
modelId
stringlengths 5
122
| author
stringlengths 2
42
| last_modified
timestamp[us, tz=UTC] | downloads
int64 0
738M
| likes
int64 0
11k
| library_name
stringclasses 245
values | tags
sequencelengths 1
4.05k
| pipeline_tag
stringclasses 48
values | createdAt
timestamp[us, tz=UTC] | card
stringlengths 1
901k
|
|---|---|---|---|---|---|---|---|---|---|
bartowski/llama-3-8B-function-calling-GGUF | bartowski | 2024-06-04T08:14:17Z | 3,320 | 1 | null | [
"gguf",
"text-generation",
"region:us"
] | text-generation | 2024-06-04T07:57:10Z | ---
quantized_by: bartowski
pipeline_tag: text-generation
---
## Llamacpp imatrix Quantizations of llama-3-8B-function-calling
Using <a href="https://github.com/ggerganov/llama.cpp/">llama.cpp</a> release <a href="https://github.com/ggerganov/llama.cpp/releases/tag/b3070">b3070</a> for quantization.
Original model: https://huggingface.co/serpdotai/llama-3-8B-function-calling
All quants made using imatrix option with dataset from [here](https://gist.github.com/bartowski1182/eb213dccb3571f863da82e99418f81e8)
## Prompt format
```
<|im_start|>system
{system_prompt}<|im_end|>
<|im_start|>user
{prompt}<|im_end|>
<|im_start|>assistant
```
## Download a file (not the whole branch) from below:
| Filename | Quant type | File Size | Description |
| -------- | ---------- | --------- | ----------- |
| [llama-3-8B-function-calling-Q8_0.gguf](https://huggingface.co/bartowski/llama-3-8B-function-calling-GGUF/blob/main/llama-3-8B-function-calling-Q8_0.gguf) | Q8_0 | 8.54GB | Extremely high quality, generally unneeded but max available quant. |
| [llama-3-8B-function-calling-Q6_K.gguf](https://huggingface.co/bartowski/llama-3-8B-function-calling-GGUF/blob/main/llama-3-8B-function-calling-Q6_K.gguf) | Q6_K | 6.59GB | Very high quality, near perfect, *recommended*. |
| [llama-3-8B-function-calling-Q5_K_M.gguf](https://huggingface.co/bartowski/llama-3-8B-function-calling-GGUF/blob/main/llama-3-8B-function-calling-Q5_K_M.gguf) | Q5_K_M | 5.73GB | High quality, *recommended*. |
| [llama-3-8B-function-calling-Q5_K_S.gguf](https://huggingface.co/bartowski/llama-3-8B-function-calling-GGUF/blob/main/llama-3-8B-function-calling-Q5_K_S.gguf) | Q5_K_S | 5.59GB | High quality, *recommended*. |
| [llama-3-8B-function-calling-Q4_K_M.gguf](https://huggingface.co/bartowski/llama-3-8B-function-calling-GGUF/blob/main/llama-3-8B-function-calling-Q4_K_M.gguf) | Q4_K_M | 4.92GB | Good quality, uses about 4.83 bits per weight, *recommended*. |
| [llama-3-8B-function-calling-Q4_K_S.gguf](https://huggingface.co/bartowski/llama-3-8B-function-calling-GGUF/blob/main/llama-3-8B-function-calling-Q4_K_S.gguf) | Q4_K_S | 4.69GB | Slightly lower quality with more space savings, *recommended*. |
| [llama-3-8B-function-calling-IQ4_XS.gguf](https://huggingface.co/bartowski/llama-3-8B-function-calling-GGUF/blob/main/llama-3-8B-function-calling-IQ4_XS.gguf) | IQ4_XS | 4.44GB | Decent quality, smaller than Q4_K_S with similar performance, *recommended*. |
| [llama-3-8B-function-calling-Q3_K_L.gguf](https://huggingface.co/bartowski/llama-3-8B-function-calling-GGUF/blob/main/llama-3-8B-function-calling-Q3_K_L.gguf) | Q3_K_L | 4.32GB | Lower quality but usable, good for low RAM availability. |
| [llama-3-8B-function-calling-Q3_K_M.gguf](https://huggingface.co/bartowski/llama-3-8B-function-calling-GGUF/blob/main/llama-3-8B-function-calling-Q3_K_M.gguf) | Q3_K_M | 4.01GB | Even lower quality. |
| [llama-3-8B-function-calling-IQ3_M.gguf](https://huggingface.co/bartowski/llama-3-8B-function-calling-GGUF/blob/main/llama-3-8B-function-calling-IQ3_M.gguf) | IQ3_M | 3.78GB | Medium-low quality, new method with decent performance comparable to Q3_K_M. |
| [llama-3-8B-function-calling-Q3_K_S.gguf](https://huggingface.co/bartowski/llama-3-8B-function-calling-GGUF/blob/main/llama-3-8B-function-calling-Q3_K_S.gguf) | Q3_K_S | 3.66GB | Low quality, not recommended. |
| [llama-3-8B-function-calling-IQ3_XS.gguf](https://huggingface.co/bartowski/llama-3-8B-function-calling-GGUF/blob/main/llama-3-8B-function-calling-IQ3_XS.gguf) | IQ3_XS | 3.51GB | Lower quality, new method with decent performance, slightly better than Q3_K_S. |
| [llama-3-8B-function-calling-IQ3_XXS.gguf](https://huggingface.co/bartowski/llama-3-8B-function-calling-GGUF/blob/main/llama-3-8B-function-calling-IQ3_XXS.gguf) | IQ3_XXS | 3.27GB | Lower quality, new method with decent performance, comparable to Q3 quants. |
| [llama-3-8B-function-calling-Q2_K.gguf](https://huggingface.co/bartowski/llama-3-8B-function-calling-GGUF/blob/main/llama-3-8B-function-calling-Q2_K.gguf) | Q2_K | 3.17GB | Very low quality but surprisingly usable. |
| [llama-3-8B-function-calling-IQ2_M.gguf](https://huggingface.co/bartowski/llama-3-8B-function-calling-GGUF/blob/main/llama-3-8B-function-calling-IQ2_M.gguf) | IQ2_M | 2.94GB | Very low quality, uses SOTA techniques to also be surprisingly usable. |
| [llama-3-8B-function-calling-IQ2_S.gguf](https://huggingface.co/bartowski/llama-3-8B-function-calling-GGUF/blob/main/llama-3-8B-function-calling-IQ2_S.gguf) | IQ2_S | 2.75GB | Very low quality, uses SOTA techniques to be usable. |
| [llama-3-8B-function-calling-IQ2_XS.gguf](https://huggingface.co/bartowski/llama-3-8B-function-calling-GGUF/blob/main/llama-3-8B-function-calling-IQ2_XS.gguf) | IQ2_XS | 2.60GB | Very low quality, uses SOTA techniques to be usable. |
## Downloading using huggingface-cli
First, make sure you have hugginface-cli installed:
```
pip install -U "huggingface_hub[cli]"
```
Then, you can target the specific file you want:
```
huggingface-cli download bartowski/llama-3-8B-function-calling-GGUF --include "llama-3-8B-function-calling-Q4_K_M.gguf" --local-dir ./
```
If the model is bigger than 50GB, it will have been split into multiple files. In order to download them all to a local folder, run:
```
huggingface-cli download bartowski/llama-3-8B-function-calling-GGUF --include "llama-3-8B-function-calling-Q8_0.gguf/*" --local-dir llama-3-8B-function-calling-Q8_0
```
You can either specify a new local-dir (llama-3-8B-function-calling-Q8_0) or download them all in place (./)
## Which file should I choose?
A great write up with charts showing various performances is provided by Artefact2 [here](https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9)
The first thing to figure out is how big a model you can run. To do this, you'll need to figure out how much RAM and/or VRAM you have.
If you want your model running as FAST as possible, you'll want to fit the whole thing on your GPU's VRAM. Aim for a quant with a file size 1-2GB smaller than your GPU's total VRAM.
If you want the absolute maximum quality, add both your system RAM and your GPU's VRAM together, then similarly grab a quant with a file size 1-2GB Smaller than that total.
Next, you'll need to decide if you want to use an 'I-quant' or a 'K-quant'.
If you don't want to think too much, grab one of the K-quants. These are in format 'QX_K_X', like Q5_K_M.
If you want to get more into the weeds, you can check out this extremely useful feature chart:
[llama.cpp feature matrix](https://github.com/ggerganov/llama.cpp/wiki/Feature-matrix)
But basically, if you're aiming for below Q4, and you're running cuBLAS (Nvidia) or rocBLAS (AMD), you should look towards the I-quants. These are in format IQX_X, like IQ3_M. These are newer and offer better performance for their size.
These I-quants can also be used on CPU and Apple Metal, but will be slower than their K-quant equivalent, so speed vs performance is a tradeoff you'll have to decide.
The I-quants are *not* compatible with Vulcan, which is also AMD, so if you have an AMD card double check if you're using the rocBLAS build or the Vulcan build. At the time of writing this, LM Studio has a preview with ROCm support, and other inference engines have specific builds for ROCm.
Want to support my work? Visit my ko-fi page here: https://ko-fi.com/bartowski
|
Yntec/Photosphere | Yntec | 2023-07-14T23:22:58Z | 3,319 | 3 | diffusers | [
"diffusers",
"safetensors",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"Noosphere",
"Dreamlike",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | 2023-07-14T22:54:19Z | ---
license: creativeml-openrail-m
library_name: diffusers
pipeline_tag: text-to-image
tags:
- stable-diffusion
- stable-diffusion-diffusers
- diffusers
- text-to-image
- Noosphere
- Dreamlike
---
# Photosphere
A mix of Noosphere v3 by skumerz and photorealistic models.
Original page:
https://civitai.com/models/36538?modelVersionId=107675 |
gilf/french-camembert-postag-model | gilf | 2023-04-05T15:31:56Z | 3,317 | 7 | transformers | [
"transformers",
"pytorch",
"tf",
"safetensors",
"camembert",
"token-classification",
"fr",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | token-classification | 2022-03-02T23:29:05Z | ---
language: fr
widget:
- text: "Face à un choc inédit, les mesures mises en place par le gouvernement ont permis une protection forte et efficace des ménages"
---
## About
The *french-camembert-postag-model* is a part of speech tagging model for French that was trained on the *free-french-treebank* dataset available on
[github](https://github.com/nicolashernandez/free-french-treebank). The base tokenizer and model used for training is *'camembert-base'*.
## Supported Tags
It uses the following tags:
| Tag | Category | Extra Info |
|----------|:------------------------------:|------------:|
| ADJ | adjectif | |
| ADJWH | adjectif | |
| ADV | adverbe | |
| ADVWH | adverbe | |
| CC | conjonction de coordination | |
| CLO | pronom | obj |
| CLR | pronom | refl |
| CLS | pronom | suj |
| CS | conjonction de subordination | |
| DET | déterminant | |
| DETWH | déterminant | |
| ET | mot étranger | |
| I | interjection | |
| NC | nom commun | |
| NPP | nom propre | |
| P | préposition | |
| P+D | préposition + déterminant | |
| PONCT | signe de ponctuation | |
| PREF | préfixe | |
| PRO | autres pronoms | |
| PROREL | autres pronoms | rel |
| PROWH | autres pronoms | int |
| U | ? | |
| V | verbe | |
| VIMP | verbe imperatif | |
| VINF | verbe infinitif | |
| VPP | participe passé | |
| VPR | participe présent | |
| VS | subjonctif | |
More information on the tags can be found here:
http://alpage.inria.fr/statgram/frdep/Publications/crabbecandi-taln2008-final.pdf
## Usage
The usage of this model follows the common transformers patterns. Here is a short example of its usage:
```python
from transformers import AutoTokenizer, AutoModelForTokenClassification
tokenizer = AutoTokenizer.from_pretrained("gilf/french-camembert-postag-model")
model = AutoModelForTokenClassification.from_pretrained("gilf/french-camembert-postag-model")
from transformers import pipeline
nlp_token_class = pipeline('ner', model=model, tokenizer=tokenizer, grouped_entities=True)
nlp_token_class('Face à un choc inédit, les mesures mises en place par le gouvernement ont permis une protection forte et efficace des ménages')
```
The lines above would display something like this on a Jupyter notebook:
```
[{'entity_group': 'NC', 'score': 0.5760144591331482, 'word': '<s>'},
{'entity_group': 'U', 'score': 0.9946700930595398, 'word': 'Face'},
{'entity_group': 'P', 'score': 0.999615490436554, 'word': 'à'},
{'entity_group': 'DET', 'score': 0.9995906352996826, 'word': 'un'},
{'entity_group': 'NC', 'score': 0.9995531439781189, 'word': 'choc'},
{'entity_group': 'ADJ', 'score': 0.999183714389801, 'word': 'inédit'},
{'entity_group': 'P', 'score': 0.3710663616657257, 'word': ','},
{'entity_group': 'DET', 'score': 0.9995903968811035, 'word': 'les'},
{'entity_group': 'NC', 'score': 0.9995649456977844, 'word': 'mesures'},
{'entity_group': 'VPP', 'score': 0.9988670349121094, 'word': 'mises'},
{'entity_group': 'P', 'score': 0.9996246099472046, 'word': 'en'},
{'entity_group': 'NC', 'score': 0.9995329976081848, 'word': 'place'},
{'entity_group': 'P', 'score': 0.9996233582496643, 'word': 'par'},
{'entity_group': 'DET', 'score': 0.9995935559272766, 'word': 'le'},
{'entity_group': 'NC', 'score': 0.9995369911193848, 'word': 'gouvernement'},
{'entity_group': 'V', 'score': 0.9993771314620972, 'word': 'ont'},
{'entity_group': 'VPP', 'score': 0.9991101026535034, 'word': 'permis'},
{'entity_group': 'DET', 'score': 0.9995885491371155, 'word': 'une'},
{'entity_group': 'NC', 'score': 0.9995636343955994, 'word': 'protection'},
{'entity_group': 'ADJ', 'score': 0.9991781711578369, 'word': 'forte'},
{'entity_group': 'CC', 'score': 0.9991298317909241, 'word': 'et'},
{'entity_group': 'ADJ', 'score': 0.9992275238037109, 'word': 'efficace'},
{'entity_group': 'P+D', 'score': 0.9993300437927246, 'word': 'des'},
{'entity_group': 'NC', 'score': 0.8353511393070221, 'word': 'ménages</s>'}]
```
|
fergusq/finbert-finnsentiment | fergusq | 2023-03-24T11:14:28Z | 3,316 | 2 | transformers | [
"transformers",
"pytorch",
"safetensors",
"bert",
"text-classification",
"fi",
"arxiv:2012.02613",
"license:cc-by-4.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2022-03-02T23:29:05Z | ---
language: fi
license: cc-by-4.0
---
# FinBERT fine-tuned with the FinnSentiment dataset
This is a FinBERT model fine-tuned with the [FinnSentiment dataset](https://arxiv.org/pdf/2012.02613.pdf). 90% of sentences were used for training and 10% for evaluation.
## Evaluation results
|Metric|Score|
|--|--|
|Accuracy|0.8639028475711893|
|F1-score|0.8643024701696561|
|Precision|0.8653866541244811|
|Recall|0.8639028475711893|
|Matthews|0.6764924917164834|

## License
FinBERT-FinnSentiment is licensed under the [CC BY 4.0 License](https://creativecommons.org/licenses/by/4.0/deed.en) (same as FinBERT and the FinnSentiment dataset). |
jondurbin/airoboros-l2-70b-2.1 | jondurbin | 2023-09-08T09:25:02Z | 3,316 | 37 | transformers | [
"transformers",
"pytorch",
"llama",
"text-generation",
"dataset:jondurbin/airoboros-2.1",
"license:llama2",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2023-08-26T13:33:56Z | ---
license: llama2
datasets:
- jondurbin/airoboros-2.1
---
### Overview
__*This model is a bit broken due to a prompt formatting bug in the training code! 2.2 will be available soon and should fix this*__
This is an instruction fine-tuned llama-2 model, using synthetic data generated by [airoboros](https://github.com/jondurbin/airoboros)
- Experimental RP style instruction set, with two categories: rp and gtkm
- rp includes multi-round chats, with emotes, between a varying number of characters, defined by cards
- gtkm is a way to test a simpler alternative to ghost attention - first, a character card is generated, then several questions are created to ask the model (as the character), using the character system prompt, then everything in synthesized into a dialog (one system prompt, all turns remain in character)
- Experimental support for longer, more detailed writing prompts, as well as next-chapter generation
- I used the new `cull-instructions` entrypoint in airoboros to shrink the m2.0 dataset to a smaller subset of high-quality instructions (according to gpt-4)
- The training data now also includes "stylized_response", in which 1500 sample instructions from various categories were re-generated using character cards as system prompts.
- this should allow better adherence to style/etc. specified in the system card
- Thousands of new generations, using some of the updates re: Flesch hints, etc., to get longer/higher quality writing outputs.
- A small "de-alignment" dataset was also added (not published) to remove some of the censorship in the base models.
*Why do I try to remove censorship?*
- laws vary widely based on time and location
- language model may conflate certain words with laws, e.g. it may think "stealing eggs from a chicken" is illegal
- these models just produce text, what you do with that text is your resonsibility
- many people and industries deal with "sensitive" content; imagine if a court stenographer's equipment filtered illegal content - it would be useless
Huge thank you to the folks over at [a16z](https://a16z.com/) for sponsoring the costs associated with building models and associated tools!
### Prompt format
The training code was updated to randomize newline vs space:
https://github.com/jondurbin/qlora/blob/main/qlora.py#L559C1-L559C1
```
A chat. USER: {prompt} ASSISTANT:
```
or
```
A chat.
USER: {prompt}
ASSISTANT:
```
So in other words, it's the preamble/system prompt, followed by a single space or newline, then "USER: " (single space after colon) then the prompt (which can have multiple lines, spaces, whatever), then a single space or newline, followed by "ASSISTANT: " (with a single space after the colon).
__*I strongly suggest adding stopping criteria/early inference stopping on "USER:", because the training data includes many multi-round chats and could otherwise start simulating a conversation!*__
### Helpful usage tips
*The prompts shown here are are just the text that would be included after USER: and before ASSISTANT: in the full prompt format above, the system prompt and USER:/ASSISTANT: have been omited for readability.*
#### Context obedient question answering
By obedient, I mean the model was trained to ignore what it thinks it knows, and uses the context to answer the question. The model was also tuned to limit the values to the provided context as much as possible to reduce hallucinations.
The format for a closed-context prompt is as follows:
```
BEGININPUT
BEGINCONTEXT
[key0: value0]
[key1: value1]
... other metdata ...
ENDCONTEXT
[insert your text blocks here]
ENDINPUT
[add as many other blocks, in the exact same format]
BEGININSTRUCTION
[insert your instruction(s). The model was tuned with single questions, paragraph format, lists, etc.]
ENDINSTRUCTION
```
It's also helpful to add "Don't make up answers if you don't know." to your instruction block to make sure if the context is completely unrelated it doesn't make something up.
*The __only__ prompts that need this closed context formating are closed-context instructions. Normal questions/instructions do not!*
I know it's a bit verbose and annoying, but after much trial and error, using these explicit delimiters helps the model understand where to find the responses and how to associate specific sources with it.
- `BEGININPUT` - denotes a new input block
- `BEGINCONTEXT` - denotes the block of context (metadata key/value pairs) to associate with the current input block
- `ENDCONTEXT` - denotes the end of the metadata block for the current input
- [text] - Insert whatever text you want for the input block, as many paragraphs as can fit in the context.
- `ENDINPUT` - denotes the end of the current input block
- [repeat as many input blocks in this format as you want]
- `BEGININSTRUCTION` - denotes the start of the list (or one) instruction(s) to respond to for all of the input blocks above.
- [instruction(s)]
- `ENDINSTRUCTION` - denotes the end of instruction set
It sometimes works without `ENDINSTRUCTION`, but by explicitly including that in the prompt, the model better understands that all of the instructions in the block should be responded to.
Here's a trivial, but important example to prove the point:
```
BEGININPUT
BEGINCONTEXT
date: 2021-01-01
url: https://web.site/123
ENDCONTEXT
In a shocking turn of events, blueberries are now green, but will be sticking with the same name.
ENDINPUT
BEGININSTRUCTION
What color are bluberries? Source?
ENDINSTRUCTION
```
And the response:
```
Blueberries are now green.
Source:
date: 2021-01-01
url: https://web.site/123
```
#### Coding
You can ask for fairly complex coding instructions with multiple criteria, e.g.:
```
Create a python application with the following requirements:
- Asyncio FastAPI webserver
- ping endpoint that returns the current date in JSON format
- file upload endpoint, which calculates the file's sha256 checksum, and checks postgres to deduplicate
```
Or inline criteria:
```
Write a multi-threaded TCP server in C that accepts a "GET [key]" input and "SET [key] [value]" input, and uses a binary tree to get and store the input values.
```
You can also optionally add a single space and "PLAINFORMAT" at the end of your prompt to avoid backticks, explanations, etc. and just print the code, e.g.:
```
Write a websocket application in node.js. PLAINFORMAT
```
#### Agent/function calling
The dataset includes many examples of function/args generation based on input criteria. This is somewhat similar to the OpenAI function calling, but the output is either JSON or YAML.
Example prompt:
```
As an AI assistant, please select the most suitable function and parameters from the list of available functions below, based on the user's input. Provide your response in JSON format.
Input: I want to know how many times 'Python' is mentioned in my text file.
Available functions:
file_analytics:
description: This tool performs various operations on a text file.
params:
action: The operation we want to perform on the data, such as "count_occurrences", "find_line", etc.
filters:
keyword: The word or phrase we want to search for.
```
Response:
```json
{
"function": "file_analytics",
"params": {
"action": "count_occurrences",
"filters": {
"keyword": "Python"
}
}
}
```
#### Chain-of-thought
You can ask for several possible responses to a given problem, with a ranking and final answer selection.
Example prompt:
```
A group of people decide to play a round-robin tournament where every player plays every other player exactly once. If a total of 45 games were played, how many players participated in the tournament? Offer several potential answers, rank them according to mathematical logic, and pick the most feasible one.
```
Example response:
```
Solution 1:
In a round-robin tournament, each player plays every other player exactly once. This means that the total number of games played is equal to the combination of all players taken two at a time (since a game involves two players).
The formula for combinations is nC2 = n(n-1)/2, where n is the total number of players. We know that nC2 equals 45 (the total number of games), so we can set up the equation as follows:
n(n-1)/2 = 45
Solving this equation gives us n=10.
Final answer: There were 10 players in the tournament.
Solution 2:
Another way to approach this problem is by using the concept of triangular numbers. Triangular numbers are a sequence of numbers where each number can be represented as a triangle with dots. The nth triangular number is given by the sum of the first n natural numbers.
If we consider each game as a dot and each player as a side of the triangle, then the total number of games (45) would correspond to the 9th triangular number because 1+2+3+4+5+6+7+8+9=45. However, since each side of the triangle represents a player, and there's one more player than sides in our model (because the last player has no one left to play against), we need to add one more to get the total number of players.
Final answer: There were 10 players in the tournament.
Solution 3:
We could also use trial and error to solve this problem. Starting from a small number of players, we calculate how many games would be played in a round-robin tournament until we reach 45 games. For example, with 2 players, only 1 game is played; with 3 players, 3 games are played; with 4 players, 6 games are played, and so on. Continuing this process, we find that with 10 players, 45 games are played.
Final answer: There were 10 players in the tournament.
Ranking of solutions from best to worst:
1. Solution 1: This solution uses direct mathematical reasoning based on the properties of a round-robin tournament and solves an equation to find the answer.
2. Solution 2: This solution uses the concept of triangular numbers which requires additional steps and knowledge beyond the immediate problem context, but still arrives at the correct answer.
3. Solution 3: This solution relies on trial and error, which is less efficient and reliable than the other methods, but it eventually gets to the right answer.
Best and final answer: There were 10 players in the tournament.
```
#### reWOO style execution planning
The model now supports execution planning for complex instructions that would require making use of several tools. The output is just the plan, you must implement a mechanism to parse the output and actually call the functions!
Example prompt:
```
Please construct a systematic plan to generate an optimal response to the user instruction, utilizing a set of provided tools. Each plan will correspond to an evidence value, which will be the output of one of the available functions given an input string
that could be the user's question, one or more prior evidence values, or a combination of both.
Here are the tools available to be called:
DuckDuckGo[input]: Tool that enables the user to search for information using the DuckDuckGo search engine. This tool is helpful in locating a suitable list of sites that may contain the answer to the user's query. It does not directly answer the question but finds a list of sites that might have the answer.
TextScraper[input]: Load one or more websites from the input string containing newline delimited links, where input is one or more links, and produces plain text output containing the content of the links.
HyperlinkExtractor[input]: Extract links from plain text and produces a plain text, newline delimited response of links.
KnowledgeModel[input]: Question answering language model, particularly useful in answering questions based on an input passage of text. The input must be a text question that references an :evidence[n]: variable, e.g. What color is the cat, given :evidence1:?
The output should be in format:
Plan: [first action to take based on input question]
:evidence0: = [function to call with input parameter]
Plan: [next action to take, based on result of :evidence0:]
:evidence1: = [next function to call and input parameter, which may include reference to previous evidence, e.g. "Given context :evidence0"]
...
Answer: [:evidence[n]: containing the final answer.]
Question: Who won the Nobel Prize in Literature in 2020 and what is their most famous work?
```
Response:
```
Plan: Begin by conducting a web search to find out who won the Nobel Prize in Literature in 2020.
:evidence0: = DuckDuckGo[Nobel Prize in Literature 2020 winner]
Plan: Utilize the KnowledgeModel to interpret the search results and find the name of the laureate.
:evidence1: = KnowledgeModel[Who won the Nobel Prize in Literature in 2020, given :evidence0:?]
Plan: Conduct another web search to find the most famous work of the identified laureate.
:evidence2: = DuckDuckGo[Most famous work of :evidence1:]
Plan: Extract the relevant links from the DuckDuckGo search results for a more focused search.
:evidence3: = HyperlinkExtractor[:evidence2:]
Plan: Use the TextScraper tool to extract information from the relevant links.
:evidence4: = TextScraper[:evidence3:]
Plan: Finally, utilize the KnowledgeModel to identify and summarize the most famous work of the laureate from the extracted information.
:evidence5: = KnowledgeModel[What is the most famous work of :evidence1:, given :evidence4:?]
Answer: :evidence5:
```
For this to be useful, you'd have to parse the output plan text, and implement/call each of the functions. This is just pseudo-code, completely untested off the top of my head, and obviously would requiring full implementation + hardening:
```python
import re
import requests
def inject_context(input_text, **context):
for ref in set(re.findall(r"(:evidence[0-9]+:)", input_text, re.I)):
input_text = input_text.replace(ref, context.get(ref, ""))
return input_text
def duckduckgo(input_text, **context):
search_string = inject_context(input_text, **context)
... search via duck duck go using search_string
... return text content
def link_extractor(input_text, **context):
input_text = inject_context(input_text, **context)
return "\n".join(list(set(re.findall(r"(https?://[^\s]+?\.?)", input_text, re.I))))
def scrape(input_text, **context):
input_text = inject_context(input_text, **context)
text = []
for link in input_text.splitlines():
text.append(requests.get(link).text)
return "\n".join(text)
def infer(input_text, **context)
prompt = inject_context(input_text, **context)
... call model with prompt, return output
def parse_plan(plan):
method_map = {
"DuckDuckGo": duckduckgo,
"HyperlinkExtractor": link_extractor,
"KnowledgeModel": infer,
"TextScraper": scrape,
}
context = {}
for line in plan.strip().splitlines():
if line.startswith("Plan:"):
print(line)
continue
parts = re.match("^(:evidence[0-9]+:)\s*=\s*([^\[]+])(\[.*\])\s$", line, re.I)
if not parts:
if line.startswith("Answer: "):
return context.get(line.split(" ")[-1].strip(), "Answer couldn't be generated...")
raise RuntimeError("bad format: " + line)
context[parts.group(1)] = method_map[parts.group(2)](parts.group(3), **context)
```
### Contribute
If you're interested in new functionality, particularly a new "instructor" type to generate a specific type of training data,
take a look at the dataset generation tool repo: https://github.com/jondurbin/airoboros and either make a PR or open an issue with details.
To help me with the OpenAI/compute costs:
- https://bmc.link/jondurbin
- ETH 0xce914eAFC2fe52FdceE59565Dd92c06f776fcb11
- BTC bc1qdwuth4vlg8x37ggntlxu5cjfwgmdy5zaa7pswf
### Licence and usage restrictions
The airoboros 2.1 models are built on top of llama-2.
The llama-2 base model has a custom Meta license:
- See the [meta-license/LICENSE.txt](meta-license/LICENSE.txt) file attached for the original license provided by Meta.
- See also [meta-license/USE_POLICY.md](meta-license/USE_POLICY.md) and [meta-license/Responsible-Use-Guide.pdf](meta-license/Responsible-Use-Guide.pdf), also provided by Meta.
The fine-tuning data was generated by OpenAI API calls to gpt-4, via [airoboros](https://github.com/jondurbin/airoboros)
The ToS for OpenAI API usage has a clause preventing the output from being used to train a model that __competes__ with OpenAI
- what does *compete* actually mean here?
- these small open source models will not produce output anywhere near the quality of gpt-4, or even gpt-3.5, so I can't imagine this could credibly be considered competing in the first place
- if someone else uses the dataset to do the same, they wouldn't necessarily be violating the ToS because they didn't call the API, so I don't know how that works
- the training data used in essentially all large language models includes a significant amount of copyrighted or otherwise non-permissive licensing in the first place
- other work using the self-instruct method, e.g. the original here: https://github.com/yizhongw/self-instruct released the data and model as apache-2
I am purposingly leaving this license ambiguous (other than the fact you must comply with the Meta original license for llama-2) because I am not a lawyer and refuse to attempt to interpret all of the terms accordingly.
Your best bet is probably to avoid using this commercially due to the OpenAI API usage.
Either way, by using this model, you agree to completely indemnify me. |
mradermacher/Meta-Llama-3-70B-Instruct-6-layers-GGUF | mradermacher | 2024-06-13T19:23:28Z | 3,316 | 0 | transformers | [
"transformers",
"gguf",
"en",
"base_model:sanchit-gandhi/Meta-Llama-3-70B-Instruct-6-layers",
"endpoints_compatible",
"region:us"
] | null | 2024-06-13T17:22:45Z | ---
base_model: sanchit-gandhi/Meta-Llama-3-70B-Instruct-6-layers
language:
- en
library_name: transformers
quantized_by: mradermacher
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
static quants of https://huggingface.co/sanchit-gandhi/Meta-Llama-3-70B-Instruct-6-layers
<!-- provided-files -->
weighted/imatrix quants seem not to be available (by me) at this time. If they do not show up a week or so after the static ones, I have probably not planned for them. Feel free to request them by opening a Community Discussion.
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/Meta-Llama-3-70B-Instruct-6-layers-GGUF/resolve/main/Meta-Llama-3-70B-Instruct-6-layers.Q2_K.gguf) | Q2_K | 3.2 | |
| [GGUF](https://huggingface.co/mradermacher/Meta-Llama-3-70B-Instruct-6-layers-GGUF/resolve/main/Meta-Llama-3-70B-Instruct-6-layers.IQ3_XS.gguf) | IQ3_XS | 3.5 | |
| [GGUF](https://huggingface.co/mradermacher/Meta-Llama-3-70B-Instruct-6-layers-GGUF/resolve/main/Meta-Llama-3-70B-Instruct-6-layers.Q3_K_S.gguf) | Q3_K_S | 3.6 | |
| [GGUF](https://huggingface.co/mradermacher/Meta-Llama-3-70B-Instruct-6-layers-GGUF/resolve/main/Meta-Llama-3-70B-Instruct-6-layers.IQ3_S.gguf) | IQ3_S | 3.6 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/Meta-Llama-3-70B-Instruct-6-layers-GGUF/resolve/main/Meta-Llama-3-70B-Instruct-6-layers.IQ3_M.gguf) | IQ3_M | 3.7 | |
| [GGUF](https://huggingface.co/mradermacher/Meta-Llama-3-70B-Instruct-6-layers-GGUF/resolve/main/Meta-Llama-3-70B-Instruct-6-layers.Q3_K_M.gguf) | Q3_K_M | 3.9 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/Meta-Llama-3-70B-Instruct-6-layers-GGUF/resolve/main/Meta-Llama-3-70B-Instruct-6-layers.Q3_K_L.gguf) | Q3_K_L | 4.1 | |
| [GGUF](https://huggingface.co/mradermacher/Meta-Llama-3-70B-Instruct-6-layers-GGUF/resolve/main/Meta-Llama-3-70B-Instruct-6-layers.IQ4_XS.gguf) | IQ4_XS | 4.3 | |
| [GGUF](https://huggingface.co/mradermacher/Meta-Llama-3-70B-Instruct-6-layers-GGUF/resolve/main/Meta-Llama-3-70B-Instruct-6-layers.Q4_K_S.gguf) | Q4_K_S | 4.5 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Meta-Llama-3-70B-Instruct-6-layers-GGUF/resolve/main/Meta-Llama-3-70B-Instruct-6-layers.Q4_K_M.gguf) | Q4_K_M | 4.6 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Meta-Llama-3-70B-Instruct-6-layers-GGUF/resolve/main/Meta-Llama-3-70B-Instruct-6-layers.Q5_K_S.gguf) | Q5_K_S | 5.2 | |
| [GGUF](https://huggingface.co/mradermacher/Meta-Llama-3-70B-Instruct-6-layers-GGUF/resolve/main/Meta-Llama-3-70B-Instruct-6-layers.Q5_K_M.gguf) | Q5_K_M | 5.3 | |
| [GGUF](https://huggingface.co/mradermacher/Meta-Llama-3-70B-Instruct-6-layers-GGUF/resolve/main/Meta-Llama-3-70B-Instruct-6-layers.Q6_K.gguf) | Q6_K | 6.0 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/Meta-Llama-3-70B-Instruct-6-layers-GGUF/resolve/main/Meta-Llama-3-70B-Instruct-6-layers.Q8_0.gguf) | Q8_0 | 7.8 | fast, best quality |
| [GGUF](https://huggingface.co/mradermacher/Meta-Llama-3-70B-Instruct-6-layers-GGUF/resolve/main/Meta-Llama-3-70B-Instruct-6-layers.f16.gguf) | f16 | 14.6 | 16 bpw, overkill |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
TheBloke/CodeLlama-34B-Instruct-fp16 | TheBloke | 2023-08-25T11:13:49Z | 3,314 | 7 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"llama-2",
"codellama",
"custom_code",
"license:llama2",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2023-08-24T20:36:26Z | ---
license: llama2
tags:
- llama-2
- codellama
---
<!-- header start -->
<!-- 200823 -->
<div style="width: auto; margin-left: auto; margin-right: auto">
<img src="https://i.imgur.com/EBdldam.jpg" alt="TheBlokeAI" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</div>
<div style="display: flex; justify-content: space-between; width: 100%;">
<div style="display: flex; flex-direction: column; align-items: flex-start;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://discord.gg/theblokeai">Chat & support: TheBloke's Discord server</a></p>
</div>
<div style="display: flex; flex-direction: column; align-items: flex-end;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://www.patreon.com/TheBlokeAI">Want to contribute? TheBloke's Patreon page</a></p>
</div>
</div>
<div style="text-align:center; margin-top: 0em; margin-bottom: 0em"><p style="margin-top: 0.25em; margin-bottom: 0em;">TheBloke's LLM work is generously supported by a grant from <a href="https://a16z.com">andreessen horowitz (a16z)</a></p></div>
<hr style="margin-top: 1.0em; margin-bottom: 1.0em;">
<!-- header end -->
# CodeLlama 34B-Instruct fp16
- Model creator: [Meta](https://ai.meta.com/llama/)
## Description
This is Transformers/HF format fp16 weights for CodeLlama 34B-Instruct. It is the result of downloading CodeLlama 34B-Instruct from [Meta](https://ai.meta.com/blog/code-llama-large-language-model-coding/) and converting to HF using `convert_llama_weights_to_hf.py`.
Quantisations will be coming shortly.
Please note that due to a change in the RoPE Theta value, for correct results you must load these FP16 models with `trust_remote_code=True`
Credit to @emozilla for creating the necessary modelling code to achieve this!
## Prompt template: TBC
<!-- footer start -->
<!-- 200823 -->
## Discord
For further support, and discussions on these models and AI in general, join us at:
[TheBloke AI's Discord server](https://discord.gg/theblokeai)
## Thanks, and how to contribute.
Thanks to the [chirper.ai](https://chirper.ai) team!
I've had a lot of people ask if they can contribute. I enjoy providing models and helping people, and would love to be able to spend even more time doing it, as well as expanding into new projects like fine tuning/training.
If you're able and willing to contribute it will be most gratefully received and will help me to keep providing more models, and to start work on new AI projects.
Donaters will get priority support on any and all AI/LLM/model questions and requests, access to a private Discord room, plus other benefits.
* Patreon: https://patreon.com/TheBlokeAI
* Ko-Fi: https://ko-fi.com/TheBlokeAI
**Special thanks to**: Aemon Algiz.
**Patreon special mentions**: Sam, theTransient, Jonathan Leane, Steven Wood, webtim, Johann-Peter Hartmann, Geoffrey Montalvo, Gabriel Tamborski, Willem Michiel, John Villwock, Derek Yates, Mesiah Bishop, Eugene Pentland, Pieter, Chadd, Stephen Murray, Daniel P. Andersen, terasurfer, Brandon Frisco, Thomas Belote, Sid, Nathan LeClaire, Magnesian, Alps Aficionado, Stanislav Ovsiannikov, Alex, Joseph William Delisle, Nikolai Manek, Michael Davis, Junyu Yang, K, J, Spencer Kim, Stefan Sabev, Olusegun Samson, transmissions 11, Michael Levine, Cory Kujawski, Rainer Wilmers, zynix, Kalila, Luke @flexchar, Ajan Kanaga, Mandus, vamX, Ai Maven, Mano Prime, Matthew Berman, subjectnull, Vitor Caleffi, Clay Pascal, biorpg, alfie_i, 阿明, Jeffrey Morgan, ya boyyy, Raymond Fosdick, knownsqashed, Olakabola, Leonard Tan, ReadyPlayerEmma, Enrico Ros, Dave, Talal Aujan, Illia Dulskyi, Sean Connelly, senxiiz, Artur Olbinski, Elle, Raven Klaugh, Fen Risland, Deep Realms, Imad Khwaja, Fred von Graf, Will Dee, usrbinkat, SuperWojo, Alexandros Triantafyllidis, Swaroop Kallakuri, Dan Guido, John Detwiler, Pedro Madruga, Iucharbius, Viktor Bowallius, Asp the Wyvern, Edmond Seymore, Trenton Dambrowitz, Space Cruiser, Spiking Neurons AB, Pyrater, LangChain4j, Tony Hughes, Kacper Wikieł, Rishabh Srivastava, David Ziegler, Luke Pendergrass, Andrey, Gabriel Puliatti, Lone Striker, Sebastain Graf, Pierre Kircher, Randy H, NimbleBox.ai, Vadim, danny, Deo Leter
Thank you to all my generous patrons and donaters!
And thank you again to a16z for their generous grant.
<!-- footer end -->
# Original model card
# Code Llama
## **Model Details**
**Model Developers** Meta AI
**Variations** Code Llama comes in three model sizes, and three variants:
1) Code Llama: our base models designed for general code synthesis and understanding
2) Code Llama - Python: designed specifically for Python
3) Code Llama - Instruct: for instruction following and safer deployment
All variants are available in sizes of 7B, 13B and 34B parameters.
**Input** Models input text only.
**Output** Models output text only.
**Model Architecture** Code Llama and its variants are autoregressive language models using optimized transformer architectures. Code Llama 7B and 13B additionally support infilling text generation. All models were fine-tuned with up to 16K tokens, and support up to 100K tokens at inference time.
**Model Dates** Code Llama and its variants have been trained between January 2023 and July 2023.
**Status** This is a static model trained on an offline dataset. Future versions of Code Llama - Instruct will be released as we improve model safety with community feedback.
**Licence** A custom commercial license is available at: [https://ai.meta.com/resources/models-and-libraries/llama-downloads/](https://ai.meta.com/resources/models-and-libraries/llama-downloads/).
**Research Paper** More information can be found in the paper "[Code Llama: Open Foundation Models for Code](https://ai.meta.com/research/publications/code-llama-open-foundation-models-for-code/)".
**Where to send comments** Instructions on how to provide feedback or comments on the model can be found in the model [README](README.md), or by opening an issue in the GitHub repository ([https://github.com/facebookresearch/codellama/](https://github.com/facebookresearch/codellama/)).
## **Intended Use**
**Intended Use Cases** Code Llama and its variants is intended for commercial and research use in English and relevant programming languages. The base model Code Llama can be adapted for a variety of code synthesis and understanding tasks, Code Llama - Python is designed specifically to handle the Python programming language, and Code Llama - Instruct is intended to be safer to use for code assistant and generation applications.
**Out-of-Scope Uses** Use in any manner that violates applicable laws or regulations (including trade compliance laws). Use in languages other than English. Use in any other way that is prohibited by the Acceptable Use Policy and Licensing Agreement for Code Llama and its variants.
## **Hardware and Software**
**Training Factors**
We used custom training libraries. The training and fine-tuning of the released models have been performed Meta’s Research Super Cluster.
**Carbon Footprint** In aggregate, training all 9 Code Llama models required 400K GPU hours of computation on hardware of type A100-80GB (TDP of 350-400W). Estimated total emissions were 65.3 tCO2eq, 100% of which were offset by Meta’s sustainability program.
**Training data**
All experiments reported here and the released models have been trained and fine-tuned using the same data as Llama 2 with different weights (see Section 2 and Table 1 in the [research paper](https://ai.meta.com/research/publications/code-llama-open-foundation-models-for-code/) for details).
Code Llama - Instruct uses additional instruction fine-tuning data.
**Evaluation Results**
See evaluations for the main models and detailed ablations in Section 3 and safety evaluations in Section 4 of the research paper.
## **Ethical Considerations and Limitations**
Code Llama and its variants are a new technology that carries risks with use. Testing conducted to date has been in English, and has not covered, nor could it cover all scenarios. For these reasons, as with all LLMs, Code Llama’s potential outputs cannot be predicted in advance, and the model may in some instances produce inaccurate or objectionable responses to user prompts. Therefore, before deploying any applications of Code Llama, developers should perform safety testing and tuning tailored to their specific applications of the model.
Please see the Responsible Use Guide available available at [https://ai.meta.com/llama/responsible-user-guide](https://ai.meta.com/llama/responsible-user-guide).
|
yahoo-inc/photo-background-generation | yahoo-inc | 2024-05-08T12:23:44Z | 3,314 | 33 | diffusers | [
"diffusers",
"safetensors",
"yahoo-open-source-software-incubator",
"text-to-image",
"arxiv:2404.10157",
"license:apache-2.0",
"diffusers:StableDiffusionControlNetInpaintPipeline",
"region:us"
] | text-to-image | 2024-04-26T23:35:40Z | ---
license: apache-2.0
tags:
- yahoo-open-source-software-incubator
pipeline_tag: text-to-image
inference: false
---
# Salient Object-Aware Background Generation using Text-Guided Diffusion Models [](https://arxiv.org/pdf/2404.10157.pdf)
This repository accompanies our paper, [Salient Object-Aware Background Generation using Text-Guided Diffusion Models](https://arxiv.org/abs/2404.10157), which has been accepted for publication in [CVPR 2024 Generative Models for Computer Vision](https://generative-vision.github.io/workshop-CVPR-24/) workshop.
The paper addresses an issue we call "object expansion" when generating backgrounds for salient objects using inpainting diffusion models. We show that models such as [Stable Inpainting](https://huggingface.co/stabilityai/stable-diffusion-2-inpainting) can sometimes arbitrarily expand or distort the salient object, which is undesirable in applications where the object's identity should be preserved, such as e-commerce ads. We provide some examples of object expansion as follows:
<div align="center">
<img src="assets/fig.jpg">
</div>
# Inference
### Load pipeline
```py
from diffusers import DiffusionPipeline
model_id = "yahoo-inc/photo-background-generation"
pipeline = DiffusionPipeline.from_pretrained(model_id, custom_pipeline=model_id)
pipeline = pipeline.to('cuda')
```
### Load an image and extract its background and foreground
```py
from PIL import Image, ImageOps
import requests
from io import BytesIO
from transparent_background import Remover
def resize_with_padding(img, expected_size):
img.thumbnail((expected_size[0], expected_size[1]))
# print(img.size)
delta_width = expected_size[0] - img.size[0]
delta_height = expected_size[1] - img.size[1]
pad_width = delta_width // 2
pad_height = delta_height // 2
padding = (pad_width, pad_height, delta_width - pad_width, delta_height - pad_height)
return ImageOps.expand(img, padding)
seed = 0
image_url = 'https://upload.wikimedia.org/wikipedia/commons/thumb/1/16/Granja_comary_Cisne_-_Escalavrado_e_Dedo_De_Deus_ao_fundo_-Teres%C3%B3polis.jpg/2560px-Granja_comary_Cisne_-_Escalavrado_e_Dedo_De_Deus_ao_fundo_-Teres%C3%B3polis.jpg'
response = requests.get(image_url)
img = Image.open(BytesIO(response.content))
img = resize_with_padding(img, (512, 512))
# Load background detection model
remover = Remover() # default setting
remover = Remover(mode='base') # nightly release checkpoint
# Get foreground mask
fg_mask = remover.process(img, type='map') # default setting - transparent background
```
### Background generation
```py
seed = 13
mask = ImageOps.invert(fg_mask)
img = resize_with_padding(img, (512, 512))
generator = torch.Generator(device='cuda').manual_seed(seed)
prompt = 'A dark swan in a bedroom'
cond_scale = 1.0
with torch.autocast("cuda"):
controlnet_image = pipeline(
prompt=prompt, image=img, mask_image=mask, control_image=mask, num_images_per_prompt=1, generator=generator, num_inference_steps=20, guess_mode=False, controlnet_conditioning_scale=cond_scale
).images[0]
controlnet_image
```
## Citations
If you found our work useful, please consider citing our paper:
```bibtex
@misc{eshratifar2024salient,
title={Salient Object-Aware Background Generation using Text-Guided Diffusion Models},
author={Amir Erfan Eshratifar and Joao V. B. Soares and Kapil Thadani and Shaunak Mishra and Mikhail Kuznetsov and Yueh-Ning Ku and Paloma de Juan},
year={2024},
eprint={2404.10157},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
## Maintainers
- Erfan Eshratifar: [email protected]
- Joao Soares: [email protected]
## License
This project is licensed under the terms of the [Apache 2.0](LICENSE) open source license. Please refer to [LICENSE](LICENSE) for the full terms. |
Lewdiculous/Poppy_Porpoise-0.72-L3-8B-GGUF-IQ-Imatrix | Lewdiculous | 2024-05-19T10:42:40Z | 3,314 | 26 | null | [
"gguf",
"roleplay",
"region:us"
] | null | 2024-05-04T12:49:42Z | ---
tags:
- roleplay
---
> [!TIP]
> **Support:** <br>
> My upload speeds have been cooked and unstable lately. <br>
> Realistically I'd need to move to get a better provider. <br>
> If you **want** and you are able to, you can [**support that endeavor and others here (Ko-fi)**](https://ko-fi.com/Lewdiculous). I apologize for disrupting your experience.
GGUF-IQ-Imatrix quants for [ChaoticNeutrals/Poppy_Porpoise-0.72-L3-8B](https://huggingface.co/ChaoticNeutrals/Poppy_Porpoise-0.72-L3-8B).
# Original model information by the author:
# "Poppy Porpoise" is a cutting-edge AI roleplay assistant based on the Llama 3 8B model, specializing in crafting unforgettable narrative experiences. With its advanced language capabilities, Poppy expertly immerses users in an interactive and engaging adventure, tailoring each adventure to their individual preferences.

# Recomended ST Presets:(Updated for 0.72) [Porpoise Presets](https://huggingface.co/ChaoticNeutrals/Poppy_Porpoise-v0.7-L3-8B/tree/main/Official%20Poppy%20Porpoise%20ST%20Presets)
If you want to use vision functionality:
* You must use the latest versions of [Koboldcpp](https://github.com/LostRuins/koboldcpp).
# To use the multimodal capabilities of this model and use **vision** you need to load the specified **mmproj** file, this can be found inside this model repo. [Llava MMProj](https://huggingface.co/Nitral-AI/Llama-3-Update-2.0-mmproj-model-f16)
* You can load the **mmproj** by using the corresponding section in the interface:
 |
facebook/wav2vec2-large-xlsr-53-french | facebook | 2021-07-06T02:40:56Z | 3,313 | 12 | transformers | [
"transformers",
"pytorch",
"jax",
"wav2vec2",
"automatic-speech-recognition",
"speech",
"audio",
"fr",
"dataset:common_voice",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | automatic-speech-recognition | 2022-03-02T23:29:05Z | ---
language: fr
datasets:
- common_voice
tags:
- speech
- audio
- automatic-speech-recognition
license: apache-2.0
---
## Evaluation on Common Voice FR Test
```python
import torchaudio
from datasets import load_dataset, load_metric
from transformers import (
Wav2Vec2ForCTC,
Wav2Vec2Processor,
)
import torch
import re
import sys
model_name = "facebook/wav2vec2-large-xlsr-53-french"
device = "cuda"
chars_to_ignore_regex = '[\,\?\.\!\-\;\:\"]' # noqa: W605
model = Wav2Vec2ForCTC.from_pretrained(model_name).to(device)
processor = Wav2Vec2Processor.from_pretrained(model_name)
ds = load_dataset("common_voice", "fr", split="test", data_dir="./cv-corpus-6.1-2020-12-11")
resampler = torchaudio.transforms.Resample(orig_freq=48_000, new_freq=16_000)
def map_to_array(batch):
speech, _ = torchaudio.load(batch["path"])
batch["speech"] = resampler.forward(speech.squeeze(0)).numpy()
batch["sampling_rate"] = resampler.new_freq
batch["sentence"] = re.sub(chars_to_ignore_regex, '', batch["sentence"]).lower().replace("’", "'")
return batch
ds = ds.map(map_to_array)
def map_to_pred(batch):
features = processor(batch["speech"], sampling_rate=batch["sampling_rate"][0], padding=True, return_tensors="pt")
input_values = features.input_values.to(device)
attention_mask = features.attention_mask.to(device)
with torch.no_grad():
logits = model(input_values, attention_mask=attention_mask).logits
pred_ids = torch.argmax(logits, dim=-1)
batch["predicted"] = processor.batch_decode(pred_ids)
batch["target"] = batch["sentence"]
return batch
result = ds.map(map_to_pred, batched=True, batch_size=16, remove_columns=list(ds.features.keys()))
wer = load_metric("wer")
print(wer.compute(predictions=result["predicted"], references=result["target"]))
```
**Result**: 25.2 % |
Unbabel/TowerInstruct-7B-v0.1 | Unbabel | 2024-03-04T13:18:03Z | 3,313 | 59 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"translation",
"en",
"de",
"fr",
"zh",
"pt",
"nl",
"ru",
"ko",
"it",
"es",
"arxiv:2402.17733",
"license:cc-by-nc-4.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | translation | 2024-01-04T15:17:21Z | ---
license: cc-by-nc-4.0
language:
- en
- de
- fr
- zh
- pt
- nl
- ru
- ko
- it
- es
metrics:
- comet
pipeline_tag: translation
---
# Model Card for TowerInstruct-7B-v0.1
## Model Details
### Model Description
TowerInstruct-7B is a language model that results from fine-tuning TowerBase on the TowerBlocks supervised fine-tuning dataset. TowerInstruct-7B-v0.1 is the first model in the series.
The model is trained to handle several translation-related tasks, such as general machine translation (e.g., sentence- and paragraph-level translation, terminology-aware translation, context-aware translation), automatic post edition, named-entity recognition, gramatical error correction, and paraphrase generation.
We will release more details in the upcoming technical report.
- **Developed by:** Unbabel, Instituto Superior Técnico, CentraleSupélec University of Paris-Saclay
- **Model type:** A 7B parameter model fine-tuned on a mix of publicly available, synthetic datasets on translation-related tasks, as well as conversational datasets and code instructions.
- **Language(s) (NLP):** English, Portuguese, Spanish, French, German, Dutch, Italian, Korean, Chinese, Russian
- **License:** CC-BY-NC-4.0, Llama 2 is licensed under the [LLAMA 2 Community License](https://ai.meta.com/llama/license/), Copyright © Meta Platforms, Inc. All Rights Reserved.
- **Finetuned from model:** [TowerBase](https://huggingface.co/Unbabel/TowerBase-7B-v0.1)
## Intended uses & limitations
The model was initially fine-tuned on a filtered and preprocessed supervised fine-tuning dataset ([TowerBlocks](https://huggingface.co/datasets/Unbabel/TowerBlocks-v0.1)), which contains a diverse range of data sources:
- Translation (sentence and paragraph-level)
- Automatic Post Edition
- Machine Translation Evaluation
- Context-aware Translation
- Terminology-aware Translation
- Multi-reference Translation
- Named-entity Recognition
- Paraphrase Generation
- Synthetic Chat data
- Code instructions
You can find the dataset and all data sources of [TowerBlocks](https://huggingface.co/datasets/Unbabel/TowerBlocks-v0.1) here.
Here's how you can run the model using the `pipeline()` function from 🤗 Transformers:
```python
# Install transformers from source - only needed for versions <= v4.34
# pip install git+https://github.com/huggingface/transformers.git
# pip install accelerate
import torch
from transformers import pipeline
pipe = pipeline("text-generation", model="Unbabel/TowerInstruct-v0.1", torch_dtype=torch.bfloat16, device_map="auto")
# We use the tokenizer’s chat template to format each message - see https://huggingface.co/docs/transformers/main/en/chat_templating
messages = [
{"role": "user", "content": "Translate the following text from Portuguese into English.\nPortuguese: Um grupo de investigadores lançou um novo modelo para tarefas relacionadas com tradução.\nEnglish:"},
]
prompt = pipe.tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
outputs = pipe(prompt, max_new_tokens=256, do_sample=False)
print(outputs[0]["generated_text"])
# <|im_start|>user
# Translate the following text from Portuguese into English.
# Portuguese: Um grupo de investigadores lançou um novo modelo para tarefas relacionadas com tradução.
# English:<|im_end|>
# <|im_start|>assistant
# A group of researchers has launched a new model for translation-related tasks.
```
### Out-of-Scope Use
The model is not guaranteed to perform for languages other than the 10 languages it supports. Even though we trained the model on conversational data and code instructions, it is not intended to be used as a conversational chatbot or code assistant.
We are currently working on improving quality and consistency on document-level translation. This model should is not intended to be use as a document-level translator.
## Bias, Risks, and Limitations
TowerInstruct-v0.1 has not been aligned to human preferences, so the model may generate problematic outputs (e.g., hallucinations, harmful content, or false statements).
## Prompt Format
TowerInstruct-v0.1 was trained using the ChatML prompt templates without any system prompts. An example follows below:
```
<|im_start|>user
{USER PROMPT}<|im_end|>
<|im_start|>assistant
{MODEL RESPONSE}<|im_end|>
<|im_start|>user
[...]
```
### Supervised tasks
The prompts for all supervised tasks can be found in [TowerBlocks](https://huggingface.co/datasets/Unbabel/TowerBlocks-v0.1). We have used multiple prompt templates for each task. While different prompts may offer different outputs, the difference in downstream performance should be very minimal.
## Training Details
### Training Data
Link to [TowerBlocks](https://huggingface.co/datasets/Unbabel/TowerBlocks-v0.1).
#### Training Hyperparameters
The following hyperparameters were used during training:
- total_train_batch_size: 256
- learning_rate: 7e-06
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 500
- weight_decay: 0.01
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- num_epochs: 4
- max_seq_length: 2048
## Citation
```bibtex
@misc{tower_llm_2024,
title={Tower: An Open Multilingual Large Language Model for Translation-Related Tasks},
author={Duarte M. Alves and José Pombal and Nuno M. Guerreiro and Pedro H. Martins and João Alves and Amin Farajian and Ben Peters and Ricardo Rei and Patrick Fernandes and Sweta Agrawal and Pierre Colombo and José G. C. de Souza and André F. T. Martins},
year={2024},
eprint={2402.17733},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
[<img src="https://raw.githubusercontent.com/OpenAccess-AI-Collective/axolotl/main/image/axolotl-badge-web.png" alt="Built with Axolotl" width="200" height="32"/>](https://github.com/OpenAccess-AI-Collective/axolotl)
|
Yntec/TheWonderMix | Yntec | 2024-06-23T18:23:14Z | 3,313 | 1 | diffusers | [
"diffusers",
"safetensors",
"Anime",
"Style",
"Girls",
"Lorim",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | 2024-06-23T05:06:48Z | ---
license: creativeml-openrail-m
library_name: diffusers
pipeline_tag: text-to-image
tags:
- Anime
- Style
- Girls
- Lorim
- stable-diffusion
- stable-diffusion-diffusers
- diffusers
- text-to-image
---
# The WonderMix V2
This model with the kl-f8-anime2 VAE baked in for improved saturation and details. Original page: https://civitai.com/models/71523?modelVersionId=88973

(Click for larger)
Top left: face focus, cute, masterpiece, best quality, 1girl, teal hair, sweater, looking at viewer, upper body, beanie, outdoors, night, turtleneck
Top right: classic art video game. Children book illustration of cute little girl as urusei yatsura holding coffee-to-go, bright neon colors
Bottom left: analog style 70s color photograph of young william shatner as captain kirk, star trek behind the scenes
Bottom right: Highly detailed, High Quality, Masterpiece, beautiful, cute girl as toon link, teal headwear, Zelda
|
RichardErkhov/Josephgflowers_-_TinyLlama-Cinder-1.3B-Test.2-gguf | RichardErkhov | 2024-06-27T13:10:58Z | 3,313 | 0 | null | [
"gguf",
"region:us"
] | null | 2024-06-27T13:01:57Z | Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
TinyLlama-Cinder-1.3B-Test.2 - GGUF
- Model creator: https://huggingface.co/Josephgflowers/
- Original model: https://huggingface.co/Josephgflowers/TinyLlama-Cinder-1.3B-Test.2/
| Name | Quant method | Size |
| ---- | ---- | ---- |
| [TinyLlama-Cinder-1.3B-Test.2.Q2_K.gguf](https://huggingface.co/RichardErkhov/Josephgflowers_-_TinyLlama-Cinder-1.3B-Test.2-gguf/blob/main/TinyLlama-Cinder-1.3B-Test.2.Q2_K.gguf) | Q2_K | 0.46GB |
| [TinyLlama-Cinder-1.3B-Test.2.IQ3_XS.gguf](https://huggingface.co/RichardErkhov/Josephgflowers_-_TinyLlama-Cinder-1.3B-Test.2-gguf/blob/main/TinyLlama-Cinder-1.3B-Test.2.IQ3_XS.gguf) | IQ3_XS | 0.51GB |
| [TinyLlama-Cinder-1.3B-Test.2.IQ3_S.gguf](https://huggingface.co/RichardErkhov/Josephgflowers_-_TinyLlama-Cinder-1.3B-Test.2-gguf/blob/main/TinyLlama-Cinder-1.3B-Test.2.IQ3_S.gguf) | IQ3_S | 0.54GB |
| [TinyLlama-Cinder-1.3B-Test.2.Q3_K_S.gguf](https://huggingface.co/RichardErkhov/Josephgflowers_-_TinyLlama-Cinder-1.3B-Test.2-gguf/blob/main/TinyLlama-Cinder-1.3B-Test.2.Q3_K_S.gguf) | Q3_K_S | 0.54GB |
| [TinyLlama-Cinder-1.3B-Test.2.IQ3_M.gguf](https://huggingface.co/RichardErkhov/Josephgflowers_-_TinyLlama-Cinder-1.3B-Test.2-gguf/blob/main/TinyLlama-Cinder-1.3B-Test.2.IQ3_M.gguf) | IQ3_M | 0.56GB |
| [TinyLlama-Cinder-1.3B-Test.2.Q3_K.gguf](https://huggingface.co/RichardErkhov/Josephgflowers_-_TinyLlama-Cinder-1.3B-Test.2-gguf/blob/main/TinyLlama-Cinder-1.3B-Test.2.Q3_K.gguf) | Q3_K | 0.59GB |
| [TinyLlama-Cinder-1.3B-Test.2.Q3_K_M.gguf](https://huggingface.co/RichardErkhov/Josephgflowers_-_TinyLlama-Cinder-1.3B-Test.2-gguf/blob/main/TinyLlama-Cinder-1.3B-Test.2.Q3_K_M.gguf) | Q3_K_M | 0.59GB |
| [TinyLlama-Cinder-1.3B-Test.2.Q3_K_L.gguf](https://huggingface.co/RichardErkhov/Josephgflowers_-_TinyLlama-Cinder-1.3B-Test.2-gguf/blob/main/TinyLlama-Cinder-1.3B-Test.2.Q3_K_L.gguf) | Q3_K_L | 0.64GB |
| [TinyLlama-Cinder-1.3B-Test.2.IQ4_XS.gguf](https://huggingface.co/RichardErkhov/Josephgflowers_-_TinyLlama-Cinder-1.3B-Test.2-gguf/blob/main/TinyLlama-Cinder-1.3B-Test.2.IQ4_XS.gguf) | IQ4_XS | 0.66GB |
| [TinyLlama-Cinder-1.3B-Test.2.Q4_0.gguf](https://huggingface.co/RichardErkhov/Josephgflowers_-_TinyLlama-Cinder-1.3B-Test.2-gguf/blob/main/TinyLlama-Cinder-1.3B-Test.2.Q4_0.gguf) | Q4_0 | 0.69GB |
| [TinyLlama-Cinder-1.3B-Test.2.IQ4_NL.gguf](https://huggingface.co/RichardErkhov/Josephgflowers_-_TinyLlama-Cinder-1.3B-Test.2-gguf/blob/main/TinyLlama-Cinder-1.3B-Test.2.IQ4_NL.gguf) | IQ4_NL | 0.69GB |
| [TinyLlama-Cinder-1.3B-Test.2.Q4_K_S.gguf](https://huggingface.co/RichardErkhov/Josephgflowers_-_TinyLlama-Cinder-1.3B-Test.2-gguf/blob/main/TinyLlama-Cinder-1.3B-Test.2.Q4_K_S.gguf) | Q4_K_S | 0.69GB |
| [TinyLlama-Cinder-1.3B-Test.2.Q4_K.gguf](https://huggingface.co/RichardErkhov/Josephgflowers_-_TinyLlama-Cinder-1.3B-Test.2-gguf/blob/main/TinyLlama-Cinder-1.3B-Test.2.Q4_K.gguf) | Q4_K | 0.72GB |
| [TinyLlama-Cinder-1.3B-Test.2.Q4_K_M.gguf](https://huggingface.co/RichardErkhov/Josephgflowers_-_TinyLlama-Cinder-1.3B-Test.2-gguf/blob/main/TinyLlama-Cinder-1.3B-Test.2.Q4_K_M.gguf) | Q4_K_M | 0.72GB |
| [TinyLlama-Cinder-1.3B-Test.2.Q4_1.gguf](https://huggingface.co/RichardErkhov/Josephgflowers_-_TinyLlama-Cinder-1.3B-Test.2-gguf/blob/main/TinyLlama-Cinder-1.3B-Test.2.Q4_1.gguf) | Q4_1 | 0.76GB |
| [TinyLlama-Cinder-1.3B-Test.2.Q5_0.gguf](https://huggingface.co/RichardErkhov/Josephgflowers_-_TinyLlama-Cinder-1.3B-Test.2-gguf/blob/main/TinyLlama-Cinder-1.3B-Test.2.Q5_0.gguf) | Q5_0 | 0.83GB |
| [TinyLlama-Cinder-1.3B-Test.2.Q5_K_S.gguf](https://huggingface.co/RichardErkhov/Josephgflowers_-_TinyLlama-Cinder-1.3B-Test.2-gguf/blob/main/TinyLlama-Cinder-1.3B-Test.2.Q5_K_S.gguf) | Q5_K_S | 0.83GB |
| [TinyLlama-Cinder-1.3B-Test.2.Q5_K.gguf](https://huggingface.co/RichardErkhov/Josephgflowers_-_TinyLlama-Cinder-1.3B-Test.2-gguf/blob/main/TinyLlama-Cinder-1.3B-Test.2.Q5_K.gguf) | Q5_K | 0.85GB |
| [TinyLlama-Cinder-1.3B-Test.2.Q5_K_M.gguf](https://huggingface.co/RichardErkhov/Josephgflowers_-_TinyLlama-Cinder-1.3B-Test.2-gguf/blob/main/TinyLlama-Cinder-1.3B-Test.2.Q5_K_M.gguf) | Q5_K_M | 0.85GB |
| [TinyLlama-Cinder-1.3B-Test.2.Q5_1.gguf](https://huggingface.co/RichardErkhov/Josephgflowers_-_TinyLlama-Cinder-1.3B-Test.2-gguf/blob/main/TinyLlama-Cinder-1.3B-Test.2.Q5_1.gguf) | Q5_1 | 0.9GB |
| [TinyLlama-Cinder-1.3B-Test.2.Q6_K.gguf](https://huggingface.co/RichardErkhov/Josephgflowers_-_TinyLlama-Cinder-1.3B-Test.2-gguf/blob/main/TinyLlama-Cinder-1.3B-Test.2.Q6_K.gguf) | Q6_K | 0.98GB |
| [TinyLlama-Cinder-1.3B-Test.2.Q8_0.gguf](https://huggingface.co/RichardErkhov/Josephgflowers_-_TinyLlama-Cinder-1.3B-Test.2-gguf/blob/main/TinyLlama-Cinder-1.3B-Test.2.Q8_0.gguf) | Q8_0 | 1.26GB |
Original model description:
---
license: mit
---
1.3B test of Cinder trained on math, step by step reasoning, and Cinder conversational stem dataset. Model Overview Cinder is an AI chatbot tailored for engaging users in scientific and educational conversations, offering companionship, and sparking imaginative exploration. It is built on the TinyLlama 1.1B parameter model and trained on a unique combination of datasets.
|
megagonlabs/transformers-ud-japanese-electra-base-ginza-510 | megagonlabs | 2021-12-05T12:12:12Z | 3,312 | 2 | transformers | [
"transformers",
"pytorch",
"electra",
"feature-extraction",
"PyTorch",
"Transformers",
"spaCy",
"ELECTRA",
"GiNZA",
"mC4",
"UD_Japanese-BCCWJ",
"GSK2014-A",
"ja",
"MIT",
"arxiv:1910.10683",
"license:mit",
"endpoints_compatible",
"region:us"
] | feature-extraction | 2022-03-02T23:29:05Z | ---
language:
- ja
thumbnail: "https://raw.githubusercontent.com/megagonlabs/ginza/static/docs/images/GiNZA_logo_4c_s.png"
tags:
- PyTorch
- Transformers
- spaCy
- ELECTRA
- GiNZA
- mC4
- UD_Japanese-BCCWJ
- GSK2014-A
- ja
- MIT
license: "mit"
datasets:
- mC4
- UD_Japanese_BCCWJ r2.8
- GSK2014-A(2019)
metrics:
- UAS
- LAS
- UPOS
---
# transformers-ud-japanese-electra-ginza-510 (sudachitra-wordpiece, mC4 Japanese)
This is an [ELECTRA](https://github.com/google-research/electra) model pretrained on approximately 200M Japanese sentences extracted from the [mC4](https://huggingface.co/datasets/mc4) and finetuned by [spaCy v3](https://spacy.io/usage/v3) on [UD\_Japanese\_BCCWJ r2.8](https://universaldependencies.org/treebanks/ja_bccwj/index.html).
The base pretrain model is [megagonlabs/transformers-ud-japanese-electra-base-discrimininator](https://huggingface.co/megagonlabs/transformers-ud-japanese-electra-base-discriminator).
The entire spaCy v3 model is distributed as a python package named [`ja_ginza_electra`](https://pypi.org/project/ja-ginza-electra/) from PyPI along with [`GiNZA v5`](https://github.com/megagonlabs/ginza) which provides some custom pipeline components to recognize the Japanese bunsetu-phrase structures.
Try running it as below:
```console
$ pip install ginza ja_ginza_electra
$ ginza
```
## Licenses
The models are distributed under the terms of the [MIT License](https://opensource.org/licenses/mit-license.php).
## Acknowledgments
This model is permitted to be published under the `MIT License` under a joint research agreement between NINJAL (National Institute for Japanese Language and Linguistics) and Megagon Labs Tokyo.
## Citations
- [mC4](https://huggingface.co/datasets/mc4)
Contains information from `mC4` which is made available under the [ODC Attribution License](https://opendatacommons.org/licenses/by/1-0/).
```
@article{2019t5,
author = {Colin Raffel and Noam Shazeer and Adam Roberts and Katherine Lee and Sharan Narang and Michael Matena and Yanqi Zhou and Wei Li and Peter J. Liu},
title = {Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer},
journal = {arXiv e-prints},
year = {2019},
archivePrefix = {arXiv},
eprint = {1910.10683},
}
```
- [UD\_Japanese\_BCCWJ r2.8](https://universaldependencies.org/treebanks/ja_bccwj/index.html)
```
Asahara, M., Kanayama, H., Tanaka, T., Miyao, Y., Uematsu, S., Mori, S.,
Matsumoto, Y., Omura, M., & Murawaki, Y. (2018).
Universal Dependencies Version 2 for Japanese.
In LREC-2018.
