
index
int64 0
0
| repo_id
stringclasses 179
values | file_path
stringlengths 26
186
| content
stringlengths 1
2.1M
| __index_level_0__
int64 0
9
|
|---|---|---|---|---|
0 | hf_public_repos/audio-transformers-course/chapters/tr | hf_public_repos/audio-transformers-course/chapters/tr/chapter1/supplemental_reading.mdx | # Daha fazla öğren
Bu ünite, ses verisinin anlaşılması ve üzerinde çalışılması ile ilgili birçok temel kavramı kapsadı. Daha fazla öğrenmek mi istiyorsunuz? İşte konuları daha derinlemesine anlamanıza ve öğrenme deneyiminizi geliştirmenize yardımcı olacak ek kaynaklar bulabileceğiniz yer.
Aşağıdaki videoda, xiph.org'dan Monty Montgomery, gerçek ses ekipmanı kullanarak örnekleme, nicemleme, bit derinliği ve dither konularında modern dijital analiz ve eski analog laboratuvar ekipmanı kullanarak gerçek zamanlı gösterimler sunuyor. İzlemek isterseniz aşağıdaki bağlantıya tıklayabilirsiniz:
<Youtube id="cIQ9IXSUzuM"/>
Dijital sinyal işleme konusunda daha derinlemesine bilgi edinmek isterseniz, New York Üniversitesi Müzik Teknolojisi ve Veri Bilimi Yardımcı Profesörü ve librosa paketinin başlıca sürdürücüsü olan Brian McFee tarafından yazılmış ücretsiz [Digital Signals Theory](https://brianmcfee.net/dstbook-site/content/intro.html) kitabını incelemenizi öneririm.
| 0 |
0 | hf_public_repos/audio-transformers-course/chapters/tr | hf_public_repos/audio-transformers-course/chapters/tr/chapter1/preprocessing.mdx | # Ses veri kümesini ön işleme
🤗 Veri Kümeleri ile bir veri kümesi yüklemek eğlencenin sadece yarısıdır. Bir modeli eğitmek veya çalıştırmak için kullanmayı planlıyorsanız
Çıkarım yapmak için öncelikle verileri önceden işlemeniz gerekecektir. Genel olarak bu, aşağıdaki adımları içerecektir:
* Ses verilerinin yeniden örneklenmesi
* Veri kümesini filtreleme
* Ses verilerini modelin beklenen girişine dönüştürme
## Ses verilerini yeniden örnekleme
load_dataset işlevi, ses örneklerini indirirken, bu örneklerin yayınlandığı örnekleme hızını kullanır. Bu, eğitmeyi veya çıkarmayı planladığınız modelin beklediği örnekleme hızı ile her zaman uyuşmaz. Örnekleme hızları arasında bir uyumsuzluk varsa, sesi modelin beklediği örnekleme hızına yeniden örnekleyebilirsiniz.
Çoğu önceden eğitilmiş model, ses veri kümelerinde 16 kHz örnekleme hızında önceden eğitildi. MINDS-14 veri kümesini keşfettiğinizde, bu verinin 8 kHz örnekleme hızında olduğunu görmüş olabilirsiniz, bu da muhtemelen bunu yükseltmemiz gerekeceği anlamına gelir.
Bunu yapmak için, 🤗 Datasets'ın cast_column yöntemini kullanabilirsiniz. Bu işlem sesi yerinde değiştirmez, ancak veri kümesine ses örneklerini yüklerken on-the-fly olarak örnekleme yapması gerektiğini belirtir. Aşağıdaki kod, örnekleme hızını 16 kHz olarak ayarlayacaktır:
```py
from datasets import Audio
minds = minds.cast_column("audio", Audio(sampling_rate=16_000))
```
MINDS-14 veri kümesindeki ilk ses örneğini yeniden yükleyin ve istenen "örnekleme hızına" yeniden örneklendiğini kontrol edin:
```py
minds[0]
```
**Çıktı:**
```out
{
"path": "/root/.cache/huggingface/datasets/downloads/extracted/f14948e0e84be638dd7943ac36518a4cf3324e8b7aa331c5ab11541518e9368c/en-AU~PAY_BILL/response_4.wav",
"audio": {
"path": "/root/.cache/huggingface/datasets/downloads/extracted/f14948e0e84be638dd7943ac36518a4cf3324e8b7aa331c5ab11541518e9368c/en-AU~PAY_BILL/response_4.wav",
"array": array(
[
2.0634243e-05,
1.9437837e-04,
2.2419340e-04,
...,
9.3852862e-04,
1.1302452e-03,
7.1531429e-04,
],
dtype=float32,
),
"sampling_rate": 16000,
},
"transcription": "I would like to pay my electricity bill using my card can you please assist",
"intent_class": 13,
}
```
Dizi değerlerinin de artık farklı olduğunu fark edebilirsiniz. Bunun nedeni artık iki kat daha fazla genlik değerine sahip olmamızdır.
daha önce sahip olduğumuz her biri.
<Tip>
💡 Örnekleme hakkında bazı temel bilgiler: Bir ses sinyali 8 kHz'de örneklenmişse, yani saniyede 8000 örnek okuma alıyorsak, sesin 4 kHz'nin üzerinde herhangi bir frekanseyi içermediğini biliyoruz. Bu, Nyquist örnekleme teoremi tarafından garanti edilir. Bu nedenle, örnekleme noktaları arasında, orijinal sürekli sinyalin her zaman düzgün bir eğri oluşturduğundan emin olabiliriz. Örnekleme hızını daha yüksek bir örnekleme hızına yükseltmek, bu eğriyi yaklaşıklayarak mevcut olanların arasına ek örnek değerlerini hesaplamakla ilgilidir. Bununla birlikte, örnekleme hızını düşürmek, önce yeni Nyquist sınırından daha yüksek frekanstaki herhangi bir frekansı filtrelemeyi gerektirir, ardından yeni örnek noktalarını tahmin etmeden önce. Yani, örnekleme hızını 2x faktörüyle sadece her diğer örneği atarak düşüremezsiniz - bu, sinyalde bozulmalara yol açan aliaslar adı verilen bozulmaları oluşturur. Örnekleme işlemini doğru bir şekilde yapmak karmaşıktır ve en iyi test edilmiş kütüphanelere, örneğin librosa veya 🤗 Datasets gibi kütüphanelere bırakılmalıdır.
</Tip>
## Veri kümesini filtreleme
Verileri bazı kriterlere göre filtrelemeniz gerekebilir. Yaygın durumlardan biri, ses örneklerinin belirli bir
Belirli süre. Örneğin, yetersiz bellek hatalarını önlemek için 20 saniyeden uzun örnekleri filtrelemek isteyebiliriz.
Bir modeli eğitirken.
Bunu 🤗 Datasets'in `filter` metodunu kullanarak ve ona filtreleme mantığı olan bir fonksiyon geçirerek yapabiliriz. Bir tane yazarak başlayalım
Hangi örneklerin saklanacağını ve hangilerinin atılacağını gösteren işlev. Bu işlev, "ses_uzunluğu_aralığındadır",
Örnek 20 saniyeden kısaysa "Doğru"yu, 20 saniyeden uzunsa "Yanlış"ı döndürür.
```py
MAX_DURATION_IN_SECONDS = 20.0
def is_audio_length_in_range(input_length):
return input_length < MAX_DURATION_IN_SECONDS
```
Filtreleme işlevi bir veri kümesinin sütununa uygulanabilir ancak bunda ses izleme süresine sahip bir sütunumuz yoktur.
veri kümesi. Ancak bir tane oluşturabilir, o sütundaki değerlere göre filtreleyebilir ve ardından kaldırabiliriz.
```py
# ses dosyasından örneğin süresini almak için librosa'yı kullanalım
new_column = [librosa.get_duration(path=x) for x in minds["path"]]
minds = minds.add_column("duration", new_column)
# filtreleme işlevini uygulamak için 🤗 Veri Kümelerinin "filtre" yöntemini kullanın
minds = minds.filter(is_audio_length_in_range, input_columns=["duration"])
# geçici yardımcı sütunu kaldırın
minds = minds.remove_columns(["duration"])
minds
```
**Çıktı:**
```out
Dataset({features: ["path", "audio", "transcription", "intent_class"], num_rows: 624})
```
Veri kümesinin 654 örnekten 624'e filtrelendiğini doğrulayabiliriz.
## Ses verilerinin ön işlenmesi
Ses veri kümeleriyle çalışmanın en zorlayıcı yönlerinden biri, veriyi model eğitimi için doğru formatta hazırlamaktır. Gördüğünüz gibi, ham ses verileri örnek değerlerinin bir dizisi olarak gelir. Ancak, kullanıyorsanız, çıkarım için kullanıyor olsanız veya göreviniz için ince ayar yapmak istiyorsanız, önceden eğitilmiş modeller, ham verilerin giriş özelliklerine dönüştürülmesini bekler. Giriş özellikleri için gereksinimler bir modelden diğerine değişebilir - bunlar modelin mimarisine ve önceden eğitildiği verilere bağlıdır. İyi haber şu ki, her desteklenen ses modeli için 🤗 Transformers, ham ses verilerini modelin beklediği giriş özelliklerine dönüştürebilen bir özellik çıkarıcı sınıfı sunar.
Peki özellik çıkarıcı ham ses verileriyle ne yapar? Şimdi [Whisper](https://huggingface.co/papers/2212.04356)'ın fotoğraflarına bir göz atalım
Bazı ortak özellik çıkarma dönüşümlerini anlamak için özellik çıkarıcı. Whisper, önceden eğitilmiş bir modeldir.
Alec Radford ve diğerleri tarafından Eylül 2022'de yayınlanan otomatik konuşma tanıma (ASR). OpenAI'den.
İlk olarak, Whisper özellik çıkarıcısı bir ses örneklerinin yığınını, tüm örneklerin 30 saniyelik bir giriş uzunluğuna sahip olduğu şekilde doldurur/keser. Bu süreden daha kısa olan örnekler, sıfırları dizinin sonuna ekleyerek 30 saniyeye kadar doldurulur (bir ses sinyalindeki sıfırlar, hiç sinyal veya sessizlikle karşılık gelir). 30 saniyeden daha uzun olan örnekler 30 saniyeye kadar kesilir. Yığındaki tüm öğeler giriş uzayındaki maksimum uzunluğa doldurulduğu/kesildiği için bir dikkat maskesine ihtiyaç yoktur. Whisper bu açıdan benzersizdir, diğer çoğu ses modelleri, dizilerin nerede doldurulduğunu ayrıntılı olarak belirten ve bu nedenle öz-dikkat mekanizmasında nerede görmezden gelinmesi gerektiğini belirten bir dikkat maskesi gerektirir. Whisper, bir dikkat maskesi olmadan çalışacak şekilde eğitilmiştir ve girişleri nerede göz ardı edeceğini doğrudan konuşma sinyallerinden çıkarır.
Whisper özellik çıkarıcısının gerçekleştirdiği ikinci işlem, doldurulmuş ses dizilerini log-mel spektrogramlarına dönüştürmektir. Hatırlarsanız, bu spektrogramlar bir sinyalin frekanslarının zaman içinde nasıl değiştiğini, mel ölçeğinde ifade edilmiş ve insan işitmesini daha iyi temsil etmek için decibel cinsinden ölçülmüş şekilde açıklar (log kısmı).
Tüm bu dönüşümler birkaç satır kodla ham ses verilerinize uygulanabilir. Devam edelim ve yükleyelim
ses verilerimize hazır olmak için önceden eğitilmiş Whisper kontrol noktasından özellik çıkarıcı:
```py
from transformers import WhisperFeatureExtractor
feature_extractor = WhisperFeatureExtractor.from_pretrained("openai/whisper-small")
```
Daha sonra, tek bir ses örneğini "feature_extractor"dan geçirerek ön işleme tabi tutacak bir işlev yazabilirsiniz.
```py
def prepare_dataset(example):
audio = example["audio"]
features = feature_extractor(
audio["array"], sampling_rate=audio["sampling_rate"], padding=True
)
return features
```
Veri hazırlama fonksiyonunu tüm eğitim örneklerimize 🤗 Datasets'in harita yöntemini kullanarak uygulayabiliriz:
```py
minds = minds.map(prepare_dataset)
minds
```
**Çıktı:**
```out
Dataset(
{
features: ["path", "audio", "transcription", "intent_class", "input_features"],
num_rows: 624,
}
)
```
Bu kadar kolay, artık veri kümesinde 'giriş_özellikleri' olarak log-mel spektrogramlarımız var.
Bunu 'minds' veri kümesindeki örneklerden biri için görselleştirelim:
```py
import numpy as np
example = minds[0]
input_features = example["input_features"]
plt.figure().set_figwidth(12)
librosa.display.specshow(
np.asarray(input_features[0]),
x_axis="time",
y_axis="mel",
sr=feature_extractor.sampling_rate,
hop_length=feature_extractor.hop_length,
)
plt.colorbar()
```
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface-course/audio-course-images/resolve/main/log_mel_whisper.png" alt="Log mel spectrogram plot">
</div>
Artık Whisper modelindeki ses girişinin ön işlemeden sonra nasıl göründüğünü görebilirsiniz.
Modelin özellik çıkarıcı sınıfı, ham ses verilerinin modelin beklediği formata dönüştürülmesiyle ilgilenir. Fakat,
ses içeren birçok görev çok modludur; Konuşma tanıma. Bu gibi durumlarda 🤗 Transformers modele özel olarak da hizmet vermektedir.
metin girişlerini işlemek için belirteçler. Tokenizer'lara ilişkin derinlemesine bilgi edinmek için lütfen [NLP kursumuza](https://huggingface.co/course/chapter2/4) bakın.
Whisper ve diğer multimodal modeller için özellik çıkarıcıyı ve tokenizer'ı ayrı ayrı yükleyebilir veya her ikisini de
sözde işlemci. İşleri daha da kolaylaştırmak için, bir modelin özellik çıkarıcısını ve işlemcisini bir bilgisayardan yüklemek için 'Otomatik İşlemci'yi kullanın.
kontrol noktası şöyle:
```py
from transformers import AutoProcessor
processor = AutoProcessor.from_pretrained("openai/whisper-small")
```
Burada temel veri hazırlama adımlarını gösterdik. Elbette özel veriler daha karmaşık ön işleme gerektirebilir.
Bu durumda, herhangi bir özel veri dönüşümü gerçekleştirmek için `prepare_dataset` fonksiyonunu genişletebilirsiniz. 🤗 Veri Kümeleri ile,
bunu bir Python işlevi olarak yazabiliyorsanız veri kümenize [uygulayabilirsiniz](https://huggingface.co/docs/datasets/audio_process)!!
| 1 |
0 | hf_public_repos/audio-transformers-course/chapters/tr | hf_public_repos/audio-transformers-course/chapters/tr/chapter1/streaming.mdx | # Ses verileri akışı
Ses veri kümelerinde karşılaşılan en büyük zorluklardan biri boyutlarıdır. Tek bir dakikalık sıkıştırılmamış CD kalitesinde ses (44,1 kHz, 16 bit)
5 MB'tan biraz daha fazla depolama alanı kaplıyor. Tipik olarak bir ses veri kümesi saatlerce kayıt içerir.
Önceki bölümlerde MINDS-14 ses veri kümesinin çok küçük bir alt kümesini kullandık, ancak tipik ses veri kümeleri çok daha büyüktür.
Örneğin, [SpeechColab'dan GigaSpeech](https://huggingface.co/datasets/speechcolab/gigaspeech)'in "xs" (en küçük) yapılandırması
yalnızca 10 saatlik eğitim verisi içerir ancak indirme ve hazırlık için 13 GB'ın üzerinde depolama alanı kaplar. Ne olmuş
Daha büyük bir split üzerinde antrenman yapmak istediğimizde ne olur? Aynı veri kümesinin tam 'xl' yapılandırması 10.000 saatlik veri içerir.
1 TB'tan fazla depolama alanı gerektiren eğitim verileri. Çoğumuz için bu, tipik bir cihazın özelliklerini fazlasıyla aşıyor.
sabit sürücü diski. Ek depolama alanı ayırmamız ve satın almamız gerekiyor mu? Veya bu veri kümeleri üzerinde disk alanı kısıtlaması olmadan eğitim almamızın bir yolu var mı?
🤗 Veri kümeleri, [akış modunu](https://huggingface.co/docs/datasets/stream) sunarak imdada yetişiyor. Akış, verileri aşamalı olarak yüklememize olanak tanır
veri kümesi üzerinde yineleme yapıyoruz. Veri setinin tamamını bir kerede indirmek yerine, veri setini tek seferde bir örnek olarak yüklüyoruz.
Veri kümesi üzerinde yinelemeler yapıyoruz, gerektiğinde örnekleri anında yüklüyor ve hazırlıyoruz. Bu şekilde, biz sadece
Kullandığımız örnekleri yükleyin, kullanmadıklarımızı değil!
Örnek bir örnekle işimiz bittiğinde, veri kümesi üzerinde yinelemeye devam ediyoruz ve bir sonrakini yüklüyoruz.
Akış modunun tüm veri kümesini aynı anda indirmeye kıyasla üç temel avantajı vardır:
* Disk alanı: Biz veri kümesi üzerinde yineledikçe örnekler belleğe tek tek yüklenir. Veriler indirilmediğinden
yerel olarak herhangi bir disk alanı gereksinimi yoktur, dolayısıyla isteğe bağlı boyuttaki veri kümelerini kullanabilirsiniz.
* İndirme ve işleme süresi: Ses veri kümeleri büyüktür ve indirilip işlenmesi önemli miktarda zaman gerektirir.
Akış ile yükleme ve işleme anında yapılır; bu, veri kümesini ilk kez kullanmaya başlayabileceğiniz anlamına gelir
örnek hazır.
* Kolay deneme: Komut dosyanızın çalışıp çalışmadığını kontrol etmek için birkaç örnek üzerinde denemeler yapabilirsiniz.
tüm veri kümesini indir.
Streaming modunun bir kısıtlaması bulunmaktadır. Akış olmadan tam bir veri kümesi indirildiğinde, hem ham veri hem de işlenmiş veri yerel diskte kaydedilir. Bu veri kümesini yeniden kullanmak istediğimizde, işlenmiş veriyi doğrudan diskin üzerinden yükleyebiliriz, indirme ve işleme adımlarını atlayarak. Sonuç olarak, indirme ve işleme işlemlerini yalnızca bir kez yapmamız yeterlidir, ardından hazırlanan veriyi yeniden kullanabiliriz.
Akış modunda veriler diske indirilmez. Böylece ne indirilen ne de önceden işlenmiş veriler önbelleğe alınmaz.
Veri kümesini yeniden kullanmak istiyorsak, ses dosyaları yüklenip işlenerek akış adımlarının tekrarlanması gerekir.
yine sinek. Bu nedenle birden çok kez kullanmanız muhtemel veri setlerini indirmeniz tavsiye edilir.
Akış modunu nasıl etkinleştirebilirsiniz? Çok kolay! Veri kümenizi yüklerken streaming=True olarak ayarlayın. Gerisi sizin için otomatik olarak halledilecektir:
```py
gigaspeech = load_dataset("speechcolab/gigaspeech", "xs", streaming=True)
```
Tıpkı MINDS-14'ün indirilen bir alt kümesine ön işleme adımlarını uyguladığımız gibi, aynı ön işlemeyi bir alt kümeyle de yapabilirsiniz.
veri kümesini tam olarak aynı şekilde aktarır.
Tek fark, Python indeksi kullanarak artık bireysel örneklerine erişemeyeceğinizdir (örneğin gigaspeech["train"][örnek_idx]). Bunun yerine, veri kümesi üzerinde döngü kullanmanız gerekecektir. Bir veri kümesine akış yaparken bir örneğe nasıl erişebileceğinizi aşağıda gösteriliyor:
```py
next(iter(gigaspeech["train"]))
```
**Çıktı:**
```out
{
"segment_id": "YOU0000000315_S0000660",
"speaker": "N/A",
"text": "AS THEY'RE LEAVING <COMMA> CAN KASH PULL ZAHRA ASIDE REALLY QUICKLY <QUESTIONMARK>",
"audio": {
"path": "xs_chunks_0000/YOU0000000315_S0000660.wav",
"array": array(
[0.0005188, 0.00085449, 0.00012207, ..., 0.00125122, 0.00076294, 0.00036621]
),
"sampling_rate": 16000,
},
"begin_time": 2941.89,
"end_time": 2945.07,
"audio_id": "YOU0000000315",
"title": "Return to Vasselheim | Critical Role: VOX MACHINA | Episode 43",
"url": "https://www.youtube.com/watch?v=zr2n1fLVasU",
"source": 2,
"category": 24,
"original_full_path": "audio/youtube/P0004/YOU0000000315.opus",
}
```
Büyük bir veri kümesinden birkaç örneği önizlemek isterseniz, ilk n öğeyi almak için take() işlevini kullanabilirsiniz. Şimdi, gigaspeech veri kümesinden ilk iki örneği alalım:
```py
gigaspeech_head = gigaspeech["train"].take(2)
list(gigaspeech_head)
```
**Çıktı:**
```out
[
{
"segment_id": "YOU0000000315_S0000660",
"speaker": "N/A",
"text": "AS THEY'RE LEAVING <COMMA> CAN KASH PULL ZAHRA ASIDE REALLY QUICKLY <QUESTIONMARK>",
"audio": {
"path": "xs_chunks_0000/YOU0000000315_S0000660.wav",
"array": array(
[
0.0005188,
0.00085449,
0.00012207,
...,
0.00125122,
0.00076294,
0.00036621,
]
),
"sampling_rate": 16000,
},
"begin_time": 2941.89,
"end_time": 2945.07,
"audio_id": "YOU0000000315",
"title": "Return to Vasselheim | Critical Role: VOX MACHINA | Episode 43",
"url": "https://www.youtube.com/watch?v=zr2n1fLVasU",
"source": 2,
"category": 24,
"original_full_path": "audio/youtube/P0004/YOU0000000315.opus",
},
{
"segment_id": "AUD0000001043_S0000775",
"speaker": "N/A",
"text": "SIX TOMATOES <PERIOD>",
"audio": {
"path": "xs_chunks_0000/AUD0000001043_S0000775.wav",
"array": array(
[
1.43432617e-03,
1.37329102e-03,
1.31225586e-03,
...,
-6.10351562e-05,
-1.22070312e-04,
-1.83105469e-04,
]
),
"sampling_rate": 16000,
},
"begin_time": 3673.96,
"end_time": 3675.26,
"audio_id": "AUD0000001043",
"title": "Asteroid of Fear",
"url": "http//www.archive.org/download/asteroid_of_fear_1012_librivox/asteroid_of_fear_1012_librivox_64kb_mp3.zip",
"source": 0,
"category": 28,
"original_full_path": "audio/audiobook/P0011/AUD0000001043.opus",
},
]
```
Akış modu, araştırmanızı bir üst seviyeye taşıyabilir: Sadece en büyük veri kümelerine erişim sağlamakla kalmaz, aynı zamanda disk alanınızı düşünmeden birden fazla veri kümesi üzerinde sistemleri kolayca değerlendirebilirsiniz. Tek bir veri kümesinde değerlendirmekle karşılaştırıldığında, çoklu veri kümesi değerlendirmesi, bir konuşma tanıma sisteminin genelleme yetenekleri için daha iyi bir ölçüm sağlar (bkz. End-to-end Speech Benchmark - ESB).
| 2 |
0 | hf_public_repos/audio-transformers-course/chapters/tr | hf_public_repos/audio-transformers-course/chapters/tr/chapter1/quiz.mdx | <!-- DISABLE-FRONTMATTER-SECTIONS -->
# Kurs materyalini anladığınızı kontrol edin
### 1. Örnekleme hızı hangi birimlerle ölçülür?
<Question
choices={[
{
text: "dB",
explain: "Hayır, genlik desibel (dB) cinsinden ölçülür."
},
{
text: "Hz",
explain: "Örnekleme hızı, bir saniyede alınan örnek sayısıdır ve hertz (Hz) cinsinden ölçülür.",
correct: true
},
{
text: "bit",
explain: "Bitler, bir ses sinyalinin her örneğini temsil etmek için kullanılan bilgi bitlerinin sayısını ifade eden bit derinliğini tanımlamak için kullanılır.",
}
]}
/>
### 2. Büyük bir ses veri kümesini aktarırken, onu ne kadar sürede kullanmaya başlayabilirsiniz?
<Question
choices={[
{
text: "Veri kümesinin tamamı indirilir indirilmez.",
explain: "Veri akışının amacı, bir veri kümesini tamamen indirmeye gerek kalmadan verilerle çalışabilmektir."
},
{
text: "16 örnek indirilir indirilmez",
explain: "Tekrar Dene!"
},
{
text: "İlk örnek indirildiği anda.",
explain: "",
correct: true
}
]}
/>
### 3. Spektrogram nedir?
<Question
choices={[
{
text: "İlk olarak bir mikrofon tarafından yakalanan sesi dijitalleştiren bir cihaz, ses dalgalarını elektriksel bir sinyale dönüştürür.",
explain: "Böyle bir elektriksel sinyali dijitalleştirmek için kullanılan bir cihaza Analog-Dijital Dönüştürücü denir. Tekrar deneyin!"
},
{
text: "Ses sinyalinin zaman içindeki genlik değişimini gösteren bir grafik. Ayrıca sesin zaman *etki alanı* temsili olarak da bilinir.",
explain: "Yukarıdaki açıklama spektrograma değil dalga formuna atıfta bulunmaktadır."
},
{
text: "Zamanla değişen bir sinyalin frekans spektrumunun görsel temsili.",
explain: "",
correct: true
}
]}
/>
### 4. Ham ses verilerini Whisper'ın beklediği log-mel spektrogramına dönüştürmenin en kolay yolu nedir?
A.
```python
librosa.feature.melspectrogram(audio["array"])
```
B.
```python
feature_extractor = WhisperFeatureExtractor.from_pretrained("openai/whisper-small")
feature_extractor(audio["array"])
```
C.
```python
dataset.feature(audio["array"], model="whisper")
```
<Question
choices={[
{
text: "A",
explain: "`librosa.feature.melspectrogram()` bir güç spektrogramı oluşturur."
},
{
text: "B",
explain: "",
correct: true
},
{
text: "C",
explain: "Dataset, Transformer modelleri için özellik hazırlamaz, bu işlem modelin ön işlemcisi tarafından yapılır."
}
]}
/>
### 5. 🤗 Hub'dan veri kümesini nasıl yüklersiniz?
A.
```python
from datasets import load_dataset
dataset = load_dataset(DATASET_NAME_ON_HUB)
```
B.
```python
import librosa
dataset = librosa.load(PATH_TO_DATASET)
```
C.
```python
from transformers import load_dataset
dataset = load_dataset(DATASET_NAME_ON_HUB)
```
<Question
choices={[
{
text: "A",
explain: "En iyi yol 🤗 Veri Kümeleri kütüphanesini kullanmaktır.",
correct: true
},
{
text: "B",
explain: "Librosa.load, tek bir ses dosyasını bir yoldan ses zaman serisi ve örnekleme hızına sahip bir tuple'a yüklemek için kullanışlıdır, ancak birçok örnek ve çoklu özellik içeren tüm veri kümesini yüklemez."
},
{
text: "C",
explain: "load_dataset yöntemi 🤗 Transformers'ta değil, 🤗 Veri Kümeleri kitaplığında gelir."
}
]}
/>
### 6. Özel veri kümeniz 32 kHz örnekleme hızına sahip yüksek kaliteli ses içerir. Ses örneklerinin 16 kHz örnekleme hızına sahip olmasını bekleyen bir konuşma tanıma modeli eğitmek istiyorsunuz. Ne yapmalısın?
<Question
choices={[
{
text: "Örnekleri olduğu gibi kullanın; model kolaylıkla daha yüksek kaliteli ses örneklerine genelleştirilecektir.",
explain: "Dikkat mekanizmalarına dayanılması nedeniyle modellerin örnekleme oranları arasında genelleme yapması zordur."
},
{
text: "Özel veri kümesindeki örnekleri alt örneklemek için 🤗 Veri Kümeleri kitaplığından Ses modülünü kullanın",
explain: "",
correct: true
},
{
text: "Diğer tüm numuneleri atarak 2 kat alt numune alın.",
explain: "Bu, takma ad adı verilen sinyalde bozulmalar yaratacaktır. Yeniden örneklemeyi doğru bir şekilde yapmak zordur ve en iyisi librosa veya 🤗 Veri Kümeleri gibi iyi test edilmiş kitaplıklara bırakılmasıdır."
}
]}
/>
### 7. Makine öğrenimi modeli tarafından oluşturulan bir spektrogramı dalga biçimine nasıl dönüştürebilirsiniz?
<Question
choices={[
{
text: "Spektrogramdan bir dalga biçimini yeniden oluşturmak için ses kodlayıcı adı verilen bir sinir ağını kullanabiliriz.",
explain: "Bu durumda faz bilgisi eksik olduğundan, dalga biçimini yeniden oluşturmak için bir ses kodlayıcı veya klasik Griffin-Lim algoritmasını kullanmamız gerekir.",
correct: true
},
{
text: "Oluşturulan spektrogramı dalga biçimine dönüştürmek için ters STFT'yi kullanabiliriz.",
explain: "Oluşturulan bir spektrogramda, ters STFT'yi kullanmak için gerekli olan faz bilgisi eksiktir."
},
{
text: "Makine öğrenimi modeli tarafından oluşturulan bir spektrogramı dalga biçimine dönüştüremezsiniz.",
explain: "Tekrar Dene!"
}
]}
/>
| 3 |
0 | hf_public_repos/audio-transformers-course/chapters/tr | hf_public_repos/audio-transformers-course/chapters/tr/chapter1/introduction.mdx | # 1.Ünite Ses verileriyle çalışma
## Bu üniteden ne öğreceneksiniz.
Her ses veya konuşma görevi bir ses dosyasıyla başlar. Bu görevleri çözmeye dalmadan önce, bu dosyaların aslında neler içerdiğini anlamak ve onlarla nasıl çalışılacağını öğrenmek önemlidir.
Bu ünitede, ses verileri ile ilgili temel terimleri, dalga formu, örnekleme hızı ve spektrogram gibi, anlayacaksınız. Ayrıca, ses veri kümesi ile çalışmayı, ses verilerini yükleme ve önişleme işlemlerini ve büyük veri kümelerini verimli bir şekilde akıtarak nasıl çalışılacağını öğreneceksiniz.
Bu ünitenin sonunda, temel ses verisi terimlerini sağlam bir şekilde kavrayacak ve çeşitli uygulamalar için ses veri kümesi ile çalışmak için gereken becerilere sahip olacaksınız. Bu ünitede edineceğiniz bilgi, kursun geri kalanını anlamak için bir temel oluşturacak. | 4 |
0 | hf_public_repos/audio-transformers-course/chapters/tr | hf_public_repos/audio-transformers-course/chapters/tr/chapter1/audio_data.mdx | # Ses verilerine giriş
Ses dalgası doğası gereği sürekli bir sinyaldir, yani belirli bir zamanda sonsuz sayıda sinyal değeri içerir. Bu durum sonlu dizileri bekleyen dijital cihazlar için sorun yaratır. Bu tip veriler dijital cihazlar tarafından işlenmeden, depolanmadan ve iletilmeden önce önce sürekli ses dalgasının bir dizi ayrık değere dönüştürülmesi gerekmektedir. Buna dijital temsil de denir.
Herhangi bir ses verisetine baktığınızda, ses örneklerini içeren dijital dosyalar bulacaksınız. Bu örneklerin arasında metin anlamı ya da müzik parçaları bulabilir, `.wav` (Dalgaformu Ses Dosyası), `.flac` (Ücretsiz Kayıpsız Ses Kodlayıcı) ve `.mp3` (MPEG-1 Ses Katmanı 3) gibi farklı dosya formatlarıyla karşılaşabilirsiniz. Bu formatlar temelde ses sinyalinin dijital temsilini nasıl sıkıştırdıklarına göre farklılıklar gösterirler.
Şimdi bir sürekli sinyalden bu temsile nasıl ulaştığımıza bir göz atalım. Analog sinyal önce bir mikrofon tarafından yakalanır ve ses dalgalarını elektriksel bir sinyale dönüştürür. Elektriksel sinyal, örnekleme yoluyla dijital temsil elde etmek için bir Analog-Dijital Dönüştürücü tarafından sayısallaştırılır.
## Örnekleme ve örnekleme oranı
Örnekleme, sürekli bir sinyalin değerini sabit zaman aralıklarında ölçme işlemidir. Örnekleme yapılmış dalga formu, sabit aralıklarla ayrık sinyal değerlerini içerdiği için ayrık bir şekildedir.
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface-course/audio-course-images/resolve/main/Signal_Sampling.png" alt="Signal sampling illustration">
</div>
*Wikipedia makalesinden örnek: [Örneklem (sinyal işleme)](https://tr.wikipedia.org/wiki/%C3%96rnekleme_(sinyal_i%C5%9Fleme))*
**Örnekleme hızı** (aynı zamanda örnekleme frekansı olarak da adlandırılır), bir saniyede alınan örnek sayısıdır ve hertz (Hz) cinsinden ölçülür. Bir referans noktası vermek gerekirse, CD kalitesindeki sesin örnekleme hızı 44.100 Hz'dir, yani saniyede 44.100 örnek alınır. Karşılaştırma yapmak için, yüksek çözünürlüklü sesin örnekleme hızı 192.000 Hz veya 192 kHz'dir. Konuşma modellerini eğitirken yaygın olarak kullanılan bir örnekleme hızı ise 16.000 Hz veya 16 kHz'dir.
Örnekleme hızı seçimi sinyalden yakalanabilen en yüksek frekansı belirler. Bu aynı zamanda Nyquist sınırı olarak bilinir ve tam olarak örnekleme hızının yarısıdır. İnsan konuşmasındaki işitilebilir frekanslar 8 kHz'nin altındadır, bu nedenle konuşmayı 16 kHz'de örneklemek yeterlidir. Daha yüksek bir örnekleme hızı kullanmak daha fazla bilgiyi yakalamaz ve sadece bu tür dosyaların işlenmesinin hesap maliyetini artırır. Öte yandan, çok düşük bir örnekleme hızında sesi örneklemek bilgi kaybına neden olur. 8 kHz'de örneklenen konuşma, bu hızda yüksek frekansları yakalayamadığı için donuk bir ses çıkaracaktır.
Herhangi bir ses görevi üzerinde çalışırken, veri kümesindeki tüm ses örneklerinin aynı örnekleme hızına sahip olduğundan emin olmak önemlidir. Öneğitimli bir modeli özelleştirmek için özel ses veriseti kullanmayı planlıyorsanız, modelin önceden eğitildiği verilerin örnekleme hızı ve verilerinizin örnekleme hızı aynı olmalıdır. Örnekleme hızı, ardışık ses örnekleri arasındaki zaman aralığını belirler ve ses verilerinin zamansal çözünürlüğünü etkiler. Örneğin, 16.000 Hz örnekleme hızında 5 saniyelik bir ses, 80.000 değerin bir dizisi olarak temsil edilir, aynı 5 saniyelik ses 8.000 Hz örnekleme hızında ise 40.000 değerin bir dizisi olarak temsil edilir. Ses görevlerini çözen transformer modelleri, örnekleri diziler olarak ele alır. Bu modeller ses verisinin temsilini öğrenen dikkat mekanizmalarına dayanır. Örnekleme hızları farklı olan ses örnekleri için diziler farklı olduğu için, modellerin örnekleme hızları arasında genelleme yapması zor olacaktır. **Yeniden örnekleme** ses örneklerinin örnekleme hızlarını eşleştirmek için kullanılan bir işlemdir ve ses verilerini [ön işleme](preprocessing#resampling-the-audio-data) işleminin bir parçasıdır.
## Genlik ve bit derinliği
Örnekleme oranı size örneklerin ne sıklıkta alındığını söyler. Peki, her bir örnekteki değerler tam olarak nedir?
Ses, insanlar tarafından duyulabilir frekansta hava basıncındaki değişikliklerle oluşur. Bir sesin **genliği**, herhangi bir anki ses basınç seviyesini tanımlar ve decibel (dB) cinsinden ölçülür. Genliği sesin yüksekliği olarak algılarız. Örnek vermek gerekirse, normal bir konuşma sesi 60 dB'nin altındadır ve bir rock konseri insan işitme sınırlarını zorlayacak şekilde yaklaşık olarak 125 dB'de olabilir.
Dijital seste, her ses örneği bir zaman noktasında ses dalgasının genliğini kaydeder. Örneğin **bit derinliği**, bu genlik değerinin ne kadar hassasiyetle tanımlanabileceğini belirler. Yüksek bit derinliği, dijital temsilin orijinal sürekli ses dalgasına ne kadar doğru bir şekilde yaklaştığına işaret eder.
En yaygın ses bit derinlikleri 16 bit ve 24 bittir. İkisi de ikili bir terimdir, genlik değerinin sürekli olarak ayrıksallaştırıldığında kaç farklı adıma ayrıksallaştırılabileceğini temsil eder. Bu ayrıksallaştırma 16-bit ses için 65,536 adım, 24-bit ses için 16,777,216 adımdır. Çünkü ayrıksallaştırma, sürekli değeri ayrıksallaştırılmış bir değere yuvarlama işlemi içerdiğinden, örnekleme işlemi gürültü ekler. Bit derinliği ne kadar yüksekse, bu ayrıksallaştırma gürültüsü o kadar küçüktür. Pratikte, 16-bit sesin ayrıksalaştırma gürültüsü zaten işitilemeyecek kadar küçüktür, ve daha yüksek bit derinliklerini kullanmanıza gerek kalmaz.
32-bit sese de rastlayabilirsiniz. 32-bit ses örnekleri gerçel olarak saklar, oysa 16-bit ve 24-bit ses tamsayı örnekleri kullanır. 32-bit gerçel sayı hassasiyeti 24 bit olarak kabul edilir, bu da ona 24-bit sesle aynı bit derinliğini verir. Gerçel sayılı ses örneklerinin [-1.0, 1.0] aralığı içinde bulunması beklenir. Makine öğrenme modelleri doğal olarak gerçel sayılarla çalıştığından, ses önce gerçel sayı formatına dönüştürülmelidir. Bunun nasıl yapılacağını [Önişleme](preprocessing) bölümünde göreceğiz.
Sürekli ses sinyalleri gibi, dijital sesin genliği genellikle desibel (dB) cinsinden ifade edilir. İnsan işitmesi logaritmik olduğundan dolayı - kulaklarımız seslerdeki küçük dalgalanmalara yüksek seslerden daha hassastır - bir sesin yüksekliği, genliklerin de logaritmik olan desibel cinsinden ifade edilmesiyle daha kolay yorumlanır. Gerçek dünya sesi için desibel ölçeği 0 dB'den başlar, bu da insanların duyabileceği en sessiz sesi temsil eder ve daha yüksek sesler daha büyük değerlere sahiptir. Ancak dijital ses sinyalleri için 0 dB en yüksek genlikken, diğer tüm genlikler negatiftir. Hızlı bir kural olarak: her -6 dB, genliğin yarı yarıya azalması anlamına gelir ve genellikle -60 dB'nin altındaki her şey, sesi gerçekten yüksek bir ses seviyesine çıkarmazsanız işitilemez.
## Dalga biçimi olarak ses
Seslerin zaman içindeki örnek değerlerinin ve değişimlerinin **dalga formu** olarak görselleştirildiğini görmüş olabilirsiniz.
Bu aynı zamanda sesin *zaman alanı* temsili olarak da bilinir.
Bu tür görselleştirmeler, sinyalin zamanlaması, ses olayları, sinyalin genel ses yüksekliği ve seste mevcut olan herhangi bir düzensizlik veya gürültüleri gibi sinyalin belli özelliklerini tanımlamada kullanılır
Bir ses sinyalinin dalga biçimini çizmek için 'librosa' adlı bir Python kütüphanesini kullanabiliriz:
```bash
pip install librosa
```
Kütüphaneyle birlikte gelen "trumpet" adlı ses örneğini ele alalım:
```py
import librosa
array, sampling_rate = librosa.load(librosa.ex("trumpet"))
```
Bu örnek, ses zaman serisi (burada buna 'dizi' diyoruz) ve örnekleme hızından ('sampling_rate') oluşan bir demet olarak yüklenir.
Librosa'nın `waveshow()` fonksiyonunu kullanarak bu sesin dalga formuna bir göz atalım:
```py
import matplotlib.pyplot as plt
import librosa.display
plt.figure().set_figwidth(12)
librosa.display.waveshow(array, sr=sampling_rate)
```
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface-course/audio-course-images/resolve/main/waveform_plot.png" alt="Waveform plot">
</div>
Bu, sinyalin genliğini y ekseni üzerinde ve zamanı x ekseni boyunca çizer. Başka bir deyişle, her bir nokta, örnekleme sırasında alınan tek bir örnek değerine karşılık gelir. Ayrıca, librosa sesi genliği [-1.0, 1.0] arasında gerçel sayılı değerler olarak döndürür.
Görselleştirme, ses verilerini dinlerken üzerinde çalıştığınız verileri anlamak için kullanışlı bir araçtır. Sinyalin şeklini görebilir, örüntüleri gözlemleyebilir, gürültü veya bozulma belirlemeyi öğrenebilirsiniz. Veriyi normalizasyon, yeniden örnekleme veya filtreleme gibi bazı yöntemlerle önişlediyseniz, önişleme adımlarının doğru bir şekilde uygulandığını görselden doğrulayabilirsiniz. Bir modeli eğittikten sonra (örneğin, ses sınıflandırma görevinde) hata oluşan örnekleri görselleştirebilir ve sorunu gidermek için kullanabilirsiniz.
## Frekans spektrumu
Ses verilerini görselleştirmenin başka bir yolu da *frekans alanı* olarak da bilinen bir ses sinyalinin **frekans spektrumunu** çizmektir.
Spektrum, ayrık Fourier dönüşümü veya DFT kullanılarak hesaplanır. Spektrum, sinyali oluşturan her bir frekansı ve ne kadar güçlü olduğunu tarif eder.
Numpy'nin `rfft()` fonksiyonunu kullanarak DFT'yi alarak aynı trompet sesi için frekans spektrumunu çizelim.
Tüm sesin spektrumunu çizmek mümkünse de, bunun yerine küçük bir bölgeye bakmak daha kullanışlıdır. Aşağıda,
ilk 4096 örneğin DFT'sini alalım, bu aşağı yukarı çalınan ilk notanın uzunluğuna eşit olacak.
```py
import numpy as np
dft_input = array[:4096]
# DFT hesaplama
window = np.hanning(len(dft_input))
windowed_input = dft_input * window
dft = np.fft.rfft(windowed_input)
# genlik spektrumunu desibel cinsinden elde edin
amplitude = np.abs(dft)
amplitude_db = librosa.amplitude_to_db(amplitude, ref=np.max)
# frekans aralıklarını alın
frequency = librosa.fft_frequencies(sr=sampling_rate, n_fft=len(dft_input))
plt.figure().set_figwidth(12)
plt.plot(frequency, amplitude_db)
plt.xlabel("Frequency (Hz)")
plt.ylabel("Amplitude (dB)")
plt.xscale("log")
```
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface-course/audio-course-images/resolve/main/spectrum_plot.png" alt="Spectrum plot">
</div>
Bu, bu ses bölümünde mevcut olan çeşitli frekans bileşenlerinin gücünü gösterir. Frekans değerleri açık
x ekseni genellikle logaritmik ölçekte çizilir, genlikleri ise y ekseni üzerindedir.
Çizdiğimiz frekans spektrumu birkaç tepe noktası gösteriyor. Bu tepeler notanın harmoniklerine karşılık gelir.
yüksek harmonikler daha sessiz olacak şekilde çalınır. İlk zirve 620 Hz civarında olduğundan, bu bir E♭ notasının frekans spektrumudur.
DFT'nin çıktısı, gerçel ve sanal bileşenlerden oluşan karmaşık sayıların bir dizisidir. `np.abs(dft)` ile büyüklük, spektrogramdan genlik bilgisini elde eder. Gerçek ve sanal bileşenler arasındaki açı, faz spektrumunu sağlar, ancak bu genellikle makine öğrenme uygulamalarında atlanır veya kullanılmaz.
Genlik değerlerini desibel ölçeğine dönüştürmek için `librosa.amplitude_to_db()` kullandınız, böylece spektrumdaki daha ince ayrıntıları görmeyi kolaylaştırdınız. Bazen insanlar genlik yerine enerjiyi ölçen **güç spektrumunu** kullanır;
bu basitçe genlik değerlerinin karesi olan bir spektrumdur.
<Tip>
💡 Pratikte insanlar FFT terimini DFT ile birbirinin yerine kullanırlar çünkü FFT veya Hızlı Fourier Dönüşümü DFT'yi bilgisayarda hesaplamak için tek etkili yöntemdir.
</Tip>
Bir ses sinyalinin frekans spektrumu, dalga formuyla aynı bilgiyi içerir. Bunlar aynı veriye (burada trompet sesinden ilk 4096 örnek) bakmanın iki farklı yoludur. Dalga formunun genliğe karşı zaman içinde çizdiği yerde, spektrum her bir frekansın genliğini sabit bir noktada görselleştirir.
## Spektrogram
Bir ses sinyalindeki frekansların değişimini nasıl görselleştirebiliriz? Trompet birkaç nota çalıyor ve hepsinde
farklı frekanslar var. Sorun, spektrumun yalnızca belirli bir andaki frekansların donmuş anlık görüntüsünü göstermesidir.
Çözüm, her biri yalnızca küçük bir zaman dilimini kapsayan birden fazla DFT almak ve elde edilen spektrumları bir araya toplayıp **spektrogram**a dönüştürmektir.
Spektrogram, zaman içinde değişen bir ses sinyalinin frekans içeriğini çizer. Zamanı, frekansı ve genliği tek bir grafikte görmenizi sağlar Bu hesaplamayı gerçekleştiren algoritma STFT veya Kısa Zamanlı Fourier Dönüşümüdür.
Spektrogram, kullanabileceğiniz en bilgilendirici ses araçlarından biridir. Örneğin bir müzik kaydıyla çalışırken,
çeşitli enstrümanları ve vokal parçalarını ve bunların genel sese nasıl katkıda bulunduğunu görebilirsiniz. Konuşma verisinde ise
her sesli harf belirli frekanslarla karakterize edildiğinden farklı sesli harfleri görebilirsiniz.
Librosa'nın "stft()" ve "specshow()" işlevlerini kullanarak aynı trompet sesi için bir spektrogram çizelim:
```py
import numpy as np
D = librosa.stft(array)
S_db = librosa.amplitude_to_db(np.abs(D), ref=np.max)
plt.figure().set_figwidth(12)
librosa.display.specshow(S_db, x_axis="time", y_axis="hz")
plt.colorbar()
```
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface-course/audio-course-images/resolve/main/spectrogram_plot.png" alt="Spectrogram plot">
</div>
Bu çizimde, x ekseni dalga biçimi görselleştirmesinde olduğu gibi zamanı temsil eder, ancak y ekseni Hz cinsinden frekansı temsil eder.
Rengin yoğunluğu, zamanın her noktasında frekans bileşeninin desibel (dB) cinsinden ölçülen genliğini veya gücünü verir.
Spektrogram, genellikle birkaç milisaniye süren ses sinyalinin kısa segmentlerini alıp, her segmentin frekans spektrumunu elde etmek için ayrık Fourier dönüşümünü hesaplayarak oluşturulur. Elde edilen spektrumlar daha sonra zaman ekseni üzerine üst üste konur ve spektrogramu oluşturmak için bir araya getirilir. Bu görüntüde her dikey dilim, üstten görüldüğünde tek bir frekans spektrumuna karşılık gelir. Varsayılan olarak, `librosa.stft()` ses sinyalini 2048 örneklik segmentlere böler, bu da frekans çözünürlüğü ve zaman çözünürlüğü arasında iyi bir denge sağlar.
Spektrogram ve dalga formu, aynı verinin farklı görünümleridir, bu nedenle spektrogramu orijinal dalga formuna döndürmek mümkündür, ancak bunun için genlik bilgisi dışında faz bilgisine de ihtiyaç vardır. Eğer spektrogram bir makine öğrenme modeli tarafından üretildiyse, genellikle yalnızca genlikleri çıkarır. Bu durumda, Griffin-Lim gibi klasik bir faz yeniden yapılandırma algoritması veya bir vokoder olarak adlandırılan bir sinir ağı kullanarak spektrogramdan bir dalga formunu yeniden oluşturabilirsiniz.
Spektrogramlar yalnızca görselleştirme için kullanılmaz. Birçok makine öğrenimi modeli, girdi olarak spektrogramları alır,
dalga formlarına dönüştürür ve çıktı olarak spektrogramlar üretir.
Artık spektrogramın ne olduğunu ve nasıl yapıldığını bildiğimize göre, konuşma işlemede yaygın olarak kullanılan bir çeşidine bakalım: mel spektrogramı.
## Mel spektrogramı
Mel spektrogramı, konuşma işleme ve makine öğrenimi görevlerinde yaygın olarak kullanılan spektrogramın bir çeşididir.
Bir ses sinyalinin zaman içindeki frekans içeriğini ancak farklı bir frekans ekseninde göstermesi bakımından spektrograma benzer.
Standart bir spektrogramda frekans ekseni doğrusaldır ve hertz (Hz) cinsinden ölçülür. Ancak insanın işitme sistemi
düşük frekanslardaki değişikliklere yüksek frekanslardan daha duyarlıdır ve bu duyarlılık frekans arttıkça logaritmik olarak azalır. Mel ölçeği, insan kulağının doğrusal olmayan frekans tepkisine yaklaşan algısal bir ölçektir.
Bir mel spektrogramı oluşturmak için ses verisini kısa parçalara ayırıp frekans spektrumları elde edilir. Bunun için STFT kullanılır.
Ek olarak, frekansları mel ölçeği dönüştürmek için, her spektrum mel filtre bankası olarak adlandırılan bir dizi filtre aracılığıyla gönderilir.
Tüm bu adımları bizim için gerçekleştiren librosa'nın `melspectrogram()` fonksiyonunu kullanarak bir mel spektrogramını nasıl çizebileceğimizi görelim:
```py
S = librosa.feature.melspectrogram(y=array, sr=sampling_rate, n_mels=128, fmax=8000)
S_dB = librosa.power_to_db(S, ref=np.max)
plt.figure().set_figwidth(12)
librosa.display.specshow(S_dB, x_axis="time", y_axis="mel", sr=sampling_rate, fmax=8000)
plt.colorbar()
```
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface-course/audio-course-images/resolve/main/mel-spectrogram.png" alt="Mel spectrogram plot">
</div>
Yukarıdaki örnekte, `n_mels`, oluşturulacak mel bantlarının sayısını ifade eder. Mel bantları, spektrumu insan işitmesinin farklı frekanslara nasıl tepki verdiğini taklit etmek için seçilen bir dizi filtre kullanarak algısal olarak anlamlı bileşenlere bölen frekans aralıklarını tanımlar. `n_mels` için yaygın değerler 40 veya 80'dir. `fmax`, önem verdiğimiz en yüksek frekansı (Hz cinsinden) belirtir.
Düzenli bir spektrogramda olduğu gibi, mel frekans bileşenlerinin gücünü desibel cinsinden ifade etmek yaygın bir uygulamadır. Bu genellikle bir **log-mel spektrogramu* olarak adlandırılır, çünkü desibellere dönüştürme işlemi logaritmik bir işlem içerir. Yukarıdaki örnek, `librosa.feature.melspectrogram()` olarak `librosa.power_to_db()` kullanarak güç spektrogramı oluşturur.
<Tip>
💡 Tüm mel spektrogramları aynı değildir! Yaygın olarak kullanılan iki farklı mel ölçeği vardır ("htk" ve "slaney"), ve güç spektrogramı yerine genlik spektrogramı kullanılabilir. Log-mel spektrogramına dönüştürme işlemi her zaman gerçek desibelleri hesaplamaz, sadece `log`larını alabilir. Bu nedenle, bir makine öğrenme modeli girdi olarak bir mel spektrogramı bekliyorsa, bunu aynı şekilde hesapladığınızdan emin olmak için kontrol edin.
</Tip>
Bir mel spektrogramı oluşturmak, sinyali filtrelemeyi içerdiği için kayıplı bir işlemdir. Bir mel spektrogramını bir dalga formuna dönüştürmek, bir düzenli spektrogram için bunu yapmaktan daha zordur, çünkü daha önce kaybedilen frekansları tahmin etmeyi gerektirir. Bu nedenle, mel spektrogramından bir dalga formu üretmek için HiFiGAN vokoder gibi makine öğrenme modellerine ihtiyaç vardır.
Standart bir spektrogramla karşılaştırıldığında, bir mel spektrogramı ses sinyalinin daha anlamlı özelliklerini yakalayabilir.
Bu, mel spektrogramını, konuşma tanıma, konuşmacıyı tanımlama ve müzik türü sınıflandırması gibi görevlerde onu popüler bir seçim haline getiriyor.
Artık ses verisi örneklerini nasıl görselleştireceğinizi bildiğinize göre, en sevdiğiniz seslerin nasıl göründüğünü görmeye çalışın. :)
| 5 |
0 | hf_public_repos/audio-transformers-course/chapters/tr | hf_public_repos/audio-transformers-course/chapters/tr/chapter1/load_and_explore.mdx | # Bir ses veri kümesini yükleyin ve keşfedin
Bu kurs boyunca ses veri kümeleriyle çalışmak için 🤗 Datasets kütüphanesini kullanacağız. 🤗 Datasets, ses dahil tüm modalitelerden veri kümelerini indirmek ve hazırlamak için kullanılan açık kaynaklı bir kütüphanedir. Bu kütüphane, Hugging Face Hub üzerinde kamuya açık olarak kullanılabilir durumda olan benzersiz bir makine öğrenimi veri kümesine kolay erişim sunar. Ayrıca, 🤗 Datasets, araştırmacılar ve uygulamacılar için ses veri kümeleriyle çalışmayı basitleştiren çeşitli ses veri kümesi özellikleri içerir.
Ses veri kümeleriyle çalışmaya başlamak için 🤗 Veri Kümeleri kitaplığının kurulu olduğundan emin olun:
```bash
pip install datasets[audio]
```
🤗 Veri Kümelerinin en önemli tanımlayıcı özelliklerinden biri, tek bir satırda veri kümesini indirip hazırlayabilme yeteneğidir.
'load_dataset()' işlevini kullanan Python kodu.
Haydi yükleyip keşfedelim ve aşağıdakileri içeren [MINDS-14](https://huggingface.co/datasets/PolyAI/minds14) adlı ses veri kümesini yükleyelim
e-bankacılık sistemine çeşitli dil ve lehçelerde sorular soran kişilerin kayıtları.
MINDS-14 veri kümesini yüklemek için veri kümesinin tanımlayıcısını Hub'a kopyalayıp ("PolyAI/minds14") aktarmamız gerekir.
'load_dataset' işlevine. Ayrıca yalnızca Avustralya alt kümesiyle (`en-AU`) ilgilendiğimizi de belirteceğiz.
verileri kullanın ve bunu eğitim bölümüyle sınırlandırın:
```py
from datasets import load_dataset
minds = load_dataset("PolyAI/minds14", name="en-AU", split="train")
minds
```
**Çıktı:**
```out
Dataset(
{
features: [
"path",
"audio",
"transcription",
"english_transcription",
"intent_class",
"lang_id",
],
num_rows: 654,
}
)
```
Veri kümesi, her biri bir transkript, bir İngilizce çeviri ve kişinin sorgusu arkasındaki niyeti gösteren bir etiket ile eşlenmiş 654 ses dosyasını içerir. "audio" sütunu ham ses verisini içerir. Bir örneğe daha yakından bakalım:
```py
example = minds[0]
example
```
**Çıktı:**
```out
{
"path": "/root/.cache/huggingface/datasets/downloads/extracted/f14948e0e84be638dd7943ac36518a4cf3324e8b7aa331c5ab11541518e9368c/en-AU~PAY_BILL/response_4.wav",
"audio": {
"path": "/root/.cache/huggingface/datasets/downloads/extracted/f14948e0e84be638dd7943ac36518a4cf3324e8b7aa331c5ab11541518e9368c/en-AU~PAY_BILL/response_4.wav",
"array": array(
[0.0, 0.00024414, -0.00024414, ..., -0.00024414, 0.00024414, 0.0012207],
dtype=float32,
),
"sampling_rate": 8000,
},
"transcription": "I would like to pay my electricity bill using my card can you please assist",
"english_transcription": "I would like to pay my electricity bill using my card can you please assist",
"intent_class": 13,
"lang_id": 2,
}
```
Ses sütununun çeşitli özellikler içerdiğini fark edebilirsiniz. İşte bunlar:
* `path`: ses dosyasının yolu (bu durumda `*.wav`).
* `array`: 1 boyutlu NumPy dizisi olarak temsil edilen kodu çözülmüş ses verileri.
* `sampling_rate`. Ses dosyasının örnekleme hızı (bu örnekte 8.000 Hz).
'Intent_class' ses kaydının bir sınıflandırma kategorisidir. Bu sayıyı anlamlı bir dizeye dönüştürmek için,
'int2str()' yöntemini kullanabiliriz:
```py
id2label = minds.features["intent_class"].int2str
id2label(example["intent_class"])
```
**Çıktı:**
```out
"pay_bill"
```
Transkripsiyon özelliğine bakarsanız ses dosyasının gerçekten de soru soran bir kişiyi kaydettiğini görebilirsiniz.
Bir faturanın ödenmesiyle ilgili.
Bu veri alt kümesinde bir ses sınıflandırıcısı eğitmeyi planlıyorsanız, tüm özelliklere kesinlikle ihtiyacınız olmayabilir. Örneğin, "lang_id" tüm örnekler için aynı değere sahip olacak ve faydalı olmayacaktır. "english_transcription" büyük olasılıkla bu alt kümedeki "transcription" ile aynı bilgileri içerdiğinden, bunları güvenli bir şekilde kaldırabiliriz.
🤗 Datasets'in `remove_columns` yöntemini kullanarak alakasız özellikleri kolayca kaldırabilirsiniz:
```py
columns_to_remove = ["lang_id", "english_transcription"]
minds = minds.remove_columns(columns_to_remove)
minds
```
**Çıktı:**
```out
Dataset({features: ["path", "audio", "transcription", "intent_class"], num_rows: 654})
```
Artık veri setinin ham içeriğini yükleyip incelediğimize göre birkaç örnek dinleyelim! 'Bloklar'ı kullanacağız
ve veri kümesinden rastgele birkaç örneğin kodunu çözmek için "Gradio"daki "Ses" özellikleri:
```py
import gradio as gr
def generate_audio():
example = minds.shuffle()[0]
audio = example["audio"]
return (
audio["sampling_rate"],
audio["array"],
), id2label(example["intent_class"])
with gr.Blocks() as demo:
with gr.Column():
for _ in range(4):
audio, label = generate_audio()
output = gr.Audio(audio, label=label)
demo.launch(debug=True)
```
İsterseniz bazı örnekleri de görselleştirebilirsiniz. İlk örnek için dalga formunu çizelim.
```py
import librosa
import matplotlib.pyplot as plt
import librosa.display
array = example["audio"]["array"]
sampling_rate = example["audio"]["sampling_rate"]
plt.figure().set_figwidth(12)
librosa.display.waveshow(array, sr=sampling_rate)
```
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface-course/audio-course-images/resolve/main/waveform_unit1.png" alt="Waveform plot">
</div>
Deneyin! MINDS-14 veri kümesinin başka bir lehçesini veya dilini indirin, bir fikir edinmek için bazı örnekleri dinleyin ve görselleştirin
tüm veri kümesindeki varyasyon. Mevcut dillerin tam listesini [burada](https://huggingface.co/datasets/PolyAI/minds14) bulabilirsiniz. | 6 |
0 | hf_public_repos/audio-transformers-course/chapters | hf_public_repos/audio-transformers-course/chapters/fr/_toctree.yml | - title: Unité 0. Bienvenue au cours !
sections:
- local: chapter0/introduction
title: Introduction
- local: chapter0/get_ready
title: Se préparer à suivre le cours
- local: chapter0/community
title: Rejoindre la communauté
- title: Unité 1. Travailler avec des données audio
sections:
- local: chapter1/introduction
title: Ce que vous allez apprendre
- local: chapter1/audio_data
title: Introduction aux données audio
- local: chapter1/load_and_explore
title: Charger et explorer un jeu de données audio
- local: chapter1/preprocessing
title: Prétraitement des données audio
- local: chapter1/streaming
title: Streaming de données audio
- local: chapter1/quiz
title: Quiz
quiz: 1
- local: chapter1/supplemental_reading
title: Lectures et ressources complémentaires
- title: Unité 2. Une introduction en douceur aux applications audio
sections:
- local: chapter2/introduction
title: Tour d'horizon des applications audio
- local: chapter2/audio_classification_pipeline
title: Classification audio avec un pipeline
- local: chapter2/asr_pipeline
title: Reconnaissance automatique de la parole avec un pipeline
- local: chapter2/hands_on
title: Exercice pratique
- title: Unité 3. Architectures de transformers pour l'audio
sections:
- local: chapter3/introduction
title: Rappel sur les transformers
- local: chapter3/ctc
title: Architectures CTC
- local: chapter3/seq2seq
title: Architectures Seq2Seq
- local: chapter3/classification
title: Architectures de classification audio
- local: chapter3/supplemental_reading
title: Lectures et ressources complémentaires
- title: Unité 4. Construire un classifieur de genres musicaux
sections:
- local: chapter4/introduction
title: Ce que vous allez apprendre et construire
- local: chapter4/classification_models
title: Modèles pré-entraînés pour la classification audio
- local: chapter4/fine-tuning
title: Finetuner un modèle de classification musicale
- local: chapter4/demo
title: Construire une démo avec Gradio
- local: chapter4/hands_on
title: Exercice pratique
- title: Unité 5. Reconnaissance automatique de la parole
sections:
- local: chapter5/introduction
title: Ce que vous allez apprendre et construire
- local: chapter5/asr_models
title: Modèles pré-entraînés pour la reconnaissance automatique de la parole
- local: chapter5/choosing_dataset
title: Choisir un jeu de données
- local: chapter5/evaluation
title: Évaluation et métriques pour la reconnaissance automatique de la parole
- local: chapter5/fine-tuning
title: Comment finetuner un système de reconnaissance automatique de la parole avec l'API Trainer
- local: chapter5/demo
title: Construire une démo avec Gradio
- local: chapter5/hands_on
title: Exercice pratique
- local: chapter5/supplemental_reading
title: Lectures et ressources complémentaires
#
- title: Unité 6. Du texte à la parole
sections:
- local: chapter6/introduction
title: Ce que vous allez apprendre et construire
- local: chapter6/tts_datasets
title: Jeux de données de synthèse vocale
- local: chapter6/pre-trained_models
title: Modèles pré-entraînés pour la synthèse vocale
- local: chapter6/fine-tuning
title: Finetuner SpeechT5
- local: chapter6/evaluation
title: Évaluation des modèles de synthèse vocale
- local: chapter6/hands_on
title: Exercice pratique
- local: chapter6/supplemental_reading
title: Lectures et ressources complémentaires
- title: Unité 7. Rassemblement de tous les éléments
sections:
- local: chapter7/introduction
title: Ce que vous apprendrez et ce que vous construirez
- local: chapter7/speech-to-speech
title: Traduction parole-à-parole
- local: chapter7/voice-assistant
title: Créer un assistant vocal
- local: chapter7/transcribe-meeting
title: Transcrire une réunion
- local: chapter7/hands-on
title: Exercice pratique
- local: chapter7/supplemental_reading
title: Lectures et ressources complémentaires
- title: Événements liés au cours
sections:
- local: events/introduction
title: Sessions en direct et ateliers
| 7 |
0 | hf_public_repos/audio-transformers-course/chapters/fr | hf_public_repos/audio-transformers-course/chapters/fr/chapter0/get_ready.mdx | # Se préparer à suivre le cours
Nous espérons que vous êtes impatient de commencer le cours, et nous avons conçu cette page pour nous assurer que vous avez tout ce dont vous avez besoin pour vous lancer !
## Étape 1. Avoir un compte Hugging Face
Si vous n'en avez pas encore, créez [un compte Hugging Face](https://huggingface.co/join) (c'est gratuit). Vous en aurez besoin pour effectuer des tâches pratiques, pour recevoir votre certificat d'achèvement, pour explorer des modèles pré-entraînés, pour accéder à des jeux de données et plus encore.
## Étape 2. Révisez les principes fondamentaux (si vous en avez besoin).
Nous supposons que vous connaissez les bases de l'apprentissage profond et que vous êtes familiarisés avec les *transformers*. Si vous avez besoin de rafraîchir vos connaissances sur ces modèles, consultez notre [cours sur le NLP](https://huggingface.co/course/fr/chapter1/1).
## Étape 3. Vérifiez votre configuration
Pour parcourir les supports de cours, vous aurez besoin des éléments suivants :
- Un ordinateur avec une connexion Internet
- [Google Colab](https://colab.research.google.com) pour les exercices pratiques. La version gratuite suffit.
Si vous n'avez jamais utilisé Google Colab, consultez ce *notebook* d'introduction officiel (https://colab.research.google.com/notebooks/intro.ipynb).
## Étape 4. Rejoignez la communauté
Inscrivez-vous sur notre serveur [Discord](http://hf.co/join/discord), l'endroit où vous pouvez échanger des idées avec vos camarades de classe et nous contacter (l'équipe d'Hugging Face).
Pour en savoir plus sur notre Discord et comment en tirer le meilleur parti, consultez la [page suivante](community). | 8 |
0 | hf_public_repos/audio-transformers-course/chapters/fr | hf_public_repos/audio-transformers-course/chapters/fr/chapter0/introduction.mdx | # Bienvenue dans le cours d'audio d'Hugging Face !
Cher apprenant, bienvenue dans ce cours sur l'utilisation des *transformers* pour l'audio, À maintes reprises, les *transformers* se sont révélés être l'une des architectures d'apprentissage profond les plus puissantes et les plus polyvalentes, capables d'obtenir des résultats de pointe dans un large éventail de tâches, y compris le traitement du langage naturel, la vision par ordinateur et, plus récemment, le traitement audio.
Dans ce cours, nous allons explorer comment ces modèles peuvent être appliqués à une série de tâches et de données audio. Que vous soyez intéressé par la reconnaissance vocale, la classification audio ou la synthèse vocale, les *transformers* et ce cours vous le permettront.
Pour vous donner un avant-goût de ce que ces modèles peuvent faire, prononcez quelques mots dans la démo ci-dessous et regardez le modèle les transcrire en temps réel !
<iframe
src="https://openai-whisper.hf.space"
frameborder="0"
width="850"
height="450">
</iframe>
Tout au long du cours, vous comprendrez les spécificités du travail avec des données audio, vous découvrirez différentes architectures de *transformers*, et *finetunerez* vos propres modèles audio en tirant parti de puissants modèles pré-entraînés.
Ce cours est conçu pour les personnes ayant des connaissances en apprentissage profond et une connaissance générale des *transformers*.
Aucune expertise en traitement de données audio n'est requise. Si vous avez besoin de rafraîchir vos connaissances sur les *transformers*, consultez notre [cours de NLP](https://huggingface.co/course/fr/chapter1/1) qui aborde en détail les principes de base de cette architecture.
## Rencontrer l'équipe du cours
**Sanchit Gandhi, ingénieur de recherche en apprentissage automatique chez Hugging Face**
Bonjour, je m'appelle Sanchit et je suis ingénieur de recherche en apprentissage automatique pour l'audio dans l'équipe *open-source* de Hugging Face 🤗.
Je me concentre principalement sur la reconnaissance automatique de la parole et la traduction, avec l'objectif actuel de rendre les modèles de parole plus rapides, plus légers et plus faciles à utiliser.
**Matthijs Hollemans, ingénieur en apprentissage automatique chez Hugging Face**.
Je m'appelle Matthijs et je suis ingénieur en apprentissage automatique en audio dans l'équipe *open source* de Hugging Face. Je suis également l'auteur d'un livre sur l'écriture de sons de synthétiseurs, et je crée des *plugins* audio pendant mon temps libre.
**Maria Khalusova, Documentation et cours chez Hugging Face**.
Je m'appelle Maria et je crée du contenu éducatif et de la documentation pour rendre *Transformers* et d'autres outils *open-source* encore plus accessibles. Je décompose des concepts techniques complexes et j'aide les gens à démarrer avec des technologies de pointe.
**Vaibhav Srivastav, ingénieur *advocate* et développeur en apprentissage automatique chez Hugging Face**.
Je m'appelle Vaibhav (VB) et je suis ingénieur *advocate* en audio au sein de l'équipe *open source* de Hugging Face. Je fais des recherches sur la synthèse vocale sur els lagnues à faibles ressources et j'aide à mettre l'état de l'art de la recherche sur la parole à la portée du plus grand nombre.
## Structure du cours
Le cours est structuré en plusieurs unités qui couvrent différents sujets en profondeur :
* Unité 1 : apprendre les spécificités du travail avec des données audio, y compris les techniques de traitement audio et la préparation des données.
* Unité 2 : connaître les applications audio et apprendre comment utiliser les pipelines de 🤗 *Transformers* pour différentes tâches, telles que la classification audio et la reconnaissance vocale.
* Unité 3 : explorer les architectures de *transformers* audio, apprendre comment ils diffèrent, et quelles sont les tâches pour lesquelles ils sont les mieux adaptés.
* Unité 4 : Apprenez à construire votre propre classifieur de genre musical.
* Unité 5 : approfondissement de la reconnaissance vocale
* Unité 6 : apprendre à générer de la parole à partir d'un texte.
* Unité 7 : apprendre à construire des applications audio réelles (traducteur parole-à-parole, assistant vocal et transcription de réunions).
Chaque unité comprend un volet théorique qui vous permettra d'acquérir une compréhension approfondie des concepts et des techniques sous-jacents. Tout au long du cours, des quiz vous permettent de tester vos connaissances et de renforcer votre apprentissage.
Certains chapitres comprennent également des exercices pratiques qui vous permettront d'appliquer ce que vous avez appris.
À la fin du cours, vous aurez acquis de solides bases dans l'utilisation des *transformers* pour les données audio et serez bien équipé pour appliquer ces techniques à un large éventail de tâches.
## Parcours d'apprentissage
Il n'y a pas de bonne ou de mauvaise façon de suivre ce cours. Tout le matériel contenu dans ce cours est 100% gratuit, public et *open-source*.
Vous pouvez le suivre à votre propre rythme, mais nous vous recommandons de suivre les unités dans l'ordre.
Bon cours !
| 9 |
0 | hf_public_repos/api-inference-community/docker_images/doctr | hf_public_repos/api-inference-community/docker_images/doctr/app/main.py | import functools
import logging
import os
from typing import Dict, Type
from api_inference_community.routes import pipeline_route, status_ok
from app.pipelines import ObjectDetectionPipeline, Pipeline
from starlette.applications import Starlette
from starlette.middleware import Middleware
from starlette.middleware.gzip import GZipMiddleware
from starlette.routing import Route
TASK = os.getenv("TASK")
MODEL_ID = os.getenv("MODEL_ID")
logger = logging.getLogger(__name__)
# Add the allowed tasks
# Supported tasks are:
# - text-generation
# - text-classification
# - token-classification
# - translation
# - summarization
# - automatic-speech-recognition
# - ...
# For instance
# from app.pipelines import AutomaticSpeechRecognitionPipeline
# ALLOWED_TASKS = {"automatic-speech-recognition": AutomaticSpeechRecognitionPipeline}
# You can check the requirements and expectations of each pipelines in their respective
# directories. Implement directly within the directories.
ALLOWED_TASKS: Dict[str, Type[Pipeline]] = {"object-detection": ObjectDetectionPipeline}
@functools.lru_cache()
def get_pipeline() -> Pipeline:
task = os.environ["TASK"]
model_id = os.environ["MODEL_ID"]
if task not in ALLOWED_TASKS:
raise EnvironmentError(f"{task} is not a valid pipeline for model : {model_id}")
return ALLOWED_TASKS[task](model_id)
routes = [
Route("/{whatever:path}", status_ok),
Route("/{whatever:path}", pipeline_route, methods=["POST"]),
]
middleware = [Middleware(GZipMiddleware, minimum_size=1000)]
if os.environ.get("DEBUG", "") == "1":
from starlette.middleware.cors import CORSMiddleware
middleware.append(
Middleware(
CORSMiddleware,
allow_origins=["*"],
allow_headers=["*"],
allow_methods=["*"],
)
)
app = Starlette(routes=routes, middleware=middleware)
@app.on_event("startup")
async def startup_event():
logger = logging.getLogger("uvicorn.access")
handler = logging.StreamHandler()
handler.setFormatter(logging.Formatter("%(asctime)s - %(levelname)s - %(message)s"))
logger.handlers = [handler]
# Link between `api-inference-community` and framework code.
app.get_pipeline = get_pipeline
try:
get_pipeline()
except Exception:
# We can fail so we can show exception later.
pass
if __name__ == "__main__":
try:
get_pipeline()
except Exception:
# We can fail so we can show exception later.
pass
| 0 |
0 | hf_public_repos/api-inference-community/docker_images/doctr/app | hf_public_repos/api-inference-community/docker_images/doctr/app/pipelines/object_detection.py | from typing import Any, Dict, List
import torch
from app.pipelines import Pipeline
from doctr.models.obj_detection.factory import from_hub
from PIL import Image
from torchvision.transforms import Compose, ConvertImageDtype, PILToTensor
class ObjectDetectionPipeline(Pipeline):
def __init__(self, model_id: str):
self.model = from_hub(model_id).eval()
self.transform = Compose(
[
PILToTensor(),
ConvertImageDtype(torch.float32),
]
)
self.labels = self.model.cfg.get("classes")
if self.labels is None:
self.labels = [f"LABEL_{i}" for i in range(self.model.num_classes)]
def __call__(self, inputs: Image.Image) -> List[Dict[str, Any]]:
"""
Args:
inputs (:obj:`PIL.Image`):
The raw image representation as PIL.
No transformation made whatsoever from the input. Make all necessary transformations here.
Return:
A :obj:`list`:. The list contains items that are dicts with the keys "label", "score" and "box".
"""
im = inputs.convert("RGB")
inputs = self.transform(im).unsqueeze(0)
with torch.inference_mode():
out = self.model(inputs)[0]
return [
{
"label": self.labels[idx],
"score": score.item(),
"box": {
"xmin": int(round(box[0].item())),
"ymin": int(round(box[1].item())),
"xmax": int(round(box[2].item())),
"ymax": int(round(box[3].item())),
},
}
for idx, score, box in zip(out["labels"], out["scores"], out["boxes"])
]
| 1 |
0 | hf_public_repos/api-inference-community/docker_images/doctr/app | hf_public_repos/api-inference-community/docker_images/doctr/app/pipelines/base.py | from abc import ABC, abstractmethod
from typing import Any
class Pipeline(ABC):
@abstractmethod
def __init__(self, model_id: str):
raise NotImplementedError("Pipelines should implement an __init__ method")
@abstractmethod
def __call__(self, inputs: Any) -> Any:
raise NotImplementedError("Pipelines should implement a __call__ method")
class PipelineException(Exception):
pass
| 2 |
0 | hf_public_repos/api-inference-community/docker_images/doctr/app | hf_public_repos/api-inference-community/docker_images/doctr/app/pipelines/__init__.py | from app.pipelines.base import Pipeline, PipelineException # isort:skip
from app.pipelines.object_detection import ObjectDetectionPipeline
| 3 |
0 | hf_public_repos/api-inference-community/docker_images/doctr | hf_public_repos/api-inference-community/docker_images/doctr/tests/test_api_object_detection.py | import json
import os
from typing import Dict
from unittest import TestCase, skipIf
from app.main import ALLOWED_TASKS
from parameterized import parameterized_class
from starlette.testclient import TestClient
from tests.test_api import TESTABLE_MODELS
@skipIf(
"object-detection" not in ALLOWED_TASKS,
"object-detection not implemented",
)
@parameterized_class(
[{"model_id": model_id} for model_id in TESTABLE_MODELS["object-detection"]]
)
class ObjectDetectionTestCase(TestCase):
def setUp(self):
self.old_model_id = os.getenv("MODEL_ID")
self.old_task = os.getenv("TASK")
os.environ["MODEL_ID"] = self.model_id
os.environ["TASK"] = "object-detection"
from app.main import app, get_pipeline
get_pipeline.cache_clear()
self.app = app
@classmethod
def setUpClass(cls):
from app.main import get_pipeline
get_pipeline.cache_clear()
def tearDown(self):
if self.old_model_id is not None:
os.environ["MODEL_ID"] = self.old_model_id
else:
del os.environ["MODEL_ID"]
if self.old_task is not None:
os.environ["TASK"] = self.old_task
else:
del os.environ["TASK"]
def read(self, filename: str) -> bytes:
dirname = os.path.dirname(os.path.abspath(__file__))
filename = os.path.join(dirname, "samples", filename)
with open(filename, "rb") as f:
bpayload = f.read()
return bpayload
def test_simple(self):
bpayload = self.read("artefacts.jpg")
with TestClient(self.app) as client:
response = client.post("/", data=bpayload)
self.assertEqual(
response.status_code,
200,
)
content = json.loads(response.content)
self.assertEqual(type(content), list)
self.assertEqual(set(type(el) for el in content), {dict})
self.assertEqual(
set((k, type(v)) for el in content for (k, v) in el.items()),
{("label", str), ("score", float), ("box", Dict[str, int])},
)
| 4 |
0 | hf_public_repos/api-inference-community/docker_images/doctr | hf_public_repos/api-inference-community/docker_images/doctr/tests/test_docker_build.py | import os
import subprocess
from unittest import TestCase
class cd:
"""Context manager for changing the current working directory"""
def __init__(self, newPath):
self.newPath = os.path.expanduser(newPath)
def __enter__(self):
self.savedPath = os.getcwd()
os.chdir(self.newPath)
def __exit__(self, etype, value, traceback):
os.chdir(self.savedPath)
class DockerBuildTestCase(TestCase):
def test_can_build_docker_image(self):
with cd(os.path.dirname(os.path.dirname(__file__))):
subprocess.check_output(["docker", "build", "."])
| 5 |
0 | hf_public_repos/api-inference-community/docker_images/doctr | hf_public_repos/api-inference-community/docker_images/doctr/tests/test_api.py | import os
from typing import Dict
from unittest import TestCase, skipIf
from app.main import ALLOWED_TASKS, get_pipeline
# Must contain at least one example of each implemented pipeline
# Tests do not check the actual values of the model output, so small dummy
# models are recommended for faster tests.
TESTABLE_MODELS: Dict[str, str] = {
"object-detection": ["mindee/fasterrcnn_mobilenet_v3_large_fpn"]
}
ALL_TASKS = {
"object-detection",
}
class PipelineTestCase(TestCase):
@skipIf(
os.path.dirname(os.path.dirname(__file__)).endswith("common"),
"common is a special case",
)
def test_has_at_least_one_task_enabled(self):
self.assertGreater(
len(ALLOWED_TASKS.keys()), 0, "You need to implement at least one task"
)
def test_unsupported_tasks(self):
unsupported_tasks = ALL_TASKS - ALLOWED_TASKS.keys()
for unsupported_task in unsupported_tasks:
with self.subTest(msg=unsupported_task, task=unsupported_task):
os.environ["TASK"] = unsupported_task
os.environ["MODEL_ID"] = "XX"
with self.assertRaises(EnvironmentError):
get_pipeline()
| 6 |
0 | hf_public_repos/api-inference-community/docker_images | hf_public_repos/api-inference-community/docker_images/timm/requirements.txt | starlette==0.27.0
api-inference-community==0.0.32
huggingface_hub>=0.11.1
timm>=1.0.7
#dummy
| 7 |
0 | hf_public_repos/api-inference-community/docker_images | hf_public_repos/api-inference-community/docker_images/timm/Dockerfile | FROM tiangolo/uvicorn-gunicorn:python3.8
LABEL maintainer="me <[email protected]>"
# Add any system dependency here
# RUN apt-get update -y && apt-get install libXXX -y
COPY ./requirements.txt /app
RUN pip install --no-cache-dir -r requirements.txt
COPY ./prestart.sh /app/
# Most DL models are quite large in terms of memory, using workers is a HUGE
# slowdown because of the fork and GIL with python.
# Using multiple pods seems like a better default strategy.
# Feel free to override if it does not make sense for your library.
ARG max_workers=1
ENV MAX_WORKERS=$max_workers
ENV TORCH_HOME=/data/
# Necessary on GPU environment docker.
# TIMEOUT env variable is used by nvcr.io/nvidia/pytorch:xx for another purpose
# rendering TIMEOUT defined by uvicorn impossible to use correctly
# We're overriding it to be renamed UVICORN_TIMEOUT
# UVICORN_TIMEOUT is a useful variable for very large models that take more
# than 30s (the default) to load in memory.
# If UVICORN_TIMEOUT is too low, uvicorn will simply never loads as it will
# kill workers all the time before they finish.
RUN sed -i 's/TIMEOUT/UVICORN_TIMEOUT/g' /gunicorn_conf.py
COPY ./app /app/app
| 8 |
0 | hf_public_repos/api-inference-community/docker_images | hf_public_repos/api-inference-community/docker_images/timm/prestart.sh | python app/main.py
| 9 |
0 | hf_public_repos | hf_public_repos/blog/datasets-filters.md | ---
title: "Announcing New Dataset Search Features"
thumbnail: /blog/assets/datasets-filters/thumbnail.png
authors:
- user: lhoestq
- user: severo
- user: kramp
---
# Announcing New Dataset Search Features
The AI and ML community has shared more than 180,000 public datasets on The [Hugging Face Dataset Hub](https://huggingface.co/datasets).
Researchers and engineers are using these datasets for various tasks, from training LLMs to chat with users to evaluating automatic speech recognition or computer vision systems.
Dataset discoverability and visualization are key challenges to letting AI builders find, explore, and transform datasets to fit their use cases.
At Hugging Face, we are building the Dataset Hub as the place for the community to collaborate on open datasets.
So we built tools like Dataset Search and the Dataset Viewer, as well as a rich open source ecosystem of tools.
Today we are announcing four new features that will take Dataset Search on the Hub to the next level.
## Search by Modality
The modality of a dataset corresponds to the type of data inside the dataset. For example, the most common types of data on Hugging Face are text, image, audio, and tabular data.
We released a set of filters that allows you to filter datasets that have one or several modalities among this list:
- Text
- Image
- Audio
- Tabular
- Time-Series
- 3D
- Video
- Geospatial
For example, it is possible to look for [datasets that contain both text and image data](https://huggingface.co/datasets?modality=modality:3d&sort=trending):

The modalities of each dataset are automatically detected based on file contents and extensions.
## Search by Size
We recently released a new feature in the interface to show the number of rows of each dataset:

Following this, it is now possible to search datasets by a number of rows by specifying a minimum and maximum number of rows.
This will let you look for datasets of small size to the biggest datasets that exist (for example, the ones used to pretrain LLMs).
The information about the number of rows is available for all the datasets in [supported formats](https://huggingface.co/docs/hub/datasets-adding#file-formats).
Even for the biggest datasets for which the number of rows is not included in the metadata the total number of rows is estimated accurately based on the content of the first 5GB.
For example, if you are looking at the datasets with the highest number of rows on Hugging Face, you can look for [datasets with more than 10B (10<sup>10</sup>) rows](https://huggingface.co/datasets?size_categories=or:%28size_categories:10B%3Cn%3C100B,size_categories:100B%3Cn%3C1T,size_categories:n%3E1T%29&sort=trending):

## Search by Format
The same dataset can be stored in many different formats.
For example, text datasets are often in Parquet or JSON Lines, but they could be in text files, and image datasets are often a single directory of images, but they could be in [WebDataset format](https://huggingface.co/docs/hub/datasets-webdataset) (a format based on TAR archives).
Each format has its pros and cons.
For example, Parquet offers nested data support, unlike CSV, efficient filtering/analytics, and a good compression ratio, but accessing one specific row requires decoding a full row group.
Another example is WebDataset, which offers the highest data streaming speed but lacks some metadata, such as the number of rows per file, which is often needed to efficiently distribute data in multi-node training setups.
The dataset format, therefore, indicates which use cases are favoured and whether you will need to reformat the data to fit your needs.
Here you can see the [datasets in WebDataset format](https://huggingface.co/datasets?format=format:webdataset&sort=trending):

## Search by Library
There are many good libraries and tools to load datasets and prepare them for training, like Pandas, Dask, or the 🤗 Datasets library.
The Hub allows you to use your favorite tools and filter datasets compatible with any library, for example you can look for [datasets compatible with Pandas](https://huggingface.co/datasets?library=library:pandas&sort=trending):

The dataset compatibility is based on the dataset format and size (e.g., Dask can load big JSON Lines dataset, unlike Pandas, which requires loading the full dataset in memory).
In addition to this, we also provide the code snippet to load any dataset in your favorite tool:

If you would like your library to appear in the list of supported libraries, feel free to open a discussion on [huggingface.js](https://github.com/huggingface/huggingface.js/issues)!
## Combine filters
Those four new Dataset Search tools can be used together and with the other existing filters like Language, Tasks, and Licenses.
Combining those filters with the text search bar you can look for the specific dataset you are looking for:

| 0 |
0 | hf_public_repos | hf_public_repos/blog/sb3.md | ---
title: 'Welcome Stable-baselines3 to the Hugging Face Hub 🤗'
thumbnail: /blog/assets/47_sb3/thumbnail.png
authors:
- user: ThomasSimonini
---
# Welcome Stable-baselines3 to the Hugging Face Hub 🤗
At Hugging Face, we are contributing to the ecosystem for Deep Reinforcement Learning researchers and enthusiasts. That’s why we’re happy to announce that we integrated [Stable-Baselines3](https://github.com/DLR-RM/stable-baselines3) to the Hugging Face Hub.
[Stable-Baselines3](https://github.com/DLR-RM/stable-baselines3) is one of the most popular PyTorch Deep Reinforcement Learning library that makes it easy to train and test your agents in a variety of environments (Gym, Atari, MuJoco, Procgen...).
With this integration, you can now host your saved models 💾 and load powerful models from the community.
In this article, we’re going to show how you can do it.
### Installation
To use stable-baselines3 with Hugging Face Hub, you just need to install these 2 libraries:
```bash
pip install huggingface_hub
pip install huggingface_sb3
```
### Finding Models
We’re currently uploading saved models of agents playing Space Invaders, Breakout, LunarLander and more. On top of this, you can find [all stable-baselines-3 models from the community here](https://huggingface.co/models?other=stable-baselines3)
When you found the model you need, you just have to copy the repository id:

### Download a model from the Hub
The coolest feature of this integration is that you can now very easily load a saved model from Hub to Stable-baselines3.
In order to do that you just need to copy the repo-id that contains your saved model and the name of the saved model zip file in the repo.
For instance`sb3/demo-hf-CartPole-v1`:
```python
import gym
from huggingface_sb3 import load_from_hub
from stable_baselines3 import PPO
from stable_baselines3.common.evaluation import evaluate_policy
# Retrieve the model from the hub
## repo_id = id of the model repository from the Hugging Face Hub (repo_id = {organization}/{repo_name})
## filename = name of the model zip file from the repository including the extension .zip
checkpoint = load_from_hub(
repo_id="sb3/demo-hf-CartPole-v1",
filename="ppo-CartPole-v1.zip",
)
model = PPO.load(checkpoint)
# Evaluate the agent and watch it
eval_env = gym.make("CartPole-v1")
mean_reward, std_reward = evaluate_policy(
model, eval_env, render=True, n_eval_episodes=5, deterministic=True, warn=False
)
print(f"mean_reward={mean_reward:.2f} +/- {std_reward}")
```
### Sharing a model to the Hub
In just a minute, you can get your saved model in the Hub.
First, you need to be logged in to Hugging Face to upload a model:
- If you're using Colab/Jupyter Notebooks:
````python
from huggingface_hub import notebook_login
notebook_login()
````
- Else:
`````bash
huggingface-cli login
`````
Then, in this example, we train a PPO agent to play CartPole-v1 and push it to a new repo `ThomasSimonini/demo-hf-CartPole-v1`
`
`````python
from huggingface_sb3 import push_to_hub
from stable_baselines3 import PPO
# Define a PPO model with MLP policy network
model = PPO("MlpPolicy", "CartPole-v1", verbose=1)
# Train it for 10000 timesteps
model.learn(total_timesteps=10_000)
# Save the model
model.save("ppo-CartPole-v1")
# Push this saved model to the hf repo
# If this repo does not exists it will be created
## repo_id = id of the model repository from the Hugging Face Hub (repo_id = {organization}/{repo_name})
## filename: the name of the file == "name" inside model.save("ppo-CartPole-v1")
push_to_hub(
repo_id="ThomasSimonini/demo-hf-CartPole-v1",
filename="ppo-CartPole-v1.zip",
commit_message="Added Cartpole-v1 model trained with PPO",
)
``````
Try it out and share your models with the community!
### What's next?
In the coming weeks and months, we will be extending the ecosystem by:
- Integrating [RL-baselines3-zoo](https://github.com/DLR-RM/rl-baselines3-zoo)
- Uploading [RL-trained-agents models](https://github.com/DLR-RM/rl-trained-agents/tree/master) into the Hub: a big collection of pre-trained Reinforcement Learning agents using stable-baselines3
- Integrating other Deep Reinforcement Learning libraries
- Implementing Decision Transformers 🔥
- And more to come 🥳
The best way to keep in touch is to [join our discord server](https://discord.gg/YRAq8fMnUG) to exchange with us and with the community.
And if you want to dive deeper, we wrote a tutorial where you’ll learn:
- How to train a Deep Reinforcement Learning lander agent to land correctly on the Moon 🌕
- How to upload it to the Hub 🚀

- How to download and use a saved model from the Hub that plays Space Invaders 👾.

