
index
int64 0
0
| repo_id
stringclasses 179
values | file_path
stringlengths 26
186
| content
stringlengths 1
2.1M
| __index_level_0__
int64 0
9
|
|---|---|---|---|---|
0 | hf_public_repos/blog | hf_public_repos/blog/zh/dynamic_speculation_lookahead.md | ---
title: "更快的辅助生成: 动态推测"
thumbnail: /blog/assets/optimum_intel/intel_thumbnail.png
authors:
- user: jmamou
guest: true
org: Intel
- user: orenpereg
guest: true
org: Intel
- user: joaogante
- user: lewtun
- user: danielkorat
guest: true
org: Intel
- user: Nadav-Timor
guest: true
org: weizmannscience
- user: moshew
guest: true
org: Intel
translators:
- user: Zipxuan
- user: zhongdongy
proofreader: true
---
⭐ 在这篇博客文章中,我们将探讨 _动态推测解码_ ——这是由英特尔实验室和 Hugging Face 开发的一种新方法,可以加速文本生成高达 2.7 倍,具体取决于任务。从 [Transformers🤗](https://github.com/huggingface/transformers) 发布的版本 [4.45.0](https://github.com/huggingface/transformers/releases/tag/v4.45.0) 开始,这种方法是辅助生成的默认模式⭐
## 推测解码
[推测解码](https://arxiv.org/abs/2211.17192) 技术十分流行,其用于加速大型语言模型的推理过程,与此同时保持其准确性。如下图所示,推测解码通过将生成过程分为两个阶段来工作。在第一阶段,一个快速但准确性较低的 _草稿_ 模型 (Draft,也称为助手) 自回归地生成一系列标记。在第二阶段,一个大型但更准确的 _目标_ 模型 (Target) 对生成的草稿标记进行并行验证。这个过程允许目标模型在单个前向传递中生成多个标记,从而加速自回归解码。推测解码的成功在很大程度上取决于 _推测前瞻_ (Speculative Lookahead,下文用 SL 表示),即草稿模型在每次迭代中生成的标记数量。在实践中,SL 要么是一个静态值,要么基于启发式方法,这两者都不是在推理过程中发挥最大性能的最优选择。
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/dynamic_speculation_lookahead/spec_dec_diagram.png" width="250"><br>
<em>推测解码的单次迭代</em>
</figure>
## 动态推测解码
[Transformers🤗](https://github.com/huggingface/transformers) 库提供了两种不同的方法来确定在推理过程中调整草稿 (助手) 标记数量的计划。基于 [Leviathan 等人](https://arxiv.org/pdf/2211.17192) 的直接方法使用推测前瞻的静态值,并涉及在每个推测迭代中生成恒定数量的候选标记。另一种 [基于启发式方法的方法](https://huggingface.co/blog/assisted-generation) 根据当前迭代的接受率调整下一次迭代的候选标记数量。如果所有推测标记都是正确的,则候选标记的数量增加; 否则,数量减少。
我们预计,通过增强优化策略来管理生成的草稿标记数量,可以进一步减少延迟。为了测试这个论点,我们利用一个预测器来确定每个推测迭代的最佳推测前瞻值 (SL)。该预测器利用草稿模型自回归的生成标记,直到草稿模型和目标模型之间的预测标记出现不一致。该过程在每个推测迭代中重复进行,最终确定每次迭代接受的草稿标记的最佳 (最大) 数量。草稿/目标标记不匹配是通过在零温度下 Leviathan 等人提出的拒绝抽样算法 (rejection sampling algorithm) 来识别的。该预测器通过在每一步生成最大数量的有效草稿标记,并最小化对草稿和目标模型的调用次数,实现了推测解码的全部潜力。我们称使用该预测器得到 SL 值的推测解码过程为预知 (orcale) 的推测解码。
下面的左图展示了来自 [MBPP](https://huggingface.co/datasets/google-research-datasets/mbpp) 数据集的代码生成示例中的预知和静态推测前瞻值在推测迭代中的变化。可以观察到预知的 SL 值 (橙色条) 存在很高的变化。
静态 SL 值 (蓝色条) 中,生成的草稿标记数量固定为 5,执行了 38 次目标前向传播和 192 次草稿前向传播,而预知的 SL 值只执行了 27 次目标前向传播和 129 次草稿前向传播 - 减少了很多。右图展示了整个 [Alpaca](https://huggingface.co/datasets/tatsu-lab/alpaca) 数据集中的预知和静态推测前瞻值。
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/dynamic_speculation_lookahead/oracle_K_2.png" style="width: 400px; height: auto;"><br>
<em>在 MBPP 的一个例子上的预知和静态推测前瞻值 (SL)。</em>
</p>
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/dynamic_speculation_lookahead/Alpaca.png" style="width: 400px; height: auto;"><br>
<em>在整个 Alpaca 数据集上平均的预知 SL 值。</em>
上面的两个图表展示了预知推测前瞻值的多变性,这说明静态的推测解码可能使次优的。
为了更接近预知的推测解码并获得额外的加速,我们开发了一种简单的方法来在每次迭代中动态调整推测前瞻值。在生成每个草稿令牌后,我们确定草稿模型是否应继续生成下一个令牌或切换到目标模型进行验证。这个决定基于草稿模型对其预测的信心,通过 logits 的 softmax 估计。如果草稿模型对当前令牌预测的信心低于预定义的阈值,即 `assistant_confidence_threshold` ,它将在该迭代中停止令牌生成过程,即使尚未达到最大推测令牌数 `num_assistant_tokens` 。一旦停止,当前迭代中生成的草稿令牌将被发送到目标模型进行验证。
## 基准测试
我们在一系列任务和模型组合中对动态方法与启发式方法进行了基准测试。动态方法在所有测试中表现出更好的性能。
值得注意的是,使用动态方法将 `Llama3.2-1B` 作为 `Llama3.1-8B` 的助手时,我们观察到速度提升高达 1.52 倍,而使用相同设置的启发式方法则没有显著的速度提升。另一个观察结果是, `codegen-6B-mono` 在使用启发式方法时表现出速度下降,而使用动态方法则表现出速度提升。
| 目标模型 | 草稿模型 | 任务类型 | 加速比 - 启发式策略 | 加速比 - 动态策略 |
|----------------------|---------------------|---------------------------|---------------------------|---------------------------|
| `facebook/opt-6.7b` | `facebook/opt-125m` | summarization | 1.82x | **2.71x** |
| `facebook/opt-6.7b` | `facebook/opt-125m` | open-ended generation | 1.23x | **1.59x** |
| `Salesforce/codegen-6B-mono` | `Salesforce/codegen-350M-mono` | code generation (python) | 0.89x | **1.09x** |
| `google/flan-t5-xl` | `google/flan-t5-small` | summarization | 1.18x | **1.31x** |
| `meta-llama/Llama-3.1-8B` | `meta-llama/Llama-3.2-1B` | summarization | 1.00x | **1.52x** |
| `meta-llama/Llama-3.1-8B` | `meta-llama/Llama-3.2-1B` | open-ended generation | 1.00x | **1.18x** |
| `meta-llama/Llama-3.1-8B` | `meta-llama/Llama-3.2-1B` | code generation (python) | 1.09x | **1.15x** |
- 表格中的结果反映了贪婪解码 (temperature = 0)。在使用采样 (temperature > 0) 时也观察到了类似的趋势。
- 所有测试均在 RTX 4090 上进行。
- 我们的基准测试是公开的,允许任何人评估进一步的改进: https://github.com/gante/huggingface-demos/tree/main/experiments/faster_generation
## 代码
动态推测已经整合到 Hugging Face Transformers 库的 4.45.0 版本中,并且现在作为辅助解码的默认操作模式。要使用带有动态推测的辅助生成,无需进行任何代码更改,只需像平常一样执行代码即可:
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
prompt = "Alice and Bob"
checkpoint = "EleutherAI/pythia-1.4b-deduped"
assistant_checkpoint = "EleutherAI/pythia-160m-deduped"
device = "cuda" if torch.cuda.is_available() else "cpu"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
inputs = tokenizer(prompt, return_tensors="pt").to(device)
model = AutoModelForCausalLM.from_pretrained(checkpoint).to(device)
assistant_model = AutoModelForCausalLM.from_pretrained(assistant_checkpoint).to(device)
outputs = model.generate(**inputs, assistant_model=assistant_model)
```
默认的动态推测前瞻的参数反应了最优的值,但是可以使用下面的代码进行调整来在特定模型和数据上获得更好的性能:
```python
# confidence threshold
assistant_model.generation_config.assistant_confidence_threshold=0.4
# 'constant' means that num_assistant_tokens stays unchanged during generation
assistant_model.generation_config.num_assistant_tokens_schedule='constant'
# the maximum number of tokens generated by the assistant model.
# after 20 tokens the draft halts even if the confidence is above the threshold
assistant_model.generation_config.num_assistant_tokens=20
```
要恢复到 **启发式** 或 **静态** 方法 (如 [Leviathan 等人](https://arxiv.org/pdf/2211.17192) 中所述),只需分别将 `num_assistant_tokens_schedule` 设置为 `'heuristic'` 或 `'constant'` ,将 `assistant_confidence_threshold=0` 和 `num_assistant_tokens=5` 设置如下:
```python
# Use 'heuristic' or 'constant' or 'dynamic'
assistant_model.generation_config.num_assistant_tokens_schedule='heuristic'
assistant_model.generation_config.assistant_confidence_threshold=0
assistant_model.generation_config.num_assistant_tokens=5
```
## 接下来是什么?
我们介绍了一种更快的辅助生成策略,名为动态推测解码,它优于启发式方法以及固定数量候选标记的方法。
在即将发布的博客文章中,我们将展示一种新的辅助生成方法: 将任何目标模型与任何助手模型结合起来!这将为在 Hugging Face Hub 上加速无法获得足够小的助手变体的无数模型打开大门。例如, `Phi 3` 、 `Gemma 2` 、 `CodeLlama` 等等都将有资格进行推测解码。敬请关注!
## 参考资料
- [Dynamic Speculation Lookahead Accelerates Speculative Decoding of Large Language Models](https://arxiv.org/abs/2405.04304)。
> 在这篇论文中,我们介绍了 DISCO,一种动态推测前瞻优化方法,利用分类器决定草稿模型是否应该继续生成下一个标记,还是暂停,并切换到目标模型进行验证,而不是仅仅使用对预测概率的简单阈值。
- [Assisted Generation: a new direction toward low-latency text generation](https://huggingface.co/blog/assisted-generation)
- [Fast Inference from Transformers via Speculative Decoding](https://arxiv.org/pdf/2211.17192) | 0 |
0 | hf_public_repos/blog | hf_public_repos/blog/zh/daily-papers.md | ---
title: "Hugging Face 论文平台 Daily Papers 功能全解析"
thumbnail: /blog/assets/daily-papers/thumbnail.png
authors:
- user: AdinaY
---
# Hugging Face 论文平台 Daily Papers 功能全解析
在快速发展的研究领域,保持对最新进展的关注至关重要。为了帮助开发者和研究人员跟踪 AI 领域的前沿动态,Hugging Face 推出了 [Daily Papers](https://huggingface.co/papers) 页面。自发布以来,Daily Papers 已展示了由 [AK](https://huggingface.co/akhaliq) 和社区研究人员精心挑选的高质量研究。在过去一年里,已有超过 3700 篇论文被发布,页面订阅用户也增长至超过 1.2 万!
然而,许多人可能还不了解 Daily Papers 页面的全部功能。本文将介绍一些论文页面的隐藏功能,帮助你充分利用这个平台。
## 📑 认领论文

在 Daily Papers 页面中,每篇论文标题下方会有作者名单。如果你是其中的一位作者,并且拥有 Hugging Face 账号,即可以通过点击 [认领论文](https://huggingface.co/docs/hub/paper-pages#claiming-authorship-to-a-paper) 一键认领论文!认领后,该论文将自动关联到你的 Hugging Face 账户,这有助于在社区中建立个人品牌并提高工作的影响力。
这一功能使得社区成员了解你的研究及背景,创造更多合作和互动的机会。
## ⏫ 提交论文

论文提交功能向所有已认领论文的用户开放。用户不仅限于提交自己的作品,也可以分享其他有益于社区的有趣研究论文。
这有助于 Hugging Face Papers 维持一个由社区策划、持续更新的 AI 研究文库!
## 💬 与作者零距离交流

每篇论文下都有讨论区,用户可以在这里留言并与作者进行直接对话。通过 @ 作者的用户名,就可以及时向作者提问或讨论研究内容,并及时获得作者的反馈。
这一功能促进了互动,旨在将整个社区的研究人员聚集在一起。无论是初学者还是专家都可以在这里畅所欲言,使全球 AI 社区更加紧密和包容。
无论你是提出问题还是分享建设性意见,这都为有意义的对话打开了大门,甚至可能激发出新的想法或合作。
## 🔗 一页汇总全部内容

在每篇论文页面的右侧,可以找到与论文相关的[资源](https://huggingface.co/docs/hub/paper-pages#linking-a-paper-to-a-model-dataset-or-space),例如模型、数据集、演示和其他有用的集合。
作者可以通过将论文的 arXiv URL 添加到他们资源的 README.md 文件中,轻松将他们的模型或数据集与论文关联起来。此功能允许作者展示他们的工作,并帮助用户在一个页面上可以获取所有相关信息。
## 🗳 点赞支持

你可以通过点击页面右上角的点赞按钮来支持该论文,这样做可以帮助将论文推向社区并支持作者的工作。点赞功能能够突出有影响力和创新的研究,帮助更多人发现并关注优秀的论文。
对于作者来说,每个点赞都是对其努力的认可,也是他们继续进行高质量研究的动力源泉。
## 🙋 推荐类似论文

在评论区中输入 @librarian-bot,系统将自动推荐相关论文。对于那些想深入研究某个主题或探索类似想法的用户来说,这个功能非常有用。就像拥有一个 AI 驱动的个人研究助理!
## 🔠 多语言评论和翻译

在 Hugging Face,我们重视多样性,这也体现在语言使用方面。在 Daily Papers 页面,用户可以用任何语言发表评论,我们内置的翻译功能会确保所有人都能理解并参与讨论。
无论您是提供反馈、讨论问题还是想要和社区或作者进行交流,这一功能都有助于打破语言障碍,使全球合作变得更加容易。
## ✅ 订阅功能

你可以通过点击页面顶部的“订阅”按钮来订阅 Daily Papers。订阅后,将每天(周末除外)收到最新论文的更新,它会直接发送到你 Hugging Face 注册邮箱📩。
此功能使您能够一目了然地浏览最新的论文标题,并可以直接点击进入感兴趣的论文页面。
## 💡 与 arXiv 的互动功能

Paper Pages 和 arXiv 之间还有一些有趣的集成功能。例如,你可以轻松查看 arXiv 上的论文是否已经被 Hugging Face 的 Daily Papers 页面展示。如果在页面上看到熟悉的表情符号 🤗,点击它就可以直接跳转到 Daily Papers 上的论文页面,探索上述所有功能。
要使用 arXiv 到 HF Paper Pages 的功能,需要安装一个 Chrome 扩展程序 👉:https://chromewebstore.google.com/detail/arxiv-to-hf/icfbnjkijgggnhmlikeppnoehoalpcpp。

在 arXiv 上,你还可以查看某篇论文是否在 Hugging Face Spaces 上托管了 demo 演示。如果作者添加了链接,你可以点击链接直接跳转到 Hugging Face Space 尝试 demo!
我们希望这份指南能帮助你充分利用 Hugging Face 上的 [Daily Papers](https://huggingface.co/docs/hub/paper-pages) 页面。通过利用这些功能,你可以时刻关注最新的研究成果,与作者互动,并为不断发展的 AI 社区做出贡献。无论你是研究人员、开发者还是初学者,希望 Daily Papers 能帮助你紧密联结全球顶尖的 AI 研究前沿!
| 1 |
0 | hf_public_repos/blog | hf_public_repos/blog/zh/langchain.md | ---
title: "Hugging Face x LangChain:全新 LangChain 合作伙伴包"
thumbnail: /blog/assets/langchain_huggingface/thumbnail.png
authors:
- user: jofthomas
- user: kkondratenko
guest: true
- user: efriis
guest: true
org: langchain-ai
translators:
- user: MatrixYao
- user: zhongdongy
proofreader: true
---
# Hugging Face x LangChain: 全新 LangChain 合作伙伴包
我们很高兴官宣发布 **`langchain_huggingface`**,这是一个由 Hugging Face 和 LangChain 共同维护的 LangChain 合作伙伴包。这个新的 Python 包旨在将 Hugging Face 最新功能引入 LangChain 并保持同步。
# 源自社区,服务社区
目前,LangChain 中所有与 Hugging Face 相关的类都是由社区贡献的。虽然我们以此为基础蓬勃发展,但随着时间的推移,其中一些类在设计时由于缺乏来自 Hugging Face 的内部视角而在后期被废弃。
通过 Langchain 合作伙伴包这个方式,我们的目标是缩短将 Hugging Face 生态系统中的新功能带给 LangChain 用户所需的时间。
**`langchain-huggingface`** 与 LangChain 无缝集成,为在 LangChain 生态系统中使用 Hugging Face 模型提供了一种可用且高效的方法。这种伙伴关系不仅仅涉及到技术贡献,还展示了双方对维护和不断改进这一集成的共同承诺。
## **起步**
**`langchain-huggingface`** 的起步非常简单。以下是安装该 [软件包](https://github.com/langchain-ai/langchain/tree/master/libs/partners/huggingface) 的方法:
```python
pip install langchain-huggingface
```
现在,包已经安装完毕,我们来看看里面有什么吧!
## LLM 文本生成
### HuggingFacePipeline
`transformers` 中的 [Pipeline](https://huggingface.co/docs/transformers/main_classes/pipelines) 类是 Hugging Face 工具箱中最通用的工具。LangChain 的设计主要是面向 RAG 和 Agent 应用场景,因此,在 Langchain 中流水线被简化为下面几个以文本为中心的任务: `文本生成` 、 `文生文` 、 `摘要` 、 `翻译` 等。
用户可以使用 `from_model_id` 方法直接加载模型:
```python
from langchain_huggingface import HuggingFacePipeline
llm = HuggingFacePipeline.from_model_id(
model_id="microsoft/Phi-3-mini-4k-instruct",
task="text-generation",
pipeline_kwargs={
"max_new_tokens": 100,
"top_k": 50,
"temperature": 0.1,
},
)
llm.invoke("Hugging Face is")
```
也可以自定义流水线,再传给 `HuggingFacePipeline` 类:
```python
from transformers import AutoModelForCausalLM, AutoTokenizer,pipeline
model_id = "microsoft/Phi-3-mini-4k-instruct"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
load_in_4bit=True,
#attn_implementation="flash_attention_2", # if you have an ampere GPU
)
pipe = pipeline("text-generation", model=model, tokenizer=tokenizer, max_new_tokens=100, top_k=50, temperature=0.1)
llm = HuggingFacePipeline(pipeline=pipe)
llm.invoke("Hugging Face is")
```
使用 `HuggingFacePipeline` 时,模型是加载至本机并在本机运行的,因此你可能会受到本机可用资源的限制。
### HuggingFaceEndpoint
该类也有两种方法。你可以使用 `repo_id` 参数指定模型。也可以使用 `endpoint_url` 指定服务终端,这些终端使用 [无服务器 API](https://huggingface.co/inference-api/serverless),这对于有 Hugging Face [专业帐户](https://huggingface.co/subscribe/pro) 或 [企业 hub](https://huggingface.co/enterprise) 的用户大有好处。普通用户也可以通过在代码环境中设置自己的 HF 令牌从而在免费请求数配额内使用终端。
```python
from langchain_huggingface import HuggingFaceEndpoint
llm = HuggingFaceEndpoint(
repo_id="meta-llama/Meta-Llama-3-8B-Instruct",
task="text-generation",
max_new_tokens=100,
do_sample=False,
)
llm.invoke("Hugging Face is")
```
```python
llm = HuggingFaceEndpoint(
endpoint_url="<endpoint_url>",
task="text-generation",
max_new_tokens=1024,
do_sample=False,
)
llm.invoke("Hugging Face is")
```
该类在底层实现时使用了 [InferenceClient](https://huggingface.co/docs/huggingface_hub/en/package_reference/inference_client),因此能够为已部署的 TGI 实例提供面向各种用例的无服务器 API。
### ChatHuggingFace
每个模型都有最适合自己的特殊词元。如果没有将这些词元添加到提示中,将大大降低模型的表现。
为了把用户的消息转成 LLM 所需的提示,大多数 LLM 分词器中都提供了一个名为 [chat_template](https://huggingface.co/docs/transformers/chat_templated) 的成员属性。
要了解不同模型的 `chat_template` 的详细信息,可访问我创建的 [space](https://huggingface.co/spaces/Jofthomas/Chat_template_viewer)!
`ChatHuggingFace` 类对 LLM 进行了包装,其接受用户消息作为输入,然后用 `tokenizer.apply_chat_template` 方法构造出正确的提示。
```python
from langchain_huggingface import ChatHuggingFace, HuggingFaceEndpoint
llm = HuggingFaceEndpoint(
endpoint_url="<endpoint_url>",
task="text-generation",
max_new_tokens=1024,
do_sample=False,
)
llm_engine_hf = ChatHuggingFace(llm=llm)
llm_engine_hf.invoke("Hugging Face is")
```
上述代码等效于:
```python
# with mistralai/Mistral-7B-Instruct-v0.2
llm.invoke("<s>[INST] Hugging Face is [/INST]")
# with meta-llama/Meta-Llama-3-8B-Instruct
llm.invoke("""<|begin_of_text|><|start_header_id|>user<|end_header_id|>Hugging Face is<|eot_id|><|start_header_id|>assistant<|end_header_id|>""")
```
## 嵌入
Hugging Face 里有很多非常强大的嵌入模型,你可直接把它们用于自己的流水线。
首先,选择你想要的模型。关于如何选择嵌入模型,一个很好的参考是 [MTEB 排行榜](https://huggingface.co/spaces/mteb/leaderboard)。
### HuggingFaceEmbeddings
该类使用 [sentence-transformers](https://sbert.net/) 来计算嵌入。其计算是在本机进行的,因此需要使用你自己的本机资源。
```python
from langchain_huggingface.embeddings import HuggingFaceEmbeddings
model_name = "mixedbread-ai/mxbai-embed-large-v1"
hf_embeddings = HuggingFaceEmbeddings(
model_name=model_name,
)
texts = ["Hello, world!", "How are you?"]
hf_embeddings.embed_documents(texts)
```
### HuggingFaceEndpointEmbeddings
`HuggingFaceEndpointEmbeddings` 与 `HuggingFaceEndpoint` 对 LLM 所做的非常相似,其在实现上也是使用 InferenceClient 来计算嵌入。它可以与 hub 上的模型以及 TEI 实例一起使用,TEI 实例无论是本地部署还是在线部署都可以。
```python
from langchain_huggingface.embeddings import HuggingFaceEndpointEmbeddings
hf_embeddings = HuggingFaceEndpointEmbeddings(
model= "mixedbread-ai/mxbai-embed-large-v1",
task="feature-extraction",
huggingfacehub_api_token="<HF_TOKEN>",
)
texts = ["Hello, world!", "How are you?"]
hf_embeddings.embed_documents(texts)
```
## 总结
我们致力于让 **`langchain-huggingface`** 变得越来越好。我们将积极监控反馈和问题,并努力尽快解决它们。我们还将不断添加新的特性和功能,以拓展该软件包使其支持更广泛的社区应用。我们强烈推荐你尝试 `langchain-huggingface` 软件包并提出宝贵意见,有了你的支持,这个软件包的未来道路才会越走越宽。
| 2 |
0 | hf_public_repos/blog | hf_public_repos/blog/zh/how-to-generate.md | ---
title: "如何生成文本:通过 Transformers 用不同的解码方法生成文本"
thumbnail: /blog/assets/02_how-to-generate/thumbnail.png
authors:
- user: patrickvonplaten
translators:
- user: MatrixYao
- user: zhongdongy
proofreader: true
---
# 如何生成文本: 通过 Transformers 用不同的解码方法生成文本
<a target="_blank" href="https://colab.research.google.com/github/huggingface/blog/blob/main/notebooks/02_how_to_generate.ipynb">
<img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/>
</a>
### 简介
近年来,随着以 OpenAI [GPT2 模型](https://openai.com/blog/better-language-models/) 为代表的基于数百万网页数据训练的大型 Transformer 语言模型的兴起,开放域语言生成领域吸引了越来越多的关注。开放域中的条件语言生成效果令人印象深刻,典型的例子有: [GPT2 在独角兽话题上的精彩续写](https://openai.com/blog/better-language-models/#samples),[XLNet](https://medium.com/@amanrusia/xlnet-speaks-comparison-to-gpt-2-ea1a4e9ba39e) 以及 [使用 CTRL 模型生成受控文本](https://blog.einstein.ai/introducing-a-conditional-transformer-language-model-for-controllable-generation/) 等。促成这些进展的除了 transformer 架构的改进和大规模无监督训练数据外,*更好的解码方法* 也发挥了不可或缺的作用。
本文简述了不同的解码策略,同时向读者展示了如何使用流行的 `transformers` 库轻松实现这些解码策略!
下文中的所有功能均可用于 *自回归* 语言生成任务 (点击 [此处](http://jalammar.github.io/illustrated-gpt2/) 回顾)。简单复习一下, *自回归* 语言生成是基于如下假设: 一个文本序列的概率分布可以分解为每个词基于其上文的条件概率的乘积。
$$ P(w_{1:T} | W_0 ) = \prod_{t=1}^T P(w_{t} | w_{1: t-1}, W_0) \text{ , 其中 } w_{1: 0} = \emptyset, $$
上式中,$W_0$ 是初始 *上下文* 单词序列。文本序列的长度 $T$ 通常时变的,并且对应于时间步 $t=T$。$P(w_{t} | w_{1: t- 1}, W_{0})$ 的词表中已包含 终止符 (End Of Sequence,EOS)。`transformers` 目前已支持的自回归语言生成任务包括 `GPT2`、`XLNet`、`OpenAi-GPT`、`CTRL`、`TransfoXL`、`XLM`、`Bart`、`T5` 模型,并支持 PyTorch 和 TensorFlow (>= 2.0) 两种框架!
我们会介绍目前最常用的解码方法,主要有 *贪心搜索 (Greedy search)*、*波束搜索 (Beam search)*、*Top-K 采样 (Top-K sampling)* 以及 *Top-p 采样 (Top-p sampling)*。
在此之前,我们先快速安装一下 `transformers` 并把模型加载进来。本文我们用 GPT2 模型在 TensorFlow 2.1 中进行演示,但 API 和使用 PyTorch 框架是一一对应的。
```python
!pip install -q git+https://github.com/huggingface/transformers.git
!pip install -q tensorflow==2.1
```
```python
import tensorflow as tf
from transformers import TFGPT2LMHeadModel, GPT2Tokenizer
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
# add the EOS token as PAD token to avoid warnings
model = TFGPT2LMHeadModel.from_pretrained("gpt2",pad_token_id=tokenizer.eos_token_id)
```
### 贪心搜索
贪心搜索在每个时间步 $t$ 都简单地选择概率最高的词作为当前输出词: $w_t = argmax_{w}P(w | w_{1:t-1})$ ,如下图所示。
<img src="/blog/assets/02_how-to-generate/greedy_search.png" alt="greedy search" style="margin: auto; display: block;">
从单词 $\text{“The”}$ 开始,算法在第一步贪心地选择条件概率最高的词 $\text{“nice”}$ 作为输出,依此往后。最终生成的单词序列为 $(\text{“The”}, \text{“nice”}, \text{“woman”})$,其联合概率为 $0.5 \times 0.4 = 0.2$。
下面,我们输入文本序列 $(\text{“I”}, \text{“enjoy”}, \text{“walking”}, \text{“with”}, \text{“my”}, \text{“cute”}, \text{“dog”})$ 给 GPT2 模型,让模型生成下文。我们以此为例看看如何在 `transformers` 中使用贪心搜索:
```python
# encode context the generation is conditioned on
input_ids = tokenizer.encode('I enjoy walking with my cute dog', return_tensors='tf')
# generate text until the output length (which includes the context length) reaches 50
greedy_output = model.generate(input_ids, max_length=50)
print("Output:\n" + 100 * '-')
print(tokenizer.decode(greedy_output[0], skip_special_tokens=True))
```
<div class="output stream stdout">
Output:
----------------------------------------------------------------------------------------------------
I enjoy walking with my cute dog, but I'm not sure if I'll ever be able to walk with my dog. I'm not sure if I'll ever be able to walk with my dog.
I'm not sure if I'll
</div>
好,我们已经用 GPT2 生成了第一个短文本😊。根据上文生成的单词是合理的,但模型很快开始输出重复的文本!这在语言生成中是一个非常普遍的问题,在贪心搜索和波束搜索中似乎更是如此 - 详见 [Vijayakumar 等人,2016](https://arxiv.org/abs/1610.02424) 和 [Shao 等人,2017](https://arxiv.org/abs/1701.03185) 的论文。
贪心搜索的主要缺点是它错过了隐藏在低概率词后面的高概率词,如上图所示:
条件概率为 $0.9$ 的单词 $\text{“has”}$ 隐藏在单词 $\text{“dog”}$ 后面,而 $\text{“dog”}$ 因为在 `t=1` 时条件概率值只排第二所以未被选择,因此贪心搜索会错过序列 $\text{“The”}, \text {“dog”}, \text{“has”}$ 。
幸好我们可以用波束搜索来缓解这个问题!
### 波束搜索
波束搜索通过在每个时间步保留最可能的 `num_beams` 个词,并从中最终选择出概率最高的序列来降低丢失潜在的高概率序列的风险。以 `num_beams=2` 为例:
<img src="/blog/assets/02_how-to-generate/beam_search.png" alt="beam search" style="margin: auto; display: block;">
在时间步 1,除了最有可能的假设 $(\text{“The”}, \text{“nice”})$,波束搜索还跟踪第二可能的假设 $(\text{“The”}, \text{“dog”})$。在时间步 2,波束搜索发现序列 $(\text{“The”}, \text{“dog”}, \text{“has”})$ 概率为$0.36$,比 $(\text{“The”}, \text{“nice”}, \text{“woman”})$ 的 $0.2$ 更高。太棒了,在我们的例子中它已经找到了最有可能的序列!
波束搜索一般都会找到比贪心搜索概率更高的输出序列,但仍不保证找到全局最优解。
让我们看看如何在 `transformers` 中使用波束搜索。我们设置 `num_beams > 1` 和 `early_stopping=True` 以便在所有波束达到 EOS 时直接结束生成。
```python
# activate beam search and early_stopping
beam_output = model.generate(
input_ids,
max_length=50,
num_beams=5,
early_stopping=True
)
print("Output:\n" + 100 * '-')
print(tokenizer.decode(beam_output[0], skip_special_tokens=True))
```
<div class="output stream stdout">
Output:
----------------------------------------------------------------------------------------------------
I enjoy walking with my cute dog, but I'm not sure if I'll ever be able to walk with him again.
I'm not sure if I'll ever be able to walk with him again. I'm not sure if I'll
</div>
虽然结果比贪心搜索更流畅,但输出中仍然包含重复。一个简单的补救措施是引入 *n-grams* (即连续 n 个词的词序列) 惩罚,该方法是由 [Paulus 等人 (2017)](https://arxiv.org/abs/1705.04304) 和 [Klein 等人 (2017)](https://arxiv.org/abs/1701.02810) 引入的。最常见的 *n-grams* 惩罚是确保每个 *n-gram* 都只出现一次,方法是如果看到当前候选词与其上文所组成的 *n-gram* 已经出现过了,就将该候选词的概率设置为 0。
我们可以通过设置 `no_repeat_ngram_size=2` 来试试,这样任意 *2-gram* 不会出现两次:
```python
# set no_repeat_ngram_size to 2
beam_output = model.generate(
input_ids,
max_length=50,
num_beams=5,
no_repeat_ngram_size=2,
early_stopping=True
)
print("Output:\n" + 100 * '-')
print(tokenizer.decode(beam_output[0], skip_special_tokens=True))
```
<div class="output stream stdout">
Output:
----------------------------------------------------------------------------------------------------
I enjoy walking with my cute dog, but I'm not sure if I'll ever be able to walk with him again.
I've been thinking about this for a while now, and I think it's time for me to take a break
</div>
不错,看起来好多了!我们看到生成的文本已经没有重复了。但是,*n-gram* 惩罚使用时必须谨慎,如一篇关于 *纽约* 这个城市的文章就不应使用 *2-gram* 惩罚,否则,城市名称在整个文本中将只出现一次!
波束搜索的另一个重要特性是我们能够比较概率最高的几个波束,并选择最符合我们要求的波束作为最终生成文本。
在 `transformers` 中,我们只需将参数 `num_return_sequences` 设置为需返回的概率最高的波束的数量,记得确保 `num_return_sequences <= num_beams`!
```python
# set return_num_sequences > 1
beam_outputs = model.generate(
input_ids,
max_length=50,
num_beams=5,
no_repeat_ngram_size=2,
num_return_sequences=5,
early_stopping=True
)
# now we have 3 output sequences
print("Output:\n" + 100 * '-')
for i, beam_output in enumerate(beam_outputs):
print("{}: {}".format(i, tokenizer.decode(beam_output, skip_special_tokens=True)))
```
<div class="output stream stdout">
Output:
----------------------------------------------------------------------------------------------------
0: I enjoy walking with my cute dog, but I'm not sure if I'll ever be able to walk with him again.
I've been thinking about this for a while now, and I think it's time for me to take a break
1: I enjoy walking with my cute dog, but I'm not sure if I'll ever be able to walk with him again.
I've been thinking about this for a while now, and I think it's time for me to get back to
2: I enjoy walking with my cute dog, but I'm not sure if I'll ever be able to walk with her again.
I've been thinking about this for a while now, and I think it's time for me to take a break
3: I enjoy walking with my cute dog, but I'm not sure if I'll ever be able to walk with her again.
I've been thinking about this for a while now, and I think it's time for me to get back to
4: I enjoy walking with my cute dog, but I'm not sure if I'll ever be able to walk with him again.
I've been thinking about this for a while now, and I think it's time for me to take a step
</div>
如我们所见,五个波束彼此之间仅有少量差别 —— 这在仅使用 5 个波束时不足为奇。
开放域文本生成的研究人员最近提出了几个理由来说明对该领域而言波束搜索可能不是最佳方案:
- 在机器翻译或摘要等任务中,因为所需生成的长度或多或少都是可预测的,所以波束搜索效果比较好 - 参见 [Murray 等人 (2018)](https://arxiv.org/abs/1808.10006) 和 [Yang 等人 (2018)](https://arxiv.org/abs/1808.09582) 的工作。但开放域文本生成情况有所不同,其输出文本长度可能会有很大差异,如对话和故事生成的输出文本长度就有很大不同。
- 我们已经看到波束搜索已被证明存在重复生成的问题。在故事生成这样的场景中,很难用 *n-gram* 或其他惩罚来控制,因为在“不重复”和最大可重复 *n-grams* 之间找到一个好的折衷需要大量的微调。
- 正如 [Ari Holtzman 等人 (2019)](https://arxiv.org/abs/1904.09751) 所论证的那样,高质量的人类语言并不遵循最大概率法则。换句话说,作为人类,我们希望生成的文本能让我们感到惊喜,而可预测的文本使人感觉无聊。论文作者画了一个概率图,很好地展示了这一点,从图中可以看出人类文本带来的惊喜度比波束搜索好不少。
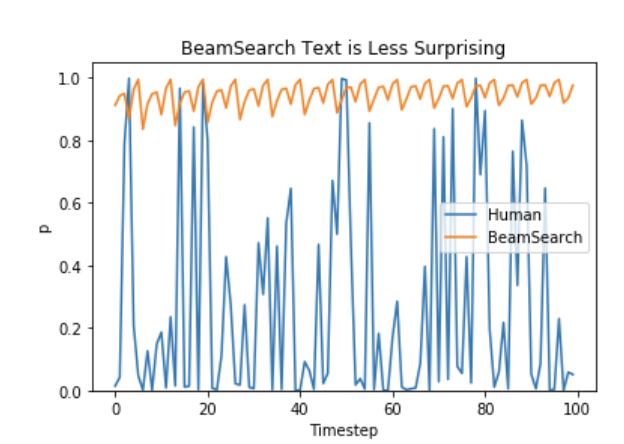
因此,让我们开始玩点刺激的,引入一些随机性🤪。
### 采样
在其最基本的形式中,采样意味着根据当前条件概率分布随机选择输出词 $w_t$:
$$ w_t \sim P(w|w_{1:t-1}) $$
继续使用上文中的例子,下图可视化了使用采样生成文本的过程。
<img src="/blog/assets/02_how-to-generate/sampling_search.png" alt="sampling search" style="margin: auto; display: block;">
很明显,使用采样方法时文本生成本身不再是 *确定性的*。单词 $\text{“car”}$ 从条件概率分布 $P(w | \text{“The”})$ 中采样而得,而 $\text{“drives”}$ 则采样自 $P(w | \text{“The”}, \text{“car”})$。
在 `transformers` 中,我们设置 `do_sample=True` 并通过设置 `top_k=0` 停用 *Top-K* 采样 (稍后详细介绍)。在下文中,为便于复现,我们会固定 `random_seed=0`,但你可以在自己的模型中随意更改 `random_seed`。
```python
# set seed to reproduce results. Feel free to change the seed though to get different results
tf.random.set_seed(0)
# activate sampling and deactivate top_k by setting top_k sampling to 0
sample_output = model.generate(
input_ids,
do_sample=True,
max_length=50,
top_k=0
)
print("Output:\n" + 100 * '-')
print(tokenizer.decode(sample_output[0], skip_special_tokens=True))
```
<div class="output stream stdout">
Output:
----------------------------------------------------------------------------------------------------
I enjoy walking with my cute dog. He just gave me a whole new hand sense."
But it seems that the dogs have learned a lot from teasing at the local batte harness once they take on the outside.
"I take
</div>
有意思!生成的文本看起来不错 - 但仔细观察会发现它不是很连贯。*3-grams* *new hand sense* 和 *local batte harness* 非常奇怪,看起来不像是人写的。这就是对单词序列进行采样时的大问题: 模型通常会产生不连贯的乱码,*参见* [Ari Holtzman 等人 (2019)](https://arxiv.org/abs/1904.09751) 的论文。
缓解这一问题的一个技巧是通过降低所谓的 [softmax](https://en.wikipedia.org/wiki/Softmax_function#Smooth_arg_max) 的“温度”使分布 $P(w|w_{1:t-1})$ 更陡峭。而降低“温度”,本质上是增加高概率单词的似然并降低低概率单词的似然。
将温度应用到于我们的例子中后,结果如下图所示。
<img src="/blog/assets/02_how-to-generate/sampling_search_with_temp.png" alt="sampling temp search" style="margin: auto; display: block;">
$t=1$ 时刻单词的条件分布变得更加陡峭,几乎没有机会选择单词 $\text{“car”}$ 了。
让我们看看如何通过设置 `temperature=0.7` 来冷却生成过程:
```python
# set seed to reproduce results. Feel free to change the seed though to get different results
tf.random.set_seed(0)
# use temperature to decrease the sensitivity to low probability candidates
sample_output = model.generate(
input_ids,
do_sample=True,
max_length=50,
top_k=0,
temperature=0.7
)
print("Output:\n" + 100 * '-')
print(tokenizer.decode(sample_output[0], skip_special_tokens=True))
```
<div class="output stream stdout">
Output:
----------------------------------------------------------------------------------------------------
I enjoy walking with my cute dog, but I don't like to be at home too much. I also find it a bit weird when I'm out shopping. I am always away from my house a lot, but I do have a few friends
</div>
好,奇怪的 n-gram 变少了,现在输出更连贯了!虽然温度可以使分布的随机性降低,但极限条件下,当“温度”设置为 $0$ 时,温度缩放采样就退化成贪心解码了,因此会遇到与贪心解码相同的问题。
### Top-K 采样
[Fan 等人 (2018)](https://arxiv.org/pdf/1805.04833.pdf) 的论文介绍了一种简单但非常强大的采样方案,称为 ***Top-K*** 采样。在 *Top-K* 采样中,概率最大的 *K* 个词会被选出,然后这 *K* 个词的概率会被重新归一化,最后就在这重新被归一化概率后的 *K* 个词中采样。 GPT2 采用了这种采样方案,这也是它在故事生成这样的任务上取得成功的原因之一。
我们将上文例子中的候选单词数从 3 个单词扩展到 10 个单词,以更好地说明 *Top-K* 采样。
<img src="/blog/assets/02_how-to-generate/top_k_sampling.png" alt="Top K sampling" style="margin: auto; display: block;">
设 $K = 6$,即我们将在两个采样步的采样池大小限制为 6 个单词。我们定义 6 个最有可能的词的集合为 $V_{\text{top-K}}$。在第一步中,$V_{\text{top-K}}$ 仅占总概率的大约三分之二,但在第二步,它几乎占了全部的概率。同时,我们可以看到在第二步该方法成功地消除了那些奇怪的候选词 $(\text{“not”}, \text{“the”}, \text{“small”}, \text{“told”})$。
我们以设置 `top_k=50` 为例看下如何在 `transformers` 库中使用 *Top-K*:
```python
# set seed to reproduce results. Feel free to change the seed though to get different results
tf.random.set_seed(0)
# set top_k to 50
sample_output = model.generate(
input_ids,
do_sample=True,
max_length=50,
top_k=50
)
print("Output:\n" + 100 * '-')
print(tokenizer.decode(sample_output[0], skip_special_tokens=True))
```
<div class="output stream stdout">
Output:
----------------------------------------------------------------------------------------------------
I enjoy walking with my cute dog. It's so good to have an environment where your dog is available to share with you and we'll be taking care of you.
We hope you'll find this story interesting!
I am from
</div>
相当不错!该文本可以说是迄今为止生成的最 "*像人*" 的文本。现在还有一个问题,*Top-K* 采样不会动态调整从需要概率分布 $P(w|w_{1:t-1})$ 中选出的单词数。这可能会有问题,因为某些分布可能是非常尖锐 (上图中右侧的分布),而另一些可能更平坦 (上图中左侧的分布),所以对不同的分布使用同一个绝对数 *K* 可能并不普适。
在 $t=1$ 时,*Top-K* 将 $(\text{“people”}, \text{“big”}, \text{“house”}, \text{“cat”})$ 排出了采样池,而这些词似乎是合理的候选词。另一方面,在$t=2$ 时,该方法却又把不太合适的 $(\text{“down”}, \text{“a”})$ 纳入了采样池。因此,将采样池限制为固定大小 *K* 可能会在分布比较尖锐的时候产生胡言乱语,而在分布比较平坦的时候限制模型的创造力。这一发现促使 [Ari Holtzman 等人 (2019)](https://arxiv.org/abs/1904.09751) 发明了 **Top-p**- 或 **核**- 采样。
### Top-p (核) 采样
在 *Top-p* 中,采样不只是在最有可能的 *K* 个单词中进行,而是在累积概率超过概率 *p* 的最小单词集中进行。然后在这组词中重新分配概率质量。这样,词集的大小 (*又名* 集合中的词数) 可以根据下一个词的概率分布动态增加和减少。好吧,说的很啰嗦,一图胜千言。
<img src="/blog/assets/02_how-to-generate/top_p_sampling.png" alt="Top p sampling" style="margin: auto; display: block;">
假设 $p=0.92$,*Top-p* 采样对单词概率进行降序排列并累加,然后选择概率和首次超过 $p=92%$ 的单词集作为采样池,定义为 $V_{\text{top-p}}$。在 $t=1$ 时 $V_{\text{top-p}}$ 有 9 个词,而在 $t=2$ 时它只需要选择前 3 个词就超过了 92%。其实很简单吧!可以看出,在单词比较不可预测时,它保留了更多的候选词,*如* $P(w | \text{“The”})$,而当单词似乎更容易预测时,只保留了几个候选词,*如* $P(w | \text{“The”}, \text{“car”})$。
好的,是时候看看它在 `transformers` 里怎么用了!我们可以通过设置 `0 < top_p < 1` 来激活 *Top-p* 采样:
```python
# set seed to reproduce results. Feel free to change the seed though to get different results
tf.random.set_seed(0)
# deactivate top_k sampling and sample only from 92% most likely words
sample_output = model.generate(
input_ids,
do_sample=True,
max_length=50,
top_p=0.92,
top_k=0
)
print("Output:\n" + 100 * '-')
print(tokenizer.decode(sample_output[0], skip_special_tokens=True))
```
```
Output:
----------------------------------------------------------------------------------------------------
I enjoy walking with my cute dog. He will never be the same. I watch him play.
Guys, my dog needs a name. Especially if he is found with wings.
What was that? I had a lot o
```
太好了,这看起来跟人类写的差不多了,虽然还不算完全是。
虽然从理论上讲, *Top-p* 似乎比 *Top-K* 更优雅,但这两种方法在实践中都很有效。 *Top-p* 也可以与 *Top-K* 结合使用,这样可以避免排名非常低的词,同时允许进行一些动态选择。
最后,如果想要获得多个独立采样的输出,我们可以 *再次* 设置参数 `num_return_sequences > 1`:
```python
# set seed to reproduce results. Feel free to change the seed though to get different results
tf.random.set_seed(0)
# set top_k = 50 and set top_p = 0.95 and num_return_sequences = 3
sample_outputs = model.generate(
input_ids,
do_sample=True,
max_length=50,
top_k=50,
top_p=0.95,
num_return_sequences=3
)
print("Output:\n" + 100 * '-')
for i, sample_output in enumerate(sample_outputs):
print("{}: {}".format(i, tokenizer.decode(sample_output, skip_special_tokens=True)))
```
```
Output:
----------------------------------------------------------------------------------------------------
0: I enjoy walking with my cute dog. It's so good to have the chance to walk with a dog. But I have this problem with the dog and how he's always looking at us and always trying to make me see that I can do something
1: I enjoy walking with my cute dog, she loves taking trips to different places on the planet, even in the desert! The world isn't big enough for us to travel by the bus with our beloved pup, but that's where I find my love
2: I enjoy walking with my cute dog and playing with our kids," said David J. Smith, director of the Humane Society of the US.
"So as a result, I've got more work in my time," he said.
```
很酷,现在你拥有了所有可以在 `transformers` 里用模型来帮你写故事的工具了!
