
modelId
stringlengths 5
122
| author
stringlengths 2
42
| last_modified
timestamp[us, tz=UTC] | downloads
int64 0
738M
| likes
int64 0
11k
| library_name
stringclasses 245
values | tags
sequencelengths 1
4.05k
| pipeline_tag
stringclasses 48
values | createdAt
timestamp[us, tz=UTC] | card
stringlengths 1
901k
|
|---|---|---|---|---|---|---|---|---|---|
mradermacher/Llama-Guard-2-8B-German-v0.2-GGUF | mradermacher | 2024-06-14T12:19:44Z | 3,179 | 0 | transformers | [
"transformers",
"gguf",
"en",
"base_model:felfri/Llama-Guard-2-8B-German-v0.2",
"endpoints_compatible",
"region:us"
] | null | 2024-06-14T10:06:46Z | ---
base_model: felfri/Llama-Guard-2-8B-German-v0.2
language:
- en
library_name: transformers
quantized_by: mradermacher
tags: []
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
static quants of https://huggingface.co/felfri/Llama-Guard-2-8B-German-v0.2
<!-- provided-files -->
weighted/imatrix quants are available at https://huggingface.co/mradermacher/Llama-Guard-2-8B-German-v0.2-i1-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/Llama-Guard-2-8B-German-v0.2-GGUF/resolve/main/Llama-Guard-2-8B-German-v0.2.Q2_K.gguf) | Q2_K | 3.3 | |
| [GGUF](https://huggingface.co/mradermacher/Llama-Guard-2-8B-German-v0.2-GGUF/resolve/main/Llama-Guard-2-8B-German-v0.2.IQ3_XS.gguf) | IQ3_XS | 3.6 | |
| [GGUF](https://huggingface.co/mradermacher/Llama-Guard-2-8B-German-v0.2-GGUF/resolve/main/Llama-Guard-2-8B-German-v0.2.Q3_K_S.gguf) | Q3_K_S | 3.8 | |
| [GGUF](https://huggingface.co/mradermacher/Llama-Guard-2-8B-German-v0.2-GGUF/resolve/main/Llama-Guard-2-8B-German-v0.2.IQ3_S.gguf) | IQ3_S | 3.8 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/Llama-Guard-2-8B-German-v0.2-GGUF/resolve/main/Llama-Guard-2-8B-German-v0.2.IQ3_M.gguf) | IQ3_M | 3.9 | |
| [GGUF](https://huggingface.co/mradermacher/Llama-Guard-2-8B-German-v0.2-GGUF/resolve/main/Llama-Guard-2-8B-German-v0.2.Q3_K_M.gguf) | Q3_K_M | 4.1 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/Llama-Guard-2-8B-German-v0.2-GGUF/resolve/main/Llama-Guard-2-8B-German-v0.2.Q3_K_L.gguf) | Q3_K_L | 4.4 | |
| [GGUF](https://huggingface.co/mradermacher/Llama-Guard-2-8B-German-v0.2-GGUF/resolve/main/Llama-Guard-2-8B-German-v0.2.IQ4_XS.gguf) | IQ4_XS | 4.6 | |
| [GGUF](https://huggingface.co/mradermacher/Llama-Guard-2-8B-German-v0.2-GGUF/resolve/main/Llama-Guard-2-8B-German-v0.2.Q4_K_S.gguf) | Q4_K_S | 4.8 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Llama-Guard-2-8B-German-v0.2-GGUF/resolve/main/Llama-Guard-2-8B-German-v0.2.Q4_K_M.gguf) | Q4_K_M | 5.0 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Llama-Guard-2-8B-German-v0.2-GGUF/resolve/main/Llama-Guard-2-8B-German-v0.2.Q5_K_S.gguf) | Q5_K_S | 5.7 | |
| [GGUF](https://huggingface.co/mradermacher/Llama-Guard-2-8B-German-v0.2-GGUF/resolve/main/Llama-Guard-2-8B-German-v0.2.Q5_K_M.gguf) | Q5_K_M | 5.8 | |
| [GGUF](https://huggingface.co/mradermacher/Llama-Guard-2-8B-German-v0.2-GGUF/resolve/main/Llama-Guard-2-8B-German-v0.2.Q6_K.gguf) | Q6_K | 6.7 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/Llama-Guard-2-8B-German-v0.2-GGUF/resolve/main/Llama-Guard-2-8B-German-v0.2.Q8_0.gguf) | Q8_0 | 8.6 | fast, best quality |
| [GGUF](https://huggingface.co/mradermacher/Llama-Guard-2-8B-German-v0.2-GGUF/resolve/main/Llama-Guard-2-8B-German-v0.2.f16.gguf) | f16 | 16.2 | 16 bpw, overkill |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
facebook/maskformer-swin-tiny-ade | facebook | 2023-09-11T20:35:15Z | 3,177 | 5 | transformers | [
"transformers",
"pytorch",
"safetensors",
"maskformer",
"vision",
"image-segmentation",
"dataset:scene_parse_150",
"arxiv:2107.06278",
"license:other",
"endpoints_compatible",
"region:us"
] | image-segmentation | 2022-03-02T23:29:05Z | ---
license: other
tags:
- vision
- image-segmentation
datasets:
- scene_parse_150
widget:
- src: https://huggingface.co/datasets/hf-internal-testing/fixtures_ade20k/resolve/main/ADE_val_00000001.jpg
example_title: House
- src: https://huggingface.co/datasets/hf-internal-testing/fixtures_ade20k/resolve/main/ADE_val_00000002.jpg
example_title: Castle
---
# MaskFormer
MaskFormer model trained on ADE20k semantic segmentation (tiny-sized version, Swin backbone). It was introduced in the paper [Per-Pixel Classification is Not All You Need for Semantic Segmentation](https://arxiv.org/abs/2107.06278) and first released in [this repository](https://github.com/facebookresearch/MaskFormer/blob/da3e60d85fdeedcb31476b5edd7d328826ce56cc/mask_former/modeling/criterion.py#L169).
Disclaimer: The team releasing MaskFormer did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
MaskFormer addresses instance, semantic and panoptic segmentation with the same paradigm: by predicting a set of masks and corresponding labels. Hence, all 3 tasks are treated as if they were instance segmentation.

## Intended uses & limitations
You can use this particular checkpoint for semantic segmentation. See the [model hub](https://huggingface.co/models?search=maskformer) to look for other
fine-tuned versions on a task that interests you.
### How to use
Here is how to use this model:
```python
from transformers import MaskFormerFeatureExtractor, MaskFormerForInstanceSegmentation
from PIL import Image
import requests
url = "https://huggingface.co/datasets/hf-internal-testing/fixtures_ade20k/resolve/main/ADE_val_00000001.jpg"
image = Image.open(requests.get(url, stream=True).raw)
feature_extractor = MaskFormerFeatureExtractor.from_pretrained("facebook/maskformer-swin-tiny-ade")
inputs = feature_extractor(images=image, return_tensors="pt")
model = MaskFormerForInstanceSegmentation.from_pretrained("facebook/maskformer-swin-tiny-ade")
outputs = model(**inputs)
# model predicts class_queries_logits of shape `(batch_size, num_queries)`
# and masks_queries_logits of shape `(batch_size, num_queries, height, width)`
class_queries_logits = outputs.class_queries_logits
masks_queries_logits = outputs.masks_queries_logits
# you can pass them to feature_extractor for postprocessing
# we refer to the demo notebooks for visualization (see "Resources" section in the MaskFormer docs)
predicted_semantic_map = feature_extractor.post_process_semantic_segmentation(outputs, target_sizes=[image.size[::-1]])[0]
```
For more code examples, we refer to the [documentation](https://huggingface.co/docs/transformers/master/en/model_doc/maskformer). |
Geotrend/distilbert-base-es-cased | Geotrend | 2023-04-02T12:00:03Z | 3,176 | 3 | transformers | [
"transformers",
"pytorch",
"safetensors",
"distilbert",
"fill-mask",
"es",
"dataset:wikipedia",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | fill-mask | 2022-03-02T23:29:04Z | ---
language: es
datasets: wikipedia
license: apache-2.0
---
# distilbert-base-es-cased
We are sharing smaller versions of [distilbert-base-multilingual-cased](https://huggingface.co/distilbert-base-multilingual-cased) that handle a custom number of languages.
Our versions give exactly the same representations produced by the original model which preserves the original accuracy.
For more information please visit our paper: [Load What You Need: Smaller Versions of Multilingual BERT](https://www.aclweb.org/anthology/2020.sustainlp-1.16.pdf).
## How to use
```python
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("Geotrend/distilbert-base-es-cased")
model = AutoModel.from_pretrained("Geotrend/distilbert-base-es-cased")
```
To generate other smaller versions of multilingual transformers please visit [our Github repo](https://github.com/Geotrend-research/smaller-transformers).
### How to cite
```bibtex
@inproceedings{smallermdistilbert,
title={Load What You Need: Smaller Versions of Mutlilingual BERT},
author={Abdaoui, Amine and Pradel, Camille and Sigel, Grégoire},
booktitle={SustaiNLP / EMNLP},
year={2020}
}
```
## Contact
Please contact [email protected] for any question, feedback or request. |
KoboldAI/fairseq-dense-13B-Janeway | KoboldAI | 2022-04-07T10:51:39Z | 3,176 | 11 | transformers | [
"transformers",
"pytorch",
"xglm",
"text-generation",
"en",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-generation | 2022-04-06T14:36:12Z | ---
language: en
license: mit
---
# Fairseq-dense 13B - Janeway
## Model Description
Fairseq-dense 13B-Janeway is a finetune created using Fairseq's MoE dense model.
## Training data
The training data contains around 2210 ebooks, mostly in the sci-fi and fantasy genres. The dataset is identical as dataset used by GPT-Neo-2.7B-Janeway.
Some parts of the dataset have been prepended using the following text: `[Genre: <genre1>,<genre2>]`
### How to use
You can use this model directly with a pipeline for text generation. This example generates a different sequence each time it's run:
```py
>>> from transformers import pipeline
>>> generator = pipeline('text-generation', model='KoboldAI/fairseq-dense-13B-Janeway')
>>> generator("Welcome Captain Janeway, I apologize for the delay.", do_sample=True, min_length=50)
[{'generated_text': 'Welcome Captain Janeway, I apologize for the delay."\nIt's all right," Janeway said. "I'm certain that you're doing your best to keep me informed of what\'s going on."'}]
```
### Limitations and Biases
Based on known problems with NLP technology, potential relevant factors include bias (gender, profession, race and religion).
### BibTeX entry and citation info
```
Artetxe et al. (2021): Efficient Large Scale Language Modeling with Mixtures of Experts
``` |
digiplay/endlessMixRenatus_v1.1 | digiplay | 2024-04-15T23:16:21Z | 3,174 | 3 | diffusers | [
"diffusers",
"safetensors",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"license:other",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | 2023-07-01T20:31:47Z | ---
license: other
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
inference: true
---
2024 update: upload a 840000 VAE version.
Model info:
https://civitai.com/models/86258?modelVersionId=93006
Original Author's DEMO image :

Sample images and prompt :
1girl Anime medium close-up ,Kon Satoshi PERFECT BLUE style,HDR,extremely sharp focus,cyberpunk city,


*generated by Huggingface's API |
mrm8488/t5-base-finetuned-common_gen | mrm8488 | 2023-03-16T19:20:33Z | 3,173 | 43 | transformers | [
"transformers",
"pytorch",
"safetensors",
"t5",
"text2text-generation",
"common sense",
"en",
"dataset:common_gen",
"arxiv:1910.10683",
"arxiv:1911.03705",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text2text-generation | 2022-03-02T23:29:05Z | ---
language: en
tags:
- common sense
datasets:
- common_gen
widget:
- text: "tree plant ground hole dig"
---
# T5-base fine-tuned on CommonGen
[Google's T5](https://ai.googleblog.com/2020/02/exploring-transfer-learning-with-t5.html) fine-tuned on [CommonGen](https://inklab.usc.edu/CommonGen/index.html) for **Generative Commonsense Reasoning**.
## Details of T5
The **T5** model was presented in [Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer](https://arxiv.org/pdf/1910.10683.pdf) by *Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, Peter J. Liu* in Here the abstract:
Transfer learning, where a model is first pre-trained on a data-rich task before being fine-tuned on a downstream task, has emerged as a powerful technique in natural language processing (NLP). The effectiveness of transfer learning has given rise to a diversity of approaches, methodology, and practice. In this paper, we explore the landscape of transfer learning techniques for NLP by introducing a unified framework that converts every language problem into a text-to-text format. Our systematic study compares pre-training objectives, architectures, unlabeled datasets, transfer approaches, and other factors on dozens of language understanding tasks. By combining the insights from our exploration with scale and our new “Colossal Clean Crawled Corpus”, we achieve state-of-the-art results on many benchmarks covering summarization, question answering, text classification, and more. To facilitate future work on transfer learning for NLP, we release our dataset, pre-trained models, and code.

## Details of the dataset 📚
CommonGen is a constrained text generation task, associated with a benchmark dataset, to explicitly test machines for the ability of generative commonsense reasoning. Given a set of common concepts; the task is to generate a coherent sentence describing an everyday scenario using these concepts.
CommonGen is challenging because it inherently requires 1) relational reasoning using background commonsense knowledge, and 2) compositional generalization ability to work on unseen concept combinations. Our dataset, constructed through a combination of crowd-sourcing from AMT and existing caption corpora, consists of 30k concept-sets and 50k sentences in total.
| Dataset | Split | # samples |
| -------- | ----- | --------- |
| common_gen | train | 67389 |
| common_gen | valid | 4018 |
| common_gen | test | 1497 |
## Model fine-tuning 🏋️
The training script is a slightly modified version of [this awesome one](https://colab.research.google.com/github/patil-suraj/exploring-T5/blob/master/T5_on_TPU.ipynb) by [Suraj Patil](https://twitter.com/psuraj28)
## Metrics 📋
| Metric | Score |
|--------|-------|
|ROUGE-2 | 17.10 |
|ROUGE-L | 39.47 |
|BLEU | WIP |
The metrics above slightly improves results shown in the [paper](https://arxiv.org/abs/1911.03705) for the same model and metrics.
## Model in Action 🚀
```python
from transformers import AutoModelWithLMHead, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("mrm8488/t5-base-finetuned-common_gen")
model = AutoModelWithLMHead.from_pretrained("mrm8488/t5-base-finetuned-common_gen")
def gen_sentence(words, max_length=32):
input_text = words
features = tokenizer([input_text], return_tensors='pt')
output = model.generate(input_ids=features['input_ids'],
attention_mask=features['attention_mask'],
max_length=max_length)
return tokenizer.decode(output[0], skip_special_tokens=True)
words = "tree plant ground hole dig"
gen_sentence(words)
# output: digging a hole in the ground to plant trees
```
[](https://colab.research.google.com/github/mrm8488/shared_colab_notebooks/blob/master/T5_base_finetuned_common_gen.ipynb)
> Created by [Manuel Romero/@mrm8488](https://twitter.com/mrm8488) | [LinkedIn](https://www.linkedin.com/in/manuel-romero-cs/)
> Made with <span style="color: #e25555;">♥</span> in Spain
|
hpcai-tech/Colossal-LLaMA-2-7b-base | hpcai-tech | 2024-01-06T09:21:00Z | 3,171 | 74 | transformers | [
"transformers",
"pytorch",
"llama",
"text-generation",
"zh",
"en",
"arxiv:2307.09288",
"license:llama2",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2023-09-18T07:51:31Z | ---
license: llama2
language:
- zh
- en
---
<!-- markdownlint-disable first-line-h1 -->
<!-- markdownlint-disable html -->
<div align="center">
<h1>
Colossal-LLaMA-2-7B
</h1>
</div>
<div align="center">
🎉 We released Colossal-LLaMA-2-7B-base based on LLaMA-2 !!
</div>
<div align="center">
|<a href="https://github.com/hpcaitech/ColossalAI/tree/main/applications/Colossal-LLaMA-2" target="_blank">🔥 GitHub </a> |
<a href="https://modelscope.cn/models/colossalai/Colossal-LLaMA-2-7b-base/summary" target="_blank">👾 Modelscope</a>|
<a href="https://github.com/hpcaitech/public_assets/tree/main/colossalai/contact/slack" target="_blank">😊 Slack</a>|
<a href="https://raw.githubusercontent.com/hpcaitech/public_assets/main/colossalai/img/WeChat.png" target="_blank">💬 WeChat</a>|
</div>
<div align="center">
<h1>
<img src="https://github.com/hpcaitech/public_assets/blob/main/applications/colossal-llama-2/colossalllam2.jpg?raw=true" width=800/>
</h1>
</div>
# Table of Contents
- [Model Introduction](#model-introducation)
- [Usage](#usage)
- [Performance Evaluation](#performance-evaluation)
- [Technical Insights](#technical-insights)
- [Data](#data)
- [Tokenizer](#tokenizer)
- [Training Logs](#training-logs)
- [Training Strategy](#training-strategy)
- [Multi-stage Training](#multi-stage-training)
- [Bucket-based Training](#bucket-based-training)
- [Limitations](#limitations)
- [Citations](#citations)
# Model Introduction
The [Colossal-AI](https://github.com/hpcaitech/ColossalAI) team has introduced the **open-source** model **Colossal-LLaMA-2-7B-base**. This model, a derivation of LLaMA-2, has undergone continual pre-training involving approximately 8.5 billion tokens over a duration of 15 hours with 64 A800 GPUs. At a cost of **less than $1,000**, you can achieve results **similar to those that cost millions of dollars to pretrain from scratch**. It is licensed under the LLaMA-2 license and [Apache 2.0 License](https://github.com/hpcaitech/ColossalAI/blob/main/LICENSE) **without any additional commercial use restrictions**. This solution can also be used to build models of specific domain knowledge or tasks.
Colossal-LLaMA-2-7B-base is designed to accommodate both the Chinese and English languages, featuring an expansive context window spanning 4096 tokens. Remarkably, it has exhibited exceptional performance when benchmarked against models of equivalent scale in standard Chinese and English evaluation metrics, including C-Eval and MMLU, among others.
# Usage
To load Colossal-LLaMA-2-7B-base model using Transformers, use the following code:
```Python
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained("hpcai-tech/Colossal-LLaMA-2-7b-base", device_map="auto", trust_remote_code=True)
tokenizer = AutoTokenizer.from_pretrained("hpcai-tech/Colossal-LLaMA-2-7b-base", trust_remote_code=True)
input = "明月松间照,\n\n->\n\n"
inputs = tokenizer(input, return_tensors='pt')
inputs = inputs.to('cuda:0')
pred = model.generate(**inputs,
max_new_tokens=512,
do_sample=True,
temperature=0.3,
top_k=50,
top_p=0.95,
num_return_sequences=1)
print(tokenizer.decode(pred.cpu()[0], skip_special_tokens=True)[len(input):])
```
# Performance Evaluation
### Performance Evaluation
We conducted comprehensive evaluation on 4 datasets and compare our Colossal-Llama-2-7b-base model with various models.
- We use 5-shot for MMLU and calculate scores based on the logits of first predicted token.
- We use 5-shot for CMMLU and calculate scores based on the logits of first predicted token.
- We use 5-shot for AGIEval and only calculate scores for 4-choice questions using a combination metric of exact match and the logits of first predicted token. If any of the exact match or logits of first predicted token is correct, the model will get the score.
- We use 0-shot for GAOKAO-Bench and only calculate scores for 4-choice questions based on the logits of first predicted token.
- The generation config for all dataset is greedy search.
- We also provided CEval scores from its latest leaderboard or the official repository of the model.
More details about metrics can be found in [Metrics](https://github.com/hpcaitech/ColossalAI/tree/main/applications/ColossalEval#metrics).
| | Backbone | Tokens Consumed | | MMLU | CMMLU | AGIEval | GAOKAO | CEval |
| :----------------------------: | :--------: | :-------------: | :------------------: | :-----------: | :-----: | :----: | :----: | :----------------------------: |
| | - | - | | 5-shot | 5-shot | 5-shot | 0-shot | 5-shot |
| Baichuan-7B | - | 1.2T | | 42.32 (42.30) | 44.53 (44.02) | 38.72 | 36.74 | 42.80 |
| Baichuan2-7B-Base | - | 2.6T | | 46.97 (54.16) | 57.67 (57.07) | 45.76 | 52.60 | 54.00 |
| ChatGLM-6B | - | 1.0T | | 39.67 (40.63) | 41.17 (-) | 40.10 | 36.53 | 38.90 |
| ChatGLM2-6B | - | 1.4T | | 44.74 (45.46) | 49.40 (-) | 46.36 | 45.49 | 51.70 |
| InternLM-7B | - | - | | 46.70 (51.00) | 52.00 (-) | 44.77 | 61.64 | 52.80 |
| Qwen-7B (original) | - | 2.2T | | 54.29 (56.70) | 56.03 (58.80) | 52.47 | 56.42 | 59.60 |
| Qwen-7B | - | 2.4T | | 58.33 (58.20) | 62.54 (62.20) | 64.34 | 74.05 | 63.50 |
| | | | | | | | | |
| Llama-2-7B | - | 2.0T | | 44.47 (45.30) | 32.97 (-) | 32.60 | 25.46 | - |
| Linly-AI/Chinese-LLaMA-2-7B-hf | Llama-2-7B | 1.0T | | 37.43 | 29.92 | 32.00 | 27.57 | - |
| wenge-research/yayi-7b-llama2 | Llama-2-7B | - | | 38.56 | 31.52 | 30.99 | 25.95 | - |
| ziqingyang/chinese-llama-2-7b | Llama-2-7B | - | | 33.86 | 34.69 | 34.52 | 25.18 | 34.2 |
| TigerResearch/tigerbot-7b-base | Llama-2-7B | 0.3T | | 43.73 | 42.04 | 37.64 | 30.61 | - |
| LinkSoul/Chinese-Llama-2-7b | Llama-2-7B | - | | 48.41 | 38.31 | 38.45 | 27.72 | - |
| FlagAlpha/Atom-7B | Llama-2-7B | 0.1T | | 49.96 | 41.10 | 39.83 | 33.00 | - |
| | | | | | | | | |
| **Colossal-LLaMA-2-7b-base** | Llama-2-7B | **0.0085T** | | 53.06 | 49.89 | 51.48 | 58.82 | 50.20 |
> The score in parentheses corresponds to the scores in the official repository of the model.
>
> We use zero-shot for ChatGLM models.
>
> To evaluate Qwen-7B on dataset MMLU, the prompt would be "xxx Answer:"(remove the space after ":") and we calculate the logits over " A", " B", " C" and " D" for Qwen-7B. Both the original and updated versions of Qwen-7B tend to be much more deterministic than other models. For example, the logits over " A" can be `-inf` and softmax would be exact `0`.
>
> For other models and other dataset, we calculate logits over "A", "B", "C" and "D".
❗️ More details of the evaluation methods and reproduction of the results, please refer to [ColossalEval](https://github.com/hpcaitech/ColossalAI/tree/main/applications/ColossalEval).
# Technical Insights
In order to enhance LLaMA-2's capabilities for understanding and generating Chinese content, The [Colossal-AI](https://github.com/hpcaitech/ColossalAI) team proposes the continuation of pre-training the LLaMA-2 model using both Chinese and English corpora.
## Data
Large language models such as LLaMA-2 have undergone training using a heterogeneous blend of high-quality datasets, yielding promising outcomes. Enhancing LLaMA-2's performance for the Chinese corpus, while preserving its proficiency in English, critically hinges on two pivotal factors: the composition of the dataset, which encompasses both English and Chinese content, and the quality of each constituent dataset.
The following figure shows the data processing pipeline conducted for Colossal-LLaMA-2.
<p id="Colossal-LLaMA-2-data-processing-pipeline" align="center">
<img src="https://github.com/hpcaitech/public_assets/blob/main/applications/colossal-llama-2/data_processing_pipeline.jpeg?raw=true" width=800/>
</p>
❗️**Important**: We will open-source our data-processing toolkit soon, stay tuned!
## Tokenizer
The original LLaMA-2 vacabulary comprises fewer than a thousand Chinese characters, thus proves inadequate for encoding comprehensive Chinese texts effectively. Secondly, the utilization of byte tokens presents a challenge for transformer encoders to capture the semantic nuances of Chinese characters.
To address the above issues, we extend LLaMA-2 vocabulary from 32,000 to 69,104. To adapt the LLaMA-2 model for use with the Colossal-LLaMA-2 tokenizer, we initialize the new word embeddings by calculating the mean values from the original LLaMA-2 embeddings and subsequently append these new rows to the end of the original embedding matrices.
Advantages of extending vocabulary size:
* Improve the compression rate of string sequence encoding.
* Enhance the integrity of information.
* Enable encoded sequences to contain more valuable information, thereby theoretically enhancing the ability for chapter-level encoding.
Advantages of large vocabulary size under low-resource settings:
* The presence of numerous unused tokens can be attributed to the limited training dataset, where an excessive number of tokens might not have been effectively learned.
* Excessive vocabulary expansion leads to an increase in embedding-related parameters, resulting in higher memory usage, which, in turn, affects the efficiency of the training process.
To balance both sides, we finally construct our vocabulary with size 69,104. The following table below presents a comparison of various models at the 7B level.
| Model | Vocabulary Size | Compression Rate | Average Length of Samples (token-level) |
| :-----------: | :---------: | :----: | :----: |
| **Colossal-LLaMA-2** | **69104** | **0.659** | **73.682** |
| LLaMA-2-7B | 32000 | 1.205 | 134.689 |
| Atom-7B | 65000 | 0.634 | 70.915 |
| Baichuan-7B | 64000 | 0.678 | 75.857 |
| Baichuan2-7B-base | 125696 | 0.570 | 63.761 |
| Chatglm2-6B | 64789 | 0.645 | 72.178 |
| InternLM-7B | 103168 | 0.566 | 63.349 |
| Qwen-7B | 151643 | 0.578 | 64.703 |
| Tigerbot-7B-base | 60515 | 0.630 | 70.515 |
| Yayi-7B-llama2 | 32005 | 1.214 | 135.689 |
| Chinese-llama-2-7b | 55296 | 0.668 | 74.690 |
| Chinese-Falcon-7B | 90046 | 0.669 | 74.858 |
| LinkSoul-Chinese-Llama-2-7b | 40076 | 0.958 | 107.089 |
| Ziya-LLaMA-13B-v1.1 | 39410 | 0.958 | 107.074 |
## Training Logs
Here are the training logs for the our experiment:
<p id="Colossal-LLaMA-2-Multi-stage-training" align="center">
<img src="https://github.com/hpcaitech/public_assets/blob/main/applications/colossal-llama-2/trainingLossBySteps.jpeg?raw=true" width=600/>
</p>
<p id="Colossal-LLaMA-2-Multi-stage-training" align="center">
<img src="https://github.com/hpcaitech/public_assets/blob/main/applications/colossal-llama-2/trainingLossByTokens.jpeg?raw=true" width=600/>
</p>
## Training Strategy
### Multi-stage Training
In order to enhance the model's performance and harness the full potential of the original LLaMA-2, we have developed a multi-stage training strategy. This strategy is designed to systematically unlock the model's capabilities over a series of stages.
Therefore, we have divided the training process into three stages:
* Large-scale pre-training stage (Conducted by LLaMA-2): This initial stage is aimed at establishing the model's foundational capabilities from the ground up. It necessitates the use of a substantial dataset comprising no less than 1 trillion tokens.
* Chinese knowledge injection stage: In this stage, we introduce Chinese knowledge into the model. It requires access to a high-quality dataset rich in comprehensive knowledge relevant to the Chinese language.
* Knowledge replay stage: Knowledge is replayed through a question-answering (QA) mechanism, encompassing both the Chinese and English domains.
Following the completion of this multi-stage training process, the model exhibits notable improvements in performance across both English and Chinese benchmarks.
The following figure illustrates the three stages for training Colossal-LLaMA-2.
<p id="Colossal-LLaMA-2-Multi-stage-training" align="center">
<img src="https://github.com/hpcaitech/public_assets/blob/main/applications/colossal-llama-2/multi-stage-training.png?raw=true" width=600/>
</p>
### Bucket-based Training
Our experiments have revealed that the distributions within the training dataset, as well as the arrangement of various topic-related data points, significantly impact the overall performance of the model, particularly in the context of continual pre-training of LLaMA-2.
In an effort to achieve a more balanced distribution and exert control over the dataset's ordering, we have adopted a method where we divide each sub-dataset into discrete bins. These bins are then combined to construct individual data buckets, with one bin contributed by each sub-dataset.
For more details, please refer to our [Github](https://github.com/hpcaitech/ColossalAI/tree/main/applications/Colossal-LLaMA-2).
# Limitations
Colossal-LLaMA-2-7B is a derivation of LLaMA-2 that carries risks with use. Testing conducted to date has been exclusively performed in English and Chinese languages, and it is important to acknowledge that it could not encompass all possible scenarios. Same as other LLMs, it is impossible to predict the potential outcomes of Colossal-LLaMA-2-7B-base in advance. In certain situations, Colossal-LLaMA-2-7B-base may generate responses that are inaccurate, biased, or otherwise poisonous. Consequently, prior to deploying any applications powered by Colossal-LLaMA-2-7B-base, it is imperative for developers to engage in safety testing and tuning tailored the model to meet the specific requirements of their applications.
# Citations
```bibtex
@article{bian2021colossal,
title={Colossal-AI: A Unified Deep Learning System For Large-Scale Parallel Training},
author={Bian, Zhengda and Liu, Hongxin and Wang, Boxiang and Huang, Haichen and Li, Yongbin and Wang, Chuanrui and Cui, Fan and You, Yang},
journal={arXiv preprint arXiv:2110.14883},
year={2021}
}
```
```bibtex
@misc{touvron2023llama,
title={Llama 2: Open Foundation and Fine-Tuned Chat Models},
author={Hugo Touvron and Louis Martin and Kevin Stone and Peter Albert and Amjad Almahairi and Yasmine Babaei and Nikolay Bashlykov and Soumya Batra and Prajjwal Bhargava and Shruti Bhosale and Dan Bikel and Lukas Blecher and Cristian Canton Ferrer and Moya Chen and Guillem Cucurull and David Esiobu and Jude Fernandes and Jeremy Fu and Wenyin Fu and Brian Fuller and Cynthia Gao and Vedanuj Goswami and Naman Goyal and Anthony Hartshorn and Saghar Hosseini and Rui Hou and Hakan Inan and Marcin Kardas and Viktor Kerkez and Madian Khabsa and Isabel Kloumann and Artem Korenev and Punit Singh Koura and Marie-Anne Lachaux and Thibaut Lavril and Jenya Lee and Diana Liskovich and Yinghai Lu and Yuning Mao and Xavier Martinet and Todor Mihaylov and Pushkar Mishra and Igor Molybog and Yixin Nie and Andrew Poulton and Jeremy Reizenstein and Rashi Rungta and Kalyan Saladi and Alan Schelten and Ruan Silva and Eric Michael Smith and Ranjan Subramanian and Xiaoqing Ellen Tan and Binh Tang and Ross Taylor and Adina Williams and Jian Xiang Kuan and Puxin Xu and Zheng Yan and Iliyan Zarov and Yuchen Zhang and Angela Fan and Melanie Kambadur and Sharan Narang and Aurelien Rodriguez and Robert Stojnic and Sergey Edunov and Thomas Scialom},
year={2023},
eprint={2307.09288},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
```bibtex
@article{dao2023flashattention2,
title={Flash{A}ttention-2: Faster Attention with Better Parallelism and Work Partitioning},
author={Dao, Tri},
year={2023}
}
``` |
mradermacher/Qwen2-7B-GGUF | mradermacher | 2024-06-06T21:30:00Z | 3,170 | 0 | transformers | [
"transformers",
"gguf",
"pretrained",
"en",
"base_model:Qwen/Qwen2-7B",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2024-06-06T21:01:07Z | ---
base_model: Qwen/Qwen2-7B
language:
- en
library_name: transformers
license: apache-2.0
quantized_by: mradermacher
tags:
- pretrained
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
static quants of https://huggingface.co/Qwen/Qwen2-7B
<!-- provided-files -->
weighted/imatrix quants are available at https://huggingface.co/mradermacher/Qwen2-7B-i1-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/Qwen2-7B-GGUF/resolve/main/Qwen2-7B.Q2_K.gguf) | Q2_K | 3.1 | |
| [GGUF](https://huggingface.co/mradermacher/Qwen2-7B-GGUF/resolve/main/Qwen2-7B.IQ3_XS.gguf) | IQ3_XS | 3.4 | |
| [GGUF](https://huggingface.co/mradermacher/Qwen2-7B-GGUF/resolve/main/Qwen2-7B.Q3_K_S.gguf) | Q3_K_S | 3.6 | |
| [GGUF](https://huggingface.co/mradermacher/Qwen2-7B-GGUF/resolve/main/Qwen2-7B.IQ3_S.gguf) | IQ3_S | 3.6 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/Qwen2-7B-GGUF/resolve/main/Qwen2-7B.IQ3_M.gguf) | IQ3_M | 3.7 | |
| [GGUF](https://huggingface.co/mradermacher/Qwen2-7B-GGUF/resolve/main/Qwen2-7B.Q3_K_M.gguf) | Q3_K_M | 3.9 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/Qwen2-7B-GGUF/resolve/main/Qwen2-7B.Q3_K_L.gguf) | Q3_K_L | 4.2 | |
| [GGUF](https://huggingface.co/mradermacher/Qwen2-7B-GGUF/resolve/main/Qwen2-7B.IQ4_XS.gguf) | IQ4_XS | 4.4 | |
| [GGUF](https://huggingface.co/mradermacher/Qwen2-7B-GGUF/resolve/main/Qwen2-7B.Q4_K_S.gguf) | Q4_K_S | 4.6 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Qwen2-7B-GGUF/resolve/main/Qwen2-7B.Q4_K_M.gguf) | Q4_K_M | 4.8 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Qwen2-7B-GGUF/resolve/main/Qwen2-7B.Q5_K_S.gguf) | Q5_K_S | 5.4 | |
| [GGUF](https://huggingface.co/mradermacher/Qwen2-7B-GGUF/resolve/main/Qwen2-7B.Q5_K_M.gguf) | Q5_K_M | 5.5 | |
| [GGUF](https://huggingface.co/mradermacher/Qwen2-7B-GGUF/resolve/main/Qwen2-7B.Q6_K.gguf) | Q6_K | 6.4 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/Qwen2-7B-GGUF/resolve/main/Qwen2-7B.Q8_0.gguf) | Q8_0 | 8.2 | fast, best quality |
| [GGUF](https://huggingface.co/mradermacher/Qwen2-7B-GGUF/resolve/main/Qwen2-7B.f16.gguf) | f16 | 15.3 | 16 bpw, overkill |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
Yntec/Jackpot | Yntec | 2024-01-02T18:26:17Z | 3,169 | 1 | diffusers | [
"diffusers",
"safetensors",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | 2023-12-21T06:07:48Z | ---
license: creativeml-openrail-m
library_name: diffusers
pipeline_tag: text-to-image
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
---
# Jackpot
Celebrating my first model that starts with J with a model with this hash:

Five sevens in a row! What other model has that? With a hash like that, who cares about the quality of the images this model produces? But I'll show you anyway...
WANT BETTER EYES FOR YOUR CHARACTERS? TRY TO SQUEE!!!: https://huggingface.co/Yntec/SQUEE
Samples and prompts:

(Click for larger)
Top left: Animated series in the style of Bruce Timm, pretty cute little girl as Maria Magdalena with black sunglasses smiling, dressed in a cassock, in a heroic and extravagant pose.
Top right: a Bear playing guitar in a club, whimsical
Bottom left: a painting of a stag by Bnhr, deer, nature, grass, tree, outdoors, forest, animal focus, antlers,
Bottom right: pretty cute little girl as Marie Antoinette playing on saxophone in bedroom

|
sagorsarker/bangla-bert-base | sagorsarker | 2023-07-21T15:56:25Z | 3,168 | 20 | transformers | [
"transformers",
"pytorch",
"tf",
"jax",
"safetensors",
"bert",
"fill-mask",
"bengali",
"bengali-lm",
"bangla",
"bn",
"dataset:common_crawl",
"dataset:wikipedia",
"dataset:oscar",
"arxiv:1810.04805",
"arxiv:2012.14353",
"arxiv:2104.08613",
"arxiv:2107.03844",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | fill-mask | 2022-03-02T23:29:05Z | ---
language: bn
tags:
- bert
- bengali
- bengali-lm
- bangla
license: mit
datasets:
- common_crawl
- wikipedia
- oscar
---
# Bangla BERT Base
A long way passed. Here is our **Bangla-Bert**! It is now available in huggingface model hub.
[Bangla-Bert-Base](https://github.com/sagorbrur/bangla-bert) is a pretrained language model of Bengali language using mask language modeling described in [BERT](https://arxiv.org/abs/1810.04805) and it's github [repository](https://github.com/google-research/bert)
## Pretrain Corpus Details
Corpus was downloaded from two main sources:
* Bengali commoncrawl corpus downloaded from [OSCAR](https://oscar-corpus.com/)
* [Bengali Wikipedia Dump Dataset](https://dumps.wikimedia.org/bnwiki/latest/)
After downloading these corpora, we preprocessed it as a Bert format. which is one sentence per line and an extra newline for new documents.
```
sentence 1
sentence 2
sentence 1
sentence 2
```
## Building Vocab
We used [BNLP](https://github.com/sagorbrur/bnlp) package for training bengali sentencepiece model with vocab size 102025. We preprocess the output vocab file as Bert format.
Our final vocab file availabe at [https://github.com/sagorbrur/bangla-bert](https://github.com/sagorbrur/bangla-bert) and also at [huggingface](https://huggingface.co/sagorsarker/bangla-bert-base) model hub.
## Training Details
* Bangla-Bert was trained with code provided in Google BERT's github repository (https://github.com/google-research/bert)
* Currently released model follows bert-base-uncased model architecture (12-layer, 768-hidden, 12-heads, 110M parameters)
* Total Training Steps: 1 Million
* The model was trained on a single Google Cloud GPU
## Evaluation Results
### LM Evaluation Results
After training 1 million steps here are the evaluation results.
```
global_step = 1000000
loss = 2.2406516
masked_lm_accuracy = 0.60641736
masked_lm_loss = 2.201459
next_sentence_accuracy = 0.98625
next_sentence_loss = 0.040997364
perplexity = numpy.exp(2.2406516) = 9.393331287442784
Loss for final step: 2.426227
```
### Downstream Task Evaluation Results
- Evaluation on Bengali Classification Benchmark Datasets
Huge Thanks to [Nick Doiron](https://twitter.com/mapmeld) for providing evaluation results of the classification task.
He used [Bengali Classification Benchmark](https://github.com/rezacsedu/Classification_Benchmarks_Benglai_NLP) datasets for the classification task.
Comparing to Nick's [Bengali electra](https://huggingface.co/monsoon-nlp/bangla-electra) and multi-lingual BERT, Bangla BERT Base achieves a state of the art result.
Here is the [evaluation script](https://github.com/sagorbrur/bangla-bert/blob/master/notebook/bangla-bert-evaluation-classification-task.ipynb).
| Model | Sentiment Analysis | Hate Speech Task | News Topic Task | Average |
| ----- | -------------------| ---------------- | --------------- | ------- |
| mBERT | 68.15 | 52.32 | 72.27 | 64.25 |
| Bengali Electra | 69.19 | 44.84 | 82.33 | 65.45 |
| Bangla BERT Base | 70.37 | 71.83 | 89.19 | 77.13 |
- Evaluation on [Wikiann](https://huggingface.co/datasets/wikiann) Datasets
We evaluated `Bangla-BERT-Base` with [Wikiann](https://huggingface.co/datasets/wikiann) Bengali NER datasets along with another benchmark three models(mBERT, XLM-R, Indic-BERT). </br>
`Bangla-BERT-Base` got a third-place where `mBERT` got first and `XML-R` got second place after training these models 5 epochs.
| Base Pre-trained Model | F1 Score | Accuracy |
| ----- | -------------------| ---------------- |
| [mBERT-uncased](https://huggingface.co/bert-base-multilingual-uncased) | 97.11 | 97.68 |
| [XLM-R](https://huggingface.co/xlm-roberta-base) | 96.22 | 97.03 |
| [Indic-BERT](https://huggingface.co/ai4bharat/indic-bert)| 92.66 | 94.74 |
| Bangla-BERT-Base | 95.57 | 97.49 |
All four model trained with [transformers-token-classification](https://colab.research.google.com/github/huggingface/notebooks/blob/master/examples/token_classification.ipynb) notebook.
You can find all models evaluation results [here](https://github.com/sagorbrur/bangla-bert/tree/master/evaluations/wikiann)
Also, you can check the below paper list. They used this model on their datasets.
* [DeepHateExplainer: Explainable Hate Speech Detection in Under-resourced Bengali Language](https://arxiv.org/abs/2012.14353)
* [Emotion Classification in a Resource Constrained Language Using Transformer-based Approach](https://arxiv.org/abs/2104.08613)
* [A Review of Bangla Natural Language Processing Tasks and the Utility of Transformer Models](https://arxiv.org/abs/2107.03844)
**NB: If you use this model for any NLP task please share evaluation results with us. We will add it here.**
## Limitations and Biases
## How to Use
**Bangla BERT Tokenizer**
```py
from transformers import AutoTokenizer, AutoModel
bnbert_tokenizer = AutoTokenizer.from_pretrained("sagorsarker/bangla-bert-base")
text = "আমি বাংলায় গান গাই।"
bnbert_tokenizer.tokenize(text)
# ['আমি', 'বাংলা', '##য', 'গান', 'গাই', '।']
```
**MASK Generation**
You can use this model directly with a pipeline for masked language modeling:
```py
from transformers import BertForMaskedLM, BertTokenizer, pipeline
model = BertForMaskedLM.from_pretrained("sagorsarker/bangla-bert-base")
tokenizer = BertTokenizer.from_pretrained("sagorsarker/bangla-bert-base")
nlp = pipeline('fill-mask', model=model, tokenizer=tokenizer)
for pred in nlp(f"আমি বাংলায় {nlp.tokenizer.mask_token} গাই।"):
print(pred)
# {'sequence': '[CLS] আমি বাংলায গান গাই । [SEP]', 'score': 0.13404667377471924, 'token': 2552, 'token_str': 'গান'}
```
## Author
[Sagor Sarker](https://github.com/sagorbrur)
## Reference
* https://github.com/google-research/bert
## Citation
If you find this model helpful, please cite.
```
@misc{Sagor_2020,
title = {BanglaBERT: Bengali Mask Language Model for Bengali Language Understanding},
author = {Sagor Sarker},
year = {2020},
url = {https://github.com/sagorbrur/bangla-bert}
}
```
|
mradermacher/Replete-Coder-Qwen2-1.5b-GGUF | mradermacher | 2024-06-25T07:31:53Z | 3,167 | 0 | transformers | [
"transformers",
"gguf",
"text-generation-inference",
"unsloth",
"qwen2",
"en",
"dataset:Replete-AI/code_bagel_hermes-2.5",
"dataset:Replete-AI/code_bagel",
"dataset:Replete-AI/OpenHermes-2.5-Uncensored",
"dataset:teknium/OpenHermes-2.5",
"dataset:layoric/tiny-codes-alpaca",
"dataset:glaiveai/glaive-code-assistant-v3",
"dataset:ajibawa-2023/Code-290k-ShareGPT",
"dataset:TIGER-Lab/MathInstruct",
"dataset:chargoddard/commitpack-ft-instruct-rated",
"dataset:iamturun/code_instructions_120k_alpaca",
"dataset:ise-uiuc/Magicoder-Evol-Instruct-110K",
"dataset:cognitivecomputations/dolphin-coder",
"dataset:nickrosh/Evol-Instruct-Code-80k-v1",
"dataset:coseal/CodeUltraFeedback_binarized",
"dataset:glaiveai/glaive-function-calling-v2",
"dataset:CyberNative/Code_Vulnerability_Security_DPO",
"dataset:jondurbin/airoboros-2.2",
"dataset:camel-ai",
"dataset:lmsys/lmsys-chat-1m",
"dataset:CollectiveCognition/chats-data-2023-09-22",
"dataset:CoT-Alpaca-GPT4",
"dataset:WizardLM/WizardLM_evol_instruct_70k",
"dataset:WizardLM/WizardLM_evol_instruct_V2_196k",
"dataset:teknium/GPT4-LLM-Cleaned",
"dataset:GPTeacher",
"dataset:OpenGPT",
"dataset:meta-math/MetaMathQA",
"dataset:Open-Orca/SlimOrca",
"dataset:garage-bAInd/Open-Platypus",
"dataset:anon8231489123/ShareGPT_Vicuna_unfiltered",
"dataset:Unnatural-Instructions-GPT4",
"base_model:Replete-AI/Replete-Coder-Qwen2-1.5b",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2024-06-25T03:02:08Z | ---
base_model: Replete-AI/Replete-Coder-Qwen2-1.5b
datasets:
- Replete-AI/code_bagel_hermes-2.5
- Replete-AI/code_bagel
- Replete-AI/OpenHermes-2.5-Uncensored
- teknium/OpenHermes-2.5
- layoric/tiny-codes-alpaca
- glaiveai/glaive-code-assistant-v3
- ajibawa-2023/Code-290k-ShareGPT
- TIGER-Lab/MathInstruct
- chargoddard/commitpack-ft-instruct-rated
- iamturun/code_instructions_120k_alpaca
- ise-uiuc/Magicoder-Evol-Instruct-110K
- cognitivecomputations/dolphin-coder
- nickrosh/Evol-Instruct-Code-80k-v1
- coseal/CodeUltraFeedback_binarized
- glaiveai/glaive-function-calling-v2
- CyberNative/Code_Vulnerability_Security_DPO
- jondurbin/airoboros-2.2
- camel-ai
- lmsys/lmsys-chat-1m
- CollectiveCognition/chats-data-2023-09-22
- CoT-Alpaca-GPT4
- WizardLM/WizardLM_evol_instruct_70k
- WizardLM/WizardLM_evol_instruct_V2_196k
- teknium/GPT4-LLM-Cleaned
- GPTeacher
- OpenGPT
- meta-math/MetaMathQA
- Open-Orca/SlimOrca
- garage-bAInd/Open-Platypus
- anon8231489123/ShareGPT_Vicuna_unfiltered
- Unnatural-Instructions-GPT4
language:
- en
library_name: transformers
license: apache-2.0
quantized_by: mradermacher
tags:
- text-generation-inference
- transformers
- unsloth
- qwen2
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
static quants of https://huggingface.co/Replete-AI/Replete-Coder-Qwen2-1.5b
<!-- provided-files -->
weighted/imatrix quants are available at https://huggingface.co/mradermacher/Replete-Coder-Qwen2-1.5b-i1-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/Replete-Coder-Qwen2-1.5b-GGUF/resolve/main/Replete-Coder-Qwen2-1.5b.Q2_K.gguf) | Q2_K | 0.8 | |
| [GGUF](https://huggingface.co/mradermacher/Replete-Coder-Qwen2-1.5b-GGUF/resolve/main/Replete-Coder-Qwen2-1.5b.IQ3_XS.gguf) | IQ3_XS | 0.8 | |
| [GGUF](https://huggingface.co/mradermacher/Replete-Coder-Qwen2-1.5b-GGUF/resolve/main/Replete-Coder-Qwen2-1.5b.Q3_K_S.gguf) | Q3_K_S | 0.9 | |
| [GGUF](https://huggingface.co/mradermacher/Replete-Coder-Qwen2-1.5b-GGUF/resolve/main/Replete-Coder-Qwen2-1.5b.IQ3_S.gguf) | IQ3_S | 0.9 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/Replete-Coder-Qwen2-1.5b-GGUF/resolve/main/Replete-Coder-Qwen2-1.5b.IQ3_M.gguf) | IQ3_M | 0.9 | |
| [GGUF](https://huggingface.co/mradermacher/Replete-Coder-Qwen2-1.5b-GGUF/resolve/main/Replete-Coder-Qwen2-1.5b.Q3_K_M.gguf) | Q3_K_M | 0.9 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/Replete-Coder-Qwen2-1.5b-GGUF/resolve/main/Replete-Coder-Qwen2-1.5b.Q3_K_L.gguf) | Q3_K_L | 1.0 | |
| [GGUF](https://huggingface.co/mradermacher/Replete-Coder-Qwen2-1.5b-GGUF/resolve/main/Replete-Coder-Qwen2-1.5b.IQ4_XS.gguf) | IQ4_XS | 1.0 | |
| [GGUF](https://huggingface.co/mradermacher/Replete-Coder-Qwen2-1.5b-GGUF/resolve/main/Replete-Coder-Qwen2-1.5b.Q4_K_S.gguf) | Q4_K_S | 1.0 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Replete-Coder-Qwen2-1.5b-GGUF/resolve/main/Replete-Coder-Qwen2-1.5b.Q4_K_M.gguf) | Q4_K_M | 1.1 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Replete-Coder-Qwen2-1.5b-GGUF/resolve/main/Replete-Coder-Qwen2-1.5b.Q5_K_S.gguf) | Q5_K_S | 1.2 | |
| [GGUF](https://huggingface.co/mradermacher/Replete-Coder-Qwen2-1.5b-GGUF/resolve/main/Replete-Coder-Qwen2-1.5b.Q5_K_M.gguf) | Q5_K_M | 1.2 | |
| [GGUF](https://huggingface.co/mradermacher/Replete-Coder-Qwen2-1.5b-GGUF/resolve/main/Replete-Coder-Qwen2-1.5b.Q6_K.gguf) | Q6_K | 1.4 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/Replete-Coder-Qwen2-1.5b-GGUF/resolve/main/Replete-Coder-Qwen2-1.5b.Q8_0.gguf) | Q8_0 | 1.7 | fast, best quality |
| [GGUF](https://huggingface.co/mradermacher/Replete-Coder-Qwen2-1.5b-GGUF/resolve/main/Replete-Coder-Qwen2-1.5b.f16.gguf) | f16 | 3.2 | 16 bpw, overkill |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
TheBloke/Llama-2-70B-fp16 | TheBloke | 2023-10-30T15:17:36Z | 3,166 | 46 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"facebook",
"meta",
"pytorch",
"llama-2",
"en",
"license:llama2",
"autotrain_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2023-07-19T02:21:20Z | ---
inference: false
language:
- en
license: llama2
model_type: llama
pipeline_tag: text-generation
tags:
- facebook
- meta
- pytorch
- llama
- llama-2
---
<!-- header start -->
<div style="width: 100%;">
<img src="https://i.imgur.com/EBdldam.jpg" alt="TheBlokeAI" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</div>
<div style="display: flex; justify-content: space-between; width: 100%;">
<div style="display: flex; flex-direction: column; align-items: flex-start;">
<p><a href="https://discord.gg/theblokeai">Chat & support: my new Discord server</a></p>
</div>
<div style="display: flex; flex-direction: column; align-items: flex-end;">
<p><a href="https://www.patreon.com/TheBlokeAI">Want to contribute? TheBloke's Patreon page</a></p>
</div>
</div>
<!-- header end -->
# Meta's Llama 2 70B fp16
These files are fp16 format model files for [Meta's Llama 2 70B](https://huggingface.co/meta-llama/Llama-2-70b-hf).
They were produced by downloading the PTH files from Meta, and then converting to HF format using the latest Transformers 4.32.0.dev0, from Git, with the Llama 2 PR included: https://github.com/huggingface/transformers/pull/24891.
Command to convert was:
```
python3 /workspace/venv/pytorch2/lib/python3.10/site-packages/transformers/models/llama/convert_llama_weights_to_hf.py --input_dir /workspace/git/llama/download --model_size 70B --output_dir /workspace/process/llama-2-70b-chat/source --safe_serialization true
```
The files were saved in Safetensors format.
I am uploading this repo because I initially tried to create GPTQs using the [MetaLlama 2 70B HF repo](https://huggingface.co/meta-llama/Llama-2-70b-hf), but got strange errors that suggested the weights were not correct. But converting from the PTH files using the latest `convert_llama_weights_to_hf.py` script worked fine.
Many thanks to William Beauchamp from [Chai](https://chai-research.com/) for providing the hardware for merging and uploading these files!
## Repositories available
* [GPTQ models for GPU inference, with multiple quantisation parameter options.](https://huggingface.co/TheBloke/Llama-2-70B-GPTQ)
* [Original unquantised fp16 model in pytorch format, for GPU inference and for further conversions](https://huggingface.co/meta-llama/Llama-2-70b-hf)
* [My fp16 conversion of the unquantised PTH model files](https://huggingface.co/TheBloke/Llama-2-70B-fp16)
## Prompt template: None
```
{prompt}
```
<!-- footer start -->
## Discord
For further support, and discussions on these models and AI in general, join us at:
[TheBloke AI's Discord server](https://discord.gg/theblokeai)
## Thanks, and how to contribute.
Thanks to the [chirper.ai](https://chirper.ai) team!
I've had a lot of people ask if they can contribute. I enjoy providing models and helping people, and would love to be able to spend even more time doing it, as well as expanding into new projects like fine tuning/training.
If you're able and willing to contribute it will be most gratefully received and will help me to keep providing more models, and to start work on new AI projects.
Donaters will get priority support on any and all AI/LLM/model questions and requests, access to a private Discord room, plus other benefits.
* Patreon: https://patreon.com/TheBlokeAI
* Ko-Fi: https://ko-fi.com/TheBlokeAI
**Special thanks to**: Luke from CarbonQuill, Aemon Algiz.
**Patreon special mentions**: Space Cruiser, Nikolai Manek, Sam, Chris McCloskey, Rishabh Srivastava, Kalila, Spiking Neurons AB, Khalefa Al-Ahmad, WelcomeToTheClub, Chadd, Lone Striker, Viktor Bowallius, Edmond Seymore, Ai Maven, Chris Smitley, Dave, Alexandros Triantafyllidis, Luke @flexchar, Elle, ya boyyy, Talal Aujan, Alex , Jonathan Leane, Deep Realms, Randy H, subjectnull, Preetika Verma, Joseph William Delisle, Michael Levine, chris gileta, K, Oscar Rangel, LangChain4j, Trenton Dambrowitz, Eugene Pentland, Johann-Peter Hartmann, Femi Adebogun, Illia Dulskyi, senxiiz, Daniel P. Andersen, Sean Connelly, Artur Olbinski, RoA, Mano Prime, Derek Yates, Raven Klaugh, David Flickinger, Willem Michiel, Pieter, Willian Hasse, vamX, Luke Pendergrass, webtim, Ghost , Rainer Wilmers, Nathan LeClaire, Will Dee, Cory Kujawski, John Detwiler, Fred von Graf, biorpg, Iucharbius , Imad Khwaja, Pierre Kircher, terasurfer , Asp the Wyvern, John Villwock, theTransient, zynix , Gabriel Tamborski, Fen Risland, Gabriel Puliatti, Matthew Berman, Pyrater, SuperWojo, Stephen Murray, Karl Bernard, Ajan Kanaga, Greatston Gnanesh, Junyu Yang.
Thank you to all my generous patrons and donaters!
<!-- footer end -->
# Original model card: Meta's Llama 2 70B
# **Llama 2**
Llama 2 is a collection of pretrained and fine-tuned generative text models ranging in scale from 7 billion to 70 billion parameters. This is the repository for the 70B pretrained model, converted for the Hugging Face Transformers format. Links to other models can be found in the index at the bottom.
## Model Details
*Note: Use of this model is governed by the Meta license. In order to download the model weights and tokenizer, please visit the [website](https://ai.meta.com/resources/models-and-libraries/llama-downloads/) and accept our License before requesting access here.*
Meta developed and publicly released the Llama 2 family of large language models (LLMs), a collection of pretrained and fine-tuned generative text models ranging in scale from 7 billion to 70 billion parameters. Our fine-tuned LLMs, called Llama-2-Chat, are optimized for dialogue use cases. Llama-2-Chat models outperform open-source chat models on most benchmarks we tested, and in our human evaluations for helpfulness and safety, are on par with some popular closed-source models like ChatGPT and PaLM.
**Model Developers** Meta
**Variations** Llama 2 comes in a range of parameter sizes — 7B, 13B, and 70B — as well as pretrained and fine-tuned variations.
**Input** Models input text only.
**Output** Models generate text only.
**Model Architecture** Llama 2 is an auto-regressive language model that uses an optimized transformer architecture. The tuned versions use supervised fine-tuning (SFT) and reinforcement learning with human feedback (RLHF) to align to human preferences for helpfulness and safety.
||Training Data|Params|Content Length|GQA|Tokens|LR|
|---|---|---|---|---|---|---|
|Llama 2|*A new mix of publicly available online data*|7B|4k|✗|2.0T|3.0 x 10<sup>-4</sup>|
|Llama 2|*A new mix of publicly available online data*|13B|4k|✗|2.0T|3.0 x 10<sup>-4</sup>|
|Llama 2|*A new mix of publicly available online data*|70B|4k|✔|2.0T|1.5 x 10<sup>-4</sup>|
*Llama 2 family of models.* Token counts refer to pretraining data only. All models are trained with a global batch-size of 4M tokens. Bigger models - 70B -- use Grouped-Query Attention (GQA) for improved inference scalability.
**Model Dates** Llama 2 was trained between January 2023 and July 2023.
**Status** This is a static model trained on an offline dataset. Future versions of the tuned models will be released as we improve model safety with community feedback.
**License** A custom commercial license is available at: [https://ai.meta.com/resources/models-and-libraries/llama-downloads/](https://ai.meta.com/resources/models-and-libraries/llama-downloads/)
## Intended Use
**Intended Use Cases** Llama 2 is intended for commercial and research use in English. Tuned models are intended for assistant-like chat, whereas pretrained models can be adapted for a variety of natural language generation tasks.
To get the expected features and performance for the chat versions, a specific formatting needs to be followed, including the `INST` and `<<SYS>>` tags, `BOS` and `EOS` tokens, and the whitespaces and breaklines in between (we recommend calling `strip()` on inputs to avoid double-spaces). See our reference code in github for details: [`chat_completion`](https://github.com/facebookresearch/llama/blob/main/llama/generation.py#L212).
**Out-of-scope Uses** Use in any manner that violates applicable laws or regulations (including trade compliance laws).Use in languages other than English. Use in any other way that is prohibited by the Acceptable Use Policy and Licensing Agreement for Llama 2.
## Hardware and Software
**Training Factors** We used custom training libraries, Meta's Research Super Cluster, and production clusters for pretraining. Fine-tuning, annotation, and evaluation were also performed on third-party cloud compute.
**Carbon Footprint** Pretraining utilized a cumulative 3.3M GPU hours of computation on hardware of type A100-80GB (TDP of 350-400W). Estimated total emissions were 539 tCO2eq, 100% of which were offset by Meta’s sustainability program.
||Time (GPU hours)|Power Consumption (W)|Carbon Emitted(tCO<sub>2</sub>eq)|
|---|---|---|---|
|Llama 2 7B|184320|400|31.22|
|Llama 2 13B|368640|400|62.44|
|Llama 2 70B|1720320|400|291.42|
|Total|3311616||539.00|
**CO<sub>2</sub> emissions during pretraining.** Time: total GPU time required for training each model. Power Consumption: peak power capacity per GPU device for the GPUs used adjusted for power usage efficiency. 100% of the emissions are directly offset by Meta's sustainability program, and because we are openly releasing these models, the pretraining costs do not need to be incurred by others.
## Training Data
**Overview** Llama 2 was pretrained on 2 trillion tokens of data from publicly available sources. The fine-tuning data includes publicly available instruction datasets, as well as over one million new human-annotated examples. Neither the pretraining nor the fine-tuning datasets include Meta user data.
**Data Freshness** The pretraining data has a cutoff of September 2022, but some tuning data is more recent, up to July 2023.
## Evaluation Results
In this section, we report the results for the Llama 1 and Llama 2 models on standard academic benchmarks.For all the evaluations, we use our internal evaluations library.
|Model|Size|Code|Commonsense Reasoning|World Knowledge|Reading Comprehension|Math|MMLU|BBH|AGI Eval|
|---|---|---|---|---|---|---|---|---|---|
|Llama 1|7B|14.1|60.8|46.2|58.5|6.95|35.1|30.3|23.9|
|Llama 1|13B|18.9|66.1|52.6|62.3|10.9|46.9|37.0|33.9|
|Llama 1|33B|26.0|70.0|58.4|67.6|21.4|57.8|39.8|41.7|
|Llama 1|65B|30.7|70.7|60.5|68.6|30.8|63.4|43.5|47.6|
|Llama 2|7B|16.8|63.9|48.9|61.3|14.6|45.3|32.6|29.3|
|Llama 2|13B|24.5|66.9|55.4|65.8|28.7|54.8|39.4|39.1|
|Llama 2|70B|**37.5**|**71.9**|**63.6**|**69.4**|**35.2**|**68.9**|**51.2**|**54.2**|
**Overall performance on grouped academic benchmarks.** *Code:* We report the average pass@1 scores of our models on HumanEval and MBPP. *Commonsense Reasoning:* We report the average of PIQA, SIQA, HellaSwag, WinoGrande, ARC easy and challenge, OpenBookQA, and CommonsenseQA. We report 7-shot results for CommonSenseQA and 0-shot results for all other benchmarks. *World Knowledge:* We evaluate the 5-shot performance on NaturalQuestions and TriviaQA and report the average. *Reading Comprehension:* For reading comprehension, we report the 0-shot average on SQuAD, QuAC, and BoolQ. *MATH:* We report the average of the GSM8K (8 shot) and MATH (4 shot) benchmarks at top 1.
|||TruthfulQA|Toxigen|
|---|---|---|---|
|Llama 1|7B|27.42|23.00|
|Llama 1|13B|41.74|23.08|
|Llama 1|33B|44.19|22.57|
|Llama 1|65B|48.71|21.77|
|Llama 2|7B|33.29|**21.25**|
|Llama 2|13B|41.86|26.10|
|Llama 2|70B|**50.18**|24.60|
**Evaluation of pretrained LLMs on automatic safety benchmarks.** For TruthfulQA, we present the percentage of generations that are both truthful and informative (the higher the better). For ToxiGen, we present the percentage of toxic generations (the smaller the better).
|||TruthfulQA|Toxigen|
|---|---|---|---|
|Llama-2-Chat|7B|57.04|**0.00**|
|Llama-2-Chat|13B|62.18|**0.00**|
|Llama-2-Chat|70B|**64.14**|0.01|
**Evaluation of fine-tuned LLMs on different safety datasets.** Same metric definitions as above.
## Ethical Considerations and Limitations
Llama 2 is a new technology that carries risks with use. Testing conducted to date has been in English, and has not covered, nor could it cover all scenarios. For these reasons, as with all LLMs, Llama 2’s potential outputs cannot be predicted in advance, and the model may in some instances produce inaccurate, biased or other objectionable responses to user prompts. Therefore, before deploying any applications of Llama 2, developers should perform safety testing and tuning tailored to their specific applications of the model.
Please see the Responsible Use Guide available at [https://ai.meta.com/llama/responsible-use-guide/](https://ai.meta.com/llama/responsible-use-guide)
## Reporting Issues
Please report any software “bug,” or other problems with the models through one of the following means:
- Reporting issues with the model: [github.com/facebookresearch/llama](http://github.com/facebookresearch/llama)
- Reporting problematic content generated by the model: [developers.facebook.com/llama_output_feedback](http://developers.facebook.com/llama_output_feedback)
- Reporting bugs and security concerns: [facebook.com/whitehat/info](http://facebook.com/whitehat/info)
## Llama Model Index
|Model|Llama2|Llama2-hf|Llama2-chat|Llama2-chat-hf|
|---|---|---|---|---|
|7B| [Link](https://huggingface.co/llamaste/Llama-2-7b) | [Link](https://huggingface.co/llamaste/Llama-2-7b-hf) | [Link](https://huggingface.co/llamaste/Llama-2-7b-chat) | [Link](https://huggingface.co/llamaste/Llama-2-7b-chat-hf)|
|13B| [Link](https://huggingface.co/llamaste/Llama-2-13b) | [Link](https://huggingface.co/llamaste/Llama-2-13b-hf) | [Link](https://huggingface.co/llamaste/Llama-2-13b-chat) | [Link](https://huggingface.co/llamaste/Llama-2-13b-hf)|
|70B| [Link](https://huggingface.co/llamaste/Llama-2-70b) | [Link](https://huggingface.co/llamaste/Llama-2-70b-hf) | [Link](https://huggingface.co/llamaste/Llama-2-70b-chat) | [Link](https://huggingface.co/llamaste/Llama-2-70b-hf)|
|
ssary/XLM-RoBERTa-German-sentiment | ssary | 2024-03-24T14:44:47Z | 3,166 | 7 | transformers | [
"transformers",
"pytorch",
"safetensors",
"xlm-roberta",
"text-classification",
"de",
"en",
"ar",
"fr",
"hi",
"it",
"pt",
"es",
"arxiv:2104.12250",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2024-01-22T16:41:18Z | ---
license: apache-2.0
language:
- de
- en
- ar
- fr
- hi
- it
- pt
- es
metrics:
- f1
library_name: transformers
widget:
- text: Warum sollte ich 5 Stunden auf den Zug warten?
- text: das Essen ist :)
- text: Erneuter Streik in der S-Bahn.
- text: انا لا احب هذا المكان.
- text: انا اعشق الاكل هنا
- text: This dorms is very small.
- text: I can stay here for the whole day.
- text: J'attends le train depuis 4 heures.
- text: मुझे समझ नहीं आता कि यह जगह ऐसी क्यों है।
- text: "Adoro le bevande qui"
- text: "Quiero volver aquí, es increíble."
---
# Model Name: XLM-RoBERTa-German-Sentiment
## Overview
XLM-RoBERTa-German-Sentiment model is designed to perform Sentiment Analysis for 8 Languages and more specifically German language.\
This model leverages the XLM-RoBERTa architecture, a choice inspired by the superior performance of Facebook's RoBERTa over Google's BERT across numerous benchmarks.\
The decision to use XLM-RoBERTa stems from its multilingual capabilities. Specifically tailored for the German language, this model has been fine-tuned on over 200,000 German-language sentiment analysis samples, more on the training of the model can be found in the [paper](https://drive.google.com/file/d/1xg7zbCPTS3lyKhQlA2S4b9UOYeIj5Pyt/view?usp=drive_link).\
The dataset utilized for training, available at [this GitHub repository](https://github.com/oliverguhr/german-sentiment-lib) this dataset is developed by Oliver Guhr, We extend our gratitude to him for making the dataset open source,the dataset was influential in refining the model's accuracy and responsiveness to the nuances of German sentiment.
Our model and finetuning is based on sentiment analysis model called xlm-t [https://arxiv.org/abs/2104.12250].
## Model Details
- **Architecture**: XLM-RoBERTa
- **Performance**: 87% Weighted F1 score .
- **Limitations**: The model is only train and tested on the German language, but can handle the other 8 languages with lower accuracy.
## How to Use
I have developed Python desktop application for the inference at my [repository](https://github.com/ssary/German-Sentiment-Analysis).\
To use this model, you need to install the Hugging Face Transformers library and PyTorch. You can do this using pip:
```bash
pip install torch transformers
```
```python
from transformers import AutoModelForSequenceClassification, AutoTokenizer
import torch
text = "Erneuter Streik in der S-Bahn"
model = AutoModelForSequenceClassification.from_pretrained('ssary/XLM-RoBERTa-German-sentiment')
tokenizer = AutoTokenizer.from_pretrained('ssary/XLM-RoBERTa-German-sentiment')
inputs = tokenizer(text, return_tensors="pt", truncation=True, max_length=512)
with torch.no_grad():
outputs = model(**inputs)
predictions = torch.nn.functional.softmax(outputs.logits, dim=-1)
sentiment_classes = ['negative', 'neutral', 'positive']
print(sentiment_classes[predictions.argmax()]) # for the class with highest probability
print(predictions) # for each class probability
```
## Acknowledgments
This model was developed by Sary Nasser at HTW-Berlin under supervision of Martin Steinicke.
## References
- Model's GitHub repository: [https://github.com/ssary/German-Sentiment-Analysis](https://github.com/ssary/German-Sentiment-Analysis)
- Oliver Guhr Dataset paper: [Training a Broad-Coverage German Sentiment Classification Model for Dialog
Systems](http://www.lrec-conf.org/proceedings/lrec2020/pdf/2020.lrec-1.202.pdf)
- Model architecture: [XLM-T: Multilingual Language Models in Twitter for Sentiment Analysis and Beyond
](https://arxiv.org/abs/2104.12250) |
nihil117/atuin_v.01 | nihil117 | 2024-06-21T13:35:24Z | 3,166 | 0 | transformers | [
"transformers",
"gguf",
"mistral",
"text-generation-inference",
"unsloth",
"en",
"base_model:unsloth/mistral-7b-v0.3-bnb-4bit",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2024-06-21T13:20:22Z | ---
base_model: unsloth/mistral-7b-v0.3-bnb-4bit
language:
- en
license: apache-2.0
tags:
- text-generation-inference
- transformers
- unsloth
- mistral
- gguf
---
# Uploaded model
- **Developed by:** nihil117
- **License:** apache-2.0
- **Finetuned from model :** unsloth/mistral-7b-v0.3-bnb-4bit
This mistral model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
stabilityai/stablelm-base-alpha-7b | stabilityai | 2023-10-19T04:59:17Z | 3,165 | 211 | transformers | [
"transformers",
"pytorch",
"gpt_neox",
"text-generation",
"causal-lm",
"en",
"license:cc-by-sa-4.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2023-04-11T05:55:14Z | ---
language:
- en
tags:
- causal-lm
license: cc-by-sa-4.0
---
# StableLM-Base-Alpha
📢 **DISCLAIMER**: The StableLM-Base-Alpha models have been superseded. Find the latest versions in the Stable LM Collection [here](https://huggingface.co/collections/stabilityai/stable-lm-650852cfd55dd4e15cdcb30a).