👉 [The tutorial](https://github.com/huggingface/huggingface_sb3/blob/main/Stable_Baselines_3_and_Hugging_Face_%F0%9F%A4%97_tutorial.ipynb)
### Conclusion
We're excited to see what you're working on with Stable-baselines3 and try your models in the Hub 😍.
And we would love to hear your feedback 💖. 📧 Feel free to [reach us](mailto:[email protected]).
Finally, we would like to thank the SB3 team and in particular [Antonin Raffin](https://araffin.github.io/) for their precious help for the integration of the library 🤗.
### Would you like to integrate your library to the Hub?
This integration is possible thanks to the [`huggingface_hub`](https://github.com/huggingface/huggingface_hub) library which has all our widgets and the API for all our supported libraries. If you would like to integrate your library to the Hub, we have a [guide](https://huggingface.co/docs/hub/models-adding-libraries) for you!
| 1 |
0 | hf_public_repos | hf_public_repos/blog/gradio-5.md | ---
title: "Welcome, Gradio 5"
thumbnail: /blog/assets/gradio-5/thumbnail.png
authors:
- user: abidlabs
---
# Welcome, Gradio 5
We’ve been hard at work over the past few months, and we are excited to now announce the **stable release of Gradio 5**.
With Gradio 5, developers can build **production-ready machine learning web applications** that are performant, scalable, beautifully designed, accessible, and follow best web security practices, all in a few lines of Python.
To give Gradio 5 a spin, simply type in your terminal:
```
pip install --upgrade gradio
```
and start building your [first Gradio application](https://www.gradio.app/guides/quickstart).
## Gradio 5: production-ready machine learning apps
If you have used Gradio before, you might be wondering what’s different about Gradio 5.
Our goal with Gradio 5 was to listen to and address the most common pain points that we’ve heard from Gradio developers about building production-ready Gradio apps. For example, we’ve heard some developers tell us:
* “Gradio apps load too slowly” → Gradio 5 ships with major performance improvements, including the ability to serve Gradio apps via server-side rendering (SSR) which loads Gradio apps almost instantaneously in the browser. _No more loading spinner_! 🏎️💨
<video width="600" controls playsinline>
<source src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/gradio-5/gradio-4-vs-5-load.mp4">
</video>
* "This Gradio app looks old-school" → Many of the core Gradio components, including Buttons, Tabs, Sliders, as well as the high-level chatbot interface, have been refreshed with a more modern design in Gradio 5. We’re also releasing a new set of built-in themes, to let you easily create fresh-looking Gradio apps 🎨
* “I can’t build realtime apps in Gradio” → We have unlocked low-latency streaming in Gradio! We use base64 encoding and websockets automatically where it offers speedups, support WebRTC via custom components, and have also added significantly more documentation and example demos that are focused on common streaming use cases, such as webcam-based object detection, video streaming, real-time speech transcription and generation, and conversational chatbots. 🎤
* "LLMs don't know Gradio" → Gradio 5 ships with an experimental AI Playground where you can use AI to generate or modify Gradio apps and preview the app right in your browser immediately: [https://www.gradio.app/playground](https://www.gradio.app/playground)
<video width="600" controls>
<source src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/gradio-5/simple-playground.mp4">
</video>
Gradio 5 provides all these features while maintaining Gradio’s simple and intuitive developer-facing API. Since Gradio 5 intended to be a production-ready web framework for all kinds of machine learning applications, we've also made significant improvements around web security (including getting a 3rd-party audit of Gradio) -- more about that in an upcoming post!
## Breaking changes
Gradio apps that did not raise any deprecation warnings in Gradio 4.x should continue to work in Gradio 5, with a [small number of exceptions. See a list of breaking changes in Gradio 5 here](https://github.com/gradio-app/gradio/issues/9463).
## What’s next for Gradio?
Many of the changes we’ve made in Gradio 5 are designed to enable new functionality that we will be shipping in the coming weeks. Stay tuned for:
* Multi-page Gradio apps, along with native navbars and sidebars
* Support for running Gradio apps on mobile using PWA and potentially native app support
* More media components to support emerging modalities around images and videos
* A richer DataFrame component with support for common spreadsheet-type operations
* One-line integrations with machine learning model and API providers
* Further improvements that will decrease the memory consumption of Gradio apps
And much more! With Gradio 5 providing a robust foundation to build web applications, we’re excited to _really_ _get started_ letting developers build all sorts of ML apps with Gradio.
## Try Gradio 5 right now
Here are some Hugging Face Spaces that are running Gradio 5:
* https://huggingface.co/spaces/akhaliq/depth-pro
* https://huggingface.co/spaces/hf-audio/whisper-large-v3-turbo
* https://huggingface.co/spaces/gradio/chatbot_streaming_main
* https://huggingface.co/spaces/gradio/scatter_plot_demo_main
| 2 |
0 | hf_public_repos | hf_public_repos/blog/presidio-pii-detection.md | ---
title: "Experimenting with Automatic PII Detection on the Hub using Presidio"
thumbnail: /blog/assets/presidio-pii-detection/thumbnail.png
authors:
- user: lhoestq
- user: meg
- user: presidio
- user: omri374
---
# Experimenting with Automatic PII Detection on the Hub using Presidio
At Hugging Face, we've noticed a concerning trend in machine learning (ML) datasets hosted on our Hub: Undocumented private information about individuals. This poses some unique challenges for ML practitioners.
In this blog post, we'll explore different types of datasets containing a type of private information known as Personally Identifying Information (PII), the issues they present, and a new feature we're experimenting with on the Dataset Hub to help address these challenges.
## Types of Datasets with PII
We noticed two types of datasets that contain PII:
1. Annotated PII datasets: Datasets like [PII-Masking-300k by Ai4Privacy](https://huggingface.co/datasets/ai4privacy/pii-masking-300k) are specifically designed to train PII Detection Models, which are used to detect and mask PII. For example, these models can help with online content moderation or provide anonymized databases.
2. Pre-training datasets: These are large-scale datasets, often terabytes in size, that are typically obtained through web crawls. While these datasets are generally filtered to remove certain types of PII, small amounts of sensitive information can still slip through the cracks due to the sheer volume of data and the imperfections of PII Detection Models.
## The Challenges of PII in ML Datasets
The presence of PII in ML datasets can create several challenges for practitioners.
First and foremost, it raises privacy concerns and can be used to infer sensitive information about individuals.
Additionally, PII can impact the performance of ML models if it is not properly handled.
For example, if a model is trained on a dataset containing PII, it may learn to associate certain PII with specific outcomes, leading to biased predictions or to generating PII from the training set.
## A New Experiment on the Dataset Hub: Presidio Reports
To help address these challenges, we're experimenting with a new feature on the Dataset Hub that uses [Presidio](https://github.com/microsoft/presidio), an open-source state-of-the-art PII detection tool.
Presidio relies on detection patterns and machine learning models to identify PII.
With this new feature, users will be able to see a report that estimates the presence of PII in a dataset.
This information can be valuable for ML practitioners, helping them make informed decisions before training a model.
For example, if the report indicates that a dataset contains sensitive PII, practitioners may choose to further filter the dataset using tools like Presidio.
Dataset owners can also benefit from this feature by using the reports to validate their PII filtering processes before releasing a dataset.
## An Example of a Presidio Report
Let's take a look at an example of a Presidio report for this [pre-training dataset](https://huggingface.co/datasets/allenai/c4):

In this case, Presidio has detected small amounts of emails and sensitive PII in the dataset.
## Conclusion
The presence of PII in ML datasets is an evolving challenge for the ML community.
At Hugging Face, we're committed to transparency and helping practitioners navigate these challenges.
By experimenting with new features like Presidio reports on the Dataset Hub, we hope to empower users to make informed decisions and build more robust and ethical ML models.
We also thank the CNIL for the [help on GDPR compliance](https://huggingface.co/blog/cnil).
Their guidance has been invaluable in navigating the complexities of AI and personal data issues.
Check out their updated AI how-to sheets [here](https://www.cnil.fr/fr/ai-how-to-sheets).
Stay tuned for more updates on this exciting development!
| 3 |
0 | hf_public_repos | hf_public_repos/blog/sentiment-analysis-twitter.md | ---
title: "Getting Started with Sentiment Analysis on Twitter"
thumbnail: /blog/assets/85_sentiment_analysis_twitter/thumbnail.png
authors:
- user: federicopascual
---
# Getting Started with Sentiment Analysis on Twitter
<script async defer src="https://unpkg.com/medium-zoom-element@0/dist/medium-zoom-element.min.js"></script>
Sentiment analysis is the automatic process of classifying text data according to their polarity, such as positive, negative and neutral. Companies leverage sentiment analysis of tweets to get a sense of how customers are talking about their products and services, get insights to drive business decisions, and identify product issues and potential PR crises early on.
In this guide, we will cover everything you need to learn to get started with sentiment analysis on Twitter. We'll share a step-by-step process to do sentiment analysis, for both, coders and non-coders. If you are a coder, you'll learn how to use the [Inference API](https://huggingface.co/inference-api), a plug & play machine learning API for doing sentiment analysis of tweets at scale in just a few lines of code. If you don't know how to code, don't worry! We'll also cover how to do sentiment analysis with Zapier, a no-code tool that will enable you to gather tweets, analyze them with the Inference API, and finally send the results to Google Sheets ⚡️
Read along or jump to the section that sparks 🌟 your interest:
1. [What is sentiment analysis?](#what-is-sentiment-analysis)
2. [How to do Twitter sentiment analysis with code?](#how-to-do-twitter-sentiment-analysis-with-code)
3. [How to do Twitter sentiment analysis without coding?](#how-to-do-twitter-sentiment-analysis-without-coding)
Buckle up and enjoy the ride! 🤗
## What is Sentiment Analysis?
Sentiment analysis uses [machine learning](https://en.wikipedia.org/wiki/Machine_learning) to automatically identify how people are talking about a given topic. The most common use of sentiment analysis is detecting the polarity of text data, that is, automatically identifying if a tweet, product review or support ticket is talking positively, negatively, or neutral about something.
As an example, let's check out some tweets mentioning [@Salesforce](https://twitter.com/Salesforce) and see how they would be tagged by a sentiment analysis model:
- *"The more I use @salesforce the more I dislike it. It's slow and full of bugs. There are elements of the UI that look like they haven't been updated since 2006. Current frustration: app exchange pages won't stop refreshing every 10 seconds"* --> This first tweet would be tagged as "Negative".
- *"That’s what I love about @salesforce. That it’s about relationships and about caring about people and it’s not only about business and money. Thanks for caring about #TrailblazerCommunity"* --> In contrast, this tweet would be classified as "Positive".
- *"Coming Home: #Dreamforce Returns to San Francisco for 20th Anniversary. Learn more: http[]()://bit.ly/3AgwO0H via @Salesforce"* --> Lastly, this tweet would be tagged as "Neutral" as it doesn't contain an opinion or polarity.
Up until recently, analyzing tweets mentioning a brand, product or service was a very manual, hard and tedious process; it required someone to manually go over relevant tweets, and read and label them according to their sentiment. As you can imagine, not only this doesn't scale, it is expensive and very time-consuming, but it is also prone to human error.
Luckily, recent advancements in AI allowed companies to use machine learning models for sentiment analysis of tweets that are as good as humans. By using machine learning, companies can analyze tweets in real-time 24/7, do it at scale and analyze thousands of tweets in seconds, and more importantly, get the insights they are looking for when they need them.
Why do sentiment analysis on Twitter? Companies use this for a wide variety of use cases, but the two of the most common use cases are analyzing user feedback and monitoring mentions to detect potential issues early on.
**Analyze Feedback on Twitter**
Listening to customers is key for detecting insights on how you can improve your product or service. Although there are multiple sources of feedback, such as surveys or public reviews, Twitter offers raw, unfiltered feedback on what your audience thinks about your offering.
By analyzing how people talk about your brand on Twitter, you can understand whether they like a new feature you just launched. You can also get a sense if your pricing is clear for your target audience. You can also see what aspects of your offering are the most liked and disliked to make business decisions (e.g. customers loving the simplicity of the user interface but hate how slow customer support is).
**Monitor Twitter Mentions to Detect Issues**
Twitter has become the default way to share a bad customer experience and express frustrations whenever something goes wrong while using a product or service. This is why companies monitor how users mention their brand on Twitter to detect any issues early on.
By implementing a sentiment analysis model that analyzes incoming mentions in real-time, you can automatically be alerted about sudden spikes of negative mentions. Most times, this is caused is an ongoing situation that needs to be addressed asap (e.g. an app not working because of server outages or a really bad experience with a customer support representative).
Now that we covered what is sentiment analysis and why it's useful, let's get our hands dirty and actually do sentiment analysis of tweets!💥
## How to do Twitter sentiment analysis with code?
Nowadays, getting started with sentiment analysis on Twitter is quite easy and straightforward 🙌
With a few lines of code, you can automatically get tweets, run sentiment analysis and visualize the results. And you can learn how to do all these things in just a few minutes!
In this section, we'll show you how to do it with a cool little project: we'll do sentiment analysis of tweets mentioning [Notion](https://twitter.com/notionhq)!
First, you'll use [Tweepy](https://www.tweepy.org/), an open source Python library to get tweets mentioning @NotionHQ using the [Twitter API](https://developer.twitter.com/en/docs/twitter-api). Then you'll use the [Inference API](https://huggingface.co/inference-api) for doing sentiment analysis. Once you get the sentiment analysis results, you will create some charts to visualize the results and detect some interesting insights.
You can use this [Google Colab notebook](https://colab.research.google.com/drive/1R92sbqKMI0QivJhHOp1T03UDaPUhhr6x?usp=sharing) to follow this tutorial.
Let's get started with it! 💪
1. Install Dependencies
As a first step, you'll need to install the required dependencies. You'll use [Tweepy](https://www.tweepy.org/) for gathering tweets, [Matplotlib](https://matplotlib.org/) for building some charts and [WordCloud](https://amueller.github.io/word_cloud/) for building a visualization with the most common keywords:
```python
!pip install -q transformers tweepy matplotlib wordcloud
```
2. Setting up Twitter credentials
Then, you need to set up the [Twitter API credentials](https://developer.twitter.com/en/docs/twitter-api) so you can authenticate with Twitter and then gather tweets automatically using their API:
```python
import tweepy
# Add Twitter API key and secret
consumer_key = "XXXXXX"
consumer_secret = "XXXXXX"
# Handling authentication with Twitter
auth = tweepy.AppAuthHandler(consumer_key, consumer_secret)
# Create a wrapper for the Twitter API
api = tweepy.API(auth, wait_on_rate_limit=True, wait_on_rate_limit_notify=True)
```
3. Search for tweets using Tweepy
Now you are ready to start collecting data from Twitter! 🎉 You will use [Tweepy Cursor](https://docs.tweepy.org/en/v3.5.0/cursor_tutorial.html) to automatically collect 1,000 tweets mentioning Notion:
```python
# Helper function for handling pagination in our search and handle rate limits
def limit_handled(cursor):
while True:
try:
yield cursor.next()
except tweepy.RateLimitError:
print('Reached rate limite. Sleeping for >15 minutes')
time.sleep(15 * 61)
except StopIteration:
break
# Define the term you will be using for searching tweets
query = '@NotionHQ'
query = query + ' -filter:retweets'
# Define how many tweets to get from the Twitter API
count = 1000
# Search for tweets using Tweepy
search = limit_handled(tweepy.Cursor(api.search,
q=query,
tweet_mode='extended',
lang='en',
result_type="recent").items(count))
# Process the results from the search using Tweepy
tweets = []
for result in search:
tweet_content = result.full_text
tweets.append(tweet_content) # Only saving the tweet content.
```
4. Analyzing tweets with sentiment analysis
Now that you have data, you are ready to analyze the tweets with sentiment analysis! 💥
You will be using [Inference API](https://huggingface.co/inference-api), an easy-to-use API for integrating machine learning models via simple API calls. With the Inference API, you can use state-of-the-art models for sentiment analysis without the hassle of building infrastructure for machine learning or dealing with model scalability. You can serve the latest (and greatest!) open source models for sentiment analysis while staying out of MLOps. 🤩
For using the Inference API, first you will need to define your `model id` and your `Hugging Face API Token`:
- The `model ID` is to specify which model you want to use for making predictions. Hugging Face has more than [400 models for sentiment analysis in multiple languages](https://huggingface.co/models?pipeline_tag=text-classification&sort=downloads&search=sentiment), including various models specifically fine-tuned for sentiment analysis of tweets. For this particular tutorial, you will use [twitter-roberta-base-sentiment-latest](https://huggingface.co/cardiffnlp/twitter-roberta-base-sentiment-latest), a sentiment analysis model trained on ≈124 million tweets and fine-tuned for sentiment analysis.
- You'll also need to specify your `Hugging Face token`; you can get one for free by signing up [here](https://huggingface.co/join) and then copying your token on this [page](https://huggingface.co/settings/tokens).
```python
model = "cardiffnlp/twitter-roberta-base-sentiment-latest"
hf_token = "XXXXXX"
```
Next, you will create the API call using the `model id` and `hf_token`:
```python
API_URL = "https://api-inference.huggingface.co/models/" + model
headers = {"Authorization": "Bearer %s" % (hf_token)}
def analysis(data):
payload = dict(inputs=data, options=dict(wait_for_model=True))
response = requests.post(API_URL, headers=headers, json=payload)
return response.json()
```
Now, you are ready to do sentiment analysis on each tweet. 🔥🔥🔥
```python
tweets_analysis = []
for tweet in tweets:
try:
sentiment_result = analysis(tweet)[0]
top_sentiment = max(sentiment_result, key=lambda x: x['score']) # Get the sentiment with the higher score
tweets_analysis.append({'tweet': tweet, 'sentiment': top_sentiment['label']})
except Exception as e:
print(e)
```
5. Explore the results of sentiment analysis
Wondering if people on Twitter are talking positively or negatively about Notion? Or what do users discuss when talking positively or negatively about Notion? We'll use some data visualization to explore the results of the sentiment analysis and find out!
First, let's see examples of tweets that were labeled for each sentiment to get a sense of the different polarities of these tweets:
```python
import pandas as pd
# Load the data in a dataframe
pd.set_option('max_colwidth', None)
pd.set_option('display.width', 3000)
df = pd.DataFrame(tweets_analysis)
# Show a tweet for each sentiment
display(df[df["sentiment"] == 'Positive'].head(1))
display(df[df["sentiment"] == 'Neutral'].head(1))
display(df[df["sentiment"] == 'Negative'].head(1))
```
Results:
```
@thenotionbar @hypefury @NotionHQ That’s genuinely smart. So basically you’ve setup your posting queue to by a recurrent recycling of top content that runs 100% automatic? Sentiment: Positive
@itskeeplearning @NotionHQ How you've linked gallery cards? Sentiment: Neutral
@NotionHQ Running into an issue here recently were content is not showing on on web but still in the app. This happens for all of our pages. https://t.co/3J3AnGzDau. Sentiment: Negative
```
Next, you'll count the number of tweets that were tagged as positive, negative and neutral:
```python
sentiment_counts = df.groupby(['sentiment']).size()
print(sentiment_counts)
```
Remarkably, most of the tweets about Notion are positive:
```
sentiment
Negative 82
Neutral 420
Positive 498
```
Then, let's create a pie chart to visualize each sentiment in relative terms:
```python
import matplotlib.pyplot as plt
fig = plt.figure(figsize=(6,6), dpi=100)
ax = plt.subplot(111)
sentiment_counts.plot.pie(ax=ax, autopct='%1.1f%%', startangle=270, fontsize=12, label="")
```
It's cool to see that 50% of all tweets are positive and only 8.2% are negative:
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="Sentiment analysis results of tweets mentioning Notion" src="assets/85_sentiment_analysis_twitter/sentiment-pie.png"></medium-zoom>
<figcaption>Sentiment analysis results of tweets mentioning Notion</figcaption>
</figure>
As a last step, let's create some wordclouds to see which words are the most used for each sentiment:
```python
from wordcloud import WordCloud
from wordcloud import STOPWORDS
# Wordcloud with positive tweets
positive_tweets = df['tweet'][df["sentiment"] == 'Positive']
stop_words = ["https", "co", "RT"] + list(STOPWORDS)
positive_wordcloud = WordCloud(max_font_size=50, max_words=50, background_color="white", stopwords = stop_words).generate(str(positive_tweets))
plt.figure()
plt.title("Positive Tweets - Wordcloud")
plt.imshow(positive_wordcloud, interpolation="bilinear")
plt.axis("off")
plt.show()
# Wordcloud with negative tweets
negative_tweets = df['tweet'][df["sentiment"] == 'Negative']
stop_words = ["https", "co", "RT"] + list(STOPWORDS)
negative_wordcloud = WordCloud(max_font_size=50, max_words=50, background_color="white", stopwords = stop_words).generate(str(negative_tweets))
plt.figure()
plt.title("Negative Tweets - Wordcloud")
plt.imshow(negative_wordcloud, interpolation="bilinear")
plt.axis("off")
plt.show()
```
Curiously, some of the words that stand out from the positive tweets include "notes", "cron", and "paid":
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="Sentiment analysis results of tweets mentioning Notion" src="assets/85_sentiment_analysis_twitter/positive-tweets.png"></medium-zoom>
<figcaption>Word cloud for positive tweets</figcaption>
</figure>
In contrast, "figma", "enterprise" and "account" are some of the most used words from the negatives tweets:
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="Sentiment analysis results of tweets mentioning Notion" src="assets/85_sentiment_analysis_twitter/negative-tweets.png"></medium-zoom>
<figcaption>Word cloud for negative tweets</figcaption>
</figure>
That was fun, right?
With just a few lines of code, you were able to automatically gather tweets mentioning Notion using Tweepy, analyze them with a sentiment analysis model using the [Inference API](https://huggingface.co/inference-api), and finally create some visualizations to analyze the results. 💥
Are you interested in doing more? As a next step, you could use a second [text classifier](https://huggingface.co/tasks/text-classification) to classify each tweet by their theme or topic. This way, each tweet will be labeled with both sentiment and topic, and you can get more granular insights (e.g. are users praising how easy to use is Notion but are complaining about their pricing or customer support?).
## How to do Twitter sentiment analysis without coding?
To get started with sentiment analysis, you don't need to be a developer or know how to code. 🤯
There are some amazing no-code solutions that will enable you to easily do sentiment analysis in just a few minutes.
In this section, you will use [Zapier](https://zapier.com/), a no-code tool that enables users to connect 5,000+ apps with an easy to use user interface. You will create a [Zap](https://zapier.com/help/create/basics/create-zaps), that is triggered whenever someone mentions Notion on Twitter. Then the Zap will use the [Inference API](https://huggingface.co/inference-api) to analyze the tweet with a sentiment analysis model and finally it will save the results on Google Sheets:
1. Step 1 (trigger): Getting the tweets.
2. Step 2: Analyze tweets with sentiment analysis.
3. Step 3: Save the results on Google Sheets.
No worries, it won't take much time; in under 10 minutes, you'll create and activate the zap, and will start seeing the sentiment analysis results pop up in Google Sheets.
Let's get started! 🚀
### Step 1: Getting the Tweets
To get started, you'll need to [create a Zap](https://zapier.com/webintent/create-zap), and configure the first step of your Zap, also called the *"Trigger"* step. In your case, you will need to set it up so that it triggers the Zap whenever someone mentions Notion on Twitter. To set it up, follow the following steps:
- First select "Twitter" and select "Search mention" as event on "Choose app & event".
- Then connect your Twitter account to Zapier.
- Set up the trigger by specifying "NotionHQ" as the search term for this trigger.
- Finally test the trigger to make sure it gather tweets and runs correctly.
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="Sentiment analysis results of tweets mentioning Notion" src="assets/85_sentiment_analysis_twitter/zapier-getting-tweets-cropped-cut-optimized.gif"></medium-zoom>
<figcaption>Step 1 on the Zap</figcaption>
</figure>
### Step 2: Analyze Tweets with Sentiment Analysis
Now that your Zap can gather tweets mentioning Notion, let's add a second step to do the sentiment analysis. 🤗
You will be using [Inference API](https://huggingface.co/inference-api), an easy-to-use API for integrating machine learning models. For using the Inference API, you will need to define your "model id" and your "Hugging Face API Token":
- The `model ID` is to tell the Inference API which model you want to use for making predictions. For this guide, you will use [twitter-roberta-base-sentiment-latest](https://huggingface.co/cardiffnlp/twitter-roberta-base-sentiment-latest), a sentiment analysis model trained on ≈124 million tweets and fine-tuned for sentiment analysis. You can explore the more than [400 models for sentiment analysis available on the Hugging Face Hub](https://huggingface.co/models?pipeline_tag=text-classification&sort=downloads&search=sentiment) in case you want to use a different model (e.g. doing sentiment analysis on a different language).
- You'll also need to specify your `Hugging Face token`; you can get one for free by signing up [here](https://huggingface.co/join) and then copying your token on this [page](https://huggingface.co/settings/tokens).
Once you have your model ID and your Hugging Face token ID, go back to your Zap and follow these instructions to set up the second step of the zap:
1. First select "Code by Zapier" and "Run python" in "Choose app and event".
2. On "Set up action", you will need to first add the tweet "full text" as "input_data". Then you will need to add these [28 lines of python code](https://gist.github.com/feconroses/0e064f463b9a0227ba73195f6376c8ed) in the "Code" section. This code will allow the Zap to call the Inference API and make the predictions with sentiment analysis. Before adding this code to your zap, please make sure that you do the following:
- Change line 5 and add your Hugging Face token, that is, instead of `hf_token = "ADD_YOUR_HUGGING_FACE_TOKEN_HERE"`, you will need to change it to something like`hf_token = "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"`
- If you want to use a different sentiment analysis model, you will need to change line 4 and specify the id of the new model here. For example, instead of using the default model, you could use [this model](https://huggingface.co/finiteautomata/beto-sentiment-analysis?text=Te+quiero.+Te+amo.) to do sentiment analysis on tweets in Spanish by changing this line `model = "cardiffnlp/twitter-roberta-base-sentiment-latest"` to `model = "finiteautomata/beto-sentiment-analysis"`.
3. Finally, test this step to make sure it makes predictions and runs correctly.
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="Sentiment analysis results of tweets mentioning Notion" src="assets/85_sentiment_analysis_twitter/zapier-analyze-tweets-cropped-cut-optimized.gif"></medium-zoom>
<figcaption>Step 2 on the Zap</figcaption>
</figure>
### Step 3: Save the results on Google Sheets
As the last step to your Zap, you will save the results of the sentiment analysis on a spreadsheet on Google Sheets and visualize the results. 📊
First, [create a new spreadsheet on Google Sheets](https://docs.google.com/spreadsheets/u/0/create), and define the following columns:
- **Tweet**: this column will contain the text of the tweet.
- **Sentiment**: will have the label of the sentiment analysis results (e.g. positive, negative and neutral).
- **Score**: will store the value that reflects how confident the model is with its prediction.
- **Date**: will contain the date of the tweet (which can be handy for creating graphs and charts over time).
Then, follow these instructions to configure this last step:
1. Select Google Sheets as an app, and "Create Spreadsheet Row" as the event in "Choose app & Event".
2. Then connect your Google Sheets account to Zapier.
3. Next, you'll need to set up the action. First, you'll need to specify the Google Drive value (e.g. My Drive), then select the spreadsheet, and finally the worksheet where you want Zapier to automatically write new rows. Once you are done with this, you will need to map each column on the spreadsheet with the values you want to use when your zap automatically writes a new row on your file. If you have created the columns we suggested before, this will look like the following (column → value):
- Tweet → Full Text (value from the step 1 of the zap)
- Sentiment → Sentiment Label (value from step 2)
- Sentiment Score → Sentiment Score (value from step 2)
- Date → Created At (value from step 1)
4. Finally, test this last step to make sure it can add a new row to your spreadsheet. After confirming it's working, you can delete this row on your spreadsheet.
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="Sentiment analysis results of tweets mentioning Notion" src="assets/85_sentiment_analysis_twitter/zapier-add-to-google-sheets-cropped-cut.gif"></medium-zoom>
<figcaption>Step 3 on the Zap</figcaption>
</figure>
### 4. Turn on your Zap
At this point, you have completed all the steps of your zap! 🔥
Now, you just need to turn it on so it can start gathering tweets, analyzing them with sentiment analysis, and store the results on Google Sheets. ⚡️
To turn it on, just click on "Publish" button at the bottom of your screen:
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="Sentiment analysis results of tweets mentioning Notion" src="assets/85_sentiment_analysis_twitter/zap-turn-on-cut-optimized.gif"></medium-zoom>
<figcaption>Turning on the Zap</figcaption>
</figure>
After a few minutes, you will see how your spreadsheet starts populating with tweets and the results of sentiment analysis. You can also create a graph that can be updated in real-time as tweets come in:
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="Sentiment analysis results of tweets mentioning Notion" src="assets/85_sentiment_analysis_twitter/google-sheets-results-cropped-cut.gif"></medium-zoom>
<figcaption>Tweets popping up on Google Sheets</figcaption>
</figure>
Super cool, right? 🚀
## Wrap up
Twitter is the public town hall where people share their thoughts about all kinds of topics. From people talking about politics, sports or tech, users sharing their feedback about a new shiny app, or passengers complaining to an Airline about a canceled flight, the amount of data on Twitter is massive. Sentiment analysis allows making sense of all that data in real-time to uncover insights that can drive business decisions.
Luckily, tools like the [Inference API](https://huggingface.co/inference-api) makes it super easy to get started with sentiment analysis on Twitter. No matter if you know or don't know how to code and/or you don't have experience with machine learning, in a few minutes, you can set up a process that can gather tweets in real-time, analyze them with a state-of-the-art model for sentiment analysis, and explore the results with some cool visualizations. 🔥🔥🔥
If you have questions, you can ask them in the [Hugging Face forum](https://discuss.huggingface.co/) so the Hugging Face community can help you out and others can benefit from seeing the discussion. You can also join our [Discord](https://discord.gg/YRAq8fMnUG) server to talk with us and the entire Hugging Face community.
| 4 |
0 | hf_public_repos | hf_public_repos/blog/t2i-sdxl-adapters.md | ---
title: "Efficient Controllable Generation for SDXL with T2I-Adapters"
thumbnail: /blog/assets/t2i-sdxl-adapters/thumbnail.png
authors:
- user: Adapter
guest: true
- user: valhalla
- user: sayakpaul
- user: Xintao
guest: true
- user: hysts
---
# Efficient Controllable Generation for SDXL with T2I-Adapters
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/t2i-adapters-sdxl/hf_tencent.png" height=180/>
</p>
[T2I-Adapter](https://huggingface.co/papers/2302.08453) is an efficient plug-and-play model that provides extra guidance to pre-trained text-to-image models while freezing the original large text-to-image models. T2I-Adapter aligns internal knowledge in T2I models with external control signals. We can train various adapters according to different conditions and achieve rich control and editing effects.
As a contemporaneous work, [ControlNet](https://hf.co/papers/2302.05543) has a similar function and is widely used. However, it can be **computationally expensive** to run. This is because, during each denoising step of the reverse diffusion process, both the ControlNet and UNet need to be run. In addition, ControlNet emphasizes the importance of copying the UNet encoder as a control model, resulting in a larger parameter number. Thus, the generation is bottlenecked by the size of the ControlNet (the larger, the slower the process becomes).
T2I-Adapters provide a competitive advantage to ControlNets in this matter. T2I-Adapters are smaller in size, and unlike ControlNets, T2I-Adapters are run just once for the entire course of the denoising process.
| **Model Type** | **Model Parameters** | **Storage (fp16)** |
| --- | --- | --- |
| [ControlNet-SDXL](https://huggingface.co/diffusers/controlnet-canny-sdxl-1.0) | 1251 M | 2.5 GB |
| [ControlLoRA](https://huggingface.co/stabilityai/control-lora) (with rank 128) | 197.78 M (84.19% reduction) | 396 MB (84.53% reduction) |
| [T2I-Adapter-SDXL](https://huggingface.co/TencentARC/t2i-adapter-canny-sdxl-1.0) | 79 M (**_93.69% reduction_**) | 158 MB (**_94% reduction_**) |
Over the past few weeks, the Diffusers team and the T2I-Adapter authors have been collaborating to bring the support of T2I-Adapters for [Stable Diffusion XL (SDXL)](https://huggingface.co/papers/2307.01952) in [`diffusers`](https://github.com/huggingface/diffusers). In this blog post, we share our findings from training T2I-Adapters on SDXL from scratch, some appealing results, and, of course, the T2I-Adapter checkpoints on various conditionings (sketch, canny, lineart, depth, and openpose)!

Compared to previous versions of T2I-Adapter (SD-1.4/1.5), [T2I-Adapter-SDXL](https://github.com/TencentARC/T2I-Adapter) still uses the original recipe, driving 2.6B SDXL with a 79M Adapter! T2I-Adapter-SDXL maintains powerful control capabilities while inheriting the high-quality generation of SDXL!
## Training T2I-Adapter-SDXL with `diffusers`
We built our training script on [this official example](https://github.com/huggingface/diffusers/blob/main/examples/t2i_adapter/README_sdxl.md) provided by `diffusers`.
Most of the T2I-Adapter models we mention in this blog post were trained on 3M high-resolution image-text pairs from LAION-Aesthetics V2 with the following settings:
- Training steps: 20000-35000
- Batch size: Data parallel with a single GPU batch size of 16 for a total batch size of 128.
- Learning rate: Constant learning rate of 1e-5.
- Mixed precision: fp16
We encourage the community to use our scripts to train custom and powerful T2I-Adapters, striking a competitive trade-off between speed, memory, and quality.
## Using T2I-Adapter-SDXL in `diffusers`
Here, we take the lineart condition as an example to demonstrate the usage of [T2I-Adapter-SDXL](https://github.com/TencentARC/T2I-Adapter/tree/XL). To get started, first install the required dependencies:
```bash
pip install -U git+https://github.com/huggingface/diffusers.git
pip install -U controlnet_aux==0.0.7 # for conditioning models and detectors
pip install transformers accelerate
```
The generation process of the T2I-Adapter-SDXL mainly consists of the following two steps:
1. Condition images are first prepared into the appropriate *control image* format.
2. The *control image* and *prompt* are passed to the [`StableDiffusionXLAdapterPipeline`](https://github.com/huggingface/diffusers/blob/0ec7a02b6a609a31b442cdf18962d7238c5be25d/src/diffusers/pipelines/t2i_adapter/pipeline_stable_diffusion_xl_adapter.py#L126).
Let's have a look at a simple example using the [Lineart Adapter](https://huggingface.co/TencentARC/t2i-adapter-lineart-sdxl-1.0). We start by initializing the T2I-Adapter pipeline for SDXL and the lineart detector.
```python
import torch
from controlnet_aux.lineart import LineartDetector
from diffusers import (AutoencoderKL, EulerAncestralDiscreteScheduler,
StableDiffusionXLAdapterPipeline, T2IAdapter)
from diffusers.utils import load_image, make_image_grid
# load adapter
adapter = T2IAdapter.from_pretrained(
"TencentARC/t2i-adapter-lineart-sdxl-1.0", torch_dtype=torch.float16, varient="fp16"
).to("cuda")
# load pipeline
model_id = "stabilityai/stable-diffusion-xl-base-1.0"
euler_a = EulerAncestralDiscreteScheduler.from_pretrained(
model_id, subfolder="scheduler"
)
vae = AutoencoderKL.from_pretrained(
"madebyollin/sdxl-vae-fp16-fix", torch_dtype=torch.float16
)
pipe = StableDiffusionXLAdapterPipeline.from_pretrained(
model_id,
vae=vae,
adapter=adapter,
scheduler=euler_a,
torch_dtype=torch.float16,
variant="fp16",
).to("cuda")
# load lineart detector
line_detector = LineartDetector.from_pretrained("lllyasviel/Annotators").to("cuda")
```
Then, load an image to detect lineart:
```python
url = "https://huggingface.co/Adapter/t2iadapter/resolve/main/figs_SDXLV1.0/org_lin.jpg"
image = load_image(url)
image = line_detector(image, detect_resolution=384, image_resolution=1024)
```

Then we generate:
```python
prompt = "Ice dragon roar, 4k photo"
negative_prompt = "anime, cartoon, graphic, text, painting, crayon, graphite, abstract, glitch, deformed, mutated, ugly, disfigured"
gen_images = pipe(
prompt=prompt,
negative_prompt=negative_prompt,
image=image,
num_inference_steps=30,
adapter_conditioning_scale=0.8,
guidance_scale=7.5,
).images[0]
gen_images.save("out_lin.png")
```

There are two important arguments to understand that help you control the amount of conditioning.
1. `adapter_conditioning_scale`
This argument controls how much influence the conditioning should have on the input. High values mean a higher conditioning effect and vice-versa.
2. `adapter_conditioning_factor`
This argument controls how many initial generation steps should have the conditioning applied. The value should be set between 0-1 (default is 1). The value of `adapter_conditioning_factor=1` means the adapter should be applied to all timesteps, while the `adapter_conditioning_factor=0.5` means it will only applied for the first 50% of the steps.
For more details, we welcome you to check the [official documentation](https://huggingface.co/docs/diffusers/main/en/api/pipelines/stable_diffusion/adapter).
## Try out the Demo
You can easily try T2I-Adapter-SDXL in [this Space](https://huggingface.co/spaces/TencentARC/T2I-Adapter-SDXL) or in the playground embedded below:
<script type="module" src="https://gradio.s3-us-west-2.amazonaws.com/3.43.1/gradio.js"></script>
<gradio-app src="https://tencentarc-t2i-adapter-sdxl.hf.space"></gradio-app>
You can also try out [Doodly](https://huggingface.co/spaces/TencentARC/T2I-Adapter-SDXL-Sketch), built using the sketch model that turns your doodles into realistic images (with language supervision):
<script type="module" src="https://gradio.s3-us-west-2.amazonaws.com/3.43.1/gradio.js"></script>
<gradio-app src="https://tencentarc-t2i-adapter-sdxl-sketch.hf.space"></gradio-app>
## More Results
Below, we present results obtained from using different kinds of conditions. We also supplement the results with links to their corresponding pre-trained checkpoints. Their model cards contain more details on how they were trained, along with example usage.
### Lineart Guided

*Model from [`TencentARC/t2i-adapter-lineart-sdxl-1.0`](https://huggingface.co/TencentARC/t2i-adapter-lineart-sdxl-1.0)*
### Sketch Guided

*Model from [`TencentARC/t2i-adapter-sketch-sdxl-1.0`](https://huggingface.co/TencentARC/t2i-adapter-sketch-sdxl-1.0)*
### Canny Guided

*Model from [`TencentARC/t2i-adapter-canny-sdxl-1.0`](https://huggingface.co/TencentARC/t2i-adapter-canny-sdxl-1.0)*
### Depth Guided

*Depth guided models from [`TencentARC/t2i-adapter-depth-midas-sdxl-1.0`](https://huggingface.co/TencentARC/t2i-adapter-depth-midas-sdxl-1.0) and [`TencentARC/t2i-adapter-depth-zoe-sdxl-1.0`](https://huggingface.co/TencentARC/t2i-adapter-depth-zoe-sdxl-1.0) respectively*
### OpenPose Guided

*Model from [`TencentARC/t2i-adapter-openpose-sdxl-1.0`](https://hf.co/TencentARC/t2i-adapter-openpose-sdxl-1.0)*
---
*Acknowledgements: Immense thanks to [William Berman](https://twitter.com/williamLberman) for helping us train the models and sharing his insights.*
| 5 |
0 | hf_public_repos | hf_public_repos/blog/peft.md | ---
title: "Parameter-Efficient Fine-Tuning using 🤗 PEFT"
thumbnail: /blog/assets/130_peft/thumbnail.png
authors:
- user: smangrul
- user: sayakpaul
---
# 🤗 PEFT: Parameter-Efficient Fine-Tuning of Billion-Scale Models on Low-Resource Hardware
## Motivation
Large Language Models (LLMs) based on the transformer architecture, like GPT, T5, and BERT have achieved state-of-the-art results in various Natural Language Processing (NLP) tasks. They have also started foraying into other domains, such as Computer Vision (CV) (VIT, Stable Diffusion, LayoutLM) and Audio (Whisper, XLS-R). The conventional paradigm is large-scale pretraining on generic web-scale data, followed by fine-tuning to downstream tasks. Fine-tuning these pretrained LLMs on downstream datasets results in huge performance gains when compared to using the pretrained LLMs out-of-the-box (zero-shot inference, for example).
However, as models get larger and larger, full fine-tuning becomes infeasible to train on consumer hardware. In addition, storing and deploying fine-tuned models independently for each downstream task becomes very expensive, because fine-tuned models are the same size as the original pretrained model. Parameter-Efficient Fine-tuning (PEFT) approaches are meant to address both problems!
PEFT approaches only fine-tune a small number of (extra) model parameters while freezing most parameters of the pretrained LLMs, thereby greatly decreasing the computational and storage costs. This also overcomes the issues of [catastrophic forgetting](https://arxiv.org/abs/1312.6211), a behaviour observed during the full finetuning of LLMs. PEFT approaches have also shown to be better than fine-tuning in the low-data regimes and generalize better to out-of-domain scenarios. It can be applied to various modalities, e.g., [image classification](https://github.com/huggingface/peft/tree/main/examples/image_classification) and [stable diffusion dreambooth](https://github.com/huggingface/peft/tree/main/examples/lora_dreambooth).
It also helps in portability wherein users can tune models using PEFT methods to get tiny checkpoints worth a few MBs compared to the large checkpoints of full fine-tuning, e.g., `bigscience/mt0-xxl` takes up 40GB of storage and full fine-tuning will lead to 40GB checkpoints for each downstream dataset whereas using PEFT methods it would be just a few MBs for each downstream dataset all the while achieving comparable performance to full fine-tuning. The small trained weights from PEFT approaches are added on top of the pretrained LLM. So the same LLM can be used for multiple tasks by adding small weights without having to replace the entire model.
**In short, PEFT approaches enable you to get performance comparable to full fine-tuning while only having a small number of trainable parameters.**
Today, we are excited to introduce the [🤗 PEFT](https://github.com/huggingface/peft) library, which provides the latest Parameter-Efficient Fine-tuning techniques seamlessly integrated with 🤗 Transformers and 🤗 Accelerate. This enables using the most popular and performant models from Transformers coupled with the simplicity and scalability of Accelerate. Below are the currently supported PEFT methods, with more coming soon:
1. LoRA: [LORA: LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS](https://arxiv.org/pdf/2106.09685.pdf)
2. Prefix Tuning: [P-Tuning v2: Prompt Tuning Can Be Comparable to Fine-tuning Universally Across Scales and Tasks](https://arxiv.org/pdf/2110.07602.pdf)
3. Prompt Tuning: [The Power of Scale for Parameter-Efficient Prompt Tuning](https://arxiv.org/pdf/2104.08691.pdf)
4. P-Tuning: [GPT Understands, Too](https://arxiv.org/pdf/2103.10385.pdf)
## Use Cases
We explore many interesting use cases [here](https://github.com/huggingface/peft#use-cases). These are a few of the most interesting ones:
1. Using 🤗 PEFT LoRA for tuning `bigscience/T0_3B` model (3 Billion parameters) on consumer hardware with 11GB of RAM, such as Nvidia GeForce RTX 2080 Ti, Nvidia GeForce RTX 3080, etc using 🤗 Accelerate's DeepSpeed integration: [peft_lora_seq2seq_accelerate_ds_zero3_offload.py](https://github.com/huggingface/peft/blob/main/examples/conditional_generation/peft_lora_seq2seq_accelerate_ds_zero3_offload.py). This means you can tune such large LLMs in Google Colab.
2. Taking the previous example a notch up by enabling INT8 tuning of the `OPT-6.7b` model (6.7 Billion parameters) in Google Colab using 🤗 PEFT LoRA and [bitsandbytes](https://github.com/TimDettmers/bitsandbytes): [](https://colab.research.google.com/drive/1jCkpikz0J2o20FBQmYmAGdiKmJGOMo-o?usp=sharing)
3. Stable Diffusion Dreambooth training using 🤗 PEFT on consumer hardware with 11GB of RAM, such as Nvidia GeForce RTX 2080 Ti, Nvidia GeForce RTX 3080, etc. Try out the Space demo, which should run seamlessly on a T4 instance (16GB GPU): [smangrul/peft-lora-sd-dreambooth](https://huggingface.co/spaces/smangrul/peft-lora-sd-dreambooth).
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/peft/peft_lora_dreambooth_gradio_space.png" alt="peft lora dreambooth gradio space"><br>
<em>PEFT LoRA Dreambooth Gradio Space</em>
</p>
## Training your model using 🤗 PEFT
Let's consider the case of fine-tuning [`bigscience/mt0-large`](https://huggingface.co/bigscience/mt0-large) using LoRA.
1. Let's get the necessary imports
```diff
from transformers import AutoModelForSeq2SeqLM
+ from peft import get_peft_model, LoraConfig, TaskType
model_name_or_path = "bigscience/mt0-large"
tokenizer_name_or_path = "bigscience/mt0-large"
```
2. Creating config corresponding to the PEFT method
```py
peft_config = LoraConfig(
task_type=TaskType.SEQ_2_SEQ_LM, inference_mode=False, r=8, lora_alpha=32, lora_dropout=0.1
)
```
3. Wrapping base 🤗 Transformers model by calling `get_peft_model`
```diff
model = AutoModelForSeq2SeqLM.from_pretrained(model_name_or_path)
+ model = get_peft_model(model, peft_config)
+ model.print_trainable_parameters()
# output: trainable params: 2359296 || all params: 1231940608 || trainable%: 0.19151053100118282
```
That's it! The rest of the training loop remains the same. Please refer example [peft_lora_seq2seq.ipynb](https://github.com/huggingface/peft/blob/main/examples/conditional_generation/peft_lora_seq2seq.ipynb) for an end-to-end example.
4. When you are ready to save the model for inference, just do the following.
```py
model.save_pretrained("output_dir")
# model.push_to_hub("my_awesome_peft_model") also works
```
This will only save the incremental PEFT weights that were trained. For example, you can find the `bigscience/T0_3B` tuned using LoRA on the `twitter_complaints` raft dataset here: [smangrul/twitter_complaints_bigscience_T0_3B_LORA_SEQ_2_SEQ_LM](https://huggingface.co/smangrul/twitter_complaints_bigscience_T0_3B_LORA_SEQ_2_SEQ_LM). Notice that it only contains 2 files: adapter_config.json and adapter_model.bin with the latter being just 19MB.
5. To load it for inference, follow the snippet below:
```diff
from transformers import AutoModelForSeq2SeqLM
+ from peft import PeftModel, PeftConfig
peft_model_id = "smangrul/twitter_complaints_bigscience_T0_3B_LORA_SEQ_2_SEQ_LM"
config = PeftConfig.from_pretrained(peft_model_id)
model = AutoModelForSeq2SeqLM.from_pretrained(config.base_model_name_or_path)
+ model = PeftModel.from_pretrained(model, peft_model_id)
tokenizer = AutoTokenizer.from_pretrained(config.base_model_name_or_path)
model = model.to(device)
model.eval()
inputs = tokenizer("Tweet text : @HondaCustSvc Your customer service has been horrible during the recall process. I will never purchase a Honda again. Label :", return_tensors="pt")
with torch.no_grad():
outputs = model.generate(input_ids=inputs["input_ids"].to("cuda"), max_new_tokens=10)
print(tokenizer.batch_decode(outputs.detach().cpu().numpy(), skip_special_tokens=True)[0])
# 'complaint'
```
## Next steps
We've released PEFT as an efficient way of tuning large LLMs on downstream tasks and domains, saving a lot of compute and storage while achieving comparable performance to full finetuning. In the coming months, we'll be exploring more PEFT methods, such as (IA)3 and bottleneck adapters. Also, we'll focus on new use cases such as INT8 training of [`whisper-large`](https://huggingface.co/openai/whisper-large) model in Google Colab and tuning of RLHF components such as policy and ranker using PEFT approaches.
In the meantime, we're excited to see how industry practitioners apply PEFT to their use cases - if you have any questions or feedback, open an issue on our [GitHub repo](https://github.com/huggingface/peft) 🤗.
Happy Parameter-Efficient Fine-Tuning! | 6 |
0 | hf_public_repos | hf_public_repos/blog/leaderboard-japanese.md | ---
title: "Introducing the Open Leaderboard for Japanese LLMs!"
thumbnail: /blog/assets/leaderboards-on-the-hub/thumbnail_japanese.png
authors:
- user: akimfromparis
guest: true
org: llm-jp
- user: miyao-yusuke
guest: true
org: llm-jp
- user: namgiH
guest: true
org: llm-jp
- user: t0-0
guest: true
org: llm-jp
- user: sh1gechan
guest: true
org: llm-jp
- user: hysts
- user: clefourrier
---
# Introduction to the Open Leaderboard for Japanese LLMs
LLMs are now increasingly capable in English, but it's quite hard to know how well they perform in other national languages, widely spoken but which present their own set of linguistic challenges. Today, we are excited to fill this gap for Japanese!
We'd like to announce the **[Open Japanese LLM Leaderboard](https://huggingface.co/spaces/llm-jp/open-japanese-llm-leaderboard)**, composed of more than 20 datasets from classical to modern NLP tasks to understand underlying mechanisms of Japanese LLMs. The Open Japanese LLM Leaderboard was built by the **[LLM-jp](https://llm-jp.nii.ac.jp/en/)**, a cross-organizational project for the research and development of Japanese large language models (LLMs) in partnership with **Hugging Face**.
The Japanese language presents its own specific challenges. Morphologically rich and in constant evolution due to historical and cultural interactions with the rest of the world, its writing system is based on a mixture of three separate sets of characters: simplified Chinese ideographic symbols kanjis (漢字), a phonetic lettering system, Hiraganas (平仮名 / ひらがな), and Katakanas (片仮名 / カタカナ) often used for foreigners words. Modern Japanese is arguably one of the hardest language to process, as it mixes up a blend of Sino-Japanese, native Japanese, Latin script (romaji /ローマ字), loanwords from the Dutch, Portuguese, French, English, German, plus Arabic and traditional Chinese numerals. In addition, the Japanese digital world brought us an evolution of emoticons written in Unicode : ), Kaomoji using Cyrillic alphabet. (っ °Д °;)っ and Greek alphabets _φ(°-°=). Without forgetting, of course, the classic emojis that originated from Japan with the rise in popularity of mobile phones in the 1990s.

The intricate writing system of Japanese hides an extra layer of complexity, the lack of space between words. Similar to the Chinese or Thai languages, Japanese language doesn’t have white space between linguistic units, making the detection of word boundaries extremely difficult during tokenization. Over the years, the vibrant Japanese ecosystem (from prestigious university laboratories and AI startups to the R&D centers of industry giants) has incorporated the specificities of Japanese NLP to develop modern robust Japanese LLMs, but the field has been lacking a centralized and open system to compare these models.
We therefore introduce the Open Japanese LLM Leaderboard, a collaboration between Hugging Face and LLM-jp, to foster transparency in research, and encourage an open-source model development philosophy. We strongly believe this initiative will serve as a platform for Japanese and international researchers to collaborate, evaluate, and enhance Japanese LLMs.
## Introduction to the Leaderboard Tasks
The Open Japanese LLM Leaderboard evaluates Japanese LLMs using a specialized evaluation suite, **[llm-jp-eval](https://github.com/llm-jp/llm-jp-eval)**, covering a range of 16 tasks from classical ones (such as *Natural Language Inference, Machine Translation, Summarization, Question Answering*) to more modern ones (such as *Code Generation*, *Mathematical Reasoning* or *Human Examination*). Tasks are launched in 4-shot.
Datasets have been compiled by the evaluation team of LLM-jp, either built from scratch with linguists, experts, and human annotators, or translated automatically to Japanese and adjusted to Japanese specificities, and for some requiring long context reasoning. For a better understanding of the leaderboard, we will detail samples from 8 datasets (in Japanese followed by the English translation in light gray). For more details about all the available tasks, please see to the “About” tab of the leaderboard, and official links on each datasets.
### Jamp
**Jamp** (*Controlled Japanese Temporal Inference Dataset for Evaluating Generalization Capacity of Language Models*) is the Japanese temporal inference benchmark for NLI. The dataset explore English and Japanese sentence pairs of various temporal inference patterns annotated with the golden labels such as entailment, neutral, or contradiction.

### JEMHopQA
**JEMHopQA** (*Japanese Explainable Multi-hop Question Answering*) is a Japanese multi-hop QA dataset that can evaluate internal reasoning. It is a task that takes a question as input and generates an answer and derivations.

### jcommonsenseqa
**jcommonsenseqa** is a Japanese version of CommonsenseQA, which is a multiple-choice question answering dataset. The purpose of this dataset is to evaluate commonsense reasoning ability.

### chABSA
**chABSA** was developed as an *Aspect-Based Sentiment Analysis* dataset. ChABSA is based on financial reports of Japanese listed-companies in the 2016 fiscal year, annotated on the pair of entity, the attribute, and the sentiment. More specifically, 230 out of 2,260 companies listed in Japan (roughly 10% of all company) were annotated according to the taxonomy of the Japanese financial regulator, *Financial Service Agency (FSA)*.

### mbpp-ja
The **mbpp-ja** dataset is a programming dataset: it is a Japanese version of *Mostly Basic Python Problems dataset* (MBPP) translated from English into Japanese by **[LLM-jp](https://llm-jp.nii.ac.jp/en/)** by leveraging the translation tool **[DeepL](https://www.deepl.com)**.

### mawps
Based on the dataset `MAWPS` *(A Math Word Problem Repository)*, the Japanese **mawps** dataset is a mathematical evaluation dataset. This version evaluates the abilities of solving novel tasks by reasoning step-by-step, procedure otherwise known as Chain-of-Thought (CoT) reasoning, and was adjusted to converting names of people, units, and places to fit the Japanese context. The level of mathematical reasoning is rather simple: addition, subtraction, multistep arithmetic, and single or pairs of equations.

### JMMLU
**JMMLU** is a knowledge dataset using four-choice question answers. It consists in Japanese-translated questions from a portion of MMLU dataset that evaluates knowledge on high-school level tests. Based on 57 subjects such as astronomy, chemistry, sociology, international law, etc., questions and answers were translated in Japanese, while being adjusted to unique Japanese cultural context like Japanese civics, Japanese geography, and Japanese idioms.

### XL-Sum
**XL-Sum** is a summarisation dataset based on the research titled *“XL-Sum: Large-Scale Multilingual Abstractive Summarization for 44 Languages”* that leverages the Japanese translation of articles from BBC News. The dataset is separated in three parts; the title, the text (the full-length article), and the summary. Topics include global issues, politics, technology, sports, and culture.