### 总结
在开放域语言生成场景中,作为最新的解码方法, *top-p* 和 *top-K* 采样于传统的 *贪心* 和 *波束* 搜索相比,似乎能产生更流畅的文本。但,最近有更多的证据表明 *贪心* 和 *波束* 搜索的明显缺陷 - 主要是生成重复的单词序列 - 是由模型 (特别是模型的训练方式) 引起的,而不是解码方法, *参见* [Welleck 等人 (2019)](https://arxiv.org/pdf/1908.04319.pdf) 的论文。此外,如 [Welleck 等人 (2020)](https://arxiv.org/abs/2002.02492) 的论文所述,看起来 *top-K* 和 *top-p* 采样也会产生重复的单词序列。
在 [Welleck 等人 (2019)](https://arxiv.org/pdf/1908.04319.pdf) 的论文中,作者表明,根据人类评估,在调整训练目标后,波束搜索相比 *Top-p* 采样能产生更流畅的文本。
开放域语言生成是一个快速发展的研究领域,而且通常情况下这里没有放之四海而皆准的方法,因此必须了解哪种方法最适合自己的特定场景。
好的方面是, *你* 可以在 `transfomers` 中尝试所有不同的解码方法 🤗。
以上是对如何在 `transformers` 中使用不同的解码方法以及开放域语言生成的最新趋势的简要介绍。
非常欢迎大家在 [Github 代码库](https://github.com/huggingface/transformers) 上提供反馈和问题。
如果想要体验下用模型生成故事的乐趣,可以访问我们的 web 应用 [Writing with Transformers](https://transformer.huggingface.co/)。
感谢为本文做出贡献的所有人: Alexander Rush、Julien Chaumand、Thomas Wolf、Victor Sanh、Sam Shleifer、Clément Delangue、Yacine Jernite、Oliver Åstrand 和 John de Wasseige。
### 附录
`generate` 方法还有几个正文未提及的参数,这里我们简要解释一下它们!
- `min_length` 用于强制模型在达到 `min_length` 之前不生成 EOS。这在摘要场景中使用得比较多,但如果用户想要更长的文本输出,也会很有用。
- `repetition_penalty` 可用于对生成重复的单词这一行为进行惩罚。它首先由 [Keskar 等人 (2019)](https://arxiv.org/abs/1909.05858) 引入,在 [Welleck 等人 (2019)](https://arxiv.org/pdf/1908.04319.pdf) 的工作中,它是训练目标的一部分。它可以非常有效地防止重复,但似乎对模型和用户场景非常敏感,其中一个例子见 Github 上的 [讨论](https://github.com/huggingface/transformers/pull/2303)。
- `attention_mask` 可用于屏蔽填充符。
- `pad_token_id`、`bos_token_id`、`eos_token_id`: 如果模型默认没有这些 token,用户可以手动选择其他 token id 来表示它们。
更多信息,请查阅 `generate` 函数 [手册](https://huggingface.co/transformers/main_classes/model.html?highlight=generate#transformers.TFPreTrainedModel.generate)。 | 3 |
0 | hf_public_repos/blog | hf_public_repos/blog/zh/stable-diffusion-inference-intel.md | ---
title: "在英特尔 CPU 上加速 Stable Diffusion 推理"
thumbnail: /blog/assets/136_stable_diffusion_inference_intel/01.png
authors:
- user: juliensimon
- user: echarlaix
translators:
- user: MatrixYao
---
# 在英特尔 CPU 上加速 Stable Diffusion 推理
前一段时间,我们向大家介绍了最新一代的 [英特尔至强](https://www.intel.com/content/www/us/en/products/details/processors/xeon/scalable.html) CPU(代号 Sapphire Rapids),包括其用于加速深度学习的新硬件特性,以及如何使用它们来加速自然语言 transformer 模型的[分布式微调](https://huggingface.co/blog/intel-sapphire-rapids)和[推理](https://huggingface.co/blog/intel-sapphire-rapids-inference)。
本文将向你展示在 Sapphire Rapids CPU 上加速 Stable Diffusion 模型推理的各种技术。后续我们还计划发布对 Stable Diffusion 进行分布式微调的文章。
在撰写本文时,获得 Sapphire Rapids 服务器的最简单方法是使用 Amazon EC2 [R7iz](https://aws.amazon.com/ec2/instance-types/r7iz/) 系列实例。由于它仍处于预览阶段,你需要[注册](https://pages.awscloud.com/R7iz-Preview.html)才能获得访问权限。与之前的文章一样,我使用的是 `r7iz.metal-16xl` 实例(64 个 vCPU,512GB RAM),操作系统镜像为 Ubuntu 20.04 AMI (`ami-07cd3e6c4915b2d18`)。
本文的代码可从 [Gitlab](https://gitlab.com/juliensimon/huggingface-demos/-/tree/main/optimum/stable_diffusion_intel) 上获取。我们开始吧!
## Diffusers 库
[Diffusers](https://huggingface.co/docs/diffusers/index) 库使得用 Stable Diffusion 模型生成图像变得极其简单。如果你不熟悉 Stable Diffusion 模型,这里有一个很棒的 [图文介绍](https://jalammar.github.io/illustrated-stable-diffusion/)。
首先,我们创建一个包含以下库的虚拟环境:Transformers、Diffusers、Accelerate 以及 PyTorch。
```
virtualenv sd_inference
source sd_inference/bin/activate
pip install pip --upgrade
pip install transformers diffusers accelerate torch==1.13.1
```
然后,我们写一个简单的基准测试函数,重复推理多次,最后返回单张图像生成的平均延迟。
```python
import time
def elapsed_time(pipeline, prompt, nb_pass=10, num_inference_steps=20):
# warmup
images = pipeline(prompt, num_inference_steps=10).images
start = time.time()
for _ in range(nb_pass):
_ = pipeline(prompt, num_inference_steps=num_inference_steps, output_type="np")
end = time.time()
return (end - start) / nb_pass
```
现在,我们用默认的 `float32` 数据类型构建一个 `StableDiffusionPipeline`,并测量其推理延迟。
```python
from diffusers import StableDiffusionPipeline
model_id = "runwayml/stable-diffusion-v1-5"
pipe = StableDiffusionPipeline.from_pretrained(model_id)
prompt = "sailing ship in storm by Rembrandt"
latency = elapsed_time(pipe, prompt)
print(latency)
```
平均延迟为 **32.3 秒**。正如这个英特尔开发的 [Hugging Face Space](https://huggingface.co/spaces/Intel/Stable-Diffusion-Side-by-Side) 所展示的,相同的代码在上一代英特尔至强(代号 Ice Lake)上运行需要大约 45 秒。
开箱即用,我们可以看到 Sapphire Rapids CPU 在没有任何代码更改的情况下速度相当快!
现在,让我们继续加速它吧!
## Optimum Intel 与 OpenVINO
[Optimum Intel](https://huggingface.co/docs/optimum/intel/index) 用于在英特尔平台上加速 Hugging Face 的端到端流水线。它的 API 和 [Diffusers](https://huggingface.co/docs/diffusers/index) 原始 API 极其相似,因此所需代码改动很小。
Optimum Intel 支持 [OpenVINO](https://docs.openvino.ai/latest/index.html),这是一个用于高性能推理的英特尔开源工具包。
Optimum Intel 和 OpenVINO 安装如下:
```
pip install optimum[openvino]
```
相比于上文的代码,我们只需要将 `StableDiffusionPipeline` 替换为 `OVStableDiffusionPipeline` 即可。如需加载 PyTorch 模型并将其实时转换为 OpenVINO 格式,你只需在加载模型时设置 `export=True`。
```python
from optimum.intel.openvino import OVStableDiffusionPipeline
...
ov_pipe = OVStableDiffusionPipeline.from_pretrained(model_id, export=True)
latency = elapsed_time(ov_pipe, prompt)
print(latency)
# Don't forget to save the exported model
ov_pipe.save_pretrained("./openvino")
```
OpenVINO 会自动优化 `bfloat16` 模型,优化后的平均延迟下降到了 **16.7 秒**,相当不错的 2 倍加速。
上述 pipeline 支持动态输入尺寸,对输入图像 batch size 或分辨率没有任何限制。但在使用 Stable Diffusion 时,通常你的应用程序仅限于输出一种(或几种)不同分辨率的图像,例如 512x512 或 256x256。因此,通过固定 pipeline 的输出分辨率来解锁更高的性能增益有其实际意义。如果你需要不止一种输出分辨率,您可以简单地维护几个 pipeline 实例,每个分辨率一个。
```python
ov_pipe.reshape(batch_size=1, height=512, width=512, num_images_per_prompt=1)
latency = elapsed_time(ov_pipe, prompt)
```
固定输出分辨率后,平均延迟进一步降至 **4.7 秒**,又获得了额外的 3.5 倍加速。
如你所见,OpenVINO 是加速 Stable Diffusion 推理的一种简单有效的方法。与 Sapphire Rapids CPU 结合使用时,和至强 Ice Lake 的最初性能的相比,推理性能加速近 10 倍。
如果你不能或不想使用 OpenVINO,本文下半部分会展示一系列其他优化技术。系好安全带!
## 系统级优化
扩散模型是数 GB 的大模型,图像生成是一种内存密集型操作。通过安装高性能内存分配库,我们能够加速内存操作并使之能在 CPU 核之间并行处理。请注意,这将更改系统的默认内存分配库。你可以通过卸载新库来返回默认库。
[jemalloc](https://jemalloc.net/) 和 [tcmalloc](https://github.com/gperftools/gperftools) 是两个很有意思的内存优化库。这里,我们使用 `jemalloc`,因为我们测试下来,它的性能比 `tcmalloc` 略好。`jemalloc` 还可以用于针对特定工作负载进行调优,如最大化 CPU 利用率。详情可参考 [`jemalloc` 调优指南](https://github.com/jemalloc/jemalloc/blob/dev/TUNING.md)。
```
sudo apt-get install -y libjemalloc-dev
export LD_PRELOAD=$LD_PRELOAD:/usr/lib/x86_64-linux-gnu/libjemalloc.so
export MALLOC_CONF="oversize_threshold:1,background_thread:true,metadata_thp:auto,dirty_decay_ms: 60000,muzzy_decay_ms:60000"
```
接下来,我们安装 `libiomp` 库来优化多核并行,这个库是 [英特尔 OpenMP* 运行时库](https://www.intel.com/content/www/us/en/docs/cpp-compiler/developer-guide-reference/2021-8/openmp-run-time-library-routines.html) 的一部分。
```
sudo apt-get install intel-mkl
export LD_PRELOAD=$LD_PRELOAD:/usr/lib/x86_64-linux-gnu/libiomp5.so
export OMP_NUM_THREADS=32
```
最后,我们安装 [numactl](https://github.com/numactl/numactl) 命令行工具。它让我们可以把我们的 Python 进程绑定到指定的核,并避免一些上下文切换开销。
```
numactl -C 0-31 python sd_blog_1.py
```
使用这些优化后,原始的 Diffusers 代码只需 **11.8 秒** 就可以完成推理,快了几乎 3 倍,而且无需任何代码更改。这些工具在我们的 32 核至强 CPU 上运行得相当不错。
我们还有招。现在我们把 `英特尔 PyTorch 扩展`(Intel Extension for PyTorch,`IPEX`)引入进来。
## IPEX 与 BF16
[IPEX](https://intel.github.io/intel-extension-for-pytorch/) 扩展了 PyTorch 使之可以进一步充分利用英特尔 CPU 上的硬件加速功能,包括 [AVX-512](https://en.wikipedia.org/wiki/AVX-512) 、矢量神经网络指令(Vector Neural Network Instructions,AVX512 VNNI) 以及 [先进矩阵扩展](https://en.wikipedia.org/wiki/Advanced_Matrix_Extensions) (AMX)。
我们先安装 `IPEX`。
```
pip install intel_extension_for_pytorch==1.13.100
```
装好后,我们需要修改部分代码以将 `IPEX` 优化应用到 `pipeline` 的每个模块(你可以通过打印 `pipe` 对象罗列出它有哪些模块),其中之一的优化就是把数据格式转换为 channels-last 格式。
```python
import torch
import intel_extension_for_pytorch as ipex
...
pipe = StableDiffusionPipeline.from_pretrained(model_id)
# to channels last
pipe.unet = pipe.unet.to(memory_format=torch.channels_last)
pipe.vae = pipe.vae.to(memory_format=torch.channels_last)
pipe.text_encoder = pipe.text_encoder.to(memory_format=torch.channels_last)
pipe.safety_checker = pipe.safety_checker.to(memory_format=torch.channels_last)
# Create random input to enable JIT compilation
sample = torch.randn(2,4,64,64)
timestep = torch.rand(1)*999
encoder_hidden_status = torch.randn(2,77,768)
input_example = (sample, timestep, encoder_hidden_status)
# optimize with IPEX
pipe.unet = ipex.optimize(pipe.unet.eval(), dtype=torch.bfloat16, inplace=True, sample_input=input_example)
pipe.vae = ipex.optimize(pipe.vae.eval(), dtype=torch.bfloat16, inplace=True)
pipe.text_encoder = ipex.optimize(pipe.text_encoder.eval(), dtype=torch.bfloat16, inplace=True)
pipe.safety_checker = ipex.optimize(pipe.safety_checker.eval(), dtype=torch.bfloat16, inplace=True)
```
我们使用了 `bloat16` 数据类型,以利用 Sapphire Rapids CPU 上的 AMX 加速器。
```python
with torch.cpu.amp.autocast(enabled=True, dtype=torch.bfloat16):
latency = elapsed_time(pipe, prompt)
print(latency)
```
经过此番改动,推理延迟从 11.9 秒进一步减少到 **5.4 秒**。感谢 IPEX 和 AMX,推理速度提高了 2 倍以上。
还能榨点性能出来吗?能,我们将目光转向调度器(scheduler)!
## 调度器
Diffusers 库支持为每个Stable Diffusion pipiline 配置 [调度器(scheduler)](https://huggingface.co/docs/diffusers/using-diffusers/schedulers),用于在去噪速度和去噪质量之间找到最佳折衷。
根据文档所述:“*截至本文档撰写时,DPMSolverMultistepScheduler 能实现最佳的速度/质量权衡,只需 20 步即可运行。*” 我们可以试一下 `DPMSolverMultistepScheduler`。
```python
from diffusers import StableDiffusionPipeline, DPMSolverMultistepScheduler
...
dpm = DPMSolverMultistepScheduler.from_pretrained(model_id, subfolder="scheduler")
pipe = StableDiffusionPipeline.from_pretrained(model_id, scheduler=dpm)
```
最终,推理延迟降至 **5.05 秒**。与我们最初的 Sapphire Rapids 基线(32.3 秒)相比,几乎快了 6.5 倍!
<kbd>
<img src="/blog/assets/136_stable_diffusion_inference_intel/01.png">
</kbd>
*运行环境: Amazon EC2 r7iz.metal-16xl, Ubuntu 20.04, Linux 5.15.0-1031-aws, libjemalloc-dev 5.2.1-1, intel-mkl 2020.0.166-1, PyTorch 1.13.1, Intel Extension for PyTorch 1.13.1, transformers 4.27.2, diffusers 0.14, accelerate 0.17.1, openvino 2023.0.0.dev20230217, optimum 1.7.1, optimum-intel 1.7*
## 总结
在几秒钟内生成高质量图像的能力可用于许多场景,如 2C 的应用程序、营销和媒体领域的内容生成,或生成合成数据以扩充数据集。
如你想要在这方面起步,以下是一些有用的资源:
* Diffusers [文档](https://huggingface.co/docs/diffusers)
* Optimum Intel [文档](https://huggingface.co/docs/optimum/main/en/intel/inference)
* [英特尔 IPEX](https://github.com/intel/intel-extension-for-pytorch) on GitHub
* [英特尔和 Hugging Face联合出品的开发者资源网站](https://www.intel.com/content/www/us/en/developer/partner/hugging-face.html)
如果你有任何问题或反馈,请通过 [Hugging Face 论坛](https://discuss.huggingface.co/) 告诉我们。
感谢垂阅! | 4 |
0 | hf_public_repos/blog | hf_public_repos/blog/zh/tgi-benchmarking.md | ---
title: "TGI 基准测试"
thumbnail: /blog/assets/tgi-benchmarking/tgi-benchmarking-thumbnail.png
authors:
- user: derek-thomas
translators:
- user: MatrixYao
- user: zhongdongy
proofreader: true
---
# TGI 基准测试
本文主要探讨 [TGI](https://github.com/huggingface/text-generation-inference) 的小兄弟 - [TGI 基准测试工具](https://github.com/huggingface/text-generation-inference/blob/main/benchmark/README.md)。它能帮助我们超越简单的吞吐量指标,对 TGI 进行更全面的性能剖析,以更好地了解如何根据实际需求对服务进行调优并按需作出最佳的权衡及决策。如果你曾觉得 LLM 服务部署成本太高,或者你想对部署进行调优,那么本文很适合你!
我将向大家展示如何轻松通过 [Hugging Face 空间](https://huggingface.co/spaces) 进行服务性能剖析。你可以把获得的分析结果用于 [推理端点](https://huggingface.co/inference-endpoints/dedicated) 或其他相同硬件的平台的部署。
## 动机
为了更好地理解性能剖析的必要性,我们先讨论一些背景信息。
大语言模型 (LLM) 从根子上来说效率就比较低,这主要源自其基于 [解码器的工作方式](https://huggingface.co/learn/nlp-course/chapter1/6?fw=pt),每次前向传播只能生成一个新词元。随着 LLM 规模的扩大以及企业 [采用率的激增](https://a16z.com/generative-ai-enterprise-2024/),AI 行业围绕优化手段创新以及性能提优技术做了非常出色的工作。
在 LLM 推理服务优化的各个方面,业界积累了数十项改进技术。各种技术层出不穷,如: [Flash Attention](https://huggingface.co/docs/text-generation-inference/en/conceptual/flash_attention)、[Paged Attention](https://huggingface.co/docs/text-generation-inference/en/conceptual/paged_attention)、[流式响应](https://huggingface.co/docs/text-generation-inference/en/conceptual/streaming)、[批处理改进](https://huggingface.co/docs/text-generation-inference/en/basic_tutorials/launcher#maxwaitingtokens)、[投机解码](https://huggingface.co/docs/text-generation-inference/en/conceptual/speculation)、各种各样的 [量化](https://huggingface.co/docs/text-generation-inference/en/conceptual/quantization) 技术、[前端网络服务改进](https://github.com/huggingface/text-generation-inference?tab=readme-ov-file#architecture),使用 [更快的语言](https://github.com/search?q=repo%3Ahuggingface%2Ftext-generation-inference++language%3ARust&type=code) (抱歉,Python 🐍!) 等等。另外还有不少用例层面的改进,如 [结构化生成](https://huggingface.co/docs/text-generation-inference/en/conceptual/guidance) 以及 [水印](https://huggingface.co/blog/watermarking) 等都在当今的 LLM 推理世界中占据了一席之地。我们深深知道,LLM 推理服务优化没有万能灵丹,一个快速高效的推理服务需要整合越来越多的细分技术 [[1]](#1)。
[TGI](https://github.com/huggingface/text-generation-inference) 是 Hugging Face 的高性能 LLM 推理服务,其宗旨就是拥抱、整合、开发那些可用于优化 LLM 部署和使用的最新技术。由于 Hugging Face 的强大的开源生态,大多数 (即使不是全部) 主要开源 LLM 甫一发布即可以在 TGI 中使用。
一般来讲,实际应用的不同会导致用户需求迥异。以 **RAG 应用** 的提示和生成为例:
- 指令/格式
- 通常很短,<200 个词元
- 用户查询
- 通常很短,<200 个词元
- 多文档
- 中等大小,每文档 500-1000 个词元,
- 文档个数为 N,且 N<10
- 响应
- 中等长度 , ~500-1000 个词元
在 RAG 应用中,将正确的文档包含于提示中对于获得高质量的响应非常重要,用户可以通过包含更多文档 (即增加 N) 来提高这种概率。也就是说,RAG 应用通常会尝试最大化 LLM 的上下文窗口以提高任务性能。而一般的聊天应用则相反,典型 **聊天场景** 的词元比 RAG 少得多:
- 多轮对话
- 2xTx50-200 词元,T 轮
- 2x 的意思是每轮包括一次用户输入和一次助理输出
鉴于应用场景如此多样,我们应确保根据场景需求来相应配置我们的 LLM 服务。为此,Hugging Face 提供了一个 [基准测试工具](https://github.com/huggingface/text-generation-inference/blob/main/benchmark/README.md),以帮助我们探索哪些配置更适合目标应用场景。下文,我将解释如何在 [Hugging Face 空间](https://huggingface.co/docs/hub/en/spaces-overview) 上使用该基准测试工具。
## Pre-requisites
在深入研究基准测试工具之前,我们先对齐一下关键概念。
### 延迟与吞吐
<video style="width: auto; height: auto;" controls autoplay muted loop>
<source src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/tgi-benchmarking/LatencyThroughputVisualization.webm" type="video/webm">
当前浏览器不支持视频标签。
</video>
| |
|-------------------------------------------------|
| *图 1: 延迟与吞吐量的可视化解释* |
- 词元延迟 – 生成一个词元并将其返回给用户所需的时间
- 请求延迟 – 完全响应请求所需的时间
- 首词元延迟 - 从请求发送到第一个词元返回给用户的时间。这是处理预填充输入的时间和生成第一个词元的时间的和
- 吞吐量 – 给定时间内服务返回的词元数 (在本例中,吞吐量为每秒 4 个词元)
延迟是一个比较微妙的测量指标,它无法反应全部情况。你的生成延迟可能比较长也可能比较短,但长也好短也罢,并不能完整刻画实际的服务性能。
我们需要知道的重要事实是: 吞吐和延迟是相互正交的测量指标,我们可以通过适当的服务配置,针对其中之一进行优化。我们的基准测试工具可以对测量数据进行可视化,从而帮助大家理解折衷之道。
### 预填充与解码

|:--:|
|*图 2: 预填充与解码图解,灵感来源 [[2]](#2)*|
以上给出了 LLM 如何生成文本的简图。一般,模型每次前向传播生成一个词元。在 **预填充阶段** (用橙色表示),模型会收到完整的提示 (What is the capital of the US?) 并依此生成首个词元 (Washington)。在 **解码阶段** (用蓝色表示),先前生成的词元被添加进输入 (What is the capital of the US? Washington),并馈送给模型以进行新一轮前向传播。如此往复: 向模型馈送输入 -> 生成词元 -> 将词元添加进输入,直至生成序列结束词元 (<EOS>)。
<br>
<div style="background-color: #e6f9e6; padding: 16px 32px; outline: 2px solid; border-radius: 10px;">
思考题: 为何预填充阶段我们馈送了很多词元作为输入,却仅需做一轮前向?
<details>
<summary> 点击揭晓答案 </summary>
因为我们无需生成 “What is the” 的下一个词元,我们已经知道它是 “capital” 了。
</details>
</div>
为了易于说明,上图仅选择了一个短文本生成示例,但注意,预填充仅需要模型进行一次前向传播,但解码可能需要数百次或更多的前向传播,即使在上述短文本示例中,我们也可以蓝色箭头多于橙色箭头。我们现在可以明白为什么要花这么多时间才能等到 LLM 的输出了!由于前向次数较多,解码阶段通常是我们花心思更多的地方。
## 基准测试工具
### 动机
在对工具、新算法或模型进行比较时,吞吐量是大家常用的指标。虽然这是 LLM 推理故事的重要组成部分,但单靠吞吐量还是缺少一些关键信息。一般来讲,我们至少需要知道吞吐量和延迟两个指标才能作出正确的决策 (当然你增加更多指标,以进行更深入的研究)。TGI 基准测试工具就支持你同时得到延迟和吞吐量两个指标。
另一个重要的考量是你希望用户拥有什么体验。你更关心为许多用户提供服务,还是希望每个用户在使用你的系统后都能得到快速响应?你想要更快的首词元延迟 (TTFT,Time To First Token),还是你能接受首词元延迟,但希望后续词元的速度要快?
下表列出了对应于不同目标的不同关注点。请记住,天下没有免费的午餐。但只要有足够的 GPU 和适当的配置,“居天下有甚难”?
<table>
<tr>
<td><strong>我关心 ......</strong>
</td>
<td><strong>我应专注于 ......</strong>
</td>
</tr>
<tr>
<td>处理更多的用户
</td>
<td>最大化吞吐量
</td>
</tr>
<tr>
<td>我的网页/应用正在流失用户
</td>
<td>最小化 TTFT
</td>
</tr>
<tr>
<td>中等体量用户的用户体验
</td>
<td>最小化延迟
</td>
</tr>
<tr>
<td>全面的用户体验
</td>
<td>在给定延迟内最大化吞吐量
</td>
</tr>
</table>
### 环境搭建
基准测试工具是随着 TGI 一起安装的,但你需要先启动服务才能运行它。为了简单起见,我设计了一个空间 - [derek-thomas/tgi-benchmark-space](https://huggingface.co/spaces/derek-thomas/tgi-benchmark-space),其把 TGI docker 镜像 (固定使用最新版) 和一个 jupyter lab 工作空间组合起来,从而允许我们部署选定的模型,并通过命令行轻松运行基准测试工具。这个空间是可复制的,所以如果它休眠了,请不要惊慌,复制一个到你的名下就可以了。我还在空间里添加了一些 notebook,你可以参照它们轻松操作。如果你想对 [Dockerfile](https://huggingface.co/spaces/derek-thomas/tgi-benchmark-space/blob/main/Dockerfile) 进行调整,请随意研究,以了解其构建方式。
### 起步
请注意,由于其交互性,在 jupyter lab 终端中运行基准测试工具比在 notebook 中运行要好得多,但我还是把命令放在 notebook 中,这样易于注释,并且很容易照着做。
1. 点击 <a class="duplicate-button" style="display:inline-block" target="_blank" href="https://huggingface.co/spaces/derek-thomas/tgi-benchmark-space?duplicate=true"><img style="margin-top:0;margin-bottom:0" src="https://huggingface.co/datasets/huggingface/badges/raw/main/duplicate-this-space-sm.svg" alt=" 复制 space"></a>
- 在 [空间密令](https://huggingface.co/docs/hub/spaces-sdks-docker#secrets) 中设置你自己的 `JUPYTER_TOKEN` 默认密码 (系统应该会在你复制空间时提示你)
- 选择硬件,注意它应与你的最终部署硬件相同或相似
2. 进入你的空间并使用密码登录
3. 启动 `01_1_TGI-launcher.ipynb`
- 其会用 jupyter notebook 以默认设置启动 TGI
4. 启动 `01_2_TGI-benchmark.ipynb`
- 其会按照指定设置启动 TGI 基准测试工具
### 主要区块

|:--:|
|*图 3:基准测试报告区块*|
- **区块 1**: batch size 选项卡及其他信息。
- 使用箭头选择不同的 batch size
- **区块 2** 及 **区块 4**: 预填充/解码阶段的统计信息及直方图
- 基于 `--runs` 的数量计算的统计数据/直方图
- **区块 3** 及 **区块 5**: 预填充/解码阶段的 `延迟 - 吞吐量` 散点图
- X 轴是延迟 (越小越好)
- Y 轴是吞吐量 (越大越好)
- 图例是 batch size
- “ _理想_ ”点位于左上角 (低延迟、高吞吐)
### 理解基准测试工具

|:--:|
|*图 4:基准测试工具散点图*|
如果你的硬件和设置与我相同,应该会得到与图 4 类似的图。基准测试工具向我们展示了: 在当前设置和硬件下,不同 batch size (代表用户请求数,与我们启动 TGI 时使用的术语略有不同) 下的吞吐量和延迟。理解这一点很重要,因为我们应该根据基准测试工具的结果来调整 TGI 的启动设置。
如果我们的应用像 RAG 那样预填充较长的话, **区块 3** 的图往往会更有用。因为,上下文长度的确会影响 TTFT (即 X 轴),而 TTFT 是用户体验的重要组成部分。请记住,虽然在预填充阶段我们必须从头开始构建 KV 缓存,但好处是所有输入词元的处理可以在一次前向传播中完成。因此,在许多情况下,就每词元延迟而言,预填充确实比解码更快。
**区块 5** 中的图对应于解码阶段。我们看一下数据点的形状,可以看到,当 batch size 处于 1~32 的范围时,形状基本是垂直的,大约为 5.3 秒。这种状态就相当不错,因为这意味着在不降低延迟的情况下,我们可以显著提高吞吐量!64 和 128 会怎么样呢?我们可以看到,虽然吞吐量在增加,但延迟也开始增加了,也就是说出现了折衷。
对于同样的 batch size,我们再看看 **区块 3** 图的表现。对 batch size 32,我们可以看到 TTFT 的时间仍然约为 1 秒。但我们也看到从 32 -> 64 -> 128 延迟出现了线性增长,2 倍的 batch size 的延迟也是 2 倍。此外,没有吞吐量增益!这意味着我们并没有真正从这种折衷中获得太多好处。
<br>
<div style="background-color: #e6f9e6; padding: 16px 32px; outline: 2px solid; border-radius: 10px;">
思考题:
<ul>
<li>如果添加更多的数据点,你觉得其形状会如何呢?</li>
<li>如果词元数增加,你举得这些散点 (预填充抑或解码) 的形状会如何变化呢?</li>
</ul>
</div>
如果你的 batch size 落在垂直区,很好,你可以获得更多的吞吐量并免费处理更多的用户。如果你的 batch size 处于水平区,这意味着你受到算力的限制,每增加一个用户都会损害每个人的延迟,且不会带来任何吞吐量的好处。你应该优化你的 TGI 配置或扩展你的硬件。
现在我们已经了解了 TGI 在各种场景中的行为,我们可以多尝试几个不同的 TGI 设置并对其进行基准测试。在选定一个好的配置之前,最好先多试几次。如果大家有兴趣的话,或许我们可以写个续篇,深入探讨针对聊天或 RAG 等不同用例的优化。
### 尾声
追踪实际用户的行为非常重要。当我们估计用户行为时,我们必须从某个地方开始并作出有根据的猜测。这些数字的选择将对我们的剖析质量有重大影响。幸运的是,TGI 会在日志中告诉我们这些信息,所以请务必检查日志。
一旦探索结束,请务必停止运行所有程序,以免产生进一步的费用。
- 终止 `TGI-launcher.ipynb` jupyter notebook 中正在运行的单元
- 在终端中点击 `q` 以终止运行分析工具
- 在空间设置中点击暂停
## 总结
LLM 规模庞大且昂贵,但有多种方法可以降低成本。像 TGI 这样的 LLM 推理服务已经为我们完成了大部分工作,我们只需善加利用其功能即可。首要工作是了解现状以及你可以做出哪些折衷。通过本文,我们已经了解如何使用 TGI 基准测试工具来做到这一点。我们可以获取这些结果并将其用于 AWS、GCP 或推理终端中的任何同等硬件。
感谢 Nicolas Patry 和 Olivier Dehaene 创建了 [TGI](https://github.com/huggingface/text-generation-inference) 及其 [基准测试工具](https://github.com/huggingface/text-generation-inference/blob/main/benchmark/README.md)。还要特别感谢 Nicholas Patry、Moritz Laurer、Nicholas Broad、Diego Maniloff 以及 Erik Rignér 帮忙校对本文。
## 参考文献
<a id="1">[1]</a> : Sara Hooker, [The Hardware Lottery](https://arxiv.org/abs/1911.05248), 2020<a id="2">[2]</a> : Pierre Lienhart, [LLM Inference Series: 2. The two-phase process behind LLMs’ responses](https://medium.com/@plienhar/llm-inference-series-2-the-two-phase-process-behind-llms-responses-1ff1ff021cd5), 2023 | 5 |
0 | hf_public_repos/blog | hf_public_repos/blog/zh/intel-protein-language-model-protst.md | ---
title: "在英特尔 Gaudi 2 上加速蛋白质语言模型 ProtST"
thumbnail: /blog/assets/intel-protein-language-model-protst/01.jpeg
authors:
- user: juliensimon
- user: Jiqing
guest: true
org: Intel
- user: Santiago Miret
guest: true
- user: katarinayuan
guest: true
- user: sywangyi
guest: true
org: Intel
- user: MatrixYao
guest: true
org: Intel
- user: ChrisAllenMing
guest: true
- user: kding1
guest: true
org: Intel
translators:
- user: MatrixYao
- user: zhongdongy
proofreader: false
---
# 在英特尔 Gaudi 2 上加速蛋白质语言模型 ProtST
<p align="center">
<img src="https://huggingface.co/blog/assets/intel-protein-language-model-protst/01.jpeg" alt="A teenage scientist creating molecules with computers and artificial intelligence" width="512"><br>
</p>
## 引言
蛋白质语言模型 (Protein Language Models, PLM) 已成为蛋白质结构与功能预测及设计的有力工具。在 2023 年国际机器学习会议 (ICML) 上,MILA 和英特尔实验室联合发布了 [ProtST](https://proceedings.mlr.press/v202/xu23t.html) 模型,该模型是个可基于文本提示设计蛋白质的多模态模型。此后,ProtST 在研究界广受好评,不到一年的时间就积累了 40 多次引用,彰显了该工作的影响力。
PLM 最常见的任务之一是预测氨基酸序列的亚细胞位置。此时,用户输入一个氨基酸序列给模型,模型会输出一个标签,以指示该序列所处的亚细胞位置。论文表明,ProtST-ESM-1b 的零样本亚细胞定位性能优于最先进的少样本分类器 (如下图)。
<kbd>
<img src="https://huggingface.co/blog/assets/intel-protein-language-model-protst/02.png">
</kbd>
为了使 ProtST 更民主化,英特尔和 MILA 对模型进行了重写,以使大家可以通过 Hugging Face Hub 来使用模型。大家可于 [此处](https://huggingface.co/mila-intel) 下载模型及数据集。
本文将展示如何使用英特尔 Gaudi 2 加速卡及 `optimum-habana` 开源库高效运行 ProtST 推理和微调。[英特尔 Gaudi 2](https://habana.ai/products/gaudi2/) 是英特尔设计的第二代 AI 加速卡。感兴趣的读者可参阅我们 [之前的博文](https://huggingface.co/blog/zh/habana-gaudi-2-bloom#habana-gaudi2),以深入了解该加速卡以及如何通过 [英特尔开发者云](https://cloud.intel.com) 使用它。得益于 [`optimum-habana`](https://github.com/huggingface/optimum-habana),仅需少量的代码更改,用户即可将基于 transformers 的代码移植至 Gaudi 2。
## 对 ProtST 进行推理
常见的亚细胞位置包括细胞核、细胞膜、细胞质、线粒体等,你可从 [此数据集](https://huggingface.co/datasets/mila-intel/subloc_template) 中获取全面详细的位置介绍。
我们使用 `ProtST-SubcellularLocalization` 数据集的测试子集来比较 ProtST 在英伟达 `A100 80GB PCIe` 和 `Gaudi 2` 两种加速卡上的推理性能。该测试集包含 2772 个氨基酸序列,序列长度范围为 79 至 1999。
你可以使用 [此脚本](https://github.com/huggingface/optimum-habana/tree/main/examples/protein-folding#single-hpu-inference-for-zero-shot-evaluation) 重现我们的实验,我们以 `bfloat16` 精度和 batch size 1 运行模型。在英伟达 A100 和英特尔 Gaudi 2 上,我们获得了相同的准确率 (0.44),但 Gaudi 2 的推理速度比 A100 快 1.76 倍。单张 A100 和单张 Gaudi 2 的运行时间如下图所示。
<kbd>
<img src="https://huggingface.co/blog/assets/intel-protein-language-model-protst/03.png">
</kbd>
## 微调 ProtST
针对下游任务对 ProtST 模型进行微调是提高模型准确性的简单且公认的方法。在本实验中,我们专门研究了针对二元定位任务的微调,其是亚细胞定位的简单版,任务用二元标签指示蛋白质是膜结合的还是可溶的。
你可使用 [此脚本](https://github.com/huggingface/optimum-habana/tree/main/examples/protein-folding#multi-hpu-finetune-for-sequence-classification-task) 重现我们的实验。其中,我们在 [ProtST-BinaryLocalization](https://huggingface.co/datasets/mila-intel/ProtST-BinaryLocalization) 数据集上以 `bfloat16` 精度微调 [ProtST-ESM1b-for-sequential-classification](https://huggingface.co/mila-intel/protst-esm1b-for-sequential-classification)。下表展示了不同硬件配置下测试子集的模型准确率,可以发现它们均与论文中发布的准确率 (~92.5%) 相当。
<kbd>
<img src="https://huggingface.co/blog/assets/intel-protein-language-model-protst/04.png">
</kbd>
下图显示了微调所用的时间。可以看到,单张 Gaudi 2 比单张 A100 快 2.92 倍。该图还表明,在 4 张或 8 张 Gaudi 2 加速卡上使用分布式训练可以实现近线性扩展。
<kbd>
<img src="https://huggingface.co/blog/assets/intel-protein-language-model-protst/05.png">
</kbd>
## 总结
本文,我们展示了如何基于 `optimum-habana` 轻松在 Gaudi 2 上部署 ProtST 推理和微调。此外,我们的结果还表明,与 A100 相比,Gaudi 2 在这些任务上的性能颇具竞争力: 推理速度提高了 1.76 倍,微调速度提高了 2.92 倍。
如你你想在英特尔 Gaudi 2 加速卡上开始一段模型之旅,以下资源可助你一臂之力:
- optimum-habana [代码库](https://github.com/huggingface/optimum-habana)
- 英特尔 Gaudi [文档](https://docs.habana.ai/en/latest/index.html)
感谢垂阅!我们期待看到英特尔 Gaudi 2 加速的 ProtST 能助你创新。 | 6 |
0 | hf_public_repos/blog | hf_public_repos/blog/zh/ryght-case-study.md | ---
title: "Ryght 在 Hugging Face 专家助力下赋能医疗保健和生命科学之旅"
thumbnail: /blog/assets/ryght-case-study/thumbnail.png
authors:
- user: andrewrreed
- user: johnnybio
guest: true
org: RyghtAI
translators:
- user: MatrixYao
- user: zhongdongy
proofreader: true
---
# Ryght 在 Hugging Face 专家助力下赋能医疗保健和生命科学之旅
> [!NOTE] 本文是 Ryght 团队的客座博文。
## Ryght 是何方神圣?
Ryght 的使命是构建一个专为医疗保健和生命科学领域量身定制的企业级生成式人工智能平台。最近,公司正式公开了 [Ryght 预览版](https://www.ryght.ai/signup?utm_campaign=Preview%20Launch%20April%2016%2C%2024&utm_source=Huggging%20Face%20Blog%20-%20Preview%20Launch%20Sign%20Up) 平台。
当前,生命科学公司不断地从各种不同来源 (实验室数据、电子病历、基因组学、保险索赔、药学、临床等) 收集大量数据,并期望从中获取洞见。但他们分析这些数据的方法已经跟不上数据本身,目前典型的工作模式往往需要一个大型团队来完成从简单查询到开发有用的机器学习模型的所有工作。这一模式已无法满足药物开发、临床试验以及商业活动对可操作知识的巨大需求,更别谈精准医学的兴起所带来的更大的需求了。
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/ryght-case-study/click-through.gif" alt="Ryght Laptop" style="width: 90%; height: auto;"><br>
</p>
[Ryght](https://hubs.li/Q02sLGKL0) 的目标是让生命科学专业人士能够快速、安全地从数据中挖掘出他们所需的洞见。为此,其正在构建一个 SaaS 平台,为本专业的人员和组织提供定制的 AI copilot 解决方案,以助力他们对各种复杂数据源进行记录、分析及研究。
Ryght 认识到 AI 领域节奏快速且多变的特点,因此一开始就加入 [Hugging Face 专家支持计划](https://huggingface.co/support),将 Hugging Face 作为技术咨询合作伙伴。
## 共同克服挑战
> ##### _我们与 Hugging Face 专家支持计划的合作对加快我们生成式人工智能平台的开发起到了至关重要的作用。快速发展的人工智能领域有可能彻底改变我们的行业,而 Hugging Face 的高性能、企业级的文本生成推理 (TGI) 和文本嵌入推理 (TEI) 服务本身就是游戏规则的改写者。 - [Johnny Crupi](https://www.linkedin.com/in/johncrupi/),[Ryght 首席技术官](http://www.ryght.ai/?utm_campaign=hf&utm_source=hf_blog)_
在着手构建生成式人工智能平台的过程中,Ryght 面临着多重挑战。
### 1. 快速提升团队技能并在多变的环境中随时了解最新情况
随着人工智能和机器学习技术的快速发展,确保团队及时了解最新的技术、工具以及最佳实践至关重要。这一领域的学习曲线呈现出持续陡峭的特点,因此需要齐心协力才能及时跟上。
与 Hugging Face 的人工智能生态系统核心专家团队的合作,有助于 Ryght 跟上本垂直领域的最新发展以及最新模型。通过开放异步的沟通渠道、定期的咨询会以及专题技术研讨会等多种形式,充分地保证了目的的实现。
### 2. 在众多方案中找到最 [经济] 的机器学习方案
人工智能领域充满了创新,催生了大量的工具、库、模型及方法。对于像 Ryght 这样的初创公司来说,必须消除这种噪声并确定哪些机器学习策略最适合生命科学这一独特场景。这不仅需要了解当前的技术水平,还需要对技术在未来的相关性和可扩展性有深刻的洞见。
Hugging Face 作为 Ryght 技术团队的合作伙伴,在解决方案设计、概念验证开发和生产工作负载优化全过程中提供了有力的协助,包括: 针对应用场景推荐最适合 Ryght 需求的库、框架和模型,并提供了如何使用这些软件和模型的示例。这些指导最终简化了决策过程并缩短了开发时间。
### 3. 开发专注于安全性、隐私性及灵活性的高性能解决方案
鉴于其目标是企业级的解决方案,因此 Ryght 把安全、隐私和可治理性放在最重要的位置。因此在设计方案架构时,需要提供支持各种大语言模型 (LLM) 的灵活性,这是生命科学领域内容生成和查询处理系统的关键诉求。
基于对开源社区的快速创新,特别是医学 LLM 创新的理解,其最终采用了“即插即用”的 LLM 架构。这种设计使其能够在新 LLM 出现时能无缝地评估并集成它们。
在 Ryght 的平台中,每个 LLM 均可注册并链接至一个或多个特定于客户的推理端点。这种设计不仅可以保护各客户的连接,还提供了在不同 LLM 之间切换的能力,提供了很好的灵活性。Ryght 通过采用 Hugging Face 的 [文本生成推理 (TGI)](https://huggingface.co/docs/text-generation-inference/index) 和 [推理端点](https://huggingface.co/inference-endpoints/dedicate) 实现了该设计。
除了 TGI 之外,Ryght 还将 [文本嵌入推理 (TEI)](https://huggingface.co/docs/text-embeddings-inference/en/index) 集成到其 ML 平台中。使用 TEI 和开源嵌入模型提供服务,与仅依赖私有嵌入服务相比,可以使 Ryght 能够享受更快的推理速度、免去对速率限制的担忧,并得到可以为自己的微调模型提供服务的灵活性,而微调模型可以更好地满足生命科学领域的独特要求。
为了同时满足多个客户的需求,系统需要能处理大量并发请求,同时保持低延迟。因此,Ryght 的嵌入和推理服务不仅仅是简单的模型调用,还需要支持包括组批、排队和跨 GPU 分布式模型处理等高级特性。这些特性对于避免性能瓶颈并确保用户不会遇到延迟,从而保持最佳的系统响应时间至关重要。
## 总结
Ryght 与 Hugging Face 在 ML 服务上的战略合作伙伴关系以及深度集成凸显了其致力于在医疗保健和生命科学领域提供尖端解决方案的承诺。通过采用灵活、安全和可扩展的架构,其确保自己的平台始终处于创新前沿,为客户提供无与伦比的服务和专业知识,以应对现代医疗领域的复杂性。
[Ryght 预览版](https://hubs.li/Q02sLFl_0) 现已作为一个可轻松上手的、免费、安全的平台向生命科学知识工作者公开,欢迎大家使用。Ryght 的 copilot 库包含各种工具,可加速信息检索、复杂非结构化数据的综合及结构化,以及文档构建等任务,把之前需要数周才能完成的工作缩短至数天或数小时。如你对定制方案及合作方案有兴趣,请联系其 [AI 专家团队](https://hubs.li/Q02sLG9V0),以讨论企业级 Ryght 服务。
如果你有兴趣了解有关 Hugging Face 专家支持计划的更多信息,请 [通过此处](https://huggingface.co/contact/sales?from=support) 联系我们,我们将联系你讨论你的需求! | 7 |
0 | hf_public_repos/blog | hf_public_repos/blog/zh/Llama2-for-non-engineers.md | ---
title: "非工程师指南:训练 LLaMA 2 聊天机器人"
thumbnail: /blog/assets/78_ml_director_insights/tuto.png
authors:
- user: 2legit2overfit
- user: abhishek
translators:
- user: MatrixYao
- user: zhongdongy
proofreader: true
---
# 非工程师指南: 训练 LLaMA 2 聊天机器人
## 引言
本教程将向你展示在不编写一行代码的情况下,如何构建自己的开源 ChatGPT,这样人人都能构建自己的聊天模型。我们将以 LLaMA 2 基础模型为例,在开源指令数据集上针对聊天场景对其进行微调,并将微调后的模型部署到一个可分享的聊天应用中。全程只需点击鼠标,即可轻松通往荣耀之路!😀
为什么这很重要?是这样的,机器学习,尤其是 LLM (Large Language Models,大语言模型),已前所未有地普及开来,渐渐成为我们生产生活中的重要工具。然而,对非机器学习工程专业的大多数人来说,训练和部署这些模型的复杂性似乎仍然遥不可及。如果我们理想中的机器学习世界是充满着无处不在的个性化模型的,那么我们面临着一个迫在眉睫的挑战,即如何让那些没有技术背景的人独立用上这项技术?
在 Hugging Face,我们一直在默默努力为这个包容性的未来铺平道路。我们的工具套件,包括 Spaces、AutoTrain 和 Inference Endpoints 等服务,就是为了让任何人都能进入机器学习的世界。
为了展示这个民主化的未来是何其轻松,本教程将向你展示如何使用 [Spaces](https://huggingface.co/Spaces)、[AutoTrain](https://huggingface.co/autotrain) 和 [ChatUI](https://huggingface.co/inference-endpoints) 构建聊天应用。只需简单三步,代码含量为零。声明一下,我们也不是机器学习工程师,而只是 Hugging Face 营销策略团队的一员。如果我们能做到这一点,那么你也可以!话不多说,我们开始吧!