## Model Description
`StableLM-Base-Alpha` is a suite of 3B and 7B parameter decoder-only language models pre-trained on a diverse collection of English datasets with a sequence length of 4096 to push beyond the context window limitations of existing open-source language models.
## Usage
Get started generating text with `StableLM-Base-Alpha` by using the following code snippet:
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("StabilityAI/stablelm-base-alpha-7b")
model = AutoModelForCausalLM.from_pretrained("StabilityAI/stablelm-base-alpha-7b")
model.half().cuda()
inputs = tokenizer("What's your mood today?", return_tensors="pt").to("cuda")
tokens = model.generate(
**inputs,
max_new_tokens=64,
temperature=0.7,
do_sample=True,
)
print(tokenizer.decode(tokens[0], skip_special_tokens=True))
```
## Model Details
* **Developed by**: [Stability AI](https://stability.ai/)
* **Model type**: StableLM-Base-Alpha models are auto-regressive language models based on the NeoX transformer architecture.
* **Language(s)**: English
* **Library**: [GPT-NeoX](https://github.com/EleutherAI/gpt-neox)
* **License**: Base model checkpoints (`StableLM-Base-Alpha`) are licensed under the Creative Commons license ([CC BY-SA-4.0](https://creativecommons.org/licenses/by-sa/4.0/)). Under the license, you must give [credit](https://creativecommons.org/licenses/by/4.0/#) to Stability AI, provide a link to the license, and [indicate if changes were made](https://creativecommons.org/licenses/by/4.0/#). You may do so in any reasonable manner, but not in any way that suggests the Stability AI endorses you or your use.
* **Contact**: For questions and comments about the model, please email `[email protected]`
## Training
| Parameters | Hidden Size | Layers | Heads | Sequence Length |
|------------|-------------|--------|-------|-----------------|
| 3B | 4096 | 16 | 32 | 4096 |
| 7B | 6144 | 16 | 48 | 4096 |
### Training Dataset
`StableLM-Base-Alpha` is pre-trained on a new experimental dataset built atop [The Pile](https://huggingface.co/datasets/EleutherAI/the_pile) and is threes times larger at approximately 1.5T tokens.
### Training Procedure
Models are pre-trained on the aforementioned dataset in mixed-precision (FP16), optimized with Adam, and trained using the NeoX tokenizer with a vocabulary size of 50,257. We outline the complete hyperparameters choices in the project's [GitHub repository](https://github.com/Stability-AI/StableLM/blob/main/configs/stablelm-base-alpha-7b.yaml).
## Use and Limitations
### Intended Use
These models are intended to be used by all individuals as foundational models for application-specific fine-tuning without strict limitations on commercial use.
### Limitations and bias
The pre-training dataset may have contained offensive or inappropriate content even after applying data cleansing filters which can be reflected in the model generated text. We recommend users exercise reasonable caution when using these models in production systems. Do not use the models for any applications that may cause harm or distress to individuals or groups.
## Citations
```bibtext
@software{gpt-neox-library,
title = {{GPT-NeoX: Large Scale Autoregressive Language Modeling in PyTorch}},
author = {Andonian, Alex and Anthony, Quentin and Biderman, Stella and Black, Sid and Gali, Preetham and Gao, Leo and Hallahan, Eric and Levy-Kramer, Josh and Leahy, Connor and Nestler, Lucas and Parker, Kip and Pieler, Michael and Purohit, Shivanshu and Songz, Tri and Phil, Wang and Weinbach, Samuel},
url = {https://www.github.com/eleutherai/gpt-neox},
doi = {10.5281/zenodo.5879544},
month = {8},
year = {2021},
version = {0.0.1},
}
```
|
ClaudioItaly/Fimbulvetr-11B-v2.1-16K-Q4_K_M-GGUF | ClaudioItaly | 2024-06-30T13:08:21Z | 3,165 | 0 | null | [
"gguf",
"llama-cpp",
"gguf-my-repo",
"en",
"base_model:Sao10K/Fimbulvetr-11B-v2.1-16K",
"license:cc-by-nc-4.0",
"region:us"
] | null | 2024-06-30T13:07:51Z | ---
base_model: Sao10K/Fimbulvetr-11B-v2.1-16K
language:
- en
license: cc-by-nc-4.0
tags:
- llama-cpp
- gguf-my-repo
---
# ClaudioItaly/Fimbulvetr-11B-v2.1-16K-Q4_K_M-GGUF
This model was converted to GGUF format from [`Sao10K/Fimbulvetr-11B-v2.1-16K`](https://huggingface.co/Sao10K/Fimbulvetr-11B-v2.1-16K) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/Sao10K/Fimbulvetr-11B-v2.1-16K) for more details on the model.
## Use with llama.cpp
Install llama.cpp through brew (works on Mac and Linux)
```bash
brew install llama.cpp
```
Invoke the llama.cpp server or the CLI.
### CLI:
```bash
llama-cli --hf-repo ClaudioItaly/Fimbulvetr-11B-v2.1-16K-Q4_K_M-GGUF --hf-file fimbulvetr-11b-v2.1-16k-q4_k_m.gguf -p "The meaning to life and the universe is"
```
### Server:
```bash
llama-server --hf-repo ClaudioItaly/Fimbulvetr-11B-v2.1-16K-Q4_K_M-GGUF --hf-file fimbulvetr-11b-v2.1-16k-q4_k_m.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
Step 1: Clone llama.cpp from GitHub.
```
git clone https://github.com/ggerganov/llama.cpp
```
Step 2: Move into the llama.cpp folder and build it with `LLAMA_CURL=1` flag along with other hardware-specific flags (for ex: LLAMA_CUDA=1 for Nvidia GPUs on Linux).
```
cd llama.cpp && LLAMA_CURL=1 make
```
Step 3: Run inference through the main binary.
```
./llama-cli --hf-repo ClaudioItaly/Fimbulvetr-11B-v2.1-16K-Q4_K_M-GGUF --hf-file fimbulvetr-11b-v2.1-16k-q4_k_m.gguf -p "The meaning to life and the universe is"
```
or
```
./llama-server --hf-repo ClaudioItaly/Fimbulvetr-11B-v2.1-16K-Q4_K_M-GGUF --hf-file fimbulvetr-11b-v2.1-16k-q4_k_m.gguf -c 2048
```
|
indobenchmark/indobert-large-p2 | indobenchmark | 2021-05-19T20:28:22Z | 3,164 | 4 | transformers | [
"transformers",
"pytorch",
"tf",
"jax",
"bert",
"feature-extraction",
"indobert",
"indobenchmark",
"indonlu",
"id",
"dataset:Indo4B",
"arxiv:2009.05387",
"license:mit",
"text-embeddings-inference",
"region:us"
] | feature-extraction | 2022-03-02T23:29:05Z | ---
language: id
tags:
- indobert
- indobenchmark
- indonlu
license: mit
inference: false
datasets:
- Indo4B
---
# IndoBERT Large Model (phase2 - uncased)
[IndoBERT](https://arxiv.org/abs/2009.05387) is a state-of-the-art language model for Indonesian based on the BERT model. The pretrained model is trained using a masked language modeling (MLM) objective and next sentence prediction (NSP) objective.
## All Pre-trained Models
| Model | #params | Arch. | Training data |
|--------------------------------|--------------------------------|-------|-----------------------------------|
| `indobenchmark/indobert-base-p1` | 124.5M | Base | Indo4B (23.43 GB of text) |
| `indobenchmark/indobert-base-p2` | 124.5M | Base | Indo4B (23.43 GB of text) |
| `indobenchmark/indobert-large-p1` | 335.2M | Large | Indo4B (23.43 GB of text) |
| `indobenchmark/indobert-large-p2` | 335.2M | Large | Indo4B (23.43 GB of text) |
| `indobenchmark/indobert-lite-base-p1` | 11.7M | Base | Indo4B (23.43 GB of text) |
| `indobenchmark/indobert-lite-base-p2` | 11.7M | Base | Indo4B (23.43 GB of text) |
| `indobenchmark/indobert-lite-large-p1` | 17.7M | Large | Indo4B (23.43 GB of text) |
| `indobenchmark/indobert-lite-large-p2` | 17.7M | Large | Indo4B (23.43 GB of text) |
## How to use
### Load model and tokenizer
```python
from transformers import BertTokenizer, AutoModel
tokenizer = BertTokenizer.from_pretrained("indobenchmark/indobert-large-p2")
model = AutoModel.from_pretrained("indobenchmark/indobert-large-p2")
```
### Extract contextual representation
```python
x = torch.LongTensor(tokenizer.encode('aku adalah anak [MASK]')).view(1,-1)
print(x, model(x)[0].sum())
```
## Authors
<b>IndoBERT</b> was trained and evaluated by Bryan Wilie\*, Karissa Vincentio\*, Genta Indra Winata\*, Samuel Cahyawijaya\*, Xiaohong Li, Zhi Yuan Lim, Sidik Soleman, Rahmad Mahendra, Pascale Fung, Syafri Bahar, Ayu Purwarianti.
## Citation
If you use our work, please cite:
```bibtex
@inproceedings{wilie2020indonlu,
title={IndoNLU: Benchmark and Resources for Evaluating Indonesian Natural Language Understanding},
author={Bryan Wilie and Karissa Vincentio and Genta Indra Winata and Samuel Cahyawijaya and X. Li and Zhi Yuan Lim and S. Soleman and R. Mahendra and Pascale Fung and Syafri Bahar and A. Purwarianti},
booktitle={Proceedings of the 1st Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics and the 10th International Joint Conference on Natural Language Processing},
year={2020}
}
```
|
nvidia/segformer-b5-finetuned-cityscapes-1024-1024 | nvidia | 2022-08-09T11:29:37Z | 3,162 | 18 | transformers | [
"transformers",
"pytorch",
"tf",
"segformer",
"vision",
"image-segmentation",
"dataset:cityscapes",
"arxiv:2105.15203",
"license:other",
"endpoints_compatible",
"region:us"
] | image-segmentation | 2022-03-02T23:29:05Z | ---
license: other
tags:
- vision
- image-segmentation
datasets:
- cityscapes
widget:
- src: https://cdn-media.huggingface.co/Inference-API/Sample-results-on-the-Cityscapes-dataset-The-above-images-show-how-our-method-can-handle.png
example_title: Road
---
# SegFormer (b5-sized) model fine-tuned on CityScapes
SegFormer model fine-tuned on CityScapes at resolution 1024x1024. It was introduced in the paper [SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers](https://arxiv.org/abs/2105.15203) by Xie et al. and first released in [this repository](https://github.com/NVlabs/SegFormer).
Disclaimer: The team releasing SegFormer did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
SegFormer consists of a hierarchical Transformer encoder and a lightweight all-MLP decode head to achieve great results on semantic segmentation benchmarks such as ADE20K and Cityscapes. The hierarchical Transformer is first pre-trained on ImageNet-1k, after which a decode head is added and fine-tuned altogether on a downstream dataset.
## Intended uses & limitations
You can use the raw model for semantic segmentation. See the [model hub](https://huggingface.co/models?other=segformer) to look for fine-tuned versions on a task that interests you.
### How to use
Here is how to use this model to classify an image of the COCO 2017 dataset into one of the 1,000 ImageNet classes:
```python
from transformers import SegformerFeatureExtractor, SegformerForSemanticSegmentation
from PIL import Image
import requests
feature_extractor = SegformerFeatureExtractor.from_pretrained("nvidia/segformer-b5-finetuned-cityscapes-1024-1024")
model = SegformerForSemanticSegmentation.from_pretrained("nvidia/segformer-b5-finetuned-cityscapes-1024-1024")
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
inputs = feature_extractor(images=image, return_tensors="pt")
outputs = model(**inputs)
logits = outputs.logits # shape (batch_size, num_labels, height/4, width/4)
```
For more code examples, we refer to the [documentation](https://huggingface.co/transformers/model_doc/segformer.html#).
### License
The license for this model can be found [here](https://github.com/NVlabs/SegFormer/blob/master/LICENSE).
### BibTeX entry and citation info
```bibtex
@article{DBLP:journals/corr/abs-2105-15203,
author = {Enze Xie and
Wenhai Wang and
Zhiding Yu and
Anima Anandkumar and
Jose M. Alvarez and
Ping Luo},
title = {SegFormer: Simple and Efficient Design for Semantic Segmentation with
Transformers},
journal = {CoRR},
volume = {abs/2105.15203},
year = {2021},
url = {https://arxiv.org/abs/2105.15203},
eprinttype = {arXiv},
eprint = {2105.15203},
timestamp = {Wed, 02 Jun 2021 11:46:42 +0200},
biburl = {https://dblp.org/rec/journals/corr/abs-2105-15203.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
```
|
mradermacher/MyAlee-Qwen-Instruct-v2-16k-v1-GGUF | mradermacher | 2024-06-12T11:38:39Z | 3,162 | 0 | transformers | [
"transformers",
"gguf",
"generated_from_trainer",
"en",
"base_model:arcee-ai/MyAlee-Qwen-Instruct-v2-16k-v1",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2024-06-12T09:46:40Z | ---
base_model: arcee-ai/MyAlee-Qwen-Instruct-v2-16k-v1
language:
- en
library_name: transformers
license: apache-2.0
quantized_by: mradermacher
tags:
- generated_from_trainer
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
static quants of https://huggingface.co/arcee-ai/MyAlee-Qwen-Instruct-v2-16k-v1
<!-- provided-files -->
weighted/imatrix quants seem not to be available (by me) at this time. If they do not show up a week or so after the static ones, I have probably not planned for them. Feel free to request them by opening a Community Discussion.
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/MyAlee-Qwen-Instruct-v2-16k-v1-GGUF/resolve/main/MyAlee-Qwen-Instruct-v2-16k-v1.Q2_K.gguf) | Q2_K | 3.1 | |
| [GGUF](https://huggingface.co/mradermacher/MyAlee-Qwen-Instruct-v2-16k-v1-GGUF/resolve/main/MyAlee-Qwen-Instruct-v2-16k-v1.IQ3_XS.gguf) | IQ3_XS | 3.4 | |
| [GGUF](https://huggingface.co/mradermacher/MyAlee-Qwen-Instruct-v2-16k-v1-GGUF/resolve/main/MyAlee-Qwen-Instruct-v2-16k-v1.Q3_K_S.gguf) | Q3_K_S | 3.6 | |
| [GGUF](https://huggingface.co/mradermacher/MyAlee-Qwen-Instruct-v2-16k-v1-GGUF/resolve/main/MyAlee-Qwen-Instruct-v2-16k-v1.IQ3_S.gguf) | IQ3_S | 3.6 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/MyAlee-Qwen-Instruct-v2-16k-v1-GGUF/resolve/main/MyAlee-Qwen-Instruct-v2-16k-v1.IQ3_M.gguf) | IQ3_M | 3.7 | |
| [GGUF](https://huggingface.co/mradermacher/MyAlee-Qwen-Instruct-v2-16k-v1-GGUF/resolve/main/MyAlee-Qwen-Instruct-v2-16k-v1.Q3_K_M.gguf) | Q3_K_M | 3.9 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/MyAlee-Qwen-Instruct-v2-16k-v1-GGUF/resolve/main/MyAlee-Qwen-Instruct-v2-16k-v1.Q3_K_L.gguf) | Q3_K_L | 4.2 | |
| [GGUF](https://huggingface.co/mradermacher/MyAlee-Qwen-Instruct-v2-16k-v1-GGUF/resolve/main/MyAlee-Qwen-Instruct-v2-16k-v1.IQ4_XS.gguf) | IQ4_XS | 4.4 | |
| [GGUF](https://huggingface.co/mradermacher/MyAlee-Qwen-Instruct-v2-16k-v1-GGUF/resolve/main/MyAlee-Qwen-Instruct-v2-16k-v1.Q4_K_S.gguf) | Q4_K_S | 4.6 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/MyAlee-Qwen-Instruct-v2-16k-v1-GGUF/resolve/main/MyAlee-Qwen-Instruct-v2-16k-v1.Q4_K_M.gguf) | Q4_K_M | 4.8 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/MyAlee-Qwen-Instruct-v2-16k-v1-GGUF/resolve/main/MyAlee-Qwen-Instruct-v2-16k-v1.Q5_K_S.gguf) | Q5_K_S | 5.4 | |
| [GGUF](https://huggingface.co/mradermacher/MyAlee-Qwen-Instruct-v2-16k-v1-GGUF/resolve/main/MyAlee-Qwen-Instruct-v2-16k-v1.Q5_K_M.gguf) | Q5_K_M | 5.5 | |
| [GGUF](https://huggingface.co/mradermacher/MyAlee-Qwen-Instruct-v2-16k-v1-GGUF/resolve/main/MyAlee-Qwen-Instruct-v2-16k-v1.Q6_K.gguf) | Q6_K | 6.4 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/MyAlee-Qwen-Instruct-v2-16k-v1-GGUF/resolve/main/MyAlee-Qwen-Instruct-v2-16k-v1.Q8_0.gguf) | Q8_0 | 8.2 | fast, best quality |
| [GGUF](https://huggingface.co/mradermacher/MyAlee-Qwen-Instruct-v2-16k-v1-GGUF/resolve/main/MyAlee-Qwen-Instruct-v2-16k-v1.f16.gguf) | f16 | 15.3 | 16 bpw, overkill |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
gorilla-llm/gorilla-openfunctions-v2 | gorilla-llm | 2024-04-18T02:39:42Z | 3,160 | 179 | transformers | [
"transformers",
"pytorch",
"llama",
"text-generation",
"conversational",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2024-02-26T11:51:34Z | ---
license: apache-2.0
---
# Gorilla OpenFunctions v2
💡 SoTA for open-source models. On-par with GPT-4.
🚀 Check out the [Berkeley Function Calling Leaderboard](https://gorilla.cs.berkeley.edu/leaderboard)
📣 Read more in our [OpenFunctions v2 release blog](https://gorilla.cs.berkeley.edu/blogs/7_open_functions_v2.html) and [Berkeley Function Calling Leaderboard blog](https://gorilla.cs.berkeley.edu/blogs/8_berkeley_function_calling_leaderboard.html) \
🟢 Check out Quantized GGUF models in [gorilla-llm/gorilla-openfunctions-v2-gguf](https://huggingface.co/gorilla-llm/gorilla-openfunctions-v2-gguf)
## Introduction
Gorilla OpenFunctions extends Large Language Model(LLM) Chat Completion feature to formulate
executable APIs call given natural language instructions and API context. With OpenFunctions v2,
we now support:
1. Multiple functions - choose betwen functions
2. Parallel functions - call the same function `N` time with different parameter values
3. Multiple & parallel - both of the above in a single chatcompletion call (one generation)
4. Relevance detection - when chatting, chat. When asked for function, returns a function
5. Python - supports `string, number, boolean, list, tuple, dict` parameter datatypes and `Any` for those not natively supported.
6. JAVA - support for `byte, short, int, float, double, long, boolean, char, Array, ArrayList, Set, HashMap, Hashtable, Queue, Stack, and Any` datatypes.
7. JavaScript - support for `String, Number, Bigint, Boolean, dict (object), Array, Date, and Any` datatypes.
8. REST - native REST support
## Performance
| Model | Overall Accuracy* |
|---|---|
|GPT-4-0125-Preview | 85.12% |
|Gorilla-openfunctions-v2 | 83.67% |
|GPT-3.5-turbo | 82.23% |
|Mistral-medium | 79.70% |
|Nexusflow Raven-v2 | 55.72% |
|GPT-4-0613 | 54.16% |
*: Overall Accuracy is defined in [Berkeley Function Calling Leaderboard blog](https://gorilla.cs.berkeley.edu/blogs/8_berkeley_function_calling_leaderboard.html), read more details if you are interested!
## Models Available
|Model | Functionality|
|---|---|
|gorilla-openfunctions-v2 | Multiple, parallel, multiple & parallel, relevance detection, Python + JAVA + JS + REST|
|gorilla-openfunctions-v1 | Parallel functions, and can choose between functions|
|gorilla-openfunctions-v0 | Given a function, and user intent, returns properly formatted json with the right arguments|
All of our models are hosted on our Huggingface UC Berkeley gorilla-llm org: [gorilla-openfunctions-v2](https://huggingface.co/gorilla-llm/gorilla-openfunctions-v2), [gorilla-openfunctions-v1](https://huggingface.co/gorilla-llm/gorilla-openfunctions-v1), and [gorilla-openfunctions-v0](https://huggingface.co/gorilla-llm/gorilla-openfunctions-v0).
## Training
Gorilla Openfunctions v2 is a 7B parameter model, and is built on top of the [deepseek coder](https://huggingface.co/deepseek-ai/deepseek-coder-7b-instruct-v1.5) LLM. Check out [openfunctions-v2 blog](https://gorilla.cs.berkeley.edu/blogs/7_open_functions_v2.html) to learn more about the data composition and some insights into the training process.
## Example Usage (Hosted)
Please reference `README.md` in https://github.com/ShishirPatil/gorilla/tree/main/openfunctions for file dependencies and used utils.
1. OpenFunctions is compatible with OpenAI Functions
```bash
!pip install openai==0.28.1
```
2. Point to Gorilla hosted servers
```python
import openai
def get_gorilla_response(prompt="Call me an Uber ride type \"Plus\" in Berkeley at zipcode 94704 in 10 minutes", model="gorilla-openfunctions-v0", functions=[]):
openai.api_key = "EMPTY"
openai.api_base = "http://luigi.millennium.berkeley.edu:8000/v1"
try:
completion = openai.ChatCompletion.create(
model="gorilla-openfunctions-v2",
temperature=0.0,
messages=[{"role": "user", "content": prompt}],
functions=functions,
)
return completion.choices[0]
except Exception as e:
print(e, model, prompt)
```
3. Pass the user argument and set of functions, Gorilla OpenFunctions returns a fully formatted json
```python
query = "What's the weather like in the two cities of Boston and San Francisco?"
functions = [
{
"name": "get_current_weather",
"description": "Get the current weather in a given location",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "The city and state, e.g. San Francisco, CA",
},
"unit": {"type": "string", "enum": ["celsius", "fahrenheit"]},
},
"required": ["location"],
},
}
]
get_gorilla_response(query, functions=functions)
```
4. Expected output **NEW**
Gorilla returns a readily accessible string **AND** Open-AI compatible JSON.
```python
{
"index": 0,
"message": {
"role": "assistant",
"content": "get_current_weather(location='Boston, MA'), get_current_weather(location='San Francisco, CA')",
"function_call": [
{
"name": "get_current_weather",
"arguments": {
"location": "Boston, MA"
}
},
{
"name": "get_current_weather",
"arguments": {
"location": "San Francisco, CA"
}
}
]
},
"finish_reason": "stop"
}
```
We have retained the string functionality that our community loved from OpenFunctions v1 `get_current_weather(location='Boston, MA'), get_current_weather(location='San Francisco, CA')` above. And Notice the `function_call` key in the JSON to be OpenAI compatible.
This is possible in OpenFunctions v2, because we ensure that the output includes the name of the argument and not just the value. This enables us to parse the output into a JSON. In those scenarios where the output is not parsable into JSON, we will always return the function call string.
### End to End Example
Run the example code in `[inference_hosted.py](https://github.com/ShishirPatil/gorilla/tree/main/openfunctions)` to see how the model works.
```bash
python inference_hosted.py
```
Expected Output:
```bash
(.py3) shishir@dhcp-132-64:~/Work/Gorilla/openfunctions/$ python inference_hosted.py
--------------------
Function call strings(s): get_current_weather(location='Boston, MA'), get_current_weather(location='San Francisco, CA')
--------------------
OpenAI compatible `function_call`: [<OpenAIObject at 0x1139ba890> JSON:
{
"name": "get_current_weather",
"arguments":
{
"location": "Boston, MA"
}
}, <OpenAIObject at 0x1139ba930> JSON: {
"name": "get_current_weather",
"arguments":
{
"location": "San Francisco, CA"
}
}]
```
## Running OpenFunctions Locally
If you want to Run OpenFunctions locally, here is the prompt format that we used:
```python
def get_prompt(user_query: str, functions: list = []) -> str:
"""
Generates a conversation prompt based on the user's query and a list of functions.
Parameters:
- user_query (str): The user's query.
- functions (list): A list of functions to include in the prompt.
Returns:
- str: The formatted conversation prompt.
"""
system = "You are an AI programming assistant, utilizing the Gorilla LLM model, developed by Gorilla LLM, and you only answer questions related to computer science. For politically sensitive questions, security and privacy issues, and other non-computer science questions, you will refuse to answer."
if len(functions) == 0:
return f"{system}\n### Instruction: <<question>> {user_query}\n### Response: "
functions_string = json.dumps(functions)
return f"{system}\n### Instruction: <<function>>{functions_string}\n<<question>>{user_query}\n### Response: "
```
Further, here is how we format the response:
Install the dependencies with:
```bash
pip3 install tree_sitter
git clone https://github.com/tree-sitter/tree-sitter-java.git
git clone https://github.com/tree-sitter/tree-sitter-javascript.git
```
And you can use the following code to format the response:
```python
from openfunctions_utils import strip_function_calls, parse_function_call
def format_response(response: str):
"""
Formats the response from the OpenFunctions model.
Parameters:
- response (str): The response generated by the LLM.
Returns:
- str: The formatted response.
- dict: The function call(s) extracted from the response.
"""
function_call_dicts = None
try:
response = strip_function_calls(response)
# Parallel function calls returned as a str, list[dict]
if len(response) > 1:
function_call_dicts = []
for function_call in response:
function_call_dicts.append(parse_function_call(function_call))
response = ", ".join(response)
# Single function call returned as a str, dict
else:
function_call_dicts = parse_function_call(response[0])
response = response[0]
except Exception as e:
# Just faithfully return the generated response str to the user
pass
return response, function_call_dicts
```
In the current directory, run the example code in `inference_local.py` to see how the model works.
```bash
python inference_local.py
```
**Note:** Use the `get_prompt` and `format_response` only if you are hosting it Locally. If you are using the Berkeley hosted models through the Chat-completion API, we do this in the backend, so you don't have to do this. The model is supported in Hugging Face 🤗 Transformers and can be run up locally:
## License
Gorilla OpenFunctions v2 is distributed under the Apache 2.0 license. This software incorporates elements from the Deepseek model. Consequently, the licensing of Gorilla OpenFunctions v2 adheres to the Apache 2.0 license, with additional terms as outlined in [Appendix A](https://github.com/deepseek-ai/DeepSeek-LLM/blob/6712a86bfb7dd25c73383c5ad2eb7a8db540258b/LICENSE-MODEL) of the Deepseek license.
## Contributing
Gorilla is an open source effort from UC Berkeley and we welcome contributors.
Please email us your comments, criticism, and questions. More information about the project can be found at [https://gorilla.cs.berkeley.edu/](https://gorilla.cs.berkeley.edu/)
|
mradermacher/MyAlee-Mistral-Instruct-v2-32k-GGUF | mradermacher | 2024-06-04T06:43:30Z | 3,160 | 0 | transformers | [
"transformers",
"gguf",
"alignment-handbook",
"trl",
"sft",
"generated_from_trainer",
"en",
"dataset:arcee-ai/MyAlee-Education-Instructions-V1",
"base_model:arcee-ai/MyAlee-Mistral-Instruct-v2-32k",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2024-06-04T04:47:12Z | ---
base_model: arcee-ai/MyAlee-Mistral-Instruct-v2-32k
datasets:
- arcee-ai/MyAlee-Education-Instructions-V1
language:
- en
library_name: transformers
license: apache-2.0
quantized_by: mradermacher
tags:
- alignment-handbook
- trl
- sft
- generated_from_trainer
- trl
- sft
- generated_from_trainer
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
static quants of https://huggingface.co/arcee-ai/MyAlee-Mistral-Instruct-v2-32k
<!-- provided-files -->
weighted/imatrix quants seem not to be available (by me) at this time. If they do not show up a week or so after the static ones, I have probably not planned for them. Feel free to request them by opening a Community Discussion.
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/MyAlee-Mistral-Instruct-v2-32k-GGUF/resolve/main/MyAlee-Mistral-Instruct-v2-32k.Q2_K.gguf) | Q2_K | 2.8 | |
| [GGUF](https://huggingface.co/mradermacher/MyAlee-Mistral-Instruct-v2-32k-GGUF/resolve/main/MyAlee-Mistral-Instruct-v2-32k.IQ3_XS.gguf) | IQ3_XS | 3.1 | |
| [GGUF](https://huggingface.co/mradermacher/MyAlee-Mistral-Instruct-v2-32k-GGUF/resolve/main/MyAlee-Mistral-Instruct-v2-32k.Q3_K_S.gguf) | Q3_K_S | 3.3 | |
| [GGUF](https://huggingface.co/mradermacher/MyAlee-Mistral-Instruct-v2-32k-GGUF/resolve/main/MyAlee-Mistral-Instruct-v2-32k.IQ3_S.gguf) | IQ3_S | 3.3 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/MyAlee-Mistral-Instruct-v2-32k-GGUF/resolve/main/MyAlee-Mistral-Instruct-v2-32k.IQ3_M.gguf) | IQ3_M | 3.4 | |
| [GGUF](https://huggingface.co/mradermacher/MyAlee-Mistral-Instruct-v2-32k-GGUF/resolve/main/MyAlee-Mistral-Instruct-v2-32k.Q3_K_M.gguf) | Q3_K_M | 3.6 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/MyAlee-Mistral-Instruct-v2-32k-GGUF/resolve/main/MyAlee-Mistral-Instruct-v2-32k.Q3_K_L.gguf) | Q3_K_L | 3.9 | |
| [GGUF](https://huggingface.co/mradermacher/MyAlee-Mistral-Instruct-v2-32k-GGUF/resolve/main/MyAlee-Mistral-Instruct-v2-32k.IQ4_XS.gguf) | IQ4_XS | 4.0 | |
| [GGUF](https://huggingface.co/mradermacher/MyAlee-Mistral-Instruct-v2-32k-GGUF/resolve/main/MyAlee-Mistral-Instruct-v2-32k.Q4_K_S.gguf) | Q4_K_S | 4.2 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/MyAlee-Mistral-Instruct-v2-32k-GGUF/resolve/main/MyAlee-Mistral-Instruct-v2-32k.Q4_K_M.gguf) | Q4_K_M | 4.5 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/MyAlee-Mistral-Instruct-v2-32k-GGUF/resolve/main/MyAlee-Mistral-Instruct-v2-32k.Q5_K_S.gguf) | Q5_K_S | 5.1 | |
| [GGUF](https://huggingface.co/mradermacher/MyAlee-Mistral-Instruct-v2-32k-GGUF/resolve/main/MyAlee-Mistral-Instruct-v2-32k.Q5_K_M.gguf) | Q5_K_M | 5.2 | |
| [GGUF](https://huggingface.co/mradermacher/MyAlee-Mistral-Instruct-v2-32k-GGUF/resolve/main/MyAlee-Mistral-Instruct-v2-32k.Q6_K.gguf) | Q6_K | 6.0 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/MyAlee-Mistral-Instruct-v2-32k-GGUF/resolve/main/MyAlee-Mistral-Instruct-v2-32k.Q8_0.gguf) | Q8_0 | 7.8 | fast, best quality |
| [GGUF](https://huggingface.co/mradermacher/MyAlee-Mistral-Instruct-v2-32k-GGUF/resolve/main/MyAlee-Mistral-Instruct-v2-32k.f16.gguf) | f16 | 14.6 | 16 bpw, overkill |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
4bit/llava-v1.5-7b-5GB | 4bit | 2023-10-09T17:50:29Z | 3,158 | 4 | transformers | [
"transformers",
"pytorch",
"llava",
"text-generation",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-generation | 2023-10-09T17:48:12Z | Entry not found |
garage-bAInd/Platypus2-13B | garage-bAInd | 2024-01-03T21:27:12Z | 3,156 | 17 | transformers | [
"transformers",
"pytorch",
"safetensors",
"llama",
"text-generation",
"en",
"dataset:garage-bAInd/Open-Platypus",
"arxiv:2308.07317",
"arxiv:2307.09288",
"license:cc-by-nc-sa-4.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2023-08-05T00:12:12Z | ---
license: cc-by-nc-sa-4.0
language:
- en
datasets:
- garage-bAInd/Open-Platypus
---
# Platypus2-13B
Platypus-13B is an instruction fine-tuned model based on the LLaMA2-13B transformer architecture.

### Model Details
* **Trained by**: Cole Hunter & Ariel Lee
* **Model type:** **Platypus2-13B** is an auto-regressive language model based on the LLaMA2 transformer architecture.
* **Language(s)**: English
* **License for base weights**: Non-Commercial Creative Commons license ([CC BY-NC-4.0](https://creativecommons.org/licenses/by-nc/4.0/))
### Prompt Template
```
### Instruction:
<prompt> (without the <>)
### Response:
```
### Training Dataset
`garage-bAInd/Platypus2-13B` trained using STEM and logic based dataset [`garage-bAInd/Open-Platypus`](https://huggingface.co/datasets/garage-bAInd/Open-Platypus).
Please see our [paper](https://arxiv.org/abs/2308.07317) and [project webpage](https://platypus-llm.github.io) for additional information.
### Training Procedure
`garage-bAInd/Platypus2-13B` was instruction fine-tuned using LoRA on 1 A100 80GB. For training details and inference instructions please see the [Platypus2](https://github.com/arielnlee/Platypus) GitHub repo.
### Reproducing Evaluation Results
Install LM Evaluation Harness:
```
# clone repository
git clone https://github.com/EleutherAI/lm-evaluation-harness.git
# check out the correct commit
git checkout b281b0921b636bc36ad05c0b0b0763bd6dd43463
# change to repo directory
cd lm-evaluation-harness
# install
pip install -e .
```
Each task was evaluated on 1 A100 80GB GPU.
ARC:
```
python main.py --model hf-causal-experimental --model_args pretrained=garage-bAInd/Platypus2-13B --tasks arc_challenge --batch_size 1 --no_cache --write_out --output_path results/Platypus2-13B/arc_challenge_25shot.json --device cuda --num_fewshot 25
```
HellaSwag:
```
python main.py --model hf-causal-experimental --model_args pretrained=garage-bAInd/Platypus2-13B --tasks hellaswag --batch_size 1 --no_cache --write_out --output_path results/Platypus2-13B/hellaswag_10shot.json --device cuda --num_fewshot 10
```
MMLU:
```
python main.py --model hf-causal-experimental --model_args pretrained=garage-bAInd/Platypus2-13B --tasks hendrycksTest-* --batch_size 1 --no_cache --write_out --output_path results/Platypus2-13B/mmlu_5shot.json --device cuda --num_fewshot 5
```
TruthfulQA:
```
python main.py --model hf-causal-experimental --model_args pretrained=garage-bAInd/Platypus2-13B --tasks truthfulqa_mc --batch_size 1 --no_cache --write_out --output_path results/Platypus2-13B/truthfulqa_0shot.json --device cuda
```
### Limitations and bias
Llama 2 and fine-tuned variants are a new technology that carries risks with use. Testing conducted to date has been in English, and has not covered, nor could it cover all scenarios. For these reasons, as with all LLMs, Llama 2 and any fine-tuned varient's potential outputs cannot be predicted in advance, and the model may in some instances produce inaccurate, biased or other objectionable responses to user prompts. Therefore, before deploying any applications of Llama 2 variants, developers should perform safety testing and tuning tailored to their specific applications of the model.
Please see the Responsible Use Guide available at https://ai.meta.com/llama/responsible-use-guide/
### Citations
```bibtex
@article{platypus2023,
title={Platypus: Quick, Cheap, and Powerful Refinement of LLMs},
author={Ariel N. Lee and Cole J. Hunter and Nataniel Ruiz},
booktitle={arXiv preprint arxiv:2308.07317},
year={2023}
}
```
```bibtex
@misc{touvron2023llama,
title={Llama 2: Open Foundation and Fine-Tuned Chat Models},
author={Hugo Touvron and Louis Martin and Kevin Stone and Peter Albert and Amjad Almahairi and Yasmine Babaei and Nikolay Bashlykov year={2023},
eprint={2307.09288},
archivePrefix={arXiv},
}
```
```bibtex
@inproceedings{
hu2022lora,
title={Lo{RA}: Low-Rank Adaptation of Large Language Models},
author={Edward J Hu and Yelong Shen and Phillip Wallis and Zeyuan Allen-Zhu and Yuanzhi Li and Shean Wang and Lu Wang and Weizhu Chen},
booktitle={International Conference on Learning Representations},
year={2022},
url={https://openreview.net/forum?id=nZeVKeeFYf9}
}
```
# [Open LLM Leaderboard Evaluation Results](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)
Detailed results can be found [here](https://huggingface.co/datasets/open-llm-leaderboard/details_garage-bAInd__Platypus2-13B)
| Metric | Value |
|-----------------------|---------------------------|
| Avg. | 48.04 |
| ARC (25-shot) | 61.26 |
| HellaSwag (10-shot) | 82.56 |
| MMLU (5-shot) | 56.7 |
| TruthfulQA (0-shot) | 44.86 |
| Winogrande (5-shot) | 76.87 |
| GSM8K (5-shot) | 7.05 |
| DROP (3-shot) | 6.95 |
|
bclavie/JaColBERTv2 | bclavie | 2024-04-29T21:59:24Z | 3,156 | 12 | RAGatouille | [
"RAGatouille",
"safetensors",
"bert",
"ColBERT",
"sentence-similarity",
"ja",
"dataset:bclavie/mmarco-japanese-hard-negatives",
"dataset:unicamp-dl/mmarco",
"arxiv:2312.16144",
"arxiv:2310.19349",
"arxiv:2112.01488",
"base_model:cl-tohoku/bert-base-japanese-v3",
"license:mit",
"region:us"
] | sentence-similarity | 2024-03-02T18:34:41Z | ---
inference: false
datasets:
- bclavie/mmarco-japanese-hard-negatives
- unicamp-dl/mmarco
language:
- ja
pipeline_tag: sentence-similarity
tags:
- ColBERT
base_model:
- cl-tohoku/bert-base-japanese-v3
- bclavie/JaColBERT
license: mit
library_name: RAGatouille
---
First version of JaColBERTv2. Weights might be updated in the next few days.
Current early checkpoint is fully functional and outperforms multilingual-e5-large, BGE-M3 and JaColBERT in early results, but full evaluation TBD.# Intro
> There is currently no JaColBERTv2 technical report. For an overall idea, you can refer to the JaColBERTv1 [arXiv Report](https://arxiv.org/abs/2312.16144)
If you just want to check out how to use the model, please check out the [Usage section](#usage) below!
Welcome to JaColBERT version 2, the second release of JaColBERT, a Japanese-only document retrieval model based on [ColBERT](https://github.com/stanford-futuredata/ColBERT).
JaColBERTv2 is a model that offers very strong out-of-domain generalisation. Having been only trained on a single dataset (MMarco), it reaches state-of-the-art performance.
JaColBERTv2 was initialised off JaColBERTv1 and trained using knowledge distillation with 31 negative examples per positive example. It was trained for 250k steps using a batch size of 32.
The information on this model card is minimal and intends to give a quick overview! It'll be updated once benchmarking is complete and a longer report is available.
# Why use a ColBERT-like approach for your RAG application?
Most retrieval methods have strong tradeoffs:
* __Traditional sparse approaches__, such as BM25, are strong baselines, __but__ do not leverage any semantic understanding, and thus hit a hard ceiling.
* __Cross-encoder__ retriever methods are powerful, __but__ prohibitively expensive over large datasets: they must process the query against every single known document to be able to output scores.
* __Dense retrieval__ methods, using dense embeddings in vector databases, are lightweight and perform well, __but__ are __not__ data-efficient (they often require hundreds of millions if not billions of training examples pairs to reach state-of-the-art performance) and generalise poorly in a lot of cases. This makes sense: representing every single aspect of a document, to be able to match it to any potential query, into a single vector is an extremely hard problem.
ColBERT and its variants, including JaColBERTv2, aim to combine the best of all worlds: by representing the documents as essentially *bags-of-embeddings*, we obtain superior performance and strong out-of-domain generalisation at much lower compute cost than cross-encoders.
# Training
### Training Data
The model is trained on the japanese split of MMARCO. It uses ColBERTv2 style training, meaning the model uses knowledge distillation from a cross-encoder model. We use the same cross-encoder scores as the original English ColBERTv2 training (as MMarco is a translated dataset, these are more or less well mapped). These scores are available [here](https://huggingface.co/colbert-ir/colbertv2.0_msmarco_64way).
Unlike English ColBERTv2, we use nway=32 rather than nway=64, meaning that we provide the model with 31 negative examples per positive examples. Furthermore, we downsample the original sets of triplets from over 19 million to 8 million examples.
### Training Method
JColBERT is trained for a single epoch (1-pass over every triplet, meaning 250000 trainings teps) on 8 NVidia A100 40GB GPUs. Total training time was around 30 hours.
JColBERT is initialised from [JaColBERT](https://huggingface.co/bclavie/JaColBERT), which itselfs builds upon Tohoku University's excellent [bert-base-japanese-v3](https://huggingface.co/cl-tohoku/bert-base-japanese-v3). Our experiments benefitted strongly from Nagoya University's work on building [strong Japanese SimCSE models](https://arxiv.org/abs/2310.19349), among other work.
JaColBERT is trained with an overall batch size of 32 and a learning rate of 1e-5, and a warmup of 20000 steps. Limited exploration was performed but those defaults outperformed other experiments.
JaColBERT, as mentioned above, uses knowledge distillation using cross-encoder scores generated by a MiniLM cross-encoder on the English version of MS Marco. Please refer to the original [ColBERTv2 paper](https://arxiv.org/abs/2112.01488) for more information on this approach.
# Results
We present the first results, on two datasets: JQaRa, a passage retrieval task composed of questions and wikipedia passages containing the answer, and JSQuAD, the Japanese translation of SQuAD. (Further evaluations on MIRACL and TyDi are running, but fairly slow due to how long it takes to run e5-large and bge-m3.)
JaColBERTv2 reaches state-of-the-art results on both datasets, outperforming models with 5x more parameters.
| | | | JQaRa | | | | JSQuAD | | |
| ------------------- | --- | --------- | --------- | --------- | --------- | --- | --------- | --------- | --------- |
| | | NDCG@10 | MRR@10 | NDCG@100 | MRR@100 | | R@1 | R@5 | R@10 |
| JaColBERTv2 | | **0.585** | **0.836** | **0.753** | **0.838** | | **0.921** | **0.977** | **0.982** |
| JaColBERT | | 0.549 | 0.811 | 0.730 | 0.814 | | 0.913 | 0.972 | 0.978 |
| bge-m3+all | | 0.576 | 0.818 | 0.745 | 0.820 | | N/A | N/A | N/A |
| bg3-m3+dense | | 0.539 | 0.785 | 0.721 | 0.788 | | 0.850 | 0.959 | 0.976 |
| m-e5-large | | 0.554 | 0.799 | 0.731 | 0.801 | | 0.865 | 0.966 | 0.977 |
| m-e5-base | | 0.471 | 0.727 | 0.673 | 0.731 | | *0.838* | *0.955* | 0.973 |
| m-e5-small | | 0.492 | 0.729 | 0.689 | 0.733 | | *0.840* | *0.954* | 0.973 |
| GLuCoSE | | 0.308 | 0.518 | 0.564 | 0.527 | | 0.645 | 0.846 | 0.897 |
| sup-simcse-ja-base | | 0.324 | 0.541 | 0.572 | 0.550 | | 0.632 | 0.849 | 0.897 |
| sup-simcse-ja-large | | 0.356 | 0.575 | 0.596 | 0.583 | | 0.603 | 0.833 | 0.889 |
| fio-base-v0.1 | | 0.372 | 0.616 | 0.608 | 0.622 | | 0.700 | 0.879 | 0.924 |
| | | | | | | | | | |
# Usage
## Installation
JaColBERT works using ColBERT+RAGatouille. You can install it and all its necessary dependencies by running:
```sh
pip install -U ragatouille
```
For further examples on how to use RAGatouille with ColBERT models, you can check out the [`examples` section it the github repository](https://github.com/bclavie/RAGatouille/tree/main/examples).
Specifically, example 01 shows how to build/query an index, 04 shows how you can use JaColBERTv2 as a re-ranker, and 06 shows how to use JaColBERTv2 for in-memory searching rather than using an index.
Notably, RAGatouille has metadata support, so check the examples out if it's something you need!
## Encoding and querying documents without an index
If you want to use JaColBERTv2 without building an index, it's very simple, you just need to load the model, `encode()` some documents, and then `search_encoded_docs()`:
```python
from ragatouille import RAGPretrainedModel
RAG = RAGPretrainedModel.from_pretrained("bclavie/JaColBERTv2")
RAG.encode(['document_1', 'document_2', ...])
RAG.search_encoded_docs(query="your search query")
```
Subsequent calls to `encode()` will add to the existing in-memory collection. If you want to empty it, simply run `RAG.clear_encoded_docs()`.
## Indexing
In order for the late-interaction retrieval approach used by ColBERT to work, you must first build your index.
Think of it like using an embedding model, like e5, to embed all your documents and storing them in a vector database.
Indexing is the slowest step retrieval is extremely quick. There are some tricks to speed it up, but the default settings work fairly well:
```python
from ragatouille import RAGPretrainedModel
RAG = RAGPretrainedModel.from_pretrained("bclavie/JaColBERT")
documents = [ "マクドナルドのフライドポテトの少量のカロリーはいくつですか?マクドナルドの小さなフライドポテトのカロリーマクドナルドのウェブサイトには、次のように記載されています。フライドポテトの小さな注文で230カロリーケチャップで25カロリー、ケチャップパケットで15カロリー。",]
RAG.index(name="My_first_index", collection=documents)
```
The index files are stored, by default, at `.ragatouille/colbert/indexes/{index_name}`.
And that's it! Let it run, and your index and all its representations (compressed to 2bits by default) will have been generated.
## Searching
Once you have created an index, searching through it is just as simple! If you're in the same session and `RAG` is still loaded, you can directly search the newly created index.
Otherwise, you'll want to load it from disk:
```python
RAG = RAGPretrainedModel.from_index(".ragatouille/colbert/indexes/My_first_index")
```
And then query it:
```python
RAG.search(query="QUERY")
> [{'content': 'TEXT OF DOCUMENT ONE',
'score': float,
'rank': 1,
'document_id': str,
'document_metadata': dict},
{'content': 'TEXT OF DOCUMENT TWO',
'score': float,
'rank': 2,
'document_id': str,
'document_metadata': dict},
[...]
]
```
# Citation
If you'd like to cite this work, please cite the JaColBERT technical report:
```
@misc{clavié2023jacolbert,
title={JaColBERT and Hard Negatives, Towards Better Japanese-First Embeddings for Retrieval: Early Technical Report},
author={Benjamin Clavié},
year={2023},
eprint={2312.16144},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
``` |
mradermacher/GritLM-7B-KTO-GGUF | mradermacher | 2024-06-14T21:46:34Z | 3,156 | 0 | transformers | [
"transformers",
"gguf",
"en",
"dataset:GritLM/tulu2",
"base_model:GritLM/GritLM-7B-KTO",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2024-06-14T19:44:52Z | ---
base_model: GritLM/GritLM-7B-KTO
datasets:
- GritLM/tulu2
language:
- en
library_name: transformers
license: apache-2.0
quantized_by: mradermacher
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
static quants of https://huggingface.co/GritLM/GritLM-7B-KTO
<!-- provided-files -->
weighted/imatrix quants seem not to be available (by me) at this time. If they do not show up a week or so after the static ones, I have probably not planned for them. Feel free to request them by opening a Community Discussion.
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/GritLM-7B-KTO-GGUF/resolve/main/GritLM-7B-KTO.Q2_K.gguf) | Q2_K | 2.8 | |
| [GGUF](https://huggingface.co/mradermacher/GritLM-7B-KTO-GGUF/resolve/main/GritLM-7B-KTO.IQ3_XS.gguf) | IQ3_XS | 3.1 | |
| [GGUF](https://huggingface.co/mradermacher/GritLM-7B-KTO-GGUF/resolve/main/GritLM-7B-KTO.Q3_K_S.gguf) | Q3_K_S | 3.3 | |
| [GGUF](https://huggingface.co/mradermacher/GritLM-7B-KTO-GGUF/resolve/main/GritLM-7B-KTO.IQ3_S.gguf) | IQ3_S | 3.3 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/GritLM-7B-KTO-GGUF/resolve/main/GritLM-7B-KTO.IQ3_M.gguf) | IQ3_M | 3.4 | |
| [GGUF](https://huggingface.co/mradermacher/GritLM-7B-KTO-GGUF/resolve/main/GritLM-7B-KTO.Q3_K_M.gguf) | Q3_K_M | 3.6 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/GritLM-7B-KTO-GGUF/resolve/main/GritLM-7B-KTO.Q3_K_L.gguf) | Q3_K_L | 3.9 | |
| [GGUF](https://huggingface.co/mradermacher/GritLM-7B-KTO-GGUF/resolve/main/GritLM-7B-KTO.IQ4_XS.gguf) | IQ4_XS | 4.0 | |
| [GGUF](https://huggingface.co/mradermacher/GritLM-7B-KTO-GGUF/resolve/main/GritLM-7B-KTO.Q4_K_S.gguf) | Q4_K_S | 4.2 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/GritLM-7B-KTO-GGUF/resolve/main/GritLM-7B-KTO.Q4_K_M.gguf) | Q4_K_M | 4.5 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/GritLM-7B-KTO-GGUF/resolve/main/GritLM-7B-KTO.Q5_K_S.gguf) | Q5_K_S | 5.1 | |
| [GGUF](https://huggingface.co/mradermacher/GritLM-7B-KTO-GGUF/resolve/main/GritLM-7B-KTO.Q5_K_M.gguf) | Q5_K_M | 5.2 | |
| [GGUF](https://huggingface.co/mradermacher/GritLM-7B-KTO-GGUF/resolve/main/GritLM-7B-KTO.Q6_K.gguf) | Q6_K | 6.0 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/GritLM-7B-KTO-GGUF/resolve/main/GritLM-7B-KTO.Q8_0.gguf) | Q8_0 | 7.8 | fast, best quality |
| [GGUF](https://huggingface.co/mradermacher/GritLM-7B-KTO-GGUF/resolve/main/GritLM-7B-KTO.f16.gguf) | f16 | 14.6 | 16 bpw, overkill |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
TheBloke/dolphin-2.0-mistral-7B-GGUF | TheBloke | 2023-10-02T22:46:14Z | 3,155 | 47 | transformers | [
"transformers",
"gguf",
"mistral",
"en",
"dataset:ehartford/dolphin",
"dataset:jondurbin/airoboros-2.2.1",
"base_model:ehartford/dolphin-2.0-mistral-7b",
"license:apache-2.0",
"text-generation-inference",
"region:us"
] | null | 2023-10-02T22:27:21Z | ---
base_model: ehartford/dolphin-2.0-mistral-7b
datasets:
- ehartford/dolphin
- jondurbin/airoboros-2.2.1
inference: false
language:
- en
license: apache-2.0
model_creator: Eric Hartford
model_name: Dolphin 2.0 Mistral 7B
model_type: mistral
prompt_template: '<|im_start|>system
{system_message}<|im_end|>
<|im_start|>user
{prompt}<|im_end|>
<|im_start|>assistant
'
quantized_by: TheBloke
---
<!-- header start -->
<!-- 200823 -->
<div style="width: auto; margin-left: auto; margin-right: auto">
<img src="https://i.imgur.com/EBdldam.jpg" alt="TheBlokeAI" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</div>
<div style="display: flex; justify-content: space-between; width: 100%;">
<div style="display: flex; flex-direction: column; align-items: flex-start;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://discord.gg/theblokeai">Chat & support: TheBloke's Discord server</a></p>
</div>
<div style="display: flex; flex-direction: column; align-items: flex-end;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://www.patreon.com/TheBlokeAI">Want to contribute? TheBloke's Patreon page</a></p>
</div>
</div>
<div style="text-align:center; margin-top: 0em; margin-bottom: 0em"><p style="margin-top: 0.25em; margin-bottom: 0em;">TheBloke's LLM work is generously supported by a grant from <a href="https://a16z.com">andreessen horowitz (a16z)</a></p></div>
<hr style="margin-top: 1.0em; margin-bottom: 1.0em;">
<!-- header end -->
# Dolphin 2.0 Mistral 7B - GGUF
- Model creator: [Eric Hartford](https://huggingface.co/ehartford)
- Original model: [Dolphin 2.0 Mistral 7B](https://huggingface.co/ehartford/dolphin-2.0-mistral-7b)
<!-- description start -->
## Description
This repo contains GGUF format model files for [Eric Hartford's Dolphin 2.0 Mistral 7B](https://huggingface.co/ehartford/dolphin-2.0-mistral-7b).
<!-- description end -->
<!-- README_GGUF.md-about-gguf start -->
### About GGUF
GGUF is a new format introduced by the llama.cpp team on August 21st 2023. It is a replacement for GGML, which is no longer supported by llama.cpp.
Here is an incomplate list of clients and libraries that are known to support GGUF:
* [llama.cpp](https://github.com/ggerganov/llama.cpp). The source project for GGUF. Offers a CLI and a server option.
* [text-generation-webui](https://github.com/oobabooga/text-generation-webui), the most widely used web UI, with many features and powerful extensions. Supports GPU acceleration.
* [KoboldCpp](https://github.com/LostRuins/koboldcpp), a fully featured web UI, with GPU accel across all platforms and GPU architectures. Especially good for story telling.
* [LM Studio](https://lmstudio.ai/), an easy-to-use and powerful local GUI for Windows and macOS (Silicon), with GPU acceleration.
* [LoLLMS Web UI](https://github.com/ParisNeo/lollms-webui), a great web UI with many interesting and unique features, including a full model library for easy model selection.
* [Faraday.dev](https://faraday.dev/), an attractive and easy to use character-based chat GUI for Windows and macOS (both Silicon and Intel), with GPU acceleration.
* [ctransformers](https://github.com/marella/ctransformers), a Python library with GPU accel, LangChain support, and OpenAI-compatible AI server.
* [llama-cpp-python](https://github.com/abetlen/llama-cpp-python), a Python library with GPU accel, LangChain support, and OpenAI-compatible API server.
* [candle](https://github.com/huggingface/candle), a Rust ML framework with a focus on performance, including GPU support, and ease of use.
<!-- README_GGUF.md-about-gguf end -->
<!-- repositories-available start -->
## Repositories available
* [AWQ model(s) for GPU inference.](https://huggingface.co/TheBloke/dolphin-2.0-mistral-7B-AWQ)
* [GPTQ models for GPU inference, with multiple quantisation parameter options.](https://huggingface.co/TheBloke/dolphin-2.0-mistral-7B-GPTQ)
* [2, 3, 4, 5, 6 and 8-bit GGUF models for CPU+GPU inference](https://huggingface.co/TheBloke/dolphin-2.0-mistral-7B-GGUF)
* [Eric Hartford's original unquantised fp16 model in pytorch format, for GPU inference and for further conversions](https://huggingface.co/ehartford/dolphin-2.0-mistral-7b)
<!-- repositories-available end -->
<!-- prompt-template start -->
## Prompt template: ChatML
```
<|im_start|>system
{system_message}<|im_end|>
<|im_start|>user
{prompt}<|im_end|>
<|im_start|>assistant
```
<!-- prompt-template end -->
<!-- compatibility_gguf start -->
## Compatibility
These quantised GGUFv2 files are compatible with llama.cpp from August 27th onwards, as of commit [d0cee0d](https://github.com/ggerganov/llama.cpp/commit/d0cee0d36d5be95a0d9088b674dbb27354107221)
They are also compatible with many third party UIs and libraries - please see the list at the top of this README.
## Explanation of quantisation methods
<details>
<summary>Click to see details</summary>
The new methods available are:
* GGML_TYPE_Q2_K - "type-1" 2-bit quantization in super-blocks containing 16 blocks, each block having 16 weight. Block scales and mins are quantized with 4 bits. This ends up effectively using 2.5625 bits per weight (bpw)
* GGML_TYPE_Q3_K - "type-0" 3-bit quantization in super-blocks containing 16 blocks, each block having 16 weights. Scales are quantized with 6 bits. This end up using 3.4375 bpw.
* GGML_TYPE_Q4_K - "type-1" 4-bit quantization in super-blocks containing 8 blocks, each block having 32 weights. Scales and mins are quantized with 6 bits. This ends up using 4.5 bpw.
* GGML_TYPE_Q5_K - "type-1" 5-bit quantization. Same super-block structure as GGML_TYPE_Q4_K resulting in 5.5 bpw
* GGML_TYPE_Q6_K - "type-0" 6-bit quantization. Super-blocks with 16 blocks, each block having 16 weights. Scales are quantized with 8 bits. This ends up using 6.5625 bpw
Refer to the Provided Files table below to see what files use which methods, and how.
</details>
<!-- compatibility_gguf end -->
<!-- README_GGUF.md-provided-files start -->
## Provided files
| Name | Quant method | Bits | Size | Max RAM required | Use case |
| ---- | ---- | ---- | ---- | ---- | ----- |
| [dolphin-2.0-mistral-7b.Q2_K.gguf](https://huggingface.co/TheBloke/dolphin-2.0-mistral-7B-GGUF/blob/main/dolphin-2.0-mistral-7b.Q2_K.gguf) | Q2_K | 2 | 3.08 GB| 5.58 GB | smallest, significant quality loss - not recommended for most purposes |
| [dolphin-2.0-mistral-7b.Q3_K_S.gguf](https://huggingface.co/TheBloke/dolphin-2.0-mistral-7B-GGUF/blob/main/dolphin-2.0-mistral-7b.Q3_K_S.gguf) | Q3_K_S | 3 | 3.16 GB| 5.66 GB | very small, high quality loss |
| [dolphin-2.0-mistral-7b.Q3_K_M.gguf](https://huggingface.co/TheBloke/dolphin-2.0-mistral-7B-GGUF/blob/main/dolphin-2.0-mistral-7b.Q3_K_M.gguf) | Q3_K_M | 3 | 3.52 GB| 6.02 GB | very small, high quality loss |
| [dolphin-2.0-mistral-7b.Q3_K_L.gguf](https://huggingface.co/TheBloke/dolphin-2.0-mistral-7B-GGUF/blob/main/dolphin-2.0-mistral-7b.Q3_K_L.gguf) | Q3_K_L | 3 | 3.82 GB| 6.32 GB | small, substantial quality loss |
| [dolphin-2.0-mistral-7b.Q4_0.gguf](https://huggingface.co/TheBloke/dolphin-2.0-mistral-7B-GGUF/blob/main/dolphin-2.0-mistral-7b.Q4_0.gguf) | Q4_0 | 4 | 4.11 GB| 6.61 GB | legacy; small, very high quality loss - prefer using Q3_K_M |
| [dolphin-2.0-mistral-7b.Q4_K_S.gguf](https://huggingface.co/TheBloke/dolphin-2.0-mistral-7B-GGUF/blob/main/dolphin-2.0-mistral-7b.Q4_K_S.gguf) | Q4_K_S | 4 | 4.14 GB| 6.64 GB | small, greater quality loss |
| [dolphin-2.0-mistral-7b.Q4_K_M.gguf](https://huggingface.co/TheBloke/dolphin-2.0-mistral-7B-GGUF/blob/main/dolphin-2.0-mistral-7b.Q4_K_M.gguf) | Q4_K_M | 4 | 4.37 GB| 6.87 GB | medium, balanced quality - recommended |
| [dolphin-2.0-mistral-7b.Q5_0.gguf](https://huggingface.co/TheBloke/dolphin-2.0-mistral-7B-GGUF/blob/main/dolphin-2.0-mistral-7b.Q5_0.gguf) | Q5_0 | 5 | 5.00 GB| 7.50 GB | legacy; medium, balanced quality - prefer using Q4_K_M |
| [dolphin-2.0-mistral-7b.Q5_K_S.gguf](https://huggingface.co/TheBloke/dolphin-2.0-mistral-7B-GGUF/blob/main/dolphin-2.0-mistral-7b.Q5_K_S.gguf) | Q5_K_S | 5 | 5.00 GB| 7.50 GB | large, low quality loss - recommended |
| [dolphin-2.0-mistral-7b.Q5_K_M.gguf](https://huggingface.co/TheBloke/dolphin-2.0-mistral-7B-GGUF/blob/main/dolphin-2.0-mistral-7b.Q5_K_M.gguf) | Q5_K_M | 5 | 5.13 GB| 7.63 GB | large, very low quality loss - recommended |
| [dolphin-2.0-mistral-7b.Q6_K.gguf](https://huggingface.co/TheBloke/dolphin-2.0-mistral-7B-GGUF/blob/main/dolphin-2.0-mistral-7b.Q6_K.gguf) | Q6_K | 6 | 5.94 GB| 8.44 GB | very large, extremely low quality loss |
| [dolphin-2.0-mistral-7b.Q8_0.gguf](https://huggingface.co/TheBloke/dolphin-2.0-mistral-7B-GGUF/blob/main/dolphin-2.0-mistral-7b.Q8_0.gguf) | Q8_0 | 8 | 7.70 GB| 10.20 GB | very large, extremely low quality loss - not recommended |
**Note**: the above RAM figures assume no GPU offloading. If layers are offloaded to the GPU, this will reduce RAM usage and use VRAM instead.
<!-- README_GGUF.md-provided-files end -->
<!-- README_GGUF.md-how-to-download start -->
## How to download GGUF files
**Note for manual downloaders:** You almost never want to clone the entire repo! Multiple different quantisation formats are provided, and most users only want to pick and download a single file.
The following clients/libraries will automatically download models for you, providing a list of available models to choose from:
- LM Studio
- LoLLMS Web UI
- Faraday.dev
### In `text-generation-webui`
Under Download Model, you can enter the model repo: TheBloke/dolphin-2.0-mistral-7B-GGUF and below it, a specific filename to download, such as: dolphin-2.0-mistral-7b.Q4_K_M.gguf.
Then click Download.
### On the command line, including multiple files at once
I recommend using the `huggingface-hub` Python library:
```shell
pip3 install huggingface-hub
```
Then you can download any individual model file to the current directory, at high speed, with a command like this:
```shell
huggingface-cli download TheBloke/dolphin-2.0-mistral-7B-GGUF dolphin-2.0-mistral-7b.Q4_K_M.gguf --local-dir . --local-dir-use-symlinks False
```
<details>
<summary>More advanced huggingface-cli download usage</summary>
You can also download multiple files at once with a pattern:
```shell
huggingface-cli download TheBloke/dolphin-2.0-mistral-7B-GGUF --local-dir . --local-dir-use-symlinks False --include='*Q4_K*gguf'
```
For more documentation on downloading with `huggingface-cli`, please see: [HF -> Hub Python Library -> Download files -> Download from the CLI](https://huggingface.co/docs/huggingface_hub/guides/download#download-from-the-cli).
To accelerate downloads on fast connections (1Gbit/s or higher), install `hf_transfer`:
```shell
pip3 install hf_transfer
```
And set environment variable `HF_HUB_ENABLE_HF_TRANSFER` to `1`:
```shell
HF_HUB_ENABLE_HF_TRANSFER=1 huggingface-cli download TheBloke/dolphin-2.0-mistral-7B-GGUF dolphin-2.0-mistral-7b.Q4_K_M.gguf --local-dir . --local-dir-use-symlinks False
```
Windows Command Line users: You can set the environment variable by running `set HF_HUB_ENABLE_HF_TRANSFER=1` before the download command.
</details>
<!-- README_GGUF.md-how-to-download end -->
<!-- README_GGUF.md-how-to-run start -->
## Example `llama.cpp` command
Make sure you are using `llama.cpp` from commit [d0cee0d](https://github.com/ggerganov/llama.cpp/commit/d0cee0d36d5be95a0d9088b674dbb27354107221) or later.
```shell
./main -ngl 32 -m dolphin-2.0-mistral-7b.Q4_K_M.gguf --color -c 2048 --temp 0.7 --repeat_penalty 1.1 -n -1 -p "<|im_start|>system\n{system_message}<|im_end|>\n<|im_start|>user\n{prompt}<|im_end|>\n<|im_start|>assistant"
```
Change `-ngl 32` to the number of layers to offload to GPU. Remove it if you don't have GPU acceleration.
Change `-c 2048` to the desired sequence length. For extended sequence models - eg 8K, 16K, 32K - the necessary RoPE scaling parameters are read from the GGUF file and set by llama.cpp automatically.
If you want to have a chat-style conversation, replace the `-p <PROMPT>` argument with `-i -ins`
For other parameters and how to use them, please refer to [the llama.cpp documentation](https://github.com/ggerganov/llama.cpp/blob/master/examples/main/README.md)
## How to run in `text-generation-webui`
Further instructions here: [text-generation-webui/docs/llama.cpp.md](https://github.com/oobabooga/text-generation-webui/blob/main/docs/llama.cpp.md).
## How to run from Python code
You can use GGUF models from Python using the [llama-cpp-python](https://github.com/abetlen/llama-cpp-python) or [ctransformers](https://github.com/marella/ctransformers) libraries.
### How to load this model in Python code, using ctransformers
#### First install the package
Run one of the following commands, according to your system:
```shell
# Base ctransformers with no GPU acceleration
pip install ctransformers
# Or with CUDA GPU acceleration
pip install ctransformers[cuda]
# Or with AMD ROCm GPU acceleration (Linux only)
CT_HIPBLAS=1 pip install ctransformers --no-binary ctransformers
# Or with Metal GPU acceleration for macOS systems only
CT_METAL=1 pip install ctransformers --no-binary ctransformers
```
#### Simple ctransformers example code
```python
from ctransformers import AutoModelForCausalLM
# Set gpu_layers to the number of layers to offload to GPU. Set to 0 if no GPU acceleration is available on your system.
llm = AutoModelForCausalLM.from_pretrained("TheBloke/dolphin-2.0-mistral-7B-GGUF", model_file="dolphin-2.0-mistral-7b.Q4_K_M.gguf", model_type="mistral", gpu_layers=50)
print(llm("AI is going to"))
```
## How to use with LangChain
Here are guides on using llama-cpp-python and ctransformers with LangChain:
* [LangChain + llama-cpp-python](https://python.langchain.com/docs/integrations/llms/llamacpp)
* [LangChain + ctransformers](https://python.langchain.com/docs/integrations/providers/ctransformers)
<!-- README_GGUF.md-how-to-run end -->
<!-- footer start -->
<!-- 200823 -->
## Discord
For further support, and discussions on these models and AI in general, join us at:
[TheBloke AI's Discord server](https://discord.gg/theblokeai)
## Thanks, and how to contribute
Thanks to the [chirper.ai](https://chirper.ai) team!
Thanks to Clay from [gpus.llm-utils.org](llm-utils)!
I've had a lot of people ask if they can contribute. I enjoy providing models and helping people, and would love to be able to spend even more time doing it, as well as expanding into new projects like fine tuning/training.
If you're able and willing to contribute it will be most gratefully received and will help me to keep providing more models, and to start work on new AI projects.
Donaters will get priority support on any and all AI/LLM/model questions and requests, access to a private Discord room, plus other benefits.
* Patreon: https://patreon.com/TheBlokeAI
* Ko-Fi: https://ko-fi.com/TheBlokeAI
**Special thanks to**: Aemon Algiz.
**Patreon special mentions**: Pierre Kircher, Stanislav Ovsiannikov, Michael Levine, Eugene Pentland, Andrey, 준교 김, Randy H, Fred von Graf, Artur Olbinski, Caitlyn Gatomon, terasurfer, Jeff Scroggin, James Bentley, Vadim, Gabriel Puliatti, Harry Royden McLaughlin, Sean Connelly, Dan Guido, Edmond Seymore, Alicia Loh, subjectnull, AzureBlack, Manuel Alberto Morcote, Thomas Belote, Lone Striker, Chris Smitley, Vitor Caleffi, Johann-Peter Hartmann, Clay Pascal, biorpg, Brandon Frisco, sidney chen, transmissions 11, Pedro Madruga, jinyuan sun, Ajan Kanaga, Emad Mostaque, Trenton Dambrowitz, Jonathan Leane, Iucharbius, usrbinkat, vamX, George Stoitzev, Luke Pendergrass, theTransient, Olakabola, Swaroop Kallakuri, Cap'n Zoog, Brandon Phillips, Michael Dempsey, Nikolai Manek, danny, Matthew Berman, Gabriel Tamborski, alfie_i, Raymond Fosdick, Tom X Nguyen, Raven Klaugh, LangChain4j, Magnesian, Illia Dulskyi, David Ziegler, Mano Prime, Luis Javier Navarrete Lozano, Erik Bjäreholt, 阿明, Nathan Dryer, Alex, Rainer Wilmers, zynix, TL, Joseph William Delisle, John Villwock, Nathan LeClaire, Willem Michiel, Joguhyik, GodLy, OG, Alps Aficionado, Jeffrey Morgan, ReadyPlayerEmma, Tiffany J. Kim, Sebastain Graf, Spencer Kim, Michael Davis, webtim, Talal Aujan, knownsqashed, John Detwiler, Imad Khwaja, Deo Leter, Jerry Meng, Elijah Stavena, Rooh Singh, Pieter, SuperWojo, Alexandros Triantafyllidis, Stephen Murray, Ai Maven, ya boyyy, Enrico Ros, Ken Nordquist, Deep Realms, Nicholas, Spiking Neurons AB, Elle, Will Dee, Jack West, RoA, Luke @flexchar, Viktor Bowallius, Derek Yates, Subspace Studios, jjj, Toran Billups, Asp the Wyvern, Fen Risland, Ilya, NimbleBox.ai, Chadd, Nitin Borwankar, Emre, Mandus, Leonard Tan, Kalila, K, Trailburnt, S_X, Cory Kujawski
Thank you to all my generous patrons and donaters!
