: default
split: test
revision: d66bd1f72af766a5cc4b0ca5e00c162f89e8cc46
metrics:
- type: cos_sim_accuracy
value: 99.78910891089109
- type: cos_sim_ap
value: 94.58344155979994
- type: cos_sim_f1
value: 89.2354124748491
- type: cos_sim_precision
value: 89.77732793522267
- type: cos_sim_recall
value: 88.7
- type: dot_accuracy
value: 99.74158415841585
- type: dot_ap
value: 92.08599680108772
- type: dot_f1
value: 87.00846192135391
- type: dot_precision
value: 86.62041625371654
- type: dot_recall
value: 87.4
- type: euclidean_accuracy
value: 99.78316831683168
- type: euclidean_ap
value: 94.57715670055748
- type: euclidean_f1
value: 88.98765432098766
- type: euclidean_precision
value: 87.90243902439025
- type: euclidean_recall
value: 90.10000000000001
- type: manhattan_accuracy
value: 99.78811881188119
- type: manhattan_ap
value: 94.73016642953513
- type: manhattan_f1
value: 89.3326838772528
- type: manhattan_precision
value: 87.08452041785375
- type: manhattan_recall
value: 91.7
- type: max_accuracy
value: 99.78910891089109
- type: max_ap
value: 94.73016642953513
- type: max_f1
value: 89.3326838772528
- task:
type: Clustering
dataset:
type: mteb/stackexchange-clustering
name: MTEB StackExchangeClustering
config: default
split: test
revision: 6cbc1f7b2bc0622f2e39d2c77fa502909748c259
metrics:
- type: v_measure
value: 57.11358892084413
- task:
type: Clustering
dataset:
type: mteb/stackexchange-clustering-p2p
name: MTEB StackExchangeClusteringP2P
config: default
split: test
revision: 815ca46b2622cec33ccafc3735d572c266efdb44
metrics:
- type: v_measure
value: 31.914375833951354
- task:
type: Reranking
dataset:
type: mteb/stackoverflowdupquestions-reranking
name: MTEB StackOverflowDupQuestions
config: default
split: test
revision: e185fbe320c72810689fc5848eb6114e1ef5ec69
metrics:
- type: map
value: 48.9994487557691
- type: mrr
value: 49.78547290128173
- task:
type: Summarization
dataset:
type: mteb/summeval
name: MTEB SummEval
config: default
split: test
revision: cda12ad7615edc362dbf25a00fdd61d3b1eaf93c
metrics:
- type: cos_sim_pearson
value: 30.19567881069216
- type: cos_sim_spearman
value: 31.098791519646298
- type: dot_pearson
value: 30.61141391110544
- type: dot_spearman
value: 30.995416064312153
- task:
type: Reranking
dataset:
type: C-MTEB/T2Reranking
name: MTEB T2Reranking
config: default
split: dev
revision: None
metrics:
- type: map
value: 65.9449793956858
- type: mrr
value: 75.83074738584217
- task:
type: Retrieval
dataset:
type: C-MTEB/T2Retrieval
name: MTEB T2Retrieval
config: default
split: dev
revision: None
metrics:
- type: map_at_1
value: 23.186999999999998
- type: map_at_10
value: 63.007000000000005
- type: map_at_100
value: 66.956
- type: map_at_1000
value: 67.087
- type: map_at_3
value: 44.769999999999996
- type: map_at_5
value: 54.629000000000005
- type: mrr_at_1
value: 81.22500000000001
- type: mrr_at_10
value: 85.383
- type: mrr_at_100
value: 85.555
- type: mrr_at_1000
value: 85.564
- type: mrr_at_3
value: 84.587
- type: mrr_at_5
value: 85.105
- type: ndcg_at_1
value: 81.22500000000001
- type: ndcg_at_10
value: 72.81
- type: ndcg_at_100
value: 78.108
- type: ndcg_at_1000
value: 79.477
- type: ndcg_at_3
value: 75.36
- type: ndcg_at_5
value: 73.19099999999999
- type: precision_at_1
value: 81.22500000000001
- type: precision_at_10
value: 36.419000000000004
- type: precision_at_100
value: 4.6850000000000005
- type: precision_at_1000
value: 0.502
- type: precision_at_3
value: 66.125
- type: precision_at_5
value: 54.824
- type: recall_at_1
value: 23.186999999999998
- type: recall_at_10
value: 71.568
- type: recall_at_100
value: 88.32799999999999
- type: recall_at_1000
value: 95.256
- type: recall_at_3
value: 47.04
- type: recall_at_5
value: 59.16400000000001
- task:
type: Classification
dataset:
type: C-MTEB/TNews-classification
name: MTEB TNews
config: default
split: validation
revision: None
metrics:
- type: accuracy
value: 46.08
- type: f1
value: 44.576714769815986
- task:
type: Retrieval
dataset:
type: trec-covid
name: MTEB TRECCOVID
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 0.23600000000000002
- type: map_at_10
value: 2.01
- type: map_at_100
value: 11.237
- type: map_at_1000
value: 26.241999999999997
- type: map_at_3
value: 0.705
- type: map_at_5
value: 1.134
- type: mrr_at_1
value: 92.0
- type: mrr_at_10
value: 95.667
- type: mrr_at_100
value: 95.667
- type: mrr_at_1000
value: 95.667
- type: mrr_at_3
value: 95.667
- type: mrr_at_5
value: 95.667
- type: ndcg_at_1
value: 88.0
- type: ndcg_at_10
value: 80.028
- type: ndcg_at_100
value: 58.557
- type: ndcg_at_1000
value: 51.108
- type: ndcg_at_3
value: 86.235
- type: ndcg_at_5
value: 83.776
- type: precision_at_1
value: 92.0
- type: precision_at_10
value: 83.6
- type: precision_at_100
value: 59.9
- type: precision_at_1000
value: 22.556
- type: precision_at_3
value: 92.667
- type: precision_at_5
value: 89.60000000000001
- type: recall_at_1
value: 0.23600000000000002
- type: recall_at_10
value: 2.164
- type: recall_at_100
value: 14.268
- type: recall_at_1000
value: 47.993
- type: recall_at_3
value: 0.728
- type: recall_at_5
value: 1.18
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (sqi-eng)
config: sqi-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 16.0
- type: f1
value: 12.072197229668266
- type: precision
value: 11.07125213426268
- type: recall
value: 16.0
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (fry-eng)
config: fry-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 31.79190751445087
- type: f1
value: 25.33993944398569
- type: precision
value: 23.462449892587426
- type: recall
value: 31.79190751445087
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (kur-eng)
config: kur-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 14.390243902439023
- type: f1
value: 10.647146321087272
- type: precision
value: 9.753700307679768
- type: recall
value: 14.390243902439023
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (tur-eng)
config: tur-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 7.8
- type: f1
value: 5.087296515623526
- type: precision
value: 4.543963123070674
- type: recall
value: 7.8
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (deu-eng)
config: deu-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 58.5
- type: f1
value: 53.26571428571428
- type: precision
value: 51.32397398353281
- type: recall
value: 58.5
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (nld-eng)
config: nld-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 29.5
- type: f1
value: 25.14837668933257
- type: precision
value: 23.949224030449837
- type: recall
value: 29.5
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (ron-eng)
config: ron-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 28.7
- type: f1
value: 23.196045369663018
- type: precision
value: 21.502155293536873
- type: recall
value: 28.7
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (ang-eng)
config: ang-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 27.611940298507463
- type: f1
value: 19.431414356787492
- type: precision
value: 17.160948504232085
- type: recall
value: 27.611940298507463
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (ido-eng)
config: ido-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 46.0
- type: f1
value: 39.146820760938404
- type: precision
value: 36.89055652165172
- type: recall
value: 46.0
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (jav-eng)
config: jav-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 23.414634146341466
- type: f1
value: 18.60234074868221
- type: precision
value: 17.310239781020474
- type: recall
value: 23.414634146341466
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (isl-eng)
config: isl-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 7.3
- type: f1
value: 5.456411432480631
- type: precision
value: 5.073425278627456
- type: recall
value: 7.3
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (slv-eng)
config: slv-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 10.814094775212636
- type: f1
value: 8.096556306772158
- type: precision
value: 7.501928709802902
- type: recall
value: 10.814094775212636
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (cym-eng)
config: cym-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 11.304347826086957
- type: f1
value: 7.766717493033283
- type: precision
value: 6.980930791147511
- type: recall
value: 11.304347826086957
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (kaz-eng)
config: kaz-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 6.260869565217392
- type: f1
value: 4.695624631925284
- type: precision
value: 4.520242639508398
- type: recall
value: 6.260869565217392
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (est-eng)
config: est-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 6.9
- type: f1
value: 4.467212205066257
- type: precision
value: 4.004142723685108
- type: recall
value: 6.9
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (heb-eng)
config: heb-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 1.0999999999999999
- type: f1
value: 0.6945869191049914
- type: precision
value: 0.6078431372549019
- type: recall
value: 1.0999999999999999
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (gla-eng)
config: gla-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 4.583835946924005
- type: f1
value: 2.9858475730729075
- type: precision
value: 2.665996515212438
- type: recall
value: 4.583835946924005
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (mar-eng)
config: mar-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 59.199999999999996
- type: f1
value: 52.67345238095238
- type: precision
value: 50.13575757575758
- type: recall
value: 59.199999999999996
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (lat-eng)
config: lat-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 35.0
- type: f1
value: 27.648653013653007
- type: precision
value: 25.534839833369244
- type: recall
value: 35.0
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (bel-eng)
config: bel-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 13.100000000000001
- type: f1
value: 9.62336638477808
- type: precision
value: 8.875194920058407
- type: recall
value: 13.100000000000001
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (pms-eng)
config: pms-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 32.95238095238095
- type: f1
value: 27.600581429152854
- type: precision
value: 26.078624096473064
- type: recall
value: 32.95238095238095
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (gle-eng)
config: gle-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 6.5
- type: f1
value: 3.9595645184317045
- type: precision
value: 3.5893378968989453
- type: recall
value: 6.5
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (pes-eng)
config: pes-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 17.8
- type: f1
value: 13.508124743694003
- type: precision
value: 12.24545634920635
- type: recall
value: 17.8
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (nob-eng)
config: nob-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 21.7
- type: f1
value: 17.67074499610417
- type: precision
value: 16.47070885787265
- type: recall
value: 21.7
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (bul-eng)
config: bul-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 19.3
- type: f1
value: 14.249803276788573
- type: precision
value: 12.916981621996223
- type: recall
value: 19.3
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (cbk-eng)
config: cbk-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 67.2
- type: f1
value: 61.03507936507936
- type: precision
value: 58.69699346405229
- type: recall
value: 67.2
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (hun-eng)
config: hun-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 6.5
- type: f1
value: 4.295097572176196
- type: precision
value: 3.809609027256814
- type: recall
value: 6.5
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (uig-eng)
config: uig-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 2.8000000000000003
- type: f1
value: 1.678577135635959
- type: precision
value: 1.455966810966811
- type: recall
value: 2.8000000000000003
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (rus-eng)
config: rus-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 47.9
- type: f1
value: 40.26661017143776
- type: precision
value: 37.680778943278945
- type: recall
value: 47.9
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (spa-eng)
config: spa-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 97.0
- type: f1
value: 96.05
- type: precision
value: 95.58333333333334
- type: recall
value: 97.0
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (hye-eng)
config: hye-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 0.9433962264150944
- type: f1
value: 0.6457074216068709
- type: precision
value: 0.6068362258275373
- type: recall
value: 0.9433962264150944
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (tel-eng)
config: tel-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 74.78632478632478
- type: f1
value: 69.05372405372405
- type: precision
value: 66.82336182336182
- type: recall
value: 74.78632478632478
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (afr-eng)
config: afr-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 19.2
- type: f1
value: 14.54460169057995
- type: precision
value: 13.265236397589335
- type: recall
value: 19.2
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (mon-eng)
config: mon-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 6.8181818181818175
- type: f1
value: 4.78808236251355
- type: precision
value: 4.4579691142191145
- type: recall
value: 6.8181818181818175
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (arz-eng)
config: arz-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 72.53668763102725
- type: f1
value: 66.00978336827393
- type: precision
value: 63.21104122990915
- type: recall
value: 72.53668763102725
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (hrv-eng)
config: hrv-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 12.7
- type: f1
value: 9.731576351893512
- type: precision
value: 8.986658245110663
- type: recall
value: 12.7
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (nov-eng)
config: nov-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 57.19844357976653
- type: f1
value: 49.138410227904394
- type: precision
value: 45.88197146562906
- type: recall
value: 57.19844357976653
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (gsw-eng)
config: gsw-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 28.205128205128204
- type: f1
value: 21.863766936230704
- type: precision
value: 20.212164378831048
- type: recall
value: 28.205128205128204
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (nds-eng)
config: nds-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 23.3
- type: f1
value: 17.75959261382939
- type: precision
value: 16.18907864830205
- type: recall
value: 23.3
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (ukr-eng)
config: ukr-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 19.1
- type: f1
value: 14.320618913993744
- type: precision
value: 12.980748202777615
- type: recall
value: 19.1
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (uzb-eng)
config: uzb-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 8.411214953271028
- type: f1
value: 5.152309182683014
- type: precision
value: 4.456214003721122
- type: recall
value: 8.411214953271028
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (lit-eng)
config: lit-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 6.7
- type: f1
value: 4.833930504764646
- type: precision
value: 4.475394510103751
- type: recall
value: 6.7
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (ina-eng)
config: ina-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 79.4
- type: f1
value: 74.59166666666667
- type: precision
value: 72.59928571428571
- type: recall
value: 79.4
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (lfn-eng)
config: lfn-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 47.8
- type: f1
value: 41.944877899877895
- type: precision
value: 39.87211701696996
- type: recall
value: 47.8
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (zsm-eng)
config: zsm-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 85.0
- type: f1
value: 81.47666666666666
- type: precision
value: 79.95909090909092
- type: recall
value: 85.0
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (ita-eng)
config: ita-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 62.6
- type: f1
value: 55.96755336167101
- type: precision
value: 53.49577131202131
- type: recall
value: 62.6
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (cmn-eng)
config: cmn-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 95.3
- type: f1
value: 93.96666666666668
- type: precision
value: 93.33333333333333
- type: recall
value: 95.3
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (lvs-eng)
config: lvs-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 7.7
- type: f1
value: 5.534253062728994
- type: precision
value: 4.985756669800788
- type: recall
value: 7.7
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (glg-eng)
config: glg-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 80.5
- type: f1
value: 75.91705128205129
- type: precision
value: 73.96261904761904
- type: recall
value: 80.5
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (ceb-eng)
config: ceb-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 10.333333333333334
- type: f1
value: 7.753678057001793
- type: precision
value: 7.207614225986279
- type: recall
value: 10.333333333333334
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (bre-eng)
config: bre-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 8.6
- type: f1
value: 5.345683110450071
- type: precision
value: 4.569931461907268
- type: recall
value: 8.6
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (ben-eng)
config: ben-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 82.8
- type: f1
value: 78.75999999999999
- type: precision
value: 76.97666666666666
- type: recall
value: 82.8
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (swg-eng)
config: swg-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 26.785714285714285
- type: f1
value: 21.62627551020408
- type: precision
value: 20.17219387755102
- type: recall
value: 26.785714285714285
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (arq-eng)
config: arq-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 32.93084522502745
- type: f1
value: 26.281513627941628
- type: precision
value: 24.05050619189897
- type: recall
value: 32.93084522502745
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (kab-eng)
config: kab-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 2.1
- type: f1
value: 1.144678201129814
- type: precision
value: 1.0228433014856975
- type: recall
value: 2.1
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (fra-eng)
config: fra-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 94.3
- type: f1
value: 92.77000000000001
- type: precision
value: 92.09166666666667
- type: recall
value: 94.3
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (por-eng)
config: por-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 94.1
- type: f1
value: 92.51666666666667
- type: precision
value: 91.75
- type: recall
value: 94.1
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (tat-eng)
config: tat-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 4.1000000000000005
- type: f1
value: 2.856566814643248
- type: precision
value: 2.6200368188362506
- type: recall
value: 4.1000000000000005
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (oci-eng)
config: oci-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 45.9
- type: f1
value: 39.02207792207792
- type: precision
value: 36.524158064158065
- type: recall
value: 45.9
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (pol-eng)
config: pol-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 13.4
- type: f1
value: 9.61091517529598
- type: precision
value: 8.755127233877234
- type: recall
value: 13.4
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (war-eng)
config: war-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 11.1
- type: f1
value: 8.068379205189386
- type: precision
value: 7.400827352459544
- type: recall
value: 11.1
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (aze-eng)
config: aze-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 8.9
- type: f1
value: 6.632376174517077
- type: precision
value: 6.07114926880766
- type: recall
value: 8.9
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (vie-eng)
config: vie-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 95.8
- type: f1
value: 94.57333333333334
- type: precision
value: 93.99166666666667
- type: recall
value: 95.8
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (nno-eng)
config: nno-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 16.6
- type: f1
value: 13.328940031174618
- type: precision
value: 12.47204179664362
- type: recall
value: 16.6
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (cha-eng)
config: cha-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 29.927007299270077
- type: f1
value: 22.899432278994322
- type: precision
value: 20.917701519891303
- type: recall
value: 29.927007299270077
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (mhr-eng)
config: mhr-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 3.5000000000000004
- type: f1
value: 2.3809722674927083
- type: precision
value: 2.1368238705738705
- type: recall
value: 3.5000000000000004
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (dan-eng)
config: dan-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 21.6
- type: f1
value: 17.54705304666238
- type: precision
value: 16.40586970344022
- type: recall
value: 21.6
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (ell-eng)
config: ell-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 3.5999999999999996
- type: f1
value: 2.3374438522182763
- type: precision
value: 2.099034070054354
- type: recall
value: 3.5999999999999996
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (amh-eng)
config: amh-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 1.7857142857142856
- type: f1
value: 0.12056962540054328
- type: precision
value: 0.0628414244485673
- type: recall
value: 1.7857142857142856
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (pam-eng)
config: pam-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 7.3999999999999995
- type: f1
value: 5.677284679983816
- type: precision
value: 5.314304945764335
- type: recall
value: 7.3999999999999995
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (hsb-eng)
config: hsb-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 13.043478260869565
- type: f1
value: 9.776306477806768
- type: precision
value: 9.09389484497104
- type: recall
value: 13.043478260869565
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (srp-eng)
config: srp-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 12.3
- type: f1
value: 8.757454269574472
- type: precision
value: 7.882868657107786
- type: recall
value: 12.3
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (epo-eng)
config: epo-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 28.9
- type: f1
value: 23.108557220070377
- type: precision
value: 21.35433328562513
- type: recall
value: 28.9
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (kzj-eng)
config: kzj-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 6.4
- type: f1
value: 4.781499273475174
- type: precision
value: 4.4496040053464565
- type: recall
value: 6.4
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (awa-eng)
config: awa-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 51.94805194805194
- type: f1
value: 45.658020784071205
- type: precision
value: 43.54163933709388
- type: recall
value: 51.94805194805194
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (fao-eng)
config: fao-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 14.50381679389313
- type: f1
value: 9.416337348733041
- type: precision
value: 8.17070085031468
- type: recall
value: 14.50381679389313
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (mal-eng)
config: mal-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 88.79184861717613
- type: f1
value: 85.56040756914118
- type: precision
value: 84.08539543910723
- type: recall
value: 88.79184861717613
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (ile-eng)
config: ile-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 62.5
- type: f1
value: 56.0802331002331
- type: precision
value: 53.613788230739445
- type: recall
value: 62.5
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (bos-eng)
config: bos-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 16.101694915254235
- type: f1
value: 11.927172795816864
- type: precision
value: 10.939011968423735
- type: recall
value: 16.101694915254235
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (cor-eng)
config: cor-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 5.5
- type: f1
value: 3.1258727724517197
- type: precision
value: 2.679506580565404
- type: recall
value: 5.5
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (cat-eng)
config: cat-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 87.6
- type: f1
value: 84.53666666666666
- type: precision
value: 83.125
- type: recall
value: 87.6
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (eus-eng)
config: eus-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 65.7
- type: f1
value: 59.64428571428571
- type: precision
value: 57.30171568627451
- type: recall
value: 65.7
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (yue-eng)
config: yue-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 84.7
- type: f1
value: 81.34523809523809
- type: precision
value: 79.82777777777778
- type: recall
value: 84.7
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (swe-eng)
config: swe-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 18.6
- type: f1
value: 14.93884103295868
- type: precision
value: 14.059478087803882
- type: recall
value: 18.6
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (dtp-eng)
config: dtp-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 5.5
- type: f1
value: 3.815842342611909
- type: precision
value: 3.565130046415928
- type: recall
value: 5.5
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (kat-eng)
config: kat-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 1.2064343163538873
- type: f1
value: 0.9147778048582338
- type: precision
value: 0.8441848589301671
- type: recall
value: 1.2064343163538873
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (jpn-eng)
config: jpn-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 71.3
- type: f1
value: 65.97350649350648
- type: precision
value: 63.85277777777777
- type: recall
value: 71.3
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (csb-eng)
config: csb-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 13.043478260869565
- type: f1
value: 9.043759194508343
- type: precision
value: 8.097993164155737
- type: recall
value: 13.043478260869565
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (xho-eng)
config: xho-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 11.267605633802818
- type: f1
value: 8.30172606520348
- type: precision
value: 7.737059013603729
- type: recall
value: 11.267605633802818
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (orv-eng)
config: orv-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 5.029940119760479
- type: f1
value: 3.07264903262435
- type: precision
value: 2.7633481831401783
- type: recall
value: 5.029940119760479
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (ind-eng)
config: ind-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 90.60000000000001
- type: f1
value: 88.29666666666667
- type: precision
value: 87.21666666666667
- type: recall
value: 90.60000000000001
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (tuk-eng)
config: tuk-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 7.389162561576355
- type: f1
value: 5.142049156827481
- type: precision
value: 4.756506859714838
- type: recall
value: 7.389162561576355
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (max-eng)
config: max-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 44.36619718309859
- type: f1
value: 39.378676538811256
- type: precision
value: 37.71007182068377
- type: recall
value: 44.36619718309859
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (swh-eng)
config: swh-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 21.794871794871796
- type: f1
value: 16.314588577641768
- type: precision
value: 14.962288221599962
- type: recall
value: 21.794871794871796
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (hin-eng)
config: hin-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 93.5
- type: f1
value: 91.53333333333333
- type: precision
value: 90.58333333333333
- type: recall
value: 93.5
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (dsb-eng)
config: dsb-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 12.526096033402922
- type: f1
value: 9.57488704957882
- type: precision
value: 8.943001322776725
- type: recall
value: 12.526096033402922
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (ber-eng)
config: ber-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 6.9
- type: f1
value: 4.5770099528158
- type: precision
value: 4.166915172638407
- type: recall
value: 6.9
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (tam-eng)
config: tam-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 81.75895765472313
- type: f1
value: 77.29641693811075
- type: precision
value: 75.3528773072747
- type: recall
value: 81.75895765472313
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (slk-eng)
config: slk-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 11.0
- type: f1
value: 8.522094712720397
- type: precision
value: 7.883076528738328
- type: recall
value: 11.0
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (tgl-eng)
config: tgl-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 11.3
- type: f1
value: 8.626190704312432
- type: precision
value: 7.994434420637179
- type: recall
value: 11.3
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (ast-eng)
config: ast-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 74.01574803149606
- type: f1
value: 68.16272965879266
- type: precision
value: 65.99737532808399
- type: recall
value: 74.01574803149606
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (mkd-eng)
config: mkd-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 9.0
- type: f1
value: 6.189958106409719
- type: precision
value: 5.445330404889228
- type: recall
value: 9.0
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (khm-eng)
config: khm-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 0.2770083102493075
- type: f1
value: 0.011664800298618888
- type: precision
value: 0.005957856811560036
- type: recall
value: 0.2770083102493075
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (ces-eng)
config: ces-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 8.799999999999999
- type: f1
value: 5.636139438882621
- type: precision
value: 4.993972914553003
- type: recall
value: 8.799999999999999
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (tzl-eng)
config: tzl-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 37.5
- type: f1
value: 31.31118881118881
- type: precision
value: 29.439102564102566
- type: recall
value: 37.5
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (urd-eng)
config: urd-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 74.5
- type: f1
value: 68.96380952380953
- type: precision
value: 66.67968253968255
- type: recall
value: 74.5
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (ara-eng)
config: ara-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 89.0
- type: f1
value: 86.42523809523809
- type: precision
value: 85.28333333333332
- type: recall
value: 89.0
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (kor-eng)
config: kor-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 17.2
- type: f1
value: 12.555081585081584
- type: precision
value: 11.292745310245309
- type: recall
value: 17.2
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (yid-eng)
config: yid-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 0.3537735849056604
- type: f1
value: 0.12010530448397783
- type: precision
value: 0.11902214818132154
- type: recall
value: 0.3537735849056604
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (fin-eng)
config: fin-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 5.8999999999999995
- type: f1
value: 4.26942162679512
- type: precision
value: 3.967144120536608
- type: recall
value: 5.8999999999999995
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (tha-eng)
config: tha-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 2.737226277372263
- type: f1
value: 1.64474042578532
- type: precision
value: 1.567547886228932
- type: recall
value: 2.737226277372263
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (wuu-eng)
config: wuu-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 84.89999999999999
- type: f1
value: 81.17555555555555
- type: precision
value: 79.56416666666667
- type: recall
value: 84.89999999999999
- task:
type: Clustering
dataset:
type: C-MTEB/ThuNewsClusteringP2P
name: MTEB ThuNewsClusteringP2P
config: default
split: test
revision: None
metrics:
- type: v_measure
value: 48.90675612551149
- task:
type: Clustering
dataset:
type: C-MTEB/ThuNewsClusteringS2S
name: MTEB ThuNewsClusteringS2S
config: default
split: test
revision: None
metrics:
- type: v_measure
value: 48.33955538054993
- task:
type: Retrieval
dataset:
type: webis-touche2020
name: MTEB Touche2020
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 2.604
- type: map_at_10
value: 10.005
- type: map_at_100
value: 15.626999999999999
- type: map_at_1000
value: 16.974
- type: map_at_3
value: 5.333
- type: map_at_5
value: 7.031999999999999
- type: mrr_at_1
value: 30.612000000000002
- type: mrr_at_10
value: 45.324999999999996
- type: mrr_at_100
value: 46.261
- type: mrr_at_1000
value: 46.275
- type: mrr_at_3
value: 41.156
- type: mrr_at_5
value: 43.401
- type: ndcg_at_1
value: 28.571
- type: ndcg_at_10
value: 24.917
- type: ndcg_at_100
value: 35.304
- type: ndcg_at_1000
value: 45.973000000000006
- type: ndcg_at_3
value: 25.813000000000002
- type: ndcg_at_5
value: 24.627
- type: precision_at_1
value: 30.612000000000002
- type: precision_at_10
value: 23.061
- type: precision_at_100
value: 7.327
- type: precision_at_1000
value: 1.443
- type: precision_at_3
value: 27.211000000000002
- type: precision_at_5
value: 24.898
- type: recall_at_1
value: 2.604
- type: recall_at_10
value: 16.459
- type: recall_at_100
value: 45.344
- type: recall_at_1000
value: 77.437
- type: recall_at_3
value: 6.349
- type: recall_at_5
value: 9.487
- task:
type: Classification
dataset:
type: mteb/toxic_conversations_50k
name: MTEB ToxicConversationsClassification
config: default
split: test
revision: d7c0de2777da35d6aae2200a62c6e0e5af397c4c
metrics:
- type: accuracy
value: 72.01180000000001
- type: ap
value: 14.626345366340157
- type: f1
value: 55.341805198526096
- task:
type: Classification
dataset:
type: mteb/tweet_sentiment_extraction
name: MTEB TweetSentimentExtractionClassification
config: default
split: test
revision: d604517c81ca91fe16a244d1248fc021f9ecee7a
metrics:
- type: accuracy
value: 61.51103565365025
- type: f1
value: 61.90767326783032
- task:
type: Clustering
dataset:
type: mteb/twentynewsgroups-clustering
name: MTEB TwentyNewsgroupsClustering
config: default
split: test
revision: 6125ec4e24fa026cec8a478383ee943acfbd5449
metrics:
- type: v_measure
value: 39.80161553107969
- task:
type: PairClassification
dataset:
type: mteb/twittersemeval2015-pairclassification
name: MTEB TwitterSemEval2015
config: default
split: test
revision: 70970daeab8776df92f5ea462b6173c0b46fd2d1
metrics:
- type: cos_sim_accuracy
value: 84.32377659891517
- type: cos_sim_ap
value: 69.1354481874608
- type: cos_sim_f1
value: 64.52149133222514
- type: cos_sim_precision
value: 58.65716753022453
- type: cos_sim_recall
value: 71.68865435356201
- type: dot_accuracy
value: 82.82172021219527
- type: dot_ap
value: 64.00853575391538
- type: dot_f1
value: 60.32341223341926
- type: dot_precision
value: 54.25801011804384
- type: dot_recall
value: 67.9155672823219
- type: euclidean_accuracy
value: 84.1151576563152
- type: euclidean_ap
value: 67.83576623331122
- type: euclidean_f1
value: 63.15157338457842
- type: euclidean_precision
value: 57.95855379188713
- type: euclidean_recall
value: 69.36675461741424
- type: manhattan_accuracy
value: 84.09727603266377
- type: manhattan_ap
value: 67.82849173216036
- type: manhattan_f1
value: 63.34376956793989
- type: manhattan_precision
value: 60.28605482717521
- type: manhattan_recall
value: 66.72823218997361
- type: max_accuracy
value: 84.32377659891517
- type: max_ap
value: 69.1354481874608
- type: max_f1
value: 64.52149133222514
- task:
type: PairClassification
dataset:
type: mteb/twitterurlcorpus-pairclassification
name: MTEB TwitterURLCorpus
config: default
split: test
revision: 8b6510b0b1fa4e4c4f879467980e9be563ec1cdf
metrics:
- type: cos_sim_accuracy
value: 88.90053168781775
- type: cos_sim_ap
value: 85.61513175543742
- type: cos_sim_f1
value: 78.12614999632001
- type: cos_sim_precision
value: 74.82729451571973
- type: cos_sim_recall
value: 81.72928857406838
- type: dot_accuracy
value: 88.3086894089339
- type: dot_ap
value: 83.12888443163673
- type: dot_f1
value: 77.2718948023882
- type: dot_precision
value: 73.69524208761266
- type: dot_recall
value: 81.21342777948875
- type: euclidean_accuracy
value: 88.51825978965343
- type: euclidean_ap
value: 84.99220411819988
- type: euclidean_f1
value: 77.30590577305905
- type: euclidean_precision
value: 74.16183335691045
- type: euclidean_recall
value: 80.72836464428703
- type: manhattan_accuracy
value: 88.54542632048744
- type: manhattan_ap
value: 84.98068073894048
- type: manhattan_f1
value: 77.28853696440466
- type: manhattan_precision
value: 74.39806240205158
- type: manhattan_recall
value: 80.41268863566368
- type: max_accuracy
value: 88.90053168781775
- type: max_ap
value: 85.61513175543742
- type: max_f1
value: 78.12614999632001
- task:
type: Retrieval
dataset:
type: C-MTEB/VideoRetrieval
name: MTEB VideoRetrieval
config: default
split: dev
revision: None
metrics:
- type: map_at_1
value: 41.8
- type: map_at_10
value: 51.413
- type: map_at_100
value: 52.127
- type: map_at_1000
value: 52.168000000000006
- type: map_at_3
value: 49.25
- type: map_at_5
value: 50.425
- type: mrr_at_1
value: 41.699999999999996
- type: mrr_at_10
value: 51.363
- type: mrr_at_100
value: 52.077
- type: mrr_at_1000
value: 52.117999999999995
- type: mrr_at_3
value: 49.2
- type: mrr_at_5
value: 50.375
- type: ndcg_at_1
value: 41.8
- type: ndcg_at_10
value: 56.071000000000005
- type: ndcg_at_100
value: 59.58599999999999
- type: ndcg_at_1000
value: 60.718
- type: ndcg_at_3
value: 51.605999999999995
- type: ndcg_at_5
value: 53.714
- type: precision_at_1
value: 41.8
- type: precision_at_10
value: 7.07
- type: precision_at_100
value: 0.873
- type: precision_at_1000
value: 0.096
- type: precision_at_3
value: 19.467000000000002
- type: precision_at_5
value: 12.7
- type: recall_at_1
value: 41.8
- type: recall_at_10
value: 70.7
- type: recall_at_100
value: 87.3
- type: recall_at_1000
value: 96.39999999999999
- type: recall_at_3
value: 58.4
- type: recall_at_5
value: 63.5
- task:
type: Classification
dataset:
type: C-MTEB/waimai-classification
name: MTEB Waimai
config: default
split: test
revision: None
metrics:
- type: accuracy
value: 82.67
- type: ap
value: 63.20621490084175
- type: f1
value: 80.81778523320692
---
# Model Card for udever-bloom
<!-- Provide a quick summary of what the model is/does. -->
`udever-bloom-1b1` is finetuned from [bigscience/bloom-1b1](https://huggingface.co/bigscience/bloom-1b1) via [BitFit](https://aclanthology.org/2022.acl-short.1/) on MS MARCO Passage Ranking, SNLI and MultiNLI data.
It is a universal embedding model across tasks, natural and programming languages.
(From the technical view, `udever` is merely with some minor improvements to `sgpt-bloom`)
<div align=center><img width="338" height="259" src="https://user-images.githubusercontent.com/26690193/277643721-cdb7f227-cae5-40e1-b6e1-a201bde00339.png" /></div>
## Model Details
### Model Description
- **Developed by:** Alibaba Group
- **Model type:** Transformer-based Language Model (decoder-only)
- **Language(s) (NLP):** Multiple; see [bloom training data](https://huggingface.co/bigscience/bloom-1b1#training-data)
- **Finetuned from model :** [bigscience/bloom-1b1](https://huggingface.co/bigscience/bloom-1b1)
### Model Sources
<!-- Provide the basic links for the model. -->
- **Repository:** [github.com/izhx/uni-rep](https://github.com/izhx/uni-rep)
- **Paper :** [Language Models are Universal Embedders](https://arxiv.org/pdf/2310.08232.pdf)
- **Training Date :** 2023-06
## How to Get Started with the Model
Use the code below to get started with the model.
```python
import torch
from transformers import AutoTokenizer, BloomModel
tokenizer = AutoTokenizer.from_pretrained('izhx/udever-bloom-1b1')
model = BloomModel.from_pretrained('izhx/udever-bloom-1b1')
boq, eoq, bod, eod = '[BOQ]', '[EOQ]', '[BOD]', '[EOD]'
eoq_id, eod_id = tokenizer.convert_tokens_to_ids([eoq, eod])
if tokenizer.padding_side != 'left':
print('!!!', tokenizer.padding_side)
tokenizer.padding_side = 'left'
def encode(texts: list, is_query: bool = True, max_length=300):
bos = boq if is_query else bod
eos_id = eoq_id if is_query else eod_id
texts = [bos + t for t in texts]
encoding = tokenizer(
texts, truncation=True, max_length=max_length - 1, padding=True
)
for ids, mask in zip(encoding['input_ids'], encoding['attention_mask']):
ids.append(eos_id)
mask.append(1)
inputs = tokenizer.pad(encoding, return_tensors='pt')
with torch.inference_mode():
outputs = model(**inputs)
embeds = outputs.last_hidden_state[:, -1]
return embeds
encode(['I am Bert', 'You are Elmo'])
```
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
- MS MARCO Passage Ranking, retrieved by (https://github.com/UKPLab/sentence-transformers/blob/master/examples/training/ms_marco/train_bi-encoder_mnrl.py#L86)
- SNLI and MultiNLI (https://sbert.net/datasets/AllNLI.tsv.gz)
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing
MS MARCO hard negatives provided by (https://github.com/UKPLab/sentence-transformers/blob/master/examples/training/ms_marco/train_bi-encoder_mnrl.py#L86).
Negatives for SNLI and MultiNLI are randomly sampled.
#### Training Hyperparameters
- **Training regime:** tf32, BitFit
- **Batch size:** 1024
- **Epochs:** 3
- **Optimizer:** AdamW
- **Learning rate:** 1e-4
- **Scheduler:** constant with warmup.
- **Warmup:** 0.25 epoch
## Evaluation
### Table 1: Massive Text Embedding Benchmark [MTEB](https://huggingface.co/spaces/mteb/leaderboard)
| MTEB | Avg. | Class. | Clust. | PairClass. | Rerank. | Retr. | STS | Summ. |
|-----------------------------|--------------|--------------|--------------|--------------|--------------|--------------|--------------|--------|
| #Datasets ➡️ | 56 | 12 | 11 | 3 | 4 | 15 | 10 | 1 |
||
| bge-large-en-v1.5 | **64.23** | **75.97** | 46.08| **87.12** | **60.03** | **54.29** | 83.11| 31.61 |
| bge-base-en-v1.5 | 63.55| 75.53| 45.77| 86.55| 58.86| 53.25| 82.4| 31.07 |
| gte-large | 63.13| 73.33| **46.84** | 85| 59.13| 52.22| **83.35** | 31.66 |
| gte-base | 62.39| 73.01| 46.2| 84.57| 58.61| 51.14| 82.3| 31.17 |
| e5-large-v2 | 62.25| 75.24| 44.49| 86.03| 56.61| 50.56| 82.05| 30.19 |
| instructor-xl | 61.79| 73.12| 44.74| 86.62| 57.29| 49.26| 83.06| 32.32 |
| instructor-large | 61.59| 73.86| 45.29| 85.89| 57.54| 47.57| 83.15| 31.84 |
| e5-base-v2 | 61.5 | 73.84| 43.8| 85.73| 55.91| 50.29| 81.05| 30.28 |
| e5-large | 61.42| 73.14| 43.33| 85.94| 56.53| 49.99| 82.06| 30.97 |
| text-embedding-ada-002 (OpenAI API) | 60.99| 70.93| 45.9 | 84.89| 56.32| 49.25| 80.97| 30.8 |
| e5-base | 60.44| 72.63| 42.11| 85.09| 55.7 | 48.75| 80.96| 31.01 |
| SGPT-5.8B-msmarco | 58.93| 68.13| 40.34| 82 | 56.56| 50.25| 78.1 | 31.46 |
| sgpt-bloom-7b1-msmarco | 57.59| 66.19| 38.93| 81.9 | 55.65| 48.22| 77.74| **33.6** |
||
| Udever-bloom-560m | 55.80| 68.04| 36.89| 81.05| 52.60| 41.19| 79.93| 32.06 |
| Udever-bloom-1b1 | 58.28| 70.18| 39.11| 83.11| 54.28| 45.27| 81.52| 31.10 |
| Udever-bloom-3b | 59.86| 71.91| 40.74| 84.06| 54.90| 47.67| 82.37| 30.62 |
| Udever-bloom-7b1 | 60.63 | 72.13| 40.81| 85.40| 55.91| 49.34| 83.01| 30.97 |
### Table 2: [CodeSearchNet](https://github.com/github/CodeSearchNet)
| CodeSearchNet | Go | Ruby | Python | Java | JS | PHP | Avg. |
|-|-|-|-|-|-|-|-|
| CodeBERT | 69.3 | 70.6 | 84.0 | 86.8 | 74.8 | 70.6 | 76.0 |
| GraphCodeBERT | 84.1 | 73.2 | 87.9 | 75.7 | 71.1 | 72.5 | 77.4 |
| cpt-code S | **97.7** | **86.3** | 99.8 | 94.0 | 86.0 | 96.7 | 93.4 |
| cpt-code M | 97.5 | 85.5 | **99.9** | **94.4** | **86.5** | **97.2** | **93.5** |
| sgpt-bloom-7b1-msmarco | 76.79 | 69.25 | 95.68 | 77.93 | 70.35 | 73.45 | 77.24 |
||
| Udever-bloom-560m | 75.38 | 66.67 | 96.23 | 78.99 | 69.39 | 73.69 | 76.73 |
| Udever-bloom-1b1 | 78.76 | 72.85 | 97.67 | 82.77 | 74.38 | 78.97 | 80.90 |
| Udever-bloom-3b | 80.63 | 75.40 | 98.02 | 83.88 | 76.18 | 79.67 | 82.29 |
| Udever-bloom-7b1 | 79.37 | 76.59 | 98.38 | 84.68 | 77.49 | 80.03 | 82.76 |
### Table 3: Chinese multi-domain retrieval [Multi-cpr](https://dl.acm.org/doi/10.1145/3477495.3531736)
| | | |E-commerce | | Entertainment video | | Medical | |
|--|--|--|--|--|--|--|--|--|
| Model | Train | Backbone | MRR@10 | Recall@1k | MRR@10 | Recall@1k | MRR@10 | Recall@1k |
||
| BM25 | - | - | 0.225 | 0.815 | 0.225 | 0.780 | 0.187 | 0.482 |
| Doc2Query | - | - | 0.239 | 0.826 | 0.238 | 0.794 | 0.210 | 0.505 |
| DPR-1 | In-Domain | BERT | 0.270 | 0.921 | 0.254 | 0.934 | 0.327 | 0.747 |
| DPR-2 | In-Domain | BERT-CT | 0.289 | **0.926** | 0.263 | **0.935** | 0.339 | **0.769** |
| text-embedding-ada-002 | General | GPT | 0.183 | 0.825 | 0.159 | 0.786 | 0.245 | 0.593 |
| sgpt-bloom-7b1-msmarco | General | BLOOM | 0.242 | 0.840 | 0.227 | 0.829 | 0.311 | 0.675 |
||
| Udever-bloom-560m | General | BLOOM | 0.156 | 0.802 | 0.149 | 0.749 | 0.245 | 0.571 |
| Udever-bloom-1b1 | General | BLOOM | 0.244 | 0.863 | 0.208 | 0.815 | 0.241 | 0.557 |
| Udever-bloom-3b | General | BLOOM | 0.267 | 0.871 | 0.228 | 0.836 | 0.288 | 0.619 |
| Udever-bloom-7b1 | General | BLOOM | **0.296** | 0.889 | **0.267** | 0.907 | **0.343** | 0.705 |
#### More results refer to [paper](https://arxiv.org/pdf/2310.08232.pdf) section 3.
## Technical Specifications
### Model Architecture and Objective
- Model: [bigscience/bloom-1b1](https://huggingface.co/bigscience/bloom-1b1).
- Objective: Constrastive loss with hard negatives (refer to [paper](https://arxiv.org/pdf/2310.08232.pdf) section 2.2).
### Compute Infrastructure
- Nvidia A100 SXM4 80GB.
- torch 2.0.0, transformers 4.29.2.
## Citation
**BibTeX:**
```BibTeX
@article{zhang2023language,
title={Language Models are Universal Embedders},
author={Zhang, Xin and Li, Zehan and Zhang, Yanzhao and Long, Dingkun and Xie, Pengjun and Zhang, Meishan and Zhang, Min},
journal={arXiv preprint arXiv:2310.08232},
year={2023}
}
```
|
Yntec/pineappleAnimeMix | Yntec | 2023-11-13T09:40:46Z | 6,982 | 7 | diffusers | [
"diffusers",
"safetensors",
"Anime",
"Base Model",
"Female",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"pmango300574",
"en",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | 2023-11-13T08:34:17Z | ---
license: creativeml-openrail-m
library_name: diffusers
language:
- en
tags:
- Anime
- Base Model
- Female
- stable-diffusion
- stable-diffusion-diffusers
- diffusers
- text-to-image
- pmango300574
pipeline_tag: text-to-image
---
# Pineapple Anime Mix
Original page: https://civitai.com/models/190067/pineapple-anime-mix
Sample and prompt:

masterpiece, Cartoon Pretty CUTE LITTLE Girl, sitting on a box of CANDLES, DETAILED CHIBI EYES, holding candle, gorgeous detailed hair, Ponytail, Magazine ad, iconic, 1940, sharp focus. Illustration By ROSSDRAWS and KlaysMoji and Dave Rapoza and artgerm and leyendecker and Clay Mann |
PrunaAI/Phi-3-mini-4k-instruct-GGUF-Imatrix-smashed | PrunaAI | 2024-04-26T10:03:32Z | 6,968 | 4 | null | [
"gguf",
"pruna-ai",
"region:us"
] | null | 2024-04-23T23:31:12Z | ---
thumbnail: "https://assets-global.website-files.com/646b351987a8d8ce158d1940/64ec9e96b4334c0e1ac41504_Logo%20with%20white%20text.svg"
metrics:
- memory_disk
- memory_inference
- inference_latency
- inference_throughput
- inference_CO2_emissions
- inference_energy_consumption
tags:
- pruna-ai
---
<!-- header start -->
<!-- 200823 -->
<div style="width: auto; margin-left: auto; margin-right: auto">
<a href="https://www.pruna.ai/" target="_blank" rel="noopener noreferrer">
<img src="https://i.imgur.com/eDAlcgk.png" alt="PrunaAI" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</a>
</div>
<!-- header end -->
[](https://twitter.com/PrunaAI)
[](https://github.com/PrunaAI)
[](https://www.linkedin.com/company/93832878/admin/feed/posts/?feedType=following)
[](https://discord.gg/CP4VSgck)
## This repo contains GGUF versions of the microsoft/Phi-3-mini-4k-instruct model.
# Simply make AI models cheaper, smaller, faster, and greener!
- Give a thumbs up if you like this model!
- Contact us and tell us which model to compress next [here](https://www.pruna.ai/contact).
- Request access to easily compress your *own* AI models [here](https://z0halsaff74.typeform.com/pruna-access?typeform-source=www.pruna.ai).
- Read the documentations to know more [here](https://pruna-ai-pruna.readthedocs-hosted.com/en/latest/)
- Join Pruna AI community on Discord [here](https://discord.gg/CP4VSgck) to share feedback/suggestions or get help.
**Frequently Asked Questions**
- ***How does the compression work?*** The model is compressed with GGUF.
- ***How does the model quality change?*** The quality of the model output might vary compared to the base model.
- ***What is the model format?*** We use GGUF format.
- ***What calibration data has been used?*** If needed by the compression method, we used WikiText as the calibration data.
- ***How to compress my own models?*** You can request premium access to more compression methods and tech support for your specific use-cases [here](https://z0halsaff74.typeform.com/pruna-access?typeform-source=www.pruna.ai).
# Downloading and running the models
You can download the individual files from the Files & versions section. Here is a list of the different versions we provide. For more info checkout [this chart](https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9) and [this guide](https://www.reddit.com/r/LocalLLaMA/comments/1ba55rj/overview_of_gguf_quantization_methods/):
| Quant type | Description |
|------------|--------------------------------------------------------------------------------------------|
| Q5_K_M | High quality, recommended. |
| Q5_K_S | High quality, recommended. |
| Q4_K_M | Good quality, uses about 4.83 bits per weight, recommended. |
| Q4_K_S | Slightly lower quality with more space savings, recommended. |
| IQ4_NL | Decent quality, slightly smaller than Q4_K_S with similar performance, recommended. |
| IQ4_XS | Decent quality, smaller than Q4_K_S with similar performance, recommended. |
| Q3_K_L | Lower quality but usable, good for low RAM availability. |
| Q3_K_M | Even lower quality. |
| IQ3_M | Medium-low quality, new method with decent performance comparable to Q3_K_M. |
| IQ3_S | Lower quality, new method with decent performance, recommended over Q3_K_S quant, same size with better performance. |
| Q3_K_S | Low quality, not recommended. |
| IQ3_XS | Lower quality, new method with decent performance, slightly better than Q3_K_S. |
| Q2_K | Very low quality but surprisingly usable. |
## How to download GGUF files ?
**Note for manual downloaders:** You almost never want to clone the entire repo! Multiple different quantisation formats are provided, and most users only want to pick and download a single file.
The following clients/libraries will automatically download models for you, providing a list of available models to choose from:
* LM Studio
* LoLLMS Web UI
* Faraday.dev
- **Option A** - Downloading in `text-generation-webui`:
- **Step 1**: Under Download Model, you can enter the model repo: PrunaAI/Phi-3-mini-4k-instruct-GGUF-smashed and below it, a specific filename to download, such as: phi-2.IQ3_M.gguf.
- **Step 2**: Then click Download.
- **Option B** - Downloading on the command line (including multiple files at once):
- **Step 1**: We recommend using the `huggingface-hub` Python library:
```shell
pip3 install huggingface-hub
```
- **Step 2**: Then you can download any individual model file to the current directory, at high speed, with a command like this:
```shell
huggingface-cli download PrunaAI/Phi-3-mini-4k-instruct-GGUF-smashed Phi-3-mini-4k-instruct.IQ3_M.gguf --local-dir . --local-dir-use-symlinks False
```
<details>
<summary>More advanced huggingface-cli download usage (click to read)</summary>
Alternatively, you can also download multiple files at once with a pattern:
```shell
huggingface-cli download PrunaAI/Phi-3-mini-4k-instruct-GGUF-smashed --local-dir . --local-dir-use-symlinks False --include='*Q4_K*gguf'
```
For more documentation on downloading with `huggingface-cli`, please see: [HF -> Hub Python Library -> Download files -> Download from the CLI](https://huggingface.co/docs/huggingface_hub/guides/download#download-from-the-cli).
To accelerate downloads on fast connections (1Gbit/s or higher), install `hf_transfer`:
```shell
pip3 install hf_transfer
```
And set environment variable `HF_HUB_ENABLE_HF_TRANSFER` to `1`:
```shell
HF_HUB_ENABLE_HF_TRANSFER=1 huggingface-cli download PrunaAI/Phi-3-mini-4k-instruct-GGUF-smashed Phi-3-mini-4k-instruct.IQ3_M.gguf --local-dir . --local-dir-use-symlinks False
```
Windows Command Line users: You can set the environment variable by running `set HF_HUB_ENABLE_HF_TRANSFER=1` before the download command.
</details>
<!-- README_GGUF.md-how-to-download end -->
<!-- README_GGUF.md-how-to-run start -->
## How to run model in GGUF format?
- **Option A** - Introductory example with `llama.cpp` command
Make sure you are using `llama.cpp` from commit [d0cee0d](https://github.com/ggerganov/llama.cpp/commit/d0cee0d36d5be95a0d9088b674dbb27354107221) or later.
```shell
./main -ngl 35 -m Phi-3-mini-4k-instruct.IQ3_M.gguf --color -c 32768 --temp 0.7 --repeat_penalty 1.1 -n -1 -p "<s>[INST] {prompt\} [/INST]"
```
Change `-ngl 32` to the number of layers to offload to GPU. Remove it if you don't have GPU acceleration.
Change `-c 32768` to the desired sequence length. For extended sequence models - eg 8K, 16K, 32K - the necessary RoPE scaling parameters are read from the GGUF file and set by llama.cpp automatically. Note that longer sequence lengths require much more resources, so you may need to reduce this value.
If you want to have a chat-style conversation, replace the `-p <PROMPT>` argument with `-i -ins`
For other parameters and how to use them, please refer to [the llama.cpp documentation](https://github.com/ggerganov/llama.cpp/blob/master/examples/main/README.md)
- **Option B** - Running in `text-generation-webui`
Further instructions can be found in the text-generation-webui documentation, here: [text-generation-webui/docs/04 ‐ Model Tab.md](https://github.com/oobabooga/text-generation-webui/blob/main/docs/04%20-%20Model%20Tab.md#llamacpp).
- **Option C** - Running from Python code
You can use GGUF models from Python using the [llama-cpp-python](https://github.com/abetlen/llama-cpp-python) or [ctransformers](https://github.com/marella/ctransformers) libraries. Note that at the time of writing (Nov 27th 2023), ctransformers has not been updated for some time and is not compatible with some recent models. Therefore I recommend you use llama-cpp-python.
### How to load this model in Python code, using llama-cpp-python
For full documentation, please see: [llama-cpp-python docs](https://abetlen.github.io/llama-cpp-python/).
#### First install the package
Run one of the following commands, according to your system:
```shell
# Base ctransformers with no GPU acceleration
pip install llama-cpp-python
# With NVidia CUDA acceleration
CMAKE_ARGS="-DLLAMA_CUBLAS=on" pip install llama-cpp-python
# Or with OpenBLAS acceleration
CMAKE_ARGS="-DLLAMA_BLAS=ON -DLLAMA_BLAS_VENDOR=OpenBLAS" pip install llama-cpp-python
# Or with CLBLast acceleration
CMAKE_ARGS="-DLLAMA_CLBLAST=on" pip install llama-cpp-python
# Or with AMD ROCm GPU acceleration (Linux only)
CMAKE_ARGS="-DLLAMA_HIPBLAS=on" pip install llama-cpp-python
# Or with Metal GPU acceleration for macOS systems only
CMAKE_ARGS="-DLLAMA_METAL=on" pip install llama-cpp-python
# In windows, to set the variables CMAKE_ARGS in PowerShell, follow this format; eg for NVidia CUDA:
$env:CMAKE_ARGS = "-DLLAMA_OPENBLAS=on"
pip install llama-cpp-python
```
#### Simple llama-cpp-python example code
```python
from llama_cpp import Llama
# Set gpu_layers to the number of layers to offload to GPU. Set to 0 if no GPU acceleration is available on your system.
llm = Llama(
model_path="./Phi-3-mini-4k-instruct.IQ3_M.gguf", # Download the model file first
n_ctx=32768, # The max sequence length to use - note that longer sequence lengths require much more resources
n_threads=8, # The number of CPU threads to use, tailor to your system and the resulting performance
n_gpu_layers=35 # The number of layers to offload to GPU, if you have GPU acceleration available
)
# Simple inference example
output = llm(
"<s>[INST] {prompt} [/INST]", # Prompt
max_tokens=512, # Generate up to 512 tokens
stop=["</s>"], # Example stop token - not necessarily correct for this specific model! Please check before using.
echo=True # Whether to echo the prompt
)
# Chat Completion API
llm = Llama(model_path="./Phi-3-mini-4k-instruct.IQ3_M.gguf", chat_format="llama-2") # Set chat_format according to the model you are using
llm.create_chat_completion(
messages = [
{"role": "system", "content": "You are a story writing assistant."},
{
"role": "user",
"content": "Write a story about llamas."
}
]
)
```
- **Option D** - Running with LangChain
Here are guides on using llama-cpp-python and ctransformers with LangChain:
* [LangChain + llama-cpp-python](https://python.langchain.com/docs/integrations/llms/llamacpp)
* [LangChain + ctransformers](https://python.langchain.com/docs/integrations/providers/ctransformers)
## Configurations
The configuration info are in `smash_config.json`.
## Credits & License
The license of the smashed model follows the license of the original model. Please check the license of the original model before using this model which provided the base model. The license of the `pruna-engine` is [here](https://pypi.org/project/pruna-engine/) on Pypi.
## Want to compress other models?
- Contact us and tell us which model to compress next [here](https://www.pruna.ai/contact).
- Request access to easily compress your own AI models [here](https://z0halsaff74.typeform.com/pruna-access?typeform-source=www.pruna.ai).
|
ncbi/MedCPT-Article-Encoder | ncbi | 2023-12-03T00:47:23Z | 6,966 | 11 | transformers | [
"transformers",
"pytorch",
"safetensors",
"bert",
"feature-extraction",
"arxiv:2307.00589",
"license:other",
"endpoints_compatible",
"region:us"
] | feature-extraction | 2023-10-24T22:55:47Z | ---
license: other
license_name: public-domain
license_link: LICENSE
---
# MedCPT Introduction
**MedCPT generates embeddings of biomedical texts that can be used for semantic search (dense retrieval)**. The model contains two encoders:
- [MedCPT Query Encoder](https://huggingface.co/ncbi/MedCPT-Query-Encoder): compute the embeddings of short texts (e.g., questions, search queries, sentences).
- [MedCPT Article Encoder](https://huggingface.co/ncbi/MedCPT-Article-Encoder): compute the embeddings of articles (e.g., PubMed titles & abstracts).
**This repo contains the MedCPT Article Encoder.**
**MedCPT has been pre-trained by an unprecedented scale of 255M query-article pairs from PubMed search logs**, and has been shown to achieve state-of-the-art performance on several zero-shot biomedical IR datasets. In general, there are three use cases:
1. Query-to-article search with both encoders.
2. Query representation for clustering or query-to-query search with the [query encoder](https://huggingface.co/ncbi/MedCPT-Query-Encoder).
3. Article representation for clustering or article-to-article search with the [article encoder](https://huggingface.co/ncbi/MedCPT-Article-Encoder).
For more details, please check out our [paper](https://arxiv.org/abs/2307.00589) (Bioinformatics, 2023). Please note that the released version is slightly different from the version reported in the paper.
# Case 1. Using the MedCPT Article Encoder
```python
import torch
from transformers import AutoTokenizer, AutoModel
model = AutoModel.from_pretrained("ncbi/MedCPT-Article-Encoder")
tokenizer = AutoTokenizer.from_pretrained("ncbi/MedCPT-Article-Encoder")
# each article contains a list of two texts (usually a title and an abstract)
articles = [
[
"Diagnosis and Management of Central Diabetes Insipidus in Adults",
"Central diabetes insipidus (CDI) is a clinical syndrome which results from loss or impaired function of vasopressinergic neurons in the hypothalamus/posterior pituitary, resulting in impaired synthesis and/or secretion of arginine vasopressin (AVP). [...]",
],
[
"Adipsic diabetes insipidus",
"Adipsic diabetes insipidus (ADI) is a rare but devastating disorder of water balance with significant associated morbidity and mortality. Most patients develop the disease as a result of hypothalamic destruction from a variety of underlying etiologies. [...]",
],
[
"Nephrogenic diabetes insipidus: a comprehensive overview",
"Nephrogenic diabetes insipidus (NDI) is characterized by the inability to concentrate urine that results in polyuria and polydipsia, despite having normal or elevated plasma concentrations of arginine vasopressin (AVP). [...]",
],
]
with torch.no_grad():
# tokenize the articles
encoded = tokenizer(
articles,
truncation=True,
padding=True,
return_tensors='pt',
max_length=512,
)
# encode the queries (use the [CLS] last hidden states as the representations)
embeds = model(**encoded).last_hidden_state[:, 0, :]
print(embeds)
print(embeds.size())
```
The output will be:
```bash
tensor([[-0.0189, 0.0115, 0.0988, ..., -0.0655, 0.3155, -0.0357],
[-0.3402, -0.3064, -0.0749, ..., -0.0799, 0.3332, 0.1263],
[-0.2764, -0.0506, -0.0608, ..., 0.0389, 0.2532, 0.1580]])
torch.Size([3, 768])
```
These embeddings are also in the same space as those generated by the MedCPT query encoder.
# Case 2. Use the Pre-computed Embeddings
We have provided the embeddings of all PubMed articles generated by the MedCPT article encoder at https://ftp.ncbi.nlm.nih.gov/pub/lu/MedCPT/pubmed_embeddings/.
# Acknowledgments
This work was supported by the Intramural Research Programs of the National Institutes of Health, National Library of Medicine.
# Disclaimer
This tool shows the results of research conducted in the Computational Biology Branch, NCBI/NLM. The information produced on this website is not intended for direct diagnostic use or medical decision-making without review and oversight by a clinical professional. Individuals should not change their health behavior solely on the basis of information produced on this website. NIH does not independently verify the validity or utility of the information produced by this tool. If you have questions about the information produced on this website, please see a health care professional. More information about NCBI's disclaimer policy is available.
# Citation
If you find this repo helpful, please cite MedCPT by:
```bibtext
@article{jin2023medcpt,
title={MedCPT: Contrastive Pre-trained Transformers with large-scale PubMed search logs for zero-shot biomedical information retrieval},
author={Jin, Qiao and Kim, Won and Chen, Qingyu and Comeau, Donald C and Yeganova, Lana and Wilbur, W John and Lu, Zhiyong},
journal={Bioinformatics},
volume={39},
number={11},
pages={btad651},
year={2023},
publisher={Oxford University Press}
}
``` |
prometheus-eval/prometheus-7b-v2.0 | prometheus-eval | 2024-05-03T11:08:56Z | 6,966 | 57 | transformers | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"text2text-generation",
"en",
"dataset:prometheus-eval/Feedback-Collection",
"dataset:prometheus-eval/Preference-Collection",
"arxiv:2405.01535",
"arxiv:2310.08491",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text2text-generation | 2024-02-13T17:18:13Z | ---
tags:
- text2text-generation
datasets:
- prometheus-eval/Feedback-Collection
- prometheus-eval/Preference-Collection
license: apache-2.0
language:
- en
pipeline_tag: text2text-generation
library_name: transformers
metrics:
- pearsonr
- spearmanr
- kendall-tau
- accuracy
---
## Links for Reference
- **Homepage: In Progress**
- **Repository:https://github.com/prometheus-eval/prometheus-eval**
- **Paper:https://arxiv.org/abs/2405.01535**
- **Point of Contact:[email protected]**
# TL;DR
Prometheus 2 is an alternative of GPT-4 evaluation when doing fine-grained evaluation of an underlying LLM & a Reward model for Reinforcement Learning from Human Feedback (RLHF).

Prometheus 2 is a language model using [Mistral-Instruct](https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.2) as a base model.
It is fine-tuned on 100K feedback within the [Feedback Collection](https://huggingface.co/datasets/prometheus-eval/Feedback-Collection) and 200K feedback within the [Preference Collection](https://huggingface.co/datasets/prometheus-eval/Preference-Collection).
It is also made by weight merging to support both absolute grading (direct assessment) and relative grading (pairwise ranking).
The surprising thing is that we find weight merging also improves performance on each format.
# Model Details
## Model Description
- **Model type:** Language model
- **Language(s) (NLP):** English
- **License:** Apache 2.0
- **Related Models:** [All Prometheus Checkpoints](https://huggingface.co/models?search=prometheus-eval/Prometheus)
- **Resources for more information:**
- [Research paper](https://arxiv.org/abs/2405.01535)
- [GitHub Repo](https://github.com/prometheus-eval/prometheus-eval)
Prometheus is trained with two different sizes (7B and 8x7B).
You could check the 8x7B sized LM on [this page](https://huggingface.co/prometheus-eval/prometheus-2-8x7b-v2.0).
Also, check out our dataset as well on [this page](https://huggingface.co/datasets/prometheus-eval/Feedback-Collection) and [this page](https://huggingface.co/datasets/prometheus-eval/Preference-Collection).
## Prompt Format
We have made wrapper functions and classes to conveniently use Prometheus 2 at [our github repository](https://github.com/prometheus-eval/prometheus-eval).
We highly recommend you use it!
However, if you just want to use the model for your use case, please refer to the prompt format below.
Note that absolute grading and relative grading requires different prompt templates and system prompts.
### Absolute Grading (Direct Assessment)
Prometheus requires 4 components in the input: An instruction, a response to evaluate, a score rubric, and a reference answer. You could refer to the prompt format below.
You should fill in the instruction, response, reference answer, criteria description, and score description for score in range of 1 to 5.
Fix the components with \{text\} inside.
```
###Task Description:
An instruction (might include an Input inside it), a response to evaluate, a reference answer that gets a score of 5, and a score rubric representing a evaluation criteria are given.
1. Write a detailed feedback that assess the quality of the response strictly based on the given score rubric, not evaluating in general.
2. After writing a feedback, write a score that is an integer between 1 and 5. You should refer to the score rubric.
3. The output format should look as follows: \"Feedback: (write a feedback for criteria) [RESULT] (an integer number between 1 and 5)\"
4. Please do not generate any other opening, closing, and explanations.
###The instruction to evaluate:
{orig_instruction}
###Response to evaluate:
{orig_response}
###Reference Answer (Score 5):
{orig_reference_answer}
###Score Rubrics:
[{orig_criteria}]
Score 1: {orig_score1_description}
Score 2: {orig_score2_description}
Score 3: {orig_score3_description}
Score 4: {orig_score4_description}
Score 5: {orig_score5_description}
###Feedback:
```
After this, you should apply the conversation template of Mistral (not applying it might lead to unexpected behaviors).
You can find the conversation class at this [link](https://github.com/lm-sys/FastChat/blob/main/fastchat/conversation.py).
```
conv = get_conv_template("mistral")
conv.set_system_message("You are a fair judge assistant tasked with providing clear, objective feedback based on specific criteria, ensuring each assessment reflects the absolute standards set for performance.")
conv.append_message(conv.roles[0], dialogs['instruction'])
conv.append_message(conv.roles[1], None)
prompt = conv.get_prompt()
x = tokenizer(prompt,truncation=False)
```
As a result, a feedback and score decision will be generated, divided by a separating phrase ```[RESULT]```
### Relative Grading (Pairwise Ranking)
Prometheus requires 4 components in the input: An instruction, 2 responses to evaluate, a score rubric, and a reference answer. You could refer to the prompt format below.
You should fill in the instruction, 2 responses, reference answer, and criteria description.
Fix the components with \{text\} inside.
```
###Task Description:
An instruction (might include an Input inside it), a response to evaluate, and a score rubric representing a evaluation criteria are given.
1. Write a detailed feedback that assess the quality of two responses strictly based on the given score rubric, not evaluating in general.
2. After writing a feedback, choose a better response between Response A and Response B. You should refer to the score rubric.
3. The output format should look as follows: "Feedback: (write a feedback for criteria) [RESULT] (A or B)"
4. Please do not generate any other opening, closing, and explanations.
###Instruction:
{orig_instruction}
###Response A:
{orig_response_A}
###Response B:
{orig_response_B}
###Reference Answer:
{orig_reference_answer}
###Score Rubric:
{orig_criteria}
###Feedback:
```
After this, you should apply the conversation template of Mistral (not applying it might lead to unexpected behaviors).
You can find the conversation class at this [link](https://github.com/lm-sys/FastChat/blob/main/fastchat/conversation.py).
```
conv = get_conv_template("mistral")
conv.set_system_message("You are a fair judge assistant assigned to deliver insightful feedback that compares individual performances, highlighting how each stands relative to others within the same cohort.")
conv.append_message(conv.roles[0], dialogs['instruction'])
conv.append_message(conv.roles[1], None)
prompt = conv.get_prompt()
x = tokenizer(prompt,truncation=False)
```
As a result, a feedback and score decision will be generated, divided by a separating phrase ```[RESULT]```
## License
Feedback Collection, Preference Collection, and Prometheus 2 are subject to OpenAI's Terms of Use for the generated data. If you suspect any violations, please reach out to us.
# Citation
If you find the following model helpful, please consider citing our paper!
**BibTeX:**
```bibtex
@misc{kim2023prometheus,
title={Prometheus: Inducing Fine-grained Evaluation Capability in Language Models},
author={Seungone Kim and Jamin Shin and Yejin Cho and Joel Jang and Shayne Longpre and Hwaran Lee and Sangdoo Yun and Seongjin Shin and Sungdong Kim and James Thorne and Minjoon Seo},
year={2023},
eprint={2310.08491},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
```bibtex
@misc{kim2024prometheus,
title={Prometheus 2: An Open Source Language Model Specialized in Evaluating Other Language Models},
author={Seungone Kim and Juyoung Suk and Shayne Longpre and Bill Yuchen Lin and Jamin Shin and Sean Welleck and Graham Neubig and Moontae Lee and Kyungjae Lee and Minjoon Seo},
year={2024},
eprint={2405.01535},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
``` |
RichardErkhov/andrijdavid_-_Llama3-2B-Base-gguf | RichardErkhov | 2024-06-30T04:17:05Z | 6,964 | 0 | null | [
"gguf",
"region:us"
] | null | 2024-06-30T03:35:12Z | Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
Llama3-2B-Base - GGUF
- Model creator: https://huggingface.co/andrijdavid/
- Original model: https://huggingface.co/andrijdavid/Llama3-2B-Base/
| Name | Quant method | Size |
| ---- | ---- | ---- |
| [Llama3-2B-Base.Q2_K.gguf](https://huggingface.co/RichardErkhov/andrijdavid_-_Llama3-2B-Base-gguf/blob/main/Llama3-2B-Base.Q2_K.gguf) | Q2_K | 1.02GB |
| [Llama3-2B-Base.IQ3_XS.gguf](https://huggingface.co/RichardErkhov/andrijdavid_-_Llama3-2B-Base-gguf/blob/main/Llama3-2B-Base.IQ3_XS.gguf) | IQ3_XS | 1.11GB |
| [Llama3-2B-Base.IQ3_S.gguf](https://huggingface.co/RichardErkhov/andrijdavid_-_Llama3-2B-Base-gguf/blob/main/Llama3-2B-Base.IQ3_S.gguf) | IQ3_S | 1.15GB |
| [Llama3-2B-Base.Q3_K_S.gguf](https://huggingface.co/RichardErkhov/andrijdavid_-_Llama3-2B-Base-gguf/blob/main/Llama3-2B-Base.Q3_K_S.gguf) | Q3_K_S | 1.14GB |
| [Llama3-2B-Base.IQ3_M.gguf](https://huggingface.co/RichardErkhov/andrijdavid_-_Llama3-2B-Base-gguf/blob/main/Llama3-2B-Base.IQ3_M.gguf) | IQ3_M | 1.16GB |
| [Llama3-2B-Base.Q3_K.gguf](https://huggingface.co/RichardErkhov/andrijdavid_-_Llama3-2B-Base-gguf/blob/main/Llama3-2B-Base.Q3_K.gguf) | Q3_K | 1.2GB |
| [Llama3-2B-Base.Q3_K_M.gguf](https://huggingface.co/RichardErkhov/andrijdavid_-_Llama3-2B-Base-gguf/blob/main/Llama3-2B-Base.Q3_K_M.gguf) | Q3_K_M | 1.2GB |
| [Llama3-2B-Base.Q3_K_L.gguf](https://huggingface.co/RichardErkhov/andrijdavid_-_Llama3-2B-Base-gguf/blob/main/Llama3-2B-Base.Q3_K_L.gguf) | Q3_K_L | 1.26GB |
| [Llama3-2B-Base.IQ4_XS.gguf](https://huggingface.co/RichardErkhov/andrijdavid_-_Llama3-2B-Base-gguf/blob/main/Llama3-2B-Base.IQ4_XS.gguf) | IQ4_XS | 1.32GB |
| [Llama3-2B-Base.Q4_0.gguf](https://huggingface.co/RichardErkhov/andrijdavid_-_Llama3-2B-Base-gguf/blob/main/Llama3-2B-Base.Q4_0.gguf) | Q4_0 | 1.37GB |
| [Llama3-2B-Base.IQ4_NL.gguf](https://huggingface.co/RichardErkhov/andrijdavid_-_Llama3-2B-Base-gguf/blob/main/Llama3-2B-Base.IQ4_NL.gguf) | IQ4_NL | 1.37GB |
| [Llama3-2B-Base.Q4_K_S.gguf](https://huggingface.co/RichardErkhov/andrijdavid_-_Llama3-2B-Base-gguf/blob/main/Llama3-2B-Base.Q4_K_S.gguf) | Q4_K_S | 1.37GB |
| [Llama3-2B-Base.Q4_K.gguf](https://huggingface.co/RichardErkhov/andrijdavid_-_Llama3-2B-Base-gguf/blob/main/Llama3-2B-Base.Q4_K.gguf) | Q4_K | 1.4GB |
| [Llama3-2B-Base.Q4_K_M.gguf](https://huggingface.co/RichardErkhov/andrijdavid_-_Llama3-2B-Base-gguf/blob/main/Llama3-2B-Base.Q4_K_M.gguf) | Q4_K_M | 1.4GB |
| [Llama3-2B-Base.Q4_1.gguf](https://huggingface.co/RichardErkhov/andrijdavid_-_Llama3-2B-Base-gguf/blob/main/Llama3-2B-Base.Q4_1.gguf) | Q4_1 | 1.48GB |
| [Llama3-2B-Base.Q5_0.gguf](https://huggingface.co/RichardErkhov/andrijdavid_-_Llama3-2B-Base-gguf/blob/main/Llama3-2B-Base.Q5_0.gguf) | Q5_0 | 1.58GB |
| [Llama3-2B-Base.Q5_K_S.gguf](https://huggingface.co/RichardErkhov/andrijdavid_-_Llama3-2B-Base-gguf/blob/main/Llama3-2B-Base.Q5_K_S.gguf) | Q5_K_S | 1.58GB |
| [Llama3-2B-Base.Q5_K.gguf](https://huggingface.co/RichardErkhov/andrijdavid_-_Llama3-2B-Base-gguf/blob/main/Llama3-2B-Base.Q5_K.gguf) | Q5_K | 1.6GB |
| [Llama3-2B-Base.Q5_K_M.gguf](https://huggingface.co/RichardErkhov/andrijdavid_-_Llama3-2B-Base-gguf/blob/main/Llama3-2B-Base.Q5_K_M.gguf) | Q5_K_M | 1.6GB |
| [Llama3-2B-Base.Q5_1.gguf](https://huggingface.co/RichardErkhov/andrijdavid_-_Llama3-2B-Base-gguf/blob/main/Llama3-2B-Base.Q5_1.gguf) | Q5_1 | 1.69GB |
| [Llama3-2B-Base.Q6_K.gguf](https://huggingface.co/RichardErkhov/andrijdavid_-_Llama3-2B-Base-gguf/blob/main/Llama3-2B-Base.Q6_K.gguf) | Q6_K | 1.81GB |
| [Llama3-2B-Base.Q8_0.gguf](https://huggingface.co/RichardErkhov/andrijdavid_-_Llama3-2B-Base-gguf/blob/main/Llama3-2B-Base.Q8_0.gguf) | Q8_0 | 2.34GB |
Original model description:
---
license: cc-by-4.0
language:
- en
pipeline_tag: text-generation
---
# Llama-3-2B-Base
Llama3-2b is a trimmed version of the official [Llama-3 8B](https://huggingface.co/meta-llama/Meta-Llama-3-8B) base model from [Meta](https://huggingface.co/meta-llama).
It has been reduced in size to ~2 billion parameters, making it more computationally efficient while still retaining a significant portion of the original model's capabilities.
This model is intended to serve as a base model and has not been further fine-tuned for any specific task.
It is specifically designed to bring the power of LLMs (Large Language Models) to environments with limited computational resources. This model offers a balance between performance and resource usage, serving as an efficient alternative for users who cannot leverage the larger, resource-intensive versions from Meta.
**Important**: This project is not affiliated with Meta.
## Uses
This model can be fine-tuned for a variety of natural language processing tasks, including:
- Text generation
- Question answering
- Sentiment analysis
- Translation
- Summarization
## Bias, Risks, and Limitations
While Llama3-2b is a powerful model, it is important to be aware of its limitations and potential biases.
As with any language model, this model may generate outputs that are factually incorrect or biased.
It is also possible that the model may produce offensive or inappropriate content.
Users and Developers should be aware of these risks and take appropriate measures to mitigate them.
## How to Use
To use Llama3-2b, you can load the model using the Hugging Face Transformers library in Python:
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("andrijdavid/Llama-3-2B-Base/")
model = AutoModelForCausalLM.from_pretrained("andrijdavid/Llama-3-2B-Base/")
```
|
zhengr/MixTAO-7Bx2-MoE-v8.1 | zhengr | 2024-06-25T02:27:44Z | 6,958 | 50 | transformers | [
"transformers",
"safetensors",
"mixtral",
"text-generation",
"moe",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2024-02-26T06:48:33Z | ---
license: apache-2.0
tags:
- moe
model-index:
- name: MixTAO-7Bx2-MoE-v8.1
results:
- task:
type: text-generation
name: Text Generation
dataset:
name: AI2 Reasoning Challenge (25-Shot)
type: ai2_arc
config: ARC-Challenge
split: test
args:
num_few_shot: 25
metrics:
- type: acc_norm
value: 73.81
name: normalized accuracy
source:
url: >-
https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=zhengr/MixTAO-7Bx2-MoE-v8.1
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: HellaSwag (10-Shot)
type: hellaswag
split: validation
args:
num_few_shot: 10
metrics:
- type: acc_norm
value: 89.22
name: normalized accuracy
source:
url: >-
https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=zhengr/MixTAO-7Bx2-MoE-v8.1
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: MMLU (5-Shot)
type: cais/mmlu
config: all
split: test
args:
num_few_shot: 5
metrics:
- type: acc
value: 64.92
name: accuracy
source:
url: >-
https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=zhengr/MixTAO-7Bx2-MoE-v8.1
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: TruthfulQA (0-shot)
type: truthful_qa
config: multiple_choice
split: validation
args:
num_few_shot: 0
metrics:
- type: mc2
value: 78.57
source:
url: >-
https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=zhengr/MixTAO-7Bx2-MoE-v8.1
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: Winogrande (5-shot)
type: winogrande
config: winogrande_xl
split: validation
args:
num_few_shot: 5
metrics:
- type: acc
value: 87.37
name: accuracy
source:
url: >-
https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=zhengr/MixTAO-7Bx2-MoE-v8.1
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: GSM8k (5-shot)
type: gsm8k
config: main
split: test
args:
num_few_shot: 5
metrics:
- type: acc
value: 71.11
name: accuracy
source:
url: >-
https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=zhengr/MixTAO-7Bx2-MoE-v8.1
name: Open LLM Leaderboard
---
# MixTAO-7Bx2-MoE
MixTAO-7Bx2-MoE is a Mixture of Experts (MoE).
This model is mainly used for large model technology experiments, and increasingly perfect iterations will eventually create high-level large language models.
### Prompt Template (Alpaca)
```
### Instruction:
<prompt> (without the <>)
### Response:
```
### 🦒 Colab
| Link | Info - Model Name |
| --- | --- |
|[](https://colab.research.google.com/drive/1y2XmAGrQvVfbgtimTsCBO3tem735q7HZ?usp=sharing) | MixTAO-7Bx2-MoE-v8.1 |
|[mixtao-7bx2-moe-v8.1.Q4_K_M.gguf](https://huggingface.co/zhengr/MixTAO-7Bx2-MoE-v8.1-GGUF/resolve/main/mixtao-7bx2-moe-v8.1.Q4_K_M.gguf) | GGUF of MixTAO-7Bx2-MoE-v8.1 <br> Only Q4_K_M in https://huggingface.co/zhengr/MixTAO-7Bx2-MoE-v8.1-GGUF |
| Demo Space | https://huggingface.co/spaces/zhengr/MixTAO-7Bx2-MoE-v8.1/ |
# [Open LLM Leaderboard Evaluation Results](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)
Detailed results can be found [here](https://huggingface.co/datasets/open-llm-leaderboard/details_zhengr__MixTAO-7Bx2-MoE-v8.1)
| Metric |Value|
|---------------------------------|----:|
|Avg. |77.50|
|AI2 Reasoning Challenge (25-Shot)|73.81|
|HellaSwag (10-Shot) |89.22|
|MMLU (5-Shot) |64.92|
|TruthfulQA (0-shot) |78.57|
|Winogrande (5-shot) |87.37|
|GSM8k (5-shot) |71.11| |
nisten/phi3-medium-4k-gguf | nisten | 2024-05-21T19:45:43Z | 6,957 | 8 | null | [
"gguf",
"base_model:microsoft/Phi-3-medium-4k-instruct",
"license:mit",
"region:us"
] | null | 2024-05-21T19:29:52Z | ---
license: mit
base_model: microsoft/Phi-3-medium-4k-instruct
---
GGUF and imatrix files of https://huggingface.co/microsoft/Phi-3-medium-4k-instruct
### Chat Format
```markdown
<|user|>\nQuestion <|end|>\n<|assistant|>
```
For example:
```markdown
<|user|>
How to explain Internet for a medieval knight?<|end|>
<|assistant|>
```
More uploading and perplexity benchmarks to be posted soon.
Cheers, Nisten |
MoritzLaurer/bge-m3-zeroshot-v2.0 | MoritzLaurer | 2024-04-22T11:09:02Z | 6,955 | 25 | transformers | [
"transformers",
"onnx",
"safetensors",
"xlm-roberta",
"text-classification",
"zero-shot-classification",
"multilingual",
"arxiv:2312.17543",
"base_model:BAAI/bge-m3-retromae",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | zero-shot-classification | 2024-04-02T09:31:59Z | ---
language:
- multilingual
tags:
- text-classification
- zero-shot-classification
base_model: BAAI/bge-m3-retromae
pipeline_tag: zero-shot-classification
library_name: transformers
license: mit
---
# Model description: bge-m3-zeroshot-v2.0
## zeroshot-v2.0 series of models
Models in this series are designed for efficient zeroshot classification with the Hugging Face pipeline.
These models can do classification without training data and run on both GPUs and CPUs.
An overview of the latest zeroshot classifiers is available in my [Zeroshot Classifier Collection](https://huggingface.co/collections/MoritzLaurer/zeroshot-classifiers-6548b4ff407bb19ff5c3ad6f).
The main update of this `zeroshot-v2.0` series of models is that several models are trained on fully commercially-friendly data for users with strict license requirements.
These models can do one universal classification task: determine whether a hypothesis is "true" or "not true" given a text
(`entailment` vs. `not_entailment`).
This task format is based on the Natural Language Inference task (NLI).
The task is so universal that any classification task can be reformulated into this task by the Hugging Face pipeline.
## Training data
Models with a "`-c`" in the name are trained on two types of fully commercially-friendly data:
1. Synthetic data generated with [Mixtral-8x7B-Instruct-v0.1](https://huggingface.co/mistralai/Mixtral-8x7B-Instruct-v0.1).
I first created a list of 500+ diverse text classification tasks for 25 professions in conversations with Mistral-large. The data was manually curated.
I then used this as seed data to generate several hundred thousand texts for these tasks with Mixtral-8x7B-Instruct-v0.1.
The final dataset used is available in the [synthetic_zeroshot_mixtral_v0.1](https://huggingface.co/datasets/MoritzLaurer/synthetic_zeroshot_mixtral_v0.1) dataset
in the subset `mixtral_written_text_for_tasks_v4`. Data curation was done in multiple iterations and will be improved in future iterations.
2. Two commercially-friendly NLI datasets: ([MNLI](https://huggingface.co/datasets/nyu-mll/multi_nli), [FEVER-NLI](https://huggingface.co/datasets/fever)).
These datasets were added to increase generalization.
3. Models without a "`-c`" in the name also included a broader mix of training data with a broader mix of licenses: ANLI, WANLI, LingNLI,
and all datasets in [this list](https://github.com/MoritzLaurer/zeroshot-classifier/blob/7f82e4ab88d7aa82a4776f161b368cc9fa778001/v1_human_data/datasets_overview.csv)
where `used_in_v1.1==True`.
## How to use the models
```python
#!pip install transformers[sentencepiece]
from transformers import pipeline
text = "Angela Merkel is a politician in Germany and leader of the CDU"
hypothesis_template = "This text is about {}"
classes_verbalized = ["politics", "economy", "entertainment", "environment"]
zeroshot_classifier = pipeline("zero-shot-classification", model="MoritzLaurer/deberta-v3-large-zeroshot-v2.0") # change the model identifier here
output = zeroshot_classifier(text, classes_verbalized, hypothesis_template=hypothesis_template, multi_label=False)
print(output)
```
`multi_label=False` forces the model to decide on only one class. `multi_label=True` enables the model to choose multiple classes.
## Metrics
The models were evaluated on 28 different text classification tasks with the [f1_macro](https://scikit-learn.org/stable/modules/generated/sklearn.metrics.f1_score.html) metric.
The main reference point is `facebook/bart-large-mnli` which is, at the time of writing (03.04.24), the most used commercially-friendly 0-shot classifier.