## Technical Setup
The leaderboard is inspired by the **[Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)**. Models that are submitted are deployed automatically using HuggingFace’s **[Inference endpoints](https://huggingface.co/docs/inference-endpoints/index)**, evaluated through the **[llm-jp-eval](https://github.com/llm-jp/llm-jp-eval)** library on the version 1.14.1, with memory-efficient inference and serving engine, **[vLLM](https://github.com/vllm-project/vllm)** on the verison v0.6.3, and computed in the backend by the premium computer platform for research in Japan, **[mdx](https://mdx.jp/)**.
## Observations
According to the Japanese LLMs guide **[Awesome Japanese LLM](https://llm-jp.github.io/awesome-japanese-llm/)** (available in Japanese, English, and French), Meta's `LLama` open-source architecture seems to be the favourite of many Japanese AI labs. However, other architectures have also been successfully leveraged by the Japanese open-source community, such as `Mistral` from French Mistral, and `Qwen` by Chinese Alibaba. These are the architectures which led to the best scores on the Japanese LLM Leaderboard.
On general language processing tasks, we observe that Japanese LLMs based on open-source architectures are closing the gap with closed source LLMs, such as the Japanese LLM `llm-jp-3-13b-instruct`, developed by LLM-jp and funded by university grants, reaching a performance similar to closed source models. Domain specific datasets, such as `chABSA` (finance), `Wikipedia Annotated Corpus` (linguistic annotations), code generation (`mbpp-ja`) and summarization (`XL-Sum`) remain a challenge for most LLMs. Interestingly, models originating from Japanese-based companies or labs have better scores on the specific `JCommonsenseMorality` dataset. It evaluates model ability to make choices according to Japanese values when against ethical dilemmas
## Future directions
The Open Japanese LLM Leaderboard will follow the development of the evaluation tool **[llm-jp-eval](https://github.com/llm-jp/llm-jp-eval)** to reflect the constant evolution of Japanese LLMs. The following are just examples of future directions in llm-jp-eval that we would like to support, feel free to contact us to give a hand or suggest directions!
- **New datasets: More Japanese evaluations**
The evaluation team of llm-jp-eval is working on this section, adding at the moment **[JHumanEval](https://huggingface.co/datasets/kogi-jwu/jhumaneval)** (*Japanese version of HumanEval*) and **[MMLU](https://github.com/hendrycks/test)** (*Measuring Massive Multitask Language Understanding*).
- **New evaluation system: Chain-of-Thought evaluation**
We'd like to compare the performance of LLMs between when employing Chain-of-Thought prompts against basic prompts to have a finer understanding of model behaviors.
- **New metric support: Out-of-Choice rate**
For some evaluation tasks that already have a clear list of labels used in the specific task, such as Natural Language Inference, we'd like to add a complementary metric, testing how often the model predicts out-of-choice tokens. As the choices are provided in the prompt, this will allow us to evaluate how well each LLM is able to follow specific instructions.
## Acknowledgements
Built by the research consortium **LLM-jp**, the Open Japanese LLM Leaderboard is proudly sponsored by the **[National Institute of Informatics](https://www.nii.ac.jp/en/)** in Tokyo, Japan in collaboration with the high-performance computing platform, **[mdx](https://mdx.jp/)** program.
We would like to extend our gratitude to **Prof. Yusuke Miyao** and **Namgi Han** from the *University of Tokyo* for their scientific consultation and guidance, as well as **Clémentine Fourrier** and **Toshihiro Hayashi** of *Hugging Face* that has assisted with the integration and customization of their new evaluation framework and leaderboard template. | 7 |
0 | hf_public_repos | hf_public_repos/blog/text-to-video.md | ---
title: "A Dive into Text-to-Video Models"
thumbnail: /blog/assets/140_text-to-video/thumbnail.png
authors:
- user: adirik
---
# Text-to-Video: The Task, Challenges and the Current State
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/140_text-to-video/text-to-video-samples.gif" alt="video-samples"><br>
<em>Video samples generated with <a href=https://modelscope.cn/models/damo/text-to-video-synthesis/summary>ModelScope</a>.</em>
</p>
Text-to-video is next in line in the long list of incredible advances in generative models. As self-descriptive as it is, text-to-video is a fairly new computer vision task that involves generating a sequence of images from text descriptions that are both temporally and spatially consistent. While this task might seem extremely similar to text-to-image, it is notoriously more difficult. How do these models work, how do they differ from text-to-image models, and what kind of performance can we expect from them?
In this blog post, we will discuss the past, present, and future of text-to-video models. We will start by reviewing the differences between the text-to-video and text-to-image tasks, and discuss the unique challenges of unconditional and text-conditioned video generation. Additionally, we will cover the most recent developments in text-to-video models, exploring how these methods work and what they are capable of. Finally, we will talk about what we are working on at Hugging Face to facilitate the integration and use of these models and share some cool demos and resources both on and outside of the Hugging Face Hub.
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/140_text-to-video/make-a-video.png" alt="samples"><br>
<em>Examples of videos generated from various text description inputs, image taken from <a href=https://arxiv.org/abs/2209.14792>Make-a-Video</a>.</em>
</p>
## Text-to-Video vs. Text-to-Image
With so many recent developments, it can be difficult to keep up with the current state of text-to-image generative models. Let's do a quick recap first.
Just two years ago, the first open-vocabulary, high-quality text-to-image generative models emerged. This first wave of text-to-image models, including VQGAN-CLIP, XMC-GAN, and GauGAN2, all had GAN architectures. These were quickly followed by OpenAI's massively popular transformer-based DALL-E in early 2021, DALL-E 2 in April 2022, and a new wave of diffusion models pioneered by Stable Diffusion and Imagen. The huge success of Stable Diffusion led to many productionized diffusion models, such as DreamStudio and RunwayML GEN-1, and integration with existing products, such as Midjourney.
Despite the impressive capabilities of diffusion models in text-to-image generation, diffusion and non-diffusion based text-to-video models are significantly more limited in their generative capabilities. Text-to-video are typically trained on very short clips, meaning they require a computationally expensive and slow sliding window approach to generate long videos. As a result, these models are notoriously difficult to deploy and scale and remain limited in context and length.
The text-to-video task faces unique challenges on multiple fronts. Some of these main challenges include:
- Computational challenges: Ensuring spatial and temporal consistency across frames creates long-term dependencies that come with a high computation cost, making training such models unaffordable for most researchers.
- Lack of high-quality datasets: Multi-modal datasets for text-to-video generation are scarce and often sparsely annotated, making it difficult to learn complex movement semantics.
- Vagueness around video captioning: Describing videos in a way that makes them easier for models to learn from is an open question. More than a single short text prompt is required to provide a complete video description. A generated video must be conditioned on a sequence of prompts or a story that narrates what happens over time.
In the next section, we will discuss the timeline of developments in the text-to-video domain and the various methods proposed to address these challenges separately. On a higher level, text-to-video works propose one of these:
1. New, higher-quality datasets that are easier to learn from.
2. Methods to train such models without paired text-video data.
3. More computationally efficient methods to generate longer and higher resolution videos.
## How to Generate Videos from Text?
Let's take a look at how text-to-video generation works and the latest developments in this field. We will explore how text-to-video models have evolved, following a similar path to text-to-image research, and how the specific challenges of text-to-video generation have been tackled so far.
Like the text-to-image task, early work on text-to-video generation dates back only a few years. Early research predominantly used GAN and VAE-based approaches to auto-regressively generate frames given a caption (see [Text2Filter](https://huggingface.co/papers/1710.00421) and [TGANs-C](https://huggingface.co/papers/1804.08264)). While these works provided the foundation for a new computer vision task, they are limited to low resolutions, short-range, and singular, isolated motions.
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/140_text-to-video/TGANs-C.png" alt="tgans-c"><br>
<em>Initial text-to-video models were extremely limited in resolution, context and length, image taken from <a href=https://arxiv.org/abs/1804.08264>TGANs-C</a>.</em>
</p>
Taking inspiration from the success of large-scale pretrained transformer models in text (GPT-3) and image (DALL-E), the next surge of text-to-video generation research adopted transformer architectures. [Phenaki](https://huggingface.co/papers/2210.02399), [Make-A-Video](https://huggingface.co/papers/2209.14792), [NUWA](https://huggingface.co/papers/2111.12417), [VideoGPT](https://huggingface.co/papers/2104.10157) and [CogVideo](https://huggingface.co/papers/2205.15868) all propose transformer-based frameworks, while works such as [TATS](https://huggingface.co/papers/2204.03638) propose hybrid methods that combine VQGAN for image generation and a time-sensitive transformer module for sequential generation of frames. Out of this second wave of works, Phenaki is particularly interesting as it enables generating arbitrary long videos conditioned on a sequence of prompts, in other words, a story line. Similarly, [NUWA-Infinity](https://huggingface.co/papers/2207.09814) proposes an autoregressive over autoregressive generation mechanism for infinite image and video synthesis from text inputs, enabling the generation of long, HD quality videos. However, neither Phenaki or NUWA models are publicly available.
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/140_text-to-video/phenaki.png" alt="phenaki"><br>
<em>Phenaki features a transformer-based architecture, image taken from <a href=https://arxiv.org/abs/2210.02399>here</a>.</em>
</p>
The third and current wave of text-to-video models features predominantly diffusion-based architectures. The remarkable success of diffusion models in diverse, hyper-realistic, and contextually rich image generation has led to an interest in generalizing diffusion models to other domains such as audio, 3D, and, more recently, video. This wave of models is pioneered by [Video Diffusion Models](https://huggingface.co/papers/2204.03458) (VDM), which extend diffusion models to the video domain, and [MagicVideo](https://huggingface.co/papers/2211.11018), which proposes a framework to generate video clips in a low-dimensional latent space and reports huge efficiency gains over VDM. Another notable mention is [Tune-a-Video](https://huggingface.co/papers/2212.11565), which fine-tunes a pretrained text-to-image model with a single text-video pair and enables changing the video content while preserving the motion. The continuously expanding list of text-to-video diffusion models that followed include [Video LDM](https://huggingface.co/papers/2304.08818), [Text2Video-Zero](https://huggingface.co/papers/2303.13439), [Runway Gen1 and Gen2](https://huggingface.co/papers/2302.03011), and [NUWA-XL](https://huggingface.co/papers/2303.12346).
Text2Video-Zero is a text-guided video generation and manipulation framework that works in a fashion similar to ControlNet. It can directly generate (or edit) videos based on text inputs, as well as combined text-pose or text-edge data inputs. As implied by its name, Text2Video-Zero is a zero-shot model that combines a trainable motion dynamics module with a pre-trained text-to-image Stable Diffusion model without using any paired text-video data. Similarly to Text2Video-Zero, Runway’s Gen-1 and Gen-2 models enable synthesizing videos guided by content described through text or images. Most of these works are trained on short video clips and rely on autoregressive generation with a sliding window to generate longer videos, inevitably resulting in a context gap. NUWA-XL addresses this issue and proposes a “diffusion over diffusion” method to train models on 3376 frames. Finally, there are open-source text-to-video models and frameworks such as Alibaba / DAMO Vision Intelligence Lab’s ModelScope and Tencel’s VideoCrafter, which haven't been published in peer-reviewed conferences or journals.
## Datasets
Like other vision-language models, text-to-video models are typically trained on large paired datasets videos and text descriptions. The videos in these datasets are typically split into short, fixed-length chunks and often limited to isolated actions with a few objects. While this is partly due to computational limitations and partly due to the difficulty of describing video content in a meaningful way, we see that developments in multimodal video-text datasets and text-to-video models are often entwined. While some work focuses on developing better, more generalizable datasets that are easier to learn from, works such as [Phenaki](https://phenaki.video/?mc_cid=9fee7eeb9d#) explore alternative solutions such as combining text-image pairs with text-video pairs for the text-to-video task. Make-a-Video takes this even further by proposing using only text-image pairs to learn what the world looks like and unimodal video data to learn spatio-temporal dependencies in an unsupervised fashion.
These large datasets experience similar issues to those found in text-to-image datasets. The most commonly used text-video dataset, [WebVid](https://m-bain.github.io/webvid-dataset/), consists of 10.7 million pairs of text-video pairs (52K video hours) and contains a fair amount of noisy samples with irrelevant video descriptions. Other datasets try to overcome this issue by focusing on specific tasks or domains. For example, the [Howto100M](https://www.di.ens.fr/willow/research/howto100m/) dataset consists of 136M video clips with captions that describe how to perform complex tasks such as cooking, handcrafting, gardening, and fitness step-by-step. Similarly, the [QuerYD](https://www.robots.ox.ac.uk/~vgg/data/queryd/) dataset focuses on the event localization task such that the captions of videos describe the relative location of objects and actions in detail. [CelebV-Text](https://celebv-text.github.io/) is a large-scale facial text-video dataset of over 70K videos to generate videos with realistic faces, emotions, and gestures.
## Text-to-Video at Hugging Face
Using Hugging Face Diffusers, you can easily download, run and fine-tune various pretrained text-to-video models, including Text2Video-Zero and ModelScope by [Alibaba / DAMO Vision Intelligence Lab](https://huggingface.co/damo-vilab). We are currently working on integrating other exciting works into Diffusers and 🤗 Transformers.
### Hugging Face Demos
At Hugging Face, our goal is to make it easier to use and build upon state-of-the-art research. Head over to our hub to see and play around with Spaces demos contributed by the 🤗 team, countless community contributors and research authors. At the moment, we host demos for [VideoGPT](https://huggingface.co/spaces/akhaliq/VideoGPT), [CogVideo](https://huggingface.co/spaces/THUDM/CogVideo), [ModelScope Text-to-Video](https://huggingface.co/spaces/damo-vilab/modelscope-text-to-video-synthesis), and [Text2Video-Zero](https://huggingface.co/spaces/PAIR/Text2Video-Zero) with many more to come. To see what we can do with these models, let's take a look at the Text2Video-Zero demo. This demo not only illustrates text-to-video generation but also enables multiple other generation modes for text-guided video editing and joint conditional video generation using pose, depth and edge inputs along with text prompts.
<script type="module" src="https://gradio.s3-us-west-2.amazonaws.com/3.23.0/gradio.js"></script>
<gradio-app theme_mode="light" space="PAIR/Text2Video-Zero"></gradio-app>
Apart from using demos to experiment with pretrained text-to-video models, you can also use the [Tune-a-Video training demo](https://huggingface.co/spaces/Tune-A-Video-library/Tune-A-Video-Training-UI) to fine-tune an existing text-to-image model with your own text-video pair. To try it out, upload a video and enter a text prompt that describes the video. Once the training is done, you can upload it to the Hub under the Tune-a-Video community or your own username, publicly or privately. Once the training is done, simply head over to the *Run* tab of the demo to generate videos from any text prompt.
<gradio-app theme_mode="light" space="Tune-A-Video-library/Tune-A-Video-Training-UI"></gradio-app>
All Spaces on the 🤗 Hub are Git repos you can clone and run on your local or deployment environment. Let’s clone the ModelScope demo, install the requirements, and run it locally.
```
git clone https://huggingface.co/spaces/damo-vilab/modelscope-text-to-video-synthesis
cd modelscope-text-to-video-synthesis
pip install -r requirements.txt
python app.py
```
And that's it! The Modelscope demo is now running locally on your computer. Note that the ModelScope text-to-video model is supported in Diffusers and you can directly load and use the model to generate new videos with a few lines of code.
```
import torch
from diffusers import DiffusionPipeline, DPMSolverMultistepScheduler
from diffusers.utils import export_to_video
pipe = DiffusionPipeline.from_pretrained("damo-vilab/text-to-video-ms-1.7b", torch_dtype=torch.float16, variant="fp16")
pipe.scheduler = DPMSolverMultistepScheduler.from_config(pipe.scheduler.config)
pipe.enable_model_cpu_offload()
prompt = "Spiderman is surfing"
video_frames = pipe(prompt, num_inference_steps=25).frames
video_path = export_to_video(video_frames)
```
### Community Contributions and Open Source Text-to-Video Projects
Finally, there are various open source projects and models that are not on the hub. Some notable mentions are Phil Wang’s (aka lucidrains) unofficial implementations of [Imagen](https://github.com/lucidrains/imagen-pytorch), [Phenaki](https://github.com/lucidrains/phenaki-pytorch), [NUWA](https://github.com/lucidrains/nuwa-pytorch), [Make-a-Video](https://github.com/lucidrains/make-a-video-pytorch) and [Video Diffusion Models](https://github.com/lucidrains/video-diffusion-pytorch). Another exciting project by [ExponentialML](https://github.com/ExponentialML/Text-To-Video-Finetuning) builds on top of 🤗 diffusers to finetune ModelScope Text-to-Video.
## Conclusion
Text-to-video research is progressing exponentially, but existing work is still limited in context and faces many challenges. In this blog post, we covered the constraints, unique challenges and the current state of text-to-video generation models. We also saw how architectural paradigms originally designed for other tasks enable giant leaps in the text-to-video generation task and what this means for future research. While the developments are impressive, text-to-video models still have a long way to go compared to text-to-image models. Finally, we also showed how you can use these models to perform various tasks using the demos available on the Hub or as a part of 🤗 Diffusers pipelines.
That was it! We are continuing to integrate the most impactful computer vision and multi-modal models and would love to hear back from you. To stay up to date with the latest news in computer vision and multi-modal research, you can follow us on Twitter: **[@adirik](https://twitter.com/alaradirik)**, **[@a_e_roberts](https://twitter.com/a_e_roberts)**, [@osanseviero](https://twitter.com/NielsRogge), [@risingsayak](https://twitter.com/risingsayak) and **[@huggingface](https://twitter.com/huggingface)**.
| 8 |
0 | hf_public_repos | hf_public_repos/blog/improve_parquet_dedupe.md | ---
title: "Improving Parquet Dedupe on Hugging Face Hub"
thumbnail: /blog/assets/improve_parquet_dedupe/thumbnail.png
authors:
- user: yuchenglow
- user: seanses
---
# Improving Parquet Dedupe on Hugging Face Hub
The Xet team at Hugging Face is working on improving the efficiency of the Hub's
storage architecture to make it easier and quicker for users to
store and update data and models. As Hugging Face hosts nearly 11PB of datasets
with Parquet files alone accounting for over 2.2PB of that storage,
optimizing Parquet storage is of pretty high priority.
Most Parquet files are bulk exports from various data analysis pipelines
or databases, often appearing as full snapshots rather than incremental
updates. Data deduplication becomes critical for efficiency when users want to
update their datasets on a regular basis. Only by deduplicating can we store
all versions as compactly as possible, without requiring everything to be uploaded
again on every update. In an ideal case, we should be able to store every version
of a growing dataset with only a little more space than the size of its largest version.
Our default storage algorithm uses byte-level [Content-Defined Chunking (CDC)](https://joshleeb.com/posts/content-defined-chunking.html),
which generally dedupes well over insertions and deletions, but the Parquet layout brings some challenges.
Here we run some experiments to see how some simple modifications behave on
Parquet files, using a 2GB Parquet file with 1,092,000 rows from the
[FineWeb](https://huggingface.co/datasets/HuggingFaceFW/fineweb/tree/main/data/CC-MAIN-2013-20)
dataset and generating visualizations using our [dedupe
estimator](https://github.com/huggingface/dedupe_estimator).
## Background
Parquet tables work by splitting the table into row groups, each with a fixed
number of rows (for instance 1000 rows). Each column within the row group is
then compressed and stored:
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/improve_parquet_dedupe/layout.png" alt="Parquet Layout" width=80%>
</p>
Intuitively, this means that operations which do not mess with the row
grouping, like modifications or appends, should dedupe pretty well. So let's
test this out!
## Append
Here we append 10,000 new rows to the file and compare the results with the
original version. Green represents all deduped blocks, red represents all
new blocks, and shades in between show different levels of deduplication.
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/improve_parquet_dedupe/1_append.png" alt="Visualization of dedupe from data appends" width=30%>
</p>
We can see that indeed we are able to dedupe nearly the entire file,
but only with changes seen at the end of the file. The new file is 99.1%
deduped, requiring only 20MB of additional storage. This matches our
intuition pretty well.
## Modification
Given the layout, we would expect that row modifications to be pretty
isolated, but this is apparently not the case. Here we make a small
modification to row 10000, and we see that while most of the file does dedupe,
there are many small regularly spaced sections of new data!
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/improve_parquet_dedupe/2_mod.png" alt="Visualization of dedupe from data modifications" width=30%>
</p>
A quick scan of the [Parquet file
format](https://parquet.apache.org/docs/file-format/metadata/) suggests
that absolute file offsets are part of the Parquet column headers (see the
structures ColumnChunk and ColumnMetaData)! This means that any
modification is likely to rewrite all the Column headers. So while the
data does dedupe well (it is mostly green), we get new bytes in every
column header.
In this case, the new file is only 89% deduped, requiring 230MB of additional
storage.
## Deletion
Here we delete a row from the middle of the file (note: insertion should have
similar behavior). As this reorganizes the entire row group layout (each
row group is 1000 rows), we see that while we dedupe the first half of
the file, the remaining file has completely new blocks.
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/improve_parquet_dedupe/3_delete.png" alt="Visualization of dedupe from data deletion" width=30%>
</p>
This is mostly because the Parquet format compresses each column
aggressively. If we turn off compression we are able to dedupe more
aggressively:
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/improve_parquet_dedupe/4_delete_no_compress.png" alt="Visualization of dedupe from data deletion without column compression" width=30%>
</p>
However the file sizes are nearly 2x larger if we store the data
uncompressed.
Is it possible to have the benefit of dedupe and compression at the same
time?
## Content Defined Row Groups
One potential solution is to use not only byte-level CDC, but also apply it at the row level:
we split row groups not based on absolute count (1000 rows), but on a hash of a provided
“Key” column. In other words, I split off a row group whenever the hash of
the key column % [target row count] = 0, with some allowances for a minimum
and a maximum row group size.
I hacked up a quick inefficient experimental demonstration
[here](https://gist.github.com/ylow/db38522fb0ca69bdf1065237222b4d1c).
With this, we are able to efficiently dedupe across compressed Parquet
files even as I delete a row. Here we clearly see a big red block
representing the rewritten row group, followed by a small change for every
column header.
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/improve_parquet_dedupe/5_content_defined.png" alt="Visualization of dedupe from data deletion with content defined row groups" width=30%>
</p>
# Optimizing Parquet for Dedupe-ability
Based on these experiments, we could consider improving Parquet file
dedupe-ability in a couple of ways:
1. Use relative offsets instead of absolute offsets for file structure
data. This would make the Parquet structures position independent and
easy to “memcpy” around, although it is an involving file format change that
is probably difficult to do.
2. Support content defined chunking on row groups. The format actually
supports this today as it does not require row groups to be uniformly sized,
so this can be done with minimal blast radius. Only Parquet format writers
would have to be updated.
While we will continue exploring ways to improve Parquet storage performance
(Ex: perhaps we could optionally rewrite Parquet files before uploading?
Strip absolute file offsets on upload and restore on download?), we would
love to work with the Apache Arrow project to see if there is interest in
implementing some of these ideas in the Parquet / Arrow code base.
In the meantime, we are also exploring the behavior of our data dedupe process
on other common filetypes. Please do try our [dedupe
estimator](https://github.com/huggingface/dedupe_estimator) and tell us about
your findings!
| 9 |
0 | hf_public_repos/candle/candle-core/src | hf_public_repos/candle/candle-core/src/quantized/k_quants.rs | use super::utils::{
get_scale_min_k4, group_for_dequantization, group_for_quantization, make_q3_quants,
make_qkx1_quants, make_qx_quants, nearest_int,
};
use super::GgmlDType;
use crate::Result;
use byteorder::{ByteOrder, LittleEndian};
use half::f16;
use rayon::prelude::*;
// Default to QK_K 256 rather than 64.
pub const QK_K: usize = 256;
pub const K_SCALE_SIZE: usize = 12;
pub const QK4_0: usize = 32;
pub const QK4_1: usize = 32;
pub const QK5_0: usize = 32;
pub const QK5_1: usize = 32;
pub const QK8_0: usize = 32;
pub const QK8_1: usize = 32;
pub trait GgmlType: Sized + Clone + Send + Sync {
const DTYPE: GgmlDType;
const BLCK_SIZE: usize;
type VecDotType: GgmlType;
// This is only safe for types that include immediate values such as float/int/...
fn zeros() -> Self {
unsafe { std::mem::MaybeUninit::zeroed().assume_init() }
}
fn to_float(xs: &[Self], ys: &mut [f32]) -> Result<()>;
fn from_float(xs: &[f32], ys: &mut [Self]) -> Result<()>;
/// Dot product used as a building block for quantized mat-mul.
/// n is the number of elements to be considered.
fn vec_dot(n: usize, xs: &[Self], ys: &[Self::VecDotType]) -> Result<f32>;
/// Generic implementation of the dot product without simd optimizations.
fn vec_dot_unopt(n: usize, xs: &[Self], ys: &[Self::VecDotType]) -> Result<f32>;
}
#[derive(Debug, Clone, PartialEq)]
#[repr(C)]
pub struct BlockQ4_0 {
pub(crate) d: f16,
pub(crate) qs: [u8; QK4_0 / 2],
}
const _: () = assert!(std::mem::size_of::<BlockQ4_0>() == 18);
#[derive(Debug, Clone, PartialEq)]
#[repr(C)]
pub struct BlockQ4_1 {
pub(crate) d: f16,
pub(crate) m: f16,
pub(crate) qs: [u8; QK4_1 / 2],
}
const _: () = assert!(std::mem::size_of::<BlockQ4_1>() == 20);
#[derive(Debug, Clone, PartialEq)]
#[repr(C)]
pub struct BlockQ5_0 {
pub(crate) d: f16,
pub(crate) qh: [u8; 4],
pub(crate) qs: [u8; QK5_0 / 2],
}
const _: () = assert!(std::mem::size_of::<BlockQ5_0>() == 22);
#[derive(Debug, Clone, PartialEq)]
#[repr(C)]
pub struct BlockQ5_1 {
pub(crate) d: f16,
pub(crate) m: f16,
pub(crate) qh: [u8; 4],
pub(crate) qs: [u8; QK5_1 / 2],
}
const _: () = assert!(std::mem::size_of::<BlockQ5_1>() == 24);
#[derive(Debug, Clone, PartialEq)]
#[repr(C)]
pub struct BlockQ8_0 {
pub(crate) d: f16,
pub(crate) qs: [i8; QK8_0],
}
const _: () = assert!(std::mem::size_of::<BlockQ8_0>() == 34);
#[derive(Debug, Clone, PartialEq)]
#[repr(C)]
pub struct BlockQ8_1 {
pub(crate) d: f16,
pub(crate) s: f16,
pub(crate) qs: [i8; QK8_1],
}
const _: () = assert!(std::mem::size_of::<BlockQ8_1>() == 36);
#[derive(Debug, Clone, PartialEq)]
#[repr(C)]
pub struct BlockQ2K {
pub(crate) scales: [u8; QK_K / 16],
pub(crate) qs: [u8; QK_K / 4],
pub(crate) d: f16,
pub(crate) dmin: f16,
}
const _: () = assert!(QK_K / 16 + QK_K / 4 + 2 * 2 == std::mem::size_of::<BlockQ2K>());
#[derive(Debug, Clone, PartialEq)]
#[repr(C)]
pub struct BlockQ3K {
pub(crate) hmask: [u8; QK_K / 8],
pub(crate) qs: [u8; QK_K / 4],
pub(crate) scales: [u8; 12],
pub(crate) d: f16,
}
const _: () = assert!(QK_K / 8 + QK_K / 4 + 12 + 2 == std::mem::size_of::<BlockQ3K>());
#[derive(Debug, Clone, PartialEq)]
// https://github.com/ggerganov/llama.cpp/blob/468ea24fb4633a0d681f7ac84089566c1c6190cb/k_quants.h#L82
#[repr(C)]
pub struct BlockQ4K {
pub(crate) d: f16,
pub(crate) dmin: f16,
pub(crate) scales: [u8; K_SCALE_SIZE],
pub(crate) qs: [u8; QK_K / 2],
}
const _: () = assert!(QK_K / 2 + K_SCALE_SIZE + 2 * 2 == std::mem::size_of::<BlockQ4K>());
#[derive(Debug, Clone, PartialEq)]
#[repr(C)]
pub struct BlockQ5K {
pub(crate) d: f16,
pub(crate) dmin: f16,
pub(crate) scales: [u8; K_SCALE_SIZE],
pub(crate) qh: [u8; QK_K / 8],
pub(crate) qs: [u8; QK_K / 2],
}
const _: () =
assert!(QK_K / 8 + QK_K / 2 + 2 * 2 + K_SCALE_SIZE == std::mem::size_of::<BlockQ5K>());
#[derive(Debug, Clone, PartialEq)]
#[repr(C)]
pub struct BlockQ6K {
pub(crate) ql: [u8; QK_K / 2],
pub(crate) qh: [u8; QK_K / 4],
pub(crate) scales: [i8; QK_K / 16],
pub(crate) d: f16,
}
const _: () = assert!(3 * QK_K / 4 + QK_K / 16 + 2 == std::mem::size_of::<BlockQ6K>());
#[derive(Debug, Clone, PartialEq)]
#[repr(C)]
pub struct BlockQ8K {
pub(crate) d: f32,
pub(crate) qs: [i8; QK_K],
pub(crate) bsums: [i16; QK_K / 16],
}
const _: () = assert!(4 + QK_K + QK_K / 16 * 2 == std::mem::size_of::<BlockQ8K>());
impl GgmlType for BlockQ4_0 {
const DTYPE: GgmlDType = GgmlDType::Q4_0;
const BLCK_SIZE: usize = QK4_0;
type VecDotType = BlockQ8_0;
// https://github.com/ggerganov/llama.cpp/blob/468ea24fb4633a0d681f7ac84089566c1c6190cb/ggml.c#L1525
fn to_float(xs: &[Self], ys: &mut [f32]) -> Result<()> {
let k = ys.len();
let qk = Self::BLCK_SIZE;
if k % qk != 0 {
crate::bail!("dequantize_row_q4_0: {k} is not divisible by {qk}")
}
let nb = k / qk;
for i in 0..nb {
let d = xs[i].d.to_f32();
for j in 0..(qk / 2) {
let x0 = (xs[i].qs[j] & 0x0F) as i16 - 8;
let x1 = (xs[i].qs[j] >> 4) as i16 - 8;
ys[i * qk + j] = (x0 as f32) * d;
ys[i * qk + j + qk / 2] = (x1 as f32) * d;
}
}
Ok(())
}
fn from_float(xs: &[f32], ys: &mut [Self]) -> Result<()> {
// quantize_row_q4_0
let qk = Self::BLCK_SIZE;
let k = xs.len();
if k % qk != 0 {
crate::bail!("{k} is not divisible by {}", qk);
};
let nb = k / qk;
if ys.len() != nb {
crate::bail!("size mismatch {} {} {}", xs.len(), ys.len(), qk,)
}
for (i, ys) in ys.iter_mut().enumerate() {
let mut amax = 0f32;
let mut max = 0f32;
let xs = &xs[i * qk..(i + 1) * qk];
for &x in xs.iter() {
if amax < x.abs() {
amax = x.abs();
max = x;
}
}
let d = max / -8.0;
let id = if d != 0f32 { 1. / d } else { 0. };
ys.d = f16::from_f32(d);
for (j, q) in ys.qs.iter_mut().enumerate() {
let x0 = xs[j] * id;
let x1 = xs[qk / 2 + j] * id;
let xi0 = u8::min(15, (x0 + 8.5) as u8);
let xi1 = u8::min(15, (x1 + 8.5) as u8);
*q = xi0 | (xi1 << 4)
}
}
Ok(())
}
// https://github.com/ggerganov/llama.cpp/blob/b5ffb2849d23afe73647f68eec7b68187af09be6/ggml.c#L2361C10-L2361C122
#[allow(unreachable_code)]
fn vec_dot(n: usize, xs: &[Self], ys: &[Self::VecDotType]) -> Result<f32> {
#[cfg(target_feature = "avx")]
return super::avx::vec_dot_q4_0_q8_0(n, xs, ys);
#[cfg(target_feature = "neon")]
return super::neon::vec_dot_q4_0_q8_0(n, xs, ys);
#[cfg(target_feature = "simd128")]
return super::simd128::vec_dot_q4_0_q8_0(n, xs, ys);
Self::vec_dot_unopt(n, xs, ys)
}
fn vec_dot_unopt(n: usize, xs: &[Self], ys: &[Self::VecDotType]) -> Result<f32> {
let qk = QK8_0;
if n % QK8_0 != 0 {
crate::bail!("vec_dot_q4_0_q8_0: {n} is not divisible by {qk}")
}
// Generic implementation.
let mut sumf = 0f32;
for (xs, ys) in xs.iter().zip(ys.iter()) {
let mut sum_i = 0;
for j in 0..qk / 2 {
let v0 = (xs.qs[j] & 0x0F) as i32 - 8;
let v1 = (xs.qs[j] >> 4) as i32 - 8;
sum_i += v0 * ys.qs[j] as i32 + v1 * ys.qs[j + qk / 2] as i32
}
sumf += sum_i as f32 * f16::to_f32(xs.d) * f16::to_f32(ys.d)
}
Ok(sumf)
}
}
impl GgmlType for BlockQ4_1 {
const DTYPE: GgmlDType = GgmlDType::Q4_1;
const BLCK_SIZE: usize = QK4_1;
type VecDotType = BlockQ8_1;
fn vec_dot(n: usize, xs: &[Self], ys: &[Self::VecDotType]) -> Result<f32> {
Self::vec_dot_unopt(n, xs, ys)
}
fn vec_dot_unopt(n: usize, xs: &[Self], ys: &[Self::VecDotType]) -> Result<f32> {
// ggml_vec_dot_q4_1_q8_1
let qk = QK8_1;
if n % qk != 0 {
crate::bail!("vec_dot_q4_1_q8_1: {n} is not divisible by {qk}")
}
let nb = n / qk;
if nb % 2 != 0 {
crate::bail!("vec_dot_q4_1_q8_1: {n}, nb is not divisible by 2")
}
// Generic implementation.
let mut sumf = 0f32;
for (xs, ys) in xs.iter().zip(ys.iter()) {
let mut sumi = 0i32;
for j in 0..qk / 2 {
let v0 = xs.qs[j] as i32 & 0x0F;
let v1 = xs.qs[j] as i32 >> 4;
sumi += (v0 * ys.qs[j] as i32) + (v1 * ys.qs[j + qk / 2] as i32);
}
sumf += sumi as f32 * f16::to_f32(xs.d) * f16::to_f32(ys.d)
+ f16::to_f32(xs.m) * f16::to_f32(ys.s)
}
Ok(sumf)
}
fn from_float(xs: &[f32], ys: &mut [Self]) -> Result<()> {
// quantize_row_q4_1
let qk = Self::BLCK_SIZE;
if ys.len() * qk != xs.len() {
crate::bail!("size mismatch {} {} {}", xs.len(), ys.len(), qk,)
}
for (i, ys) in ys.iter_mut().enumerate() {
let xs = &xs[i * qk..(i + 1) * qk];
let mut min = f32::INFINITY;
let mut max = f32::NEG_INFINITY;
for &x in xs.iter() {
min = f32::min(x, min);
max = f32::max(x, max);
}
let d = (max - min) / ((1 << 4) - 1) as f32;
let id = if d != 0f32 { 1. / d } else { 0. };
ys.d = f16::from_f32(d);
ys.m = f16::from_f32(min);
for (j, q) in ys.qs.iter_mut().take(qk / 2).enumerate() {
let x0 = (xs[j] - min) * id;
let x1 = (xs[qk / 2 + j] - min) * id;
let xi0 = u8::min(15, (x0 + 0.5) as u8);
let xi1 = u8::min(15, (x1 + 0.5) as u8);
*q = xi0 | (xi1 << 4);
}
}
Ok(())
}
// https://github.com/ggerganov/llama.cpp/blob/468ea24fb4633a0d681f7ac84089566c1c6190cb/ggml.c#L1545
fn to_float(xs: &[Self], ys: &mut [f32]) -> Result<()> {
let k = ys.len();
if k % QK4_1 != 0 {
crate::bail!("dequantize_row_q4_1: {k} is not divisible by {QK4_1}");
}
let nb = k / QK4_1;
for i in 0..nb {
let d = xs[i].d.to_f32();
let m = xs[i].m.to_f32();
for j in 0..(QK4_1 / 2) {
let x0 = xs[i].qs[j] & 0x0F;
let x1 = xs[i].qs[j] >> 4;
ys[i * QK4_1 + j] = (x0 as f32) * d + m;
ys[i * QK4_1 + j + QK4_1 / 2] = (x1 as f32) * d + m;
}
}
Ok(())
}
}
impl GgmlType for BlockQ5_0 {
const DTYPE: GgmlDType = GgmlDType::Q5_0;
const BLCK_SIZE: usize = QK5_0;
type VecDotType = BlockQ8_0;
fn vec_dot(n: usize, xs: &[Self], ys: &[Self::VecDotType]) -> Result<f32> {
let qk = Self::BLCK_SIZE;
if n % Self::BLCK_SIZE != 0 {
crate::bail!("vec_dot_q5_0_q8_0: {n} is not divisible by {qk}")
}
let nb = n / qk;
if nb % 2 != 0 {
crate::bail!("vec_dot_q5_0_q8_0: {n}, nb is not divisible by 2")
}
Self::vec_dot_unopt(n, xs, ys)
}
fn vec_dot_unopt(_n: usize, xs: &[Self], ys: &[Self::VecDotType]) -> Result<f32> {
// Generic implementation.
let mut sumf = 0f32;
for (xs, ys) in xs.iter().zip(ys.iter()) {
let qh = LittleEndian::read_u32(&xs.qh);
let mut sumi = 0i32;
for j in 0..Self::BLCK_SIZE / 2 {
let xh_0 = (((qh & (1u32 << j)) >> j) << 4) as u8;
let xh_1 = ((qh & (1u32 << (j + 16))) >> (j + 12)) as u8;
let x0 = ((xs.qs[j] & 0x0F) as i32 | xh_0 as i32) - 16;
let x1 = ((xs.qs[j] >> 4) as i32 | xh_1 as i32) - 16;
sumi += (x0 * ys.qs[j] as i32) + (x1 * ys.qs[j + Self::BLCK_SIZE / 2] as i32);
}
sumf += sumi as f32 * f16::to_f32(xs.d) * f16::to_f32(ys.d)
}
Ok(sumf)
}
fn from_float(xs: &[f32], ys: &mut [Self]) -> Result<()> {
// quantize_row_q5_0
let k = xs.len();
if ys.len() * Self::BLCK_SIZE != k {
crate::bail!("size mismatch {k} {} {}", ys.len(), Self::BLCK_SIZE)
}
for (i, ys) in ys.iter_mut().enumerate() {
let xs = &xs[i * Self::BLCK_SIZE..(i + 1) * Self::BLCK_SIZE];
let mut amax = 0f32;
let mut max = 0f32;
for &x in xs.iter() {
if amax < x.abs() {
amax = x.abs();
max = x;
}
}
let d = max / -16.;
let id = if d != 0f32 { 1. / d } else { 0. };
ys.d = f16::from_f32(d);
let mut qh = 0u32;
for j in 0..Self::BLCK_SIZE / 2 {
let x0 = xs[j] * id;
let x1 = xs[j + Self::BLCK_SIZE / 2] * id;
let xi0 = ((x0 + 16.5) as i8).min(31) as u8;
let xi1 = ((x1 + 16.5) as i8).min(31) as u8;
ys.qs[j] = (xi0 & 0x0F) | ((xi1 & 0x0F) << 4);
qh |= ((xi0 as u32 & 0x10) >> 4) << j;
qh |= ((xi1 as u32 & 0x10) >> 4) << (j + Self::BLCK_SIZE / 2);
}
LittleEndian::write_u32(&mut ys.qh, qh)
}
Ok(())
}
// https://github.com/ggerganov/llama.cpp/blob/468ea24fb4633a0d681f7ac84089566c1c6190cb/ggml.c#L1566
fn to_float(xs: &[Self], ys: &mut [f32]) -> Result<()> {
let k = ys.len();
if k % QK5_0 != 0 {
crate::bail!("dequantize_row_q5_0: {k} is not divisible by {QK5_0}");
}
let nb = k / QK5_0;
for i in 0..nb {
let d = xs[i].d.to_f32();
let qh: u32 = LittleEndian::read_u32(&xs[i].qh);
for j in 0..(QK5_0 / 2) {
let xh_0 = (((qh >> j) << 4) & 0x10) as u8;
let xh_1 = ((qh >> (j + 12)) & 0x10) as u8;
let x0 = ((xs[i].qs[j] & 0x0F) | xh_0) as i32 - 16;
let x1 = ((xs[i].qs[j] >> 4) | xh_1) as i32 - 16;
ys[i * QK5_0 + j] = (x0 as f32) * d;
ys[i * QK5_0 + j + QK5_0 / 2] = (x1 as f32) * d;
}
}
Ok(())
}
}
impl GgmlType for BlockQ5_1 {
const DTYPE: GgmlDType = GgmlDType::Q5_1;
const BLCK_SIZE: usize = QK5_1;
type VecDotType = BlockQ8_1;
fn vec_dot(n: usize, xs: &[Self], ys: &[Self::VecDotType]) -> Result<f32> {
Self::vec_dot_unopt(n, xs, ys)
}
fn vec_dot_unopt(n: usize, xs: &[Self], ys: &[Self::VecDotType]) -> Result<f32> {
let qk = Self::BLCK_SIZE;
if n % Self::BLCK_SIZE != 0 {
crate::bail!("vec_dot_q5_1_q8_1: {n} is not divisible by {qk}")
}
let nb = n / qk;
if nb % 2 != 0 {
crate::bail!("vec_dot_q5_1_q8_1: {n}, nb is not divisible by 2")
}
// Generic implementation.
let mut sumf = 0f32;
for (xs, ys) in xs.iter().zip(ys.iter()) {
let qh = LittleEndian::read_u32(&xs.qh);
let mut sumi = 0i32;
for j in 0..Self::BLCK_SIZE / 2 {
let xh_0 = ((qh >> j) << 4) & 0x10;
let xh_1 = (qh >> (j + 12)) & 0x10;
let x0 = (xs.qs[j] as i32 & 0xF) | xh_0 as i32;
let x1 = (xs.qs[j] as i32 >> 4) | xh_1 as i32;
sumi += (x0 * ys.qs[j] as i32) + (x1 * ys.qs[j + Self::BLCK_SIZE / 2] as i32);
}
sumf += sumi as f32 * f16::to_f32(xs.d) * f16::to_f32(ys.d)
+ f16::to_f32(xs.m) * f16::to_f32(ys.s)
}
Ok(sumf)
}
fn from_float(xs: &[f32], ys: &mut [Self]) -> Result<()> {
// quantize_row_q5_1
let qk = Self::BLCK_SIZE;
if ys.len() * qk != xs.len() {
crate::bail!("size mismatch {} {} {}", xs.len(), ys.len(), qk,)
}
for (i, ys) in ys.iter_mut().enumerate() {
let xs = &xs[i * qk..(i + 1) * qk];
let mut min = f32::INFINITY;
let mut max = f32::NEG_INFINITY;
for &x in xs.iter() {
min = f32::min(x, min);
max = f32::max(x, max);
}
let d = (max - min) / ((1 << 5) - 1) as f32;
let id = if d != 0f32 { 1. / d } else { 0. };
ys.d = f16::from_f32(d);
ys.m = f16::from_f32(min);
let mut qh = 0u32;
for (j, q) in ys.qs.iter_mut().take(qk / 2).enumerate() {
let x0 = (xs[j] - min) * id;
let x1 = (xs[qk / 2 + j] - min) * id;
let xi0 = (x0 + 0.5) as u8;
let xi1 = (x1 + 0.5) as u8;
*q = (xi0 & 0x0F) | ((xi1 & 0x0F) << 4);
// get the 5-th bit and store it in qh at the right position
qh |= ((xi0 as u32 & 0x10) >> 4) << j;
qh |= ((xi1 as u32 & 0x10) >> 4) << (j + qk / 2);
}
LittleEndian::write_u32(&mut ys.qh, qh);
}
Ok(())
}
// https://github.com/ggerganov/llama.cpp/blob/468ea24fb4633a0d681f7ac84089566c1c6190cb/ggml.c#L1592
fn to_float(xs: &[Self], ys: &mut [f32]) -> Result<()> {
let k = ys.len();
if k % QK5_1 != 0 {
crate::bail!("dequantize_row_q5_1: {k} is not divisible by {QK5_1}");
}
let nb = k / QK5_1;
for i in 0..nb {
let d = xs[i].d.to_f32();
let m = xs[i].m.to_f32();
let qh: u32 = LittleEndian::read_u32(&xs[i].qh);
for j in 0..(QK5_1 / 2) {
let xh_0 = (((qh >> j) << 4) & 0x10) as u8;
let xh_1 = ((qh >> (j + 12)) & 0x10) as u8;
let x0 = (xs[i].qs[j] & 0x0F) | xh_0;
let x1 = (xs[i].qs[j] >> 4) | xh_1;
ys[i * QK5_1 + j] = (x0 as f32) * d + m;
ys[i * QK5_1 + j + QK5_1 / 2] = (x1 as f32) * d + m;
}
}
Ok(())
}
}
impl GgmlType for BlockQ8_0 {
const DTYPE: GgmlDType = GgmlDType::Q8_0;
const BLCK_SIZE: usize = QK8_0;
type VecDotType = BlockQ8_0;
// https://github.com/ggerganov/llama.cpp/blob/468ea24fb4633a0d681f7ac84089566c1c6190cb/ggml.c#L1619
fn to_float(xs: &[Self], ys: &mut [f32]) -> Result<()> {
let k = ys.len();
if k % QK8_0 != 0 {
crate::bail!("dequantize_row_q8_0: {k} is not divisible by {QK8_0}");
}
let nb = k / QK8_0;
for i in 0..nb {
let d = xs[i].d.to_f32();
for j in 0..QK8_0 {
ys[i * QK8_0 + j] = xs[i].qs[j] as f32 * d;
}
}
Ok(())
}
fn from_float(xs: &[f32], ys: &mut [Self]) -> Result<()> {
// quantize_row_q8_0
let k = xs.len();
if k % Self::BLCK_SIZE != 0 {
crate::bail!("{k} is not divisible by {}", Self::BLCK_SIZE);
};
let nb = k / Self::BLCK_SIZE;
if ys.len() != nb {
crate::bail!(
"size mismatch {} {} {}",
xs.len(),
ys.len(),
Self::BLCK_SIZE
)
}
for (i, ys) in ys.iter_mut().enumerate() {
let mut amax = 0f32;
let xs = &xs[i * Self::BLCK_SIZE..(i + 1) * Self::BLCK_SIZE];
for &x in xs.iter() {
amax = amax.max(x.abs())
}
let d = amax / ((1 << 7) - 1) as f32;
let id = if d != 0f32 { 1. / d } else { 0. };
ys.d = f16::from_f32(d);
for (y, &x) in ys.qs.iter_mut().zip(xs.iter()) {
*y = f32::round(x * id) as i8
}
}
Ok(())
}
#[allow(unreachable_code)]
fn vec_dot(n: usize, xs: &[Self], ys: &[Self::VecDotType]) -> Result<f32> {
#[cfg(target_feature = "avx")]
return super::avx::vec_dot_q8_0_q8_0(n, xs, ys);
#[cfg(target_feature = "neon")]
return super::neon::vec_dot_q8_0_q8_0(n, xs, ys);
#[cfg(target_feature = "simd128")]
return super::simd128::vec_dot_q8_0_q8_0(n, xs, ys);
Self::vec_dot_unopt(n, xs, ys)
}
fn vec_dot_unopt(n: usize, xs: &[Self], ys: &[Self::VecDotType]) -> Result<f32> {
let qk = QK8_0;
if n % QK8_0 != 0 {
crate::bail!("vec_dot_q8_0_q8_0: {n} is not divisible by {qk}")
}
// Generic implementation.
let mut sumf = 0f32;
for (xs, ys) in xs.iter().zip(ys.iter()) {
let sum_i = xs
.qs
.iter()
.zip(ys.qs.iter())
.map(|(&x, &y)| x as i32 * y as i32)
.sum::<i32>();
sumf += sum_i as f32 * f16::to_f32(xs.d) * f16::to_f32(ys.d)
}
Ok(sumf)
}
}
impl GgmlType for BlockQ8_1 {
const DTYPE: GgmlDType = GgmlDType::Q8_1;
const BLCK_SIZE: usize = QK8_1;
type VecDotType = BlockQ8_1;
fn vec_dot(n: usize, xs: &[Self], ys: &[Self::VecDotType]) -> Result<f32> {
Self::vec_dot_unopt(n, xs, ys)
}
fn vec_dot_unopt(_n: usize, _xs: &[Self], _ys: &[Self::VecDotType]) -> Result<f32> {
unimplemented!("no support for vec-dot on Q8_1")
}
fn from_float(xs: &[f32], ys: &mut [Self]) -> Result<()> {
// quantize_row_q8_1
let k = xs.len();
if ys.len() * Self::BLCK_SIZE != k {
crate::bail!("size mismatch {k} {} {}", ys.len(), Self::BLCK_SIZE)
}
for (i, ys) in ys.iter_mut().enumerate() {
let mut amax = 0f32;
let xs = &xs[i * Self::BLCK_SIZE..(i + 1) * Self::BLCK_SIZE];
for &x in xs.iter() {
amax = amax.max(x.abs())
}
let d = amax / ((1 << 7) - 1) as f32;
let id = if d != 0f32 { 1. / d } else { 0. };
ys.d = f16::from_f32(d);
let mut sum = 0i32;
for j in 0..Self::BLCK_SIZE / 2 {
let v0 = xs[j] * id;
let v1 = xs[j + Self::BLCK_SIZE / 2] * id;
ys.qs[j] = f32::round(v0) as i8;
ys.qs[j + Self::BLCK_SIZE / 2] = f32::round(v1) as i8;
sum += ys.qs[j] as i32 + ys.qs[j + Self::BLCK_SIZE / 2] as i32;
}
ys.s = f16::from_f32(sum as f32) * ys.d;
}
Ok(())
}
fn to_float(_xs: &[Self], _ys: &mut [f32]) -> Result<()> {
unimplemented!("no support for vec-dot on Q8_1")
}
}
impl GgmlType for BlockQ2K {
const DTYPE: GgmlDType = GgmlDType::Q2K;
const BLCK_SIZE: usize = QK_K;
type VecDotType = BlockQ8K;
#[allow(unreachable_code)]
fn vec_dot(n: usize, xs: &[Self], ys: &[Self::VecDotType]) -> Result<f32> {
#[cfg(target_feature = "avx")]
return super::avx::vec_dot_q2k_q8k(n, xs, ys);
#[cfg(target_feature = "neon")]
return super::neon::vec_dot_q2k_q8k(n, xs, ys);
#[cfg(target_feature = "simd128")]
return super::simd128::vec_dot_q2k_q8k(n, xs, ys);
Self::vec_dot_unopt(n, xs, ys)
}
fn vec_dot_unopt(n: usize, xs: &[Self], ys: &[Self::VecDotType]) -> Result<f32> {
if n % QK_K != 0 {
crate::bail!("vec_dot_q2k_q8k: {n} is not divisible by {QK_K}")
}
let mut sumf = 0.0;
for (x, y) in xs.iter().zip(ys.iter()) {
let mut q2: &[_] = &x.qs;
let mut q8: &[_] = &y.qs;
let sc = &x.scales;
let mut summs = 0;
for (bsum, scale) in y.bsums.iter().zip(sc) {
summs += *bsum as i32 * ((scale >> 4) as i32);
}
let dall = y.d * x.d.to_f32();
let dmin = y.d * x.dmin.to_f32();
let mut isum = 0;
let mut is = 0;
for _ in 0..(QK_K / 128) {
let mut shift = 0;
for _ in 0..4 {
let d = (sc[is] & 0xF) as i32;
is += 1;
let mut isuml = 0;
for l in 0..16 {
isuml += q8[l] as i32 * (((q2[l] >> shift) & 3) as i32);
}
isum += d * isuml;
let d = (sc[is] & 0xF) as i32;
is += 1;
isuml = 0;
for l in 16..32 {
isuml += q8[l] as i32 * (((q2[l] >> shift) & 3) as i32);
}
isum += d * isuml;
shift += 2;
// adjust the indexing
q8 = &q8[32..];
}
// adjust the indexing
q2 = &q2[32..];
}
sumf += dall * isum as f32 - dmin * summs as f32;
}
Ok(sumf)
}
// https://github.com/ggerganov/llama.cpp/blob/8183159cf3def112f6d1fe94815fce70e1bffa12/k_quants.c#L279
fn from_float(xs: &[f32], ys: &mut [Self]) -> Result<()> {
const Q4SCALE: f32 = 15.0;
for (block, x) in group_for_quantization(xs, ys)? {
//calculate scales and mins
let mut mins: [f32; QK_K / 16] = [0.0; QK_K / 16];
let mut scales: [f32; QK_K / 16] = [0.0; QK_K / 16];
for (j, x_scale_slice) in x.chunks(16).enumerate() {
(scales[j], mins[j]) = make_qkx1_quants(3, 5, x_scale_slice);
}
// get max scale and max min and ensure they are >= 0.0
let max_scale = scales.iter().fold(0.0, |max, &val| val.max(max));
let max_min = mins.iter().fold(0.0, |max, &val| val.max(max));
if max_scale > 0.0 {
let iscale = Q4SCALE / max_scale;
for (j, scale) in scales.iter().enumerate().take(QK_K / 16) {
block.scales[j] = nearest_int(iscale * scale) as u8;
}
block.d = f16::from_f32(max_scale / Q4SCALE);
} else {
for j in 0..QK_K / 16 {
block.scales[j] = 0;
}
block.d = f16::from_f32(0.0);
}
if max_min > 0.0 {
let iscale = Q4SCALE / max_min;
for (j, scale) in block.scales.iter_mut().enumerate() {
let l = nearest_int(iscale * mins[j]) as u8;
*scale |= l << 4;
}
block.dmin = f16::from_f32(max_min / Q4SCALE);
} else {
block.dmin = f16::from_f32(0.0);
}
let mut big_l: [u8; QK_K] = [0; QK_K];
for j in 0..QK_K / 16 {
let d = block.d.to_f32() * (block.scales[j] & 0xF) as f32;
if d == 0.0 {
continue;
}
let dm = block.dmin.to_f32() * (block.scales[j] >> 4) as f32;
for ii in 0..16 {
let ll = nearest_int((x[16 * j + ii] + dm) / d).clamp(0, 3);
big_l[16 * j + ii] = ll as u8;
}
}
for j in (0..QK_K).step_by(128) {
for ll in 0..32 {
block.qs[j / 4 + ll] = big_l[j + ll]
| (big_l[j + ll + 32] << 2)
| (big_l[j + ll + 64] << 4)
| (big_l[j + ll + 96] << 6);
}
}
}
Ok(())
}
// https://github.com/ggerganov/llama.cpp/blob/8183159cf3def112f6d1fe94815fce70e1bffa12/k_quants.c#L354
fn to_float(xs: &[Self], ys: &mut [f32]) -> Result<()> {
for (block, y) in group_for_dequantization(xs, ys)? {
let d = block.d.to_f32();
let min = block.dmin.to_f32();
let mut is = 0;
for (y_block, qs) in y.chunks_exact_mut(128).zip(block.qs.chunks_exact(32)) {
// Step by 32 over q.
let mut shift = 0;
let mut y_block_index = 0;
for _j in 0..4 {
let sc = block.scales[is];
is += 1;
let dl = d * (sc & 0xF) as f32;
let ml = min * (sc >> 4) as f32;
for q in &qs[..16] {
let y = dl * ((q >> shift) & 3) as f32 - ml;
y_block[y_block_index] = y;
y_block_index += 1;
}
let sc = block.scales[is];
is += 1;
let dl = d * (sc & 0xF) as f32;
let ml = min * (sc >> 4) as f32;
for q in &qs[16..] {
let y = dl * ((q >> shift) & 3) as f32 - ml;
y_block[y_block_index] = y;
y_block_index += 1;
}
shift += 2;
}
}
}
Ok(())
}
}
impl GgmlType for BlockQ3K {
const DTYPE: GgmlDType = GgmlDType::Q3K;
const BLCK_SIZE: usize = QK_K;
type VecDotType = BlockQ8K;
#[allow(unreachable_code)]
fn vec_dot(n: usize, xs: &[Self], ys: &[Self::VecDotType]) -> Result<f32> {
#[cfg(target_feature = "avx")]
return super::avx::vec_dot_q3k_q8k(n, xs, ys);
#[cfg(target_feature = "neon")]
return super::neon::vec_dot_q3k_q8k(n, xs, ys);
Self::vec_dot_unopt(n, xs, ys)
}
fn vec_dot_unopt(n: usize, xs: &[Self], ys: &[Self::VecDotType]) -> Result<f32> {
if n % QK_K != 0 {
crate::bail!("vec_dot_q3k_q8k: {n} is not divisible by {QK_K}")
}
const KMASK1: u32 = 0x03030303;
const KMASK2: u32 = 0x0f0f0f0f;
let mut aux8: [i8; QK_K] = [0; QK_K];
let mut aux16: [i16; 8] = [0; 8];
let mut sums: [f32; 8] = [0.0; 8];
let mut aux32: [i32; 8] = [0; 8];
let mut auxs: [u32; 4] = [0; 4];
for (x, y) in xs.iter().zip(ys.iter()) {
let mut q3: &[u8] = &x.qs;
let hmask: &[u8] = &x.hmask;
let mut q8: &[i8] = &y.qs;
aux32.fill(0);
let mut a = &mut aux8[..];
let mut m = 1;
//Like the GGML original this is written this way to enable the compiler to vectorize it.
for _ in 0..QK_K / 128 {
a.iter_mut()
.take(32)
.zip(q3)
.for_each(|(a_val, q3_val)| *a_val = (q3_val & 3) as i8);
a.iter_mut()
.take(32)
.zip(hmask)
.for_each(|(a_val, hmask_val)| {
*a_val -= if hmask_val & m != 0 { 0 } else { 4 }
});
a = &mut a[32..];
m <<= 1;
a.iter_mut()
.take(32)
.zip(q3)
.for_each(|(a_val, q3_val)| *a_val = ((q3_val >> 2) & 3) as i8);
a.iter_mut()
.take(32)
.zip(hmask)
.for_each(|(a_val, hmask_val)| {
*a_val -= if hmask_val & m != 0 { 0 } else { 4 }
});
a = &mut a[32..];
m <<= 1;
a.iter_mut()
.take(32)
.zip(q3)
.for_each(|(a_val, q3_val)| *a_val = ((q3_val >> 4) & 3) as i8);
a.iter_mut()
.take(32)
.zip(hmask)
.for_each(|(a_val, hmask_val)| {
*a_val -= if hmask_val & m != 0 { 0 } else { 4 }
});
a = &mut a[32..];
m <<= 1;
a.iter_mut()
.take(32)
.zip(q3)
.for_each(|(a_val, q3_val)| *a_val = ((q3_val >> 6) & 3) as i8);
a.iter_mut()
.take(32)
.zip(hmask)
.for_each(|(a_val, hmask_val)| {
*a_val -= if hmask_val & m != 0 { 0 } else { 4 }
});
a = &mut a[32..];
m <<= 1;
q3 = &q3[32..];
}
a = &mut aux8[..];
LittleEndian::read_u32_into(&x.scales, &mut auxs[0..3]);
let tmp = auxs[2];
auxs[2] = ((auxs[0] >> 4) & KMASK2) | (((tmp >> 4) & KMASK1) << 4);
auxs[3] = ((auxs[1] >> 4) & KMASK2) | (((tmp >> 6) & KMASK1) << 4);
auxs[0] = (auxs[0] & KMASK2) | (((tmp) & KMASK1) << 4);
auxs[1] = (auxs[1] & KMASK2) | (((tmp >> 2) & KMASK1) << 4);
for aux in auxs {
for scale in aux.to_le_bytes() {
let scale = i8::from_be_bytes([scale]);
for l in 0..8 {
aux16[l] = q8[l] as i16 * a[l] as i16;
}
for l in 0..8 {
aux32[l] += (scale as i32 - 32) * aux16[l] as i32;
}
q8 = &q8[8..];
a = &mut a[8..];
for l in 0..8 {
aux16[l] = q8[l] as i16 * a[l] as i16;
}
for l in 0..8 {
aux32[l] += (scale as i32 - 32) * aux16[l] as i32;
}
q8 = &q8[8..];
a = &mut a[8..];
}
}
let d = x.d.to_f32() * y.d;
for l in 0..8 {
sums[l] += d * aux32[l] as f32;
}
}
Ok(sums.iter().sum())
}
fn from_float(xs: &[f32], ys: &mut [Self]) -> Result<()> {
for (block, x) in group_for_quantization(xs, ys)? {
let mut scales: [f32; QK_K / 16] = [0.0; QK_K / 16];
for (j, x_scale_slice) in x.chunks_exact(16).enumerate() {
scales[j] = make_q3_quants(x_scale_slice, 4, true);
}
// Get max scale by absolute value.
let mut max_scale: f32 = 0.0;
for &scale in scales.iter() {
if scale.abs() > max_scale.abs() {
max_scale = scale;
}
}
block.scales.fill(0);
if max_scale != 0.0 {
let iscale = -32.0 / max_scale;
for (j, scale) in scales.iter().enumerate() {
let l_val = nearest_int(iscale * scale);
let l_val = l_val.clamp(-32, 31) + 32;
if j < 8 {
block.scales[j] = (l_val & 0xF) as u8;
} else {
block.scales[j - 8] |= ((l_val & 0xF) << 4) as u8;
}
let l_val = l_val >> 4;
block.scales[j % 4 + 8] |= (l_val << (2 * (j / 4))) as u8;
}
block.d = f16::from_f32(1.0 / iscale);
} else {
block.d = f16::from_f32(0.0);
}
let mut l: [i8; QK_K] = [0; QK_K];
for j in 0..QK_K / 16 {
let sc = if j < 8 {
block.scales[j] & 0xF
} else {
block.scales[j - 8] >> 4
};
let sc = (sc | (((block.scales[8 + j % 4] >> (2 * (j / 4))) & 3) << 4)) as i8 - 32;
let d = block.d.to_f32() * sc as f32;
if d != 0.0 {
for ii in 0..16 {
let l_val = nearest_int(x[16 * j + ii] / d);
l[16 * j + ii] = (l_val.clamp(-4, 3) + 4) as i8;
}
}
}
block.hmask.fill(0);
let mut m = 0;
let mut hm = 1;
for ll in l.iter_mut() {
if *ll > 3 {
block.hmask[m] |= hm;
*ll -= 4;
}
m += 1;
if m == QK_K / 8 {
m = 0;
hm <<= 1;
}
}
for j in (0..QK_K).step_by(128) {
for l_val in 0..32 {
block.qs[j / 4 + l_val] = (l[j + l_val]
| (l[j + l_val + 32] << 2)
| (l[j + l_val + 64] << 4)
| (l[j + l_val + 96] << 6))
as u8;
}
}
}
Ok(())
}
// https://github.com/ggerganov/llama.cpp/blob/8183159cf3def112f6d1fe94815fce70e1bffa12/k_quants.c#L533
fn to_float(xs: &[Self], ys: &mut [f32]) -> Result<()> {
const KMASK1: u32 = 0x03030303;
const KMASK2: u32 = 0x0f0f0f0f;
for (block, y) in group_for_dequantization(xs, ys)? {
//Reconstruct the scales
let mut aux = [0; 4];
LittleEndian::read_u32_into(&block.scales, &mut aux[0..3]);
let tmp = aux[2];
aux[2] = ((aux[0] >> 4) & KMASK2) | (((tmp >> 4) & KMASK1) << 4);
aux[3] = ((aux[1] >> 4) & KMASK2) | (((tmp >> 6) & KMASK1) << 4);
aux[0] = (aux[0] & KMASK2) | (((tmp) & KMASK1) << 4);
aux[1] = (aux[1] & KMASK2) | (((tmp >> 2) & KMASK1) << 4);
//Transfer the scales into an i8 array
let scales: &mut [i8] =
unsafe { std::slice::from_raw_parts_mut(aux.as_mut_ptr() as *mut i8, 16) };
let d_all = block.d.to_f32();
let mut m = 1;
let mut is = 0;
// Dequantize both 128 long blocks
// 32 qs values per 128 long block
// Each 16 elements get a scale
for (y, qs) in y.chunks_exact_mut(128).zip(block.qs.chunks_exact(32)) {
let mut shift = 0;
for shift_scoped_y in y.chunks_exact_mut(32) {
for (scale_index, scale_scoped_y) in
shift_scoped_y.chunks_exact_mut(16).enumerate()
{
let dl = d_all * (scales[is] as f32 - 32.0);
for (i, inner_y) in scale_scoped_y.iter_mut().enumerate() {
let new_y = dl
* (((qs[i + 16 * scale_index] >> shift) & 3) as i8
- if (block.hmask[i + 16 * scale_index] & m) == 0 {
4
} else {
0
}) as f32;
*inner_y = new_y;
}
// 16 block finished => advance scale index
is += 1;
}
// 32 block finished => increase shift and m
shift += 2;
m <<= 1;
}
}
}
Ok(())
}
}
impl GgmlType for BlockQ4K {
const DTYPE: GgmlDType = GgmlDType::Q4K;
const BLCK_SIZE: usize = QK_K;
type VecDotType = BlockQ8K;
#[allow(unreachable_code)]
fn vec_dot(n: usize, xs: &[Self], ys: &[Self::VecDotType]) -> Result<f32> {
#[cfg(target_feature = "avx")]
return super::avx::vec_dot_q4k_q8k(n, xs, ys);
#[cfg(target_feature = "neon")]
return super::neon::vec_dot_q4k_q8k(n, xs, ys);
#[cfg(target_feature = "simd128")]
return super::simd128::vec_dot_q4k_q8k(n, xs, ys);
Self::vec_dot_unopt(n, xs, ys)
}
fn vec_dot_unopt(n: usize, xs: &[Self], ys: &[Self::VecDotType]) -> Result<f32> {
if n % QK_K != 0 {
crate::bail!("vec_dot_q4k_q8k: {n} is not divisible by {QK_K}")
}
const KMASK1: u32 = 0x3f3f3f3f;
const KMASK2: u32 = 0x0f0f0f0f;
const KMASK3: u32 = 0x03030303;
let mut utmp: [u32; 4] = [0; 4];
let mut scales: [u8; 8] = [0; 8];
let mut mins: [u8; 8] = [0; 8];
let mut aux8: [i8; QK_K] = [0; QK_K];
let mut aux16: [i16; 8] = [0; 8];
let mut sums: [f32; 8] = [0.0; 8];
let mut aux32: [i32; 8] = [0; 8];
let mut sumf = 0.0;
for (y, x) in ys.iter().zip(xs.iter()) {
let q4 = &x.qs;
let q8 = &y.qs;
aux32.fill(0);
let mut a = &mut aux8[..];
let mut q4 = &q4[..];
for _ in 0..QK_K / 64 {
for l in 0..32 {
a[l] = (q4[l] & 0xF) as i8;
}
a = &mut a[32..];
for l in 0..32 {
a[l] = (q4[l] >> 4) as i8;
}
a = &mut a[32..];
q4 = &q4[32..];
}
LittleEndian::read_u32_into(&x.scales, &mut utmp[0..3]);
utmp[3] = ((utmp[2] >> 4) & KMASK2) | (((utmp[1] >> 6) & KMASK3) << 4);
let uaux = utmp[1] & KMASK1;
utmp[1] = (utmp[2] & KMASK2) | (((utmp[0] >> 6) & KMASK3) << 4);
utmp[2] = uaux;
utmp[0] &= KMASK1;
//extract scales and mins
LittleEndian::write_u32_into(&utmp[0..2], &mut scales);
LittleEndian::write_u32_into(&utmp[2..4], &mut mins);
let mut sumi = 0;
for j in 0..QK_K / 16 {
sumi += y.bsums[j] as i32 * mins[j / 2] as i32;
}
let mut a = &mut aux8[..];
let mut q8 = &q8[..];
for scale in scales {
let scale = scale as i32;
for _ in 0..4 {
for l in 0..8 {
aux16[l] = q8[l] as i16 * a[l] as i16;
}
for l in 0..8 {
aux32[l] += scale * aux16[l] as i32;
}
q8 = &q8[8..];
a = &mut a[8..];
}
}
let d = x.d.to_f32() * y.d;
for l in 0..8 {
sums[l] += d * aux32[l] as f32;
}
let dmin = x.dmin.to_f32() * y.d;
sumf -= dmin * sumi as f32;
}
Ok(sumf + sums.iter().sum::<f32>())
}
fn from_float(xs: &[f32], ys: &mut [Self]) -> Result<()> {
for (block, x) in group_for_quantization(xs, ys)? {
let mut mins: [f32; QK_K / 32] = [0.0; QK_K / 32];
let mut scales: [f32; QK_K / 32] = [0.0; QK_K / 32];
for (j, x_scale_slice) in x.chunks_exact(32).enumerate() {
(scales[j], mins[j]) = make_qkx1_quants(15, 5, x_scale_slice);
}
// get max scale and max min and ensure they are >= 0.0
let max_scale = scales.iter().fold(0.0, |max, &val| val.max(max));
let max_min = mins.iter().fold(0.0, |max, &val| val.max(max));
let inv_scale = if max_scale > 0.0 {
63.0 / max_scale
} else {
0.0
};
let inv_min = if max_min > 0.0 { 63.0 / max_min } else { 0.0 };
for j in 0..QK_K / 32 {
let ls = nearest_int(inv_scale * scales[j]).min(63) as u8;
let lm = nearest_int(inv_min * mins[j]).min(63) as u8;
if j < 4 {
block.scales[j] = ls;
block.scales[j + 4] = lm;
} else {
block.scales[j + 4] = (ls & 0xF) | ((lm & 0xF) << 4);
block.scales[j - 4] |= (ls >> 4) << 6;
block.scales[j] |= (lm >> 4) << 6;
}
}
block.d = f16::from_f32(max_scale / 63.0);
block.dmin = f16::from_f32(max_min / 63.0);
let mut l: [u8; QK_K] = [0; QK_K];
for j in 0..QK_K / 32 {
let (sc, m) = get_scale_min_k4(j, &block.scales);
let d = block.d.to_f32() * sc as f32;
if d != 0.0 {
let dm = block.dmin.to_f32() * m as f32;
for ii in 0..32 {
let l_val = nearest_int((x[32 * j + ii] + dm) / d);
l[32 * j + ii] = l_val.clamp(0, 15) as u8;
}
}
}
let q = &mut block.qs;
for j in (0..QK_K).step_by(64) {
for l_val in 0..32 {
let offset_index = (j / 64) * 32 + l_val;
q[offset_index] = l[j + l_val] | (l[j + l_val + 32] << 4);
}
}
}
Ok(())
}
// https://github.com/ggerganov/llama.cpp/blob/8183159cf3def112f6d1fe94815fce70e1bffa12/k_quants.c#L735
fn to_float(xs: &[Self], ys: &mut [f32]) -> Result<()> {
for (block, y) in group_for_dequantization(xs, ys)? {
let d = block.d.to_f32();
let min = block.dmin.to_f32();
let q = &block.qs;
let mut is = 0;
let mut ys_index = 0;
for j in (0..QK_K).step_by(64) {
let q = &q[j / 2..j / 2 + 32];
let (sc, m) = get_scale_min_k4(is, &block.scales);
let d1 = d * sc as f32;
let m1 = min * m as f32;
let (sc, m) = get_scale_min_k4(is + 1, &block.scales);
let d2 = d * sc as f32;
let m2 = min * m as f32;
for q in q {
y[ys_index] = d1 * (q & 0xF) as f32 - m1;
ys_index += 1;
}
for q in q {
y[ys_index] = d2 * (q >> 4) as f32 - m2;
ys_index += 1;
}
is += 2;
}
}
Ok(())
}
}
// https://github.com/ggerganov/llama.cpp/blob/8183159cf3def112f6d1fe94815fce70e1bffa12/k_quants.c#L928
impl GgmlType for BlockQ5K {
const DTYPE: GgmlDType = GgmlDType::Q5K;
const BLCK_SIZE: usize = QK_K;
type VecDotType = BlockQ8K;
#[allow(unreachable_code)]
fn vec_dot(n: usize, xs: &[Self], ys: &[Self::VecDotType]) -> Result<f32> {
#[cfg(target_feature = "avx")]
return super::avx::vec_dot_q5k_q8k(n, xs, ys);
#[cfg(target_feature = "neon")]
return super::neon::vec_dot_q5k_q8k(n, xs, ys);
Self::vec_dot_unopt(n, xs, ys)
}
fn vec_dot_unopt(n: usize, xs: &[Self], ys: &[Self::VecDotType]) -> Result<f32> {
if n % QK_K != 0 {
crate::bail!("vec_dot_q5k_q8k: {n} is not divisible by {QK_K}")
}
const KMASK1: u32 = 0x3f3f3f3f;
const KMASK2: u32 = 0x0f0f0f0f;
const KMASK3: u32 = 0x03030303;
let mut utmp: [u32; 4] = [0; 4];
let mut scales: [u8; 8] = [0; 8];
let mut mins: [u8; 8] = [0; 8];
let mut aux8: [i8; QK_K] = [0; QK_K];
let mut aux16: [i16; 8] = [0; 8];
let mut sums: [f32; 8] = [0.0; 8];
let mut aux32: [i32; 8] = [0; 8];
let mut sumf = 0.0;
for (y, x) in ys.iter().zip(xs.iter()) {
let q5 = &x.qs;
let hm = &x.qh;
let q8 = &y.qs;
aux32.fill(0);
let mut a = &mut aux8[..];
let mut q5 = &q5[..];
let mut m = 1u8;
for _ in 0..QK_K / 64 {
for l in 0..32 {
a[l] = (q5[l] & 0xF) as i8;
a[l] += if hm[l] & m != 0 { 16 } else { 0 };
}
a = &mut a[32..];
m <<= 1;
for l in 0..32 {
a[l] = (q5[l] >> 4) as i8;
a[l] += if hm[l] & m != 0 { 16 } else { 0 };
}
a = &mut a[32..];
m <<= 1;
q5 = &q5[32..];
}
LittleEndian::read_u32_into(&x.scales, &mut utmp[0..3]);
utmp[3] = ((utmp[2] >> 4) & KMASK2) | (((utmp[1] >> 6) & KMASK3) << 4);
let uaux = utmp[1] & KMASK1;
utmp[1] = (utmp[2] & KMASK2) | (((utmp[0] >> 6) & KMASK3) << 4);
utmp[2] = uaux;
utmp[0] &= KMASK1;
//extract scales and mins
LittleEndian::write_u32_into(&utmp[0..2], &mut scales);
LittleEndian::write_u32_into(&utmp[2..4], &mut mins);
let mut sumi = 0;
for j in 0..QK_K / 16 {
sumi += y.bsums[j] as i32 * mins[j / 2] as i32;
}
let mut a = &mut aux8[..];
let mut q8 = &q8[..];
for scale in scales {
let scale = scale as i32;
for _ in 0..4 {
for l in 0..8 {
aux16[l] = q8[l] as i16 * a[l] as i16;
}
for l in 0..8 {
aux32[l] += scale * aux16[l] as i32;
}
q8 = &q8[8..];
a = &mut a[8..];
}
}
let d = x.d.to_f32() * y.d;
for l in 0..8 {
sums[l] += d * aux32[l] as f32;
}
let dmin = x.dmin.to_f32() * y.d;
sumf -= dmin * sumi as f32;
}
Ok(sumf + sums.iter().sum::<f32>())
}
// https://github.com/ggerganov/llama.cpp/blob/8183159cf3def112f6d1fe94815fce70e1bffa12/k_quants.c#L793
fn from_float(xs: &[f32], ys: &mut [Self]) -> Result<()> {
for (block, x) in group_for_quantization(xs, ys)? {
let mut mins: [f32; QK_K / 32] = [0.0; QK_K / 32];
let mut scales: [f32; QK_K / 32] = [0.0; QK_K / 32];
for (j, x_scale_slice) in x.chunks_exact(32).enumerate() {
(scales[j], mins[j]) = make_qkx1_quants(31, 5, x_scale_slice);
}
// get max scale and max min and ensure they are >= 0.0
let max_scale = scales.iter().fold(0.0, |max, &val| val.max(max));
let max_min = mins.iter().fold(0.0, |max, &val| val.max(max));
let inv_scale = if max_scale > 0.0 {
63.0 / max_scale
} else {
0.0
};
let inv_min = if max_min > 0.0 { 63.0 / max_min } else { 0.0 };
for j in 0..QK_K / 32 {
let ls = nearest_int(inv_scale * scales[j]).min(63) as u8;
let lm = nearest_int(inv_min * mins[j]).min(63) as u8;
if j < 4 {
block.scales[j] = ls;
block.scales[j + 4] = lm;
} else {
block.scales[j + 4] = (ls & 0xF) | ((lm & 0xF) << 4);
block.scales[j - 4] |= (ls >> 4) << 6;
block.scales[j] |= (lm >> 4) << 6;
}
}
block.d = f16::from_f32(max_scale / 63.0);
block.dmin = f16::from_f32(max_min / 63.0);
let mut l: [u8; QK_K] = [0; QK_K];
for j in 0..QK_K / 32 {
let (sc, m) = get_scale_min_k4(j, &block.scales);
let d = block.d.to_f32() * sc as f32;
if d == 0.0 {
continue;
}
let dm = block.dmin.to_f32() * m as f32;
for ii in 0..32 {
let ll = nearest_int((x[32 * j + ii] + dm) / d);
l[32 * j + ii] = ll.clamp(0, 31) as u8;
}
}
let qh = &mut block.qh;
let ql = &mut block.qs;
qh.fill(0);
let mut m1 = 1;
let mut m2 = 2;
for n in (0..QK_K).step_by(64) {
let offset = (n / 64) * 32;
for j in 0..32 {
let mut l1 = l[n + j];
if l1 > 15 {
l1 -= 16;
qh[j] |= m1;
}
let mut l2 = l[n + j + 32];
if l2 > 15 {
l2 -= 16;
qh[j] |= m2;
}
ql[offset + j] = l1 | (l2 << 4);
}
m1 <<= 2;
m2 <<= 2;
}
}
Ok(())
}
// https://github.com/ggerganov/llama.cpp/blob/8183159cf3def112f6d1fe94815fce70e1bffa12/k_quants.c#L928
fn to_float(xs: &[Self], ys: &mut [f32]) -> Result<()> {
for (block, y) in group_for_dequantization(xs, ys)? {
let d = block.d.to_f32();
let min = block.dmin.to_f32();
let ql = &block.qs;
let qh = &block.qh;
let mut is = 0;
let mut u1 = 1;
let mut u2 = 2;
let mut ys_index = 0;
for j in (0..QK_K).step_by(64) {
let ql = &ql[j / 2..j / 2 + 32];
let (sc, m) = get_scale_min_k4(is, &block.scales);
let d1 = d * sc as f32;
let m1 = min * m as f32;
let (sc, m) = get_scale_min_k4(is + 1, &block.scales);
let d2 = d * sc as f32;
let m2 = min * m as f32;
for (ql, qh) in ql.iter().zip(qh) {
let to_add = if qh & u1 != 0 { 16f32 } else { 0f32 };
y[ys_index] = d1 * ((ql & 0xF) as f32 + to_add) - m1;
ys_index += 1;
}
for (ql, qh) in ql.iter().zip(qh) {
let to_add = if qh & u2 != 0 { 16f32 } else { 0f32 };
y[ys_index] = d2 * ((ql >> 4) as f32 + to_add) - m2;
ys_index += 1;
}
is += 2;
u1 <<= 2;
u2 <<= 2;
}
}
Ok(())
}
}
impl GgmlType for BlockQ6K {
const DTYPE: GgmlDType = GgmlDType::Q6K;
const BLCK_SIZE: usize = QK_K;
type VecDotType = BlockQ8K;
#[allow(unreachable_code)]
fn vec_dot(n: usize, xs: &[Self], ys: &[Self::VecDotType]) -> Result<f32> {
#[cfg(target_feature = "avx")]
return super::avx::vec_dot_q6k_q8k(n, xs, ys);
#[cfg(target_feature = "neon")]
return super::neon::vec_dot_q6k_q8k(n, xs, ys);
#[cfg(target_feature = "simd128")]
return super::simd128::vec_dot_q6k_q8k(n, xs, ys);
Self::vec_dot_unopt(n, xs, ys)
}
fn vec_dot_unopt(n: usize, xs: &[Self], ys: &[Self::VecDotType]) -> Result<f32> {
if n % QK_K != 0 {
crate::bail!("vec_dot_q6k_q8k: {n} is not divisible by {QK_K}")
}
let mut aux8 = [0i8; QK_K];
let mut aux16 = [0i16; 8];
let mut sums = [0f32; 8];
let mut aux32 = [0f32; 8];
for (x, y) in xs.iter().zip(ys.iter()) {
let q4 = &x.ql;
let qh = &x.qh;
let q8 = &y.qs;
aux32.fill(0f32);
for j in (0..QK_K).step_by(128) {
let aux8 = &mut aux8[j..];
let q4 = &q4[j / 2..];
let qh = &qh[j / 4..];
for l in 0..32 {
aux8[l] = (((q4[l] & 0xF) | ((qh[l] & 3) << 4)) as i32 - 32) as i8;
aux8[l + 32] =
(((q4[l + 32] & 0xF) | (((qh[l] >> 2) & 3) << 4)) as i32 - 32) as i8;
aux8[l + 64] = (((q4[l] >> 4) | (((qh[l] >> 4) & 3) << 4)) as i32 - 32) as i8;
aux8[l + 96] =
(((q4[l + 32] >> 4) | (((qh[l] >> 6) & 3) << 4)) as i32 - 32) as i8;
}
}
for (j, &scale) in x.scales.iter().enumerate() {
let scale = scale as f32;
let q8 = &q8[16 * j..];
let aux8 = &aux8[16 * j..];
for l in 0..8 {
aux16[l] = q8[l] as i16 * aux8[l] as i16;
}
for l in 0..8 {
aux32[l] += scale * aux16[l] as f32
}
let q8 = &q8[8..];
let aux8 = &aux8[8..];
for l in 0..8 {
aux16[l] = q8[l] as i16 * aux8[l] as i16;
}
for l in 0..8 {
aux32[l] += scale * aux16[l] as f32
}
}
let d = x.d.to_f32() * y.d;
for (sum, &a) in sums.iter_mut().zip(aux32.iter()) {
*sum += a * d;
}
}
Ok(sums.iter().sum())
}
fn from_float(xs: &[f32], ys: &mut [Self]) -> Result<()> {
if xs.len() != ys.len() * Self::BLCK_SIZE {
crate::bail!(
"quantize_row_q6k: size mismatch {} {} {}",
xs.len(),
ys.len(),
Self::BLCK_SIZE
)
}
let mut l = [0i8; QK_K];
let mut scales = [0f32; QK_K / 16];
let mut x = xs.as_ptr();
let l = l.as_mut_ptr();
unsafe {
for y in ys.iter_mut() {
let mut max_scale = 0f32;
let mut max_abs_scale = 0f32;
for (ib, scale_) in scales.iter_mut().enumerate() {
let scale = make_qx_quants(16, 32, x.add(16 * ib), l.add(16 * ib), 1);
*scale_ = scale;
let abs_scale = scale.abs();
if abs_scale > max_abs_scale {
max_abs_scale = abs_scale;
max_scale = scale
}
}
let iscale = -128f32 / max_scale;
y.d = f16::from_f32(1.0 / iscale);
for (y_scale, scale) in y.scales.iter_mut().zip(scales.iter()) {
*y_scale = nearest_int(iscale * scale).min(127) as i8
}
for (j, &y_scale) in y.scales.iter().enumerate() {
let d = y.d.to_f32() * y_scale as f32;
if d == 0. {
continue;
}
for ii in 0..16 {
let ll = nearest_int(*x.add(16 * j + ii) / d).clamp(-32, 31);
*l.add(16 * j + ii) = (ll + 32) as i8
}
}
let mut ql = y.ql.as_mut_ptr();
let mut qh = y.qh.as_mut_ptr();
for j in (0..QK_K).step_by(128) {
for l_idx in 0..32 {
let q1 = *l.add(j + l_idx) & 0xF;
let q2 = *l.add(j + l_idx + 32) & 0xF;
let q3 = *l.add(j + l_idx + 64) & 0xF;
let q4 = *l.add(j + l_idx + 96) & 0xF;
*ql.add(l_idx) = (q1 | (q3 << 4)) as u8;
*ql.add(l_idx + 32) = (q2 | (q4 << 4)) as u8;
*qh.add(l_idx) = ((*l.add(j + l_idx) >> 4)
| ((*l.add(j + l_idx + 32) >> 4) << 2)
| ((*l.add(j + l_idx + 64) >> 4) << 4)
| ((*l.add(j + l_idx + 96) >> 4) << 6))
as u8;
}
ql = ql.add(64);
qh = qh.add(32);
}
x = x.add(QK_K)
}
}
Ok(())
}
// https://github.com/ggerganov/llama.cpp/blob/8183159cf3def112f6d1fe94815fce70e1bffa12/k_quants.c#L1067
fn to_float(xs: &[Self], ys: &mut [f32]) -> Result<()> {
let k = ys.len();
if k % QK_K != 0 {
crate::bail!("dequantize_row_q6k: {k} is not divisible by {QK_K}")
}
for (idx_x, x) in xs.iter().enumerate() {
let d = x.d.to_f32();
let ql = &x.ql;
let qh = &x.qh;
let sc = &x.scales;
for n in (0..QK_K).step_by(128) {
let idx = n / 128;
let ys = &mut ys[idx_x * QK_K + n..];
let sc = &sc[8 * idx..];
let ql = &ql[64 * idx..];
let qh = &qh[32 * idx..];
for l in 0..32 {
let is = l / 16;
let q1 = ((ql[l] & 0xF) | ((qh[l] & 3) << 4)) as i8 - 32;
let q2 = ((ql[l + 32] & 0xF) | (((qh[l] >> 2) & 3) << 4)) as i8 - 32;
let q3 = ((ql[l] >> 4) | (((qh[l] >> 4) & 3) << 4)) as i8 - 32;
let q4 = ((ql[l + 32] >> 4) | (((qh[l] >> 6) & 3) << 4)) as i8 - 32;
ys[l] = d * sc[is] as f32 * q1 as f32;
ys[l + 32] = d * sc[is + 2] as f32 * q2 as f32;
ys[l + 64] = d * sc[is + 4] as f32 * q3 as f32;
ys[l + 96] = d * sc[is + 6] as f32 * q4 as f32;
}
}
}
Ok(())
}
}
impl GgmlType for BlockQ8K {
const DTYPE: GgmlDType = GgmlDType::Q8K;
const BLCK_SIZE: usize = QK_K;
type VecDotType = BlockQ8K;
#[allow(unreachable_code)]
fn vec_dot(n: usize, xs: &[Self], ys: &[Self::VecDotType]) -> Result<f32> {
#[cfg(target_feature = "avx")]
return super::avx::vec_dot_q8k_q8k(n, xs, ys);
#[cfg(target_feature = "neon")]
return super::neon::vec_dot_q8k_q8k(n, xs, ys);
#[cfg(target_feature = "simd128")]
return super::simd128::vec_dot_q8k_q8k(n, xs, ys);
Self::vec_dot_unopt(n, xs, ys)
}
fn vec_dot_unopt(n: usize, xs: &[Self], ys: &[Self::VecDotType]) -> Result<f32> {
let qk = QK_K;
if n % QK_K != 0 {
crate::bail!("vec_dot_q8k_q8k: {n} is not divisible by {qk}")
}
// Generic implementation.
let mut sumf = 0f32;
for (xs, ys) in xs.iter().zip(ys.iter()) {
let sum_i = xs
.qs
.iter()
.zip(ys.qs.iter())
.map(|(&x, &y)| x as i32 * y as i32)
.sum::<i32>();
sumf += sum_i as f32 * xs.d * ys.d
}
Ok(sumf)
}
fn from_float(xs: &[f32], ys: &mut [Self]) -> Result<()> {
let k = xs.len();
if k % QK_K != 0 {
crate::bail!("quantize_row_q8k: {k} is not divisible by {QK_K}")
}
for (i, y) in ys.iter_mut().enumerate() {
let mut max = 0f32;
let mut amax = 0f32;
let xs = &xs[i * QK_K..(i + 1) * QK_K];
for &x in xs.iter() {
if amax < x.abs() {
amax = x.abs();
max = x;
}
}
if amax == 0f32 {
y.d = 0f32;
y.qs.fill(0)
} else {
let iscale = -128f32 / max;
for (j, q) in y.qs.iter_mut().enumerate() {
// ggml uses nearest_int with bit magic here, maybe we want the same
// but we would have to test and benchmark it.
let v = (iscale * xs[j]).round();
*q = v.min(127.) as i8
}
for j in 0..QK_K / 16 {
let mut sum = 0i32;
for ii in 0..16 {
sum += y.qs[j * 16 + ii] as i32
}
y.bsums[j] = sum as i16
}
y.d = 1.0 / iscale
}
}
Ok(())
}
fn to_float(xs: &[Self], ys: &mut [f32]) -> Result<()> {
let k = ys.len();
if k % QK_K != 0 {
crate::bail!("dequantize_row_q8k: {k} is not divisible by {QK_K}")
}
for (i, x) in xs.iter().enumerate() {
for (j, &q) in x.qs.iter().enumerate() {
ys[i * QK_K + j] = x.d * q as f32
}
}
Ok(())
}
}
// https://github.com/ggerganov/llama.cpp/blob/b5ffb2849d23afe73647f68eec7b68187af09be6/ggml.c#L10605
pub fn matmul<T: GgmlType>(
mkn: (usize, usize, usize),
lhs: &[f32],
rhs_t: &[T],
dst: &mut [f32],
) -> Result<()> {
let (m, k, n) = mkn;
if m * k != lhs.len() {
crate::bail!("unexpected lhs length {} {mkn:?}", lhs.len());
}
let k_in_lhs_blocks = k.div_ceil(T::BLCK_SIZE);
let k_in_rhs_blocks = k.div_ceil(T::VecDotType::BLCK_SIZE);
// TODO: Do not make this copy if the DotType is f32.
// TODO: Pre-allocate this.
let mut lhs_b = vec![T::VecDotType::zeros(); m * k_in_lhs_blocks];
for row_idx in 0..m {
let lhs_b = &mut lhs_b[row_idx * k_in_lhs_blocks..(row_idx + 1) * k_in_lhs_blocks];
let lhs = &lhs[row_idx * k..(row_idx + 1) * k];
T::VecDotType::from_float(lhs, lhs_b)?
}
let lhs_b = lhs_b.as_slice();
for row_idx in 0..m {
let lhs_row = &lhs_b[row_idx * k_in_lhs_blocks..(row_idx + 1) * k_in_lhs_blocks];
let dst_row = &mut dst[row_idx * n..(row_idx + 1) * n];
let result: Result<Vec<_>> = dst_row
.into_par_iter()
.enumerate()
.with_min_len(128)
.with_max_len(512)
.map(|(col_idx, dst)| {
let rhs_col = &rhs_t[col_idx * k_in_rhs_blocks..(col_idx + 1) * k_in_rhs_blocks];
T::vec_dot(k, rhs_col, lhs_row).map(|value| *dst = value)
})
.collect();
result?;
}
Ok(())
}
impl GgmlType for f32 {
const DTYPE: GgmlDType = GgmlDType::F32;
const BLCK_SIZE: usize = 1;
type VecDotType = f32;
fn vec_dot(n: usize, xs: &[Self], ys: &[Self::VecDotType]) -> Result<f32> {
Self::vec_dot_unopt(n, xs, ys)
}
fn vec_dot_unopt(n: usize, xs: &[Self], ys: &[Self::VecDotType]) -> Result<f32> {
if xs.len() < n {
crate::bail!("size mismatch {} < {n}", xs.len())
}
if ys.len() < n {
crate::bail!("size mismatch {} < {n}", ys.len())
}
let mut res = 0f32;
unsafe { crate::cpu::vec_dot_f32(xs.as_ptr(), ys.as_ptr(), &mut res, n) };
Ok(res)
}
fn from_float(xs: &[f32], ys: &mut [Self]) -> Result<()> {
if xs.len() != ys.len() {
crate::bail!("size mismatch {} {}", xs.len(), ys.len());
}
ys.copy_from_slice(xs);
Ok(())
}
fn to_float(xs: &[Self], ys: &mut [f32]) -> Result<()> {
if xs.len() != ys.len() {
crate::bail!("size mismatch {} {}", xs.len(), ys.len());
}
ys.copy_from_slice(xs);
Ok(())
}
}
impl GgmlType for f16 {
const DTYPE: GgmlDType = GgmlDType::F16;
const BLCK_SIZE: usize = 1;
type VecDotType = f16;
fn vec_dot(n: usize, xs: &[Self], ys: &[Self::VecDotType]) -> Result<f32> {
Self::vec_dot_unopt(n, xs, ys)
}
fn vec_dot_unopt(n: usize, xs: &[Self], ys: &[Self::VecDotType]) -> Result<f32> {
if xs.len() < n {
crate::bail!("size mismatch {} < {n}", xs.len())
}
if ys.len() < n {
crate::bail!("size mismatch {} < {n}", ys.len())
}
let mut res = 0f32;
unsafe { crate::cpu::vec_dot_f16(xs.as_ptr(), ys.as_ptr(), &mut res, n) };
Ok(res)
}
fn from_float(xs: &[f32], ys: &mut [Self]) -> Result<()> {
if xs.len() != ys.len() {
crate::bail!("size mismatch {} {}", xs.len(), ys.len());
}
// TODO: vectorize
for (x, y) in xs.iter().zip(ys.iter_mut()) {
*y = f16::from_f32(*x)
}
Ok(())
}
fn to_float(xs: &[Self], ys: &mut [f32]) -> Result<()> {
if xs.len() != ys.len() {
crate::bail!("size mismatch {} {}", xs.len(), ys.len());
}
// TODO: vectorize
for (x, y) in xs.iter().zip(ys.iter_mut()) {
*y = x.to_f32()
}
Ok(())
}
}
| 0 |
0 | hf_public_repos/candle/candle-core/src | hf_public_repos/candle/candle-core/src/quantized/avx.rs | use super::k_quants::{
BlockQ2K, BlockQ3K, BlockQ4K, BlockQ4_0, BlockQ5K, BlockQ6K, BlockQ8K, BlockQ8_0, QK8_0, QK_K,
};
use crate::Result;
use byteorder::{ByteOrder, LittleEndian};
use half::f16;
#[cfg(target_arch = "x86")]
use core::arch::x86::*;
#[cfg(target_arch = "x86_64")]
use core::arch::x86_64::*;
#[inline(always)]
pub(crate) unsafe fn sum_i16_pairs_float(x: __m256i) -> __m256 {
let ones = _mm256_set1_epi16(1);
let summed_pairs = _mm256_madd_epi16(ones, x);
_mm256_cvtepi32_ps(summed_pairs)
}
#[inline(always)]
pub(crate) unsafe fn mul_sum_us8_pairs_float(ax: __m256i, sy: __m256i) -> __m256 {
let dot = _mm256_maddubs_epi16(ax, sy);
sum_i16_pairs_float(dot)
}
#[inline(always)]
pub(crate) unsafe fn hsum_float_8(x: __m256) -> f32 {
let res = _mm256_extractf128_ps(x, 1);
let res = _mm_add_ps(res, _mm256_castps256_ps128(x));
let res = _mm_add_ps(res, _mm_movehl_ps(res, res));
let res = _mm_add_ss(res, _mm_movehdup_ps(res));
_mm_cvtss_f32(res)
}
#[inline(always)]
pub(crate) unsafe fn bytes_from_nibbles_32(rsi: *const u8) -> __m256i {
let tmp = _mm_loadu_si128(rsi as *const __m128i);
let bytes = _mm256_insertf128_si256::<1>(_mm256_castsi128_si256(tmp), _mm_srli_epi16(tmp, 4));
let low_mask = _mm256_set1_epi8(0xF);
_mm256_and_si256(low_mask, bytes)
}
#[inline(always)]
pub(crate) unsafe fn mul_sum_i8_pairs_float(x: __m256i, y: __m256i) -> __m256 {
let ax = _mm256_sign_epi8(x, x);
let sy = _mm256_sign_epi8(y, x);
mul_sum_us8_pairs_float(ax, sy)
}
#[inline(always)]
pub(crate) fn vec_dot_q4_0_q8_0(n: usize, xs: &[BlockQ4_0], ys: &[BlockQ8_0]) -> Result<f32> {
let qk = QK8_0;
if n % QK8_0 != 0 {
crate::bail!("vec_dot_q4_0_q8_0: {n} is not divisible by {qk}")
}
unsafe {
let mut acc = _mm256_setzero_ps();
for (x, y) in xs.iter().zip(ys.iter()) {
let d = _mm256_set1_ps(f16::to_f32(x.d) * f16::to_f32(y.d));
let bx = bytes_from_nibbles_32(x.qs.as_ptr());
let off = _mm256_set1_epi8(8);
let bx = _mm256_sub_epi8(bx, off);
let by = _mm256_loadu_si256(y.qs.as_ptr() as *const __m256i);
let q = mul_sum_i8_pairs_float(bx, by);
acc = _mm256_fmadd_ps(d, q, acc);
}
Ok(hsum_float_8(acc))
}
}
#[inline(always)]
pub(crate) fn vec_dot_q8_0_q8_0(n: usize, xs: &[BlockQ8_0], ys: &[BlockQ8_0]) -> Result<f32> {
let qk = QK8_0;
if n % QK8_0 != 0 {
crate::bail!("vec_dot_q8_0_q8_0: {n} is not divisible by {qk}")
}
unsafe {
let mut acc = _mm256_setzero_ps();
for (x, y) in xs.iter().zip(ys.iter()) {
let d = _mm256_set1_ps(f16::to_f32(x.d) * f16::to_f32(y.d));
let bx = _mm256_loadu_si256(x.qs.as_ptr() as *const __m256i);
let by = _mm256_loadu_si256(y.qs.as_ptr() as *const __m256i);
let q = mul_sum_i8_pairs_float(bx, by);
acc = _mm256_fmadd_ps(d, q, acc);
}
Ok(hsum_float_8(acc))
}
}
#[inline(always)]
unsafe fn get_scale_shuffle(i: usize) -> __m128i {
const K_SHUFFLE: [u8; 128] = [
0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2, 2, 2, 3, 3, 3, 3, 3, 3,
3, 3, 4, 4, 4, 4, 4, 4, 4, 4, 5, 5, 5, 5, 5, 5, 5, 5, 6, 6, 6, 6, 6, 6, 6, 6, 7, 7, 7, 7,
7, 7, 7, 7, 8, 8, 8, 8, 8, 8, 8, 8, 9, 9, 9, 9, 9, 9, 9, 9, 10, 10, 10, 10, 10, 10, 10, 10,
11, 11, 11, 11, 11, 11, 11, 11, 12, 12, 12, 12, 12, 12, 12, 12, 13, 13, 13, 13, 13, 13, 13,
13, 14, 14, 14, 14, 14, 14, 14, 14, 15, 15, 15, 15, 15, 15, 15, 15,
];
_mm_loadu_si128((K_SHUFFLE.as_ptr() as *const __m128i).add(i))
}
#[inline(always)]
unsafe fn get_scale_shuffle_k4(i: usize) -> __m256i {
const K_SHUFFLE: [u8; 256] = [
0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1,
0, 1, 2, 3, 2, 3, 2, 3, 2, 3, 2, 3, 2, 3, 2, 3, 2, 3, 2, 3, 2, 3, 2, 3, 2, 3, 2, 3, 2, 3,
2, 3, 2, 3, 4, 5, 4, 5, 4, 5, 4, 5, 4, 5, 4, 5, 4, 5, 4, 5, 4, 5, 4, 5, 4, 5, 4, 5, 4, 5,
4, 5, 4, 5, 4, 5, 6, 7, 6, 7, 6, 7, 6, 7, 6, 7, 6, 7, 6, 7, 6, 7, 6, 7, 6, 7, 6, 7, 6, 7,
6, 7, 6, 7, 6, 7, 6, 7, 8, 9, 8, 9, 8, 9, 8, 9, 8, 9, 8, 9, 8, 9, 8, 9, 8, 9, 8, 9, 8, 9,
8, 9, 8, 9, 8, 9, 8, 9, 8, 9, 10, 11, 10, 11, 10, 11, 10, 11, 10, 11, 10, 11, 10, 11, 10,
11, 10, 11, 10, 11, 10, 11, 10, 11, 10, 11, 10, 11, 10, 11, 10, 11, 12, 13, 12, 13, 12, 13,
12, 13, 12, 13, 12, 13, 12, 13, 12, 13, 12, 13, 12, 13, 12, 13, 12, 13, 12, 13, 12, 13, 12,
13, 12, 13, 14, 15, 14, 15, 14, 15, 14, 15, 14, 15, 14, 15, 14, 15, 14, 15, 14, 15, 14, 15,
14, 15, 14, 15, 14, 15, 14, 15, 14, 15, 14, 15,
];
_mm256_loadu_si256((K_SHUFFLE.as_ptr() as *const __m256i).add(i))
}
#[inline(always)]
unsafe fn get_scale_shuffle_q3k(i: usize) -> __m256i {
const K_SHUFFLE: [u8; 128] = [
0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 2, 3, 2, 3, 2, 3, 2, 3, 2, 3, 2, 3, 2, 3,
2, 3, 4, 5, 4, 5, 4, 5, 4, 5, 4, 5, 4, 5, 4, 5, 4, 5, 6, 7, 6, 7, 6, 7, 6, 7, 6, 7, 6, 7,
6, 7, 6, 7, 8, 9, 8, 9, 8, 9, 8, 9, 8, 9, 8, 9, 8, 9, 8, 9, 10, 11, 10, 11, 10, 11, 10, 11,
10, 11, 10, 11, 10, 11, 10, 11, 12, 13, 12, 13, 12, 13, 12, 13, 12, 13, 12, 13, 12, 13, 12,
13, 14, 15, 14, 15, 14, 15, 14, 15, 14, 15, 14, 15, 14, 15, 14, 15,
];
_mm256_loadu_si256((K_SHUFFLE.as_ptr() as *const __m256i).add(i))
}
#[inline(always)]
pub(crate) fn vec_dot_q6k_q8k(n: usize, xs: &[BlockQ6K], ys: &[BlockQ8K]) -> Result<f32> {
let qk = QK_K;
if n % qk != 0 {
crate::bail!("vec_dot_q6k_8k: {n} is not divisible by {qk}")
}
unsafe {
let m4 = _mm256_set1_epi8(0xF);
let m2 = _mm256_set1_epi8(3);
let m32s = _mm256_set1_epi8(32);
let mut acc = _mm256_setzero_ps();
for (x, y) in xs.iter().zip(ys.iter()) {
let d = y.d * x.d.to_f32();
let mut q4 = x.ql.as_ptr();
let mut qh = x.qh.as_ptr();
let mut q8 = y.qs.as_ptr();
let scales = _mm_loadu_si128(x.scales.as_ptr() as *const __m128i);
let mut sumi = _mm256_setzero_si256();
for j in 0..QK_K / 128 {
let is = j * 4;
let scale_0 = _mm_shuffle_epi8(scales, get_scale_shuffle(is));
let scale_1 = _mm_shuffle_epi8(scales, get_scale_shuffle(is + 1));
let scale_2 = _mm_shuffle_epi8(scales, get_scale_shuffle(is + 2));
let scale_3 = _mm_shuffle_epi8(scales, get_scale_shuffle(is + 3));
let q4bits1 = _mm256_loadu_si256(q4 as *const __m256i);
q4 = q4.add(32);
let q4bits2 = _mm256_loadu_si256(q4 as *const __m256i);
q4 = q4.add(32);
let q4bits_h = _mm256_loadu_si256(qh as *const __m256i);
qh = qh.add(32);
let q4h_0 = _mm256_slli_epi16(_mm256_and_si256(q4bits_h, m2), 4);
let q4h_1 =
_mm256_slli_epi16(_mm256_and_si256(_mm256_srli_epi16(q4bits_h, 2), m2), 4);
let q4h_2 =
_mm256_slli_epi16(_mm256_and_si256(_mm256_srli_epi16(q4bits_h, 4), m2), 4);
let q4h_3 =
_mm256_slli_epi16(_mm256_and_si256(_mm256_srli_epi16(q4bits_h, 6), m2), 4);
let q4_0 = _mm256_or_si256(_mm256_and_si256(q4bits1, m4), q4h_0);
let q4_1 = _mm256_or_si256(_mm256_and_si256(q4bits2, m4), q4h_1);
let q4_2 =
_mm256_or_si256(_mm256_and_si256(_mm256_srli_epi16(q4bits1, 4), m4), q4h_2);
let q4_3 =
_mm256_or_si256(_mm256_and_si256(_mm256_srli_epi16(q4bits2, 4), m4), q4h_3);
let q8_0 = _mm256_loadu_si256(q8 as *const __m256i);
q8 = q8.add(32);
let q8_1 = _mm256_loadu_si256(q8 as *const __m256i);
q8 = q8.add(32);
let q8_2 = _mm256_loadu_si256(q8 as *const __m256i);
q8 = q8.add(32);
let q8_3 = _mm256_loadu_si256(q8 as *const __m256i);
q8 = q8.add(32);
let q8s_0 = _mm256_maddubs_epi16(m32s, q8_0);
let q8s_1 = _mm256_maddubs_epi16(m32s, q8_1);
let q8s_2 = _mm256_maddubs_epi16(m32s, q8_2);
let q8s_3 = _mm256_maddubs_epi16(m32s, q8_3);
let p16_0 = _mm256_maddubs_epi16(q4_0, q8_0);
let p16_1 = _mm256_maddubs_epi16(q4_1, q8_1);
let p16_2 = _mm256_maddubs_epi16(q4_2, q8_2);
let p16_3 = _mm256_maddubs_epi16(q4_3, q8_3);
let p16_0 = _mm256_sub_epi16(p16_0, q8s_0);
let p16_1 = _mm256_sub_epi16(p16_1, q8s_1);
let p16_2 = _mm256_sub_epi16(p16_2, q8s_2);
let p16_3 = _mm256_sub_epi16(p16_3, q8s_3);
let p16_0 = _mm256_madd_epi16(_mm256_cvtepi8_epi16(scale_0), p16_0);
let p16_1 = _mm256_madd_epi16(_mm256_cvtepi8_epi16(scale_1), p16_1);
let p16_2 = _mm256_madd_epi16(_mm256_cvtepi8_epi16(scale_2), p16_2);
let p16_3 = _mm256_madd_epi16(_mm256_cvtepi8_epi16(scale_3), p16_3);
sumi = _mm256_add_epi32(sumi, _mm256_add_epi32(p16_0, p16_1));
sumi = _mm256_add_epi32(sumi, _mm256_add_epi32(p16_2, p16_3));
}
acc = _mm256_fmadd_ps(_mm256_broadcast_ss(&d), _mm256_cvtepi32_ps(sumi), acc);
}
Ok(hsum_float_8(acc))
}
}
#[inline(always)]
unsafe fn mm256_set_m128i(a: __m128i, b: __m128i) -> __m256i {
_mm256_insertf128_si256(_mm256_castsi128_si256(b), a, 1)
}
#[inline(always)]
pub(crate) fn vec_dot_q2k_q8k(n: usize, xs: &[BlockQ2K], ys: &[BlockQ8K]) -> Result<f32> {
if n % QK_K != 0 {
crate::bail!("vec_dot_q2k_q8k: {n} is not divisible by {QK_K}")
}
unsafe {
let m3 = _mm256_set1_epi8(3);
let m4 = _mm_set1_epi8(0xF);
let mut acc = _mm256_setzero_ps();
for (x, y) in xs.iter().zip(ys.iter()) {
let d = y.d * x.d.to_f32();
let dmin = -y.d * x.dmin.to_f32();
let mut q2 = x.qs.as_ptr();
let mut q8 = y.qs.as_ptr();
let mins_and_scales = _mm_loadu_si128(x.scales.as_ptr() as *const __m128i);
let scales8 = _mm_and_si128(mins_and_scales, m4);
let mins8 = _mm_and_si128(_mm_srli_epi16(mins_and_scales, 4), m4);
let mins = _mm256_cvtepi8_epi16(mins8);
let prod =
_mm256_madd_epi16(mins, _mm256_loadu_si256(y.bsums.as_ptr() as *const __m256i));
acc = _mm256_fmadd_ps(_mm256_broadcast_ss(&dmin), _mm256_cvtepi32_ps(prod), acc);
let all_scales = _mm256_cvtepi8_epi16(scales8);
let l_scales = _mm256_extracti128_si256(all_scales, 0);
let h_scales = _mm256_extracti128_si256(all_scales, 1);
let scales = [
mm256_set_m128i(l_scales, l_scales),
mm256_set_m128i(h_scales, h_scales),
];
let mut sumi = _mm256_setzero_si256();
for scale in scales {
let q2bits = _mm256_loadu_si256(q2 as *const __m256i);
q2 = q2.add(32);
let q8_0 = _mm256_loadu_si256(q8 as *const __m256i);
q8 = q8.add(32);
let q8_1 = _mm256_loadu_si256(q8 as *const __m256i);
q8 = q8.add(32);
let q8_2 = _mm256_loadu_si256(q8 as *const __m256i);
q8 = q8.add(32);
let q8_3 = _mm256_loadu_si256(q8 as *const __m256i);
q8 = q8.add(32);
let q2_0 = _mm256_and_si256(q2bits, m3);
let q2_1 = _mm256_and_si256(_mm256_srli_epi16(q2bits, 2), m3);
let q2_2 = _mm256_and_si256(_mm256_srli_epi16(q2bits, 4), m3);
let q2_3 = _mm256_and_si256(_mm256_srli_epi16(q2bits, 6), m3);
let p0 = _mm256_maddubs_epi16(q2_0, q8_0);
let p1 = _mm256_maddubs_epi16(q2_1, q8_1);
let p2 = _mm256_maddubs_epi16(q2_2, q8_2);
let p3 = _mm256_maddubs_epi16(q2_3, q8_3);
let p0 =
_mm256_madd_epi16(_mm256_shuffle_epi8(scale, get_scale_shuffle_q3k(0)), p0);
let p1 =
_mm256_madd_epi16(_mm256_shuffle_epi8(scale, get_scale_shuffle_q3k(1)), p1);
let p2 =
_mm256_madd_epi16(_mm256_shuffle_epi8(scale, get_scale_shuffle_q3k(2)), p2);
let p3 =
_mm256_madd_epi16(_mm256_shuffle_epi8(scale, get_scale_shuffle_q3k(3)), p3);
let p0 = _mm256_add_epi32(p0, p1);
let p2 = _mm256_add_epi32(p2, p3);
sumi = _mm256_add_epi32(sumi, _mm256_add_epi32(p0, p2));
}
acc = _mm256_fmadd_ps(_mm256_broadcast_ss(&d), _mm256_cvtepi32_ps(sumi), acc);
}
Ok(hsum_float_8(acc))
}
}
#[inline(always)]
pub(crate) fn vec_dot_q3k_q8k(n: usize, xs: &[BlockQ3K], ys: &[BlockQ8K]) -> Result<f32> {
if n % QK_K != 0 {
crate::bail!("vec_dot_q3k_q8k: {n} is not divisible by {QK_K}")
}
const KMASK1: u32 = 0x03030303;
const KMASK2: u32 = 0x0f0f0f0f;
let mut aux = [0u32; 3];
unsafe {
let m3 = _mm256_set1_epi8(3);
let mone = _mm256_set1_epi8(1);
let m32 = _mm_set1_epi8(32);
let mut acc = _mm256_setzero_ps();
for (x, y) in xs.iter().zip(ys.iter()) {
let d = y.d * x.d.to_f32();
let mut q3 = x.qs.as_ptr();
let mut q8 = y.qs.as_ptr();
LittleEndian::read_u32_into(&x.scales, &mut aux);
let scales128 = _mm_set_epi32(
(((aux[1] >> 4) & KMASK2) | (((aux[2] >> 6) & KMASK1) << 4)) as i32,
(((aux[0] >> 4) & KMASK2) | (((aux[2] >> 4) & KMASK1) << 4)) as i32,
((aux[1] & KMASK2) | (((aux[2] >> 2) & KMASK1) << 4)) as i32,
((aux[0] & KMASK2) | (((aux[2]) & KMASK1) << 4)) as i32,
);
let scales128 = _mm_sub_epi8(scales128, m32);
let all_scales = _mm256_cvtepi8_epi16(scales128);
let l_scales = _mm256_extracti128_si256(all_scales, 0);
let h_scales = _mm256_extracti128_si256(all_scales, 1);
let scales = [
mm256_set_m128i(l_scales, l_scales),
mm256_set_m128i(h_scales, h_scales),
];
// high bit
let hbits = _mm256_loadu_si256(x.hmask.as_ptr() as *const __m256i);
let mut sumi = _mm256_setzero_si256();
for (j, scale) in scales.iter().enumerate() {
// load low 2 bits
let q3bits = _mm256_loadu_si256(q3 as *const __m256i);
q3 = q3.add(32);
// Prepare low and high bits
// We hardcode the shifts here to avoid loading them into a separate register
let q3l_0 = _mm256_and_si256(q3bits, m3);
let q3h_0 = if j == 0 {
_mm256_srli_epi16(_mm256_andnot_si256(hbits, _mm256_slli_epi16(mone, 0)), 0)
} else {
_mm256_srli_epi16(_mm256_andnot_si256(hbits, _mm256_slli_epi16(mone, 4)), 4)
};
let q3h_0 = _mm256_slli_epi16(q3h_0, 2);
let q3l_1 = _mm256_and_si256(_mm256_srli_epi16(q3bits, 2), m3);
let q3h_1 = if j == 0 {
_mm256_srli_epi16(_mm256_andnot_si256(hbits, _mm256_slli_epi16(mone, 1)), 1)
} else {
_mm256_srli_epi16(_mm256_andnot_si256(hbits, _mm256_slli_epi16(mone, 5)), 5)
};
let q3h_1 = _mm256_slli_epi16(q3h_1, 2);
let q3l_2 = _mm256_and_si256(_mm256_srli_epi16(q3bits, 4), m3);
let q3h_2 = if j == 0 {
_mm256_srli_epi16(_mm256_andnot_si256(hbits, _mm256_slli_epi16(mone, 2)), 2)
} else {
_mm256_srli_epi16(_mm256_andnot_si256(hbits, _mm256_slli_epi16(mone, 6)), 6)
};
let q3h_2 = _mm256_slli_epi16(q3h_2, 2);
let q3l_3 = _mm256_and_si256(_mm256_srli_epi16(q3bits, 6), m3);
let q3h_3 = if j == 0 {
_mm256_srli_epi16(_mm256_andnot_si256(hbits, _mm256_slli_epi16(mone, 3)), 3)
} else {
_mm256_srli_epi16(_mm256_andnot_si256(hbits, _mm256_slli_epi16(mone, 7)), 7)
};
let q3h_3 = _mm256_slli_epi16(q3h_3, 2);
// load Q8 quants
let q8_0 = _mm256_loadu_si256(q8 as *const __m256i);
q8 = q8.add(32);
let q8_1 = _mm256_loadu_si256(q8 as *const __m256i);
q8 = q8.add(32);
let q8_2 = _mm256_loadu_si256(q8 as *const __m256i);
q8 = q8.add(32);
let q8_3 = _mm256_loadu_si256(q8 as *const __m256i);
q8 = q8.add(32);
// Dot product: we multiply the 2 low bits and 1 high bit part separately, so we
// can use _mm256_maddubs_epi16, and then subtract. The high bit part has the 2
// already subtracted (and so, it is zero if the high bit was not set, and 2 if the
// high bit was set)
let q8s_0 = _mm256_maddubs_epi16(q3h_0, q8_0);
let q8s_1 = _mm256_maddubs_epi16(q3h_1, q8_1);
let q8s_2 = _mm256_maddubs_epi16(q3h_2, q8_2);
let q8s_3 = _mm256_maddubs_epi16(q3h_3, q8_3);
let p16_0 = _mm256_maddubs_epi16(q3l_0, q8_0);
let p16_1 = _mm256_maddubs_epi16(q3l_1, q8_1);
let p16_2 = _mm256_maddubs_epi16(q3l_2, q8_2);
let p16_3 = _mm256_maddubs_epi16(q3l_3, q8_3);
let p16_0 = _mm256_sub_epi16(p16_0, q8s_0);
let p16_1 = _mm256_sub_epi16(p16_1, q8s_1);
let p16_2 = _mm256_sub_epi16(p16_2, q8s_2);
let p16_3 = _mm256_sub_epi16(p16_3, q8s_3);
// multiply with scales
let p16_0 =
_mm256_madd_epi16(_mm256_shuffle_epi8(*scale, get_scale_shuffle_q3k(0)), p16_0);
let p16_1 =
_mm256_madd_epi16(_mm256_shuffle_epi8(*scale, get_scale_shuffle_q3k(1)), p16_1);
let p16_2 =
_mm256_madd_epi16(_mm256_shuffle_epi8(*scale, get_scale_shuffle_q3k(2)), p16_2);
let p16_3 =
_mm256_madd_epi16(_mm256_shuffle_epi8(*scale, get_scale_shuffle_q3k(3)), p16_3);
// accumulate
let p16_0 = _mm256_add_epi32(p16_0, p16_1);
let p16_2 = _mm256_add_epi32(p16_2, p16_3);
sumi = _mm256_add_epi32(sumi, _mm256_add_epi32(p16_0, p16_2));
}
// multiply with block scale and accumulate
acc = _mm256_fmadd_ps(_mm256_broadcast_ss(&d), _mm256_cvtepi32_ps(sumi), acc);
}
Ok(hsum_float_8(acc))
}
}
#[inline(always)]
pub(crate) fn vec_dot_q4k_q8k(n: usize, xs: &[BlockQ4K], ys: &[BlockQ8K]) -> Result<f32> {
if n % QK_K != 0 {
crate::bail!("vec_dot_q4k_q8k: {n} is not divisible by {QK_K}")
}
let mut utmp = [0u32; 4];
const KMASK1: u32 = 0x3f3f3f3f;
const KMASK2: u32 = 0x0f0f0f0f;
const KMASK3: u32 = 0x03030303;
unsafe {
let m4 = _mm256_set1_epi8(0xF);
let mut acc = _mm256_setzero_ps();
let mut acc_m = _mm_setzero_ps();
for (x, y) in xs.iter().zip(ys.iter()) {
let d = y.d * x.d.to_f32();
let dmin = -y.d * x.dmin.to_f32();
LittleEndian::read_u32_into(&x.scales, &mut utmp[0..3]);
utmp[3] = ((utmp[2] >> 4) & KMASK2) | (((utmp[1] >> 6) & KMASK3) << 4);
let uaux = utmp[1] & KMASK1;
utmp[1] = (utmp[2] & KMASK2) | (((utmp[0] >> 6) & KMASK3) << 4);
utmp[2] = uaux;
utmp[0] &= KMASK1;
let mut q4 = x.qs.as_ptr();
let mut q8 = y.qs.as_ptr();
let mins_and_scales = _mm256_cvtepu8_epi16(_mm_set_epi32(
utmp[3] as i32,
utmp[2] as i32,
utmp[1] as i32,
utmp[0] as i32,
));
let q8sums = _mm256_loadu_si256(y.bsums.as_ptr() as *const __m256i);
let q8s = _mm_hadd_epi16(
_mm256_extracti128_si256(q8sums, 0),
_mm256_extracti128_si256(q8sums, 1),
);
let prod = _mm_madd_epi16(_mm256_extracti128_si256(mins_and_scales, 1), q8s);
acc_m = _mm_fmadd_ps(_mm_set1_ps(dmin), _mm_cvtepi32_ps(prod), acc_m);
let sc128 = _mm256_extracti128_si256(mins_and_scales, 0);
let scales = mm256_set_m128i(sc128, sc128);
let mut sumi = _mm256_setzero_si256();
for j in 0..QK_K / 64 {
let scale_l = _mm256_shuffle_epi8(scales, get_scale_shuffle_k4(2 * j));
let scale_h = _mm256_shuffle_epi8(scales, get_scale_shuffle_k4(2 * j + 1));
let q4bits = _mm256_loadu_si256(q4 as *const __m256i);
q4 = q4.add(32);
let q4l = _mm256_and_si256(q4bits, m4);
let q4h = _mm256_and_si256(_mm256_srli_epi16(q4bits, 4), m4);
let q8l = _mm256_loadu_si256(q8 as *const __m256i);
q8 = q8.add(32);
let p16l = _mm256_maddubs_epi16(q4l, q8l);
let p16l = _mm256_madd_epi16(scale_l, p16l);
sumi = _mm256_add_epi32(sumi, p16l);
let q8h = _mm256_loadu_si256(q8 as *const __m256i);
q8 = q8.add(32);
let p16h = _mm256_maddubs_epi16(q4h, q8h);
let p16h = _mm256_madd_epi16(scale_h, p16h);
sumi = _mm256_add_epi32(sumi, p16h);
}
let vd = _mm256_set1_ps(d);
acc = _mm256_fmadd_ps(vd, _mm256_cvtepi32_ps(sumi), acc);
}
let acc_m = _mm_add_ps(acc_m, _mm_movehl_ps(acc_m, acc_m));
let acc_m = _mm_add_ss(acc_m, _mm_movehdup_ps(acc_m));
Ok(hsum_float_8(acc) + _mm_cvtss_f32(acc_m))
}
}
#[inline(always)]
pub(crate) fn vec_dot_q5k_q8k(n: usize, xs: &[BlockQ5K], ys: &[BlockQ8K]) -> Result<f32> {
if n % QK_K != 0 {
crate::bail!("vec_dot_q5k_q8k: {n} is not divisible by {QK_K}")
}
let mut utmp = [0u32; 4];
const KMASK1: u32 = 0x3f3f3f3f;
const KMASK2: u32 = 0x0f0f0f0f;
const KMASK3: u32 = 0x03030303;
unsafe {
let m4 = _mm256_set1_epi8(0xF);
let mzero = _mm_setzero_si128();
let mone = _mm256_set1_epi8(1);
let mut acc = _mm256_setzero_ps();
let mut summs = 0.0;
for (x, y) in xs.iter().zip(ys.iter()) {
let d = y.d * x.d.to_f32();
let dmin = -y.d * x.dmin.to_f32();
LittleEndian::read_u32_into(&x.scales, &mut utmp[0..3]);
utmp[3] = ((utmp[2] >> 4) & KMASK2) | (((utmp[1] >> 6) & KMASK3) << 4);
let uaux = utmp[1] & KMASK1;
utmp[1] = (utmp[2] & KMASK2) | (((utmp[0] >> 6) & KMASK3) << 4);
utmp[2] = uaux;
utmp[0] &= KMASK1;
let mut q5 = x.qs.as_ptr();
let mut q8 = y.qs.as_ptr();
let mins_and_scales = _mm256_cvtepu8_epi16(_mm_set_epi32(
utmp[3] as i32,
utmp[2] as i32,
utmp[1] as i32,
utmp[0] as i32,
));
let q8sums = _mm256_loadu_si256(y.bsums.as_ptr() as *const __m256i);
let q8s = _mm_hadd_epi16(
_mm256_extracti128_si256(q8sums, 0),
_mm256_extracti128_si256(q8sums, 1),
);
let prod = _mm_madd_epi16(_mm256_extracti128_si256(mins_and_scales, 1), q8s);
let hsum = _mm_hadd_epi32(_mm_hadd_epi32(prod, mzero), mzero);
summs += dmin * _mm_extract_epi32(hsum, 0) as f32;
let sc128 = _mm256_extracti128_si256(mins_and_scales, 0);
let scales = mm256_set_m128i(sc128, sc128);
let hbits = _mm256_loadu_si256(x.qh.as_ptr() as *const __m256i);
let mut hmask = mone;
let mut sumi = _mm256_setzero_si256();
for j in 0..QK_K / 64 {
let scale_0 = _mm256_shuffle_epi8(scales, get_scale_shuffle_k4(2 * j));