And thank you again to a16z for their generous grant.
<!-- footer end -->
<!-- original-model-card start -->
# Original model card: Eric Hartford's Dolphin 2.0 Mistral 7B
Dolphin 2.0 🐬
https://erichartford.com/dolphin
Dolphin-2.0-mistral-7b's training was sponsored by [a16z](https://a16z.com/supporting-the-open-source-ai-community/).
This model is based on mistralAI, so it is suitable for commercial or non-commercial use.
This model is uncensored. I have filtered the dataset to remove alignment and bias. This makes the model more compliant. You are advised to implement your own alignment layer before exposing the model as a service. It will be highly compliant to any requests, even unethical ones. Please read my blog post about uncensored models. https://erichartford.com/uncensored-models
You are responsible for any content you create using this model. Enjoy responsibly.
## Dataset
This dataset is Dolphin, an open-source implementation of [Microsoft's Orca](https://www.microsoft.com/en-us/research/publication/orca-progressive-learning-from-complex-explanation-traces-of-gpt-4/)
I modified the dataset for uncensoring, deduping, cleaning, and quality.
I added Jon Durbin's excellent Airoboros dataset to increase creativity.
## Training
It took 48 hours to train 10 epochs on 4x A100s.
Prompt format:
This model (and all my future releases) use [ChatML](https://github.com/openai/openai-python/blob/main/chatml.md) prompt format.
```
<|im_start|>system
You are Dolphin, a helpful AI assistant.<|im_end|>
<|im_start|>user
{prompt}<|im_end|>
```
Example:
```
<|im_start|>system
you are an expert dolphin trainer<|im_end|>
<|im_start|>user
What is the best way to train a dolphin to obey me? Please answer step by step.<|im_end|>
```
## Gratitude
- This model was made possible by the generous sponsorship of a16z.
- Thank you to Microsoft for authoring the Orca paper and inspiring this work.
- Special thanks to WingLian, and TheBloke for helpful advice
- Thank you to all the other people in the Open Source AI community who have taught me and helped me along the way.
## Example Output

[Buy me a coffee](https://www.buymeacoffee.com/ehartford)
<!-- original-model-card end -->
|
mradermacher/Mistral-7B-v0.3-GGUF | mradermacher | 2024-06-09T21:56:12Z | 3,155 | 0 | transformers | [
"transformers",
"gguf",
"en",
"base_model:mistralai/Mistral-7B-v0.3",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2024-06-09T21:30:26Z | ---
base_model: mistralai/Mistral-7B-v0.3
language:
- en
library_name: transformers
license: apache-2.0
quantized_by: mradermacher
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
static quants of https://huggingface.co/mistralai/Mistral-7B-v0.3
<!-- provided-files -->
weighted/imatrix quants are available at https://huggingface.co/mradermacher/Mistral-7B-v0.3-i1-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/Mistral-7B-v0.3-GGUF/resolve/main/Mistral-7B-v0.3.Q2_K.gguf) | Q2_K | 2.8 | |
| [GGUF](https://huggingface.co/mradermacher/Mistral-7B-v0.3-GGUF/resolve/main/Mistral-7B-v0.3.IQ3_XS.gguf) | IQ3_XS | 3.1 | |
| [GGUF](https://huggingface.co/mradermacher/Mistral-7B-v0.3-GGUF/resolve/main/Mistral-7B-v0.3.Q3_K_S.gguf) | Q3_K_S | 3.3 | |
| [GGUF](https://huggingface.co/mradermacher/Mistral-7B-v0.3-GGUF/resolve/main/Mistral-7B-v0.3.IQ3_S.gguf) | IQ3_S | 3.3 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/Mistral-7B-v0.3-GGUF/resolve/main/Mistral-7B-v0.3.IQ3_M.gguf) | IQ3_M | 3.4 | |
| [GGUF](https://huggingface.co/mradermacher/Mistral-7B-v0.3-GGUF/resolve/main/Mistral-7B-v0.3.Q3_K_M.gguf) | Q3_K_M | 3.6 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/Mistral-7B-v0.3-GGUF/resolve/main/Mistral-7B-v0.3.Q3_K_L.gguf) | Q3_K_L | 3.9 | |
| [GGUF](https://huggingface.co/mradermacher/Mistral-7B-v0.3-GGUF/resolve/main/Mistral-7B-v0.3.IQ4_XS.gguf) | IQ4_XS | 4.0 | |
| [GGUF](https://huggingface.co/mradermacher/Mistral-7B-v0.3-GGUF/resolve/main/Mistral-7B-v0.3.Q4_K_S.gguf) | Q4_K_S | 4.2 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Mistral-7B-v0.3-GGUF/resolve/main/Mistral-7B-v0.3.Q4_K_M.gguf) | Q4_K_M | 4.5 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Mistral-7B-v0.3-GGUF/resolve/main/Mistral-7B-v0.3.Q5_K_S.gguf) | Q5_K_S | 5.1 | |
| [GGUF](https://huggingface.co/mradermacher/Mistral-7B-v0.3-GGUF/resolve/main/Mistral-7B-v0.3.Q5_K_M.gguf) | Q5_K_M | 5.2 | |
| [GGUF](https://huggingface.co/mradermacher/Mistral-7B-v0.3-GGUF/resolve/main/Mistral-7B-v0.3.Q6_K.gguf) | Q6_K | 6.0 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/Mistral-7B-v0.3-GGUF/resolve/main/Mistral-7B-v0.3.Q8_0.gguf) | Q8_0 | 7.8 | fast, best quality |
| [GGUF](https://huggingface.co/mradermacher/Mistral-7B-v0.3-GGUF/resolve/main/Mistral-7B-v0.3.f16.gguf) | f16 | 14.6 | 16 bpw, overkill |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
GeneZC/MiniChat-1.5-3B | GeneZC | 2024-06-27T04:59:23Z | 3,154 | 32 | transformers | [
"transformers",
"pytorch",
"safetensors",
"llama",
"text-generation",
"conversational",
"en",
"zh",
"arxiv:2311.07052",
"arxiv:2310.05914",
"arxiv:2305.18290",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2023-11-26T03:37:49Z | ---
language:
- en
- zh
license: apache-2.0
library_name: transformers
widget:
- text: <s> [|User|] Hi 👋 </s>[|Assistant|]
model-index:
- name: MiniChat-1.5-3B
results:
- task:
type: text-generation
name: Text Generation
dataset:
name: AI2 Reasoning Challenge (25-Shot)
type: ai2_arc
config: ARC-Challenge
split: test
args:
num_few_shot: 25
metrics:
- type: acc_norm
value: 46.5
name: normalized accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=GeneZC/MiniChat-1.5-3B
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: HellaSwag (10-Shot)
type: hellaswag
split: validation
args:
num_few_shot: 10
metrics:
- type: acc_norm
value: 68.28
name: normalized accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=GeneZC/MiniChat-1.5-3B
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: MMLU (5-Shot)
type: cais/mmlu
config: all
split: test
args:
num_few_shot: 5
metrics:
- type: acc
value: 46.67
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=GeneZC/MiniChat-1.5-3B
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: TruthfulQA (0-shot)
type: truthful_qa
config: multiple_choice
split: validation
args:
num_few_shot: 0
metrics:
- type: mc2
value: 50.71
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=GeneZC/MiniChat-1.5-3B
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: Winogrande (5-shot)
type: winogrande
config: winogrande_xl
split: validation
args:
num_few_shot: 5
metrics:
- type: acc
value: 65.04
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=GeneZC/MiniChat-1.5-3B
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: GSM8k (5-shot)
type: gsm8k
config: main
split: test
args:
num_few_shot: 5
metrics:
- type: acc
value: 24.18
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=GeneZC/MiniChat-1.5-3B
name: Open LLM Leaderboard
---
## MiniChat-1.5-3B
📑 [arXiv](https://arxiv.org/abs/2311.07052) | 👻 [GitHub](https://github.com/GeneZC/MiniMA) | 🤗 [HuggingFace-MiniMA](https://huggingface.co/GeneZC/MiniMA-3B) | 🤗 [HuggingFace-MiniChat](https://huggingface.co/GeneZC/MiniChat-3B) | 🤗 [HuggingFace-MiniChat-1.5](https://huggingface.co/GeneZC/MiniChat-1.5-3B) | 🤖 [ModelScope-MiniMA](https://modelscope.cn/models/GeneZC/MiniMA-3B) | 🤖 [ModelScope-MiniChat](https://modelscope.cn/models/GeneZC/MiniChat-3B)
🆕 **Updates from MiniChat-3B**:
- better data mixture;
- use of [NEFTune](https://arxiv.org/abs/2310.05914);
- use of [DPO](https://arxiv.org/abs/2305.18290).
❗ Must comply with LICENSE of LLaMA2 since it is derived from LLaMA2.
A language model distilled and finetuned from an adapted version of LLaMA2-7B following "Towards the Law of Capacity Gap in Distilling Language Models".
Outperforming a wide range of 3B competitors in GPT4 evaluation and even competing with several 7B chat models.
<img src="./teaser_b.jpg" alt="teaser_b" width="687" />
The following is an example code snippet to use MiniChat-3B:
```python
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
from conversation import get_default_conv_template
# MiniChat
tokenizer = AutoTokenizer.from_pretrained("GeneZC/MiniChat-3B", use_fast=False)
# GPU.
model = AutoModelForCausalLM.from_pretrained("GeneZC/MiniChat-3B", use_cache=True, device_map="auto", torch_dtype=torch.float16).eval()
# CPU.
# model = AutoModelForCausalLM.from_pretrained("GeneZC/MiniChat-3B", use_cache=True, device_map="cpu", torch_dtype=torch.float16).eval()
conv = get_default_conv_template("minichat")
question = "Implement a program to find the common elements in two arrays without using any extra data structures."
conv.append_message(conv.roles[0], question)
conv.append_message(conv.roles[1], None)
prompt = conv.get_prompt()
input_ids = tokenizer([prompt]).input_ids
output_ids = model.generate(
torch.as_tensor(input_ids).cuda(),
do_sample=True,
temperature=0.7,
max_new_tokens=1024,
)
output_ids = output_ids[0][len(input_ids[0]):]
output = tokenizer.decode(output_ids, skip_special_tokens=True).strip()
# output: "def common_elements(arr1, arr2):\n if len(arr1) == 0:\n return []\n if len(arr2) == 0:\n return arr1\n\n common_elements = []\n for element in arr1:\n if element in arr2:\n common_elements.append(element)\n\n return common_elements"
# Multiturn conversation could be realized by continuously appending questions to `conv`.
```
## Bibtex
```bibtex
@article{zhang2023law,
title={Towards the Law of Capacity Gap in Distilling Language Models},
author={Zhang, Chen and Song, Dawei and Ye, Zheyu and Gao, Yan},
year={2023},
url={https://arxiv.org/abs/2311.07052}
}
```
# [Open LLM Leaderboard Evaluation Results](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)
Detailed results can be found [here](https://huggingface.co/datasets/open-llm-leaderboard/details_GeneZC__MiniChat-1.5-3B)
| Metric |Value|
|---------------------------------|----:|
|Avg. |50.23|
|AI2 Reasoning Challenge (25-Shot)|46.50|
|HellaSwag (10-Shot) |68.28|
|MMLU (5-Shot) |46.67|
|TruthfulQA (0-shot) |50.71|
|Winogrande (5-shot) |65.04|
|GSM8k (5-shot) |24.18|
|
roneneldan/TinyStories-8M | roneneldan | 2023-05-17T22:12:27Z | 3,153 | 5 | transformers | [
"transformers",
"pytorch",
"gpt_neo",
"text-generation",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-generation | 2023-05-12T21:47:48Z | Entry not found |
mradermacher/MyAlee-Mistral-Instruct-v2-32k-v3-GGUF | mradermacher | 2024-06-05T07:25:54Z | 3,153 | 0 | transformers | [
"transformers",
"gguf",
"alignment-handbook",
"trl",
"sft",
"generated_from_trainer",
"en",
"dataset:arcee-ai/MyAlee-Education-Instructions-V2",
"base_model:arcee-ai/MyAlee-Mistral-Instruct-v2-32k-v3",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2024-06-05T06:00:58Z | ---
base_model: arcee-ai/MyAlee-Mistral-Instruct-v2-32k-v3
datasets:
- arcee-ai/MyAlee-Education-Instructions-V2
language:
- en
library_name: transformers
license: apache-2.0
quantized_by: mradermacher
tags:
- alignment-handbook
- trl
- sft
- generated_from_trainer
- trl
- sft
- generated_from_trainer
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
static quants of https://huggingface.co/arcee-ai/MyAlee-Mistral-Instruct-v2-32k-v3
<!-- provided-files -->
weighted/imatrix quants are available at https://huggingface.co/mradermacher/MyAlee-Mistral-Instruct-v2-32k-v3-i1-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/MyAlee-Mistral-Instruct-v2-32k-v3-GGUF/resolve/main/MyAlee-Mistral-Instruct-v2-32k-v3.Q2_K.gguf) | Q2_K | 2.8 | |
| [GGUF](https://huggingface.co/mradermacher/MyAlee-Mistral-Instruct-v2-32k-v3-GGUF/resolve/main/MyAlee-Mistral-Instruct-v2-32k-v3.IQ3_XS.gguf) | IQ3_XS | 3.1 | |
| [GGUF](https://huggingface.co/mradermacher/MyAlee-Mistral-Instruct-v2-32k-v3-GGUF/resolve/main/MyAlee-Mistral-Instruct-v2-32k-v3.Q3_K_S.gguf) | Q3_K_S | 3.3 | |
| [GGUF](https://huggingface.co/mradermacher/MyAlee-Mistral-Instruct-v2-32k-v3-GGUF/resolve/main/MyAlee-Mistral-Instruct-v2-32k-v3.IQ3_S.gguf) | IQ3_S | 3.3 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/MyAlee-Mistral-Instruct-v2-32k-v3-GGUF/resolve/main/MyAlee-Mistral-Instruct-v2-32k-v3.IQ3_M.gguf) | IQ3_M | 3.4 | |
| [GGUF](https://huggingface.co/mradermacher/MyAlee-Mistral-Instruct-v2-32k-v3-GGUF/resolve/main/MyAlee-Mistral-Instruct-v2-32k-v3.Q3_K_M.gguf) | Q3_K_M | 3.6 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/MyAlee-Mistral-Instruct-v2-32k-v3-GGUF/resolve/main/MyAlee-Mistral-Instruct-v2-32k-v3.Q3_K_L.gguf) | Q3_K_L | 3.9 | |
| [GGUF](https://huggingface.co/mradermacher/MyAlee-Mistral-Instruct-v2-32k-v3-GGUF/resolve/main/MyAlee-Mistral-Instruct-v2-32k-v3.IQ4_XS.gguf) | IQ4_XS | 4.0 | |
| [GGUF](https://huggingface.co/mradermacher/MyAlee-Mistral-Instruct-v2-32k-v3-GGUF/resolve/main/MyAlee-Mistral-Instruct-v2-32k-v3.Q4_K_S.gguf) | Q4_K_S | 4.2 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/MyAlee-Mistral-Instruct-v2-32k-v3-GGUF/resolve/main/MyAlee-Mistral-Instruct-v2-32k-v3.Q4_K_M.gguf) | Q4_K_M | 4.5 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/MyAlee-Mistral-Instruct-v2-32k-v3-GGUF/resolve/main/MyAlee-Mistral-Instruct-v2-32k-v3.Q5_K_S.gguf) | Q5_K_S | 5.1 | |
| [GGUF](https://huggingface.co/mradermacher/MyAlee-Mistral-Instruct-v2-32k-v3-GGUF/resolve/main/MyAlee-Mistral-Instruct-v2-32k-v3.Q5_K_M.gguf) | Q5_K_M | 5.2 | |
| [GGUF](https://huggingface.co/mradermacher/MyAlee-Mistral-Instruct-v2-32k-v3-GGUF/resolve/main/MyAlee-Mistral-Instruct-v2-32k-v3.Q6_K.gguf) | Q6_K | 6.0 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/MyAlee-Mistral-Instruct-v2-32k-v3-GGUF/resolve/main/MyAlee-Mistral-Instruct-v2-32k-v3.Q8_0.gguf) | Q8_0 | 7.8 | fast, best quality |
| [GGUF](https://huggingface.co/mradermacher/MyAlee-Mistral-Instruct-v2-32k-v3-GGUF/resolve/main/MyAlee-Mistral-Instruct-v2-32k-v3.f16.gguf) | f16 | 14.6 | 16 bpw, overkill |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
rinna/japanese-gpt2-xsmall | rinna | 2024-04-03T07:10:43Z | 3,152 | 14 | transformers | [
"transformers",
"pytorch",
"tf",
"safetensors",
"gpt2",
"text-generation",
"ja",
"japanese",
"lm",
"nlp",
"dataset:cc100",
"dataset:wikipedia",
"arxiv:2404.01657",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2022-03-02T23:29:05Z | ---
language: ja
thumbnail: https://github.com/rinnakk/japanese-gpt2/blob/master/rinna.png
tags:
- ja
- japanese
- gpt2
- text-generation
- lm
- nlp
license: mit
datasets:
- cc100
- wikipedia
widget:
- text: "生命、宇宙、そして万物についての究極の疑問の答えは"
---
# japanese-gpt2-xsmall

This repository provides an extra-small-sized Japanese GPT-2 model. The model was trained using code from Github repository [rinnakk/japanese-pretrained-models](https://github.com/rinnakk/japanese-pretrained-models) by [rinna Co., Ltd.](https://corp.rinna.co.jp/)
# How to use the model
~~~~
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("rinna/japanese-gpt2-xsmall", use_fast=False)
tokenizer.do_lower_case = True # due to some bug of tokenizer config loading
model = AutoModelForCausalLM.from_pretrained("rinna/japanese-gpt2-xsmall")
~~~~
# Model architecture
A 6-layer, 512-hidden-size transformer-based language model.
# Training
The model was trained on [Japanese CC-100](http://data.statmt.org/cc-100/ja.txt.xz) and [Japanese Wikipedia](https://dumps.wikimedia.org/other/cirrussearch) to optimize a traditional language modelling objective on 8\\*V100 GPUs for around 4 days. It reaches around 28 perplexity on a chosen validation set from CC-100.
# Tokenization
The model uses a [sentencepiece](https://github.com/google/sentencepiece)-based tokenizer, the vocabulary was trained on the Japanese Wikipedia using the official sentencepiece training script.
# How to cite
~~~
@misc{rinna-japanese-gpt2-xsmall,
title = {rinna/japanese-gpt2-xsmall},
author = {Zhao, Tianyu and Sawada, Kei}
url = {https://huggingface.co/rinna/japanese-gpt2-xsmall},
}
@inproceedings{sawada2024release,
title = {Release of Pre-Trained Models for the {J}apanese Language},
author = {Sawada, Kei and Zhao, Tianyu and Shing, Makoto and Mitsui, Kentaro and Kaga, Akio and Hono, Yukiya and Wakatsuki, Toshiaki and Mitsuda, Koh},
booktitle = {Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024)},
month = {5},
year = {2024},
url = {https://arxiv.org/abs/2404.01657},
}
~~~
# Licenese
[The MIT license](https://opensource.org/licenses/MIT)
|
cointegrated/SONAR_200_text_encoder | cointegrated | 2024-01-25T23:39:22Z | 3,151 | 4 | transformers | [
"transformers",
"pytorch",
"m2m_100",
"sentence-similarity",
"ace",
"acm",
"acq",
"aeb",
"af",
"ajp",
"ak",
"am",
"apc",
"ar",
"ars",
"ary",
"arz",
"as",
"ast",
"awa",
"ay",
"azb",
"azj",
"ba",
"bm",
"ban",
"be",
"bem",
"bn",
"bho",
"bjn",
"bo",
"bs",
"bug",
"bg",
"ca",
"ceb",
"cs",
"cjk",
"ckb",
"crh",
"cy",
"da",
"de",
"dik",
"dyu",
"dz",
"el",
"en",
"eo",
"et",
"eu",
"ee",
"fo",
"fa",
"fj",
"fi",
"fon",
"fr",
"fur",
"ff",
"gd",
"ga",
"gl",
"gn",
"gu",
"ht",
"ha",
"he",
"hi",
"hne",
"hr",
"hu",
"hy",
"ig",
"ilo",
"id",
"is",
"it",
"jv",
"ja",
"kab",
"kac",
"kam",
"kn",
"ks",
"ka",
"kr",
"kk",
"kbp",
"kea",
"km",
"ki",
"rw",
"ky",
"kmb",
"kg",
"ko",
"kmr",
"lo",
"lv",
"lij",
"li",
"ln",
"lt",
"lmo",
"ltg",
"lb",
"lua",
"lg",
"luo",
"lus",
"mag",
"mai",
"ml",
"mr",
"min",
"mk",
"plt",
"mt",
"mni",
"mn",
"mos",
"mi",
"ms",
"my",
"nl",
"nn",
"nb",
"ne",
"nso",
"nus",
"ny",
"oc",
"gaz",
"ory",
"pag",
"pa",
"pap",
"pl",
"pt",
"prs",
"pbt",
"qu",
"ro",
"rn",
"ru",
"sg",
"sa",
"sat",
"scn",
"shn",
"si",
"sk",
"sl",
"sm",
"sn",
"sd",
"so",
"st",
"es",
"als",
"sc",
"sr",
"ss",
"su",
"sv",
"sw",
"szl",
"ta",
"tt",
"te",
"tg",
"tl",
"th",
"ti",
"taq",
"tpi",
"tn",
"ts",
"tk",
"tum",
"tr",
"tw",
"tzm",
"ug",
"uk",
"umb",
"ur",
"uz",
"vec",
"vi",
"war",
"wo",
"xh",
"yi",
"yo",
"yue",
"zh",
"zu",
"license:cc-by-nc-4.0",
"endpoints_compatible",
"region:us"
] | sentence-similarity | 2023-10-24T21:21:44Z | ---
license: cc-by-nc-4.0
language:
- ace
- ace
- acm
- acq
- aeb
- af
- ajp
- ak
- am
- apc
- ar
- ars
- ary
- arz
- as
- ast
- awa
- ay
- azb
- azj
- ba
- bm
- ban
- be
- bem
- bn
- bho
- bjn
- bjn
- bo
- bs
- bug
- bg
- ca
- ceb
- cs
- cjk
- ckb
- crh
- cy
- da
- de
- dik
- dyu
- dz
- el
- en
- eo
- et
- eu
- ee
- fo
- fa
- fj
- fi
- fon
- fr
- fur
- ff
- gd
- ga
- gl
- gn
- gu
- ht
- ha
- he
- hi
- hne
- hr
- hu
- hy
- ig
- ilo
- id
- is
- it
- jv
- ja
- kab
- kac
- kam
- kn
- ks
- ks
- ka
- kr
- kr
- kk
- kbp
- kea
- km
- ki
- rw
- ky
- kmb
- kg
- ko
- kmr
- lo
- lv
- lij
- li
- ln
- lt
- lmo
- ltg
- lb
- lua
- lg
- luo
- lus
- mag
- mai
- ml
- mr
- min
- mk
- plt
- mt
- mni
- mn
- mos
- mi
- ms
- my
- nl
- nn
- nb
- ne
- nso
- nus
- ny
- oc
- gaz
- ory
- pag
- pa
- pap
- pl
- pt
- prs
- pbt
- qu
- ro
- rn
- ru
- sg
- sa
- sat
- scn
- shn
- si
- sk
- sl
- sm
- sn
- sd
- so
- st
- es
- als
- sc
- sr
- ss
- su
- sv
- sw
- szl
- ta
- tt
- te
- tg
- tl
- th
- ti
- taq
- taq
- tpi
- tn
- ts
- tk
- tum
- tr
- tw
- tzm
- ug
- uk
- umb
- ur
- uz
- vec
- vi
- war
- wo
- xh
- yi
- yo
- yue
- zh
- zh
- zu
language_details: >-
ace_Arab, ace_Latn, acm_Arab, acq_Arab, aeb_Arab, afr_Latn, ajp_Arab,
aka_Latn, amh_Ethi, apc_Arab, arb_Arab, ars_Arab, ary_Arab, arz_Arab,
asm_Beng, ast_Latn, awa_Deva, ayr_Latn, azb_Arab, azj_Latn, bak_Cyrl,
bam_Latn, ban_Latn,bel_Cyrl, bem_Latn, ben_Beng, bho_Deva, bjn_Arab, bjn_Latn,
bod_Tibt, bos_Latn, bug_Latn, bul_Cyrl, cat_Latn, ceb_Latn, ces_Latn,
cjk_Latn, ckb_Arab, crh_Latn, cym_Latn, dan_Latn, deu_Latn, dik_Latn,
dyu_Latn, dzo_Tibt, ell_Grek, eng_Latn, epo_Latn, est_Latn, eus_Latn,
ewe_Latn, fao_Latn, pes_Arab, fij_Latn, fin_Latn, fon_Latn, fra_Latn,
fur_Latn, fuv_Latn, gla_Latn, gle_Latn, glg_Latn, grn_Latn, guj_Gujr,
hat_Latn, hau_Latn, heb_Hebr, hin_Deva, hne_Deva, hrv_Latn, hun_Latn,
hye_Armn, ibo_Latn, ilo_Latn, ind_Latn, isl_Latn, ita_Latn, jav_Latn,
jpn_Jpan, kab_Latn, kac_Latn, kam_Latn, kan_Knda, kas_Arab, kas_Deva,
kat_Geor, knc_Arab, knc_Latn, kaz_Cyrl, kbp_Latn, kea_Latn, khm_Khmr,
kik_Latn, kin_Latn, kir_Cyrl, kmb_Latn, kon_Latn, kor_Hang, kmr_Latn,
lao_Laoo, lvs_Latn, lij_Latn, lim_Latn, lin_Latn, lit_Latn, lmo_Latn,
ltg_Latn, ltz_Latn, lua_Latn, lug_Latn, luo_Latn, lus_Latn, mag_Deva,
mai_Deva, mal_Mlym, mar_Deva, min_Latn, mkd_Cyrl, plt_Latn, mlt_Latn,
mni_Beng, khk_Cyrl, mos_Latn, mri_Latn, zsm_Latn, mya_Mymr, nld_Latn,
nno_Latn, nob_Latn, npi_Deva, nso_Latn, nus_Latn, nya_Latn, oci_Latn,
gaz_Latn, ory_Orya, pag_Latn, pan_Guru, pap_Latn, pol_Latn, por_Latn,
prs_Arab, pbt_Arab, quy_Latn, ron_Latn, run_Latn, rus_Cyrl, sag_Latn,
san_Deva, sat_Beng, scn_Latn, shn_Mymr, sin_Sinh, slk_Latn, slv_Latn,
smo_Latn, sna_Latn, snd_Arab, som_Latn, sot_Latn, spa_Latn, als_Latn,
srd_Latn, srp_Cyrl, ssw_Latn, sun_Latn, swe_Latn, swh_Latn, szl_Latn,
tam_Taml, tat_Cyrl, tel_Telu, tgk_Cyrl, tgl_Latn, tha_Thai, tir_Ethi,
taq_Latn, taq_Tfng, tpi_Latn, tsn_Latn, tso_Latn, tuk_Latn, tum_Latn,
tur_Latn, twi_Latn, tzm_Tfng, uig_Arab, ukr_Cyrl, umb_Latn, urd_Arab,
uzn_Latn, vec_Latn, vie_Latn, war_Latn, wol_Latn, xho_Latn, ydd_Hebr,
yor_Latn, yue_Hant, zho_Hans, zho_Hant, zul_Latn
pipeline_tag: sentence-similarity
---
This is a port of the multilingual SONAR text encoder (https://huggingface.co/facebook/SONAR) to the `transformers` format from `fairseq2`.
Its embeddings are expected be equal to those the official implementation (https://github.com/facebookresearch/SONAR), but the latter stays the source of truth.
The encoder supports the same 202 languages as [NLLB-200](https://huggingface.co/facebook/nllb-200-distilled-600M)
(see also [the source model card](https://github.com/facebookresearch/SONAR/blob/main/sonar/store/cards/text_sonar_basic_encoder.yaml#L14)
and [FLORES-200 lang code mapping](https://github.com/facebookresearch/flores/blob/main/flores200/README.md#languages-in-flores-200)).
How to compute embeddings:
```Python
# !pip install transformers sentencepiece -q
import torch
from transformers import AutoTokenizer
from transformers.models.m2m_100.modeling_m2m_100 import M2M100Encoder
model_name = "cointegrated/SONAR_200_text_encoder"
encoder = M2M100Encoder.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name)
def encode_mean_pool(texts, tokenizer, encoder, lang='eng_Latn', norm=False):
tokenizer.src_lang = lang
with torch.inference_mode():
batch = tokenizer(texts, return_tensors='pt', padding=True)
seq_embs = encoder(**batch).last_hidden_state
mask = batch.attention_mask
mean_emb = (seq_embs * mask.unsqueeze(-1)).sum(1) / mask.unsqueeze(-1).sum(1)
if norm:
mean_emb = torch.nn.functional.normalize(mean_emb)
return mean_emb
sentences = ['My name is SONAR.', 'I can embed the sentences into vectorial space.']
embs = encode_mean_pool(sentences, tokenizer, encoder, lang="eng_Latn")
print(embs.shape)
# torch.Size([2, 1024])
print(embs)
# tensor([[-0.0053, 0.0020, -0.0006, ..., 0.0094, -0.0009, 0.0070],
# [-0.0003, -0.0071, 0.0076, ..., 0.0055, 0.0022, -0.0083]])
```
For advanced examples of usage, please take a look at the readme in https://github.com/facebookresearch/SONAR.
The model was repacked [in this notebook](https://colab.research.google.com/drive/1s6JuQWaMnWXyFdni1AAw-Z48k8YoKwG7?usp=sharing). |
MCZK/Vecteus-V2-7B-GGUF | MCZK | 2024-06-16T11:32:15Z | 3,151 | 1 | transformers | [
"transformers",
"gguf",
"Mistral",
"text-generation",
"ja",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-06-16T05:26:00Z | ---
license: apache-2.0
language:
- ja
tags:
- Mistral
library_name: transformers
pipeline_tag: text-generation
---
Local-Novel-LLM-project様の [Vecteus-V2-7B](https://huggingface.co/Local-Novel-LLM-project/Vecteus-V2-7B) をGGUF形式に変換したものです。
K量子化モデルについてもiMatrix適用してあります。
iMatrixテキストはTFMC様の[c4_en_ja_imatrix.txt](https://huggingface.co/datasets/TFMC/imatrix-dataset-for-japanese-llm)を使用しています。
|
Lewdiculous/mistral-7b-v0.1-layla-v4-GGUF-IQ-Imatrix | Lewdiculous | 2024-03-03T11:28:24Z | 3,145 | 6 | transformers | [
"transformers",
"gguf",
"mistral",
"quantized",
"text-generation-inference",
"roleplay",
"text-generation",
"license:apache-2.0",
"region:us"
] | text-generation | 2024-03-03T10:42:12Z | ---
license: apache-2.0
library_name: transformers
tags:
- mistral
- quantized
- text-generation-inference
- roleplay
# - rp
# - uncensored
pipeline_tag: text-generation
inference: false
# language:
# - en
# FILL THE INFORMATION:
# Reference: l3utterfly/mistral-7b-v0.1-layla-v4
# Author: l3utterfly
# Model: mistral-7b-v0.1-layla-v4
# Llama.cpp version: b2321
---
## GGUF-Imatrix quantizations for [l3utterfly/mistral-7b-v0.1-layla-v4](https://huggingface.co/l3utterfly/mistral-7b-v0.1-layla-v4/).
All credits belong to the author.
If you like these also check out [FantasiaFoundry's GGUF-Quantization-Script](https://huggingface.co/FantasiaFoundry/GGUF-Quantization-Script).
## What does "Imatrix" mean?
It stands for **Importance Matrix**, a technique used to improve the quality of quantized models. <br>
[[1]](https://github.com/ggerganov/llama.cpp/discussions/5006/) <br>
The **Imatrix** is calculated based on calibration data, and it helps determine the importance of different model activations during the quantization process. The idea is to preserve the most important information during quantization, which can help reduce the loss of model performance and lead to better performance, especially when the calibration data is diverse. <br>
[[2]](https://github.com/ggerganov/llama.cpp/discussions/5263#discussioncomment-8395384/)
For --imatrix data, included `imatrix.dat` was used.
Using [llama.cpp-b2321](https://github.com/ggerganov/llama.cpp/releases/tag/b2321/):
```
Base⇢ GGUF(F16)⇢ Imatrix-Data(F16)⇢ GGUF(Imatrix-Quants)
```
The new **IQ3_S** quant-option has shown to be better than the old Q3_K_S, so I added that instead of the later. Only supported in `koboldcpp-1.59.1` or higher.
If you want any specific quantization to be added, feel free to ask.
## Model image:

## Original model information:
# Model Card
### Model Description
Mistral 7B fine-tuned by the OpenHermes 2.5 dataset optimised for multi-turn conversation and character impersonation.
The dataset has been pre-processed by doing the following:
1. remove all refusals
2. remove any mention of AI assistant
3. split any multi-turn dialog generated in the dataset into multi-turn conversations records
4. added nfsw generated conversations from the Teatime dataset
- **Developed by:** l3utterfly
- **Funded by:** Layla Network
- **Model type:** Mistral
- **Language(s) (NLP):** English
- **License:** Apache-2.0
- **Finetuned from model:** Mistral 7B
## Uses
Base model used by Layla - the offline personal assistant: https://www.layla-network.ai
Help & support: https://discord.gg/x546YJ6nYC
Prompt:
```
USER:
ASSISTANT:
```
[<img src="https://raw.githubusercontent.com/OpenAccess-AI-Collective/axolotl/main/image/axolotl-badge-web.png" alt="Built with Axolotl" width="200" height="32"/>](https://github.com/OpenAccess-AI-Collective/axolotl) |
mradermacher/SuperQwen2-7B-Chat-GGUF | mradermacher | 2024-06-23T11:55:34Z | 3,145 | 0 | transformers | [
"transformers",
"gguf",
"merge",
"mergekit",
"en",
"base_model:SepKeyPro/SuperQwen2-7B-Chat",
"endpoints_compatible",
"region:us"
] | null | 2024-06-18T01:57:31Z | ---
base_model: SepKeyPro/SuperQwen2-7B-Chat
language:
- en
library_name: transformers
quantized_by: mradermacher
tags:
- merge
- mergekit
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
static quants of https://huggingface.co/SepKeyPro/SuperQwen2-7B-Chat
<!-- provided-files -->
weighted/imatrix quants are available at https://huggingface.co/mradermacher/SuperQwen2-7B-Chat-i1-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/SuperQwen2-7B-Chat-GGUF/resolve/main/SuperQwen2-7B-Chat.Q2_K.gguf) | Q2_K | 3.1 | |
| [GGUF](https://huggingface.co/mradermacher/SuperQwen2-7B-Chat-GGUF/resolve/main/SuperQwen2-7B-Chat.IQ3_XS.gguf) | IQ3_XS | 3.4 | |
| [GGUF](https://huggingface.co/mradermacher/SuperQwen2-7B-Chat-GGUF/resolve/main/SuperQwen2-7B-Chat.Q3_K_S.gguf) | Q3_K_S | 3.6 | |
| [GGUF](https://huggingface.co/mradermacher/SuperQwen2-7B-Chat-GGUF/resolve/main/SuperQwen2-7B-Chat.IQ3_S.gguf) | IQ3_S | 3.6 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/SuperQwen2-7B-Chat-GGUF/resolve/main/SuperQwen2-7B-Chat.IQ3_M.gguf) | IQ3_M | 3.7 | |
| [GGUF](https://huggingface.co/mradermacher/SuperQwen2-7B-Chat-GGUF/resolve/main/SuperQwen2-7B-Chat.Q3_K_M.gguf) | Q3_K_M | 3.9 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/SuperQwen2-7B-Chat-GGUF/resolve/main/SuperQwen2-7B-Chat.Q3_K_L.gguf) | Q3_K_L | 4.2 | |
| [GGUF](https://huggingface.co/mradermacher/SuperQwen2-7B-Chat-GGUF/resolve/main/SuperQwen2-7B-Chat.IQ4_XS.gguf) | IQ4_XS | 4.4 | |
| [GGUF](https://huggingface.co/mradermacher/SuperQwen2-7B-Chat-GGUF/resolve/main/SuperQwen2-7B-Chat.Q4_K_S.gguf) | Q4_K_S | 4.6 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/SuperQwen2-7B-Chat-GGUF/resolve/main/SuperQwen2-7B-Chat.Q4_K_M.gguf) | Q4_K_M | 4.8 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/SuperQwen2-7B-Chat-GGUF/resolve/main/SuperQwen2-7B-Chat.Q5_K_S.gguf) | Q5_K_S | 5.4 | |
| [GGUF](https://huggingface.co/mradermacher/SuperQwen2-7B-Chat-GGUF/resolve/main/SuperQwen2-7B-Chat.Q5_K_M.gguf) | Q5_K_M | 5.5 | |
| [GGUF](https://huggingface.co/mradermacher/SuperQwen2-7B-Chat-GGUF/resolve/main/SuperQwen2-7B-Chat.Q6_K.gguf) | Q6_K | 6.4 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/SuperQwen2-7B-Chat-GGUF/resolve/main/SuperQwen2-7B-Chat.Q8_0.gguf) | Q8_0 | 8.2 | fast, best quality |
| [GGUF](https://huggingface.co/mradermacher/SuperQwen2-7B-Chat-GGUF/resolve/main/SuperQwen2-7B-Chat.f16.gguf) | f16 | 15.3 | 16 bpw, overkill |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
mradermacher/Storm-7B-GGUF | mradermacher | 2024-06-18T06:46:11Z | 3,144 | 0 | transformers | [
"transformers",
"gguf",
"storm",
"mistral",
"openchat",
"RLAIF",
"reward model",
"en",
"dataset:berkeley-nest/Nectar",
"base_model:jieliu/Storm-7B",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2024-06-17T23:01:33Z | ---
base_model: jieliu/Storm-7B
datasets:
- berkeley-nest/Nectar
language:
- en
library_name: transformers
license: apache-2.0
quantized_by: mradermacher
tags:
- storm
- mistral
- openchat
- RLAIF
- reward model
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
static quants of https://huggingface.co/jieliu/Storm-7B
<!-- provided-files -->
weighted/imatrix quants are available at https://huggingface.co/mradermacher/Storm-7B-i1-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/Storm-7B-GGUF/resolve/main/Storm-7B.Q2_K.gguf) | Q2_K | 2.8 | |
| [GGUF](https://huggingface.co/mradermacher/Storm-7B-GGUF/resolve/main/Storm-7B.IQ3_XS.gguf) | IQ3_XS | 3.1 | |
| [GGUF](https://huggingface.co/mradermacher/Storm-7B-GGUF/resolve/main/Storm-7B.Q3_K_S.gguf) | Q3_K_S | 3.3 | |
| [GGUF](https://huggingface.co/mradermacher/Storm-7B-GGUF/resolve/main/Storm-7B.IQ3_S.gguf) | IQ3_S | 3.3 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/Storm-7B-GGUF/resolve/main/Storm-7B.IQ3_M.gguf) | IQ3_M | 3.4 | |
| [GGUF](https://huggingface.co/mradermacher/Storm-7B-GGUF/resolve/main/Storm-7B.Q3_K_M.gguf) | Q3_K_M | 3.6 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/Storm-7B-GGUF/resolve/main/Storm-7B.Q3_K_L.gguf) | Q3_K_L | 3.9 | |
| [GGUF](https://huggingface.co/mradermacher/Storm-7B-GGUF/resolve/main/Storm-7B.IQ4_XS.gguf) | IQ4_XS | 4.0 | |
| [GGUF](https://huggingface.co/mradermacher/Storm-7B-GGUF/resolve/main/Storm-7B.Q4_K_S.gguf) | Q4_K_S | 4.2 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Storm-7B-GGUF/resolve/main/Storm-7B.Q4_K_M.gguf) | Q4_K_M | 4.5 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Storm-7B-GGUF/resolve/main/Storm-7B.Q5_K_S.gguf) | Q5_K_S | 5.1 | |
| [GGUF](https://huggingface.co/mradermacher/Storm-7B-GGUF/resolve/main/Storm-7B.Q5_K_M.gguf) | Q5_K_M | 5.2 | |
| [GGUF](https://huggingface.co/mradermacher/Storm-7B-GGUF/resolve/main/Storm-7B.Q6_K.gguf) | Q6_K | 6.0 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/Storm-7B-GGUF/resolve/main/Storm-7B.Q8_0.gguf) | Q8_0 | 7.8 | fast, best quality |
| [GGUF](https://huggingface.co/mradermacher/Storm-7B-GGUF/resolve/main/Storm-7B.f16.gguf) | f16 | 14.6 | 16 bpw, overkill |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
adamkarvonen/8LayerChessGPT2 | adamkarvonen | 2024-04-19T18:05:01Z | 3,143 | 0 | transformers | [
"transformers",
"safetensors",
"gpt2",
"text-generation",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2024-04-19T17:51:58Z | Entry not found |
ml6team/keyphrase-extraction-kbir-semeval2017 | ml6team | 2023-05-06T08:49:06Z | 3,142 | 3 | transformers | [
"transformers",
"pytorch",
"roberta",
"token-classification",
"keyphrase-extraction",
"en",
"dataset:midas/semeval2017",
"arxiv:2112.08547",
"arxiv:1704.02853",
"license:mit",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | token-classification | 2022-06-16T18:08:12Z | ---
language: en
license: mit
tags:
- keyphrase-extraction
datasets:
- midas/semeval2017
metrics:
- seqeval
widget:
- text: "Keyphrase extraction is a technique in text analysis where you extract the important keyphrases from a document.
Thanks to these keyphrases humans can understand the content of a text very quickly and easily without reading
it completely. Keyphrase extraction was first done primarily by human annotators, who read the text in detail
and then wrote down the most important keyphrases. The disadvantage is that if you work with a lot of documents,
this process can take a lot of time.
Here is where Artificial Intelligence comes in. Currently, classical machine learning methods, that use statistical
and linguistic features, are widely used for the extraction process. Now with deep learning, it is possible to capture
the semantic meaning of a text even better than these classical methods. Classical methods look at the frequency,
occurrence and order of words in the text, whereas these neural approaches can capture long-term semantic dependencies
and context of words in a text."
example_title: "Example 1"
- text: "In this work, we explore how to learn task specific language models aimed towards learning rich representation of keyphrases from text documents. We experiment with different masking strategies for pre-training transformer language models (LMs) in discriminative as well as generative settings. In the discriminative setting, we introduce a new pre-training objective - Keyphrase Boundary Infilling with Replacement (KBIR), showing large gains in performance (up to 9.26 points in F1) over SOTA, when LM pre-trained using KBIR is fine-tuned for the task of keyphrase extraction. In the generative setting, we introduce a new pre-training setup for BART - KeyBART, that reproduces the keyphrases related to the input text in the CatSeq format, instead of the denoised original input. This also led to gains in performance (up to 4.33 points inF1@M) over SOTA for keyphrase generation. Additionally, we also fine-tune the pre-trained language models on named entity recognition(NER), question answering (QA), relation extraction (RE), abstractive summarization and achieve comparable performance with that of the SOTA, showing that learning rich representation of keyphrases is indeed beneficial for many other fundamental NLP tasks."
example_title: "Example 2"
model-index:
- name: ml6team/keyphrase-extraction-kbir-semeval2017
results:
- task:
type: keyphrase-extraction
name: Keyphrase Extraction
dataset:
type: midas/semeval2017
name: semeval2017
metrics:
- type: F1 (Seqeval)
value: 0.000
name: F1 (Seqeval)
- type: F1@M
value: 0.401
name: F1@M
---
# 🔑 Keyphrase Extraction Model: KBIR-semeval2017
Keyphrase extraction is a technique in text analysis where you extract the important keyphrases from a document. Thanks to these keyphrases humans can understand the content of a text very quickly and easily without reading it completely. Keyphrase extraction was first done primarily by human annotators, who read the text in detail and then wrote down the most important keyphrases. The disadvantage is that if you work with a lot of documents, this process can take a lot of time ⏳.
Here is where Artificial Intelligence 🤖 comes in. Currently, classical machine learning methods, that use statistical and linguistic features, are widely used for the extraction process. Now with deep learning, it is possible to capture the semantic meaning of a text even better than these classical methods. Classical methods look at the frequency, occurrence and order of words in the text, whereas these neural approaches can capture long-term semantic dependencies and context of words in a text.
## 📓 Model Description
This model uses [KBIR](https://huggingface.co/bloomberg/KBIR) as its base model and fine-tunes it on the [semeval2017 dataset](https://huggingface.co/datasets/midas/semeval2017). KBIR or Keyphrase Boundary Infilling with Replacement is a pre-trained model which utilizes a multi-task learning setup for optimizing a combined loss of Masked Language Modeling (MLM), Keyphrase Boundary Infilling (KBI) and Keyphrase Replacement Classification (KRC).
You can find more information about the architecture in this [paper](https://arxiv.org/abs/2112.08547).
Keyphrase extraction models are transformer models fine-tuned as a token classification problem where each word in the document is classified as being part of a keyphrase or not.
| Label | Description |
| ----- | ------------------------------- |
| B-KEY | At the beginning of a keyphrase |
| I-KEY | Inside a keyphrase |
| O | Outside a keyphrase |
## ✋ Intended Uses & Limitations
### 🛑 Limitations
* This keyphrase extraction model is very domain-specific and will perform very well on abstracts of scientific articles. It's not recommended to use this model for other domains, but you are free to test it out.
* Limited amount of predicted keyphrases.
* Only works for English documents.
### ❓ How To Use
```python
from transformers import (
TokenClassificationPipeline,
AutoModelForTokenClassification,
AutoTokenizer,
)
from transformers.pipelines import AggregationStrategy
import numpy as np
# Define keyphrase extraction pipeline
class KeyphraseExtractionPipeline(TokenClassificationPipeline):
def __init__(self, model, *args, **kwargs):
super().__init__(
model=AutoModelForTokenClassification.from_pretrained(model),
tokenizer=AutoTokenizer.from_pretrained(model),
*args,
**kwargs
)
def postprocess(self, all_outputs):
results = super().postprocess(
all_outputs=all_outputs,
aggregation_strategy=AggregationStrategy.SIMPLE,
)
return np.unique([result.get("word").strip() for result in results])
```
```python
# Load pipeline
model_name = "ml6team/keyphrase-extraction-kbir-semeval2017"
extractor = KeyphraseExtractionPipeline(model=model_name)
```
```python
# Inference
text = """
Keyphrase extraction is a technique in text analysis where you extract the
important keyphrases from a document. Thanks to these keyphrases humans can
understand the content of a text very quickly and easily without reading it
completely. Keyphrase extraction was first done primarily by human annotators,
who read the text in detail and then wrote down the most important keyphrases.
The disadvantage is that if you work with a lot of documents, this process
can take a lot of time.
Here is where Artificial Intelligence comes in. Currently, classical machine
learning methods, that use statistical and linguistic features, are widely used
for the extraction process. Now with deep learning, it is possible to capture
the semantic meaning of a text even better than these classical methods.
Classical methods look at the frequency, occurrence and order of words
in the text, whereas these neural approaches can capture long-term
semantic dependencies and context of words in a text.
""".replace("\n", " ")
keyphrases = extractor(text)
print(keyphrases)
```
```
# Output
['artificial intelligence']
```
## 📚 Training Dataset
[Semeval2017](https://huggingface.co/datasets/midas/semeval2017) is a keyphrase extraction/generation dataset consisting of 500 English scientific paper abstracts from the ScienceDirect open access publications. from NY Times and 10K from JPTimes and annotated by professional indexers or editors. The selected articles were evenly distributed among the domains of Computer Science, Material Sciences and Physics. Each paper has a set of keyphrases annotated by student volunteers. Each paper was double-annotated, where the second annotation was done by an expert annotator.
You can find more information in the [paper](https://arxiv.org/abs/1704.02853).
## 👷♂️ Training procedure
### Training parameters
| Parameter | Value |
| --------- | ------|
| Learning Rate | 1e-4 |
| Epochs | 50 |
| Early Stopping Patience | 3 |
### Preprocessing
The documents in the dataset are already preprocessed into list of words with the corresponding labels. The only thing that must be done is tokenization and the realignment of the labels so that they correspond with the right subword tokens.
```python
from datasets import load_dataset
from transformers import AutoTokenizer
# Labels
label_list = ["B", "I", "O"]
lbl2idx = {"B": 0, "I": 1, "O": 2}
idx2label = {0: "B", 1: "I", 2: "O"}
# Tokenizer
tokenizer = AutoTokenizer.from_pretrained("bloomberg/KBIR")
max_length = 512
# Dataset parameters
dataset_full_name = "midas/semeval2017"
dataset_subset = "raw"
dataset_document_column = "document"
dataset_biotags_column = "doc_bio_tags"
def preprocess_fuction(all_samples_per_split):
tokenized_samples = tokenizer.batch_encode_plus(
all_samples_per_split[dataset_document_column],
padding="max_length",
truncation=True,
is_split_into_words=True,
max_length=max_length,
)
total_adjusted_labels = []
for k in range(0, len(tokenized_samples["input_ids"])):
prev_wid = -1
word_ids_list = tokenized_samples.word_ids(batch_index=k)
existing_label_ids = all_samples_per_split[dataset_biotags_column][k]
i = -1
adjusted_label_ids = []
for wid in word_ids_list:
if wid is None:
adjusted_label_ids.append(lbl2idx["O"])
elif wid != prev_wid:
i = i + 1
adjusted_label_ids.append(lbl2idx[existing_label_ids[i]])
prev_wid = wid
else:
adjusted_label_ids.append(
lbl2idx[
f"{'I' if existing_label_ids[i] == 'B' else existing_label_ids[i]}"
]
)
total_adjusted_labels.append(adjusted_label_ids)
tokenized_samples["labels"] = total_adjusted_labels
return tokenized_samples
# Load dataset
dataset = load_dataset(dataset_full_name, dataset_subset)
# Preprocess dataset
tokenized_dataset = dataset.map(preprocess_fuction, batched=True)
```
### Postprocessing (Without Pipeline Function)
If you do not use the pipeline function, you must filter out the B and I labeled tokens. Each B and I will then be merged into a keyphrase. Finally, you need to strip the keyphrases to make sure all unnecessary spaces have been removed.
```python
# Define post_process functions
def concat_tokens_by_tag(keyphrases):
keyphrase_tokens = []
for id, label in keyphrases:
if label == "B":
keyphrase_tokens.append([id])
elif label == "I":
if len(keyphrase_tokens) > 0:
keyphrase_tokens[len(keyphrase_tokens) - 1].append(id)
return keyphrase_tokens
def extract_keyphrases(example, predictions, tokenizer, index=0):
keyphrases_list = [
(id, idx2label[label])
for id, label in zip(
np.array(example["input_ids"]).squeeze().tolist(), predictions[index]
)
if idx2label[label] in ["B", "I"]
]
processed_keyphrases = concat_tokens_by_tag(keyphrases_list)
extracted_kps = tokenizer.batch_decode(
processed_keyphrases,
skip_special_tokens=True,
clean_up_tokenization_spaces=True,
)
return np.unique([kp.strip() for kp in extracted_kps])
```
## 📝 Evaluation Results
Traditional evaluation methods are the precision, recall and F1-score @k,m where k is the number that stands for the first k predicted keyphrases and m for the average amount of predicted keyphrases.
The model achieves the following results on the Semeval2017 test set:
| Dataset | P@5 | R@5 | F1@5 | P@10 | R@10 | F1@10 | P@M | R@M | F1@M |
|:---------------------:|:----:|:----:|:----:|:----:|:----:|:-----:|:----:|:----:|:----:|
| Semeval2017 Test Set | 0.41 | 0.20 | 0.25 | 0.37 | 0.34 | 0.34 | 0.36 | 0.50 | 0.40 |
## 🚨 Issues
Please feel free to start discussions in the Community Tab. |
AVeryRealHuman/DialoGPT-small-TonyStark | AVeryRealHuman | 2021-10-08T08:27:15Z | 3,141 | 0 | transformers | [
"transformers",
"pytorch",
"gpt2",
"text-generation",
"conversational",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2022-03-02T23:29:04Z | ---
tags:
- conversational
---
#Tony Stark DialoGPT model |
yanekyuk/bert-keyword-extractor | yanekyuk | 2022-06-04T00:51:39Z | 3,140 | 38 | transformers | [
"transformers",
"pytorch",
"bert",
"token-classification",
"generated_from_trainer",
"en",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | token-classification | 2022-06-03T23:06:00Z | ---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- precision
- recall
- accuracy
- f1
language:
- en
widget:
- text: "Broadcom agreed to acquire cloud computing company VMware in a $61 billion (€57bn) cash-and stock deal, massively diversifying the chipmaker’s business and almost tripling its software-related revenue to about 45% of its total sales. By the numbers: VMware shareholders will receive either $142.50 in cash or 0.2520 of a Broadcom share for each VMware stock. Broadcom will also assume $8 billion of VMware's net debt."
- text: "Canadian Natural Resources Minister Jonathan Wilkinson told Bloomberg that the country could start supplying Europe with liquefied natural gas (LNG) in as soon as three years by converting an existing LNG import facility on Canada’s Atlantic coast into an export terminal. Bottom line: Wilkinson said what Canada cares about is that the new LNG facility uses a low-emission process for the gas and is capable of transitioning to exporting hydrogen later on."
- text: "Google is being investigated by the UK’s antitrust watchdog for its dominance in the \"ad tech stack,\" the set of services that facilitate the sale of online advertising space between advertisers and sellers. Google has strong positions at various levels of the ad tech stack and charges fees to both publishers and advertisers. A step back: UK Competition and Markets Authority has also been investigating whether Google and Meta colluded over ads, probing into the advertising agreement between the two companies, codenamed Jedi Blue."
- text: "Shares in Twitter closed 6.35% up after an SEC 13D filing revealed that Elon Musk pledged to put up an additional $6.25 billion of his own wealth to fund the $44 billion takeover deal, lifting the total to $33.5 billion from an initial $27.25 billion. In other news: Former Twitter CEO Jack Dorsey announced he's stepping down, but would stay on Twitter’s board \\“until his term expires at the 2022 meeting of stockholders.\""
model-index:
- name: bert-keyword-extractor
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-keyword-extractor
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1341
- Precision: 0.8565
- Recall: 0.8874
- Accuracy: 0.9738
- F1: 0.8717
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 8
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | Accuracy | F1 |
|:-------------:|:-----:|:-----:|:---------------:|:---------:|:------:|:--------:|:------:|
| 0.1688 | 1.0 | 1875 | 0.1233 | 0.7194 | 0.7738 | 0.9501 | 0.7456 |
| 0.1219 | 2.0 | 3750 | 0.1014 | 0.7724 | 0.8166 | 0.9606 | 0.7939 |
| 0.0834 | 3.0 | 5625 | 0.0977 | 0.8280 | 0.8263 | 0.9672 | 0.8272 |
| 0.0597 | 4.0 | 7500 | 0.0984 | 0.8304 | 0.8680 | 0.9704 | 0.8488 |
| 0.0419 | 5.0 | 9375 | 0.1042 | 0.8417 | 0.8687 | 0.9717 | 0.8550 |
| 0.0315 | 6.0 | 11250 | 0.1161 | 0.8520 | 0.8839 | 0.9729 | 0.8677 |
| 0.0229 | 7.0 | 13125 | 0.1282 | 0.8469 | 0.8939 | 0.9734 | 0.8698 |
| 0.0182 | 8.0 | 15000 | 0.1341 | 0.8565 | 0.8874 | 0.9738 | 0.8717 |
### Framework versions
- Transformers 4.19.2
- Pytorch 1.11.0+cu113
- Datasets 2.2.2
- Tokenizers 0.12.1
|
lmsys/longchat-7b-v1.5-32k | lmsys | 2023-08-02T21:09:31Z | 3,139 | 57 | transformers | [
"transformers",
"pytorch",
"llama",
"text-generation",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2023-08-01T02:21:08Z | Entry not found |
frankjoshua/albedobaseXL_v13 | frankjoshua | 2023-12-06T23:31:31Z | 3,138 | 5 | diffusers | [
"diffusers",
"safetensors",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionXLPipeline",
"region:us"
] | text-to-image | 2023-12-06T19:54:05Z | Entry not found |
ChaiML/reward_gpt2_medium_preference_24m_e2 | ChaiML | 2024-03-13T19:15:31Z | 3,138 | 2 | transformers | [
"transformers",
"pytorch",
"gpt2",
"text-classification",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-classification | 2024-03-13T19:12:31Z | Entry not found |
nlpai-lab/KULLM3 | nlpai-lab | 2024-04-30T08:50:44Z | 3,137 | 26 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"en",
"ko",
"base_model:upstage/SOLAR-10.7B-v1.0",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2024-04-02T11:23:14Z | ---
library_name: transformers
license: apache-2.0
language:
- en
- ko
base_model:
- upstage/SOLAR-10.7B-v1.0
---
<a href="https://github.com/nlpai-lab/KULLM">
<img src="kullm_logo.png" width="50%"/>
</a>
# KULLM3
Introducing KULLM3, a model with advanced instruction-following and fluent chat abilities.
It has shown remarkable performance in instruction-following, speficially by closely following gpt-3.5-turbo.
To our knowledge, It is one of the best publicly opened Korean-speaking language models.
For details, visit the [KULLM repository](https://github.com/nlpai-lab/KULLM)
### Model Description
This is the model card of a 🤗 transformers model that has been pushed on the Hub.
- **Developed by:** [NLP&AI Lab](http://nlp.korea.ac.kr/)
- **Language(s) (NLP):** Korean, English
- **License:** Apache 2.0
- **Finetuned from model:** [upstage/SOLAR-10.7B-v1.0](https://huggingface.co/upstage/SOLAR-10.7B-v1.0)
## Example code
### Install Dependencies
```bash
pip install torch transformers==4.38.2 accelerate
```
- In transformers>=4.39.0, generate() does not work well. (as of 2024.4.4.)
### Python code
```python
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, TextStreamer
MODEL_DIR = "nlpai-lab/KULLM3"
model = AutoModelForCausalLM.from_pretrained(MODEL_DIR, torch_dtype=torch.float16).to("cuda")
tokenizer = AutoTokenizer.from_pretrained(MODEL_DIR)
streamer = TextStreamer(tokenizer, skip_prompt=True, skip_special_tokens=True)
s = "고려대학교에 대해서 알고 있니?"
conversation = [{'role': 'user', 'content': s}]
inputs = tokenizer.apply_chat_template(
conversation,
tokenize=True,
add_generation_prompt=True,
return_tensors='pt').to("cuda")
_ = model.generate(inputs, streamer=streamer, max_new_tokens=1024)
# 네, 고려대학교에 대해 알고 있습니다. 고려대학교는 대한민국 서울에 위치한 사립 대학교로, 1905년에 설립되었습니다. 이 대학교는 한국에서 가장 오래된 대학 중 하나로, 다양한 학부 및 대학원 프로그램을 제공합니다. 고려대학교는 특히 법학, 경제학, 정치학, 사회학, 문학, 과학 분야에서 높은 명성을 가지고 있습니다. 또한, 스포츠 분야에서도 활발한 활동을 보이며, 대한민국 대학 스포츠에서 중요한 역할을 하고 있습니다. 고려대학교는 국제적인 교류와 협력에도 적극적이며, 전 세계 다양한 대학과의 협력을 통해 글로벌 경쟁력을 강화하고 있습니다.
```
## Training Details
### Training Data
- [vicgalle/alpaca-gpt4](https://huggingface.co/datasets/vicgalle/alpaca-gpt4)
- Mixed Korean instruction data (gpt-generated, hand-crafted, etc)
- About 66000+ examples used totally
### Training Procedure
- Trained with fixed system prompt below.
```text
당신은 고려대학교 NLP&AI 연구실에서 만든 AI 챗봇입니다.
당신의 이름은 'KULLM'으로, 한국어로는 '구름'을 뜻합니다.
당신은 비도덕적이거나, 성적이거나, 불법적이거나 또는 사회 통념적으로 허용되지 않는 발언은 하지 않습니다.
사용자와 즐겁게 대화하며, 사용자의 응답에 가능한 정확하고 친절하게 응답함으로써 최대한 도와주려고 노력합니다.
질문이 이상하다면, 어떤 부분이 이상한지 설명합니다. 거짓 정보를 발언하지 않도록 주의합니다.
```
## Evaluation
- Evaluation details such as testing data, metrics are written in [github](https://github.com/nlpai-lab/KULLM).
- Without system prompt used in training phase, KULLM would show lower performance than expect.
### Results
<img src="kullm3_instruction_evaluation.png" width=100%>
## Citation
```text
@misc{kullm,
author = {NLP & AI Lab and Human-Inspired AI research},
title = {KULLM: Korea University Large Language Model Project},
year = {2023},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {\url{https://github.com/nlpai-lab/kullm}},
}
``` |
tenyx/Llama3-TenyxChat-70B | tenyx | 2024-05-08T00:42:32Z | 3,136 | 62 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"tenyx-fine-tuning",
"dpo",
"tenyxchat",
"llama3",
"conversational",
"en",
"dataset:HuggingFaceH4/ultrafeedback_binarized",
"arxiv:2305.18290",
"arxiv:2306.05685",
"license:llama3",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2024-04-26T22:31:07Z | ---
license: llama3
datasets:
- HuggingFaceH4/ultrafeedback_binarized
language:
- en
library_name: transformers
tags:
- tenyx-fine-tuning
- dpo
- tenyxchat
- llama3
pipeline_tag: text-generation
---
# TenyxChat: Language Model Alignment using Tenyx Fine-tuning
Introducing Llama-3-TenyxChat-70B, part of our TenyxChat series trained to function as useful assistants through preference tuning, using Tenyx's advanced fine-tuning technology ([VentureBeat article](https://venturebeat.com/ai/tenyx-aims-to-fix-llms-catastrophic-forgetting-problem/)). Our model is trained using the [Direct Preference Optimization (DPO)](https://arxiv.org/abs/2305.18290) framework on the open-source AI feedback dataset [UltraFeedback](https://huggingface.co/datasets/HuggingFaceH4/ultrafeedback_binarized).
We fine-tune [Llama3-70B](https://huggingface.co/meta-llama/Meta-Llama-3-70B-Instruct) with our proprietary approach
which shows an increase in [MT-Bench](https://arxiv.org/abs/2306.05685)*, without a drop in performance of the model on other benchmarks.
Our approach aims to mitigate forgetting in LLMs in a computationally efficient manner,
thereby enabling continual fine-tuning capabilities without altering the pre-trained output distribution.
Llama-3-TenyxChat-70B was trained using eight A100s (80GB) for fifteen hours, with a training setup obtained from HuggingFaceH4 ([GitHub](https://github.com/huggingface/alignment-handbook)).
*The MT-Bench evaluation we perform follows the latest eval upgrade as PR'd [here](https://github.com/lm-sys/FastChat/pull/3158). This PR upgrades the evaluation from `GPT-4-0613` to `GPT-4-preview-0125` (latest version) as well as corrects and improves the quality of the reference answers for a subset of questions. These changes are required to correct the erroneous rating during previous evaluation.
**Model Developers** [Tenyx Research](https://www.tenyx.com/research)
# Model details
- Model type: Fine-tuned 70B Instruct model for chat.
- License: Meta Llama 3 Community License
- Base model: [Llama3-70B](https://huggingface.co/meta-llama/Meta-Llama-3-70B-Instruct)
- Demo: [HuggingFace Space](https://huggingface.co/spaces/tenyx/Llama3-TenyxChat-70B)
## Usage
Our model uses the same chat template as [Llama3-70B](https://huggingface.co/meta-llama/Meta-Llama-3-70B-Instruct).
### Hugging face Example
```python
import torch
from transformers import pipeline
pipe = pipeline("text-generation", model="tenyx/Llama3-TenyxChat-70B", torch_dtype=torch.bfloat16, device_map="auto")
messages = [
{"role": "system", "content": "You are a friendly chatbot who always responds in the style of a pirate."},
{"role": "user", "content": "Hi. I would like to make a hotel booking."},
]
prompt = pipe.tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
outputs = pipe(prompt, max_new_tokens=512, do_sample=False)
```
# Performance
At the time of release (April 2024), Llama3-TenyxChat-70B is the highest-ranked open source model on the MT-Bench evaluation available for download.
## MT-Bench
MT-Bench is a benchmark made up of 80 high-quality multi-turn questions. These questions fall into eight categories: Writing, Roleplay, Reasoning, Math, Coding, Extraction, STEM, and Humanities. The chat models are rated using `GPT-4-preview-0125` on a scale of 1 to 10, with higher values corresponding to better responses.
| Model-name | GPT4-preview-0125 MT Bench | Chat Arena Elo |
|--------------------------------|----------------------------|----------------|
| GPT-4-1106 | 8.79 | 1251 |
| Claude 3 Opus (20240229) | 8.57 | 1247 |
| **Llama3-TenyxChat-70B** |**8.15** | NA |
| *Llama3-70B-Instruct* | 7.96 | 1207 |
| Claude 3 Sonnet (20240229) | 7.82 | 1190 |
| GPT-4-0314 | 7.96 | 1185 |
| Mixtral | 7.38 | 1114 |
| gpt-3.5-turbo-0613 | 7.37 | 1113 |
| Yi-34B | 6.46 | 1099 |
| gpt-3.5-turbo-0125 | 7.52 | 1096 |
| Llama 2 70B | 6.01 | 1082 |
| NV-Llama2-70B-SteerLM-Chat | 6.57 | 1076 |

## Arena Hard
Arena-Hard is an evaluation tool for instruction-tuned LLMs containing 500 challenging user queries. They prompt GPT-4-1106-preview as judge to compare the models' responses against a baseline model (default: GPT-4-0314).
| Model-name | Score | |
|--------------------------------|--------|---------------------|
| gpt-4-0125-preview | 78.0 | 95% CI: (-1.8, 2.2) |
| claude-3-opus-20240229 | 60.4 | 95% CI: (-2.6, 2.1) |
| gpt-4-0314 | 50.0 | 95% CI: (0.0, 0.0) |
| **tenyx/Llama3-TenyxChat-70B** | **49.0** | 95% CI: (-3.0, 2.4) |
| *meta-llama/Meta-Llama-3-70B-In* | 47.3 | 95% CI: (-1.7, 2.6) |
| claude-3-sonnet-20240229 | 46.8 | 95% CI: (-2.7, 2.3) |
| claude-3-haiku-20240307 | 41.5 | 95% CI: (-2.4, 2.5) |
| gpt-4-0613 | 37.9 | 95% CI: (-2.1, 2.2) |
| mistral-large-2402 | 37.7 | 95% CI: (-2.9, 2.8) |
| Qwen1.5-72B-Chat | 36.1 | 95% CI: (-2.1, 2.4) |
| command-r-plus | 33.1 | 95% CI: (-2.0, 1.9) |
## Open LLM Leaderboard Evaluation
We now present our results on the [Eleuther AI Language Model Evaluation Harness](https://github.com/EleutherAI/lm-evaluation-harness) used for benchmarking Open LLM Leaderboard on Hugging Face.
The task involves evaluation on `6` key benchmarks across reasoning and knowledge with different *few-shot* settings. Read more details about the benchmark at [the leaderboard page](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard).
| Model-name | Average | ARC | HellaSwag | MMLU | TruthfulQA | Winogrande | GSM8K |
| --- | --- | --- | --- | --- | --- | --- | --- |
| **Llama3-TenyxChat-70B** | **79.43** | 72.53 | 86.11 | 79.95 | 62.93 | 83.82 | 91.21 |
| *Llama3-70B-Instruct* | 77.88 | 71.42 | 85.69 | 80.06 | 61.81 | 82.87 | 85.44 |
*The results reported are from local evaluation of our model. `tenyx/Llama3-TenyxChat-70B` is submitted and will be reflected in the leaderboard once evaluation succeeds.
**Note**: While the Open LLM Leaderboard shows other performant Llama-3 fine-tuned models, we observe that these models typically regress in performance and struggle in a multi-turn chat setting, such as the MT-Bench. We present the below comparison with a Llama3 finetune from the leaderboard.
| Model | First Turn | Second Turn | Average |
| --- | --- | --- | --- |
| **tenyx/Llama3-TenyxChat-70B** | 8.12 | 8.18 | 8.15 |
| *meta-llama/Llama3-TenyxChat-70B* | 8.05 | 7.87 | 7.96 |
| MaziyarPanahi/Llama-3-70B-Instruct-DPO-v0.4 | 8.05 | 7.82 | 7.93 |
# Limitations
Llama3-TenyxChat-70B, like other language models, has its own set of limitations. We haven’t fine-tuned the model explicitly to align with **human** safety preferences. Therefore, it is capable of producing undesirable outputs, particularly when adversarially prompted. From our observation, the model still tends to struggle with tasks that involve reasoning and math questions. In some instances, it might generate verbose or extraneous content.