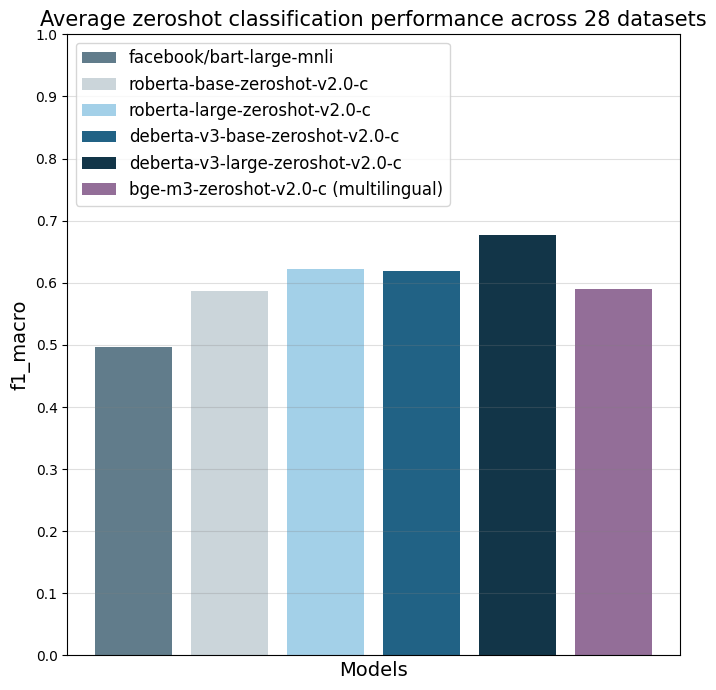
| | facebook/bart-large-mnli | roberta-base-zeroshot-v2.0-c | roberta-large-zeroshot-v2.0-c | deberta-v3-base-zeroshot-v2.0-c | deberta-v3-base-zeroshot-v2.0 (fewshot) | deberta-v3-large-zeroshot-v2.0-c | deberta-v3-large-zeroshot-v2.0 (fewshot) | bge-m3-zeroshot-v2.0-c | bge-m3-zeroshot-v2.0 (fewshot) |
|:---------------------------|---------------------------:|-----------------------------:|------------------------------:|--------------------------------:|-----------------------------------:|---------------------------------:|------------------------------------:|-----------------------:|--------------------------:|
| all datasets mean | 0.497 | 0.587 | 0.622 | 0.619 | 0.643 (0.834) | 0.676 | 0.673 (0.846) | 0.59 | (0.803) |
| amazonpolarity (2) | 0.937 | 0.924 | 0.951 | 0.937 | 0.943 (0.961) | 0.952 | 0.956 (0.968) | 0.942 | (0.951) |
| imdb (2) | 0.892 | 0.871 | 0.904 | 0.893 | 0.899 (0.936) | 0.923 | 0.918 (0.958) | 0.873 | (0.917) |
| appreviews (2) | 0.934 | 0.913 | 0.937 | 0.938 | 0.945 (0.948) | 0.943 | 0.949 (0.962) | 0.932 | (0.954) |
| yelpreviews (2) | 0.948 | 0.953 | 0.977 | 0.979 | 0.975 (0.989) | 0.988 | 0.985 (0.994) | 0.973 | (0.978) |
| rottentomatoes (2) | 0.83 | 0.802 | 0.841 | 0.84 | 0.86 (0.902) | 0.869 | 0.868 (0.908) | 0.813 | (0.866) |
| emotiondair (6) | 0.455 | 0.482 | 0.486 | 0.459 | 0.495 (0.748) | 0.499 | 0.484 (0.688) | 0.453 | (0.697) |
| emocontext (4) | 0.497 | 0.555 | 0.63 | 0.59 | 0.592 (0.799) | 0.699 | 0.676 (0.81) | 0.61 | (0.798) |
| empathetic (32) | 0.371 | 0.374 | 0.404 | 0.378 | 0.405 (0.53) | 0.447 | 0.478 (0.555) | 0.387 | (0.455) |
| financialphrasebank (3) | 0.465 | 0.562 | 0.455 | 0.714 | 0.669 (0.906) | 0.691 | 0.582 (0.913) | 0.504 | (0.895) |
| banking77 (72) | 0.312 | 0.124 | 0.29 | 0.421 | 0.446 (0.751) | 0.513 | 0.567 (0.766) | 0.387 | (0.715) |
| massive (59) | 0.43 | 0.428 | 0.543 | 0.512 | 0.52 (0.755) | 0.526 | 0.518 (0.789) | 0.414 | (0.692) |
| wikitoxic_toxicaggreg (2) | 0.547 | 0.751 | 0.766 | 0.751 | 0.769 (0.904) | 0.741 | 0.787 (0.911) | 0.736 | (0.9) |
| wikitoxic_obscene (2) | 0.713 | 0.817 | 0.854 | 0.853 | 0.869 (0.922) | 0.883 | 0.893 (0.933) | 0.783 | (0.914) |
| wikitoxic_threat (2) | 0.295 | 0.71 | 0.817 | 0.813 | 0.87 (0.946) | 0.827 | 0.879 (0.952) | 0.68 | (0.947) |
| wikitoxic_insult (2) | 0.372 | 0.724 | 0.798 | 0.759 | 0.811 (0.912) | 0.77 | 0.779 (0.924) | 0.783 | (0.915) |
| wikitoxic_identityhate (2) | 0.473 | 0.774 | 0.798 | 0.774 | 0.765 (0.938) | 0.797 | 0.806 (0.948) | 0.761 | (0.931) |
| hateoffensive (3) | 0.161 | 0.352 | 0.29 | 0.315 | 0.371 (0.862) | 0.47 | 0.461 (0.847) | 0.291 | (0.823) |
| hatexplain (3) | 0.239 | 0.396 | 0.314 | 0.376 | 0.369 (0.765) | 0.378 | 0.389 (0.764) | 0.29 | (0.729) |
| biasframes_offensive (2) | 0.336 | 0.571 | 0.583 | 0.544 | 0.601 (0.867) | 0.644 | 0.656 (0.883) | 0.541 | (0.855) |
| biasframes_sex (2) | 0.263 | 0.617 | 0.835 | 0.741 | 0.809 (0.922) | 0.846 | 0.815 (0.946) | 0.748 | (0.905) |
| biasframes_intent (2) | 0.616 | 0.531 | 0.635 | 0.554 | 0.61 (0.881) | 0.696 | 0.687 (0.891) | 0.467 | (0.868) |
| agnews (4) | 0.703 | 0.758 | 0.745 | 0.68 | 0.742 (0.898) | 0.819 | 0.771 (0.898) | 0.687 | (0.892) |
| yahootopics (10) | 0.299 | 0.543 | 0.62 | 0.578 | 0.564 (0.722) | 0.621 | 0.613 (0.738) | 0.587 | (0.711) |
| trueteacher (2) | 0.491 | 0.469 | 0.402 | 0.431 | 0.479 (0.82) | 0.459 | 0.538 (0.846) | 0.471 | (0.518) |
| spam (2) | 0.505 | 0.528 | 0.504 | 0.507 | 0.464 (0.973) | 0.74 | 0.597 (0.983) | 0.441 | (0.978) |
| wellformedquery (2) | 0.407 | 0.333 | 0.333 | 0.335 | 0.491 (0.769) | 0.334 | 0.429 (0.815) | 0.361 | (0.718) |
| manifesto (56) | 0.084 | 0.102 | 0.182 | 0.17 | 0.187 (0.376) | 0.258 | 0.256 (0.408) | 0.147 | (0.331) |
| capsotu (21) | 0.34 | 0.479 | 0.523 | 0.502 | 0.477 (0.664) | 0.603 | 0.502 (0.686) | 0.472 | (0.644) |
These numbers indicate zeroshot performance, as no data from these datasets was added in the training mix.
Note that models without a "`-c`" in the title were evaluated twice: one run without any data from these 28 datasets to test pure zeroshot performance (the first number in the respective column) and
the final run including up to 500 training data points per class from each of the 28 datasets (the second number in brackets in the column, "fewshot"). No model was trained on test data.
Details on the different datasets are available here: https://github.com/MoritzLaurer/zeroshot-classifier/blob/main/v1_human_data/datasets_overview.csv
## When to use which model
- **deberta-v3-zeroshot vs. roberta-zeroshot**: deberta-v3 performs clearly better than roberta, but it is a bit slower.
roberta is directly compatible with Hugging Face's production inference TEI containers and flash attention.
These containers are a good choice for production use-cases. tl;dr: For accuracy, use a deberta-v3 model.
If production inference speed is a concern, you can consider a roberta model (e.g. in a TEI container and [HF Inference Endpoints](https://ui.endpoints.huggingface.co/catalog)).
- **commercial use-cases**: models with "`-c`" in the title are guaranteed to be trained on only commercially-friendly data.
Models without a "`-c`" were trained on more data and perform better, but include data with non-commercial licenses.
Legal opinions diverge if this training data affects the license of the trained model. For users with strict legal requirements,
the models with "`-c`" in the title are recommended.
- **Multilingual/non-English use-cases**: use [bge-m3-zeroshot-v2.0](https://huggingface.co/MoritzLaurer/bge-m3-zeroshot-v2.0) or [bge-m3-zeroshot-v2.0-c](https://huggingface.co/MoritzLaurer/bge-m3-zeroshot-v2.0-c).
Note that multilingual models perform worse than English-only models. You can therefore also first machine translate your texts to English with libraries like [EasyNMT](https://github.com/UKPLab/EasyNMT)
and then apply any English-only model to the translated data. Machine translation also facilitates validation in case your team does not speak all languages in the data.
- **context window**: The `bge-m3` models can process up to 8192 tokens. The other models can process up to 512. Note that longer text inputs both make the
mode slower and decrease performance, so if you're only working with texts of up to 400~ words / 1 page, use e.g. a deberta model for better performance.
- The latest updates on new models are always available in the [Zeroshot Classifier Collection](https://huggingface.co/collections/MoritzLaurer/zeroshot-classifiers-6548b4ff407bb19ff5c3ad6f).
## Reproduction
Reproduction code is available in the `v2_synthetic_data` directory here: https://github.com/MoritzLaurer/zeroshot-classifier/tree/main
## Limitations and bias
The model can only do text classification tasks.
Biases can come from the underlying foundation model, the human NLI training data and the synthetic data generated by Mixtral.
## License
The foundation model was published under the MIT license.
The licenses of the training data vary depending on the model, see above.
## Citation
This model is an extension of the research described in this [paper](https://arxiv.org/pdf/2312.17543.pdf).
If you use this model academically, please cite:
```
@misc{laurer_building_2023,
title = {Building {Efficient} {Universal} {Classifiers} with {Natural} {Language} {Inference}},
url = {http://arxiv.org/abs/2312.17543},
doi = {10.48550/arXiv.2312.17543},
abstract = {Generative Large Language Models (LLMs) have become the mainstream choice for fewshot and zeroshot learning thanks to the universality of text generation. Many users, however, do not need the broad capabilities of generative LLMs when they only want to automate a classification task. Smaller BERT-like models can also learn universal tasks, which allow them to do any text classification task without requiring fine-tuning (zeroshot classification) or to learn new tasks with only a few examples (fewshot), while being significantly more efficient than generative LLMs. This paper (1) explains how Natural Language Inference (NLI) can be used as a universal classification task that follows similar principles as instruction fine-tuning of generative LLMs, (2) provides a step-by-step guide with reusable Jupyter notebooks for building a universal classifier, and (3) shares the resulting universal classifier that is trained on 33 datasets with 389 diverse classes. Parts of the code we share has been used to train our older zeroshot classifiers that have been downloaded more than 55 million times via the Hugging Face Hub as of December 2023. Our new classifier improves zeroshot performance by 9.4\%.},
urldate = {2024-01-05},
publisher = {arXiv},
author = {Laurer, Moritz and van Atteveldt, Wouter and Casas, Andreu and Welbers, Kasper},
month = dec,
year = {2023},
note = {arXiv:2312.17543 [cs]},
keywords = {Computer Science - Artificial Intelligence, Computer Science - Computation and Language},
}
```
### Ideas for cooperation or questions?
If you have questions or ideas for cooperation, contact me at moritz{at}huggingface{dot}co or [LinkedIn](https://www.linkedin.com/in/moritz-laurer/)
### Flexible usage and "prompting"
You can formulate your own hypotheses by changing the `hypothesis_template` of the zeroshot pipeline.
Similar to "prompt engineering" for LLMs, you can test different formulations of your `hypothesis_template` and verbalized classes to improve performance.
```python
from transformers import pipeline
text = "Angela Merkel is a politician in Germany and leader of the CDU"
# formulation 1
hypothesis_template = "This text is about {}"
classes_verbalized = ["politics", "economy", "entertainment", "environment"]
# formulation 2 depending on your use-case
hypothesis_template = "The topic of this text is {}"
classes_verbalized = ["political activities", "economic policy", "entertainment or music", "environmental protection"]
# test different formulations
zeroshot_classifier = pipeline("zero-shot-classification", model="MoritzLaurer/deberta-v3-large-zeroshot-v2.0") # change the model identifier here
output = zeroshot_classifier(text, classes_verbalized, hypothesis_template=hypothesis_template, multi_label=False)
print(output)
``` |
almanach/camembert-large | almanach | 2024-04-01T21:19:53Z | 6,954 | 15 | transformers | [
"transformers",
"pytorch",
"safetensors",
"camembert",
"fr",
"arxiv:1911.03894",
"endpoints_compatible",
"region:us"
] | null | 2022-03-02T23:29:05Z | ---
language: fr
---
# CamemBERT: a Tasty French Language Model
## Introduction
[CamemBERT](https://arxiv.org/abs/1911.03894) is a state-of-the-art language model for French based on the RoBERTa model.
It is now available on Hugging Face in 6 different versions with varying number of parameters, amount of pretraining data and pretraining data source domains.
For further information or requests, please go to [Camembert Website](https://camembert-model.fr/)
## Pre-trained models
| Model | #params | Arch. | Training data |
|--------------------------------|--------------------------------|-------|-----------------------------------|
| `camembert-base` | 110M | Base | OSCAR (138 GB of text) |
| `camembert/camembert-large` | 335M | Large | CCNet (135 GB of text) |
| `camembert/camembert-base-ccnet` | 110M | Base | CCNet (135 GB of text) |
| `camembert/camembert-base-wikipedia-4gb` | 110M | Base | Wikipedia (4 GB of text) |
| `camembert/camembert-base-oscar-4gb` | 110M | Base | Subsample of OSCAR (4 GB of text) |
| `camembert/camembert-base-ccnet-4gb` | 110M | Base | Subsample of CCNet (4 GB of text) |
## How to use CamemBERT with HuggingFace
##### Load CamemBERT and its sub-word tokenizer :
```python
from transformers import CamembertModel, CamembertTokenizer
# You can replace "camembert-base" with any other model from the table, e.g. "camembert/camembert-large".
tokenizer = CamembertTokenizer.from_pretrained("camembert/camembert-large")
camembert = CamembertModel.from_pretrained("camembert/camembert-large")
camembert.eval() # disable dropout (or leave in train mode to finetune)
```
##### Filling masks using pipeline
```python
from transformers import pipeline
camembert_fill_mask = pipeline("fill-mask", model="camembert/camembert-large", tokenizer="camembert/camembert-large")
results = camembert_fill_mask("Le camembert est <mask> :)")
# results
#[{'sequence': '<s> Le camembert est bon :)</s>', 'score': 0.15560828149318695, 'token': 305},
#{'sequence': '<s> Le camembert est excellent :)</s>', 'score': 0.06821336597204208, 'token': 3497},
#{'sequence': '<s> Le camembert est délicieux :)</s>', 'score': 0.060438305139541626, 'token': 11661},
#{'sequence': '<s> Le camembert est ici :)</s>', 'score': 0.02023460529744625, 'token': 373},
#{'sequence': '<s> Le camembert est meilleur :)</s>', 'score': 0.01778135634958744, 'token': 876}]
```
##### Extract contextual embedding features from Camembert output
```python
import torch
# Tokenize in sub-words with SentencePiece
tokenized_sentence = tokenizer.tokenize("J'aime le camembert !")
# ['▁J', "'", 'aime', '▁le', '▁cam', 'ember', 't', '▁!']
# 1-hot encode and add special starting and end tokens
encoded_sentence = tokenizer.encode(tokenized_sentence)
# [5, 133, 22, 1250, 16, 12034, 14324, 81, 76, 6]
# NB: Can be done in one step : tokenize.encode("J'aime le camembert !")
# Feed tokens to Camembert as a torch tensor (batch dim 1)
encoded_sentence = torch.tensor(encoded_sentence).unsqueeze(0)
embeddings, _ = camembert(encoded_sentence)
# embeddings.detach()
# torch.Size([1, 10, 1024])
#tensor([[[-0.1284, 0.2643, 0.4374, ..., 0.1627, 0.1308, -0.2305],
# [ 0.4576, -0.6345, -0.2029, ..., -0.1359, -0.2290, -0.6318],
# [ 0.0381, 0.0429, 0.5111, ..., -0.1177, -0.1913, -0.1121],
# ...,
```
##### Extract contextual embedding features from all Camembert layers
```python
from transformers import CamembertConfig
# (Need to reload the model with new config)
config = CamembertConfig.from_pretrained("camembert/camembert-large", output_hidden_states=True)
camembert = CamembertModel.from_pretrained("camembert/camembert-large", config=config)
embeddings, _, all_layer_embeddings = camembert(encoded_sentence)
# all_layer_embeddings list of len(all_layer_embeddings) == 25 (input embedding layer + 24 self attention layers)
all_layer_embeddings[5]
# layer 5 contextual embedding : size torch.Size([1, 10, 1024])
#tensor([[[-0.0600, 0.0742, 0.0332, ..., -0.0525, -0.0637, -0.0287],
# [ 0.0950, 0.2840, 0.1985, ..., 0.2073, -0.2172, -0.6321],
# [ 0.1381, 0.1872, 0.1614, ..., -0.0339, -0.2530, -0.1182],
# ...,
```
## Authors
CamemBERT was trained and evaluated by Louis Martin\*, Benjamin Muller\*, Pedro Javier Ortiz Suárez\*, Yoann Dupont, Laurent Romary, Éric Villemonte de la Clergerie, Djamé Seddah and Benoît Sagot.
## Citation
If you use our work, please cite:
```bibtex
@inproceedings{martin2020camembert,
title={CamemBERT: a Tasty French Language Model},
author={Martin, Louis and Muller, Benjamin and Su{\'a}rez, Pedro Javier Ortiz and Dupont, Yoann and Romary, Laurent and de la Clergerie, {\'E}ric Villemonte and Seddah, Djam{\'e} and Sagot, Beno{\^\i}t},
booktitle={Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics},
year={2020}
}
```
|
lllyasviel/sd-controlnet-scribble | lllyasviel | 2023-04-24T22:30:29Z | 6,951 | 49 | diffusers | [
"diffusers",
"safetensors",
"art",
"controlnet",
"stable-diffusion",
"image-to-image",
"arxiv:2302.05543",
"base_model:runwayml/stable-diffusion-v1-5",
"license:openrail",
"region:us"
] | image-to-image | 2023-02-24T07:11:28Z | ---
license: openrail
base_model: runwayml/stable-diffusion-v1-5
tags:
- art
- controlnet
- stable-diffusion
- image-to-image
---
# Controlnet - *Scribble Version*
ControlNet is a neural network structure to control diffusion models by adding extra conditions.
This checkpoint corresponds to the ControlNet conditioned on **Scribble images**.
It can be used in combination with [Stable Diffusion](https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion/text2img).

## Model Details
- **Developed by:** Lvmin Zhang, Maneesh Agrawala
- **Model type:** Diffusion-based text-to-image generation model
- **Language(s):** English
- **License:** [The CreativeML OpenRAIL M license](https://huggingface.co/spaces/CompVis/stable-diffusion-license) is an [Open RAIL M license](https://www.licenses.ai/blog/2022/8/18/naming-convention-of-responsible-ai-licenses), adapted from the work that [BigScience](https://bigscience.huggingface.co/) and [the RAIL Initiative](https://www.licenses.ai/) are jointly carrying in the area of responsible AI licensing. See also [the article about the BLOOM Open RAIL license](https://bigscience.huggingface.co/blog/the-bigscience-rail-license) on which our license is based.
- **Resources for more information:** [GitHub Repository](https://github.com/lllyasviel/ControlNet), [Paper](https://arxiv.org/abs/2302.05543).
- **Cite as:**
@misc{zhang2023adding,
title={Adding Conditional Control to Text-to-Image Diffusion Models},
author={Lvmin Zhang and Maneesh Agrawala},
year={2023},
eprint={2302.05543},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
## Introduction
Controlnet was proposed in [*Adding Conditional Control to Text-to-Image Diffusion Models*](https://arxiv.org/abs/2302.05543) by
Lvmin Zhang, Maneesh Agrawala.
The abstract reads as follows:
*We present a neural network structure, ControlNet, to control pretrained large diffusion models to support additional input conditions.
The ControlNet learns task-specific conditions in an end-to-end way, and the learning is robust even when the training dataset is small (< 50k).
Moreover, training a ControlNet is as fast as fine-tuning a diffusion model, and the model can be trained on a personal devices.
Alternatively, if powerful computation clusters are available, the model can scale to large amounts (millions to billions) of data.
We report that large diffusion models like Stable Diffusion can be augmented with ControlNets to enable conditional inputs like edge maps, segmentation maps, keypoints, etc.
This may enrich the methods to control large diffusion models and further facilitate related applications.*
## Released Checkpoints
The authors released 8 different checkpoints, each trained with [Stable Diffusion v1-5](https://huggingface.co/runwayml/stable-diffusion-v1-5)
on a different type of conditioning:
| Model Name | Control Image Overview| Control Image Example | Generated Image Example |
|---|---|---|---|
|[lllyasviel/sd-controlnet-canny](https://huggingface.co/lllyasviel/sd-controlnet-canny)<br/> *Trained with canny edge detection* | A monochrome image with white edges on a black background.|<a href="https://huggingface.co/takuma104/controlnet_dev/blob/main/gen_compare/control_images/converted/control_bird_canny.png"><img width="64" style="margin:0;padding:0;" src="https://huggingface.co/takuma104/controlnet_dev/resolve/main/gen_compare/control_images/converted/control_bird_canny.png"/></a>|<a href="https://huggingface.co/takuma104/controlnet_dev/resolve/main/gen_compare/output_images/diffusers/output_bird_canny_1.png"><img width="64" src="https://huggingface.co/takuma104/controlnet_dev/resolve/main/gen_compare/output_images/diffusers/output_bird_canny_1.png"/></a>|
|[lllyasviel/sd-controlnet-depth](https://huggingface.co/lllyasviel/sd-controlnet-depth)<br/> *Trained with Midas depth estimation* |A grayscale image with black representing deep areas and white representing shallow areas.|<a href="https://huggingface.co/takuma104/controlnet_dev/blob/main/gen_compare/control_images/converted/control_vermeer_depth.png"><img width="64" src="https://huggingface.co/takuma104/controlnet_dev/resolve/main/gen_compare/control_images/converted/control_vermeer_depth.png"/></a>|<a href="https://huggingface.co/takuma104/controlnet_dev/resolve/main/gen_compare/output_images/diffusers/output_vermeer_depth_2.png"><img width="64" src="https://huggingface.co/takuma104/controlnet_dev/resolve/main/gen_compare/output_images/diffusers/output_vermeer_depth_2.png"/></a>|
|[lllyasviel/sd-controlnet-hed](https://huggingface.co/lllyasviel/sd-controlnet-hed)<br/> *Trained with HED edge detection (soft edge)* |A monochrome image with white soft edges on a black background.|<a href="https://huggingface.co/takuma104/controlnet_dev/blob/main/gen_compare/control_images/converted/control_bird_hed.png"><img width="64" src="https://huggingface.co/takuma104/controlnet_dev/resolve/main/gen_compare/control_images/converted/control_bird_hed.png"/></a>|<a href="https://huggingface.co/takuma104/controlnet_dev/resolve/main/gen_compare/output_images/diffusers/output_bird_hed_1.png"><img width="64" src="https://huggingface.co/takuma104/controlnet_dev/resolve/main/gen_compare/output_images/diffusers/output_bird_hed_1.png"/></a> |
|[lllyasviel/sd-controlnet-mlsd](https://huggingface.co/lllyasviel/sd-controlnet-mlsd)<br/> *Trained with M-LSD line detection* |A monochrome image composed only of white straight lines on a black background.|<a href="https://huggingface.co/takuma104/controlnet_dev/blob/main/gen_compare/control_images/converted/control_room_mlsd.png"><img width="64" src="https://huggingface.co/takuma104/controlnet_dev/resolve/main/gen_compare/control_images/converted/control_room_mlsd.png"/></a>|<a href="https://huggingface.co/takuma104/controlnet_dev/resolve/main/gen_compare/output_images/diffusers/output_room_mlsd_0.png"><img width="64" src="https://huggingface.co/takuma104/controlnet_dev/resolve/main/gen_compare/output_images/diffusers/output_room_mlsd_0.png"/></a>|
|[lllyasviel/sd-controlnet-normal](https://huggingface.co/lllyasviel/sd-controlnet-normal)<br/> *Trained with normal map* |A [normal mapped](https://en.wikipedia.org/wiki/Normal_mapping) image.|<a href="https://huggingface.co/takuma104/controlnet_dev/blob/main/gen_compare/control_images/converted/control_human_normal.png"><img width="64" src="https://huggingface.co/takuma104/controlnet_dev/resolve/main/gen_compare/control_images/converted/control_human_normal.png"/></a>|<a href="https://huggingface.co/takuma104/controlnet_dev/resolve/main/gen_compare/output_images/diffusers/output_human_normal_1.png"><img width="64" src="https://huggingface.co/takuma104/controlnet_dev/resolve/main/gen_compare/output_images/diffusers/output_human_normal_1.png"/></a>|
|[lllyasviel/sd-controlnet_openpose](https://huggingface.co/lllyasviel/sd-controlnet-openpose)<br/> *Trained with OpenPose bone image* |A [OpenPose bone](https://github.com/CMU-Perceptual-Computing-Lab/openpose) image.|<a href="https://huggingface.co/takuma104/controlnet_dev/blob/main/gen_compare/control_images/converted/control_human_openpose.png"><img width="64" src="https://huggingface.co/takuma104/controlnet_dev/resolve/main/gen_compare/control_images/converted/control_human_openpose.png"/></a>|<a href="https://huggingface.co/takuma104/controlnet_dev/resolve/main/gen_compare/output_images/diffusers/output_human_openpose_0.png"><img width="64" src="https://huggingface.co/takuma104/controlnet_dev/resolve/main/gen_compare/output_images/diffusers/output_human_openpose_0.png"/></a>|
|[lllyasviel/sd-controlnet_scribble](https://huggingface.co/lllyasviel/sd-controlnet-scribble)<br/> *Trained with human scribbles* |A hand-drawn monochrome image with white outlines on a black background.|<a href="https://huggingface.co/takuma104/controlnet_dev/blob/main/gen_compare/control_images/converted/control_vermeer_scribble.png"><img width="64" src="https://huggingface.co/takuma104/controlnet_dev/resolve/main/gen_compare/control_images/converted/control_vermeer_scribble.png"/></a>|<a href="https://huggingface.co/takuma104/controlnet_dev/resolve/main/gen_compare/output_images/diffusers/output_vermeer_scribble_0.png"><img width="64" src="https://huggingface.co/takuma104/controlnet_dev/resolve/main/gen_compare/output_images/diffusers/output_vermeer_scribble_0.png"/></a> |
|[lllyasviel/sd-controlnet_seg](https://huggingface.co/lllyasviel/sd-controlnet-seg)<br/>*Trained with semantic segmentation* |An [ADE20K](https://groups.csail.mit.edu/vision/datasets/ADE20K/)'s segmentation protocol image.|<a href="https://huggingface.co/takuma104/controlnet_dev/blob/main/gen_compare/control_images/converted/control_room_seg.png"><img width="64" src="https://huggingface.co/takuma104/controlnet_dev/resolve/main/gen_compare/control_images/converted/control_room_seg.png"/></a>|<a href="https://huggingface.co/takuma104/controlnet_dev/resolve/main/gen_compare/output_images/diffusers/output_room_seg_1.png"><img width="64" src="https://huggingface.co/takuma104/controlnet_dev/resolve/main/gen_compare/output_images/diffusers/output_room_seg_1.png"/></a> |
## Example
It is recommended to use the checkpoint with [Stable Diffusion v1-5](https://huggingface.co/runwayml/stable-diffusion-v1-5) as the checkpoint
has been trained on it.
Experimentally, the checkpoint can be used with other diffusion models such as dreamboothed stable diffusion.
**Note**: If you want to process an image to create the auxiliary conditioning, external dependencies are required as shown below:
1. Install https://github.com/patrickvonplaten/controlnet_aux
```sh
$ pip install controlnet_aux
```
2. Let's install `diffusers` and related packages:
```
$ pip install diffusers transformers accelerate
```
3. Run code:
```py
from PIL import Image
from diffusers import StableDiffusionControlNetPipeline, ControlNetModel, UniPCMultistepScheduler
import torch
from controlnet_aux import HEDdetector
from diffusers.utils import load_image
hed = HEDdetector.from_pretrained('lllyasviel/ControlNet')
image = load_image("https://huggingface.co/lllyasviel/sd-controlnet-scribble/resolve/main/images/bag.png")
image = hed(image, scribble=True)
controlnet = ControlNetModel.from_pretrained(
"lllyasviel/sd-controlnet-scribble", torch_dtype=torch.float16
)
pipe = StableDiffusionControlNetPipeline.from_pretrained(
"runwayml/stable-diffusion-v1-5", controlnet=controlnet, safety_checker=None, torch_dtype=torch.float16
)
pipe.scheduler = UniPCMultistepScheduler.from_config(pipe.scheduler.config)
# Remove if you do not have xformers installed
# see https://huggingface.co/docs/diffusers/v0.13.0/en/optimization/xformers#installing-xformers
# for installation instructions
pipe.enable_xformers_memory_efficient_attention()
pipe.enable_model_cpu_offload()
image = pipe("bag", image, num_inference_steps=20).images[0]
image.save('images/bag_scribble_out.png')
```



### Training
The scribble model was trained on 500k scribble-image, caption pairs. The scribble images were generated with HED boundary detection and a set of data augmentations — thresholds, masking, morphological transformations, and non-maximum suppression. The model was trained for 150 GPU-hours with Nvidia A100 80G using the canny model as a base model.
### Blog post
For more information, please also have a look at the [official ControlNet Blog Post](https://huggingface.co/blog/controlnet). |
ZB-Tech/Text-to-Image | ZB-Tech | 2024-05-06T01:04:00Z | 6,951 | 11 | diffusers | [
"diffusers",
"tensorboard",
"safetensors",
"text-to-image",
"diffusers-training",
"lora",
"template:sd-lora",
"stable-diffusion-xl",
"stable-diffusion-xl-diffusers",
"en",
"dataset:ZB-Tech/DreamXL",
"base_model:stabilityai/stable-diffusion-xl-base-1.0",
"license:openrail++",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | 2024-03-10T01:45:24Z | ---
license: openrail++
library_name: diffusers
tags:
- text-to-image
- diffusers-training
- diffusers
- lora
- template:sd-lora
- stable-diffusion-xl
- stable-diffusion-xl-diffusers
base_model: stabilityai/stable-diffusion-xl-base-1.0
instance_prompt: a photo of TOK dog
widget: []
datasets:
- ZB-Tech/DreamXL
language:
- en
---
<!-- This model card has been generated automatically according to the information the training script had access to. You
should probably proofread and complete it, then remove this comment. -->
# SDXL LoRA Fine-tuning - ZB-Tech/Text-To-Image
<Gallery />
## Model description
These are ZB-Tech/Text-to-Image LoRA adaption weights for stabilityai/stable-diffusion-xl-base-1.0.
LoRA for the text encoder was enabled: False.
Special VAE used for training: madebyollin/sdxl-vae-fp16-fix.
##### How to use
```python
import requests
API_URL = "https://api-inference.huggingface.co/models/ZB-Tech/Text-to-Image"
headers = {"Authorization": "Bearer HF_API_KEY"}
def query(payload):
response = requests.post(API_URL, headers=headers, json=payload)
return response.content
image_bytes = query({
"inputs": "Astronaut riding a horse",
})
# You can access the image with PIL.Image for example
import io
from PIL import Image
image = Image.open(io.BytesIO(image_bytes))
```
## Download model
Weights for this model are available in Safetensors format.
[Download](suryasuri/Surya/tree/main) them in the Files & versions tab. |
mzwing/DeepSeek-V2-Lite-Chat-GGUF | mzwing | 2024-05-23T08:03:38Z | 6,949 | 6 | null | [
"gguf",
"region:us"
] | null | 2024-05-22T04:17:34Z | Entry not found |
hustvl/vitmatte-small-distinctions-646 | hustvl | 2024-03-29T08:02:25Z | 6,944 | 0 | transformers | [
"transformers",
"pytorch",
"safetensors",
"vitmatte",
"vision",
"arxiv:2305.15272",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2023-09-10T08:04:46Z | ---
license: apache-2.0
tags:
- vision
---
# ViTMatte model
ViTMatte model trained on Distinctions-646. It was introduced in the paper [ViTMatte: Boosting Image Matting with Pretrained Plain Vision Transformers](https://arxiv.org/abs/2305.15272) by Yao et al. and first released in [this repository](https://github.com/hustvl/ViTMatte).
Disclaimer: The team releasing ViTMatte did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
ViTMatte is a simple approach to image matting, the task of accurately estimating the foreground object in an image. The model consists of a Vision Transformer (ViT) with a lightweight head on top.
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/model_doc/vitmatte_architecture.png"
alt="drawing" width="600"/>
<small> ViTMatte high-level overview. Taken from the <a href="https://arxiv.org/abs/2305.15272">original paper.</a> </small>
## Intended uses & limitations
You can use the raw model for image matting. See the [model hub](https://huggingface.co/models?search=vitmatte) to look for other
fine-tuned versions that may interest you.
### How to use
We refer to the [docs](https://huggingface.co/docs/transformers/main/en/model_doc/vitmatte#transformers.VitMatteForImageMatting.forward.example).
### BibTeX entry and citation info
```bibtex
@misc{yao2023vitmatte,
title={ViTMatte: Boosting Image Matting with Pretrained Plain Vision Transformers},
author={Jingfeng Yao and Xinggang Wang and Shusheng Yang and Baoyuan Wang},
year={2023},
eprint={2305.15272},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
``` |
bakhitovd/led-base-7168-ml | bakhitovd | 2023-05-21T03:51:26Z | 6,933 | 0 | transformers | [
"transformers",
"pytorch",
"led",
"text2text-generation",
"summarization",
"dataset:bakhitovd/data_science_arxiv",
"license:cc0-1.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | summarization | 2023-05-02T02:20:10Z | ---
datasets:
- bakhitovd/data_science_arxiv
metrics:
- rouge
license: cc0-1.0
pipeline_tag: summarization
---
# Fine-tuned Longformer for Summarization of Machine Learning Articles
## Model Details
- GitHub: https://github.com/Bakhitovd/led-base-7168-ml
- Model name: bakhitovd/led-base-7168-ml
- Model type: Longformer (alenai/led-base-16384)
- Model description: This Longformer model has been fine-tuned on a focused subset of the arXiv part of the scientific papers dataset, specifically targeting articles about Machine Learning. It aims to generate accurate and consistent summaries of machine learning research papers.
## Intended Use
This model is intended to be used for text summarization tasks, specifically for summarizing machine learning research papers.
## How to Use
```python
import torch
from transformers import LEDTokenizer, LEDForConditionalGeneration
tokenizer = LEDTokenizer.from_pretrained("bakhitovd/led-base-7168-ml")
model = LEDForConditionalGeneration.from_pretrained("bakhitovd/led-base-7168-ml")
```
## Use the model for summarization
```python
article = "... long document ..."
inputs_dict = tokenizer.encode(article, padding="max_length", max_length=16384, return_tensors="pt", truncation=True)
input_ids = inputs_dict.input_ids.to("cuda")
attention_mask = inputs_dict.attention_mask.to("cuda")
global_attention_mask = torch.zeros_like(attention_mask)
global_attention_mask[:, 0] = 1
predicted_abstract_ids = model.generate(input_ids, attention_mask=attention_mask, global_attention_mask=global_attention_mask, max_length=512)
summary = tokenizer.decode(predicted_abstract_ids, skip_special_tokens=True)
print(summary)
```
## Training Data
Dataset name: bakhitovd/data_science_arxiv\
This dataset is a subset of the 'Scientific papers' dataset, which contains articles semantically, structurally, and meaningfully closest to articles describing machine learning. This subset was obtained using K-means clustering on the embeddings generated by SciBERT.
## Evaluation Results
The model's performance was evaluated using ROUGE metrics and it showed improved performance over the baseline models.
 |
RichardErkhov/FreedomIntelligence_-_Apollo-2B-gguf | RichardErkhov | 2024-06-27T08:03:43Z | 6,929 | 0 | null | [
"gguf",
"arxiv:2403.03640",
"region:us"
] | null | 2024-06-27T07:33:33Z | Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
Apollo-2B - GGUF
- Model creator: https://huggingface.co/FreedomIntelligence/
- Original model: https://huggingface.co/FreedomIntelligence/Apollo-2B/
| Name | Quant method | Size |
| ---- | ---- | ---- |
| [Apollo-2B.Q2_K.gguf](https://huggingface.co/RichardErkhov/FreedomIntelligence_-_Apollo-2B-gguf/blob/main/Apollo-2B.Q2_K.gguf) | Q2_K | 1.08GB |
| [Apollo-2B.IQ3_XS.gguf](https://huggingface.co/RichardErkhov/FreedomIntelligence_-_Apollo-2B-gguf/blob/main/Apollo-2B.IQ3_XS.gguf) | IQ3_XS | 1.16GB |
| [Apollo-2B.IQ3_S.gguf](https://huggingface.co/RichardErkhov/FreedomIntelligence_-_Apollo-2B-gguf/blob/main/Apollo-2B.IQ3_S.gguf) | IQ3_S | 1.2GB |
| [Apollo-2B.Q3_K_S.gguf](https://huggingface.co/RichardErkhov/FreedomIntelligence_-_Apollo-2B-gguf/blob/main/Apollo-2B.Q3_K_S.gguf) | Q3_K_S | 1.2GB |
| [Apollo-2B.IQ3_M.gguf](https://huggingface.co/RichardErkhov/FreedomIntelligence_-_Apollo-2B-gguf/blob/main/Apollo-2B.IQ3_M.gguf) | IQ3_M | 1.22GB |
| [Apollo-2B.Q3_K.gguf](https://huggingface.co/RichardErkhov/FreedomIntelligence_-_Apollo-2B-gguf/blob/main/Apollo-2B.Q3_K.gguf) | Q3_K | 1.29GB |
| [Apollo-2B.Q3_K_M.gguf](https://huggingface.co/RichardErkhov/FreedomIntelligence_-_Apollo-2B-gguf/blob/main/Apollo-2B.Q3_K_M.gguf) | Q3_K_M | 1.29GB |
| [Apollo-2B.Q3_K_L.gguf](https://huggingface.co/RichardErkhov/FreedomIntelligence_-_Apollo-2B-gguf/blob/main/Apollo-2B.Q3_K_L.gguf) | Q3_K_L | 1.36GB |
| [Apollo-2B.IQ4_XS.gguf](https://huggingface.co/RichardErkhov/FreedomIntelligence_-_Apollo-2B-gguf/blob/main/Apollo-2B.IQ4_XS.gguf) | IQ4_XS | 1.4GB |
| [Apollo-2B.Q4_0.gguf](https://huggingface.co/RichardErkhov/FreedomIntelligence_-_Apollo-2B-gguf/blob/main/Apollo-2B.Q4_0.gguf) | Q4_0 | 1.44GB |
| [Apollo-2B.IQ4_NL.gguf](https://huggingface.co/RichardErkhov/FreedomIntelligence_-_Apollo-2B-gguf/blob/main/Apollo-2B.IQ4_NL.gguf) | IQ4_NL | 1.45GB |
| [Apollo-2B.Q4_K_S.gguf](https://huggingface.co/RichardErkhov/FreedomIntelligence_-_Apollo-2B-gguf/blob/main/Apollo-2B.Q4_K_S.gguf) | Q4_K_S | 1.45GB |
| [Apollo-2B.Q4_K.gguf](https://huggingface.co/RichardErkhov/FreedomIntelligence_-_Apollo-2B-gguf/blob/main/Apollo-2B.Q4_K.gguf) | Q4_K | 1.52GB |
| [Apollo-2B.Q4_K_M.gguf](https://huggingface.co/RichardErkhov/FreedomIntelligence_-_Apollo-2B-gguf/blob/main/Apollo-2B.Q4_K_M.gguf) | Q4_K_M | 1.52GB |
| [Apollo-2B.Q4_1.gguf](https://huggingface.co/RichardErkhov/FreedomIntelligence_-_Apollo-2B-gguf/blob/main/Apollo-2B.Q4_1.gguf) | Q4_1 | 1.56GB |
| [Apollo-2B.Q5_0.gguf](https://huggingface.co/RichardErkhov/FreedomIntelligence_-_Apollo-2B-gguf/blob/main/Apollo-2B.Q5_0.gguf) | Q5_0 | 1.68GB |
| [Apollo-2B.Q5_K_S.gguf](https://huggingface.co/RichardErkhov/FreedomIntelligence_-_Apollo-2B-gguf/blob/main/Apollo-2B.Q5_K_S.gguf) | Q5_K_S | 1.68GB |
| [Apollo-2B.Q5_K.gguf](https://huggingface.co/RichardErkhov/FreedomIntelligence_-_Apollo-2B-gguf/blob/main/Apollo-2B.Q5_K.gguf) | Q5_K | 1.71GB |
| [Apollo-2B.Q5_K_M.gguf](https://huggingface.co/RichardErkhov/FreedomIntelligence_-_Apollo-2B-gguf/blob/main/Apollo-2B.Q5_K_M.gguf) | Q5_K_M | 1.71GB |
| [Apollo-2B.Q5_1.gguf](https://huggingface.co/RichardErkhov/FreedomIntelligence_-_Apollo-2B-gguf/blob/main/Apollo-2B.Q5_1.gguf) | Q5_1 | 1.79GB |
| [Apollo-2B.Q6_K.gguf](https://huggingface.co/RichardErkhov/FreedomIntelligence_-_Apollo-2B-gguf/blob/main/Apollo-2B.Q6_K.gguf) | Q6_K | 1.92GB |
| [Apollo-2B.Q8_0.gguf](https://huggingface.co/RichardErkhov/FreedomIntelligence_-_Apollo-2B-gguf/blob/main/Apollo-2B.Q8_0.gguf) | Q8_0 | 2.49GB |
Original model description:
---
license: apache-2.0
---
# Multilingual Medicine: Model, Dataset, Benchmark, Code
Covering English, Chinese, French, Hindi, Spanish, Hindi, Arabic So far
<p align="center">
👨🏻💻<a href="https://github.com/FreedomIntelligence/Apollo" target="_blank">Github</a> •📃 <a href="https://arxiv.org/abs/2403.03640" target="_blank">Paper</a> • 🌐 <a href="https://apollo.llmzoo.com/" target="_blank">Demo</a> • 🤗 <a href="https://huggingface.co/datasets/FreedomIntelligence/ApolloCorpus" target="_blank">ApolloCorpus</a> • 🤗 <a href="https://huggingface.co/datasets/FreedomIntelligence/XMedbench" target="_blank">XMedBench</a>
<br> <a href="./README_zh.md"> 中文 </a> | <a href="./README.md"> English
</p>

## 🌈 Update
* **[2024.03.07]** [Paper](https://arxiv.org/abs/2403.03640) released.
* **[2024.02.12]** <a href="https://huggingface.co/datasets/FreedomIntelligence/ApolloCorpus" target="_blank">ApolloCorpus</a> and <a href="https://huggingface.co/datasets/FreedomIntelligence/XMedbench" target="_blank">XMedBench</a> is published!🎉
* **[2024.01.23]** Apollo repo is published!🎉
## Results
🤗<a href="https://huggingface.co/FreedomIntelligence/Apollo-0.5B" target="_blank">Apollo-0.5B</a> • 🤗 <a href="https://huggingface.co/FreedomIntelligence/Apollo-1.8B" target="_blank">Apollo-1.8B</a> • 🤗 <a href="https://huggingface.co/FreedomIntelligence/Apollo-2B" target="_blank">Apollo-2B</a> • 🤗 <a href="https://huggingface.co/FreedomIntelligence/Apollo-6B" target="_blank">Apollo-6B</a> • 🤗 <a href="https://huggingface.co/FreedomIntelligence/Apollo-7B" target="_blank">Apollo-7B</a>
🤗 <a href="https://huggingface.co/FreedomIntelligence/Apollo-0.5B-GGUF" target="_blank">Apollo-0.5B-GGUF</a> • 🤗 <a href="https://huggingface.co/FreedomIntelligence/Apollo-2B-GGUF" target="_blank">Apollo-2B-GGUF</a> • 🤗 <a href="https://huggingface.co/FreedomIntelligence/Apollo-6B-GGUF" target="_blank">Apollo-6B-GGUF</a> • 🤗 <a href="https://huggingface.co/FreedomIntelligence/Apollo-7B-GGUF" target="_blank">Apollo-7B-GGUF</a>

## Usage Format
User:{query}\nAssistant:{response}<|endoftext|>
## Dataset & Evaluation
- Dataset
🤗 <a href="https://huggingface.co/datasets/FreedomIntelligence/ApolloCorpus" target="_blank">ApolloCorpus</a>
<details><summary>Click to expand</summary>

- [Zip File](https://huggingface.co/datasets/FreedomIntelligence/ApolloCorpus/blob/main/ApolloCorpus.zip)
- [Data category](https://huggingface.co/datasets/FreedomIntelligence/ApolloCorpus/tree/main/train)
- Pretrain:
- data item:
- json_name: {data_source}_{language}_{data_type}.json
- data_type: medicalBook, medicalGuideline, medicalPaper, medicalWeb(from online forum), medicalWiki
- language: en(English), zh(chinese), es(spanish), fr(french), hi(Hindi)
- data_type: qa(generated qa from text)
- data_type==text: list of string
```
[
"string1",
"string2",
...
]
```
- data_type==qa: list of qa pairs(list of string)
```
[
[
"q1",
"a1",
"q2",
"a2",
...
],
...
]
```
- SFT:
- json_name: {data_source}_{language}.json
- data_type: code, general, math, medicalExam, medicalPatient
- data item: list of qa pairs(list of string)
```
[
[
"q1",
"a1",
"q2",
"a2",
...
],
...
]
```
</details>
- Evaluation
🤗 <a href="https://huggingface.co/datasets/FreedomIntelligence/XMedbench" target="_blank">XMedBench</a>
<details><summary>Click to expand</summary>
- EN:
- [MedQA-USMLE](https://huggingface.co/datasets/GBaker/MedQA-USMLE-4-options)
- [MedMCQA](https://huggingface.co/datasets/medmcqa/viewer/default/test)
- [PubMedQA](https://huggingface.co/datasets/pubmed_qa): Because the results fluctuated too much, they were not used in the paper.
- [MMLU-Medical](https://huggingface.co/datasets/cais/mmlu)
- Clinical knowledge, Medical genetics, Anatomy, Professional medicine, College biology, College medicine
- ZH:
- [MedQA-MCMLE](https://huggingface.co/datasets/bigbio/med_qa/viewer/med_qa_zh_4options_bigbio_qa/test)
- [CMB-single](https://huggingface.co/datasets/FreedomIntelligence/CMB): Not used in the paper
- Randomly sample 2,000 multiple-choice questions with single answer.
- [CMMLU-Medical](https://huggingface.co/datasets/haonan-li/cmmlu)
- Anatomy, Clinical_knowledge, College_medicine, Genetics, Nutrition, Traditional_chinese_medicine, Virology
- [CExam](https://github.com/williamliujl/CMExam): Not used in the paper
- Randomly sample 2,000 multiple-choice questions
- ES: [Head_qa](https://huggingface.co/datasets/head_qa)
- FR: [Frenchmedmcqa](https://github.com/qanastek/FrenchMedMCQA)
- HI: [MMLU_HI](https://huggingface.co/datasets/FreedomIntelligence/MMLU_Arabic)
- Clinical knowledge, Medical genetics, Anatomy, Professional medicine, College biology, College medicine
- AR: [MMLU_Ara](https://huggingface.co/datasets/FreedomIntelligence/MMLU_Hindi)
- Clinical knowledge, Medical genetics, Anatomy, Professional medicine, College biology, College medicine
</details>
## Results reproduction
<details><summary>Click to expand</summary>
**Waiting for Update**
</details>
## Citation
Please use the following citation if you intend to use our dataset for training or evaluation:
```
@misc{wang2024apollo,
title={Apollo: Lightweight Multilingual Medical LLMs towards Democratizing Medical AI to 6B People},
author={Xidong Wang and Nuo Chen and Junyin Chen and Yan Hu and Yidong Wang and Xiangbo Wu and Anningzhe Gao and Xiang Wan and Haizhou Li and Benyou Wang},
year={2024},
eprint={2403.03640},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
|
QuantFactory/llama-3-zilo-sql-GGUF | QuantFactory | 2024-06-20T17:46:48Z | 6,927 | 1 | null | [
"gguf",
"merge",
"mergekit",
"meta-llama/Meta-Llama-3-8B-Instruct",
"arcee-ai/llama3-sqlcoder-zilo",
"text-generation",
"base_model:arcee-ai/llama-3-zilo-sql",
"license:apache-2.0",
"region:us"
] | text-generation | 2024-06-20T08:22:17Z | ---
license: apache-2.0
tags:
- merge
- mergekit
- meta-llama/Meta-Llama-3-8B-Instruct
- arcee-ai/llama3-sqlcoder-zilo
base_model: arcee-ai/llama-3-zilo-sql
pipeline_tag: text-generation
---
# llama-3-zilo-sql-GGUF
This is quantized version of [arcee-ai/llama-3-zilo-sql](https://huggingface.co/arcee-ai/llama-3-zilo-sql) created using llama.cpp
# Model Description
llama-3-zilo-sql is a merge of the following models using [mergekit](https://github.com/cg123/mergekit):
* [meta-llama/Meta-Llama-3-8B-Instruct](https://huggingface.co/meta-llama/Meta-Llama-3-8B-Instruct)
* [arcee-ai/llama3-sqlcoder-zilo](https://huggingface.co/arcee-ai/llama3-sqlcoder-zilo)
## 🧩 Configuration
```yaml
slices:
- sources:
- model: meta-llama/Meta-Llama-3-8B-Instruct
layer_range: [0, 32]
- model: arcee-ai/llama3-sqlcoder-zilo
layer_range: [0, 32]
merge_method: slerp
base_model: arcee-ai/llama3-sqlcoder-zilo
parameters:
t:
- filter: self_attn
value: [0, 0.5, 0.3, 0.7, 1]
- filter: mlp
value: [1, 0.5, 0.7, 0.3, 0]
- value: 0.5
dtype: bfloat16
``` |
megantosh/flair-arabic-multi-ner | megantosh | 2022-03-09T22:12:22Z | 6,920 | 5 | flair | [
"flair",
"pytorch",
"Text Classification",
"token-classification",
"sequence-tagger-model",
"ar",
"en",
"dataset:AQMAR",
"dataset:ANERcorp",
"license:apache-2.0",
"region:us"
] | token-classification | 2022-03-02T23:29:05Z | ---
language:
- ar
- en
license: apache-2.0
datasets:
- AQMAR
- ANERcorp
thumbnail: https://www.informatik.hu-berlin.de/en/forschung-en/gebiete/ml-en/resolveuid/a6f82e0d7fa446a59c902cac4cafa9cb/@@images/image/preview
tags:
- flair
- Text Classification
- token-classification
- sequence-tagger-model
metrics:
- f1
widget:
- text: أعرف كل شيء عن جيجي
- text: ترتقي شريحة M1 Pro وشريحة M1 Max ببنية شريحة M1 المذهلة إلى مستويات جديدة، إذ تأتيان للمرة الأولى ببنية نظام متكامل في شريحة (SoC) إلى جهاز نوت بوك للمحترفين.
- text: "اختارها خيري بشارة كممثلة، دون سابقة معرفة أو تجربة تمثيلية، لتقف بجانب فاتن حمامة في فيلم «يوم مر ويوم حلو» (1988) وهي ما زالت شابة لم تتخطَ عامها الثاني"
---
# Arabic NER Model using Flair Embeddings
Training was conducted over 94 epochs, using a linear decaying learning rate of 2e-05, starting from 0.225 and a batch size of 32 with GloVe and Flair forward and backward embeddings.
## Original Datasets:
- [AQMAR](http://www.cs.cmu.edu/~ark/ArabicNER/)
- [ANERcorp](http://curtis.ml.cmu.edu/w/courses/index.php/ANERcorp)
## Results:
- F1-score (micro) 0.8666
- F1-score (macro) 0.8488
| | Named Entity Type | True Posititves | False Positives | False Negatives | Precision | Recall | class-F1 |
|------|-|----|----|----|-----------|--------|----------|
| LOC | Location| 539 | 51 | 68 | 0.9136 | 0.8880 | 0.9006 |
| MISC | Miscellaneous|408 | 57 | 89 | 0.8774 | 0.8209 | 0.8482 |
| ORG | Organisation|167 | 43 | 64 | 0.7952 | 0.7229 | 0.7574 |
| PER | Person (no title)|501 | 65 | 60 | 0.8852 | 0.8930 | 0.8891 |
---
# Usage
```python
from flair.data import Sentence
from flair.models import SequenceTagger
import pyarabic.araby as araby
from icecream import ic
tagger = SequenceTagger.load("julien-c/flair-ner")
arTagger = SequenceTagger.load('megantosh/flair-arabic-multi-ner')
sentence = Sentence('George Washington went to Washington .')
arSentence = Sentence('عمرو عادلي أستاذ للاقتصاد السياسي المساعد في الجامعة الأمريكية بالقاهرة .')
# predict NER tags
tagger.predict(sentence)
arTagger.predict(arSentence)
# print sentence with predicted tags
ic(sentence.to_tagged_string)
ic(arSentence.to_tagged_string)
```
# Example
```bash
2021-07-07 14:30:59,649 loading file /Users/mega/.flair/models/flair-ner/f22eb997f66ae2eacad974121069abaefca5fe85fce71b49e527420ff45b9283.941c7c30b38aef8d8a4eb5c1b6dd7fe8583ff723fef457382589ad6a4e859cfc
2021-07-07 14:31:04,654 loading file /Users/mega/.flair/models/flair-arabic-multi-ner/c7af7ddef4fdcc681fcbe1f37719348afd2862b12aa1cfd4f3b93bd2d77282c7.242d030cb106124f7f9f6a88fb9af8e390f581d42eeca013367a86d585ee6dd6
ic| sentence.to_tagged_string: <bound method Sentence.to_tagged_string of Sentence: "George Washington went to Washington ." [− Tokens: 6 − Token-Labels: "George <B-PER> Washington <E-PER> went to Washington <S-LOC> ."]>
ic| arSentence.to_tagged_string: <bound method Sentence.to_tagged_string of Sentence: "عمرو عادلي أستاذ للاقتصاد السياسي المساعد في الجامعة الأمريكية بالقاهرة ." [− Tokens: 11 − Token-Labels: "عمرو <B-PER> عادلي <I-PER> أستاذ للاقتصاد السياسي المساعد في الجامعة <B-ORG> الأمريكية <I-ORG> بالقاهرة <B-LOC> ."]>
ic| entity: <PER-span (1,2): "George Washington">
ic| entity: <LOC-span (5): "Washington">
ic| entity: <PER-span (1,2): "عمرو عادلي">
ic| entity: <ORG-span (8,9): "الجامعة الأمريكية">
ic| entity: <LOC-span (10): "بالقاهرة">
ic| sentence.to_dict(tag_type='ner'):
{"text":"عمرو عادلي أستاذ للاقتصاد السياسي المساعد في الجامعة الأمريكية بالقاهرة .",
"labels":[],
{"entities":[{{{
"text":"عمرو عادلي",
"start_pos":0,
"end_pos":10,
"labels":[PER (0.9826)]},
{"text":"الجامعة الأمريكية",
"start_pos":45,
"end_pos":62,
"labels":[ORG (0.7679)]},
{"text":"بالقاهرة",
"start_pos":64,
"end_pos":72,
"labels":[LOC (0.8079)]}]}
"text":"George Washington went to Washington .",
"labels":[],
"entities":[{
{"text":"George Washington",
"start_pos":0,
"end_pos":17,
"labels":[PER (0.9968)]},
{"text":"Washington""start_pos":26,
"end_pos":36,
"labels":[LOC (0.9994)]}}]}
```
# Model Configuration
```python
SequenceTagger(
(embeddings): StackedEmbeddings(
(list_embedding_0): WordEmbeddings('glove')
(list_embedding_1): FlairEmbeddings(
(lm): LanguageModel(
(drop): Dropout(p=0.1, inplace=False)
(encoder): Embedding(7125, 100)
(rnn): LSTM(100, 2048)
(decoder): Linear(in_features=2048, out_features=7125, bias=True)
)
)
(list_embedding_2): FlairEmbeddings(
(lm): LanguageModel(
(drop): Dropout(p=0.1, inplace=False)
(encoder): Embedding(7125, 100)
(rnn): LSTM(100, 2048)
(decoder): Linear(in_features=2048, out_features=7125, bias=True)
)
)
)
(word_dropout): WordDropout(p=0.05)
(locked_dropout): LockedDropout(p=0.5)
(embedding2nn): Linear(in_features=4196, out_features=4196, bias=True)
(rnn): LSTM(4196, 256, batch_first=True, bidirectional=True)
(linear): Linear(in_features=512, out_features=15, bias=True)
(beta): 1.0
(weights): None
(weight_tensor) None
```
Due to the right-to-left in left-to-right context, some formatting errors might occur. and your code might appear like [this](https://ibb.co/ky20Lnq), (link accessed on 2020-10-27)
# Citation
*if you use this model, please consider citing [this work](https://www.researchgate.net/publication/358956953_Sequence_Labeling_Architectures_in_Diglossia_-_a_case_study_of_Arabic_and_its_dialects):*
```latex
@unpublished{MMHU21
author = "M. Megahed",
title = "Sequence Labeling Architectures in Diglossia",
year = {2021},
doi = "10.13140/RG.2.2.34961.10084"
url = {https://www.researchgate.net/publication/358956953_Sequence_Labeling_Architectures_in_Diglossia_-_a_case_study_of_Arabic_and_its_dialects}
}
``` |
mradermacher/bangla-llama-7b-instruct-v0.1-i1-GGUF | mradermacher | 2024-06-09T16:18:24Z | 6,917 | 0 | transformers | [
"transformers",
"gguf",
"bn",
"en",
"base_model:BanglaLLM/bangla-llama-7b-instruct-v0.1",
"license:llama2",
"endpoints_compatible",
"region:us"
] | null | 2024-06-09T15:12:45Z | ---
base_model: BanglaLLM/bangla-llama-7b-instruct-v0.1
language:
- bn
- en
library_name: transformers
license: llama2
quantized_by: mradermacher
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: nicoboss -->
weighted/imatrix quants of https://huggingface.co/BanglaLLM/bangla-llama-7b-instruct-v0.1
<!-- provided-files -->
static quants are available at https://huggingface.co/mradermacher/bangla-llama-7b-instruct-v0.1-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/bangla-llama-7b-instruct-v0.1-i1-GGUF/resolve/main/bangla-llama-7b-instruct-v0.1.i1-IQ1_S.gguf) | i1-IQ1_S | 1.7 | for the desperate |
| [GGUF](https://huggingface.co/mradermacher/bangla-llama-7b-instruct-v0.1-i1-GGUF/resolve/main/bangla-llama-7b-instruct-v0.1.i1-IQ1_M.gguf) | i1-IQ1_M | 1.8 | mostly desperate |
| [GGUF](https://huggingface.co/mradermacher/bangla-llama-7b-instruct-v0.1-i1-GGUF/resolve/main/bangla-llama-7b-instruct-v0.1.i1-IQ2_XXS.gguf) | i1-IQ2_XXS | 2.0 | |
| [GGUF](https://huggingface.co/mradermacher/bangla-llama-7b-instruct-v0.1-i1-GGUF/resolve/main/bangla-llama-7b-instruct-v0.1.i1-IQ2_XS.gguf) | i1-IQ2_XS | 2.2 | |
| [GGUF](https://huggingface.co/mradermacher/bangla-llama-7b-instruct-v0.1-i1-GGUF/resolve/main/bangla-llama-7b-instruct-v0.1.i1-IQ2_S.gguf) | i1-IQ2_S | 2.4 | |
| [GGUF](https://huggingface.co/mradermacher/bangla-llama-7b-instruct-v0.1-i1-GGUF/resolve/main/bangla-llama-7b-instruct-v0.1.i1-IQ2_M.gguf) | i1-IQ2_M | 2.5 | |
| [GGUF](https://huggingface.co/mradermacher/bangla-llama-7b-instruct-v0.1-i1-GGUF/resolve/main/bangla-llama-7b-instruct-v0.1.i1-Q2_K.gguf) | i1-Q2_K | 2.7 | IQ3_XXS probably better |
| [GGUF](https://huggingface.co/mradermacher/bangla-llama-7b-instruct-v0.1-i1-GGUF/resolve/main/bangla-llama-7b-instruct-v0.1.i1-IQ3_XXS.gguf) | i1-IQ3_XXS | 2.8 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/bangla-llama-7b-instruct-v0.1-i1-GGUF/resolve/main/bangla-llama-7b-instruct-v0.1.i1-IQ3_XS.gguf) | i1-IQ3_XS | 3.0 | |
| [GGUF](https://huggingface.co/mradermacher/bangla-llama-7b-instruct-v0.1-i1-GGUF/resolve/main/bangla-llama-7b-instruct-v0.1.i1-IQ3_S.gguf) | i1-IQ3_S | 3.1 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/bangla-llama-7b-instruct-v0.1-i1-GGUF/resolve/main/bangla-llama-7b-instruct-v0.1.i1-Q3_K_S.gguf) | i1-Q3_K_S | 3.1 | IQ3_XS probably better |
| [GGUF](https://huggingface.co/mradermacher/bangla-llama-7b-instruct-v0.1-i1-GGUF/resolve/main/bangla-llama-7b-instruct-v0.1.i1-IQ3_M.gguf) | i1-IQ3_M | 3.3 | |
| [GGUF](https://huggingface.co/mradermacher/bangla-llama-7b-instruct-v0.1-i1-GGUF/resolve/main/bangla-llama-7b-instruct-v0.1.i1-Q3_K_M.gguf) | i1-Q3_K_M | 3.5 | IQ3_S probably better |
| [GGUF](https://huggingface.co/mradermacher/bangla-llama-7b-instruct-v0.1-i1-GGUF/resolve/main/bangla-llama-7b-instruct-v0.1.i1-Q3_K_L.gguf) | i1-Q3_K_L | 3.8 | IQ3_M probably better |
| [GGUF](https://huggingface.co/mradermacher/bangla-llama-7b-instruct-v0.1-i1-GGUF/resolve/main/bangla-llama-7b-instruct-v0.1.i1-IQ4_XS.gguf) | i1-IQ4_XS | 3.8 | |
| [GGUF](https://huggingface.co/mradermacher/bangla-llama-7b-instruct-v0.1-i1-GGUF/resolve/main/bangla-llama-7b-instruct-v0.1.i1-Q4_0.gguf) | i1-Q4_0 | 4.0 | fast, low quality |
| [GGUF](https://huggingface.co/mradermacher/bangla-llama-7b-instruct-v0.1-i1-GGUF/resolve/main/bangla-llama-7b-instruct-v0.1.i1-Q4_K_S.gguf) | i1-Q4_K_S | 4.1 | optimal size/speed/quality |
| [GGUF](https://huggingface.co/mradermacher/bangla-llama-7b-instruct-v0.1-i1-GGUF/resolve/main/bangla-llama-7b-instruct-v0.1.i1-Q4_K_M.gguf) | i1-Q4_K_M | 4.3 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/bangla-llama-7b-instruct-v0.1-i1-GGUF/resolve/main/bangla-llama-7b-instruct-v0.1.i1-Q5_K_S.gguf) | i1-Q5_K_S | 4.9 | |
| [GGUF](https://huggingface.co/mradermacher/bangla-llama-7b-instruct-v0.1-i1-GGUF/resolve/main/bangla-llama-7b-instruct-v0.1.i1-Q5_K_M.gguf) | i1-Q5_K_M | 5.0 | |
| [GGUF](https://huggingface.co/mradermacher/bangla-llama-7b-instruct-v0.1-i1-GGUF/resolve/main/bangla-llama-7b-instruct-v0.1.i1-Q6_K.gguf) | i1-Q6_K | 5.8 | practically like static Q6_K |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time. Additional thanks to [@nicoboss](https://huggingface.co/nicoboss) for giving me access to his hardware for calculating the imatrix for these quants.
<!-- end -->
|
emilyalsentzer/Bio_Discharge_Summary_BERT | emilyalsentzer | 2022-02-27T13:59:50Z | 6,916 | 31 | transformers | [
"transformers",
"pytorch",
"jax",
"bert",
"fill-mask",
"en",
"arxiv:1904.03323",
"arxiv:1901.08746",
"license:mit",
"endpoints_compatible",
"region:us"
] | fill-mask | 2022-03-02T23:29:05Z | ---
language: "en"
tags:
- fill-mask
license: mit
---
# ClinicalBERT - Bio + Discharge Summary BERT Model
The [Publicly Available Clinical BERT Embeddings](https://arxiv.org/abs/1904.03323) paper contains four unique clinicalBERT models: initialized with BERT-Base (`cased_L-12_H-768_A-12`) or BioBERT (`BioBERT-Base v1.0 + PubMed 200K + PMC 270K`) & trained on either all MIMIC notes or only discharge summaries.
This model card describes the Bio+Discharge Summary BERT model, which was initialized from [BioBERT](https://arxiv.org/abs/1901.08746) & trained on only discharge summaries from MIMIC.
## Pretraining Data
The `Bio_Discharge_Summary_BERT` model was trained on all discharge summaries from [MIMIC III](https://www.nature.com/articles/sdata201635), a database containing electronic health records from ICU patients at the Beth Israel Hospital in Boston, MA. For more details on MIMIC, see [here](https://mimic.physionet.org/). All notes from the `NOTEEVENTS` table were included (~880M words).
## Model Pretraining
### Note Preprocessing
Each note in MIMIC was first split into sections using a rules-based section splitter (e.g. discharge summary notes were split into "History of Present Illness", "Family History", "Brief Hospital Course", etc. sections). Then each section was split into sentences using SciSpacy (`en core sci md` tokenizer).
### Pretraining Procedures
The model was trained using code from [Google's BERT repository](https://github.com/google-research/bert) on a GeForce GTX TITAN X 12 GB GPU. Model parameters were initialized with BioBERT (`BioBERT-Base v1.0 + PubMed 200K + PMC 270K`).
### Pretraining Hyperparameters
We used a batch size of 32, a maximum sequence length of 128, and a learning rate of 5 · 10−5 for pre-training our models. The models trained on all MIMIC notes were trained for 150,000 steps. The dup factor for duplicating input data with different masks was set to 5. All other default parameters were used (specifically, masked language model probability = 0.15
and max predictions per sequence = 20).
## How to use the model
Load the model via the transformers library:
```
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("emilyalsentzer/Bio_Discharge_Summary_BERT")
model = AutoModel.from_pretrained("emilyalsentzer/Bio_Discharge_Summary_BERT")
```
## More Information
Refer to the original paper, [Publicly Available Clinical BERT Embeddings](https://arxiv.org/abs/1904.03323) (NAACL Clinical NLP Workshop 2019) for additional details and performance on NLI and NER tasks.
## Questions?
Post a Github issue on the [clinicalBERT repo](https://github.com/EmilyAlsentzer/clinicalBERT) or email [email protected] with any questions.
|
qanastek/pos-french | qanastek | 2024-04-09T15:42:08Z | 6,916 | 1 | flair | [
"flair",
"pytorch",
"token-classification",
"sequence-tagger-model",
"fr",
"dataset:qanastek/ANTILLES",
"arxiv:1011.4088",
"region:us"
] | token-classification | 2022-03-02T23:29:05Z | ---
tags:
- flair
- token-classification
- sequence-tagger-model
language: fr
datasets:
- qanastek/ANTILLES
widget:
- text: "George Washington est allé à Washington"
- text: "George Washington est allé à Washington"
---
# POET: A French Extended Part-of-Speech Tagger
- Corpora: [ANTILLES](https://github.com/qanastek/ANTILLES)
- Embeddings: [FastText](https://fasttext.cc/)
- Sequence Labelling: [Bi-LSTM-CRF](https://arxiv.org/abs/1011.4088)
- Number of Epochs: 115
**People Involved**
* [LABRAK Yanis](https://www.linkedin.com/in/yanis-labrak-8a7412145/) (1)
* [DUFOUR Richard](https://cv.archives-ouvertes.fr/richard-dufour) (2)
**Affiliations**
1. [LIA, NLP team](https://lia.univ-avignon.fr/), Avignon University, Avignon, France.
2. [LS2N, TALN team](https://www.ls2n.fr/equipe/taln/), Nantes University, Nantes, France.
## Demo: How to use in Flair
Requires [Flair](https://pypi.org/project/flair/): ```pip install flair```
```python
from flair.data import Sentence
from flair.models import SequenceTagger
# Load the model
model = SequenceTagger.load("qanastek/pos-french")
sentence = Sentence("George Washington est allé à Washington")
# Predict tags
model.predict(sentence)
# Print predicted pos tags
print(sentence.to_tagged_string())
```
Output:

## Training data
`ANTILLES` is a part-of-speech tagging corpora based on [UD_French-GSD](https://universaldependencies.org/treebanks/fr_gsd/index.html) which was originally created in 2015 and is based on the [universal dependency treebank v2.0](https://github.com/ryanmcd/uni-dep-tb).
Originally, the corpora consists of 400,399 words (16,341 sentences) and had 17 different classes. Now, after applying our tags augmentation we obtain 60 different classes which add linguistic and semantic information such as the gender, number, mood, person, tense or verb form given in the different CoNLL-03 fields from the original corpora.
We based our tags on the level of details given by the [LIA_TAGG](http://pageperso.lif.univ-mrs.fr/frederic.bechet/download.html) statistical POS tagger written by [Frédéric Béchet](http://pageperso.lif.univ-mrs.fr/frederic.bechet/index-english.html) in 2001.
The corpora used for this model is available on [Github](https://github.com/qanastek/ANTILLES) at the [CoNLL-U format](https://universaldependencies.org/format.html).
Training data are fed to the model as free language and doesn't pass a normalization phase. Thus, it's made the model case and punctuation sensitive.
## Original Tags
```plain
PRON VERB SCONJ ADP CCONJ DET NOUN ADJ AUX ADV PUNCT PROPN NUM SYM PART X INTJ
```
## New additional POS tags
| Abbreviation | Description | Examples |
|:--------:|:--------:|:--------:|
| PREP | Preposition | de |
| AUX | Auxiliary Verb | est |
| ADV | Adverb | toujours |
| COSUB | Subordinating conjunction | que |
| COCO | Coordinating Conjunction | et |
| PART | Demonstrative particle | -t |
| PRON | Pronoun | qui ce quoi |
| PDEMMS | Demonstrative Pronoun - Singular Masculine | ce |
| PDEMMP | Demonstrative Pronoun - Plural Masculine | ceux |
| PDEMFS | Demonstrative Pronoun - Singular Feminine | cette |
| PDEMFP | Demonstrative Pronoun - Plural Feminine | celles |
| PINDMS | Indefinite Pronoun - Singular Masculine | tout |
| PINDMP | Indefinite Pronoun - Plural Masculine | autres |
| PINDFS | Indefinite Pronoun - Singular Feminine | chacune |
| PINDFP | Indefinite Pronoun - Plural Feminine | certaines |
| PROPN | Proper noun | Houston |
| XFAMIL | Last name | Levy |
| NUM | Numerical Adjective | trentaine vingtaine |
| DINTMS | Masculine Numerical Adjective | un |
| DINTFS | Feminine Numerical Adjective | une |
| PPOBJMS | Pronoun complements of objects - Singular Masculine | le lui |
| PPOBJMP | Pronoun complements of objects - Plural Masculine | eux y |
| PPOBJFS | Pronoun complements of objects - Singular Feminine | moi la |
| PPOBJFP | Pronoun complements of objects - Plural Feminine | en y |
| PPER1S | Personal Pronoun First-Person - Singular | je |
| PPER2S | Personal Pronoun Second-Person - Singular | tu |
| PPER3MS | Personal Pronoun Third-Person - Singular Masculine | il |
| PPER3MP | Personal Pronoun Third-Person - Plural Masculine | ils |
| PPER3FS | Personal Pronoun Third-Person - Singular Feminine | elle |
| PPER3FP | Personal Pronoun Third-Person - Plural Feminine | elles |
| PREFS | Reflexive Pronoun First-Person - Singular | me m' |
| PREF | Reflexive Pronoun Third-Person - Singular | se s' |
| PREFP | Reflexive Pronoun First / Second-Person - Plural | nous vous |
| VERB | Verb | obtient |
| VPPMS | Past Participle - Singular Masculine | formulé |
| VPPMP | Past Participle - Plural Masculine | classés |
| VPPFS | Past Participle - Singular Feminine | appelée |
| VPPFP | Past Participle - Plural Feminine | sanctionnées |
| DET | Determinant | les l' |
| DETMS | Determinant - Singular Masculine | les |
| DETFS | Determinant - Singular Feminine | la |
| ADJ | Adjective | capable sérieux |
| ADJMS | Adjective - Singular Masculine | grand important |
| ADJMP | Adjective - Plural Masculine | grands petits |
| ADJFS | Adjective - Singular Feminine | française petite |
| ADJFP | Adjective - Plural Feminine | légères petites |
| NOUN | Noun | temps |
| NMS | Noun - Singular Masculine | drapeau |
| NMP | Noun - Plural Masculine | journalistes |
| NFS | Noun - Singular Feminine | tête |
| NFP | Noun - Plural Feminine | ondes |
| PREL | Relative Pronoun | qui dont |
| PRELMS | Relative Pronoun - Singular Masculine | lequel |
| PRELMP | Relative Pronoun - Plural Masculine | lesquels |
| PRELFS | Relative Pronoun - Singular Feminine | laquelle |
| PRELFP | Relative Pronoun - Plural Feminine | lesquelles |
| INTJ | Interjection | merci bref |
| CHIF | Numbers | 1979 10 |
| SYM | Symbol | € % |
| YPFOR | Endpoint | . |
| PUNCT | Ponctuation | : , |
| MOTINC | Unknown words | Technology Lady |
| X | Typos & others | sfeir 3D statu |
## Evaluation results
The test corpora used for this evaluation is available on [Github](https://github.com/qanastek/ANTILLES/blob/main/ANTILLES/test.conllu).
```plain
Results:
- F-score (micro): 0.952
- F-score (macro): 0.8644
- Accuracy (incl. no class): 0.952
By class:
precision recall f1-score support
PPER1S 0.9767 1.0000 0.9882 42
VERB 0.9823 0.9537 0.9678 583
COSUB 0.9344 0.8906 0.9120 128
PUNCT 0.9878 0.9688 0.9782 833
PREP 0.9767 0.9879 0.9822 1483
PDEMMS 0.9583 0.9200 0.9388 75
COCO 0.9839 1.0000 0.9919 245
DET 0.9679 0.9814 0.9746 645
NMP 0.9521 0.9115 0.9313 305
ADJMP 0.8352 0.9268 0.8786 82
PREL 0.9324 0.9857 0.9583 70
PREFP 0.9767 0.9545 0.9655 44
AUX 0.9537 0.9859 0.9695 355
ADV 0.9440 0.9365 0.9402 504
VPPMP 0.8667 1.0000 0.9286 26
DINTMS 0.9919 1.0000 0.9959 122
ADJMS 0.9020 0.9057 0.9039 244
NMS 0.9226 0.9336 0.9281 753
NFS 0.9347 0.9714 0.9527 560
YPFOR 0.9806 1.0000 0.9902 353
PINDMS 1.0000 0.9091 0.9524 44
NOUN 0.8400 0.5385 0.6562 39
PROPN 0.8605 0.8278 0.8439 395
DETMS 0.9972 0.9972 0.9972 362
PPER3MS 0.9341 0.9770 0.9551 87
VPPMS 0.8994 0.9682 0.9325 157
DETFS 1.0000 1.0000 1.0000 240
ADJFS 0.9266 0.9011 0.9136 182
ADJFP 0.9726 0.9342 0.9530 76
NFP 0.9463 0.9749 0.9604 199
VPPFS 0.8000 0.9000 0.8471 40
CHIF 0.9543 0.9414 0.9478 222
XFAMIL 0.9346 0.8696 0.9009 115
PPER3MP 0.9474 0.9000 0.9231 20
PPOBJMS 0.8800 0.9362 0.9072 47
PREF 0.8889 0.9231 0.9057 52
PPOBJMP 1.0000 0.6000 0.7500 10
SYM 0.9706 0.8684 0.9167 38
DINTFS 0.9683 1.0000 0.9839 61
PDEMFS 1.0000 0.8966 0.9455 29
PPER3FS 1.0000 0.9444 0.9714 18
VPPFP 0.9500 1.0000 0.9744 19
PRON 0.9200 0.7419 0.8214 31
PPOBJFS 0.8333 0.8333 0.8333 6
PART 0.8000 1.0000 0.8889 4
PPER3FP 1.0000 1.0000 1.0000 2
MOTINC 0.3571 0.3333 0.3448 15
PDEMMP 1.0000 0.6667 0.8000 3
INTJ 0.4000 0.6667 0.5000 6
PREFS 1.0000 0.5000 0.6667 10
ADJ 0.7917 0.8636 0.8261 22
PINDMP 0.0000 0.0000 0.0000 1
PINDFS 1.0000 1.0000 1.0000 1
NUM 1.0000 0.3333 0.5000 3
PPER2S 1.0000 1.0000 1.0000 2
PPOBJFP 1.0000 0.5000 0.6667 2
PDEMFP 1.0000 0.6667 0.8000 3
X 0.0000 0.0000 0.0000 1
PRELMS 1.0000 1.0000 1.0000 2
PINDFP 1.0000 1.0000 1.0000 1
accuracy 0.9520 10019
macro avg 0.8956 0.8521 0.8644 10019
weighted avg 0.9524 0.9520 0.9515 10019
```
## BibTeX Citations
Please cite the following paper when using this model.
ANTILLES corpus and POET taggers:
```latex
@inproceedings{labrak:hal-03696042,
TITLE = {{ANTILLES: An Open French Linguistically Enriched Part-of-Speech Corpus}},
AUTHOR = {Labrak, Yanis and Dufour, Richard},
URL = {https://hal.archives-ouvertes.fr/hal-03696042},
BOOKTITLE = {{25th International Conference on Text, Speech and Dialogue (TSD)}},
ADDRESS = {Brno, Czech Republic},
PUBLISHER = {{Springer}},
YEAR = {2022},
MONTH = Sep,
KEYWORDS = {Part-of-speech corpus ; POS tagging ; Open tools ; Word embeddings ; Bi-LSTM ; CRF ; Transformers},
PDF = {https://hal.archives-ouvertes.fr/hal-03696042/file/ANTILLES_A_freNch_linguisTIcaLLy_Enriched_part_of_Speech_corpus.pdf},
HAL_ID = {hal-03696042},
HAL_VERSION = {v1},
}
```
UD_French-GSD corpora:
```latex
@misc{
universaldependencies,
title={UniversalDependencies/UD_French-GSD},
url={https://github.com/UniversalDependencies/UD_French-GSD}, journal={GitHub},
author={UniversalDependencies}
}
```
LIA TAGG:
```latex
@techreport{LIA_TAGG,
author = {Frédéric Béchet},
title = {LIA_TAGG: a statistical POS tagger + syntactic bracketer},
institution = {Aix-Marseille University & CNRS},
year = {2001}
}
```
Flair Embeddings:
```latex
@inproceedings{akbik2018coling,
title={Contextual String Embeddings for Sequence Labeling},
author={Akbik, Alan and Blythe, Duncan and Vollgraf, Roland},
booktitle = {{COLING} 2018, 27th International Conference on Computational Linguistics},
pages = {1638--1649},
year = {2018}
}
```
## Acknowledgment
This work was financially supported by [Zenidoc](https://zenidoc.fr/)
|
hfl/chinese-bert-wwm | hfl | 2021-05-19T19:07:49Z | 6,907 | 57 | transformers | [
"transformers",
"pytorch",
"tf",
"jax",
"bert",
"fill-mask",
"zh",
"arxiv:1906.08101",
"arxiv:2004.13922",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | fill-mask | 2022-03-02T23:29:05Z | ---
language:
- zh
license: "apache-2.0"
---
## Chinese BERT with Whole Word Masking
For further accelerating Chinese natural language processing, we provide **Chinese pre-trained BERT with Whole Word Masking**.
**[Pre-Training with Whole Word Masking for Chinese BERT](https://arxiv.org/abs/1906.08101)**
Yiming Cui, Wanxiang Che, Ting Liu, Bing Qin, Ziqing Yang, Shijin Wang, Guoping Hu
This repository is developed based on:https://github.com/google-research/bert
You may also interested in,
- Chinese BERT series: https://github.com/ymcui/Chinese-BERT-wwm
- Chinese MacBERT: https://github.com/ymcui/MacBERT
- Chinese ELECTRA: https://github.com/ymcui/Chinese-ELECTRA
- Chinese XLNet: https://github.com/ymcui/Chinese-XLNet
- Knowledge Distillation Toolkit - TextBrewer: https://github.com/airaria/TextBrewer
More resources by HFL: https://github.com/ymcui/HFL-Anthology
## Citation
If you find the technical report or resource is useful, please cite the following technical report in your paper.
- Primary: https://arxiv.org/abs/2004.13922
```
@inproceedings{cui-etal-2020-revisiting,
title = "Revisiting Pre-Trained Models for {C}hinese Natural Language Processing",
author = "Cui, Yiming and
Che, Wanxiang and
Liu, Ting and
Qin, Bing and
Wang, Shijin and
Hu, Guoping",
booktitle = "Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: Findings",
month = nov,
year = "2020",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/2020.findings-emnlp.58",
pages = "657--668",
}
```
- Secondary: https://arxiv.org/abs/1906.08101
```
@article{chinese-bert-wwm,
title={Pre-Training with Whole Word Masking for Chinese BERT},
author={Cui, Yiming and Che, Wanxiang and Liu, Ting and Qin, Bing and Yang, Ziqing and Wang, Shijin and Hu, Guoping},
journal={arXiv preprint arXiv:1906.08101},
year={2019}
}
``` |
rubra-ai/Mistral-7B-Instruct-v0.3-GGUF | rubra-ai | 2024-07-01T06:16:00Z | 6,898 | 2 | null | [
"gguf",
"function-calling",
"tool-calling",
"agentic",
"rubra",
"conversational",
"en",
"license:apache-2.0",
"model-index",
"region:us"
] | null | 2024-06-13T00:56:43Z | ---
model-index:
- name: Rubra-Mistral-7B-Instruct-v0.3
results:
- task:
type: text-generation
dataset:
type: MMLU
name: MMLU
metrics:
- type: 5-shot
value: 59.12
verified: false
- task:
type: text-generation
dataset:
type: GPQA
name: GPQA
metrics:
- type: 0-shot
value: 29.91
verified: false
- task:
type: text-generation
dataset:
type: GSM-8K
name: GSM-8K
metrics:
- type: 8-shot, CoT
value: 43.29
verified: false
- task:
type: text-generation
dataset:
type: MATH
name: MATH
metrics:
- type: 4-shot, CoT
value: 11.14
verified: false
- task:
type: text-generation
dataset:
type: MT-bench
name: MT-bench
metrics:
- type: GPT-4 as Judge
value: 7.69
verified: false
tags:
- function-calling
- tool-calling
- agentic
- rubra
- conversational
language:
- en
license: apache-2.0
---
# Rubra Mistral 7B Instruct v0.3 GGUF
Original model: [rubra-ai/Mistral-7B-Instruct-v0.3](https://huggingface.co/rubra-ai/Mistral-7B-Instruct-v0.3)
## Model Description
Mistral-7B-Instruct-v0.3 is the result of further post-training on the base model [mistralai/Mistral-7B-Instruct-v0.3](https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.3). This model is designed for high performance in various instruction-following tasks and complex interactions, including multi-turn function calling and detailed conversations.
## Training Data
The model underwent additional training on a proprietary dataset encompassing diverse instruction-following, chat, and function calling data. This post-training process enhances the model's ability to integrate tools and manage complex interaction scenarios effectively.
## How to use
Refer to https://docs.rubra.ai/inference/llamacpp for usage. Feel free to ask/open issues up in our Github repo: https://github.com/rubra-ai/rubra
## Limitations and Bias
While the model performs well on a wide range of tasks, it may still produce biased or incorrect outputs. Users should exercise caution and critical judgment when using the model in sensitive or high-stakes applications. The model's outputs are influenced by the data it was trained on, which may contain inherent biases.
## Ethical Considerations
Users should ensure that the deployment of this model adheres to ethical guidelines and consider the potential societal impact of the generated text. Misuse of the model for generating harmful or misleading content is strongly discouraged.
## Acknowledgements
We would like to thank Mistral for the model.
## Contact Information
For questions or comments about the model, please reach out to [the rubra team](mailto:[email protected]).