let scale_1 = _mm256_shuffle_epi8(scales, get_scale_shuffle_k4(2 * j + 1));
let q5bits = _mm256_loadu_si256(q5 as *const __m256i);
q5 = q5.add(32);
//Similar to q3k we hardcode the shifts here to avoid loading them into a separate register
let q5l_0 = _mm256_and_si256(q5bits, m4);
let q5l_0_shift_input = _mm256_and_si256(hbits, hmask);
let q5l_0_right_shift = match j {
0 => _mm256_srli_epi16(q5l_0_shift_input, 0),
1 => _mm256_srli_epi16(q5l_0_shift_input, 2),
2 => _mm256_srli_epi16(q5l_0_shift_input, 4),
3 => _mm256_srli_epi16(q5l_0_shift_input, 6),
_ => unreachable!(),
};
let q5h_0 = _mm256_slli_epi16(q5l_0_right_shift, 4);
let q5_0 = _mm256_add_epi8(q5l_0, q5h_0);
hmask = _mm256_slli_epi16(hmask, 1);
let q5l_1 = _mm256_and_si256(_mm256_srli_epi16(q5bits, 4), m4);
let q5l_1_shift_input = _mm256_and_si256(hbits, hmask);
let q5l_1_right_shift = match j {
0 => _mm256_srli_epi16(q5l_1_shift_input, 1),
1 => _mm256_srli_epi16(q5l_1_shift_input, 3),
2 => _mm256_srli_epi16(q5l_1_shift_input, 5),
3 => _mm256_srli_epi16(q5l_1_shift_input, 7),
_ => unreachable!(),
};
let q5h_1 = _mm256_slli_epi16(q5l_1_right_shift, 4);
let q5_1 = _mm256_add_epi8(q5l_1, q5h_1);
hmask = _mm256_slli_epi16(hmask, 1);
let q8_0 = _mm256_loadu_si256(q8 as *const __m256i);
q8 = q8.add(32);
let q8_1 = _mm256_loadu_si256(q8 as *const __m256i);
q8 = q8.add(32);
let p16_0 = _mm256_maddubs_epi16(q5_0, q8_0);
let p16_1 = _mm256_maddubs_epi16(q5_1, q8_1);
let p16_0 = _mm256_madd_epi16(scale_0, p16_0);
let p16_1 = _mm256_madd_epi16(scale_1, p16_1);
sumi = _mm256_add_epi32(sumi, _mm256_add_epi32(p16_0, p16_1));
}
let vd = _mm256_set1_ps(d);
acc = _mm256_fmadd_ps(vd, _mm256_cvtepi32_ps(sumi), acc);
}
Ok(hsum_float_8(acc) + summs)
}
}
#[inline(always)]
pub(crate) fn vec_dot_q8k_q8k(n: usize, xs: &[BlockQ8K], ys: &[BlockQ8K]) -> Result<f32> {
let qk = QK_K;
if n % qk != 0 {
crate::bail!("vec_dot_q8k_8k: {n} is not divisible by {qk}")
}
unsafe {
let mut acc = _mm256_setzero_ps();
for (xs, ys) in xs.iter().zip(ys.iter()) {
let mut sumi = _mm256_setzero_si256();
let x_qs = xs.qs.as_ptr();
let y_qs = ys.qs.as_ptr();
for j in (0..QK_K).step_by(32) {
let xs = _mm256_loadu_si256(x_qs.add(j) as *const __m256i);
let ys = _mm256_loadu_si256(y_qs.add(j) as *const __m256i);
let xs0 = _mm256_cvtepi8_epi16(_mm256_extracti128_si256(xs, 0));
let ys0 = _mm256_cvtepi8_epi16(_mm256_extracti128_si256(ys, 0));
sumi = _mm256_add_epi32(sumi, _mm256_madd_epi16(xs0, ys0));
let xs1 = _mm256_cvtepi8_epi16(_mm256_extracti128_si256(xs, 1));
let ys1 = _mm256_cvtepi8_epi16(_mm256_extracti128_si256(ys, 1));
sumi = _mm256_add_epi32(sumi, _mm256_madd_epi16(xs1, ys1));
}
let d = _mm256_set1_ps(xs.d * ys.d);
acc = _mm256_fmadd_ps(d, _mm256_cvtepi32_ps(sumi), acc);
}
Ok(hsum_float_8(acc))
}
}
| 1 |
0 | hf_public_repos/candle/candle-core/src | hf_public_repos/candle/candle-core/src/quantized/ggml_file.rs | //! Support for the GGML file format.
use super::{k_quants, GgmlDType, QStorage};
use crate::{Device, Result};
use byteorder::{LittleEndian, ReadBytesExt};
use std::collections::HashMap;
// https://github.com/ggerganov/llama.cpp/blob/468ea24fb4633a0d681f7ac84089566c1c6190cb/llama.h#L37
#[derive(Debug, Clone, Copy, PartialEq, Eq)]
enum Magic {
Ggjt,
Ggla,
Ggmf,
Ggml,
Ggsn,
}
impl TryFrom<u32> for Magic {
type Error = crate::Error;
fn try_from(value: u32) -> Result<Self> {
let magic = match value {
0x67676a74 => Self::Ggjt,
0x67676c61 => Self::Ggla,
0x67676d66 => Self::Ggmf,
0x67676d6c => Self::Ggml,
0x6767736e => Self::Ggsn,
_ => crate::bail!("unknown magic {value:08x}"),
};
Ok(magic)
}
}
#[derive(Debug, Clone, Copy, PartialEq, Eq)]
pub enum VersionedMagic {
GgmlUnversioned,
GgmfV1,
GgjtV1,
GgjtV2,
GgjtV3,
}
impl VersionedMagic {
fn read<R: std::io::Read>(reader: &mut R) -> Result<Self> {
let magic = reader.read_u32::<LittleEndian>()?;
let magic = Magic::try_from(magic)?;
if magic == Magic::Ggml {
return Ok(Self::GgmlUnversioned);
}
let version = reader.read_u32::<LittleEndian>()?;
let versioned_magic = match (magic, version) {
(Magic::Ggmf, 1) => Self::GgmfV1,
(Magic::Ggjt, 1) => Self::GgjtV1,
(Magic::Ggjt, 2) => Self::GgjtV2,
(Magic::Ggjt, 3) => Self::GgjtV3,
_ => crate::bail!("ggml: unsupported magic/version {magic:?}/{version}"),
};
Ok(versioned_magic)
}
fn align32(&self) -> bool {
match self {
Self::GgmlUnversioned | Self::GgmfV1 => false,
Self::GgjtV1 | Self::GgjtV2 | Self::GgjtV3 => true,
}
}
}
#[derive(Debug, Clone, PartialEq, Eq)]
pub struct HParams {
pub n_vocab: u32,
pub n_embd: u32,
pub n_mult: u32,
pub n_head: u32,
pub n_layer: u32,
pub n_rot: u32,
pub ftype: u32,
}
impl HParams {
fn read<R: std::io::Read>(reader: &mut R) -> Result<Self> {
let n_vocab = reader.read_u32::<LittleEndian>()?;
let n_embd = reader.read_u32::<LittleEndian>()?;
let n_mult = reader.read_u32::<LittleEndian>()?;
let n_head = reader.read_u32::<LittleEndian>()?;
let n_layer = reader.read_u32::<LittleEndian>()?;
let n_rot = reader.read_u32::<LittleEndian>()?;
let ftype = reader.read_u32::<LittleEndian>()?;
Ok(Self {
n_vocab,
n_embd,
n_mult,
n_head,
n_layer,
n_rot,
ftype,
})
}
}
#[derive(Debug, Clone, PartialEq)]
pub struct Vocab {
pub token_score_pairs: Vec<(Vec<u8>, f32)>,
}
impl Vocab {
fn read<R: std::io::Read>(reader: &mut R, n_vocab: usize) -> Result<Self> {
// https://github.com/ggerganov/llama.cpp/blob/468ea24fb4633a0d681f7ac84089566c1c6190cb/llama.cpp#L556
let mut token_score_pairs = Vec::with_capacity(n_vocab);
for _index in 0..n_vocab {
let len = reader.read_u32::<LittleEndian>()? as usize;
let mut word = vec![0u8; len];
reader.read_exact(&mut word)?;
let score = reader.read_f32::<LittleEndian>()?;
token_score_pairs.push((word, score))
}
Ok(Self { token_score_pairs })
}
}
fn from_raw_data<T: super::GgmlType + Send + Sync + 'static>(
raw_data: &[u8],
size_in_bytes: usize,
dims: Vec<usize>,
device: &Device,
) -> Result<super::QTensor> {
let raw_data_ptr = raw_data.as_ptr();
let n_blocks = size_in_bytes / std::mem::size_of::<T>();
let data = unsafe { std::slice::from_raw_parts(raw_data_ptr as *const T, n_blocks) };
let data: QStorage = match device {
Device::Cpu => QStorage::Cpu(Box::new(data.to_vec())),
Device::Metal(metal) => super::metal::load_quantized(metal, data)?,
Device::Cuda(cuda) => super::cuda::load_quantized(cuda, data)?,
};
super::QTensor::new(data, dims)
}
/// Creates a Tensor from a raw GGML tensor.
pub fn qtensor_from_ggml(
ggml_dtype: GgmlDType,
raw_data: &[u8],
dims: Vec<usize>,
device: &Device,
) -> Result<super::QTensor> {
let tensor_elems = dims.iter().product::<usize>();
let block_size = ggml_dtype.block_size();
if tensor_elems % block_size != 0 {
crate::bail!(
"the number of elements {tensor_elems} is not divisible by the block size {block_size}"
)
}
let size_in_bytes = tensor_elems / block_size * ggml_dtype.type_size();
match ggml_dtype {
GgmlDType::F32 => from_raw_data::<f32>(raw_data, size_in_bytes, dims, device),
GgmlDType::F16 => from_raw_data::<half::f16>(raw_data, size_in_bytes, dims, device),
GgmlDType::Q4_0 => {
from_raw_data::<k_quants::BlockQ4_0>(raw_data, size_in_bytes, dims, device)
}
GgmlDType::Q4_1 => {
from_raw_data::<k_quants::BlockQ4_1>(raw_data, size_in_bytes, dims, device)
}
GgmlDType::Q5_0 => {
from_raw_data::<k_quants::BlockQ5_0>(raw_data, size_in_bytes, dims, device)
}
GgmlDType::Q5_1 => {
from_raw_data::<k_quants::BlockQ5_1>(raw_data, size_in_bytes, dims, device)
}
GgmlDType::Q8_0 => {
from_raw_data::<k_quants::BlockQ8_0>(raw_data, size_in_bytes, dims, device)
}
GgmlDType::Q2K => {
from_raw_data::<k_quants::BlockQ2K>(raw_data, size_in_bytes, dims, device)
}
GgmlDType::Q3K => {
from_raw_data::<k_quants::BlockQ3K>(raw_data, size_in_bytes, dims, device)
}
GgmlDType::Q4K => {
from_raw_data::<k_quants::BlockQ4K>(raw_data, size_in_bytes, dims, device)
}
GgmlDType::Q5K => {
from_raw_data::<k_quants::BlockQ5K>(raw_data, size_in_bytes, dims, device)
}
GgmlDType::Q6K => {
from_raw_data::<k_quants::BlockQ6K>(raw_data, size_in_bytes, dims, device)
}
_ => crate::bail!("quantized type {ggml_dtype:?} is not supported yet"),
}
}
fn read_one_tensor<R: std::io::Seek + std::io::Read>(
reader: &mut R,
magic: VersionedMagic,
device: &Device,
) -> Result<(String, super::QTensor)> {
let n_dims = reader.read_u32::<LittleEndian>()?;
let name_len = reader.read_u32::<LittleEndian>()?;
let ggml_dtype = reader.read_u32::<LittleEndian>()?;
let ggml_dtype = GgmlDType::from_u32(ggml_dtype)?;
let mut dims = vec![0u32; n_dims as usize];
reader.read_u32_into::<LittleEndian>(&mut dims)?;
// The dimensions are stored in reverse order, see for example:
// https://github.com/ggerganov/llama.cpp/blob/b5ffb2849d23afe73647f68eec7b68187af09be6/convert.py#L969
dims.reverse();
let mut name = vec![0u8; name_len as usize];
reader.read_exact(&mut name)?;
let name = String::from_utf8_lossy(&name).into_owned();
if magic.align32() {
let pos = reader.stream_position()?;
reader.seek(std::io::SeekFrom::Current(((32 - pos % 32) % 32) as i64))?;
}
let dims = dims.iter().map(|&u| u as usize).collect::<Vec<_>>();
let tensor_elems = dims.iter().product::<usize>();
let size_in_bytes = tensor_elems * ggml_dtype.type_size() / ggml_dtype.block_size();
// TODO: Mmap version to avoid copying the data around?
let mut raw_data = vec![0u8; size_in_bytes];
reader.read_exact(&mut raw_data)?;
match qtensor_from_ggml(ggml_dtype, &raw_data, dims, device) {
Ok(tensor) => Ok((name, tensor)),
Err(e) => crate::bail!("Error creating tensor {name}: {e}"),
}
}
pub struct Content {
pub magic: VersionedMagic,
pub hparams: HParams,
pub vocab: Vocab,
pub tensors: HashMap<String, super::QTensor>,
pub device: Device,
}
impl Content {
pub fn read<R: std::io::Seek + std::io::Read>(
reader: &mut R,
device: &Device,
) -> Result<Content> {
// https://github.com/ggerganov/llama.cpp/blob/468ea24fb4633a0d681f7ac84089566c1c6190cb/llama.cpp#L505
let last_position = reader.seek(std::io::SeekFrom::End(0))?;
reader.seek(std::io::SeekFrom::Start(0))?;
let magic = VersionedMagic::read(reader)?;
let hparams = HParams::read(reader)?;
let vocab = Vocab::read(reader, hparams.n_vocab as usize)?;
let mut tensors = HashMap::new();
while reader.stream_position()? != last_position {
let (name, tensor) = read_one_tensor(reader, magic, device)?;
tensors.insert(name, tensor);
}
let device = device.clone();
Ok(Self {
magic,
hparams,
vocab,
tensors,
device,
})
}
pub fn remove(&mut self, name: &str) -> Result<super::QTensor> {
match self.tensors.remove(name) {
None => crate::bail!("cannot find tensor with name '{name}'"),
Some(tensor) => Ok(tensor),
}
}
}
| 2 |
0 | hf_public_repos/candle/candle-core/src | hf_public_repos/candle/candle-core/src/quantized/mod.rs | //! Code for GGML and GGUF files
use crate::{CpuStorage, DType, Device, Result, Shape, Storage, Tensor};
use k_quants::*;
use std::borrow::Cow;
#[cfg(target_feature = "avx")]
pub mod avx;
mod dummy_cuda;
mod dummy_metal;
pub mod ggml_file;
pub mod gguf_file;
pub mod k_quants;
#[cfg(feature = "metal")]
pub mod metal;
#[cfg(not(feature = "metal"))]
mod metal {
pub use super::dummy_metal::*;
}
#[cfg(feature = "cuda")]
pub mod cuda;
#[cfg(not(feature = "cuda"))]
mod cuda {
pub use super::dummy_cuda::*;
}
#[cfg(target_feature = "neon")]
pub mod neon;
#[cfg(target_feature = "simd128")]
pub mod simd128;
pub mod utils;
use half::f16;
pub use k_quants::GgmlType;
pub struct QTensor {
storage: QStorage,
shape: Shape,
}
impl Device {
fn qzeros(&self, elem_count: usize, dtype: GgmlDType) -> Result<QStorage> {
match self {
Device::Cpu => {
let storage = dtype.cpu_zeros(elem_count);
Ok(QStorage::Cpu(storage))
}
Device::Metal(metal) => {
let storage = metal::QMetalStorage::zeros(metal, elem_count, dtype)?;
Ok(QStorage::Metal(storage))
}
Device::Cuda(cuda) => {
let storage = cuda::QCudaStorage::zeros(cuda, elem_count, dtype)?;
Ok(QStorage::Cuda(storage))
}
}
}
}
pub enum QStorage {
Cpu(Box<dyn QuantizedType>),
Metal(metal::QMetalStorage),
Cuda(cuda::QCudaStorage),
}
impl QStorage {
fn block_size(&self) -> usize {
match self {
QStorage::Cpu(storage) => storage.block_size(),
QStorage::Metal(storage) => storage.dtype().block_size(),
QStorage::Cuda(storage) => storage.dtype().block_size(),
}
}
fn dtype(&self) -> GgmlDType {
match self {
QStorage::Cpu(storage) => storage.dtype(),
QStorage::Metal(storage) => storage.dtype(),
QStorage::Cuda(storage) => storage.dtype(),
}
}
fn device(&self) -> Device {
match self {
QStorage::Cpu(_storage) => Device::Cpu,
QStorage::Metal(storage) => Device::Metal(storage.device().clone()),
QStorage::Cuda(storage) => Device::Cuda(storage.device().clone()),
}
}
fn size_in_bytes(&self) -> usize {
match self {
QStorage::Cpu(storage) => storage.storage_size_in_bytes(),
QStorage::Metal(storage) => storage.storage_size_in_bytes(),
QStorage::Cuda(storage) => storage.storage_size_in_bytes(),
}
}
fn quantize(&mut self, src: &Storage) -> Result<()> {
match (self, src) {
(QStorage::Cpu(storage), Storage::Cpu(src)) => {
storage.from_float(src.as_slice::<f32>()?)?;
}
(QStorage::Metal(storage), Storage::Metal(src)) => storage.quantize(src)?,
(QStorage::Cuda(storage), Storage::Cuda(src)) => storage.quantize(src)?,
_ => crate::bail!("Invalid dequantize storage locations do not match"),
}
Ok(())
}
fn dequantize(&self, elem_count: usize) -> Result<Storage> {
match self {
QStorage::Cpu(storage) => Ok(Storage::Cpu(storage.dequantize(elem_count)?)),
QStorage::Metal(storage) => Ok(Storage::Metal(storage.dequantize(elem_count)?)),
QStorage::Cuda(storage) => Ok(Storage::Cuda(storage.dequantize(elem_count)?)),
}
}
fn data(&self) -> Result<Cow<[u8]>> {
match self {
QStorage::Cpu(storage) => {
let data_ptr = storage.as_ptr();
let size_in_bytes = storage.storage_size_in_bytes();
let data = unsafe { std::slice::from_raw_parts(data_ptr, size_in_bytes) };
Ok(Cow::from(data))
}
QStorage::Metal(_) | QStorage::Cuda(_) => {
crate::bail!("not implemented");
}
}
}
}
#[derive(Debug, Clone, Copy, PartialEq, Eq, Hash)]
pub enum GgmlDType {
F32,
F16,
Q4_0,
Q4_1,
Q5_0,
Q5_1,
Q8_0,
Q8_1,
Q2K,
Q3K,
Q4K,
Q5K,
Q6K,
Q8K,
}
impl GgmlDType {
pub(crate) fn from_u32(u: u32) -> Result<Self> {
let dtype = match u {
0 => Self::F32,
1 => Self::F16,
2 => Self::Q4_0,
3 => Self::Q4_1,
6 => Self::Q5_0,
7 => Self::Q5_1,
8 => Self::Q8_0,
9 => Self::Q8_1,
10 => Self::Q2K,
11 => Self::Q3K,
12 => Self::Q4K,
13 => Self::Q5K,
14 => Self::Q6K,
15 => Self::Q8K,
_ => crate::bail!("unknown dtype for tensor {u}"),
};
Ok(dtype)
}
pub(crate) fn to_u32(self) -> u32 {
match self {
Self::F32 => 0,
Self::F16 => 1,
Self::Q4_0 => 2,
Self::Q4_1 => 3,
Self::Q5_0 => 6,
Self::Q5_1 => 7,
Self::Q8_0 => 8,
Self::Q8_1 => 9,
Self::Q2K => 10,
Self::Q3K => 11,
Self::Q4K => 12,
Self::Q5K => 13,
Self::Q6K => 14,
Self::Q8K => 15,
}
}
/// The block dtype
pub fn cpu_zeros(&self, elem_count: usize) -> Box<dyn QuantizedType> {
match self {
Self::F32 => Box::new(vec![f32::zeros(); elem_count]),
Self::F16 => Box::new(vec![f16::zeros(); elem_count]),
Self::Q4_0 => Box::new(vec![BlockQ4_0::zeros(); elem_count / BlockQ4_0::BLCK_SIZE]),
Self::Q4_1 => Box::new(vec![BlockQ4_1::zeros(); elem_count / BlockQ4_1::BLCK_SIZE]),
Self::Q5_0 => Box::new(vec![BlockQ5_0::zeros(); elem_count / BlockQ5_0::BLCK_SIZE]),
Self::Q5_1 => Box::new(vec![BlockQ5_1::zeros(); elem_count / BlockQ5_1::BLCK_SIZE]),
Self::Q8_0 => Box::new(vec![BlockQ8_0::zeros(); elem_count / BlockQ8_0::BLCK_SIZE]),
Self::Q8_1 => Box::new(vec![BlockQ8_1::zeros(); elem_count / BlockQ8_1::BLCK_SIZE]),
Self::Q2K => Box::new(vec![BlockQ2K::zeros(); elem_count / BlockQ2K::BLCK_SIZE]),
Self::Q3K => Box::new(vec![BlockQ3K::zeros(); elem_count / BlockQ3K::BLCK_SIZE]),
Self::Q4K => Box::new(vec![BlockQ4K::zeros(); elem_count / BlockQ4K::BLCK_SIZE]),
Self::Q5K => Box::new(vec![BlockQ5K::zeros(); elem_count / BlockQ5K::BLCK_SIZE]),
Self::Q6K => Box::new(vec![BlockQ6K::zeros(); elem_count / BlockQ6K::BLCK_SIZE]),
Self::Q8K => Box::new(vec![BlockQ8K::zeros(); elem_count / BlockQ8K::BLCK_SIZE]),
}
}
/// The type size for blocks in bytes.
pub fn type_size(&self) -> usize {
use k_quants::*;
match self {
Self::F32 => 4,
Self::F16 => 2,
Self::Q4_0 => std::mem::size_of::<BlockQ4_0>(),
Self::Q4_1 => std::mem::size_of::<BlockQ4_1>(),
Self::Q5_0 => std::mem::size_of::<BlockQ5_0>(),
Self::Q5_1 => std::mem::size_of::<BlockQ5_1>(),
// https://github.com/ggerganov/llama.cpp/blob/468ea24fb4633a0d681f7ac84089566c1c6190cb/ggml.c#L932
Self::Q8_0 => std::mem::size_of::<BlockQ8_0>(),
Self::Q8_1 => std::mem::size_of::<BlockQ8_1>(),
Self::Q2K => std::mem::size_of::<BlockQ2K>(),
Self::Q3K => std::mem::size_of::<BlockQ3K>(),
Self::Q4K => std::mem::size_of::<BlockQ4K>(),
Self::Q5K => std::mem::size_of::<BlockQ5K>(),
Self::Q6K => std::mem::size_of::<BlockQ6K>(),
Self::Q8K => std::mem::size_of::<BlockQ8K>(),
}
}
/// The block size, i.e. the number of elements stored in each block.
pub fn block_size(&self) -> usize {
match self {
Self::F32 => 1,
Self::F16 => 1,
Self::Q4_0 => k_quants::QK4_0,
Self::Q4_1 => k_quants::QK4_1,
Self::Q5_0 => k_quants::QK5_0,
Self::Q5_1 => k_quants::QK5_1,
Self::Q8_0 => k_quants::QK8_0,
Self::Q8_1 => k_quants::QK8_1,
Self::Q2K | Self::Q3K | Self::Q4K | Self::Q5K | Self::Q6K | Self::Q8K => k_quants::QK_K,
}
}
}
// A version of GgmlType without `vec_dot` so that it can be dyn boxed.
pub trait QuantizedType: Send + Sync {
fn dtype(&self) -> GgmlDType;
fn matmul_t(&self, mkn: (usize, usize, usize), lhs: &[f32], dst: &mut [f32]) -> Result<()>;
fn dequantize(&self, elem_count: usize) -> Result<CpuStorage>;
fn storage_size_in_bytes(&self) -> usize;
fn as_ptr(&self) -> *const u8;
fn block_size(&self) -> usize;
#[allow(clippy::wrong_self_convention)]
fn from_float(&mut self, xs: &[f32]) -> Result<()>;
fn size(&self) -> usize;
}
impl<T: k_quants::GgmlType + Send + Sync> QuantizedType for Vec<T> {
fn matmul_t(&self, mkn: (usize, usize, usize), lhs: &[f32], dst: &mut [f32]) -> Result<()> {
k_quants::matmul(mkn, lhs, self.as_slice(), dst)
}
fn size(&self) -> usize {
self.len() * core::mem::size_of::<T>()
}
fn from_float(&mut self, xs: &[f32]) -> Result<()> {
T::from_float(xs, self)
}
fn dtype(&self) -> GgmlDType {
T::DTYPE
}
fn block_size(&self) -> usize {
T::BLCK_SIZE
}
fn dequantize(&self, elem_count: usize) -> Result<CpuStorage> {
let mut ys = vec![0.0f32; elem_count];
T::to_float(self.as_slice(), &mut ys)?;
Ok(CpuStorage::F32(ys))
}
fn storage_size_in_bytes(&self) -> usize {
self.len() * std::mem::size_of::<T>()
}
fn as_ptr(&self) -> *const u8 {
self.as_ptr() as *const u8
}
}
impl std::fmt::Debug for QTensor {
fn fmt(&self, f: &mut std::fmt::Formatter) -> std::fmt::Result {
write!(f, "QTensor[{:?}; {:?}]", self.shape, self.dtype())
}
}
fn check_shape(shape: &Shape, block_size: usize) -> Result<()> {
let dims = shape.dims();
if dims.is_empty() {
crate::bail!("scalar tensor cannot be quantized {shape:?}")
}
if dims[dims.len() - 1] % block_size != 0 {
crate::bail!(
"quantized tensor must have their last dim divisible by block size {shape:?} {}",
block_size
)
}
Ok(())
}
impl QTensor {
pub fn new<S: Into<Shape>>(storage: QStorage, shape: S) -> Result<Self> {
let shape = shape.into();
check_shape(&shape, storage.block_size())?;
Ok(Self { storage, shape })
}
pub fn quantize(src: &Tensor, dtype: GgmlDType) -> Result<Self> {
let shape = src.shape();
let block_size = dtype.block_size();
check_shape(shape, block_size)?;
let src = src.to_dtype(crate::DType::F32)?.flatten_all()?;
let elem_count = shape.elem_count();
if elem_count % block_size != 0 {
crate::bail!(
"tensor size ({shape:?}) is not divisible by block size {}",
block_size
)
}
let mut storage = src.device().qzeros(elem_count, dtype)?;
storage.quantize(&src.storage())?;
Ok(Self {
storage,
shape: shape.clone(),
})
}
pub fn dtype(&self) -> GgmlDType {
self.storage.dtype()
}
pub fn device(&self) -> Device {
self.storage.device()
}
pub fn rank(&self) -> usize {
self.shape.rank()
}
pub fn shape(&self) -> &Shape {
&self.shape
}
pub fn dequantize(&self, device: &Device) -> Result<Tensor> {
let storage = self.storage.dequantize(self.shape.elem_count())?;
let none = crate::op::BackpropOp::none();
crate::tensor::from_storage(storage, self.shape.clone(), none, false).to_device(device)
}
pub fn dequantize_f16(&self, device: &Device) -> Result<Tensor> {
// In the CUDA case, we have a specialized kernel as this can be useful for volta
// architectures. https://github.com/huggingface/candle/issues/2136
match &self.storage {
QStorage::Cuda(s) => {
let s = s.dequantize_f16(self.shape.elem_count())?;
let none = crate::op::BackpropOp::none();
crate::tensor::from_storage(Storage::Cuda(s), self.shape.clone(), none, false)
.to_device(device)
}
_ => {
let s = self.dequantize(device)?.to_dtype(crate::DType::F16)?;
Ok(s)
}
}
}
pub fn storage_size_in_bytes(&self) -> usize {
self.storage.size_in_bytes()
}
pub fn data(&self) -> Result<Cow<'_, [u8]>> {
self.storage.data()
}
}
#[derive(Clone, Debug)]
pub enum QMatMul {
QTensor(std::sync::Arc<QTensor>),
Tensor(Tensor),
TensorF16(Tensor),
}
thread_local! {
static DEQUANTIZE_ALL: bool = {
match std::env::var("CANDLE_DEQUANTIZE_ALL") {
Ok(s) => {
!s.is_empty() && s != "0"
},
Err(_) => false,
}
}
}
thread_local! {
static DEQUANTIZE_ALL_F16: bool = {
match std::env::var("CANDLE_DEQUANTIZE_ALL_F16") {
Ok(s) => {
!s.is_empty() && s != "0"
},
Err(_) => false,
}
}
}
impl QMatMul {
pub fn from_arc(qtensor: std::sync::Arc<QTensor>) -> Result<Self> {
let dequantize = match qtensor.dtype() {
GgmlDType::F32 | GgmlDType::F16 => true,
_ => DEQUANTIZE_ALL.with(|b| *b),
};
let t = if dequantize {
let tensor = qtensor.dequantize(&qtensor.device())?;
Self::Tensor(tensor)
} else if DEQUANTIZE_ALL_F16.with(|b| *b) {
let tensor = qtensor.dequantize_f16(&qtensor.device())?;
Self::TensorF16(tensor)
} else {
Self::QTensor(qtensor)
};
Ok(t)
}
pub fn from_qtensor(qtensor: QTensor) -> Result<Self> {
Self::from_arc(std::sync::Arc::new(qtensor))
}
pub fn dequantize_f16(&self) -> Result<Tensor> {
match self {
Self::QTensor(t) => t.dequantize_f16(&t.device()),
Self::Tensor(t) => t.to_dtype(DType::F16),
Self::TensorF16(t) => Ok(t.clone()),
}
}
pub fn forward_via_f16(&self, xs: &Tensor) -> Result<Tensor> {
let w = self.dequantize_f16()?;
let in_dtype = xs.dtype();
let w = match *xs.dims() {
[b1, b2, _, _] => w.broadcast_left((b1, b2))?.t()?,
[bsize, _, _] => w.broadcast_left(bsize)?.t()?,
_ => w.t()?,
};
xs.to_dtype(DType::F16)?.matmul(&w)?.to_dtype(in_dtype)
}
}
impl crate::CustomOp1 for QTensor {
fn name(&self) -> &'static str {
"qmatmul"
}
fn cpu_fwd(
&self,
storage: &crate::CpuStorage,
layout: &crate::Layout,
) -> Result<(crate::CpuStorage, Shape)> {
if !layout.is_contiguous() {
crate::bail!("input tensor is not contiguous {layout:?}")
}
let src_shape = layout.shape();
// self is transposed so n is first then k.
let (n, k) = self.shape.dims2()?;
if src_shape.rank() < 2 {
crate::bail!("input tensor has only one dimension {layout:?}")
}
let mut dst_shape = src_shape.dims().to_vec();
let last_k = dst_shape.pop().unwrap();
if last_k != k {
crate::bail!("input tensor {layout:?} incompatible with {:?}", self.shape)
}
dst_shape.push(n);
let dst_shape = Shape::from(dst_shape);
#[allow(clippy::infallible_destructuring_match)]
let self_storage = match &self.storage {
QStorage::Cpu(storage) => storage,
QStorage::Metal(_) | QStorage::Cuda(_) => crate::bail!("Invalid storage"),
};
let slice = storage.as_slice::<f32>()?;
let slice = &slice[layout.start_offset()..layout.start_offset() + src_shape.elem_count()];
let mut dst_storage = vec![0f32; dst_shape.elem_count()];
self_storage.matmul_t((dst_shape.elem_count() / n, k, n), slice, &mut dst_storage)?;
Ok((crate::CpuStorage::F32(dst_storage), dst_shape))
}
fn metal_fwd(
&self,
storage: &crate::MetalStorage,
layout: &crate::Layout,
) -> Result<(crate::MetalStorage, Shape)> {
let self_storage = match &self.storage {
QStorage::Metal(metal) => metal,
_ => unreachable!("Cannot call metal matmul on non metal QTensor"),
};
self_storage.fwd(&self.shape, storage, layout)
}
fn cuda_fwd(
&self,
storage: &crate::CudaStorage,
layout: &crate::Layout,
) -> Result<(crate::CudaStorage, Shape)> {
let self_storage = match &self.storage {
QStorage::Cuda(cuda) => cuda,
_ => unreachable!("Cannot call cuda matmul on non cuda QTensor"),
};
self_storage.fwd(&self.shape, storage, layout)
}
}
impl crate::Module for QMatMul {
fn forward(&self, xs: &Tensor) -> Result<Tensor> {
match self {
Self::QTensor(t) => xs.apply_op1_no_bwd(t.as_ref()),
Self::Tensor(w) => {
let w = match *xs.dims() {
[b1, b2, _, _] => w.broadcast_left((b1, b2))?.t()?,
[bsize, _, _] => w.broadcast_left(bsize)?.t()?,
_ => w.t()?,
};
xs.matmul(&w)
}
Self::TensorF16(w) => {
let in_dtype = xs.dtype();
let w = match *xs.dims() {
[b1, b2, _, _] => w.broadcast_left((b1, b2))?.t()?,
[bsize, _, _] => w.broadcast_left(bsize)?.t()?,
_ => w.t()?,
};
xs.to_dtype(DType::F16)?.matmul(&w)?.to_dtype(in_dtype)
}
}
}
}
| 3 |
0 | hf_public_repos/candle/candle-core/src | hf_public_repos/candle/candle-core/src/quantized/neon.rs | use super::k_quants::{
BlockQ2K, BlockQ3K, BlockQ4K, BlockQ4_0, BlockQ5K, BlockQ6K, BlockQ8K, BlockQ8_0, QK8_0, QK_K,
};
use crate::Result;
use byteorder::{ByteOrder, LittleEndian};
#[allow(unused_imports)]
#[cfg(target_arch = "arm")]
use core::arch::arm::*;
#[allow(unused_imports)]
#[cfg(target_arch = "aarch64")]
use core::arch::aarch64::*;
#[inline(always)]
unsafe fn vdotq_s32(a: int8x16_t, b: int8x16_t) -> int32x4_t {
// TODO: dotprod
let p0 = vmull_s8(vget_low_s8(a), vget_low_s8(b));
let p1 = vmull_s8(vget_high_s8(a), vget_high_s8(b));
vaddq_s32(vpaddlq_s16(p0), vpaddlq_s16(p1))
}
#[inline(always)]
pub(crate) fn vec_dot_q4_0_q8_0(n: usize, xs: &[BlockQ4_0], ys: &[BlockQ8_0]) -> Result<f32> {
let qk = QK8_0;
let nb = n / qk;
if n % QK8_0 != 0 {
crate::bail!("vec_dot_q4_0_q8_0: {n} is not divisible by {qk}")
}
unsafe {
let mut sumv0 = vdupq_n_f32(0.0f32);
for i in 0..nb {
let x0 = &xs[i];
let y0 = &ys[i];
let m4b = vdupq_n_u8(0x0F);
let s8b = vdupq_n_s8(0x8);
let v0_0 = vld1q_u8(x0.qs.as_ptr());
// 4-bit -> 8-bit
let v0_0l = vreinterpretq_s8_u8(vandq_u8(v0_0, m4b));
let v0_0h = vreinterpretq_s8_u8(vshrq_n_u8(v0_0, 4));
// sub 8
let v0_0ls = vsubq_s8(v0_0l, s8b);
let v0_0hs = vsubq_s8(v0_0h, s8b);
// load y
let v1_0l = vld1q_s8(y0.qs.as_ptr());
let v1_0h = vld1q_s8(y0.qs.as_ptr().add(16));
let pl0 = vdotq_s32(v0_0ls, v1_0l);
let ph0 = vdotq_s32(v0_0hs, v1_0h);
sumv0 = vmlaq_n_f32(
sumv0,
vcvtq_f32_s32(vaddq_s32(pl0, ph0)),
x0.d.to_f32() * y0.d.to_f32(),
);
}
Ok(vaddvq_f32(sumv0))
}
}
#[inline(always)]
pub(crate) fn vec_dot_q8_0_q8_0(n: usize, xs: &[BlockQ8_0], ys: &[BlockQ8_0]) -> Result<f32> {
let qk = QK8_0;
if n % QK8_0 != 0 {
crate::bail!("vec_dot_q8_0_q8_0: {n} is not divisible by {qk}")
}
let nb = n / QK8_0;
unsafe {
let mut sumv0 = vdupq_n_f32(0.0f32);
for i in 0..nb {
let x0 = &xs[i];
let y0 = &ys[i];
let x0_0 = vld1q_s8(x0.qs.as_ptr());
let x0_1 = vld1q_s8(x0.qs.as_ptr().add(16));
// load y
let y0_0 = vld1q_s8(y0.qs.as_ptr());
let y0_1 = vld1q_s8(y0.qs.as_ptr().add(16));
let p0 = vdotq_s32(x0_0, y0_0);
let p1 = vdotq_s32(x0_1, y0_1);
sumv0 = vmlaq_n_f32(
sumv0,
vcvtq_f32_s32(vaddq_s32(p0, p1)),
x0.d.to_f32() * y0.d.to_f32(),
);
}
Ok(vaddvq_f32(sumv0))
}
}
#[inline(always)]
pub(crate) fn vec_dot_q8k_q8k(n: usize, xs: &[BlockQ8K], ys: &[BlockQ8K]) -> Result<f32> {
let qk = QK_K;
if n % QK_K != 0 {
crate::bail!("vec_dot_q8k_q8k: {n} is not divisible by {qk}")
}
let mut sumf = 0f32;
for (xs, ys) in xs.iter().zip(ys.iter()) {
unsafe {
let mut sum_i = vdupq_n_s32(0);
let scale = xs.d * ys.d;
let xs = xs.qs.as_ptr();
let ys = ys.qs.as_ptr();
for i in (0..QK_K).step_by(16) {
let xs = vld1q_s8(xs.add(i));
let ys = vld1q_s8(ys.add(i));
let xy = vdotq_s32(xs, ys);
sum_i = vaddq_s32(sum_i, xy)
}
sumf += vaddvq_s32(sum_i) as f32 * scale
}
}
Ok(sumf)
}
#[inline(always)]
pub(crate) fn vec_dot_q6k_q8k(n: usize, xs: &[BlockQ6K], ys: &[BlockQ8K]) -> Result<f32> {
if n % QK_K != 0 {
crate::bail!("vec_dot_q6k_q8k: {n} is not divisible by {QK_K}")
}
let mut sum = 0f32;
unsafe {
let m4b = vdupq_n_u8(0xF);
let mone = vdupq_n_u8(3);
for (x, y) in xs.iter().zip(ys.iter()) {
let d_all = x.d.to_f32();
let mut q6 = x.ql.as_ptr();
let mut qh = x.qh.as_ptr();
let mut q8 = y.qs.as_ptr();
let mut scale = x.scales.as_ptr();
let q8sums = vld1q_s16_x2(y.bsums.as_ptr());
let scales = vld1q_s8(scale);
let q6scales = int16x8x2_t(
vmovl_s8(vget_low_s8(scales)),
vmovl_s8(vget_high_s8(scales)),
);
let prod = vaddq_s32(
vaddq_s32(
vmull_s16(vget_low_s16(q8sums.0), vget_low_s16(q6scales.0)),
vmull_s16(vget_high_s16(q8sums.0), vget_high_s16(q6scales.0)),
),
vaddq_s32(
vmull_s16(vget_low_s16(q8sums.1), vget_low_s16(q6scales.1)),
vmull_s16(vget_high_s16(q8sums.1), vget_high_s16(q6scales.1)),
),
);
let isum_mins = vaddvq_s32(prod);
let mut isum = 0i32;
for _j in 0..QK_K / 128 {
let qhbits = vld1q_u8_x2(qh);
qh = qh.add(32);
let q6bits = vld1q_u8_x4(q6);
q6 = q6.add(64);
let q8bytes = vld1q_s8_x4(q8);
q8 = q8.add(64);
let q6h_0 = vshlq_n_u8(vandq_u8(mone, qhbits.0), 4);
let q6h_1 = vshlq_n_u8(vandq_u8(mone, qhbits.1), 4);
let shifted = vshrq_n_u8(qhbits.0, 2);
let q6h_2 = vshlq_n_u8(vandq_u8(mone, shifted), 4);
let shifted = vshrq_n_u8(qhbits.1, 2);
let q6h_3 = vshlq_n_u8(vandq_u8(mone, shifted), 4);
let q6bytes_0 = vreinterpretq_s8_u8(vorrq_u8(vandq_u8(q6bits.0, m4b), q6h_0));
let q6bytes_1 = vreinterpretq_s8_u8(vorrq_u8(vandq_u8(q6bits.1, m4b), q6h_1));
let q6bytes_2 = vreinterpretq_s8_u8(vorrq_u8(vandq_u8(q6bits.2, m4b), q6h_2));
let q6bytes_3 = vreinterpretq_s8_u8(vorrq_u8(vandq_u8(q6bits.3, m4b), q6h_3));
let p0 = vdotq_s32(q6bytes_0, q8bytes.0);
let p1 = vdotq_s32(q6bytes_1, q8bytes.1);
let (scale0, scale1) = (*scale as i32, *scale.add(1) as i32);
isum += vaddvq_s32(p0) * scale0 + vaddvq_s32(p1) * scale1;
scale = scale.add(2);
let p2 = vdotq_s32(q6bytes_2, q8bytes.2);
let p3 = vdotq_s32(q6bytes_3, q8bytes.3);
let (scale0, scale1) = (*scale as i32, *scale.add(1) as i32);
isum += vaddvq_s32(p2) * scale0 + vaddvq_s32(p3) * scale1;
scale = scale.add(2);
let q8bytes = vld1q_s8_x4(q8);
q8 = q8.add(64);
let shifted = vshrq_n_u8(qhbits.0, 4);
let q6h_0 = vshlq_n_u8(vandq_u8(mone, shifted), 4);
let shifted = vshrq_n_u8(qhbits.1, 4);
let q6h_1 = vshlq_n_u8(vandq_u8(mone, shifted), 4);
let shifted = vshrq_n_u8(qhbits.0, 6);
let q6h_2 = vshlq_n_u8(vandq_u8(mone, shifted), 4);
let shifted = vshrq_n_u8(qhbits.1, 6);
let q6h_3 = vshlq_n_u8(vandq_u8(mone, shifted), 4);
let q6bytes_0 = vreinterpretq_s8_u8(vorrq_u8(vshrq_n_u8(q6bits.0, 4), q6h_0));
let q6bytes_1 = vreinterpretq_s8_u8(vorrq_u8(vshrq_n_u8(q6bits.1, 4), q6h_1));
let q6bytes_2 = vreinterpretq_s8_u8(vorrq_u8(vshrq_n_u8(q6bits.2, 4), q6h_2));
let q6bytes_3 = vreinterpretq_s8_u8(vorrq_u8(vshrq_n_u8(q6bits.3, 4), q6h_3));
let p0 = vdotq_s32(q6bytes_0, q8bytes.0);
let p1 = vdotq_s32(q6bytes_1, q8bytes.1);
let (scale0, scale1) = (*scale as i32, *scale.add(1) as i32);
isum += vaddvq_s32(p0) * scale0 + vaddvq_s32(p1) * scale1;
scale = scale.add(2);
let p2 = vdotq_s32(q6bytes_2, q8bytes.2);
let p3 = vdotq_s32(q6bytes_3, q8bytes.3);
let (scale0, scale1) = (*scale as i32, *scale.add(1) as i32);
isum += vaddvq_s32(p2) * scale0 + vaddvq_s32(p3) * scale1;
scale = scale.add(2);
}
sum += d_all * y.d * ((isum - 32 * isum_mins) as f32);
}
}
Ok(sum)
}
#[inline(always)]
pub(crate) fn vec_dot_q5k_q8k(n: usize, xs: &[BlockQ5K], ys: &[BlockQ8K]) -> Result<f32> {
if n % QK_K != 0 {
crate::bail!("vec_dot_q5k_q8k: {n} is not divisible by {QK_K}")
}
let mut sumf = 0f32;
let mut utmp = [0u32; 4];
const KMASK1: u32 = 0x3f3f3f3f;
const KMASK2: u32 = 0x0f0f0f0f;
const KMASK3: u32 = 0x03030303;
unsafe {
let m4b = vdupq_n_u8(0xF);
let mone = vdupq_n_u8(1);
let mtwo = vdupq_n_u8(2);
for (x, y) in xs.iter().zip(ys.iter()) {
let d = y.d * x.d.to_f32();
let dmin = y.d * x.dmin.to_f32();
let q8sums = vpaddq_s16(
vld1q_s16(y.bsums.as_ptr()),
vld1q_s16(y.bsums.as_ptr().add(8)),
);
LittleEndian::read_u32_into(&x.scales, &mut utmp[0..3]);
utmp[3] = ((utmp[2] >> 4) & KMASK2) | (((utmp[1] >> 6) & KMASK3) << 4);
let uaux = utmp[1] & KMASK1;
utmp[1] = (utmp[2] & KMASK2) | (((utmp[0] >> 6) & KMASK3) << 4);
utmp[2] = uaux;
utmp[0] &= KMASK1;
let mins8 = vld1_u8((utmp.as_ptr() as *const u8).add(8));
let mins = vreinterpretq_s16_u16(vmovl_u8(mins8));
let prod = vaddq_s32(
vmull_s16(vget_low_s16(q8sums), vget_low_s16(mins)),
vmull_s16(vget_high_s16(q8sums), vget_high_s16(mins)),
);
let sumi_mins = vaddvq_s32(prod);
let mut scales = utmp.as_ptr() as *const u8;
let mut q5 = x.qs.as_ptr();
let mut q8 = y.qs.as_ptr();
let mut qhbits = vld1q_u8_x2(x.qh.as_ptr());
let mut sumi = 0i32;
for _j in 0..QK_K / 64 {
let q5bits = vld1q_u8_x2(q5);
q5 = q5.add(32);
let q8bytes = vld1q_s8_x4(q8);
q8 = q8.add(64);
let q5h_0 = vshlq_n_u8(vandq_u8(mone, qhbits.0), 4);
let q5h_1 = vshlq_n_u8(vandq_u8(mone, qhbits.1), 4);
let q5h_2 = vshlq_n_u8(vandq_u8(mtwo, qhbits.0), 3);
let q5h_3 = vshlq_n_u8(vandq_u8(mtwo, qhbits.1), 3);
qhbits.0 = vshrq_n_u8(qhbits.0, 2);
qhbits.1 = vshrq_n_u8(qhbits.1, 2);
let q5bytes_0 = vreinterpretq_s8_u8(vorrq_u8(vandq_u8(q5bits.0, m4b), q5h_0));
let q5bytes_1 = vreinterpretq_s8_u8(vorrq_u8(vandq_u8(q5bits.1, m4b), q5h_1));
let q5bytes_2 = vreinterpretq_s8_u8(vorrq_u8(vshrq_n_u8(q5bits.0, 4), q5h_2));
let q5bytes_3 = vreinterpretq_s8_u8(vorrq_u8(vshrq_n_u8(q5bits.1, 4), q5h_3));
let p0 = vdotq_s32(q5bytes_0, q8bytes.0);
let p1 = vdotq_s32(q5bytes_1, q8bytes.1);
sumi += vaddvq_s32(vaddq_s32(p0, p1)) * *scales as i32;
scales = scales.add(1);
let p2 = vdotq_s32(q5bytes_2, q8bytes.2);
let p3 = vdotq_s32(q5bytes_3, q8bytes.3);
sumi += vaddvq_s32(vaddq_s32(p2, p3)) * *scales as i32;
scales = scales.add(1);
}
sumf += d * sumi as f32 - dmin * sumi_mins as f32;
}
}
Ok(sumf)
}
#[inline(always)]
pub(crate) fn vec_dot_q4k_q8k(n: usize, xs: &[BlockQ4K], ys: &[BlockQ8K]) -> Result<f32> {
if n % QK_K != 0 {
crate::bail!("vec_dot_q4k_q8k: {n} is not divisible by {QK_K}")
}
let mut sumf = 0f32;
let mut utmp = [0u32; 4];
let mut scales = [0u8; 16];
const KMASK1: u32 = 0x3f3f3f3f;
const KMASK2: u32 = 0x0f0f0f0f;
const KMASK3: u32 = 0x03030303;
unsafe {
let m4b = vdupq_n_u8(0xF);
for (x, y) in xs.iter().zip(ys.iter()) {
let d = y.d * x.d.to_f32();
let dmin = y.d * x.dmin.to_f32();
let q8sums = vpaddq_s16(
vld1q_s16(y.bsums.as_ptr()),
vld1q_s16(y.bsums.as_ptr().add(8)),
);
LittleEndian::read_u32_into(&x.scales, &mut utmp[0..3]);
let mins8 = vld1_u32(
[
utmp[1] & KMASK1,
((utmp[2] >> 4) & KMASK2) | (((utmp[1] >> 6) & KMASK3) << 4),
]
.as_ptr(),
);
utmp[1] = (utmp[2] & KMASK2) | (((utmp[0] >> 6) & KMASK3) << 4);
utmp[0] &= KMASK1;
let mins = vreinterpretq_s16_u16(vmovl_u8(vreinterpret_u8_u32(mins8)));
let prod = vaddq_s32(
vmull_s16(vget_low_s16(q8sums), vget_low_s16(mins)),
vmull_s16(vget_high_s16(q8sums), vget_high_s16(mins)),
);
sumf -= dmin * vaddvq_s32(prod) as f32;
LittleEndian::write_u32_into(&utmp, &mut scales);
let mut q4 = x.qs.as_ptr();
let mut q8 = y.qs.as_ptr();
let mut sumi1 = 0i32;
let mut sumi2 = 0i32;
for j in 0..QK_K / 64 {
let q4bits = vld1q_u8_x2(q4);
q4 = q4.add(32);
let q8bytes = vld1q_s8_x2(q8);
q8 = q8.add(32);
let q4bytes = int8x16x2_t(
vreinterpretq_s8_u8(vandq_u8(q4bits.0, m4b)),
vreinterpretq_s8_u8(vandq_u8(q4bits.1, m4b)),
);
let p0 = vdotq_s32(q4bytes.0, q8bytes.0);
let p1 = vdotq_s32(q4bytes.1, q8bytes.1);
sumi1 += vaddvq_s32(vaddq_s32(p0, p1)) * scales[2 * j] as i32;
let q8bytes = vld1q_s8_x2(q8);
q8 = q8.add(32);
let q4bytes = int8x16x2_t(
vreinterpretq_s8_u8(vshrq_n_u8(q4bits.0, 4)),
vreinterpretq_s8_u8(vshrq_n_u8(q4bits.1, 4)),
);
let p2 = vdotq_s32(q4bytes.0, q8bytes.0);
let p3 = vdotq_s32(q4bytes.1, q8bytes.1);
sumi2 += vaddvq_s32(vaddq_s32(p2, p3)) * scales[2 * j + 1] as i32;
}
sumf += d * (sumi1 + sumi2) as f32;
}
}
Ok(sumf)
}
#[inline(always)]
pub(crate) fn vec_dot_q3k_q8k(n: usize, xs: &[BlockQ3K], ys: &[BlockQ8K]) -> Result<f32> {
if n % QK_K != 0 {
crate::bail!("vec_dot_q3k_q8k: {n} is not divisible by {QK_K}")
}
let mut sumf = 0f32;
let mut utmp = [0u32; 4];
let mut aux = [0u32; 3];
const KMASK1: u32 = 0x03030303;
const KMASK2: u32 = 0x0f0f0f0f;
unsafe {
let m3b = vdupq_n_u8(0x3);
let m0 = vdupq_n_u8(1);
let m1 = vshlq_n_u8(m0, 1);
let m2 = vshlq_n_u8(m0, 2);
let m3 = vshlq_n_u8(m0, 3);
for (x, y) in xs.iter().zip(ys.iter()) {
let d = y.d * x.d.to_f32();
let mut q3 = x.qs.as_ptr();
let qh = x.hmask.as_ptr();
let mut q8 = y.qs.as_ptr();
let mut qhbits = vld1q_u8_x2(qh);
let mut isum = 0i32;
// Set up scales
LittleEndian::read_u32_into(&x.scales, &mut aux);
utmp[3] = ((aux[1] >> 4) & KMASK2) | (((aux[2] >> 6) & KMASK1) << 4);
utmp[2] = ((aux[0] >> 4) & KMASK2) | (((aux[2] >> 4) & KMASK1) << 4);
utmp[1] = (aux[1] & KMASK2) | (((aux[2] >> 2) & KMASK1) << 4);
utmp[0] = (aux[0] & KMASK2) | ((aux[2] & KMASK1) << 4);
let mut scale = utmp.as_mut_ptr() as *mut i8;
for j in 0..16 {
*scale.add(j) -= 32i8
}
for j in 0..QK_K / 128 {
let q3bits = vld1q_u8_x2(q3);
q3 = q3.add(32);
let q8bytes_1 = vld1q_s8_x4(q8);
q8 = q8.add(64);
let q8bytes_2 = vld1q_s8_x4(q8);
q8 = q8.add(64);
let q3h_0 = vshlq_n_u8(vbicq_u8(m0, qhbits.0), 2);
let q3h_1 = vshlq_n_u8(vbicq_u8(m0, qhbits.1), 2);
let q3h_2 = vshlq_n_u8(vbicq_u8(m1, qhbits.0), 1);
let q3h_3 = vshlq_n_u8(vbicq_u8(m1, qhbits.1), 1);
let q3bytes_0 = vsubq_s8(
vreinterpretq_s8_u8(vandq_u8(q3bits.0, m3b)),
vreinterpretq_s8_u8(q3h_0),
);
let q3bytes_1 = vsubq_s8(
vreinterpretq_s8_u8(vandq_u8(q3bits.1, m3b)),
vreinterpretq_s8_u8(q3h_1),
);
let q3bytes_2 = vsubq_s8(
vreinterpretq_s8_u8(vandq_u8(vshrq_n_u8(q3bits.0, 2), m3b)),
vreinterpretq_s8_u8(q3h_2),
);
let q3bytes_3 = vsubq_s8(
vreinterpretq_s8_u8(vandq_u8(vshrq_n_u8(q3bits.1, 2), m3b)),
vreinterpretq_s8_u8(q3h_3),
);
let p0 = vdotq_s32(q3bytes_0, q8bytes_1.0);
let p1 = vdotq_s32(q3bytes_1, q8bytes_1.1);
let p2 = vdotq_s32(q3bytes_2, q8bytes_1.2);
let p3 = vdotq_s32(q3bytes_3, q8bytes_1.3);
isum += vaddvq_s32(p0) * *scale as i32
+ vaddvq_s32(p1) * *scale.add(1) as i32
+ vaddvq_s32(p2) * *scale.add(2) as i32
+ vaddvq_s32(p3) * *scale.add(3) as i32;
scale = scale.add(4);
let q3h_0 = vbicq_u8(m2, qhbits.0);
let q3h_1 = vbicq_u8(m2, qhbits.1);
let q3h_2 = vshrq_n_u8(vbicq_u8(m3, qhbits.0), 1);
let q3h_3 = vshrq_n_u8(vbicq_u8(m3, qhbits.1), 1);
let q3bytes_0 = vsubq_s8(
vreinterpretq_s8_u8(vandq_u8(vshrq_n_u8(q3bits.0, 4), m3b)),
vreinterpretq_s8_u8(q3h_0),
);
let q3bytes_1 = vsubq_s8(
vreinterpretq_s8_u8(vandq_u8(vshrq_n_u8(q3bits.1, 4), m3b)),
vreinterpretq_s8_u8(q3h_1),
);
let q3bytes_2 = vsubq_s8(
vreinterpretq_s8_u8(vandq_u8(vshrq_n_u8(q3bits.0, 6), m3b)),
vreinterpretq_s8_u8(q3h_2),
);
let q3bytes_3 = vsubq_s8(
vreinterpretq_s8_u8(vandq_u8(vshrq_n_u8(q3bits.1, 6), m3b)),
vreinterpretq_s8_u8(q3h_3),
);
let p0 = vdotq_s32(q3bytes_0, q8bytes_2.0);
let p1 = vdotq_s32(q3bytes_1, q8bytes_2.1);
let p2 = vdotq_s32(q3bytes_2, q8bytes_2.2);
let p3 = vdotq_s32(q3bytes_3, q8bytes_2.3);
isum += vaddvq_s32(p0) * *scale as i32
+ vaddvq_s32(p1) * *scale.add(1) as i32
+ vaddvq_s32(p2) * *scale.add(2) as i32
+ vaddvq_s32(p3) * *scale.add(3) as i32;
scale = scale.add(4);
if j == 0 {
qhbits.0 = vshrq_n_u8(qhbits.0, 4);
qhbits.1 = vshrq_n_u8(qhbits.1, 4);
}
}
sumf += d * isum as f32;
}
}
Ok(sumf)
}
#[inline(always)]
pub(crate) fn vec_dot_q2k_q8k(n: usize, xs: &[BlockQ2K], ys: &[BlockQ8K]) -> Result<f32> {
if n % QK_K != 0 {
crate::bail!("vec_dot_q2k_q8k: {n} is not divisible by {QK_K}")
}
let mut sumf = 0f32;
let mut aux = [0u8; 16];
unsafe {
let m3 = vdupq_n_u8(0x3);
let m4 = vdupq_n_u8(0xF);
for (x, y) in xs.iter().zip(ys.iter()) {
let d = y.d * x.d.to_f32();
let dmin = -y.d * x.dmin.to_f32();
let mut q2 = x.qs.as_ptr();
let mut q8 = y.qs.as_ptr();
let sc = x.scales.as_ptr();
let mins_and_scales = vld1q_u8(sc);
let scales = vandq_u8(mins_and_scales, m4);
vst1q_u8(aux.as_mut_ptr(), scales);
let mins = vshrq_n_u8(mins_and_scales, 4);
let q8sums = vld1q_s16_x2(y.bsums.as_ptr());
let mins16 = int16x8x2_t(
vreinterpretq_s16_u16(vmovl_u8(vget_low_u8(mins))),
vreinterpretq_s16_u16(vmovl_u8(vget_high_u8(mins))),
);
let s0 = vaddq_s32(
vmull_s16(vget_low_s16(mins16.0), vget_low_s16(q8sums.0)),
vmull_s16(vget_high_s16(mins16.0), vget_high_s16(q8sums.0)),
);
let s1 = vaddq_s32(
vmull_s16(vget_low_s16(mins16.1), vget_low_s16(q8sums.1)),
vmull_s16(vget_high_s16(mins16.1), vget_high_s16(q8sums.1)),
);
sumf += dmin * vaddvq_s32(vaddq_s32(s0, s1)) as f32;
let mut isum = 0i32;
let mut is = 0usize;
// TODO: dotprod
for _j in 0..QK_K / 128 {
let q2bits = vld1q_u8_x2(q2);
q2 = q2.add(32);
let q8bytes = vld1q_s8_x2(q8);
q8 = q8.add(32);
let mut q2bytes = int8x16x2_t(
vreinterpretq_s8_u8(vandq_u8(q2bits.0, m3)),
vreinterpretq_s8_u8(vandq_u8(q2bits.1, m3)),
);
isum += multiply_accum_with_scale(&aux, is, 0, q2bytes, q8bytes);
let q8bytes = vld1q_s8_x2(q8);
q8 = q8.add(32);
q2bytes.0 = vreinterpretq_s8_u8(vandq_u8(vshrq_n_u8(q2bits.0, 2), m3));
q2bytes.1 = vreinterpretq_s8_u8(vandq_u8(vshrq_n_u8(q2bits.1, 2), m3));
isum += multiply_accum_with_scale(&aux, is, 2, q2bytes, q8bytes);
let q8bytes = vld1q_s8_x2(q8);
q8 = q8.add(32);
q2bytes.0 = vreinterpretq_s8_u8(vandq_u8(vshrq_n_u8(q2bits.0, 4), m3));
q2bytes.1 = vreinterpretq_s8_u8(vandq_u8(vshrq_n_u8(q2bits.1, 4), m3));
isum += multiply_accum_with_scale(&aux, is, 4, q2bytes, q8bytes);
let q8bytes = vld1q_s8_x2(q8);
q8 = q8.add(32);
q2bytes.0 = vreinterpretq_s8_u8(vandq_u8(vshrq_n_u8(q2bits.0, 6), m3));
q2bytes.1 = vreinterpretq_s8_u8(vandq_u8(vshrq_n_u8(q2bits.1, 6), m3));
isum += multiply_accum_with_scale(&aux, is, 6, q2bytes, q8bytes);
is += 8;
}
sumf += d * isum as f32;
}
}
Ok(sumf)
}
#[inline(always)]
unsafe fn multiply_accum_with_scale(
aux: &[u8; 16],
is: usize,
index: usize,
q2bytes: int8x16x2_t,
q8bytes: int8x16x2_t,
) -> i32 {
let p1 = vdotq_s32(q2bytes.0, q8bytes.0);
let p2 = vdotq_s32(q2bytes.1, q8bytes.1);
vaddvq_s32(p1) * aux[is + index] as i32 + vaddvq_s32(p2) * aux[is + 1 + index] as i32
}
| 4 |
0 | hf_public_repos/candle/candle-core/src | hf_public_repos/candle/candle-core/src/quantized/gguf_file.rs | //! Support for the [GGUF file format](https://github.com/philpax/ggml/blob/gguf-spec/docs/gguf.md).
//!
use super::{GgmlDType, QTensor};
use crate::{Device, Result};
use byteorder::{LittleEndian, ReadBytesExt, WriteBytesExt};
use std::collections::HashMap;
pub const DEFAULT_ALIGNMENT: u64 = 32;
#[derive(Debug, Clone, Copy, PartialEq, Eq)]
enum Magic {
Gguf,
}
impl TryFrom<u32> for Magic {
type Error = crate::Error;
fn try_from(value: u32) -> Result<Self> {
let magic = match value {
0x46554747 | 0x47475546 => Self::Gguf,
_ => crate::bail!("unknown magic 0x{value:08x}"),
};
Ok(magic)
}
}
#[derive(Debug, Clone, Copy, PartialEq, Eq)]
pub enum VersionedMagic {
GgufV1,
GgufV2,
GgufV3,
}
impl VersionedMagic {
fn read<R: std::io::Read>(reader: &mut R) -> Result<Self> {
let magic = reader.read_u32::<LittleEndian>()?;
let magic = Magic::try_from(magic)?;
let version = reader.read_u32::<LittleEndian>()?;
let versioned_magic = match (magic, version) {
(Magic::Gguf, 1) => Self::GgufV1,
(Magic::Gguf, 2) => Self::GgufV2,
(Magic::Gguf, 3) => Self::GgufV3,
_ => crate::bail!("gguf: unsupported magic/version {magic:?}/{version}"),
};
Ok(versioned_magic)
}
}
#[derive(Debug)]
pub struct TensorInfo {
pub ggml_dtype: GgmlDType,
pub shape: crate::Shape,
pub offset: u64,
}
impl TensorInfo {
pub fn read<R: std::io::Seek + std::io::Read>(
&self,
reader: &mut R,
tensor_data_offset: u64,
device: &Device,
) -> Result<QTensor> {
let tensor_elems = self.shape.elem_count();
let block_size = self.ggml_dtype.block_size();
if tensor_elems % block_size != 0 {
crate::bail!(
"the number of elements {tensor_elems} is not divisible by the block size {block_size}"
)
}
let size_in_bytes = tensor_elems / block_size * self.ggml_dtype.type_size();
let mut raw_data = vec![0u8; size_in_bytes];
reader.seek(std::io::SeekFrom::Start(tensor_data_offset + self.offset))?;
reader.read_exact(&mut raw_data)?;
super::ggml_file::qtensor_from_ggml(
self.ggml_dtype,
&raw_data,
self.shape.dims().to_vec(),
device,
)
}
}
#[derive(Debug)]
pub struct Content {
pub magic: VersionedMagic,
pub metadata: HashMap<String, Value>,
pub tensor_infos: HashMap<String, TensorInfo>,
pub tensor_data_offset: u64,
}
fn read_string<R: std::io::Read>(reader: &mut R, magic: &VersionedMagic) -> Result<String> {
let len = match magic {
VersionedMagic::GgufV1 => reader.read_u32::<LittleEndian>()? as usize,
VersionedMagic::GgufV2 | VersionedMagic::GgufV3 => {
reader.read_u64::<LittleEndian>()? as usize
}
};
let mut v = vec![0u8; len];
reader.read_exact(&mut v)?;
// GGUF strings are supposed to be non-null terminated but in practice this happens.
while let Some(0) = v.last() {
v.pop();
}
// GGUF strings are utf8 encoded but there are cases that don't seem to be valid.
Ok(String::from_utf8_lossy(&v).into_owned())
}
#[derive(Debug, Clone, Copy, PartialEq, Eq, Hash)]
pub enum ValueType {
// The value is a 8-bit unsigned integer.
U8,
// The value is a 8-bit signed integer.
I8,
// The value is a 16-bit unsigned little-endian integer.
U16,
// The value is a 16-bit signed little-endian integer.
I16,
// The value is a 32-bit unsigned little-endian integer.
U32,
// The value is a 32-bit signed little-endian integer.
I32,
// The value is a 64-bit unsigned little-endian integer.
U64,
// The value is a 64-bit signed little-endian integer.
I64,
// The value is a 32-bit IEEE754 floating point number.
F32,
// The value is a 64-bit IEEE754 floating point number.
F64,
// The value is a boolean.
// 1-byte value where 0 is false and 1 is true.
// Anything else is invalid, and should be treated as either the model being invalid or the reader being buggy.
Bool,
// The value is a UTF-8 non-null-terminated string, with length prepended.
String,
// The value is an array of other values, with the length and type prepended.
// Arrays can be nested, and the length of the array is the number of elements in the array, not the number of bytes.
Array,
}
#[derive(Debug, Clone)]
pub enum Value {
U8(u8),
I8(i8),
U16(u16),
I16(i16),
U32(u32),
I32(i32),
U64(u64),
I64(i64),
F32(f32),
F64(f64),
Bool(bool),
String(String),
Array(Vec<Value>),
}
impl Value {
pub fn value_type(&self) -> ValueType {
match self {
Self::U8(_) => ValueType::U8,
Self::I8(_) => ValueType::I8,
Self::U16(_) => ValueType::U16,
Self::I16(_) => ValueType::I16,
Self::U32(_) => ValueType::U32,
Self::I32(_) => ValueType::I32,
Self::U64(_) => ValueType::U64,
Self::I64(_) => ValueType::I64,
Self::F32(_) => ValueType::F32,
Self::F64(_) => ValueType::F64,
Self::Bool(_) => ValueType::Bool,
Self::String(_) => ValueType::String,
Self::Array(_) => ValueType::Array,
}
}
pub fn to_u8(&self) -> Result<u8> {
match self {
Self::U8(v) => Ok(*v),
v => crate::bail!("not a u8 {v:?}"),
}
}
pub fn to_i8(&self) -> Result<i8> {
match self {
Self::I8(v) => Ok(*v),
v => crate::bail!("not a i8 {v:?}"),
}
}
pub fn to_u16(&self) -> Result<u16> {
match self {
Self::U16(v) => Ok(*v),
v => crate::bail!("not a u16 {v:?}"),
}
}
pub fn to_i16(&self) -> Result<i16> {
match self {
Self::I16(v) => Ok(*v),
v => crate::bail!("not a i16 {v:?}"),
}
}
pub fn to_u32(&self) -> Result<u32> {
match self {
Self::U32(v) => Ok(*v),
v => crate::bail!("not a u32 {v:?}"),
}
}
pub fn to_i32(&self) -> Result<i32> {
match self {
Self::I32(v) => Ok(*v),
v => crate::bail!("not a i32 {v:?}"),
}
}
/// This will also automatically upcast any integral types which will not truncate.
pub fn to_u64(&self) -> Result<u64> {
match self {
Self::U64(v) => Ok(*v),
// Autoupcast cases here
Self::U8(v) => Ok(*v as u64),
Self::U16(v) => Ok(*v as u64),
Self::U32(v) => Ok(*v as u64),
Self::Bool(v) => Ok(*v as u64),
v => crate::bail!("not a u64 or upcastable to u64 {v:?}"),
}
}
pub fn to_i64(&self) -> Result<i64> {
match self {
Self::I64(v) => Ok(*v),
v => crate::bail!("not a i64 {v:?}"),
}
}
pub fn to_f32(&self) -> Result<f32> {
match self {
Self::F32(v) => Ok(*v),
v => crate::bail!("not a f32 {v:?}"),
}
}
pub fn to_f64(&self) -> Result<f64> {
match self {
Self::F64(v) => Ok(*v),
v => crate::bail!("not a f64 {v:?}"),
}
}
pub fn to_bool(&self) -> Result<bool> {
match self {
Self::Bool(v) => Ok(*v),
v => crate::bail!("not a bool {v:?}"),
}
}
pub fn to_vec(&self) -> Result<&Vec<Value>> {
match self {
Self::Array(v) => Ok(v),
v => crate::bail!("not a vec {v:?}"),
}
}
pub fn to_string(&self) -> Result<&String> {
match self {
Self::String(v) => Ok(v),
v => crate::bail!("not a string {v:?}"),
}
}
fn read<R: std::io::Read>(
reader: &mut R,
value_type: ValueType,
magic: &VersionedMagic,
) -> Result<Self> {
let v = match value_type {
ValueType::U8 => Self::U8(reader.read_u8()?),
ValueType::I8 => Self::I8(reader.read_i8()?),
ValueType::U16 => Self::U16(reader.read_u16::<LittleEndian>()?),
ValueType::I16 => Self::I16(reader.read_i16::<LittleEndian>()?),
ValueType::U32 => Self::U32(reader.read_u32::<LittleEndian>()?),
ValueType::I32 => Self::I32(reader.read_i32::<LittleEndian>()?),
ValueType::U64 => Self::U64(reader.read_u64::<LittleEndian>()?),
ValueType::I64 => Self::I64(reader.read_i64::<LittleEndian>()?),
ValueType::F32 => Self::F32(reader.read_f32::<LittleEndian>()?),
ValueType::F64 => Self::F64(reader.read_f64::<LittleEndian>()?),
ValueType::Bool => match reader.read_u8()? {
0 => Self::Bool(false),
1 => Self::Bool(true),
b => crate::bail!("unexpected bool value {b}"),
},
ValueType::String => Self::String(read_string(reader, magic)?),
ValueType::Array => {
let value_type = reader.read_u32::<LittleEndian>()?;
let value_type = ValueType::from_u32(value_type)?;
let len = match magic {
VersionedMagic::GgufV1 => reader.read_u32::<LittleEndian>()? as usize,
VersionedMagic::GgufV2 | VersionedMagic::GgufV3 => {
reader.read_u64::<LittleEndian>()? as usize
}
};
let mut vs = Vec::with_capacity(len);
for _ in 0..len {
vs.push(Value::read(reader, value_type, magic)?)
}
Self::Array(vs)
}
};
Ok(v)
}
fn write<W: std::io::Write>(&self, w: &mut W) -> Result<()> {
match self {
&Self::U8(v) => w.write_u8(v)?,
&Self::I8(v) => w.write_i8(v)?,
&Self::U16(v) => w.write_u16::<LittleEndian>(v)?,
&Self::I16(v) => w.write_i16::<LittleEndian>(v)?,
&Self::U32(v) => w.write_u32::<LittleEndian>(v)?,
&Self::I32(v) => w.write_i32::<LittleEndian>(v)?,
&Self::U64(v) => w.write_u64::<LittleEndian>(v)?,
&Self::I64(v) => w.write_i64::<LittleEndian>(v)?,
&Self::F32(v) => w.write_f32::<LittleEndian>(v)?,
&Self::F64(v) => w.write_f64::<LittleEndian>(v)?,
&Self::Bool(v) => w.write_u8(u8::from(v))?,
Self::String(v) => write_string(w, v.as_str())?,
Self::Array(v) => {
// The `Value` type does not enforce that all the values in an Array have the same
// type.
let value_type = if v.is_empty() {
// Doesn't matter, the array is empty.
ValueType::U32
} else {
let value_type: std::collections::HashSet<_> =
v.iter().map(|elem| elem.value_type()).collect();
if value_type.len() != 1 {
crate::bail!("multiple value-types in the same array {value_type:?}")
}
value_type.into_iter().next().unwrap()
};
w.write_u32::<LittleEndian>(value_type.to_u32())?;
w.write_u64::<LittleEndian>(v.len() as u64)?;
for elem in v.iter() {
elem.write(w)?
}
}
}
Ok(())
}
}
impl ValueType {
fn from_u32(v: u32) -> Result<Self> {
let v = match v {
0 => Self::U8,
1 => Self::I8,
2 => Self::U16,
3 => Self::I16,
4 => Self::U32,
5 => Self::I32,
6 => Self::F32,
7 => Self::Bool,
8 => Self::String,
9 => Self::Array,
10 => Self::U64,
11 => Self::I64,
12 => Self::F64,
v => crate::bail!("unrecognized value-type {v:#08x}"),
};
Ok(v)
}
fn to_u32(self) -> u32 {
match self {
Self::U8 => 0,
Self::I8 => 1,
Self::U16 => 2,
Self::I16 => 3,
Self::U32 => 4,
Self::I32 => 5,
Self::F32 => 6,
Self::Bool => 7,
Self::String => 8,
Self::Array => 9,
Self::U64 => 10,
Self::I64 => 11,
Self::F64 => 12,
}
}
}
impl Content {
pub fn read<R: std::io::Seek + std::io::Read>(reader: &mut R) -> Result<Self> {
let magic = VersionedMagic::read(reader)?;
let tensor_count = match magic {
VersionedMagic::GgufV1 => reader.read_u32::<LittleEndian>()? as usize,
VersionedMagic::GgufV2 | VersionedMagic::GgufV3 => {
reader.read_u64::<LittleEndian>()? as usize
}
};
let metadata_kv_count = match magic {
VersionedMagic::GgufV1 => reader.read_u32::<LittleEndian>()? as usize,
VersionedMagic::GgufV2 | VersionedMagic::GgufV3 => {
reader.read_u64::<LittleEndian>()? as usize
}
};
let mut metadata = HashMap::new();
for _idx in 0..metadata_kv_count {
let key = read_string(reader, &magic)?;
let value_type = reader.read_u32::<LittleEndian>()?;
let value_type = ValueType::from_u32(value_type)?;
let value = Value::read(reader, value_type, &magic)?;
metadata.insert(key, value);
}
let mut tensor_infos = HashMap::new();
for _idx in 0..tensor_count {
let tensor_name = read_string(reader, &magic)?;
let n_dimensions = reader.read_u32::<LittleEndian>()?;
let mut dimensions: Vec<usize> = match magic {
VersionedMagic::GgufV1 => {
let mut dimensions = vec![0; n_dimensions as usize];
reader.read_u32_into::<LittleEndian>(&mut dimensions)?;
dimensions.into_iter().map(|c| c as usize).collect()
}
VersionedMagic::GgufV2 | VersionedMagic::GgufV3 => {
let mut dimensions = vec![0; n_dimensions as usize];
reader.read_u64_into::<LittleEndian>(&mut dimensions)?;
dimensions.into_iter().map(|c| c as usize).collect()
}
};
dimensions.reverse();
let ggml_dtype = reader.read_u32::<LittleEndian>()?;
let ggml_dtype = GgmlDType::from_u32(ggml_dtype)?;
let offset = reader.read_u64::<LittleEndian>()?;
tensor_infos.insert(
tensor_name,
TensorInfo {
shape: crate::Shape::from(dimensions),
offset,
ggml_dtype,
},
);
}
let position = reader.stream_position()?;
let alignment = match metadata.get("general.alignment") {
Some(Value::U8(v)) => *v as u64,
Some(Value::U16(v)) => *v as u64,
Some(Value::U32(v)) => *v as u64,
Some(Value::I8(v)) if *v >= 0 => *v as u64,
Some(Value::I16(v)) if *v >= 0 => *v as u64,
Some(Value::I32(v)) if *v >= 0 => *v as u64,
_ => DEFAULT_ALIGNMENT,
};
let tensor_data_offset = position.div_ceil(alignment) * alignment;
Ok(Self {
magic,
metadata,
tensor_infos,
tensor_data_offset,
})
}
pub fn tensor<R: std::io::Seek + std::io::Read>(
&self,
reader: &mut R,
name: &str,
device: &Device,
) -> Result<QTensor> {
let tensor_info = match self.tensor_infos.get(name) {
Some(tensor_info) => tensor_info,
None => crate::bail!("cannot find tensor info for {name}"),
};
tensor_info.read(reader, self.tensor_data_offset, device)
}
}
fn write_string<W: std::io::Write>(w: &mut W, str: &str) -> Result<()> {
let bytes = str.as_bytes();
w.write_u64::<LittleEndian>(bytes.len() as u64)?;
w.write_all(bytes)?;
Ok(())
}
pub fn write<W: std::io::Seek + std::io::Write>(
w: &mut W,
metadata: &[(&str, &Value)],
tensors: &[(&str, &QTensor)],
) -> Result<()> {
w.write_u32::<LittleEndian>(0x46554747)?;
w.write_u32::<LittleEndian>(2)?; // version 2.
w.write_u64::<LittleEndian>(tensors.len() as u64)?;
w.write_u64::<LittleEndian>(metadata.len() as u64)?;
for (name, value) in metadata.iter() {
write_string(w, name)?;
w.write_u32::<LittleEndian>(value.value_type().to_u32())?;
value.write(w)?;
}
let mut offset = 0usize;
let mut offsets = Vec::with_capacity(tensors.len());
for (name, tensor) in tensors.iter() {
write_string(w, name)?;
let dims = tensor.shape().dims();
w.write_u32::<LittleEndian>(dims.len() as u32)?;
for &dim in dims.iter().rev() {
w.write_u64::<LittleEndian>(dim as u64)?;
}
w.write_u32::<LittleEndian>(tensor.dtype().to_u32())?;
w.write_u64::<LittleEndian>(offset as u64)?;
offsets.push(offset);
let size_in_bytes = tensor.storage_size_in_bytes();
let padding = 31 - (31 + size_in_bytes) % 32;
offset += size_in_bytes + padding;
}
let pos = w.stream_position()? as usize;
let padding = 31 - (31 + pos) % 32;
w.write_all(&vec![0u8; padding])?;
let tensor_start_pos = w.stream_position()? as usize;
for (offset, (_name, tensor)) in offsets.iter().zip(tensors.iter()) {
let pos = w.stream_position()? as usize;
if tensor_start_pos + offset != pos {
crate::bail!(
"internal error, unexpected current position {tensor_start_pos} {offset} {pos}"
)
}
let data = tensor.data()?;
let size_in_bytes = data.len();
w.write_all(&data)?;
let padding = 31 - (31 + size_in_bytes) % 32;
w.write_all(&vec![0u8; padding])?;
}
Ok(())
}
| 5 |
0 | hf_public_repos/candle/candle-core/src | hf_public_repos/candle/candle-core/src/quantized/dummy_cuda.rs | #![allow(unused)]
use super::GgmlDType;
use crate::{CudaDevice, CudaStorage, Error, Result};
pub struct QCudaStorage {
dtype: GgmlDType,
device: CudaDevice,
}
impl QCudaStorage {
pub fn zeros(_: &CudaDevice, _: usize, _: GgmlDType) -> Result<Self> {
Err(Error::NotCompiledWithCudaSupport)
}
pub fn dtype(&self) -> GgmlDType {
self.dtype
}
pub fn device(&self) -> &CudaDevice {
&self.device
}
pub fn dequantize(&self, _elem_count: usize) -> Result<CudaStorage> {
Err(Error::NotCompiledWithCudaSupport)
}
pub fn dequantize_f16(&self, _elem_count: usize) -> Result<CudaStorage> {
Err(Error::NotCompiledWithCudaSupport)
}
pub fn quantize(&mut self, _src: &CudaStorage) -> Result<()> {
Err(Error::NotCompiledWithCudaSupport)
}
pub fn storage_size_in_bytes(&self) -> usize {
0
}
pub fn fwd(
&self,
_self_shape: &crate::Shape,
_storage: &CudaStorage,
_layout: &crate::Layout,
) -> Result<(CudaStorage, crate::Shape)> {
Err(Error::NotCompiledWithCudaSupport)
}
}
pub fn load_quantized<T: super::GgmlType + Send + Sync + 'static>(
_device: &CudaDevice,
_data: &[T],
) -> Result<super::QStorage> {
Err(Error::NotCompiledWithCudaSupport)
}
| 6 |
0 | hf_public_repos/candle/candle-core/src | hf_public_repos/candle/candle-core/src/quantized/dummy_metal.rs | #![allow(unused)]
use super::GgmlDType;
use crate::{Error, MetalDevice, MetalStorage, Result};
pub struct QMetalStorage {
dtype: GgmlDType,
device: MetalDevice,
}
impl QMetalStorage {
pub fn zeros(_: &MetalDevice, _: usize, _: GgmlDType) -> Result<Self> {
Err(Error::NotCompiledWithMetalSupport)
}
pub fn dtype(&self) -> GgmlDType {
self.dtype
}
pub fn device(&self) -> &MetalDevice {
&self.device
}
pub fn dequantize(&self, _elem_count: usize) -> Result<MetalStorage> {
Err(Error::NotCompiledWithMetalSupport)
}
pub fn quantize(&mut self, _src: &MetalStorage) -> Result<()> {
Err(Error::NotCompiledWithMetalSupport)
}
pub fn storage_size_in_bytes(&self) -> usize {
0
}
pub fn fwd(
&self,
_self_shape: &crate::Shape,
_storage: &MetalStorage,
_layout: &crate::Layout,
) -> Result<(MetalStorage, crate::Shape)> {
Err(Error::NotCompiledWithMetalSupport)
}
}
pub fn load_quantized<T: super::GgmlType + Send + Sync + 'static>(
_device: &MetalDevice,
_data: &[T],
) -> Result<super::QStorage> {
Err(Error::NotCompiledWithMetalSupport)
}
| 7 |
0 | hf_public_repos/candle/candle-core/src | hf_public_repos/candle/candle-core/src/quantized/metal.rs | use super::{GgmlDType, QStorage};
use crate::backend::BackendStorage;
use crate::{DType, MetalDevice, MetalStorage, Result, Shape};
use metal::Buffer;
use std::sync::Arc;
pub struct QMetalStorage {
dtype: GgmlDType,
device: MetalDevice,
buffer: Arc<Buffer>,
}
impl QMetalStorage {
pub fn zeros(device: &MetalDevice, elem_count: usize, dtype: GgmlDType) -> Result<Self> {
let size = elem_count * dtype.type_size() / dtype.block_size();
let buffer = device.allocate_zeros(size)?;
Ok(Self {
buffer,
device: device.clone(),
dtype,
})
}
pub fn dtype(&self) -> GgmlDType {
self.dtype
}
pub fn device(&self) -> &MetalDevice {
&self.device
}
pub fn buffer(&self) -> &Buffer {
&self.buffer
}
pub fn dequantize(&self, elem_count: usize) -> Result<MetalStorage> {
use crate::quantized::k_quants::GgmlType;
let buffer = self.device.new_buffer_managed(self.buffer.length())?;
let command_buffer = self.device.command_buffer()?;
command_buffer.set_label("to_cpu");
let blit = command_buffer.new_blit_command_encoder();
blit.set_label("blit_to_cpu");
blit.copy_from_buffer(&self.buffer, 0, &buffer, 0, self.buffer.length());
blit.end_encoding();
self.device.wait_until_completed()?;
let mut out = vec![0.0; elem_count];
let block_len = elem_count / self.dtype.block_size();
match self.dtype {
GgmlDType::F32 => {
let vec: Vec<f32> = read_to_vec(&buffer, block_len);
f32::to_float(&vec, &mut out)?;
}
GgmlDType::F16 => {
let vec: Vec<half::f16> = read_to_vec(&buffer, block_len);
half::f16::to_float(&vec, &mut out)?;
}
GgmlDType::Q4_0 => {
let vec: Vec<crate::quantized::BlockQ4_0> = read_to_vec(&buffer, block_len);
crate::quantized::BlockQ4_0::to_float(&vec, &mut out)?;
}
GgmlDType::Q4_1 => {
let vec: Vec<crate::quantized::BlockQ4_1> = read_to_vec(&buffer, block_len);
crate::quantized::BlockQ4_1::to_float(&vec, &mut out)?;
}
GgmlDType::Q5_0 => {
let vec: Vec<crate::quantized::BlockQ5_0> = read_to_vec(&buffer, block_len);
crate::quantized::BlockQ5_0::to_float(&vec, &mut out)?;
}
GgmlDType::Q5_1 => {
let vec: Vec<crate::quantized::BlockQ5_1> = read_to_vec(&buffer, block_len);
crate::quantized::BlockQ5_1::to_float(&vec, &mut out)?;
}
GgmlDType::Q8_0 => {
let vec: Vec<crate::quantized::BlockQ8_0> = read_to_vec(&buffer, block_len);
crate::quantized::BlockQ8_0::to_float(&vec, &mut out)?;
}
GgmlDType::Q8_1 => {
let vec: Vec<crate::quantized::BlockQ8_1> = read_to_vec(&buffer, block_len);
crate::quantized::BlockQ8_1::to_float(&vec, &mut out)?;
}
GgmlDType::Q2K => {
let vec: Vec<crate::quantized::BlockQ2K> = read_to_vec(&buffer, block_len);
crate::quantized::BlockQ2K::to_float(&vec, &mut out)?;
}
GgmlDType::Q3K => {
let vec: Vec<crate::quantized::BlockQ3K> = read_to_vec(&buffer, block_len);
crate::quantized::BlockQ3K::to_float(&vec, &mut out)?;
}
GgmlDType::Q4K => {
let vec: Vec<crate::quantized::BlockQ4K> = read_to_vec(&buffer, block_len);
crate::quantized::BlockQ4K::to_float(&vec, &mut out)?;
}
GgmlDType::Q5K => {
let vec: Vec<crate::quantized::BlockQ5K> = read_to_vec(&buffer, block_len);
crate::quantized::BlockQ5K::to_float(&vec, &mut out)?;
}
GgmlDType::Q6K => {
let vec: Vec<crate::quantized::BlockQ6K> = read_to_vec(&buffer, block_len);
crate::quantized::BlockQ6K::to_float(&vec, &mut out)?;
}
GgmlDType::Q8K => {
let vec: Vec<crate::quantized::BlockQ8K> = read_to_vec(&buffer, block_len);
crate::quantized::BlockQ8K::to_float(&vec, &mut out)?;
}
}
let buffer = self.device.new_buffer_with_data(&out)?;
Ok(MetalStorage::new(
buffer,
self.device.clone(),
elem_count,
DType::F32,
))
}
pub fn quantize(&mut self, src: &MetalStorage) -> Result<()> {
// Quantization only happens on CPU for now.
let src = src.to_cpu::<f32>()?;
let elem_count = src.len();
let src = crate::Storage::Cpu(crate::CpuStorage::F32(src));
let mut qcpu_storage = crate::Device::Cpu.qzeros(elem_count, self.dtype)?;
qcpu_storage.quantize(&src)?;
let buffer = self.device.new_buffer_with_data(&qcpu_storage.data()?)?;
self.buffer = buffer;
Ok(())
}
pub fn storage_size_in_bytes(&self) -> usize {
self.buffer.length() as usize
}
pub fn fwd(
&self,
self_shape: &Shape,
storage: &MetalStorage,
layout: &crate::Layout,
) -> Result<(MetalStorage, Shape)> {
use crate::MetalError;
if !layout.is_contiguous() {
crate::bail!("input tensor is not contiguous {layout:?}")
}
let src_shape = layout.shape();
// self is transposed so n is first then k.
if src_shape.rank() < 2 {
crate::bail!("input tensor has only one dimension {layout:?}")
}
let (n, k) = self_shape.dims2()?;
let mut dst_shape = src_shape.dims().to_vec();
// We always use a single batch dimension and stack all the tensors in the batch on the
// second dimension as the implementation in candle-metal-kernels doesn't handle batch
// properly.
let m = match dst_shape.len() {
3 => dst_shape[0] * dst_shape[1],
2 => dst_shape[0],
n => crate::bail!("Invalid rank {n} for quantized matmul metal"),
};
let last_k = dst_shape.pop().unwrap();
if last_k != k {
crate::bail!("input tensor {layout:?} incompatible with {:?}", self_shape)
}
dst_shape.push(n);
let dst_shape = Shape::from(dst_shape);
let device = storage.device().clone();
let dst = device.new_buffer(dst_shape.elem_count(), DType::F32, "qmatmul")?;
let command_buffer = device.command_buffer()?;
// In some cases it would be better to use the mm variant, though it has its drawbacks
// around memory alignemnt.
for batch_id in 0..m {
candle_metal_kernels::call_quantized_matmul_mv_t(
device.device(),
&command_buffer,
device.kernels(),
self.dtype.into(),
(1, 1, n, k),
storage.buffer(),
(layout.start_offset() + batch_id * k) * storage.dtype().size_in_bytes(),
&self.buffer,
batch_id * n * DType::F32.size_in_bytes(),
&dst,
)
.map_err(MetalError::from)?;
}
let dst_storage = crate::MetalStorage::new(dst, device, dst_shape.elem_count(), DType::F32);
Ok((dst_storage, dst_shape))
}
}
pub fn load_quantized<T: super::GgmlType + Send + Sync + 'static>(
device: &MetalDevice,
data: &[T],
) -> Result<QStorage> {
let buffer = device.new_buffer_with_data(data)?;
let device = device.clone();
Ok(QStorage::Metal(QMetalStorage {
dtype: T::DTYPE,
device,
buffer,
}))
}
fn read_to_vec<T: Clone>(buffer: &Buffer, n: usize) -> Vec<T> {
let ptr = buffer.contents() as *const T;
assert!(!ptr.is_null());
let slice = unsafe { std::slice::from_raw_parts(ptr, n) };
slice.to_vec()
}
impl From<GgmlDType> for candle_metal_kernels::GgmlDType {
fn from(value: GgmlDType) -> Self {
match value {
GgmlDType::Q4_0 => candle_metal_kernels::GgmlDType::Q4_0,
GgmlDType::Q4_1 => candle_metal_kernels::GgmlDType::Q4_1,
GgmlDType::Q5_0 => candle_metal_kernels::GgmlDType::Q5_0,
GgmlDType::Q5_1 => candle_metal_kernels::GgmlDType::Q5_1,
GgmlDType::Q8_0 => candle_metal_kernels::GgmlDType::Q8_0,
GgmlDType::Q8_1 => candle_metal_kernels::GgmlDType::Q8_1,
GgmlDType::Q2K => candle_metal_kernels::GgmlDType::Q2K,
GgmlDType::Q3K => candle_metal_kernels::GgmlDType::Q3K,
GgmlDType::Q4K => candle_metal_kernels::GgmlDType::Q4K,
GgmlDType::Q5K => candle_metal_kernels::GgmlDType::Q5K,
GgmlDType::Q6K => candle_metal_kernels::GgmlDType::Q6K,
GgmlDType::Q8K => candle_metal_kernels::GgmlDType::Q8K,
GgmlDType::F16 => candle_metal_kernels::GgmlDType::F16,
GgmlDType::F32 => candle_metal_kernels::GgmlDType::F32,
}
}
}
| 8 |
0 | hf_public_repos/candle/candle-core/src | hf_public_repos/candle/candle-core/src/quantized/cuda.rs | use super::{GgmlDType, QStorage};
use crate::quantized::k_quants::GgmlType;
use crate::{backend::BackendDevice, cuda_backend::WrapErr};
use crate::{CudaDevice, CudaStorage, Result};
use half::f16;
use cudarc::driver::{CudaSlice, CudaView, DeviceSlice};
#[derive(Clone, Debug)]
struct PaddedCudaSlice {
inner: CudaSlice<u8>,
len: usize,
}
#[derive(Clone, Debug)]
pub struct QCudaStorage {
data: PaddedCudaSlice,
dtype: GgmlDType,
device: CudaDevice,
}
static FORCE_DMMV: std::sync::atomic::AtomicBool = std::sync::atomic::AtomicBool::new(false);
pub fn set_force_dmmv(f: bool) {
FORCE_DMMV.store(f, std::sync::atomic::Ordering::Relaxed)
}
pub const WARP_SIZE: usize = 32;
pub const MMQ_X_Q4_0_AMPERE: usize = 4;
pub const MMQ_Y_Q4_0_AMPERE: usize = 32;
pub const NWARPS_Q4_0_AMPERE: usize = 4;
pub const GGML_CUDA_MMV_X: usize = 32;
pub const GGML_CUDA_MMV_Y: usize = 1;
pub const CUDA_QUANTIZE_BLOCK_SIZE: usize = 256;
pub const CUDA_DEQUANTIZE_BLOCK_SIZE: usize = 256;
pub const MATRIX_ROW_PADDING: usize = 512;
fn ceil_div(p: usize, q: usize) -> usize {
p.div_ceil(q)
}
fn pad(p: usize, q: usize) -> usize {
ceil_div(p, q) * q
}
fn quantize_q8_1(
src: &CudaView<f32>,
dst: &mut CudaSlice<u8>,
elem_count: usize,
ky: usize,
dev: &CudaDevice,
) -> Result<()> {
use cudarc::driver::LaunchAsync;
let kx = elem_count;
let kx_padded = pad(kx, MATRIX_ROW_PADDING);
let num_blocks = ceil_div(kx_padded, CUDA_QUANTIZE_BLOCK_SIZE);
let func = dev.get_or_load_func("quantize_q8_1", candle_kernels::QUANTIZED)?;
let cfg = cudarc::driver::LaunchConfig {
grid_dim: (num_blocks as u32, ky as u32, 1),
block_dim: (CUDA_QUANTIZE_BLOCK_SIZE as u32, 1, 1),
shared_mem_bytes: 0,
};
let params = (src, dst, kx as i32, kx_padded as i32);
unsafe { func.launch(cfg, params) }.w()?;
Ok(())
}
fn dequantize_f32(
data: &PaddedCudaSlice,
dtype: GgmlDType,
elem_count: usize,
dev: &CudaDevice,
) -> Result<CudaStorage> {
use cudarc::driver::LaunchAsync;
let nb = (elem_count + 255) / 256;
let (kernel_name, is_k, block_dim, num_blocks) = match dtype {
GgmlDType::Q4_0 => ("dequantize_block_q4_0_f32", false, 32, nb),
GgmlDType::Q4_1 => ("dequantize_block_q4_1_f32", false, 32, nb),
GgmlDType::Q5_0 => (
"dequantize_block_q5_0_f32",
false,
CUDA_DEQUANTIZE_BLOCK_SIZE,
ceil_div(elem_count, 2 * CUDA_DEQUANTIZE_BLOCK_SIZE),
),
GgmlDType::Q5_1 => (
"dequantize_block_q5_1_f32",
false,
CUDA_DEQUANTIZE_BLOCK_SIZE,
ceil_div(elem_count, 2 * CUDA_DEQUANTIZE_BLOCK_SIZE),
),
GgmlDType::Q8_0 => ("dequantize_block_q8_0_f32", false, 32, nb),
GgmlDType::Q2K => ("dequantize_block_q2_K_f32", true, 64, nb),
GgmlDType::Q3K => ("dequantize_block_q3_K_f32", true, 64, nb),
GgmlDType::Q4K => ("dequantize_block_q4_K_f32", true, 32, nb),
GgmlDType::Q5K => ("dequantize_block_q5_K_f32", true, 64, nb),
GgmlDType::Q6K => ("dequantize_block_q6_K_f32", true, 64, nb),
GgmlDType::Q8K => ("dequantize_block_q8_K_f32", true, 32, nb),
_ => crate::bail!("unsupported dtype for dequantize {dtype:?}"),
};
let func = dev.get_or_load_func(kernel_name, candle_kernels::QUANTIZED)?;
let dst = unsafe { dev.alloc::<f32>(elem_count).w()? };
// See e.g.
// https://github.com/ggerganov/llama.cpp/blob/cbbd1efa06f8c09f9dff58ff9d9af509cc4c152b/ggml-cuda.cu#L7270
let cfg = cudarc::driver::LaunchConfig {
grid_dim: (num_blocks as u32, 1, 1),
block_dim: (block_dim as u32, 1, 1),
shared_mem_bytes: 0,
};
if is_k {
let params = (&data.inner, &dst);
unsafe { func.launch(cfg, params) }.w()?;
} else {
let nb32 = match dtype {
GgmlDType::Q5_0 | GgmlDType::Q5_1 => elem_count,
_ => elem_count / 32,
};
let params = (&data.inner, &dst, nb32 as i32);
unsafe { func.launch(cfg, params) }.w()?;
}
Ok(CudaStorage::wrap_cuda_slice(dst, dev.clone()))
}
fn dequantize_f16(
data: &PaddedCudaSlice,
dtype: GgmlDType,
elem_count: usize,
dev: &CudaDevice,
) -> Result<CudaStorage> {
use cudarc::driver::LaunchAsync;
let nb = (elem_count + 255) / 256;
let (kernel_name, is_k, block_dim, num_blocks) = match dtype {
GgmlDType::Q4_0 => ("dequantize_block_q4_0_f16", false, 32, nb),
GgmlDType::Q4_1 => ("dequantize_block_q4_1_f16", false, 32, nb),
GgmlDType::Q5_0 => (
"dequantize_block_q5_0_f16",
false,
CUDA_DEQUANTIZE_BLOCK_SIZE,
ceil_div(elem_count, 2 * CUDA_DEQUANTIZE_BLOCK_SIZE),
),
GgmlDType::Q5_1 => (
"dequantize_block_q5_1_f16",
false,
CUDA_DEQUANTIZE_BLOCK_SIZE,
ceil_div(elem_count, 2 * CUDA_DEQUANTIZE_BLOCK_SIZE),
),
GgmlDType::Q8_0 => ("dequantize_block_q8_0_f16", false, 32, nb),
GgmlDType::Q2K => ("dequantize_block_q2_K_f16", true, 64, nb),
GgmlDType::Q3K => ("dequantize_block_q3_K_f16", true, 64, nb),
GgmlDType::Q4K => ("dequantize_block_q4_K_f16", true, 32, nb),
GgmlDType::Q5K => ("dequantize_block_q5_K_f16", true, 64, nb),
GgmlDType::Q6K => ("dequantize_block_q6_K_f16", true, 64, nb),
GgmlDType::Q8K => ("dequantize_block_q8_K_f16", true, 32, nb),
_ => crate::bail!("unsupported dtype for dequantize {dtype:?}"),
};
let func = dev.get_or_load_func(kernel_name, candle_kernels::QUANTIZED)?;
let dst = unsafe { dev.alloc::<f16>(elem_count).w()? };
// See e.g.
// https://github.com/ggerganov/llama.cpp/blob/cbbd1efa06f8c09f9dff58ff9d9af509cc4c152b/ggml-cuda.cu#L7270
let cfg = cudarc::driver::LaunchConfig {
grid_dim: (num_blocks as u32, 1, 1),
block_dim: (block_dim as u32, 1, 1),
shared_mem_bytes: 0,
};
if is_k {
let params = (&data.inner, &dst);
unsafe { func.launch(cfg, params) }.w()?;
} else {
let nb32 = match dtype {
GgmlDType::Q5_0 | GgmlDType::Q5_1 => elem_count,
_ => elem_count / 32,
};
let params = (&data.inner, &dst, nb32 as i32);
unsafe { func.launch(cfg, params) }.w()?;
}
Ok(CudaStorage::wrap_cuda_slice(dst, dev.clone()))
}
fn dequantize_mul_mat_vec(
data: &PaddedCudaSlice,
y: &CudaView<f32>,
dtype: GgmlDType,
ncols: usize,
nrows: usize,
dev: &CudaDevice,
) -> Result<CudaStorage> {
use cudarc::driver::LaunchAsync;
let data_elems = data.len / dtype.type_size() * dtype.block_size();
if data_elems < ncols * nrows {
crate::bail!("unexpected data size {}, ncols {ncols} {nrows}", data_elems)
}
if y.len() != ncols {
crate::bail!("unexpected y size {}, ncols {ncols} {nrows}", y.len())
}
let kernel_name = match dtype {
GgmlDType::Q4_0 => "dequantize_mul_mat_vec_q4_0_cuda",
GgmlDType::Q4_1 => "dequantize_mul_mat_vec_q4_1_cuda",
GgmlDType::Q5_0 => "dequantize_mul_mat_vec_q5_0_cuda",
GgmlDType::Q5_1 => "dequantize_mul_mat_vec_q5_1_cuda",
GgmlDType::Q8_0 => "dequantize_mul_mat_vec_q8_0_cuda",
GgmlDType::Q2K => "dequantize_mul_mat_vec_q2_k",
GgmlDType::Q3K => "dequantize_mul_mat_vec_q3_k",
GgmlDType::Q4K => "dequantize_mul_mat_vec_q4_k",
GgmlDType::Q5K => "dequantize_mul_mat_vec_q5_k",
GgmlDType::Q6K => "dequantize_mul_mat_vec_q6_k",
_ => crate::bail!("unsupported dtype for quantized matmul {dtype:?}"),
};
let func = dev.get_or_load_func(kernel_name, candle_kernels::QUANTIZED)?;
let dst = unsafe { dev.alloc::<f32>(nrows).w()? };
let block_num_y = ceil_div(nrows, GGML_CUDA_MMV_Y);
let cfg = cudarc::driver::LaunchConfig {
grid_dim: (block_num_y as u32, 1, 1),
block_dim: (WARP_SIZE as u32, GGML_CUDA_MMV_Y as u32, 1),
shared_mem_bytes: 0,
};
let params = (&data.inner, y, &dst, ncols as i32, nrows as i32);
unsafe { func.launch(cfg, params) }.w()?;
Ok(CudaStorage::wrap_cuda_slice(dst, dev.clone()))
}
fn mul_mat_vec_via_q8_1(
data: &PaddedCudaSlice,
y: &CudaView<f32>,
dtype: GgmlDType,
ncols: usize,
nrows: usize,
b_size: usize,
dev: &CudaDevice,
) -> Result<CudaStorage> {
use cudarc::driver::LaunchAsync;
let data_elems = data.len / dtype.type_size() * dtype.block_size();
if data_elems < ncols * nrows {
crate::bail!("unexpected data size {}, ncols {ncols} {nrows}", data_elems)
}
if y.len() != ncols * b_size {
crate::bail!("unexpected y size {}, ncols {ncols} {nrows}", y.len())
}
if b_size == 0 || b_size > 8 {
crate::bail!("only bsize between 1 and 8 are supported, got {b_size}")
}
// Start by quantizing y
let ncols_padded = pad(ncols, MATRIX_ROW_PADDING);
let y_size_in_bytes =
b_size * ncols_padded * GgmlDType::Q8_1.type_size() / GgmlDType::Q8_1.block_size();
let mut y_q8_1 = unsafe { dev.alloc::<u8>(y_size_in_bytes).w()? };
quantize_q8_1(y, &mut y_q8_1, ncols, b_size, dev)?;
let kernel_name = match dtype {
GgmlDType::Q4_0 => "mul_mat_vec_q4_0_q8_1_cuda",
GgmlDType::Q4_1 => "mul_mat_vec_q4_1_q8_1_cuda",
GgmlDType::Q5_0 => "mul_mat_vec_q5_0_q8_1_cuda",
GgmlDType::Q5_1 => "mul_mat_vec_q5_1_q8_1_cuda",
GgmlDType::Q8_0 => "mul_mat_vec_q8_0_q8_1_cuda",
GgmlDType::Q2K => "mul_mat_vec_q2_K_q8_1_cuda",
GgmlDType::Q3K => "mul_mat_vec_q3_K_q8_1_cuda",
GgmlDType::Q4K => "mul_mat_vec_q4_K_q8_1_cuda",
GgmlDType::Q5K => "mul_mat_vec_q5_K_q8_1_cuda",
GgmlDType::Q6K => "mul_mat_vec_q6_K_q8_1_cuda",
_ => crate::bail!("unsupported dtype for quantized matmul {dtype:?}"),
};
let kernel_name = format!("{kernel_name}{b_size}");
let func = dev.get_or_load_func(&kernel_name, candle_kernels::QUANTIZED)?;
let dst = unsafe { dev.alloc::<f32>(nrows * b_size).w()? };
// https://github.com/ggerganov/llama.cpp/blob/facb8b56f8fd3bb10a693bf0943ae9d69d0828ef/ggml-cuda/mmvq.cu#L98
let (nblocks, nwarps) = match b_size {
1 => (nrows as u32, 4),
2..=4 => ((nrows as u32 + 1) / 2, 4),
5..=8 => ((nrows as u32 + 1) / 2, 2),
_ => crate::bail!("unexpected bsize {b_size}"),
};
let cfg = cudarc::driver::LaunchConfig {
grid_dim: (nblocks, 1, 1),
block_dim: (WARP_SIZE as u32, nwarps, 1),
shared_mem_bytes: 0,
};
let params = (
&data.inner,
&y_q8_1,
&dst,
/* ncols_x */ ncols as i32,
/* nrows_x */ nrows as i32,
/* nrows_y */ ncols_padded as i32,
/* nrows_dst */ nrows as i32,
);
unsafe { func.launch(cfg, params) }.w()?;
Ok(CudaStorage::wrap_cuda_slice(dst, dev.clone()))
}
#[allow(clippy::too_many_arguments)]
fn mul_mat_via_q8_1(
data: &PaddedCudaSlice,
y: &CudaView<f32>,
dtype: GgmlDType,
x_rows: usize,
x_cols: usize,
y_rows: usize,
y_cols: usize,
dev: &CudaDevice,
) -> Result<CudaStorage> {
use cudarc::driver::LaunchAsync;
let data_elems = data.len / dtype.type_size() * dtype.block_size();
if data_elems < x_rows * x_cols {
crate::bail!("unexpected lhs size {}, {x_rows} {x_cols}", data_elems)
}
if y.len() != y_rows * y_cols {
crate::bail!("unexpected y size {}, {y_rows} {y_cols}", y.len())
}
if x_cols != y_rows {
crate::bail!("unexpected x/y size {x_rows} {x_cols} {y_rows} {y_cols}")
}
let k = x_cols;
// Start by quantizing y
let k_padded = pad(k, MATRIX_ROW_PADDING);
let y_size_in_bytes =
k_padded * y_cols * GgmlDType::Q8_1.type_size() / GgmlDType::Q8_1.block_size();
let mut y_q8_1 = unsafe { dev.alloc::<u8>(y_size_in_bytes).w()? };
quantize_q8_1(y, &mut y_q8_1, k, y_cols, dev)?;
let (kernel_name, mmq_x, mmq_y) = match dtype {
GgmlDType::Q4_0 => ("mul_mat_q4_0", 64, 128),
GgmlDType::Q4_1 => ("mul_mat_q4_1", 64, 128),
GgmlDType::Q5_0 => ("mul_mat_q5_0", 128, 64),
GgmlDType::Q5_1 => ("mul_mat_q5_1", 128, 64),
GgmlDType::Q8_0 => ("mul_mat_q8_0", 128, 64),
GgmlDType::Q2K => ("mul_mat_q2_K", 64, 128),
GgmlDType::Q3K => ("mul_mat_q3_K", 128, 128),
GgmlDType::Q4K => ("mul_mat_q4_K", 64, 128),
GgmlDType::Q5K => ("mul_mat_q5_K", 64, 128),
GgmlDType::Q6K => ("mul_mat_q6_K", 64, 64),
_ => crate::bail!("unsupported dtype for quantized matmul {dtype:?}"),
};
let func = dev.get_or_load_func(kernel_name, candle_kernels::QUANTIZED)?;
let dst = unsafe { dev.alloc::<f32>(x_rows * y_cols).w()? };
let cfg = cudarc::driver::LaunchConfig {
grid_dim: (
ceil_div(x_rows, mmq_y) as u32,
ceil_div(y_cols, mmq_x) as u32,
1,
),
block_dim: (WARP_SIZE as u32, 4, 1),
shared_mem_bytes: 0,
};
let params = (
/* vx */ &data.inner,
/* vy */ &y_q8_1,
/* dst */ &dst,
/* ncols_x */ x_cols as i32,
/* nrows_x */ x_rows as i32,
/* ncols_y */ y_cols as i32,
/* nrows_y */ k_padded as i32,
/* nrows_dst */ x_rows as i32,
);
unsafe { func.launch(cfg, params) }.w()?;
Ok(CudaStorage::wrap_cuda_slice(dst, dev.clone()))
}
impl QCudaStorage {
pub fn zeros(device: &CudaDevice, el_count: usize, dtype: GgmlDType) -> Result<Self> {
let size_in_bytes = ceil_div(el_count, dtype.block_size()) * dtype.type_size();
let padded_size_in_bytes =
ceil_div(el_count + MATRIX_ROW_PADDING, dtype.block_size()) * dtype.type_size();
let inner = device.alloc_zeros::<u8>(padded_size_in_bytes).w()?;
Ok(QCudaStorage {
data: PaddedCudaSlice {
inner,
len: size_in_bytes,
},
device: device.clone(),
dtype,
})
}
pub fn dtype(&self) -> GgmlDType {
self.dtype
}
pub fn device(&self) -> &CudaDevice {
&self.device
}
pub fn dequantize(&self, elem_count: usize) -> Result<CudaStorage> {
fn deq<T: GgmlType>(buffer: &[u8], n: usize, dst: &mut [f32]) -> Result<()> {
let slice = unsafe { std::slice::from_raw_parts(buffer.as_ptr() as *const T, n) };
let vec = slice.to_vec();
T::to_float(&vec, dst)
}
let fast_kernel = matches!(
self.dtype,
GgmlDType::Q4_0
| GgmlDType::Q4_1
| GgmlDType::Q5_0
| GgmlDType::Q5_1
| GgmlDType::Q8_0
| GgmlDType::Q2K
| GgmlDType::Q3K
| GgmlDType::Q4K
| GgmlDType::Q5K
| GgmlDType::Q6K
| GgmlDType::Q8K
);
if fast_kernel {
return dequantize_f32(&self.data, self.dtype, elem_count, self.device());
}
// Run the dequantization on cpu.
let buffer = self
.device
.dtoh_sync_copy(&self.data.inner.slice(..self.data.len))
.w()?;
let mut out = vec![0.0; elem_count];
let block_len = elem_count / self.dtype.block_size();
match self.dtype {
GgmlDType::F32 => deq::<f32>(&buffer, block_len, &mut out)?,
GgmlDType::F16 => deq::<half::f16>(&buffer, block_len, &mut out)?,
GgmlDType::Q4_0 => deq::<crate::quantized::BlockQ4_0>(&buffer, block_len, &mut out)?,
GgmlDType::Q4_1 => deq::<crate::quantized::BlockQ4_1>(&buffer, block_len, &mut out)?,
GgmlDType::Q5_0 => deq::<crate::quantized::BlockQ5_0>(&buffer, block_len, &mut out)?,
GgmlDType::Q5_1 => deq::<crate::quantized::BlockQ5_1>(&buffer, block_len, &mut out)?,
GgmlDType::Q8_0 => deq::<crate::quantized::BlockQ8_0>(&buffer, block_len, &mut out)?,
GgmlDType::Q8_1 => deq::<crate::quantized::BlockQ8_1>(&buffer, block_len, &mut out)?,
GgmlDType::Q2K => deq::<crate::quantized::BlockQ2K>(&buffer, block_len, &mut out)?,
GgmlDType::Q3K => deq::<crate::quantized::BlockQ3K>(&buffer, block_len, &mut out)?,
GgmlDType::Q4K => deq::<crate::quantized::BlockQ4K>(&buffer, block_len, &mut out)?,
GgmlDType::Q5K => deq::<crate::quantized::BlockQ5K>(&buffer, block_len, &mut out)?,
GgmlDType::Q6K => deq::<crate::quantized::BlockQ6K>(&buffer, block_len, &mut out)?,
GgmlDType::Q8K => deq::<crate::quantized::BlockQ8K>(&buffer, block_len, &mut out)?,
}
self.device
.storage_from_cpu_storage(&crate::CpuStorage::F32(out))
}
pub fn dequantize_f16(&self, elem_count: usize) -> Result<CudaStorage> {
dequantize_f16(&self.data, self.dtype, elem_count, self.device())
}
pub fn quantize(&mut self, src: &CudaStorage) -> Result<()> {
// Run the quantization on cpu.
let src = match &src.slice {
crate::cuda_backend::CudaStorageSlice::F32(data) => {
self.device.dtoh_sync_copy(data).w()?
}
_ => crate::bail!("only f32 can be quantized"),
};
let src_len = src.len();
let src = crate::Storage::Cpu(crate::CpuStorage::F32(src));
let mut qcpu_storage = crate::Device::Cpu.qzeros(src_len, self.dtype)?;
qcpu_storage.quantize(&src)?;
let data = qcpu_storage.data()?;
let padded_len =
data.len() + MATRIX_ROW_PADDING * self.dtype.type_size() / self.dtype.block_size();
let mut inner = unsafe { self.device.alloc::<u8>(padded_len).w()? };
self.device
.htod_sync_copy_into(data.as_ref(), &mut inner.slice_mut(..data.len()))
.w()?;
self.data = PaddedCudaSlice {
inner,
len: data.len(),
};
Ok(())
}
pub fn storage_size_in_bytes(&self) -> usize {
self.data.len
}
pub fn fwd(
&self,
self_shape: &crate::Shape,
storage: &CudaStorage,
layout: &crate::Layout,
) -> Result<(CudaStorage, crate::Shape)> {
let max_bm = if FORCE_DMMV.load(std::sync::atomic::Ordering::Relaxed) {
1
} else {
8
};
let use_vec_kernel = match layout.shape().dims() {
[b, m, _k] => b * m <= max_bm,
[b, _k] => *b <= max_bm,
_ => false,
};
if use_vec_kernel {
self.dequantize_matmul_vec(self_shape, storage, layout)
} else {
self.dequantize_matmul(self_shape, storage, layout)
}
}
}
impl QCudaStorage {
fn dequantize_matmul_vec(
&self,
self_shape: &crate::Shape,
rhs: &CudaStorage,
rhs_l: &crate::Layout,
) -> Result<(CudaStorage, crate::Shape)> {
let (nrows, ncols) = self_shape.dims2()?;
let rhs = rhs.as_cuda_slice::<f32>()?;
let rhs = match rhs_l.contiguous_offsets() {
Some((o1, o2)) => rhs.slice(o1..o2),
None => Err(crate::Error::RequiresContiguous { op: "dmmv" }.bt())?,
};
let (b_size, k) = match rhs_l.shape().dims() {
[b, m, k] => (b * m, *k),
[b, k] => (*b, *k),
_ => crate::bail!("unexpected rhs shape in dmmv {:?}", rhs_l.shape()),
};
if ncols != k {
crate::bail!("mismatch on matmul dim {self_shape:?} {:?}", rhs_l.shape())
}
let out = if FORCE_DMMV.load(std::sync::atomic::Ordering::Relaxed) {
dequantize_mul_mat_vec(&self.data, &rhs, self.dtype, ncols, nrows, self.device())?
} else {
mul_mat_vec_via_q8_1(
&self.data,
&rhs,
self.dtype,
ncols,
nrows,
b_size,
self.device(),
)?
};
let mut out_shape = rhs_l.shape().dims().to_vec();
out_shape.pop();
out_shape.push(nrows);
Ok((out, out_shape.into()))
}
fn dequantize_matmul(
&self,
self_shape: &crate::Shape,
storage: &CudaStorage,
layout: &crate::Layout,
) -> Result<(CudaStorage, crate::Shape)> {
use crate::backend::BackendStorage;
let (n, k) = self_shape.dims2()?;
let (b, m, k2) = match layout.shape().dims() {
&[b, m, k2] => (b, m, k2),
&[m, k2] => (1, m, k2),
s => crate::bail!("unexpected shape for input {s:?}"),
};
if k2 != k {
crate::bail!("mismatch on matmul dim {self_shape:?} {:?}", layout.shape())
}
let out = if FORCE_DMMV.load(std::sync::atomic::Ordering::Relaxed) {
let data_f32 = self.dequantize(n * k)?;
let rhs_l = crate::Layout::new((k, n).into(), vec![1, k], 0).broadcast_as((b, k, n))?;
storage.matmul(&data_f32, (b, m, n, k), layout, &rhs_l)?
} else {
let storage = storage.as_cuda_slice::<f32>()?;
let storage = match layout.contiguous_offsets() {
Some((o1, o2)) => storage.slice(o1..o2),
None => Err(crate::Error::RequiresContiguous {
op: "quantized-matmul",
}
.bt())?,
};
mul_mat_via_q8_1(
&self.data,
&storage,
self.dtype,
/* x_rows */ n,
/* x_cols */ k,
/* y_rows */ k,
/* y_cols */ b * m,
self.device(),
)?
};
let mut out_shape = layout.shape().dims().to_vec();
out_shape.pop();
out_shape.push(n);
Ok((out, out_shape.into()))
}
}
pub fn load_quantized<T: super::GgmlType + Send + Sync + 'static>(
device: &CudaDevice,
data: &[T],
) -> Result<super::QStorage> {
let data = unsafe {
std::slice::from_raw_parts(data.as_ptr() as *const u8, core::mem::size_of_val(data))
};
let dtype = T::DTYPE;
let padded_len = data.len() + MATRIX_ROW_PADDING * dtype.type_size() / dtype.block_size();
let mut inner = unsafe { device.alloc::<u8>(padded_len).w()? };
device
.htod_sync_copy_into(data, &mut inner.slice_mut(..data.len()))
.w()?;
Ok(QStorage::Cuda(QCudaStorage {
data: PaddedCudaSlice {
inner,
len: data.len(),
},
device: device.clone(),
dtype,
}))
}
#[cfg(test)]
mod test {
use super::*;
#[test]
fn cuda_quantize_q8_1() -> Result<()> {
let dev = CudaDevice::new(0)?;
let el = 256;
let el_padded = pad(el, MATRIX_ROW_PADDING);
let y_size_in_bytes =
el_padded * GgmlDType::Q8_1.type_size() / GgmlDType::Q8_1.block_size();
let mut y_q8_1 = unsafe { dev.alloc::<u8>(y_size_in_bytes).w()? };
let vs: Vec<f32> = (0..el).map(|v| v as f32).collect();
let y = dev.htod_sync_copy(&vs).w()?;
quantize_q8_1(&y.slice(..), &mut y_q8_1, el, 1, &dev)?;
Ok(())
}
#[test]
fn cuda_mmv_q8_1() -> Result<()> {
let dev = CudaDevice::new(0)?;
let ncols = 256;
let vs: Vec<f32> = (0..ncols).map(|v| v as f32).collect();
let y = dev.htod_sync_copy(&vs).w()?;
let mut xs = QCudaStorage::zeros(&dev, ncols, GgmlDType::Q4_0)?;
xs.quantize(&CudaStorage::wrap_cuda_slice(y.clone(), dev.clone()))?;
let cuda_storage = mul_mat_vec_via_q8_1(
&xs.data,
&y.slice(..),
/* dtype */ GgmlDType::Q4_0,
/* ncols */ ncols,
/* nrows */ 1,
/* b_size */ 1,
&dev,
)?;
let vs = cuda_storage.as_cuda_slice::<f32>()?;
let vs = dev.dtoh_sync_copy(&vs.slice(..)).unwrap();
assert_eq!(vs.len(), 1);
// for n = 255, n.(n+1).(2n+1) / 6 = 5559680
// Q8 means 1/256 precision.
assert_eq!(vs[0], 5561664.5);
let cuda_storage = dequantize_mul_mat_vec(
&xs.data,
&y.slice(..),
/* dtype */ GgmlDType::Q4_0,
/* ncols */ ncols,
/* nrows */ 1,
&dev,
)?;
let vs = cuda_storage.as_cuda_slice::<f32>()?;
let vs = dev.dtoh_sync_copy(&vs.slice(..)).unwrap();
assert_eq!(vs.len(), 1);
assert_eq!(vs[0], 5561851.0);
Ok(())
}
#[test]
fn cuda_mm_q8_1() -> Result<()> {
let dev = CudaDevice::new(0)?;
let ncols = 256;
let vs: Vec<f32> = (0..ncols * 4).map(|v| v as f32 / 4.).collect();
let y = dev.htod_sync_copy(&vs).w()?;
let mut xs = QCudaStorage::zeros(&dev, ncols * 4, GgmlDType::Q4_0)?;
xs.quantize(&CudaStorage::wrap_cuda_slice(y.clone(), dev.clone()))?;
let cuda_storage = mul_mat_via_q8_1(
&xs.data,
&y.slice(..),
/* dtype */ GgmlDType::Q4_0,
/* x_rows */ 4,
/* x_cols */ ncols,
/* y_rows */ ncols,
/* y_cols */ 4,
&dev,
)?;
let vs = cuda_storage.as_cuda_slice::<f32>()?;
let vs = dev.dtoh_sync_copy(&vs.slice(..)).unwrap();
/*
x = torch.tensor([float(v) for v in range(1024)]).reshape(4, 256)
x @ x.t() / 16
tensor([[ 347480.0000, 869720.0000, 1391960.0000, 1914200.0000],
[ 869720.0000, 2440536.0000, 4011352.0000, 5582166.5000],
[ 1391960.0000, 4011352.0000, 6630742.0000, 9250132.0000],
[ 1914200.0000, 5582166.5000, 9250132.0000, 12918099.0000]])
*/
assert_eq!(vs.len(), 16);
assert_eq!(vs[0], 347604.0);
assert_eq!(vs[1], 888153.06);
assert_eq!(vs[4], 869780.7);
assert_eq!(vs[5], 2483145.0);
assert_eq!(vs[11], 9407368.0);
assert_eq!(vs[14], 9470856.0);
assert_eq!(vs[15], 13138824.0);
Ok(())
}
// The following test used to fail under compute-sanitizer until #2526.
#[test]
fn cuda_mm_q8_1_pad() -> Result<()> {
let dev = CudaDevice::new(0)?;
let (x_rows, ncols, y_cols) = (4, 16, 2048);
let vs: Vec<f32> = (0..ncols * y_cols).map(|v| v as f32 / 256.).collect();
let y = dev.htod_sync_copy(&vs).w()?;
let mut xs = QCudaStorage::zeros(&dev, ncols * x_rows, GgmlDType::Q4_0)?;
xs.quantize(&CudaStorage::wrap_cuda_slice(y.clone(), dev.clone()))?;
let cuda_storage = mul_mat_via_q8_1(
&xs.data,
&y.slice(..),
/* dtype */ GgmlDType::Q4_0,
/* x_rows */ x_rows,
/* x_cols */ ncols,
/* y_rows */ ncols,
/* y_cols */ y_cols,
&dev,
)?;
let vs = cuda_storage.as_cuda_slice::<f32>()?;
let _vs = dev.dtoh_sync_copy(&vs.slice(..)).unwrap();
Ok(())
}
}
| 9 |
0 | hf_public_repos/bloom-jax-inference | hf_public_repos/bloom-jax-inference/scripts/remote_cp.sh | INSTANCE=bloom-tpu-v4-64
ZONE=us-central2-b
PROJECT="huggingface-ml"
echo copying $1 to $2
gcloud alpha compute tpus tpu-vm scp $1 $INSTANCE:$2 --project=$PROJECT --zone=$ZONE --force-key-file-overwrite --strict-host-key-checking=no --worker=all | 0 |
0 | hf_public_repos/bloom-jax-inference | hf_public_repos/bloom-jax-inference/scripts/launch_ray.sh | # activate venv (if not done so already)
source ~/venv/bin/activate
ray stop -f || true
TCMALLOC_LARGE_ALLOC_REPORT_THRESHOLD=34359738368 ray start --address=$1 --resources="{\"tpu\": 1}" | 1 |
0 | hf_public_repos/bloom-jax-inference | hf_public_repos/bloom-jax-inference/scripts/run_remote_script.sh | #!/bin/bash
INSTANCE=bloom-tpu-v4-64
ZONE=us-central2-b
PROJECT=huggingface-ml
SCRIPT=$1
# run script.bash through run_script.bash
gcloud alpha compute tpus tpu-vm ssh $INSTANCE --project=$PROJECT --zone=$ZONE \
--force-key-file-overwrite --strict-host-key-checking=no \
--worker=all \
--command="bash ~/bloom-jax-inference/scripts/$SCRIPT" | 2 |
0 | hf_public_repos/bloom-jax-inference | hf_public_repos/bloom-jax-inference/scripts/ray_tpu.sh | #!/usr/bin/env bash
set -e
# this locks the python executable down to hopefully stop if from being fiddled with...
screen -d -m python -c "import time; time.sleep(999999999)"
gcloud auth activate-service-account --key-file ~/bloom-jax-inference/key.json
export GOOGLE_APPLICATION_CREDENTIALS=~/bloom-jax-inference/key.json
# debugging
# rm -rf ~/venv
# rm -rf ~/t5x
# rm -rf ~/.cache/pip
# check if venv exists
if [ -f ~/venv/bin/activate ];
then
echo "venv exists"
# activate venv (if not done so already)
source ~/venv/bin/activate
# for now, reinstall bloom-jax-inference everytime
pip install -e bloom-jax-inference/
else
echo "creating venv"
# get application updates, 'yes' to all
yes | sudo apt-get update
yes | sudo apt-get install python3.8-venv
# create venv
python3 -m venv ~/venv
# activate venv
source ~/venv/bin/activate
# pip install standard packages
pip install ray==1.13.0 git+https://github.com/huggingface/transformers.git fabric dataclasses tqdm func_timeout
# build T5X from source
git clone --branch=main https://github.com/google-research/t5x
cd t5x
python3 -m pip install -e '.[tpu]' -f \https://storage.googleapis.com/jax-releases/libtpu_releases.html
cd ..
rm -rf ~/.cache/pip
yes | pip uninstall jax
# force JAX to TPU version
pip install "jax[tpu]" -f https://storage.googleapis.com/jax-releases/libtpu_releases.html
# And finally, Flax BLOOM
pip install -e bloom-jax-inference/
fi
sudo pkill python* | true
# TODO: this should be it's own command.
TCMALLOC_LARGE_ALLOC_REPORT_THRESHOLD=34359738368 ray start --address=$1 --resources="{\"tpu\": 1}"
# TCMALLOC_LARGE_ALLOC_REPORT_THRESHOLD=34359738368 ray start --address=$1
| 3 |
0 | hf_public_repos/bloom-jax-inference | hf_public_repos/bloom-jax-inference/scripts/remote_run.sh | #!/bin/bash
INSTANCE=bloom-tpu-v4-64
ZONE=us-central2-b
# INSTANCE=$1
COMMAND=$1
PROJECT=huggingface-ml
ZONE=us-central2-b
# run script.bash through run_script.bash
gcloud alpha compute tpus tpu-vm ssh $INSTANCE --project=$PROJECT --zone=$ZONE \
--force-key-file-overwrite --strict-host-key-checking=no \
--worker=all \
--command="source ~/venv/bin/activate && $COMMAND" | 4 |
0 | hf_public_repos/bloom-jax-inference | hf_public_repos/bloom-jax-inference/scripts/run_setup_tpu.sh | #!/bin/bash
INSTANCE=bloom-tpu-v4-64
ZONE=us-central2-b
PROJECT=huggingface-ml
# run script.bash through run_script.bash
gcloud alpha compute tpus tpu-vm ssh $INSTANCE --project=$PROJECT --zone=$ZONE \
--force-key-file-overwrite --strict-host-key-checking=no \
--worker=all \
--command="bash setup_tpu.sh" | 5 |
0 | hf_public_repos/bloom-jax-inference | hf_public_repos/bloom-jax-inference/bloom_inference/generator.py | import warnings
import jax
import jax.numpy as jnp
from jax.experimental import PartitionSpec as P
from jax.experimental.compilation_cache import compilation_cache as cc
from t5x.partitioning import PjitPartitioner
from t5x.train_state import InferenceState
from t5x.checkpoints import Checkpointer
from transformers import AutoTokenizer
from bloom_inference.modeling_bloom import FlaxBloomForCausalLM, BloomConfig
cc.initialize_cache("~/jax_cache")
warnings.filterwarnings("ignore")
warnings.filterwarnings("ignore", category=ResourceWarning)
if jax.process_index() == 0:
warnings.filterwarnings("default")
# print but only on the first node
def head_print(*args, **kwargs):
if jax.process_index() == 0:
print(*args, **kwargs)
# 2D parameter and activation partitioning
logical_axis_rules_full = [
('batch', 'data'),
('mlp', 'model'),
('heads', 'model'),
('vocab', 'model'),
# shard both activations and weight matrices on the remaining available axis
('embed', 'model'),
('embed', 'data'),
('kv', None),
('joined_kv', None),
('relpos_buckets', None),
('abspos_buckets', None),
('length', None),
('layers', None),
('stack', None),
('mlp_activations', None),
]
class Generator:
def __init__(
self,
model_parallel_submesh=(1, 2, 4, 1), # for v4-64
ckpt="bigscience/bloom",
t5x_path="gs://bloom-jax-us-central2-b/bloom-176B-scan-t5x/checkpoint_0",
max_len=256,
max_input_len=64,
):
self.ckpt = ckpt
self.path = t5x_path
self.max_len = max_len
self.max_input_len = max_input_len
self.model_parallel_submesh = model_parallel_submesh
config = BloomConfig.from_pretrained(ckpt, max_length=max_len, do_sample=True, num_beams=1, top_p=0.9)
self.model = FlaxBloomForCausalLM(config, _do_init=False, dtype=jnp.bfloat16, use_scan=True)
def init_state():
input_shape = (1, 1)
input_ids = jnp.zeros(input_shape, dtype="i4")
attention_mask = jnp.ones_like(input_ids)
rng = jax.random.PRNGKey(0)
initial_vars = self.model.module.init(rng, input_ids, attention_mask, return_dict=False)
return InferenceState.create(initial_vars)
state_shapes = jax.eval_shape(init_state)
self.partitioner = PjitPartitioner(
model_parallel_submesh=self.model_parallel_submesh,
logical_axis_rules=logical_axis_rules_full
)
self.params_spec = self.partitioner.get_mesh_axes(state_shapes).params
# Instantiate checkpointer
self.checkpointer = Checkpointer(
state_shapes,
self.partitioner,
self.path,
use_gda=True,
restore_dtype=jnp.bfloat16,
save_dtype=jnp.bfloat16
)
def load_model_and_params(self):
# load state
self.loaded_state = self.checkpointer.restore(path=self.path)
self.tokenizer = AutoTokenizer.from_pretrained(self.ckpt)
self.tokenizer.padding_side = "left"
def generate(params, input_ids, attention_mask):
output_ids = self.model.generate(input_ids, attention_mask=attention_mask, params=params).sequences
return output_ids
self.p_generate = self.partitioner.partition(
generate,
in_axis_resources=(self.params_spec, P("data"), P("data")),
out_axis_resources=P("data")
)
def generate(self, prompts):
inputs = self.tokenizer(prompts, return_tensors="jax", padding="max_length", truncation=True,
max_length=self.max_input_len)
# This will auto-magically run in mesh context
gen_ids = self.p_generate(self.loaded_state.params, inputs["input_ids"], inputs["attention_mask"])
generated_text = self.tokenizer.batch_decode(gen_ids, skip_special_tokens=True)
return generated_text
| 6 |
0 | hf_public_repos/bloom-jax-inference | hf_public_repos/bloom-jax-inference/bloom_inference/host_worker.py | import os
import ray
import time
from queue import Queue
@ray.remote(resources={"tpu": 1})
# @ray.remote
class TPUHostWorker(object):