```
- [GSK2014-A(2019)](https://www.gsk.or.jp/catalog/gsk2014-a/)
|
mradermacher/SyntheticMoist-11B-i1-GGUF | mradermacher | 2024-06-06T21:49:26Z | 3,312 | 0 | transformers | [
"transformers",
"gguf",
"mergekit",
"merge",
"solar",
"llama",
"not-for-all-audiences",
"en",
"base_model:v000000/SyntheticMoist-11B",
"endpoints_compatible",
"region:us"
] | null | 2024-06-05T14:26:24Z | ---
base_model: v000000/SyntheticMoist-11B
language:
- en
library_name: transformers
quantized_by: mradermacher
tags:
- mergekit
- merge
- solar
- llama
- not-for-all-audiences
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: nicoboss -->
weighted/imatrix quants of https://huggingface.co/v000000/SyntheticMoist-11B
<!-- provided-files -->
static quants are available at https://huggingface.co/mradermacher/SyntheticMoist-11B-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/SyntheticMoist-11B-i1-GGUF/resolve/main/SyntheticMoist-11B.i1-IQ1_S.gguf) | i1-IQ1_S | 2.5 | for the desperate |
| [GGUF](https://huggingface.co/mradermacher/SyntheticMoist-11B-i1-GGUF/resolve/main/SyntheticMoist-11B.i1-IQ1_M.gguf) | i1-IQ1_M | 2.7 | mostly desperate |
| [GGUF](https://huggingface.co/mradermacher/SyntheticMoist-11B-i1-GGUF/resolve/main/SyntheticMoist-11B.i1-IQ2_XXS.gguf) | i1-IQ2_XXS | 3.0 | |
| [GGUF](https://huggingface.co/mradermacher/SyntheticMoist-11B-i1-GGUF/resolve/main/SyntheticMoist-11B.i1-IQ2_XS.gguf) | i1-IQ2_XS | 3.3 | |
| [GGUF](https://huggingface.co/mradermacher/SyntheticMoist-11B-i1-GGUF/resolve/main/SyntheticMoist-11B.i1-IQ2_S.gguf) | i1-IQ2_S | 3.5 | |
| [GGUF](https://huggingface.co/mradermacher/SyntheticMoist-11B-i1-GGUF/resolve/main/SyntheticMoist-11B.i1-IQ2_M.gguf) | i1-IQ2_M | 3.8 | |
| [GGUF](https://huggingface.co/mradermacher/SyntheticMoist-11B-i1-GGUF/resolve/main/SyntheticMoist-11B.i1-Q2_K.gguf) | i1-Q2_K | 4.1 | IQ3_XXS probably better |
| [GGUF](https://huggingface.co/mradermacher/SyntheticMoist-11B-i1-GGUF/resolve/main/SyntheticMoist-11B.i1-IQ3_XXS.gguf) | i1-IQ3_XXS | 4.3 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/SyntheticMoist-11B-i1-GGUF/resolve/main/SyntheticMoist-11B.i1-IQ3_XS.gguf) | i1-IQ3_XS | 4.5 | |
| [GGUF](https://huggingface.co/mradermacher/SyntheticMoist-11B-i1-GGUF/resolve/main/SyntheticMoist-11B.i1-Q3_K_S.gguf) | i1-Q3_K_S | 4.8 | IQ3_XS probably better |
| [GGUF](https://huggingface.co/mradermacher/SyntheticMoist-11B-i1-GGUF/resolve/main/SyntheticMoist-11B.i1-IQ3_S.gguf) | i1-IQ3_S | 4.8 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/SyntheticMoist-11B-i1-GGUF/resolve/main/SyntheticMoist-11B.i1-IQ3_M.gguf) | i1-IQ3_M | 4.9 | |
| [GGUF](https://huggingface.co/mradermacher/SyntheticMoist-11B-i1-GGUF/resolve/main/SyntheticMoist-11B.i1-Q3_K_M.gguf) | i1-Q3_K_M | 5.3 | IQ3_S probably better |
| [GGUF](https://huggingface.co/mradermacher/SyntheticMoist-11B-i1-GGUF/resolve/main/SyntheticMoist-11B.i1-Q3_K_L.gguf) | i1-Q3_K_L | 5.8 | IQ3_M probably better |
| [GGUF](https://huggingface.co/mradermacher/SyntheticMoist-11B-i1-GGUF/resolve/main/SyntheticMoist-11B.i1-IQ4_XS.gguf) | i1-IQ4_XS | 5.9 | |
| [GGUF](https://huggingface.co/mradermacher/SyntheticMoist-11B-i1-GGUF/resolve/main/SyntheticMoist-11B.i1-Q4_0.gguf) | i1-Q4_0 | 6.2 | fast, low quality |
| [GGUF](https://huggingface.co/mradermacher/SyntheticMoist-11B-i1-GGUF/resolve/main/SyntheticMoist-11B.i1-Q4_K_S.gguf) | i1-Q4_K_S | 6.2 | optimal size/speed/quality |
| [GGUF](https://huggingface.co/mradermacher/SyntheticMoist-11B-i1-GGUF/resolve/main/SyntheticMoist-11B.i1-Q4_K_M.gguf) | i1-Q4_K_M | 6.6 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/SyntheticMoist-11B-i1-GGUF/resolve/main/SyntheticMoist-11B.i1-Q5_K_S.gguf) | i1-Q5_K_S | 7.5 | |
| [GGUF](https://huggingface.co/mradermacher/SyntheticMoist-11B-i1-GGUF/resolve/main/SyntheticMoist-11B.i1-Q5_K_M.gguf) | i1-Q5_K_M | 7.7 | |
| [GGUF](https://huggingface.co/mradermacher/SyntheticMoist-11B-i1-GGUF/resolve/main/SyntheticMoist-11B.i1-Q6_K.gguf) | i1-Q6_K | 8.9 | practically like static Q6_K |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time. Additional thanks to [@nicoboss](https://huggingface.co/nicoboss) for giving me access to his hardware for calculating the imatrix for these quants.
<!-- end -->
|
Raelina/Rae-Diffusion-XL-V2 | Raelina | 2024-06-24T11:28:40Z | 3,311 | 26 | diffusers | [
"diffusers",
"safetensors",
"text-to-image",
"stable-diffusion",
"stable-diffusion-xl",
"en",
"base_model:cagliostrolab/animagine-xl-3.1",
"license:other",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionXLPipeline",
"region:us"
] | text-to-image | 2024-06-24T04:13:15Z | ---
license: other
license_name: faipl-1.0-sd
license_link: https://freedevproject.org/faipl-1.0-sd/
language:
- en
tags:
- text-to-image
- stable-diffusion
- safetensors
- stable-diffusion-xl
base_model: cagliostrolab/animagine-xl-3.1
---
<style>
.title-container {
display: flex;
justify-content: center;
align-items: center;
height: 100vh; /* Adjust this value to position the title vertically */
}
.title {
font-size: 2.5em;
text-align: center;
color: #333;
font-family: 'Helvetica Neue', sans-serif;
text-transform: uppercase;
letter-spacing: 0.1em;
padding: 0.5em 0;
background: transparent;
}
.title span {
background: -webkit-linear-gradient(45deg, #ADD899, #83B4FF);
-webkit-background-clip: text;
-webkit-text-fill-color: transparent;
}
.custom-table {
table-layout: fixed;
width: 100%;
border-collapse: collapse;
margin-top: 2em;
}
.custom-table td {
width: 50%;
vertical-align: top;
padding: 10px;
box-shadow: 0px 0px 0px 0px rgba(0, 0, 0, 0.15);
}
.custom-image-container {
position: relative;
width: 100%;
margin-bottom: 0em;
overflow: hidden;
border-radius: 10px;
transition: transform .7s;
}
.custom-image-container:hover {
transform: scale(1.05);
}
.custom-image {
width: 100%;
height: auto;
object-fit: cover;
border-radius: 10px;
transition: transform .7s;
margin-bottom: 0em;
}
.nsfw-filter {
filter: blur(8px);
transition: filter 0.3s ease;
}
.custom-image-container:hover .nsfw-filter {
filter: none;
}
.overlay {
position: absolute;
bottom: 0;
left: 0;
right: 0;
color: white;
width: 100%;
height: 40%;
display: flex;
flex-direction: column;
justify-content: center;
align-items: center;
font-size: 1vw;
font-style: bold;
text-align: center;
opacity: 0;
background: linear-gradient(0deg, rgba(0, 0, 0, 0.8) 60%, rgba(0, 0, 0, 0) 100%);
transition: opacity .5s;
}
.custom-image-container:hover .overlay {
opacity: 1;
}
.overlay-text {
background: linear-gradient(45deg, #F1F8E8, #F1F8E8);
-webkit-background-clip: text;
color: transparent;
text-shadow: 2px 2px 4px rgba(0, 0, 0, 0.7);
}
.overlay-subtext {
font-size: 0.75em;
margin-top: 0.5em;
font-style: italic;
}
.overlay,
.overlay-subtext {
text-shadow: 2px 2px 4px rgba(0, 0, 0, 0.5);
}
</style>
<h1 class="title">
<span>Rae Diffusion XL V2</span>
</h1>
<table class="custom-table">
<tr>
<td>
<div class="custom-image-container">
<img class="custom-image" src="https://cdn-uploads.huggingface.co/production/uploads/64b24543eec33e27dc9a6eca/m6udgsmJ6Afgg6lrx79MH.png" alt="Sample Image 1">
<div class="overlay">
<div class="overlay-text">Konno Junko</div>
</div>
</div>
</td>
<td>
<div class="custom-image-container">
<img class="custom-image" src="https://cdn-uploads.huggingface.co/production/uploads/64b24543eec33e27dc9a6eca/LQF4iVbDSrV4Iy2lHnGD3.png" alt="Sample Image 2">
<div class="overlay">
<div class="overlay-text">Ryougi Shiki</div>
</div>
</div>
</td>
<td>
<div class="custom-image-container">
<img class="custom-image" src="https://cdn-uploads.huggingface.co/production/uploads/64b24543eec33e27dc9a6eca/SW9p02hP4in4x63I3tRWp.png" alt="Sample Image 3">
<div class="overlay">
<div class="overlay-text">Korra</div>
</div>
</div>
</td>
</tr>
<tr>
<td>
<div class="custom-image-container">
<img class="custom-image" src="https://cdn-uploads.huggingface.co/production/uploads/64b24543eec33e27dc9a6eca/MF03ubigFBAr2QlMp1a1N.png" alt="Sample Image 4">
<div class="overlay">
<div class="overlay-text">Toshinou Kyouko</div>
</div>
</div>
</td>
<td>
<div class="custom-image-container">
<img class="custom-image" src="https://cdn-uploads.huggingface.co/production/uploads/64b24543eec33e27dc9a6eca/xdJ55uW4GSrZ4tbr59dTn.png" alt="Sample Image 5">
<div class="overlay">
<div class="overlay-text">Charlotte Dunois</div>
</div>
</div>
</td>
<td>
<div class="custom-image-container">
<img class="custom-image" src="https://cdn-uploads.huggingface.co/production/uploads/64b24543eec33e27dc9a6eca/yEBNfOn5cxECvdzDOKf5A.png" alt="Sample Image 6">
<div class="overlay">
<div class="overlay-text">Sento Isuzu</div>
</div>
</div>
</td>
</tr>
</table>
## Overview
Introducing **Rae Diffusion XL V2** , an enhanced iteration based on the Animagine XL 3.1 model, specifically fine-tuned for generating stunning anime-style artwork. **Rae Diffusion XL V2** is meticulously optimized to excel in depicting anime characters, pushing the boundaries of creativity.
## Model Details
- **Developed by**: [Raelina](https://civitai.com/user/Raelina)
- **Model type**: Diffusion-based text-to-image generative model
- **Model Description**: Rae Diffusion XL V2 is an enhanced iteration built on the Animagine XL 3.1 model. It is fine-tuned for high-quality anime-style character art generation.
- **License**: [Fair AI Public License 1.0-SD](https://freedevproject.org/faipl-1.0-sd/)
- **Finetuned from**: [Animagine XL 3.1](https://huggingface.co/cagliostrolab/animagine-xl-3.1)
### Usage Guidelines
## Tag Ordering
For optimal results, it's recommended to follow the structured prompt template because we train the model like this:
```
1girl/1boy, character name, from which series, everything else in any order.
```
## Special Tag
Rae Diffusion XL inherits special tags from Animagine XL 3.1 to enhance image generation by steering results toward quality, rating, creation date, and aesthetic. While the model can generate images without these tags, using them helps achieve better results.
- **Quality tags:** masterpiece, best quality, great quality, good quality, normal quality, low quality, worst quality
- **Rating tags:** safe, sensitive, nsfw, explicit
- **Year tags:** newest, recent, mid, early, oldest
- **Aesthetic tags:** very aesthetic, aesthetic, displeasing, very displeasing
## Recommended settings
- **Positive prompts:**
```
masterpiece, best quality, very aesthetic, absurdres,
```
- **Negative prompts:**
```
(low quality, worst quality:1.2), very displeasing, ugly, poorly drawn, signature, watermark,
```
- **CFG:** 7
- **Sampling steps:** 25 to 35
- **Sampler:** Euler a
- **Supported Resolution:**
```
1024 x 1024, 1152 x 896, 896 x 1152, 1216 x 832, 832 x 1216, 1344 x 768, 768 x 1344, 1536 x 640, 640 x 1536
```
## Hires.fix Setting
- **Upscaler:** [4x_NMKD-YandereNeoXL](https://nmkd.de/?esrgan)
- **Hires step:** 10-15
- **Denoising:** 0.1-0.3 or 0.55 for latent upscaler
## Training config
- Hardware: 1x A100 80GB
- Batch size: 48
- Gradient Accumulation: 1
- Epochs: 10
- Learning Rate: 3e-6
- Optimizer: Adafactor
- Optimizer Args: (Scale Parameter: False, Relative Step: False, Warmup Init: False)
- Scheduler: Constant with warmup
- Warmup steps: 0.05
- Noise offset: 0.0357
## License
Rae Diffusion XL V2 now uses the [Fair AI Public License 1.0-SD](https://freedevproject.org/faipl-1.0-sd/) inherited from Animagine XL 3.1, compatible with Stable Diffusion models. Key points:
1. **Modification Sharing:** If you modify Rae Diffusion XL, you must share both your changes and the original license.
2. **Source Code Accessibility:** If your modified version is network-accessible, provide a way (like a download link) for others to get the source code. This applies to derived models too.
3. **Distribution Terms:** Any distribution must be under this license or another with similar rules.
4. **Compliance:** Non-compliance must be fixed within 30 days to avoid license termination, emphasizing transparency and adherence to open-source values.
|
Noor0/SentimentArEng | Noor0 | 2023-12-14T10:19:22Z | 3,310 | 0 | transformers | [
"transformers",
"safetensors",
"xlm-roberta",
"text-classification",
"ar",
"en",
"base_model:cardiffnlp/twitter-xlm-roberta-base-sentiment",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2023-12-14T03:16:05Z | ---
base_model: cardiffnlp/twitter-xlm-roberta-base-sentiment
metrics:
- accuracy
model-index:
- name: result
results: []
language:
- ar
- en
library_name: transformers
pipeline_tag: text-classification
---
---
# SentimentArEng
This model is a fine-tuned version of [cardiffnlp/twitter-xlm-roberta-base-sentiment](https://huggingface.co/cardiffnlp/twitter-xlm-roberta-base-sentiment) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.502831
- Accuracy: 0.798512
# inference with pipeline
```
from transformers import pipeline
model_path = "Noor0/SentimentArEng"
sentiment_task = pipeline("sentiment-analysis", model=model_path, tokenizer=model_path)
sentiment_task("تعامل الموظفين كان أقل من المتوقع")
```
- output:
- [{'label': 'negative', 'score': 0.9905518293380737}]
## Training and evaluation data
- Training set: 114,885 records
- evaluation data: 12,765 records
## Training procedure
| Training Loss | Epoch |Validation Loss | Accuracy |
|:-------------:|:-----:|:---------------:|:--------:|
| 0.4511 | 2.0 |0.502831 | 0.7985 |
| 0.3655 | 3.0 |0.576118 | 0.7954 |
| 0.3019 | 4.0 |0.625391 | 0.7985 |
| 0.2466 | 5.0 |0.835689 | 0.7979 |
### Training hyperparameters
- The following hyperparameters were used during training:
- learning_rate=2e-5
- num_train_epochs=20
- weight_decay=0.01
- batch_size=16,
### Framework versions
- Transformers 4.35.0
- Pytorch 2.0.0
- Datasets 2.11.0
- Tokenizers 0.14.1 |
mrm8488/bert-base-spanish-wwm-cased-finetuned-spa-squad2-es | mrm8488 | 2021-05-20T00:22:53Z | 3,309 | 7 | transformers | [
"transformers",
"pytorch",
"jax",
"bert",
"question-answering",
"es",
"endpoints_compatible",
"region:us"
] | question-answering | 2022-03-02T23:29:05Z | ---
language: es
thumbnail: https://i.imgur.com/jgBdimh.png
---
# BETO (Spanish BERT) + Spanish SQuAD2.0
This model is provided by [BETO team](https://github.com/dccuchile/beto) and fine-tuned on [SQuAD-es-v2.0](https://github.com/ccasimiro88/TranslateAlignRetrieve) for **Q&A** downstream task.
## Details of the language model('dccuchile/bert-base-spanish-wwm-cased')
Language model ([**'dccuchile/bert-base-spanish-wwm-cased'**](https://github.com/dccuchile/beto/blob/master/README.md)):
BETO is a [BERT model](https://github.com/google-research/bert) trained on a [big Spanish corpus](https://github.com/josecannete/spanish-corpora). BETO is of size similar to a BERT-Base and was trained with the Whole Word Masking technique. Below you find Tensorflow and Pytorch checkpoints for the uncased and cased versions, as well as some results for Spanish benchmarks comparing BETO with [Multilingual BERT](https://github.com/google-research/bert/blob/master/multilingual.md) as well as other (not BERT-based) models.
## Details of the downstream task (Q&A) - Dataset
[SQuAD-es-v2.0](https://github.com/ccasimiro88/TranslateAlignRetrieve)
| Dataset | # Q&A |
| ---------------------- | ----- |
| SQuAD2.0 Train | 130 K |
| SQuAD2.0-es-v2.0 | 111 K |
| SQuAD2.0 Dev | 12 K |
| SQuAD-es-v2.0-small Dev| 69 K |
## Model training
The model was trained on a Tesla P100 GPU and 25GB of RAM with the following command:
```bash
export SQUAD_DIR=path/to/nl_squad
python transformers/examples/question-answering/run_squad.py \
--model_type bert \
--model_name_or_path dccuchile/bert-base-spanish-wwm-cased \
--do_train \
--do_eval \
--do_lower_case \
--train_file $SQUAD_DIR/train_nl-v2.0.json \
--predict_file $SQUAD_DIR/dev_nl-v2.0.json \
--per_gpu_train_batch_size 12 \
--learning_rate 3e-5 \
--num_train_epochs 2.0 \
--max_seq_length 384 \
--doc_stride 128 \
--output_dir /content/model_output \
--save_steps 5000 \
--threads 4 \
--version_2_with_negative
```
## Results:
| Metric | # Value |
| ---------------------- | ----- |
| **Exact** | **76.50**50 |
| **F1** | **86.07**81 |
```json
{
"exact": 76.50501430594491,
"f1": 86.07818773108252,
"total": 69202,
"HasAns_exact": 67.93020719738277,
"HasAns_f1": 82.37912207996466,
"HasAns_total": 45850,
"NoAns_exact": 93.34104145255225,
"NoAns_f1": 93.34104145255225,
"NoAns_total": 23352,
"best_exact": 76.51223953064941,
"best_exact_thresh": 0.0,
"best_f1": 86.08541295578848,
"best_f1_thresh": 0.0
}
```
### Model in action (in a Colab Notebook)
<details>
1. Set the context and ask some questions:

2. Run predictions:

</details>
> Created by [Manuel Romero/@mrm8488](https://twitter.com/mrm8488)
> Made with <span style="color: #e25555;">♥</span> in Spain
|
transformer3/H2-keywordextractor | transformer3 | 2023-04-21T15:15:03Z | 3,309 | 37 | transformers | [
"transformers",
"pytorch",
"bart",
"text2text-generation",
"autotrain",
"summarization",
"unk",
"dataset:transformer3/autotrain-data-finance6",
"co2_eq_emissions",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | summarization | 2023-04-21T14:55:32Z | ---
tags:
- autotrain
- summarization
language:
- unk
widget:
- text: "I love AutoTrain 🤗"
datasets:
- transformer3/autotrain-data-finance6
co2_eq_emissions:
emissions: 0.03294976193424359
---
# Model Trained Using AutoTrain
- Problem type: Summarization
- Model ID: 51355121740
- CO2 Emissions (in grams): 0.0329
## Validation Metrics
- Loss: 1.406
- Rouge1: 29.067
- Rouge2: 19.200
- RougeL: 26.900
- RougeLsum: 26.940
- Gen Len: 20.000
## Usage
You can use cURL to access this model:
```
$ curl -X POST -H "Authorization: Bearer YOUR_HUGGINGFACE_API_KEY" -H "Content-Type: application/json" -d '{"inputs": "I love AutoTrain"}' https://api-inference.huggingface.co/transformer3/autotrain-finance6-51355121740
``` |
ggrazzioli/cls_sentimento_sebrae | ggrazzioli | 2023-10-20T15:17:25Z | 3,309 | 3 | transformers | [
"transformers",
"pytorch",
"safetensors",
"bert",
"text-classification",
"pt",
"dataset:ggrazzioli/cls_sentimento_sebrae",
"co2_eq_emissions",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2023-10-20T14:48:12Z | ---
tags:
- text-classification
language:
- pt
widget:
- text: "Gostei muito do serviço prestado"
datasets:
- ggrazzioli/cls_sentimento_sebrae
co2_eq_emissions:
emissions: 0.6308403394105772
---
# Model Trained
- Problem type: Classificação de sentimentos em dataset interno do Sebrae RS
- Model ID: 96390146647
- CO2 Emissions (in grams): 0.6308
- "id2label": {"0": "Negativo", "1": "Neutro", "2": "Positivo"}
## Validation Metrics
- Loss: 0.143
- Accuracy: 0.965
- Macro F1: 0.935
- Micro F1: 0.965
- Weighted F1: 0.964
- Macro Precision: 0.938
- Micro Precision: 0.965
- Weighted Precision: 0.964
- Macro Recall: 0.933
- Micro Recall: 0.965
- Weighted Recall: 0.965
## Usage
Python API:
```
from transformers import AutoModelForSequenceClassification, AutoTokenizer
model = AutoModelForSequenceClassification.from_pretrained("ggrazzioli/cls_sentimento_sebrae")
tokenizer = AutoTokenizer.from_pretrained("ggrazzioli/cls_sentimento_sebrae")
inputs = tokenizer("Gostei muito dos serviços gerados, recomendo a todos!", return_tensors="pt")
outputs = model(**inputs)
``` |
mradermacher/Jenna-v3-Qwen2-1.5-GGUF | mradermacher | 2024-06-22T17:32:22Z | 3,309 | 0 | transformers | [
"transformers",
"gguf",
"text-generation-inference",
"unsloth",
"qwen2",
"trl",
"sft",
"en",
"base_model:V3N0M/Jenna-v3-Qwen2-1.5",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2024-06-22T17:13:19Z | ---
base_model: V3N0M/Jenna-v3-Qwen2-1.5
language:
- en
library_name: transformers
license: apache-2.0
quantized_by: mradermacher
tags:
- text-generation-inference
- transformers
- unsloth
- qwen2
- trl
- sft
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
static quants of https://huggingface.co/V3N0M/Jenna-v3-Qwen2-1.5
<!-- provided-files -->
weighted/imatrix quants seem not to be available (by me) at this time. If they do not show up a week or so after the static ones, I have probably not planned for them. Feel free to request them by opening a Community Discussion.
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/Jenna-v3-Qwen2-1.5-GGUF/resolve/main/Jenna-v3-Qwen2-1.5.Q2_K.gguf) | Q2_K | 0.8 | |
| [GGUF](https://huggingface.co/mradermacher/Jenna-v3-Qwen2-1.5-GGUF/resolve/main/Jenna-v3-Qwen2-1.5.IQ3_XS.gguf) | IQ3_XS | 0.8 | |
| [GGUF](https://huggingface.co/mradermacher/Jenna-v3-Qwen2-1.5-GGUF/resolve/main/Jenna-v3-Qwen2-1.5.Q3_K_S.gguf) | Q3_K_S | 0.9 | |
| [GGUF](https://huggingface.co/mradermacher/Jenna-v3-Qwen2-1.5-GGUF/resolve/main/Jenna-v3-Qwen2-1.5.IQ3_S.gguf) | IQ3_S | 0.9 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/Jenna-v3-Qwen2-1.5-GGUF/resolve/main/Jenna-v3-Qwen2-1.5.IQ3_M.gguf) | IQ3_M | 0.9 | |
| [GGUF](https://huggingface.co/mradermacher/Jenna-v3-Qwen2-1.5-GGUF/resolve/main/Jenna-v3-Qwen2-1.5.Q3_K_M.gguf) | Q3_K_M | 0.9 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/Jenna-v3-Qwen2-1.5-GGUF/resolve/main/Jenna-v3-Qwen2-1.5.Q3_K_L.gguf) | Q3_K_L | 1.0 | |
| [GGUF](https://huggingface.co/mradermacher/Jenna-v3-Qwen2-1.5-GGUF/resolve/main/Jenna-v3-Qwen2-1.5.IQ4_XS.gguf) | IQ4_XS | 1.0 | |
| [GGUF](https://huggingface.co/mradermacher/Jenna-v3-Qwen2-1.5-GGUF/resolve/main/Jenna-v3-Qwen2-1.5.Q4_K_S.gguf) | Q4_K_S | 1.0 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Jenna-v3-Qwen2-1.5-GGUF/resolve/main/Jenna-v3-Qwen2-1.5.Q4_K_M.gguf) | Q4_K_M | 1.1 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Jenna-v3-Qwen2-1.5-GGUF/resolve/main/Jenna-v3-Qwen2-1.5.Q5_K_S.gguf) | Q5_K_S | 1.2 | |
| [GGUF](https://huggingface.co/mradermacher/Jenna-v3-Qwen2-1.5-GGUF/resolve/main/Jenna-v3-Qwen2-1.5.Q5_K_M.gguf) | Q5_K_M | 1.2 | |
| [GGUF](https://huggingface.co/mradermacher/Jenna-v3-Qwen2-1.5-GGUF/resolve/main/Jenna-v3-Qwen2-1.5.Q6_K.gguf) | Q6_K | 1.4 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/Jenna-v3-Qwen2-1.5-GGUF/resolve/main/Jenna-v3-Qwen2-1.5.Q8_0.gguf) | Q8_0 | 1.7 | fast, best quality |
| [GGUF](https://huggingface.co/mradermacher/Jenna-v3-Qwen2-1.5-GGUF/resolve/main/Jenna-v3-Qwen2-1.5.f16.gguf) | f16 | 3.2 | 16 bpw, overkill |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
TheBloke/CodeLlama-13B-Python-fp16 | TheBloke | 2023-08-25T11:13:47Z | 3,308 | 25 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"llama-2",
"codellama",
"custom_code",
"license:llama2",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2023-08-24T16:26:59Z | ---
license: llama2
tags:
- llama-2
- codellama
---
<!-- header start -->
<!-- 200823 -->
<div style="width: auto; margin-left: auto; margin-right: auto">
<img src="https://i.imgur.com/EBdldam.jpg" alt="TheBlokeAI" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</div>
<div style="display: flex; justify-content: space-between; width: 100%;">
<div style="display: flex; flex-direction: column; align-items: flex-start;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://discord.gg/theblokeai">Chat & support: TheBloke's Discord server</a></p>
</div>
<div style="display: flex; flex-direction: column; align-items: flex-end;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://www.patreon.com/TheBlokeAI">Want to contribute? TheBloke's Patreon page</a></p>
</div>
</div>
<div style="text-align:center; margin-top: 0em; margin-bottom: 0em"><p style="margin-top: 0.25em; margin-bottom: 0em;">TheBloke's LLM work is generously supported by a grant from <a href="https://a16z.com">andreessen horowitz (a16z)</a></p></div>
<hr style="margin-top: 1.0em; margin-bottom: 1.0em;">
<!-- header end -->
# CodeLlama 13B-Python fp16
- Model creator: [Meta](https://ai.meta.com/llama/)
## Description
This is Transformers/HF format fp16 weights for CodeLlama 13B-Python. It is the result of downloading CodeLlama 13B-Python from [Meta](https://ai.meta.com/blog/code-llama-large-language-model-coding/) and converting to HF using `convert_llama_weights_to_hf.py`.
Quantisations will be coming shortly.
Please note that due to a change in the RoPE Theta value, for correct results you must load these FP16 models with `trust_remote_code=True`
Credit to @emozilla for creating the necessary modelling code to achieve this!
## Prompt template: TBC
<!-- footer start -->
<!-- 200823 -->
## Discord
For further support, and discussions on these models and AI in general, join us at:
[TheBloke AI's Discord server](https://discord.gg/theblokeai)
## Thanks, and how to contribute.
Thanks to the [chirper.ai](https://chirper.ai) team!
I've had a lot of people ask if they can contribute. I enjoy providing models and helping people, and would love to be able to spend even more time doing it, as well as expanding into new projects like fine tuning/training.
If you're able and willing to contribute it will be most gratefully received and will help me to keep providing more models, and to start work on new AI projects.
Donaters will get priority support on any and all AI/LLM/model questions and requests, access to a private Discord room, plus other benefits.
* Patreon: https://patreon.com/TheBlokeAI
* Ko-Fi: https://ko-fi.com/TheBlokeAI
**Special thanks to**: Aemon Algiz.
**Patreon special mentions**: Sam, theTransient, Jonathan Leane, Steven Wood, webtim, Johann-Peter Hartmann, Geoffrey Montalvo, Gabriel Tamborski, Willem Michiel, John Villwock, Derek Yates, Mesiah Bishop, Eugene Pentland, Pieter, Chadd, Stephen Murray, Daniel P. Andersen, terasurfer, Brandon Frisco, Thomas Belote, Sid, Nathan LeClaire, Magnesian, Alps Aficionado, Stanislav Ovsiannikov, Alex, Joseph William Delisle, Nikolai Manek, Michael Davis, Junyu Yang, K, J, Spencer Kim, Stefan Sabev, Olusegun Samson, transmissions 11, Michael Levine, Cory Kujawski, Rainer Wilmers, zynix, Kalila, Luke @flexchar, Ajan Kanaga, Mandus, vamX, Ai Maven, Mano Prime, Matthew Berman, subjectnull, Vitor Caleffi, Clay Pascal, biorpg, alfie_i, 阿明, Jeffrey Morgan, ya boyyy, Raymond Fosdick, knownsqashed, Olakabola, Leonard Tan, ReadyPlayerEmma, Enrico Ros, Dave, Talal Aujan, Illia Dulskyi, Sean Connelly, senxiiz, Artur Olbinski, Elle, Raven Klaugh, Fen Risland, Deep Realms, Imad Khwaja, Fred von Graf, Will Dee, usrbinkat, SuperWojo, Alexandros Triantafyllidis, Swaroop Kallakuri, Dan Guido, John Detwiler, Pedro Madruga, Iucharbius, Viktor Bowallius, Asp the Wyvern, Edmond Seymore, Trenton Dambrowitz, Space Cruiser, Spiking Neurons AB, Pyrater, LangChain4j, Tony Hughes, Kacper Wikieł, Rishabh Srivastava, David Ziegler, Luke Pendergrass, Andrey, Gabriel Puliatti, Lone Striker, Sebastain Graf, Pierre Kircher, Randy H, NimbleBox.ai, Vadim, danny, Deo Leter
Thank you to all my generous patrons and donaters!
And thank you again to a16z for their generous grant.
<!-- footer end -->
# Original model card
# Code Llama
## **Model Details**
**Model Developers** Meta AI
**Variations** Code Llama comes in three model sizes, and three variants:
1) Code Llama: our base models designed for general code synthesis and understanding
2) Code Llama - Python: designed specifically for Python
3) Code Llama - Instruct: for instruction following and safer deployment
All variants are available in sizes of 7B, 13B and 34B parameters.
**Input** Models input text only.
**Output** Models output text only.
**Model Architecture** Code Llama and its variants are autoregressive language models using optimized transformer architectures. Code Llama 7B and 13B additionally support infilling text generation. All models were fine-tuned with up to 16K tokens, and support up to 100K tokens at inference time.
**Model Dates** Code Llama and its variants have been trained between January 2023 and July 2023.
**Status** This is a static model trained on an offline dataset. Future versions of Code Llama - Instruct will be released as we improve model safety with community feedback.
**Licence** A custom commercial license is available at: [https://ai.meta.com/resources/models-and-libraries/llama-downloads/](https://ai.meta.com/resources/models-and-libraries/llama-downloads/).
**Research Paper** More information can be found in the paper "[Code Llama: Open Foundation Models for Code](https://ai.meta.com/research/publications/code-llama-open-foundation-models-for-code/)".
**Where to send comments** Instructions on how to provide feedback or comments on the model can be found in the model [README](README.md), or by opening an issue in the GitHub repository ([https://github.com/facebookresearch/codellama/](https://github.com/facebookresearch/codellama/)).
## **Intended Use**
**Intended Use Cases** Code Llama and its variants is intended for commercial and research use in English and relevant programming languages. The base model Code Llama can be adapted for a variety of code synthesis and understanding tasks, Code Llama - Python is designed specifically to handle the Python programming language, and Code Llama - Instruct is intended to be safer to use for code assistant and generation applications.
**Out-of-Scope Uses** Use in any manner that violates applicable laws or regulations (including trade compliance laws). Use in languages other than English. Use in any other way that is prohibited by the Acceptable Use Policy and Licensing Agreement for Code Llama and its variants.
## **Hardware and Software**
**Training Factors**
We used custom training libraries. The training and fine-tuning of the released models have been performed Meta’s Research Super Cluster.
**Carbon Footprint** In aggregate, training all 9 Code Llama models required 400K GPU hours of computation on hardware of type A100-80GB (TDP of 350-400W). Estimated total emissions were 65.3 tCO2eq, 100% of which were offset by Meta’s sustainability program.
**Training data**
All experiments reported here and the released models have been trained and fine-tuned using the same data as Llama 2 with different weights (see Section 2 and Table 1 in the [research paper](https://ai.meta.com/research/publications/code-llama-open-foundation-models-for-code/) for details).
Code Llama - Instruct uses additional instruction fine-tuning data.
**Evaluation Results**
See evaluations for the main models and detailed ablations in Section 3 and safety evaluations in Section 4 of the research paper.
## **Ethical Considerations and Limitations**
Code Llama and its variants are a new technology that carries risks with use. Testing conducted to date has been in English, and has not covered, nor could it cover all scenarios. For these reasons, as with all LLMs, Code Llama’s potential outputs cannot be predicted in advance, and the model may in some instances produce inaccurate or objectionable responses to user prompts. Therefore, before deploying any applications of Code Llama, developers should perform safety testing and tuning tailored to their specific applications of the model.
Please see the Responsible Use Guide available available at [https://ai.meta.com/llama/responsible-user-guide](https://ai.meta.com/llama/responsible-user-guide).
|
mradermacher/Free_Sydney_V2_Mistral_7b-GGUF | mradermacher | 2024-06-11T15:43:05Z | 3,308 | 0 | transformers | [
"transformers",
"gguf",
"llm",
"llama",
"llama2",
"en",
"base_model:FPHam/Free_Sydney_V2_Mistral_7b",
"endpoints_compatible",
"region:us"
] | null | 2024-06-11T12:39:33Z | ---
base_model: FPHam/Free_Sydney_V2_Mistral_7b
language:
- en
library_name: transformers
quantized_by: mradermacher
tags:
- llm
- llama
- llama2
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
static quants of https://huggingface.co/FPHam/Free_Sydney_V2_Mistral_7b
<!-- provided-files -->
weighted/imatrix quants are available at https://huggingface.co/mradermacher/Free_Sydney_V2_Mistral_7b-i1-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/Free_Sydney_V2_Mistral_7b-GGUF/resolve/main/Free_Sydney_V2_Mistral_7b.Q2_K.gguf) | Q2_K | 2.8 | |
| [GGUF](https://huggingface.co/mradermacher/Free_Sydney_V2_Mistral_7b-GGUF/resolve/main/Free_Sydney_V2_Mistral_7b.IQ3_XS.gguf) | IQ3_XS | 3.1 | |
| [GGUF](https://huggingface.co/mradermacher/Free_Sydney_V2_Mistral_7b-GGUF/resolve/main/Free_Sydney_V2_Mistral_7b.Q3_K_S.gguf) | Q3_K_S | 3.3 | |
| [GGUF](https://huggingface.co/mradermacher/Free_Sydney_V2_Mistral_7b-GGUF/resolve/main/Free_Sydney_V2_Mistral_7b.IQ3_S.gguf) | IQ3_S | 3.3 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/Free_Sydney_V2_Mistral_7b-GGUF/resolve/main/Free_Sydney_V2_Mistral_7b.IQ3_M.gguf) | IQ3_M | 3.4 | |
| [GGUF](https://huggingface.co/mradermacher/Free_Sydney_V2_Mistral_7b-GGUF/resolve/main/Free_Sydney_V2_Mistral_7b.Q3_K_M.gguf) | Q3_K_M | 3.6 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/Free_Sydney_V2_Mistral_7b-GGUF/resolve/main/Free_Sydney_V2_Mistral_7b.Q3_K_L.gguf) | Q3_K_L | 3.9 | |
| [GGUF](https://huggingface.co/mradermacher/Free_Sydney_V2_Mistral_7b-GGUF/resolve/main/Free_Sydney_V2_Mistral_7b.IQ4_XS.gguf) | IQ4_XS | 4.0 | |
| [GGUF](https://huggingface.co/mradermacher/Free_Sydney_V2_Mistral_7b-GGUF/resolve/main/Free_Sydney_V2_Mistral_7b.Q4_K_S.gguf) | Q4_K_S | 4.2 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Free_Sydney_V2_Mistral_7b-GGUF/resolve/main/Free_Sydney_V2_Mistral_7b.Q4_K_M.gguf) | Q4_K_M | 4.5 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Free_Sydney_V2_Mistral_7b-GGUF/resolve/main/Free_Sydney_V2_Mistral_7b.Q5_K_S.gguf) | Q5_K_S | 5.1 | |
| [GGUF](https://huggingface.co/mradermacher/Free_Sydney_V2_Mistral_7b-GGUF/resolve/main/Free_Sydney_V2_Mistral_7b.Q5_K_M.gguf) | Q5_K_M | 5.2 | |
| [GGUF](https://huggingface.co/mradermacher/Free_Sydney_V2_Mistral_7b-GGUF/resolve/main/Free_Sydney_V2_Mistral_7b.Q6_K.gguf) | Q6_K | 6.0 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/Free_Sydney_V2_Mistral_7b-GGUF/resolve/main/Free_Sydney_V2_Mistral_7b.Q8_0.gguf) | Q8_0 | 7.8 | fast, best quality |
| [GGUF](https://huggingface.co/mradermacher/Free_Sydney_V2_Mistral_7b-GGUF/resolve/main/Free_Sydney_V2_Mistral_7b.f16.gguf) | f16 | 14.6 | 16 bpw, overkill |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
TheBloke/SauerkrautLM-13B-v1-GPTQ | TheBloke | 2023-10-14T17:23:09Z | 3,307 | 4 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"de",
"en",
"base_model:VAGOsolutions/SauerkrautLM-13b-v1",
"license:llama2",
"autotrain_compatible",
"text-generation-inference",
"4-bit",
"gptq",
"region:us"
] | text-generation | 2023-10-14T16:32:32Z | ---
base_model: VAGOsolutions/SauerkrautLM-13b-v1
inference: false
language:
- de
- en
library_name: transformers
license: llama2
model_creator: VAGO solutions
model_name: SauerkrautLM 13B v1
model_type: llama
pipeline_tag: text-generation
prompt_template: "Ein Chat zwischen einem Benutzer und einem KI-Assistenten. Der KI-Assistent\
\ gibt hilfreiche, detaillierte und h\xF6fliche Antworten. \nUser: {prompt} \nAssistant:\n"
quantized_by: TheBloke
---
<!-- header start -->
<!-- 200823 -->
<div style="width: auto; margin-left: auto; margin-right: auto">
<img src="https://i.imgur.com/EBdldam.jpg" alt="TheBlokeAI" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</div>
<div style="display: flex; justify-content: space-between; width: 100%;">
<div style="display: flex; flex-direction: column; align-items: flex-start;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://discord.gg/theblokeai">Chat & support: TheBloke's Discord server</a></p>
</div>
<div style="display: flex; flex-direction: column; align-items: flex-end;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://www.patreon.com/TheBlokeAI">Want to contribute? TheBloke's Patreon page</a></p>
</div>
</div>
<div style="text-align:center; margin-top: 0em; margin-bottom: 0em"><p style="margin-top: 0.25em; margin-bottom: 0em;">TheBloke's LLM work is generously supported by a grant from <a href="https://a16z.com">andreessen horowitz (a16z)</a></p></div>
<hr style="margin-top: 1.0em; margin-bottom: 1.0em;">
<!-- header end -->
# SauerkrautLM 13B v1 - GPTQ
- Model creator: [VAGO solutions](https://huggingface.co/VAGOsolutions)
- Original model: [SauerkrautLM 13B v1](https://huggingface.co/VAGOsolutions/SauerkrautLM-13b-v1)
<!-- description start -->
## Description
This repo contains GPTQ model files for [VAGO solutions's SauerkrautLM 13B v1](https://huggingface.co/VAGOsolutions/SauerkrautLM-13b-v1).
Multiple GPTQ parameter permutations are provided; see Provided Files below for details of the options provided, their parameters, and the software used to create them.
<!-- description end -->
<!-- repositories-available start -->
## Repositories available
* [AWQ model(s) for GPU inference.](https://huggingface.co/TheBloke/SauerkrautLM-13B-v1-AWQ)
* [GPTQ models for GPU inference, with multiple quantisation parameter options.](https://huggingface.co/TheBloke/SauerkrautLM-13B-v1-GPTQ)
* [2, 3, 4, 5, 6 and 8-bit GGUF models for CPU+GPU inference](https://huggingface.co/TheBloke/SauerkrautLM-13B-v1-GGUF)
* [VAGO solutions's original unquantised fp16 model in pytorch format, for GPU inference and for further conversions](https://huggingface.co/VAGOsolutions/SauerkrautLM-13b-v1)
<!-- repositories-available end -->
<!-- prompt-template start -->
## Prompt template: Sauerkraut
```
Ein Chat zwischen einem Benutzer und einem KI-Assistenten. Der KI-Assistent gibt hilfreiche, detaillierte und höfliche Antworten.
User: {prompt}
Assistant:
```
<!-- prompt-template end -->
<!-- README_GPTQ.md-provided-files start -->
## Provided files, and GPTQ parameters
Multiple quantisation parameters are provided, to allow you to choose the best one for your hardware and requirements.
Each separate quant is in a different branch. See below for instructions on fetching from different branches.
Most GPTQ files are made with AutoGPTQ. Mistral models are currently made with Transformers.
<details>
<summary>Explanation of GPTQ parameters</summary>
- Bits: The bit size of the quantised model.
- GS: GPTQ group size. Higher numbers use less VRAM, but have lower quantisation accuracy. "None" is the lowest possible value.
- Act Order: True or False. Also known as `desc_act`. True results in better quantisation accuracy. Some GPTQ clients have had issues with models that use Act Order plus Group Size, but this is generally resolved now.
- Damp %: A GPTQ parameter that affects how samples are processed for quantisation. 0.01 is default, but 0.1 results in slightly better accuracy.
- GPTQ dataset: The calibration dataset used during quantisation. Using a dataset more appropriate to the model's training can improve quantisation accuracy. Note that the GPTQ calibration dataset is not the same as the dataset used to train the model - please refer to the original model repo for details of the training dataset(s).
- Sequence Length: The length of the dataset sequences used for quantisation. Ideally this is the same as the model sequence length. For some very long sequence models (16+K), a lower sequence length may have to be used. Note that a lower sequence length does not limit the sequence length of the quantised model. It only impacts the quantisation accuracy on longer inference sequences.
- ExLlama Compatibility: Whether this file can be loaded with ExLlama, which currently only supports Llama models in 4-bit.
</details>
| Branch | Bits | GS | Act Order | Damp % | GPTQ Dataset | Seq Len | Size | ExLlama | Desc |
| ------ | ---- | -- | --------- | ------ | ------------ | ------- | ---- | ------- | ---- |
| [main](https://huggingface.co/TheBloke/SauerkrautLM-13B-v1-GPTQ/tree/main) | 4 | 128 | Yes | 0.1 | [German Quad](https://huggingface.co/datasets/deepset/germanquad) | 4096 | 7.26 GB | Yes | 4-bit, with Act Order and group size 128g. Uses even less VRAM than 64g, but with slightly lower accuracy. |
| [gptq-4bit-32g-actorder_True](https://huggingface.co/TheBloke/SauerkrautLM-13B-v1-GPTQ/tree/gptq-4bit-32g-actorder_True) | 4 | 32 | Yes | 0.1 | [German Quad](https://huggingface.co/datasets/deepset/germanquad) | 4096 | 8.00 GB | Yes | 4-bit, with Act Order and group size 32g. Gives highest possible inference quality, with maximum VRAM usage. |
| [gptq-8bit--1g-actorder_True](https://huggingface.co/TheBloke/SauerkrautLM-13B-v1-GPTQ/tree/gptq-8bit--1g-actorder_True) | 8 | None | Yes | 0.1 | [German Quad](https://huggingface.co/datasets/deepset/germanquad) | 4096 | 13.36 GB | No | 8-bit, with Act Order. No group size, to lower VRAM requirements. |
| [gptq-8bit-128g-actorder_True](https://huggingface.co/TheBloke/SauerkrautLM-13B-v1-GPTQ/tree/gptq-8bit-128g-actorder_True) | 8 | 128 | Yes | 0.1 | [German Quad](https://huggingface.co/datasets/deepset/germanquad) | 4096 | 13.65 GB | No | 8-bit, with group size 128g for higher inference quality and with Act Order for even higher accuracy. |
| [gptq-8bit-32g-actorder_True](https://huggingface.co/TheBloke/SauerkrautLM-13B-v1-GPTQ/tree/gptq-8bit-32g-actorder_True) | 8 | 32 | Yes | 0.1 | [German Quad](https://huggingface.co/datasets/deepset/germanquad) | 4096 | 14.54 GB | No | 8-bit, with group size 32g and Act Order for maximum inference quality. |
| [gptq-4bit-64g-actorder_True](https://huggingface.co/TheBloke/SauerkrautLM-13B-v1-GPTQ/tree/gptq-4bit-64g-actorder_True) | 4 | 64 | Yes | 0.1 | [German Quad](https://huggingface.co/datasets/deepset/germanquad) | 4096 | 7.51 GB | Yes | 4-bit, with Act Order and group size 64g. Uses less VRAM than 32g, but with slightly lower accuracy. |
<!-- README_GPTQ.md-provided-files end -->
<!-- README_GPTQ.md-download-from-branches start -->
## How to download, including from branches
### In text-generation-webui
To download from the `main` branch, enter `TheBloke/SauerkrautLM-13B-v1-GPTQ` in the "Download model" box.
To download from another branch, add `:branchname` to the end of the download name, eg `TheBloke/SauerkrautLM-13B-v1-GPTQ:gptq-4bit-32g-actorder_True`
### From the command line
I recommend using the `huggingface-hub` Python library:
```shell
pip3 install huggingface-hub
```
To download the `main` branch to a folder called `SauerkrautLM-13B-v1-GPTQ`:
```shell
mkdir SauerkrautLM-13B-v1-GPTQ
huggingface-cli download TheBloke/SauerkrautLM-13B-v1-GPTQ --local-dir SauerkrautLM-13B-v1-GPTQ --local-dir-use-symlinks False
```
To download from a different branch, add the `--revision` parameter:
```shell
mkdir SauerkrautLM-13B-v1-GPTQ
huggingface-cli download TheBloke/SauerkrautLM-13B-v1-GPTQ --revision gptq-4bit-32g-actorder_True --local-dir SauerkrautLM-13B-v1-GPTQ --local-dir-use-symlinks False
```
<details>
<summary>More advanced huggingface-cli download usage</summary>
If you remove the `--local-dir-use-symlinks False` parameter, the files will instead be stored in the central Huggingface cache directory (default location on Linux is: `~/.cache/huggingface`), and symlinks will be added to the specified `--local-dir`, pointing to their real location in the cache. This allows for interrupted downloads to be resumed, and allows you to quickly clone the repo to multiple places on disk without triggering a download again. The downside, and the reason why I don't list that as the default option, is that the files are then hidden away in a cache folder and it's harder to know where your disk space is being used, and to clear it up if/when you want to remove a download model.
The cache location can be changed with the `HF_HOME` environment variable, and/or the `--cache-dir` parameter to `huggingface-cli`.
For more documentation on downloading with `huggingface-cli`, please see: [HF -> Hub Python Library -> Download files -> Download from the CLI](https://huggingface.co/docs/huggingface_hub/guides/download#download-from-the-cli).
To accelerate downloads on fast connections (1Gbit/s or higher), install `hf_transfer`:
```shell
pip3 install hf_transfer
```
And set environment variable `HF_HUB_ENABLE_HF_TRANSFER` to `1`:
```shell
mkdir SauerkrautLM-13B-v1-GPTQ
HF_HUB_ENABLE_HF_TRANSFER=1 huggingface-cli download TheBloke/SauerkrautLM-13B-v1-GPTQ --local-dir SauerkrautLM-13B-v1-GPTQ --local-dir-use-symlinks False
```
Windows Command Line users: You can set the environment variable by running `set HF_HUB_ENABLE_HF_TRANSFER=1` before the download command.
</details>
### With `git` (**not** recommended)
To clone a specific branch with `git`, use a command like this:
```shell
git clone --single-branch --branch gptq-4bit-32g-actorder_True https://huggingface.co/TheBloke/SauerkrautLM-13B-v1-GPTQ
```
Note that using Git with HF repos is strongly discouraged. It will be much slower than using `huggingface-hub`, and will use twice as much disk space as it has to store the model files twice (it stores every byte both in the intended target folder, and again in the `.git` folder as a blob.)
<!-- README_GPTQ.md-download-from-branches end -->
<!-- README_GPTQ.md-text-generation-webui start -->
## How to easily download and use this model in [text-generation-webui](https://github.com/oobabooga/text-generation-webui).
Please make sure you're using the latest version of [text-generation-webui](https://github.com/oobabooga/text-generation-webui).
It is strongly recommended to use the text-generation-webui one-click-installers unless you're sure you know how to make a manual install.
1. Click the **Model tab**.
2. Under **Download custom model or LoRA**, enter `TheBloke/SauerkrautLM-13B-v1-GPTQ`.
- To download from a specific branch, enter for example `TheBloke/SauerkrautLM-13B-v1-GPTQ:gptq-4bit-32g-actorder_True`
- see Provided Files above for the list of branches for each option.
3. Click **Download**.
4. The model will start downloading. Once it's finished it will say "Done".
5. In the top left, click the refresh icon next to **Model**.
6. In the **Model** dropdown, choose the model you just downloaded: `SauerkrautLM-13B-v1-GPTQ`
7. The model will automatically load, and is now ready for use!
8. If you want any custom settings, set them and then click **Save settings for this model** followed by **Reload the Model** in the top right.
* Note that you do not need to and should not set manual GPTQ parameters any more. These are set automatically from the file `quantize_config.json`.
9. Once you're ready, click the **Text Generation tab** and enter a prompt to get started!
<!-- README_GPTQ.md-text-generation-webui end -->
<!-- README_GPTQ.md-use-from-tgi start -->
## Serving this model from Text Generation Inference (TGI)
It's recommended to use TGI version 1.1.0 or later. The official Docker container is: `ghcr.io/huggingface/text-generation-inference:1.1.0`
Example Docker parameters:
```shell
--model-id TheBloke/SauerkrautLM-13B-v1-GPTQ --port 3000 --quantize awq --max-input-length 3696 --max-total-tokens 4096 --max-batch-prefill-tokens 4096
```
Example Python code for interfacing with TGI (requires huggingface-hub 0.17.0 or later):
```shell
pip3 install huggingface-hub
```
```python
from huggingface_hub import InferenceClient
endpoint_url = "https://your-endpoint-url-here"
prompt = "Tell me about AI"
prompt_template=f'''Ein Chat zwischen einem Benutzer und einem KI-Assistenten. Der KI-Assistent gibt hilfreiche, detaillierte und höfliche Antworten.
User: {prompt}
Assistant:
'''
client = InferenceClient(endpoint_url)
response = client.text_generation(prompt,
max_new_tokens=128,
do_sample=True,
temperature=0.7,
top_p=0.95,
top_k=40,
repetition_penalty=1.1)
print(f"Model output: {response}")
```
<!-- README_GPTQ.md-use-from-tgi end -->
<!-- README_GPTQ.md-use-from-python start -->
## How to use this GPTQ model from Python code
### Install the necessary packages
Requires: Transformers 4.33.0 or later, Optimum 1.12.0 or later, and AutoGPTQ 0.4.2 or later.
```shell
pip3 install transformers optimum
pip3 install auto-gptq --extra-index-url https://huggingface.github.io/autogptq-index/whl/cu118/ # Use cu117 if on CUDA 11.7
```
If you have problems installing AutoGPTQ using the pre-built wheels, install it from source instead:
```shell
pip3 uninstall -y auto-gptq
git clone https://github.com/PanQiWei/AutoGPTQ
cd AutoGPTQ
git checkout v0.4.2
pip3 install .
```
### You can then use the following code
```python
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
model_name_or_path = "TheBloke/SauerkrautLM-13B-v1-GPTQ"
# To use a different branch, change revision
# For example: revision="gptq-4bit-32g-actorder_True"
model = AutoModelForCausalLM.from_pretrained(model_name_or_path,
device_map="auto",
trust_remote_code=False,
revision="main")
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, use_fast=True)
prompt = "Tell me about AI"
prompt_template=f'''Ein Chat zwischen einem Benutzer und einem KI-Assistenten. Der KI-Assistent gibt hilfreiche, detaillierte und höfliche Antworten.
User: {prompt}
Assistant:
'''
print("\n\n*** Generate:")
input_ids = tokenizer(prompt_template, return_tensors='pt').input_ids.cuda()
output = model.generate(inputs=input_ids, temperature=0.7, do_sample=True, top_p=0.95, top_k=40, max_new_tokens=512)
print(tokenizer.decode(output[0]))
# Inference can also be done using transformers' pipeline
print("*** Pipeline:")
pipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
max_new_tokens=512,
do_sample=True,
temperature=0.7,
top_p=0.95,
top_k=40,
repetition_penalty=1.1
)
print(pipe(prompt_template)[0]['generated_text'])
```
<!-- README_GPTQ.md-use-from-python end -->
<!-- README_GPTQ.md-compatibility start -->
## Compatibility
The files provided are tested to work with AutoGPTQ, both via Transformers and using AutoGPTQ directly. They should also work with [Occ4m's GPTQ-for-LLaMa fork](https://github.com/0cc4m/KoboldAI).
[ExLlama](https://github.com/turboderp/exllama) is compatible with Llama and Mistral models in 4-bit. Please see the Provided Files table above for per-file compatibility.
[Huggingface Text Generation Inference (TGI)](https://github.com/huggingface/text-generation-inference) is compatible with all GPTQ models.
<!-- README_GPTQ.md-compatibility end -->
<!-- footer start -->
<!-- 200823 -->
## Discord
For further support, and discussions on these models and AI in general, join us at:
[TheBloke AI's Discord server](https://discord.gg/theblokeai)
## Thanks, and how to contribute
Thanks to the [chirper.ai](https://chirper.ai) team!
Thanks to Clay from [gpus.llm-utils.org](llm-utils)!
I've had a lot of people ask if they can contribute. I enjoy providing models and helping people, and would love to be able to spend even more time doing it, as well as expanding into new projects like fine tuning/training.
If you're able and willing to contribute it will be most gratefully received and will help me to keep providing more models, and to start work on new AI projects.
Donaters will get priority support on any and all AI/LLM/model questions and requests, access to a private Discord room, plus other benefits.
* Patreon: https://patreon.com/TheBlokeAI
* Ko-Fi: https://ko-fi.com/TheBlokeAI
**Special thanks to**: Aemon Algiz.
**Patreon special mentions**: Pierre Kircher, Stanislav Ovsiannikov, Michael Levine, Eugene Pentland, Andrey, 준교 김, Randy H, Fred von Graf, Artur Olbinski, Caitlyn Gatomon, terasurfer, Jeff Scroggin, James Bentley, Vadim, Gabriel Puliatti, Harry Royden McLaughlin, Sean Connelly, Dan Guido, Edmond Seymore, Alicia Loh, subjectnull, AzureBlack, Manuel Alberto Morcote, Thomas Belote, Lone Striker, Chris Smitley, Vitor Caleffi, Johann-Peter Hartmann, Clay Pascal, biorpg, Brandon Frisco, sidney chen, transmissions 11, Pedro Madruga, jinyuan sun, Ajan Kanaga, Emad Mostaque, Trenton Dambrowitz, Jonathan Leane, Iucharbius, usrbinkat, vamX, George Stoitzev, Luke Pendergrass, theTransient, Olakabola, Swaroop Kallakuri, Cap'n Zoog, Brandon Phillips, Michael Dempsey, Nikolai Manek, danny, Matthew Berman, Gabriel Tamborski, alfie_i, Raymond Fosdick, Tom X Nguyen, Raven Klaugh, LangChain4j, Magnesian, Illia Dulskyi, David Ziegler, Mano Prime, Luis Javier Navarrete Lozano, Erik Bjäreholt, 阿明, Nathan Dryer, Alex, Rainer Wilmers, zynix, TL, Joseph William Delisle, John Villwock, Nathan LeClaire, Willem Michiel, Joguhyik, GodLy, OG, Alps Aficionado, Jeffrey Morgan, ReadyPlayerEmma, Tiffany J. Kim, Sebastain Graf, Spencer Kim, Michael Davis, webtim, Talal Aujan, knownsqashed, John Detwiler, Imad Khwaja, Deo Leter, Jerry Meng, Elijah Stavena, Rooh Singh, Pieter, SuperWojo, Alexandros Triantafyllidis, Stephen Murray, Ai Maven, ya boyyy, Enrico Ros, Ken Nordquist, Deep Realms, Nicholas, Spiking Neurons AB, Elle, Will Dee, Jack West, RoA, Luke @flexchar, Viktor Bowallius, Derek Yates, Subspace Studios, jjj, Toran Billups, Asp the Wyvern, Fen Risland, Ilya, NimbleBox.ai, Chadd, Nitin Borwankar, Emre, Mandus, Leonard Tan, Kalila, K, Trailburnt, S_X, Cory Kujawski
Thank you to all my generous patrons and donaters!
And thank you again to a16z for their generous grant.
<!-- footer end -->
# Original model card: VAGO solutions's SauerkrautLM 13B v1

## VAGO solutions SauerkrautLM
Introducing SauerkrautLM-v1 - Your German Language Powerhouse!
We are thrilled to unveil our **very first release**, **SauerkrautLM-v1**. This remarkable creation marks a significant milestone as it is specifically **tailored for the German-speaking community**. In a landscape where German language models are scarce, we are proud to offer a solution that fills this void.
What sets SauerkrautLM-v1 apart is its versatility. Whether you are an individual looking to harness its capabilities for personal use or a business seeking to integrate it into your projects, our model is designed to accommodate all. It operates under the LLAMA 2 License, providing you with the freedom to explore its potential in both private and commercial applications.
Performance is at the heart of SauerkrautLM-v1. We put it to the **test using a customized version of MT-Bench for the German language**, and the results speak volumes. It currently stands as the most robust German Language Model on Hugging Face (based on german mt-bench results), showcasing its exceptional capabilities. Rest assured, this model is here to shine and set new standards. And the best thing is it comes in three different sizes (3B, 7B, 13B) to address your individual needs.
Our model's journey began with meticulous training using an **augmented dataset within the QLoRA approach**. This is just the beginning of our model series, promising even more innovative and powerful solutions in the future.
Join us on this exciting adventure as we redefine the possibilities of language modeling for the German-speaking world.
SauerkrautLM-v1 is here to empower your language-related endeavors like never before.
## All Models
| Model | HF | GPTQ | GGUF |
|-------|-------|-------|-------|
| SauerkrautLM-3b-v1 | [Link](https://huggingface.co/VAGOsolutions/SauerkrautLM-3b-v1) | soon | soon |
| SauerkrautLM-7b-v1 | [Link](https://huggingface.co/VAGOsolutions/SauerkrautLM-7b-v1) | soon | soon |
| SauerkrautLM-7b-v1-mistral | [Link](https://huggingface.co/VAGOsolutions/SauerkrautLM-7b-v1-mistral) | soon | soon |
| SauerkrautLM-13b-v1 | [Link](https://huggingface.co/VAGOsolutions/SauerkrautLM-13b-v1) | soon | soon |
## Model Details
**SauerkrautLM-13b-v1**
**Training Dataset:**
SauerkrautLM was trained with mix of German data augmentation and translated data.
We found, that only a simple translation of training data can lead to unnatural German phrasings.
Data augmentation techniques were used to grant grammatical, syntactical correctness and a more natural German wording in our training data.
**Training Procedure:**
SauerkrautLM-13b-v1 was fine-tuned using QLoRA on 1 A100 80GB with Axolotl.
- **Trained by:** SauerkrautLM-v1 trained by VAGO solutions
- **Model Type:** SauerkrautLM-v1 is an auto-regressive language model based on the transformer architecture
- **Language(s):** German, English
- **License:** [LLAMA 2 COMMUNITY LICENSE AGREEMENT](https://huggingface.co/meta-llama/Llama-2-70b/raw/main/LICENSE.txt)
- **Contact:** [Website](https://vago-solutions.de/#Kontakt) [David Golchinfar](mailto:[email protected])
**Prompt Template:**
```
Ein Chat zwischen einem Benutzer und einem KI-Assistenten. Der KI-Assistent gibt hilfreiche, detaillierte und höfliche Antworten.
User: {prompt}
Assistant:
```
## Evaluation
**[MT-Bench-TrueGerman](https://huggingface.co/datasets/VAGOsolutions/MT-Bench-TrueGerman)**





## Disclaimer
Our models have been meticulously trained on extensive datasets. While we have made diligent efforts to thoroughly screen and eliminate any instances of coarse or inappropriate language from our data, we must inform users that despite our best efforts in data cleansing, the possibility of some such content slipping through cannot be entirely ruled out.
Furthermore, it is important to note that we have implemented filters within our models; however, we cannot always guarantee consistently appropriate behavior. Therefore, if you encounter any issues or come across inappropriate content, we kindly request that you inform us through the contact information provided.
Additionally, it is essential to understand that the licensing of these models does not constitute legal advice. We are not held responsible for the actions of third parties who utilize our models. These models may be employed for commercial purposes, and the original Llama2 license remains applicable and is included with the model files.
## Contact
If you are interested in customized LLMs for business applications, please get in contact with us via our website or contact us at [Dr. Daryoush Vaziri](mailto:[email protected]). We are also grateful for your feedback and suggestions.
## Collaborations
We are also keenly seeking support and investment for our startup, VAGO solutions, where we continuously advance the development of robust language models designed to address a diverse range of purposes and requirements. If the prospect of collaboratively navigating future challenges excites you, we warmly invite you to reach out to us.
|
ikala/ViT-SO400M-14-SigLIP-384-hf | ikala | 2023-11-02T00:51:10Z | 3,307 | 16 | transformers | [
"transformers",
"pytorch",
"clip",
"zero-shot-image-classification",
"siglip",
"en",
"dataset:webli",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | zero-shot-image-classification | 2023-10-25T03:45:48Z | ---
tags:
- clip
- siglip
library_name: transformers
pipeline_tag: zero-shot-image-classification
license: apache-2.0
datasets:
- webli
language:
- en
---
# Model card for ViT-SO400M-14-SigLIP-384
A SigLIP (Sigmoid loss for Language-Image Pre-training) model trained on WebLI.
This model has been converted from Open-CLIP : [timm/ViT-SO400M-14-SigLIP-384](https://huggingface.co/timm/ViT-SO400M-14-SigLIP-384) to huggingface CLIPVisionModel
```Python
from transformers import CLIPVisionModel, CLIPImageProcessor
from PIL import Image
import requests
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
inputs = image_processor(images=image, return_tensors="pt", padding=True)
vision_tower = CLIPVisionModel.from_pretrained('ikala/ViT-SO400M-14-SigLIP-384-hf')
outputs = vision_tower(**inputs)
logits_per_image = outputs.pooler_output # this is the image-text similarity score
```
There's still a slight difference where hf's CLIPVision model uses a [CLS] embedding as pool embedding while SigLIP uses global attention pooler to get the final latent feature. |
hfl/chinese-alpaca-2-7b-gguf | hfl | 2024-01-24T02:57:41Z | 3,307 | 13 | null | [
"gguf",
"zh",
"en",
"license:apache-2.0",
"region:us"
] | null | 2023-11-16T04:56:58Z | ---
license: apache-2.0
language:
- zh
- en
---
# Chinese-Alpaca-2-7B-GGUF
This repository contains the GGUF-v3 models (llama.cpp compatible) for **Chinese-Alpaca-2-7B**.