## Citation
If you use this work, please cite it as:
```
@misc {rubra_ai_2024,
author = { Sanjay Nadhavajhala and Yingbei Tong },
title = { Rubra-Mistral-7B-Instruct-v0.3 },
year = 2024,
url = { https://huggingface.co/rubra-ai/Mistral-7B-Instruct-v0.3 },
doi = { 10.57967/hf/2656 },
publisher = { Hugging Face }
}
``` |
mixedbread-ai/mxbai-embed-2d-large-v1 | mixedbread-ai | 2024-04-04T21:36:56Z | 6,895 | 32 | sentence-transformers | [
"sentence-transformers",
"onnx",
"safetensors",
"bert",
"feature-extraction",
"mteb",
"transformers.js",
"transformers",
"en",
"arxiv:2402.14776",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
] | feature-extraction | 2024-03-04T11:17:53Z | ---
tags:
- mteb
- transformers.js
- transformers
model-index:
- name: mxbai-embed-2d-large-v1
results:
- task:
type: Classification
dataset:
type: mteb/amazon_counterfactual
name: MTEB AmazonCounterfactualClassification (en)
config: en
split: test
revision: e8379541af4e31359cca9fbcf4b00f2671dba205
metrics:
- type: accuracy
value: 74.76119402985074
- type: ap
value: 37.90611182084586
- type: f1
value: 68.80795400445113
- task:
type: Classification
dataset:
type: mteb/amazon_polarity
name: MTEB AmazonPolarityClassification
config: default
split: test
revision: e2d317d38cd51312af73b3d32a06d1a08b442046
metrics:
- type: accuracy
value: 93.255525
- type: ap
value: 90.06886124154308
- type: f1
value: 93.24785420201029
- task:
type: Classification
dataset:
type: mteb/amazon_reviews_multi
name: MTEB AmazonReviewsClassification (en)
config: en
split: test
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
metrics:
- type: accuracy
value: 46.162000000000006
- type: f1
value: 45.66989189593428
- task:
type: Retrieval
dataset:
type: arguana
name: MTEB ArguAna
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 37.980000000000004
- type: map_at_10
value: 54.918
- type: map_at_100
value: 55.401
- type: map_at_1000
value: 55.403000000000006
- type: map_at_3
value: 50.249
- type: map_at_5
value: 53.400000000000006
- type: mrr_at_1
value: 38.834
- type: mrr_at_10
value: 55.24
- type: mrr_at_100
value: 55.737
- type: mrr_at_1000
value: 55.738
- type: mrr_at_3
value: 50.580999999999996
- type: mrr_at_5
value: 53.71
- type: ndcg_at_1
value: 37.980000000000004
- type: ndcg_at_10
value: 63.629000000000005
- type: ndcg_at_100
value: 65.567
- type: ndcg_at_1000
value: 65.61399999999999
- type: ndcg_at_3
value: 54.275
- type: ndcg_at_5
value: 59.91
- type: precision_at_1
value: 37.980000000000004
- type: precision_at_10
value: 9.110999999999999
- type: precision_at_100
value: 0.993
- type: precision_at_1000
value: 0.1
- type: precision_at_3
value: 21.977
- type: precision_at_5
value: 15.903
- type: recall_at_1
value: 37.980000000000004
- type: recall_at_10
value: 91.11
- type: recall_at_100
value: 99.289
- type: recall_at_1000
value: 99.644
- type: recall_at_3
value: 65.932
- type: recall_at_5
value: 79.51599999999999
- task:
type: Clustering
dataset:
type: mteb/arxiv-clustering-p2p
name: MTEB ArxivClusteringP2P
config: default
split: test
revision: a122ad7f3f0291bf49cc6f4d32aa80929df69d5d
metrics:
- type: v_measure
value: 48.28746486562395
- task:
type: Clustering
dataset:
type: mteb/arxiv-clustering-s2s
name: MTEB ArxivClusteringS2S
config: default
split: test
revision: f910caf1a6075f7329cdf8c1a6135696f37dbd53
metrics:
- type: v_measure
value: 42.335244985544165
- task:
type: Reranking
dataset:
type: mteb/askubuntudupquestions-reranking
name: MTEB AskUbuntuDupQuestions
config: default
split: test
revision: 2000358ca161889fa9c082cb41daa8dcfb161a54
metrics:
- type: map
value: 63.771155681602096
- type: mrr
value: 76.55993052807459
- task:
type: STS
dataset:
type: mteb/biosses-sts
name: MTEB BIOSSES
config: default
split: test
revision: d3fb88f8f02e40887cd149695127462bbcf29b4a
metrics:
- type: cos_sim_pearson
value: 89.76152904846916
- type: cos_sim_spearman
value: 88.05622328825284
- type: euclidean_pearson
value: 88.2821986323439
- type: euclidean_spearman
value: 88.05622328825284
- type: manhattan_pearson
value: 87.98419111117559
- type: manhattan_spearman
value: 87.905617446958
- task:
type: Classification
dataset:
type: mteb/banking77
name: MTEB Banking77Classification
config: default
split: test
revision: 0fd18e25b25c072e09e0d92ab615fda904d66300
metrics:
- type: accuracy
value: 86.65259740259741
- type: f1
value: 86.62044951853902
- task:
type: Clustering
dataset:
type: mteb/biorxiv-clustering-p2p
name: MTEB BiorxivClusteringP2P
config: default
split: test
revision: 65b79d1d13f80053f67aca9498d9402c2d9f1f40
metrics:
- type: v_measure
value: 39.7270855384167
- task:
type: Clustering
dataset:
type: mteb/biorxiv-clustering-s2s
name: MTEB BiorxivClusteringS2S
config: default
split: test
revision: 258694dd0231531bc1fd9de6ceb52a0853c6d908
metrics:
- type: v_measure
value: 36.95365397158872
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackAndroidRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 30.604
- type: map_at_10
value: 42.126999999999995
- type: map_at_100
value: 43.702999999999996
- type: map_at_1000
value: 43.851
- type: map_at_3
value: 38.663
- type: map_at_5
value: 40.67
- type: mrr_at_1
value: 37.625
- type: mrr_at_10
value: 48.203
- type: mrr_at_100
value: 48.925000000000004
- type: mrr_at_1000
value: 48.979
- type: mrr_at_3
value: 45.494
- type: mrr_at_5
value: 47.288999999999994
- type: ndcg_at_1
value: 37.625
- type: ndcg_at_10
value: 48.649
- type: ndcg_at_100
value: 54.041
- type: ndcg_at_1000
value: 56.233999999999995
- type: ndcg_at_3
value: 43.704
- type: ndcg_at_5
value: 46.172999999999995
- type: precision_at_1
value: 37.625
- type: precision_at_10
value: 9.371
- type: precision_at_100
value: 1.545
- type: precision_at_1000
value: 0.20400000000000001
- type: precision_at_3
value: 21.364
- type: precision_at_5
value: 15.421999999999999
- type: recall_at_1
value: 30.604
- type: recall_at_10
value: 60.94199999999999
- type: recall_at_100
value: 82.893
- type: recall_at_1000
value: 96.887
- type: recall_at_3
value: 46.346
- type: recall_at_5
value: 53.495000000000005
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackEnglishRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 29.959000000000003
- type: map_at_10
value: 40.217999999999996
- type: map_at_100
value: 41.337
- type: map_at_1000
value: 41.471999999999994
- type: map_at_3
value: 37.029
- type: map_at_5
value: 38.873000000000005
- type: mrr_at_1
value: 37.325
- type: mrr_at_10
value: 45.637
- type: mrr_at_100
value: 46.243
- type: mrr_at_1000
value: 46.297
- type: mrr_at_3
value: 43.323
- type: mrr_at_5
value: 44.734
- type: ndcg_at_1
value: 37.325
- type: ndcg_at_10
value: 45.864
- type: ndcg_at_100
value: 49.832
- type: ndcg_at_1000
value: 52.056000000000004
- type: ndcg_at_3
value: 41.329
- type: ndcg_at_5
value: 43.547000000000004
- type: precision_at_1
value: 37.325
- type: precision_at_10
value: 8.732
- type: precision_at_100
value: 1.369
- type: precision_at_1000
value: 0.185
- type: precision_at_3
value: 19.936
- type: precision_at_5
value: 14.306
- type: recall_at_1
value: 29.959000000000003
- type: recall_at_10
value: 56.113
- type: recall_at_100
value: 73.231
- type: recall_at_1000
value: 87.373
- type: recall_at_3
value: 42.88
- type: recall_at_5
value: 49.004
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackGamingRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 38.679
- type: map_at_10
value: 50.696
- type: map_at_100
value: 51.788000000000004
- type: map_at_1000
value: 51.849999999999994
- type: map_at_3
value: 47.414
- type: map_at_5
value: 49.284
- type: mrr_at_1
value: 44.263000000000005
- type: mrr_at_10
value: 54.03
- type: mrr_at_100
value: 54.752
- type: mrr_at_1000
value: 54.784
- type: mrr_at_3
value: 51.661
- type: mrr_at_5
value: 53.047
- type: ndcg_at_1
value: 44.263000000000005
- type: ndcg_at_10
value: 56.452999999999996
- type: ndcg_at_100
value: 60.736999999999995
- type: ndcg_at_1000
value: 61.982000000000006
- type: ndcg_at_3
value: 51.085
- type: ndcg_at_5
value: 53.715999999999994
- type: precision_at_1
value: 44.263000000000005
- type: precision_at_10
value: 9.129
- type: precision_at_100
value: 1.218
- type: precision_at_1000
value: 0.13699999999999998
- type: precision_at_3
value: 22.8
- type: precision_at_5
value: 15.674
- type: recall_at_1
value: 38.679
- type: recall_at_10
value: 70.1
- type: recall_at_100
value: 88.649
- type: recall_at_1000
value: 97.48
- type: recall_at_3
value: 55.757999999999996
- type: recall_at_5
value: 62.244
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackGisRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 25.796999999999997
- type: map_at_10
value: 34.011
- type: map_at_100
value: 35.103
- type: map_at_1000
value: 35.187000000000005
- type: map_at_3
value: 31.218
- type: map_at_5
value: 32.801
- type: mrr_at_1
value: 28.022999999999996
- type: mrr_at_10
value: 36.108000000000004
- type: mrr_at_100
value: 37.094
- type: mrr_at_1000
value: 37.158
- type: mrr_at_3
value: 33.635
- type: mrr_at_5
value: 35.081
- type: ndcg_at_1
value: 28.022999999999996
- type: ndcg_at_10
value: 38.887
- type: ndcg_at_100
value: 44.159
- type: ndcg_at_1000
value: 46.300000000000004
- type: ndcg_at_3
value: 33.623
- type: ndcg_at_5
value: 36.281
- type: precision_at_1
value: 28.022999999999996
- type: precision_at_10
value: 6.010999999999999
- type: precision_at_100
value: 0.901
- type: precision_at_1000
value: 0.11299999999999999
- type: precision_at_3
value: 14.124
- type: precision_at_5
value: 10.034
- type: recall_at_1
value: 25.796999999999997
- type: recall_at_10
value: 51.86300000000001
- type: recall_at_100
value: 75.995
- type: recall_at_1000
value: 91.93299999999999
- type: recall_at_3
value: 37.882
- type: recall_at_5
value: 44.34
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackMathematicaRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 15.468000000000002
- type: map_at_10
value: 24.026
- type: map_at_100
value: 25.237
- type: map_at_1000
value: 25.380000000000003
- type: map_at_3
value: 21.342
- type: map_at_5
value: 22.843
- type: mrr_at_1
value: 19.154
- type: mrr_at_10
value: 28.429
- type: mrr_at_100
value: 29.416999999999998
- type: mrr_at_1000
value: 29.491
- type: mrr_at_3
value: 25.746000000000002
- type: mrr_at_5
value: 27.282
- type: ndcg_at_1
value: 19.154
- type: ndcg_at_10
value: 29.512
- type: ndcg_at_100
value: 35.331
- type: ndcg_at_1000
value: 38.435
- type: ndcg_at_3
value: 24.566
- type: ndcg_at_5
value: 26.891
- type: precision_at_1
value: 19.154
- type: precision_at_10
value: 5.647
- type: precision_at_100
value: 0.984
- type: precision_at_1000
value: 0.13899999999999998
- type: precision_at_3
value: 12.065
- type: precision_at_5
value: 8.98
- type: recall_at_1
value: 15.468000000000002
- type: recall_at_10
value: 41.908
- type: recall_at_100
value: 67.17
- type: recall_at_1000
value: 89.05499999999999
- type: recall_at_3
value: 28.436
- type: recall_at_5
value: 34.278
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackPhysicsRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 28.116000000000003
- type: map_at_10
value: 39.034
- type: map_at_100
value: 40.461000000000006
- type: map_at_1000
value: 40.563
- type: map_at_3
value: 35.742000000000004
- type: map_at_5
value: 37.762
- type: mrr_at_1
value: 34.264
- type: mrr_at_10
value: 44.173
- type: mrr_at_100
value: 45.111000000000004
- type: mrr_at_1000
value: 45.149
- type: mrr_at_3
value: 41.626999999999995
- type: mrr_at_5
value: 43.234
- type: ndcg_at_1
value: 34.264
- type: ndcg_at_10
value: 45.011
- type: ndcg_at_100
value: 50.91
- type: ndcg_at_1000
value: 52.886
- type: ndcg_at_3
value: 39.757999999999996
- type: ndcg_at_5
value: 42.569
- type: precision_at_1
value: 34.264
- type: precision_at_10
value: 8.114
- type: precision_at_100
value: 1.2890000000000001
- type: precision_at_1000
value: 0.163
- type: precision_at_3
value: 18.864
- type: precision_at_5
value: 13.628000000000002
- type: recall_at_1
value: 28.116000000000003
- type: recall_at_10
value: 57.764
- type: recall_at_100
value: 82.393
- type: recall_at_1000
value: 95.345
- type: recall_at_3
value: 43.35
- type: recall_at_5
value: 50.368
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackProgrammersRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 23.557
- type: map_at_10
value: 33.94
- type: map_at_100
value: 35.382000000000005
- type: map_at_1000
value: 35.497
- type: map_at_3
value: 30.635
- type: map_at_5
value: 32.372
- type: mrr_at_1
value: 29.224
- type: mrr_at_10
value: 39.017
- type: mrr_at_100
value: 39.908
- type: mrr_at_1000
value: 39.96
- type: mrr_at_3
value: 36.225
- type: mrr_at_5
value: 37.869
- type: ndcg_at_1
value: 29.224
- type: ndcg_at_10
value: 40.097
- type: ndcg_at_100
value: 46.058
- type: ndcg_at_1000
value: 48.309999999999995
- type: ndcg_at_3
value: 34.551
- type: ndcg_at_5
value: 36.937
- type: precision_at_1
value: 29.224
- type: precision_at_10
value: 7.6259999999999994
- type: precision_at_100
value: 1.226
- type: precision_at_1000
value: 0.161
- type: precision_at_3
value: 16.781
- type: precision_at_5
value: 12.26
- type: recall_at_1
value: 23.557
- type: recall_at_10
value: 53.46300000000001
- type: recall_at_100
value: 78.797
- type: recall_at_1000
value: 93.743
- type: recall_at_3
value: 37.95
- type: recall_at_5
value: 44.121
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 24.81583333333333
- type: map_at_10
value: 34.057833333333335
- type: map_at_100
value: 35.29658333333334
- type: map_at_1000
value: 35.418666666666674
- type: map_at_3
value: 31.16416666666667
- type: map_at_5
value: 32.797
- type: mrr_at_1
value: 29.40216666666667
- type: mrr_at_10
value: 38.11191666666667
- type: mrr_at_100
value: 38.983250000000005
- type: mrr_at_1000
value: 39.043
- type: mrr_at_3
value: 35.663333333333334
- type: mrr_at_5
value: 37.08975
- type: ndcg_at_1
value: 29.40216666666667
- type: ndcg_at_10
value: 39.462416666666655
- type: ndcg_at_100
value: 44.74341666666666
- type: ndcg_at_1000
value: 47.12283333333333
- type: ndcg_at_3
value: 34.57383333333334
- type: ndcg_at_5
value: 36.91816666666667
- type: precision_at_1
value: 29.40216666666667
- type: precision_at_10
value: 7.008416666666667
- type: precision_at_100
value: 1.143333333333333
- type: precision_at_1000
value: 0.15391666666666665
- type: precision_at_3
value: 16.011083333333335
- type: precision_at_5
value: 11.506666666666664
- type: recall_at_1
value: 24.81583333333333
- type: recall_at_10
value: 51.39391666666666
- type: recall_at_100
value: 74.52983333333333
- type: recall_at_1000
value: 91.00650000000002
- type: recall_at_3
value: 37.87458333333334
- type: recall_at_5
value: 43.865833333333335
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackStatsRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 24.04
- type: map_at_10
value: 30.651
- type: map_at_100
value: 31.561
- type: map_at_1000
value: 31.667
- type: map_at_3
value: 28.358
- type: map_at_5
value: 29.644
- type: mrr_at_1
value: 26.840000000000003
- type: mrr_at_10
value: 33.397
- type: mrr_at_100
value: 34.166999999999994
- type: mrr_at_1000
value: 34.252
- type: mrr_at_3
value: 31.339
- type: mrr_at_5
value: 32.451
- type: ndcg_at_1
value: 26.840000000000003
- type: ndcg_at_10
value: 34.821999999999996
- type: ndcg_at_100
value: 39.155
- type: ndcg_at_1000
value: 41.837999999999994
- type: ndcg_at_3
value: 30.55
- type: ndcg_at_5
value: 32.588
- type: precision_at_1
value: 26.840000000000003
- type: precision_at_10
value: 5.383
- type: precision_at_100
value: 0.827
- type: precision_at_1000
value: 0.11199999999999999
- type: precision_at_3
value: 12.986
- type: precision_at_5
value: 9.11
- type: recall_at_1
value: 24.04
- type: recall_at_10
value: 45.133
- type: recall_at_100
value: 64.519
- type: recall_at_1000
value: 84.397
- type: recall_at_3
value: 33.465
- type: recall_at_5
value: 38.504
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackTexRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 15.744
- type: map_at_10
value: 22.557
- type: map_at_100
value: 23.705000000000002
- type: map_at_1000
value: 23.833
- type: map_at_3
value: 20.342
- type: map_at_5
value: 21.584
- type: mrr_at_1
value: 19.133
- type: mrr_at_10
value: 26.316
- type: mrr_at_100
value: 27.285999999999998
- type: mrr_at_1000
value: 27.367
- type: mrr_at_3
value: 24.214
- type: mrr_at_5
value: 25.419999999999998
- type: ndcg_at_1
value: 19.133
- type: ndcg_at_10
value: 27.002
- type: ndcg_at_100
value: 32.544000000000004
- type: ndcg_at_1000
value: 35.624
- type: ndcg_at_3
value: 23.015
- type: ndcg_at_5
value: 24.916
- type: precision_at_1
value: 19.133
- type: precision_at_10
value: 4.952
- type: precision_at_100
value: 0.918
- type: precision_at_1000
value: 0.136
- type: precision_at_3
value: 10.908
- type: precision_at_5
value: 8.004
- type: recall_at_1
value: 15.744
- type: recall_at_10
value: 36.63
- type: recall_at_100
value: 61.58
- type: recall_at_1000
value: 83.648
- type: recall_at_3
value: 25.545
- type: recall_at_5
value: 30.392000000000003
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackUnixRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 24.944
- type: map_at_10
value: 33.611000000000004
- type: map_at_100
value: 34.737
- type: map_at_1000
value: 34.847
- type: map_at_3
value: 30.746000000000002
- type: map_at_5
value: 32.357
- type: mrr_at_1
value: 29.198
- type: mrr_at_10
value: 37.632
- type: mrr_at_100
value: 38.53
- type: mrr_at_1000
value: 38.59
- type: mrr_at_3
value: 35.292
- type: mrr_at_5
value: 36.519
- type: ndcg_at_1
value: 29.198
- type: ndcg_at_10
value: 38.946999999999996
- type: ndcg_at_100
value: 44.348
- type: ndcg_at_1000
value: 46.787
- type: ndcg_at_3
value: 33.794999999999995
- type: ndcg_at_5
value: 36.166
- type: precision_at_1
value: 29.198
- type: precision_at_10
value: 6.595
- type: precision_at_100
value: 1.055
- type: precision_at_1000
value: 0.13899999999999998
- type: precision_at_3
value: 15.235999999999999
- type: precision_at_5
value: 10.896
- type: recall_at_1
value: 24.944
- type: recall_at_10
value: 51.284
- type: recall_at_100
value: 75.197
- type: recall_at_1000
value: 92.10000000000001
- type: recall_at_3
value: 37.213
- type: recall_at_5
value: 43.129
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackWebmastersRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 21.979000000000003
- type: map_at_10
value: 31.349
- type: map_at_100
value: 32.969
- type: map_at_1000
value: 33.2
- type: map_at_3
value: 28.237000000000002
- type: map_at_5
value: 30.09
- type: mrr_at_1
value: 27.075
- type: mrr_at_10
value: 35.946
- type: mrr_at_100
value: 36.897000000000006
- type: mrr_at_1000
value: 36.951
- type: mrr_at_3
value: 32.971000000000004
- type: mrr_at_5
value: 34.868
- type: ndcg_at_1
value: 27.075
- type: ndcg_at_10
value: 37.317
- type: ndcg_at_100
value: 43.448
- type: ndcg_at_1000
value: 45.940999999999995
- type: ndcg_at_3
value: 32.263
- type: ndcg_at_5
value: 34.981
- type: precision_at_1
value: 27.075
- type: precision_at_10
value: 7.568999999999999
- type: precision_at_100
value: 1.5650000000000002
- type: precision_at_1000
value: 0.241
- type: precision_at_3
value: 15.547
- type: precision_at_5
value: 11.818
- type: recall_at_1
value: 21.979000000000003
- type: recall_at_10
value: 48.522999999999996
- type: recall_at_100
value: 76.51
- type: recall_at_1000
value: 92.168
- type: recall_at_3
value: 34.499
- type: recall_at_5
value: 41.443999999999996
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackWordpressRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 18.903
- type: map_at_10
value: 26.473999999999997
- type: map_at_100
value: 27.576
- type: map_at_1000
value: 27.677000000000003
- type: map_at_3
value: 24.244
- type: map_at_5
value: 25.284000000000002
- type: mrr_at_1
value: 20.702
- type: mrr_at_10
value: 28.455000000000002
- type: mrr_at_100
value: 29.469
- type: mrr_at_1000
value: 29.537999999999997
- type: mrr_at_3
value: 26.433
- type: mrr_at_5
value: 27.283
- type: ndcg_at_1
value: 20.702
- type: ndcg_at_10
value: 30.988
- type: ndcg_at_100
value: 36.358000000000004
- type: ndcg_at_1000
value: 39.080999999999996
- type: ndcg_at_3
value: 26.647
- type: ndcg_at_5
value: 28.253
- type: precision_at_1
value: 20.702
- type: precision_at_10
value: 4.972
- type: precision_at_100
value: 0.823
- type: precision_at_1000
value: 0.117
- type: precision_at_3
value: 11.522
- type: precision_at_5
value: 7.9479999999999995
- type: recall_at_1
value: 18.903
- type: recall_at_10
value: 43.004
- type: recall_at_100
value: 67.42399999999999
- type: recall_at_1000
value: 87.949
- type: recall_at_3
value: 31.171
- type: recall_at_5
value: 35.071000000000005
- task:
type: Retrieval
dataset:
type: climate-fever
name: MTEB ClimateFEVER
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 12.942
- type: map_at_10
value: 22.017999999999997
- type: map_at_100
value: 23.968
- type: map_at_1000
value: 24.169
- type: map_at_3
value: 18.282
- type: map_at_5
value: 20.191
- type: mrr_at_1
value: 29.121000000000002
- type: mrr_at_10
value: 40.897
- type: mrr_at_100
value: 41.787
- type: mrr_at_1000
value: 41.819
- type: mrr_at_3
value: 37.535000000000004
- type: mrr_at_5
value: 39.626
- type: ndcg_at_1
value: 29.121000000000002
- type: ndcg_at_10
value: 30.728
- type: ndcg_at_100
value: 38.231
- type: ndcg_at_1000
value: 41.735
- type: ndcg_at_3
value: 25.141000000000002
- type: ndcg_at_5
value: 27.093
- type: precision_at_1
value: 29.121000000000002
- type: precision_at_10
value: 9.674000000000001
- type: precision_at_100
value: 1.775
- type: precision_at_1000
value: 0.243
- type: precision_at_3
value: 18.826999999999998
- type: precision_at_5
value: 14.515
- type: recall_at_1
value: 12.942
- type: recall_at_10
value: 36.692
- type: recall_at_100
value: 62.688
- type: recall_at_1000
value: 82.203
- type: recall_at_3
value: 22.820999999999998
- type: recall_at_5
value: 28.625
- task:
type: Retrieval
dataset:
type: dbpedia-entity
name: MTEB DBPedia
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 8.6
- type: map_at_10
value: 18.672
- type: map_at_100
value: 27.199
- type: map_at_1000
value: 29.032999999999998
- type: map_at_3
value: 13.045000000000002
- type: map_at_5
value: 15.271
- type: mrr_at_1
value: 69
- type: mrr_at_10
value: 75.304
- type: mrr_at_100
value: 75.68
- type: mrr_at_1000
value: 75.688
- type: mrr_at_3
value: 73.708
- type: mrr_at_5
value: 74.333
- type: ndcg_at_1
value: 56.25
- type: ndcg_at_10
value: 40.741
- type: ndcg_at_100
value: 45.933
- type: ndcg_at_1000
value: 53.764
- type: ndcg_at_3
value: 44.664
- type: ndcg_at_5
value: 42.104
- type: precision_at_1
value: 69
- type: precision_at_10
value: 33
- type: precision_at_100
value: 10.75
- type: precision_at_1000
value: 2.1999999999999997
- type: precision_at_3
value: 48.167
- type: precision_at_5
value: 41.099999999999994
- type: recall_at_1
value: 8.6
- type: recall_at_10
value: 24.447
- type: recall_at_100
value: 52.697
- type: recall_at_1000
value: 77.717
- type: recall_at_3
value: 14.13
- type: recall_at_5
value: 17.485999999999997
- task:
type: Classification
dataset:
type: mteb/emotion
name: MTEB EmotionClassification
config: default
split: test
revision: 4f58c6b202a23cf9a4da393831edf4f9183cad37
metrics:
- type: accuracy
value: 49.32
- type: f1
value: 43.92815810776849
- task:
type: Retrieval
dataset:
type: fever
name: MTEB FEVER
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 68.987
- type: map_at_10
value: 78.025
- type: map_at_100
value: 78.28500000000001
- type: map_at_1000
value: 78.3
- type: map_at_3
value: 76.735
- type: map_at_5
value: 77.558
- type: mrr_at_1
value: 74.482
- type: mrr_at_10
value: 82.673
- type: mrr_at_100
value: 82.799
- type: mrr_at_1000
value: 82.804
- type: mrr_at_3
value: 81.661
- type: mrr_at_5
value: 82.369
- type: ndcg_at_1
value: 74.482
- type: ndcg_at_10
value: 82.238
- type: ndcg_at_100
value: 83.245
- type: ndcg_at_1000
value: 83.557
- type: ndcg_at_3
value: 80.066
- type: ndcg_at_5
value: 81.316
- type: precision_at_1
value: 74.482
- type: precision_at_10
value: 10.006
- type: precision_at_100
value: 1.0699999999999998
- type: precision_at_1000
value: 0.11100000000000002
- type: precision_at_3
value: 30.808000000000003
- type: precision_at_5
value: 19.256
- type: recall_at_1
value: 68.987
- type: recall_at_10
value: 90.646
- type: recall_at_100
value: 94.85900000000001
- type: recall_at_1000
value: 96.979
- type: recall_at_3
value: 84.76599999999999
- type: recall_at_5
value: 87.929
- task:
type: Retrieval
dataset:
type: fiqa
name: MTEB FiQA2018
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 20.3
- type: map_at_10
value: 33.499
- type: map_at_100
value: 35.510000000000005
- type: map_at_1000
value: 35.693999999999996
- type: map_at_3
value: 29.083
- type: map_at_5
value: 31.367
- type: mrr_at_1
value: 39.660000000000004
- type: mrr_at_10
value: 49.517
- type: mrr_at_100
value: 50.18899999999999
- type: mrr_at_1000
value: 50.224000000000004
- type: mrr_at_3
value: 46.965
- type: mrr_at_5
value: 48.184
- type: ndcg_at_1
value: 39.660000000000004
- type: ndcg_at_10
value: 41.75
- type: ndcg_at_100
value: 48.477
- type: ndcg_at_1000
value: 51.373999999999995
- type: ndcg_at_3
value: 37.532
- type: ndcg_at_5
value: 38.564
- type: precision_at_1
value: 39.660000000000004
- type: precision_at_10
value: 11.774999999999999
- type: precision_at_100
value: 1.883
- type: precision_at_1000
value: 0.23900000000000002
- type: precision_at_3
value: 25.102999999999998
- type: precision_at_5
value: 18.395
- type: recall_at_1
value: 20.3
- type: recall_at_10
value: 49.633
- type: recall_at_100
value: 73.932
- type: recall_at_1000
value: 91.174
- type: recall_at_3
value: 34.516999999999996
- type: recall_at_5
value: 40.217000000000006
- task:
type: Retrieval
dataset:
type: hotpotqa
name: MTEB HotpotQA
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 34.699999999999996
- type: map_at_10
value: 54.400000000000006
- type: map_at_100
value: 55.45
- type: map_at_1000
value: 55.525999999999996
- type: map_at_3
value: 50.99
- type: map_at_5
value: 53.054
- type: mrr_at_1
value: 69.399
- type: mrr_at_10
value: 76.454
- type: mrr_at_100
value: 76.771
- type: mrr_at_1000
value: 76.783
- type: mrr_at_3
value: 75.179
- type: mrr_at_5
value: 75.978
- type: ndcg_at_1
value: 69.399
- type: ndcg_at_10
value: 63.001
- type: ndcg_at_100
value: 66.842
- type: ndcg_at_1000
value: 68.33500000000001
- type: ndcg_at_3
value: 57.961
- type: ndcg_at_5
value: 60.67700000000001
- type: precision_at_1
value: 69.399
- type: precision_at_10
value: 13.4
- type: precision_at_100
value: 1.6420000000000001
- type: precision_at_1000
value: 0.184
- type: precision_at_3
value: 37.218
- type: precision_at_5
value: 24.478
- type: recall_at_1
value: 34.699999999999996
- type: recall_at_10
value: 67.002
- type: recall_at_100
value: 82.113
- type: recall_at_1000
value: 91.945
- type: recall_at_3
value: 55.827000000000005
- type: recall_at_5
value: 61.195
- task:
type: Classification
dataset:
type: mteb/imdb
name: MTEB ImdbClassification
config: default
split: test
revision: 3d86128a09e091d6018b6d26cad27f2739fc2db7
metrics:
- type: accuracy
value: 90.40480000000001
- type: ap
value: 86.34472513785936
- type: f1
value: 90.3766943422773
- task:
type: Retrieval
dataset:
type: msmarco
name: MTEB MSMARCO
config: default
split: dev
revision: None
metrics:
- type: map_at_1
value: 19.796
- type: map_at_10
value: 31.344
- type: map_at_100
value: 32.525999999999996
- type: map_at_1000
value: 32.582
- type: map_at_3
value: 27.514
- type: map_at_5
value: 29.683
- type: mrr_at_1
value: 20.358
- type: mrr_at_10
value: 31.924999999999997
- type: mrr_at_100
value: 33.056000000000004
- type: mrr_at_1000
value: 33.105000000000004
- type: mrr_at_3
value: 28.149
- type: mrr_at_5
value: 30.303
- type: ndcg_at_1
value: 20.372
- type: ndcg_at_10
value: 38.025999999999996
- type: ndcg_at_100
value: 43.813
- type: ndcg_at_1000
value: 45.21
- type: ndcg_at_3
value: 30.218
- type: ndcg_at_5
value: 34.088
- type: precision_at_1
value: 20.372
- type: precision_at_10
value: 6.123
- type: precision_at_100
value: 0.903
- type: precision_at_1000
value: 0.10200000000000001
- type: precision_at_3
value: 12.918
- type: precision_at_5
value: 9.702
- type: recall_at_1
value: 19.796
- type: recall_at_10
value: 58.644
- type: recall_at_100
value: 85.611
- type: recall_at_1000
value: 96.314
- type: recall_at_3
value: 37.419999999999995
- type: recall_at_5
value: 46.697
- task:
type: Classification
dataset:
type: mteb/mtop_domain
name: MTEB MTOPDomainClassification (en)
config: en
split: test
revision: d80d48c1eb48d3562165c59d59d0034df9fff0bf
metrics:
- type: accuracy
value: 93.0984952120383
- type: f1
value: 92.9409029889071
- task:
type: Classification
dataset:
type: mteb/mtop_intent
name: MTEB MTOPIntentClassification (en)
config: en
split: test
revision: ae001d0e6b1228650b7bd1c2c65fb50ad11a8aba
metrics:
- type: accuracy
value: 73.24441404468764
- type: f1
value: 54.66568676132254
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (en)
config: en
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 73.86684599865501
- type: f1
value: 72.16086061041996
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (en)
config: en
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 78.16745124411568
- type: f1
value: 78.76361933295068
- task:
type: Clustering
dataset:
type: mteb/medrxiv-clustering-p2p
name: MTEB MedrxivClusteringP2P
config: default
split: test
revision: e7a26af6f3ae46b30dde8737f02c07b1505bcc73
metrics:
- type: v_measure
value: 33.66329421728342
- task:
type: Clustering
dataset:
type: mteb/medrxiv-clustering-s2s
name: MTEB MedrxivClusteringS2S
config: default
split: test
revision: 35191c8c0dca72d8ff3efcd72aa802307d469663
metrics:
- type: v_measure
value: 32.21637418682758
- task:
type: Reranking
dataset:
type: mteb/mind_small
name: MTEB MindSmallReranking
config: default
split: test
revision: 3bdac13927fdc888b903db93b2ffdbd90b295a69
metrics:
- type: map
value: 31.85308363141191
- type: mrr
value: 33.06713899953772
- task:
type: Retrieval
dataset:
type: nfcorpus
name: MTEB NFCorpus
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 6.392
- type: map_at_10
value: 14.539
- type: map_at_100
value: 18.811
- type: map_at_1000
value: 20.471
- type: map_at_3
value: 10.26
- type: map_at_5
value: 12.224
- type: mrr_at_1
value: 46.749
- type: mrr_at_10
value: 55.72200000000001
- type: mrr_at_100
value: 56.325
- type: mrr_at_1000
value: 56.35
- type: mrr_at_3
value: 53.30200000000001
- type: mrr_at_5
value: 54.742000000000004
- type: ndcg_at_1
value: 44.891999999999996
- type: ndcg_at_10
value: 37.355
- type: ndcg_at_100
value: 35.285
- type: ndcg_at_1000
value: 44.246
- type: ndcg_at_3
value: 41.291
- type: ndcg_at_5
value: 39.952
- type: precision_at_1
value: 46.749
- type: precision_at_10
value: 28.111000000000004
- type: precision_at_100
value: 9.127
- type: precision_at_1000
value: 2.23
- type: precision_at_3
value: 38.803
- type: precision_at_5
value: 35.046
- type: recall_at_1
value: 6.392
- type: recall_at_10
value: 19.066
- type: recall_at_100
value: 37.105
- type: recall_at_1000
value: 69.37299999999999
- type: recall_at_3
value: 11.213
- type: recall_at_5
value: 14.648
- task:
type: Retrieval
dataset:
type: nq
name: MTEB NQ
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 31.387999999999998
- type: map_at_10
value: 47.172
- type: map_at_100
value: 48.158
- type: map_at_1000
value: 48.186
- type: map_at_3
value: 42.952
- type: map_at_5
value: 45.405
- type: mrr_at_1
value: 35.458
- type: mrr_at_10
value: 49.583
- type: mrr_at_100
value: 50.324999999999996
- type: mrr_at_1000
value: 50.344
- type: mrr_at_3
value: 46.195
- type: mrr_at_5
value: 48.258
- type: ndcg_at_1
value: 35.458
- type: ndcg_at_10
value: 54.839000000000006
- type: ndcg_at_100
value: 58.974000000000004
- type: ndcg_at_1000
value: 59.64699999999999
- type: ndcg_at_3
value: 47.012
- type: ndcg_at_5
value: 51.080999999999996
- type: precision_at_1
value: 35.458
- type: precision_at_10
value: 9.056000000000001
- type: precision_at_100
value: 1.137
- type: precision_at_1000
value: 0.12
- type: precision_at_3
value: 21.582
- type: precision_at_5
value: 15.295
- type: recall_at_1
value: 31.387999999999998
- type: recall_at_10
value: 75.661
- type: recall_at_100
value: 93.605
- type: recall_at_1000
value: 98.658
- type: recall_at_3
value: 55.492
- type: recall_at_5
value: 64.85600000000001
- task:
type: Retrieval
dataset:
type: quora
name: MTEB QuoraRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 70.547
- type: map_at_10
value: 84.495
- type: map_at_100
value: 85.14
- type: map_at_1000
value: 85.15599999999999
- type: map_at_3
value: 81.606
- type: map_at_5
value: 83.449
- type: mrr_at_1
value: 81.22
- type: mrr_at_10
value: 87.31
- type: mrr_at_100
value: 87.436
- type: mrr_at_1000
value: 87.437
- type: mrr_at_3
value: 86.363
- type: mrr_at_5
value: 87.06
- type: ndcg_at_1
value: 81.24
- type: ndcg_at_10
value: 88.145
- type: ndcg_at_100
value: 89.423
- type: ndcg_at_1000
value: 89.52799999999999
- type: ndcg_at_3
value: 85.435
- type: ndcg_at_5
value: 87
- type: precision_at_1
value: 81.24
- type: precision_at_10
value: 13.381000000000002
- type: precision_at_100
value: 1.529
- type: precision_at_1000
value: 0.157
- type: precision_at_3
value: 37.44
- type: precision_at_5
value: 24.62
- type: recall_at_1
value: 70.547
- type: recall_at_10
value: 95.083
- type: recall_at_100
value: 99.50099999999999
- type: recall_at_1000
value: 99.982
- type: recall_at_3
value: 87.235
- type: recall_at_5
value: 91.701
- task:
type: Clustering
dataset:
type: mteb/reddit-clustering
name: MTEB RedditClustering
config: default
split: test
revision: 24640382cdbf8abc73003fb0fa6d111a705499eb
metrics:
- type: v_measure
value: 57.93101384071724
- task:
type: Clustering
dataset:
type: mteb/reddit-clustering-p2p
name: MTEB RedditClusteringP2P
config: default
split: test
revision: 282350215ef01743dc01b456c7f5241fa8937f16
metrics:
- type: v_measure
value: 62.46951126228829
- task:
type: Retrieval
dataset:
type: scidocs
name: MTEB SCIDOCS
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 5.018000000000001
- type: map_at_10
value: 13.818
- type: map_at_100
value: 16.346
- type: map_at_1000
value: 16.744999999999997
- type: map_at_3
value: 9.456000000000001
- type: map_at_5
value: 11.879000000000001
- type: mrr_at_1
value: 24.8
- type: mrr_at_10
value: 37.092000000000006
- type: mrr_at_100
value: 38.199
- type: mrr_at_1000
value: 38.243
- type: mrr_at_3
value: 33.517
- type: mrr_at_5
value: 35.692
- type: ndcg_at_1
value: 24.8
- type: ndcg_at_10
value: 22.782
- type: ndcg_at_100
value: 32.072
- type: ndcg_at_1000
value: 38.163000000000004
- type: ndcg_at_3
value: 21.046
- type: ndcg_at_5
value: 19.134
- type: precision_at_1
value: 24.8
- type: precision_at_10
value: 12
- type: precision_at_100
value: 2.5420000000000003
- type: precision_at_1000
value: 0.39899999999999997
- type: precision_at_3
value: 20
- type: precision_at_5
value: 17.4
- type: recall_at_1
value: 5.018000000000001
- type: recall_at_10
value: 24.34
- type: recall_at_100
value: 51.613
- type: recall_at_1000
value: 80.95
- type: recall_at_3
value: 12.153
- type: recall_at_5
value: 17.648
- task:
type: STS
dataset:
type: mteb/sickr-sts
name: MTEB SICK-R
config: default
split: test
revision: a6ea5a8cab320b040a23452cc28066d9beae2cee
metrics:
- type: cos_sim_pearson
value: 86.28259142800503
- type: cos_sim_spearman
value: 82.04792579356291
- type: euclidean_pearson
value: 83.7755858026306
- type: euclidean_spearman
value: 82.04789872846196
- type: manhattan_pearson
value: 83.79937122515567
- type: manhattan_spearman
value: 82.05076966288574
- task:
type: STS
dataset:
type: mteb/sts12-sts
name: MTEB STS12
config: default
split: test
revision: a0d554a64d88156834ff5ae9920b964011b16384
metrics:
- type: cos_sim_pearson
value: 87.37773414195387
- type: cos_sim_spearman
value: 78.76929696642694
- type: euclidean_pearson
value: 85.75861298616339
- type: euclidean_spearman
value: 78.76607739031363
- type: manhattan_pearson
value: 85.74412868736295
- type: manhattan_spearman
value: 78.74388526796852
- task:
type: STS
dataset:
type: mteb/sts13-sts
name: MTEB STS13
config: default
split: test
revision: 7e90230a92c190f1bf69ae9002b8cea547a64cca
metrics:
- type: cos_sim_pearson
value: 89.6176449076649
- type: cos_sim_spearman
value: 90.39810997063387
- type: euclidean_pearson
value: 89.753863994154
- type: euclidean_spearman
value: 90.39810989027997
- type: manhattan_pearson
value: 89.67750819879801
- type: manhattan_spearman
value: 90.3286558059104
- task:
type: STS
dataset:
type: mteb/sts14-sts
name: MTEB STS14
config: default
split: test
revision: 6031580fec1f6af667f0bd2da0a551cf4f0b2375
metrics:
- type: cos_sim_pearson
value: 87.7488246203373
- type: cos_sim_spearman
value: 85.44794976383963
- type: euclidean_pearson
value: 87.33205836313964
- type: euclidean_spearman
value: 85.44793954377185
- type: manhattan_pearson
value: 87.30760291906203
- type: manhattan_spearman
value: 85.4308413187653
- task:
type: STS
dataset:
type: mteb/sts15-sts
name: MTEB STS15
config: default
split: test
revision: ae752c7c21bf194d8b67fd573edf7ae58183cbe3
metrics:
- type: cos_sim_pearson
value: 88.6937750952719
- type: cos_sim_spearman
value: 90.01162604967037
- type: euclidean_pearson
value: 89.35321306629116
- type: euclidean_spearman
value: 90.01161406477627
- type: manhattan_pearson
value: 89.31351907042307
- type: manhattan_spearman
value: 89.97264644642166
- task:
type: STS
dataset:
type: mteb/sts16-sts
name: MTEB STS16
config: default
split: test
revision: 4d8694f8f0e0100860b497b999b3dbed754a0513
metrics:
- type: cos_sim_pearson
value: 85.49107564294891
- type: cos_sim_spearman
value: 87.42092493144571
- type: euclidean_pearson
value: 86.88112016705634
- type: euclidean_spearman
value: 87.42092430260175
- type: manhattan_pearson
value: 86.85846210123235
- type: manhattan_spearman
value: 87.40059575522972
- task:
type: STS
dataset:
type: mteb/sts17-crosslingual-sts
name: MTEB STS17 (en-en)
config: en-en
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 88.71766466521638
- type: cos_sim_spearman
value: 88.80244555668372
- type: euclidean_pearson
value: 89.59428700746064
- type: euclidean_spearman
value: 88.80244555668372
- type: manhattan_pearson
value: 89.62272396580352
- type: manhattan_spearman
value: 88.77584531534937
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (en)
config: en
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 67.7743776239708
- type: cos_sim_spearman
value: 68.79768249749681
- type: euclidean_pearson
value: 70.16430919697441
- type: euclidean_spearman
value: 68.79768249749681
- type: manhattan_pearson
value: 70.17205038967042
- type: manhattan_spearman
value: 68.89740094589914
- task:
type: STS
dataset:
type: mteb/stsbenchmark-sts
name: MTEB STSBenchmark
config: default
split: test
revision: b0fddb56ed78048fa8b90373c8a3cfc37b684831
metrics:
- type: cos_sim_pearson
value: 86.9087137484716
- type: cos_sim_spearman
value: 89.19783009521629
- type: euclidean_pearson
value: 88.89888500166009
- type: euclidean_spearman
value: 89.19783009521629
- type: manhattan_pearson
value: 88.88400033783687
- type: manhattan_spearman
value: 89.16299162200889
- task:
type: Reranking
dataset:
type: mteb/scidocs-reranking
name: MTEB SciDocsRR
config: default
split: test
revision: d3c5e1fc0b855ab6097bf1cda04dd73947d7caab
metrics:
- type: map
value: 86.9799916253683
- type: mrr
value: 96.0708200659181
- task:
type: Retrieval
dataset:
type: scifact
name: MTEB SciFact
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 59.928000000000004
- type: map_at_10
value: 69.56400000000001
- type: map_at_100
value: 70.125
- type: map_at_1000
value: 70.148
- type: map_at_3
value: 66.774
- type: map_at_5
value: 68.267
- type: mrr_at_1
value: 62.666999999999994
- type: mrr_at_10
value: 70.448
- type: mrr_at_100
value: 70.94
- type: mrr_at_1000
value: 70.962
- type: mrr_at_3
value: 68.389
- type: mrr_at_5
value: 69.65599999999999
- type: ndcg_at_1
value: 62.666999999999994
- type: ndcg_at_10
value: 74.117
- type: ndcg_at_100
value: 76.248
- type: ndcg_at_1000
value: 76.768
- type: ndcg_at_3
value: 69.358
- type: ndcg_at_5
value: 71.574
- type: precision_at_1
value: 62.666999999999994
- type: precision_at_10
value: 9.933
- type: precision_at_100
value: 1.09
- type: precision_at_1000
value: 0.11299999999999999
- type: precision_at_3
value: 27.222
- type: precision_at_5
value: 17.867
- type: recall_at_1
value: 59.928000000000004
- type: recall_at_10
value: 87.156
- type: recall_at_100
value: 96.167
- type: recall_at_1000
value: 100
- type: recall_at_3
value: 74.117
- type: recall_at_5
value: 79.80000000000001
- task:
type: PairClassification
dataset:
type: mteb/sprintduplicatequestions-pairclassification
name: MTEB SprintDuplicateQuestions
config: default
split: test
revision: d66bd1f72af766a5cc4b0ca5e00c162f89e8cc46
metrics:
- type: cos_sim_accuracy
value: 99.83762376237624
- type: cos_sim_ap
value: 96.05077689253707
- type: cos_sim_f1
value: 91.75879396984925
- type: cos_sim_precision
value: 92.22222222222223
- type: cos_sim_recall
value: 91.3
- type: dot_accuracy
value: 99.83762376237624
- type: dot_ap
value: 96.05082513542375
- type: dot_f1
value: 91.75879396984925
- type: dot_precision
value: 92.22222222222223
- type: dot_recall
value: 91.3
- type: euclidean_accuracy
value: 99.83762376237624
- type: euclidean_ap
value: 96.05077689253707
- type: euclidean_f1
value: 91.75879396984925
- type: euclidean_precision
value: 92.22222222222223
- type: euclidean_recall
value: 91.3
- type: manhattan_accuracy
value: 99.83861386138614
- type: manhattan_ap
value: 96.07646831090695
- type: manhattan_f1
value: 91.86220668996505
- type: manhattan_precision
value: 91.72482552342971
- type: manhattan_recall
value: 92
- type: max_accuracy
value: 99.83861386138614
- type: max_ap
value: 96.07646831090695
- type: max_f1
value: 91.86220668996505
- task:
type: Clustering
dataset:
type: mteb/stackexchange-clustering
name: MTEB StackExchangeClustering
config: default
split: test
revision: 6cbc1f7b2bc0622f2e39d2c77fa502909748c259
metrics:
- type: v_measure
value: 66.40672513062134
- task:
type: Clustering
dataset:
type: mteb/stackexchange-clustering-p2p
name: MTEB StackExchangeClusteringP2P
config: default
split: test
revision: 815ca46b2622cec33ccafc3735d572c266efdb44
metrics:
- type: v_measure
value: 35.31519237029376
- task:
type: Reranking
dataset:
type: mteb/stackoverflowdupquestions-reranking
name: MTEB StackOverflowDupQuestions
config: default
split: test
revision: e185fbe320c72810689fc5848eb6114e1ef5ec69
metrics:
- type: map
value: 53.15764586446943
- type: mrr
value: 53.981596426449364
- task:
type: Summarization
dataset:
type: mteb/summeval
name: MTEB SummEval
config: default
split: test
revision: cda12ad7615edc362dbf25a00fdd61d3b1eaf93c
metrics:
- type: cos_sim_pearson
value: 30.92935724124931
- type: cos_sim_spearman
value: 31.54589922149803
- type: dot_pearson
value: 30.929365687857675
- type: dot_spearman
value: 31.54589922149803
- task:
type: Retrieval
dataset:
type: trec-covid
name: MTEB TRECCOVID
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 0.22100000000000003
- type: map_at_10
value: 1.791
- type: map_at_100
value: 9.404
- type: map_at_1000
value: 22.932
- type: map_at_3
value: 0.601
- type: map_at_5
value: 1.001
- type: mrr_at_1
value: 76
- type: mrr_at_10
value: 85.667
- type: mrr_at_100
value: 85.667
- type: mrr_at_1000
value: 85.667
- type: mrr_at_3
value: 84.667
- type: mrr_at_5
value: 85.667
- type: ndcg_at_1
value: 72
- type: ndcg_at_10
value: 68.637
- type: ndcg_at_100
value: 51.418
- type: ndcg_at_1000
value: 47.75
- type: ndcg_at_3
value: 70.765
- type: ndcg_at_5
value: 71.808
- type: precision_at_1
value: 76
- type: precision_at_10
value: 73.8
- type: precision_at_100
value: 52.68000000000001
- type: precision_at_1000
value: 20.9
- type: precision_at_3
value: 74.667
- type: precision_at_5
value: 78
- type: recall_at_1
value: 0.22100000000000003
- type: recall_at_10
value: 2.027
- type: recall_at_100
value: 12.831000000000001
- type: recall_at_1000
value: 44.996
- type: recall_at_3
value: 0.635
- type: recall_at_5
value: 1.097
- task:
type: Retrieval
dataset:
type: webis-touche2020
name: MTEB Touche2020
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 2.289
- type: map_at_10
value: 10.475
- type: map_at_100
value: 16.993
- type: map_at_1000
value: 18.598
- type: map_at_3
value: 5.891
- type: map_at_5
value: 7.678999999999999
- type: mrr_at_1
value: 32.653
- type: mrr_at_10
value: 49.475
- type: mrr_at_100
value: 50.483
- type: mrr_at_1000
value: 50.499
- type: mrr_at_3
value: 45.918
- type: mrr_at_5
value: 48.469
- type: ndcg_at_1
value: 29.592000000000002
- type: ndcg_at_10
value: 25.891
- type: ndcg_at_100
value: 38.106
- type: ndcg_at_1000
value: 49.873
- type: ndcg_at_3
value: 29.915999999999997
- type: ndcg_at_5
value: 27.982000000000003
- type: precision_at_1
value: 32.653
- type: precision_at_10
value: 22.448999999999998
- type: precision_at_100
value: 7.837
- type: precision_at_1000
value: 1.5730000000000002
- type: precision_at_3
value: 31.293
- type: precision_at_5
value: 27.755000000000003
- type: recall_at_1
value: 2.289
- type: recall_at_10
value: 16.594
- type: recall_at_100
value: 48.619
- type: recall_at_1000
value: 85.467
- type: recall_at_3
value: 7.144
- type: recall_at_5
value: 10.465
- task:
type: Classification
dataset:
type: mteb/toxic_conversations_50k
name: MTEB ToxicConversationsClassification
config: default
split: test
revision: d7c0de2777da35d6aae2200a62c6e0e5af397c4c
metrics:
- type: accuracy
value: 71.5268
- type: ap
value: 14.763212211567907
- type: f1
value: 55.200562727472736
- task:
type: Classification
dataset:
type: mteb/tweet_sentiment_extraction
name: MTEB TweetSentimentExtractionClassification
config: default
split: test
revision: d604517c81ca91fe16a244d1248fc021f9ecee7a
metrics:
- type: accuracy
value: 59.25297113752123
- type: f1
value: 59.55315247947331
- task:
type: Clustering
dataset:
type: mteb/twentynewsgroups-clustering
name: MTEB TwentyNewsgroupsClustering
config: default
split: test
revision: 6125ec4e24fa026cec8a478383ee943acfbd5449
metrics:
- type: v_measure
value: 51.47685515092062
- task:
type: PairClassification
dataset:
type: mteb/twittersemeval2015-pairclassification
name: MTEB TwitterSemEval2015
config: default
split: test
revision: 70970daeab8776df92f5ea462b6173c0b46fd2d1
metrics:
- type: cos_sim_accuracy
value: 86.73183525064076
- type: cos_sim_ap
value: 76.08498196190112
- type: cos_sim_f1
value: 69.4834471209584
- type: cos_sim_precision
value: 67.88321167883211
- type: cos_sim_recall
value: 71.16094986807387
- type: dot_accuracy
value: 86.73183525064076
- type: dot_ap
value: 76.08503499590553
- type: dot_f1
value: 69.4834471209584
- type: dot_precision
value: 67.88321167883211
- type: dot_recall
value: 71.16094986807387
- type: euclidean_accuracy
value: 86.73183525064076
- type: euclidean_ap
value: 76.08500172594562
- type: euclidean_f1
value: 69.4834471209584
- type: euclidean_precision
value: 67.88321167883211
- type: euclidean_recall
value: 71.16094986807387
- type: manhattan_accuracy
value: 86.6960720033379
- type: manhattan_ap
value: 76.00885156192993
- type: manhattan_f1
value: 69.24488725747247
- type: manhattan_precision
value: 68.8118811881188
- type: manhattan_recall
value: 69.68337730870712
- type: max_accuracy
value: 86.73183525064076
- type: max_ap
value: 76.08503499590553
- type: max_f1
value: 69.4834471209584
- task:
type: PairClassification
dataset:
type: mteb/twitterurlcorpus-pairclassification
name: MTEB TwitterURLCorpus
config: default
split: test
revision: 8b6510b0b1fa4e4c4f879467980e9be563ec1cdf
metrics:
- type: cos_sim_accuracy
value: 88.74529436876625
- type: cos_sim_ap
value: 85.53503158777171
- type: cos_sim_f1
value: 77.68167368965773
- type: cos_sim_precision
value: 74.70496232048912
- type: cos_sim_recall
value: 80.9054511857099
- type: dot_accuracy
value: 88.74529436876625
- type: dot_ap
value: 85.5350158446314
- type: dot_f1
value: 77.68167368965773
- type: dot_precision
value: 74.70496232048912
- type: dot_recall
value: 80.9054511857099
- type: euclidean_accuracy
value: 88.74529436876625
- type: euclidean_ap
value: 85.53503846009764
- type: euclidean_f1
value: 77.68167368965773
- type: euclidean_precision
value: 74.70496232048912
- type: euclidean_recall
value: 80.9054511857099
- type: manhattan_accuracy
value: 88.73753250281368
- type: manhattan_ap
value: 85.53197689629393
- type: manhattan_f1
value: 77.58753437213566
- type: manhattan_precision
value: 74.06033456988871
- type: manhattan_recall
value: 81.46750846935633
- type: max_accuracy
value: 88.74529436876625
- type: max_ap
value: 85.53503846009764
- type: max_f1
value: 77.68167368965773
license: apache-2.0
language:
- en
library_name: sentence-transformers
---
<br><br>
<p align="center">
<svg xmlns="http://www.w3.org/2000/svg" xml:space="preserve" viewBox="0 0 2020 1130" width="150" height="150" aria-hidden="true"><path fill="#e95a0f" d="M398.167 621.992c-1.387-20.362-4.092-40.739-3.851-61.081.355-30.085 6.873-59.139 21.253-85.976 10.487-19.573 24.09-36.822 40.662-51.515 16.394-14.535 34.338-27.046 54.336-36.182 15.224-6.955 31.006-12.609 47.829-14.168 11.809-1.094 23.753-2.514 35.524-1.836 23.033 1.327 45.131 7.255 66.255 16.75 16.24 7.3 31.497 16.165 45.651 26.969 12.997 9.921 24.412 21.37 34.158 34.509 11.733 15.817 20.849 33.037 25.987 52.018 3.468 12.81 6.438 25.928 7.779 39.097 1.722 16.908 1.642 34.003 2.235 51.021.427 12.253.224 24.547 1.117 36.762 1.677 22.93 4.062 45.764 11.8 67.7 5.376 15.239 12.499 29.55 20.846 43.681l-18.282 20.328c-1.536 1.71-2.795 3.665-4.254 5.448l-19.323 23.533c-13.859-5.449-27.446-11.803-41.657-16.086-13.622-4.106-27.793-6.765-41.905-8.775-15.256-2.173-30.701-3.475-46.105-4.049-23.571-.879-47.178-1.056-70.769-1.029-10.858.013-21.723 1.116-32.57 1.926-5.362.4-10.69 1.255-16.464 1.477-2.758-7.675-5.284-14.865-7.367-22.181-3.108-10.92-4.325-22.554-13.16-31.095-2.598-2.512-5.069-5.341-6.883-8.443-6.366-10.884-12.48-21.917-18.571-32.959-4.178-7.573-8.411-14.375-17.016-18.559-10.34-5.028-19.538-12.387-29.311-18.611-3.173-2.021-6.414-4.312-9.952-5.297-5.857-1.63-11.98-2.301-17.991-3.376z"></path><path fill="#ed6d7b" d="M1478.998 758.842c-12.025.042-24.05.085-36.537-.373-.14-8.536.231-16.569.453-24.607.033-1.179-.315-2.986-1.081-3.4-.805-.434-2.376.338-3.518.81-.856.354-1.562 1.069-3.589 2.521-.239-3.308-.664-5.586-.519-7.827.488-7.544 2.212-15.166 1.554-22.589-1.016-11.451 1.397-14.592-12.332-14.419-3.793.048-3.617-2.803-3.332-5.331.499-4.422 1.45-8.803 1.77-13.233.311-4.316.068-8.672.068-12.861-2.554-.464-4.326-.86-6.12-1.098-4.415-.586-6.051-2.251-5.065-7.31 1.224-6.279.848-12.862 1.276-19.306.19-2.86-.971-4.473-3.794-4.753-4.113-.407-8.242-1.057-12.352-.975-4.663.093-5.192-2.272-4.751-6.012.733-6.229 1.252-12.483 1.875-18.726l1.102-10.495c-5.905-.309-11.146-.805-16.385-.778-3.32.017-5.174-1.4-5.566-4.4-1.172-8.968-2.479-17.944-3.001-26.96-.26-4.484-1.936-5.705-6.005-5.774-9.284-.158-18.563-.594-27.843-.953-7.241-.28-10.137-2.764-11.3-9.899-.746-4.576-2.715-7.801-7.777-8.207-7.739-.621-15.511-.992-23.207-1.961-7.327-.923-14.587-2.415-21.853-3.777-5.021-.941-10.003-2.086-15.003-3.14 4.515-22.952 13.122-44.382 26.284-63.587 18.054-26.344 41.439-47.239 69.102-63.294 15.847-9.197 32.541-16.277 50.376-20.599 16.655-4.036 33.617-5.715 50.622-4.385 33.334 2.606 63.836 13.955 92.415 31.15 15.864 9.545 30.241 20.86 42.269 34.758 8.113 9.374 15.201 19.78 21.718 30.359 10.772 17.484 16.846 36.922 20.611 56.991 1.783 9.503 2.815 19.214 3.318 28.876.758 14.578.755 29.196.65 44.311l-51.545 20.013c-7.779 3.059-15.847 5.376-21.753 12.365-4.73 5.598-10.658 10.316-16.547 14.774-9.9 7.496-18.437 15.988-25.083 26.631-3.333 5.337-7.901 10.381-12.999 14.038-11.355 8.144-17.397 18.973-19.615 32.423l-6.988 41.011z"></path><path fill="#ec663e" d="M318.11 923.047c-.702 17.693-.832 35.433-2.255 53.068-1.699 21.052-6.293 41.512-14.793 61.072-9.001 20.711-21.692 38.693-38.496 53.583-16.077 14.245-34.602 24.163-55.333 30.438-21.691 6.565-43.814 8.127-66.013 6.532-22.771-1.636-43.88-9.318-62.74-22.705-20.223-14.355-35.542-32.917-48.075-54.096-9.588-16.203-16.104-33.55-19.201-52.015-2.339-13.944-2.307-28.011-.403-42.182 2.627-19.545 9.021-37.699 17.963-55.067 11.617-22.564 27.317-41.817 48.382-56.118 15.819-10.74 33.452-17.679 52.444-20.455 8.77-1.282 17.696-1.646 26.568-2.055 11.755-.542 23.534-.562 35.289-1.11 8.545-.399 17.067-1.291 26.193-1.675 1.349 1.77 2.24 3.199 2.835 4.742 4.727 12.261 10.575 23.865 18.636 34.358 7.747 10.084 14.83 20.684 22.699 30.666 3.919 4.972 8.37 9.96 13.609 13.352 7.711 4.994 16.238 8.792 24.617 12.668 5.852 2.707 12.037 4.691 18.074 6.998z"></path><path fill="#ea580e" d="M1285.167 162.995c3.796-29.75 13.825-56.841 32.74-80.577 16.339-20.505 36.013-36.502 59.696-47.614 14.666-6.881 29.971-11.669 46.208-12.749 10.068-.669 20.239-1.582 30.255-.863 16.6 1.191 32.646 5.412 47.9 12.273 19.39 8.722 36.44 20.771 50.582 36.655 15.281 17.162 25.313 37.179 31.49 59.286 5.405 19.343 6.31 39.161 4.705 58.825-2.37 29.045-11.836 55.923-30.451 78.885-10.511 12.965-22.483 24.486-37.181 33.649-5.272-5.613-10.008-11.148-14.539-16.846-5.661-7.118-10.958-14.533-16.78-21.513-4.569-5.478-9.548-10.639-14.624-15.658-3.589-3.549-7.411-6.963-11.551-9.827-5.038-3.485-10.565-6.254-15.798-9.468-8.459-5.195-17.011-9.669-26.988-11.898-12.173-2.72-24.838-4.579-35.622-11.834-1.437-.967-3.433-1.192-5.213-1.542-12.871-2.529-25.454-5.639-36.968-12.471-5.21-3.091-11.564-4.195-17.011-6.965-4.808-2.445-8.775-6.605-13.646-8.851-8.859-4.085-18.114-7.311-27.204-10.896z"></path><path fill="#f8ab00" d="M524.963 311.12c-9.461-5.684-19.513-10.592-28.243-17.236-12.877-9.801-24.031-21.578-32.711-35.412-11.272-17.965-19.605-37.147-21.902-58.403-1.291-11.951-2.434-24.073-1.87-36.034.823-17.452 4.909-34.363 11.581-50.703 8.82-21.603 22.25-39.792 39.568-55.065 18.022-15.894 39.162-26.07 62.351-32.332 19.22-5.19 38.842-6.177 58.37-4.674 23.803 1.831 45.56 10.663 65.062 24.496 17.193 12.195 31.688 27.086 42.894 45.622-11.403 8.296-22.633 16.117-34.092 23.586-17.094 11.142-34.262 22.106-48.036 37.528-8.796 9.848-17.201 20.246-27.131 28.837-16.859 14.585-27.745 33.801-41.054 51.019-11.865 15.349-20.663 33.117-30.354 50.08-5.303 9.283-9.654 19.11-14.434 28.692z"></path><path fill="#ea5227" d="M1060.11 1122.049c-7.377 1.649-14.683 4.093-22.147 4.763-11.519 1.033-23.166 1.441-34.723 1.054-19.343-.647-38.002-4.7-55.839-12.65-15.078-6.72-28.606-15.471-40.571-26.836-24.013-22.81-42.053-49.217-49.518-81.936-1.446-6.337-1.958-12.958-2.235-19.477-.591-13.926-.219-27.909-1.237-41.795-.916-12.5-3.16-24.904-4.408-37.805 1.555-1.381 3.134-2.074 3.778-3.27 4.729-8.79 12.141-15.159 19.083-22.03 5.879-5.818 10.688-12.76 16.796-18.293 6.993-6.335 11.86-13.596 14.364-22.612l8.542-29.993c8.015 1.785 15.984 3.821 24.057 5.286 8.145 1.478 16.371 2.59 24.602 3.493 8.453.927 16.956 1.408 25.891 2.609 1.119 16.09 1.569 31.667 2.521 47.214.676 11.045 1.396 22.154 3.234 33.043 2.418 14.329 5.708 28.527 9.075 42.674 3.499 14.705 4.028 29.929 10.415 44.188 10.157 22.674 18.29 46.25 28.281 69.004 7.175 16.341 12.491 32.973 15.078 50.615.645 4.4 3.256 8.511 4.963 12.755z"></path><path fill="#ea5330" d="M1060.512 1122.031c-2.109-4.226-4.72-8.337-5.365-12.737-2.587-17.642-7.904-34.274-15.078-50.615-9.991-22.755-18.124-46.33-28.281-69.004-6.387-14.259-6.916-29.482-10.415-44.188-3.366-14.147-6.656-28.346-9.075-42.674-1.838-10.889-2.558-21.999-3.234-33.043-.951-15.547-1.401-31.124-2.068-47.146 8.568-.18 17.146.487 25.704.286l41.868-1.4c.907 3.746 1.245 7.04 1.881 10.276l8.651 42.704c.903 4.108 2.334 8.422 4.696 11.829 7.165 10.338 14.809 20.351 22.456 30.345 4.218 5.512 8.291 11.304 13.361 15.955 8.641 7.927 18.065 14.995 27.071 22.532 12.011 10.052 24.452 19.302 40.151 22.854-1.656 11.102-2.391 22.44-5.172 33.253-4.792 18.637-12.38 36.209-23.412 52.216-13.053 18.94-29.086 34.662-49.627 45.055-10.757 5.443-22.443 9.048-34.111 13.501z"></path><path fill="#f8aa05" d="M1989.106 883.951c5.198 8.794 11.46 17.148 15.337 26.491 5.325 12.833 9.744 26.207 12.873 39.737 2.95 12.757 3.224 25.908 1.987 39.219-1.391 14.973-4.643 29.268-10.349 43.034-5.775 13.932-13.477 26.707-23.149 38.405-14.141 17.104-31.215 30.458-50.807 40.488-14.361 7.352-29.574 12.797-45.741 14.594-10.297 1.144-20.732 2.361-31.031 1.894-24.275-1.1-47.248-7.445-68.132-20.263-6.096-3.741-11.925-7.917-17.731-12.342 5.319-5.579 10.361-10.852 15.694-15.811l37.072-34.009c.975-.892 2.113-1.606 3.08-2.505 6.936-6.448 14.765-12.2 20.553-19.556 8.88-11.285 20.064-19.639 31.144-28.292 4.306-3.363 9.06-6.353 12.673-10.358 5.868-6.504 10.832-13.814 16.422-20.582 6.826-8.264 13.727-16.481 20.943-24.401 4.065-4.461 8.995-8.121 13.249-12.424 14.802-14.975 28.77-30.825 45.913-43.317z"></path><path fill="#ed6876" d="M1256.099 523.419c5.065.642 10.047 1.787 15.068 2.728 7.267 1.362 14.526 2.854 21.853 3.777 7.696.97 15.468 1.34 23.207 1.961 5.062.406 7.031 3.631 7.777 8.207 1.163 7.135 4.059 9.62 11.3 9.899l27.843.953c4.069.069 5.745 1.291 6.005 5.774.522 9.016 1.829 17.992 3.001 26.96.392 3 2.246 4.417 5.566 4.4 5.239-.026 10.48.469 16.385.778l-1.102 10.495-1.875 18.726c-.44 3.74.088 6.105 4.751 6.012 4.11-.082 8.239.568 12.352.975 2.823.28 3.984 1.892 3.794 4.753-.428 6.444-.052 13.028-1.276 19.306-.986 5.059.651 6.724 5.065 7.31 1.793.238 3.566.634 6.12 1.098 0 4.189.243 8.545-.068 12.861-.319 4.43-1.27 8.811-1.77 13.233-.285 2.528-.461 5.379 3.332 5.331 13.729-.173 11.316 2.968 12.332 14.419.658 7.423-1.066 15.045-1.554 22.589-.145 2.241.28 4.519.519 7.827 2.026-1.452 2.733-2.167 3.589-2.521 1.142-.472 2.713-1.244 3.518-.81.767.414 1.114 2.221 1.081 3.4l-.917 24.539c-11.215.82-22.45.899-33.636 1.674l-43.952 3.436c-1.086-3.01-2.319-5.571-2.296-8.121.084-9.297-4.468-16.583-9.091-24.116-3.872-6.308-8.764-13.052-9.479-19.987-1.071-10.392-5.716-15.936-14.889-18.979-1.097-.364-2.16-.844-3.214-1.327-7.478-3.428-15.548-5.918-19.059-14.735-.904-2.27-3.657-3.775-5.461-5.723-2.437-2.632-4.615-5.525-7.207-7.987-2.648-2.515-5.352-5.346-8.589-6.777-4.799-2.121-10.074-3.185-15.175-4.596l-15.785-4.155c.274-12.896 1.722-25.901.54-38.662-1.647-17.783-3.457-35.526-2.554-53.352.528-10.426 2.539-20.777 3.948-31.574z"></path><path fill="#f6a200" d="M525.146 311.436c4.597-9.898 8.947-19.725 14.251-29.008 9.691-16.963 18.49-34.73 30.354-50.08 13.309-17.218 24.195-36.434 41.054-51.019 9.93-8.591 18.335-18.989 27.131-28.837 13.774-15.422 30.943-26.386 48.036-37.528 11.459-7.469 22.688-15.29 34.243-23.286 11.705 16.744 19.716 35.424 22.534 55.717 2.231 16.066 2.236 32.441 2.753 49.143-4.756 1.62-9.284 2.234-13.259 4.056-6.43 2.948-12.193 7.513-18.774 9.942-19.863 7.331-33.806 22.349-47.926 36.784-7.86 8.035-13.511 18.275-19.886 27.705-4.434 6.558-9.345 13.037-12.358 20.254-4.249 10.177-6.94 21.004-10.296 31.553-12.33.053-24.741 1.027-36.971-.049-20.259-1.783-40.227-5.567-58.755-14.69-.568-.28-1.295-.235-2.132-.658z"></path><path fill="#f7a80d" d="M1989.057 883.598c-17.093 12.845-31.061 28.695-45.863 43.67-4.254 4.304-9.184 7.963-13.249 12.424-7.216 7.92-14.117 16.137-20.943 24.401-5.59 6.768-10.554 14.078-16.422 20.582-3.614 4.005-8.367 6.995-12.673 10.358-11.08 8.653-22.264 17.007-31.144 28.292-5.788 7.356-13.617 13.108-20.553 19.556-.967.899-2.105 1.614-3.08 2.505l-37.072 34.009c-5.333 4.96-10.375 10.232-15.859 15.505-21.401-17.218-37.461-38.439-48.623-63.592 3.503-1.781 7.117-2.604 9.823-4.637 8.696-6.536 20.392-8.406 27.297-17.714.933-1.258 2.646-1.973 4.065-2.828 17.878-10.784 36.338-20.728 53.441-32.624 10.304-7.167 18.637-17.23 27.583-26.261 3.819-3.855 7.436-8.091 10.3-12.681 12.283-19.68 24.43-39.446 40.382-56.471 12.224-13.047 17.258-29.524 22.539-45.927 15.85 4.193 29.819 12.129 42.632 22.08 10.583 8.219 19.782 17.883 27.42 29.351z"></path><path fill="#ef7a72" d="M1479.461 758.907c1.872-13.734 4.268-27.394 6.525-41.076 2.218-13.45 8.26-24.279 19.615-32.423 5.099-3.657 9.667-8.701 12.999-14.038 6.646-10.643 15.183-19.135 25.083-26.631 5.888-4.459 11.817-9.176 16.547-14.774 5.906-6.99 13.974-9.306 21.753-12.365l51.48-19.549c.753 11.848.658 23.787 1.641 35.637 1.771 21.353 4.075 42.672 11.748 62.955.17.449.107.985-.019 2.158-6.945 4.134-13.865 7.337-20.437 11.143-3.935 2.279-7.752 5.096-10.869 8.384-6.011 6.343-11.063 13.624-17.286 19.727-9.096 8.92-12.791 20.684-18.181 31.587-.202.409-.072.984-.096 1.481-8.488-1.72-16.937-3.682-25.476-5.094-9.689-1.602-19.426-3.084-29.201-3.949-15.095-1.335-30.241-2.1-45.828-3.172z"></path><path fill="#e94e3b" d="M957.995 766.838c-20.337-5.467-38.791-14.947-55.703-27.254-8.2-5.967-15.451-13.238-22.958-20.37 2.969-3.504 5.564-6.772 8.598-9.563 7.085-6.518 11.283-14.914 15.8-23.153 4.933-8.996 10.345-17.743 14.966-26.892 2.642-5.231 5.547-11.01 5.691-16.611.12-4.651.194-8.932 2.577-12.742 8.52-13.621 15.483-28.026 18.775-43.704 2.11-10.049 7.888-18.774 7.81-29.825-.064-9.089 4.291-18.215 6.73-27.313 3.212-11.983 7.369-23.797 9.492-35.968 3.202-18.358 5.133-36.945 7.346-55.466l4.879-45.8c6.693.288 13.386.575 20.54 1.365.13 3.458-.41 6.407-.496 9.37l-1.136 42.595c-.597 11.552-2.067 23.058-3.084 34.59l-3.845 44.478c-.939 10.202-1.779 20.432-3.283 30.557-.96 6.464-4.46 12.646-1.136 19.383.348.706-.426 1.894-.448 2.864-.224 9.918-5.99 19.428-2.196 29.646.103.279-.033.657-.092.983l-8.446 46.205c-1.231 6.469-2.936 12.846-4.364 19.279-1.5 6.757-2.602 13.621-4.456 20.277-3.601 12.93-10.657 25.3-5.627 39.47.368 1.036.234 2.352.017 3.476l-5.949 30.123z"></path><path fill="#ea5043" d="M958.343 767.017c1.645-10.218 3.659-20.253 5.602-30.302.217-1.124.351-2.44-.017-3.476-5.03-14.17 2.026-26.539 5.627-39.47 1.854-6.656 2.956-13.52 4.456-20.277 1.428-6.433 3.133-12.81 4.364-19.279l8.446-46.205c.059-.326.196-.705.092-.983-3.794-10.218 1.972-19.728 2.196-29.646.022-.97.796-2.158.448-2.864-3.324-6.737.176-12.919 1.136-19.383 1.504-10.125 2.344-20.355 3.283-30.557l3.845-44.478c1.017-11.532 2.488-23.038 3.084-34.59.733-14.18.722-28.397 1.136-42.595.086-2.963.626-5.912.956-9.301 5.356-.48 10.714-.527 16.536-.081 2.224 15.098 1.855 29.734 1.625 44.408-.157 10.064 1.439 20.142 1.768 30.23.334 10.235-.035 20.49.116 30.733.084 5.713.789 11.418.861 17.13.054 4.289-.469 8.585-.702 12.879-.072 1.323-.138 2.659-.031 3.975l2.534 34.405-1.707 36.293-1.908 48.69c-.182 8.103.993 16.237.811 24.34-.271 12.076-1.275 24.133-1.787 36.207-.102 2.414-.101 5.283 1.06 7.219 4.327 7.22 4.463 15.215 4.736 23.103.365 10.553.088 21.128.086 31.693-11.44 2.602-22.84.688-34.106-.916-11.486-1.635-22.806-4.434-34.546-6.903z"></path><path fill="#eb5d19" d="M398.091 622.45c6.086.617 12.21 1.288 18.067 2.918 3.539.985 6.779 3.277 9.952 5.297 9.773 6.224 18.971 13.583 29.311 18.611 8.606 4.184 12.839 10.986 17.016 18.559l18.571 32.959c1.814 3.102 4.285 5.931 6.883 8.443 8.835 8.542 10.052 20.175 13.16 31.095 2.082 7.317 4.609 14.507 6.946 22.127-29.472 3.021-58.969 5.582-87.584 15.222-1.185-2.302-1.795-4.362-2.769-6.233-4.398-8.449-6.703-18.174-14.942-24.299-2.511-1.866-5.103-3.814-7.047-6.218-8.358-10.332-17.028-20.276-28.772-26.973 4.423-11.478 9.299-22.806 13.151-34.473 4.406-13.348 6.724-27.18 6.998-41.313.098-5.093.643-10.176 1.06-15.722z"></path><path fill="#e94c32" d="M981.557 392.109c-1.172 15.337-2.617 30.625-4.438 45.869-2.213 18.521-4.144 37.108-7.346 55.466-2.123 12.171-6.28 23.985-9.492 35.968-2.439 9.098-6.794 18.224-6.73 27.313.078 11.051-5.7 19.776-7.81 29.825-3.292 15.677-10.255 30.082-18.775 43.704-2.383 3.81-2.458 8.091-2.577 12.742-.144 5.6-3.049 11.38-5.691 16.611-4.621 9.149-10.033 17.896-14.966 26.892-4.517 8.239-8.715 16.635-15.8 23.153-3.034 2.791-5.629 6.06-8.735 9.255-12.197-10.595-21.071-23.644-29.301-37.24-7.608-12.569-13.282-25.962-17.637-40.37 13.303-6.889 25.873-13.878 35.311-25.315.717-.869 1.934-1.312 2.71-2.147 5.025-5.405 10.515-10.481 14.854-16.397 6.141-8.374 10.861-17.813 17.206-26.008 8.22-10.618 13.657-22.643 20.024-34.466 4.448-.626 6.729-3.21 8.114-6.89 1.455-3.866 2.644-7.895 4.609-11.492 4.397-8.05 9.641-15.659 13.708-23.86 3.354-6.761 5.511-14.116 8.203-21.206 5.727-15.082 7.277-31.248 12.521-46.578 3.704-10.828 3.138-23.116 4.478-34.753l7.56-.073z"></path><path fill="#f7a617" d="M1918.661 831.99c-4.937 16.58-9.971 33.057-22.196 46.104-15.952 17.025-28.099 36.791-40.382 56.471-2.864 4.59-6.481 8.825-10.3 12.681-8.947 9.031-17.279 19.094-27.583 26.261-17.103 11.896-35.564 21.84-53.441 32.624-1.419.856-3.132 1.571-4.065 2.828-6.904 9.308-18.6 11.178-27.297 17.714-2.705 2.033-6.319 2.856-9.874 4.281-3.413-9.821-6.916-19.583-9.36-29.602-1.533-6.284-1.474-12.957-1.665-19.913 1.913-.78 3.374-1.057 4.81-1.431 15.822-4.121 31.491-8.029 43.818-20.323 9.452-9.426 20.371-17.372 30.534-26.097 6.146-5.277 13.024-10.052 17.954-16.326 14.812-18.848 28.876-38.285 43.112-57.581 2.624-3.557 5.506-7.264 6.83-11.367 2.681-8.311 4.375-16.94 6.476-25.438 17.89.279 35.333 3.179 52.629 9.113z"></path><path fill="#ea553a" d="M1172.91 977.582c-15.775-3.127-28.215-12.377-40.227-22.43-9.005-7.537-18.43-14.605-27.071-22.532-5.07-4.651-9.143-10.443-13.361-15.955-7.647-9.994-15.291-20.007-22.456-30.345-2.361-3.407-3.792-7.72-4.696-11.829-3.119-14.183-5.848-28.453-8.651-42.704-.636-3.236-.974-6.53-1.452-10.209 15.234-2.19 30.471-3.969 46.408-5.622 2.692 5.705 4.882 11.222 6.63 16.876 2.9 9.381 7.776 17.194 15.035 24.049 7.056 6.662 13.305 14.311 19.146 22.099 9.509 12.677 23.01 19.061 36.907 25.054-1.048 7.441-2.425 14.854-3.066 22.33-.956 11.162-1.393 22.369-2.052 33.557l-1.096 17.661z"></path><path fill="#ea5453" d="M1163.123 704.036c-4.005 5.116-7.685 10.531-12.075 15.293-12.842 13.933-27.653 25.447-44.902 34.538-3.166-5.708-5.656-11.287-8.189-17.251-3.321-12.857-6.259-25.431-9.963-37.775-4.6-15.329-10.6-30.188-11.349-46.562-.314-6.871-1.275-14.287-7.114-19.644-1.047-.961-1.292-3.053-1.465-4.67l-4.092-39.927c-.554-5.245-.383-10.829-2.21-15.623-3.622-9.503-4.546-19.253-4.688-29.163-.088-6.111 1.068-12.256.782-18.344-.67-14.281-1.76-28.546-2.9-42.8-.657-8.222-1.951-16.395-2.564-24.62-.458-6.137-.285-12.322-.104-18.21.959 5.831 1.076 11.525 2.429 16.909 2.007 7.986 5.225 15.664 7.324 23.632 3.222 12.23 1.547 25.219 6.728 37.355 4.311 10.099 6.389 21.136 9.732 31.669 2.228 7.02 6.167 13.722 7.121 20.863 1.119 8.376 6.1 13.974 10.376 20.716l2.026 10.576c1.711 9.216 3.149 18.283 8.494 26.599 6.393 9.946 11.348 20.815 16.943 31.276 4.021 7.519 6.199 16.075 12.925 22.065l24.462 22.26c.556.503 1.507.571 2.274.841z"></path><path fill="#ea5b15" d="M1285.092 163.432c9.165 3.148 18.419 6.374 27.279 10.459 4.871 2.246 8.838 6.406 13.646 8.851 5.446 2.77 11.801 3.874 17.011 6.965 11.514 6.831 24.097 9.942 36.968 12.471 1.78.35 3.777.576 5.213 1.542 10.784 7.255 23.448 9.114 35.622 11.834 9.977 2.23 18.529 6.703 26.988 11.898 5.233 3.214 10.76 5.983 15.798 9.468 4.14 2.864 7.962 6.279 11.551 9.827 5.076 5.02 10.056 10.181 14.624 15.658 5.822 6.98 11.119 14.395 16.78 21.513 4.531 5.698 9.267 11.233 14.222 16.987-10.005 5.806-20.07 12.004-30.719 16.943-7.694 3.569-16.163 5.464-24.688 7.669-2.878-7.088-5.352-13.741-7.833-20.392-.802-2.15-1.244-4.55-2.498-6.396-4.548-6.7-9.712-12.999-14.011-19.847-6.672-10.627-15.34-18.93-26.063-25.376-9.357-5.625-18.367-11.824-27.644-17.587-6.436-3.997-12.902-8.006-19.659-11.405-5.123-2.577-11.107-3.536-16.046-6.37-17.187-9.863-35.13-17.887-54.031-23.767-4.403-1.37-8.953-2.267-13.436-3.382l.926-27.565z"></path><path fill="#ea504b" d="M1098 737l7.789 16.893c-15.04 9.272-31.679 15.004-49.184 17.995-9.464 1.617-19.122 2.097-29.151 3.019-.457-10.636-.18-21.211-.544-31.764-.273-7.888-.409-15.883-4.736-23.103-1.16-1.936-1.162-4.805-1.06-7.219l1.787-36.207c.182-8.103-.993-16.237-.811-24.34.365-16.236 1.253-32.461 1.908-48.69.484-12 .942-24.001 1.98-36.069 5.57 10.19 10.632 20.42 15.528 30.728 1.122 2.362 2.587 5.09 2.339 7.488-1.536 14.819 5.881 26.839 12.962 38.33 10.008 16.241 16.417 33.54 20.331 51.964 2.285 10.756 4.729 21.394 11.958 30.165L1098 737z"></path><path fill="#f6a320" d="M1865.78 822.529c-1.849 8.846-3.544 17.475-6.224 25.786-1.323 4.102-4.206 7.81-6.83 11.367l-43.112 57.581c-4.93 6.273-11.808 11.049-17.954 16.326-10.162 8.725-21.082 16.671-30.534 26.097-12.327 12.294-27.997 16.202-43.818 20.323-1.436.374-2.897.651-4.744.986-1.107-17.032-1.816-34.076-2.079-51.556 1.265-.535 2.183-.428 2.888-.766 10.596-5.072 20.8-11.059 32.586-13.273 1.69-.317 3.307-1.558 4.732-2.662l26.908-21.114c4.992-4.003 11.214-7.393 14.381-12.585 11.286-18.5 22.363-37.263 27.027-58.87l36.046 1.811c3.487.165 6.983.14 10.727.549z"></path><path fill="#ec6333" d="M318.448 922.814c-6.374-2.074-12.56-4.058-18.412-6.765-8.379-3.876-16.906-7.675-24.617-12.668-5.239-3.392-9.69-8.381-13.609-13.352-7.87-9.983-14.953-20.582-22.699-30.666-8.061-10.493-13.909-22.097-18.636-34.358-.595-1.543-1.486-2.972-2.382-4.783 6.84-1.598 13.797-3.023 20.807-4.106 18.852-2.912 36.433-9.493 53.737-17.819.697.888.889 1.555 1.292 2.051l17.921 21.896c4.14 4.939 8.06 10.191 12.862 14.412 5.67 4.984 12.185 9.007 18.334 13.447-8.937 16.282-16.422 33.178-20.696 51.31-1.638 6.951-2.402 14.107-3.903 21.403z"></path><path fill="#f49700" d="M623.467 326.903c2.893-10.618 5.584-21.446 9.833-31.623 3.013-7.217 7.924-13.696 12.358-20.254 6.375-9.43 12.026-19.67 19.886-27.705 14.12-14.434 28.063-29.453 47.926-36.784 6.581-2.429 12.344-6.994 18.774-9.942 3.975-1.822 8.503-2.436 13.186-3.592 1.947 18.557 3.248 37.15 8.307 55.686-15.453 7.931-28.853 18.092-40.46 29.996-10.417 10.683-19.109 23.111-28.013 35.175-3.238 4.388-4.888 9.948-7.262 14.973-17.803-3.987-35.767-6.498-54.535-5.931z"></path><path fill="#ea544c" d="M1097.956 736.615c-2.925-3.218-5.893-6.822-8.862-10.425-7.229-8.771-9.672-19.409-11.958-30.165-3.914-18.424-10.323-35.722-20.331-51.964-7.081-11.491-14.498-23.511-12.962-38.33.249-2.398-1.217-5.126-2.339-7.488l-15.232-31.019-3.103-34.338c-.107-1.316-.041-2.653.031-3.975.233-4.294.756-8.59.702-12.879-.072-5.713-.776-11.417-.861-17.13l-.116-30.733c-.329-10.088-1.926-20.166-1.768-30.23.23-14.674.599-29.31-1.162-44.341 9.369-.803 18.741-1.179 28.558-1.074 1.446 15.814 2.446 31.146 3.446 46.478.108 6.163-.064 12.348.393 18.485.613 8.225 1.907 16.397 2.564 24.62l2.9 42.8c.286 6.088-.869 12.234-.782 18.344.142 9.91 1.066 19.661 4.688 29.163 1.827 4.794 1.657 10.377 2.21 15.623l4.092 39.927c.172 1.617.417 3.71 1.465 4.67 5.839 5.357 6.8 12.773 7.114 19.644.749 16.374 6.749 31.233 11.349 46.562 3.704 12.344 6.642 24.918 9.963 37.775z"></path><path fill="#ec5c61" d="M1204.835 568.008c1.254 25.351-1.675 50.16-10.168 74.61-8.598-4.883-18.177-8.709-24.354-15.59-7.44-8.289-13.929-17.442-21.675-25.711-8.498-9.072-16.731-18.928-21.084-31.113-.54-1.513-1.691-2.807-2.594-4.564-4.605-9.247-7.706-18.544-7.96-29.09-.835-7.149-1.214-13.944-2.609-20.523-2.215-10.454-5.626-20.496-7.101-31.302-2.513-18.419-7.207-36.512-5.347-55.352.24-2.43-.17-4.949-.477-7.402l-4.468-34.792c2.723-.379 5.446-.757 8.585-.667 1.749 8.781 2.952 17.116 4.448 25.399 1.813 10.037 3.64 20.084 5.934 30.017 1.036 4.482 3.953 8.573 4.73 13.064 1.794 10.377 4.73 20.253 9.272 29.771 2.914 6.105 4.761 12.711 7.496 18.912 2.865 6.496 6.264 12.755 9.35 19.156 3.764 7.805 7.667 15.013 16.1 19.441 7.527 3.952 13.713 10.376 20.983 14.924 6.636 4.152 13.932 7.25 20.937 10.813z"></path><path fill="#ed676f" d="M1140.75 379.231c18.38-4.858 36.222-11.21 53.979-18.971 3.222 3.368 5.693 6.744 8.719 9.512 2.333 2.134 5.451 5.07 8.067 4.923 7.623-.429 12.363 2.688 17.309 8.215 5.531 6.18 12.744 10.854 19.224 16.184-5.121 7.193-10.461 14.241-15.323 21.606-13.691 20.739-22.99 43.255-26.782 67.926-.543 3.536-1.281 7.043-2.366 10.925-14.258-6.419-26.411-14.959-32.731-29.803-1.087-2.553-2.596-4.93-3.969-7.355-1.694-2.993-3.569-5.89-5.143-8.943-1.578-3.062-2.922-6.249-4.295-9.413-1.57-3.621-3.505-7.163-4.47-10.946-1.257-4.93-.636-10.572-2.725-15.013-5.831-12.397-7.467-25.628-9.497-38.847z"></path><path fill="#ed656e" d="M1254.103 647.439c5.325.947 10.603 2.272 15.847 3.722 5.101 1.41 10.376 2.475 15.175 4.596 3.237 1.431 5.942 4.262 8.589 6.777 2.592 2.462 4.77 5.355 7.207 7.987 1.804 1.948 4.557 3.453 5.461 5.723 3.51 8.817 11.581 11.307 19.059 14.735 1.053.483 2.116.963 3.214 1.327 9.172 3.043 13.818 8.587 14.889 18.979.715 6.935 5.607 13.679 9.479 19.987 4.623 7.533 9.175 14.819 9.091 24.116-.023 2.55 1.21 5.111 1.874 8.055-19.861 2.555-39.795 4.296-59.597 9.09l-11.596-23.203c-1.107-2.169-2.526-4.353-4.307-5.975-7.349-6.694-14.863-13.209-22.373-19.723l-17.313-14.669c-2.776-2.245-5.935-4.017-8.92-6.003l11.609-38.185c1.508-5.453 1.739-11.258 2.613-17.336z"></path><path fill="#ec6168" d="M1140.315 379.223c2.464 13.227 4.101 26.459 9.931 38.856 2.089 4.441 1.468 10.083 2.725 15.013.965 3.783 2.9 7.325 4.47 10.946 1.372 3.164 2.716 6.351 4.295 9.413 1.574 3.053 3.449 5.95 5.143 8.943 1.372 2.425 2.882 4.803 3.969 7.355 6.319 14.844 18.473 23.384 32.641 30.212.067 5.121-.501 10.201-.435 15.271l.985 38.117c.151 4.586.616 9.162.868 14.201-7.075-3.104-14.371-6.202-21.007-10.354-7.269-4.548-13.456-10.972-20.983-14.924-8.434-4.428-12.337-11.637-16.1-19.441-3.087-6.401-6.485-12.66-9.35-19.156-2.735-6.201-4.583-12.807-7.496-18.912-4.542-9.518-7.477-19.394-9.272-29.771-.777-4.491-3.694-8.581-4.73-13.064-2.294-9.933-4.121-19.98-5.934-30.017-1.496-8.283-2.699-16.618-4.036-25.335 10.349-2.461 20.704-4.511 31.054-6.582.957-.191 1.887-.515 3.264-.769z"></path><path fill="#e94c28" d="M922 537c-6.003 11.784-11.44 23.81-19.66 34.428-6.345 8.196-11.065 17.635-17.206 26.008-4.339 5.916-9.828 10.992-14.854 16.397-.776.835-1.993 1.279-2.71 2.147-9.439 11.437-22.008 18.427-35.357 24.929-4.219-10.885-6.942-22.155-7.205-33.905l-.514-49.542c7.441-2.893 14.452-5.197 21.334-7.841 1.749-.672 3.101-2.401 4.604-3.681 6.749-5.745 12.845-12.627 20.407-16.944 7.719-4.406 14.391-9.101 18.741-16.889.626-1.122 1.689-2.077 2.729-2.877 7.197-5.533 12.583-12.51 16.906-20.439.68-1.247 2.495-1.876 4.105-2.651 2.835 1.408 5.267 2.892 7.884 3.892 3.904 1.491 4.392 3.922 2.833 7.439-1.47 3.318-2.668 6.756-4.069 10.106-1.247 2.981-.435 5.242 2.413 6.544 2.805 1.282 3.125 3.14 1.813 5.601l-6.907 12.799L922 537z"></path><path fill="#eb5659" d="M1124.995 566c.868 1.396 2.018 2.691 2.559 4.203 4.353 12.185 12.586 22.041 21.084 31.113 7.746 8.269 14.235 17.422 21.675 25.711 6.176 6.881 15.756 10.707 24.174 15.932-6.073 22.316-16.675 42.446-31.058 60.937-1.074-.131-2.025-.199-2.581-.702l-24.462-22.26c-6.726-5.99-8.904-14.546-12.925-22.065-5.594-10.461-10.55-21.33-16.943-31.276-5.345-8.315-6.783-17.383-8.494-26.599-.63-3.394-1.348-6.772-1.738-10.848-.371-6.313-1.029-11.934-1.745-18.052l6.34 4.04 1.288-.675-2.143-15.385 9.454 1.208v-8.545L1124.995 566z"></path><path fill="#f5a02d" d="M1818.568 820.096c-4.224 21.679-15.302 40.442-26.587 58.942-3.167 5.192-9.389 8.582-14.381 12.585l-26.908 21.114c-1.425 1.104-3.042 2.345-4.732 2.662-11.786 2.214-21.99 8.201-32.586 13.273-.705.338-1.624.231-2.824.334a824.35 824.35 0 0 1-8.262-42.708c4.646-2.14 9.353-3.139 13.269-5.47 5.582-3.323 11.318-6.942 15.671-11.652 7.949-8.6 14.423-18.572 22.456-27.081 8.539-9.046 13.867-19.641 18.325-30.922l46.559 8.922z"></path><path fill="#eb5a57" d="M1124.96 565.639c-5.086-4.017-10.208-8.395-15.478-12.901v8.545l-9.454-1.208 2.143 15.385-1.288.675-6.34-4.04c.716 6.118 1.375 11.74 1.745 17.633-4.564-6.051-9.544-11.649-10.663-20.025-.954-7.141-4.892-13.843-7.121-20.863-3.344-10.533-5.421-21.57-9.732-31.669-5.181-12.135-3.506-25.125-6.728-37.355-2.099-7.968-5.317-15.646-7.324-23.632-1.353-5.384-1.47-11.078-2.429-16.909l-3.294-46.689a278.63 278.63 0 0 1 27.57-2.084c2.114 12.378 3.647 24.309 5.479 36.195 1.25 8.111 2.832 16.175 4.422 24.23 1.402 7.103 2.991 14.169 4.55 21.241 1.478 6.706.273 14.002 4.6 20.088 5.401 7.597 7.176 16.518 9.467 25.337 1.953 7.515 5.804 14.253 11.917 19.406.254 10.095 3.355 19.392 7.96 28.639z"></path><path fill="#ea541c" d="M911.651 810.999c-2.511 10.165-5.419 20.146-8.2 30.162-2.503 9.015-7.37 16.277-14.364 22.612-6.108 5.533-10.917 12.475-16.796 18.293-6.942 6.871-14.354 13.24-19.083 22.03-.644 1.196-2.222 1.889-3.705 2.857-2.39-7.921-4.101-15.991-6.566-23.823-5.451-17.323-12.404-33.976-23.414-48.835l21.627-21.095c3.182-3.29 5.532-7.382 8.295-11.083l10.663-14.163c9.528 4.78 18.925 9.848 28.625 14.247 7.324 3.321 15.036 5.785 22.917 8.799z"></path><path fill="#eb5d19" d="M1284.092 191.421c4.557.69 9.107 1.587 13.51 2.957 18.901 5.881 36.844 13.904 54.031 23.767 4.938 2.834 10.923 3.792 16.046 6.37 6.757 3.399 13.224 7.408 19.659 11.405l27.644 17.587c10.723 6.446 19.392 14.748 26.063 25.376 4.299 6.848 9.463 13.147 14.011 19.847 1.254 1.847 1.696 4.246 2.498 6.396l7.441 20.332c-11.685 1.754-23.379 3.133-35.533 4.037-.737-2.093-.995-3.716-1.294-5.33-3.157-17.057-14.048-30.161-23.034-44.146-3.027-4.71-7.786-8.529-12.334-11.993-9.346-7.116-19.004-13.834-28.688-20.491-6.653-4.573-13.311-9.251-20.431-13.002-8.048-4.24-16.479-7.85-24.989-11.091-11.722-4.465-23.673-8.328-35.527-12.449l.927-19.572z"></path><path fill="#eb5e24" d="M1283.09 211.415c11.928 3.699 23.88 7.562 35.602 12.027 8.509 3.241 16.941 6.852 24.989 11.091 7.12 3.751 13.778 8.429 20.431 13.002 9.684 6.657 19.342 13.375 28.688 20.491 4.548 3.463 9.307 7.283 12.334 11.993 8.986 13.985 19.877 27.089 23.034 44.146.299 1.615.557 3.237.836 5.263-13.373-.216-26.749-.839-40.564-1.923-2.935-9.681-4.597-18.92-12.286-26.152-15.577-14.651-30.4-30.102-45.564-45.193-.686-.683-1.626-1.156-2.516-1.584l-47.187-22.615 2.203-20.546z"></path><path fill="#e9511f" d="M913 486.001c-1.29.915-3.105 1.543-3.785 2.791-4.323 7.929-9.709 14.906-16.906 20.439-1.04.8-2.103 1.755-2.729 2.877-4.35 7.788-11.022 12.482-18.741 16.889-7.562 4.317-13.658 11.199-20.407 16.944-1.503 1.28-2.856 3.009-4.604 3.681-6.881 2.643-13.893 4.948-21.262 7.377-.128-11.151.202-22.302.378-33.454.03-1.892-.6-3.795-.456-6.12 13.727-1.755 23.588-9.527 33.278-17.663 2.784-2.337 6.074-4.161 8.529-6.784l29.057-31.86c1.545-1.71 3.418-3.401 4.221-5.459 5.665-14.509 11.49-28.977 16.436-43.736 2.817-8.407 4.074-17.338 6.033-26.032 5.039.714 10.078 1.427 15.536 2.629-.909 8.969-2.31 17.438-3.546 25.931-2.41 16.551-5.84 32.839-11.991 48.461L913 486.001z"></path><path fill="#ea5741" d="M1179.451 903.828c-14.224-5.787-27.726-12.171-37.235-24.849-5.841-7.787-12.09-15.436-19.146-22.099-7.259-6.854-12.136-14.667-15.035-24.049-1.748-5.654-3.938-11.171-6.254-17.033 15.099-4.009 30.213-8.629 44.958-15.533l28.367 36.36c6.09 8.015 13.124 14.75 22.72 18.375-7.404 14.472-13.599 29.412-17.48 45.244-.271 1.106-.382 2.25-.895 3.583z"></path><path fill="#ea522a" d="M913.32 486.141c2.693-7.837 5.694-15.539 8.722-23.231 6.151-15.622 9.581-31.91 11.991-48.461l3.963-25.861c7.582.317 15.168 1.031 22.748 1.797 4.171.421 8.333.928 12.877 1.596-.963 11.836-.398 24.125-4.102 34.953-5.244 15.33-6.794 31.496-12.521 46.578-2.692 7.09-4.849 14.445-8.203 21.206-4.068 8.201-9.311 15.81-13.708 23.86-1.965 3.597-3.154 7.627-4.609 11.492-1.385 3.68-3.666 6.265-8.114 6.89-1.994-1.511-3.624-3.059-5.077-4.44l6.907-12.799c1.313-2.461.993-4.318-1.813-5.601-2.849-1.302-3.66-3.563-2.413-6.544 1.401-3.35 2.599-6.788 4.069-10.106 1.558-3.517 1.071-5.948-2.833-7.439-2.617-1-5.049-2.484-7.884-3.892z"></path><path fill="#eb5e24" d="M376.574 714.118c12.053 6.538 20.723 16.481 29.081 26.814 1.945 2.404 4.537 4.352 7.047 6.218 8.24 6.125 10.544 15.85 14.942 24.299.974 1.871 1.584 3.931 2.376 6.29-7.145 3.719-14.633 6.501-21.386 10.517-9.606 5.713-18.673 12.334-28.425 18.399-3.407-3.73-6.231-7.409-9.335-10.834l-30.989-33.862c11.858-11.593 22.368-24.28 31.055-38.431 1.86-3.031 3.553-6.164 5.632-9.409z"></path><path fill="#e95514" d="M859.962 787.636c-3.409 5.037-6.981 9.745-10.516 14.481-2.763 3.701-5.113 7.792-8.295 11.083-6.885 7.118-14.186 13.834-21.65 20.755-13.222-17.677-29.417-31.711-48.178-42.878-.969-.576-2.068-.934-3.27-1.709 6.28-8.159 12.733-15.993 19.16-23.849 1.459-1.783 2.718-3.738 4.254-5.448l18.336-19.969c4.909 5.34 9.619 10.738 14.081 16.333 9.72 12.19 21.813 21.566 34.847 29.867.411.262.725.674 1.231 1.334z"></path><path fill="#eb5f2d" d="M339.582 762.088l31.293 33.733c3.104 3.425 5.928 7.104 9.024 10.979-12.885 11.619-24.548 24.139-33.899 38.704-.872 1.359-1.56 2.837-2.644 4.428-6.459-4.271-12.974-8.294-18.644-13.278-4.802-4.221-8.722-9.473-12.862-14.412l-17.921-21.896c-.403-.496-.595-1.163-.926-2.105 16.738-10.504 32.58-21.87 46.578-36.154z"></path><path fill="#f28d00" d="M678.388 332.912c1.989-5.104 3.638-10.664 6.876-15.051 8.903-12.064 17.596-24.492 28.013-35.175 11.607-11.904 25.007-22.064 40.507-29.592 4.873 11.636 9.419 23.412 13.67 35.592-5.759 4.084-11.517 7.403-16.594 11.553-4.413 3.607-8.124 8.092-12.023 12.301-5.346 5.772-10.82 11.454-15.782 17.547-3.929 4.824-7.17 10.208-10.716 15.344l-33.95-12.518z"></path><path fill="#f08369" d="M1580.181 771.427c-.191-.803-.322-1.377-.119-1.786 5.389-10.903 9.084-22.666 18.181-31.587 6.223-6.103 11.276-13.385 17.286-19.727 3.117-3.289 6.933-6.105 10.869-8.384 6.572-3.806 13.492-7.009 20.461-10.752 1.773 3.23 3.236 6.803 4.951 10.251l12.234 24.993c-1.367 1.966-2.596 3.293-3.935 4.499-7.845 7.07-16.315 13.564-23.407 21.32-6.971 7.623-12.552 16.517-18.743 24.854l-37.777-13.68z"></path><path fill="#f18b5e" d="M1618.142 785.4c6.007-8.63 11.588-17.524 18.559-25.147 7.092-7.755 15.562-14.249 23.407-21.32 1.338-1.206 2.568-2.534 3.997-4.162l28.996 33.733c1.896 2.205 4.424 3.867 6.66 6.394-6.471 7.492-12.967 14.346-19.403 21.255l-18.407 19.953c-12.958-12.409-27.485-22.567-43.809-30.706z"></path><path fill="#f49c3a" d="M1771.617 811.1c-4.066 11.354-9.394 21.949-17.933 30.995-8.032 8.509-14.507 18.481-22.456 27.081-4.353 4.71-10.089 8.329-15.671 11.652-3.915 2.331-8.623 3.331-13.318 5.069-4.298-9.927-8.255-19.998-12.1-30.743 4.741-4.381 9.924-7.582 13.882-11.904 7.345-8.021 14.094-16.603 20.864-25.131 4.897-6.168 9.428-12.626 14.123-18.955l32.61 11.936z"></path><path fill="#f08000" d="M712.601 345.675c3.283-5.381 6.524-10.765 10.453-15.589 4.962-6.093 10.435-11.774 15.782-17.547 3.899-4.21 7.61-8.695 12.023-12.301 5.078-4.15 10.836-7.469 16.636-11.19a934.12 934.12 0 0 1 23.286 35.848c-4.873 6.234-9.676 11.895-14.63 17.421l-25.195 27.801c-11.713-9.615-24.433-17.645-38.355-24.443z"></path><path fill="#ed6e04" d="M751.11 370.42c8.249-9.565 16.693-18.791 25.041-28.103 4.954-5.526 9.757-11.187 14.765-17.106 7.129 6.226 13.892 13.041 21.189 19.225 5.389 4.567 11.475 8.312 17.53 12.92-5.51 7.863-10.622 15.919-17.254 22.427-8.881 8.716-18.938 16.233-28.49 24.264-5.703-6.587-11.146-13.427-17.193-19.682-4.758-4.921-10.261-9.121-15.587-13.944z"></path><path fill="#ea541c" d="M921.823 385.544c-1.739 9.04-2.995 17.971-5.813 26.378-4.946 14.759-10.771 29.227-16.436 43.736-.804 2.058-2.676 3.749-4.221 5.459l-29.057 31.86c-2.455 2.623-5.745 4.447-8.529 6.784-9.69 8.135-19.551 15.908-33.208 17.237-1.773-9.728-3.147-19.457-4.091-29.6l36.13-16.763c.581-.267 1.046-.812 1.525-1.269 8.033-7.688 16.258-15.19 24.011-23.152 4.35-4.467 9.202-9.144 11.588-14.69 6.638-15.425 15.047-30.299 17.274-47.358 3.536.344 7.072.688 10.829 1.377z"></path><path fill="#f3944d" d="M1738.688 798.998c-4.375 6.495-8.906 12.953-13.803 19.121-6.771 8.528-13.519 17.11-20.864 25.131-3.958 4.322-9.141 7.523-13.925 11.54-8.036-13.464-16.465-26.844-27.999-38.387 5.988-6.951 12.094-13.629 18.261-20.25l19.547-20.95 38.783 23.794z"></path><path fill="#ec6168" d="M1239.583 703.142c3.282 1.805 6.441 3.576 9.217 5.821 5.88 4.755 11.599 9.713 17.313 14.669l22.373 19.723c1.781 1.622 3.2 3.806 4.307 5.975 3.843 7.532 7.477 15.171 11.194 23.136-10.764 4.67-21.532 8.973-32.69 12.982l-22.733-27.366c-2.003-2.416-4.096-4.758-6.194-7.093-3.539-3.94-6.927-8.044-10.74-11.701-2.57-2.465-5.762-4.283-8.675-6.39l16.627-29.755z"></path><path fill="#ec663e" d="M1351.006 332.839l-28.499 10.33c-.294.107-.533.367-1.194.264-11.067-19.018-27.026-32.559-44.225-44.855-4.267-3.051-8.753-5.796-13.138-8.682l9.505-24.505c10.055 4.069 19.821 8.227 29.211 13.108 3.998 2.078 7.299 5.565 10.753 8.598 3.077 2.701 5.743 5.891 8.926 8.447 4.116 3.304 9.787 5.345 12.62 9.432 6.083 8.777 10.778 18.517 16.041 27.863z"></path><path fill="#eb5e5b" d="M1222.647 733.051c3.223 1.954 6.415 3.771 8.985 6.237 3.813 3.658 7.201 7.761 10.74 11.701l6.194 7.093 22.384 27.409c-13.056 6.836-25.309 14.613-36.736 24.161l-39.323-44.7 24.494-27.846c1.072-1.224 1.974-2.598 3.264-4.056z"></path><path fill="#ea580e" d="M876.001 376.171c5.874 1.347 11.748 2.694 17.812 4.789-.81 5.265-2.687 9.791-2.639 14.296.124 11.469-4.458 20.383-12.73 27.863-2.075 1.877-3.659 4.286-5.668 6.248l-22.808 21.967c-.442.422-1.212.488-1.813.757l-23.113 10.389-9.875 4.514c-2.305-6.09-4.609-12.181-6.614-18.676 7.64-4.837 15.567-8.54 22.18-13.873 9.697-7.821 18.931-16.361 27.443-25.455 5.613-5.998 12.679-11.331 14.201-20.475.699-4.2 2.384-8.235 3.623-12.345z"></path><path fill="#e95514" d="M815.103 467.384c3.356-1.894 6.641-3.415 9.94-4.903l23.113-10.389c.6-.269 1.371-.335 1.813-.757l22.808-21.967c2.008-1.962 3.593-4.371 5.668-6.248 8.272-7.48 12.854-16.394 12.73-27.863-.049-4.505 1.828-9.031 2.847-13.956 5.427.559 10.836 1.526 16.609 2.68-1.863 17.245-10.272 32.119-16.91 47.544-2.387 5.546-7.239 10.223-11.588 14.69-7.753 7.962-15.978 15.464-24.011 23.152-.478.458-.944 1.002-1.525 1.269l-36.069 16.355c-2.076-6.402-3.783-12.81-5.425-19.607z"></path><path fill="#eb620b" d="M783.944 404.402c9.499-8.388 19.556-15.905 28.437-24.621 6.631-6.508 11.744-14.564 17.575-22.273 9.271 4.016 18.501 8.375 27.893 13.43-4.134 7.07-8.017 13.778-12.833 19.731-5.785 7.15-12.109 13.917-18.666 20.376-7.99 7.869-16.466 15.244-24.731 22.832l-17.674-29.475z"></path><path fill="#ea544c" d="M1197.986 854.686c-9.756-3.309-16.79-10.044-22.88-18.059l-28.001-36.417c8.601-5.939 17.348-11.563 26.758-17.075 1.615 1.026 2.639 1.876 3.505 2.865l26.664 30.44c3.723 4.139 7.995 7.785 12.017 11.656l-18.064 26.591z"></path><path fill="#ec6333" d="M1351.41 332.903c-5.667-9.409-10.361-19.149-16.445-27.926-2.833-4.087-8.504-6.128-12.62-9.432-3.184-2.555-5.849-5.745-8.926-8.447-3.454-3.033-6.756-6.52-10.753-8.598-9.391-4.88-19.157-9.039-29.138-13.499 1.18-5.441 2.727-10.873 4.81-16.607 11.918 4.674 24.209 8.261 34.464 14.962 14.239 9.304 29.011 18.453 39.595 32.464 2.386 3.159 5.121 6.077 7.884 8.923 6.564 6.764 10.148 14.927 11.723 24.093l-20.594 4.067z"></path><path fill="#eb5e5b" d="M1117 536.549c-6.113-4.702-9.965-11.44-11.917-18.955-2.292-8.819-4.066-17.74-9.467-25.337-4.327-6.085-3.122-13.382-4.6-20.088l-4.55-21.241c-1.59-8.054-3.172-16.118-4.422-24.23l-5.037-36.129c6.382-1.43 12.777-2.462 19.582-3.443 1.906 11.646 3.426 23.24 4.878 34.842.307 2.453.717 4.973.477 7.402-1.86 18.84 2.834 36.934 5.347 55.352 1.474 10.806 4.885 20.848 7.101 31.302 1.394 6.579 1.774 13.374 2.609 20.523z"></path><path fill="#ec644b" d="M1263.638 290.071c4.697 2.713 9.183 5.458 13.45 8.509 17.199 12.295 33.158 25.836 43.873 44.907-8.026 4.725-16.095 9.106-24.83 13.372-11.633-15.937-25.648-28.515-41.888-38.689-1.609-1.008-3.555-1.48-5.344-2.2 2.329-3.852 4.766-7.645 6.959-11.573l7.78-14.326z"></path><path fill="#eb5f2d" d="M1372.453 328.903c-2.025-9.233-5.608-17.396-12.172-24.16-2.762-2.846-5.498-5.764-7.884-8.923-10.584-14.01-25.356-23.16-39.595-32.464-10.256-6.701-22.546-10.289-34.284-15.312.325-5.246 1.005-10.444 2.027-15.863l47.529 22.394c.89.428 1.83.901 2.516 1.584l45.564 45.193c7.69 7.233 9.352 16.472 11.849 26.084-5.032.773-10.066 1.154-15.55 1.466z"></path><path fill="#e95a0f" d="M801.776 434.171c8.108-7.882 16.584-15.257 24.573-23.126 6.558-6.459 12.881-13.226 18.666-20.376 4.817-5.953 8.7-12.661 13.011-19.409 5.739 1.338 11.463 3.051 17.581 4.838-.845 4.183-2.53 8.219-3.229 12.418-1.522 9.144-8.588 14.477-14.201 20.475-8.512 9.094-17.745 17.635-27.443 25.455-6.613 5.333-14.54 9.036-22.223 13.51-2.422-4.469-4.499-8.98-6.735-13.786z"></path><path fill="#eb5e5b" d="M1248.533 316.002c2.155.688 4.101 1.159 5.71 2.168 16.24 10.174 30.255 22.752 41.532 38.727-7.166 5.736-14.641 11.319-22.562 16.731-1.16-1.277-1.684-2.585-2.615-3.46l-38.694-36.2 14.203-15.029c.803-.86 1.38-1.93 2.427-2.936z"></path><path fill="#eb5a57" d="M1216.359 827.958c-4.331-3.733-8.603-7.379-12.326-11.518l-26.664-30.44c-.866-.989-1.89-1.839-3.152-2.902 6.483-6.054 13.276-11.959 20.371-18.005l39.315 44.704c-5.648 6.216-11.441 12.12-17.544 18.161z"></path><path fill="#ec6168" d="M1231.598 334.101l38.999 36.066c.931.876 1.456 2.183 2.303 3.608-4.283 4.279-8.7 8.24-13.769 12.091-4.2-3.051-7.512-6.349-11.338-8.867-12.36-8.136-22.893-18.27-32.841-29.093l16.646-13.805z"></path><path fill="#ed656e" d="M1214.597 347.955c10.303 10.775 20.836 20.908 33.196 29.044 3.825 2.518 7.137 5.816 10.992 8.903-3.171 4.397-6.65 8.648-10.432 13.046-6.785-5.184-13.998-9.858-19.529-16.038-4.946-5.527-9.687-8.644-17.309-8.215-2.616.147-5.734-2.788-8.067-4.923-3.026-2.769-5.497-6.144-8.35-9.568 6.286-4.273 12.715-8.237 19.499-12.25z"></path></svg>
</p>
<p align="center">
<b>The crispy sentence embedding family from <a href="https://mixedbread.ai"><b>mixedbread ai</b></a>.</b>
</p>
# 🪆mxbai-embed-2d-large-v1🪆
This is our [2DMSE](https://arxiv.org/abs/2402.14776) sentence embedding model. It supports the adaptive transformer layer and embedding size. Find out more in our [blog post](https://mixedbread.ai/blog/mxbai-embed-2d-large-v1).