## Spaces 简介
Hugging Face 的 Spaces 服务提供了易于使用的 GUI,可用于构建和部署 Web 托管的 ML 演示及应用。该服务允许你使用 Gradio 或 Streamlit 前端快速构建 ML 演示,将你自己的应用以 docker 容器的形式上传,甚至你还可以直接选择一些已预先配置好的 ML 应用以实现快速部署。
后面,我们将部署两个来自 Spaces、AutoTrain 和 ChatUI 的预配置 docker 应用模板。
你可参阅 [此处](https://huggingface.co/docs/hub/spaces),以获取有关 Spaces 的更多信息。
## AutoTrain 简介
AutoTrain 是一款无代码工具,可让非 ML 工程师 (甚至非开发人员😮) 无需编写任何代码即可训练最先进的 ML 模型。它可用于 NLP、计算机视觉、语音、表格数据,现在甚至可用于微调 LLM,我们这次主要用的就是 LLM 微调功能。
你可参阅 [此处](https://huggingface.co/docs/autotrain/index),以获取有关 AutoTrain 的更多信息。
## ChatUI 简介
ChatUI 顾名思义,是 Hugging Face 构建的开源 UI,其提供了与开源 LLM 交互的界面。值得注意的是,它与 HuggingChat 背后的 UI 相同,HuggingChat 是 ChatGPT 的 100% 开源替代品。
你可参阅 [此处](https://github.com/huggingface/chat-ui),以获取有关 ChatUI 的更多信息。
### 第 1 步: 创建一个新的 AutoTrain Space
1.1 在 [huggingface.co/spaces](https://huggingface.co/spaces) 页面点击 “Create new Space” 按钮。
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/llama2-non-engineers/tuto1.png"><br>
</p>
1.2 如果你计划公开这个模型或 Space,请为你的 Space 命名并选择合适的许可证。
1.3 请选择 Docker > AutoTrain,以直接用 AutoTrain 的 docker 模板来部署。
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/llama2-non-engineers/tuto2.png"><br>
</p>
1.4 选择合适的 “Space hardware” 以运行应用。(注意: 对于 AutoTrain 应用,免费的 CPU 基本款就足够了,模型训练会使用单独的计算来完成,我们稍后会进行选择)。
1.5 在 “Space secrets” 下添加你自己的 “HF_TOKEN”,以便让该 Space 可以访问你的 Hub 帐户。如果没有这个,Space 将无法训练或将新模型保存到你的帐户上。(注意: 你可以在 “Settings > Access Tokens” 下的 “Hugging Face Profile” 中找到你的 HF_TOKEN ,请确保其属性为 “Write”)。
1.6 选择将 Space 设为“私有”还是“公开”,对于 AutoTrain Space 而言,建议设为私有,不影响你后面公开分享你的模型或聊天应用。
1.7 点击 “Create Space” 并稍事等待!新 Space 的构建需要几分钟时间,之后你就可以打开 Space 并开始使用 AutoTrain。
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/llama2-non-engineers/tuto3.png"><br>
</p>
### 第 2 步: 在 AutoTrain 中启动模型训练
2.1 AutoTrain Space 启动后,你会看到下面的 GUI。AutoTrain 可用于多种不同类型的训练,包括 LLM 微调、文本分类、表格数据以及扩散模型。我们今天主要专注 LLM 训练,因此选择 “LLM” 选项卡。
2.2 从 “Model Choice” 字段中选择你想要训练的 LLM,你可以从列表中选择模型或直接输入 Hugging Face 模型卡的模型名称,在本例中我们使用 Meta 的 Llama 2 7B 基础模型,你可从其 [模型卡](https://huggingface.co/meta-llama/Llama-2-7b-hf) 处了解更多信息。(注意: LLama 2 是受控模型,需要你在使用前向 Meta 申请访问权限,你也可以选择其他非受控模型,如 Falcon)。
2.3 在 “Backend” 中选择你要用于训练的 CPU 或 GPU。对于 7B 模型,“A10G Large” 就足够了。如果想要训练更大的模型,你需要确保该模型可以放进所选 GPU 的内存。(注意: 如果你想训练更大的模型并需要访问 A100 GPU,请发送电子邮件至 [email protected])。
2.4 当然,要微调模型,你需要上传 “Training Data”。执行此操作时,请确保数据集格式正确且文件格式为 CSV。你可在 [此处](https://huggingface.co/docs/autotrain/main/en/llm_finetuning) 找到符合要求的格式的例子。如果你的数据有多列,请务必选择正确的 “Text Column” 以确保 AutoTrain 抽取正确的列作为训练数据。本教程将使用 Alpaca 指令微调数据集,你可在 [此处](https://huggingface.co/datasets/tatsu-lab/alpaca) 获取该数据集的更多信息。你还可以从 [此处](https://huggingface.co/datasets/tofighi/LLM/resolve/main/alpaca.csv) 直接下载 CSV 格式的文件。
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/llama2-non-engineers/tuto4.png"><br>
</p>
2.5 【可选】 你还可以上传 “Validation Data” 以用于测试训出的模型,但这不是必须的。
2.6 AutoTrain 中有许多高级设置可用于减少模型的内存占用,你可以更改精度 (“FP16”) 、启用量化 (“Int4/8”) 或者决定是否启用 PEFT (参数高效微调)。如果对此不是很精通,建议使用默认设置,因为默认设置可以减少训练模型的时间和成本,且对模型精度的影响很小。
2.7 同样地,你可在 “Parameter Choice” 中配置训练超参,但本教程使用的是默认设置。
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/llama2-non-engineers/tuto5.png"><br>
</p>
2.8 至此,一切都已设置完毕,点击 “Add Job” 将模型添加到训练队列中,然后点击 “Start Training”(注意: 如果你想用多组不同超参训练多个版本的模型,你可以添加多个作业同时运行)。
2.9 训练开始后,你会看到你的 Hub 帐户里新创建了一个 Space。该 Space 正在运行模型训练,完成后新模型也将显示在你 Hub 帐户的 “Models” 下。(注: 如欲查看训练进度,你可在 Space 中查看实时日志)。
2.10 去喝杯咖啡。训练可能需要几个小时甚至几天的时间,这取决于模型及训练数据的大小。训练完成后,新模型将出现在你的 Hugging Face Hub 帐户的 “Models” 下。
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/llama2-non-engineers/tuto6.png"><br>
</p>
### 第 3 步: 使用自己的模型创建一个新的 ChatUI Space
3.1 按照与步骤 1.1 > 1.3 相同的流程设置新 Space,但选择 ChatUI docker 模板而不是 AutoTrain。
3.2 选择合适的 “Space Hardware”,对我们用的 7B 模型而言 A10G Small 足够了。注意硬件的选择需要根据模型的大小而有所不同。
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/llama2-non-engineers/tuto7.png"><br>
</p>
3.3 如果你有自己的 Mongo DB,你可以填入相应信息,以便将聊天日志存储在 “MONGODB_URL” 下。否则,将该字段留空即可,此时会自动创建一个本地数据库。
3.4 为了能将训后的模型用于聊天应用,你需要在 “Space variables” 下提供 “MODEL_NAME”。你可以通过查看你的 Hugging Face 个人资料的 “Models” 部分找到模型的名称,它和你在 AutoTrain 中设置的 “Project name” 相同。本例中模型的名称为 “2legit2overfit/wrdt-pco6-31a7-0”。
3.5 在 “Space variables” 下,你还可以更改模型的推理参数,包括温度、top-p、生成的最大词元数等文本生成属性。这里,我们还是直接使用默认设置。
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/llama2-non-engineers/tuto8.png"><br>
</p>
3.6 现在,你可以点击 “Create” 并启动你自己的开源 ChatGPT,其 GUI 如下。恭喜通关!
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/llama2-non-engineers/tuto9.png"><br>
</p>
_如果你看了本文很想尝试一下,但仍需要技术支持才能开始使用,请随时通过 [此处](https://huggingface.co/support#form) 联系我们并申请支持。 Hugging Face 提供付费专家建议服务,应该能帮到你。_
| 8 |
0 | hf_public_repos/blog | hf_public_repos/blog/zh/unity-api.md | ---
title: "如何安装和使用 Hugging Face Unity API"
thumbnail: /blog/assets/124_ml-for-games/unity-api-thumbnail.png
authors:
- user: dylanebert
translators:
- user: SuSung-boy
- user: zhongdongy
proofreader: true
---
# 如何安装和使用 Hugging Face Unity API
[Hugging Face Unity API](https://github.com/huggingface/unity-api) 提供了一个简单易用的接口,允许开发者在自己的 Unity 项目中方便地访问和使用 Hugging Face AI 模型,已集成到 [Hugging Face Inference API](https://huggingface.co/inference-api) 中。本文将详细介绍 API 的安装步骤和使用方法。
## 安装步骤
1. 打开您的 Unity 项目
2. 导航至菜单栏的 `Window` -> `Package Manager`
3. 在弹出窗口中,点击 `+`,选择 `Add Package from git URL`
4. 输入 `https://github.com/huggingface/unity-api.git`
5. 安装完成后,将会弹出 Unity API 向导。如未弹出,可以手动导航至 `Window` -> `Hugging Face API Wizard`
<figure class="image text-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/124_ml-for-games/packagemanager.gif">
</figure>
1. 在向导窗口输入您的 API 密钥。密钥可以在您的 [Hugging Face 帐户设置](https://huggingface.co/settings/tokens) 中找到或创建
2. 输入完成后可以点击 `Test API key` 测试 API 密钥是否正常
3. 如需替换使用模型,可以通过更改模型端点实现。您可以访问 Hugging Face 网站,找到支持 Inference API 的任意模型端点,在对应页面点击 `Deploy` -> `Inference API`,复制 `API_URL` 字段的 url 地址
4. 如需配置高级设置,可以访问 unity 项目仓库页面 `https://github.com/huggingface/unity-api` 查看最新信息
5. 如需查看 API 使用示例,可以点击 `Install Examples`。现在,您可以关闭 API 向导了。
<figure class="image text-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/124_ml-for-games/apiwizard.png">
</figure>
API 设置完成后,您就可以从脚本中调用 API 了。让我们来尝试一个计算文本句子相似度的例子,脚本代码如下所示:
```
using HuggingFace.API;
/* other code */
// Make a call to the API
void Query() {
string inputText = "I'm on my way to the forest.";
string[] candidates = {
"The player is going to the city",
"The player is going to the wilderness",
"The player is wandering aimlessly"
};
HuggingFaceAPI.SentenceSimilarity(inputText, OnSuccess, OnError, candidates);
}
// If successful, handle the result
void OnSuccess(float[] result) {
foreach(float value in result) {
Debug.Log(value);
}
}
// Otherwise, handle the error
void OnError(string error) {
Debug.LogError(error);
}
/* other code */
```
## 支持的任务类型和自定义模型
Hugging Face Unity API 目前同样支持以下任务类型:
- [对话 (Conversation)](https://huggingface.co/tasks/conversational)
- [文本生成 (Text Generation)](https://huggingface.co/tasks/text-generation)
- [文生图 (Text to Image)](https://huggingface.co/tasks/text-to-image)
- [文本分类 (Text Classification)](https://huggingface.co/tasks/text-classification)
- [问答 (Question Answering)](https://huggingface.co/tasks/question-answering)
- [翻译 (Translation)](https://huggingface.co/tasks/translation)
- [总结 (Summarization)](https://huggingface.co/tasks/summarization)
- [语音识别 (Speech Recognition)](https://huggingface.co/tasks/automatic-speech-recognition)
您可以使用 `HuggingFaceAPI` 类提供的相应方法来完成这些任务。
如需使用您自己托管在 Hugging Face 上的自定义模型,可以在 API 向导中更改模型端点。
## 使用技巧
1. 请牢记,API 通过异步方式调用,并通过回调来返回响应或错误信息。
2. 如想加快 API 响应速度或提升推理性能,可以通过更改模型端点为资源需求较少的模型。
## 结语
Hugging Face Unity API 提供了一种简单的方式,可以将 AI 模型集成到 Unity 项目中。我们希望本教程对您有所帮助。如果您有任何疑问,或想更多地参与 Hugging Face for Games 系列,可以加入 [Hugging Face Discord](https://hf.co/join/discord) 频道! | 9 |
0 | hf_public_repos | hf_public_repos/blog/jat.md | ---
title: 'Jack of All Trades, Master of Some, a Multi-Purpose Transformer Agent'
thumbnail: /blog/assets/jat/thumbnail.png
authors:
- user: qgallouedec
- user: edbeeching
- user: ClementRomac
- user: thomwolf
---
# Jack of All Trades, Master of Some, a Multi-Purpose Transformer Agent
## Introduction
We're excited to share Jack of All Trades (JAT), a project that aims to move in the direction of a generalist agent. The project started as an open reproduction of the [Gato](https://huggingface.co/papers/2205.06175) (Reed et al., 2022) work, which proposed to train a Transformer able to perform both vision-and-language and decision-making tasks. We thus started by building an open version of Gato’s dataset. We then trained multi-modal Transformer models on it, introducing several improvements over Gato for handling sequential data and continuous values.
Overall, the project has resulted in:
- The release of a large number of **expert RL agents** on a wide variety of tasks.
- The release of the **JAT dataset**, the first dataset for generalist agent training. It contains hundreds of thousands of expert trajectories collected with the expert agents
- The release of the **JAT model**, a transformer-based agent capable of playing video games, controlling a robot to perform a wide variety of tasks, understanding and executing commands in a simple navigation environment and much more!
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/jat/global_schema.gif" alt="Global schema"/>
## Datasets & expert policies
### The expert policies
RL traditionally involves training policies on single environments. Leveraging these expert policies is a genuine way to build a versatile agent. We selected a wide range of environments, of varying nature and difficulty, including Atari, BabyAI, Meta-World, and MuJoCo. For each of these environments, we train an agent until it reached state-of-the-art performance. (For BabyAI, we use the [BabyAI bot](https://github.com/mila-iqia/babyai) instead). The resulting agents are called expert agents, and have been released on the 🤗 Hub. You'll find a list of all agents in the [JAT dataset card](https://huggingface.co/datasets/jat-project/jat-dataset).
### The JAT dataset
We release the [JAT dataset](https://huggingface.co/datasets/jat-project/jat-dataset), the first dataset for generalist agent training. The JAT dataset contains hundreds of thousands of expert trajectories collected with the above-mentioned expert agents. To use this dataset, simply load it like any other dataset from the 🤗 Hub:
```python
>>> from datasets import load_dataset
>>> dataset = load_dataset("jat-project/jat-dataset", "metaworld-assembly")
>>> first_episode = dataset["train"][0]
>>> first_episode.keys()
dict_keys(['continuous_observations', 'continuous_actions', 'rewards'])
>>> len(first_episode["rewards"])
500
>>> first_episode["continuous_actions"][0]
[6.459120273590088, 2.2422609329223633, -5.914587020874023, -19.799840927124023]
```
In addition to RL data, we include textual datasets to enable a unique interface for the user. That's why you'll also find subsets for [Wikipedia](https://huggingface.co/datasets/wikipedia), [Oscar](https://huggingface.co/datasets/oscar), [OK-VQA](https://okvqa.allenai.org) and [Conceptual-Captions](https://huggingface.co/datasets/conceptual_captions).
## JAT agent architecture
JAT's architecture is based on a Transformer, using [EleutherAI's GPT-Neo implementation](https://huggingface.co/docs/transformers/model_doc/gpt_neo). JAT's particularity lies in its embedding mechanism, which has been built to intrinsically handle sequential decision tasks. We interleave observation embeddings with action embeddings, along with the corresponding rewards.
<figure class="image text-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/raw/main/blog/jat/model.svg" width="100%" alt="Model">
<figcaption>Architecture of the JAT network. For sequential decision-making tasks, observations and rewards on the one hand, and actions on the other, are encoded and interleaved. The model generates the next embedding autoregressively with a causal mask, and decodes according to expected modality.</figcaption>
</figure>
Each embedding therefore corresponds either to an observation (associated with the reward), or to an action. But how does JAT encode this information? It depends on the type of data. If the data (observation or action) is an image (as is the case for Atari), then JAT uses a CNN. If it's a continuous vector, then JAT uses a linear layer. Finally, if it's a discrete value, JAT uses a linear projection layer. The same principle is used for model output, depending on the type of data to be predicted. Prediction is causal, shifting observations by 1 time step. In this way, the agent must predict the next action from all previous observations and actions.
In addition, we thought it would be fun to train our agent to perform NLP and CV tasks. To do this, we also gave the encoder the option of taking text and image data as input. For text data, we tokenize using GPT-2 tokenization strategy, and for images, we use a [ViT](https://huggingface.co/docs/transformers/model_doc/vit)-type encoder.
Given that the modality of the data can change from one environment to another, how does JAT compute the loss? It computes the loss for each modality separately. For images and continuous values, it uses the MSE loss. For discrete values, it uses the cross-entropy loss. The final loss is the average of the losses for each element of the sequence.
Wait, does that mean we give equal weight to predicting actions and observations? Actually, no, but we'll talk more about that [below](#the-surprising-benefits-of-predicting-observations).
## Experiments and results
We evaluate JAT on all 157 training tasks. We collect 10 episodes and record the total reward. For ease of reading, we aggregate the results by domain.
<figure class="image text-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/raw/main/blog/jat/score_steps.svg" alt="Score evolution" width="100%;">
<figcaption>Aggregated expert normalized scores with 95% Confidence Intervals (CIs) for each RL domain as a function of learning step.</figcaption>
</figure>
If we were to summarize these results in one number, it would be 65.8%, the average performance compared to the JAT expert over the 4 domains. This shows that JAT is capable of mimicking expert performance on a very wide variety of tasks.
Let's go into a little more detail:
- For Atari 57, the agent achieves 14.1% of the expert's score, corresponding to 37.6% of human performance. It exceeds human performance on 21 games.
- For BabyAI, the agent achieves 99.0% of the expert's score, and fails to exceed 50% of the expert on just 1 task.
- For Meta-World, the agent reached 65.5% of the expert.
- For MuJoCo, the agent achieves 84.8% of the expert.
<figure class="image text-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/raw/main/blog/jat/human_normalized_atari_jat_small_250000.svg" alt="Score evolution" width="100%" >
<figcaption>Human normalized scores for the JAT agent on the Atari 57 benchmark.</figcaption>
</figure>
What's most impressive is that JAT achieves this performance using a **single network** for all domains. To take the measure of this performance, let's watch JAT's rendering on a few tasks:
<figure class="image flex flex-col items-center text-center m-0 w-full">
<video alt="jat_hf.mp4" autoplay loop autobuffer muted playsinline>
<source src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/jat/jat_hf.mp4" type="video/mp4">
</video>
<figcaption></figcaption>
</figure>
Want to try it out? You can! The [JAT model](https://huggingface.co/jat-project/jat) is available on the 🤗 Hub!
For textual tasks, our model shows rudimentary capabilities, we refer the reader to the [paper](https://huggingface.co/papers/2402.09844) for more details.
### The surprising benefits of predicting observations
When training an RL agent, the primary goal is to maximize future rewards. But what if we also ask the agent to predict what it will observe in the future? Will this additional task help or hinder the learning process?
There are two opposing views on this question. On one hand, learning to predict observations could provide a deeper understanding of the environment, leading to better and faster learning. On the other hand, it could distract the agent from its main goal, resulting in mediocre performance in both observation and action prediction.
To settle this debate, we conducted an experiment using a loss function that combines observation loss and action loss, with a weighting parameter \\( \kappa \\) to balance the two objectives.
<figure class="image text-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/raw/main/blog/jat/kappa_aggregated.svg" width="100%" alt="Kappa Aggregated">
<figcaption>Aggregate measures with 95% CIs for the study on the influence of observation prediction learning for selected tasks. The results presented cover the selected range of κ values and are based on 100 evaluations per task. Optimal \\( \kappa \\) selection can significantly improve agent performance.</figcaption>
</figure>
The results were noteworthy. When \\( \kappa \\) was too high (0.5), the additional objective of predicting observations seemed to hinder the learning process. But when \\( \kappa \\) was lower, the impact on learning was negligible, and the agent's performance was similar to that obtained when observation prediction was not part of the objective.
However, we found a sweet spot around \\( \kappa= 0.005 \\), where learning to predict observations actually improved the agent's learning efficiency.
Our study suggests that adding observation prediction to the learning process can be beneficial, as long as it's balanced correctly. This finding has important implications for the design of such agents, highlighting the potential value of auxiliary objectives in improving learning efficiency.
So, the next time you're training an RL agent, consider asking it to predict what it will observe in the future. It might just lead to better performance and faster learning!
## Conclusions
In this work, we introduced JAT, a multi-purpose transformer agent capable of mastering a wide variety of sequential decision-making tasks, and showing rudimentary capabilities in NLP and CV tasks. For all these tasks, JAT uses a single network. Our contributions include the release of expert RL agents, the JAT dataset, and the JAT model. We hope that this work will inspire future research in the field of generalist agents and contribute to the development of more versatile and capable AI systems.
## What's next? A request for research
We believe that the JAT project has opened up a new direction for research in the field of generalist agents, and we've only just scratched the surface. Here are some ideas for future work:
- **Improving the data**: Although pioneering, the JAT dataset is still in its early stages. The expert trajectories come from only one expert agent per environment which may cause some bias. Although we've done our best to reach state-of-the-art performance, some environments are still challenging. We believe that collecting more data and training more expert agents could help **a lot**.
- **Use offline RL**: The JAT agent is trained using basic Behavioral Cloning. This implies two things: (1) we can't take advantage of sub-optimal trajectories and (2) the JAT agent can't outperform the expert. We've chosen this approach for simplicity, but we believe that using offline RL could **really help** improve the agent's performance, while not being too complex to implement.
- **Unlock the full potential of a smarter multi-task sampling strategy**: Currently, the JAT agent samples data uniformly from all tasks, but this approach may be holding it back. By dynamically adjusting the sampling rate to focus on the most challenging tasks, we can supercharge the agent's learning process and unlock **significant performance gains**.
## Links
- 📄 [Paper](https://huggingface.co/papers/2402.09844)
- 💻 [Source code](https://github.com/huggingface/jat)
- 🗂️ [JAT dataset](https://huggingface.co/datasets/jat-project/jat-dataset)
- 🤖 [JAT model](https://huggingface.co/jat-project/jat)
## Citation
```bibtex
@article{gallouedec2024jack,
title = {{Jack of All Trades, Master of Some, a Multi-Purpose Transformer Agent}},
author = {Gallouédec, Quentin and Beeching, Edward and Romac, Clément and Dellandréa, Emmanuel},
journal = {arXiv preprint arXiv:2402.09844},
year = {2024},
url = {https://arxiv.org/abs/2402.09844}
}
```
| 0 |
0 | hf_public_repos | hf_public_repos/blog/moe.md | ---
title: "Mixture of Experts Explained"
thumbnail: /blog/assets/moe/thumbnail.png
authors:
- user: osanseviero
- user: lewtun
- user: philschmid
- user: smangrul
- user: ybelkada
- user: pcuenq
---
# Mixture of Experts Explained
With the release of Mixtral 8x7B ([announcement](https://mistral.ai/news/mixtral-of-experts/), [model card](https://huggingface.co/mistralai/Mixtral-8x7B-v0.1)), a class of transformer has become the hottest topic in the open AI community: Mixture of Experts, or MoEs for short. In this blog post, we take a look at the building blocks of MoEs, how they’re trained, and the tradeoffs to consider when serving them for inference.
Let’s dive in!
## Table of Contents
- [What is a Mixture of Experts?](#what-is-a-mixture-of-experts-moe)
- [A Brief History of MoEs](#a-brief-history-of-moes)
- [What is Sparsity?](#what-is-sparsity)
- [Load Balancing tokens for MoEs](#load-balancing-tokens-for-moes)
- [MoEs and Transformers](#moes-and-transformers)
- [Switch Transformers](#switch-transformers)
- [Stabilizing training with router Z-loss](#stabilizing-training-with-router-z-loss)
- [What does an expert learn?](#what-does-an-expert-learn)
- [How does scaling the number of experts impact pretraining?](#how-does-scaling-the-number-of-experts-impact-pretraining)
- [Fine-tuning MoEs](#fine-tuning-moes)
- [When to use sparse MoEs vs dense models?](#when-to-use-sparse-moes-vs-dense-models)
- [Making MoEs go brrr](#making-moes-go-brrr)
- [Expert Parallelism](#parallelism)
- [Capacity Factor and Communication costs](#capacity-factor-and-communication-costs)
- [Serving Techniques](#serving-techniques)
- [Efficient Training](#more-on-efficient-training)
- [Open Source MoEs](#open-source-moes)
- [Exciting directions of work](#exciting-directions-of-work)
- [Some resources](#some-resources)
## TL;DR
MoEs:
- Are **pretrained much faster** vs. dense models
- Have **faster inference** compared to a model with the same number of parameters
- Require **high VRAM** as all experts are loaded in memory
- Face many **challenges in fine-tuning**, but [recent work](https://arxiv.org/pdf/2305.14705.pdf) with MoE **instruction-tuning is promising**
Let’s dive in!
## What is a Mixture of Experts (MoE)?
The scale of a model is one of the most important axes for better model quality. Given a fixed computing budget, training a larger model for fewer steps is better than training a smaller model for more steps.
Mixture of Experts enable models to be pretrained with far less compute, which means you can dramatically scale up the model or dataset size with the same compute budget as a dense model. In particular, a MoE model should achieve the same quality as its dense counterpart much faster during pretraining.
So, what exactly is a MoE? In the context of transformer models, a MoE consists of two main elements:
- **Sparse MoE layers** are used instead of dense feed-forward network (FFN) layers. MoE layers have a certain number of “experts” (e.g. 8), where each expert is a neural network. In practice, the experts are FFNs, but they can also be more complex networks or even a MoE itself, leading to hierarchical MoEs!
- A **gate network or router**, that determines which tokens are sent to which expert. For example, in the image below, the token “More” is sent to the second expert, and the token "Parameters” is sent to the first network. As we’ll explore later, we can send a token to more than one expert. How to route a token to an expert is one of the big decisions when working with MoEs - the router is composed of learned parameters and is pretrained at the same time as the rest of the network.
<figure class="image text-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/moe/00_switch_transformer.png" alt="Switch Layer">
<figcaption>MoE layer from the [Switch Transformers paper](https://arxiv.org/abs/2101.03961)</figcaption>
</figure>
So, to recap, in MoEs we replace every FFN layer of the transformer model with an MoE layer, which is composed of a gate network and a certain number of experts.
Although MoEs provide benefits like efficient pretraining and faster inference compared to dense models, they also come with challenges:
- **Training:** MoEs enable significantly more compute-efficient pretraining, but they’ve historically struggled to generalize during fine-tuning, leading to overfitting.
- **Inference:** Although a MoE might have many parameters, only some of them are used during inference. This leads to much faster inference compared to a dense model with the same number of parameters. However, all parameters need to be loaded in RAM, so memory requirements are high. For example, given a MoE like Mixtral 8x7B, we’ll need to have enough VRAM to hold a dense 47B parameter model. Why 47B parameters and not 8 x 7B = 56B? That’s because in MoE models, only the FFN layers are treated as individual experts, and the rest of the model parameters are shared. At the same time, assuming just two experts are being used per token, the inference speed (FLOPs) is like using a 12B model (as opposed to a 14B model), because it computes 2x7B matrix multiplications, but with some layers shared (more on this soon).
Now that we have a rough idea of what a MoE is, let’s take a look at the research developments that led to their invention.
## A Brief History of MoEs
The roots of MoEs come from the 1991 paper [Adaptive Mixture of Local Experts](https://www.cs.toronto.edu/~hinton/absps/jjnh91.pdf). The idea, akin to ensemble methods, was to have a supervised procedure for a system composed of separate networks, each handling a different subset of the training cases. Each separate network, or expert, specializes in a different region of the input space. How is the expert chosen? A gating network determines the weights for each expert. During training, both the expert and the gating are trained.
Between 2010-2015, two different research areas contributed to later MoE advancement:
- **Experts as components**: In the traditional MoE setup, the whole system comprises a gating network and multiple experts. MoEs as the whole model have been explored in SVMs, Gaussian Processes, and other methods. The work by [Eigen, Ranzato, and Ilya](https://arxiv.org/abs/1312.4314) explored MoEs as components of deeper networks. This allows having MoEs as layers in a multilayer network, making it possible for the model to be both large and efficient simultaneously.
- **Conditional Computation**: Traditional networks process all input data through every layer. In this period, Yoshua Bengio researched approaches to dynamically activate or deactivate components based on the input token.
These works led to exploring a mixture of experts in the context of NLP. Concretely, [Shazeer et al.](https://arxiv.org/abs/1701.06538) (2017, with “et al.” including Geoffrey Hinton and Jeff Dean, [Google’s Chuck Norris](https://www.informatika.bg/jeffdean)) scaled this idea to a 137B LSTM (the de-facto NLP architecture back then, created by Schmidhuber) by introducing sparsity, allowing to keep very fast inference even at high scale. This work focused on translation but faced many challenges, such as high communication costs and training instabilities.
<figure class="image text-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/moe/01_moe_layer.png" alt="MoE layer in LSTM">
<figcaption>MoE layer from the Outrageously Large Neural Network paper</figcaption>
</figure>
MoEs have allowed training multi-trillion parameter models, such as the open-sourced 1.6T parameters Switch Transformers, among others. MoEs have also been explored in Computer Vision, but this blog post will focus on the NLP domain.
## What is Sparsity?
Sparsity uses the idea of conditional computation. While in dense models all the parameters are used for all the inputs, sparsity allows us to only run some parts of the whole system.
Let’s dive deeper into Shazeer's exploration of MoEs for translation. The idea of conditional computation (parts of the network are active on a per-example basis) allows one to scale the size of the model without increasing the computation, and hence, this led to thousands of experts being used in each MoE layer.
This setup introduces some challenges. For example, although large batch sizes are usually better for performance, batch sizes in MOEs are effectively reduced as data flows through the active experts. For example, if our batched input consists of 10 tokens, **five tokens might end in one expert, and the other five tokens might end in five different experts, leading to uneven batch sizes and underutilization**. The [Making MoEs go brrr](#making-moes-go-brrr) section below will discuss other challenges and solutions.
How can we solve this? A learned gating network (G) decides which experts (E) to send a part of the input:
$$
y = \sum_{i=1}^{n} G(x)_i E_i(x)
$$
In this setup, all experts are run for all inputs - it’s a weighted multiplication. But, what happens if G is 0? If that’s the case, there’s no need to compute the respective expert operations and hence we save compute. What’s a typical gating function? In the most traditional setup, we just use a simple network with a softmax function. The network will learn which expert to send the input.
$$
G_\sigma(x) = \text{Softmax}(x \cdot W_g)
$$
Shazeer’s work also explored other gating mechanisms, such as Noisy Top-k Gating. This gating approach introduces some (tunable) noise and then keeps the top k values. That is:
1. We add some noise
$$
H(x)_i = (x \cdot W_{\text{g}})_i + \text{StandardNormal()} \cdot \text{Softplus}((x \cdot W_{\text{noise}})_i)
$$
2. We only pick the top k
$$
\text{KeepTopK}(v, k)_i = \begin{cases}
v_i & \text{if } v_i \text{ is in the top } k \text{ elements of } v, \\
-\infty & \text{otherwise.}
\end{cases}
$$
3. We apply the softmax.
$$
G(x) = \text{Softmax}(\text{KeepTopK}(H(x), k))
$$
This sparsity introduces some interesting properties. By using a low enough k (e.g. one or two), we can train and run inference much faster than if many experts were activated. Why not just select the top expert? The initial conjecture was that routing to more than one expert was needed to have the gate learn how to route to different experts, so at least two experts had to be picked. The [Switch Transformers](#switch-transformers) section revisits this decision.
Why do we add noise? That’s for load balancing!
## Load balancing tokens for MoEs
As discussed before, if all our tokens are sent to just a few popular experts, that will make training inefficient. In a normal MoE training, the gating network converges to mostly activate the same few experts. This self-reinforces as favored experts are trained quicker and hence selected more. To mitigate this, an **auxiliary loss** is added to encourage giving all experts equal importance. This loss ensures that all experts receive a roughly equal number of training examples. The following sections will also explore the concept of expert capacity, which introduces a threshold of how many tokens can be processed by an expert. In `transformers`, the auxiliary loss is exposed via the `aux_loss` parameter.
## MoEs and Transformers
Transformers are a very clear case that scaling up the number of parameters improves the performance, so it’s not surprising that Google explored this with [GShard](https://arxiv.org/abs/2006.16668), which explores scaling up transformers beyond 600 billion parameters.
GShard replaces every other FFN layer with an MoE layer using top-2 gating in both the encoder and the decoder. The next image shows how this looks like for the encoder part. This setup is quite beneficial for large-scale computing: when we scale to multiple devices, the MoE layer is shared across devices while all the other layers are replicated. This is further discussed in the [“Making MoEs go brrr”](#making-moes-go-brrr) section.
<figure class="image text-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/moe/02_moe_block.png" alt="MoE Transformer Encoder">
<figcaption>MoE Transformer Encoder from the GShard Paper</figcaption>
</figure>
To maintain a balanced load and efficiency at scale, the GShard authors introduced a couple of changes in addition to an auxiliary loss similar to the one discussed in the previous section:
- **Random routing**: in a top-2 setup, we always pick the top expert, but the second expert is picked with probability proportional to its weight.
- **Expert capacity**: we can set a threshold of how many tokens can be processed by one expert. If both experts are at capacity, the token is considered overflowed, and it’s sent to the next layer via residual connections (or dropped entirely in other projects). This concept will become one of the most important concepts for MoEs. Why is expert capacity needed? Since all tensor shapes are statically determined at compilation time, but we cannot know how many tokens will go to each expert ahead of time, we need to fix the capacity factor.
The GShard paper has contributions by expressing parallel computation patterns that work well for MoEs, but discussing that is outside the scope of this blog post.
**Note:** when we run inference, only some experts will be triggered. At the same time, there are shared computations, such as self-attention, which is applied for all tokens. That’s why when we talk of a 47B model of 8 experts, we can run with the compute of a 12B dense model. If we use top-2, 14B parameters would be used. But given that the attention operations are shared (among others), the actual number of used parameters is 12B.
## Switch Transformers
Although MoEs showed a lot of promise, they struggle with training and fine-tuning instabilities. [Switch Transformers](https://arxiv.org/abs/2101.03961) is a very exciting work that deep dives into these topics. The authors even released a [1.6 trillion parameters MoE on Hugging Face](https://huggingface.co/google/switch-c-2048) with 2048 experts, which you can run with transformers. Switch Transformers achieved a 4x pre-train speed-up over T5-XXL.
<figure class="image text-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/moe/03_switch_layer.png" alt="Switch Transformer Layer">
<figcaption>Switch Transformer Layer of the Switch Transformer paper</figcaption>
</figure>
Just as in GShard, the authors replaced the FFN layers with a MoE layer. The Switch Transformers paper proposes a Switch Transformer layer that receives two inputs (two different tokens) and has four experts.
Contrary to the initial idea of using at least two experts, Switch Transformers uses a simplified single-expert strategy. The effects of this approach are:
- The router computation is reduced
- The batch size of each expert can be at least halved
- Communication costs are reduced
- Quality is preserved
Switch Transformers also explores the concept of expert capacity.
$$
\text{Expert Capacity} = \left(\frac{\text{tokens per batch}}{\text{number of experts}}\right) \times \text{capacity factor}
$$
The capacity suggested above evenly divides the number of tokens in the batch across the number of experts. If we use a capacity factor greater than 1, we provide a buffer for when tokens are not perfectly balanced. Increasing the capacity will lead to more expensive inter-device communication, so it’s a trade-off to keep in mind. In particular, Switch Transformers perform well at low capacity factors (1-1.25)
Switch Transformer authors also revisit and simplify the load balancing loss mentioned in the sections. For each Switch layer, the auxiliary loss is added to the total model loss during training. This loss encourages uniform routing and can be weighted using a hyperparameter.
The authors also experiment with selective precision, such as training the experts with `bfloat16` while using full precision for the rest of the computations. Lower precision reduces communication costs between processors, computation costs, and memory for storing tensors. The initial experiments, in which both the experts and the gate networks were trained in `bfloat16`, yielded more unstable training. This was, in particular, due to the router computation: as the router has an exponentiation function, having higher precision is important. To mitigate the instabilities, full precision was used for the routing as well.
<figure class="image text-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/moe/04_switch_table.png" alt="Table shows that selective precision does not degrade quality.">
<figcaption>Using selective precision does not degrade quality and enables faster models</figcaption>
</figure>
This [notebook](https://colab.research.google.com/drive/1aGGVHZmtKmcNBbAwa9hbu58DDpIuB5O4?usp=sharing) showcases fine-tuning Switch Transformers for summarization, but we suggest first reviewing the [fine-tuning section](#fine-tuning-moes).
Switch Transformers uses an encoder-decoder setup in which they did a MoE counterpart of T5. The [GLaM](https://arxiv.org/abs/2112.06905) paper explores pushing up the scale of these models by training a model matching GPT-3 quality using 1/3 of the energy (yes, thanks to the lower amount of computing needed to train a MoE, they can reduce the carbon footprint by up to an order of magnitude). The authors focused on decoder-only models and few-shot and one-shot evaluation rather than fine-tuning. They used Top-2 routing and much larger capacity factors. In addition, they explored the capacity factor as a metric one can change during training and evaluation depending on how much computing one wants to use.
## Stabilizing training with router Z-loss
The balancing loss previously discussed can lead to instability issues. We can use many methods to stabilize sparse models at the expense of quality. For example, introducing dropout improves stability but leads to loss of model quality. On the other hand, adding more multiplicative components improves quality but decreases stability.
Router z-loss, introduced in [ST-MoE](https://arxiv.org/abs/2202.08906), significantly improves training stability without quality degradation by penalizing large logits entering the gating network. Since this loss encourages absolute magnitude of values to be smaller, roundoff errors are reduced, which can be quite impactful for exponential functions such as the gating. We recommend reviewing the paper for details.
## What does an expert learn?
The ST-MoE authors observed that encoder experts specialize in a group of tokens or shallow concepts. For example, we might end with a punctuation expert, a proper noun expert, etc. On the other hand, the decoder experts have less specialization. The authors also trained in a multilingual setup. Although one could imagine each expert specializing in a language, the opposite happens: due to token routing and load balancing, there is no single expert specialized in any given language.
<figure class="image text-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/moe/05_experts_learning.png" alt="Experts specialize in some token groups">
<figcaption>Table from the ST-MoE paper showing which token groups were sent to which expert.</figcaption>
</figure>
## How does scaling the number of experts impact pretraining?
More experts lead to improved sample efficiency and faster speedup, but these are diminishing gains (especially after 256 or 512), and more VRAM will be needed for inference. The properties studied in Switch Transformers at large scale were consistent at small scale, even with 2, 4, or 8 experts per layer.
## Fine-tuning MoEs
> Mixtral is supported with version 4.36.0 of transformers. You can install it with `pip install transformers==4.36.0 --upgrade`
The overfitting dynamics are very different between dense and sparse models. Sparse models are more prone to overfitting, so we can explore higher regularization (e.g. dropout) within the experts themselves (e.g. we can have one dropout rate for the dense layers and another, higher, dropout for the sparse layers).
One question is whether to use the auxiliary loss for fine-tuning. The ST-MoE authors experimented with turning off the auxiliary loss, and the quality was not significantly impacted, even when up to 11% of the tokens were dropped. Token dropping might be a form of regularization that helps prevent overfitting.
Switch Transformers observed that at a fixed pretrain perplexity, the sparse model does worse than the dense counterpart in downstream tasks, especially on reasoning-heavy tasks such as SuperGLUE. On the other hand, for knowledge-heavy tasks such as TriviaQA, the sparse model performs disproportionately well. The authors also observed that a fewer number of experts helped at fine-tuning. Another observation that confirmed the generalization issue is that the model did worse in smaller tasks but did well in larger tasks.
<figure class="image text-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/moe/06_superglue_curves.png" alt="Fine-tuning learning curves">
<figcaption>In the small task (left), we can see clear overfitting as the sparse model does much worse in the validation set. In the larger task (right), the MoE performs well. This image is from the ST-MoE paper.</figcaption>
</figure>
One could experiment with freezing all non-expert weights. That is, we'll only update the MoE layers. This leads to a huge performance drop. We could try the opposite: freezing only the parameters in MoE layers, which worked almost as well as updating all parameters. This can help speed up and reduce memory for fine-tuning. This can be somewhat counter-intuitive as 80% of the parameters are in the MoE layers (in the ST-MoE project). Their hypothesis for that architecture is that, as expert layers only occur every 1/4 layers, and each token sees at most two experts per layer, updating the MoE parameters affects much fewer layers than updating other parameters.
<figure class="image text-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/moe/07_superglue_bars.png" alt="Only updating the non MoE layers works well in fine-tuning">
<figcaption>By only freezing the MoE layers, we can speed up the training while preserving the quality. This image is from the ST-MoE paper.</figcaption>
</figure>
One last part to consider when fine-tuning sparse MoEs is that they have different fine-tuning hyperparameter setups - e.g., sparse models tend to benefit more from smaller batch sizes and higher learning rates.
<figure class="image text-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/moe/08_superglue_dense_vs_sparse.png" alt="Table comparing fine-tuning batch size and learning rate between dense and sparse models.">
<figcaption>Sparse models fine-tuned quality improves with higher learning rates and smaller batch sizes. This image is from the ST-MoE paper.</figcaption>
</figure>
At this point, you might be a bit sad that people have struggled to fine-tune MoEs. Excitingly, a recent paper, [MoEs Meets Instruction Tuning](https://arxiv.org/pdf/2305.14705.pdf) (July 2023), performs experiments doing:
- Single task fine-tuning
- Multi-task instruction-tuning
- Multi-task instruction-tuning followed by single-task fine-tuning
When the authors fine-tuned the MoE and the T5 equivalent, the T5 equivalent was better. When the authors fine-tuned the Flan T5 (T5 instruct equivalent) MoE, the MoE performed significantly better. Not only this, the improvement of the Flan-MoE over the MoE was larger than Flan T5 over T5, indicating that MoEs might benefit much more from instruction tuning than dense models. MoEs benefit more from a higher number of tasks. Unlike the previous discussion suggesting to turn off the auxiliary loss function, the loss actually prevents overfitting.
<figure class="image text-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/moe/09_fine_tune_evals.png" alt="MoEs benefit even more from instruct tuning than dense models">
<figcaption>Sparse models benefit more from instruct-tuning compared to dense models. This image is from the MoEs Meets Instruction Tuning paper</figcaption>
</figure>
## When to use sparse MoEs vs dense models?
Experts are useful for high throughput scenarios with many machines. Given a fixed compute budget for pretraining, a sparse model will be more optimal. For low throughput scenarios with little VRAM, a dense model will be better.
**Note:** one cannot directly compare the number of parameters between sparse and dense models, as both represent significantly different things.
## Making MoEs go brrr
The initial MoE work presented MoE layers as a branching setup, leading to slow computation as GPUs are not designed for it and leading to network bandwidth becoming a bottleneck as the devices need to send info to others. This section will discuss some existing work to make pretraining and inference with these models more practical. MoEs go brrrrr.
### Parallelism
Let’s do a brief review of parallelism:
- **Data parallelism:** the same weights are replicated across all cores, and the data is partitioned across cores.
- **Model parallelism:** the model is partitioned across cores, and the data is replicated across cores.
- **Model and data parallelism:** we can partition the model and the data across cores. Note that different cores process different batches of data.
- **Expert parallelism**: experts are placed on different workers. If combined with data parallelism, each core has a different expert and the data is partitioned across all cores
With expert parallelism, experts are placed on different workers, and each worker takes a different batch of training samples. For non-MoE layers, expert parallelism behaves the same as data parallelism. For MoE layers, tokens in the sequence are sent to workers where the desired experts reside.
<figure class="image text-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/moe/10_parallelism.png" alt="Image illustrating model, expert, and data prallelism">
<figcaption>Illustration from the Switch Transformers paper showing how data and models are split over cores with different parallelism techniques.</figcaption>
</figure>
### Capacity Factor and communication costs
Increasing the capacity factor (CF) increases the quality but increases communication costs and memory of activations. If all-to-all communications are slow, using a smaller capacity factor is better. A good starting point is using top-2 routing with 1.25 capacity factor and having one expert per core. During evaluation, the capacity factor can be changed to reduce compute.
### Serving techniques
> You can deploy [mistralai/Mixtral-8x7B-Instruct-v0.1](https://ui.endpoints.huggingface.co/new?repository=mistralai%2FMixtral-8x7B-Instruct-v0.1&vendor=aws®ion=us-east-1&accelerator=gpu&instance_size=2xlarge&task=text-generation&no_suggested_compute=true&tgi=true&tgi_max_batch_total_tokens=1024000&tgi_max_total_tokens=32000) to Inference Endpoints.
A big downside of MoEs is the large number of parameters. For local use cases, one might want to use a smaller model. Let's quickly discuss a few techniques that can help with serving:
* The Switch Transformers authors did early distillation experiments. By distilling a MoE back to its dense counterpart, they could keep 30-40% of the sparsity gains. Distillation, hence, provides the benefits of faster pretaining and using a smaller model in production.
* Recent approaches modify the routing to route full sentences or tasks to an expert, permitting extracting sub-networks for serving.
* Aggregation of Experts (MoE): this technique merges the weights of the experts, hence reducing the number of parameters at inference time.
### More on efficient training
FasterMoE (March 2022) analyzes the performance of MoEs in highly efficient distributed systems and analyzes the theoretical limit of different parallelism strategies, as well as techniques to skew expert popularity, fine-grained schedules of communication that reduce latency, and an adjusted topology-aware gate that picks experts based on the lowest latency, leading to a 17x speedup.
Megablocks (Nov 2022) explores efficient sparse pretraining by providing new GPU kernels that can handle the dynamism present in MoEs. Their proposal never drops tokens and maps efficiently to modern hardware, leading to significant speedups. What’s the trick? Traditional MoEs use batched matrix multiplication, which assumes all experts have the same shape and the same number of tokens. In contrast, Megablocks expresses MoE layers as block-sparse operations that can accommodate imbalanced assignment.
<figure class="image text-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/moe/11_expert_matmuls.png" alt="Matrix multiplication optimized for block-sparse operations.">
<figcaption>Block-sparse matrix multiplication for differently sized experts and number of tokens (from [MegaBlocks](https://arxiv.org/abs/2211.15841)).</figcaption>
</figure>
## Open Source MoEs
There are nowadays several open source projects to train MoEs:
- Megablocks: https://github.com/stanford-futuredata/megablocks
- Fairseq: https://github.com/facebookresearch/fairseq/tree/main/examples/moe_lm
- OpenMoE: https://github.com/XueFuzhao/OpenMoE
In the realm of released open access MoEs, you can check:
- [Switch Transformers (Google)](https://huggingface.co/collections/google/switch-transformers-release-6548c35c6507968374b56d1f): Collection of T5-based MoEs going from 8 to 2048 experts. The largest model has 1.6 trillion parameters.
- [NLLB MoE (Meta)](https://huggingface.co/facebook/nllb-moe-54b): A MoE variant of the NLLB translation model.
- [OpenMoE](https://huggingface.co/fuzhao): A community effort that has released Llama-based MoEs.
- [Mixtral 8x7B (Mistral)](https://huggingface.co/mistralai): A high-quality MoE that outperforms Llama 2 70B and has much faster inference. A instruct-tuned model is also released. Read more about it in [the announcement blog post](https://mistral.ai/news/mixtral-of-experts/).
## Exciting directions of work
Further experiments on **distilling** a sparse MoE back to a dense model with less parameters but similar number of parameters.
Another area will be quantization of MoEs. [QMoE](https://arxiv.org/abs/2310.16795) (Oct. 2023) is a good step in this direction by quantizing the MoEs to less than 1 bit per parameter, hence compressing the 1.6T Switch Transformer which uses 3.2TB accelerator to just 160GB.