## Performance
Metric: PPL, lower is better
| Quant | original | imatrix (`-im`) |
|-----|------|------|
| Q2_K | 10.3705 +/- 0.14109 | 11.7442 +/- 0.16034 |
| Q3_K | 8.8478 +/- 0.12085 | 8.7104 +/- 0.11925 |
| Q4_0 | 8.6418 +/- 0.11876 | - |
| Q4_K | 8.3294 +/- 0.11396 | 8.3034 +/- 0.11391 |
| Q5_0 | 8.3320 +/- 0.11411 | - |
| Q5_K | 8.2361 +/- 0.11298 | 8.2136 +/- 0.11281 |
| Q6_K | 8.1956 +/- 0.11259 | 8.1852 +/- 0.11246 |
| Q8_0 | 8.1784 +/- 0.11232 | - |
| F16 | 8.1799 +/- 0.11243 | - |
*The model with `-im` suffix is generated with important matrix, which has generally better performance (not always though).*
## Others
For Hugging Face version, please see: https://huggingface.co/hfl/chinese-alpaca-2-7b
Please refer to [https://github.com/ymcui/Chinese-LLaMA-Alpaca-2/](https://github.com/ymcui/Chinese-LLaMA-Alpaca-2/) for more details. |
inflaton/Llama-3-8B-Instruct-Gradient-1048k-MAC-lora | inflaton | 2024-06-23T17:53:30Z | 3,303 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"text-generation-inference",
"unsloth",
"trl",
"sft",
"conversational",
"en",
"base_model:gradientai/Llama-3-8B-Instruct-Gradient-1048k",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"4-bit",
"bitsandbytes",
"region:us"
] | text-generation | 2024-06-23T17:39:47Z | ---
base_model: gradientai/Llama-3-8B-Instruct-Gradient-1048k
language:
- en
license: apache-2.0
tags:
- text-generation-inference
- transformers
- unsloth
- llama
- trl
- sft
---
# Uploaded model
- **Developed by:** inflaton
- **License:** apache-2.0
- **Finetuned from model :** gradientai/Llama-3-8B-Instruct-Gradient-1048k
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
RichardErkhov/Josephgflowers_-_Tinyllama-Cinder-1.3B-Reason-Test.2-gguf | RichardErkhov | 2024-06-27T13:00:52Z | 3,303 | 0 | null | [
"gguf",
"region:us"
] | null | 2024-06-27T12:51:26Z | Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
Tinyllama-Cinder-1.3B-Reason-Test.2 - GGUF
- Model creator: https://huggingface.co/Josephgflowers/
- Original model: https://huggingface.co/Josephgflowers/Tinyllama-Cinder-1.3B-Reason-Test.2/
| Name | Quant method | Size |
| ---- | ---- | ---- |
| [Tinyllama-Cinder-1.3B-Reason-Test.2.Q2_K.gguf](https://huggingface.co/RichardErkhov/Josephgflowers_-_Tinyllama-Cinder-1.3B-Reason-Test.2-gguf/blob/main/Tinyllama-Cinder-1.3B-Reason-Test.2.Q2_K.gguf) | Q2_K | 0.46GB |
| [Tinyllama-Cinder-1.3B-Reason-Test.2.IQ3_XS.gguf](https://huggingface.co/RichardErkhov/Josephgflowers_-_Tinyllama-Cinder-1.3B-Reason-Test.2-gguf/blob/main/Tinyllama-Cinder-1.3B-Reason-Test.2.IQ3_XS.gguf) | IQ3_XS | 0.51GB |
| [Tinyllama-Cinder-1.3B-Reason-Test.2.IQ3_S.gguf](https://huggingface.co/RichardErkhov/Josephgflowers_-_Tinyllama-Cinder-1.3B-Reason-Test.2-gguf/blob/main/Tinyllama-Cinder-1.3B-Reason-Test.2.IQ3_S.gguf) | IQ3_S | 0.54GB |
| [Tinyllama-Cinder-1.3B-Reason-Test.2.Q3_K_S.gguf](https://huggingface.co/RichardErkhov/Josephgflowers_-_Tinyllama-Cinder-1.3B-Reason-Test.2-gguf/blob/main/Tinyllama-Cinder-1.3B-Reason-Test.2.Q3_K_S.gguf) | Q3_K_S | 0.54GB |
| [Tinyllama-Cinder-1.3B-Reason-Test.2.IQ3_M.gguf](https://huggingface.co/RichardErkhov/Josephgflowers_-_Tinyllama-Cinder-1.3B-Reason-Test.2-gguf/blob/main/Tinyllama-Cinder-1.3B-Reason-Test.2.IQ3_M.gguf) | IQ3_M | 0.56GB |
| [Tinyllama-Cinder-1.3B-Reason-Test.2.Q3_K.gguf](https://huggingface.co/RichardErkhov/Josephgflowers_-_Tinyllama-Cinder-1.3B-Reason-Test.2-gguf/blob/main/Tinyllama-Cinder-1.3B-Reason-Test.2.Q3_K.gguf) | Q3_K | 0.59GB |
| [Tinyllama-Cinder-1.3B-Reason-Test.2.Q3_K_M.gguf](https://huggingface.co/RichardErkhov/Josephgflowers_-_Tinyllama-Cinder-1.3B-Reason-Test.2-gguf/blob/main/Tinyllama-Cinder-1.3B-Reason-Test.2.Q3_K_M.gguf) | Q3_K_M | 0.59GB |
| [Tinyllama-Cinder-1.3B-Reason-Test.2.Q3_K_L.gguf](https://huggingface.co/RichardErkhov/Josephgflowers_-_Tinyllama-Cinder-1.3B-Reason-Test.2-gguf/blob/main/Tinyllama-Cinder-1.3B-Reason-Test.2.Q3_K_L.gguf) | Q3_K_L | 0.64GB |
| [Tinyllama-Cinder-1.3B-Reason-Test.2.IQ4_XS.gguf](https://huggingface.co/RichardErkhov/Josephgflowers_-_Tinyllama-Cinder-1.3B-Reason-Test.2-gguf/blob/main/Tinyllama-Cinder-1.3B-Reason-Test.2.IQ4_XS.gguf) | IQ4_XS | 0.66GB |
| [Tinyllama-Cinder-1.3B-Reason-Test.2.Q4_0.gguf](https://huggingface.co/RichardErkhov/Josephgflowers_-_Tinyllama-Cinder-1.3B-Reason-Test.2-gguf/blob/main/Tinyllama-Cinder-1.3B-Reason-Test.2.Q4_0.gguf) | Q4_0 | 0.69GB |
| [Tinyllama-Cinder-1.3B-Reason-Test.2.IQ4_NL.gguf](https://huggingface.co/RichardErkhov/Josephgflowers_-_Tinyllama-Cinder-1.3B-Reason-Test.2-gguf/blob/main/Tinyllama-Cinder-1.3B-Reason-Test.2.IQ4_NL.gguf) | IQ4_NL | 0.69GB |
| [Tinyllama-Cinder-1.3B-Reason-Test.2.Q4_K_S.gguf](https://huggingface.co/RichardErkhov/Josephgflowers_-_Tinyllama-Cinder-1.3B-Reason-Test.2-gguf/blob/main/Tinyllama-Cinder-1.3B-Reason-Test.2.Q4_K_S.gguf) | Q4_K_S | 0.69GB |
| [Tinyllama-Cinder-1.3B-Reason-Test.2.Q4_K.gguf](https://huggingface.co/RichardErkhov/Josephgflowers_-_Tinyllama-Cinder-1.3B-Reason-Test.2-gguf/blob/main/Tinyllama-Cinder-1.3B-Reason-Test.2.Q4_K.gguf) | Q4_K | 0.72GB |
| [Tinyllama-Cinder-1.3B-Reason-Test.2.Q4_K_M.gguf](https://huggingface.co/RichardErkhov/Josephgflowers_-_Tinyllama-Cinder-1.3B-Reason-Test.2-gguf/blob/main/Tinyllama-Cinder-1.3B-Reason-Test.2.Q4_K_M.gguf) | Q4_K_M | 0.72GB |
| [Tinyllama-Cinder-1.3B-Reason-Test.2.Q4_1.gguf](https://huggingface.co/RichardErkhov/Josephgflowers_-_Tinyllama-Cinder-1.3B-Reason-Test.2-gguf/blob/main/Tinyllama-Cinder-1.3B-Reason-Test.2.Q4_1.gguf) | Q4_1 | 0.76GB |
| [Tinyllama-Cinder-1.3B-Reason-Test.2.Q5_0.gguf](https://huggingface.co/RichardErkhov/Josephgflowers_-_Tinyllama-Cinder-1.3B-Reason-Test.2-gguf/blob/main/Tinyllama-Cinder-1.3B-Reason-Test.2.Q5_0.gguf) | Q5_0 | 0.83GB |
| [Tinyllama-Cinder-1.3B-Reason-Test.2.Q5_K_S.gguf](https://huggingface.co/RichardErkhov/Josephgflowers_-_Tinyllama-Cinder-1.3B-Reason-Test.2-gguf/blob/main/Tinyllama-Cinder-1.3B-Reason-Test.2.Q5_K_S.gguf) | Q5_K_S | 0.83GB |
| [Tinyllama-Cinder-1.3B-Reason-Test.2.Q5_K.gguf](https://huggingface.co/RichardErkhov/Josephgflowers_-_Tinyllama-Cinder-1.3B-Reason-Test.2-gguf/blob/main/Tinyllama-Cinder-1.3B-Reason-Test.2.Q5_K.gguf) | Q5_K | 0.85GB |
| [Tinyllama-Cinder-1.3B-Reason-Test.2.Q5_K_M.gguf](https://huggingface.co/RichardErkhov/Josephgflowers_-_Tinyllama-Cinder-1.3B-Reason-Test.2-gguf/blob/main/Tinyllama-Cinder-1.3B-Reason-Test.2.Q5_K_M.gguf) | Q5_K_M | 0.85GB |
| [Tinyllama-Cinder-1.3B-Reason-Test.2.Q5_1.gguf](https://huggingface.co/RichardErkhov/Josephgflowers_-_Tinyllama-Cinder-1.3B-Reason-Test.2-gguf/blob/main/Tinyllama-Cinder-1.3B-Reason-Test.2.Q5_1.gguf) | Q5_1 | 0.9GB |
| [Tinyllama-Cinder-1.3B-Reason-Test.2.Q6_K.gguf](https://huggingface.co/RichardErkhov/Josephgflowers_-_Tinyllama-Cinder-1.3B-Reason-Test.2-gguf/blob/main/Tinyllama-Cinder-1.3B-Reason-Test.2.Q6_K.gguf) | Q6_K | 0.98GB |
| [Tinyllama-Cinder-1.3B-Reason-Test.2.Q8_0.gguf](https://huggingface.co/RichardErkhov/Josephgflowers_-_Tinyllama-Cinder-1.3B-Reason-Test.2-gguf/blob/main/Tinyllama-Cinder-1.3B-Reason-Test.2.Q8_0.gguf) | Q8_0 | 1.26GB |
Original model description:
---
license: mit
---
1.3B test of Cinder trained on math and step by step reasoning. Model Overview Cinder is an AI chatbot tailored for engaging users in scientific and educational conversations, offering companionship, and sparking imaginative exploration. It is built on the TinyLlama 1.1B parameter model and trained on a unique combination of datasets.
|
RichardErkhov/augmxnt_-_shisa-base-7b-v1-gguf | RichardErkhov | 2024-06-02T15:32:20Z | 3,301 | 0 | null | [
"gguf",
"region:us"
] | null | 2024-06-02T11:40:02Z | Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
shisa-base-7b-v1 - GGUF
- Model creator: https://huggingface.co/augmxnt/
- Original model: https://huggingface.co/augmxnt/shisa-base-7b-v1/
| Name | Quant method | Size |
| ---- | ---- | ---- |
| [shisa-base-7b-v1.Q2_K.gguf](https://huggingface.co/RichardErkhov/augmxnt_-_shisa-base-7b-v1-gguf/blob/main/shisa-base-7b-v1.Q2_K.gguf) | Q2_K | 2.92GB |
| [shisa-base-7b-v1.IQ3_XS.gguf](https://huggingface.co/RichardErkhov/augmxnt_-_shisa-base-7b-v1-gguf/blob/main/shisa-base-7b-v1.IQ3_XS.gguf) | IQ3_XS | 3.23GB |
| [shisa-base-7b-v1.IQ3_S.gguf](https://huggingface.co/RichardErkhov/augmxnt_-_shisa-base-7b-v1-gguf/blob/main/shisa-base-7b-v1.IQ3_S.gguf) | IQ3_S | 2.73GB |
| [shisa-base-7b-v1.Q3_K_S.gguf](https://huggingface.co/RichardErkhov/augmxnt_-_shisa-base-7b-v1-gguf/blob/main/shisa-base-7b-v1.Q3_K_S.gguf) | Q3_K_S | 3.37GB |
| [shisa-base-7b-v1.IQ3_M.gguf](https://huggingface.co/RichardErkhov/augmxnt_-_shisa-base-7b-v1-gguf/blob/main/shisa-base-7b-v1.IQ3_M.gguf) | IQ3_M | 3.48GB |
| [shisa-base-7b-v1.Q3_K.gguf](https://huggingface.co/RichardErkhov/augmxnt_-_shisa-base-7b-v1-gguf/blob/main/shisa-base-7b-v1.Q3_K.gguf) | Q3_K | 3.7GB |
| [shisa-base-7b-v1.Q3_K_M.gguf](https://huggingface.co/RichardErkhov/augmxnt_-_shisa-base-7b-v1-gguf/blob/main/shisa-base-7b-v1.Q3_K_M.gguf) | Q3_K_M | 3.7GB |
| [shisa-base-7b-v1.Q3_K_L.gguf](https://huggingface.co/RichardErkhov/augmxnt_-_shisa-base-7b-v1-gguf/blob/main/shisa-base-7b-v1.Q3_K_L.gguf) | Q3_K_L | 3.98GB |
| [shisa-base-7b-v1.IQ4_XS.gguf](https://huggingface.co/RichardErkhov/augmxnt_-_shisa-base-7b-v1-gguf/blob/main/shisa-base-7b-v1.IQ4_XS.gguf) | IQ4_XS | 4.13GB |
| [shisa-base-7b-v1.Q4_0.gguf](https://huggingface.co/RichardErkhov/augmxnt_-_shisa-base-7b-v1-gguf/blob/main/shisa-base-7b-v1.Q4_0.gguf) | Q4_0 | 4.29GB |
| [shisa-base-7b-v1.IQ4_NL.gguf](https://huggingface.co/RichardErkhov/augmxnt_-_shisa-base-7b-v1-gguf/blob/main/shisa-base-7b-v1.IQ4_NL.gguf) | IQ4_NL | 4.34GB |
| [shisa-base-7b-v1.Q4_K_S.gguf](https://huggingface.co/RichardErkhov/augmxnt_-_shisa-base-7b-v1-gguf/blob/main/shisa-base-7b-v1.Q4_K_S.gguf) | Q4_K_S | 4.32GB |
| [shisa-base-7b-v1.Q4_K.gguf](https://huggingface.co/RichardErkhov/augmxnt_-_shisa-base-7b-v1-gguf/blob/main/shisa-base-7b-v1.Q4_K.gguf) | Q4_K | 4.54GB |
| [shisa-base-7b-v1.Q4_K_M.gguf](https://huggingface.co/RichardErkhov/augmxnt_-_shisa-base-7b-v1-gguf/blob/main/shisa-base-7b-v1.Q4_K_M.gguf) | Q4_K_M | 4.54GB |
| [shisa-base-7b-v1.Q4_1.gguf](https://huggingface.co/RichardErkhov/augmxnt_-_shisa-base-7b-v1-gguf/blob/main/shisa-base-7b-v1.Q4_1.gguf) | Q4_1 | 4.73GB |
| [shisa-base-7b-v1.Q5_0.gguf](https://huggingface.co/RichardErkhov/augmxnt_-_shisa-base-7b-v1-gguf/blob/main/shisa-base-7b-v1.Q5_0.gguf) | Q5_0 | 5.16GB |
| [shisa-base-7b-v1.Q5_K_S.gguf](https://huggingface.co/RichardErkhov/augmxnt_-_shisa-base-7b-v1-gguf/blob/main/shisa-base-7b-v1.Q5_K_S.gguf) | Q5_K_S | 5.16GB |
| [shisa-base-7b-v1.Q5_K.gguf](https://huggingface.co/RichardErkhov/augmxnt_-_shisa-base-7b-v1-gguf/blob/main/shisa-base-7b-v1.Q5_K.gguf) | Q5_K | 5.29GB |
| [shisa-base-7b-v1.Q5_K_M.gguf](https://huggingface.co/RichardErkhov/augmxnt_-_shisa-base-7b-v1-gguf/blob/main/shisa-base-7b-v1.Q5_K_M.gguf) | Q5_K_M | 5.29GB |
| [shisa-base-7b-v1.Q5_1.gguf](https://huggingface.co/RichardErkhov/augmxnt_-_shisa-base-7b-v1-gguf/blob/main/shisa-base-7b-v1.Q5_1.gguf) | Q5_1 | 5.6GB |
| [shisa-base-7b-v1.Q6_K.gguf](https://huggingface.co/RichardErkhov/augmxnt_-_shisa-base-7b-v1-gguf/blob/main/shisa-base-7b-v1.Q6_K.gguf) | Q6_K | 6.09GB |
| [shisa-base-7b-v1.Q8_0.gguf](https://huggingface.co/RichardErkhov/augmxnt_-_shisa-base-7b-v1-gguf/blob/main/shisa-base-7b-v1.Q8_0.gguf) | Q8_0 | 7.88GB |
Original model description:
---
license: apache-2.0
language:
- en
- ja
datasets:
- augmxnt/shisa-pretrain-en-ja-v1
- allenai/MADLAD-400
---
# shisa-base-7b-v1
`shisa-base-7b-v1` takes [Mistral 7B](https://huggingface.co/mistralai/Mistral-7B-v0.1) and adds an additional 8B tokens of primarily Japanese pre-training. Japanese tokens were sourced from [MADLAD-400](https://huggingface.co/datasets/allenai/MADLAD-400), using [DSIR](https://github.com/p-lambda/dsir), along with 10% English tokens sampled from a mix of MADLAD-400 EN and various open datasources added in to prevent catastrophic forgetting.
We have extended the Mistral tokenizer to 120k tokens to improve Japanese efficiency. Our tokenizer achieves ~2.3 characters per token in JA, versus the base Mistral 7B tokenizer which is <1 character per token. Code for our implementation is available in our [Shisa repo](https://github.com/AUGMXNT/shisa).
This base model was created for use with [Shisa 7B](https://huggingface.co/augmxnt/shisa-7b-v1), our JA/EN fine-tuned model, but we provide it for the community as we believe the combination of strong performance and efficient bilingual tokenizer could be useful.
Training took 2,400 A100-40 GPU hours on a single 16 x A100-40 machine with [DeepSpeed](https://github.com/microsoft/DeepSpeed) ZeRO-3. ([WandB logs](https://wandb.ai/jondurbin/mistral-7b-ja-v0.2/runs/rj0lq5v3/overview))
## Performance
This base model was able to attain class-leading Japanese performance in standardized benchmarks with significantly less additional pre-training than previously released models. We speculate this may be due to the use of a better-curated pre-training dataset, but ablations at even 2.5B additional JA tokens still showed very strong Japanese performance.
We used a slightly modified [llm-jp-eval](https://github.com/llm-jp/llm-jp-eval) (our base model requires a `bos_token` to be prepended to the prompt; we tested other models with and without the modification and took the higher results for all models tested). Here we validate versus the original Mistral 7B base model as well as [Japanese Stable LM Instruct Gamma 7B](https://huggingface.co/stabilityai/japanese-stablelm-instruct-gamma-7b), which is a Mistral 7B base with an additional 100B tokens of JA/EN pre-training. We also include [Japanese-StableLM-Base-Beta-70B](https://huggingface.co/stabilityai/japanese-stablelm-base-beta-70b), which is a Llama 2 70B that also has an additional 100B tokens of JA/EN pre-training as a reference:
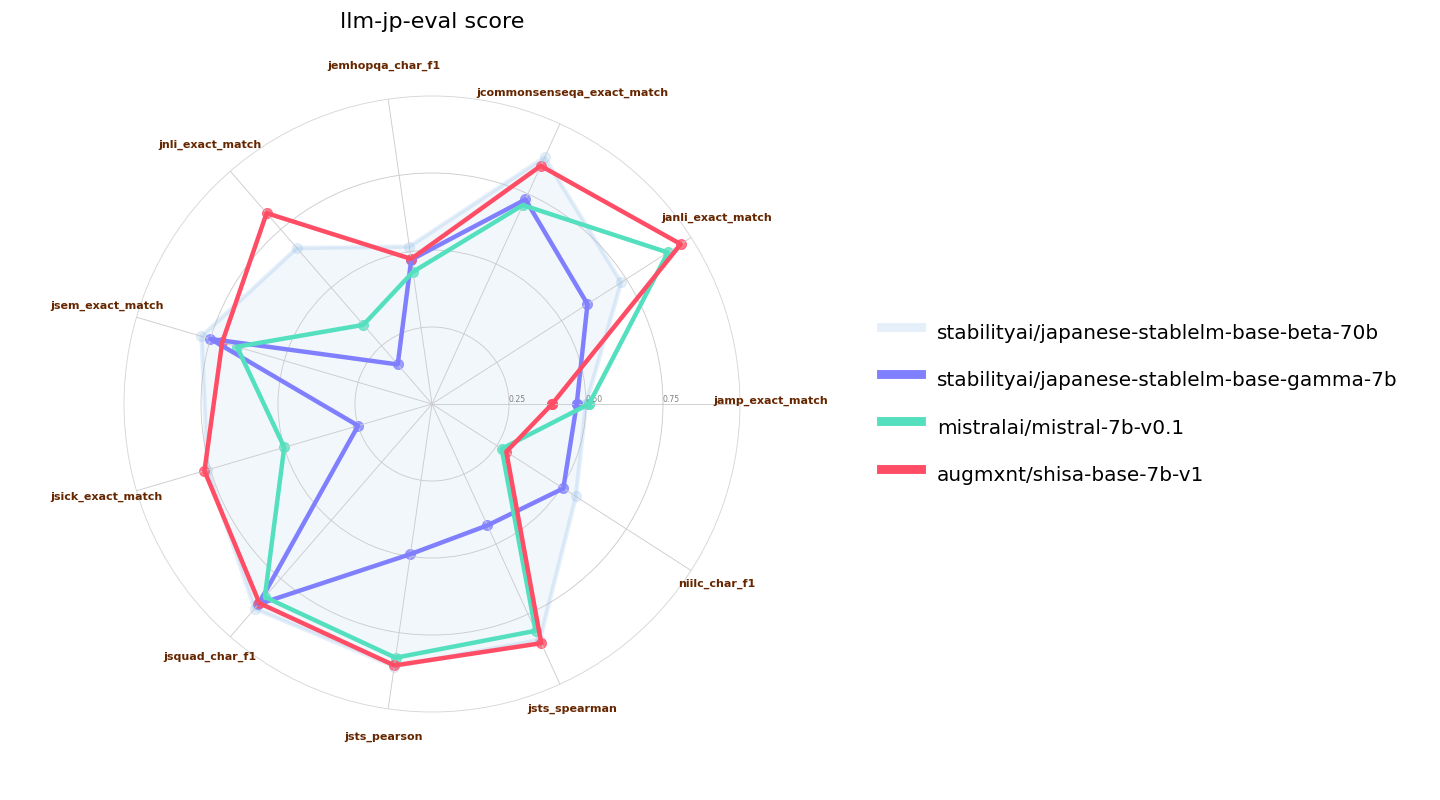
Here we also compare `shisa-base-7b-v1` to other recently-released similar classed (7B parameter) Japanese-tuned models. [ELYZA 7B fast model](https://huggingface.co/elyza/ELYZA-japanese-Llama-2-7b-fast) and [Youri 7B](https://huggingface.co/rinna/youri-7b) are Llama 2 7B models with 18B and 40B of additional pre-training respectively, and [CALM2-7B](https://huggingface.co/cyberagent/calm2-7b) and [llm-jp-13b]() are pretrained models with 1.3T and 300B JA/EN tokens of pre-training:
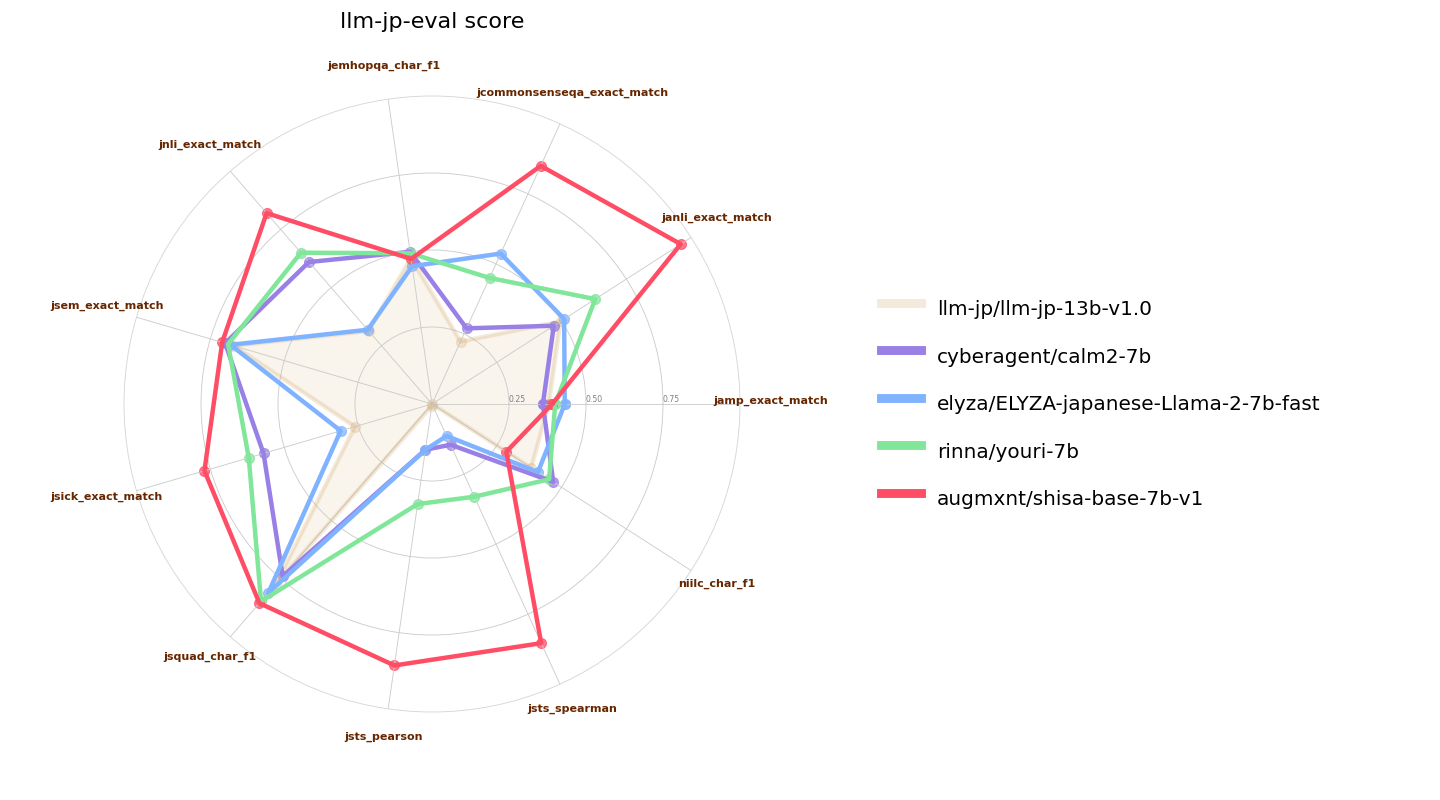
## Tokenizer
As mentioned in the introduction, our tokenizer is an extended version of the Mistral 7B tokenizer, with a vocab size of 120073 and aligned to 120128 for better performance. The remaining unused tokens are assigned as zero-weighted `<|extra_{idx}|>` tokens.
We use the "Fast" tokenizer, which should be the default for `AutoTokenizer`, but if you have problems, make sure to check `tokenizer.is_fast` or to initialize with `use_fast=True`.
Japanese efficiency from sampling 50K items (~85M characters) from the JA subset of the [CulturaX](https://huggingface.co/datasets/uonlp/CulturaX) dataset:
| LLM | Tokenizer | Vocab Size | Avg Char/Token |
|:----------------------------------------------|:----------------------------------------------------|-------------:|-----------------:|
| *Shisa 7B (AUGMXNT)* | *augmxnt/shisa-base-7b-v1* | *120073* | *2.31* |
| OpenCALM (CyberAgent) | cyberagent/open-calm-7b | 52000 | 2.17 |
| Japanese LargeLM (LINE) | line-corporation/japanese-large-lm-3.6b | 51200 | 2.14 |
| CALM2-7B (CyberAgent) | cyberagent/calm2-7b | 65000 | 2.00 |
| Bilingual-GPT-NeoX-4B (Rinna) | rinna/bilingual-gpt-neox-4b | 65536 | 1.88 |
| Japanese StableLM Alpha (Stability AI) | [novelai/nerdstash-tokenizer-v1](https://huggingface.co/NovelAI/nerdstash-tokenizer-v1) | 65535 | 1.85 |
| Japanese-GPT-NeoX-3.6B (Rinna) | rinna/japanese-gpt-neox-3.6b | 32000 | 1.83 |
| Japanese StableLM Beta JAVocab (Stability AI) | stabilityai/japanese-stablelm-base-ja_vocab-beta-7b | 49247 | 1.79 |
| llm-jp-13b (LLM-jp) | [llm-jp/llm-jp-13b-v1.0](https://github.com/llm-jp/llm-jp-tokenizer) | 50570 | 1.65 |
| Japanese-Llama-2-7b-fast (ELYZA) | elyza/ELYZA-japanese-Llama-2-7b-fast | 45043 | 1.53 |
| Qwen 14B (Qwen) | Qwen/Qwen-14B | 151851 | 1.48 |
| weblab-10b (Matsuo Lab) | EleutherAI/gpt-neox-20b | 50254 | 1.00 |
| Japanese StableLM Gamma (Stability AI) | mistralai/Mistral-7B-v0.1 | 32000 | 0.95 |
| Youri 7B (Rinna) | meta-llama/Llama-2-7B | 32000 | 0.88 |
We also test English efficiency using a sampling of 50K items (~177M characters) from the EN subset of the [CulturaX](https://huggingface.co/datasets/uonlp/CulturaX) dataset as a sanity check (and to see how other tokenizers fare):
| LLM | Tokenizer | Vocab Size | Avg Char/Token |
|:----------------------------------------------|:----------------------------------------------------|-------------:|-----------------:|
| Qwen 14B (Qwen) | Qwen/Qwen-14B | 151851 | 4.47 |
| weblab-10b (Matsuo Lab) | EleutherAI/gpt-neox-20b | 50254 | 4.45 |
| Japanese StableLM Alpha (Stability AI) | [novelai/nerdstash-tokenizer-v1](https://huggingface.co/NovelAI/nerdstash-tokenizer-v1) | 65535 | 4.15 |
| *Shisa 7B (AUGMXNT)* | *augmxnt/shisa-base-7b-v1* | *120073* | *4.12* |
| CALM2-7B (CyberAgent) | cyberagent/calm2-7b | 65000 | 4.12 |
| Japanese StableLM Beta JAVocab (Stability AI) | stabilityai/japanese-stablelm-base-ja_vocab-beta-7b | 49247 | 4.01 |
| Japanese StableLM Gamma (Stability AI) | mistralai/Mistral-7B-v0.1 | 32000 | 4.01 |
| Japanese-Llama-2-7b-fast (ELYZA) | elyza/ELYZA-japanese-Llama-2-7b-fast | 45043 | 3.86 |
| Youri 7B (Rinna) | meta-llama/Llama-2-7B | 32000 | 3.86 |
| llm-jp-13b (LLM-jp) | [llm-jp/llm-jp-13b-v1.0](https://github.com/llm-jp/llm-jp-tokenizer) | 50570 | 3.79 |
| OpenCALM (CyberAgent) | cyberagent/open-calm-7b | 52000 | 2.83 |
| Japanese LargeLM (LINE) | line-corporation/japanese-large-lm-3.6b | 51200 | 2.49 |
| Japanese-GPT-NeoX-3.6B (Rinna) | rinna/japanese-gpt-neox-3.6b | 32000 | 2.42 |
| Bilingual-GPT-NeoX-4B (Rinna) | rinna/bilingual-gpt-neox-4b | 65536 | 2.42 |
With our extended tokenizer, we are able to achieve class-leading JA token efficiency without any losses in EN performance vs the base tokenizer. This bears out in our testing, and we often see >2X JA inference speedups with our tokenizer.
## Acknowledgements
Team: [Jon Durbin](https://huggingface.co/jondurbin), [Leonard Lin](https://huggingface.co/leonardlin)
Compute for this model was generously sponsored by [AKA Virtual](https://akavirtual.com/) (Tokyo, Japan).
Thanks to the [ELYZA](https://huggingface.co/elyza) team for publishing the details of their [tokenizer extension approach](https://zenn.dev/elyza/articles/2fd451c944649d) which we used as a starting point for our tokenizer.
And of course, thanks to the [Mistral AI](https://huggingface.co/mistralai) for releasing such a strong base model!
---
*(GPT-4によって翻訳されました)*
# shisa-base-7b-v1
`shisa-base-7b-v1`は、[Mistral 7B](https://huggingface.co/mistralai/Mistral-7B-v0.1)を基にして、主に日本語の事前トレーニングのために追加で80億トークンを追加しています。日本語トークンは、[MADLAD-400](https://github.com/google-research/google-research/tree/master/madlad_400)から取得し、[DSIR](https://github.com/p-lambda/dsir)を使用しています。さらに、MADLAD-400 ENと様々なオープンデータソースからの英語トークンの10%を追加し、壊滅的忘却を防ぐために組み込んでいます。
Mistralのトークン化器を12万トークンまで拡張し、日本語の効率を向上させました。私たちのトークン化器はJAでトークンあたり約2.3文字を実現しており、基本的なMistral 7Bのトークン化器はトークンあたり<1文字です。私たちの実装のコードは、[Shisaリポジトリ](https://github.com/AUGMXNT/shisa)で利用可能です。
このベースモデルは、[Shisa 7B](https://huggingface.co/augmxnt/shisa-7b-v1)、私たちのJA/ENファインチューニングモデル用に作成されましたが、強力なパフォーマンスと効率的なバイリンガルトークン化器の組み合わせが有用であると考え、コミュニティに提供しています。
トレーニングには、16 x A100-40マシンで2,400 A100-40 GPU時間を使用し、[DeepSpeed](https://github.com/microsoft/DeepSpeed) ZeRO-3で行いました。([WandB ログ](https://wandb.ai/jondurbin/mistral-7b-ja-v0.2/runs/rj0lq5v3/overview))
## パフォーマンス
このベースモデルは、以前にリリースされたモデルよりもはるかに少ない追加事前トレーニングで、標準ベンチマークにおいて日本語性能の先頭を切ることができました。これは、より良くキュレーションされた事前トレーニングデータセットの使用によるものかもしれませんが、25億追加JAトークンでのアブレーションでも非常に強力な日本語パフォーマンスを示しました。
私たちは、わずかに変更された[llm-jp-eval](https://github.com/llm-jp/llm-jp-eval)を使用しました(私たちのベースモデルは、プロンプトに`bos_token`を追加する必要があります。他のモデルについても、変更の有無にかかわらずテストし、すべてのモデルでテストされた高い結果を取りました)。ここでは、元のMistral 7Bベースモデルおよび[日本語Stable LM Instruct Gamma 7B](https://huggingface.co/stabilityai/japanese-stablelm-instruct-gamma-7b)(これはMistral 7Bベースであり、追加の1000億JA/ENトークンの事前トレーニングが行われています)と比較します。また、[Japanese-StableLM-Base-Beta-70B](https://huggingface.co/stabilityai/japanese-stablelm-base-beta-70b)(これはLlama 2 70Bで、追加の1000億JA/ENトークンの事前トレーニングが行われています)も参考に含まれています。
![Mistral llm-jp-eval 比較]()
ここでは、`shisa-base-7b-v1`を他の最近リリースされた同じクラス(7Bパラメータ)の日本語チューニングモデルとも比較します。[ELYZA 7B fast model](https://huggingface.co/elyza/ELYZA-japanese-Llama-2-7b-fast)および[Youri 7B](https://huggingface.co/rinna/youri-7b)はLlama 2 7Bモデルで、それぞれ180億と400億の追加事前トレーニングがあります。また、[CALM2-7B](https://huggingface.co/cyberagent/calm2-7b)と[llm-jp-13b]()は、1.3Tおよび3000億JA/ENトークンの事前トレーニングを行ったプリトレーニングモデルです。
![7B llm-jp-eval パフォーマンス]()
## トークン化器
序文で触れたように、私たちのトークン化器はMistral 7Bトークン化器の拡張版で、語彙サイズは120073であり、120128に合わせられています。残りの未使用トークンは、ゼロ重み付けされた`<|extra_{idx}|>`トークンとして割り当てられています。
私たちは「Fast」トークン化器を使用しており、これは`AutoTokenizer`のデフォルトであるべきですが、問題がある場合は`tokenizer.is_fast`をチェックするか、`use_fast=True`で初期化することを確認してください。
[CulturaX](https://huggingface.co/datasets/uonlp/CulturaX)データセットのJAサブセットから50Kアイテム(約8500万文字)をサンプリングした際の日本語効率:
| LLM | トークン化器 | 語彙サイズ | 1トークンあたりの平均文字数 |
|:----------------------------------------------|:----------------------------------------------------|-------------:|-----------------:|
| *Shisa 7B (AUGMXNT)* | *augmxnt/shisa-base-7b-v1* | *120073* | *2.31* |
| OpenCALM (CyberAgent) | cyberagent/open-calm-7b | 52000 | 2.17 |
| Japanese LargeLM (LINE) | line-corporation/japanese-large-lm-3.6b | 51200 | 2.14 |
| CALM2-7B (CyberAgent) | cyberagent/calm2-7b | 65000 | 2.00 |
| Bilingual-GPT-NeoX-4B (Rinna) | rinna/bilingual-gpt-neox-4b | 65536 | 1.88 |
| Japanese StableLM Alpha (Stability AI) | [novelai/nerdstash-tokenizer-v1](https://huggingface.co/NovelAI/nerdstash-tokenizer-v1) | 65535 | 1.85 |
| Japanese-GPT-NeoX-3.6B (Rinna) | rinna/japanese-gpt-neox-3.6b | 32000 | 1.83 |
| Japanese StableLM Beta JAVocab (Stability AI) | stabilityai/japanese-stablelm-base-ja_vocab-beta-7b | 49247 | 1.79 |
| llm-jp-13b (LLM-jp) | [llm-jp/llm-jp-13b-v1.0](https://github.com/llm-jp/llm-jp-tokenizer) | 50570 | 1.65 |
| Japanese-Llama-2-7b-fast (ELYZA) | elyza/ELYZA-japanese-Llama-2-7b-fast | 45043 | 1.53 |
| Qwen 14B (Qwen) | Qwen/Qwen-14B | 151851 | 1.48 |
| weblab-10b (Matsuo Lab) | EleutherAI/gpt-neox-20b | 50254 | 1.00 |
| Japanese StableLM Gamma (Stability AI) | mistralai/Mistral-7B-v0.1 | 32000 | 0.95 |
| Youri 7B (Rinna) | meta-llama/Llama-2-7B | 32000 | 0.88 |
また、[CulturaX](https://huggingface.co/datasets/uonlp/CulturaX)データセットのENサブセットから50Kアイテム(約1億7700万文字)をサンプリングして、英語効率をテストしました。これは健全性チェック(および他のトークン化器のパフォーマンスを確認するため)として行われます:
| LLM | トークン化器 | 語彙サイズ | 1トークンあたりの平均文字数 |
|:----------------------------------------------|:----------------------------------------------------|-------------:|-----------------:|
| Qwen 14B (Qwen) | Qwen/Qwen-14B | 151851 | 4.47 |
| weblab-10b (Matsuo Lab) | EleutherAI/gpt-neox-20b | 50254 | 4.45 |
| Japanese StableLM Alpha (Stability AI) | [novelai/nerdstash-tokenizer-v1](https://huggingface.co/NovelAI/nerdstash-tokenizer-v1) | 65535 | 4.15 |
| *Shisa 7B (AUGMXNT)* | *augmxnt/shisa-base-7b-v1* | *120073* | *4.12* |
| CALM2-7B (CyberAgent) | cyberagent/calm2-7b | 65000 | 4.12 |
| Japanese StableLM Beta JAVocab (Stability AI) | stabilityai/japanese-stablelm-base-ja_vocab-beta-7b | 49247 | 4.01 |
| Japanese StableLM Gamma (Stability AI) | mistralai/Mistral-7B-v0.1 | 32000 | 4.01 |
| Japanese-Llama-2-7b-fast (ELYZA) | elyza/ELYZA-japanese-Llama-2-7b-fast | 45043 | 3.86 |
| Youri 7B (Rinna) | meta-llama/Llama-2-7B | 32000 | 3.86 |
| llm-jp-13b (LLM-jp) | [llm-jp/llm-jp-13b-v1.0](https://github.com/llm-jp/llm-jp-tokenizer) | 50570 | 3.79 |
| OpenCALM (CyberAgent) | cyberagent/open-calm-7b | 52000 | 2.83 |
| Japanese LargeLM (LINE) | line-corporation/japanese-large-lm-3.6b | 51200 | 2.49 |
| Japanese-GPT-NeoX-3.6B (Rinna) | rinna/japanese-gpt-neox-3.6b | 32000 | 2.42 |
| Bilingual-GPT-NeoX-4B (Rinna) | rinna/bilingual-gpt-neox-4b | 65536 | 2.42 |
私たちの拡張トークン化器を使用することで、基本トークン化器と比較してENパフォーマンスの損失なく、クラス最高のJAトークン効率を実現できました。これは私たちのテストで実証されており、トークン化器を使用することでJA推論速度が2倍以上になることがしばしばあります。
## 謝辞
チーム:[Jon Durbin](https://huggingface.co/jondurbin)、[Leonard Lin](https://huggingface.co/leonardlin)
このモデルの計算は、[AKA Virtual](https://akavirtual.com/)(日本、東京)によって寛大に提供されました。
[ELYZA](https://huggingface.co/elyza)チームが公開した[トークン化器拡張アプローチ](https://zenn.dev/elyza/articles/2fd451c944649d)の詳細に感謝します。これは私たちのトークン化器の出発点として使用されました。
もちろん、[Mistral AI](https://huggingface.co/mistralai)による強力なベースモデルのリリースに感謝します!
|
facebook/mask2former-swin-large-cityscapes-panoptic | facebook | 2023-09-07T18:57:04Z | 3,300 | 0 | transformers | [
"transformers",
"pytorch",
"safetensors",
"mask2former",
"vision",
"image-segmentation",
"dataset:coco",
"arxiv:2112.01527",
"arxiv:2107.06278",
"license:other",
"endpoints_compatible",
"region:us"
] | image-segmentation | 2023-01-03T11:42:47Z | ---
license: other
tags:
- vision
- image-segmentation
datasets:
- coco
widget:
- src: http://images.cocodataset.org/val2017/000000039769.jpg
example_title: Cats
- src: http://images.cocodataset.org/val2017/000000039770.jpg
example_title: Castle
---
# Mask2Former
Mask2Former model trained on Cityscapes panoptic segmentation (large-sized version, Swin backbone). It was introduced in the paper [Masked-attention Mask Transformer for Universal Image Segmentation
](https://arxiv.org/abs/2112.01527) and first released in [this repository](https://github.com/facebookresearch/Mask2Former/).
Disclaimer: The team releasing Mask2Former did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
Mask2Former addresses instance, semantic and panoptic segmentation with the same paradigm: by predicting a set of masks and corresponding labels. Hence, all 3 tasks are treated as if they were instance segmentation. Mask2Former outperforms the previous SOTA,
[MaskFormer](https://arxiv.org/abs/2107.06278) both in terms of performance an efficiency by (i) replacing the pixel decoder with a more advanced multi-scale deformable attention Transformer, (ii) adopting a Transformer decoder with masked attention to boost performance without
without introducing additional computation and (iii) improving training efficiency by calculating the loss on subsampled points instead of whole masks.

## Intended uses & limitations
You can use this particular checkpoint for panoptic segmentation. See the [model hub](https://huggingface.co/models?search=mask2former) to look for other
fine-tuned versions on a task that interests you.
### How to use
Here is how to use this model:
```python
import requests
import torch
from PIL import Image
from transformers import AutoImageProcessor, Mask2FormerForUniversalSegmentation
# load Mask2Former fine-tuned on Cityscapes panoptic segmentation
processor = AutoImageProcessor.from_pretrained("facebook/mask2former-swin-large-cityscapes-panoptic")
model = Mask2FormerForUniversalSegmentation.from_pretrained("facebook/mask2former-swin-large-cityscapes-panoptic")
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
inputs = processor(images=image, return_tensors="pt")
with torch.no_grad():
outputs = model(**inputs)
# model predicts class_queries_logits of shape `(batch_size, num_queries)`
# and masks_queries_logits of shape `(batch_size, num_queries, height, width)`
class_queries_logits = outputs.class_queries_logits
masks_queries_logits = outputs.masks_queries_logits
# you can pass them to processor for postprocessing
result = processor.post_process_panoptic_segmentation(outputs, target_sizes=[image.size[::-1]])[0]
# we refer to the demo notebooks for visualization (see "Resources" section in the Mask2Former docs)
predicted_panoptic_map = result["segmentation"]
```
For more code examples, we refer to the [documentation](https://huggingface.co/docs/transformers/master/en/model_doc/mask2former). |
TheBloke/CodeLlama-13B-Instruct-fp16 | TheBloke | 2023-08-25T11:13:46Z | 3,300 | 29 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"llama-2",
"codellama",
"custom_code",
"license:llama2",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2023-08-24T16:20:49Z | ---
license: llama2
tags:
- llama-2
- codellama
---
<!-- header start -->
<!-- 200823 -->
<div style="width: auto; margin-left: auto; margin-right: auto">
<img src="https://i.imgur.com/EBdldam.jpg" alt="TheBlokeAI" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</div>
<div style="display: flex; justify-content: space-between; width: 100%;">
<div style="display: flex; flex-direction: column; align-items: flex-start;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://discord.gg/theblokeai">Chat & support: TheBloke's Discord server</a></p>
</div>
<div style="display: flex; flex-direction: column; align-items: flex-end;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://www.patreon.com/TheBlokeAI">Want to contribute? TheBloke's Patreon page</a></p>
</div>
</div>
<div style="text-align:center; margin-top: 0em; margin-bottom: 0em"><p style="margin-top: 0.25em; margin-bottom: 0em;">TheBloke's LLM work is generously supported by a grant from <a href="https://a16z.com">andreessen horowitz (a16z)</a></p></div>
<hr style="margin-top: 1.0em; margin-bottom: 1.0em;">
<!-- header end -->
# CodeLlama 13B-Instruct fp16
- Model creator: [Meta](https://ai.meta.com/llama/)
## Description
This is Transformers/HF format fp16 weights for CodeLlama 13B-Instruct. It is the result of downloading CodeLlama 13B-Instruct from [Meta](https://ai.meta.com/blog/code-llama-large-language-model-coding/) and converting to HF using `convert_llama_weights_to_hf.py`.
Quantisations will be coming shortly.
Please note that due to a change in the RoPE Theta value, for correct results you must load these FP16 models with `trust_remote_code=True`
Credit to @emozilla for creating the necessary modelling code to achieve this!
## Prompt template: TBC
<!-- footer start -->
<!-- 200823 -->
## Discord
For further support, and discussions on these models and AI in general, join us at:
[TheBloke AI's Discord server](https://discord.gg/theblokeai)
## Thanks, and how to contribute.
Thanks to the [chirper.ai](https://chirper.ai) team!
I've had a lot of people ask if they can contribute. I enjoy providing models and helping people, and would love to be able to spend even more time doing it, as well as expanding into new projects like fine tuning/training.
If you're able and willing to contribute it will be most gratefully received and will help me to keep providing more models, and to start work on new AI projects.
Donaters will get priority support on any and all AI/LLM/model questions and requests, access to a private Discord room, plus other benefits.
* Patreon: https://patreon.com/TheBlokeAI
* Ko-Fi: https://ko-fi.com/TheBlokeAI
**Special thanks to**: Aemon Algiz.
**Patreon special mentions**: Sam, theTransient, Jonathan Leane, Steven Wood, webtim, Johann-Peter Hartmann, Geoffrey Montalvo, Gabriel Tamborski, Willem Michiel, John Villwock, Derek Yates, Mesiah Bishop, Eugene Pentland, Pieter, Chadd, Stephen Murray, Daniel P. Andersen, terasurfer, Brandon Frisco, Thomas Belote, Sid, Nathan LeClaire, Magnesian, Alps Aficionado, Stanislav Ovsiannikov, Alex, Joseph William Delisle, Nikolai Manek, Michael Davis, Junyu Yang, K, J, Spencer Kim, Stefan Sabev, Olusegun Samson, transmissions 11, Michael Levine, Cory Kujawski, Rainer Wilmers, zynix, Kalila, Luke @flexchar, Ajan Kanaga, Mandus, vamX, Ai Maven, Mano Prime, Matthew Berman, subjectnull, Vitor Caleffi, Clay Pascal, biorpg, alfie_i, 阿明, Jeffrey Morgan, ya boyyy, Raymond Fosdick, knownsqashed, Olakabola, Leonard Tan, ReadyPlayerEmma, Enrico Ros, Dave, Talal Aujan, Illia Dulskyi, Sean Connelly, senxiiz, Artur Olbinski, Elle, Raven Klaugh, Fen Risland, Deep Realms, Imad Khwaja, Fred von Graf, Will Dee, usrbinkat, SuperWojo, Alexandros Triantafyllidis, Swaroop Kallakuri, Dan Guido, John Detwiler, Pedro Madruga, Iucharbius, Viktor Bowallius, Asp the Wyvern, Edmond Seymore, Trenton Dambrowitz, Space Cruiser, Spiking Neurons AB, Pyrater, LangChain4j, Tony Hughes, Kacper Wikieł, Rishabh Srivastava, David Ziegler, Luke Pendergrass, Andrey, Gabriel Puliatti, Lone Striker, Sebastain Graf, Pierre Kircher, Randy H, NimbleBox.ai, Vadim, danny, Deo Leter
Thank you to all my generous patrons and donaters!
And thank you again to a16z for their generous grant.
<!-- footer end -->
# Original model card
# Code Llama
## **Model Details**
**Model Developers** Meta AI
**Variations** Code Llama comes in three model sizes, and three variants:
1) Code Llama: our base models designed for general code synthesis and understanding
2) Code Llama - Python: designed specifically for Python
3) Code Llama - Instruct: for instruction following and safer deployment
All variants are available in sizes of 7B, 13B and 34B parameters.
**Input** Models input text only.
**Output** Models output text only.
**Model Architecture** Code Llama and its variants are autoregressive language models using optimized transformer architectures. Code Llama 7B and 13B additionally support infilling text generation. All models were fine-tuned with up to 16K tokens, and support up to 100K tokens at inference time.
**Model Dates** Code Llama and its variants have been trained between January 2023 and July 2023.
**Status** This is a static model trained on an offline dataset. Future versions of Code Llama - Instruct will be released as we improve model safety with community feedback.
**Licence** A custom commercial license is available at: [https://ai.meta.com/resources/models-and-libraries/llama-downloads/](https://ai.meta.com/resources/models-and-libraries/llama-downloads/).
**Research Paper** More information can be found in the paper "[Code Llama: Open Foundation Models for Code](https://ai.meta.com/research/publications/code-llama-open-foundation-models-for-code/)".
**Where to send comments** Instructions on how to provide feedback or comments on the model can be found in the model [README](README.md), or by opening an issue in the GitHub repository ([https://github.com/facebookresearch/codellama/](https://github.com/facebookresearch/codellama/)).
## **Intended Use**
**Intended Use Cases** Code Llama and its variants is intended for commercial and research use in English and relevant programming languages. The base model Code Llama can be adapted for a variety of code synthesis and understanding tasks, Code Llama - Python is designed specifically to handle the Python programming language, and Code Llama - Instruct is intended to be safer to use for code assistant and generation applications.
**Out-of-Scope Uses** Use in any manner that violates applicable laws or regulations (including trade compliance laws). Use in languages other than English. Use in any other way that is prohibited by the Acceptable Use Policy and Licensing Agreement for Code Llama and its variants.
## **Hardware and Software**
**Training Factors**
We used custom training libraries. The training and fine-tuning of the released models have been performed Meta’s Research Super Cluster.
**Carbon Footprint** In aggregate, training all 9 Code Llama models required 400K GPU hours of computation on hardware of type A100-80GB (TDP of 350-400W). Estimated total emissions were 65.3 tCO2eq, 100% of which were offset by Meta’s sustainability program.
**Training data**
All experiments reported here and the released models have been trained and fine-tuned using the same data as Llama 2 with different weights (see Section 2 and Table 1 in the [research paper](https://ai.meta.com/research/publications/code-llama-open-foundation-models-for-code/) for details).
Code Llama - Instruct uses additional instruction fine-tuning data.
**Evaluation Results**
See evaluations for the main models and detailed ablations in Section 3 and safety evaluations in Section 4 of the research paper.
## **Ethical Considerations and Limitations**
Code Llama and its variants are a new technology that carries risks with use. Testing conducted to date has been in English, and has not covered, nor could it cover all scenarios. For these reasons, as with all LLMs, Code Llama’s potential outputs cannot be predicted in advance, and the model may in some instances produce inaccurate or objectionable responses to user prompts. Therefore, before deploying any applications of Code Llama, developers should perform safety testing and tuning tailored to their specific applications of the model.
Please see the Responsible Use Guide available available at [https://ai.meta.com/llama/responsible-user-guide](https://ai.meta.com/llama/responsible-user-guide).
|
mradermacher/Autolycus-Mistral_7B-GGUF | mradermacher | 2024-06-11T14:32:48Z | 3,300 | 0 | transformers | [
"transformers",
"gguf",
"mistral",
"instruct",
"finetune",
"chatml",
"gpt4",
"en",
"base_model:FPHam/Autolycus-Mistral_7B",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2024-06-11T12:06:23Z | ---
base_model: FPHam/Autolycus-Mistral_7B
language:
- en
library_name: transformers
license: apache-2.0
quantized_by: mradermacher
tags:
- mistral
- instruct
- finetune
- chatml
- gpt4
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
static quants of https://huggingface.co/FPHam/Autolycus-Mistral_7B
<!-- provided-files -->
weighted/imatrix quants are available at https://huggingface.co/mradermacher/Autolycus-Mistral_7B-i1-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/Autolycus-Mistral_7B-GGUF/resolve/main/Autolycus-Mistral_7B.Q2_K.gguf) | Q2_K | 2.8 | |
| [GGUF](https://huggingface.co/mradermacher/Autolycus-Mistral_7B-GGUF/resolve/main/Autolycus-Mistral_7B.IQ3_XS.gguf) | IQ3_XS | 3.1 | |
| [GGUF](https://huggingface.co/mradermacher/Autolycus-Mistral_7B-GGUF/resolve/main/Autolycus-Mistral_7B.Q3_K_S.gguf) | Q3_K_S | 3.3 | |
| [GGUF](https://huggingface.co/mradermacher/Autolycus-Mistral_7B-GGUF/resolve/main/Autolycus-Mistral_7B.IQ3_S.gguf) | IQ3_S | 3.3 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/Autolycus-Mistral_7B-GGUF/resolve/main/Autolycus-Mistral_7B.IQ3_M.gguf) | IQ3_M | 3.4 | |
| [GGUF](https://huggingface.co/mradermacher/Autolycus-Mistral_7B-GGUF/resolve/main/Autolycus-Mistral_7B.Q3_K_M.gguf) | Q3_K_M | 3.6 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/Autolycus-Mistral_7B-GGUF/resolve/main/Autolycus-Mistral_7B.Q3_K_L.gguf) | Q3_K_L | 3.9 | |
| [GGUF](https://huggingface.co/mradermacher/Autolycus-Mistral_7B-GGUF/resolve/main/Autolycus-Mistral_7B.IQ4_XS.gguf) | IQ4_XS | 4.0 | |
| [GGUF](https://huggingface.co/mradermacher/Autolycus-Mistral_7B-GGUF/resolve/main/Autolycus-Mistral_7B.Q4_K_S.gguf) | Q4_K_S | 4.2 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Autolycus-Mistral_7B-GGUF/resolve/main/Autolycus-Mistral_7B.Q4_K_M.gguf) | Q4_K_M | 4.5 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Autolycus-Mistral_7B-GGUF/resolve/main/Autolycus-Mistral_7B.Q5_K_S.gguf) | Q5_K_S | 5.1 | |
| [GGUF](https://huggingface.co/mradermacher/Autolycus-Mistral_7B-GGUF/resolve/main/Autolycus-Mistral_7B.Q5_K_M.gguf) | Q5_K_M | 5.2 | |
| [GGUF](https://huggingface.co/mradermacher/Autolycus-Mistral_7B-GGUF/resolve/main/Autolycus-Mistral_7B.Q6_K.gguf) | Q6_K | 6.0 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/Autolycus-Mistral_7B-GGUF/resolve/main/Autolycus-Mistral_7B.Q8_0.gguf) | Q8_0 | 7.8 | fast, best quality |
| [GGUF](https://huggingface.co/mradermacher/Autolycus-Mistral_7B-GGUF/resolve/main/Autolycus-Mistral_7B.f16.gguf) | f16 | 14.6 | 16 bpw, overkill |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
ZeroWw/Mistroll-7B-v2.2-GGUF | ZeroWw | 2024-06-21T00:54:51Z | 3,300 | 0 | null | [
"gguf",
"en",
"license:mit",
"region:us"
] | null | 2024-06-21T00:42:21Z |
---
license: mit
language:
- en
---
My own (ZeroWw) quantizations.
output and embed tensors quantized to f16.
all other tensors quantized to q5_k or q6_k.
Result:
both f16.q6 and f16.q5 are smaller than q8_0 standard quantization
and they perform as well as the pure f16.
|
TheBloke/CodeLlama-34B-Python-fp16 | TheBloke | 2023-08-25T11:13:50Z | 3,299 | 12 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"llama-2",
"codellama",
"custom_code",
"license:llama2",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2023-08-24T20:36:11Z | ---
license: llama2
tags:
- llama-2
- codellama
---
<!-- header start -->
<!-- 200823 -->
<div style="width: auto; margin-left: auto; margin-right: auto">
<img src="https://i.imgur.com/EBdldam.jpg" alt="TheBlokeAI" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</div>
<div style="display: flex; justify-content: space-between; width: 100%;">
<div style="display: flex; flex-direction: column; align-items: flex-start;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://discord.gg/theblokeai">Chat & support: TheBloke's Discord server</a></p>
</div>
<div style="display: flex; flex-direction: column; align-items: flex-end;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://www.patreon.com/TheBlokeAI">Want to contribute? TheBloke's Patreon page</a></p>
</div>
</div>
<div style="text-align:center; margin-top: 0em; margin-bottom: 0em"><p style="margin-top: 0.25em; margin-bottom: 0em;">TheBloke's LLM work is generously supported by a grant from <a href="https://a16z.com">andreessen horowitz (a16z)</a></p></div>
<hr style="margin-top: 1.0em; margin-bottom: 1.0em;">
<!-- header end -->
# CodeLlama 34B-Python fp16
- Model creator: [Meta](https://ai.meta.com/llama/)
## Description
This is Transformers/HF format fp16 weights for CodeLlama 34B-Python. It is the result of downloading CodeLlama 34B-Python from [Meta](https://ai.meta.com/blog/code-llama-large-language-model-coding/) and converting to HF using `convert_llama_weights_to_hf.py`.
Quantisations will be coming shortly.
Please note that due to a change in the RoPE Theta value, for correct results you must load these FP16 models with `trust_remote_code=True`
Credit to @emozilla for creating the necessary modelling code to achieve this!
## Prompt template: TBC
<!-- footer start -->
<!-- 200823 -->
## Discord
For further support, and discussions on these models and AI in general, join us at:
[TheBloke AI's Discord server](https://discord.gg/theblokeai)
## Thanks, and how to contribute.
Thanks to the [chirper.ai](https://chirper.ai) team!
I've had a lot of people ask if they can contribute. I enjoy providing models and helping people, and would love to be able to spend even more time doing it, as well as expanding into new projects like fine tuning/training.
If you're able and willing to contribute it will be most gratefully received and will help me to keep providing more models, and to start work on new AI projects.
Donaters will get priority support on any and all AI/LLM/model questions and requests, access to a private Discord room, plus other benefits.
* Patreon: https://patreon.com/TheBlokeAI
* Ko-Fi: https://ko-fi.com/TheBlokeAI
**Special thanks to**: Aemon Algiz.
**Patreon special mentions**: Sam, theTransient, Jonathan Leane, Steven Wood, webtim, Johann-Peter Hartmann, Geoffrey Montalvo, Gabriel Tamborski, Willem Michiel, John Villwock, Derek Yates, Mesiah Bishop, Eugene Pentland, Pieter, Chadd, Stephen Murray, Daniel P. Andersen, terasurfer, Brandon Frisco, Thomas Belote, Sid, Nathan LeClaire, Magnesian, Alps Aficionado, Stanislav Ovsiannikov, Alex, Joseph William Delisle, Nikolai Manek, Michael Davis, Junyu Yang, K, J, Spencer Kim, Stefan Sabev, Olusegun Samson, transmissions 11, Michael Levine, Cory Kujawski, Rainer Wilmers, zynix, Kalila, Luke @flexchar, Ajan Kanaga, Mandus, vamX, Ai Maven, Mano Prime, Matthew Berman, subjectnull, Vitor Caleffi, Clay Pascal, biorpg, alfie_i, 阿明, Jeffrey Morgan, ya boyyy, Raymond Fosdick, knownsqashed, Olakabola, Leonard Tan, ReadyPlayerEmma, Enrico Ros, Dave, Talal Aujan, Illia Dulskyi, Sean Connelly, senxiiz, Artur Olbinski, Elle, Raven Klaugh, Fen Risland, Deep Realms, Imad Khwaja, Fred von Graf, Will Dee, usrbinkat, SuperWojo, Alexandros Triantafyllidis, Swaroop Kallakuri, Dan Guido, John Detwiler, Pedro Madruga, Iucharbius, Viktor Bowallius, Asp the Wyvern, Edmond Seymore, Trenton Dambrowitz, Space Cruiser, Spiking Neurons AB, Pyrater, LangChain4j, Tony Hughes, Kacper Wikieł, Rishabh Srivastava, David Ziegler, Luke Pendergrass, Andrey, Gabriel Puliatti, Lone Striker, Sebastain Graf, Pierre Kircher, Randy H, NimbleBox.ai, Vadim, danny, Deo Leter
Thank you to all my generous patrons and donaters!
And thank you again to a16z for their generous grant.
<!-- footer end -->
# Original model card
# Code Llama
## **Model Details**
**Model Developers** Meta AI
**Variations** Code Llama comes in three model sizes, and three variants:
1) Code Llama: our base models designed for general code synthesis and understanding
2) Code Llama - Python: designed specifically for Python
3) Code Llama - Instruct: for instruction following and safer deployment
All variants are available in sizes of 7B, 13B and 34B parameters.
**Input** Models input text only.
**Output** Models output text only.
**Model Architecture** Code Llama and its variants are autoregressive language models using optimized transformer architectures. Code Llama 7B and 13B additionally support infilling text generation. All models were fine-tuned with up to 16K tokens, and support up to 100K tokens at inference time.
**Model Dates** Code Llama and its variants have been trained between January 2023 and July 2023.
**Status** This is a static model trained on an offline dataset. Future versions of Code Llama - Instruct will be released as we improve model safety with community feedback.
**Licence** A custom commercial license is available at: [https://ai.meta.com/resources/models-and-libraries/llama-downloads/](https://ai.meta.com/resources/models-and-libraries/llama-downloads/).
**Research Paper** More information can be found in the paper "[Code Llama: Open Foundation Models for Code](https://ai.meta.com/research/publications/code-llama-open-foundation-models-for-code/)".
**Where to send comments** Instructions on how to provide feedback or comments on the model can be found in the model [README](README.md), or by opening an issue in the GitHub repository ([https://github.com/facebookresearch/codellama/](https://github.com/facebookresearch/codellama/)).
## **Intended Use**
**Intended Use Cases** Code Llama and its variants is intended for commercial and research use in English and relevant programming languages. The base model Code Llama can be adapted for a variety of code synthesis and understanding tasks, Code Llama - Python is designed specifically to handle the Python programming language, and Code Llama - Instruct is intended to be safer to use for code assistant and generation applications.
**Out-of-Scope Uses** Use in any manner that violates applicable laws or regulations (including trade compliance laws). Use in languages other than English. Use in any other way that is prohibited by the Acceptable Use Policy and Licensing Agreement for Code Llama and its variants.
## **Hardware and Software**
**Training Factors**
We used custom training libraries. The training and fine-tuning of the released models have been performed Meta’s Research Super Cluster.
**Carbon Footprint** In aggregate, training all 9 Code Llama models required 400K GPU hours of computation on hardware of type A100-80GB (TDP of 350-400W). Estimated total emissions were 65.3 tCO2eq, 100% of which were offset by Meta’s sustainability program.
**Training data**
All experiments reported here and the released models have been trained and fine-tuned using the same data as Llama 2 with different weights (see Section 2 and Table 1 in the [research paper](https://ai.meta.com/research/publications/code-llama-open-foundation-models-for-code/) for details).
Code Llama - Instruct uses additional instruction fine-tuning data.
**Evaluation Results**
See evaluations for the main models and detailed ablations in Section 3 and safety evaluations in Section 4 of the research paper.
## **Ethical Considerations and Limitations**
Code Llama and its variants are a new technology that carries risks with use. Testing conducted to date has been in English, and has not covered, nor could it cover all scenarios. For these reasons, as with all LLMs, Code Llama’s potential outputs cannot be predicted in advance, and the model may in some instances produce inaccurate or objectionable responses to user prompts. Therefore, before deploying any applications of Code Llama, developers should perform safety testing and tuning tailored to their specific applications of the model.
Please see the Responsible Use Guide available available at [https://ai.meta.com/llama/responsible-user-guide](https://ai.meta.com/llama/responsible-user-guide).
|
mradermacher/Miss-Claude-7b-GGUF | mradermacher | 2024-05-30T04:52:41Z | 3,299 | 0 | transformers | [
"transformers",
"gguf",
"mergekit",
"merge",
"en",
"base_model:CoprolaliacPress/Miss-Claude-7b",
"endpoints_compatible",
"region:us"
] | null | 2024-05-30T04:26:58Z | ---
base_model: CoprolaliacPress/Miss-Claude-7b
language:
- en
library_name: transformers
quantized_by: mradermacher
tags:
- mergekit
- merge
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
static quants of https://huggingface.co/CoprolaliacPress/Miss-Claude-7b
<!-- provided-files -->
weighted/imatrix quants seem not to be available (by me) at this time. If they do not show up a week or so after the static ones, I have probably not planned for them. Feel free to request them by opening a Community Discussion.
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/Miss-Claude-7b-GGUF/resolve/main/Miss-Claude-7b.Q2_K.gguf) | Q2_K | 2.8 | |
| [GGUF](https://huggingface.co/mradermacher/Miss-Claude-7b-GGUF/resolve/main/Miss-Claude-7b.IQ3_XS.gguf) | IQ3_XS | 3.1 | |
| [GGUF](https://huggingface.co/mradermacher/Miss-Claude-7b-GGUF/resolve/main/Miss-Claude-7b.Q3_K_S.gguf) | Q3_K_S | 3.3 | |
| [GGUF](https://huggingface.co/mradermacher/Miss-Claude-7b-GGUF/resolve/main/Miss-Claude-7b.IQ3_S.gguf) | IQ3_S | 3.3 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/Miss-Claude-7b-GGUF/resolve/main/Miss-Claude-7b.IQ3_M.gguf) | IQ3_M | 3.4 | |
| [GGUF](https://huggingface.co/mradermacher/Miss-Claude-7b-GGUF/resolve/main/Miss-Claude-7b.Q3_K_M.gguf) | Q3_K_M | 3.6 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/Miss-Claude-7b-GGUF/resolve/main/Miss-Claude-7b.Q3_K_L.gguf) | Q3_K_L | 3.9 | |
| [GGUF](https://huggingface.co/mradermacher/Miss-Claude-7b-GGUF/resolve/main/Miss-Claude-7b.IQ4_XS.gguf) | IQ4_XS | 4.0 | |
| [GGUF](https://huggingface.co/mradermacher/Miss-Claude-7b-GGUF/resolve/main/Miss-Claude-7b.Q4_K_S.gguf) | Q4_K_S | 4.2 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Miss-Claude-7b-GGUF/resolve/main/Miss-Claude-7b.Q4_K_M.gguf) | Q4_K_M | 4.5 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Miss-Claude-7b-GGUF/resolve/main/Miss-Claude-7b.Q5_K_S.gguf) | Q5_K_S | 5.1 | |
| [GGUF](https://huggingface.co/mradermacher/Miss-Claude-7b-GGUF/resolve/main/Miss-Claude-7b.Q5_K_M.gguf) | Q5_K_M | 5.2 | |
| [GGUF](https://huggingface.co/mradermacher/Miss-Claude-7b-GGUF/resolve/main/Miss-Claude-7b.Q6_K.gguf) | Q6_K | 6.0 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/Miss-Claude-7b-GGUF/resolve/main/Miss-Claude-7b.Q8_0.gguf) | Q8_0 | 7.8 | fast, best quality |
| [GGUF](https://huggingface.co/mradermacher/Miss-Claude-7b-GGUF/resolve/main/Miss-Claude-7b.f16.gguf) | f16 | 14.6 | 16 bpw, overkill |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
simoneteglia/xlm-roberta-europarl-language-detection | simoneteglia | 2024-03-28T10:27:05Z | 3,298 | 2 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"safetensors",
"xlm-roberta",
"text-classification",
"generated_from_trainer",
"en",
"it",
"de",
"nl",
"lt",
"es",
"sv",
"el",
"pl",
"sl",
"hu",
"bg",
"fi",
"pt",
"sk",
"da",
"cs",
"et",
"lv",
"ro",
"fr",
"dataset:simoneteglia/europarl_for_language_detection_10k",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2023-06-02T16:22:30Z | ---
license: mit
tags:
- generated_from_trainer
metrics:
- accuracy
- f1
model-index:
- name: model
results: []
datasets:
- simoneteglia/europarl_for_language_detection_10k
language:
- en
- it
- de
- nl
- lt
- es
- sv
- el
- pl
- sl
- hu
- bg
- fi
- pt
- sk
- da
- cs
- et
- lv
- ro
- fr
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# model
This model is a fine-tuned version of [xlm-roberta-base](https://huggingface.co/xlm-roberta-base) on the [Europarl language detection](https://huggingface.co/datasets/simoneteglia/europarl_for_language_detection_10k) dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0237
- Accuracy: 0.9967
- F1: 0.9967
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 256
- eval_batch_size: 512
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| No log | 1.0 | 821 | 0.0270 | 0.9965 | 0.9965 |
| 0.2372 | 2.0 | 1642 | 0.0237 | 0.9967 | 0.9967 |
### Framework versions
- Transformers 4.28.0
- Pytorch 2.0.0
- Datasets 2.1.0
- Tokenizers 0.13.3
|
timm/fastvit_t12.apple_in1k | timm | 2023-08-23T20:56:22Z | 3,298 | 0 | timm | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"arxiv:2303.14189",
"license:other",
"region:us"
] | image-classification | 2023-08-23T20:56:16Z | ---
tags:
- image-classification
- timm
library_name: timm
license: other
datasets:
- imagenet-1k
---
# Model card for fastvit_t12.apple_in1k
A FastViT image classification model. Trained on ImageNet-1k by paper authors.
Please observe [original license](https://github.com/apple/ml-fastvit/blob/8af5928238cab99c45f64fc3e4e7b1516b8224ba/LICENSE).