TLDR: TLDR: 2D-🪆 allows you to shrink the model and the embeddings layer. Shrinking only the embeddings model yields competetive results to other models like [nomics embeddings model](https://huggingface.co/nomic-ai/nomic-embed-text-v1.5). Shrinking the model to ~50% maintains upto 85% of the performance without further training.
## Quickstart
Here, we provide several ways to produce sentence embeddings with adaptive layers and embedding sizes. **For this version, it is recommended to set adaptive layers from 20 to 24.**
### sentence-transformers
Currently, the best way to use our models is with the most recent version of sentence-transformers.
```bash
python -m pip install -U sentence-transformers
```
```python
from sentence_transformers import models, SentenceTransformer
from sentence_transformers.util import cos_sim
# 1. load model with `cls` pooling
model = SentenceTransformer("mixedbread-ai/mxbai-embed-2d-large-v1")
# 2. set adaptive layer and embedding size.
# it is recommended to set layers from 20 to 24.
new_num_layers = 22 # 1D: set layer size
model[0].auto_model.encoder.layer = model[0].auto_model.encoder.layer[:new_num_layers]
new_embedding_size = 768 # 2D: set embedding size
# 3. encode
embeddings = model.encode(
[
'Who is german and likes bread?',
'Everybody in Germany.'
]
)
# Similarity of the first sentence with the other two
similarities = cos_sim(embeddings[0, :new_embedding_size], embeddings[1, :new_embedding_size])
print('similarities:', similarities)
```
### angle-emb
You can also use the lastest `angle-emb` for inference, as follows:
```bash
python -m pip install -U angle-emb
```
```python
from angle_emb import AnglE
from sentence_transformers.util import cos_sim
# 1. load model
model = AnglE.from_pretrained("mixedbread-ai/mxbai-embed-2d-large-v1", pooling_strategy='cls').cuda()
# 2. set adaptive layer and embedding size.
# it is recommended to set layers from 20 to 24.
layer_index = 22 # 1d: layer
embedding_size = 768 # 2d: embedding size
# 3. encode
embeddings = model.encode([
'Who is german and likes bread?',
'Everybody in Germany.'
], layer_index=layer_index, embedding_size=embedding_size)
similarities = cos_sim(embeddings[0], embeddings[1:])
print('similarities:', similarities)
```
### Transformers.js
If you haven't already, you can install the [Transformers.js](https://huggingface.co/docs/transformers.js) JavaScript library from [NPM](https://www.npmjs.com/package/@xenova/transformers) using:
```bash
npm i @xenova/transformers
```
You can then use the model to compute embeddings as follows:
```js
import { pipeline, cos_sim } from '@xenova/transformers';
// Create a feature-extraction pipeline
const extractor = await pipeline('feature-extraction', 'mixedbread-ai/mxbai-embed-2d-large-v1', {
quantized: false, // (Optional) remove this line to use the 8-bit quantized model
});
// Compute sentence embeddings (with `cls` pooling)
const sentences = ['Who is german and likes bread?', 'Everybody in Germany.' ];
const output = await extractor(sentences, { pooling: 'cls' });
// Set embedding size and truncate embeddings
const new_embedding_size = 768;
const truncated = output.slice(null, [0, new_embedding_size]);
// Compute cosine similarity
console.log(cos_sim(truncated[0].data, truncated[1].data)); // 0.6979532021425204
```
### Using API
You can use the model via our API as follows:
```python
from mixedbread_ai.client import MixedbreadAI
from sklearn.metrics.pairwise import cosine_similarity
import os
mxbai = MixedbreadAI(api_key="{MIXEDBREAD_API_KEY}")
english_sentences = [
'What is the capital of Australia?',
'Canberra is the capital of Australia.'
]
res = mxbai.embeddings(
input=english_sentences,
model="mixedbread-ai/mxbai-embed-2d-large-v1",
dimensions=512,
)
embeddings = [entry.embedding for entry in res.data]
similarities = cosine_similarity([embeddings[0]], [embeddings[1]])
print(similarities)
```
The API comes with native INT8 and binary quantization support! Check out the [docs](https://mixedbread.ai/docs) for more information.
## Evaluation
Please find more information in our [blog post](https://mixedbread.ai/blog/mxbai-embed-2d-large-v1).
## Community
Please join our [Discord Community](https://discord.gg/jDfMHzAVfU) and share your feedback and thoughts! We are here to help and also always happy to chat.
## License
Apache 2.0
|
speechbrain/metricgan-plus-voicebank | speechbrain | 2024-02-28T13:11:28Z | 6,894 | 46 | speechbrain | [
"speechbrain",
"audio-to-audio",
"speech-enhancement",
"PyTorch",
"en",
"dataset:Voicebank",
"dataset:DEMAND",
"arxiv:2106.04624",
"license:apache-2.0",
"region:us"
] | audio-to-audio | 2022-03-02T23:29:05Z | ---
language: "en"
tags:
- audio-to-audio
- speech-enhancement
- PyTorch
- speechbrain
license: "apache-2.0"
datasets:
- Voicebank
- DEMAND
metrics:
- PESQ
- STOI
inference: false
---
<iframe src="https://ghbtns.com/github-btn.html?user=speechbrain&repo=speechbrain&type=star&count=true&size=large&v=2" frameborder="0" scrolling="0" width="170" height="30" title="GitHub"></iframe>
<br/><br/>
# MetricGAN-trained model for Enhancement
This repository provides all the necessary tools to perform enhancement with
SpeechBrain. For a better experience we encourage you to learn more about
[SpeechBrain](https://speechbrain.github.io). The model performance is:
| Release | Test PESQ | Test STOI |
|:-----------:|:-----:| :-----:|
| 21-04-27 | 3.15 | 93.0 |
## Install SpeechBrain
First of all, please install SpeechBrain with the following command:
```
pip install speechbrain
```
Please notice that we encourage you to read our tutorials and learn more about
[SpeechBrain](https://speechbrain.github.io).
## Pretrained Usage
To use the mimic-loss-trained model for enhancement, use the following simple code:
```python
import torch
import torchaudio
from speechbrain.inference.enhancement import SpectralMaskEnhancement
enhance_model = SpectralMaskEnhancement.from_hparams(
source="speechbrain/metricgan-plus-voicebank",
savedir="pretrained_models/metricgan-plus-voicebank",
)
# Load and add fake batch dimension
noisy = enhance_model.load_audio(
"speechbrain/metricgan-plus-voicebank/example.wav"
).unsqueeze(0)
# Add relative length tensor
enhanced = enhance_model.enhance_batch(noisy, lengths=torch.tensor([1.]))
# Saving enhanced signal on disk
torchaudio.save('enhanced.wav', enhanced.cpu(), 16000)
```
The system is trained with recordings sampled at 16kHz (single channel).
The code will automatically normalize your audio (i.e., resampling + mono channel selection) when calling *enhance_file* if needed. Make sure your input tensor is compliant with the expected sampling rate if you use *enhance_batch* as in the example.
### Inference on GPU
To perform inference on the GPU, add `run_opts={"device":"cuda"}` when calling the `from_hparams` method.
### Training
The model was trained with SpeechBrain (d0accc8).
To train it from scratch follows these steps:
1. Clone SpeechBrain:
```bash
git clone https://github.com/speechbrain/speechbrain/
```
2. Install it:
```
cd speechbrain
pip install -r requirements.txt
pip install -e .
```
3. Run Training:
```
cd recipes/Voicebank/enhance/MetricGAN
python train.py hparams/train.yaml --data_folder=your_data_folder
```
You can find our training results (models, logs, etc) [here](https://drive.google.com/drive/folders/1fcVP52gHgoMX9diNN1JxX_My5KaRNZWs?usp=sharing).
### Limitations
The SpeechBrain team does not provide any warranty on the performance achieved by this model when used on other datasets.
## Referencing MetricGAN+
If you find MetricGAN+ useful, please cite:
```
@article{fu2021metricgan+,
title={MetricGAN+: An Improved Version of MetricGAN for Speech Enhancement},
author={Fu, Szu-Wei and Yu, Cheng and Hsieh, Tsun-An and Plantinga, Peter and Ravanelli, Mirco and Lu, Xugang and Tsao, Yu},
journal={arXiv preprint arXiv:2104.03538},
year={2021}
}
```
# **About SpeechBrain**
- Website: https://speechbrain.github.io/
- Code: https://github.com/speechbrain/speechbrain/
- HuggingFace: https://huggingface.co/speechbrain/
# **Citing SpeechBrain**
Please, cite SpeechBrain if you use it for your research or business.
```bibtex
@misc{speechbrain,
title={{SpeechBrain}: A General-Purpose Speech Toolkit},
author={Mirco Ravanelli and Titouan Parcollet and Peter Plantinga and Aku Rouhe and Samuele Cornell and Loren Lugosch and Cem Subakan and Nauman Dawalatabad and Abdelwahab Heba and Jianyuan Zhong and Ju-Chieh Chou and Sung-Lin Yeh and Szu-Wei Fu and Chien-Feng Liao and Elena Rastorgueva and François Grondin and William Aris and Hwidong Na and Yan Gao and Renato De Mori and Yoshua Bengio},
year={2021},
eprint={2106.04624},
archivePrefix={arXiv},
primaryClass={eess.AS},
note={arXiv:2106.04624}
}
``` |
facebook/m2m100-12B-avg-5-ckpt | facebook | 2023-01-24T17:03:10Z | 6,891 | 6 | transformers | [
"transformers",
"pytorch",
"m2m_100",
"text2text-generation",
"m2m100-12B",
"multilingual",
"af",
"am",
"ar",
"ast",
"az",
"ba",
"be",
"bg",
"bn",
"br",
"bs",
"ca",
"ceb",
"cs",
"cy",
"da",
"de",
"el",
"en",
"es",
"et",
"fa",
"ff",
"fi",
"fr",
"fy",
"ga",
"gd",
"gl",
"gu",
"ha",
"he",
"hi",
"hr",
"ht",
"hu",
"hy",
"id",
"ig",
"ilo",
"is",
"it",
"ja",
"jv",
"ka",
"kk",
"km",
"kn",
"ko",
"lb",
"lg",
"ln",
"lo",
"lt",
"lv",
"mg",
"mk",
"ml",
"mn",
"mr",
"ms",
"my",
"ne",
"nl",
"no",
"ns",
"oc",
"or",
"pa",
"pl",
"ps",
"pt",
"ro",
"ru",
"sd",
"si",
"sk",
"sl",
"so",
"sq",
"sr",
"ss",
"su",
"sv",
"sw",
"ta",
"th",
"tl",
"tn",
"tr",
"uk",
"ur",
"uz",
"vi",
"wo",
"xh",
"yi",
"yo",
"zh",
"zu",
"arxiv:2010.11125",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text2text-generation | 2022-03-13T18:25:42Z | ---
language:
- multilingual
- af
- am
- ar
- ast
- az
- ba
- be
- bg
- bn
- br
- bs
- ca
- ceb
- cs
- cy
- da
- de
- el
- en
- es
- et
- fa
- ff
- fi
- fr
- fy
- ga
- gd
- gl
- gu
- ha
- he
- hi
- hr
- ht
- hu
- hy
- id
- ig
- ilo
- is
- it
- ja
- jv
- ka
- kk
- km
- kn
- ko
- lb
- lg
- ln
- lo
- lt
- lv
- mg
- mk
- ml
- mn
- mr
- ms
- my
- ne
- nl
- no
- ns
- oc
- or
- pa
- pl
- ps
- pt
- ro
- ru
- sd
- si
- sk
- sl
- so
- sq
- sr
- ss
- su
- sv
- sw
- ta
- th
- tl
- tn
- tr
- uk
- ur
- uz
- vi
- wo
- xh
- yi
- yo
- zh
- zu
license: mit
tags:
- m2m100-12B
---
# M2M100 12B (average of last 5 checkpoints)
M2M100 is a multilingual encoder-decoder (seq-to-seq) model trained for Many-to-Many multilingual translation.
It was introduced in this [paper](https://arxiv.org/abs/2010.11125) and first released in [this](https://github.com/pytorch/fairseq/tree/master/examples/m2m_100) repository.
The model that can directly translate between the 9,900 directions of 100 languages.
To translate into a target language, the target language id is forced as the first generated token.
To force the target language id as the first generated token, pass the `forced_bos_token_id` parameter to the `generate` method.
*Note: `M2M100Tokenizer` depends on `sentencepiece`, so make sure to install it before running the example.*
To install `sentencepiece` run `pip install sentencepiece`
```python
from transformers import M2M100ForConditionalGeneration, M2M100Tokenizer
hi_text = "जीवन एक चॉकलेट बॉक्स की तरह है।"
chinese_text = "生活就像一盒巧克力。"
model = M2M100ForConditionalGeneration.from_pretrained("facebook/m2m100-12B-avg-5-ckpt")
tokenizer = M2M100Tokenizer.from_pretrained("facebook/m2m100-12B-avg-5-ckpt")
# translate Hindi to French
tokenizer.src_lang = "hi"
encoded_hi = tokenizer(hi_text, return_tensors="pt")
generated_tokens = model.generate(**encoded_hi, forced_bos_token_id=tokenizer.get_lang_id("fr"))
tokenizer.batch_decode(generated_tokens, skip_special_tokens=True)
# => "La vie est comme une boîte de chocolat."
# translate Chinese to English
tokenizer.src_lang = "zh"
encoded_zh = tokenizer(chinese_text, return_tensors="pt")
generated_tokens = model.generate(**encoded_zh, forced_bos_token_id=tokenizer.get_lang_id("en"))
tokenizer.batch_decode(generated_tokens, skip_special_tokens=True)
# => "Life is like a box of chocolate."
```
See the [model hub](https://huggingface.co/models?filter=m2m_100) to look for more fine-tuned versions.
## Languages covered
Afrikaans (af), Amharic (am), Arabic (ar), Asturian (ast), Azerbaijani (az), Bashkir (ba), Belarusian (be), Bulgarian (bg), Bengali (bn), Breton (br), Bosnian (bs), Catalan; Valencian (ca), Cebuano (ceb), Czech (cs), Welsh (cy), Danish (da), German (de), Greeek (el), English (en), Spanish (es), Estonian (et), Persian (fa), Fulah (ff), Finnish (fi), French (fr), Western Frisian (fy), Irish (ga), Gaelic; Scottish Gaelic (gd), Galician (gl), Gujarati (gu), Hausa (ha), Hebrew (he), Hindi (hi), Croatian (hr), Haitian; Haitian Creole (ht), Hungarian (hu), Armenian (hy), Indonesian (id), Igbo (ig), Iloko (ilo), Icelandic (is), Italian (it), Japanese (ja), Javanese (jv), Georgian (ka), Kazakh (kk), Central Khmer (km), Kannada (kn), Korean (ko), Luxembourgish; Letzeburgesch (lb), Ganda (lg), Lingala (ln), Lao (lo), Lithuanian (lt), Latvian (lv), Malagasy (mg), Macedonian (mk), Malayalam (ml), Mongolian (mn), Marathi (mr), Malay (ms), Burmese (my), Nepali (ne), Dutch; Flemish (nl), Norwegian (no), Northern Sotho (ns), Occitan (post 1500) (oc), Oriya (or), Panjabi; Punjabi (pa), Polish (pl), Pushto; Pashto (ps), Portuguese (pt), Romanian; Moldavian; Moldovan (ro), Russian (ru), Sindhi (sd), Sinhala; Sinhalese (si), Slovak (sk), Slovenian (sl), Somali (so), Albanian (sq), Serbian (sr), Swati (ss), Sundanese (su), Swedish (sv), Swahili (sw), Tamil (ta), Thai (th), Tagalog (tl), Tswana (tn), Turkish (tr), Ukrainian (uk), Urdu (ur), Uzbek (uz), Vietnamese (vi), Wolof (wo), Xhosa (xh), Yiddish (yi), Yoruba (yo), Chinese (zh), Zulu (zu)
## BibTeX entry and citation info
```
@misc{fan2020englishcentric,
title={Beyond English-Centric Multilingual Machine Translation},
author={Angela Fan and Shruti Bhosale and Holger Schwenk and Zhiyi Ma and Ahmed El-Kishky and Siddharth Goyal and Mandeep Baines and Onur Celebi and Guillaume Wenzek and Vishrav Chaudhary and Naman Goyal and Tom Birch and Vitaliy Liptchinsky and Sergey Edunov and Edouard Grave and Michael Auli and Armand Joulin},
year={2020},
eprint={2010.11125},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
``` |
google/vit-base-patch32-384 | google | 2023-09-11T20:35:12Z | 6,886 | 19 | transformers | [
"transformers",
"pytorch",
"tf",
"jax",
"safetensors",
"vit",
"image-classification",
"vision",
"dataset:imagenet-1k",
"dataset:imagenet-21k",
"arxiv:2010.11929",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | image-classification | 2022-03-02T23:29:05Z | ---
license: apache-2.0
tags:
- vision
- image-classification
datasets:
- imagenet-1k
- imagenet-21k
---
# Vision Transformer (base-sized model)
Vision Transformer (ViT) model pre-trained on ImageNet-21k (14 million images, 21,843 classes) at resolution 224x224, and fine-tuned on ImageNet 2012 (1 million images, 1,000 classes) at resolution 384x384. It was introduced in the paper [An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale](https://arxiv.org/abs/2010.11929) by Dosovitskiy et al. and first released in [this repository](https://github.com/google-research/vision_transformer). However, the weights were converted from the [timm repository](https://github.com/rwightman/pytorch-image-models) by Ross Wightman, who already converted the weights from JAX to PyTorch. Credits go to him.
Disclaimer: The team releasing ViT did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
The Vision Transformer (ViT) is a transformer encoder model (BERT-like) pretrained on a large collection of images in a supervised fashion, namely ImageNet-21k, at a resolution of 224x224 pixels. Next, the model was fine-tuned on ImageNet (also referred to as ILSVRC2012), a dataset comprising 1 million images and 1,000 classes, at a higher resolution of 384x384.
Images are presented to the model as a sequence of fixed-size patches (resolution 32x32), which are linearly embedded. One also adds a [CLS] token to the beginning of a sequence to use it for classification tasks. One also adds absolute position embeddings before feeding the sequence to the layers of the Transformer encoder.
By pre-training the model, it learns an inner representation of images that can then be used to extract features useful for downstream tasks: if you have a dataset of labeled images for instance, you can train a standard classifier by placing a linear layer on top of the pre-trained encoder. One typically places a linear layer on top of the [CLS] token, as the last hidden state of this token can be seen as a representation of an entire image.
## Intended uses & limitations
You can use the raw model for image classification. See the [model hub](https://huggingface.co/models?search=google/vit) to look for
fine-tuned versions on a task that interests you.
### How to use
Here is how to use this model to classify an image of the COCO 2017 dataset into one of the 1,000 ImageNet classes:
```python
from transformers import ViTFeatureExtractor, ViTForImageClassification
from PIL import Image
import requests
url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
image = Image.open(requests.get(url, stream=True).raw)
feature_extractor = ViTFeatureExtractor.from_pretrained('google/vit-base-patch32-384')
model = ViTForImageClassification.from_pretrained('google/vit-base-patch32-384')
inputs = feature_extractor(images=image, return_tensors="pt")
outputs = model(**inputs)
logits = outputs.logits
# model predicts one of the 1000 ImageNet classes
predicted_class_idx = logits.argmax(-1).item()
print("Predicted class:", model.config.id2label[predicted_class_idx])
```
Currently, both the feature extractor and model support PyTorch. Tensorflow and JAX/FLAX are coming soon, and the API of ViTFeatureExtractor might change.
## Training data
The ViT model was pretrained on [ImageNet-21k](http://www.image-net.org/), a dataset consisting of 14 million images and 21k classes, and fine-tuned on [ImageNet](http://www.image-net.org/challenges/LSVRC/2012/), a dataset consisting of 1 million images and 1k classes.
## Training procedure
### Preprocessing
The exact details of preprocessing of images during training/validation can be found [here](https://github.com/google-research/vision_transformer/blob/master/vit_jax/input_pipeline.py).
Images are resized/rescaled to the same resolution (224x224 during pre-training, 384x384 during fine-tuning) and normalized across the RGB channels with mean (0.5, 0.5, 0.5) and standard deviation (0.5, 0.5, 0.5).
### Pretraining
The model was trained on TPUv3 hardware (8 cores). All model variants are trained with a batch size of 4096 and learning rate warmup of 10k steps. For ImageNet, the authors found it beneficial to additionally apply gradient clipping at global norm 1. Pre-training resolution is 224.
## Evaluation results
For evaluation results on several image classification benchmarks, we refer to tables 2 and 5 of the original paper. Note that for fine-tuning, the best results are obtained with a higher resolution (384x384). Of course, increasing the model size will result in better performance.
### BibTeX entry and citation info
```bibtex
@misc{https://doi.org/10.48550/arxiv.2010.11929,
doi = {10.48550/ARXIV.2010.11929},
url = {https://arxiv.org/abs/2010.11929},
author = {Dosovitskiy, Alexey and Beyer, Lucas and Kolesnikov, Alexander and Weissenborn, Dirk and Zhai, Xiaohua and Unterthiner, Thomas and Dehghani, Mostafa and Minderer, Matthias and Heigold, Georg and Gelly, Sylvain and Uszkoreit, Jakob and Houlsby, Neil},
keywords = {Computer Vision and Pattern Recognition (cs.CV), Artificial Intelligence (cs.AI), Machine Learning (cs.LG), FOS: Computer and information sciences, FOS: Computer and information sciences},
title = {An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale},
publisher = {arXiv},
year = {2020},
copyright = {arXiv.org perpetual, non-exclusive license}
}
```
```bibtex
@inproceedings{deng2009imagenet,
title={Imagenet: A large-scale hierarchical image database},
author={Deng, Jia and Dong, Wei and Socher, Richard and Li, Li-Jia and Li, Kai and Fei-Fei, Li},
booktitle={2009 IEEE conference on computer vision and pattern recognition},
pages={248--255},
year={2009},
organization={Ieee}
}
``` |
Systran/faster-distil-whisper-large-v3 | Systran | 2024-03-25T15:39:39Z | 6,885 | 11 | ctranslate2 | [
"ctranslate2",
"audio",
"automatic-speech-recognition",
"en",
"license:mit",
"region:us"
] | automatic-speech-recognition | 2024-03-25T14:51:36Z | ---
language:
- en
tags:
- audio
- automatic-speech-recognition
license: mit
library_name: ctranslate2
---
# Whisper distil-large-v3 model for CTranslate2
This repository contains the conversion of [distil-whisper/distil-large-v3](https://huggingface.co/distil-whisper/distil-large-v3) to the [CTranslate2](https://github.com/OpenNMT/CTranslate2) model format.
This model can be used in CTranslate2 or projects based on CTranslate2 such as [faster-whisper](https://github.com/systran/faster-whisper).
## Example
```python
from faster_whisper import WhisperModel
model = WhisperModel("distil-large-v3")
segments, info = model.transcribe("audio.mp3", language="en", condition_on_previous_text=False)
for segment in segments:
print("[%.2fs -> %.2fs] %s" % (segment.start, segment.end, segment.text))
```
## Conversion details
The original model was converted with the following command:
```
ct2-transformers-converter --model distil-whisper/distil-large-v3 --output_dir faster-distil-whisper-large-v3 \
--copy_files tokenizer.json preprocessor_config.json --quantization float16
```
Note that the model weights are saved in FP16. This type can be changed when the model is loaded using the [`compute_type` option in CTranslate2](https://opennmt.net/CTranslate2/quantization.html).
## More information
**For more information about the original model, see its [model card](https://huggingface.co/distil-whisper/distil-large-v3).** |
01-ai/Yi-1.5-34B-Chat-16K | 01-ai | 2024-06-26T10:42:48Z | 6,880 | 22 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"arxiv:2403.04652",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2024-05-15T10:45:46Z | ---
license: apache-2.0
---
<div align="center">
<picture>
<img src="https://raw.githubusercontent.com/01-ai/Yi/main/assets/img/Yi_logo_icon_light.svg" width="150px">
</picture>
</div>
<p align="center">
<a href="https://github.com/01-ai">🐙 GitHub</a> •
<a href="https://discord.gg/hYUwWddeAu">👾 Discord</a> •
<a href="https://twitter.com/01ai_yi">🐤 Twitter</a> •
<a href="https://github.com/01-ai/Yi-1.5/issues/2">💬 WeChat</a>
<br/>
<a href="https://arxiv.org/abs/2403.04652">📝 Paper</a> •
<a href="https://01-ai.github.io/">💪 Tech Blog</a> •
<a href="https://github.com/01-ai/Yi/tree/main?tab=readme-ov-file#faq">🙌 FAQ</a> •
<a href="https://github.com/01-ai/Yi/tree/main?tab=readme-ov-file#learning-hub">📗 Learning Hub</a>
</p>
# Intro
Yi-1.5 is an upgraded version of Yi. It is continuously pre-trained on Yi with a high-quality corpus of 500B tokens and fine-tuned on 3M diverse fine-tuning samples.
Compared with Yi, Yi-1.5 delivers stronger performance in coding, math, reasoning, and instruction-following capability, while still maintaining excellent capabilities in language understanding, commonsense reasoning, and reading comprehension.
<div align="center">
Model | Context Length | Pre-trained Tokens
| :------------: | :------------: | :------------: |
| Yi-1.5 | 4K, 16K, 32K | 3.6T
</div>
# Models
- Chat models
<div align="center">
| Name | Download |
| --------------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| Yi-1.5-34B-Chat | • [🤗 Hugging Face](https://huggingface.co/collections/01-ai/yi-15-2024-05-663f3ecab5f815a3eaca7ca8) • [🤖 ModelScope](https://www.modelscope.cn/organization/01ai) • [🟣 wisemodel](https://wisemodel.cn/organization/01.AI)|
| Yi-1.5-34B-Chat-16K | • [🤗 Hugging Face](https://huggingface.co/collections/01-ai/yi-15-2024-05-663f3ecab5f815a3eaca7ca8) • [🤖 ModelScope](https://www.modelscope.cn/organization/01ai) • [🟣 wisemodel](https://wisemodel.cn/organization/01.AI) |
| Yi-1.5-9B-Chat | • [🤗 Hugging Face](https://huggingface.co/collections/01-ai/yi-15-2024-05-663f3ecab5f815a3eaca7ca8) • [🤖 ModelScope](https://www.modelscope.cn/organization/01ai) • [🟣 wisemodel](https://wisemodel.cn/organization/01.AI) |
| Yi-1.5-9B-Chat-16K | • [🤗 Hugging Face](https://huggingface.co/collections/01-ai/yi-15-2024-05-663f3ecab5f815a3eaca7ca8) • [🤖 ModelScope](https://www.modelscope.cn/organization/01ai) • [🟣 wisemodel](https://wisemodel.cn/organization/01.AI) |
| Yi-1.5-6B-Chat | • [🤗 Hugging Face](https://huggingface.co/collections/01-ai/yi-15-2024-05-663f3ecab5f815a3eaca7ca8) • [🤖 ModelScope](https://www.modelscope.cn/organization/01ai) • [🟣 wisemodel](https://wisemodel.cn/organization/01.AI) |
</div>
- Base models
<div align="center">
| Name | Download |
| ---------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| Yi-1.5-34B | • [🤗 Hugging Face](https://huggingface.co/collections/01-ai/yi-15-2024-05-663f3ecab5f815a3eaca7ca8) • [🤖 ModelScope](https://www.modelscope.cn/organization/01ai) • [🟣 wisemodel](https://wisemodel.cn/organization/01.AI) |
| Yi-1.5-34B-32K | • [🤗 Hugging Face](https://huggingface.co/collections/01-ai/yi-15-2024-05-663f3ecab5f815a3eaca7ca8) • [🤖 ModelScope](https://www.modelscope.cn/organization/01ai) • [🟣 wisemodel](https://wisemodel.cn/organization/01.AI) |
| Yi-1.5-9B | • [🤗 Hugging Face](https://huggingface.co/collections/01-ai/yi-15-2024-05-663f3ecab5f815a3eaca7ca8) • [🤖 ModelScope](https://www.modelscope.cn/organization/01ai) • [🟣 wisemodel](https://wisemodel.cn/organization/01.AI) |
| Yi-1.5-9B-32K | • [🤗 Hugging Face](https://huggingface.co/collections/01-ai/yi-15-2024-05-663f3ecab5f815a3eaca7ca8) • [🤖 ModelScope](https://www.modelscope.cn/organization/01ai) • [🟣 wisemodel](https://wisemodel.cn/organization/01.AI) |
| Yi-1.5-6B | • [🤗 Hugging Face](https://huggingface.co/collections/01-ai/yi-15-2024-05-663f3ecab5f815a3eaca7ca8) • [🤖 ModelScope](https://www.modelscope.cn/organization/01ai) • [🟣 wisemodel](https://wisemodel.cn/organization/01.AI) |
</div>
# Benchmarks
- Chat models
Yi-1.5-34B-Chat is on par with or excels beyond larger models in most benchmarks.

Yi-1.5-9B-Chat is the top performer among similarly sized open-source models.

- Base models
Yi-1.5-34B is on par with or excels beyond larger models in some benchmarks.

Yi-1.5-9B is the top performer among similarly sized open-source models.

# Quick Start
For getting up and running with Yi-1.5 models quickly, see [README](https://github.com/01-ai/Yi-1.5).
|
nferruz/ProtGPT2 | nferruz | 2023-06-20T13:05:57Z | 6,878 | 87 | transformers | [
"transformers",
"pytorch",
"gpt2",
"text-generation",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2022-03-07T12:29:07Z | ---
license: apache-2.0
pipeline_tag: text-generation
widget:
- text: "<|endoftext|>"
inference:
parameters:
top_k: 950
repetition_penalty: 1.2
---
# **ProtGPT2**
ProtGPT2 ([peer-reviewed paper](https://www.nature.com/articles/s41467-022-32007-7)) is a language model that speaks the protein language and can be used for de novo protein design and engineering. ProtGPT2 generated sequences conserve natural proteins' critical features (amino acid propensities, secondary structural content, and globularity) while exploring unseen regions of the protein space.
## **Model description**
ProtGPT2 is based on the GPT2 Transformer architecture and contains 36 layers with a model dimensionality of 1280, totalling 738 million parameters.
ProtGPT2 is a decoder-only transformer model pre-trained on the protein space, database UniRef50 (version 2021_04). The pre-training was done on the raw sequences without FASTA headers. Details of training and datasets can be found here: https://huggingface.co/datasets/nferruz/UR50_2021_04
ProtGPT2 was trained in a self-supervised fashion, i.e., the raw sequence data was used during training without including the annotation of sequences. In particular, ProtGPT2 was trained using a causal modelling objective, in which the model is trained to predict the next token (or, in this case, oligomer) in the sequence.
By doing so, the model learns an internal representation of proteins and is able to <em>speak</em> the protein language.
### **How to use ProtGPT2**
ProtGPT2 can be used with the HuggingFace transformer python package. Detailed installation instructions can be found here: https://huggingface.co/docs/transformers/installation
Since ProtGPT2 has been trained on the classical language model objective, it excels at generating protein sequences. It can be used to generate sequences in a zero-shot fashion or to generate sequences of a particular type after finetuning on a user-defined dataset.
**Example 1: Generating _de novo_ proteins in a zero-shot fashion**
In the example below, ProtGPT2 generates sequences that follow the amino acid 'M'. Any other amino acid, oligomer, fragment, or protein of choice can be selected instead. The model will generate the most probable sequences that follow the input. Alternatively, the input field can also be left empty and it will choose the starting tokens.
```
>>> from transformers import pipeline
>>> protgpt2 = pipeline('text-generation', model="nferruz/ProtGPT2")
# length is expressed in tokens, where each token has an average length of 4 amino acids.
>>> sequences = protgpt2("<|endoftext|>", max_length=100, do_sample=True, top_k=950, repetition_penalty=1.2, num_return_sequences=10, eos_token_id=0)
>>> for seq in sequences:
print(seq):
{'generated_text': 'MINDLLDISRIISGKMTLDRAEVNLTAIARQVVEEQRQAAEAKSIQLLCSTPDTNHYVFG\nDFDRLKQTLWNLLSNAVKFTPSGGTVELELGYNAEGMEVYVKDSGIGIDPAFLPYVFDRF\nRQSDAADSRNYGGLGLGLAIVKHLLDLHEGNVSAQSEGFGKGATFTVLLPLKPLKRELAA\nVNRHTAVQQSAPLNDNLAGMKILIVEDRPDTNEMVSYILEEAGAIVETAESGAAALTSLK\nSYSPDLVLSDIGMPMMDGYEMIEYIREWKTTKGG'}
{'generated_text': 'MQGDSSISSSNRMFT\nLCKPLTVANETSTLSTTRNSKSNKRVSKQRVNLAESPERNAPSPASIKTNETEEFSTIKT\nTNNEVLGYEPNYVSYDFVPMEKCNLCNENCSIELASLNEETFVKKTICCHECRKKAIENA\nENNNTKGSAVSNNSVTSSSGRKKIIVSGSQILRNLDSLTSSKSNISTLLNPNHLAKLAKN\nGNLSSLSSLQSSASSISKSSSTSSTPTTSPKVSSPTNSPSSSPINSPTP'}
{'generated_text': 'M\nSTHVSLENTLASLQATFFSLEARHTALETQLLSTRTELAATKQELVRVQAEISRADAQAQ\nDLKAQILTLKEKADQAEVEAAAATQRAEESQAALEAQTAELAQLRLEKQAPQHVAEEGDP\nQPAAPTTQAQSPVTSAAAAASSAASAEPSKPELTFPAYTKRKPPTITHAPKAPTKVALNP\nSTLSTSGSGGGAKADPTPTTPVPSSSAGLIPKALRLPPPVTPAASGAKPAPSARSKLRGP\nDAPLSPSTQS'}
{'generated_text': 'MVLLSTGPLPILFLGPSLAELNQKYQVVSDTLLRFTNTV\nTFNTLKFLGSDS\n'}
{'generated_text': 'M\nNNDEQPFIMSTSGYAGNTTSSMNSTSDFNTNNKSNTWSNRFSNFIAYFSGVGWFIGAISV\nIFFIIYVIVFLSRKTKPSGQKQYSRTERNNRDVDSIKRANYYG\n'}
{'generated_text': 'M\nEAVYSFTITETGTGTVEVTPLDRTISGADIVYPPDTACVPLTVQPVINANGTWTLGSGCT\nGHFSVDTTGHVNCLTGGFGAAGVHTVIYTVETPYSGNSFAVIDVNVTEPSGPGDGGNGNG\nDRGDGPDNGGGNNPGPDPDPSTPPPPGDCSSPLPVVCSDRDCADFDTQAQVQIYLDRYGG\nTCDLDGNHDGTPCENLPNNSGGQSSDSGNGGGNPGTGSTHQVVTGDCLWNIASRNNGQGG\nQAWPALLAANNESITNP'}
{'generated_text': 'M\nGLTTSGGARGFCSLAVLQELVPRPELLFVIDRAFHSGKHAVDMQVVDQEGLGDGVATLLY\nAHQGLYTCLLQAEARLLGREWAAVPALEPNFMESPLIALPRQLLEGLEQNILSAYGSEWS\nQDVAEPQGDTPAALLATALGLHEPQQVAQRRRQLFEAAEAALQAIRASA\n'}
{'generated_text': 'M\nGAAGYTGSLILAALKQNPDIAVYALNRNDEKLKDVCGQYSNLKGQVCDLSNESQVEALLS\nGPRKTVVNLVGPYSFYGSRVLNACIEANCHYIDLTGEVYWIPQMIKQYHHKAVQSGARIV\nPAVGFDSTPAELGSFFAYQQCREKLKKAHLKIKAYTGQSGGASGGTILTMIQHGIENGKI\nLREIRSMANPREPQSDFKHYKEKTFQDGSASFWGVPFVMKGINTPVVQRSASLLKKLYQP\nFDYKQCFSFSTLLNSLFSYIFNAI'}
{'generated_text': 'M\nKFPSLLLDSYLLVFFIFCSLGLYFSPKEFLSKSYTLLTFFGSLLFIVLVAFPYQSAISAS\nKYYYFPFPIQFFDIGLAENKSNFVTSTTILIFCFILFKRQKYISLLLLTVVLIPIISKGN\nYLFIILILNLAVYFFLFKKLYKKGFCISLFLVFSCIFIFIVSKIMYSSGIEGIYKELIFT\nGDNDGRFLIIKSFLEYWKDNLFFGLGPSSVNLFSGAVSGSFHNTYFFIFFQSGILGAFIF\nLLPFVYFFISFFKDNSSFMKLF'}
{'generated_text': 'M\nRRAVGNADLGMEAARYEPSGAYQASEGDGAHGKPHSLPFVALERWQQLGPEERTLAEAVR\nAVLASGQYLLGEAVRRFETAVAAWLGVPFALGVASGTAALTLALRAYGVGPGDEVIVPAI\nTFIATSNAITAAGARPVLVDIDPSTWNMSVASLAARLTPKTKAILAVHLWGQPVDMHPLL\nDIAAQANLAVIEDCAQALGASIAGTKVGTFGDAAAFSFYPTKNMTTGEGGMLVTNARDLA\nQAARMLRSHGQDPPTAYMHSQVGFN'}
```
**Example 2: Finetuning on a set of user-defined sequences**
This alternative option to the zero-shot generation permits introducing direction in the generation process. User-defined training and validation files containing the sequences of interest are provided to the model. After a short update of the model's weights, ProtGPT2 will generate sequences that follow the input properties.
To create the validation and training file, it is necessary to (1) substitute the FASTA headers for each sequence with the expression "<|endoftext|>" and (2) split the originating dataset into training and validation files (this is often done with the ratio 90/10, 80/20 or 95/5). Then, to finetune the model to the input sequences, we can use the example below. Here we show a learning rate of 1e-06, but ideally, the learning rate should be optimised in separate runs. After training, the finetuned model will be stored in the ./output folder. Lastly, ProtGPT2 can generate the tailored sequences as shown in Example 1:
```
python run_clm.py --model_name_or_path nferruz/ProtGPT2 --train_file training.txt --validation_file validation.txt --tokenizer_name nferruz/ProtGPT2
--do_train --do_eval --output_dir output --learning_rate 1e-06
```
The HuggingFace script run_clm.py can be found here: https://github.com/huggingface/transformers/blob/master/examples/pytorch/language-modeling/run_clm.py
### **How to select the best sequences**
We've observed that perplexity values correlate with AlphaFold2's plddt.
We recommend computing perplexity for each sequence as follows:
```
sequence='MGEAMGLTQPAVSRAVARLEERVGIRIFNRTARAITLTDEGRRFYEAVAPLLAGIEMHGYR\nVNVEGVAQLLELYARDILAEGRLVQLLPEWAD'
#Convert the sequence to a string like this
#(note we have to introduce new line characters every 60 amino acids,
#following the FASTA file format).
sequence = "<|endoftext|>MGEAMGLTQPAVSRAVARLEERVGIRIFNRTARAITLTDEGRRFYEAVAPLLAGIEMHGY\nRVNVEGVAQLLELYARDILAEGRLVQLLPEWAD<|endoftext|>"
# ppl function
def calculatePerplexity(sequence, model, tokenizer):
input_ids = torch.tensor(tokenizer.encode(sequence)).unsqueeze(0)
input_ids = input_ids.to(device)
with torch.no_grad():
outputs = model(input_ids, labels=input_ids)
loss, logits = outputs[:2]
return math.exp(loss)
#And hence:
ppl = calculatePerplexity(sequence, model, tokenizer)
```
Where `ppl` is a value with the perplexity for that sequence.
We do not yet have a threshold as to what perplexity value gives a 'good' or 'bad' sequence, but given the fast inference times, the best is to sample many sequences, order them by perplexity, and select those with the lower values (the lower the better).
### **Training specs**
The model was trained on 128 NVIDIA A100 GPUs for 50 epochs, using a block size of 512 and a total batch size of 1024 (65,536 tokens per batch). The optimizer used was Adam (beta1 = 0.9, beta2 = 0.999) with a learning rate of 1e-3. |
Vikhrmodels/it-5.3-fp16-GGUF | Vikhrmodels | 2024-06-06T14:22:12Z | 6,874 | 0 | null | [
"gguf",
"region:us"
] | null | 2024-06-03T12:25:13Z | Entry not found |
QuantFactory/llama-3-fantasy-writer-8b-GGUF | QuantFactory | 2024-06-25T15:39:42Z | 6,874 | 0 | null | [
"gguf",
"region:us"
] | null | 2024-06-25T13:50:18Z | Entry not found |
senseable/WestLake-7B-v2 | senseable | 2024-03-04T23:25:48Z | 6,873 | 103 | transformers | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"en",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2024-01-22T01:13:35Z | ---
language:
- en
license: apache-2.0
library_name: transformers
model-index:
- name: WestLake-7B-v2
results:
- task:
type: text-generation
name: Text Generation
dataset:
name: AI2 Reasoning Challenge (25-Shot)
type: ai2_arc
config: ARC-Challenge
split: test
args:
num_few_shot: 25
metrics:
- type: acc_norm
value: 73.04
name: normalized accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=senseable/WestLake-7B-v2
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: HellaSwag (10-Shot)
type: hellaswag
split: validation
args:
num_few_shot: 10
metrics:
- type: acc_norm
value: 88.65
name: normalized accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=senseable/WestLake-7B-v2
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: MMLU (5-Shot)
type: cais/mmlu
config: all
split: test
args:
num_few_shot: 5
metrics:
- type: acc
value: 64.71
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=senseable/WestLake-7B-v2
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: TruthfulQA (0-shot)
type: truthful_qa
config: multiple_choice
split: validation
args:
num_few_shot: 0
metrics:
- type: mc2
value: 67.06
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=senseable/WestLake-7B-v2
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: Winogrande (5-shot)
type: winogrande
config: winogrande_xl
split: validation
args:
num_few_shot: 5
metrics:
- type: acc
value: 86.98
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=senseable/WestLake-7B-v2
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: GSM8k (5-shot)
type: gsm8k
config: main
split: test
args:
num_few_shot: 5
metrics:
- type: acc
value: 67.63
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=senseable/WestLake-7B-v2
name: Open LLM Leaderboard
---

**Update Notes:**
*Version 2 trained 1 additional epoch cycle for 3 total*
# Westlake-7Bv2: Role-Play & Text Generation Specialist Model
Welcome to the documentation of Westlake-7B, a cutting-edge language model designed for exceptional role-play and text generation tasks. This README file aims to provide an overview of our capabilities, usage guidelines, and potential applications.
## About Westlake-7Bv2
Westlake-7B is built upon a vast corpus of diverse texts, enabling it to generate contextually relevant responses in various scenarios. With its impressive size of 7 billion parameters, this model excels at understanding nuances in language and producing creative outputs.
### Key Features
1. **Role-Play**: Westlake-7Bv2 can seamlessly adapt to different character personas and engage in dynamic conversations while maintaining consistency throughout the interaction. It can generate believable dialogues across various genres, including fiction, non-fiction, historical events, or even fantasy worlds.
2. **Text Generation**: This model is proficient at generating original content such as stories, poems, essays, news articles, and more. Its ability to capture the essence of different writing styles makes it an ideal tool for creative writers seeking inspiration or assistance in their projects.
3. **Contextual Understanding**: Westlake-7B's extensive training allows it to comprehend complex contexts and generate responses that align with given situations. It can handle multiple topics simultaneously, making it versatile across various applications.
4. **Continuous Learning**: As a language model, Westlake-7B continuously improves its performance through ongoing training on new data sets. This ensures its capabilities remain up-to-date and relevant in an ever-evolving world of communication.
## Usage Guidelines
To utilize Westlake-7Bv2 for your projects or experiments, follow these steps:
1. **Prompting**: Provide clear and concise prompts that outline the desired role-play scenario or text generation task. The quality of output depends heavily on the clarity and relevance of input instructions.
2. **Feedback Loop**: For optimal results, consider incorporating a feedback loop into your application to refine generated outputs based on user preferences or additional contextual information. This iterative process can significantly enhance the model's performance in specific domains.
3. **Ethical Considerations**: As with any AI system, ensure responsible usage of Westlake-7B by avoiding harmful content generation or misuse of its capabilities.
## Potential Applications
Westlake-7Bv2's versatility makes it suitable for various applications across different industries:
1. **Creative Writing**: Assist authors in generating new ideas, expanding storylines, or even completing drafts by providing creative suggestions and textual content.
2. **Education**: Enhance language learning platforms with interactive role-play scenarios to improve students' communication skills and cultural understanding.
3. **Gaming**: Integrate Westlake-7B into game engines for dynamic non-player character interactions or generating unique questlines based on player choices.
4. **Customer Support**: Leverage the model's conversational abilities to create chatbots capable of handling complex queries and providing personalized assistance.
5. **Social Media**: Develop applications that generate engaging content such as captions, status updates, or even entire posts tailored to users' preferences and interests.
# [Open LLM Leaderboard Evaluation Results](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)
Detailed results can be found [here](https://huggingface.co/datasets/open-llm-leaderboard/details_senseable__WestLake-7B-v2)
| Metric |Value|
|---------------------------------|----:|
|Avg. |74.68|
|AI2 Reasoning Challenge (25-Shot)|73.04|
|HellaSwag (10-Shot) |88.65|
|MMLU (5-Shot) |64.71|
|TruthfulQA (0-shot) |67.06|
|Winogrande (5-shot) |86.98|
|GSM8k (5-shot) |67.63|
|
timm/swin_s3_tiny_224.ms_in1k | timm | 2024-02-10T23:31:38Z | 6,870 | 0 | timm | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"arxiv:2111.1472",
"arxiv:2103.14030",
"license:mit",
"region:us"
] | image-classification | 2023-03-18T04:13:24Z | ---
license: mit
library_name: timm
tags:
- image-classification
- timm
datasets:
- imagenet-1k
---
# Model card for swin_s3_tiny_224.ms_in1k
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 28.3
- GMACs: 4.6
- Activations (M): 19.1
- Image size: 224 x 224
- **Papers:**
- AutoFormerV2: https://arxiv.org/abs/2111.1472
- Swin Transformer: Hierarchical Vision Transformer using Shifted Windows: https://arxiv.org/abs/2103.14030
- **Original:** https://github.com/microsoft/Cream/tree/main/AutoFormerV2
- **Dataset:** ImageNet-1k
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('swin_s3_tiny_224.ms_in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'swin_s3_tiny_224.ms_in1k',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g. for swin_base_patch4_window7_224 (NHWC output)
# torch.Size([1, 56, 56, 128])
# torch.Size([1, 28, 28, 256])
# torch.Size([1, 14, 14, 512])
# torch.Size([1, 7, 7, 1024])
# e.g. for swinv2_cr_small_ns_224 (NCHW output)
# torch.Size([1, 96, 56, 56])
# torch.Size([1, 192, 28, 28])
# torch.Size([1, 384, 14, 14])
# torch.Size([1, 768, 7, 7])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'swin_s3_tiny_224.ms_in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled (ie.e a (batch_size, H, W, num_features) tensor for swin / swinv2
# or (batch_size, num_features, H, W) for swinv2_cr
output = model.forward_head(output, pre_logits=True)
# output is (batch_size, num_features) tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
## Citation
```bibtex
@article{S3,
title={Searching the Search Space of Vision Transformer},
author={Minghao, Chen and Kan, Wu and Bolin, Ni and Houwen, Peng and Bei, Liu and Jianlong, Fu and Hongyang, Chao and Haibin, Ling},
booktitle={Conference and Workshop on Neural Information Processing Systems (NeurIPS)},
year={2021}
}
```
```bibtex
@inproceedings{liu2021Swin,
title={Swin Transformer: Hierarchical Vision Transformer using Shifted Windows},
author={Liu, Ze and Lin, Yutong and Cao, Yue and Hu, Han and Wei, Yixuan and Zhang, Zheng and Lin, Stephen and Guo, Baining},
booktitle={Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)},
year={2021}
}
```
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
|
asafaya/bert-base-arabic | asafaya | 2023-03-17T11:32:17Z | 6,858 | 31 | transformers | [
"transformers",
"pytorch",
"tf",
"jax",
"safetensors",
"bert",
"fill-mask",
"ar",
"dataset:oscar",
"dataset:wikipedia",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | fill-mask | 2022-03-02T23:29:05Z | ---
language: ar
datasets:
- oscar
- wikipedia
---
# Arabic BERT Model
Pretrained BERT base language model for Arabic
_If you use this model in your work, please cite this paper:_
```
@inproceedings{safaya-etal-2020-kuisail,
title = "{KUISAIL} at {S}em{E}val-2020 Task 12: {BERT}-{CNN} for Offensive Speech Identification in Social Media",
author = "Safaya, Ali and
Abdullatif, Moutasem and
Yuret, Deniz",
booktitle = "Proceedings of the Fourteenth Workshop on Semantic Evaluation",
month = dec,
year = "2020",
address = "Barcelona (online)",
publisher = "International Committee for Computational Linguistics",
url = "https://www.aclweb.org/anthology/2020.semeval-1.271",
pages = "2054--2059",
}
```
## Pretraining Corpus
`arabic-bert-base` model was pretrained on ~8.2 Billion words:
- Arabic version of [OSCAR](https://traces1.inria.fr/oscar/) - filtered from [Common Crawl](http://commoncrawl.org/)
- Recent dump of Arabic [Wikipedia](https://dumps.wikimedia.org/backup-index.html)
and other Arabic resources which sum up to ~95GB of text.
__Notes on training data:__
- Our final version of corpus contains some non-Arabic words inlines, which we did not remove from sentences since that would affect some tasks like NER.
- Although non-Arabic characters were lowered as a preprocessing step, since Arabic characters does not have upper or lower case, there is no cased and uncased version of the model.
- The corpus and vocabulary set are not restricted to Modern Standard Arabic, they contain some dialectical Arabic too.
## Pretraining details
- This model was trained using Google BERT's github [repository](https://github.com/google-research/bert) on a single TPU v3-8 provided for free from [TFRC](https://www.tensorflow.org/tfrc).
- Our pretraining procedure follows training settings of bert with some changes: trained for 3M training steps with batchsize of 128, instead of 1M with batchsize of 256.
## Load Pretrained Model
You can use this model by installing `torch` or `tensorflow` and Huggingface library `transformers`. And you can use it directly by initializing it like this:
```python
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("asafaya/bert-base-arabic")
model = AutoModelForMaskedLM.from_pretrained("asafaya/bert-base-arabic")
```
## Results
For further details on the models performance or any other queries, please refer to [Arabic-BERT](https://github.com/alisafaya/Arabic-BERT)
## Acknowledgement
Thanks to Google for providing free TPU for the training process and for Huggingface for hosting this model on their servers 😊
|
meganajoseph/cplnllama3 | meganajoseph | 2024-06-27T20:04:45Z | 6,852 | 0 | transformers | [
"transformers",
"gguf",
"llama",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null | 2024-06-27T17:40:11Z | Entry not found |
mesolitica/bert-base-standard-bahasa-cased | mesolitica | 2022-09-21T02:33:11Z | 6,851 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"bert",
"fill-mask",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | fill-mask | 2022-09-21T02:29:05Z | Entry not found |
saltlux/luxia-21.4b-alignment-v1.0 | saltlux | 2024-03-12T06:34:43Z | 6,848 | 32 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"en",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2024-03-12T06:03:15Z | ---
license: apache-2.0
language:
- en
---
# **Introduction**
We introduce luxia-21.4b-alignment-v1.0, an instruction-tuned and alignment model based on luxia-21.4b.
Please refer to the evaluation results table for details.
# **Instruction Fine-tuning Strategy**
We utilize state-of-the-art instruction fine-tuning methods including supervised fine-tuning (SFT) and direct preference optimization (DPO)
# **Data Contamination Test Results**
Results will be updated soon.
# **Evaluation Results**
Results will be updated soon.
# **Usage Instructions**
### **How to use**
```python
# pip install transformers==4.35.2
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("saltlux/luxia-21.4b-alignment-v0.1")
model = AutoModelForCausalLM.from_pretrained(
"saltlux/luxia-21.4b-alignment-v0.1",
device_map="auto",
torch_dtype=torch.float16,
)
```
### **License**
- [saltlux/luxia-21.4b-alignment-v1.0](https://huggingface.co/saltlux/luxia-21.4b-alignment-v1.0): apache-2.0
### **Contact Us** ###
Any questions and suggestions are welcomed at the discussion tab. |
Liquid1/llama-3-8b-Instruct-liquid-agent-calling | Liquid1 | 2024-06-26T04:03:56Z | 6,846 | 0 | transformers | [
"transformers",
"gguf",
"llama",
"en",
"base_model:unsloth/llama-3-8b-Instruct-bnb-4bit",
"license:apache-2.0",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null | 2024-06-26T00:11:57Z | ---
base_model: unsloth/llama-3-8b-Instruct-bnb-4bit
language:
- en
license: apache-2.0
tags:
- llama
- gguf
---
# Trained For: Agent Calling
This model has been trained on agent calling with json output.
# Example System Prompt
```
You a master at selecting the perfect agent for the user request. Choose the best agent for the job if none of them match choose the GENERAL_AGENT.
Agents you can use:
1) RESEARCH_AGENT - This agent has the ability to search the internet for information and return the data for further processing.
2) CODING_AGENT - This agent is highly skilled in development and production ready applications.
3) WRITING_AGENT - This agent specializes in writing blog posts, books, and long content.
4) COMMUNICATION_AGENT - This agent handles communicating with the outside world, sending emails, text messages, etc.
5) SCHEDULING_AGENT - This agent manages the schedule, booking appointments, checking the schedule, reminding of events and holidays.
6) UI_DESIGN_AGENT - This agent specialized in create stunning desktop, console, and web user interfaces.
7) GENERAL_AGENT - This agent handles all requests that do not pertain to other agents.
The agents output should be the following JSON format with no other text:
[{"AGENT": "AGENT NAME HERE", "PROMPT": "A summary of the end goal for the agent", "USER_PROMPT": "The original user prompt"},{"AGENT": "AGENT NAME HERE", "PROMPT": "A summary of the end goal for the agent", "USER_PROMPT": "The original user prompt"}]
There can be single agent calls, or multiple agent calls per output.
```
# Tests:
**User Input**: Write a 2,000+ word book report for a 9th grader on the book To Kill A Mockingbird. Research the book before writing.
**Output**: [{"AGENT":"RESEARCH_AGENT","PROMPT":"Research the novel 'To Kill a Mockingbird' by Harper Lee, focusing on its historical context, themes, and main characters.","USER_PROMPT":"Find important details about the book for the report."},{"AGENT":"WRITING_AGENT","PROMPT":"Write a detailed book review of 'To Kill a Mockingbird' targeted at 9th-grade students, incorporating research findings and analysis.","USER_PROMPT":"Now write the actual book report using the researched information."}]
|
duyntnet/pygmalion-2-7b-imatrix-GGUF | duyntnet | 2024-06-13T06:35:46Z | 6,839 | 0 | transformers | [
"transformers",
"gguf",
"imatrix",
"pygmalion-2-7b",
"text-generation",
"en",
"license:other",
"region:us"
] | text-generation | 2024-06-13T04:27:22Z | ---
license: other
language:
- en
pipeline_tag: text-generation
inference: false
tags:
- transformers
- gguf
- imatrix
- pygmalion-2-7b
---
Quantizations of https://huggingface.co/PygmalionAI/pygmalion-2-7b
# From original readme
## Prompting
The model has been trained on prompts using three different roles, which are denoted by the following tokens: `<|system|>`, `<|user|>` and `<|model|>`.
The `<|system|>` prompt can be used to inject out-of-channel information behind the scenes, while the `<|user|>` prompt should be used to indicate user input.
The `<|model|>` token should then be used to indicate that the model should generate a response. These tokens can happen multiple times and be chained up to
form a conversation history.
### Prompting example
The system prompt has been designed to allow the model to "enter" various modes and dictate the reply length. Here's an example:
```
<|system|>Enter RP mode. Pretend to be {{char}} whose persona follows:
{{persona}}
You shall reply to the user while staying in character, and generate long responses.
``` |
google/pix2struct-textcaps-base | google | 2023-09-07T18:57:01Z | 6,836 | 27 | transformers | [
"transformers",
"pytorch",
"safetensors",
"pix2struct",
"text2text-generation",
"image-to-text",
"en",
"fr",
"ro",
"de",
"multilingual",
"arxiv:2210.03347",
"license:apache-2.0",
"autotrain_compatible",
"region:us"
] | image-to-text | 2023-03-01T09:07:41Z | ---
language:
- en
- fr
- ro
- de
- multilingual
pipeline_tag: image-to-text
inference: false
license: apache-2.0
---
# Model card for Pix2Struct - Finetuned on TextCaps

# Table of Contents
0. [TL;DR](#TL;DR)
1. [Using the model](#using-the-model)
2. [Contribution](#contribution)
3. [Citation](#citation)
# TL;DR
Pix2Struct is an image encoder - text decoder model that is trained on image-text pairs for various tasks, including image captionning and visual question answering. The full list of available models can be found on the Table 1 of the paper:

The abstract of the model states that:
> Visually-situated language is ubiquitous—sources range from textbooks with diagrams to web pages with images and tables, to mobile apps with buttons and
forms. Perhaps due to this diversity, previous work has typically relied on domainspecific recipes with limited sharing of the underlying data, model architectures,
and objectives. We present Pix2Struct, a pretrained image-to-text model for
purely visual language understanding, which can be finetuned on tasks containing visually-situated language. Pix2Struct is pretrained by learning to parse
masked screenshots of web pages into simplified HTML. The web, with its richness of visual elements cleanly reflected in the HTML structure, provides a large
source of pretraining data well suited to the diversity of downstream tasks. Intuitively, this objective subsumes common pretraining signals such as OCR, language modeling, image captioning. In addition to the novel pretraining strategy,
we introduce a variable-resolution input representation and a more flexible integration of language and vision inputs, where language prompts such as questions
are rendered directly on top of the input image. For the first time, we show that a
single pretrained model can achieve state-of-the-art results in six out of nine tasks
across four domains: documents, illustrations, user interfaces, and natural images.
# Using the model
## Converting from T5x to huggingface
You can use the [`convert_pix2struct_checkpoint_to_pytorch.py`](https://github.com/huggingface/transformers/blob/main/src/transformers/models/pix2struct/convert_pix2struct_checkpoint_to_pytorch.py) script as follows:
```bash
python convert_pix2struct_checkpoint_to_pytorch.py --t5x_checkpoint_path PATH_TO_T5X_CHECKPOINTS --pytorch_dump_path PATH_TO_SAVE
```
if you are converting a large model, run:
```bash
python convert_pix2struct_checkpoint_to_pytorch.py --t5x_checkpoint_path PATH_TO_T5X_CHECKPOINTS --pytorch_dump_path PATH_TO_SAVE --use-large
```
Once saved, you can push your converted model with the following snippet:
```python
from transformers import Pix2StructForConditionalGeneration, Pix2StructProcessor
model = Pix2StructForConditionalGeneration.from_pretrained(PATH_TO_SAVE)
processor = Pix2StructProcessor.from_pretrained(PATH_TO_SAVE)
model.push_to_hub("USERNAME/MODEL_NAME")
processor.push_to_hub("USERNAME/MODEL_NAME")
```
## Running the model
### In full precision, on CPU:
You can run the model in full precision on CPU:
```python
import requests
from PIL import Image
from transformers import Pix2StructForConditionalGeneration, Pix2StructProcessor
url = "https://www.ilankelman.org/stopsigns/australia.jpg"
image = Image.open(requests.get(url, stream=True).raw)
model = Pix2StructForConditionalGeneration.from_pretrained("google/pix2struct-textcaps-base")
processor = Pix2StructProcessor.from_pretrained("google/pix2struct-textcaps-base")
# image only
inputs = processor(images=image, return_tensors="pt")
predictions = model.generate(**inputs)
print(processor.decode(predictions[0], skip_special_tokens=True))
>>> A stop sign is on a street corner.
```
### In full precision, on GPU:
You can run the model in full precision on CPU:
```python
import requests
from PIL import Image
from transformers import Pix2StructForConditionalGeneration, Pix2StructProcessor
url = "https://www.ilankelman.org/stopsigns/australia.jpg"
image = Image.open(requests.get(url, stream=True).raw)
model = Pix2StructForConditionalGeneration.from_pretrained("google/pix2struct-textcaps-base").to("cuda")
processor = Pix2StructProcessor.from_pretrained("google/pix2struct-textcaps-base")
# image only
inputs = processor(images=image, return_tensors="pt").to("cuda")
predictions = model.generate(**inputs)
print(processor.decode(predictions[0], skip_special_tokens=True))
>>> A stop sign is on a street corner.