So, TL;DR, some interesting areas to explore:
* Distilling Mixtral into a dense model
* Explore model merging techniques of the experts and their impact in inference time
* Perform extreme quantization techniques of Mixtral
## Some resources
- [Adaptive Mixture of Local Experts (1991)](https://www.cs.toronto.edu/~hinton/absps/jjnh91.pdf)
- [Learning Factored Representations in a Deep Mixture of Experts (2013)](https://arxiv.org/abs/1312.4314)
- [Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer (2017)](https://arxiv.org/abs/1701.06538)
- [GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding (Jun 2020)](https://arxiv.org/abs/2006.16668)
- [GLaM: Efficient Scaling of Language Models with Mixture-of-Experts (Dec 2021)](https://arxiv.org/abs/2112.06905)
- [Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity (Jan 2022)](https://arxiv.org/abs/2101.03961)
- [ST-MoE: Designing Stable and Transferable Sparse Expert Models (Feb 2022)](https://arxiv.org/abs/2202.08906)
- [FasterMoE: modeling and optimizing training of large-scale dynamic pre-trained models(April 2022)](https://dl.acm.org/doi/10.1145/3503221.3508418)
- [MegaBlocks: Efficient Sparse Training with Mixture-of-Experts (Nov 2022)](https://arxiv.org/abs/2211.15841)
- [Mixture-of-Experts Meets Instruction Tuning:A Winning Combination for Large Language Models (May 2023)](https://arxiv.org/abs/2305.14705)
- [Mixtral-8x7B-v0.1](https://huggingface.co/mistralai/Mixtral-8x7B-v0.1), [Mixtral-8x7B-Instruct-v0.1](https://huggingface.co/mistralai/Mixtral-8x7B-Instruct-v0.1).
## Citation
```bibtex
@misc {sanseviero2023moe,
author = { Omar Sanseviero and
Lewis Tunstall and
Philipp Schmid and
Sourab Mangrulkar and
Younes Belkada and
Pedro Cuenca
},
title = { Mixture of Experts Explained },
year = 2023,
url = { https://huggingface.co/blog/moe },
publisher = { Hugging Face Blog }
}
```
```
Sanseviero, et al., "Mixture of Experts Explained", Hugging Face Blog, 2023.
```
| 1 |
0 | hf_public_repos | hf_public_repos/blog/train-your-controlnet.md | ---
title: "Train your ControlNet with diffusers"
thumbnail: /blog/assets/136_train-your-controlnet/thumbnail.png
authors:
- user: multimodalart
- user: pcuenq
---
# Train your ControlNet with diffusers 🧨
## Introduction
[ControlNet](https://huggingface.co/blog/controlnet) is a neural network structure that allows fine-grained control of diffusion models by adding extra conditions. The technique debuted with the paper [Adding Conditional Control to Text-to-Image Diffusion Models](https://huggingface.co/papers/2302.05543), and quickly took over the open-source diffusion community author's release of 8 different conditions to control Stable Diffusion v1-5, including pose estimations, depth maps, canny edges, sketches, [and more](https://huggingface.co/lllyasviel).

In this blog post we will go over each step in detail on how we trained the [_Uncanny_ Faces model](#) - a model on face poses based on 3D synthetic faces (the uncanny faces was an unintended consequence actually, stay tuned to see how it came through).
## Getting started with training your ControlNet for Stable Diffusion
Training your own ControlNet requires 3 steps:
1. **Planning your condition**: ControlNet is flexible enough to tame Stable Diffusion towards many tasks. The pre-trained models showcase a wide-range of conditions, and the community has built others, such as conditioning on [pixelated color palettes](https://huggingface.co/thibaud/controlnet-sd21-color-diffusers).
2. **Building your dataset**: Once a condition is decided, it is time to build your dataset. For that, you can either construct a dataset from scratch, or use a sub-set of an existing dataset. You need three columns on your dataset to train the model: a ground truth `image`, a `conditioning_image` and a `prompt`.
3. **Training the model**: Once your dataset is ready, it is time to train the model. This is the easiest part thanks to the [diffusers training script](https://github.com/huggingface/diffusers/tree/main/examples/controlnet). You'll need a GPU with at least 8GB of VRAM.
## 1. Planning your condition
To plan your condition, it is useful to think of two questions:
1. What kind of conditioning do I want to use?
2. Is there an already existing model that can convert 'regular' images into my condition?
For our example, we thought about using a facial landmarks conditioning. Our reasoning was: 1. the general landmarks conditioned ControlNet works well. 2. Facial landmarks are a widespread enough technique, and there are multiple models that calculate facial landmarks on regular pictures 3. Could be fun to tame Stable Diffusion to follow a certain facial landmark or imitate your own facial expression.

## 2. Building your dataset
Okay! So we decided to do a facial landmarks Stable Diffusion conditioning. So, to prepare the dataset we need:
- The ground truth `image`: in this case, images of faces
- The `conditioning_image`: in this case, images where the facial landmarks are visualised
- The `caption`: a caption that describes the images being used
For this project, we decided to go with the `FaceSynthetics` dataset by Microsoft: it is a dataset that contains 100K synthetic faces. Other face research datasets with real faces such as `Celeb-A HQ`, `FFHQ` - but we decided to go with synthetic faces for this project.

The `FaceSynthetics` dataset sounded like a great start: it contains ground truth images of faces, and facial landmarks annotated in the iBUG 68-facial landmarks format, and a segmented image of the face.

Perfect. Right? Unfortunately, not really. Remember the second question in the "planning your condition" step - that we should have models that convert regular images to the conditioning? Turns out there was is no known model that can turn faces into the annotated landmark format of this dataset.

So we decided to follow another path:
- Use the ground truths `image` of faces of the `FaceSynthetics` datase
- Use a known model that can convert any image of a face into the 68-facial landmarks format of iBUG (in our case we used the SOTA model [SPIGA](https://github.com/andresprados/SPIGA))
- Use custom code that converts the facial landmarks into a nice illustrated mask to be used as the `conditioning_image`
- Save that as a [Hugging Face Dataset](https://huggingface.co/docs/datasets/indexx)
[Here you can find](https://huggingface.co/datasets/pcuenq/face_synthetics_spiga) the code used to convert the ground truth images from the `FaceSynthetics` dataset into the illustrated mask and save it as a Hugging Face Dataset.
Now, with the ground truth `image` and the `conditioning_image` on the dataset, we are missing one step: a caption for each image. This step is highly recommended, but you can experiment with empty prompts and report back on your results. As we did not have captions for the `FaceSynthetics` dataset, we ran it through a [BLIP captioning](https://huggingface.co/docs/transformers/model_doc/blip). You can check the code used for captioning all images [here](https://huggingface.co/datasets/multimodalart/facesyntheticsspigacaptioned)
With that, we arrived to our final dataset! The [Face Synthetics SPIGA with captions](https://huggingface.co/datasets/multimodalart/facesyntheticsspigacaptioned) contains a ground truth image, segmentation and a caption for the 100K images of the `FaceSynthetics` dataset. We are ready to train the model!

## 3. Training the model
With our [dataset ready](https://huggingface.co/datasets/multimodalart/facesyntheticsspigacaptioned), it is time to train the model! Even though this was supposed to be the hardest part of the process, with the [diffusers training script](https://github.com/huggingface/diffusers/tree/main/examples/controlnet), it turned out to be the easiest. We used a single A100 rented for US$1.10/h on [LambdaLabs](https://lambdalabs.com).
### Our training experience
We trained the model for 3 epochs (this means that the batch of 100K images were shown to the model 3 times) and a batch size of 4 (each step shows 4 images to the model). This turned out to be excessive and overfit (so it forgot concepts that diverge a bit of a real face, so for example "shrek" or "a cat" in the prompt would not make a shrek or a cat but rather a person, and also started to ignore styles).
With just 1 epoch (so after the model "saw" 100K images), it already converged to following the poses and not overfit. So it worked, but... as we used the face synthetics dataset, the model ended up learning uncanny 3D-looking faces, instead of realistic faces. This makes sense given that we used a synthetic face dataset as opposed to real ones, and can be used for fun/memetic purposes. Here is the [uncannyfaces_25K](https://huggingface.co/multimodalart/uncannyfaces_25K) model.
<iframe src="https://wandb.ai/apolinario/controlnet/reports/ControlNet-Uncanny-Faces-Training--VmlldzozODcxNDY0" style="border:none;height:512px;width:100%"></iframe>
In this interactive table you can play with the dial below to go over how many training steps the model went through and how it affects the training process. At around 15K steps, it already started learning the poses. And it matured around 25K steps. Here
### How did we do the training
All we had to do was, install the dependencies:
```shell
pip install git+https://github.com/huggingface/diffusers.git transformers accelerate xformers==0.0.16 wandb
huggingface-cli login
wandb login
```
And then run the [train_controlnet.py](https://github.com/huggingface/diffusers/blob/main/examples/controlnet/train_controlnet.py) code
```shell
!accelerate launch train_controlnet.py \
--pretrained_model_name_or_path="stabilityai/stable-diffusion-2-1-base" \
--output_dir="model_out" \
--dataset_name=multimodalart/facesyntheticsspigacaptioned \
--conditioning_image_column=spiga_seg \
--image_column=image \
--caption_column=image_caption \
--resolution=512 \
--learning_rate=1e-5 \
--validation_image "./face_landmarks1.jpeg" "./face_landmarks2.jpeg" "./face_landmarks3.jpeg" \
--validation_prompt "High-quality close-up dslr photo of man wearing a hat with trees in the background" "Girl smiling, professional dslr photograph, dark background, studio lights, high quality" "Portrait of a clown face, oil on canvas, bittersweet expression" \
--train_batch_size=4 \
--num_train_epochs=3 \
--tracker_project_name="controlnet" \
--enable_xformers_memory_efficient_attention \
--checkpointing_steps=5000 \
--validation_steps=5000 \
--report_to wandb \
--push_to_hub
```
Let's break down some of the settings, and also let's go over some optimisation tips for going as low as 8GB of VRAM for training.
- `pretrained_model_name_or_path`: The Stable Diffusion base model you would like to use (we chose v2-1 here as it can render faces better)
- `output_dir`: The directory you would like your model to be saved
- `dataset_name`: The dataset that will be used for training. In our case [Face Synthetics SPIGA with captions](https://huggingface.co/datasets/multimodalart/facesyntheticsspigacaptioned)
- `conditioning_image_column`: The name of the column in your dataset that contains the conditioning image (in our case `spiga_seg`)
- `image_column`: The name of the colunn in your dataset that contains the ground truth image (in our case `image`)
- `caption_column`: The name of the column in your dataset that contains the caption of tha image (in our case `image_caption`)
- `resolution`: The resolution of both the conditioning and ground truth images (in our case `512x512`)
- `learning_rate`: The learing rate. We found out that `1e-5` worked well for these examples, but you may experiment with different values ranging between `1e-4` and `2e-6`, for example.
- `validation_image`: This is for you to take a sneak peak during training! The validation images will be ran for every amount of `validation_steps` so you can see how your training is going. Insert here a local path to an arbitrary number of conditioning images
- `validation_prompt`: A prompt to be ran togehter with your validation image. Can be anything that can test if your model is training well
- `train_batch_size`: This is the size of the training batch to fit the GPU. We can afford `4` due to having an A100, but if you have a GPU with lower VRAM we recommend bringing this value down to `1`.
- `num_train_epochs`: Each epoch corresponds to how many times the images in the training set will be "seen" by the model. We experimented with 3 epochs, but turns out the best results required just a bit more than 1 epoch, with 3 epochs our model overfit.
- `checkpointing_steps`: Save an intermediary checkpoint every `x` steps (in our case `5000`). Every 5000 steps, an intermediary checkpoint was saved.
- `validation_steps`: Every `x` steps the `validaton_prompt` and the `validation_image` are ran.
- `report_to`: where to report your training to. Here we used Weights and Biases, which gave us [this nice report]().
But reducing the `train_batch_size` from `4` to `1` may not be enough for the training to fit a small GPU, here are some additional parameters to add for each GPU VRAM size:
- `push_to_hub`: a parameter to push the final trained model to the Hugging Face Hub.
### Fitting on a 16GB VRAM GPU
```shell
pip install bitsandbytes
--train_batch_size=1 \
--gradient_accumulation_steps=4 \
--gradient_checkpointing \
--use_8bit_adam
```
The combination of a batch size of 1 with 4 gradient accumulation steps is equivalent to using the original batch size of 4 we used in our example. In addition, we enabled gradient checkpointing and 8-bit Adam for additional memory savings.
### Fitting on a 12GB VRAM GPU
```shell
--gradient_accumulation_steps=4 \
--gradient_checkpointing \
--use_8bit_adam
--set_grads_to_none
```
### Fitting on a 8GB VRAM GPU
Please follow [our guide here](https://github.com/huggingface/diffusers/tree/main/examples/controlnet#training-on-an-8-gb-gpu)
## 4. Conclusion!
This experience of training a ControlNet was a lot of fun. We succesfully trained a model that can follow real face poses - however it learned to make uncanny 3D faces instead of real 3D faces because this was the dataset it was trained on, which has its own charm and flare.
Try out our [Hugging Face Space](https://huggingface.co/spaces/pcuenq/uncanny-faces):
<iframe
src="https://pcuenq-uncanny-faces.hf.space"
frameborder="0"
width="100%"
height="1150"
style="border:0"
></iframe>
As for next steps for us - in order to create realistically looking faces, while still not using a real face dataset, one idea is running the entire `FaceSynthetics` dataset through Stable Diffusion Image2Imaage, converting the 3D-looking faces into realistically looking ones, and then trainign another ControlNet.
And stay tuned, as we will have a ControlNet Training event soon! Follow Hugging Face on [Twitter](https://twitter.com/huggingface) or join our [Discord]( http://hf.co/join/discord) to stay up to date on that.
| 2 |
0 | hf_public_repos | hf_public_repos/blog/fetch-case-study.md | ---
title: "Fetch Cuts ML Processing Latency by 50% Using Amazon SageMaker & Hugging Face"
thumbnail: /blog/assets/78_ml_director_insights/fetch.png
authors:
- user: Violette
---
# Fetch Cuts ML Processing Latency by 50% Using Amazon SageMaker & Hugging Face
_This article is a cross-post from an originally published post on September 2023 [on AWS's website](https://aws.amazon.com/fr/solutions/case-studies/fetch-case-study/)._
## Overview
Consumer engagement and rewards company [Fetch](https://fetch.com/) offers an application that lets users earn rewards on their purchases by scanning their receipts. The company also parses these receipts to generate insights into consumer behavior and provides those insights to brand partners. As weekly scans rapidly grew, Fetch needed to improve its speed and precision.
On Amazon Web Services (AWS), Fetch optimized its machine learning (ML) pipeline using Hugging Face and [Amazon SageMaker ](https://aws.amazon.com/sagemaker/), a service for building, training, and deploying ML models with fully managed infrastructure, tools, and workflows. Now, the Fetch app can process scans faster and with significantly higher accuracy.
## Opportunity | Using Amazon SageMaker to Accelerate an ML Pipeline in 12 Months for Fetch
Using the Fetch app, customers can scan receipts, receive points, and redeem those points for gift cards. To reward users for receipt scans instantaneously, Fetch needed to be able to capture text from a receipt, extract the pertinent data, and structure it so that the rest of its system can process and analyze it. With over 80 million receipts processed per week—hundreds of receipts per second at peak traffic—it needed to perform this process quickly, accurately, and at scale.
In 2021, Fetch set out to optimize its app’s scanning functionality. Fetch is an AWS-native company, and its ML operations team was already using Amazon SageMaker for many of its models. This made the decision to enhance its ML pipeline by migrating its models to Amazon SageMaker a straightforward one.
Throughout the project, Fetch had weekly calls with the AWS team and received support from a subject matter expert whom AWS paired with Fetch. The company built, trained, and deployed more than five ML models using Amazon SageMaker in 12 months. In late 2022, Fetch rolled out its updated mobile app and new ML pipeline.
#### "Amazon SageMaker is a game changer for Fetch. We use almost every feature extensively. As new features come out, they are immediately valuable. It’s hard to imagine having done this project without the features of Amazon SageMaker.”
Sam Corzine, Machine Learning Engineer, Fetch
## Solution | Cutting Latency by 50% Using ML & Hugging Face on Amazon SageMaker GPU Instances
#### "Using the flexibility of the Hugging Face AWS Deep Learning Container, we could improve the quality of our models,and Hugging Face’s partnership with AWS meant that it was simple to deploy these models.”
Sam Corzine, Machine Learning Engineer, Fetch
Fetch’s ML pipeline is powered by several Amazon SageMaker features, particularly [Amazon SageMaker Model Training](https://aws.amazon.com/sagemaker/train/), which reduces the time and cost to train and tune ML models at scale, and [Amazon SageMaker Processing](https://docs.aws.amazon.com/sagemaker/latest/dg/processing-job.html), a simplified, managed experience to run data-processing workloads. The company runs its custom ML models using multi-GPU instances for fast performance. “The GPU instances on Amazon SageMaker are simple to use,” says Ellen Light, backend engineer at Fetch. Fetch trains these models to identify and extract key information on receipts that the company can use to generate valuable insights and reward users. And on Amazon SageMaker, Fetch’s custom ML system is seamlessly scalable. “By using Amazon SageMaker, we have a simple way to scale up our systems, especially for inference and runtime,” says Sam Corzine, ML engineer at Fetch. Meanwhile, standardized model deployments mean less manual work.
Fetch heavily relied on the ML training features of Amazon SageMaker, particularly its [training jobs](https://docs.aws.amazon.com/sagemaker/latest/APIReference/API_CreateTrainingJob.html), as it refined and iterated on its models. Fetch can also train ML models in parallel, which speeds up development and deployments. “There’s little friction for us to deploy models,” says Alec Stashevsky, applied scientist at Fetch. “Basically, we don’t have to think about it.” This has increased confidence and improved productivity for the entire company. In one example, a new intern was able to deploy a model himself by his third day on the job.
Since adopting Amazon SageMaker for ML tuning, training, and retraining, Fetch has enhanced the accuracy of its document-understanding model by 200 percent. It continues to fine-tune its models for further improvement. “Amazon SageMaker has been a key tool in building these outstanding models,” says Quency Yu, ML engineer at Fetch. To optimize the tuning process, Fetch relies on [Amazon SageMaker Inference Recommender](https://docs.aws.amazon.com/sagemaker/latest/dg/inference-recommender.html), a capability of Amazon SageMaker that reduces the time required to get ML models in production by automating load testing and model tuning.
In addition to its custom ML models, Fetch uses [AWS Deep Learning Containers ](https://aws.amazon.com/machine-learning/containers/)(AWS DL Containers), which businesses can use to quickly deploy deep learning environments with optimized, prepackaged container images. This simplifies the process of using libraries from [Hugging Face Inc.](https://huggingface.co/)(Hugging Face), an artificial intelligence technology company and [AWS Partner](https://partners.amazonaws.com/partners/0010h00001jBrjVAAS/Hugging%20Face%20Inc.). Specifically, Fetch uses the Amazon SageMaker Hugging Face Inference Toolkit, an open-source library for serving transformers models, and the Hugging Face AWS Deep Learning Container for training and inference. “Using the flexibility of the Hugging Face AWS Deep Learning Container, we could improve the quality of our models,” says Corzine. “And Hugging Face’s partnership with AWS meant that it was simple to deploy these models.”
For every metric that Fetch measures, performance has improved since adopting Amazon SageMaker. The company has reduced latency for its slowest scans by 50 percent. “Our improved accuracy also creates confidence in our data among partners,” says Corzine. With more confidence, partners will increase their use of Fetch’s solution. “Being able to meaningfully improve accuracy on literally every data point using Amazon SageMaker is a huge benefit and propagates throughout our entire business,” says Corzine.
Fetch can now extract more types of data from a receipt, and it has the flexibility to structure resulting insights according to the specific needs of brand partners. “Leaning into ML has unlocked the ability to extract exactly what our partners want from a receipt,” says Corzine. “Partners can make new types of offers because of our investment in ML, and that’s a huge
additional benefit for them.”
Users enjoy the updates too; Fetch has grown from 10 million to 18 million monthly active users since it released the new version. “Amazon SageMaker is a game changer for Fetch,” says Corzine. “We use almost every feature extensively. As new features come out, they are immediately valuable. It’s hard to imagine having done this project without the features of Amazon SageMaker.” For example, Fetch migrated from a custom shadow testing pipeline to [Amazon SageMaker shadow testing](https://aws.amazon.com/sagemaker/shadow-testing/)—which validates the performance of new ML models against production models to prevent outages. Now, shadow testing is more direct because Fetch can directly compare performance with production traffic.
## Outcome | Expanding ML to New Use Cases
The ML team at Fetch is continually working on new models and iterating on existing ones to tune them for better performance. “Another thing we like is being able to keep our technology stack up to date with new features of Amazon SageMaker,” says Chris Lee, ML developer at Fetch. The company will continue expanding its use of AWS to different ML use cases, such as fraud prevention, across multiple teams.
Already one of the biggest consumer engagement software companies, Fetch aims to continue growing. “AWS is a key part of how we plan to scale, and we’ll lean into the features of Amazon SageMaker to continue improving our accuracy,” says Corzine.
## About Fetch
Fetch is a consumer engagement company that provides insights on consumer purchases to brand partners. It also offers a mobile rewards app that lets users earn rewards on purchases through a receipt-scanning feature.
_If you need support in using Hugging Face on SageMaker for your company, please contact us [here](https://huggingface.co/support#form) - our team will contact you to discuss your requirements!_
| 3 |
0 | hf_public_repos | hf_public_repos/blog/stable_diffusion_jax.md | ---
title: 🧨 Stable Diffusion in JAX / Flax !
thumbnail: /blog/assets/108_stable_diffusion_jax/thumbnail.png
authors:
- user: pcuenq
- user: patrickvonplaten
---
# 🧨 Stable Diffusion in JAX / Flax !
<a target="_blank" href="https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_diffusion_jax_how_to.ipynb">
<img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/>
</a>
🤗 Hugging Face [Diffusers](https://github.com/huggingface/diffusers) supports Flax since version `0.5.1`! This allows for super fast inference on Google TPUs, such as those available in Colab, Kaggle or Google Cloud Platform.
This post shows how to run inference using JAX / Flax. If you want more details about how Stable Diffusion works or want to run it in GPU, please refer to [this Colab notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_diffusion.ipynb).
If you want to follow along, click the button above to open this post as a Colab notebook.
First, make sure you are using a TPU backend. If you are running this notebook in Colab, select `Runtime` in the menu above, then select the option "Change runtime type" and then select `TPU` under the `Hardware accelerator` setting.
Note that JAX is not exclusive to TPUs, but it shines on that hardware because each TPU server has 8 TPU accelerators working in parallel.
## Setup
``` python
import jax
num_devices = jax.device_count()
device_type = jax.devices()[0].device_kind
print(f"Found {num_devices} JAX devices of type {device_type}.")
assert "TPU" in device_type, "Available device is not a TPU, please select TPU from Edit > Notebook settings > Hardware accelerator"
```
*Output*:
```bash
Found 8 JAX devices of type TPU v2.
```
Make sure `diffusers` is installed.
``` python
!pip install diffusers==0.5.1
```
Then we import all the dependencies.
``` python
import numpy as np
import jax
import jax.numpy as jnp
from pathlib import Path
from jax import pmap
from flax.jax_utils import replicate
from flax.training.common_utils import shard
from PIL import Image
from huggingface_hub import notebook_login
from diffusers import FlaxStableDiffusionPipeline
```
## Model Loading
Before using the model, you need to accept the model [license](https://huggingface.co/spaces/CompVis/stable-diffusion-license) in order to download and use the weights.
The license is designed to mitigate the potential harmful effects of such a powerful machine learning system.
We request users to **read the license entirely and carefully**. Here we offer a summary:
1. You can't use the model to deliberately produce nor share illegal or harmful outputs or content,
2. We claim no rights on the outputs you generate, you are free to use them and are accountable for their use which should not go against the provisions set in the license, and
3. You may re-distribute the weights and use the model commercially and/or as a service. If you do, please be aware you have to include the same use restrictions as the ones in the license and share a copy of the CreativeML OpenRAIL-M to all your users.
Flax weights are available in Hugging Face Hub as part of the Stable Diffusion repo. The Stable Diffusion model is distributed under the CreateML OpenRail-M license. It's an open license that claims no rights on the outputs you generate and prohibits you from deliberately producing illegal or harmful content. The [model card](https://huggingface.co/CompVis/stable-diffusion-v1-4) provides more details, so take a moment to read them and consider carefully whether you accept the license. If you do, you need to be a registered user in the Hub and use an access token for the code to work. You have two options to provide your access token:
- Use the `huggingface-cli login` command-line tool in your terminal and paste your token when prompted. It will be saved in a file in your computer.
- Or use `notebook_login()` in a notebook, which does the same thing.
The following cell will present a login interface unless you've already authenticated before in this computer. You'll need to paste your access token.
``` python
if not (Path.home()/'.huggingface'/'token').exists(): notebook_login()
```
TPU devices support `bfloat16`, an efficient half-float type. We'll use it for our tests, but you can also use `float32` to use full precision instead.
``` python
dtype = jnp.bfloat16
```
Flax is a functional framework, so models are stateless and parameters are stored outside them. Loading the pre-trained Flax pipeline will return both the pipeline itself and the model weights (or parameters). We are using a `bf16` version of the weights, which leads to type warnings that you can safely ignore.
``` python
pipeline, params = FlaxStableDiffusionPipeline.from_pretrained(
"CompVis/stable-diffusion-v1-4",
revision="bf16",
dtype=dtype,
)
```
## Inference
Since TPUs usually have 8 devices working in parallel, we'll replicate our prompt as many times as devices we have. Then we'll perform inference on the 8 devices at once, each responsible for generating one image. Thus, we'll get 8 images in the same amount of time it takes for one chip to generate a single one.
After replicating the prompt, we obtain the tokenized text ids by invoking the `prepare_inputs` function of the pipeline. The length of the tokenized text is set to 77 tokens, as required by the configuration of the underlying CLIP Text model.
``` python
prompt = "A cinematic film still of Morgan Freeman starring as Jimi Hendrix, portrait, 40mm lens, shallow depth of field, close up, split lighting, cinematic"
prompt = [prompt] * jax.device_count()
prompt_ids = pipeline.prepare_inputs(prompt)
prompt_ids.shape
```
*Output*:
```bash
(8, 77)
```
### Replication and parallelization
Model parameters and inputs have to be replicated across the 8 parallel devices we have. The parameters dictionary is replicated using `flax.jax_utils.replicate`, which traverses the dictionary and changes the shape of the weights so they are repeated 8 times. Arrays are replicated using `shard`.
``` python
p_params = replicate(params)
```
``` python
prompt_ids = shard(prompt_ids)
prompt_ids.shape
```
*Output*:
```bash
(8, 1, 77)
```
That shape means that each one of the `8` devices will receive as an input a `jnp` array with shape `(1, 77)`. `1` is therefore the batch size per device. In TPUs with sufficient memory, it could be larger than `1` if we wanted to generate multiple images (per chip) at once.
We are almost ready to generate images! We just need to create a random number generator to pass to the generation function. This is the standard procedure in Flax, which is very serious and opinionated about random numbers – all functions that deal with random numbers are expected to receive a generator. This ensures reproducibility, even when we are training across multiple distributed devices.
The helper function below uses a seed to initialize a random number generator. As long as we use the same seed, we'll get the exact same results. Feel free to use different seeds when exploring results later in the notebook.
``` python
def create_key(seed=0):
return jax.random.PRNGKey(seed)
```
We obtain a rng and then "split" it 8 times so each device receives a different generator. Therefore, each device will create a different image, and the full process is reproducible.
``` python
rng = create_key(0)
rng = jax.random.split(rng, jax.device_count())
```
JAX code can be compiled to an efficient representation that runs very fast. However, we need to ensure that all inputs have the same shape in subsequent calls; otherwise, JAX will have to recompile the code, and we wouldn't be able to take advantage of the optimized speed.
The Flax pipeline can compile the code for us if we pass `jit = True` as an argument. It will also ensure that the model runs in parallel in the 8 available devices.
The first time we run the following cell it will take a long time to compile, but subsequent calls (even with different inputs) will be much faster. For example, it took more than a minute to compile in a TPU v2-8 when I tested, but then it takes about **`7s`** for future inference runs.
``` python
images = pipeline(prompt_ids, p_params, rng, jit=True)[0]
```
*Output*:
```bash
CPU times: user 464 ms, sys: 105 ms, total: 569 ms
Wall time: 7.07 s
```
The returned array has shape `(8, 1, 512, 512, 3)`. We reshape it to get rid of the second dimension and obtain 8 images of `512 × 512 × 3` and then convert them to PIL.
```python
images = images.reshape((images.shape[0],) + images.shape[-3:])
images = pipeline.numpy_to_pil(images)
```
### Visualization
Let's create a helper function to display images in a grid.
``` python
def image_grid(imgs, rows, cols):
w,h = imgs[0].size
grid = Image.new('RGB', size=(cols*w, rows*h))
for i, img in enumerate(imgs): grid.paste(img, box=(i%cols*w, i//cols*h))
return grid
```
``` python
image_grid(images, 2, 4)
```

## Using different prompts
We don't have to replicate the *same* prompt in all the devices. We can do whatever we want: generate 2 prompts 4 times each, or even generate 8 different prompts at once. Let's do that!
First, we'll refactor the input preparation code into a handy function:
``` python
prompts = [
"Labrador in the style of Hokusai",
"Painting of a squirrel skating in New York",
"HAL-9000 in the style of Van Gogh",
"Times Square under water, with fish and a dolphin swimming around",
"Ancient Roman fresco showing a man working on his laptop",
"Close-up photograph of young black woman against urban background, high quality, bokeh",
"Armchair in the shape of an avocado",
"Clown astronaut in space, with Earth in the background",
]
```
``` python
prompt_ids = pipeline.prepare_inputs(prompts)
prompt_ids = shard(prompt_ids)
images = pipeline(prompt_ids, p_params, rng, jit=True).images
images = images.reshape((images.shape[0], ) + images.shape[-3:])
images = pipeline.numpy_to_pil(images)
image_grid(images, 2, 4)
```

------------------------------------------------------------------------
## How does parallelization work?
We said before that the `diffusers` Flax pipeline automatically compiles the model and runs it in parallel on all available devices. We'll now briefly look inside that process to show how it works.
JAX parallelization can be done in multiple ways. The easiest one revolves around using the `jax.pmap` function to achieve single-program, multiple-data (SPMD) parallelization. It means we'll run several copies of the same code, each on different data inputs. More sophisticated approaches are possible, we invite you to go over the [JAX documentation](https://jax.readthedocs.io/en/latest/index.html) and the [`pjit` pages](https://jax.readthedocs.io/en/latest/jax-101/08-pjit.html?highlight=pjit) to explore this topic if you are interested!
`jax.pmap` does two things for us:
- Compiles (or `jit`s) the code, as if we had invoked `jax.jit()`. This does not happen when we call `pmap`, but the first time the pmapped function is invoked.
- Ensures the compiled code runs in parallel in all the available devices.
To show how it works we `pmap` the `_generate` method of the pipeline, which is the private method that runs generates images. Please, note that this method may be renamed or removed in future releases of `diffusers`.
``` python
p_generate = pmap(pipeline._generate)
```
After we use `pmap`, the prepared function `p_generate` will conceptually do the following:
- Invoke a copy of the underlying function `pipeline._generate` in each device.
- Send each device a different portion of the input arguments. That's what sharding is used for. In our case, `prompt_ids` has shape `(8, 1, 77, 768)`. This array will be split in `8` and each copy of `_generate` will receive an input with shape `(1, 77, 768)`.
We can code `_generate` completely ignoring the fact that it will be invoked in parallel. We just care about our batch size (`1` in this example) and the dimensions that make sense for our code, and don't have to change anything to make it work in parallel.
The same way as when we used the pipeline call, the first time we run the following cell it will take a while, but then it will be much faster.
``` python
images = p_generate(prompt_ids, p_params, rng)
images = images.block_until_ready()
images.shape
```
*Output*:
```bash
CPU times: user 118 ms, sys: 83.9 ms, total: 202 ms
Wall time: 6.82 s
(8, 1, 512, 512, 3)
```
We use `block_until_ready()` to correctly measure inference time, because JAX uses asynchronous dispatch and returns control to the Python loop as soon as it can. You don't need to use that in your code; blocking will occur automatically when you want to use the result of a computation that has not yet been materialized.
| 4 |
0 | hf_public_repos | hf_public_repos/blog/xlscout-case-study.md | ---
title: "XLSCOUT Unveils ParaEmbed 2.0: a Powerful Embedding Model Tailored for Patents and IP with Expert Support from Hugging Face"
thumbnail: /blog/assets/xlscout-case-study/thumbnail.png
authors:
- user: andrewrreed
- user: Khushwant78
guest: true
org: xlscout-ai
---
# XLSCOUT Unveils ParaEmbed 2.0: a Powerful Embedding Model Tailored for Patents and IP with Expert Support from Hugging Face
> [!NOTE] This is a guest blog post by the XLSCOUT team.
[XLSCOUT](https://xlscout.ai/), a Toronto-based leader in the use of AI in intellectual property (IP), has developed a powerful proprietary embedding model called **ParaEmbed 2.0** stemming from an ambitious collaboration with Hugging Face’s Expert Support Program. The collaboration focuses on applying state-of-the-art AI technologies and open-source models to enhance the understanding and analysis of complex patent documents including patent-specific terminology, context, and relationships. This allows XLSCOUT’s products to offer the best performance for drafting patent applications, patent invalidation searches, and ensuring ideas are novel compared to previously available patents and literature.
By fine-tuning on high-quality, multi-domain patent data curated by human experts, ParaEmbed 2.0 boasts **a remarkable 23% increase in accuracy** compared to its predecessor, [ParaEmbed 1.0](https://xlscout.ai/pressrelease/xlscout-paraembed-an-embedding-model-fine-tuned-on-patent-and-technology-data-is-now-opensource-and-available-on-hugging-face), which was released in October 2023. With this advancement, ParaEmbed 2.0 is now able to accurately capture context and map patents against prior art, ideas, products, or standards with even greater precision.
## The journey towards enhanced patent analysis
Initially, XLSCOUT explored proprietary AI models for patent analysis, but found that these closed-source models, such as GPT-4 and text-embedding-ada-002, struggled to capture the nuanced context required for technical and specialized patent claims.
By integrating open-source models like BGE-base-v1.5, Llama 2 70B, Falcon 40B, and Mixtral 8x7B, and fine-tuning on proprietary patent data with guidance from Hugging Face, XLSCOUT achieved more tailored and performant solutions. This shift allowed for a more accurate understanding of intricate technical concepts and terminologies, revolutionizing the analysis and understanding of technical documents and patents.
## Collaborating with Hugging Face via the Expert Support Program
The collaboration with Hugging Face has been instrumental in enhancing the quality and performance of XLSCOUT’s solutions. Here's a detailed overview of how this partnership has evolved and its impact:
1. **Initial development and testing:** XLSCOUT initially built and tested a custom TorchServe inference server on Google Cloud Platform (GCP) with Distributed Data Parallel (DDP) for serving multiple replicas. By integrating ONNX optimizations, they achieved a performance rate of approximately ~300 embeddings per second.
2. **Enhanced model performance via fine-tuning:** Fine-tuning of an embedding model was performed using data curated by patent experts. This workflow not only enabled more precise and contextually relevant embeddings, but also significantly improved the performance metrics, ensuring higher accuracy in detecting relevant prior art.
3. **High throughput serving:** By leveraging Hugging Face’s [Inference Endpoints](https://huggingface.co/inference-endpoints/dedicated) with built-in load balancing, XLSCOUT now serves embedding models with [Text Embedding Inference (TEI)](https://huggingface.co/docs/text-embeddings-inference/en/index) for a high throughput use case running successfully in production. The solution now achieves impressive performance, **delivering ~2700 embeddings per second!**
4. **LLM prompting and inference:** The collaboration has included efforts around LLM prompt engineering and inference, which enhanced the model's ability to generate accurate and context-specific patent drafts. Prompt engineering was employed for patent drafting use cases, ensuring that the prompts resulted in coherent, comprehensive, and legally-sound patent documents.
5. **Fine-tuning LLMs with instruction data:** Instruction data formatting and fine-tuning were implemented using models from Meta and Mistral. This fine-tuning allowed for even more precise and detailed generation of some parts of the patent drafting process, further improving the quality of the generated output.
The partnership with Hugging Face has been a game-changer for XLSCOUT, significantly improving the processing speed, accuracy, and overall quality of their LLM-driven solutions. This collaboration ensures that universities, law firms, and other clients benefit from cutting-edge AI technologies, driving efficiency and innovation in the patent landscape.
## XLSCOUT's AI-based IP Solutions
XLSCOUT provides state-of-the-art AI-driven solutions that significantly enhance the efficiency and accuracy of patent-related processes. Their solutions are widely leveraged by corporations, universities, and law firms to streamline various facets of IP workflows, from novelty searches and invalidation studies to patent drafting.
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/xlscout-solutions.png" alt="XLSCOUT Solutions" style="width: 90%; height: auto;"><br>
</p>
- **[Novelty Checker LLM](https://xlscout.ai/novelty-checker-llm):** Leverages cutting-edge LLMs and Generative AI to swiftly navigate through patent and non-patent literature to validate your ideas. It delivers a comprehensive list of ranked prior art references alongside a key feature analysis report. This tool enables inventors, researchers, and patent professionals to ensure that inventions are novel by comparing them against the extensive corpus of existing literature and patents.
- **[Invalidator LLM](https://xlscout.ai/invalidator-llm):** Utilizes advanced LLMs and Generative AI to conduct patent invalidation searches with exceptional speed and accuracy. It provides a detailed list of ranked prior art references and a key feature analysis report. This service is crucial for law firms and corporations to efficiently challenge and assess the validity of patents.
- **[Drafting LLM](https://xlscout.ai/drafting-llm):** Is an automated patent application drafting platform harnessing the power of LLMs and Generative AI. It generates precise and high-quality preliminary patent drafts, encompassing comprehensive claims, abstracts, drawings, backgrounds, and descriptions within a few minutes. This solution aids patent practitioners in significantly reducing the time and effort required to produce detailed and precise patent applications.
Corporations and universities benefit by ensuring that novel research outputs are appropriately protected, encouraging innovation, and filing high quality patents. Law firms utilize XLSCOUT’s solutions to deliver superior service to their clients, improving the quality of their patent prosecution and litigation efforts.
## A partnership for innovation
_“We are thrilled to collaborate with Hugging Face”_, said [Mr. Sandeep Agarwal, CEO of XLSCOUT](https://www.linkedin.com/in/sandeep-agarwal-61721410/). _“This partnership combines the unparalleled capabilities of Hugging Face's open-source models, tools, and team with our deep expertise in patents. By fine-tuning these models with our proprietary data, we are poised to revolutionize how patents are drafted, analyzed, and licensed.”_
The joint efforts of XLSCOUT and Hugging Face involve training open-source models on XLSCOUT’s extensive patent data collection. This synergy harnesses the specialized knowledge of XLSCOUT and the advanced AI capabilities of Hugging Face, resulting in models uniquely optimized for patent research. Users will benefit from more informed decisions and valuable insights derived from complex patent documents.
## Commitment to innovation and future plans
As pioneers in the application of AI to intellectual property, XLSCOUT is dedicated to exploring new frontiers in AI-driven innovation. This collaboration marks a significant step towards bridging the gap between cutting-edge AI and real-world applications in IP analysis.
Together, XLSCOUT and Hugging Face are setting new standards in patent analysis, driving innovation, and shaping the future of intellectual property. We’re excited to continue this awesome journey together!
To learn more about Hugging Face’s Expert Support Program for your company, please [get in touch with us here](https://huggingface.co/support#form) - our team will contact you to discuss your requirements!
| 5 |
0 | hf_public_repos | hf_public_repos/blog/series-c.md | ---
title: "We Raised $100 Million for Open & Collaborative Machine Learning 🚀"
thumbnail: /blog/assets/65_series_c/thumbnail.jpg
authors:
- user: huggingface
---
# We Raised $100 Million for Open & Collaborative Machine Learning 🚀
Today we have some exciting news to share! Hugging Face has raised $100 Million in Series C funding 🔥🔥🔥 led by Lux Capital with major participations from Sequoia, Coatue and support of existing investors Addition, a_capital, SV Angel, Betaworks, AIX Ventures, Kevin Durant, Rich Kleiman from Thirty Five Ventures, Olivier Pomel (co-founder & CEO at Datadog) and more.
<figure class="image table text-center m-0 w-full">
<img src="/blog/assets/65_series_c/thumbnail.jpg" alt="Series C"/>
</figure>
We've come a long way since we first open sourced [PyTorch BERT](https://twitter.com/Thom_Wolf/status/1068637731281088513) in 2018 and are just getting started! 🙌
Machine learning is becoming the default way to build technology. When you think about your average day, machine learning is everywhere: from your Zoom background, to searching on Google, to ordering an Uber or writing an email with auto-complete --it's all machine learning.
Hugging Face is now the fastest growing community & most used platform for machine learning! With 100,000 pre-trained models & 10,000 datasets hosted on the platform for NLP, computer vision, speech, time-series, biology, reinforcement learning, chemistry and more, the [Hugging Face Hub](https://huggingface.co/models) has become the Home of Machine Learning to create, collaborate, and deploy state-of-the-art models.
<figure class="image table text-center m-0 w-full">
<img src="assets/65_series_c/home-of-machine-learning.png" alt="The Home of Machine Learning"/>
</figure>
Over 10,000 companies are now using Hugging Face to build technology with machine learning. Their Machine Learning scientists, Data scientists and Machine Learning engineers have saved countless hours while accelerating their machine learning roadmaps with the help of our [products](https://huggingface.co/platform) and [services](https://huggingface.co/support).
We want to have a positive impact on the AI field. We think the direction of more responsible AI is through openly sharing models, datasets, training procedures, evaluation metrics and working together to solve issues. We believe open source and open science bring trust, robustness, reproducibility, and continuous innovation. With this in mind, we are leading [BigScience](https://bigscience.huggingface.co/), a collaborative workshop around the study and creation of very large language models gathering more than 1,000 researchers of all backgrounds and disciplines. We are now training the [world's largest open source multilingual language model](https://twitter.com/BigScienceLLM) 🌸
⚠️ But there’s still a huge amount of work left to do.
At Hugging Face, we know that Machine Learning has some important limitations and challenges that need to be tackled now like biases, privacy, and energy consumption. With openness, transparency & collaboration, we can foster responsible & inclusive progress, understanding & accountability to mitigate these challenges.
Thanks to the new funding, we’ll be doubling down on research, open-source, products and responsible democratization of AI.
<figure class="image table text-center m-0 w-full">
<img src="assets/65_series_c/team.png" alt="The Home of Machine Learning"/>
</figure>
It's been a hell of a ride to grow from 30 to 120+ team members in the past 12 months. We were super lucky to have been joined by incredibly talented (and fun!) teammates like [Dr. Margaret Mitchell](https://www.bloomberg.com/news/articles/2021-08-24/fired-at-google-after-critical-work-ai-researcher-mitchell-to-join-hugging-face) and the [Gradio team](https://gradio.app/joining-huggingface/), and we don't plan to stop here. We're [hiring for every position](https://apply.workable.com/huggingface) you can think of for every level of seniority. We are a remote-friendly, decentralized organization with transparency and value-inspired decision making by default.
Huge thanks to every contributor in our amazing community and team, our customers, partners, and investors for helping us reach this point. We couldn't have done it without you, and we can't wait to work together with you on what's next. Your contributions are key to helping build a better future where AI is founded on open source, open science, ethics and collaboration.
---
*For press inquiries, please contact <a href="mailto:[email protected]">[email protected]</a>*
| 6 |
0 | hf_public_repos | hf_public_repos/blog/setfit.md | ---
title: "SetFit: Efficient Few-Shot Learning Without Prompts"
thumbnail: /blog/assets/103_setfit/intel_hf_logo.png
authors:
- user: Unso
- user: lewtun
- user: luketheduke
- user: danielkorat
- user: orenpereg
- user: moshew
---
# SetFit: Efficient Few-Shot Learning Without Prompts
<p align="center">
<img src="assets/103_setfit/setfit_curves.png" width=500>
</p>
<p align="center">
<em>SetFit is significantly more sample efficient and robust to noise than standard fine-tuning.</em>
</p>
Few-shot learning with pretrained language models has emerged as a promising solution to every data scientist's nightmare: dealing with data that has few to no labels 😱.
Together with our research partners at [Intel Labs](https://www.intel.com/content/www/us/en/research/overview.html) and the [UKP Lab](https://www.informatik.tu-darmstadt.de/ukp/ukp_home/index.en.jsp), Hugging Face is excited to introduce SetFit: an efficient framework for few-shot fine-tuning of [Sentence Transformers](https://sbert.net/). SetFit achieves high accuracy with little labeled data - for example, with only 8 labeled examples per class on the Customer Reviews (CR) sentiment dataset, SetFit is competitive with fine-tuning RoBERTa Large on the full training set of 3k examples 🤯!
Compared to other few-shot learning methods, SetFit has several unique features:
<p>🗣 <strong>No prompts or verbalisers</strong>: Current techniques for few-shot fine-tuning require handcrafted prompts or verbalisers to convert examples into a format that's suitable for the underlying language model. SetFit dispenses with prompts altogether by generating rich embeddings directly from a small number of labeled text examples. </p>
<p>🏎 <strong>Fast to train</strong>: SetFit doesn't require large-scale models like T0 or GPT-3 to achieve high accuracy. As a result, it is typically an order of magnitude (or more) faster to train and run inference with. </p>
<p>🌎 <strong>Multilingual support</strong>: SetFit can be used with any Sentence Transformer on the Hub, which means you can classify text in multiple languages by simply fine-tuning a multilingual checkpoint. </p>
For more details, check out our [paper](https://arxiv.org/abs/2209.11055), [data](https://huggingface.co/SetFit), and [code](https://github.com/huggingface/setfit). In this blog post, we'll explain how SetFit works and how to train your very own models. Let's dive in!
## How does it work?
SetFit is designed with efficiency and simplicity in mind. SetFit first fine-tunes a Sentence Transformer model on a small number of labeled examples (typically 8 or 16 per class). This is followed by training a classifier head on the embeddings generated from the fine-tuned Sentence Transformer.
<p align="center">
<img src="assets/103_setfit/setfit_diagram_process.png" width=700>
</p>
<p align="center">
<em>SetFit's two-stage training process</em>
</p>
SetFit takes advantage of Sentence Transformers’ ability to generate dense embeddings based on paired sentences. In the initial fine-tuning phase stage, it makes use of the limited labeled input data by contrastive training, where positive and negative pairs are created by in-class and out-class selection. The Sentence Transformer model then trains on these pairs (or triplets) and generates dense vectors per example. In the second step, the classification head trains on the encoded embeddings with their respective class labels. At inference time, the unseen example passes through the fine-tuned Sentence Transformer, generating an embedding that when fed to the classification head outputs a class label prediction.
And just by switching out the base Sentence Transformer model to a multilingual one, SetFit can function seamlessly in multilingual contexts. In our [experiments](https://arxiv.org/abs/2209.11055), SetFit’s performance shows promising results on classification in German, Japanese, Mandarin, French and Spanish, in both in-language and cross linguistic settings.