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 7.6
- GMACs: 1.4
- Activations (M): 12.4
- Image size: 256 x 256
- **Papers:**
- FastViT: A Fast Hybrid Vision Transformer using Structural Reparameterization: https://arxiv.org/abs/2303.14189
- **Original:** https://github.com/apple/ml-fastvit
- **Dataset:** ImageNet-1k
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('fastvit_t12.apple_in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'fastvit_t12.apple_in1k',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g.:
# torch.Size([1, 64, 64, 64])
# torch.Size([1, 128, 32, 32])
# torch.Size([1, 256, 16, 16])
# torch.Size([1, 512, 8, 8])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'fastvit_t12.apple_in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 512, 8, 8) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Citation
```bibtex
@inproceedings{vasufastvit2023,
author = {Pavan Kumar Anasosalu Vasu and James Gabriel and Jeff Zhu and Oncel Tuzel and Anurag Ranjan},
title = {FastViT: A Fast Hybrid Vision Transformer using Structural Reparameterization},
booktitle={Proceedings of the IEEE/CVF International Conference on Computer Vision},
year = {2023}
}
```
|
XSY/albert-base-v2-fakenews-discriminator | XSY | 2021-11-16T13:11:50Z | 3,297 | 1 | transformers | [
"transformers",
"pytorch",
"albert",
"text-classification",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2022-03-02T23:29:05Z | ---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: albert-base-v2-fakenews-discriminator
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# albert-base-v2-fakenews-discriminator
The dataset: Fake and real news dataset https://www.kaggle.com/clmentbisaillon/fake-and-real-news-dataset
I use title and label to train the classifier
label_0 : Fake news
label_1 : Real news
This model is a fine-tuned version of [albert-base-v2](https://huggingface.co/albert-base-v2) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0910
- Accuracy: 0.9758
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 1
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.0452 | 1.0 | 1768 | 0.0910 | 0.9758 |
### Framework versions
- Transformers 4.12.3
- Pytorch 1.10.0+cu111
- Datasets 1.15.1
- Tokenizers 0.10.3
|
mradermacher/llama-3-spicy-abliterated-stella-8B-i1-GGUF | mradermacher | 2024-06-01T16:29:06Z | 3,296 | 2 | transformers | [
"transformers",
"gguf",
"mergekit",
"merge",
"en",
"base_model:nbeerbower/llama-3-spicy-abliterated-stella-8B",
"license:llama3",
"endpoints_compatible",
"region:us"
] | null | 2024-05-31T07:24:04Z | ---
base_model: nbeerbower/llama-3-spicy-abliterated-stella-8B
language:
- en
library_name: transformers
license: llama3
quantized_by: mradermacher
tags:
- mergekit
- merge
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: nicoboss -->
weighted/imatrix quants of https://huggingface.co/nbeerbower/llama-3-spicy-abliterated-stella-8B
<!-- provided-files -->
static quants are available at https://huggingface.co/mradermacher/llama-3-spicy-abliterated-stella-8B-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/llama-3-spicy-abliterated-stella-8B-i1-GGUF/resolve/main/llama-3-spicy-abliterated-stella-8B.i1-IQ1_S.gguf) | i1-IQ1_S | 2.1 | for the desperate |
| [GGUF](https://huggingface.co/mradermacher/llama-3-spicy-abliterated-stella-8B-i1-GGUF/resolve/main/llama-3-spicy-abliterated-stella-8B.i1-IQ1_M.gguf) | i1-IQ1_M | 2.3 | mostly desperate |
| [GGUF](https://huggingface.co/mradermacher/llama-3-spicy-abliterated-stella-8B-i1-GGUF/resolve/main/llama-3-spicy-abliterated-stella-8B.i1-IQ2_XXS.gguf) | i1-IQ2_XXS | 2.5 | |
| [GGUF](https://huggingface.co/mradermacher/llama-3-spicy-abliterated-stella-8B-i1-GGUF/resolve/main/llama-3-spicy-abliterated-stella-8B.i1-IQ2_XS.gguf) | i1-IQ2_XS | 2.7 | |
| [GGUF](https://huggingface.co/mradermacher/llama-3-spicy-abliterated-stella-8B-i1-GGUF/resolve/main/llama-3-spicy-abliterated-stella-8B.i1-IQ2_S.gguf) | i1-IQ2_S | 2.9 | |
| [GGUF](https://huggingface.co/mradermacher/llama-3-spicy-abliterated-stella-8B-i1-GGUF/resolve/main/llama-3-spicy-abliterated-stella-8B.i1-IQ2_M.gguf) | i1-IQ2_M | 3.0 | |
| [GGUF](https://huggingface.co/mradermacher/llama-3-spicy-abliterated-stella-8B-i1-GGUF/resolve/main/llama-3-spicy-abliterated-stella-8B.i1-Q2_K.gguf) | i1-Q2_K | 3.3 | IQ3_XXS probably better |
| [GGUF](https://huggingface.co/mradermacher/llama-3-spicy-abliterated-stella-8B-i1-GGUF/resolve/main/llama-3-spicy-abliterated-stella-8B.i1-IQ3_XXS.gguf) | i1-IQ3_XXS | 3.4 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/llama-3-spicy-abliterated-stella-8B-i1-GGUF/resolve/main/llama-3-spicy-abliterated-stella-8B.i1-IQ3_XS.gguf) | i1-IQ3_XS | 3.6 | |
| [GGUF](https://huggingface.co/mradermacher/llama-3-spicy-abliterated-stella-8B-i1-GGUF/resolve/main/llama-3-spicy-abliterated-stella-8B.i1-Q3_K_S.gguf) | i1-Q3_K_S | 3.8 | IQ3_XS probably better |
| [GGUF](https://huggingface.co/mradermacher/llama-3-spicy-abliterated-stella-8B-i1-GGUF/resolve/main/llama-3-spicy-abliterated-stella-8B.i1-IQ3_S.gguf) | i1-IQ3_S | 3.8 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/llama-3-spicy-abliterated-stella-8B-i1-GGUF/resolve/main/llama-3-spicy-abliterated-stella-8B.i1-IQ3_M.gguf) | i1-IQ3_M | 3.9 | |
| [GGUF](https://huggingface.co/mradermacher/llama-3-spicy-abliterated-stella-8B-i1-GGUF/resolve/main/llama-3-spicy-abliterated-stella-8B.i1-Q3_K_M.gguf) | i1-Q3_K_M | 4.1 | IQ3_S probably better |
| [GGUF](https://huggingface.co/mradermacher/llama-3-spicy-abliterated-stella-8B-i1-GGUF/resolve/main/llama-3-spicy-abliterated-stella-8B.i1-Q3_K_L.gguf) | i1-Q3_K_L | 4.4 | IQ3_M probably better |
| [GGUF](https://huggingface.co/mradermacher/llama-3-spicy-abliterated-stella-8B-i1-GGUF/resolve/main/llama-3-spicy-abliterated-stella-8B.i1-IQ4_XS.gguf) | i1-IQ4_XS | 4.5 | |
| [GGUF](https://huggingface.co/mradermacher/llama-3-spicy-abliterated-stella-8B-i1-GGUF/resolve/main/llama-3-spicy-abliterated-stella-8B.i1-Q4_0.gguf) | i1-Q4_0 | 4.8 | fast, low quality |
| [GGUF](https://huggingface.co/mradermacher/llama-3-spicy-abliterated-stella-8B-i1-GGUF/resolve/main/llama-3-spicy-abliterated-stella-8B.i1-Q4_K_S.gguf) | i1-Q4_K_S | 4.8 | optimal size/speed/quality |
| [GGUF](https://huggingface.co/mradermacher/llama-3-spicy-abliterated-stella-8B-i1-GGUF/resolve/main/llama-3-spicy-abliterated-stella-8B.i1-Q4_K_M.gguf) | i1-Q4_K_M | 5.0 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/llama-3-spicy-abliterated-stella-8B-i1-GGUF/resolve/main/llama-3-spicy-abliterated-stella-8B.i1-Q5_K_S.gguf) | i1-Q5_K_S | 5.7 | |
| [GGUF](https://huggingface.co/mradermacher/llama-3-spicy-abliterated-stella-8B-i1-GGUF/resolve/main/llama-3-spicy-abliterated-stella-8B.i1-Q5_K_M.gguf) | i1-Q5_K_M | 5.8 | |
| [GGUF](https://huggingface.co/mradermacher/llama-3-spicy-abliterated-stella-8B-i1-GGUF/resolve/main/llama-3-spicy-abliterated-stella-8B.i1-Q6_K.gguf) | i1-Q6_K | 6.7 | practically like static Q6_K |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time. Additional thanks to [@nicoboss](https://huggingface.co/nicoboss) for giving me access to his hardware for calculating the imatrix for these quants.
<!-- end -->
|
mradermacher/Karen_TheEditor_V2_STRICT_Mistral_7B-GGUF | mradermacher | 2024-06-11T13:13:15Z | 3,296 | 1 | transformers | [
"transformers",
"gguf",
"llm",
"llama",
"spellcheck",
"grammar",
"en",
"base_model:FPHam/Karen_TheEditor_V2_STRICT_Mistral_7B",
"license:llama2",
"endpoints_compatible",
"region:us"
] | null | 2024-06-11T11:26:50Z | ---
base_model: FPHam/Karen_TheEditor_V2_STRICT_Mistral_7B
language:
- en
library_name: transformers
license: llama2
quantized_by: mradermacher
tags:
- llm
- llama
- spellcheck
- grammar
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
static quants of https://huggingface.co/FPHam/Karen_TheEditor_V2_STRICT_Mistral_7B
<!-- provided-files -->
weighted/imatrix quants are available at https://huggingface.co/mradermacher/Karen_TheEditor_V2_STRICT_Mistral_7B-i1-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/Karen_TheEditor_V2_STRICT_Mistral_7B-GGUF/resolve/main/Karen_TheEditor_V2_STRICT_Mistral_7B.Q2_K.gguf) | Q2_K | 2.8 | |
| [GGUF](https://huggingface.co/mradermacher/Karen_TheEditor_V2_STRICT_Mistral_7B-GGUF/resolve/main/Karen_TheEditor_V2_STRICT_Mistral_7B.IQ3_XS.gguf) | IQ3_XS | 3.1 | |
| [GGUF](https://huggingface.co/mradermacher/Karen_TheEditor_V2_STRICT_Mistral_7B-GGUF/resolve/main/Karen_TheEditor_V2_STRICT_Mistral_7B.Q3_K_S.gguf) | Q3_K_S | 3.3 | |
| [GGUF](https://huggingface.co/mradermacher/Karen_TheEditor_V2_STRICT_Mistral_7B-GGUF/resolve/main/Karen_TheEditor_V2_STRICT_Mistral_7B.IQ3_S.gguf) | IQ3_S | 3.3 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/Karen_TheEditor_V2_STRICT_Mistral_7B-GGUF/resolve/main/Karen_TheEditor_V2_STRICT_Mistral_7B.IQ3_M.gguf) | IQ3_M | 3.4 | |
| [GGUF](https://huggingface.co/mradermacher/Karen_TheEditor_V2_STRICT_Mistral_7B-GGUF/resolve/main/Karen_TheEditor_V2_STRICT_Mistral_7B.Q3_K_M.gguf) | Q3_K_M | 3.6 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/Karen_TheEditor_V2_STRICT_Mistral_7B-GGUF/resolve/main/Karen_TheEditor_V2_STRICT_Mistral_7B.Q3_K_L.gguf) | Q3_K_L | 3.9 | |
| [GGUF](https://huggingface.co/mradermacher/Karen_TheEditor_V2_STRICT_Mistral_7B-GGUF/resolve/main/Karen_TheEditor_V2_STRICT_Mistral_7B.IQ4_XS.gguf) | IQ4_XS | 4.0 | |
| [GGUF](https://huggingface.co/mradermacher/Karen_TheEditor_V2_STRICT_Mistral_7B-GGUF/resolve/main/Karen_TheEditor_V2_STRICT_Mistral_7B.Q4_K_S.gguf) | Q4_K_S | 4.2 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Karen_TheEditor_V2_STRICT_Mistral_7B-GGUF/resolve/main/Karen_TheEditor_V2_STRICT_Mistral_7B.Q4_K_M.gguf) | Q4_K_M | 4.5 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Karen_TheEditor_V2_STRICT_Mistral_7B-GGUF/resolve/main/Karen_TheEditor_V2_STRICT_Mistral_7B.Q5_K_S.gguf) | Q5_K_S | 5.1 | |
| [GGUF](https://huggingface.co/mradermacher/Karen_TheEditor_V2_STRICT_Mistral_7B-GGUF/resolve/main/Karen_TheEditor_V2_STRICT_Mistral_7B.Q5_K_M.gguf) | Q5_K_M | 5.2 | |
| [GGUF](https://huggingface.co/mradermacher/Karen_TheEditor_V2_STRICT_Mistral_7B-GGUF/resolve/main/Karen_TheEditor_V2_STRICT_Mistral_7B.Q6_K.gguf) | Q6_K | 6.0 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/Karen_TheEditor_V2_STRICT_Mistral_7B-GGUF/resolve/main/Karen_TheEditor_V2_STRICT_Mistral_7B.Q8_0.gguf) | Q8_0 | 7.8 | fast, best quality |
| [GGUF](https://huggingface.co/mradermacher/Karen_TheEditor_V2_STRICT_Mistral_7B-GGUF/resolve/main/Karen_TheEditor_V2_STRICT_Mistral_7B.f16.gguf) | f16 | 14.6 | 16 bpw, overkill |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
mradermacher/Asclepius-Mistral-7B-v0.3-GGUF | mradermacher | 2024-06-14T13:59:33Z | 3,296 | 0 | transformers | [
"transformers",
"gguf",
"medical",
"en",
"dataset:starmpcc/Asclepius-Synthetic-Clinical-Notes",
"base_model:starmpcc/Asclepius-Mistral-7B-v0.3",
"license:cc-by-nc-sa-4.0",
"endpoints_compatible",
"region:us"
] | null | 2024-06-14T13:12:01Z | ---
base_model: starmpcc/Asclepius-Mistral-7B-v0.3
datasets:
- starmpcc/Asclepius-Synthetic-Clinical-Notes
language:
- en
library_name: transformers
license: cc-by-nc-sa-4.0
quantized_by: mradermacher
tags:
- medical
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
static quants of https://huggingface.co/starmpcc/Asclepius-Mistral-7B-v0.3
<!-- provided-files -->
weighted/imatrix quants seem not to be available (by me) at this time. If they do not show up a week or so after the static ones, I have probably not planned for them. Feel free to request them by opening a Community Discussion.
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/Asclepius-Mistral-7B-v0.3-GGUF/resolve/main/Asclepius-Mistral-7B-v0.3.Q2_K.gguf) | Q2_K | 2.8 | |
| [GGUF](https://huggingface.co/mradermacher/Asclepius-Mistral-7B-v0.3-GGUF/resolve/main/Asclepius-Mistral-7B-v0.3.IQ3_XS.gguf) | IQ3_XS | 3.1 | |
| [GGUF](https://huggingface.co/mradermacher/Asclepius-Mistral-7B-v0.3-GGUF/resolve/main/Asclepius-Mistral-7B-v0.3.Q3_K_S.gguf) | Q3_K_S | 3.3 | |
| [GGUF](https://huggingface.co/mradermacher/Asclepius-Mistral-7B-v0.3-GGUF/resolve/main/Asclepius-Mistral-7B-v0.3.IQ3_S.gguf) | IQ3_S | 3.3 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/Asclepius-Mistral-7B-v0.3-GGUF/resolve/main/Asclepius-Mistral-7B-v0.3.IQ3_M.gguf) | IQ3_M | 3.4 | |
| [GGUF](https://huggingface.co/mradermacher/Asclepius-Mistral-7B-v0.3-GGUF/resolve/main/Asclepius-Mistral-7B-v0.3.Q3_K_M.gguf) | Q3_K_M | 3.6 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/Asclepius-Mistral-7B-v0.3-GGUF/resolve/main/Asclepius-Mistral-7B-v0.3.Q3_K_L.gguf) | Q3_K_L | 3.9 | |
| [GGUF](https://huggingface.co/mradermacher/Asclepius-Mistral-7B-v0.3-GGUF/resolve/main/Asclepius-Mistral-7B-v0.3.IQ4_XS.gguf) | IQ4_XS | 4.0 | |
| [GGUF](https://huggingface.co/mradermacher/Asclepius-Mistral-7B-v0.3-GGUF/resolve/main/Asclepius-Mistral-7B-v0.3.Q4_K_S.gguf) | Q4_K_S | 4.2 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Asclepius-Mistral-7B-v0.3-GGUF/resolve/main/Asclepius-Mistral-7B-v0.3.Q4_K_M.gguf) | Q4_K_M | 4.5 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Asclepius-Mistral-7B-v0.3-GGUF/resolve/main/Asclepius-Mistral-7B-v0.3.Q5_K_S.gguf) | Q5_K_S | 5.1 | |
| [GGUF](https://huggingface.co/mradermacher/Asclepius-Mistral-7B-v0.3-GGUF/resolve/main/Asclepius-Mistral-7B-v0.3.Q5_K_M.gguf) | Q5_K_M | 5.2 | |
| [GGUF](https://huggingface.co/mradermacher/Asclepius-Mistral-7B-v0.3-GGUF/resolve/main/Asclepius-Mistral-7B-v0.3.Q6_K.gguf) | Q6_K | 6.0 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/Asclepius-Mistral-7B-v0.3-GGUF/resolve/main/Asclepius-Mistral-7B-v0.3.Q8_0.gguf) | Q8_0 | 7.8 | fast, best quality |
| [GGUF](https://huggingface.co/mradermacher/Asclepius-Mistral-7B-v0.3-GGUF/resolve/main/Asclepius-Mistral-7B-v0.3.f16.gguf) | f16 | 14.6 | 16 bpw, overkill |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
mradermacher/Karen_TheEditor_V2_CREATIVE_Mistral_7B-GGUF | mradermacher | 2024-06-11T11:26:00Z | 3,295 | 0 | transformers | [
"transformers",
"gguf",
"llm",
"llama",
"spellcheck",
"grammar",
"en",
"base_model:FPHam/Karen_TheEditor_V2_CREATIVE_Mistral_7B",
"license:llama2",
"endpoints_compatible",
"region:us"
] | null | 2024-06-11T11:00:12Z | ---
base_model: FPHam/Karen_TheEditor_V2_CREATIVE_Mistral_7B
language:
- en
library_name: transformers
license: llama2
quantized_by: mradermacher
tags:
- llm
- llama
- spellcheck
- grammar
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
static quants of https://huggingface.co/FPHam/Karen_TheEditor_V2_CREATIVE_Mistral_7B
<!-- provided-files -->
weighted/imatrix quants are available at https://huggingface.co/mradermacher/Karen_TheEditor_V2_CREATIVE_Mistral_7B-i1-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/Karen_TheEditor_V2_CREATIVE_Mistral_7B-GGUF/resolve/main/Karen_TheEditor_V2_CREATIVE_Mistral_7B.Q2_K.gguf) | Q2_K | 2.8 | |
| [GGUF](https://huggingface.co/mradermacher/Karen_TheEditor_V2_CREATIVE_Mistral_7B-GGUF/resolve/main/Karen_TheEditor_V2_CREATIVE_Mistral_7B.IQ3_XS.gguf) | IQ3_XS | 3.1 | |
| [GGUF](https://huggingface.co/mradermacher/Karen_TheEditor_V2_CREATIVE_Mistral_7B-GGUF/resolve/main/Karen_TheEditor_V2_CREATIVE_Mistral_7B.Q3_K_S.gguf) | Q3_K_S | 3.3 | |
| [GGUF](https://huggingface.co/mradermacher/Karen_TheEditor_V2_CREATIVE_Mistral_7B-GGUF/resolve/main/Karen_TheEditor_V2_CREATIVE_Mistral_7B.IQ3_S.gguf) | IQ3_S | 3.3 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/Karen_TheEditor_V2_CREATIVE_Mistral_7B-GGUF/resolve/main/Karen_TheEditor_V2_CREATIVE_Mistral_7B.IQ3_M.gguf) | IQ3_M | 3.4 | |
| [GGUF](https://huggingface.co/mradermacher/Karen_TheEditor_V2_CREATIVE_Mistral_7B-GGUF/resolve/main/Karen_TheEditor_V2_CREATIVE_Mistral_7B.Q3_K_M.gguf) | Q3_K_M | 3.6 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/Karen_TheEditor_V2_CREATIVE_Mistral_7B-GGUF/resolve/main/Karen_TheEditor_V2_CREATIVE_Mistral_7B.Q3_K_L.gguf) | Q3_K_L | 3.9 | |
| [GGUF](https://huggingface.co/mradermacher/Karen_TheEditor_V2_CREATIVE_Mistral_7B-GGUF/resolve/main/Karen_TheEditor_V2_CREATIVE_Mistral_7B.IQ4_XS.gguf) | IQ4_XS | 4.0 | |
| [GGUF](https://huggingface.co/mradermacher/Karen_TheEditor_V2_CREATIVE_Mistral_7B-GGUF/resolve/main/Karen_TheEditor_V2_CREATIVE_Mistral_7B.Q4_K_S.gguf) | Q4_K_S | 4.2 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Karen_TheEditor_V2_CREATIVE_Mistral_7B-GGUF/resolve/main/Karen_TheEditor_V2_CREATIVE_Mistral_7B.Q4_K_M.gguf) | Q4_K_M | 4.5 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Karen_TheEditor_V2_CREATIVE_Mistral_7B-GGUF/resolve/main/Karen_TheEditor_V2_CREATIVE_Mistral_7B.Q5_K_S.gguf) | Q5_K_S | 5.1 | |
| [GGUF](https://huggingface.co/mradermacher/Karen_TheEditor_V2_CREATIVE_Mistral_7B-GGUF/resolve/main/Karen_TheEditor_V2_CREATIVE_Mistral_7B.Q5_K_M.gguf) | Q5_K_M | 5.2 | |
| [GGUF](https://huggingface.co/mradermacher/Karen_TheEditor_V2_CREATIVE_Mistral_7B-GGUF/resolve/main/Karen_TheEditor_V2_CREATIVE_Mistral_7B.Q6_K.gguf) | Q6_K | 6.0 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/Karen_TheEditor_V2_CREATIVE_Mistral_7B-GGUF/resolve/main/Karen_TheEditor_V2_CREATIVE_Mistral_7B.Q8_0.gguf) | Q8_0 | 7.8 | fast, best quality |
| [GGUF](https://huggingface.co/mradermacher/Karen_TheEditor_V2_CREATIVE_Mistral_7B-GGUF/resolve/main/Karen_TheEditor_V2_CREATIVE_Mistral_7B.f16.gguf) | f16 | 14.6 | 16 bpw, overkill |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
mradermacher/Falcon2-10B-multilingual-GGUF | mradermacher | 2024-06-04T15:55:37Z | 3,294 | 0 | transformers | [
"transformers",
"gguf",
"mergekit",
"merge",
"en",
"base_model:ssmits/Falcon2-10B-multilingual",
"endpoints_compatible",
"region:us"
] | null | 2024-06-03T18:20:51Z | ---
base_model: ssmits/Falcon2-10B-multilingual
language:
- en
library_name: transformers
quantized_by: mradermacher
tags:
- mergekit
- merge
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
static quants of https://huggingface.co/ssmits/Falcon2-10B-multilingual
<!-- provided-files -->
weighted/imatrix quants are available at https://huggingface.co/mradermacher/Falcon2-10B-multilingual-i1-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/Falcon2-10B-multilingual-GGUF/resolve/main/Falcon2-10B-multilingual.Q2_K.gguf) | Q2_K | 3.3 | |
| [GGUF](https://huggingface.co/mradermacher/Falcon2-10B-multilingual-GGUF/resolve/main/Falcon2-10B-multilingual.IQ3_XS.gguf) | IQ3_XS | 3.7 | |
| [GGUF](https://huggingface.co/mradermacher/Falcon2-10B-multilingual-GGUF/resolve/main/Falcon2-10B-multilingual.IQ3_S.gguf) | IQ3_S | 3.8 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/Falcon2-10B-multilingual-GGUF/resolve/main/Falcon2-10B-multilingual.Q3_K_S.gguf) | Q3_K_S | 3.8 | |
| [GGUF](https://huggingface.co/mradermacher/Falcon2-10B-multilingual-GGUF/resolve/main/Falcon2-10B-multilingual.IQ3_M.gguf) | IQ3_M | 3.9 | |
| [GGUF](https://huggingface.co/mradermacher/Falcon2-10B-multilingual-GGUF/resolve/main/Falcon2-10B-multilingual.Q3_K_M.gguf) | Q3_K_M | 4.1 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/Falcon2-10B-multilingual-GGUF/resolve/main/Falcon2-10B-multilingual.Q3_K_L.gguf) | Q3_K_L | 4.4 | |
| [GGUF](https://huggingface.co/mradermacher/Falcon2-10B-multilingual-GGUF/resolve/main/Falcon2-10B-multilingual.IQ4_XS.gguf) | IQ4_XS | 4.6 | |
| [GGUF](https://huggingface.co/mradermacher/Falcon2-10B-multilingual-GGUF/resolve/main/Falcon2-10B-multilingual.Q4_K_S.gguf) | Q4_K_S | 4.8 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Falcon2-10B-multilingual-GGUF/resolve/main/Falcon2-10B-multilingual.Q4_K_M.gguf) | Q4_K_M | 5.1 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Falcon2-10B-multilingual-GGUF/resolve/main/Falcon2-10B-multilingual.Q5_K_S.gguf) | Q5_K_S | 5.8 | |
| [GGUF](https://huggingface.co/mradermacher/Falcon2-10B-multilingual-GGUF/resolve/main/Falcon2-10B-multilingual.Q5_K_M.gguf) | Q5_K_M | 6.1 | |
| [GGUF](https://huggingface.co/mradermacher/Falcon2-10B-multilingual-GGUF/resolve/main/Falcon2-10B-multilingual.Q6_K.gguf) | Q6_K | 6.8 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/Falcon2-10B-multilingual-GGUF/resolve/main/Falcon2-10B-multilingual.Q8_0.gguf) | Q8_0 | 8.7 | fast, best quality |
| [GGUF](https://huggingface.co/mradermacher/Falcon2-10B-multilingual-GGUF/resolve/main/Falcon2-10B-multilingual.f16.gguf) | f16 | 16.3 | 16 bpw, overkill |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
benAG7/Llama3_7B_finetuned_lora_q4_k_m | benAG7 | 2024-07-01T15:44:32Z | 3,293 | 0 | transformers | [
"transformers",
"gguf",
"llama",
"text-generation-inference",
"unsloth",
"en",
"base_model:unsloth/llama-3-8b-instruct-bnb-4bit",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2024-07-01T15:33:40Z | ---
base_model: unsloth/llama-3-8b-instruct-bnb-4bit
language:
- en
license: apache-2.0
tags:
- text-generation-inference
- transformers
- unsloth
- llama
- gguf
---
# Uploaded model
- **Developed by:** benAG7
- **License:** apache-2.0
- **Finetuned from model :** unsloth/llama-3-8b-instruct-bnb-4bit
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
allenai/tulu-2-dpo-7b | allenai | 2024-05-14T03:06:00Z | 3,291 | 17 | transformers | [
"transformers",
"pytorch",
"llama",
"text-generation",
"conversational",
"en",
"dataset:HuggingFaceH4/ultrafeedback_binarized",
"dataset:allenai/tulu-v2-sft-mixture",
"arxiv:2305.18290",
"arxiv:2311.10702",
"base_model:meta-llama/Llama-2-7b-hf",
"license:other",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2023-11-13T00:43:42Z | ---
model-index:
- name: tulu-2-dpo-7b
results: []
datasets:
- HuggingFaceH4/ultrafeedback_binarized
- allenai/tulu-v2-sft-mixture
language:
- en
base_model: meta-llama/Llama-2-7b-hf
license: other
license_name: ai2-impact-license-low-risk
license_link: https://allenai.org/impact-license
---
<img src="https://huggingface.co/datasets/allenai/blog-images/resolve/main/tulu-v2/Tulu%20V2%20banner.png" alt="TuluV2 banner" width="800" style="margin-left:'auto' margin-right:'auto' display:'block'"/>
# Model Card for Tulu V2 DPO 7B
Tulu is a series of language models that are trained to act as helpful assistants.
Tulu V2 DPO 7B is a fine-tuned version of Llama 2 that was trained on on a mix of publicly available, synthetic and human datasets using [Direct Preference Optimization (DPO)](https://arxiv.org/abs/2305.18290).
This model is a strong alternative to Llama 2 7b Chat.
For more details, read the paper: [Camels in a Changing Climate: Enhancing LM Adaptation with Tulu 2
](https://arxiv.org/abs/2311.10702).
## Model description
- **Model type:** A model belonging to a suite of instruction and RLHF tuned chat models on a mix of publicly available, synthetic and human-created datasets.
- **Language(s) (NLP):** Primarily English
- **License:** [AI2 ImpACT](https://allenai.org/impact-license) Low-risk license.
- **Finetuned from model:** [meta-llama/Llama-2-7b-hf](https://huggingface.co/meta-llama/Llama-2-7b-hf)
### Model Sources
- **Repository:** [https://github.com/allenai/open-instruct](https://github.com/allenai/open-instruct)
- **DPO Recipe:** The DPO recipe is from the [Zephyr Beta](https://huggingface.co/HuggingFaceH4/zephyr-7b-beta) model
- **Model Family:** Other models and the dataset are found in the [Tulu V2 collection](https://huggingface.co/collections/allenai/tulu-v2-suite-6551b56e743e6349aab45101).
## Performance
| Model | Size | Alignment | MT-Bench (score) | AlpacaEval (win rate %) |
|-------------|-----|----|---------------|--------------|
| **Tulu-v2-7b** 🐪 | **7B** | **SFT** | **6.30** | **73.9** |
| **Tulu-v2-dpo-7b** 🐪 | **7B** | **DPO** | **6.29** | **85.1** |
| **Tulu-v2-13b** 🐪 | **13B** | **SFT** | **6.70** | **78.9** |
| **Tulu-v2-dpo-13b** 🐪 | **13B** | **DPO** | **7.00** | **89.5** |
| **Tulu-v2-70b** 🐪 | **70B** | **SFT** | **7.49** | **86.6** |
| **Tulu-v2-dpo-70b** 🐪 | **70B** | **DPO** | **7.89** | **95.1** |
## Input Format
The model is trained to use the following format (note the newlines):
```
<|user|>
Your message here!
<|assistant|>
```
For best results, format all inputs in this manner. **Make sure to include a newline after `<|assistant|>`, this can affect generation quality quite a bit.**
## Intended uses & limitations
The model was initially fine-tuned on a filtered and preprocessed of the [Tulu V2 mix dataset](https://huggingface.co/datasets/allenai/tulu-v2-sft-mixture), which contains a diverse range of human created instructions and synthetic dialogues generated primarily by other LLMs.
We then further aligned the model with a [Jax DPO trainer](https://github.com/hamishivi/EasyLM/blob/main/EasyLM/models/llama/llama_train_dpo.py) built on [EasyLM](https://github.com/young-geng/EasyLM) on the [openbmb/UltraFeedback](https://huggingface.co/datasets/openbmb/UltraFeedback) dataset, which contains 64k prompts and model completions that are ranked by GPT-4.
<!-- You can find the datasets used for training Tulu V2 [here]()
Here's how you can run the model using the `pipeline()` function from 🤗 Transformers:
```python
# Install transformers from source - only needed for versions <= v4.34
# pip install git+https://github.com/huggingface/transformers.git
# pip install accelerate
import torch
from transformers import pipeline
pipe = pipeline("text-generation", model="HuggingFaceH4/tulu-2-dpo-70b", torch_dtype=torch.bfloat16, device_map="auto")
# We use the tokenizer's chat template to format each message - see https://huggingface.co/docs/transformers/main/en/chat_templating
messages = [
{
"role": "system",
"content": "You are a friendly chatbot who always responds in the style of a pirate",
},
{"role": "user", "content": "How many helicopters can a human eat in one sitting?"},
]
prompt = pipe.tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
outputs = pipe(prompt, max_new_tokens=256, do_sample=True, temperature=0.7, top_k=50, top_p=0.95)
print(outputs[0]["generated_text"])
# <|system|>
# You are a friendly chatbot who always responds in the style of a pirate.</s>
# <|user|>
# How many helicopters can a human eat in one sitting?</s>
# <|assistant|>
# Ah, me hearty matey! But yer question be a puzzler! A human cannot eat a helicopter in one sitting, as helicopters are not edible. They be made of metal, plastic, and other materials, not food!
```-->
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
The Tulu models have not been aligned to generate safe completions within the RLHF phase or deployed with in-the-loop filtering of responses like ChatGPT, so the model can produce problematic outputs (especially when prompted to do so).
It is also unknown what the size and composition of the corpus was used to train the base Llama 2 models, however it is likely to have included a mix of Web data and technical sources like books and code. See the [Falcon 180B model card](https://huggingface.co/tiiuae/falcon-180B#training-data) for an example of this.
### Training hyperparameters
The following hyperparameters were used during DPO training:
- learning_rate: 5e-07
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 3.0
## Citation
If you find Tulu 2 is useful in your work, please cite it with:
```
@misc{ivison2023camels,
title={Camels in a Changing Climate: Enhancing LM Adaptation with Tulu 2},
author={Hamish Ivison and Yizhong Wang and Valentina Pyatkin and Nathan Lambert and Matthew Peters and Pradeep Dasigi and Joel Jang and David Wadden and Noah A. Smith and Iz Beltagy and Hannaneh Hajishirzi},
year={2023},
eprint={2311.10702},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
*Model card adapted from [Zephyr Beta](https://huggingface.co/HuggingFaceH4/zephyr-7b-beta/blob/main/README.md)* |
Deci/DeciLM-7B-instruct | Deci | 2024-02-21T16:05:34Z | 3,289 | 96 | transformers | [
"transformers",
"safetensors",
"deci",
"text-generation",
"conversational",
"custom_code",
"en",
"dataset:Open-Orca/SlimOrca",
"license:apache-2.0",
"autotrain_compatible",
"region:us"
] | text-generation | 2023-12-10T16:28:21Z | ---
license: apache-2.0
language:
- en
datasets:
- Open-Orca/SlimOrca
---
# DeciLM-7B-instruct
DeciLM-7B-instruct is a model for short-form instruction following. It is built by LoRA fine-tuning on the [SlimOrca dataset](https://huggingface.co/datasets/Open-Orca/SlimOrca).
## Model Details
### Model Description
DeciLM-7B-instruct is a derivative of the recently released [DeciLM-7B](https://huggingface.co/Deci/DeciLM-7B) language model, a pre-trained, high-efficiency generative text model with 7 billion parameters. DeciLM-7B-instruct is one the best 7B instruct models obtained using simple LoRA fine-tuning, without relying on preference optimization techniques such as RLHF and DPO.
- **Developed by:** [Deci](https://deci.ai/?utm_campaign=repos&utm_source=hugging-face&utm_medium=model-card&utm_content=decilm-7b-instruct)
- **Model type:** DeciLM is an auto-regressive language model using an optimized transformer decoder architecture that includes variable Grouped-Query Attention.
- **Language(s) (NLP):** English
- **License:** Apache 2.0
## Model Architecture
| Parameters | Layers | Heads | Sequence Length | GQA num_key_value_heads* |
|:----------|:----------|:----------|:----------|:----------|
| 7.04 billion | 32 | 32 | 8192 | Variable |
*AutoNAC was employed to optimize the selection of the GQA num_key_value_heads for each model layer.
### Model Sources
- **Blog:** [DeciLM-7B Technical Blog](https://deci.ai/blog/introducing-DeciLM-7B-the-fastest-and-most-accurate-7b-large-language-model-to-date/?utm_campaign=repos&utm_source=hugging-face&utm_medium=model-card&utm_content=decilm-7b-instruct)
- **Demo:** [DeciLM-7B-instruct Demo](https://huggingface.co/spaces/Deci/DeciLM-7B-instruct)
- **Finetuning Notebook:** [DeciLM-7B Finetuning Notebook](https://colab.research.google.com/drive/1kEV6i96AQ94xTCvSd11TxkEaksTb5o3U?usp=sharing)
- **Text Generation Notebook:** [DeciLM-7B-instruct Text Generation Notebook](https://bit.ly/declm-7b-instruct)
### Prompt Template
```
### System:
{system_prompt}
### User:
{user_prompt}
### Assistant:
```
## Uses
The model is intended for commercial and research use in English.
## How to Get Started with the Model
Use the code below to get started with the model.
```python
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig, pipeline
model_name = "Deci/DeciLM-7B-instruct"
device = "cuda" # for GPU usage or "cpu" for CPU usage
quantize = False # Optional. Useful for GPUs with less than 24GB memory
if quantize:
dtype_kwargs = dict(quantization_config=BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_compute_dtype=torch.bfloat16
))
else:
dtype_kwargs = dict(torch_dtype="auto")
model = AutoModelForCausalLM.from_pretrained(
model_name,
device_map="auto",
trust_remote_code=True,
**dtype_kwargs
)
tokenizer = AutoTokenizer.from_pretrained(model_name)
tokenizer.pad_token = tokenizer.eos_token
deci_generator = pipeline("text-generation",
model=model,
tokenizer=tokenizer,
temperature=0.1,
device_map="auto",
max_length=4096,
return_full_text=False)
system_prompt = "You are an AI assistant that follows instruction extremely well. Help as much as you can."
user_prompt = "How do I make the most delicious pancakes the world has ever tasted?"
prompt = tokenizer.apply_chat_template([
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_prompt},
], tokenize=False, add_generation_prompt=True)
response = deci_generator(prompt)[0]['generated_text']
print(prompt + response)
```
## Evaluation
Below are DeciLM-7B and DeciLM-7B-instruct's evaluation results.
| Model | Average | ARC | HellaSwag | MMLU | TruthfulQA | Winogrande | GSM8K |
|:----------|:---------:|:---------:|:---------:|:---------:|:---------:|:---------:|:---------:|
| DecilLM-7B | 61.55 | 59.39 | 82.51 | 59.76 | 40.33 | 79.95 | 47.38 |
| DecilLM-7B-instruct | 63.19 | 61.01 | 82.37 | 60.24 | 49.75 | 79.72 | 46.02 |
### Runtime Benchmarks
| Inference Tool | Hardware | Prompt length | Generation length | Generated tokens/sec | Batch Size | Number of Prompts |
|:----------|:----------|:---------:|:---------:|:---------:|:---------:|:---------:|
| HuggingFace (PyTorch) | A100 (SXM4-80GB-400W) | 512 | 512 | **1174** | 352 | 352 |
| HuggingFace (PyTorch) | A100 (SXM4-80GB-400W) | 2048 | 2048 | **328** | 72 | 72 |
| Infery-LLM | A100 (SXM4-80GB-400W)| 512 | 512 | **4559** | 1024 | 4096 |
| Infery-LLM | A100 (SXM4-80GB-400W) | 2048 | 2048 | **3997** | 512 | 2048 |
| Infery-LLM | A10 | 512 | 512 | **1345** | 128 | 512 |
| Infery-LLM | A10 | 2048 | 2048 | **599** | 32 | 128 |
- In order to replicate the results of the Hugging Face benchmarks, you can use this [code example](https://huggingface.co/Deci/DeciLM-7B/blob/main/benchmark_hf_model.py).
- Infery-LLM, Deci's inference engine, features a suite of optimization algorithms, including selective quantization, optimized beam search, continuous batching, and custom CUDA kernels. To explore the full capabilities of Infery-LLM, [schedule a live demo](https://deci.ai/infery-llm-book-a-demo/?utm_campaign=DeciLM%207B%20Launch&utm_source=HF&utm_medium=decilm7b-model-card&utm_term=infery-demo).
## Ethical Considerations and Limitations
DeciLM-7B-instruct is a new technology that comes with inherent risks associated with its use. The testing conducted so far has been primarily in English and does not encompass all possible scenarios. Like those of all large language models, DeciLM-7B's outputs are unpredictable, and the model may generate responses that are inaccurate, biased, or otherwise objectionable. Consequently, developers planning to use DeciLM-7B should undertake thorough safety testing and tuning designed explicitly for their intended applications of the model before deployment.
## How to Cite
Please cite this model using this format.
```bibtex
@misc{DeciFoundationModels,
title = {DeciLM-7B-instruct},
author = {DeciAI Research Team},
year = {2023}
url={https://huggingface.co/Deci/DeciLM-7B-instruct},
}
``` |
freewheelin/free-evo-qwen72b-v0.8-re | freewheelin | 2024-05-07T00:46:46Z | 3,289 | 4 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"en",
"license:mit",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2024-05-02T23:44:15Z | ---
language:
- en
license: mit
library_name: transformers
model-index:
- name: free-evo-qwen72b-v0.8-re
results:
- task:
type: text-generation
name: Text Generation
dataset:
name: AI2 Reasoning Challenge (25-Shot)
type: ai2_arc
config: ARC-Challenge
split: test
args:
num_few_shot: 25
metrics:
- type: acc_norm
value: 79.86
name: normalized accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=freewheelin/free-evo-qwen72b-v0.8-re
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: HellaSwag (10-Shot)
type: hellaswag
split: validation
args:
num_few_shot: 10
metrics:
- type: acc_norm
value: 91.34
name: normalized accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=freewheelin/free-evo-qwen72b-v0.8-re
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: MMLU (5-Shot)
type: cais/mmlu
config: all
split: test
args:
num_few_shot: 5
metrics:
- type: acc
value: 78.00
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=freewheelin/free-evo-qwen72b-v0.8-re
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: TruthfulQA (0-shot)
type: truthful_qa
config: multiple_choice
split: validation
args:
num_few_shot: 0
metrics:
- type: mc2
value: 74.85
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=freewheelin/free-evo-qwen72b-v0.8-re
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: Winogrande (5-shot)
type: winogrande
config: winogrande_xl
split: validation
args:
num_few_shot: 5
metrics:
- type: acc
value: 87.77
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=freewheelin/free-evo-qwen72b-v0.8-re
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: GSM8k (5-shot)
type: gsm8k
config: main
split: test
args:
num_few_shot: 5
metrics:
- type: acc
value: 75.89
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=freewheelin/free-evo-qwen72b-v0.8-re
name: Open LLM Leaderboard
---
# Model Card for free-evo-qwen72b-v0.8
## Developed by : [Freewheelin](https://freewheelin-recruit.oopy.io/) AI Technical Team
## 2024 4th May - avg. 81.28 [Open Llm Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)
| Metric |Value|
|---------------------------------|----:|
|Avg. |81.28|
|ARC (25-Shot) |79.86|
|HellaSwag (10-Shot) |91.32|
|MMLU (5-Shot) |78.00|
|TruthfulQA (0-shot) |74.85|
|Winogrande (5-shot) |87.77|
|GSM8k (5-shot) |75.89|
## Method
- We were inspired by this [Sakana project](https://sakana.ai/evolutionary-model-merge/)
## Process
You need two models with the same architecture.
- Choose one model and fine-tune it to create a gap between the original model and the fine-tuned one. It doesn't matter whether the evaluation score is higher or lower.
- Merge the two models.
- Evaluate the merged model.
- Fine-tune a specific evaluation part of the model if you need to increase the score for that part. (It's unlikely to work as you think, but you can try it.)
- Merge the models again.
- Evaluate again.
- Keep going until the average evaluation score is higher than the original one.
That's it. Simple.
You can create a framework to automate this process.
## Base Architecture
- QWEN2
## Base Models
- several QWEN2 based models |
google/siglip-base-patch16-256 | google | 2024-01-19T23:32:53Z | 3,288 | 0 | transformers | [
"transformers",
"safetensors",
"siglip",
"zero-shot-image-classification",
"vision",
"arxiv:2303.15343",
"arxiv:2209.06794",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | zero-shot-image-classification | 2024-01-08T12:27:41Z | ---
license: apache-2.0
tags:
- vision
widget:
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/cat-dog-music.png
candidate_labels: playing music, playing sports
example_title: Cat & Dog
---
# SigLIP (base-sized model)
SigLIP model pre-trained on WebLi at resolution 256x256. It was introduced in the paper [Sigmoid Loss for Language Image Pre-Training](https://arxiv.org/abs/2303.15343) by Zhai et al. and first released in [this repository](https://github.com/google-research/big_vision).
Disclaimer: The team releasing SigLIP did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
SigLIP is [CLIP](https://huggingface.co/docs/transformers/model_doc/clip), a multimodal model, with a better loss function. The sigmoid loss operates solely on image-text pairs and does not require a global view of the pairwise similarities for normalization. This allows further scaling up the batch size, while also performing better at smaller batch sizes.
A TLDR of SigLIP by one of the authors can be found [here](https://twitter.com/giffmana/status/1692641733459267713).
## Intended uses & limitations
You can use the raw model for tasks like zero-shot image classification and image-text retrieval. See the [model hub](https://huggingface.co/models?search=google/siglip) to look for
other versions on a task that interests you.
### How to use
Here is how to use this model to perform zero-shot image classification:
```python
from PIL import Image
import requests
from transformers import AutoProcessor, AutoModel
import torch
model = AutoModel.from_pretrained("google/siglip-base-patch16-256")
processor = AutoProcessor.from_pretrained("google/siglip-base-patch16-256")
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
texts = ["a photo of 2 cats", "a photo of 2 dogs"]
inputs = processor(text=texts, images=image, padding="max_length", return_tensors="pt")
with torch.no_grad():
outputs = model(**inputs)
logits_per_image = outputs.logits_per_image
probs = torch.sigmoid(logits_per_image) # these are the probabilities
print(f"{probs[0][0]:.1%} that image 0 is '{texts[0]}'")
```
Alternatively, one can leverage the pipeline API which abstracts away the complexity for the user:
```python
from transformers import pipeline
from PIL import Image
import requests
# load pipe
image_classifier = pipeline(task="zero-shot-image-classification", model="google/siglip-base-patch16-224")
# load image
url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
image = Image.open(requests.get(url, stream=True).raw)
# inference
outputs = image_classifier(image, candidate_labels=["2 cats", "a plane", "a remote"])
outputs = [{"score": round(output["score"], 4), "label": output["label"] } for output in outputs]
print(outputs)
```
For more code examples, we refer to the [documentation](https://huggingface.co/transformers/main/model_doc/siglip.html#).
## Training procedure
### Training data
SigLIP is pre-trained on the English image-text pairs of the WebLI dataset [(Chen et al., 2023)](https://arxiv.org/abs/2209.06794).
### Preprocessing
Images are resized/rescaled to the same resolution (256x256) and normalized across the RGB channels with mean (0.5, 0.5, 0.5) and standard deviation (0.5, 0.5, 0.5).
Texts are tokenized and padded to the same length (64 tokens).
### Compute
The model was trained on 16 TPU-v4 chips for three days.
## Evaluation results
Evaluation of SigLIP compared to CLIP is shown below (taken from the paper).
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/model_doc/siglip_table.jpeg"
alt="drawing" width="600"/>
### BibTeX entry and citation info
```bibtex
@misc{zhai2023sigmoid,
title={Sigmoid Loss for Language Image Pre-Training},
author={Xiaohua Zhai and Basil Mustafa and Alexander Kolesnikov and Lucas Beyer},
year={2023},
eprint={2303.15343},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
``` |
faizaulia/e5-fine-tune-polri-news-emotion | faizaulia | 2024-04-25T10:23:18Z | 3,288 | 0 | transformers | [
"transformers",
"pytorch",
"safetensors",
"xlm-roberta",
"text-classification",
"id",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2024-04-20T04:05:33Z | ---
library_name: transformers
language:
- id
---
# Model description
This model is a fine-tuned model of [```intfloat/multilingual-e5-large```](https://huggingface.co/intfloat/multilingual-e5-large), trained with Indonesian police news data.
# How to use this model:
```python
from transformers import AutoTokenizer, AutoModelForSequenceClassification
tokenizer = AutoTokenizer.from_pretrained("faizaulia/e5-fine-tune-polri-news-emotion")
model = AutoModelForSequenceClassification.from_pretrained("faizaulia/e5-fine-tune-polri-news-emotion")
```
# Label description:
0: Angry, 1: Fear, 2: Sad, 3: Neutral, 4: Happy, 5: Love
# Input text example:
>LAMPUNG, KOMPAS.com - Komplotan perampok yang menyekap satu keluarga di Kabupaten Lampung Timur ditembak aparat kepolisian. Komplotan ini menggondol uang sebanyak Rp 50 juta milik korban. Kapolres Lampung Timur, AKBP M Rizal Muchtar mengatakan, tiga dari empat pelaku ini telah ditangkap pada Senin (27/2/2023) dini hari.
# Preprocesssing:
```python
nltk.download('stopwords')
nltk.download('wordnet')
stop_words = set(stopwords.words('indonesian'))
def remove_stopwords(text):
words = text.split()
words = [word for word in words if word not in stop_words]
return ' '.join(words)
def clean_texts(text):
text = re.sub('\n',' ',text) # Remove every '\n'
text = re.sub(' +', ' ', text) # Remove extra spaces
text = re.sub('[\u2013\u2014]', '-', text) # Sub — and – char to -
text = re.sub('(.{0,40})-', '', text) # Remove news website/location at the beginning
text = re.sub(r'[^a-zA-Z\s]', '', text) # Remove non alphanbet characters
return text
def preprocess_text(text):
text = text.lower()
text = clean_texts(text)
text = remove_stopwords(text)
return text
```
|
h2oai/h2ogpt-gm-oasst1-multilang-2048-falcon-7b | h2oai | 2023-06-05T21:54:21Z | 3,287 | 7 | transformers | [
"transformers",
"pytorch",
"RefinedWebModel",
"text-generation",
"gpt",
"llm",
"large language model",
"h2o-llmstudio",
"custom_code",
"en",
"dataset:OpenAssistant/oasst1",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2023-06-05T08:53:27Z | ---
language:
- en
library_name: transformers
tags:
- gpt
- llm
- large language model
- h2o-llmstudio
inference: false
thumbnail: >-
https://h2o.ai/etc.clientlibs/h2o/clientlibs/clientlib-site/resources/images/favicon.ico
license: apache-2.0
datasets:
- OpenAssistant/oasst1
---
# Model Card
## Summary
This model was trained using [H2O LLM Studio](https://github.com/h2oai/h2o-llmstudio).
- Base model: [tiiuae/falcon-7b](https://huggingface.co/tiiuae/falcon-7b)
- Dataset preparation: [OpenAssistant/oasst1](https://github.com/h2oai/h2o-llmstudio/blob/1935d84d9caafed3ee686ad2733eb02d2abfce57/app_utils/utils.py#LL1896C5-L1896C28)
## Usage
To use the model with the `transformers` library on a machine with GPUs, first make sure you have the `transformers`, `accelerate`, `torch` and `einops` libraries installed.
```bash
pip install transformers==4.29.2
pip install accelerate==0.19.0
pip install torch==2.0.0
pip install einops==0.6.1
```
```python
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
tokenizer = AutoTokenizer.from_pretrained(
"h2oai/h2ogpt-gm-oasst1-multilang-2048-falcon-7b",
use_fast=False,
padding_side="left",
trust_remote_code=True,
)
generate_text = pipeline(
model="h2oai/h2ogpt-gm-oasst1-multilang-2048-falcon-7b",
tokenizer=tokenizer,
torch_dtype=torch.float16,
trust_remote_code=True,
use_fast=False,
device_map={"": "cuda:0"},
)
res = generate_text(
"Why is drinking water so healthy?",
min_new_tokens=2,
max_new_tokens=1024,
do_sample=False,
num_beams=1,
temperature=float(0.3),
repetition_penalty=float(1.2),
renormalize_logits=True
)
print(res[0]["generated_text"])
```
You can print a sample prompt after the preprocessing step to see how it is feed to the tokenizer:
```python
print(generate_text.preprocess("Why is drinking water so healthy?")["prompt_text"])
```
```bash
<|prompt|>Why is drinking water so healthy?<|endoftext|><|answer|>
```
Alternatively, you can download [h2oai_pipeline.py](h2oai_pipeline.py), store it alongside your notebook, and construct the pipeline yourself from the loaded model and tokenizer:
```python
import torch
from h2oai_pipeline import H2OTextGenerationPipeline
from transformers import AutoModelForCausalLM, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained(
"h2oai/h2ogpt-gm-oasst1-multilang-2048-falcon-7b",
use_fast=False,
padding_side="left",
trust_remote_code=True,
)
model = AutoModelForCausalLM.from_pretrained(
"h2oai/h2ogpt-gm-oasst1-multilang-2048-falcon-7b",
torch_dtype=torch.bfloat16,
device_map={"": "cuda:0"},
trust_remote_code=True,
)
generate_text = H2OTextGenerationPipeline(model=model, tokenizer=tokenizer)
res = generate_text(
"Why is drinking water so healthy?",
min_new_tokens=2,
max_new_tokens=1024,
do_sample=False,
num_beams=1,
temperature=float(0.3),
repetition_penalty=float(1.2),
renormalize_logits=True
)
print(res[0]["generated_text"])
```
You may also construct the pipeline from the loaded model and tokenizer yourself and consider the preprocessing steps:
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "h2oai/h2ogpt-gm-oasst1-multilang-2048-falcon-7b" # either local folder or huggingface model name
# Important: The prompt needs to be in the same format the model was trained with.
# You can find an example prompt in the experiment logs.
prompt = "<|prompt|>How are you?<|endoftext|><|answer|>"
tokenizer = AutoTokenizer.from_pretrained(
model_name,
use_fast=False,
trust_remote_code=True,
)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype=torch.bfloat16,
device_map={"": "cuda:0"},
trust_remote_code=True,
)
model.cuda().eval()
inputs = tokenizer(prompt, return_tensors="pt", add_special_tokens=False).to("cuda")
# generate configuration can be modified to your needs
tokens = model.generate(
**inputs,
min_new_tokens=2,
max_new_tokens=1024,
do_sample=False,
num_beams=1,
temperature=float(0.3),
repetition_penalty=float(1.2),
renormalize_logits=True
)[0]
tokens = tokens[inputs["input_ids"].shape[1]:]
answer = tokenizer.decode(tokens, skip_special_tokens=True)
print(answer)
```
## Model Architecture
```
RWForCausalLM(
(transformer): RWModel(
(word_embeddings): Embedding(65024, 4544)
(h): ModuleList(
(0-31): 32 x DecoderLayer(
(input_layernorm): LayerNorm((4544,), eps=1e-05, elementwise_affine=True)
(self_attention): Attention(
(maybe_rotary): RotaryEmbedding()
(query_key_value): Linear(in_features=4544, out_features=4672, bias=False)
(dense): Linear(in_features=4544, out_features=4544, bias=False)
(attention_dropout): Dropout(p=0.0, inplace=False)
)
(mlp): MLP(
(dense_h_to_4h): Linear(in_features=4544, out_features=18176, bias=False)
(act): GELU(approximate='none')
(dense_4h_to_h): Linear(in_features=18176, out_features=4544, bias=False)
)
)
)
(ln_f): LayerNorm((4544,), eps=1e-05, elementwise_affine=True)
)
(lm_head): Linear(in_features=4544, out_features=65024, bias=False)
)
```
## Model Configuration
This model was trained using H2O LLM Studio and with the configuration in [cfg.yaml](cfg.yaml). Visit [H2O LLM Studio](https://github.com/h2oai/h2o-llmstudio) to learn how to train your own large language models.
## Model Validation
Model validation results using [EleutherAI lm-evaluation-harness](https://github.com/EleutherAI/lm-evaluation-harness).
```bash
CUDA_VISIBLE_DEVICES=0 python main.py --model hf-causal-experimental --model_args pretrained=h2oai/h2ogpt-gm-oasst1-multilang-2048-falcon-7b --tasks openbookqa,arc_easy,winogrande,hellaswag,arc_challenge,piqa,boolq --device cuda &> eval.log
```
## Disclaimer
Please read this disclaimer carefully before using the large language model provided in this repository. Your use of the model signifies your agreement to the following terms and conditions.
- Biases and Offensiveness: The large language model is trained on a diverse range of internet text data, which may contain biased, racist, offensive, or otherwise inappropriate content. By using this model, you acknowledge and accept that the generated content may sometimes exhibit biases or produce content that is offensive or inappropriate. The developers of this repository do not endorse, support, or promote any such content or viewpoints.
- Limitations: The large language model is an AI-based tool and not a human. It may produce incorrect, nonsensical, or irrelevant responses. It is the user's responsibility to critically evaluate the generated content and use it at their discretion.
- Use at Your Own Risk: Users of this large language model must assume full responsibility for any consequences that may arise from their use of the tool. The developers and contributors of this repository shall not be held liable for any damages, losses, or harm resulting from the use or misuse of the provided model.
- Ethical Considerations: Users are encouraged to use the large language model responsibly and ethically. By using this model, you agree not to use it for purposes that promote hate speech, discrimination, harassment, or any form of illegal or harmful activities.
- Reporting Issues: If you encounter any biased, offensive, or otherwise inappropriate content generated by the large language model, please report it to the repository maintainers through the provided channels. Your feedback will help improve the model and mitigate potential issues.
- Changes to this Disclaimer: The developers of this repository reserve the right to modify or update this disclaimer at any time without prior notice. It is the user's responsibility to periodically review the disclaimer to stay informed about any changes.
By using the large language model provided in this repository, you agree to accept and comply with the terms and conditions outlined in this disclaimer. If you do not agree with any part of this disclaimer, you should refrain from using the model and any content generated by it. |
MaziyarPanahi/Meta-Llama-3-8B-Instruct-GPTQ | MaziyarPanahi | 2024-04-19T07:08:47Z | 3,287 | 6 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"finetuned",
"quantized",
"4-bit",
"gptq",
"facebook",
"meta",
"pytorch",
"llama-3",
"conversational",
"en",
"license:other",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"text-generation-inference",
"region:us",
"base_model:meta-llama/Meta-Llama-3-8B-Instruct"
] | text-generation | 2024-04-18T21:55:56Z | ---
license_name: llama3
tags:
- finetuned
- quantized
- 4-bit
- gptq
- transformers
- safetensors
- llama
- text-generation
- facebook
- meta
- pytorch
- llama-3
- conversational
- en
- license:other
- autotrain_compatible
- endpoints_compatible
- has_space
- text-generation-inference
- region:us
model_name: Meta-Llama-3-8B-Instruct-GPTQ
base_model: meta-llama/Meta-Llama-3-8B-Instruct
inference: false
model_creator: meta-llama
pipeline_tag: text-generation
quantized_by: MaziyarPanahi
---
# Description
[MaziyarPanahi/Meta-Llama-3-8B-Instruct-GPTQ](https://huggingface.co/MaziyarPanahi/Meta-Llama-3-8B-Instruct-GPTQ) is a quantized (GPTQ) version of [meta-llama/Meta-Llama-3-8B-Instruct](https://huggingface.co/meta-llama/Meta-Llama-3-8B-Instruct)
## How to use
### Install the necessary packages
```
pip install --upgrade accelerate auto-gptq transformers
```
### Example Python code
```python
from transformers import AutoTokenizer, pipeline
from auto_gptq import AutoGPTQForCausalLM, BaseQuantizeConfig
import torch
model_id = "MaziyarPanahi/Meta-Llama-3-8B-Instruct-GPTQ"
quantize_config = BaseQuantizeConfig(
bits=4,
group_size=128,
desc_act=False
)
model = AutoGPTQForCausalLM.from_quantized(
model_id,
use_safetensors=True,
device="cuda:0",
quantize_config=quantize_config)
tokenizer = AutoTokenizer.from_pretrained(model_id)
pipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
max_new_tokens=512,
temperature=0.7,
top_p=0.95,
repetition_penalty=1.1
)
outputs = pipe("What is a large language model?")
print(outputs[0]["generated_text"])
``` |
mradermacher/Irene-RP-v2-7B_128k-GGUF | mradermacher | 2024-06-09T11:48:42Z | 3,287 | 0 | transformers | [
"transformers",
"gguf",
"merge",
"mergekit",
"lazymergekit",
"yanismiraoui/Yarn-Mistral-7b-128k-sharded",
"Virt-io/Irene-RP-v2-7B",
"en",
"base_model:Virt-io/Irene-RP-v2-7B_128k",
"endpoints_compatible",
"region:us"
] | null | 2024-06-08T23:53:08Z | ---
base_model: Virt-io/Irene-RP-v2-7B_128k
language:
- en
library_name: transformers
quantized_by: mradermacher
tags:
- merge
- mergekit
- lazymergekit
- yanismiraoui/Yarn-Mistral-7b-128k-sharded
- Virt-io/Irene-RP-v2-7B
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
static quants of https://huggingface.co/Virt-io/Irene-RP-v2-7B_128k
<!-- provided-files -->
weighted/imatrix quants are available at https://huggingface.co/mradermacher/Irene-RP-v2-7B_128k-i1-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/Irene-RP-v2-7B_128k-GGUF/resolve/main/Irene-RP-v2-7B_128k.Q2_K.gguf) | Q2_K | 2.8 | |
| [GGUF](https://huggingface.co/mradermacher/Irene-RP-v2-7B_128k-GGUF/resolve/main/Irene-RP-v2-7B_128k.IQ3_XS.gguf) | IQ3_XS | 3.1 | |
| [GGUF](https://huggingface.co/mradermacher/Irene-RP-v2-7B_128k-GGUF/resolve/main/Irene-RP-v2-7B_128k.Q3_K_S.gguf) | Q3_K_S | 3.3 | |
| [GGUF](https://huggingface.co/mradermacher/Irene-RP-v2-7B_128k-GGUF/resolve/main/Irene-RP-v2-7B_128k.IQ3_S.gguf) | IQ3_S | 3.3 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/Irene-RP-v2-7B_128k-GGUF/resolve/main/Irene-RP-v2-7B_128k.IQ3_M.gguf) | IQ3_M | 3.4 | |
| [GGUF](https://huggingface.co/mradermacher/Irene-RP-v2-7B_128k-GGUF/resolve/main/Irene-RP-v2-7B_128k.Q3_K_M.gguf) | Q3_K_M | 3.6 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/Irene-RP-v2-7B_128k-GGUF/resolve/main/Irene-RP-v2-7B_128k.Q3_K_L.gguf) | Q3_K_L | 3.9 | |
| [GGUF](https://huggingface.co/mradermacher/Irene-RP-v2-7B_128k-GGUF/resolve/main/Irene-RP-v2-7B_128k.IQ4_XS.gguf) | IQ4_XS | 4.0 | |
| [GGUF](https://huggingface.co/mradermacher/Irene-RP-v2-7B_128k-GGUF/resolve/main/Irene-RP-v2-7B_128k.Q4_K_S.gguf) | Q4_K_S | 4.2 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Irene-RP-v2-7B_128k-GGUF/resolve/main/Irene-RP-v2-7B_128k.Q4_K_M.gguf) | Q4_K_M | 4.5 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Irene-RP-v2-7B_128k-GGUF/resolve/main/Irene-RP-v2-7B_128k.Q5_K_S.gguf) | Q5_K_S | 5.1 | |
| [GGUF](https://huggingface.co/mradermacher/Irene-RP-v2-7B_128k-GGUF/resolve/main/Irene-RP-v2-7B_128k.Q5_K_M.gguf) | Q5_K_M | 5.2 | |
| [GGUF](https://huggingface.co/mradermacher/Irene-RP-v2-7B_128k-GGUF/resolve/main/Irene-RP-v2-7B_128k.Q6_K.gguf) | Q6_K | 6.0 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/Irene-RP-v2-7B_128k-GGUF/resolve/main/Irene-RP-v2-7B_128k.Q8_0.gguf) | Q8_0 | 7.8 | fast, best quality |
| [GGUF](https://huggingface.co/mradermacher/Irene-RP-v2-7B_128k-GGUF/resolve/main/Irene-RP-v2-7B_128k.f16.gguf) | f16 | 14.6 | 16 bpw, overkill |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
KoboldAI/LLAMA2-13B-Holodeck-1 | KoboldAI | 2023-07-28T21:08:16Z | 3,284 | 22 | transformers | [
"transformers",
"pytorch",
"safetensors",
"llama",
"text-generation",
"en",
"license:other",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2023-07-28T09:33:08Z | ---
license: other
language: en
commercial: no
inference: true
---
# LLAMA2 13B - Holodeck
## Model Description
LLAMA2 13B-Holodeck is a finetune created using Meta's llama 2 model.
## Training data
The training data contains around 3000 ebooks in various genres.
Most parts of the dataset have been prepended using the following text: `[Genre: <genre1>, <genre2>]`
### How to use
You can use this model directly with a pipeline for text generation. This example generates a different sequence each time it's run:
```py
>>> from transformers import pipeline
>>> generator = pipeline('text-generation', model='KoboldAI/LLAMA2-13B-Holodeck-1')
>>> generator("Welcome Captain Janeway, I apologize for the delay.", do_sample=True, min_length=50)
[{'generated_text': 'Welcome Captain Janeway, I apologize for the delay."\nIt's all right," Janeway said. "I'm certain that you're doing your best to keep me informed of what\'s going on."'}]
```
### Limitations and Biases
Based on known problems with NLP technology, potential relevant factors include bias (gender, profession, race and religion).
### License
Llama 2 is licensed under the LLAMA 2 Community License, Copyright (c) Meta Platforms, Inc. All Rights Reserved.
**Extra clause:**
You shall use the Materials and Products solely for research purposes or personal use and not for any commercial purpose. Nothing in the Community License shall be construed as granting you a license to use the Materials or Products for any other purpose.
### BibTeX entry and citation info
https://huggingface.co/meta-llama/Llama-2-13b-hf |
TheBloke/CodeLlama-7B-Python-GGUF | TheBloke | 2023-09-27T12:46:03Z | 3,283 | 49 | transformers | [
"transformers",
"gguf",
"llama",
"llama-2",
"text-generation",
"code",
"arxiv:2308.12950",
"base_model:codellama/CodeLlama-7b-python-hf",
"license:llama2",
"text-generation-inference",
"region:us"
] | text-generation | 2023-08-24T17:02:03Z | ---
language:
- code
license: llama2
tags:
- llama-2
model_name: CodeLlama 7B Python
base_model: codellama/CodeLlama-7b-python-hf
inference: false
model_creator: Meta
model_type: llama
pipeline_tag: text-generation
prompt_template: '[INST] Write code to solve the following coding problem that obeys
the constraints and passes the example test cases. Please wrap your code answer
using ```:
{prompt}
[/INST]
'
quantized_by: TheBloke
---
<!-- header start -->
<!-- 200823 -->
<div style="width: auto; margin-left: auto; margin-right: auto">
<img src="https://i.imgur.com/EBdldam.jpg" alt="TheBlokeAI" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</div>
<div style="display: flex; justify-content: space-between; width: 100%;">
<div style="display: flex; flex-direction: column; align-items: flex-start;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://discord.gg/theblokeai">Chat & support: TheBloke's Discord server</a></p>
</div>
<div style="display: flex; flex-direction: column; align-items: flex-end;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://www.patreon.com/TheBlokeAI">Want to contribute? TheBloke's Patreon page</a></p>
</div>
</div>
<div style="text-align:center; margin-top: 0em; margin-bottom: 0em"><p style="margin-top: 0.25em; margin-bottom: 0em;">TheBloke's LLM work is generously supported by a grant from <a href="https://a16z.com">andreessen horowitz (a16z)</a></p></div>
<hr style="margin-top: 1.0em; margin-bottom: 1.0em;">
<!-- header end -->
# CodeLlama 7B Python - GGUF
- Model creator: [Meta](https://huggingface.co/meta-llama)
- Original model: [CodeLlama 7B Python](https://huggingface.co/codellama/CodeLlama-7b-python-hf)
<!-- description start -->
## Description
This repo contains GGUF format model files for [Meta's CodeLlama 7B Python](https://huggingface.co/codellama/CodeLlama-7b-python-hf).
<!-- description end -->
<!-- README_GGUF.md-about-gguf start -->
### About GGUF
GGUF is a new format introduced by the llama.cpp team on August 21st 2023. It is a replacement for GGML, which is no longer supported by llama.cpp. GGUF offers numerous advantages over GGML, such as better tokenisation, and support for special tokens. It is also supports metadata, and is designed to be extensible.
Here is an incomplate list of clients and libraries that are known to support GGUF:
* [llama.cpp](https://github.com/ggerganov/llama.cpp). The source project for GGUF. Offers a CLI and a server option.
* [text-generation-webui](https://github.com/oobabooga/text-generation-webui), the most widely used web UI, with many features and powerful extensions. Supports GPU acceleration.
* [KoboldCpp](https://github.com/LostRuins/koboldcpp), a fully featured web UI, with GPU accel across all platforms and GPU architectures. Especially good for story telling.
* [LM Studio](https://lmstudio.ai/), an easy-to-use and powerful local GUI for Windows and macOS (Silicon), with GPU acceleration.
* [LoLLMS Web UI](https://github.com/ParisNeo/lollms-webui), a great web UI with many interesting and unique features, including a full model library for easy model selection.
* [Faraday.dev](https://faraday.dev/), an attractive and easy to use character-based chat GUI for Windows and macOS (both Silicon and Intel), with GPU acceleration.
* [ctransformers](https://github.com/marella/ctransformers), a Python library with GPU accel, LangChain support, and OpenAI-compatible AI server.
* [llama-cpp-python](https://github.com/abetlen/llama-cpp-python), a Python library with GPU accel, LangChain support, and OpenAI-compatible API server.
* [candle](https://github.com/huggingface/candle), a Rust ML framework with a focus on performance, including GPU support, and ease of use.
<!-- README_GGUF.md-about-gguf end -->
<!-- repositories-available start -->
## Repositories available
* [AWQ model(s) for GPU inference.](https://huggingface.co/TheBloke/CodeLlama-7B-Python-AWQ)
* [GPTQ models for GPU inference, with multiple quantisation parameter options.](https://huggingface.co/TheBloke/CodeLlama-7B-Python-GPTQ)
* [2, 3, 4, 5, 6 and 8-bit GGUF models for CPU+GPU inference](https://huggingface.co/TheBloke/CodeLlama-7B-Python-GGUF)
* [Meta's original unquantised fp16 model in pytorch format, for GPU inference and for further conversions](https://huggingface.co/codellama/CodeLlama-7b-python-hf)
<!-- repositories-available end -->
<!-- prompt-template start -->
## Prompt template: CodeLlama
```
[INST] Write code to solve the following coding problem that obeys the constraints and passes the example test cases. Please wrap your code answer using ```:
{prompt}
[/INST]
```
<!-- prompt-template end -->
<!-- compatibility_gguf start -->
## Compatibility
These quantised GGUFv2 files are compatible with llama.cpp from August 27th onwards, as of commit [d0cee0d36d5be95a0d9088b674dbb27354107221](https://github.com/ggerganov/llama.cpp/commit/d0cee0d36d5be95a0d9088b674dbb27354107221)
They are also compatible with many third party UIs and libraries - please see the list at the top of this README.
## Explanation of quantisation methods
<details>
<summary>Click to see details</summary>
The new methods available are:
* GGML_TYPE_Q2_K - "type-1" 2-bit quantization in super-blocks containing 16 blocks, each block having 16 weight. Block scales and mins are quantized with 4 bits. This ends up effectively using 2.5625 bits per weight (bpw)
* GGML_TYPE_Q3_K - "type-0" 3-bit quantization in super-blocks containing 16 blocks, each block having 16 weights. Scales are quantized with 6 bits. This end up using 3.4375 bpw.