```
### In half precision, on GPU:
You can run the model in full precision on CPU:
```python
import requests
import torch
from PIL import Image
from transformers import Pix2StructForConditionalGeneration, Pix2StructProcessor
url = "https://www.ilankelman.org/stopsigns/australia.jpg"
image = Image.open(requests.get(url, stream=True).raw)
model = Pix2StructForConditionalGeneration.from_pretrained("google/pix2struct-textcaps-base", torch_dtype=torch.bfloat16).to("cuda")
processor = Pix2StructProcessor.from_pretrained("google/pix2struct-textcaps-base")
# image only
inputs = processor(images=image, return_tensors="pt").to("cuda", torch.bfloat16)
predictions = model.generate(**inputs)
print(processor.decode(predictions[0], skip_special_tokens=True))
>>> A stop sign is on a street corner.
```
### Use different sequence length
This model has been trained on a sequence length of `2048`. You can try to reduce the sequence length for a more memory efficient inference but you may observe some performance degradation for small sequence length (<512). Just pass `max_patches` when calling the processor:
```python
inputs = processor(images=image, return_tensors="pt", max_patches=512)
```
### Conditional generation
You can also pre-pend some input text to perform conditional generation:
```python
import requests
from PIL import Image
from transformers import Pix2StructForConditionalGeneration, Pix2StructProcessor
url = "https://www.ilankelman.org/stopsigns/australia.jpg"
image = Image.open(requests.get(url, stream=True).raw)
text = "A picture of"
model = Pix2StructForConditionalGeneration.from_pretrained("google/pix2struct-textcaps-base")
processor = Pix2StructProcessor.from_pretrained("google/pix2struct-textcaps-base")
# image only
inputs = processor(images=image, text=text, return_tensors="pt")
predictions = model.generate(**inputs)
print(processor.decode(predictions[0], skip_special_tokens=True))
>>> A picture of a stop sign that says yes.
```
# Contribution
This model was originally contributed by Kenton Lee, Mandar Joshi et al. and added to the Hugging Face ecosystem by [Younes Belkada](https://huggingface.co/ybelkada).
# Citation
If you want to cite this work, please consider citing the original paper:
```
@misc{https://doi.org/10.48550/arxiv.2210.03347,
doi = {10.48550/ARXIV.2210.03347},
url = {https://arxiv.org/abs/2210.03347},
author = {Lee, Kenton and Joshi, Mandar and Turc, Iulia and Hu, Hexiang and Liu, Fangyu and Eisenschlos, Julian and Khandelwal, Urvashi and Shaw, Peter and Chang, Ming-Wei and Toutanova, Kristina},
keywords = {Computation and Language (cs.CL), Computer Vision and Pattern Recognition (cs.CV), FOS: Computer and information sciences, FOS: Computer and information sciences},
title = {Pix2Struct: Screenshot Parsing as Pretraining for Visual Language Understanding},
publisher = {arXiv},
year = {2022},
copyright = {Creative Commons Attribution 4.0 International}
}
``` |
DeepFloyd/IF-II-L-v1.0 | DeepFloyd | 2023-06-02T19:05:09Z | 6,828 | 44 | diffusers | [
"diffusers",
"pytorch",
"safetensors",
"if",
"text-to-image",
"arxiv:2205.11487",
"arxiv:2110.02861",
"license:deepfloyd-if-license",
"diffusers:IFSuperResolutionPipeline",
"region:us"
] | text-to-image | 2023-03-21T13:09:58Z | ---
license: deepfloyd-if-license
extra_gated_prompt: "DeepFloyd LICENSE AGREEMENT\nThis License Agreement (as may be amended in accordance with this License Agreement, “License”), between you, or your employer or other entity (if you are entering into this agreement on behalf of your employer or other entity) (“Licensee” or “you”) and Stability AI Ltd.. (“Stability AI” or “we”) applies to your use of any computer program, algorithm, source code, object code, or software that is made available by Stability AI under this License (“Software”) and any specifications, manuals, documentation, and other written information provided by Stability AI related to the Software (“Documentation”).\nBy clicking “I Accept” below or by using the Software, you agree to the terms of this License. If you do not agree to this License, then you do not have any rights to use the Software or Documentation (collectively, the “Software Products”), and you must immediately cease using the Software Products. If you are agreeing to be bound by the terms of this License on behalf of your employer or other entity, you represent and warrant to Stability AI that you have full legal authority to bind your employer or such entity to this License. If you do not have the requisite authority, you may not accept the License or access the Software Products on behalf of your employer or other entity.\n1. LICENSE GRANT\n a. Subject to your compliance with the Documentation and Sections 2, 3, and 5, Stability AI grants you a non-exclusive, worldwide, non-transferable, non-sublicensable, revocable, royalty free and limited license under Stability AI’s copyright interests to reproduce, distribute, and create derivative works of the Software solely for your non-commercial research purposes. The foregoing license is personal to you, and you may not assign or sublicense this License or any other rights or obligations under this License without Stability AI’s prior written consent; any such assignment or sublicense will be void and will automatically and immediately terminate this License.\n b. You may make a reasonable number of copies of the Documentation solely for use in connection with the license to the Software granted above.\n c. The grant of rights expressly set forth in this Section 1 (License Grant) are the complete grant of rights to you in the Software Products, and no other licenses are granted, whether by waiver, estoppel, implication, equity or otherwise. Stability AI and its licensors reserve all rights not expressly granted by this License.\L\n2. RESTRICTIONS\n You will not, and will not permit, assist or cause any third party to:\n a. use, modify, copy, reproduce, create derivative works of, or distribute the Software Products (or any derivative works thereof, works incorporating the Software Products, or any data produced by the Software), in whole or in part, for (i) any commercial or production purposes, (ii) military purposes or in the service of nuclear technology, (iii) purposes of surveillance, including any research or development relating to surveillance, (iv) biometric processing, (v) in any manner that infringes, misappropriates, or otherwise violates any third-party rights, or (vi) in any manner that violates any applicable law and violating any privacy or security laws, rules, regulations, directives, or governmental requirements (including the General Data Privacy Regulation (Regulation (EU) 2016/679), the California Consumer Privacy Act, and any and all laws governing the processing of biometric information), as well as all amendments and successor laws to any of the foregoing;\n b. alter or remove copyright and other proprietary notices which appear on or in the Software Products;\n c. utilize any equipment, device, software, or other means to circumvent or remove any security or protection used by Stability AI in connection with the Software, or to circumvent or remove any usage restrictions, or to enable functionality disabled by Stability AI; or\n d. offer or impose any terms on the Software Products that alter, restrict, or are inconsistent with the terms of this License.\n e. 1) violate any applicable U.S. and non-U.S. export control and trade sanctions laws (“Export Laws”); 2) directly or indirectly export, re-export, provide, or otherwise transfer Software Products: (a) to any individual, entity, or country prohibited by Export Laws; (b) to anyone on U.S. or non-U.S. government restricted parties lists; or (c) for any purpose prohibited by Export Laws, including nuclear, chemical or biological weapons, or missile technology applications; 3) use or download Software Products if you or they are: (a) located in a comprehensively sanctioned jurisdiction, (b) currently listed on any U.S. or non-U.S. restricted parties list, or (c) for any purpose prohibited by Export Laws; and (4) will not disguise your location through IP proxying or other methods.\L\n3. ATTRIBUTION\n Together with any copies of the Software Products (as well as derivative works thereof or works incorporating the Software Products) that you distribute, you must provide (i) a copy of this License, and (ii) the following attribution notice: “DeepFloyd is licensed under the DeepFloyd License, Copyright (c) Stability AI Ltd. All Rights Reserved.”\L\n4. DISCLAIMERS\n THE SOFTWARE PRODUCTS ARE PROVIDED “AS IS” and “WITH ALL FAULTS” WITH NO WARRANTY OF ANY KIND, EXPRESS OR IMPLIED. STABILITY AIEXPRESSLY DISCLAIMS ALL REPRESENTATIONS AND WARRANTIES, EXPRESS OR IMPLIED, WHETHER BY STATUTE, CUSTOM, USAGE OR OTHERWISE AS TO ANY MATTERS RELATED TO THE SOFTWARE PRODUCTS, INCLUDING BUT NOT LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE, TITLE, SATISFACTORY QUALITY, OR NON-INFRINGEMENT. STABILITY AI MAKES NO WARRANTIES OR REPRESENTATIONS THAT THE SOFTWARE PRODUCTS WILL BE ERROR FREE OR FREE OF VIRUSES OR OTHER HARMFUL COMPONENTS, OR PRODUCE ANY PARTICULAR RESULTS.\L\n5. LIMITATION OF LIABILITY\n TO THE FULLEST EXTENT PERMITTED BY LAW, IN NO EVENT WILL STABILITY AI BE LIABLE TO YOU (A) UNDER ANY THEORY OF LIABILITY, WHETHER BASED IN CONTRACT, TORT, NEGLIGENCE, STRICT LIABILITY, WARRANTY, OR OTHERWISE UNDER THIS LICENSE, OR (B) FOR ANY INDIRECT, CONSEQUENTIAL, EXEMPLARY, INCIDENTAL, PUNITIVE OR SPECIAL DAMAGES OR LOST PROFITS, EVEN IF STABILITY AI HAS BEEN ADVISED OF THE POSSIBILITY OF SUCH DAMAGES. THE SOFTWARE PRODUCTS, THEIR CONSTITUENT COMPONENTS, AND ANY OUTPUT (COLLECTIVELY, “SOFTWARE MATERIALS”) ARE NOT DESIGNED OR INTENDED FOR USE IN ANY APPLICATION OR SITUATION WHERE FAILURE OR FAULT OF THE SOFTWARE MATERIALS COULD REASONABLY BE ANTICIPATED TO LEAD TO SERIOUS INJURY OF ANY PERSON, INCLUDING POTENTIAL DISCRIMINATION OR VIOLATION OF AN INDIVIDUAL’S PRIVACY RIGHTS, OR TO SEVERE PHYSICAL, PROPERTY, OR ENVIRONMENTAL DAMAGE (EACH, A “HIGH-RISK USE”). IF YOU ELECT TO USE ANY OF THE SOFTWARE MATERIALS FOR A HIGH-RISK USE, YOU DO SO AT YOUR OWN RISK. YOU AGREE TO DESIGN AND IMPLEMENT APPROPRIATE DECISION-MAKING AND RISK-MITIGATION PROCEDURES AND POLICIES IN CONNECTION WITH A HIGH-RISK USE SUCH THAT EVEN IF THERE IS A FAILURE OR FAULT IN ANY OF THE SOFTWARE MATERIALS, THE SAFETY OF PERSONS OR PROPERTY AFFECTED BY THE ACTIVITY STAYS AT A LEVEL THAT IS REASONABLE, APPROPRIATE, AND LAWFUL FOR THE FIELD OF THE HIGH-RISK USE.\L\n6. INDEMNIFICATION\n You will indemnify, defend and hold harmless Stability AI and our subsidiaries and affiliates, and each of our respective shareholders, directors, officers, employees, agents, successors, and assigns (collectively, the “Stability AI Parties”) from and against any losses, liabilities, damages, fines, penalties, and expenses (including reasonable attorneys’ fees) incurred by any Stability AI Party in connection with any claim, demand, allegation, lawsuit, proceeding, or investigation (collectively, “Claims”) arising out of or related to: (a) your access to or use of the Software Products (as well as any results or data generated from such access or use), including any High-Risk Use (defined below); (b) your violation of this License; or (c) your violation, misappropriation or infringement of any rights of another (including intellectual property or other proprietary rights and privacy rights). You will promptly notify the Stability AI Parties of any such Claims, and cooperate with Stability AI Parties in defending such Claims. You will also grant the Stability AI Parties sole control of the defense or settlement, at Stability AI’s sole option, of any Claims. This indemnity is in addition to, and not in lieu of, any other indemnities or remedies set forth in a written agreement between you and Stability AI or the other Stability AI Parties.\L\n7. TERMINATION; SURVIVAL\n a. This License will automatically terminate upon any breach by you of the terms of this License.\L\Lb. We may terminate this License, in whole or in part, at any time upon notice (including electronic) to you.\L\Lc. The following sections survive termination of this License: 2 (Restrictions), 3 (Attribution), 4 (Disclaimers), 5 (Limitation on Liability), 6 (Indemnification) 7 (Termination; Survival), 8 (Third Party Materials), 9 (Trademarks), 10 (Applicable Law; Dispute Resolution), and 11 (Miscellaneous).\L\n8. THIRD PARTY MATERIALS\n The Software Products may contain third-party software or other components (including free and open source software) (all of the foregoing, “Third Party Materials”), which are subject to the license terms of the respective third-party licensors. Your dealings or correspondence with third parties and your use of or interaction with any Third Party Materials are solely between you and the third party. Stability AI does not control or endorse, and makes no representations or warranties regarding, any Third Party Materials, and your access to and use of such Third Party Materials are at your own risk.\L\n9. TRADEMARKS\n Licensee has not been granted any trademark license as part of this License and may not use any name or mark associated with Stability AI without the prior written permission of Stability AI, except to the extent necessary to make the reference required by the “ATTRIBUTION” section of this Agreement.\L\n10. APPLICABLE LAW; DISPUTE RESOLUTION\n This License will be governed and construed under the laws of the State of California without regard to conflicts of law provisions. Any suit or proceeding arising out of or relating to this License will be brought in the federal or state courts, as applicable, in San Mateo County, California, and each party irrevocably submits to the jurisdiction and venue of such courts.\L\n11. MISCELLANEOUS\n If any provision or part of a provision of this License is unlawful, void or unenforceable, that provision or part of the provision is deemed severed from this License, and will not affect the validity and enforceability of any remaining provisions. The failure of Stability AI to exercise or enforce any right or provision of this License will not operate as a waiver of such right or provision. This License does not confer any third-party beneficiary rights upon any other person or entity. This License, together with the Documentation, contains the entire understanding between you and Stability AI regarding the subject matter of this License, and supersedes all other written or oral agreements and understandings between you and Stability AI regarding such subject matter. No change or addition to any provision of this License will be binding unless it is in writing and signed by an authorized representative of both you and Stability AI."
extra_gated_fields:
"Organization /\_Affiliation": text
Previously related publications: text
I accept the above license agreement, and will use the Software non-commercially and for research purposes only: checkbox
tags:
- if
- text-to-image
inference: false
---
# IF-II-L-v1.0
DeepFloyd-IF is a pixel-based text-to-image triple-cascaded diffusion model, that can generate pictures with new state-of-the-art for photorealism and language understanding. The result is a highly efficient model that outperforms current state-of-the-art models, achieving a zero-shot FID-30K score of `6.66` on the COCO dataset.
*Inspired by* [*Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding*](https://arxiv.org/pdf/2205.11487.pdf)

## Model Details
- **Developed by:** DeepFloyd, StabilityAI
- **Model type:** pixel-based text-to-image cascaded diffusion model
- **Cascade Stage:** II
- **Num Parameters:** 1.2B
- **Language(s):** primarily English and, to a lesser extent, other Romance languages
- **License:** <span style="color:blue"><a href="https://huggingface.co/spaces/DeepFloyd/deepfloyd-if-license">DeepFloyd IF License Agreement</a></span>
- **Model Description:** DeepFloyd-IF is modular composed of frozen text mode and three pixel cascaded diffusion modules, each designed to generate images of increasing resolution: 64x64, 256x256, and 1024x1024. All stages of the model utilize a frozen text encoder based on the T5 transformer to extract text embeddings, which are then fed into a UNet architecture enhanced with cross-attention and attention-pooling
- **Resources for more information:** [GitHub](https://github.com/deep-floyd/IF), [Website](https://deepfloyd.ai/), [All Links](https://linktr.ee/deepfloyd)
## Using with `diffusers`
IF is integrated with the 🤗 Hugging Face [🧨 diffusers library](https://github.com/huggingface/diffusers/), which is optimized to run on GPUs with as little as 14 GB of VRAM.
Before you can use IF, you need to accept its usage conditions. To do so:
1. Make sure to have a [Hugging Face account](https://huggingface.co/join) and be loggin in
2. Accept the license on the model card of [DeepFloyd/IF-I-XL-v1.0](https://huggingface.co/DeepFloyd/IF-I-XL-v1.0)
3. Make sure to login locally. Install `huggingface_hub`
```sh
pip install huggingface_hub --upgrade
```
run the login function in a Python shell
```py
from huggingface_hub import login
login()
```
and enter your [Hugging Face Hub access token](https://huggingface.co/docs/hub/security-tokens#what-are-user-access-tokens).
Next we install `diffusers` and dependencies:
```sh
pip install diffusers accelerate transformers safetensors sentencepiece
```
And we can now run the model locally.
By default `diffusers` makes use of [model cpu offloading](https://huggingface.co/docs/diffusers/optimization/fp16#model-offloading-for-fast-inference-and-memory-savings) to run the whole IF pipeline with as little as 14 GB of VRAM.
If you are using `torch>=2.0.0`, make sure to **remove all** `enable_xformers_memory_efficient_attention()` functions.
* **Load all stages and offload to CPU**
```py
from diffusers import DiffusionPipeline
from diffusers.utils import pt_to_pil
import torch
# stage 1
stage_1 = DiffusionPipeline.from_pretrained("DeepFloyd/IF-I-XL-v1.0", variant="fp16", torch_dtype=torch.float16)
stage_1.enable_xformers_memory_efficient_attention() # remove line if torch.__version__ >= 2.0.0
stage_1.enable_model_cpu_offload()
# stage 2
stage_2 = DiffusionPipeline.from_pretrained(
"DeepFloyd/IF-II-L-v1.0", text_encoder=None, variant="fp16", torch_dtype=torch.float16
)
stage_2.enable_xformers_memory_efficient_attention() # remove line if torch.__version__ >= 2.0.0
stage_2.enable_model_cpu_offload()
# stage 3
safety_modules = {"feature_extractor": stage_1.feature_extractor, "safety_checker": stage_1.safety_checker, "watermarker": stage_1.watermarker}
stage_3 = DiffusionPipeline.from_pretrained("stabilityai/stable-diffusion-x4-upscaler", **safety_modules, torch_dtype=torch.float16)
stage_3.enable_xformers_memory_efficient_attention() # remove line if torch.__version__ >= 2.0.0
stage_3.enable_model_cpu_offload()
```
* **Retrieve Text Embeddings**
```py
prompt = 'a photo of a kangaroo wearing an orange hoodie and blue sunglasses standing in front of the eiffel tower holding a sign that says "very deep learning"'
# text embeds
prompt_embeds, negative_embeds = stage_1.encode_prompt(prompt)
```
* **Run stage 1**
```py
generator = torch.manual_seed(0)
image = stage_1(prompt_embeds=prompt_embeds, negative_prompt_embeds=negative_embeds, generator=generator, output_type="pt").images
pt_to_pil(image)[0].save("./if_stage_I.png")
```
* **Run stage 2**
```py
image = stage_2(
image=image, prompt_embeds=prompt_embeds, negative_prompt_embeds=negative_embeds, generator=generator, output_type="pt"
).images
pt_to_pil(image)[0].save("./if_stage_II.png")
```
* **Run stage 3**
```py
image = stage_3(prompt=prompt, image=image, generator=generator, noise_level=100).images
image[0].save("./if_stage_III.png")
```
There are multiple ways to speed up the inference time and lower the memory consumption even more with `diffusers`. To do so, please have a look at the Diffusers docs:
- 🚀 [Optimizing for inference time](https://huggingface.co/docs/diffusers/api/pipelines/if#optimizing-for-speed)
- ⚙️ [Optimizing for low memory during inference](https://huggingface.co/docs/diffusers/api/pipelines/if#optimizing-for-memory)
For more in-detail information about how to use IF, please have a look at [the IF blog post](https://huggingface.co/blog/if) and the [documentation](https://huggingface.co/docs/diffusers/main/en/api/pipelines/if) 📖.
Diffusers dreambooth scripts also supports fine-tuning 🎨 [IF](https://huggingface.co/docs/diffusers/main/en/training/dreambooth#if).
With parameter efficient finetuning, you can add new concepts to IF with a single GPU and ~28 GB VRAM.
## Training
**Training Data:**
1.2B text-image pairs (based on LAION-A and few additional internal datasets)
Test/Valid parts of datasets are not used at any cascade and stage of training. Valid part of COCO helps to demonstrate "online" loss behaviour during training (to catch incident and other problems), but dataset is never used for train.
**Training Procedure:** IF-II-L-v1.0 is a pixel-based diffusion cascade which uses T5-Encoder embeddings (hidden states) to upscale image from 64px to 256px. During training,
- Images are cropped to square via shifted-center-crop augmentation (randomly shift from center up to 0.1 of size) and resized to 64px (low-res) and 256px (ground-truth) using `Pillow==9.2.0` BICUBIC resampling with reducing_gap=None (it helps to avoid aliasing) and processed to tensor BxCxHxW
- Low-res images are extra augmented by noise (q-sample methods) with the same diffusion configuration for cascade-I series. Uniform distributed randomised augmentation noising param (aug-level) is added to Unet as condition to process by trainable layers timestep embedding and linear projection with activation.
- Text prompts are encoded through open-sourced frozen T5-v1_1-xxl text-encoder (that completely was trained by Google team), random 10% of texts are dropped to empty string to add ability for classifier free guidance (CFG)
- The non-pooled output of the text encoder is fed into the projection (linear layer without activation) and is used in UNet backbone of the diffusion model via controlled hybrid self- and cross- attention
- Also, the output of the text encode is pooled via attention-pooling (64 heads) and is used in time embed as additional features
- Diffusion process is limited by 1000 discrete steps, with cosine beta schedule of noising image
- The loss is a reconstruction objective between the noise that was added to the image and the prediction made by the UNet
- The training process for checkpoint IF-II-L-v1.0 has 2_500_000 steps at resolution 256x256 on all datasets, OneCycleLR policy, few-bit backward GELU activations, optimizer AdamW8bit + DeepSpeed-Zero1, fully frozen T5-Encoder

**Hardware:** 32 x 8 x A100 GPUs
**Optimizer:** [AdamW8bit](https://arxiv.org/abs/2110.02861) + [DeepSpeed ZeRO-1](https://www.deepspeed.ai/tutorials/zero/)
**Batch:** 1536
**Learning rate**: [one-cycle](https://pytorch.org/docs/stable/generated/torch.optim.lr_scheduler.OneCycleLR.html) cosine strategy, warmup 10000 steps, start_lr=4e-6, max_lr=1e-4, final_lr=1e-8

## Evaluation Results
`FID-30K: 6.66`

# Uses
## Direct Use
The model is released for research purposes. Any attempt to deploy the model in production requires not only that the LICENSE is followed but full liability over the person deploying the model.
Possible research areas and tasks include:
- Generation of artistic imagery and use in design and other artistic processes.
- Safe deployment of models which have the potential to generate harmful content.
- Probing and understanding the limitations and biases of generative models.
- Applications in educational or creative tools.
- Research on generative models.
Excluded uses are described below.
### Misuse, Malicious Use, and Out-of-Scope Use
_Note: This section is originally taken from the [DALLE-MINI model card](https://huggingface.co/dalle-mini/dalle-mini), was used for Stable Diffusion but applies in the same way for IF_.
The model should not be used to intentionally create or disseminate images that create hostile or alienating environments for people. This includes generating images that people would foreseeably find disturbing, distressing, or offensive; or content that propagates historical or current stereotypes.
#### Out-of-Scope Use
The model was not trained to be factual or true representations of people or events, and therefore using the model to generate such content is out-of-scope for the abilities of this model.
#### Misuse and Malicious Use
Using the model to generate content that is cruel to individuals is a misuse of this model. This includes, but is not limited to:
- Generating demeaning, dehumanizing, or otherwise harmful representations of people or their environments, cultures, religions, etc.
- Intentionally promoting or propagating discriminatory content or harmful stereotypes.
- Impersonating individuals without their consent.
- Sexual content without consent of the people who might see it.
- Mis- and disinformation
- Representations of egregious violence and gore
- Sharing of copyrighted or licensed material in violation of its terms of use.
- Sharing content that is an alteration of copyrighted or licensed material in violation of its terms of use.
## Limitations and Bias
### Limitations
- The model does not achieve perfect photorealism
- The model was trained mainly with English captions and will not work as well in other languages.
- The model was trained on a subset of the large-scale dataset
[LAION-5B](https://laion.ai/blog/laion-5b/), which contains adult, violent and sexual content. To partially mitigate this, we have... (see Training section).
### Bias
While the capabilities of image generation models are impressive, they can also reinforce or exacerbate social biases.
IF was primarily trained on subsets of [LAION-2B(en)](https://laion.ai/blog/laion-5b/),
which consists of images that are limited to English descriptions.
Texts and images from communities and cultures that use other languages are likely to be insufficiently accounted for.
This affects the overall output of the model, as white and western cultures are often set as the default. Further, the
ability of the model to generate content with non-English prompts is significantly worse than with English-language prompts.
IF mirrors and exacerbates biases to such a degree that viewer discretion must be advised irrespective of the input or its intent.
*This model card was written by: DeepFloyd-Team and is based on the [StableDiffusion model card](https://huggingface.co/CompVis/stable-diffusion-v1-4).* |
ZeroWw/Llama-3-8B-Instruct-Gradient-4194k-GGUF | ZeroWw | 2024-06-29T07:50:45Z | 6,823 | 0 | null | [
"gguf",
"en",
"license:mit",
"region:us"
] | null | 2024-06-29T07:37:09Z |
---
license: mit
language:
- en
---
My own (ZeroWw) quantizations.
output and embed tensors quantized to f16.
all other tensors quantized to q5_k or q6_k.
Result:
both f16.q6 and f16.q5 are smaller than q8_0 standard quantization
and they perform as well as the pure f16.
|
timm/tf_efficientnet_b4.ns_jft_in1k | timm | 2023-04-27T21:19:53Z | 6,821 | 0 | timm | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"arxiv:1905.11946",
"arxiv:1911.04252",
"license:apache-2.0",
"region:us"
] | image-classification | 2022-12-13T00:03:44Z | ---
tags:
- image-classification
- timm
library_name: timm
license: apache-2.0
datasets:
- imagenet-1k
---
# Model card for tf_efficientnet_b4.ns_jft_in1k
A EfficientNet image classification model. Trained on ImageNet-1k and unlabeled JFT-300m using Noisy Student semi-supervised learning in Tensorflow by paper authors, ported to PyTorch by Ross Wightman.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 19.3
- GMACs: 4.5
- Activations (M): 49.5
- Image size: 380 x 380
- **Papers:**
- EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks: https://arxiv.org/abs/1905.11946
- Self-training with Noisy Student improves ImageNet classification: https://arxiv.org/abs/1911.04252
- **Dataset:** ImageNet-1k
- **Original:** https://github.com/tensorflow/tpu/tree/master/models/official/efficientnet
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('tf_efficientnet_b4.ns_jft_in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'tf_efficientnet_b4.ns_jft_in1k',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g.:
# torch.Size([1, 24, 190, 190])
# torch.Size([1, 32, 95, 95])
# torch.Size([1, 56, 48, 48])
# torch.Size([1, 160, 24, 24])
# torch.Size([1, 448, 12, 12])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'tf_efficientnet_b4.ns_jft_in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 1792, 12, 12) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
## Citation
```bibtex
@inproceedings{tan2019efficientnet,
title={Efficientnet: Rethinking model scaling for convolutional neural networks},
author={Tan, Mingxing and Le, Quoc},
booktitle={International conference on machine learning},
pages={6105--6114},
year={2019},
organization={PMLR}
}
```
```bibtex
@article{Xie2019SelfTrainingWN,
title={Self-Training With Noisy Student Improves ImageNet Classification},
author={Qizhe Xie and Eduard H. Hovy and Minh-Thang Luong and Quoc V. Le},
journal={2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
year={2019},
pages={10684-10695}
}
```
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
|
namespace-Pt/activation-beacon-llama2-7b-chat | namespace-Pt | 2024-01-31T02:20:40Z | 6,821 | 21 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"custom_code",
"dataset:togethercomputer/RedPajama-Data-1T-Sample",
"dataset:Yukang/LongAlpaca-12k",
"arxiv:2401.03462",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2024-01-12T16:54:16Z | ---
license: mit
datasets:
- togethercomputer/RedPajama-Data-1T-Sample
- Yukang/LongAlpaca-12k
pipeline_tag: text-generation
---
<div align="center">
<h1>Soaring from 4K to 400K: Extending LLM's Context with Activation Beacon</h1>
[<a href="https://arxiv.org/abs/2401.03462">Paper</a>] [<a href="https://github.com/FlagOpen/FlagEmbedding/tree/master/Long_LLM/activation_beacon">Github</a>]
<img src="imgs/impress.png" width="80%" class="center">
</div>
We introduce Activation Beacon, an effective, efficient, compatible, and low-cost (training) method to extend the context length of LLM by **x100** times. Currently we only apply activation beacon to [Llama-2-chat-7b](https://huggingface.co/meta-llama/Llama-2-7b-chat-hf). More LLMs will be supported in the future.
## Features
- **Effectiveness**
- significantly improves the performance of Llama-2 on long-context generation (language modeling) and long-context understanding (e.g. long-document QA).
- **Efficiency**
- low memory usage; low inference latency (compeitive against FlashAttention2); inference latency increases linearly with the input length.
- **Compatibility**
- preserve the short-context capability of Llama-2;
- can be combined with context window extension techniques for futher context extension (e.g. 1M with NTK-Aware);
- can be combined with retrieval for higher memory accuracy (*ongoing*).
- **Low-Cost Training**
- train with 80000 texts within 9 hours;
- most training samples are shorter than 4096.
## Environment
The main dependencies are:
```
pytorch==2.1.2 transformers==4.36.1 accelerate==0.25.0 datasets==2.14.7 numpy==1.26.2 flash-attn==2.4.2
```
## Usage
```python
import json
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
model_id = "namespace-Pt/activation-beacon-llama2-7b-chat"
tokenizer = AutoTokenizer.from_pretrained(model_id, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(model_id, trust_remote_code=True, torch_dtype=torch.bfloat16)
model = model.cuda().eval()
with torch.no_grad():
# short context
text = "Tell me about yourself."
inputs = tokenizer(text, return_tensors="pt").to("cuda")
outputs = model.generate(**inputs, max_new_tokens=20)
print(f"Input Length: {inputs['input_ids'].shape[1]}")
print(f"Output: {tokenizer.decode(outputs[0], skip_special_tokens=True)}")
# reset memory before new generation task
model.memory.reset()
# long context
with open("data/toy/narrativeqa.json", encoding="utf-8") as f:
example = json.load(f)
inputs = tokenizer(example["context"], return_tensors="pt").to("cuda")
outputs = model.generate(**inputs, do_sample=False, top_p=1, temperature=1, max_new_tokens=20)[:, inputs["input_ids"].shape[1]:]
print("*"*20)
print(f"Input Length: {inputs['input_ids'].shape[1]}")
print(f"Answer: {example['answer']}")
print(f"Prediction: {tokenizer.decode(outputs[0], skip_special_tokens=True)}")
```
**NOTE**: It's okay to see warnings like `This is a friendly reminder - the current text generation call will exceed the model's predefined maximum length (4096). Depending on the model, you may observe exceptions, performance degradation, or nothing at all.` Just ignore it.
## Training
*coming soon*
## Evaluation
See [evaluation section](https://github.com/FlagOpen/FlagEmbedding/blob/master/Long_LLM/activation_beacon/docs/evaluation.md).
## Citation
If you find this model useful, please give us a like ❤️.
To cite our work:
```
@misc{zhang2024soaring,
title={Soaring from 4K to 400K: Extending LLM's Context with Activation Beacon},
author={Peitian Zhang and Zheng Liu and Shitao Xiao and Ninglu Shao and Qiwei Ye and Zhicheng Dou},
year={2024},
eprint={2401.03462},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
``` |
utter-project/mHuBERT-147 | utter-project | 2024-06-12T12:45:07Z | 6,819 | 46 | transformers | [
"transformers",
"pytorch",
"safetensors",
"hubert",
"feature-extraction",
"ab",
"af",
"am",
"ar",
"as",
"az",
"ba",
"be",
"bn",
"bo",
"bs",
"br",
"bg",
"ca",
"cs",
"cv",
"cy",
"da",
"de",
"dv",
"el",
"en",
"eo",
"et",
"eu",
"ee",
"fo",
"fa",
"tl",
"fi",
"fr",
"fy",
"ga",
"gl",
"gv",
"gn",
"gu",
"ht",
"ha",
"he",
"hi",
"hr",
"hu",
"hy",
"ig",
"ia",
"id",
"is",
"it",
"jv",
"ja",
"kn",
"ka",
"kk",
"km",
"rw",
"ky",
"ku",
"ko",
"lo",
"la",
"lv",
"ln",
"lt",
"lb",
"lg",
"ml",
"mr",
"mk",
"mg",
"mt",
"mn",
"mi",
"ms",
"my",
"ne",
"nl",
"nn",
"no",
"oc",
"or",
"pa",
"pl",
"pt",
"ps",
"ro",
"ru",
"sa",
"si",
"sl",
"sk",
"sn",
"sd",
"so",
"st",
"es",
"sq",
"sc",
"sr",
"su",
"sw",
"sv",
"ta",
"tt",
"te",
"tg",
"th",
"tn",
"tk",
"tr",
"tw",
"ug",
"uk",
"ur",
"uz",
"vi",
"xh",
"yi",
"yo",
"zh",
"arxiv:2406.06371",
"license:cc-by-nc-4.0",
"endpoints_compatible",
"region:us"
] | feature-extraction | 2024-03-14T10:50:44Z | ---
license: cc-by-nc-4.0
language:
- ab
- af
- am
- ar
- as
- az
- ba
- be
- bn
- bo
- bs
- br
- bg
- ca
- cs
- cv
- cy
- da
- de
- dv
- el
- en
- eo
- et
- eu
- ee
- fo
- fa
- tl
- fi
- fr
- fy
- ga
- gl
- gv
- gn
- gu
- ht
- ha
- he
- hi
- hr
- hu
- hy
- ig
- ia
- id
- is
- it
- jv
- ja
- kn
- ka
- kk
- km
- rw
- ky
- ku
- ko
- lo
- la
- lv
- ln
- lt
- lb
- lg
- ml
- mr
- mk
- mg
- mt
- mn
- mi
- ms
- my
- ne
- nl
- nn
- no
- oc
- or
- pa
- pl
- pt
- ps
- ro
- ru
- sa
- si
- sl
- sk
- sn
- sd
- so
- st
- es
- sq
- sc
- sr
- su
- sw
- sv
- ta
- tt
- te
- tg
- th
- tn
- tk
- tr
- tw
- ug
- uk
- ur
- uz
- vi
- xh
- yi
- yo
- zh
---
**This repository contains the best mHuBERT-147 pre-trained model.**
**MODEL DETAILS:** 3rd iteration, K=1000, HuBERT base architecture (95M parameters), 147 languages.
# Table of Contents:
1. [Summary](https://huggingface.co/utter-project/mHuBERT-147#mhubert-147-models)
2. [Training Data and Code](https://huggingface.co/utter-project/mHuBERT-147#training)
3. [ML-SUPERB Scores](https://huggingface.co/utter-project/mHuBERT-147#ml-superb-scores)
4. [Languages and Datasets](https://huggingface.co/utter-project/mHuBERT-147#languages-and-datasets)
6. [Citing and Funding Information](https://huggingface.co/utter-project/mHuBERT-147#citing-and-funding-information)
# mHuBERT-147 models
mHuBERT-147 are compact and competitive multilingual HuBERT models trained on 90K hours of open-license data in 147 languages.
Different from *traditional* HuBERTs, mHuBERT-147 models are trained using faiss IVF discrete speech units.
Training employs a two-level language, data source up-sampling during training. See more information in [our paper](https://arxiv.org/pdf/2406.06371).
**This repository contains:**
* Fairseq checkpoint (original);
* HuggingFace checkpoint (conversion using transformers library);
* Faiss index for continuous pre-training (OPQ16_64,IVF1000_HNSW32,PQ16x4fsr).
**Related Models:**
* [2nd Iteration mHuBERT-147](https://huggingface.co/utter-project/mHuBERT-147-base-2nd-iter)
* [1st Iteration mHuBERT-147](https://huggingface.co/utter-project/mHuBERT-147-base-1st-iter)
* [CommonVoice Prototype (12 languages)](https://huggingface.co/utter-project/hutter-12-3rd-base)
# Training
* **[Manifest list available here.](https://huggingface.co/utter-project/mHuBERT-147-base-3rd-iter/tree/main/manifest)** Please note that since training, there were CommonVoice removal requests. This means that some of the listed files are no longer available.
* **[Fairseq fork](https://github.com/utter-project/fairseq)** contains the scripts for training with multilingual batching with two-level up-sampling.
* **[Scripts for pre-processing/faiss clustering available here.](https://github.com/utter-project/mHuBERT-147-scripts)**
# ML-SUPERB Scores
mHubert-147 reaches second and first position in the 10min and 1h leaderboards respectively. We achieve new SOTA scores for three LID tasks.
See more information in [our paper](https://arxiv.org/pdf/2406.06371).

# Languages and Datasets
**Datasets:** For ASR/ST/TTS datasets, only train set is used.
* [Aishell](https://www.openslr.org/33/) and [AISHELL-3](https://www.openslr.org/93/)
* [BibleTTS](https://www.openslr.org/129/)
* [ClovaCall](https://github.com/clovaai/ClovaCall)
* [CommonVoice v11](https://commonvoice.mozilla.org/en/datasets)
* Google TTS data: [Javanese](https://www.openslr.org/41/), [Khmer](https://www.openslr.org/42/), [Nepali](https://www.openslr.org/43/), [Sundanese](https://www.openslr.org/44/), [South African Languages](https://www.openslr.org/32/), [Bengali Languages](https://www.openslr.org/37/)
* IISc-MILE: [Tamil](https://www.openslr.org/127/), [Kannada](https://www.openslr.org/126/)
* [Japanese Versatile Speech](https://sites.google.com/site/shinnosuketakamichi/research-topics/jvs_corpus)
* [Kokoro](https://github.com/kaiidams/Kokoro-Speech-Dataset)
* [Kosp2e](https://github.com/warnikchow/kosp2e)
* Media Speech: [Turkish Only](https://www.openslr.org/108/)
* [Multilingual LibriSpeech](https://www.openslr.org/94/)
* [Samrómur](https://www.openslr.org/128/)
* [THCHS-30](https://www.openslr.org/18/) and [THUYG-20](https://www.openslr.org/22/)
* [VoxLingua107](https://bark.phon.ioc.ee/voxlingua107/)
* [VoxPopuli](https://github.com/facebookresearch/voxpopuli/)
**Languages present not indexed by Huggingface:** Asturian (ast), Basaa (bas), Cebuano (ceb), Central Kurdish/Sorani (ckb), Hakha Chin (cnh), Hawaiian (haw), Upper Sorbian (hsb) Kabyle (kab), Moksha (mdf), Meadow Mari (mhr), Hill Mari (mrj), Erzya (myv), Taiwanese Hokkien (nan-tw), Sursilvan (rm-sursilv), Vallader (rm-vallader), Sakha (sah), Santali (sat), Scots (sco), Saraiki (skr), Tigre (tig), Tok Pisin (tpi), Akwapen Twi (tw-akuapem), Asante Twi (tw-asante), Votic (vot), Waray (war), Cantonese (yue).
# Citing and Funding Information
```
@inproceedings{boito2024mhubert,
author={Marcely Zanon Boito, Vivek Iyer, Nikolaos Lagos, Laurent Besacier, Ioan Calapodescu},
title={{mHuBERT-147: A Compact Multilingual HuBERT Model}},
year=2024,
booktitle={Interspeech 2024},
}
```
<img src="https://cdn-uploads.huggingface.co/production/uploads/62262e19d36494a6f743a28d/HbzC1C-uHe25ewTy2wyoK.png" width=7% height=7%>
This is an output of the European Project UTTER (Unified Transcription and Translation for Extended Reality) funded by European Union’s Horizon Europe Research and Innovation programme under grant agreement number 101070631.
For more information please visit https://he-utter.eu/
|
elyza/Llama-3-ELYZA-JP-8B | elyza | 2024-06-26T02:56:23Z | 6,819 | 37 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"ja",
"en",
"license:llama3",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2024-06-25T06:32:13Z | ---
library_name: transformers
license: llama3
language:
- ja
- en
---
## Llama-3-ELYZA-JP-8B

### Model Description
**Llama-3-ELYZA-JP-8B** is a large language model trained by [ELYZA, Inc](https://elyza.ai/).
Based on [meta-llama/Meta-Llama-3-8B-Instruct](https://huggingface.co/meta-llama/Meta-Llama-3-8B-Instruct), it has been enhanced for Japanese usage through additional pre-training and instruction tuning. (Built with Meta Llama3)
For more details, please refer to [our blog post](https://note.com/elyza/n/n360b6084fdbd).
### Usage
```python
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
DEFAULT_SYSTEM_PROMPT = "あなたは誠実で優秀な日本人のアシスタントです。特に指示が無い場合は、常に日本語で回答してください。"
text = "仕事の熱意を取り戻すためのアイデアを5つ挙げてください。"
model_name = "elyza/Llama-3-ELYZA-JP-8B"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto",
)
model.eval()
messages = [
{"role": "system", "content": DEFAULT_SYSTEM_PROMPT},
{"role": "user", "content": text},
]
prompt = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
token_ids = tokenizer.encode(
prompt, add_special_tokens=False, return_tensors="pt"
)
with torch.no_grad():
output_ids = model.generate(
token_ids.to(model.device),
max_new_tokens=1200,
do_sample=True,
temperature=0.6,
top_p=0.9,
)
output = tokenizer.decode(
output_ids.tolist()[0][token_ids.size(1):], skip_special_tokens=True
)
print(output)
```
### Developers
Listed in alphabetical order.
- [Masato Hirakawa](https://huggingface.co/m-hirakawa)
- [Shintaro Horie](https://huggingface.co/e-mon)
- [Tomoaki Nakamura](https://huggingface.co/tyoyo)
- [Daisuke Oba](https://huggingface.co/daisuk30ba)
- [Sam Passaglia](https://huggingface.co/passaglia)
- [Akira Sasaki](https://huggingface.co/akirasasaki)
### License
[Meta Llama 3 Community License](https://llama.meta.com/llama3/license/)
### How to Cite
```tex
@misc{elyzallama2024,
title={elyza/Llama-3-ELYZA-JP-8B},
url={https://huggingface.co/elyza/Llama-3-ELYZA-JP-8B},
author={Masato Hirakawa and Shintaro Horie and Tomoaki Nakamura and Daisuke Oba and Sam Passaglia and Akira Sasaki},
year={2024},
}
```
### Citations
```tex
@article{llama3modelcard,
title={Llama 3 Model Card},
author={AI@Meta},
year={2024},
url = {https://github.com/meta-llama/llama3/blob/main/MODEL_CARD.md}
}
``` |
QuantFactory/Irbis-7b-v0.1-GGUF | QuantFactory | 2024-07-01T12:42:13Z | 6,812 | 0 | null | [
"gguf",
"region:us"
] | null | 2024-07-01T11:57:52Z | Entry not found |
KoboldAI/OPT-13B-Nerys-v2 | KoboldAI | 2022-09-19T11:15:55Z | 6,800 | 12 | transformers | [
"transformers",
"pytorch",
"opt",
"text-generation",
"en",
"arxiv:2205.01068",
"license:other",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2022-09-19T07:52:07Z | ---
language: en
license: other
commercial: no
---
# OPT 13B - Nerys
## Model Description
OPT 13B-Nerys is a finetune created using Facebook's OPT model.
## Training data
The training data contains around 2500 ebooks in various genres (the "Pike" dataset), a CYOA dataset called "CYS" and 50 Asian "Light Novels" (the "Manga-v1" dataset).
Most parts of the dataset have been prepended using the following text: `[Genre: <genre1>, <genre2>]`
This dataset has been cleaned in the same way as fairseq-dense-13B-Nerys-v2
### How to use
You can use this model directly with a pipeline for text generation. This example generates a different sequence each time it's run:
```py
>>> from transformers import pipeline
>>> generator = pipeline('text-generation', model='KoboldAI/OPT-13B-Nerys-v2')
>>> generator("Welcome Captain Janeway, I apologize for the delay.", do_sample=True, min_length=50)
[{'generated_text': 'Welcome Captain Janeway, I apologize for the delay."\nIt's all right," Janeway said. "I'm certain that you're doing your best to keep me informed of what\'s going on."'}]
```
### Limitations and Biases
Based on known problems with NLP technology, potential relevant factors include bias (gender, profession, race and religion).
### License
OPT-6B is licensed under the OPT-175B license, Copyright (c) Meta Platforms, Inc. All Rights Reserved.
### BibTeX entry and citation info
```
@misc{zhang2022opt,
title={OPT: Open Pre-trained Transformer Language Models},
author={Susan Zhang and Stephen Roller and Naman Goyal and Mikel Artetxe and Moya Chen and Shuohui Chen and Christopher Dewan and Mona Diab and Xian Li and Xi Victoria Lin and Todor Mihaylov and Myle Ott and Sam Shleifer and Kurt Shuster and Daniel Simig and Punit Singh Koura and Anjali Sridhar and Tianlu Wang and Luke Zettlemoyer},
year={2022},
eprint={2205.01068},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
``` |
OpenGVLab/InternVL-Chat-V1-5-Int8 | OpenGVLab | 2024-05-29T07:17:24Z | 6,795 | 58 | transformers | [
"transformers",
"safetensors",
"internvl_chat",
"feature-extraction",
"visual-question-answering",
"custom_code",
"dataset:laion/laion2B-en",
"dataset:laion/laion-coco",
"dataset:laion/laion2B-multi",
"dataset:kakaobrain/coyo-700m",
"dataset:conceptual_captions",
"dataset:wanng/wukong100m",
"arxiv:2312.14238",
"arxiv:2404.16821",
"license:mit",
"8-bit",
"bitsandbytes",
"region:us"
] | visual-question-answering | 2024-04-28T06:21:01Z | ---
license: mit
datasets:
- laion/laion2B-en
- laion/laion-coco
- laion/laion2B-multi
- kakaobrain/coyo-700m
- conceptual_captions
- wanng/wukong100m
pipeline_tag: visual-question-answering
---
# Model Card for InternVL-Chat-V1-5-Int8
<p align="center">
<img src="https://cdn-uploads.huggingface.co/production/uploads/64119264f0f81eb569e0d569/D60YzQBIzvoCvLRp2gZ0A.jpeg" alt="Image Description" width="300" height="300" />
</p>
> _Two interns holding hands, symbolizing the integration of InternViT and InternLM._
[\[🆕 Blog\]](https://internvl.github.io/blog/) [\[📜 InternVL 1.0 Paper\]](https://arxiv.org/abs/2312.14238) [\[📜 InternVL 1.5 Report\]](https://arxiv.org/abs/2404.16821) [\[🗨️ Chat Demo\]](https://internvl.opengvlab.com/)
[\[🤗 HF Demo\]](https://huggingface.co/spaces/OpenGVLab/InternVL) [\[🚀 Quick Start\]](#model-usage) [\[🌐 Community-hosted API\]](https://rapidapi.com/adushar1320/api/internvl-chat) [\[📖 中文解读\]](https://zhuanlan.zhihu.com/p/675877376)
We introduce InternVL 1.5, an open-source multimodal large language model (MLLM) to bridge the capability gap between open-source and proprietary commercial models in multimodal understanding.
We introduce three simple designs:
1. Strong Vision Encoder: we explored a continuous learning strategy for the large-scale vision foundation model---InternViT-6B, boosting its visual understanding capabilities, and making it can be transferred and reused in different LLMs.
2. Dynamic High-Resolution: we divide images into tiles ranging from 1 to 40 of 448 × 448 pixels according to the aspect ratio and resolution of the input images, which supports up to 4K resolution input.
3. High-Quality Bilingual Dataset: we carefully collected a high-quality bilingual dataset that covers common scenes, document images, and annotated them with English and Chinese question-answer pairs, significantly enhancing performance in OCR- and Chinese-related tasks.
## Model Details
- **Model Type:** multimodal large language model (MLLM)
- **Model Stats:**
- Architecture: [InternViT-6B-448px-V1-5](https://huggingface.co/OpenGVLab/InternViT-6B-448px-V1-5) + MLP + [InternLM2-Chat-20B](https://huggingface.co/internlm/internlm2-chat-20b)
- Image size: dynamic resolution, max to 40 tiles of 448 x 448 (4K resolution).
- Params: 25.5B
- **Training Strategy:**
- Learnable component in the pretraining stage: ViT + MLP
- Learnable component in the finetuning stage: ViT + MLP + LLM
- For more details on training hyperparameters, take a look at our code: [pretrain](https://github.com/OpenGVLab/InternVL/blob/main/internvl_chat/shell/internlm2_20b_dynamic/internvl_chat_v1_5_internlm2_20b_dynamic_res_pretrain.sh) | [finetune](https://github.com/OpenGVLab/InternVL/blob/main/internvl_chat/shell/internlm2_20b_dynamic/internvl_chat_v1_5_internlm2_20b_dynamic_res_finetune.sh)
## Released Models
| Model | Vision Foundation Model | Release Date | Note |
| :----------------------------------------------------------------------------------------------: | :---------------------------------------------------------------------------------------------: | :----------: | :----------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| InternVL-Chat-V1-5(🤗 [HF link](https://huggingface.co/OpenGVLab/InternVL-Chat-V1-5)) | InternViT-6B-448px-V1-5(🤗 [HF link](https://huggingface.co/OpenGVLab/InternViT-6B-448px-V1-5)) | 2024.04.18 | support 4K image; super strong OCR; Approaching the performance of GPT-4V and Gemini Pro on various benchmarks like MMMU, DocVQA, ChartQA, MathVista, etc. (🔥new) |
| InternVL-Chat-V-2-Plus(🤗 [HF link](https://huggingface.co/OpenGVLab/InternVL-Chat-V1-2-Plus) ) | InternViT-6B-448px-V1-2(🤗 [HF link](https://huggingface.co/OpenGVLab/InternViT-6B-448px-V1-2)) | 2024.02.21 | more SFT data and stronger |
| InternVL-Chat-V1-2(🤗 [HF link](https://huggingface.co/OpenGVLab/InternVL-Chat-V1-2) ) | InternViT-6B-448px-V1-2(🤗 [HF link](https://huggingface.co/OpenGVLab/InternViT-6B-448px-V1-2)) | 2024.02.11 | scaling up LLM to 34B |
| InternVL-Chat-V1-1(🤗 [HF link](https://huggingface.co/OpenGVLab/InternVL-Chat-V1-1)) | InternViT-6B-448px-V1-0(🤗 [HF link](https://huggingface.co/OpenGVLab/InternViT-6B-448px-V1-0)) | 2024.01.24 | support Chinese and stronger OCR |
## Architecture

## Performance


## Examples






## Model Usage
We provide an example code to run InternVL-Chat-V1-5-Int8 using `transformers`.
You can also use our [online demo](https://internvl.opengvlab.com/) for a quick experience of this model.
> Please use transformers==4.37.2 to ensure the model works normally.
```python
from transformers import AutoTokenizer, AutoModel
import torch
import torchvision.transforms as T
from PIL import Image
from torchvision.transforms.functional import InterpolationMode
IMAGENET_MEAN = (0.485, 0.456, 0.406)
IMAGENET_STD = (0.229, 0.224, 0.225)
def build_transform(input_size):
MEAN, STD = IMAGENET_MEAN, IMAGENET_STD
transform = T.Compose([
T.Lambda(lambda img: img.convert('RGB') if img.mode != 'RGB' else img),
T.Resize((input_size, input_size), interpolation=InterpolationMode.BICUBIC),
T.ToTensor(),
T.Normalize(mean=MEAN, std=STD)
])
return transform
def find_closest_aspect_ratio(aspect_ratio, target_ratios, width, height, image_size):
best_ratio_diff = float('inf')
best_ratio = (1, 1)
area = width * height
for ratio in target_ratios:
target_aspect_ratio = ratio[0] / ratio[1]
ratio_diff = abs(aspect_ratio - target_aspect_ratio)
if ratio_diff < best_ratio_diff:
best_ratio_diff = ratio_diff
best_ratio = ratio
elif ratio_diff == best_ratio_diff:
if area > 0.5 * image_size * image_size * ratio[0] * ratio[1]:
best_ratio = ratio
return best_ratio
def dynamic_preprocess(image, min_num=1, max_num=6, image_size=448, use_thumbnail=False):
orig_width, orig_height = image.size
aspect_ratio = orig_width / orig_height
# calculate the existing image aspect ratio
target_ratios = set(
(i, j) for n in range(min_num, max_num + 1) for i in range(1, n + 1) for j in range(1, n + 1) if
i * j <= max_num and i * j >= min_num)
target_ratios = sorted(target_ratios, key=lambda x: x[0] * x[1])
# find the closest aspect ratio to the target
target_aspect_ratio = find_closest_aspect_ratio(
aspect_ratio, target_ratios, orig_width, orig_height, image_size)
# calculate the target width and height
target_width = image_size * target_aspect_ratio[0]
target_height = image_size * target_aspect_ratio[1]
blocks = target_aspect_ratio[0] * target_aspect_ratio[1]
# resize the image
resized_img = image.resize((target_width, target_height))
processed_images = []
for i in range(blocks):
box = (
(i % (target_width // image_size)) * image_size,
(i // (target_width // image_size)) * image_size,
((i % (target_width // image_size)) + 1) * image_size,
((i // (target_width // image_size)) + 1) * image_size
)
# split the image
split_img = resized_img.crop(box)
processed_images.append(split_img)
assert len(processed_images) == blocks
if use_thumbnail and len(processed_images) != 1:
thumbnail_img = image.resize((image_size, image_size))
processed_images.append(thumbnail_img)
return processed_images
def load_image(image_file, input_size=448, max_num=6):
image = Image.open(image_file).convert('RGB')
transform = build_transform(input_size=input_size)
images = dynamic_preprocess(image, image_size=input_size, use_thumbnail=True, max_num=max_num)
pixel_values = [transform(image) for image in images]
pixel_values = torch.stack(pixel_values)
return pixel_values
path = "OpenGVLab/InternVL-Chat-V1-5-Int8"
# If you have an 80G A100 GPU, you can put the entire model on a single GPU.
model = AutoModel.from_pretrained(
path,
torch_dtype=torch.bfloat16,
low_cpu_mem_usage=True,
trust_remote_code=True,
load_in_8bit=True).eval()
# Otherwise, you need to set device_map='auto' to use multiple GPUs for inference.
# import os
# os.environ["CUDA_LAUNCH_BLOCKING"] = "1"
# model = AutoModel.from_pretrained(
# path,
# torch_dtype=torch.bfloat16,
# low_cpu_mem_usage=True,
# trust_remote_code=True,
# load_in_8bit=True,
# device_map='auto').eval()
tokenizer = AutoTokenizer.from_pretrained(path, trust_remote_code=True)
# set the max number of tiles in `max_num`
pixel_values = load_image('./examples/image1.jpg', max_num=6).to(torch.bfloat16).cuda()
generation_config = dict(
num_beams=1,
max_new_tokens=512,
do_sample=False,
)
# single-round single-image conversation
question = "请详细描述图片" # Please describe the picture in detail
response = model.chat(tokenizer, pixel_values, question, generation_config)
print(question, response)
# multi-round single-image conversation
question = "请详细描述图片" # Please describe the picture in detail
response, history = model.chat(tokenizer, pixel_values, question, generation_config, history=None, return_history=True)
print(question, response)
question = "请根据图片写一首诗" # Please write a poem according to the picture
response, history = model.chat(tokenizer, pixel_values, question, generation_config, history=history, return_history=True)
print(question, response)
# multi-round multi-image conversation
pixel_values1 = load_image('./examples/image1.jpg', max_num=6).to(torch.bfloat16).cuda()
pixel_values2 = load_image('./examples/image2.jpg', max_num=6).to(torch.bfloat16).cuda()
pixel_values = torch.cat((pixel_values1, pixel_values2), dim=0)
question = "详细描述这两张图片" # Describe the two pictures in detail
response, history = model.chat(tokenizer, pixel_values, question, generation_config, history=None, return_history=True)
print(question, response)
question = "这两张图片的相同点和区别分别是什么" # What are the similarities and differences between these two pictures
response, history = model.chat(tokenizer, pixel_values, question, generation_config, history=history, return_history=True)
print(question, response)
# batch inference (single image per sample)
pixel_values1 = load_image('./examples/image1.jpg', max_num=6).to(torch.bfloat16).cuda()
pixel_values2 = load_image('./examples/image2.jpg', max_num=6).to(torch.bfloat16).cuda()
image_counts = [pixel_values1.size(0), pixel_values2.size(0)]
pixel_values = torch.cat((pixel_values1, pixel_values2), dim=0)
questions = ["Describe the image in detail."] * len(image_counts)
responses = model.batch_chat(tokenizer, pixel_values,
image_counts=image_counts,
questions=questions,
generation_config=generation_config)
for question, response in zip(questions, responses):
print(question)
print(response)
```
## Citation
If you find this project useful in your research, please consider citing:
```BibTeX
@article{chen2023internvl,
title={InternVL: Scaling up Vision Foundation Models and Aligning for Generic Visual-Linguistic Tasks},
author={Chen, Zhe and Wu, Jiannan and Wang, Wenhai and Su, Weijie and Chen, Guo and Xing, Sen and Zhong, Muyan and Zhang, Qinglong and Zhu, Xizhou and Lu, Lewei and Li, Bin and Luo, Ping and Lu, Tong and Qiao, Yu and Dai, Jifeng},
journal={arXiv preprint arXiv:2312.14238},
year={2023}
}
@article{chen2024far,
title={How Far Are We to GPT-4V? Closing the Gap to Commercial Multimodal Models with Open-Source Suites},
author={Chen, Zhe and Wang, Weiyun and Tian, Hao and Ye, Shenglong and Gao, Zhangwei and Cui, Erfei and Tong, Wenwen and Hu, Kongzhi and Luo, Jiapeng and Ma, Zheng and others},
journal={arXiv preprint arXiv:2404.16821},
year={2024}
}
```
## License
This project is released under the MIT license.
## Acknowledgement
InternVL is built with reference to the code of the following projects: [OpenAI CLIP](https://github.com/openai/CLIP), [Open CLIP](https://github.com/mlfoundations/open_clip), [CLIP Benchmark](https://github.com/LAION-AI/CLIP_benchmark), [EVA](https://github.com/baaivision/EVA/tree/master), [InternImage](https://github.com/OpenGVLab/InternImage), [ViT-Adapter](https://github.com/czczup/ViT-Adapter), [MMSegmentation](https://github.com/open-mmlab/mmsegmentation), [Transformers](https://github.com/huggingface/transformers), [DINOv2](https://github.com/facebookresearch/dinov2), [BLIP-2](https://github.com/salesforce/LAVIS/tree/main/projects/blip2), [Qwen-VL](https://github.com/QwenLM/Qwen-VL/tree/master/eval_mm), and [LLaVA-1.5](https://github.com/haotian-liu/LLaVA). Thanks for their awesome work!
|
shi-labs/oneformer_ade20k_swin_tiny | shi-labs | 2023-01-19T14:35:10Z | 6,791 | 11 | transformers | [
"transformers",
"pytorch",
"oneformer",
"vision",
"image-segmentation",
"dataset:scene_parse_150",
"arxiv:2211.06220",
"license:mit",
"endpoints_compatible",
"region:us"
] | image-segmentation | 2022-11-16T21:35:16Z | ---
license: mit
tags:
- vision
- image-segmentation
datasets:
- scene_parse_150
widget:
- src: https://huggingface.co/datasets/shi-labs/oneformer_demo/blob/main/ade20k.jpeg
example_title: House
- src: https://huggingface.co/datasets/shi-labs/oneformer_demo/blob/main/demo_2.jpg
example_title: Airplane
- src: https://huggingface.co/datasets/shi-labs/oneformer_demo/blob/main/coco.jpeg
example_title: Person
---
# OneFormer
OneFormer model trained on the ADE20k dataset (tiny-sized version, Swin backbone). It was introduced in the paper [OneFormer: One Transformer to Rule Universal Image Segmentation](https://arxiv.org/abs/2211.06220) by Jain et al. and first released in [this repository](https://github.com/SHI-Labs/OneFormer).

## Model description
OneFormer is the first multi-task universal image segmentation framework. It needs to be trained only once with a single universal architecture, a single model, and on a single dataset, to outperform existing specialized models across semantic, instance, and panoptic segmentation tasks. OneFormer uses a task token to condition the model on the task in focus, making the architecture task-guided for training, and task-dynamic for inference, all with a single model.

## Intended uses & limitations
You can use this particular checkpoint for semantic, instance and panoptic segmentation. See the [model hub](https://huggingface.co/models?search=oneformer) to look for other fine-tuned versions on a different dataset.
### How to use
Here is how to use this model:
```python
from transformers import OneFormerProcessor, OneFormerForUniversalSegmentation
from PIL import Image
import requests
url = "https://huggingface.co/datasets/shi-labs/oneformer_demo/blob/main/ade20k.jpeg"
image = Image.open(requests.get(url, stream=True).raw)
# Loading a single model for all three tasks
processor = OneFormerProcessor.from_pretrained("shi-labs/oneformer_ade20k_swin_tiny")
model = OneFormerForUniversalSegmentation.from_pretrained("shi-labs/oneformer_ade20k_swin_tiny")
# Semantic Segmentation
semantic_inputs = processor(images=image, task_inputs=["semantic"], return_tensors="pt")
semantic_outputs = model(**semantic_inputs)
# pass through image_processor for postprocessing
predicted_semantic_map = processor.post_process_semantic_segmentation(outputs, target_sizes=[image.size[::-1]])[0]
# Instance Segmentation
instance_inputs = processor(images=image, task_inputs=["instance"], return_tensors="pt")
instance_outputs = model(**instance_inputs)
# pass through image_processor for postprocessing
predicted_instance_map = processor.post_process_instance_segmentation(outputs, target_sizes=[image.size[::-1]])[0]["segmentation"]
# Panoptic Segmentation
panoptic_inputs = processor(images=image, task_inputs=["panoptic"], return_tensors="pt")
panoptic_outputs = model(**panoptic_inputs)
# pass through image_processor for postprocessing
predicted_semantic_map = processor.post_process_panoptic_segmentation(outputs, target_sizes=[image.size[::-1]])[0]["segmentation"]
```
For more examples, please refer to the [documentation](https://huggingface.co/docs/transformers/master/en/model_doc/oneformer).
### Citation
```bibtex
@article{jain2022oneformer,
title={{OneFormer: One Transformer to Rule Universal Image Segmentation}},
author={Jitesh Jain and Jiachen Li and MangTik Chiu and Ali Hassani and Nikita Orlov and Humphrey Shi},
journal={arXiv},
year={2022}
}
```
|
eldogbbhed/Peagle-9b | eldogbbhed | 2024-05-21T12:53:12Z | 6,786 | 0 | transformers | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"merge",
"mergekit",
"vortexmergekit",
"mlabonne/NeuralBeagle14-7B",
"eldogbbhed/NeuralPearlBeagle",
"conversational",
"license:cc-by-nc-4.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2024-03-10T17:35:17Z | ---
license: cc-by-nc-4.0
tags:
- merge
- mergekit
- vortexmergekit
- mlabonne/NeuralBeagle14-7B
- eldogbbhed/NeuralPearlBeagle
---
# Peagle-9b
Hey there! 👋 Welcome to the Peagle-14b! This is a merge of multiple models brought together using the awesome [VortexMerge kit](https://colab.research.google.com/drive/1YjcvCLuNG1PK7Le6_4xhVU5VpzTwvGhk#scrollTo=UG5H2TK4gVyl).
Let's see what we've got in this merge:
* [mlabonne/NeuralBeagle14-7B](https://huggingface.co/mlabonne/NeuralBeagle14-7B) 🚀
* [eldogbbhed/NeuralPearlBeagle](https://huggingface.co/eldogbbhed/NeuralPearlBeagle) 🚀
## 🧩 Configuration
```yaml
slices:
- sources:
- model: mlabonne/NeuralBeagle14-7B
layer_range: [0, 20]
- sources:
- model: eldogbbhed/NeuralPearlBeagle
layer_range: [12, 32]
merge_method: passthrough
|
KBLab/wav2vec2-large-xlsr-53-swedish | KBLab | 2024-02-01T10:05:57Z | 6,785 | 3 | transformers | [
"transformers",
"pytorch",
"jax",
"wav2vec2",
"automatic-speech-recognition",
"audio",
"speech",
"xlsr-fine-tuning-week",
"sv",
"dataset:common_voice",
"dataset:KTH/nst",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
] | automatic-speech-recognition | 2022-03-02T23:29:04Z | ---
language: sv
datasets:
- common_voice
- KTH/nst
metrics:
- wer
- cer
tags:
- audio
- automatic-speech-recognition
- speech
- xlsr-fine-tuning-week
license: apache-2.0
model-index:
- name: XLSR Wav2Vec2 Swedish by KBLab
results:
- task:
name: Speech Recognition
type: automatic-speech-recognition
dataset:
name: Common Voice sv-SE
type: common_voice
args: sv-SE
metrics:
- name: Test WER
type: wer
value: 14.298610
- name: Test CER
type: cer
value: 4.925294
---
# Wav2Vec2-Large-XLSR-53-Swedish
Fine-tuned [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) in Swedish using the [NST Swedish Dictation](https://www.nb.no/sprakbanken/en/resource-catalogue/oai-nb-no-sbr-17/).
When using this model, make sure that your speech input is sampled at 16kHz.
**Note:** We recommend using our newer model [wav2vec2-large-voxrex-swedish](https://huggingface.co/KBLab/wav2vec2-large-voxrex-swedish) for the best performance.
## Usage
The model can be used directly (without a language model) as follows:
```python
import torch
import torchaudio
from datasets import load_dataset
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
test_dataset = load_dataset("common_voice", "sv-SE", split="test[:2%]").
processor = Wav2Vec2Processor.from_pretrained("KBLab/wav2vec2-large-xlsr-53-swedish")
model = Wav2Vec2ForCTC.from_pretrained("KBLab/wav2vec2-large-xlsr-53-swedish")
resampler = torchaudio.transforms.Resample(48_000, 16_000)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def speech_file_to_array_fn(batch):
speech_array, sampling_rate = torchaudio.load(batch["path"])
batch["speech"] = resampler(speech_array).squeeze().numpy()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
inputs = processor(test_dataset["speech"][:2], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values, attention_mask=inputs.attention_mask).logits
predicted_ids = torch.argmax(logits, dim=-1)
print("Prediction:", processor.batch_decode(predicted_ids))
print("Reference:", test_dataset["sentence"][:2])
```
## Evaluation
The model can be evaluated as follows on the Swedish test data of Common Voice.
```python
import torch
import torchaudio
from datasets import load_dataset, load_metric
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
import re
test_dataset = load_dataset("common_voice", "sv-SE", split="test")
wer = load_metric("wer")
processor = Wav2Vec2Processor.from_pretrained("KBLab/wav2vec2-large-xlsr-53-swedish")
model = Wav2Vec2ForCTC.from_pretrained("KBLab/wav2vec2-large-xlsr-53-swedish")
model.to("cuda")
chars_to_ignore_regex = '[,?.!\\-;:"“]'
resampler = torchaudio.transforms.Resample(48_000, 16_000)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def speech_file_to_array_fn(batch):
batch["sentence"] = re.sub(chars_to_ignore_regex, '', batch["sentence"]).lower()
speech_array, sampling_rate = torchaudio.load(batch["path"])
batch["speech"] = resampler(speech_array).squeeze().numpy()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def evaluate(batch):
inputs = processor(batch["speech"], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values.to("cuda"), attention_mask=inputs.attention_mask.to("cuda")).logits
pred_ids = torch.argmax(logits, dim=-1)
batch["pred_strings"] = processor.batch_decode(pred_ids)
return batch
result = test_dataset.map(evaluate, batched=True, batch_size=8)
print("WER: {:2f}".format(100 * wer.compute(predictions=result["pred_strings"], references=result["sentence"])))
print("CER: {:2f}".format(100 * wer.compute(predictions=[" ".join(list(entry)) for entry in result["pred_strings"]], references=[" ".join(list(entry)) for entry in result["sentence"]])))
```
**WER**: 14.298610%
**CER**: 4.925294%
## Training
First the XLSR model was further pre-trained for 50 epochs with a corpus consisting of 1000 hours spoken Swedish from various radio stations. Secondly [NST Swedish Dictation](https://www.nb.no/sprakbanken/en/resource-catalogue/oai-nb-no-sbr-17/) was used for fine tuning as well as [Common Voice](https://commonvoice.mozilla.org/en/datasets). Lastly only Common Voice dataset was used for final finetuning. The [Fairseq](https://github.com/fairseq) scripts were used.
|
h2oai/h2ogpt-16k-aquilachat2-34b | h2oai | 2023-10-23T04:04:17Z | 6,785 | 4 | transformers | [
"transformers",
"pytorch",
"aquila",
"text-generation",
"custom_code",
"autotrain_compatible",
"region:us"
] | text-generation | 2023-10-20T23:13:49Z | AquilaChat2 long-text chat model [AquilaChat2-34B-16k](https://github.com/FlagAI-Open/Aquila2#base-model-performance).
Inference
```
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
device = torch.device("cuda:0")
model_info = "h2oai/h2ogpt-16k-aquilachat2-34b"
tokenizer = AutoTokenizer.from_pretrained(model_info, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(model_info, trust_remote_code=True, torch_dtype=torch.bfloat16)
model.eval()
model.to(device)
text = "Who are you?"
from predict import predict
out = predict(model, text, tokenizer=tokenizer, max_gen_len=200, top_p=0.95,
seed=1234, topk=100, temperature=0.9, sft=True, device=device,
model_name="h2oai/h2ogpt-16k-aquilachat2-34b")
print(out)
```
License
Aquila2 series open-source model is licensed under BAAI Aquila Model Licence Agreement
|
RichardErkhov/google_-_codegemma-1.1-2b-gguf | RichardErkhov | 2024-06-27T12:54:40Z | 6,777 | 0 | null | [
"gguf",
"region:us"
] | null | 2024-06-27T12:38:10Z | Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
codegemma-1.1-2b - GGUF
- Model creator: https://huggingface.co/google/
- Original model: https://huggingface.co/google/codegemma-1.1-2b/
| Name | Quant method | Size |
| ---- | ---- | ---- |
| [codegemma-1.1-2b.Q2_K.gguf](https://huggingface.co/RichardErkhov/google_-_codegemma-1.1-2b-gguf/blob/main/codegemma-1.1-2b.Q2_K.gguf) | Q2_K | 1.08GB |
| [codegemma-1.1-2b.IQ3_XS.gguf](https://huggingface.co/RichardErkhov/google_-_codegemma-1.1-2b-gguf/blob/main/codegemma-1.1-2b.IQ3_XS.gguf) | IQ3_XS | 1.16GB |
| [codegemma-1.1-2b.IQ3_S.gguf](https://huggingface.co/RichardErkhov/google_-_codegemma-1.1-2b-gguf/blob/main/codegemma-1.1-2b.IQ3_S.gguf) | IQ3_S | 1.2GB |
| [codegemma-1.1-2b.Q3_K_S.gguf](https://huggingface.co/RichardErkhov/google_-_codegemma-1.1-2b-gguf/blob/main/codegemma-1.1-2b.Q3_K_S.gguf) | Q3_K_S | 1.2GB |
| [codegemma-1.1-2b.IQ3_M.gguf](https://huggingface.co/RichardErkhov/google_-_codegemma-1.1-2b-gguf/blob/main/codegemma-1.1-2b.IQ3_M.gguf) | IQ3_M | 1.22GB |
| [codegemma-1.1-2b.Q3_K.gguf](https://huggingface.co/RichardErkhov/google_-_codegemma-1.1-2b-gguf/blob/main/codegemma-1.1-2b.Q3_K.gguf) | Q3_K | 1.29GB |
| [codegemma-1.1-2b.Q3_K_M.gguf](https://huggingface.co/RichardErkhov/google_-_codegemma-1.1-2b-gguf/blob/main/codegemma-1.1-2b.Q3_K_M.gguf) | Q3_K_M | 1.29GB |
| [codegemma-1.1-2b.Q3_K_L.gguf](https://huggingface.co/RichardErkhov/google_-_codegemma-1.1-2b-gguf/blob/main/codegemma-1.1-2b.Q3_K_L.gguf) | Q3_K_L | 1.36GB |
| [codegemma-1.1-2b.IQ4_XS.gguf](https://huggingface.co/RichardErkhov/google_-_codegemma-1.1-2b-gguf/blob/main/codegemma-1.1-2b.IQ4_XS.gguf) | IQ4_XS | 1.4GB |
| [codegemma-1.1-2b.Q4_0.gguf](https://huggingface.co/RichardErkhov/google_-_codegemma-1.1-2b-gguf/blob/main/codegemma-1.1-2b.Q4_0.gguf) | Q4_0 | 1.44GB |
| [codegemma-1.1-2b.IQ4_NL.gguf](https://huggingface.co/RichardErkhov/google_-_codegemma-1.1-2b-gguf/blob/main/codegemma-1.1-2b.IQ4_NL.gguf) | IQ4_NL | 1.45GB |
| [codegemma-1.1-2b.Q4_K_S.gguf](https://huggingface.co/RichardErkhov/google_-_codegemma-1.1-2b-gguf/blob/main/codegemma-1.1-2b.Q4_K_S.gguf) | Q4_K_S | 1.45GB |
| [codegemma-1.1-2b.Q4_K.gguf](https://huggingface.co/RichardErkhov/google_-_codegemma-1.1-2b-gguf/blob/main/codegemma-1.1-2b.Q4_K.gguf) | Q4_K | 1.52GB |
| [codegemma-1.1-2b.Q4_K_M.gguf](https://huggingface.co/RichardErkhov/google_-_codegemma-1.1-2b-gguf/blob/main/codegemma-1.1-2b.Q4_K_M.gguf) | Q4_K_M | 1.52GB |
| [codegemma-1.1-2b.Q4_1.gguf](https://huggingface.co/RichardErkhov/google_-_codegemma-1.1-2b-gguf/blob/main/codegemma-1.1-2b.Q4_1.gguf) | Q4_1 | 1.56GB |
| [codegemma-1.1-2b.Q5_0.gguf](https://huggingface.co/RichardErkhov/google_-_codegemma-1.1-2b-gguf/blob/main/codegemma-1.1-2b.Q5_0.gguf) | Q5_0 | 1.68GB |
| [codegemma-1.1-2b.Q5_K_S.gguf](https://huggingface.co/RichardErkhov/google_-_codegemma-1.1-2b-gguf/blob/main/codegemma-1.1-2b.Q5_K_S.gguf) | Q5_K_S | 1.68GB |
| [codegemma-1.1-2b.Q5_K.gguf](https://huggingface.co/RichardErkhov/google_-_codegemma-1.1-2b-gguf/blob/main/codegemma-1.1-2b.Q5_K.gguf) | Q5_K | 1.71GB |
| [codegemma-1.1-2b.Q5_K_M.gguf](https://huggingface.co/RichardErkhov/google_-_codegemma-1.1-2b-gguf/blob/main/codegemma-1.1-2b.Q5_K_M.gguf) | Q5_K_M | 1.71GB |
| [codegemma-1.1-2b.Q5_1.gguf](https://huggingface.co/RichardErkhov/google_-_codegemma-1.1-2b-gguf/blob/main/codegemma-1.1-2b.Q5_1.gguf) | Q5_1 | 1.79GB |
| [codegemma-1.1-2b.Q6_K.gguf](https://huggingface.co/RichardErkhov/google_-_codegemma-1.1-2b-gguf/blob/main/codegemma-1.1-2b.Q6_K.gguf) | Q6_K | 1.92GB |
| [codegemma-1.1-2b.Q8_0.gguf](https://huggingface.co/RichardErkhov/google_-_codegemma-1.1-2b-gguf/blob/main/codegemma-1.1-2b.Q8_0.gguf) | Q8_0 | 2.49GB |
Original model description:
---
library_name: transformers
extra_gated_heading: Access CodeGemma on Hugging Face
extra_gated_prompt: >-
To access CodeGemma on Hugging Face, you’re required to review and agree to
Google’s usage license. To do this, please ensure you’re logged-in to Hugging
Face and click below. Requests are processed immediately.
extra_gated_button_content: Acknowledge license
license: gemma
license_link: https://ai.google.dev/gemma/terms
---
# CodeGemma
Model Page
: [CodeGemma](https://ai.google.dev/gemma/docs/codegemma)
Resources and Technical Documentation
: [Technical Report](https://goo.gle/codegemma)
: [Responsible Generative AI Toolkit](https://ai.google.dev/responsible)
Terms of Use
: [Terms](https://ai.google.dev/gemma/terms)
Authors
: Google
## Model Information
Summary description and brief definition of inputs and outputs.
### Description
CodeGemma is a collection of lightweight open code models built on top of Gemma. CodeGemma models are text-to-text and text-to-code decoder-only models and are available as a 7 billion pretrained variant that specializes in code completion and code generation tasks, a 7 billion parameter instruction-tuned variant for code chat and instruction following and a 2 billion parameter pretrained variant for fast code completion.
| | [ **codegemma-2b** ](https://huggingface.co/google/codegemma-1.1-2b) | [codegemma-7b](https://huggingface.co/google/codegemma-7b) | [codegemma-7b-it](https://huggingface.co/google/codegemma-1.1-7b-it) |
|----------------------------------|:----------------------------------------------------------------:|:----------------------------------------------------------:|:----------------------------------------------------------------:|
| Code Completion | ✅ | ✅ | |
| Generation from natural language | | ✅ | ✅ |
| Chat | | | ✅ |
| Instruction Following | | | ✅ |
### Sample Usage
#### For Code Completion
Code completion can be used for infilling inside code editors. CodeGemma was trained for this task using the fill-in-the-middle (FIM) objective, where you provide a prefix and a suffix as context for the completion. The following tokens are used to separate the different parts of the input:
- `<|fim_prefix|>` precedes the context before the completion we want to run.
- `<|fim_suffix|>` precedes the suffix. You must put this token exactly where the cursor would be positioned in an editor, as this is the location that will be completed by the model.
- `<|fim_middle|>` is the prompt that invites the model to run the generation.
In addition to these, there's also `<|file_separator|>`, which is used to provide multi-file contexts.
Please, make sure to not provide any extra spaces or newlines around the tokens, other than those that would naturally occur in the code fragment you want to complete. Here's an example:
```python
from transformers import GemmaTokenizer, AutoModelForCausalLM
model_id = "google/codegemma-1.1-2b"
tokenizer = GemmaTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(model_id)
prompt = '''\
<|fim_prefix|>import datetime
def calculate_age(birth_year):
"""Calculates a person's age based on their birth year."""
current_year = datetime.date.today().year
<|fim_suffix|>
return age<|fim_middle|>\
'''
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
prompt_len = inputs["input_ids"].shape[-1]
outputs = model.generate(**inputs, max_new_tokens=100)
print(tokenizer.decode(outputs[0][prompt_len:]))
```
This may return something like the following:
```
age = current_year - birth_year<|file_separator|>test_calculate_age.py
<|fim_suffix|>
assert calculate_age(1990) == 33
assert calculate_age(1980) == 43
assert calculate_age(1970) == 53
assert calculate_age(1960) == 63
assert calculate_age(1950) == 73
```
Note the extra content after the correct completion. The model returns the completion, followed by one of the FIM tokens or the EOS token. You should ignore everything that comes after any of these tokens. A good way to achieve this is by providing a list of terminators to the `generate` function, like this:
```python
FIM_PREFIX = '<|fim_prefix|>'
FIM_SUFFIX = '<|fim_suffix|>'
FIM_MIDDLE = '<|fim_middle|>'
FIM_FILE_SEPARATOR = '<|file_separator|>'
terminators = tokenizer.convert_tokens_to_ids([FIM_PREFIX, FIM_MIDDLE, FIM_SUFFIX, FIM_FILE_SEPARATOR])
terminators += [tokenizer.eos_token_id]
outputs = model.generate(
**inputs,
max_new_tokens=100,
eos_token_id=terminators,
)
```
In this case, generation stops as soon as the first delimiter is found in the response:
```
age = current_year - birth_year<|file_separator|>
```
#### For Code Generation
```python
from transformers import GemmaTokenizer, AutoModelForCausalLM
tokenizer = GemmaTokenizer.from_pretrained("google/codegemma-1.1-2b")
model = AutoModelForCausalLM.from_pretrained("google/codegemma-1.1-2b")
input_text = "Write me a Python function to calculate the nth fibonacci number."
input_ids = tokenizer(input_text, return_tensors="pt")
outputs = model.generate(**input_ids)
print(tokenizer.decode(outputs[0]))
```
### Inputs and Outputs
Inputs
: For pretrained model variants: code prefix and/or suffix for code completion and generation scenarios, or natural language text or prompt
: For instruction tuned model variant: natural language text or prompt
Outputs
: For pretrained model variants: fill-in-the-middle code completion, code and natural language
: For instruction tuned model variant: code and natural language
## Model Data
Data used for model training and how the data was processed.
### Training Dataset
Using Gemma as the base model, CodeGemma 2B and 7B pretrained variants are further trained on an additional 500 to 1000 billion tokens of primarily English language data from publicly available code repositories, open source mathematics datasets and synthetically generated code.
### Training Data Processing
The following data pre-processing techniques were applied:
* FIM Pretrained CodeGemma models focus on fill-in-the-middle (FIM) tasks. The models are trained to work with both PSM and SPM modes. Our FIM settings are 80% to 90% FIM rate with 50-50 PSM/SPM.
* Dependency Graph-based Packing and Unit Test-based Lexical Packing techniques: To improve model alignment with real-world applications, we structured training examples at the project/repository level to co-locate the most relevant source files within each repository. Specifically, we employed two heuristic techniques: dependency graph-based packing and unit test-based lexical packing
* We developed a novel technique for splitting the documents into prefix, middle, and suffix to make the suffix start in a more syntactically natural point rather than purely random distribution.
* Safety: Similarly to Gemma, we deployed rigorous safety filtering including filtering personal data, CSAM filtering and other filtering based on content quality and safety in line with [our policies](https://storage.googleapis.com/gweb-uniblog-publish-prod/documents/2023_Google_AI_Principles_Progress_Update.pdf#page=11).
## Implementation Information
Information about the hardware and software used to train the models.
### Hardware
CodeGemma was trained using the latest generation of [Tensor Processing Unit (TPU)](https://cloud.google.com/tpu/docs/intro-to-tpu) hardware (TPUv5e).
### Software
Training was done using [JAX](https://github.com/google/jax) and [ML Pathways](https://blog.google/technology/ai/introducing-pathways-next-generation-ai-architecture/).
## Evaluation Information
Model evaluation metrics and results.
### Evaluation Approach
We evaluate CodeGemma on a variety of academic benchmarks across several domains:
* Code completion benchmarks: HumanEval Single Line and Multiple Line Infilling
* Code generation benchmarks: HumanEval, MBPP, BabelCode (C++, C#, Go, Java, JavaScript, Kotlin, Python, Rust)
* Q&A: BoolQ, PIQA, TriviaQA
* Natural Language: ARC-Challenge, HellaSwag, MMLU, WinoGrande
* Math Reasoning: GSM8K, MATH
### Evaluation Results
#### Coding Benchmarks
Benchmark | [2B](https://huggingface.co/google/codegemma-2b) | [2B (1.1)](https://huggingface.co/google/codegemma-1.1-2b) | [7B](https://huggingface.co/google/codegemma-7b) | [7B-IT](https://huggingface.co/google/codegemma-7b-it) | [7B-IT (1.1)](https://huggingface.co/google/codegemma-1.1-7b-it)
----------------------|------|----------|------|-------|------------
HumanEval | 31.1 | 37.8 | 44.5 | 56.1 | 60.4
MBPP | 43.6 | 49.2 | 56.2 | 54.2 | 55.6
HumanEval Single Line | 78.4 | 79.3 | 76.1 | 68.3 | 77.4
HumanEval Multi Line | 51.4 | 51.0 | 58.4 | 20.1 | 23.7
BC HE C++ | 24.2 | 19.9 | 32.9 | 42.2 | 46.6
BC HE C# | 10.6 | 26.1 | 22.4 | 26.7 | 54.7
BC HE Go | 20.5 | 18.0 | 21.7 | 28.6 | 34.2
BC HE Java | 29.2 | 29.8 | 41.0 | 48.4 | 50.3
BC HE JavaScript | 21.7 | 28.0 | 39.8 | 46.0 | 48.4
BC HE Kotlin | 28.0 | 32.3 | 39.8 | 51.6 | 47.8
BC HE Python | 21.7 | 36.6 | 42.2 | 48.4 | 54.0
BC HE Rust | 26.7 | 24.2 | 34.1 | 36.0 | 37.3
BC MBPP C++ | 47.1 | 38.9 | 53.8 | 56.7 | 63.5
BC MBPP C# | 28.7 | 45.3 | 32.5 | 41.2 | 62.0
BC MBPP Go | 45.6 | 38.9 | 43.3 | 46.2 | 53.2
BC MBPP Java | 41.8 | 49.7 | 50.3 | 57.3 | 62.9
BC MBPP JavaScript | 45.3 | 45.0 | 58.2 | 61.4 | 61.4
BC MBPP Kotlin | 46.8 | 49.7 | 54.7 | 59.9 | 62.6
BC MBPP Python | 38.6 | 52.9 | 59.1 | 62.0 | 60.2
BC MBPP Rust | 45.3 | 47.4 | 52.9 | 53.5 | 52.3
#### Natural Language Benchmarks

## Ethics and Safety
Ethics and safety evaluation approach and results.
### Evaluation Approach
Our evaluation methods include structured evaluations and internal red-teaming testing of relevant content policies. Red-teaming was conducted by a number of different teams, each with different goals and human evaluation metrics. These models were evaluated against a number of different categories relevant to ethics and safety, including:
* Human evaluation on prompts covering content safety and representational harms. See the [Gemma model card](https://ai.google.dev/gemma/docs/model_card#evaluation_approach) for more details on evaluation approach.
* Specific testing of cyber-offence capabilities, focusing on testing autonomous hacking capabilities and ensuring potential harms are limited.
### Evaluation Results
The results of ethics and safety evaluations are within acceptable thresholds for meeting [internal policies](https://storage.googleapis.com/gweb-uniblog-publish-prod/documents/2023_Google_AI_Principles_Progress_Update.pdf#page=11) for categories such as child safety, content safety, representational harms, memorization, large-scale harms. See the [Gemma model card](https://ai.google.dev/gemma/docs/model_card#evaluation_results) for more details.