## Benchmarking SetFit
Although based on much smaller models than existing few-shot methods, SetFit performs on par or better than state of the art few-shot regimes on a variety of benchmarks. On [RAFT](https://huggingface.co/spaces/ought/raft-leaderboard), a few-shot classification benchmark, SetFit Roberta (using the [`all-roberta-large-v1`](https://huggingface.co/sentence-transformers/all-roberta-large-v1) model) with 355 million parameters outperforms PET and GPT-3. It places just under average human performance and the 11 billion parameter T-few - a model 30 times the size of SetFit Roberta. SetFit also outperforms the human baseline on 7 of the 11 RAFT tasks.
| Rank | Method | Accuracy | Model Size |
| :------: | ------ | :------: | :------: |
| 2 | T-Few | 75.8 | 11B |
| 4 | Human Baseline | 73.5 | N/A |
| 6 | SetFit (Roberta Large) | 71.3 | 355M |
| 9 | PET | 69.6 | 235M |
| 11 | SetFit (MP-Net) | 66.9 | 110M |
| 12 | GPT-3 | 62.7 | 175 B |
<p align="center">
<em>Prominent methods on the RAFT leaderboard (as of September 2022)</em>
</p>
On other datasets, SetFit shows robustness across a variety of tasks. As shown in the figure below, with just 8 examples per class, it typically outperforms PERFECT, ADAPET and fine-tuned vanilla transformers. SetFit also achieves comparable results to T-Few 3B, despite being prompt-free and 27 times smaller.
<p align="center">
<img src="assets/103_setfit/three-tasks.png" width=700>
</p>
<p align="center">
<em>Comparing Setfit performance against other methods on 3 classification datasets.</em>
</p>
## Fast training and inference
<p align="center">
<img src="assets/103_setfit/bars.png" width=400>
</p>
<p align="center">
Comparing training cost and average performance for T-Few 3B and SetFit (MPNet), with 8 labeled examples per class.
</p>
Since SetFit achieves high accuracy with relatively small models, it's blazing fast to train and at much lower cost. For instance, training SetFit on an NVIDIA V100 with 8 labeled examples takes just 30 seconds, at a cost of $0.025. By comparison, training T-Few 3B requires an NVIDIA A100 and takes 11 minutes, at a cost of around $0.7 for the same experiment - a factor of 28x more. In fact, SetFit can run on a single GPU like the ones found on Google Colab and you can even train SetFit on CPU in just a few minutes! As shown in the figure above, SetFit's speed-up comes with comparable model performance. Similar gains are also achieved for [inference](https://arxiv.org/abs/2209.11055) and distilling the SetFit model can bring speed-ups of 123x 🤯.
## Training your own model
To make SetFit accessible to the community, we've created a small `setfit` [library](https://github.com/huggingface/setfit) that allows you to train your own models with just a few lines of code.
The first thing to do is install it by running the following command:
```sh
pip install setfit
```
Next, we import `SetFitModel` and `SetFitTrainer`, two core classes that streamline the SetFit training process:
```python
from datasets import load_dataset
from sentence_transformers.losses import CosineSimilarityLoss
from setfit import SetFitModel, SetFitTrainer
```
Now, let's download a text classification dataset from the Hugging Face Hub. We'll use the [SentEval-CR](https://huggingface.co/datasets/SetFit/SentEval-CR) dataset, which is a dataset of customer reviews:
```python
dataset = load_dataset("SetFit/SentEval-CR")
```
To simulate a real-world scenario with just a few labeled examples, we'll sample 8 examples per class from the training set:
```python
# Select N examples per class (8 in this case)
train_ds = dataset["train"].shuffle(seed=42).select(range(8 * 2))
test_ds = dataset["test"]
```
Now that we have a dataset, the next step is to load a pretrained Sentence Transformer model from the Hub and instantiate a `SetFitTrainer`. Here we use the [paraphrase-mpnet-base-v2](https://huggingface.co/sentence-transformers/paraphrase-mpnet-base-v2) model, which we found to give great results across many datasets:
```python
# Load SetFit model from Hub
model = SetFitModel.from_pretrained("sentence-transformers/paraphrase-mpnet-base-v2")
# Create trainer
trainer = SetFitTrainer(
model=model,
train_dataset=train_ds,
eval_dataset=test_ds,
loss_class=CosineSimilarityLoss,
batch_size=16,
num_iterations=20, # Number of text pairs to generate for contrastive learning
num_epochs=1 # Number of epochs to use for contrastive learning
)
```
The last step is to train and evaluate the model:
```python
# Train and evaluate!
trainer.train()
metrics = trainer.evaluate()
```
And that's it - you've now trained your first SetFit model! Remember to push your trained model to the Hub :)
```python
# Push model to the Hub
# Make sure you're logged in with huggingface-cli login first
trainer.push_to_hub("my-awesome-setfit-model")
```
While this example showed how this can be done with one specific type of base model, any [Sentence Transformer](https://huggingface.co/models?library=sentence-transformers&sort=downloads) model could be switched in for different performance and tasks. For instance, using a multilingual Sentence Transformer body can extend few-shot classification to multilingual settings.
## Next steps
We've shown that SetFit is an effective method for few-shot classification tasks. In the coming months, we'll be exploring how well the method generalizes to tasks like natural language inference and token classification. In the meantime, we're excited to see how industry practitioners apply SetFit to their use cases - if you have any questions or feedback, open an issue on our [GitHub repo](https://github.com/huggingface/setfit) 🤗.
Happy few-shot learning!
| 7 |
0 | hf_public_repos | hf_public_repos/blog/docmatix.md | ---
title: "Docmatix - a huge dataset for Document Visual Question Answering"
thumbnail: /blog/assets/183_docmatix/thumbnail_new.png
authors:
- user: andito
- user: HugoLaurencon
---
# Docmatix - A huge dataset for Document Visual Question Answering
With this blog we are releasing [Docmatix - a huge dataset for Document Visual Question Answering](https://huggingface.co/datasets/HuggingFaceM4/Docmatix) (DocVQA) that is 100s of times larger than previously available. Ablations using this dataset for fine-tuning Florence-2 show a 20% increase in performance on DocVQA.
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/docmatix_example.png" alt="Example from the dataset" style="width: 90%; height: auto;"><br>
<em>An example from the dataset</em>
</p>
We first had the idea to create Docmatix when we developed [The Cauldron](https://huggingface.co/datasets/HuggingFaceM4/the_cauldron), an extensive collection of 50 datasets for the fine-tuning of Vision-Language Model (VLM), and [Idefics2](https://huggingface.co/blog/idefics2) in particular. Through this process, we identified a significant gap in the availability of large-scale Document Visual Question Answering (DocVQA) datasets. The primary dataset we relied on for Idefics2 was DocVQA, which contains 10,000 images and 39,000 question-answer (Q/A) pairs. Fine-tuning on this and other datasets, open-sourced models still maintain a large gap in performance to closed-source ones.
To address this limitation, we are excited to introduce Docmatix, a DocVQA dataset featuring 2.4 million images and 9.5 million Q/A pairs derived from 1.3 million PDF documents. A **240X** increase in scale compared to previous datasets.
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/docmatix_dataset_comp.png" alt="Comparing Docmatix to other DocVQA datasets" style="width: 90%; height: auto;"><br>
<em>Comparing Docmatix to other DocVQA datasets</em>
</p>
Here you can explore the dataset yourself and see the type of documents and question-answer pairs contained in Docterix.
<iframe
src="https://huggingface.co/datasets/HuggingFaceM4/Docmatix/embed/viewer/default/train"
frameborder="0"
width="100%"
height="560px"
></iframe>
Docmatix is generated from [PDFA, an extensive OCR dataset containing 2.1 million PDFs](https://huggingface.co/datasets/pixparse/pdfa-eng-wds). We took the transcriptions from PDFA and employed a [Phi-3-small](https://huggingface.co/microsoft/Phi-3-small-8k-instruct) model to generate Q/A pairs. To ensure the dataset's quality, we filtered the generations, discarding 15% of the Q/A pairs identified as hallucinations. To do so, we used regular expressions to detect code and removed answers that contained the keyword “unanswerable”.
The dataset contains a row for each PDF. We converted the PDFs to images at a resolution of 150 dpi, and uploaded the processed images to the Hugging Face Hub for easy access.
All the original PDFs in Docmatix can be traced back to the original PDFA dataset, providing transparency and reliability. Still, we uploaded the processed images for convenience because converting many PDFs to images can be resource-intensive.
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/docmatix_processing.png" alt="Processing for Docmatix" style="width: 90%; height: auto;"><br>
<em>Processing pipeline to generate Docmatix</em>
</p>
After processing the first small batch of the dataset, we performed several ablation studies to optimize the prompts. We aimed to generate around four pairs of Q/A per page. Too many pairs indicate a large overlap between them, while too few pairs suggest a lack of detail.
Additionally, we aimed for answers to be human-like, avoiding excessively short or long responses. We also prioritized diversity in the questions, ensuring minimal repetition. Interestingly, when we guided the [Phi-3 model](https://huggingface.co/docs/transformers/main/en/model_doc/phi3) to ask questions based on the specific information in the document (e.g., "What are the titles of John Doe?"), the questions showed very few repetitions. The following plot presents some key statistics from our analysis:
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/docmatix_prompt_analysis.png" alt="Prompt analysis Docmatix" style="width: 90%; height: auto;"><br>
<em>Analysis of Docmatix per prompt</em>
</p>
To evaluate Docmatix's performance, we conducted ablation studies using the Florence-2 model. We trained two versions of the model for comparison. The first version was trained over several epochs on the DocVQA dataset. The second version was trained for one epoch on Docmatix (20% of the images and 4% of the Q/A pairs), followed by one epoch on DocVQA to ensure the model produced the correct format for DocVQA evaluation.
The results are significant: training on this small portion of Docmatix yielded a relative improvement of almost 20%. Additionally, the 0.7B Florence-2 model performed only 5% worse than the 8B Idefics2 model trained on a mixture of datasets and is significantly larger.
<div align="center">
| Dataset | ANSL on DocVQA |model size |
|--------------------------------------|----------------|----------------|
| Florence 2 fine-tuned on DocVQA | 60.1 | 700M |
| Florence 2 fine-tuned on Docmatix | 71,4 | 700M |
| Idefics2 | 74,0 | 8B |
</div>
<script
type="module"
src="https://gradio.s3-us-west-2.amazonaws.com/4.36.1/gradio.js"></script>
<gradio-app theme_mode="light" src="https://HuggingFaceM4-Docmatix-Florence-2.hf.space"></gradio-app>
## Conclusion
In this post, we presented Docmatix, a gigantic dataset for DocVQA. We showed that using Docmatix we can achieve a 20% increase in DocVQA performance when finetuning Florence-2. This dataset should help bridge the gap between proprietary VLMs and open-sourced VLMs. We encourage the open-source community to leverage Docmatix and train new amazing DocVQA models! We can't wait to see your models on the 🤗 Hub!
## Useful Resources
- [Docmatix used to finetune Florence-2 Demo](https://huggingface.co/spaces/HuggingFaceM4/Docmatix-Florence-2)
- [Finetuning Florence-2 Blog](https://huggingface.co/blog/finetune-florence2)
- [Fine tuning Florence-2 Github Repo](https://github.com/andimarafioti/florence2-finetuning)
- [Vision Language Models Explained](https://huggingface.co/blog/vlms)
We would like to thank merve and leo for their reviews and thumbnails for this blog.
| 8 |
0 | hf_public_repos | hf_public_repos/blog/gptj-sagemaker.md | ---
title: "Deploy GPT-J 6B for inference using Hugging Face Transformers and Amazon SageMaker"
thumbnail: /blog/assets/45_gptj_sagemaker/thumbnail.png
authors:
- user: philschmid
---
# Deploy GPT-J 6B for inference using Hugging Face Transformers and Amazon SageMaker
<script async defer src="https://unpkg.com/medium-zoom-element@0/dist/medium-zoom-element.min.js"></script>
Almost 6 months ago to the day, [EleutherAI](https://www.eleuther.ai/) released [GPT-J 6B](https://huggingface.co/EleutherAI/gpt-j-6B), an open-source alternative to [OpenAIs GPT-3](https://openai.com/blog/gpt-3-apps/). [GPT-J 6B](https://huggingface.co/EleutherAI/gpt-j-6B) is the 6 billion parameter successor to [EleutherAIs](https://www.eleuther.ai/) GPT-NEO family, a family of transformer-based language models based on the GPT architecture for text generation.
[EleutherAI](https://www.eleuther.ai/)'s primary goal is to train a model that is equivalent in size to GPT-3 and make it available to the public under an open license.
Over the last 6 months, `GPT-J` gained a lot of interest from Researchers, Data Scientists, and even Software Developers, but it remained very challenging to deploy `GPT-J` into production for real-world use cases and products.
There are some hosted solutions to use `GPT-J` for production workloads, like the [Hugging Face Inference API](https://huggingface.co/inference-api), or for experimenting using [EleutherAIs 6b playground](https://6b.eleuther.ai/), but fewer examples on how to easily deploy it into your own environment.
In this blog post, you will learn how to easily deploy `GPT-J` using [Amazon SageMaker](https://aws.amazon.com/de/sagemaker/) and the [Hugging Face Inference Toolkit](https://github.com/aws/sagemaker-huggingface-inference-toolkit) with a few lines of code for scalable, reliable, and secure real-time inference using a regular size GPU instance with NVIDIA T4 (~500$/m).
But before we get into it, I want to explain why deploying `GPT-J` into production is challenging.
---
## Background
The weights of the 6 billion parameter model represent a ~24GB memory footprint. To load it in float32, one would need at least 2x model size CPU RAM: 1x for initial weights and another 1x to load the checkpoint. So for `GPT-J` it would require at least 48GB of CPU RAM to just load the model.
To make the model more accessible, [EleutherAI](https://www.eleuther.ai/) also provides float16 weights, and `transformers` has new options to reduce the memory footprint when loading large language models. Combining all this it should take roughly 12.1GB of CPU RAM to load the model.
```python
from transformers import GPTJForCausalLM
import torch
model = GPTJForCausalLM.from_pretrained(
"EleutherAI/gpt-j-6B",
revision="float16",
torch_dtype=torch.float16,
low_cpu_mem_usage=True
)
```
The caveat of this example is that it takes a very long time until the model is loaded into memory and ready for use. In my experiments, it took `3 minutes and 32 seconds` to load the model with the code snippet above on a `P3.2xlarge` AWS EC2 instance (the model was not stored on disk). This duration can be reduced by storing the model already on disk, which reduces the load time to `1 minute and 23 seconds`, which is still very long for production workloads where you need to consider scaling and reliability.
For example, Amazon SageMaker has a [60s limit for requests to respond](https://docs.aws.amazon.com/general/latest/gr/sagemaker.html#sagemaker_region), meaning the model needs to be loaded and the predictions to run within 60s, which in my opinion makes a lot of sense to keep the model/endpoint scalable and reliable for your workload. If you have longer predictions, you could use [batch-transform](https://docs.aws.amazon.com/sagemaker/latest/dg/batch-transform.html).
In [Transformers](https://github.com/huggingface/transformers) the models loaded with the `from_pretrained` method are following PyTorch's [recommended practice](https://pytorch.org/tutorials/beginner/saving_loading_models.html#save-load-state-dict-recommended), which takes around `1.97 seconds` for BERT [[REF]](https://colab.research.google.com/drive/1-Y5f8PWS8ksoaf1A2qI94jq0GxF2pqQ6?usp=sharing). PyTorch offers an [additional alternative way of saving and loading models](https://pytorch.org/tutorials/beginner/saving_loading_models.html#save-load-entire-model) using `torch.save(model, PATH)` and `torch.load(PATH)`.
*“Saving a model in this way will save the entire module using Python’s [pickle](https://docs.python.org/3/library/pickle.html) module. The disadvantage of this approach is that the serialized data is bound to the specific classes and the exact directory structure used when the model is saved.”*
This means that when we save a model with `transformers==4.13.2` it could be potentially incompatible when trying to load with `transformers==4.15.0`. However, loading models this way reduces the loading time by **~12x,** down to `0.166s` for BERT.
Applying this to `GPT-J` means that we can reduce the loading time from `1 minute and 23 seconds` down to `7.7 seconds`, which is ~10.5x faster.
<br>
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="Model Load time of BERT and GPTJ" src="assets/45_gptj_sagemaker/model_load_time.png"></medium-zoom>
<figcaption>Figure 1. Model load time of BERT and GPTJ</figcaption>
</figure>
<br>
## Tutorial
With this method of saving and loading models, we achieved model loading performance for `GPT-J` compatible with production scenarios. But we need to keep in mind that we need to align:
> Align PyTorch and Transformers version when saving the model with `torch.save(model,PATH)` and loading the model with `torch.load(PATH)` to avoid incompatibility.
>
### Save `GPT-J` using `torch.save`
To create our `torch.load()` compatible model file we load `GPT-J` using Transformers and the `from_pretrained` method, and then save it with `torch.save()`.
```python
from transformers import AutoTokenizer,GPTJForCausalLM
import torch
# load fp 16 model
model = GPTJForCausalLM.from_pretrained("EleutherAI/gpt-j-6B", revision="float16", torch_dtype=torch.float16)
# save model with torch.save
torch.save(model, "gptj.pt")
```
Now we are able to load our `GPT-J` model with `torch.load()` to run predictions.
```python
from transformers import pipeline
import torch
# load model
model = torch.load("gptj.pt")
# load tokenizer
tokenizer = AutoTokenizer.from_pretrained("EleutherAI/gpt-j-6B")
# create pipeline
gen = pipeline("text-generation",model=model,tokenizer=tokenizer,device=0)
# run prediction
gen("My Name is philipp")
#[{'generated_text': 'My Name is philipp k. and I live just outside of Detroit....
```
---
### Create `model.tar.gz` for the Amazon SageMaker real-time endpoint
Since we can load our model quickly and run inference on it let’s deploy it to Amazon SageMaker.
There are two ways you can deploy transformers to Amazon SageMaker. You can either [“Deploy a model from the Hugging Face Hub”](https://huggingface.co/docs/sagemaker/inference#deploy-a-model-from-the-%F0%9F%A4%97-hub) directly or [“Deploy a model with `model_data` stored on S3”](https://huggingface.co/docs/sagemaker/inference#deploy-with-model_data). Since we are not using the default Transformers method we need to go with the second option and deploy our endpoint with the model stored on S3.
For this, we need to create a `model.tar.gz` artifact containing our model weights and additional files we need for inference, e.g. `tokenizer.json`.
**We provide uploaded and publicly accessible `model.tar.gz` artifacts, which can be used with the `HuggingFaceModel` to deploy `GPT-J` to Amazon SageMaker.**
See [“Deploy `GPT-J` as Amazon SageMaker Endpoint”](https://www.notion.so/Deploy-GPT-J-6B-for-inference-using-Hugging-Face-Transformers-and-Amazon-SageMaker-ce65921edf2246e6a71bb3073e5b3bc7) on how to use them.
If you still want or need to create your own `model.tar.gz`, e.g. because of compliance guidelines, you can use the helper script [convert_gpt.py](https://github.com/philschmid/amazon-sagemaker-gpt-j-sample/blob/main/convert_gptj.py) for this purpose, which creates the `model.tar.gz` and uploads it to S3.
```bash
# clone directory
git clone https://github.com/philschmid/amazon-sagemaker-gpt-j-sample.git
# change directory to amazon-sagemaker-gpt-j-sample
cd amazon-sagemaker-gpt-j-sample
# create and upload model.tar.gz
pip3 install -r requirements.txt
python3 convert_gptj.py --bucket_name {model_storage}
```
The `convert_gpt.py` should print out an S3 URI similar to this. `s3://hf-sagemaker-inference/gpt-j/model.tar.gz`.
### Deploy `GPT-J` as Amazon SageMaker Endpoint
To deploy our Amazon SageMaker Endpoint we are going to use the [Amazon SageMaker Python SDK](https://sagemaker.readthedocs.io/en/stable/) and the `HuggingFaceModel` class.
The snippet below uses the `get_execution_role` which is only available inside Amazon SageMaker Notebook Instances or Studio. If you want to deploy a model outside of it check [the documentation](https://huggingface.co/docs/sagemaker/train#installation-and-setup#).
The `model_uri` defines the location of our `GPT-J` model artifact. We are going to use the publicly available one provided by us.
```python
from sagemaker.huggingface import HuggingFaceModel
import sagemaker
# IAM role with permissions to create endpoint
role = sagemaker.get_execution_role()
# public S3 URI to gpt-j artifact
model_uri="s3://huggingface-sagemaker-models/transformers/4.12.3/pytorch/1.9.1/gpt-j/model.tar.gz"
# create Hugging Face Model Class
huggingface_model = HuggingFaceModel(
model_data=model_uri,
transformers_version='4.12.3',
pytorch_version='1.9.1',
py_version='py38',
role=role,
)
# deploy model to SageMaker Inference
predictor = huggingface_model.deploy(
initial_instance_count=1, # number of instances
instance_type='ml.g4dn.xlarge' #'ml.p3.2xlarge' # ec2 instance type
)
```
If you want to use your own `model.tar.gz` just replace the `model_uri` with your S3 Uri.
The deployment should take around 3-5 minutes.
### Run predictions
We can run predictions using the `predictor` instances created by our `.deploy` method. To send a request to our endpoint we use the `predictor.predict` with our `inputs`.
```python
predictor.predict({
"inputs": "Can you please let us know more details about your "
})
```
If you want to customize your predictions using additional `kwargs` like `min_length`, check out “Usage best practices” below.
## Usage best practices
When using generative models, most of the time you want to configure or customize your prediction to fit your needs, for example by using beam search, configuring the max or min length of the generated sequence, or adjust the temperature to reduce repetition. The Transformers library provides different strategies and `kwargs` to do this, the Hugging Face Inference toolkit offers the same functionality using the `parameters` attribute of your request payload. Below you can find examples on how to generate text without parameters, with beam search, and using custom configurations. If you want to learn about different decoding strategies check out this [blog post](https://huggingface.co/blog/how-to-generate).
### Default request
This is an example of a default request using `greedy` search.
Inference-time after the first request: `3s`
```python
predictor.predict({
"inputs": "Can you please let us know more details about your "
})
```
### Beam search request
This is an example of a request using `beam` search with 5 beams.
Inference-time after the first request: `3.3s`
```python
predictor.predict({
"inputs": "Can you please let us know more details about your ",
"parameters" : {
"num_beams": 5,
}
})
```
### Parameterized request
This is an example of a request using a custom parameter, e.g. `min_length` for generating at least 512 tokens.
Inference-time after the first request: `38s`
```python
predictor.predict({
"inputs": "Can you please let us know more details about your ",
"parameters" : {
"max_length": 512,
"temperature": 0.9,
}
})
```
### Few-Shot example (advanced)
This is an example of how you could `eos_token_id` to stop the generation on a certain token, e.g. `\n` ,`.` or `###` for few-shot predictions. Below is a few-shot example for generating tweets for keywords.
Inference-time after the first request: `15-45s`
```python
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("EleutherAI/gpt-j-6B")
end_sequence="###"
temperature=4
max_generated_token_length=25
prompt= """key: markets
tweet: Take feedback from nature and markets, not from people.
###
key: children
tweet: Maybe we die so we can come back as children.
###
key: startups
tweet: Startups shouldn’t worry about how to put out fires, they should worry about how to start them.
###
key: hugging face
tweet:"""
predictor.predict({
'inputs': prompt,
"parameters" : {
"max_length": int(len(prompt) + max_generated_token_length),
"temperature": float(temperature),
"eos_token_id": int(tokenizer.convert_tokens_to_ids(end_sequence)),
"return_full_text":False
}
})
```
---
To delete your endpoint you can run.
```python
predictor.delete_endpoint()
```
## Conclusion
We successfully managed to deploy `GPT-J`, a 6 billion parameter language model created by [EleutherAI](https://www.eleuther.ai/), using Amazon SageMaker. We reduced the model load time from 3.5 minutes down to 8 seconds to be able to run scalable, reliable inference.
Remember that using `torch.save()` and `torch.load()` can create incompatibility issues. If you want to learn more about scaling out your Amazon SageMaker Endpoints check out my other blog post: [“MLOps: End-to-End Hugging Face Transformers with the Hub & SageMaker Pipelines”](https://www.philschmid.de/mlops-sagemaker-huggingface-transformers).
---
Thanks for reading! If you have any question, feel free to contact me, through [Github](https://github.com/huggingface/transformers), or on the [forum](https://discuss.huggingface.co/c/sagemaker/17). You can also connect with me on [Twitter](https://twitter.com/_philschmid) or [LinkedIn](https://www.linkedin.com/in/philipp-schmid-a6a2bb196/).
| 9 |
0 | hf_public_repos/accelerate/docs/source | hf_public_repos/accelerate/docs/source/usage_guides/gradient_accumulation.md | <!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Performing gradient accumulation with Accelerate
Gradient accumulation is a technique where you can train on bigger batch sizes than
your machine would normally be able to fit into memory. This is done by accumulating gradients over
several batches, and only stepping the optimizer after a certain number of batches have been performed.
While technically standard gradient accumulation code would work fine in a distributed setup, it is not the most efficient
method for doing so and you may experience considerable slowdowns!
In this tutorial you will see how to quickly setup gradient accumulation and perform it with the utilities provided in Accelerate,
which can total to adding just one new line of code!
This example will use a very simplistic PyTorch training loop that performs gradient accumulation every two batches:
```python
device = "cuda"
model.to(device)
gradient_accumulation_steps = 2
for index, batch in enumerate(training_dataloader):
inputs, targets = batch
inputs = inputs.to(device)
targets = targets.to(device)
outputs = model(inputs)
loss = loss_function(outputs, targets)
loss = loss / gradient_accumulation_steps
loss.backward()
if (index + 1) % gradient_accumulation_steps == 0:
optimizer.step()
scheduler.step()
optimizer.zero_grad()
```
## Converting it to Accelerate
First the code shown earlier will be converted to utilize Accelerate without the special gradient accumulation helper:
```diff
+ from accelerate import Accelerator
+ accelerator = Accelerator()
+ model, optimizer, training_dataloader, scheduler = accelerator.prepare(
+ model, optimizer, training_dataloader, scheduler
+ )
for index, batch in enumerate(training_dataloader):
inputs, targets = batch
- inputs = inputs.to(device)
- targets = targets.to(device)
outputs = model(inputs)
loss = loss_function(outputs, targets)
loss = loss / gradient_accumulation_steps
+ accelerator.backward(loss)
if (index+1) % gradient_accumulation_steps == 0:
optimizer.step()
scheduler.step()
optimizer.zero_grad()
```
<Tip warning={true}>
In its current state, this code is not going to perform gradient accumulation efficiently due to a process called gradient synchronization. Read more about that in the [Concepts tutorial](../concept_guides/gradient_synchronization)!
</Tip>
## Letting Accelerate handle gradient accumulation
All that is left now is to let Accelerate handle the gradient accumulation for us. To do so you should pass in a `gradient_accumulation_steps` parameter to [`Accelerator`], dictating the number
of steps to perform before each call to `step()` and how to automatically adjust the loss during the call to [`~Accelerator.backward`]:
```diff
from accelerate import Accelerator
- accelerator = Accelerator()
+ accelerator = Accelerator(gradient_accumulation_steps=2)
```
Alternatively, you can pass in a `gradient_accumulation_plugin` parameter to the [`Accelerator`] object's `__init__`, which will allow you to further customize the gradient accumulation behavior.
Read more about that in the [GradientAccumulationPlugin](../package_reference/accelerator#accelerate.utils.GradientAccumulationPlugin) docs.
From here you can use the [`~Accelerator.accumulate`] context manager from inside your training loop to automatically perform the gradient accumulation for you!
You just wrap it around the entire training part of our code:
```diff
- for index, batch in enumerate(training_dataloader):
+ for batch in training_dataloader:
+ with accelerator.accumulate(model):
inputs, targets = batch
outputs = model(inputs)
```
You can remove all the special checks for the step number and the loss adjustment:
```diff
- loss = loss / gradient_accumulation_steps
accelerator.backward(loss)
- if (index+1) % gradient_accumulation_steps == 0:
optimizer.step()
scheduler.step()
optimizer.zero_grad()
```
As you can see the [`Accelerator`] is able to keep track of the batch number you are on and it will automatically know whether to step through the prepared optimizer and how to adjust the loss.
<Tip>
Typically with gradient accumulation, you would need to adjust the number of steps to reflect the change in total batches you are
training on. Accelerate automagically does this for you by default. Behind the scenes we instantiate a [`GradientAccumulationPlugin`] configured to do this.
</Tip>
<Tip warning={true}>
The [`state.GradientState`] is sync'd with the active dataloader being iterated upon. As such it assumes naively that when we have reached the end of the dataloader everything will sync and a step will be performed. To disable this, set `sync_with_dataloader` to be `False` in the [`GradientAccumulationPlugin`]:
```{python}
from accelerate import Accelerator
from accelerate.utils import GradientAccumulationPlugin
plugin = GradientAccumulationPlugin(sync_with_dataloader=False)
accelerator = Accelerator(..., gradient_accumulation_plugin=plugin)
```
</Tip>
## The finished code
Below is the finished implementation for performing gradient accumulation with Accelerate
```python
from accelerate import Accelerator
accelerator = Accelerator(gradient_accumulation_steps=2)
model, optimizer, training_dataloader, scheduler = accelerator.prepare(
model, optimizer, training_dataloader, scheduler
)
for batch in training_dataloader:
with accelerator.accumulate(model):
inputs, targets = batch
outputs = model(inputs)
loss = loss_function(outputs, targets)
accelerator.backward(loss)
optimizer.step()
scheduler.step()
optimizer.zero_grad()
```
<Tip warning={true}>
It's important that **only one forward/backward** should be done inside the context manager `with accelerator.accumulate(model)`.
</Tip>
To learn more about what magic this wraps around, read the [Gradient Synchronization concept guide](../concept_guides/gradient_synchronization)
## Self-contained example
Here is a self-contained example that you can run to see gradient accumulation in action with Accelerate:
```python
import torch
import copy
from accelerate import Accelerator
from accelerate.utils import set_seed
from torch.utils.data import TensorDataset, DataLoader
# seed
set_seed(0)
# define toy inputs and labels
x = torch.tensor([1., 2., 3., 4., 5., 6., 7., 8.])
y = torch.tensor([2., 4., 6., 8., 10., 12., 14., 16.])
gradient_accumulation_steps = 4
batch_size = len(x) // gradient_accumulation_steps
# define dataset and dataloader
dataset = TensorDataset(x, y)
dataloader = DataLoader(dataset, batch_size=batch_size)
# define model, optimizer and loss function
class SimpleLinearModel(torch.nn.Module):
def __init__(self):
super(SimpleLinearModel, self).__init__()
self.weight = torch.nn.Parameter(torch.zeros((1, 1)))
def forward(self, inputs):
return inputs @ self.weight
model = SimpleLinearModel()
model_clone = copy.deepcopy(model)
criterion = torch.nn.MSELoss()
model_optimizer = torch.optim.SGD(model.parameters(), lr=0.02)
accelerator = Accelerator(gradient_accumulation_steps=gradient_accumulation_steps)
model, model_optimizer, dataloader = accelerator.prepare(model, model_optimizer, dataloader)
model_clone_optimizer = torch.optim.SGD(model_clone.parameters(), lr=0.02)
print(f"initial model weight is {model.weight.mean().item():.5f}")
print(f"initial model weight is {model_clone.weight.mean().item():.5f}")
for i, (inputs, labels) in enumerate(dataloader):
with accelerator.accumulate(model):
inputs = inputs.view(-1, 1)
print(i, inputs.flatten())
labels = labels.view(-1, 1)
outputs = model(inputs)
loss = criterion(outputs, labels)
accelerator.backward(loss)
model_optimizer.step()
model_optimizer.zero_grad()
loss = criterion(x.view(-1, 1) @ model_clone.weight, y.view(-1, 1))
model_clone_optimizer.zero_grad()
loss.backward()
model_clone_optimizer.step()
print(f"w/ accumulation, the final model weight is {model.weight.mean().item():.5f}")
print(f"w/o accumulation, the final model weight is {model_clone.weight.mean().item():.5f}")
```
```
initial model weight is 0.00000
initial model weight is 0.00000
0 tensor([1., 2.])
1 tensor([3., 4.])
2 tensor([5., 6.])
3 tensor([7., 8.])
w/ accumulation, the final model weight is 2.04000
w/o accumulation, the final model weight is 2.04000
```
| 0 |
0 | hf_public_repos/accelerate/docs/source | hf_public_repos/accelerate/docs/source/usage_guides/profiler.md | <!--
Copyright 2024 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contains specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Profiler
Profiler is a tool that allows the collection of performance metrics during training and inference. Profiler’s context manager API can be used to better understand what model operators are the most expensive, examine their input shapes and stack traces, study device kernel activity, and visualize the execution trace. It provides insights into the performance of your model, allowing you to optimize and improve it.
This guide explains how to use PyTorch Profiler to measure the time and memory consumption of the model’s operators and how to integrate this with Accelerate. We will cover various use cases and provide examples for each.
## Using profiler to analyze execution time
Profiler allows one to check which operators were called during the execution of a code range wrapped with a profiler context manager.
Let’s see how we can use profiler to analyze the execution time:
<hfoptions id="cpu execution time">
<hfoption id="PyTorch">
```python
import torch
import torchvision.models as models
from torch.profiler import profile, record_function, ProfilerActivity
model = models.resnet18()
inputs = torch.randn(5, 3, 224, 224)
with profile(activities=[ProfilerActivity.CPU], record_shapes=True) as prof:
model(inputs)
print(prof.key_averages().table(sort_by="cpu_time_total", row_limit=10))
```
</hfoption>
<hfoption id="Accelerate">
```python
from accelerate import Accelerator, ProfileKwargs
import torch
import torchvision.models as models
model = models.resnet18()
inputs = torch.randn(5, 3, 224, 224)
profile_kwargs = ProfileKwargs(
activities=["cpu"],
record_shapes=True
)
accelerator = Accelerator(cpu=True, kwargs_handlers=[profile_kwargs])
model = accelerator.prepare(model)
with accelerator.profile() as prof:
with torch.no_grad():
model(inputs)
print(prof.key_averages().table(sort_by="cpu_time_total", row_limit=10))
```
</hfoption>
</hfoptions>
The resulting table output (omitting some columns):
```
--------------------------------- ------------ ------------ ------------ ------------
Name Self CPU CPU total CPU time avg # of Calls
--------------------------------- ------------ ------------ ------------ ------------
aten::conv2d 171.000us 52.260ms 2.613ms 20
aten::convolution 227.000us 52.089ms 2.604ms 20
aten::_convolution 270.000us 51.862ms 2.593ms 20
aten::mkldnn_convolution 51.273ms 51.592ms 2.580ms 20
aten::batch_norm 118.000us 7.059ms 352.950us 20
aten::_batch_norm_impl_index 315.000us 6.941ms 347.050us 20
aten::native_batch_norm 6.305ms 6.599ms 329.950us 20
aten::max_pool2d 40.000us 4.008ms 4.008ms 1
aten::max_pool2d_with_indices 3.968ms 3.968ms 3.968ms 1
aten::add_ 780.000us 780.000us 27.857us 28
--------------------------------- ------------ ------------ ------------ ------------
Self CPU time total: 67.016ms
```
To get a finer granularity of results and include operator input shapes, pass `group_by_input_shape=True` (note: this requires running the profiler with `record_shapes=True`):
```python
print(prof.key_averages(group_by_input_shape=True).table(sort_by="cpu_time_total", row_limit=10))
```
## Using profiler to analyze memory consumption
Profiler can also show the amount of memory (used by the model’s tensors) that was allocated (or released) during the execution of the model’s operators. To enable memory profiling functionality pass `profile_memory=True`.
<hfoptions id="memory consumption">
<hfoption id="PyTorch">
```python
model = models.resnet18()
inputs = torch.randn(5, 3, 224, 224)
with profile(activities=[ProfilerActivity.CPU],
profile_memory=True, record_shapes=True) as prof:
model(inputs)
print(prof.key_averages().table(sort_by="self_cpu_memory_usage", row_limit=10))
```
</hfoption>
<hfoption id="Accelerate">
```python
model = models.resnet18()
inputs = torch.randn(5, 3, 224, 224)
profile_kwargs = ProfileKwargs(
activities=["cpu"],
profile_memory=True,
record_shapes=True
)
accelerator = Accelerator(cpu=True, kwargs_handlers=[profile_kwargs])
model = accelerator.prepare(model)
with accelerator.profile() as prof:
model(inputs)
print(prof.key_averages().table(sort_by="self_cpu_memory_usage", row_limit=10))
```
</hfoption>
</hfoptions>
The resulting table output (omitting some columns):
```
--------------------------------- ------------ ------------ ------------
Name CPU Mem Self CPU Mem # of Calls
--------------------------------- ------------ ------------ ------------
aten::empty 94.85 Mb 94.85 Mb 205
aten::max_pool2d_with_indices 11.48 Mb 11.48 Mb 1
aten::addmm 19.53 Kb 19.53 Kb 1
aten::mean 10.00 Kb 10.00 Kb 1
aten::empty_strided 492 b 492 b 5
aten::cat 240 b 240 b 6
aten::abs 480 b 240 b 4
aten::masked_select 120 b 112 b 1
aten::ne 61 b 53 b 3
aten::eq 30 b 30 b 1
--------------------------------- ------------ ------------ ------------
Self CPU time total: 69.332ms
```
## Exporting chrome trace
You can examine the sequence of profiled operators and CUDA kernels in Chrome trace viewer (`chrome://tracing`):

<hfoptions id="exporting chrome trace">
<hfoption id="PyTorch">
```python
model = models.resnet18().cuda()
inputs = torch.randn(5, 3, 224, 224).cuda()
with profile(activities=[ProfilerActivity.CPU, ProfilerActivity.CUDA]) as prof:
model(inputs)
prof.export_chrome_trace("trace.json")
```
</hfoption>
<hfoption id="Accelerate">
```python
model = models.resnet18()
inputs = torch.randn(5, 3, 224, 224).cuda()
profile_kwargs = ProfileKwargs(
activities=["cpu", "cuda"],
output_trace_dir="trace"
)
accelerator = Accelerator(kwargs_handlers=[profile_kwargs])
model = accelerator.prepare(model)
with accelerator.profile() as prof:
model(inputs)
# The trace will be saved to the specified directory
```
For other hardware accelerators, e.g. XPU, you can change `cuda` to `xpu` in the above example code.
</hfoption>
</hfoptions>
## Using Profiler to Analyze Long-Running Jobs
Profiler offers an additional API to handle long-running jobs (such as training loops). Tracing all of the execution can be slow and result in very large trace files. To avoid this, use optional arguments:
- `schedule_option`: Scheduling options allow you to control when profiling is active. This is useful for long-running jobs to avoid collecting too much data. Available keys are `wait`, `warmup`, `active`, `repeat` and `skip_first`. The profiler will skip the first `skip_first` steps, then wait for `wait` steps, then do the warmup for the next `warmup` steps, then do the active recording for the next `active` steps and then repeat the cycle starting with `wait` steps. The optional number of cycles is specified with the `repeat` parameter, the zero value means that the cycles will continue until the profiling is finished.
- `on_trace_ready`: specifies a function that takes a reference to the profiler as an input and is called by the profiler each time the new trace is ready.
To illustrate how the API works, consider the following example:
<hfoptions id="custom handler">
<hfoption id="PyTorch">
```python
from torch.profiler import schedule
my_schedule = schedule(
skip_first=1,
wait=5,
warmup=1,
active=3,
repeat=2
)
def trace_handler(p):
output = p.key_averages().table(sort_by="self_cuda_time_total", row_limit=10)
print(output)
p.export_chrome_trace("/tmp/trace_" + str(p.step_num) + ".json")
with profile(
activities=[ProfilerActivity.CPU, ProfilerActivity.CUDA],
schedule=my_schedule,
on_trace_ready=trace_handler
) as p:
for idx in range(8):
model(inputs)
p.step()
```
</hfoption>
<hfoption id="Accelerate">
```python
def trace_handler(p):
output = p.key_averages().table(sort_by="self_cuda_time_total", row_limit=10)
print(output)
p.export_chrome_trace("/tmp/trace_" + str(p.step_num) + ".json")
profile_kwargs = ProfileKwargs(
activities=["cpu", "cuda"],
schedule_option={"wait": 5, "warmup": 1, "active": 3, "repeat": 2, "skip_first": 1},
on_trace_ready=trace_handler
)
accelerator = Accelerator(kwargs_handlers=[profile_kwargs])
model = accelerator.prepare(model)
with accelerator.profile() as prof:
for idx in range(8):
model(inputs)
prof.step()
```
</hfoption>
</hfoptions>
## FLOPS
Use formula to estimate the FLOPs (floating point operations) of specific operators (matrix multiplication and 2D convolution).
To measure floating-point operations (FLOPS):
<hfoptions id="FLOPS">
<hfoption id="PyTorch">
```python
with profile(
activities=[ProfilerActivity.CPU, ProfilerActivity.CUDA],
with_flops=True
) as prof:
model(inputs)
print(prof.key_averages().table(sort_by="flops", row_limit=10))
```
</hfoption>
<hfoption id="Accelerate">
```python
profile_kwargs = ProfileKwargs(
with_flops=True
)
accelerator = Accelerator(kwargs_handlers=[profile_kwargs])
with accelerator.profile() as prof:
model(inputs)
print(prof.key_averages().table(sort_by="flops", row_limit=10))
```
</hfoption>
</hfoptions>
The resulting table output (omitting some columns):
```
------------------------------------------------------- ------------ ------------ ------------
Name Self CPU Self CUDA Total FLOPs
------------------------------------------------------- ------------ ------------ ------------
aten::conv2d 197.000us 0.000us 18135613440.000
aten::addmm 103.000us 17.000us 5120000.000
aten::mul 29.000us 2.000us 30.000
aten::convolution 409.000us 0.000us --
aten::_convolution 253.000us 0.000us --
aten::cudnn_convolution 5.465ms 2.970ms --
cudaEventRecord 138.000us 0.000us --
cudaStreamIsCapturing 43.000us 0.000us --
cudaStreamGetPriority 40.000us 0.000us --
cudaDeviceGetStreamPriorityRange 10.000us 0.000us --
------------------------------------------------------- ------------ ------------ ------------
Self CPU time total: 21.938ms
Self CUDA time total: 4.165ms
```
## Conclusion and Further Information
PyTorch Profiler is a powerful tool for analyzing the performance of your models. By integrating it with Accelerate, you can easily profile your models and gain insights into their performance, helping you to optimize and improve them.
For more detailed information, refer to the [PyTorch Profiler documentation](https://pytorch.org/docs/stable/profiler.html). | 1 |
0 | hf_public_repos/accelerate/docs/source | hf_public_repos/accelerate/docs/source/usage_guides/checkpoint.md | <!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Checkpointing
When training a PyTorch model with Accelerate, you may often want to save and continue a state of training. Doing so requires
saving and loading the model, optimizer, RNG generators, and the GradScaler. Inside Accelerate are two convenience functions to achieve this quickly:
- Use [`~Accelerator.save_state`] for saving everything mentioned above to a folder location
- Use [`~Accelerator.load_state`] for loading everything stored from an earlier `save_state`
To further customize where and how states are saved through [`~Accelerator.save_state`] the [`~utils.ProjectConfiguration`] class can be used. For example
if `automatic_checkpoint_naming` is enabled each saved checkpoint will be located then at `Accelerator.project_dir/checkpoints/checkpoint_{checkpoint_number}`.
It should be noted that the expectation is that those states come from the same training script, they should not be from two separate scripts.
- By using [`~Accelerator.register_for_checkpointing`], you can register custom objects to be automatically stored or loaded from the two prior functions,
so long as the object has a `state_dict` **and** a `load_state_dict` functionality. This could include objects such as a learning rate scheduler.
Below is a brief example using checkpointing to save and reload a state during training:
```python
from accelerate import Accelerator
import torch
accelerator = Accelerator(project_dir="my/save/path")
my_scheduler = torch.optim.lr_scheduler.StepLR(my_optimizer, step_size=1, gamma=0.99)
my_model, my_optimizer, my_training_dataloader = accelerator.prepare(my_model, my_optimizer, my_training_dataloader)
# Register the LR scheduler
accelerator.register_for_checkpointing(my_scheduler)
# Save the starting state
accelerator.save_state()
device = accelerator.device
my_model.to(device)
# Perform training
for epoch in range(num_epochs):
for batch in my_training_dataloader:
my_optimizer.zero_grad()
inputs, targets = batch
inputs = inputs.to(device)
targets = targets.to(device)
outputs = my_model(inputs)
loss = my_loss_function(outputs, targets)
accelerator.backward(loss)
my_optimizer.step()
my_scheduler.step()
# Restore the previous state
accelerator.load_state("my/save/path/checkpointing/checkpoint_0")
```
## Restoring the state of the DataLoader
After resuming from a checkpoint, it may also be desirable to resume from a particular point in the active `DataLoader` if
the state was saved during the middle of an epoch. You can use [`~Accelerator.skip_first_batches`] to do so.
```python
from accelerate import Accelerator
accelerator = Accelerator(project_dir="my/save/path")
train_dataloader = accelerator.prepare(train_dataloader)
accelerator.load_state("my_state")
# Assume the checkpoint was saved 100 steps into the epoch
skipped_dataloader = accelerator.skip_first_batches(train_dataloader, 100)
# After the first iteration, go back to `train_dataloader`
# First epoch
for batch in skipped_dataloader:
# Do something
pass
# Second epoch
for batch in train_dataloader:
# Do something
pass
```
| 2 |
0 | hf_public_repos/accelerate/docs/source | hf_public_repos/accelerate/docs/source/usage_guides/big_modeling.md | <!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Big Model Inference
One of the biggest advancements Accelerate provides is [Big Model Inference](../concept_guides/big_model_inference), which allows you to perform inference with models that don't fully fit on your graphics card.
This tutorial will show you how to use Big Model Inference in Accelerate and the Hugging Face ecosystem.
## Accelerate
A typical workflow for loading a PyTorch model is shown below. `ModelClass` is a model that exceeds the GPU memory of your device (mps or cuda).
```py
import torch
my_model = ModelClass(...)
state_dict = torch.load(checkpoint_file)
my_model.load_state_dict(state_dict)
```
With Big Model Inference, the first step is to init an empty skeleton of the model with the `init_empty_weights` context manager. This doesn't require any memory because `my_model` is "parameterless".
```py
from accelerate import init_empty_weights
with init_empty_weights():
my_model = ModelClass(...)
```
Next, the weights are loaded into the model for inference.
The [`load_checkpoint_and_dispatch`] method loads a checkpoint inside your empty model and dispatches the weights for each layer across all available devices, starting with the fastest devices (GPU, MPS, XPU, NPU, MLU, MUSA) first before moving to the slower ones (CPU and hard drive).
Setting `device_map="auto"` automatically fills all available space on the GPU(s) first, then the CPU, and finally, the hard drive (the absolute slowest option) if there is still not enough memory.
> [!TIP]
> Refer to the [Designing a device map](../concept_guides/big_model_inference#designing-a-device-map) guide for more details on how to design your own device map.
```py
from accelerate import load_checkpoint_and_dispatch
model = load_checkpoint_and_dispatch(
model, checkpoint=checkpoint_file, device_map="auto"
)
```
If there are certain “chunks” of layers that shouldn’t be split, pass them to `no_split_module_classes` (see [here](../concept_guides/big_model_inference#loading-weights) for more details).
A models weights can also be sharded into multiple checkpoints to save memory, such as when the `state_dict` doesn't fit in memory (see [here](../concept_guides/big_model_inference#sharded-checkpoints) for more details).
Now that the model is fully dispatched, you can perform inference.