* GGML_TYPE_Q4_K - "type-1" 4-bit quantization in super-blocks containing 8 blocks, each block having 32 weights. Scales and mins are quantized with 6 bits. This ends up using 4.5 bpw.
* GGML_TYPE_Q5_K - "type-1" 5-bit quantization. Same super-block structure as GGML_TYPE_Q4_K resulting in 5.5 bpw
* GGML_TYPE_Q6_K - "type-0" 6-bit quantization. Super-blocks with 16 blocks, each block having 16 weights. Scales are quantized with 8 bits. This ends up using 6.5625 bpw
Refer to the Provided Files table below to see what files use which methods, and how.
</details>
<!-- compatibility_gguf end -->
<!-- README_GGUF.md-provided-files start -->
## Provided files
| Name | Quant method | Bits | Size | Max RAM required | Use case |
| ---- | ---- | ---- | ---- | ---- | ----- |
| [codellama-7b-python.Q2_K.gguf](https://huggingface.co/TheBloke/CodeLlama-7B-Python-GGUF/blob/main/codellama-7b-python.Q2_K.gguf) | Q2_K | 2 | 2.83 GB| 5.33 GB | smallest, significant quality loss - not recommended for most purposes |
| [codellama-7b-python.Q3_K_S.gguf](https://huggingface.co/TheBloke/CodeLlama-7B-Python-GGUF/blob/main/codellama-7b-python.Q3_K_S.gguf) | Q3_K_S | 3 | 2.95 GB| 5.45 GB | very small, high quality loss |
| [codellama-7b-python.Q3_K_M.gguf](https://huggingface.co/TheBloke/CodeLlama-7B-Python-GGUF/blob/main/codellama-7b-python.Q3_K_M.gguf) | Q3_K_M | 3 | 3.30 GB| 5.80 GB | very small, high quality loss |
| [codellama-7b-python.Q3_K_L.gguf](https://huggingface.co/TheBloke/CodeLlama-7B-Python-GGUF/blob/main/codellama-7b-python.Q3_K_L.gguf) | Q3_K_L | 3 | 3.60 GB| 6.10 GB | small, substantial quality loss |
| [codellama-7b-python.Q4_0.gguf](https://huggingface.co/TheBloke/CodeLlama-7B-Python-GGUF/blob/main/codellama-7b-python.Q4_0.gguf) | Q4_0 | 4 | 3.83 GB| 6.33 GB | legacy; small, very high quality loss - prefer using Q3_K_M |
| [codellama-7b-python.Q4_K_S.gguf](https://huggingface.co/TheBloke/CodeLlama-7B-Python-GGUF/blob/main/codellama-7b-python.Q4_K_S.gguf) | Q4_K_S | 4 | 3.86 GB| 6.36 GB | small, greater quality loss |
| [codellama-7b-python.Q4_K_M.gguf](https://huggingface.co/TheBloke/CodeLlama-7B-Python-GGUF/blob/main/codellama-7b-python.Q4_K_M.gguf) | Q4_K_M | 4 | 4.08 GB| 6.58 GB | medium, balanced quality - recommended |
| [codellama-7b-python.Q5_0.gguf](https://huggingface.co/TheBloke/CodeLlama-7B-Python-GGUF/blob/main/codellama-7b-python.Q5_0.gguf) | Q5_0 | 5 | 4.65 GB| 7.15 GB | legacy; medium, balanced quality - prefer using Q4_K_M |
| [codellama-7b-python.Q5_K_S.gguf](https://huggingface.co/TheBloke/CodeLlama-7B-Python-GGUF/blob/main/codellama-7b-python.Q5_K_S.gguf) | Q5_K_S | 5 | 4.65 GB| 7.15 GB | large, low quality loss - recommended |
| [codellama-7b-python.Q5_K_M.gguf](https://huggingface.co/TheBloke/CodeLlama-7B-Python-GGUF/blob/main/codellama-7b-python.Q5_K_M.gguf) | Q5_K_M | 5 | 4.78 GB| 7.28 GB | large, very low quality loss - recommended |
| [codellama-7b-python.Q6_K.gguf](https://huggingface.co/TheBloke/CodeLlama-7B-Python-GGUF/blob/main/codellama-7b-python.Q6_K.gguf) | Q6_K | 6 | 5.53 GB| 8.03 GB | very large, extremely low quality loss |
| [codellama-7b-python.Q8_0.gguf](https://huggingface.co/TheBloke/CodeLlama-7B-Python-GGUF/blob/main/codellama-7b-python.Q8_0.gguf) | Q8_0 | 8 | 7.16 GB| 9.66 GB | very large, extremely low quality loss - not recommended |
**Note**: the above RAM figures assume no GPU offloading. If layers are offloaded to the GPU, this will reduce RAM usage and use VRAM instead.
<!-- README_GGUF.md-provided-files end -->
<!-- README_GGUF.md-how-to-download start -->
## How to download GGUF files
**Note for manual downloaders:** You almost never want to clone the entire repo! Multiple different quantisation formats are provided, and most users only want to pick and download a single file.
The following clients/libraries will automatically download models for you, providing a list of available models to choose from:
- LM Studio
- LoLLMS Web UI
- Faraday.dev
### In `text-generation-webui`
Under Download Model, you can enter the model repo: TheBloke/CodeLlama-7B-Python-GGUF and below it, a specific filename to download, such as: codellama-7b-python.q4_K_M.gguf.
Then click Download.
### On the command line, including multiple files at once
I recommend using the `huggingface-hub` Python library:
```shell
pip3 install huggingface-hub>=0.17.1
```
Then you can download any individual model file to the current directory, at high speed, with a command like this:
```shell
huggingface-cli download TheBloke/CodeLlama-7B-Python-GGUF codellama-7b-python.q4_K_M.gguf --local-dir . --local-dir-use-symlinks False
```
<details>
<summary>More advanced huggingface-cli download usage</summary>
You can also download multiple files at once with a pattern:
```shell
huggingface-cli download TheBloke/CodeLlama-7B-Python-GGUF --local-dir . --local-dir-use-symlinks False --include='*Q4_K*gguf'
```
For more documentation on downloading with `huggingface-cli`, please see: [HF -> Hub Python Library -> Download files -> Download from the CLI](https://huggingface.co/docs/huggingface_hub/guides/download#download-from-the-cli).
To accelerate downloads on fast connections (1Gbit/s or higher), install `hf_transfer`:
```shell
pip3 install hf_transfer
```
And set environment variable `HF_HUB_ENABLE_HF_TRANSFER` to `1`:
```shell
HUGGINGFACE_HUB_ENABLE_HF_TRANSFER=1 huggingface-cli download TheBloke/CodeLlama-7B-Python-GGUF codellama-7b-python.q4_K_M.gguf --local-dir . --local-dir-use-symlinks False
```
Windows CLI users: Use `set HUGGINGFACE_HUB_ENABLE_HF_TRANSFER=1` before running the download command.
</details>
<!-- README_GGUF.md-how-to-download end -->
<!-- README_GGUF.md-how-to-run start -->
## Example `llama.cpp` command
Make sure you are using `llama.cpp` from commit [d0cee0d36d5be95a0d9088b674dbb27354107221](https://github.com/ggerganov/llama.cpp/commit/d0cee0d36d5be95a0d9088b674dbb27354107221) or later.
```shell
./main -ngl 32 -m codellama-7b-python.q4_K_M.gguf --color -c 4096 --temp 0.7 --repeat_penalty 1.1 -n -1 -p "[INST] Write code to solve the following coding problem that obeys the constraints and passes the example test cases. Please wrap your code answer using ```:\n{prompt}\n[/INST]"
```
Change `-ngl 32` to the number of layers to offload to GPU. Remove it if you don't have GPU acceleration.
Change `-c 4096` to the desired sequence length. For extended sequence models - eg 8K, 16K, 32K - the necessary RoPE scaling parameters are read from the GGUF file and set by llama.cpp automatically.
If you want to have a chat-style conversation, replace the `-p <PROMPT>` argument with `-i -ins`
For other parameters and how to use them, please refer to [the llama.cpp documentation](https://github.com/ggerganov/llama.cpp/blob/master/examples/main/README.md)
## How to run in `text-generation-webui`
Further instructions here: [text-generation-webui/docs/llama.cpp.md](https://github.com/oobabooga/text-generation-webui/blob/main/docs/llama.cpp.md).
## How to run from Python code
You can use GGUF models from Python using the [llama-cpp-python](https://github.com/abetlen/llama-cpp-python) or [ctransformers](https://github.com/marella/ctransformers) libraries.
### How to load this model from Python using ctransformers
#### First install the package
```bash
# Base ctransformers with no GPU acceleration
pip install ctransformers>=0.2.24
# Or with CUDA GPU acceleration
pip install ctransformers[cuda]>=0.2.24
# Or with ROCm GPU acceleration
CT_HIPBLAS=1 pip install ctransformers>=0.2.24 --no-binary ctransformers
# Or with Metal GPU acceleration for macOS systems
CT_METAL=1 pip install ctransformers>=0.2.24 --no-binary ctransformers
```
#### Simple example code to load one of these GGUF models
```python
from ctransformers import AutoModelForCausalLM
# Set gpu_layers to the number of layers to offload to GPU. Set to 0 if no GPU acceleration is available on your system.
llm = AutoModelForCausalLM.from_pretrained("TheBloke/CodeLlama-7B-Python-GGUF", model_file="codellama-7b-python.q4_K_M.gguf", model_type="llama", gpu_layers=50)
print(llm("AI is going to"))
```
## How to use with LangChain
Here's guides on using llama-cpp-python or ctransformers with LangChain:
* [LangChain + llama-cpp-python](https://python.langchain.com/docs/integrations/llms/llamacpp)
* [LangChain + ctransformers](https://python.langchain.com/docs/integrations/providers/ctransformers)
<!-- README_GGUF.md-how-to-run end -->
<!-- footer start -->
<!-- 200823 -->
## Discord
For further support, and discussions on these models and AI in general, join us at:
[TheBloke AI's Discord server](https://discord.gg/theblokeai)
## Thanks, and how to contribute
Thanks to the [chirper.ai](https://chirper.ai) team!
Thanks to Clay from [gpus.llm-utils.org](llm-utils)!
I've had a lot of people ask if they can contribute. I enjoy providing models and helping people, and would love to be able to spend even more time doing it, as well as expanding into new projects like fine tuning/training.
If you're able and willing to contribute it will be most gratefully received and will help me to keep providing more models, and to start work on new AI projects.
Donaters will get priority support on any and all AI/LLM/model questions and requests, access to a private Discord room, plus other benefits.
* Patreon: https://patreon.com/TheBlokeAI
* Ko-Fi: https://ko-fi.com/TheBlokeAI
**Special thanks to**: Aemon Algiz.
**Patreon special mentions**: Alicia Loh, Stephen Murray, K, Ajan Kanaga, RoA, Magnesian, Deo Leter, Olakabola, Eugene Pentland, zynix, Deep Realms, Raymond Fosdick, Elijah Stavena, Iucharbius, Erik Bjäreholt, Luis Javier Navarrete Lozano, Nicholas, theTransient, John Detwiler, alfie_i, knownsqashed, Mano Prime, Willem Michiel, Enrico Ros, LangChain4j, OG, Michael Dempsey, Pierre Kircher, Pedro Madruga, James Bentley, Thomas Belote, Luke @flexchar, Leonard Tan, Johann-Peter Hartmann, Illia Dulskyi, Fen Risland, Chadd, S_X, Jeff Scroggin, Ken Nordquist, Sean Connelly, Artur Olbinski, Swaroop Kallakuri, Jack West, Ai Maven, David Ziegler, Russ Johnson, transmissions 11, John Villwock, Alps Aficionado, Clay Pascal, Viktor Bowallius, Subspace Studios, Rainer Wilmers, Trenton Dambrowitz, vamX, Michael Levine, 준교 김, Brandon Frisco, Kalila, Trailburnt, Randy H, Talal Aujan, Nathan Dryer, Vadim, 阿明, ReadyPlayerEmma, Tiffany J. Kim, George Stoitzev, Spencer Kim, Jerry Meng, Gabriel Tamborski, Cory Kujawski, Jeffrey Morgan, Spiking Neurons AB, Edmond Seymore, Alexandros Triantafyllidis, Lone Striker, Cap'n Zoog, Nikolai Manek, danny, ya boyyy, Derek Yates, usrbinkat, Mandus, TL, Nathan LeClaire, subjectnull, Imad Khwaja, webtim, Raven Klaugh, Asp the Wyvern, Gabriel Puliatti, Caitlyn Gatomon, Joseph William Delisle, Jonathan Leane, Luke Pendergrass, SuperWojo, Sebastain Graf, Will Dee, Fred von Graf, Andrey, Dan Guido, Daniel P. Andersen, Nitin Borwankar, Elle, Vitor Caleffi, biorpg, jjj, NimbleBox.ai, Pieter, Matthew Berman, terasurfer, Michael Davis, Alex, Stanislav Ovsiannikov
Thank you to all my generous patrons and donaters!
And thank you again to a16z for their generous grant.
<!-- footer end -->
<!-- original-model-card start -->
# Original model card: Meta's CodeLlama 7B Python
# **Code Llama**
Code Llama is a collection of pretrained and fine-tuned generative text models ranging in scale from 7 billion to 34 billion parameters. This is the repository for the 7B Python specialist version in the Hugging Face Transformers format. This model is designed for general code synthesis and understanding. Links to other models can be found in the index at the bottom.
| | Base Model | Python | Instruct |
| --- | ----------------------------------------------------------------------------- | ------------------------------------------------------------------------------------------- | ----------------------------------------------------------------------------------------------- |
| 7B | [codellama/CodeLlama-7b-hf](https://huggingface.co/codellama/CodeLlama-7b-hf) | [codellama/CodeLlama-7b-Python-hf](https://huggingface.co/codellama/CodeLlama-7b-Python-hf) | [codellama/CodeLlama-7b-Instruct-hf](https://huggingface.co/codellama/CodeLlama-7b-Instruct-hf) |
| 13B | [codellama/CodeLlama-13b-hf](https://huggingface.co/codellama/CodeLlama-13b-hf) | [codellama/CodeLlama-13b-Python-hf](https://huggingface.co/codellama/CodeLlama-13b-Python-hf) | [codellama/CodeLlama-13b-Instruct-hf](https://huggingface.co/codellama/CodeLlama-13b-Instruct-hf) |
| 34B | [codellama/CodeLlama-34b-hf](https://huggingface.co/codellama/CodeLlama-34b-hf) | [codellama/CodeLlama-34b-Python-hf](https://huggingface.co/codellama/CodeLlama-34b-Python-hf) | [codellama/CodeLlama-34b-Instruct-hf](https://huggingface.co/codellama/CodeLlama-34b-Instruct-hf) |
## Model Use
To use this model, please make sure to install transformers from `main` until the next version is released:
```bash
pip install git+https://github.com/huggingface/transformers.git@main accelerate
```
Model capabilities:
- [x] Code completion.
- [ ] Infilling.
- [ ] Instructions / chat.
- [x] Python specialist.
## Model Details
*Note: Use of this model is governed by the Meta license. Meta developed and publicly released the Code Llama family of large language models (LLMs).
**Model Developers** Meta
**Variations** Code Llama comes in three model sizes, and three variants:
* Code Llama: base models designed for general code synthesis and understanding
* Code Llama - Python: designed specifically for Python
* Code Llama - Instruct: for instruction following and safer deployment
All variants are available in sizes of 7B, 13B and 34B parameters.
**This repository contains the Python version of the 7B parameters model.**
**Input** Models input text only.
**Output** Models generate text only.
**Model Architecture** Code Llama is an auto-regressive language model that uses an optimized transformer architecture.
**Model Dates** Code Llama and its variants have been trained between January 2023 and July 2023.
**Status** This is a static model trained on an offline dataset. Future versions of Code Llama - Instruct will be released as we improve model safety with community feedback.
**License** A custom commercial license is available at: [https://ai.meta.com/resources/models-and-libraries/llama-downloads/](https://ai.meta.com/resources/models-and-libraries/llama-downloads/)
**Research Paper** More information can be found in the paper "[Code Llama: Open Foundation Models for Code](https://ai.meta.com/research/publications/code-llama-open-foundation-models-for-code/)" or its [arXiv page](https://arxiv.org/abs/2308.12950).
## Intended Use
**Intended Use Cases** Code Llama and its variants is intended for commercial and research use in English and relevant programming languages. The base model Code Llama can be adapted for a variety of code synthesis and understanding tasks, Code Llama - Python is designed specifically to handle the Python programming language, and Code Llama - Instruct is intended to be safer to use for code assistant and generation applications.
**Out-of-Scope Uses** Use in any manner that violates applicable laws or regulations (including trade compliance laws). Use in languages other than English. Use in any other way that is prohibited by the Acceptable Use Policy and Licensing Agreement for Code Llama and its variants.
## Hardware and Software
**Training Factors** We used custom training libraries. The training and fine-tuning of the released models have been performed Meta’s Research Super Cluster.
**Carbon Footprint** In aggregate, training all 9 Code Llama models required 400K GPU hours of computation on hardware of type A100-80GB (TDP of 350-400W). Estimated total emissions were 65.3 tCO2eq, 100% of which were offset by Meta’s sustainability program.
## Training Data
All experiments reported here and the released models have been trained and fine-tuned using the same data as Llama 2 with different weights (see Section 2 and Table 1 in the [research paper](https://ai.meta.com/research/publications/code-llama-open-foundation-models-for-code/) for details).
## Evaluation Results
See evaluations for the main models and detailed ablations in Section 3 and safety evaluations in Section 4 of the research paper.
## Ethical Considerations and Limitations
Code Llama and its variants are a new technology that carries risks with use. Testing conducted to date has been in English, and has not covered, nor could it cover all scenarios. For these reasons, as with all LLMs, Code Llama’s potential outputs cannot be predicted in advance, and the model may in some instances produce inaccurate or objectionable responses to user prompts. Therefore, before deploying any applications of Code Llama, developers should perform safety testing and tuning tailored to their specific applications of the model.
Please see the Responsible Use Guide available available at [https://ai.meta.com/llama/responsible-user-guide](https://ai.meta.com/llama/responsible-user-guide).
<!-- original-model-card end -->
|
TheBloke/Guanaco-7B-Uncensored-GGUF | TheBloke | 2023-09-27T12:48:27Z | 3,283 | 13 | transformers | [
"transformers",
"gguf",
"llama",
"conversational",
"en",
"dataset:Fredithefish/openassistant-guanaco-unfiltered",
"base_model:Fredithefish/Guanaco-7b-Uncensored",
"license:apache-2.0",
"text-generation-inference",
"region:us"
] | text-generation | 2023-09-08T07:50:48Z | ---
language:
- en
license: apache-2.0
library_name: transformers
datasets:
- Fredithefish/openassistant-guanaco-unfiltered
model_name: Guanaco 7B Uncensored
base_model: Fredithefish/Guanaco-7b-Uncensored
inference: false
model_creator: Fredithefish
model_type: llama
pipeline_tag: conversational
prompt_template: '### Human: {prompt}
### Assistant:
'
quantized_by: TheBloke
---
<!-- header start -->
<!-- 200823 -->
<div style="width: auto; margin-left: auto; margin-right: auto">
<img src="https://i.imgur.com/EBdldam.jpg" alt="TheBlokeAI" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</div>
<div style="display: flex; justify-content: space-between; width: 100%;">
<div style="display: flex; flex-direction: column; align-items: flex-start;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://discord.gg/theblokeai">Chat & support: TheBloke's Discord server</a></p>
</div>
<div style="display: flex; flex-direction: column; align-items: flex-end;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://www.patreon.com/TheBlokeAI">Want to contribute? TheBloke's Patreon page</a></p>
</div>
</div>
<div style="text-align:center; margin-top: 0em; margin-bottom: 0em"><p style="margin-top: 0.25em; margin-bottom: 0em;">TheBloke's LLM work is generously supported by a grant from <a href="https://a16z.com">andreessen horowitz (a16z)</a></p></div>
<hr style="margin-top: 1.0em; margin-bottom: 1.0em;">
<!-- header end -->
# Guanaco 7B Uncensored - GGUF
- Model creator: [Fredithefish](https://huggingface.co/Fredithefish)
- Original model: [Guanaco 7B Uncensored](https://huggingface.co/Fredithefish/Guanaco-7b-Uncensored)
<!-- description start -->
## Description
This repo contains GGUF format model files for [Fredithefish's Guanaco 7B Uncensored](https://huggingface.co/Fredithefish/Guanaco-7b-Uncensored).
<!-- description end -->
<!-- README_GGUF.md-about-gguf start -->
### About GGUF
GGUF is a new format introduced by the llama.cpp team on August 21st 2023. It is a replacement for GGML, which is no longer supported by llama.cpp. GGUF offers numerous advantages over GGML, such as better tokenisation, and support for special tokens. It is also supports metadata, and is designed to be extensible.
Here is an incomplate list of clients and libraries that are known to support GGUF:
* [llama.cpp](https://github.com/ggerganov/llama.cpp). The source project for GGUF. Offers a CLI and a server option.
* [text-generation-webui](https://github.com/oobabooga/text-generation-webui), the most widely used web UI, with many features and powerful extensions. Supports GPU acceleration.
* [KoboldCpp](https://github.com/LostRuins/koboldcpp), a fully featured web UI, with GPU accel across all platforms and GPU architectures. Especially good for story telling.
* [LM Studio](https://lmstudio.ai/), an easy-to-use and powerful local GUI for Windows and macOS (Silicon), with GPU acceleration.
* [LoLLMS Web UI](https://github.com/ParisNeo/lollms-webui), a great web UI with many interesting and unique features, including a full model library for easy model selection.
* [Faraday.dev](https://faraday.dev/), an attractive and easy to use character-based chat GUI for Windows and macOS (both Silicon and Intel), with GPU acceleration.
* [ctransformers](https://github.com/marella/ctransformers), a Python library with GPU accel, LangChain support, and OpenAI-compatible AI server.
* [llama-cpp-python](https://github.com/abetlen/llama-cpp-python), a Python library with GPU accel, LangChain support, and OpenAI-compatible API server.
* [candle](https://github.com/huggingface/candle), a Rust ML framework with a focus on performance, including GPU support, and ease of use.
<!-- README_GGUF.md-about-gguf end -->
<!-- repositories-available start -->
## Repositories available
* [AWQ model(s) for GPU inference.](https://huggingface.co/TheBloke/Guanaco-7B-Uncensored-AWQ)
* [GPTQ models for GPU inference, with multiple quantisation parameter options.](https://huggingface.co/TheBloke/Guanaco-7B-Uncensored-GPTQ)
* [2, 3, 4, 5, 6 and 8-bit GGUF models for CPU+GPU inference](https://huggingface.co/TheBloke/Guanaco-7B-Uncensored-GGUF)
* [Fredithefish's original unquantised fp16 model in pytorch format, for GPU inference and for further conversions](https://huggingface.co/Fredithefish/Guanaco-7b-Uncensored)
<!-- repositories-available end -->
<!-- prompt-template start -->
## Prompt template: Guanaco
```
### Human: {prompt}
### Assistant:
```
<!-- prompt-template end -->
<!-- licensing start -->
## Licensing
The creator of the source model has listed its license as `apache-2.0`, and this quantization has therefore used that same license.
As this model is based on Llama 2, it is also subject to the Meta Llama 2 license terms, and the license files for that are additionally included. It should therefore be considered as being claimed to be licensed under both licenses. I contacted Hugging Face for clarification on dual licensing but they do not yet have an official position. Should this change, or should Meta provide any feedback on this situation, I will update this section accordingly.
In the meantime, any questions regarding licensing, and in particular how these two licenses might interact, should be directed to the original model repository: [Fredithefish's Guanaco 7B Uncensored](https://huggingface.co/Fredithefish/Guanaco-7b-Uncensored).
<!-- licensing end -->
<!-- compatibility_gguf start -->
## Compatibility
These quantised GGUFv2 files are compatible with llama.cpp from August 27th onwards, as of commit [d0cee0d36d5be95a0d9088b674dbb27354107221](https://github.com/ggerganov/llama.cpp/commit/d0cee0d36d5be95a0d9088b674dbb27354107221)
They are also compatible with many third party UIs and libraries - please see the list at the top of this README.
## Explanation of quantisation methods
<details>
<summary>Click to see details</summary>
The new methods available are:
* GGML_TYPE_Q2_K - "type-1" 2-bit quantization in super-blocks containing 16 blocks, each block having 16 weight. Block scales and mins are quantized with 4 bits. This ends up effectively using 2.5625 bits per weight (bpw)
* GGML_TYPE_Q3_K - "type-0" 3-bit quantization in super-blocks containing 16 blocks, each block having 16 weights. Scales are quantized with 6 bits. This end up using 3.4375 bpw.
* GGML_TYPE_Q4_K - "type-1" 4-bit quantization in super-blocks containing 8 blocks, each block having 32 weights. Scales and mins are quantized with 6 bits. This ends up using 4.5 bpw.
* GGML_TYPE_Q5_K - "type-1" 5-bit quantization. Same super-block structure as GGML_TYPE_Q4_K resulting in 5.5 bpw
* GGML_TYPE_Q6_K - "type-0" 6-bit quantization. Super-blocks with 16 blocks, each block having 16 weights. Scales are quantized with 8 bits. This ends up using 6.5625 bpw
Refer to the Provided Files table below to see what files use which methods, and how.
</details>
<!-- compatibility_gguf end -->
<!-- README_GGUF.md-provided-files start -->
## Provided files
| Name | Quant method | Bits | Size | Max RAM required | Use case |
| ---- | ---- | ---- | ---- | ---- | ----- |
| [guanaco-7b-uncensored.Q2_K.gguf](https://huggingface.co/TheBloke/Guanaco-7B-Uncensored-GGUF/blob/main/guanaco-7b-uncensored.Q2_K.gguf) | Q2_K | 2 | 2.83 GB| 5.33 GB | smallest, significant quality loss - not recommended for most purposes |
| [guanaco-7b-uncensored.Q3_K_S.gguf](https://huggingface.co/TheBloke/Guanaco-7B-Uncensored-GGUF/blob/main/guanaco-7b-uncensored.Q3_K_S.gguf) | Q3_K_S | 3 | 2.95 GB| 5.45 GB | very small, high quality loss |
| [guanaco-7b-uncensored.Q3_K_M.gguf](https://huggingface.co/TheBloke/Guanaco-7B-Uncensored-GGUF/blob/main/guanaco-7b-uncensored.Q3_K_M.gguf) | Q3_K_M | 3 | 3.30 GB| 5.80 GB | very small, high quality loss |
| [guanaco-7b-uncensored.Q3_K_L.gguf](https://huggingface.co/TheBloke/Guanaco-7B-Uncensored-GGUF/blob/main/guanaco-7b-uncensored.Q3_K_L.gguf) | Q3_K_L | 3 | 3.60 GB| 6.10 GB | small, substantial quality loss |
| [guanaco-7b-uncensored.Q4_0.gguf](https://huggingface.co/TheBloke/Guanaco-7B-Uncensored-GGUF/blob/main/guanaco-7b-uncensored.Q4_0.gguf) | Q4_0 | 4 | 3.83 GB| 6.33 GB | legacy; small, very high quality loss - prefer using Q3_K_M |
| [guanaco-7b-uncensored.Q4_K_S.gguf](https://huggingface.co/TheBloke/Guanaco-7B-Uncensored-GGUF/blob/main/guanaco-7b-uncensored.Q4_K_S.gguf) | Q4_K_S | 4 | 3.86 GB| 6.36 GB | small, greater quality loss |
| [guanaco-7b-uncensored.Q4_K_M.gguf](https://huggingface.co/TheBloke/Guanaco-7B-Uncensored-GGUF/blob/main/guanaco-7b-uncensored.Q4_K_M.gguf) | Q4_K_M | 4 | 4.08 GB| 6.58 GB | medium, balanced quality - recommended |
| [guanaco-7b-uncensored.Q5_0.gguf](https://huggingface.co/TheBloke/Guanaco-7B-Uncensored-GGUF/blob/main/guanaco-7b-uncensored.Q5_0.gguf) | Q5_0 | 5 | 4.65 GB| 7.15 GB | legacy; medium, balanced quality - prefer using Q4_K_M |
| [guanaco-7b-uncensored.Q5_K_S.gguf](https://huggingface.co/TheBloke/Guanaco-7B-Uncensored-GGUF/blob/main/guanaco-7b-uncensored.Q5_K_S.gguf) | Q5_K_S | 5 | 4.65 GB| 7.15 GB | large, low quality loss - recommended |
| [guanaco-7b-uncensored.Q5_K_M.gguf](https://huggingface.co/TheBloke/Guanaco-7B-Uncensored-GGUF/blob/main/guanaco-7b-uncensored.Q5_K_M.gguf) | Q5_K_M | 5 | 4.78 GB| 7.28 GB | large, very low quality loss - recommended |
| [guanaco-7b-uncensored.Q6_K.gguf](https://huggingface.co/TheBloke/Guanaco-7B-Uncensored-GGUF/blob/main/guanaco-7b-uncensored.Q6_K.gguf) | Q6_K | 6 | 5.53 GB| 8.03 GB | very large, extremely low quality loss |
| [guanaco-7b-uncensored.Q8_0.gguf](https://huggingface.co/TheBloke/Guanaco-7B-Uncensored-GGUF/blob/main/guanaco-7b-uncensored.Q8_0.gguf) | Q8_0 | 8 | 7.16 GB| 9.66 GB | very large, extremely low quality loss - not recommended |
**Note**: the above RAM figures assume no GPU offloading. If layers are offloaded to the GPU, this will reduce RAM usage and use VRAM instead.
<!-- README_GGUF.md-provided-files end -->
<!-- README_GGUF.md-how-to-download start -->
## How to download GGUF files
**Note for manual downloaders:** You almost never want to clone the entire repo! Multiple different quantisation formats are provided, and most users only want to pick and download a single file.
The following clients/libraries will automatically download models for you, providing a list of available models to choose from:
- LM Studio
- LoLLMS Web UI
- Faraday.dev
### In `text-generation-webui`
Under Download Model, you can enter the model repo: TheBloke/Guanaco-7B-Uncensored-GGUF and below it, a specific filename to download, such as: guanaco-7b-uncensored.q4_K_M.gguf.
Then click Download.
### On the command line, including multiple files at once
I recommend using the `huggingface-hub` Python library:
```shell
pip3 install huggingface-hub>=0.17.1
```
Then you can download any individual model file to the current directory, at high speed, with a command like this:
```shell
huggingface-cli download TheBloke/Guanaco-7B-Uncensored-GGUF guanaco-7b-uncensored.q4_K_M.gguf --local-dir . --local-dir-use-symlinks False
```
<details>
<summary>More advanced huggingface-cli download usage</summary>
You can also download multiple files at once with a pattern:
```shell
huggingface-cli download TheBloke/Guanaco-7B-Uncensored-GGUF --local-dir . --local-dir-use-symlinks False --include='*Q4_K*gguf'
```
For more documentation on downloading with `huggingface-cli`, please see: [HF -> Hub Python Library -> Download files -> Download from the CLI](https://huggingface.co/docs/huggingface_hub/guides/download#download-from-the-cli).
To accelerate downloads on fast connections (1Gbit/s or higher), install `hf_transfer`:
```shell
pip3 install hf_transfer
```
And set environment variable `HF_HUB_ENABLE_HF_TRANSFER` to `1`:
```shell
HUGGINGFACE_HUB_ENABLE_HF_TRANSFER=1 huggingface-cli download TheBloke/Guanaco-7B-Uncensored-GGUF guanaco-7b-uncensored.q4_K_M.gguf --local-dir . --local-dir-use-symlinks False
```
Windows CLI users: Use `set HUGGINGFACE_HUB_ENABLE_HF_TRANSFER=1` before running the download command.
</details>
<!-- README_GGUF.md-how-to-download end -->
<!-- README_GGUF.md-how-to-run start -->
## Example `llama.cpp` command
Make sure you are using `llama.cpp` from commit [d0cee0d36d5be95a0d9088b674dbb27354107221](https://github.com/ggerganov/llama.cpp/commit/d0cee0d36d5be95a0d9088b674dbb27354107221) or later.
```shell
./main -ngl 32 -m guanaco-7b-uncensored.q4_K_M.gguf --color -c 4096 --temp 0.7 --repeat_penalty 1.1 -n -1 -p "### Human: {prompt}\n### Assistant:"
```
Change `-ngl 32` to the number of layers to offload to GPU. Remove it if you don't have GPU acceleration.
Change `-c 4096` to the desired sequence length. For extended sequence models - eg 8K, 16K, 32K - the necessary RoPE scaling parameters are read from the GGUF file and set by llama.cpp automatically.
If you want to have a chat-style conversation, replace the `-p <PROMPT>` argument with `-i -ins`
For other parameters and how to use them, please refer to [the llama.cpp documentation](https://github.com/ggerganov/llama.cpp/blob/master/examples/main/README.md)
## How to run in `text-generation-webui`
Further instructions here: [text-generation-webui/docs/llama.cpp.md](https://github.com/oobabooga/text-generation-webui/blob/main/docs/llama.cpp.md).
## How to run from Python code
You can use GGUF models from Python using the [llama-cpp-python](https://github.com/abetlen/llama-cpp-python) or [ctransformers](https://github.com/marella/ctransformers) libraries.
### How to load this model from Python using ctransformers
#### First install the package
```bash
# Base ctransformers with no GPU acceleration
pip install ctransformers>=0.2.24
# Or with CUDA GPU acceleration
pip install ctransformers[cuda]>=0.2.24
# Or with ROCm GPU acceleration
CT_HIPBLAS=1 pip install ctransformers>=0.2.24 --no-binary ctransformers
# Or with Metal GPU acceleration for macOS systems
CT_METAL=1 pip install ctransformers>=0.2.24 --no-binary ctransformers
```
#### Simple example code to load one of these GGUF models
```python
from ctransformers import AutoModelForCausalLM
# Set gpu_layers to the number of layers to offload to GPU. Set to 0 if no GPU acceleration is available on your system.
llm = AutoModelForCausalLM.from_pretrained("TheBloke/Guanaco-7B-Uncensored-GGUF", model_file="guanaco-7b-uncensored.q4_K_M.gguf", model_type="llama", gpu_layers=50)
print(llm("AI is going to"))
```
## How to use with LangChain
Here's guides on using llama-cpp-python or ctransformers with LangChain:
* [LangChain + llama-cpp-python](https://python.langchain.com/docs/integrations/llms/llamacpp)
* [LangChain + ctransformers](https://python.langchain.com/docs/integrations/providers/ctransformers)
<!-- README_GGUF.md-how-to-run end -->
<!-- footer start -->
<!-- 200823 -->
## Discord
For further support, and discussions on these models and AI in general, join us at:
[TheBloke AI's Discord server](https://discord.gg/theblokeai)
## Thanks, and how to contribute
Thanks to the [chirper.ai](https://chirper.ai) team!
Thanks to Clay from [gpus.llm-utils.org](llm-utils)!
I've had a lot of people ask if they can contribute. I enjoy providing models and helping people, and would love to be able to spend even more time doing it, as well as expanding into new projects like fine tuning/training.
If you're able and willing to contribute it will be most gratefully received and will help me to keep providing more models, and to start work on new AI projects.
Donaters will get priority support on any and all AI/LLM/model questions and requests, access to a private Discord room, plus other benefits.
* Patreon: https://patreon.com/TheBlokeAI
* Ko-Fi: https://ko-fi.com/TheBlokeAI
**Special thanks to**: Aemon Algiz.
**Patreon special mentions**: Alicia Loh, Stephen Murray, K, Ajan Kanaga, RoA, Magnesian, Deo Leter, Olakabola, Eugene Pentland, zynix, Deep Realms, Raymond Fosdick, Elijah Stavena, Iucharbius, Erik Bjäreholt, Luis Javier Navarrete Lozano, Nicholas, theTransient, John Detwiler, alfie_i, knownsqashed, Mano Prime, Willem Michiel, Enrico Ros, LangChain4j, OG, Michael Dempsey, Pierre Kircher, Pedro Madruga, James Bentley, Thomas Belote, Luke @flexchar, Leonard Tan, Johann-Peter Hartmann, Illia Dulskyi, Fen Risland, Chadd, S_X, Jeff Scroggin, Ken Nordquist, Sean Connelly, Artur Olbinski, Swaroop Kallakuri, Jack West, Ai Maven, David Ziegler, Russ Johnson, transmissions 11, John Villwock, Alps Aficionado, Clay Pascal, Viktor Bowallius, Subspace Studios, Rainer Wilmers, Trenton Dambrowitz, vamX, Michael Levine, 준교 김, Brandon Frisco, Kalila, Trailburnt, Randy H, Talal Aujan, Nathan Dryer, Vadim, 阿明, ReadyPlayerEmma, Tiffany J. Kim, George Stoitzev, Spencer Kim, Jerry Meng, Gabriel Tamborski, Cory Kujawski, Jeffrey Morgan, Spiking Neurons AB, Edmond Seymore, Alexandros Triantafyllidis, Lone Striker, Cap'n Zoog, Nikolai Manek, danny, ya boyyy, Derek Yates, usrbinkat, Mandus, TL, Nathan LeClaire, subjectnull, Imad Khwaja, webtim, Raven Klaugh, Asp the Wyvern, Gabriel Puliatti, Caitlyn Gatomon, Joseph William Delisle, Jonathan Leane, Luke Pendergrass, SuperWojo, Sebastain Graf, Will Dee, Fred von Graf, Andrey, Dan Guido, Daniel P. Andersen, Nitin Borwankar, Elle, Vitor Caleffi, biorpg, jjj, NimbleBox.ai, Pieter, Matthew Berman, terasurfer, Michael Davis, Alex, Stanislav Ovsiannikov
Thank you to all my generous patrons and donaters!
And thank you again to a16z for their generous grant.
<!-- footer end -->
<!-- original-model-card start -->
# Original model card: Fredithefish's Guanaco 7B Uncensored
<img src="https://huggingface.co/Fredithefish/Guanaco-3B-Uncensored/resolve/main/Guanaco-Uncensored.jpg" alt="Alt Text" width="295"/>
# ✨ Guanaco - 7B - Uncensored ✨
Guanaco-7B-Uncensored has been fine-tuned for 4 epochs on the [Unfiltered Guanaco Dataset.](https://huggingface.co/datasets/Fredithefish/openassistant-guanaco-unfiltered) using [Llama-2-7b](https://hf.co/meta-llama/Llama-2-7b-hf) as the base model.
<br>The model does not perform well with languages other than English.
<br>Please note: This model is designed to provide responses without content filtering or censorship. It generates answers without denials.
## Special thanks
I would like to thank AutoMeta for providing me with the computing power necessary to train this model.
### Prompt Template
```
### Human: {prompt} ### Assistant:
```
### Dataset
The model has been fine-tuned on the V2 of the Guanaco unfiltered dataset.
<!-- original-model-card end -->
|
mradermacher/SnowLotus-v2-10.7B-i1-GGUF | mradermacher | 2024-06-19T12:18:08Z | 3,283 | 1 | transformers | [
"transformers",
"gguf",
"Roleplay",
"Solar",
"Mistral",
"Text Generation",
"merge",
"en",
"base_model:BlueNipples/SnowLotus-v2-10.7B",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2024-06-16T14:46:03Z | ---
base_model: BlueNipples/SnowLotus-v2-10.7B
language:
- en
library_name: transformers
license: apache-2.0
quantized_by: mradermacher
tags:
- Roleplay
- Solar
- Mistral
- Text Generation
- merge
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: nicoboss -->
weighted/imatrix quants of https://huggingface.co/BlueNipples/SnowLotus-v2-10.7B
<!-- provided-files -->
static quants are available at https://huggingface.co/mradermacher/SnowLotus-v2-10.7B-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/SnowLotus-v2-10.7B-i1-GGUF/resolve/main/SnowLotus-v2-10.7B.i1-IQ1_S.gguf) | i1-IQ1_S | 2.5 | for the desperate |
| [GGUF](https://huggingface.co/mradermacher/SnowLotus-v2-10.7B-i1-GGUF/resolve/main/SnowLotus-v2-10.7B.i1-IQ1_M.gguf) | i1-IQ1_M | 2.7 | mostly desperate |
| [GGUF](https://huggingface.co/mradermacher/SnowLotus-v2-10.7B-i1-GGUF/resolve/main/SnowLotus-v2-10.7B.i1-IQ2_XXS.gguf) | i1-IQ2_XXS | 3.0 | |
| [GGUF](https://huggingface.co/mradermacher/SnowLotus-v2-10.7B-i1-GGUF/resolve/main/SnowLotus-v2-10.7B.i1-IQ2_XS.gguf) | i1-IQ2_XS | 3.3 | |
| [GGUF](https://huggingface.co/mradermacher/SnowLotus-v2-10.7B-i1-GGUF/resolve/main/SnowLotus-v2-10.7B.i1-IQ2_S.gguf) | i1-IQ2_S | 3.5 | |
| [GGUF](https://huggingface.co/mradermacher/SnowLotus-v2-10.7B-i1-GGUF/resolve/main/SnowLotus-v2-10.7B.i1-IQ2_M.gguf) | i1-IQ2_M | 3.8 | |
| [GGUF](https://huggingface.co/mradermacher/SnowLotus-v2-10.7B-i1-GGUF/resolve/main/SnowLotus-v2-10.7B.i1-Q2_K.gguf) | i1-Q2_K | 4.1 | IQ3_XXS probably better |
| [GGUF](https://huggingface.co/mradermacher/SnowLotus-v2-10.7B-i1-GGUF/resolve/main/SnowLotus-v2-10.7B.i1-IQ3_XXS.gguf) | i1-IQ3_XXS | 4.3 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/SnowLotus-v2-10.7B-i1-GGUF/resolve/main/SnowLotus-v2-10.7B.i1-IQ3_XS.gguf) | i1-IQ3_XS | 4.5 | |
| [GGUF](https://huggingface.co/mradermacher/SnowLotus-v2-10.7B-i1-GGUF/resolve/main/SnowLotus-v2-10.7B.i1-Q3_K_S.gguf) | i1-Q3_K_S | 4.8 | IQ3_XS probably better |
| [GGUF](https://huggingface.co/mradermacher/SnowLotus-v2-10.7B-i1-GGUF/resolve/main/SnowLotus-v2-10.7B.i1-IQ3_S.gguf) | i1-IQ3_S | 4.8 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/SnowLotus-v2-10.7B-i1-GGUF/resolve/main/SnowLotus-v2-10.7B.i1-IQ3_M.gguf) | i1-IQ3_M | 4.9 | |
| [GGUF](https://huggingface.co/mradermacher/SnowLotus-v2-10.7B-i1-GGUF/resolve/main/SnowLotus-v2-10.7B.i1-Q3_K_M.gguf) | i1-Q3_K_M | 5.3 | IQ3_S probably better |
| [GGUF](https://huggingface.co/mradermacher/SnowLotus-v2-10.7B-i1-GGUF/resolve/main/SnowLotus-v2-10.7B.i1-Q3_K_L.gguf) | i1-Q3_K_L | 5.8 | IQ3_M probably better |
| [GGUF](https://huggingface.co/mradermacher/SnowLotus-v2-10.7B-i1-GGUF/resolve/main/SnowLotus-v2-10.7B.i1-IQ4_XS.gguf) | i1-IQ4_XS | 5.9 | |
| [GGUF](https://huggingface.co/mradermacher/SnowLotus-v2-10.7B-i1-GGUF/resolve/main/SnowLotus-v2-10.7B.i1-Q4_0.gguf) | i1-Q4_0 | 6.2 | fast, low quality |
| [GGUF](https://huggingface.co/mradermacher/SnowLotus-v2-10.7B-i1-GGUF/resolve/main/SnowLotus-v2-10.7B.i1-Q4_K_S.gguf) | i1-Q4_K_S | 6.2 | optimal size/speed/quality |
| [GGUF](https://huggingface.co/mradermacher/SnowLotus-v2-10.7B-i1-GGUF/resolve/main/SnowLotus-v2-10.7B.i1-Q4_K_M.gguf) | i1-Q4_K_M | 6.6 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/SnowLotus-v2-10.7B-i1-GGUF/resolve/main/SnowLotus-v2-10.7B.i1-Q5_K_S.gguf) | i1-Q5_K_S | 7.5 | |
| [GGUF](https://huggingface.co/mradermacher/SnowLotus-v2-10.7B-i1-GGUF/resolve/main/SnowLotus-v2-10.7B.i1-Q5_K_M.gguf) | i1-Q5_K_M | 7.7 | |
| [GGUF](https://huggingface.co/mradermacher/SnowLotus-v2-10.7B-i1-GGUF/resolve/main/SnowLotus-v2-10.7B.i1-Q6_K.gguf) | i1-Q6_K | 8.9 | practically like static Q6_K |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time. Additional thanks to [@nicoboss](https://huggingface.co/nicoboss) for giving me access to his hardware for calculating the imatrix for these quants.
<!-- end -->
|
KnutJaegersberg/black_goo_recipe_a | KnutJaegersberg | 2023-08-31T04:46:17Z | 3,280 | 0 | transformers | [
"transformers",
"pytorch",
"llama",
"text-generation",
"custom_code",
"license:cc-by-nc-4.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2023-08-30T21:50:21Z | ---
license: cc-by-nc-4.0
---
Prompt template
```
### Instruction:
What is the difference between operant and classical conditioning?
### Response:
Classical conditioning is a learning process that occurs when an organism is exposed to a stimulus that elicits a response. This response is referred to as a conditioned response (CR). The stimulus that elicits the response is called the conditioned stimulus (CS). The organism's response to the CS is called the unconditioned response (UR).
Operant conditioning is a learning process that occurs when an organism is exposed to a stimulus that elicits a response. This response is referred to as an operant response (OR). The stimulus that elicits the response is called the operant stimulus (OS). The organism's response to the OS is called the operant response (OR).
Classical conditioning and operant conditioning are two different types of learning. Classical conditioning involves the association of a CS with a UR, while operant conditioning involves the association of an OS with an OR.
In classical conditioning, the CS is paired with the UR over time, resulting in the UR becoming conditioned to the CS. This process is referred to as Pavlovian conditioning. In operant conditioning, the OS is paired with the OR over time, resulting in the OR becoming conditioned to the OS. This process is referred to as instrumental conditioning.
Both classical conditioning and operant conditioning are important in learning and behavior modification. However, they differ in the way they are used and the types of responses they elicit.
In conclusion, classical conditioning and operant conditioning are two different types of learning that occur when an organism is exposed to a stimulus that elicits a response. Classical conditioning involves the association of a CS with a UR, while operant conditioning involves the association of an OS with an OR.
```
|
panopstor/EveryDream | panopstor | 2024-06-24T18:26:17Z | 3,279 | 10 | diffusers | [
"diffusers",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | 2022-11-17T03:28:15Z | ---
license: creativeml-openrail-m
---
This is simply a clone of Stable Diffusion 1.5 with the improved MSE VAE, along with a few other test files. |
rinna/youri-7b-chat | rinna | 2024-04-03T08:21:40Z | 3,279 | 15 | transformers | [
"transformers",
"pytorch",
"safetensors",
"llama",
"text-generation",
"ja",
"en",
"dataset:databricks/databricks-dolly-15k",
"dataset:kunishou/databricks-dolly-15k-ja",
"dataset:izumi-lab/llm-japanese-dataset",
"arxiv:2307.09288",
"arxiv:2404.01657",
"license:llama2",
"model-index",
"autotrain_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2023-10-30T15:12:30Z | ---
language:
- ja
- en
license: llama2
datasets:
- databricks/databricks-dolly-15k
- kunishou/databricks-dolly-15k-ja
- izumi-lab/llm-japanese-dataset
thumbnail: https://github.com/rinnakk/japanese-pretrained-models/blob/master/rinna.png
inference: false
model-index:
- name: youri-7b-chat
results:
- task:
type: text-generation
name: Text Generation
dataset:
name: AI2 Reasoning Challenge (25-Shot)
type: ai2_arc
config: ARC-Challenge
split: test
args:
num_few_shot: 25
metrics:
- type: acc_norm
value: 51.19
name: normalized accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=rinna/youri-7b-chat
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: HellaSwag (10-Shot)
type: hellaswag
split: validation
args:
num_few_shot: 10
metrics:
- type: acc_norm
value: 76.09
name: normalized accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=rinna/youri-7b-chat
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: MMLU (5-Shot)
type: cais/mmlu
config: all
split: test
args:
num_few_shot: 5
metrics:
- type: acc
value: 46.06
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=rinna/youri-7b-chat
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: TruthfulQA (0-shot)
type: truthful_qa
config: multiple_choice
split: validation
args:
num_few_shot: 0
metrics:
- type: mc2
value: 41.17
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=rinna/youri-7b-chat
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: Winogrande (5-shot)
type: winogrande
config: winogrande_xl
split: validation
args:
num_few_shot: 5
metrics:
- type: acc
value: 75.06
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=rinna/youri-7b-chat
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: GSM8k (5-shot)
type: gsm8k
config: main
split: test
args:
num_few_shot: 5
metrics:
- type: acc
value: 1.52
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=rinna/youri-7b-chat
name: Open LLM Leaderboard
---
# `rinna/youri-7b-chat`

# Overview
The model is the instruction-tuned version of [`rinna/youri-7b`](https://huggingface.co/rinna/youri-7b). It adopts a chat-style input format.
* **Model architecture**
A 32-layer, 4096-hidden-size transformer-based language model. Refer to the [llama2 paper](https://arxiv.org/abs/2307.09288) for architecture details.
* **Fine-tuning**
The fine-tuning data is the subset of the following datasets.
* [Databricks Dolly data](https://huggingface.co/datasets/databricks/databricks-dolly-15k)
* [Japanese Databricks Dolly data](https://huggingface.co/datasets/kunishou/databricks-dolly-15k-ja)
* [Anthropic HH RLHF data](https://huggingface.co/datasets/Anthropic/hh-rlhf) and its Japanese translation
* [FLAN Instruction Tuning data](https://github.com/google-research/FLAN) and its Japanese translation
* [Izumi lab LLM Japanese dataset](https://github.com/masanorihirano/llm-japanese-dataset/tree/main)
* The following sections are used
* alt
* aozora-txt
* CourseraParallel
* ParaNatCom
* Tab-delimited_Bilingual_Sentence_Pairs
* tanaka-corpus
* wikinews
* wordnet
* yasashi-japanese
* The [remaining sections](https://github.com/masanorihirano/llm-japanese-dataset/tree/main/datasets-cc-by-sa) contain commonly used evaluation corpora so they are skipped to prevent data leak.
* **Contributors**
- [Tianyu Zhao](https://huggingface.co/tianyuz)
- [Kei Sawada](https://huggingface.co/keisawada)
---
# Benchmarking
Please refer to [rinna's LM benchmark page](https://rinnakk.github.io/research/benchmarks/lm/index.html).
---
# How to use the model
~~~~python
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("rinna/youri-7b-chat")
model = AutoModelForCausalLM.from_pretrained("rinna/youri-7b-chat")
if torch.cuda.is_available():
model = model.to("cuda")
instruction = "次の日本語を英語に翻訳してください。"
input = "自然言語による指示に基づきタスクが解けるよう学習させることを Instruction tuning と呼びます。"
context = [
{
"speaker": "設定",
"text": instruction
},
{
"speaker": "ユーザー",
"text": input
}
]
prompt = [
f"{uttr['speaker']}: {uttr['text']}"
for uttr in context
]
prompt = "\n".join(prompt)
prompt = (
prompt
+ "\n"
+ "システム: "
)
token_ids = tokenizer.encode(prompt, add_special_tokens=False, return_tensors="pt")
with torch.no_grad():
output_ids = model.generate(
token_ids.to(model.device),
max_new_tokens=200,
do_sample=True,
temperature=0.5,
pad_token_id=tokenizer.pad_token_id,
bos_token_id=tokenizer.bos_token_id,
eos_token_id=tokenizer.eos_token_id
)
output = tokenizer.decode(output_ids.tolist()[0])
print(output)
"""
設定: 次の日本語を英語に翻訳してください。
ユーザー: 自然言語による指示に基づきタスクが解けるよう学習させることを Instruction tuning と呼びます。
システム: Learning to solve tasks based on natural language instructions is called instruction tuning.</s>
"""
output = output[len(prompt):-len("</s>")].strip()
input = "大規模言語モデル(だいきぼげんごモデル、英: large language model、LLM)は、多数のパラメータ(数千万から数十億)を持つ人工ニューラルネットワークで構成されるコンピュータ言語モデルで、膨大なラベルなしテキストを使用して自己教師あり学習または半教師あり学習によって訓練が行われる。"
context.extend([
{
"speaker": "システム",
"text": output
},
{
"speaker": "ユーザー",
"text": input
}
])
prompt = [
f"{uttr['speaker']}: {uttr['text']}"
for uttr in context
]
prompt = "\n".join(prompt)
prompt = (
prompt
+ "\n"
+ "システム: "
)
token_ids = tokenizer.encode(prompt, add_special_tokens=False, return_tensors="pt")
with torch.no_grad():
output_ids = model.generate(
token_ids.to(model.device),
max_new_tokens=200,
do_sample=True,
temperature=0.5,
pad_token_id=tokenizer.pad_token_id,
bos_token_id=tokenizer.bos_token_id,
eos_token_id=tokenizer.eos_token_id
)
output = tokenizer.decode(output_ids.tolist()[0])
print(output)
"""
設定: 次の日本語を英語に翻訳してください。
ユーザー: 自然言語による指示に基づきタスクが解けるよう学習させることを Instruction tuning と呼びます。
システム: Learning to solve tasks based on natural language instructions is called instruction tuning.
ユーザー: 大規模言語モデル(だいきぼげんごモデル、英: large language model、LLM)は、多数のパラメータ(数千万から数十億)を持つ人工ニューラルネットワークで構成されるコンピュータ言語モデルで、膨大なラベルなしテ キストを使用して自己教師あり学習または半教師あり学習によって訓練が行われる。
システム: Large language models (LLMs) are computer language models consisting of a deep artificial neural network with millions to billions of parameters that are trained by self-supervised learning or semi-supervised learning using vast unlabeled text corpora.</s>
"""
~~~~
---
# Tokenization
The model uses the original llama-2 tokenizer.
---
# How to cite
~~~
@misc{rinna-youri-7b-chat,
title = {rinna/youri-7b-chat},
author={Zhao, Tianyu and Sawada, Kei}
url = {https://huggingface.co/rinna/youri-7b-chat},
}
@inproceedings{sawada2024release,
title = {Release of Pre-Trained Models for the {J}apanese Language},
author = {Sawada, Kei and Zhao, Tianyu and Shing, Makoto and Mitsui, Kentaro and Kaga, Akio and Hono, Yukiya and Wakatsuki, Toshiaki and Mitsuda, Koh},
booktitle = {Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024)},
month = {5},
year = {2024},
url = {https://arxiv.org/abs/2404.01657},
}
~~~
---
# License
[The llama2 license](https://ai.meta.com/llama/license/)
# [Open LLM Leaderboard Evaluation Results](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)
Detailed results can be found [here](https://huggingface.co/datasets/open-llm-leaderboard/details_rinna__youri-7b-chat)
| Metric |Value|
|---------------------------------|----:|
|Avg. |48.51|
|AI2 Reasoning Challenge (25-Shot)|51.19|
|HellaSwag (10-Shot) |76.09|
|MMLU (5-Shot) |46.06|
|TruthfulQA (0-shot) |41.17|
|Winogrande (5-shot) |75.06|
|GSM8k (5-shot) | 1.52|
|
stabilityai/stablelm-tuned-alpha-3b | stabilityai | 2023-04-19T12:38:16Z | 3,278 | 112 | transformers | [
"transformers",
"pytorch",
"gpt_neox",
"text-generation",
"causal-lm",
"en",
"dataset:dmayhem93/ChatCombined",
"dataset:tatsu-lab/alpaca",
"dataset:nomic-ai/gpt4all_prompt_generations",
"dataset:Dahoas/full-hh-rlhf",
"dataset:jeffwan/sharegpt_vicuna",
"dataset:HuggingFaceH4/databricks_dolly_15k",
"license:cc-by-nc-sa-4.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2023-04-19T02:10:24Z | ---
language:
- en
tags:
- causal-lm
license:
- cc-by-nc-sa-4.0
datasets:
- dmayhem93/ChatCombined
- tatsu-lab/alpaca
- nomic-ai/gpt4all_prompt_generations
- Dahoas/full-hh-rlhf
- jeffwan/sharegpt_vicuna
- HuggingFaceH4/databricks_dolly_15k
---
# StableLM-Tuned-Alpha
## Model Description
`StableLM-Tuned-Alpha` is a suite of 3B and 7B parameter decoder-only language models built on top of the `StableLM-Base-Alpha` models and further fine-tuned on various chat and instruction-following datasets.
## Usage
Get started chatting with `StableLM-Tuned-Alpha` by using the following code snippet:
```python
from transformers import AutoModelForCausalLM, AutoTokenizer, StoppingCriteria, StoppingCriteriaList
tokenizer = AutoTokenizer.from_pretrained("StabilityAI/stablelm-tuned-alpha-7b")
model = AutoModelForCausalLM.from_pretrained("StabilityAI/stablelm-tuned-alpha-7b")
model.half().cuda()
class StopOnTokens(StoppingCriteria):
def __call__(self, input_ids: torch.LongTensor, scores: torch.FloatTensor, **kwargs) -> bool:
stop_ids = [50278, 50279, 50277, 1, 0]
for stop_id in stop_ids:
if input_ids[0][-1] == stop_id:
return True
return False
system_prompt = """<|SYSTEM|># StableLM Tuned (Alpha version)
- StableLM is a helpful and harmless open-source AI language model developed by StabilityAI.
- StableLM is excited to be able to help the user, but will refuse to do anything that could be considered harmful to the user.
- StableLM is more than just an information source, StableLM is also able to write poetry, short stories, and make jokes.
- StableLM will refuse to participate in anything that could harm a human.
"""
prompt = f"{system_prompt}<|USER|>What's your mood today?<|ASSISTANT|>"
inputs = tokenizer(prompt, return_tensors="pt").to("cuda")
tokens = model.generate(
**inputs,
max_new_tokens=64,
temperature=0.7,
do_sample=True,
stopping_criteria=StoppingCriteriaList([StopOnTokens()])
)
print(tokenizer.decode(tokens[0], skip_special_tokens=True))
```
StableLM Tuned should be used with prompts formatted to `<|SYSTEM|>...<|USER|>...<|ASSISTANT|>...`
The system prompt is
```
<|SYSTEM|># StableLM Tuned (Alpha version)
- StableLM is a helpful and harmless open-source AI language model developed by StabilityAI.
- StableLM is excited to be able to help the user, but will refuse to do anything that could be considered harmful to the user.
- StableLM is more than just an information source, StableLM is also able to write poetry, short stories, and make jokes.
- StableLM will refuse to participate in anything that could harm a human.
```
## Model Details
* **Developed by**: [Stability AI](https://stability.ai/)
* **Model type**: StableLM-Tuned-Alpha models are auto-regressive language models based on the NeoX transformer architecture.
* **Language(s)**: English
* **Library**: [HuggingFace Transformers](https://github.com/huggingface/transformers)
* **License**: Fine-tuned checkpoints (`StableLM-Tuned-Alpha`) are licensed under the Non-Commercial Creative Commons license ([CC BY-NC-SA-4.0](https://creativecommons.org/licenses/by-nc-sa/4.0/)), in-line with the original non-commercial license specified by [Stanford Alpaca](https://github.com/tatsu-lab/stanford_alpaca).
* **Contact**: For questions and comments about the model, please email `[email protected]`
## Training
| Parameters | Hidden Size | Layers | Heads | Sequence Length |
|------------|-------------|--------|-------|-----------------|
| 3B | 4096 | 16 | 32 | 4096 |
| 7B | 6144 | 16 | 48 | 4096 |
### Training Dataset
`StableLM-Tuned-Alpha` models are fine-tuned on a combination of five datasets:
[Alpaca](https://huggingface.co/datasets/tatsu-lab/alpaca), a dataset of 52,000 instructions and demonstrations generated by OpenAI's `text-davinci-003` engine.
[GPT4All Prompt Generations](https://huggingface.co/datasets/nomic-ai/gpt4all_prompt_generations), which consists of 400k prompts and responses generated by GPT-4;
[Anthropic HH](https://huggingface.co/datasets/Dahoas/full-hh-rlhf), made up of preferences about AI assistant helpfulness and harmlessness;
[DataBricks Dolly](https://github.com/databrickslabs/dolly), comprising 15k instruction/responses generated by Databricks employees in capability domains from the InstructGPT paper, including brainstorming, classification, closed QA, generation, information extraction, open QA and summarization;
and [ShareGPT Vicuna (English subset)](https://huggingface.co/datasets/jeffwan/sharegpt_vicuna), a dataset of conversations retrieved from [ShareGPT](https://sharegpt.com/).
### Training Procedure
Models are learned via supervised fine-tuning on the aforementioned datasets, trained in mixed-precision (FP16), and optimized with AdamW. We outline the following hyperparameters:
| Parameters | Batch Size | Learning Rate | Warm-up | Weight Decay | Betas |
|------------|------------|---------------|---------|--------------|-------------|
| 3B | 256 | 2e-5 | 50 | 0.01 | (0.9, 0.99) |
| 7B | 128 | 2e-5 | 100 | 0.01 | (0.9, 0.99) |
## Use and Limitations
### Intended Use
These models are intended to be used by the open-source community chat-like applications in adherence with the [CC BY-NC-SA-4.0](https://creativecommons.org/licenses/by-nc-sa/4.0/) license.
### Limitations and bias
Although the aforementioned datasets help to steer the base language models into "safer" distributions of text, not all biases and toxicity can be mitigated through fine-tuning. We ask that users be mindful of such potential issues that can arise in generated responses. Do not treat model outputs as substitutes for human judgment or as sources of truth. Please use responsibly.
## Acknowledgements
This work would not have been possible without the helpful hand of Dakota Mahan ([@dmayhem93](https://huggingface.co/dmayhem93)).
## Citations
```bibtex
@misc{alpaca,
author = {Rohan Taori and Ishaan Gulrajani and Tianyi Zhang and Yann Dubois and Xuechen Li and Carlos Guestrin and Percy Liang and Tatsunori B. Hashimoto },
title = {Stanford Alpaca: An Instruction-following LLaMA model},
year = {2023},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {\url{https://github.com/tatsu-lab/stanford_alpaca}},
}
```
```bibtext
@misc{vicuna2023,
title = {Vicuna: An Open-Source Chatbot Impressing GPT-4 with 90%* ChatGPT Quality},
url = {https://vicuna.lmsys.org},
author = {Chiang, Wei-Lin and Li, Zhuohan and Lin, Zi and Sheng, Ying and Wu, Zhanghao and Zhang, Hao and Zheng, Lianmin and Zhuang, Siyuan and Zhuang, Yonghao and Gonzalez, Joseph E. and Stoica, Ion and Xing, Eric P.},
month = {March},
year = {2023}
}
```
```bibtex
@misc{gpt4all,
author = {Yuvanesh Anand and Zach Nussbaum and Brandon Duderstadt and Benjamin Schmidt and Andriy Mulyar},
title = {GPT4All: Training an Assistant-style Chatbot with Large Scale Data Distillation from GPT-3.5-Turbo},
year = {2023},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {\url{https://github.com/nomic-ai/gpt4all}},
}
```
|
TheBloke/leo-hessianai-13B-chat-bilingual-GPTQ | TheBloke | 2023-09-28T12:20:48Z | 3,278 | 4 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"custom_code",
"en",
"de",
"dataset:LeoLM/OpenSchnabeltier",
"dataset:OpenAssistant/OASST-DE",
"dataset:FreedomIntelligence/alpaca-gpt4-deutsch",
"dataset:FreedomIntelligence/evol-instruct-deutsch",
"dataset:LeoLM/German_Poems",
"dataset:LeoLM/German_Songs",
"dataset:garage-bAInd/Open-Platypus",
"dataset:WizardLM/WizardLM_evol_instruct_70k",
"dataset:bjoernp/oasst25-08-23-filtered",
"base_model:LeoLM/leo-hessianai-13b-chat-bilingual",
"license:llama2",
"autotrain_compatible",
"text-generation-inference",
"4-bit",
"gptq",
"region:us"
] | text-generation | 2023-09-28T10:56:50Z | ---
base_model: LeoLM/leo-hessianai-13b-chat-bilingual
datasets:
- LeoLM/OpenSchnabeltier
- OpenAssistant/OASST-DE
- FreedomIntelligence/alpaca-gpt4-deutsch
- FreedomIntelligence/evol-instruct-deutsch
- LeoLM/German_Poems
- LeoLM/German_Songs
- garage-bAInd/Open-Platypus
- WizardLM/WizardLM_evol_instruct_70k
- bjoernp/oasst25-08-23-filtered
inference: false
language:
- en
- de
library_name: transformers
license: llama2
model_creator: LAION LeoLM
model_name: Leo Hessianai 13B Chat Bilingual
model_type: llama
pipeline_tag: text-generation
prompt_template: '<|im_start|>system
{system_message}<|im_end|>
<|im_start|>user
{prompt}<|im_end|>
<|im_start|>assistant
'
quantized_by: TheBloke
---
<!-- header start -->
<!-- 200823 -->
<div style="width: auto; margin-left: auto; margin-right: auto">
<img src="https://i.imgur.com/EBdldam.jpg" alt="TheBlokeAI" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</div>
<div style="display: flex; justify-content: space-between; width: 100%;">
<div style="display: flex; flex-direction: column; align-items: flex-start;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://discord.gg/theblokeai">Chat & support: TheBloke's Discord server</a></p>
</div>
<div style="display: flex; flex-direction: column; align-items: flex-end;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://www.patreon.com/TheBlokeAI">Want to contribute? TheBloke's Patreon page</a></p>
</div>
</div>
<div style="text-align:center; margin-top: 0em; margin-bottom: 0em"><p style="margin-top: 0.25em; margin-bottom: 0em;">TheBloke's LLM work is generously supported by a grant from <a href="https://a16z.com">andreessen horowitz (a16z)</a></p></div>
<hr style="margin-top: 1.0em; margin-bottom: 1.0em;">
<!-- header end -->
# Leo Hessianai 13B Chat Bilingual - GPTQ
- Model creator: [LAION LeoLM](https://huggingface.co/LeoLM)
- Original model: [Leo Hessianai 13B Chat Bilingual](https://huggingface.co/LeoLM/leo-hessianai-13b-chat-bilingual)
<!-- description start -->
## Description
This repo contains GPTQ model files for [LAION LeoLM's Leo Hessianai 13B Chat Bilingual](https://huggingface.co/LeoLM/leo-hessianai-13b-chat-bilingual).
Multiple GPTQ parameter permutations are provided; see Provided Files below for details of the options provided, their parameters, and the software used to create them.
<!-- description end -->
<!-- repositories-available start -->
## Repositories available
* [AWQ model(s) for GPU inference.](https://huggingface.co/TheBloke/leo-hessianai-13B-chat-bilingual-AWQ)
* [GPTQ models for GPU inference, with multiple quantisation parameter options.](https://huggingface.co/TheBloke/leo-hessianai-13B-chat-bilingual-GPTQ)
* [2, 3, 4, 5, 6 and 8-bit GGUF models for CPU+GPU inference](https://huggingface.co/TheBloke/leo-hessianai-13B-chat-bilingual-GGUF)
* [LAION LeoLM's original unquantised fp16 model in pytorch format, for GPU inference and for further conversions](https://huggingface.co/LeoLM/leo-hessianai-13b-chat-bilingual)
<!-- repositories-available end -->
<!-- prompt-template start -->
## Prompt template: ChatML
```
<|im_start|>system
{system_message}<|im_end|>
<|im_start|>user
{prompt}<|im_end|>
<|im_start|>assistant
```
<!-- prompt-template end -->
<!-- README_GPTQ.md-provided-files start -->
## Provided files, and GPTQ parameters
Multiple quantisation parameters are provided, to allow you to choose the best one for your hardware and requirements.
Each separate quant is in a different branch. See below for instructions on fetching from different branches.
All recent GPTQ files are made with AutoGPTQ, and all files in non-main branches are made with AutoGPTQ. Files in the `main` branch which were uploaded before August 2023 were made with GPTQ-for-LLaMa.
<details>
<summary>Explanation of GPTQ parameters</summary>
- Bits: The bit size of the quantised model.
- GS: GPTQ group size. Higher numbers use less VRAM, but have lower quantisation accuracy. "None" is the lowest possible value.
- Act Order: True or False. Also known as `desc_act`. True results in better quantisation accuracy. Some GPTQ clients have had issues with models that use Act Order plus Group Size, but this is generally resolved now.
- Damp %: A GPTQ parameter that affects how samples are processed for quantisation. 0.01 is default, but 0.1 results in slightly better accuracy.
- GPTQ dataset: The calibration dataset used during quantisation. Using a dataset more appropriate to the model's training can improve quantisation accuracy. Note that the GPTQ calibration dataset is not the same as the dataset used to train the model - please refer to the original model repo for details of the training dataset(s).
- Sequence Length: The length of the dataset sequences used for quantisation. Ideally this is the same as the model sequence length. For some very long sequence models (16+K), a lower sequence length may have to be used. Note that a lower sequence length does not limit the sequence length of the quantised model. It only impacts the quantisation accuracy on longer inference sequences.
- ExLlama Compatibility: Whether this file can be loaded with ExLlama, which currently only supports Llama models in 4-bit.