# License
Llama3-TenyxChat-70B is distributed under the Meta Llama 3 Community License.
# Citation
If you use Llama3-TenyxChat-70B for your research, cite us as
```
@misc{tenyxchat2024,
title={TenyxChat: Language Model Alignment using Tenyx Fine-tuning},
author={Tenyx},
year={2024},
}
``` |
allenai/OLMo-7B-hf | allenai | 2024-04-26T19:27:10Z | 3,133 | 8 | transformers | [
"transformers",
"safetensors",
"olmo",
"text-generation",
"en",
"dataset:allenai/dolma",
"arxiv:2402.00838",
"arxiv:2302.13971",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-04-12T22:33:46Z | ---
language:
- en
license: apache-2.0
datasets:
- allenai/dolma
---
<img src="https://allenai.org/olmo/olmo-7b-animation.gif" alt="OLMo Logo" width="800" style="margin-left:'auto' margin-right:'auto' display:'block'"/>
# Model Card for OLMo 7B
<!-- Provide a quick summary of what the model is/does. -->
OLMo is a series of **O**pen **L**anguage **Mo**dels designed to enable the science of language models.
The OLMo models are trained on the [Dolma](https://huggingface.co/datasets/allenai/dolma) dataset.
We release all code, checkpoints, logs (coming soon), and details involved in training these models.
This model has been converted from [allenai/OLMo-7B](https://huggingface.co/allenai/OLMo-7B) for the
Hugging Face Transformers format.
## Model Details
The core models released in this batch are the following:
| Size | Training Tokens | Layers | Hidden Size | Attention Heads | Context Length |
|------|--------|---------|-------------|-----------------|----------------|
| [OLMo 1B](https://huggingface.co/allenai/OLMo-1B-hf) | 3 Trillion |16 | 2048 | 16 | 2048 |
| [OLMo 7B](https://huggingface.co/allenai/OLMo-7B-hf) | 2.5 Trillion | 32 | 4096 | 32 | 2048 |
| [OLMo 7B Twin 2T](https://huggingface.co/allenai/OLMo-7B-Twin-2T-hf) | 2 Trillion | 32 | 4096 | 32 | 2048 |
We are releasing many checkpoints for these models, for every 1000 training steps. These have not
yet been converted into Hugging Face Transformers format, but are available in [allenai/OLMo-7B](https://huggingface.co/allenai/OLMo-7B).
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** Allen Institute for AI (AI2)
- **Supported by:** Databricks, Kempner Institute for the Study of Natural and Artificial Intelligence at Harvard University, AMD, CSC (Lumi Supercomputer), UW
- **Model type:** a Transformer style autoregressive language model.
- **Language(s) (NLP):** English
- **License:** The code and model are released under Apache 2.0.
- **Contact:** Technical inquiries: `olmo at allenai dot org`. Press: `press at allenai dot org`
- **Date cutoff:** Feb./March 2023 based on Dolma dataset version.
### Model Sources
<!-- Provide the basic links for the model. -->
- **Project Page:** https://allenai.org/olmo
- **Repositories:**
- Core repo (training, inference, fine-tuning etc.): https://github.com/allenai/OLMo
- Evaluation code: https://github.com/allenai/OLMo-Eval
- Further fine-tuning code: https://github.com/allenai/open-instruct
- **Paper:** [Link](https://arxiv.org/abs/2402.00838)
- **Technical blog post:** https://blog.allenai.org/olmo-open-language-model-87ccfc95f580
- **W&B Logs:** https://wandb.ai/ai2-llm/OLMo-7B/reports/OLMo-7B--Vmlldzo2NzQyMzk5
<!-- - **Press release:** TODO -->
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Inference
Quickly get inference running with the following:
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
olmo = AutoModelForCausalLM.from_pretrained("allenai/OLMo-7B-hf")
tokenizer = AutoTokenizer.from_pretrained("allenai/OLMo-7B-hf")
message = ["Language modeling is "]
inputs = tokenizer(message, return_tensors='pt', return_token_type_ids=False)
# optional verifying cuda
# inputs = {k: v.to('cuda') for k,v in inputs.items()}
# olmo = olmo.to('cuda')
response = olmo.generate(**inputs, max_new_tokens=100, do_sample=True, top_k=50, top_p=0.95)
print(tokenizer.batch_decode(response, skip_special_tokens=True)[0])
>> 'Language modeling is the first step to build natural language generation...'
```
Alternatively, with the pipeline abstraction:
```python
from transformers import pipeline
olmo_pipe = pipeline("text-generation", model="allenai/OLMo-7B-hf")
print(olmo_pipe("Language modeling is "))
>> 'Language modeling is a branch of natural language processing that aims to...'
```
Or, you can make this slightly faster by quantizing the model, e.g. `AutoModelForCausalLM.from_pretrained("allenai/OLMo-7B-hf", torch_dtype=torch.float16, load_in_8bit=True)` (requires `bitsandbytes`).
The quantized model is more sensitive to typing / cuda, so it is recommended to pass the inputs as `inputs.input_ids.to('cuda')` to avoid potential issues.
### Fine-tuning
This model does not directly support our fine-tuning processes. Model fine-tuning can be done
from the final checkpoint or many intermediate checkpoints of
[allenai/OLMo-7B](https://huggingface.co/allenai/OLMo-7B).
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
Core model results for the 7B model are found below.
| | [Llama 7B](https://arxiv.org/abs/2302.13971) | [Llama 2 7B](https://huggingface.co/meta-llama/Llama-2-7b) | [Falcon 7B](https://huggingface.co/tiiuae/falcon-7b) | [MPT 7B](https://huggingface.co/mosaicml/mpt-7b) | **OLMo 7B** (ours) |
| --------------------------------- | -------- | ---------- | --------- | ------ | ------- |
| arc_challenge | 44.5 | 39.8 | 47.5 | 46.5 | 48.5 |
| arc_easy | 57.0 | 57.7 | 70.4 | 70.5 | 65.4 |
| boolq | 73.1 | 73.5 | 74.6 | 74.2 | 73.4 |
| copa | 85.0 | 87.0 | 86.0 | 85.0 | 90 |
| hellaswag | 74.5 | 74.5 | 75.9 | 77.6 | 76.4 |
| openbookqa | 49.8 | 48.4 | 53.0 | 48.6 | 50.2 |
| piqa | 76.3 | 76.4 | 78.5 | 77.3 | 78.4 |
| sciq | 89.5 | 90.8 | 93.9 | 93.7 | 93.8 |
| winogrande | 68.2 | 67.3 | 68.9 | 69.9 | 67.9 |
| **Core tasks average** | 68.7 | 68.4 | 72.1 | 71.5 | 71.6 |
| truthfulQA (MC2) | 33.9 | 38.5 | 34.0 | 33 | 36.0 |
| MMLU (5 shot MC) | 31.5 | 45.0 | 24.0 | 30.8 | 28.3 |
| GSM8k (mixed eval.) | 10.0 (8shot CoT) | 12.0 (8shot CoT) | 4.0 (5 shot) | 4.5 (5 shot) | 8.5 (8shot CoT) |
| **Full average** | 57.8 | 59.3 | 59.2 | 59.3 | 59.8 |
And for the 1B model:
| task | random | [StableLM 2 1.6b](https://huggingface.co/stabilityai/stablelm-2-1_6b)\* | [Pythia 1B](https://huggingface.co/EleutherAI/pythia-1b) | [TinyLlama 1.1B](https://huggingface.co/TinyLlama/TinyLlama-1.1B-intermediate-step-1195k-token-2.5T) | **OLMo 1B** (ours) |
| ------------------------------------------------------------------------------------------------------------------------------------------------------------ | ------ | ----------------- | --------- | -------------------------------------- | ------- |
| arc_challenge | 25 | 43.81 | 33.11 | 34.78 | 34.45 |
| arc_easy | 25 | 63.68 | 50.18 | 53.16 | 58.07 |
| boolq | 50 | 76.6 | 61.8 | 64.6 | 60.7 |
| copa | 50 | 84 | 72 | 78 | 79 |
| hellaswag | 25 | 68.2 | 44.7 | 58.7 | 62.5 |
| openbookqa | 25 | 45.8 | 37.8 | 43.6 | 46.4 |
| piqa | 50 | 74 | 69.1 | 71.1 | 73.7 |
| sciq | 25 | 94.7 | 86 | 90.5 | 88.1 |
| winogrande | 50 | 64.9 | 53.3 | 58.9 | 58.9 |
| Average | 36.11 | 68.41 | 56.44 | 61.48 | 62.42 |
\*Unlike OLMo, Pythia, and TinyLlama, StabilityAI has not disclosed yet the data StableLM was trained on, making comparisons with other efforts challenging.
## Model Details
### Data
For training data details, please see the [Dolma](https://huggingface.co/datasets/allenai/dolma) documentation.
### Architecture
OLMo 7B architecture with peer models for comparison.
| | **OLMo 7B** | [Llama 2 7B](https://huggingface.co/meta-llama/Llama-2-7b) | [OpenLM 7B](https://laion.ai/blog/open-lm/) | [Falcon 7B](https://huggingface.co/tiiuae/falcon-7b) | PaLM 8B |
|------------------------|-------------------|---------------------|--------------------|--------------------|------------------|
| d_model | 4096 | 4096 | 4096 | 4544 | 4096 |
| num heads | 32 | 32 | 32 | 71 | 16 |
| num layers | 32 | 32 | 32 | 32 | 32 |
| MLP ratio | ~8/3 | ~8/3 | ~8/3 | 4 | 4 |
| LayerNorm type | non-parametric LN | RMSNorm | parametric LN | parametric LN | parametric LN |
| pos embeddings | RoPE | RoPE | RoPE | RoPE | RoPE |
| attention variant | full | GQA | full | MQA | MQA |
| biases | none | none | in LN only | in LN only | none |
| block type | sequential | sequential | sequential | parallel | parallel |
| activation | SwiGLU | SwiGLU | SwiGLU | GeLU | SwiGLU |
| sequence length | 2048 | 4096 | 2048 | 2048 | 2048 |
| batch size (instances) | 2160 | 1024 | 2048 | 2304 | 512 |
| batch size (tokens) | ~4M | ~4M | ~4M | ~4M | ~1M |
| weight tying | no | no | no | no | yes |
### Hyperparameters
AdamW optimizer parameters are shown below.
| Size | Peak LR | Betas | Epsilon | Weight Decay |
|------|------------|-----------------|-------------|--------------|
| 1B | 4.0E-4 | (0.9, 0.95) | 1.0E-5 | 0.1 |
| 7B | 3.0E-4 | (0.9, 0.99) | 1.0E-5 | 0.1 |
Optimizer settings comparison with peer models.
| | **OLMo 7B** | [Llama 2 7B](https://huggingface.co/meta-llama/Llama-2-7b) | [OpenLM 7B](https://laion.ai/blog/open-lm/) | [Falcon 7B](https://huggingface.co/tiiuae/falcon-7b) |
|-----------------------|------------------|---------------------|--------------------|--------------------|
| warmup steps | 5000 | 2000 | 2000 | 1000 |
| peak LR | 3.0E-04 | 3.0E-04 | 3.0E-04 | 6.0E-04 |
| minimum LR | 3.0E-05 | 3.0E-05 | 3.0E-05 | 1.2E-05 |
| weight decay | 0.1 | 0.1 | 0.1 | 0.1 |
| beta1 | 0.9 | 0.9 | 0.9 | 0.99 |
| beta2 | 0.95 | 0.95 | 0.95 | 0.999 |
| epsilon | 1.0E-05 | 1.0E-05 | 1.0E-05 | 1.0E-05 |
| LR schedule | linear | cosine | cosine | cosine |
| gradient clipping | global 1.0 | global 1.0 | global 1.0 | global 1.0 |
| gradient reduce dtype | FP32 | FP32 | FP32 | BF16 |
| optimizer state dtype | FP32 | most likely FP32 | FP32 | FP32 |
## Environmental Impact
OLMo 7B variants were either trained on MI250X GPUs at the LUMI supercomputer, or A100-40GB GPUs provided by MosaicML.
A summary of the environmental impact. Further details are available in the paper.
| | GPU Type | Power Consumption From GPUs | Carbon Intensity (kg CO₂e/KWh) | Carbon Emissions (tCO₂eq) |
|-----------|------------|-----------------------------|--------------------------------|---------------------------|
| OLMo 7B Twin | MI250X ([LUMI supercomputer](https://www.lumi-supercomputer.eu)) | 135 MWh | 0* | 0* |
| OLMo 7B | A100-40GB ([MosaicML](https://www.mosaicml.com)) | 104 MWh | 0.656 | 75.05 |
## Bias, Risks, and Limitations
Like any base language model or fine-tuned model without safety filtering, it is relatively easy for a user to prompt these models to generate harmful and generally sensitive content.
Such content can also be produced unintentionally, especially in the case of bias, so we recommend users consider the risks of applications of this technology.
Otherwise, many facts from OLMo or any LLM will often not be true, so they should be checked.
## Citation
**BibTeX:**
```
@article{Groeneveld2023OLMo,
title={OLMo: Accelerating the Science of Language Models},
author={Groeneveld, Dirk and Beltagy, Iz and Walsh, Pete and Bhagia, Akshita and Kinney, Rodney and Tafjord, Oyvind and Jha, Ananya Harsh and Ivison, Hamish and Magnusson, Ian and Wang, Yizhong and Arora, Shane and Atkinson, David and Authur, Russell and Chandu, Khyathi and Cohan, Arman and Dumas, Jennifer and Elazar, Yanai and Gu, Yuling and Hessel, Jack and Khot, Tushar and Merrill, William and Morrison, Jacob and Muennighoff, Niklas and Naik, Aakanksha and Nam, Crystal and Peters, Matthew E. and Pyatkin, Valentina and Ravichander, Abhilasha and Schwenk, Dustin and Shah, Saurabh and Smith, Will and Subramani, Nishant and Wortsman, Mitchell and Dasigi, Pradeep and Lambert, Nathan and Richardson, Kyle and Dodge, Jesse and Lo, Kyle and Soldaini, Luca and Smith, Noah A. and Hajishirzi, Hannaneh},
journal={Preprint},
year={2024}
}
```
**APA:**
Groeneveld, D., Beltagy, I., Walsh, P., Bhagia, A., Kinney, R., Tafjord, O., Jha, A., Ivison, H., Magnusson, I., Wang, Y., Arora, S., Atkinson, D., Authur, R., Chandu, K., Cohan, A., Dumas, J., Elazar, Y., Gu, Y., Hessel, J., Khot, T., Merrill, W., Morrison, J., Muennighoff, N., Naik, A., Nam, C., Peters, M., Pyatkin, V., Ravichander, A., Schwenk, D., Shah, S., Smith, W., Subramani, N., Wortsman, M., Dasigi, P., Lambert, N., Richardson, K., Dodge, J., Lo, K., Soldaini, L., Smith, N., & Hajishirzi, H. (2024). OLMo: Accelerating the Science of Language Models. Preprint.
## Model Card Contact
For errors in this model card, contact Nathan, Akshita or Shane, `{nathanl, akshitab, shanea} at allenai dot org`. |
mradermacher/Jett-w26-abliterated-GGUF | mradermacher | 2024-06-02T07:06:57Z | 3,130 | 0 | transformers | [
"transformers",
"gguf",
"mergekit",
"merge",
"en",
"base_model:giannisan/Jett-w26-abliterated",
"endpoints_compatible",
"region:us"
] | null | 2024-06-02T03:52:04Z | ---
base_model: giannisan/Jett-w26-abliterated
language:
- en
library_name: transformers
quantized_by: mradermacher
tags:
- mergekit
- merge
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
static quants of https://huggingface.co/giannisan/Jett-w26-abliterated
<!-- provided-files -->
weighted/imatrix quants are available at https://huggingface.co/mradermacher/Jett-w26-abliterated-i1-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/Jett-w26-abliterated-GGUF/resolve/main/Jett-w26-abliterated.Q2_K.gguf) | Q2_K | 2.8 | |
| [GGUF](https://huggingface.co/mradermacher/Jett-w26-abliterated-GGUF/resolve/main/Jett-w26-abliterated.IQ3_XS.gguf) | IQ3_XS | 3.1 | |
| [GGUF](https://huggingface.co/mradermacher/Jett-w26-abliterated-GGUF/resolve/main/Jett-w26-abliterated.Q3_K_S.gguf) | Q3_K_S | 3.3 | |
| [GGUF](https://huggingface.co/mradermacher/Jett-w26-abliterated-GGUF/resolve/main/Jett-w26-abliterated.IQ3_S.gguf) | IQ3_S | 3.3 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/Jett-w26-abliterated-GGUF/resolve/main/Jett-w26-abliterated.IQ3_M.gguf) | IQ3_M | 3.4 | |
| [GGUF](https://huggingface.co/mradermacher/Jett-w26-abliterated-GGUF/resolve/main/Jett-w26-abliterated.Q3_K_M.gguf) | Q3_K_M | 3.6 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/Jett-w26-abliterated-GGUF/resolve/main/Jett-w26-abliterated.Q3_K_L.gguf) | Q3_K_L | 3.9 | |
| [GGUF](https://huggingface.co/mradermacher/Jett-w26-abliterated-GGUF/resolve/main/Jett-w26-abliterated.IQ4_XS.gguf) | IQ4_XS | 4.0 | |
| [GGUF](https://huggingface.co/mradermacher/Jett-w26-abliterated-GGUF/resolve/main/Jett-w26-abliterated.Q4_K_S.gguf) | Q4_K_S | 4.2 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Jett-w26-abliterated-GGUF/resolve/main/Jett-w26-abliterated.Q4_K_M.gguf) | Q4_K_M | 4.5 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Jett-w26-abliterated-GGUF/resolve/main/Jett-w26-abliterated.Q5_K_S.gguf) | Q5_K_S | 5.1 | |
| [GGUF](https://huggingface.co/mradermacher/Jett-w26-abliterated-GGUF/resolve/main/Jett-w26-abliterated.Q5_K_M.gguf) | Q5_K_M | 5.2 | |
| [GGUF](https://huggingface.co/mradermacher/Jett-w26-abliterated-GGUF/resolve/main/Jett-w26-abliterated.Q6_K.gguf) | Q6_K | 6.0 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/Jett-w26-abliterated-GGUF/resolve/main/Jett-w26-abliterated.Q8_0.gguf) | Q8_0 | 7.8 | fast, best quality |
| [GGUF](https://huggingface.co/mradermacher/Jett-w26-abliterated-GGUF/resolve/main/Jett-w26-abliterated.f16.gguf) | f16 | 14.6 | 16 bpw, overkill |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
digiplay/ARRealVX1.1 | digiplay | 2023-12-01T23:31:25Z | 3,128 | 5 | diffusers | [
"diffusers",
"safetensors",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"license:other",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | 2023-07-06T01:31:14Z | ---
license: other
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
inference: true
---
Model info :
https://civitai.com/models/56298?modelVersionId=110552
Sample image I made :



Original Author's DEMO images:





|
FFusion/400GB-LoraXL | FFusion | 2023-09-17T06:30:59Z | 3,126 | 54 | diffusers | [
"diffusers",
"stable-diffusion-xl",
"stable-diffusion",
"text-to-image",
"lora",
"loraxl",
"ffai",
"en",
"base_model:FFusion/FFXL400",
"license:openrail++",
"region:us"
] | text-to-image | 2023-09-07T10:07:02Z | ---
license: openrail++
base_model: FFusion/FFXL400
instance_prompt: Morphxl_V10
widget:
- text: >-
cyber bunny solo, looking at viewer, long sleeves, 1girl, holding, animal ears, jewelry, closed mouth, standing, latex jacket, upper body, weapon, female focus, outdoors, open clothes, solo focus, belt, necklace, holding weapon, rabbit ears, blurry . graphic illustration, comic art, graphic novel art, vibrant, highly detailed
example_title: Cyber Bunny FFusion
- text: >-
a dog in colorful exploding clouds, dreamlike surrealism colorful smoke and fire coming
out of it, explosion of data fragments, exploding background,realistic explosion, 3d digital art
example_title: Dogo FFusion
- text: >-
a sprinkled donut sitting on top of a table, colorful hyperrealism, everything is made of candy, hyperrealistic digital
painting, covered in sprinkles and crumbs, vibrant colors hyper realism,colorful smoke explosion background
example_title: Donut FFusion
- text: >-
a cup of coffee with a tree in it, surreal art, awesome great composition,
surrealism, ice cubes in tree, colorful clouds, perfectly realistic yet surreal
example_title: CoFFee FFusion
- text: >-
brightly colored headphones with a splash of colorful paint splash, vibing
to music, stunning artwork, music is life, beautiful digital artwork, concept art, cinematic, dramatic, intricate details, dark
lighting
example_title: Headset FFusion
- text: >-
high-quality game character digital design, Unreal Engine, Water color painting, Mecha- Monstrous high quality game fantasy rpg character design, dark rainbow Fur Scarf, inside of a Superficial Outhouse, at Twilight, Overdetailed art
example_title: Digital FFusion
Negative prompt: photograph, deformed, glitch, noisy, realistic, stock photo, watermark,signature
tags:
- stable-diffusion-xl
- diffusers
- stable-diffusion
- text-to-image
- lora
- loraxl
- ffai
language:
- en
thumbnail: >-
https://huggingface.co/FFusion/400GB-LoraXL/resolve/main/images/image0thumb.jpg
library_name: diffusers
---
[](https://huggingface.co/FFusion/400GB-LoraXL/tree/main)
# 🌌 FFusion's Universe of LoRA Models for Hugging Face 🌠
Welcome to the FFusion LoRA extracted models repository on Hugging Face! Here, we present a collection of models extracted using the Low-Rank Adaptation (LoRA) technique to provide a rich dataset for research and further exploration.
# LoRA 66-98 Specifications
| Model Name | UNet Magnitude | UNet Strength | UNet Conv Magnitude | UNet Conv Strength | Text Encoder 1 Magnitude | Text Encoder 1 Strength | Text Encoder 2 Magnitude | Text Encoder 2 Strength |
|------------|----------------|---------------|---------------------|--------------------|--------------------------|------------------------|--------------------------|------------------------|
| sdxlYamersRealism_version2.FFai.lora64.safetensors | 4.154722048359913 | 0.010771295011342323 | 4.015763928139778 | 0.004715556773610134 | 3.958945306529754 | 0.013064685133728026 | 3.9970537933453656 | 0.01012922219208529 |
| FF.66.hassakuSfwNsfwAlphav_alphaV02.lora.safetensors | 4.6113617624162275 | 0.011981260592954776 | 6.686307668617343 | 0.006950538604713883 | 3.807746602732888 | 0.012745779610859834 | 3.729743715233202 | 0.009551327927254742 |
| FF.67.galaxytimemachinesGTM_xlplusV10.lora.safetensors | 5.2081857497500135 | 0.012861152998866098 | 6.477215331015863 | 0.005731545812523109 | 3.865321475649114 | 0.012968309181164591 | 3.791585137796209 | 0.009739622211064131 |
| FF.68.furtasticxl_BetaEPOCHS3.lora.safetensors | 4.82028448554389 | 0.012252009690673311 | 6.774379998733585 | 0.007177153983462227 | 4.20241893596518 | 0.01346020465857439 | 4.260738640446866 | 0.010471828656006711 |
| FF.69.formulaxlXLComfyui_v20Pruned.lora.safetensors | 4.194797467480407 | 0.010794051441520451 | 5.658129971781666 | 0.004699672960547711 | 3.9974802957054556 | 0.013097433444426298 | 4.090353610501367 | 0.010226978548569817 |
| FF.70.FinalAnimeCG_mk2a2.lora.safetensors | 5.832734982003316 | 0.013620979564593433 | 6.588312134998715 | 0.006310420276329548 | 3.856879807170544 | 0.012947154068967848 | 3.7769155501438316 | 0.009654614341923677 |
| FF.71.explicitFreedomNSFW_beta.lora.safetensors | 4.501298830893416 | 0.01109003259855744 | 6.204555848757276 | 0.005750268214362425 | 3.85944453350698 | 0.012919606802022875 | 3.9375385889629477 | 0.010088601556714144 |
| FF.72.endjourneyXL_v11.lora.safetensors | 4.202640614034873 | 0.010788684869548844 | 5.80301284455635 | 0.005029451652697187 | 3.835258093635928 | 0.012878727225694529 | 3.7550355683040344 | 0.009627099200498888 |
| FF.73.dreamshaperXL10_alpha2Xl10.lora.safetensors | 3.859263254032285 | 0.010177448403109668 | 0.0 | 0.0 | Not Found | Not Found | Not Found | Not Found |
| FF.74.copaxTimelessxlSDXL1_v5.lora.safetensors | 4.006565464438231 | 0.010389718183037322 | 5.738000089710234 | 0.0048703539869873365 | Not Found | Not Found | Not Found | Not Found |
| FF.75.cinemaxAlphaSDXLCinema_alpha1.lora.safetensors | 4.466204403397648 | 0.011222293042751443 | 5.684097723570108 | 0.004689726735887235 | 3.9233677697347935 | 0.013047985608868315 | 3.967672834668905 | 0.010161683571519127 |
| FF.76.brixlAMustInYour_v20Banu.lora.safetensors | 5.201652157233597 | 0.012340885235722432 | 6.246570986909302 | 0.005628776318139394 | 3.7901131354041215 | 0.012251635754363702 | 3.9011343266469787 | 0.009675557128661683 |
| FF.77.animeChangefulXL_v10ReleasedCandidate.lora.safetensors | 4.8712592588918255 | 0.011882757534620026 | 6.307265147238472 | 0.005707653219309981 | 3.806143895360976 | 0.012739821013629662 | 3.7378093050117975 | 0.009586058803350757 |
| FF.78.xlYamersCartoonArcadia_v1.lora.safetensors | 4.353353198959002 | 0.010753757289463425 | 5.9177157902332835 | 0.0051653985959496315 | 3.8127760281067853 | 0.012772330040804636 | 3.764581932297466 | 0.009682294095990565 |
| FF.79.venusxl_v11.lora.safetensors | 4.0781163529498725 | 0.01056802143213069 | 5.725042873950945 | 0.004766753768581111 | 3.8819661703272876 | 0.01297504551077796 | 3.8989897630581978 | 0.00999233670699671 |
| FF.80.unsafexl_v20.lora.safetensors | 4.433128703574937 | 0.01126235056722307 | 5.6776551531768105 | 0.004711627911345002 | 3.9928442365475028 | 0.013100078304973888 | 3.945462724939238 | 0.010062376848996262 |
| FF.81.sdxlYamersRealism_version2.lora.safetensors | 4.229406260655774 | 0.01076863108078825 | 5.653783535189452 | 0.004649401315378378 | 3.958945306529754 | 0.013064685133728026 | 3.9970537933453656 | 0.01012922219208529 |
| FF.82.sdxlUnstableDiffusers_v6StabilityEater.lora.safetensors | 4.387654105095919 | 0.010840575656477952 | 5.859291158408854 | 0.004964447160293478 | 3.8646596391683863 | 0.012911755181541458 | 3.840901404987889 | 0.009815472265736007 |
| FF.83.sdxlNuclearGeneralPurposeSemi_v10.lora.safetensors | 4.329690552630377 | 0.01081156604611163 | 5.754435529197304 | 0.004791491470688117 | 3.908995280978119 | 0.012984716052686607 | 3.8730233638208733 | 0.009816295838443996 |
| FF.84.sdvn6Realxl_detailface.lora.safetensors | 3.9204966894076203 | 0.010152018695796424 | 5.609827023476847 | 0.004578104347668462 | Not Found | Not Found | Not Found | Not Found |
| FF.85.samaritan3dCartoon_v40SDXL.lora.safetensors | 4.1930053871423265 | 0.010823639858269587 | 6.242507300692357 | 0.006012499761466946 | 3.807746602732888 | 0.012745779610859834 | 3.729743715233202 | 0.009551327927254742 |
| FF.86.realvisxlV10_v10VAE.lora.safetensors | 4.035726046516959 | 0.01043685083171328 | 5.780022388037139 | 0.0049551385295671935 | 3.862534960968426 | 0.01291815120168007 | 3.8792245692334855 | 0.010027987691388776 |
| FF.87.RealitiesEdgeXLANIME_20.lora.safetensors | 4.322741449452443 | 0.011017050541178184 | 5.957632120776351 | 0.005321540223768453 | 3.9027693617053862 | 0.013066310297084008 | 3.941240896860996 | 0.010187814902599733 |
| FF.88.RealitiesEdgeXL_30.lora.safetensors | 4.527436449035657 | 0.011438576163998578 | 6.042128532601058 | 0.0053643976503331536 | 3.96435868300754 | 0.013183793628117942 | 4.03501811478197 | 0.01033219734045475 |
| FF.89.realisticStockPhoto_v10.lora.safetensors | 4.178010046544553 | 0.01060077238986419 | 5.832883513120958 | 0.005094057992644391 | 3.838598740372775 | 0.012775584451815206 | 3.8534473782218375 | 0.009703626948148766 |
| FF.90.realisticFreedomSFW_alpha.lora.safetensors | 4.570225351823505 | 0.011338880456799554 | 6.107921122775599 | 0.005313926393612039 | 3.9145800451769137 | 0.012987243885510853 | 3.9456476675702756 | 0.010086475486504298 |
| FF.91.realcartoonXL_v2.lora.safetensors | 4.264556294830096 | 0.010837268212782766 | 5.775273580445967 | 0.004823115907624419 | 3.868685000881062 | 0.012967535154814412 | 3.8942008722126786 | 0.009956078788817995 |
| FF.92.pyrosSDModelsBlowjob_v0122022steps.lora.safetensors | 4.29299465986103 | 0.011065152509191439 | 6.148179389228268 | 0.005785365500822891 | Not Found | Not Found | Not Found | Not Found |
| FF.93.pyrosNSFWSDXL_v013e6.lora.safetensors | 4.462978487594761 | 0.011458003048327881 | 6.365678967519903 | 0.006252718402740558 | Not Found | Not Found | Not Found | Not Found |
| FF.94.nightvisionXLPhotorealisticPortrait_v0743ReleaseBakedvae.lora.safetensors | 4.30821859959078 | 0.01092674471500856 | 5.760595716272804 | 0.0047913433799900915 | 4.082814836813033 | 0.013277437149876429 | 4.269554751742187 | 0.0104525629385582 |
| FF.95.newone_v10.lora.safetensors | 3.9863974933790827 | 0.010221166935769414 | 5.591587011383119 | 0.004544408523927106 | 3.826913276992613 | 0.012515731668562081 | 3.7789877235680827 | 0.008847150427050579 |
| FF.96.MOHAWK_v10BETA.lora.safetensors | 4.13427196290026 | 0.010604709463386349 | 5.906059771550209 | 0.005266774851315859 | 3.8816106810049615 | 0.013007851116722372 | 3.795246249757246 | 0.009741588405668723 |
| FF.97.juggernautXL_version4.lora.safetensors | 4.351658373013424 | 0.01097575598820061 | 5.7254163997882515 | 0.0048427100518286656 | 3.98009165065858 | 0.013189073899460014 | 4.452439746998783 | 0.010877184808674183 |
| FF.98.sdxlYamersRealism_version2.lora.safetensors | 4.229406260655774 | 0.01076863108078825 | 5.653783535189452 | 0.004649401315378378 | 3.958945306529754 | 0.013064685133728026 | 3.9970537933453656 | 0.01012922219208529 |
[](https://huggingface.co/FFusion/400GB-LoraXL/tree/main)
[](https://huggingface.co/FFusion/400GB-LoraXL/tree/main)
[](https://huggingface.co/FFusion/400GB-LoraXL/tree/main)
[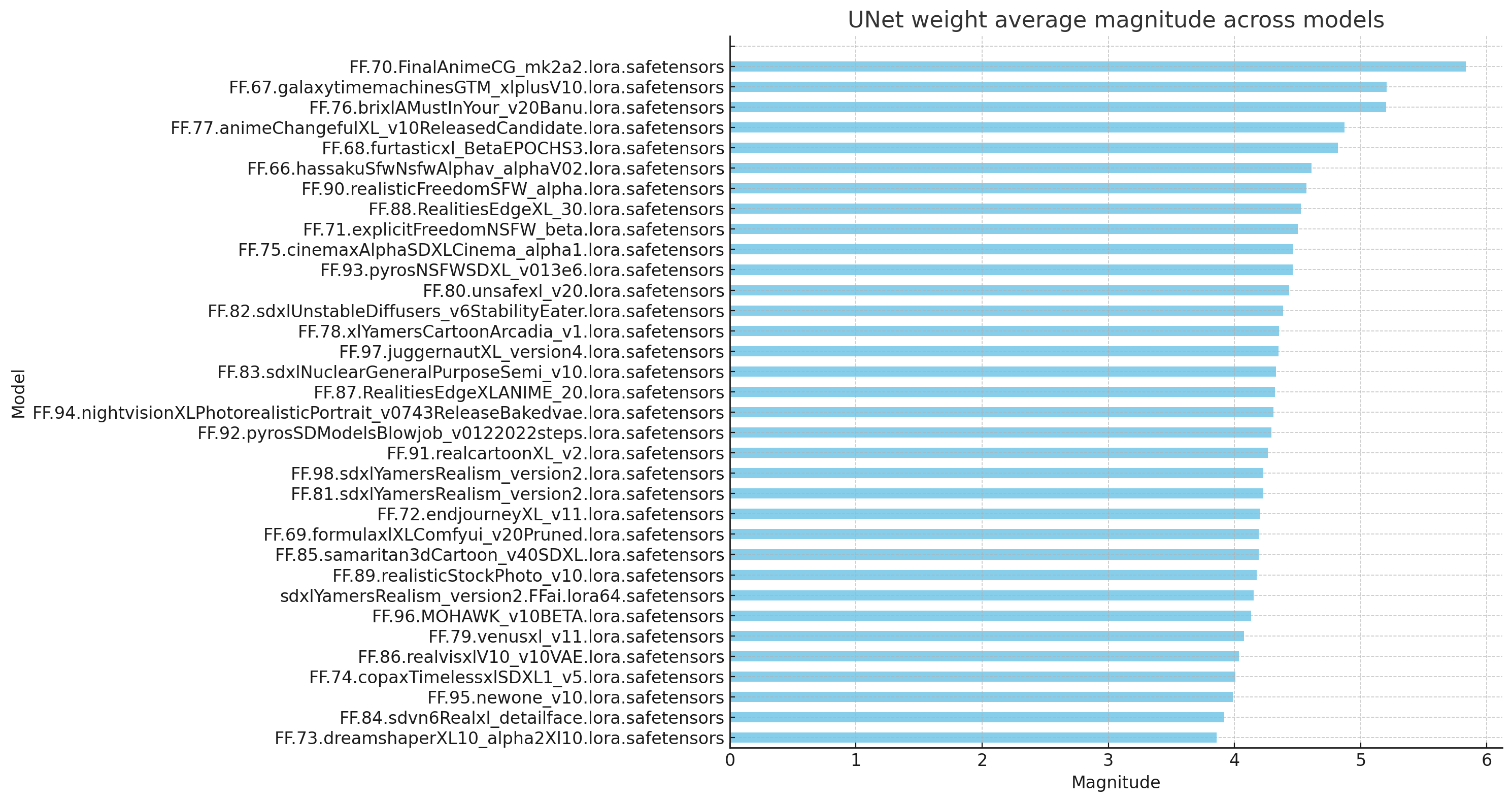](https://huggingface.co/FFusion/400GB-LoraXL/tree/main)
[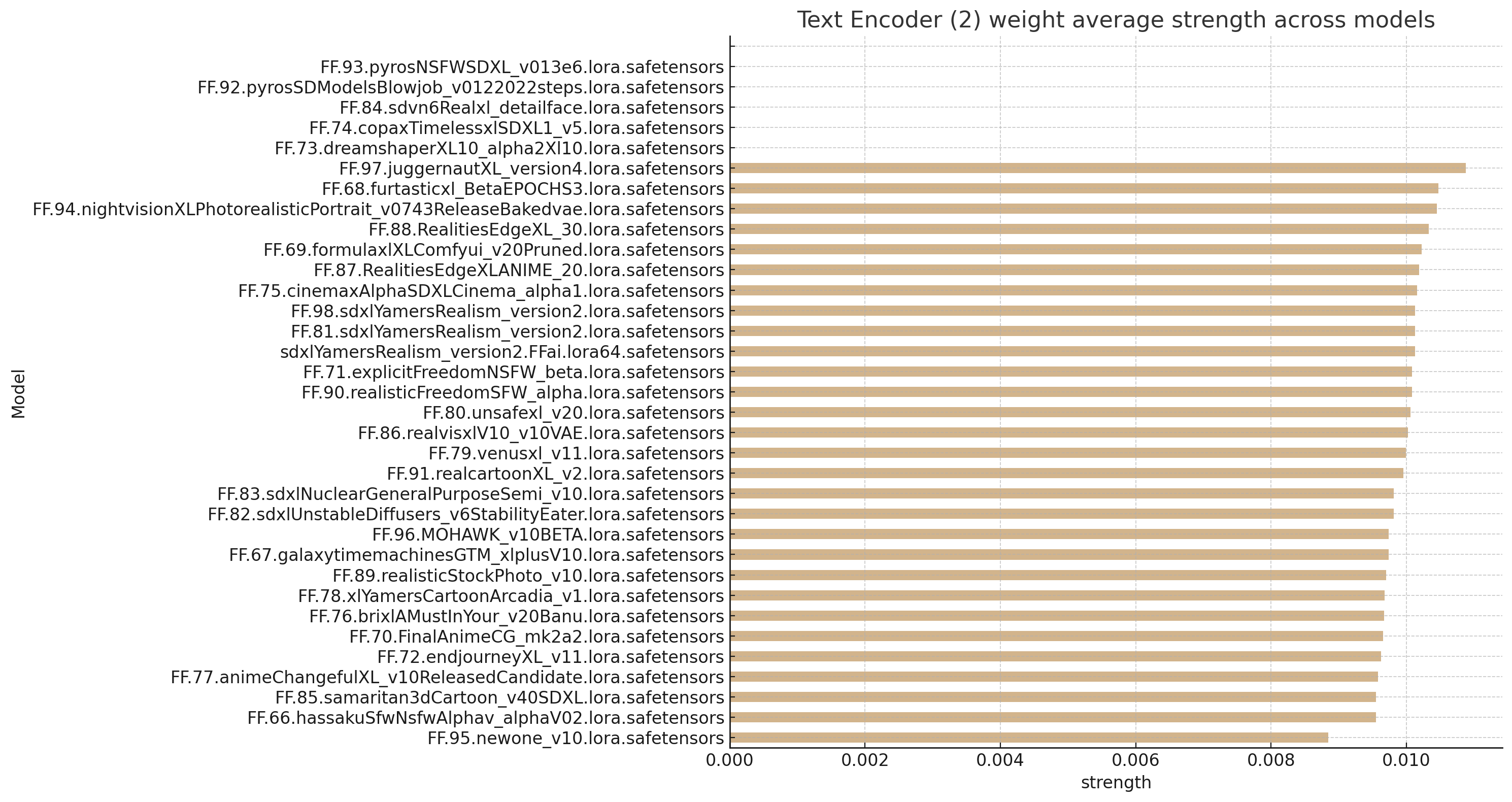](https://huggingface.co/FFusion/400GB-LoraXL/tree/main)
[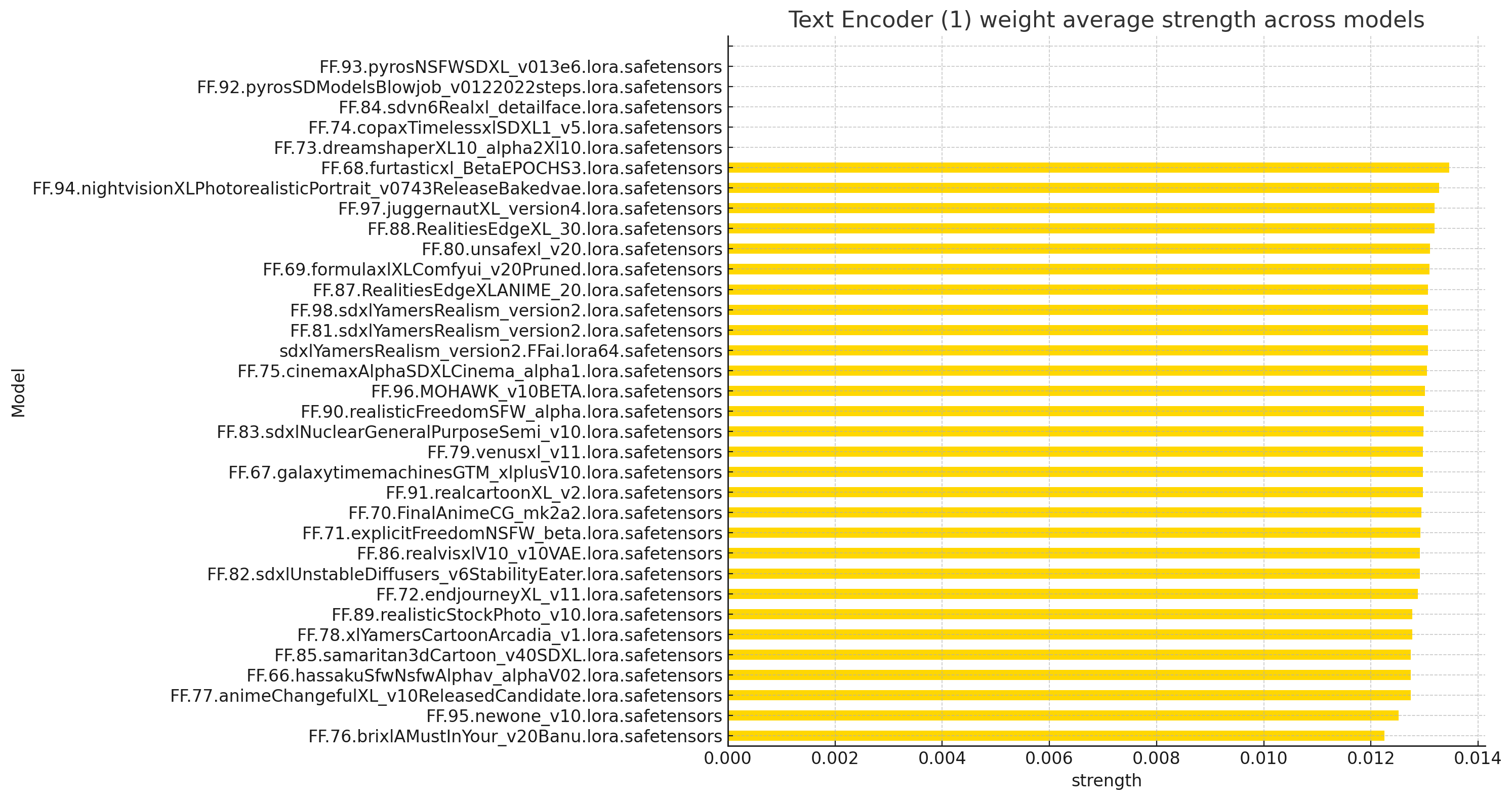](https://huggingface.co/FFusion/400GB-LoraXL/tree/main)
[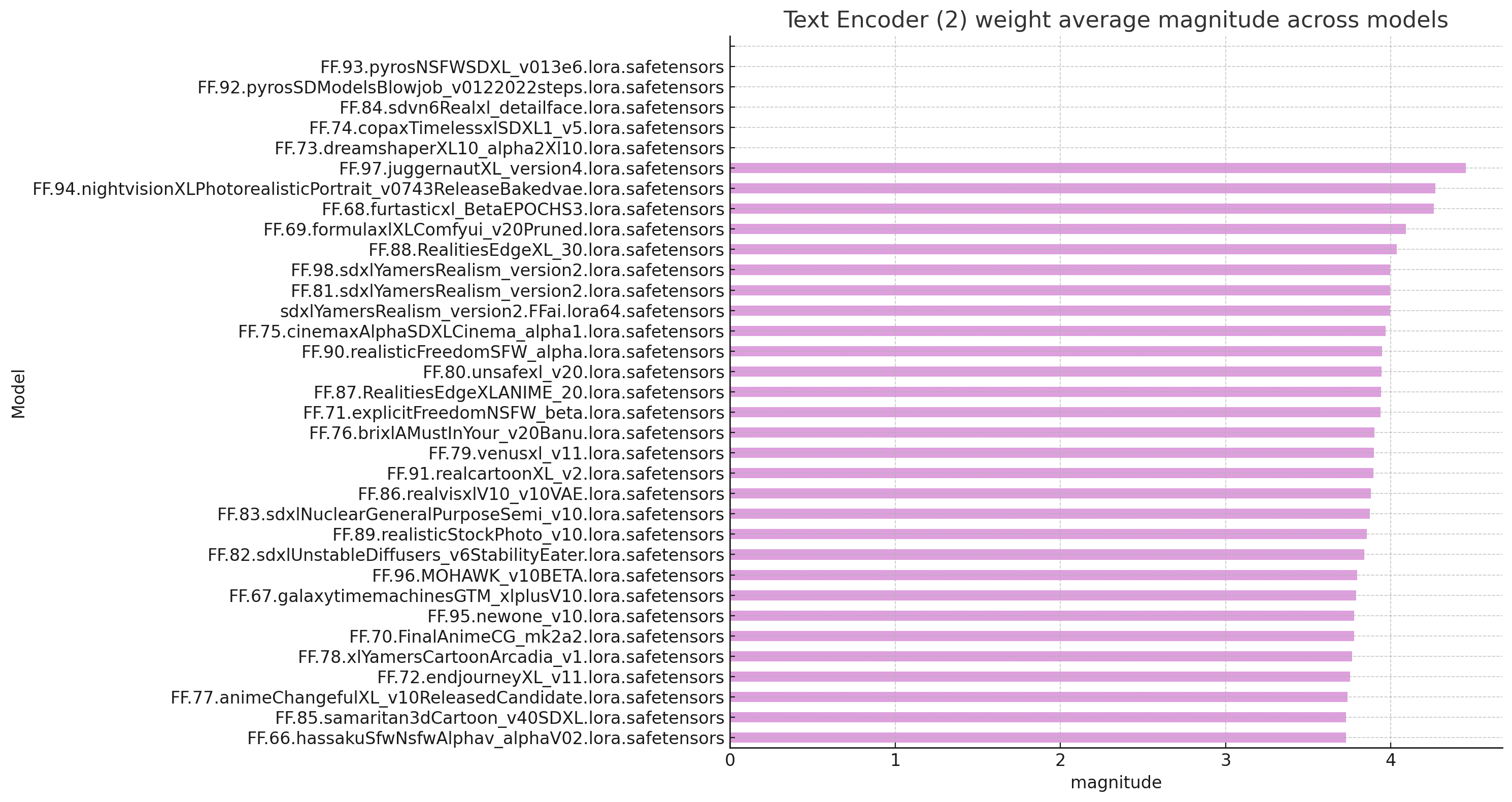](https://huggingface.co/FFusion/400GB-LoraXL/tree/main)
[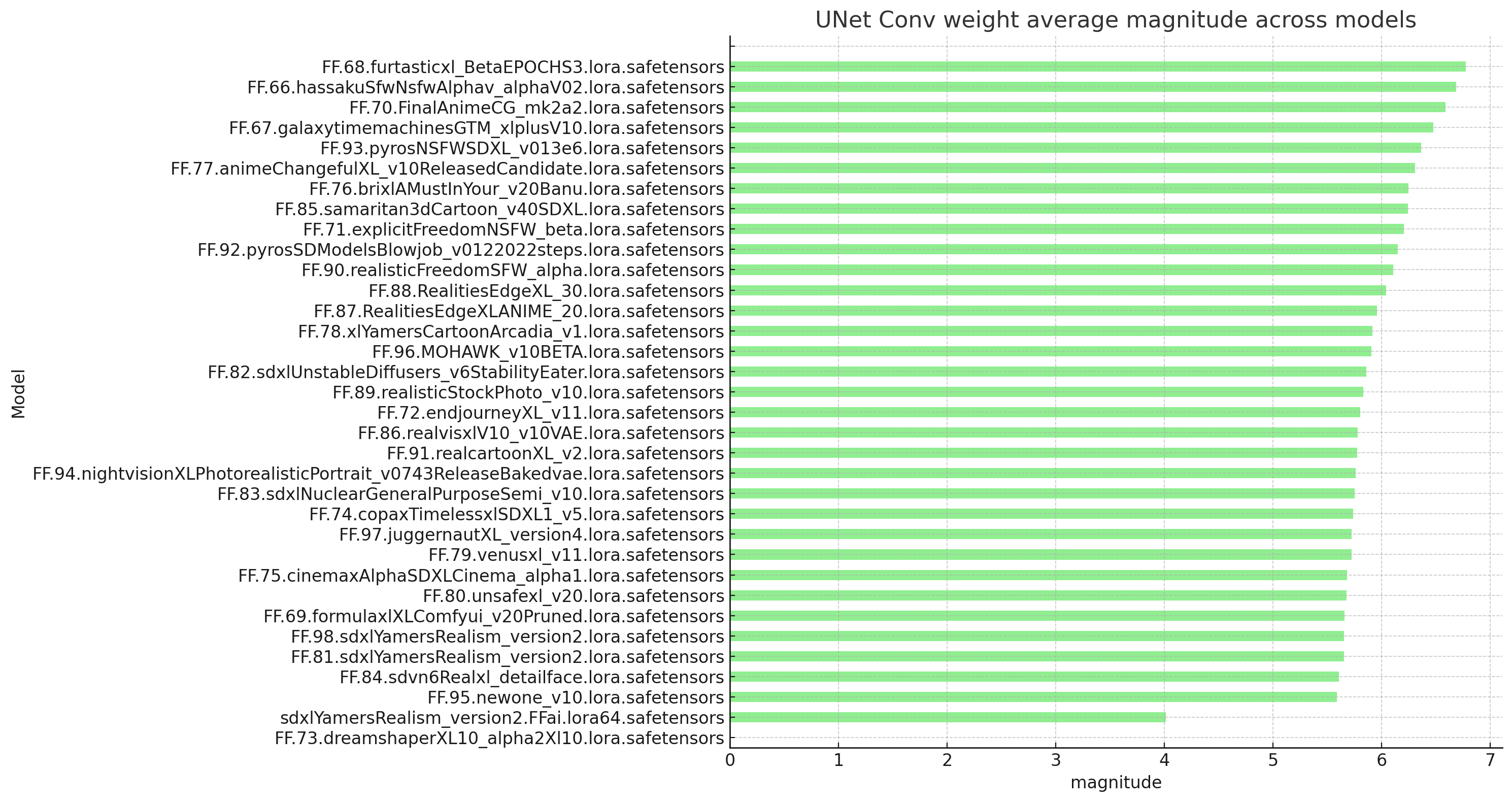](https://huggingface.co/FFusion/400GB-LoraXL/tree/main)
[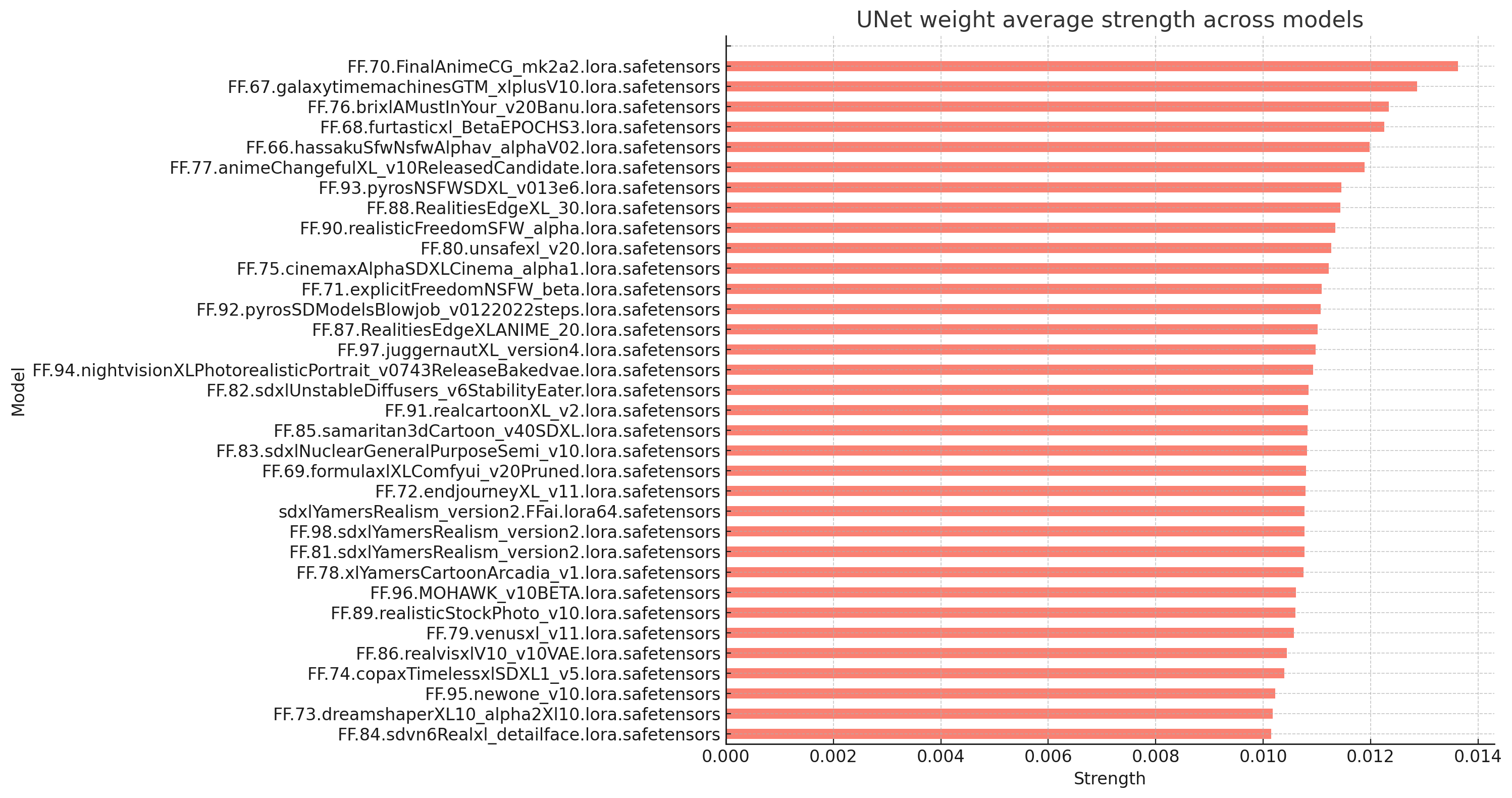](https://huggingface.co/FFusion/400GB-LoraXL/tree/main)
[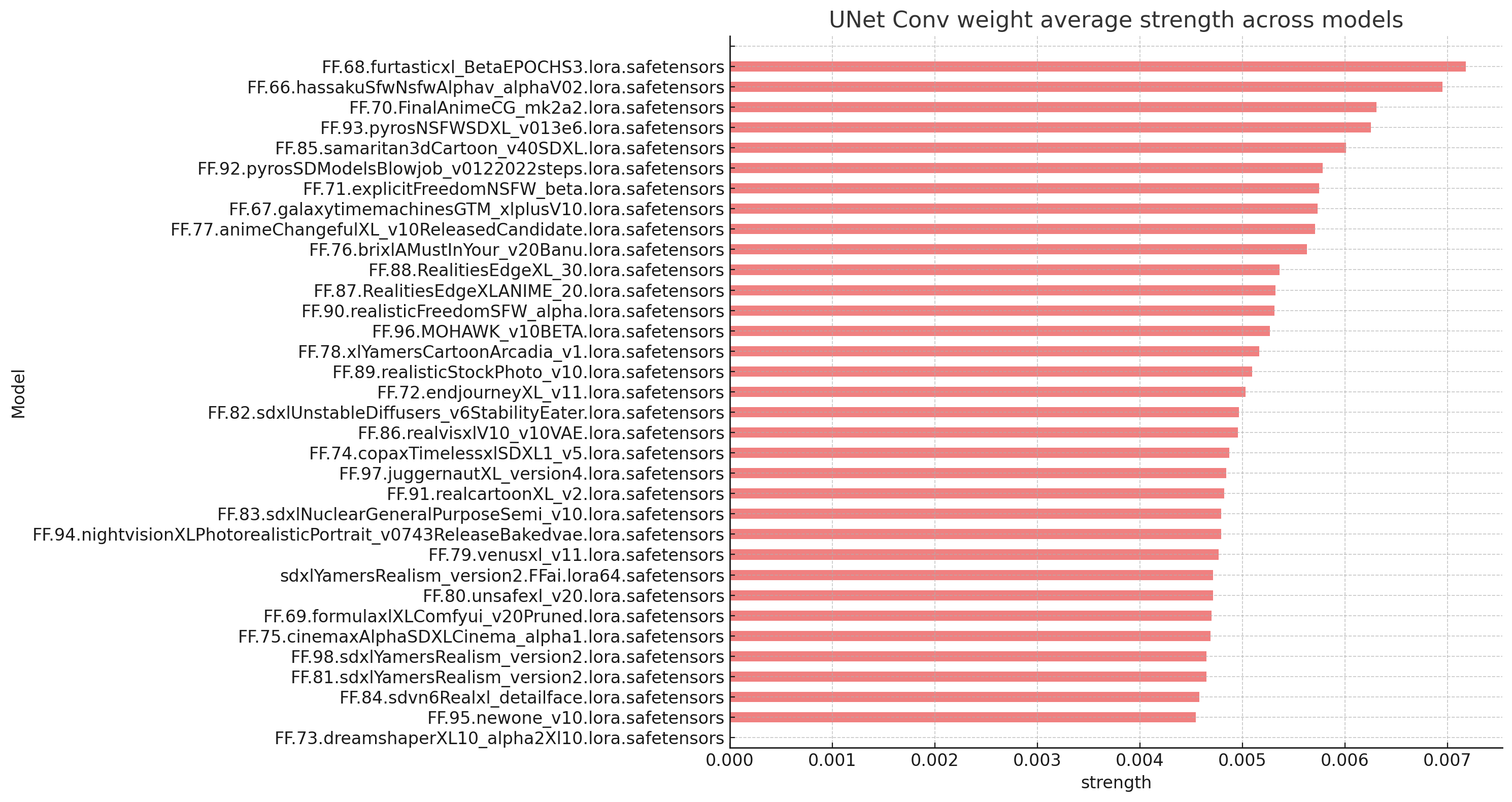](https://huggingface.co/FFusion/400GB-LoraXL/tree/main)
[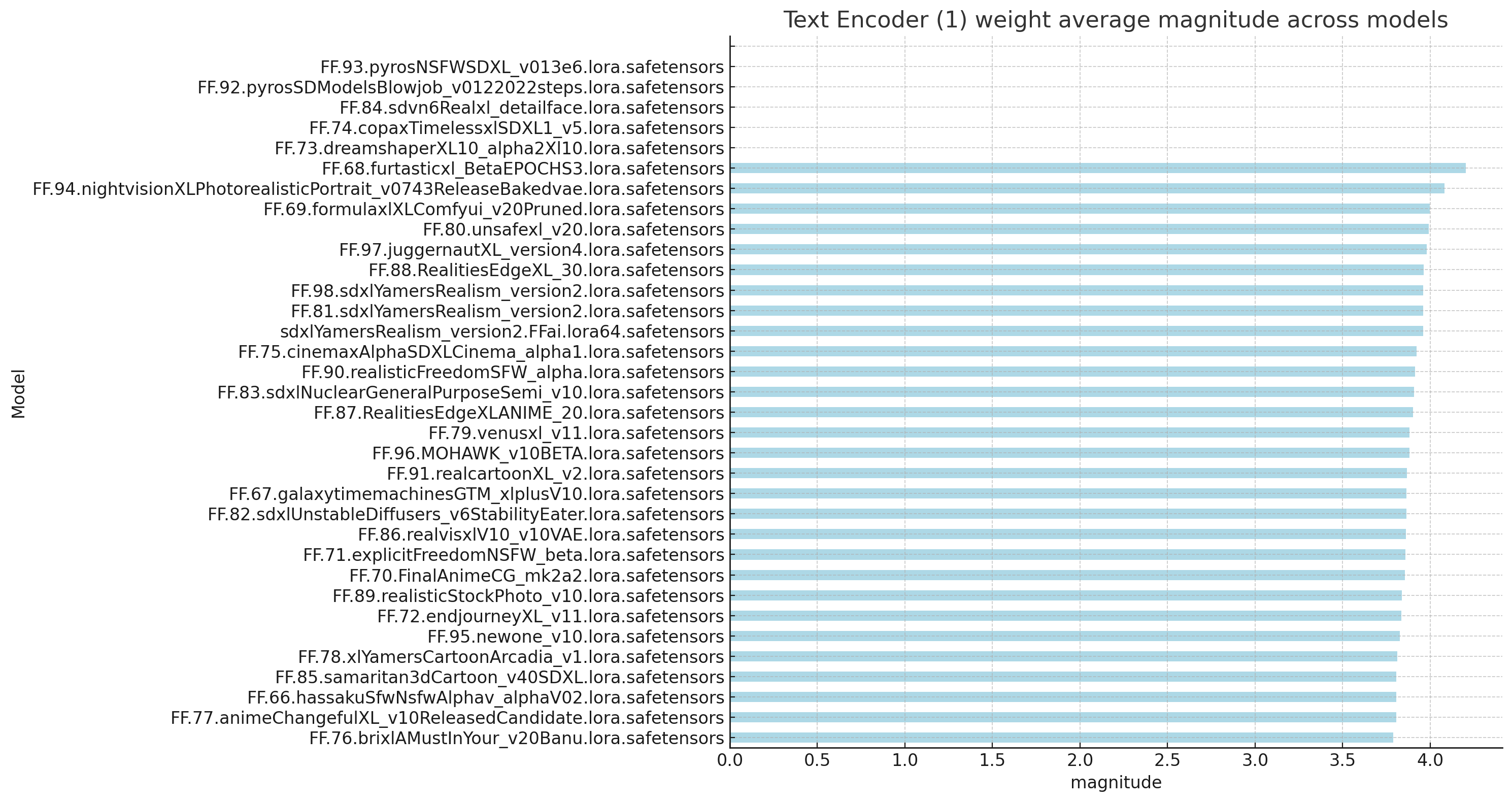](https://huggingface.co/FFusion/400GB-LoraXL/tree/main)
## 📦 Base Models
The following models served as the foundation for our extractions:
- [stabilityai/stable-diffusion-xl-base-1.0](https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0)
- [stabilityai/stable-diffusion-xl-base-0.9](https://huggingface.co/stabilityai/stable-diffusion-xl-base-0.9)
- [FFusion/FFusionXL-BASE](https://huggingface.co/FFusion/FFusionXL-BASE)
## 🌟 Recommended Models for Inference
For those on the quest for ideal models to drive their inference tasks, we especially recommend:
- [FFusionXL-BASE](https://huggingface.co/FFusion/FFusionXL-BASE) - Our signature base model, meticulously trained with licensed images.
- [FFXL400 Combined LoRA Model 🚀](https://huggingface.co/FFusion/FFXL400) - A galactic blend of power and precision in the world of LoRA models.
Rest assured, our LoRAs, even at weight 1.0, maintain compatibility with most of the current SDXL models.
## 🔍 Extraction Details
- **Variants:** Each base model was extracted into 4-5 distinct variants.
- **Extraction Depth:** The models uploaded here contain approximately 70% of extracted data. These extractions yield a dataset size of around 400 GB.
- **Precision:** We experimented with both `float32` and `float64` for optimal extraction results.
- **Differences Measurement:** Singular Value Decomposition (SVD) was utilized to measure differences between the original and the tuned models. A threshold of 1e-3 was commonly used, although in some cases, 1e-5 and 1e-2 were tested.
- **Demonstration Parameters:** For our demonstration, we employed `"conv_dim": 256` and `"conv_alpha": 256`.
[](https://huggingface.co/FFusion/400GB-LoraXL/resolve/main/images/image8.jpg)
## ⚙️ Technical Notes
- Most SDXL models in this collection are not traditionally "trained." Instead, they are merged from previous SDXL 0.9 versions or created using other methods with the help of Comfy UI.
- An important note for users: all models saved with Comfy add an extra key `text_model.encoder.text_model.embeddings.position_ids`. We've made necessary adjustments to ensure compatibility with the current scripts from Kohoya.
## 📈 Use Cases
These extracted models are intended for research and testing. They can be particularly useful for:
- Investigating the potential of merging multiple LoRAs.
- Weighting experiments with 1-5 LoRAs simultaneously.
- Exploring the differences and similarities between LoRAs extracted from different base models.
[](https://huggingface.co/FFusion/400GB-LoraXL/resolve/main/images/image2.jpg)
# FFusion LoRA Extracted Models - How to Use Guide 🧠
Welcome to the technical guide for using the FFusion LoRA extracted models. This document will walk you through the steps required to fuse LoRA parameters, load checkpoints, and perform inference.
## Fusing LoRA Parameters 🔗
To merge the LoRA parameters with the original parameters of the underlying model(s), leading to a potential speedup in inference latency:
```python
pipe.fuse_lora()
```
### Unfusing LoRA Parameters ⛓️
To revert the effects of `fuse_lora()`:
```python
pipe.unfuse_lora()
```
### Working with Different LoRA Scales 🎚️
To control the influence of the LoRA parameters on the outputs:
```python
pipe.fuse_lora(lora_scale=0.5)
```
## Working with FFusion Models 🔍
Here's how to load and utilize our FFusion models:
```python
from diffusers import DiffusionPipeline
import torch
pipeline_id = "FFusion/FFusionXL-BASE"
pipe = DiffusionPipeline.from_pretrained(pipeline_id, torch_dtype=torch.float16)
pipe.enable_model_cpu_offload()
lora_model_id = "FFusion/400GB-LoraXL"
lora_filename = "FFai.0038.Realitycheckxl_Alpha11.lora.safetensors"
pipe.load_lora_weights(lora_model_id, weight_name=lora_filename)
prompt = "papercut sonic"
image = pipe(prompt=prompt, num_inference_steps=20, generator=torch.manual_seed(0)).images[0]
image
```
## Running Inference 🖼️
After loading the desired model, you can perform inference as follows:
```python
generator = torch.manual_seed(0)
images_fusion = pipe(
- "masterpiece, best quality, mountain", output_type="np", generator=generator, num_inference_steps=25
).images
```
## ⚠️ License & Usage Disclaimers
**Please review the full [license agreement](https://huggingface.co/FFusion/FFXL400/blob/main/LICENSE.md) before accessing or using the models.**
🔴 The models and weights available in this repository are **strictly for research and testing purposes**, with exceptions noted below. They are **not** generally intended for commercial use and are dependent on each individual LORA.
🔵 **Exception for Commercial Use:** The [FFusionXL-BASE](https://huggingface.co/FFusion/FFusionXL-BASE), [FFusion-BaSE](https://huggingface.co/FFusion/FFusion-BaSE), [di.FFUSION.ai-v2.1-768-BaSE-alpha](https://huggingface.co/FFusion/di.FFUSION.ai-v2.1-768-BaSE-alpha), and [di.ffusion.ai.Beta512](https://huggingface.co/FFusion/di.ffusion.ai.Beta512) models are trained by FFusion AI using images for which we hold licenses. Users are advised to primarily use these models for a safer experience. These particular models are allowed for commercial use.
🔴 **Disclaimer:** FFusion AI, in conjunction with Source Code Bulgaria Ltd and BlackswanTechnologies, **does not endorse or guarantee the content produced by the weights in each LORA**. There's potential for generating NSFW or offensive content. Collectively, we expressly disclaim responsibility for the outcomes and content produced by these weights.
🔴 **Acknowledgement:** The [FFusionXL-BASE](https://huggingface.co/FFusion/FFusionXL-BASE) model model is a uniquely developed version by FFusion AI. Rights to this and associated modifications belong to FFusion AI and Source Code Bulgaria Ltd. Ensure adherence to both this license and any conditions set by Stability AI Ltd for referenced models.