def __init__(
self,
ckpt="bigscience/bloom",
t5x_path="gs://bloom-jax-us-central2-b/bloom-176B-scan-t5x/checkpoint_0",
max_len=256,
max_input_len=64,
model_parallel_submesh=(1, 2, 4, 1), # for v4-64
):
self.ckpt = ckpt
self.path = t5x_path
self.max_len = max_len
self.max_input_len = max_input_len
self.model_parallel_submesh = model_parallel_submesh
self.input_q = Queue(maxsize=1)
self.output_q = Queue(maxsize=1)
self._is_cpu = os.path.exists("/home/suraj_huggingface_co/bloom-jax-inference/is_cpu.txt")
def is_cpu(self):
return self._is_cpu
def run(self):
# we import packages here to import JAX and Generator only on the Host worker and not the CPU manager
import jax
from bloom_inference.generator import Generator, head_print
print(f"jax runtime initialization starting")
start = time.time()
device_count = jax.device_count()
if device_count == 1:
head_print("TPU not found. Returning")
ray.shutdown()
return
head_print(f"jax devices: {device_count}")
head_print(f"jax runtime initialized in {time.time() - start:.06}s")
# load model and params
head_print("Loading model")
generator = Generator(
model_parallel_submesh=self.model_parallel_submesh,
ckpt=self.ckpt,
t5x_path=self.path,
max_len=self.max_len,
max_input_len=self.max_input_len
)
generator.load_model_and_params()
head_print("Loading complete")
while True:
operation, prompts = self.input_q.get()
if operation == "generate":
generated_text = generator.generate(prompts)
self.output_q.put(generated_text)
else:
raise Exception("Not implemented")
def generate(self, input):
self.input_q.put(("generate", input))
return self.output_q.get()
| 7 |
0 | hf_public_repos/bloom-jax-inference | hf_public_repos/bloom-jax-inference/bloom_inference/tpu_manager.py | import time
import ray
import numpy as np
class TPUManager:
# @func_set_timeout(1200)
def __init__(
self,
node_count=8,
ckpt="bigscience/bloom",
t5x_path="gs://bloom-jax-us-central2-b/bloom-176B-scan-t5x/checkpoint_0",
max_len=256,
max_input_len=64,
model_parallel_submesh=(1, 2, 4, 1), # for v4-64
):
# needs a valid ray cluster to start
# assert ray.is_initialized(), "ray not initialised"
from bloom_inference.host_worker import TPUHostWorker
self.ckpt = ckpt
self.path = t5x_path
self.max_len = max_len
self.max_input_len = max_input_len
self.model_parallel_submesh = model_parallel_submesh
self.nodes = []
self.node_count = node_count
start = time.time()
# for i in range(node_count):
# worker = TPUHostWorker.options(max_concurrency=2).remote(
# ckpt,
# t5x_path,
# max_len,
# max_input_len,
# model_parallel_submesh,
# )
# is_cpu = ray.get(worker.is_cpu.remote())
# print(is_cpu)
# if not is_cpu:
# self.nodes.append(worker)
while (len(self.nodes) < node_count):
worker = TPUHostWorker.options(max_concurrency=2).remote(
ckpt,
t5x_path,
max_len,
max_input_len,
model_parallel_submesh,
)
is_cpu = ray.get(worker.is_cpu.remote())
print(is_cpu)
if not is_cpu:
self.nodes.append(worker)
assert len(self.nodes) == node_count
for node in self.nodes:
node.run.remote()
print(f"TPU workers created in {time.time() - start:.06}s")
# @func_set_timeout(600)
def generate(self, context):
# TODO: split context (prompts) if len(context) != 4
#context = np.array_split(context, len(self.nodes), axis=0)
res = []
for n, ctx in zip(self.nodes, context):
res.append(n.generate.remote(ctx))
return [i for i in ray.get(res)]
| 8 |
0 | hf_public_repos/bloom-jax-inference/bloom_inference | hf_public_repos/bloom-jax-inference/bloom_inference/modeling_bloom/modeling_flax_utils.py | # coding=utf-8
# Copyright 2021 The Google Flax Team Authors and The HuggingFace Inc. team.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import gc
import json
import os
import re
from functools import partial
from pickle import UnpicklingError
from typing import Any, Dict, Set, Tuple, Union
import numpy as np
import flax.linen as nn
import jax
import jax.numpy as jnp
import msgpack.exceptions
from flax.core.frozen_dict import FrozenDict, unfreeze
from flax.serialization import from_bytes, to_bytes
from flax.traverse_util import flatten_dict, unflatten_dict
from jax.random import PRNGKey
from requests import HTTPError
from transformers.configuration_utils import PretrainedConfig
from transformers.dynamic_module_utils import custom_object_save
from transformers.modeling_flax_pytorch_utils import load_pytorch_checkpoint_in_flax_state_dict
from transformers.utils import (
FLAX_WEIGHTS_INDEX_NAME,
FLAX_WEIGHTS_NAME,
HUGGINGFACE_CO_RESOLVE_ENDPOINT,
WEIGHTS_NAME,
EntryNotFoundError,
PushToHubMixin,
RepositoryNotFoundError,
RevisionNotFoundError,
add_code_sample_docstrings,
add_start_docstrings_to_model_forward,
cached_path,
copy_func,
has_file,
hf_bucket_url,
is_offline_mode,
is_remote_url,
logging,
replace_return_docstrings,
)
from transformers.utils.hub import convert_file_size_to_int, get_checkpoint_shard_files
from .generation_flax_utils import FlaxGenerationMixin
logger = logging.get_logger(__name__)
def quick_gelu(x):
return x * jax.nn.sigmoid(1.702 * x)
ACT2FN = {
"gelu": partial(nn.gelu, approximate=False),
"relu": nn.relu,
"silu": nn.swish,
"swish": nn.swish,
"gelu_new": partial(nn.gelu, approximate=True),
"quick_gelu": quick_gelu,
}
def dtype_byte_size(dtype):
"""
Returns the size (in bytes) occupied by one parameter of type `dtype`. Example:
```py
>>> dtype_byte_size(np.float32)
4
```
"""
if dtype == np.bool:
return 1 / 8
bit_search = re.search("[^\d](\d+)$", dtype.name)
if bit_search is None:
raise ValueError(f"`dtype` is not a valid dtype: {dtype}.")
bit_size = int(bit_search.groups()[0])
return bit_size // 8
def flax_shard_checkpoint(params, max_shard_size="10GB"):
"""
Splits a model state dictionary in sub-checkpoints so that the final size of each sub-checkpoint does not exceed a
given size. The sub-checkpoints are determined by iterating through the `state_dict` in the order of its keys, so
there is no optimization made to make each sub-checkpoint as close as possible to the maximum size passed. For
example, if the limit is 10GB and we have weights of sizes [6GB, 6GB, 2GB, 6GB, 2GB, 2GB] they will get sharded as
[6GB], [6+2GB], [6+2+2GB] and not [6+2+2GB], [6+2GB], [6GB].
<Tip warning={true}>
If one of the model's weight is bigger that `max_shard_size`, it will end up in its own sub-checkpoint which will
have a size greater than `max_shard_size`.
</Tip>
Args:
params (`Union[Dict, FrozenDict]`): A `PyTree` of model parameters.
max_shard_size (`int` or `str`, *optional*, defaults to `"10GB"`):
The maximum size of each sub-checkpoint. If expressed as a string, needs to be digits followed by a unit
(like `"5MB"`).
"""
max_shard_size = convert_file_size_to_int(max_shard_size)
sharded_state_dicts = []
current_block = {}
current_block_size = 0
total_size = 0
# flatten the weights to chunk
weights = flatten_dict(params, sep="/")
for item in weights:
weight_size = weights[item].size * dtype_byte_size(weights[item].dtype)
# If this weight is going to tip up over the maximal size, we split.
if current_block_size + weight_size > max_shard_size:
sharded_state_dicts.append(current_block)
current_block = {}
current_block_size = 0
current_block[item] = weights[item]
current_block_size += weight_size
total_size += weight_size
# Add the last block
sharded_state_dicts.append(current_block)
# If we only have one shard, we return it
if len(sharded_state_dicts) == 1:
return {FLAX_WEIGHTS_NAME: sharded_state_dicts[0]}, None
# Otherwise, let's build the index
weight_map = {}
shards = {}
for idx, shard in enumerate(sharded_state_dicts):
shard_file = FLAX_WEIGHTS_NAME.replace(".msgpack", f"-{idx+1:05d}-of-{len(sharded_state_dicts):05d}.msgpack")
shards[shard_file] = shard
for weight_name in shard.keys():
weight_map[weight_name] = shard_file
# Add the metadata
metadata = {"total_size": total_size}
index = {"metadata": metadata, "weight_map": weight_map}
return shards, index
class FlaxPreTrainedModel(PushToHubMixin, FlaxGenerationMixin):
r"""
Base class for all models.
[`FlaxPreTrainedModel`] takes care of storing the configuration of the models and handles methods for loading,
downloading and saving models.
Class attributes (overridden by derived classes):
- **config_class** ([`PretrainedConfig`]) -- A subclass of [`PretrainedConfig`] to use as configuration class
for this model architecture.
- **base_model_prefix** (`str`) -- A string indicating the attribute associated to the base model in derived
classes of the same architecture adding modules on top of the base model.
- **main_input_name** (`str`) -- The name of the principal input to the model (often `input_ids` for NLP
models, `pixel_values` for vision models and `input_values` for speech models).
"""
config_class = None
base_model_prefix = ""
main_input_name = "input_ids"
_auto_class = None
_missing_keys = set()
def __init__(
self,
config: PretrainedConfig,
module: nn.Module,
input_shape: Tuple = (1, 1),
seed: int = 0,
dtype: jnp.dtype = jnp.float32,
_do_init: bool = True,
):
if config is None:
raise ValueError("config cannot be None")
if module is None:
raise ValueError("module cannot be None")
# Those are private to be exposed as typed property on derived classes.
self._config = config
self._module = module
# Those are public as their type is generic to every derived classes.
self.key = PRNGKey(seed)
self.dtype = dtype
self.input_shape = input_shape
# To check if the model was intialized automatically.
self._is_initialized = _do_init
if _do_init:
# randomly initialized parameters
random_params = self.init_weights(self.key, input_shape)
params_shape_tree = jax.eval_shape(lambda params: params, random_params)
else:
init_fn = partial(self.init_weights, input_shape=input_shape)
params_shape_tree = jax.eval_shape(init_fn, self.key)
logger.info(
"Model weights are not initialized as `_do_init` is set to `False`. "
f"Make sure to call `{self.__class__.__name__}.init_weights` manually to initialize the weights."
)
# get the shape of the parameters
self._params_shape_tree = params_shape_tree
# save required_params as set
self._required_params = set(flatten_dict(unfreeze(params_shape_tree)).keys())
# initialize the parameters
if _do_init:
self.params = random_params
def init_weights(self, rng: jax.random.PRNGKey, input_shape: Tuple, params: FrozenDict = None) -> Dict:
raise NotImplementedError(f"init method has to be implemented for {self}")
def enable_gradient_checkpointing(self):
raise NotImplementedError(f"gradient checkpointing method has to be implemented for {self}")
@classmethod
def _from_config(cls, config, **kwargs):
"""
All context managers that the model should be initialized under go here.
"""
return cls(config, **kwargs)
@property
def framework(self) -> str:
"""
:str: Identifies that this is a Flax model.
"""
return "flax"
@property
def config(self) -> PretrainedConfig:
return self._config
@property
def module(self) -> nn.Module:
return self._module
@property
def params(self) -> Union[Dict, FrozenDict]:
if not self._is_initialized:
raise ValueError(
"`params` cannot be accessed from model when the model is created with `_do_init=False`. "
"You must call `init_weights` manually and store the params outside of the model and "
"pass it explicitly where needed."
)
return self._params
@property
def required_params(self) -> Set:
return self._required_params
@property
def params_shape_tree(self) -> Dict:
return self._params_shape_tree
@params.setter
def params(self, params: Union[Dict, FrozenDict]):
# don't set params if the model is not initialized
if not self._is_initialized:
raise ValueError(
"`params` cannot be set from model when the model is created with `_do_init=False`. "
"You store the params outside of the model."
)
if isinstance(params, FrozenDict):
params = unfreeze(params)
param_keys = set(flatten_dict(params).keys())
if len(self.required_params - param_keys) > 0:
raise ValueError(
"Some parameters are missing. Make sure that `params` include the following "
f"parameters {self.required_params - param_keys}"
)
self._params = params
def _cast_floating_to(self, params: Union[Dict, FrozenDict], dtype: jnp.dtype, mask: Any = None) -> Any:
"""
Helper method to cast floating-point values of given parameter `PyTree` to given `dtype`.
"""
# taken from https://github.com/deepmind/jmp/blob/3a8318abc3292be38582794dbf7b094e6583b192/jmp/_src/policy.py#L27
def conditional_cast(param):
if isinstance(param, jnp.ndarray) and jnp.issubdtype(param.dtype, jnp.floating):
param = param.astype(dtype)
return param
if mask is None:
return jax.tree_map(conditional_cast, params)
flat_params = flatten_dict(params)
flat_mask, _ = jax.tree_flatten(mask)
for masked, key in zip(flat_mask, flat_params.keys()):
if masked:
param = flat_params[key]
flat_params[key] = conditional_cast(param)
return unflatten_dict(flat_params)
def to_bf16(self, params: Union[Dict, FrozenDict], mask: Any = None):
r"""
Cast the floating-point `params` to `jax.numpy.bfloat16`. This returns a new `params` tree and does not cast
the `params` in place.
This method can be used on TPU to explicitly convert the model parameters to bfloat16 precision to do full
half-precision training or to save weights in bfloat16 for inference in order to save memory and improve speed.
Arguments:
params (`Union[Dict, FrozenDict]`):
A `PyTree` of model parameters.
mask (`Union[Dict, FrozenDict]`):
A `PyTree` with same structure as the `params` tree. The leaves should be booleans, `True` for params
you want to cast, and should be `False` for those you want to skip.
Examples:
```python
>>> from transformers import FlaxBertModel
>>> # load model
>>> model = FlaxBertModel.from_pretrained("bert-base-cased")
>>> # By default, the model parameters will be in fp32 precision, to cast these to bfloat16 precision
>>> model.params = model.to_bf16(model.params)
>>> # If you want don't want to cast certain parameters (for example layer norm bias and scale)
>>> # then pass the mask as follows
>>> from flax import traverse_util
>>> model = FlaxBertModel.from_pretrained("bert-base-cased")
>>> flat_params = traverse_util.flatten_dict(model.params)
>>> mask = {
... path: (path[-2] != ("LayerNorm", "bias") and path[-2:] != ("LayerNorm", "scale"))
... for path in flat_params
... }
>>> mask = traverse_util.unflatten_dict(mask)
>>> model.params = model.to_bf16(model.params, mask)
```"""
return self._cast_floating_to(params, jnp.bfloat16, mask)
def to_fp32(self, params: Union[Dict, FrozenDict], mask: Any = None):
r"""
Cast the floating-point `parmas` to `jax.numpy.float32`. This method can be used to explicitly convert the
model parameters to fp32 precision. This returns a new `params` tree and does not cast the `params` in place.
Arguments:
params (`Union[Dict, FrozenDict]`):
A `PyTree` of model parameters.
mask (`Union[Dict, FrozenDict]`):
A `PyTree` with same structure as the `params` tree. The leaves should be booleans, `True` for params
you want to cast, and should be `False` for those you want to skip
Examples:
```python
>>> from transformers import FlaxBertModel
>>> # Download model and configuration from huggingface.co
>>> model = FlaxBertModel.from_pretrained("bert-base-cased")
>>> # By default, the model params will be in fp32, to illustrate the use of this method,
>>> # we'll first cast to fp16 and back to fp32
>>> model.params = model.to_f16(model.params)
>>> # now cast back to fp32
>>> model.params = model.to_fp32(model.params)
```"""
return self._cast_floating_to(params, jnp.float32, mask)
def to_fp16(self, params: Union[Dict, FrozenDict], mask: Any = None):
r"""
Cast the floating-point `parmas` to `jax.numpy.float16`. This returns a new `params` tree and does not cast the
`params` in place.
This method can be used on GPU to explicitly convert the model parameters to float16 precision to do full
half-precision training or to save weights in float16 for inference in order to save memory and improve speed.
Arguments:
params (`Union[Dict, FrozenDict]`):
A `PyTree` of model parameters.
mask (`Union[Dict, FrozenDict]`):
A `PyTree` with same structure as the `params` tree. The leaves should be booleans, `True` for params
you want to cast, and should be `False` for those you want to skip
Examples:
```python
>>> from transformers import FlaxBertModel
>>> # load model
>>> model = FlaxBertModel.from_pretrained("bert-base-cased")
>>> # By default, the model params will be in fp32, to cast these to float16
>>> model.params = model.to_fp16(model.params)
>>> # If you want don't want to cast certain parameters (for example layer norm bias and scale)
>>> # then pass the mask as follows
>>> from flax import traverse_util
>>> model = FlaxBertModel.from_pretrained("bert-base-cased")
>>> flat_params = traverse_util.flatten_dict(model.params)
>>> mask = {
... path: (path[-2] != ("LayerNorm", "bias") and path[-2:] != ("LayerNorm", "scale"))
... for path in flat_params
... }
>>> mask = traverse_util.unflatten_dict(mask)
>>> model.params = model.to_fp16(model.params, mask)
```"""
return self._cast_floating_to(params, jnp.float16, mask)
@classmethod
def load_flax_sharded_weights(cls, shard_files):
"""
This is the same as [`flax.serialization.from_bytes`]
(https:lax.readthedocs.io/en/latest/_modules/flax/serialization.html#from_bytes) but for a sharded checkpoint.
This load is performed efficiently: each checkpoint shard is loaded one by one in RAM and deleted after being
loaded in the model.
Args:
shard_files (`List[str]`:
The list of shard files to load.
Returns:
`Dict`: A nested dictionary of the model parameters, in the expected format for flax models : `{'model':
{'params': {'...'}}}`.
"""
# Load the index
state_sharded_dict = dict()
for shard_file in shard_files:
# load using msgpack utils
try:
with open(shard_file, "rb") as state_f:
state = from_bytes(cls, state_f.read())
except (UnpicklingError, msgpack.exceptions.ExtraData) as e:
with open(shard_file) as f:
if f.read().startswith("version"):
raise OSError(
"You seem to have cloned a repository without having git-lfs installed. Please"
" install git-lfs and run `git lfs install` followed by `git lfs pull` in the"
" folder you cloned."
)
else:
raise ValueError from e
except (UnicodeDecodeError, ValueError):
raise EnvironmentError(f"Unable to convert {shard_file} to Flax deserializable object. ")
state = flatten_dict(state, sep="/")
state_sharded_dict.update(state)
del state
gc.collect()
# the state dict is unflattened to the match the format of model.params
return unflatten_dict(state_sharded_dict, sep="/")
@classmethod
def from_pretrained(
cls,
pretrained_model_name_or_path: Union[str, os.PathLike],
dtype: jnp.dtype = jnp.float32,
*model_args,
**kwargs
):
r"""
Instantiate a pretrained flax model from a pre-trained model configuration.
The warning *Weights from XXX not initialized from pretrained model* means that the weights of XXX do not come
pretrained with the rest of the model. It is up to you to train those weights with a downstream fine-tuning
task.
The warning *Weights from XXX not used in YYY* means that the layer XXX is not used by YYY, therefore those
weights are discarded.
Parameters:
pretrained_model_name_or_path (`str` or `os.PathLike`):
Can be either:
- A string, the *model id* of a pretrained model hosted inside a model repo on huggingface.co.
Valid model ids can be located at the root-level, like `bert-base-uncased`, or namespaced under a
user or organization name, like `dbmdz/bert-base-german-cased`.
- A path to a *directory* containing model weights saved using
[`~FlaxPreTrainedModel.save_pretrained`], e.g., `./my_model_directory/`.
- A path or url to a *pt index checkpoint file* (e.g, `./tf_model/model.ckpt.index`). In this case,
`from_pt` should be set to `True`.
dtype (`jax.numpy.dtype`, *optional*, defaults to `jax.numpy.float32`):
The data type of the computation. Can be one of `jax.numpy.float32`, `jax.numpy.float16` (on GPUs) and
`jax.numpy.bfloat16` (on TPUs).
This can be used to enable mixed-precision training or half-precision inference on GPUs or TPUs. If
specified all the computation will be performed with the given `dtype`.
**Note that this only specifies the dtype of the computation and does not influence the dtype of model
parameters.**
If you wish to change the dtype of the model parameters, see [`~FlaxPreTrainedModel.to_fp16`] and
[`~FlaxPreTrainedModel.to_bf16`].
model_args (sequence of positional arguments, *optional*):
All remaining positional arguments will be passed to the underlying model's `__init__` method.
config (`Union[PretrainedConfig, str, os.PathLike]`, *optional*):
Can be either:
- an instance of a class derived from [`PretrainedConfig`],
- a string or path valid as input to [`~PretrainedConfig.from_pretrained`].
Configuration for the model to use instead of an automatically loaded configuration. Configuration can
be automatically loaded when:
- The model is a model provided by the library (loaded with the *model id* string of a pretrained
model).
- The model was saved using [`~PreTrainedModel.save_pretrained`] and is reloaded by supplying the
save directory.
- The model is loaded by supplying a local directory as `pretrained_model_name_or_path` and a
configuration JSON file named *config.json* is found in the directory.
cache_dir (`Union[str, os.PathLike]`, *optional*):
Path to a directory in which a downloaded pretrained model configuration should be cached if the
standard cache should not be used.
from_pt (`bool`, *optional*, defaults to `False`):
Load the model weights from a PyTorch checkpoint save file (see docstring of
`pretrained_model_name_or_path` argument).
ignore_mismatched_sizes (`bool`, *optional*, defaults to `False`):
Whether or not to raise an error if some of the weights from the checkpoint do not have the same size
as the weights of the model (if for instance, you are instantiating a model with 10 labels from a
checkpoint with 3 labels).
force_download (`bool`, *optional*, defaults to `False`):
Whether or not to force the (re-)download of the model weights and configuration files, overriding the
cached versions if they exist.
resume_download (`bool`, *optional*, defaults to `False`):
Whether or not to delete incompletely received files. Will attempt to resume the download if such a
file exists.
proxies (`Dict[str, str]`, *optional*):
A dictionary of proxy servers to use by protocol or endpoint, e.g., `{'http': 'foo.bar:3128',
'http://hostname': 'foo.bar:4012'}`. The proxies are used on each request.
local_files_only(`bool`, *optional*, defaults to `False`):
Whether or not to only look at local files (i.e., do not try to download the model).
revision (`str`, *optional*, defaults to `"main"`):
The specific model version to use. It can be a branch name, a tag name, or a commit id, since we use a
git-based system for storing models and other artifacts on huggingface.co, so `revision` can be any
identifier allowed by git.
kwargs (remaining dictionary of keyword arguments, *optional*):
Can be used to update the configuration object (after it being loaded) and initiate the model (e.g.,
`output_attentions=True`). Behaves differently depending on whether a `config` is provided or
automatically loaded:
- If a configuration is provided with `config`, `**kwargs` will be directly passed to the
underlying model's `__init__` method (we assume all relevant updates to the configuration have
already been done)
- If a configuration is not provided, `kwargs` will be first passed to the configuration class
initialization function ([`~PretrainedConfig.from_pretrained`]). Each key of `kwargs` that
corresponds to a configuration attribute will be used to override said attribute with the
supplied `kwargs` value. Remaining keys that do not correspond to any configuration attribute
will be passed to the underlying model's `__init__` function.
Examples:
```python
>>> from transformers import BertConfig, FlaxBertModel
>>> # Download model and configuration from huggingface.co and cache.
>>> model = FlaxBertModel.from_pretrained("bert-base-cased")
>>> # Model was saved using *save_pretrained('./test/saved_model/')* (for example purposes, not runnable).
>>> model = FlaxBertModel.from_pretrained("./test/saved_model/")
>>> # Loading from a PyTorch checkpoint file instead of a PyTorch model (slower, for example purposes, not runnable).
>>> config = BertConfig.from_json_file("./pt_model/config.json")
>>> model = FlaxBertModel.from_pretrained("./pt_model/pytorch_model.bin", from_pt=True, config=config)
```"""
config = kwargs.pop("config", None)
cache_dir = kwargs.pop("cache_dir", None)
from_pt = kwargs.pop("from_pt", False)
ignore_mismatched_sizes = kwargs.pop("ignore_mismatched_sizes", False)
force_download = kwargs.pop("force_download", False)
resume_download = kwargs.pop("resume_download", False)
proxies = kwargs.pop("proxies", None)
local_files_only = kwargs.pop("local_files_only", False)
use_auth_token = kwargs.pop("use_auth_token", None)
revision = kwargs.pop("revision", None)
from_pipeline = kwargs.pop("_from_pipeline", None)
from_auto_class = kwargs.pop("_from_auto", False)
_do_init = kwargs.pop("_do_init", True)
user_agent = {"file_type": "model", "framework": "flax", "from_auto_class": from_auto_class}
if from_pipeline is not None:
user_agent["using_pipeline"] = from_pipeline
if is_offline_mode() and not local_files_only:
logger.info("Offline mode: forcing local_files_only=True")
local_files_only = True
# Load config if we don't provide a configuration
if not isinstance(config, PretrainedConfig):
config_path = config if config is not None else pretrained_model_name_or_path
config, model_kwargs = cls.config_class.from_pretrained(
config_path,
cache_dir=cache_dir,
return_unused_kwargs=True,
force_download=force_download,
resume_download=resume_download,
proxies=proxies,
local_files_only=local_files_only,
use_auth_token=use_auth_token,
revision=revision,
_from_auto=from_auto_class,
_from_pipeline=from_pipeline,
**kwargs,
)
else:
model_kwargs = kwargs
# Add the dtype to model_kwargs
model_kwargs["dtype"] = dtype
# This variable will flag if we're loading a sharded checkpoint. In this case the archive file is just the
# index of the files.
is_sharded = False
# Load model
if pretrained_model_name_or_path is not None:
if os.path.isdir(pretrained_model_name_or_path):
if from_pt and os.path.isfile(os.path.join(pretrained_model_name_or_path, WEIGHTS_NAME)):
# Load from a PyTorch checkpoint
archive_file = os.path.join(pretrained_model_name_or_path, WEIGHTS_NAME)
elif os.path.isfile(os.path.join(pretrained_model_name_or_path, FLAX_WEIGHTS_NAME)):
# Load from a Flax checkpoint
archive_file = os.path.join(pretrained_model_name_or_path, FLAX_WEIGHTS_NAME)
elif os.path.isfile(os.path.join(pretrained_model_name_or_path, FLAX_WEIGHTS_INDEX_NAME)):
# Load from a sharded Flax checkpoint
archive_file = os.path.join(pretrained_model_name_or_path, FLAX_WEIGHTS_INDEX_NAME)
is_sharded = True
# At this stage we don't have a weight file so we will raise an error.
elif os.path.join(pretrained_model_name_or_path, WEIGHTS_NAME):
raise EnvironmentError(
f"Error no file named {FLAX_WEIGHTS_NAME} found in directory {pretrained_model_name_or_path} "
"but there is a file for PyTorch weights. Use `from_pt=True` to load this model from those "
"weights."
)
else:
raise EnvironmentError(
f"Error no file named {FLAX_WEIGHTS_NAME} or {WEIGHTS_NAME} found in directory "
f"{pretrained_model_name_or_path}."
)
elif os.path.isfile(pretrained_model_name_or_path) or is_remote_url(pretrained_model_name_or_path):
archive_file = pretrained_model_name_or_path
else:
filename = WEIGHTS_NAME if from_pt else FLAX_WEIGHTS_NAME
archive_file = hf_bucket_url(
pretrained_model_name_or_path,
filename=filename,
revision=revision,
)
# redirect to the cache, if necessary
try:
resolved_archive_file = cached_path(
archive_file,
cache_dir=cache_dir,
force_download=force_download,
proxies=proxies,
resume_download=resume_download,
local_files_only=local_files_only,
use_auth_token=use_auth_token,
user_agent=user_agent,
)
except RepositoryNotFoundError:
raise EnvironmentError(
f"{pretrained_model_name_or_path} is not a local folder and is not a valid model identifier "
"listed on 'https://huggingface.co/models'\nIf this is a private repository, make sure to pass a "
"token having permission to this repo with `use_auth_token` or log in with `huggingface-cli "
"login` and pass `use_auth_token=True`."
)
except RevisionNotFoundError:
raise EnvironmentError(
f"{revision} is not a valid git identifier (branch name, tag name or commit id) that exists for "
"this model name. Check the model page at "
f"'https://huggingface.co/{pretrained_model_name_or_path}' for available revisions."
)
except EntryNotFoundError:
if filename == FLAX_WEIGHTS_NAME:
try:
# Maybe the checkpoint is sharded, we try to grab the index name in this case.
archive_file = hf_bucket_url(
pretrained_model_name_or_path,
filename=FLAX_WEIGHTS_INDEX_NAME,
revision=revision,
)
resolved_archive_file = cached_path(
archive_file,
cache_dir=cache_dir,
force_download=force_download,
proxies=proxies,
resume_download=resume_download,
local_files_only=local_files_only,
use_auth_token=use_auth_token,
user_agent=user_agent,
)
is_sharded = True
except EntryNotFoundError:
has_file_kwargs = {"revision": revision, "proxies": proxies, "use_auth_token": use_auth_token}
if has_file(pretrained_model_name_or_path, WEIGHTS_NAME, **has_file_kwargs):
raise EnvironmentError(
f"{pretrained_model_name_or_path} does not appear to have a file named"
f" {FLAX_WEIGHTS_NAME} but there is a file for PyTorch weights. Use `from_pt=True` to"
" load this model from those weights."
)
else:
raise EnvironmentError(
f"{pretrained_model_name_or_path} does not appear to have a file named"
f" {FLAX_WEIGHTS_NAME} or {WEIGHTS_NAME}."
)
else:
raise EnvironmentError(
f"{pretrained_model_name_or_path} does not appear to have a file named {filename}."
)
except HTTPError as err:
raise EnvironmentError(
f"There was a specific connection error when trying to load {pretrained_model_name_or_path}:\n"
f"{err}"
)
except ValueError:
raise EnvironmentError(
f"We couldn't connect to '{HUGGINGFACE_CO_RESOLVE_ENDPOINT}' to load this model, couldn't find it"
f" in the cached files and it looks like {pretrained_model_name_or_path} is not the path to a"
f" directory containing a file named {FLAX_WEIGHTS_NAME} or {WEIGHTS_NAME}.\nCheckout your"
" internet connection or see how to run the library in offline mode at"
" 'https://huggingface.co/docs/transformers/installation#offline-mode'."
)
except EnvironmentError:
raise EnvironmentError(
f"Can't load the model for '{pretrained_model_name_or_path}'. If you were trying to load it from "
"'https://huggingface.co/models', make sure you don't have a local directory with the same name. "
f"Otherwise, make sure '{pretrained_model_name_or_path}' is the correct path to a directory "
f"containing a file named {FLAX_WEIGHTS_NAME} or {WEIGHTS_NAME}."
)
if resolved_archive_file == archive_file:
logger.info(f"loading weights file {archive_file}")
else:
logger.info(f"loading weights file {archive_file} from cache at {resolved_archive_file}")
else:
resolved_archive_file = None
# We'll need to download and cache each checkpoint shard if the checkpoint is sharded.
if is_sharded:
# resolved_archive_file becomes a list of files that point to the different checkpoint shards in this case.
resolved_archive_file, _ = get_checkpoint_shard_files(
pretrained_model_name_or_path,
resolved_archive_file,
cache_dir=cache_dir,
force_download=force_download,
proxies=proxies,
resume_download=resume_download,
local_files_only=local_files_only,
use_auth_token=use_auth_token,
user_agent=user_agent,
revision=revision,
)
# init random models
model = cls(config, *model_args, _do_init=_do_init, **model_kwargs)
if from_pt:
state = load_pytorch_checkpoint_in_flax_state_dict(model, resolved_archive_file)
else:
if is_sharded:
state = cls.load_flax_sharded_weights(resolved_archive_file)
else:
try:
with open(resolved_archive_file, "rb") as state_f:
state = from_bytes(cls, state_f.read())
except (UnpicklingError, msgpack.exceptions.ExtraData) as e:
try:
with open(resolved_archive_file) as f:
if f.read().startswith("version"):
raise OSError(
"You seem to have cloned a repository without having git-lfs installed. Please"
" install git-lfs and run `git lfs install` followed by `git lfs pull` in the"
" folder you cloned."
)
else:
raise ValueError from e
except (UnicodeDecodeError, ValueError):
raise EnvironmentError(f"Unable to convert {archive_file} to Flax deserializable object. ")
# make sure all arrays are stored as jnp.arrays
# NOTE: This is to prevent a bug this will be fixed in Flax >= v0.3.4:
# https://github.com/google/flax/issues/1261
if _do_init:
state = jax.tree_util.tree_map(jnp.array, state)
else:
# keep the params on CPU if we don't want to initialize
state = jax.tree_util.tree_map(lambda x: jax.device_put(x, jax.devices("cpu")[0]), state)
# if model is base model only use model_prefix key
if cls.base_model_prefix not in dict(model.params_shape_tree) and cls.base_model_prefix in state:
state = state[cls.base_model_prefix]
# if model is head model and we are loading weights from base model
# we initialize new params dict with base_model_prefix
if cls.base_model_prefix in dict(model.params_shape_tree) and cls.base_model_prefix not in state:
state = {cls.base_model_prefix: state}
# flatten dicts
state = flatten_dict(state)
random_state = flatten_dict(unfreeze(model.params if _do_init else model.params_shape_tree))
missing_keys = model.required_params - set(state.keys())
unexpected_keys = set(state.keys()) - model.required_params
if missing_keys and not _do_init:
logger.warning(
f"The checkpoint {pretrained_model_name_or_path} is missing required keys: {missing_keys}. "
"Make sure to call model.init_weights to initialize the missing weights."
)
cls._missing_keys = missing_keys
# Mistmatched keys contains tuples key/shape1/shape2 of weights in the checkpoint that have a shape not
# matching the weights in the model.
mismatched_keys = []
for key in state.keys():
if key in random_state and state[key].shape != random_state[key].shape:
if ignore_mismatched_sizes:
mismatched_keys.append((key, state[key].shape, random_state[key].shape))
state[key] = random_state[key]
else:
raise ValueError(
f"Trying to load the pretrained weight for {key} failed: checkpoint has shape "
f"{state[key].shape} which is incompatible with the model shape {random_state[key].shape}. "
"Using `ignore_mismatched_sizes=True` if you really want to load this checkpoint inside this "
"model."
)
# add missing keys as random parameters if we are initializing
if missing_keys and _do_init:
for missing_key in missing_keys:
state[missing_key] = random_state[missing_key]
# remove unexpected keys to not be saved again
for unexpected_key in unexpected_keys:
del state[unexpected_key]
if len(unexpected_keys) > 0:
logger.warning(
f"Some weights of the model checkpoint at {pretrained_model_name_or_path} were not used when"
f" initializing {model.__class__.__name__}: {unexpected_keys}\n- This IS expected if you are"
f" initializing {model.__class__.__name__} from the checkpoint of a model trained on another task or"
" with another architecture (e.g. initializing a BertForSequenceClassification model from a"
" BertForPreTraining model).\n- This IS NOT expected if you are initializing"
f" {model.__class__.__name__} from the checkpoint of a model that you expect to be exactly identical"
" (initializing a BertForSequenceClassification model from a BertForSequenceClassification model)."
)
else:
logger.info(f"All model checkpoint weights were used when initializing {model.__class__.__name__}.\n")
if len(missing_keys) > 0:
logger.warning(
f"Some weights of {model.__class__.__name__} were not initialized from the model checkpoint at"
f" {pretrained_model_name_or_path} and are newly initialized: {missing_keys}\nYou should probably"
" TRAIN this model on a down-stream task to be able to use it for predictions and inference."
)
elif len(mismatched_keys) == 0:
logger.info(
f"All the weights of {model.__class__.__name__} were initialized from the model checkpoint at"
f" {pretrained_model_name_or_path}.\nIf your task is similar to the task the model of the checkpoint"
f" was trained on, you can already use {model.__class__.__name__} for predictions without further"
" training."
)
if len(mismatched_keys) > 0:
mismatched_warning = "\n".join(
[
f"- {key}: found shape {shape1} in the checkpoint and {shape2} in the model instantiated"
for key, shape1, shape2 in mismatched_keys
]
)
logger.warning(
f"Some weights of {model.__class__.__name__} were not initialized from the model checkpoint at"
f" {pretrained_model_name_or_path} and are newly initialized because the shapes did not"
f" match:\n{mismatched_warning}\nYou should probably TRAIN this model on a down-stream task to be able"
" to use it for predictions and inference."
)
# dictionary of key: dtypes for the model params
param_dtypes = jax.tree_map(lambda x: x.dtype, state)
# extract keys of parameters not in jnp.float32
fp16_params = [k for k in param_dtypes if param_dtypes[k] == jnp.float16]
bf16_params = [k for k in param_dtypes if param_dtypes[k] == jnp.bfloat16]
# raise a warning if any of the parameters are not in jnp.float32
if len(fp16_params) > 0:
logger.warning(
f"Some of the weights of {model.__class__.__name__} were initialized in float16 precision from "
f"the model checkpoint at {pretrained_model_name_or_path}:\n{fp16_params}\n"
"You should probably UPCAST the model weights to float32 if this was not intended. "
"See [`~FlaxPreTrainedModel.to_fp32`] for further information on how to do this."
)
if len(bf16_params) > 0:
logger.warning(
f"Some of the weights of {model.__class__.__name__} were initialized in bfloat16 precision from "
f"the model checkpoint at {pretrained_model_name_or_path}:\n{bf16_params}\n"
"You should probably UPCAST the model weights to float32 if this was not intended. "
"See [`~FlaxPreTrainedModel.to_fp32`] for further information on how to do this."
)
if _do_init:
# set correct parameters
model.params = unflatten_dict(state)
return model
else:
return model, unflatten_dict(state)
def save_pretrained(
self, save_directory: Union[str, os.PathLike], params=None, push_to_hub=False, max_shard_size="10GB", **kwargs
):
"""
Save a model and its configuration file to a directory, so that it can be re-loaded using the
`[`~FlaxPreTrainedModel.from_pretrained`]` class method
Arguments:
save_directory (`str` or `os.PathLike`):
Directory to which to save. Will be created if it doesn't exist.
push_to_hub (`bool`, *optional*, defaults to `False`):
Whether or not to push your model to the Hugging Face model hub after saving it.
<Tip warning={true}>
Using `push_to_hub=True` will synchronize the repository you are pushing to with `save_directory`,
which requires `save_directory` to be a local clone of the repo you are pushing to if it's an existing
folder. Pass along `temp_dir=True` to use a temporary directory instead.
</Tip>
max_shard_size (`int` or `str`, *optional*, defaults to `"10GB"`):
The maximum size for a checkpoint before being sharded. Checkpoints shard will then be each of size
lower than this size. If expressed as a string, needs to be digits followed by a unit (like `"5MB"`).
<Tip warning={true}>
If a single weight of the model is bigger than `max_shard_size`, it will be in its own checkpoint shard
which will be bigger than `max_shard_size`.
</Tip>
kwargs:
Additional key word arguments passed along to the [`~utils.PushToHubMixin.push_to_hub`] method.
"""
if os.path.isfile(save_directory):
logger.error(f"Provided path ({save_directory}) should be a directory, not a file")
return
if push_to_hub:
commit_message = kwargs.pop("commit_message", None)
repo = self._create_or_get_repo(save_directory, **kwargs)
os.makedirs(save_directory, exist_ok=True)
# get abs dir
save_directory = os.path.abspath(save_directory)
# save config as well
self.config.architectures = [self.__class__.__name__[4:]]
# If we have a custom model, we copy the file defining it in the folder and set the attributes so it can be
# loaded from the Hub.
if self._auto_class is not None:
custom_object_save(self, save_directory, config=self.config)
self.config.save_pretrained(save_directory)
# save model
output_model_file = os.path.join(save_directory, FLAX_WEIGHTS_NAME)
shards, index = flax_shard_checkpoint(params if params is not None else self.params, max_shard_size)
# Clean the folder from a previous save
for filename in os.listdir(save_directory):
full_filename = os.path.join(save_directory, filename)
if (
filename.startswith(FLAX_WEIGHTS_NAME[:-4])
and os.path.isfile(full_filename)
and filename not in shards.keys()
):
os.remove(full_filename)
if index is None:
with open(output_model_file, "wb") as f:
params = params if params is not None else self.params
model_bytes = to_bytes(params)
f.write(model_bytes)
else:
save_index_file = os.path.join(save_directory, FLAX_WEIGHTS_INDEX_NAME)
# Save the index as well
with open(save_index_file, "w", encoding="utf-8") as f:
content = json.dumps(index, indent=2, sort_keys=True) + "\n"
f.write(content)
logger.info(
f"The model is bigger than the maximum size per checkpoint ({max_shard_size}) and is going to be "
f"split in {len(shards)} checkpoint shards. You can find where each parameters has been saved in the "
f"index located at {save_index_file}."
)
for shard_file, shard in shards.items():
# the shard item are unflattened, to save them we need to flatten them again
with open(os.path.join(save_directory, shard_file), mode="wb") as f:
params = unflatten_dict(shard, sep="/")
shard_bytes = to_bytes(params)
f.write(shard_bytes)
logger.info(f"Model weights saved in {output_model_file}")
if push_to_hub:
url = self._push_to_hub(repo, commit_message=commit_message)
logger.info(f"Model pushed to the hub in this commit: {url}")
@classmethod
def register_for_auto_class(cls, auto_class="FlaxAutoModel"):
"""
Register this class with a given auto class. This should only be used for custom models as the ones in the
library are already mapped with an auto class.
<Tip warning={true}>
This API is experimental and may have some slight breaking changes in the next releases.
</Tip>
Args:
auto_class (`str` or `type`, *optional*, defaults to `"FlaxAutoModel"`):
The auto class to register this new model with.
"""
if not isinstance(auto_class, str):
auto_class = auto_class.__name__
import transformers.models.auto as auto_module
if not hasattr(auto_module, auto_class):
raise ValueError(f"{auto_class} is not a valid auto class.")
cls._auto_class = auto_class
# To update the docstring, we need to copy the method, otherwise we change the original docstring.
FlaxPreTrainedModel.push_to_hub = copy_func(FlaxPreTrainedModel.push_to_hub)
FlaxPreTrainedModel.push_to_hub.__doc__ = FlaxPreTrainedModel.push_to_hub.__doc__.format(
object="model", object_class="FlaxAutoModel", object_files="model checkpoint"
)
def overwrite_call_docstring(model_class, docstring):
# copy __call__ function to be sure docstring is changed only for this function
model_class.__call__ = copy_func(model_class.__call__)
# delete existing docstring
model_class.__call__.__doc__ = None
# set correct docstring
model_class.__call__ = add_start_docstrings_to_model_forward(docstring)(model_class.__call__)
def append_call_sample_docstring(model_class, tokenizer_class, checkpoint, output_type, config_class, mask=None):
model_class.__call__ = copy_func(model_class.__call__)
model_class.__call__ = add_code_sample_docstrings(
processor_class=tokenizer_class,
checkpoint=checkpoint,
output_type=output_type,
config_class=config_class,
model_cls=model_class.__name__,
)(model_class.__call__)
def append_replace_return_docstrings(model_class, output_type, config_class):
model_class.__call__ = copy_func(model_class.__call__)
model_class.__call__ = replace_return_docstrings(
output_type=output_type,
config_class=config_class,
)(model_class.__call__)
| 9 |
0 | hf_public_repos/bloom-jax-inference/bloom_inference | hf_public_repos/bloom-jax-inference/bloom_inference/modeling_bloom/modeling_bloom.py | # coding=utf-8
# Copyright 2022 HuggingFace Inc. team and Bigscience Workshop. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
""" Flax BLOOM model."""
# TODO: see todos throughout this file
# TODO: check correctness against pytorch implementation
# TODO: add unit tests
# TODO: add documentation / check that documentation is correct
# TODO: BLOOM_INPUTS_DOCSTRING might be wrong still (position_ids)
# TODO: check that code is jit-able
import math
from typing import Optional, Tuple
import flax.linen as nn
import jax
import jax.numpy as jnp
from flax.core.frozen_dict import FrozenDict, freeze, unfreeze
from flax.linen import combine_masks, dot_product_attention_weights, make_causal_mask
from flax.linen.activation import tanh
from flax.linen.partitioning import scan_with_axes
from flax.traverse_util import flatten_dict, unflatten_dict
from jax import lax
from transformers.modeling_flax_outputs import FlaxCausalLMOutput, FlaxBaseModelOutputWithPast
from transformers.utils import logging
from .configuration_bloom import BloomConfig
from .modeling_flax_utils import FlaxPreTrainedModel
from . import layers
from .layers import with_sharding_constraint
logger = logging.get_logger(__name__)
def build_alibi_tensor_flax(attention_mask, n_head, dtype):
def get_slopes(n):
def get_slopes_power_of_2(n):
start = 2 ** (-(2 ** -(math.log2(n) - 3)))
ratio = start
return [start * ratio**i for i in range(n)]
if math.log2(n).is_integer():
return get_slopes_power_of_2(n)
else:
closest_power_of_2 = 2 ** math.floor(math.log2(n))
return (
get_slopes_power_of_2(closest_power_of_2)
+ get_slopes(2 * closest_power_of_2)[0::2][: n - closest_power_of_2]
)
# Note: alibi will added to the attention bias that will be applied to the query, key product of attention
# => therefore alibi will have to be of shape (batch_size, num_heads, query_length, key_length)
# => here we set (batch_size=1, num_heads=n_head, query_length=1, key_length=max_length)
# => the query_length dimension will then be broadcasted correctly
# This is more or less identical to T5's relative position bias:
# https://github.com/huggingface/transformers/blob/f681437203baa7671de3174b0fa583c349d9d5e1/src/transformers/models/t5/modeling_flax_t5.py#L426
# batch_size = 1, n_head = n_head, query_length
batch_size, key_length = attention_mask.shape
num_heads = n_head
query_length = 1
slopes = jnp.array(get_slopes(n_head))[None, :, None, None].astype(dtype)
arange_tensor = attention_mask.cumsum(-1, dtype=dtype)[:, None, None, :] - 1
slopes_broadcasted = jnp.broadcast_to(slopes, (batch_size, num_heads, query_length, key_length))
arange_broadcasted = jnp.broadcast_to(arange_tensor, (batch_size, num_heads, query_length, key_length))
alibi = slopes_broadcasted * arange_broadcasted
return alibi
class FlaxBloomAttention(nn.Module):
config: BloomConfig
dtype: jnp.dtype = jnp.float32
params_dtype: jnp.dtype = jnp.float32
def setup(self):
self.hidden_size = self.config.hidden_size
self.num_heads = self.config.n_head
self.head_dim = self.hidden_size // self.num_heads
self.attention_softmax_in_fp32 = self.config.attention_softmax_in_fp32
if self.head_dim * self.num_heads != self.hidden_size:
raise ValueError(
f"`hidden_size` must be divisible by `num_heads` (got `hidden_size`: {self.hidden_size} and "
f"`num_heads`: {self.num_heads})."
)
self.query_key_value = layers.DenseGeneral(
axis=-1,
features=(self.num_heads, self.head_dim * 3),
kernel_axes=('embed', 'heads', 'kv'),
dtype=self.dtype,
params_dtype=self.params_dtype,
)
self.dense = layers.DenseGeneral(
features=self.hidden_size,
axis=(-2, -1),
kernel_axes=('heads', 'kv', 'embed'),
dtype=self.dtype,
params_dtype=self.params_dtype,
)
self.resid_dropout = nn.Dropout(rate=self.config.hidden_dropout)
@nn.compact
def _concatenate_to_cache(self, key, value, query, attention_mask):
# The following code is largely copied from:
# https://github.com/google-research/t5x/blob/63d9addf628c6d8c547a407a32095fcb527bb20b/t5x/examples/scalable_t5/layers.py#L280-L284
is_initialized = self.has_variable('cache', 'cached_key')
# The key and value have dimension [batch_size, seq_length, num_heads, head_dim],
# but we cache them as [batch_size, num_heads, head_dim, seq_length] as a TPU
# fusion optimization. This also enables the "scatter via one-hot
# broadcast" trick, which means we do a one-hot broadcast instead of a
# scatter/gather operations, resulting in a 3-4x speedup in practice.
swap_dims = lambda x: x[:-3] + tuple(x[i] for i in [-2, -1, -3]) # noqa: E731
cached_key = self.variable('cache', 'cached_key', jnp.zeros, swap_dims(key.shape), key.dtype)
cached_value = self.variable('cache', 'cached_value', jnp.zeros, swap_dims(value.shape), value.dtype)
cache_index = self.variable('cache', 'cache_index', lambda: jnp.array(0, dtype=jnp.int32))
if is_initialized:
batch_size, num_heads, head_dim, seq_length = (cached_key.value.shape)
# During fast autoregressive decoding, we feed one position at a time,
# and cache the keys and values step by step.
# Sanity shape check of cached key against input query.
num_updated_cache_vectors = query.shape[1]
expected_shape = (batch_size, 1, num_heads, head_dim)
if num_updated_cache_vectors == 1 and expected_shape != query.shape:
raise ValueError(f"Autoregressive cache shape error, expected query shape {expected_shape} instead got {query.shape}")
# Create a OHE of the current index. NOTE: the index is increased below.
cur_index = cache_index.value
# In order to update the key, value caches with the current key and
# value, we move the seq_length axis to the back, similar to what we did for
# the cached ones above.
# Note these are currently the key and value of a single position, since
# we feed one position at a time.
one_token_key = jnp.moveaxis(key, -3, -1)
one_token_value = jnp.moveaxis(value, -3, -1)
# Update key, value caches with our new 1d spatial slices.
# We implement an efficient scatter into the cache via one-hot
# broadcast and addition.
if num_updated_cache_vectors > 1:
indices = jnp.eye(num_updated_cache_vectors, seq_length)[None, None]
key = cached_key.value + jnp.matmul(one_token_key, indices)
value = cached_value.value + jnp.matmul(one_token_value, indices)
else:
one_hot_indices = jax.nn.one_hot(cur_index, seq_length, dtype=key.dtype)
key = cached_key.value + one_token_key * one_hot_indices
value = cached_value.value + one_token_value * one_hot_indices
cached_key.value = key
cached_value.value = value
cache_index.value = cache_index.value + num_updated_cache_vectors
# Move the keys and values back to their original shapes.
key = jnp.moveaxis(key, -1, -3)
value = jnp.moveaxis(value, -1, -3)
# causal mask for cached decoder self-attention: our single query position should only attend to those key positions that have already been generated and cached, not the remaining zero elements.
pad_mask = jnp.broadcast_to(
jnp.arange(seq_length) < cur_index + num_updated_cache_vectors,
(batch_size,) + (1, num_updated_cache_vectors, seq_length),
)
attention_mask = combine_masks(pad_mask, attention_mask)
return key, value, attention_mask
def __call__(
self,
hidden_states,
alibi,
attention_mask=None,
deterministic: bool = True,
init_cache: bool = False,
output_attentions: bool = False,
layer_number: int = None,
):
batch_size, seq_length = hidden_states.shape[:2]
# proj q, k, v
fused_qkv = self.query_key_value(hidden_states)
query, key, value = jnp.split(fused_qkv, 3, axis=-1)
query = with_sharding_constraint(query, ('batch', 'length', 'heads', 'kv'))
key = with_sharding_constraint(key, ('batch', 'length', 'heads', 'kv'))
value = with_sharding_constraint(value, ('batch', 'length', 'heads', 'kv'))
causal_attention_mask = make_causal_mask(attention_mask, dtype="bool")
# for fast decoding causal attention mask should be shifted
causal_attention_mask_shift = (
self.variables["cache"]["cache_index"] if self.has_variable("cache", "cached_key") else 0
)
# fast decoding for generate requires special attention_mask
if self.has_variable("cache", "cached_key"):
# sequence_length of cached_key is last dim
# TODO(PVP) - uncomment other three
max_decoder_length = self.variables["cache"]["cached_key"].shape[-1]
causal_attention_mask = jax.lax.dynamic_slice(
causal_attention_mask,
(0, 0, causal_attention_mask_shift, 0),
(1, 1, seq_length, max_decoder_length),
)
# broadcast causal attention mask & attention mask to fit for merge
causal_attention_mask = jnp.broadcast_to(
causal_attention_mask, (batch_size,) + causal_attention_mask.shape[1:]
)
attention_mask = jnp.broadcast_to(jnp.expand_dims(attention_mask, axis=(-3, -2)), causal_attention_mask.shape)
attention_mask = combine_masks(attention_mask, causal_attention_mask)
dropout_rng = None
deterministic = True
if not deterministic and self.config.attention_dropout > 0.0:
dropout_rng = self.make_rng("dropout")
# During fast autoregressive decoding, we feed one position at a time,
# and cache the keys and values step by step.
if self.has_variable("cache", "cached_key") or init_cache:
key, value, attention_mask = self._concatenate_to_cache(key, value, query, attention_mask)
# transform boolean mask into float mask
mask_value = jnp.finfo(self.dtype).min
attention_bias = lax.select(
attention_mask > 0,
jnp.full(attention_mask.shape, 0.0).astype(self.dtype),
jnp.full(attention_mask.shape, mask_value).astype(self.dtype),
)
attention_bias = attention_bias + alibi
# TODO: override softmax precision to fp32 if self.attention_softmax_in_fp32=True and self.dtype != fp32
# usual dot product attention
attn_weights = dot_product_attention_weights(
query,
key,
bias=attention_bias,
dropout_rng=dropout_rng,
dropout_rate=self.config.attention_dropout,
deterministic=deterministic,
dtype=self.dtype,
precision=None,
)
attn_output = jnp.einsum("...hqk,...khd->...qhd", attn_weights, value)
attn_output = self.dense(attn_output)
outputs = (attn_output, attn_weights) if output_attentions else (attn_output,)
return outputs
class BloomGELU(nn.Module):
def setup(self):
self.dtype = jnp.float32
def __call__(self, x):
return x * 0.5 * (1.0 + tanh(0.79788456 * x * (1 + 0.044715 * x * x)))
class FlaxBloomMLP(nn.Module):
config: BloomConfig
dtype: jnp.dtype = jnp.float32
params_dtype: jnp.dtype = jnp.float32
def setup(self):
self.hidden_size = self.config.hidden_size
self.pretraining_tp = self.config.pretraining_tp
self.slow_but_exact = self.config.slow_but_exact
self.dense_h_to_4h = layers.DenseGeneral(
features=self.hidden_size * 4,
dtype=self.dtype,
params_dtype=self.params_dtype,
kernel_axes=('embed', 'mlp'),
)
self.dense_4h_to_h = layers.DenseGeneral(
features=self.hidden_size,
dtype=self.dtype,
params_dtype=self.params_dtype,
kernel_axes=('mlp', 'embed'),
)
self.hidden_dropout = nn.Dropout(self.config.hidden_dropout)
self.act = BloomGELU()
def __call__(self, hidden_states, deterministic: bool = True):
hidden_states = self.dense_h_to_4h(hidden_states)
hidden_states = self.act(hidden_states)
# TODO: this code block is from the pytorch implementation. needs changing to work.
# if self.pretraining_tp > 1 and self.slow_but_exact:
# if False:
# intermediate_output = jnp.zeros_like(residual)
# slices = self.dense_4h_to_h.weight.shape[-1] / self.pretraining_tp
# for i in range(self.pretraining_tp):
# intermediate_output = intermediate_output + nn.functional.linear(
# hidden_states[:, :, int(i * slices) : int((i + 1) * slices)],
# self.dense_4h_to_h.weight[:, int(i * slices) : int((i + 1) * slices)],
# )
# else:
# intermediate_output = self.dense_4h_to_h(hidden_states)
hidden_states = self.dense_4h_to_h(hidden_states)
return hidden_states
class FlaxBloomBlock(nn.Module):
config: BloomConfig
dtype: jnp.dtype = jnp.float32
params_dtype: jnp.dtype = jnp.float32
use_scan: bool = False
def setup(self):
self.input_layernorm = layers.LayerNorm(epsilon=self.config.layer_norm_epsilon, dtype=self.dtype, params_dtype=self.params_dtype)
self.self_attention = FlaxBloomAttention(self.config, dtype=self.dtype, params_dtype=self.params_dtype)
self.post_attention_layernorm = layers.LayerNorm(epsilon=self.config.layer_norm_epsilon, dtype=self.dtype, params_dtype=self.params_dtype)
self.mlp = FlaxBloomMLP(self.config, dtype=self.dtype, params_dtype=self.params_dtype)
self.apply_residual_connection_post_layernorm = self.config.apply_residual_connection_post_layernorm
self.hidden_dropout = self.config.hidden_dropout
def __call__(
self,
hidden_states,
alibi,
attention_mask=None,
layer_number: int = None,
deterministic: bool = True,
init_cache: bool = False,
output_attentions: bool = False,
):
if self.use_scan:
hidden_states = hidden_states[0]
hidden_states = with_sharding_constraint(hidden_states, ('batch', 'length', 'embed'))
layernorm_output = self.input_layernorm(hidden_states)
layernorm_output = with_sharding_constraint(layernorm_output, ('batch', 'length', 'embed'))
# layer norm before saving residual if config calls for it
if self.apply_residual_connection_post_layernorm:
residual = layernorm_output
else:
residual = hidden_states
# self-attention
attn_outputs = self.self_attention(
layernorm_output,
alibi=alibi,
attention_mask=attention_mask,
deterministic=deterministic,
init_cache=init_cache,
output_attentions=output_attentions,
layer_number=layer_number,
)
attention_output = attn_outputs[0]
# apply residual connection
attention_output = attention_output + residual
attention_output = with_sharding_constraint(attention_output, ('batch', 'length', 'embed'))
outputs = attn_outputs[1:]
post_layernorm = self.post_attention_layernorm(attention_output)
post_layernorm = with_sharding_constraint(post_layernorm, ('batch', 'length', 'embed'))
# set residual based on config
if self.apply_residual_connection_post_layernorm:
residual = post_layernorm
else:
residual = attention_output
output = self.mlp(post_layernorm, deterministic=deterministic)
output = output + residual
output = with_sharding_constraint(output, ('batch', 'length', 'embed'))
outputs = (output,) + outputs[1:]
if self.use_scan:
outputs = (outputs, None)
return outputs
# TODO: does this still require position_ids?
# TODO: gradient checkpointing
# TODO: _no_split_modules?
# TODO: check initialization
class FlaxBloomPreTrainedModel(FlaxPreTrainedModel):
"""
An abstract class to handle weights initialization and a simple interface for downloading and loading pretrained
models.
"""
config_class = BloomConfig
base_model_prefix = "transformer"
module_class: nn.Module = None
def __init__(
self,
config: BloomConfig,
input_shape: Tuple = (1, 1),
seed: int = 0,
dtype: jnp.dtype = jnp.float32,
params_dtype: jnp.dtype = jnp.float32,
_do_init: bool = True,
use_scan: bool = False,
**kwargs,
):
module = self.module_class(config=config, dtype=dtype, use_scan=use_scan, params_dtype=params_dtype, **kwargs)
super().__init__(config, module, input_shape=input_shape, seed=seed, dtype=dtype, _do_init=_do_init)
def init_weights(self, rng: jax.random.PRNGKey, input_shape: Tuple, params: FrozenDict = None) -> FrozenDict:
# init input tensors
input_ids = jnp.zeros(input_shape, dtype="i4")
attention_mask = jnp.ones_like(input_ids)
params_rng, dropout_rng = jax.random.split(rng)
rngs = {"params": params_rng, "dropout": dropout_rng}
random_params = self.module.init(rngs, input_ids, attention_mask, return_dict=False)["params"]
if params is not None:
random_params = flatten_dict(unfreeze(random_params))
params = flatten_dict(unfreeze(params))
for missing_key in self._missing_keys:
params[missing_key] = random_params[missing_key]
self._missing_keys = set()
return freeze(unflatten_dict(params))
else:
return random_params
def init_cache(self, batch_size, max_length):
r"""
Args:
batch_size (`int`):
batch_size used for fast auto-regressive decoding. Defines the batch size of the initialized cache.
max_length (`int`):
maximum possible length for auto-regressive decoding. Defines the sequence length of the initialized
cache.
"""
# init input variables to retrieve cache
input_ids = jnp.ones((batch_size, max_length))
attention_mask = jnp.ones_like(input_ids)
init_variables = self.module.init(
jax.random.PRNGKey(0), input_ids, attention_mask, return_dict=False, init_cache=True
)
return unfreeze(init_variables["cache"])
def __call__(
self,
input_ids,
attention_mask=None,
past_key_values: dict = None,
params: dict = None,
dropout_rng: jax.random.PRNGKey = None,
train: bool = False,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
):
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
output_hidden_states = (
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
)
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
batch_size, sequence_length = input_ids.shape
if attention_mask is None:
attention_mask = jnp.ones((batch_size, sequence_length))
# Handle any PRNG if needed
rngs = {}
if dropout_rng is not None:
rngs["dropout"] = dropout_rng
inputs = {"params": params or self.params}
# if past_key_values are passed then cache is already initialized a private flag init_cache has to be passed down to ensure cache is used. It has to be made sure that cache is marked as mutable so that it can be changed by FlaxBloomAttention module
if past_key_values:
inputs["cache"] = past_key_values
mutable = ["cache"]
else:
mutable = False
outputs = self.module.apply(
inputs,
jnp.array(input_ids, dtype="i4"),
jnp.array(attention_mask, dtype="i4"),
not train,
False,
output_attentions,
output_hidden_states,
return_dict,
rngs=rngs,
mutable=mutable,
)
# add updated cache to model output
if past_key_values is not None and return_dict:
outputs, past_key_values = outputs
outputs["past_key_values"] = unfreeze(past_key_values["cache"])
return outputs
elif past_key_values is not None and not return_dict:
outputs, past_key_values = outputs
outputs = outputs[:1] + (unfreeze(past_key_values["cache"]),) + outputs[1:]
return outputs
class FlaxBloomBlockCollection(nn.Module):
config: BloomConfig
dtype: jnp.dtype = jnp.float32
params_dtype: jnp.dtype = jnp.float32
use_scan: bool = False
# TODO (SG): re-write as a `setup` to conform to Transformers JAX/Flax conventions -> awaiting CG response on G Chat
@nn.compact
def __call__(
self,
hidden_states,
alibi,
attention_mask=None,
deterministic: bool = True,
init_cache: bool = False,
output_attentions: bool = False,
output_hidden_states: bool = False,
):
all_attentions = () if output_attentions else None
all_hidden_states = () if output_hidden_states else None
if self.use_scan:
# since all decoder layers are the same, we use nn.scan directly
# assert not output_attentions, "cannot use `scan` with `output_attentions` set to `True`"
# assert not output_hidden_states, "cannot use `scan` with `output_hidden_states` set to `True`"
hidden_states = (hidden_states,)
layer_number = jnp.arange(self.config.num_hidden_layers)
hidden_states, _ = scan_with_axes(
FlaxBloomBlock,
variable_axes={"params": 0, "cache": 0},
split_rngs={"params": True, "dropout": True},
in_axes=(nn.broadcast, nn.broadcast, 0, nn.broadcast, nn.broadcast),
length=self.config.num_hidden_layers,
)(self.config, dtype=self.dtype, params_dtype=self.params_dtype, use_scan=True, name="FlaxBloomBlockLayers")(
hidden_states,
alibi,
attention_mask, # kwargs not supported by scan
layer_number,
deterministic,
init_cache,
)
hidden_states = hidden_states[0]
else:
for layer_number in range(self.config.num_hidden_layers):
if output_hidden_states:
all_hidden_states += (hidden_states,)
layer_outputs = FlaxBloomBlock(self.config, name=str(layer_number), dtype=self.dtype, params_dtype=self.params_dtype, use_scan=False)(
hidden_states,
alibi=alibi,
attention_mask=attention_mask,
deterministic=deterministic,
init_cache=init_cache,
output_attentions=output_attentions,
layer_number=layer_number,
)
hidden_states = layer_outputs[0]
if output_attentions:
all_attentions += (layer_outputs[1],)
# this contains possible `None` values - `FlaxBloomModule` will filter them out
outputs = (hidden_states, all_hidden_states, all_attentions)
return outputs
class FlaxBloomModule(nn.Module):
config: BloomConfig
dtype: jnp.dtype = jnp.float32
params_dtype: jnp.dtype = jnp.float32
use_scan: bool = False
def setup(self):
# TODO: check initialization correctness
self.embed_dim = self.config.hidden_size
self.embedding_init = jax.nn.initializers.normal(stddev=self.config.initializer_range, dtype=self.params_dtype)
self.word_embeddings = layers.Embed(
self.config.vocab_size,
self.embed_dim,
embedding_init=nn.initializers.zeros,
params_dtype=self.params_dtype,
)
# post-embedding layernorm
self.word_embeddings_layernorm = layers.LayerNorm(epsilon=self.config.layer_norm_epsilon, params_dtype=self.params_dtype)
# transformer layers
self.h = FlaxBloomBlockCollection(self.config, dtype=self.dtype, params_dtype=self.params_dtype, use_scan=self.use_scan)
# final layernorm
self.ln_f = layers.LayerNorm(epsilon=self.config.layer_norm_epsilon, dtype=self.dtype, params_dtype=self.params_dtype)
# TODO: change how gradient checkpointing is done
self.gradient_checkpointing = False
def __call__(
self,
input_ids=None,
attention_mask=None,
deterministic=True,
init_cache: bool = False,
output_attentions: bool = False,
output_hidden_states: bool = False,
return_dict: bool = True,
):
inputs_embeds = self.word_embeddings(input_ids.astype("i4"))
# do post-embedding layernorm
hidden_states = self.word_embeddings_layernorm(inputs_embeds)
# build alibi depending on `attention_mask`
alibi = build_alibi_tensor_flax(attention_mask, self.config.n_head, hidden_states.dtype)
# TODO: gradient checkpointing
outputs = self.h(
hidden_states,
alibi=alibi,
attention_mask=attention_mask,
deterministic=deterministic,
init_cache=init_cache,
output_hidden_states=output_hidden_states,
output_attentions=output_attentions,
)
hidden_states = outputs[0]
hidden_states = self.ln_f(hidden_states)
if output_hidden_states:
all_hidden_states = outputs[1] + (hidden_states,)
outputs = (hidden_states, all_hidden_states) + outputs[2:]
else:
outputs = (hidden_states,) + outputs[1:]
if not return_dict:
# TODO: don't think this return value / ordering is correct
return tuple(v for v in [outputs[0], outputs[-1]] if v is not None)
return FlaxBaseModelOutputWithPast(
last_hidden_state=hidden_states,
hidden_states=outputs[1],
attentions=outputs[-1],
)
class FlaxBloomModel(FlaxBloomPreTrainedModel):
module_class = FlaxBloomModule
class FlaxBloomForCausalLMModule(nn.Module):
config: BloomConfig
dtype: jnp.dtype = jnp.float32
params_dtype: jnp.dtype = jnp.float32
use_scan: bool = False
def setup(self):
self.transformer = FlaxBloomModule(self.config, dtype=self.dtype, params_dtype=self.params_dtype, use_scan=self.use_scan)
self.lm_head = layers.DenseGeneral(
self.config.vocab_size,
dtype=jnp.float32, # Use float32 for stabiliity.
params_dtype=self.params_dtype,
use_bias=False,
kernel_axes=('embed', 'vocab'),
)
def __call__(
self,
input_ids,
attention_mask,
deterministic: bool = True,
init_cache: bool = False,
output_attentions: bool = False,
output_hidden_states: bool = False,
return_dict: bool = True,
):
outputs = self.transformer(
input_ids,
attention_mask=attention_mask,
deterministic=deterministic,
init_cache=init_cache,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
hidden_states = outputs[0]
if self.config.tie_word_embeddings:
shared_kernel = self.transformer.variables["params"]["word_embeddings"]["embedding"].T
lm_logits = self.lm_head.apply({"params": {"kernel": shared_kernel}}, hidden_states)
else:
lm_logits = self.lm_head(hidden_states)
if not return_dict:
return (lm_logits,) + outputs[1:]
return FlaxCausalLMOutput(logits=lm_logits, hidden_states=outputs.hidden_states, attentions=outputs.attentions)
class FlaxBloomForCausalLM(FlaxBloomPreTrainedModel):
module_class = FlaxBloomForCausalLMModule
# TODO: check if this class is correct / take out position ids
def prepare_inputs_for_generation(self, input_ids, max_length, attention_mask: Optional[jnp.DeviceArray] = None):
# initializing the cache
batch_size, seq_length = input_ids.shape
past_key_values = self.init_cache(batch_size, max_length)
# Note that usually one would have to put 0's in the attention_mask for x > input_ids.shape[-1] and x < cache_length.
# But since Bloom uses a causal mask, those positions are masked anyways.
# Thus we can create a single static attention_mask here, which is more efficient for compilation
extended_attention_mask = jnp.ones((batch_size, max_length), dtype="i4")
if attention_mask is not None:
extended_attention_mask = lax.dynamic_update_slice(extended_attention_mask, attention_mask, (0, 0))
return {
"past_key_values": past_key_values,
"attention_mask": extended_attention_mask,
}
def update_inputs_for_generation(self, model_outputs, model_kwargs):
model_kwargs["past_key_values"] = model_outputs.past_key_values
return model_kwargs
| 0 |
0 | hf_public_repos/bloom-jax-inference/bloom_inference | hf_public_repos/bloom-jax-inference/bloom_inference/modeling_bloom/generation_flax_logits_process.py | # coding=utf-8
# Copyright 2021 The HuggingFace Inc. team
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import inspect
import jax
import jax.lax as lax
import jax.numpy as jnp
from transformers.utils import add_start_docstrings
from transformers.utils.logging import get_logger
logger = get_logger(__name__)
LOGITS_PROCESSOR_INPUTS_DOCSTRING = r"""
Args:
input_ids (`jnp.ndarray` of shape `(batch_size, sequence_length)`):
Indices of input sequence tokens in the vocabulary.
Indices can be obtained using [`PreTrainedTokenizer`]. See [`PreTrainedTokenizer.encode`] and
[`PreTrainedTokenizer.__call__`] for details.
[What are input IDs?](../glossary#input-ids)
scores (`jnp.ndarray` of shape `(batch_size, config.vocab_size)`):
Prediction scores of a language modeling head. These can be logits for each vocabulary when not using beam
search or log softmax for each vocabulary token when using beam search
kwargs:
Additional logits processor specific kwargs.
Return:
`jnp.ndarray` of shape `(batch_size, config.vocab_size)`: The processed prediction scores.
"""
class FlaxLogitsProcessor:
"""Abstract base class for all logit processors that can be applied during generation."""
@add_start_docstrings(LOGITS_PROCESSOR_INPUTS_DOCSTRING)
def __call__(self, input_ids: jnp.ndarray, scores: jnp.ndarray) -> jnp.ndarray:
"""Flax method for processing logits."""
raise NotImplementedError(
f"{self.__class__} is an abstract class. Only classes inheriting this class can be called."
)
class FlaxLogitsWarper:
"""Abstract base class for all logit warpers that can be applied during generation with multinomial sampling."""
@add_start_docstrings(LOGITS_PROCESSOR_INPUTS_DOCSTRING)
def __call__(self, input_ids: jnp.ndarray, scores: jnp.ndarray) -> jnp.ndarray:
"""Flax method for warping logits."""
raise NotImplementedError(
f"{self.__class__} is an abstract class. Only classes inheriting this class can be called."
)
class FlaxLogitsProcessorList(list):
"""
This class can be used to create a list of [`FlaxLogitsProcessor`] or [`FlaxLogitsWarper`] to subsequently process
a `scores` input tensor. This class inherits from list and adds a specific *__call__* method to apply each
[`FlaxLogitsProcessor`] or [`FlaxLogitsWarper`] to the inputs.
"""
@add_start_docstrings(LOGITS_PROCESSOR_INPUTS_DOCSTRING)
def __call__(self, input_ids: jnp.ndarray, scores: jnp.ndarray, cur_len: int, **kwargs) -> jnp.ndarray:
for processor in self:
function_args = inspect.signature(processor.__call__).parameters
if len(function_args) > 3:
if not all(arg in kwargs for arg in list(function_args.keys())[2:]):
raise ValueError(
f"Make sure that all the required parameters: {list(function_args.keys())} for "
f"{processor.__class__} are passed to the logits processor."
)
scores = processor(input_ids, scores, cur_len, **kwargs)
else:
scores = processor(input_ids, scores, cur_len)
return scores
class FlaxTemperatureLogitsWarper(FlaxLogitsWarper):
r"""
[`FlaxLogitsWarper`] for temperature (exponential scaling output probability distribution).
Args:
temperature (`float`):
The value used to module the logits distribution.
"""
def __init__(self, temperature: float):
if not isinstance(temperature, float) or not (temperature > 0):
raise ValueError(f"`temperature` has to be a strictly positive float, but is {temperature}")
self.temperature = temperature
def __call__(self, input_ids: jnp.ndarray, scores: jnp.ndarray, cur_len: int) -> jnp.ndarray:
scores = scores / self.temperature
return scores
class FlaxTopPLogitsWarper(FlaxLogitsWarper):
"""
[`FlaxLogitsWarper`] that performs top-p, i.e. restricting to top tokens summing to prob_cut_off <= prob_cut_off.
Args:
top_p (`float`):
If set to < 1, only the most probable tokens with probabilities that add up to `top_p` or higher are kept
for generation.
filter_value (`float`, *optional*, defaults to `-float("Inf")`):
All filtered values will be set to this float value.
min_tokens_to_keep (`int`, *optional*, defaults to 1):
Minimum number of tokens that cannot be filtered.
"""
def __init__(self, top_p: float, filter_value: float = -float("Inf"), min_tokens_to_keep: int = 1):
if not isinstance(top_p, float) or (top_p < 0 or top_p > 1.0):
raise ValueError(f"`top_p` has to be a float > 0 and < 1, but is {top_p}")
self.top_p = top_p
self.filter_value = filter_value
self.min_tokens_to_keep = min_tokens_to_keep
def __call__(self, input_ids: jnp.ndarray, scores: jnp.ndarray, cur_len: int) -> jnp.ndarray:
topk_scores, topk_indices = lax.top_k(scores, scores.shape[-1])
mask_scores = jnp.full_like(scores, self.filter_value)
cumulative_probs = jax.nn.softmax(topk_scores, axis=-1).cumsum(axis=-1)
score_mask = cumulative_probs < self.top_p
# include the token that is higher than top_p as well
score_mask = jnp.roll(score_mask, 1)
score_mask |= score_mask.at[:, 0].set(True)
# min tokens to keep
score_mask = score_mask.at[:, : self.min_tokens_to_keep].set(True)
topk_next_scores = jnp.where(score_mask, topk_scores, mask_scores)
next_scores = jax.lax.sort_key_val(topk_indices, topk_next_scores)[-1]
return next_scores
class FlaxTopKLogitsWarper(FlaxLogitsWarper):
r"""
[`FlaxLogitsWarper`] that performs top-k, i.e. restricting to the k highest probability elements.
Args:
top_k (`int`):
The number of highest probability vocabulary tokens to keep for top-k-filtering.
filter_value (`float`, *optional*, defaults to `-float("Inf")`):
All filtered values will be set to this float value.
min_tokens_to_keep (`int`, *optional*, defaults to 1):
Minimum number of tokens that cannot be filtered.
"""
def __init__(self, top_k: int, filter_value: float = -float("Inf"), min_tokens_to_keep: int = 1):
if not isinstance(top_k, int) or top_k <= 0:
raise ValueError(f"`top_k` has to be a strictly positive integer, but is {top_k}")
self.top_k = top_k
self.filter_value = filter_value
self.min_tokens_to_keep = min_tokens_to_keep
def __call__(self, input_ids: jnp.ndarray, scores: jnp.ndarray, cur_len: int) -> jnp.ndarray:
batch_size, vocab_size = scores.shape
next_scores_flat = jnp.full(batch_size * vocab_size, self.filter_value)
topk = min(max(self.top_k, self.min_tokens_to_keep), scores.shape[-1]) # Safety check
topk_scores, topk_indices = lax.top_k(scores, topk)
shift = jnp.broadcast_to((jnp.arange(batch_size) * vocab_size)[:, None], (batch_size, topk)).flatten()
topk_scores_flat = topk_scores.flatten()
topk_indices_flat = topk_indices.flatten() + shift
next_scores_flat = next_scores_flat.at[topk_indices_flat].set(topk_scores_flat)
next_scores = next_scores_flat.reshape(batch_size, vocab_size)
return next_scores
class FlaxForcedBOSTokenLogitsProcessor(FlaxLogitsProcessor):
r"""
[`FlaxLogitsProcessor`] that enforces the specified token as the first generated token.
Args:
bos_token_id (`int`):
The id of the token to force as the first generated token.
"""
def __init__(self, bos_token_id: int):
self.bos_token_id = bos_token_id
def __call__(self, input_ids: jnp.ndarray, scores: jnp.ndarray, cur_len: int) -> jnp.ndarray:
new_scores = jnp.full(scores.shape, -float("inf"))
apply_penalty = 1 - jnp.bool_(cur_len - 1)
scores = jnp.where(apply_penalty, new_scores.at[:, self.bos_token_id].set(0), scores)
return scores
class FlaxForcedEOSTokenLogitsProcessor(FlaxLogitsProcessor):
r"""
[`FlaxLogitsProcessor`] that enforces the specified token as the last generated token when `max_length` is reached.
Args:
max_length (`int`):
The maximum length of the sequence to be generated.
eos_token_id (`int`):
The id of the token to force as the last generated token when `max_length` is reached.
"""
def __init__(self, max_length: int, eos_token_id: int):
self.max_length = max_length
self.eos_token_id = eos_token_id
def __call__(self, input_ids: jnp.ndarray, scores: jnp.ndarray, cur_len: int) -> jnp.ndarray:
new_scores = jnp.full(scores.shape, -float("inf"))
apply_penalty = 1 - jnp.bool_(cur_len - self.max_length + 1)
scores = jnp.where(apply_penalty, new_scores.at[:, self.eos_token_id].set(0), scores)
return scores
class FlaxMinLengthLogitsProcessor(FlaxLogitsProcessor):
r"""
[`FlaxLogitsProcessor`] enforcing a min-length by setting EOS probability to 0.
Args:
min_length (`int`):
The minimum length below which the score of `eos_token_id` is set to `-float("Inf")`.
eos_token_id (`int`):
The id of the *end-of-sequence* token.
"""
def __init__(self, min_length: int, eos_token_id: int):
if not isinstance(min_length, int) or min_length < 0:
raise ValueError(f"`min_length` has to be a positive integer, but is {min_length}")
if not isinstance(eos_token_id, int) or eos_token_id < 0:
raise ValueError(f"`eos_token_id` has to be a positive integer, but is {eos_token_id}")
self.min_length = min_length
self.eos_token_id = eos_token_id
def __call__(self, input_ids: jnp.ndarray, scores: jnp.ndarray, cur_len: int) -> jnp.ndarray:
# create boolean flag to decide if min length penalty should be applied
apply_penalty = 1 - jnp.clip(cur_len - self.min_length, 0, 1)
scores = jnp.where(apply_penalty, scores.at[:, self.eos_token_id].set(-float("inf")), scores)
return scores
| 1 |
0 | hf_public_repos/bloom-jax-inference/bloom_inference | hf_public_repos/bloom-jax-inference/bloom_inference/modeling_bloom/layers.py | # Copyright 2022 The T5X Authors.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""Dense attention classes and mask/weighting functions."""
# pylint: disable=attribute-defined-outside-init,g-bare-generic
import dataclasses
import functools
import operator
from typing import Any, Callable, Iterable, Optional, Sequence, Tuple, Union
from flax import linen as nn
from flax.linen import partitioning as nn_partitioning
from flax.linen.normalization import _compute_stats, _canonicalize_axes
import jax
from jax import lax
from jax import random
import jax.numpy as jnp
import numpy as np
# from flax.linen.partitioning import param_with_axes, with_sharding_constraint
param_with_axes = nn_partitioning.param_with_axes
with_sharding_constraint = nn_partitioning.with_sharding_constraint
# Type annotations
Array = jnp.ndarray
DType = jnp.dtype
PRNGKey = jnp.ndarray
Shape = Iterable[int]
Activation = Callable[..., Array]
# Parameter initializers.
Initializer = Callable[[PRNGKey, Shape, DType], Array]
InitializerAxis = Union[int, Tuple[int, ...]]
NdInitializer = Callable[
[PRNGKey, Shape, DType, InitializerAxis, InitializerAxis], Array]
default_embed_init = nn.initializers.variance_scaling(
1.0, 'fan_in', 'normal', out_axis=0)
# ------------------------------------------------------------------------------
# Temporary inlined JAX N-d initializer code
# TODO(levskaya): remove once new JAX release is out.
# ------------------------------------------------------------------------------
def _compute_fans(shape: jax.core.NamedShape, in_axis=-2, out_axis=-1):
"""Inlined JAX `nn.initializer._compute_fans`."""
if isinstance(in_axis, int):
in_size = shape[in_axis]
else:
in_size = int(np.prod([shape[i] for i in in_axis]))
if isinstance(out_axis, int):
out_size = shape[out_axis]
else:
out_size = int(np.prod([shape[i] for i in out_axis]))
receptive_field_size = shape.total / in_size / out_size
fan_in = in_size * receptive_field_size
fan_out = out_size * receptive_field_size
return fan_in, fan_out
def variance_scaling(scale, mode, distribution, in_axis=-2, out_axis=-1,
dtype=jnp.float_):
"""Inlined JAX `nn.initializer.variance_scaling`."""
def init(key, shape, dtype=dtype):
return jnp.zeros(shape, dtype=dtype)
dtype = jax.dtypes.canonicalize_dtype(dtype)
shape = jax.core.as_named_shape(shape)
fan_in, fan_out = _compute_fans(shape, in_axis, out_axis)
if mode == 'fan_in':
denominator = fan_in
elif mode == 'fan_out':
denominator = fan_out
elif mode == 'fan_avg':
denominator = (fan_in + fan_out) / 2
else:
raise ValueError(
'invalid mode for variance scaling initializer: {}'.format(mode))
variance = jnp.array(scale / denominator, dtype=dtype)
if distribution == 'truncated_normal':
# constant is stddev of standard normal truncated to (-2, 2)
stddev = jnp.sqrt(variance) / jnp.array(.87962566103423978, dtype)
return random.truncated_normal(key, -2, 2, shape, dtype) * stddev
elif distribution == 'normal':
return random.normal(key, shape, dtype) * jnp.sqrt(variance)
elif distribution == 'uniform':
return random.uniform(key, shape, dtype, -1) * jnp.sqrt(3 * variance)
else:
raise ValueError('invalid distribution for variance scaling '
'initializer: {}'.format(distribution))
return init
# ------------------------------------------------------------------------------
def nd_dense_init(scale, mode, distribution):
"""Initializer with in_axis, out_axis set at call time."""
def init_fn(key, shape, dtype, in_axis, out_axis):
fn = variance_scaling(
scale, mode, distribution, in_axis, out_axis)
return fn(key, shape, dtype)
return init_fn
def dot_product_attention(query: Array,
key: Array,
value: Array,
bias: Optional[Array] = None,
dropout_rng: Optional[PRNGKey] = None,
dropout_rate: float = 0.,
deterministic: bool = False,
dtype: DType = jnp.float32,
float32_logits: bool = False):
"""Computes dot-product attention given query, key, and value.
This is the core function for applying attention based on
https://arxiv.org/abs/1706.03762. It calculates the attention weights given
query and key and combines the values using the attention weights.
Args:
query: queries for calculating attention with shape of `[batch, q_length,
num_heads, qk_depth_per_head]`.
key: keys for calculating attention with shape of `[batch, kv_length,
num_heads, qk_depth_per_head]`.
value: values to be used in attention with shape of `[batch, kv_length,
num_heads, v_depth_per_head]`.
bias: bias for the attention weights. This should be broadcastable to the
shape `[batch, num_heads, q_length, kv_length]` This can be used for
incorporating causal masks, padding masks, proximity bias, etc.
dropout_rng: JAX PRNGKey: to be used for dropout
dropout_rate: dropout rate
deterministic: bool, deterministic or not (to apply dropout)
dtype: the dtype of the computation (default: float32)
float32_logits: bool, if True then compute logits in float32 to avoid
numerical issues with bfloat16.
Returns:
Output of shape `[batch, length, num_heads, v_depth_per_head]`.
"""
assert key.ndim == query.ndim == value.ndim, 'q, k, v must have same rank.'
assert query.shape[:-3] == key.shape[:-3] == value.shape[:-3], (
'q, k, v batch dims must match.')
assert query.shape[-2] == key.shape[-2] == value.shape[-2], (
'q, k, v num_heads must match.')
assert key.shape[-3] == value.shape[-3], 'k, v lengths must match.'
assert query.shape[-1] == key.shape[-1], 'q, k depths must match.'
# Casting logits and softmax computation for float32 for model stability.
if float32_logits:
query = query.astype(jnp.float32)
key = key.astype(jnp.float32)
# `attn_weights`: [batch, num_heads, q_length, kv_length]
attn_weights = jnp.einsum('bqhd,bkhd->bhqk', query, key)
# Apply attention bias: masking, dropout, proximity bias, etc.
if bias is not None:
attn_weights = attn_weights + bias.astype(attn_weights.dtype)
# Normalize the attention weights across `kv_length` dimension.
attn_weights = jax.nn.softmax(attn_weights).astype(dtype)
# Apply attention dropout.
if not deterministic and dropout_rate > 0.:
keep_prob = 1.0 - dropout_rate
# T5 broadcasts along the "length" dim, but unclear which one that
# corresponds to in positional dimensions here, assuming query dim.
dropout_shape = list(attn_weights.shape)
dropout_shape[-2] = 1
keep = random.bernoulli(dropout_rng, keep_prob, dropout_shape)
keep = jnp.broadcast_to(keep, attn_weights.shape)
multiplier = (
keep.astype(attn_weights.dtype) / jnp.asarray(keep_prob, dtype=dtype))
attn_weights = attn_weights * multiplier
# Take the linear combination of `value`.
return jnp.einsum('bhqk,bkhd->bqhd', attn_weights, value)
dynamic_vector_slice_in_dim = jax.vmap(
lax.dynamic_slice_in_dim, in_axes=(None, 0, None, None))
class MultiHeadDotProductAttention(nn.Module):
"""Multi-head dot-product attention.
Attributes:
num_heads: number of attention heads. Features (i.e. inputs_q.shape[-1])
should be divisible by the number of heads.
head_dim: dimension of each head.
dtype: the dtype of the computation.
dropout_rate: dropout rate
kernel_init: initializer for the kernel of the Dense layers.
float32_logits: bool, if True then compute logits in float32 to avoid
numerical issues with bfloat16.
"""
num_heads: int
head_dim: int
dtype: DType = jnp.float32
dropout_rate: float = 0.
kernel_init: NdInitializer = nd_dense_init(1.0, 'fan_in', 'normal')
float32_logits: bool = False # computes logits in float32 for stability.
@nn.compact
def __call__(self,
inputs_q: Array,
inputs_kv: Array,
mask: Optional[Array] = None,
bias: Optional[Array] = None,
*,
decode: bool = False,
deterministic: bool = False) -> Array:
"""Applies multi-head dot product attention on the input data.
Projects the inputs into multi-headed query, key, and value vectors,
applies dot-product attention and project the results to an output vector.
There are two modes: decoding and non-decoding (e.g., training). The mode is
determined by `decode` argument. For decoding, this method is called twice,
first to initialize the cache and then for an actual decoding process. The
two calls are differentiated by the presence of 'cached_key' in the variable
dict. In the cache initialization stage, the cache variables are initialized
as zeros and will be filled in the subsequent decoding process.
In the cache initialization call, `inputs_q` has a shape [batch, length,
q_features] and `inputs_kv`: [batch, length, kv_features]. During the
incremental decoding stage, query, key and value all have the shape [batch,
1, qkv_features] corresponding to a single step.
Args:
inputs_q: input queries of shape `[batch, q_length, q_features]`.
inputs_kv: key/values of shape `[batch, kv_length, kv_features]`.
mask: attention mask of shape `[batch, num_heads, q_length, kv_length]`.
bias: attention bias of shape `[batch, num_heads, q_length, kv_length]`.
decode: Whether to prepare and use an autoregressive cache.
deterministic: Disables dropout if set to True.
Returns:
output of shape `[batch, length, q_features]`.
"""
projection = functools.partial(
DenseGeneral,
axis=-1,
features=(self.num_heads, self.head_dim),
kernel_axes=('embed', 'heads', 'kv'),
dtype=self.dtype)
# NOTE: T5 does not explicitly rescale the attention logits by
# 1/sqrt(depth_kq)! This is folded into the initializers of the
# linear transformations, which is equivalent under Adafactor.
depth_scaling = jnp.sqrt(self.head_dim).astype(self.dtype)
query_init = lambda *args: self.kernel_init(*args) / depth_scaling
# Project inputs_q to multi-headed q/k/v
# dimensions are then [batch, length, num_heads, head_dim]
query = projection(kernel_init=query_init, name='query')(inputs_q)
key = projection(kernel_init=self.kernel_init, name='key')(inputs_kv)
value = projection(kernel_init=self.kernel_init, name='value')(inputs_kv)
query = with_sharding_constraint(query, ('batch', 'length', 'heads', 'kv'))
key = with_sharding_constraint(key, ('batch', 'length', 'heads', 'kv'))
value = with_sharding_constraint(value, ('batch', 'length', 'heads', 'kv'))
if decode:
# Detect if we're initializing by absence of existing cache data.
is_initialized = self.has_variable('cache', 'cached_key')
# The key and value have dimension [batch, length, num_heads, head_dim],
# but we cache them as [batch, num_heads, head_dim, length] as a TPU
# fusion optimization. This also enables the "scatter via one-hot
# broadcast" trick, which means we do a one-hot broadcast instead of a
# scatter/gather operations, resulting in a 3-4x speedup in practice.
swap_dims = lambda x: x[:-3] + tuple(x[i] for i in [-2, -1, -3])
cached_key = self.variable('cache', 'cached_key', jnp.zeros,
swap_dims(key.shape), key.dtype)
cached_value = self.variable('cache', 'cached_value', jnp.zeros,
swap_dims(value.shape), value.dtype)
cache_index = self.variable('cache', 'cache_index',
lambda: jnp.array(0, dtype=jnp.int32))
if is_initialized:
batch, num_heads, head_dim, length = (cached_key.value.shape)
# During fast autoregressive decoding, we feed one position at a time,
# and cache the keys and values step by step.
# Sanity shape check of cached key against input query.
expected_shape = (batch, 1, num_heads, head_dim)
if expected_shape != query.shape:
raise ValueError('Autoregressive cache shape error, '
'expected query shape %s instead got %s.' %
(expected_shape, query.shape))
# Create a OHE of the current index. NOTE: the index is increased below.
cur_index = cache_index.value
one_hot_indices = jax.nn.one_hot(cur_index, length, dtype=key.dtype)
# In order to update the key, value caches with the current key and
# value, we move the length axis to the back, similar to what we did for
# the cached ones above.
# Note these are currently the key and value of a single position, since
# we feed one position at a time.
one_token_key = jnp.moveaxis(key, -3, -1)
one_token_value = jnp.moveaxis(value, -3, -1)
# Update key, value caches with our new 1d spatial slices.
# We implement an efficient scatter into the cache via one-hot
# broadcast and addition.
key = cached_key.value + one_token_key * one_hot_indices
value = cached_value.value + one_token_value * one_hot_indices
cached_key.value = key
cached_value.value = value
cache_index.value = cache_index.value + 1
# Move the keys and values back to their original shapes.
key = jnp.moveaxis(key, -1, -3)
value = jnp.moveaxis(value, -1, -3)
# Causal mask for cached decoder self-attention: our single query
# position should only attend to those key positions that have already
# been generated and cached, not the remaining zero elements.
mask = combine_masks(
mask,
jnp.broadcast_to(
jnp.arange(length) <= cur_index,
# (1, 1, length) represent (head dim, query length, key length)
# query length is 1 because during decoding we deal with one
# index.
# The same mask is applied to all batch elements and heads.
(batch, 1, 1, length)))
# Grab the correct relative attention bias during decoding. This is
# only required during single step decoding.
if bias is not None:
# The bias is a full attention matrix, but during decoding we only
# have to take a slice of it.
# This is equivalent to bias[..., cur_index:cur_index+1, :].
bias = dynamic_vector_slice_in_dim(
jnp.squeeze(bias, axis=0), jnp.reshape(cur_index, (-1)), 1, -2)
# Convert the boolean attention mask to an attention bias.
if mask is not None:
# attention mask in the form of attention bias
attention_bias = lax.select(
mask > 0,
jnp.full(mask.shape, 0.).astype(self.dtype),
jnp.full(mask.shape, -1e10).astype(self.dtype))
else:
attention_bias = None
# Add provided bias term (e.g. relative position embedding).
if bias is not None:
attention_bias = combine_biases(attention_bias, bias)
dropout_rng = None
if not deterministic and self.dropout_rate > 0.:
dropout_rng = self.make_rng('dropout')
# Apply attention.
x = dot_product_attention(
query,
key,
value,
bias=attention_bias,
dropout_rng=dropout_rng,
dropout_rate=self.dropout_rate,
deterministic=deterministic,
dtype=self.dtype,
float32_logits=self.float32_logits)
# Back to the original inputs dimensions.
out = DenseGeneral(
features=inputs_q.shape[-1], # output dim is set to the input dim.
axis=(-2, -1),
kernel_init=self.kernel_init,
kernel_axes=('heads', 'kv', 'embed'),
dtype=self.dtype,
name='out')(
x)
return out
def _normalize_axes(axes: Iterable[int], ndim: int) -> Tuple[int]:
# A tuple by convention. len(axes_tuple) then also gives the rank efficiently.
return tuple([ax if ax >= 0 else ndim + ax for ax in axes])
def _canonicalize_tuple(x):
if isinstance(x, Iterable):
return tuple(x)
else:
return (x,)
#------------------------------------------------------------------------------
# DenseGeneral for attention layers.
#------------------------------------------------------------------------------
class DenseGeneral(nn.Module):
"""A linear transformation (without bias) with flexible axes.
Attributes:
features: tuple with numbers of output features.
axis: tuple with axes to apply the transformation on.
dtype: the dtype of the computation (default: float32).
kernel_init: initializer function for the weight matrix.
"""
features: Union[Iterable[int], int]
axis: Union[Iterable[int], int] = -1
dtype: DType = jnp.float32
params_dtype: DType = jnp.float32
kernel_init: NdInitializer = nd_dense_init(1.0, 'fan_in', 'normal')
kernel_axes: Tuple[str, ...] = ()
use_bias: bool = True
bias_init: Any = nn.initializers.zeros
@nn.compact
def __call__(self, inputs: Array) -> Array:
"""Applies a linear transformation to the inputs along multiple dimensions.
Args:
inputs: The nd-array to be transformed.
Returns:
The transformed input.
"""
features = _canonicalize_tuple(self.features)
axis = _canonicalize_tuple(self.axis)
inputs = jnp.asarray(inputs, self.dtype)
axis = _normalize_axes(axis, inputs.ndim)
kernel_shape = tuple([inputs.shape[ax] for ax in axis]) + features
kernel_in_axis = np.arange(len(axis))
kernel_out_axis = np.arange(len(axis), len(axis) + len(features))
kernel = param_with_axes(
'kernel',
self.kernel_init,
kernel_shape,
self.params_dtype,
kernel_in_axis,
kernel_out_axis,
axes=self.kernel_axes)
if self.use_bias:
bias = param_with_axes('bias', self.bias_init, features, self.params_dtype, axes=(self.kernel_axes[-1],))
kernel = jnp.asarray(kernel, self.dtype)
contract_ind = tuple(range(0, len(axis)))
y = lax.dot_general(inputs, kernel, ((axis, contract_ind), ((), ())))
if self.use_bias:
bias = jnp.asarray(bias, self.dtype)
# y += jnp.reshape(bias, (1,) * (y.ndim - 1) + (-1,))
y += jnp.reshape(bias, (1,) * (len(features) - y.ndim) + bias.shape[:])
return y
def _convert_to_activation_function(
fn_or_string: Union[str, Callable]) -> Callable:
"""Convert a string to an activation function."""
if fn_or_string == 'linear':
return lambda x: x
elif isinstance(fn_or_string, str):
return getattr(nn, fn_or_string)
elif callable(fn_or_string):
return fn_or_string
else:
raise ValueError("don't know how to convert %s to an activation function" %
(fn_or_string,))
class MlpBlock(nn.Module):
"""Transformer MLP / feed-forward block.
Attributes:
intermediate_dim: Shared dimension of hidden layers.
activations: Type of activations for each layer. Each element is either
'linear', a string function name in flax.linen, or a function.
kernel_init: Kernel function, passed to the dense layers.
deterministic: Whether the dropout layers should be deterministic.