</details>
| Branch | Bits | GS | Act Order | Damp % | GPTQ Dataset | Seq Len | Size | ExLlama | Desc |
| ------ | ---- | -- | --------- | ------ | ------------ | ------- | ---- | ------- | ---- |
| [main](https://huggingface.co/TheBloke/leo-hessianai-13B-chat-bilingual-GPTQ/tree/main) | 4 | 128 | Yes | 0.1 | [German Quad](https://huggingface.co/datasets/deepset/germanquad) | 8192 | 7.26 GB | Yes | 4-bit, with Act Order and group size 128g. Uses even less VRAM than 64g, but with slightly lower accuracy. |
| [gptq-4bit-32g-actorder_True](https://huggingface.co/TheBloke/leo-hessianai-13B-chat-bilingual-GPTQ/tree/gptq-4bit-32g-actorder_True) | 4 | 32 | Yes | 0.1 | [German Quad](https://huggingface.co/datasets/deepset/germanquad) | 8192 | 8.01 GB | Yes | 4-bit, with Act Order and group size 32g. Gives highest possible inference quality, with maximum VRAM usage. |
| [gptq-8bit--1g-actorder_True](https://huggingface.co/TheBloke/leo-hessianai-13B-chat-bilingual-GPTQ/tree/gptq-8bit--1g-actorder_True) | 8 | None | Yes | 0.1 | [German Quad](https://huggingface.co/datasets/deepset/germanquad) | 8192 | 13.36 GB | No | 8-bit, with Act Order. No group size, to lower VRAM requirements. |
| [gptq-8bit-128g-actorder_True](https://huggingface.co/TheBloke/leo-hessianai-13B-chat-bilingual-GPTQ/tree/gptq-8bit-128g-actorder_True) | 8 | 128 | Yes | 0.1 | [German Quad](https://huggingface.co/datasets/deepset/germanquad) | 8192 | 13.66 GB | No | 8-bit, with group size 128g for higher inference quality and with Act Order for even higher accuracy. |
| [gptq-8bit-32g-actorder_True](https://huggingface.co/TheBloke/leo-hessianai-13B-chat-bilingual-GPTQ/tree/gptq-8bit-32g-actorder_True) | 8 | 32 | Yes | 0.1 | [German Quad](https://huggingface.co/datasets/deepset/germanquad) | 8192 | 14.55 GB | No | 8-bit, with group size 32g and Act Order for maximum inference quality. |
| [gptq-4bit-64g-actorder_True](https://huggingface.co/TheBloke/leo-hessianai-13B-chat-bilingual-GPTQ/tree/gptq-4bit-64g-actorder_True) | 4 | 64 | Yes | 0.1 | [German Quad](https://huggingface.co/datasets/deepset/germanquad) | 8192 | 7.51 GB | Yes | 4-bit, with Act Order and group size 64g. Uses less VRAM than 32g, but with slightly lower accuracy. |
<!-- README_GPTQ.md-provided-files end -->
<!-- README_GPTQ.md-download-from-branches start -->
## How to download, including from branches
### In text-generation-webui
To download from the `main` branch, enter `TheBloke/leo-hessianai-13B-chat-bilingual-GPTQ` in the "Download model" box.
To download from another branch, add `:branchname` to the end of the download name, eg `TheBloke/leo-hessianai-13B-chat-bilingual-GPTQ:gptq-4bit-32g-actorder_True`
### From the command line
I recommend using the `huggingface-hub` Python library:
```shell
pip3 install huggingface-hub
```
To download the `main` branch to a folder called `leo-hessianai-13B-chat-bilingual-GPTQ`:
```shell
mkdir leo-hessianai-13B-chat-bilingual-GPTQ
huggingface-cli download TheBloke/leo-hessianai-13B-chat-bilingual-GPTQ --local-dir leo-hessianai-13B-chat-bilingual-GPTQ --local-dir-use-symlinks False
```
To download from a different branch, add the `--revision` parameter:
```shell
mkdir leo-hessianai-13B-chat-bilingual-GPTQ
huggingface-cli download TheBloke/leo-hessianai-13B-chat-bilingual-GPTQ --revision gptq-4bit-32g-actorder_True --local-dir leo-hessianai-13B-chat-bilingual-GPTQ --local-dir-use-symlinks False
```
<details>
<summary>More advanced huggingface-cli download usage</summary>
If you remove the `--local-dir-use-symlinks False` parameter, the files will instead be stored in the central Huggingface cache directory (default location on Linux is: `~/.cache/huggingface`), and symlinks will be added to the specified `--local-dir`, pointing to their real location in the cache. This allows for interrupted downloads to be resumed, and allows you to quickly clone the repo to multiple places on disk without triggering a download again. The downside, and the reason why I don't list that as the default option, is that the files are then hidden away in a cache folder and it's harder to know where your disk space is being used, and to clear it up if/when you want to remove a download model.
The cache location can be changed with the `HF_HOME` environment variable, and/or the `--cache-dir` parameter to `huggingface-cli`.
For more documentation on downloading with `huggingface-cli`, please see: [HF -> Hub Python Library -> Download files -> Download from the CLI](https://huggingface.co/docs/huggingface_hub/guides/download#download-from-the-cli).
To accelerate downloads on fast connections (1Gbit/s or higher), install `hf_transfer`:
```shell
pip3 install hf_transfer
```
And set environment variable `HF_HUB_ENABLE_HF_TRANSFER` to `1`:
```shell
mkdir leo-hessianai-13B-chat-bilingual-GPTQ
HF_HUB_ENABLE_HF_TRANSFER=1 huggingface-cli download TheBloke/leo-hessianai-13B-chat-bilingual-GPTQ --local-dir leo-hessianai-13B-chat-bilingual-GPTQ --local-dir-use-symlinks False
```
Windows Command Line users: You can set the environment variable by running `set HF_HUB_ENABLE_HF_TRANSFER=1` before the download command.
</details>
### With `git` (**not** recommended)
To clone a specific branch with `git`, use a command like this:
```shell
git clone --single-branch --branch gptq-4bit-32g-actorder_True https://huggingface.co/TheBloke/leo-hessianai-13B-chat-bilingual-GPTQ
```
Note that using Git with HF repos is strongly discouraged. It will be much slower than using `huggingface-hub`, and will use twice as much disk space as it has to store the model files twice (it stores every byte both in the intended target folder, and again in the `.git` folder as a blob.)
<!-- README_GPTQ.md-download-from-branches end -->
<!-- README_GPTQ.md-text-generation-webui start -->
## How to easily download and use this model in [text-generation-webui](https://github.com/oobabooga/text-generation-webui).
Please make sure you're using the latest version of [text-generation-webui](https://github.com/oobabooga/text-generation-webui).
It is strongly recommended to use the text-generation-webui one-click-installers unless you're sure you know how to make a manual install.
1. Click the **Model tab**.
2. Under **Download custom model or LoRA**, enter `TheBloke/leo-hessianai-13B-chat-bilingual-GPTQ`.
- To download from a specific branch, enter for example `TheBloke/leo-hessianai-13B-chat-bilingual-GPTQ:gptq-4bit-32g-actorder_True`
- see Provided Files above for the list of branches for each option.
3. Click **Download**.
4. The model will start downloading. Once it's finished it will say "Done".
5. In the top left, click the refresh icon next to **Model**.
6. In the **Model** dropdown, choose the model you just downloaded: `leo-hessianai-13B-chat-bilingual-GPTQ`
7. The model will automatically load, and is now ready for use!
8. If you want any custom settings, set them and then click **Save settings for this model** followed by **Reload the Model** in the top right.
* Note that you do not need to and should not set manual GPTQ parameters any more. These are set automatically from the file `quantize_config.json`.
9. Once you're ready, click the **Text Generation tab** and enter a prompt to get started!
<!-- README_GPTQ.md-text-generation-webui end -->
<!-- README_GPTQ.md-use-from-python start -->
## How to use this GPTQ model from Python code
### Install the necessary packages
Requires: Transformers 4.33.0 or later, Optimum 1.12.0 or later, and AutoGPTQ 0.4.2 or later.
```shell
pip3 install transformers optimum
pip3 install auto-gptq --extra-index-url https://huggingface.github.io/autogptq-index/whl/cu118/ # Use cu117 if on CUDA 11.7
```
If you have problems installing AutoGPTQ using the pre-built wheels, install it from source instead:
```shell
pip3 uninstall -y auto-gptq
git clone https://github.com/PanQiWei/AutoGPTQ
cd AutoGPTQ
git checkout v0.4.2
pip3 install .
```
### You can then use the following code
```python
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
model_name_or_path = "TheBloke/leo-hessianai-13B-chat-bilingual-GPTQ"
# To use a different branch, change revision
# For example: revision="gptq-4bit-32g-actorder_True"
model = AutoModelForCausalLM.from_pretrained(model_name_or_path,
device_map="auto",
trust_remote_code=False,
revision="main")
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, use_fast=True)
prompt = "Tell me about AI"
prompt_template=f'''<|im_start|>system
{system_message}<|im_end|>
<|im_start|>user
{prompt}<|im_end|>
<|im_start|>assistant
'''
print("\n\n*** Generate:")
input_ids = tokenizer(prompt_template, return_tensors='pt').input_ids.cuda()
output = model.generate(inputs=input_ids, temperature=0.7, do_sample=True, top_p=0.95, top_k=40, max_new_tokens=512)
print(tokenizer.decode(output[0]))
# Inference can also be done using transformers' pipeline
print("*** Pipeline:")
pipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
max_new_tokens=512,
do_sample=True,
temperature=0.7,
top_p=0.95,
top_k=40,
repetition_penalty=1.1
)
print(pipe(prompt_template)[0]['generated_text'])
```
<!-- README_GPTQ.md-use-from-python end -->
<!-- README_GPTQ.md-compatibility start -->
## Compatibility
The files provided are tested to work with AutoGPTQ, both via Transformers and using AutoGPTQ directly. They should also work with [Occ4m's GPTQ-for-LLaMa fork](https://github.com/0cc4m/KoboldAI).
[ExLlama](https://github.com/turboderp/exllama) is compatible with Llama models in 4-bit. Please see the Provided Files table above for per-file compatibility.
[Huggingface Text Generation Inference (TGI)](https://github.com/huggingface/text-generation-inference) is compatible with all GPTQ models.
<!-- README_GPTQ.md-compatibility end -->
<!-- footer start -->
<!-- 200823 -->
## Discord
For further support, and discussions on these models and AI in general, join us at:
[TheBloke AI's Discord server](https://discord.gg/theblokeai)
## Thanks, and how to contribute
Thanks to the [chirper.ai](https://chirper.ai) team!
Thanks to Clay from [gpus.llm-utils.org](llm-utils)!
I've had a lot of people ask if they can contribute. I enjoy providing models and helping people, and would love to be able to spend even more time doing it, as well as expanding into new projects like fine tuning/training.
If you're able and willing to contribute it will be most gratefully received and will help me to keep providing more models, and to start work on new AI projects.
Donaters will get priority support on any and all AI/LLM/model questions and requests, access to a private Discord room, plus other benefits.
* Patreon: https://patreon.com/TheBlokeAI
* Ko-Fi: https://ko-fi.com/TheBlokeAI
**Special thanks to**: Aemon Algiz.
**Patreon special mentions**: Alicia Loh, Stephen Murray, K, Ajan Kanaga, RoA, Magnesian, Deo Leter, Olakabola, Eugene Pentland, zynix, Deep Realms, Raymond Fosdick, Elijah Stavena, Iucharbius, Erik Bjäreholt, Luis Javier Navarrete Lozano, Nicholas, theTransient, John Detwiler, alfie_i, knownsqashed, Mano Prime, Willem Michiel, Enrico Ros, LangChain4j, OG, Michael Dempsey, Pierre Kircher, Pedro Madruga, James Bentley, Thomas Belote, Luke @flexchar, Leonard Tan, Johann-Peter Hartmann, Illia Dulskyi, Fen Risland, Chadd, S_X, Jeff Scroggin, Ken Nordquist, Sean Connelly, Artur Olbinski, Swaroop Kallakuri, Jack West, Ai Maven, David Ziegler, Russ Johnson, transmissions 11, John Villwock, Alps Aficionado, Clay Pascal, Viktor Bowallius, Subspace Studios, Rainer Wilmers, Trenton Dambrowitz, vamX, Michael Levine, 준교 김, Brandon Frisco, Kalila, Trailburnt, Randy H, Talal Aujan, Nathan Dryer, Vadim, 阿明, ReadyPlayerEmma, Tiffany J. Kim, George Stoitzev, Spencer Kim, Jerry Meng, Gabriel Tamborski, Cory Kujawski, Jeffrey Morgan, Spiking Neurons AB, Edmond Seymore, Alexandros Triantafyllidis, Lone Striker, Cap'n Zoog, Nikolai Manek, danny, ya boyyy, Derek Yates, usrbinkat, Mandus, TL, Nathan LeClaire, subjectnull, Imad Khwaja, webtim, Raven Klaugh, Asp the Wyvern, Gabriel Puliatti, Caitlyn Gatomon, Joseph William Delisle, Jonathan Leane, Luke Pendergrass, SuperWojo, Sebastain Graf, Will Dee, Fred von Graf, Andrey, Dan Guido, Daniel P. Andersen, Nitin Borwankar, Elle, Vitor Caleffi, biorpg, jjj, NimbleBox.ai, Pieter, Matthew Berman, terasurfer, Michael Davis, Alex, Stanislav Ovsiannikov
Thank you to all my generous patrons and donaters!
And thank you again to a16z for their generous grant.
<!-- footer end -->
# Original model card: LAION LeoLM's Leo Hessianai 13B Chat Bilingual
# LAION LeoLM: **L**inguistically **E**nhanced **O**pen **L**anguage **M**odel
Meet LeoLM, the first open and commercially available German Foundation Language Model built on Llama-2.
Our models extend Llama-2's capabilities into German through continued pretraining on a large corpus of German-language and mostly locality specific text.
Thanks to a compute grant at HessianAI's new supercomputer **42**, we release two foundation models trained with 8k context length,
[`LeoLM/leo-hessianai-7b`](https://huggingface.co/LeoLM/leo-hessianai-7b) and [`LeoLM/leo-hessianai-13b`](https://huggingface.co/LeoLM/leo-hessianai-13b) under the [Llama-2 community license](https://huggingface.co/meta-llama/Llama-2-70b/raw/main/LICENSE.txt) (70b also coming soon! 👀).
With this release, we hope to bring a new wave of opportunities to German open-source and commercial LLM research and accelerate adoption.
Read our [blog post]() or our paper (preprint coming soon) for more details!
*A project by Björn Plüster and Christoph Schuhmann in collaboration with LAION and HessianAI.*
## LeoLM Chat
`LeoLM/leo-hessianai-13b-chat-bilingual` is a bilingual English-German chat model built on our foundation model `LeoLM/leo-hessianai-13b` and finetuned on a selection of German translateed instruction datasets and their English counterparts.
The model performs exceptionally well on writing, explanation and discussion tasks but struggles somewhat with math and advanced reasoning. See our MT-Bench scores:
```
{
"first_turn": 6.13125,
"second_turn": 4.88125,
"categories": {
"writing": 6.75,
"roleplay": 5.55,
"reasoning": 3.3,
"math": 2.25,
"coding": 3.9,
"extraction": 5.8,
"stem": 7.55,
"humanities": 8.95
},
"average": 5.50625
}
```
## Model Details
- **Finetuned from:** [LeoLM/leo-hessianai-13b](https://huggingface.co/LeoLM/leo-hessianai-13b)
- **Model type:** Causal decoder-only transformer language model
- **Language:** English and German
- **Demo:** [Web Demo]()
- **License:** [LLAMA 2 COMMUNITY LICENSE AGREEMENT](https://huggingface.co/meta-llama/Llama-2-70b/raw/main/LICENSE.txt)
- **Contact:** [LAION Discord](https://discord.com/invite/eq3cAMZtCC) or [Björn Plüster](mailto:[email protected])
## Use in 🤗Transformers
First install direct dependencies:
```
pip install transformers torch sentencepiece
```
If you want faster inference using flash-attention2, you need to install these dependencies:
```bash
pip install packaging ninja
pip install flash-attn==v2.1.1 --no-build-isolation
pip install git+https://github.com/HazyResearch/[email protected]#subdirectory=csrc/rotary
```
Then load the model in transformers:
```python
from transformers import pipeline
import torch
system_prompt = """<|im_start|>system
Dies ist eine Unterhaltung zwischen einem intelligenten, hilfsbereitem KI-Assistenten und einem Nutzer.
Der Assistent gibt ausführliche, hilfreiche und ehrliche Antworten.<|im_end|>
"""
prompt_format = "<|im_start|>user\n{prompt}<|im_end|>\n<|im_start|>assistant\n"
prompt = "Erkläre mir wie die Fahrradwegesituation in Hamburg ist."
generator = pipeline(model="LeoLM/leo-hessianai-13b-chat-bilingual", device="cuda", torch_dtype=torch.float16, trust_remote_code=True) # True for flash-attn2 else False
print(generator(prompt_format.format(prompt=prompt), do_sample=True, top_p=0.95, max_length=8192))
```
"*Als KI kann ich keine persönlichen Beobachtungen teilen, aber ich kann einige allgemeine Informationen zur Fahrradwegesituation in Hamburg liefern. Im Vergleich zu vielen anderen großen Städten hat Hamburg eine hohe Anzahl von Fahrradfahrern und nimmt seine Verantwortung für nachhaltige Verkehrsmittel sehr ernst. Es gibt viele Fahrradwege und separate Fahrspuren, die Radfahrern ermöglichen, zusammen mit dem Autoverkehr zu fahren. Diese Fahrradspuren sind oft mit Markierungen gekennzeichnet und durch physische Trennungen von anderen Fahrspuren abgegrenzt. Darüber hinaus gibt es viele Fahrradstraßen, auf denen Radfahrer Vorfahrt haben und Autos langsamer fahren müssen.*
*In einigen städtischen Gebieten können Fahrradwege jedoch eng oder überfüllt sein, besonders während der Stoßzeiten. Es gibt auch viele Kreuzungen, an denen Radfahrer anhalten und auf Grün warten müssen, ähnlich wie Autofahrer. Insgesamt ist die Fahrradinfrastruktur in Hamburg ziemlich gut, aber wie überall gibt es immer Raum für Verbesserungen.*"
## Prompting / Prompt Template
Prompt dialogue template (ChatML format):
```
"""
<|im_start|>system
{system_message}<|im_end|>
<|im_start|>user
{prompt}<|im_end|>
<|im_start|>assistant
"""
```
The model input can contain multiple conversation turns between user and assistant, e.g.
```
<|im_start|>user
{prompt 1}<|im_end|>
<|im_start|>assistant
{reply 1}<|im_end|>
<|im_start|>user
{prompt 2}<|im_end|>
<|im_start|>assistant
(...)
```
## Ethical Considerations and Limitations
LeoLM has been tested in English and German, and has not covered, nor could it cover all scenarios.
For these reasons, as with all LLMs, the potential outputs of `LeoLM/leo-hessianai-7b-chat` cannot be predicted
in advance, and the model may in some instances produce inaccurate, biased or other objectionable responses
to user prompts. Therefore, before deploying any applications of `LeoLM/leo-hessianai-7b-chat`, developers should
perform safety testing and tuning tailored to their specific applications of the model.
Please see Meta's [Responsible Use Guide](https://ai.meta.com/llama/responsible-use-guide/).
## Finetuning Details
| Hyperparameter | Value |
|---|---|
| Num epochs | 3 |
| Examples per epoch | 233275 |
| Global batch size | 256 |
| Learning rate | 3e-5 |
| Warmup steps | 100 |
| LR scheduler | Cosine |
| Adam betas | (0.9, 0.95) |
| Weight decay | 0.001 |
## Dataset Details
```
## Stats for 'Subset of LeoLM/OpenSchnabeltier' (21314 samples (100.0%))
-----------------
Accepted: 21314/21314 (100.0%)
Accepted tokens: 8134690
Skipped: 0 (0.0%)
Min tokens per sample: 25
Max tokens per sample: 1202
Avg tokens per sample: 381.65947264708643
-----------------
## Stats for 'Subset of garage-bAInd/Open-Platypus' (24427 samples (100.0%))
-----------------
Accepted: 24427/24427 (100.0%)
Accepted tokens: 9549043
Skipped: 0 (0.0%)
Min tokens per sample: 23
Max tokens per sample: 5054
Avg tokens per sample: 390.9216440823679
-----------------
## Stats for 'Subset of WizardLM/WizardLM_evol_instruct_70k' (68600 samples (100.0%))
-----------------
Accepted: 68600/68600 (100.0%)
Accepted tokens: 33045040
Skipped: 0 (0.0%)
Min tokens per sample: 18
Max tokens per sample: 11810
Avg tokens per sample: 481.7061224489796
-----------------
## Stats for 'Subset of FreedomIntelligence/evol-instruct-deutsch' (57841 samples (100.0%))
-----------------
Accepted: 57841/57841 (100.0%)
Accepted tokens: 42958192
Skipped: 0 (0.0%)
Min tokens per sample: 33
Max tokens per sample: 5507
Avg tokens per sample: 742.6944900675991
-----------------
## Stats for 'Subset of FreedomIntelligence/alpaca-gpt4-deutsch' (48969 samples (100.0%))
-----------------
Accepted: 48969/48969 (100.0%)
Accepted tokens: 13372005
Skipped: 0 (0.0%)
Min tokens per sample: 19
Max tokens per sample: 1359
Avg tokens per sample: 273.07082031489307
-----------------
## Stats for 'Subset of LeoLM/German_Songs' (490 samples (100.0%))
-----------------
Accepted: 490/490 (100.0%)
Accepted tokens: 618642
Skipped: 0 (0.0%)
Min tokens per sample: 747
Max tokens per sample: 1678
Avg tokens per sample: 1262.534693877551
-----------------
## Stats for 'Subset of LeoLM/German_Poems' (392 samples (100.0%))
-----------------
Accepted: 392/392 (100.0%)
Accepted tokens: 187897
Skipped: 0 (0.0%)
Min tokens per sample: 231
Max tokens per sample: 826
Avg tokens per sample: 479.3290816326531
-----------------
## Stats for 'Subset of OpenAssistant/OASST_DE' (3646 samples (100.0%))
-----------------
Accepted: 3646/3646 (100.0%)
Accepted tokens: 2338738
Skipped: 0 (0.0%)
Min tokens per sample: 29
Max tokens per sample: 2484
Avg tokens per sample: 641.4530992868897
-----------------
## Stats for 'Subset of bjoernp/oasst25-08-23-filtered' (8922 samples (100.0%))
-----------------
Accepted: 8922/8922 (100.0%)
Accepted tokens: 4526427
Skipped: 0 (0.0%)
Min tokens per sample: 23
Max tokens per sample: 5407
Avg tokens per sample: 507.3332212508406
-----------------
## Stats for 'total' (235632 samples (100.0%))
-----------------
Accepted: 235632/235632 (100.0%)
Accepted tokens: 115862397
Skipped: 0 (0.0%)
Min tokens per sample: 18
Max tokens per sample: 11810
Avg tokens per sample: 491.70909299246284
-----------------
```
|
mradermacher/H4rmoniousOrpoLlama-3-8B-Instruct-GGUF | mradermacher | 2024-06-17T00:56:27Z | 3,278 | 0 | transformers | [
"transformers",
"gguf",
"en",
"base_model:neovalle/H4rmoniousOrpoLlama-3-8B-Instruct",
"endpoints_compatible",
"region:us"
] | null | 2024-06-17T00:28:16Z | ---
base_model: neovalle/H4rmoniousOrpoLlama-3-8B-Instruct
language:
- en
library_name: transformers
quantized_by: mradermacher
tags: []
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
static quants of https://huggingface.co/neovalle/H4rmoniousOrpoLlama-3-8B-Instruct
<!-- provided-files -->
weighted/imatrix quants seem not to be available (by me) at this time. If they do not show up a week or so after the static ones, I have probably not planned for them. Feel free to request them by opening a Community Discussion.
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/H4rmoniousOrpoLlama-3-8B-Instruct-GGUF/resolve/main/H4rmoniousOrpoLlama-3-8B-Instruct.Q2_K.gguf) | Q2_K | 3.3 | |
| [GGUF](https://huggingface.co/mradermacher/H4rmoniousOrpoLlama-3-8B-Instruct-GGUF/resolve/main/H4rmoniousOrpoLlama-3-8B-Instruct.IQ3_XS.gguf) | IQ3_XS | 3.6 | |
| [GGUF](https://huggingface.co/mradermacher/H4rmoniousOrpoLlama-3-8B-Instruct-GGUF/resolve/main/H4rmoniousOrpoLlama-3-8B-Instruct.Q3_K_S.gguf) | Q3_K_S | 3.8 | |
| [GGUF](https://huggingface.co/mradermacher/H4rmoniousOrpoLlama-3-8B-Instruct-GGUF/resolve/main/H4rmoniousOrpoLlama-3-8B-Instruct.IQ3_S.gguf) | IQ3_S | 3.8 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/H4rmoniousOrpoLlama-3-8B-Instruct-GGUF/resolve/main/H4rmoniousOrpoLlama-3-8B-Instruct.IQ3_M.gguf) | IQ3_M | 3.9 | |
| [GGUF](https://huggingface.co/mradermacher/H4rmoniousOrpoLlama-3-8B-Instruct-GGUF/resolve/main/H4rmoniousOrpoLlama-3-8B-Instruct.Q3_K_M.gguf) | Q3_K_M | 4.1 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/H4rmoniousOrpoLlama-3-8B-Instruct-GGUF/resolve/main/H4rmoniousOrpoLlama-3-8B-Instruct.Q3_K_L.gguf) | Q3_K_L | 4.4 | |
| [GGUF](https://huggingface.co/mradermacher/H4rmoniousOrpoLlama-3-8B-Instruct-GGUF/resolve/main/H4rmoniousOrpoLlama-3-8B-Instruct.IQ4_XS.gguf) | IQ4_XS | 4.6 | |
| [GGUF](https://huggingface.co/mradermacher/H4rmoniousOrpoLlama-3-8B-Instruct-GGUF/resolve/main/H4rmoniousOrpoLlama-3-8B-Instruct.Q4_K_S.gguf) | Q4_K_S | 4.8 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/H4rmoniousOrpoLlama-3-8B-Instruct-GGUF/resolve/main/H4rmoniousOrpoLlama-3-8B-Instruct.Q4_K_M.gguf) | Q4_K_M | 5.0 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/H4rmoniousOrpoLlama-3-8B-Instruct-GGUF/resolve/main/H4rmoniousOrpoLlama-3-8B-Instruct.Q5_K_S.gguf) | Q5_K_S | 5.7 | |
| [GGUF](https://huggingface.co/mradermacher/H4rmoniousOrpoLlama-3-8B-Instruct-GGUF/resolve/main/H4rmoniousOrpoLlama-3-8B-Instruct.Q5_K_M.gguf) | Q5_K_M | 5.8 | |
| [GGUF](https://huggingface.co/mradermacher/H4rmoniousOrpoLlama-3-8B-Instruct-GGUF/resolve/main/H4rmoniousOrpoLlama-3-8B-Instruct.Q6_K.gguf) | Q6_K | 6.7 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/H4rmoniousOrpoLlama-3-8B-Instruct-GGUF/resolve/main/H4rmoniousOrpoLlama-3-8B-Instruct.Q8_0.gguf) | Q8_0 | 8.6 | fast, best quality |
| [GGUF](https://huggingface.co/mradermacher/H4rmoniousOrpoLlama-3-8B-Instruct-GGUF/resolve/main/H4rmoniousOrpoLlama-3-8B-Instruct.f16.gguf) | f16 | 16.2 | 16 bpw, overkill |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
WillianMar1o/UNIFAHETREINAMENTO123 | WillianMar1o | 2024-06-30T22:36:44Z | 3,278 | 0 | transformers | [
"transformers",
"pytorch",
"gguf",
"llama",
"text-generation",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2024-06-30T22:10:29Z | ---
license: mit
---
|
h2oai/h2ogpt-gm-oasst1-en-xgen-7b-8k | h2oai | 2023-06-30T09:17:46Z | 3,276 | 11 | transformers | [
"transformers",
"pytorch",
"llama",
"text-generation",
"gpt",
"llm",
"large language model",
"h2o-llmstudio",
"en",
"dataset:OpenAssistant/oasst1",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2023-06-30T08:14:51Z | ---
language:
- en
library_name: transformers
tags:
- gpt
- llm
- large language model
- h2o-llmstudio
inference: false
thumbnail: >-
https://h2o.ai/etc.clientlibs/h2o/clientlibs/clientlib-site/resources/images/favicon.ico
license: apache-2.0
datasets:
- OpenAssistant/oasst1
---
# Model Card
## Summary
This model was trained using [H2O LLM Studio](https://github.com/h2oai/h2o-llmstudio).
- Base model: [Salesforce/xgen-7b-8k-base](https://huggingface.co/Salesforce/xgen-7b-8k-base)
- Dataset preparation: [OpenAssistant/oasst1](https://github.com/h2oai/h2o-llmstudio/blob/1935d84d9caafed3ee686ad2733eb02d2abfce57/app_utils/utils.py#LL1896C5-L1896C28) personalized
## Usage
To use the model with the `transformers` library on a machine with GPUs, first make sure you have the `transformers`, `accelerate` and `torch` libraries installed.
```bash
pip install transformers==4.30.1
pip install accelerate==0.20.3
pip install torch==2.0.0
pip install tiktoken==0.4.0
```
```python
import torch
from transformers import pipeline
generate_text = pipeline(
model="h2oai/h2ogpt-gm-oasst1-en-xgen-7b-8k",
torch_dtype="auto",
trust_remote_code=True,
use_fast=True,
device_map={"": "cuda:0"},
)
res = generate_text(
"Why is drinking water so healthy?",
min_new_tokens=2,
max_new_tokens=1024,
do_sample=False,
num_beams=1,
temperature=float(0.3),
repetition_penalty=float(1.2),
renormalize_logits=True
)
print(res[0]["generated_text"])
```
You can print a sample prompt after the preprocessing step to see how it is feed to the tokenizer:
```python
print(generate_text.preprocess("Why is drinking water so healthy?")["prompt_text"])
```
```bash
<|prompt|>Why is drinking water so healthy?<|endoftext|><|answer|>
```
Alternatively, you can download [h2oai_pipeline.py](h2oai_pipeline.py), store it alongside your notebook, and construct the pipeline yourself from the loaded model and tokenizer. If the model and the tokenizer are fully supported in the `transformers` package, this will allow you to set `trust_remote_code=False`.
```python
import torch
from h2oai_pipeline import H2OTextGenerationPipeline
from transformers import AutoModelForCausalLM, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained(
"h2oai/h2ogpt-gm-oasst1-en-xgen-7b-8k",
use_fast=True,
padding_side="left",
trust_remote_code=True,
)
model = AutoModelForCausalLM.from_pretrained(
"h2oai/h2ogpt-gm-oasst1-en-xgen-7b-8k",
torch_dtype="auto",
device_map={"": "cuda:0"},
trust_remote_code=True,
)
generate_text = H2OTextGenerationPipeline(model=model, tokenizer=tokenizer)
res = generate_text(
"Why is drinking water so healthy?",
min_new_tokens=2,
max_new_tokens=1024,
do_sample=False,
num_beams=1,
temperature=float(0.3),
repetition_penalty=float(1.2),
renormalize_logits=True
)
print(res[0]["generated_text"])
```
You may also construct the pipeline from the loaded model and tokenizer yourself and consider the preprocessing steps:
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "h2oai/h2ogpt-gm-oasst1-en-xgen-7b-8k" # either local folder or huggingface model name
# Important: The prompt needs to be in the same format the model was trained with.
# You can find an example prompt in the experiment logs.
prompt = "<|prompt|>How are you?<|endoftext|><|answer|>"
tokenizer = AutoTokenizer.from_pretrained(
model_name,
use_fast=True,
trust_remote_code=True,
)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map={"": "cuda:0"},
trust_remote_code=True,
)
model.cuda().eval()
inputs = tokenizer(prompt, return_tensors="pt", add_special_tokens=False).to("cuda")
# generate configuration can be modified to your needs
tokens = model.generate(
**inputs,
min_new_tokens=2,
max_new_tokens=1024,
do_sample=False,
num_beams=1,
temperature=float(0.3),
repetition_penalty=float(1.2),
renormalize_logits=True
)[0]
tokens = tokens[inputs["input_ids"].shape[1]:]
answer = tokenizer.decode(tokens, skip_special_tokens=True)
print(answer)
```
## Model Architecture
```
LlamaForCausalLM(
(model): LlamaModel(
(embed_tokens): Embedding(51200, 4096, padding_idx=0)
(layers): ModuleList(
(0-31): 32 x LlamaDecoderLayer(
(self_attn): LlamaAttention(
(q_proj): Linear(in_features=4096, out_features=4096, bias=False)
(k_proj): Linear(in_features=4096, out_features=4096, bias=False)
(v_proj): Linear(in_features=4096, out_features=4096, bias=False)
(o_proj): Linear(in_features=4096, out_features=4096, bias=False)
(rotary_emb): LlamaRotaryEmbedding()
)
(mlp): LlamaMLP(
(gate_proj): Linear(in_features=4096, out_features=11008, bias=False)
(down_proj): Linear(in_features=11008, out_features=4096, bias=False)
(up_proj): Linear(in_features=4096, out_features=11008, bias=False)
(act_fn): SiLUActivation()
)
(input_layernorm): LlamaRMSNorm()
(post_attention_layernorm): LlamaRMSNorm()
)
)
(norm): LlamaRMSNorm()
)
(lm_head): Linear(in_features=4096, out_features=51200, bias=False)
)
```
## Model Configuration
This model was trained using H2O LLM Studio and with the configuration in [cfg.yaml](cfg.yaml). Visit [H2O LLM Studio](https://github.com/h2oai/h2o-llmstudio) to learn how to train your own large language models.
## Disclaimer
Please read this disclaimer carefully before using the large language model provided in this repository. Your use of the model signifies your agreement to the following terms and conditions.
- Biases and Offensiveness: The large language model is trained on a diverse range of internet text data, which may contain biased, racist, offensive, or otherwise inappropriate content. By using this model, you acknowledge and accept that the generated content may sometimes exhibit biases or produce content that is offensive or inappropriate. The developers of this repository do not endorse, support, or promote any such content or viewpoints.
- Limitations: The large language model is an AI-based tool and not a human. It may produce incorrect, nonsensical, or irrelevant responses. It is the user's responsibility to critically evaluate the generated content and use it at their discretion.
- Use at Your Own Risk: Users of this large language model must assume full responsibility for any consequences that may arise from their use of the tool. The developers and contributors of this repository shall not be held liable for any damages, losses, or harm resulting from the use or misuse of the provided model.
- Ethical Considerations: Users are encouraged to use the large language model responsibly and ethically. By using this model, you agree not to use it for purposes that promote hate speech, discrimination, harassment, or any form of illegal or harmful activities.
- Reporting Issues: If you encounter any biased, offensive, or otherwise inappropriate content generated by the large language model, please report it to the repository maintainers through the provided channels. Your feedback will help improve the model and mitigate potential issues.
- Changes to this Disclaimer: The developers of this repository reserve the right to modify or update this disclaimer at any time without prior notice. It is the user's responsibility to periodically review the disclaimer to stay informed about any changes.
By using the large language model provided in this repository, you agree to accept and comply with the terms and conditions outlined in this disclaimer. If you do not agree with any part of this disclaimer, you should refrain from using the model and any content generated by it. |
beomi/Llama-3-KoEn-8B | beomi | 2024-05-27T06:16:06Z | 3,276 | 6 | transformers | [
"transformers",
"pytorch",
"safetensors",
"llama",
"text-generation",
"facebook",
"meta",
"llama-3",
"llama-3-ko",
"conversational",
"en",
"ko",
"arxiv:2310.04799",
"license:cc-by-nc-sa-4.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2024-05-01T12:18:52Z | ---
language:
- en
- ko
license: cc-by-nc-sa-4.0
tags:
- facebook
- meta
- pytorch
- llama
- llama-3
- llama-3-ko
pipeline_tag: text-generation
license_name: llama3
license_link: LICENSE
---
> Update @ 2024.05.01: Pre-Release Llama-3-KoEn-8B model & [Llama-3-KoEn-8B-Instruct-preview](https://huggingface.co/beomi/Llama-3-KoEn-8B-Instruct-preview)
## Model Details
**Llama-3-KoEn-8B**
Llama-3-KoEn-8B model is continued pretrained language model based on Llama-3-8B.
This model is trained with Korean+English corpus.
The train was done on TPUv4-256, with the warm support from TRC program by Google.
**Note for [Llama-3-KoEn-8B-Instruct-preview](https://huggingface.co/beomi/Llama-3-KoEn-8B-Instruct-preview)**
With applying the idea from [Chat Vector paper](https://arxiv.org/abs/2310.04799), I released Instruction model named [Llama-3-KoEn-8B-Instruct-preview](https://huggingface.co/beomi/Llama-3-KoEn-8B-Instruct-preview).
Since it is NOT finetuned with any Korean instruction set(indeed `preview`), but it would be great starting point for creating new Chat/Instruct models.
**Model developers** Junbum Lee (Beomi)
**Variations** Llama-3-KoEn comes in one size — 8B.
**Input** Models input text only.
**Output** Models generate text and code only.
**Model Architecture** Llama 3 is an auto-regressive language model that uses an optimized transformer architecture.
<table>
<tr>
<td>
</td>
<td><strong>Training Data</strong>
</td>
<td><strong>Params</strong>
</td>
<td><strong>Context length</strong>
</td>
<td><strong>GQA</strong>
</td>
<td><strong>Token count</strong>
</td>
<td><strong>Knowledge cutoff</strong>
</td>
</tr>
<tr>
<td rowspan="2" >Llama-3-KoEn
</td>
<td rowspan="2" >Same as *Llama-2-KoEn Dataset
</td>
<td>8B
</td>
<td>8k
</td>
<td>Yes
</td>
<td rowspan="2" >80B+
</td>
<td>Jun, 2023
</td>
</tr>
</table>
**Model Release Date** Pre-release @ 2024.05.01
**Status** This is a static model trained on an offline dataset.
**License** CC-By-NC-SA-4.0 + Llama3 License: [https://llama.meta.com/llama3/license](https://llama.meta.com/llama3/license)
## Intended Use
**Intended Use Cases** Llama 3 is intended for commercial and research use in English. Instruction tuned models are intended for assistant-like chat, whereas pretrained models can be adapted for a variety of natural language generation tasks.
**Out-of-scope** Use in any manner that violates applicable laws or regulations (including trade compliance laws). Use in any other way that is prohibited by the Acceptable Use Policy and Llama 3 Community License. Use in languages other than English**.
**Note: Developers may fine-tune Llama 3 models for languages beyond English provided they comply with the Llama 3 Community License and the Acceptable Use Policy.
## How to use
TBD
### Responsibility & Safety
We believe that an open approach to AI leads to better, safer products, faster innovation, and a bigger overall market. We are committed to Responsible AI development and took a series of steps to limit misuse and harm and support the open source community.
Foundation models are widely capable technologies that are built to be used for a diverse range of applications. They are not designed to meet every developer preference on safety levels for all use cases, out-of-the-box, as those by their nature will differ across different applications.
Rather, responsible LLM-application deployment is achieved by implementing a series of safety best practices throughout the development of such applications, from the model pre-training, fine-tuning and the deployment of systems composed of safeguards to tailor the safety needs specifically to the use case and audience.
As part of the Llama 3 release, we updated our [Responsible Use Guide](https://llama.meta.com/responsible-use-guide/) to outline the steps and best practices for developers to implement model and system level safety for their application. We also provide a set of resources including [Meta Llama Guard 2](https://llama.meta.com/purple-llama/) and [Code Shield](https://llama.meta.com/purple-llama/) safeguards. These tools have proven to drastically reduce residual risks of LLM Systems, while maintaining a high level of helpfulness. We encourage developers to tune and deploy these safeguards according to their needs and we provide a [reference implementation](https://github.com/meta-llama/llama-recipes/tree/main/recipes/responsible_ai) to get you started.
#### Responsible release
In addition to responsible use considerations outlined above, we followed a rigorous process that requires us to take extra measures against misuse and critical risks before we make our release decision.
Misuse
If you access or use Llama 3, you agree to the Acceptable Use Policy. The most recent copy of this policy can be found at [https://llama.meta.com/llama3/use-policy/](https://llama.meta.com/llama3/use-policy/).
## Ethical Considerations and Limitations
The core values of Llama 3 are openness, inclusivity and helpfulness. It is meant to serve everyone, and to work for a wide range of use cases. It is thus designed to be accessible to people across many different backgrounds, experiences and perspectives. Llama 3 addresses users and their needs as they are, without insertion unnecessary judgment or normativity, while reflecting the understanding that even content that may appear problematic in some cases can serve valuable purposes in others. It respects the dignity and autonomy of all users, especially in terms of the values of free thought and expression that power innovation and progress.
But Llama 3 is a new technology, and like any new technology, there are risks associated with its use. Testing conducted to date has been in English, and has not covered, nor could it cover, all scenarios. For these reasons, as with all LLMs, Llama 3’s potential outputs cannot be predicted in advance, and the model may in some instances produce inaccurate, biased or other objectionable responses to user prompts. Therefore, before deploying any applications of Llama 3 models, developers should perform safety testing and tuning tailored to their specific applications of the model. As outlined in the Responsible Use Guide, we recommend incorporating [Purple Llama](https://github.com/facebookresearch/PurpleLlama) solutions into your workflows and specifically [Llama Guard](https://ai.meta.com/research/publications/llama-guard-llm-based-input-output-safeguard-for-human-ai-conversations/) which provides a base model to filter input and output prompts to layer system-level safety on top of model-level safety.
Please see the Responsible Use Guide available at [http://llama.meta.com/responsible-use-guide](http://llama.meta.com/responsible-use-guide)
## Citation instructions
**Llama-3-Open-Ko**
```
@article{llama3koen,
title={Llama-3-KoEn},
author={L, Junbum},
year={2024},
url={https://huggingface.co/beomi/Llama-3-KoEn-8B}
}
```
**Original Llama-3**
```
@article{llama3modelcard,
title={Llama 3 Model Card},
author={AI@Meta},
year={2024},
url = {https://github.com/meta-llama/llama3/blob/main/MODEL_CARD.md}
}
``` |
mradermacher/Phoenix-GGUF | mradermacher | 2024-06-08T13:43:26Z | 3,276 | 0 | transformers | [
"transformers",
"gguf",
"dpo",
"alignment-handbook",
"de",
"base_model:DRXD1000/Phoenix",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2024-06-08T03:32:16Z | ---
base_model: DRXD1000/Phoenix
language:
- de
library_name: transformers
license: apache-2.0
quantized_by: mradermacher
tags:
- dpo
- alignment-handbook
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
static quants of https://huggingface.co/DRXD1000/Phoenix
<!-- provided-files -->
weighted/imatrix quants are available at https://huggingface.co/mradermacher/Phoenix-i1-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/Phoenix-GGUF/resolve/main/Phoenix.Q2_K.gguf) | Q2_K | 2.8 | |
| [GGUF](https://huggingface.co/mradermacher/Phoenix-GGUF/resolve/main/Phoenix.IQ3_XS.gguf) | IQ3_XS | 3.1 | |
| [GGUF](https://huggingface.co/mradermacher/Phoenix-GGUF/resolve/main/Phoenix.Q3_K_S.gguf) | Q3_K_S | 3.3 | |
| [GGUF](https://huggingface.co/mradermacher/Phoenix-GGUF/resolve/main/Phoenix.IQ3_S.gguf) | IQ3_S | 3.3 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/Phoenix-GGUF/resolve/main/Phoenix.IQ3_M.gguf) | IQ3_M | 3.4 | |
| [GGUF](https://huggingface.co/mradermacher/Phoenix-GGUF/resolve/main/Phoenix.Q3_K_M.gguf) | Q3_K_M | 3.6 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/Phoenix-GGUF/resolve/main/Phoenix.Q3_K_L.gguf) | Q3_K_L | 3.9 | |
| [GGUF](https://huggingface.co/mradermacher/Phoenix-GGUF/resolve/main/Phoenix.IQ4_XS.gguf) | IQ4_XS | 4.0 | |
| [GGUF](https://huggingface.co/mradermacher/Phoenix-GGUF/resolve/main/Phoenix.Q4_K_S.gguf) | Q4_K_S | 4.2 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Phoenix-GGUF/resolve/main/Phoenix.Q4_K_M.gguf) | Q4_K_M | 4.5 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Phoenix-GGUF/resolve/main/Phoenix.Q5_K_S.gguf) | Q5_K_S | 5.1 | |
| [GGUF](https://huggingface.co/mradermacher/Phoenix-GGUF/resolve/main/Phoenix.Q5_K_M.gguf) | Q5_K_M | 5.2 | |
| [GGUF](https://huggingface.co/mradermacher/Phoenix-GGUF/resolve/main/Phoenix.Q6_K.gguf) | Q6_K | 6.0 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/Phoenix-GGUF/resolve/main/Phoenix.Q8_0.gguf) | Q8_0 | 7.8 | fast, best quality |
| [GGUF](https://huggingface.co/mradermacher/Phoenix-GGUF/resolve/main/Phoenix.f16.gguf) | f16 | 14.6 | 16 bpw, overkill |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
mradermacher/OpenKunoichi-7B-slerp-GGUF | mradermacher | 2024-06-09T18:24:15Z | 3,276 | 0 | transformers | [
"transformers",
"gguf",
"merge",
"mergekit",
"lazymergekit",
"openchat/openchat-3.5-0106",
"SanjiWatsuki/Kunoichi-DPO-v2-7B",
"en",
"base_model:adastra9257/OpenKunoichi-7B-slerp",
"endpoints_compatible",
"region:us"
] | null | 2024-06-09T17:57:28Z | ---
base_model: adastra9257/OpenKunoichi-7B-slerp
language:
- en
library_name: transformers
quantized_by: mradermacher
tags:
- merge
- mergekit
- lazymergekit
- openchat/openchat-3.5-0106
- SanjiWatsuki/Kunoichi-DPO-v2-7B
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
static quants of https://huggingface.co/adastra9257/OpenKunoichi-7B-slerp
<!-- provided-files -->
weighted/imatrix quants seem not to be available (by me) at this time. If they do not show up a week or so after the static ones, I have probably not planned for them. Feel free to request them by opening a Community Discussion.
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/OpenKunoichi-7B-slerp-GGUF/resolve/main/OpenKunoichi-7B-slerp.Q2_K.gguf) | Q2_K | 2.8 | |
| [GGUF](https://huggingface.co/mradermacher/OpenKunoichi-7B-slerp-GGUF/resolve/main/OpenKunoichi-7B-slerp.IQ3_XS.gguf) | IQ3_XS | 3.1 | |
| [GGUF](https://huggingface.co/mradermacher/OpenKunoichi-7B-slerp-GGUF/resolve/main/OpenKunoichi-7B-slerp.Q3_K_S.gguf) | Q3_K_S | 3.3 | |
| [GGUF](https://huggingface.co/mradermacher/OpenKunoichi-7B-slerp-GGUF/resolve/main/OpenKunoichi-7B-slerp.IQ3_S.gguf) | IQ3_S | 3.3 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/OpenKunoichi-7B-slerp-GGUF/resolve/main/OpenKunoichi-7B-slerp.IQ3_M.gguf) | IQ3_M | 3.4 | |
| [GGUF](https://huggingface.co/mradermacher/OpenKunoichi-7B-slerp-GGUF/resolve/main/OpenKunoichi-7B-slerp.Q3_K_M.gguf) | Q3_K_M | 3.6 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/OpenKunoichi-7B-slerp-GGUF/resolve/main/OpenKunoichi-7B-slerp.Q3_K_L.gguf) | Q3_K_L | 3.9 | |
| [GGUF](https://huggingface.co/mradermacher/OpenKunoichi-7B-slerp-GGUF/resolve/main/OpenKunoichi-7B-slerp.IQ4_XS.gguf) | IQ4_XS | 4.0 | |
| [GGUF](https://huggingface.co/mradermacher/OpenKunoichi-7B-slerp-GGUF/resolve/main/OpenKunoichi-7B-slerp.Q4_K_S.gguf) | Q4_K_S | 4.2 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/OpenKunoichi-7B-slerp-GGUF/resolve/main/OpenKunoichi-7B-slerp.Q4_K_M.gguf) | Q4_K_M | 4.5 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/OpenKunoichi-7B-slerp-GGUF/resolve/main/OpenKunoichi-7B-slerp.Q5_K_S.gguf) | Q5_K_S | 5.1 | |
| [GGUF](https://huggingface.co/mradermacher/OpenKunoichi-7B-slerp-GGUF/resolve/main/OpenKunoichi-7B-slerp.Q5_K_M.gguf) | Q5_K_M | 5.2 | |
| [GGUF](https://huggingface.co/mradermacher/OpenKunoichi-7B-slerp-GGUF/resolve/main/OpenKunoichi-7B-slerp.Q6_K.gguf) | Q6_K | 6.0 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/OpenKunoichi-7B-slerp-GGUF/resolve/main/OpenKunoichi-7B-slerp.Q8_0.gguf) | Q8_0 | 7.8 | fast, best quality |
| [GGUF](https://huggingface.co/mradermacher/OpenKunoichi-7B-slerp-GGUF/resolve/main/OpenKunoichi-7B-slerp.f16.gguf) | f16 | 14.6 | 16 bpw, overkill |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
KnutJaegersberg/deacon-13b | KnutJaegersberg | 2023-12-03T15:06:45Z | 3,275 | 1 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"custom_code",
"dataset:KnutJaegersberg/facehugger",
"license:cc-by-nc-4.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2023-09-20T06:35:12Z | ---
license: cc-by-nc-4.0
datasets:
- KnutJaegersberg/facehugger
---

This model was fine tuned on AI filtered subsets of GPT-4 based subset of the Dolphin dataset and EvolInstruct V2.
It has not been explicitly aligned to positive, negative or bureaucratically prescribed value systems.
It might kill us all! Time to shit your pants, regulators. I literally put black goo on Dolphin-7B sperm, which then fertilized Evolved Instructions...
What's different is evil... ;)
I intend to train 3 sizes.
Prompt Example:
```
### System:
You are an AI assistant. User will give you a task. Your goal is to complete the task as faithfully as you can. While performing the task think step-by-step and justify your steps.
### Instruction:
How do you fine tune a large language model?
### Response:
```
# [Open LLM Leaderboard Evaluation Results](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)
Detailed results can be found [here](https://huggingface.co/datasets/open-llm-leaderboard/details_KnutJaegersberg__deacon-13b)
| Metric | Value |
|-----------------------|---------------------------|
| Avg. | 46.78 |
| ARC (25-shot) | 57.85 |
| HellaSwag (10-shot) | 82.63 |
| MMLU (5-shot) | 55.25 |
| TruthfulQA (0-shot) | 39.33 |
| Winogrande (5-shot) | 76.32 |
| GSM8K (5-shot) | 10.39 |
| DROP (3-shot) | 5.67 |
|
mradermacher/kpopLlama-3-8B-sentiment_3_1-GGUF | mradermacher | 2024-06-18T14:03:26Z | 3,274 | 1 | transformers | [
"transformers",
"gguf",
"en",
"base_model:k4west/kpopLlama-3-8B-sentiment_3_1",
"endpoints_compatible",
"region:us"
] | null | 2024-06-18T12:02:27Z | ---
base_model: k4west/kpopLlama-3-8B-sentiment_3_1
language:
- en
library_name: transformers
quantized_by: mradermacher
tags: []
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
static quants of https://huggingface.co/k4west/kpopLlama-3-8B-sentiment_3_1
<!-- provided-files -->
weighted/imatrix quants seem not to be available (by me) at this time. If they do not show up a week or so after the static ones, I have probably not planned for them. Feel free to request them by opening a Community Discussion.
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/kpopLlama-3-8B-sentiment_3_1-GGUF/resolve/main/kpopLlama-3-8B-sentiment_3_1.Q2_K.gguf) | Q2_K | 3.3 | |
| [GGUF](https://huggingface.co/mradermacher/kpopLlama-3-8B-sentiment_3_1-GGUF/resolve/main/kpopLlama-3-8B-sentiment_3_1.IQ3_XS.gguf) | IQ3_XS | 3.6 | |
| [GGUF](https://huggingface.co/mradermacher/kpopLlama-3-8B-sentiment_3_1-GGUF/resolve/main/kpopLlama-3-8B-sentiment_3_1.Q3_K_S.gguf) | Q3_K_S | 3.8 | |
| [GGUF](https://huggingface.co/mradermacher/kpopLlama-3-8B-sentiment_3_1-GGUF/resolve/main/kpopLlama-3-8B-sentiment_3_1.IQ3_S.gguf) | IQ3_S | 3.8 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/kpopLlama-3-8B-sentiment_3_1-GGUF/resolve/main/kpopLlama-3-8B-sentiment_3_1.IQ3_M.gguf) | IQ3_M | 3.9 | |
| [GGUF](https://huggingface.co/mradermacher/kpopLlama-3-8B-sentiment_3_1-GGUF/resolve/main/kpopLlama-3-8B-sentiment_3_1.Q3_K_M.gguf) | Q3_K_M | 4.1 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/kpopLlama-3-8B-sentiment_3_1-GGUF/resolve/main/kpopLlama-3-8B-sentiment_3_1.Q3_K_L.gguf) | Q3_K_L | 4.4 | |
| [GGUF](https://huggingface.co/mradermacher/kpopLlama-3-8B-sentiment_3_1-GGUF/resolve/main/kpopLlama-3-8B-sentiment_3_1.IQ4_XS.gguf) | IQ4_XS | 4.6 | |
| [GGUF](https://huggingface.co/mradermacher/kpopLlama-3-8B-sentiment_3_1-GGUF/resolve/main/kpopLlama-3-8B-sentiment_3_1.Q4_K_S.gguf) | Q4_K_S | 4.8 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/kpopLlama-3-8B-sentiment_3_1-GGUF/resolve/main/kpopLlama-3-8B-sentiment_3_1.Q4_K_M.gguf) | Q4_K_M | 5.0 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/kpopLlama-3-8B-sentiment_3_1-GGUF/resolve/main/kpopLlama-3-8B-sentiment_3_1.Q5_K_S.gguf) | Q5_K_S | 5.7 | |
| [GGUF](https://huggingface.co/mradermacher/kpopLlama-3-8B-sentiment_3_1-GGUF/resolve/main/kpopLlama-3-8B-sentiment_3_1.Q5_K_M.gguf) | Q5_K_M | 5.8 | |
| [GGUF](https://huggingface.co/mradermacher/kpopLlama-3-8B-sentiment_3_1-GGUF/resolve/main/kpopLlama-3-8B-sentiment_3_1.Q6_K.gguf) | Q6_K | 6.7 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/kpopLlama-3-8B-sentiment_3_1-GGUF/resolve/main/kpopLlama-3-8B-sentiment_3_1.Q8_0.gguf) | Q8_0 | 8.6 | fast, best quality |
| [GGUF](https://huggingface.co/mradermacher/kpopLlama-3-8B-sentiment_3_1-GGUF/resolve/main/kpopLlama-3-8B-sentiment_3_1.f16.gguf) | f16 | 16.2 | 16 bpw, overkill |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
MaziyarPanahi/Mixtral-8x22B-v0.1-GGUF | MaziyarPanahi | 2024-04-15T20:30:10Z | 3,273 | 73 | transformers | [
"transformers",
"gguf",
"mixtral",
"text-generation",
"quantized",
"2-bit",
"3-bit",
"4-bit",
"5-bit",
"6-bit",
"8-bit",
"16-bit",
"GGUF",
"moe",
"fr",
"en",
"es",
"it",
"de",
"base_model:v2ray/Mixtral-8x22B-v0.1",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2024-04-10T10:26:05Z | ---
license: apache-2.0
base_model: v2ray/Mixtral-8x22B-v0.1
inference: false
model_creator: MaziyarPanahi
model_name: Mixtral-8x22B-v0.1-GGUF
pipeline_tag: text-generation
quantized_by: MaziyarPanahi
tags:
- quantized
- 2-bit
- 3-bit
- 4-bit
- 5-bit
- 6-bit
- 8-bit
- 16-bit
- GGUF
- mixtral
- moe
language:
- fr
- en
- es
- it
- de
---
<img src="./mixtral-8x22b.jpeg" width="600" />
# Mixtral-8x22B-v0.1-GGUF
On April 10th, [@MistralAI](https://huggingface.co/mistralai) released a model named "Mixtral 8x22B," an 176B MoE via magnet link (torrent):
- 141B MoE with ~35B active
- Context length of 65k tokens
- The base model can be fine-tuned
- Requires ~260GB VRAM in fp16, 73GB in int4
- Licensed under Apache 2.0, according to their Discord
- Available on @huggingface (community)
- Utilizes a tokenizer similar to previous models
The GGUF and quantized models here are based on [v2ray/Mixtral-8x22B-v0.1](https://huggingface.co/v2ray/Mixtral-8x22B-v0.1) model
## How to download
You can download only the quants you need instead of cloning the entire repository as follows:
```
huggingface-cli download MaziyarPanahi/WizardLM-2-8x22B-GGUF --local-dir . --include '*Q2_K*gguf'
```
## Load sharded model
`llama_load_model_from_file` will detect the number of files and will load additional tensors from the rest of files.
```sh
llama.cpp/main -m Mixtral-8x22B-v0.1.Q2_K-00001-of-00005.gguf -p "Building a website can be done in 10 simple steps:\nStep 1:" -n 1024 -e
```
The output from `Q2_K` quantized model:
```
system_info: n_threads = 64 / 128 | AVX = 1 | AVX_VNNI = 0 | AVX2 = 1 | AVX512 = 0 | AVX512_VBMI = 0 | AVX512_VNNI = 0 | FMA = 1 | NEON = 0 | ARM_FMA = 0 | F16C = 1 | FP16_VA = 0 | WASM_SIMD = 0 | BLAS = 0 | SSE3 = 1 | SSSE3 = 1 | VSX = 0 | MATMUL_INT8 = 0 |
sampling:
repeat_last_n = 64, repeat_penalty = 1.000, frequency_penalty = 0.000, presence_penalty = 0.000
top_k = 40, tfs_z = 1.000, top_p = 0.950, min_p = 0.050, typical_p = 1.000, temp = 0.800
mirostat = 0, mirostat_lr = 0.100, mirostat_ent = 5.000
sampling order:
CFG -> Penalties -> top_k -> tfs_z -> typical_p -> top_p -> min_p -> temperature
generate: n_ctx = 512, n_batch = 2048, n_predict = 1024, n_keep = 1
Building a website can be done in 10 simple steps:
Step 1: Pick a domain name
The domain name is your address on the Internet. It’s what people type into the browser to get to your website. It’s important to pick a domain name that is easy to remember and relates to your business. For example, if you were a plumber, you could register a domain like fixitplumbing.com. You can check the availability of a domain name with the WHOIS lookup tool. If your domain is available, you can register it at a domain registrar like GoDaddy.com or Domain.com.
Step 2: Sign up for a web hosting account
Web hosting is the service that stores your website files and makes them available to people on the Internet. It’s important to pick a web hosting provider that is reliable and has good customer service. Some popular web hosting providers include Bluehost, Hostgator, and Dreamhost.
Step 3: Create a website template
A website template is a pre-designed website that you can use as a starting point for your own website. There are many free website templates available online. Once you’ve found a template you like, you can download it and start customizing it to fit your needs.
Step 4: Add your content
Once you’ve chosen a template, you’ll need to add your own content to it. This includes things like your company logo, contact information, and text about your business. You can also add photos and videos to make your website more engaging.
Step 5: Test your website
Before you make your website live, it’s important to test it out. This includes checking for broken links, typos, and making sure that all of your content is correct. You can also ask friends or family to test your website and give you feedback.
Step 6: Launch your website
Once you’re happy with your website, you can make it live on the Internet. This process is called “launching” your website. You’ll need to upload your website files to your web hosting account and then point your domain name to your hosting account. Once you’ve done this, your website will be available to people on the Internet.
Step 7: Promote your website
Just because you’ve built a website doesn’t mean people will automatically find it. You need to promote your website to get people to visit it. This includes things like search engine optimization (SEO) and social media marketing.
Step 8: Track your website’s progress
Once you’ve built your website, you need to track its progress. This includes things like traffic, search engine rankings, and conversion rates. By tracking your website’s progress, you can make sure that it’s working properly and that people are finding it.
Step 9: Keep your website up-to-date
Just because you’ve built your website doesn’t mean you’re done. You need to keep your website up-to-date by adding new content and fixing any errors that occur. By keeping your website up-to-date, you can make sure that it’s always available to people on the Internet.
Step 10: Repeat steps 1-10
Once you’ve built your website, you need to promote it so that people can find it. You can do this by adding your website to search engines, directories, and social media sites. You can also promote your website by word-of-mouth and by giving people your business card.
Once you’ve promoted your website, you need to keep track of how it’s doing. You can do this by using website analytics tools. These tools will help you see how many people are visiting your website, where they’re coming from, and what they’re doing on your site.
If you want to keep your website up-to-date, you need to add new content on a regular basis. You can do this by writing blog posts, creating infographics, or recording videos. You can also add new content by updating your website’s design and by adding new features.
By following these steps, you can build a website that’s available to people on the Internet. You can also keep your website
```
Since this appears to be a base model, it will keep on generating.
## Credit
- [MistralAI](https://huggingface.co/mistralai) for opening the weights
- [v2ray](https://huggingface.co/v2ray/) for downloading, converting, and sharing it with the community [Mixtral-8x22B-v0.1](https://huggingface.co/v2ray/Mixtral-8x22B-v0.1)
- [philschmid](https://huggingface.co/philschmid) for the photo he shared on his Twitter
▄▄▄░░
▄▄▄▄▄█████████░░░░
▄▄▄▄▄▄████████████████████░░░░░
█████████████████████████████░░░░░
▄▄▄▄▄▄█████░░░ █████████████████████████████░░░░░
▄▄▄▄▄██████████████████░░░░░░ ██████████████████████████████░░░░░
▄█████████████████████████████░░░░░░░░██████████████████████████████░░░░░
███████████████████████████████░░░░░░░██████████████████████████████░░░░░
███████████████████████████████░░░░░░░██████████████████████████████░░░░░
███████████████████████████████░░░░░░███████████████████████████████░░░░░
████████████████████████████████░░░░░███████████████████████████████░░░░░
████████████████████████████████░░░░████████████████████████████████░░░░░
█████████████████████████████████░░░████████████████████████████████░░░░░
█████████████████████████████████░░░████████████░███████████████████░░░░░
██████████████████████████████████░█████████████░███████████████████░░░░░
███████████████████░██████████████▄█████████████░███████████████████░░░░░
███████████████████░███████████████████████████░░███████████████████░░░░░
███████████████████░░██████████████████████████░░███████████████████░░░░░
███████████████████░░█████████████████████████░░░███████████████████░░░░░
███████████████████░░░████████████████████████░░░███████████████████░░░░░
███████████████████░░░████████████████████████░░░███████████████████░░░░░
███████████████████░░░░██████████████████████░░░░███████████████████░░░░░
███████████████████░░░░██████████████████████░░░░███████████████████░░░░░
███████████████████░░░░░█████████████████████░░░░███████████████████░░░░░
███████████████████░░░░░████████████████████░░░░░███████████████████░░░░░
███████████████████░░░░░░███████████████████░░░░░███████████████████░░░░░
███████████████████░░░░░░██████████████████░░░░░░███████████████████░░░░░
███████████████████░░░░░░░█████████████████░░░░░░███████████████████░░░░░
███████████████████░░░░░░░█████████████████░░░░░░███████████████████░░░░░
███████████████████░░░░░░░░███████████████░░░░░░░██████████░░░░░░░░░░░░░░
███████████████████░░░░░░░░███████████████░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░
███████████████████░░░░░░░░███████████░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░
███████████████████░░░░░░░░░██░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░
███████████████░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░
██████████░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░ ░░░░░░░
░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░ ░░░
░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░ ░░░░░░░░░░░░░░░░░░
░░░░░░░░░░░░░░░░░░░░░░░░░░░░
░░░░░░░░░░░░░░░░░
░░░░░ |
csarron/bert-base-uncased-squad-v1 | csarron | 2023-04-05T17:54:11Z | 3,272 | 12 | transformers | [
"transformers",
"pytorch",
"jax",
"safetensors",
"bert",
"question-answering",
"bert-base",
"en",
"dataset:squad",
"license:mit",
"model-index",
"endpoints_compatible",
"region:us"
] | question-answering | 2022-03-02T23:29:05Z | ---
language: en
license: mit
tags:
- question-answering
- bert
- bert-base
datasets:
- squad
metrics:
- squad
widget:
- text: Which name is also used to describe the Amazon rainforest in English?
context: 'The Amazon rainforest (Portuguese: Floresta Amazônica or Amazônia; Spanish:
Selva Amazónica, Amazonía or usually Amazonia; French: Forêt amazonienne; Dutch:
Amazoneregenwoud), also known in English as Amazonia or the Amazon Jungle, is
a moist broadleaf forest that covers most of the Amazon basin of South America.
This basin encompasses 7,000,000 square kilometres (2,700,000 sq mi), of which
5,500,000 square kilometres (2,100,000 sq mi) are covered by the rainforest. This
region includes territory belonging to nine nations. The majority of the forest
is contained within Brazil, with 60% of the rainforest, followed by Peru with
13%, Colombia with 10%, and with minor amounts in Venezuela, Ecuador, Bolivia,
Guyana, Suriname and French Guiana. States or departments in four nations contain
"Amazonas" in their names. The Amazon represents over half of the planet''s remaining
rainforests, and comprises the largest and most biodiverse tract of tropical rainforest
in the world, with an estimated 390 billion individual trees divided into 16,000
species.'
- text: How many square kilometers of rainforest is covered in the basin?
context: 'The Amazon rainforest (Portuguese: Floresta Amazônica or Amazônia; Spanish:
Selva Amazónica, Amazonía or usually Amazonia; French: Forêt amazonienne; Dutch:
Amazoneregenwoud), also known in English as Amazonia or the Amazon Jungle, is
a moist broadleaf forest that covers most of the Amazon basin of South America.
This basin encompasses 7,000,000 square kilometres (2,700,000 sq mi), of which
5,500,000 square kilometres (2,100,000 sq mi) are covered by the rainforest. This
region includes territory belonging to nine nations. The majority of the forest
is contained within Brazil, with 60% of the rainforest, followed by Peru with
13%, Colombia with 10%, and with minor amounts in Venezuela, Ecuador, Bolivia,
Guyana, Suriname and French Guiana. States or departments in four nations contain
"Amazonas" in their names. The Amazon represents over half of the planet''s remaining
rainforests, and comprises the largest and most biodiverse tract of tropical rainforest
in the world, with an estimated 390 billion individual trees divided into 16,000
species.'
model-index:
- name: csarron/bert-base-uncased-squad-v1
results:
- task:
type: question-answering
name: Question Answering
dataset:
name: squad
type: squad
config: plain_text
split: validation
metrics:
- type: exact_match
value: 80.9104
name: Exact Match
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiNDJlOWQ0OTE0ZjRhMTQwNDY5MjVhYmZiN2RmYzY0OWJiOWUyNjcyMWU5N2I3YmU0OThjZTVjNTc2MjM2Yzg5NiIsInZlcnNpb24iOjF9.cuJ34B-ngUur5wKGhfhVP8FM6NX4IFrIJEdXypbLQJw1i8M5Bb2EeIs-0M5n35YIx2PfqSQcnVj_jP8vLUk4Dg
- type: f1
value: 88.2302
name: F1
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiYmE4NzFmNDA3MDRiODk3ZDg5NWYyNjczOGE5YjdkZWQ0ZmEzNWU5YjFjMzc1ODA2OGRjYzU0Y2M5MmU0NGNhYSIsInZlcnNpb24iOjF9.phmkVWF3I-rl2xrHW0EW9OQqzfuefoqNjWplOpFdzJuW8d2C4sJ8snW0Ikw9kQqZaBCdwdkmsf5VTgOupHb8Dw
---
## BERT-base uncased model fine-tuned on SQuAD v1
This model was fine-tuned from the HuggingFace [BERT](https://www.aclweb.org/anthology/N19-1423/) base uncased checkpoint on [SQuAD1.1](https://rajpurkar.github.io/SQuAD-explorer).
This model is case-insensitive: it does not make a difference between english and English.
## Details
| Dataset | Split | # samples |
| -------- | ----- | --------- |
| SQuAD1.1 | train | 90.6K |
| SQuAD1.1 | eval | 11.1k |
### Fine-tuning
- Python: `3.7.5`
- Machine specs:
`CPU: Intel(R) Core(TM) i7-6800K CPU @ 3.40GHz`
`Memory: 32 GiB`
`GPUs: 2 GeForce GTX 1070, each with 8GiB memory`
`GPU driver: 418.87.01, CUDA: 10.1`
- script:
```shell
# after install https://github.com/huggingface/transformers
cd examples/question-answering
mkdir -p data
wget -O data/train-v1.1.json https://rajpurkar.github.io/SQuAD-explorer/dataset/train-v1.1.json
wget -O data/dev-v1.1.json https://rajpurkar.github.io/SQuAD-explorer/dataset/dev-v1.1.json
python run_squad.py \
--model_type bert \
--model_name_or_path bert-base-uncased \
--do_train \
--do_eval \
--do_lower_case \
--train_file train-v1.1.json \
--predict_file dev-v1.1.json \
--per_gpu_train_batch_size 12 \
--per_gpu_eval_batch_size=16 \
--learning_rate 3e-5 \
--num_train_epochs 2.0 \
--max_seq_length 320 \
--doc_stride 128 \
--data_dir data \
--output_dir data/bert-base-uncased-squad-v1 2>&1 | tee train-energy-bert-base-squad-v1.log
```
It took about 2 hours to finish.