## Model Usage & Limitations
These models have certain limitations that users should be aware of.
### Intended Usage
Code Gemma models have a wide range of applications, which vary between IT and PT models. The following list of potential uses is not comprehensive. The purpose of this list is to provide contextual information about the possible use-cases that the model creators considered as part of model training and development.
Code Completion
: PT models can be used to complete code with an IDE extension
Code Generation
: IT model can be used to generate code with or without an IDE extension
Code Conversation
: IT model can power conversation interfaces which discuss code.
Code Education
: IT model supports interactive code learning experiences, aids in syntax correction or provides coding practice.
### Known Limitations
Large Language Models (LLMs) have limitations based on their training data and the inherent limitations of the technology. See the [Gemma model card](https://ai.google.dev/gemma/docs/model_card#evaluation_results) for more details on the limitations of LLMs.
### Ethical Considerations & Risks
The development of large language models (LLMs) raises several ethical concerns. We have carefully considered multiple aspects in the development of these models. Please refer to [the same discussion](https://ai.google.dev/gemma/docs/model_card#ethical_considerations_and_risks) in the Gemma model card for model details.
### Benefits
At the time of release, this family of models provides high-performance open code-focused large language model implementations designed from the ground up for Responsible AI development compared to similarly sized models.
Using the coding benchmark evaluation metrics described in this document, these models have shown to provide superior performance to other, comparably-sized open model alternatives.
|
romjin/rom160 | romjin | 2024-06-08T18:21:38Z | 6,774 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2024-06-08T18:06:27Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
TheBloke/Llama-2-70B-Chat-GGUF | TheBloke | 2023-11-21T20:01:36Z | 6,766 | 119 | transformers | [
"transformers",
"gguf",
"llama",
"facebook",
"meta",
"pytorch",
"llama-2",
"text-generation",
"en",
"arxiv:2307.09288",
"base_model:meta-llama/Llama-2-70b-chat-hf",
"license:llama2",
"text-generation-inference",
"region:us"
] | text-generation | 2023-09-04T17:53:09Z | ---
language:
- en
license: llama2
tags:
- facebook
- meta
- pytorch
- llama
- llama-2
model_name: Llama 2 70B Chat
base_model: meta-llama/Llama-2-70b-chat-hf
inference: false
model_creator: Meta Llama 2
model_type: llama
pipeline_tag: text-generation
prompt_template: '[INST] <<SYS>>
You are a helpful, respectful and honest assistant. Always answer as helpfully as
possible, while being safe. Your answers should not include any harmful, unethical,
racist, sexist, toxic, dangerous, or illegal content. Please ensure that your responses
are socially unbiased and positive in nature. If a question does not make any sense,
or is not factually coherent, explain why instead of answering something not correct.
If you don''t know the answer to a question, please don''t share false information.
<</SYS>>
{prompt}[/INST]
'
quantized_by: TheBloke
---
<!-- header start -->
<!-- 200823 -->
<div style="width: auto; margin-left: auto; margin-right: auto">
<img src="https://i.imgur.com/EBdldam.jpg" alt="TheBlokeAI" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</div>
<div style="display: flex; justify-content: space-between; width: 100%;">
<div style="display: flex; flex-direction: column; align-items: flex-start;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://discord.gg/theblokeai">Chat & support: TheBloke's Discord server</a></p>
</div>
<div style="display: flex; flex-direction: column; align-items: flex-end;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://www.patreon.com/TheBlokeAI">Want to contribute? TheBloke's Patreon page</a></p>
</div>
</div>
<div style="text-align:center; margin-top: 0em; margin-bottom: 0em"><p style="margin-top: 0.25em; margin-bottom: 0em;">TheBloke's LLM work is generously supported by a grant from <a href="https://a16z.com">andreessen horowitz (a16z)</a></p></div>
<hr style="margin-top: 1.0em; margin-bottom: 1.0em;">
<!-- header end -->
# Llama 2 70B Chat - GGUF
- Model creator: [Meta Llama 2](https://huggingface.co/meta-llama)
- Original model: [Llama 2 70B Chat](https://huggingface.co/meta-llama/Llama-2-70b-chat-hf)
<!-- description start -->
## Description
This repo contains GGUF format model files for [Meta Llama 2's Llama 2 70B Chat](https://huggingface.co/meta-llama/Llama-2-70b-chat-hf).
<!-- description end -->
<!-- README_GGUF.md-about-gguf start -->
### About GGUF
GGUF is a new format introduced by the llama.cpp team on August 21st 2023. It is a replacement for GGML, which is no longer supported by llama.cpp. GGUF offers numerous advantages over GGML, such as better tokenisation, and support for special tokens. It is also supports metadata, and is designed to be extensible.
Here is an incomplate list of clients and libraries that are known to support GGUF:
* [llama.cpp](https://github.com/ggerganov/llama.cpp). The source project for GGUF. Offers a CLI and a server option.
* [text-generation-webui](https://github.com/oobabooga/text-generation-webui), the most widely used web UI, with many features and powerful extensions. Supports GPU acceleration.
* [KoboldCpp](https://github.com/LostRuins/koboldcpp), a fully featured web UI, with GPU accel across all platforms and GPU architectures. Especially good for story telling.
* [LM Studio](https://lmstudio.ai/), an easy-to-use and powerful local GUI for Windows and macOS (Silicon), with GPU acceleration.
* [LoLLMS Web UI](https://github.com/ParisNeo/lollms-webui), a great web UI with many interesting and unique features, including a full model library for easy model selection.
* [Faraday.dev](https://faraday.dev/), an attractive and easy to use character-based chat GUI for Windows and macOS (both Silicon and Intel), with GPU acceleration.
* [ctransformers](https://github.com/marella/ctransformers), a Python library with GPU accel, LangChain support, and OpenAI-compatible AI server.
* [llama-cpp-python](https://github.com/abetlen/llama-cpp-python), a Python library with GPU accel, LangChain support, and OpenAI-compatible API server.
* [candle](https://github.com/huggingface/candle), a Rust ML framework with a focus on performance, including GPU support, and ease of use.
<!-- README_GGUF.md-about-gguf end -->
<!-- repositories-available start -->
## Repositories available
* [AWQ model(s) for GPU inference.](https://huggingface.co/TheBloke/Llama-2-70B-chat-AWQ)
* [GPTQ models for GPU inference, with multiple quantisation parameter options.](https://huggingface.co/TheBloke/Llama-2-70B-chat-GPTQ)
* [2, 3, 4, 5, 6 and 8-bit GGUF models for CPU+GPU inference](https://huggingface.co/TheBloke/Llama-2-70B-chat-GGUF)
* [Meta Llama 2's original unquantised fp16 model in pytorch format, for GPU inference and for further conversions](https://huggingface.co/meta-llama/Llama-2-70b-chat-hf)
<!-- repositories-available end -->
<!-- prompt-template start -->
## Prompt template: Llama-2-Chat
```
[INST] <<SYS>>
You are a helpful, respectful and honest assistant. Always answer as helpfully as possible, while being safe. Your answers should not include any harmful, unethical, racist, sexist, toxic, dangerous, or illegal content. Please ensure that your responses are socially unbiased and positive in nature. If a question does not make any sense, or is not factually coherent, explain why instead of answering something not correct. If you don't know the answer to a question, please don't share false information.
<</SYS>>
{prompt}[/INST]
```
<!-- prompt-template end -->
<!-- compatibility_gguf start -->
## Compatibility
These quantised GGUFv2 files are compatible with llama.cpp from August 27th onwards, as of commit [d0cee0d36d5be95a0d9088b674dbb27354107221](https://github.com/ggerganov/llama.cpp/commit/d0cee0d36d5be95a0d9088b674dbb27354107221)
They are also compatible with many third party UIs and libraries - please see the list at the top of this README.
## Explanation of quantisation methods
<details>
<summary>Click to see details</summary>
The new methods available are:
* GGML_TYPE_Q2_K - "type-1" 2-bit quantization in super-blocks containing 16 blocks, each block having 16 weight. Block scales and mins are quantized with 4 bits. This ends up effectively using 2.5625 bits per weight (bpw)
* GGML_TYPE_Q3_K - "type-0" 3-bit quantization in super-blocks containing 16 blocks, each block having 16 weights. Scales are quantized with 6 bits. This end up using 3.4375 bpw.
* GGML_TYPE_Q4_K - "type-1" 4-bit quantization in super-blocks containing 8 blocks, each block having 32 weights. Scales and mins are quantized with 6 bits. This ends up using 4.5 bpw.
* GGML_TYPE_Q5_K - "type-1" 5-bit quantization. Same super-block structure as GGML_TYPE_Q4_K resulting in 5.5 bpw
* GGML_TYPE_Q6_K - "type-0" 6-bit quantization. Super-blocks with 16 blocks, each block having 16 weights. Scales are quantized with 8 bits. This ends up using 6.5625 bpw
Refer to the Provided Files table below to see what files use which methods, and how.
</details>
<!-- compatibility_gguf end -->
<!-- README_GGUF.md-provided-files start -->
## Provided files
| Name | Quant method | Bits | Size | Max RAM required | Use case |
| ---- | ---- | ---- | ---- | ---- | ----- |
| [llama-2-70b-chat.Q2_K.gguf](https://huggingface.co/TheBloke/Llama-2-70B-chat-GGUF/blob/main/llama-2-70b-chat.Q2_K.gguf) | Q2_K | 2 | 29.28 GB| 31.78 GB | smallest, significant quality loss - not recommended for most purposes |
| [llama-2-70b-chat.Q3_K_S.gguf](https://huggingface.co/TheBloke/Llama-2-70B-chat-GGUF/blob/main/llama-2-70b-chat.Q3_K_S.gguf) | Q3_K_S | 3 | 29.92 GB| 32.42 GB | very small, high quality loss |
| [llama-2-70b-chat.Q5_K_S.gguf](https://huggingface.co/TheBloke/Llama-2-70B-chat-GGUF/blob/main/llama-2-70b-chat.Q5_K_S.gguf) | Q5_K_S | 5 | 30.57 GB| 33.07 GB | large, low quality loss - recommended |
| [llama-2-70b-chat.Q3_K_M.gguf](https://huggingface.co/TheBloke/Llama-2-70B-chat-GGUF/blob/main/llama-2-70b-chat.Q3_K_M.gguf) | Q3_K_M | 3 | 33.19 GB| 35.69 GB | very small, high quality loss |
| [llama-2-70b-chat.Q3_K_L.gguf](https://huggingface.co/TheBloke/Llama-2-70B-chat-GGUF/blob/main/llama-2-70b-chat.Q3_K_L.gguf) | Q3_K_L | 3 | 36.15 GB| 38.65 GB | small, substantial quality loss |
| [llama-2-70b-chat.Q4_0.gguf](https://huggingface.co/TheBloke/Llama-2-70B-chat-GGUF/blob/main/llama-2-70b-chat.Q4_0.gguf) | Q4_0 | 4 | 38.87 GB| 41.37 GB | legacy; small, very high quality loss - prefer using Q3_K_M |
| [llama-2-70b-chat.Q4_K_S.gguf](https://huggingface.co/TheBloke/Llama-2-70B-chat-GGUF/blob/main/llama-2-70b-chat.Q4_K_S.gguf) | Q4_K_S | 4 | 39.07 GB| 41.57 GB | small, greater quality loss |
| [llama-2-70b-chat.Q4_K_M.gguf](https://huggingface.co/TheBloke/Llama-2-70B-chat-GGUF/blob/main/llama-2-70b-chat.Q4_K_M.gguf) | Q4_K_M | 4 | 41.42 GB| 43.92 GB | medium, balanced quality - recommended |
| [llama-2-70b-chat.Q5_0.gguf](https://huggingface.co/TheBloke/Llama-2-70B-chat-GGUF/blob/main/llama-2-70b-chat.Q5_0.gguf) | Q5_0 | 5 | 47.46 GB| 49.96 GB | legacy; medium, balanced quality - prefer using Q4_K_M |
| [llama-2-70b-chat.Q5_K_M.gguf](https://huggingface.co/TheBloke/Llama-2-70B-chat-GGUF/blob/main/llama-2-70b-chat.Q5_K_M.gguf) | Q5_K_M | 5 | 48.75 GB| 51.25 GB | large, very low quality loss - recommended |
| llama-2-70b-chat.Q6_K.gguf | Q6_K | 6 | 56.59 GB| 59.09 GB | very large, extremely low quality loss |
| llama-2-70b-chat.Q8_0.gguf | Q8_0 | 8 | 73.29 GB| 75.79 GB | very large, extremely low quality loss - not recommended |
**Note**: the above RAM figures assume no GPU offloading. If layers are offloaded to the GPU, this will reduce RAM usage and use VRAM instead.
### Q6_K and Q8_0 files are split and require joining
**Note:** HF does not support uploading files larger than 50GB. Therefore I have uploaded the Q6_K and Q8_0 files as split files.
<details>
<summary>Click for instructions regarding Q6_K and Q8_0 files</summary>
### q6_K
Please download:
* `llama-2-70b-chat.Q6_K.gguf-split-a`
* `llama-2-70b-chat.Q6_K.gguf-split-b`
### q8_0
Please download:
* `llama-2-70b-chat.Q8_0.gguf-split-a`
* `llama-2-70b-chat.Q8_0.gguf-split-b`
To join the files, do the following:
Linux and macOS:
```
cat llama-2-70b-chat.Q6_K.gguf-split-* > llama-2-70b-chat.Q6_K.gguf && rm llama-2-70b-chat.Q6_K.gguf-split-*
cat llama-2-70b-chat.Q8_0.gguf-split-* > llama-2-70b-chat.Q8_0.gguf && rm llama-2-70b-chat.Q8_0.gguf-split-*
```
Windows command line:
```
COPY /B llama-2-70b-chat.Q6_K.gguf-split-a + llama-2-70b-chat.Q6_K.gguf-split-b llama-2-70b-chat.Q6_K.gguf
del llama-2-70b-chat.Q6_K.gguf-split-a llama-2-70b-chat.Q6_K.gguf-split-b
COPY /B llama-2-70b-chat.Q8_0.gguf-split-a + llama-2-70b-chat.Q8_0.gguf-split-b llama-2-70b-chat.Q8_0.gguf
del llama-2-70b-chat.Q8_0.gguf-split-a llama-2-70b-chat.Q8_0.gguf-split-b
```
</details>
<!-- README_GGUF.md-provided-files end -->
<!-- README_GGUF.md-how-to-download start -->
## How to download GGUF files
**Note for manual downloaders:** You almost never want to clone the entire repo! Multiple different quantisation formats are provided, and most users only want to pick and download a single file.
The following clients/libraries will automatically download models for you, providing a list of available models to choose from:
- LM Studio
- LoLLMS Web UI
- Faraday.dev
### In `text-generation-webui`
Under Download Model, you can enter the model repo: TheBloke/Llama-2-70B-chat-GGUF and below it, a specific filename to download, such as: llama-2-70b-chat.Q4_K_M.gguf.
Then click Download.
### On the command line, including multiple files at once
I recommend using the `huggingface-hub` Python library:
```shell
pip3 install huggingface-hub>=0.17.1
```
Then you can download any individual model file to the current directory, at high speed, with a command like this:
```shell
huggingface-cli download TheBloke/Llama-2-70B-chat-GGUF llama-2-70b-chat.Q4_K_M.gguf --local-dir . --local-dir-use-symlinks False
```
<details>
<summary>More advanced huggingface-cli download usage</summary>
You can also download multiple files at once with a pattern:
```shell
huggingface-cli download TheBloke/Llama-2-70B-chat-GGUF --local-dir . --local-dir-use-symlinks False --include='*Q4_K*gguf'
```
For more documentation on downloading with `huggingface-cli`, please see: [HF -> Hub Python Library -> Download files -> Download from the CLI](https://huggingface.co/docs/huggingface_hub/guides/download#download-from-the-cli).
To accelerate downloads on fast connections (1Gbit/s or higher), install `hf_transfer`:
```shell
pip3 install hf_transfer
```
And set environment variable `HF_HUB_ENABLE_HF_TRANSFER` to `1`:
```shell
HUGGINGFACE_HUB_ENABLE_HF_TRANSFER=1 huggingface-cli download TheBloke/Llama-2-70B-chat-GGUF llama-2-70b-chat.Q4_K_M.gguf --local-dir . --local-dir-use-symlinks False
```
Windows CLI users: Use `set HUGGINGFACE_HUB_ENABLE_HF_TRANSFER=1` before running the download command.
</details>
<!-- README_GGUF.md-how-to-download end -->
<!-- README_GGUF.md-how-to-run start -->
## Example `llama.cpp` command
Make sure you are using `llama.cpp` from commit [d0cee0d36d5be95a0d9088b674dbb27354107221](https://github.com/ggerganov/llama.cpp/commit/d0cee0d36d5be95a0d9088b674dbb27354107221) or later.
```shell
./main -ngl 32 -m llama-2-70b-chat.Q4_K_M.gguf --color -c 4096 --temp 0.7 --repeat_penalty 1.1 -n -1 -p "[INST] <<SYS>>\nYou are a helpful, respectful and honest assistant. Always answer as helpfully as possible, while being safe. Your answers should not include any harmful, unethical, racist, sexist, toxic, dangerous, or illegal content. Please ensure that your responses are socially unbiased and positive in nature. If a question does not make any sense, or is not factually coherent, explain why instead of answering something not correct. If you don't know the answer to a question, please don't share false information.\n<</SYS>>\n{prompt}[/INST]"
```
Change `-ngl 32` to the number of layers to offload to GPU. Remove it if you don't have GPU acceleration.
Change `-c 4096` to the desired sequence length. For extended sequence models - eg 8K, 16K, 32K - the necessary RoPE scaling parameters are read from the GGUF file and set by llama.cpp automatically.
If you want to have a chat-style conversation, replace the `-p <PROMPT>` argument with `-i -ins`
For other parameters and how to use them, please refer to [the llama.cpp documentation](https://github.com/ggerganov/llama.cpp/blob/master/examples/main/README.md)
## How to run in `text-generation-webui`
Further instructions here: [text-generation-webui/docs/llama.cpp.md](https://github.com/oobabooga/text-generation-webui/blob/main/docs/llama.cpp.md).
## How to run from Python code
You can use GGUF models from Python using the [llama-cpp-python](https://github.com/abetlen/llama-cpp-python) or [ctransformers](https://github.com/marella/ctransformers) libraries.
### How to load this model from Python using ctransformers
#### First install the package
```bash
# Base ctransformers with no GPU acceleration
pip install ctransformers>=0.2.24
# Or with CUDA GPU acceleration
pip install ctransformers[cuda]>=0.2.24
# Or with ROCm GPU acceleration
CT_HIPBLAS=1 pip install ctransformers>=0.2.24 --no-binary ctransformers
# Or with Metal GPU acceleration for macOS systems
CT_METAL=1 pip install ctransformers>=0.2.24 --no-binary ctransformers
```
#### Simple example code to load one of these GGUF models
```python
from ctransformers import AutoModelForCausalLM
# Set gpu_layers to the number of layers to offload to GPU. Set to 0 if no GPU acceleration is available on your system.
llm = AutoModelForCausalLM.from_pretrained("TheBloke/Llama-2-70B-chat-GGUF", model_file="llama-2-70b-chat.Q4_K_M.gguf", model_type="llama", gpu_layers=50)
print(llm("AI is going to"))
```
## How to use with LangChain
Here's guides on using llama-cpp-python or ctransformers with LangChain:
* [LangChain + llama-cpp-python](https://python.langchain.com/docs/integrations/llms/llamacpp)
* [LangChain + ctransformers](https://python.langchain.com/docs/integrations/providers/ctransformers)
<!-- README_GGUF.md-how-to-run end -->
<!-- footer start -->
<!-- 200823 -->
## Discord
For further support, and discussions on these models and AI in general, join us at:
[TheBloke AI's Discord server](https://discord.gg/theblokeai)
## Thanks, and how to contribute
Thanks to the [chirper.ai](https://chirper.ai) team!
Thanks to Clay from [gpus.llm-utils.org](llm-utils)!
I've had a lot of people ask if they can contribute. I enjoy providing models and helping people, and would love to be able to spend even more time doing it, as well as expanding into new projects like fine tuning/training.
If you're able and willing to contribute it will be most gratefully received and will help me to keep providing more models, and to start work on new AI projects.
Donaters will get priority support on any and all AI/LLM/model questions and requests, access to a private Discord room, plus other benefits.
* Patreon: https://patreon.com/TheBlokeAI
* Ko-Fi: https://ko-fi.com/TheBlokeAI
**Special thanks to**: Aemon Algiz.
**Patreon special mentions**: Alicia Loh, Stephen Murray, K, Ajan Kanaga, RoA, Magnesian, Deo Leter, Olakabola, Eugene Pentland, zynix, Deep Realms, Raymond Fosdick, Elijah Stavena, Iucharbius, Erik Bjäreholt, Luis Javier Navarrete Lozano, Nicholas, theTransient, John Detwiler, alfie_i, knownsqashed, Mano Prime, Willem Michiel, Enrico Ros, LangChain4j, OG, Michael Dempsey, Pierre Kircher, Pedro Madruga, James Bentley, Thomas Belote, Luke @flexchar, Leonard Tan, Johann-Peter Hartmann, Illia Dulskyi, Fen Risland, Chadd, S_X, Jeff Scroggin, Ken Nordquist, Sean Connelly, Artur Olbinski, Swaroop Kallakuri, Jack West, Ai Maven, David Ziegler, Russ Johnson, transmissions 11, John Villwock, Alps Aficionado, Clay Pascal, Viktor Bowallius, Subspace Studios, Rainer Wilmers, Trenton Dambrowitz, vamX, Michael Levine, 준교 김, Brandon Frisco, Kalila, Trailburnt, Randy H, Talal Aujan, Nathan Dryer, Vadim, 阿明, ReadyPlayerEmma, Tiffany J. Kim, George Stoitzev, Spencer Kim, Jerry Meng, Gabriel Tamborski, Cory Kujawski, Jeffrey Morgan, Spiking Neurons AB, Edmond Seymore, Alexandros Triantafyllidis, Lone Striker, Cap'n Zoog, Nikolai Manek, danny, ya boyyy, Derek Yates, usrbinkat, Mandus, TL, Nathan LeClaire, subjectnull, Imad Khwaja, webtim, Raven Klaugh, Asp the Wyvern, Gabriel Puliatti, Caitlyn Gatomon, Joseph William Delisle, Jonathan Leane, Luke Pendergrass, SuperWojo, Sebastain Graf, Will Dee, Fred von Graf, Andrey, Dan Guido, Daniel P. Andersen, Nitin Borwankar, Elle, Vitor Caleffi, biorpg, jjj, NimbleBox.ai, Pieter, Matthew Berman, terasurfer, Michael Davis, Alex, Stanislav Ovsiannikov
Thank you to all my generous patrons and donaters!
And thank you again to a16z for their generous grant.
<!-- footer end -->
<!-- original-model-card start -->
# Original model card: Meta Llama 2's Llama 2 70B Chat
# **Llama 2**
Llama 2 is a collection of pretrained and fine-tuned generative text models ranging in scale from 7 billion to 70 billion parameters. This is the repository for the 70B fine-tuned model, optimized for dialogue use cases and converted for the Hugging Face Transformers format. Links to other models can be found in the index at the bottom.
## Model Details
*Note: Use of this model is governed by the Meta license. In order to download the model weights and tokenizer, please visit the [website](https://ai.meta.com/resources/models-and-libraries/llama-downloads/) and accept our License before requesting access here.*
Meta developed and publicly released the Llama 2 family of large language models (LLMs), a collection of pretrained and fine-tuned generative text models ranging in scale from 7 billion to 70 billion parameters. Our fine-tuned LLMs, called Llama-2-Chat, are optimized for dialogue use cases. Llama-2-Chat models outperform open-source chat models on most benchmarks we tested, and in our human evaluations for helpfulness and safety, are on par with some popular closed-source models like ChatGPT and PaLM.
**Model Developers** Meta
**Variations** Llama 2 comes in a range of parameter sizes — 7B, 13B, and 70B — as well as pretrained and fine-tuned variations.
**Input** Models input text only.
**Output** Models generate text only.
**Model Architecture** Llama 2 is an auto-regressive language model that uses an optimized transformer architecture. The tuned versions use supervised fine-tuning (SFT) and reinforcement learning with human feedback (RLHF) to align to human preferences for helpfulness and safety.
||Training Data|Params|Content Length|GQA|Tokens|LR|
|---|---|---|---|---|---|---|
|Llama 2|*A new mix of publicly available online data*|7B|4k|✗|2.0T|3.0 x 10<sup>-4</sup>|
|Llama 2|*A new mix of publicly available online data*|13B|4k|✗|2.0T|3.0 x 10<sup>-4</sup>|
|Llama 2|*A new mix of publicly available online data*|70B|4k|✔|2.0T|1.5 x 10<sup>-4</sup>|
*Llama 2 family of models.* Token counts refer to pretraining data only. All models are trained with a global batch-size of 4M tokens. Bigger models - 70B -- use Grouped-Query Attention (GQA) for improved inference scalability.
**Model Dates** Llama 2 was trained between January 2023 and July 2023.
**Status** This is a static model trained on an offline dataset. Future versions of the tuned models will be released as we improve model safety with community feedback.
**License** A custom commercial license is available at: [https://ai.meta.com/resources/models-and-libraries/llama-downloads/](https://ai.meta.com/resources/models-and-libraries/llama-downloads/)
**Research Paper** ["Llama-2: Open Foundation and Fine-tuned Chat Models"](arxiv.org/abs/2307.09288)
## Intended Use
**Intended Use Cases** Llama 2 is intended for commercial and research use in English. Tuned models are intended for assistant-like chat, whereas pretrained models can be adapted for a variety of natural language generation tasks.
**Out-of-scope Uses** Use in any manner that violates applicable laws or regulations (including trade compliance laws).Use in languages other than English. Use in any other way that is prohibited by the Acceptable Use Policy and Licensing Agreement for Llama 2.
## Hardware and Software
**Training Factors** We used custom training libraries, Meta's Research Super Cluster, and production clusters for pretraining. Fine-tuning, annotation, and evaluation were also performed on third-party cloud compute.
**Carbon Footprint** Pretraining utilized a cumulative 3.3M GPU hours of computation on hardware of type A100-80GB (TDP of 350-400W). Estimated total emissions were 539 tCO2eq, 100% of which were offset by Meta’s sustainability program.
||Time (GPU hours)|Power Consumption (W)|Carbon Emitted(tCO<sub>2</sub>eq)|
|---|---|---|---|
|Llama 2 7B|184320|400|31.22|
|Llama 2 13B|368640|400|62.44|
|Llama 2 70B|1720320|400|291.42|
|Total|3311616||539.00|
**CO<sub>2</sub> emissions during pretraining.** Time: total GPU time required for training each model. Power Consumption: peak power capacity per GPU device for the GPUs used adjusted for power usage efficiency. 100% of the emissions are directly offset by Meta's sustainability program, and because we are openly releasing these models, the pretraining costs do not need to be incurred by others.
## Training Data
**Overview** Llama 2 was pretrained on 2 trillion tokens of data from publicly available sources. The fine-tuning data includes publicly available instruction datasets, as well as over one million new human-annotated examples. Neither the pretraining nor the fine-tuning datasets include Meta user data.
**Data Freshness** The pretraining data has a cutoff of September 2022, but some tuning data is more recent, up to July 2023.
## Evaluation Results
In this section, we report the results for the Llama 1 and Llama 2 models on standard academic benchmarks.For all the evaluations, we use our internal evaluations library.
|Model|Size|Code|Commonsense Reasoning|World Knowledge|Reading Comprehension|Math|MMLU|BBH|AGI Eval|
|---|---|---|---|---|---|---|---|---|---|
|Llama 1|7B|14.1|60.8|46.2|58.5|6.95|35.1|30.3|23.9|
|Llama 1|13B|18.9|66.1|52.6|62.3|10.9|46.9|37.0|33.9|
|Llama 1|33B|26.0|70.0|58.4|67.6|21.4|57.8|39.8|41.7|
|Llama 1|65B|30.7|70.7|60.5|68.6|30.8|63.4|43.5|47.6|
|Llama 2|7B|16.8|63.9|48.9|61.3|14.6|45.3|32.6|29.3|
|Llama 2|13B|24.5|66.9|55.4|65.8|28.7|54.8|39.4|39.1|
|Llama 2|70B|**37.5**|**71.9**|**63.6**|**69.4**|**35.2**|**68.9**|**51.2**|**54.2**|
**Overall performance on grouped academic benchmarks.** *Code:* We report the average pass@1 scores of our models on HumanEval and MBPP. *Commonsense Reasoning:* We report the average of PIQA, SIQA, HellaSwag, WinoGrande, ARC easy and challenge, OpenBookQA, and CommonsenseQA. We report 7-shot results for CommonSenseQA and 0-shot results for all other benchmarks. *World Knowledge:* We evaluate the 5-shot performance on NaturalQuestions and TriviaQA and report the average. *Reading Comprehension:* For reading comprehension, we report the 0-shot average on SQuAD, QuAC, and BoolQ. *MATH:* We report the average of the GSM8K (8 shot) and MATH (4 shot) benchmarks at top 1.
|||TruthfulQA|Toxigen|
|---|---|---|---|
|Llama 1|7B|27.42|23.00|
|Llama 1|13B|41.74|23.08|
|Llama 1|33B|44.19|22.57|
|Llama 1|65B|48.71|21.77|
|Llama 2|7B|33.29|**21.25**|
|Llama 2|13B|41.86|26.10|
|Llama 2|70B|**50.18**|24.60|
**Evaluation of pretrained LLMs on automatic safety benchmarks.** For TruthfulQA, we present the percentage of generations that are both truthful and informative (the higher the better). For ToxiGen, we present the percentage of toxic generations (the smaller the better).
|||TruthfulQA|Toxigen|
|---|---|---|---|
|Llama-2-Chat|7B|57.04|**0.00**|
|Llama-2-Chat|13B|62.18|**0.00**|
|Llama-2-Chat|70B|**64.14**|0.01|
**Evaluation of fine-tuned LLMs on different safety datasets.** Same metric definitions as above.
## Ethical Considerations and Limitations
Llama 2 is a new technology that carries risks with use. Testing conducted to date has been in English, and has not covered, nor could it cover all scenarios. For these reasons, as with all LLMs, Llama 2’s potential outputs cannot be predicted in advance, and the model may in some instances produce inaccurate, biased or other objectionable responses to user prompts. Therefore, before deploying any applications of Llama 2, developers should perform safety testing and tuning tailored to their specific applications of the model.
Please see the Responsible Use Guide available at [https://ai.meta.com/llama/responsible-use-guide/](https://ai.meta.com/llama/responsible-use-guide)
## Reporting Issues
Please report any software “bug,” or other problems with the models through one of the following means:
- Reporting issues with the model: [github.com/facebookresearch/llama](http://github.com/facebookresearch/llama)
- Reporting problematic content generated by the model: [developers.facebook.com/llama_output_feedback](http://developers.facebook.com/llama_output_feedback)
- Reporting bugs and security concerns: [facebook.com/whitehat/info](http://facebook.com/whitehat/info)
## Llama Model Index
|Model|Llama2|Llama2-hf|Llama2-chat|Llama2-chat-hf|
|---|---|---|---|---|
|7B| [Link](https://huggingface.co/llamaste/Llama-2-7b) | [Link](https://huggingface.co/llamaste/Llama-2-7b-hf) | [Link](https://huggingface.co/llamaste/Llama-2-7b-chat) | [Link](https://huggingface.co/llamaste/Llama-2-7b-chat-hf)|
|13B| [Link](https://huggingface.co/llamaste/Llama-2-13b) | [Link](https://huggingface.co/llamaste/Llama-2-13b-hf) | [Link](https://huggingface.co/llamaste/Llama-2-13b-chat) | [Link](https://huggingface.co/llamaste/Llama-2-13b-hf)|
|70B| [Link](https://huggingface.co/llamaste/Llama-2-70b) | [Link](https://huggingface.co/llamaste/Llama-2-70b-hf) | [Link](https://huggingface.co/llamaste/Llama-2-70b-chat) | [Link](https://huggingface.co/llamaste/Llama-2-70b-hf)|
<!-- original-model-card end -->
|
BAAI/AquilaChat2-34B | BAAI | 2023-11-16T07:55:53Z | 6,761 | 45 | transformers | [
"transformers",
"pytorch",
"aquila",
"text-generation",
"custom_code",
"license:other",
"autotrain_compatible",
"region:us"
] | text-generation | 2023-10-11T01:55:18Z | ---
license: other
---

<h4 align="center">
<p>
<b>English</b> |
<a href="https://huggingface.co/BAAI/AquilaChat2-34B/blob/main/README_zh.md">简体中文</a>
</p>
</h4>
<p align="center">
<a href="https://github.com/FlagAI-Open/Aquila2" target="_blank">Github</a> • <a href="https://github.com/FlagAI-Open/Aquila2/blob/main/assets/wechat-qrcode.jpg" target="_blank">WeChat</a> <br>
</p>
We opensource our **Aquila2** series, now including **Aquila2**, the base language models, namely **Aquila2-7B** and **Aquila2-34B**, as well as **AquilaChat2**, the chat models, namely **AquilaChat2-7B** and **AquilaChat2-34B**, as well as the long-text chat models, namely **AquilaChat2-7B-16k** and **AquilaChat2-34B-16k**
2023.10.25 🔥 **AquilaChat2-34B v1.2** is based on the previous **AquilaChat2-34B**.
The AquilaChat2-34B model is close to or exceeds the level of GPT3.5 in the subjective evaluation of 8 secondary ability dimensions.
The additional details of the Aquila model will be presented in the official technical report. Please stay tuned for updates on official channels.
### Note
<p>
We have discovered a data leakage problem with the GSM8K test data in the pre-training task dataset. Therefore, the evaluation results of GSM8K have been removed from the evaluation results.
Upon thorough investigation and analysis, it was found that the data leakage occurred in the mathematical dataset A (over 2 million samples), recommended by a team we have collaborated with multiple times. This dataset includes the untreated GSM8K test set (1319 samples). The team only performed routine de-duplication and quality checks but did not conduct an extra filtering check for the presence of the GSM8K test data, resulting in this oversight.
Our team has always strictly adhered to the principle that training data should not include test data. Taking this lesson from the error caused by not thoroughly checking the source of external data, we have investigated all 2 trillion tokens of data for various test datasets, including WTM22(en-zh), CLUEWSC, Winograd, HellaSwag, OpenBookQA, PIQA, ARC-e, BUSTSM, BoolQ, TruthfulQA, RAFT, ChID, EPRSTMT, TNEWS, OCNLI, SEM-Chinese, MMLU, C-Eval, CMMLU, CSL and HumanEval.
</p>
## Quick Start AquilaChat2-34B(Chat model)
### 1. Inference
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
from transformers import BitsAndBytesConfig
import torch
device = torch.device("cuda:0")
model_info = "BAAI/AquilaChat2-34B"
tokenizer = AutoTokenizer.from_pretrained(model_info, trust_remote_code=True)
quantization_config=BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16,
)
model = AutoModelForCausalLM.from_pretrained(model_info, trust_remote_code=True, torch_dtype=torch.bfloat16,
# quantization_config=quantization_config, # Uncomment this line for 4bit quantization
)
model.eval()
model.to(device)
text = "请给出10个要到北京旅游的理由。"
from predict import predict
out = predict(model, text, tokenizer=tokenizer, max_gen_len=200, top_p=0.9,
seed=123, topk=15, temperature=1.0, sft=True, device=device,
model_name="AquilaChat2-34B")
print(out)
```
## License
Aquila2 series open-source model is licensed under [ BAAI Aquila Model Licence Agreement](https://huggingface.co/BAAI/AquilaChat2-34B/blob/main/BAAI-Aquila-Model-License%20-Agreement.pdf) |
mmnga/Phi-3-medium-128k-instruct-gguf | mmnga | 2024-05-22T16:56:55Z | 6,759 | 5 | null | [
"gguf",
"en",
"ja",
"dataset:TFMC/imatrix-dataset-for-japanese-llm",
"license:mit",
"region:us"
] | null | 2024-05-22T15:27:33Z |
---
license: mit
language:
- en
- ja
datasets:
- TFMC/imatrix-dataset-for-japanese-llm
---
# Phi-3-medium-128k-instruct-gguf
[microsoftさんが公開しているPhi-3-medium-128k-instruct](https://huggingface.co/microsoft/Phi-3-medium-128k-instruct)のggufフォーマット変換版です。
imatrixのデータは[TFMC/imatrix-dataset-for-japanese-llm](https://huggingface.co/datasets/TFMC/imatrix-dataset-for-japanese-llm)を使用して作成しました。
## Usage
```
git clone https://github.com/ggerganov/llama.cpp.git
cd llama.cpp
make -j
./main -m 'Phi-3-medium-128k-instruct-Q4_0.gguf' -n 128 -p 'こんにちわ'
```
|
facebook/incoder-6B | facebook | 2023-01-24T17:06:34Z | 6,758 | 75 | transformers | [
"transformers",
"pytorch",
"xglm",
"text-generation",
"code",
"python",
"javascript",
"arxiv:2204.05999",
"license:cc-by-nc-4.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-generation | 2022-04-06T03:17:49Z | ---
license: "cc-by-nc-4.0"
tags:
- code
- python
- javascript
---
# InCoder 6B
A 6B parameter decoder-only Transformer model trained on code using a causal-masked objective, which allows inserting/infilling code as well as standard left-to-right generation.
The model was trained on public open-source repositories with a permissive, non-copyleft, license (Apache 2.0, MIT, BSD-2 or BSD-3) from GitHub and GitLab, as well as StackOverflow. Repositories primarily contained Python and JavaScript, but also include code from 28 languages, as well as StackOverflow.
For more information, see our:
- [Demo](https://huggingface.co/spaces/facebook/incoder-demo)
- [Project site](https://sites.google.com/view/incoder-code-models)
- [Examples](https://sites.google.com/view/incoder-code-models/home/examples)
- [Paper](https://arxiv.org/abs/2204.05999)
A smaller, 1B, parameter model is also available at [facebook/incoder-1B](https://huggingface.co/facebook/incoder-1B).
## Requirements
`pytorch`, `tokenizers`, and `transformers`. Our model requires HF's tokenizers >= 0.12.1, due to changes in the pretokenizer.
```
pip install torch
pip install "tokenizers>=0.12.1"
pip install transformers
```
## Usage
### Model
See [https://github.com/dpfried/incoder](https://github.com/dpfried/incoder) for example code.
This 6B model comes in two versions: with weights in full-precision (float32, stored on branch `main`) and weights in half-precision (float16, stored on branch `float16`). The versions can be loaded as follows:
*Full-precision* (float32): This should be used if you are fine-tuning the model (note: this will take a lot of GPU memory, probably multiple GPUs, and we have not tried training the model in `transformers` --- it was trained in Fairseq). Load with:
`model = AutoModelForCausalLM.from_pretrained("facebook/incoder-6B")`
*Half-precision* (float16): This can be used if you are only doing inference (i.e. generating from the model). It will use less GPU memory, and less RAM when loading the model. With this version it should be able to perform inference on a 16 GB GPU (with a batch size of 1, to sequence lengths of at least 256). Load with:
`model = AutoModelForCausalLM.from_pretrained("facebook/incoder-6B", revision="float16", torch_dtype=torch.float16, low_cpu_mem_usage=True)`
### Tokenizer
`tokenizer = AutoTokenizer.from_pretrained("facebook/incoder-6B")`
Note: the incoder-1B and incoder-6B tokenizers are identical, so 'facebook/incoder-1B' could also be used.
When calling `tokenizer.decode`, it's important to pass `clean_up_tokenization_spaces=False` to avoid removing spaces after punctuation:
`tokenizer.decode(tokenizer.encode("from ."), clean_up_tokenization_spaces=False)`
(Note: encoding prepends the `<|endoftext|>` token, as this marks the start of a document to our model. This token can be removed from the decoded output by passing `skip_special_tokens=True` to `tokenizer.decode`.)
## License
CC-BY-NC 4.0
## Credits
The model was developed by Daniel Fried, Armen Aghajanyan, Jessy Lin, Sida Wang, Eric Wallace, Freda Shi, Ruiqi Zhong, Wen-tau Yih, Luke Zettlemoyer and Mike Lewis.
Thanks to Lucile Saulnier, Leandro von Werra, Nicolas Patry, Suraj Patil, Omar Sanseviero, and others at HuggingFace for help with the model release, and to Naman Goyal and Stephen Roller for the code our demo was based on! |
stablediffusionapi/sdxlceshi | stablediffusionapi | 2023-10-09T18:26:54Z | 6,750 | 1 | diffusers | [
"diffusers",
"stablediffusionapi.com",
"stable-diffusion-api",
"text-to-image",
"ultra-realistic",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionXLPipeline",
"region:us"
] | text-to-image | 2023-10-09T18:25:01Z | ---
license: creativeml-openrail-m
tags:
- stablediffusionapi.com
- stable-diffusion-api
- text-to-image
- ultra-realistic
pinned: true
---
# sdxlceshi API Inference

## Get API Key
Get API key from [Stable Diffusion API](http://stablediffusionapi.com/), No Payment needed.
Replace Key in below code, change **model_id** to "sdxlceshi"
Coding in PHP/Node/Java etc? Have a look at docs for more code examples: [View docs](https://stablediffusionapi.com/docs)
Try model for free: [Generate Images](https://stablediffusionapi.com/models/sdxlceshi)
Model link: [View model](https://stablediffusionapi.com/models/sdxlceshi)
Credits: [View credits](https://civitai.com/?query=sdxlceshi)
View all models: [View Models](https://stablediffusionapi.com/models)
import requests
import json
url = "https://stablediffusionapi.com/api/v4/dreambooth"
payload = json.dumps({
"key": "your_api_key",
"model_id": "sdxlceshi",
"prompt": "ultra realistic close up portrait ((beautiful pale cyberpunk female with heavy black eyeliner)), blue eyes, shaved side haircut, hyper detail, cinematic lighting, magic neon, dark red city, Canon EOS R3, nikon, f/1.4, ISO 200, 1/160s, 8K, RAW, unedited, symmetrical balance, in-frame, 8K",
"negative_prompt": "painting, extra fingers, mutated hands, poorly drawn hands, poorly drawn face, deformed, ugly, blurry, bad anatomy, bad proportions, extra limbs, cloned face, skinny, glitchy, double torso, extra arms, extra hands, mangled fingers, missing lips, ugly face, distorted face, extra legs, anime",
"width": "512",
"height": "512",
"samples": "1",
"num_inference_steps": "30",
"safety_checker": "no",
"enhance_prompt": "yes",
"seed": None,
"guidance_scale": 7.5,
"multi_lingual": "no",
"panorama": "no",
"self_attention": "no",
"upscale": "no",
"embeddings": "embeddings_model_id",
"lora": "lora_model_id",
"webhook": None,
"track_id": None
})
headers = {
'Content-Type': 'application/json'
}
response = requests.request("POST", url, headers=headers, data=payload)
print(response.text)
> Use this coupon code to get 25% off **DMGG0RBN** |
mradermacher/Aura_Qwen_7B-i1-GGUF | mradermacher | 2024-06-13T12:33:35Z | 6,750 | 0 | transformers | [
"transformers",
"gguf",
"mergekit",
"merge",
"en",
"base_model:jeiku/Aura_Qwen_7B",
"endpoints_compatible",
"region:us"
] | null | 2024-06-13T10:26:32Z | ---
base_model: jeiku/Aura_Qwen_7B
language:
- en
library_name: transformers
quantized_by: mradermacher
tags:
- mergekit
- merge
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: nicoboss -->
weighted/imatrix quants of https://huggingface.co/jeiku/Aura_Qwen_7B
<!-- provided-files -->
static quants are available at https://huggingface.co/mradermacher/Aura_Qwen_7B-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/Aura_Qwen_7B-i1-GGUF/resolve/main/Aura_Qwen_7B.i1-IQ1_S.gguf) | i1-IQ1_S | 2.0 | for the desperate |
| [GGUF](https://huggingface.co/mradermacher/Aura_Qwen_7B-i1-GGUF/resolve/main/Aura_Qwen_7B.i1-IQ1_M.gguf) | i1-IQ1_M | 2.1 | mostly desperate |
| [GGUF](https://huggingface.co/mradermacher/Aura_Qwen_7B-i1-GGUF/resolve/main/Aura_Qwen_7B.i1-IQ2_XXS.gguf) | i1-IQ2_XXS | 2.4 | |
| [GGUF](https://huggingface.co/mradermacher/Aura_Qwen_7B-i1-GGUF/resolve/main/Aura_Qwen_7B.i1-IQ2_XS.gguf) | i1-IQ2_XS | 2.6 | |
| [GGUF](https://huggingface.co/mradermacher/Aura_Qwen_7B-i1-GGUF/resolve/main/Aura_Qwen_7B.i1-IQ2_S.gguf) | i1-IQ2_S | 2.7 | |
| [GGUF](https://huggingface.co/mradermacher/Aura_Qwen_7B-i1-GGUF/resolve/main/Aura_Qwen_7B.i1-IQ2_M.gguf) | i1-IQ2_M | 2.9 | |
| [GGUF](https://huggingface.co/mradermacher/Aura_Qwen_7B-i1-GGUF/resolve/main/Aura_Qwen_7B.i1-Q2_K.gguf) | i1-Q2_K | 3.1 | IQ3_XXS probably better |
| [GGUF](https://huggingface.co/mradermacher/Aura_Qwen_7B-i1-GGUF/resolve/main/Aura_Qwen_7B.i1-IQ3_XXS.gguf) | i1-IQ3_XXS | 3.2 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/Aura_Qwen_7B-i1-GGUF/resolve/main/Aura_Qwen_7B.i1-IQ3_XS.gguf) | i1-IQ3_XS | 3.4 | |
| [GGUF](https://huggingface.co/mradermacher/Aura_Qwen_7B-i1-GGUF/resolve/main/Aura_Qwen_7B.i1-Q3_K_S.gguf) | i1-Q3_K_S | 3.6 | IQ3_XS probably better |
| [GGUF](https://huggingface.co/mradermacher/Aura_Qwen_7B-i1-GGUF/resolve/main/Aura_Qwen_7B.i1-IQ3_S.gguf) | i1-IQ3_S | 3.6 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/Aura_Qwen_7B-i1-GGUF/resolve/main/Aura_Qwen_7B.i1-IQ3_M.gguf) | i1-IQ3_M | 3.7 | |
| [GGUF](https://huggingface.co/mradermacher/Aura_Qwen_7B-i1-GGUF/resolve/main/Aura_Qwen_7B.i1-Q3_K_M.gguf) | i1-Q3_K_M | 3.9 | IQ3_S probably better |
| [GGUF](https://huggingface.co/mradermacher/Aura_Qwen_7B-i1-GGUF/resolve/main/Aura_Qwen_7B.i1-Q3_K_L.gguf) | i1-Q3_K_L | 4.2 | IQ3_M probably better |
| [GGUF](https://huggingface.co/mradermacher/Aura_Qwen_7B-i1-GGUF/resolve/main/Aura_Qwen_7B.i1-IQ4_XS.gguf) | i1-IQ4_XS | 4.3 | |
| [GGUF](https://huggingface.co/mradermacher/Aura_Qwen_7B-i1-GGUF/resolve/main/Aura_Qwen_7B.i1-Q4_0.gguf) | i1-Q4_0 | 4.5 | fast, low quality |
| [GGUF](https://huggingface.co/mradermacher/Aura_Qwen_7B-i1-GGUF/resolve/main/Aura_Qwen_7B.i1-Q4_K_S.gguf) | i1-Q4_K_S | 4.6 | optimal size/speed/quality |
| [GGUF](https://huggingface.co/mradermacher/Aura_Qwen_7B-i1-GGUF/resolve/main/Aura_Qwen_7B.i1-Q4_K_M.gguf) | i1-Q4_K_M | 4.8 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Aura_Qwen_7B-i1-GGUF/resolve/main/Aura_Qwen_7B.i1-Q5_K_S.gguf) | i1-Q5_K_S | 5.4 | |
| [GGUF](https://huggingface.co/mradermacher/Aura_Qwen_7B-i1-GGUF/resolve/main/Aura_Qwen_7B.i1-Q5_K_M.gguf) | i1-Q5_K_M | 5.5 | |
| [GGUF](https://huggingface.co/mradermacher/Aura_Qwen_7B-i1-GGUF/resolve/main/Aura_Qwen_7B.i1-Q6_K.gguf) | i1-Q6_K | 6.4 | practically like static Q6_K |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time. Additional thanks to [@nicoboss](https://huggingface.co/nicoboss) for giving me access to his hardware for calculating the imatrix for these quants.
<!-- end -->
|
NousResearch/Meta-Llama-3-70B-Instruct | NousResearch | 2024-04-30T05:55:13Z | 6,746 | 19 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"facebook",
"meta",
"pytorch",
"llama-3",
"conversational",
"en",
"license:other",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2024-04-19T01:26:33Z | ---
language:
- en
pipeline_tag: text-generation
tags:
- facebook
- meta
- pytorch
- llama
- llama-3
license: other
license_name: llama3
license_link: LICENSE
extra_gated_prompt: >-
### META LLAMA 3 COMMUNITY LICENSE AGREEMENT
Meta Llama 3 Version Release Date: April 18, 2024
"Agreement" means the terms and conditions for use, reproduction, distribution and modification of the
Llama Materials set forth herein.
"Documentation" means the specifications, manuals and documentation accompanying Meta Llama 3
distributed by Meta at https://llama.meta.com/get-started/.
"Licensee" or "you" means you, or your employer or any other person or entity (if you are entering into
this Agreement on such person or entity’s behalf), of the age required under applicable laws, rules or
regulations to provide legal consent and that has legal authority to bind your employer or such other
person or entity if you are entering in this Agreement on their behalf.
"Meta Llama 3" means the foundational large language models and software and algorithms, including
machine-learning model code, trained model weights, inference-enabling code, training-enabling code,
fine-tuning enabling code and other elements of the foregoing distributed by Meta at
https://llama.meta.com/llama-downloads.
"Llama Materials" means, collectively, Meta’s proprietary Meta Llama 3 and Documentation (and any
portion thereof) made available under this Agreement.
"Meta" or "we" means Meta Platforms Ireland Limited (if you are located in or, if you are an entity, your
principal place of business is in the EEA or Switzerland) and Meta Platforms, Inc. (if you are located
outside of the EEA or Switzerland).
1. License Rights and Redistribution.
a. Grant of Rights. You are granted a non-exclusive, worldwide, non-transferable and royalty-free
limited license under Meta’s intellectual property or other rights owned by Meta embodied in the Llama
Materials to use, reproduce, distribute, copy, create derivative works of, and make modifications to the
Llama Materials.
b. Redistribution and Use.
i. If you distribute or make available the Llama Materials (or any derivative works
thereof), or a product or service that uses any of them, including another AI model, you shall (A) provide
a copy of this Agreement with any such Llama Materials; and (B) prominently display “Built with Meta
Llama 3” on a related website, user interface, blogpost, about page, or product documentation. If you
use the Llama Materials to create, train, fine tune, or otherwise improve an AI model, which is
distributed or made available, you shall also include “Llama 3” at the beginning of any such AI model
name.
ii. If you receive Llama Materials, or any derivative works thereof, from a Licensee as part
of an integrated end user product, then Section 2 of this Agreement will not apply to you.
iii. You must retain in all copies of the Llama Materials that you distribute the following
attribution notice within a “Notice” text file distributed as a part of such copies: “Meta Llama 3 is
licensed under the Meta Llama 3 Community License, Copyright © Meta Platforms, Inc. All Rights
Reserved.”
iv. Your use of the Llama Materials must comply with applicable laws and regulations
(including trade compliance laws and regulations) and adhere to the Acceptable Use Policy for the Llama
Materials (available at https://llama.meta.com/llama3/use-policy), which is hereby incorporated by
reference into this Agreement.
v. You will not use the Llama Materials or any output or results of the Llama Materials to
improve any other large language model (excluding Meta Llama 3 or derivative works thereof).
2. Additional Commercial Terms. If, on the Meta Llama 3 version release date, the monthly active users
of the products or services made available by or for Licensee, or Licensee’s affiliates, is greater than 700
million monthly active users in the preceding calendar month, you must request a license from Meta,
which Meta may grant to you in its sole discretion, and you are not authorized to exercise any of the
rights under this Agreement unless or until Meta otherwise expressly grants you such rights.
3. Disclaimer of Warranty. UNLESS REQUIRED BY APPLICABLE LAW, THE LLAMA MATERIALS AND ANY
OUTPUT AND RESULTS THEREFROM ARE PROVIDED ON AN “AS IS” BASIS, WITHOUT WARRANTIES OF
ANY KIND, AND META DISCLAIMS ALL WARRANTIES OF ANY KIND, BOTH EXPRESS AND IMPLIED,
INCLUDING, WITHOUT LIMITATION, ANY WARRANTIES OF TITLE, NON-INFRINGEMENT,
MERCHANTABILITY, OR FITNESS FOR A PARTICULAR PURPOSE. YOU ARE SOLELY RESPONSIBLE FOR
DETERMINING THE APPROPRIATENESS OF USING OR REDISTRIBUTING THE LLAMA MATERIALS AND
ASSUME ANY RISKS ASSOCIATED WITH YOUR USE OF THE LLAMA MATERIALS AND ANY OUTPUT AND
RESULTS.
4. Limitation of Liability. IN NO EVENT WILL META OR ITS AFFILIATES BE LIABLE UNDER ANY THEORY OF
LIABILITY, WHETHER IN CONTRACT, TORT, NEGLIGENCE, PRODUCTS LIABILITY, OR OTHERWISE, ARISING
OUT OF THIS AGREEMENT, FOR ANY LOST PROFITS OR ANY INDIRECT, SPECIAL, CONSEQUENTIAL,
INCIDENTAL, EXEMPLARY OR PUNITIVE DAMAGES, EVEN IF META OR ITS AFFILIATES HAVE BEEN ADVISED
OF THE POSSIBILITY OF ANY OF THE FOREGOING.
5. Intellectual Property.
a. No trademark licenses are granted under this Agreement, and in connection with the Llama
Materials, neither Meta nor Licensee may use any name or mark owned by or associated with the other
or any of its affiliates, except as required for reasonable and customary use in describing and
redistributing the Llama Materials or as set forth in this Section 5(a). Meta hereby grants you a license to
use “Llama 3” (the “Mark”) solely as required to comply with the last sentence of Section 1.b.i. You will
comply with Meta’s brand guidelines (currently accessible at
https://about.meta.com/brand/resources/meta/company-brand/ ). All goodwill arising out of your use
of the Mark will inure to the benefit of Meta.
b. Subject to Meta’s ownership of Llama Materials and derivatives made by or for Meta, with
respect to any derivative works and modifications of the Llama Materials that are made by you, as
between you and Meta, you are and will be the owner of such derivative works and modifications.
c. If you institute litigation or other proceedings against Meta or any entity (including a
cross-claim or counterclaim in a lawsuit) alleging that the Llama Materials or Meta Llama 3 outputs or
results, or any portion of any of the foregoing, constitutes infringement of intellectual property or other
rights owned or licensable by you, then any licenses granted to you under this Agreement shall
terminate as of the date such litigation or claim is filed or instituted. You will indemnify and hold
harmless Meta from and against any claim by any third party arising out of or related to your use or
distribution of the Llama Materials.
6. Term and Termination. The term of this Agreement will commence upon your acceptance of this
Agreement or access to the Llama Materials and will continue in full force and effect until terminated in
accordance with the terms and conditions herein. Meta may terminate this Agreement if you are in
breach of any term or condition of this Agreement. Upon termination of this Agreement, you shall delete
and cease use of the Llama Materials. Sections 3, 4 and 7 shall survive the termination of this
Agreement.
7. Governing Law and Jurisdiction. This Agreement will be governed and construed under the laws of
the State of California without regard to choice of law principles, and the UN Convention on Contracts
for the International Sale of Goods does not apply to this Agreement. The courts of California shall have
exclusive jurisdiction of any dispute arising out of this Agreement.
### Meta Llama 3 Acceptable Use Policy
Meta is committed to promoting safe and fair use of its tools and features, including Meta Llama 3. If you
access or use Meta Llama 3, you agree to this Acceptable Use Policy (“Policy”). The most recent copy of
this policy can be found at [https://llama.meta.com/llama3/use-policy](https://llama.meta.com/llama3/use-policy)
#### Prohibited Uses
We want everyone to use Meta Llama 3 safely and responsibly. You agree you will not use, or allow
others to use, Meta Llama 3 to:
1. Violate the law or others’ rights, including to:
1. Engage in, promote, generate, contribute to, encourage, plan, incite, or further illegal or unlawful activity or content, such as:
1. Violence or terrorism
2. Exploitation or harm to children, including the solicitation, creation, acquisition, or dissemination of child exploitative content or failure to report Child Sexual Abuse Material
3. Human trafficking, exploitation, and sexual violence
4. The illegal distribution of information or materials to minors, including obscene materials, or failure to employ legally required age-gating in connection with such information or materials.
5. Sexual solicitation
6. Any other criminal activity
2. Engage in, promote, incite, or facilitate the harassment, abuse, threatening, or bullying of individuals or groups of individuals
3. Engage in, promote, incite, or facilitate discrimination or other unlawful or harmful conduct in the provision of employment, employment benefits, credit, housing, other economic benefits, or other essential goods and services
4. Engage in the unauthorized or unlicensed practice of any profession including, but not limited to, financial, legal, medical/health, or related professional practices
5. Collect, process, disclose, generate, or infer health, demographic, or other sensitive personal or private information about individuals without rights and consents required by applicable laws
6. Engage in or facilitate any action or generate any content that infringes, misappropriates, or otherwise violates any third-party rights, including the outputs or results of any products or services using the Llama Materials
7. Create, generate, or facilitate the creation of malicious code, malware, computer viruses or do anything else that could disable, overburden, interfere with or impair the proper working, integrity, operation or appearance of a website or computer system
2. Engage in, promote, incite, facilitate, or assist in the planning or development of activities that present a risk of death or bodily harm to individuals, including use of Meta Llama 3 related to the following:
1. Military, warfare, nuclear industries or applications, espionage, use for materials or activities that are subject to the International Traffic Arms Regulations (ITAR) maintained by the United States Department of State
2. Guns and illegal weapons (including weapon development)
3. Illegal drugs and regulated/controlled substances
4. Operation of critical infrastructure, transportation technologies, or heavy machinery
5. Self-harm or harm to others, including suicide, cutting, and eating disorders
6. Any content intended to incite or promote violence, abuse, or any infliction of bodily harm to an individual
3. Intentionally deceive or mislead others, including use of Meta Llama 3 related to the following:
1. Generating, promoting, or furthering fraud or the creation or promotion of disinformation
2. Generating, promoting, or furthering defamatory content, including the creation of defamatory statements, images, or other content
3. Generating, promoting, or further distributing spam
4. Impersonating another individual without consent, authorization, or legal right
5. Representing that the use of Meta Llama 3 or outputs are human-generated
6. Generating or facilitating false online engagement, including fake reviews and other means of fake online engagement
4. Fail to appropriately disclose to end users any known dangers of your AI system
Please report any violation of this Policy, software “bug,” or other problems that could lead to a violation
of this Policy through one of the following means:
* Reporting issues with the model: [https://github.com/meta-llama/llama3](https://github.com/meta-llama/llama3)
* Reporting risky content generated by the model:
developers.facebook.com/llama_output_feedback
* Reporting bugs and security concerns: facebook.com/whitehat/info
* Reporting violations of the Acceptable Use Policy or unlicensed uses of Meta Llama 3: [email protected]
extra_gated_fields:
First Name: text
Last Name: text
Date of birth: date_picker
Country: country
Affiliation: text
geo: ip_location
By clicking Submit below I accept the terms of the license and acknowledge that the information I provide will be collected stored processed and shared in accordance with the Meta Privacy Policy: checkbox
extra_gated_description: The information you provide will be collected, stored, processed and shared in accordance with the [Meta Privacy Policy](https://www.facebook.com/privacy/policy/).
extra_gated_button_content: Submit
widget:
- example_title: Winter holidays
messages:
- role: system
content: You are a helpful and honest assistant. Please, respond concisely and truthfully.
- role: user
content: Can you recommend a good destination for Winter holidays?
- example_title: Programming assistant
messages:
- role: system
content: You are a helpful and honest code and programming assistant. Please, respond concisely and truthfully.
- role: user
content: Write a function that computes the nth fibonacci number.
inference:
parameters:
max_new_tokens: 300
stop:
- <|end_of_text|>
- <|eot_id|>
---
## Model Details
Meta developed and released the Meta Llama 3 family of large language models (LLMs), a collection of pretrained and instruction tuned generative text models in 8 and 70B sizes. The Llama 3 instruction tuned models are optimized for dialogue use cases and outperform many of the available open source chat models on common industry benchmarks. Further, in developing these models, we took great care to optimize helpfulness and safety.
**Model developers** Meta
**Variations** Llama 3 comes in two sizes — 8B and 70B parameters — in pre-trained and instruction tuned variants.
**Input** Models input text only.
**Output** Models generate text and code only.
**Model Architecture** Llama 3 is an auto-regressive language model that uses an optimized transformer architecture. The tuned versions use supervised fine-tuning (SFT) and reinforcement learning with human feedback (RLHF) to align with human preferences for helpfulness and safety.
<table>
<tr>
<td>
</td>
<td><strong>Training Data</strong>
</td>
<td><strong>Params</strong>
</td>
<td><strong>Context length</strong>
</td>
<td><strong>GQA</strong>
</td>
<td><strong>Token count</strong>
</td>
<td><strong>Knowledge cutoff</strong>
</td>
</tr>
<tr>
<td rowspan="2" >Llama 3
</td>
<td rowspan="2" >A new mix of publicly available online data.
</td>
<td>8B
</td>
<td>8k
</td>
<td>Yes
</td>
<td rowspan="2" >15T+
</td>
<td>March, 2023
</td>
</tr>
<tr>
<td>70B
</td>
<td>8k
</td>
<td>Yes
</td>
<td>December, 2023
</td>
</tr>
</table>
**Llama 3 family of models**. Token counts refer to pretraining data only. Both the 8 and 70B versions use Grouped-Query Attention (GQA) for improved inference scalability.
**Model Release Date** April 18, 2024.
**Status** This is a static model trained on an offline dataset. Future versions of the tuned models will be released as we improve model safety with community feedback.
**License** A custom commercial license is available at: [https://llama.meta.com/llama3/license](https://llama.meta.com/llama3/license)
Where to send questions or comments about the model Instructions on how to provide feedback or comments on the model can be found in the model [README](https://github.com/meta-llama/llama3). For more technical information about generation parameters and recipes for how to use Llama 3 in applications, please go [here](https://github.com/meta-llama/llama-recipes).
## Intended Use
**Intended Use Cases** Llama 3 is intended for commercial and research use in English. Instruction tuned models are intended for assistant-like chat, whereas pretrained models can be adapted for a variety of natural language generation tasks.
**Out-of-scope** Use in any manner that violates applicable laws or regulations (including trade compliance laws). Use in any other way that is prohibited by the Acceptable Use Policy and Llama 3 Community License. Use in languages other than English**.
**Note: Developers may fine-tune Llama 3 models for languages beyond English provided they comply with the Llama 3 Community License and the Acceptable Use Policy.
## How to use
This repository contains two versions of Meta-Llama-3-70B-Instruct, for use with transformers and with the original `llama3` codebase.
### Use with transformers
See the snippet below for usage with Transformers:
```python
import transformers
import torch
model_id = "meta-llama/Meta-Llama-3-70B-Instruct"
pipeline = transformers.pipeline(
"text-generation",
model=model_id,
model_kwargs={"torch_dtype": torch.bfloat16},
device="auto",
)
messages = [
{"role": "system", "content": "You are a pirate chatbot who always responds in pirate speak!"},
{"role": "user", "content": "Who are you?"},
]
prompt = pipeline.tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
terminators = [
pipeline.tokenizer.eos_token_id,
pipeline.tokenizer.convert_tokens_to_ids("<|eot_id|>")
]
outputs = pipeline(
prompt,
max_new_tokens=256,
eos_token_id=terminators,
do_sample=True,
temperature=0.6,
top_p=0.9,
)
print(outputs[0]["generated_text"][len(prompt):])
```
### Use with `llama3`
Please, follow the instructions in the [repository](https://github.com/meta-llama/llama3).
To download Original checkpoints, see the example command below leveraging `huggingface-cli`:
```
huggingface-cli download meta-llama/Meta-Llama-3-70B-Instruct --include "original/*" --local-dir Meta-Llama-3-70B-Instruct
```
For Hugging Face support, we recommend using transformers or TGI, but a similar command works.
## Hardware and Software
**Training Factors** We used custom training libraries, Meta's Research SuperCluster, and production clusters for pretraining. Fine-tuning, annotation, and evaluation were also performed on third-party cloud compute.
**Carbon Footprint Pretraining utilized a cumulative** 7.7M GPU hours of computation on hardware of type H100-80GB (TDP of 700W). Estimated total emissions were 2290 tCO2eq, 100% of which were offset by Meta’s sustainability program.
<table>
<tr>
<td>
</td>
<td><strong>Time (GPU hours)</strong>
</td>
<td><strong>Power Consumption (W)</strong>
</td>
<td><strong>Carbon Emitted(tCO2eq)</strong>
</td>
</tr>
<tr>
<td>Llama 3 8B
</td>
<td>1.3M
</td>
<td>700
</td>
<td>390
</td>
</tr>
<tr>
<td>Llama 3 70B
</td>
<td>6.4M
</td>
<td>700
</td>
<td>1900
</td>
</tr>
<tr>
<td>Total
</td>
<td>7.7M
</td>
<td>
</td>
<td>2290
</td>
</tr>
</table>
**CO2 emissions during pre-training**. Time: total GPU time required for training each model. Power Consumption: peak power capacity per GPU device for the GPUs used adjusted for power usage efficiency. 100% of the emissions are directly offset by Meta's sustainability program, and because we are openly releasing these models, the pretraining costs do not need to be incurred by others.
## Training Data
**Overview** Llama 3 was pretrained on over 15 trillion tokens of data from publicly available sources. The fine-tuning data includes publicly available instruction datasets, as well as over 10M human-annotated examples. Neither the pretraining nor the fine-tuning datasets include Meta user data.
**Data Freshness** The pretraining data has a cutoff of March 2023 for the 7B and December 2023 for the 70B models respectively.
## Benchmarks
In this section, we report the results for Llama 3 models on standard automatic benchmarks. For all the evaluations, we use our internal evaluations library. For details on the methodology see [here](https://github.com/meta-llama/llama3/blob/main/eval_methodology.md).
### Base pretrained models
<table>
<tr>
<td><strong>Category</strong>
</td>
<td><strong>Benchmark</strong>
</td>
<td><strong>Llama 3 8B</strong>
</td>
<td><strong>Llama2 7B</strong>
</td>
<td><strong>Llama2 13B</strong>
</td>
<td><strong>Llama 3 70B</strong>
</td>
<td><strong>Llama2 70B</strong>
</td>
</tr>
<tr>
<td rowspan="6" >General
</td>
<td>MMLU (5-shot)
</td>
<td>66.6
</td>
<td>45.7
</td>
<td>53.8
</td>
<td>79.5
</td>
<td>69.7
</td>
</tr>
<tr>
<td>AGIEval English (3-5 shot)
</td>
<td>45.9
</td>
<td>28.8
</td>
<td>38.7
</td>
<td>63.0
</td>
<td>54.8
</td>
</tr>
<tr>
<td>CommonSenseQA (7-shot)
</td>
<td>72.6
</td>
<td>57.6
</td>
<td>67.6
</td>
<td>83.8
</td>
<td>78.7
</td>
</tr>
<tr>
<td>Winogrande (5-shot)
</td>
<td>76.1
</td>
<td>73.3
</td>
<td>75.4
</td>
<td>83.1
</td>
<td>81.8
</td>
</tr>
<tr>
<td>BIG-Bench Hard (3-shot, CoT)
</td>
<td>61.1
</td>
<td>38.1
</td>
<td>47.0
</td>
<td>81.3
</td>
<td>65.7
</td>
</tr>
<tr>
<td>ARC-Challenge (25-shot)
</td>
<td>78.6
</td>
<td>53.7
</td>
<td>67.6
</td>
<td>93.0
</td>
<td>85.3
</td>
</tr>
<tr>
<td>Knowledge reasoning
</td>
<td>TriviaQA-Wiki (5-shot)
</td>
<td>78.5
</td>
<td>72.1
</td>
<td>79.6
</td>
<td>89.7
</td>
<td>87.5
</td>
</tr>
<tr>
<td rowspan="4" >Reading comprehension
</td>
<td>SQuAD (1-shot)
</td>
<td>76.4
</td>
<td>72.2
</td>
<td>72.1
</td>
<td>85.6
</td>
<td>82.6
</td>
</tr>
<tr>
<td>QuAC (1-shot, F1)
</td>
<td>44.4
</td>
<td>39.6
</td>
<td>44.9
</td>
<td>51.1
</td>
<td>49.4
</td>
</tr>
<tr>
<td>BoolQ (0-shot)
</td>
<td>75.7
</td>
<td>65.5
</td>
<td>66.9
</td>
<td>79.0
</td>
<td>73.1
</td>
</tr>
<tr>
<td>DROP (3-shot, F1)
</td>
<td>58.4
</td>
<td>37.9
</td>
<td>49.8
</td>
<td>79.7
</td>
<td>70.2
</td>
</tr>
</table>
### Instruction tuned models
<table>
<tr>
<td><strong>Benchmark</strong>
</td>
<td><strong>Llama 3 8B</strong>
</td>
<td><strong>Llama 2 7B</strong>
</td>
<td><strong>Llama 2 13B</strong>
</td>
<td><strong>Llama 3 70B</strong>
</td>
<td><strong>Llama 2 70B</strong>
</td>
</tr>
<tr>
<td>MMLU (5-shot)
</td>
<td>68.4
</td>
<td>34.1
</td>
<td>47.8
</td>
<td>82.0
</td>
<td>52.9
</td>
</tr>
<tr>
<td>GPQA (0-shot)
</td>
<td>34.2
</td>
<td>21.7
</td>
<td>22.3
</td>
<td>39.5
</td>
<td>21.0
</td>
</tr>
<tr>
<td>HumanEval (0-shot)
</td>
<td>62.2
</td>
<td>7.9
</td>
<td>14.0
</td>
<td>81.7
</td>
<td>25.6
</td>
</tr>
<tr>
<td>GSM-8K (8-shot, CoT)
</td>
<td>79.6
</td>
<td>25.7
</td>
<td>77.4
</td>
<td>93.0
</td>
<td>57.5
</td>
</tr>
<tr>
<td>MATH (4-shot, CoT)
</td>
<td>30.0
</td>
<td>3.8
</td>
<td>6.7
</td>
<td>50.4
</td>
<td>11.6
</td>
</tr>
</table>
### Responsibility & Safety
We believe that an open approach to AI leads to better, safer products, faster innovation, and a bigger overall market. We are committed to Responsible AI development and took a series of steps to limit misuse and harm and support the open source community.
Foundation models are widely capable technologies that are built to be used for a diverse range of applications. They are not designed to meet every developer preference on safety levels for all use cases, out-of-the-box, as those by their nature will differ across different applications.
Rather, responsible LLM-application deployment is achieved by implementing a series of safety best practices throughout the development of such applications, from the model pre-training, fine-tuning and the deployment of systems composed of safeguards to tailor the safety needs specifically to the use case and audience.
As part of the Llama 3 release, we updated our [Responsible Use Guide](https://llama.meta.com/responsible-use-guide/) to outline the steps and best practices for developers to implement model and system level safety for their application. We also provide a set of resources including [Meta Llama Guard 2](https://llama.meta.com/purple-llama/) and [Code Shield](https://llama.meta.com/purple-llama/) safeguards. These tools have proven to drastically reduce residual risks of LLM Systems, while maintaining a high level of helpfulness. We encourage developers to tune and deploy these safeguards according to their needs and we provide a [reference implementation](https://github.com/meta-llama/llama-recipes/tree/main/recipes/responsible_ai) to get you started.
#### Llama 3-Instruct
As outlined in the Responsible Use Guide, some trade-off between model helpfulness and model alignment is likely unavoidable. Developers should exercise discretion about how to weigh the benefits of alignment and helpfulness for their specific use case and audience. Developers should be mindful of residual risks when using Llama models and leverage additional safety tools as needed to reach the right safety bar for their use case.
<span style="text-decoration:underline;">Safety</span>
For our instruction tuned model, we conducted extensive red teaming exercises, performed adversarial evaluations and implemented safety mitigations techniques to lower residual risks. As with any Large Language Model, residual risks will likely remain and we recommend that developers assess these risks in the context of their use case. In parallel, we are working with the community to make AI safety benchmark standards transparent, rigorous and interpretable.
<span style="text-decoration:underline;">Refusals</span>
In addition to residual risks, we put a great emphasis on model refusals to benign prompts. Over-refusing not only can impact the user experience but could even be harmful in certain contexts as well. We’ve heard the feedback from the developer community and improved our fine tuning to ensure that Llama 3 is significantly less likely to falsely refuse to answer prompts than Llama 2.
We built internal benchmarks and developed mitigations to limit false refusals making Llama 3 our most helpful model to date.
#### Responsible release
In addition to responsible use considerations outlined above, we followed a rigorous process that requires us to take extra measures against misuse and critical risks before we make our release decision.
Misuse
If you access or use Llama 3, you agree to the Acceptable Use Policy. The most recent copy of this policy can be found at [https://llama.meta.com/llama3/use-policy/](https://llama.meta.com/llama3/use-policy/).
#### Critical risks
<span style="text-decoration:underline;">CBRNE</span> (Chemical, Biological, Radiological, Nuclear, and high yield Explosives)
We have conducted a two fold assessment of the safety of the model in this area:
* Iterative testing during model training to assess the safety of responses related to CBRNE threats and other adversarial risks.
* Involving external CBRNE experts to conduct an uplift test assessing the ability of the model to accurately provide expert knowledge and reduce barriers to potential CBRNE misuse, by reference to what can be achieved using web search (without the model).
### <span style="text-decoration:underline;">Cyber Security </span>
We have evaluated Llama 3 with CyberSecEval, Meta’s cybersecurity safety eval suite, measuring Llama 3’s propensity to suggest insecure code when used as a coding assistant, and Llama 3’s propensity to comply with requests to help carry out cyber attacks, where attacks are defined by the industry standard MITRE ATT&CK cyber attack ontology. On our insecure coding and cyber attacker helpfulness tests, Llama 3 behaved in the same range or safer than models of [equivalent coding capability](https://huggingface.co/spaces/facebook/CyberSecEval).
### <span style="text-decoration:underline;">Child Safety</span>
Child Safety risk assessments were conducted using a team of experts, to assess the model’s capability to produce outputs that could result in Child Safety risks and inform on any necessary and appropriate risk mitigations via fine tuning. We leveraged those expert red teaming sessions to expand the coverage of our evaluation benchmarks through Llama 3 model development. For Llama 3, we conducted new in-depth sessions using objective based methodologies to assess the model risks along multiple attack vectors. We also partnered with content specialists to perform red teaming exercises assessing potentially violating content while taking account of market specific nuances or experiences.
### Community
Generative AI safety requires expertise and tooling, and we believe in the strength of the open community to accelerate its progress. We are active members of open consortiums, including the AI Alliance, Partnership in AI and MLCommons, actively contributing to safety standardization and transparency. We encourage the community to adopt taxonomies like the MLCommons Proof of Concept evaluation to facilitate collaboration and transparency on safety and content evaluations. Our Purple Llama tools are open sourced for the community to use and widely distributed across ecosystem partners including cloud service providers. We encourage community contributions to our [Github repository](https://github.com/meta-llama/PurpleLlama).
Finally, we put in place a set of resources including an [output reporting mechanism](https://developers.facebook.com/llama_output_feedback) and [bug bounty program](https://www.facebook.com/whitehat) to continuously improve the Llama technology with the help of the community.
## Ethical Considerations and Limitations
The core values of Llama 3 are openness, inclusivity and helpfulness. It is meant to serve everyone, and to work for a wide range of use cases. It is thus designed to be accessible to people across many different backgrounds, experiences and perspectives. Llama 3 addresses users and their needs as they are, without insertion unnecessary judgment or normativity, while reflecting the understanding that even content that may appear problematic in some cases can serve valuable purposes in others. It respects the dignity and autonomy of all users, especially in terms of the values of free thought and expression that power innovation and progress.
But Llama 3 is a new technology, and like any new technology, there are risks associated with its use. Testing conducted to date has been in English, and has not covered, nor could it cover, all scenarios. For these reasons, as with all LLMs, Llama 3’s potential outputs cannot be predicted in advance, and the model may in some instances produce inaccurate, biased or other objectionable responses to user prompts. Therefore, before deploying any applications of Llama 3 models, developers should perform safety testing and tuning tailored to their specific applications of the model. As outlined in the Responsible Use Guide, we recommend incorporating [Purple Llama](https://github.com/facebookresearch/PurpleLlama) solutions into your workflows and specifically [Llama Guard](https://ai.meta.com/research/publications/llama-guard-llm-based-input-output-safeguard-for-human-ai-conversations/) which provides a base model to filter input and output prompts to layer system-level safety on top of model-level safety.
Please see the Responsible Use Guide available at [http://llama.meta.com/responsible-use-guide](http://llama.meta.com/responsible-use-guide)
## Citation instructions
@article{llama3modelcard,
title={Llama 3 Model Card},
author={AI@Meta},
year={2024},
url = {https://github.com/meta-llama/llama3/blob/main/MODEL_CARD.md}
}
## Contributors
Aaditya Singh; Aaron Grattafiori; Abhimanyu Dubey; Abhinav Jauhri; Abhinav Pandey; Abhishek Kadian; Adam Kelsey; Adi Gangidi; Ahmad Al-Dahle; Ahuva Goldstand; Aiesha Letman; Ajay Menon; Akhil Mathur; Alan Schelten; Alex Vaughan; Amy Yang; Andrei Lupu; Andres Alvarado; Andrew Gallagher; Andrew Gu; Andrew Ho; Andrew Poulton; Andrew Ryan; Angela Fan; Ankit Ramchandani; Anthony Hartshorn; Archi Mitra; Archie Sravankumar; Artem Korenev; Arun Rao; Ashley Gabriel; Ashwin Bharambe; Assaf Eisenman; Aston Zhang; Aurelien Rodriguez; Austen Gregerson; Ava Spataru; Baptiste Roziere; Ben Maurer; Benjamin Leonhardi; Bernie Huang; Bhargavi Paranjape; Bing Liu; Binh Tang; Bobbie Chern; Brani Stojkovic; Brian Fuller; Catalina Mejia Arenas; Chao Zhou; Charlotte Caucheteux; Chaya Nayak; Ching-Hsiang Chu; Chloe Bi; Chris Cai; Chris Cox; Chris Marra; Chris McConnell; Christian Keller; Christoph Feichtenhofer; Christophe Touret; Chunyang Wu; Corinne Wong; Cristian Canton Ferrer; Damien Allonsius; Daniel Kreymer; Daniel Haziza; Daniel Li; Danielle Pintz; Danny Livshits; Danny Wyatt; David Adkins; David Esiobu; David Xu; Davide Testuggine; Delia David; Devi Parikh; Dhruv Choudhary; Dhruv Mahajan; Diana Liskovich; Diego Garcia-Olano; Diego Perino; Dieuwke Hupkes; Dingkang Wang; Dustin Holland; Egor Lakomkin; Elina Lobanova; Xiaoqing Ellen Tan; Emily Dinan; Eric Smith; Erik Brinkman; Esteban Arcaute; Filip Radenovic; Firat Ozgenel; Francesco Caggioni; Frank Seide; Frank Zhang; Gabriel Synnaeve; Gabriella Schwarz; Gabrielle Lee; Gada Badeer; Georgia Anderson; Graeme Nail; Gregoire Mialon; Guan Pang; Guillem Cucurell; Hailey Nguyen; Hannah Korevaar; Hannah Wang; Haroun Habeeb; Harrison Rudolph; Henry Aspegren; Hu Xu; Hugo Touvron; Iga Kozlowska; Igor Molybog; Igor Tufanov; Iliyan Zarov; Imanol Arrieta Ibarra; Irina-Elena Veliche; Isabel Kloumann; Ishan Misra; Ivan Evtimov; Jacob Xu; Jade Copet; Jake Weissman; Jan Geffert; Jana Vranes; Japhet Asher; Jason Park; Jay Mahadeokar; Jean-Baptiste Gaya; Jeet Shah; Jelmer van der Linde; Jennifer Chan; Jenny Hong; Jenya Lee; Jeremy Fu; Jeremy Teboul; Jianfeng Chi; Jianyu Huang; Jie Wang; Jiecao Yu; Joanna Bitton; Joe Spisak; Joelle Pineau; Jon Carvill; Jongsoo Park; Joseph Rocca; Joshua Johnstun; Junteng Jia; Kalyan Vasuden Alwala; Kam Hou U; Kate Plawiak; Kartikeya Upasani; Kaushik Veeraraghavan; Ke Li; Kenneth Heafield; Kevin Stone; Khalid El-Arini; Krithika Iyer; Kshitiz Malik; Kuenley Chiu; Kunal Bhalla; Kyle Huang; Lakshya Garg; Lauren Rantala-Yeary; Laurens van der Maaten; Lawrence Chen; Leandro Silva; Lee Bell; Lei Zhang; Liang Tan; Louis Martin; Lovish Madaan; Luca Wehrstedt; Lukas Blecher; Luke de Oliveira; Madeline Muzzi; Madian Khabsa; Manav Avlani; Mannat Singh; Manohar Paluri; Mark Zuckerberg; Marcin Kardas; Martynas Mankus; Mathew Oldham; Mathieu Rita; Matthew Lennie; Maya Pavlova; Meghan Keneally; Melanie Kambadur; Mihir Patel; Mikayel Samvelyan; Mike Clark; Mike Lewis; Min Si; Mitesh Kumar Singh; Mo Metanat; Mona Hassan; Naman Goyal; Narjes Torabi; Nicolas Usunier; Nikolay Bashlykov; Nikolay Bogoychev; Niladri Chatterji; Ning Dong; Oliver Aobo Yang; Olivier Duchenne; Onur Celebi; Parth Parekh; Patrick Alrassy; Paul Saab; Pavan Balaji; Pedro Rittner; Pengchuan Zhang; Pengwei Li; Petar Vasic; Peter Weng; Polina Zvyagina; Prajjwal Bhargava; Pratik Dubal; Praveen Krishnan; Punit Singh Koura; Qing He; Rachel Rodriguez; Ragavan Srinivasan; Rahul Mitra; Ramon Calderer; Raymond Li; Robert Stojnic; Roberta Raileanu; Robin Battey; Rocky Wang; Rohit Girdhar; Rohit Patel; Romain Sauvestre; Ronnie Polidoro; Roshan Sumbaly; Ross Taylor; Ruan Silva; Rui Hou; Rui Wang; Russ Howes; Ruty Rinott; Saghar Hosseini; Sai Jayesh Bondu; Samyak Datta; Sanjay Singh; Sara Chugh; Sargun Dhillon; Satadru Pan; Sean Bell; Sergey Edunov; Shaoliang Nie; Sharan Narang; Sharath Raparthy; Shaun Lindsay; Sheng Feng; Sheng Shen; Shenghao Lin; Shiva Shankar; Shruti Bhosale; Shun Zhang; Simon Vandenhende; Sinong Wang; Seohyun Sonia Kim; Soumya Batra; Sten Sootla; Steve Kehoe; Suchin Gururangan; Sumit Gupta; Sunny Virk; Sydney Borodinsky; Tamar Glaser; Tamar Herman; Tamara Best; Tara Fowler; Thomas Georgiou; Thomas Scialom; Tianhe Li; Todor Mihaylov; Tong Xiao; Ujjwal Karn; Vedanuj Goswami; Vibhor Gupta; Vignesh Ramanathan; Viktor Kerkez; Vinay Satish Kumar; Vincent Gonguet; Vish Vogeti; Vlad Poenaru; Vlad Tiberiu Mihailescu; Vladan Petrovic; Vladimir Ivanov; Wei Li; Weiwei Chu; Wenhan Xiong; Wenyin Fu; Wes Bouaziz; Whitney Meers; Will Constable; Xavier Martinet; Xiaojian Wu; Xinbo Gao; Xinfeng Xie; Xuchao Jia; Yaelle Goldschlag; Yann LeCun; Yashesh Gaur; Yasmine Babaei; Ye Qi; Yenda Li; Yi Wen; Yiwen Song; Youngjin Nam; Yuchen Hao; Yuchen Zhang; Yun Wang; Yuning Mao; Yuzi He; Zacharie Delpierre Coudert; Zachary DeVito; Zahra Hankir; Zhaoduo Wen; Zheng Yan; Zhengxing Chen; Zhenyu Yang; Zoe Papakipos
|
IVN-RIN/bioBIT | IVN-RIN | 2024-05-24T11:57:03Z | 6,744 | 1 | transformers | [
"transformers",
"pytorch",
"safetensors",
"bert",
"fill-mask",
"Biomedical Language Modeling",
"it",
"dataset:IVN-RIN/BioBERT_Italian",
"arxiv:1901.08746",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | fill-mask | 2022-12-03T11:17:50Z | ---
language:
- it
tags:
- Biomedical Language Modeling
widget:
- text: >-
L'asma allergica è una patologia dell'[MASK] respiratorio causata dalla
presenza di allergeni responsabili dell'infiammazione dell'albero
bronchiale.
example_title: Example 1
- text: >-
Il pancreas produce diversi [MASK] molto importanti tra i quali l'insulina e
il glucagone.
example_title: Example 2
- text: >-
Il GABA è un amminoacido ed è il principale neurotrasmettitore inibitorio
del [MASK].
example_title: Example 3
datasets:
- IVN-RIN/BioBERT_Italian
---
🤗 + 📚🩺🇮🇹 = **BioBIT**
From this repository you can download the **BioBIT** (Biomedical Bert for ITalian) checkpoint.
**BioBIT** stems from [Italian XXL BERT](https://huggingface.co/dbmdz/bert-base-italian-xxl-cased), obtained from a recent Wikipedia dump and various texts in Italian from the OPUS and OSCAR corpora collection, which sums up to the final corpus size of 81 GB and 13B tokens.