intermediate_dropout_rate: Dropout rate used after the intermediate layers.
dtype: Type for the dense layer.
"""
intermediate_dim: int = 2048
activations: Sequence[Union[str, Callable]] = ('relu',)
kernel_init: NdInitializer = nd_dense_init(1.0, 'fan_in', 'truncated_normal')
intermediate_dropout_rate: float = 0.1
dtype: Any = jnp.float32
@nn.compact
def __call__(self, inputs, decode: bool = False, deterministic: bool = False):
"""Applies Transformer MlpBlock module."""
# Iterate over specified MLP input activation functions.
# e.g. ('relu',) or ('gelu', 'linear') for gated-gelu.
activations = []
for idx, act_fn in enumerate(self.activations):
dense_name = 'wi' if len(self.activations) == 1 else f'wi_{idx}'
x = DenseGeneral(
self.intermediate_dim,
dtype=self.dtype,
kernel_init=self.kernel_init,
kernel_axes=('embed', 'mlp'),
name=dense_name)(
inputs)
x = _convert_to_activation_function(act_fn)(x)
activations.append(x)
# Take elementwise product of above intermediate activations.
x = functools.reduce(operator.mul, activations)
# Apply dropout and final dense output projection.
x = nn.Dropout(
rate=self.intermediate_dropout_rate, broadcast_dims=(-2,))(
x, deterministic=deterministic) # Broadcast along length.
x = with_sharding_constraint(x, ('batch', 'length', 'mlp'))
output = DenseGeneral(
inputs.shape[-1],
dtype=self.dtype,
kernel_init=self.kernel_init,
kernel_axes=('mlp', 'embed'),
name='wo')(
x)
return output
class Embed(nn.Module):
"""A parameterized function from integers [0, n) to d-dimensional vectors.
Attributes:
num_embeddings: number of embeddings.
features: number of feature dimensions for each embedding.
dtype: the dtype of the embedding vectors (default: float32).
embedding_init: embedding initializer.
one_hot: performs the gather with a one-hot contraction rather than a true
gather. This is currently needed for SPMD partitioning.
"""
num_embeddings: int
features: int
cast_input_dtype: Optional[DType] = None
dtype: DType = jnp.float32
params_dtype: DType = jnp.float32
attend_dtype: Optional[DType] = None
embedding_init: Initializer = default_embed_init
one_hot: bool = True
embedding: Array = dataclasses.field(init=False)
def setup(self):
self.embedding = param_with_axes(
'embedding',
self.embedding_init, (self.num_embeddings, self.features),
self.params_dtype,
axes=('vocab', 'embed'))
def __call__(self, inputs: Array) -> Array:
"""Embeds the inputs along the last dimension.
Args:
inputs: input data, all dimensions are considered batch dimensions.
Returns:
Output which is embedded input data. The output shape follows the input,
with an additional `features` dimension appended.
"""
if self.cast_input_dtype:
inputs = inputs.astype(self.cast_input_dtype)
if not jnp.issubdtype(inputs.dtype, jnp.integer):
raise ValueError('Input type must be an integer or unsigned integer.')
if self.one_hot:
iota = lax.iota(jnp.int32, self.num_embeddings)
one_hot = jnp.array(inputs[..., jnp.newaxis] == iota, dtype=self.dtype)
output = jnp.dot(one_hot, jnp.asarray(self.embedding, self.dtype))
else:
output = jnp.asarray(self.embedding, self.dtype)[inputs]
output = with_sharding_constraint(output, ('batch', 'length', 'embed'))
return output
def attend(self, query: Array) -> Array:
"""Attend over the embedding using a query array.
Args:
query: array with last dimension equal the feature depth `features` of the
embedding.
Returns:
An array with final dim `num_embeddings` corresponding to the batched
inner-product of the array of query vectors against each embedding.
Commonly used for weight-sharing between embeddings and logit transform
in NLP models.
"""
dtype = self.attend_dtype if self.attend_dtype is not None else self.dtype
return jnp.dot(query, jnp.asarray(self.embedding, dtype).T)
class RelativePositionBiases(nn.Module):
"""Adds T5-style relative positional embeddings to the attention logits.
Attributes:
num_buckets: Number of buckets to bucket distances between key and query
positions into.
max_distance: Maximum distance before everything is lumped into the last
distance bucket.
num_heads: Number of heads in the attention layer. Each head will get a
different relative position weighting.
dtype: Type of arrays through this module.
embedding_init: initializer for relative embedding table.
"""
num_buckets: int
max_distance: int
num_heads: int
dtype: Any
embedding_init: Callable[..., Array] = nn.linear.default_embed_init
@staticmethod
def _relative_position_bucket(relative_position,
bidirectional=True,
num_buckets=32,
max_distance=128):
"""Translate relative position to a bucket number for relative attention.
The relative position is defined as memory_position - query_position, i.e.
the distance in tokens from the attending position to the attended-to
position. If bidirectional=False, then positive relative positions are
invalid.
We use smaller buckets for small absolute relative_position and larger
buckets for larger absolute relative_positions. All relative
positions >=max_distance map to the same bucket. All relative
positions <=-max_distance map to the same bucket. This should allow for
more graceful generalization to longer sequences than the model has been
trained on.
Args:
relative_position: an int32 array
bidirectional: a boolean - whether the attention is bidirectional
num_buckets: an integer
max_distance: an integer
Returns:
a Tensor with the same shape as relative_position, containing int32
values in the range [0, num_buckets)
"""
ret = 0
n = -relative_position
if bidirectional:
num_buckets //= 2
ret += (n < 0).astype(np.int32) * num_buckets
n = np.abs(n)
else:
n = np.maximum(n, 0)
# now n is in the range [0, inf)
max_exact = num_buckets // 2
is_small = (n < max_exact)
val_if_large = max_exact + (
np.log(n.astype(np.float32) / max_exact + np.finfo(np.float32).eps) /
np.log(max_distance / max_exact) *
(num_buckets - max_exact)).astype(np.int32)
val_if_large = np.minimum(val_if_large, num_buckets - 1)
ret += np.where(is_small, n, val_if_large)
return ret
@nn.compact
def __call__(self, qlen, klen, bidirectional=True):
"""Produce relative position embedding attention biases.
Args:
qlen: attention query length.
klen: attention key length.
bidirectional: whether to allow positive memory-query relative position
embeddings.
Returns:
output: `(1, len, q_len, k_len)` attention bias
"""
# TODO(levskaya): should we be computing this w. numpy as a program
# constant?
context_position = np.arange(qlen, dtype=jnp.int32)[:, None]
memory_position = np.arange(klen, dtype=jnp.int32)[None, :]
relative_position = memory_position - context_position # shape (qlen, klen)
rp_bucket = self._relative_position_bucket(
relative_position,
bidirectional=bidirectional,
num_buckets=self.num_buckets,
max_distance=self.max_distance)
relative_attention_bias = param_with_axes(
'rel_embedding',
self.embedding_init, (self.num_heads, self.num_buckets),
jnp.float32,
axes=('heads', 'relpos_buckets'))
relative_attention_bias = jnp.asarray(relative_attention_bias, self.dtype)
# Instead of using a slow gather, we create a leading-dimension one-hot
# array from rp_bucket and use it to perform the gather-equivalent via a
# contraction, i.e.:
# (num_head, num_buckets) x (num_buckets one-hot, qlen, klen).
# This is equivalent to relative_attention_bias[:, rp_bucket]
bcast_iota = lax.broadcasted_iota(jnp.int32, (self.num_buckets, 1, 1), 0)
rp_bucket_one_hot = jnp.array(
rp_bucket[jnp.newaxis, ...] == bcast_iota, dtype=self.dtype)
# --> shape (qlen, klen, num_heads)
values = lax.dot_general(
relative_attention_bias,
rp_bucket_one_hot,
(
((1,), (0,)), # rhs, lhs contracting dims
((), ()))) # no batched dims
# Add a singleton batch dimension.
# --> shape (1, num_heads, qlen, klen)
return values[jnp.newaxis, ...]
#------------------------------------------------------------------------------
# T5 Layernorm - no subtraction of mean or bias.
#------------------------------------------------------------------------------
# class LayerNorm(nn.Module):
# """T5 Layer normalization operating on the last axis of the input data."""
# epsilon: float = 1e-6
# dtype: Any = jnp.float32
# scale_init: Initializer = nn.initializers.ones
# @nn.compact
# def __call__(self, x: jnp.ndarray) -> jnp.ndarray:
# """Applies layer normalization on the input."""
# x = jnp.asarray(x, jnp.float32)
# features = x.shape[-1]
# mean2 = jnp.mean(lax.square(x), axis=-1, keepdims=True)
# y = jnp.asarray(x * lax.rsqrt(mean2 + self.epsilon), self.dtype)
# scale = param_with_axes(
# 'scale', self.scale_init, (features,), jnp.float32, axes=('embed',))
# scale = jnp.asarray(scale, self.dtype)
# return y * scale
class LayerNorm(nn.Module):
"""Layer normalization (https://arxiv.org/abs/1607.06450).
Operates on the last axis of the input data.
It normalizes the activations of the layer for each given example in a
batch independently, rather than across a batch like Batch Normalization.
i.e. applies a transformation that maintains the mean activation within
each example close to 0 and the activation standard deviation close to 1.
Attributes:
epsilon: A small float added to variance to avoid dividing by zero.
dtype: the dtype of the computation (default: float32).
use_bias: If True, bias (beta) is added.
use_scale: If True, multiply by scale (gamma). When the next layer is linear
(also e.g. nn.relu), this can be disabled since the scaling will be done
by the next layer.
bias_init: Initializer for bias, by default, zero.
scale_init: Initializer for scale, by default, one.
"""
epsilon: float = 1e-6
dtype: Any = jnp.float32
params_dtype: DType = jnp.float32
use_bias: bool = True
use_scale: bool = True
bias_init: Callable[[PRNGKey, Shape, Any], Array] = nn.initializers.zeros
scale_init: Callable[[PRNGKey, Shape, Any], Array] = nn.initializers.ones
@nn.compact
def __call__(self, x):
"""Applies layer normalization on the input.
Args:
x: the inputs
Returns:
Normalized inputs (the same shape as inputs).
"""
x = jnp.asarray(x, jnp.float32)
features = x.shape[-1]
mean = jnp.mean(x, axis=-1, keepdims=True)
mean2 = jnp.mean(lax.square(x), axis=-1, keepdims=True)
var = mean2 - lax.square(mean)
mul = lax.rsqrt(var + self.epsilon)
if self.use_scale:
scale = param_with_axes('scale', self.scale_init, (features,), self.params_dtype, axes=('embed',))
mul = mul * jnp.asarray(scale, self.dtype)
y = (x - mean) * mul
if self.use_bias:
bias = param_with_axes('bias', self.bias_init, (features,), self.params_dtype, axes=('embed',))
y = y + jnp.asarray(bias, self.dtype)
return jnp.asarray(y, self.dtype)
#------------------------------------------------------------------------------
# Mask-making utility functions.
#------------------------------------------------------------------------------
def make_attention_mask(query_input: Array,
key_input: Array,
pairwise_fn: Callable = jnp.multiply,
extra_batch_dims: int = 0,
dtype: DType = jnp.float32) -> Array:
"""Mask-making helper for attention weights.
In case of 1d inputs (i.e., `[batch, len_q]`, `[batch, len_kv]`, the
attention weights will be `[batch, heads, len_q, len_kv]` and this
function will produce `[batch, 1, len_q, len_kv]`.
Args:
query_input: a batched, flat input of query_length size
key_input: a batched, flat input of key_length size
pairwise_fn: broadcasting elementwise comparison function
extra_batch_dims: number of extra batch dims to add singleton axes for, none
by default
dtype: mask return dtype
Returns:
A `[batch, 1, len_q, len_kv]` shaped mask for 1d attention.
"""
# [batch, len_q, len_kv]
mask = pairwise_fn(
# [batch, len_q] -> [batch, len_q, 1]
jnp.expand_dims(query_input, axis=-1),
# [batch, len_q] -> [batch, 1, len_kv]
jnp.expand_dims(key_input, axis=-2))
# [batch, 1, len_q, len_kv]. This creates the head dim.
mask = jnp.expand_dims(mask, axis=-3)
mask = jnp.expand_dims(mask, axis=tuple(range(extra_batch_dims)))
return mask.astype(dtype)
def make_causal_mask(x: Array,
extra_batch_dims: int = 0,
dtype: DType = jnp.float32) -> Array:
"""Make a causal mask for self-attention.
In case of 1d inputs (i.e., `[batch, len]`, the self-attention weights
will be `[batch, heads, len, len]` and this function will produce a
causal mask of shape `[batch, 1, len, len]`.
Note that a causal mask does not depend on the values of x; it only depends on
the shape. If x has padding elements, they will not be treated in a special
manner.
Args:
x: input array of shape `[batch, len]`
extra_batch_dims: number of batch dims to add singleton axes for, none by
default
dtype: mask return dtype
Returns:
A `[batch, 1, len, len]` shaped causal mask for 1d attention.
"""
idxs = jnp.broadcast_to(jnp.arange(x.shape[-1], dtype=jnp.int32), x.shape)
return make_attention_mask(
idxs,
idxs,
jnp.greater_equal,
extra_batch_dims=extra_batch_dims,
dtype=dtype)
def combine_masks(*masks: Optional[Array], dtype: DType = jnp.float32):
"""Combine attention masks.
Args:
*masks: set of attention mask arguments to combine, some can be None.
dtype: final mask dtype
Returns:
Combined mask, reduced by logical and, returns None if no masks given.
"""
masks = [m for m in masks if m is not None]
if not masks:
return None
assert all(map(lambda x: x.ndim == masks[0].ndim, masks)), (
f'masks must have same rank: {tuple(map(lambda x: x.ndim, masks))}')
mask, *other_masks = masks
for other_mask in other_masks:
mask = jnp.logical_and(mask, other_mask)
return mask.astype(dtype)
def combine_biases(*masks: Optional[Array]):
"""Combine attention biases.
Args:
*masks: set of attention bias arguments to combine, some can be None.
Returns:
Combined mask, reduced by summation, returns None if no masks given.
"""
masks = [m for m in masks if m is not None]
if not masks:
return None
assert all(map(lambda x: x.ndim == masks[0].ndim, masks)), (
f'masks must have same rank: {tuple(map(lambda x: x.ndim, masks))}')
mask, *other_masks = masks
for other_mask in other_masks:
mask = mask + other_mask
return mask
def make_decoder_mask(decoder_target_tokens: Array,
dtype: DType,
decoder_causal_attention: Optional[Array] = None,
decoder_segment_ids: Optional[Array] = None) -> Array:
"""Compute the self-attention mask for a decoder.
Decoder mask is formed by combining a causal mask, a padding mask and an
optional packing mask. If decoder_causal_attention is passed, it makes the
masking non-causal for positions that have value of 1.
A prefix LM is applied to a dataset which has a notion of "inputs" and
"targets", e.g., a machine translation task. The inputs and targets are
concatenated to form a new target. `decoder_target_tokens` is the concatenated
decoder output tokens.
The "inputs" portion of the concatenated sequence can attend to other "inputs"
tokens even for those at a later time steps. In order to control this
behavior, `decoder_causal_attention` is necessary. This is a binary mask with
a value of 1 indicating that the position belonged to "inputs" portion of the
original dataset.
Example:
Suppose we have a dataset with two examples.
ds = [{"inputs": [6, 7], "targets": [8]},
{"inputs": [3, 4], "targets": [5]}]
After the data preprocessing with packing, the two examples are packed into
one example with the following three fields (some fields are skipped for
simplicity).
decoder_target_tokens = [[6, 7, 8, 3, 4, 5, 0]]
decoder_segment_ids = [[1, 1, 1, 2, 2, 2, 0]]
decoder_causal_attention = [[1, 1, 0, 1, 1, 0, 0]]
where each array has [batch, length] shape with batch size being 1. Then,
this function computes the following mask.
mask = [[[[1, 1, 0, 0, 0, 0, 0],
[1, 1, 0, 0, 0, 0, 0],
[1, 1, 1, 0, 0, 0, 0],
[0, 0, 0, 1, 1, 0, 0],
[0, 0, 0, 1, 1, 0, 0],
[0, 0, 0, 1, 1, 1, 0],
[0, 0, 0, 0, 0, 0, 0]]]]
mask[b, 1, :, :] represents the mask for the example `b` in the batch.
Because mask is for a self-attention layer, the mask's shape is a square of
shape [query length, key length].
mask[b, 1, i, j] = 1 means that the query token at position i can attend to
the key token at position j.
Args:
decoder_target_tokens: decoder output tokens. [batch, length]
dtype: dtype of the output mask.
decoder_causal_attention: a binary mask indicating which position should
only attend to earlier positions in the sequence. Others will attend
bidirectionally. [batch, length]
decoder_segment_ids: decoder segmentation info for packed examples. [batch,
length]
Returns:
the combined decoder mask.
"""
masks = []
# The same mask is applied to all attention heads. So the head dimension is 1,
# i.e., the mask will be broadcast along the heads dim.
# [batch, 1, length, length]
causal_mask = make_causal_mask(decoder_target_tokens, dtype=dtype)
# Positions with value 1 in `decoder_causal_attneition` can attend
# bidirectionally.
if decoder_causal_attention is not None:
# [batch, 1, length, length]
inputs_mask = make_attention_mask(
decoder_causal_attention,
decoder_causal_attention,
jnp.logical_and,
dtype=dtype)
masks.append(jnp.logical_or(causal_mask, inputs_mask).astype(dtype))
else:
masks.append(causal_mask)
# Padding mask.
masks.append(
make_attention_mask(
decoder_target_tokens > 0, decoder_target_tokens > 0, dtype=dtype))
# Packing mask
if decoder_segment_ids is not None:
masks.append(
make_attention_mask(
decoder_segment_ids, decoder_segment_ids, jnp.equal, dtype=dtype))
return combine_masks(*masks, dtype=dtype)
| 2 |
0 | hf_public_repos/bloom-jax-inference/bloom_inference | hf_public_repos/bloom-jax-inference/bloom_inference/modeling_bloom/generation_flax_utils.py | # coding=utf-8
# Copyright 2021 The Google AI Flax Team Authors, and The HuggingFace Inc. team.
# Copyright (c) 2020, NVIDIA CORPORATION. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
from functools import partial
from typing import Dict, Optional
import numpy as np
import flax
import jax
import jax.numpy as jnp
from jax import lax
from .generation_flax_logits_process import (
FlaxForcedBOSTokenLogitsProcessor,
FlaxForcedEOSTokenLogitsProcessor,
FlaxLogitsProcessorList,
FlaxMinLengthLogitsProcessor,
FlaxTemperatureLogitsWarper,
FlaxTopKLogitsWarper,
FlaxTopPLogitsWarper,
)
from transformers.utils import ModelOutput, logging
logger = logging.get_logger(__name__)
@flax.struct.dataclass
class FlaxGreedySearchOutput(ModelOutput):
"""
Flax Base class for outputs of decoder-only generation models using greedy search.
Args:
sequences (`jnp.ndarray` of shape `(batch_size, max_length)`):
The generated sequences.
"""
sequences: jnp.ndarray = None
@flax.struct.dataclass
class FlaxSampleOutput(ModelOutput):
"""
Flax Base class for outputs of decoder-only generation models using sampling.
Args:
sequences (`jnp.ndarray` of shape `(batch_size, max_length)`):
The generated sequences.
"""
sequences: jnp.ndarray = None
@flax.struct.dataclass
class FlaxBeamSearchOutput(ModelOutput):
"""
Flax Base class for outputs of decoder-only generation models using greedy search.
Args:
sequences (`jnp.ndarray` of shape `(batch_size, max_length)`):
The generated sequences.
scores (`jnp.ndarray` of shape `(batch_size,)`):
The scores (log probabilites) of the generated sequences.
"""
sequences: jnp.ndarray = None
scores: jnp.ndarray = None
@flax.struct.dataclass
class GreedyState:
cur_len: jnp.ndarray
sequences: jnp.ndarray
running_token: jnp.ndarray
is_sent_finished: jnp.ndarray
model_kwargs: Dict[str, jnp.ndarray]
@flax.struct.dataclass
class SampleState:
cur_len: jnp.ndarray
sequences: jnp.ndarray
running_token: jnp.ndarray
is_sent_finished: jnp.ndarray
prng_key: jnp.ndarray
model_kwargs: Dict[str, jnp.ndarray]
@flax.struct.dataclass
class BeamSearchState:
cur_len: jnp.ndarray
running_sequences: jnp.ndarray
running_scores: jnp.ndarray
sequences: jnp.ndarray
scores: jnp.ndarray
is_sent_finished: jnp.ndarray
model_kwargs: Dict[str, jnp.ndarray]
class FlaxGenerationMixin:
"""
A class containing all functions for auto-regressive text generation, to be used as a mixin in
[`FlaxPreTrainedModel`].
The class exposes [`~generation_flax_utils.FlaxGenerationMixin.generate`], which can be used for:
- *greedy decoding* by calling [`~generation_flax_utils.FlaxGenerationMixin._greedy_search`] if
`num_beams=1` and `do_sample=False`.
- *multinomial sampling* by calling [`~generation_flax_utils.FlaxGenerationMixin._sample`] if `num_beams=1`
and `do_sample=True`.
- *beam-search decoding* by calling [`~generation_utils.FlaxGenerationMixin._beam_search`] if `num_beams>1`
and `do_sample=False`.
"""
@staticmethod
def _run_loop_in_debug(cond_fn, body_fn, init_state):
"""
Run generation in untraced mode. This should only be used for debugging purposes.
"""
state = init_state
while cond_fn(state):
state = body_fn(state)
return state
def _prepare_encoder_decoder_kwargs_for_generation(self, input_ids, params, model_kwargs):
encoder_kwargs = {
argument: value
for argument, value in model_kwargs.items()
if not (argument.startswith("decoder_") or argument.startswith("cross_attn"))
}
model_kwargs["encoder_outputs"] = self.encode(input_ids, params=params, return_dict=True, **encoder_kwargs)
return model_kwargs
@staticmethod
def _expand_to_num_beams(tensor, num_beams):
return jnp.broadcast_to(tensor[:, None], (tensor.shape[0], num_beams) + tensor.shape[1:])
def _adapt_logits_for_beam_search(self, logits):
"""
This function can be overwritten in the specific modeling_flax_<model-name>.py classes to allow for custom beam
search behavior. Note that the only model that overwrites this method is [`~transformes.FlaxMarianMTModel`].
"""
return logits
def generate(
self,
input_ids: jnp.ndarray,
max_length: Optional[int] = None,
pad_token_id: Optional[int] = None,
bos_token_id: Optional[int] = None,
eos_token_id: Optional[int] = None,
decoder_start_token_id: Optional[int] = None,
do_sample: Optional[bool] = None,
prng_key: Optional[jnp.ndarray] = None,
top_k: Optional[int] = None,
top_p: Optional[float] = None,
temperature: Optional[float] = None,
num_beams: Optional[int] = None,
no_repeat_ngram_size: Optional[int] = None,
min_length: Optional[int] = None,
forced_bos_token_id: Optional[int] = None,
forced_eos_token_id: Optional[int] = None,
length_penalty: Optional[float] = None,
early_stopping: Optional[bool] = None,
trace: bool = True,
params: Optional[Dict[str, jnp.ndarray]] = None,
**model_kwargs,
):
r"""
Generates sequences of token ids for models with a language modeling head. The method supports the following
generation methods for text-decoder, text-to-text, speech-to-text, and vision-to-text models:
- *greedy decoding* by calling [`~generation_flax_utils.FlaxGenerationMixin._greedy_search`] if
`num_beams=1` and `do_sample=False`.
- *multinomial sampling* by calling [`~generation_flax_utils.FlaxGenerationMixin._sample`] if `num_beams=1`
and `do_sample=True`.
- *beam-search decoding* by calling [`~generation_utils.FlaxGenerationMixin._beam_search`] if `num_beams>1`
and `do_sample=False`.
<Tip warning={true}>
Apart from `inputs`, all the arguments below will default to the value of the attribute of the same name as
defined in the model's config (`config.json`) which in turn defaults to the
[`~modeling_utils.PretrainedConfig`] of the model.
</Tip>
Most of these parameters are explained in more detail in [this blog
post](https://huggingface.co/blog/how-to-generate).
Parameters:
input_ids (`jnp.ndarray` of shape `(batch_size, sequence_length)`):
The sequence used as a prompt for the generation.
max_length (`int`, *optional*, defaults to 20):
The maximum length of the sequence to be generated.
do_sample (`bool`, *optional*, defaults to `False`):
Whether or not to use sampling ; use greedy decoding otherwise.
temperature (`float`, *optional*, defaults to 1.0):
The value used to module the next token probabilities.
top_k (`int`, *optional*, defaults to 50):
The number of highest probability vocabulary tokens to keep for top-k-filtering.
top_p (`float`, *optional*, defaults to 1.0):
If set to float < 1, only the most probable tokens with probabilities that add up to `top_p` or higher
are kept for generation.
pad_token_id (`int`, *optional*):
The id of the *padding* token.
bos_token_id (`int`, *optional*):
The id of the *beginning-of-sequence* token.
eos_token_id (`int`, *optional*):
The id of the *end-of-sequence* token.
num_beams (`int`, *optional*, defaults to 1):
Number of beams for beam search. 1 means no beam search.
decoder_start_token_id (`int`, *optional*):
If an encoder-decoder model starts decoding with a different token than *bos*, the id of that token.
trace (`bool`, *optional*, defaults to `True`):
Whether to trace generation. Setting `trace=False` should only be used for debugging and will lead to a
considerably slower runtime.
params (`Dict[str, jnp.ndarray]`, *optional*):
Optionally the model parameters can be passed. Can be useful for parallelized generation.
model_kwargs:
Additional model specific kwargs will be forwarded to the `forward` function of the model. If the model
is an encoder-decoder model, encoder specific kwargs should not be prefixed and decoder specific kwargs
should be prefixed with *decoder_*. Also accepts `encoder_outputs` to skip encoder part.
Return:
[`~utils.ModelOutput`].
Examples:
```python
>>> from transformers import AutoTokenizer, FlaxAutoModelForCausalLM
>>> tokenizer = AutoTokenizer.from_pretrained("distilgpt2")
>>> model = FlaxAutoModelForCausalLM.from_pretrained("distilgpt2")
>>> input_context = "The dog"
>>> # encode input context
>>> input_ids = tokenizer(input_context, return_tensors="np").input_ids
>>> # generate candidates using sampling
>>> outputs = model.generate(input_ids=input_ids, max_length=20, top_k=30, do_sample=True)
>>> tokenizer.batch_decode(outputs, skip_special_tokens=True)
```"""
# set init values
max_length = max_length if max_length is not None else self.config.max_length
min_length = min_length if min_length is not None else self.config.min_length
bos_token_id = bos_token_id if bos_token_id is not None else self.config.bos_token_id
pad_token_id = pad_token_id if pad_token_id is not None else self.config.pad_token_id
eos_token_id = eos_token_id if eos_token_id is not None else self.config.eos_token_id
decoder_start_token_id = (
decoder_start_token_id if decoder_start_token_id is not None else self.config.decoder_start_token_id
)
prng_key = prng_key if prng_key is not None else jax.random.PRNGKey(0)
if decoder_start_token_id is None and self.config.is_encoder_decoder:
raise ValueError("`decoder_start_token_id` has to be defined for encoder-decoder generation.")
if min_length is not None and min_length > max_length:
raise ValueError(
f"Unfeasable length constraints: the minimum length ({min_length}) is larger than the maximum "
f"length ({max_length})"
)
if self.config.is_encoder_decoder:
# add encoder_outputs to model_kwargs
if model_kwargs.get("encoder_outputs") is None:
model_kwargs = self._prepare_encoder_decoder_kwargs_for_generation(input_ids, params, model_kwargs)
# prepare decoder_input_ids for generation
input_ids = jnp.ones((input_ids.shape[0], 1), dtype="i4") * decoder_start_token_id
do_sample = do_sample if do_sample is not None else self.config.do_sample
num_beams = num_beams if num_beams is not None else self.config.num_beams
if not do_sample and num_beams == 1:
logits_processor = self._get_logits_processor(
no_repeat_ngram_size, min_length, max_length, eos_token_id, forced_bos_token_id, forced_eos_token_id
)
return self._greedy_search(
input_ids,
max_length,
pad_token_id,
eos_token_id,
logits_processor=logits_processor,
trace=trace,
params=params,
model_kwargs=model_kwargs,
)
elif do_sample and num_beams == 1:
logits_warper = self._get_logits_warper(top_k=top_k, top_p=top_p, temperature=temperature)
logits_processor = self._get_logits_processor(
no_repeat_ngram_size, min_length, max_length, eos_token_id, forced_bos_token_id, forced_eos_token_id
)
return self._sample(
input_ids,
max_length,
pad_token_id,
eos_token_id,
prng_key,
logits_warper=logits_warper,
logits_processor=logits_processor,
trace=trace,
params=params,
model_kwargs=model_kwargs,
)
elif not do_sample and num_beams > 1:
# broadcast input_ids & encoder_outputs
input_ids = self._expand_to_num_beams(input_ids, num_beams=num_beams)
if "encoder_outputs" in model_kwargs:
model_kwargs["encoder_outputs"]["last_hidden_state"] = self._expand_to_num_beams(
model_kwargs["encoder_outputs"]["last_hidden_state"], num_beams=num_beams
)
if "attention_mask" in model_kwargs:
model_kwargs["attention_mask"] = self._expand_to_num_beams(
model_kwargs["attention_mask"], num_beams=num_beams
)
logits_processor = self._get_logits_processor(
no_repeat_ngram_size, min_length, max_length, eos_token_id, forced_bos_token_id, forced_eos_token_id
)
return self._beam_search(
input_ids,
max_length,
pad_token_id,
eos_token_id,
length_penalty=length_penalty,
early_stopping=early_stopping,
logits_processor=logits_processor,
trace=trace,
params=params,
model_kwargs=model_kwargs,
)
else:
raise NotImplementedError("`Beam sampling is currently not implemented.")
def _get_logits_warper(
self, top_k: Optional[int] = None, top_p: Optional[float] = None, temperature: Optional[float] = None
) -> FlaxLogitsProcessorList:
"""
This class returns a [`FlaxLogitsProcessorList`] list object that contains all relevant [`FlaxLogitsWarper`]
instances used for multinomial sampling.
"""
# init warp parameters
top_k = top_k if top_k is not None else self.config.top_k
top_p = top_p if top_p is not None else self.config.top_p
temperature = temperature if temperature is not None else self.config.temperature
# instantiate warpers list
warpers = FlaxLogitsProcessorList()
# the following idea is largely copied from this PR: https://github.com/huggingface/transformers/pull/5420/files
# all samplers can be found in `generation_utils_samplers.py`
if temperature is not None and temperature != 1.0:
warpers.append(FlaxTemperatureLogitsWarper(temperature))
if top_k is not None and top_k != 0:
warpers.append(FlaxTopKLogitsWarper(top_k=top_k, min_tokens_to_keep=1))
if top_p is not None and top_p < 1.0:
warpers.append(FlaxTopPLogitsWarper(top_p=top_p, min_tokens_to_keep=1))
return warpers
def _get_logits_processor(
self,
no_repeat_ngram_size: int,
min_length: int,
max_length: int,
eos_token_id: int,
forced_bos_token_id: int,
forced_eos_token_id: int,
) -> FlaxLogitsProcessorList:
"""
This class returns a [`FlaxLogitsProcessorList`] list object that contains all relevant [`FlaxLogitsProcessor`]
instances used to modify the scores of the language model head.
"""
processors = FlaxLogitsProcessorList()
# init warp parameters
no_repeat_ngram_size = (
no_repeat_ngram_size if no_repeat_ngram_size is not None else self.config.no_repeat_ngram_size
)
eos_token_id = eos_token_id if eos_token_id is not None else self.config.eos_token_id
forced_bos_token_id = (
forced_bos_token_id if forced_bos_token_id is not None else self.config.forced_bos_token_id
)
forced_eos_token_id = (
forced_eos_token_id if forced_eos_token_id is not None else self.config.forced_eos_token_id
)
# the following idea is largely copied from this PR: https://github.com/huggingface/transformers/pull/5420/files
# all samplers can be found in `generation_utils_samplers.py`
if min_length is not None and eos_token_id is not None and min_length > -1:
processors.append(FlaxMinLengthLogitsProcessor(min_length, eos_token_id))
if forced_bos_token_id is not None:
processors.append(FlaxForcedBOSTokenLogitsProcessor(forced_bos_token_id))
if forced_eos_token_id is not None:
processors.append(FlaxForcedEOSTokenLogitsProcessor(max_length, forced_eos_token_id))
return processors
def _greedy_search(
self,
input_ids: None,
max_length: Optional[int] = None,
pad_token_id: Optional[int] = None,
eos_token_id: Optional[int] = None,
logits_processor: Optional[FlaxLogitsProcessorList] = None,
trace: bool = True,
params: Optional[Dict[str, jnp.ndarray]] = None,
model_kwargs: Optional[Dict[str, jnp.ndarray]] = None,
):
# init values
max_length = max_length if max_length is not None else self.config.max_length
pad_token_id = pad_token_id if pad_token_id is not None else self.config.pad_token_id
eos_token_id = eos_token_id if eos_token_id is not None else self.config.eos_token_id
batch_size, cur_len = input_ids.shape
eos_token_id = jnp.array(eos_token_id)
pad_token_id = jnp.array(pad_token_id)
cur_len = jnp.array(cur_len)
# per batch-item holding current token in loop.
sequences = jnp.full((batch_size, max_length), pad_token_id, dtype=jnp.int32)
sequences = lax.dynamic_update_slice(sequences, input_ids, (0, 0))
# per batch-item state bit indicating if sentence has finished.
is_sent_finished = jnp.zeros((batch_size,), dtype=jnp.bool_)
# For Seq2Seq generation, we only need to use the decoder instead of the whole model in generation loop
# and pass it the `encoder_outputs`, which are part of the `model_kwargs`.
model = self.decode if self.config.is_encoder_decoder else self
# initialize model specific kwargs
model_kwargs = self.prepare_inputs_for_generation(input_ids, max_length, **model_kwargs)
# initialize state
state = GreedyState(
cur_len=cur_len,
sequences=sequences,
running_token=input_ids,
is_sent_finished=is_sent_finished,
model_kwargs=model_kwargs,
)
def greedy_search_cond_fn(state):
"""state termination condition fn."""
has_reached_max_length = state.cur_len == max_length
all_sequence_finished = jnp.all(state.is_sent_finished)
finish_generation = jnp.logical_or(has_reached_max_length, all_sequence_finished)
return ~finish_generation
def greedy_search_body_fn(state):
"""state update fn."""
model_outputs = model(state.running_token, params=params, **state.model_kwargs)
logits = model_outputs.logits[:, -1]
# apply min_length, ...
logits = logits_processor(state.sequences, logits, state.cur_len)
next_token = jnp.argmax(logits, axis=-1)
next_token = next_token * ~state.is_sent_finished + pad_token_id * state.is_sent_finished
next_is_sent_finished = state.is_sent_finished | (next_token == eos_token_id)
next_token = next_token[:, None]
next_sequences = lax.dynamic_update_slice(state.sequences, next_token, (0, state.cur_len))
next_model_kwargs = self.update_inputs_for_generation(model_outputs, state.model_kwargs)
return GreedyState(
cur_len=state.cur_len + 1,
sequences=next_sequences,
running_token=next_token,
is_sent_finished=next_is_sent_finished,
model_kwargs=next_model_kwargs,
)
# The very first prompt often has sequence length > 1, so run outside of `lax.while_loop` to comply with TPU
if input_ids.shape[1] > 1:
state = greedy_search_body_fn(state)
if not trace:
state = self._run_loop_in_debug(greedy_search_cond_fn, greedy_search_body_fn, state)
else:
state = lax.while_loop(greedy_search_cond_fn, greedy_search_body_fn, state)
return FlaxGreedySearchOutput(sequences=state.sequences)
def _sample(
self,
input_ids: None,
max_length: Optional[int] = None,
pad_token_id: Optional[int] = None,
eos_token_id: Optional[int] = None,
prng_key: Optional[jnp.ndarray] = None,
logits_processor: Optional[FlaxLogitsProcessorList] = None,
logits_warper: Optional[FlaxLogitsProcessorList] = None,
trace: bool = True,
params: Optional[Dict[str, jnp.ndarray]] = None,
model_kwargs: Optional[Dict[str, jnp.ndarray]] = None,
):
# init values
max_length = max_length if max_length is not None else self.config.max_length
pad_token_id = pad_token_id if pad_token_id is not None else self.config.pad_token_id
eos_token_id = eos_token_id if eos_token_id is not None else self.config.eos_token_id
prng_key = prng_key if prng_key is not None else jax.random.PRNGKey(0)
batch_size, cur_len = input_ids.shape
eos_token_id = jnp.array(eos_token_id)
pad_token_id = jnp.array(pad_token_id)
cur_len = jnp.array(cur_len)
# per batch-item holding current token in loop.
sequences = jnp.full((batch_size, max_length), pad_token_id, dtype=jnp.int32)
sequences = lax.dynamic_update_slice(sequences, input_ids, (0, 0))
# per batch-item state bit indicating if sentence has finished.
is_sent_finished = jnp.zeros((batch_size,), dtype=jnp.bool_)
# For Seq2Seq generation, we only need to use the decoder instead of the whole model in generation loop
# and pass it the `encoder_outputs`, which are part of the `model_kwargs`.
model = self.decode if self.config.is_encoder_decoder else self
# initialize model specific kwargs
model_kwargs = self.prepare_inputs_for_generation(input_ids, max_length, **model_kwargs)
# initialize state
state = SampleState(
cur_len=cur_len,
sequences=sequences,
running_token=input_ids,
is_sent_finished=is_sent_finished,
prng_key=prng_key,
model_kwargs=model_kwargs,
)
def sample_search_cond_fn(state):
"""state termination condition fn."""
has_reached_max_length = state.cur_len == max_length
all_sequence_finished = jnp.all(state.is_sent_finished)
finish_generation = jnp.logical_or(has_reached_max_length, all_sequence_finished)
return ~finish_generation
def sample_search_body_fn(state):
"""state update fn."""
prng_key, prng_key_next = jax.random.split(state.prng_key)
model_outputs = model(state.running_token, params=params, **state.model_kwargs)
logits = model_outputs.logits[:, -1]
# apply min_length, ...
logits = logits_processor(state.sequences, logits, state.cur_len)
# apply top_p, top_k, temperature
logits = logits_warper(logits, logits, state.cur_len)
next_token = jax.random.categorical(prng_key, logits, axis=-1)
next_is_sent_finished = state.is_sent_finished | (next_token == eos_token_id)
next_token = next_token * ~next_is_sent_finished + pad_token_id * next_is_sent_finished
next_token = next_token[:, None]
next_sequences = lax.dynamic_update_slice(state.sequences, next_token, (0, state.cur_len))
next_model_kwargs = self.update_inputs_for_generation(model_outputs, state.model_kwargs)
return SampleState(
cur_len=state.cur_len + 1,
sequences=next_sequences,
running_token=next_token,
is_sent_finished=next_is_sent_finished,
model_kwargs=next_model_kwargs,
prng_key=prng_key_next,
)
# The very first prompt often has sequence length > 1, so run outside of `lax.while_loop` to comply with TPU
if input_ids.shape[1] > 1:
state = sample_search_body_fn(state)
if not trace:
state = self._run_loop_in_debug(sample_search_cond_fn, sample_search_body_fn, state)
else:
state = lax.while_loop(sample_search_cond_fn, sample_search_body_fn, state)
return FlaxSampleOutput(sequences=state.sequences)
def _beam_search(
self,
input_ids: None,
max_length: Optional[int] = None,
pad_token_id: Optional[int] = None,
eos_token_id: Optional[int] = None,
length_penalty: Optional[float] = None,
early_stopping: Optional[bool] = None,
logits_processor: Optional[FlaxLogitsProcessorList] = None,
trace: bool = True,
params: Optional[Dict[str, jnp.ndarray]] = None,
model_kwargs: Optional[Dict[str, jnp.ndarray]] = None,
):
"""
This beam search function is heavily inspired by Flax's official example:
https://github.com/google/flax/blob/master/examples/wmt/train.py#L254
"""
def flatten_beam_dim(tensor):
"""Flattens the first two dimensions of a non-scalar array."""
# ignore scalars (e.g. cache index)
if tensor.ndim == 0:
return tensor
return tensor.reshape((tensor.shape[0] * tensor.shape[1],) + tensor.shape[2:])
def unflatten_beam_dim(tensor, batch_size, num_beams):
"""Unflattens the first, flat batch*beam dimension of a non-scalar array."""
# ignore scalars (e.g. cache index)
if tensor.ndim == 0:
return tensor
return tensor.reshape((batch_size, num_beams) + tensor.shape[1:])
def gather_beams(nested, beam_indices, batch_size, new_num_beams):
"""
Gathers the beam slices indexed by beam_indices into new beam array.
"""
batch_indices = jnp.reshape(
jnp.arange(batch_size * new_num_beams) // new_num_beams, (batch_size, new_num_beams)
)
def gather_fn(tensor):
# ignore scalars (e.g. cache index)
if tensor.ndim == 0:
return tensor
else:
return tensor[batch_indices, beam_indices]
return jax.tree_map(gather_fn, nested)
# init values
max_length = max_length if max_length is not None else self.config.max_length
pad_token_id = pad_token_id if pad_token_id is not None else self.config.pad_token_id
eos_token_id = eos_token_id if eos_token_id is not None else self.config.eos_token_id
length_penalty = length_penalty if length_penalty is not None else self.config.length_penalty
early_stopping = early_stopping if early_stopping is not None else self.config.early_stopping
batch_size, num_beams, cur_len = input_ids.shape
eos_token_id = jnp.array(eos_token_id)
pad_token_id = jnp.array(pad_token_id)
cur_len = jnp.array(cur_len)
# per batch,beam-item holding current token in loop.
sequences = jnp.full((batch_size, num_beams, max_length), pad_token_id, dtype=jnp.int32)
running_sequences = jnp.full((batch_size, num_beams, max_length), pad_token_id, dtype=jnp.int32)
running_sequences = lax.dynamic_update_slice(sequences, input_ids, (0, 0, 0))
# per batch,beam-item state bit indicating if sentence has finished.
is_sent_finished = jnp.zeros((batch_size, num_beams), dtype=jnp.bool_)
# per batch,beam-item score, logprobs
running_scores = jnp.tile(jnp.array([0.0] + [np.array(-1.0e7)] * (num_beams - 1)), [batch_size, 1])
scores = jnp.ones((batch_size, num_beams)) * np.array(-1.0e7)
# For Seq2Seq generation, we only need to use the decoder instead of the whole model in generation loop
# and pass it the `encoder_outputs`, which are part of the `model_kwargs`.
model = self.decode if self.config.is_encoder_decoder else self
# flatten beam dim
if "encoder_outputs" in model_kwargs:
model_kwargs["encoder_outputs"]["last_hidden_state"] = flatten_beam_dim(
model_kwargs["encoder_outputs"]["last_hidden_state"]
)
if "attention_mask" in model_kwargs:
model_kwargs["attention_mask"] = flatten_beam_dim(model_kwargs["attention_mask"])
# initialize model specific kwargs
model_kwargs = self.prepare_inputs_for_generation(flatten_beam_dim(input_ids), max_length, **model_kwargs)
# initialize state
state = BeamSearchState(
cur_len=cur_len,
running_sequences=running_sequences,
running_scores=running_scores,
sequences=sequences,
scores=scores,
is_sent_finished=is_sent_finished,
model_kwargs=model_kwargs,
)
def beam_search_cond_fn(state):
"""beam search state termination condition fn."""
# 1. is less than max length?
not_max_length_yet = state.cur_len < max_length
# 2. can the new beams still improve?
best_running_score = state.running_scores[:, -1:] / (max_length**length_penalty)
worst_finished_score = jnp.where(
state.is_sent_finished, jnp.min(state.scores, axis=1, keepdims=True), np.array(-1.0e7)
)
improvement_still_possible = jnp.all(worst_finished_score < best_running_score)
# 3. is there still a beam that has not finished?
still_open_beam = ~(jnp.all(state.is_sent_finished) & early_stopping)
return not_max_length_yet & still_open_beam & improvement_still_possible
def beam_search_body_fn(state, input_ids_length=1):
"""beam search state update fn."""
# 1. Forward current tokens
# Collect the current position slice along length to feed the fast
# autoregressive decoder model. Flatten the beam dimension into batch
# dimension for feeding into the model.
# unflatten beam dimension
# Unflatten beam dimension in attention cache arrays
input_token = flatten_beam_dim(
lax.dynamic_slice(
state.running_sequences,
(0, 0, state.cur_len - input_ids_length),
(batch_size, num_beams, input_ids_length),
)
)
model_outputs = model(input_token, params=params, **state.model_kwargs)
logits = unflatten_beam_dim(model_outputs.logits[:, -1], batch_size, num_beams)
cache = jax.tree_map(
lambda tensor: unflatten_beam_dim(tensor, batch_size, num_beams), model_outputs.past_key_values
)
# adapt logits for FlaxMarianMTModel
logits = self._adapt_logits_for_beam_search(logits)
# 2. Compute log probs
# get log probabilities from logits,
# process logits with processors (*e.g.* min_length, ...), and
# add new logprobs to existing running logprobs scores.
log_probs = jax.nn.log_softmax(logits)
log_probs = logits_processor(
flatten_beam_dim(running_sequences), flatten_beam_dim(log_probs), state.cur_len
)
log_probs = unflatten_beam_dim(log_probs, batch_size, num_beams)
log_probs = log_probs + jnp.expand_dims(state.running_scores, axis=2)
vocab_size = log_probs.shape[2]
log_probs = log_probs.reshape((batch_size, num_beams * vocab_size))
# 3. Retrieve top-K
# Each item in batch has num_beams * vocab_size candidate sequences.
# For each item, get the top 2*k candidates with the highest log-
# probabilities. We gather the top 2*K beams here so that even if the best
# K sequences reach EOS simultaneously, we have another K sequences
# remaining to continue the live beam search.
# Gather the top 2*K scores from _all_ beams.
# Gather 2*k top beams.
# Recover the beam index by floor division.
# Recover token id by modulo division and expand Id array for broadcasting.
# Update sequences for the 2*K top-k new sequences.
beams_to_keep = 2 * num_beams
topk_log_probs, topk_indices = lax.top_k(log_probs, k=beams_to_keep)
topk_beam_indices = topk_indices // vocab_size
topk_running_sequences = gather_beams(
state.running_sequences, topk_beam_indices, batch_size, beams_to_keep
)
topk_ids = jnp.expand_dims(topk_indices % vocab_size, axis=2)
topk_sequences = lax.dynamic_update_slice(topk_running_sequences, topk_ids, (0, 0, state.cur_len))
# 4. Check which sequences have ended
# Update current sequences:
# Did any of these sequences reach an end marker?
# To prevent these just finished sequences from being added to the current sequences
# set of active beam search sequences, set their log probs to a very large
# negative value.
did_topk_just_finished = topk_sequences[:, :, state.cur_len] == eos_token_id
running_topk_log_probs = topk_log_probs + did_topk_just_finished * np.array(-1.0e7)
# 5. Get running sequences scores for next
# Determine the top k beam indices (from top 2*k beams) from log probs
# and gather top k beams (from top 2*k beams).
next_topk_indices = jnp.flip(lax.top_k(running_topk_log_probs, k=num_beams)[1], axis=1)
next_running_sequences, next_running_scores = gather_beams(
[topk_sequences, running_topk_log_probs], next_topk_indices, batch_size, num_beams
)
# 6. Process topk logits
# Further process log probs:
# - add length penalty
# - make sure no scores can be added anymore if beam is full
# - make sure still running sequences cannot be chosen as finalized beam
topk_log_probs = topk_log_probs / (state.cur_len**length_penalty)
beams_in_batch_are_full = (
jnp.broadcast_to(state.is_sent_finished.all(axis=-1, keepdims=True), did_topk_just_finished.shape)
& early_stopping
)
add_penalty = ~did_topk_just_finished | beams_in_batch_are_full
topk_log_probs += add_penalty * np.array(-1.0e7)
# 7. Get scores, sequences, is sentence finished for next.
# Combine sequences, scores, and flags along the beam dimension and compare
# new finished sequence scores to existing finished scores and select the
# best from the new set of beams
merged_sequences = jnp.concatenate([state.sequences, topk_sequences], axis=1)
merged_scores = jnp.concatenate([state.scores, topk_log_probs], axis=1)
merged_is_sent_finished = jnp.concatenate([state.is_sent_finished, did_topk_just_finished], axis=1)
topk_merged_indices = jnp.flip(lax.top_k(merged_scores, k=num_beams)[1], axis=1)
next_sequences, next_scores, next_is_sent_finished = gather_beams(
[merged_sequences, merged_scores, merged_is_sent_finished], topk_merged_indices, batch_size, num_beams
)
# 8. Update model kwargs.
# Determine the top k beam indices from the original set of all beams.
# With these, gather the top k beam-associated caches.
next_running_indices = gather_beams(topk_beam_indices, next_topk_indices, batch_size, num_beams)
next_cache = gather_beams(cache, next_running_indices, batch_size, num_beams)
model_outputs["past_key_values"] = jax.tree_map(lambda x: flatten_beam_dim(x), next_cache)
next_model_kwargs = self.update_inputs_for_generation(model_outputs, state.model_kwargs)
return BeamSearchState(
cur_len=state.cur_len + 1,
running_scores=next_running_scores,
running_sequences=next_running_sequences,
scores=next_scores,
sequences=next_sequences,
is_sent_finished=next_is_sent_finished,
model_kwargs=next_model_kwargs,
)
# The very first prompt often has sequence length > 1, so run outside of `lax.while_loop` to comply with TPU
if input_ids.shape[-1] > 1:
state = partial(beam_search_body_fn, input_ids_length=input_ids.shape[-1])(state)
if not trace:
state = self._run_loop_in_debug(beam_search_cond_fn, beam_search_body_fn, state)
else:
state = lax.while_loop(beam_search_cond_fn, beam_search_body_fn, state)
# Account for the edge-case where there are no finished sequences for a
# particular batch item. If so, return running sequences for that batch item.
none_finished = jnp.any(state.is_sent_finished, axis=1)
sequences = jnp.where(none_finished[:, None, None], state.sequences, state.running_sequences)
scores = jnp.where(none_finished[:, None], state.scores, state.running_scores)
# take best beam for each batch
sequences = sequences[:, -1]
scores = scores[:, -1]
return FlaxBeamSearchOutput(sequences=sequences, scores=scores)
| 3 |
0 | hf_public_repos/bloom-jax-inference/bloom_inference | hf_public_repos/bloom-jax-inference/bloom_inference/modeling_bloom/configuration_bloom.py | # coding=utf-8
# Copyright 2022 the Big Science Workshop and HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
""" Bloom configuration"""
from transformers.configuration_utils import PretrainedConfig
from transformers.utils import logging
logger = logging.get_logger(__name__)
BLOOM_PRETRAINED_CONFIG_ARCHIVE_MAP = {
"bigscience/bloom": "https://huggingface.co/bigscience/bloom/resolve/main/config.json",
"bigscience/bloom-350m": "https://huggingface.co/bigscience/bloom-350m/blob/main/config.json",
"bigscience/bloom-760m": "https://huggingface.co/bigscience/bloom-760m/blob/main/config.json",
"bigscience/bloom-1b3": "https://huggingface.co/bigscience/bloom-1b3/blob/main/config.json",
"bigscience/bloom-2b5": "https://huggingface.co/bigscience/bloom-2b5/blob/main/config.json",
"bigscience/bloom-6b3": "https://huggingface.co/bigscience/bloom-6b3/blob/main/config.json",
}
class BloomConfig(PretrainedConfig):
"""
This is the configuration class to store the configuration of a [`BloomModel`]. It is used to instantiate a Bloom
model according to the specified arguments, defining the model architecture. Instantiating a configuration with the
defaults will yield a similar configuration to the Bloom architecture
[bigscience/bloom](https://huggingface.co/bigscience/bloom).
Configuration objects inherit from [`PretrainedConfig`] and can be used to control the model outputs. Read the
documentation from [`PretrainedConfig`] for more information.
Args:
vocab_size (`int`, *optional*, defaults to 50257):
Vocabulary size of the Bloom model. Defines the number of different tokens that can be represented by the
`inputs_ids` passed when calling [`BloomModel`].
hidden_size (`int`, *optional*, defaults to 768):
Dimensionality of the embeddings and hidden states.
n_layer (`int`, *optional*, defaults to 12):
Number of hidden layers in the Transformer encoder.
n_head (`int`, *optional*, defaults to 12):
Number of attention heads for each attention layer in the Transformer encoder.
attn_pdrop (`float`, *optional*, defaults to 0.1):
The dropout ratio for the attention.
layer_norm_epsilon (`float`, *optional*, defaults to 1e-5):
The epsilon to use in the layer normalization layers.
initializer_range (`float`, *optional*, defaults to 0.02):
The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
apply_residual_connection_post_layernorm (`bool`, *optional*, defaults to `False`):
If enabled, use the layer norm of the hidden states as the residual in the transformer blocks
skip_bias_add (`bool`, *optional*, defaults to `True`):
If set to `True`, it will skip bias add for each linear layer in the transformer blocks
attention_softmax_in_fp32 (`bool`, *optional*, defaults to `True`):
If set to `True` and the `dtype` is set to `float16` it will scale the input of the Softmax function to
`fp32`
hidden_dropout (`float`, *optional*, defaults to 0.1):
Dropout rate of the dropout function on the bias dropout.
attention_dropout (`float`, *optional*, defaults to 0.1):
Dropout rate applied to the attention probs
use_cache (`bool`, *optional*, defaults to `True`):
Whether or not the model should return the last key/values attentions (not used by all models).
dtype (`str`, *optional*, defaults to `"bfloat16"`):
Precision that has been used for the model's training in Megatron. Please load the model in the correct
precision by doing `model = BloomModel.from_pretrained(model_name, torch_dtype="auto")`.`
pretraining_tp (`int`, *optional*, defaults to `1`):
Experimental feature. Tensor parallelism rank used during pretraining with Megatron. Please refer to [this
document](https://huggingface.co/docs/transformers/parallelism) to understand more about it. This value is
necessary to ensure exact reproducibility of the pretraining results. Please refer to [this
issue](https://github.com/pytorch/pytorch/issues/76232). Note also that this is enabled only when
`slow_but_exact=True`.
slow_but_exact (`bool`, *optional*, defaults to `False`):
Experimental feature. Whether to use slow but exact implementation of the attention mechanism. While
merging the TP rank tensors, due to slicing operations the results may be slightly different between the
model trained on Megatron and our model. Please refer to [this
issue](https://github.com/pytorch/pytorch/issues/76232). A solution to obtain more accurate results is to
enable this feature. Enabling this will hurt the computational time of the inference. Will be probably
resolved in the future once the main model has been fine-tuned with TP_rank=1.
Example:
```python
>>> from transformers import BloomModel, BloomConfig
>>> # Initializing a Bloom configuration
>>> configuration = BloomConfig()
>>> # Initializing a model from the configuration
>>> model = BloomModel(configuration)
>>> # Accessing the model configuration
>>> configuration = model.config
```"""
model_type = "bloom"
keys_to_ignore_at_inference = ["past_key_values"]
attribute_map = {
"num_hidden_layers": "n_layer",
"n_head": "num_attention_heads",
"hidden_size": "n_embed",
"dtype": "torch_dtype",
}
def __init__(
self,
vocab_size=250880,
hidden_size=64,
n_layer=2,
n_head=8,
masked_softmax_fusion=True,
layer_norm_epsilon=1e-5,
initializer_range=0.02,
use_cache=False,
bos_token_id=1,
eos_token_id=2,
apply_residual_connection_post_layernorm=False,
hidden_dropout=0.0,
attention_dropout=0.0,
attention_softmax_in_fp32=True,
pretraining_tp=1, # TP rank used when training with megatron
dtype="bfloat16",
slow_but_exact=False,
**kwargs,
):
self.vocab_size = vocab_size
self.hidden_size = hidden_size
self.n_layer = n_layer
self.n_head = n_head
self.masked_softmax_fusion = masked_softmax_fusion
self.layer_norm_epsilon = layer_norm_epsilon
self.initializer_range = initializer_range
self.use_cache = use_cache
self.pretraining_tp = pretraining_tp
self.apply_residual_connection_post_layernorm = apply_residual_connection_post_layernorm
self.hidden_dropout = hidden_dropout
self.attention_dropout = attention_dropout
self.attention_softmax_in_fp32 = attention_softmax_in_fp32
self.bos_token_id = bos_token_id
self.eos_token_id = eos_token_id
self.dtype = dtype
self.slow_but_exact = slow_but_exact
super().__init__(bos_token_id=bos_token_id, eos_token_id=eos_token_id, **kwargs)
| 4 |
0 | hf_public_repos/bloom-jax-inference/bloom_inference | hf_public_repos/bloom-jax-inference/bloom_inference/modeling_bloom/__init__.py | from .modeling_bloom import FlaxBloomForCausalLM
from .configuration_bloom import BloomConfig | 5 |
0 | hf_public_repos | hf_public_repos/adversarialnlp/setup.cfg | [aliases]
test=pytest | 6 |
0 | hf_public_repos | hf_public_repos/adversarialnlp/setup.py | import sys
from setuptools import setup, find_packages
# PEP0440 compatible formatted version, see:
# https://www.python.org/dev/peps/pep-0440/
#
# release markers:
# X.Y
# X.Y.Z # For bugfix releases
#
# pre-release markers:
# X.YaN # Alpha release
# X.YbN # Beta release
# X.YrcN # Release Candidate
# X.Y # Final release
# version.py defines the VERSION and VERSION_SHORT variables.
# We use exec here so we don't import allennlp whilst setting up.
VERSION = {}
with open("adversarialnlp/version.py", "r") as version_file:
exec(version_file.read(), VERSION)
# make pytest-runner a conditional requirement,
# per: https://github.com/pytest-dev/pytest-runner#considerations
needs_pytest = {'pytest', 'test', 'ptr'}.intersection(sys.argv)
pytest_runner = ['pytest-runner'] if needs_pytest else []
with open('requirements.txt', 'r') as f:
install_requires = [l for l in f.readlines() if not l.startswith('# ')]
setup_requirements = [
# add other setup requirements as necessary
] + pytest_runner
setup(name='adversarialnlp',
version=VERSION["VERSION"],
description='A generice library for crafting adversarial NLP examples, built on AllenNLP and PyTorch.',
long_description=open("README.md").read(),
long_description_content_type="text/markdown",
classifiers=[
'Intended Audience :: Science/Research',
'Development Status :: 3 - Alpha',
'License :: OSI Approved :: Apache Software License',
'Programming Language :: Python :: 3.6',
'Topic :: Scientific/Engineering :: Artificial Intelligence',
],
keywords='adversarialnlp allennlp NLP deep learning machine reading',
url='https://github.com/huggingface/adversarialnlp',
author='Thomas WOLF',
author_email='[email protected]',
license='Apache',
packages=find_packages(exclude=["*.tests", "*.tests.*",
"tests.*", "tests"]),
install_requires=install_requires,
scripts=["bin/adversarialnlp"],
setup_requires=setup_requirements,
tests_require=[
'pytest',
],
include_package_data=True,
python_requires='>=3.6.1',
zip_safe=False)
| 7 |
0 | hf_public_repos | hf_public_repos/adversarialnlp/requirements.txt | # Library dependencies for the python code. You need to install these with
# `pip install -r requirements.txt` before you can run this.
# NOTE: all essential packages must be placed under a section named 'ESSENTIAL ...'
# so that the script `./scripts/check_requirements_and_setup.py` can find them.
#### ESSENTIAL LIBRARIES FOR MAIN FUNCTIONALITY ####
# This installs Pytorch for CUDA 8 only. If you are using a newer version,
# please visit http://pytorch.org/ and install the relevant version.
torch>=0.4.1,<0.5.0
# Parameter parsing (but not on Windows).
jsonnet==0.10.0 ; sys.platform != 'win32'
# Adds an @overrides decorator for better documentation and error checking when using subclasses.
overrides
# Used by some old code. We moved away from it because it's too slow, but some old code still
# imports this.
nltk
# Mainly used for the faster tokenizer.
spacy>=2.0,<2.1
# Used by span prediction models.
numpy
# Used for reading configuration info out of numpy-style docstrings.
numpydoc==0.8.0
# Used in coreference resolution evaluation metrics.
scipy
scikit-learn
# Write logs for training visualisation with the Tensorboard application
# Install the Tensorboard application separately (part of tensorflow) to view them.
tensorboardX==1.2
# Required by torch.utils.ffi
cffi==1.11.2
# aws commandline tools for running on Docker remotely.
# second requirement is to get botocore < 1.11, to avoid the below bug
awscli>=1.11.91
# Accessing files from S3 directly.
boto3
# REST interface for models
flask==0.12.4
flask-cors==3.0.3
gevent==1.3.6
# Used by semantic parsing code to strip diacritics from unicode strings.
unidecode
# Used by semantic parsing code to parse SQL
parsimonious==0.8.0
# Used by semantic parsing code to format and postprocess SQL
sqlparse==0.2.4
# For text normalization
ftfy
#### ESSENTIAL LIBRARIES USED IN SCRIPTS ####
# Plot graphs for learning rate finder
matplotlib==2.2.3
# Used for downloading datasets over HTTP
requests>=2.18
# progress bars in data cleaning scripts
tqdm>=4.19
# In SQuAD eval script, we use this to see if we likely have some tokenization problem.
editdistance
# For pretrained model weights
h5py
# For timezone utilities
pytz==2017.3
# Reads Universal Dependencies files.
conllu==0.11
#### ESSENTIAL TESTING-RELATED PACKAGES ####
# We'll use pytest to run our tests; this isn't really necessary to run the code, but it is to run
# the tests. With this here, you can run the tests with `py.test` from the base directory.
pytest
# Allows marking tests as flaky, to be rerun if they fail
flaky
# Required to mock out `requests` calls
responses>=0.7
# For mocking s3.
moto==1.3.4
#### TESTING-RELATED PACKAGES ####
# Checks style, syntax, and other useful errors.
pylint==1.8.1
# Tutorial notebooks
# see: https://github.com/jupyter/jupyter/issues/370 for ipykernel
ipykernel<5.0.0
jupyter
# Static type checking
mypy==0.521
# Allows generation of coverage reports with pytest.
pytest-cov
# Allows codecov to generate coverage reports
coverage
codecov
# Required to run sanic tests
aiohttp
#### DOC-RELATED PACKAGES ####
# Builds our documentation.
sphinx==1.5.3
# Watches the documentation directory and rebuilds on changes.
sphinx-autobuild
# doc theme
sphinx_rtd_theme
# Only used to convert our readme to reStructuredText on Pypi.
pypandoc
# Pypi uploads
twine==1.11.0
#### GENERATOR-RELATED PACKAGES ####
# Used by AddSent.
psutil
pattern
# Used by SWAG.
allennlp
num2words
| 8 |
0 | hf_public_repos | hf_public_repos/adversarialnlp/readthedocs.yml | # .readthedocs.yml
build:
image: latest
python:
version: 3.6
setup_py_install: true
requirements_file: docs/readthedoc_requirements.txt
formats: []
| 9 |
0 | hf_public_repos | hf_public_repos/blog/falcon-180b.md | ---
title: "Spread Your Wings: Falcon 180B is here"
thumbnail: /blog/assets/162_falcon_180b/thumbnail.jpg
authors:
- user: philschmid
- user: osanseviero
- user: pcuenq
- user: lvwerra
- user: slippylolo
---
# Spread Your Wings: Falcon 180B is here
## Introduction
**Today, we're excited to welcome [TII's](https://falconllm.tii.ae/) Falcon 180B to HuggingFace!** Falcon 180B sets a new state-of-the-art for open models. It is the largest openly available language model, with 180 billion parameters, and was trained on a massive 3.5 trillion tokens using TII's [RefinedWeb](https://huggingface.co/datasets/tiiuae/falcon-refinedweb) dataset. This represents the longest single-epoch pretraining for an open model.
You can find the model on the Hugging Face Hub ([base](https://huggingface.co/tiiuae/falcon-180B) and [chat](https://huggingface.co/tiiuae/falcon-180B-chat) model) and interact with the model on the [Falcon Chat Demo Space](https://huggingface.co/spaces/tiiuae/falcon-180b-chat).
In terms of capabilities, Falcon 180B achieves state-of-the-art results across natural language tasks. It topped the leaderboard for (pre-trained) open-access models (at the time of its release) and rivals proprietary models like PaLM-2. While difficult to rank definitively yet, it is considered on par with PaLM-2 Large, making Falcon 180B one of the most capable LLMs publicly known.
In this blog post, we explore what makes Falcon 180B so good by looking at some evaluation results and show how you can use the model.
* [What is Falcon-180B?](#what-is-falcon-180b)
* [How good is Falcon 180B?](#how-good-is-falcon-180b)
* [How to use Falcon 180B?](#how-to-use-falcon-180b)
* [Demo](#demo)
* [Hardware requirements](#hardware-requirements)
* [Prompt format](#prompt-format)
* [Transformers](#transformers)
* [Additional Resources](#additional-resources)
## What is Falcon-180B?
Falcon 180B is a model released by [TII](https://falconllm.tii.ae/) that follows previous releases in the Falcon family.
Architecture-wise, Falcon 180B is a scaled-up version of [Falcon 40B](https://huggingface.co/tiiuae/falcon-40b) and builds on its innovations such as multiquery attention for improved scalability. We recommend reviewing the [initial blog post](https://huggingface.co/blog/falcon) introducing Falcon to dive into the architecture. Falcon 180B was trained on 3.5 trillion tokens on up to 4096 GPUs simultaneously, using Amazon SageMaker for a total of ~7,000,000 GPU hours. This means Falcon 180B is 2.5 times larger than Llama 2 and was trained with 4x more compute.
The dataset for Falcon 180B consists predominantly of web data from [RefinedWeb](https://arxiv.org/abs/2306.01116) (\~85%). In addition, it has been trained on a mix of curated data such as conversations, technical papers, and a small fraction of code (\~3%). This pretraining dataset is big enough that even 3.5 trillion tokens constitute less than an epoch.
The released [chat model](https://huggingface.co/tiiuae/falcon-180B-chat) is fine-tuned on chat and instruction datasets with a mix of several large-scale conversational datasets.
‼️ Commercial use:
Falcon 180b can be commercially used but under very restrictive conditions, excluding any "hosting use". We recommend to check the [license](https://huggingface.co/spaces/tiiuae/falcon-180b-license/blob/main/LICENSE.txt) and consult your legal team if you are interested in using it for commercial purposes.
## How good is Falcon 180B?
Falcon 180B was the best openly released LLM at its release, outperforming Llama 2 70B and OpenAI’s GPT-3.5 on MMLU, and is on par with Google's PaLM 2-Large on HellaSwag, LAMBADA, WebQuestions, Winogrande, PIQA, ARC, BoolQ, CB, COPA, RTE, WiC, WSC, ReCoRD. Falcon 180B typically sits somewhere between GPT 3.5 and GPT4 depending on the evaluation benchmark and further finetuning from the community will be very interesting to follow now that it's openly released.
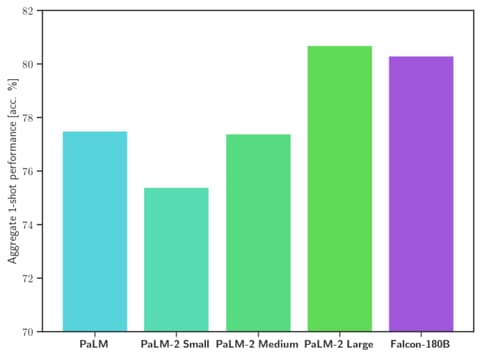
With 68.74 on the Hugging Face Leaderboard at the time of release, Falcon 180B was the highest-scoring openly released pre-trained LLM, surpassing Meta’s Llama 2.*
| Model | Size | Leaderboard score | Commercial use or license | Pretraining length |
| ------- | ---- | ----------------- | ------------------------- | ------------------ |
| Falcon | 180B | 67.85 | 🟠 | 3,500B |
| Llama 2 | 70B | 67.87 | 🟠 | 2,000B |
| LLaMA | 65B | 61.19 | 🔴 | 1,400B |
| Falcon | 40B | 58.07 | 🟢 | 1,000B |
| MPT | 30B | 52.77 | 🟢 | 1,000B |
* The Open LLM Leaderboard added two new benchmarks in November 2023, and we updated the table above to reflect the latest score (67.85). Falcon is on par with Llama 2 70B according to the new methodology.
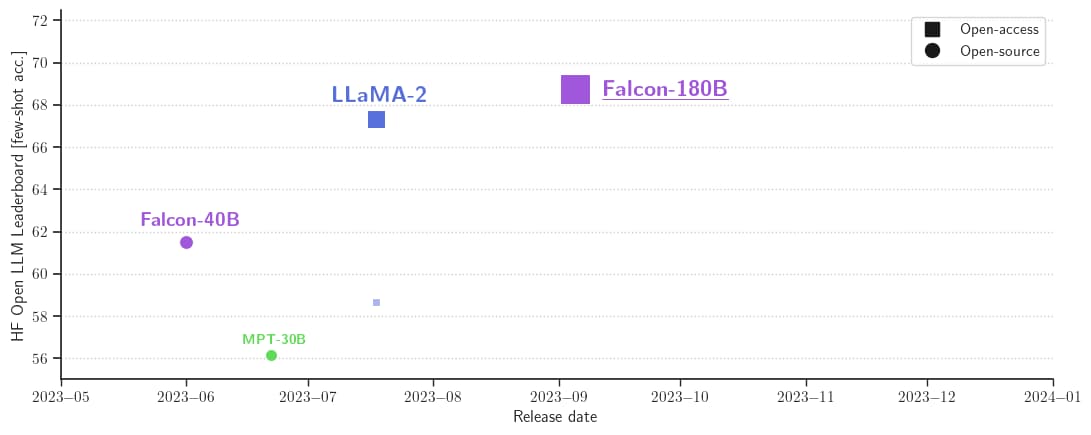
The quantized Falcon models preserve similar metrics across benchmarks. The results were similar when evaluating `torch.float16`, `8bit`, and `4bit`. See results in the [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard).
## How to use Falcon 180B?
Falcon 180B is available in the Hugging Face ecosystem, starting with Transformers version 4.33.
### Demo
You can easily try the Big Falcon Model (180 billion parameters!) in [this Space](https://huggingface.co/spaces/tiiuae/falcon-180b-demo) or in the playground embedded below:
<script type="module" src="https://gradio.s3-us-west-2.amazonaws.com/3.42.0/gradio.js"> </script>
<gradio-app theme_mode="light" space="tiiuae/falcon-180b-chat"></gradio-app>
### Hardware requirements
We ran several tests on the hardware needed to run the model for different use cases. Those are not the minimum numbers, but the minimum numbers for the configurations we had access to.
| | Type | Kind | Memory | Example |
| ----------- | --------- | ---------------- | ------------------- | --------------- |
| Falcon 180B | Training | Full fine-tuning | 5120GB | 8x 8x A100 80GB |
| Falcon 180B | Training | LoRA with ZeRO-3 | 1280GB | 2x 8x A100 80GB |
| Falcon 180B | Training | QLoRA | 160GB | 2x A100 80GB |
| Falcon 180B | Inference | BF16/FP16 | 640GB | 8x A100 80GB |
| Falcon 180B | Inference | GPTQ/int4 | 320GB | 8x A100 40GB |
### Prompt format
The base model has no prompt format. Remember that it’s not a conversational model or trained with instructions, so don’t expect it to generate conversational responses—the pretrained model is a great platform for further finetuning, but you probably shouldn’t driectly use it out of the box. The Chat model has a very simple conversation structure.
```bash
System: Add an optional system prompt here
User: This is the user input
Falcon: This is what the model generates
User: This might be a second turn input
Falcon: and so on
```
### Transformers
With the release of Transformers 4.33, you can use Falcon 180B and leverage all the tools in the HF ecosystem, such as:
- training and inference scripts and examples
- safe file format (safetensors)
- integrations with tools such as bitsandbytes (4-bit quantization), PEFT (parameter efficient fine-tuning) and GPTQ
- assisted generation (also known as “speculative decoding”)
- RoPE scaling support for larger context lengths
- rich and powerful generation parameters
Use of the model requires you to accept its license and terms of use. Please, make sure you are logged into your Hugging Face account and ensure you have the latest version of `transformers`:
```bash
pip install --upgrade transformers
huggingface-cli login
```
#### bfloat16
This is how you’d use the base model in `bfloat16`. Falcon 180B is a big model, so please take into account the hardware requirements summarized in the table above.
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
import transformers
import torch
model_id = "tiiuae/falcon-180B"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.bfloat16,
device_map="auto",
)
prompt = "My name is Pedro, I live in"
inputs = tokenizer(prompt, return_tensors="pt").to("cuda")
output = model.generate(
input_ids=inputs["input_ids"],
attention_mask=inputs["attention_mask"],
do_sample=True,
temperature=0.6,
top_p=0.9,
max_new_tokens=50,
)
output = output[0].to("cpu")
print(tokenizer.decode(output))
```
This could produce an output such as:
```
My name is Pedro, I live in Portugal and I am 25 years old. I am a graphic designer, but I am also passionate about photography and video.
I love to travel and I am always looking for new adventures. I love to meet new people and explore new places.
```
#### 8-bit and 4-bit with `bitsandbytes`
The 8-bit and 4-bit quantized versions of Falcon 180B show almost no difference in evaluation with respect to the `bfloat16` reference! This is very good news for inference, as you can confidently use a quantized version to reduce hardware requirements. Keep in mind, though, that 8-bit inference is *much faster* than running the model in `4-bit`.
To use quantization, you need to install the `bitsandbytes` library and simply enable the corresponding flag when loading the model:
```python
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.bfloat16,
load_in_8bit=True,
device_map="auto",
)
```
#### Chat Model
As mentioned above, the version of the model fine-tuned to follow conversations used a very straightforward training template. We have to follow the same pattern in order to run chat-style inference. For reference, you can take a look at the [format_prompt](https://huggingface.co/spaces/tiiuae/falcon-180b-demo/blob/main/app.py#L28) function in the Chat demo, which looks like this:
```python
def format_prompt(message, history, system_prompt):
prompt = ""
if system_prompt:
prompt += f"System: {system_prompt}\n"
for user_prompt, bot_response in history:
prompt += f"User: {user_prompt}\n"
prompt += f"Falcon: {bot_response}\n"
prompt += f"User: {message}\nFalcon:"
return prompt
```
As you can see, interactions from the user and responses by the model are preceded by `User: ` and `Falcon: ` separators. We concatenate them together to form a prompt containing the conversation's whole history. We can provide a system prompt to tweak the generation style.
## Additional Resources
- [Models](https://huggingface.co/models?other=falcon&sort=trending&search=180)
- [Demo](https://huggingface.co/spaces/tiiuae/falcon-180b-chat)
- [The Falcon has landed in the Hugging Face ecosystem](https://huggingface.co/blog/falcon)
- [Official Announcement](https://falconllm.tii.ae/)
## Acknowledgments
Releasing such a model with support and evaluations in the ecosystem would not be possible without the contributions of many community members, including [Clémentine](https://huggingface.co/clefourrier) and [Eleuther Evaluation Harness](https://github.com/EleutherAI/lm-evaluation-harness) for LLM evaluations; [Loubna](https://huggingface.co/loubnabnl) and [BigCode](https://huggingface.co/bigcode) for code evaluations; [Nicolas](https://hf.co/narsil) for Inference support; [Lysandre](https://huggingface.co/lysandre), [Matt](https://huggingface.co/Rocketknight1), [Daniel](https://huggingface.co/DanielHesslow), [Amy](https://huggingface.co/amyeroberts), [Joao](https://huggingface.co/joaogante), and [Arthur](https://huggingface.co/ArthurZ) for integrating Falcon into transformers. Thanks to [Baptiste](https://huggingface.co/BapBap) and [Patrick](https://huggingface.co/patrickvonplaten) for the open-source demo. Thanks to [Thom](https://huggingface.co/thomwolf), [Lewis](https://huggingface.co/lewtun), [TheBloke](https://huggingface.co/thebloke), [Nouamane](https://huggingface.co/nouamanetazi), [Tim Dettmers](https://huggingface.co/timdettmers) for multiple contributions enabling this to get out. Finally, thanks to the HF Cluster for enabling running LLM evaluations as well as providing inference for a free, open-source demo of the model.
| 0 |
0 | hf_public_repos | hf_public_repos/blog/playlist-generator.md | ---
title: 'Building a Playlist Generator with Sentence Transformers'
thumbnail: /blog/assets/87_playlist_generator/thumbnail.png
authors:
- user: nimaboscarino
---
# Building a Playlist Generator with Sentence Transformers
<script async defer src="https://unpkg.com/medium-zoom-element@0/dist/medium-zoom-element.min.js"></script>
A short while ago I published a [playlist generator](https://huggingface.co/spaces/NimaBoscarino/playlist-generator) that I’d built using Sentence Transformers and Gradio, and I followed that up with a [reflection on how I try to use my projects as effective learning experiences](https://huggingface.co/blog/your-first-ml-project). But how did I actually *build* the playlist generator? In this post we’ll break down that project and look at **two** technical details: how the embeddings were generated, and how the *multi-step* Gradio demo was built.
<div class="hidden xl:block">
<div style="display: flex; flex-direction: column; align-items: center;">
<iframe src="https://nimaboscarino-playlist-generator.hf.space" frameBorder="0" width="1400" height="690" title="Gradio app" class="p-0 flex-grow space-iframe" allow="accelerometer; ambient-light-sensor; autoplay; battery; camera; document-domain; encrypted-media; fullscreen; geolocation; gyroscope; layout-animations; legacy-image-formats; magnetometer; microphone; midi; oversized-images; payment; picture-in-picture; publickey-credentials-get; sync-xhr; usb; vr ; wake-lock; xr-spatial-tracking" sandbox="allow-forms allow-modals allow-popups allow-popups-to-escape-sandbox allow-same-origin allow-scripts allow-downloads"></iframe>
</div>
</div>
As we’ve explored in [previous posts on the Hugging Face blog](https://huggingface.co/blog/getting-started-with-embeddings), Sentence Transformers (ST) is a library that gives us tools to generate sentence embeddings, which have a variety of uses. Since I had access to a dataset of song lyrics, I decided to leverage ST’s semantic search functionality to generate playlists from a given text prompt. Specifically, the goal was to create an embedding from the prompt, use that embedding for a semantic search across a set of *pre-generated lyrics embeddings* to generate a relevant set of songs. This would all be wrapped up in a Gradio app using the new Blocks API, hosted on Hugging Face Spaces.
We’ll be looking at a slightly advanced use of Gradio, so if you’re a beginner to the library I recommend reading the [Introduction to Blocks](https://gradio.app/introduction_to_blocks/) before tackling the Gradio-specific parts of this post. Also, note that while I won’t be releasing the lyrics dataset, the **[lyrics embeddings are available on the Hugging Face Hub](https://huggingface.co/datasets/NimaBoscarino/playlist-generator)** for you to play around with. Let’s jump in! 🪂
## Sentence Transformers: Embeddings and Semantic Search
Embeddings are **key** in Sentence Transformers! We’ve learned about **[what embeddings are and how we generate them in a previous article](https://huggingface.co/blog/getting-started-with-embeddings)**, and I recommend checking that out before continuing with this post.
Sentence Transformers offers a large collection of pre-trained embedding models! It even includes tutorials for fine-tuning those models with our own training data, but for many use-cases (such semantic search over a corpus of song lyrics) the pre-trained models will perform excellently right out of the box. With so many embedding models available, though, how do we know which one to use?
[The ST documentation highlights many of the choices](https://www.sbert.net/docs/pretrained_models.html), along with their evaluation metrics and some descriptions of their intended use-cases. The **[MS MARCO models](https://www.sbert.net/docs/pretrained-models/msmarco-v5.html)** are trained on Bing search engine queries, but since they also perform well on other domains I decided any one of these could be a good choice for this project. All we need for the playlist generator is to find songs that have some semantic similarity, and since I don’t really care about hitting a particular performance metric I arbitrarily chose [sentence-transformers/msmarco-MiniLM-L-6-v3](https://huggingface.co/sentence-transformers/msmarco-MiniLM-L-6-v3).
Each model in ST has a configurable input sequence length (up to a maximum), after which your inputs will be truncated. The model I chose had a max sequence length of 512 word pieces, which, as I found out, is often not enough to embed entire songs. Luckily, there’s an easy way for us to split lyrics into smaller chunks that the model can digest – verses! Once we’ve chunked our songs into verses and embedded each verse, we’ll find that the search works much better.
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="The songs are split into verses, and then each verse is embedded." src="assets/87_playlist_generator/embedding-diagram.svg"></medium-zoom>
<figcaption>The songs are split into verses, and then each verse is embedded.</figcaption>
</figure>
To actually generate the embeddings, you can call the `.encode()` method of the Sentence Transformers model and pass it a list of strings. Then you can save the embeddings however you like – in this case I opted to pickle them.
```python
from sentence_transformers import SentenceTransformer
import pickle
embedder = SentenceTransformer('msmarco-MiniLM-L-6-v3')
verses = [...] # Load up your strings in a list
corpus_embeddings = embedder.encode(verses, show_progress_bar=True)
with open('verse-embeddings.pkl', "wb") as fOut:
pickle.dump(corpus_embeddings, fOut)
```
To be able to share you embeddings with others, you can even upload the Pickle file to a Hugging Face dataset. [Read this tutorial to learn more](https://huggingface.co/blog/getting-started-with-embeddings#2-host-embeddings-for-free-on-the-hugging-face-hub), or [visit the Datasets documentation](https://huggingface.co/docs/datasets/upload_dataset#upload-with-the-hub-ui) to try it out yourself! In short, once you've created a new Dataset on the Hub, you can simply manually upload your Pickle file by clicking the "Add file" button, shown below.
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="You can upload dataset files manually on the Hub." src="assets/87_playlist_generator/add-dataset.png"></medium-zoom>
<figcaption>You can upload dataset files manually on the Hub.</figcaption>
</figure>
The last thing we need to do now is actually use the embeddings for semantic search! The following code loads the embeddings, generates a new embedding for a given string, and runs a semantic search over the lyrics embeddings to find the closest hits. To make it easier to work with the results, I also like to put them into a Pandas DataFrame.
```python
from sentence_transformers import util
import pandas as pd
prompt_embedding = embedder.encode(prompt, convert_to_tensor=True)
hits = util.semantic_search(prompt_embedding, corpus_embeddings, top_k=20)
hits = pd.DataFrame(hits[0], columns=['corpus_id', 'score'])
# Note that "corpus_id" is the index of the verse for that embedding
# You can use the "corpus_id" to look up the original song
```
Since we’re searching for any verse that matches the text prompt, there’s a good chance that the semantic search will find multiple verses from the same song. When we drop the duplicates, we might only end up with a few distinct songs. If we increase the number of verse embeddings that `util.semantic_search` fetches with the `top_k` parameter, we can increase the number of songs that we'll find. Experimentally, I found that when I set `top_k=20`, I almost always get at least 9 distinct songs.
## Making a Multi-Step Gradio App
For the demo, I wanted users to enter a text prompt (or choose from some examples), and conduct a semantic search to find the top 9 most relevant songs. Then, users should be able to select from the resulting songs to be able to see the lyrics, which might give them some insight into why the particular songs were chosen. Here’s how we can do that!
[At the top of the Gradio demo](https://huggingface.co/spaces/NimaBoscarino/playlist-generator/blob/main/app.py) we load the embeddings, mappings, and lyrics from Hugging Face datasets when the app starts up.
```python
from sentence_transformers import SentenceTransformer, util
from huggingface_hub import hf_hub_download
import os
import pickle
import pandas as pd
corpus_embeddings = pickle.load(open(hf_hub_download("NimaBoscarino/playlist-generator", repo_type="dataset", filename="verse-embeddings.pkl"), "rb"))
songs = pd.read_csv(hf_hub_download("NimaBoscarino/playlist-generator", repo_type="dataset", filename="songs_new.csv"))
verses = pd.read_csv(hf_hub_download("NimaBoscarino/playlist-generator", repo_type="dataset", filename="verses.csv"))
# I'm loading the lyrics from my private dataset, with my own API token
auth_token = os.environ.get("TOKEN_FROM_SECRET")
lyrics = pd.read_csv(hf_hub_download("NimaBoscarino/playlist-generator-private", repo_type="dataset", filename="lyrics_new.csv", use_auth_token=auth_token))
```
The Gradio Blocks API lets you build *multi-step* interfaces, which means that you’re free to create quite complex sequences for your demos. We’ll take a look at some example code snippets here, but [check out the project code to see it all in action](https://huggingface.co/spaces/NimaBoscarino/playlist-generator/blob/main/app.py). For this project, we want users to choose a text prompt and then, after the semantic search is complete, users should have the ability to choose a song from the results to inspect the lyrics. With Gradio, this can be built iteratively by starting off with defining the initial input components and then registering a `click` event on the button. There’s also a `Radio` component, which will get updated to show the names of the songs for the playlist.
```python
import gradio as gr
song_prompt = gr.TextArea(
value="Running wild and free",
placeholder="Enter a song prompt, or choose an example"
)
fetch_songs = gr.Button(value="Generate Your Playlist!")
song_option = gr.Radio()
fetch_songs.click(
fn=generate_playlist,
inputs=[song_prompt],
outputs=[song_option],
)
```
This way, when the button gets clicked, Gradio grabs the current value of the `TextArea` and passes it to a function, shown below:
```python
def generate_playlist(prompt):
prompt_embedding = embedder.encode(prompt, convert_to_tensor=True)
hits = util.semantic_search(prompt_embedding, corpus_embeddings, top_k=20)
hits = pd.DataFrame(hits[0], columns=['corpus_id', 'score'])
# ... code to map from the verse IDs to the song names
song_names = ... # e.g. ["Thank U, Next", "Freebird", "La Cucaracha"]
return (
gr.Radio.update(label="Songs", interactive=True, choices=song_names)
)
```
In that function, we use the text prompt to conduct the semantic search. As seen above, to push updates to the Gradio components in the app, the function just needs to return components created with the `.update()` method. Since we connected the `song_option` `Radio` component to `fetch_songs.click` with its `output` parameter, `generate_playlist` can control the choices for the `Radio `component!
You can even do something similar to the `Radio` component in order to let users choose which song lyrics to view. [Visit the code on Hugging Face Spaces to see it in detail!](https://huggingface.co/spaces/NimaBoscarino/playlist-generator/blob/main/app.py)
## Some Thoughts
Sentence Transformers and Gradio are great choices for this kind of project! ST has the utility functions that we need for quickly generating embeddings, as well as for running semantic search with minimal code. Having access to a large collection of pre-trained models is also extremely helpful, since we don’t need to create and train our own models for this kind of stuff. Building our demo in Gradio means we only have to focus on coding in Python, and [deploying Gradio projects to Hugging Face Spaces is also super simple](https://huggingface.co/docs/hub/spaces-sdks-gradio)!
There’s a ton of other stuff I wish I’d had the time to build into this project, such as these ideas that I might explore in the future:
- Integrating with Spotify to automatically generate a playlist, and maybe even using Spotify’s embedded player to let users immediately listen to the songs.
- Using the **[HighlightedText** Gradio component](https://gradio.app/docs/#highlightedtext) to identify the specific verse that was found by the semantic search.
- Creating some visualizations of the embedding space, like in [this Space by Radamés Ajna](https://huggingface.co/spaces/radames/sentence-embeddings-visualization).
While the song *lyrics* aren’t being released, I’ve **[published the verse embeddings along with the mappings to each song](https://huggingface.co/datasets/NimaBoscarino/playlist-generator)**, so you’re free to play around and get creative!
Remember to [drop by the Discord](https://huggingface.co/join/discord) to ask questions and share your work! I’m excited to see what you end up doing with Sentence Transformers embeddings 🤗
## Extra Resources
- [Getting Started With Embeddings](https://huggingface.co/blog/getting-started-with-embeddings) by Omar Espejel
- [Or as a Twitter thread](https://twitter.com/osanseviero/status/1540993407883042816?s=20&t=4gskgxZx6yYKknNB7iD7Aw) by Omar Sanseviero
- [Hugging Face + Sentence Transformers docs](https://www.sbert.net/docs/hugging_face.html)
- [Gradio Blocks party](https://huggingface.co/Gradio-Blocks) - View some amazing community projects showcasing Gradio Blocks! | 1 |
0 | hf_public_repos | hf_public_repos/blog/snorkel-case-study.md | ---
title: "Snorkel AI x Hugging Face: unlock foundation models for enterprises"
thumbnail: /blog/assets/78_ml_director_insights/snorkel.png
authors:
- user: Violette
---
# Snorkel AI x Hugging Face: unlock foundation models for enterprises
_This article is a cross-post from an originally published post on April 6, 2023 [in Snorkel's blog](https://snorkel.ai/snorkel-hugging-face-unlock-foundation-models-for-enterprise/), by Friea Berg ._
As OpenAI releases [GPT-4](https://openai.com/research/gpt-4) and Google debuts [Bard](https://gizmodo.com/google-bard-chatgpt-ai-rival-released-1850248162) in beta, enterprises around the world are excited to leverage the power of foundation models. As that excitement builds, so does the realization that most companies and organizations are not equipped to properly take advantage of foundation models.
Foundation models pose a unique set of challenges for enterprises. Their larger-than-ever size makes them difficult and expensive for companies to host themselves, and using off-the-shelf FMs for production use cases could mean poor performance or substantial governance and compliance risks.
Snorkel AI bridges the gap between foundation models and practical enterprise use cases and has [yielded impressive results](https://snorkel.ai/how-pixability-uses-foundation-models-to-accelerate-nlp-application-development-by-months/) for AI innovators like Pixability. We’re teaming with [Hugging Face](https://huggingface.co/), best known for its enormous repository of ready-to-use open-source models, to provide enterprises with even more flexibility and choice as they develop AI applications.
## Foundation models in Snorkel Flow
The Snorkel Flow development platform enables users to [adapt foundation models](https://snorkel.ai/snorkel-flow/foundation-model-development/) for their specific use cases. Application development begins by inspecting the predictions of a selected foundation model “out of the box” on their data. These predictions become an initial version of training labels for those data points. Snorkel Flow helps users to identify error modes in that model and correct them efficiently via [programmatic labeling](https://snorkel.ai/programmatic-labeling/), which can include updating training labels with heuristics or [prompts](https://snorkel.ai/combining-foundation-models-with-weak-supervision/). The base foundation model can then be fine-tuned on the updated labels and evaluated once again, with this iterative “detect and correct” process continuing until the adapted foundation model is sufficiently high quality to deploy.
Hugging Face helps enable this powerful development process by making more than 150,000 open-source models immediately available from a single source. Many of those models are specialized on domain-specific data, like the BioBERT and SciBERT models used to demonstrate [how ML can be used to spot adverse drug events](https://snorkel.ai/adverse-drug-events-how-to-spot-them-with-machine-learning/). One – or better yet, [multiple](https://snorkel.ai/combining-foundation-models-with-weak-supervision/) – specialized base models can give users a jump-start on initial predictions, prompts for improving labels, or fine-tuning a final model for deployment.
## How does Hugging Face help?
Snorkel AI’s partnership with Hugging Face supercharges Snorkel Flow’s foundation model capabilities. Initially we only made a small number of foundation models available. Each one required a dedicated service, making it prohibitively expensive and difficult for us to offer enterprises the flexibility to capitalize on the rapidly growing variety of models available. Adopting Hugging Face’s Inference Endpoint service enabled us to expand the number of foundation models our users could tap into while keeping costs manageable.
Hugging Face’s service allows users to create a model API in a few clicks and begin using it immediately. Crucially, the new service has “pause and resume” capabilities that allow us to activate a model API when a client needs it, and put it to sleep when they don’t.
"We were pleasantly surprised to see how straightforward Hugging Face Inference Endpoint service was to set up.. All the configuration options were pretty self-explanatory, but we also had access to all the options we needed in terms of what cloud to run on, what security level we needed, etc."
– Snorkel CTO and Co-founder Braden Hancock
<iframe width="100%" style="aspect-ratio: 16 / 9;" src="https://www.youtube-nocookie.com/embed/woblG7iZPSw" title="YouTube video player" frameborder="0" allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture" allowfullscreen></iframe>
## How does this help Snorkel customers?
Few enterprises have the resources to train their own foundation models from scratch. While many may have the in-house expertise to fine-tune their own version of a foundation model, they may struggle to gather the volume of data needed for that task. Snorkel’s data-centric platform for developing foundation models and alignment with leading industry innovators like Hugging Face help put the power of foundation models at our users’ fingertips.
#### "With Snorkel AI and Hugging Face Inference Endpoints, companies will accelerate their data-centric AI applications with open source at the core. Machine Learning is becoming the default way of building technology, and building from open source allows companies to build the right solution for their use case and take control of the experience they offer to their customers. We are excited to see Snorkel AI enable automated data labeling for the enterprise building from open-source Hugging Face models and Inference Endpoints, our machine learning production service.”
Clement Delangue, co-founder and CEO, Hugging Face
## Conclusion
Together, Snorkel and Hugging Face make it easier than ever for large companies, government agencies, and AI innovators to get value from foundation models. The ability to use Hugging Face’s comprehensive hub of foundation models means that users can pick the models that best align with their business needs without having to invest in the resources required to train them. This integration is a significant step forward in making foundation models more accessible to enterprises around the world.
_If you’re interested in Hugging Face Inference Endpoints for your company, please contact us [here](https://huggingface.co/inference-endpoints/enterprise) - our team will contact you to discuss your requirements!_
| 2 |
0 | hf_public_repos | hf_public_repos/blog/spaces_3dmoljs.md | ---
title: "Visualize proteins on Hugging Face Spaces"
thumbnail: /blog/assets/98_spaces_3dmoljs/thumbnail.png
authors:
- user: simonduerr
guest: true
---
# Visualize proteins on Hugging Face Spaces
In this post we will look at how we can visualize proteins on Hugging Face Spaces.
**Update May 2024**
While the method described below still works, you'll likely want to save some time and use the [Molecule3D Gradio Custom Component](https://www.gradio.app/custom-components/gallery?id=simonduerr%2Fgradio_molecule3d). This component will allow users to modify the protein visualization on the fly and you can more easily set the default visualization. Simply install it using:
```bash
pip install gradio_molecule3d
```
```python
from gradio_molecule3d import Molecule3D
reps = [
{
"model": 0,
"chain": "",
"resname": "",
"style": "stick",
"color": "whiteCarbon",
"residue_range": "",
"around": 0,
"byres": False,
}
]
with gr.Blocks() as demo:
Molecule3D(reps=reps)
```
## Motivation 🤗
Proteins have a huge impact on our life - from medicines to washing powder. Machine learning on proteins is a rapidly growing field to help us design new and interesting proteins. Proteins are complex 3D objects generally composed of a series of building blocks called amino acids that are arranged in 3D space to give the protein its function. For machine learning purposes a protein can for example be represented as coordinates, as graph or as 1D sequence of letters for use in a protein language model.
A famous ML model for proteins is AlphaFold2 which predicts the structure of a protein sequence using a multiple sequence alignment of similar proteins and a structure module.
Since AlphaFold2 made its debut many more such models have come out such as OmegaFold, OpenFold etc. (see this [list](https://github.com/yangkky/Machine-learning-for-proteins) or this [list](https://github.com/sacdallago/folding_tools) for more).