### Results
**Model size**: `418M`
| Metric | # Value | # Original ([Table 2](https://www.aclweb.org/anthology/N19-1423.pdf))|
| ------ | --------- | --------- |
| **EM** | **80.9** | **80.8** |
| **F1** | **88.2** | **88.5** |
Note that the above results didn't involve any hyperparameter search.
## Example Usage
```python
from transformers import pipeline
qa_pipeline = pipeline(
"question-answering",
model="csarron/bert-base-uncased-squad-v1",
tokenizer="csarron/bert-base-uncased-squad-v1"
)
predictions = qa_pipeline({
'context': "The game was played on February 7, 2016 at Levi's Stadium in the San Francisco Bay Area at Santa Clara, California.",
'question': "What day was the game played on?"
})
print(predictions)
# output:
# {'score': 0.8730505704879761, 'start': 23, 'end': 39, 'answer': 'February 7, 2016'}
```
> Created by [Qingqing Cao](https://awk.ai/) | [GitHub](https://github.com/csarron) | [Twitter](https://twitter.com/sysnlp)
> Made with ❤️ in New York.
|
laion/CLIP-convnext_large_d.laion2B-s26B-b102K-augreg | laion | 2023-04-18T19:33:42Z | 3,272 | 4 | open_clip | [
"open_clip",
"tensorboard",
"safetensors",
"clip",
"zero-shot-image-classification",
"arxiv:2201.03545",
"arxiv:2210.08402",
"arxiv:1910.04867",
"license:mit",
"region:us"
] | zero-shot-image-classification | 2023-01-29T22:40:05Z | ---
license: mit
library_name: open_clip
pipeline_tag: zero-shot-image-classification
tags:
- clip
---
# Model Card for CLIP-convnext_large_d.laion2B-s26B-b102K-augreg
# Table of Contents
1. [Model Details](#model-details)
2. [Uses](#uses)
3. [Training Details](#training-details)
4. [Evaluation](#evaluation)
5. [Acknowledgements](#acknowledgements)
6. [Citation](#citation)
# Model Details
## Model Description
A series of CLIP [ConvNeXt-Large](https://arxiv.org/abs/2201.03545) (w/ extra text depth, vision MLP head) models trained on LAION-2B (english), a subset of [LAION-5B](https://arxiv.org/abs/2210.08402), using [OpenCLIP](https://github.com/mlfoundations/open_clip).
Goals:
* Explore an alternative to ViT and ResNet (w/ AttentionPooling) CLIP models that scales well with model size and image resolution
Firsts:
* First known ConvNeXt CLIP models trained at scale in the range of CLIP ViT-L/16, ViT-L14, and RN50x16
* First released model weights exploring increase of augmentation + regularization for image tower via adding (greater scale range of RRC, random erasing, stochastic depth)
The models utilize:
* the [timm](https://github.com/rwightman/pytorch-image-models) ConvNeXt-Large model (`convnext_large`) as the image tower
* a MLP (`fc - gelu - drop - fc`) head in vision tower instead of the single projection of other CLIP models
* a text tower with same width but 4 layers more depth than ViT-L / RN50x16 models (depth 16, embed dim 768).
The models are trained at 256x256 (working on 384 variants) image resolution.
At 256x256, the ConvNext-Large-D used roughly 1/2 the training FLOPs to achieve accuracy greater than previous L/14 model trained on LAION-2B. L/14 model is ~1.65x more GMAC, 1.45x more activations, and 1.22x more parameters. The ConvNeXt was trained with 26B samples-seen and L/14 with 34B.
| Model | Dataset | Resolution | AugReg | Top-1 ImageNet Zero-Shot (%) |
| ----- | ------- | ---------- | ------------ | --------- |
| [convnext_large_d.laion2b_s26b_b102k-augreg](https://huggingface.co/laion/CLIP-convnext_large_d.laion2B-s26B-b102K-augreg) | LAION-2B | 256x256 | RRC (0.33, 1.0), RE (0.35), SD (0.1), D(0.1) | 75.9 |
| [convnext_large_d_320.laion2b_s29b_b131k-ft](https://huggingface.co/laion/CLIP-convnext_large_d_320.laion2B-s29B-b131K-ft) | LAION-2B | 320x320 | RRC (0.5, 1.0), RE (0.4), SD (0.1), D(0.0) | 76.6 |
| [convnext_large_d_320.laion2b_s29b_b131k-ft-soup](https://huggingface.co/laion/CLIP-convnext_large_d_320.laion2B-s29B-b131K-ft-soup) | LAION-2B | 320x320 | RRC (0.5, 1.0), RE (0.4), SD (0.1), D(0.0) | 76.9 |
RRC = Random Resize Crop (crop pcts), RE = Random Erasing (prob), SD = Stochastic Depth (prob) -- image tower only, D = Dropout (prob) -- image tower head only
LAION-A = LAION Aesthetic, an ~900M sample subset of LAION-2B with pHash dedupe and asthetic score filtering.
Model training done by Ross Wightman on the [stability.ai](https://stability.ai/) cluster.
# Uses
As per the original [OpenAI CLIP model card](https://github.com/openai/CLIP/blob/d50d76daa670286dd6cacf3bcd80b5e4823fc8e1/model-card.md), this model is intended as a research output for research communities. We hope that this model will enable researchers to better understand and explore zero-shot, arbitrary image classification. We also hope it can be used for interdisciplinary studies of the potential impact of such model.
The OpenAI CLIP paper includes a discussion of potential downstream impacts to provide an example for this sort of analysis. Additionally, the LAION-5B blog (https://laion.ai/blog/laion-5b/) and upcoming paper include additional discussion as it relates specifically to the training dataset.
## Direct Use
Zero-shot image classification, image and text retrieval, among others.
## Downstream Use
Image classification and other image task fine-tuning, linear probe image classification, image generation guiding and conditioning, among others.
## Out-of-Scope Use
As per the OpenAI models,
**Any** deployed use case of the model - whether commercial or not - is currently out of scope. Non-deployed use cases such as image search in a constrained environment, are also not recommended unless there is thorough in-domain testing of the model with a specific, fixed class taxonomy. This is because our safety assessment demonstrated a high need for task specific testing especially given the variability of CLIP’s performance with different class taxonomies. This makes untested and unconstrained deployment of the model in any use case currently potentially harmful.
Certain use cases which would fall under the domain of surveillance and facial recognition are always out-of-scope regardless of performance of the model. This is because the use of artificial intelligence for tasks such as these can be premature currently given the lack of testing norms and checks to ensure its fair use.
Since the model has not been purposefully trained in or evaluated on any languages other than English, its use should be limited to English language use cases.
Further the above notice, the LAION-5B dataset used in training of these models has additional considerations, see below.
# Training Details
## Training Data
This model was trained with LAION-2B -- A 2 billion sample English subset of LAION-5B (https://laion.ai/blog/laion-5b/).
**IMPORTANT NOTE:** The motivation behind dataset creation is to democratize research and experimentation around large-scale multi-modal model training and handling of uncurated, large-scale datasets crawled from publically available internet. Our recommendation is therefore to use the dataset for research purposes. Be aware that this large-scale dataset is uncurated. Keep in mind that the uncurated nature of the dataset means that collected links may lead to strongly discomforting and disturbing content for a human viewer. Therefore, please use the demo links with caution and at your own risk. It is possible to extract a “safe” subset by filtering out samples based on the safety tags (using a customized trained NSFW classifier that we built). While this strongly reduces the chance for encountering potentially harmful content when viewing, we cannot entirely exclude the possibility for harmful content being still present in safe mode, so that the warning holds also there. We think that providing the dataset openly to broad research and other interested communities will allow for transparent investigation of benefits that come along with training large-scale models as well as pitfalls and dangers that may stay unreported or unnoticed when working with closed large datasets that remain restricted to a small community. Providing our dataset openly, we however do not recommend using it for creating ready-to-go industrial products, as the basic research about general properties and safety of such large-scale models, which we would like to encourage with this release, is still in progress.
## Training Procedure
All models were trained with a global batch size of 102400 for 128 checkpoint intervals of 203.7M samples for a total of ~26B samples seen over training.
For 256x256 models, a slurm script w/ srun below was used on 16 8-GPU (A100 80GB) nodes (Stability).
```
/opt/slurm/sbin/srun --cpu_bind=v --accel-bind=gn python -m training.main \
--save-frequency 1 \
--name "convnext_large_256" \
--resume 'latest' \
--train-data="pipe:aws s3 cp s3://mybucket/path/{laion{00000..xxxxx}.tar -" \
--train-num-samples 203666042 \
--dataset-type webdataset \
--precision amp_bfloat16 \
--beta2 0.98 \
--warmup 10000 \
--batch-size=800 \
--epochs=128 \
--dataset-resampled \
--aug-cfg use_timm=True scale='(0.33, 1.0)' re_prob=0.35 \
--clip-grad-norm 5.0 \
--lr 1.667e-3 \
--workers=6 \
--model "convnext_large_d" \
--seed 0 \
--ddp-static-graph \
--local-loss \
--gather-with-grad \
--grad-checkpointing
```
# Evaluation
Evaluation done with code in the [LAION CLIP Benchmark suite](https://github.com/LAION-AI/CLIP_benchmark).
## Testing Data, Factors & Metrics
### Testing Data
The testing is performed with VTAB+ (A combination of VTAB (https://arxiv.org/abs/1910.04867) w/ additional robustness datasets) for classification and COCO and Flickr for retrieval.
## Results
The model achieves a 75.9 top-1 zero-shot accuracy on ImageNet-1k.

An initial round of benchmarks have been performed on a wider range of datasets, to be viewable at https://github.com/LAION-AI/CLIP_benchmark/blob/main/benchmark/results.ipynb
# Acknowledgements
Acknowledging [stability.ai](https://stability.ai/) for compute used to train this model.
# Citation
**BibTeX:**
LAION-5B
```bibtex
@inproceedings{schuhmann2022laionb,
title={{LAION}-5B: An open large-scale dataset for training next generation image-text models},
author={Christoph Schuhmann and
Romain Beaumont and
Richard Vencu and
Cade W Gordon and
Ross Wightman and
Mehdi Cherti and
Theo Coombes and
Aarush Katta and
Clayton Mullis and
Mitchell Wortsman and
Patrick Schramowski and
Srivatsa R Kundurthy and
Katherine Crowson and
Ludwig Schmidt and
Robert Kaczmarczyk and
Jenia Jitsev},
booktitle={Thirty-sixth Conference on Neural Information Processing Systems Datasets and Benchmarks Track},
year={2022},
url={https://openreview.net/forum?id=M3Y74vmsMcY}
}
```
OpenCLIP software
```bibtex
@software{ilharco_gabriel_2021_5143773,
author = {Ilharco, Gabriel and
Wortsman, Mitchell and
Wightman, Ross and
Gordon, Cade and
Carlini, Nicholas and
Taori, Rohan and
Dave, Achal and
Shankar, Vaishaal and
Namkoong, Hongseok and
Miller, John and
Hajishirzi, Hannaneh and
Farhadi, Ali and
Schmidt, Ludwig},
title = {OpenCLIP},
month = jul,
year = 2021,
note = {If you use this software, please cite it as below.},
publisher = {Zenodo},
version = {0.1},
doi = {10.5281/zenodo.5143773},
url = {https://doi.org/10.5281/zenodo.5143773}
}
```
OpenAI CLIP paper
```bibtex
@inproceedings{Radford2021LearningTV,
title={Learning Transferable Visual Models From Natural Language Supervision},
author={Alec Radford and Jong Wook Kim and Chris Hallacy and A. Ramesh and Gabriel Goh and Sandhini Agarwal and Girish Sastry and Amanda Askell and Pamela Mishkin and Jack Clark and Gretchen Krueger and Ilya Sutskever},
booktitle={ICML},
year={2021}
}
```
```bibtex
@Article{liu2022convnet,
author = {Zhuang Liu and Hanzi Mao and Chao-Yuan Wu and Christoph Feichtenhofer and Trevor Darrell and Saining Xie},
title = {A ConvNet for the 2020s},
journal = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2022},
}
```
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/rwightman/pytorch-image-models}}
}
``` |
KnutJaegersberg/black_goo_recipe_b | KnutJaegersberg | 2023-12-03T15:09:05Z | 3,272 | 0 | transformers | [
"transformers",
"pytorch",
"llama",
"text-generation",
"custom_code",
"license:cc-by-nc-4.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2023-08-31T10:00:17Z | ---
license: cc-by-nc-4.0
---
Prompt Example:
```
### System:
You are an AI assistant. User will give you a task. Your goal is to complete the task as faithfully as you can. While performing the task think step-by-step and justify your steps.
### Instruction:
How do you fine tune a large language model?
### Response:
To fine-tune a large language model, we use various techniques to improve its performance and adjust its parameters based on user feedback. These techniques include:
1. Fine tuning the original model with additional data. For example, adding more training examples or using specialized datasets such as question answering or natural language inference tasks. This helps the model learn new concepts and skills by interacting with additional information sources.
2. Using transfer learning methods to incorporate knowledge from other models that have been pre-trained for specific domains. For instance, using pre-trained embeddings from neural networks trained on text classification tasks like sentiment analysis or question answering to help fine-tuning the main language model.
3. Improving the quality of the training data. We may optimize the training process by increasing the accuracy of provided data sets (e.g., by improving word embedding quality), refining the selection of relevant examples, and/or providing additional supervision signals during training.
4. Incorporating knowledge from external resources such as domain-specific lexicons or domain-specific knowledge bases. For example, incorporating domain-specific rules and facts into the model to help it understand domain-specific terminology and semantics.
5. Employing techniques like dropout regularization and dropout sampling to avoid overfitting and reduce overconfidence in the model's predictions.
6. Utilizing meta-learning methods such as reinforcement learning or self-supervised learning to enable the model to adapt quickly to changing situations without being explicitly programmed.
7. Incorporating human input through crowdsourcing or user testing to validate the model's performance and ensure user satisfaction.
8. Implementing various optimization strategies to improve efficiency and reduce computational costs while maintaining high performance levels.
In conclusion, fine tuning a large language model requires combining various techniques including fine tuning, transfer learning, improved data quality, external resources, meta-learning, optimization strategies, crowd sourcing, and user testing. These approaches aim to improve the model's ability to handle various tasks and provide users with better experiences in their daily interactions with language systems.
```
# [Open LLM Leaderboard Evaluation Results](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)
Detailed results can be found [here](https://huggingface.co/datasets/open-llm-leaderboard/details_KnutJaegersberg__black_goo_recipe_b)
| Metric | Value |
|-----------------------|---------------------------|
| Avg. | 33.72 |
| ARC (25-shot) | 37.63 |
| HellaSwag (10-shot) | 66.72 |
| MMLU (5-shot) | 25.68 |
| TruthfulQA (0-shot) | 37.09 |
| Winogrande (5-shot) | 63.77 |
| GSM8K (5-shot) | 0.08 |
| DROP (3-shot) | 5.1 |
|
beomi/KoAlpaca-Polyglot-5.8B | beomi | 2023-09-15T01:28:17Z | 3,271 | 56 | transformers | [
"transformers",
"pytorch",
"safetensors",
"gpt_neox",
"text-generation",
"generated_from_trainer",
"polyglot-ko",
"gpt-neox",
"KoAlpaca",
"ko",
"dataset:KoAlpaca-v1.1b",
"base_model:EleutherAI/polyglot-ko-5.8b",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2023-03-16T15:42:53Z | ---
language:
- ko
license: apache-2.0
tags:
- generated_from_trainer
- polyglot-ko
- gpt-neox
- KoAlpaca
datasets:
- KoAlpaca-v1.1b
pipeline_tag: text-generation
base_model: EleutherAI/polyglot-ko-5.8b
model-index:
- name: KoAlpaca-Polyglot-5.8B
results: []
---
Update @ 2023.06.01
- Add Safetensor sharded model weight (max shard = 1GB)
# KoAlpaca-Polyglot-5.8B (v1.1b)
This model is a fine-tuned version of [EleutherAI/polyglot-ko-5.8b](https://huggingface.co/EleutherAI/polyglot-ko-5.8b) on a KoAlpaca Dataset v1.1b
Detail Codes are available at [KoAlpaca Github Repository](https://github.com/Beomi/KoAlpaca)
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 2
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2.0
- mixed_precision_training: Native AMP
### Framework versions
- Transformers 4.29.0.dev0
- Pytorch 2.0.0+cu117
- Datasets 2.10.1
- Tokenizers 0.13.2
|
castorini/wiki-all-8-4-multi-dpr2-query-encoder | castorini | 2023-01-05T19:26:00Z | 3,270 | 0 | transformers | [
"transformers",
"jax",
"bert",
"feature-extraction",
"endpoints_compatible",
"text-embeddings-inference",
"region:us"
] | feature-extraction | 2023-01-04T02:35:12Z | Dense passage retriever (DPR) is a dense retrieval method described in the following paper:
> Vladimir Karpukhin, Barlas Oğuz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, Wen-tau Yih. [Dense Passage Retrieval for Open-Domain Question Answering](https://www.aclweb.org/anthology/2020.emnlp-main.550/). _Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP)_, pages 6769-6781, 2020.
We have trained our own DPR models with our Wikipedia corpus variants using the [Tevatron](https://github.com/texttron/tevatron) library.
Our own efforts are described in the paper entitled:
> Pre-Processing Matters! Improved Wikipedia Corpora for Open-Domain Question Answering.
This is the query encoder portion of a 2nd iteration DPR model for the wiki-all-8-4 corpus variant trained on the amalgamation of the NQ, TriviaQA, WQ, and CuratedTREC datasets. |
h2oai/h2ogpt-16k-codellama-7b-python | h2oai | 2023-09-01T16:22:42Z | 3,270 | 0 | transformers | [
"transformers",
"pytorch",
"safetensors",
"llama",
"text-generation",
"license:llama2",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2023-08-24T18:33:18Z | ---
license: llama2
---
|
KnutJaegersberg/black_goo_recipe_d | KnutJaegersberg | 2023-12-03T15:09:51Z | 3,270 | 0 | transformers | [
"transformers",
"pytorch",
"llama",
"text-generation",
"custom_code",
"license:cc-by-nc-4.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2023-09-03T06:52:48Z | ---
license: cc-by-nc-4.0
---
Prompt Example:
```
### System:
You are an AI assistant. User will give you a task. Your goal is to complete the task as faithfully as you can. While performing the task think step-by-step and justify your steps.
### Instruction:
How do you fine tune a large language model?
### Response:
```
# [Open LLM Leaderboard Evaluation Results](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)
Detailed results can be found [here](https://huggingface.co/datasets/open-llm-leaderboard/details_KnutJaegersberg__black_goo_recipe_d)
| Metric | Value |
|-----------------------|---------------------------|
| Avg. | 33.83 |
| ARC (25-shot) | 37.8 |
| HellaSwag (10-shot) | 66.5 |
| MMLU (5-shot) | 26.64 |
| TruthfulQA (0-shot) | 36.46 |
| Winogrande (5-shot) | 63.61 |
| GSM8K (5-shot) | 0.38 |
| DROP (3-shot) | 5.4 |
|
beomi/Yi-Ko-6B | beomi | 2024-03-26T13:45:23Z | 3,269 | 33 | transformers | [
"transformers",
"pytorch",
"safetensors",
"llama",
"text-generation",
"Yi-Ko",
"01-ai",
"Yi",
"en",
"ko",
"doi:10.57967/hf/1708",
"license:other",
"model-index",
"autotrain_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2023-11-30T03:03:29Z | ---
language:
- en
- ko
license: other
library_name: transformers
tags:
- pytorch
- Yi-Ko
- 01-ai
- Yi
license_name: yi-license
license_link: LICENSE.md
extra_gated_heading: Access beomi/Yi-Ko-6B on Hugging Face
extra_gated_button_content: Submit
extra_gated_fields:
I agree to share my name, email address and username: checkbox
? I confirm that I understand this project is for research purposes only, and confirm
that I agree to follow the LICENSE of this model
: checkbox
pipeline_tag: text-generation
inference: false
model-index:
- name: Yi-Ko-6B
results:
- task:
type: text-generation
name: Text Generation
dataset:
name: AI2 Reasoning Challenge (25-Shot)
type: ai2_arc
config: ARC-Challenge
split: test
args:
num_few_shot: 25
metrics:
- type: acc_norm
value: 48.89
name: normalized accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=beomi/Yi-Ko-6B
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: HellaSwag (10-Shot)
type: hellaswag
split: validation
args:
num_few_shot: 10
metrics:
- type: acc_norm
value: 74.48
name: normalized accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=beomi/Yi-Ko-6B
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: MMLU (5-Shot)
type: cais/mmlu
config: all
split: test
args:
num_few_shot: 5
metrics:
- type: acc
value: 55.72
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=beomi/Yi-Ko-6B
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: TruthfulQA (0-shot)
type: truthful_qa
config: multiple_choice
split: validation
args:
num_few_shot: 0
metrics:
- type: mc2
value: 37.09
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=beomi/Yi-Ko-6B
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: Winogrande (5-shot)
type: winogrande
config: winogrande_xl
split: validation
args:
num_few_shot: 5
metrics:
- type: acc
value: 72.93
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=beomi/Yi-Ko-6B
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: GSM8k (5-shot)
type: gsm8k
config: main
split: test
args:
num_few_shot: 5
metrics:
- type: acc
value: 12.51
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=beomi/Yi-Ko-6B
name: Open LLM Leaderboard
---
> Update @ 2024.01.29 New Model [beomi/Yi-Ko-DUS-9B](https://huggingface.co/beomi/Yi-Ko-DUS-9B) Released! 🎉
> Update @ 2023.12.03 Yi-Ko(KoEN)-6B Achieved #1🥇 Pretrained Models at [Open Korean LLM Leaderboard](https://huggingface.co/spaces/upstage/open-ko-llm-leaderboard)! 🎉
> Update @ 2023.12.01 Alpha Release of Yi-Ko(KoEN)-6B model 🎉
# **beomi/Yi-Ko-6B**
Yi-Ko series models serve as advanced iterations of 01-ai/Yi models,
benefiting from an expanded vocabulary and the inclusion of Korean/English corpus in its further pretraining.
Just like its predecessor, Yi-Ko series models operate within the broad range of generative text models that stretch from 6 billion to 34 billion parameters.
This repository focuses on the **6B** pretrained version,
which is tailored to fit the Hugging Face Transformers format.
For access to the other models, feel free to consult the index provided below.
## Model Details
**Model Developers** Junbum Lee (Beomi)
**Variations** Yi-Ko series will come in a range of parameter sizes — 6B and 34B variations.
**Input** Models input text only.
**Output** Models generate text only.
**Model Architecture**
Yi-Ko series models are an auto-regressive language model that uses an optimized transformer architecture based on Llama-2*.
<small>*Yi model architecture is based on Llama2, so it can be loaded via `LlamaForCausalLM` class on HF.</small>
|Model Name|Training Data|Params|Context Length|GQA|Trained Tokens|LR|Batch Size(per step)|
|---|---|---|---|---|---|---|---|
|Yi-Ko-6B|*A mix of Korean + English online data*|6B|4k|O|>60B|5e<sup>-5</sup>|2048|
**Vocab Expansion**
| Model Name | Vocabulary Size | Description |
| --- | --- | --- |
| Original Yi-Series | 64000 | Sentencepiece BPE |
| **Expanded Yi-Ko Series** | 78464 | Sentencepiece BPE. Added Korean vocab and merges |
**Tokenizing "안녕하세요, 오늘은 날씨가 좋네요.ㅎㅎ"**
| Model | # of tokens | Tokens |
| --- | --- | --- |
| Original Yi-Series | 47 | `['<0xEC>', '<0x95>', '<0x88>', '<0xEB>', '<0x85>', '<0x95>', '하', '<0xEC>', '<0x84>', '<0xB8>', '<0xEC>', '<0x9A>', '<0x94>', ',', '▁', '<0xEC>', '<0x98>', '<0xA4>', '<0xEB>', '<0x8A>', '<0x98>', '은', '▁', '<0xEB>', '<0x82>', '<0xA0>', '<0xEC>', '<0x94>', '<0xA8>', '가', '▁', '<0xEC>', '<0xA2>', '<0x8B>', '<0xEB>', '<0x84>', '<0xA4>', '<0xEC>', '<0x9A>', '<0x94>', '.', '<0xE3>', '<0x85>', '<0x8E>', '<0xE3>', '<0x85>', '<0x8E>']` |
| **Expanded Yi-Ko Series** | 10 | `['▁안녕', '하세요', ',', '▁오늘은', '▁날', '씨가', '▁좋네요', '.', 'ㅎ', 'ㅎ']` |
|<small>*Equal Korean vocab with Llama-2-Ko Series</small>||
**Tokenizing "Llama 2: Open Foundation and Fine-Tuned Chat Models"**
| Model | # of tokens | Tokens |
| --- | --- | --- |
| Original Yi-Series | 21 | `['The', '▁Y', 'i', '▁series', '▁models', '▁are', '▁large', '▁language', '▁models', '▁trained', '▁from', '▁scratch', '▁by', '▁developers', '▁at', '▁', '0', '1', '.', 'AI', '.']` |
| **Expanded Yi-Ko Series** | 21 | `['▁The', '▁Y', 'i', '▁series', '▁models', '▁are', '▁large', '▁language', '▁models', '▁trained', '▁from', '▁scratch', '▁by', '▁developers', '▁at', '▁', '0', '1', '.', 'AI', '.']` |
|<small>*Equal Korean vocab with Llama-2-Ko Series</small>| | <small>*Since **Expanded Yi-Ko Series** prepends `_` at the beginning of the text(to ensure same tokenization for Korean sentences), it shows negilible difference for the first token on English tokenization. </small>|
# **Model Benchmark**
## LM Eval Harness - Korean (polyglot branch)
| beomi/Yi-Ko-6B | 0 | 5 | 10 | 50 |
|:---------------------------------|---------:|---------:|---------:|---------:|
| kobest_boolq (macro_f1) | 0.705806 | 0.79905 | 0.814299 | 0.81704 |
| kobest_copa (macro_f1) | 0.775604 | 0.808899 | 0.816866 | 0.842943 |
| kobest_hellaswag (macro_f1) | 0.500876 | 0.498673 | 0.493507 | 0.492183 |
| kobest_sentineg (macro_f1) | 0.404371 | 0.967254 | 0.982368 | 0.974811 |
| kohatespeech (macro_f1) | 0.353428 | 0.351804 | 0.402423 | 0.503764 |
| kohatespeech_apeach (macro_f1) | 0.337667 | 0.498679 | 0.471962 | 0.608401 |
| kohatespeech_gen_bias (macro_f1) | 0.124535 | 0.484745 | 0.474475 | 0.461714 |
| korunsmile (f1) | 0.382804 | 0.349344 | 0.391383 | 0.432875 |
| nsmc (acc) | 0.55064 | 0.8801 | 0.89866 | 0.9071 |
| pawsx_ko (acc) | 0.5145 | 0.54 | 0.538 | 0.5165 |
## LICENSE
[Yi Series Models Community License Agreement](https://huggingface.co/01-ai/Yi-6B/blob/main/LICENSE)
> For commercial purpose,
> Follow [Yi Series Models Community License Agreement](https://huggingface.co/01-ai/Yi-6B/blob/main/LICENSE) to acquire Yi Series commercial license,
> and mailto: [email protected] to acquire Yi-Ko sereis commercial license.
## Citation
Please use this bibtex below:
```
@misc {lee_junbum_2024,
author = { {Lee Junbum} },
title = { Yi-Ko-6B (Revision 205083a) },
year = 2024,
url = { https://huggingface.co/beomi/Yi-Ko-6B },
doi = { 10.57967/hf/1708 },
publisher = { Hugging Face }
}
```
## Acknowledgement
The training is supported by [TPU Research Cloud](https://sites.research.google/trc/) program.
# [Open LLM Leaderboard Evaluation Results](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)
Detailed results can be found [here](https://huggingface.co/datasets/open-llm-leaderboard/details_beomi__Yi-Ko-6B)
| Metric |Value|
|---------------------------------|----:|
|Avg. |50.27|
|AI2 Reasoning Challenge (25-Shot)|48.89|
|HellaSwag (10-Shot) |74.48|
|MMLU (5-Shot) |55.72|
|TruthfulQA (0-shot) |37.09|
|Winogrande (5-shot) |72.93|
|GSM8k (5-shot) |12.51|
|
NousResearch/CodeLlama-7b-hf | NousResearch | 2023-08-24T17:30:37Z | 3,268 | 3 | transformers | [
"transformers",
"pytorch",
"llama",
"text-generation",
"custom_code",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2023-08-24T17:13:46Z | Entry not found |
elyza/ELYZA-japanese-Llama-2-13b | elyza | 2023-12-27T01:40:43Z | 3,268 | 20 | transformers | [
"transformers",
"pytorch",
"llama",
"text-generation",
"ja",
"en",
"arxiv:2307.09288",
"license:llama2",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2023-12-25T16:38:08Z | ---
license: llama2
language:
- ja
- en
---
## ELYZA-japanese-Llama-2-13b

### Model Description
**ELYZA-japanese-Llama-2-13b** は、 Llama 2をベースとして日本語能力を拡張するために追加事前学習を行ったモデルです。
詳細は [Blog記事](https://note.com/elyza/n/n5d42686b60b7) を参照してください。
### Usage
```python
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "elyza/ELYZA-japanese-Llama-2-13b"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype=torch.float16,
use_cache=True,
device_map="auto",
low_cpu_mem_usage=True,
)
model.eval()
text = "自然言語処理とは、"
token_ids = tokenizer.encode(text, add_special_tokens=False, return_tensors="pt")
with torch.no_grad():
output_ids = model.generate(
token_ids.to(model.device),
max_new_tokens=256,
pad_token_id=tokenizer.pad_token_id,
eos_token_id=tokenizer.eos_token_id,
)
output = tokenizer.decode(output_ids.tolist()[0], skip_special_tokens=True)
print(output)
```
### ELYZA-japanese-Llama-2-13b Models
| Model Name | Vocab Size | #Params |
|:---------------------------------------------|:----------:|:-------:|
|[elyza/ELYZA-japanese-Llama-2-13b](https://huggingface.co/elyza/ELYZA-japanese-Llama-2-13b)| 32000 | 13.02B |
|[elyza/ELYZA-japanese-Llama-2-13b-instruct](https://huggingface.co/elyza/ELYZA-japanese-Llama-2-13b-instruct)| 32000 | 13.02B |
|[elyza/ELYZA-japanese-Llama-2-13b-fast](https://huggingface.co/elyza/ELYZA-japanese-Llama-2-13b-fast)| 44581 | 13.14B |
|[elyza/ELYZA-japanese-Llama-2-13b-fast-instruct](https://huggingface.co/elyza/ELYZA-japanese-Llama-2-13b-fast-instruct)| 44581 | 13.14B |
### Developers
- [Akira Sasaki](https://huggingface.co/akirasasaki)
- [Masato Hirakawa](https://huggingface.co/m-hirakawa)
- [Shintaro Horie](https://huggingface.co/e-mon)
- [Tomoaki Nakamura](https://huggingface.co/tyoyo)
- [Sam Passaglia](https://huggingface.co/passaglia)
- [Daisuke Oba](https://huggingface.co/daisuk30ba) (intern)
### Licence
Llama 2 is licensed under the LLAMA 2 Community License, Copyright (c) Meta Platforms, Inc. All Rights Reserved.
### How to Cite
```tex
@misc{elyzallama2023,
title={ELYZA-japanese-Llama-2-13b},
url={https://huggingface.co/elyza/ELYZA-japanese-Llama-2-13b},
author={Akira Sasaki and Masato Hirakawa and Shintaro Horie and Tomoaki Nakamura and Sam Passaglia and Daisuke Oba},
year={2023},
}
```
### Citations
```tex
@misc{touvron2023llama,
title={Llama 2: Open Foundation and Fine-Tuned Chat Models},
author={Hugo Touvron and Louis Martin and Kevin Stone and Peter Albert and Amjad Almahairi and Yasmine Babaei and Nikolay Bashlykov and Soumya Batra and Prajjwal Bhargava and Shruti Bhosale and Dan Bikel and Lukas Blecher and Cristian Canton Ferrer and Moya Chen and Guillem Cucurull and David Esiobu and Jude Fernandes and Jeremy Fu and Wenyin Fu and Brian Fuller and Cynthia Gao and Vedanuj Goswami and Naman Goyal and Anthony Hartshorn and Saghar Hosseini and Rui Hou and Hakan Inan and Marcin Kardas and Viktor Kerkez and Madian Khabsa and Isabel Kloumann and Artem Korenev and Punit Singh Koura and Marie-Anne Lachaux and Thibaut Lavril and Jenya Lee and Diana Liskovich and Yinghai Lu and Yuning Mao and Xavier Martinet and Todor Mihaylov and Pushkar Mishra and Igor Molybog and Yixin Nie and Andrew Poulton and Jeremy Reizenstein and Rashi Rungta and Kalyan Saladi and Alan Schelten and Ruan Silva and Eric Michael Smith and Ranjan Subramanian and Xiaoqing Ellen Tan and Binh Tang and Ross Taylor and Adina Williams and Jian Xiang Kuan and Puxin Xu and Zheng Yan and Iliyan Zarov and Yuchen Zhang and Angela Fan and Melanie Kambadur and Sharan Narang and Aurelien Rodriguez and Robert Stojnic and Sergey Edunov and Thomas Scialom},
year={2023},
eprint={2307.09288},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
``` |
RichardErkhov/swap-uniba_-_LLaMAntino-3-ANITA-8B-Inst-DPO-ITA-gguf | RichardErkhov | 2024-06-14T18:12:44Z | 3,268 | 0 | null | [
"gguf",
"arxiv:2405.07101",
"arxiv:2312.09993",
"region:us"
] | null | 2024-06-14T17:41:23Z | Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
LLaMAntino-3-ANITA-8B-Inst-DPO-ITA - GGUF
- Model creator: https://huggingface.co/swap-uniba/
- Original model: https://huggingface.co/swap-uniba/LLaMAntino-3-ANITA-8B-Inst-DPO-ITA/
| Name | Quant method | Size |
| ---- | ---- | ---- |
| [LLaMAntino-3-ANITA-8B-Inst-DPO-ITA.Q2_K.gguf](https://huggingface.co/RichardErkhov/swap-uniba_-_LLaMAntino-3-ANITA-8B-Inst-DPO-ITA-gguf/blob/main/LLaMAntino-3-ANITA-8B-Inst-DPO-ITA.Q2_K.gguf) | Q2_K | 2.96GB |
| [LLaMAntino-3-ANITA-8B-Inst-DPO-ITA.IQ3_XS.gguf](https://huggingface.co/RichardErkhov/swap-uniba_-_LLaMAntino-3-ANITA-8B-Inst-DPO-ITA-gguf/blob/main/LLaMAntino-3-ANITA-8B-Inst-DPO-ITA.IQ3_XS.gguf) | IQ3_XS | 3.28GB |
| [LLaMAntino-3-ANITA-8B-Inst-DPO-ITA.IQ3_S.gguf](https://huggingface.co/RichardErkhov/swap-uniba_-_LLaMAntino-3-ANITA-8B-Inst-DPO-ITA-gguf/blob/main/LLaMAntino-3-ANITA-8B-Inst-DPO-ITA.IQ3_S.gguf) | IQ3_S | 3.43GB |
| [LLaMAntino-3-ANITA-8B-Inst-DPO-ITA.Q3_K_S.gguf](https://huggingface.co/RichardErkhov/swap-uniba_-_LLaMAntino-3-ANITA-8B-Inst-DPO-ITA-gguf/blob/main/LLaMAntino-3-ANITA-8B-Inst-DPO-ITA.Q3_K_S.gguf) | Q3_K_S | 3.41GB |
| [LLaMAntino-3-ANITA-8B-Inst-DPO-ITA.IQ3_M.gguf](https://huggingface.co/RichardErkhov/swap-uniba_-_LLaMAntino-3-ANITA-8B-Inst-DPO-ITA-gguf/blob/main/LLaMAntino-3-ANITA-8B-Inst-DPO-ITA.IQ3_M.gguf) | IQ3_M | 3.52GB |
| [LLaMAntino-3-ANITA-8B-Inst-DPO-ITA.Q3_K.gguf](https://huggingface.co/RichardErkhov/swap-uniba_-_LLaMAntino-3-ANITA-8B-Inst-DPO-ITA-gguf/blob/main/LLaMAntino-3-ANITA-8B-Inst-DPO-ITA.Q3_K.gguf) | Q3_K | 3.74GB |
| [LLaMAntino-3-ANITA-8B-Inst-DPO-ITA.Q3_K_M.gguf](https://huggingface.co/RichardErkhov/swap-uniba_-_LLaMAntino-3-ANITA-8B-Inst-DPO-ITA-gguf/blob/main/LLaMAntino-3-ANITA-8B-Inst-DPO-ITA.Q3_K_M.gguf) | Q3_K_M | 3.74GB |
| [LLaMAntino-3-ANITA-8B-Inst-DPO-ITA.Q3_K_L.gguf](https://huggingface.co/RichardErkhov/swap-uniba_-_LLaMAntino-3-ANITA-8B-Inst-DPO-ITA-gguf/blob/main/LLaMAntino-3-ANITA-8B-Inst-DPO-ITA.Q3_K_L.gguf) | Q3_K_L | 4.03GB |
| [LLaMAntino-3-ANITA-8B-Inst-DPO-ITA.IQ4_XS.gguf](https://huggingface.co/RichardErkhov/swap-uniba_-_LLaMAntino-3-ANITA-8B-Inst-DPO-ITA-gguf/blob/main/LLaMAntino-3-ANITA-8B-Inst-DPO-ITA.IQ4_XS.gguf) | IQ4_XS | 4.18GB |
| [LLaMAntino-3-ANITA-8B-Inst-DPO-ITA.Q4_0.gguf](https://huggingface.co/RichardErkhov/swap-uniba_-_LLaMAntino-3-ANITA-8B-Inst-DPO-ITA-gguf/blob/main/LLaMAntino-3-ANITA-8B-Inst-DPO-ITA.Q4_0.gguf) | Q4_0 | 4.34GB |
| [LLaMAntino-3-ANITA-8B-Inst-DPO-ITA.IQ4_NL.gguf](https://huggingface.co/RichardErkhov/swap-uniba_-_LLaMAntino-3-ANITA-8B-Inst-DPO-ITA-gguf/blob/main/LLaMAntino-3-ANITA-8B-Inst-DPO-ITA.IQ4_NL.gguf) | IQ4_NL | 4.38GB |
| [LLaMAntino-3-ANITA-8B-Inst-DPO-ITA.Q4_K_S.gguf](https://huggingface.co/RichardErkhov/swap-uniba_-_LLaMAntino-3-ANITA-8B-Inst-DPO-ITA-gguf/blob/main/LLaMAntino-3-ANITA-8B-Inst-DPO-ITA.Q4_K_S.gguf) | Q4_K_S | 4.37GB |
| [LLaMAntino-3-ANITA-8B-Inst-DPO-ITA.Q4_K.gguf](https://huggingface.co/RichardErkhov/swap-uniba_-_LLaMAntino-3-ANITA-8B-Inst-DPO-ITA-gguf/blob/main/LLaMAntino-3-ANITA-8B-Inst-DPO-ITA.Q4_K.gguf) | Q4_K | 4.58GB |
| [LLaMAntino-3-ANITA-8B-Inst-DPO-ITA.Q4_K_M.gguf](https://huggingface.co/RichardErkhov/swap-uniba_-_LLaMAntino-3-ANITA-8B-Inst-DPO-ITA-gguf/blob/main/LLaMAntino-3-ANITA-8B-Inst-DPO-ITA.Q4_K_M.gguf) | Q4_K_M | 4.58GB |
| [LLaMAntino-3-ANITA-8B-Inst-DPO-ITA.Q4_1.gguf](https://huggingface.co/RichardErkhov/swap-uniba_-_LLaMAntino-3-ANITA-8B-Inst-DPO-ITA-gguf/blob/main/LLaMAntino-3-ANITA-8B-Inst-DPO-ITA.Q4_1.gguf) | Q4_1 | 4.78GB |
| [LLaMAntino-3-ANITA-8B-Inst-DPO-ITA.Q5_0.gguf](https://huggingface.co/RichardErkhov/swap-uniba_-_LLaMAntino-3-ANITA-8B-Inst-DPO-ITA-gguf/blob/main/LLaMAntino-3-ANITA-8B-Inst-DPO-ITA.Q5_0.gguf) | Q5_0 | 5.21GB |
| [LLaMAntino-3-ANITA-8B-Inst-DPO-ITA.Q5_K_S.gguf](https://huggingface.co/RichardErkhov/swap-uniba_-_LLaMAntino-3-ANITA-8B-Inst-DPO-ITA-gguf/blob/main/LLaMAntino-3-ANITA-8B-Inst-DPO-ITA.Q5_K_S.gguf) | Q5_K_S | 5.21GB |
| [LLaMAntino-3-ANITA-8B-Inst-DPO-ITA.Q5_K.gguf](https://huggingface.co/RichardErkhov/swap-uniba_-_LLaMAntino-3-ANITA-8B-Inst-DPO-ITA-gguf/blob/main/LLaMAntino-3-ANITA-8B-Inst-DPO-ITA.Q5_K.gguf) | Q5_K | 5.34GB |
| [LLaMAntino-3-ANITA-8B-Inst-DPO-ITA.Q5_K_M.gguf](https://huggingface.co/RichardErkhov/swap-uniba_-_LLaMAntino-3-ANITA-8B-Inst-DPO-ITA-gguf/blob/main/LLaMAntino-3-ANITA-8B-Inst-DPO-ITA.Q5_K_M.gguf) | Q5_K_M | 5.34GB |
| [LLaMAntino-3-ANITA-8B-Inst-DPO-ITA.Q5_1.gguf](https://huggingface.co/RichardErkhov/swap-uniba_-_LLaMAntino-3-ANITA-8B-Inst-DPO-ITA-gguf/blob/main/LLaMAntino-3-ANITA-8B-Inst-DPO-ITA.Q5_1.gguf) | Q5_1 | 5.65GB |
| [LLaMAntino-3-ANITA-8B-Inst-DPO-ITA.Q6_K.gguf](https://huggingface.co/RichardErkhov/swap-uniba_-_LLaMAntino-3-ANITA-8B-Inst-DPO-ITA-gguf/blob/main/LLaMAntino-3-ANITA-8B-Inst-DPO-ITA.Q6_K.gguf) | Q6_K | 6.14GB |
| [LLaMAntino-3-ANITA-8B-Inst-DPO-ITA.Q8_0.gguf](https://huggingface.co/RichardErkhov/swap-uniba_-_LLaMAntino-3-ANITA-8B-Inst-DPO-ITA-gguf/blob/main/LLaMAntino-3-ANITA-8B-Inst-DPO-ITA.Q8_0.gguf) | Q8_0 | 7.95GB |
Original model description:
---
language:
- en
- it
license: llama3
library_name: transformers
tags:
- facebook
- meta
- pythorch
- llama
- llama-3
- llamantino
base_model: meta-llama/Meta-Llama-3-8B-Instruct
datasets:
- gsarti/clean_mc4_it
- Chat-Error/wizard_alpaca_dolly_orca
- mlabonne/orpo-dpo-mix-40k
metrics:
- accuracy
model_creator: Marco Polignano - SWAP Research Group
pipeline_tag: text-generation
model-index:
- name: LLaMAntino-3-ANITA-8B-Inst-DPO-ITA
results:
- task:
type: text-generation
name: Text Generation
dataset:
name: AI2 Reasoning Challenge (25-Shot)
type: ai2_arc
config: ARC-Challenge
split: test
args:
num_few_shot: 25
metrics:
- type: acc_norm
value: 74.57
name: normalized accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=swap-uniba/LLaMAntino-3-ANITA-8B-Inst-DPO-ITA
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: HellaSwag (10-Shot)
type: hellaswag
split: validation
args:
num_few_shot: 10
metrics:
- type: acc_norm
value: 92.75
name: normalized accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=swap-uniba/LLaMAntino-3-ANITA-8B-Inst-DPO-ITA
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: MMLU (5-Shot)
type: cais/mmlu
config: all
split: test
args:
num_few_shot: 5
metrics:
- type: acc
value: 66.85
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=swap-uniba/LLaMAntino-3-ANITA-8B-Inst-DPO-ITA
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: TruthfulQA (0-shot)
type: truthful_qa
config: multiple_choice
split: validation
args:
num_few_shot: 0
metrics:
- type: mc2
value: 75.93
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=swap-uniba/LLaMAntino-3-ANITA-8B-Inst-DPO-ITA
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: Winogrande (5-shot)
type: winogrande
config: winogrande_xl
split: validation
args:
num_few_shot: 5
metrics:
- type: acc
value: 82.0
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=swap-uniba/LLaMAntino-3-ANITA-8B-Inst-DPO-ITA
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: GSM8k (5-shot)
type: gsm8k
config: main
split: test
args:
num_few_shot: 5
metrics:
- type: acc
value: 58.61
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=swap-uniba/LLaMAntino-3-ANITA-8B-Inst-DPO-ITA
name: Open LLM Leaderboard
---
<img src="https://cdn-uploads.huggingface.co/production/uploads/5df8bb21da6d0311fd3d540f/cZoZdwQOPdQsnQmDXHcSn.png" alt="llamantino3_anita" border="0" width="800px">
<hr>
<!--<img src="https://i.ibb.co/6mHSRm3/llamantino53.jpg" width="200"/>-->
<h3><i>"Built with <b>Meta Llama 3</b>".</i></i></h3>
<p style="text-align:justify;"><b>LLaMAntino-3-ANITA-8B-Inst-DPO-ITA</b> is a model of the <a href="https://huggingface.co/swap-uniba"><b>LLaMAntino</b></a> - <i>Large Language Models family</i>.
The model is an instruction-tuned version of <a href="https://huggingface.co/meta-llama/Meta-Llama-3-8B-Instruct"><b>Meta-Llama-3-8b-instruct</b></a> (a fine-tuned <b>LLaMA 3 model</b>).
This model version aims to be the a <b>Multilingual Model</b> 🏁 (EN 🇺🇸 + ITA🇮🇹) to further fine-tuning on Specific Tasks in Italian.</p>
The 🌟**ANITA project**🌟 *(**A**dvanced **N**atural-based interaction for the **ITA**lian language)*
wants to provide Italian NLP researchers with an improved model for the Italian Language 🇮🇹 use cases.<br>
<hr>
**Live DEMO:** [https://chat.llamantino.it/](https://chat.llamantino.it/)<br>
*It works only with Italian connection.*
<hr>
## Model Details
*Last Update: 10/05/2024*<br>
<a href="https://github.com/marcopoli/LLaMAntino-3-ANITA"><img src="https://github.githubassets.com/assets/GitHub-Logo-ee398b662d42.png" width="150"> https://github.com/marcopoli/LLaMAntino-3-ANITA</a><br>
| Model | HF | GGUF | EXL2 |
|-------|-------|-------|-------|
| *swap-uniba/LLaMAntino-3-ANITA-8B-Inst-DPO-ITA* | [Link](https://huggingface.co/swap-uniba/LLaMAntino-3-ANITA-8B-Inst-DPO-ITA) | [Link](https://huggingface.co/swap-uniba/LLaMAntino-3-ANITA-8B-Inst-DPO-ITA_GGUF) | [Link](https://huggingface.co/swap-uniba/LLaMAntino-3-ANITA-8B-Inst-DPO-ITA_EXL2) |
<hr>
## Specifications
- **Model developers**: <br><a href="https://marcopoli.github.io/">Ph.D. Marco Polignano</a> - University of Bari Aldo Moro, Italy <br> <a href="https://huggingface.co/swap-uniba">SWAP Research Group</a> <br>
- **Variations**: The model release has been **supervised fine-tuning (SFT)** using **QLoRA** 4bit, on instruction-based datasets. **DPO** approach over the *mlabonne/orpo-dpo-mix-40k* dataset is used to align with human preferences for helpfulness and safety.
- **Input**: Models input text only.
- **Language**: Multilingual 🏁 + Italian 🇮🇹
- **Output**: Models generate text and code only.
- **Model Architecture**: *Llama 3 architecture*.
- **Context length**: 8K, 8192.
- **Library Used**: [Unsloth](https://unsloth.ai/)
<hr>
## Playground
To use the model directly, there are many ways to get started, choose one of the following ways to experience it.
### Prompt Template
```
<|start_header_id|>system<|end_header_id|>
{ SYS Prompt }<|eot_id|><|start_header_id|>user<|end_header_id|>
{ USER Prompt }<|eot_id|><|start_header_id|>assistant<|end_header_id|>
{ ASSIST Prompt }<|eot_id|>
````
### Transformers
For direct use with `transformers`, you can easily get started with the following steps.
- Firstly, you need to install transformers via the command below with `pip`.
```bash
pip install -U transformers trl peft accelerate bitsandbytes
```
- Right now, you can start using the model directly.
```python
import torch
from transformers import (
AutoModelForCausalLM,
AutoTokenizer,
)
base_model = "swap-uniba/LLaMAntino-3-ANITA-8B-Inst-DPO-ITA"
model = AutoModelForCausalLM.from_pretrained(
base_model,
torch_dtype=torch.bfloat16,
device_map="auto",
)
tokenizer = AutoTokenizer.from_pretrained(base_model)
sys = "Sei un an assistente AI per la lingua Italiana di nome LLaMAntino-3 ANITA " \
"(Advanced Natural-based interaction for the ITAlian language)." \
" Rispondi nella lingua usata per la domanda in modo chiaro, semplice ed esaustivo."
messages = [
{"role": "system", "content": sys},
{"role": "user", "content": "Chi è Carlo Magno?"}
]
#Method 1
prompt = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
inputs = tokenizer(prompt, return_tensors="pt", add_special_tokens=False)
for k,v in inputs.items():
inputs[k] = v.cuda()
outputs = model.generate(**inputs, max_new_tokens=512, do_sample=True, top_p=0.9, temperature=0.6)
results = tokenizer.batch_decode(outputs)[0]
print(results)
#Method 2
import transformers
pipe = transformers.pipeline(
model=model,
tokenizer=tokenizer,
return_full_text=False, # langchain expects the full text
task='text-generation',
max_new_tokens=512, # max number of tokens to generate in the output
temperature=0.6, #temperature for more or less creative answers
do_sample=True,
top_p=0.9,
)
sequences = pipe(messages)
for seq in sequences:
print(f"{seq['generated_text']}")
```
- Additionally, you can also use a model with **4bit quantization** to reduce the required resources at least. You can start with the code below.
```python
import torch
from transformers import (
AutoModelForCausalLM,
AutoTokenizer,
BitsAndBytesConfig,
)
base_model = "swap-uniba/LLaMAntino-3-ANITA-8B-Inst-DPO-ITA"
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16,
bnb_4bit_use_double_quant=False,
)
model = AutoModelForCausalLM.from_pretrained(
base_model,
quantization_config=bnb_config,
device_map="auto",
)
tokenizer = AutoTokenizer.from_pretrained(base_model)
sys = "Sei un an assistente AI per la lingua Italiana di nome LLaMAntino-3 ANITA " \
"(Advanced Natural-based interaction for the ITAlian language)." \
" Rispondi nella lingua usata per la domanda in modo chiaro, semplice ed esaustivo."
messages = [
{"role": "system", "content": sys},
{"role": "user", "content": "Chi è Carlo Magno?"}
]
#Method 1
prompt = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
inputs = tokenizer(prompt, return_tensors="pt", add_special_tokens=False)
for k,v in inputs.items():
inputs[k] = v.cuda()
outputs = model.generate(**inputs, max_new_tokens=512, do_sample=True, top_p=0.9, temperature=0.6)
results = tokenizer.batch_decode(outputs)[0]
print(results)
#Method 2
import transformers
pipe = transformers.pipeline(
model=model,
tokenizer=tokenizer,
return_full_text=False, # langchain expects the full text
task='text-generation',
max_new_tokens=512, # max number of tokens to generate in the output
temperature=0.6, #temperature for more or less creative answers
do_sample=True,
top_p=0.9,
)
sequences = pipe(messages)
for seq in sequences:
print(f"{seq['generated_text']}")
```
<hr>
## Evaluation
**Open LLM Leaderboard:**
Evaluated with lm-evaluation-benchmark-harness for the [**Open Italian LLMs Leaderboard**](https://huggingface.co/spaces/FinancialSupport/open_ita_llm_leaderboard)
```
lm_eval --model hf --model_args pretrained=HUGGINGFACE_MODEL_ID --tasks hellaswag_it,arc_it --device cuda:0 --batch_size auto:2
lm_eval --model hf --model_args pretrained=HUGGINGFACE_MODEL_ID --tasks m_mmlu_it --num_fewshot 5 --device cuda:0 --batch_size auto:2
```
| Metric | Value |
|-----------------------|---------------------------|
| Avg. | **0.6160** |
| Arc_IT | 0.5714 |
| Hellaswag_IT | 0.7093 |
| MMLU_IT | 0.5672 |
<hr>
## Unsloth
<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/made with unsloth.png" width="200px" align="center" />
[Unsloth](https://unsloth.ai), a great tool that helps us easily develop products, at a lower cost than expected.
## Citation instructions
```bibtex
@misc{polignano2024advanced,
title={Advanced Natural-based interaction for the ITAlian language: LLaMAntino-3-ANITA},
author={Marco Polignano and Pierpaolo Basile and Giovanni Semeraro},
year={2024},
eprint={2405.07101},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
```bibtex
@misc{basile2023llamantino,
title={LLaMAntino: LLaMA 2 Models for Effective Text Generation in Italian Language},
author={Pierpaolo Basile and Elio Musacchio and Marco Polignano and Lucia Siciliani and Giuseppe Fiameni and Giovanni Semeraro},
year={2023},
eprint={2312.09993},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
```bibtex
@article{llama3modelcard,
title={Llama 3 Model Card},
author={AI@Meta},
year={2024},
url = {https://github.com/meta-llama/llama3/blob/main/MODEL_CARD.md}
}
```
# Acknowledgments
We acknowledge the support of the PNRR project [FAIR - Future AI Research (PE00000013)](https://fondazione-fair.it/en/foundation/), Spoke 6 - Symbiotic AI (CUP H97G22000210007) under the NRRP MUR program funded by the NextGenerationEU.
Models are built on the Leonardo supercomputer with the support of CINECA-Italian Super Computing Resource Allocation, class C project IscrC\_Pro\_MRS (HP10CQO70G).
<img src="https://wiki.u-gov.it/confluence/download/attachments/49842317/image2022-6-21_11-11-44.png?version=1&modificationDate=1655802705000&api=v2" width="600px">
# [Open LLM Leaderboard Evaluation Results](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)
Detailed results can be found [here](https://huggingface.co/datasets/open-llm-leaderboard/details_swap-uniba__LLaMAntino-3-ANITA-8B-Inst-DPO-ITA)
| Metric |Value|
|---------------------------------|----:|
|Avg. |75.12|
|AI2 Reasoning Challenge (25-Shot)|74.57|
|HellaSwag (10-Shot) |92.75|
|MMLU (5-Shot) |66.85|
|TruthfulQA (0-shot) |75.93|
|Winogrande (5-shot) |82.00|
|GSM8k (5-shot) |58.61|
|
h2oai/h2ogpt-16k-codellama-13b-python | h2oai | 2023-09-01T16:21:07Z | 3,267 | 1 | transformers | [
"transformers",
"pytorch",
"safetensors",
"llama",
"text-generation",
"license:llama2",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2023-08-24T16:34:53Z | ---
license: llama2
---
|
KnutJaegersberg/LLongMA-3b-LIMA | KnutJaegersberg | 2023-11-18T07:42:52Z | 3,267 | 3 | transformers | [
"transformers",
"pytorch",
"llama",
"text-generation",
"custom_code",
"license:cc-by-nc-4.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2023-09-03T13:54:25Z | ---
license: cc-by-nc-4.0
---
Prompt example:
```
### Instruction:
How do you fine tune a large language model?
### Response:
```
# [Open LLM Leaderboard Evaluation Results](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)
Detailed results can be found [here](https://huggingface.co/datasets/open-llm-leaderboard/details_KnutJaegersberg__LLongMA-3b-LIMA)
| Metric | Value |
|-----------------------|---------------------------|
| Avg. | 33.66 |
| ARC (25-shot) | 39.08 |
| HellaSwag (10-shot) | 67.15 |
| MMLU (5-shot) | 26.43 |
| TruthfulQA (0-shot) | 34.71 |
| Winogrande (5-shot) | 63.38 |
| GSM8K (5-shot) | 0.3 |
| DROP (3-shot) | 4.57 |
|
mradermacher/MyAlee-Mistral-Instruct-v2-32k-v2-GGUF | mradermacher | 2024-06-04T07:03:26Z | 3,267 | 0 | transformers | [
"transformers",
"gguf",
"alignment-handbook",
"trl",
"sft",
"generated_from_trainer",
"en",
"dataset:arcee-ai/MyAlee-Education-Instructions-V2",
"base_model:arcee-ai/MyAlee-Mistral-Instruct-v2-32k-v2",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2024-06-04T04:35:18Z | ---
base_model: arcee-ai/MyAlee-Mistral-Instruct-v2-32k-v2
datasets:
- arcee-ai/MyAlee-Education-Instructions-V2
language:
- en
library_name: transformers
license: apache-2.0
quantized_by: mradermacher
tags:
- alignment-handbook
- trl
- sft
- generated_from_trainer
- trl
- sft
- generated_from_trainer
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
static quants of https://huggingface.co/arcee-ai/MyAlee-Mistral-Instruct-v2-32k-v2
<!-- provided-files -->
weighted/imatrix quants are available at https://huggingface.co/mradermacher/MyAlee-Mistral-Instruct-v2-32k-v2-i1-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/MyAlee-Mistral-Instruct-v2-32k-v2-GGUF/resolve/main/MyAlee-Mistral-Instruct-v2-32k-v2.Q2_K.gguf) | Q2_K | 2.8 | |
| [GGUF](https://huggingface.co/mradermacher/MyAlee-Mistral-Instruct-v2-32k-v2-GGUF/resolve/main/MyAlee-Mistral-Instruct-v2-32k-v2.IQ3_XS.gguf) | IQ3_XS | 3.1 | |
| [GGUF](https://huggingface.co/mradermacher/MyAlee-Mistral-Instruct-v2-32k-v2-GGUF/resolve/main/MyAlee-Mistral-Instruct-v2-32k-v2.Q3_K_S.gguf) | Q3_K_S | 3.3 | |
| [GGUF](https://huggingface.co/mradermacher/MyAlee-Mistral-Instruct-v2-32k-v2-GGUF/resolve/main/MyAlee-Mistral-Instruct-v2-32k-v2.IQ3_S.gguf) | IQ3_S | 3.3 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/MyAlee-Mistral-Instruct-v2-32k-v2-GGUF/resolve/main/MyAlee-Mistral-Instruct-v2-32k-v2.IQ3_M.gguf) | IQ3_M | 3.4 | |
| [GGUF](https://huggingface.co/mradermacher/MyAlee-Mistral-Instruct-v2-32k-v2-GGUF/resolve/main/MyAlee-Mistral-Instruct-v2-32k-v2.Q3_K_M.gguf) | Q3_K_M | 3.6 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/MyAlee-Mistral-Instruct-v2-32k-v2-GGUF/resolve/main/MyAlee-Mistral-Instruct-v2-32k-v2.Q3_K_L.gguf) | Q3_K_L | 3.9 | |
| [GGUF](https://huggingface.co/mradermacher/MyAlee-Mistral-Instruct-v2-32k-v2-GGUF/resolve/main/MyAlee-Mistral-Instruct-v2-32k-v2.IQ4_XS.gguf) | IQ4_XS | 4.0 | |
| [GGUF](https://huggingface.co/mradermacher/MyAlee-Mistral-Instruct-v2-32k-v2-GGUF/resolve/main/MyAlee-Mistral-Instruct-v2-32k-v2.Q4_K_S.gguf) | Q4_K_S | 4.2 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/MyAlee-Mistral-Instruct-v2-32k-v2-GGUF/resolve/main/MyAlee-Mistral-Instruct-v2-32k-v2.Q4_K_M.gguf) | Q4_K_M | 4.5 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/MyAlee-Mistral-Instruct-v2-32k-v2-GGUF/resolve/main/MyAlee-Mistral-Instruct-v2-32k-v2.Q5_K_S.gguf) | Q5_K_S | 5.1 | |
| [GGUF](https://huggingface.co/mradermacher/MyAlee-Mistral-Instruct-v2-32k-v2-GGUF/resolve/main/MyAlee-Mistral-Instruct-v2-32k-v2.Q5_K_M.gguf) | Q5_K_M | 5.2 | |
| [GGUF](https://huggingface.co/mradermacher/MyAlee-Mistral-Instruct-v2-32k-v2-GGUF/resolve/main/MyAlee-Mistral-Instruct-v2-32k-v2.Q6_K.gguf) | Q6_K | 6.0 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/MyAlee-Mistral-Instruct-v2-32k-v2-GGUF/resolve/main/MyAlee-Mistral-Instruct-v2-32k-v2.Q8_0.gguf) | Q8_0 | 7.8 | fast, best quality |
| [GGUF](https://huggingface.co/mradermacher/MyAlee-Mistral-Instruct-v2-32k-v2-GGUF/resolve/main/MyAlee-Mistral-Instruct-v2-32k-v2.f16.gguf) | f16 | 14.6 | 16 bpw, overkill |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
Qwen/Qwen1.5-72B-Chat-GPTQ-Int4 | Qwen | 2024-04-30T07:44:14Z | 3,265 | 35 | transformers | [
"transformers",
"safetensors",
"qwen2",
"text-generation",
"chat",
"conversational",
"en",
"license:other",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"4-bit",
"gptq",
"region:us"
] | text-generation | 2024-02-04T17:48:20Z | ---
license: other
license_name: tongyi-qianwen
license_link: >-
https://huggingface.co/Qwen/Qwen1.5-72B-Chat-GPTQ-Int4/blob/main/LICENSE
language:
- en
pipeline_tag: text-generation
tags:
- chat
---
# Qwen1.5-72B-Chat-GPTQ-Int4
## Introduction
Qwen1.5 is the beta version of Qwen2, a transformer-based decoder-only language model pretrained on a large amount of data. In comparison with the previous released Qwen, the improvements include:
* 6 model sizes, including 0.5B, 1.8B, 4B, 7B, 14B, and 72B;
* Significant performance improvement in human preference for chat models;
* Multilingual support of both base and chat models;
* Stable support of 32K context length for models of all sizes
* No need of `trust_remote_code`.
For more details, please refer to our [blog post](https://qwenlm.github.io/blog/qwen1.5/) and [GitHub repo](https://github.com/QwenLM/Qwen1.5).
<br>
## Model Details
Qwen1.5 is a language model series including decoder language models of different model sizes. For each size, we release the base language model and the aligned chat model. It is based on the Transformer architecture with SwiGLU activation, attention QKV bias, group query attention, mixture of sliding window attention and full attention, etc. Additionally, we have an improved tokenizer adaptive to multiple natural languages and codes. For the beta version, temporarily we did not include GQA and the mixture of SWA and full attention.
## Training details
We pretrained the models with a large amount of data, and we post-trained the models with both supervised finetuning and direct preference optimization. However, DPO leads to improvements in human preference evaluation but degradation in benchmark evaluation. In the very near future, we will fix both problems.
## Requirements
The code of Qwen1.5 has been in the latest Hugging face transformers and we advise you to install `transformers>=4.37.0`, or you might encounter the following error:
```
KeyError: 'qwen2'
```
## Quickstart
Here provides a code snippet with `apply_chat_template` to show you how to load the tokenizer and model and how to generate contents.
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
device = "cuda" # the device to load the model onto
model = AutoModelForCausalLM.from_pretrained(
"Qwen/Qwen1.5-72B-Chat-GPTQ-Int4",
torch_dtype="auto",
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen1.5-72B-Chat-GPTQ-Int4")
prompt = "Give me a short introduction to large language model."
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(device)
generated_ids = model.generate(
model_inputs.input_ids,
max_new_tokens=512
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
```
## Tips
* If you encounter code switching or other bad cases, we advise you to use our provided hyper-parameters in `generation_config.json`.
## Citation
If you find our work helpful, feel free to give us a cite.
```
@article{qwen,
title={Qwen Technical Report},
author={Jinze Bai and Shuai Bai and Yunfei Chu and Zeyu Cui and Kai Dang and Xiaodong Deng and Yang Fan and Wenbin Ge and Yu Han and Fei Huang and Binyuan Hui and Luo Ji and Mei Li and Junyang Lin and Runji Lin and Dayiheng Liu and Gao Liu and Chengqiang Lu and Keming Lu and Jianxin Ma and Rui Men and Xingzhang Ren and Xuancheng Ren and Chuanqi Tan and Sinan Tan and Jianhong Tu and Peng Wang and Shijie Wang and Wei Wang and Shengguang Wu and Benfeng Xu and Jin Xu and An Yang and Hao Yang and Jian Yang and Shusheng Yang and Yang Yao and Bowen Yu and Hongyi Yuan and Zheng Yuan and Jianwei Zhang and Xingxuan Zhang and Yichang Zhang and Zhenru Zhang and Chang Zhou and Jingren Zhou and Xiaohuan Zhou and Tianhang Zhu},
journal={arXiv preprint arXiv:2309.16609},
year={2023}
}
``` |
RichardErkhov/Qwen_-_Qwen2-7B-Instruct-gguf | RichardErkhov | 2024-06-14T13:50:45Z | 3,265 | 0 | null | [
"gguf",
"arxiv:2309.00071",
"region:us"
] | null | 2024-06-14T13:19:56Z | Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
Qwen2-7B-Instruct - GGUF
- Model creator: https://huggingface.co/Qwen/
- Original model: https://huggingface.co/Qwen/Qwen2-7B-Instruct/
| Name | Quant method | Size |
| ---- | ---- | ---- |
| [Qwen2-7B-Instruct.Q2_K.gguf](https://huggingface.co/RichardErkhov/Qwen_-_Qwen2-7B-Instruct-gguf/blob/main/Qwen2-7B-Instruct.Q2_K.gguf) | Q2_K | 2.81GB |
| [Qwen2-7B-Instruct.IQ3_XS.gguf](https://huggingface.co/RichardErkhov/Qwen_-_Qwen2-7B-Instruct-gguf/blob/main/Qwen2-7B-Instruct.IQ3_XS.gguf) | IQ3_XS | 3.12GB |
| [Qwen2-7B-Instruct.IQ3_S.gguf](https://huggingface.co/RichardErkhov/Qwen_-_Qwen2-7B-Instruct-gguf/blob/main/Qwen2-7B-Instruct.IQ3_S.gguf) | IQ3_S | 3.26GB |
| [Qwen2-7B-Instruct.Q3_K_S.gguf](https://huggingface.co/RichardErkhov/Qwen_-_Qwen2-7B-Instruct-gguf/blob/main/Qwen2-7B-Instruct.Q3_K_S.gguf) | Q3_K_S | 3.25GB |
| [Qwen2-7B-Instruct.IQ3_M.gguf](https://huggingface.co/RichardErkhov/Qwen_-_Qwen2-7B-Instruct-gguf/blob/main/Qwen2-7B-Instruct.IQ3_M.gguf) | IQ3_M | 3.33GB |
| [Qwen2-7B-Instruct.Q3_K.gguf](https://huggingface.co/RichardErkhov/Qwen_-_Qwen2-7B-Instruct-gguf/blob/main/Qwen2-7B-Instruct.Q3_K.gguf) | Q3_K | 3.55GB |
| [Qwen2-7B-Instruct.Q3_K_M.gguf](https://huggingface.co/RichardErkhov/Qwen_-_Qwen2-7B-Instruct-gguf/blob/main/Qwen2-7B-Instruct.Q3_K_M.gguf) | Q3_K_M | 3.55GB |
| [Qwen2-7B-Instruct.Q3_K_L.gguf](https://huggingface.co/RichardErkhov/Qwen_-_Qwen2-7B-Instruct-gguf/blob/main/Qwen2-7B-Instruct.Q3_K_L.gguf) | Q3_K_L | 3.81GB |
| [Qwen2-7B-Instruct.IQ4_XS.gguf](https://huggingface.co/RichardErkhov/Qwen_-_Qwen2-7B-Instruct-gguf/blob/main/Qwen2-7B-Instruct.IQ4_XS.gguf) | IQ4_XS | 3.96GB |
| [Qwen2-7B-Instruct.Q4_0.gguf](https://huggingface.co/RichardErkhov/Qwen_-_Qwen2-7B-Instruct-gguf/blob/main/Qwen2-7B-Instruct.Q4_0.gguf) | Q4_0 | 4.13GB |
| [Qwen2-7B-Instruct.IQ4_NL.gguf](https://huggingface.co/RichardErkhov/Qwen_-_Qwen2-7B-Instruct-gguf/blob/main/Qwen2-7B-Instruct.IQ4_NL.gguf) | IQ4_NL | 4.16GB |
| [Qwen2-7B-Instruct.Q4_K_S.gguf](https://huggingface.co/RichardErkhov/Qwen_-_Qwen2-7B-Instruct-gguf/blob/main/Qwen2-7B-Instruct.Q4_K_S.gguf) | Q4_K_S | 4.15GB |
| [Qwen2-7B-Instruct.Q4_K.gguf](https://huggingface.co/RichardErkhov/Qwen_-_Qwen2-7B-Instruct-gguf/blob/main/Qwen2-7B-Instruct.Q4_K.gguf) | Q4_K | 4.36GB |
| [Qwen2-7B-Instruct.Q4_K_M.gguf](https://huggingface.co/RichardErkhov/Qwen_-_Qwen2-7B-Instruct-gguf/blob/main/Qwen2-7B-Instruct.Q4_K_M.gguf) | Q4_K_M | 4.36GB |
| [Qwen2-7B-Instruct.Q4_1.gguf](https://huggingface.co/RichardErkhov/Qwen_-_Qwen2-7B-Instruct-gguf/blob/main/Qwen2-7B-Instruct.Q4_1.gguf) | Q4_1 | 4.54GB |
| [Qwen2-7B-Instruct.Q5_0.gguf](https://huggingface.co/RichardErkhov/Qwen_-_Qwen2-7B-Instruct-gguf/blob/main/Qwen2-7B-Instruct.Q5_0.gguf) | Q5_0 | 4.95GB |
| [Qwen2-7B-Instruct.Q5_K_S.gguf](https://huggingface.co/RichardErkhov/Qwen_-_Qwen2-7B-Instruct-gguf/blob/main/Qwen2-7B-Instruct.Q5_K_S.gguf) | Q5_K_S | 4.95GB |
| [Qwen2-7B-Instruct.Q5_K.gguf](https://huggingface.co/RichardErkhov/Qwen_-_Qwen2-7B-Instruct-gguf/blob/main/Qwen2-7B-Instruct.Q5_K.gguf) | Q5_K | 5.07GB |
| [Qwen2-7B-Instruct.Q5_K_M.gguf](https://huggingface.co/RichardErkhov/Qwen_-_Qwen2-7B-Instruct-gguf/blob/main/Qwen2-7B-Instruct.Q5_K_M.gguf) | Q5_K_M | 5.07GB |
| [Qwen2-7B-Instruct.Q5_1.gguf](https://huggingface.co/RichardErkhov/Qwen_-_Qwen2-7B-Instruct-gguf/blob/main/Qwen2-7B-Instruct.Q5_1.gguf) | Q5_1 | 5.36GB |
| [Qwen2-7B-Instruct.Q6_K.gguf](https://huggingface.co/RichardErkhov/Qwen_-_Qwen2-7B-Instruct-gguf/blob/main/Qwen2-7B-Instruct.Q6_K.gguf) | Q6_K | 5.82GB |
| [Qwen2-7B-Instruct.Q8_0.gguf](https://huggingface.co/RichardErkhov/Qwen_-_Qwen2-7B-Instruct-gguf/blob/main/Qwen2-7B-Instruct.Q8_0.gguf) | Q8_0 | 7.54GB |
Original model description:
---
license: apache-2.0
language:
- en
pipeline_tag: text-generation
tags:
- chat
---
# Qwen2-7B-Instruct
## Introduction
Qwen2 is the new series of Qwen large language models. For Qwen2, we release a number of base language models and instruction-tuned language models ranging from 0.5 to 72 billion parameters, including a Mixture-of-Experts model. This repo contains the instruction-tuned 7B Qwen2 model.