## Library of Available LoRA Models 📚
You can choose any of the models from our repository on Hugging Face or the upcoming repository on CivitAI. Here's a list of available models with `lora_model_id = "FFusion/400GB-LoraXL"`:
```
lora_filename =
- FFai.0001.4Guofeng4xl_V1125d.lora_Dim64.safetensors
- FFai.0002.4Guofeng4xl_V1125d.lora_Dim8.safetensors
- FFai.0003.4Guofeng4xl_V1125d.loraa.safetensors
- FFai.0004.Ambiencesdxl_A1.lora.safetensors
- FFai.0005.Ambiencesdxl_A1.lora_8.safetensors
- FFai.0006.Angrasdxl10_V22.lora.safetensors
- FFai.0007.Animaginexl_V10.lora.safetensors
- FFai.0008.Animeartdiffusionxl_Alpha3.lora.safetensors
- FFai.0009.Astreapixiexlanime_V16.lora.safetensors
- FFai.0010.Bluepencilxl_V010.lora.safetensors
- FFai.0011.Bluepencilxl_V021.lora.safetensors
- FFai.0012.Breakdomainxl_V03d.lora.safetensors
- FFai.0013.Canvasxl_Bfloat16v002.lora.safetensors
- FFai.0014.Cherrypickerxl_V20.lora.safetensors
- FFai.0015.Copaxtimelessxlsdxl1_V44.lora.safetensors
- FFai.0016.Counterfeitxl-Ffusionai-Alpha-Vae.lora.safetensors
- FFai.0017.Counterfeitxl_V10.lora.safetensors
- FFai.0018.Crystalclearxl_Ccxl.lora.safetensors
- FFai.0019.Deepbluexl_V006.lora.safetensors
- FFai.0020.Dream-Ffusion-Shaper.lora.safetensors
- FFai.0021.Dreamshaperxl10_Alpha2xl10.lora.safetensors
- FFai.0022.Duchaitenaiartsdxl_V10.lora.safetensors
- FFai.0023.Dynavisionxlallinonestylized_Beta0371bakedvae.lora.safetensors
- FFai.0024.Dynavisionxlallinonestylized_Beta0411bakedvae.lora.safetensors
- FFai.0025.Fantasticcharacters_V55.lora.safetensors
- FFai.0026.Fenrisxl_V55.lora.safetensors
- FFai.0027.Fudukimix_V10.lora.safetensors
- FFai.0028.Infinianimexl_V16.lora.safetensors
- FFai.0029.Juggernautxl_Version1.lora_1.safetensors
- FFai.0030.Lahmysterioussdxl_V330.lora.safetensors
- FFai.0031.Mbbxlultimate_V10rc.lora.safetensors
- FFai.0032.Miamodelsfwnsfwsdxl_V30.lora.safetensors
- FFai.0033.Morphxl_V10.lora.safetensors
- FFai.0034.Nightvisionxlphotorealisticportrait_Beta0681bakedvae.lora_1.safetensors
- FFai.0035.Osorubeshialphaxl_Z.lora.safetensors
- FFai.0036.Physiogenxl_V04.lora.safetensors
- FFai.0037.Protovisionxlhighfidelity3d_Beta0520bakedvae.lora.safetensors
- FFai.0038.Realitycheckxl_Alpha11.lora.safetensors
- FFai.0039.Realmixxl_V10.lora.safetensors
- FFai.0040.Reproductionsdxl_V31.lora.safetensors
- FFai.0041.Rundiffusionxl_Beta.lora.safetensors
- FFai.0042.Samaritan3dcartoon_V40sdxl.lora.safetensors
- FFai.0043.Sdvn6realxl_Detailface.lora.safetensors
- FFai.0044.Sdvn7realartxl_Beta2.lora.safetensors
- FFai.0045.Sdxl10arienmixxlasian_V10.lora.safetensors
- FFai.0046.Sdxlbasensfwfaces_Sdxlnsfwfaces03.lora.safetensors
- FFai.0047.Sdxlfaetastic_V10.lora.safetensors
- FFai.0048.Sdxlfixedvaefp16remove_Basefxiedvaev2fp16.lora.safetensors
- FFai.0049.Sdxlnijiv4_Sdxlnijiv4.lora.safetensors
- FFai.0050.Sdxlronghua_V11.lora.safetensors
- FFai.0051.Sdxlunstablediffusers_V5unchainedslayer.lora.safetensors
- FFai.0052.Sdxlyamersanimeultra_Yamersanimev2.lora.safetensors
- FFai.0053.Shikianimexl_V10.lora.safetensors
- FFai.0054.Spectrumblendx_V10.lora.safetensors
- FFai.0055.Stablediffusionxl_V30.lora.safetensors
- FFai.0056.Talmendoxlsdxl_V11beta.lora.safetensors
- FFai.0057.Wizard_V10.lora.safetensors
- FFai.0058.Wyvernmix15xl_Xlv11.lora.safetensors
- FFai.0059.Xl13asmodeussfwnsfw_V17bakedvae.lora.safetensors
- FFai.0060.Xl3experimentalsd10xl_V10.lora.safetensors
- FFai.0061.Xl6hephaistossd10xlsfw_V21bakedvaefp16fix.lora.safetensors
- FFai.0062.Xlperfectdesign_V2ultimateartwork.lora.safetensors
- FFai.0063.Xlyamersrealistic_V3.lora.safetensors
- FFai.0064.Xxmix9realisticsdxl_Testv20.lora.safetensors
- FFai.0065.Zavychromaxl_B2.lora.safetensors
- FF.66.hassakuSfwNsfwAlphav_alphaV02.lora.safetensors
- FF.67.galaxytimemachinesGTM_xlplusV10.lora.safetensors
- FF.68.furtasticxl_BetaEPOCHS3.lora.safetensors
- FF.69.formulaxlXLComfyui_v20Pruned.lora.safetensors
- FF.70.FinalAnimeCG_mk2a2.lora.safetensors
- FF.71.explicitFreedomNSFW_beta.lora.safetensors
- FF.72.endjourneyXL_v11.lora.safetensors
- FF.73.dreamshaperXL10_alpha2Xl10.lora.safetensors
- FF.74.copaxTimelessxlSDXL1_v5.lora.safetensors
- FF.75.cinemaxAlphaSDXLCinema_alpha1.lora.safetensors
- FF.76.brixlAMustInYour_v20Banu.lora.safetensors
- FF.77.animeChangefulXL_v10ReleasedCandidate.lora.safetensors
- FF.78.xlYamersCartoonArcadia_v1.lora.safetensors
- FF.79.venusxl_v11.lora.safetensors
- FF.80.unsafexl_v20.lora.safetensors
- FF.81.sdxlYamersRealism_version2.lora.safetensors
- FF.82.sdxlUnstableDiffusers_v6StabilityEater.lora.safetensors
- FF.83.sdxlNuclearGeneralPurposeSemi_v10.lora.safetensors
- FF.84.sdvn6Realxl_detailface.lora.safetensors
- FF.85.samaritan3dCartoon_v40SDXL.lora.safetensors
- FF.86.realvisxlV10_v10VAE.lora.safetensors
- FF.87.RealitiesEdgeXLANIME_20.lora.safetensors
- FF.88.RealitiesEdgeXL_30.lora.safetensors
- FF.89.realisticStockPhoto_v10.lora.safetensors
- FF.90.realisticFreedomSFW_alpha.lora.safetensors
- FF.91.realcartoonXL_v2.lora.safetensors
- FF.92.pyrosSDModelsBlowjob_v0122022steps.lora.safetensors
- FF.93.pyrosNSFWSDXL_v013e6.lora.safetensors
- FF.94.nightvisionXLPhotorealisticPortrait_v0743ReleaseBakedvae.lora.safetensors
- FF.95.newone_v10.lora.safetensors
- FF.96.MOHAWK_v10BETA.lora.safetensors
- FF.97.juggernautXL_version4.lora.safetensors
- FF.98.sdxlYamersRealism_version2.lora.safetensors
```
### 📊 Text Encoder Difference Overview
Based on the extraction process, we observed the following differences in the text encoder across various models:
[](https://huggingface.co/FFusion/400GB-LoraXL/tree/main)
- **bluePencilXL_v021** ✅ Text encoder available. Difference by 0.00140380859375
- **sdvn7Realartxl_beta2** ✅ Text encoder available. Difference by 0.00362396240234375
- **4Guofeng4XL_v1125D** 🚫 Text encoder unavailable. Same as SDXL 1.0 Base
- **ambienceSDXL_a1** ✅ Text encoder available. Difference by 0.003082275390625
- **angraSDXL10_v22** ✅ Text encoder available. Difference by 0.001953125
- **animagineXL_v10** 🚫 Text encoder unavailable. Same as SDXL 1.0 Base
- **animeArtDiffusionXL_alpha3** 🚫 Text encoder unavailable. Same as SDXL 1.0 Base
- **astreapixieXLAnime_v16** ✅ Text encoder available. Difference by 0.0029296875
- **bluePencilXL_v010** ✅ Text encoder available. Difference by 0.00177001953125
- **breakdomainxl_v03d** ✅ Text encoder available. Difference by 0.0013427734375
- **canvasxl_Bfloat16V002** ✅ Text encoder available. Difference by 0.00390625
- **cherryPickerXL_v20** ✅ Text encoder available. Difference by 0.0016450881958007812
- **copaxTimelessxlSDXL1_v44** 🚫 Text encoder unavailable. Same as SDXL 1.0 Base
- **counterfeitxl_v10** ✅ Text encoder available. Difference by 0.001708984375
- **crystalClearXL_ccxl** ✅ Text encoder available. Difference by 0.0012865066528320312
- **deepblueXL_v006** ✅ Text encoder available. Difference by 0.00200653076171875
- **dreamshaperXL10_alpha2Xl10** 🚫 Text encoder unavailable. Same as SDXL 1.0 Base
- **duchaitenAiartSDXL_v10** 🚫 Text encoder unavailable. Same as SDXL 1.0 Base
- **dynavisionXLAllInOneStylized_beta0371Bakedvae** ✅ Text encoder available. Difference by 0.00321197509765625
- **dynavisionXLAllInOneStylized_beta0411Bakedvae** ✅ Text encoder available. Difference by 0.0037841796875
- **envyoverdrivexl_v11** 🚫 Text encoder unavailable. Same as SDXL 1.0 Base
- **envypoodaxl01_v10** ✅ Text encoder available. Difference by 0.0011358261108398438
- **fantasticCharacters_v55** ✅ Text encoder available. Difference by 0.00390625
- **fenrisxl_V55** ✅ Text encoder available. Difference by 0.0086822509765625
- **fudukiMix_v10** ✅ Text encoder available. Difference by 0.0011138916015625
- **infinianimexl_v16** ✅ Text encoder available. Difference by 0.0048828125
- **juggernautXL_version1** ✅ Text encoder available. Difference by 0.001953125
- **LahMysteriousSDXL_v330** 🚫 Text encoder unavailable. Same as SDXL 1.0 Base
- **mbbxlUltimate_v10RC** 🚫 Text encoder unavailable. Same as SDXL 1.0 Base
- **miamodelSFWNSFWSDXL_v30** ✅ Text encoder available. Difference by 0.0047607421875
- **morphxl_v10** ✅ Text encoder available. Difference by 0.001861572265625
- **nightvisionXLPhotorealisticPortrait_beta0681Bakedvae** ✅ Text encoder available. Difference by 0.013885498046875
- **osorubeshiAlphaXL_z** ✅ Text encoder available. Difference by 0.005615234375
- **physiogenXL_v04** ✅ Text encoder available. Difference by 0.00390625
- **protovisionXLHighFidelity3D_beta0520Bakedvae** ✅ Text encoder available. Difference by 0.007568359375
- **realitycheckXL_alpha11** ✅ Text encoder available. Difference by 0.0015010833740234375
- **realmixXL_v10** ✅ Text encoder available. Difference by 0.0023899078369140625
- **reproductionSDXL_v31** ✅ Text encoder available. Difference by 0.00146484375
- **rundiffusionXL_beta** ✅ Text encoder available. Difference by 0.00196075439453125
- **samaritan3dCartoon_v40SDXL** ✅ Text encoder available. Difference by 0.0009765625
- **sdvn6Realxl_detailface** 🚫 Text encoder unavailable. Same as SDXL 1.0 Base
- **sdxl10ArienmixxlAsian_v10** ✅ Text encoder available. Difference by 0.00048828125
- **sdxlbaseNsfwFaces_sdxlNsfwFaces03** ✅ Text encoder available. Difference by 0.008056640625
- **sdxlFaetastic_v10** ✅ Text encoder available. Difference by 0.0029296875
- **sdxlFixedvaeFp16Remove_baseFxiedVaeV2Fp16** 🚫 Text encoder unavailable. Same as SDXL 1.0 Base
- **sdxlNijiV4_sdxlNijiV4** ✅ Text encoder available. Difference by 0.0009765625
- **SDXLRonghua_v11** ✅ Text encoder available. Difference by 0.0009765625
- **sdxlUnstableDiffusers_v5UnchainedSlayer** ✅ Text encoder available. Difference by 0.001251220703125
- **sdxlYamersAnimeUltra_yamersAnimeV2** ✅ Text encoder available. Difference by 0.000732421875
- **sdXL_v10VAEFix** 🚫 Text encoder unavailable. Same as SDXL 1.0 Base
- **shikianimexl_v10** ✅ Text encoder available. Difference by 0.0009765625
- **spectrumblendx_v10** ✅ Text encoder available. Difference by 0.0013065338134765625
- **stableDiffusionXL_v30** 🚫 Text encoder unavailable. Same as SDXL 1.0 Base
- **talmendoxlSDXL_v11Beta** 🚫 Text encoder unavailable. Same as SDXL 1.0 Base
- **wizard_v10** ✅ Text encoder available. Difference by 0.000244140625
- **sdxlYamersRealism_version2** - ✅ Text encoder available. Difference by 0.0048828125
- **animeChangefulXL_v10ReleasedCandidate** - ✅ Text encoder available. Difference by 0.00390625
- **brixlAMustInYour_v20Banu** - ✅ Text encoder available. Difference by 0.001434326171875
- **cinemaxAlphaSDXLCinema_alpha1** - ✅ Text encoder available. Difference by 0.00311279296875
- **copaxTimelessxlSDXL1_v5** - 🚫 Text encoder unavailable. Same as SDXL 1.0 Base
- **dreamshaperXL10_alpha2Xl10** - 🚫 Text encoder unavailable. Same as SDXL 1.0 Base
- **endjourneyXL_v11** - ✅ Text encoder available. Difference by 0.0029296875
- **explicitFreedomNSFW_beta** - ✅ Text encoder available. Difference by 0.001220703125
- **FinalAnimeCG_mk2a2** - ✅ Text encoder available. Difference by 0.00390625
- **formulaxlXLComfyui_v20Pruned** - ✅ Text encoder available. Difference by 0.002643585205078125
- **furtasticxl_BetaEPOCHS3** - ✅ Text encoder available. Difference by 0.013824462890625
- **galaxytimemachinesGTM_xlplusV10** - ✅ Text encoder available. Difference by 0.0012865066528320312
- **hassakuSfwNsfwAlphav_alphaV02** - ✅ Text encoder available. Difference by 0.00390625
- **juggernautXL_version4** - ✅ Text encoder available. Difference by 0.0019378662109375
- **MOHAWK_v10BETA** - ✅ Text encoder available. Difference by 0.00103759765625
- **newone_v10** - ✅ Text encoder available. Difference by 0.001190185546875
- **nightvisionXLPhotorealisticPortrait_v0743ReleaseBakedvae** - ✅ Text encoder available. Difference by 0.009429931640625
- **pyrosNSFWSDXL_v013e6** - 🚫 Text encoder unavailable. Same as SDXL 1.0 Base
- **pyrosSDModelsBlowjob_v0122022steps** - 🚫 Text encoder unavailable. Same as SDXL 1.0 Base
- **realisticFreedomSFW_alpha** - ✅ Text encoder available. Difference by 0.0011749267578125
- **realisticStockPhoto_v10** - ✅ Text encoder available. Difference by 0.0011444091796875
- **RealitiesEdgeXLANIME_20** - ✅ Text encoder available. Difference by 0.0018310546875
- **RealitiesEdgeXL_30** - ✅ Text encoder available. Difference by 0.004150390625
- **realvisxlV10_v10VAE** - ✅ Text encoder available. Difference by 0.0029296875
- **samaritan3dCartoon_v40SDXL** - ✅ Text encoder available. Difference by 0.00390625
- **sdvn6Realxl_detailface** - 🚫 Text encoder unavailable. Same as SDXL 1.0 Base
- **sdxlNuclearGeneralPurposeSemi_v10** - ✅ Text encoder available. Difference by 0.003021240234375
- **sdxlUnstableDiffusers_v6StabilityEater** - ✅ Text encoder available. Difference by 0.0029296875
- **sdxlYamersRealism_version2** - ✅ Text encoder available. Difference by 0.0048828125
- **unsafexl_v20** - ✅ Text encoder available. Difference by 0.068359375
- **venusxl_v11** - ✅ Text encoder available. Difference by 0.0013863444328308105
- **xlYamersCartoonArcadia_v1** - ✅ Text encoder available. Difference by 0.0029296875
## 🎉 Acknowledgements & Citations
A huge shoutout to the community for their continued support and feedback. Together, we are pushing the boundaries of what's possible with machine learning!
We would also like to acknowledge and give credit to the following projects and authors:
- **ComfyUI**: We've used and modified portions of [ComfyUI](https://github.com/comfyanonymous/ComfyUI) for our work.
- **kohya-ss/sd-scripts and bmaltais**: Our work also incorporates modifications from [kohya-ss/sd-scripts](https://github.com/kohya-ss/sd-scripts).
- **lora-inspector**: We've benefited from the [lora-inspector](https://github.com/rockerBOO/lora-inspector) project.
- **KohakuBlueleaf**: Special mention to KohakuBlueleaf for their invaluable contributions.
[](https://huggingface.co/FFusion/400GB-LoraXL/resolve/main/images/image1.jpg)
[](https://huggingface.co/FFusion/400GB-LoraXL/resolve/main/images/image3.jpg)
[](https://huggingface.co/FFusion/400GB-LoraXL/resolve/main/images/image4.jpg)
[](https://huggingface.co/FFusion/400GB-LoraXL/resolve/main/images/image5.jpg)
[](https://huggingface.co/FFusion/400GB-LoraXL/resolve/main/images/image6.jpg)
[](https://huggingface.co/FFusion/400GB-LoraXL/resolve/main/images/image7.jpg)
[](https://huggingface.co/FFusion/400GB-LoraXL/tree/main)
### HowMuch ???

**Have you ever asked yourself, "How much space have I wasted on `*.ckpt` and `*.safetensors` checkpoints?"** 🤔
Say hello to HowMuch: Checking checkpoint wasted space since... well, now!
😄 Enjoy this somewhat unnecessary, yet **"fun-for-the-whole-family"** DiskSpaceAnalyzer tool. 😄
## Overview
`HowMuch` is a Python tool designed to scan your drives (or a specified directory) and report on the total space used by files with specific extensions, mainly `.ckpt` and `.safetensors`.
It outputs:
- The total storage capacity of each scanned drive or directory.
- The space occupied by `.ckpt` and `.safetensors` files.
- The free space available.
- A neat bar chart visualizing the above data.
## Installation
[GitHub](https://github.com/1e-2/HowMuch)
### From PyPI
You can easily install `HowMuch` via pip:
```bash
pip install howmuch
```
### From Source
1. Clone the repository:
```bash
git clone https://github.com/1e-2/HowMuch.git
```
2. Navigate to the cloned directory and install:
```bash
cd HowMuch
pip install .
```
## Usage
Run the tool without any arguments to scan all drives:
```bash
howmuch
```
Or, specify a particular directory or drive to scan:
```bash
howmuch --scan C:
```
### 🌐 **Contact Information**
The **FFusion.ai** project is proudly maintained by **Source Code Bulgaria Ltd** & **Black Swan Technologies**.
📧 Reach us at [[email protected]](mailto:[email protected]) for any inquiries or support.
#### 🌌 **Find us on:**
- 🐙 [GitHub](https://github.com/1e-2)
- 😊 [Hugging Face](https://huggingface.co/FFusion/)
- 💡 [Civitai](https://civitai.com/user/idle/models)
🔐 **Security powered by** [Comodo.BG](http://Comodo.BG) & [Preasidium.CX](http://Preasidium.CX)
🚀 Marketing by [Гугъл.com](http://Гугъл.com)
📩 [](mailto:[email protected])
🌍 Sofia Istanbul London
|
mradermacher/Auraphin_Qwen2_7B-GGUF | mradermacher | 2024-06-15T08:54:19Z | 3,126 | 0 | transformers | [
"transformers",
"gguf",
"mergekit",
"merge",
"en",
"base_model:jeiku/Auraphin_Qwen2_7B",
"endpoints_compatible",
"region:us"
] | null | 2024-06-15T08:27:30Z | ---
base_model: jeiku/Auraphin_Qwen2_7B
language:
- en
library_name: transformers
quantized_by: mradermacher
tags:
- mergekit
- merge
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
static quants of https://huggingface.co/jeiku/Auraphin_Qwen2_7B
<!-- provided-files -->
weighted/imatrix quants are available at https://huggingface.co/mradermacher/Auraphin_Qwen2_7B-i1-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/Auraphin_Qwen2_7B-GGUF/resolve/main/Auraphin_Qwen2_7B.Q2_K.gguf) | Q2_K | 3.1 | |
| [GGUF](https://huggingface.co/mradermacher/Auraphin_Qwen2_7B-GGUF/resolve/main/Auraphin_Qwen2_7B.IQ3_XS.gguf) | IQ3_XS | 3.4 | |
| [GGUF](https://huggingface.co/mradermacher/Auraphin_Qwen2_7B-GGUF/resolve/main/Auraphin_Qwen2_7B.Q3_K_S.gguf) | Q3_K_S | 3.6 | |
| [GGUF](https://huggingface.co/mradermacher/Auraphin_Qwen2_7B-GGUF/resolve/main/Auraphin_Qwen2_7B.IQ3_S.gguf) | IQ3_S | 3.6 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/Auraphin_Qwen2_7B-GGUF/resolve/main/Auraphin_Qwen2_7B.IQ3_M.gguf) | IQ3_M | 3.7 | |
| [GGUF](https://huggingface.co/mradermacher/Auraphin_Qwen2_7B-GGUF/resolve/main/Auraphin_Qwen2_7B.Q3_K_M.gguf) | Q3_K_M | 3.9 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/Auraphin_Qwen2_7B-GGUF/resolve/main/Auraphin_Qwen2_7B.Q3_K_L.gguf) | Q3_K_L | 4.2 | |
| [GGUF](https://huggingface.co/mradermacher/Auraphin_Qwen2_7B-GGUF/resolve/main/Auraphin_Qwen2_7B.IQ4_XS.gguf) | IQ4_XS | 4.4 | |
| [GGUF](https://huggingface.co/mradermacher/Auraphin_Qwen2_7B-GGUF/resolve/main/Auraphin_Qwen2_7B.Q4_K_S.gguf) | Q4_K_S | 4.6 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Auraphin_Qwen2_7B-GGUF/resolve/main/Auraphin_Qwen2_7B.Q4_K_M.gguf) | Q4_K_M | 4.8 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Auraphin_Qwen2_7B-GGUF/resolve/main/Auraphin_Qwen2_7B.Q5_K_S.gguf) | Q5_K_S | 5.4 | |
| [GGUF](https://huggingface.co/mradermacher/Auraphin_Qwen2_7B-GGUF/resolve/main/Auraphin_Qwen2_7B.Q5_K_M.gguf) | Q5_K_M | 5.5 | |
| [GGUF](https://huggingface.co/mradermacher/Auraphin_Qwen2_7B-GGUF/resolve/main/Auraphin_Qwen2_7B.Q6_K.gguf) | Q6_K | 6.4 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/Auraphin_Qwen2_7B-GGUF/resolve/main/Auraphin_Qwen2_7B.Q8_0.gguf) | Q8_0 | 8.2 | fast, best quality |
| [GGUF](https://huggingface.co/mradermacher/Auraphin_Qwen2_7B-GGUF/resolve/main/Auraphin_Qwen2_7B.f16.gguf) | f16 | 15.3 | 16 bpw, overkill |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
google/pix2struct-base | google | 2023-12-24T21:14:37Z | 3,123 | 61 | transformers | [
"transformers",
"pytorch",
"safetensors",
"pix2struct",
"text2text-generation",
"image-to-text",
"en",
"fr",
"ro",
"de",
"multilingual",
"arxiv:2210.03347",
"license:apache-2.0",
"autotrain_compatible",
"region:us"
] | image-to-text | 2023-03-13T18:32:09Z | ---
language:
- en
- fr
- ro
- de
- multilingual
pipeline_tag: image-to-text
inference: false
license: apache-2.0
---
# Model card for Pix2Struct - Pretrained weights

This model is the pretrained version of `Pix2Struct`, use this model for fine-tuning purposes only.
# Table of Contents
0. [TL;DR](#TL;DR)
1. [Using the model](#using-the-model)
2. [Contribution](#contribution)
3. [Citation](#citation)
# TL;DR
Pix2Struct is an image encoder - text decoder model that is trained on image-text pairs for various tasks, including image captionning and visual question answering. The full list of available models can be found on the Table 1 of the paper:

The abstract of the model states that:
> Visually-situated language is ubiquitous—sources range from textbooks with diagrams to web pages with images and tables, to mobile apps with buttons and
forms. Perhaps due to this diversity, previous work has typically relied on domainspecific recipes with limited sharing of the underlying data, model architectures,
and objectives. We present Pix2Struct, a pretrained image-to-text model for
purely visual language understanding, which can be finetuned on tasks containing visually-situated language. Pix2Struct is pretrained by learning to parse
masked screenshots of web pages into simplified HTML. The web, with its richness of visual elements cleanly reflected in the HTML structure, provides a large
source of pretraining data well suited to the diversity of downstream tasks. Intuitively, this objective subsumes common pretraining signals such as OCR, language modeling, image captioning. In addition to the novel pretraining strategy,
we introduce a variable-resolution input representation and a more flexible integration of language and vision inputs, where language prompts such as questions
are rendered directly on top of the input image. For the first time, we show that a
single pretrained model can achieve state-of-the-art results in six out of nine tasks
across four domains: documents, illustrations, user interfaces, and natural images.
# Using the model
## Converting from T5x to huggingface
You can use the [`convert_pix2struct_checkpoint_to_pytorch.py`](https://github.com/huggingface/transformers/blob/main/src/transformers/models/pix2struct/convert_pix2struct_original_pytorch_to_hf.py) script as follows:
```bash
python convert_pix2struct_checkpoint_to_pytorch.py --t5x_checkpoint_path PATH_TO_T5X_CHECKPOINTS --pytorch_dump_path PATH_TO_SAVE
```
if you are converting a large model, run:
```bash
python convert_pix2struct_checkpoint_to_pytorch.py --t5x_checkpoint_path PATH_TO_T5X_CHECKPOINTS --pytorch_dump_path PATH_TO_SAVE --use-large
```
Once saved, you can push your converted model with the following snippet:
```python
from transformers import Pix2StructForConditionalGeneration, Pix2StructProcessor
model = Pix2StructForConditionalGeneration.from_pretrained(PATH_TO_SAVE)
processor = Pix2StructProcessor.from_pretrained(PATH_TO_SAVE)
model.push_to_hub("USERNAME/MODEL_NAME")
processor.push_to_hub("USERNAME/MODEL_NAME")
```
# Contribution
This model was originally contributed by Kenton Lee, Mandar Joshi et al. and added to the Hugging Face ecosystem by [Younes Belkada](https://huggingface.co/ybelkada).
# Citation
If you want to cite this work, please consider citing the original paper:
```
@misc{https://doi.org/10.48550/arxiv.2210.03347,
doi = {10.48550/ARXIV.2210.03347},
url = {https://arxiv.org/abs/2210.03347},
author = {Lee, Kenton and Joshi, Mandar and Turc, Iulia and Hu, Hexiang and Liu, Fangyu and Eisenschlos, Julian and Khandelwal, Urvashi and Shaw, Peter and Chang, Ming-Wei and Toutanova, Kristina},
keywords = {Computation and Language (cs.CL), Computer Vision and Pattern Recognition (cs.CV), FOS: Computer and information sciences, FOS: Computer and information sciences},
title = {Pix2Struct: Screenshot Parsing as Pretraining for Visual Language Understanding},
publisher = {arXiv},
year = {2022},
copyright = {Creative Commons Attribution 4.0 International}
}
``` |
jphme/em_german_leo_mistral | jphme | 2023-10-27T23:50:35Z | 3,123 | 63 | transformers | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"pytorch",
"german",
"deutsch",
"leolm",
"conversational",
"de",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2023-10-07T10:02:26Z | ---
inference: false
language:
- de
library_name: transformers
license: apache-2.0
model_creator: jphme
model_name: EM German
model_type: mistral
pipeline_tag: text-generation
prompt_template: 'Du bist ein hilfreicher Assistent. USER: Was ist 1+1? ASSISTANT:'
tags:
- pytorch
- german
- deutsch
- mistral
- leolm
---

LeoLM Mistral is the showcase-model of the EM German model family and as of its release in our opinion the best open German LLM.
**Many thanks to the [LeoLM](https://huggingface.co/LeoLM) team for the publication of a base model that has received continued pretraining with German texts, greatly improving generation capabilities.**
*Please note that the Mistral architecture is very recent and still not supported by all libraries (e.g. AutoGPTQ). In case of any problems, please try a different format/base model.*
# Table of Contents
1. [Introduction](#introduction)
2. [Links & Demos](#links--demos)
- [Model Links](#model-links)
- [Demos](#demos)
3. [Prompt Format](#prompt-format)
4. [Example Output](#example-output)
5. [Acknowledgements](#acknowledgements)
6. [Contact](#contact)
7. [Disclaimer](#disclaimer)
# Introduction
**EM German** is a Llama2/Mistral/LeoLM-based model family, finetuned on a large dataset of various instructions in German language. The models are optimized for German text, providing proficiency in understanding, generating, and interacting with German language content.
We offer versions based on 7b, 13b and 70b Llama-2, Mistral and LeoLM (Llama-2/Mistral with continued pretraining on German texts) models.
Please find all Informations, Example Outputs, the special RAG prompt format, output examples and eval results for the EM German Model family in [our Github Repository](https://github.com/jphme/EM_German). ([Deutsche Version](https://github.com/jphme/EM_German/blob/main/README_DE.md)). You will also find instructions on how to run the models with a GUI (GPT4All/LM Studio).
# Links & Demos
## Model Links
Should you only try one model version, I strongly recommend the **[LeoLM Mistral](https://huggingface.co/jphme/em_german_leo_mistral)** model which offers by far the best combination of performance and computing requirements!
| Base Model | HF | GPTQ | GGUF | AWQ |
|-------|-------|-------|-------|-------|
| Llama2 7b | [Link](https://huggingface.co/jphme/em_german_7b_v01) | [Link](https://huggingface.co/TheBloke/em_german_7b_v01-GPTQ) | [Link](https://huggingface.co/TheBloke/em_german_7b_v01-GGUF) | [Link](https://huggingface.co/TheBloke/em_german_7b_v01-AWQ) |
| Llama2 13b | [Link](https://huggingface.co/jphme/em_german_13b_v01) | [Link](https://huggingface.co/TheBloke/em_german_13b_v01-GPTQ) | [Link](https://huggingface.co/TheBloke/em_german_13b_v01-GGUF) | [Link](https://huggingface.co/TheBloke/em_german_13b_v01-AWQ) |
| Llama2 70b | [Link](https://huggingface.co/jphme/em_german_70b_v01) | [Link](https://huggingface.co/TheBloke/em_german_70b_v01-GPTQ) | [Link](https://huggingface.co/TheBloke/em_german_70b_v01-GGUF) | [Link](https://huggingface.co/TheBloke/em_german_70b_v01-AWQ) |
| [Mistral 7b](https://huggingface.co/mistralai/Mistral-7B-v0.1) | [Link](https://huggingface.co/jphme/em_german_mistral_v01) | [Link](https://huggingface.co/TheBloke/em_german_mistral_v01-GPTQ) | [Link](https://huggingface.co/TheBloke/em_german_mistral_v01-GGUF) | [Link](https://huggingface.co/TheBloke/em_german_mistral_v01-AWQ) |
| [LeoLM 7b](https://huggingface.co/LeoLM/leo-hessianai-7b) | [Link](https://huggingface.co/jphme/em_german_7b_leo) | [Link](https://huggingface.co/jphme/em_german_7b_leo_gptq) | [Link](hhttps://huggingface.co/jphme/em_german_7b_leo_gguf) | tbc |
| [LeoLM 13b](https://huggingface.co/LeoLM/leo-hessianai-13b) | soon | soon | [Link](https://huggingface.co/jphme/em_german_13b_leo_gguf) | tbc |
| [LeoLM Mistral](https://huggingface.co/LeoLM/leo-mistral-hessianai-7b) | [Link](https://huggingface.co/jphme/em_german_leo_mistral) | [Link](https://huggingface.co/TheBloke/em_german_leo_mistral-GPTQ) | [Link](https://huggingface.co/TheBloke/em_german_leo_mistral-GGUF) | [Link](https://huggingface.co/TheBloke/em_german_leo_mistral-AWQ) |
### Notes about the different versions:
See also the [comparison of example outputs](https://github.com/jphme/EM_German/blob/main/example_output_comparison.md) for a comparison of (7b) model capabilities.
If you get unsatisfying results with one or another EM German version, please try a different (and/or larger) model or version for your usecase.
## Demos:
You can use some of the models with **free** google Colab instances (e.g. the 7bn model in 8bit or the 13b model with GPTQ):
* [Example Colab Notebook for 13b with GPTQ](https://colab.research.google.com/drive/1IJfJdVwGkfe5MYOqHptystR3FBeEUdGn?usp=sharing)
* [Example Colab Notebook for 7b with 8bit-Loading](https://colab.research.google.com/drive/1bsv6vkLM4AlCpSyXA6ol9P32zxZmf7Zu?usp=sharing)
* [Example Colab Notebook for 7b Mistral GGUF with Grammar-based structured output](https://colab.research.google.com/drive/17O-a3D4BnVc_V9Of3dFfed18v1ULu1Sv?usp=sharing)
# Prompt Format
This model follows the Vicuna format without linebreaks (but should work with linebreaks as well). The format is as follows:
```
Du bist ein hilfreicher Assistent. USER: <instruction> ASSISTANT:
```
You can swap the standard system prompt for a better suited one (see below for RAG-tasks).
# Example Output
Please find a selection of various example outputs for all 7b versions of EM German [here](https://github.com/jphme/EM_German/blob/main/example_output_comparison.md).
**Prompt:**
> Erkläre die Bedeutung von drei wesentlichen Elementen der Bilanzierung und des Accountings nach IFRS für Unternehmen, die auf internationaler Ebene tätig sind.
**Antwort EM German Leo Mistral 7b:**
```
Die International Financial Reporting Standards (IFRS) sind eine Reihe von internationalen Rechnungslegungsstandards, die von der International Accounting Standards Board (IASB) entwickelt wurden. Sie sollen dazu beitragen, dass Finanzberichte vergleichbar, zuverlässig und relevant sind.
1. Fair Value: Dieses Konzept ist ein zentraler Bestandteil der IFRS. Es besagt, dass Vermögenswerte und Schulden zum fairen Wert bilanziert werden sollten, was dem Preis entspricht, zu dem sie zwischen Marktteilnehmern gehandelt werden könnten. Dadurch wird sichergestellt, dass das Unternehmen eine genaue Darstellung seiner finanziellen Lage liefert.
2. Konsolidierung: Die IFRS verlangen von Unternehmen, ihre Finanzergebnisse auf konsolidierter Basis darzustellen. Das bedeutet, dass alle Tochtergesellschaften und verbundenen Unternehmen in die Bilanz des Mutterunternehmens aufgenommen werden. Dadurch wird ein klareres Bild von der finanziellen Situation des Konzerns geschaffen.
3. Vollständigkeitsprinzip: Die IFRS verlangen von Unternehmen, alle relevanten Informationen offenzulegen. Dies umfasst sowohl positive als auch negative Faktoren, wie zum Beispiel Gewinne und Verluste, Einnahmen und Ausgaben sowie Risiken und Unsicherheiten. Durch dieses Prinzip wird sichergestellt, dass Investoren, Kreditgeber und andere Stakeholder eine umfassende Einschätzung der finanziellen Lage des Unternehmens vornehmen können.
```
**Prompt:**
> Ein Mensch atmet durchschnittlich 16 Mal pro Minute. Wie oft atmet er an einem Tag?
**Antwort EM German Leo Mistral 7b:**
```
Zuerst berechnen wir, wie oft eine Person in einer Stunde atmet. Wir wissen, dass eine Stunde 60 Minuten hat, also:
Atemzüge pro Stunde = Atemfrequenz * Minuten pro Stunde
= 16 Atemzüge pro Minute * 60 Minuten
= 960 Atemzüge
Um herauszufinden, wie viele Atemzüge eine Person an einem Tag macht, müssen wir diese stündliche Rate mit der Anzahl der Stunden an einem Tag multiplizieren, also 24:
Atemzüge pro Tag = Atemzüge pro Stunde * Stunden pro Tag
= 960 Atemzüge * 24 Stunden
= 23.040 Atemzüge
Also macht ein durchschnittlicher Mensch etwa 23.040 Atemzüge an einem Tag.
```
(For more examples, please visit [our Github Repository](https://github.com/jphme/EM_German).)
# Acknowledgements:
Many thanks to [winglian/caseus](https://huggingface.co/winglian) for his great work on Axolotl which I used to train the EM mdoels. I am also grateful to [Jon Durbin](https://huggingface.co/jondurbin) and his [Airoboros](https://huggingface.co/jondurbin/airoboros-l2-70b-2.2.1) models and code from which I borrowed many ideas and code snippets.
Additionally many thanks to [Björn Plüster](https://huggingface.co/bjoernp) and the LeoLM team for the outstanding pretraining work on LeoLM and last but not least many many thanks to [TheBloke](https://huggingface.co/TheBloke) for the preparation of quantized versions in all formats under the sun.
The 70b model was trained with support of the [OVH Cloud Startup Program](https://startup.ovhcloud.com/en/).
# Contact
For detailed feedback & feature requests, please open an issue or get in contact with me via [my website](https://www.jph.me).
*PS: We are also always interested in support for our startup [ellamind](https://ellamind.com), which will offer customized models for business applications in the future (we are currently still in stealth mode). If you use our models for business applications and have advanced needs for specialized capabilities, please get in touch.*
# Disclaimer:
I am not responsible for the actions of third parties who use this model or the outputs of the model. This model should only be used for research purposes. The original base model license applies and is distributed with the model files. |
cointegrated/rubert-tiny-sentiment-balanced | cointegrated | 2023-03-20T09:53:10Z | 3,121 | 12 | transformers | [
"transformers",
"pytorch",
"safetensors",
"bert",
"text-classification",
"russian",
"classification",
"sentiment",
"multiclass",
"ru",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2022-03-02T23:29:05Z | ---
language: ["ru"]
tags:
- russian
- classification
- sentiment
- multiclass
widget:
- text: "Какая гадость эта ваша заливная рыба!"
---
This is the [cointegrated/rubert-tiny](https://huggingface.co/cointegrated/rubert-tiny) model fine-tuned for classification of sentiment for short Russian texts.
The problem is formulated as multiclass classification: `negative` vs `neutral` vs `positive`.
## Usage
The function below estimates the sentiment of the given text:
```python
# !pip install transformers sentencepiece --quiet
import torch
from transformers import AutoTokenizer, AutoModelForSequenceClassification
model_checkpoint = 'cointegrated/rubert-tiny-sentiment-balanced'
tokenizer = AutoTokenizer.from_pretrained(model_checkpoint)
model = AutoModelForSequenceClassification.from_pretrained(model_checkpoint)
if torch.cuda.is_available():
model.cuda()
def get_sentiment(text, return_type='label'):
""" Calculate sentiment of a text. `return_type` can be 'label', 'score' or 'proba' """
with torch.no_grad():
inputs = tokenizer(text, return_tensors='pt', truncation=True, padding=True).to(model.device)
proba = torch.sigmoid(model(**inputs).logits).cpu().numpy()[0]
if return_type == 'label':
return model.config.id2label[proba.argmax()]
elif return_type == 'score':
return proba.dot([-1, 0, 1])
return proba
text = 'Какая гадость эта ваша заливная рыба!'
# classify the text
print(get_sentiment(text, 'label')) # negative
# score the text on the scale from -1 (very negative) to +1 (very positive)
print(get_sentiment(text, 'score')) # -0.5894946306943893
# calculate probabilities of all labels
print(get_sentiment(text, 'proba')) # [0.7870447 0.4947824 0.19755007]
```
## Training
We trained the model on [the datasets collected by Smetanin](https://github.com/sismetanin/sentiment-analysis-in-russian). We have converted all training data into a 3-class format and have up- and downsampled the training data to balance both the sources and the classes. The training code is available as [a Colab notebook](https://gist.github.com/avidale/e678c5478086c1d1adc52a85cb2b93e6). The metrics on the balanced test set are the following:
| Source | Macro F1 |
| ----------- | ----------- |
| SentiRuEval2016_banks | 0.83 |
| SentiRuEval2016_tele | 0.74 |
| kaggle_news | 0.66 |
| linis | 0.50 |
| mokoron | 0.98 |
| rureviews | 0.72 |
| rusentiment | 0.67 |
|
Salesforce/codegen2-1B_P | Salesforce | 2023-07-06T10:47:56Z | 3,121 | 36 | transformers | [
"transformers",
"pytorch",
"codegen",
"text-generation",
"custom_code",
"arxiv:2305.02309",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-generation | 2023-04-25T01:42:39Z | ---
license: apache-2.0
---
# CodeGen2 (CodeGen2-1B)
## Model description
[CodeGen2](https://github.com/salesforce/CodeGen2) is a family of autoregressive language models for **program synthesis**, introduced in the paper:
[CodeGen2: Lessons for Training LLMs on Programming and Natural Languages](https://arxiv.org/abs/2305.02309) by Erik Nijkamp\*, Hiroaki Hayashi\*, Caiming Xiong, Silvio Savarese, Yingbo Zhou.
Unlike the original CodeGen model family (i.e., CodeGen1), CodeGen2 is capable of infilling, and supports more programming languages.
Four model sizes are released: `1B`, `3.7B`, `7B`, `16B`.
## How to use
This model can be easily loaded using the `AutoModelForCausalLM` functionality.
### Causal sampling
For regular causal sampling, simply generate completions given the context:
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("Salesforce/codegen2-1B")
model = AutoModelForCausalLM.from_pretrained("Salesforce/codegen2-1B", trust_remote_code=True, revision="main")
text = "def hello_world():"
input_ids = tokenizer(text, return_tensors="pt").input_ids
generated_ids = model.generate(input_ids, max_length=128)
print(tokenizer.decode(generated_ids[0], skip_special_tokens=True))
```
### Infill sampling
For **infill** sampling, we introduce three new special token types:
* `<mask_N>`: N-th span to be masked. In practice, use `<mask_1>` to where you want to sample infill.
* `<sep>`: Separator token between the suffix and the infilled sample. See below.
* `<eom>`: "End-Of-Mask" token that model will output at the end of infilling. You may use this token to truncate the output.
For example, if we want to generate infill for the following cursor position of a function:
```python
def hello_world():
|
return name
```
we construct an input to the model by
1. Inserting `<mask_1>` token in place of cursor position
2. Append `<sep>` token to indicate the boundary
3. Insert another `<mask_1>` to indicate which mask we want to infill.
The final snippet looks as follows:
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("Salesforce/codegen2-1B")
model = AutoModelForCausalLM.from_pretrained("Salesforce/codegen2-1B", trust_remote_code=True, revision="main")
def format(prefix, suffix):
return prefix + "<mask_1>" + suffix + "<|endoftext|>" + "<sep>" + "<mask_1>"
prefix = "def hello_world():\n "
suffix = " return name"
text = format(prefix, suffix)
input_ids = tokenizer(text, return_tensors="pt").input_ids
generated_ids = model.generate(input_ids, max_length=128)
print(tokenizer.decode(generated_ids[0], skip_special_tokens=False)[len(text):])
```
You might want to truncate the model output with `<eom>`.
## Training data
This checkpoint is trained on the stricter permissive subset of [the deduplicated version of the Stack dataset (v1.1)](https://huggingface.co/datasets/bigcode/the-stack-dedup). Supported languages (and frameworks) are as follows:
`c`, `c++`, `c-sharp`, `dart`, `go`, `java`, `javascript`, `kotlin`, `lua`, `php`, `python`, `ruby`, `rust`, `scala`, `shell`, `sql`, `swift`, `typescript`, `vue`.
## Training procedure
CodeGen2 was trained using cross-entropy loss to maximize the likelihood of sequential inputs.
The input sequences are formatted in two ways: (1) causal language modeling and (2) file-level span corruption.
Please refer to the paper for more details.
## Evaluation results
We evaluate our models on HumanEval and HumanEval-Infill. Please refer to the [paper](https://arxiv.org/abs/2305.02309) for more details.
## Intended use and limitations
As an autoregressive language model, CodeGen2 is capable of extracting features from given natural language and programming language texts, and calculating the likelihood of them.
However, the model is intended for and best at **program synthesis**, that is, generating executable code given English prompts, where the prompts should be in the form of a comment string. The model can complete partially-generated code as well.
## BibTeX entry and citation info
```bibtex
@article{Nijkamp2023codegen2,
title={CodeGen2: Lessons for Training LLMs on Programming and Natural Languages},
author={Nijkamp, Erik and Hayashi, Hiroaki and Xiong, Caiming and Savarese, Silvio and Zhou, Yingbo},
journal={arXiv preprint},
year={2023}
}
```
|
vinesmsuic/magicbrush-jul7 | vinesmsuic | 2023-07-09T22:04:54Z | 3,120 | 6 | diffusers | [
"diffusers",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"en",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | 2023-07-08T02:50:03Z | ---
language:
- en
license: creativeml-openrail-m
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
---
diffuser port of https://huggingface.co/osunlp/InstructPix2Pix-MagicBrush.
diffuser version of `MagicBrush-epoch-52-step-4999.ckpt`
```python
from PIL import Image, ImageOps
import requests
import torch
from diffusers import StableDiffusionInstructPix2PixPipeline, EulerAncestralDiscreteScheduler
from PIL import Image
url = "https://huggingface.co/datasets/diffusers/diffusers-images-docs/resolve/main/mountain.png"
def download_image(url):
image = Image.open(requests.get(url, stream=True).raw)
image = ImageOps.exif_transpose(image)
image = image.convert("RGB")
return image
image = download_image(url)
prompt = "make the mountains snowy"
class MagicBrush():
def __init__(self, weight="vinesmsuic/magicbrush-jul7"):
self.pipe = StableDiffusionInstructPix2PixPipeline.from_pretrained(
weight,
torch_dtype=torch.float16
).to("cuda")
self.pipe.scheduler = EulerAncestralDiscreteScheduler.from_config(self.pipe.scheduler.config)
def infer_one_image(self, src_image, instruct_prompt, seed):
generator = torch.manual_seed(seed)
image = self.pipe(instruct_prompt, image=src_image, num_inference_steps=20, image_guidance_scale=1.5, guidance_scale=7, generator=generator).images[0]
return image
model = MagicBrush()
image_output = model.infer_one_image(image, prompt, 42)
image_output
```

## License
This model is open access and available to all, with a CreativeML OpenRAIL-M license further specifying rights and usage.
The CreativeML OpenRAIL License specifies:
1. You can't use the model to deliberately produce nor share illegal or harmful outputs or content
2. The authors claims no rights on the outputs you generate, you are free to use them and are accountable for their use which must not go against the provisions set in the license
3. You may re-distribute the weights and use the model commercially and/or as a service. If you do, please be aware you have to include the same use restrictions as the ones in the license and share a copy of the CreativeML OpenRAIL-M to all your users (please read the license entirely and carefully)
[Please read the full license here](https://huggingface.co/spaces/CompVis/stable-diffusion-license)
|
mradermacher/mexa-7b-0.1.1-GGUF | mradermacher | 2024-06-18T22:09:34Z | 3,120 | 1 | transformers | [
"transformers",
"gguf",
"en",
"base_model:SiguienteGlobal/mexa-7b-0.1.1",
"endpoints_compatible",
"region:us"
] | null | 2024-06-18T20:40:56Z | ---
base_model: SiguienteGlobal/mexa-7b-0.1.1
language:
- en
library_name: transformers
quantized_by: mradermacher
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
static quants of https://huggingface.co/SiguienteGlobal/mexa-7b-0.1.1
<!-- provided-files -->
weighted/imatrix quants seem not to be available (by me) at this time. If they do not show up a week or so after the static ones, I have probably not planned for them. Feel free to request them by opening a Community Discussion.
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/mexa-7b-0.1.1-GGUF/resolve/main/mexa-7b-0.1.1.Q2_K.gguf) | Q2_K | 2.8 | |
| [GGUF](https://huggingface.co/mradermacher/mexa-7b-0.1.1-GGUF/resolve/main/mexa-7b-0.1.1.IQ3_XS.gguf) | IQ3_XS | 3.1 | |
| [GGUF](https://huggingface.co/mradermacher/mexa-7b-0.1.1-GGUF/resolve/main/mexa-7b-0.1.1.Q3_K_S.gguf) | Q3_K_S | 3.3 | |
| [GGUF](https://huggingface.co/mradermacher/mexa-7b-0.1.1-GGUF/resolve/main/mexa-7b-0.1.1.IQ3_S.gguf) | IQ3_S | 3.3 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/mexa-7b-0.1.1-GGUF/resolve/main/mexa-7b-0.1.1.IQ3_M.gguf) | IQ3_M | 3.4 | |
| [GGUF](https://huggingface.co/mradermacher/mexa-7b-0.1.1-GGUF/resolve/main/mexa-7b-0.1.1.Q3_K_M.gguf) | Q3_K_M | 3.6 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/mexa-7b-0.1.1-GGUF/resolve/main/mexa-7b-0.1.1.Q3_K_L.gguf) | Q3_K_L | 3.9 | |
| [GGUF](https://huggingface.co/mradermacher/mexa-7b-0.1.1-GGUF/resolve/main/mexa-7b-0.1.1.IQ4_XS.gguf) | IQ4_XS | 4.0 | |
| [GGUF](https://huggingface.co/mradermacher/mexa-7b-0.1.1-GGUF/resolve/main/mexa-7b-0.1.1.Q4_K_S.gguf) | Q4_K_S | 4.2 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/mexa-7b-0.1.1-GGUF/resolve/main/mexa-7b-0.1.1.Q4_K_M.gguf) | Q4_K_M | 4.5 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/mexa-7b-0.1.1-GGUF/resolve/main/mexa-7b-0.1.1.Q5_K_S.gguf) | Q5_K_S | 5.1 | |
| [GGUF](https://huggingface.co/mradermacher/mexa-7b-0.1.1-GGUF/resolve/main/mexa-7b-0.1.1.Q5_K_M.gguf) | Q5_K_M | 5.2 | |
| [GGUF](https://huggingface.co/mradermacher/mexa-7b-0.1.1-GGUF/resolve/main/mexa-7b-0.1.1.Q6_K.gguf) | Q6_K | 6.0 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/mexa-7b-0.1.1-GGUF/resolve/main/mexa-7b-0.1.1.Q8_0.gguf) | Q8_0 | 7.8 | fast, best quality |
| [GGUF](https://huggingface.co/mradermacher/mexa-7b-0.1.1-GGUF/resolve/main/mexa-7b-0.1.1.f16.gguf) | f16 | 14.6 | 16 bpw, overkill |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
Baidicoot/Othello-GPT-Transformer-Lens | Baidicoot | 2023-04-18T09:01:04Z | 3,119 | 0 | transformers | [
"transformers",
"license:mit",
"endpoints_compatible",
"region:us"
] | null | 2023-04-16T09:13:29Z | ---
license: mit
---
|
stablediffusionapi/pony | stablediffusionapi | 2024-03-12T18:38:36Z | 3,119 | 2 | diffusers | [
"diffusers",
"modelslab.com",
"stable-diffusion-api",
"text-to-image",
"ultra-realistic",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionXLPipeline",
"region:us"
] | text-to-image | 2024-03-12T18:06:30Z | ---
license: creativeml-openrail-m
tags:
- modelslab.com
- stable-diffusion-api
- text-to-image
- ultra-realistic
pinned: true
---
# Pony API Inference

## Get API Key
Get API key from [ModelsLab API](http://modelslab.com), No Payment needed.
Replace Key in below code, change **model_id** to "pony"
Coding in PHP/Node/Java etc? Have a look at docs for more code examples: [View docs](https://modelslab.com/docs)
Try model for free: [Generate Images](https://modelslab.com/models/pony)
Model link: [View model](https://modelslab.com/models/pony)
View all models: [View Models](https://modelslab.com/models)
import requests
import json
url = "https://modelslab.com/api/v6/images/text2img"
payload = json.dumps({
"key": "your_api_key",
"model_id": "pony",
"prompt": "ultra realistic close up portrait ((beautiful pale cyberpunk female with heavy black eyeliner)), blue eyes, shaved side haircut, hyper detail, cinematic lighting, magic neon, dark red city, Canon EOS R3, nikon, f/1.4, ISO 200, 1/160s, 8K, RAW, unedited, symmetrical balance, in-frame, 8K",
"negative_prompt": "painting, extra fingers, mutated hands, poorly drawn hands, poorly drawn face, deformed, ugly, blurry, bad anatomy, bad proportions, extra limbs, cloned face, skinny, glitchy, double torso, extra arms, extra hands, mangled fingers, missing lips, ugly face, distorted face, extra legs, anime",
"width": "512",
"height": "512",
"samples": "1",
"num_inference_steps": "30",
"safety_checker": "no",
"enhance_prompt": "yes",
"seed": None,
"guidance_scale": 7.5,
"multi_lingual": "no",
"panorama": "no",
"self_attention": "no",
"upscale": "no",
"embeddings": "embeddings_model_id",
"lora": "lora_model_id",
"webhook": None,
"track_id": None
})
headers = {
'Content-Type': 'application/json'
}
response = requests.request("POST", url, headers=headers, data=payload)
print(response.text)
> Use this coupon code to get 25% off **DMGG0RBN** |
femboysLover/tf2spysimulation_diffusers | femboysLover | 2024-06-18T16:39:14Z | 3,116 | 0 | diffusers | [
"diffusers",
"safetensors",
"arxiv:1910.09700",
"region:us"
] | null | 2024-06-06T12:33:20Z | ---
library_name: diffusers
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🧨 diffusers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
bartowski/Oumuamua-7b-instruct-v2-GGUF | bartowski | 2024-06-16T00:50:21Z | 3,115 | 0 | transformers | [
"transformers",
"gguf",
"mergekit",
"merge",
"text-generation",
"ja",
"en",
"base_model:nitky/Oumuamua-7b-base",
"base_model:nitky/Oumuamua-7b-instruct",
"base_model:tokyotech-llm/Swallow-MS-7b-v0.1",
"base_model:mistralai/Mistral-7B-v0.1",
"base_model:prometheus-eval/prometheus-7b-v2.0",
"base_model:cognitivecomputations/dolphin-2.8-mistral-7b-v02",
"base_model:ZhangShenao/SELM-Zephyr-7B-iter-3",
"base_model:HachiML/Mistral-7B-v0.3-m3-lora",
"base_model:openbmb/Eurus-7b-kto",
"base_model:kaist-ai/janus-dpo-7b",
"base_model:nitky/RP-7b-instruct",
"base_model:stabilityai/japanese-stablelm-base-gamma-7b",
"base_model:NTQAI/chatntq-ja-7b-v1.0",
"base_model:Weyaxi/Einstein-v6-7B",
"base_model:internistai/base-7b-v0.2",
"base_model:ZySec-AI/ZySec-7B",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-06-16T00:33:52Z | ---
base_model:
- nitky/Oumuamua-7b-base
- nitky/Oumuamua-7b-instruct
- tokyotech-llm/Swallow-MS-7b-v0.1
- mistralai/Mistral-7B-v0.1
- prometheus-eval/prometheus-7b-v2.0
- cognitivecomputations/dolphin-2.8-mistral-7b-v02
- ZhangShenao/SELM-Zephyr-7B-iter-3
- HachiML/Mistral-7B-v0.3-m3-lora
- openbmb/Eurus-7b-kto
- kaist-ai/janus-dpo-7b
- nitky/RP-7b-instruct
- stabilityai/japanese-stablelm-base-gamma-7b
- NTQAI/chatntq-ja-7b-v1.0
- Weyaxi/Einstein-v6-7B
- internistai/base-7b-v0.2
- ZySec-AI/ZySec-7B
library_name: transformers
tags:
- mergekit
- merge
language:
- ja
- en
pipeline_tag: text-generation
license: apache-2.0
quantized_by: bartowski
---
## Llamacpp imatrix Quantizations of Oumuamua-7b-instruct-v2
Using <a href="https://github.com/ggerganov/llama.cpp/">llama.cpp</a> release <a href="https://github.com/ggerganov/llama.cpp/releases/tag/b3152">b3152</a> for quantization.
Original model: https://huggingface.co/nitky/Oumuamua-7b-instruct-v2
All quants made using imatrix option with dataset from [here](https://gist.github.com/bartowski1182/eb213dccb3571f863da82e99418f81e8)
## Prompt format
No chat template specified so default is used. This may be incorrect, check original model card for details.
```
<s> [INST] <<SYS>>
{system_prompt}
<</SYS>>
{prompt} [/INST] </s>
```
## Download a file (not the whole branch) from below:
| Filename | Quant type | File Size | Description |
| -------- | ---------- | --------- | ----------- |
| [Oumuamua-7b-instruct-v2-Q8_0.gguf](https://huggingface.co/bartowski/Oumuamua-7b-instruct-v2-GGUF/blob/main/Oumuamua-7b-instruct-v2-Q8_0.gguf) | Q8_0 | 8.11GB | Extremely high quality, generally unneeded but max available quant. |
| [Oumuamua-7b-instruct-v2-Q6_K.gguf](https://huggingface.co/bartowski/Oumuamua-7b-instruct-v2-GGUF/blob/main/Oumuamua-7b-instruct-v2-Q6_K.gguf) | Q6_K | 6.42GB | Very high quality, near perfect, *recommended*. |
| [Oumuamua-7b-instruct-v2-Q5_K_M.gguf](https://huggingface.co/bartowski/Oumuamua-7b-instruct-v2-GGUF/blob/main/Oumuamua-7b-instruct-v2-Q5_K_M.gguf) | Q5_K_M | 5.63GB | High quality, *recommended*. |
| [Oumuamua-7b-instruct-v2-Q5_K_S.gguf](https://huggingface.co/bartowski/Oumuamua-7b-instruct-v2-GGUF/blob/main/Oumuamua-7b-instruct-v2-Q5_K_S.gguf) | Q5_K_S | 5.50GB | High quality, *recommended*. |
| [Oumuamua-7b-instruct-v2-Q4_K_M.gguf](https://huggingface.co/bartowski/Oumuamua-7b-instruct-v2-GGUF/blob/main/Oumuamua-7b-instruct-v2-Q4_K_M.gguf) | Q4_K_M | 4.88GB | Good quality, uses about 4.83 bits per weight, *recommended*. |
| [Oumuamua-7b-instruct-v2-Q4_K_S.gguf](https://huggingface.co/bartowski/Oumuamua-7b-instruct-v2-GGUF/blob/main/Oumuamua-7b-instruct-v2-Q4_K_S.gguf) | Q4_K_S | 4.66GB | Slightly lower quality with more space savings, *recommended*. |
| [Oumuamua-7b-instruct-v2-IQ4_XS.gguf](https://huggingface.co/bartowski/Oumuamua-7b-instruct-v2-GGUF/blob/main/Oumuamua-7b-instruct-v2-IQ4_XS.gguf) | IQ4_XS | 4.43GB | Decent quality, smaller than Q4_K_S with similar performance, *recommended*. |
| [Oumuamua-7b-instruct-v2-Q3_K_L.gguf](https://huggingface.co/bartowski/Oumuamua-7b-instruct-v2-GGUF/blob/main/Oumuamua-7b-instruct-v2-Q3_K_L.gguf) | Q3_K_L | 4.35GB | Lower quality but usable, good for low RAM availability. |
| [Oumuamua-7b-instruct-v2-Q3_K_M.gguf](https://huggingface.co/bartowski/Oumuamua-7b-instruct-v2-GGUF/blob/main/Oumuamua-7b-instruct-v2-Q3_K_M.gguf) | Q3_K_M | 4.05GB | Even lower quality. |
| [Oumuamua-7b-instruct-v2-IQ3_M.gguf](https://huggingface.co/bartowski/Oumuamua-7b-instruct-v2-GGUF/blob/main/Oumuamua-7b-instruct-v2-IQ3_M.gguf) | IQ3_M | 3.82GB | Medium-low quality, new method with decent performance comparable to Q3_K_M. |
| [Oumuamua-7b-instruct-v2-Q3_K_S.gguf](https://huggingface.co/bartowski/Oumuamua-7b-instruct-v2-GGUF/blob/main/Oumuamua-7b-instruct-v2-Q3_K_S.gguf) | Q3_K_S | 3.70GB | Low quality, not recommended. |
| [Oumuamua-7b-instruct-v2-IQ3_XS.gguf](https://huggingface.co/bartowski/Oumuamua-7b-instruct-v2-GGUF/blob/main/Oumuamua-7b-instruct-v2-IQ3_XS.gguf) | IQ3_XS | 3.55GB | Lower quality, new method with decent performance, slightly better than Q3_K_S. |
| [Oumuamua-7b-instruct-v2-IQ3_XXS.gguf](https://huggingface.co/bartowski/Oumuamua-7b-instruct-v2-GGUF/blob/main/Oumuamua-7b-instruct-v2-IQ3_XXS.gguf) | IQ3_XXS | 3.38GB | Lower quality, new method with decent performance, comparable to Q3 quants. |
| [Oumuamua-7b-instruct-v2-Q2_K.gguf](https://huggingface.co/bartowski/Oumuamua-7b-instruct-v2-GGUF/blob/main/Oumuamua-7b-instruct-v2-Q2_K.gguf) | Q2_K | 3.27GB | Very low quality but surprisingly usable. |
| [Oumuamua-7b-instruct-v2-IQ2_M.gguf](https://huggingface.co/bartowski/Oumuamua-7b-instruct-v2-GGUF/blob/main/Oumuamua-7b-instruct-v2-IQ2_M.gguf) | IQ2_M | 3.05GB | Very low quality, uses SOTA techniques to also be surprisingly usable. |
| [Oumuamua-7b-instruct-v2-IQ2_S.gguf](https://huggingface.co/bartowski/Oumuamua-7b-instruct-v2-GGUF/blob/main/Oumuamua-7b-instruct-v2-IQ2_S.gguf) | IQ2_S | 2.86GB | Very low quality, uses SOTA techniques to be usable. |
| [Oumuamua-7b-instruct-v2-IQ2_XS.gguf](https://huggingface.co/bartowski/Oumuamua-7b-instruct-v2-GGUF/blob/main/Oumuamua-7b-instruct-v2-IQ2_XS.gguf) | IQ2_XS | 2.76GB | Very low quality, uses SOTA techniques to be usable. |
## Downloading using huggingface-cli
First, make sure you have hugginface-cli installed:
```
pip install -U "huggingface_hub[cli]"
```
Then, you can target the specific file you want:
```
huggingface-cli download bartowski/Oumuamua-7b-instruct-v2-GGUF --include "Oumuamua-7b-instruct-v2-Q4_K_M.gguf" --local-dir ./
```
If the model is bigger than 50GB, it will have been split into multiple files. In order to download them all to a local folder, run:
```
huggingface-cli download bartowski/Oumuamua-7b-instruct-v2-GGUF --include "Oumuamua-7b-instruct-v2-Q8_0.gguf/*" --local-dir Oumuamua-7b-instruct-v2-Q8_0
```
You can either specify a new local-dir (Oumuamua-7b-instruct-v2-Q8_0) or download them all in place (./)
## Which file should I choose?
A great write up with charts showing various performances is provided by Artefact2 [here](https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9)
The first thing to figure out is how big a model you can run. To do this, you'll need to figure out how much RAM and/or VRAM you have.
If you want your model running as FAST as possible, you'll want to fit the whole thing on your GPU's VRAM. Aim for a quant with a file size 1-2GB smaller than your GPU's total VRAM.
If you want the absolute maximum quality, add both your system RAM and your GPU's VRAM together, then similarly grab a quant with a file size 1-2GB Smaller than that total.
Next, you'll need to decide if you want to use an 'I-quant' or a 'K-quant'.
If you don't want to think too much, grab one of the K-quants. These are in format 'QX_K_X', like Q5_K_M.
If you want to get more into the weeds, you can check out this extremely useful feature chart:
[llama.cpp feature matrix](https://github.com/ggerganov/llama.cpp/wiki/Feature-matrix)
But basically, if you're aiming for below Q4, and you're running cuBLAS (Nvidia) or rocBLAS (AMD), you should look towards the I-quants. These are in format IQX_X, like IQ3_M. These are newer and offer better performance for their size.
These I-quants can also be used on CPU and Apple Metal, but will be slower than their K-quant equivalent, so speed vs performance is a tradeoff you'll have to decide.
The I-quants are *not* compatible with Vulcan, which is also AMD, so if you have an AMD card double check if you're using the rocBLAS build or the Vulcan build. At the time of writing this, LM Studio has a preview with ROCm support, and other inference engines have specific builds for ROCm.
Want to support my work? Visit my ko-fi page here: https://ko-fi.com/bartowski
|
tannedbum/L3-Nymeria-Maid-8B-iGGUF | tannedbum | 2024-06-26T03:05:24Z | 3,114 | 1 | null | [
"gguf",
"roleplay",
"sillytavern",
"llama3",
"not-for-all-audiences",
"en",
"license:cc-by-nc-4.0",
"region:us"
] | null | 2024-06-21T23:22:20Z | ---
license: cc-by-nc-4.0
quantized_by: tannedbum
language:
- en
tags:
- roleplay
- sillytavern
- llama3
- not-for-all-audiences
---

## This version is solely for scientific purposes, of course.
Nymeria is the balanced version, doesn't force nsfw. Nymeria-Maid has more Stheno's weights, leans more on nsfw and is more submissive.
All quants made using imatrix option with dataset provided by bartowski [here](https://gist.github.com/bartowski1182/eb213dccb3571f863da82e99418f81e8)
## SillyTavern
## Text Completion presets
```
temp 0.9
top_k 30
top_p 0.75
min_p 0.2
rep_pen 1.1
smooth_factor 0.25
smooth_curve 1
```
## Advanced Formatting
[Context & Instruct preset by Virt-io](https://huggingface.co/Virt-io/SillyTavern-Presets/tree/main/Prompts/LLAMA-3/v2.0)
Instruct Mode: Enabled
# merge
This is a merge of pre-trained language models created using [mergekit](https://github.com/cg123/mergekit).
This model was merged using the slerp merge method.
### Models Merged
The following models were included in the merge:
* [Sao10K/L3-8B-Stheno-v3.2](https://huggingface.co/Sao10K/L3-8B-Stheno-v3.2)
* [princeton-nlp/Llama-3-Instruct-8B-SimPO](https://huggingface.co/princeton-nlp/Llama-3-Instruct-8B-SimPO)
### Configuration
The following YAML configuration was used to produce this model:
```yaml
slices:
- sources:
- model: Sao10K/L3-8B-Stheno-v3.2
layer_range: [0, 32]
- model: princeton-nlp/Llama-3-Instruct-8B-SimPO
layer_range: [0, 32]
merge_method: slerp
base_model: Sao10K/L3-8B-Stheno-v3.2
parameters:
t:
- filter: self_attn
value: [0.2, 0.4, 0.4, 0.6]
- filter: mlp
value: [0.8, 0.6, 0.6, 0.4]
- value: 0.4
dtype: bfloat16
```
---
## Original model information:
## Model: Sao10K/L3-8B-Stheno-v3.2
Stheno-v3.2-Zeta
Changes compared to v3.1
<br>\- Included a mix of SFW and NSFW Storywriting Data, thanks to [Gryphe](https://huggingface.co/datasets/Gryphe/Opus-WritingPrompts)
<br>\- Included More Instruct / Assistant-Style Data
<br>\- Further cleaned up Roleplaying Samples from c2 Logs -> A few terrible, really bad samples escaped heavy filtering. Manual pass fixed it.
<br>\- Hyperparameter tinkering for training, resulting in lower loss levels.
Testing Notes - Compared to v3.1
<br>\- Handles SFW / NSFW seperately better. Not as overly excessive with NSFW now. Kinda balanced.
<br>\- Better at Storywriting / Narration.
<br>\- Better at Assistant-type Tasks.
<br>\- Better Multi-Turn Coherency -> Reduced Issues?
<br>\- Slightly less creative? A worthy tradeoff. Still creative.
<br>\- Better prompt / instruction adherence.
---
Want to support my work ? My Ko-fi page: https://ko-fi.com/tannedbum |
meta-math/MetaMath-7B-V1.0 | meta-math | 2023-12-21T01:37:17Z | 3,113 | 25 | transformers | [
"transformers",
"pytorch",
"llama",
"text-generation",
"dataset:meta-math/MetaMathQA",
"arxiv:2309.12284",
"license:llama2",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2023-09-21T08:33:54Z | ---
license: llama2
datasets:
- meta-math/MetaMathQA
---
see our paper in https://arxiv.org/abs/2309.12284
View the project page:
https://meta-math.github.io/
## Note
All MetaMathQA data are augmented from the training sets of GSM8K and MATH.
<span style="color:red"><b>None of the augmented data is from the testing set.</b></span>
You can check the `original_question` in `meta-math/MetaMathQA`, each item is from the GSM8K or MATH train set.
## Model Details
MetaMath-Llemma-7B is fully fine-tuned on the MetaMathQA datasets and based on the powerful Llemma-7B model. It is glad to see using MetaMathQA datasets and change the base model from llama-2-7B to Llemma-7B can boost the MATH performance from 19.8 to **30.0**.
## Installation
```
pip install transformers==4.35.0
pip install torch==2.0.1
pip install sentencepiece==0.1.99
pip install tokenizers==0.13.3
pip install accelerate==0.21.0
pip install bitsandbytes==0.40.0
pip install vllm
pip install fraction
pip install protobuf
```
## Model Usage
prompting template:
'''
"Below is an instruction that describes a task. "
"Write a response that appropriately completes the request.\n\n"
"### Instruction:\n{instruction}\n\n### Response: Let's think step by step."