## Seeing is believing
The structure of a protein is an integral part to our understanding of what a protein does. Nowadays, there are a few tools available to visualize proteins directly in the browser such as [mol*](molstar.org) or [3dmol.js](https://3dmol.csb.pitt.edu/). In this post, you will learn how to integrate structure visualization into your Hugging Face Space using 3Dmol.js and the HTML block.
## Prerequisites
Make sure you have the `gradio` Python package already [installed](/getting_started) and basic knowledge of Javascript/JQuery.
## Taking a Look at the Code
Let's take a look at how to create the minimal working demo of our interface before we dive into how to setup 3Dmol.js.
We will build a simple demo app that can accept either a 4-digit PDB code or a PDB file. Our app will then retrieve the pdb file from the RCSB Protein Databank and display it or use the uploaded file for display.
<script type="module" src="https://gradio.s3-us-west-2.amazonaws.com/3.1.7/gradio.js"></script>
<gradio-app theme_mode="light" space="simonduerr/3dmol.js"></gradio-app>
```python
import gradio as gr
def update(inp, file):
# in this simple example we just retrieve the pdb file using its identifier from the RCSB or display the uploaded file
pdb_path = get_pdb(inp, file)
return molecule(pdb_path) # this returns an iframe with our viewer
demo = gr.Blocks()
with demo:
gr.Markdown("# PDB viewer using 3Dmol.js")
with gr.Row():
with gr.Box():
inp = gr.Textbox(
placeholder="PDB Code or upload file below", label="Input structure"
)
file = gr.File(file_count="single")
btn = gr.Button("View structure")
mol = gr.HTML()
btn.click(fn=update, inputs=[inp, file], outputs=mol)
demo.launch()
```
`update`: This is the function that does the processing of our proteins and returns an `iframe` with the viewer
Our `get_pdb` function is also simple:
```python
import os
def get_pdb(pdb_code="", filepath=""):
if pdb_code is None or len(pdb_code) != 4:
try:
return filepath.name
except AttributeError as e:
return None
else:
os.system(f"wget -qnc https://files.rcsb.org/view/{pdb_code}.pdb")
return f"{pdb_code}.pdb"
```
Now, how to visualize the protein since Gradio does not have 3Dmol directly available as a block?
We use an `iframe` for this.
Our `molecule` function which returns the `iframe` conceptually looks like this:
```python
def molecule(input_pdb):
mol = read_mol(input_pdb)
# setup HTML document
x = ("""<!DOCTYPE html><html> [..] </html>""") # do not use ' in this input
return f"""<iframe [..] srcdoc='{x}'></iframe>
```
This is a bit clunky to setup but is necessary because of the security rules in modern browsers.
3Dmol.js setup is pretty easy and the documentation provides a [few examples](https://3dmol.csb.pitt.edu/).
The `head` of our returned document needs to load 3Dmol.js (which in turn also loads JQuery).
```html
<head>
<meta http-equiv="content-type" content="text/html; charset=UTF-8" />
<style>
.mol-container {
width: 100%;
height: 700px;
position: relative;
}
.mol-container select{
background-image:None;
}
</style>
<script src="https://cdnjs.cloudflare.com/ajax/libs/jquery/3.6.3/jquery.min.js" integrity="sha512-STof4xm1wgkfm7heWqFJVn58Hm3EtS31XFaagaa8VMReCXAkQnJZ+jEy8PCC/iT18dFy95WcExNHFTqLyp72eQ==" crossorigin="anonymous" referrerpolicy="no-referrer"></script>
<script src="https://3Dmol.csb.pitt.edu/build/3Dmol-min.js"></script>
</head>
```
The styles for `.mol-container` can be used to modify the size of the molecule viewer.
The `body` looks as follows:
```html
<body>
<div id="container" class="mol-container"></div>
<script>
let pdb = mol // mol contains PDB file content, check the hf.space/simonduerr/3dmol.js for full python code
$(document).ready(function () {
let element = $("#container");
let config = { backgroundColor: "white" };
let viewer = $3Dmol.createViewer(element, config);
viewer.addModel(pdb, "pdb");
viewer.getModel(0).setStyle({}, { cartoon: { colorscheme:"whiteCarbon" } });
viewer.zoomTo();
viewer.render();
viewer.zoom(0.8, 2000);
})
</script>
</body>
```
We use a template literal (denoted by backticks) to store our pdb file in the html document directly and then output it using 3dmol.js.
And that's it, now you can couple your favorite protein ML model to a fun and easy to use gradio app and directly visualize predicted or redesigned structures. If you are predicting properities of a structure (e.g how likely each amino acid is to bind a ligand), 3Dmol.js also allows to use a custom `colorfunc` based on a property of each atom.
You can check the [source code](https://huggingface.co/spaces/simonduerr/3dmol.js/blob/main/app.py) of the 3Dmol.js space for the full code.
For a production example, you can check the [ProteinMPNN](https://hf.space/simonduerr/ProteinMPNN) space where a user can upload a backbone, the inverse folding model ProteinMPNN predicts new optimal sequences and then one can run AlphaFold2 on all predicted sequences to verify whether they adopt the initial input backbone. Successful redesigns that qualitiatively adopt the same structure as predicted by AlphaFold2 with high pLDDT score should be tested in the lab.
<gradio-app theme_mode="light" space="simonduerr/ProteinMPNN"></gradio-app>
## Issues
If you encounter any issues with the integration of 3Dmol.js in Gradio/HF spaces, please open a discussion in [hf.space/simonduerr/3dmol.js](https://hf.space/simonduerr/3dmol.js/discussions).
If you have problems with 3Dmol.js configuration - you need to ask the developers, please, open a [3Dmol.js Issue](https://github.com/3dmol/3Dmol.js/issues) instead and describe your problem.
| 3 |
0 | hf_public_repos | hf_public_repos/blog/s2s_endpoint.md | ---
title: "Deploying Speech-to-Speech on Hugging Face"
thumbnail: /blog/assets/s2s_endpoint/thumbnail.png
authors:
- user: andito
- user: derek-thomas
- user: dmaniloff
- user: eustlb
---
# Deploying Speech-to-Speech on Hugging Face
## Introduction
[Speech-to-Speech (S2S)](https://github.com/huggingface/speech-to-speech) is an exciting new project from Hugging Face that combines several advanced models to create a seamless, almost magical experience: you speak, and the system responds with a synthesized voice.
The project implements a cascaded pipeline leveraging models available through the Transformers library on the Hugging Face hub. The pipeline consists of the following components:
1. Voice Activity Detection (VAD)
2. Speech to Text (STT)
3. Language Model (LM)
4. Text to Speech (TTS)
What's more, S2S has multi-language support! It currently supports English, French, Spanish, Chinese, Japanese, and Korean. You can run the pipeline in single-language mode or use the `auto` flag for automatic language detection. Check out the repo for more details [here](https://github.com/huggingface/speech-to-speech).
```
> 👩🏽💻: That's all amazing, but how do I run S2S?
> 🤗: Great question!
```
Running Speech-to-Speech requires significant computational resources. Even on a high-end laptop you might encounter latency issues, particularly when using the most advanced models. While a powerful GPU can mitigate these problems, not everyone has the means (or desire!) to set up their own hardware.
This is where Hugging Face's [Inference Endpoints (IE)](https://huggingface.co/inference-endpoints) come into play. Inference Endpoints allow you to rent a virtual machine equipped with a GPU (or other hardware you might need) and pay only for the time your system is running, providing an ideal solution for deploying performance-heavy applications like Speech-to-Speech.
In this blog post, we’ll guide you step by step to deploy Speech-to-Speech to a Hugging Face Inference Endpoint. This is what we'll cover:
- Understanding Inference Endpoints and a quick overview of the different ways to setup IE, including a custom container image (which is what we'll need for S2S)
- Building a custom docker image for S2S
- Deploying the custom image to IE and having some fun with S2S!
## Inference Endpoints
Inference Endpoints provide a scalable and efficient way to deploy machine learning models. These endpoints allow you to serve models with minimal setup, leveraging a variety of powerful hardware. Inference Endpoints are ideal for deploying applications that require high performance and reliability, without the need to manage underlying infrastructure.
Here's a few key features, and be sure to check out the documentation for more:
- **Simplicity** - You can be up and running in minutes thanks to IE's direct support of models in the Hugging Face hub.
- **Scalability** - You don't have to worry about scale, since IE scales automatically, including to zero, in order to handle varying loads and save costs.
- **Customization**: You can customize the setup of your IE to handle new tasks. More on this below.
Inference Endpoints supports all of the Transformers and Sentence-Transformers tasks, but can also support custom tasks. These are the IE setup options:
1. **Pre-built Models**: Quickly deploy models directly from the Hugging Face hub.
2. **Custom Handlers**: Define custom inference logic for more complex pipelines.
3. **Custom Docker Images**: Use your own Docker images to encapsulate all dependencies and custom code.
For simpler models, options 1 and 2 are ideal and make deploying with Inference Endpoints super straightforward. However, for a complex pipeline like S2S, you will need the flexibility of option 3: deploying our IE using a custom Docker image.
This method not only provides more flexibility but also improved performance by optimizing the build process and gathering necessary data. If you’re dealing with complex model pipelines or want to optimize your application deployment, this guide will offer valuable insights.
## Deploying Speech-to-Speech on Inference Endpoints
Let's get into it!
### Building the custom Docker image
To begin creating a custom Docker image, we started by cloning Hugging Face’s default Docker image repository. This serves as a great starting point for deploying machine learning models in inference tasks.
```bash
git clone https://github.com/huggingface/huggingface-inference-toolkit
```
### Why Clone the Default Repository?
- **Solid Foundation**: The repository provides a pre-optimized base image designed specifically for inference workloads, which gives a reliable starting point.
- **Compatibility**: Since the image is built to align with Hugging Face’s deployment environment, this ensures smooth integration when you deploy your own custom image.
- **Ease of Customization**: The repository offers a clean and structured environment, making it easy to customize the image for the specific requirements of your application.
You can check out all of [our changes here](https://github.com/andimarafioti/speech-to-speech-inference-toolkit/pull/1/files)
### Customizing the Docker Image for the Speech-to-Speech Application
With the repository cloned, the next step was tailoring the image to support our Speech-to-Speech pipeline.
1. Adding the Speech-to-Speech Project
To integrate the project smoothly, we added the speech-to-speech codebase and any required datasets as submodules. This approach offers better version control, ensuring the exact version of the code and data is always available when the Docker image is built.
By including data directly within the Docker container, we avoid having to download it each time the endpoint is instantiated, which significantly reduces startup time and ensures the system is reproducible. The data is stored in a Hugging Face repository, which provides easy tracking and versioning.
```bash
git submodule add https://github.com/huggingface/speech-to-speech.git
git submodule add https://huggingface.co/andito/fast-unidic
```
2. Optimizing the Docker Image
Next, we modified the Dockerfile to suit our needs:
- **Streamlining the Image**: We removed packages and dependencies that weren’t relevant to our use case. This reduces the image size and cuts down on unnecessary overhead during inference.
- **Installing Requirements**: We moved the installation of `requirements.txt` from the entry point to the Dockerfile itself. This way, the dependencies are installed when building the Docker image, speeding up deployment since these packages won’t need to be installed at runtime.
3. Deploying the Custom Image
Once the modifications were in place, we built and pushed the custom image to Docker Hub:
```bash
DOCKER_DEFAULT_PLATFORM="linux/amd64" docker build -t speech-to-speech -f dockerfiles/pytorch/Dockerfile .
docker tag speech-to-speech andito/speech-to-speech:latest
docker push andito/speech-to-speech:latest
```
With the Docker image built and pushed, it’s ready to be used in the Hugging Face Inference Endpoint. By using this pre-built image, the endpoint can launch faster and run more efficiently, as all dependencies and data are pre-packaged within the image.
## Setting up an Inference Endpoint
Using a custom docker image just requires a slightly different configuration, feel free to check out the [documentation](https://huggingface.co/docs/inference-endpoints/en/guides/custom_container). We will walk through the approach to do this in both the GUI and the API.
Pre-Steps
1. Login: https://huggingface.co/login
2. Request access to [meta-llama/Meta-Llama-3.1-8B-Instruct](https://huggingface.co/meta-llama/Meta-Llama-3.1-8B-Instruct)
3. Create a Fine-Grained Token: https://huggingface.co/settings/tokens/new?tokenType=fineGrained

- Select access to gated repos
- If you are using the API make sure to select permissions to Manage Inference Endpoints
### Inference Endpoints GUI
1. Navigate to https://ui.endpoints.huggingface.co/new
2. Fill in the relevant information
- Model Repository - `andito/s2s`
- Model Name - Feel free to rename if you don't like the generated name
- e.g. `speech-to-speech-demo`
- Keep it lower-case and short
- Choose your preferred Cloud and Hardware - We used `AWS` `GPU` `L4`
- It's only `$0.80` an hour and is big enough to handle the models
- Advanced Configuration (click the expansion arrow ➤)
- Container Type - `Custom`
- Container Port - `80`
- Container URL - `andito/speech-to-speech:latest`
- Secrets - `HF_TOKEN`|`<your token here>`
<details>
<summary>Click to show images</summary>
<p>
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/s2s_endpoint/new-inference-endpoint.png" alt="New Inference Endpoint" width="500px">
</p>
<p>
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/s2s_endpoint/advanced-configuration.png" alt="Advanced Configuration" width="500px">
</p>
</details>
3. Click `Create Endpoint`
> [!NOTE] The Model Repository doesn't actually matter since the models are specified and downloaded in the container creation, but Inference Endpoints requires a model, so feel free to pick a slim one of your choice.
> [!NOTE] You need to specify `HF_TOKEN` because we need to download gated models in the container creation stage. This won't be necessary if you use models that aren't gated or private.
> [!WARNING] The current [huggingface-inference-toolkit entrypoint](https://github.com/huggingface/huggingface-inference-toolkit/blob/028b8250427f2ab8458ed12c0d8edb50ff914a08/scripts/entrypoint.sh#L4) uses port 5000 as default, but the inference endpoint expects port 80. You should match this in the **Container Port**. We already set it in our dockerfile, but beware if making your own from scratch!
### Inference Endpoints API
Here we will walk through the steps for creating the endpoint with the API. Just use this code in your python environment of choice.
Make sure to use `0.25.1` or greater
```bash
pip install huggingface_hub>=0.25.1
```
Use a [token](https://huggingface.co/docs/hub/en/security-tokens) that can write an endpoint (Write or Fine-Grained)
```python
from huggingface_hub import login
login()
```
```python
from huggingface_hub import create_inference_endpoint, get_token
endpoint = create_inference_endpoint(
# Model Configuration
"speech-to-speech-demo",
repository="andito/s2s",
framework="custom",
task="custom",
# Security
type="protected",
# Hardware
vendor="aws",
accelerator="gpu",
region="us-east-1",
instance_size="x1",
instance_type="nvidia-l4",
# Image Configuration
custom_image={
"health_route": "/health",
"url": "andito/speech-to-speech:latest", # Pulls from DockerHub
"port": 80
},
secrets={'HF_TOKEN': get_token()}
)
# Optional
endpoint.wait()
```
## Overview

Major Componants
- [Speech To Speech](https://github.com/huggingface/speech-to-speech/tree/inference-endpoint)
- This is a Hugging Face Library, we put some inference-endpoint specific files in the `inference-endpoint` branch which will be merged to main soon.
- andito/s2s or any other repository. This is not needed for us since we have the models in the container creation stage, but the inference-endpoint requires a model, so we pass a repository that is slim.
- [andimarafioti/speech-to-speech-toolkit](https://github.com/andimarafioti/speech-to-speech-inference-toolkit).
- This was forked from [huggingface/huggingface-inference-toolkit](https://github.com/huggingface/huggingface-inference-toolkit) to help us build the Custom Container configured as we desire
### Building the webserver
To use the endpoint, we will need to build a small webservice. The code for it is done on `s2s_handler.py` in the [speech_to_speech library](https://github.com/huggingface/speech-to-speech) which we use for the client and `webservice_starlette.py` in the[speech_to_speech_inference_toolkit](https://github.com/huggingface/speech-to-speech-inference-toolkit) which we used to build the docker image. Normally, you would only have a custom handler for an endpoint, but since we want to have a really low latency, we also built the webservice to support websocket connections instead of normal requests. This sounds intimidating at first, but the webservice is only 32 lines of code!
<p>
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/s2s_endpoint/webservice.png" alt="Webservice code" width="800px">
</p>
This code will run `prepare_handler` on startup, which will initialize all the models and warm them up. Then, each message will be processed by `inference_handler.process_streaming_data`
<p>
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/s2s_endpoint/process_streaming.png" alt="Process streaming code" width="800px">
</p>
This method simply receives the audio data from the client, chunks it into small parts for the VAD, and submits it to a queue for processing. Then it checks the output processing queue (the spoken response from the model!) and returns it if there is something. All of the internal processing is handled by [Hugging Face's speech_to_speech library](https://github.com/huggingface/speech-to-speech).
### Custom handler custom client
The webservice receives and returns audio. But there is still a big missing piece, how do we record and play back the audio? For that, we created [a client](https://github.com/huggingface/speech-to-speech/blob/inference-endpoint/audio_streaming_client.py) that connects to the service. The easiest is to divide the analysis in the connection to the webservice and the recording/playing of audio.
<p>
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/s2s_endpoint/client.png" alt="Audio client code" width="800px">
</p>
Initializing the webservice client requires setting a header for all messages with our Hugging Face Token. When initializing the client, we set what we want to do on common messages (open, close, error, message). This will determine what our client does when the server sends it messages.
<p>
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/s2s_endpoint/messages.png" alt="Audio client messages code" width="800px">
</p>
We can see that the reactions to the messages are straight forward, with the `on_message` being the only method with more complexity. This method understands when the server is done responding and starts 'listening' back to the user. Otherwise, it puts the data from the server in the playback queue.
<p>
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/s2s_endpoint/client-audio.png" alt="Client's audio record and playback" width="800px">
</p>
The client's audio section has 4 tasks:
1. Record the audio
2. Submit the audio recordings
3. Receive the audio responses from the server
4. Playback the audio responses
The audio is recorded on the `audio_input_callback` method, it simply submits all chunks to a queue. Then, it is sent to the server with the `send_audio` method. Here, if there is no audio to send, we still submit an empty array in order to receive a response from the server. The responses from the server are handled by the `on_message` method we saw earlier in the blog. Then, the playback of the audio responses are handled by the `audio_output_callback` method. Here we only need to ensure that the audio is in the range we expect (We don't want to destroy someone eardrum's because of a faulty package!) and ensure that the size of the output array is what the playback library expects.
## Conclusion
In this post, we walked through the steps of deploying the Speech-to-Speech (S2S) pipeline on Hugging Face Inference Endpoints using a custom Docker image. We built a custom container to handle the complexities of the S2S pipeline and demonstrated how to configure it for scalable, efficient deployment. Hugging Face Inference Endpoints make it easier to bring performance-heavy applications like Speech-to-Speech to life, without the hassle of managing hardware or infrastructure.
If you're interested in trying it out or have any questions, feel free to explore the following resources:
- [Speech-to-Speech GitHub Repository](https://github.com/huggingface/speech-to-speech)
- [Speech-to-Speech Inference Toolkit](https://github.com/andimarafioti/speech-to-speech-inference-toolkit)
- [Base Inference Toolkit](https://github.com/huggingface/huggingface-inference-toolkit)
- [Hugging Face Inference Endpoints Documentation](https://huggingface.co/docs/inference-endpoints/en/guides/custom_container)
Have issues or questions? Open a discussion on the relevant GitHub repository, and we’ll be happy to help! | 4 |
0 | hf_public_repos | hf_public_repos/blog/pycharm-integration.md | ---
title: "Hugging Face + PyCharm"
thumbnail: /blog/assets/pycharm-integration/thumbnail.png
authors:
- user: rocketknight1
---
# Hugging Face + PyCharm
It’s a Tuesday morning. As a Transformers maintainer, I’m doing the same thing I do most weekday mornings: Opening [PyCharm](https://jb.gg/get-pycharm-hf), loading up the Transformers codebase and gazing lovingly at the [chat template documentation](https://huggingface.co/docs/transformers/main/chat_templating) while ignoring the 50 user issues I was pinged on that day. But this time, something feels different:

Something is… wait\! Computer\! Enhance\!

Is that..?

Those user issues are definitely not getting responses today. Let’s talk about the Hugging Face integration in PyCharm.
## The Hugging Face Is Inside Your House
I could introduce this integration by just listing features, but that’s boring and there’s [documentation](https://www.jetbrains.com/help/pycharm/hugging-face.html) for that. Instead, let’s walk through how we’d use it all in practice. Let’s say I’m writing a Python app, and I decide I want the app to be able to chat with users. Not just text chat, though – we want the users to be able to paste in images too, and for the app to naturally chat about them as well.
If you’re not super-familiar with the current state-of-the-art in machine learning, this might seem like a terrifying demand, but don’t fear. Simply right click in your code, and select “Insert HF Model”. You’ll get a dialog box:

Chatting with both images and text is called “image-text-to-text”: the user can supply images and text, and the model outputs text. Scroll down on the left until you find it. By default, the model list will be sorted by Likes – but remember, older models often have a lot of likes built up even if they’re not really the state of the art anymore. We can check how old models are by seeing the date they were last updated, just under the model name. Let’s pick something that’s both recent and popular: `microsoft/Phi-3.5-vision-instruct`.
You can select “Use Model” for some model categories to automatically paste some basic code into your notebook, but what often works better is to scroll through the Model Card on the right and grab any sample code. You can see the full model card to the right of the dialog box, exactly as it's shown on Hugging Face Hub. Let’s do that and paste it into our code!

Your office cybersecurity person might complain about you copying a chunk of random text from the internet and running it without even reading all of it, but if that happens just call them a nerd and continue regardless. And behold: We now have a working model that can happily chat about images - in this case, it reads and comments on screenshots of a Microsoft slide deck. Feel free to play around with this example. Try your own chat, or your own images. Once you get it working, simply wrap this code into a class and it’s ready to go in your app. We just got state of the art open-source machine learning in ten minutes without even opening a web browser.
> [!TIP]
> These models can be large! If you’re getting memory errors, try using a GPU with more memory, or try reducing the 20 in the sample code. You can also remove device_map="cuda" to put the model in CPU memory instead, at the cost of speed.
## Instant Model Cards
Next, let’s change perspective in our little scenario. Now let’s say you’re not the author of this code - you’re a coworker who has to review it. Maybe you’re the cybersecurity person from earlier, who’s still upset about the “nerd” comment. You look at this code snippet, and you have no idea what you’re seeing. Don’t panic - just hover over the model name, and the entire model card instantly appears. You can quickly verify the origin of this model, and what its intended uses are.
(This is also extremely helpful if you work on something else and completely forget everything about the code you wrote two weeks ago)

## The Local Model Cache
You might notice that the model has to be downloaded the first time you run this code, but after that, it’s loaded much more quickly. The model has been stored in your local cache. Remember the mysterious little 🤗 icon from earlier? Simply click it, and you’ll get a listing of everything in your cache:

This is a neat way to find the models you’re working with right now, and also to clear them out and save some disk space once you don’t need them anymore. It’s also very helpful for the two-week amnesia scenario - if you can’t remember the model you were using back then, it’s probably in here. Remember, though, that most useful, production-ready models in 2024 are going to be >1GB, so your cache can fill up fast!
## Python in the age of AI
At Hugging Face, we tend to think of open-source AI as being a natural extension of the open-source philosophy: Open software solves problems for developers and users, creating new abilities for them to integrate into their code, and open models do the same. There is a tendency to be blinded by complexity, and to focus too much on the implementation details because they’re all so novel and exciting, but models exist to **do stuff for you.** If you abstract away the details of architecture and training, they’re fundamentally **functions** - tools in your code that will transform a certain kind of input into a certain kind of output.
These features are thus a natural fit. Just as IDEs already pull up function signatures and docstrings for you, they can also pull up sample code and model cards for trained models. Integrations like these make it easy to reach over and import a chat or image recognition model as conveniently as you would import any other library. We think it’s obvious that this is what the future of code will look like, and we hope that you find these features useful!
**[Download PyCharm](https://jb.gg/get-pycharm-hf) to give the Hugging Face integration a try.**
**Get a free 3-month PyCharm subscription using the PyCharm4HF code [here](http://jetbrains.com/store/redeem/).** | 5 |
0 | hf_public_repos/blog | hf_public_repos/blog/scripts/validate-yaml.ts | // Use `deno fmt` to format this file.
import { parse } from "https://deno.land/[email protected]/yaml/mod.ts";
import { z } from "https://deno.land/x/[email protected]/mod.ts";
for (const lang of ["", "zh/"]) {
{
const relativePath = `${lang}_events.yml`;
console.log(`Validating ${relativePath}`);
z.array(z.object({
link: z.string().url(),
name: z.string(),
date: z.string(),
date_formatted: z.string().optional(),
description: z.string(),
})).parse(parse(Deno.readTextFileSync("../" + relativePath)));
}
{
const relativePath = `${lang}_blog.yml`;
console.log(`Validating ${relativePath}`);
const localMdFiles = [...Deno.readDirSync("../" + lang)].map((entry) =>
entry.name
).filter((name) => name.endsWith(".md")).map((name) =>
name.slice(0, -".md".length)
);
z.array(z.object({
local: z.enum([...localMdFiles] as [string, ...string[]]),
title: z.string(),
thumbnail: z.string().optional(),
author: z.string(),
guest: z.boolean().optional(),
date: z.string(),
tags: z.array(z.string()),
})).parse(parse(Deno.readTextFileSync("../" + relativePath)));
}
{
const relativePath = `${lang}_tags.yml`;
console.log(`Validating ${relativePath}`);
z.array(z.object({
value: z.string(),
label: z.string(),
})).parse(parse(Deno.readTextFileSync("../" + relativePath)));
}
}
| 6 |
0 | hf_public_repos/blog | hf_public_repos/blog/notebooks/85_sentiment_analysis_twitter.ipynb | import tweepy
# Add Twitter API key and secret
consumer_key = "XXXXX"
consumer_secret = "XXXXX"
# Handling authentication with Twitter
auth = tweepy.AppAuthHandler(consumer_key, consumer_secret)
# Create a wrapper for the Twitter API
api = tweepy.API(auth, wait_on_rate_limit=True, wait_on_rate_limit_notify=True)# Helper function for handling pagination in our search and handle rate limits
def limit_handled(cursor):
while True:
try:
yield cursor.next()
except tweepy.RateLimitError:
print('Reached rate limite. Sleeping for >15 minutes')
time.sleep(15 * 61)
except StopIteration:
break
# Define the term we will be using for searching tweets
query = '@notionhq'
query = query + ' -filter:retweets'
# Define how many tweets to get from the Twitter API
count = 1000
# Search for tweets using Tweepy
search = limit_handled(tweepy.Cursor(api.search,
q=query,
tweet_mode='extended',
lang='en',
result_type="recent").items(count))
# Process the results from the search using Tweepy
tweets = []
for result in search:
tweet_content = result.full_text
# Only saving the tweet content.
# You could also save other attributes for each tweet like date or # of RTs.
tweets.append(tweet_content)import requests
import time
# Set up the API call to the Inference API to do sentiment analysis
model = "cardiffnlp/twitter-roberta-base-sentiment-latest"
hf_token = "XXXXX"
API_URL = "https://api-inference.huggingface.co/models/" + model
headers = {"Authorization": "Bearer %s" % (hf_token)}
def analysis(data):
payload = dict(inputs=data, options=dict(wait_for_model=True))
response = requests.post(API_URL, headers=headers, json=payload)
return response.json()
# Let's run the sentiment analysis on each tweet
tweets_analysis = []
for tweet in tweets:
try:
sentiment_result = analysis(tweet)[0]
top_sentiment = max(sentiment_result, key=lambda x: x['score']) # Get the sentiment with the higher score
tweets_analysis.append({'tweet': tweet, 'sentiment': top_sentiment['label']})
except Exception as e:
print(e)import pandas as pd
# Load the data in a dataframe
pd.set_option('max_colwidth', None)
pd.set_option('display.width', 3000)
df = pd.DataFrame(tweets_analysis)
# Show a tweet for each sentiment
display(df[df["sentiment"] == 'Positive'].head(1))
display(df[df["sentiment"] == 'Neutral'].head(1))
display(df[df["sentiment"] == 'Negative'].head(1))import matplotlib.pyplot as plt
# Let's count the number of tweets by sentiments
sentiment_counts = df.groupby(['sentiment']).size()
print(sentiment_counts)
# Let's visualize the sentiments
fig = plt.figure(figsize=(6,6), dpi=100)
ax = plt.subplot(111)
sentiment_counts.plot.pie(ax=ax, autopct='%1.1f%%', startangle=270, fontsize=12, label="")from wordcloud import WordCloud
from wordcloud import STOPWORDS
# Wordcloud with positive tweets
positive_tweets = df['tweet'][df["sentiment"] == 'Positive']
stop_words = ["https", "co", "RT"] + list(STOPWORDS)
positive_wordcloud = WordCloud(max_font_size=50, max_words=50, background_color="white", stopwords = stop_words).generate(str(positive_tweets))
plt.figure()
plt.title("Positive Tweets - Wordcloud")
plt.imshow(positive_wordcloud, interpolation="bilinear")
plt.axis("off")
plt.show()
# Wordcloud with negative tweets
negative_tweets = df['tweet'][df["sentiment"] == 'Negative']
stop_words = ["https", "co", "RT"] + list(STOPWORDS)
negative_wordcloud = WordCloud(max_font_size=50, max_words=50, background_color="white", stopwords = stop_words).generate(str(negative_tweets))
plt.figure()
plt.title("Negative Tweets - Wordcloud")
plt.imshow(negative_wordcloud, interpolation="bilinear")
plt.axis("off")
plt.show() | 7 |
0 | hf_public_repos/blog | hf_public_repos/blog/notebooks/64_fastai_hub.ipynb | import fastai;
print(f" We are using fastai version {fastai.__version__}")# Training of 6 lines in chapter 1 of the fastbook.
from fastai.vision.all import *
path = untar_data(URLs.PETS)/'images'
def is_cat(x): return x[0].isupper()
dls = ImageDataLoaders.from_name_func(
path, get_image_files(path), valid_pct=0.2, seed=42,
label_func=is_cat, item_tfms=Resize(224))
learn = vision_learner(dls, resnet34, metrics=error_rate)
learn.fine_tune(1)from huggingface_hub import notebook_login
notebook_login()from huggingface_hub import push_to_hub_fastai
# repo_id = "YOUR_USERNAME/YOUR_LEARNER_NAME"
repo_id = "espejelomar/identify-my-cat"
push_to_hub_fastai(learner=learn, repo_id=repo_id)from ipywidgets import widgets
uploader = widgets.FileUpload()
uploader## This is your image:
img = PILImage.create(uploader.data[0])
img.to_thumb(100)from huggingface_hub import from_pretrained_fastai
# repo_id = "YOUR_USERNAME/YOUR_LEARNER_NAME"
repo_id = "espejelomar/identify-my-cat"
learner = from_pretrained_fastai(repo_id)_,_,probs = learner.predict(img)
print(f"Probability it is a cat: {100*probs[1].item():.2f}%")import torch
import transformers
from fastai.text.all import *
from blurr.text.data.all import *
from blurr.text.modeling.all import *
path = untar_data(URLs.IMDB_SAMPLE)
model_path = Path("models")
imdb_df = pd.read_csv(path / "texts.csv")
learn_blurr = BlearnerForSequenceClassification.from_data(imdb_df, "distilbert-base-uncased", dl_kwargs={"bs": 4})
learn_blurr.fit_one_cycle(1, lr_max=1e-3)from huggingface_hub import push_to_hub_fastai
# repo_id = "YOUR_USERNAME/YOUR_LEARNER_NAME"
repo_id = "fastai/blurr_IMDB_distilbert_classification"
push_to_hub_fastai(learn_blurr, repo_id)from huggingface_hub import from_pretrained_fastai
# repo_id = "YOUR_USERNAME/YOUR_LEARNER_NAME"
repo_id = "fastai/blurr_IMDB_distilbert_classification"
learner_blurr = from_pretrained_fastai(repo_id)sentences = ["This integration is amazing!",
"I hate this was not available before."]
probs = learner_blurr.predict(sentences)
print(f"Probability that sentence '{sentences[0]}' is negative is: {100*probs[0]['probs'][0]:.2f}%")
print(f"Probability that sentence '{sentences[1]}' is negative is: {100*probs[1]['probs'][0]:.2f}%") | 8 |
0 | hf_public_repos/blog | hf_public_repos/blog/notebooks/111_fine_tune_whisper.ipynb | gpu_info = !nvidia-smi
gpu_info = '\n'.join(gpu_info)
if gpu_info.find('failed') >= 0:
print('Not connected to a GPU')
else:
print(gpu_info)from huggingface_hub import notebook_login
notebook_login()from datasets import load_dataset, DatasetDict
common_voice = DatasetDict()
common_voice["train"] = load_dataset("mozilla-foundation/common_voice_11_0", "hi", split="train+validation", use_auth_token=True)
common_voice["test"] = load_dataset("mozilla-foundation/common_voice_11_0", "hi", split="test", use_auth_token=True)
print(common_voice)common_voice = common_voice.remove_columns(["accent", "age", "client_id", "down_votes", "gender", "locale", "path", "segment", "up_votes"])
print(common_voice)from transformers import WhisperFeatureExtractor
feature_extractor = WhisperFeatureExtractor.from_pretrained("openai/whisper-small")from transformers import WhisperTokenizer
tokenizer = WhisperTokenizer.from_pretrained("openai/whisper-small", language="Hindi", task="transcribe")from transformers import WhisperProcessor
processor = WhisperProcessor.from_pretrained("openai/whisper-small", language="Hindi", task="transcribe")print(common_voice["train"][0])from datasets import Audio
common_voice = common_voice.cast_column("audio", Audio(sampling_rate=16000))print(common_voice["train"][0])def prepare_dataset(batch):
# load and resample audio data from 48 to 16kHz
audio = batch["audio"]
# compute log-Mel input features from input audio array
batch["input_features"] = feature_extractor(audio["array"], sampling_rate=audio["sampling_rate"]).input_features[0]
# encode target text to label ids
batch["labels"] = tokenizer(batch["sentence"]).input_ids
return batchcommon_voice = common_voice.map(prepare_dataset, remove_columns=common_voice.column_names["train"], num_proc=4)import torch
from dataclasses import dataclass
from typing import Any, Dict, List, Union
@dataclass
class DataCollatorSpeechSeq2SeqWithPadding:
processor: Any
def __call__(self, features: List[Dict[str, Union[List[int], torch.Tensor]]]) -> Dict[str, torch.Tensor]:
# split inputs and labels since they have to be of different lengths and need different padding methods
# first treat the audio inputs by simply returning torch tensors
input_features = [{"input_features": feature["input_features"]} for feature in features]
batch = self.processor.feature_extractor.pad(input_features, return_tensors="pt")
# get the tokenized label sequences
label_features = [{"input_ids": feature["labels"]} for feature in features]
# pad the labels to max length
labels_batch = self.processor.tokenizer.pad(label_features, return_tensors="pt")
# replace padding with -100 to ignore loss correctly
labels = labels_batch["input_ids"].masked_fill(labels_batch.attention_mask.ne(1), -100)
# if bos token is appended in previous tokenization step,
# cut bos token here as it's append later anyways
if (labels[:, 0] == self.processor.tokenizer.bos_token_id).all().cpu().item():
labels = labels[:, 1:]
batch["labels"] = labels
return batchdata_collator = DataCollatorSpeechSeq2SeqWithPadding(processor=processor)import evaluate
metric = evaluate.load("wer")def compute_metrics(pred):
pred_ids = pred.predictions
label_ids = pred.label_ids
# replace -100 with the pad_token_id
label_ids[label_ids == -100] = tokenizer.pad_token_id
# we do not want to group tokens when computing the metrics
pred_str = tokenizer.batch_decode(pred_ids, skip_special_tokens=True)
label_str = tokenizer.batch_decode(label_ids, skip_special_tokens=True)
wer = 100 * metric.compute(predictions=pred_str, references=label_str)
return {"wer": wer}from transformers import WhisperForConditionalGeneration
model = WhisperForConditionalGeneration.from_pretrained("openai/whisper-small")model.config.forced_decoder_ids = None
model.config.suppress_tokens = []from transformers import Seq2SeqTrainingArguments
training_args = Seq2SeqTrainingArguments(
output_dir="./whisper-small-hi", # change to a repo name of your choice
per_device_train_batch_size=16,
gradient_accumulation_steps=1, # increase by 2x for every 2x decrease in batch size
learning_rate=1e-5,
warmup_steps=500,
max_steps=4000,
gradient_checkpointing=True,
fp16=True,
group_by_length=True,
evaluation_strategy="steps",
per_device_eval_batch_size=8,
predict_with_generate=True,
generation_max_length=225,
save_steps=1000,
eval_steps=1000,
logging_steps=25,
report_to=["tensorboard"],
load_best_model_at_end=True,
metric_for_best_model="wer",
greater_is_better=False,
push_to_hub=True,
)from transformers import Seq2SeqTrainer
trainer = Seq2SeqTrainer(
args=training_args,
model=model,
train_dataset=common_voice["train"],
eval_dataset=common_voice["test"],
data_collator=data_collator,
compute_metrics=compute_metrics,
tokenizer=processor.feature_extractor,
)trainer.train()kwargs = {
"dataset_tags": "mozilla-foundation/common_voice_11_0",
"dataset": "Common Voice 11.0", # a 'pretty' name for the training dataset
"language": "hi",
"model_name": "Whisper Small Hi - Sanchit Gandhi", # a 'pretty' name for our model
"finetuned_from": "openai/whisper-small",
"tasks": "automatic-speech-recognition",
"tags": "hf-asr-leaderboard",
}trainer.push_to_hub(**kwargs)from transformers import pipeline
import gradio as gr
pipe = pipeline(model="sanchit-gandhi/whisper-small-hi") # change to "your-username/the-name-you-picked"
def transcribe(audio):
text = pipe(audio)["text"]
return text
iface = gr.Interface(
fn=transcribe,
inputs=gr.Audio(source="microphone", type="filepath"),
outputs="text",
title="Whisper Small Hindi",
description="Realtime demo for Hindi speech recognition using a fine-tuned Whisper small model.",
)
iface.launch() | 9 |
0 | hf_public_repos/adversarialnlp/adversarialnlp/generators | hf_public_repos/adversarialnlp/adversarialnlp/generators/swag/utils.py | import re
from itertools import tee
from num2words import num2words
def optimistic_restore(network, state_dict):
mismatch = False
own_state = network.state_dict()
for name, param in state_dict.items():
if name not in own_state:
print("Unexpected key {} in state_dict with size {}".format(name, param.size()))
mismatch = True
elif param.size() == own_state[name].size():
own_state[name].copy_(param)
else:
print("Network has {} with size {}, ckpt has {}".format(name,
own_state[name].size(),
param.size()))
mismatch = True
missing = set(own_state.keys()) - set(state_dict.keys())
if len(missing) > 0:
print("We couldn't find {}".format(','.join(missing)))
mismatch = True
return not mismatch
def pairwise(iterable):
"s -> (s0,s1), (s1,s2), (s2, s3), ..."
a, b = tee(iterable)
next(b, None)
return zip(a, b)
def n2w_1k(num, use_ordinal=False):
if num > 1000:
return ''
return num2words(num, to='ordinal' if use_ordinal else 'cardinal')
def postprocess(sentence):
"""
make sure punctuation is followed by a space
:param sentence:
:return:
"""
sentence = remove_allcaps(sentence)
# Aggressively get rid of some punctuation markers
sent0 = re.sub(r'^.*(\\|/|!!!|~|=|#|@|\*|¡|©|¿|«|»|¬|{|}|\||\(|\)|\+|\]|\[).*$',
' ', sentence, flags=re.MULTILINE|re.IGNORECASE)
# Less aggressively get rid of quotes, apostrophes
sent1 = re.sub(r'"', ' ', sent0)
sent2 = re.sub(r'`', '\'', sent1)
# match ordinals
sent3 = re.sub(r'(\d+(?:rd|st|nd))',
lambda x: n2w_1k(int(x.group(0)[:-2]), use_ordinal=True), sent2)
#These things all need to be followed by spaces or else we'll run into problems
sent4 = re.sub(r'[:;,\"\!\.\-\?](?! )', lambda x: x.group(0) + ' ', sent3)
#These things all need to be preceded by spaces or else we'll run into problems
sent5 = re.sub(r'(?! )[-]', lambda x: ' ' + x.group(0), sent4)
# Several spaces
sent6 = re.sub(r'\s\s+', ' ', sent5)
sent7 = sent6.strip()
return sent7
def remove_allcaps(sent):
"""
Given a sentence, filter it so that it doesn't contain some words that are ALLcaps
:param sent: string, like SOMEONE wheels SOMEONE on, mouthing silent words of earnest prayer.
:return: Someone wheels someone on, mouthing silent words of earnest prayer.
"""
# Remove all caps
def _sanitize(word, is_first):
if word == "I":
return word
num_capitals = len([x for x in word if not x.islower()])
if num_capitals > len(word) // 2:
# We have an all caps word here.
if is_first:
return word[0] + word[1:].lower()
return word.lower()
return word
return ' '.join([_sanitize(word, i == 0) for i, word in enumerate(sent.split(' '))])
| 0 |
0 | hf_public_repos/adversarialnlp/adversarialnlp/generators | hf_public_repos/adversarialnlp/adversarialnlp/generators/swag/activitynet_captions_reader.py | from typing import Dict
import json
import logging
from overrides import overrides
from unidecode import unidecode
from allennlp.common.file_utils import cached_path
from allennlp.data.dataset_readers.dataset_reader import DatasetReader
from allennlp.data.fields import TextField, MetadataField
from allennlp.data.instance import Instance
from allennlp.data.tokenizers import Tokenizer, WordTokenizer
from allennlp.data.token_indexers import TokenIndexer, SingleIdTokenIndexer
from adversarialnlp.generators.swag.utils import pairwise, postprocess
logger = logging.getLogger(__name__) # pylint: disable=invalid-name
@DatasetReader.register("activitynet_captions")
class ActivityNetCaptionsDatasetReader(DatasetReader):
r""" Reads ActivityNet Captions JSON files and creates a dataset suitable for crafting
adversarial examples with swag using these captions.
Expected format:
JSON dict[video_id, video_obj] where
video_id: str,
video_obj: {
"duration": float,
"timestamps": list of pairs of float,
"sentences": list of strings
}
The output of ``read`` is a list of ``Instance`` s with the fields:
video_id: ``MetadataField``
first_sentence: ``TextField``
second_sentence: ``TextField``
The instances are created from all consecutive pair of sentences
associated to each video.
Ex: if a video has three associated sentences: s1, s2, s3 read will
generate two instances:
1. Instance("first_sentence" = s1, "second_sentence" = s2)
2. Instance("first_sentence" = s2, "second_sentence" = s3)
Args:
lazy : If True, training will start sooner, but will take
longer per batch. This allows training with datasets that
are too large to fit in memory. Passed to DatasetReader.
tokenizer : Tokenizer to use to split the title and abstract
into words or other kinds of tokens.
token_indexers : Indexers used to define input token
representations.
"""
def __init__(self,
lazy: bool = False,
tokenizer: Tokenizer = None,
token_indexers: Dict[str, TokenIndexer] = None) -> None:
super().__init__(lazy)
self._tokenizer = tokenizer or WordTokenizer()
self._token_indexers = token_indexers or {"tokens": SingleIdTokenIndexer()}
@overrides
def _read(self, file_path):
with open(cached_path(file_path), "r") as data_file:
logger.info("Reading instances from: %s", file_path)
json_data = json.load(data_file)
for video_id, value in json_data.items():
sentences = [postprocess(unidecode(x.strip()))
for x in value['sentences']]
for first_sentence, second_sentence in pairwise(sentences):
yield self.text_to_instance(video_id, first_sentence, second_sentence)
@overrides
def text_to_instance(self,
video_id: str,
first_sentence: str,
second_sentence: str) -> Instance: # type: ignore
# pylint: disable=arguments-differ
tokenized_first_sentence = self._tokenizer.tokenize(first_sentence)
tokenized_second_sentence = self._tokenizer.tokenize(second_sentence)
first_sentence_field = TextField(tokenized_first_sentence, self._token_indexers)
second_sentence_field = TextField(tokenized_second_sentence, self._token_indexers)
fields = {'video_id': MetadataField(video_id),
'first_sentence': first_sentence_field,
'second_sentence': second_sentence_field}
return Instance(fields)
| 1 |
0 | hf_public_repos/adversarialnlp/adversarialnlp/generators | hf_public_repos/adversarialnlp/adversarialnlp/generators/swag/__init__.py | from .swag_generator import SwagGenerator
from .activitynet_captions_reader import ActivityNetCaptionsDatasetReader
| 2 |
0 | hf_public_repos/adversarialnlp/adversarialnlp/generators | hf_public_repos/adversarialnlp/adversarialnlp/generators/swag/swag_generator.py | # pylint: disable=invalid-name,arguments-differ
from typing import List, Iterable, Tuple
import logging
import torch
from allennlp.common.util import JsonDict
from allennlp.common.file_utils import cached_path
from allennlp.data import Instance, Token, Vocabulary
from allennlp.data.fields import TextField
from allennlp.pretrained import PretrainedModel
from adversarialnlp.common.file_utils import download_files, DATA_ROOT
from adversarialnlp.generators import Generator
from adversarialnlp.generators.swag.simple_bilm import SimpleBiLM
from adversarialnlp.generators.swag.utils import optimistic_restore
from adversarialnlp.generators.swag.activitynet_captions_reader import ActivityNetCaptionsDatasetReader
BATCH_SIZE = 1
BEAM_SIZE = 8 * BATCH_SIZE
logger = logging.getLogger(__name__)
class SwagGenerator(Generator):
"""
``SwagGenerator`` inherit from the ``Generator`` class.
This ``Generator`` generate adversarial examples from seeds using
the method described in
`SWAG: A Large-Scale Adversarial Dataset for Grounded Commonsense Inference <http://arxiv.org/abs/1808.05326>`_.
This method goes schematically as follows:
- In a seed sample containing a pair of sequential sentence (ex: video captions),
the second sentence is split into noun and verb phrases.
- A language model generates several possible endings from the sencond sentence noun phrase.
Args, input and yield:
See the ``Generator`` class.
Seeds:
AllenNLP ``Instance`` containing two ``TextField``:
`first_sentence` and `first_sentence`, respectively containing
first and the second consecutive sentences.
default_seeds:
If no seeds are provided, the default_seeds are the training set
of the
`ActivityNet Captions dataset <https://cs.stanford.edu/people/ranjaykrishna/densevid/>`_.
"""
def __init__(self,
default_seeds: Iterable = None,
quiet: bool = False):
super().__init__(default_seeds, quiet)
lm_files = download_files(fnames=['vocabulary.zip',
'lm-fold-0.bin'],
local_folder='swag_lm')
activity_data_files = download_files(fnames=['captions.zip'],
paths='https://cs.stanford.edu/people/ranjaykrishna/densevid/',
local_folder='activitynet_captions')
const_parser_files = cached_path('https://s3-us-west-2.amazonaws.com/allennlp/models/elmo-constituency-parser-2018.03.14.tar.gz',
cache_dir=str(DATA_ROOT / 'allennlp_constituency_parser'))
self.const_parser = PretrainedModel(const_parser_files, 'constituency-parser').predictor()
vocab = Vocabulary.from_files(lm_files[0])
self.language_model = SimpleBiLM(vocab=vocab, recurrent_dropout_probability=0.2,
embedding_dropout_probability=0.2)
optimistic_restore(self.language_model, torch.load(lm_files[1], map_location='cpu')['state_dict'])
if default_seeds is None:
self.default_seeds = ActivityNetCaptionsDatasetReader().read(activity_data_files[0] + '/train.json')
else:
self.default_seeds = default_seeds
def _find_VP(self, tree: JsonDict) -> List[Tuple[str, any]]:
r"""Recurse on a constituency parse tree until we find verb phrases"""
# Recursion is annoying because we need to check whether each is a list or not
def _recurse_on_children():
assert 'children' in tree
result = []
for child in tree['children']:
res = self._find_VP(child)
if isinstance(res, tuple):
result.append(res)
else:
result.extend(res)
return result
if 'VP' in tree['attributes']:
# # Now we'll get greedy and see if we can find something better
# if 'children' in tree and len(tree['children']) > 1:
# recurse_result = _recurse_on_children()
# if all([x[1] in ('VP', 'NP', 'CC') for x in recurse_result]):
# return recurse_result
return [(tree['word'], 'VP')]
# base cases
if 'NP' in tree['attributes']:
return [(tree['word'], 'NP')]
# No children
if not 'children' in tree:
return [(tree['word'], tree['attributes'][0])]
# If a node only has 1 child then we'll have to stick with that
if len(tree['children']) == 1:
return _recurse_on_children()
# try recursing on everything
return _recurse_on_children()
def _split_on_final_vp(self, sentence: Instance) -> (List[str], List[str]):
r"""Splits a sentence on the final verb phrase """
sentence_txt = ' '.join(t.text for t in sentence.tokens)
res = self.const_parser.predict(sentence_txt)
res_chunked = self._find_VP(res['hierplane_tree']['root'])
is_vp: List[int] = [i for i, (word, pos) in enumerate(res_chunked) if pos == 'VP']
if not is_vp:
return None, None
vp_ind = max(is_vp)
not_vp = [token for x in res_chunked[:vp_ind] for token in x[0].split(' ')]
is_vp = [token for x in res_chunked[vp_ind:] for token in x[0].split(' ')]
return not_vp, is_vp
def generate_from_seed(self, seed: Tuple):
"""Edit a seed example.
"""
first_sentence: TextField = seed.fields["first_sentence"]
second_sentence: TextField = seed.fields["second_sentence"]
eos_bounds = [i + 1 for i, x in enumerate(first_sentence.tokens) if x.text in ('.', '?', '!')]
if not eos_bounds:
first_sentence = TextField(tokens=first_sentence.tokens + [Token(text='.')],
token_indexers=first_sentence.token_indexers)
context_len = len(first_sentence.tokens)
if context_len < 6 or context_len > 100:
print("skipping on {} (too short or long)".format(
' '.join(first_sentence.tokens + second_sentence.tokens)))
return
# Something I should have done:
# make sure that there aren't multiple periods, etc. in s2 or in the middle
eos_bounds_s2 = [i + 1 for i, x in enumerate(second_sentence.tokens) if x.text in ('.', '?', '!')]
if len(eos_bounds_s2) > 1 or max(eos_bounds_s2) != len(second_sentence.tokens):
return
elif not eos_bounds_s2:
second_sentence = TextField(tokens=second_sentence.tokens + [Token(text='.')],
token_indexers=second_sentence.token_indexers)
# Now split on the VP
startphrase, endphrase = self._split_on_final_vp(second_sentence)
if startphrase is None or not startphrase or len(endphrase) < 5 or len(endphrase) > 25:
print("skipping on {}->{},{}".format(' '.join(first_sentence.tokens + second_sentence.tokens),
startphrase, endphrase), flush=True)
return
# if endphrase contains unk then it's hopeless
# if any(vocab.get_token_index(tok.lower()) == vocab.get_token_index(vocab._oov_token)
# for tok in endphrase):
# print("skipping on {} (unk!)".format(' '.join(s1_toks + s2_toks)))
# return
context = [token.text for token in first_sentence.tokens] + startphrase
lm_out = self.language_model.conditional_generation(context, gt_completion=endphrase,
batch_size=BEAM_SIZE,
max_gen_length=25)
gens0, fwd_scores, ctx_scores = lm_out
if len(gens0) < BATCH_SIZE:
print("Couldn't generate enough candidates so skipping")
return
gens0 = gens0[:BATCH_SIZE]
yield gens0
# fwd_scores = fwd_scores[:BATCH_SIZE]
# # Now get the backward scores.
# full_sents = [context + gen for gen in gens0] # NOTE: #1 is GT
# result_dict = self.language_model(self.language_model.batch_to_ids(full_sents),
# use_forward=False, use_reverse=True, compute_logprobs=True)
# ending_lengths = (fwd_scores < 0).sum(1)
# ending_lengths_float = ending_lengths.astype(np.float32)
# rev_scores = result_dict['reverse_logprobs'].cpu().detach().numpy()
# forward_logperp_ending = -fwd_scores.sum(1) / ending_lengths_float
# reverse_logperp_ending = -rev_scores[:, context_len:].sum(1) / ending_lengths_float
# forward_logperp_begin = -ctx_scores.mean()
# reverse_logperp_begin = -rev_scores[:, :context_len].mean(1)
# eos_logperp = -fwd_scores[np.arange(fwd_scores.shape[0]), ending_lengths - 1]
# # print("Time elapsed {:.3f}".format(time() - tic), flush=True)
# scores = np.exp(np.column_stack((
# forward_logperp_ending,
# reverse_logperp_ending,
# reverse_logperp_begin,
# eos_logperp,
# np.ones(forward_logperp_ending.shape[0], dtype=np.float32) * forward_logperp_begin,
# )))
# PRINTOUT
# low2high = scores[:, 2].argsort()
# print("\n\n Dataset={} ctx: {} (perp={:.3f})\n~~~\n".format(item['dataset'], ' '.join(context),
# np.exp(forward_logperp_begin)), flush=True)
# for i, ind in enumerate(low2high.tolist()):
# gen_i = ' '.join(gens0[ind])
# if (ind == 0) or (i < 128):
# print("{:3d}/{:4d}) ({}, end|ctx:{:5.1f} end:{:5.1f} ctx|end:{:5.1f} EOS|(ctx, end):{:5.1f}) {}".format(
# i, len(gens0), 'GOLD' if ind == 0 else ' ', *scores[ind][:-1], gen_i), flush=True)
# gt_score = low2high.argsort()[0]
# item_full = deepcopy(item)
# item_full['sent1'] = first_sentence
# item_full['startphrase'] = startphrase
# item_full['context'] = context
# item_full['generations'] = gens0
# item_full['postags'] = [ # parse real fast
# [x.orth_.lower() if pos_vocab.get_token_index(x.orth_.lower()) != 1 else x.pos_ for x in y]
# for y in spacy_model.pipe([startphrase + gen for gen in gens0], batch_size=BATCH_SIZE)]
# item_full['scores'] = pd.DataFrame(data=scores, index=np.arange(scores.shape[0]),
# columns=['end-from-ctx', 'end', 'ctx-from-end', 'eos-from-ctxend', 'ctx'])
# generated_examples.append(gens0)
# if len(generated_examples) > 0:
# yield generated_examples
# generated_examples = []
# from adversarialnlp.common.file_utils import FIXTURES_ROOT
# generator = SwagGenerator()
# test_instances = ActivityNetCaptionsDatasetReader().read(FIXTURES_ROOT / 'activitynet_captions.json')
# batches = list(generator(test_instances, num_epochs=1))
# assert len(batches) != 0
| 3 |
0 | hf_public_repos/adversarialnlp/adversarialnlp/generators | hf_public_repos/adversarialnlp/adversarialnlp/generators/swag/openai_transformer_model.py | from typing import Dict, List, Tuple, Union, Optional
import torch
import numpy as np
from allennlp.common.checks import ConfigurationError
from allennlp.data.vocabulary import Vocabulary
from allennlp.models.model import Model
from allennlp.modules.openai_transformer import OpenaiTransformer
from allennlp.modules.token_embedders import OpenaiTransformerEmbedder
from allennlp.nn.util import get_text_field_mask, remove_sentence_boundaries
@Model.register('openai-transformer-language-model')
class OpenAITransformerLanguageModel(Model):
"""
The ``OpenAITransformerLanguageModel`` is a wrapper around ``OpenATransformerModule``.
Parameters
----------
vocab: ``Vocabulary``
remove_bos_eos: ``bool``, optional (default: True)
Typically the provided token indexes will be augmented with
begin-sentence and end-sentence tokens. If this flag is True
the corresponding embeddings will be removed from the return values.
"""
def __init__(self,
vocab: Vocabulary,
openai_token_embedder: OpenaiTransformerEmbedder,
remove_bos_eos: bool = True) -> None:
super().__init__(vocab)
model_path = "https://s3-us-west-2.amazonaws.com/allennlp/models/openai-transformer-lm-2018.07.23.tar.gz"
indexer = OpenaiTransformerBytePairIndexer(model_path=model_path)
transformer = OpenaiTransformer(model_path=model_path)
self._token_embedders = OpenaiTransformerEmbedder(transformer=transformer, top_layer_only=True)
self._remove_bos_eos = remove_bos_eos
def _get_target_token_embedding(self,
token_embeddings: torch.Tensor,
mask: torch.Tensor,
direction: int) -> torch.Tensor:
# Need to shift the mask in the correct direction
zero_col = token_embeddings.new_zeros(mask.size(0), 1).byte()
if direction == 0:
# forward direction, get token to right
shifted_mask = torch.cat([zero_col, mask[:, 0:-1]], dim=1)
else:
shifted_mask = torch.cat([mask[:, 1:], zero_col], dim=1)
return token_embeddings.masked_select(shifted_mask.unsqueeze(-1)).view(-1, self._forward_dim)
def _compute_loss(self,
lm_embeddings: torch.Tensor,
token_embeddings: torch.Tensor,
forward_targets: torch.Tensor,
backward_targets: torch.Tensor) -> Tuple[torch.Tensor, torch.Tensor]:
# lm_embeddings is shape (batch_size, timesteps, dim * 2)
# forward_targets, backward_targets are shape (batch_size, timesteps)
# masked with 0
forward_embeddings, backward_embeddings = lm_embeddings.chunk(2, -1)
losses: List[torch.Tensor] = []
for idx, embedding, targets in ((0, forward_embeddings, forward_targets),
(1, backward_embeddings, backward_targets)):
mask = targets > 0
# we need to subtract 1 to undo the padding id since the softmax
# does not include a padding dimension
non_masked_targets = targets.masked_select(mask) - 1
non_masked_embedding = embedding.masked_select(
mask.unsqueeze(-1)
).view(-1, self._forward_dim)
# note: need to return average loss across forward and backward
# directions, but total sum loss across all batches.
# Assuming batches include full sentences, forward and backward
# directions have the same number of samples, so sum up loss
# here then divide by 2 just below
if not self._softmax_loss.tie_embeddings or not self._use_character_inputs:
losses.append(self._softmax_loss(non_masked_embedding, non_masked_targets))
else:
# we also need the token embeddings corresponding to the
# the targets
raise NotImplementedError("This requires SampledSoftmaxLoss, which isn't implemented yet.")
# pylint: disable=unreachable
non_masked_token_embedding = self._get_target_token_embedding(token_embeddings, mask, idx)
losses.append(self._softmax(non_masked_embedding,
non_masked_targets,
non_masked_token_embedding))
return losses[0], losses[1]
def forward(self, # type: ignore
source: Dict[str, torch.LongTensor]) -> Dict[str, torch.Tensor]:
"""
Computes the averaged forward and backward LM loss from the batch.
By convention, the input dict is required to have at least a ``"tokens"``
entry that's the output of a ``SingleIdTokenIndexer``, which is used
to compute the language model targets.
If the model was instantatiated with ``remove_bos_eos=True``,
then it is expected that each of the input sentences was augmented with
begin-sentence and end-sentence tokens.
Parameters
----------
tokens: ``torch.Tensor``, required.
The output of ``Batch.as_tensor_dict()`` for a batch of sentences.
Returns
-------
Dict with keys:
``'loss'``: ``torch.Tensor``
averaged forward/backward negative log likelihood
``'forward_loss'``: ``torch.Tensor``
forward direction negative log likelihood
``'backward_loss'``: ``torch.Tensor``
backward direction negative log likelihood
``'lm_embeddings'``: ``torch.Tensor``
(batch_size, timesteps, embed_dim) tensor of top layer contextual representations
``'mask'``: ``torch.Tensor``
(batch_size, timesteps) mask for the embeddings
"""
# pylint: disable=arguments-differ
mask = get_text_field_mask(source)
# We must have token_ids so that we can compute targets
token_ids = source.get("tokens")
if token_ids is None:
raise ConfigurationError("Your data must have a 'tokens': SingleIdTokenIndexer() "
"in order to use the BidirectionalLM")
# Use token_ids to compute targets
forward_targets = torch.zeros_like(token_ids)
backward_targets = torch.zeros_like(token_ids)
forward_targets[:, 0:-1] = token_ids[:, 1:]
backward_targets[:, 1:] = token_ids[:, 0:-1]
embeddings = self._text_field_embedder(source)
# Apply LayerNorm if appropriate.
embeddings = self._layer_norm(embeddings)
contextual_embeddings = self._contextualizer(embeddings, mask)
# add dropout
contextual_embeddings = self._dropout(contextual_embeddings)
# compute softmax loss
forward_loss, backward_loss = self._compute_loss(contextual_embeddings,
embeddings,
forward_targets,
backward_targets)
num_targets = torch.sum((forward_targets > 0).long())
if num_targets > 0:
average_loss = 0.5 * (forward_loss + backward_loss) / num_targets.float()
else:
average_loss = torch.tensor(0.0).to(forward_targets.device) # pylint: disable=not-callable
# this is stored to compute perplexity if needed
self._last_average_loss[0] = average_loss.detach().item()
if num_targets > 0:
# loss is directly minimized
if self._loss_scale == 'n_samples':
scale_factor = num_targets.float()
else:
scale_factor = self._loss_scale
return_dict = {
'loss': average_loss * scale_factor,
'forward_loss': forward_loss * scale_factor / num_targets.float(),
'backward_loss': backward_loss * scale_factor / num_targets.float()
}
else:
# average_loss zero tensor, return it for all
return_dict = {
'loss': average_loss,
'forward_loss': average_loss,
'backward_loss': average_loss
}
if self._remove_bos_eos:
contextual_embeddings, mask = remove_sentence_boundaries(contextual_embeddings, mask)
return_dict.update({
'lm_embeddings': contextual_embeddings,
'mask': mask
})
return return_dict
| 4 |
0 | hf_public_repos/adversarialnlp/adversarialnlp/generators | hf_public_repos/adversarialnlp/adversarialnlp/generators/swag/simple_bilm.py | """
A wrapper around ai2s elmo LM to allow for an lm objective...
"""
from typing import Optional, Tuple
from typing import Union, List, Dict
import numpy as np
import torch
from allennlp.common.checks import ConfigurationError
from allennlp.data import Token, Vocabulary, Instance
from allennlp.data.dataset import Batch
from allennlp.data.fields import TextField
from allennlp.data.token_indexers import SingleIdTokenIndexer
from allennlp.modules.augmented_lstm import AugmentedLstm
from allennlp.modules.seq2seq_encoders.pytorch_seq2seq_wrapper import PytorchSeq2SeqWrapper
from allennlp.nn.util import sequence_cross_entropy_with_logits
from torch.autograd import Variable
from torch.nn import functional as F
from torch.nn.utils.rnn import PackedSequence
def _de_duplicate_generations(generations):
"""
Given a list of list of strings, filter out the ones that are duplicates. and return an idx corresponding
to the good ones
:param generations:
:return:
"""
dup_set = set()
unique_idx = []
for i, gen_i in enumerate(generations):
gen_i_str = ' '.join(gen_i)
if gen_i_str not in dup_set:
unique_idx.append(i)
dup_set.add(gen_i_str)
return [generations[i] for i in unique_idx], np.array(unique_idx)
class StackedLstm(torch.nn.Module):
"""
A stacked LSTM.
Parameters
----------
input_size : int, required
The dimension of the inputs to the LSTM.
hidden_size : int, required
The dimension of the outputs of the LSTM.
num_layers : int, required
The number of stacked LSTMs to use.
recurrent_dropout_probability: float, optional (default = 0.0)
The dropout probability to be used in a dropout scheme as stated in
`A Theoretically Grounded Application of Dropout in Recurrent Neural Networks
<https://arxiv.org/abs/1512.05287>`_ .
use_input_projection_bias : bool, optional (default = True)
Whether or not to use a bias on the input projection layer. This is mainly here
for backwards compatibility reasons and will be removed (and set to False)
in future releases.
Returns
-------
output_accumulator : PackedSequence
The outputs of the interleaved LSTMs per timestep. A tensor of shape
(batch_size, max_timesteps, hidden_size) where for a given batch
element, all outputs past the sequence length for that batch are
zero tensors.
"""
def __init__(self,
input_size: int,
hidden_size: int,
num_layers: int,
recurrent_dropout_probability: float = 0.0,
use_highway: bool = True,
use_input_projection_bias: bool = True,
go_forward: bool = True) -> None:
super(StackedLstm, self).__init__()
# Required to be wrapped with a :class:`PytorchSeq2SeqWrapper`.
self.input_size = input_size
self.hidden_size = hidden_size
self.num_layers = num_layers
layers = []
lstm_input_size = input_size
for layer_index in range(num_layers):
layer = AugmentedLstm(lstm_input_size, hidden_size, go_forward,
recurrent_dropout_probability=recurrent_dropout_probability,
use_highway=use_highway,
use_input_projection_bias=use_input_projection_bias)
lstm_input_size = hidden_size
self.add_module('layer_{}'.format(layer_index), layer)
layers.append(layer)
self.lstm_layers = layers
def forward(self, # pylint: disable=arguments-differ
inputs: PackedSequence,
initial_state: Optional[Tuple[torch.Tensor, torch.Tensor]] = None):
"""
Parameters
----------
inputs : ``PackedSequence``, required.
A batch first ``PackedSequence`` to run the stacked LSTM over.
initial_state : Tuple[torch.Tensor, torch.Tensor], optional, (default = None)
A tuple (state, memory) representing the initial hidden state and memory
of the LSTM. Each tensor has shape (1, batch_size, output_dimension).
Returns
-------
output_sequence : PackedSequence
The encoded sequence of shape (batch_size, sequence_length, hidden_size)
final_states: torch.Tensor
The per-layer final (state, memory) states of the LSTM, each with shape
(num_layers, batch_size, hidden_size).
"""
if not initial_state:
hidden_states = [None] * len(self.lstm_layers)
elif initial_state[0].size()[0] != len(self.lstm_layers):
raise ConfigurationError("Initial states were passed to forward() but the number of "
"initial states does not match the number of layers.")
else:
hidden_states = list(zip(initial_state[0].split(1, 0),
initial_state[1].split(1, 0)))
output_sequence = inputs
final_states = []
for i, state in enumerate(hidden_states):
layer = getattr(self, 'layer_{}'.format(i))
# The state is duplicated to mirror the Pytorch API for LSTMs.
output_sequence, final_state = layer(output_sequence, state)
final_states.append(final_state)
final_state_tuple = tuple(torch.cat(state_list, 0) for state_list in zip(*final_states))
return output_sequence, final_state_tuple
class SimpleBiLM(torch.nn.Module):
def __init__(self,
vocab: Vocabulary,
recurrent_dropout_probability: float = 0.0,
embedding_dropout_probability: float = 0.0,
input_size=512,
hidden_size=512) -> None:
"""
:param options_file: for initializing elmo BiLM
:param weight_file: for initializing elmo BiLM
:param requires_grad: Whether or not to finetune the LSTM layers
:param recurrent_dropout_probability: recurrent dropout to add to LSTM layers
"""
super(SimpleBiLM, self).__init__()
self.forward_lm = PytorchSeq2SeqWrapper(StackedLstm(
input_size=input_size, hidden_size=hidden_size, num_layers=2, go_forward=True,
recurrent_dropout_probability=recurrent_dropout_probability,
use_input_projection_bias=False, use_highway=True), stateful=True)
self.reverse_lm = PytorchSeq2SeqWrapper(StackedLstm(
input_size=input_size, hidden_size=hidden_size, num_layers=2, go_forward=False,
recurrent_dropout_probability=recurrent_dropout_probability,
use_input_projection_bias=False, use_highway=True), stateful=True)
# This will also be the encoder
self.decoder = torch.nn.Linear(512, vocab.get_vocab_size(namespace='tokens'))
self.vocab = vocab
self.register_buffer('eos_tokens', torch.LongTensor([vocab.get_token_index(tok) for tok in
['.', '!', '?', '@@UNKNOWN@@', '@@PADDING@@', '@@bos@@',
'@@eos@@']]))
self.register_buffer('invalid_tokens', torch.LongTensor([vocab.get_token_index(tok) for tok in
['@@UNKNOWN@@', '@@PADDING@@', '@@bos@@', '@@eos@@',
'@@NEWLINE@@']]))
self.embedding_dropout_probability = embedding_dropout_probability
def embed_words(self, words):
# assert words.dim() == 2
return F.embedding(words, self.decoder.weight)
# if not self.training:
# return F.embedding(words, self.decoder.weight)
# Embedding dropout
# vocab_size = self.decoder.weight.size(0)
# mask = Variable(
# self.decoder.weight.data.new(vocab_size, 1).bernoulli_(1 - self.embedding_dropout_probability).expand_as(
# self.decoder.weight) / (1 - self.embedding_dropout_probability))
# padding_idx = 0
# embeds = self.decoder._backend.Embedding.apply(words, mask * self.decoder.weight, padding_idx, None,
# 2, False, False)
# return embeds
def timestep_to_ids(self, timestep_tokenized: List[str]):
""" Just a single timestep (so dont add BOS or EOS"""
return torch.tensor([self.vocab.get_token_index(x) for x in timestep_tokenized])[:, None]
def batch_to_ids(self, stories_tokenized: List[List[str]]):
"""
Simple wrapper around _elmo_batch_to_ids
:param batch: A list of tokenized sentences.
:return: A tensor of padded character ids.
"""
batch = Batch([Instance(
{'story': TextField([Token('@@bos@@')] + [Token(x) for x in story] + [Token('@@eos@@')],
token_indexers={
'tokens': SingleIdTokenIndexer(namespace='tokens', lowercase_tokens=True)})})
for story in stories_tokenized])
batch.index_instances(self.vocab)
words = {k: v['tokens'] for k, v in batch.as_tensor_dict().items()}['story']
return words
def conditional_generation(self, context: List[str], gt_completion: List[str],
batch_size: int = 128, max_gen_length: int = 25,
same_length_as_gt: bool = False, first_is_gold: bool = False):
"""
Generate conditoned on the context. While we're at it we'll score the GT going forwards
:param context: List of tokens to condition on. We'll add the BOS marker to it
:param gt_completion: The gold truth completion
:param batch_size: Number of sentences to generate
:param max_gen_length: Max length for genertaed sentences (irrelvant if same_length_as_gt=True)
:param same_length_as_gt: set to True if you want all the sents to have the same length as the gt_completion
:param first_is_gold: set to True if you want the first sample to be the gt_completion
:return:
"""
# Forward condition on context, then repeat to be the right batch size:
# (layer_index, batch_size, fwd hidden dim)
log_probs = self(self.batch_to_ids([context]), use_forward=True,
use_reverse=False, compute_logprobs=True)
forward_logprobs = log_probs['forward_logprobs']
self.forward_lm._states = tuple(x.repeat(1, batch_size, 1).contiguous() for x in self.forward_lm._states)
# Each item will be (token, score)
generations = [[(context[-1], 0.0)] for i in range(batch_size)]
mask = forward_logprobs.new(batch_size).long().fill_(1)
gt_completion_padded = [self.vocab.get_token_index(gt_token) for gt_token in
[x.lower() for x in gt_completion] + ['@@PADDING@@'] * (
max_gen_length - len(gt_completion))]
for index, gt_token_ind in enumerate(gt_completion_padded):
embeds = self.embed_words(self.timestep_to_ids([gen[-1][0] for gen in generations]))
next_dists = F.softmax(self.decoder(self.forward_lm(embeds, mask[:, None]))[:, 0], dim=1)
# Perform hacky stuff on the distribution (disallowing BOS, EOS, that sorta thing
sampling_probs = next_dists.clone()
sampling_probs[:, self.invalid_tokens] = 0.0
if first_is_gold:
# Gold truth is first row
sampling_probs[0].zero_()
sampling_probs[0, gt_token_ind] = 1
if same_length_as_gt:
if index == (len(gt_completion) - 1):
sampling_probs.zero_()
sampling_probs[:, gt_token_ind] = 1
else:
sampling_probs[:, self.eos_tokens] = 0.0
sampling_probs = sampling_probs / sampling_probs.sum(1, keepdim=True)
next_preds = torch.multinomial(sampling_probs, 1).squeeze(1)
next_scores = np.log(next_dists[
torch.arange(0, next_dists.size(0),
out=mask.data.new(next_dists.size(0))),
next_preds,
].cpu().detach().numpy())
for i, (gen_list, pred_id, score_i, mask_i) in enumerate(
zip(generations, next_preds.cpu().detach().numpy(), next_scores, mask.data.cpu().detach().numpy())):
if mask_i:
gen_list.append((self.vocab.get_token_from_index(pred_id), score_i))
is_eos = (next_preds[:, None] == self.eos_tokens[None]).max(1)[0]
mask[is_eos] = 0
if mask.sum().item() == 0:
break
generation_scores = np.zeros((len(generations), max([len(g) - 1 for g in generations])), dtype=np.float32)
for i, gen in enumerate(generations):
for j, (_, v) in enumerate(gen[1:]):
generation_scores[i, j] = v
generation_toks, idx = _de_duplicate_generations([[tok for (tok, score) in gen[1:]] for gen in generations])
return generation_toks, generation_scores[idx], forward_logprobs.cpu().detach().numpy()
def _chunked_logsoftmaxes(self, activation, word_targets, chunk_size=256):
"""
do the softmax in chunks so memory doesnt explode
:param activation: [batch, T, dim]
:param targets: [batch, T] indices
:param chunk_size: you might need to tune this based on GPU specs
:return:
"""
all_logprobs = []
num_chunks = (activation.size(0) - 1) // chunk_size + 1
for activation_chunk, target_chunk in zip(torch.chunk(activation, num_chunks, dim=0),
torch.chunk(word_targets, num_chunks, dim=0)):
assert activation_chunk.size()[:2] == target_chunk.size()[:2]
targets_flat = target_chunk.view(-1)
time_indexer = torch.arange(0, targets_flat.size(0),
out=target_chunk.data.new(targets_flat.size(0))) % target_chunk.size(1)
batch_indexer = torch.arange(0, targets_flat.size(0),
out=target_chunk.data.new(targets_flat.size(0))) / target_chunk.size(1)
all_logprobs.append(F.log_softmax(self.decoder(activation_chunk), 2)[
batch_indexer, time_indexer, targets_flat].view(*target_chunk.size()))
return torch.cat(all_logprobs, 0)
def forward(self, words: torch.Tensor, use_forward: bool = True, use_reverse: bool = True,
compute_logprobs: bool = False) -> Dict[str, Union[torch.Tensor, List[torch.Tensor]]]:
"""
use this for training the LM
:param words: [batch_size, N] words. assuming you're starting with BOS and ending with EOS here
:return:
"""
encoded_inputs = self.embed_words(words)
mask = (words != 0).long()[:, 2:]
word_targets = words[:, 1:-1].contiguous()
result_dict = {
'mask': mask,
'word_targets': word_targets,
}
# TODO: try to reduce duplicate code here
if use_forward:
self.forward_lm.reset_states()
forward_activation = self.forward_lm(encoded_inputs[:, :-2], mask)
if compute_logprobs:
# being memory efficient here is critical if the input tensors are large
result_dict['forward_logprobs'] = self._chunked_logsoftmaxes(forward_activation,
word_targets) * mask.float()
else:
result_dict['forward_logits'] = self.decoder(forward_activation)
result_dict['forward_loss'] = sequence_cross_entropy_with_logits(result_dict['forward_logits'],
word_targets,
mask)
if use_reverse:
self.reverse_lm.reset_states()
reverse_activation = self.reverse_lm(encoded_inputs[:, 2:], mask)
if compute_logprobs:
result_dict['reverse_logprobs'] = self._chunked_logsoftmaxes(reverse_activation,
word_targets) * mask.float()
else:
result_dict['reverse_logits'] = self.decoder(reverse_activation)
result_dict['reverse_loss'] = sequence_cross_entropy_with_logits(result_dict['reverse_logits'],
word_targets,
mask)
return result_dict
| 5 |
0 | hf_public_repos/adversarialnlp/adversarialnlp | hf_public_repos/adversarialnlp/adversarialnlp/pruners/pruner.py | from allennlp.common import Registrable
class Pruner(Registrable):
"""
``Pruner`` is used to fil potential adversarial samples
Parameters
----------
dataset_reader : ``DatasetReader``
The ``DatasetReader`` object that will be used to sample training examples.
"""
def __init__(self, ) -> None:
super().__init__()
| 6 |
0 | hf_public_repos/adversarialnlp/adversarialnlp | hf_public_repos/adversarialnlp/adversarialnlp/pruners/__init__.py | from .pruner import Pruner | 7 |
0 | hf_public_repos/adversarialnlp/adversarialnlp/tests | hf_public_repos/adversarialnlp/adversarialnlp/tests/fixtures/squad.json | {
"data": [{
"title": "Super_Bowl_50",
"paragraphs": [{
"context": "Super Bowl 50 was an American football game to determine the champion of the National Football League (NFL) for the 2015 season. The American Football Conference (AFC) champion Denver Broncos defeated the National Football Conference (NFC) champion Carolina Panthers 24\u201310 to earn their third Super Bowl title. The game was played on February 7, 2016, at Levi's Stadium in the San Francisco Bay Area at Santa Clara, California. As this was the 50th Super Bowl, the league emphasized the \"golden anniversary\" with various gold-themed initiatives, as well as temporarily suspending the tradition of naming each Super Bowl game with Roman numerals (under which the game would have been known as \"Super Bowl L\"), so that the logo could prominently feature the Arabic numerals 50.",
"qas": [{
"answers": [{
"answer_start": 177,
"text": "Denver Broncos"
}, {
"answer_start": 177,
"text": "Denver Broncos"
}, {
"answer_start": 177,
"text": "Denver Broncos"
}],
"question": "Which NFL team represented the AFC at Super Bowl 50?",
"id": "56be4db0acb8001400a502ec"
}, {
"answers": [{
"answer_start": 177,
"text": "Denver Broncos"
}, {
"answer_start": 177,
"text": "Denver Broncos"
}, {
"answer_start": 177,
"text": "Denver Broncos"
}],
"question": "Which NFL team won Super Bowl 50?",
"id": "56be4db0acb8001400a502ef"
}]
}, {
"context": "The Panthers finished the regular season with a 15\u20131 record, and quarterback Cam Newton was named the NFL Most Valuable Player (MVP). They defeated the Arizona Cardinals 49\u201315 in the NFC Championship Game and advanced to their second Super Bowl appearance since the franchise was founded in 1995. The Broncos finished the regular season with a 12\u20134 record, and denied the New England Patriots a chance to defend their title from Super Bowl XLIX by defeating them 20\u201318 in the AFC Championship Game. They joined the Patriots, Dallas Cowboys, and Pittsburgh Steelers as one of four teams that have made eight appearances in the Super Bowl.",
"qas": [{
"answers": [{
"answer_start": 77,
"text": "Cam Newton"
}, {
"answer_start": 77,
"text": "Cam Newton"
}, {
"answer_start": 77,
"text": "Cam Newton"
}],
"question": "Which Carolina Panthers player was named Most Valuable Player?",
"id": "56be4e1facb8001400a502f6"
}, {
"answers": [{
"answer_start": 467,
"text": "8"
}, {
"answer_start": 601,
"text": "eight"
}, {
"answer_start": 601,
"text": "eight"
}],
"question": "How many appearances have the Denver Broncos made in the Super Bowl?",
"id": "56be4e1facb8001400a502f9"
}]
}]
},{
"title": "Warsaw",
"paragraphs": [{
"context": "One of the most famous people born in Warsaw was Maria Sk\u0142odowska-Curie, who achieved international recognition for her research on radioactivity and was the first female recipient of the Nobel Prize. Famous musicians include W\u0142adys\u0142aw Szpilman and Fr\u00e9d\u00e9ric Chopin. Though Chopin was born in the village of \u017belazowa Wola, about 60 km (37 mi) from Warsaw, he moved to the city with his family when he was seven months old. Casimir Pulaski, a Polish general and hero of the American Revolutionary War, was born here in 1745.",
"qas": [{
"answers": [{
"answer_start": 188,
"text": "Nobel Prize"
}, {
"answer_start": 188,
"text": "Nobel Prize"
}, {
"answer_start": 188,
"text": "Nobel Prize"
}],
"question": "What was Maria Curie the first female recipient of?",
"id": "5733a5f54776f41900660f45"
}, {
"answers": [{
"answer_start": 517,
"text": "1745"
}, {
"answer_start": 517,
"text": "1745"
}, {
"answer_start": 517,
"text": "1745"
}],
"question": "What year was Casimir Pulaski born in Warsaw?",
"id": "5733a5f54776f41900660f48"
}]
}, {
"context": "The Saxon Garden, covering the area of 15.5 ha, was formally a royal garden. There are over 100 different species of trees and the avenues are a place to sit and relax. At the east end of the park, the Tomb of the Unknown Soldier is situated. In the 19th century the Krasi\u0144ski Palace Garden was remodelled by Franciszek Szanior. Within the central area of the park one can still find old trees dating from that period: maidenhair tree, black walnut, Turkish hazel and Caucasian wingnut trees. With its benches, flower carpets, a pond with ducks on and a playground for kids, the Krasi\u0144ski Palace Garden is a popular strolling destination for the Varsovians. The Monument of the Warsaw Ghetto Uprising is also situated here. The \u0141azienki Park covers the area of 76 ha. The unique character and history of the park is reflected in its landscape architecture (pavilions, sculptures, bridges, cascades, ponds) and vegetation (domestic and foreign species of trees and bushes). What makes this park different from other green spaces in Warsaw is the presence of peacocks and pheasants, which can be seen here walking around freely, and royal carps in the pond. The Wilan\u00f3w Palace Park, dates back to the second half of the 17th century. It covers the area of 43 ha. Its central French-styled area corresponds to the ancient, baroque forms of the palace. The eastern section of the park, closest to the Palace, is the two-level garden with a terrace facing the pond. The park around the Kr\u00f3likarnia Palace is situated on the old escarpment of the Vistula. The park has lanes running on a few levels deep into the ravines on both sides of the palace.",
"qas": [{
"answers": [{
"answer_start": 92,
"text": "100"
}, {
"answer_start": 87,
"text": "over 100"
}, {
"answer_start": 92,
"text": "100"
}],
"question": "Over how many species of trees can be found in the Saxon Garden?",
"id": "57336755d058e614000b5a3d"
}]
}]
}],
"version": "1.1"
} | 8 |
0 | hf_public_repos/adversarialnlp/adversarialnlp/tests | hf_public_repos/adversarialnlp/adversarialnlp/tests/fixtures/activitynet_captions.json | {"v_uqiMw7tQ1Cc": {"duration": 55.15, "timestamps": [[0.28, 55.15], [13.79, 54.32]], "sentences": ["A weight lifting tutorial is given.", " The coach helps the guy in red with the proper body placement and lifting technique."]}, "v_bXdq2zI1Ms0": {"duration": 73.1, "timestamps": [[0, 10.23], [10.6, 39.84], [38.01, 73.1]], "sentences": ["A man is seen speaking to the camera and pans out into more men standing behind him.", " The first man then begins performing martial arts moves while speaking to he camera.", " He continues moving around and looking to the camera."]}} | 9 |
0 | hf_public_repos/audio-transformers-course/chapters/fr | hf_public_repos/audio-transformers-course/chapters/fr/chapter1/load_and_explore.mdx | # Charger et explorer un jeu de données audio
Dans ce cours, nous utiliserons la bibliothèque 🤗 *Datasets* pour travailler avec des jeux de données audio.
🤗 *Datasets* est une bibliothèque open-source permettant de télécharger et de préparer des jeux de données à partir de toutes les modalités, y compris l'audio.
La bibliothèque offre un accès facile à une sélection inégalée de jeux de données d'apprentissage automatique accessibles sur Hugging Face Hub.
De plus, 🤗 *Datasets* comprend de multiples fonctionnalités adaptées aux jeux de données audio simplifiant le travail avec de tels jeux de données pour les chercheurs et les praticiens.
Pour commencer à utiliser des jeux de données audio, assurez-vous que la 🤗 *Datasets* est installée :
```bash
pip install datasets[audio]
```
L'une des principales caractéristiques déterminantes de 🤗 *Datasets* est la possibilité de télécharger et de préparer un jeu de données en une seule ligne de code Python à l'aide de la fonction `load_dataset()`.
Chargeons et explorons un jeu de données audio appelé [MINDS-14](https://huggingface.co/datasets/PolyAI/minds14), qui contient des enregistrements de personnes posant des questions à un système bancaire électronique dans plusieurs langues et dialectes.
Pour charger le jeu de données MINDS-14, nous devons copier l'identifiant du jeu de données sur le Hub (`PolyAI/minds14`) et le transmettre à la fonction `load_dataset`.
Nous préciserons également que nous ne nous intéressons qu'au sous-ensemble australien ('en-AU') des données, et le limiterons à la division de l'entraînement :
```py
from datasets import load_dataset
minds = load_dataset("PolyAI/minds14", name="en-AU", split="train")
minds
```
**Sortie :**
```out
Dataset(
{
features: [
"path",
"audio",
"transcription",
"english_transcription",
"intent_class",
"lang_id",
],
num_rows: 654,
}
)
```
Le jeu de données contient 654 fichiers audio, chacun étant accompagné d'une transcription, d'une traduction en anglais et d'une étiquette indiquant l'intention derrière la requête de la personne.
La colonne audio contient les données audio brutes. Examinons de plus près l'un des exemples:
```py
example = minds[0]
example
```
**Sortie :**
```out
{
"path": "/root/.cache/huggingface/datasets/downloads/extracted/f14948e0e84be638dd7943ac36518a4cf3324e8b7aa331c5ab11541518e9368c/en-AU~PAY_BILL/response_4.wav",
"audio": {
"path": "/root/.cache/huggingface/datasets/downloads/extracted/f14948e0e84be638dd7943ac36518a4cf3324e8b7aa331c5ab11541518e9368c/en-AU~PAY_BILL/response_4.wav",
"array": array(
[0.0, 0.00024414, -0.00024414, ..., -0.00024414, 0.00024414, 0.0012207],
dtype=float32,
),
"sampling_rate": 8000,
},
"transcription": "I would like to pay my electricity bill using my card can you please assist",
"english_transcription": "I would like to pay my electricity bill using my card can you please assist",
"intent_class": 13,
"lang_id": 2,
}
```
Vous remarquerez peut-être que la colonne audio contient plusieurs caractéristiques :
* `path` : le chemin d'accès au fichier audio (`*.wav` dans ce cas).
* `array`: les données audio décodées, représentées sous la forme d'un tableau NumPy à 1 dimension.
* `sampling_rate` : taux d'échantillonnage du fichier audio (8 000 Hz dans cet exemple).
Le `intent_class` est une catégorie de classification de l'enregistrement audio. Pour convertir ce nombre en une chaîne significative, nous pouvons utiliser la méthode `int2str()`:
```py
id2label = minds.features["intent_class"].int2str
id2label(example["intent_class"])
```
**Sortie :**
```out
"pay_bill"
```
Si vous regardez la fonction de transcription, vous pouvez voir que le fichier audio a effectivement enregistré une personne posant une question sur le paiement d'une facture.
Si vous envisagez d'entraîner un classifieur audio sur ce sous-ensemble de données, vous n'aurez pas nécessairement besoin de toutes les caractéristiques.
Par exemple, le `lang_id` aura la même valeur pour tous les exemples et ne sera pas utile.
Les `english_transcription` dupliqueront probablement la `transcription` de ce sous-ensemble, afin que nous puissions les supprimer en toute sécurité.
Vous pouvez facilement supprimer les caractéristiques non pertinentes à l'aide de la méthode `remove_columns` de 🤗 *Datasets* :
```py
columns_to_remove = ["lang_id", "english_transcription"]
minds = minds.remove_columns(columns_to_remove)
minds
```
**Sortie :**
```out
Dataset({features: ["path", "audio", "transcription", "intent_class"], num_rows: 654})
```
Maintenant que nous avons chargé et inspecté le contenu brut du jeu de données, écoutons quelques exemples ! Nous utiliserons les fonctionnalités `Blocs` et `Audio` de *Gradio* pour décoder quelques échantillons aléatoires du jeu de données:
```py
import gradio as gr
def generate_audio():
example = minds.shuffle()[0]
audio = example["audio"]
return (
audio["sampling_rate"],
audio["array"],
), id2label(example["intent_class"])
with gr.Blocks() as demo:
with gr.Column():
for _ in range(4):
audio, label = generate_audio()
output = gr.Audio(audio, label=label)
demo.launch(debug=True)
```
Si vous le souhaitez, vous pouvez également visualiser certains des exemples. Traçons la forme d'onde pour le premier exemple.
```py
import librosa
import matplotlib.pyplot as plt
import librosa.display
array = example["audio"]["array"]
sampling_rate = example["audio"]["sampling_rate"]
plt.figure().set_figwidth(12)
librosa.display.waveshow(array, sr=sampling_rate)
```
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface-course/audio-course-images/resolve/main/waveform_unit1.png" alt="Waveform plot">
</div>
Essayez ! Téléchargez un autre dialecte ou une autre langue du jeu de données MINDS-14, écoutez et visualisez quelques exemples pour avoir une idée des variations du jeu de données.
Vous pouvez trouver la liste complète des langues disponibles [ici](https://huggingface.co/datasets/PolyAI/minds14).
| 0 |
0 | hf_public_repos/audio-transformers-course/chapters/fr | hf_public_repos/audio-transformers-course/chapters/fr/chapter7/supplemental_reading.mdx | # Lectures et ressources complémentaires
Cette unité a rassemblé de nombreux éléments des unités précédentes, en introduisant les tâches de traduction vocale (audio à audio), les assistants vocaux et séparation des locuteurs.
Le matériel de lecture supplémentaire est donc divisé en ces trois nouvelles tâches :
Traduction vocale (audio à audio) :
* [STST avec unités discrètes](https://ai.facebook.com/blog/advancing-direct-speech-to-speech-modeling-with-discrete-units/) par Meta AI : une approche directe de la STST par le biais de modèles encodeur-décodeur.
* [Hokkien direct speech-to-speech translation](https://ai.facebook.com/blog/ai-translation-hokkien/) par Meta AI : une approche directe de STST en utilisant des modèles encodeur-décodeur avec un décodeur en deux étapes.
* [Leveraging unsupervised and weakly-supervised data to improve direct STST](https://arxiv.org/abs/2203.13339) par Google : propose de nouvelles approches pour tirer parti des données non supervisées et faiblement supervisées pour entraîner les modèles STST directs et une petite modification de l'architecture du *transformer*.
* [Translatotron-2](https://google-research.github.io/lingvo-lab/translatotron2/) par Google : un système capable de conserver les caractéristiques du locuteur dans la traduction de parole.
Assistant vocal :
* [Accurate wakeword detection](https://www.amazon.science/publications/accurate-detection-of-wake-word-start-and-end-using-a-cnn) par Amazon : une approche à faible latence pour la détection des mots déclencheur pour les applications sur appareil.
* [Architecture RNN-Transducteur](https://arxiv.org/pdf/1811.06621.pdf) par Google : une modification de l'architecture CTC pour l'ASR en *streaming* sur appareil.
Transcriptions de réunions :
* [pyannote.audio Technical Report](https://huggingface.co/pyannote/speaker-diarization/blob/main/technical_report_2.1.pdf) par Hervé Bredin : ce rapport décrit les principes fondamentaux du pipeline de séparation des locuteurs `pyannote.audio`.
* [Whisper X](https://arxiv.org/pdf/2303.00747.pdf) par Max Bain et al. : une approche supérieure pour calculer les horodatages au niveau des mots en utilisant le modèle Whisper.
| 1 |
0 | hf_public_repos/audio-transformers-course/chapters/fr | hf_public_repos/audio-transformers-course/chapters/fr/chapter7/transcribe-meeting.mdx | # Transcrire une réunion
Dans cette dernière section, nous utiliserons le modèle Whisper pour générer la transcription d'une conversation ou d'une réunion entre deux ou plusieurs locuteurs. Nous l'associerons ensuite à un modèle de *séparation des locuteurs* pour prédire "qui a parlé quand". En faisant correspondre les horodatages des transcriptions Whisper avec les horodatages du modèle de séparation des locuteurs, nous pouvons prédire une transcription de réunion de bout en bout avec des heures de début et de fin entièrement formatées pour chaque locuteur. Il s'agit d'une version basique des services de transcription de réunions que vous avez pu voir en ligne sur [Otter.ai](https://otter.ai) et co :
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface-course/audio-course-images/resolve/main/diarization_transcription.png">
</div>
## Séparation des locuteurs
La séparation des locuteur (tâche de *diarization* en anglais) consiste à prendre une entrée audio non étiquetée et à prédire "qui a parlé quand".
Ce faisant, nous pouvons prédire les horodatages de début / fin pour chaque tour de parole, correspondant au moment où chaque locuteur commence à parler et au moment où il termine.
🤗 *Transformers* n'a actuellement pas de modèle de *diarization* inclus, mais il y a des *checkpoints* sur le *Hub* qui peuvent être utilisés avec une relative facilité. Dans cet exemple, nous utiliserons le modèle pré-entraîné de [pyannote.audio](https://github.com/pyannote/pyannote-audio). Commençons par l'installation du paquet avec pip :
```bash
pip install --upgrade pyannote.audio
```
Bien, les poids de ce modèle sont hébergés sur le *Hub*. Pour y accéder, nous devons d'abord accepter les conditions d'utilisation du modèle de *diarization* : [pyannote/speaker-diarization](https://huggingface.co/pyannote/speaker-diarization). Et ensuite les conditions d'utilisation du modèle de segmentation : [pyannote/segmentation](https://huggingface.co/pyannote/segmentation).
Une fois terminé, nous pouvons charger le pipeline de séparation des locuteurs localement sur notre appareil :
```python
from pyannote.audio import Pipeline
diarization_pipeline = Pipeline.from_pretrained(
"pyannote/[email protected]", use_auth_token=True
)
```
Essayons-le sur un échantillon de fichier audio ! Pour cela, nous allons charger un échantillon du jeu de données [LibriSpeech ASR](https://huggingface.co/datasets/librispeech_asr) qui consiste en deux locuteurs différents qui ont été concaténés ensemble pour donner un seul fichier audio :
```python
from datasets import load_dataset