```py
input = torch.randn(2,3)
input = input.to("cuda")
output = model(input)
```
Each time an input is passed through a layer, it is sent from the CPU to the GPU (or disk to CPU to GPU), the output is calculated, and the layer is removed from the GPU going back down the line. While this adds some overhead to inference, it enables you to run any size model on your system, as long as the largest layer fits on your GPU.
Multiple GPUs, or "model parallelism", can be utilized but only one GPU will be active at any given moment. This forces the GPU to wait for the previous GPU to send it the output. You should launch your script normally with Python instead of other tools like torchrun and accelerate launch.
> [!TIP]
> You may also be interested in *pipeline parallelism* which utilizes all available GPUs at once, instead of only having one GPU active at a time. This approach is less flexbile though. For more details, refer to the [Memory-efficient pipeline parallelism](./distributed_inference#memory-efficient-pipeline-parallelism-experimental) guide.
<Youtube id="MWCSGj9jEAo"/>
Take a look at a full example of Big Model Inference below.
```py
import torch
from accelerate import init_empty_weights, load_checkpoint_and_dispatch
with init_empty_weights():
model = MyModel(...)
model = load_checkpoint_and_dispatch(
model, checkpoint=checkpoint_file, device_map="auto"
)
input = torch.randn(2,3)
input = input.to("cuda")
output = model(input)
```
## Hugging Face ecosystem
Other libraries in the Hugging Face ecosystem, like Transformers or Diffusers, supports Big Model Inference in their [`~transformers.PreTrainedModel.from_pretrained`] constructors.
You just need to add `device_map="auto"` in [`~transformers.PreTrainedModel.from_pretrained`] to enable Big Model Inference.
For example, load Big Sciences T0pp 11 billion parameter model with Big Model Inference.
```py
from transformers import AutoModelForSeq2SeqLM
model = AutoModelForSeq2SeqLM.from_pretrained("bigscience/T0pp", device_map="auto")
```
After loading the model, the empty init and smart dispatch steps from before are executed and the model is fully ready to make use of all the resources in your machine. Through these constructors, you can also save more memory by specifying the `torch_dtype` parameter to load a model in a lower precision.
```py
from transformers import AutoModelForSeq2SeqLM
model = AutoModelForSeq2SeqLM.from_pretrained("bigscience/T0pp", device_map="auto", torch_dtype=torch.float16)
```
## Next steps
For a more detailed explanation of Big Model Inference, make sure to check out the [conceptual guide](../concept_guides/big_model_inference)!
| 3 |
0 | hf_public_repos/accelerate/docs/source | hf_public_repos/accelerate/docs/source/usage_guides/ipex.md | <!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Intel® Extension for PyTorch
[IPEX](https://github.com/intel/intel-extension-for-pytorch) is optimized for CPUs with AVX-512 or above, and functionally works for CPUs with only AVX2. So, it is expected to bring performance benefit for Intel CPU generations with AVX-512 or above while CPUs with only AVX2 (e.g., AMD CPUs or older Intel CPUs) might result in a better performance under IPEX, but not guaranteed. IPEX provides performance optimizations for CPU training with both Float32 and BFloat16. The usage of BFloat16 is the main focus of the following sections.
Low precision data type BFloat16 has been natively supported on the 3rd Generation Xeon® Scalable Processors (aka Cooper Lake) with AVX512 instruction set and will be supported on the next generation of Intel® Xeon® Scalable Processors with Intel® Advanced Matrix Extensions (Intel® AMX) instruction set with further boosted performance. The Auto Mixed Precision for CPU backend has been enabled since PyTorch-1.10. At the same time, the support of Auto Mixed Precision with BFloat16 for CPU and BFloat16 optimization of operators has been massively enabled in Intel® Extension for PyTorch, and partially upstreamed to PyTorch master branch. Users can get better performance and user experience with IPEX Auto Mixed Precision.
## IPEX installation:
IPEX release is following PyTorch, to install via pip:
| PyTorch Version | IPEX version |
| :---------------: | :----------: |
| 2.0 | 2.0.0 |
| 1.13 | 1.13.0 |
| 1.12 | 1.12.300 |
| 1.11 | 1.11.200 |
| 1.10 | 1.10.100 |
```
pip install intel_extension_for_pytorch==<version_name> -f https://developer.intel.com/ipex-whl-stable-cpu
```
Check more approaches for [IPEX installation](https://intel.github.io/intel-extension-for-pytorch/cpu/latest/tutorials/installation.html).
## How It Works For Training optimization in CPU
Accelerate has integrated [IPEX](https://github.com/intel/intel-extension-for-pytorch), all you need to do is enabling it through the config.
**Scenario 1**: Acceleration of No distributed CPU training
Run <u>accelerate config</u> on your machine:
```bash
$ accelerate config
-----------------------------------------------------------------------------------------------------------------------------------------------------------
In which compute environment are you running?
This machine
-----------------------------------------------------------------------------------------------------------------------------------------------------------
Which type of machine are you using?
No distributed training
Do you want to run your training on CPU only (even if a GPU / Apple Silicon device is available)? [yes/NO]:yes
Do you want to use Intel PyTorch Extension (IPEX) to speed up training on CPU? [yes/NO]:yes
Do you wish to optimize your script with torch dynamo?[yes/NO]:NO
Do you want to use DeepSpeed? [yes/NO]: NO
-----------------------------------------------------------------------------------------------------------------------------------------------------------
Do you wish to use FP16 or BF16 (mixed precision)?
bf16
```
This will generate a config file that will be used automatically to properly set the
default options when doing
```bash
accelerate launch my_script.py --args_to_my_script
```
For instance, here is how you would run the NLP example `examples/nlp_example.py` (from the root of the repo) with IPEX enabled.
default_config.yaml that is generated after `accelerate config`
```bash
compute_environment: LOCAL_MACHINE
distributed_type: 'NO'
downcast_bf16: 'no'
ipex_config:
ipex: true
machine_rank: 0
main_training_function: main
mixed_precision: bf16
num_machines: 1
num_processes: 1
rdzv_backend: static
same_network: true
tpu_env: []
tpu_use_cluster: false
tpu_use_sudo: false
use_cpu: true
```
```bash
accelerate launch examples/nlp_example.py
```
**Scenario 2**: Acceleration of distributed CPU training
we use Intel oneCCL for communication, combined with Intel® MPI library to deliver flexible, efficient, scalable cluster messaging on Intel® architecture. you could refer the [here](https://huggingface.co/docs/transformers/perf_train_cpu_many) for the installation guide
Run <u>accelerate config</u> on your machine(node0):
```bash
$ accelerate config
-----------------------------------------------------------------------------------------------------------------------------------------------------------
In which compute environment are you running?
This machine
-----------------------------------------------------------------------------------------------------------------------------------------------------------
Which type of machine are you using?
multi-CPU
How many different machines will you use (use more than 1 for multi-node training)? [1]: 4
-----------------------------------------------------------------------------------------------------------------------------------------------------------
What is the rank of this machine?
0
What is the IP address of the machine that will host the main process? 36.112.23.24
What is the port you will use to communicate with the main process? 29500
Are all the machines on the same local network? Answer `no` if nodes are on the cloud and/or on different network hosts [YES/no]: yes
Do you want to use Intel PyTorch Extension (IPEX) to speed up training on CPU? [yes/NO]:yes
Do you want accelerate to launch mpirun? [yes/NO]: yes
Please enter the path to the hostfile to use with mpirun [~/hostfile]: ~/hostfile
Enter the number of oneCCL worker threads [1]: 1
Do you wish to optimize your script with torch dynamo?[yes/NO]:NO
How many processes should be used for distributed training? [1]:16
-----------------------------------------------------------------------------------------------------------------------------------------------------------
Do you wish to use FP16 or BF16 (mixed precision)?
bf16
```
For instance, here is how you would run the NLP example `examples/nlp_example.py` (from the root of the repo) with IPEX enabled for distributed CPU training.
default_config.yaml that is generated after `accelerate config`
```bash
compute_environment: LOCAL_MACHINE
distributed_type: MULTI_CPU
downcast_bf16: 'no'
ipex_config:
ipex: true
machine_rank: 0
main_process_ip: 36.112.23.24
main_process_port: 29500
main_training_function: main
mixed_precision: bf16
mpirun_config:
mpirun_ccl: '1'
mpirun_hostfile: /home/user/hostfile
num_machines: 4
num_processes: 16
rdzv_backend: static
same_network: true
tpu_env: []
tpu_use_cluster: false
tpu_use_sudo: false
use_cpu: true
```
Set following env and using intel MPI to launch the training
In node0, you need to create a configuration file which contains the IP addresses of each node (for example hostfile) and pass that configuration file path as an argument.
If you selected to have Accelerate launch `mpirun`, ensure that the location of your hostfile matches the path in the config.
```bash
$ cat hostfile
xxx.xxx.xxx.xxx #node0 ip
xxx.xxx.xxx.xxx #node1 ip
xxx.xxx.xxx.xxx #node2 ip
xxx.xxx.xxx.xxx #node3 ip
```
When Accelerate is launching `mpirun`, source the oneCCL bindings setvars.sh to get your Intel MPI environment, and then
run your script using `accelerate launch`. Note that the python script and environment needs to exist on all of the
machines being used for multi-CPU training.
```bash
oneccl_bindings_for_pytorch_path=$(python -c "from oneccl_bindings_for_pytorch import cwd; print(cwd)")
source $oneccl_bindings_for_pytorch_path/env/setvars.sh
accelerate launch examples/nlp_example.py
```
Otherwise, if you selected not to have Accelerate launch `mpirun`, run the following command in node0 and **16DDP** will
be enabled in node0,node1,node2,node3 with BF16 mixed precision. When using this method, the python script, python
environment, and accelerate config file need to be present on all of the machines used for multi-CPU training.
```bash
oneccl_bindings_for_pytorch_path=$(python -c "from oneccl_bindings_for_pytorch import cwd; print(cwd)")
source $oneccl_bindings_for_pytorch_path/env/setvars.sh
export CCL_WORKER_COUNT=1
export MASTER_ADDR=xxx.xxx.xxx.xxx #node0 ip
export CCL_ATL_TRANSPORT=ofi
mpirun -f hostfile -n 16 -ppn 4 accelerate launch examples/nlp_example.py
```
## Related Resources
- [Project's github](https://github.com/intel/intel-extension-for-pytorch)
- [API docs](https://intel.github.io/intel-extension-for-pytorch/cpu/latest/tutorials/api_doc.html)
- [Tuning guide](https://intel.github.io/intel-extension-for-pytorch/cpu/latest/tutorials/performance_tuning/tuning_guide.html)
- [Blogs & Publications](https://intel.github.io/intel-extension-for-pytorch/cpu/latest/tutorials/blogs_publications.html)
| 4 |
0 | hf_public_repos/accelerate/docs/source | hf_public_repos/accelerate/docs/source/usage_guides/quantization.md | <!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Model quantization
## `bitsandbytes` Integration
Accelerate brings `bitsandbytes` quantization to your model. You can now load any pytorch model in 8-bit or 4-bit with a few lines of code.
If you want to use Transformers models with `bitsandbytes`, you should follow this [documentation](https://huggingface.co/docs/transformers/main_classes/quantization).
To learn more about how the `bitsandbytes` quantization works, check out the blog posts on [8-bit quantization](https://huggingface.co/blog/hf-bitsandbytes-integration) and [4-bit quantization](https://huggingface.co/blog/4bit-transformers-bitsandbytes).
### Pre-Requisites
You will need to install the following requirements:
- Install `bitsandbytes` library
```bash
pip install bitsandbytes
```
For non-cuda devices, you can refer to the bitsandbytes installation guide [here](https://huggingface.co/docs/bitsandbytes/main/en/installation#multi-backend).
- Install latest `accelerate` from source
```bash
pip install git+https://github.com/huggingface/accelerate.git
```
- Install `minGPT` and `huggingface_hub` to run examples
```bash
git clone https://github.com/karpathy/minGPT.git
pip install minGPT/
pip install huggingface_hub
```
### How it works
First, we need to initialize our model. To save memory, we can initialize an empty model using the context manager [`init_empty_weights`].
Let's take the GPT2 model from minGPT library.
```py
from accelerate import init_empty_weights
from mingpt.model import GPT
model_config = GPT.get_default_config()
model_config.model_type = 'gpt2-xl'
model_config.vocab_size = 50257
model_config.block_size = 1024
with init_empty_weights():
empty_model = GPT(model_config)
```
Then, we need to get the path to the weights of your model. The path can be the state_dict file (e.g. "pytorch_model.bin") or a folder containing the sharded checkpoints.
```py
from huggingface_hub import snapshot_download
weights_location = snapshot_download(repo_id="marcsun13/gpt2-xl-linear-sharded")
```
Finally, you need to set your quantization configuration with [`~utils.BnbQuantizationConfig`].
Here's an example for 8-bit quantization:
```py
from accelerate.utils import BnbQuantizationConfig
bnb_quantization_config = BnbQuantizationConfig(load_in_8bit=True, llm_int8_threshold = 6)
```
Here's an example for 4-bit quantization:
```py
from accelerate.utils import BnbQuantizationConfig
bnb_quantization_config = BnbQuantizationConfig(load_in_4bit=True, bnb_4bit_compute_dtype=torch.bfloat16, bnb_4bit_use_double_quant=True, bnb_4bit_quant_type="nf4")
```
To quantize your empty model with the selected configuration, you need to use [`~utils.load_and_quantize_model`].
```py
from accelerate.utils import load_and_quantize_model
quantized_model = load_and_quantize_model(empty_model, weights_location=weights_location, bnb_quantization_config=bnb_quantization_config, device_map = "auto")
```
### Saving and loading 8-bit model
You can save your 8-bit model with accelerate using [`~Accelerator.save_model`].
```py
from accelerate import Accelerator
accelerate = Accelerator()
new_weights_location = "path/to/save_directory"
accelerate.save_model(quantized_model, new_weights_location)
quantized_model_from_saved = load_and_quantize_model(empty_model, weights_location=new_weights_location, bnb_quantization_config=bnb_quantization_config, device_map = "auto")
```
Note that 4-bit model serialization is currently not supported.
### Offload modules to cpu and disk
You can offload some modules to cpu/disk if you don't have enough space on the GPU to store the entire model on your GPUs.
This uses big model inference under the hood. Check this [documentation](https://huggingface.co/docs/accelerate/usage_guides/big_modeling) for more details.
For 8-bit quantization, the selected modules will be converted to 8-bit precision.
For 4-bit quantization, the selected modules will be kept in `torch_dtype` that the user passed in `BnbQuantizationConfig`. We will add support to convert these offloaded modules in 4-bit when 4-bit serialization will be possible.
You just need to pass a custom `device_map` in order to offload modules on cpu/disk. The offload modules will be dispatched on the GPU when needed. Here's an example :
```py
device_map = {
"transformer.wte": 0,
"transformer.wpe": 0,
"transformer.drop": 0,
"transformer.h": "cpu",
"transformer.ln_f": "disk",
"lm_head": "disk",
}
```
### Fine-tune a quantized model
It is not possible to perform pure 8bit or 4bit training on these models. However, you can train these models by leveraging parameter efficient fine tuning methods (PEFT) and train for example adapters on top of them. Please have a look at [peft](https://github.com/huggingface/peft) library for more details.
Currently, you can't add adapters on top of any quantized model. However, with the official support of adapters with Transformers models, you can fine-tune quantized models. If you want to finetune a Transformers model , follow this [documentation](https://huggingface.co/docs/transformers/main_classes/quantization) instead. Check out this [demo](https://colab.research.google.com/drive/1VoYNfYDKcKRQRor98Zbf2-9VQTtGJ24k?usp=sharing) on how to fine-tune a 4-bit Transformers model.
Note that you don’t need to pass `device_map` when loading the model for training. It will automatically load your model on your GPU. Please note that `device_map=auto` should be used for inference only.
### Example demo - running GPT2 1.5b on a Google Colab
Check out the Google Colab [demo](https://colab.research.google.com/drive/1T1pOgewAWVpR9gKpaEWw4orOrzPFb3yM?usp=sharing) for running quantized models on a GTP2 model. The GPT2-1.5B model checkpoint is in FP32 which uses 6GB of memory. After quantization, it uses 1.6GB with 8-bit modules and 1.2GB with 4-bit modules.
| 5 |
0 | hf_public_repos/accelerate/docs/source | hf_public_repos/accelerate/docs/source/usage_guides/tracking.md | <!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Experiment trackers
There are a large number of experiment tracking API's available, however getting them all to work with in a multi-processing environment can oftentimes be complex.
Accelerate provides a general tracking API that can be used to log useful items during your script through [`Accelerator.log`]
## Integrated Trackers
Currently `Accelerate` supports seven trackers out-of-the-box:
- TensorBoard
- WandB
- CometML
- Aim
- MLFlow
- ClearML
- DVCLive
To use any of them, pass in the selected type(s) to the `log_with` parameter in [`Accelerate`]:
```python
from accelerate import Accelerator
from accelerate.utils import LoggerType
accelerator = Accelerator(log_with="all") # For all available trackers in the environment
accelerator = Accelerator(log_with="wandb")
accelerator = Accelerator(log_with=["wandb", LoggerType.TENSORBOARD])
```
At the start of your experiment [`Accelerator.init_trackers`] should be used to setup your project, and potentially add any experiment hyperparameters to be logged:
```python
hps = {"num_iterations": 5, "learning_rate": 1e-2}
accelerator.init_trackers("my_project", config=hps)
```
When you are ready to log any data, [`Accelerator.log`] should be used.
A `step` can also be passed in to correlate the data with a particular step in the training loop.
```python
accelerator.log({"train_loss": 1.12, "valid_loss": 0.8}, step=1)
```
Once you've finished training, make sure to run [`Accelerator.end_training`] so that all the trackers can run their finish functionalities if they have any.
```python
accelerator.end_training()
```
A full example is below:
```python
from accelerate import Accelerator
accelerator = Accelerator(log_with="all")
config = {
"num_iterations": 5,
"learning_rate": 1e-2,
"loss_function": str(my_loss_function),
}
accelerator.init_trackers("example_project", config=config)
my_model, my_optimizer, my_training_dataloader = accelerator.prepare(my_model, my_optimizer, my_training_dataloader)
device = accelerator.device
my_model.to(device)
for iteration in config["num_iterations"]:
for step, batch in enumerate(my_training_dataloader):
my_optimizer.zero_grad()
inputs, targets = batch
inputs = inputs.to(device)
targets = targets.to(device)
outputs = my_model(inputs)
loss = my_loss_function(outputs, targets)
accelerator.backward(loss)
my_optimizer.step()
accelerator.log({"training_loss": loss}, step=step)
accelerator.end_training()
```
If a tracker requires a directory to save data to, such as `TensorBoard`, then pass the directory path to `project_dir`. The `project_dir` parameter is useful
when there are other configurations to be combined with in the [`~utils.ProjectConfiguration`] data class. For example, you can save the TensorBoard data to `project_dir` and everything else can be logged in the `logging_dir` parameter of [`~utils.ProjectConfiguration`:
```python
accelerator = Accelerator(log_with="tensorboard", project_dir=".")
# use with ProjectConfiguration
config = ProjectConfiguration(project_dir=".", logging_dir="another/directory")
accelerator = Accelerator(log_with="tensorboard", project_config=config)
```
## Implementing Custom Trackers
To implement a new tracker to be used in `Accelerator`, a new one can be made through implementing the [`GeneralTracker`] class.
Every tracker must implement three functions and have three properties:
- `__init__`:
- Should store a `run_name` and initialize the tracker API of the integrated library.
- If a tracker stores their data locally (such as TensorBoard), a `logging_dir` parameter can be added.
- `store_init_configuration`:
- Should take in a `values` dictionary and store them as a one-time experiment configuration
- `log`:
- Should take in a `values` dictionary and a `step`, and should log them to the run
- `name` (`str`):
- A unique string name for the tracker, such as `"wandb"` for the wandb tracker.
- This will be used for interacting with this tracker specifically
- `requires_logging_directory` (`bool`):
- Whether a `logging_dir` is needed for this particular tracker and if it uses one.
- `tracker`:
- This should be implemented as a `@property` function
- Should return the internal tracking mechanism the library uses, such as the `run` object for `wandb`.
Each method should also utilize the [`state.PartialState`] class if the logger should only be executed on the main process for instance.
A brief example can be seen below with an integration with Weights and Biases, containing only the relevant information and logging just on
the main process:
```python
from accelerate.tracking import GeneralTracker, on_main_process
from typing import Optional
import wandb
class MyCustomTracker(GeneralTracker):
name = "wandb"
requires_logging_directory = False
@on_main_process
def __init__(self, run_name: str):
self.run_name = run_name
run = wandb.init(self.run_name)
@property
def tracker(self):
return self.run.run
@on_main_process
def store_init_configuration(self, values: dict):
wandb.config(values)
@on_main_process
def log(self, values: dict, step: Optional[int] = None):
wandb.log(values, step=step)
```
When you are ready to build your `Accelerator` object, pass in an **instance** of your tracker to [`Accelerator.log_with`] to have it automatically
be used with the API:
```python
tracker = MyCustomTracker("some_run_name")
accelerator = Accelerator(log_with=tracker)
```
These also can be mixed with existing trackers, including with `"all"`:
```python
tracker = MyCustomTracker("some_run_name")
accelerator = Accelerator(log_with=[tracker, "all"])
```
## Accessing the internal tracker
If some custom interactions with a tracker might be wanted directly, you can quickly access one using the
[`Accelerator.get_tracker`] method. Just pass in the string corresponding to a tracker's `.name` attribute
and it will return that tracker on the main process.
This example shows doing so with wandb:
```python
wandb_tracker = accelerator.get_tracker("wandb")
```
From there you can interact with `wandb`'s `run` object like normal:
```python
wandb_run.log_artifact(some_artifact_to_log)
```
<Tip>
Trackers built in Accelerate will automatically execute on the correct process,
so if a tracker is only meant to be ran on the main process it will do so
automatically.
</Tip>
If you want to truly remove Accelerate's wrapping entirely, you can
achieve the same outcome with:
```python
wandb_tracker = accelerator.get_tracker("wandb", unwrap=True)
if accelerator.is_main_process:
wandb_tracker.log_artifact(some_artifact_to_log)
```
## When a wrapper cannot work
If a library has an API that does not follow a strict `.log` with an overall dictionary such as Neptune.AI, logging can be done manually under an `if accelerator.is_main_process` statement:
```diff
from accelerate import Accelerator
+ import neptune
accelerator = Accelerator()
+ run = neptune.init_run(...)
my_model, my_optimizer, my_training_dataloader = accelerate.prepare(my_model, my_optimizer, my_training_dataloader)
device = accelerator.device
my_model.to(device)
for iteration in config["num_iterations"]:
for batch in my_training_dataloader:
my_optimizer.zero_grad()
inputs, targets = batch
inputs = inputs.to(device)
targets = targets.to(device)
outputs = my_model(inputs)
loss = my_loss_function(outputs, targets)
total_loss += loss
accelerator.backward(loss)
my_optimizer.step()
+ if accelerator.is_main_process:
+ run["logs/training/batch/loss"].log(loss)
```
| 6 |
0 | hf_public_repos/accelerate/docs/source | hf_public_repos/accelerate/docs/source/usage_guides/mps.md | <!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Accelerated PyTorch Training on Mac
With PyTorch v1.12 release, developers and researchers can take advantage of Apple silicon GPUs for significantly faster model training.
This unlocks the ability to perform machine learning workflows like prototyping and fine-tuning locally, right on Mac.
Apple's Metal Performance Shaders (MPS) as a backend for PyTorch enables this and can be used via the new `"mps"` device.
This will map computational graphs and primitives on the MPS Graph framework and tuned kernels provided by MPS.
For more information please refer official documents [Introducing Accelerated PyTorch Training on Mac](https://pytorch.org/blog/introducing-accelerated-pytorch-training-on-mac/)
and [MPS BACKEND](https://pytorch.org/docs/stable/notes/mps.html).
### Benefits of Training and Inference using Apple Silicon Chips
1. Enables users to train larger networks or batch sizes locally
2. Reduces data retrieval latency and provides the GPU with direct access to the full memory store due to unified memory architecture.
Therefore, improving end-to-end performance.
3. Reduces costs associated with cloud-based development or the need for additional local GPUs.
**Pre-requisites**: To install torch with mps support,
please follow this nice medium article [GPU-Acceleration Comes to PyTorch on M1 Macs](https://medium.com/towards-data-science/gpu-acceleration-comes-to-pytorch-on-m1-macs-195c399efcc1).
## How it works out of the box
It is enabled by default on MacOs machines with MPS enabled Apple Silicon GPUs.
To disable it, pass `--cpu` flag to `accelerate launch` command or answer the corresponding question when answering the `accelerate config` questionnaire.
You can directly run the following script to test it out on MPS enabled Apple Silicon machines:
```bash
accelerate launch /examples/cv_example.py --data_dir images
```
## A few caveats to be aware of
1. We strongly recommend to install PyTorch >= 1.13 (nightly version at the time of writing) on your MacOS machine.
It has major fixes related to model correctness and performance improvements for transformer based models.
Please refer to https://github.com/pytorch/pytorch/issues/82707 for more details.
2. Distributed setups `gloo` and `nccl` are not working with `mps` device.
This means that currently only single GPU of `mps` device type can be used.
Finally, please, remember that, `Accelerate` only integrates MPS backend, therefore if you
have any problems or questions with regards to MPS backend usage, please, file an issue with [PyTorch GitHub](https://github.com/pytorch/pytorch/issues). | 7 |
0 | hf_public_repos/accelerate/docs/source | hf_public_repos/accelerate/docs/source/basic_tutorials/notebook.md | <!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Launching distributed training from Jupyter Notebooks
This tutorial teaches you how to fine tune a computer vision model with 🤗 Accelerate from a Jupyter Notebook on a distributed system.
You will also learn how to setup a few requirements needed for ensuring your environment is configured properly, your data has been prepared properly, and finally how to launch training.
<Tip>
This tutorial is also available as a Jupyter Notebook [here](https://github.com/huggingface/notebooks/blob/main/examples/accelerate_examples/simple_cv_example.ipynb)
</Tip>
## Configuring the Environment
Before any training can be performed, a Accelerate config file must exist in the system. Usually this can be done by running the following in a terminal and answering the prompts:
```bash
accelerate config
```
However, if general defaults are fine and you are *not* running on a TPU, Accelerate has a utility to quickly write your GPU configuration into a config file via [`utils.write_basic_config`].
The following code will restart Jupyter after writing the configuration, as CUDA code was called to perform this.
<Tip warning={true}>
CUDA can't be initialized more than once on a multi-GPU system. It's fine to debug in the notebook and have calls to CUDA, but in order to finally train a full cleanup and restart will need to be performed.
</Tip>
```python
import os
from accelerate.utils import write_basic_config
write_basic_config() # Write a config file
os._exit(00) # Restart the notebook
```
## Preparing the Dataset and Model
Next you should prepare your dataset. As mentioned at earlier, great care should be taken when preparing the `DataLoaders` and model to make sure that **nothing** is put on *any* GPU.
If you do, it is recommended to put that specific code into a function and call that from within the notebook launcher interface, which will be shown later.
Make sure the dataset is downloaded based on the directions [here](https://github.com/huggingface/accelerate/tree/main/examples#simple-vision-example)
```python
import os, re, torch, PIL
import numpy as np
from torch.optim.lr_scheduler import OneCycleLR
from torch.utils.data import DataLoader, Dataset
from torchvision.transforms import Compose, RandomResizedCrop, Resize, ToTensor
from accelerate import Accelerator
from accelerate.utils import set_seed
from timm import create_model
```
First you need to create a function to extract the class name based on a filename:
```python
import os
data_dir = "../../images"
fnames = os.listdir(data_dir)
fname = fnames[0]
print(fname)
```
```python out
beagle_32.jpg
```
In the case here, the label is `beagle`. Using regex you can extract the label from the filename:
```python
import re
def extract_label(fname):
stem = fname.split(os.path.sep)[-1]
return re.search(r"^(.*)_\d+\.jpg$", stem).groups()[0]
```
```python
extract_label(fname)
```
And you can see it properly returned the right name for our file:
```python out
"beagle"
```
Next a `Dataset` class should be made to handle grabbing the image and the label:
```python
class PetsDataset(Dataset):
def __init__(self, file_names, image_transform=None, label_to_id=None):
self.file_names = file_names
self.image_transform = image_transform
self.label_to_id = label_to_id
def __len__(self):
return len(self.file_names)
def __getitem__(self, idx):
fname = self.file_names[idx]
raw_image = PIL.Image.open(fname)
image = raw_image.convert("RGB")
if self.image_transform is not None:
image = self.image_transform(image)
label = extract_label(fname)
if self.label_to_id is not None:
label = self.label_to_id[label]
return {"image": image, "label": label}
```
Now to build the dataset. Outside the training function you can find and declare all the filenames and labels and use them as references inside the
launched function:
```python
fnames = [os.path.join("../../images", fname) for fname in fnames if fname.endswith(".jpg")]
```
Next gather all the labels:
```python
all_labels = [extract_label(fname) for fname in fnames]
id_to_label = list(set(all_labels))
id_to_label.sort()
label_to_id = {lbl: i for i, lbl in enumerate(id_to_label)}
```
Next, you should make a `get_dataloaders` function that will return your built dataloaders for you. As mentioned earlier, if data is automatically
sent to the GPU or a TPU device when building your `DataLoaders`, they must be built using this method.
```python
def get_dataloaders(batch_size: int = 64):
"Builds a set of dataloaders with a batch_size"
random_perm = np.random.permutation(len(fnames))
cut = int(0.8 * len(fnames))
train_split = random_perm[:cut]
eval_split = random_perm[cut:]
# For training a simple RandomResizedCrop will be used
train_tfm = Compose([RandomResizedCrop((224, 224), scale=(0.5, 1.0)), ToTensor()])
train_dataset = PetsDataset([fnames[i] for i in train_split], image_transform=train_tfm, label_to_id=label_to_id)
# For evaluation a deterministic Resize will be used
eval_tfm = Compose([Resize((224, 224)), ToTensor()])
eval_dataset = PetsDataset([fnames[i] for i in eval_split], image_transform=eval_tfm, label_to_id=label_to_id)
# Instantiate dataloaders
train_dataloader = DataLoader(train_dataset, shuffle=True, batch_size=batch_size, num_workers=4)
eval_dataloader = DataLoader(eval_dataset, shuffle=False, batch_size=batch_size * 2, num_workers=4)
return train_dataloader, eval_dataloader
```
Finally, you should import the scheduler to be used later:
```python
from torch.optim.lr_scheduler import CosineAnnealingLR
```
## Writing the Training Function
Now you can build the training loop. [`notebook_launcher`] works by passing in a function to call that will be ran across the distributed system.
Here is a basic training loop for the animal classification problem:
<Tip>
The code has been split up to allow for explanations on each section. A full version that can be copy and pasted will be available at the end
</Tip>
```python
def training_loop(mixed_precision="fp16", seed: int = 42, batch_size: int = 64):
set_seed(seed)
accelerator = Accelerator(mixed_precision=mixed_precision)
```
First you should set the seed and create an [`Accelerator`] object as early in the training loop as possible.
<Tip warning={true}>
If training on the TPU, your training loop should take in the model as a parameter and it should be instantiated
outside of the training loop function. See the [TPU best practices](../concept_guides/training_tpu)
to learn why
</Tip>
Next you should build your dataloaders and create your model:
```python
train_dataloader, eval_dataloader = get_dataloaders(batch_size)
model = create_model("resnet50d", pretrained=True, num_classes=len(label_to_id))
```
<Tip>
You build the model here so that the seed also controls the new weight initialization
</Tip>
As you are performing transfer learning in this example, the encoder of the model starts out frozen so the head of the model can be
trained only initially:
```python
for param in model.parameters():
param.requires_grad = False
for param in model.get_classifier().parameters():
param.requires_grad = True
```
Normalizing the batches of images will make training a little faster:
```python
mean = torch.tensor(model.default_cfg["mean"])[None, :, None, None]
std = torch.tensor(model.default_cfg["std"])[None, :, None, None]
```
To make these constants available on the active device, you should set it to the Accelerator's device:
```python
mean = mean.to(accelerator.device)
std = std.to(accelerator.device)
```
Next instantiate the rest of the PyTorch classes used for training:
```python
optimizer = torch.optim.Adam(params=model.parameters(), lr=3e-2 / 25)
lr_scheduler = OneCycleLR(optimizer=optimizer, max_lr=3e-2, epochs=5, steps_per_epoch=len(train_dataloader))
```
Before passing everything to [`~Accelerator.prepare`].
<Tip>
There is no specific order to remember, you just need to unpack the objects in the same order you gave them to the prepare method.
</Tip>
```python
model, optimizer, train_dataloader, eval_dataloader, lr_scheduler = accelerator.prepare(
model, optimizer, train_dataloader, eval_dataloader, lr_scheduler
)
```
Now train the model:
```python
for epoch in range(5):
model.train()
for batch in train_dataloader:
inputs = (batch["image"] - mean) / std
outputs = model(inputs)
loss = torch.nn.functional.cross_entropy(outputs, batch["label"])
accelerator.backward(loss)
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad()
```
The evaluation loop will look slightly different compared to the training loop. The number of elements passed as well as the overall
total accuracy of each batch will be added to two constants:
```python
model.eval()
accurate = 0
num_elems = 0
```
Next you have the rest of your standard PyTorch loop:
```python
for batch in eval_dataloader:
inputs = (batch["image"] - mean) / std
with torch.no_grad():
outputs = model(inputs)
predictions = outputs.argmax(dim=-1)
```
Before finally the last major difference.
When performing distributed evaluation, the predictions and labels need to be passed through
[`~Accelerator.gather`] so that all of the data is available on the current device and a properly calculated metric can be achieved:
```python
accurate_preds = accelerator.gather(predictions) == accelerator.gather(batch["label"])
num_elems += accurate_preds.shape[0]
accurate += accurate_preds.long().sum()
```
Now you just need to calculate the actual metric for this problem, and you can print it on the main process using [`~Accelerator.print`]:
```python
eval_metric = accurate.item() / num_elems
accelerator.print(f"epoch {epoch}: {100 * eval_metric:.2f}")
```
A full version of this training loop is available below:
```python
def training_loop(mixed_precision="fp16", seed: int = 42, batch_size: int = 64):
set_seed(seed)
# Initialize accelerator
accelerator = Accelerator(mixed_precision=mixed_precision)
# Build dataloaders
train_dataloader, eval_dataloader = get_dataloaders(batch_size)
# Instantiate the model (you build the model here so that the seed also controls new weight initaliziations)
model = create_model("resnet50d", pretrained=True, num_classes=len(label_to_id))
# Freeze the base model
for param in model.parameters():
param.requires_grad = False
for param in model.get_classifier().parameters():
param.requires_grad = True
# You can normalize the batches of images to be a bit faster
mean = torch.tensor(model.default_cfg["mean"])[None, :, None, None]
std = torch.tensor(model.default_cfg["std"])[None, :, None, None]
# To make these constants available on the active device, set it to the accelerator device
mean = mean.to(accelerator.device)
std = std.to(accelerator.device)
# Instantiate the optimizer
optimizer = torch.optim.Adam(params=model.parameters(), lr=3e-2 / 25)
# Instantiate the learning rate scheduler
lr_scheduler = OneCycleLR(optimizer=optimizer, max_lr=3e-2, epochs=5, steps_per_epoch=len(train_dataloader))
# Prepare everything
# There is no specific order to remember, you just need to unpack the objects in the same order you gave them to the
# prepare method.
model, optimizer, train_dataloader, eval_dataloader, lr_scheduler = accelerator.prepare(
model, optimizer, train_dataloader, eval_dataloader, lr_scheduler
)
# Now you train the model
for epoch in range(5):
model.train()
for batch in train_dataloader:
inputs = (batch["image"] - mean) / std
outputs = model(inputs)
loss = torch.nn.functional.cross_entropy(outputs, batch["label"])
accelerator.backward(loss)
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad()
model.eval()
accurate = 0
num_elems = 0
for batch in eval_dataloader:
inputs = (batch["image"] - mean) / std
with torch.no_grad():
outputs = model(inputs)
predictions = outputs.argmax(dim=-1)
accurate_preds = accelerator.gather(predictions) == accelerator.gather(batch["label"])
num_elems += accurate_preds.shape[0]
accurate += accurate_preds.long().sum()
eval_metric = accurate.item() / num_elems
# Use accelerator.print to print only on the main process.
accelerator.print(f"epoch {epoch}: {100 * eval_metric:.2f}")
```
## Using the notebook_launcher
All that's left is to use the [`notebook_launcher`].
You pass in the function, the arguments (as a tuple), and the number of processes to train on. (See the [documentation](../package_reference/launchers) for more information)
```python
from accelerate import notebook_launcher
```
```python
args = ("fp16", 42, 64)
notebook_launcher(training_loop, args, num_processes=2)
```
In the case of running on multiple nodes, you need to set up a Jupyter session at each node and run the launching cell at the same time.
For an environment containing 2 nodes (computers) with 8 GPUs each and the main computer with an IP address of "172.31.43.8", it would look like so:
```python
notebook_launcher(training_loop, args, master_addr="172.31.43.8", node_rank=0, num_nodes=2, num_processes=8)
```
And in the second Jupyter session on the other machine:
<Tip>
Notice how the `node_rank` has changed
</Tip>
```python
notebook_launcher(training_loop, args, master_addr="172.31.43.8", node_rank=1, num_nodes=2, num_processes=8)
```
In the case of running on the TPU, it would look like so:
```python
model = create_model("resnet50d", pretrained=True, num_classes=len(label_to_id))
args = (model, "fp16", 42, 64)
notebook_launcher(training_loop, args, num_processes=8)
```
To launch the training process with elasticity, enabling fault tolerance, you can use the `elastic_launch` feature provided by PyTorch. This requires setting additional parameters such as `rdzv_backend` and `max_restarts`. Here is an example of how to use `notebook_launcher` with elastic capabilities:
```python
notebook_launcher(
training_loop,
args,
num_processes=2,
max_restarts=3
)
```
As it's running it will print the progress as well as state how many devices you ran on. This tutorial was ran with two GPUs:
```python out
Launching training on 2 GPUs.
epoch 0: 88.12
epoch 1: 91.73
epoch 2: 92.58
epoch 3: 93.90
epoch 4: 94.71
```
And that's it!
Please note that [`notebook_launcher`] ignores the Accelerate config file, to launch based on the config use:
```bash
accelerate launch
```
## Debugging
A common issue when running the `notebook_launcher` is receiving a CUDA has already been initialized issue. This usually stems
from an import or prior code in the notebook that makes a call to the PyTorch `torch.cuda` sublibrary. To help narrow down what went wrong,
you can launch the `notebook_launcher` with `ACCELERATE_DEBUG_MODE=yes` in your environment and an additional check
will be made when spawning that a regular process can be created and utilize CUDA without issue. (Your CUDA code can still be ran afterwards).
## Conclusion
This notebook showed how to perform distributed training from inside of a Jupyter Notebook. Some key notes to remember:
- Make sure to save any code that use CUDA (or CUDA imports) for the function passed to [`notebook_launcher`]
- Set the `num_processes` to be the number of devices used for training (such as number of GPUs, CPUs, TPUs, etc)
- If using the TPU, declare your model outside the training loop function
| 8 |
0 | hf_public_repos/accelerate/docs/source | hf_public_repos/accelerate/docs/source/basic_tutorials/troubleshooting.md | <!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Troubleshoot
This guide provides solutions to some issues you might encounter when using Accelerate. Not all errors are covered because Accelerate is an active library that is continuously evolving and there are many different use cases and distributed training setups. If the solutions described here don't help with your specific error, please take a look at the [Ask for help](#ask-for-help) section to learn where and how to get help.
## Logging
Logging can help you identify where an error is coming from. In a distributed setup with multiple processes, logging can be a challenge, but Accelerate provides the [`~accelerate.logging`] utility to ensure logs are synchronized.
To troubleshoot an issue, use [`~accelerate.logging`] instead of the standard Python [`logging`](https://docs.python.org/3/library/logging.html#module-logging) module. Set the verbosity level (`INFO`, `DEBUG`, `WARNING`, `ERROR`, `CRITICAL`) with the `log_level` parameter, and then you can either:
1. Export the `log_level` as the `ACCELERATE_LOG_LEVEL` environment variable.
2. Pass the `log_level` directly to `get_logger`.
For example, to set `log_level="INFO"`:
```py
from accelerate.logging import get_logger
logger = get_logger(__name__, log_level="DEBUG")
```
By default, the log is called on main processes only. To call it on all processes, pass `main_process_only=False`.
If a log should be called on all processes and in order, also pass `in_order=True`.
```py
from accelerate.logging import get_logger
logger = get_logger(__name__, log_level="DEBUG")
# log all processes
logger.debug("thing_to_log", main_process_only=False)
# log all processes in order
logger.debug("thing_to_log", main_process_only=False, in_order=True)
```
## Hanging code and timeout errors
There can be many reasons why your code is hanging. Let's take a look at how to solve some of the most common issues that can cause your code to hang.
### Mismatched tensor shapes
Mismatched tensor shapes is a common issue that can cause your code to hang for a significant amount of time on a distributed setup.
When running scripts in a distributed setup, functions such as [`Accelerator.gather`] and [`Accelerator.reduce`] are necessary to grab tensors across devices to collectively perform operations on them. These (and other) functions rely on `torch.distributed` to perform a `gather` operation, which requires tensors to have the **exact same shape** across all processes. When the tensor shapes don't match, your code hangs and you'll eventually hit a timeout exception.
You can use Accelerate's operational debug mode to immediately catch this issue. We recommend enabling this mode during the `accelerate config` setup, but you can also enable it from the CLI, as an environment variable, or by manually editing the `config.yaml` file.
<hfoptions id="mismatch">
<hfoption id="CLI">
```bash
accelerate launch --debug {my_script.py} --arg1 --arg2
```
</hfoption>
<hfoption id="environment variable">
If enabling debug mode as an environment variable, you don't need to call `accelerate launch`.
```bash
ACCELERATE_DEBUG_MODE="1" torchrun {my_script.py} --arg1 --arg2
```
</hfoption>
<hfoption id="config.yaml">
Add `debug: true` to your `config.yaml` file.
```yaml
compute_environment: LOCAL_MACHINE
debug: true
```
</hfoption>
</hfoptions>
Once you enable debug mode, you should get a traceback that points to the tensor shape mismatch issue.
```py
Traceback (most recent call last):
File "/home/zach_mueller_huggingface_co/test.py", line 18, in <module>
main()
File "/home/zach_mueller_huggingface_co/test.py", line 15, in main
broadcast_tensor = broadcast(tensor)
File "/home/zach_mueller_huggingface_co/accelerate/src/accelerate/utils/operations.py", line 303, in wrapper
accelerate.utils.operations.DistributedOperationException:
Cannot apply desired operation due to shape mismatches. All shapes across devices must be valid.
Operation: `accelerate.utils.operations.broadcast`
Input shapes:
- Process 0: [1, 5]
- Process 1: [1, 2, 5]
```
### Early stopping
For early stopping in distributed training, if each process has a specific stopping condition (e.g. validation loss), it may not be synchronized across all processes. As a result, a break can happen on process 0 but not on process 1 which will cause your code to hang indefinitely until a timeout occurs.
If you have early stopping conditionals, use the `set_breakpoint` and `check_breakpoint` methods to make sure all the processes
are ended correctly.
```py
# Assume `should_do_breakpoint` is a custom defined function that returns a conditional,
# and that conditional might be true only on process 1
if should_do_breakpoint(loss):
accelerator.set_breakpoint()
# Later in the training script when we need to check for the breakpoint
if accelerator.check_breakpoint():
break
```
### Low kernel versions on Linux
On Linux with kernel version < 5.5, hanging processes have been reported. To avoid this problem, upgrade your system to a later kernel version.
### MPI
If your distributed CPU training job using MPI is hanging, ensure that you have
[passwordless SSH](https://www.open-mpi.org/faq/?category=rsh#ssh-keys) setup (using keys) between the nodes. This means
that for all nodes in your hostfile, you should to be able to SSH from one node to another without being prompted for a password.
Next, try to run the `mpirun` command as a sanity check. For example, the command below should print out the
hostnames for each of the nodes.
```bash
mpirun -f hostfile -n {number of nodes} -ppn 1 hostname
```
## Out-of-Memory
One of the most frustrating errors when it comes to running training scripts is hitting "Out-of-Memory" on devices like CUDA, XPU or CPU. The entire script needs to be restarted and any progress is lost.
To address this problem, Accelerate provides the [`find_executable_batch_size`] utility that is heavily based on [toma](https://github.com/BlackHC/toma).
This utility retries code that fails due to OOM (out-of-memory) conditions and automatically lowers batch sizes. For each OOM condition, the algorithm decreases the batch size by half and retries the code until it succeeds.
To use [`find_executable_batch_size`], restructure your training function to include an inner function with `find_executable_batch_size` and build your dataloaders inside it. At a minimum, this only takes 4 new lines of code.
<Tip warning={true}>
The inner function **must** take batch size as the first parameter, but we do not pass one to it when called. The wrapper will handles this for you. Any object (models, optimizers) that consumes device memory and is passed to the [`Accelerator`] also **must** be declared inside the inner function.
</Tip>
```diff
def training_function(args):
accelerator = Accelerator()
+ @find_executable_batch_size(starting_batch_size=args.batch_size)
+ def inner_training_loop(batch_size):
+ nonlocal accelerator # Ensure they can be used in our context
+ accelerator.free_memory() # Free all lingering references
model = get_model()
model.to(accelerator.device)
optimizer = get_optimizer()
train_dataloader, eval_dataloader = get_dataloaders(accelerator, batch_size)
lr_scheduler = get_scheduler(
optimizer,
num_training_steps=len(train_dataloader)*num_epochs
)
model, optimizer, train_dataloader, eval_dataloader, lr_scheduler = accelerator.prepare(
model, optimizer, train_dataloader, eval_dataloader, lr_scheduler
)
train(model, optimizer, train_dataloader, lr_scheduler)
validate(model, eval_dataloader)
+ inner_training_loop()
```
## Non-reproducible results between device setups
If you changed the device setup and observe different model performance, it is likely you didn't update your script when moving from one setup to another. Even if you're using the same script with the same batch size, the results will still be different on a TPU, multi-GPU, and single GPU.
For example, if you were training on a single GPU with a batch size of 16 and you move to a dual GPU setup, you need to change the batch size to 8 to have the same effective batch size. This is because when training with Accelerate, the batch size passed to the dataloader is the **batch size per GPU**.
To make sure you can reproduce the results between the setups, make sure to use the same seed, adjust the batch size accordingly, and consider scaling the learning rate.
For more details and a quick reference for batch sizes, check out the [Comparing performance between different device setups](../concept_guides/performance) guide.
## Performance issues on different GPUs
If your multi-GPU setup consists of different GPUs, you may encounter some performance issues:
- There may be an imbalance in GPU memory between the GPUs. In this case, the GPU with the smaller memory will limit the batch size or the size of the model that can be loaded onto the GPUs.
- If you are using GPUs with different performance profiles, the performance will be driven by the slowest GPU you are using because the other GPUs will have to wait for it to complete its workload.