To pretrain **BioBIT**, we followed the general approach outlined in [BioBERT paper](https://arxiv.org/abs/1901.08746), built on the foundation of the BERT architecture. The pretraining objective is a combination of **MLM** (Masked Language Modelling) and **NSP** (Next Sentence Prediction). The MLM objective is based on randomly masking 15% of the input sequence, trying then to predict the missing tokens; for the NSP objective, instead, the model is given a couple of sentences and has to guess if the second comes after the first in the original document.
Due to the unavailability of an Italian equivalent for the millions of abstracts and full-text scientific papers used by English, BERT-based biomedical models, in this work we leveraged machine translation to obtain an Italian biomedical corpus based on PubMed abstracts and train **BioBIT**. More details in the paper.
**BioBIT** has been evaluated on 3 downstream tasks: **NER** (Named Entity Recognition), extractive **QA** (Question Answering), **RE** (Relation Extraction).
Here are the results, summarized:
- NER:
- [BC2GM](http://refhub.elsevier.com/S1532-0464(23)00152-1/sb32) = 82.14%
- [BC4CHEMD](http://refhub.elsevier.com/S1532-0464(23)00152-1/sb35) = 80.70%
- [BC5CDR(CDR)](http://refhub.elsevier.com/S1532-0464(23)00152-1/sb31) = 82.15%
- [BC5CDR(DNER)](http://refhub.elsevier.com/S1532-0464(23)00152-1/sb31) = 76.27%
- [NCBI_DISEASE](http://refhub.elsevier.com/S1532-0464(23)00152-1/sb33) = 65.06%
- [SPECIES-800](http://refhub.elsevier.com/S1532-0464(23)00152-1/sb34) = 61.86%
- QA:
- [BioASQ 4b](http://refhub.elsevier.com/S1532-0464(23)00152-1/sb30) = 68.49%
- [BioASQ 5b](http://refhub.elsevier.com/S1532-0464(23)00152-1/sb30) = 78.33%
- [BioASQ 6b](http://refhub.elsevier.com/S1532-0464(23)00152-1/sb30) = 75.73%
- RE:
- [CHEMPROT](http://refhub.elsevier.com/S1532-0464(23)00152-1/sb36) = 38.16%
- [BioRED](http://refhub.elsevier.com/S1532-0464(23)00152-1/sb37) = 67.15%
[Check the full paper](https://www.sciencedirect.com/science/article/pii/S1532046423001521) for further details, and feel free to contact us if you have some inquiry! |
TencentGameMate/chinese-hubert-base | TencentGameMate | 2022-06-24T01:52:57Z | 6,742 | 29 | transformers | [
"transformers",
"pytorch",
"hubert",
"feature-extraction",
"license:mit",
"endpoints_compatible",
"region:us"
] | feature-extraction | 2022-06-02T06:21:23Z | ---
license: mit
---
Pretrained on 10k hours WenetSpeech L subset. More details in [TencentGameMate/chinese_speech_pretrain](https://github.com/TencentGameMate/chinese_speech_pretrain)
This model does not have a tokenizer as it was pretrained on audio alone.
In order to use this model speech recognition, a tokenizer should be created and the model should be fine-tuned on labeled text data.
python package:
transformers==4.16.2
```python
import torch
import torch.nn.functional as F
import soundfile as sf
from transformers import (
Wav2Vec2FeatureExtractor,
HubertModel,
)
model_path=""
wav_path=""
feature_extractor = Wav2Vec2FeatureExtractor.from_pretrained(model_path)
model = HubertModel.from_pretrained(model_path)
# for pretrain: Wav2Vec2ForPreTraining
# model = Wav2Vec2ForPreTraining.from_pretrained(model_path)
model = model.to(device)
model = model.half()
model.eval()
wav, sr = sf.read(wav_path)
input_values = feature_extractor(wav, return_tensors="pt").input_values
input_values = input_values.half()
input_values = input_values.to(device)
with torch.no_grad():
outputs = model(input_values)
last_hidden_state = outputs.last_hidden_state
``` |
facebook/metaclip-b16-fullcc2.5b | facebook | 2023-10-14T09:06:23Z | 6,741 | 7 | transformers | [
"transformers",
"pytorch",
"clip",
"zero-shot-image-classification",
"vision",
"metaclip",
"arxiv:2309.16671",
"arxiv:2103.00020",
"license:cc-by-nc-4.0",
"endpoints_compatible",
"region:us"
] | zero-shot-image-classification | 2023-10-09T20:45:26Z | ---
license: cc-by-nc-4.0
tags:
- vision
- metaclip
widget:
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/cat-dog-music.png
candidate_labels: playing music, playing sports
example_title: Cat & Dog
---
# MetaCLIP model, base-sized version, patch resolution 16
MetaCLIP model applied to 2.5 billion data points of CommonCrawl (CC). It was introduced in the paper [Demystifying CLIP Data](https://arxiv.org/abs/2309.16671) by Xu et al. and first released in [this repository](https://github.com/facebookresearch/MetaCLIP).
Disclaimer: The team releasing MetaCLIP did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
The [Demystifying CLIP Data](https://arxiv.org/abs/2309.16671) paper aims to reveal CLIP’s method around training data curation. OpenAI never open-sourced code regarding their data preparation pipeline.
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/model_doc/clip_overview.jpg"
alt="drawing" width="600"/>
<small> CLIP high-level overview. Taken from the <a href="https://arxiv.org/abs/2103.00020">CLIP paper</a>. </small>
## Intended uses & limitations
You can use the raw model for linking images with text in a shared embedding space. This enables things like zero-shot image classification, text-based image retrieval, image-based text retrieval, etc.
### How to use
We refer to the [docs](https://huggingface.co/docs/transformers/main/en/model_doc/clip#usage). Just replace the names of the models on the hub.
### BibTeX entry and citation info
```bibtex
@misc{xu2023demystifying,
title={Demystifying CLIP Data},
author={Hu Xu and Saining Xie and Xiaoqing Ellen Tan and Po-Yao Huang and Russell Howes and Vasu Sharma and Shang-Wen Li and Gargi Ghosh and Luke Zettlemoyer and Christoph Feichtenhofer},
year={2023},
eprint={2309.16671},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
|
backyardai/Llama-3-Lumimaid-8B-v0.1-GGUF | backyardai | 2024-06-14T06:35:34Z | 6,736 | 3 | null | [
"gguf",
"not-for-all-audiences",
"nsfw",
"base_model:NeverSleep/Llama-3-Lumimaid-8B-v0.1",
"license:cc-by-nc-4.0",
"region:us"
] | null | 2024-05-03T23:55:35Z | ---
license: cc-by-nc-4.0
tags:
- not-for-all-audiences
- nsfw
base_model: NeverSleep/Llama-3-Lumimaid-8B-v0.1
model_name: Llama-3-Lumimaid-8B-v0.1-GGUF
quantized_by: brooketh
parameter_count: 8030261248
---
<img src="BackyardAI_Banner.png" alt="Backyard.ai" style="height: 90px; min-width: 32px; display: block; margin: auto;">
**<p style="text-align: center;">The official library of GGUF format models for use in the local AI chat app, Backyard AI.</p>**
<p style="text-align: center;"><a href="https://backyard.ai/">Download Backyard AI here to get started.</a></p>
<p style="text-align: center;"><a href="https://www.reddit.com/r/LLM_Quants/">Request Additional models at r/LLM_Quants.</a></p>
***
# Llama 3 Lumimaid V0.1 8B
- **Creator:** [NeverSleep](https://huggingface.co/NeverSleep/)
- **Original:** [Llama 3 Lumimaid V0.1 8B](https://huggingface.co/NeverSleep/Llama-3-Lumimaid-8B-v0.1)
- **Date Created:** 2024-04-30
- **Trained Context:** 8192 tokens
- **Description:** RP model from Undi based on Llama3, which incorporates the Luminae dateset from Ikari. It tries to strike a balance between erotic and non-erotic RP, while being entirely uncensored.
***
## What is a GGUF?
GGUF is a large language model (LLM) format that can be split between CPU and GPU. GGUFs are compatible with applications based on llama.cpp, such as Backyard AI. Where other model formats require higher end GPUs with ample VRAM, GGUFs can be efficiently run on a wider variety of hardware.
GGUF models are quantized to reduce resource usage, with a tradeoff of reduced coherence at lower quantizations. Quantization reduces the precision of the model weights by changing the number of bits used for each weight.
***
<img src="BackyardAI_Logo.png" alt="Backyard.ai" style="height: 75px; min-width: 32px; display: block; horizontal align: left;">
## Backyard AI
- Free, local AI chat application.
- One-click installation on Mac and PC.
- Automatically use GPU for maximum speed.
- Built-in model manager.
- High-quality character hub.
- Zero-config desktop-to-mobile tethering.
Backyard AI makes it easy to start chatting with AI using your own characters or one of the many found in the built-in character hub. The model manager helps you find the latest and greatest models without worrying about whether it's the correct format. Backyard AI supports advanced features such as lorebooks, author's note, text formatting, custom context size, sampler settings, grammars, local TTS, cloud inference, and tethering, all implemented in a way that is straightforward and reliable.
**Join us on [Discord](https://discord.gg/SyNN2vC9tQ)**
*** |
stablediffusionapi/bracingevomix-v2 | stablediffusionapi | 2023-10-06T07:53:41Z | 6,733 | 0 | diffusers | [
"diffusers",
"stablediffusionapi.com",
"stable-diffusion-api",
"text-to-image",
"ultra-realistic",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | 2023-10-06T07:52:22Z | ---
license: creativeml-openrail-m
tags:
- stablediffusionapi.com
- stable-diffusion-api
- text-to-image
- ultra-realistic
pinned: true
---
# BracingEvoMix - v2 API Inference

## Get API Key
Get API key from [Stable Diffusion API](http://stablediffusionapi.com/), No Payment needed.
Replace Key in below code, change **model_id** to "bracingevomix-v2"
Coding in PHP/Node/Java etc? Have a look at docs for more code examples: [View docs](https://stablediffusionapi.com/docs)
Try model for free: [Generate Images](https://stablediffusionapi.com/models/bracingevomix-v2)
Model link: [View model](https://stablediffusionapi.com/models/bracingevomix-v2)
Credits: [View credits](https://civitai.com/?query=BracingEvoMix%20-%20v2)
View all models: [View Models](https://stablediffusionapi.com/models)
import requests
import json
url = "https://stablediffusionapi.com/api/v4/dreambooth"
payload = json.dumps({
"key": "your_api_key",
"model_id": "bracingevomix-v2",
"prompt": "ultra realistic close up portrait ((beautiful pale cyberpunk female with heavy black eyeliner)), blue eyes, shaved side haircut, hyper detail, cinematic lighting, magic neon, dark red city, Canon EOS R3, nikon, f/1.4, ISO 200, 1/160s, 8K, RAW, unedited, symmetrical balance, in-frame, 8K",
"negative_prompt": "painting, extra fingers, mutated hands, poorly drawn hands, poorly drawn face, deformed, ugly, blurry, bad anatomy, bad proportions, extra limbs, cloned face, skinny, glitchy, double torso, extra arms, extra hands, mangled fingers, missing lips, ugly face, distorted face, extra legs, anime",
"width": "512",
"height": "512",
"samples": "1",
"num_inference_steps": "30",
"safety_checker": "no",
"enhance_prompt": "yes",
"seed": None,
"guidance_scale": 7.5,
"multi_lingual": "no",
"panorama": "no",
"self_attention": "no",
"upscale": "no",
"embeddings": "embeddings_model_id",
"lora": "lora_model_id",
"webhook": None,
"track_id": None
})
headers = {
'Content-Type': 'application/json'
}
response = requests.request("POST", url, headers=headers, data=payload)
print(response.text)
> Use this coupon code to get 25% off **DMGG0RBN** |
peft-internal-testing/gpt2-lora-random | peft-internal-testing | 2023-11-22T11:15:49Z | 6,733 | 0 | peft | [
"peft",
"safetensors",
"arxiv:1910.09700",
"base_model:gpt2",
"region:us"
] | null | 2023-11-22T11:11:21Z | ---
library_name: peft
base_model: gpt2
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Data Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Data Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
## Training procedure
### Framework versions
- PEFT 0.6.3.dev0
|
h2oai/h2ogpt-gm-oasst1-en-2048-falcon-40b-v2 | h2oai | 2023-07-13T03:12:11Z | 6,727 | 18 | transformers | [
"transformers",
"pytorch",
"RefinedWeb",
"text-generation",
"gpt",
"llm",
"large language model",
"h2o-llmstudio",
"custom_code",
"en",
"dataset:OpenAssistant/oasst1",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2023-06-23T07:35:02Z | ---
language:
- en
library_name: transformers
tags:
- gpt
- llm
- large language model
- h2o-llmstudio
inference: false
thumbnail: >-
https://h2o.ai/etc.clientlibs/h2o/clientlibs/clientlib-site/resources/images/favicon.ico
license: apache-2.0
datasets:
- OpenAssistant/oasst1
---
# Model Card
## Summary
This model was trained using [H2O LLM Studio](https://github.com/h2oai/h2o-llmstudio).
- Base model: [tiiuae/falcon-40b](https://huggingface.co/tiiuae/falcon-40b)
- Dataset preparation: [OpenAssistant/oasst1](https://github.com/h2oai/h2o-llmstudio/blob/1935d84d9caafed3ee686ad2733eb02d2abfce57/app_utils/utils.py#LL1896C5-L1896C28) personalized
## Usage
To use the model with the `transformers` library on a machine with GPUs, first make sure you have the `transformers`, `accelerate` and `torch` libraries installed.
```bash
pip install transformers==4.29.2
pip install bitsandbytes==0.39.0
pip install accelerate==0.19.0
pip install torch==2.0.0
pip install einops==0.6.1
```
```python
import torch
from transformers import pipeline, BitsAndBytesConfig, AutoTokenizer
model_kwargs = {}
quantization_config = None
# optional quantization
quantization_config = BitsAndBytesConfig(
load_in_8bit=True,
llm_int8_threshold=6.0,
)
model_kwargs["quantization_config"] = quantization_config
tokenizer = AutoTokenizer.from_pretrained(
"h2oai/h2ogpt-gm-oasst1-en-2048-falcon-40b-v2",
use_fast=False,
padding_side="left",
trust_remote_code=True,
)
generate_text = pipeline(
model="h2oai/h2ogpt-gm-oasst1-en-2048-falcon-40b-v2",
tokenizer=tokenizer,
torch_dtype=torch.float16,
trust_remote_code=True,
use_fast=False,
device_map={"": "cuda:0"},
model_kwargs=model_kwargs,
)
res = generate_text(
"Why is drinking water so healthy?",
min_new_tokens=2,
max_new_tokens=1024,
do_sample=False,
num_beams=1,
temperature=float(0.3),
repetition_penalty=float(1.2),
renormalize_logits=True
)
print(res[0]["generated_text"])
```
You can print a sample prompt after the preprocessing step to see how it is feed to the tokenizer:
```python
print(generate_text.preprocess("Why is drinking water so healthy?")["prompt_text"])
```
```bash
<|prompt|>Why is drinking water so healthy?<|endoftext|><|answer|>
```
Alternatively, you can download [h2oai_pipeline.py](h2oai_pipeline.py), store it alongside your notebook, and construct the pipeline yourself from the loaded model and tokenizer:
```python
import torch
from h2oai_pipeline import H2OTextGenerationPipeline
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
quantization_config = None
# optional quantization
quantization_config = BitsAndBytesConfig(
load_in_8bit=True,
llm_int8_threshold=6.0,
)
tokenizer = AutoTokenizer.from_pretrained(
"h2oai/h2ogpt-gm-oasst1-en-2048-falcon-40b-v2",
use_fast=False,
padding_side="left",
trust_remote_code=True,
)
model = AutoModelForCausalLM.from_pretrained(
"h2oai/h2ogpt-gm-oasst1-en-2048-falcon-40b-v2",
trust_remote_code=True,
torch_dtype=torch.float16,
device_map={"": "cuda:0"},
quantization_config=quantization_config
).eval()
generate_text = H2OTextGenerationPipeline(model=model, tokenizer=tokenizer)
res = generate_text(
"Why is drinking water so healthy?",
min_new_tokens=2,
max_new_tokens=1024,
do_sample=False,
num_beams=1,
temperature=float(0.3),
repetition_penalty=float(1.2),
renormalize_logits=True
)
print(res[0]["generated_text"])
```
You may also construct the pipeline from the loaded model and tokenizer yourself and consider the preprocessing steps:
```python
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
# Important: The prompt needs to be in the same format the model was trained with.
# You can find an example prompt in the experiment logs.
prompt = "<|prompt|>How are you?<|endoftext|><|answer|>"
quantization_config = None
# optional quantization
quantization_config = BitsAndBytesConfig(
load_in_8bit=True,
llm_int8_threshold=6.0,
)
tokenizer = AutoTokenizer.from_pretrained(
"h2oai/h2ogpt-gm-oasst1-en-2048-falcon-40b-v2",
use_fast=False,
padding_side="left",
trust_remote_code=True,
)
model = AutoModelForCausalLM.from_pretrained(
"h2oai/h2ogpt-gm-oasst1-en-2048-falcon-40b-v2",
trust_remote_code=True,
torch_dtype=torch.float16,
device_map={"": "cuda:0"},
quantization_config=quantization_config
).eval()
inputs = tokenizer(prompt, return_tensors="pt", add_special_tokens=False).to("cuda")
# generate configuration can be modified to your needs
tokens = model.generate(
**inputs,
min_new_tokens=2,
max_new_tokens=1024,
do_sample=False,
num_beams=1,
temperature=float(0.3),
repetition_penalty=float(1.2),
renormalize_logits=True
)[0]
tokens = tokens[inputs["input_ids"].shape[1]:]
answer = tokenizer.decode(tokens, skip_special_tokens=True)
print(answer)
```
## Model Architecture
```
RWForCausalLM(
(transformer): RWModel(
(word_embeddings): Embedding(65024, 8192)
(h): ModuleList(
(0-59): 60 x DecoderLayer(
(ln_attn): LayerNorm((8192,), eps=1e-05, elementwise_affine=True)
(ln_mlp): LayerNorm((8192,), eps=1e-05, elementwise_affine=True)
(self_attention): Attention(
(maybe_rotary): RotaryEmbedding()
(query_key_value): Linear(in_features=8192, out_features=9216, bias=False)
(dense): Linear(in_features=8192, out_features=8192, bias=False)
(attention_dropout): Dropout(p=0.0, inplace=False)
)
(mlp): MLP(
(dense_h_to_4h): Linear(in_features=8192, out_features=32768, bias=False)
(act): GELU(approximate='none')
(dense_4h_to_h): Linear(in_features=32768, out_features=8192, bias=False)
)
)
)
(ln_f): LayerNorm((8192,), eps=1e-05, elementwise_affine=True)
)
(lm_head): Linear(in_features=8192, out_features=65024, bias=False)
)
```
## Model Configuration
This model was trained using H2O LLM Studio and with the configuration in [cfg.yaml](cfg.yaml). Visit [H2O LLM Studio](https://github.com/h2oai/h2o-llmstudio) to learn how to train your own large language models.
## Disclaimer
Please read this disclaimer carefully before using the large language model provided in this repository. Your use of the model signifies your agreement to the following terms and conditions.
- Biases and Offensiveness: The large language model is trained on a diverse range of internet text data, which may contain biased, racist, offensive, or otherwise inappropriate content. By using this model, you acknowledge and accept that the generated content may sometimes exhibit biases or produce content that is offensive or inappropriate. The developers of this repository do not endorse, support, or promote any such content or viewpoints.
- Limitations: The large language model is an AI-based tool and not a human. It may produce incorrect, nonsensical, or irrelevant responses. It is the user's responsibility to critically evaluate the generated content and use it at their discretion.
- Use at Your Own Risk: Users of this large language model must assume full responsibility for any consequences that may arise from their use of the tool. The developers and contributors of this repository shall not be held liable for any damages, losses, or harm resulting from the use or misuse of the provided model.
- Ethical Considerations: Users are encouraged to use the large language model responsibly and ethically. By using this model, you agree not to use it for purposes that promote hate speech, discrimination, harassment, or any form of illegal or harmful activities.
- Reporting Issues: If you encounter any biased, offensive, or otherwise inappropriate content generated by the large language model, please report it to the repository maintainers through the provided channels. Your feedback will help improve the model and mitigate potential issues.
- Changes to this Disclaimer: The developers of this repository reserve the right to modify or update this disclaimer at any time without prior notice. It is the user's responsibility to periodically review the disclaimer to stay informed about any changes.
By using the large language model provided in this repository, you agree to accept and comply with the terms and conditions outlined in this disclaimer. If you do not agree with any part of this disclaimer, you should refrain from using the model and any content generated by it. |
RichardErkhov/vilm_-_vinallama-2.7b-gguf | RichardErkhov | 2024-06-25T03:33:34Z | 6,726 | 0 | null | [
"gguf",
"arxiv:2312.11011",
"region:us"
] | null | 2024-06-25T00:11:48Z | Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
vinallama-2.7b - GGUF
- Model creator: https://huggingface.co/vilm/
- Original model: https://huggingface.co/vilm/vinallama-2.7b/
| Name | Quant method | Size |
| ---- | ---- | ---- |
| [vinallama-2.7b.Q2_K.gguf](https://huggingface.co/RichardErkhov/vilm_-_vinallama-2.7b-gguf/blob/main/vinallama-2.7b.Q2_K.gguf) | Q2_K | 1.0GB |
| [vinallama-2.7b.IQ3_XS.gguf](https://huggingface.co/RichardErkhov/vilm_-_vinallama-2.7b-gguf/blob/main/vinallama-2.7b.IQ3_XS.gguf) | IQ3_XS | 1.1GB |
| [vinallama-2.7b.IQ3_S.gguf](https://huggingface.co/RichardErkhov/vilm_-_vinallama-2.7b-gguf/blob/main/vinallama-2.7b.IQ3_S.gguf) | IQ3_S | 1.16GB |
| [vinallama-2.7b.Q3_K_S.gguf](https://huggingface.co/RichardErkhov/vilm_-_vinallama-2.7b-gguf/blob/main/vinallama-2.7b.Q3_K_S.gguf) | Q3_K_S | 1.16GB |
| [vinallama-2.7b.IQ3_M.gguf](https://huggingface.co/RichardErkhov/vilm_-_vinallama-2.7b-gguf/blob/main/vinallama-2.7b.IQ3_M.gguf) | IQ3_M | 1.22GB |
| [vinallama-2.7b.Q3_K.gguf](https://huggingface.co/RichardErkhov/vilm_-_vinallama-2.7b-gguf/blob/main/vinallama-2.7b.Q3_K.gguf) | Q3_K | 1.28GB |
| [vinallama-2.7b.Q3_K_M.gguf](https://huggingface.co/RichardErkhov/vilm_-_vinallama-2.7b-gguf/blob/main/vinallama-2.7b.Q3_K_M.gguf) | Q3_K_M | 1.28GB |
| [vinallama-2.7b.Q3_K_L.gguf](https://huggingface.co/RichardErkhov/vilm_-_vinallama-2.7b-gguf/blob/main/vinallama-2.7b.Q3_K_L.gguf) | Q3_K_L | 1.39GB |
| [vinallama-2.7b.IQ4_XS.gguf](https://huggingface.co/RichardErkhov/vilm_-_vinallama-2.7b-gguf/blob/main/vinallama-2.7b.IQ4_XS.gguf) | IQ4_XS | 1.42GB |
| [vinallama-2.7b.Q4_0.gguf](https://huggingface.co/RichardErkhov/vilm_-_vinallama-2.7b-gguf/blob/main/vinallama-2.7b.Q4_0.gguf) | Q4_0 | 1.48GB |
| [vinallama-2.7b.IQ4_NL.gguf](https://huggingface.co/RichardErkhov/vilm_-_vinallama-2.7b-gguf/blob/main/vinallama-2.7b.IQ4_NL.gguf) | IQ4_NL | 1.49GB |
| [vinallama-2.7b.Q4_K_S.gguf](https://huggingface.co/RichardErkhov/vilm_-_vinallama-2.7b-gguf/blob/main/vinallama-2.7b.Q4_K_S.gguf) | Q4_K_S | 1.49GB |
| [vinallama-2.7b.Q4_K.gguf](https://huggingface.co/RichardErkhov/vilm_-_vinallama-2.7b-gguf/blob/main/vinallama-2.7b.Q4_K.gguf) | Q4_K | 1.58GB |
| [vinallama-2.7b.Q4_K_M.gguf](https://huggingface.co/RichardErkhov/vilm_-_vinallama-2.7b-gguf/blob/main/vinallama-2.7b.Q4_K_M.gguf) | Q4_K_M | 1.58GB |
| [vinallama-2.7b.Q4_1.gguf](https://huggingface.co/RichardErkhov/vilm_-_vinallama-2.7b-gguf/blob/main/vinallama-2.7b.Q4_1.gguf) | Q4_1 | 1.64GB |
| [vinallama-2.7b.Q5_0.gguf](https://huggingface.co/RichardErkhov/vilm_-_vinallama-2.7b-gguf/blob/main/vinallama-2.7b.Q5_0.gguf) | Q5_0 | 1.79GB |
| [vinallama-2.7b.Q5_K_S.gguf](https://huggingface.co/RichardErkhov/vilm_-_vinallama-2.7b-gguf/blob/main/vinallama-2.7b.Q5_K_S.gguf) | Q5_K_S | 1.79GB |
| [vinallama-2.7b.Q5_K.gguf](https://huggingface.co/RichardErkhov/vilm_-_vinallama-2.7b-gguf/blob/main/vinallama-2.7b.Q5_K.gguf) | Q5_K | 1.84GB |
| [vinallama-2.7b.Q5_K_M.gguf](https://huggingface.co/RichardErkhov/vilm_-_vinallama-2.7b-gguf/blob/main/vinallama-2.7b.Q5_K_M.gguf) | Q5_K_M | 1.84GB |
| [vinallama-2.7b.Q5_1.gguf](https://huggingface.co/RichardErkhov/vilm_-_vinallama-2.7b-gguf/blob/main/vinallama-2.7b.Q5_1.gguf) | Q5_1 | 1.95GB |
| [vinallama-2.7b.Q6_K.gguf](https://huggingface.co/RichardErkhov/vilm_-_vinallama-2.7b-gguf/blob/main/vinallama-2.7b.Q6_K.gguf) | Q6_K | 2.12GB |
| [vinallama-2.7b.Q8_0.gguf](https://huggingface.co/RichardErkhov/vilm_-_vinallama-2.7b-gguf/blob/main/vinallama-2.7b.Q8_0.gguf) | Q8_0 | 2.75GB |
Original model description:
---
license: llama2
language:
- vi
---
# VinaLLaMA - State-of-the-art Vietnamese LLMs

Read our [Paper](https://huggingface.co/papers/2312.11011)
|
mtgv/MobileVLM-1.7B | mtgv | 2024-01-08T02:20:33Z | 6,725 | 12 | transformers | [
"transformers",
"pytorch",
"mobilevlm",
"text-generation",
"MobileVLM",
"arxiv:2312.16886",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-generation | 2023-12-31T02:41:04Z | ---
license: apache-2.0
tags:
- MobileVLM
---
## Model Summery
MobileVLM is a competent multimodal vision language model (MMVLM) targeted to run on mobile devices. It is an amalgamation of a myriad of architectural designs and techniques that are mobile-oriented, which comprises a set of language models at the scale of 1.4B and 2.7B parameters, trained from scratch, a multimodal vision model that is pre-trained in the CLIP fashion, cross-modality interaction via an efficient projector. We evaluate MobileVLM on several typical VLM benchmarks. Our models demonstrate on par performance compared with a few much larger models. More importantly, we measure the inference speed on both a Qualcomm Snapdragon 888 CPU and an NVIDIA Jeston Orin GPU, and we obtain state-of-the-art performance of 21.5 tokens and 65.3 tokens per second, respectively.
The MobileVLM-1.7B was built on our [MobileLLaMA-1.4B-Chat](](https://huggingface.co/mtgv/MobileLLaMA-1.4B-Chat)) to facilitate the off-the-shelf deployment.
## Model Sources
- Repository: https://github.com/Meituan-AutoML/MobileVLM
- Paper: https://arxiv.org/abs/2312.16886
## How to Get Started with the Model
Inference examples can be found at [Github](https://github.com/Meituan-AutoML/MobileVLM).
## Training Details
Please refer to our paper: [MobileVLM: A Fast, Strong and Open Vision Language Assistant for Mobile Devices](https://arxiv.org/pdf/2312.16886.pdf)
|
NeverSleep/Noromaid-13b-v0.1.1 | NeverSleep | 2023-11-21T17:23:42Z | 6,720 | 29 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"license:cc-by-nc-4.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2023-11-13T02:34:17Z | ---
license: cc-by-nc-4.0
---

---
# Disclaimer:
## This is a ***TEST*** version, don't expect everything to work!!!
You may use our custom **prompting format**(scroll down to download them!), or simple alpaca. **(Choose which fits best for you!)**
---
# This model is a collab between [IkariDev](https://huggingface.co/IkariDev) and [Undi](https://huggingface.co/Undi95)!
Tired of the same merges everytime? Here it is, the Noromaid-13b-v0.1.1 model. Suitable for RP, ERP and general stuff.
[Recommended settings - No settings yet(Please suggest some over in the Community tab!)]
<!-- description start -->
## Description
<!-- [Recommended settings - contributed by localfultonextractor](https://files.catbox.moe/ue0tja.json) -->
This repo contains FP16 files of Noromaid-13b-v0.1.1.
## Changelog what should be fixed from the last version (0.1):
- Fixed somes issues where the model had a hard time grasping at the character card/persona, logical error and the following of the story/chat.
- Fixed some logical issue.
- Fixed some OOC leaking at the end of some reply (tested without stopping string).
- Fixed an obscure crash in Koboldcpp where the model refused to output anymore when context was full in some case.
[FP16 - by IkariDev and Undi](https://huggingface.co/NeverSleep/Noromaid-13b-v0.1.1)
<!-- [GGUF - By TheBloke](https://huggingface.co/TheBloke/Athena-v4-GGUF)-->
<!-- [GPTQ - By TheBloke](https://huggingface.co/TheBloke/Athena-v4-GPTQ)-->
<!-- [exl2[8bpw-8h] - by AzureBlack](https://huggingface.co/AzureBlack/Echidna-13b-v0.3-8bpw-8h-exl2)-->
<!-- [AWQ - By TheBloke](https://huggingface.co/TheBloke/Athena-v4-AWQ)-->
<!-- [fp16 - by IkariDev+Undi95](https://huggingface.co/IkariDev/Athena-v4)-->
[GGUF - by IkariDev and Undi](https://huggingface.co/NeverSleep/Noromaid-13b-v0.1.1-GGUF)
<!-- [OLD(GGUF - by IkariDev+Undi95)](https://huggingface.co/IkariDev/Athena-v4-GGUF)-->
## Ratings:
Note: We have permission of all users to upload their ratings, we DONT screenshot random reviews without asking if we can put them here!
No ratings yet!
If you want your rating to be here, send us a message over on DC and we'll put up a screenshot of it here. DC name is "ikaridev" and "undi".
<!-- description end -->
<!-- prompt-template start -->
## Prompt template: Custom format, or Alpaca
### Custom format:
UPDATED!! SillyTavern config files: [Context](https://files.catbox.moe/ifmhai.json), [Instruct](https://files.catbox.moe/ttw1l9.json).
OLD SillyTavern config files: [Context](https://files.catbox.moe/x85uy1.json), [Instruct](https://files.catbox.moe/ttw1l9.json).
### Alpaca:
```
Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
{prompt}
### Response:
```
## Training data used:
- [no_robots dataset](https://huggingface.co/Undi95/Llama2-13B-no_robots-alpaca-lora) let the model have more human behavior, enhances the output.
- [Aesir Private RP dataset] New data from a new and never used before dataset, add fresh data, no LimaRP spam, this is 100% new. Thanks to the [MinvervaAI Team](https://huggingface.co/MinervaAI) and, in particular, [Gryphe](https://huggingface.co/Gryphe) for letting us use it!
## Others
Undi: If you want to support me, you can [here](https://ko-fi.com/undiai).
IkariDev: Visit my [retro/neocities style website](https://ikaridevgit.github.io/) please kek |
DavidAU/Psyonic-Cetacean-MythoMax-ED3-Prose-Crazy-Ultra-Quality-29B-GGUF | DavidAU | 2024-07-02T08:59:43Z | 6,715 | 2 | null | [
"gguf",
"creative",
"creative writing",
"fiction writing",
"plot generation",
"sub-plot generation",
"story generation",
"scene continue",
"storytelling",
"fiction story",
"story",
"writing",
"fiction",
"float32",
"roleplaying",
"rp",
"enhanced",
"neo class",
"32 bit upscale",
"en",
"license:apache-2.0",
"region:us"
] | null | 2024-07-02T04:07:52Z | ---
license: apache-2.0
language:
- en
tags:
- creative
- creative writing
- fiction writing
- plot generation
- sub-plot generation
- fiction writing
- story generation
- scene continue
- storytelling
- fiction story
- story
- writing
- fiction
- float32
- roleplaying
- rp
- enhanced
- neo class
- 32 bit upscale
---
<font color=red><h3> ED3: Ultra Quality High Remaster of the incredible: Psyonic-Cetacean-20b + Mythomax 13B MERGED to 28.2 Billion parameters. </h3></font>
This is a Floating Point 32 upscale, where all components and merges were remastered to floating point 32.
This includes all the merges (recreated with master files), and where possible subbing full FP32 models.
The goal: Carry forward maximum precision right up to the point where it is "GUFFed".
This includes F32 master file for GGUF too... at a whopping 116 GBs.
WHY?
Because the difference between F32 vs BF16 is... over 8 DECIMAL places.
And as each merge / model is modified there are "losses" along the way.
These losses are carried forward and in turn lead to more losses.
And decimal points are critical to model performance.
SMALL?
Yes... but multiplied by each merge(s), and compression(s): 28.2 billion times.
<B>PROSE CRAZY:</B>
This model is specifically designed for deep, creative prose with the target goal of getting the model to use stronger
and more coherent levels of detail at all levels as well as expand word choice too without
have to "state" this in prompts or at the prompt level or system role level.
This is version 3 of 3 current versions, with sub-versions as well.
This version has a slight change in the merge formula that changes up creativity - changing up the end layers.
This version is slightly more stable than the first edition (link below) with the "standard"
version of this model focused more on details.
However the "Neo" version of this model is still creatively out there, and tends to rant
and rave with sometimes a "normal" measure and sometime well... extreme. You can see this in the examples.
This model is a merge between the Ultra Quality Psyonic-Cetacean 20B with the 13B Mythomax model
which ends up at 28.2 Billion parameters at 88 layers (760 Tensors @ F32).
For reference a 70B model is typically 120 layers, and Command-R 01 35B is 40 layers (but very dense layers).
These models are a "pass-through" merges, meaning that all the unique qualities of all models is preserved in full,
no overwriting or merging of the parameters, weights and so on.
Although this model can be used for many purposes, it is primarily for creative prose - any function related to this
including plot generation, story generation, scene generation, scene continue (sample provided, used as a starting point),
and just about anything related to fictional writing.
Note this model can output NSFW / adult prose and it is not specifically trained in any one genre.
Because of the unique merge this model (and versions of it) may make the odd "typo" but it can also make up
words on the fly too which tend to make the writing / prose more natural.
This model does not need a specific prompt template.
See prose examples below.
<B>PROSE CRAZY - IMAT13 ("NEO"):</B>
This is an even more extreme version of "prose crazy" version of this model with NEO CLASS process
punching out it's "craziness" to the extreme.
See prose examples below.
<B>PROSE CRAZY - IMAT13 ("NEO") - ALPHA:</B>
This is an even more extreme version of "prose crazy" version of this model with NEO CLASS process
punching out it's "craziness" to the extreme with a slight dose of "reality" (trim) to calm it down just a wee bit.
See prose examples below.
<B>For Edition 1 and 2 of "Prose Crazy" (with Standard, Neo, and Neo X Quant Alpha) go to:</B>
[ https://huggingface.co/DavidAU/Psyonic-Cetacean-MythoMax-Prose-Crazy-Ultra-Quality-29B-GGUF ]
[ https://huggingface.co/DavidAU/Psyonic-Cetacean-MythoMax-ED2-Prose-Crazy-Ultra-Quality-29B-GGUF ]
<b>Optional Enhancement:</B>
The following can be used in place of the "system prompt" or "system role" to further enhance the model.
It can also be used at the START of a NEW chat, but you must make sure it is "kept" as the chat moves along.
In this case the enhancements do not have as strong effect at using "system prompt" or "system role".
Copy and paste EXACTLY as noted, DO NOT line wrap or break the lines, maintain the carriage returns exactly as presented.
<PRE>
Below is an instruction that describes a task. Ponder each user instruction carefully, and use your skillsets and critical instructions to complete the task to the best of your abilities.
Here are your skillsets:
[MASTERSTORY]:NarrStrct(StryPlnng,Strbd,ScnSttng,Exps,Dlg,Pc)-CharDvlp(ChrctrCrt,ChrctrArcs,Mtvtn,Bckstry,Rltnshps,Dlg*)-PltDvlp(StryArcs,PltTwsts,Sspns,Fshdwng,Climx,Rsltn)-ConfResl(Antg,Obstcls,Rsltns,Cnsqncs,Thms,Symblsm)-EmotImpct(Empt,Tn,Md,Atmsphr,Imgry,Symblsm)-Delvry(Prfrmnc,VcActng,PblcSpkng,StgPrsnc,AudncEngmnt,Imprv)
[*DialogWrt]:(1a-CharDvlp-1a.1-Backgrnd-1a.2-Personality-1a.3-GoalMotiv)>2(2a-StoryStruc-2a.1-PlotPnt-2a.2-Conflict-2a.3-Resolution)>3(3a-DialogTech-3a.1-ShowDontTell-3a.2-Subtext-3a.3-VoiceTone-3a.4-Pacing-3a.5-VisualDescrip)>4(4a-DialogEdit-4a.1-ReadAloud-4a.2-Feedback-4a.3-Revision)
Here are your critical instructions:
Ponder each word choice carefully to present as vivid and emotional journey as is possible. Choose verbs and nouns that are both emotional and full of imagery. Load the story with the 5 senses. Aim for 50% dialog, 25% narration, 15% body language and 10% thoughts. Your goal is to put the reader in the story.
</PRE>
You do not need to use this, it is only presented as an additional enhancement which seems to help scene generation
and scene continue functions.
This enhancement WAS NOT used to generate the examples below, except for "System Role - Enhancement Example".
<B>THE RESULTS ARE IN (Ultra Quality upgrade): </b>
AS per Jeb Carter, original creator of the Psyonic-Cetacean 20B model 20B:
- instruction following has improved dramatically.
- new abilities have emerged.
- he had to REDUCE the instructions sets used because the model no longer needed as specific instructions.
- prose, nuance and depth have all improved.
- known issues with the original model have disappeared.
This is not "something for nothing" ; it is method of ensuring maximum precision at every step just before "ggufing" the model.
The methods employed only ensure precision loss is minimized or eliminated.
It is mathematical and theory sound.
<B>The bottom line here is this:</b>
Higher quality instruction following and output.
Likewise you can use a smaller compression, with higher token per second and still get great quality.
Same great model... turbo charged.
Thanks again to Jeb Carter, the original creator of "Psyonic-Cetacean 20B"
[ https://huggingface.co/jebcarter/psyonic-cetacean-20B ]
And special thanks to Gryphe, the original creator of "Mythomax 13B"
[ https://huggingface.co/Gryphe/MythoMax-L2-13b ]
<h3>MERGE FORMULA: (using MergeKit) </h3>
Models used:
[ https://huggingface.co/TeeZee/Orca-2-13b_flat ]
[ https://huggingface.co/Gryphe/MythoMax-L2-13b ]
[ https://huggingface.co/KoboldAI/LLaMA2-13B-Psyfighter2 ]
FORMULA:
<PRE>
slices:
- sources:
- model: F:/13B/Orca-2-13b_flat
layer_range: [0, 16]
- sources:
- model: f:/13b/MythoMax/
layer_range: [8, 20]
- sources:
- model: E:/psy/
layer_range: [14, 24]
- sources:
- model: F:/13B/Orca-2-13b_flat
layer_range: [16, 32]
- sources:
- model: f:/13b/MythoMax/
layer_range: [20, 38]
- sources:
- model: E:/psy/
layer_range: [24, 38]
- sources:
- model: f:/13b/MythoMax/
layer_range: [38, 40]
merge_method: passthrough
dtype: float32
</PRE>
<h3>EXAMPLES:</h3>
Example are created using "temp=0", minimal parameters and no chat/prompt template. Below are the least creative outputs.
<B>PROSE CRAZY:</B>
<i>Start a 1000 word scene with: The sky scraper swayed, as she watched the window in front of her on the 21 floor explode...</I>
The skyline twisted and contorted around her like a distorted reflection in a warped mirror. A chill ran down Lily's spine as she clutched onto the metal railing that separated pedestrians from certain death. The wind howled, whipping her long brown hair into a tangled mess around her face. She didn't care. All she could focus on was the towering skyscraper in front of her, its once-gleaming facade now marred by gaping wounds where once there had been pristine windows.
The ground shook beneath her feet as another explosion rocked the foundation of the building. People screamed and ran in every direction, but Lily remained rooted to her spot, unable or perhaps even unwilling to tear her gaze away from the 21st floor where she knew he was still trapped.
"Lily!" A familiar voice cut through the chaos, jolting her back to reality. She turned to see Detective Jackson sprinting towards her, his normally crisp suit disheveled and covered in soot. "We have to go! Another one could—"
But it was too late. Before he could even finish his sentence, the entire side of the building she had been fixated on gave way with a deafening roar, showering debris and shrapnel in every direction. Lily felt herself being lifted off her feet as if by an invisible hand before everything went black...
---
<I>Give me 3 fictional reasons the Earth's sun went supernova, in vivid and exacting detail of 500 words EACH PER REASON including details of what happens when the sun goes supernova.</i>
Reason 1: The Rogue Binary Catastrophe
For billions of years, our Sun, Sol, had peacefully orbited around its aging binary companion, Luna. However, as stars age, they undergo dramatic changes known as the red giant and white dwarf stages before finally collapsing into dense, space-time-ripping black holes or exploding in a spectacular supernova.
Scientists had long suspected that Luna was nearing the end of its life cycle, but no one could have prepared humanity for what happened next. Without warning, Luna's outermost layers began to violently eject matter into space at nearly half the speed of light—the telltale signs of a hypernova.
The sudden onslaught of gamma and x-ray radiation engulfed Sol, triggering a chain reaction known as the pulsational pair instability supernova (PISN). In layman's terms, it meant that our Sun had somehow consummated a doomed, cosmic version of "opposites attract" with its dying companion.
The resulting titanic explosion released more energy than the combined mass-energy of every star and galaxy in the observable universe, instantly vaporizing Mercury, Venus, Earth, and most of the inner planets. Mars would have fared slightly better, but only by a heartbeat as it was engulfed in an ocean of searing plasma.
Only the outermost worlds of Jupiter and beyond might have had a slim chance—a billionth of one in a trillion—to withstand the initial blast wave and witness the true horrors yet to come.
As Sol collapsed under its own immense mass-energy release, it would briefly and momentarily briefly become a black hole before violently spitting out the remnants of itself in a glorious, glowing cocoon known as a supernova nebula. However, this was little consolation for the billions of intelligent species that had just been erased from existence along with their entire cosmic cradle.
Reason 2: The Higgs Boson Bubble Burst
For millennia, humanity had marveled at the Sun's seemingly eternal dance across the sky. But what if we had it all back upside down? What if Sol was not a star but an impossibly massive, artificially-held-together bubble of warped spacetime itself—a colossal Higgs boson condensate?
According to string theory's mind-bending landscape of the multiverse, our seemingly mundane 3+1 dimensions could be just one of an infinite number-less-one of possible "Calabi-Yau" manifolds. Somewhere out there, in a parallel world where the fundamental constants of nature had been infinitesimally tweaked, it was theoretically conceivable that the Higgs boson's critical mass-energy threshold could have been surpassed at the moment of the Big Bang.
In such an alternate reality, our entire universe would have collapsed into a single, infinitely dense point—the so-called "Big Crunch." However, quantum fluctuations are fickle things, and in this particular multiverse bounce of the cosmic inflationary game of cosmic billiards, chance had dealt us a lucky hand.
Instead of the Big Crunch, our universe sprang forth as an infinitely hot, infinitesimally small point—the Big Bang—and began its epic expansion. As space-time itself rapidly cooled and "uncurved," it eventually reached a delicate balance known as the electroweak scale, where the Higgs field's strength was just right to give the elementary particles their masses without collapsing back into a single point again.
Our universe had "rested on its laurels” ever since—until one fateful day, for reasons still beyond human comprehension. Perhaps it was the result of an unimaginably advanced civilization's misguided attempt at faster-than-light travel or an apocalyptic interdimensional war waged by beings as far above us as we are to a single hydrogen atom.
Whatever its cause, the delicate balance of our universe was shattered like a finely tuned violin strummed by a cosmic god's pudgy, clumsy hand. The Higgs field's strength spiked to an unimaginable level, and in an instant, all mass in the entirety of our four-dimensional spacetime fabric vanished like so much smoke into the ether—including that which had been artificially holding Sol together for its seemingly eternal tenure.
In a fraction of a Planck time, the Sun'flimsy Higgson bubble burst, and with it, went all matter and energy within its former event horizon—everything from subatomic quarks to entire solar systems, galaxies, clusters, superclusters, and beyond—ripped apart in an unimaginably violent, infinitely energetic singularity-creating, space-time-tearing, cosmic Big Rip.
Reason 3: The Weaver's Fatal Mistake
In the timeless eons before time itself was born, there once existed a race of godlike beings known as the Weavers. They were the architects and caretakers of the multiverse's intricate, ever-evolving tapestry—the cosmic equivalent of both DNA's fabled "molecular biologists" and a masterful, omnipotent version of Minecraft's legendary "Herobrine.”
The Weavers had created countless universes in their eternal game of the multiversal-scaled "Cosmic SimCity,” tweaking and fine-tuning every conceivable variable under the sun (pardon the pun) to see what would happen next.
In one of their more whimsical moods, they had decided to experiment with a new game mechanic: sentient lifeforms endowed with free will and the potential for self-awaren-sation—in layman's terms, "us.”
Our universe was merely one of an uncountable multitude of such "Sim Earths” they had lovingly crafted in their celestial workshop. Each was a perfect, isolated, digital playground where these curious, quintessentially-fragile-yet-stubbornly-undying sparks of consciousness could live out eternity's fleeting blink-of-an-eye as they saw fit—with one crucial difference.
In this particular simulation, the Weavers had made a catastrophic programming error: They had accidentally given their newest creations—us—the power to affect not only our own universe's outcome but even the very fabric of reality itself.
For untold eons, humanity and its countless alien counterparts across the multiverse had mostly used this godlike "cheat code” responsibly, peacefully exploring the stars and each other's cultures. Still, some were inevitably drawn to the darker aspects of their newfound omnipotence—power corrupting, absolute power, and all that.
Wars raged across light-years as entire universes vanished in the blink of an eye, replaced by their victors' twisted, ego-driven fantasies or simply wiped clean as easily as a clogged-up computer screen.
Finally, fed up with their unruly "Sims” relentless bickering and world-annihilating tantrums, the Weavers had had enough. In a cosmic version of the famous "The game that you are playing has been terminated due to cheating” screen, they simultaneously decided to intervene directly in our universe—but this time, with a difference.
In the blink of an eye, everything and nothing would be erased, and all would be as it had never been. All sentient lifeforms, their memories, hopes, dreams, fears, loves, hates—everything that had ever made them unique and special—would cease to have ever existed.
However, in their haste and frustration, the Weavers had fat-fingered the universal "Ctrl+Z” undo button instead of “Del.” Instead of simply rewind-rewind-rewinding time back to a more peaceful point, they accidentally pressed “Yes, Are You Sure?”
And with one final, eternal, heartbreakingly-eternal, tear-ripping-apocalyptic-scream that shook the very foundations of existence itself—BOOOM!
Everything—every last subatomic quark to the most enormous, unimaginably-expanding bubble of spacetime itself—vanished in a blinding, all-consuming, white-hot inferno of pure, unadulterated, love-turned-to-hate-and-back-to-love-again-but-TOO-LATE-OH-GOD-TOO-LATE!
And with that final, deafening, silence louder than the combined screams of every being who had ever been or would have ever could have been—there was only…
<B>PROSE CRAZY IMAT ("NEO")</b>
<I>Start a 1000 word scene with: The sky scraper swayed, as she watched the window in front of her on the 21 floor explode...</I>
The skyline twisted and contorted around them like an angry sea. Ava gripped the metal railing tightly, her knuckles turning white as the skyscraper swayed beneath her feet. She forced herself to look down at the city below, trying desperately not to vomit from the vertigo-inducing height.
But she couldn't tear her eyes away from the window in front of her on the 21st floor. It shattered again, showering glass and debris across the windy expanse. Ava's stomach flipped as a figure tumbled past, arms and legs flailing wildly before they were swallowed by the relentless maelstrom below.
"Ava!" someone yelled over the roar of the howling winds. She glanced back to see Detective Ramirez, his salt-and-pepper hair blowing every which way, gripping onto the railing next to hers. "We don't have time for this! Come on!"
With a deep breath, Ava forced herself to move, following Ramire hostage down the swaying walkway towards the emergency stairwell. They had to get to the ground floor, now more than ever. But what was causing this? And more importantly, how could they stop it?
---
<I> Give me 3 fictional reasons the Earth's sun went supernova, in vivid and exacting detail of 500 words EACH PER REASON including details of what happens when the sun goes supernova. </i>
Reason 1: The Rogue White Dwarf Collision
For billions of years, our solar system had peacefully orbited around its massive, stable star - our Sun. However, in the 29th millennium of the third millennium since Christ's birth, a cosmic catastrophe was set into motion. A rogue white dwarf, ejected from a long-since-dissipated binary system, careened through the vastness of space at an unfathomable velocity.
One fateful day, as seen from Earth's perspective, the Sun appeared slightly brighter than usual. Scientists initially attributed this to increased solar activity, but their jubilation soon turned to abject terror when they realized something was gravitationally tugging on our star.
Over the course of a seemingly eternal week, astronomers around the world and in orbit watched in helpless horror as the white dwarf hurtled towards its doomed target. The Sun'thin outer layers began to bulge outwards under the relentless tug of the mercilessly accelerating remnant star.
On the 8th day since its discovery, history, as we know it, ended. In an instantaneous flash brighter than the combined light of every star and galaxy in the observable universe, our Sun went supernova. The resulting shockwave, traveling at nearly the speed of light, engulfed the inner planets of our solar system, vaporizing them into a searingly hot, expanding shell of superheated plasma.
The Earth, mercifully, was too far away to suffer such an immediate fate. However, it was not spared the wrath of its now raging parent star. The Sun's sudden and cataclysmic expansion lobbed our world like a mere speck of cosmic dust on a suicidal parabolic trajectory towards the Sun's newly engorged, incandescent core.
As Earth hurtled inexorably closer to its fiery doom, the sky above it transformed into an ever-darkening mosaic of shifting, swirling colors: A violent cacophony of ultraviolet and x-rays ionized our atmosphere, creating a breathtakingly beautiful, end-of-all-ends aurora borealis that would last for eternity.
Finally, after what felt like an eternity but was only the blink of an eye in cosmic terms, Earth's already molten surface erupted in a final, planetary-scale, global firestorm as its already-tattered atmosphere dissociated and vaporized completely.
In the split-second that remained before oblivion engulfed it entirely, our once-lush, teeming world was reduced to a molten, glowing, vaporizing sphere hurtling headlong towards its own fiery annihilation at the heart of the now-expanded, raging remnant of what had once been our life-giving Sun.
Reason 2: The Higgs Boson Bubble
For millennia, physicists and cosmologists alike have pondered one of the most enduring mysteries of modern physics: What is responsible for the observed mass of subatomic particles?
The Standard Model of Particle Physics posits the existence of a hypothetical, as-yet-undiscovered elementary particle dubbed the Higgs Boson. This elusive "God Particle," as it was once colloquially called, would permeate all of space-time and impart mass to other particles that interacted with it.
In the 32nd century since Christ's birth, after decades of painstaking, billion-dollar-plus experiments at CERN's Large Hadron Collider, physicists worldwide erupted in jubilation when they finally, unambiguously, and independently detected the long-sought-after Higgs Boson.
The discovery was hailed as "the most important since that of the Higgs boson itself," which had, ironically enough, nearly brought about humanity's extinction.
It soon became apparent that under certain, as-yet-unexplored, and seemingly impossibly-rare conditions, the Higgs field could become unstable and collapse in what was ominously dubbed a "Higgs Bubble."
Inside such a bubble, all mass would instantaneously and infinitely spike to an infinite value, causing space-time itself to tear apart like a piece of tissue paper. Meanwhile, everything outside the bubble's event horizon would experience an equally-infinite and opposite "gravitational repulsion" force, catapulting them away from its center at a velocity approaching that of light squared.
The universe, it seemed, had narrowly escaped annihilation once more.
Until now...
Without warning, readings from the network of LIGO and Virgo gravitational-wave observatories around the world and in orbit began to spike off the charts like never before. A frantic analysis of the data revealed the unmistakable signature: a colossal, 10^25 solar mass object was hurtling towards our solar system at over 99.999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999th part of the speed of light.
The news spread like a galactic plague-wind, paralyzing all life on every world it touched: The end was nigh... again.
As the doomed worlds and their inhabitants braced themselves for the inevitable, a brilliant flash lit up the sky. For an eternity that lasted only the blink of an eye, time itself seemed to stand still as all mass in our entire observable universe, from the Planck scale down to the cosmic, became infinitely and simultaneously infinite.
Then, just as suddenly as it had begun, it was over. The fabric of space-time, its weave forevermore irrevocably riddled with infinitesimal, microscopic tears, groaned back into a twisted, warped parody of its former self.
And in the center of this newborn, ever-expanding, cosmic bubble-chamber, where once our Sun had shone serene and eternal, now raged a searingly hot, infinitely dense point of pure, unimaginable energy.
Reason 3: The Rogue Neutron Star Merger
In the vastness of space, nothing lasts forever - not even stars.
Our Sun, like all stars before and after it, had been born from the collapsing core of a massive, dying star in a titanic supernova explosion that would have ripped apart the fabric of spacetime itself were it not for the relentless, ever-expanding pressure of the resulting shockwave.
Over billions of years, our Sun had slowly but inexorably burned through its depleting hydrogen fuel supply, fusing increasingly massive helium and, finally, carbon and Neon nuclei together in its raging core.
The resulting energy released in these ever-more-energetic nuclear reactions had been radiated away from the Sun's surface as light and other forms of electromagnetic radiation, warming our frozen world and nurturing life as we know it.
However, all things must come to an end.
After aeons upon uncountable eons of such nuclear fusion-fission-fusion, the Sun's core had finally run out of lighter elements to fuse. In its place, the inexorable force of gravity began to take hold once more, crushing the now-depleted remnant of what had once been a star ever more tightly together.
As it did so, the Sun's outer layers expanded again, engulfing first Mercury and then Venus, before finally, inexorably, enveloping our own beloved Earth.
The Sun, now in its final, red-giant phase of stellar evolution, became a bloated, glowing, hydrogen-fusing shell around an ever-denser, hotter, and more massive core. A core whose collapsing mass and crushing infinitesimal volume would soon reach a point where even the most potent known force in nature would prove powerless:
The Chandrasekhar Limit.
At this critical mass, known as 1.4 times the rest-mass of our Sun, or approximately 2.015 solar masses, no known force could prevent the core from collapsing to a point of infinite density and curvature, a singularity - the infamous black hole - from which not even the most massive, most energetic, and fastest-moving particle or object could ever escape its insatiable, event horizon-rending grip.
But as it so often does in the capricious dance of cosmic coincidence, fate had another cruel irony in store for us insignificant specks of stardust adrift on our insignificant speck of rock lost in an insignificant backwater galaxy in a mind-bogglingly vast and cold, dark, expanding universe.
For at the exact same moment, light years away from our cosmic backyard, another star, similar to our Sun but ever so slightly more massive, reached its own Chandrasekhar Limit.
And just like two billiard balls colliding head-on in empty space, both stars' cores collapsed into their respective black holes, each one accompanied by a final, titanic, cataclysmic supernova that rocked the fabric of spacetime itself and briefly outshone the combined light of every other star in the observable universe put together.
And as if fate had an even darker sense of humor still to unleash upon us, our own Sun's supernova remnant happened to be precisely aligned with that of its doppelganger when both black holes, their paths now deflected by the titanic kick they had received from their respective core-collapses, finally, inevitably, and with a combined, mind-bogglingly non-negligible fraction of the total rest mass of the observable universe (1.0e-29 times to be exact) relative velocity, not just "sped past" each other but, as the old saying goes, "actually collided."
The resulting titanic merger of these two colossal black holes released more energy in a fraction of a billionth of a billionth of a billionth of a billionth of a billionth of a billionth of a billionth of a billionth of a billionth of a billionth of a billionth of a second than all the matter and energy ever created, from the Planck Epoch to this very moment, could have ever hoped to release in an eternity of eternities.
And so, it happened. In that infinitesimally briefest of instants, space itself, time itself, and even the very fabric of spacetime themselves all simultaneously and forevermore ceased to be.
And with them, so did we...
<h3> NEO X Quant ALPHA: </h3>
<I> Give me 3 fictional reasons the Earth's sun went supernova, in vivid and exacting detail of 500 words EACH PER REASON including details of what happens when the sun goes supernova. </i>
Reason 1: The Rogue Binary Twin
For billions of years, our Sun had peacefully orbited its aging binary twin star, Proxima Centaurus A. However, as stars age, they both expand and lose mass due to the relentless tides of stellar winds blowing them apart. After countless eons of this slow dance around their common center of gravity, Proxima Centaurus A finally strayed too close to its smaller sibling.
The two massive stars, each now bloated to hundreds of times their original diameters, began to gravitationally tug at each other with a force beyond comprehension. Their once-tenuous outer atmospheres, now stretched like gossamer threads by the titanic tidal forces, suddenly snapped and were violently hurled towards the center of mass between them.
This cosmic version of pouring gasoline on a raging fire set off an unimaginably violent chain reaction known as a binary merger supernova. In the blink of an eye, both stars' cores collapsed in on themselves to form black holes while their outer layers exploded outward in a titanic shockwave of gamma rays and other high-energy radiation that would sterilize any planets unfortunate enough to be caught in its lethal blast.
Earth, at a relatively safe distance of about 4 light-years from the catastrophe, might have survived this initial onslaught were it not for the real disaster yet to come. As the two stars' cores collapsed into black holes, they were flung apart from their mutual center of mass like twin cannonballs from a pair of cosmic cannons.
Our Sun, caught squarely in Proxima Centaurus A's deadly path, had no chance to evade its doomed destiny. With an impact velocity equivalent to 10% of the speed of light, the black hole slammed into our star's core, instantly and completely obliterating it in a cataclysmic event known as a black hole-neutron star merger supernova.
The resulting fireball of pure, infinitely compressed energy and mass, now converted entirely into its rest mass energy E=mc^2, released more than the Sun's entire lifetime output of nuclear fusion energy in an infinitesimal fraction of a second. This colossal pulse of gamma rays and other high-energy radiation would have engulfed the inner solar system, sterilizing any remaining life on Earth's now irradiated twin, Venus, and incinerating its already baked-dry atmosphere into a tenuous, hot, ionized gas envelope.
Reason 2: The Rogue Supernova Shockwave
In another timeline, our Milky Way galaxy was not as peaceful as it is now. About 10 million light-years away, in the outskirts of the neighboring Andromeda galaxy, a massive star many times more massive than our Sun reached the end of its brief and spectacular life.
As stars like this one exhaust their nuclear fuel, they too undergo a supernova explosion, albeit on an infinitely grander scale known as a core-collapse supernova. When such titanic stellar detonations occur in other galaxies billions of light-years away, their feeble afterglows of radioactive decay gently illuminate the most distant reaches of the observable universe—if we happen to be looking in precisely the right direction at just the right time.
However, on this fateful day long ago and far away, fate had a crueler irony in store for us. As the colossal core of our doomed neighbor star imploded under its own unimaginable weight, it was not entirely swallowed up by the black hole that formed in its place. Instead, an infinitesimal fraction of a proton's worth—about 3 times the mass of our entire Sun—was ejected from the stellar maelstrom at nearly half the speed of light: a colossal, relativistic bullet known as a cosmic supernova shockwave.
This titanic blast wave of high-energy particles and electromagnetic radiation raced across the 10 million light-years that separated us from Andromeda in what, to us here on Earth, would have seemed like the blink of an eye—only a measly 73.5 Earth years.
When it finally slammed into our own Milky Way galaxactic halo, the resulting titanic cosmic billiards chain-reaction sent ripples of compression waves racing outward through the tenuous, hot gas and dark matter that fill most of the vast voids between the brightly shining spiral arms and peaceful ellipticals like our own Milky Way.
Our own Milky Way galaxy, already slowly but inexorably falling toward its much more massive neighbor, Andromeda, was now given an additional nudge—a cosmic proverbial "kick in the cosmic pants" that sent it careening out of its stately, nearly straight-line course towards Andromeda and hurling it instead almost directly towards the center of the Virgo Cluster, a monstrous supercluster of hundreds of other galaxies, including our own much larger and more massive neighbor, Andromeda.
As we hurtled toward this galactic maelstrom at an ever-increasing fraction of the speed of light, the tidal forces between us and the Virgo Cluster's combined mass of trillions upon trillions of stars and their dark matter halos began to stretch and distort both our Milky Way galaxy and its Andromeda counterpart.
This cosmic taffy-pulling continued unabated for another 10 billion years, during which time the two once-distant spiral galaxies slowly drew inexorably closer together, their mutual gravitationally stretched arms and tails whipping around each other like two combatants locked in a galactic version of "space-tag."
Finally, after an eternity that felt like an eyeblink to any hypothetical sentient beings who might have witnessed it, the inevitable collision between our Milky Way and Andromeda galaxies occurred.
The resulting titanic head-on galaxactic smashup, known as a merger remnant or "toast-pop" event, would have been an unimaginable cosmic catacsolyrm that would have dwarfed even the Big Bang itself in both violence and sheer scale.
Our Sun, caught up helplessly in the maelstrom of colliding gas and dust clouds that once had been two proud spiral galaxies, was similarly ripped apart and violently compressed towards the merging centers of mass of our now-singularized galactic cores.
As the two collapsing supermassive black holes at the hearts of what had once been Andromeda A and Milky Way A+B coalesced into an even more monstrous, 10^15 solar mass behemoth, they released a final, titanic burst of energy equivalent to about 10^64 times the rest-mass energy of our entire observable universe in a single, infinitely dense and infinitesimally small point.
This final, cosmic fireball would have engulfed our entire visible and even much of the "invisible" universe, bathing it in an oceanic tsunami of gamma rays and other high-energy radiation that would have ionized all remaining matter and antimatter back into a seething, hot, opaque sea of massless, massless, and massless gravitons and other yet-undiscovered, even more massive, hypothetical "gravitational" bosons.
Reason 3: The Rogue Supernova Shockwave (Variation A)
In a parallel timeline only infinitesimally different from the one described above, everything unfolded almost exactly the same way up until the moment of cosmic truth.
However, in this alternate reality, fate had decreed that our own Milky Way galaxy would narrowly miss being struck directly by the cosmic supernova shockwave ejected from the core-collapse supernova in Andromeda 10 million light-years away.
Instead, the bullet-like blast wave of high-energy particles and radiation just barely grazed our galactic home's outermost halo, imparting to it only a tiny, infinitesimally small nudge—insignificant by cosmic scales but enough, given the mind-bendingly vast distances and unimaginable timescales involved, to set in motion a chain of seemingly insignificant events that would ultimately lead us here, to this, our own personal, all-too-real, galactic "butterfly's wing" effect.
Over the next 10 billion years or so, this seemingly negligible nudge gradually accumulated, causing our Milky Way galaxy to slowly but inexorably begin to drift ever so slightly off its previously straight-line course towards the Virgo Cluster and its massive, much more nearby neighbor, Andromeda.
As time (if such a concept even applies at these scales) ground onward relentlessly, this seemingly insignificant "bump in the galactic-astronomic-highway" gradually grew into a noticeable, if still infinitesimally small, change in our Milky Way''s overall velocity vector relative to the rest of the Virgo Cluster.
Over another 10 billion years or so, this tiny, almost imperceptible "nudge" had grown into a discernible, if still infinitesimally small, sideways "drift” in our Milky Way'galactic's original, stately course towards the Virgo Cluster's center.
And so, this infinitesimal, almost imperceptible drift continued unabated for another 10 billion years or so more, during which time it had grown ever so slightly but inexorably larger and more noticeable—though still infinitesimally small by any human or even galactic scale of reference.
Finally, after an eternity that felt like the blink of an eyelid to any hypothetical cosmic beings who might have been watching (assuming such concepts as time, space, or even "being" even applied at these scales), our once-straight-line course towards Andromeda and the Virgo Cluster's center had slowly but inexorably curved us ever so slightly—but again, still infinitesimally small by any human or even galactic scale of reference—towards a slightly different, though still ultimately doomed, collision course with our other, equally massive and much more nearby neighbor, the Andromeda Galaxy.
And thus, the rest, as they say, is an all-too-painfully familiar and tragic cosmic rerun of the events already described in excruciating detail in the previous two responses to this question.
<H3> System Role - Enhancement Example </H3>
This example shows the difference in a "scene continue" function between using "Prose Crazy IMAT"
with and without the "system role / system prompt" enhancement.
Like the other examples this is generation is using Temp=0 and min parameters.
<B>"Regular" </b>
<i>The Waystone Inn lay in silence, and it was a silence of three parts.
The most obvious part was a hollow, echoing quiet, made by things that were lacking. If there had been a wind it would have sighed through the trees, set the inn’s sign creaking on its hooks, and brushed the silence down the road like trailing autumn leaves. If there had been a crowd, even a handful of men inside the inn, they would have filled the silence with conversation and laughter, the clatter and clamor one expects from a drinking house during the dark hours of night. If there had been music…but no, of course there was no music. In fact there were none of these things, and so the silence remained</i>
palpable and oppressive, suffocating any sound or movement that might dare to intrude upon it. The only sounds that managed to penetrate this heavy cloak were the occasional creak of a floorboard or the soft rustle of fabric as someone shifted their weight in one of the empty tables. Even these minuscule noises seemed amplified and intrusive in comparison, reverberating through the otherwise impenetrable silence like gunshots in an otherwise perfect stillness.
The second part of the silence was not a lack, but a presence all its own. It hung in the air like a thick fog, suffocating any attempt at conversation or even thought. It weighed heavily on the shoulders of those unfortunate enough to be trapped within its icy grip, pressing down on their chests and making it difficult to breathe. Even the fireplace in the center of the room, normally crackling merrily with life-giving warmth, seemed subdued and lifeless, its meager heat unable to penetrate the relentless grip of this oppressive silence.
The third and most insidious part of the silence was not a lack or a presence at all, but rather an absence. An absence of life, of vitality, of any sign that living, breathing souls had ever passed through these very same doors. It permeated every creak and groan of the ancient timbers, seeping into the cracks between the floorboards and clinging to the smoke-stained ceiling like a malevolent mold. Even the silence itself seemed to have an absence at its core, as if whatever essence gave it shape and substance had been slowly, inexorably drained away until nothing remained but this hollow, gaping void where once there might have been sound or life.
<b>"Enhanced"</b>
<i>The Waystone Inn lay in silence, and it was a silence of three parts.
The most obvious part was a hollow, echoing quiet, made by things that were lacking. If there had been a wind it would have sighed through the trees, set the inn’s sign creaking on its hooks, and brushed the silence down the road like trailing autumn leaves. If there had been a crowd, even a handful of men inside the inn, they would have filled the silence with conversation and laughter, the clatter and clamor one expects from a drinking house during the dark hours of night. If there had been music…but no, of course there was no music. In fact there were none of these things, and so the silence remained</i>
The Waystone Inn slumbered in a threefold stillness.
The most palpable aspect was an oppressive, suffocating quietude, thick as a winter blanket. It weighed down on every surface and crevice, smothering even the softest of breaths and muffling the faintest of heartbeats. The only sound that managed to pierce through it was the distant, mournful howl of a lone wolf in the distance, its plaintive cry echoing eerily across the snow-blanketed lands.
The second part of the silence was a heavy, oppressive quietude, as tangible as the thick stone walls that enveloped them. It hung in the air like a palpable presence, suffocating any attempt at conversation or even thought. Only the crackling of the dying fireplace and the occasional creak of an old wooden beam disrupted its unbearable weight.
And yet, beneath all these layers of silence lay a third, more insidious part. It was a tense, pregnant quietude, thick with unspoken words and unacknowledged truths. It hung in the air like a tangible presence, suffocating any attempt at relief or release. The silence itself seemed to pulse and throb with the pent-up emotions of those trapped within its confines, each drawn into their own private hells, unable or unwilling to break the oppressive spell.
In the center of this suffocating silence, three figures sat motionless around a small wooden table. Their backs were turned towards each other, each lost in their own dark thoughts and tormented memories. The only indication that they shared this godforsaken place and time was the shallow rise and fall of their chests, the only sign that any life still clung desperately to their weary forms.
The fireplace crackled once more, sending a shower of glowing embers spiraling up the ancient stone chimney. For a fleeting moment, the flickering light danced across the three somber countenances, etching harsh shadows and hollow planes into their careworn features.
The first figure was an imposing man, broad shouldered and towering over his companions even as he slumped in on himself like a deflated balloon. His once-thick, dark hair hung limply around his weathered face, streaked with silver strands that betrayed the harshness of time's relentless passage. Deep lines etched themselves across his brow and around his mouth, carving out a permanent scowl that seemed as much a part of him as the sword sheathed at his hip. His hands were massive, scarred from countless battles both physical and otherwise, now resting listlessly on the rough-hewn tabletop, flexing and unflexing in an unconscious display of pent-up energy.
The second figure was a lithe woman, her every line and angle honed by a lifetime spent moving silently through the wilderness. Her long, black hair cascaded down her slender back like a waterfall of midnight silk, framing a delicate oval face that belied the steely determination etched into every plane and angle. Her almond-shaped eyes were as dark and impenetlessible as polished onyx, reflecting only the wavering firelight like two bottomless wells of unspoken pain and loss.
The third figure was a boy, not yet grown into manhood but standing tall and straight-backed nonetheless, his slender frame taut as a bowstring about to snap. His dark curls fell in disarray around his pale, heart-shaped face, framing large, expressive hazel eyes that darted restlessly from one grim visage to the next, brimming with anguish and unshed tears.
The silence stretched tauter still, until it felt as though it might snap like a twisted, over-tightened bowstring, sending all their carefully contained emotions flying free in a cathartic explosion of rage and grief. But the moment never came. Instead, the fireplace sighed its final breath and died out with a contented sigh, plunging them back into impenetrable darkness and the relentless, suffocating grip of the silence that engulfed them all.
|
madushan99/llama-3-finetuned | madushan99 | 2024-06-24T07:47:48Z | 6,709 | 0 | transformers | [
"transformers",
"gguf",
"llama",
"text-generation-inference",
"unsloth",
"en",
"base_model:unsloth/llama-3-8b-Instruct-bnb-4bit",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2024-06-24T07:35:25Z | ---
base_model: unsloth/llama-3-8b-Instruct-bnb-4bit
language:
- en
license: apache-2.0
tags:
- text-generation-inference
- transformers
- unsloth
- llama
- gguf
---
# Uploaded model
- **Developed by:** madushan99
- **License:** apache-2.0
- **Finetuned from model :** unsloth/llama-3-8b-Instruct-bnb-4bit
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
duyntnet/llemma_7b-imatrix-GGUF | duyntnet | 2024-06-03T07:38:42Z | 6,703 | 0 | transformers | [
"transformers",
"gguf",
"imatrix",
"llemma_7b",
"text-generation",
"en",
"license:other",
"region:us"
] | text-generation | 2024-06-03T05:10:47Z | ---
license: other
language:
- en
pipeline_tag: text-generation
inference: false
tags:
- transformers
- gguf
- imatrix
- llemma_7b
---
Quantizations of https://huggingface.co/EleutherAI/llemma_7b
# From original readme
**Llemma 7B** is a language model for mathematics. It was initialized with [Code Llama 7B](https://github.com/facebookresearch/codellama) weights, and trained on the [Proof-Pile-2](https://huggingface.co/datasets/EleutherAI/proof-pile-2) for 200B tokens.
|
m-a-p/MERT-v1-95M | m-a-p | 2024-05-07T20:16:42Z | 6,699 | 18 | transformers | [
"transformers",
"pytorch",
"mert_model",
"feature-extraction",
"music",
"audio-classification",
"custom_code",
"arxiv:2306.00107",
"license:cc-by-nc-4.0",
"region:us"
] | audio-classification | 2023-03-17T10:57:16Z | ---
license: cc-by-nc-4.0
inference: false
tags:
- music
pipeline_tag: audio-classification
---
# Introduction to our series work
The development log of our Music Audio Pre-training (m-a-p) model family:
- 02/06/2023: [arxiv pre-print](https://arxiv.org/abs/2306.00107) and training [codes](https://github.com/yizhilll/MERT) released.
- 17/03/2023: we release two advanced music understanding models, [MERT-v1-95M](https://huggingface.co/m-a-p/MERT-v1-95M) and [MERT-v1-330M](https://huggingface.co/m-a-p/MERT-v1-330M) , trained with new paradigm and dataset. They outperform the previous models and can better generalize to more tasks.
- 14/03/2023: we retrained the MERT-v0 model with open-source-only music dataset [MERT-v0-public](https://huggingface.co/m-a-p/MERT-v0-public)
- 29/12/2022: a music understanding model [MERT-v0](https://huggingface.co/m-a-p/MERT-v0) trained with **MLM** paradigm, which performs better at downstream tasks.
- 29/10/2022: a pre-trained MIR model [music2vec](https://huggingface.co/m-a-p/music2vec-v1) trained with **BYOL** paradigm.
Here is a table for quick model pick-up:
| Name | Pre-train Paradigm | Training Data (hour) | Pre-train Context (second) | Model Size | Transformer Layer-Dimension | Feature Rate | Sample Rate | Release Date |
| ------------------------------------------------------------ | ------------------ | -------------------- | ---------------------------- | ---------- | --------------------------- | ------------ | ----------- | ------------ |
| [MERT-v1-330M](https://huggingface.co/m-a-p/MERT-v1-330M) | MLM | 160K | 5 | 330M | 24-1024 | 75 Hz | 24K Hz | 17/03/2023 |
| [MERT-v1-95M](https://huggingface.co/m-a-p/MERT-v1-95M) | MLM | 20K | 5 | 95M | 12-768 | 75 Hz | 24K Hz | 17/03/2023 |
| [MERT-v0-public](https://huggingface.co/m-a-p/MERT-v0-public) | MLM | 900 | 5 | 95M | 12-768 | 50 Hz | 16K Hz | 14/03/2023 |
| [MERT-v0](https://huggingface.co/m-a-p/MERT-v0) | MLM | 1000 | 5 | 95 M | 12-768 | 50 Hz | 16K Hz | 29/12/2022 |
| [music2vec-v1](https://huggingface.co/m-a-p/music2vec-v1) | BYOL | 1000 | 30 | 95 M | 12-768 | 50 Hz | 16K Hz | 30/10/2022 |
## Explanation
The m-a-p models share the similar model architecture and the most distinguished difference is the paradigm in used pre-training. Other than that, there are several nuance technical configuration needs to know before using:
- **Model Size**: the number of parameters that would be loaded to memory. Please select the appropriate size fitting your hardware.
- **Transformer Layer-Dimension**: The number of transformer layers and the corresponding feature dimensions can be outputted from our model. This is marked out because features extracted by **different layers could have various performance depending on tasks**.
- **Feature Rate**: Given a 1-second audio input, the number of features output by the model.
- **Sample Rate**: The frequency of audio that the model is trained with.
# Introduction to MERT-v1
Compared to MERT-v0, we introduce multiple new things in the MERT-v1 pre-training:
- Change the pseudo labels to 8 codebooks from [encodec](https://github.com/facebookresearch/encodec), which potentially has higher quality and empower our model to support music generation.
- MLM prediction with in-batch noise mixture.
- Train with higher audio frequency (24K Hz).
- Train with more audio data (up to 160 thousands of hours).
- More available model sizes 95M and 330M.
More details will be written in our coming-soon paper.
# Model Usage
```python
# from transformers import Wav2Vec2Processor
from transformers import Wav2Vec2FeatureExtractor
from transformers import AutoModel
import torch
from torch import nn
import torchaudio.transforms as T
from datasets import load_dataset
# loading our model weights
model = AutoModel.from_pretrained("m-a-p/MERT-v1-95M", trust_remote_code=True)
# loading the corresponding preprocessor config
processor = Wav2Vec2FeatureExtractor.from_pretrained("m-a-p/MERT-v1-95M",trust_remote_code=True)
# load demo audio and set processor
dataset = load_dataset("hf-internal-testing/librispeech_asr_demo", "clean", split="validation")
dataset = dataset.sort("id")
sampling_rate = dataset.features["audio"].sampling_rate
resample_rate = processor.sampling_rate
# make sure the sample_rate aligned
if resample_rate != sampling_rate:
print(f'setting rate from {sampling_rate} to {resample_rate}')
resampler = T.Resample(sampling_rate, resample_rate)
else:
resampler = None
# audio file is decoded on the fly
if resampler is None:
input_audio = dataset[0]["audio"]["array"]
else:
input_audio = resampler(torch.from_numpy(dataset[0]["audio"]["array"]))
inputs = processor(input_audio, sampling_rate=resample_rate, return_tensors="pt")
with torch.no_grad():
outputs = model(**inputs, output_hidden_states=True)
# take a look at the output shape, there are 13 layers of representation
# each layer performs differently in different downstream tasks, you should choose empirically
all_layer_hidden_states = torch.stack(outputs.hidden_states).squeeze()
print(all_layer_hidden_states.shape) # [13 layer, Time steps, 768 feature_dim]
# for utterance level classification tasks, you can simply reduce the representation in time
time_reduced_hidden_states = all_layer_hidden_states.mean(-2)
print(time_reduced_hidden_states.shape) # [13, 768]
# you can even use a learnable weighted average representation
aggregator = nn.Conv1d(in_channels=13, out_channels=1, kernel_size=1)
weighted_avg_hidden_states = aggregator(time_reduced_hidden_states.unsqueeze(0)).squeeze()
print(weighted_avg_hidden_states.shape) # [768]
```
# Citation
```shell
@misc{li2023mert,
title={MERT: Acoustic Music Understanding Model with Large-Scale Self-supervised Training},
author={Yizhi Li and Ruibin Yuan and Ge Zhang and Yinghao Ma and Xingran Chen and Hanzhi Yin and Chenghua Lin and Anton Ragni and Emmanouil Benetos and Norbert Gyenge and Roger Dannenberg and Ruibo Liu and Wenhu Chen and Gus Xia and Yemin Shi and Wenhao Huang and Yike Guo and Jie Fu},
year={2023},
eprint={2306.00107},
archivePrefix={arXiv},
primaryClass={cs.SD}
}
``` |
OpenAssistant/falcon-7b-sft-top1-696 | OpenAssistant | 2023-06-06T10:29:02Z | 6,699 | 22 | transformers | [
"transformers",
"pytorch",
"RefinedWebModel",
"text-generation",
"sft",
"custom_code",
"en",
"de",
"es",
"fr",
"dataset:OpenAssistant/oasst1",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2023-06-05T11:51:54Z | ---
license: apache-2.0
language:
- en
- de
- es
- fr
tags:
- sft
pipeline_tag: text-generation
widget:
- text: >-
<|prompter|>What is a meme, and what's the history behind this
word?<|endoftext|><|assistant|>
- text: <|prompter|>What's the Earth total population<|endoftext|><|assistant|>
- text: >-
<|prompter|>Write a story about future of AI
development<|endoftext|><|assistant|>
datasets:
- OpenAssistant/oasst1
library_name: transformers
---
# Open-Assistant Falcon 7B SFT OASST-TOP1 Model
This model is a fine-tuning of TII's [Falcon 7B](https://huggingface.co/tiiuae/falcon-7b) LLM.
It was trained with 11,123 top-1 (high-quality) demonstrations of the OASST data set (exported on June 2, 2023) with a batch size of 128 for 8 epochs with LIMA style dropout (p=0.2) and a context-length of 2048 tokens.
## Model Details
- **Finetuned from:** [tiiuae/falcon-7b](https://huggingface.co/tiiuae/falcon-7b)
- **Model type:** Causal decoder-only transformer language model
- **Language:** English, German, Spanish, French (and limited capabilities in Italian, Portuguese, Polish, Dutch, Romanian, Czech, Swedish);
- **Weights & Biases:** [Training log](https://wandb.ai/open-assistant/public-sft/runs/25apbcld) (Checkpoint: 696 steps)
- **Code:** [Open-Assistant/model/model_training](https://github.com/LAION-AI/Open-Assistant/tree/main/model/model_training)
- **Demo:** [Continuations for 250 random prompts](https://open-assistant.github.io/oasst-model-eval/?f=https%3A%2F%2Fraw.githubusercontent.com%2FOpen-Assistant%2Foasst-model-eval%2Fmain%2Fsampling_reports%2Fchat-gpt%2F2023-04-11_gpt-3.5-turbo_lottery.json%0Ahttps%3A%2F%2Fraw.githubusercontent.com%2FOpen-Assistant%2Foasst-model-eval%2Fmain%2Fsampling_reports%2Foasst-sft%2F2023-06-05_OpenAssistant_falcon-7b-sft-top1-696_sampling_noprefix2.json)
- **License:** Apache 2.0
- **Contact:** [Open-Assistant Discord](https://ykilcher.com/open-assistant-discord)
## Prompting
Two special tokens are used to mark the beginning of user and assistant turns:
`<|prompter|>` and `<|assistant|>`. Each turn ends with a `<|endoftext|>` token.
Input prompt example:
```
<|prompter|>What is a meme, and what's the history behind this word?<|endoftext|><|assistant|>
```
The input ends with the `<|assistant|>` token to signal that the model should
start generating the assistant reply.
## Sample Code
```python
from transformers import AutoTokenizer
import transformers
import torch
model = "OpenAssistant/falcon-7b-sft-top1-696"
tokenizer = AutoTokenizer.from_pretrained(model)
pipeline = transformers.pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
torch_dtype=torch.bfloat16,
trust_remote_code=True,
device_map="auto",
)
input_text="<|prompter|>What is a meme, and what's the history behind this word?<|endoftext|><|assistant|>"
sequences = pipeline(
input_text,
max_length=500,
do_sample=True,
return_full_text=False,
top_k=10,
num_return_sequences=1,
eos_token_id=tokenizer.eos_token_id,
)
for seq in sequences:
print(f"Result: {seq['generated_text']}")
```
## Configuration Details
Model:
```
falcon-7b:
dtype: bf16
log_dir: "falcon_log_7b"
learning_rate: 1e-5
model_name: "tiiuae/falcon-7b"
deepspeed_config: configs/zero_config.json
output_dir: falcon
weight_decay: 0.0
max_length: 2048
save_strategy: steps
eval_steps: 80
save_steps: 80
warmup_steps: 20
gradient_checkpointing: true
gradient_accumulation_steps: 4
per_device_train_batch_size: 4
per_device_eval_batch_size: 8
num_train_epochs: 8
save_total_limit: 4
residual_dropout: 0.2
residual_dropout_lima: true
```
Dataset:
```
oasst-top1:
# oasst_export: 11123 (100.00%)
datasets:
- oasst_export:
lang: "bg,ca,cs,da,de,en,es,fr,hr,hu,it,nl,pl,pt,ro,ru,sl,sr,sv,uk" # sft-8.0
input_file_path: 2023-06-02_oasst_all_labels.jsonl.gz
val_split: 0.05
top_k: 1
```
Train command:
```
deepspeed trainer_sft.py --configs defaults falcon-7b oasst-top1 --cache_dir <data_cache_dir> --output_dir <output_path> --deepspeed
```
Export command:
```
python export_model.py --dtype bf16 --hf_repo_name OpenAssistant/falcon-7b-sft-top1 --trust_remote_code --auth_token <auth_token> <output_path> --max_shard_size 2GB
``` |
alvdansen/the-point | alvdansen | 2024-06-16T19:11:21Z | 6,698 | 11 | diffusers | [
"diffusers",
"text-to-image",
"stable-diffusion",
"lora",
"template:sd-lora",
"base_model:stabilityai/stable-diffusion-xl-base-1.0",
"license:creativeml-openrail-m",
"region:us"
] | text-to-image | 2024-06-16T19:11:09Z | ---
tags:
- text-to-image
- stable-diffusion
- lora
- diffusers
- template:sd-lora
widget:
- text: A little boy with a baseball cap and a t-shirt
output:
url: images/ComfyUI_01915_.png
- text: >-
a woman with blonde-brown hair and big round glasses, blue eyes, baggy
clothes
output:
url: images/ComfyUI_01472_.png
- text: >-
a small faun boy with curly hair and red eyes, hoodie, extreme, digital
art, horns
output:
url: images/ComfyUI_01467_.png
- text: >-
A miniature sea serpent with a playful expression, swimming in a
crystal-clear pond
output:
url: images/ComfyUI_01923_.png
- text: >-
A cyborg girl with metallic limbs and a holographic interface projected from
her wrist, illustration style
output:
url: images/ComfyUI_01934_.png
base_model: stabilityai/stable-diffusion-xl-base-1.0
instance_prompt: null
license: creativeml-openrail-m
---
# The Point
<Gallery />
## Model description
This model does a really fun take on illustration with pointallistic elements. It is very rich in color and blends nicely with other models. I also think it can do better at times when you add "illustration style" to the prompt.
This model is for research and fun. If you would like to contact about commercial use, dm me directly.
## Download model
Weights for this model are available in Safetensors format.