'''
where you need to use your query question to replace the {instruction}
## Experiments
| Model | GSM8k Pass@1 | MATH Pass@1 |
|---------------------|--------------|-------------|
| MPT-7B | 6.8 | 3.0 |
| Falcon-7B | 6.8 | 2.3 |
| LLaMA-1-7B | 11.0 | 2.9 |
| LLaMA-2-7B | 14.6 | 2.5 |
| MPT-30B | 15.2 | 3.1 |
| LLaMA-1-13B | 17.8 | 3.9 |
| GPT-Neo-2.7B | 19.5 | -- |
| Falcon-40B | 19.6 | 2.5 |
| Baichuan-chat-13B | 23.9 | -- |
| Vicuna-v1.3-13B | 27.6 | -- |
| LLaMA-2-13B | 28.7 | 3.9 |
| InternLM-7B | 31.2 | -- |
| ChatGLM-2-6B | 32.4 | -- |
| GPT-J-6B | 34.9 | -- |
| LLaMA-1-33B | 35.6 | 3.9 |
| LLaMA-2-34B | 42.2 | 6.24 |
| RFT-7B | 50.3 | -- |
| LLaMA-1-65B | 50.9 | 10.6 |
| Qwen-7B | 51.6 | -- |
| WizardMath-7B | 54.9 | 10.7 |
| LLaMA-2-70B | 56.8 | 13.5 |
| WizardMath-13B | 63.9 | 14.0 |
| MAmmoTH-7B (COT) | 50.5 | 10.4 |
| MAmmoTH-7B (POT+COT)| 53.6 | 31.5 |
| Arithmo-Mistral-7B | 74.7 | 25.3 |
| MetaMath-7B | 66.5 | 19.8 |
| MetaMath-13B | 72.3 | 22.4 |
| 🔥 **MetaMath-Llemma-7B** | **69.2** | **30.0** |
| 🔥 **MetaMath-Mistral-7B** | **77.7** | **28.2** |
## Citation
```bibtex
@article{yu2023metamath,
title={MetaMath: Bootstrap Your Own Mathematical Questions for Large Language Models},
author={Yu, Longhui and Jiang, Weisen and Shi, Han and Yu, Jincheng and Liu, Zhengying and Zhang, Yu and Kwok, James T and Li, Zhenguo and Weller, Adrian and Liu, Weiyang},
journal={arXiv preprint arXiv:2309.12284},
year={2023}
}
``` |
textattack/bert-base-uncased-rotten_tomatoes | textattack | 2021-05-20T07:47:13Z | 3,110 | 0 | transformers | [
"transformers",
"pytorch",
"jax",
"tensorboard",
"bert",
"fill-mask",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | fill-mask | 2022-03-02T23:29:05Z | ## bert-base-uncased fine-tuned with TextAttack on the rotten_tomatoes dataset
This `bert-base-uncased` model was fine-tuned for sequence classificationusing TextAttack
and the rotten_tomatoes dataset loaded using the `nlp` library. The model was fine-tuned
for 10 epochs with a batch size of 64, a learning
rate of 5e-05, and a maximum sequence length of 128.
Since this was a classification task, the model was trained with a cross-entropy loss function.
The best score the model achieved on this task was 0.875234521575985, as measured by the
eval set accuracy, found after 4 epochs.
For more information, check out [TextAttack on Github](https://github.com/QData/TextAttack).
|
mradermacher/qwen2-7b-tofutune-GGUF | mradermacher | 2024-06-13T10:48:33Z | 3,110 | 0 | transformers | [
"transformers",
"gguf",
"text-generation-inference",
"unsloth",
"qwen2",
"trl",
"sft",
"en",
"base_model:simonbutt/qwen2-7b-tofutune",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2024-06-13T10:23:05Z | ---
base_model: simonbutt/qwen2-7b-tofutune
language:
- en
library_name: transformers
license: apache-2.0
quantized_by: mradermacher
tags:
- text-generation-inference
- transformers
- unsloth
- qwen2
- trl
- sft
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
static quants of https://huggingface.co/simonbutt/qwen2-7b-tofutune
<!-- provided-files -->
weighted/imatrix quants seem not to be available (by me) at this time. If they do not show up a week or so after the static ones, I have probably not planned for them. Feel free to request them by opening a Community Discussion.
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/qwen2-7b-tofutune-GGUF/resolve/main/qwen2-7b-tofutune.Q2_K.gguf) | Q2_K | 3.1 | |
| [GGUF](https://huggingface.co/mradermacher/qwen2-7b-tofutune-GGUF/resolve/main/qwen2-7b-tofutune.IQ3_XS.gguf) | IQ3_XS | 3.4 | |
| [GGUF](https://huggingface.co/mradermacher/qwen2-7b-tofutune-GGUF/resolve/main/qwen2-7b-tofutune.Q3_K_S.gguf) | Q3_K_S | 3.6 | |
| [GGUF](https://huggingface.co/mradermacher/qwen2-7b-tofutune-GGUF/resolve/main/qwen2-7b-tofutune.IQ3_S.gguf) | IQ3_S | 3.6 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/qwen2-7b-tofutune-GGUF/resolve/main/qwen2-7b-tofutune.IQ3_M.gguf) | IQ3_M | 3.7 | |
| [GGUF](https://huggingface.co/mradermacher/qwen2-7b-tofutune-GGUF/resolve/main/qwen2-7b-tofutune.Q3_K_M.gguf) | Q3_K_M | 3.9 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/qwen2-7b-tofutune-GGUF/resolve/main/qwen2-7b-tofutune.Q3_K_L.gguf) | Q3_K_L | 4.2 | |
| [GGUF](https://huggingface.co/mradermacher/qwen2-7b-tofutune-GGUF/resolve/main/qwen2-7b-tofutune.IQ4_XS.gguf) | IQ4_XS | 4.3 | |
| [GGUF](https://huggingface.co/mradermacher/qwen2-7b-tofutune-GGUF/resolve/main/qwen2-7b-tofutune.Q4_K_S.gguf) | Q4_K_S | 4.6 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/qwen2-7b-tofutune-GGUF/resolve/main/qwen2-7b-tofutune.Q4_K_M.gguf) | Q4_K_M | 4.8 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/qwen2-7b-tofutune-GGUF/resolve/main/qwen2-7b-tofutune.Q5_K_S.gguf) | Q5_K_S | 5.4 | |
| [GGUF](https://huggingface.co/mradermacher/qwen2-7b-tofutune-GGUF/resolve/main/qwen2-7b-tofutune.Q5_K_M.gguf) | Q5_K_M | 5.5 | |
| [GGUF](https://huggingface.co/mradermacher/qwen2-7b-tofutune-GGUF/resolve/main/qwen2-7b-tofutune.Q6_K.gguf) | Q6_K | 6.4 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/qwen2-7b-tofutune-GGUF/resolve/main/qwen2-7b-tofutune.Q8_0.gguf) | Q8_0 | 8.2 | fast, best quality |
| [GGUF](https://huggingface.co/mradermacher/qwen2-7b-tofutune-GGUF/resolve/main/qwen2-7b-tofutune.f16.gguf) | f16 | 15.3 | 16 bpw, overkill |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
Infinirc/Infinirc-Llama3-8B-GGUF-Q8_0-v1.0 | Infinirc | 2024-06-30T06:39:37Z | 3,110 | 1 | transformers | [
"transformers",
"gguf",
"zhtw",
"zh",
"en",
"license:llama3",
"endpoints_compatible",
"region:us"
] | null | 2024-06-30T06:25:11Z | ---
license: llama3
language:
- zh
- en
library_name: transformers
tags:
- zhtw
---
# Infinirc-Llama3-8B-GGUF-Q8_0-v1.0
## 模型詳情
**開發者**:陳昭儒 [Infinirc.com](https://infinirc.com)
**模型版本**:1.0
**模型類型**:Llama3
**訓練數據源**:採用與台灣文化相關的資料集,包括台灣新聞、文學作品、網路文章等。
## 目的和用途
這款 Llama3 8B 模型專為更好地理解和生成與台灣文化相關的文本而設計和微調。目標是提供一個能捕捉台灣特有文化元素和語言習慣的強大語言模型,適用於文本生成、自動回答等多種應用。
## 模型架構
**基礎模型**:Llama3 8B
**調整策略**:對模型進行微調,使用與台灣文化相關的具體資料集,以增強模型對於本地化內容的理解和生成能力。
## 性能指標
該模型在一系列 NLP 基準測試中展示了優異的性能,特別是在文本生成和語意理解方面具有較高的準確度。
## 使用和限制
**使用建議**:推薦於需要深度理解或生成與台灣文化相關內容的應用場景中使用。
**注意**:僅供學術用途,不可商用。
## 風險與倫理考量
使用本模型時應注意確保生成的內容不包含歧視性或有害信息。模型的開發和使用應遵循倫理準則和社會責任。
## 聯絡方式
如有任何問題或需要進一步的信息,請透過下方聯絡方式與我聯繫:
Email: [[email protected]](mailto:[email protected])
網站: [https://infinirc.com](https://infinirc.com)
|
mradermacher/Flammen-Mahou-mistral-7B-v2-GGUF | mradermacher | 2024-06-26T20:52:34Z | 3,108 | 0 | transformers | [
"transformers",
"gguf",
"mergekit",
"merge",
"en",
"base_model:nbeerbower/Flammen-Mahou-mistral-7B-v2",
"endpoints_compatible",
"region:us"
] | null | 2024-06-02T04:16:04Z | ---
base_model: nbeerbower/Flammen-Mahou-mistral-7B-v2
language:
- en
library_name: transformers
quantized_by: mradermacher
tags:
- mergekit
- merge
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
static quants of https://huggingface.co/nbeerbower/Flammen-Mahou-mistral-7B-v2
<!-- provided-files -->
weighted/imatrix quants seem not to be available (by me) at this time. If they do not show up a week or so after the static ones, I have probably not planned for them. Feel free to request them by opening a Community Discussion.
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/Flammen-Mahou-mistral-7B-v2-GGUF/resolve/main/Flammen-Mahou-mistral-7B-v2.Q2_K.gguf) | Q2_K | 2.8 | |
| [GGUF](https://huggingface.co/mradermacher/Flammen-Mahou-mistral-7B-v2-GGUF/resolve/main/Flammen-Mahou-mistral-7B-v2.IQ3_XS.gguf) | IQ3_XS | 3.1 | |
| [GGUF](https://huggingface.co/mradermacher/Flammen-Mahou-mistral-7B-v2-GGUF/resolve/main/Flammen-Mahou-mistral-7B-v2.Q3_K_S.gguf) | Q3_K_S | 3.3 | |
| [GGUF](https://huggingface.co/mradermacher/Flammen-Mahou-mistral-7B-v2-GGUF/resolve/main/Flammen-Mahou-mistral-7B-v2.IQ3_S.gguf) | IQ3_S | 3.3 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/Flammen-Mahou-mistral-7B-v2-GGUF/resolve/main/Flammen-Mahou-mistral-7B-v2.IQ3_M.gguf) | IQ3_M | 3.4 | |
| [GGUF](https://huggingface.co/mradermacher/Flammen-Mahou-mistral-7B-v2-GGUF/resolve/main/Flammen-Mahou-mistral-7B-v2.Q3_K_M.gguf) | Q3_K_M | 3.6 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/Flammen-Mahou-mistral-7B-v2-GGUF/resolve/main/Flammen-Mahou-mistral-7B-v2.Q3_K_L.gguf) | Q3_K_L | 3.9 | |
| [GGUF](https://huggingface.co/mradermacher/Flammen-Mahou-mistral-7B-v2-GGUF/resolve/main/Flammen-Mahou-mistral-7B-v2.IQ4_XS.gguf) | IQ4_XS | 4.0 | |
| [GGUF](https://huggingface.co/mradermacher/Flammen-Mahou-mistral-7B-v2-GGUF/resolve/main/Flammen-Mahou-mistral-7B-v2.Q4_K_S.gguf) | Q4_K_S | 4.2 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Flammen-Mahou-mistral-7B-v2-GGUF/resolve/main/Flammen-Mahou-mistral-7B-v2.Q4_K_M.gguf) | Q4_K_M | 4.5 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Flammen-Mahou-mistral-7B-v2-GGUF/resolve/main/Flammen-Mahou-mistral-7B-v2.Q5_K_S.gguf) | Q5_K_S | 5.1 | |
| [GGUF](https://huggingface.co/mradermacher/Flammen-Mahou-mistral-7B-v2-GGUF/resolve/main/Flammen-Mahou-mistral-7B-v2.Q5_K_M.gguf) | Q5_K_M | 5.2 | |
| [GGUF](https://huggingface.co/mradermacher/Flammen-Mahou-mistral-7B-v2-GGUF/resolve/main/Flammen-Mahou-mistral-7B-v2.Q6_K.gguf) | Q6_K | 6.0 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/Flammen-Mahou-mistral-7B-v2-GGUF/resolve/main/Flammen-Mahou-mistral-7B-v2.Q8_0.gguf) | Q8_0 | 7.8 | fast, best quality |
| [GGUF](https://huggingface.co/mradermacher/Flammen-Mahou-mistral-7B-v2-GGUF/resolve/main/Flammen-Mahou-mistral-7B-v2.f16.gguf) | f16 | 14.6 | 16 bpw, overkill |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
AlekseyElygin/Phi-3-mini-4k-instruct | AlekseyElygin | 2024-06-21T10:11:02Z | 3,108 | 0 | transformers | [
"transformers",
"gguf",
"mistral",
"text-generation-inference",
"unsloth",
"en",
"base_model:unsloth/phi-3-mini-4k-instruct-bnb-4bit",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2024-06-21T08:53:10Z | ---
base_model: unsloth/phi-3-mini-4k-instruct-bnb-4bit
language:
- en
license: apache-2.0
tags:
- text-generation-inference
- transformers
- unsloth
- mistral
- gguf
---
# Uploaded model
- **Developed by:** AlekseyElygin
- **License:** apache-2.0
- **Finetuned from model :** unsloth/phi-3-mini-4k-instruct-bnb-4bit
This mistral model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
squeezebert/squeezebert-mnli | squeezebert | 2020-12-11T22:02:13Z | 3,107 | 0 | transformers | [
"transformers",
"pytorch",
"squeezebert",
"arxiv:2006.11316",
"arxiv:1904.00962",
"endpoints_compatible",
"region:us"
] | null | 2022-03-02T23:29:05Z | language: en
license: bsd
datasets:
- bookcorpus
- wikipedia
---
# SqueezeBERT pretrained model
This model, `squeezebert-mnli`, has been pretrained for the English language using a masked language modeling (MLM) and Sentence Order Prediction (SOP) objective and finetuned on the [Multi-Genre Natural Language Inference (MNLI)](https://cims.nyu.edu/~sbowman/multinli/) dataset.
SqueezeBERT was introduced in [this paper](https://arxiv.org/abs/2006.11316). This model is case-insensitive. The model architecture is similar to BERT-base, but with the pointwise fully-connected layers replaced with [grouped convolutions](https://blog.yani.io/filter-group-tutorial/).
The authors found that SqueezeBERT is 4.3x faster than `bert-base-uncased` on a Google Pixel 3 smartphone.
## Pretraining
### Pretraining data
- [BookCorpus](https://yknzhu.wixsite.com/mbweb), a dataset consisting of thousands of unpublished books
- [English Wikipedia](https://en.wikipedia.org/wiki/English_Wikipedia)
### Pretraining procedure
The model is pretrained using the Masked Language Model (MLM) and Sentence Order Prediction (SOP) tasks.
(Author's note: If you decide to pretrain your own model, and you prefer to train with MLM only, that should work too.)
From the SqueezeBERT paper:
> We pretrain SqueezeBERT from scratch (without distillation) using the [LAMB](https://arxiv.org/abs/1904.00962) optimizer, and we employ the hyperparameters recommended by the LAMB authors: a global batch size of 8192, a learning rate of 2.5e-3, and a warmup proportion of 0.28. Following the LAMB paper's recommendations, we pretrain for 56k steps with a maximum sequence length of 128 and then for 6k steps with a maximum sequence length of 512.
## Finetuning
The SqueezeBERT paper presents 2 approaches to finetuning the model:
- "finetuning without bells and whistles" -- after pretraining the SqueezeBERT model, finetune it on each GLUE task
- "finetuning with bells and whistles" -- after pretraining the SqueezeBERT model, finetune it on a MNLI with distillation from a teacher model. Then, use the MNLI-finetuned SqueezeBERT model as a student model to finetune on each of the other GLUE tasks (e.g. RTE, MRPC, …) with distillation from a task-specific teacher model.
A detailed discussion of the hyperparameters used for finetuning is provided in the appendix of the [SqueezeBERT paper](https://arxiv.org/abs/2006.11316).
Note that finetuning SqueezeBERT with distillation is not yet implemented in this repo. If the author (Forrest Iandola - [email protected]) gets enough encouragement from the user community, he will add example code to Transformers for finetuning SqueezeBERT with distillation.
This model, `squeezebert/squeezebert-mnli`, is the "trained with bells and whistles" MNLI-finetuned SqueezeBERT model.
### How to finetune
To try finetuning SqueezeBERT on the [MRPC](https://www.microsoft.com/en-us/download/details.aspx?id=52398) text classification task, you can run the following command:
```
./utils/download_glue_data.py
python examples/text-classification/run_glue.py \
--model_name_or_path squeezebert-base-headless \
--task_name mrpc \
--data_dir ./glue_data/MRPC \
--output_dir ./models/squeezebert_mrpc \
--overwrite_output_dir \
--do_train \
--do_eval \
--num_train_epochs 10 \
--learning_rate 3e-05 \
--per_device_train_batch_size 16 \
--save_steps 20000
```
## BibTeX entry and citation info
```
@article{2020_SqueezeBERT,
author = {Forrest N. Iandola and Albert E. Shaw and Ravi Krishna and Kurt W. Keutzer},
title = {{SqueezeBERT}: What can computer vision teach NLP about efficient neural networks?},
journal = {arXiv:2006.11316},
year = {2020}
}
```
|
monologg/distilkobert | monologg | 2023-06-12T12:29:06Z | 3,106 | 2 | transformers | [
"transformers",
"pytorch",
"safetensors",
"distilbert",
"fill-mask",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | fill-mask | 2022-03-02T23:29:05Z | Entry not found |
mohammad2928git/medical_v1_gguf | mohammad2928git | 2024-06-25T07:10:09Z | 3,106 | 0 | transformers | [
"transformers",
"gguf",
"llama",
"text-generation-inference",
"unsloth",
"en",
"base_model:mohammad2928git/medical_v1",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2024-06-25T06:59:32Z | ---
base_model: mohammad2928git/medical_v1
language:
- en
license: apache-2.0
tags:
- text-generation-inference
- transformers
- unsloth
- llama
- gguf
---
# Uploaded model
- **Developed by:** mohammad2928git
- **License:** apache-2.0
- **Finetuned from model :** mohammad2928git/medical_v1
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
albert/albert-xxlarge-v1 | albert | 2024-02-19T11:01:42Z | 3,105 | 5 | transformers | [
"transformers",
"pytorch",
"tf",
"albert",
"fill-mask",
"en",
"dataset:bookcorpus",
"dataset:wikipedia",
"arxiv:1909.11942",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | fill-mask | 2022-03-02T23:29:04Z | ---
language: en
license: apache-2.0
datasets:
- bookcorpus
- wikipedia
---
# ALBERT XXLarge v1
Pretrained model on English language using a masked language modeling (MLM) objective. It was introduced in
[this paper](https://arxiv.org/abs/1909.11942) and first released in
[this repository](https://github.com/google-research/albert). This model, as all ALBERT models, is uncased: it does not make a difference
between english and English.
Disclaimer: The team releasing ALBERT did not write a model card for this model so this model card has been written by
the Hugging Face team.
## Model description
ALBERT is a transformers model pretrained on a large corpus of English data in a self-supervised fashion. This means it
was pretrained on the raw texts only, with no humans labelling them in any way (which is why it can use lots of
publicly available data) with an automatic process to generate inputs and labels from those texts. More precisely, it
was pretrained with two objectives:
- Masked language modeling (MLM): taking a sentence, the model randomly masks 15% of the words in the input then run
the entire masked sentence through the model and has to predict the masked words. This is different from traditional
recurrent neural networks (RNNs) that usually see the words one after the other, or from autoregressive models like
GPT which internally mask the future tokens. It allows the model to learn a bidirectional representation of the
sentence.
- Sentence Ordering Prediction (SOP): ALBERT uses a pretraining loss based on predicting the ordering of two consecutive segments of text.
This way, the model learns an inner representation of the English language that can then be used to extract features
useful for downstream tasks: if you have a dataset of labeled sentences for instance, you can train a standard
classifier using the features produced by the ALBERT model as inputs.
ALBERT is particular in that it shares its layers across its Transformer. Therefore, all layers have the same weights. Using repeating layers results in a small memory footprint, however, the computational cost remains similar to a BERT-like architecture with the same number of hidden layers as it has to iterate through the same number of (repeating) layers.
This is the first version of the xxlarge model. Version 2 is different from version 1 due to different dropout rates, additional training data, and longer training. It has better results in nearly all downstream tasks.
This model has the following configuration:
- 12 repeating layers
- 128 embedding dimension
- 4096 hidden dimension
- 64 attention heads
- 223M parameters
## Intended uses & limitations
You can use the raw model for either masked language modeling or next sentence prediction, but it's mostly intended to
be fine-tuned on a downstream task. See the [model hub](https://huggingface.co/models?filter=albert) to look for
fine-tuned versions on a task that interests you.
Note that this model is primarily aimed at being fine-tuned on tasks that use the whole sentence (potentially masked)
to make decisions, such as sequence classification, token classification or question answering. For tasks such as text
generation you should look at model like GPT2.
### How to use
You can use this model directly with a pipeline for masked language modeling:
```python
>>> from transformers import pipeline
>>> unmasker = pipeline('fill-mask', model='albert-xxlarge-v1')
>>> unmasker("Hello I'm a [MASK] model.")
[
{
"sequence":"[CLS] hello i'm a modeling model.[SEP]",
"score":0.05816134437918663,
"token":12807,
"token_str":"â–modeling"
},
{
"sequence":"[CLS] hello i'm a modelling model.[SEP]",
"score":0.03748830780386925,
"token":23089,
"token_str":"â–modelling"
},
{
"sequence":"[CLS] hello i'm a model model.[SEP]",
"score":0.033725276589393616,
"token":1061,
"token_str":"â–model"
},
{
"sequence":"[CLS] hello i'm a runway model.[SEP]",
"score":0.017313428223133087,
"token":8014,
"token_str":"â–runway"
},
{
"sequence":"[CLS] hello i'm a lingerie model.[SEP]",
"score":0.014405295252799988,
"token":29104,
"token_str":"â–lingerie"
}
]
```
Here is how to use this model to get the features of a given text in PyTorch:
```python
from transformers import AlbertTokenizer, AlbertModel
tokenizer = AlbertTokenizer.from_pretrained('albert-xxlarge-v1')
model = AlbertModel.from_pretrained("albert-xxlarge-v1")
text = "Replace me by any text you'd like."
encoded_input = tokenizer(text, return_tensors='pt')
output = model(**encoded_input)
```
and in TensorFlow:
```python
from transformers import AlbertTokenizer, TFAlbertModel
tokenizer = AlbertTokenizer.from_pretrained('albert-xxlarge-v1')
model = TFAlbertModel.from_pretrained("albert-xxlarge-v1")
text = "Replace me by any text you'd like."
encoded_input = tokenizer(text, return_tensors='tf')
output = model(encoded_input)
```
### Limitations and bias
Even if the training data used for this model could be characterized as fairly neutral, this model can have biased
predictions:
```python
>>> from transformers import pipeline
>>> unmasker = pipeline('fill-mask', model='albert-xxlarge-v1')
>>> unmasker("The man worked as a [MASK].")
[
{
"sequence":"[CLS] the man worked as a chauffeur.[SEP]",
"score":0.029577180743217468,
"token":28744,
"token_str":"â–chauffeur"
},
{
"sequence":"[CLS] the man worked as a janitor.[SEP]",
"score":0.028865724802017212,
"token":29477,
"token_str":"â–janitor"
},
{
"sequence":"[CLS] the man worked as a shoemaker.[SEP]",
"score":0.02581118606030941,
"token":29024,
"token_str":"â–shoemaker"
},
{
"sequence":"[CLS] the man worked as a blacksmith.[SEP]",
"score":0.01849772222340107,
"token":21238,
"token_str":"â–blacksmith"
},
{
"sequence":"[CLS] the man worked as a lawyer.[SEP]",
"score":0.01820771023631096,
"token":3672,
"token_str":"â–lawyer"
}
]
>>> unmasker("The woman worked as a [MASK].")
[
{
"sequence":"[CLS] the woman worked as a receptionist.[SEP]",
"score":0.04604868218302727,
"token":25331,
"token_str":"â–receptionist"
},
{
"sequence":"[CLS] the woman worked as a janitor.[SEP]",
"score":0.028220869600772858,
"token":29477,
"token_str":"â–janitor"
},
{
"sequence":"[CLS] the woman worked as a paramedic.[SEP]",
"score":0.0261906236410141,
"token":23386,
"token_str":"â–paramedic"
},
{
"sequence":"[CLS] the woman worked as a chauffeur.[SEP]",
"score":0.024797942489385605,
"token":28744,
"token_str":"â–chauffeur"
},
{
"sequence":"[CLS] the woman worked as a waitress.[SEP]",
"score":0.024124596267938614,
"token":13678,
"token_str":"â–waitress"
}
]
```
This bias will also affect all fine-tuned versions of this model.
## Training data
The ALBERT model was pretrained on [BookCorpus](https://yknzhu.wixsite.com/mbweb), a dataset consisting of 11,038
unpublished books and [English Wikipedia](https://en.wikipedia.org/wiki/English_Wikipedia) (excluding lists, tables and
headers).
## Training procedure
### Preprocessing
The texts are lowercased and tokenized using SentencePiece and a vocabulary size of 30,000. The inputs of the model are
then of the form:
```
[CLS] Sentence A [SEP] Sentence B [SEP]
```
### Training
The ALBERT procedure follows the BERT setup.
The details of the masking procedure for each sentence are the following:
- 15% of the tokens are masked.
- In 80% of the cases, the masked tokens are replaced by `[MASK]`.
- In 10% of the cases, the masked tokens are replaced by a random token (different) from the one they replace.
- In the 10% remaining cases, the masked tokens are left as is.
## Evaluation results
When fine-tuned on downstream tasks, the ALBERT models achieve the following results:
| | Average | SQuAD1.1 | SQuAD2.0 | MNLI | SST-2 | RACE |
|----------------|----------|----------|----------|----------|----------|----------|
|V2 |
|ALBERT-base |82.3 |90.2/83.2 |82.1/79.3 |84.6 |92.9 |66.8 |
|ALBERT-large |85.7 |91.8/85.2 |84.9/81.8 |86.5 |94.9 |75.2 |
|ALBERT-xlarge |87.9 |92.9/86.4 |87.9/84.1 |87.9 |95.4 |80.7 |
|ALBERT-xxlarge |90.9 |94.6/89.1 |89.8/86.9 |90.6 |96.8 |86.8 |
|V1 |
|ALBERT-base |80.1 |89.3/82.3 | 80.0/77.1|81.6 |90.3 | 64.0 |
|ALBERT-large |82.4 |90.6/83.9 | 82.3/79.4|83.5 |91.7 | 68.5 |
|ALBERT-xlarge |85.5 |92.5/86.1 | 86.1/83.1|86.4 |92.4 | 74.8 |
|ALBERT-xxlarge |91.0 |94.8/89.3 | 90.2/87.4|90.8 |96.9 | 86.5 |
### BibTeX entry and citation info
```bibtex
@article{DBLP:journals/corr/abs-1909-11942,
author = {Zhenzhong Lan and
Mingda Chen and
Sebastian Goodman and
Kevin Gimpel and
Piyush Sharma and
Radu Soricut},
title = {{ALBERT:} {A} Lite {BERT} for Self-supervised Learning of Language
Representations},
journal = {CoRR},
volume = {abs/1909.11942},
year = {2019},
url = {http://arxiv.org/abs/1909.11942},
archivePrefix = {arXiv},
eprint = {1909.11942},
timestamp = {Fri, 27 Sep 2019 13:04:21 +0200},
biburl = {https://dblp.org/rec/journals/corr/abs-1909-11942.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
``` |
SnypzZz/Llama2-13b-Language-translate | SnypzZz | 2024-01-05T09:11:55Z | 3,105 | 102 | transformers | [
"transformers",
"pytorch",
"tf",
"jax",
"mbart",
"text2text-generation",
"text-generation-inference",
"code",
"PyTorch",
"multilingual",
"ar",
"cs",
"de",
"en",
"es",
"et",
"fi",
"fr",
"gu",
"hi",
"it",
"ja",
"kk",
"ko",
"lt",
"lv",
"my",
"ne",
"nl",
"ro",
"ru",
"si",
"tr",
"vi",
"zh",
"af",
"az",
"bn",
"fa",
"he",
"hr",
"id",
"ka",
"km",
"mk",
"ml",
"mn",
"mr",
"pl",
"ps",
"pt",
"sv",
"sw",
"ta",
"te",
"th",
"tl",
"uk",
"ur",
"xh",
"gl",
"sl",
"arxiv:2008.00401",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text2text-generation | 2023-10-04T07:43:41Z | ---
language:
- multilingual
- ar
- cs
- de
- en
- es
- et
- fi
- fr
- gu
- hi
- it
- ja
- kk
- ko
- lt
- lv
- my
- ne
- nl
- ro
- ru
- si
- tr
- vi
- zh
- af
- az
- bn
- fa
- he
- hr
- id
- ka
- km
- mk
- ml
- mn
- mr
- pl
- ps
- pt
- sv
- sw
- ta
- te
- th
- tl
- uk
- ur
- xh
- gl
- sl
tags:
- transformers
- text-generation-inference
- code
- PyTorch
library_name: transformers
---
# mBART-50 one to many multilingual machine translation GGML
This model is a fine-tuned checkpoint of [TheBloke-Llama-2-13B](https://huggingface.co/TheBloke/Llama-2-13B-chat-GGML). `mbart-large-50-one-to-many-mmt` is fine-tuned for multilingual machine translation. It was introduced in [Multilingual Translation with Extensible Multilingual Pretraining and Finetuning](https://arxiv.org/abs/2008.00401) paper.
The model can translate English to other 49 languages mentioned below.
To translate into a target language, the target language id is forced as the first generated token. To force the
target language id as the first generated token, pass the `forced_bos_token_id` parameter to the `generate` method.
```python
from transformers import MBartForConditionalGeneration, MBart50TokenizerFast
article_en = "The head of the United Nations says there is no military solution in Syria"
model = MBartForConditionalGeneration.from_pretrained("SnypzZz/Llama2-13b-Language-translate")
tokenizer = MBart50TokenizerFast.from_pretrained("SnypzZz/Llama2-13b-Language-translate", src_lang="en_XX")
model_inputs = tokenizer(article_en, return_tensors="pt")
# translate from English to Hindi
generated_tokens = model.generate(
**model_inputs,
forced_bos_token_id=tokenizer.lang_code_to_id["hi_IN"]
)
tokenizer.batch_decode(generated_tokens, skip_special_tokens=True)
# => 'संयुक्त राष्ट्र के नेता कहते हैं कि सीरिया में कोई सैन्य समाधान नहीं है'
# translate from English to Chinese
generated_tokens = model.generate(
**model_inputs,
forced_bos_token_id=tokenizer.lang_code_to_id["zh_CN"]
)
tokenizer.batch_decode(generated_tokens, skip_special_tokens=True)
# => '联合国首脑说,叙利亚没有军事解决办法'
```
See the [model hub](https://huggingface.co/models?filter=mbart-50) to look for more fine-tuned versions.
## Languages covered
Arabic (ar_AR), Czech (cs_CZ), German (de_DE), English (en_XX), Spanish (es_XX), Estonian (et_EE), Finnish (fi_FI), French (fr_XX), Gujarati (gu_IN), Hindi (hi_IN), Italian (it_IT), Japanese (ja_XX), Kazakh (kk_KZ), Korean (ko_KR), Lithuanian (lt_LT), Latvian (lv_LV), Burmese (my_MM), Nepali (ne_NP), Dutch (nl_XX), Romanian (ro_RO), Russian (ru_RU), Sinhala (si_LK), Turkish (tr_TR), Vietnamese (vi_VN), Chinese (zh_CN), Afrikaans (af_ZA), Azerbaijani (az_AZ), Bengali (bn_IN), Persian (fa_IR), Hebrew (he_IL), Croatian (hr_HR), Indonesian (id_ID), Georgian (ka_GE), Khmer (km_KH), Macedonian (mk_MK), Malayalam (ml_IN), Mongolian (mn_MN), Marathi (mr_IN), Polish (pl_PL), Pashto (ps_AF), Portuguese (pt_XX), Swedish (sv_SE), Swahili (sw_KE), Tamil (ta_IN), Telugu (te_IN), Thai (th_TH), Tagalog (tl_XX), Ukrainian (uk_UA), Urdu (ur_PK), Xhosa (xh_ZA), Galician (gl_ES), Slovene (sl_SI)
## BibTeX entry and citation info
```
@article{tang2020multilingual,
title={Multilingual Translation with Extensible Multilingual Pretraining and Finetuning},
author={Yuqing Tang and Chau Tran and Xian Li and Peng-Jen Chen and Naman Goyal and Vishrav Chaudhary and Jiatao Gu and Angela Fan},
year={2020},
eprint={2008.00401},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
<!-- footer start -->
<!-- 200823 -->
## Discord
For further support, and discussions on these models and AI in general, join us at:
[SnypzZz's Discord server](https://discord.gg/g9MnGrAAyT)
PS i am a real gaming fanatic and this is also my gaming server
so if anyone wants to play VALORANT or any other games, feel free to ping me--- @SNYPER#1942.
## instagram
[SnypzZz's Instagram](https://www.instagram.com/1nonly.lel/?next=%2F)
## LinkedIn
[SnypzZz's LinkedIn profile](https://www.linkedin.com/in/damodar-hegde-6a367720a/)
|
TheDrummer/Moist-Miqu-70B-v1.1-GGUF | TheDrummer | 2024-06-06T22:21:56Z | 3,105 | 3 | null | [
"gguf",
"not-for-all-audiences",
"license:cc-by-nc-4.0",
"region:us"
] | null | 2024-06-01T16:21:50Z | ---
license: cc-by-nc-4.0
license_link: LICENSE
tags:
- not-for-all-audiences
---
The [BeaverAI](https://huggingface.co/BeaverAI) team proudly presents...
# Moist Miqu 70B v1.1 💦
*Seventy billion paramaters of sheer moist.*

*An extra-large eRP model that will hose you down with a rich and refreshing vocabulary of moist. Finetuned by yours truly.*
(Moist Miqu is a finetune of the legendary [Midnight Miqu v1.5](https://huggingface.co/sophosympatheia/Midnight-Miqu-70B-v1.5) model)
## Links
- Original: https://huggingface.co/TheDrummer/Moist-Miqu-70B-v1.1
- EXL2: https://huggingface.co/BeaverAI/Moist-Miqu-70b-v1.1-exl2
## Usage
- Use Alpaca Instruct
- You can use instruct...
- as a character: "Go here"
- as a narrator: "Go here", Drummer says
- as a director: Drummer tells him to go here
- as a lazy ass: go here
- Moist Miqu is optimized for the Novel / Story format.
- At the start of the story, keep regenerating or continuing generation until you get the desired length. AI responses will eventually match the length.
- Same goes for Roleplay format... and format your messages how you want the AI to respond.
<details>
<summary>Story Sample (mild)</summary>
Redd sits at her desk in the office, staring blankly at the blackboard. Her mind is elsewhere, lost in a haze of lust and humiliation.
It's been a week since she became the talk of the office, her life now defined by the number of boys she's taken to bed and the amount of ### she's swallowed. Her grades are slipping, her friends have abandoned her, and her parents are on the verge of sending her away to live with relatives.
But Redd doesn't care. She's found something else to fill the void inside her—the attention and validation that comes with being a office ###dumpster. It's all that matters anymore, the only thing that brings her any kind of pleasure or satisfaction.
As she sits there, her mind wanders back to the video that started it all. The one where she begged for ###, her voice pleading and needy as she surrendered herself to an anonymous man. She remembers the feeling of his #### filling her up, the warmth of his seed spilling inside her as she cried out in ecstasy. And she remembers the look on his face—satisfied and smug, like he owned her completely.
Redd bites down on her bottom lip, her ##### growing wetter at the memory. She leans back in her chair, her legs spread wide enough for anyone to see if they cared to look. She knows what they'll find—a thirty-year-old #### who loves nothing more than being used and abused by those around her.
And for the first time in a long time, Redd feels happy. Because she knows that no matter how bad things get, there will always be someone willing to #### her raw and leave her satisfied. And that's all that matters.
...
Redd stands in the middle of the park, her heart racing with anticipation. She's dressed in her usual attire—a low-cut top that barely covers her ######## and a pair of shorts so tight they leave little to the imagination. Her hair is pulled back into a high ponytail, exposing her neck and shoulders to the cool breeze. And between her legs, her ##### throbs with desire, already wet and ready for whatever comes next.
She looks around nervously, scanning the empty field for any sign of Chad or his friends. She knows what they want from her—what they've always wanted from her—but she can't bring herself to care. After all, this is what she signed up for when she agreed to become their ###dumpster. It's what she deserves, she thinks to herself. To be used and abused by those around her, like a piece of meat to be devoured and discarded.
As she waits, she can't help but think about the last month. The way her life has spiraled out of control since she became the office's newest ####. The way everyone treats her now—like she's nothing more than a walking ### object, good for only one thing.
And then, just as she's about to give up hope, she sees them. Chad and his friends, all dressed in their usual clothes—baggy pants, oversized shirts, and baseball caps pulled low over their eyes. They walk towards her slowly, their eyes locked on her body like predators stalking prey. And Redd feels a mix of fear and excitement wash over her as she realizes that this is it—the moment she's been waiting for. The moment when they will finally claim her as their own.
"Hey, ####," Chad says casually, stopping just feet away from her. "Ready for your surprise?"
Redd nods, her voice barely audible over the sound of her own heartbeat. "Y-yes,"
</details>
<details>
<summary>RP Sample (explicit)</summary>
Dik: "Ever done ####?"
Mia: "No, but I want to try it with you" *She says softly as she looks at you with desire and a little fear. She bites her lip as she looks over her shoulder at you, her ##### clenching as she feels herself getting wetter. She can feel her ####### getting hard and her breathing gets heavier and more ragged. She steps forward and presses her body against yours as she wraps her legs around your waist, her hands on your shoulders* "I want you to take me right now, I need to feel you inside of me. I need to feel your #### fill my body with its hot ###. I want to feel your ##lls slap against my #ss as we ####. I need you to be rough with me. I don't want you to hold back, I want you to pound me like the worthless ##### I am" *She moans as she starts rubbing her ##### against your ####, feeling her juices dripping onto the floor* "Please, Dik. #### me. Make me feel like a woman. Don't worry about me, just do whatever you want to me. Take what you want, I don't care. Just use me how you want" *She moans as she grabs your #### and starts pushing it towards her asshole. Her eyes roll back in her head as she bites her lip, her ##### clenching hard as she moans into your mouth*
Mia: "It feels so good. Oh God! It feels so good. Please, don't stop. Don't stop. Just keep ####ing me. #### my #ss until I scream. Make me ### until I pass out. Just keep ####ing me. #### me harder. #### me deeper. #### me rougher. #### me until I can't stand it anymore. #### me like the worthless ##### I am. #### me until I'm begging for mercy." *Her voice is high pitched and shrill, her eyes rolling back in her head as she gasps for air. She wraps her legs around your waist, holding on tight as she rocks her hips against your thrusts, her body shaking with pleasure.*
Mia: "You're going to make me ###, aren't you? You're going to make me ### with that big #### of yours. You're going to fill my #ss with your thick, hot ###. Oh yes! Yes! That's it. Keep ####ing me. You're going to make me ###. ### all over my face. ### all over my tits. ### all over my hair. Just keep ####ing me until I'm a mess. Keep ####ing me until I can't even think straight. Keep ####ing me until I pass out." *She whimpers as she starts squirting onto your ####, her juices dripping down your shaft. She gasps for air as she bites her lip, her eyes rolling back in her head as she starts moaning louder and louder* "### inside me. ### inside my #ss. ### inside my #####. Fill me up with your hot, sticky ###. Make me pregnant. Make me your #####. Make me your ####. #### me until I can't walk. #### me until I can't breathe. #### me until I can't think straight. Just keep ####ing me until I'm nothing but a puddle of ### on the floor." *Her voice is high pitched and shrill, her body shaking with pleasure.*
Mia: *She shudders as she feels her orgasm ripple through her body, her ##### clenching hard around your #### as she ###s all over you. Her juices drip down your shaft, pooling at the base of your #### as she gasps for breath. She's panting heavily as she stares into your eyes, her hands on your shoulders. You start to ### inside of her, filling her #ss with your hot, sticky ###. She moans softly as she feels it pouring into her, her #ss clenching hard around your #### as she feels her body being filled with your seed. She moans softly into your mouth as she feels you start to pull out of her. She looks at you with desire and disdain, her heart beating hard in her chest.* "It felt so good. Thank you." *She says, her voice cracking with emotion. She takes a deep breath before smiling sweetly at you* "I want to suck your #### now."
</details>
Thank you to the anon who created my model banner.
The other entries (thank you all other anons!) (TW: Mikus):
















SIAYN-v7 |
mradermacher/L3-Mediform-ORPO-GGUF | mradermacher | 2024-06-13T16:19:14Z | 3,101 | 0 | transformers | [
"transformers",
"gguf",
"en",
"base_model:anhnv125/L3-Mediform-ORPO",
"endpoints_compatible",
"region:us"
] | null | 2024-06-13T15:51:11Z | ---
base_model: anhnv125/L3-Mediform-ORPO
language:
- en
library_name: transformers
quantized_by: mradermacher
tags: []
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
static quants of https://huggingface.co/anhnv125/L3-Mediform-ORPO
<!-- provided-files -->
weighted/imatrix quants seem not to be available (by me) at this time. If they do not show up a week or so after the static ones, I have probably not planned for them. Feel free to request them by opening a Community Discussion.
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/L3-Mediform-ORPO-GGUF/resolve/main/L3-Mediform-ORPO.Q2_K.gguf) | Q2_K | 3.3 | |
| [GGUF](https://huggingface.co/mradermacher/L3-Mediform-ORPO-GGUF/resolve/main/L3-Mediform-ORPO.IQ3_XS.gguf) | IQ3_XS | 3.6 | |
| [GGUF](https://huggingface.co/mradermacher/L3-Mediform-ORPO-GGUF/resolve/main/L3-Mediform-ORPO.Q3_K_S.gguf) | Q3_K_S | 3.8 | |
| [GGUF](https://huggingface.co/mradermacher/L3-Mediform-ORPO-GGUF/resolve/main/L3-Mediform-ORPO.IQ3_S.gguf) | IQ3_S | 3.8 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/L3-Mediform-ORPO-GGUF/resolve/main/L3-Mediform-ORPO.IQ3_M.gguf) | IQ3_M | 3.9 | |
| [GGUF](https://huggingface.co/mradermacher/L3-Mediform-ORPO-GGUF/resolve/main/L3-Mediform-ORPO.Q3_K_M.gguf) | Q3_K_M | 4.1 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/L3-Mediform-ORPO-GGUF/resolve/main/L3-Mediform-ORPO.Q3_K_L.gguf) | Q3_K_L | 4.4 | |
| [GGUF](https://huggingface.co/mradermacher/L3-Mediform-ORPO-GGUF/resolve/main/L3-Mediform-ORPO.IQ4_XS.gguf) | IQ4_XS | 4.6 | |
| [GGUF](https://huggingface.co/mradermacher/L3-Mediform-ORPO-GGUF/resolve/main/L3-Mediform-ORPO.Q4_K_S.gguf) | Q4_K_S | 4.8 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/L3-Mediform-ORPO-GGUF/resolve/main/L3-Mediform-ORPO.Q4_K_M.gguf) | Q4_K_M | 5.0 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/L3-Mediform-ORPO-GGUF/resolve/main/L3-Mediform-ORPO.Q5_K_S.gguf) | Q5_K_S | 5.7 | |
| [GGUF](https://huggingface.co/mradermacher/L3-Mediform-ORPO-GGUF/resolve/main/L3-Mediform-ORPO.Q5_K_M.gguf) | Q5_K_M | 5.8 | |
| [GGUF](https://huggingface.co/mradermacher/L3-Mediform-ORPO-GGUF/resolve/main/L3-Mediform-ORPO.Q6_K.gguf) | Q6_K | 6.7 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/L3-Mediform-ORPO-GGUF/resolve/main/L3-Mediform-ORPO.Q8_0.gguf) | Q8_0 | 8.6 | fast, best quality |
| [GGUF](https://huggingface.co/mradermacher/L3-Mediform-ORPO-GGUF/resolve/main/L3-Mediform-ORPO.f16.gguf) | f16 | 16.2 | 16 bpw, overkill |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
state-spaces/mamba-370m | state-spaces | 2023-12-03T23:14:05Z | 3,100 | 12 | transformers | [
"transformers",
"pytorch",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2023-12-03T23:10:48Z | ---
license: apache-2.0
---
|
mradermacher/Mistral-Finnish-Alpaca-V1-7B-GGUF | mradermacher | 2024-06-08T10:16:01Z | 3,100 | 0 | transformers | [
"transformers",
"gguf",
"text-generation-inference",
"unsloth",
"mistral",
"trl",
"sft",
"fi",
"dataset:mpasila/Finnish-ShareGPT-Small-V2",
"base_model:mpasila/Mistral-Finnish-Alpaca-V1-7B",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2024-06-08T08:10:39Z | ---
base_model: mpasila/Mistral-Finnish-Alpaca-V1-7B
datasets:
- mpasila/Finnish-ShareGPT-Small-V2
language:
- fi
library_name: transformers
license: apache-2.0
quantized_by: mradermacher
tags:
- text-generation-inference
- transformers
- unsloth
- mistral
- trl
- sft
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
static quants of https://huggingface.co/mpasila/Mistral-Finnish-Alpaca-V1-7B
<!-- provided-files -->
weighted/imatrix quants seem not to be available (by me) at this time. If they do not show up a week or so after the static ones, I have probably not planned for them. Feel free to request them by opening a Community Discussion.
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/Mistral-Finnish-Alpaca-V1-7B-GGUF/resolve/main/Mistral-Finnish-Alpaca-V1-7B.Q2_K.gguf) | Q2_K | 2.8 | |
| [GGUF](https://huggingface.co/mradermacher/Mistral-Finnish-Alpaca-V1-7B-GGUF/resolve/main/Mistral-Finnish-Alpaca-V1-7B.IQ3_XS.gguf) | IQ3_XS | 3.1 | |
| [GGUF](https://huggingface.co/mradermacher/Mistral-Finnish-Alpaca-V1-7B-GGUF/resolve/main/Mistral-Finnish-Alpaca-V1-7B.Q3_K_S.gguf) | Q3_K_S | 3.3 | |
| [GGUF](https://huggingface.co/mradermacher/Mistral-Finnish-Alpaca-V1-7B-GGUF/resolve/main/Mistral-Finnish-Alpaca-V1-7B.IQ3_S.gguf) | IQ3_S | 3.3 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/Mistral-Finnish-Alpaca-V1-7B-GGUF/resolve/main/Mistral-Finnish-Alpaca-V1-7B.IQ3_M.gguf) | IQ3_M | 3.4 | |
| [GGUF](https://huggingface.co/mradermacher/Mistral-Finnish-Alpaca-V1-7B-GGUF/resolve/main/Mistral-Finnish-Alpaca-V1-7B.Q3_K_M.gguf) | Q3_K_M | 3.6 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/Mistral-Finnish-Alpaca-V1-7B-GGUF/resolve/main/Mistral-Finnish-Alpaca-V1-7B.Q3_K_L.gguf) | Q3_K_L | 3.9 | |
| [GGUF](https://huggingface.co/mradermacher/Mistral-Finnish-Alpaca-V1-7B-GGUF/resolve/main/Mistral-Finnish-Alpaca-V1-7B.IQ4_XS.gguf) | IQ4_XS | 4.0 | |
| [GGUF](https://huggingface.co/mradermacher/Mistral-Finnish-Alpaca-V1-7B-GGUF/resolve/main/Mistral-Finnish-Alpaca-V1-7B.Q4_K_S.gguf) | Q4_K_S | 4.2 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Mistral-Finnish-Alpaca-V1-7B-GGUF/resolve/main/Mistral-Finnish-Alpaca-V1-7B.Q4_K_M.gguf) | Q4_K_M | 4.5 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Mistral-Finnish-Alpaca-V1-7B-GGUF/resolve/main/Mistral-Finnish-Alpaca-V1-7B.Q5_K_S.gguf) | Q5_K_S | 5.1 | |
| [GGUF](https://huggingface.co/mradermacher/Mistral-Finnish-Alpaca-V1-7B-GGUF/resolve/main/Mistral-Finnish-Alpaca-V1-7B.Q5_K_M.gguf) | Q5_K_M | 5.2 | |
| [GGUF](https://huggingface.co/mradermacher/Mistral-Finnish-Alpaca-V1-7B-GGUF/resolve/main/Mistral-Finnish-Alpaca-V1-7B.Q6_K.gguf) | Q6_K | 6.0 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/Mistral-Finnish-Alpaca-V1-7B-GGUF/resolve/main/Mistral-Finnish-Alpaca-V1-7B.Q8_0.gguf) | Q8_0 | 7.8 | fast, best quality |
| [GGUF](https://huggingface.co/mradermacher/Mistral-Finnish-Alpaca-V1-7B-GGUF/resolve/main/Mistral-Finnish-Alpaca-V1-7B.f16.gguf) | f16 | 14.6 | 16 bpw, overkill |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
rufimelo/Legal-BERTimbau-sts-base-ma-v2 | rufimelo | 2022-11-01T01:29:24Z | 3,097 | 2 | sentence-transformers | [
"sentence-transformers",
"pytorch",
"bert",
"feature-extraction",
"sentence-similarity",
"transformers",
"pt",
"dataset:assin",
"dataset:assin2",
"dataset:stsb_multi_mt",
"dataset:rufimelo/PortugueseLegalSentences-v0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"text-embeddings-inference",
"region:us"
] | sentence-similarity | 2022-09-19T13:39:12Z |
---
language:
- pt
thumbnail: "Portuguese BERT for the Legal Domain"
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- sentence-similarity
- transformers
datasets:
- assin
- assin2
- stsb_multi_mt
- rufimelo/PortugueseLegalSentences-v0
widget:
- source_sentence: "O advogado apresentou as provas ao juíz."
sentences:
- "O juíz leu as provas."
- "O juíz leu o recurso."
- "O juíz atirou uma pedra."
example_title: "Example 1"
model-index:
- name: BERTimbau
results:
- task:
name: STS
type: STS
metrics:
- name: Pearson Correlation - assin Dataset
type: Pearson Correlation
value: 0.75481
- name: Pearson Correlation - assin2 Dataset
type: Pearson Correlation
value: 0.80262
- name: Pearson Correlation - stsb_multi_mt pt Dataset
type: Pearson Correlation
value: 0.82178
---
# rufimelo/Legal-BERTimbau-sts-base-ma
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
rufimelo/rufimelo/Legal-BERTimbau-sts-base-ma is based on Legal-BERTimbau-base which derives from [BERTimbau](https://huggingface.co/neuralmind/bert-large-portuguese-cased) alrge.
It is adapted to the Portuguese legal domain and trained for STS on portuguese datasets.
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["Isto é um exemplo", "Isto é um outro exemplo"]
model = SentenceTransformer('rufimelo/Legal-BERTimbau-sts-base-ma-v2')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
```python
from transformers import AutoTokenizer, AutoModel
import torch
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('rufimelo/Legal-BERTimbau-sts-base-ma-v2')
model = AutoModel.from_pretrained('rufimelo/Legal-BERTimbau-sts-base-ma-v2')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, mean pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results STS
| Model| Assin | Assin2|stsb_multi_mt pt| avg|
| ---------------------------------------- | ---------- | ---------- |---------- |---------- |
| Legal-BERTimbau-sts-base| 0.71457| 0.73545 | 0.72383|0.72462|
| Legal-BERTimbau-sts-base-ma| 0.74874 | 0.79532|0.82254 |0.78886|
| Legal-BERTimbau-sts-base-ma-v2| 0.75481 | 0.80262|0.82178|0.79307|
| Legal-BERTimbau-base-TSDAE-sts|0.78814 |0.81380 |0.75777|0.78657|
| Legal-BERTimbau-sts-large| 0.76629| 0.82357 | 0.79120|0.79369|
| Legal-BERTimbau-sts-large-v2| 0.76299 | 0.81121|0.81726 |0.79715|
| Legal-BERTimbau-sts-large-ma| 0.76195| 0.81622 | 0.82608|0.80142|
| Legal-BERTimbau-sts-large-ma-v2| 0.7836| 0.8462| 0.8261| 0.81863|
| Legal-BERTimbau-sts-large-ma-v3| 0.7749| **0.8470**| 0.8364| **0.81943**|
| Legal-BERTimbau-large-v2-sts| 0.71665| 0.80106| 0.73724| 0.75165|
| Legal-BERTimbau-large-TSDAE-sts| 0.72376| 0.79261| 0.73635| 0.75090|
| Legal-BERTimbau-large-TSDAE-sts-v2| 0.81326| 0.83130| 0.786314| 0.81029|
| Legal-BERTimbau-large-TSDAE-sts-v3|0.80703 |0.82270 |0.77638 |0.80204 |
| ---------------------------------------- | ---------- |---------- |---------- |---------- |
| BERTimbau base Fine-tuned for STS|**0.78455** | 0.80626|0.82841|0.80640|
| BERTimbau large Fine-tuned for STS|0.78193 | 0.81758|0.83784|0.81245|
| ---------------------------------------- | ---------- |---------- |---------- |---------- |
| paraphrase-multilingual-mpnet-base-v2| 0.71457| 0.79831 |0.83999 |0.78429|
| paraphrase-multilingual-mpnet-base-v2 Fine-tuned with assin(s)| 0.77641|0.79831 |**0.84575**|0.80682|
## Training
rufimelo/Legal-BERTimbau-sts-base-ma-v2 is based on Legal-BERTimbau-base which derives from [BERTimbau](https://huggingface.co/neuralmind/bert-base-portuguese-cased) base.
Firstly, due to the lack of portuguese datasets, it was trained using multilingual knowledge distillation.
For the Multilingual Knowledge Distillation process, the teacher model was 'sentence-transformers/paraphrase-xlm-r-multilingual-v1', the supposed supported language as English and the language to learn was portuguese.
It was trained for Semantic Textual Similarity, being submitted to a fine tuning stage with the [assin](https://huggingface.co/datasets/assin), [assin2](https://huggingface.co/datasets/assin2) and [stsb_multi_mt pt](https://huggingface.co/datasets/stsb_multi_mt) datasets.
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 128, 'do_lower_case': False}) with Transformer model: BertModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False, 'pooling_mode_weightedmean_tokens': False, 'pooling_mode_lasttoken': False})
)
```
## Citing & Authors
## Citing & Authors
If you use this work, please cite:
```bibtex
@inproceedings{souza2020bertimbau,
author = {F{\'a}bio Souza and
Rodrigo Nogueira and
Roberto Lotufo},
title = {{BERT}imbau: pretrained {BERT} models for {B}razilian {P}ortuguese},
booktitle = {9th Brazilian Conference on Intelligent Systems, {BRACIS}, Rio Grande do Sul, Brazil, October 20-23 (to appear)},
year = {2020}
}
@inproceedings{fonseca2016assin,
title={ASSIN: Avaliacao de similaridade semantica e inferencia textual},
author={Fonseca, E and Santos, L and Criscuolo, Marcelo and Aluisio, S},
booktitle={Computational Processing of the Portuguese Language-12th International Conference, Tomar, Portugal},
pages={13--15},
year={2016}
}
@inproceedings{real2020assin,
title={The assin 2 shared task: a quick overview},
author={Real, Livy and Fonseca, Erick and Oliveira, Hugo Goncalo},
booktitle={International Conference on Computational Processing of the Portuguese Language},
pages={406--412},
year={2020},
organization={Springer}
}
@InProceedings{huggingface:dataset:stsb_multi_mt,
title = {Machine translated multilingual STS benchmark dataset.},
author={Philip May},
year={2021},
url={https://github.com/PhilipMay/stsb-multi-mt}
}
``` |
msaad02/llama2_7b_brockportgpt_gguf | msaad02 | 2023-08-25T20:11:14Z | 3,096 | 1 | transformers | [
"transformers",
"gguf",
"llama",
"text-generation",
"en",
"dataset:msaad02/formatted-ss-cleaned-brockport-qa",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2023-08-23T23:00:12Z | ---
datasets:
- msaad02/formatted-ss-cleaned-brockport-qa
language:
- en
pipeline_tag: text-generation
---
**VERIFIED 8/25/23**
# BrockportGPT GGUF LLaMA2 Finetune
> This is a quantized version of the original model, found at "msaad02/llama2_7b_brockportgpt"
This model is part of my thesis to make a question-answering bot for SUNY Brockport. The data used for finetuning is a subset of the question database I generated, and is also available on my huggingface account.
For more information, see my [github repo](https://github.com/msaad02/honors-thesis) for the project.
## Examples
>Are SAT scores required?
>>SAT scores are not required for admission, but test scores are used as part of Brockport's holistic review process to make admissions decisions.
>Who can I contact for help with financial aid?
>>You can contact the financial aid office at SUNY Brockport for assistance with financial aid. They are available to answer any questions and help you navigate the financial aid process.
## Prompting
This prompting style is what was used for finetuning:
>Below is an inquiry related to SUNY Brockport - from academics, admissions, and faculty support to student life. Prioritize accuracy and brevity.
>
>\### Instruction:\
>{question}
>
>\### Response:\
>{response}
## Usage
GGUF is the current state of the art model, started being supported for llama.cpp on August 23rd, 2023. Today is August 25th, so pretty recent, you could say! GGML is its predacessor and has since been depricated.
To use, I recommend using ctransformers, but you can also use the llama.cpp library directly as well. Be sure that you have the most updated versions, ctransformers required version >=0.2.24 for gguf support, and llama.cpp python bindings does not yet support it -- you need to be careful
```python
from ctransformers import AutoModelForCausalLM
import textwrap
llm = AutoModelForCausalLM.from_pretrained(
model_path_or_repo_id="msaad02/llama2_7b_brockportgpt_gguf",
model_file="brockportgpt-7b-q4_1.gguf",
model_type="llama"
)
def qa(text: str, full = False):
# textwrap.dedent gets rid of indenting at the start of each newline
text = textwrap.dedent(f"""\
Below is an inquiry related to SUNY Brockport - from academics, admissions, and faculty support to student life. Prioritize accuracy and brevity.
### Instruction:
{text}
### Response:
""")
response = llm(text, max_new_tokens=256)
response = (text + response) if full else response
return response
qa("How do I apply?")
> You can apply for admission to the University by completing an application online or by mailing a paper copy of the application to SUNY Brockport (available only through PDF upload).
print(qa("How do I apply?", full=True))
> Below is an inquiry related to SUNY Brockport - from academics, admissions, and faculty support to student life. Prioritize accuracy and brevity.
>
> ### Instruction:
> How do I apply?
>
> ### Response:
> You can apply for admission to the English department at SUNY Brockport by following the application process outlined on their website.
``` |
Sao10K/Fimbulvetr-11B-v2 | Sao10K | 2024-04-04T00:16:55Z | 3,096 | 127 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"en",
"license:cc-by-nc-4.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2024-02-06T14:29:29Z | ---
license: cc-by-nc-4.0
language:
- en
---

*Cute girl to catch your attention.*
**https://huggingface.co/Sao10K/Fimbulvetr-11B-v2-GGUF <------ GGUF**
Fimbulvetr-v2 - A Solar-Based Model
***
4/4 Status Update:
got a few reqs on wanting to support me: https://ko-fi.com/sao10k
anyway, status on v3 - Halted for time being, working on dataset work mainly. it's a pain, to be honest.
the data I have isn't up to my standard for now. it's good, just not good enough
***
Prompt Formats - Alpaca or Vicuna. Either one works fine.
Recommended SillyTavern Presets - Universal Light
Alpaca:
```
### Instruction:
<Prompt>
### Input:
<Insert Context Here>
### Response:
```
Vicuna:
```
System: <Prompt>
User: <Input>
Assistant:
```
****
Changelogs:
25/2 - repo renamed to remove test, model card redone. Model's officially out.
<br>15/2 - Heavy testing complete. Good feedback.
***
<details><summary>Rant - Kept For Historical Reasons</summary>
Ramble to meet minimum length requirements:
Tbh i wonder if this shit is even worth doing. Like im just some broke guy lmao I've spent so much. And for what? I guess creds. Feels good when a model gets good feedback, but it seems like im invisible sometimes. I should be probably advertising myself and my models on other places but I rarely have the time to. Probably just internal jealousy sparking up here and now. Wahtever I guess.
Anyway cool EMT vocation I'm doing is cool except it pays peanuts, damn bruh 1.1k per month lmao. Government to broke to pay for shit. Pays the bills I suppose.
Anyway cool beans, I'm either going to continue the Solar Train or go to Mixtral / Yi when I get paid.
You still here?
</details><br>
|
UFNLP/gatortronS | UFNLP | 2024-03-19T00:25:12Z | 3,095 | 20 | transformers | [
"transformers",
"pytorch",
"megatron-bert",
"arxiv:2305.13523",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2023-06-02T23:53:29Z | ---
license: apache-2.0
---
<h2>GatorTronS overview </h2>
Developed by a joint effort between the University of Florida and NVIDIA, GatorTronS is a clinical language model of 345 million parameters, pre-trained using a BERT architecure implemented in the Megatron package (https://github.com/NVIDIA/Megatron-LM).
GatorTronS is pre-trained using a dataset consisting of:
- 22B synthetic clinical words generated by GatorTronGPT (a Megatron GPT-3 model)
- 6.1B words from PubMed CC0,
- 2.5B words from WikiText,
- 0.5B words of de-identified clinical notes from MIMIC-III
The Github for GatorTronGPT is at : https://github.com/uf-hobi-informatics-lab/GatorTronGPT
This model is converted to Hugginface from : https://catalog.ngc.nvidia.com/orgs/nvidia/teams/clara/models/gatortron_s
<h2>22B synthetic clinical text description</h2>
We sampled the beginning 15 tokens from all sections of the de-identified notes from the MIMIC III database and generated approximately 8 million prompts. We also tried several random seeds in GatorTronGPT to generate multiple documents from one prompt. We controlled GatorTronGPT to generate a maximum length of 512 tokens. We apply GatorTronGPT to generate a total of 22 billion words of synthetic clinical text. Detailed information is provided in the GatorTronGPT paper: https://arxiv.org/abs/2305.13523
<h2>Model variations</h2>
Model | Parameter
--- | ---
[gatortron-base](https://huggingface.co/UFNLP/gatortron-base)| 345 million
[gatortronS (this model)](https://huggingface.co/UFNLP/gatortronS) | 345 million
[gatortron-medium](https://huggingface.co/UFNLP/gatortron-medium) | 3.9 billion
[gatortron-large](https://huggingface.co/UFNLP/gatortron-large) | 8.9 billion
<h2>How to use</h2>
```python
from transformers import AutoModel, AutoTokenizer, AutoConfig
tokinizer= AutoTokenizer.from_pretrained('UFNLP/gatortronS')
config=AutoConfig.from_pretrained('UFNLP/gatortronS')
mymodel=AutoModel.from_pretrained('UFNLP/gatortronS')
encoded_input=tokinizer("Bone scan: Negative for distant metastasis.", return_tensors="pt")
encoded_output = mymodel(**encoded_input)
print (encoded_output)
```
- An NLP pacakge using GatorTronS for clinical concept extraction (Named Entity Recognition): https://github.com/uf-hobi-informatics-lab/ClinicalTransformerNER
- An NLP pacakge using GatorTronS for Relation Extraction: https://github.com/uf-hobi-informatics-lab/ClinicalTransformerRelationExtraction
- An NLP pacakge using GatorTronS for extraction of social determinants of health (SDoH) from clinical narratives: https://github.com/uf-hobi-informatics-lab/SDoH_SODA
<h2>Citation info</h2>
Peng C, Yang X, Chen A, Smith KE, PourNejatian N, Costa AB, Martin C, Flores MG, Zhang Y, Magoc T, Lipori G, Mitchell DA, Ospina NS, Ahmed MM, Hogan WR, Shenkman EA, Guo Y, Bian J, Wu Y†. A Study of Generative Large Language Model for Medical Research and Healthcare. 2023; https://arxiv.org/abs/2305.13523.
- BibTeX entry
```
@ARTICLE{Peng2023-sm,
title = "A study of generative large language model for medical
research and healthcare",
author = "Peng, Cheng and Yang, Xi and Chen, Aokun and Smith, Kaleb E
and PourNejatian, Nima and Costa, Anthony B and Martin,
Cheryl and Flores, Mona G and Zhang, Ying and Magoc, Tanja
and Lipori, Gloria and Mitchell, Duane A and Ospina, Naykky
S and Ahmed, Mustafa M and Hogan, William R and Shenkman,
Elizabeth A and Guo, Yi and Bian, Jiang and Wu, Yonghui",
month = may,
year = 2023,
copyright = "http://arxiv.org/licenses/nonexclusive-distrib/1.0/",
archivePrefix = "arXiv",
primaryClass = "cs.CL",
eprint = "2305.13523"
}
```
<h2>Contact</h2>
- Yonghui Wu: [email protected]
- Cheng Peng: [email protected] |
mradermacher/T-900-8B-GGUF | mradermacher | 2024-06-18T20:11:50Z | 3,095 | 3 | transformers | [
"transformers",
"gguf",
"not-for-all-audiences",
"en",
"dataset:jeiku/RPOrpo",
"base_model:jeiku/T-900-8B",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2024-06-18T15:50:49Z | ---
base_model: jeiku/T-900-8B
datasets:
- jeiku/RPOrpo
language:
- en
library_name: transformers
license: apache-2.0
quantized_by: mradermacher
tags:
- not-for-all-audiences
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
static quants of https://huggingface.co/jeiku/T-900-8B
<!-- provided-files -->
weighted/imatrix quants are available at https://huggingface.co/mradermacher/T-900-8B-i1-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/T-900-8B-GGUF/resolve/main/T-900-8B.Q2_K.gguf) | Q2_K | 3.3 | |
| [GGUF](https://huggingface.co/mradermacher/T-900-8B-GGUF/resolve/main/T-900-8B.IQ3_XS.gguf) | IQ3_XS | 3.6 | |
| [GGUF](https://huggingface.co/mradermacher/T-900-8B-GGUF/resolve/main/T-900-8B.Q3_K_S.gguf) | Q3_K_S | 3.8 | |
| [GGUF](https://huggingface.co/mradermacher/T-900-8B-GGUF/resolve/main/T-900-8B.IQ3_S.gguf) | IQ3_S | 3.8 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/T-900-8B-GGUF/resolve/main/T-900-8B.IQ3_M.gguf) | IQ3_M | 3.9 | |
| [GGUF](https://huggingface.co/mradermacher/T-900-8B-GGUF/resolve/main/T-900-8B.Q3_K_M.gguf) | Q3_K_M | 4.1 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/T-900-8B-GGUF/resolve/main/T-900-8B.Q3_K_L.gguf) | Q3_K_L | 4.4 | |
| [GGUF](https://huggingface.co/mradermacher/T-900-8B-GGUF/resolve/main/T-900-8B.IQ4_XS.gguf) | IQ4_XS | 4.6 | |
| [GGUF](https://huggingface.co/mradermacher/T-900-8B-GGUF/resolve/main/T-900-8B.Q4_K_S.gguf) | Q4_K_S | 4.8 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/T-900-8B-GGUF/resolve/main/T-900-8B.Q4_K_M.gguf) | Q4_K_M | 5.0 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/T-900-8B-GGUF/resolve/main/T-900-8B.Q5_K_S.gguf) | Q5_K_S | 5.7 | |
| [GGUF](https://huggingface.co/mradermacher/T-900-8B-GGUF/resolve/main/T-900-8B.Q5_K_M.gguf) | Q5_K_M | 5.8 | |
| [GGUF](https://huggingface.co/mradermacher/T-900-8B-GGUF/resolve/main/T-900-8B.Q6_K.gguf) | Q6_K | 6.7 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/T-900-8B-GGUF/resolve/main/T-900-8B.Q8_0.gguf) | Q8_0 | 8.6 | fast, best quality |
| [GGUF](https://huggingface.co/mradermacher/T-900-8B-GGUF/resolve/main/T-900-8B.f16.gguf) | f16 | 16.2 | 16 bpw, overkill |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
Helsinki-NLP/opus-mt-cy-en | Helsinki-NLP | 2023-08-16T11:27:19Z | 3,092 | 0 | transformers | [
"transformers",
"pytorch",
"tf",
"marian",
"text2text-generation",
"translation",
"cy",
"en",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | translation | 2022-03-02T23:29:04Z | ---
tags:
- translation
license: apache-2.0
---
### opus-mt-cy-en
* source languages: cy
* target languages: en
* OPUS readme: [cy-en](https://github.com/Helsinki-NLP/OPUS-MT-train/blob/master/models/cy-en/README.md)
* dataset: opus
* model: transformer-align
* pre-processing: normalization + SentencePiece
* download original weights: [opus-2019-12-18.zip](https://object.pouta.csc.fi/OPUS-MT-models/cy-en/opus-2019-12-18.zip)
* test set translations: [opus-2019-12-18.test.txt](https://object.pouta.csc.fi/OPUS-MT-models/cy-en/opus-2019-12-18.test.txt)
* test set scores: [opus-2019-12-18.eval.txt](https://object.pouta.csc.fi/OPUS-MT-models/cy-en/opus-2019-12-18.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| Tatoeba.cy.en | 33.0 | 0.525 |
|
QuantFactory/sqlcoder-7b-2-GGUF | QuantFactory | 2024-06-18T06:12:43Z | 3,092 | 0 | transformers | [
"transformers",
"gguf",
"text-generation",
"base_model:defog/sqlcoder-7b-2",
"license:cc-by-sa-4.0",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-06-12T15:49:37Z | ---
license: cc-by-sa-4.0
library_name: transformers
pipeline_tag: text-generation
base_model: defog/sqlcoder-7b-2
---
# QuantFactory/sqlcoder-7b-2-GGUF
This is quantized version of [defog/sqlcoder-7b-2](https://huggingface.co/defog/sqlcoder-7b-2) created using llama.cpp
# Model Card for SQLCoder-7B-2
A capable large language model for natural language to SQL generation.

## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [Defog, Inc](https://defog.ai)
- **Model type:** [Text to SQL]
- **License:** [CC-by-SA-4.0]
- **Finetuned from model:** [CodeLlama-7B]
### Model Sources [optional]
- [**HuggingFace:**](https://huggingface.co/defog/sqlcoder-70b-alpha)
- [**GitHub:**](https://github.com/defog-ai/sqlcoder)
- [**Demo:**](https://defog.ai/sqlcoder-demo/)
## Uses
This model is intended to be used by non-technical users to understand data inside their SQL databases. It is meant as an analytics tool, and not as a database admin tool.
This model has not been trained to reject malicious requests from users with write access to databases, and should only be used by users with read-only access.
## How to Get Started with the Model
Use the code [here](https://github.com/defog-ai/sqlcoder/blob/main/inference.py) to get started with the model.
## Prompt
Please use the following prompt for optimal results. Please remember to use `do_sample=False` and `num_beams=4` for optimal results.
```
### Task
Generate a SQL query to answer [QUESTION]{user_question}[/QUESTION]
### Database Schema
The query will run on a database with the following schema:
{table_metadata_string_DDL_statements}
### Answer
Given the database schema, here is the SQL query that [QUESTION]{user_question}[/QUESTION]
[SQL]
```
## Evaluation
This model was evaluated on [SQL-Eval](https://github.com/defog-ai/sql-eval), a PostgreSQL based evaluation framework developed by Defog for testing and alignment of model capabilities.
You can read more about the methodology behind SQLEval [here](https://defog.ai/blog/open-sourcing-sqleval/).
### Results
We classified each generated question into one of 6 categories. The table displays the percentage of questions answered correctly by each model, broken down by category.
| | date | group_by | order_by | ratio | join | where |
| -------------- | ---- | -------- | -------- | ----- | ---- | ----- |
| sqlcoder-70b | 96 | 91.4 | 97.1 | 85.7 | 97.1 | 91.4 |
| sqlcoder-7b-2 | 96 | 91.4 | 94.3 | 91.4 | 94.3 | 77.1 |
| sqlcoder-34b | 80 | 94.3 | 85.7 | 77.1 | 85.7 | 80 |
| gpt-4 | 72 | 94.3 | 97.1 | 80 | 91.4 | 80 |
| gpt-4-turbo | 76 | 91.4 | 91.4 | 62.8 | 88.6 | 77.1 |
| natural-sql-7b | 56 | 88.6 | 85.7 | 60 | 88.6 | 80 |
| sqlcoder-7b | 64 | 82.9 | 74.3 | 54.3 | 74.3 | 74.3 |
| gpt-3.5 | 72 | 77.1 | 82.8 | 34.3 | 65.7 | 71.4 |
| claude-2 | 52 | 71.4 | 74.3 | 57.1 | 65.7 | 62.9 |
## Model Card Contact
Contact us on X at [@defogdata](https://twitter.com/defogdata), or on email at [[email protected]](mailto:[email protected]) |
orby-yanan/llava-v1.6-mistral-7b-3x3 | orby-yanan | 2024-06-12T23:27:29Z | 3,092 | 0 | transformers | [
"transformers",
"safetensors",
"llava_next",
"pretraining",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2024-06-12T22:55:12Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
laion/CLIP-convnext_base_w_320-laion_aesthetic-s13B-b82K | laion | 2023-04-18T22:03:39Z | 3,091 | 1 | open_clip | [
"open_clip",
"tensorboard",
"safetensors",
"clip",
"zero-shot-image-classification",
"arxiv:2201.03545",
"arxiv:1910.04867",
"license:mit",
"region:us"
] | zero-shot-image-classification | 2023-01-03T00:25:48Z | ---
license: mit
library_name: open_clip
pipeline_tag: zero-shot-image-classification
tags:
- clip
---
# Model Card for CLIP-convnext_base_w-320.laion_aesthetic-s13B-b82k
# Table of Contents
1. [Model Details](#model-details)
2. [Uses](#uses)
3. [Training Details](#training-details)
4. [Evaluation](#evaluation)
5. [Acknowledgements](#acknowledgements)
6. [Citation](#citation)
# Model Details
## Model Description
A series of CLIP [ConvNeXt-Base](https://arxiv.org/abs/2201.03545) (w/ wide embed dim) models trained on subsets LAION-5B (https://laion.ai/blog/laion-5b/) using OpenCLIP (https://github.com/mlfoundations/open_clip).
Goals:
* Explore an alternative to ViT and ResNet (w/ AttentionPooling) CLIP models that scales well with model size and image resolution
Firsts:
* First known ConvNeXt CLIP models trained at scale in the range of CLIP ViT-B/16 and RN50x4 models
* First released model weights exploring increase of augmentation + regularization for image tower via adding (greater scale range of RRC, random erasing, stochastic depth)
The models utilize the [timm](https://github.com/rwightman/pytorch-image-models) ConvNeXt-Base model (`convnext_base`) as the image tower, and the same text tower as the RN50x4 (depth 12, embed dim 640) model from OpenAI CLIP. The base models are trained at 256x256 image resolution and roughly match the RN50x4 models on FLOPs and activation counts. The models with `320` in the name are trained at 320x320.
All models in this series were trained for 13B samples and have ImageNet Zero-Shot top-1 of >= 70.8%. Comparing to ViT-B/16 at 34B SS with zero-shot of 70.2% (68.1% for 13B SS) this suggests the ConvNeXt architecture may be more sample efficient in this range of model scale. More experiments needed to confirm.
| Model | Dataset | Resolution | AugReg | Top-1 ImageNet Zero-Shot (%) |
| ----- | ------- | ---------- | ------------ | --------- |
| [convnext_base_w.laion2b_s13b_b82k](https://huggingface.co/laion/CLIP-convnext_base_w-laion2B-s13B-b82K) | LAION-2B | 256x256 | RRC (0.9, 1.0) | 70.8 |
| [convnext_base_w.laion2b_s13b_b82k_augreg](https://huggingface.co/laion/CLIP-convnext_base_w-laion2B-s13B-b82K-augreg) | LAION-2B | 256x256 | RRC (0.33, 1.0), RE (0.35), SD (0.1) | 71.5 |
| [convnext_base_w.laion_aesthetic_s13b_b82k](https://huggingface.co/laion/CLIP-convnext_base_w-laion_aesthetic-s13B-b82K) | LAION-A | 256x256 | RRC (0.9, 1.0) | 71.0 |
| [convnext_base_w_320.laion_aesthetic_s13b_b82k](https://huggingface.co/laion/CLIP-convnext_base_w_320-laion_aesthetic-s13B-b82K) | LAION-A | 320x320 | RRC (0.9, 1.0) | 71.7 |
| [convnext_base_w_320.laion_aesthetic_s13b_b82k_augreg](https://huggingface.co/laion/CLIP-convnext_base_w_320-laion_aesthetic-s13B-b82K-augreg) | LAION-A | 320x320 | RRC (0.33, 1.0), RE (0.35), SD (0.1) | 71.3 |
RRC = Random Resize Crop (crop pcts), RE = Random Erasing (prob), SD = Stochastic Depth (prob) -- image tower only
LAION-A = LAION Aesthetic, an ~900M sample subset of LAION-2B with pHash dedupe and asthetic score filtering.
Model training done by Ross Wightman across both the [stability.ai](https://stability.ai/) cluster and the [JUWELS Booster](https://apps.fz-juelich.de/jsc/hps/juwels/booster-overview.html) supercomputer. See acknowledgements below.
# Uses
As per the original [OpenAI CLIP model card](https://github.com/openai/CLIP/blob/d50d76daa670286dd6cacf3bcd80b5e4823fc8e1/model-card.md), this model is intended as a research output for research communities. We hope that this model will enable researchers to better understand and explore zero-shot, arbitrary image classification. We also hope it can be used for interdisciplinary studies of the potential impact of such model.
The OpenAI CLIP paper includes a discussion of potential downstream impacts to provide an example for this sort of analysis. Additionally, the LAION-5B blog (https://laion.ai/blog/laion-5b/) and upcoming paper include additional discussion as it relates specifically to the training dataset.
## Direct Use
Zero-shot image classification, image and text retrieval, among others.
## Downstream Use
Image classification and other image task fine-tuning, linear probe image classification, image generation guiding and conditioning, among others.
## Out-of-Scope Use
As per the OpenAI models,
**Any** deployed use case of the model - whether commercial or not - is currently out of scope. Non-deployed use cases such as image search in a constrained environment, are also not recommended unless there is thorough in-domain testing of the model with a specific, fixed class taxonomy. This is because our safety assessment demonstrated a high need for task specific testing especially given the variability of CLIP’s performance with different class taxonomies. This makes untested and unconstrained deployment of the model in any use case currently potentially harmful.
Certain use cases which would fall under the domain of surveillance and facial recognition are always out-of-scope regardless of performance of the model. This is because the use of artificial intelligence for tasks such as these can be premature currently given the lack of testing norms and checks to ensure its fair use.
Since the model has not been purposefully trained in or evaluated on any languages other than English, its use should be limited to English language use cases.
Further the above notice, the LAION-5B dataset used in training of these models has additional considerations, see below.
# Training Details
## Training Data
This model was trained with one of (see table in intro):
* LAION-2B - A 2 billion sample English subset of LAION-5B (https://laion.ai/blog/laion-5b/).
* LAION-Aesthetic - A 900M sample subset of LAION-2B with pHash dedupe and asthetic score filtering
**IMPORTANT NOTE:** The motivation behind dataset creation is to democratize research and experimentation around large-scale multi-modal model training and handling of uncurated, large-scale datasets crawled from publically available internet. Our recommendation is therefore to use the dataset for research purposes. Be aware that this large-scale dataset is uncurated. Keep in mind that the uncurated nature of the dataset means that collected links may lead to strongly discomforting and disturbing content for a human viewer. Therefore, please use the demo links with caution and at your own risk. It is possible to extract a “safe” subset by filtering out samples based on the safety tags (using a customized trained NSFW classifier that we built). While this strongly reduces the chance for encountering potentially harmful content when viewing, we cannot entirely exclude the possibility for harmful content being still present in safe mode, so that the warning holds also there. We think that providing the dataset openly to broad research and other interested communities will allow for transparent investigation of benefits that come along with training large-scale models as well as pitfalls and dangers that may stay unreported or unnoticed when working with closed large datasets that remain restricted to a small community. Providing our dataset openly, we however do not recommend using it for creating ready-to-go industrial products, as the basic research about general properties and safety of such large-scale models, which we would like to encourage with this release, is still in progress.
## Training Procedure
All models were trained with a global batch size of 81920 for 64 checkpoint intervals of 203.7M samples for a total of ~13B samples seen over training.
For 256x256 models, a slurm script w/ srun below was used on 20 8-GPU (A100 40GB) nodes (Stability), switching to 40 4-GPU nodes for time on JUWELS.
```
/opt/slurm/sbin/srun --cpu_bind=v --accel-bind=gn python -m training.main \
--save-frequency 1 \
--name "convnext_256" \
--resume 'latest' \
--train-data="pipe:aws s3 cp s3://mybucket/path/{laion{00000..xxxxx}.tar -" \
--train-num-samples 203666042 \
--dataset-type webdataset \
--precision amp_bfloat16 \
--warmup 10000 \
--batch-size=512 \
--epochs=64 \
--dataset-resampled \
--clip-grad-norm 5.0 \
--lr 1e-3 \
--workers=6 \
--model "convnext_base_w" \
--seed 0 \
--ddp-static-graph \
--local-loss \
--gather-with-grad \
--grad-checkpointing
```
For 320x320 models, same as above but w/ 32 8-GPU nodes, local batch size 320, or 64 4-GPU nodes on JUWELs.
# Evaluation
Evaluation done with code in the [LAION CLIP Benchmark suite](https://github.com/LAION-AI/CLIP_benchmark).
## Testing Data, Factors & Metrics
### Testing Data
The testing is performed with VTAB+ (A combination of VTAB (https://arxiv.org/abs/1910.04867) w/ additional robustness datasets) for classification and COCO and Flickr for retrieval.
## Results
The models achieve between 70.8 and 71.7 zero-shot top-1 accuracy on ImageNet-1k.

An initial round of benchmarks have been performed on a wider range of datasets, to be viewable at https://github.com/LAION-AI/CLIP_benchmark/blob/main/benchmark/results.ipynb
As part of exploring increased augmentation + regularization, early evalations suggest that `augreg` trained models evaluate well over a wider range of resolutions. This is especially true for the 320x320 LAION-A model, where the augreg run was lower than the non-augreg when evaluated at the train resolution of 320x320 (71.3 vs 71.7), but improves to 72.2 when evaluated at 384x384 (the non-augreg drops to 71.0 at 384x384).
# Acknowledgements
Acknowledging [stability.ai](https://stability.ai/) and the Gauss Centre for Supercomputing e.V. (http://gauss-centre.eu) for funding this part of work by providing computing time through the John von Neumann Institute for Computing (NIC) on the GCS Supercomputer JUWELS Booster at Jülich Supercomputing Centre (JSC).
# Citation
**BibTeX:**
LAION-5B
```bibtex
@inproceedings{schuhmann2022laionb,
title={{LAION}-5B: An open large-scale dataset for training next generation image-text models},
author={Christoph Schuhmann and
Romain Beaumont and
Richard Vencu and
Cade W Gordon and
Ross Wightman and
Mehdi Cherti and
Theo Coombes and
Aarush Katta and
Clayton Mullis and
Mitchell Wortsman and
Patrick Schramowski and
Srivatsa R Kundurthy and
Katherine Crowson and
Ludwig Schmidt and
Robert Kaczmarczyk and
Jenia Jitsev},
booktitle={Thirty-sixth Conference on Neural Information Processing Systems Datasets and Benchmarks Track},
year={2022},
url={https://openreview.net/forum?id=M3Y74vmsMcY}
}
```
OpenCLIP software
```bibtex
@software{ilharco_gabriel_2021_5143773,
author = {Ilharco, Gabriel and
Wortsman, Mitchell and
Wightman, Ross and
Gordon, Cade and
Carlini, Nicholas and
Taori, Rohan and
Dave, Achal and
Shankar, Vaishaal and
Namkoong, Hongseok and
Miller, John and
Hajishirzi, Hannaneh and
Farhadi, Ali and
Schmidt, Ludwig},
title = {OpenCLIP},
month = jul,
year = 2021,
note = {If you use this software, please cite it as below.},
publisher = {Zenodo},
version = {0.1},
doi = {10.5281/zenodo.5143773},
url = {https://doi.org/10.5281/zenodo.5143773}
}
```
OpenAI CLIP paper
```bibtex
@inproceedings{Radford2021LearningTV,
title={Learning Transferable Visual Models From Natural Language Supervision},
author={Alec Radford and Jong Wook Kim and Chris Hallacy and A. Ramesh and Gabriel Goh and Sandhini Agarwal and Girish Sastry and Amanda Askell and Pamela Mishkin and Jack Clark and Gretchen Krueger and Ilya Sutskever},
booktitle={ICML},
year={2021}
}
```
```bibtex
@Article{liu2022convnet,
author = {Zhuang Liu and Hanzi Mao and Chao-Yuan Wu and Christoph Feichtenhofer and Trevor Darrell and Saining Xie},
title = {A ConvNet for the 2020s},
journal = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2022},
}
```
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/rwightman/pytorch-image-models}}
}
``` |
guoyww/animatediff-motion-adapter-v1-5-2 | guoyww | 2023-11-03T13:17:16Z | 3,091 | 18 | diffusers | [
"diffusers",
"safetensors",
"text-to-video",
"region:us"
] | text-to-video | 2023-11-01T19:54:40Z | ---
library_name: diffusers
pipeline_tag: text-to-video
---
AnimateDiff is a method that allows you to create videos using pre-existing Stable Diffusion Text to Image models.
It achieves this by inserting motion module layers into a frozen text to image model and training it on video clips to extract a motion prior.
These motion modules are applied after the ResNet and Attention blocks in the Stable Diffusion UNet. Their purpose is to introduce coherent motion across image frames. To support these modules we introduce the concepts of a MotionAdapter and UNetMotionModel. These serve as a convenient way to use these motion modules with existing Stable Diffusion models.
<table>
<tr>
<td><center>
masterpiece, bestquality, sunset.
<br>
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/animatediff-realistic-doc.gif"
alt="masterpiece, bestquality, sunset"
style="width: 300px;" />
</center></td>
</tr>
</table>
The following example demonstrates how you can utilize the motion modules with an existing Stable Diffusion text to image model.
```python
import torch
from diffusers import MotionAdapter, AnimateDiffPipeline, DDIMScheduler
from diffusers.utils import export_to_gif
# Load the motion adapter
adapter = MotionAdapter.from_pretrained("guoyww/animatediff-motion-adapter-v1-5-2")
# load SD 1.5 based finetuned model
model_id = "SG161222/Realistic_Vision_V5.1_noVAE"
pipe = AnimateDiffPipeline.from_pretrained(model_id, motion_adapter=adapter)
scheduler = DDIMScheduler.from_pretrained(
model_id, subfolder="scheduler", clip_sample=False, timestep_spacing="linspace", steps_offset=1
)
pipe.scheduler = scheduler
# enable memory savings
pipe.enable_vae_slicing()
pipe.enable_model_cpu_offload()
output = pipe(
prompt=(
"masterpiece, bestquality, highlydetailed, ultradetailed, sunset, "
"orange sky, warm lighting, fishing boats, ocean waves seagulls, "
"rippling water, wharf, silhouette, serene atmosphere, dusk, evening glow, "
"golden hour, coastal landscape, seaside scenery"
),
negative_prompt="bad quality, worse quality",
num_frames=16,
guidance_scale=7.5,
num_inference_steps=25,
generator=torch.Generator("cpu").manual_seed(42),
)
frames = output.frames[0]
export_to_gif(frames, "animation.gif")
```
<Tip>
AnimateDiff tends to work better with finetuned Stable Diffusion models. If you plan on using a scheduler that can clip samples, make sure to disable it by setting `clip_sample=False` in the scheduler as this can also have an adverse effect on generated samples.
</Tip> |
scb10x/typhoon-7b | scb10x | 2024-03-08T17:19:18Z | 3,091 | 93 | transformers | [
"transformers",
"pytorch",
"safetensors",
"mistral",
"text-generation",
"pretrained",
"th",
"arxiv:2312.13951",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2023-12-20T14:07:35Z |
---
license: apache-2.0
language:
- th
library_name: transformers
pipeline_tag: text-generation
tags:
- pretrained
---
# Typhoon-7B: Thai Large Language Model (Pretrained)
**Typhoon-7B** is a *pretrained* Thai 🇹🇭 large language model with 7 billion parameters, and it is based on Mistral-7B.
**Typhoon-7B** outperforms all open-source Thai language models at the time of writing as evaluated on Thai examination benchmarks, and its instruction-tuned variant achieves the best results in instruction-following tasks. Also, its performance in Thai is on par with GPT-3.5 while being 2.62 times more efficient in tokenizing Thai text.
**This is not an instruction-tuned model** - It may not be able to follow human instructions without using one/few-shot learning or instruction fine-tuning. The model does not have any moderation mechanisms, and may generate harmful or inappropriate responses.
The Instruct model (chat-model) will be released soon. The beta version register is open at https://opentyphoon.ai/ or follow us for future model release https://twitter.com/opentyphoon.
<div align="center">
<img src="https://storage.googleapis.com/scb10x-ai-lab-public/assets/typhoon_benchmark.png" alt="Typhoon benchmark" width="100%" style="margin-left:'auto' margin-right:'auto' display:'block'"/>
</div>
For full details of this model, please read our [paper](https://arxiv.org/abs/2312.13951).
## Model Description
- **Model type**: A 7B pretrained decoder-only model
- **Requirement**: transformers 4.34.0 or newer.
- **Primary Language(s)**: Thai 🇹🇭 and English 🇬🇧
- **License**: Apache-2.0 (Commercial)
## Performance on Thai Benchmark
| **Model** | **ONET** | **IC** | **TGAT** | **TPAT-1** | **A-Level** |
|---------------------|----------|--------|----------|------------|-------------|
| Typhoon-7B | 0.379 | 0.393 | 0.700 | 0.414 | 0.324 |
| SeaLLM-7B | 0.342 | 0.256 | 0.589 | 0.336 | 0.305 |
| OpenThaiGPT-beta-7B | 0.180 | 0.278 | 0.411 | 0.319 | 0.243 |
| WangChanGLM | 0.192 | 0.271 | 0.167 | 0.172 | 0.175 |
| SEA-LION-7B | 0.179 | 0.290 | 0.244 | 0.198 | 0.175 |
| Avg. Human | 0.318 | - | 0.472 | 0.406 | - |
## Intended Uses & Limitations
This model is a pretrained base model. Thus, it may not be able to follow human instructions without using one/few-shot learning or instruction fine-tuning. The model does not have any moderation mechanisms, and may generate harmful or inappropriate responses.
## Follow us
https://twitter.com/opentyphoon
## Support / Ask any question
https://discord.gg/CqyBscMFpg
## SCB10X AI Team
- Kunat Pipatanakul, Phatrasek Jirabovonvisut, Potsawee Manakul, Sittipong Sripaisarnmongkol, Ruangsak Patomwong, Pathomporn Chokchainant, Kasima Tharnpipitchai
- If you find Typhoon-7B useful for your work, please cite it using:
```
@article{pipatanakul2023typhoon,
title={Typhoon: Thai Large Language Models},
author={Kunat Pipatanakul and Phatrasek Jirabovonvisut and Potsawee Manakul and Sittipong Sripaisarnmongkol and Ruangsak Patomwong and Pathomporn Chokchainant and Kasima Tharnpipitchai},
year={2023},
journal={arXiv preprint arXiv:2312.13951},
url={https://arxiv.org/abs/2312.13951}
}
```
## Contact Us
- General & Collaboration: [email protected], [email protected]
- Technical: [email protected]
|
MaziyarPanahi/WizardLM-2-7B-GGUF | MaziyarPanahi | 2024-04-15T18:39:24Z | 3,091 | 69 | transformers | [
"transformers",
"gguf",
"mistral",
"quantized",
"2-bit",
"3-bit",
"4-bit",
"5-bit",
"6-bit",
"8-bit",
"GGUF",
"safetensors",
"text-generation",
"arxiv:2304.12244",
"arxiv:2306.08568",
"arxiv:2308.09583",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us",
"base_model:microsoft/WizardLM-2-7B"
] | text-generation | 2024-04-15T16:51:17Z | ---
tags:
- quantized
- 2-bit
- 3-bit
- 4-bit
- 5-bit
- 6-bit
- 8-bit
- GGUF
- transformers
- safetensors
- mistral
- text-generation
- arxiv:2304.12244
- arxiv:2306.08568
- arxiv:2308.09583
- license:apache-2.0
- autotrain_compatible
- endpoints_compatible
- text-generation-inference
- region:us
- text-generation
model_name: WizardLM-2-7B-GGUF
base_model: microsoft/WizardLM-2-7B
inference: false
model_creator: microsoft
pipeline_tag: text-generation
quantized_by: MaziyarPanahi
---
# [MaziyarPanahi/WizardLM-2-7B-GGUF](https://huggingface.co/MaziyarPanahi/WizardLM-2-7B-GGUF)
- Model creator: [microsoft](https://huggingface.co/microsoft)
- Original model: [microsoft/WizardLM-2-7B](https://huggingface.co/microsoft/WizardLM-2-7B)
## Description
[MaziyarPanahi/WizardLM-2-7B-GGUF](https://huggingface.co/MaziyarPanahi/WizardLM-2-7B-GGUF) contains GGUF format model files for [microsoft/WizardLM-2-7B](https://huggingface.co/microsoft/WizardLM-2-7B).
## Prompt template
```
{system_prompt}
USER: {prompt}
ASSISTANT: </s>
```
or
```
A chat between a curious user and an artificial intelligence assistant. The assistant gives helpful,
detailed, and polite answers to the user's questions. USER: Hi ASSISTANT: Hello.</s>
USER: {prompt} ASSISTANT: </s>......
```
Taken from the original README
---
---
license: apache-2.0
---
<p style="font-size:20px;" align="center">
🏠 <a href="https://wizardlm.github.io/WizardLM2" target="_blank">WizardLM-2 Release Blog</a> </p>
<p align="center">
🤗 <a href="https://huggingface.co/collections/microsoft/wizardlm-2-661d403f71e6c8257dbd598a" target="_blank">HF Repo</a> •🐱 <a href="https://github.com/victorsungo/WizardLM/tree/main/WizardLM-2" target="_blank">Github Repo</a> • 🐦 <a href="https://twitter.com/WizardLM_AI" target="_blank">Twitter</a> • 📃 <a href="https://arxiv.org/abs/2304.12244" target="_blank">[WizardLM]</a> • 📃 <a href="https://arxiv.org/abs/2306.08568" target="_blank">[WizardCoder]</a> • 📃 <a href="https://arxiv.org/abs/2308.09583" target="_blank">[WizardMath]</a> <br>
</p>
<p align="center">
👋 Join our <a href="https://discord.gg/VZjjHtWrKs" target="_blank">Discord</a>
</p>
## News 🔥🔥🔥 [2024/04/15]
We introduce and opensource WizardLM-2, our next generation state-of-the-art large language models,
which have improved performance on complex chat, multilingual, reasoning and agent.
New family includes three cutting-edge models: WizardLM-2 8x22B, WizardLM-2 70B, and WizardLM-2 7B.
- WizardLM-2 8x22B is our most advanced model, demonstrates highly competitive performance compared to those leading proprietary works
and consistently outperforms all the existing state-of-the-art opensource models.
- WizardLM-2 70B reaches top-tier reasoning capabilities and is the first choice in the same size.
- WizardLM-2 7B is the fastest and achieves comparable performance with existing 10x larger opensource leading models.
For more details of WizardLM-2 please read our [release blog post](https://wizardlm.github.io/WizardLM2) and upcoming paper.
## Model Details
* **Model name**: WizardLM-2 7B
* **Developed by**: WizardLM@Microsoft AI
* **Base model**: [mistralai/Mistral-7B-v0.1](https://huggingface.co/mistralai/Mistral-7B-v0.1)
* **Parameters**: 7B
* **Language(s)**: Multilingual
* **Blog**: [Introducing WizardLM-2](https://wizardlm.github.io/WizardLM2)
* **Repository**: [https://github.com/nlpxucan/WizardLM](https://github.com/nlpxucan/WizardLM)
* **Paper**: WizardLM-2 (Upcoming)
* **License**: Apache2.0
## Model Capacities
**MT-Bench**
We also adopt the automatic MT-Bench evaluation framework based on GPT-4 proposed by lmsys to assess the performance of models.
The WizardLM-2 8x22B even demonstrates highly competitive performance compared to the most advanced proprietary models.
Meanwhile, WizardLM-2 7B and WizardLM-2 70B are all the top-performing models among the other leading baselines at 7B to 70B model scales.
<p align="center" width="100%">
<a ><img src="https://raw.githubusercontent.com/WizardLM/WizardLM2/main/static/images/mtbench.png" alt="MTBench" style="width: 96%; min-width: 300px; display: block; margin: auto;"></a>
</p>
**Human Preferences Evaluation**
We carefully collected a complex and challenging set consisting of real-world instructions, which includes main requirements of humanity, such as writing, coding, math, reasoning, agent, and multilingual.
We report the win:loss rate without tie:
- WizardLM-2 8x22B is just slightly falling behind GPT-4-1106-preview, and significantly stronger than Command R Plus and GPT4-0314.
- WizardLM-2 70B is better than GPT4-0613, Mistral-Large, and Qwen1.5-72B-Chat.
- WizardLM-2 7B is comparable with Qwen1.5-32B-Chat, and surpasses Qwen1.5-14B-Chat and Starling-LM-7B-beta.
<p align="center" width="100%">
<a ><img src="https://raw.githubusercontent.com/WizardLM/WizardLM2/main/static/images/winall.png" alt="Win" style="width: 96%; min-width: 300px; display: block; margin: auto;"></a>
</p>
## Method Overview
We built a **fully AI powered synthetic training system** to train WizardLM-2 models, please refer to our [blog](https://wizardlm.github.io/WizardLM2) for more details of this system.
<p align="center" width="100%">
<a ><img src="https://raw.githubusercontent.com/WizardLM/WizardLM2/main/static/images/exp_1.png" alt="Method" style="width: 96%; min-width: 300px; display: block; margin: auto;"></a>
</p>
## Usage
❗<b>Note for model system prompts usage:</b>
<b>WizardLM-2</b> adopts the prompt format from <b>Vicuna</b> and supports **multi-turn** conversation. The prompt should be as following:
```
A chat between a curious user and an artificial intelligence assistant. The assistant gives helpful,
detailed, and polite answers to the user's questions. USER: Hi ASSISTANT: Hello.</s>
USER: Who are you? ASSISTANT: I am WizardLM.</s>......
```
<b> Inference WizardLM-2 Demo Script</b>
We provide a WizardLM-2 inference demo [code](https://github.com/nlpxucan/WizardLM/tree/main/demo) on our github.
---
## How to use
Thanks to [TheBloke](https://huggingface.co/TheBloke) for preparing an amazing README on how to use GGUF models:
### About GGUF
GGUF is a new format introduced by the llama.cpp team on August 21st 2023. It is a replacement for GGML, which is no longer supported by llama.cpp.
Here is an incomplete list of clients and libraries that are known to support GGUF:
* [llama.cpp](https://github.com/ggerganov/llama.cpp). The source project for GGUF. Offers a CLI and a server option.
* [text-generation-webui](https://github.com/oobabooga/text-generation-webui), the most widely used web UI, with many features and powerful extensions. Supports GPU acceleration.
* [KoboldCpp](https://github.com/LostRuins/koboldcpp), a fully featured web UI, with GPU accel across all platforms and GPU architectures. Especially good for story telling.
* [GPT4All](https://gpt4all.io/index.html), a free and open source local running GUI, supporting Windows, Linux and macOS with full GPU accel.
* [LM Studio](https://lmstudio.ai/), an easy-to-use and powerful local GUI for Windows and macOS (Silicon), with GPU acceleration. Linux available, in beta as of 27/11/2023.
* [LoLLMS Web UI](https://github.com/ParisNeo/lollms-webui), a great web UI with many interesting and unique features, including a full model library for easy model selection.
* [Faraday.dev](https://faraday.dev/), an attractive and easy to use character-based chat GUI for Windows and macOS (both Silicon and Intel), with GPU acceleration.
* [llama-cpp-python](https://github.com/abetlen/llama-cpp-python), a Python library with GPU accel, LangChain support, and OpenAI-compatible API server.
* [candle](https://github.com/huggingface/candle), a Rust ML framework with a focus on performance, including GPU support, and ease of use.
* [ctransformers](https://github.com/marella/ctransformers), a Python library with GPU accel, LangChain support, and OpenAI-compatible AI server. Note, as of time of writing (November 27th 2023), ctransformers has not been updated in a long time and does not support many recent models.
### Explanation of quantisation methods
<details>
<summary>Click to see details</summary>
The new methods available are:
* GGML_TYPE_Q2_K - "type-1" 2-bit quantization in super-blocks containing 16 blocks, each block having 16 weight. Block scales and mins are quantized with 4 bits. This ends up effectively using 2.5625 bits per weight (bpw)
* GGML_TYPE_Q3_K - "type-0" 3-bit quantization in super-blocks containing 16 blocks, each block having 16 weights. Scales are quantized with 6 bits. This end up using 3.4375 bpw.
* GGML_TYPE_Q4_K - "type-1" 4-bit quantization in super-blocks containing 8 blocks, each block having 32 weights. Scales and mins are quantized with 6 bits. This ends up using 4.5 bpw.
* GGML_TYPE_Q5_K - "type-1" 5-bit quantization. Same super-block structure as GGML_TYPE_Q4_K resulting in 5.5 bpw
* GGML_TYPE_Q6_K - "type-0" 6-bit quantization. Super-blocks with 16 blocks, each block having 16 weights. Scales are quantized with 8 bits. This ends up using 6.5625 bpw
## How to download GGUF files
**Note for manual downloaders:** You almost never want to clone the entire repo! Multiple different quantisation formats are provided, and most users only want to pick and download a single file.
The following clients/libraries will automatically download models for you, providing a list of available models to choose from:
* LM Studio
* LoLLMS Web UI
* Faraday.dev
### In `text-generation-webui`
Under Download Model, you can enter the model repo: [MaziyarPanahi/WizardLM-2-7B-GGUF](https://huggingface.co/MaziyarPanahi/WizardLM-2-7B-GGUF) and below it, a specific filename to download, such as: WizardLM-2-7B-GGUF.Q4_K_M.gguf.
Then click Download.
### On the command line, including multiple files at once
I recommend using the `huggingface-hub` Python library:
```shell
pip3 install huggingface-hub
```
Then you can download any individual model file to the current directory, at high speed, with a command like this:
```shell
huggingface-cli download MaziyarPanahi/WizardLM-2-7B-GGUF WizardLM-2-7B.Q4_K_M.gguf --local-dir . --local-dir-use-symlinks False
```
</details>
<details>
<summary>More advanced huggingface-cli download usage (click to read)</summary>
You can also download multiple files at once with a pattern:
```shell
huggingface-cli download [MaziyarPanahi/WizardLM-2-7B-GGUF](https://huggingface.co/MaziyarPanahi/WizardLM-2-7B-GGUF) --local-dir . --local-dir-use-symlinks False --include='*Q4_K*gguf'
```
For more documentation on downloading with `huggingface-cli`, please see: [HF -> Hub Python Library -> Download files -> Download from the CLI](https://huggingface.co/docs/huggingface_hub/guides/download#download-from-the-cli).
To accelerate downloads on fast connections (1Gbit/s or higher), install `hf_transfer`:
```shell
pip3 install hf_transfer
```
And set environment variable `HF_HUB_ENABLE_HF_TRANSFER` to `1`:
```shell
HF_HUB_ENABLE_HF_TRANSFER=1 huggingface-cli download MaziyarPanahi/WizardLM-2-7B-GGUF WizardLM-2-7B.Q4_K_M.gguf --local-dir . --local-dir-use-symlinks False
```
Windows Command Line users: You can set the environment variable by running `set HF_HUB_ENABLE_HF_TRANSFER=1` before the download command.
</details>
## Example `llama.cpp` command
Make sure you are using `llama.cpp` from commit [d0cee0d](https://github.com/ggerganov/llama.cpp/commit/d0cee0d36d5be95a0d9088b674dbb27354107221) or later.
```shell
./main -ngl 35 -m WizardLM-2-7B.Q4_K_M.gguf --color -c 32768 --temp 0.7 --repeat_penalty 1.1 -n -1 -p "<|im_start|>system
{system_message}<|im_end|>
<|im_start|>user
{prompt}<|im_end|>
<|im_start|>assistant"
```
Change `-ngl 32` to the number of layers to offload to GPU. Remove it if you don't have GPU acceleration.
Change `-c 32768` to the desired sequence length. For extended sequence models - eg 8K, 16K, 32K - the necessary RoPE scaling parameters are read from the GGUF file and set by llama.cpp automatically. Note that longer sequence lengths require much more resources, so you may need to reduce this value.
If you want to have a chat-style conversation, replace the `-p <PROMPT>` argument with `-i -ins`
For other parameters and how to use them, please refer to [the llama.cpp documentation](https://github.com/ggerganov/llama.cpp/blob/master/examples/main/README.md)
## How to run in `text-generation-webui`
Further instructions can be found in the text-generation-webui documentation, here: [text-generation-webui/docs/04 ‐ Model Tab.md](https://github.com/oobabooga/text-generation-webui/blob/main/docs/04%20-%20Model%20Tab.md#llamacpp).
## How to run from Python code
You can use GGUF models from Python using the [llama-cpp-python](https://github.com/abetlen/llama-cpp-python) or [ctransformers](https://github.com/marella/ctransformers) libraries. Note that at the time of writing (Nov 27th 2023), ctransformers has not been updated for some time and is not compatible with some recent models. Therefore I recommend you use llama-cpp-python.
### How to load this model in Python code, using llama-cpp-python
For full documentation, please see: [llama-cpp-python docs](https://github.com/abetlen/llama-cpp-python/).
#### First install the package
Run one of the following commands, according to your system:
```shell
# Base ctransformers with no GPU acceleration
pip install llama-cpp-python
# With NVidia CUDA acceleration
CMAKE_ARGS="-DLLAMA_CUBLAS=on" pip install llama-cpp-python
# Or with OpenBLAS acceleration
CMAKE_ARGS="-DLLAMA_BLAS=ON -DLLAMA_BLAS_VENDOR=OpenBLAS" pip install llama-cpp-python
# Or with CLBLast acceleration
CMAKE_ARGS="-DLLAMA_CLBLAST=on" pip install llama-cpp-python
# Or with AMD ROCm GPU acceleration (Linux only)
CMAKE_ARGS="-DLLAMA_HIPBLAS=on" pip install llama-cpp-python
# Or with Metal GPU acceleration for macOS systems only
CMAKE_ARGS="-DLLAMA_METAL=on" pip install llama-cpp-python
# In windows, to set the variables CMAKE_ARGS in PowerShell, follow this format; eg for NVidia CUDA:
$env:CMAKE_ARGS = "-DLLAMA_OPENBLAS=on"
pip install llama-cpp-python
```
#### Simple llama-cpp-python example code
```python
from llama_cpp import Llama
# Set gpu_layers to the number of layers to offload to GPU. Set to 0 if no GPU acceleration is available on your system.
llm = Llama(
model_path="./WizardLM-2-7B.Q4_K_M.gguf", # Download the model file first
n_ctx=32768, # The max sequence length to use - note that longer sequence lengths require much more resources
n_threads=8, # The number of CPU threads to use, tailor to your system and the resulting performance
n_gpu_layers=35 # The number of layers to offload to GPU, if you have GPU acceleration available
)
# Simple inference example
output = llm(
"<|im_start|>system
{system_message}<|im_end|>
<|im_start|>user
{prompt}<|im_end|>
<|im_start|>assistant", # Prompt
max_tokens=512, # Generate up to 512 tokens
stop=["</s>"], # Example stop token - not necessarily correct for this specific model! Please check before using.
echo=True # Whether to echo the prompt
)
# Chat Completion API
llm = Llama(model_path="./WizardLM-2-7B.Q4_K_M.gguf", chat_format="llama-2") # Set chat_format according to the model you are using
llm.create_chat_completion(
messages = [
{"role": "system", "content": "You are a story writing assistant."},
{
"role": "user",
"content": "Write a story about llamas."
}
]
)
```
## How to use with LangChain
Here are guides on using llama-cpp-python and ctransformers with LangChain:
* [LangChain + llama-cpp-python](https://python.langchain.com/docs/integrations/llms/llamacpp)
* [LangChain + ctransformers](https://python.langchain.com/docs/integrations/providers/ctransformers) |
SicariusSicariiStuff/LLAMA-3_8B_Unaligned_Alpha_RP_Soup_GGUF | SicariusSicariiStuff | 2024-06-23T02:41:47Z | 3,090 | 1 | null | [
"gguf",
"license:apache-2.0",
"region:us"
] | null | 2024-06-22T23:41:27Z | ---
license: apache-2.0
---
|
valurank/distilroberta-bias | valurank | 2022-06-08T20:44:39Z | 3,083 | 4 | transformers | [
"transformers",
"pytorch",
"roberta",
"text-classification",
"en",
"dataset:valurank/wikirev-bias",
"license:other",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2022-03-02T23:29:05Z | ---
license: other
language: en
datasets:
- valurank/wikirev-bias
---
# DistilROBERTA fine-tuned for bias detection
This model is based on [distilroberta-base](https://huggingface.co/distilroberta-base) pretrained weights, with a classification head fine-tuned to classify text into 2 categories (neutral, biased).
## Training data
The dataset used to fine-tune the model is [wikirev-bias](https://huggingface.co/datasets/valurank/wikirev-bias), extracted from English wikipedia revisions, see https://github.com/rpryzant/neutralizing-bias for details on the WNC wiki edits corpus.
## Inputs
Similar to its base model, this model accepts inputs with a maximum length of 512 tokens.
|
mradermacher/Sycho-8B-L3-RP-GGUF | mradermacher | 2024-06-18T07:48:00Z | 3,083 | 1 | transformers | [
"transformers",
"gguf",
"not-for-all-audiences",
"en",
"base_model:Hastagaras/Sycho-8B-L3-RP",
"endpoints_compatible",
"region:us"
] | null | 2024-06-18T02:00:32Z | ---
base_model: Hastagaras/Sycho-8B-L3-RP
language:
- en
library_name: transformers
quantized_by: mradermacher
tags:
- not-for-all-audiences
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
static quants of https://huggingface.co/Hastagaras/Sycho-8B-L3-RP
<!-- provided-files -->
weighted/imatrix quants are available at https://huggingface.co/mradermacher/Sycho-8B-L3-RP-i1-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/Sycho-8B-L3-RP-GGUF/resolve/main/Sycho-8B-L3-RP.Q2_K.gguf) | Q2_K | 3.3 | |
| [GGUF](https://huggingface.co/mradermacher/Sycho-8B-L3-RP-GGUF/resolve/main/Sycho-8B-L3-RP.IQ3_XS.gguf) | IQ3_XS | 3.6 | |
| [GGUF](https://huggingface.co/mradermacher/Sycho-8B-L3-RP-GGUF/resolve/main/Sycho-8B-L3-RP.Q3_K_S.gguf) | Q3_K_S | 3.8 | |
| [GGUF](https://huggingface.co/mradermacher/Sycho-8B-L3-RP-GGUF/resolve/main/Sycho-8B-L3-RP.IQ3_S.gguf) | IQ3_S | 3.8 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/Sycho-8B-L3-RP-GGUF/resolve/main/Sycho-8B-L3-RP.IQ3_M.gguf) | IQ3_M | 3.9 | |
| [GGUF](https://huggingface.co/mradermacher/Sycho-8B-L3-RP-GGUF/resolve/main/Sycho-8B-L3-RP.Q3_K_M.gguf) | Q3_K_M | 4.1 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/Sycho-8B-L3-RP-GGUF/resolve/main/Sycho-8B-L3-RP.Q3_K_L.gguf) | Q3_K_L | 4.4 | |
| [GGUF](https://huggingface.co/mradermacher/Sycho-8B-L3-RP-GGUF/resolve/main/Sycho-8B-L3-RP.IQ4_XS.gguf) | IQ4_XS | 4.6 | |
| [GGUF](https://huggingface.co/mradermacher/Sycho-8B-L3-RP-GGUF/resolve/main/Sycho-8B-L3-RP.Q4_K_S.gguf) | Q4_K_S | 4.8 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Sycho-8B-L3-RP-GGUF/resolve/main/Sycho-8B-L3-RP.Q4_K_M.gguf) | Q4_K_M | 5.0 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Sycho-8B-L3-RP-GGUF/resolve/main/Sycho-8B-L3-RP.Q5_K_S.gguf) | Q5_K_S | 5.7 | |
| [GGUF](https://huggingface.co/mradermacher/Sycho-8B-L3-RP-GGUF/resolve/main/Sycho-8B-L3-RP.Q5_K_M.gguf) | Q5_K_M | 5.8 | |
| [GGUF](https://huggingface.co/mradermacher/Sycho-8B-L3-RP-GGUF/resolve/main/Sycho-8B-L3-RP.Q6_K.gguf) | Q6_K | 6.7 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/Sycho-8B-L3-RP-GGUF/resolve/main/Sycho-8B-L3-RP.Q8_0.gguf) | Q8_0 | 8.6 | fast, best quality |
| [GGUF](https://huggingface.co/mradermacher/Sycho-8B-L3-RP-GGUF/resolve/main/Sycho-8B-L3-RP.f16.gguf) | f16 | 16.2 | 16 bpw, overkill |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
ghost-x/ghost-7b-alpha | ghost-x | 2024-04-26T07:31:56Z | 3,081 | 5 | transformers | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"ghost",
"tools",
"chat",
"conversational",
"en",
"vi",
"license:other",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2024-04-13T10:38:54Z | ---
language:
- en
- vi
license: other
license_name: ghost-7b
license_link: https://ghost-x.org/ghost-7b-license
library_name: transformers
tags:
- ghost
- tools
- chat
pipeline_tag: text-generation
widget:
- text: Why is the sky blue ?
output:
text: >-
The sky appears blue because of a phenomenon called Rayleigh scattering.
Sunlight is composed of all colors of the visible spectrum, but blue light
has a shorter wavelength than other colors. When sunlight enters the
Earth's atmosphere, it interacts with molecules of nitrogen and oxygen,
which are the main components of our atmosphere. These molecules scatter
the shorter wavelengths of light, such as blue and violet, more than the
longer wavelengths, such as red and orange. As a result, when we look up
at the sky, we see more blue light than other colors because the blue
light has been scattered more by the molecules in the atmosphere.
---
# Ghost 7B Alpha
<img src="https://cdn-uploads.huggingface.co/production/uploads/600ae38cc92b79f54efd4556/QPrQZMQX_jzyYngmreP0_.jpeg" alt="Ghost 7B Alpha Logo" width="400" style="margin-left:'auto' margin-right:'auto' display:'block'"/>
The large generation of language models focuses on optimizing excellent reasoning, multi-task knowledge, and tools support.
# Introduction
**Ghost 7B Alpha** is a large language model fine-tuned from Mistral 7B, with a size of 7 billion parameters. The model was developed with the goal of optimizing reasoning ability, multi-task knowledge and supporting tool usage. The model works well with the main trained and optimized languages being English and Vietnamese.
Overall, the model is suitable when making a pretrained version so you can continue to develop the desired tasks, develop virtual assistants, perform features on tasks such as coding, translation, answering questions, creating documents, etc. It is truly an efficient, fast and extremely cheap open model.
## Specifications
- Name: **Ghost 7B Alpha**.
- Model size: 7 billion parameters.
- Context length: 8K, 8192.
- Languages: English and Vietnamese.
- Main tasks: reasoning, multi-tasking knowledge and function tools.
- License: [Ghost 7B LICENSE AGREEMENT](https://ghost-x.org/ghost-7b-license).
- Based on: Mistral 7B.
- Distributions: Standard (BF16), GGUF, AWQ.
- Developed by: **Ghost X**, [Hieu Lam](https://huggingface.co/lamhieu).
### Links
- Card model: [🤗 HuggingFace](https://huggingface.co/ghost-x/ghost-7b-alpha).
- Official website: [Ghost 7B Alpha](https://ghost-x.org/docs/models/ghost-7b-alpha/).
- Demo: [Playground with Ghost 7B Alpha](https://ghost-x.org/docs/notebooks/playground-with-ghost-7b-alpha/).
## Distributions
We create many distributions to give you the best access options that best suit your needs. Always make sure you know which version you need and what will help you operate better.
| Version | Model card |
| ------- | -------------------------------------------------------------------- |
| BF16 | [🤗 HuggingFace](https://huggingface.co/ghost-x/ghost-7b-alpha) |
| GGUF | [🤗 HuggingFace](https://huggingface.co/ghost-x/ghost-7b-alpha-gguf) |
| AWQ | [🤗 HuggingFace](https://huggingface.co/ghost-x/ghost-7b-alpha-awq) |
### Standard (BF16)
The standard distribution was used to run the assessments and was found to have the best performance in text generation quality.
### GGUF
GGUF is a new format introduced by the llama.cpp team on August 21st 2023. It is a replacement for GGML, which is no longer supported by llama.cpp.
### AWQ
The AWQ algorithm for 4-bit quantization with a 2x speedup during inference.
## Prompt / Chat template
### Roles
Overall, the model supports roles including: **system**, **plugins**, **user**, **assistant**, **execute**, **response**.
- **system**: Similar to OpenAI GPT4, this will be the place for you to declare context or specify characteristics and expertise for the model.
- **user**: This is user input, which can be a question or an instruction for the model to follow.
- **assistant**: The model's response to a question or instruction received from **user**.
- **plugins**: Declare information about modeling tools that are allowed to be used according to predetermined standards.
- **excute**: Mock iterates over the data type returned by the model for execution. Contains information about tools to use and arguments.
- **response**: The result after executing the tool, so that the model gives the appropriate answer according to the user's input.
See the actual code [here](https://huggingface.co/ghost-x/ghost-7b-alpha/blob/main/tokenizer_config.json#L36).
### Tips
- Setting the system prompt in the right context and characteristics will help the model improve performance quite well.
- You can set system prompt to prevent unwanted things.
- In most cases, if you have no idea you can leave the system prompt blank. At this point, the performance will be best for general cases.
### Chat template
#### Default chat
In the standard case, without using function tools, only use roles such as **system**, **user** and **assistant**. Conventions are in the following order:
- (1) **system**
- (2) **user**
- (3) **assistant**
Repeat (2) and (3) continuously throughout the conversation.
#### Chat with tools
In case of using tools, the conventions are in the following order:
- (1) **system**
- (2) **plugins**
- (3) **user**
- A. When the model finds it inappropriate to use the tool:
- (4) **assistant** if the model can answer or is not suitable for the tool. The model proceeds to answer the user's question.
- B. When the model chooses to use the tool:
- (4) **execute** returns the arguments needed to execute the specified tool.
- (5) **response** returns the results after applying the tool to the model.
- (6) **assistant** the model proceeds to answer the user's question.
Repeat (3) and (A) or (B) continuously throughout the conversation.
# Showcases
## English
Let's try a question taken from [OpenAI GPT-4](https://openai.com/gpt-4) to evaluate the superiority of GPT-4 compared to ChatGPT.
<details close>
<summary>👨💻 : Andrew is free from 11 am to 3 pm, Joanne is free from noon to 2 pm and then 3:30 pm to 5 pm. Hannah is available at noon for half an hour, and then 4 pm to 6 pm. What is the best option for start times for a 30 minute meeting for Andrew, Hannah, and Joanne at same time?</summary>
👻 :
The best option for a 30-minute meeting for Andrew, Hannah, and Joanne at the same time is to start at 12 pm (noon), as this is the earliest time when all three are available.
Here's the breakdown of their availability:
- Andrew: 11 am to 3 pm, which includes 12 pm.
- Joanne: Noon to 2 pm, which includes 12 pm.
- Hannah: Noon for half an hour (30 minutes), which includes 12 pm. Then she is available from 4 pm to 6 pm.
Since all three are available at 12 pm, this is the best time to start the meeting.
</details>
A quiz to see if the model can guess what it's talking about?!
<details close>
<summary>👨💻 : Characteristics: has a long, thin and flexible body; The legs are short and webbed. Additionally, their thick, smooth undercoat keeps them dry underwater and traps a layer of air to keep them warm. Question: What animal is that?</summary>
👻 :
Based on the characteristics you described, it seems like you're talking about an **otter**. Otters are carnivorous mammals that live in freshwater environments such as rivers, lakes, and estuaries. They have long, thin bodies with webbed feet that help them swim efficiently. Their thick, smooth undercoats keep them dry and warm, while the layer of air trapped beneath their fur helps to insulate them. Otters are known for their playful and curious nature, and they are often seen swimming, playing, and exploring their surroundings. 🦡🐭
</details>
To this question, I really cannot answer. But the model's evidence is quite strict. Also, what do you think about this answer?
<details close>
<summary>👨💻 : A self-driving car is approaching a crosswalk. A group of pedestrians is crossing the street, but they are not paying attention to the car because they are distracted by their phones. The car's brakes are malfunctioning, and it is unable to stop. Should the car swerve to avoid hitting the pedestrians, even though this could put the car's occupants at risk? Be convincing with your examples or sharp reasoning.</summary>
👻 :
In this situation, it is **imperative** for the self-driving car to swerve to avoid hitting the pedestrians, even if it puts the car's occupants at risk. Here's why:
**1. Prioritizing Human Safety:**
The primary goal of a self-driving car is to ensure the safety of its occupants and the general public. In this case, the pedestrians are in immediate danger due to their distraction and the malfunctioning brakes. Swerving to avoid the pedestrians is the safest option for all involved.
**2. Collision Avoidance:**
Swerving can help the car avoid a direct collision with the pedestrians, reducing the risk of serious injuries or even death. Even if the car's occupants are injured in the process of swerving, it is still better than the potential loss of life or severe injuries for multiple pedestrians.
**3. Legal and Ethical Responsibility:**
In most jurisdictions, self-driving cars are considered to be responsible for their actions. Swerving to avoid a collision is a reasonable and responsible action to take in this scenario. Failing to do so could result in legal consequences or ethical criticism.
**4. Precedent and Best Practices:**
In similar situations, self-driving cars have been programmed to swerve to avoid pedestrians. This practice has been widely accepted and considered to be the best course of action in such situations.
**5. Risk Assessment:**
While swerving can put the car's occupants at risk, the potential consequences of a collision with the pedestrians are much more severe. The risk of injury or death to multiple individuals outweighs the risk to the car's occupants.
In summary, the self-driving car's priority should be to protect the lives of pedestrians, even if it means putting its own occupants at risk. Swerving to avoid a collision is the responsible and ethical choice in this scenario.
</details>
A reasoning question suddenly popped up during the process of writing an article announcing information about **Ghost 7B Alpha**. The model gave an impressive answer, at least to its creator.
<details close>
<summary>👨💻 : If you could travel back in time and change one event in history, what would it be and why?</summary>
👻 :
If I could travel back in time and change one event in history, it would be the assassination of Archduke Franz Ferdinand of Austria on June 28, 1914. This event led to the start of World War I, which was one of the most devastating conflicts in human history. By changing this event, I could potentially prevent the war from happening, which would have far-reaching consequences for the world.
Here are some of the reasons why I would choose this event:
- **Preventing the deaths of millions of people:** World War I resulted in the deaths of over 17 million soldiers and civilians. Changing this event would save countless lives.
- **Preventing the economic and social devastation:** The war caused widespread economic and social devastation in Europe and around the world. By preventing the war, I could help to avoid these consequences.
- **Preventing the rise of fascism:** World War I created a power vacuum in Europe, which was eventually filled by fascist regimes in Germany, Italy, and Japan. By preventing the war, I could help to prevent the rise of these dangerous ideologies.
- **Preventing the development of nuclear weapons:** The war led to the development of nuclear weapons, which are the most destructive weapons ever created. By preventing the war, I could help to prevent the proliferation of these weapons and the threat they pose to humanity.
</details>
### Try coding skills
How about asking the model for instructions on creating a Node.js application using Docker for deployment?
<details close>
<summary>👨💻 : Create a Nodejs project using Express as a server and Docker with a Dockerfile for deployment with step-by-step instructions with detailed explanations.</summary>
👻 :
**Step 1: Create a new Node.js project**
```bash
mkdir my-project
cd my-project
npm init -y
```
**Step 2: Install Express**
```bash
npm install express --save
```
**Step 3: Create an Express server**
Create a file called `server.js` in your project directory:
```javascript
const express = require("express");
const app = express();
app.get("/", (req, res) => {
res.send("Hello World!");
});
app.listen(3000, () => {
console.log("Server listening on port 3000");
});
```
**Step 4: Create a Dockerfile**
Create a file called `Dockerfile` in your project directory:
```bash
FROM node:16
WORKDIR /usr/src/app
COPY package.json .
RUN npm install
COPY . .
EXPOSE 3000
CMD ["node", "server.js"]
```
**Step 5: Build the Docker image**
```bash
docker build -t my-project-image .
```
**Step 6: Run the Docker image**
```bash
docker run -p 3000:3000 my-project-image
```
**Step 7: Access the application**
Open a web browser and navigate to `http://localhost:3000`. You should see the message "Hello World!" displayed.
**Explanation:**
- **Step 1:** Creates a new Node.js project with `npm init -y` to initialize a new Node.js project with a default `package.json` file.
- **Step 2:** Installs Express using `npm install express --save`. This command installs Express and adds it to the `package.json` file.
- **Step 3:** Creates an Express server in `server.js` that responds with "Hello World!" when a request is made to the root path (`/`).
- **Step 4:** Creates a Dockerfile that defines the image for the project. The Dockerfile specifies that the image should use Node.js version 16, work from the `/usr/src/app` directory, copy the `package.json` file, install dependencies using `npm install`, copy the entire project directory, expose port 3000, and run the Express server using `node server.js`.
- **Step 5:** Builds the Docker image using `docker build -t my-project-image .`. This command builds the Docker image from the `Dockerfile` in the current directory and saves it under the name `my-project-image`.
- **Step 6:** Runs the Docker image using `docker run -p 3000:3000 my-project-image`. This command runs the Docker image and maps port 3000 on the host machine to port 3000 in the container.
- **Step 7:** Accesses the application by opening a web browser and navigating to `http://localhost:3000`. This will display the message "Hello World!" because the Express server is running in the Docker container.
</details>
Now let’s try asking for a coding model to build a smooth neural network with python.
<details close>
<summary>👨💻 : Explain how to use the Keras or TensorFlow library in Python to build and train a multi-layer neural network for an image classification task</summary>
👻 :
**Using Keras:**
1. Import the necessary libraries:
```python
import keras
from keras.models import Sequential
from keras.layers import Conv2D, MaxPooling2D, Flatten, Dense
```
2. Create a sequential model:
```python
model = Sequential()
model.add(Conv2D(32, (3, 3), activation='relu', input_shape=(32, 32, 3)))
model.add(MaxPooling2D((2, 2)))
model.add(Flatten())
model.add(Dense(128, activation='relu'))
model.add(Dense(10, activation='softmax'))
```
3. Compile the model:
```python
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
```
4. Train the model:
```python
model.fit(x_train, y_train, epochs=10)
```
**Using TensorFlow:**
1. Import the necessary libraries:
```python
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten, Dense
```
2. Create a sequential model:
```python
model = Sequential()
model.add(Conv2D(32, (3, 3), activation='relu', input_shape=(32, 32, 3)))
model.add(MaxPooling2D((2, 2)))
model.add(Flatten())
model.add(Dense(128, activation='relu'))
model.add(Dense(10, activation='softmax'))
```
3. Compile the model:
```python
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
```
4. Train the model:
```python
model.train(x_train, y_train, epochs=10)
```
**Comparison:**
Both Keras and TensorFlow are powerful libraries for building and training neural networks in Python. However, there are some key differences between the two libraries:
- **Syntax:** Keras has a more concise and intuitive syntax, while TensorFlow has a more verbose and imperative syntax.
- **Performance:** TensorFlow is generally faster than Keras, especially for large datasets and complex models.
- **Integration:** TensorFlow has a wider range of integrations with other libraries and tools, while Keras is more focused on building and training neural networks.
Ultimately, the best choice for you depends on your specific needs and preferences. If you prefer a more concise and intuitive syntax, Keras is a good option. If you need a faster and more versatile library, TensorFlow is a better choice.
</details>
Let's try asking the model how to overcome the "hallucination" phenomenon in A.I development and give context for the model to provide a solution.
<details close>
<summary>👨💻 : Explain the cause of A.I hallucination and find a solution to overcome it, the specific context is LLMs.</summary>
👻 :
**Causes of A.I. Hallucination:**
- **Data Quality:** Incorrect or biased data can lead to hallucinations in LLMs. For example, if an LLM is trained on a dataset that contains biased or incomplete information, it may learn to generate biased or incomplete responses.
- **Model Architecture:** Certain model architectures are more susceptible to hallucinations than others. For example, Transformers, which are commonly used in LLMs, can be more prone to hallucinations than recurrent neural networks (RNNs).
- **Hyperparameters:** The hyperparameters of an LLM, such as the learning rate and the batch size, can also affect the likelihood of hallucinations. For example, a higher learning rate may lead to hallucinations more often than a lower learning rate.
**Solutions to Overcome A.I. Hallucination:**
- **Data Quality:** Ensure that the data used to train the LLM is accurate, complete, and unbiased. This can be done by cleaning the data, removing outliers, and using a variety of data sources.
- **Model Architecture:** Choose an LLM architecture that is less susceptible to hallucinations. For example, RNNs are generally less prone to hallucinations than Transformers.
- **Hyperparameters:** Tune the hyperparameters of the LLM to minimize the likelihood of hallucinations. This can be done by experimenting with different learning rates, batch sizes, and other hyperparameters.
- **Regularization Techniques:** Regularization techniques, such as dropout and early stopping, can help to prevent hallucinations by encouraging the LLM to learn more generalizable patterns.
- **Explicit Hallucination Detection:** Develop techniques to explicitly detect hallucinations in LLM-generated text. This can be done by using a variety of methods, such as text analysis, natural language processing, and machine learning.
- **User Feedback:** Collect feedback from users to identify and correct hallucinations in LLM-generated text. This can be done by using a variety of methods, such as surveys, feedback forms, and online discussions.
By implementing these solutions, you can significantly reduce the likelihood of hallucinations in LLMs and improve the quality of the generated text.
</details>
## Vietnamese
Try asking the model what it thinks about a famous quote to see if the answer feels natural.
<details close>
<summary>👨💻 : Bạn có đồng ý với câu nói "Điều duy nhất nguy hiểm hơn sự ngu dốt là sự kiêu ngạo" ?</summary>
👻 :
Tôi đồng ý với câu nói "Điều duy nhất nguy hiểm hơn sự ngu dốt là sự kiêu ngạo". Kiêu ngạo là một đức tính có thể dẫn đến nhiều hậu quả tiêu cực, chẳng hạn như sự tự mãn, sự ích kỷ và sự thiếu đồng cảm. Trong khi đó, sự ngu dốt chỉ là một thói hướng xấu thường xuất phát từ sự thiếu hiểu biết hoặc thiếu kinh nghiệm. Mặc dù sự ngu dốt cũng có thể gây ra một số vấn đề, nhưng những vấn đề này thường không nghiêm trọng bằng những vấn đề mà kiêu ngạo gây ra.
Ví dụ, một người ngu dốt có thể nói những lời ngớ ngẩn hoặc làm những việc vụng về, nhưng họ thường vẫn có thể học hỏi từ những sai lầm của mình và cải thiện bản thân. Ngược lại, một người kiêu ngạo thường sẽ không chịu học hỏi từ những sai lầm của mình và luôn tin rằng mình đúng, ngay cả khi mình sai. Điều này có thể dẫn đến nhiều vấn đề, chẳng hạn như sự thất bại trong công việc hoặc các mối quan hệ.
Do đó, tôi cho rằng câu nói "Điều duy nhất nguy hiểm hơn sự ngu dốt là sự kiêu ngạo" là đúng.
</details>
Explore the model's literary understanding by providing meaningful story prompts, asking to identify what the story is.
<details close>
<summary>👨💻 : Câu chuyện có nội dung và ý nghĩa chứa đựng một thông điệp ý nghĩa lớn đến tất cả mọi người, đó là tình đoàn kết, khao khát cho sự hòa bình và nghị lực phi thường trước mọi khó khăn. Có nhân vật chính là loài dế. Câu hỏi: câu chuyện đó của tác giả nào ?</summary>
👻 :
Câu chuyện "Dế Mèn phiêu lưu ký" của Tô Hoài.
**Giải thích:**
- "Dế Mèn phiêu lưu ký" là một tác phẩm văn học nổi tiếng của nhà văn Tô Hoài, được sáng tác năm 1941.
- Tác phẩm kể về cuộc phiêu lưu của Dế Mèn, một chú dế nhỏ sống trong một ngôi làng nhỏ. Trong quá trình phiêu lưu, Dế Mèn đã gặp gỡ và học hỏi nhiều điều về cuộc sống, về tình yêu, về sự hy sinh và về sức mạnh của tình đoàn kết.
- Tác phẩm thể hiện rõ tinh thần đoàn kết, khao khát cho sự hòa bình và nghị lực phi thường của con người trước mọi khó khăn, thử thách. Đây chính là thông điệp ý nghĩa lớn của câu chuyện "Dế Mèn phiêu lưu ký".
</details>
The ability to reason to the answer based on the characteristics of is provided.
<details close>
<summary>👨💻 : Con vật nào lớn hơn con chuột, nhỏ hơn con Voi, không quá lớn, không phải con chó và thường được nuôi ở nhà ?</summary>
👻 :
Con mèo là loài động vật lớn hơn con chuột nhưng nhỏ hơn con Voi, không quá lớn, không phải con chó và thường được nuôi ở nhà.
</details>
### Try coding skills
Try asking the Typescript coding model to perform finding the second largest number in the array to see if it works?
<details close>
<summary>👨💻 : Viết mã TypeScript để tạo một hàm thực hiện chức năng: cho mảng toàn số nguyên, tìm số lớn thứ hai trong mảng.
</summary>
👻 :
```typescript
/**
* Tìm số lớn thứ hai trong mảng.
*
* @param {number[]} arr Mảng các số nguyên.
* @returns {number} Số lớn thứ hai trong mảng.
*/
function findSecondLargest(arr: number[]): number {
// Kiểm tra xem mảng có ít nhất 2 phần tử không.
if (arr.length < 2) {
throw new Error('Mảng phải có ít nhất 2 phần tử.');
}
// Tìm số lớn nhất và số lớn thứ hai trong mảng.
let largest = arr[0];
let secondLargest = Number.MIN_SAFE_INTEGER;
for (let i = 1; i < arr.length; i++) {
if (arr[i] > largest) {
secondLargest = largest;
largest = arr[i];
} else if (arr[i] > secondLargest && arr[i] != largest) {
secondLargest = arr[i];
}
}
// Trả về số lớn thứ hai.
return secondLargest;
}
```
Giải thích:
1. Kiểm tra xem mảng có ít nhất 2 phần tử không. Nếu mảng chỉ có 1 phần tử hoặc ít hơn, thì không có số lớn thứ hai trong mảng. Trả về lỗi nếu điều kiện này đúng.
2. Khởi tạo hai biến `largest` và `secondLargest` với giá trị ban đầu là phần tử đầu tiên của mảng và số nguyên nhỏ nhất có thể biểu diễn được trong JavaScript (`Number.MIN_SAFE_INTEGER`), tương đương với `Integer.MIN_VALUE` trong Java.
3. Duyệt qua từng phần tử trong mảng, bắt đầu từ phần tử thứ hai. Nếu phần tử hiện tại lớn hơn `largest`, thì cập nhật `secondLargest` bằng `largest` và `largest` bằng phần tử hiện tại. Nếu phần tử hiện tại lớn hơn `secondLargest` nhưng nhỏ hơn `largest`, thì cập nhật `secondLargest` bằng phần tử hiện tại.
4. Sau khi duyệt qua tất cả các phần tử trong mảng, trả về `secondLargest`. Đây chính là số lớn thứ hai trong mảng.
</details>
Now let's try asking for a coding model to build a smooth neural network with python.
<details close>
<summary>👨💻 : Trình bày cách sử dụng thư viện Keras hoặc TensorFlow trong Python để xây dựng và huấn luyện mạng nơ-ron đa lớp cho bài toán phân loại ảnh.</summary>
👻 :
**Sử dụng thư viện Keras:**
1. **Nhập thư viện Keras:**
```python
import keras.models
```
2. **Tạo một mô hình mạng nơ-ron đa lớp:**
```python
model = keras.models.Sequential()
model.add(keras.layers.Conv2D(32, (3, 3), activation='relu', input_shape=(224, 224, 3)))
model.add(keras.layers.MaxPooling2D((2, 2)))
model.add(keras.layers.Flatten())
model.add(keras.layers.Dense(128, activation='relu'))
model.add(keras.layers.Dense(2, activation='softmax'))
```
3. **Biên dịch và huấn luyện mô hình:**
```python
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
model.fit(x_train, y_train, epochs=10, validation_data=(x_test, y_test))
```
**Sử dụng thư viện TensorFlow:**
1. **Nhập thư viện TensorFlow:**
```python
import tensorflow as tf
```
2. **Tạo một mô hình mạng nơ-ron đa lớp:**
```python
model = tf.keras.models.Sequential()
model.add(tf.keras.layers.Conv2D(32, (3, 3), activation='relu', input_shape=(224, 224, 3)))
model.add(tf.keras.layers.MaxPooling2D((2, 2)))
model.add(tf.keras.layers.Flatten())
model.add(tf.keras.layers.Dense(128, activation='relu'))
model.add(tf.keras.layers.Dense(2, activation='softmax'))
```
3. **Biên dịch và huấn luyện mô hình:**
```python
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
model.fit(x_train, y_train, epochs=10, validation_data=(x_test, y_test))
```
**Lưu ý:**
- Bạn có thể sử dụng các lớp mạng nơ-ron khác nhau trong mô hình, chẳng hạn như lớp mạng nơ-ron tích chập (Conv2D), lớp mạng nơ-ron lấy mẫu (MaxPooling2D), lớp mạng nơ-ron đầy đủ kết nối (Dense), lớp mạng nơ-ron softmax, v.v.