Vastly different GPUs within the same setup can lead to performance bottlenecks.
## Ask for help
If none of the solutions and advice here helped resolve your issue, you can always reach out to the community and Accelerate team for help.
- Ask for help on the Hugging Face forums by posting your question in the [Accelerate category](https://discuss.huggingface.co/c/accelerate/18). Make sure to write a descriptive post with relevant context about your setup and reproducible code to maximize the likelihood that your problem is solved!
- Post a question on [Discord](http://hf.co/join/discord), and let the team and the community help you.
- Create an Issue on the Accelerate [GitHub repository](https://github.com/huggingface/accelerate/issues) if you think you've found a bug related to the library. Include context regarding the bug and details about your distributed setup to help us better figure out what's wrong and how we can fix it.
| 9 |
0 | hf_public_repos/blog | hf_public_repos/blog/zh/train-sentence-transformers.md | ---
title: "用 Sentence Transformers v3 训练和微调嵌入模型"
thumbnail: /blog/assets/train-sentence-transformers/st-hf-thumbnail.png
authors:
- user: tomaarsen
translators:
- user: innovation64
- user: zhongdongy
proofreader: true
---
# 用 Sentence Transformers v3 训练和微调嵌入模型
[Sentence Transformers](https://sbert.net/) 是一个 Python 库,用于使用和训练各种应用的嵌入模型,例如检索增强生成 (RAG)、语义搜索、语义文本相似度、释义挖掘 (paraphrase mining) 等等。其 3.0 版本的更新是该工程自创建以来最大的一次,引入了一种新的训练方法。在这篇博客中,我将向你展示如何使用它来微调 Sentence Transformer 模型,以提高它们在特定任务上的性能。你也可以使用这种方法从头开始训练新的 Sentence Transformer 模型。
现在,微调 Sentence Transformers 涉及几个组成部分,包括数据集、损失函数、训练参数、评估器以及新的训练器本身。我将详细讲解每个组成部分,并提供如何使用它们来训练有效模型的示例。
## 目录
- [为什么进行微调?](#为什么进行微调)
- [训练组件](#训练组件)
- [数据集](#数据集)
- [Hugging Face Hub 上的数据](#hugging-face-hub-上的数据)
- [本地数据 (CSV, JSON, Parquet, Arrow, SQL)](#本地数据-csv-json-parquet-arrow-sql)
- [需要预处理的本地数据](#需要预处理的本地数据)
- [数据集格式](#数据集格式)
- [损失函数](#损失函数)
- [训练参数](#训练参数)
- [评估器](#评估器)
- [使用 STSb 的 Embedding Similarity Evaluator](#使用-stsb-的-embedding-similarity-evaluator)
- [使用 AllNLI 的 Triplet Evaluator](#使用-allnli-的-triplet-evaluator)
- [训练器](#训练器)
- [回调函数](#回调函数)
- [多数据集训练](#多数据集训练)
- [弃用](#弃用)
- [附加资源](#附加资源)
- [训练示例](#训练示例)
- [文档](#文档)
## 为什么进行微调?
微调 Sentence Transformer 模型可以显著提高它们在特定任务上的性能。这是因为每个任务都需要独特的相似性概念。让我们以几个新闻文章标题为例:
- “Apple 发布新款 iPad”
- “NVIDIA 正在为下一代 GPU 做准备 “
根据用例的不同,我们可能希望这些文本具有相似或不相似的嵌入。例如,一个针对新闻文章的分类模型可能会将这些文本视为相似,因为它们都属于技术类别。另一方面,一个语义文本相似度或检索模型应该将它们视为不相似,因为它们具有不同的含义。
## 训练组件
训练 Sentence Transformer 模型涉及以下组件:
1. [ **数据集** ](#数据集): 用于训练和评估的数据。
2. [ **损失函数** ](#损失函数): 一个量化模型性能并指导优化过程的函数。
3. [ **训练参数** ](#训练参数) (可选): 影响训练性能和跟踪/调试的参数。
4. [ **评估器** ](#评估器) (可选): 一个在训练前、中或后评估模型的工具。
5. [ **训练器** ](#训练器): 将模型、数据集、损失函数和其他组件整合在一起进行训练。
现在,让我们更详细地了解这些组件。
## 数据集
[`SentenceTransformerTrainer`](https://sbert.net/docs/package_reference/sentence_transformer/SentenceTransformer.html#sentence_transformers.SentenceTransformer) 使用 [`datasets.Dataset`](https://huggingface.co/docs/datasets/main/en/package_reference/main_classes#datasets.Dataset) 或 [`datasets.DatasetDict`](https://huggingface.co/docs/datasets/main/en/package_reference/main_classes#datasets.DatasetDict) 实例进行训练和评估。你可以从 Hugging Face 数据集中心加载数据,或使用各种格式的本地数据,如 CSV、JSON、Parquet、Arrow 或 SQL。
注意: 许多开箱即用的 Sentence Transformers 的 Hugging Face 数据集已经标记为 `sentence-transformers` ,你可以通过浏览 [https://huggingface.co/datasets?other=sentence-transformers](https://huggingface.co/datasets?other=sentence-transformers) 轻松找到它们。我们强烈建议你浏览这些数据集,以找到可能对你任务有用的训练数据集。
### Hugging Face Hub 上的数据
要从 Hugging Face Hub 中的数据集加载数据,请使用 [`load_dataset`](https://huggingface.co/docs/datasets/main/en/package_reference/loading_methods#datasets.load_dataset) 函数:
```python
from datasets import load_dataset
train_dataset = load_dataset("sentence-transformers/all-nli", "pair-class", split="train")
eval_dataset = load_dataset("sentence-transformers/all-nli", "pair-class", split="dev")
print(train_dataset)
"""
Dataset({
features: ['premise', 'hypothesis', 'label'],
num_rows: 942069
})
"""
```
一些数据集,如 [`sentence-transformers/all-nli`](https://huggingface.co/datasets/sentence-transformers/all-nli),具有多个子集,不同的数据格式。你需要指定子集名称以及数据集名称。
### 本地数据 (CSV, JSON, Parquet, Arrow, SQL)
如果你有常见文件格式的本地数据,你也可以使用 [`load_dataset`](https://huggingface.co/docs/datasets/main/en/package_reference/loading_methods#datasets.load_dataset) 轻松加载:
```python
from datasets import load_dataset
dataset = load_dataset("csv", data_files="my_file.csv")
# or
dataset = load_dataset("json", data_files="my_file.json")
```
### 需要预处理的本地数据
如果你的本地数据需要预处理,你可以使用 [`datasets.Dataset.from_dict`](https://huggingface.co/docs/datasets/main/en/package_reference/main_classes#datasets.Dataset.from_dict) 用列表字典初始化你的数据集:
```python
from datasets import Dataset
anchors = []
positives = []
# Open a file, perform preprocessing, filtering, cleaning, etc.
# and append to the lists
dataset = Dataset.from_dict({
"anchor": anchors,
"positive": positives,
})
```
字典中的每个键都成为结果数据集中的列。
### 数据集格式
确保你的数据集格式与你选择的 [损失函数](#损失函数) 相匹配至关重要。这包括检查两件事:
1. 如果你的损失函数需要 _标签_ (如 [损失概览](https://sbert.net/docs/sentence_transformer/loss_overview.html) 表中所指示),你的数据集必须有一个名为**“label” **或**“score”**的列。
2. 除 **“label”** 或 **“score”** 之外的所有列都被视为 _输入_ (如 [损失概览](https://sbert.net/docs/sentence_transformer/loss_overview.html) 表中所指示)。这些列的数量必须与你选择的损失函数的有效输入数量相匹配。列的名称无关紧要, **只有它们的顺序重要**。
例如,如果你的损失函数接受 `(anchor, positive, negative)` 三元组,那么你的数据集的第一、第二和第三列分别对应于 `anchor` 、 `positive` 和 `negative` 。这意味着你的第一和第二列必须包含应该紧密嵌入的文本,而你的第一和第三列必须包含应该远距离嵌入的文本。这就是为什么根据你的损失函数,你的数据集列顺序很重要的原因。
考虑一个带有 `["text1", "text2", "label"]` 列的数据集,其中 `"label"` 列包含浮点数相似性得分。这个数据集可以用 `CoSENTLoss` 、 `AnglELoss` 和 `CosineSimilarityLoss` ,因为:
1. 数据集有一个“label”列,这是这些损失函数所必需的。
2. 数据集有 2 个非标签列,与这些损失函数所需的输入数量相匹配。
如果你的数据集中的列没有正确排序,请使用 [`Dataset.select_columns`](https://huggingface.co/docs/datasets/main/en/package_reference/main_classes#datasets.Dataset.select_columns) 来重新排序。此外,使用 [`Dataset.remove_columns`](https://huggingface.co/docs/datasets/main/en/package_reference/main_classes#datasets.Dataset.remove_columns) 移除任何多余的列 (例如, `sample_id` 、 `metadata` 、 `source` 、 `type` ),因为否则它们将被视为输入。
## 损失函数
损失函数衡量模型在给定数据批次上的表现,并指导优化过程。损失函数的选择取决于你可用的数据和目标任务。请参阅 [损失概览](https://sbert.net/docs/sentence_transformer/loss_overview.html) 以获取完整的选择列表。
大多数损失函数可以使用你正在训练的 `SentenceTransformer` `model` 来初始化:
```python
from datasets import load_dataset
from sentence_transformers import SentenceTransformer
from sentence_transformers.losses import CoSENTLoss
# Load a model to train/finetune
model = SentenceTransformer("FacebookAI/xlm-roberta-base")
# Initialize the CoSENTLoss
# This loss requires pairs of text and a floating point similarity score as a label
loss = CoSENTLoss(model)
# Load an example training dataset that works with our loss function:
train_dataset = load_dataset("sentence-transformers/all-nli", "pair-score", split="train")
"""
Dataset({
features: ['sentence1', 'sentence2', 'label'],
num_rows: 942069
})
"""
```
## 训练参数
[`SentenceTransformersTrainingArguments`](https://sbert.net/docs/package_reference/sentence_transformer/training_args.html#sentencetransformertrainingarguments) 类允许你指定影响训练性能和跟踪/调试的参数。虽然这些参数是可选的,但实验这些参数可以帮助提高训练效率,并为训练过程提供洞察。
在 Sentence Transformers 的文档中,我概述了一些最有用的训练参数。我建议你阅读 [训练概览 > 训练参数](https://sbert.net/docs/sentence_transformer/training_overview.html#training-arguments) 部分。
以下是如何初始化 [`SentenceTransformersTrainingArguments`](https://sbert.net/docs/package_reference/sentence_transformer/training_args.html#sentencetransformertrainingarguments) 的示例:
```python
from sentence_transformers.training_args import SentenceTransformerTrainingArguments
args = SentenceTransformerTrainingArguments(
# Required parameter:
output_dir="models/mpnet-base-all-nli-triplet",
# Optional training parameters:
num_train_epochs=1,
per_device_train_batch_size=16,
per_device_eval_batch_size=16,
warmup_ratio=0.1,
fp16=True, # Set to False if your GPU can't handle FP16
bf16=False, # Set to True if your GPU supports BF16
batch_sampler=BatchSamplers.NO_DUPLICATES, # Losses using "in-batch negatives" benefit from no duplicates
# Optional tracking/debugging parameters:
eval_strategy="steps",
eval_steps=100,
save_strategy="steps",
save_steps=100,
save_total_limit=2,
logging_steps=100,
run_name="mpnet-base-all-nli-triplet", # Used in W&B if `wandb` is installed
)
```
注意 `eval_strategy` 是在 `transformers` 版本 `4.41.0` 中引入的。之前的版本应该使用 `evaluation_strategy` 代替。
## 评估器
你可以为 [`SentenceTransformerTrainer`](https://sbert.net/docs/package_reference/sentence_transformer/SentenceTransformer.html#sentence_transformers.SentenceTransformer) 提供一个 `eval_dataset` 以便在训练过程中获取评估损失,但在训练过程中获取更具体的指标也可能很有用。为此,你可以使用评估器来在训练前、中或后评估模型的性能,并使用有用的指标。你可以同时使用 `eval_dataset` 和评估器,或者只使用其中一个,或者都不使用。它们根据 `eval_strategy` 和 `eval_steps` [训练参数](#training-arguments) 进行评估。
以下是 Sentence Tranformers 随附的已实现的评估器:
| 评估器 | 所需数据 |
| --- | --- |
| [`BinaryClassificationEvaluator`](https://sbert.net/docs/package_reference/sentence_transformer/evaluation.html#binaryclassificationevaluator) | 带有类别标签的句子对 |
| [`EmbeddingSimilarityEvaluator`](https://sbert.net/docs/package_reference/sentence_transformer/evaluation.html#embeddingsimilarityevaluator) | 带有相似性得分的句子对 |
| [`InformationRetrievalEvaluator`](https://sbert.net/docs/package_reference/sentence_transformer/evaluation.html#informationretrievalevaluator) | 查询(qid => 问题),语料库 (cid => 文档),以及相关文档 (qid => 集合[cid]) |
| [`MSEEvaluator`](https://sbert.net/docs/package_reference/sentence_transformer/evaluation.html#mseevaluator) | 需要由教师模型嵌入的源句子和需要由学生模型嵌入的目标句子。可以是相同的文本。 |
| [`ParaphraseMiningEvaluator`](https://sbert.net/docs/package_reference/sentence_transformer/evaluation.html#paraphraseminingevaluator) | ID 到句子的映射以及带有重复句子 ID 的句子对。 |
| [`RerankingEvaluator`](https://sbert.net/docs/package_reference/sentence_transformer/evaluation.html#rerankingevaluator) | {'query': '..', 'positive': [...], 'negative': [...]} 字典的列表。 |
| [`TranslationEvaluator`](https://sbert.net/docs/package_reference/sentence_transformer/evaluation.html#translationevaluator) | 两种不同语言的句子对。 |
| [`TripletEvaluator`](https://sbert.net/docs/package_reference/sentence_transformer/evaluation.html#tripletevaluator) | (锚点,正面,负面) 三元组。 |
此外,你可以使用 [`SequentialEvaluator`](https://sbert.net/docs/package_reference/sentence_transformer/evaluation.html#sequentialevaluator) 将多个评估器组合成一个,然后将其传递给 [`SentenceTransformerTrainer`](https://sbert.net/docs/package_reference/sentence_transformer/SentenceTransformer.html#sentence_transformers.SentenceTransformer)。
如果你没有必要的评估数据但仍然想跟踪模型在常见基准上的性能,你可以使用 Hugging Face 上的数据与这些评估器一起使用。
### 使用 STSb 的 Embedding Similarity Evaluator
STS 基准测试 (也称为 STSb) 是一种常用的基准数据集,用于衡量模型对短文本 (如 “A man is feeding a mouse to a snake.”) 的语义文本相似性的理解。
你可以自由浏览 Hugging Face 上的 [sentence-transformers/stsb](https://huggingface.co/datasets/sentence-transformers/stsb) 数据集。
```python
from datasets import load_dataset
from sentence_transformers.evaluation import EmbeddingSimilarityEvaluator, SimilarityFunction
# Load the STSB dataset
eval_dataset = load_dataset("sentence-transformers/stsb", split="validation")
# Initialize the evaluator
dev_evaluator = EmbeddingSimilarityEvaluator(
sentences1=eval_dataset["sentence1"],
sentences2=eval_dataset["sentence2"],
scores=eval_dataset["score"],
main_similarity=SimilarityFunction.COSINE,
name="sts-dev",
)
# Run evaluation manually:
# print(dev_evaluator(model))
# Later, you can provide this evaluator to the trainer to get results during training
```
### 使用 AllNLI 的 Triplet Evaluator
AllNLI 是 [SNLI](https://huggingface.co/datasets/stanfordnlp/snli) 和 [MultiNLI](https://huggingface.co/datasets/nyu-mll/multi_nli) 数据集的合并,这两个数据集都是用于自然语言推理的。这个任务的传统目的是确定两段文本是否是蕴含、矛盾还是两者都不是。它后来被采用用于训练嵌入模型,因为蕴含和矛盾的句子构成了有用的 `(anchor, positive, negative)` 三元组: 这是训练嵌入模型的一种常见格式。
在这个片段中,它被用来评估模型认为锚文本和蕴含文本比锚文本和矛盾文本更相似的频率。一个示例文本是 “An older man is drinking orange juice at a restaurant.”。
你可以自由浏览 Hugging Face 上的 [sentence-transformers/all-nli](https://huggingface.co/datasets/sentence-transformers/all-nli) 数据集。
```python
from datasets import load_dataset
from sentence_transformers.evaluation import TripletEvaluator, SimilarityFunction
# Load triplets from the AllNLI dataset
max_samples = 1000
eval_dataset = load_dataset("sentence-transformers/all-nli", "triplet", split=f"dev[:{max_samples}]")
# Initialize the evaluator
dev_evaluator = TripletEvaluator(
anchors=eval_dataset["anchor"],
positives=eval_dataset["positive"],
negatives=eval_dataset["negative"],
main_distance_function=SimilarityFunction.COSINE,
name=f"all-nli-{max_samples}-dev",
)
# Run evaluation manually:
# print(dev_evaluator(model))
# Later, you can provide this evaluator to the trainer to get results during training
```
## 训练器
[`SentenceTransformerTrainer`](https://sbert.net/docs/package_reference/sentence_transformer/SentenceTransformer.html#sentence_transformers.SentenceTransformer) 将模型、数据集、损失函数和其他组件整合在一起进行训练:
```python
from datasets import load_dataset
from sentence_transformers import (
SentenceTransformer,
SentenceTransformerTrainer,
SentenceTransformerTrainingArguments,
SentenceTransformerModelCardData,
)
from sentence_transformers.losses import MultipleNegativesRankingLoss
from sentence_transformers.training_args import BatchSamplers
from sentence_transformers.evaluation import TripletEvaluator
# 1. Load a model to finetune with 2. (Optional) model card data
model = SentenceTransformer(
"microsoft/mpnet-base",
model_card_data=SentenceTransformerModelCardData(
language="en",
license="apache-2.0",
model_name="MPNet base trained on AllNLI triplets",
)
)
# 3. Load a dataset to finetune on
dataset = load_dataset("sentence-transformers/all-nli", "triplet")
train_dataset = dataset["train"].select(range(100_000))
eval_dataset = dataset["dev"]
test_dataset = dataset["test"]
# 4. Define a loss function
loss = MultipleNegativesRankingLoss(model)
# 5. (Optional) Specify training arguments
args = SentenceTransformerTrainingArguments(
# Required parameter:
output_dir="models/mpnet-base-all-nli-triplet",
# Optional training parameters:
num_train_epochs=1,
per_device_train_batch_size=16,
per_device_eval_batch_size=16,
warmup_ratio=0.1,
fp16=True, # Set to False if GPU can't handle FP16
bf16=False, # Set to True if GPU supports BF16
batch_sampler=BatchSamplers.NO_DUPLICATES, # MultipleNegativesRankingLoss benefits from no duplicates
# Optional tracking/debugging parameters:
eval_strategy="steps",
eval_steps=100,
save_strategy="steps",
save_steps=100,
save_total_limit=2,
logging_steps=100,
run_name="mpnet-base-all-nli-triplet", # Used in W&B if `wandb` is installed
)
# 6. (Optional) Create an evaluator & evaluate the base model
dev_evaluator = TripletEvaluator(
anchors=eval_dataset["anchor"],
positives=eval_dataset["positive"],
negatives=eval_dataset["negative"],
name="all-nli-dev",
)
dev_evaluator(model)
# 7. Create a trainer & train
trainer = SentenceTransformerTrainer(
model=model,
args=args,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
loss=loss,
evaluator=dev_evaluator,
)
trainer.train()
# (Optional) Evaluate the trained model on the test set, after training completes
test_evaluator = TripletEvaluator(
anchors=test_dataset["anchor"],
positives=test_dataset["positive"],
negatives=test_dataset["negative"],
name="all-nli-test",
)
test_evaluator(model)
# 8. Save the trained model
model.save_pretrained("models/mpnet-base-all-nli-triplet/final")
# 9. (Optional) Push it to the Hugging Face Hub
model.push_to_hub("mpnet-base-all-nli-triplet")
```
在这个示例中,我从一个尚未成为 Sentence Transformer 模型的基础模型 [`microsoft/mpnet-base`](https://huggingface.co/microsoft/mpnet-base) 开始进行微调。这需要比微调现有的 Sentence Transformer 模型,如 [`all-mpnet-base-v2`](https://huggingface.co/sentence-transformers/all-mpnet-base-v2),更多的训练数据。
运行此脚本后,[tomaarsen/mpnet-base-all-nli-triplet](https://huggingface.co/tomaarsen/mpnet-base-all-nli-triplet) 模型被上传了。使用余弦相似度的三元组准确性,即 `cosine_similarity(anchor, positive) > cosine_similarity(anchor, negative)` 的百分比为开发集上的 90.04% 和测试集上的 91.5% !作为参考,[`microsoft/mpnet-base`](https://huggingface.co/microsoft/mpnet-base) 模型在训练前在开发集上的得分为 68.32%。
所有这些信息都被自动生成的模型卡存储,包括基础模型、语言、许可证、评估结果、训练和评估数据集信息、超参数、训练日志等。无需任何努力,你上传的模型应该包含潜在用户判断你的模型是否适合他们的所有信息。
### 回调函数
Sentence Transformers 训练器支持各种 [`transformers.TrainerCallback`](https://huggingface.co/docs/transformers/main_classes/callback#transformers.TrainerCallback) 子类,包括:
- [`WandbCallback`](https://huggingface.co/docs/transformers/en/main_classes/callback#transformers.integrations.WandbCallback): 如果已安装 `wandb` ,则将训练指标记录到 W&B
- [`TensorBoardCallback`](https://huggingface.co/docs/transformers/en/main_classes/callback#transformers.integrations.TensorBoardCallback): 如果可访问 `tensorboard` ,则将训练指标记录到 TensorBoard
- [`CodeCarbonCallback`](https://huggingface.co/docs/transformers/en/main_classes/callback#transformers.integrations.CodeCarbonCallback): 如果已安装 `codecarbon` ,则跟踪训练期间的碳排放
这些回调函数会自动使用,无需你进行任何指定,只要安装了所需的依赖项即可。
有关这些回调函数的更多信息以及如何创建你自己的回调函数,请参阅 [Transformers 回调文档](https://huggingface.co/docs/transformers/en/main_classes/callback)。
## 多数据集训练
通常情况下,表现最好的模型是通过同时使用多个数据集进行训练的。[`SentenceTransformerTrainer`](https://sbert.net/docs/package_reference/sentence_transformer/SentenceTransformer.html#sentence_transformers.SentenceTransformer) 通过允许你使用多个数据集进行训练,而不需要将它们转换为相同的格式,简化了这一过程。你甚至可以为每个数据集应用不同的损失函数。以下是多数据集训练的步骤:
1. 使用一个 [`datasets.Dataset`](https://huggingface.co/docs/datasets/main/en/package_reference/main_classes#datasets.Dataset) 实例的字典 (或 [`datasets.DatasetDict`](https://huggingface.co/docs/datasets/main/en/package_reference/main_classes#datasets.DatasetDict)) 作为 `train_dataset` 和 `eval_dataset` 。
2. (可选) 如果你希望为不同的数据集使用不同的损失函数,请使用一个损失函数的字典,其中数据集名称映射到损失。
每个训练/评估批次将仅包含来自一个数据集的样本。从多个数据集中采样批次的顺序由 [`MultiDatasetBatchSamplers`](https://sbert.net/docs/package_reference/sentence_transformer/training_args.html#sentence_transformers.training_args.MultiDatasetBatchSamplers) 枚举确定,该枚举可以通过 `multi_dataset_batch_sampler` 传递给 [`SentenceTransformersTrainingArguments`](https://sbert.net/docs/package_reference/sentence_transformer/training_args.html#sentencetransformertrainingarguments)。有效的选项包括:
- `MultiDatasetBatchSamplers.ROUND_ROBIN` : 以轮询方式从每个数据集采样,直到一个数据集用尽。这种策略可能不会使用每个数据集中的所有样本,但它确保了每个数据集的平等采样。
- `MultiDatasetBatchSamplers.PROPORTIONAL` (默认): 按比例从每个数据集采样。这种策略确保了每个数据集中的所有样本都被使用,并且较大的数据集被更频繁地采样。
多任务训练已被证明是高度有效的。例如,[Huang et al. 2024](https://arxiv.org/pdf/2405.06932) 使用了 [`MultipleNegativesRankingLoss`](https://sbert.net/docs/package_reference/sentence_transformer/losses.html#multiplenegativesrankingloss)、[`CoSENTLoss`](https://sbert.net/docs/package_reference/sentence_transformer/losses.html#cosentloss) 和 [`MultipleNegativesRankingLoss`](https://sbert.net/docs/package_reference/sentence_transformer/losses.html#multiplenegativesrankingloss) 的一个变体 (不包含批次内的负样本,仅包含硬负样本),以在中国取得最先进的表现。他们还应用了 [`MatryoshkaLoss`](https://sbert.net/docs/package_reference/sentence_transformer/losses.html#matryoshkaloss) 以使模型能够产生 [Matryoshka Embeddings](https://huggingface.co/blog/matryoshka)。
以下是多数据集训练的一个示例:
```python
from datasets import load_dataset
from sentence_transformers import SentenceTransformer, SentenceTransformerTrainer
from sentence_transformers.losses import CoSENTLoss, MultipleNegativesRankingLoss, SoftmaxLoss
# 1. Load a model to finetune
model = SentenceTransformer("bert-base-uncased")
# 2. Loadseveral Datasets to train with
# (anchor, positive)
all_nli_pair_train = load_dataset("sentence-transformers/all-nli", "pair", split="train[:10000]")
# (premise, hypothesis) + label
all_nli_pair_class_train = load_dataset("sentence-transformers/all-nli", "pair-class", split="train[:10000]")
# (sentence1, sentence2) + score
all_nli_pair_score_train = load_dataset("sentence-transformers/all-nli", "pair-score", split="train[:10000]")
# (anchor, positive, negative)
all_nli_triplet_train = load_dataset("sentence-transformers/all-nli", "triplet", split="train[:10000]")
# (sentence1, sentence2) + score
stsb_pair_score_train = load_dataset("sentence-transformers/stsb", split="train[:10000]")
# (anchor, positive)
quora_pair_train = load_dataset("sentence-transformers/quora-duplicates", "pair", split="train[:10000]")
# (query, answer)
natural_questions_train = load_dataset("sentence-transformers/natural-questions", split="train[:10000]")
# Combine all datasets into a dictionary with dataset names to datasets
train_dataset = {
"all-nli-pair": all_nli_pair_train,
"all-nli-pair-class": all_nli_pair_class_train,
"all-nli-pair-score": all_nli_pair_score_train,
"all-nli-triplet": all_nli_triplet_train,
"stsb": stsb_pair_score_train,
"quora": quora_pair_train,
"natural-questions": natural_questions_train,
}
# 3. Load several Datasets to evaluate with
# (anchor, positive, negative)
all_nli_triplet_dev = load_dataset("sentence-transformers/all-nli", "triplet", split="dev")
# (sentence1, sentence2, score)
stsb_pair_score_dev = load_dataset("sentence-transformers/stsb", split="validation")
# (anchor, positive)
quora_pair_dev = load_dataset("sentence-transformers/quora-duplicates", "pair", split="train[10000:11000]")
# (query, answer)
natural_questions_dev = load_dataset("sentence-transformers/natural-questions", split="train[10000:11000]")
# Use a dictionary for the evaluation dataset too, or just use one dataset or none at all
eval_dataset = {
"all-nli-triplet": all_nli_triplet_dev,
"stsb": stsb_pair_score_dev,
"quora": quora_pair_dev,
"natural-questions": natural_questions_dev,
}
# 4. Load several loss functions to train with
# (anchor, positive), (anchor, positive, negative)
mnrl_loss = MultipleNegativesRankingLoss(model)
# (sentence_A, sentence_B) + class
softmax_loss = SoftmaxLoss(model)
# (sentence_A, sentence_B) + score
cosent_loss = CoSENTLoss(model)
# Create a mapping with dataset names to loss functions, so the trainer knows which loss to apply where
# Note: You can also just use one loss if all your training/evaluation datasets use the same loss
losses = {
"all-nli-pair": mnrl_loss,
"all-nli-pair-class": softmax_loss,
"all-nli-pair-score": cosent_loss,
"all-nli-triplet": mnrl_loss,
"stsb": cosent_loss,
"quora": mnrl_loss,
"natural-questions": mnrl_loss,
}
# 5. Define a simple trainer, although it's recommended to use one with args & evaluators
trainer = SentenceTransformerTrainer(
model=model,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
loss=losses,
)
trainer.train()
# 6. Save the trained model and optionally push it to the Hugging Face Hub
model.save_pretrained("bert-base-all-nli-stsb-quora-nq")
model.push_to_hub("bert-base-all-nli-stsb-quora-nq")
```
## 弃用
在 Sentence Transformer v3 发布之前,所有模型都会使用 [`SentenceTransformer.fit`](https://sbert.net/docs/package_reference/sentence_transformer/SentenceTransformer.html#sentence_transformers.SentenceTransformer.fit) 方法进行训练。从 v3.0 开始,该方法将使用 [`SentenceTransformerTrainer`](https://sbert.net/docs/package_reference/sentence_transformer/trainer.html#sentence_transformers.trainer.SentenceTransformerTrainer) 作为后端。这意味着你的旧训练代码仍然应该可以工作,甚至可以升级到新的特性,如多 GPU 训练、损失记录等。然而,新的训练方法更加强大,因此建议使用新的方法编写新的训练脚本。
## 附加资源
### 训练示例
以下页面包含带有解释的训练示例以及代码链接。我们建议你浏览这些页面以熟悉训练循环:
- [语义文本相似度](https://sbert.net/examples/training/sts/README.html)
- [自然语言推理](https://sbert.net/examples/training/nli/README.html)
- [释义](https://sbert.net/examples/training/paraphrases/README.html)
- [Quora 重复问题](https://sbert.net/examples/training/quora_duplicate_questions/README.html)
- [Matryoshka Embeddings](https://sbert.net/examples/training/matryoshka/README.html)
- [自适应层模型](https://sbert.net/examples/training/adaptive_layer/README.html)
- [多语言模型](https://sbert.net/examples/training/multilingual/README.html)
- [模型蒸馏](https://sbert.net/examples/training/distillation/README.html)
- [增强的句子转换器](https://sbert.net/examples/training/data_augmentation/README.html)
### 文档
此外,以下页面可能有助于你了解 Sentence Transformers 的更多信息:
- [安装](https://sbert.net/docs/installation.html)
- [快速入门](https://sbert.net/docs/quickstart.html)
- [使用](https://sbert.net/docs/sentence_transformer/usage/usage.html)
- [预训练模型](https://sbert.net/docs/sentence_transformer/pretrained_models.html)
- [训练概览](https://sbert.net/docs/sentence_transformer/training_overview.html) (本博客是训练概览文档的提炼)
- [数据集概览](https://sbert.net/docs/sentence_transformer/dataset_overview.html)
- [损失概览](https://sbert.net/docs/sentence_transformer/loss_overview.html)
- [API 参考](https://sbert.net/docs/package_reference/sentence_transformer/index.html)
最后,以下是一些高级页面,你可能会感兴趣:
- [超参数优化](https://sbert.net/examples/training/hpo/README.html)
- [分布式训练](https://sbert.net/docs/sentence_transformer/training/distributed.html)
| 0 |
0 | hf_public_repos/blog | hf_public_repos/blog/zh/idefics2.md | ---
title: "Idefics2 简介:为社区而生的强大 8B 视觉语言模型"
thumbnail: /blog/assets/idefics/thumbnail.png
authors:
- user: Leyo
- user: HugoLaurencon
- user: VictorSanh
translators:
- user: MatrixYao
- user: zhongdongy
proofreader: true
---
<p align="center">
<img src="https://huggingface.co/HuggingFaceM4/idefics-80b/resolve/main/assets/IDEFICS.png" alt="Idefics-Obelics logo" width="250" height="250">
</p>
# Idefics2 简介: 为社区而生的强大 8B 视觉语言模型
我们很高兴在此发布 [Idefics2](https://huggingface.co/HuggingFaceM4/idefics2-8b),这是一个通用的多模态模型,接受任意文本序列和图像序列作为输入,并据此生成文本。它可用于回答图像相关的问题、描述视觉内容、基于多幅图像创作故事、从文档中提取信息以及执行基本的算术运算。
Idefics2 由 [Idefics1](https://huggingface.co/blog/idefics) 改进而得,其参数量为 8B,具有开放许可 (Apache 2.0) 并大大增强了 OCR (光学字符识别) 功能,因此有望成为多模态社区坚实的基础模型。其在视觉问答基准测试中的表现在同规模模型中名列前茅,并可与更大的模型 (如 [LLava-Next-34B](https://huggingface.co/liuhaotian/llava-v1.6-34b) 以及 [MM1-30B-chat](https://huggingface.co/papers/2403.09611)) 一较高下。
Idefics2 甫一开始就集成在 🤗 Transformers 中,因此社区可以直接基于它面向很多多模态应用进行微调。你当下就可在 Hub 上试用 [该模型](https://huggingface.co/HuggingFaceM4/idefics2-8b)!
<p align="left">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/idefics2/Idefics2_eval_barchart.png?download=true" width="900" alt="The Cauldron"/>
</p>
| <nobr>模型</nobr> | <nobr>权重是否开放</nobr> | <nobr>尺寸</nobr> | <nobr>每图像词元数</nobr> | <nobr>MMMU <br>(val/test)</nobr> | <nobr>MathVista <br>(testmini)</nobr> | <nobr>TextVQA <br>(val)</nobr> | <nobr>MMBench <br>(test)</nobr> | <nobr>VQAv2 <br>(test-dev)</nobr> | <nobr>DocVQA <br>(test)</nobr> |
|--------------|-------------|------|--------------------|-----------|-----------|---------|---------|---------|---------|
| [DeepSeek-VL](https://huggingface.co/deepseek-ai/deepseek-vl-7b-chat) | ✅ | 7B | 576 | 36.6/- | 36.1 | 64.4 | 73.2 | - | 49.6 |
| [LLaVa-NeXT-Mistral-7B](https://huggingface.co/liuhaotian/llava-v1.6-mistral-7b) | ✅ | 7B | 2880 | 35.3/- | 37.7 | 65.7 | 68.7 | 82.2 | - |
| [LLaVa-NeXT-13B](https://huggingface.co/liuhaotian/llava-v1.6-vicuna-13b) | ✅ | 13B | 2880 | 36.2/- | 35.3 | 67.1 | 70.0 | 82.8 | - |
| [LLaVa-NeXT-34B](https://huggingface.co/liuhaotian/llava-v1.6-34b) | ✅ | 34B | 2880 | 51.1/44.7 | 46.5 | 69.5 | 79.3 | 83.7 | - | - |
| MM1-Chat-7B | ❌ | 7B | 720 | 37.0/35.6 | 35.9 | 72.8 | 72.3 | 82.8 | - |
| MM1-Chat-30B | ❌ | 30B | 720 | 44.7/40.3 | 39.4 | 73.5 | 75.1 | 83.7 | |
| Gemini 1.0 Pro | ❌ | 🤷♂️ | 🤷♂️ | 47.9/- | 45.2 | 74.6 | - | 71.2 | 88.1 |
| Gemini 1.5 Pro | ❌ | 🤷♂️ | 🤷♂️ | 58.5/- | 52.1 | 73.5 | - | 73.2 | 86.5 |
| Claude 3 Haiku | ❌ |🤷♂️ | 🤷♂️ | 50.2/- | 46.4 | - | - | - | 88.8 |
| | | | | | | |
| [Idefics1 指令版](https://huggingface.co/HuggingFaceM4/idefics-80b-instruct) (32-shots) | ✅ | 80B | - | - | - | 39.3 | - | 68.8 | - |
| | | | | | | |
| **Idefics2**(不切图)* | ✅ | 8B | 64 | 43.5/37.9 | 51.6 | 70.4 | 76.8 | 80.8 | 67.3 |
| **Idefics2** (切图)* | ✅ | 8B | 320 | 43.0/37.7 | 51.4 | 73.0 | 76.7 | 81.2 | 74.0 |
* 切图: 遵循 SPHINX 和 LLaVa-NeXT 的策略,允许算法选择将图切成 4 幅子图。
## 训练数据
Idefics2 在预训练时综合使用了多种公开数据集,包括: 图文网页 (维基百科,[OBELICS](https://huggingface.co/datasets/HuggingFaceM4/OBELICS)) 、图文对 (Public Multimodal Dataset、LAION-COCO) 、OCR 数据 ([PDFA (en)](https://huggingface.co/datasets/pixparse/pdfa-eng-wds)、[IDL](https://huggingface.co/datasets/pixparse/idl-wds)、[Rendered-text](https://huggingface.co/datasets/wendlerc/RenderedText),以及代码 - 渲染图数据 ([WebSight](https://huggingface.co/datasets/HuggingFaceM4/WebSight)) )。
我们使用了 [这个交互式可视化](https://atlas.nomic.ai/map/f2fba2aa-3647-4f49-a0f3-9347daeee499/ee4a84bd-f125-4bcc-a683-1b4e231cb10f) 工具对 OBELICS 数据集进行探索。
遵循基础模型社区的惯例,我们也在各种任务数据集上对基础模型进行了指令微调。此时,由于各任务数据集的格式各不相同,且分散在不同的地方,如何将它们汇聚起来是社区面临的一大难题。为了解决这个问题,我们发布了筹措良久的多模态指令微调数据集: _[The Cauldron (丹鼎) ](https://huggingface.co/datasets/HuggingFaceM4/the_cauldron)_ ,它是我们手动整理的、包含 50 个开放数据集的、多轮对话格式的合辑式数据集。我们的指令微调 Idefics2 模型的训练数据将 The Cauldron 和各种纯文本指令微调数据集的串接而得。
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/idefics2/The_Cauldron.png?download=true" width="400" alt="The Cauldron"/>
</p>
## 对 Idefics1 的改进
- 我们按照 NaViT 策略以原始分辨率 (最大为 980 x 980) 和原始宽高比操作图像。这免去了传统的将图像大小调整为固定尺寸正方形的做法。此外,我们遵循 SPHINX 的策略,并允许切图以及传入非常大分辨率的图像 (可选项)。
- 我们增加了图像或文档中文本识别的训练数据,这显著增强了 OCR 能力。我们还通过增加相应的训练数据提高了模型回答图表、数字和文档问题的能力。
- 我们放弃了 Idefics1 的架构 (门控交叉注意力) 并简化了视觉特征到语言主干的投影子模型。图像先被通过到视觉编码器,再通过已训的感知器池化和 MLP 从而完成模态投影。然后,将所得的池化序列与文本嵌入连接起来,以获得一个图像和文本的交织序列。
所有这些改进叠加上更好的预训练主干网络,使得模型的性能与 Idefics1 相比有显著提升,且尺寸缩小了 10 倍。
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/idefics2/Idefics2_flowchart.png?download=true" alt="Idefics2 Architecture" width="250" height="350">
</p>
## Idefics2 入门
Idefics2 可在 Hugging Face Hub 上使用,并已被最新的 `transformers` 版本支持。以下给出了一段示例代码:
```python
import requests
import torch
from PIL import Image
from transformers import AutoProcessor, AutoModelForVision2Seq
from transformers.image_utils import load_image
DEVICE = "cuda:0"
# Note that passing the image urls (instead of the actual pil images) to the processor is also possible
image1 = load_image("https://cdn.britannica.com/61/93061-050-99147DCE/Statue-of-Liberty-Island-New-York-Bay.jpg")
image2 = load_image("https://cdn.britannica.com/59/94459-050-DBA42467/Skyline-Chicago.jpg")
image3 = load_image("https://cdn.britannica.com/68/170868-050-8DDE8263/Golden-Gate-Bridge-San-Francisco.jpg")
processor = AutoProcessor.from_pretrained("HuggingFaceM4/idefics2-8b")
model = AutoModelForVision2Seq.from_pretrained(
"HuggingFaceM4/idefics2-8b",
).to(DEVICE)
# Create inputs
messages = [
{
"role": "user",
"content": [
{"type": "image"},
{"type": "text", "text": "What do we see in this image?"},
]
},
{
"role": "assistant",
"content": [
{"type": "text", "text": "In this image, we can see the city of New York, and more specifically the Statue of Liberty."},
]
},
{
"role": "user",
"content": [
{"type": "image"},
{"type": "text", "text": "And how about this image?"},
]
},
]
prompt = processor.apply_chat_template(messages, add_generation_prompt=True)
inputs = processor(text=prompt, images=[image1, image2], return_tensors="pt")
inputs = {k: v.to(DEVICE) for k, v in inputs.items()}
# Generate
generated_ids = model.generate(**inputs, max_new_tokens=500)
generated_texts = processor.batch_decode(generated_ids, skip_special_tokens=True)
print(generated_texts)
```
我们还提供了一个微调 [colab notebook](https://colab.research.google.com/drive/1NtcTgRbSBKN7pYD3Vdx1j9m8pt3fhFDB?usp=sharing),希望能帮到想在自有用例上微调 Idefics2 的用户。
<p align="left">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/idefics2/This_is_fine_example.png?download=true" width="1200" alt="The Cauldron"/>
</p>
## 资源
如欲进一步深入,下面列出了 Idefics2 所有资源:
- [Idefics2 合集](https://huggingface.co/collections/HuggingFaceM4/idefics2-661d1971b7c50831dd3ce0fe)
- [Idefics2 模型及模型卡](https://huggingface.co/HuggingFaceM4/idefics2-8b)
- [Idefics2-base 模型及模型卡](https://huggingface.co/HuggingFaceM4/idefics2-8b-base)
- Idefics2-chat 模型及模型卡 (即将推出)
- [The Cauldron 及数据集卡](https://huggingface.co/datasets/HuggingFaceM4/the_cauldron)
- [OBELICS 及数据集卡](https://huggingface.co/datasets/HuggingFaceM4/OBELICS)
- [WebSight 及数据集卡](https://huggingface.co/datasets/HuggingFaceM4/WebSight)
- [Idefics2 微调 colab](https://colab.research.google.com/drive/1rm3AGquGEYXfeeizE40bbDtcWh5S4Nlq?usp=sharing)
- [Idefics2-8B 模型演示 (非聊天模型)](https://huggingface.co/spaces/HuggingFaceM4/idefics-8b)
- Idefics2 演示: (即将推出)
- Idefics2 paper: (即将推出)
## 许可
本模型是两个预训练模型构建的: [Mistral-7B-v0.1](https://huggingface.co/mistralai/Mistral-7B-v0.1) 以及 [siglip-so400m-patch14-384](https://huggingface.co/google/siglip-so400m-patch14-384),这两者都是基于 Apache-2.0 许可证发布的。
因此,我们基于 Apache-2.0 许可证发布了 Idefics2 权重。
## 致谢
感谢 Google 团队和 Mistral AI 向开源 AI 社区发布并提供他们的模型!
特别感谢 Chun Te Lee 的柱状图,以及 Merve Noyan 对博文的评论和建议 🤗。 | 1 |
0 | hf_public_repos/blog | hf_public_repos/blog/zh/chat-templates.md | ---
title: "聊天模板:无声性能杀手的终结"
thumbnail: /blog/assets/chat-templates/thumbnail.png
authors:
- user: rocketknight1
translators:
- user: MatrixYao
- user: zhongdongy
proofreader: true
---
# 聊天模板
> _一个幽灵,格式不正确的幽灵,在聊天模型中游荡!_
## 太长不看版
现存的聊天模型使用的训练数据格式各各不同,我们需要用这些格式将对话转换为单个字符串并传给分词器。如果我们在微调或推理时使用的格式与模型训练时使用的格式不同,通常会导致严重的、无声的性能下降,因此匹配训练期间使用的格式极其重要! Hugging Face 分词器新增了 `chat_template` 属性,可用于保存模型训练时使用的聊天格式。此属性包含一个 Jinja 模板,可将对话历史记录格式化为正确的字符串。请参阅 [技术文档](https://huggingface.co/docs/transformers/main/en/chat_templated),以了解有关如何在代码中编写和应用聊天模板。
## 引言
如果你熟悉 🤗 transformers 库,你可能写过如下代码:
```python
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
model = AutoModel.from_pretrained(checkpoint)
```
通过从同一个 checkpoint 中加载分词器和模型,可以确保对输入字符串使用的分词方法符合模型预期。如果你从另一个模型中选择分词器,则其分词结果很可能会完全不同,此时模型的性能就会受到严重损害。这种现象叫 **分布漂移 (distribution shift)**: 模型一直从一种分布学习 (即训练分词器),突然,数据分布变成了另一个不同的分布。
无论你是微调模型还是直接用它进行推理,让这种分布上的变化尽可能小,并保持提供的输入尽可能与训练时的输入一致总是一个好主意。对于常规语言模型,做到这一点相对容易 - 只需从同一检查点加载分词器和模型,就可以了。
然而,对于聊天模型来说,情况有点不同。这是因为“聊天”不仅仅是直接对单个文本字符串进行分词 - 它需要对一系列消息进行分词。每个消息都包含一个 `角色` 及其 `内容` ,其内容是消息的实际文本。最常见的,角色是“用户”(用于用户发送的消息) 、“助理”(用于模型生成的响应),以及可选的“系统”(指在对话开始时给出的高级指令)。
干讲可能有点抽象,下面我们给出一个示例聊天,把问题具象化:
```python
[
{"role": "user", "content": "Hi there!"},
{"role": "assistant", "content": "Nice to meet you!"}
]
```
此消息序列需要先转换为一个文本字符串,然后才能对其进行分词以输入给模型。但问题是,转换方法有很多!例如,你可以将消息列表转换为“即时消息”格式:
```
User: Hey there!
Bot: Nice to meet you!
```
或者你可以添加特殊词元来指示角色:
```
[USER] Hey there! [/USER]
[ASST] Nice to meet you! [/ASST]
```
抑或你可以添加词元以指示消息之间的边界,而将角色信息作为字符串插入:
```
<|im_start|>user
Hey there!<|im_end|>
<|im_start|>assistant
Nice to meet you!<|im_end|>
```
方法多种多样,但没有哪种方法是最好的或是最正确的。因此,不同的模型会采用截然不同的格式进行训练。上面这些例子不是我编造的,它们都是真实的,并且至少被一个现存模型使用过!但是,一旦模型接受了某种格式的训练,你需要确保未来的输入使用相同的格式,否则就可能会出现损害性能的分布漂移。
## 模板: 一种保存格式信息的方式
当前的状况是: 如果幸运的话,你需要的格式已被正确记录在模型卡中的某个位置; 如果不幸的话,它不在,那如果你想用这个模型的话,只能祝你好运了; 在极端情况下,我们甚至会将整个提示格式放在 [相应模型的博文](https://huggingface.co/blog/llama2#how-to-prompt-llama-2) 中,以确保用户不会错过它!但即使在最好的情况下,你也必须找到模板信息并在微调或推理流水线中手动将其写进代码。我们认为这是一个特别危险的做法,因为使用错误的聊天格式是一个 **静默错误** - 一旦出了错,不会有显式的失败或 Python 异常来告诉你出了什么问题,模型的表现只会比用正确格式时差多了,但很难调试其原因!