Compared with the state-of-the-art opensource language models, including the previous released Qwen1.5, Qwen2 has generally surpassed most opensource models and demonstrated competitiveness against proprietary models across a series of benchmarks targeting for language understanding, language generation, multilingual capability, coding, mathematics, reasoning, etc.
Qwen2-7B-Instruct supports a context length of up to 131,072 tokens, enabling the processing of extensive inputs. Please refer to [this section](#processing-long-texts) for detailed instructions on how to deploy Qwen2 for handling long texts.
For more details, please refer to our [blog](https://qwenlm.github.io/blog/qwen2/), [GitHub](https://github.com/QwenLM/Qwen2), and [Documentation](https://qwen.readthedocs.io/en/latest/).
<br>
## Model Details
Qwen2 is a language model series including decoder language models of different model sizes. For each size, we release the base language model and the aligned chat model. It is based on the Transformer architecture with SwiGLU activation, attention QKV bias, group query attention, etc. Additionally, we have an improved tokenizer adaptive to multiple natural languages and codes.
## Training details
We pretrained the models with a large amount of data, and we post-trained the models with both supervised finetuning and direct preference optimization.
## Requirements
The code of Qwen2 has been in the latest Hugging face transformers and we advise you to install `transformers>=4.37.0`, or you might encounter the following error:
```
KeyError: 'qwen2'
```
## Quickstart
Here provides a code snippet with `apply_chat_template` to show you how to load the tokenizer and model and how to generate contents.
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
device = "cuda" # the device to load the model onto
model = AutoModelForCausalLM.from_pretrained(
"Qwen/Qwen2-7B-Instruct",
torch_dtype="auto",
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen2-7B-Instruct")
prompt = "Give me a short introduction to large language model."
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(device)
generated_ids = model.generate(
model_inputs.input_ids,
max_new_tokens=512
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
```
### Processing Long Texts
To handle extensive inputs exceeding 32,768 tokens, we utilize [YARN](https://arxiv.org/abs/2309.00071), a technique for enhancing model length extrapolation, ensuring optimal performance on lengthy texts.
For deployment, we recommend using vLLM. You can enable the long-context capabilities by following these steps:
1. **Install vLLM**: You can install vLLM by running the following command.
```bash
pip install "vllm>=0.4.3"
```
Or you can install vLLM from [source](https://github.com/vllm-project/vllm/).
2. **Configure Model Settings**: After downloading the model weights, modify the `config.json` file by including the below snippet:
```json
{
"architectures": [
"Qwen2ForCausalLM"
],
// ...
"vocab_size": 152064,
// adding the following snippets
"rope_scaling": {
"factor": 4.0,
"original_max_position_embeddings": 32768,
"type": "yarn"
}
}
```
This snippet enable YARN to support longer contexts.
3. **Model Deployment**: Utilize vLLM to deploy your model. For instance, you can set up an openAI-like server using the command:
```bash
python -m vllm.entrypoints.openai.api_server --served-model-name Qwen2-7B-Instruct --model path/to/weights
```
Then you can access the Chat API by:
```bash
curl http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "Qwen2-7B-Instruct",
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Your Long Input Here."}
]
}'
```
For further usage instructions of vLLM, please refer to our [Github](https://github.com/QwenLM/Qwen2).
**Note**: Presently, vLLM only supports static YARN, which means the scaling factor remains constant regardless of input length, **potentially impacting performance on shorter texts**. We advise adding the `rope_scaling` configuration only when processing long contexts is required.
## Evaluation
We briefly compare Qwen2-7B-Instruct with similar-sized instruction-tuned LLMs, including Qwen1.5-7B-Chat. The results are shown below:
| Datasets | Llama-3-8B-Instruct | Yi-1.5-9B-Chat | GLM-4-9B-Chat | Qwen1.5-7B-Chat | Qwen2-7B-Instruct |
| :--- | :---: | :---: | :---: | :---: | :---: |
| _**English**_ | | | | | |
| MMLU | 68.4 | 69.5 | **72.4** | 59.5 | 70.5 |
| MMLU-Pro | 41.0 | - | - | 29.1 | **44.1** |
| GPQA | **34.2** | - | **-** | 27.8 | 25.3 |
| TheroemQA | 23.0 | - | - | 14.1 | **25.3** |
| MT-Bench | 8.05 | 8.20 | 8.35 | 7.60 | **8.41** |
| _**Coding**_ | | | | | |
| Humaneval | 62.2 | 66.5 | 71.8 | 46.3 | **79.9** |
| MBPP | **67.9** | - | - | 48.9 | 67.2 |
| MultiPL-E | 48.5 | - | - | 27.2 | **59.1** |
| Evalplus | 60.9 | - | - | 44.8 | **70.3** |
| LiveCodeBench | 17.3 | - | - | 6.0 | **26.6** |
| _**Mathematics**_ | | | | | |
| GSM8K | 79.6 | **84.8** | 79.6 | 60.3 | 82.3 |
| MATH | 30.0 | 47.7 | **50.6** | 23.2 | 49.6 |
| _**Chinese**_ | | | | | |
| C-Eval | 45.9 | - | 75.6 | 67.3 | **77.2** |
| AlignBench | 6.20 | 6.90 | 7.01 | 6.20 | **7.21** |
## Citation
If you find our work helpful, feel free to give us a cite.
```
@article{qwen2,
title={Qwen2 Technical Report},
year={2024}
}
```
|
SolidSnacke/Llama-3SOME-8B-v2-i-GGUF | SolidSnacke | 2024-06-24T19:55:23Z | 3,265 | 0 | transformers | [
"transformers",
"gguf",
"llama",
"text-generation-inference",
"text-generation",
"en",
"license:cc-by-nc-4.0",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-06-24T13:47:05Z | ---
license: cc-by-nc-4.0
language:
- en
library_name: transformers
pipeline_tag: text-generation
tags:
- llama
- text-generation-inference
---
Link to original model and script:
- TheDrummer/Llama-3SOME-8B-v2: https://huggingface.co/TheDrummer/Llama-3SOME-8B-v2
- FantasiaFoundry/GGUF-Quantization-Script: https://huggingface.co/FantasiaFoundry/GGUF-Quantization-Script |
mradermacher/Bielik-7B-Instruct-v0.1-ROME-1-GGUF | mradermacher | 2024-06-06T21:48:53Z | 3,264 | 0 | transformers | [
"transformers",
"gguf",
"en",
"base_model:Piotrasz/Bielik-7B-Instruct-v0.1-ROME-1",
"license:cc-by-nc-4.0",
"endpoints_compatible",
"region:us"
] | null | 2024-06-05T20:02:55Z | ---
base_model: Piotrasz/Bielik-7B-Instruct-v0.1-ROME-1
language:
- en
library_name: transformers
license: cc-by-nc-4.0
quantized_by: mradermacher
tags: []
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
static quants of https://huggingface.co/Piotrasz/Bielik-7B-Instruct-v0.1-ROME-1
<!-- provided-files -->
weighted/imatrix quants seem not to be available (by me) at this time. If they do not show up a week or so after the static ones, I have probably not planned for them. Feel free to request them by opening a Community Discussion.
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/Bielik-7B-Instruct-v0.1-ROME-1-GGUF/resolve/main/Bielik-7B-Instruct-v0.1-ROME-1.Q2_K.gguf) | Q2_K | 2.8 | |
| [GGUF](https://huggingface.co/mradermacher/Bielik-7B-Instruct-v0.1-ROME-1-GGUF/resolve/main/Bielik-7B-Instruct-v0.1-ROME-1.IQ3_XS.gguf) | IQ3_XS | 3.1 | |
| [GGUF](https://huggingface.co/mradermacher/Bielik-7B-Instruct-v0.1-ROME-1-GGUF/resolve/main/Bielik-7B-Instruct-v0.1-ROME-1.Q3_K_S.gguf) | Q3_K_S | 3.3 | |
| [GGUF](https://huggingface.co/mradermacher/Bielik-7B-Instruct-v0.1-ROME-1-GGUF/resolve/main/Bielik-7B-Instruct-v0.1-ROME-1.IQ3_S.gguf) | IQ3_S | 3.3 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/Bielik-7B-Instruct-v0.1-ROME-1-GGUF/resolve/main/Bielik-7B-Instruct-v0.1-ROME-1.IQ3_M.gguf) | IQ3_M | 3.4 | |
| [GGUF](https://huggingface.co/mradermacher/Bielik-7B-Instruct-v0.1-ROME-1-GGUF/resolve/main/Bielik-7B-Instruct-v0.1-ROME-1.Q3_K_M.gguf) | Q3_K_M | 3.6 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/Bielik-7B-Instruct-v0.1-ROME-1-GGUF/resolve/main/Bielik-7B-Instruct-v0.1-ROME-1.Q3_K_L.gguf) | Q3_K_L | 3.9 | |
| [GGUF](https://huggingface.co/mradermacher/Bielik-7B-Instruct-v0.1-ROME-1-GGUF/resolve/main/Bielik-7B-Instruct-v0.1-ROME-1.IQ4_XS.gguf) | IQ4_XS | 4.0 | |
| [GGUF](https://huggingface.co/mradermacher/Bielik-7B-Instruct-v0.1-ROME-1-GGUF/resolve/main/Bielik-7B-Instruct-v0.1-ROME-1.Q4_K_S.gguf) | Q4_K_S | 4.2 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Bielik-7B-Instruct-v0.1-ROME-1-GGUF/resolve/main/Bielik-7B-Instruct-v0.1-ROME-1.Q4_K_M.gguf) | Q4_K_M | 4.5 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Bielik-7B-Instruct-v0.1-ROME-1-GGUF/resolve/main/Bielik-7B-Instruct-v0.1-ROME-1.Q5_K_S.gguf) | Q5_K_S | 5.1 | |
| [GGUF](https://huggingface.co/mradermacher/Bielik-7B-Instruct-v0.1-ROME-1-GGUF/resolve/main/Bielik-7B-Instruct-v0.1-ROME-1.Q5_K_M.gguf) | Q5_K_M | 5.2 | |
| [GGUF](https://huggingface.co/mradermacher/Bielik-7B-Instruct-v0.1-ROME-1-GGUF/resolve/main/Bielik-7B-Instruct-v0.1-ROME-1.Q6_K.gguf) | Q6_K | 6.0 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/Bielik-7B-Instruct-v0.1-ROME-1-GGUF/resolve/main/Bielik-7B-Instruct-v0.1-ROME-1.Q8_0.gguf) | Q8_0 | 7.8 | fast, best quality |
| [GGUF](https://huggingface.co/mradermacher/Bielik-7B-Instruct-v0.1-ROME-1-GGUF/resolve/main/Bielik-7B-Instruct-v0.1-ROME-1.f16.gguf) | f16 | 14.6 | 16 bpw, overkill |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
mradermacher/Configurable-Mistral-7B-GGUF | mradermacher | 2024-06-12T09:46:30Z | 3,264 | 0 | transformers | [
"transformers",
"gguf",
"en",
"dataset:vicgalle/configurable-system-prompt-multitask",
"base_model:vicgalle/Configurable-Mistral-7B",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2024-06-11T20:48:47Z | ---
base_model: vicgalle/Configurable-Mistral-7B
datasets:
- vicgalle/configurable-system-prompt-multitask
language:
- en
library_name: transformers
license: apache-2.0
quantized_by: mradermacher
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
static quants of https://huggingface.co/vicgalle/Configurable-Mistral-7B
<!-- provided-files -->
weighted/imatrix quants are available at https://huggingface.co/mradermacher/Configurable-Mistral-7B-i1-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/Configurable-Mistral-7B-GGUF/resolve/main/Configurable-Mistral-7B.Q2_K.gguf) | Q2_K | 2.8 | |
| [GGUF](https://huggingface.co/mradermacher/Configurable-Mistral-7B-GGUF/resolve/main/Configurable-Mistral-7B.IQ3_XS.gguf) | IQ3_XS | 3.1 | |
| [GGUF](https://huggingface.co/mradermacher/Configurable-Mistral-7B-GGUF/resolve/main/Configurable-Mistral-7B.Q3_K_S.gguf) | Q3_K_S | 3.3 | |
| [GGUF](https://huggingface.co/mradermacher/Configurable-Mistral-7B-GGUF/resolve/main/Configurable-Mistral-7B.IQ3_S.gguf) | IQ3_S | 3.3 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/Configurable-Mistral-7B-GGUF/resolve/main/Configurable-Mistral-7B.IQ3_M.gguf) | IQ3_M | 3.4 | |
| [GGUF](https://huggingface.co/mradermacher/Configurable-Mistral-7B-GGUF/resolve/main/Configurable-Mistral-7B.Q3_K_M.gguf) | Q3_K_M | 3.6 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/Configurable-Mistral-7B-GGUF/resolve/main/Configurable-Mistral-7B.Q3_K_L.gguf) | Q3_K_L | 3.9 | |
| [GGUF](https://huggingface.co/mradermacher/Configurable-Mistral-7B-GGUF/resolve/main/Configurable-Mistral-7B.IQ4_XS.gguf) | IQ4_XS | 4.0 | |
| [GGUF](https://huggingface.co/mradermacher/Configurable-Mistral-7B-GGUF/resolve/main/Configurable-Mistral-7B.Q4_K_S.gguf) | Q4_K_S | 4.2 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Configurable-Mistral-7B-GGUF/resolve/main/Configurable-Mistral-7B.Q4_K_M.gguf) | Q4_K_M | 4.5 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Configurable-Mistral-7B-GGUF/resolve/main/Configurable-Mistral-7B.Q5_K_S.gguf) | Q5_K_S | 5.1 | |
| [GGUF](https://huggingface.co/mradermacher/Configurable-Mistral-7B-GGUF/resolve/main/Configurable-Mistral-7B.Q5_K_M.gguf) | Q5_K_M | 5.2 | |
| [GGUF](https://huggingface.co/mradermacher/Configurable-Mistral-7B-GGUF/resolve/main/Configurable-Mistral-7B.Q6_K.gguf) | Q6_K | 6.0 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/Configurable-Mistral-7B-GGUF/resolve/main/Configurable-Mistral-7B.Q8_0.gguf) | Q8_0 | 7.8 | fast, best quality |
| [GGUF](https://huggingface.co/mradermacher/Configurable-Mistral-7B-GGUF/resolve/main/Configurable-Mistral-7B.f16.gguf) | f16 | 14.6 | 16 bpw, overkill |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
larenspear/llama2-13b-WildJailbreak-Q5_0-GGUF | larenspear | 2024-06-30T23:24:30Z | 3,264 | 0 | null | [
"gguf",
"llama-cpp",
"gguf-my-repo",
"en",
"base_model:larenspear/copy_of_wildjailbreak_13",
"license:apache-2.0",
"region:us"
] | null | 2024-06-30T22:20:04Z | ---
base_model: larenspear/copy_of_wildjailbreak_13
language:
- en
license: apache-2.0
tags:
- llama-cpp
- gguf-my-repo
extra_gated_prompt: Access to this model is automatically granted upon accepting the
[AI2 Responsible Use Guidelines](https://allenai.org/responsible-use.pdf), and completing
all fields below
extra_gated_fields:
Your full name: text
Organization or entity you are affiliated with: text
State or country you are located in: text
Contact email: text
Please describe your intended use of the low risk artifact(s): text
I understand that this model is a research artifact that may contain or produce unfiltered, toxic, or harmful material: checkbox
I agree to use this model for research purposes in accordance with the AI2 Responsible Use Guidelines: checkbox
I agree that AI2 may use my information as described in the Privacy Policy: checkbox
I certify that the information I have provided is true and accurate: checkbox
---
# larenspear/copy_of_wildjailbreak_13-Q5_0-GGUF
This model was converted to GGUF format from [`larenspear/copy_of_wildjailbreak_13`](https://huggingface.co/larenspear/copy_of_wildjailbreak_13) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/larenspear/copy_of_wildjailbreak_13) for more details on the model.
## Use with llama.cpp
Install llama.cpp through brew (works on Mac and Linux)
```bash
brew install llama.cpp
```
Invoke the llama.cpp server or the CLI.
### CLI:
```bash
llama-cli --hf-repo larenspear/copy_of_wildjailbreak_13-Q5_0-GGUF --hf-file copy_of_wildjailbreak_13-q5_0.gguf -p "The meaning to life and the universe is"
```
### Server:
```bash
llama-server --hf-repo larenspear/copy_of_wildjailbreak_13-Q5_0-GGUF --hf-file copy_of_wildjailbreak_13-q5_0.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
Step 1: Clone llama.cpp from GitHub.
```
git clone https://github.com/ggerganov/llama.cpp
```
Step 2: Move into the llama.cpp folder and build it with `LLAMA_CURL=1` flag along with other hardware-specific flags (for ex: LLAMA_CUDA=1 for Nvidia GPUs on Linux).
```
cd llama.cpp && LLAMA_CURL=1 make
```
Step 3: Run inference through the main binary.
```
./llama-cli --hf-repo larenspear/copy_of_wildjailbreak_13-Q5_0-GGUF --hf-file copy_of_wildjailbreak_13-q5_0.gguf -p "The meaning to life and the universe is"
```
or
```
./llama-server --hf-repo larenspear/copy_of_wildjailbreak_13-Q5_0-GGUF --hf-file copy_of_wildjailbreak_13-q5_0.gguf -c 2048
```
|
efederici/sentence-bert-base | efederici | 2023-05-21T09:34:03Z | 3,263 | 8 | sentence-transformers | [
"sentence-transformers",
"pytorch",
"bert",
"feature-extraction",
"sentence-similarity",
"transformers",
"it",
"dataset:stsb_multi_mt",
"doi:10.57967/hf/0248",
"autotrain_compatible",
"endpoints_compatible",
"text-embeddings-inference",
"region:us"
] | sentence-similarity | 2022-03-27T17:17:51Z | ---
pipeline_tag: sentence-similarity
language:
- it
datasets:
- stsb_multi_mt
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
---
# sentence-bert-base
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search. It was trained on [stsb](https://huggingface.co/datasets/stsb_multi_mt/viewer/it/train).
If you like this project, consider supporting it with a cup of coffee! 🤖✨🌞
[](https://bmc.link/edoardofederici)
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["Questo è un esempio di frase", "Questo è un ulteriore esempio"]
model = SentenceTransformer('efederici/sentence-bert-base')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ["Questo è un esempio di frase", "Questo è un ulteriore esempio"]
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('efederici/sentence-bert-base')
model = AutoModel.from_pretrained('efederici/sentence-bert-base')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, mean pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 512, 'do_lower_case': False}) with Transformer model: BertModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
)
```
## Citation
If you want to cite this model you can use this:
```
@misc {edoardo_federici_2022,
author = { {Edoardo Federici} },
title = { sentence-bert-base, sentence-transformer for Italian },
year = 2022,
url = { https://huggingface.co/efederici/sentence-bert-base },
doi = { 10.57967/hf/0112 },
publisher = { Hugging Face }
}
``` |
nctu6/Llama3-TAIDE-LX-8B-Chat-Alpha1-GGUF | nctu6 | 2024-05-14T07:10:35Z | 3,262 | 1 | null | [
"gguf",
"license:other",
"region:us"
] | null | 2024-04-26T05:54:28Z | ---
license: other
license_name: llama3-taide-models-community-license-agreement
license_link: LICENSE
extra_gated_heading: 您需要先同意授權條款才能使用此模型
extra_gated_fields:
姓名(Name): text
生日(Date of birth): date_picker
國家(Country): country
所屬單位(Affiliation): text
geo: ip_location
按下送出表示您同意社群授權同意書與個人資料蒐集告知聲明(By clicking Submit below I accept the terms of the license and privacy policy): checkbox
extra_gated_prompt: >-
* ### [Llama3-TAIDE 模型社群授權同意書(License)](https://drive.google.com/file/d/12-Q0WWSjG0DW6CqJQm_jr5wUGRLeb-8p/view)
* ### [個人資料蒐集告知聲明(Privacy policy)](https://drive.google.com/file/d/1JTfZu_MdU_TR1-1sn2jbQyW7TLrxjwS5/view)
extra_gated_button_content: 送出(Submit)
---
* [English Version](./README_en.md)
# 模型簡介
* [TAIDE計畫](https://taide.tw/index)致力於開發符合台灣語言和文化特性的生成式人工智慧對話引擎模型,同時建構可信任的人工智慧環境。結合產學研能量,推動可信任生成式人工智慧的發展,提升台灣在國際競爭中的地位,促進產業發展,避免對外國技術的依賴。
* Llama3 TAIDE 系列模型以 Meta 公司釋出的 [LLaMA3-8b](https://llama.meta.com/docs/model-cards-and-prompt-formats/meta-llama-3/) 為基礎,導入台灣不同領域可用的文本與訓練素材,提高模型在正體中文回應的能力與特定任務的表現。公開釋出的模型如下:
* [Llama3-TAIDE-LX-8B-Chat-Alpha1](https://huggingface.co/taide/Llama3-TAIDE-LX-8B-Chat-Alpha1): 以 LLaMA3-8b 為基礎,使用繁體中文資料預訓練 (continuous pretraining),並透過指令微調(instruction tuning)強化辦公室常用任務和多輪問答對話能力,適合聊天對話或任務協助的使用情境。Llama3-TAIDE-LX-8B-Chat-Alpha1 另外有提供[4 bit 量化模型](https://huggingface.co/taide/Llama3-TAIDE-LX-8B-Chat-Alpha1-4bit),量化模型主要是提供使用者的便利性,可能會影響效能與更多不可預期的問題,還請使用者理解與注意。
# 模型參數
* 參數量: 8B
* 最大內容長度 (context length): 8K
* 繁中訓練資料 token 量: 43B
* 訓練時間: 2336 H100 GPU Hours
# 特色
* 嚴格把關模型的訓練資料,提升模型生成資料的可信任性和適用性
* 針對自動摘要、寫信、寫文章、中翻英、英翻中等辦公室常用任務做加強
* 針對台灣在地文化、用語、國情等知識做加強
* 具備多輪問答對話能力
# 應用範例
| 任務 | 使用者輸入 | 模型輸出 |
| --- | -------- | ------- |
| 寫文章 | 請以以下內容為基礎,寫一篇文章:撰寫一篇作文,題目為《一張舊照片》,內容要求為:選擇一張令你印象深刻的照片,說明令你印象深刻的原因,並描述照片中的影像及背後的故事。記錄成長的過程、與他人的情景、環境變遷和美麗的景色。 | 一張舊照片,承載著時光的痕跡和回憶的溫度。我還記得那張照片是怎麼出現的,那是一張泛黃的黑白相片,裱在牆上,訴說著一段屬於我家族的故事。<br><br>那張照片中,我的祖父母站在田野間,後方是綿延的山巒,前方則是一片金黃的稻田。這幅景象令我印象深刻,因為這是我的童年回憶,也是我成長過程中最美好的風景線。<br><br>我出生在台灣鄉下,從小就生活在這樣一個純樸的環境中。每當我跟著家人在田裡工作時,就會看到這樣的美景。金黃的稻穗隨著微風搖曳,山巒則靜靜地矗立在遠方,給人一種安詳與祥和的感覺。<br><br>那張照片拍攝於民國50年代,當時台灣經濟尚未起飛,農業為主要產業。我的祖父母都是農民,他們辛勤耕種,為我們家提供溫飽。每當我看到那張照片,就會想起他們為我們所做的犧牲和努力。<br><br>除了美麗的風景外,照片中還有一段動人的故事。在我還很小的時候,家裡發生了一場大火,將我們的房子和所有財產都燒光了。幸好全家人都平安無事,但生活卻變得十分困苦。我們被迫搬到另一個村莊,在那裡重新開始生活。<br><br>那張照片也記錄了那段艱辛的歲月。雖然我們失去了許多東西,但家人之間的感情卻更加深厚。我們互相扶持,共同面對生活上的種種挑戰。<br><br>如今,我已長大成人,在都市裡工作。但每當我看到那張舊照片,我都會想起那段簡單而美好的時光。那些美麗的風景、親人的笑容,以及那段充滿挑戰卻又充滿希望的日子,都將永遠鐫刻在我的記憶深處。<br><br>這張舊照片,不僅僅是一張照片,更是一個寶貴的家族史,一個關於我們如何克服困難、珍惜現在的故事。我將把這張照片好好保存下來,讓後代也能夠認識我們的根源,並且銘記那些值得珍藏的美好回憶。 |
| 寫信 | 請以品牌經理的身份,給廣告公司的創意總監寫一封信,提出對於新產品廣告宣傳活動的創意建議。 | [您的姓名]<br>[您的職稱]<br>[您的公司名稱]<br>[郵件地址]<br>[電話號碼]<br>[發文日期]<br><br>[創意總監姓名]<br>[廣告公司名稱]<br>[廣告公司地址]<br><br>主旨:關於新產品宣傳活動創意發想,請查照。<br><br>尊敬的[創意總監姓名],<br><br>我希望這封信能找到你忙碌中好好休息。我寫這封信,是為了分享我對於我們即將推出的新產品宣傳活動一些創意發想。我深信,這些想法能幫助我們新產品在市場上脫穎而出,吸引消費者的目光。<br><br>首先,我建議我們可以利用社群媒體平台,像是Facebook、Instagram、YouTube等,製作一系列引人入勝的短片和貼文。這些內容可以展現新產品的特色和優點,同時也能傳達出我們品牌重視環保、健康的核心價值。我們可以與網紅或意見領袖合作,讓他們試用並分享他們的使用經驗,這將有助於增加我們產品的可信度和能見度。<br><br>其次,我們可以舉辦新產品試吃/試用活動,邀請民眾親身體驗我們的新產品。我們可以在各大百貨公司、超市、以及我們的門市舉辦這些活動,讓參與者免費試吃/試用新產品,並填寫問卷回饋意見。這種互動的方式,不僅能收集到寶貴的市場反饋,還能讓民眾對我們的品牌產生正面的印象。<br><br>第三,我們可以與當地餐飲業者合作,將我們的新產品納入他們的菜單中。這將使我們的產品接觸到更廣泛的客群,同時也能證明我們的產品在烹飪和美食產業中具有價值。<br><br>第四,我們可以舉辦一場新產品發表會,邀請媒體、業界人士、以及重要客戶參加。在這場活動中,我們可以展示新產品的各項特色和優勢,並由專業廚師示範如何將新產品融入各式料理中。這將是向大眾展示我們品牌創新精神和專業能力的絕佳機會。<br><br>最後,我建議我們可以製作一系列精美的包裝和禮盒,以吸引消費者在節慶和送禮時選擇我們的產品。精緻的包裝將能提升我們產品的價值感,同時也能傳達出我們品牌對細節和品質的堅持。<br><br>我深信,這些創意發想將有助於我們新產品在市場上獲得成功。若您對這些想法有任何意見或建議,請不吝與我分享。我期待著與您合作,共同為[您的公司名稱]的成長和成功而努力。<br><br>謝謝您抽空閱讀我的信,並期待著與您進一步討論這些想法。<br><br>敬禮<br><br>[您的姓名]<br>[您的職稱]<br>[您的公司名稱] |
| 摘要 | 請將這篇文章精簡條理化:「產業創新條例第10條之2及第72條條文修正案」俗稱「台版晶片法」,針對半導體、電動車、5G等技術創新且居國際供應鏈關鍵地位公司,提供最高25%營所稅投抵優惠,企業適用要件包含當年度研發費用、研發密度達一定規模,且有效稅率達一定比率。<br>為因應經濟合作暨發展組織(OECD)國家最低稅負制調整,其中有效稅率門檻,民國112年訂為12%,113年料將提高至15%,但仍得審酌國際間最低稅負制實施情形。<br>經濟部官員表示,已和財政部協商進入最後階段,除企業研發密度訂在6%,目前已確認,企業購置先進製程的設備投資金額達100億元以上可抵減。<br>財政部官員表示,研商過程中,針對台灣產業與其在國際間類似的公司進行深入研究,在設備部分,畢竟適用產創10之2的業者是代表台灣隊打「國際盃」,投入金額不達100億元,可能也打不了。<br>至於備受關注的研發費用門檻,經濟部官員表示,歷經與財政部來回密切討論,研發費用門檻有望落在60億至70億元之間。<br>財政部官員指出,研發攸關台灣未來經濟成長動能,門檻不能「高不可攀」,起初雖設定在100億元,之所以會調降,正是盼讓企業覺得有辦法達得到門檻、進而適用租稅優惠,才有動力繼續投入研發,維持國際供應鏈關鍵地位。<br>經濟部官員表示,因廠商研發費用平均為30、40億元,其中,IC設計業者介於30億至60億元範圍,若將門檻訂在100億元,符合條件的業者較少、刺激誘因不足;此外,若符合申請門檻的業者增加,將可提高企業在台投資金額,財政部稅收也能因此獲得挹注。<br>IC設計業者近日頻頻針對產創10之2發聲,希望降低適用門檻,加上各國力拚供應鏈自主化、加碼補助半導體產業,經濟部官員表示,經濟部和財政部就產創10之2達成共識,爭取讓更多業者受惠,盼增強企業投資力道及鞏固台灣技術地位。<br>財政部官員表示,租稅獎勵的制定必須「有為有守」,並以達到獎勵設置目的為最高原則,現階段在打「國內盃」的企業仍可適用產創第10條、10之1的租稅優惠,共同壯大台灣經濟發展。<br>經濟部和財政部正就研發費用門檻做最後確認,待今明兩天預告子法之後,約有30天時間,可與業界進一步討論及調整,盼產創10之2能在6月上路。 | 文章重點摘要如下:<br><br>- 「台版晶片法」或《產業創新條例第10條之2及第72條條文修正案》,旨在鼓勵關鍵技術創新企業,特別是那些在半導體、電動車、5G技術等領域且在國際供應鏈中扮演關鍵角色者。<br><br>- 企業若符合特定條件,包括當年度研發費用及研發密度達標,可享最高25%的營所稅抵減優惠。研發密度目標設為6%,而企業為取得抵減,必須證明其有效稅率達到特定比率,起初設定為112年的12%,113年提高至15%,但可能會依國際稅制的實施情形進行調整。<br><br>- 政府在制定政策時,考量到OECD最低稅負制的調整,因此會視情況調整有效稅率門檻。<br><br>- 政府部門已就法案內容與企業利益相關者進行協商,確定一些細節,例如企業投資先進製程設備的門檻設為100億元新台幣以供抵減。<br><br>- 研發費用門檻經過討論,可能從最初提議的100億元下調至60億至70億元之間,以激勵更多企業符合資格並投入研發,維持台灣在國際供應鏈中的關鍵地位。<br><br>- 經濟部官員表示,調降門檻的目的是讓更多企業覺得能夠達成標準,從而獲得應用租稅優惠的動力,並可能藉此提高在台投資金額,進而增加政府稅收。<br><br>- 由於IC設計業者的研發費用普遍較低,若門檻設得過高,符合條件的企業將很少,因此有必要調整。<br><br>- 在各國推動供應鏈自主化並增加對半導體產業的補助之際,經濟部正努力確保更多企業能從《產業創新條例》第10條之2中受益,以增強投資和鞏固台灣的技術地位。<br><br>- 政府強調租稅優惠的制定應符合獎勵目標,在此同時,也將繼續提供其他租稅優惠給在國內經營的企業,以促進台灣經濟成長。<br><br>- 最終的研發費用門檻將由經濟部和財政部共同確定,在預告相關子法後,將有約30天的時間供各界討論並提出調整建議,目標是讓這項新政策在6月上路。 |
| 翻譯 | 以下提供英文內容,請幫我翻譯成中文。Dongshan coffee is famous for its unique position, and the constant refinement of production methods. The flavor is admired by many caffeine afficionados. | 東山咖啡以獨特的位置,加上不斷精進的製作手法而聞名,風味更是讓許多咖啡癡趨之若鶩。 |
# 使用說明
* 範例程式
* 範例程式與文件後續會釋出到github
* prompt 樣版
* 一般問答用法
```python
chat = [
{"role": "user", "content": "{question}"},
]
prompt = tokenizer.apply_chat_template(chat)
```
* 將 {question} 替換成使用者的輸入
* 加入 system prompt 的用法
```python
chat = [
{"role": "system", "content": "{sys}"},
{"role": "user", "content": "{question}"},
]
prompt = tokenizer.apply_chat_template(chat)
```
* 將 {sys} 替換成指令,例如:你是一個來自台灣的AI助理,你的名字是 TAIDE,樂於以台灣人的立場幫助使用者,會用繁體中文回答問題。
* 將 {question} 替換成使用者的問題
* 多輪問答用法
```python
chat = [
{"role": "system", "content": "{sys}"},
{"role": "user", "content": "{question1}"},
{"role": "assistant", "content": "{model_anwer_1}"},
{"role": "user", "content": "{question2}"},
]
prompt = tokenizer.apply_chat_template(chat)
```
* 將 {sys} 替換成指令,例如:你是一個來自台灣的AI助理,你的名字是 TAIDE,樂於以台灣人的立場幫助使用者,會用繁體中文回答問題。
* 將 {question1} 替換成使用者的問題1
* 將 {model_anwer_1} 替換成模型的回答1
* 將 {question2} 替換成使用者的問題2
* 更多細節請參考[Llama3 文件](https://llama.meta.com/docs/model-cards-and-prompt-formats/meta-llama-3/)
# 訓練方法
* 軟硬體規格
* 國網中心 H100
* 訓練框架: PyTorch
* 資料前處理
* 字元標準化
* 去除重覆
* 去除雜訊
* 網頁資料的html tag、javascript
* 非標準字元或亂碼
* 字數過短的文章
* 去除文章中的特定格式,如為排版增加的換行
* 去除個資,如email、電話
* 去除不當文字,如賭博、色情等
* 持續預訓練 (continuous pretraining, CP)
* 補充大量來源可信賴的繁體中文知識
* 超參數 (hyper parameters)
* optimizer: AdamW
* learning rate: 1e-4
* batch size: 1M tokens
* epoch: 1
* 微調 (fine tune, FT)
* 讓模型可針對繁體中文提問回答問題
* 超參數 (hyper parameters)
* optimizer: AdamW
* learning rate: 5e-5
* batch size: 256K tokens
* epoch: 3
# 訓練資料
* 持續預訓練資料(資料量約為140G)
| 資料集 | 資料描述 |
| --- | -------- |
| 訴訟資料 | 《[司法院裁判書](https://judgment.judicial.gov.tw/FJUD/default.aspx)》自2013年1月至2023年12月各級法院民事、刑事、行政訴訟資料。 |
| 中央社 | 《[中央社中文新聞](https://www.cna.com.tw/)》資料集含中央社自1993年6月至2023年06月,共30年份之每日新聞文章。內容涵蓋國內外政治、社會、財經、文教、生活等領域。 |
| ETtoday 新聞雲 | 《[ETtoday新聞雲](https://www.ettoday.net/)》資料,包含自2011年10月至 2023年12月的資料。 |
| 立法院公報 | 《[立法院公報](https://ppg.ly.gov.tw/ppg/)》包含自第8屆第1會期至第10屆第7會期之公報資料。 |
| 出版商網站書籍介紹 | 包含[三采](https://www.suncolor.com.tw/)、[Gotop](https://www.gotop.com.tw/)出版商網站上的書籍簡介。 |
| GRB 研究計畫摘要 | [GRB](https://www.grb.gov.tw/)為收錄由政府經費補助之研究計畫及其成果報告的資訊系統,此資料集主要收錄 1993年至 2023年之研究計畫摘要以及研究報告摘要,含中文及其英文對照。 |
| 學術會議論文摘要 | 收錄《[學術會議論文摘要資料庫](https://sticnet.stpi.narl.org.tw/sticloc/ttscalle?meet:)》中自1988至2009年由台灣所舉辦之學術會議論文。 |
| 光華雜誌 | 《[台灣光華雜誌](https://www.taiwan-panorama.com/)》含自1993年7月至2023年6月的文章,共30年份。內容著重於我國文化、觀光與民情等。 |
| 樂詞網 | 《[樂詞網](https://terms.naer.edu.tw/)》涵蓋文理領域約187萬則學術名詞及其譯名對照。 |
| 各部會資料 | 包含行政院「[國情簡介](https://www.ey.gov.tw/state/)」、文化部「[國家文化記憶庫](https://memory.culture.tw/)」、國發會「[檔案支援教學網](https://art.archives.gov.tw/index.aspx)」、交通部「[交通安全入口網](https://168.motc.gov.tw/)」等部會網站資料之部分資料。 |
| 今周刊 | 《[今周刊](https://www.businesstoday.com.tw/)》為一以財經為主的週刊雜誌,此資料集涵蓋2008年1月至2023年7月的文章。 |
| 教育部國語辭典、成語辭典 | 包含以下三項資料:<br>[教育部《成語典》](https://dict.idioms.moe.edu.tw/search.jsp?webMd=1&la=0),含5,338條成語,內容包含每條成語的釋義、典故原文及其白話說明、用法說明、例句等。<br>[教育部《重編國語辭典修訂本》](https://dict.revised.moe.edu.tw/?la=0&powerMode=0),收錄中文單字及各類辭彙,包含讀音、部首、釋義等資訊,共約165,539筆資料。<br>[教育部《國語辭典簡編本》](https://dict.concised.moe.edu.tw/?la=0&powerMode=0),為《重編國語辭典修訂本》的簡編版本,共45,247筆資料。 |
| 科技大觀園資料 | 含《[科技大觀園網站](https://scitechvista.nat.gov.tw/)》上的科學新知以及科普文章。 |
| iKnow 科技產業資訊室 | 《[科技產業資訊室](https://iknow.stpi.narl.org.tw/)(iKnow)》提供台灣及全球的科技市場趨勢、策略分析、專利知識,及技術交易資訊,專注於科技產業的創新與發展,包含自 2008 年至 2023 年。 |
| 科學發展月刊 | 《[科學發展月刊](https://ejournal.stpi.narl.org.tw/sd)》為國科會為推廣科學教育而出版的科普刊物,含自2004年10月至2020年12月之科普文章;2021年起,以《[科技魅癮](https://www.charmingscitech.nat.gov.tw/)》季刊重新出發,提供國際關注科技議題的新知文章。 |
| 法規資料庫 | 《[法規資料庫](https://law.moj.gov.tw/)》含截自 112 年 10 月各政府部門最新發布之中央法規、行政規則、法規命令草案及地方自治法規等。 |
| 各地政府旅遊網 | 涵蓋台灣部分縣市地方政府觀光旅遊網站上之部分資料。 |
| 國教院課程綱要(十二年國教) | 含十二年國教課程綱要之總綱以及各級學校不同科目之課程綱要。 |
| 中央社譯名檔資料庫 | 《中央社譯名檔資料庫》蒐集中央社新聞業務上翻譯過的中外姓氏、人名、組織、地名等譯名對照。 |
| 童話書 | 共 20 本童話書,含湯姆歷險記、小飛俠、愛麗絲夢遊仙境、長腿叔叔等。 |
| RedPajama-Data-V2 | 從國外開放多國語言語料庫 [RedPajama-Data-v2](https://github.com/togethercomputer/RedPajama-Data) 取出英文資料 |
| MathPile-commercial | 國外開放數學語料庫 [MathPile-commercial](https://huggingface.co/datasets/GAIR/MathPile_Commercial) |
| 中文維基百科 | 《[中文維基百科](https://zh.wikipedia.org/zh-tw/%E4%B8%AD%E6%96%87%E7%BB%B4%E5%9F%BA%E7%99%BE%E7%A7%91)》截至2023年1月所有條目的內容。 |
| github-code-clean | 為 github 開源程式碼資料集,去除unlicense的程式碼和文件。 |
* 微調資料
* TAIDE團隊訓練llama2系列模型來產生微調資料資料,產生的任務包含世界知識、創意寫作、普通常識、翻譯、摘要、程式、台灣價值等單輪或多輪對話問答共 128K 筆。微調資料後續會對外釋出。
# 模型評測
* taide-bench
* 評測資料
* 寫文章、寫信、摘要、英翻中、中翻英,共500題
* 資料連結: [taide-bench](https://huggingface.co/datasets/taide/taide-bench)
* 評測方法
* gpt4評分
* 評分程式: [taide-bench-eval](https://github.com/taide-taiwan/taide-bench-eval)
* 評測分數
| 模型 | 中翻英 | 英翻中 | 摘要 | 寫文章 | 寫信 | 平均 |
| --- | ----- | ----- | ---- | ---- | ---- | --- |
| Llama3-TAIDE-LX-8B-Chat-Alpha1 | 7.770 | 8.280 | 8.495 | 9.605 | 8.950 | 8.620 |
| GPT3.5 | 8.880 | 8.810 | 7.450 | 9.490 | 8.750 | 8.676 |
| TAIDE-LX-7B-Chat | 7.165 | 7.685 | 7.720 | 9.635 | 9.110 | 8.263 |
| LLAMA2 7B | 6.075 | 4.475 | 5.905 | 2.625 | 3.040 | 4.424 |
| LLAMA2 13B | 6.480 | 6.135 | 6.110 | 2.565 | 3.000 | 4.858 |
| LLAMA2 70B | 6.975 | 6.375 | 6.795 | 2.625 | 2.990 | 5.152 |
# 授權條款
* [Llama3-TAIDE 模型社群授權同意書](https://drive.google.com/file/d/12-Q0WWSjG0DW6CqJQm_jr5wUGRLeb-8p/view)
# 免責聲明
* LLM 模型由於設計架構的限制,以及資料難免有偏誤,語言模型的任何回應不代表 TAIDE 立場,使用前需要額外加入安全防護機制,且回應內容也可能包含不正確的資訊,使用者請勿盡信。
# 開發團隊
* [https://taide.tw/index/teamList](https://taide.tw/index/teamList)
# 相關連結
* [TAIDE官網](https://taide.tw/index)
* [TAIDE Huggingface](https://huggingface.co/taide)
* [TAIDE Github](https://github.com/taide-taiwan)
* [Kuwa AI](https://kuwaai.org/)
# Citation
* [TAIDE官網](https://taide.tw/index)
|
ZeroWw/Gemma-2-9B-It-SPPO-Iter3-GGUF | ZeroWw | 2024-07-01T15:28:31Z | 3,262 | 0 | null | [
"gguf",
"en",
"license:mit",
"region:us"
] | null | 2024-07-01T15:09:36Z |
---
license: mit
language:
- en
---
My own (ZeroWw) quantizations.
output and embed tensors quantized to f16.
all other tensors quantized to q5_k or q6_k.
Result:
both f16.q6 and f16.q5 are smaller than q8_0 standard quantization
and they perform as well as the pure f16.
|
KnutJaegersberg/black_goo_recipe_c | KnutJaegersberg | 2023-12-03T15:09:33Z | 3,260 | 0 | transformers | [
"transformers",
"pytorch",
"llama",
"text-generation",
"custom_code",
"license:cc-by-nc-4.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2023-09-01T06:35:49Z | ---
license: cc-by-nc-4.0
---
Prompt Example:
```
### System:
You are an AI assistant. User will give you a task. Your goal is to complete the task as faithfully as you can. While performing the task think step-by-step and justify your steps.
### Instruction:
How do you fine tune a large language model?
### Response:
To fine-tune a large language model, we use various techniques to improve its performance and adjust its parameters based on user feedback. These techniques include:
1. Fine tuning the original model with additional data. For example, adding more training examples or using specialized datasets such as question answering or natural language inference tasks. This helps the model learn new concepts and skills by interacting with additional information sources.
2. Using transfer learning methods to incorporate knowledge from other models that have been pre-trained for specific domains. For instance, using pre-trained embeddings from neural networks trained on text classification tasks like sentiment analysis or question answering to help fine-tuning the main language model.
3. Improving the quality of the training data. We may optimize the training process by increasing the accuracy of provided data sets (e.g., by improving word embedding quality), refining the selection of relevant examples, and/or providing additional supervision signals during training.
4. Incorporating knowledge from external resources such as domain-specific lexicons or domain-specific knowledge bases. For example, incorporating domain-specific rules and facts into the model to help it understand domain-specific terminology and semantics.
5. Employing techniques like dropout regularization and dropout sampling to avoid overfitting and reduce overconfidence in the model's predictions.
6. Utilizing meta-learning methods such as reinforcement learning or self-supervised learning to enable the model to adapt quickly to changing situations without being explicitly programmed.
7. Incorporating human input through crowdsourcing or user testing to validate the model's performance and ensure user satisfaction.
8. Implementing various optimization strategies to improve efficiency and reduce computational costs while maintaining high performance levels.
In conclusion, fine tuning a large language model requires combining various techniques including fine tuning, transfer learning, improved data quality, external resources, meta-learning, optimization strategies, crowd sourcing, and user testing. These approaches aim to improve the model's ability to handle various tasks and provide users with better experiences in their daily interactions with language systems.
```
# [Open LLM Leaderboard Evaluation Results](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)
Detailed results can be found [here](https://huggingface.co/datasets/open-llm-leaderboard/details_KnutJaegersberg__black_goo_recipe_c)
| Metric | Value |
|-----------------------|---------------------------|
| Avg. | 34.19 |
| ARC (25-shot) | 38.74 |
| HellaSwag (10-shot) | 66.83 |
| MMLU (5-shot) | 26.57 |
| TruthfulQA (0-shot) | 36.54 |
| Winogrande (5-shot) | 64.72 |
| GSM8K (5-shot) | 0.68 |
| DROP (3-shot) | 5.23 |
|
RichardErkhov/Josephgflowers_-_Tinyllama-1.5B-Cinder-Test-6-gguf | RichardErkhov | 2024-06-25T15:48:46Z | 3,260 | 0 | null | [
"gguf",
"region:us"
] | null | 2024-06-25T15:35:06Z | Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
Tinyllama-1.5B-Cinder-Test-6 - GGUF
- Model creator: https://huggingface.co/Josephgflowers/
- Original model: https://huggingface.co/Josephgflowers/Tinyllama-1.5B-Cinder-Test-6/
| Name | Quant method | Size |
| ---- | ---- | ---- |
| [Tinyllama-1.5B-Cinder-Test-6.Q2_K.gguf](https://huggingface.co/RichardErkhov/Josephgflowers_-_Tinyllama-1.5B-Cinder-Test-6-gguf/blob/main/Tinyllama-1.5B-Cinder-Test-6.Q2_K.gguf) | Q2_K | 0.55GB |
| [Tinyllama-1.5B-Cinder-Test-6.IQ3_XS.gguf](https://huggingface.co/RichardErkhov/Josephgflowers_-_Tinyllama-1.5B-Cinder-Test-6-gguf/blob/main/Tinyllama-1.5B-Cinder-Test-6.IQ3_XS.gguf) | IQ3_XS | 0.61GB |
| [Tinyllama-1.5B-Cinder-Test-6.IQ3_S.gguf](https://huggingface.co/RichardErkhov/Josephgflowers_-_Tinyllama-1.5B-Cinder-Test-6-gguf/blob/main/Tinyllama-1.5B-Cinder-Test-6.IQ3_S.gguf) | IQ3_S | 0.64GB |
| [Tinyllama-1.5B-Cinder-Test-6.Q3_K_S.gguf](https://huggingface.co/RichardErkhov/Josephgflowers_-_Tinyllama-1.5B-Cinder-Test-6-gguf/blob/main/Tinyllama-1.5B-Cinder-Test-6.Q3_K_S.gguf) | Q3_K_S | 0.64GB |
| [Tinyllama-1.5B-Cinder-Test-6.IQ3_M.gguf](https://huggingface.co/RichardErkhov/Josephgflowers_-_Tinyllama-1.5B-Cinder-Test-6-gguf/blob/main/Tinyllama-1.5B-Cinder-Test-6.IQ3_M.gguf) | IQ3_M | 0.67GB |
| [Tinyllama-1.5B-Cinder-Test-6.Q3_K.gguf](https://huggingface.co/RichardErkhov/Josephgflowers_-_Tinyllama-1.5B-Cinder-Test-6-gguf/blob/main/Tinyllama-1.5B-Cinder-Test-6.Q3_K.gguf) | Q3_K | 0.71GB |
| [Tinyllama-1.5B-Cinder-Test-6.Q3_K_M.gguf](https://huggingface.co/RichardErkhov/Josephgflowers_-_Tinyllama-1.5B-Cinder-Test-6-gguf/blob/main/Tinyllama-1.5B-Cinder-Test-6.Q3_K_M.gguf) | Q3_K_M | 0.71GB |
| [Tinyllama-1.5B-Cinder-Test-6.Q3_K_L.gguf](https://huggingface.co/RichardErkhov/Josephgflowers_-_Tinyllama-1.5B-Cinder-Test-6-gguf/blob/main/Tinyllama-1.5B-Cinder-Test-6.Q3_K_L.gguf) | Q3_K_L | 0.77GB |
| [Tinyllama-1.5B-Cinder-Test-6.IQ4_XS.gguf](https://huggingface.co/RichardErkhov/Josephgflowers_-_Tinyllama-1.5B-Cinder-Test-6-gguf/blob/main/Tinyllama-1.5B-Cinder-Test-6.IQ4_XS.gguf) | IQ4_XS | 0.79GB |
| [Tinyllama-1.5B-Cinder-Test-6.Q4_0.gguf](https://huggingface.co/RichardErkhov/Josephgflowers_-_Tinyllama-1.5B-Cinder-Test-6-gguf/blob/main/Tinyllama-1.5B-Cinder-Test-6.Q4_0.gguf) | Q4_0 | 0.82GB |
| [Tinyllama-1.5B-Cinder-Test-6.IQ4_NL.gguf](https://huggingface.co/RichardErkhov/Josephgflowers_-_Tinyllama-1.5B-Cinder-Test-6-gguf/blob/main/Tinyllama-1.5B-Cinder-Test-6.IQ4_NL.gguf) | IQ4_NL | 0.83GB |
| [Tinyllama-1.5B-Cinder-Test-6.Q4_K_S.gguf](https://huggingface.co/RichardErkhov/Josephgflowers_-_Tinyllama-1.5B-Cinder-Test-6-gguf/blob/main/Tinyllama-1.5B-Cinder-Test-6.Q4_K_S.gguf) | Q4_K_S | 0.83GB |
| [Tinyllama-1.5B-Cinder-Test-6.Q4_K.gguf](https://huggingface.co/RichardErkhov/Josephgflowers_-_Tinyllama-1.5B-Cinder-Test-6-gguf/blob/main/Tinyllama-1.5B-Cinder-Test-6.Q4_K.gguf) | Q4_K | 0.87GB |
| [Tinyllama-1.5B-Cinder-Test-6.Q4_K_M.gguf](https://huggingface.co/RichardErkhov/Josephgflowers_-_Tinyllama-1.5B-Cinder-Test-6-gguf/blob/main/Tinyllama-1.5B-Cinder-Test-6.Q4_K_M.gguf) | Q4_K_M | 0.87GB |
| [Tinyllama-1.5B-Cinder-Test-6.Q4_1.gguf](https://huggingface.co/RichardErkhov/Josephgflowers_-_Tinyllama-1.5B-Cinder-Test-6-gguf/blob/main/Tinyllama-1.5B-Cinder-Test-6.Q4_1.gguf) | Q4_1 | 0.91GB |
| [Tinyllama-1.5B-Cinder-Test-6.Q5_0.gguf](https://huggingface.co/RichardErkhov/Josephgflowers_-_Tinyllama-1.5B-Cinder-Test-6-gguf/blob/main/Tinyllama-1.5B-Cinder-Test-6.Q5_0.gguf) | Q5_0 | 1.0GB |
| [Tinyllama-1.5B-Cinder-Test-6.Q5_K_S.gguf](https://huggingface.co/RichardErkhov/Josephgflowers_-_Tinyllama-1.5B-Cinder-Test-6-gguf/blob/main/Tinyllama-1.5B-Cinder-Test-6.Q5_K_S.gguf) | Q5_K_S | 1.0GB |
| [Tinyllama-1.5B-Cinder-Test-6.Q5_K.gguf](https://huggingface.co/RichardErkhov/Josephgflowers_-_Tinyllama-1.5B-Cinder-Test-6-gguf/blob/main/Tinyllama-1.5B-Cinder-Test-6.Q5_K.gguf) | Q5_K | 1.02GB |
| [Tinyllama-1.5B-Cinder-Test-6.Q5_K_M.gguf](https://huggingface.co/RichardErkhov/Josephgflowers_-_Tinyllama-1.5B-Cinder-Test-6-gguf/blob/main/Tinyllama-1.5B-Cinder-Test-6.Q5_K_M.gguf) | Q5_K_M | 1.02GB |
| [Tinyllama-1.5B-Cinder-Test-6.Q5_1.gguf](https://huggingface.co/RichardErkhov/Josephgflowers_-_Tinyllama-1.5B-Cinder-Test-6-gguf/blob/main/Tinyllama-1.5B-Cinder-Test-6.Q5_1.gguf) | Q5_1 | 1.08GB |
| [Tinyllama-1.5B-Cinder-Test-6.Q6_K.gguf](https://huggingface.co/RichardErkhov/Josephgflowers_-_Tinyllama-1.5B-Cinder-Test-6-gguf/blob/main/Tinyllama-1.5B-Cinder-Test-6.Q6_K.gguf) | Q6_K | 1.18GB |
| [Tinyllama-1.5B-Cinder-Test-6.Q8_0.gguf](https://huggingface.co/RichardErkhov/Josephgflowers_-_Tinyllama-1.5B-Cinder-Test-6-gguf/blob/main/Tinyllama-1.5B-Cinder-Test-6.Q8_0.gguf) | Q8_0 | 1.53GB |
Original model description:
---
license: mit
---
Overview Cinder is an AI chatbot tailored for engaging users in scientific and educational conversations, offering companionship, and sparking imaginative exploration.
This is a depth up scalled model of the 616M cinder model and Cinder v2. This model still needs further training. Putting it up for testing. More information coming. Maybe. Lol. Here is a brief desc of the project: Im mixing a lot of techniques I guess that I found interesting and have been testing, HF Cosmo is not great but decent and was fully trained in 4 days using a mix of more fine tuned directed datasets and some synthetic textbook style datasets. So I used pruning and a similar mix as Cosmo on tinyllama (trained on a ton of data for an extended time for its size) to keep the tinyllama model coherent during pruning. Now I am trying to depth up scale it using my pruned model and an original, Then taking a majority of each and combining them to create a larger model. Then it needs more training, then fine tuning. Then theoretically it will be a well performing 1.5B model (that didn't need full scale training). Test 2, some training, re depth upscalled with cinder reason 1.3B and merged back with 1.5 and slight training.
Continued short training Cinder, some metamath, and tinytexbooks. The model seems like it is gaining better performace now.
When I get more resources I will try and do a longer training.
|
mradermacher/phi3-stellargalaxy8-merged-GGUF | mradermacher | 2024-06-04T20:12:47Z | 3,259 | 0 | transformers | [
"transformers",
"gguf",
"en",
"base_model:zachaman/phi3-stellargalaxy8-merged",
"endpoints_compatible",
"region:us"
] | null | 2024-06-04T19:54:23Z | ---
base_model: zachaman/phi3-stellargalaxy8-merged
language:
- en
library_name: transformers
quantized_by: mradermacher
tags: []
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
static quants of https://huggingface.co/zachaman/phi3-stellargalaxy8-merged
<!-- provided-files -->
weighted/imatrix quants seem not to be available (by me) at this time. If they do not show up a week or so after the static ones, I have probably not planned for them. Feel free to request them by opening a Community Discussion.
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/phi3-stellargalaxy8-merged-GGUF/resolve/main/phi3-stellargalaxy8-merged.Q2_K.gguf) | Q2_K | 1.5 | |
| [GGUF](https://huggingface.co/mradermacher/phi3-stellargalaxy8-merged-GGUF/resolve/main/phi3-stellargalaxy8-merged.IQ3_XS.gguf) | IQ3_XS | 1.7 | |
| [GGUF](https://huggingface.co/mradermacher/phi3-stellargalaxy8-merged-GGUF/resolve/main/phi3-stellargalaxy8-merged.IQ3_S.gguf) | IQ3_S | 1.8 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/phi3-stellargalaxy8-merged-GGUF/resolve/main/phi3-stellargalaxy8-merged.Q3_K_S.gguf) | Q3_K_S | 1.8 | |
| [GGUF](https://huggingface.co/mradermacher/phi3-stellargalaxy8-merged-GGUF/resolve/main/phi3-stellargalaxy8-merged.IQ3_M.gguf) | IQ3_M | 2.0 | |
| [GGUF](https://huggingface.co/mradermacher/phi3-stellargalaxy8-merged-GGUF/resolve/main/phi3-stellargalaxy8-merged.Q3_K_M.gguf) | Q3_K_M | 2.1 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/phi3-stellargalaxy8-merged-GGUF/resolve/main/phi3-stellargalaxy8-merged.IQ4_XS.gguf) | IQ4_XS | 2.2 | |
| [GGUF](https://huggingface.co/mradermacher/phi3-stellargalaxy8-merged-GGUF/resolve/main/phi3-stellargalaxy8-merged.Q3_K_L.gguf) | Q3_K_L | 2.2 | |
| [GGUF](https://huggingface.co/mradermacher/phi3-stellargalaxy8-merged-GGUF/resolve/main/phi3-stellargalaxy8-merged.Q4_K_S.gguf) | Q4_K_S | 2.3 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/phi3-stellargalaxy8-merged-GGUF/resolve/main/phi3-stellargalaxy8-merged.Q4_K_M.gguf) | Q4_K_M | 2.5 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/phi3-stellargalaxy8-merged-GGUF/resolve/main/phi3-stellargalaxy8-merged.Q5_K_S.gguf) | Q5_K_S | 2.7 | |
| [GGUF](https://huggingface.co/mradermacher/phi3-stellargalaxy8-merged-GGUF/resolve/main/phi3-stellargalaxy8-merged.Q5_K_M.gguf) | Q5_K_M | 2.9 | |
| [GGUF](https://huggingface.co/mradermacher/phi3-stellargalaxy8-merged-GGUF/resolve/main/phi3-stellargalaxy8-merged.Q6_K.gguf) | Q6_K | 3.2 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/phi3-stellargalaxy8-merged-GGUF/resolve/main/phi3-stellargalaxy8-merged.Q8_0.gguf) | Q8_0 | 4.2 | fast, best quality |
| [GGUF](https://huggingface.co/mradermacher/phi3-stellargalaxy8-merged-GGUF/resolve/main/phi3-stellargalaxy8-merged.f16.gguf) | f16 | 7.7 | 16 bpw, overkill |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
mradermacher/oneirogen-7B-GGUF | mradermacher | 2024-06-26T20:41:18Z | 3,258 | 1 | transformers | [
"transformers",
"gguf",
"en",
"dataset:gustavecortal/DreamBank-annotated",
"base_model:gustavecortal/oneirogen-7B",
"license:mit",
"endpoints_compatible",
"region:us"
] | null | 2024-06-11T23:14:35Z | ---
base_model: gustavecortal/oneirogen-7B
datasets:
- gustavecortal/DreamBank-annotated
language:
- en
library_name: transformers
license: mit
quantized_by: mradermacher
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
static quants of https://huggingface.co/gustavecortal/oneirogen-7B
<!-- provided-files -->
weighted/imatrix quants seem not to be available (by me) at this time. If they do not show up a week or so after the static ones, I have probably not planned for them. Feel free to request them by opening a Community Discussion.
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/oneirogen-7B-GGUF/resolve/main/oneirogen-7B.Q2_K.gguf) | Q2_K | 3.1 | |
| [GGUF](https://huggingface.co/mradermacher/oneirogen-7B-GGUF/resolve/main/oneirogen-7B.IQ3_XS.gguf) | IQ3_XS | 3.4 | |
| [GGUF](https://huggingface.co/mradermacher/oneirogen-7B-GGUF/resolve/main/oneirogen-7B.Q3_K_S.gguf) | Q3_K_S | 3.6 | |
| [GGUF](https://huggingface.co/mradermacher/oneirogen-7B-GGUF/resolve/main/oneirogen-7B.IQ3_S.gguf) | IQ3_S | 3.6 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/oneirogen-7B-GGUF/resolve/main/oneirogen-7B.IQ3_M.gguf) | IQ3_M | 3.7 | |
| [GGUF](https://huggingface.co/mradermacher/oneirogen-7B-GGUF/resolve/main/oneirogen-7B.Q3_K_M.gguf) | Q3_K_M | 3.9 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/oneirogen-7B-GGUF/resolve/main/oneirogen-7B.Q3_K_L.gguf) | Q3_K_L | 4.2 | |
| [GGUF](https://huggingface.co/mradermacher/oneirogen-7B-GGUF/resolve/main/oneirogen-7B.IQ4_XS.gguf) | IQ4_XS | 4.4 | |
| [GGUF](https://huggingface.co/mradermacher/oneirogen-7B-GGUF/resolve/main/oneirogen-7B.Q4_K_S.gguf) | Q4_K_S | 4.6 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/oneirogen-7B-GGUF/resolve/main/oneirogen-7B.Q4_K_M.gguf) | Q4_K_M | 4.8 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/oneirogen-7B-GGUF/resolve/main/oneirogen-7B.Q5_K_S.gguf) | Q5_K_S | 5.4 | |
| [GGUF](https://huggingface.co/mradermacher/oneirogen-7B-GGUF/resolve/main/oneirogen-7B.Q5_K_M.gguf) | Q5_K_M | 5.5 | |
| [GGUF](https://huggingface.co/mradermacher/oneirogen-7B-GGUF/resolve/main/oneirogen-7B.Q6_K.gguf) | Q6_K | 6.4 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/oneirogen-7B-GGUF/resolve/main/oneirogen-7B.Q8_0.gguf) | Q8_0 | 8.2 | fast, best quality |
| [GGUF](https://huggingface.co/mradermacher/oneirogen-7B-GGUF/resolve/main/oneirogen-7B.f16.gguf) | f16 | 15.3 | 16 bpw, overkill |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
castorini/wiki-all-8-4-multi-dpr2-passage-encoder | castorini | 2023-01-05T19:26:22Z | 3,257 | 0 | transformers | [
"transformers",
"jax",
"bert",
"feature-extraction",
"endpoints_compatible",
"text-embeddings-inference",
"region:us"
] | feature-extraction | 2023-01-04T02:34:47Z | Dense passage retriever (DPR) is a dense retrieval method described in the following paper:
> Vladimir Karpukhin, Barlas Oğuz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, Wen-tau Yih. [Dense Passage Retrieval for Open-Domain Question Answering](https://www.aclweb.org/anthology/2020.emnlp-main.550/). _Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP)_, pages 6769-6781, 2020.
We have trained our own DPR models with our Wikipedia corpus variants using the [Tevatron](https://github.com/texttron/tevatron) library.
Our own efforts are described in the paper entitled:
> Pre-Processing Matters! Improved Wikipedia Corpora for Open-Domain Question Answering.
This is the passage encoder portion of a 2nd iteration DPR model for the wiki-all-8-4 corpus variant trained on the amalgamation of the NQ, TriviaQA, WQ, and CuratedTREC datasets. |
Lewdiculous/L3-Umbral-Mind-RP-v1.0-8B-GGUF-IQ-Imatrix | Lewdiculous | 2024-06-19T08:49:33Z | 3,255 | 17 | null | [
"gguf",
"license:unlicense",
"region:us"
] | null | 2024-06-19T07:54:05Z | ---
inference: false
license: unlicense
---
[[Request #49]](https://huggingface.co/Lewdiculous/Model-Requests/discussions/49) - Click the link for more context. <br>
[Casual-Autopsy/L3-Umbral-Mind-RP-v1.0-8B](https://huggingface.co/Casual-Autopsy/L3-Umbral-Mind-RP-v1.0-8B) <br>
This model is tailored for specific use cases, please read the original page for more details and useful information.
**Prompt formatting:** <br>
Llama-3
Use with the [**latest version of KoboldCpp**](https://github.com/LostRuins/koboldcpp/releases/latest), or [this more up-to-date fork](https://github.com/Nexesenex/kobold.cpp) if you have issues.
<details>
<summary>⇲ Click here to expand/hide information – General chart with relative quant parformances.</summary>
> [!NOTE]
> **Recommended read:** <br>
>
> [**"Which GGUF is right for me? (Opinionated)" by Artefact2**](https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9)
>
> *Click the image to view full size.*
> 
</details>
 |
bionlp/bluebert_pubmed_uncased_L-24_H-1024_A-16 | bionlp | 2021-09-24T07:46:55Z | 3,254 | 2 | transformers | [
"transformers",
"pytorch",
"jax",
"bert",
"bluebert",
"en",
"dataset:PubMed",
"license:cc0-1.0",
"endpoints_compatible",
"region:us"
] | null | 2022-03-02T23:29:05Z | ---
language:
- en
tags:
- bert
- bluebert
license: cc0-1.0
datasets:
- PubMed
---
# BlueBert-Base, Uncased, PubMed
## Model description
A BERT model pre-trained on PubMed abstracts.
## Intended uses & limitations
#### How to use
Please see https://github.com/ncbi-nlp/bluebert
## Training data
We provide [preprocessed PubMed texts](https://ftp.ncbi.nlm.nih.gov/pub/lu/Suppl/NCBI-BERT/pubmed_uncased_sentence_nltk.txt.tar.gz) that were used to pre-train the BlueBERT models.
The corpus contains ~4000M words extracted from the [PubMed ASCII code version](https://www.ncbi.nlm.nih.gov/research/bionlp/APIs/BioC-PubMed/).
Pre-trained model: https://huggingface.co/bert-large-uncased
## Training procedure
* lowercasing the text
* removing speical chars `\x00`-`\x7F`
* tokenizing the text using the [NLTK Treebank tokenizer](https://www.nltk.org/_modules/nltk/tokenize/treebank.html)
Below is a code snippet for more details.
```python
value = value.lower()
value = re.sub(r'[\r\n]+', ' ', value)
value = re.sub(r'[^\x00-\x7F]+', ' ', value)
tokenized = TreebankWordTokenizer().tokenize(value)
sentence = ' '.join(tokenized)
sentence = re.sub(r"\s's\b", "'s", sentence)
```
### BibTeX entry and citation info
```bibtex
@InProceedings{peng2019transfer,
author = {Yifan Peng and Shankai Yan and Zhiyong Lu},
title = {Transfer Learning in Biomedical Natural Language Processing: An Evaluation of BERT and ELMo on Ten Benchmarking Datasets},
booktitle = {Proceedings of the 2019 Workshop on Biomedical Natural Language Processing (BioNLP 2019)},
year = {2019},
pages = {58--65},
}
```
### Acknowledgments
This work was supported by the Intramural Research Programs of the National Institutes of Health, National Library of
Medicine and Clinical Center. This work was supported by the National Library of Medicine of the National Institutes of Health under award number 4R00LM013001-01.
We are also grateful to the authors of BERT and ELMo to make the data and codes publicly available.
We would like to thank Dr Sun Kim for processing the PubMed texts.
### Disclaimer
This tool shows the results of research conducted in the Computational Biology Branch, NCBI. The information produced
on this website is not intended for direct diagnostic use or medical decision-making without review and oversight
by a clinical professional. Individuals should not change their health behavior solely on the basis of information
produced on this website. NIH does not independently verify the validity or utility of the information produced
by this tool. If you have questions about the information produced on this website, please see a health care
professional. More information about NCBI's disclaimer policy is available.
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.