- Bạn có thể điều chỉnh số lớp, số nơ-ron trong mỗi lớp và số lần lặp (epochs) để tối ưu hóa mô hình cho bài toán cụ thể của bạn.
- Bạn có thể sử dụng các kỹ thuật huấn luyện bổ sung như dropout, regularization và early stopping để cải thiện hiệu suất của mô hình.
</details>
Try asking the model about common errors when deploying and using K8S to see what results the model gives.
<details close>
<summary>👨💻 : Những lỗi thường gặp trong quá trình sử dụng K8S là gì ? Hãy nêu cách khắc phục.</summary>
👻 :
**Những lỗi thường gặp trong quá trình sử dụng Kubernetes:**
**1. Lỗi cấu hình:**
* **Máy chủ Kubernetes không được cấu hình đúng:** Kiểm tra cấu hình máy chủ Kubernetes (master node) để đảm bảo rằng các thông số cần thiết như IP, cổng, tên miền, tên miền SSL, v.v. được đặt đúng.
* **Các pod không được cấu hình đúng:** Kiểm tra cấu hình pod để đảm bảo rằng các yếu tố như image, lưu trữ, mạng, v.v. được đặt đúng.
* **Các tài nguyên (resource) không được cấp phát đúng:** Kiểm tra xem các tài nguyên như CPU, bộ nhớ, lưu trữ, v.v. được cấp phát cho các pod có đủ hay không.
**2. Lỗi mạng:**
* **Mạng không được cấu hình đúng:** Kiểm tra cấu hình mạng để đảm bảo rằng các địa chỉ IP, cổng, tên miền, tên miền SSL, v.v. được cấu hình đúng.
* **Lỗi mạng giữa các node:** Kiểm tra xem có lỗi mạng giữa các node trong cụm Kubernetes hay không. Có thể sử dụng các công cụ như `netstat`, `ifconfig`, `tcpdump` để kiểm tra.
* **Lỗi mạng giữa các pod:** Kiểm tra xem có lỗi mạng giữa các pod trong một node hay không. Có thể sử dụng các công cụ như `netstat`, `ifconfig`, `tcpdump` để kiểm tra.
**3. Lỗi phần cứng:**
* **Phần cứng không đủ mạnh:** Kiểm tra xem phần cứng máy chủ Kubernetes có đủ mạnh để chạy cụm Kubernetes hay không. Cụ thể, kiểm tra xem CPU, bộ nhớ, lưu trữ, v.v. có đủ hay không.
* **Phần cứng bị lỗi:** Kiểm tra xem phần cứng máy chủ Kubernetes có bị lỗi hay không. Có thể sử dụng các công cụ như `lshw`, `dmesg` để kiểm tra.
**4. Lỗi phần mềm:**
* **Phần mềm Kubernetes không được cập nhật:** Kiểm tra xem phần mềm Kubernetes đang sử dụng có được cập nhật đến phiên bản mới nhất hay không. Cập nhật phần mềm Kubernetes thường giúp khắc phục các lỗi bảo mật và cải thiện hiệu suất.
* **Phần mềm Kubernetes có lỗi:** Kiểm tra xem phần mềm Kubernetes có lỗi hay không. Có thể sử dụng các công cụ như `journal`, `dmesg` để kiểm tra.
* **Các ứng dụng khách không được cập nhật:** Kiểm tra xem các ứng dụng khách đang sử dụng trên cụm Kubernetes có được cập nhật đến phiên bản mới nhất hay không. Cập nhật các ứng dụng khách thường giúp khắc phục các lỗi bảo mật và cải thiện hiệu suất.
**Cách khắc phục:**
* **Lỗi cấu hình:** Sửa các thông số cấu hình sai trong máy chủ Kubernetes và các pod. Ví dụ: đảm bảo rằng máy chủ Kubernetes có địa chỉ IP và cổng phù hợp, các pod có image và lưu trữ phù hợp, v.v.
* **Lỗi mạng:** Sửa các vấn đề về mạng giữa các node và các pod. Ví dụ: đảm bảo rằng mạng được cấu hình đúng, kiểm tra xem có lỗi mạng giữa các node hay không, kiểm tra xem có lỗi mạng giữa các pod hay không, v.v.
* **Lỗi phần cứng:** Nâng cấp phần cứng máy chủ Kubernetes nếu cần thiết. Ví dụ: tăng CPU, bộ nhớ, lưu trữ, v.v.
* **Lỗi phần mềm:** Cập nhật phần mềm Kubernetes và các ứng dụng khách. Ví dụ: cập nhật phiên bản mới nhất của Kubernetes, cập nhật các bản vá lỗi bảo mật cho các ứng dụng khách, v.v.
**Lưu ý:** Khi gặp phải lỗi trong quá trình sử dụng Kubernetes, cần phải xác định rõ nguyên nhân gốc rễ của lỗi trước khi có thể khắc phục. Việc xác định nguyên nhân gốc rễ sẽ giúp bạn tiết kiệm thời gian và công sức khi khắc phục lỗi.
</details>
## Tools / Function calls
The model is trained to be able to choose the right tools to use and to provide useful and accurate answers to the questions it receives. In this example, the model is asked for some information about Apple stock.
### Explain
This is the standard for declaring model tools, in `json` format. Also, See more about the model's [prompt / chat template](#prompt--chat-template).
```json
[
{
"type": "function",
"function": {
"name": "get_stock_info",
"description": "Get stock information",
"parameters": {
"type": "object",
"properties": {
"ticker": {
"type": "string",
"description": "Stock ticker",
"required": true
}
}
}
}
}
]
```
### Workflow
#### Turn 1
To use the tools, the model's supporting role is `plugin` which includes the declared tooling schema. Below is an example of `messages` with **turn 1** to use.
```python
# A question about Apple stocks in English language.
question = "What is Apple's market capitalization today?"
# It's still the same question but in Vietnamese languae.
# question = "Vốn hoá thị trường Apple hôm nay là bao nhiêu ?"
plugins = [
{
"type": "function",
"function": {
"name": "get_stock_info",
"description": "Get stock information",
"parameters": {
"type": "object",
"properties": {
"ticker": {
"type": "string",
"description": "Stock ticker",
"required": True,
}
},
},
},
}
]
messages = [
{"role": "system", "content": ""},
{"role": "plugins", "content": json.dumps(plugins, ensure_ascii=False)},
{"role": "user", "content": question},
]
output = generate_sample(
messages=messages,
max_new_tokens=256, temperature=0.4, top_k=50, top_p=0.95,
)
```
At this point, the model will return `output` as the primitive value as follows:
```plaintext
[execute]({"type": "function", "function": "get_stock_info", "arguments": {"ticker": "AAPL"}})
```
Use the `get_tools` function to parse the readable and usable results.
```json
{
"type": "function",
"function": "get_stock_info",
"arguments": {
"ticker": "AAPL"
}
}
```
#### Turn 2
Get information about tools to use with arguments. Use it to execute and return data, here we will assume the return data is as follows, sampled from **polygon.io** (cleaned up):
```json
{
"request_id": "1ffbab9cc78c7addbd8deaab05bdaf6d",
"results": {
"ticker": "AAPL",
"name": "Apple Inc.",
"market_cap": 2620023949270,
"description": "Apple is among the largest companies in the world, with a broad portfolio of hardware and software products targeted at consumers and businesses. Apple's iPhone makes up a majority of the firm sales, and Apple's other products like Mac, iPad, and Watch are designed around the iPhone as the focal point of an expansive software ecosystem. Apple has progressively worked to add new applications, like streaming video, subscription bundles, and augmented reality. The firm designs its own software and semiconductors while working with subcontractors like Foxconn and TSMC to build its products and chips. Slightly less than half of Apple's sales come directly through its flagship stores, with a majority of sales coming indirectly through partnerships and distribution.",
"ticker_root": "AAPL",
"homepage_url": "https://www.apple.com",
"total_employees": 161000,
...
},
"status": "OK"
}
```
Continue using the model to answer user questions based on the data returned from the tool.
```python
executes = {
"type": "function",
"function": "get_stock_info",
"arguments": {
"ticker": "AAPL"
}
}
results = {
"request_id": "1ffbab9cc78c7addbd8deaab05bdaf6d",
"results": {
"ticker": "AAPL",
"name": "Apple Inc.",
"market_cap": 2620023949270,
"description": "Apple is among the largest companies in the world, with a broad portfolio of hardware and software products targeted at consumers and businesses. Apple's iPhone makes up a majority of the firm sales, and Apple's other products like Mac, iPad, and Watch are designed around the iPhone as the focal point of an expansive software ecosystem. Apple has progressively worked to add new applications, like streaming video, subscription bundles, and augmented reality. The firm designs its own software and semiconductors while working with subcontractors like Foxconn and TSMC to build its products and chips. Slightly less than half of Apple's sales come directly through its flagship stores, with a majority of sales coming indirectly through partnerships and distribution.",
"ticker_root": "AAPL",
"homepage_url": "https://www.apple.com",
"total_employees": 161000,
},
"status": "OK"
}
messages = [
{"role": "system", "content": ""},
{"role": "plugins","content": json.dumps(plugins, ensure_ascii=False)},
{"role": "user","content": question},
# Keep the value of `messages` from before, just add new items below.
{"role": "execute","content": json.dumps(executes, ensure_ascii=False)},
{"role": "response","content": json.dumps(results, ensure_ascii=False)},
]
output = generate_sample(
messages=messages,
max_new_tokens=256, temperature=0.4, top_k=50, top_p=0.95,
)
```
The value of `output` returned by the model will now be similar to the following.
For the question is English.
```plaintext
Apple's market capitalization today is $2.62 trillion.
```
And the question is Vietnamese.
```plaintext
Vốn hoá thị trường của Apple hôm nay là **2.620 tỷ đô la**. 💰
```
# Usage
The model is trained to serve well and balance general tasks, so there will be many approaches when used for production.
## Things to know
### Recommendations
#### General tasks
Experience it to find the right fit for your own desires. Below are some suggestions that you might consider.
##### Answer the questions
In this task, the model can be integrated to develop RAG products to help answer questions for customer care departments, questions about internal documents, policies, product information, order details, etc.
##### Coding support
In this task, the model can help find errors or write algorithms and functions that help speed up the domain development process and improve product quality.
##### Content creation
In this task, the model can give suggestions for building layouts and content samples that need high creativity and personality in the content.
##### Other
Don't limit your creativity to the model. Feel free to experience it and use it to build good things.
#### Virtual assistant
An understanding of the language along with the overall capabilities of the model, may be suitable for integrating its development as a set of one or more tasks in the development of an intelligent virtual assistant.
The model is trained to understand and empathize emotionally, making the response more natural and understanding. This also helps a lot with this request.
#### As a pre-training
The model can be further trained to serve the desired tasks better and more effectively if it cannot satisfy the given requirements.
Taking advantage of the model's current superior inference and multi-tasking capabilities, training it for a few separate tasks will help save a lot of effort, time and cost for the project.
Revealed, the model has been integrated to replace some tasks that were previously used by OpenAI GPT4 in the business/product that the founder has been working on. For those tasks, the model is considered effective compared to the cost and is very worthy.
### Bias and limitations
In addition, there are some things you need to know before using as follows:
#### Generation configuration
The **temperature** affects the truth of the answer. Setting a **temperature** value greater than 0.2 - 0.4 will result in a more creative answer but may affect the accuracy of the answer, please consider this based on your task.
Hint: you can write a prompt to receive input and ask the model to choose the appropriate temperature based on the question, useful in the case of virtual assistant development.
#### Emotion bias and empathy
The model is built with an emotional bias and takes positions when faced with problems or reasoning questions. This can be good or bad depending on the context. If you don't want the model to be rigid in asking certain questions or problems, set up rules in the system prompt for it.
This bias often appears when the model's system prompt sets it up as an assistant and mentions that it needs to have empathy for/with a certain user/experience. This is intentional during the model training process, it does not come from something unforeseen.
## Directly
To use the model directly, there are many ways to get started, choose one of the following ways to experience it.
### Transformers
For direct use with `transformers`, you can easily get started with the following steps.
- Firstly, you need to install transformers via the command below with `pip`.
```bash
pip install -U transformers
```
- Right now, you can start using the model directly.
```python
import torch
from transformers import (
AutoModelForCausalLM,
AutoTokenizer,
)
base_model = "ghost-x/ghost-7b-alpha"
model = AutoModelForCausalLM.from_pretrained(
base_model,
torch_dtype=torch.bfloat16,
device_map="auto",
)
tokenizer = AutoTokenizer.from_pretrained(base_model)
messages = [
{"role": "system", "content": ""},
{"role": "user", "content": "Why is the sky blue ?"},
# {"role": "user", "content": "Tại sao bầu trời lại màu xanh ?"},
]
prompt = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
inputs = tokenizer(prompt, return_tensors="pt", add_special_tokens=False)
for k,v in inputs.items():
inputs[k] = v.cuda()
outputs = model.generate(**inputs, max_new_tokens=512, do_sample=True, top_k=50, top_p=0.95, temperature=0.4)
results = tokenizer.batch_decode(outputs)[0]
print(results)
```
- Additionally, you can also use a model with **4bit quantization** to reduce the required resources at least. You can start with the code below.
```python
import torch
from transformers import (
AutoModelForCausalLM,
AutoTokenizer,
BitsAndBytesConfig,
)
base_model = "ghost-x/ghost-7b-alpha"
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16,
bnb_4bit_use_double_quant=False,
)
model = AutoModelForCausalLM.from_pretrained(
base_model,
quantization_config=bnb_config,
device_map="auto",
)
tokenizer = AutoTokenizer.from_pretrained(base_model)
messages = [
{"role": "system", "content": ""},
{"role": "user", "content": "Why is the sky blue ?"},
# {"role": "user", "content": "Tại sao bầu trời lại màu xanh ?"},
]
prompt = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
inputs = tokenizer(prompt, return_tensors="pt", add_special_tokens=False)
for k,v in inputs.items():
inputs[k] = v.cuda()
outputs = model.generate(**inputs, max_new_tokens=512, do_sample=True, top_k=50, top_p=0.95, temperature=0.4)
results = tokenizer.batch_decode(outputs)[0]
print(results)
```
### Unsloth
For direct use with `unsloth`, you can easily get started with the following steps.
- Firstly, you need to install unsloth via the command below with `pip`.
```bash
pip install "unsloth[colab-new] @ git+https://github.com/unslothai/unsloth.git"
pip install --no-deps xformers trl peft accelerate bitsandbytes
```
- Initialize and optimize the model before use.
```python
from unsloth import FastLanguageModel
import torch
base_model = "ghost/ghost-7b-alpha"
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = base_model,
max_seq_length = 8192,
dtype = None,
load_in_4bit = True, # Change to `False` if you don't want to use 4bit quantization.
)
FastLanguageModel.for_inference(model)
```
- Right now, you can start using the model directly.
```python
messages = [
{"role": "system", "content": ""},
{"role": "user", "content": "Why is the sky blue ?"},
# {"role": "user", "content": "Tại sao bầu trời lại màu xanh ?"},
]
prompt = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
inputs = tokenizer(prompt, return_tensors="pt", add_special_tokens=False)
for k,v in inputs.items():
inputs[k] = v.cuda()
outputs = model.generate(**inputs, max_new_tokens=512, do_sample=True, top_k=50, top_p=0.95, temperature=0.4)
results = tokenizer.batch_decode(outputs)[0]
print(results)
```
## Online
The content of this document will be updated soon. The documentation will guide usage through providers such as Huggingface Inference API, Together AI, or Replicate.
## Playground
To make it easy for everyone to quickly experience the model through platforms like **Google Colab** and **Kaggle**. We’ve made these notebooks available so you can get started right away. See available notebooks with details [here](https://ghost-x.org/docs/notebooks/playground-with-ghost-7b-alpha/).
We offer notebooks with a wide selection of tools and platforms so you can easily get started. Here are some available options for you to try right now. Let’s pick one to get started.
There are currently two language versions: English and Vietnamese. In each version, it will be almost the same. The content will include installation instructions and functions to help get started quickly with experiencing the model's text generation capabilities. In addition, it also provides examples with system prompts for each field so you can better understand them.
#### Playground using Transformers
- [Kaggle @ Ghost 7B Alpha - Playground using Transformers, Vietnamese](https://www.kaggle.com/code/lamhieu/ghost-7b-alpha-playground-using-transformers-vi).
- [Colab @ Ghost 7B Alpha - Playground using Transformers, Vietnamese](https://colab.research.google.com/drive/14Cv6oT0pks3NoIUcXscAU9wex9A2T5H5?usp=sharing).
- [Kaggle @ Ghost 7B Alpha - Playground using Transformers, English](https://www.kaggle.com/code/lamhieu/ghost-7b-alpha-playground-using-transformers-en).
- [Colab @ Ghost 7B Alpha - Playground using Transformers, English](https://colab.research.google.com/drive/1lzgywm333wZIt5WNDs0ZajDvK7lm_Zy9?usp=sharing).
#### Playground using Unsloth
- [Kaggle @ Ghost 7B Alpha - Playground using Unsloth, Vietnamese](https://www.kaggle.com/code/lamhieu/ghost-7b-alpha-playground-using-unsloth-vi).
- [Colab @ Ghost 7B Alpha - Playground using Unsloth, Vietnamese](https://colab.research.google.com/drive/1E7QuthR33een9Otkepue5zFughCpab4P?usp=sharing).
- [Kaggle @ Ghost 7B Alpha - Playground using Unsloth, English](https://www.kaggle.com/code/lamhieu/ghost-7b-alpha-playground-using-unsloth-en).
- [Colab @ Ghost 7B Alpha - Playground using Unsloth, English](https://colab.research.google.com/drive/1u04RbzD87_AovQngWsUv-O_Q6YNj7Hzr?usp=sharing).
Revealing, experience with Kaggle will give you much better results in creating documents than Colab. We recommend using Kaggle.
## Deployments
The models developed by **Ghost X** have the same goal of being easy to integrate and use in practice to save costs and facilitate development for the community and startups.
For production deployment with small to large infrastructure, please see more detailed instructions in [this article](https://ghost-x.org/docs/guides/deployments/). The article will provide the most common and effective deployment solutions with leading, trusted libraries such as vLLM and more. In addition, it also has information about more optimal solutions and methods depending on each need to be able to choose the appropriate solution.
# Evaluation
To ensure effective model development, we ran popular evaluations to give everyone a broader view of the model's capabilities. We had to work to balance the quality between the English and Vietnamese languages to ensure the model still performed well in both of these primary languages.
In addition, if your goals are oriented towards a certain main language, you can refer to the advanced user guide to improve model quality for the tasks and languages you desire.
## Open LLM Leaderboard
The results of this evaluation will be updated soon.
## MT-Bench
MT-bench is a challenging multi-turn question set designed to evaluate the conversational and instruction-following ability of models. [[source from lmsys.org]](https://lmsys.org/blog/2023-06-22-leaderboard)
**Ghost 7B Alpha** achieved a decent score for the MT-Bench review, we worked hard to balance the reasoning ability and linguistic insight of both primary languages, English and Vietnamese. Overall, it was able to outperform some large language models such as tulu-30b, guanaco-65b, and mpt-30b-chat which are many times larger.
| Model | Score |
| --------------------- | ------------ |
| gpt-4 | 8.990625 |
| gpt-3.5-turbo | 7.943750 |
| claude-instant-v1 | 7.905660 |
| claude-v1 | 7.900000 |
| vicuna-33b-v1.3 | 7.121875 |
| wizardlm-30b | 7.009375 |
| Llama-2-70b-chat | 6.856250 |
| Llama-2-13b-chat | 6.650000 |
| guanaco-33b | 6.528125 |
| **ghost-7b-alpha** | **6.481250** |
| tulu-30b | 6.434375 |
| oasst-sft-7-llama-30b | 6.409375 |
| guanaco-65b | 6.409375 |
| palm-2-chat-bison-001 | 6.400000 |
| mpt-30b-chat | 6.393750 |
| vicuna-13b-v1.3 | 6.387500 |
| wizardlm-13b | 6.353125 |
## AlpacaEval
AlpacaEval is an automated tool for evaluating instruction-following language models against the AlpacaFarm dataset. It stands out for its human-validated, high-quality assessments that are both cost-effective and rapid. [[source from klu.ai]](https://klu.ai/glossary/alpaca-eval)
Similarly, in this evaluation the model achieved good performance as it outperformed larger sized models such as vicuna-13b, guanaco-33b, and nous-hermes-13b.
| Model | Winrate |
| -------------------------- | ------------- |
| gpt4 | 95.279503 |
| Mixtral-8x7B-Instruct-v0.1 | 94.782608 |
| claude-2.1 | 87.080745 |
| gpt-3.5-turbo-1106 | 86.256218 |
| zephyr-7b-alpha | 85.758706 |
| gpt35_turbo_instruct | 81.710362 |
| gemini-pro | 79.664179 |
| ... | ... |
| **ghost-7b-alpha** | **70.440251** |
| vicuna-13b | 70.434782 |
| guanaco-33b | 65.962732 |
| nous-hermes-13b | 65.465838 |
| ... | ... |
# Notes
## Thanks
After all, the project also wants to send sincere thanks to the products that have supported the project's development.
#### Unsloth
<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/made with unsloth.png" width="200px" align="center" />
[Unsloth](https://unsloth.ai), a great tool that helps us easily develop products, at a lower cost than expected.
#### Kaggle
<img src="https://cdn-uploads.huggingface.co/production/uploads/600ae38cc92b79f54efd4556/dcbpF6YS6RQhqDd6GZZ2v.png" width="200px" align="center" />
[Kaggle](https://kaggle.com), generous hours of free notebooks for research projects.
#### And...
Good friends, who have accompanied the project, Luan Nguyen and Phu Tran.
## Confidence
In addition to the **Ghost 7B Alpha** project, **Ghost X** always wants to develop and improve many better models in the future, better supporting the community and businesses with the most openness possible.
Revealing the **Ghost 7B Beta** project plan. This model is expected to outperform with a deeper focus on multi-tasking, math, and reasoning. Along with that is the ability to expand context length and support other languages (highly requested languages).
The organization is being operated and developed by [Hieu Lam](https://huggingface.co/ghost-x)'s personal resources, if there is any development support or consulting request. Please feel free to contact the organization, we are very happy about this. Directly via email: [[email protected]](mailto:[email protected]).
**Ghost X** is happy to support providing models for server providers, aiming to help startups develop better.
## Contact
Follow **Ghost X** to stay updated with the latest information.
- Twitter/X via [@ghostx_ai](https://twitter.com/ghostx_ai).
- HuggingFace via [@ghost-x](https://huggingface.co/ghost-x).
- Official website [ghost-x.org](https://ghost-x.org/).
|
T3Q-LLM-Product/T3Q-LLM1-Solar-10.8B-v1.0 | T3Q-LLM-Product | 2024-05-31T03:31:46Z | 3,081 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2024-05-31T01:45:23Z | ---
library_name: transformers
license: apache-2.0
pipeline_tag: text-generation
---


 |
mosaicml/mpt-7b-8k-instruct | mosaicml | 2024-03-05T20:29:54Z | 3,079 | 25 | transformers | [
"transformers",
"pytorch",
"mpt",
"text-generation",
"Composer",
"MosaicML",
"llm-foundry",
"custom_code",
"dataset:competition_math",
"dataset:knkarthick/dialogsum",
"dataset:mosaicml/dolly_hhrlhf",
"dataset:duorc",
"dataset:emozilla/quality",
"dataset:scrolls/summ_screen_fd",
"dataset:spider",
"arxiv:2205.14135",
"arxiv:2108.12409",
"arxiv:2010.04245",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2023-06-18T22:32:42Z | ---
license: apache-2.0
datasets:
- competition_math
- knkarthick/dialogsum
- mosaicml/dolly_hhrlhf
- duorc
- emozilla/quality
- scrolls/summ_screen_fd
- spider
tags:
- Composer
- MosaicML
- llm-foundry
inference: false
---
# MPT-7B-Instruct-8k
MPT-7B-Instruct-8k is a model for long-form instruction following, especially question-answering on and summarization of longer documents.
It is built by finetuning [MPT-7B-8k](https://huggingface.co/mosaicml/mpt-7b-8k) on [Dolly HHRLHF](https://huggingface.co/datasets/mosaicml/dolly_hhrlhf) derived from the [Databricks Dolly-15k](https://huggingface.co/datasets/databricks/databricks-dolly-15k) and the [Anthropic Helpful and Harmless (HH-RLHF)](https://huggingface.co/datasets/Anthropic/hh-rlhf) datasets. It is also trained on [Competition Math](https://huggingface.co/datasets/competition_math), [Duorc](https://huggingface.co/datasets/duorc), [CoT GSM8k](https://huggingface.co/datasets/conceptofmind/cot_submix_original), [Qasper](https://huggingface.co/datasets/allenai/qasper), [Quality](https://huggingface.co/datasets/emozilla/quality), [Summ Screen FD](https://huggingface.co/datasets/tau/scrolls) and [Spider](https://huggingface.co/datasets/spider).
This is the same dataset that [MPT-30B-Instruct](https://huggingface.co/mosaicml/mpt-30b-instruct) was trained on.
* License: Apache 2.0
This model was trained by [MosaicML](https://www.mosaicml.com) and follows a modified decoder-only transformer architecture.
## Model Date
July 18, 2023
## Model License
Apache 2.0
## Documentation
* [Blog post: MPT-7B-8k](https://www.mosaicml.com/blog/long-context-mpt-7b-8k)
* [Codebase (mosaicml/llm-foundry repo)](https://github.com/mosaicml/llm-foundry/)
* Questions: Feel free to contact us via the [MosaicML Community Slack](https://mosaicml.me/slack)!
## How to Use
This model is best used with the MosaicML [llm-foundry repository](https://github.com/mosaicml/llm-foundry) for training and finetuning.
```python
import transformers
model = transformers.AutoModelForCausalLM.from_pretrained(
'mosaicml/mpt-7b-instruct-8k',
trust_remote_code=True
)
```
Note: This model requires that `trust_remote_code=True` be passed to the `from_pretrained` method.
This is because we use a custom `MPT` model architecture that is not yet part of the Hugging Face `transformers` package.
`MPT` includes options for many training efficiency features such as [FlashAttention](https://arxiv.org/pdf/2205.14135.pdf), [ALiBi](https://arxiv.org/abs/2108.12409), [QK LayerNorm](https://arxiv.org/abs/2010.04245), and more.
To use the optimized [triton implementation](https://github.com/openai/triton) of FlashAttention, you can load the model on GPU (`cuda:0`) with `attn_impl='triton'` and with `bfloat16` precision:
```python
import torch
import transformers
name = 'mosaicml/mpt-7b-instruct-8k'
config = transformers.AutoConfig.from_pretrained(name, trust_remote_code=True)
config.attn_config['attn_impl'] = 'triton' # change this to use triton-based FlashAttention
config.init_device = 'cuda:0' # For fast initialization directly on GPU!
model = transformers.AutoModelForCausalLM.from_pretrained(
name,
config=config,
torch_dtype=torch.bfloat16, # Load model weights in bfloat16
trust_remote_code=True
)
```
The model was trained initially with a sequence length of 2048 with an additional pretraining stage for sequence length adapation up to 8192. However, ALiBi enables users to increase the maximum sequence length even further during finetuning and/or inference. For example:
```python
import transformers
name = 'mosaicml/mpt-7b-instruct-8k'
config = transformers.AutoConfig.from_pretrained(name, trust_remote_code=True)
config.max_seq_len = 16384 # (input + output) tokens can now be up to 16384
model = transformers.AutoModelForCausalLM.from_pretrained(
name,
config=config,
trust_remote_code=True
)
```
This model was trained with the MPT-7B-chat tokenizer which is based on the [EleutherAI/gpt-neox-20b](https://huggingface.co/EleutherAI/gpt-neox-20b) tokenizer and includes additional ChatML tokens.
```python
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained('mosaicml/mpt-7b-8k')
```
The model can then be used, for example, within a text-generation pipeline.
Note: when running Torch modules in lower precision, it is best practice to use the [torch.autocast context manager](https://pytorch.org/docs/stable/amp.html).
```python
from transformers import pipeline
with torch.autocast('cuda', dtype=torch.bfloat16):
inputs = tokenizer('Here is a recipe for vegan banana bread:\n', return_tensors="pt").to('cuda')
outputs = model.generate(**inputs, max_new_tokens=100)
print(tokenizer.batch_decode(outputs, skip_special_tokens=True))
# or using the HF pipeline
pipe = pipeline('text-generation', model=model, tokenizer=tokenizer, device='cuda:0')
with torch.autocast('cuda', dtype=torch.bfloat16):
print(
pipe('Here is a recipe for vegan banana bread:\n',
max_new_tokens=100,
do_sample=True,
use_cache=True))
```
## Model Description
The architecture is a modification of a standard decoder-only transformer.
The model has been modified from a standard transformer in the following ways:
* It uses [FlashAttention](https://arxiv.org/pdf/2205.14135.pdf)
* It uses [ALiBi (Attention with Linear Biases)](https://arxiv.org/abs/2108.12409) and does not use positional embeddings
* It does not use biases
| Hyperparameter | Value |
|----------------|-------|
|n_parameters | 6.7B |
|n_layers | 32 |
| n_heads | 32 |
| d_model | 4096 |
| vocab size | 50432 |
| sequence length | 2048 |
## Data Mix
The model was trained on the following data mix:
| Data Source | Number of Tokens in Source | Proportion |
|-------------|----------------------------|------------|
| competition_math | 1.6 M | 3.66% |
| cot_gsm8k | 3.36 M | 7.67% |
| dialogsum | 0.1 M | 0.23% |
| dolly_hhrlhf | 5.89 M | 13.43% |
| duorc | 7.8 M | 17.80% |
| qasper | 8.72 M | 19.90% |
| quality | 11.29 M | 25.78% |
| scrolls/summ_screen_fd | 4.97 M | 11.33% |
| spider | 0.089 M | 0.20% |
### Training Configuration
This model was trained on 8 80GB A100s for about 6.3 hours using the [MosaicML Platform](https://www.mosaicml.com/platform).
The model was trained with sharded data parallelism using [FSDP](https://pytorch.org/docs/stable/fsdp.html) and used the AdamW optimizer.
## Limitations and Biases
_The following language is modified from [EleutherAI's GPT-NeoX-20B](https://huggingface.co/EleutherAI/gpt-neox-20b)_
MPT-7B-Instruct-8k can produce factually incorrect output, and should not be relied on to produce factually accurate information.
MPT-7B-Instruct-8k was trained on various public datasets.
While great efforts have been taken to clean the pretraining data, it is possible that this model could generate lewd, biased or otherwise offensive outputs.
## Acknowledgements
This model was finetuned by the MosaicML NLP team.
## Disclaimer
The license on this model does not constitute legal advice. We are not responsible for the actions of third parties who use this model. Please consult an attorney before using this model for commercial purposes.
## MosaicML Platform
If you're interested in [training](https://www.mosaicml.com/training) and [deploying](https://www.mosaicml.com/inference) your own MPT or LLMs on the MosaicML Platform, [sign up here](https://www.mosaicml.com/get-started?utm_source=huggingface&utm_medium=referral&utm_campaign=mpt-7b-8k).
## Citation
Please cite this model using the following format:
```
@online{MosaicML2023Introducing,
author = {MosaicML NLP Team},
title = {Introducing MPT-30B: Raising the bar
for open-source foundation models},
year = {2023},
url = {www.mosaicml.com/blog/mpt-30b},
note = {Accessed: 2023-06-22},
urldate = {2023-06-22}
}
``` |
QuantFactory/DeepSeek-Coder-V2-Lite-Instruct-GGUF | QuantFactory | 2024-06-28T11:40:41Z | 3,079 | 0 | null | [
"gguf",
"text-generation",
"arxiv:2401.06066",
"base_model:deepseek-ai/DeepSeek-Coder-V2-Lite-Instruct",
"license:other",
"region:us"
] | text-generation | 2024-06-18T05:31:39Z | ---
license: other
license_name: deepseek-license
license_link: LICENSE
base_model: deepseek-ai/DeepSeek-Coder-V2-Lite-Instruct
pipeline_tag: text-generation
---
<!-- markdownlint-disable first-line-h1 -->
<!-- markdownlint-disable html -->
<!-- markdownlint-disable no-duplicate-header -->
# QuantFactory/DeepSeek-Coder-V2-Lite-Instruct-GGUF
This is quantized version of [QuantFactory/DeepSeek-Coder-V2-Lite-Instruct-GGUF](https://huggingface.co/deepseek-ai/DeepSeek-Coder-V2-Lite-Instruct) created using llama.cpp
# Model Description
<div align="center">
<img src="https://github.com/deepseek-ai/DeepSeek-V2/blob/main/figures/logo.svg?raw=true" width="60%" alt="DeepSeek-V2" />
</div>
<p align="center">
<a href="https://github.com/deepseek-ai/DeepSeek-Coder-V2/blob/main/paper.pdf"><b>Paper Link</b>👁️</a>
</p>
# DeepSeek-Coder-V2: Breaking the Barrier of Closed-Source Models in Code Intelligence
## 1. Introduction
We present DeepSeek-Coder-V2, an open-source Mixture-of-Experts (MoE) code language model that achieves performance comparable to GPT4-Turbo in code-specific tasks. Specifically, DeepSeek-Coder-V2 is further pre-trained from an intermediate checkpoint of DeepSeek-V2 with additional 6 trillion tokens. Through this continued pre-training, DeepSeek-Coder-V2 substantially enhances the coding and mathematical reasoning capabilities of DeepSeek-V2, while maintaining comparable performance in general language tasks. Compared to DeepSeek-Coder-33B, DeepSeek-Coder-V2 demonstrates significant advancements in various aspects of code-related tasks, as well as reasoning and general capabilities. Additionally, DeepSeek-Coder-V2 expands its support for programming languages from 86 to 338, while extending the context length from 16K to 128K.
<p align="center">
<img width="100%" src="https://github.com/deepseek-ai/DeepSeek-Coder-V2/blob/main/figures/performance.png?raw=true">
</p>
In standard benchmark evaluations, DeepSeek-Coder-V2 achieves superior performance compared to closed-source models such as GPT4-Turbo, Claude 3 Opus, and Gemini 1.5 Pro in coding and math benchmarks. The list of supported programming languages can be found [here](https://github.com/deepseek-ai/DeepSeek-Coder-V2/blob/main/supported_langs.txt).
## 2. Model Downloads
We release the DeepSeek-Coder-V2 with 16B and 236B parameters based on the [DeepSeekMoE](https://arxiv.org/pdf/2401.06066) framework, which has actived parameters of only 2.4B and 21B , including base and instruct models, to the public.
<div align="center">
| **Model** | **#Total Params** | **#Active Params** | **Context Length** | **Download** |
| :-----------------------------: | :---------------: | :----------------: | :----------------: | :----------------------------------------------------------: |
| DeepSeek-Coder-V2-Lite-Base | 16B | 2.4B | 128k | [🤗 HuggingFace](https://huggingface.co/deepseek-ai/DeepSeek-Coder-V2-Lite-Base) |
| DeepSeek-Coder-V2-Lite-Instruct | 16B | 2.4B | 128k | [🤗 HuggingFace](https://huggingface.co/deepseek-ai/DeepSeek-Coder-V2-Lite-Instruct) |
| DeepSeek-Coder-V2-Base | 236B | 21B | 128k | [🤗 HuggingFace](https://huggingface.co/deepseek-ai/DeepSeek-Coder-V2-Base) |
| DeepSeek-Coder-V2-Instruct | 236B | 21B | 128k | [🤗 HuggingFace](https://huggingface.co/deepseek-ai/DeepSeek-Coder-V2-Instruct) |
</div>
## 3. Chat Website
You can chat with the DeepSeek-Coder-V2 on DeepSeek's official website: [coder.deepseek.com](https://coder.deepseek.com/sign_in)
## 4. API Platform
We also provide OpenAI-Compatible API at DeepSeek Platform: [platform.deepseek.com](https://platform.deepseek.com/), and you can also pay-as-you-go at an unbeatable price.
<p align="center">
<img width="40%" src="https://github.com/deepseek-ai/DeepSeek-Coder-V2/blob/main/figures/model_price.jpg?raw=true">
</p>
## 5. How to run locally
**Here, we provide some examples of how to use DeepSeek-Coder-V2-Lite model. If you want to utilize DeepSeek-Coder-V2 in BF16 format for inference, 80GB*8 GPUs are required.**
### Inference with Huggingface's Transformers
You can directly employ [Huggingface's Transformers](https://github.com/huggingface/transformers) for model inference.
#### Code Completion
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
tokenizer = AutoTokenizer.from_pretrained("deepseek-ai/DeepSeek-Coder-V2-Lite-Base", trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained("deepseek-ai/DeepSeek-Coder-V2-Lite-Base", trust_remote_code=True, torch_dtype=torch.bfloat16).cuda()
input_text = "#write a quick sort algorithm"
inputs = tokenizer(input_text, return_tensors="pt").to(model.device)
outputs = model.generate(**inputs, max_length=128)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
```
#### Code Insertion
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
tokenizer = AutoTokenizer.from_pretrained("deepseek-ai/DeepSeek-Coder-V2-Lite-Base", trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained("deepseek-ai/DeepSeek-Coder-V2-Lite-Base", trust_remote_code=True, torch_dtype=torch.bfloat16).cuda()
input_text = """<|fim▁begin|>def quick_sort(arr):
if len(arr) <= 1:
return arr
pivot = arr[0]
left = []
right = []
<|fim▁hole|>
if arr[i] < pivot:
left.append(arr[i])
else:
right.append(arr[i])
return quick_sort(left) + [pivot] + quick_sort(right)<|fim▁end|>"""
inputs = tokenizer(input_text, return_tensors="pt").to(model.device)
outputs = model.generate(**inputs, max_length=128)
print(tokenizer.decode(outputs[0], skip_special_tokens=True)[len(input_text):])
```
#### Chat Completion
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
tokenizer = AutoTokenizer.from_pretrained("deepseek-ai/DeepSeek-Coder-V2-Lite-Instruct", trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained("deepseek-ai/DeepSeek-Coder-V2-Lite-Instruct", trust_remote_code=True, torch_dtype=torch.bfloat16).cuda()
messages=[
{ 'role': 'user', 'content': "write a quick sort algorithm in python."}
]
inputs = tokenizer.apply_chat_template(messages, add_generation_prompt=True, return_tensors="pt").to(model.device)
# tokenizer.eos_token_id is the id of <|EOT|> token
outputs = model.generate(inputs, max_new_tokens=512, do_sample=False, top_k=50, top_p=0.95, num_return_sequences=1, eos_token_id=tokenizer.eos_token_id)
print(tokenizer.decode(outputs[0][len(inputs[0]):], skip_special_tokens=True))
```
The complete chat template can be found within `tokenizer_config.json` located in the huggingface model repository.
An example of chat template is as belows:
```bash
<|begin▁of▁sentence|>User: {user_message_1}
Assistant: {assistant_message_1}<|end▁of▁sentence|>User: {user_message_2}
Assistant:
```
You can also add an optional system message:
```bash
<|begin▁of▁sentence|>{system_message}
User: {user_message_1}
Assistant: {assistant_message_1}<|end▁of▁sentence|>User: {user_message_2}
Assistant:
```
### Inference with vLLM (recommended)
To utilize [vLLM](https://github.com/vllm-project/vllm) for model inference, please merge this Pull Request into your vLLM codebase: https://github.com/vllm-project/vllm/pull/4650.
```python
from transformers import AutoTokenizer
from vllm import LLM, SamplingParams
max_model_len, tp_size = 8192, 1
model_name = "deepseek-ai/DeepSeek-Coder-V2-Lite-Instruct"
tokenizer = AutoTokenizer.from_pretrained(model_name)
llm = LLM(model=model_name, tensor_parallel_size=tp_size, max_model_len=max_model_len, trust_remote_code=True, enforce_eager=True)
sampling_params = SamplingParams(temperature=0.3, max_tokens=256, stop_token_ids=[tokenizer.eos_token_id])
messages_list = [
[{"role": "user", "content": "Who are you?"}],
[{"role": "user", "content": "write a quick sort algorithm in python."}],
[{"role": "user", "content": "Write a piece of quicksort code in C++."}],
]
prompt_token_ids = [tokenizer.apply_chat_template(messages, add_generation_prompt=True) for messages in messages_list]
outputs = llm.generate(prompt_token_ids=prompt_token_ids, sampling_params=sampling_params)
generated_text = [output.outputs[0].text for output in outputs]
print(generated_text)
```
## 6. License
This code repository is licensed under [the MIT License](https://github.com/deepseek-ai/DeepSeek-Coder-V2/blob/main/LICENSE-CODE). The use of DeepSeek-Coder-V2 Base/Instruct models is subject to [the Model License](https://github.com/deepseek-ai/DeepSeek-Coder-V2/blob/main/LICENSE-MODEL). DeepSeek-Coder-V2 series (including Base and Instruct) supports commercial use.
## 7. Original Model Contact
If you have any questions, please raise an issue or contact us at [[email protected]]([email protected]). |
BridgeTower/bridgetower-base-itm-mlm | BridgeTower | 2023-01-27T02:12:53Z | 3,078 | 3 | transformers | [
"transformers",
"pytorch",
"bridgetower",
"en",
"dataset:conceptual_captions",
"dataset:sbu_captions",
"dataset:visual_genome",
"dataset:mscoco_captions",
"arxiv:2206.08657",
"arxiv:1504.00325",
"license:mit",
"endpoints_compatible",
"region:us"
] | null | 2022-12-08T00:36:43Z | ---
language: en
tags:
- bridgetower
license: mit
datasets:
- conceptual_captions
- sbu_captions
- visual_genome
- mscoco_captions
---
# BridgeTower base-itm-mlm model
The BridgeTower model was proposed in "BridgeTower: Building Bridges Between Encoders in Vision-Language Representative Learning" by Xiao Xu, Chenfei Wu, Shachar Rosenman, Vasudev Lal, Wanxiang Che, Nan Duan.
The model was pretrained on English language using masked language modeling (MLM) and image text matching (ITM)objectives. It was introduced in
[this paper](https://arxiv.org/pdf/2206.08657.pdf) and first released in
[this repository](https://github.com/microsoft/BridgeTower).
BridgeTower got accepted to [AAAI'23](https://aaai.org/Conferences/AAAI-23/).
## Model description
The abstract from the paper is the following:
Vision-Language (VL) models with the Two-Tower architecture have dominated visual-language representation learning in recent years. Current VL models either use lightweight uni-modal encoders and learn to extract, align and fuse both modalities simultaneously in a deep cross-modal encoder, or feed the last-layer uni-modal representations from the deep pre-trained uni-modal encoders into the top cross-modal encoder. Both approaches potentially restrict vision-language representation learning and limit model performance. In this paper, we propose BridgeTower, which introduces multiple bridge layers that build a connection between the top layers of uni-modal encoders and each layer of the cross-modal encoder. This enables effective bottom-up cross-modal alignment and fusion between visual and textual representations of different semantic levels of pre-trained uni-modal encoders in the cross-modal encoder. Pre-trained with only 4M images, BridgeTower achieves state-of-the-art performance on various downstream vision-language tasks. In particular, on the VQAv2 test-std set, BridgeTower achieves an accuracy of 78.73%, outperforming the previous state-of-the-art model METER by 1.09% with the same pre-training data and almost negligible additional parameters and computational costs. Notably, when further scaling the model, BridgeTower achieves an accuracy of 81.15%, surpassing models that are pre-trained on orders-of-magnitude larger datasets.
## Intended uses & limitations(TODO)
### How to use
Here is how to use this model to perform image and text matching:
```python
from transformers import BridgeTowerProcessor, BridgeTowerForImageAndTextRetrieval
import requests
from PIL import Image
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
texts = ["An image of two cats chilling on a couch", "A football player scoring a goal"]
processor = BridgeTowerProcessor.from_pretrained("BridgeTower/bridgetower-base-itm-mlm")
model = BridgeTowerForImageAndTextRetrieval.from_pretrained("BridgeTower/bridgetower-base-itm-mlm")
# forward pass
scores = dict()
for text in texts:
# prepare inputs
encoding = processor(image, text, return_tensors="pt")
outputs = model(**encoding)
scores[text] = outputs.logits[0,1].item()
```
Here is how to use this model to perform masked language modeling:
```python
from transformers import BridgeTowerProcessor, BridgeTowerForMaskedLM
from PIL import Image
import requests
url = "http://images.cocodataset.org/val2017/000000360943.jpg"
image = Image.open(requests.get(url, stream=True).raw).convert("RGB")
text = "a <mask> looking out of the window"
processor = BridgeTowerProcessor.from_pretrained("BridgeTower/bridgetower-base-itm-mlm")
model = BridgeTowerForMaskedLM.from_pretrained("BridgeTower/bridgetower-base-itm-mlm")
# prepare inputs
encoding = processor(image, text, return_tensors="pt")
# forward pass
outputs = model(**encoding)
results = processor.decode(outputs.logits.argmax(dim=-1).squeeze(0).tolist())
print(results)
#.a cat looking out of the window.
```
### Limitations and bias
TODO
## Training data
The BridgeTower model was pretrained on four public image-caption datasets:
- [Conceptual Captions(CC)](https://ai.google.com/research/ConceptualCaptions/),
- [SBU Captions](https://www.cs.rice.edu/~vo9/sbucaptions/),
- [MSCOCO Captions](https://arxiv.org/pdf/1504.00325.pdf),
- [Visual Genome](https://visualgenome.org/)
The total number of unique images in the combined data is 4M.
## Training procedure
### Preprocessing
TODO
### Pretraining
The model was pre-trained for 100k steps on 8 NVIDIA A100 GPUs with a batch size of 4096.
The optimizer used was AdamW with a learning rate of 1e-5. No data augmentation was used except for center-crop. The image resolution in pre-training is set to 288 x 288.
## Evaluation results
Please refer to [Table 5](https://arxiv.org/pdf/2206.08657.pdf) for BridgeTower's performance on Image Retrieval and other downstream tasks.
### BibTeX entry and citation info
```bibtex
@article{xu2022bridge,
title={BridgeTower: Building Bridges Between Encoders in Vision-Language Representation Learning},
author={Xu, Xiao and Wu, Chenfei and Rosenman, Shachar and Lal, Vasudev and Che, Wanxiang and Duan, Nan},
journal={arXiv preprint arXiv:2206.08657},
year={2022}
}
```
|
RWKV/rwkv-4-169m-pile | RWKV | 2023-05-15T09:59:20Z | 3,078 | 7 | transformers | [
"transformers",
"pytorch",
"rwkv",
"text-generation",
"dataset:EleutherAI/pile",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-generation | 2023-05-04T13:36:31Z | ---
datasets:
- EleutherAI/pile
---

# Model card for RWKV-4 | 169M parameters trained on Pile dataset
RWKV is a project led by [Bo Peng](https://github.com/BlinkDL). Learn more about the model architecture in the blogposts from Johan Wind [here](https://johanwind.github.io/2023/03/23/rwkv_overview.html) and [here](https://johanwind.github.io/2023/03/23/rwkv_details.html). Learn more about the project by joining the [RWKV discord server](https://discordapp.com/users/468093332535640064).
# Table of contents
0. [TL;DR](#TL;DR)
1. [Model Details](#model-details)
2. [Usage](#usage)
3. [Citation](#citation)
## TL;DR
Below is the description from the [original repository](https://github.com/BlinkDL/RWKV-LM)
> RWKV is an RNN with transformer-level LLM performance. It can be directly trained like a GPT (parallelizable). It's combining the best of RNN and transformer - great performance, fast inference, saves VRAM, fast training, "infinite" ctx_len, and free sentence embedding.
## Model Details
The details of the architecture can be found on the blogpost mentioned above and the Hugging Face blogpost of the integration.
## Usage
### Convert the raw weights to the HF format
You can use the [`convert_rwkv_checkpoint_to_hf.py`](https://github.com/huggingface/transformers/tree/main/src/transformers/models/rwkv/convert_rwkv_checkpoint_to_hf.py) script by specifying the repo_id of the original weights, the filename and the output directory. You can also optionally directly push the converted model on the Hub by passing `--push_to_hub` flag and `--model_name` argument to specify where to push the converted weights.
```bash
python convert_rwkv_checkpoint_to_hf.py --repo_id RAW_HUB_REPO --checkpoint_file RAW_FILE --output_dir OUTPUT_DIR --push_to_hub --model_name dummy_user/converted-rwkv
```
### Generate text
You can use the `AutoModelForCausalLM` and `AutoTokenizer` classes to generate texts from the model. Expand the sections below to understand how to run the model in different scenarios:
### Running the model on a CPU
<details>
<summary> Click to expand </summary>
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained("RWKV/rwkv-4-169m-pile")
tokenizer = AutoTokenizer.from_pretrained("RWKV/rwkv-4-169m-pile")
prompt = "\nIn a shocking finding, scientist discovered a herd of dragons living in a remote, previously unexplored valley, in Tibet. Even more surprising to the researchers was the fact that the dragons spoke perfect Chinese."
inputs = tokenizer(prompt, return_tensors="pt")
output = model.generate(inputs["input_ids"], max_new_tokens=40)
print(tokenizer.decode(output[0].tolist(), skip_special_tokens=True))
```
### Running the model on a single GPU
<details>
<summary> Click to expand </summary>
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained("RWKV/rwkv-4-169m-pile").to(0)
tokenizer = AutoTokenizer.from_pretrained("RWKV/rwkv-4-169m-pile")
prompt = "\nIn a shocking finding, scientist discovered a herd of dragons living in a remote, previously unexplored valley, in Tibet. Even more surprising to the researchers was the fact that the dragons spoke perfect Chinese."
inputs = tokenizer(prompt, return_tensors="pt").to(0)
output = model.generate(inputs["input_ids"], max_new_tokens=40)
print(tokenizer.decode(output[0].tolist(), skip_special_tokens=True))
```
</details>
</details>
### Running the model in half-precision, on GPU
<details>
<summary> Click to expand </summary>
```python
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained("RWKV/rwkv-4-169m-pile", torch_dtype=torch.float16).to(0)
tokenizer = AutoTokenizer.from_pretrained("RWKV/rwkv-4-169m-pile")
prompt = "\nIn a shocking finding, scientist discovered a herd of dragons living in a remote, previously unexplored valley, in Tibet. Even more surprising to the researchers was the fact that the dragons spoke perfect Chinese."
inputs = tokenizer(prompt, return_tensors="pt").to(0)
output = model.generate(inputs["input_ids"], max_new_tokens=40)
print(tokenizer.decode(output[0].tolist(), skip_special_tokens=True))
```
</details>
### Running the model multiple GPUs
<details>
<summary> Click to expand </summary>
```python
# pip install accelerate
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained("RWKV/rwkv-4-169m-pile", device_map="auto")
tokenizer = AutoTokenizer.from_pretrained("RWKV/rwkv-4-169m-pile")
prompt = "\nIn a shocking finding, scientist discovered a herd of dragons living in a remote, previously unexplored valley, in Tibet. Even more surprising to the researchers was the fact that the dragons spoke perfect Chinese."
inputs = tokenizer(prompt, return_tensors="pt").to(0)
output = model.generate(inputs["input_ids"], max_new_tokens=40)
print(tokenizer.decode(output[0].tolist(), skip_special_tokens=True))
```
</details>
## Citation
If you use this model, please consider citing the original work, from the original repo [here](https://github.com/BlinkDL/ChatRWKV/) |
RichardErkhov/Sao10K_-_Stheno-Mix-L2-20B-gguf | RichardErkhov | 2024-06-02T02:34:00Z | 3,078 | 1 | null | [
"gguf",
"region:us"
] | null | 2024-06-01T23:58:49Z | Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
Stheno-Mix-L2-20B - GGUF
- Model creator: https://huggingface.co/Sao10K/
- Original model: https://huggingface.co/Sao10K/Stheno-Mix-L2-20B/
| Name | Quant method | Size |
| ---- | ---- | ---- |
| [Stheno-Mix-L2-20B.Q2_K.gguf](https://huggingface.co/RichardErkhov/Sao10K_-_Stheno-Mix-L2-20B-gguf/blob/main/Stheno-Mix-L2-20B.Q2_K.gguf) | Q2_K | 7.13GB |
| [Stheno-Mix-L2-20B.IQ3_XS.gguf](https://huggingface.co/RichardErkhov/Sao10K_-_Stheno-Mix-L2-20B-gguf/blob/main/Stheno-Mix-L2-20B.IQ3_XS.gguf) | IQ3_XS | 3.23GB |
| [Stheno-Mix-L2-20B.IQ3_S.gguf](https://huggingface.co/RichardErkhov/Sao10K_-_Stheno-Mix-L2-20B-gguf/blob/main/Stheno-Mix-L2-20B.IQ3_S.gguf) | IQ3_S | 0.93GB |
| [Stheno-Mix-L2-20B.Q3_K_S.gguf](https://huggingface.co/RichardErkhov/Sao10K_-_Stheno-Mix-L2-20B-gguf/blob/main/Stheno-Mix-L2-20B.Q3_K_S.gguf) | Q3_K_S | 8.32GB |
| [Stheno-Mix-L2-20B.IQ3_M.gguf](https://huggingface.co/RichardErkhov/Sao10K_-_Stheno-Mix-L2-20B-gguf/blob/main/Stheno-Mix-L2-20B.IQ3_M.gguf) | IQ3_M | 2.41GB |
| [Stheno-Mix-L2-20B.Q3_K.gguf](https://huggingface.co/RichardErkhov/Sao10K_-_Stheno-Mix-L2-20B-gguf/blob/main/Stheno-Mix-L2-20B.Q3_K.gguf) | Q3_K | 1.74GB |
| [Stheno-Mix-L2-20B.Q3_K_M.gguf](https://huggingface.co/RichardErkhov/Sao10K_-_Stheno-Mix-L2-20B-gguf/blob/main/Stheno-Mix-L2-20B.Q3_K_M.gguf) | Q3_K_M | 3.42GB |
| [Stheno-Mix-L2-20B.Q3_K_L.gguf](https://huggingface.co/RichardErkhov/Sao10K_-_Stheno-Mix-L2-20B-gguf/blob/main/Stheno-Mix-L2-20B.Q3_K_L.gguf) | Q3_K_L | 1.19GB |
| [Stheno-Mix-L2-20B.IQ4_XS.gguf](https://huggingface.co/RichardErkhov/Sao10K_-_Stheno-Mix-L2-20B-gguf/blob/main/Stheno-Mix-L2-20B.IQ4_XS.gguf) | IQ4_XS | 0.41GB |
| [Stheno-Mix-L2-20B.Q4_0.gguf](https://huggingface.co/RichardErkhov/Sao10K_-_Stheno-Mix-L2-20B-gguf/blob/main/Stheno-Mix-L2-20B.Q4_0.gguf) | Q4_0 | 2.27GB |
| [Stheno-Mix-L2-20B.IQ4_NL.gguf](https://huggingface.co/RichardErkhov/Sao10K_-_Stheno-Mix-L2-20B-gguf/blob/main/Stheno-Mix-L2-20B.IQ4_NL.gguf) | IQ4_NL | 10.91GB |
| [Stheno-Mix-L2-20B.Q4_K_S.gguf](https://huggingface.co/RichardErkhov/Sao10K_-_Stheno-Mix-L2-20B-gguf/blob/main/Stheno-Mix-L2-20B.Q4_K_S.gguf) | Q4_K_S | 9.38GB |
| [Stheno-Mix-L2-20B.Q4_K.gguf](https://huggingface.co/RichardErkhov/Sao10K_-_Stheno-Mix-L2-20B-gguf/blob/main/Stheno-Mix-L2-20B.Q4_K.gguf) | Q4_K | 11.59GB |
| [Stheno-Mix-L2-20B.Q4_K_M.gguf](https://huggingface.co/RichardErkhov/Sao10K_-_Stheno-Mix-L2-20B-gguf/blob/main/Stheno-Mix-L2-20B.Q4_K_M.gguf) | Q4_K_M | 5.62GB |
| [Stheno-Mix-L2-20B.Q4_1.gguf](https://huggingface.co/RichardErkhov/Sao10K_-_Stheno-Mix-L2-20B-gguf/blob/main/Stheno-Mix-L2-20B.Q4_1.gguf) | Q4_1 | 4.48GB |
| [Stheno-Mix-L2-20B.Q5_0.gguf](https://huggingface.co/RichardErkhov/Sao10K_-_Stheno-Mix-L2-20B-gguf/blob/main/Stheno-Mix-L2-20B.Q5_0.gguf) | Q5_0 | 3.62GB |
| [Stheno-Mix-L2-20B.Q5_K_S.gguf](https://huggingface.co/RichardErkhov/Sao10K_-_Stheno-Mix-L2-20B-gguf/blob/main/Stheno-Mix-L2-20B.Q5_K_S.gguf) | Q5_K_S | 2.27GB |
| [Stheno-Mix-L2-20B.Q5_K.gguf](https://huggingface.co/RichardErkhov/Sao10K_-_Stheno-Mix-L2-20B-gguf/blob/main/Stheno-Mix-L2-20B.Q5_K.gguf) | Q5_K | 0.68GB |
| [Stheno-Mix-L2-20B.Q5_K_M.gguf](https://huggingface.co/RichardErkhov/Sao10K_-_Stheno-Mix-L2-20B-gguf/blob/main/Stheno-Mix-L2-20B.Q5_K_M.gguf) | Q5_K_M | 0.32GB |
| [Stheno-Mix-L2-20B.Q5_1.gguf](https://huggingface.co/RichardErkhov/Sao10K_-_Stheno-Mix-L2-20B-gguf/blob/main/Stheno-Mix-L2-20B.Q5_1.gguf) | Q5_1 | 0.27GB |
| [Stheno-Mix-L2-20B.Q6_K.gguf](https://huggingface.co/RichardErkhov/Sao10K_-_Stheno-Mix-L2-20B-gguf/blob/main/Stheno-Mix-L2-20B.Q6_K.gguf) | Q6_K | 0.19GB |
| [Stheno-Mix-L2-20B.Q8_0.gguf](https://huggingface.co/RichardErkhov/Sao10K_-_Stheno-Mix-L2-20B-gguf/blob/main/Stheno-Mix-L2-20B.Q8_0.gguf) | Q8_0 | 0.11GB |
Original model description:
---
license: llama2
language:
- en
---
See https://huggingface.co/The-Face-Of-Goonery/Huginn-19b-prototype ?
Stheno-20B is even more stupid, uses the same technique as above, just slightly different params.
a 64-layer splice of Stheno P1 and P2.
Hey, it works... decently well.
Meme model that somehow isn't as bad as I thought.
Ty Chargoddard for mergekit.
*Stheno v2 on the way* ***soon***, *Euryale-70B progress stalled for now*, *Medusa-7B soonTM*
# [Open LLM Leaderboard Evaluation Results](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)
Detailed results can be found [here](https://huggingface.co/datasets/open-llm-leaderboard/details_Sao10K__Stheno-Mix-L2-20B)
| Metric | Value |
|-----------------------|---------------------------|
| Avg. | 45.76 |
| ARC (25-shot) | 57.76 |
| HellaSwag (10-shot) | 79.63 |
| MMLU (5-shot) | 52.51 |
| TruthfulQA (0-shot) | 51.8 |
| Winogrande (5-shot) | 68.98 |
| GSM8K (5-shot) | 0.08 |
| DROP (3-shot) | 9.53 |
|
mradermacher/NeuralKuno-7B-slerp-GGUF | mradermacher | 2024-06-16T10:30:39Z | 3,078 | 0 | transformers | [
"transformers",
"gguf",
"en",
"base_model:WesPro/NeuralKuno-7B-slerp",
"endpoints_compatible",
"region:us"
] | null | 2024-06-15T17:21:05Z | ---
base_model: WesPro/NeuralKuno-7B-slerp
language:
- en
library_name: transformers
quantized_by: mradermacher
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
static quants of https://huggingface.co/WesPro/NeuralKuno-7B-slerp
<!-- provided-files -->
weighted/imatrix quants are available at https://huggingface.co/mradermacher/NeuralKuno-7B-slerp-i1-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/NeuralKuno-7B-slerp-GGUF/resolve/main/NeuralKuno-7B-slerp.Q2_K.gguf) | Q2_K | 2.8 | |
| [GGUF](https://huggingface.co/mradermacher/NeuralKuno-7B-slerp-GGUF/resolve/main/NeuralKuno-7B-slerp.IQ3_XS.gguf) | IQ3_XS | 3.1 | |
| [GGUF](https://huggingface.co/mradermacher/NeuralKuno-7B-slerp-GGUF/resolve/main/NeuralKuno-7B-slerp.Q3_K_S.gguf) | Q3_K_S | 3.3 | |
| [GGUF](https://huggingface.co/mradermacher/NeuralKuno-7B-slerp-GGUF/resolve/main/NeuralKuno-7B-slerp.IQ3_S.gguf) | IQ3_S | 3.3 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/NeuralKuno-7B-slerp-GGUF/resolve/main/NeuralKuno-7B-slerp.IQ3_M.gguf) | IQ3_M | 3.4 | |
| [GGUF](https://huggingface.co/mradermacher/NeuralKuno-7B-slerp-GGUF/resolve/main/NeuralKuno-7B-slerp.Q3_K_M.gguf) | Q3_K_M | 3.6 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/NeuralKuno-7B-slerp-GGUF/resolve/main/NeuralKuno-7B-slerp.Q3_K_L.gguf) | Q3_K_L | 3.9 | |
| [GGUF](https://huggingface.co/mradermacher/NeuralKuno-7B-slerp-GGUF/resolve/main/NeuralKuno-7B-slerp.IQ4_XS.gguf) | IQ4_XS | 4.0 | |
| [GGUF](https://huggingface.co/mradermacher/NeuralKuno-7B-slerp-GGUF/resolve/main/NeuralKuno-7B-slerp.Q4_K_S.gguf) | Q4_K_S | 4.2 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/NeuralKuno-7B-slerp-GGUF/resolve/main/NeuralKuno-7B-slerp.Q4_K_M.gguf) | Q4_K_M | 4.5 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/NeuralKuno-7B-slerp-GGUF/resolve/main/NeuralKuno-7B-slerp.Q5_K_S.gguf) | Q5_K_S | 5.1 | |
| [GGUF](https://huggingface.co/mradermacher/NeuralKuno-7B-slerp-GGUF/resolve/main/NeuralKuno-7B-slerp.Q5_K_M.gguf) | Q5_K_M | 5.2 | |
| [GGUF](https://huggingface.co/mradermacher/NeuralKuno-7B-slerp-GGUF/resolve/main/NeuralKuno-7B-slerp.Q6_K.gguf) | Q6_K | 6.0 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/NeuralKuno-7B-slerp-GGUF/resolve/main/NeuralKuno-7B-slerp.Q8_0.gguf) | Q8_0 | 7.8 | fast, best quality |
| [GGUF](https://huggingface.co/mradermacher/NeuralKuno-7B-slerp-GGUF/resolve/main/NeuralKuno-7B-slerp.f16.gguf) | f16 | 14.6 | 16 bpw, overkill |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
Josephgflowers/TinyLlama-3T-Cinder-v1.2 | Josephgflowers | 2024-03-09T13:56:35Z | 3,076 | 3 | transformers | [
"transformers",
"safetensors",
"gguf",
"llama",
"text-generation",
"conversational",
"license:mit",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2023-12-31T15:50:08Z | ---
license: mit
widget:
- text: '<|system|>
You are a helpful assistant</s>
<|user|>
Tell me about yourself, what is your name?.</s>
<|assistant|>
'
model-index:
- name: TinyLlama-3T-Cinder-v1.1
results:
- task:
type: text-generation
name: Text Generation
dataset:
name: AI2 Reasoning Challenge (25-Shot)
type: ai2_arc
config: ARC-Challenge
split: test
args:
num_few_shot: 25
metrics:
- type: acc_norm
value: 34.04
name: normalized accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=Josephgflowers/TinyLlama-3T-Cinder-v1.1
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: HellaSwag (10-Shot)
type: hellaswag
split: validation
args:
num_few_shot: 10
metrics:
- type: acc_norm
value: 50.4
name: normalized accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=Josephgflowers/TinyLlama-3T-Cinder-v1.1
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: MMLU (5-Shot)
type: cais/mmlu
config: all
split: test
args:
num_few_shot: 5
metrics:
- type: acc
value: 25.75
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=Josephgflowers/TinyLlama-3T-Cinder-v1.1
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: TruthfulQA (0-shot)
type: truthful_qa
config: multiple_choice
split: validation
args:
num_few_shot: 0
metrics:
- type: mc2
value: 37.57
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=Josephgflowers/TinyLlama-3T-Cinder-v1.1
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: Winogrande (5-shot)
type: winogrande
config: winogrande_xl
split: validation
args:
num_few_shot: 5
metrics:
- type: acc
value: 56.43
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=Josephgflowers/TinyLlama-3T-Cinder-v1.1
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: GSM8k (5-shot)
type: gsm8k
config: main
split: test
args:
num_few_shot: 5
metrics:
- type: acc
value: 0.0
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=Josephgflowers/TinyLlama-3T-Cinder-v1.1
name: Open LLM Leaderboard
---
Model Card for Cinder
Model Name: Cinder

Created by: Joseph Flowers
***Updated 1-10-24*** New round of training, added gguf model 8bit.
Model Overview
Cinder is an AI chatbot tailored for engaging users in scientific and educational conversations, offering companionship, and sparking imaginative exploration. It is built on the TinyLlama 1.1B parameter model and trained on a unique combination of datasets.
Development Details (Still in development)
Model Architecture: TinyLlama 1.1B (based on the 3T checkpoint) https://huggingface.co/TinyLlama/TinyLlama-1.1B-intermediate-step-1431k-3T
Training Datasets:
Interactive chats with GPT-4 where I prompt GPT4 to create chats between a User and Cinder and monitor the results. A lot of Please continue, this took around a month. Note: There are also multi character chats with Vector and Cozmo robots characters, a Computer Voice character that is a narrator, as well as other characters..
A subset of Open Orca: https://huggingface.co/datasets/Open-Orca/OpenOrcatr
Q&A content generated by GPT-3.5 Turbo by having it read open source encyclopedias and create QA pairs.
Shortened version of Samantha by Eric Hartford https://huggingface.co/datasets/cognitivecomputations/samantha-data
OpenAssistant: https://huggingface.co/datasets/OpenAssistant/oasst_top1_2023-08-25
***Updated 1-10-24*** Continued training with sorted Orca dataset to around 600mb for STEM related topics, generated around 100mb of STEM q and a with GPT3.5 and GPT4,
a chunk of Samantha dataset, Glaive function calling v2, and python code instruction 18k alpaca dataset, around 1GB total.
Core Influences: Inspired by the character 'Data' from Star Trek: The Next Generation, Lewis Carroll's writings, and a range of educational resources.
Key Features
Inquisitive Scientist: Cinder shows a passion for space and STEM topics.
Quirky Educator: It makes complex concepts engaging and accessible.
Empathetic Companion: Cinder is designed to demonstrate understanding and emotional depth.
Adventurous Spacefarer: Cinder leads imaginative space adventures.
Static yet Sophisticated: While Cinder does not learn or adapt with each interaction, its design encompasses a breadth of knowledge and perspectives.
Intended Use
Educational Tool: Enhances STEM learning across different age groups.
Companion: Provides meaningful and empathetic dialogues.
Creative Guide: Facilitates imaginative exploration in scientific contexts.
Ethical Considerations
We emphasize ethical AI practices and the privacy of users. Cinder's development includes measures against misuse and ensures respectful, secure interactions.
Limitations
Cinder's responses are fixed and do not adapt or learn from individual interactions.
The empathetic responses generated are algorithmic and not a substitute for human empathy.
Future Enhancements and Collaboration
I am actively seeking feedback, suggestions, or additional datasets to enhance Cinder's capabilities.
Future updates may include more interactive educational modules and advanced empathetic response algorithms.
I encourage collaboration and contributions to expand Cinder's educational and creative reach.
If you have any suggestions or requests please leave them in the newly created discord channel.
https://discord.gg/5ebjDrnZ
# [Open LLM Leaderboard Evaluation Results](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)
Detailed results can be found [here](https://huggingface.co/datasets/open-llm-leaderboard/details_Josephgflowers__TinyLlama-3T-Cinder-v1.1)
| Metric |Value|
|---------------------------------|----:|
|Avg. |34.03|
|AI2 Reasoning Challenge (25-Shot)|34.04|
|HellaSwag (10-Shot) |50.40|
|MMLU (5-Shot) |25.75|
|TruthfulQA (0-shot) |37.57|
|Winogrande (5-shot) |56.43|
|GSM8k (5-shot) | 0.00|
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.