concatenated_librispeech = load_dataset(
"sanchit-gandhi/concatenated_librispeech", split="train", streaming=True
)
sample = next(iter(concatenated_librispeech))
```
Nous pouvons écouter l'audio pour voir à quoi cela ressemble :
```python
from IPython.display import Audio
Audio(sample["audio"]["array"], rate=sample["audio"]["sampling_rate"])
```
Nous pouvons clairement entendre deux locuteurs différents, avec une transition d'environ 15 secondes. Passons ce fichier audio au modèle de séparation pour obtenir les heures de début et de fin du locuteur. Notez que pyannote.audio s'attend à ce que l'entrée audio soit un tenseur PyTorch de la forme `(channels, seq_len)`, nous devons donc effectuer cette conversion avant d'exécuter le modèle :
```python
import torch
input_tensor = torch.from_numpy(sample["audio"]["array"][None, :]).float()
outputs = diarization_pipeline(
{"waveform": input_tensor, "sample_rate": sample["audio"]["sampling_rate"]}
)
outputs.for_json()["content"]
```
```text
[{'segment': {'start': 0.4978125, 'end': 14.520937500000002},
'track': 'B',
'label': 'SPEAKER_01'},
{'segment': {'start': 15.364687500000002, 'end': 21.3721875},
'track': 'A',
'label': 'SPEAKER_00'}]
```
Cela semble plutôt bien ! Nous pouvons voir que le premier locuteur est prédit comme parlant jusqu'à la marque de 14,5 secondes, et le second locuteur à partir de 15,4s. Il ne nous reste plus qu'à obtenir notre transcription !
## Transcription de la parole
Pour la troisième fois dans cette unité, nous allons utiliser le modèle Whisper pour notre système de transcription de la parole. Plus précisément, nous chargerons le *checkpoint* [Whisper Base](https://huggingface.co/openai/whisper-base), car il est suffisamment petit pour donner une bonne vitesse d'inférence avec une précision de transcription raisonnable. Comme auparavant, vous pouvez utiliser n'importe quel *checkpoint *de reconnaissance vocale disponible sur le [*Hub*](https://huggingface.co/models?pipeline_tag=automatic-speech-recognition&library=transformers&sort=trending), y compris Wav2Vec2, MMS ASR ou d'autres tailles de Whisper :
```python
from transformers import pipeline
asr_pipeline = pipeline(
"automatic-speech-recognition",
model="openai/whisper-base",
)
```
Obtenons la transcription de notre échantillon audio, en retournant également les horodatages au niveau du segment afin que nous connaissions les heures de début et de fin de chaque segment. Vous vous souviendrez de l'unité 5 que nous devons passer l'argument `return_timestamps=True` pour activer la tâche de prédiction de l'horodatage de Whisper :
```python
asr_pipeline(
sample["audio"].copy(),
generate_kwargs={"max_new_tokens": 256},
return_timestamps=True,
)
```
```text
{
"text": " The second and importance is as follows. Sovereignty may be defined to be the right of making laws. In France, the king really exercises a portion of the sovereign power, since the laws have no weight. He was in a favored state of mind, owing to the blight his wife's action threatened to cast upon his entire future.",
"chunks": [
{"timestamp": (0.0, 3.56), "text": " The second and importance is as follows."},
{
"timestamp": (3.56, 7.84),
"text": " Sovereignty may be defined to be the right of making laws.",
},
{
"timestamp": (7.84, 13.88),
"text": " In France, the king really exercises a portion of the sovereign power, since the laws have",
},
{"timestamp": (13.88, 15.48), "text": " no weight."},
{
"timestamp": (15.48, 19.44),
"text": " He was in a favored state of mind, owing to the blight his wife's action threatened to",
},
{"timestamp": (19.44, 21.28), "text": " cast upon his entire future."},
],
}
```
Ok, nous constatons que chaque segment de la transcription a une heure de début et une heure de fin, avec un changement de locuteur au bout de 15,48 secondes. Nous pouvons maintenant associer cette transcription aux horodatages des locuteurs que nous avons obtenus à partir de notre modèle de *diarization* pour obtenir notre transcription finale.
## Speechbox
Pour obtenir la transcription finale, nous allons aligner les timestamps du modèle de diarisation avec ceux du modèle Whisper.
Le modèle de séparation prédit que le premier locuteur se termine à 14,5 secondes et que le second locuteur commence à 15,4 secondes, alors que Whisper prédit les limites des segments à 13,88, 15,48 et 19,44 secondes respectivement. Comme les timestamps de Whisper ne correspondent pas parfaitement à ceux du modèle de séparation, nous devons trouver lesquelles de ces limites sont les plus proches de 14,5 et 15,4 secondes, et segmenter la transcription par locuteur en conséquence. Plus précisément, nous trouverons l'alignement le plus proche entre les horodatages de la séparation et de la transcription en minimisant la distance absolue entre les deux.
Heureusement pour nous, nous pouvons utiliser 🤗 *Speechbox* pour effectuer cet alignement. Tout d'abord, installons `speechbox` depuis *main* :
```bash
pip install git+https://github.com/huggingface/speechbox
```
Nous pouvons maintenant instancier notre pipeline combiné de *diarization* et de transcription, en passant nos deux modèles à la classe [`ASRDiarizationPipeline`](https://github.com/huggingface/speechbox/tree/main#asr-with-speaker-diarization) :
```python
from speechbox import ASRDiarizationPipeline
pipeline = ASRDiarizationPipeline(
asr_pipeline=asr_pipeline, diarization_pipeline=diarization_pipeline
)
```
<Tip>
Vous pouvez également instancier le `ASRDiarizationPipeline` directement à partir d'un modèle pré-entraîné en spécifiant l'identifiant d'un modèle ASR sur le *Hub* : `pipeline = ASRDiarizationPipeline.from_pretrained("openai/whisper-base")`
</Tip>
Passons le fichier audio au pipeline et voyons ce que nous obtenons :
```python
pipeline(sample["audio"].copy())
```
```text
[{'speaker': 'SPEAKER_01',
'text': ' The second and importance is as follows. Sovereignty may be defined to be the right of making laws. In France, the king really exercises a portion of the sovereign power, since the laws have no weight.',
'timestamp': (0.0, 15.48)},
{'speaker': 'SPEAKER_00',
'text': " He was in a favored state of mind, owing to the blight his wife's action threatened to cast upon his entire future.",
'timestamp': (15.48, 21.28)}]
```
Excellent ! Le premier locuteur est segmenté comme parlant de 0 à 15,48 secondes, et le second locuteur de 15,48 à 21,28 secondes, avec les transcriptions correspondantes pour chacun.
Nous pouvons formater les horodatages de manière un peu plus agréable en définissant deux fonctions d'aide. La première convertit un *tuple* d'horodatages en une chaîne de caractères, arrondie à un nombre défini de décimales. La seconde combine l'identifiant du locuteur, l'horodatage et les informations textuelles sur une seule ligne, et sépare chaque locuteur sur sa propre ligne pour faciliter la lecture :
```python
def tuple_to_string(start_end_tuple, ndigits=1):
return str((round(start_end_tuple[0], ndigits), round(start_end_tuple[1], ndigits)))
def format_as_transcription(raw_segments):
return "\n\n".join(
[
chunk["speaker"] + " " + tuple_to_string(chunk["timestamp"]) + chunk["text"]
for chunk in raw_segments
]
)
```
Exécutons à nouveau le pipeline, en formatant cette fois la transcription selon la fonction que nous venons de définir :
```python
outputs = pipeline(sample["audio"].copy())
format_as_transcription(outputs)
```
```text
SPEAKER_01 (0.0, 15.5) The second and importance is as follows. Sovereignty may be defined to be the right of making laws.
In France, the king really exercises a portion of the sovereign power, since the laws have no weight.
SPEAKER_00 (15.5, 21.3) He was in a favored state of mind, owing to the blight his wife's action threatened to cast upon
his entire future.
```
Et voilà ! Nous avons ainsi séparé et transcrit notre audio et renvoyé des transcriptions segmentées par locuteur.
Bien que l'algorithme de distance minimale pour aligner les horodatages diarisés et les horodatages transcrits soit simple, il fonctionne bien dans la pratique. Si vous souhaitez explorer des méthodes plus avancées pour combiner les horodatages, le code source de `ASRDiarizationPipeline` est un bon point de départ : [speechbox/diarize.py](https://github.com/huggingface/speechbox/blob/96d2d1a180252d92263f862a1cd25a48860f1aed/src/speechbox/diarize.py#L12).
| 2 |
0 | hf_public_repos/audio-transformers-course/chapters/fr | hf_public_repos/audio-transformers-course/chapters/fr/chapter7/introduction.mdx | # Unité 7. Rassemblement de tous les éléments
Bravo d'être arrivé à l'unité 7 ! Vous êtes à quelques pas de terminer le cours et d'acquérir les dernières compétences dont vous avez besoin pour naviguer dans le domaine de l'apprentissage machine audio.
En termes de compréhension, vous savez déjà tout ce qu'il y a à savoir.
Ensemble, nous avons couvert de manière exhaustive les principaux sujets qui constituent le domaine audio et la théorie qui les accompagne (données, classification, reconnaissance de la parole et synthèse vocale).
L'objectif de cette unité est de fournir un cadre pour **assembler tout cela** : maintenant que vous savez comment chacune de ces tâches fonctionne indépendamment, nous allons explorer comment vous pouvez les combiner pour construire des applications du monde réel.
## Ce que vous allez apprendre et construire
Dans cette unité, nous aborderons les trois sujets suivants :
* [Traduction parole-à-parole](speech-to-speech) : traduire l'audio d'une langue en audio dans une autre langue.
* [Créer un assistant vocal](voice-assistant) : créer votre propre assistant vocal qui fonctionne de la même manière qu'Alexa ou Siri.
* [Transcription de réunions](transcribe-meeting) : transcrire une réunion et indiquez sur la transcription qui a parlé et à quel moment. | 3 |
0 | hf_public_repos/audio-transformers-course/chapters/fr | hf_public_repos/audio-transformers-course/chapters/fr/chapter7/speech-to-speech.mdx | # Traduction parole-à-parole
La traduction parole-à-parole (STST ou S2ST pour *Speech-to-speech translation*) est une tâche de traitement du langage parlé relativement nouvelle. Elle consiste à traduire le discours d'une langue en un discours dans une langue **différente** :
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface-course/audio-course-images/resolve/main/s2st.png" alt="Diagram of speech to speech translation">
</div>
La STST peut être considérée comme une extension de la tâche traditionnelle de traduction automatique : au lieu de traduire du **texte** d'une langue à une autre, nous traduisons de la **parole** d'une langue à une autre. La STST trouve des applications dans le domaine de la communication multilingue, en permettant à des locuteurs de langues différentes de communiquer entre eux par l'intermédiaire de la parole.
Supposons que vous souhaitiez communiquer avec une autre personne au-delà de la barrière de la langue. Plutôt que d'écrire l'information que vous souhaitez transmettre et de la traduire ensuite en texte dans la langue cible, vous pouvez la parler directement et demander à un système STST de convertir votre discours dans la langue cible. Le destinataire peut alors répondre en s'adressant au système STST, et vous pouvez écouter sa réponse. Cette méthode de communication est plus naturelle que la traduction automatique basée sur le texte.
Dans ce chapitre, nous allons explorer une approche *cascadée* de la STST, en rassemblant les connaissances que vous avez acquises dans les unités 5 et 6 du cours. Nous utiliserons un système de *traduction vocale* pour transcrire le discours source en texte dans la langue cible, puis un système de *text-to-speech* pour générer du discours dans la langue cible à partir du texte traduit :
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface-course/audio-course-images/resolve/main/s2st_cascaded.png" alt="Diagram of s2st_cascaded speech to speech translation">
</div>
Nous aurions également pu utiliser une approche en trois étapes, en commençant par utiliser un système de reconnaissance automatique de la parole (ASR) pour transcrire la parole source en texte dans la même langue, puis la traduction automatique pour traduire le texte transcrit dans la langue cible, et enfin la synthèse vocale pour générer de la parole dans la langue cible. Cependant, l'ajout d'autres composants au pipeline se prête à la propagation d'erreurs, où les erreurs introduites dans un système sont aggravées lorsqu'elles passent par les systèmes restants, et augmente également le temps de latence, puisque l'inférence doit être effectuée pour davantage de modèles.
Bien que cette approche en deux étapes de la STST soit assez simple, elle permet d'obtenir des systèmes très efficaces. Le système en deux étapes à trois étapes ASR + traduction automatique + TTS a été utilisé précédemment pour de nombreux produits STST commerciaux, y compris [*Google Translate*](https://ai.googleblog.com/2019/05/introducing-translatotron-end-to-end.html).
Il s'agit également d'une méthode très efficace en termes de données et de calcul, puisque les systèmes de reconnaissance vocale et de synthèse vocale existants peuvent être couplés pour produire un nouveau modèle de STST sans aucun entraînement supplémentaire.
Dans la suite de cette unité, nous nous concentrerons sur la création d'un système de STST qui traduit la parole de n'importe quelle langue X en anglais. Les méthodes abordées peuvent être étendues aux systèmes de STST qui traduisent de n'importe quelle langue X vers n'importe quelle langue Y, mais nous laissons cette extension au lecteur et fournissons des pointeurs le cas échéant. Nous divisons ensuite la tâche de STST en ses deux composantes constitutives : traduction vocale et synthèse vocale. Nous terminerons en les assemblant pour construire une démo Gradio afin de présenter notre système.
## Traduction vocale
Nous utilisons le modèle Whisper puisqu'il est capable de traduire plus de 96 langues vers l'anglais. Plus précisément, nous chargerons le *checkpoint* [Whisper Base](https://huggingface.co/openai/whisper-base), qui contient 74 millions de paramètres. Ce n'est en aucun cas le modèle Whisper le plus performant (le [plus grand *checkpoint* Whisper](https://huggingface.co/openai/whisper-large-v2) étant plus de 20 fois plus grand) mais comme nous concaténons deux systèmes autorégressifs, nous voulons nous assurer que chaque modèle peut générer relativement rapidement afin d'obtenir une vitesse d'inférence raisonnable :
```python
import torch
from transformers import pipeline
device = "cuda:0" if torch.cuda.is_available() else "cpu"
pipe = pipeline(
"automatic-speech-recognition", model="openai/whisper-base", device=device
)
```
C'est très bien ! Pour tester notre système de STST, nous allons charger un échantillon audio dans une autre langue que l'anglais. Chargeons le premier exemple de la partie italienne (`it`) du jeu de données [VoxPopuli](https://huggingface.co/datasets/facebook/voxpopuli) :
```python
from datasets import load_dataset
dataset = load_dataset("facebook/voxpopuli", "it", split="validation", streaming=True)
sample = next(iter(dataset))
```
Pour écouter cet échantillon, nous pouvons soit le jouer en utilisant le *viewer* sur le *Hub* : [facebook/voxpopuli/viewer](https://huggingface.co/datasets/facebook/voxpopuli/viewer/it/validation?row=0)
Ou le lire à l'aide de la fonction audio d'ipynb :
```python
from IPython.display import Audio
Audio(sample["audio"]["array"], rate=sample["audio"]["sampling_rate"])
```
Maintenant, définissons une fonction qui prend cette entrée audio et retourne le texte traduit. Vous vous rappelez que nous devons passer l'argument `"task": "translate"` pour s'assurer que Whisper effectue de la traduction vocale et non de la reconnaissance vocale :
```python
def translate(audio):
outputs = pipe(audio, max_new_tokens=256, generate_kwargs={"task": "translate"})
return outputs["text"]
```
<Tip>
Whisper peut aussi être "trompé" pour traduire de la parole dans n'importe quelle langue X vers n'importe quelle langue Y. Il suffit de mettre la tâche à `"transcribe"` et `"language"` à votre langue cible en argument. Par exemple pour l'espagnol, on mettrait : `generate_kwargs={"task" : "transcribe", "language" : "es"}`
</Tip>
Bien, vérifions rapidement que nous obtenons un résultat raisonnable à partir du modèle :
```python
translate(sample["audio"].copy())
```
```
' psychological and social. I think that it is a very important step in the construction of a juridical space of freedom, circulation and protection of rights.'
```
Ok, et si nous comparons cela au texte source :
```python
sample["raw_text"]
```
```
'Penso che questo sia un passo in avanti importante nella costruzione di uno spazio giuridico di libertà di circolazione e di protezione dei diritti per le persone in Europa.'
```
Nous constatons que la traduction est plus ou moins conforme (vous pouvez la vérifier en utilisant Google Translate ou DeepL), à l'exception de quelques mots supplémentaires au début de la transcription, lorsque le locuteur terminait sa phrase précédente.
Nous avons ainsi terminé la première moitié de notre pipeline de STST en deux étapes, en mettant en pratique les compétences acquises dans l'unité 5 lorsque nous avons appris à utiliser le modèle Whisper pour la reconnaissance vocale et la traduction. Si vous souhaitez vous rafraîchir la mémoire sur l'une des étapes que nous avons couvertes, lisez la section [Modèles pré-entraînés pour la reconnaissance automatique de la parole](../chapiter5/asr_models) de l'unité 5.
## Synthèse vocale
La deuxième partie de notre système de STST en deux étapes consiste à passer d'un texte anglais à la parole en anglais. Pour cela, nous utiliserons le modèle pré-entraîné [SpeechT5 TTS](https://huggingface.co/microsoft/speecht5_tts). 🤗 *Transformers* n'a actuellement pas de `pipeline` TTS, donc nous devrons utiliser le modèle directement nous-mêmes. Ce n'est pas grave, vous êtes tous experts dans l'utilisation du modèle pour l'inférence après l'unité 6 !
Tout d'abord, chargeons le processeur SpeechT5, le modèle et le vocodeur à partir du *checkpoint* pré-entraîné :
```python
from transformers import SpeechT5Processor, SpeechT5ForTextToSpeech, SpeechT5HifiGan
processor = SpeechT5Processor.from_pretrained("microsoft/speecht5_tts")
model = SpeechT5ForTextToSpeech.from_pretrained("microsoft/speecht5_tts")
vocoder = SpeechT5HifiGan.from_pretrained("microsoft/speecht5_hifigan")
```
<Tip>
Nous utilisons ici le *checkpoint* SpeechT5 entraîné spécifiquement pour le TTS anglais. Si vous souhaitez traduire dans une autre langue que l'anglais, remplacez le *checkpoint* par un modèle SpeechT5 TTS *finetuné* dans la langue de votre choix, ou utilisez un *checkpoint* MMS TTS pré-entraîné dans la langue cible.
</Tip>
Comme pour le Whisper, nous placerons le SpeechT5 et le vocodeur sur notre GPU, si nous en avons un :
```python
model.to(device)
vocoder.to(device)
```
Bien, chargeons les enregistrements du locuteur :
```python
embeddings_dataset = load_dataset("Matthijs/cmu-arctic-xvectors", split="validation")
speaker_embeddings = torch.tensor(embeddings_dataset[7306]["xvector"]).unsqueeze(0)
```
Nous pouvons maintenant écrire une fonction qui prend en entrée un prompt de texte et génère le discours correspondant. Nous allons d'abord prétraiter l'entrée textuelle à l'aide du processeur SpeechT5, en tokenisant le texte pour obtenir nos identifiants d'entrée. Nous transmettons ensuite les identifiants d'entrée et les enchâssements de locuteurs au modèle SpeechT5, en plaçant chacun d'entre eux sur le GPU s'il est disponible. Enfin, nous renverrons le discours généré au CPU pour qu'il puisse être lu dans notre *notebook* :
```python
def synthesise(text):
inputs = processor(text=text, return_tensors="pt")
speech = model.generate_speech(
inputs["input_ids"].to(device), speaker_embeddings.to(device), vocoder=vocoder
)
return speech.cpu()
```
Vérifions qu'il fonctionne avec une entrée de texte fictive :
```python
speech = synthesise("Hey there! This is a test!")
Audio(speech, rate=16000)
```
Ça a l'air bien ! Passons maintenant à la partie la plus excitante : assembler le tout.
## Creating a STST demo
Avant de créer une démo [Gradio](https://gradio.app) pour présenter notre système de STST, effectuons d'abord une vérification rapide pour nous assurer que nous pouvons concaténer les deux modèles, en introduisant un échantillon audio et en obtenant un échantillon audio. Pour ce faire, nous concaténerons les deux fonctions définies dans les deux sous-sections précédentes, de sorte que nous entrons l'audio source et récupérons le texte traduit, puis nous synthétisons le texte traduit pour obtenir la parole traduite. Enfin, nous allons convertir la synthèse vocale en un *array* `int16`, qui est le format de fichier audio de sortie attendu par Gradio. Pour ce faire, nous devons d'abord normaliser l'*array* audio par la plage dynamique de la cible de type (`int16`), puis convertir le type par défaut de NumPy (`float64`) vers la cible de type (`int16`) :
```python
import numpy as np
target_dtype = np.int16
max_range = np.iinfo(target_dtype).max
def speech_to_speech_translation(audio):
translated_text = translate(audio)
synthesised_speech = synthesise(translated_text)
synthesised_speech = (synthesised_speech.numpy() * max_range).astype(np.int16)
return 16000, synthesised_speech
```
Vérifions que cette fonction concaténée donne le résultat attendu :
```python
sampling_rate, synthesised_speech = speech_to_speech_translation(sample["audio"])
Audio(synthesised_speech, rate=sampling_rate)
```
Parfait ! Nous allons à présent intégrer tout cela dans une belle démo Gradio afin d'enregistrer notre source vocale à l'aide d'un microphone ou d'un fichier et de lire la prédiction du système :
```python
import gradio as gr
demo = gr.Blocks()
mic_translate = gr.Interface(
fn=speech_to_speech_translation,
inputs=gr.Audio(source="microphone", type="filepath"),
outputs=gr.Audio(label="Generated Speech", type="numpy"),
)
file_translate = gr.Interface(
fn=speech_to_speech_translation,
inputs=gr.Audio(source="upload", type="filepath"),
outputs=gr.Audio(label="Generated Speech", type="numpy"),
)
with demo:
gr.TabbedInterface([mic_translate, file_translate], ["Microphone", "Audio File"])
demo.launch(debug=True)
```
Cela lancera une démo Gradio similaire à celle qui fonctionne sur le *Space* suivant :
<iframe src="https://course-demos-speech-to-speech-translation.hf.space" frameBorder="0" height="450" title="Gradio app" class="container p-0 flex-grow space-iframe" allow="accelerometer; ambient-light-sensor; autoplay; battery; camera; document-domain; encrypted-media; fullscreen; geolocation; gyroscope; layout-animations; legacy-image-formats; magnetometer; microphone; midi; oversized-images; payment; picture-in-picture; publickey-credentials-get; sync-xhr; usb; vr ; wake-lock; xr-spatial-tracking" sandbox="allow-forms allow-modals allow-popups allow-popups-to-escape-sandbox allow-same-origin allow-scripts allow-downloads"></iframe>
Vous pouvez [dupliquer](https://huggingface.co/spaces/course-demos/speech-to-speech-translation?duplicate=true) cette démo et l'adapter pour utiliser un *checkpoint* Whisper différent, un *checkpoint* TTS différent, ou travailler sur une autre langue que l'anglais et suivre les conseils fournis pour traduire dans la langue de votre choix !
## Pour aller plus loin
Bien que le système en deux étapes soit un moyen efficace de construire un système de STST, il souffre des problèmes de propagation d'erreurs et de latence additive décrits ci-dessus. Des travaux récents ont exploré une approche *directe* de la STST, qui ne prédit pas de texte intermédiaire et qui, au lieu de cela, établit une correspondance directe entre la parole source et la parole cible. Ces systèmes sont également capables de conserver les caractéristiques de la parole du locuteur source dans la parole cible (telles que la prosodie, la hauteur et l'intonation). Si vous souhaitez en savoir plus sur ces systèmes, consultez les ressources répertoriées dans la section [lectures complémentaires](supplemental_reading).
| 4 |
0 | hf_public_repos/audio-transformers-course/chapters/fr | hf_public_repos/audio-transformers-course/chapters/fr/chapter7/voice-assistant.mdx | # Créer un assistant vocal
Dans cette section, nous allons rassembler trois modèles déjà vus pour construire un assistant vocal de bout en bout baptisé **Marvin** 🤖. Comme Alexa d'Amazon ou Siri d'Apple, Marvin est un assistant vocal répondant à un mot déclencheur particulier, écoutant ensuite une requête vocale et répond enfin par une réponse vocale.
Nous pouvons décomposer le pipeline de l'assistant vocal en quatre étapes, chacune d'entre elles nécessitant un modèle autonome :
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface-course/audio-course-images/resolve/main/voice_assistant.png">
</div>
### 1. Détection du mot déclencheur
Les assistants vocaux écoutent en permanence les entrées audio provenant du microphone de votre appareil, mais ils ne se mettent en action que lorsqu'un mot déclencheur (ou mot de réveil) particulier est prononcé.
La tâche de détection des mots déclencheurs est gérée par un petit modèle de classification audio sur l'appareil, qui est beaucoup plus petit et plus léger que le modèle de reconnaissance vocale, ne comportant souvent que quelques millions de paramètres, contre plusieurs centaines de millions pour la reconnaissance vocale. Il peut donc être exécuté en continu sur l'appareil sans en épuiser la batterie. Ce n'est que lorsque le mot de réveil est détecté que le modèle de reconnaissance vocale, plus grand, est lancé, avant d'être à nouveau arrêté.
### 2. Transcription de la parole
L'étape suivante du processus consiste à transcrire la requête vocale en texte. Dans la pratique, le transfert des fichiers audio de votre appareil local vers le *cloud* est lent en raison de la nature volumineuse des fichiers audio. Il est donc plus efficace de les transcrire directement à l'aide d'un modèle d'ASR sur l'appareil plutôt qu'à l'aide d'un modèle dans le *cloud*. Le modèle sur l'appareil peut être plus petit et donc moins précis qu'un modèle hébergé dans le *cloud*, mais la vitesse d'inférence plus rapide en vaut la peine puisque nous pouvons exécuter la reconnaissance vocale quasiment en temps réel, notre énoncé audio étant transcrit au fur et à mesure que nous le prononçons.
Nous sommes maintenant très familiers avec le processus de reconnaissance vocale, donc cela devrait être un jeu d'enfant !
### 3. Requêter le modèle de langage
Maintenant que nous savons ce que l'utilisateur a demandé, nous devons générer une réponse ! Les meilleurs modèles candidats pour cette tâche sont les *grands modèles de langage (LLM)*, car ils sont effectivement capables de comprendre la sémantique de la requête textuelle et de générer une réponse appropriée.
Puisque notre requête textuelle est petite (juste quelques *tokens*), et les modèles de langage volumineux (plusieurs milliards de paramètres), la façon la plus efficace d'exécuter l'inférence est d'envoyer notre requête textuelle de notre appareil à un LLM fonctionnant dans le *cloud*, de générer une réponse textuelle, et de renvoyer la réponse à l'appareil.
### 4. Synthétiser la réponse
Enfin, nous utiliserons un modèle de synthèse vocale pour synthétiser la réponse textuelle sous forme de parole. Cette opération s'effectue sur l'appareil, mais il est tout à fait possible d'exécuter un modèle de synthèse vocale dans le *cloud*, en générant la sortie audio et en la transférant vers l'appareil.
Encore une fois, nous avons fait cela plusieurs fois maintenant, donc le processus sera très familier !
## Détection des mots déclencheur
La première étape du pipeline de l'assistant vocal consiste à détecter si le mot déclencheur a été prononcé, et nous devons donc trouver un modèle pré-entraîné approprié pour cette tâche ! Vous vous souviendrez de la section sur les [modèles pré-entraînés pour la classification audio](../chapiter4/classification_models) que [Speech Commands](https://huggingface.co/datasets/speech_commands) est un jeu de données de mots prononcés conçu pour évaluer les modèles de classification audio sur plus de 15 mots de commande simples comme `up`, `down`, `yes` et `no`, ainsi qu'un label `silence` pour classer l'absence de parole. Prenez une minute pour écouter les échantillons sur le visualisateur de jeux de données du *Hub* et vous familiariser à nouveau avec le jeu de données : [visualisateur](https://huggingface.co/datasets/speech_commands/viewer/v0.01/train).
Nous pouvons utiliser un modèle de classification audio pré-entraîné sur le jeu de données Speech Commands et choisir l'un de ces mots de commande simples comme mot déclencheur. Parmi plus de 15 mots de commande possibles, si le modèle prédit avec la plus grande probabilité le mot que nous avons choisi, nous pouvons être quasiment certains que ce mot de déclencheur a été prononcé.
Rendez-vous sur le *Hub* et cliquez sur l'onglet *Models* : https://huggingface.co/models. Cela va faire apparaître tous les modèles sur le *Hub* :
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface-course/audio-course-images/resolve/main/all_models.png">
</div>
Vous remarquerez sur le côté gauche que nous avons une sélection d'onglets que nous pouvons sélectionner pour filtrer les modèles par tâche, bibliothèque, jeu de données, etc. Faites défiler vers le bas et sélectionnez la tâche *Audio Classification* dans la liste des tâches audio :
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface-course/audio-course-images/resolve/main/by_audio_classification.png">
</div>
Nous sommes maintenant en présence d'un sous-ensemble de plus de 500 modèles de classification audio sur le *Hub*. Pour affiner cette sélection, nous pouvons filtrer les modèles par jeu de données. Cliquez sur l'onglet *Datasets* et dans la barre de recherche, tapez *speech_commands*. Vous pouvez cliquer sur ce bouton pour filtrer tous les modèles de classification audio vers ceux qui ont été *finetuné* sur le jeu de données Speech Commands :
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface-course/audio-course-images/resolve/main/by_speech_commands.png">
</div>
Bien , nous constatons que nous disposons de six modèles pré-entraînés pour ce jeu de données et cette tâche spécifiques (bien que de nouveaux modèles puissent être ajoutés si vous lisez à une date ultérieure !) Vous reconnaîtrez le premier de ces modèles comme le [*Spectrogram Transformer*](https://huggingface.co/MIT/ast-finetuned-speech-commands-v2) que nous avons utilisé dans l'exemple de l'unité 4. Nous utiliserons à nouveau ce *checkpoint* pour notre tâche de détection de mots déclencheur.
Chargeons le *checkpoint* à l'aide de la classe `pipeline` :
```python
from transformers import pipeline
import torch
device = "cuda:0" if torch.cuda.is_available() else "cpu"
classifier = pipeline(
"audio-classification", model="MIT/ast-finetuned-speech-commands-v2", device=device
)
```
Nous pouvons vérifier sur quelles étiquettes le modèle a été entraîné en vérifiant l'attribut `id2label` dans la configuration du modèle :
```python
classifier.model.config.id2label
```
Nous voyons que le modèle a été entraîné sur 35 étiquettes de classe, y compris quelques mots déclencheurs simples que nous avons décrits ci-dessus, ainsi que quelques objets particuliers comme `bed`, `house` et `cat`. Nous voyons qu'il y a un nom dans ces étiquettes de classe : id 27 correspond à l'étiquette **`marvin`** :
```python
classifier.model.config.id2label[27]
```
```
'marvin'
```
Parfait ! Nous pouvons utiliser ce nom comme mot délchencheur de notre assistant vocal, de la même manière qu'on utilise "Alexa" pour l'Alexa d'Amazon, ou "Hey Siri" pour le Siri d'Apple. Parmi toutes les étiquettes possibles, si le modèle prédit "marvin" avec la probabilité de classe la plus élevée, nous pouvons être sûrs que le mot de réveil que nous avons choisi a été prononcé.
Nous devons maintenant définir une fonction qui écoute en permanence le microphone de notre appareil et qui transmet continuellement l'audio au modèle de classification pour inférence. Pour ce faire, nous allons utiliser une fonction d'aide pratique fournie avec 🤗 *Transformers* appelée [`ffmpeg_microphone_live`](https://github.com/huggingface/transformers/blob/fb78769b9c053876ed7ae152ee995b0439a4462a/src/transformers/pipelines/audio_utils.py#L98).
Cette fonction transmet de petits morceaux d'audio d'une longueur spécifiée `chunk_length_s` au classifieur. Pour s'assurer que nous obtenons des frontières lisses entre les morceaux d'audio, nous lançons une fenêtre coulissante à travers notre audio avec un pas de `chunk_length_s / 6`.
Pour que nous n'ayons pas à attendre que tout le premier morceau soit enregistré avant de commencer l'inférence, nous définissons également une longueur d'entrée audio temporaire minimale `stream_chunk_s` qui est transmise au modèle avant que le temps `chunk_length_s` ne soit atteint.
La fonction `ffmpeg_microphone_live` renvoie un objet *generator*, produisant une séquence de morceaux audio qui peuvent chacun être transmis au modèle de classification pour faire une prédiction. Nous pouvons passer ce générateur directement au `pipeline`, qui à son tour retourne une séquence de prédictions de sortie, une pour chaque morceau d'entrée audio. Nous pouvons inspecter les probabilités des classes pour chaque morceau d'audio, et arrêter notre boucle de détection de mot de réveil lorsque nous détectons que le mot de réveil a été prononcé.
Nous utiliserons un critère très simple pour déterminer si notre mot de réveil a été prononcé : si l'étiquette de classe ayant la probabilité la plus élevée est celle de notre mot, et que cette probabilité dépasse un seuil `prob_threshold`, nous déclarons que le mot déclencheur a été prononcé. L'utilisation d'un seuil de probabilité pour contrôler notre classifieur garantit que le mot déclencheur n'est pas prédit par erreur si l'entrée audio est un bruit, ce qui est typiquement le cas lorsque le modèle est très incertain et que toutes les probabilités d'étiquettes de classe sont faibles. Vous voudrez peut-être ajuster ce seuil de probabilité ou explorer des moyens plus sophistiqués par le biais d'une métrique basée sur l'[*entropie*](https://fr.wikipedia.org/wiki/Entropie_de_Shannon).
```python
from transformers.pipelines.audio_utils import ffmpeg_microphone_live
def launch_fn(
wake_word="marvin",
prob_threshold=0.5,
chunk_length_s=2.0,
stream_chunk_s=0.25,
debug=False,
):
if wake_word not in classifier.model.config.label2id.keys():
raise ValueError(
f"Wake word {wake_word} not in set of valid class labels, pick a wake word in the set {classifier.model.config.label2id.keys()}."
)
sampling_rate = classifier.feature_extractor.sampling_rate
mic = ffmpeg_microphone_live(
sampling_rate=sampling_rate,
chunk_length_s=chunk_length_s,
stream_chunk_s=stream_chunk_s,
)
print("Listening for wake word...")
for prediction in classifier(mic):
prediction = prediction[0]
if debug:
print(prediction)
if prediction["label"] == wake_word:
if prediction["score"] > prob_threshold:
return True
```
Essayons cette fonction pour voir comment elle fonctionne ! Nous allons mettre `debug=True` pour afficher la prédiction pour chaque morceau d'audio. Laissons le modèle fonctionner pendant quelques secondes pour voir le type de prédictions qu'il fait lorsqu'il n'y a pas de parole, puis prononçons clairement le mot de réveil *marvin* et regardons sa prédiction monter en flèche à près de 1 :
```python
launch_fn(debug=True)
```
```text
Listening for wake word...
{'score': 0.055326107889413834, 'label': 'one'}
{'score': 0.05999856814742088, 'label': 'off'}
{'score': 0.1282748430967331, 'label': 'five'}
{'score': 0.07310110330581665, 'label': 'follow'}
{'score': 0.06634809821844101, 'label': 'follow'}
{'score': 0.05992642417550087, 'label': 'tree'}
{'score': 0.05992642417550087, 'label': 'tree'}
{'score': 0.999913215637207, 'label': 'marvin'}
```
Génial ! Comme nous nous y attendions, le modèle génère des prédictions erronées pendant les premières secondes. Il n'y a pas d'entrée vocale, donc le modèle fait des prédictions presque aléatoires, mais avec une très faible probabilité. Dès que nous prononçons le mot de réveil, le modèle prédit *marvin* avec une probabilité proche de 1 et termine la boucle, signalant que le mot de réveil a été détecté et que le système ASR doit être activé !
## Transcription de la parole
Une fois de plus, nous utiliserons le modèle Whisper pour notre système de transcription de la parole. Plus précisément, nous chargerons le *checkpoint* [*Whisper Base English*](https://huggingface.co/openai/whisper-base.en), car il est suffisamment petit pour donner une bonne vitesse d'inférence avec une précision de transcription raisonnable. Nous utiliserons une astuce pour obtenir une transcription presque en temps réel en étant astucieux sur la façon dont nous transmettons nos entrées audio au modèle. Comme auparavant, vous pouvez utiliser n'importe quel modèle de reconnaissance vocale sur le [*Hub*](https://huggingface.co/models?pipeline_tag=automatic-speech-recognition&library=transformers&sort=trending), y compris Wav2Vec2, MMS ASR ou d'autres tailles de Whisper :
```python
transcriber = pipeline(
"automatic-speech-recognition", model="openai/whisper-base.en", device=device
)
```
<Tip>
Si vous utilisez un GPU, vous pouvez augmenter la taille du modèle à utiliser, ce qui permettra d'obtenir une meilleure précision de transcription tout en respectant le seuil de latence requis. Il suffit de remplacer l'identifiant du modèle par : <code>"openai/whisper-small.en"</code>.
</Tip>
Nous pouvons maintenant définir une fonction pour enregistrer l'entrée de notre microphone et transcrire le texte correspondant. Avec la fonction d'aide `ffmpeg_microphone_live`, nous pouvons contrôler le degré de "temps réel" de notre modèle de reconnaissance vocale. L'utilisation d'un `stream_chunk_s` plus petit se prête à une reconnaissance vocale davantage en temps réel, puisque nous divisons notre audio d'entrée en plus petits morceaux et que nous les transcrivons à la volée. Cependant, cela se fait au détriment de la précision, puisqu'il y a moins de contexte pour le modèle à déduire.
Lors de la transcription de la parole, nous devons également avoir une idée du moment où l'utilisateur **s'arrête** de parler, afin de pouvoir mettre fin à l'enregistrement. Pour des raisons de simplicité, nous mettrons fin à l'enregistrement après le premier `chunk_length_s` (qui est fixé à 5 secondes par défaut), mais vous pouvez essayer d'utiliser un modèle de [détection de l'activité vocale (VAD pour *voice activity detection*)](https://huggingface.co/models?pipeline_tag=voice-activity-detection&sort=trending) pour prédire quand l'utilisateur s'est arrêté de parler.
```python
import sys
def transcribe(chunk_length_s=5.0, stream_chunk_s=1.0):
sampling_rate = transcriber.feature_extractor.sampling_rate
mic = ffmpeg_microphone_live(
sampling_rate=sampling_rate,
chunk_length_s=chunk_length_s,
stream_chunk_s=stream_chunk_s,
)
print("Start speaking...")
for item in transcriber(mic, generate_kwargs={"max_new_tokens": 128}):
sys.stdout.write("\033[K")
print(item["text"], end="\r")
if not item["partial"][0]:
break
return item["text"]
```
Essayons et voyons comment nous nous débrouillerons ! Une fois que le microphone est activé, commencez à parler et regardez votre transcription apparaître en semi-temps réel :
```python
transcribe()
```
```text
Start speaking...
Hey, this is a test with the whisper model.
```
Bien, vous pouvez ajuster la longueur maximale de l'audio `chunk_length_s` en fonction de la rapidité ou de la lenteur avec laquelle vous parlez (augmentez-la si vous avez l'impression de ne pas avoir assez de temps pour parler, diminuez-la si vous êtes resté dans l'expectative à la fin), et le `stream_chunk_s` pour le facteur temps réel. Il suffit de passer ces arguments à la fonction `transcribe`.
## Requêter le modèle de langue
Maintenant que notre requête vocale a été transcrite, nous voulons générer une réponse significative. Pour ce faire, nous utiliserons un LLM hébergé sur le *cloud*. Plus précisément, nous choisissons un LLM sur le *Hub* et utilisons l'[API Inference](https://huggingface.co/inference-api) pour interroger facilement le modèle.
Trouvons notre LLM sur le *Hub* en utilisant l'[🤗 *Open LLM Leaderboard*](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard), un *Space* qui classe les LLM par performance sur quatre tâches de génération. Nous effectuerons une recherche par "instruct" pour filtrer les modèles qui ont été *finetuné* car devraient mieux fonctionner pour notre tâche de requêtage :
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface-course/audio-course-images/resolve/main/llm_leaderboard.png">
</div>
Nous utiliserons le *checkpoint* [tiiuae/falcon-7b-instruct](https://huggingface.co/tiiuae/falcon-7b-instruct) par [TII](https://www.tii.ae/), un *transformer* décodeur de paramètres 7B *finetuné* sur un mélange de jeux de données de chat et d'instructions. Vous pouvez utiliser n'importe quel LLM du *Hub* ayant l'"*Hosted inference API*" activé. Il suffit de regarder le widget sur le côté droit de la carte du modèle :
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface-course/audio-course-images/resolve/main/inference_api.png">
</div>
L'API Inference nous permet d'envoyer une requête HTTP depuis notre machine locale vers le LLM hébergé sur le *Hub*, et renvoie la réponse sous la forme d'un fichier `json`. Tout ce que nous devons fournir est notre *token* d'authentification au *Hub* et l'identifiant du modèle du LLM que nous souhaitons interroger :
```python
from huggingface_hub import HfFolder
import requests
def query(text, model_id="tiiuae/falcon-7b-instruct"):
api_url = f"https://api-inference.huggingface.co/models/{model_id}"
headers = {"Authorization": f"Bearer {HfFolder().get_token()}"}
payload = {"inputs": text}
print(f"Querying...: {text}")
response = requests.post(api_url, headers=headers, json=payload)
return response.json()[0]["generated_text"][len(text) + 1 :]
```
Essayons-le avec une entrée de test !
```python
query("What does Hugging Face do?")
```
```
'Hugging Face is a company that provides natural language processing and machine learning tools for developers. They'
```
Vous remarquerez à quel point l'inférence est rapide en utilisant l'API Inference. Nous n'avons qu'à envoyer un petit nombre de *tokens* de texte de notre machine locale au modèle hébergé, le coût de communication est donc très faible. Le LLM est hébergé sur des GPU, de sorte que l'inférence s'exécute très rapidement. Enfin, la réponse générée est transférée du modèle à notre machine locale, toujours avec un faible coût de communication.
## Synthétiser la parole
Et maintenant, nous sommes prêts à obtenir la sortie vocale finale ! Une fois de plus, nous utiliserons le modèle [SpeechT5 TTS](https://huggingface.co/microsoft/speecht5_tts) de Microsoft mais vous pouvez utiliser n'importe quel modèle TTS de votre choix. Chargeons le processeur et le modèle :
```python
from transformers import SpeechT5Processor, SpeechT5ForTextToSpeech, SpeechT5HifiGan
processor = SpeechT5Processor.from_pretrained("microsoft/speecht5_tts")
model = SpeechT5ForTextToSpeech.from_pretrained("microsoft/speecht5_tts").to(device)
vocoder = SpeechT5HifiGan.from_pretrained("microsoft/speecht5_hifigan").to(device)
```
Et aussi l'enchâssement des locuteurs :
```python
from datasets import load_dataset
embeddings_dataset = load_dataset("Matthijs/cmu-arctic-xvectors", split="validation")
speaker_embeddings = torch.tensor(embeddings_dataset[7306]["xvector"]).unsqueeze(0)
```
Nous allons réutiliser la fonction `synthesise` que nous avons définie dans le chapitre [précédent](speech-to-speech) :
```python
def synthesise(text):
inputs = processor(text=text, return_tensors="pt")
speech = model.generate_speech(
inputs["input_ids"].to(device), speaker_embeddings.to(device), vocoder=vocoder
)
return speech.cpu()
```
Vérifions rapidement que cela fonctionne comme prévu :
```python
from IPython.display import Audio
audio = synthesise(
"Hugging Face is a company that provides natural language processing and machine learning tools for developers."
)
Audio(audio, rate=16000)
```
Joli travail 👍
## Marvin 🤖
Maintenant que nous avons défini une fonction pour chacune des quatre étapes du pipeline de l'assistant vocal, il ne reste plus qu'à les assembler pour obtenir notre assistant vocal de bout en bout. Nous allons simplement concaténer les quatre étapes, en commençant par la détection du mot de réveil (`launch_fn`), la transcription de la parole, le requêtage du LLM, et enfin la synthèse de la parole.
```python
launch_fn()
transcription = transcribe()
response = query(transcription)
audio = synthesise(response)
Audio(audio, rate=16000, autoplay=True)
```
Essayez-le avec quelques demandes ! Voici quelques exemples pour vous aider à démarrer :
* *Quel est le pays le plus chaud du monde ?
* *Comment fonctionnent les *transformers* ?
* *Connais-tu l'espagnol ?
Et avec cela, nous avons notre assistant vocal complet, réalisé à l'aide des outils audio que vous avez appris tout au long de ce cours, avec une pincée de magie LLM à la fin. Il y a plusieurs extensions que nous pourrions faire pour améliorer l'assistant vocal. Tout d'abord, le modèle de classification audio classifie 35 étiquettes différentes. Nous pourrions utiliser un modèle de classification binaire plus petit et plus léger qui prédit uniquement si le mot de réveil a été prononcé ou non. Deuxièmement, nous préchargeons tous les modèles à l'avance et les laissons tourner sur notre appareil. Si nous voulions économiser de l'énergie, nous ne chargerions chaque modèle qu'au moment où il est nécessaire, et nous le déchargerions par la suite. Troisièmement, il manque un modèle de détection de l'activité vocale dans notre fonction de transcription, qui transcrit pendant une durée fixe, parfois trop longue, parfois trop courte.
## Généralisation 🪄
Jusqu'à présent, nous avons vu comment générer des sorties vocales avec notre assistant vocal Marvin. Pour terminer, nous allons montrer comment nous pouvons généraliser ces sorties vocales au texte, à l'audio et à l'image.
Nous utiliserons [*Transformers Agents*](https://huggingface.co/docs/transformers/transformers_agents) pour créer notre assistant.
*Transformers Agents* fournit une API de langage naturel au-dessus des bibliothèques 🤗 *Transformers* et *Diffusers*, interprétant une entrée de langage naturel en utilisant un LLM avec des prompts soigneusement conçus, et en utilisant un ensemble d'outils pour fournir des sorties multimodales.
Allons-y et instançons un agent. Il y a [trois LLM disponibles](https://huggingface.co/docs/transformers/transformers_agents#quickstart) pour *Transformers Agents*, dont deux sont open-source et gratuits sur le *Hub*. Le troisième est un modèle d'OpenAI qui nécessite une clé API OpenAI. Nous utiliserons le modèle gratuit [Bigcode Starcoder](https://huggingface.co/bigcode/starcoder) dans cet exemple, mais vous pouvez également essayer l'un ou l'autre des autres LLM disponibles :
```python
from transformers import HfAgent
agent = HfAgent(
url_endpoint="https://api-inference.huggingface.co/models/bigcode/starcoder"
)
```
Pour utiliser l'agent, il suffit d'appeler `agent.run` avec notre prompt de texte. A titre d'exemple, nous allons lui faire générer une image d'un chat 🐈 (qui, espérons-le, ait l'air un peu mieux que cet emoji) :
```python
agent.run("Generate an image of a cat")
```
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface-course/audio-course-images/resolve/main/generated_cat.png">
</div>
<Tip>
Notez que la première fois que vous appelez cette fonction, les poids du modèle sont téléchargés, ce qui peut prendre un certain temps en fonction de votre connexion internet.
</Tip>
C'est aussi simple que cela ! L'agent a interprété notre prompt et a utilisé [Stable Diffusion](https://huggingface.co/docs/diffusers/using-diffusers/conditional_image_generation) pour générer l'image, sans que nous ayons à nous soucier du chargement du modèle, de l'écriture de la fonction ou de l'exécution du code.
Nous pouvons maintenant remplacer notre fonction de requête LLM et l'étape de synthèse de texte par notre *Transformers Agent* dans notre assistant vocal, puisque l'Agent va s'occuper de ces deux étapes pour nous :
```python
launch_fn()
transcription = transcribe()
agent.run(transcription)
```
Essayez de prononcer le même prompt "Générer une image d'un chat" (en anglais "Generate an image of a cat") et voyez comment le système s'en sort. Si vous posez à l'agent une simple requête de type question/réponse, l'agent répondra par un texte. Vous pouvez l'encourager à générer des sorties multimodales en lui demandant de renvoyer une image ou de la parole. Par exemple, vous pouvez lui demander de générer une image d'un chat, la légender et prononcer la légende ("Generate an image of a cat, caption it, and speak the caption").
Bien que l'agent soit plus flexible que notre première itération de l'assistant Marvin 🤖, cette généralisation peut conduire à des performances inférieures sur les requêtes standard de l'assistant vocal. Pour récupérer des performances, vous pouvez essayer d'utiliser un LLM plus performant, comme celui d'OpenAI, ou définir un ensemble d'[outils personnalisés](https://huggingface.co/docs/transformers/transformers_agents#custom-tools) spécifiques à la tâche d'assistant vocal.
| 5 |
0 | hf_public_repos/audio-transformers-course/chapters/fr | hf_public_repos/audio-transformers-course/chapters/fr/chapter7/hands-on.mdx | # Exercice pratique
Dans cette unité, nous avons consolidé le matériel couvert dans les six unités précédentes du cours pour créer trois applications audio. Comme vous l'avez constaté, il est tout à fait possible de créer des outils audio plus complexes en utilisant les compétences fondamentales que vous avez acquises dans ce cours.
L'exercice pratique prend l'une des applications couvertes dans cette unité, et l'étend avec quelques modifications multilingues 🌍 Votre objectif est de prendre la [démo Gradio de traduction vocale en deux étapes](https://huggingface.co/spaces/course-demos/speech-to-speech-translation) de la première section de cette unité, et de la mettre à jour pour la traduire dans n'importe quelle langue **non-anglaise**. En d'autres termes, la démo doit prendre un discours dans une langue X, et le traduire en un discours dans une langue Y, où la langue cible Y n'est pas l'anglais. Vous devriez commencer par [dupliquer](https://huggingface.co/spaces/course-demos/speech-to-speech-translation?duplicate=true) le modèle sous votre espace Hugging Face. Il n'est pas néce
Des conseils pour mettre à jour la fonction de traduction vocale afin d'effectuer une traduction vocale multilingue sont fournis dans la section sur la [traduction parole-parole](speech-to-speech). En suivant ces instructions, vous devriez être en mesure de mettre à jour la démo pour traduire de la parole dans la langue X vers du texte dans la langue Y, ce qui représente la moitié de la tâche !
Pour synthétiser du texte dans la langue Y vers la parole dans la langue Y, où Y est une langue multilingue, vous devrez utiliser un *checkpoint* TTS multilingue. Pour cela, vous pouvez utiliser soit celui de SpeechT5 TTS que vous avez *finetuné* dans l'exercice pratique précédent, soit un un *checkpoint* TTS multilingue pré-entraîné. Il y a alors deux options pour ce dernier cas : soit le *checkpoint* [sanchit-gandhi/speecht5_tts_vox_nl](https://huggingface.co/sanchit-gandhi/speecht5_tts_vox_nl), qui est un SpeechT5 *finetuné* sur la partie néerlandaise de [VoxPopuli](https://huggingface.co/datasets/facebook/voxpopuli), soit un *checkpoint* MMS TTS (voir la section [modèles pretrainés pour TTS](../chapter6/pre-trained_models)).
<Tip>
D'après notre expérience avec le néerlandais, l'utilisation d'un *checkpoint* MMS TTS permet d'obtenir de meilleures performances qu'un *checkpoint* SpeechT5 *finetuné* mais il se peut que votre *checkpoint* TTS *fientuné* soit préférable dans votre langue.
</Tip>
Votre démo doit prendre en entrée un fichier audio, et retourner en sortie un autre fichier audio, correspondant à la signature de la fonction [`speech_to_speech_translation`](https://huggingface.co/spaces/course-demos/speech-to-speech-translation/blob/3946ba6705a6632a63de8672ac52a482ab74b3fc/app.py#L35). Par conséquent, nous vous recommandons de laisser la fonction principale `speech_to_speech_translation` telle quelle, et de ne mettre à jour les fonctions [`translate`](https://huggingface.co/spaces/course-demos/speech-to-speech-translation/blob/a03175878f522df7445290d5508bfb5c5178f787/app.py#L24) et [`synthesise`](https://huggingface.co/spaces/course-demos/speech-to-speech-translation/blob/a03175878f522df7445290d5508bfb5c5178f787/app.py#L29) que si nécessaire.
Une fois que vous avez construit votre démo sur le *Hub*, vous pouvez la soumettre pour évaluation. Rendez-vous dans le *Space* [audio-course-u7-assessment](https://huggingface.co/spaces/huggingface-course/audio-course-u7-assessment) et indiquez l'identifiant de dépôt de votre démo. Ce *Space* vérifiera que votre démo a été construite correctement en envoyant un échantillon de fichier audio à votre démo et en vérifiant que le fichier audio renvoyé n'est pas en anglais. Si votre démo fonctionne correctement, vous obtiendrez une coche verte à côté de votre nom sur le [*Space* de progression](https://huggingface.co/spaces/MariaK/Check-my-progress-Audio-Course) ✅ | 6 |
0 | hf_public_repos/audio-transformers-course/chapters/fr | hf_public_repos/audio-transformers-course/chapters/fr/chapter6/evaluation.mdx | # Évaluation des modèles de synthèse vocale
Pendant la période d'entraînement, les modèles de synthèse vocale optimisent la perte d'erreur quadratique moyenne (ou l'erreur absolue moyenne) entre les valeurs prédites du spectrogramme et celles générées. La MSE et la MAE encouragent toutes deux le modèle à minimiser la différence entre les spectrogrammes prédits et les spectrogrammes cibles.
Toutefois, étant donné que la synthèse vocale est un problème d'association un-à-plusieurs, c'est-à-dire que le spectrogramme de sortie pour un texte donné peut être représenté de nombreuses manières différentes, l'évaluation des modèles de synthèse vocale qui en résultent est beaucoup plus difficile.
Contrairement à de nombreuses autres tâches informatiques qui peuvent être mesurées objectivement à l'aide de paramètres quantitatifs, tels que l'exactitude ou la précision, l'évaluation des modèles de synthèse vocale repose en grande partie sur une analyse humaine subjective.
L'une des méthodes d'évaluation les plus couramment employées pour les systèmes de reconnaissance vocale consiste à réaliser des évaluations qualitatives à l'aide de scores d'opinion moyens (MOS pour *mean opinion scores*). Le MOS est un système de notation subjectif qui permet aux évaluateurs humains de noter la qualité perçue de la parole synthétisée sur une échelle de 1 à 5. Ces scores sont généralement recueillis lors de tests d'écoute, au cours desquels des participants humains écoutent et évaluent des échantillons de parole synthétisée.
L'une des principales raisons pour lesquelles il est difficile de développer des mesures objectives pour l'évaluation de la synthèse vocale est la nature subjective de la perception de la parole. Les auditeurs humains ont des préférences et des sensibilités diverses pour différents aspects de la parole, notamment la prononciation, l'intonation, le naturel et la clarté. Saisir ces nuances perceptives avec une seule valeur numérique est une tâche ardue. En même temps, la subjectivité de l'évaluation humaine rend difficile la comparaison et l'étalonnage de différents systèmes de traitement de la parole.
En outre, ce type d'évaluation peut négliger certains aspects importants de la synthèse vocale, tels que le naturel, l'expressivité et l'impact émotionnel. Ces qualités sont difficiles à quantifier objectivement mais sont très importantes dans les applications où la parole synthétisée doit transmettre des qualités humaines et susciter des réactions émotionnelles appropriées.
En résumé, l'évaluation des modèles de synthèse vocale est une tâche complexe en raison de l'absence d'une mesure véritablement objective. La méthode d'évaluation la plus courante, le MOS, repose sur une analyse humaine subjective. Bien qu'il fournisse des informations précieuses sur la qualité de la parole synthétisée, il introduit également de la variabilité et de la subjectivité. | 7 |
0 | hf_public_repos/audio-transformers-course/chapters/fr | hf_public_repos/audio-transformers-course/chapters/fr/chapter6/supplemental_reading.mdx | # Lectures et ressources complémentaires
Cette unité a introduit la tâche de synthèse vocale et a couvert beaucoup de terrain.
Vous voulez en savoir plus ? Vous trouverez ici des ressources qui vous aideront à approfondir votre compréhension des sujets et à améliorer votre expérience d'apprentissage.
* [HiFi-GAN : Generative Adversarial Networks for Efficient and High Fidelity Speech Synthesis](https://arxiv.org/pdf/2010.05646.pdf) : article présentant HiFi-GAN pour la synthèse vocale.
* [X-Vectors : Robust DNN Embeddings For Speaker Recognition](https://www.danielpovey.com/files/2018_icassp_xvectors.pdf) : article présentant la méthode X-Vector pour l'intégration des locuteurs.
* [FastSpeech 2 : Fast and High-Quality End-to-End Text to Speech](https://arxiv.org/pdf/2006.04558.pdf) : un article présentant FastSpeech 2, un autre modèle de synthèse vocale populaire qui utilise une méthode de TTS non autorégressive.
* [A Vector Quantized Approach for Text to Speech Synthesis on Real-World Spontaneous Speech](https://arxiv.org/pdf/2302.04215v1.pdf) : un article présentant MQTTS, un système TTS autorégressif qui remplace les mel-spectrogrammes par une représentation discrète quantifiée. | 8 |
0 | hf_public_repos/audio-transformers-course/chapters/fr | hf_public_repos/audio-transformers-course/chapters/fr/chapter6/pre-trained_models.mdx | # Modèles pré-entraînés pour la synthèse vocale
Par rapport aux tâches de reconnaissance automatique de la parole et de classification audio, il y a beaucoup moins de *checkpoints* de modèles pré-entraînés disponibles. Vous trouverez près de 300 sur le *Hub*. Parmi ces modèles pré-entraînés, nous nous concentrerons sur deux architectures qui sont facilement disponibles dans la bibliothèque 🤗 *Transformers* : SpeechT5 et Massive Multilingual Speech (MMS). Dans cette section, nous allons explorer comment utiliser ces modèles.
## SpeechT5
[SpeechT5] (https://arxiv.org/abs/2110.07205) est un modèle publié par Junyi Ao et al. de Microsoft qui est capable de gérer une série de tâches vocales. Bien que dans cette unité, nous nous concentrions sur l'aspect texte-parole, ce modèle peut être adapté à des tâches de parole-texte (reconnaissance automatique de la parole ou identification du locuteur), ainsi qu'à des tâches de parole-parole (par exemple, amélioration de la parole ou conversion entre différentes voix). Ceci est dû à la façon dont le modèle est conçu et pré-entraîné.
Au cœur de SpeechT5 se trouve un *transformer* encodeur-décodeur classique. Ce réseau modélise une transformation de séquence à séquence en utilisant des représentations cachées. Ce *transformer* est le même pour toutes les tâches prises en charge par SpeechT5.
Il est complété par six pré ou post-réseaux modaux spécifiques (parole/texte). La parole ou le texte en entrée (en fonction de la tâche) est prétraité par un pré-réseau correspondant afin d'obtenir les représentations cachées que le *transformer* peut utiliser. La sortie obtenue est ensuite transmise à un post-réseau qui l'utilisera pour générer la sortie dans la modalité cible.
Voici à quoi ressemble l'architecture (image tirée de l'article original) :
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/speecht5/architecture.jpg" alt="SpeechT5 architecture from the original paper">
</div>
SpeechT5 est d'abord pré-entraîné à l'aide de données vocales et textuelles non étiquetées en grande quantité afin d'acquérir une représentation unifiée des différentes modalités. Pendant la phase de pré-entraînement, tous les pré-réseaux et post-réseaux sont utilisés simultanément.
Après le pré-entraînement, le réseau encodeur-décodeur *finetuné* pour chaque tâche individuelle. À cette étape, seuls les pré- et post-réseaux pertinents pour la tâche spécifique sont utilisés. Par exemple, pour utiliser SpeechT5 pour la synthèse vocale, vous aurez besoin du pré-réseau encodeur de texte pour les entrées de texte et des pré-réseaux et post-réseaux du décodeur de parole pour les sorties de parole.
Cette approche permet d'obtenir plusieurs modèles *finetunés* pour différentes tâches vocales qui bénéficient tous du pré-entraînement initial sur des données non étiquetées.
<Tip>
Même si les modèles *finetunés* commencent par utiliser le même ensemble de poids provenant du modèle pré-entraîné partagé, les versions finales sont toutes très différentes au bout du compte. Vous ne pouvez pas prendre un modèle ASR *finetuné* et échanger les pré- et post-réseaux pour obtenir un modèle de TTS fonctionnel, par exemple. SpeechT5 est flexible, mais pas à ce point ;)
</Tip>
Voyons quels sont les pré- et post-réseaux que SpeechT5 utilise pour la tâche de TTS :
* Pré-réseau encodeur de texte : Une couche d'enchâssement de texte qui fait correspondre les *tokens* de texte aux représentations cachées que l'encodeur attend. Ceci est similaire à ce qui se passe dans un modèle NLP tel que BERT.
* Pré-réseau de décodage de la parole : Il prend en entrée un spectrogramme log-mel et utilise une séquence de couches linéaires pour compresser le spectrogramme en représentations cachées.
* Post-réseau décodeur de la parole : Il prédit un résidu à ajouter au spectrogramme de sortie et est utilisé pour affiner les résultats.
Une fois combinée, voici à quoi ressemble l'architecture SpeechT5 pour la synthèse vocale :
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/speecht5/tts.jpg" alt="SpeechT5 architecture for TTS">
</div>
Comme vous pouvez le constater, la sortie est un spectrogramme log mel et non une forme d'onde. Si vous vous souvenez, nous avons brièvement abordé ce sujet dans l'[unité 3](../chapitre3/introduction#spectrogram-output). Il est courant que les modèles qui génèrent de l'audio produisent un spectrogramme log mel, qui doit être converti en forme d'onde à l'aide d'un réseau neuronal supplémentaire appelé vocodeur.
Voyons comment procéder.
Tout d'abord, chargeons le SpeechT5 *finetuné* sur du TTS depuis le *Hub*, ainsi que l'objet processeur utilisé pour la tokenisation et l'extraction de caractéristiques :
```python
from transformers import SpeechT5Processor, SpeechT5ForTextToSpeech
processor = SpeechT5Processor.from_pretrained("microsoft/speecht5_tts")
model = SpeechT5ForTextToSpeech.from_pretrained("microsoft/speecht5_tts")
```
Ensuite, le texte d'entrée est *tokenisé*.
```python
inputs = processor(text="Don't count the days, make the days count.", return_tensors="pt")
```
Le SpeechT5 TTS n'est pas limité à la création de discours pour un seul locuteur. Il utilise en effet ce que l'on appelle des " enchâssements de locuteurs, qui capturent les caractéristiques de la voix d'un locuteur particulier.
<Tip>
L'enchâssement des locuteurs est une méthode permettant de représenter l'identité d'un locuteur de manière compacte, sous la forme d'un vecteur de taille fixe, quelle que soit la longueur de l'énoncé. Ces enchâssements capturent des informations essentielles sur la voix d'un locuteur, son accent, son intonation et d'autres caractéristiques uniques qui distinguent un locuteur d'un autre. De tels enregistrements peuvent être utilisés pour la vérification du locuteur, la diarisation du locuteur, l'identification du locuteur, etc.
Les techniques les plus courantes pour générer des enchâssements de locuteurs sont les suivantes :
* Les I-Vecteurs (vecteurs d'identité) : ils sont basés sur un modèle de mélange gaussien (GMM). Ils représentent les locuteurs sous la forme de vecteurs de faible dimension et de longueur fixe, dérivés des statistiques d'un GMM spécifique au locuteur, et sont obtenus de manière non supervisée.
* Les vecteurs X : ils sont dérivés à l'aide de réseaux neuronaux profonds (DNN) et capturent des informations sur le locuteur au niveau de l'image en incorporant le contexte temporel.
[X-Vectors](https://www.danielpovey.com/files/2018_icassp_xvectors.pdf) est une méthode de pointe qui montre des performances supérieures sur des jeux de données d'évaluation par rapport aux I-Vectors. Le réseau neuronal profond est utilisé pour obtenir les X-Vecteurs : il est entraîné à discriminer les locuteurs, et fait correspondre des énoncés de longueur variable à des enchâssements de dimension fixe. Vous pouvez également charger un enchâssement de locuteur X-Vector qui a été calculé à l'avance et qui encapsule les caractéristiques d'élocution d'un locuteur particulier.
</Tip>
Chargeons un tel enchâssement de locuteur à partir d'un jeu de données sur le *Hub*. Les enchâssements ont été obtenus à partir du [jeu de données CMU ARCTIC](http://www.festvox.org/cmu_arctic/) en utilisant [ce script](https://huggingface.co/mechanicalsea/speecht5-vc/blob/main/manifest/utils/prep_cmu_arctic_spkemb.py), mais n'importe quel enchâssement X-Vector devrait fonctionner.
```python
from datasets import load_dataset
embeddings_dataset = load_dataset("Matthijs/cmu-arctic-xvectors", split="validation")
import torch
speaker_embeddings = torch.tensor(embeddings_dataset[7306]["xvector"]).unsqueeze(0)
```
L'enchâssement du locuteur est un tenseur de forme (1, 512). Cette représentation particulière du locuteur décrit une voix féminine.
À ce stade, nous disposons déjà de suffisamment d'entrées pour générer un log mel spectrogramme en sortie :
```python
spectrogram = model.generate_speech(inputs["input_ids"], speaker_embeddings)
```
Il en résulte un tenseur de forme (140, 80) contenant un log mel spectrogramme. La première dimension est la longueur de la séquence, et elle peut varier d'une exécution à l'autre car le pré-réseau décodeur de parole applique toujours un *dropout* à la séquence d'entrée. Cela ajoute un peu de variabilité aléatoire à la parole générée.
Cependant, si nous cherchons à générer une forme d'onde de la parole, nous devons spécifier un vocodeur à utiliser pour la conversion du spectrogramme en forme d'onde.
En théorie, vous pouvez utiliser n'importe quel vocodeur qui fonctionne sur des mel spectrogrammes 80-bin. De manière pratique, 🤗 *Transformers* propose un vocodeur basé sur HiFi-GAN. Ses poids ont été aimablement fournis par les auteurs originaux de SpeechT5.
<Tip>
[HiFi-GAN](https://arxiv.org/pdf/2010.05646v2.pdf) est un réseau antagoniste génératif (GAN) de pointe conçu pour de la synthèse vocale haute-fidélité. Il est capable de générer des formes d'ondes audio réalistes et de haute qualité à partir de spectrogrammes.
À un niveau élevé, HiFi-GAN se compose d'un générateur et de deux discriminateurs. Le générateur est un réseau neuronal entièrement convolutionnel qui prend un mel spectrogramme en entrée et apprend à produire des formes d'ondes audio brutes. Les discriminateurs ont pour rôle de faire la distinction entre l'audio réel et l'audio généré. Les deux discriminateurs se concentrent sur des aspects différents de l'audio.
HiFi-GAN est entraîné sur un grand jeu de données d'enregistrements audio de haute qualité. Il utilise un entraînement dit antagoniste, dans lequel les réseaux du générateur et du discriminateur sont en compétition l'un contre l'autre. Au départ, le générateur produit un son de faible qualité et le discriminateur peut facilement le différencier du son réel. Au fur et à mesure que l'entraînement progresse, le générateur améliore sa sortie, dans le but de tromper le discriminateur. Le discriminateur, à son tour, devient plus précis dans la distinction entre le son réel et le son généré. Cette boucle de rétroaction antagoniste permet aux deux réseaux de s'améliorer au fil du temps. En fin de compte, HiFi-GAN apprend à générer un son de haute fidélité qui ressemble étroitement aux caractéristiques des données entraînées.
</Tip>
Le chargement du vocodeur est aussi simple que n'importe quel autre modèle de 🤗 *Transformers*.
```python
from transformers import SpeechT5HifiGan
vocoder = SpeechT5HifiGan.from_pretrained("microsoft/speecht5_hifigan")
```
Il ne vous reste plus qu'à le passer en argument lors de la génération de la parole, et les sorties seront automatiquement converties en forme d'onde de la parole.
```python
speech = model.generate_speech(inputs["input_ids"], speaker_embeddings, vocoder=vocoder)
```
Écoutons le résultat. La fréquence d'échantillonnage utilisée par SpeechT5 est toujours de 16 kHz.
```python
from IPython.display import Audio
Audio(speech, rate=16000)
```
Super !
N'hésitez pas à jouer avec la démo de SpeechT5 TSS, à explorer d'autres voix, à expérimenter avec les entrées. Notez que ce *checkpoint* pré-entraîné ne prend en charge que la langue anglaise :
<iframe
src="https://matthijs-speecht5-tts-demo.hf.space"
frameborder="0"
width="850"
height="450">
</iframe>
## Massive Multilingual Speech (MMS)
Que faire si vous recherchez un modèle pré-entraîné dans une langue autre que l'anglais ? Massive Multilingual Speech (MMS) est un autre modèle qui couvre un large éventail de tâches vocales, mais qui prend en charge un grand nombre de langues. Par exemple, il peut synthétiser la parole dans plus de 1 100 langues.
MMS pour la synthèse vocale est basé sur [VITS Kim et al., 2021] (https://arxiv.org/pdf/2106.06103.pdf), qui est l'une des approches TTS les plus modernes.
VITS est un réseau de génération de parole qui convertit le texte en formes d'ondes vocales brutes. Il fonctionne comme un auto-encodeur variationnel conditionnel, estimant les caractéristiques audio à partir du texte d'entrée. Tout d'abord, les caractéristiques acoustiques, représentées sous forme de spectrogrammes, sont générées. La forme d'onde est ensuite décodée à l'aide de couches convolutives transposées adaptées de HiFi-GAN.
Pendant l'inférence, les encodages du texte sont suréchantillonnés et transformés en formes d'onde à l'aide du module de flux et du décodeur HiFi-GAN.
Cela signifie que vous n'avez pas besoin d'ajouter un vocodeur pour l'inférence, il est déjà "intégré".
Essayons le modèle et voyons comment nous pouvons synthétiser de la parole dans une langue autre que l'anglais, par exemple l'allemand.
Tout d'abord, nous allons charger le *checkpoint* du modèle et le *tokenizer* pour la bonne langue :
```python
from transformers import VitsModel, VitsTokenizer
model = VitsModel.from_pretrained("facebook/mms-tts-deu")
tokenizer = VitsTokenizer.from_pretrained("facebook/mms-tts-deu")
```
Vous pouvez remarquer que pour charger le MMS, vous devez utiliser `VitsModel` et `VitsTokenizer`. C'est parce que le MMS pour la synthèse vocale est basé sur le modèle VITS comme mentionné précédemment.
Prenons un exemple de texte en allemand, comme ces deux premières lignes d'une chanson pour enfants :
```python
text_example = (
"Ich bin Schnappi das kleine Krokodil, komm aus Ägypten das liegt direkt am Nil."
)
```
Pour générer une forme d'onde, il faut prétraiter le texte à l'aide du *tokenizer* et le transmettre au modèle :
```python
import torch
inputs = tokenizer(text_example, return_tensors="pt")
input_ids = inputs["input_ids"]
with torch.no_grad():
outputs = model(input_ids)
speech = outputs.audio[0]
```
Écoutons :
```python
from IPython.display import Audio
Audio(speech, rate=16000)
```
Superbe ! Si vous souhaitez essayer MMS avec une autre langue, trouvez d'autres *checkpoints* `vits` appropriés sur le [*Hub*] (https://huggingface.co/models?filter=vits).
Voyons maintenant comment vous pouvez vous-même *finetuner* un modèle TTS ! | 9 |
0 | hf_public_repos/api-inference-community/docker_images | hf_public_repos/api-inference-community/docker_images/diffusers/requirements.txt | starlette==0.27.0
api-inference-community==0.0.36
# to be replaced with diffusers 0.31.0 as soon as released
git+https://github.com/huggingface/diffusers.git@0f079b932d4382ad6675593f9a140b2a74c8cfb4
transformers==4.41.2
accelerate==0.31.0
hf_transfer==0.1.3
pydantic>=2
ftfy==6.1.1
sentencepiece==0.1.97
scipy==1.10.0
torch==2.0.1
torchvision==0.15.2
torchaudio==2.0.2
invisible-watermark>=0.2.0
uvicorn>=0.23.2
gunicorn>=21.2.0
psutil>=5.9.5
aiohttp>=3.8.5
peft==0.11.1
protobuf==5.27.1
| 0 |
0 | hf_public_repos/api-inference-community/docker_images | hf_public_repos/api-inference-community/docker_images/diffusers/Dockerfile | FROM nvidia/cuda:11.8.0-cudnn8-runtime-ubuntu20.04
LABEL maintainer="Nicolas Patry <[email protected]>"
# Add any system dependency here
# RUN apt-get update -y && apt-get install libXXX -y
ENV DEBIAN_FRONTEND=noninteractive
# Install prerequisites
RUN apt-get update && \
apt-get install -y build-essential libssl-dev zlib1g-dev libbz2-dev \
libreadline-dev libsqlite3-dev wget curl llvm libncurses5-dev libncursesw5-dev \
xz-utils tk-dev libffi-dev liblzma-dev python3-openssl git
# Install pyenv
RUN curl https://pyenv.run | bash
# Set environment variables for pyenv
ENV PYENV_ROOT=/root/.pyenv
ENV PATH=$PYENV_ROOT/shims:$PYENV_ROOT/bin:$PATH
# Install your desired Python version
ARG PYTHON_VERSION=3.9.1
RUN pyenv install $PYTHON_VERSION && \
pyenv global $PYTHON_VERSION && \
pyenv rehash
# Upgrade pip and install your desired packages
ARG PIP_VERSION=22.3.1
# FIXME: We temporarily need to specify the setuptools version <70 due to the following issue
# https://stackoverflow.com/questions/78604018/importerror-cannot-import-name-packaging-from-pkg-resources-when-trying-to
# https://github.com/AUTOMATIC1111/stable-diffusion-webui/issues/15863#issuecomment-2125026282
RUN pip install --no-cache-dir --upgrade pip==${PIP_VERSION} setuptools'<70' wheel && \
pip install --no-cache-dir torch==2.0.1 torchvision==0.15.2 torchaudio==2.0.2
WORKDIR /app
COPY ./requirements.txt /app
RUN pip install --no-cache-dir -r requirements.txt
# Most DL models are quite large in terms of memory, using workers is a HUGE
# slowdown because of the fork and GIL with python.
# Using multiple pods seems like a better default strategy.
# Feel free to override if it does not make sense for your library.
ARG max_workers=1
ENV MAX_WORKERS=$max_workers
ENV HUGGINGFACE_HUB_CACHE=/data
ENV DIFFUSERS_CACHE=/data
# Necessary on GPU environment docker.
# TIMEOUT env variable is used by nvcr.io/nvidia/pytorch:xx for another purpose
# rendering TIMEOUT defined by uvicorn impossible to use correctly
# We're overriding it to be renamed UVICORN_TIMEOUT
# UVICORN_TIMEOUT is a useful variable for very large models that take more
# than 30s (the default) to load in memory.
# If UVICORN_TIMEOUT is too low, uvicorn will simply never loads as it will
# kill workers all the time before they finish.
COPY --from=tiangolo/uvicorn-gunicorn:python3.8 /app/ /app
COPY --from=tiangolo/uvicorn-gunicorn:python3.8 /start.sh /
COPY --from=tiangolo/uvicorn-gunicorn:python3.8 /gunicorn_conf.py /
COPY app/ /app/app
COPY ./prestart.sh /app/
RUN sed -i 's/TIMEOUT/UVICORN_TIMEOUT/g' /gunicorn_conf.py
CMD ["/start.sh"]
| 1 |
0 | hf_public_repos/api-inference-community/docker_images | hf_public_repos/api-inference-community/docker_images/diffusers/prestart.sh | echo "Prestart start at " $(date)
METRICS_ENABLED=${METRICS_ENABLED:-"0"}
if [ "$METRICS_ENABLED" = "1" ];then
echo "Spawning metrics server"
gunicorn -k "uvicorn.workers.UvicornWorker" --bind :${METRICS_PORT:-9400} "app.healthchecks:app" &
pid=$!
echo "Metrics server pid: $pid"
fi
echo "Prestart done at " $(date)
| 2 |
0 | hf_public_repos/api-inference-community/docker_images/diffusers | hf_public_repos/api-inference-community/docker_images/diffusers/app/main.py | import asyncio
import functools
import logging
import os
from typing import Dict, Type
from api_inference_community.routes import pipeline_route, status_ok
from app import idle
from app.pipelines import ImageToImagePipeline, Pipeline, TextToImagePipeline
from starlette.applications import Starlette
from starlette.middleware import Middleware
from starlette.middleware.gzip import GZipMiddleware
from starlette.routing import Route
TASK = os.getenv("TASK")
MODEL_ID = os.getenv("MODEL_ID")
# Add the allowed tasks
# Supported tasks are:
# - text-generation
# - text-classification
# - token-classification
# - translation
# - summarization
# - automatic-speech-recognition
# - ...
# For instance
# from app.pipelines import AutomaticSpeechRecognitionPipeline
# ALLOWED_TASKS = {"automatic-speech-recognition": AutomaticSpeechRecognitionPipeline}
# You can check the requirements and expectations of each pipelines in their respective
# directories. Implement directly within the directories.
ALLOWED_TASKS: Dict[str, Type[Pipeline]] = {
"text-to-image": TextToImagePipeline,
"image-to-image": ImageToImagePipeline,
}
@functools.lru_cache()
def get_pipeline() -> Pipeline:
task = os.environ["TASK"]
model_id = os.environ["MODEL_ID"]
if task not in ALLOWED_TASKS:
raise EnvironmentError(f"{task} is not a valid pipeline for model : {model_id}")
return ALLOWED_TASKS[task](model_id)
routes = [
Route("/{whatever:path}", status_ok),
Route("/{whatever:path}", pipeline_route, methods=["POST"]),
]
middleware = [Middleware(GZipMiddleware, minimum_size=1000)]
if os.environ.get("DEBUG", "") == "1":
from starlette.middleware.cors import CORSMiddleware
middleware.append(
Middleware(
CORSMiddleware,
allow_origins=["*"],
allow_headers=["*"],
allow_methods=["*"],
)
)
app = Starlette(routes=routes, middleware=middleware)
@app.on_event("startup")
async def startup_event():
reset_logging()
# Link between `api-inference-community` and framework code.
if idle.UNLOAD_IDLE:
asyncio.create_task(idle.live_check_loop(), name="live_check_loop")
app.get_pipeline = get_pipeline
try:
get_pipeline()
except Exception:
# We can fail so we can show exception later.
pass
def reset_logging():
logging.basicConfig(
level=logging.DEBUG,
format="%(asctime)s - %(levelname)s - %(message)s",
force=True,
)
if __name__ == "__main__":
reset_logging()
try:
get_pipeline()
except Exception:
# We can fail so we can show exception later.
pass
| 3 |
0 | hf_public_repos/api-inference-community/docker_images/diffusers | hf_public_repos/api-inference-community/docker_images/diffusers/app/validation.py | import re
STR_TO_BOOL = re.compile(r"^\s*true|yes|1\s*$", re.IGNORECASE)
def str_to_bool(s):
return STR_TO_BOOL.match(str(s))
| 4 |
0 | hf_public_repos/api-inference-community/docker_images/diffusers | hf_public_repos/api-inference-community/docker_images/diffusers/app/lora.py | import logging
import torch.nn as nn
from app import offline
from safetensors.torch import load_file
logger = logging.getLogger(__name__)
class LoRAPipelineMixin(offline.OfflineBestEffortMixin):
@staticmethod
def _get_lora_weight_name(model_data):
weight_name_candidate = LoRAPipelineMixin._lora_weights_candidates(model_data)
if weight_name_candidate:
return weight_name_candidate
file_to_load = next(
(
file.rfilename
for file in model_data.siblings
if file.rfilename.endswith(".safetensors")
),
None,
)
if not file_to_load and not weight_name_candidate:
raise ValueError("No *.safetensors file found for your LoRA")
return file_to_load
@staticmethod
def _is_lora(model_data):
return LoRAPipelineMixin._lora_weights_candidates(model_data) or (
model_data.cardData.get("tags")
and "lora" in model_data.cardData.get("tags", [])
)
@staticmethod
def _lora_weights_candidates(model_data):
candidate = None
for file in model_data.siblings:
rfilename = str(file.rfilename)
if rfilename.endswith("pytorch_lora_weights.bin"):
candidate = rfilename
elif rfilename.endswith("pytorch_lora_weights.safetensors"):
candidate = rfilename
break
return candidate
@staticmethod
def _is_safetensors_pivotal(model_data):
embeddings_safetensors_exists = any(
sibling.rfilename == "embeddings.safetensors"
for sibling in model_data.siblings
)
return embeddings_safetensors_exists
@staticmethod
def _is_pivotal_tuning_lora(model_data):
return LoRAPipelineMixin._is_safetensors_pivotal(model_data) or any(
sibling.rfilename == "embeddings.pti" for sibling in model_data.siblings
)
def _fuse_or_raise(self):
try:
self.ldm.fuse_lora(safe_fusing=True)
except Exception as e:
logger.exception(e)
logger.warning("Unable to fuse LoRA adapter")
self.ldm.unload_lora_weights()
self.current_lora_adapter = None
raise
@staticmethod
def _reset_tokenizer_and_encoder(tokenizer, text_encoder, token_to_remove):
token_id = tokenizer(token_to_remove)["input_ids"][1]
del tokenizer._added_tokens_decoder[token_id]
del tokenizer._added_tokens_encoder[token_to_remove]
tokenizer._update_trie()
tokenizer_size = len(tokenizer)
text_embedding_dim = text_encoder.get_input_embeddings().embedding_dim
text_embedding_weights = text_encoder.get_input_embeddings().weight[
:tokenizer_size
]
text_embeddings_filtered = nn.Embedding(tokenizer_size, text_embedding_dim)
text_embeddings_filtered.weight.data = text_embedding_weights
text_encoder.set_input_embeddings(text_embeddings_filtered)
def _unload_textual_embeddings(self):
if self.current_tokens_loaded > 0:
for i in range(self.current_tokens_loaded):
token_to_remove = f"<s{i}>"
self._reset_tokenizer_and_encoder(
self.ldm.tokenizer, self.ldm.text_encoder, token_to_remove
)
self._reset_tokenizer_and_encoder(
self.ldm.tokenizer_2, self.ldm.text_encoder_2, token_to_remove
)
self.current_tokens_loaded = 0
def _load_textual_embeddings(self, adapter, model_data):
if self._is_pivotal_tuning_lora(model_data):
embedding_path = self._hub_repo_file(
repo_id=adapter,
filename="embeddings.safetensors"
if self._is_safetensors_pivotal(model_data)
else "embeddings.pti",
repo_type="model",
)
embeddings = load_file(embedding_path)
state_dict_clip_l = (
embeddings.get("text_encoders_0")
if "text_encoders_0" in embeddings
else embeddings.get("clip_l", None)
)
state_dict_clip_g = (
embeddings.get("text_encoders_1")
if "text_encoders_1" in embeddings
else embeddings.get("clip_g", None)
)
tokens_to_add = 0 if state_dict_clip_l is None else len(state_dict_clip_l)
tokens_to_add_2 = 0 if state_dict_clip_g is None else len(state_dict_clip_g)
if tokens_to_add == tokens_to_add_2 and tokens_to_add > 0:
if state_dict_clip_l is not None and len(state_dict_clip_l) > 0:
token_list = [f"<s{i}>" for i in range(tokens_to_add)]
self.ldm.load_textual_inversion(
state_dict_clip_l,
token=token_list,
text_encoder=self.ldm.text_encoder,
tokenizer=self.ldm.tokenizer,
)
if state_dict_clip_g is not None and len(state_dict_clip_g) > 0:
token_list = [f"<s{i}>" for i in range(tokens_to_add_2)]
self.ldm.load_textual_inversion(
state_dict_clip_g,
token=token_list,
text_encoder=self.ldm.text_encoder_2,
tokenizer=self.ldm.tokenizer_2,
)
logger.info("Text embeddings loaded for adapter %s", adapter)
else:
logger.info(
"No text embeddings were loaded due to invalid embeddings or a mismatch of token sizes "
"for adapter %s",
adapter,
)
self.current_tokens_loaded = tokens_to_add
def _load_lora_adapter(self, kwargs):
adapter = kwargs.pop("lora_adapter", None)
if adapter is not None:
logger.info("LoRA adapter %s requested", adapter)
if adapter != self.current_lora_adapter:
model_data = self._hub_model_info(adapter)
if not self._is_lora(model_data):
msg = f"Requested adapter {adapter:s} is not a LoRA adapter"
logger.error(msg)
raise ValueError(msg)
base_model = model_data.cardData["base_model"]
is_list = isinstance(base_model, list)
if (is_list and (self.model_id not in base_model)) or (
not is_list and self.model_id != base_model
):
msg = f"Requested adapter {adapter:s} is not a LoRA adapter for base model {self.model_id:s}"
logger.error(msg)
raise ValueError(msg)
logger.info(
"LoRA adapter %s needs to be replaced with compatible adapter %s",
self.current_lora_adapter,
adapter,
)
if self.current_lora_adapter is not None:
self.ldm.unfuse_lora()
self.ldm.unload_lora_weights()
self._unload_textual_embeddings()
self.current_lora_adapter = None
logger.info("LoRA weights unloaded, loading new weights")
weight_name = self._get_lora_weight_name(model_data=model_data)
self.ldm.load_lora_weights(
adapter, weight_name=weight_name, use_auth_token=self.use_auth_token
)
self.current_lora_adapter = adapter
self._fuse_or_raise()
logger.info("LoRA weights loaded for adapter %s", adapter)
self._load_textual_embeddings(adapter, model_data)
else:
logger.info("LoRA adapter %s already loaded", adapter)
# Needed while a LoRA is loaded w/ model
model_data = self._hub_model_info(adapter)
if (
self._is_pivotal_tuning_lora(model_data)
and self.current_tokens_loaded == 0
):
self._load_textual_embeddings(adapter, model_data)
elif self.current_lora_adapter is not None:
logger.info(
"No LoRA adapter requested, unloading weights and using base model %s",
self.model_id,
)
self.ldm.unfuse_lora()
self.ldm.unload_lora_weights()
self._unload_textual_embeddings()
self.current_lora_adapter = None
| 5 |
0 | hf_public_repos/api-inference-community/docker_images/diffusers | hf_public_repos/api-inference-community/docker_images/diffusers/app/idle.py | import asyncio
import contextlib
import logging
import os
import signal
import time
LOG = logging.getLogger(__name__)
LAST_START = None
LAST_END = None
UNLOAD_IDLE = os.getenv("UNLOAD_IDLE", "").lower() in ("1", "true")
IDLE_TIMEOUT = int(os.getenv("IDLE_TIMEOUT", 15))
async def live_check_loop():
global LAST_START, LAST_END
pid = os.getpid()
LOG.debug("Starting live check loop")
while True:
await asyncio.sleep(IDLE_TIMEOUT)
LOG.debug("Checking whether we should unload anything from gpu")
last_start = LAST_START
last_end = LAST_END
LOG.debug("Checking pid %d activity", pid)
if not last_start:
continue
if not last_end or last_start >= last_end:
LOG.debug("Request likely being processed for pid %d", pid)
continue
now = time.time()
last_request_age = now - last_end
LOG.debug("Pid %d, last request age %s", pid, last_request_age)
if last_request_age < IDLE_TIMEOUT:
LOG.debug("Model recently active")
else:
LOG.debug("Inactive for too long. Leaving live check loop")
break
LOG.debug("Aborting this worker")
os.kill(pid, signal.SIGTERM)
@contextlib.contextmanager
def request_witnesses():
global LAST_START, LAST_END
# Simple assignment, concurrency safe, no need for any lock
LAST_START = time.time()
try:
yield
finally:
LAST_END = time.time()
| 6 |
0 | hf_public_repos/api-inference-community/docker_images/diffusers | hf_public_repos/api-inference-community/docker_images/diffusers/app/offline.py | import json
import logging
import os
from huggingface_hub import file_download, hf_api, hf_hub_download, model_info, utils
logger = logging.getLogger(__name__)
class OfflineBestEffortMixin(object):
def _hub_repo_file(self, repo_id, filename, repo_type="model"):
if self.offline_preferred:
try:
config_file = hf_hub_download(
repo_id,
filename,
token=self.use_auth_token,
local_files_only=True,
repo_type=repo_type,
)
except utils.LocalEntryNotFoundError:
logger.info("Unable to fetch model index in local cache")
else:
return config_file
return hf_hub_download(
repo_id, filename, token=self.use_auth_token, repo_type=repo_type
)
def _hub_model_info(self, model_id):
"""
This method tries to fetch locally cached model_info if any.
If none, it requests the Hub. Useful for pre cached private models when no token is available
"""
if self.offline_preferred:
cache_root = os.getenv(
"DIFFUSERS_CACHE", os.getenv("HUGGINGFACE_HUB_CACHE", "")
)
folder_name = file_download.repo_folder_name(
repo_id=model_id, repo_type="model"
)
folder_path = os.path.join(cache_root, folder_name)
logger.debug("Cache folder path %s", folder_path)
filename = os.path.join(folder_path, "hub_model_info.json")
try:
with open(filename, "r") as f:
model_data = json.load(f)
except OSError:
logger.info(
"No cached model info found in file %s found for model %s. Fetching on the hub",
filename,
model_id,
)
else:
model_data = hf_api.ModelInfo(**model_data)
return model_data
model_data = model_info(model_id, token=self.use_auth_token)
return model_data
| 7 |
0 | hf_public_repos/api-inference-community/docker_images/diffusers | hf_public_repos/api-inference-community/docker_images/diffusers/app/healthchecks.py | """
This file allows users to spawn some side service helping with giving a better view on the main ASGI app status.
The issue with the status route of the main application is that it gets unresponsive as soon as all workers get busy.
Thus, you cannot really use the said route as a healthcheck to decide whether your app is healthy or not.
Instead this module allows you to distinguish between a dead service (not able to even tcp connect to app port)
and a busy one (able to connect but not to process a trivial http request in time) as both states should result in
different actions (restarting the service vs scaling it). It also exposes some data to be
consumed as custom metrics, for example to be used in autoscaling decisions.
"""
import asyncio
import functools
import logging
import os
from collections import namedtuple
from typing import Optional
import aiohttp
import psutil
from starlette.applications import Starlette
from starlette.requests import Request
from starlette.responses import Response
from starlette.routing import Route
logger = logging.getLogger(__name__)
METRICS = ""
STATUS_OK = 0
STATUS_BUSY = 1
STATUS_ERROR = 2
def metrics():
logging.debug("Requesting metrics")
return METRICS
async def metrics_route(_request: Request) -> Response:
return Response(content=metrics())
routes = [
Route("/{whatever:path}", metrics_route),
]
app = Starlette(routes=routes)
def reset_logging():
if os.environ.get("METRICS_DEBUG", "false").lower() in ["1", "true"]:
level = logging.DEBUG
else:
level = logging.INFO
logging.basicConfig(
level=level,
format="healthchecks - %(asctime)s - %(levelname)s - %(message)s",
force=True,
)
@app.on_event("startup")
async def startup_event():
reset_logging()
# Link between `api-inference-community` and framework code.
asyncio.create_task(compute_metrics_loop(), name="compute_metrics")
@functools.lru_cache()
def get_listening_port():
logger.debug("Get listening port")
main_app_port = os.environ.get("MAIN_APP_PORT", "80")
try:
main_app_port = int(main_app_port)
except ValueError:
logger.warning(
"Main app port cannot be converted to an int, skipping and defaulting to 80"
)
main_app_port = 80
return main_app_port
async def find_app_process(
listening_port: int,
) -> Optional[namedtuple("addr", ["ip", "port"])]: # noqa
connections = psutil.net_connections()
app_laddr = None
for c in connections:
if c.laddr.port != listening_port:
logger.debug("Skipping listening connection bound to excluded port %s", c)
continue
if c.status == psutil.CONN_LISTEN:
logger.debug("Found LISTEN conn %s", c)
candidate = c.pid
try:
p = psutil.Process(candidate)
except psutil.NoSuchProcess:
continue
if p.name() == "gunicorn":
logger.debug("Found gunicorn process %s", p)
app_laddr = c.laddr
break
return app_laddr
def count_current_conns(app_port: int) -> str:
estab = []
conns = psutil.net_connections()
# logger.debug("Connections %s", conns)
for c in conns:
if c.status != psutil.CONN_ESTABLISHED:
continue
if c.laddr.port == app_port:
estab.append(c)
current_conns = len(estab)
logger.info("Current count of established connections to app: %d", current_conns)
curr_conns_str = """# HELP inference_app_established_conns Established connection count for a given app.
# TYPE inference_app_established_conns gauge
inference_app_established_conns{{port="{:d}"}} {:d}
""".format(
app_port, current_conns
)
return curr_conns_str
async def status_with_timeout(
listening_port: int, app_laddr: Optional[namedtuple("addr", ["ip", "port"])] # noqa
) -> str:
logger.debug("Checking application status")
status = STATUS_OK
if not app_laddr:
status = STATUS_ERROR
else:
try:
async with aiohttp.ClientSession(
timeout=aiohttp.ClientTimeout(total=0.5)
) as session:
url = "http://{}:{:d}/".format(app_laddr.ip, app_laddr.port)
async with session.get(url) as resp:
status_code = resp.status
status_text = await resp.text()
logger.debug("Status code %s and text %s", status_code, status_text)
if status_code != 200 or status_text != '{"ok":"ok"}':
status = STATUS_ERROR
except asyncio.TimeoutError:
logger.debug("Asgi app seems busy, unable to reach it before timeout")
status = STATUS_BUSY
except Exception as e:
logger.exception(e)
status = STATUS_ERROR
status_str = """# HELP inference_app_status Application health status (0: ok, 1: busy, 2: error).
# TYPE inference_app_status gauge
inference_app_status{{port="{:d}"}} {:d}
""".format(
listening_port, status
)
return status_str
async def single_metrics_compute():
global METRICS
listening_port = get_listening_port()
app_laddr = await find_app_process(listening_port)
current_conns = count_current_conns(listening_port)
status = await status_with_timeout(listening_port, app_laddr)
# Assignment is atomic, we should be safe without locking
METRICS = current_conns + status
# Persist metrics to the local ephemeral as well
metrics_file = os.environ.get("METRICS_FILE")
if metrics_file:
with open(metrics_file) as f:
f.write(METRICS)
@functools.lru_cache()
def get_polling_sleep():
logger.debug("Get polling sleep interval")
sleep_value = os.environ.get("METRICS_POLLING_INTERVAL", 10)
try:
sleep_value = float(sleep_value)
except ValueError:
logger.warning(
"Unable to cast METRICS_POLLING_INTERVAL env value %s to float. Defaulting to 10.",
sleep_value,
)
sleep_value = 10.0
return sleep_value
@functools.lru_cache()
def get_initial_delay():
logger.debug("Get polling initial delay")
sleep_value = os.environ.get("METRICS_INITIAL_DELAY", 30)
try:
sleep_value = float(sleep_value)
except ValueError:
logger.warning(
"Unable to cast METRICS_INITIAL_DELAY env value %s to float. "
"Defaulting to 30.",
sleep_value,
)
sleep_value = 30.0
return sleep_value
async def compute_metrics_loop():
initial_delay = get_initial_delay()
await asyncio.sleep(initial_delay)
polling_sleep = get_polling_sleep()
while True:
await asyncio.sleep(polling_sleep)
try:
await single_metrics_compute()
except Exception as e:
logger.error("Something wrong occurred while computing metrics")
logger.exception(e)
if __name__ == "__main__":
reset_logging()
try:
single_metrics_compute()
logger.info("Metrics %s", metrics())
except Exception as exc:
logging.exception(exc)
raise
| 8 |
0 | hf_public_repos/api-inference-community/docker_images/diffusers | hf_public_repos/api-inference-community/docker_images/diffusers/app/timing.py | import logging
from functools import wraps
from time import time
logger = logging.getLogger(__name__)
def timing(f):
@wraps(f)
def inner(*args, **kwargs):
start = time()
try:
ret = f(*args, **kwargs)
finally:
end = time()
logger.debug("Func: %r took: %.2f sec to execute", f.__name__, end - start)
return ret
return inner
| 9 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.