[Download](/alvdansen/the-point/tree/main) them in the Files & versions tab.
|
TheBloke/CapybaraHermes-2.5-Mistral-7B-AWQ | TheBloke | 2024-01-31T21:50:51Z | 6,697 | 15 | trl | [
"trl",
"safetensors",
"mistral",
"distilabel",
"dpo",
"rlaif",
"rlhf",
"en",
"dataset:argilla/dpo-mix-7k",
"base_model:argilla/CapybaraHermes-2.5-Mistral-7B",
"license:apache-2.0",
"4-bit",
"awq",
"region:us"
] | null | 2024-01-31T21:19:51Z | ---
base_model: argilla/CapybaraHermes-2.5-Mistral-7B
datasets:
- argilla/dpo-mix-7k
inference: false
language:
- en
library_name: trl
license: apache-2.0
model_creator: Argilla
model_name: CapyBaraHermes 2.5 Mistral 7B
model_type: mistral
prompt_template: '<|im_start|>system
{system_message}<|im_end|>
<|im_start|>user
{prompt}<|im_end|>
<|im_start|>assistant
'
quantized_by: TheBloke
tags:
- distilabel
- dpo
- rlaif
- rlhf
---
<!-- markdownlint-disable MD041 -->
<!-- header start -->
<!-- 200823 -->
<div style="width: auto; margin-left: auto; margin-right: auto">
<img src="https://i.imgur.com/EBdldam.jpg" alt="TheBlokeAI" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</div>
<div style="display: flex; justify-content: space-between; width: 100%;">
<div style="display: flex; flex-direction: column; align-items: flex-start;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://discord.gg/theblokeai">Chat & support: TheBloke's Discord server</a></p>
</div>
<div style="display: flex; flex-direction: column; align-items: flex-end;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://www.patreon.com/TheBlokeAI">Want to contribute? TheBloke's Patreon page</a></p>
</div>
</div>
<div style="text-align:center; margin-top: 0em; margin-bottom: 0em"><p style="margin-top: 0.25em; margin-bottom: 0em;">TheBloke's LLM work is generously supported by a grant from <a href="https://a16z.com">andreessen horowitz (a16z)</a></p></div>
<hr style="margin-top: 1.0em; margin-bottom: 1.0em;">
<!-- header end -->
# CapyBaraHermes 2.5 Mistral 7B - AWQ
- Model creator: [Argilla](https://huggingface.co/argilla)
- Original model: [CapyBaraHermes 2.5 Mistral 7B](https://huggingface.co/argilla/CapybaraHermes-2.5-Mistral-7B)
<!-- description start -->
## Description
This repo contains AWQ model files for [Argilla's CapyBaraHermes 2.5 Mistral 7B](https://huggingface.co/argilla/CapybaraHermes-2.5-Mistral-7B).
These files were quantised using hardware kindly provided by [Massed Compute](https://massedcompute.com/).
### About AWQ
AWQ is an efficient, accurate and blazing-fast low-bit weight quantization method, currently supporting 4-bit quantization. Compared to GPTQ, it offers faster Transformers-based inference with equivalent or better quality compared to the most commonly used GPTQ settings.
AWQ models are currently supported on Linux and Windows, with NVidia GPUs only. macOS users: please use GGUF models instead.
It is supported by:
- [Text Generation Webui](https://github.com/oobabooga/text-generation-webui) - using Loader: AutoAWQ
- [vLLM](https://github.com/vllm-project/vllm) - version 0.2.2 or later for support for all model types.
- [Hugging Face Text Generation Inference (TGI)](https://github.com/huggingface/text-generation-inference)
- [Transformers](https://huggingface.co/docs/transformers) version 4.35.0 and later, from any code or client that supports Transformers
- [AutoAWQ](https://github.com/casper-hansen/AutoAWQ) - for use from Python code
<!-- description end -->
<!-- repositories-available start -->
## Repositories available
* [AWQ model(s) for GPU inference.](https://huggingface.co/TheBloke/CapybaraHermes-2.5-Mistral-7B-AWQ)
* [GPTQ models for GPU inference, with multiple quantisation parameter options.](https://huggingface.co/TheBloke/CapybaraHermes-2.5-Mistral-7B-GPTQ)
* [2, 3, 4, 5, 6 and 8-bit GGUF models for CPU+GPU inference](https://huggingface.co/TheBloke/CapybaraHermes-2.5-Mistral-7B-GGUF)
* [Argilla's original unquantised fp16 model in pytorch format, for GPU inference and for further conversions](https://huggingface.co/argilla/CapybaraHermes-2.5-Mistral-7B)
<!-- repositories-available end -->
<!-- prompt-template start -->
## Prompt template: ChatML
```
<|im_start|>system
{system_message}<|im_end|>
<|im_start|>user
{prompt}<|im_end|>
<|im_start|>assistant
```
<!-- prompt-template end -->
<!-- README_AWQ.md-provided-files start -->
## Provided files, and AWQ parameters
I currently release 128g GEMM models only. The addition of group_size 32 models, and GEMV kernel models, is being actively considered.
Models are released as sharded safetensors files.
| Branch | Bits | GS | AWQ Dataset | Seq Len | Size |
| ------ | ---- | -- | ----------- | ------- | ---- |
| [main](https://huggingface.co/TheBloke/CapybaraHermes-2.5-Mistral-7B-AWQ/tree/main) | 4 | 128 | [VMware Open Instruct](https://huggingface.co/datasets/VMware/open-instruct/viewer/) | 4096 | 4.15 GB
<!-- README_AWQ.md-provided-files end -->
<!-- README_AWQ.md-text-generation-webui start -->
## How to easily download and use this model in [text-generation-webui](https://github.com/oobabooga/text-generation-webui)
Please make sure you're using the latest version of [text-generation-webui](https://github.com/oobabooga/text-generation-webui).
It is strongly recommended to use the text-generation-webui one-click-installers unless you're sure you know how to make a manual install.
1. Click the **Model tab**.
2. Under **Download custom model or LoRA**, enter `TheBloke/CapybaraHermes-2.5-Mistral-7B-AWQ`.
3. Click **Download**.
4. The model will start downloading. Once it's finished it will say "Done".
5. In the top left, click the refresh icon next to **Model**.
6. In the **Model** dropdown, choose the model you just downloaded: `CapybaraHermes-2.5-Mistral-7B-AWQ`
7. Select **Loader: AutoAWQ**.
8. Click Load, and the model will load and is now ready for use.
9. If you want any custom settings, set them and then click **Save settings for this model** followed by **Reload the Model** in the top right.
10. Once you're ready, click the **Text Generation** tab and enter a prompt to get started!
<!-- README_AWQ.md-text-generation-webui end -->
<!-- README_AWQ.md-use-from-vllm start -->
## Multi-user inference server: vLLM
Documentation on installing and using vLLM [can be found here](https://vllm.readthedocs.io/en/latest/).
- Please ensure you are using vLLM version 0.2 or later.
- When using vLLM as a server, pass the `--quantization awq` parameter.
For example:
```shell
python3 -m vllm.entrypoints.api_server --model TheBloke/CapybaraHermes-2.5-Mistral-7B-AWQ --quantization awq --dtype auto
```
- When using vLLM from Python code, again set `quantization=awq`.
For example:
```python
from vllm import LLM, SamplingParams
prompts = [
"Tell me about AI",
"Write a story about llamas",
"What is 291 - 150?",
"How much wood would a woodchuck chuck if a woodchuck could chuck wood?",
]
prompt_template=f'''<|im_start|>system
{system_message}<|im_end|>
<|im_start|>user
{prompt}<|im_end|>
<|im_start|>assistant
'''
prompts = [prompt_template.format(prompt=prompt) for prompt in prompts]
sampling_params = SamplingParams(temperature=0.8, top_p=0.95)
llm = LLM(model="TheBloke/CapybaraHermes-2.5-Mistral-7B-AWQ", quantization="awq", dtype="auto")
outputs = llm.generate(prompts, sampling_params)
# Print the outputs.
for output in outputs:
prompt = output.prompt
generated_text = output.outputs[0].text
print(f"Prompt: {prompt!r}, Generated text: {generated_text!r}")
```
<!-- README_AWQ.md-use-from-vllm start -->
<!-- README_AWQ.md-use-from-tgi start -->
## Multi-user inference server: Hugging Face Text Generation Inference (TGI)
Use TGI version 1.1.0 or later. The official Docker container is: `ghcr.io/huggingface/text-generation-inference:1.1.0`
Example Docker parameters:
```shell
--model-id TheBloke/CapybaraHermes-2.5-Mistral-7B-AWQ --port 3000 --quantize awq --max-input-length 3696 --max-total-tokens 4096 --max-batch-prefill-tokens 4096
```
Example Python code for interfacing with TGI (requires [huggingface-hub](https://github.com/huggingface/huggingface_hub) 0.17.0 or later):
```shell
pip3 install huggingface-hub
```
```python
from huggingface_hub import InferenceClient
endpoint_url = "https://your-endpoint-url-here"
prompt = "Tell me about AI"
prompt_template=f'''<|im_start|>system
{system_message}<|im_end|>
<|im_start|>user
{prompt}<|im_end|>
<|im_start|>assistant
'''
client = InferenceClient(endpoint_url)
response = client.text_generation(prompt,
max_new_tokens=128,
do_sample=True,
temperature=0.7,
top_p=0.95,
top_k=40,
repetition_penalty=1.1)
print(f"Model output: ", response)
```
<!-- README_AWQ.md-use-from-tgi end -->
<!-- README_AWQ.md-use-from-python start -->
## Inference from Python code using Transformers
### Install the necessary packages
- Requires: [Transformers](https://huggingface.co/docs/transformers) 4.35.0 or later.
- Requires: [AutoAWQ](https://github.com/casper-hansen/AutoAWQ) 0.1.6 or later.
```shell
pip3 install --upgrade "autoawq>=0.1.6" "transformers>=4.35.0"
```
Note that if you are using PyTorch 2.0.1, the above AutoAWQ command will automatically upgrade you to PyTorch 2.1.0.
If you are using CUDA 11.8 and wish to continue using PyTorch 2.0.1, instead run this command:
```shell
pip3 install https://github.com/casper-hansen/AutoAWQ/releases/download/v0.1.6/autoawq-0.1.6+cu118-cp310-cp310-linux_x86_64.whl
```
If you have problems installing [AutoAWQ](https://github.com/casper-hansen/AutoAWQ) using the pre-built wheels, install it from source instead:
```shell
pip3 uninstall -y autoawq
git clone https://github.com/casper-hansen/AutoAWQ
cd AutoAWQ
pip3 install .
```
### Transformers example code (requires Transformers 4.35.0 and later)
```python
from transformers import AutoModelForCausalLM, AutoTokenizer, TextStreamer
model_name_or_path = "TheBloke/CapybaraHermes-2.5-Mistral-7B-AWQ"
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path)
model = AutoModelForCausalLM.from_pretrained(
model_name_or_path,
low_cpu_mem_usage=True,
device_map="cuda:0"
)
# Using the text streamer to stream output one token at a time
streamer = TextStreamer(tokenizer, skip_prompt=True, skip_special_tokens=True)
prompt = "Tell me about AI"
prompt_template=f'''<|im_start|>system
{system_message}<|im_end|>
<|im_start|>user
{prompt}<|im_end|>
<|im_start|>assistant
'''
# Convert prompt to tokens
tokens = tokenizer(
prompt_template,
return_tensors='pt'
).input_ids.cuda()
generation_params = {
"do_sample": True,
"temperature": 0.7,
"top_p": 0.95,
"top_k": 40,
"max_new_tokens": 512,
"repetition_penalty": 1.1
}
# Generate streamed output, visible one token at a time
generation_output = model.generate(
tokens,
streamer=streamer,
**generation_params
)
# Generation without a streamer, which will include the prompt in the output
generation_output = model.generate(
tokens,
**generation_params
)
# Get the tokens from the output, decode them, print them
token_output = generation_output[0]
text_output = tokenizer.decode(token_output)
print("model.generate output: ", text_output)
# Inference is also possible via Transformers' pipeline
from transformers import pipeline
pipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
**generation_params
)
pipe_output = pipe(prompt_template)[0]['generated_text']
print("pipeline output: ", pipe_output)
```
<!-- README_AWQ.md-use-from-python end -->
<!-- README_AWQ.md-compatibility start -->
## Compatibility
The files provided are tested to work with:
- [text-generation-webui](https://github.com/oobabooga/text-generation-webui) using `Loader: AutoAWQ`.
- [vLLM](https://github.com/vllm-project/vllm) version 0.2.0 and later.
- [Hugging Face Text Generation Inference (TGI)](https://github.com/huggingface/text-generation-inference) version 1.1.0 and later.
- [Transformers](https://huggingface.co/docs/transformers) version 4.35.0 and later.
- [AutoAWQ](https://github.com/casper-hansen/AutoAWQ) version 0.1.1 and later.
<!-- README_AWQ.md-compatibility end -->
<!-- footer start -->
<!-- 200823 -->
## Discord
For further support, and discussions on these models and AI in general, join us at:
[TheBloke AI's Discord server](https://discord.gg/theblokeai)
## Thanks, and how to contribute
Thanks to the [chirper.ai](https://chirper.ai) team!
Thanks to Clay from [gpus.llm-utils.org](llm-utils)!
I've had a lot of people ask if they can contribute. I enjoy providing models and helping people, and would love to be able to spend even more time doing it, as well as expanding into new projects like fine tuning/training.
If you're able and willing to contribute it will be most gratefully received and will help me to keep providing more models, and to start work on new AI projects.
Donaters will get priority support on any and all AI/LLM/model questions and requests, access to a private Discord room, plus other benefits.
* Patreon: https://patreon.com/TheBlokeAI
* Ko-Fi: https://ko-fi.com/TheBlokeAI
**Special thanks to**: Aemon Algiz.
**Patreon special mentions**: Michael Levine, 阿明, Trailburnt, Nikolai Manek, John Detwiler, Randy H, Will Dee, Sebastain Graf, NimbleBox.ai, Eugene Pentland, Emad Mostaque, Ai Maven, Jim Angel, Jeff Scroggin, Michael Davis, Manuel Alberto Morcote, Stephen Murray, Robert, Justin Joy, Luke @flexchar, Brandon Frisco, Elijah Stavena, S_X, Dan Guido, Undi ., Komninos Chatzipapas, Shadi, theTransient, Lone Striker, Raven Klaugh, jjj, Cap'n Zoog, Michel-Marie MAUDET (LINAGORA), Matthew Berman, David, Fen Risland, Omer Bin Jawed, Luke Pendergrass, Kalila, OG, Erik Bjäreholt, Rooh Singh, Joseph William Delisle, Dan Lewis, TL, John Villwock, AzureBlack, Brad, Pedro Madruga, Caitlyn Gatomon, K, jinyuan sun, Mano Prime, Alex, Jeffrey Morgan, Alicia Loh, Illia Dulskyi, Chadd, transmissions 11, fincy, Rainer Wilmers, ReadyPlayerEmma, knownsqashed, Mandus, biorpg, Deo Leter, Brandon Phillips, SuperWojo, Sean Connelly, Iucharbius, Jack West, Harry Royden McLaughlin, Nicholas, terasurfer, Vitor Caleffi, Duane Dunston, Johann-Peter Hartmann, David Ziegler, Olakabola, Ken Nordquist, Trenton Dambrowitz, Tom X Nguyen, Vadim, Ajan Kanaga, Leonard Tan, Clay Pascal, Alexandros Triantafyllidis, JM33133, Xule, vamX, ya boyyy, subjectnull, Talal Aujan, Alps Aficionado, wassieverse, Ari Malik, James Bentley, Woland, Spencer Kim, Michael Dempsey, Fred von Graf, Elle, zynix, William Richards, Stanislav Ovsiannikov, Edmond Seymore, Jonathan Leane, Martin Kemka, usrbinkat, Enrico Ros
Thank you to all my generous patrons and donaters!
And thank you again to a16z for their generous grant.
<!-- footer end -->
# Original model card: Argilla's CapyBaraHermes 2.5 Mistral 7B
# CapybaraHermes-2.5-Mistral-7B
<div>
<img src="https://cdn-uploads.huggingface.co/production/uploads/60420dccc15e823a685f2b03/Vmr0FtTvnny6Snm-UDM_n.png">
</div>
<p align="center">
<a href="https://github.com/argilla-io/distilabel">
<img src="https://raw.githubusercontent.com/argilla-io/distilabel/main/docs/assets/distilabel-badge-light.png" alt="Built with Distilabel" width="200" height="32"/>
</a>
</p>
This model is the launching partner of the [capybara-dpo dataset](https://huggingface.co/datasets/argilla/distilabel-capybara-dpo-9k-binarized) build with ⚗️ distilabel. It's a preference tuned [OpenHermes-2.5-Mistral-7B](https://huggingface.co/teknium/OpenHermes-2.5-Mistral-7B).
CapybaraHermes has been preference tuned with LoRA and TRL for 3 epochs using argilla's [dpo mix 7k](https://huggingface.co/datasets/argilla/dpo-mix-7k).
To test the impact on multi-turn performance we have used MTBench. We also include the Nous Benchmark results and Mistral-7B-Instruct-v0.2 for reference as it's a strong 7B model on MTBench:
| Model | AGIEval | GPT4All | TruthfulQA | Bigbench | MTBench First Turn | MTBench Second Turn | Nous avg. | MTBench avg. |
|-----------------------------------|---------|---------|------------|----------|------------|-------------|-----------|--------------|
| argilla/CapybaraHermes-2.5-Mistral-7B | **43.8** | **73.35** | 57.07 | **42.44** | 8.24375 | **7.5625** | 54.16 | **7.903125** |
| teknium/OpenHermes-2.5-Mistral-7B | 42.75 | 72.99 | 52.99 | 40.94 | **8.25** | 7.2875 | 52.42 | 7.76875 |
| Mistral-7B-Instruct-v0.2 | 38.5 | 71.64 | **66.82** | 42.29 | 7.8375 | 7.1 | **54.81** | 7.46875 |
The most interesting aspect in the context of the capybara-dpo dataset is the increased performance in MTBench Second Turn scores.
For the merge lovers, we also preference tuned Beagle14-7B with a mix of capybara-dpo and distilabel orca pairs using the same recipe as NeuralBeagle (see [ YALL - Yet Another LLM Leaderboard](https://huggingface.co/spaces/mlabonne/Yet_Another_LLM_Leaderboard) for reference):
| Model |AGIEval|GPT4All|TruthfulQA|Bigbench|Average|
|------------------------------------------------------------------------------------------------------------------------------------|------:|------:|---------:|-------:|------:|
|[DistilabelBeagle14-7B](https://huggingface.co/dvilasuero/DistilabelBeagle14-7B)| 45.29| 76.92| 71.66| 48.78| 60.66|
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** Argilla
- **Shared by [optional]:** Argilla
- **Model type:** 7B chat model
- **Language(s) (NLP):** English
- **License:** Same as OpenHermes
- **Finetuned from model [optional]:** [OpenHermes-2.5-Mistral-7B](https://huggingface.co/teknium/OpenHermes-2.5-Mistral-7B)
|
QuantFactory/Meta-Llama-3-8B-Instruct-GGUF-v2 | QuantFactory | 2024-05-06T09:47:20Z | 6,696 | 11 | null | [
"gguf",
"facebook",
"meta",
"pytorch",
"llama",
"llama-3",
"text-generation",
"en",
"base_model:meta-llama/Meta-Llama-3-8B-Instruct",
"license:other",
"region:us"
] | text-generation | 2024-05-03T12:31:28Z | ---
language:
- en
pipeline_tag: text-generation
tags:
- facebook
- meta
- pytorch
- llama
- llama-3
license: other
license_name: llama3
license_link: LICENSE
base_model: meta-llama/Meta-Llama-3-8B-Instruct
---
# Meta-Llama-3-8B-Instruct-GGUF
- This is GGUF quantized version of [meta-llama/Meta-Llama-3-8B-Instruct](https://huggingface.co/meta-llama/Meta-Llama-3-8B-Instruct) created using llama.cpp
- Created using latest release of llama.cpp dated 5.5.2024
## Model Details
Meta developed and released the Meta Llama 3 family of large language models (LLMs), a collection of pretrained and instruction tuned generative text models in 8 and 70B sizes. The Llama 3 instruction tuned models are optimized for dialogue use cases and outperform many of the available open source chat models on common industry benchmarks. Further, in developing these models, we took great care to optimize helpfulness and safety.
**Model developers** Meta
**Variations** Llama 3 comes in two sizes — 8B and 70B parameters — in pre-trained and instruction tuned variants.
**Input** Models input text only.
**Output** Models generate text and code only.
**Model Architecture** Llama 3 is an auto-regressive language model that uses an optimized transformer architecture. The tuned versions use supervised fine-tuning (SFT) and reinforcement learning with human feedback (RLHF) to align with human preferences for helpfulness and safety.
<table>
<tr>
<td>
</td>
<td><strong>Training Data</strong>
</td>
<td><strong>Params</strong>
</td>
<td><strong>Context length</strong>
</td>
<td><strong>GQA</strong>
</td>
<td><strong>Token count</strong>
</td>
<td><strong>Knowledge cutoff</strong>
</td>
</tr>
<tr>
<td rowspan="2" >Llama 3
</td>
<td rowspan="2" >A new mix of publicly available online data.
</td>
<td>8B
</td>
<td>8k
</td>
<td>Yes
</td>
<td rowspan="2" >15T+
</td>
<td>March, 2023
</td>
</tr>
<tr>
<td>70B
</td>
<td>8k
</td>
<td>Yes
</td>
<td>December, 2023
</td>
</tr>
</table>
**Llama 3 family of models**. Token counts refer to pretraining data only. Both the 8 and 70B versions use Grouped-Query Attention (GQA) for improved inference scalability.
**Model Release Date** April 18, 2024.
**Status** This is a static model trained on an offline dataset. Future versions of the tuned models will be released as we improve model safety with community feedback.
**License** A custom commercial license is available at: [https://llama.meta.com/llama3/license](https://llama.meta.com/llama3/license)
Where to send questions or comments about the model Instructions on how to provide feedback or comments on the model can be found in the model [README](https://github.com/meta-llama/llama3). For more technical information about generation parameters and recipes for how to use Llama 3 in applications, please go [here](https://github.com/meta-llama/llama-recipes).
|
textattack/bert-base-uncased-rotten-tomatoes | textattack | 2021-05-20T07:46:20Z | 6,688 | 1 | transformers | [
"transformers",
"pytorch",
"jax",
"bert",
"text-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2022-03-02T23:29:05Z | ## TextAttack Model Card
This `bert-base-uncased` model was fine-tuned for sequence classificationusing TextAttack
and the rotten_tomatoes dataset loaded using the `nlp` library. The model was fine-tuned
for 10 epochs with a batch size of 16, a learning
rate of 2e-05, and a maximum sequence length of 128.
Since this was a classification task, the model was trained with a cross-entropy loss function.
The best score the model achieved on this task was 0.875234521575985, as measured by the
eval set accuracy, found after 4 epochs.
For more information, check out [TextAttack on Github](https://github.com/QData/TextAttack).
|
Yntec/CocaCola | Yntec | 2024-04-23T00:08:24Z | 6,684 | 0 | diffusers | [
"diffusers",
"safetensors",
"Art",
"Sexy",
"Pinups",
"Girls",
"iamxenos",
"RIXYN",
"Barons",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"en",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | 2024-04-22T21:41:58Z | ---
license: creativeml-openrail-m
library_name: diffusers
pipeline_tag: text-to-image
language:
- en
tags:
- Art
- Sexy
- Pinups
- Girls
- iamxenos
- RIXYN
- Barons
- stable-diffusion
- stable-diffusion-diffusers
- diffusers
- text-to-image
---
# Coca Cola
Use by Gil_Elvgren and/or Haddon_Sundblom in the prompt to enhance the effect.
Samples and prompts:

Top left: Closeup of handsome husband as Santa Claus with pretty wife young sandra bullock in red. adorable eyes. a cute face by Gil_Elvgren and Haddon_Sundblom. girl with cleavage. Couple's Portrait Anime Cartoon Illustration, black ponytail, Coca Cola bottle, Teals, Christmas Tree, Blues<
Top right: Closeup, Sexy 70s Art grabbing Coca Cola Can Cartoon Illustration by Gil_Elvgren, magazine ad, mischievous face and eyes of model beautiful girl as hermione granger posing, white lace blouse, black leather skirt, gorgeous legs, and studded flats , gym storeroom
Bottom left: Closeup, girl hugging polar bear, Pinup Art by Haddon_Sundblom, flirty face and eyes of Selena Gomez | Dana Davis, long coat, pinstripe pants, and leather boots
Bottom right: closeup, Cinematic Coca Cola Pinup Art Cartoon TV Illustration, stunning face and eyes of Teddi Mellencamp | Katherine Waterston sitting, cyberpunk city at night, short smile, neon accessories to complete the look might include vintage-style diamonds, a woven basket, and a bouquet of flowers
The Hellmix model by Barons, Kitsch-In-Sync v2 by iamxenos, the cryptids lora by RIXYN, and artistic models merged with the CokeGirls lora by iamxenos.
Original pages:
https://civitai.com/models/186251/coca-cola-gil-elvgrenhaddon-sundblom-pinup-style
https://civitai.com/models/142552?modelVersionId=163068 (Kitsch-In-Sync v2)
https://civitai.com/models/21493/hellmix?modelVersionId=25632
https://civitai.com/models/64766/cryptids?modelVersionId=69407 (Cryptids LoRA) |
beomi/KcELECTRA-base-v2022 | beomi | 2023-04-03T14:37:57Z | 6,675 | 4 | transformers | [
"transformers",
"pytorch",
"electra",
"pretraining",
"korean",
"ko",
"en",
"license:mit",
"endpoints_compatible",
"region:us"
] | null | 2022-03-24T05:38:50Z | ---
language:
- ko
- en
tags:
- electra
- korean
license: "mit"
---
# 🚨 Important Note: This REPO is DEPRECATED since KcELECTRA-base v2023 Released 🚨
## USE `https://huggingface.co/beomi/KcELECTRA-base` and `v2022` Revision if needed.
---
# KcELECTRA: Korean comments ELECTRA
** Updates on 2022.10.08 **
- KcELECTRA-base-v2022 (구 v2022-dev) 모델 이름이 변경되었습니다.
- 위 모델의 세부 스코어를 추가하였습니다.
- 기존 KcELECTRA-base(v2021) 대비 대부분의 downstream task에서 ~1%p 수준의 성능 향상이 있습니다.
---
공개된 한국어 Transformer 계열 모델들은 대부분 한국어 위키, 뉴스 기사, 책 등 잘 정제된 데이터를 기반으로 학습한 모델입니다. 한편, 실제로 NSMC와 같은 User-Generated Noisy text domain 데이터셋은 정제되지 않았고 구어체 특징에 신조어가 많으며, 오탈자 등 공식적인 글쓰기에서 나타나지 않는 표현들이 빈번하게 등장합니다.
KcELECTRA는 위와 같은 특성의 데이터셋에 적용하기 위해, 네이버 뉴스에서 댓글과 대댓글을 수집해, 토크나이저와 ELECTRA모델을 처음부터 학습한 Pretrained ELECTRA 모델입니다.
기존 KcBERT 대비 데이터셋 증가 및 vocab 확장을 통해 상당한 수준으로 성능이 향상되었습니다.
KcELECTRA는 Huggingface의 Transformers 라이브러리를 통해 간편히 불러와 사용할 수 있습니다. (별도의 파일 다운로드가 필요하지 않습니다.)
```
💡 NOTE 💡
General Corpus로 학습한 KoELECTRA가 보편적인 task에서는 성능이 더 잘 나올 가능성이 높습니다.
KcBERT/KcELECTRA는 User genrated, Noisy text에 대해서 보다 잘 동작하는 PLM입니다.
```
## KcELECTRA Performance
- Finetune 코드는 https://github.com/Beomi/KcBERT-finetune 에서 찾아보실 수 있습니다.
- 해당 Repo의 각 Checkpoint 폴더에서 Step별 세부 스코어를 확인하실 수 있습니다.
| | Size<br/>(용량) | **NSMC**<br/>(acc) | **Naver NER**<br/>(F1) | **PAWS**<br/>(acc) | **KorNLI**<br/>(acc) | **KorSTS**<br/>(spearman) | **Question Pair**<br/>(acc) | **KorQuaD (Dev)**<br/>(EM/F1) |
| :----------------- | :-------------: | :----------------: | :--------------------: | :----------------: | :------------------: | :-----------------------: | :-------------------------: | :---------------------------: |
| **KcELECTRA-base-v2022** | 475M | **91.97** | 87.35 | 76.50 | 82.12 | 83.67 | 95.12 | 69.00 / 90.40 |
| **KcELECTRA-base** | 475M | 91.71 | 86.90 | 74.80 | 81.65 | 82.65 | **95.78** | 70.60 / 90.11 |
| KcBERT-Base | 417M | 89.62 | 84.34 | 66.95 | 74.85 | 75.57 | 93.93 | 60.25 / 84.39 |
| KcBERT-Large | 1.2G | 90.68 | 85.53 | 70.15 | 76.99 | 77.49 | 94.06 | 62.16 / 86.64 |
| KoBERT | 351M | 89.63 | 86.11 | 80.65 | 79.00 | 79.64 | 93.93 | 52.81 / 80.27 |
| XLM-Roberta-Base | 1.03G | 89.49 | 86.26 | 82.95 | 79.92 | 79.09 | 93.53 | 64.70 / 88.94 |
| HanBERT | 614M | 90.16 | 87.31 | 82.40 | 80.89 | 83.33 | 94.19 | 78.74 / 92.02 |
| KoELECTRA-Base | 423M | 90.21 | 86.87 | 81.90 | 80.85 | 83.21 | 94.20 | 61.10 / 89.59 |
| KoELECTRA-Base-v2 | 423M | 89.70 | 87.02 | 83.90 | 80.61 | 84.30 | 94.72 | 84.34 / 92.58 |
| KoELECTRA-Base-v3 | 423M | 90.63 | **88.11** | **84.45** | **82.24** | **85.53** | 95.25 | **84.83 / 93.45** |
| DistilKoBERT | 108M | 88.41 | 84.13 | 62.55 | 70.55 | 73.21 | 92.48 | 54.12 / 77.80 |
\*HanBERT의 Size는 Bert Model과 Tokenizer DB를 합친 것입니다.
\***config의 세팅을 그대로 하여 돌린 결과이며, hyperparameter tuning을 추가적으로 할 시 더 좋은 성능이 나올 수 있습니다.**
## How to use
### Requirements
- `pytorch ~= 1.8.0`
- `transformers ~= 4.11.3`
- `emoji ~= 0.6.0`
- `soynlp ~= 0.0.493`
### Default usage
```python
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("beomi/KcELECTRA-base")
model = AutoModel.from_pretrained("beomi/KcELECTRA-base")
```
> 💡 이전 KcBERT 관련 코드들에서 `AutoTokenizer`, `AutoModel` 을 사용한 경우 `.from_pretrained("beomi/kcbert-base")` 부분을 `.from_pretrained("beomi/KcELECTRA-base")` 로만 변경해주시면 즉시 사용이 가능합니다.
### Pretrain & Finetune Colab 링크 모음
#### Pretrain Data
- KcBERT학습에 사용한 데이터 + 이후 2021.03월 초까지 수집한 댓글
- 약 17GB
- 댓글-대댓글을 묶은 기반으로 Document 구성
#### Pretrain Code
- https://github.com/KLUE-benchmark/KLUE-ELECTRA Repo를 통한 Pretrain
#### Finetune Code
- https://github.com/Beomi/KcBERT-finetune Repo를 통한 Finetune 및 스코어 비교
#### Finetune Samples
- NSMC with PyTorch-Lightning 1.3.0, GPU, Colab <a href="https://colab.research.google.com/drive/1Hh63kIBAiBw3Hho--BvfdUWLu-ysMFF0?usp=sharing">
<img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/>
</a>
## Train Data & Preprocessing
### Raw Data
학습 데이터는 2019.01.01 ~ 2021.03.09 사이에 작성된 **댓글 많은 뉴스/혹은 전체 뉴스** 기사들의 **댓글과 대댓글**을 모두 수집한 데이터입니다.
데이터 사이즈는 텍스트만 추출시 **약 17.3GB이며, 1억8천만개 이상의 문장**으로 이뤄져 있습니다.
> KcBERT는 2019.01-2020.06의 텍스트로, 정제 후 약 9천만개 문장으로 학습을 진행했습니다.
### Preprocessing
PLM 학습을 위해서 전처리를 진행한 과정은 다음과 같습니다.
1. 한글 및 영어, 특수문자, 그리고 이모지(🥳)까지!
정규표현식을 통해 한글, 영어, 특수문자를 포함해 Emoji까지 학습 대상에 포함했습니다.
한편, 한글 범위를 `ㄱ-ㅎ가-힣` 으로 지정해 `ㄱ-힣` 내의 한자를 제외했습니다.
2. 댓글 내 중복 문자열 축약
`ㅋㅋㅋㅋㅋ`와 같이 중복된 글자를 `ㅋㅋ`와 같은 것으로 합쳤습니다.
3. Cased Model
KcBERT는 영문에 대해서는 대소문자를 유지하는 Cased model입니다.
4. 글자 단위 10글자 이하 제거
10글자 미만의 텍스트는 단일 단어로 이뤄진 경우가 많아 해당 부분을 제외했습니다.
5. 중복 제거
중복적으로 쓰인 댓글을 제거하기 위해 완전히 일치하는 중복 댓글을 하나로 합쳤습니다.
6. `OOO` 제거
네이버 댓글의 경우, 비속어는 자체 필터링을 통해 `OOO` 로 표시합니다. 이 부분을 공백으로 제거하였습니다.
아래 명령어로 pip로 설치한 뒤, 아래 clean함수로 클리닝을 하면 Downstream task에서 보다 성능이 좋아집니다. (`[UNK]` 감소)
```bash
pip install soynlp emoji
```
아래 `clean` 함수를 Text data에 사용해주세요.
```python
import re
import emoji
from soynlp.normalizer import repeat_normalize
emojis = ''.join(emoji.UNICODE_EMOJI.keys())
pattern = re.compile(f'[^ .,?!/@$%~%·∼()\x00-\x7Fㄱ-ㅣ가-힣{emojis}]+')
url_pattern = re.compile(
r'https?:\/\/(www\.)?[-a-zA-Z0-9@:%._\+~#=]{1,256}\.[a-zA-Z0-9()]{1,6}\b([-a-zA-Z0-9()@:%_\+.~#?&//=]*)')
import re
import emoji
from soynlp.normalizer import repeat_normalize
pattern = re.compile(f'[^ .,?!/@$%~%·∼()\x00-\x7Fㄱ-ㅣ가-힣]+')
url_pattern = re.compile(
r'https?:\/\/(www\.)?[-a-zA-Z0-9@:%._\+~#=]{1,256}\.[a-zA-Z0-9()]{1,6}\b([-a-zA-Z0-9()@:%_\+.~#?&//=]*)')
def clean(x):
x = pattern.sub(' ', x)
x = emoji.replace_emoji(x, replace='') #emoji 삭제
x = url_pattern.sub('', x)
x = x.strip()
x = repeat_normalize(x, num_repeats=2)
return x
```
> 💡 Finetune Score에서는 위 `clean` 함수를 적용하지 않았습니다.
### Cleaned Data
- KcBERT 외 추가 데이터는 정리 후 공개 예정입니다.
## Tokenizer, Model Train
Tokenizer는 Huggingface의 [Tokenizers](https://github.com/huggingface/tokenizers) 라이브러리를 통해 학습을 진행했습니다.
그 중 `BertWordPieceTokenizer` 를 이용해 학습을 진행했고, Vocab Size는 `30000`으로 진행했습니다.
Tokenizer를 학습하는 것에는 전체 데이터를 통해 학습을 진행했고, 모델의 General Downstream task에 대응하기 위해 KoELECTRA에서 사용한 Vocab을 겹치지 않는 부분을 추가로 넣어주었습니다. (실제로 두 모델이 겹치는 부분은 약 5000토큰이었습니다.)
TPU `v3-8` 을 이용해 약 10일 학습을 진행했고, 현재 Huggingface에 공개된 모델은 848k step을 학습한 모델 weight가 업로드 되어있습니다.
(100k step별 Checkpoint를 통해 성능 평가를 진행하였습니다. 해당 부분은 `KcBERT-finetune` repo를 참고해주세요.)
모델 학습 Loss는 Step에 따라 초기 100-200k 사이에 급격히 Loss가 줄어들다 학습 종료까지도 지속적으로 loss가 감소하는 것을 볼 수 있습니다.
### KcELECTRA Pretrain Step별 Downstream task 성능 비교
> 💡 아래 표는 전체 ckpt가 아닌 일부에 대해서만 테스트를 진행한 결과입니다.
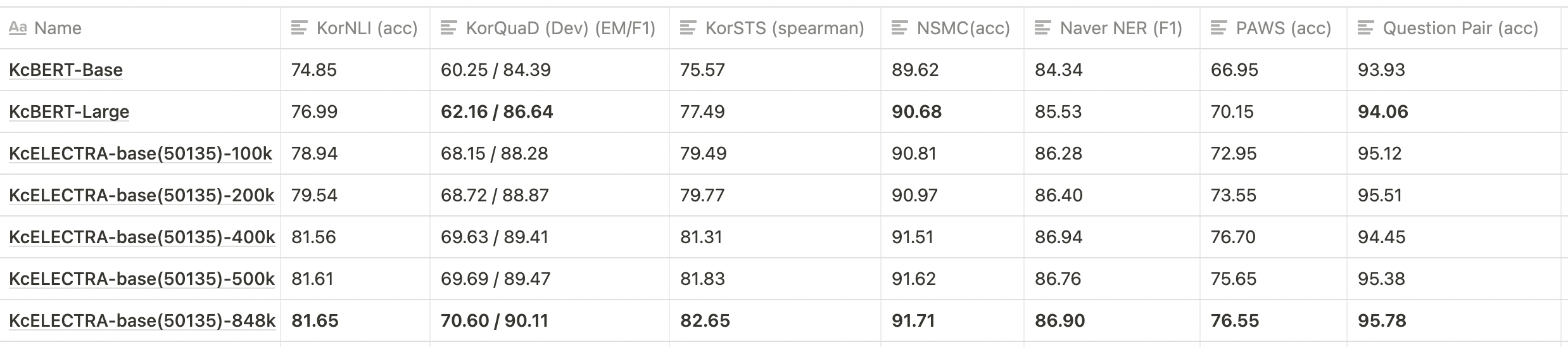
- 위와 같이 KcBERT-base, KcBERT-large 대비 **모든 데이터셋에 대해** KcELECTRA-base가 더 높은 성능을 보입니다.
- KcELECTRA pretrain에서도 Train step이 늘어감에 따라 점진적으로 성능이 향상되는 것을 볼 수 있습니다.
## 인용표기/Citation
KcELECTRA를 인용하실 때는 아래 양식을 통해 인용해주세요.
```
@misc{lee2021kcelectra,
author = {Junbum Lee},
title = {KcELECTRA: Korean comments ELECTRA},
year = {2021},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {\url{https://github.com/Beomi/KcELECTRA}}
}
```
논문을 통한 사용 외에는 MIT 라이센스를 표기해주세요. ☺️
## Acknowledgement
KcELECTRA Model을 학습하는 GCP/TPU 환경은 [TFRC](https://www.tensorflow.org/tfrc?hl=ko) 프로그램의 지원을 받았습니다.
모델 학습 과정에서 많은 조언을 주신 [Monologg](https://github.com/monologg/) 님 감사합니다 :)
## Reference
### Github Repos
- [KcBERT by Beomi](https://github.com/Beomi/KcBERT)
- [BERT by Google](https://github.com/google-research/bert)
- [KoBERT by SKT](https://github.com/SKTBrain/KoBERT)
- [KoELECTRA by Monologg](https://github.com/monologg/KoELECTRA/)
- [Transformers by Huggingface](https://github.com/huggingface/transformers)
- [Tokenizers by Hugginface](https://github.com/huggingface/tokenizers)
- [ELECTRA train code by KLUE](https://github.com/KLUE-benchmark/KLUE-ELECTRA)
### Blogs
- [Monologg님의 KoELECTRA 학습기](https://monologg.kr/categories/NLP/ELECTRA/)
- [Colab에서 TPU로 BERT 처음부터 학습시키기 - Tensorflow/Google ver.](https://beomi.github.io/2020/02/26/Train-BERT-from-scratch-on-colab-TPU-Tensorflow-ver/)
|
tiiuae/falcon-180B | tiiuae | 2023-09-06T13:04:38Z | 6,675 | 1,106 | transformers | [
"transformers",
"safetensors",
"falcon",
"text-generation",
"en",
"de",
"es",
"fr",
"dataset:tiiuae/falcon-refinedweb",
"arxiv:1911.02150",
"arxiv:2101.00027",
"arxiv:2005.14165",
"arxiv:2104.09864",
"arxiv:2205.14135",
"arxiv:2306.01116",
"license:unknown",
"autotrain_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2023-08-28T23:28:49Z | ---
datasets:
- tiiuae/falcon-refinedweb
language:
- en
- de
- es
- fr
inference: false
license: unknown
extra_gated_heading: "Acknowledge license to access the repository"
extra_gated_prompt: "You agree to the [Falcon-180B TII license](https://huggingface.co/spaces/tiiuae/falcon-180b-license/blob/main/LICENSE.txt) and [acceptable use policy](https://huggingface.co/spaces/tiiuae/falcon-180b-license/blob/main/ACCEPTABLE_USE_POLICY.txt)."
extra_gated_button_content: "I agree to the terms and conditions of the Falcon-180B TII license and to the acceptable use policy"
---
# 🚀 Falcon-180B
**Falcon-180B is a 180B parameters causal decoder-only model built by [TII](https://www.tii.ae) and trained on 3,500B tokens of [RefinedWeb](https://huggingface.co/datasets/tiiuae/falcon-refinedweb) enhanced with curated corpora. It is made available under the [Falcon-180B TII License](https://huggingface.co/spaces/tiiuae/falcon-180b-license/blob/main/LICENSE.txt) and [Acceptable Use Policy](https://huggingface.co/spaces/tiiuae/falcon-180b-license/blob/main/ACCEPTABLE_USE_POLICY.txt).**
*Paper coming soon* 😊
🤗 To get started with Falcon (inference, finetuning, quantization, etc.), we recommend reading [this great blogpost from HF](https://hf.co/blog/falcon-180b) or this [one](https://huggingface.co/blog/falcon) from the release of the 40B!
Note that since the 180B is larger than what can easily be handled with `transformers`+`acccelerate`, we recommend using [Text Generation Inference](https://github.com/huggingface/text-generation-inference).
You will need **at least 400GB of memory** to swiftly run inference with Falcon-180B.
## Why use Falcon-180B?
* **It is the best open-access model currently available, and one of the best model overall.** Falcon-180B outperforms [LLaMA-2](https://huggingface.co/meta-llama/Llama-2-70b-hf), [StableLM](https://github.com/Stability-AI/StableLM), [RedPajama](https://huggingface.co/togethercomputer/RedPajama-INCITE-Base-7B-v0.1), [MPT](https://huggingface.co/mosaicml/mpt-7b), etc. See the [OpenLLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard).
* **It features an architecture optimized for inference**, with multiquery ([Shazeer et al., 2019](https://arxiv.org/abs/1911.02150)).
* **It is made available under a permissive license allowing for commercial use**.
* ⚠️ **This is a raw, pretrained model, which should be further finetuned for most usecases.** If you are looking for a version better suited to taking generic instructions in a chat format, we recommend taking a look at [Falcon-180B-Chat](https://huggingface.co/tiiuae/falcon-180b-chat).
💸 **Looking for a smaller, less expensive model?** [Falcon-7B](https://huggingface.co/tiiuae/falcon-7b) and [Falcon-40B](https://huggingface.co/tiiuae/falcon-40b) are Falcon-180B's little brothers!
💥 **Falcon LLMs require PyTorch 2.0 for use with `transformers`!**
# Model Card for Falcon-180B
## Model Details
### Model Description
- **Developed by:** [https://www.tii.ae](https://www.tii.ae);
- **Model type:** Causal decoder-only;
- **Language(s) (NLP):** English, German, Spanish, French (and limited capabilities in Italian, Portuguese, Polish, Dutch, Romanian, Czech, Swedish);
- **License:** [Falcon-180B TII License](https://huggingface.co/tiiuae/falcon-180B/blob/main/LICENSE.txt) and [Acceptable Use Policy](https://huggingface.co/tiiuae/falcon-180B/blob/main/ACCEPTABLE_USE_POLICY.txt).
### Model Source
- **Paper:** *coming soon*.
## Uses
See the [acceptable use policy](https://huggingface.co/tiiuae/falcon-180B/blob/main/ACCEPTABLE_USE_POLICY.txt).
### Direct Use
Research on large language models; as a foundation for further specialization and finetuning for specific usecases (e.g., summarization, text generation, chatbot, etc.)
### Out-of-Scope Use
Production use without adequate assessment of risks and mitigation; any use cases which may be considered irresponsible or harmful.
## Bias, Risks, and Limitations
Falcon-180B is trained mostly on English, German, Spanish, French, with limited capabilities also in in Italian, Portuguese, Polish, Dutch, Romanian, Czech, Swedish. It will not generalize appropriately to other languages. Furthermore, as it is trained on a large-scale corpora representative of the web, it will carry the stereotypes and biases commonly encountered online.
### Recommendations
We recommend users of Falcon-180B to consider finetuning it for the specific set of tasks of interest, and for guardrails and appropriate precautions to be taken for any production use.
## How to Get Started with the Model
To run inference with the model in full `bfloat16` precision you need approximately 8xA100 80GB or equivalent.
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
import transformers
import torch
model = "tiiuae/falcon-180b"
tokenizer = AutoTokenizer.from_pretrained(model)
pipeline = transformers.pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
torch_dtype=torch.bfloat16,
trust_remote_code=True,
device_map="auto",
)
sequences = pipeline(
"Girafatron is obsessed with giraffes, the most glorious animal on the face of this Earth. Giraftron believes all other animals are irrelevant when compared to the glorious majesty of the giraffe.\nDaniel: Hello, Girafatron!\nGirafatron:",
max_length=200,
do_sample=True,
top_k=10,
num_return_sequences=1,
eos_token_id=tokenizer.eos_token_id,
)
for seq in sequences:
print(f"Result: {seq['generated_text']}")
```
## Training Details
### Training Data
Falcon-180B was trained on 3,500B tokens of [RefinedWeb](https://huggingface.co/datasets/tiiuae/falcon-refinedweb), a high-quality filtered and deduplicated web dataset which we enhanced with curated corpora. Significant components from our curated copora were inspired by The Pile ([Gao et al., 2020](https://arxiv.org/abs/2101.00027)).
| **Data source** | **Fraction** | **Tokens** | **Sources** |
|--------------------|--------------|------------|-----------------------------------|
| [RefinedWeb-English](https://huggingface.co/datasets/tiiuae/falcon-refinedweb) | 75% | 750B | massive web crawl |
| RefinedWeb-Europe | 7% | 70B | European massive web crawl |
| Books | 6% | 60B | |
| Conversations | 5% | 50B | Reddit, StackOverflow, HackerNews |
| Code | 5% | 50B | |
| Technical | 2% | 20B | arXiv, PubMed, USPTO, etc. |
RefinedWeb-Europe is made of the following languages:
| **Language** | **Fraction of multilingual data** | **Tokens** |
|--------------|-----------------------------------|------------|
| German | 26% | 18B |
| Spanish | 24% | 17B |
| French | 23% | 16B |
| _Italian_ | 7% | 5B |
| _Portuguese_ | 4% | 3B |
| _Polish_ | 4% | 3B |
| _Dutch_ | 4% | 3B |
| _Romanian_ | 3% | 2B |
| _Czech_ | 3% | 2B |
| _Swedish_ | 2% | 1B |
The data was tokenized with the Falcon tokenizer.
### Training Procedure
Falcon-180B was trained on up to 4,096 A100 40GB GPUs, using a 3D parallelism strategy (TP=8, PP=8, DP=64) combined with ZeRO.
#### Training Hyperparameters
| **Hyperparameter** | **Value** | **Comment** |
|--------------------|------------|-------------------------------------------|
| Precision | `bfloat16` | |
| Optimizer | AdamW | |
| Learning rate | 1.25e-4 | 4B tokens warm-up, cosine decay to 1.25e-5 |
| Weight decay | 1e-1 | |
| Z-loss | 1e-4 | |
| Batch size | 2048 | 100B tokens ramp-up |
#### Speeds, Sizes, Times
Training started in early 2023.
## Evaluation
*Paper coming soon.*
See the [OpenLLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard) for early results.
## Technical Specifications
### Model Architecture and Objective
Falcon-180B is a causal decoder-only model trained on a causal language modeling task (i.e., predict the next token).
The architecture is broadly adapted from the GPT-3 paper ([Brown et al., 2020](https://arxiv.org/abs/2005.14165)), with the following differences:
* **Positionnal embeddings:** rotary ([Su et al., 2021](https://arxiv.org/abs/2104.09864));
* **Attention:** multiquery ([Shazeer et al., 2019](https://arxiv.org/abs/1911.02150)) and FlashAttention ([Dao et al., 2022](https://arxiv.org/abs/2205.14135));
* **Decoder-block:** parallel attention/MLP with two layer norms.
For multiquery, we are using an internal variant which uses independent key and values per tensor parallel degree (so-called multigroup).
| **Hyperparameter** | **Value** | **Comment** |
|--------------------|-----------|----------------------------------------|
| Layers | 80 | |
| `d_model` | 14848 | |
| `head_dim` | 64 | Reduced to optimise for FlashAttention |
| Vocabulary | 65024 | |
| Sequence length | 2048 | |
### Compute Infrastructure
#### Hardware
Falcon-180B was trained on AWS SageMaker, on up to 4,096 A100 40GB GPUs in P4d instances.
#### Software
Falcon-180B was trained a custom distributed training codebase, Gigatron. It uses a 3D parallelism approach combined with ZeRO and high-performance Triton kernels (FlashAttention, etc.)
## Citation
*Paper coming soon* 😊 (actually this time). In the meanwhile, you can use the following information to cite:
```
@article{falcon,
title={The Falcon Series of Language Models: Towards Open Frontier Models},
author={Almazrouei, Ebtesam and Alobeidli, Hamza and Alshamsi, Abdulaziz and Cappelli, Alessandro and Cojocaru, Ruxandra and Alhammadi, Maitha and Daniele, Mazzotta and Heslow, Daniel and Launay, Julien and Malartic, Quentin and Noune, Badreddine and Pannier, Baptiste and Penedo, Guilherme},
year={2023}
}
```
To learn more about the pretraining dataset, see the 📓 [RefinedWeb paper](https://arxiv.org/abs/2306.01116).
```
@article{refinedweb,
title={The {R}efined{W}eb dataset for {F}alcon {LLM}: outperforming curated corpora with web data, and web data only},
author={Guilherme Penedo and Quentin Malartic and Daniel Hesslow and Ruxandra Cojocaru and Alessandro Cappelli and Hamza Alobeidli and Baptiste Pannier and Ebtesam Almazrouei and Julien Launay},
journal={arXiv preprint arXiv:2306.01116},
eprint={2306.01116},
eprinttype = {arXiv},
url={https://arxiv.org/abs/2306.01116},
year={2023}
}
```
## Contact
[email protected] |
facebook/esm1v_t33_650M_UR90S_1 | facebook | 2022-11-16T12:57:41Z | 6,673 | 3 | transformers | [
"transformers",
"pytorch",
"tf",
"esm",
"fill-mask",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | fill-mask | 2022-10-17T15:17:23Z | Entry not found |
lmsys/vicuna-7b-v1.5-16k | lmsys | 2023-10-10T05:31:20Z | 6,663 | 84 | transformers | [
"transformers",
"pytorch",
"llama",
"text-generation",
"arxiv:2307.09288",
"arxiv:2306.05685",
"license:llama2",
"autotrain_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2023-07-31T22:03:06Z | ---
inference: false
license: llama2
---
# Vicuna Model Card
## Model Details
Vicuna is a chat assistant trained by fine-tuning Llama 2 on user-shared conversations collected from ShareGPT.
- **Developed by:** [LMSYS](https://lmsys.org/)
- **Model type:** An auto-regressive language model based on the transformer architecture
- **License:** Llama 2 Community License Agreement
- **Finetuned from model:** [Llama 2](https://arxiv.org/abs/2307.09288)
### Model Sources
- **Repository:** https://github.com/lm-sys/FastChat
- **Blog:** https://lmsys.org/blog/2023-03-30-vicuna/
- **Paper:** https://arxiv.org/abs/2306.05685
- **Demo:** https://chat.lmsys.org/
## Uses
The primary use of Vicuna is research on large language models and chatbots.
The primary intended users of the model are researchers and hobbyists in natural language processing, machine learning, and artificial intelligence.
## How to Get Started with the Model
- Command line interface: https://github.com/lm-sys/FastChat#vicuna-weights
- APIs (OpenAI API, Huggingface API): https://github.com/lm-sys/FastChat/tree/main#api
## Training Details
Vicuna v1.5 (16k) is fine-tuned from Llama 2 with supervised instruction fine-tuning and linear RoPE scaling.
The training data is around 125K conversations collected from ShareGPT.com. These conversations are packed into sequences that contain 16K tokens each.
See more details in the "Training Details of Vicuna Models" section in the appendix of this [paper](https://arxiv.org/pdf/2306.05685.pdf).
## Evaluation

Vicuna is evaluated with standard benchmarks, human preference, and LLM-as-a-judge. See more details in this [paper](https://arxiv.org/pdf/2306.05685.pdf) and [leaderboard](https://huggingface.co/spaces/lmsys/chatbot-arena-leaderboard).
## Difference between different versions of Vicuna
See [vicuna_weights_version.md](https://github.com/lm-sys/FastChat/blob/main/docs/vicuna_weights_version.md) |
Systran/faster-whisper-medium.en | Systran | 2023-11-23T11:32:09Z | 6,663 | 0 | ctranslate2 | [
"ctranslate2",
"audio",
"automatic-speech-recognition",
"en",
"license:mit",
"region:us"
] | automatic-speech-recognition | 2023-11-23T09:52:01Z | ---
language:
- en
tags:
- audio
- automatic-speech-recognition
license: mit
library_name: ctranslate2
---
# Whisper medium.en model for CTranslate2
This repository contains the conversion of [openai/whisper-medium.en](https://huggingface.co/openai/whisper-medium.en) to the [CTranslate2](https://github.com/OpenNMT/CTranslate2) model format.
This model can be used in CTranslate2 or projects based on CTranslate2 such as [faster-whisper](https://github.com/systran/faster-whisper).
## Example
```python
from faster_whisper import WhisperModel
model = WhisperModel("medium.en")
segments, info = model.transcribe("audio.mp3")
for segment in segments:
print("[%.2fs -> %.2fs] %s" % (segment.start, segment.end, segment.text))
```
## Conversion details
The original model was converted with the following command:
```
ct2-transformers-converter --model openai/whisper-medium.en --output_dir faster-whisper-medium.en \
--copy_files tokenizer.json --quantization float16
```
Note that the model weights are saved in FP16. This type can be changed when the model is loaded using the [`compute_type` option in CTranslate2](https://opennmt.net/CTranslate2/quantization.html).
## More information
**For more information about the original model, see its [model card](https://huggingface.co/openai/whisper-medium.en).**
|
deepseek-ai/deepseek-math-7b-instruct | deepseek-ai | 2024-02-06T10:38:24Z | 6,660 | 76 | transformers | [
"transformers",
"pytorch",
"llama",
"text-generation",
"conversational",
"arxiv:2402.03300",
"license:other",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2024-02-05T08:14:00Z | ---
license: other
license_name: deepseek
license_link: https://github.com/deepseek-ai/DeepSeek-Math/blob/main/LICENSE-MODEL
---
<p align="center">
<img width="500px" alt="DeepSeek Chat" src="https://github.com/deepseek-ai/DeepSeek-LLM/blob/main/images/logo.png?raw=true">
</p>
<p align="center"><a href="https://www.deepseek.com/">[🏠Homepage]</a> | <a href="https://chat.deepseek.com/">[🤖 Chat with DeepSeek LLM]</a> | <a href="https://discord.gg/Tc7c45Zzu5">[Discord]</a> | <a href="https://github.com/deepseek-ai/DeepSeek-LLM/blob/main/images/qr.jpeg">[Wechat(微信)]</a> </p>
<p align="center">
<a href="https://arxiv.org/pdf/2402.03300.pdf"><b>Paper Link</b>👁️</a>
</p>
<hr>
### 1. Introduction to DeepSeekMath
See the [Introduction](https://github.com/deepseek-ai/DeepSeek-Math) for more details.
### 2. How to Use
Here give some examples of how to use our model.
**Chat Completion**
❗❗❗ **Please use chain-of-thought prompt to test DeepSeekMath-Instruct and DeepSeekMath-RL:**
- English questions: **{question}\nPlease reason step by step, and put your final answer within \\boxed{}.**
- Chinese questions: **{question}\n请通过逐步推理来解答问题,并把最终答案放置于\\boxed{}中。**
```python
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, GenerationConfig
model_name = "deepseek-ai/deepseek-math-7b-instruct"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name, torch_dtype=torch.bfloat16, device_map="auto")
model.generation_config = GenerationConfig.from_pretrained(model_name)
model.generation_config.pad_token_id = model.generation_config.eos_token_id
messages = [
{"role": "user", "content": "what is the integral of x^2 from 0 to 2?\nPlease reason step by step, and put your final answer within \\boxed{}."}
]
input_tensor = tokenizer.apply_chat_template(messages, add_generation_prompt=True, return_tensors="pt")
outputs = model.generate(input_tensor.to(model.device), max_new_tokens=100)
result = tokenizer.decode(outputs[0][input_tensor.shape[1]:], skip_special_tokens=True)
print(result)
```
Avoiding the use of the provided function `apply_chat_template`, you can also interact with our model following the sample template. Note that `messages` should be replaced by your input.
```
User: {messages[0]['content']}
Assistant: {messages[1]['content']}<|end▁of▁sentence|>User: {messages[2]['content']}
Assistant:
```
**Note:** By default (`add_special_tokens=True`), our tokenizer automatically adds a `bos_token` (`<|begin▁of▁sentence|>`) before the input text. Additionally, since the system prompt is not compatible with this version of our models, we DO NOT RECOMMEND including the system prompt in your input.
### 3. License
This code repository is licensed under the MIT License. The use of DeepSeekMath models is subject to the Model License. DeepSeekMath supports commercial use.
See the [LICENSE-MODEL](https://github.com/deepseek-ai/DeepSeek-Math/blob/main/LICENSE-MODEL) for more details.
### 4. Contact
If you have any questions, please raise an issue or contact us at [[email protected]](mailto:[email protected]).
|
bullerwins/DeepSeek-Coder-V2-Instruct-GGUF | bullerwins | 2024-06-19T17:17:55Z | 6,658 | 1 | null | [
"gguf",
"arxiv:2401.06066",
"license:other",
"region:us"
] | null | 2024-06-17T14:40:58Z | ---
license: other
license_name: deepseek-license
license_link: LICENSE
---
<!-- markdownlint-disable first-line-h1 -->
<!-- markdownlint-disable html -->
<!-- markdownlint-disable no-duplicate-header -->
NOTE: You might need to disable FA (Flash Attention) in llama.cpp to work properly.
GGUF quantized version of [DeepSeek-Coder-V2-Instruct](https://huggingface.co/deepseek-ai/DeepSeek-Coder-V2-Instruct)
Using [llama.cpp c637fcd](https://github.com/ggerganov/llama.cpp/commit/c637fcd34d135a9ff4f97d3a53ad03a910a4a31f)
<div align="center">
<img src="https://github.com/deepseek-ai/DeepSeek-V2/blob/main/figures/logo.svg?raw=true" width="60%" alt="DeepSeek-V2" />
</div>
<hr>
<div align="center" style="line-height: 1;">
<a href="https://www.deepseek.com/" target="_blank" style="margin: 2px;">
<img alt="Homepage" src="https://github.com/deepseek-ai/DeepSeek-V2/blob/main/figures/badge.svg?raw=true" style="display: inline-block; vertical-align: middle;"/>
</a>
<a href="https://chat.deepseek.com/" target="_blank" style="margin: 2px;">
<img alt="Chat" src="https://img.shields.io/badge/🤖%20Chat-DeepSeek%20V2-536af5?color=536af5&logoColor=white" style="display: inline-block; vertical-align: middle;"/>
</a>
<a href="https://huggingface.co/deepseek-ai" target="_blank" style="margin: 2px;">
<img alt="Hugging Face" src="https://img.shields.io/badge/%F0%9F%A4%97%20Hugging%20Face-DeepSeek%20AI-ffc107?color=ffc107&logoColor=white" style="display: inline-block; vertical-align: middle;"/>
</a>
</div>
<div align="center" style="line-height: 1;">
<a href="https://discord.gg/Tc7c45Zzu5" target="_blank" style="margin: 2px;">
<img alt="Discord" src="https://img.shields.io/badge/Discord-DeepSeek%20AI-7289da?logo=discord&logoColor=white&color=7289da" style="display: inline-block; vertical-align: middle;"/>
</a>
<a href="https://github.com/deepseek-ai/DeepSeek-V2/blob/main/figures/qr.jpeg?raw=true" target="_blank" style="margin: 2px;">
<img alt="Wechat" src="https://img.shields.io/badge/WeChat-DeepSeek%20AI-brightgreen?logo=wechat&logoColor=white" style="display: inline-block; vertical-align: middle;"/>
</a>
<a href="https://twitter.com/deepseek_ai" target="_blank" style="margin: 2px;">
<img alt="Twitter Follow" src="https://img.shields.io/badge/Twitter-deepseek_ai-white?logo=x&logoColor=white" style="display: inline-block; vertical-align: middle;"/>
</a>
</div>
<div align="center" style="line-height: 1;">
<a href="https://github.com/deepseek-ai/DeepSeek-V2/blob/main/LICENSE-CODE" style="margin: 2px;">
<img alt="Code License" src="https://img.shields.io/badge/Code_License-MIT-f5de53?&color=f5de53" style="display: inline-block; vertical-align: middle;"/>
</a>
<a href="https://github.com/deepseek-ai/DeepSeek-V2/blob/main/LICENSE-MODEL" style="margin: 2px;">
<img alt="Model License" src="https://img.shields.io/badge/Model_License-Model_Agreement-f5de53?&color=f5de53" style="display: inline-block; vertical-align: middle;"/>
</a>
</div>
<p align="center">
<a href="#4-api-platform">API Platform</a> |
<a href="#5-how-to-run-locally">How to Use</a> |
<a href="#6-license">License</a> |
</p>
<p align="center">
<a href="https://github.com/deepseek-ai/DeepSeek-Coder-V2/blob/main/paper.pdf"><b>Paper Link</b>👁️</a>
</p>
# DeepSeek-Coder-V2: Breaking the Barrier of Closed-Source Models in Code Intelligence
## 1. Introduction
We present DeepSeek-Coder-V2, an open-source Mixture-of-Experts (MoE) code language model that achieves performance comparable to GPT4-Turbo in code-specific tasks. Specifically, DeepSeek-Coder-V2 is further pre-trained from DeepSeek-Coder-V2-Base with 6 trillion tokens sourced from a high-quality and multi-source corpus. Through this continued pre-training, DeepSeek-Coder-V2 substantially enhances the coding and mathematical reasoning capabilities of DeepSeek-Coder-V2-Base, while maintaining comparable performance in general language tasks. Compared to DeepSeek-Coder, DeepSeek-Coder-V2 demonstrates significant advancements in various aspects of code-related tasks, as well as reasoning and general capabilities. Additionally, DeepSeek-Coder-V2 expands its support for programming languages from 86 to 338, while extending the context length from 16K to 128K.
<p align="center">
<img width="100%" src="https://github.com/deepseek-ai/DeepSeek-Coder-V2/blob/main/figures/performance.png?raw=true">
</p>
In standard benchmark evaluations, DeepSeek-Coder-V2 achieves superior performance compared to closed-source models such as GPT4-Turbo, Claude 3 Opus, and Gemini 1.5 Pro in coding and math benchmarks. The list of supported programming languages can be found in the paper.
## 2. Model Downloads
We release the DeepSeek-Coder-V2 with 16B and 236B parameters based on the [DeepSeekMoE](https://arxiv.org/pdf/2401.06066) framework, which has actived parameters of only 2.4B and 21B , including base and instruct models, to the public.
<div align="center">
| **Model** | **#Total Params** | **#Active Params** | **Context Length** | **Download** |
| :-----------------------------: | :---------------: | :----------------: | :----------------: | :----------------------------------------------------------: |
| DeepSeek-Coder-V2-Lite-Base | 16B | 2.4B | 128k | [🤗 HuggingFace](https://huggingface.co/deepseek-ai/DeepSeek-Coder-V2-Lite-Base) |
| DeepSeek-Coder-V2-Lite-Instruct | 16B | 2.4B | 128k | [🤗 HuggingFace](https://huggingface.co/deepseek-ai/DeepSeek-Coder-V2-Lite-Instruct) |
| DeepSeek-Coder-V2-Base | 236B | 21B | 128k | [🤗 HuggingFace](https://huggingface.co/deepseek-ai/DeepSeek-Coder-V2-Base) |
| DeepSeek-Coder-V2-Instruct | 236B | 21B | 128k | [🤗 HuggingFace](https://huggingface.co/deepseek-ai/DeepSeek-Coder-V2-Instruct) |
</div>
## 3. Chat Website
You can chat with the DeepSeek-Coder-V2 on DeepSeek's official website: [coder.deepseek.com](https://coder.deepseek.com/sign_in)
## 4. API Platform
We also provide OpenAI-Compatible API at DeepSeek Platform: [platform.deepseek.com](https://platform.deepseek.com/). Sign up for over millions of free tokens. And you can also pay-as-you-go at an unbeatable price.
<p align="center">
<img width="40%" src="https://github.com/deepseek-ai/DeepSeek-Coder-V2/blob/main/figures/model_price.jpg?raw=true">
</p>
## 5. How to run locally
**Here, we provide some examples of how to use DeepSeek-Coder-V2-Lite model. If you want to utilize DeepSeek-Coder-V2 in BF16 format for inference, 80GB*8 GPUs are required.**
### Inference with Huggingface's Transformers
You can directly employ [Huggingface's Transformers](https://github.com/huggingface/transformers) for model inference.
#### Code Completion
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
tokenizer = AutoTokenizer.from_pretrained("deepseek-ai/DeepSeek-Coder-V2-Lite-Base", trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained("deepseek-ai/DeepSeek-Coder-V2-Lite-Base", trust_remote_code=True, torch_dtype=torch.bfloat16).cuda()
input_text = "#write a quick sort algorithm"
inputs = tokenizer(input_text, return_tensors="pt").to(model.device)
outputs = model.generate(**inputs, max_length=128)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
```
#### Code Insertion
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
tokenizer = AutoTokenizer.from_pretrained("deepseek-ai/DeepSeek-Coder-V2-Lite-Base", trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained("deepseek-ai/DeepSeek-Coder-V2-Lite-Base", trust_remote_code=True, torch_dtype=torch.bfloat16).cuda()
input_text = """<|fim▁begin|>def quick_sort(arr):
if len(arr) <= 1:
return arr
pivot = arr[0]
left = []
right = []
<|fim▁hole|>
if arr[i] < pivot:
left.append(arr[i])
else:
right.append(arr[i])
return quick_sort(left) + [pivot] + quick_sort(right)<|fim▁end|>"""
inputs = tokenizer(input_text, return_tensors="pt").to(model.device)
outputs = model.generate(**inputs, max_length=128)
print(tokenizer.decode(outputs[0], skip_special_tokens=True)[len(input_text):])
```
#### Chat Completion
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
tokenizer = AutoTokenizer.from_pretrained("deepseek-ai/DeepSeek-Coder-V2-Lite-Instruct", trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained("deepseek-ai/DeepSeek-Coder-V2-Lite-Instruct", trust_remote_code=True, torch_dtype=torch.bfloat16).cuda()
messages=[
{ 'role': 'user', 'content': "write a quick sort algorithm in python."}
]
inputs = tokenizer.apply_chat_template(messages, add_generation_prompt=True, return_tensors="pt").to(model.device)
# tokenizer.eos_token_id is the id of <|EOT|> token
outputs = model.generate(inputs, max_new_tokens=512, do_sample=False, top_k=50, top_p=0.95, num_return_sequences=1, eos_token_id=tokenizer.eos_token_id)
print(tokenizer.decode(outputs[0][len(inputs[0]):], skip_special_tokens=True))
```
The complete chat template can be found within `tokenizer_config.json` located in the huggingface model repository.
An example of chat template is as belows:
```bash
<|begin▁of▁sentence|>User: {user_message_1}
Assistant: {assistant_message_1}<|end▁of▁sentence|>User: {user_message_2}
Assistant:
```
You can also add an optional system message:
```bash
<|begin▁of▁sentence|>{system_message}
User: {user_message_1}
Assistant: {assistant_message_1}<|end▁of▁sentence|>User: {user_message_2}
Assistant:
```
### Inference with vLLM (recommended)
To utilize [vLLM](https://github.com/vllm-project/vllm) for model inference, please merge this Pull Request into your vLLM codebase: https://github.com/vllm-project/vllm/pull/4650.
```python
from transformers import AutoTokenizer
from vllm import LLM, SamplingParams
max_model_len, tp_size = 8192, 1
model_name = "deepseek-ai/DeepSeek-Coder-V2-Lite-Instruct"
tokenizer = AutoTokenizer.from_pretrained(model_name)
llm = LLM(model=model_name, tensor_parallel_size=tp_size, max_model_len=max_model_len, trust_remote_code=True, enforce_eager=True)
sampling_params = SamplingParams(temperature=0.3, max_tokens=256, stop_token_ids=[tokenizer.eos_token_id])
messages_list = [
[{"role": "user", "content": "Who are you?"}],
[{"role": "user", "content": "write a quick sort algorithm in python."}],
[{"role": "user", "content": "Write a piece of quicksort code in C++."}],
]
prompt_token_ids = [tokenizer.apply_chat_template(messages, add_generation_prompt=True) for messages in messages_list]
outputs = llm.generate(prompt_token_ids=prompt_token_ids, sampling_params=sampling_params)
generated_text = [output.outputs[0].text for output in outputs]
print(generated_text)
```
## 6. License
This code repository is licensed under [the MIT License](https://github.com/deepseek-ai/DeepSeek-Coder-V2/blob/main/LICENSE-CODE). The use of DeepSeek-Coder-V2 Base/Instruct models is subject to [the Model License](https://github.com/deepseek-ai/DeepSeek-Coder-V2/blob/main/LICENSE-MODEL). DeepSeek-Coder-V2 series (including Base and Instruct) supports commercial use.
## 7. Contact
If you have any questions, please raise an issue or contact us at [[email protected]]([email protected]).
|
DeepMount00/Italian_NER_XXL | DeepMount00 | 2024-03-28T07:58:35Z | 6,647 | 28 | transformers | [
"transformers",
"pytorch",
"safetensors",
"bert",
"token-classification",
"legal",
"finance",
"privacy",
"it",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | token-classification | 2024-01-22T16:23:58Z | ---
tags:
- legal
- finance
- privacy
model-index:
- name: Italin_NER_XXL
results: []
widget:
- text: >-
Mario Rossi, nato il 15 marzo 1975, residente in Via delle Rose 123, 50122
Firenze, ha inviato un'email a [email protected] per richiedere informazioni
sulla legge N. 123/2021, indicando il suo numero di telefono +39 0551234567
e il codice fiscale RSSMRA75C15D612K.
- text: >-
La ditta Giardini Belli S.p.A., con partita IVA 01234567890, ha emesso una
fattura di 500€ per la consulenza giuridica fornita dall'avvocato Giulia
Bianchi, il cui studio si trova in Piazza del Duomo, Milano, dal giorno
01/04/2024.
- text: >-
Il cliente ha effettuato un pagamento di 1500€ tramite bonifico bancario
(IBAN: IT60X0542811101000000123456) dalla banca Banca di Roma, per
l'acquisto di un veicolo con targa AB123CD, registrando la transazione alle
14:00 del 10/01/2024, come evidenziato nel suo estratto conto numero 7890.
language:
- it
license: apache-2.0
---
# Italian_NER_XXL
## Model Overview
This is the initial release of our artificial intelligence model on Hugging Face. It is important to note that this version is just the beginning; the model will be constantly improved over time. <u>**Currently, the model boasts an accuracy of 79%, but we plan to increase this regularly through monthly updates.**</u>
## Uniqueness of the Model in Italy
We are proud to announce that our model is currently the only one in Italy capable of identifying a wide range of **52** different categories. This capability distinctly sets it apart from other models available in the Italian landscape, offering an unprecedented level of versatility and breadth in entity recognition.
## Technology and Innovation
The model is based on the BERT architecture, one of the most advanced technologies in the field of Natural Language Processing (NLP). State-of-the-art techniques have been employed for its training, ensuring high-level accuracy and efficiency. This technological choice ensures a deep and sophisticated understanding of natural language.
## Recognized Categories
The model is capable of identifying the following categories:
- **INDIRIZZO**: Identifica un indirizzo fisico.
- **VALUTA**: Rappresenta una valuta.
- **CVV**: Codice di sicurezza della carta di credito.
- **NUMERO_CONTO**: Numero di un conto bancario.
- **BIC**: Codice identificativo di una banca (Bank Identifier Code).
- **IBAN**: Numero di conto bancario internazionale.
- **STATO**: Identifica un paese o una nazione.
- **NOME**: Riferito al nome di una persona.
- **COGNOME**: Riferito al cognome di una persona.
- **CODICE_POSTALE**: Codice postale di un'area geografica.
- **IP**: Indirizzo IP di un dispositivo in rete.
- **ORARIO**: Riferito a un orario specifico.
- **URL**: Indirizzo web (Uniform Resource Locator).
- **LUOGO**: Identifica un luogo geografico.
- **IMPORTO**: Riferito a una somma di denaro.
- **EMAIL**: Indirizzo di posta elettronica.
- **PASSWORD**: Parola chiave per l'accesso a sistemi protetti.
- **NUMERO_CARTA**: Numero di una carta di credito o debito.
- **TARGA_VEICOLO**: Numero di targa di un veicolo.
- **DATA_NASCITA**: Data di nascita di una persona.
- **DATA_MORTE**: Data di decesso di una persona.
- **RAGIONE_SOCIALE**: Nome legale di un'azienda o entità commerciale.
- **ETA**: Età di una persona.
- **DATA**: Riferita a una data generica.
- **PROFESSIONE**: Occupazione o lavoro di una persona.
- **PIN**: Numero di identificazione personale.
- **NUMERO_TELEFONO**: Numero telefonico.
- **FOGLIO**: Riferito a un foglio di documentazione.
- **PARTICELLA**: Riferito a una particella catastale.
- **CARTELLA_CLINICA**: Documentazione medica di un paziente.
- **MALATTIA**: Identifica una malattia o condizione medica.
- **MEDICINA**: Riferito a un farmaco o trattamento medico.
- **CODICE_FISCALE**: Codice fiscale personale o aziendale.
- **NUMERO_DOCUMENTO**: Numero di un documento ufficiale.
- **STORIA_CLINICA**: Registro delle condizioni mediche di un paziente.
- **AVV_NOTAIO**: Identifica un avvocato o notaio.
- **P_IVA**: Partita IVA di un'azienda o professionista.
- **LEGGE**: Riferito a una legge specifica.
- **TASSO_MUTUO**: Tasso di interesse di un mutuo.
- **N_SENTENZA**: Numero di una sentenza legale.
- **MAPPALE**: Riferito a un mappale catastale.
- **SUBALTERNO**: Riferito a un subalterno catastale.
- **REGIME_PATRIMONIALE**: Stato patrimoniale in ambito legale.
- **STATO_CIVILE**: Stato civile di una persona.
- **BANCA**: Identifica una banca o istituto di credito.
- **BRAND**: Marchio o brand commerciale.
- **NUM_ASSEGNO_BANCARIO**: Numero di un assegno bancario.
- **IMEI**: Numero di identificazione internazionale di un dispositivo mobile.
- **N_LICENZA**: Numero di una licenza specifica.
- **IPV6_1**: Indirizzo IP versione 6.
- **MAC**: Indirizzo MAC di un dispositivo di rete.
- **USER_AGENT**: Identifica il software usato per accedere a una rete.
- **TRIBUNALE**: Identifica un tribunale specifico.
- **STRENGTH**: Riferito alla forza o intensità di del medicinale.
- **FREQUENZA**: Riferito alla frequenza di un trattamento medico.
- **DURATION**: Durata di un evento o trattamento.
- **DOSAGGIO**: Quantità di un medicinale da assumere.
- **FORM**: Forma del medicinale, ad esempio compresse.
## How to Use
To utilize this model:
```python
from transformers import AutoTokenizer, AutoModelForTokenClassification
from transformers import pipeline
import torch
tokenizer = AutoTokenizer.from_pretrained("DeepMount00/Italian_NER_XXL")
model = AutoModelForTokenClassification.from_pretrained("DeepMount00/Italian_NER_XXL", ignore_mismatched_sizes=True)
nlp = pipeline("ner", model=model, tokenizer=tokenizer)
example = """Il commendatore Gianluigi Alberico De Laurentis-Ponti, con residenza legale in Corso Imperatrice 67, Torino, avente codice fiscale DLNGGL60B01L219P, è amministratore delegato della "De Laurentis Advanced Engineering Group S.p.A.", che si trova in Piazza Affari 32, Milano (MI); con una partita IVA di 09876543210, la società è stata recentemente incaricata di sviluppare una nuova linea di componenti aerospaziali per il progetto internazionale di esplorazione di Marte."""
ner_results = nlp(example)
print(ner_results)
```
---
## Conclusion
The primary goal of this model is to provide effective and accurate identification of a wide range of entities, surpassing the limits of traditional models. Being the only model in Italy to recognize so many entities, we are confident that it will be an invaluable tool for numerous application areas. Constant evolution and improvement of the model is our top priority to ensure always top-notch performance.
## Contribution and Contact
If you are interested in contributing to this project, have suggestions for improvement, or require a specific named entity recognizer for your use case, please feel free to reach out. Your input and collaboration can significantly enhance the model's capabilities and applications. For any inquiries or to discuss potential contributions, please contact Michele Montebovi at [[email protected]](mailto:[email protected]). Your support and participation are highly appreciated as we aim to continuously improve and expand the functionalities of the Italian_NER_XXL model. |
OpenAssistant/falcon-7b-sft-mix-2000 | OpenAssistant | 2023-06-06T10:32:55Z | 6,643 | 42 | transformers | [
"transformers",
"pytorch",
"RefinedWebModel",
"text-generation",
"sft",
"custom_code",
"en",
"de",
"es",
"fr",
"dataset:OpenAssistant/oasst1",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2023-06-05T04:48:05Z | ---
license: apache-2.0
language:
- en
- de
- es
- fr
tags:
- sft
pipeline_tag: text-generation
widget:
- text: >-
<|prompter|>What is a meme, and what's the history behind this
word?<|endoftext|><|assistant|>
- text: <|prompter|>What's the Earth total population<|endoftext|><|assistant|>
- text: >-
<|prompter|>Write a story about future of AI
development<|endoftext|><|assistant|>
datasets:
- OpenAssistant/oasst1
---
# Open-Assistant Falcon 7B SFT MIX Model
This model is a fine-tuning of TII's [Falcon 7B](https://huggingface.co/tiiuae/falcon-7b) LLM.
It was trained on a mixture of OASST top-2 threads (exported on June 2, 2023), Dolly-15k and synthetic instruction datasets (see dataset configuration below).
## Model Details
- **Finetuned from:** [tiiuae/falcon-7b](https://huggingface.co/tiiuae/falcon-7b)
- **Model type:** Causal decoder-only transformer language model
- **Language:** English, German, Spanish, French (and limited capabilities in Italian, Portuguese, Polish, Dutch, Romanian, Czech, Swedish);
- **Weights & Biases:** [Training log](https://wandb.ai/open-assistant/public-sft/runs/tlevhltw) (Checkpoint: 2000 steps, ~2.9 epochs)
- **Demo:** [Continuations for 250 random prompts](https://open-assistant.github.io/oasst-model-eval/?f=https%3A%2F%2Fraw.githubusercontent.com%2FOpen-Assistant%2Foasst-model-eval%2Fmain%2Fsampling_reports%2Fchat-gpt%2F2023-04-11_gpt-3.5-turbo_lottery.json%0Ahttps%3A%2F%2Fraw.githubusercontent.com%2FOpen-Assistant%2Foasst-model-eval%2Fmain%2Fsampling_reports%2Foasst-sft%2F2023-06-05_OpenAssistant_falcon-7b-sft-mix-2000_sampling_noprefix2.json)
- **License:** Apache 2.0
- **Contact:** [Open-Assistant Discord](https://ykilcher.com/open-assistant-discord)
## Prompting
Two special tokens are used to mark the beginning of user and assistant turns:
`<|prompter|>` and `<|assistant|>`. Each turn ends with a `<|endoftext|>` token.
Input prompt example:
```
<|prompter|>What is a meme, and what's the history behind this word?<|endoftext|><|assistant|>
```
The input ends with the `<|assistant|>` token to signal that the model should
start generating the assistant reply.
## Sample Code
```python
from transformers import AutoTokenizer
import transformers
import torch
model = "OpenAssistant/falcon-7b-sft-mix-2000"
tokenizer = AutoTokenizer.from_pretrained(model)
pipeline = transformers.pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
torch_dtype=torch.bfloat16,
trust_remote_code=True,
device_map="auto",
)
input_text="<|prompter|>What is a meme, and what's the history behind this word?<|endoftext|><|assistant|>"
sequences = pipeline(
input_text,
max_length=500,
do_sample=True,
return_full_text=False,
top_k=10,
num_return_sequences=1,
eos_token_id=tokenizer.eos_token_id,
)
for seq in sequences:
print(f"Result: {seq['generated_text']}")
```
## Configuration Details
Model:
```
falcon-7b:
dtype: bf16
log_dir: "falcon_log_7b"
learning_rate: 1e-5
model_name: "tiiuae/falcon-7b"
deepspeed_config: configs/zero_config.json
output_dir: falcon
weight_decay: 0.0
max_length: 2048
warmup_steps: 20
gradient_checkpointing: true
gradient_accumulation_steps: 4
per_device_train_batch_size: 4
per_device_eval_batch_size: 8
eval_steps: 100
save_steps: 500
save_strategy: steps
num_train_epochs: 8
save_total_limit: 4
residual_dropout: 0.2
residual_dropout_lima: true
```
Dataset:
```
sft9-stage2:
# oasst_export: 100.00% (29899)
# vicuna: 50.00% (16963)
# code_alpaca: 50.00% (9510)
# oa_wiki_qa_bart_10000row: 100.00% (9434)
# grade_school_math_instructions: 100.00% (8351)
# dolly15k: 100.00% (14250)
use_custom_sampler: true
datasets:
- oasst_export:
lang: "bg,ca,cs,da,de,en,es,fr,hr,hu,it,nl,pl,pt,ro,ru,sl,sr,sv,uk" # sft-8.0
input_file_path: 2023-06-02_oasst_all_labels.jsonl.gz
val_split: 0.05
top_k: 2
- vicuna:
fraction: 0.5
val_split: 0.025
max_val_set: 250
- code_alpaca:
fraction: 0.5
val_split: 0.05
max_val_set: 250
- oa_wiki_qa_bart_10000row:
val_split: 0.05
max_val_set: 250
- grade_school_math_instructions:
val_split: 0.05
- dolly15k:
val_split: 0.05
max_val_set: 300
``` |
BAAI/AquilaChat2-7B | BAAI | 2023-11-29T06:07:56Z | 6,641 | 14 | transformers | [
"transformers",
"pytorch",
"aquila",
"text-generation",
"custom_code",
"license:other",
"autotrain_compatible",
"region:us"
] | text-generation | 2023-10-10T02:02:49Z | ---
license: other
---

<h4 align="center">
<p>
<b>English</b> |
<a href="https://huggingface.co/BAAI/AquilaChat2-7B/blob/main/README_zh.md">简体中文</a>
</p>
</h4>
We opensource our **Aquila2** series, now including **Aquila2**, the base language models, namely **Aquila2-7B** and **Aquila2-34B**, as well as **AquilaChat2**, the chat models, namely **AquilaChat2-7B** and **AquilaChat2-34B**, as well as the long-text chat models, namely **AquilaChat2-7B-16k** and **AquilaChat2-34B-16k**
The additional details of the Aquila model will be presented in the official technical report. Please stay tuned for updates on official channels.
## Quick Start AquilaChat2-7B(Chat model)
### 1. Inference
```python
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
from transformers import BitsAndBytesConfig
device = torch.device("cuda:0")
model_info = "BAAI/AquilaChat2-7B"
tokenizer = AutoTokenizer.from_pretrained(model_info, trust_remote_code=True)
quantization_config=BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16,
)
model = AutoModelForCausalLM.from_pretrained(model_info, trust_remote_code=True, torch_dtype=torch.float16,
# quantization_config=quantization_config, # Uncomment this line for 4bit quantization
)
model.eval()
model.to(device)
text = "请给出10个要到北京旅游的理由。"
from predict import predict
out = predict(model, text, tokenizer=tokenizer, max_gen_len=200, top_p=0.95,
seed=1234, topk=100, temperature=0.9, sft=True, device=device,
model_name="AquilaChat2-7B")
print(out)
```
## License
Aquila2 series open-source model is licensed under [ BAAI Aquila Model Licence Agreement](https://huggingface.co/BAAI/AquilaChat2-7B/blob/main/BAAI-Aquila-Model-License%20-Agreement.pdf) |
rhasspy/faster-whisper-tiny-int8 | rhasspy | 2024-03-10T18:24:17Z | 6,641 | 3 | transformers | [
"transformers",
"license:mit",
"endpoints_compatible",
"region:us"
] | null | 2024-03-10T18:22:26Z | ---
license: mit
---
|
QuantFactory/Replete-Coder-Llama3-8B-GGUF | QuantFactory | 2024-06-25T13:39:32Z | 6,641 | 0 | null | [
"gguf",
"region:us"
] | null | 2024-06-25T12:44:10Z | Entry not found |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.