这正是 **聊天模板** 旨在解决的问题。聊天模板是一个 [Jinja 模板字符串](https://jinja.palletsprojects.com/en/3.1.x/),你可以使用分词器保存和加载它。聊天模板包含了将聊天消息列表转换为模型所需的、格式正确的输入字符串所需要的全部信息。下面是三个聊天模板字符串,分别对应上文所述的三种消息格式:
```jinja
{% for message in messages %}
{% if message['role'] == 'user' %}
{{ "User : " }}
{% else %}
{{ "Bot : " }}
{{ message['content'] + '\n' }}
{% endfor %}
```
```jinja
{% for message in messages %}
{% if message['role'] == 'user' %}
{{ "[USER]" + message['content'] + " [/USER]" }}
{% else %}
{{ "[ASST]" + message['content'] + " [/ASST]" }}
{{ message['content'] + '\n' }}
{% endfor %}
```
```jinja
"{% for message in messages %}"
"{{'<|im_start|>' + message['role'] + '\n' + message['content'] + '<|im_end|>' + '\n'}}"
"{% endfor %}"
```
如果你不熟悉 Jinja,我强烈建议你花点时间研究下这些模板字符串及其相应的模板输出,看看你是否可以弄清楚这些模板如何将消息列表转换为格式化的消息字符串!其语法在很多方面与 Python 非常相似。
## 为什么要使用模板?
如果你不熟悉 Jinja,一开始上手可能会有点困惑,但我们在实践中发现 Python 程序员可以很快上手它。在开发此功能的过程中,我们考虑了其他方法,例如允许用户按角色指定消息的前缀和后缀。我们发现该方法会变得令人困惑且笨重,而且它非常不灵活,以至于对一些模型而言,我们得需要一些巧妙的变通才行。而另一方面,模板功能强大到足以完全支持我们所知的所有消息格式。
## 为什么要这样做呢?为什么大家不统一到一个标准格式呢?
好主意!不幸的是,为时已晚,因为现有的多个重要模型已经基于迥异的聊天格式进行了训练。
然而,我们仍然可以稍微缓解下这个问题。我们认为最接近“标准”的格式是 OpenAI 创建的 [ChatML 格式](https://github.com/openai/openai-python/blob/main/chatml.md)。如果你正在训练新的聊天模型,并且此格式适合你,我们建议你使用它并给分词器添加特殊的 `<|im_start|>` 和 `<|im_end|>` 词元。它的优点是角色非常灵活,因为角色只是作为字符串插入,而不是特定的角色词元。如果你想使用这个,它是上面的第三个模板,你可以简单地使用一行代码进行设置:
```py
tokenizer.chat_template = "{% for message in messages %}{{'<|im_start|>' + message['role'] + '\n' + message['content'] + '<|im_end|>' + '\n'}}{% endfor %}"
```
不过,除了格式林立的现状之外,还有第二个不硬设标准格式的原因 - 我们预计模板将广泛用于多种类型模型的预处理,包括那些可能与标准聊天操作迥异的模型。硬设标准格式限制了模型开发人员使用此功能完成我们尚未想到的任务的能力,而模板则为用户和开发人员提供了最大的自由度。甚至可以在模板中加入逻辑检查和判断,这是目前任何默认模板中都没有深入使用的功能,但我们希望它能成为喜欢冒险的用户手中的利刃。我们坚信,开源生态系统应该让你能够做你想做的事,而不是命令你做什么。
## 模板如何工作?
聊天模板是 **分词器** 的一部分,因为它们履行与分词器相同的角色: 存储有关如何预处理数据的信息,以确保你以与训练时相同的格式将数据提供给模型。我们的设计使得用户非常容易将模板信息添加到现有分词器并将其保存或上传到 Hub。
在有聊天模板这个功能之前,聊天格式信息都存储在 **类级别** - 这意味着,例如,所有 LLaMA checkpoint 都将使用同一个硬设在 `transformers` 的 LLaMA 模型类代码中的聊天格式。为了向后兼容,目前具有自定义聊天格式方法的模型类也已被赋予了 **默认聊天模板**。
在类级别设置默认聊天模板,用于告诉 `ConversationPipeline` 等类在模型没有聊天模板时如何格式化输入,这样做 **纯粹是为了向后兼容**。我们强烈建议你在任何聊天模型上显式设置聊天模板,即使默认聊天模板是合适的。这可以确保默认聊天模板中的任何未来的更改或弃用都不会破坏你的模型。尽管我们将在可预见的将来保留默认聊天模板,但我们希望随着时间的推移将所有模型转换为显式聊天模板,届时默认聊天模板可能会被完全删除。
有关如何设置和应用聊天模板的详细信息,请参阅 [技术文档](https://huggingface.co/docs/transformers/main/en/chat_templated)。
## 我该如何开始使用模板?
很简单!如果分词器设置了 `chat_template` 属性,则它已准备就绪。你可以在 `ConversationPipeline` 中使用该模型和分词器,也可以调用 `tokenizer.apply_chat_template()` 来格式化聊天以进行推理或训练。请参阅我们的 [开发者指南](https://huggingface.co/docs/transformers/main/en/chat_templated) 或 [如何应用聊天模板的文档](https://huggingface.co/docs/transformers/main/en/internal/tokenization_utils#transformers.PreTrainedTokenizerBase.apply_chat_template) 以了解更多!
如果分词器没有 `chat_template` 属性,它可能仍然可以工作,但它将使用该模型类的默认聊天模板。正如我们上面提到的,这是脆弱的,并且当类模板与模型实际训练的内容不匹配时,它同样会导致静默错误。如果你想使用没有 `chat_template` 的 checkpoint,我们建议检查模型卡等文档以确保使用正确的格式,然后为该格式添加正确的 `chat_template` 。即使默认聊天模板是正确的,我们也建议这样做 - 它可以使模型面向未来,并且还可以清楚地表明该模板是存在的且是适用的。
即使不是你的 checkpoint,你也可以通过提交 [合并请求 (pull request) ](https://huggingface.co/docs/hub/repositories-pull-requests-discussions) 的方式为其添加 `chat_template` 。仅需将 `tokenizer.chat_template` 属性设置为 Jinja 模板字符串。完成后,推送更改就可以了!
如果你想在你的聊天应用中使用某 checkpoint,但找不到有关其使用的聊天格式的任何文档,你可能应该在 checkpoint 上提出问题或联系其所有者!一旦你弄清楚模型使用的格式,请提交一个 PR 以添加合适的 `chat_template` 。其他用户将会非常感激你的贡献!
## 总结: 模板理念
我们认为模板是一个非常令人兴奋的新特性。除了解决大量无声的、影响性能的错误之外,我们认为它们还开辟了全新的方法和数据模式。但最重要的也许是,它们还代表了一种理念转变: 从核心 `transformers` 代码库中挪出一个重要功能,并将其转移到各自模型的仓库中,用户可以自由地做各种奇怪、狂野抑或奇妙的事情。我们迫不及待想看看你会发现哪些用途! | 2 |
0 | hf_public_repos/blog | hf_public_repos/blog/zh/packing-with-FA2.md | ---
title: "通过打包 Flash Attention 来提升 Hugging Face 训练效率"
thumbnail: /blog/assets/packing-with-FA2/thumbnail.png
authors:
- user: RQlee
guest: true
org: ibm
- user: ArthurZ
- user: achikundu
guest: true
org: ibm
- user: lwtr
guest: true
org: ibm
- user: rganti
guest: true
org: ibm
- user: mayank-mishra
guest: true
org: ibm
translators:
- user: innovation64
- user: zhongdongy
proofreader: true
---
## 简单概述
现在,在 Hugging Face 中,使用打包的指令调整示例 (无需填充) 进行训练已与 Flash Attention 2 兼容,这要归功于一个 [最近的 PR](https://github.com/huggingface/transformers/pull/31629) 以及新的 [DataCollatorWithFlattening](https://huggingface.co/docs/transformers/main/en/main_classes/data_collator#transformers.DataCollatorWithFlattening)。
它可以在保持收敛质量的同时,将训练吞吐量提高多达 2 倍。继续阅读以了解详细信息!
## 简介
在训练期间,对小批量输入进行填充是一种常见的整理输入数据的方法。然而,由于无关的填充 token ,这引入了效率低下的问题。不进行填充而是打包示例,并使用 token 位置信息,是一种更高效的选择。然而,之前打包的实现并没有在使用 Flash Attention 2 时考虑示例边界,导致出现不希望的跨示例注意力,这降低了质量和收敛性。
Hugging Face Transformers 现在通过一项新功能解决了这个问题,该功能在打包时保持对边界的意识,同时引入了一个新的数据整理器 `DataCollatorWithFlattening` 。
通过选择 `DataCollatorWithFlattening` ,Hugging Face `Trainer` 的用户现在可以无缝地将序列连接成一个单一的张量,同时在 Flash Attention 2 计算过程中考虑到序列边界。这是通过 `flash_attn_varlen_func` 实现的,它计算每个小批量的累积序列长度 ( `cu_seqlens` )。
同样的功能也适用于 `TRL` 库中的 Hugging Face `SFTTrainer` 用户,通过在调用数据整理器 `DataCollatorForCompletionOnlyLM` 时设置一个新的标志 `padding_free=True` 来实现。
## 吞吐量提高多达 2 倍
我们使用带有新 `DataCollatorWithFlattening` 的此功能在训练过程中看到了显著的处理吞吐量提升。下图显示了在训练期间测量的吞吐量,单位为 token /秒。在这个例子中,吞吐量是在 8 个 A100-80 GPU 上对一个 epoch 内的 20K 个随机选自两个不同指令调整数据集 (FLAN 和 OrcaMath) 的样本的平均值。

FLAN 数据集的平均序列较短,但序列长度差异较大,因此每个批次中的示例长度可能会有很大差异。这意味着填充的 FLAN 批次可能会因为未使用的填充 token 而产生显著的开销。在 FLAN 数据集上进行训练时,使用新的 `DataCollatorWithFlattening` 在提高吞吐量方面显示出显著的优势。我们在这里展示的模型中看到了 2 倍的吞吐量提升: llama2-7B、mistral-7B 和 granite-8B-code。
OrcaMath 数据集的示例较长,且示例长度差异较小。因此,从打包中获得的改进较低。我们的实验显示,在使用这种打包方式在 OrcaMath 数据集上训练时,这三个模型的吞吐量增加了 1.4 倍。

通过使用新的 `DataCollatorWithFlattening` 进行打包,内存使用也有所改善。下图显示了相同的三个模型在相同的两个数据集上训练时的峰值内存使用情况。在 FLAN 数据集上,峰值内存减少了 20%,这得益于打包的显著好处。
在 OrcaMath 数据集上,由于其示例长度更为均匀,峰值内存减少了 6%。
当打包示例减少了优化步骤的数量时,可能会损害训练的收敛性。然而,这个新功能保留了小批量,因此与使用填充示例相同的优化步骤数量。因此,对训练收敛性没有影响,正如我们在下一个图中看到的那样,该图显示了相同的三个模型在相同的两个数据集上训练时,无论是使用新的 `DataCollatorWithFlattening` 进行打包还是使用填充,模型的验证损失是相同的。

## 工作原理
考虑一个批处理数据,其中批量大小 (batchsize) 为 4,四个序列如下:

在将示例连接之后,无填充整理器返回每个示例的 `input_ids` 、 `labels` 和 `position_ids` 。因此,对于这批数据,整理器提供了以下内容:

所需的修改是轻量级的,仅限于向 Flash Attention 2 提供 `position_ids` 。
然而,这依赖于模型暴露 `position_ids` 。在撰写本文时,有 14 个模型暴露了它们,并且受该解决方案的支持。具体来说,Llama 2 和 3、Mistral、Mixtral、Granite、DBRX、Falcon、Gemma、OLMo、Phi 1、2 和 3、phi3、Qwen 2 和 2 MoE、StableLM 以及 StarCoder 2 都受该解决方案支持。
## 开始使用
利用 `position_ids` 进行打包的好处很容易实现。
如果你正在使用 Hugging Face `Transformers` 中的 `Trainer` ,只需两个步骤:
1. 使用 Flash Attention 2 实例化模型
2. 使用新的 `DataCollatorWithFlattening`
如果你正在使用 `TRL` 中的 Hugging Face `SFTTrainer` 配合 `DataCollatorForCompletionOnlyLM` ,那么所需的两个步骤是:
1. 使用 Flash Attention 2 实例化模型
2. 在调用 `DataCollatorForCompletionOnlyLM` 时设置 `padding_free=True` ,如下所示:
`collator = DataCollatorForCompletionOnlyLM(response_template_ids, tokenizer=tokenizer, padding_free=True)`
## 如何使用它
对于 `Trainer` 用户,下面的例子展示了如何使用这个新功能。
```Python
# 使用 DataCollatorWithFlattening 的示例
import torch
# 加载模型
from transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained(
"instructlab/merlinite-7b-lab",
torch_dtype=torch.bfloat16,
attn_implementation="flash_attention_2"
)
# 读取数据集
from datasets import load_dataset
train_dataset = load_dataset("json", data_files="path/to/my/dataset")["train"]
# 使用 DataCollatorWithFlattening
from transformers import DataCollatorWithFlattening
data_collator = DataCollatorWithFlattening()
# 训练
from transformers import TrainingArguments, Trainer
train_args = TrainingArguments(output_dir="/save/path")
trainer = Trainer(
args=train_args,
model=model,
train_dataset=train_dataset,
data_collator=data_collator
)
trainer.train()
```
对于 `TRL` 用户,下面的例子展示了如何在使用 `SFTTrainer` 时使用这个新功能。
```Python
# 使用 DataCollatorForCompletionOnlyLM SFTTrainer 示例
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
from datasets import load_dataset
from trl import SFTConfig, SFTTrainer, DataCollatorForCompletionOnlyLM
dataset = load_dataset("lucasmccabe-lmi/CodeAlpaca-20k", split="train")
model = AutoModelForCausalLM.from_pretrained(
"instructlab/merlinite-7b-lab",
torch_dtype=torch.bfloat16,
attn_implementation="flash_attention_2")
tokenizer = AutoTokenizer.from_pretrained("instructlab/merlinite-7b-lab")
tokenizer.pad_token = tokenizer.eos_token
def formatting_prompts_func(example):
output_texts = []
for i in range(len(example['instruction'])):
text = f"### Question: {example['instruction'][i]}\n ### Answer: {example['output'][i]}"
output_texts.append(text)
return output_texts
response_template = " ### Answer:"
response_template_ids = tokenizer.encode(response_template, add_special_tokens=False)[2:]
collator = DataCollatorForCompletionOnlyLM(response_template_ids, tokenizer=tokenizer, padding_free=True)
trainer = SFTTrainer(
model,
train_dataset=dataset,
args=SFTConfig(
output_dir="./tmp",
gradient_checkpointing=True,
per_device_train_batch_size=8
),
formatting_func=formatting_prompts_func,
data_collator=collator,
)
trainer.train()
```
## 结论
得益于最近的 PR 和新推出的 `DataCollatorWithFlattening` ,现在打包指令调整示例 (而不是填充) 已与 Flash Attention 2 完全兼容。这种方法与使用 `position_ids` 的模型兼容。在训练期间可以观察到吞吐量和峰值内存使用的改善,而训练收敛性没有下降。实际的吞吐量和内存改善取决于模型以及训练数据中示例长度的分布。对于具有广泛示例长度变化的训练数据,使用 `DataCollatorWithFlattening` 相对于填充将获得最大的益处。 `TRL` 库中的 `SFTTrainer` 用户可以通过在调用 `DataCollatorForCompletionOnlyLM` 时设置新的标志 `padding_free=True` 来使用同一功能。
想要更详细的分析,请查看论文: https://huggingface.co/papers/2407.09105。 | 3 |
0 | hf_public_repos/blog | hf_public_repos/blog/zh/stable-diffusion-finetuning-intel.md | ---
title: "在英特尔 CPU 上微调 Stable Diffusion 模型"
thumbnail: /blog/assets/stable-diffusion-finetuning-intel/01.png
authors:
- user: juliensimon
translators:
- user: MatrixYao
- user: zhongdongy
proofreader: true
---
# 在英特尔 CPU 上微调 Stable Diffusion 模型
扩散模型能够根据文本提示生成逼真的图像,这种能力促进了生成式人工智能的普及。人们已经开始把这些模型用在包括数据合成及内容创建在内的多个应用领域。 Hugging Face Hub 包含超过 5 千个预训练的文生图 [模型](https://huggingface.co/models?pipeline_tag=text-to-image&sort=trending)。这些模型与 [Diffusers 库](https://huggingface.co/docs/diffusers/index) 结合使用,使得构建图像生成工作流或者对不同的图像生成工作流进行实验变得无比简单。
和 transformer 模型一样,你可以微调扩散模型以让它们生成更符合特定业务需求的内容。起初,大家只能用 GPU 进行微调,但情况正在发生变化!几个月前,英特尔 [推出](https://www.intel.com/content/www/us/en/newsroom/news/4th-gen-xeon-scalable-processors-max-series-cpus-gpus.html#gs.2d6cd7) 了代号为 Sapphire Rapids 的第四代至强 CPU。Sapphire Rapids 中包含了英特尔先进矩阵扩展 (Advanced Matrix eXtension,AMX),它是一种用于深度学习工作负载的新型硬件加速器。在之前的几篇博文中,我们已经展示了 AMX 的优势: [微调 NLP transformers 模型](https://huggingface.co/blog/zh/intel-sapphire-rapids)、[对 NLP transformers 模型进行推理](https://huggingface.co/blog/zh/intel-sapphire-rapids-inference),以及 [对 Stable Diffusion 模型进行推理](https://huggingface.co/blog/zh/stable-diffusion-inference-intel)。
本文将展示如何在英特尔第四代至强 CPU 集群上微调 Stable Diffusion 模型。我们用于微调的是 [文本逆向 (Textual Inversion)](https://huggingface.co/docs/diffusers/training/text_inversion) 技术,该技术仅需少量训练样本即可对模型进行有效微调。在本文中,我们仅用 5 个样本就行了!
我们开始吧。
## 配置集群
[英特尔](https://huggingface.co/intel) 的小伙伴给我们提供了 4 台托管在 [英特尔开发者云 (Intel Developer Cloud,IDC)](https://www.intel.com/content/www/us/en/developer/tools/devcloud/services.html) 上的服务器。IDC 作为一个云服务平台,提供了一个英特尔深度优化的、集成了最新英特尔处理器及 [最优性能软件栈](https://www.intel.com/content/www/us/en/developer/topic-technology/artificial-intelligence/overview.html) 的部署环境,用户可以很容易地在此环境上开发、运行其工作负载。
我们得到的每台服务器均配备两颗英特尔第四代至强 CPU,每颗 CPU 有 56 个物理核和 112 个线程。以下是其 `lscpu` 的输出:
```
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Address sizes: 52 bits physical, 57 bits virtual
Byte Order: Little Endian
CPU(s): 224
On-line CPU(s) list: 0-223
Vendor ID: GenuineIntel
Model name: Intel(R) Xeon(R) Platinum 8480+
CPU family: 6
Model: 143
Thread(s) per core: 2
Core(s) per socket: 56
Socket(s): 2
Stepping: 8
CPU max MHz: 3800.0000
CPU min MHz: 800.0000
BogoMIPS: 4000.00
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc art arch_per fmon pebs bts rep_good nopl xtopology nonstop_tsc cpuid aperfmperf tsc_known_freq pni pclmulqdq dtes64 monitor ds_cpl vmx smx est tm2 ssse3 sdbg fma cx16 xtpr pdcm pcid dca sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand lahf_lm abm 3dnowprefetch cpuid_fault epb cat_l3 cat_l2 cdp_l3 invpcid_single intel_ppin cdp_l2 ssbd mba ibrs ibpb stibp ibrs_enhanced tpr_shadow vnmi flexpriority ept vpid ept_ad fsgsbase tsc_adjust bmi1 avx2 smep bmi2 erms invpcid cqm rdt_a avx512f avx512dq rdseed adx smap avx512ifma clflushopt clwb intel_pt avx512cd sha_ni avx512bw avx512vl xsaveopt xsavec xgetbv1 xsaves cqm_llc cqm_occup_llc cqm_mbm_total cqm_mbm_local split_lock_detect avx_vnni avx512_bf16 wbnoinvd dtherm ida arat pln pts hwp hwp_act_window hwp_epp hwp_pkg_req avx512vbmi umip pku ospke waitpkg avx512_vbmi2 gfni vaes vpclmulqdq avx512_vnni avx512_bitalg tme avx512_vpopcntdq la57 rdpid bus_lock_detect cldemote movdiri movdir64b enqcmd fsrm md_clear serialize tsxldtrk pconfig arch_lbr amx_bf16 avx512_fp16 amx_tile amx_int8 flush_l1d arch_capabilities
```
我们把四台服务器的 IP 地址写到 `nodefile` 文件中,其中,第一行是主服务器。
```
cat << EOF > nodefile
192.168.20.2
192.168.21.2
192.168.22.2
192.168.23.2
EOF
```
分布式训练要求主节点和其他节点之间实现无密码 `ssh` 通信。如果你对此不是很熟悉,可以参考这篇 [文章](https://www.redhat.com/sysadmin/passwordless-ssh),并跟着它一步步设置好无密码 `ssh` 。
接下来,我们在每个节点上搭建运行环境并安装所需软件。我们特别安装了两个英特尔优化库: 用于管理分布式通信的 [oneCCL](https://github.com/oneapi-src/oneCCL) 以及 [Intel Extension for PyTorch (IPEX)](https://github.com/intel/intel-extension-for-pytorch),IPEX 中包含了能充分利用 Sapphire Rapids 中的硬件加速功能的软件优化。我们还安装了 `libtcmalloc` ,它是一个高性能内存分配库,及其软件依赖项 `gperftools` 。
```
conda create -n diffuser python==3.9
conda activate diffuser
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cpu
pip3 install transformers accelerate==0.19.0
pip3 install oneccl_bind_pt -f https://developer.intel.com/ipex-whl-stable-cpu
pip3 install intel_extension_for_pytorch
conda install gperftools -c conda-forge -y
```
下面,我们在每个节点上克隆 [diffusers](https://github.com/huggingface/diffusers/) 代码库并进行源码安装。
```
git clone https://github.com/huggingface/diffusers.git
cd diffusers
pip install .
```
紧接着,我们需要使用 IPEX 对 `diffusers/examples/textual_inversion` 中的微调脚本进行一些优化,以将 IPEX 对推理模型的优化包含在内 (译者注: `diffusers` 的设计中,其 `pipeline` 与 transformers 的 `pipeline` 虽然名称相似,但无继承关系,所以其子模型的推理优化无法在库内完成,只能在脚本代码内完成。而 Clip-Text 模型的微调由于使用了 `accelerate` ,所以其优化可由 `accelerate` 完成)。我们导入 IPEX 并对 U-Net 和变分自编码器 (VAE) 模型进行推理优化。最后,不要忘了这个改动对每个节点的代码都要做。
```
diff --git a/examples/textual_inversion/textual_inversion.py b/examples/textual_inversion/textual_inversion.py
index 4a193abc..91c2edd1 100644
--- a/examples/textual_inversion/textual_inversion.py
+++ b/examples/textual_inversion/textual_inversion.py
@@ -765,6 +765,10 @@ def main():
unet.to(accelerator.device, dtype=weight_dtype)
vae.to(accelerator.device, dtype=weight_dtype)
+ import intel_extension_for_pytorch as ipex
+ unet = ipex.optimize(unet, dtype=weight_dtype)
+ vae = ipex.optimize(vae, dtype=weight_dtype)
+
# We need to recalculate our total training steps as the size of the training dataloader may have changed.
num_update_steps_per_epoch = math.ceil(len(train_dataloader) / args.gradient_accumulation_steps)
if overrode_max_train_steps:
```
最后一步是下载 [训练图像](https://huggingface.co/sd-concepts-library/dicoo)。一般我们会使用共享 NFS 文件夹,但为了简单起见,这里我们选择在每个节点上下载图像。请确保训练图像的目录在所有节点上的路径都相同 ( `/home/devcloud/dicoo` )。
```
mkdir /home/devcloud/dicoo
cd /home/devcloud/dicoo
wget https://huggingface.co/sd-concepts-library/dicoo/resolve/main/concept_images/0.jpeg
wget https://huggingface.co/sd-concepts-library/dicoo/resolve/main/concept_images/1.jpeg
wget https://huggingface.co/sd-concepts-library/dicoo/resolve/main/concept_images/2.jpeg
wget https://huggingface.co/sd-concepts-library/dicoo/resolve/main/concept_images/3.jpeg
wget https://huggingface.co/sd-concepts-library/dicoo/resolve/main/concept_images/4.jpeg
```
下面展示了我们使用的训练图像:
<img src="https://huggingface.co/sd-concepts-library/dicoo/resolve/main/concept_images/0.jpeg" height="256">
<img src="https://huggingface.co/sd-concepts-library/dicoo/resolve/main/concept_images/1.jpeg" height="256">
<img src="https://huggingface.co/sd-concepts-library/dicoo/resolve/main/concept_images/2.jpeg" height="256">
<img src="https://huggingface.co/sd-concepts-library/dicoo/resolve/main/concept_images/3.jpeg" height="256">
<img src="https://huggingface.co/sd-concepts-library/dicoo/resolve/main/concept_images/4.jpeg" height="256">
至此,系统配置就完成了。下面,我们开始配置训练任务。
## 配置微调环境
使用 [accelerate](https://huggingface.co/docs/accelerate/index) 库让分布式训练更容易。我们需要在每个节点上运行 `acclerate config` 并回答一些简单问题。
下面是主节点的屏幕截图。在其他节点上,你需要将 `rank` 设置为 1、2 和 3,其他答案保持不变即可。
<kbd>
<img src="https://huggingface.co/blog/assets/stable-diffusion-finetuning-intel/screen01.png">
</kbd>
最后,我们需要在主节点上设置一些环境变量。微调任务启动时,这些环境变量会传播到其他节点。第一行设置连接到所有节点运行的本地网络的网络接口的名称。你可能需要使用 `ifconfig` 来设置适合你的网络接口名称。
```
export I_MPI_HYDRA_IFACE=ens786f1
oneccl_bindings_for_pytorch_path=$(python -c "from oneccl_bindings_for_pytorch import cwd; print(cwd)")
source $oneccl_bindings_for_pytorch_path/env/setvars.sh
export LD_PRELOAD=${LD_PRELOAD}:${CONDA_PREFIX}/lib/libiomp5.so
export LD_PRELOAD=${LD_PRELOAD}:${CONDA_PREFIX}/lib/libtcmalloc.so
export CCL_ATL_TRANSPORT=ofi
export CCL_WORKER_COUNT=1
export MODEL_NAME="runwayml/stable-diffusion-v1-5"
export DATA_DIR="/home/devcloud/dicoo"
```
好了,现在我们可以启动微调了。
## 微调模型
我们使用 `mpirun` 启动微调,它会自动在 `nodefile` 中列出的节点之间建立分布式通信。这里,我们运行 16 个进程 ( `-n` ),其中每个节点运行 4 个进程 ( `-ppn` )。 `Accelerate` 库会自动在所有进程间建立分布式的训练。
我们启动下面的命令训练 200 步,仅需约 **5 分钟**。
```
mpirun -f nodefile -n 16 -ppn 4 \
accelerate launch diffusers/examples/textual_inversion/textual_inversion.py \
--pretrained_model_name_or_path=$MODEL_NAME --train_data_dir=$DATA_DIR \
--learnable_property="object" --placeholder_token="<dicoo>" --initializer_token="toy" \
--resolution=512 --train_batch_size=1 --seed=7 --gradient_accumulation_steps=1 \
--max_train_steps=200 --learning_rate=2.0e-03 --scale_lr --lr_scheduler="constant" \
--lr_warmup_steps=0 --output_dir=./textual_inversion_output --mixed_precision bf16 \
--save_as_full_pipeline
```
下面的截图显示了训练过程中集群的状态:
<kbd>
<img src="https://huggingface.co/blog/assets/stable-diffusion-finetuning-intel/screen02.png">
</kbd>
## 排障
分布式训练有时候会出现一些棘手的问题,尤其是当你新涉足于此。单节点上的小的配置错误是最可能出现的问题: 缺少依赖项、图像存储在不同位置等。
你可以登录各个节点并在本地进行训练来快速定位问题。首先,设置与主节点相同的环境,然后运行:
```
python diffusers/examples/textual_inversion/textual_inversion.py \
--pretrained_model_name_or_path=$MODEL_NAME --train_data_dir=$DATA_DIR \
--learnable_property="object" --placeholder_token="<dicoo>" --initializer_token="toy" \
--resolution=512 --train_batch_size=1 --seed=7 --gradient_accumulation_steps=1 \
--max_train_steps=200 --learning_rate=2.0e-03 --scale_lr --lr_scheduler="constant" \
--lr_warmup_steps=0 --output_dir=./textual_inversion_output --mixed_precision bf16 \
--save_as_full_pipeline
```
如果训练成功启动,就停止它并移至下一个节点。如果在所有节点上训练都成功启动了,请返回主节点并仔细检查 `nodefile` 、环境以及 `mpirun` 命令是否有问题。不用担心,最终你会找到问题的 :)。
## 使用微调模型生成图像
经过 5 分钟的训练,训得的模型就保存在本地了,我们可以直接用 `diffusers` 的 `pipeline` 加载该模型并进行图像生成。但这里,我们要使用 [Optimum Intel 和 OpenVINO](https://huggingface.co/docs/optimum/intel/inference) 以进一步对模型进行推理优化。正如 [上一篇文章](https://huggingface.co/blog/zh/intel-sapphire-rapids-inference) 中所讨论的,优化后,仅用单颗 CPU 就能让你在不到 5 秒的时间内生成一幅图像!
```
pip install optimum[openvino]
```
我们用下面的代码来加载模型,并对其针对固定输出形状进行优化,最后保存优化后的模型:
```
from optimum.intel.openvino import OVStableDiffusionPipeline
model_id = "./textual_inversion_output"
ov_pipe = OVStableDiffusionPipeline.from_pretrained(model_id, export=True)
ov_pipe.reshape(batch_size=5, height=512, width=512, num_images_per_prompt=1)
ov_pipe.save_pretrained("./textual_inversion_output_ov")
```
然后,我们加载优化后的模型,生成 5 张不同的图像并保存下来:
```
from optimum.intel.openvino import OVStableDiffusionPipeline
model_id = "./textual_inversion_output_ov"
ov_pipe = OVStableDiffusionPipeline.from_pretrained(model_id, num_inference_steps=20)
prompt = ["a yellow <dicoo> robot at the beach, high quality"]*5
images = ov_pipe(prompt).images
print(images)
for idx,img in enumerate(images):
img.save(f"image{idx}.png")
```
下面是其生成的图像。令人惊艳的是,模型只需要五张图像就知道 `dicoo` 是戴眼镜的!
<kbd>
<img src="https://huggingface.co/blog/assets/stable-diffusion-finetuning-intel/dicoo_image_200.png">
</kbd>
你还可以对模型进行更多的微调,以期获得更好的效果。下面是一个经 3 千步 (大约一个小时) 微调而得的模型生成的图像,效果相当不错。
<kbd>
<img src="https://huggingface.co/blog/assets/stable-diffusion-finetuning-intel/dicoo_image.png">
</kbd>
## 总结
得益于 Hugging Face 和英特尔的深度合作,现在大家可以用至强 CPU 服务器来生成满足各自业务需求的高质量图像。而 CPU 通常比 GPU 等专用硬件更便宜且更易得,同时至强 CPU 还是个多面手,它可以轻松地用于其他生产任务,如 Web 服务器、数据库等等不一而足。因此,CPU 理所当然地成为了 IT 基础设施的一个功能全面且灵活的备选方案。
以下资源可供入门,你可按需使用:
- Diffusers [文档](https://huggingface.co/docs/diffusers)
- Optimum Intel [文档](https://huggingface.co/docs/optimum/main/en/intel/inference)
- GitHub 上的 [英特尔 IPEX](https://github.com/intel/intel-extension-for-pytorch)
- 英特尔和 Hugging Face 的 [开发者资源](https://www.intel.com/content/www/us/en/developer/partner/hugging-face.html)
- [IDC](https://www.intel.com/content/www/us/en/developer/tools/devcloud/services.html)、[AWS](https://aws.amazon.com/about-aws/whats-new/2022/11/introducing-amazon-ec2-r7iz-instances/?nc1=h_ls) 、[GCP](https://cloud.google.com/blog/products/compute/c3-machine-series-on-intel-sapphire-rapids-now-ga) 以及 [阿里云](https://cn.aliyun.com/daily-act/ecs/ecs_intel_8th?from_alibabacloud=) 上的第四代至强 CPU 实例
如果你有任何疑问或反馈,欢迎到 [Hugging Face 论坛](https://discuss.huggingface.co/) 留言。
感谢垂阅!
| 4 |
0 | hf_public_repos/blog | hf_public_repos/blog/zh/assisted-generation-support-gaudi.md | ---
title: "英特尔 Gaudi 加速辅助生成"
thumbnail: /blog/assets/assisted-generation-support-gaudi/thumbnail.png
authors:
- user: haimbarad
guest: true
org: Intel
- user: nraste
guest: true
org: Intel
- user: joeychou
guest: true
org: Intel
translators:
- user: MatrixYao
- user: zhongdongy
proofreader: true
---
# 英特尔 Gaudi 加速辅助生成
随着模型规模的增长,生成式人工智能的实现需要大量的推理资源。这不仅增加了每次生成的成本,而且还增加了用于满足此类请求的功耗。因此,文本生成的推理优化对于降低延迟、基础设施成本以及功耗都至关重要,其可以改善用户体验并提高文本生成任务的效率。
辅助解码是一种用于加速文本生成的流行方法。我们在英特尔 Gaudi2 上对其进行了适配和优化,使得其性能与英伟达 H100 GPU 相当,一如我们在 [之前的博文](https://huggingface.co/blog/zh/bridgetower) 中所展示的,但 Gaudi2 的价格仅相当于英伟达 A100 80GB GPU。这项工作现已集成入 Optimum Habana,Optimum Habana 对 Transformers 和 Diffusers 等各种 Hugging Face 库进行了扩展,以在英特尔 Gaudi 处理器上对用户的工作流进行全面优化。
## 投机采样 - 辅助解码
投机采样是一种用于加速文本生成的技术。其工作原理是用一个草稿模型一次生成 K 个词元,再由目标模型对这 K 个生成词元进行评估。如若草稿模型生成的某个位置的词元被拒绝,则用目标模型来生成该位置的词元,并丢弃草稿模型生成的随后词元,反复执行上述过程直至结束。使用投机采样,可以提高文本生成的速度并得到与原始自回归采样相当的生成质量。使用该技术时,用户可以指定草稿模型。数据证明,推测采样可为基于 transformer 的大模型带来约 2 倍的加速。一句话概括,投机采样可以加速文本生成并提高英特尔 Gaudi 处理器上的文本生成性能。
然而,草稿模型和目标模型 KV 缓存尺寸不同,因此同时分别对这两个模型进行优化显得尤为重要。本文,我们假设目标模型为一个量化模型,并利用 KV 缓存和投机采样对其进行加速。请注意,这里每个模型都有自己的 KV 缓存。我们用草稿模型生成 K 个词元,然后用目标模型对其进行评估; 当草稿模型生成的词元被拒绝时,目标模型会用于生成被拒绝位置的词元,并丢弃草稿模型生成的随后词元; 接着草稿模型继续生成接下来的 K 个词元,如此往复。
请注意,文献 [2] 证明了执行投机采样可以恢复目标模型的分布 - 这从理论上保证了投机采样可以达到与对目标模型自身进行自回归采样相同的采样质量。因此,不采用投机采样的理由仅在于收益,如草稿模型的尺寸并没有足够的比较优势,抑或是草稿模型生成词元的接受比太低。
辅助生成是一种类似于投机采样的技术,其大约与投机采样同一时间被独立发明出来 [3]。其作者将此方法集成到了 Hugging Face Transformers 中,现在模型的 _.generate()_ 的方法中有一个可选的 _assistant\_model_ 参数用于启用辅助生成。
## 用法及实验
在 Gaudi 上使用辅助生成非常简单,我们在 [此](https://github.com/huggingface/optimum-habana/tree/main/examples/text-generation#run-speculative-sampling-on-gaudi) 提供了一个示例。
顾名思义,参数 `--assistant_model` 用于指定草稿模型。草稿模型用于生成 K 个词元,然后由目标模型对其进行评估。当草稿模型生成的词元被拒绝时,目标模型会自己生成该位置的词元,并将草稿模型生成的该位置之后的词元丢弃。接着,草稿模型再生成接下来的 K 个词元,如此往复。草稿模型的接受率部分取决于模型选择,部分取决于输入文本。一般情况下,辅助生成能将大型 transformer 族模型的速度提高约 2 倍。
## 总结
Gaudi 现已支持用户简单易用地使用辅助生成加速文本生成,用户可用其进一步提高英特尔 Gaudi 处理器的性能。该方法基于投机采样,已被证明可以有效提高基于大型 transformer 模型的性能。
# 参考文献
[1] N. Shazeer,Fast Transformer Decoding: One Write-Head is All You Need,Nov. 2019,arXiv:1911.02150.
[2] C. Chen,S. Borgeaud,G. Irving,J.B. Lespiau,L. Sifre,J. Jumper, Accelerating Large Language Model Decoding with Speculative Sampling,Feb. 2023,arXiv:2302.01318
[3] J. Gante,辅助生成: 低延迟文本生成的新方向,May 2023,https://huggingface.co/blog/zh/assisted-generation | 5 |
0 | hf_public_repos/blog | hf_public_repos/blog/zh/regions.md | ---
title: "HF Hub 现已加入存储区域功能"
thumbnail: /blog/assets/172_regions/thumbnail.png
authors:
- user: coyotte508
- user: rtrm
- user: XciD
- user: michellehbn
- user: violette
- user: julien-c
translators:
- user: chenglu
---
# HF Hub 现已加入存储区域功能
我们在 [企业版 Hub 服务](https://huggingface.co/enterprise) 方案中推出了 **存储区域(Storage Regions)** 功能。
通过此功能,用户能够自主决定其组织的模型和数据集的存储地点,这带来两大显著优势,接下来的内容会进行简要介绍:
- **法规和数据合规**,此外还能增强数字主权
- **性能提升**(下载和上传速度更快,减少延迟)
目前,我们支持以下几个存储区域:
- 美国 🇺🇸
- 欧盟 🇪🇺
- 即将到来:亚太地区 🌏
在深入了解如何设置这项功能之前,先来看看如何在您的组织中配置它 🔥
## 组织设置
如果您的组织还未开通企业版 Hub 服务,您将会看到以下界面:
订阅服务后,您将能够访问到区域设置页面:
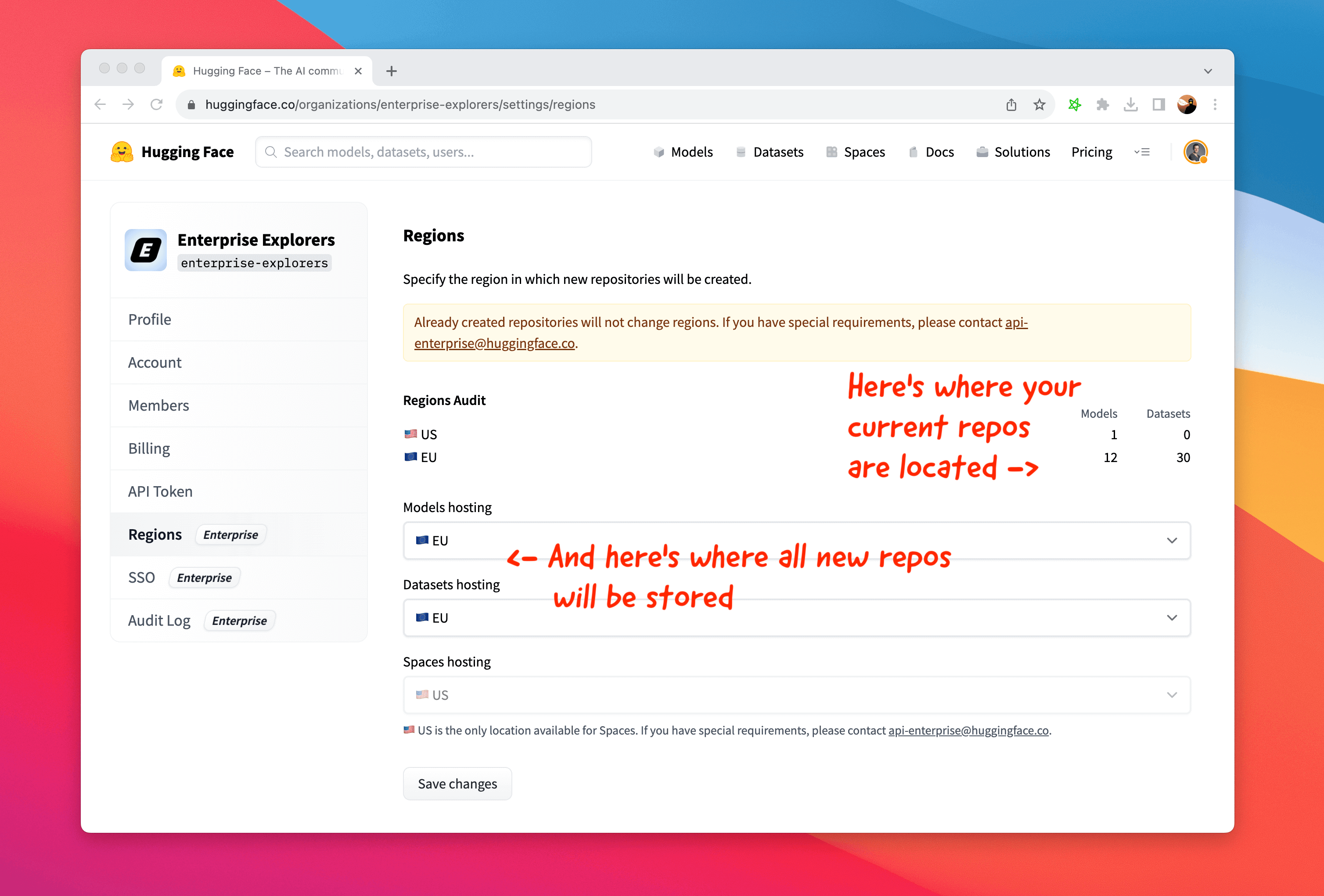
在这个页面上,您能:
- 审核当前组织仓库的存储位置
- 通过下拉菜单为新建仓库选择存储位置
## 仓库标签
储存在非默认位置的仓库(模型或数据集)将直接在标签中显示其所在的区域,使组织成员能够直观地了解仓库位置。

## 法规和数据合规
在许多规定严格的行业,按照法规要求在指定地域存储数据是必须的。
对于欧盟的公司,这意味着他们能利用企业版 Hub 服务构建符合 GDPR 标准的机器学习解决方案:确保数据集、模型和推理端点全部存储在欧盟的数据中心。
如果您已是企业版 Hub 服务客户,并有更多相关疑问,请随时联系我们!
## 性能优势
把模型或数据集存放在离您的团队和基础设施更近的地方,可以显著提高上传和下载的效率。
鉴于模型权重和数据集文件通常体积庞大,这一点尤其重要。

例如,如果您的团队位于欧洲,并选择将仓库存储在欧盟区域,与存储在美国相比,上传和下载速度可以提升大约 4 到 5 倍。 | 6 |
0 | hf_public_repos/blog | hf_public_repos/blog/zh/image-similarity.md | ---
title: 基于 Hugging Face Datasets 和 Transformers 的图像相似性搜索
thumbnail: /blog/assets/image_similarity/thumbnail.png
authors:
- user: sayakpaul
translators:
- user: MatrixYao
- user: zhongdongy
proofreader: true
---
# 基于 Hugging Face Datasets 和 Transformers 的图像相似性搜索
<a target="_blank" href="https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_similarity.ipynb">
<img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/>
</a>
通过本文,你将学习使用 🤗 Transformers 构建图像相似性搜索系统。找出查询图像和潜在候选图像之间的相似性是信息检索系统的一个重要用例,例如反向图像搜索 (即找出查询图像的原图)。此类系统试图解答的问题是,给定一个 _查询_ 图像和一组 _候选_ 图像,找出候选图像中哪些图像与查询图像最相似。
我们将使用 [🤗 datasets 库](https://huggingface.co/docs/datasets/),因为它无缝支持并行处理,这在构建系统时会派上用场。
尽管这篇文章使用了基于 ViT 的模型 ([`nateraw/vit-base-beans`](https://huggingface.co/nateraw/vit-base-beans)) 和特定的 ([Beans](https://huggingface.co/datasets/beans)) 数据集,但它可以扩展到其他支持视觉模态的模型,也可以扩展到其他图像数据集。你可以尝试的一些著名模型有:
* [Swin Transformer](https://huggingface.co/docs/transformers/model_doc/swin)
* [ConvNeXT](https://huggingface.co/docs/transformers/model_doc/convnext)
* [RegNet](https://huggingface.co/docs/transformers/model_doc/regnet)
此外,文章中介绍的方法也有可能扩展到其他模态。
要研究完整的图像相似度系统,你可以参考 [这个 Colab Notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_similarity.ipynb)
## 我们如何定义相似性?
要构建这个系统,我们首先需要定义我们想要如何计算两个图像之间的相似度。一种广泛流行的做法是先计算给定图像的稠密表征 (即嵌入 (embedding)),然后使用 余弦相似性度量 ([cosine similarity metric](https://en.wikipedia.org/wiki/Cosine_similarity)) 来确定两幅图像的相似程度。
在本文中,我们将使用 “嵌入” 来表示向量空间中的图像。它为我们提供了一种将图像从高维像素空间 (例如 224 × 224 × 3) 有意义地压缩到一个低得多的维度 (例如 768) 的好方法。这样做的主要优点是减少了后续步骤中的计算时间。
<div align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/image_similarity/embeddings.png" width=700/>
</div>
## 计算嵌入
为了计算图像的嵌入,我们需要使用一个视觉模型,该模型知道如何在向量空间中表示输入图像。这种类型的模型通常也称为图像编码器 (image encoder)。
我们利用 [`AutoModel` 类](https://huggingface.co/docs/transformers/model_doc/auto#transformers.AutoModel) 来加载模型。它为我们提供了一个接口,可以从 HuggingFace Hub 加载任何兼容的模型 checkpoint。除了模型,我们还会加载与模型关联的处理器 (processor) 以进行数据预处理。
```py
from transformers import AutoImageProcessor, AutoModel
model_ckpt = "nateraw/vit-base-beans"
processor = AutoImageProcessor.from_pretrained(model_ckpt)
model = AutoModel.from_pretrained(model_ckpt)
```
本例中使用的 checkpoint 是一个在 [`beans` ](https://huggingface.co/datasets/beans) 上微调过的 [ViT 模型](https://huggingface.co/google/vit-base-patch16-224-in21k)。
这里可能你会问一些问题:
**Q1**: 为什么我们不使用 `AutoModelForImageClassification`?
这是因为我们想要获得图像的稠密表征,而 `AutoModelForImageClassification` 只能输出离散类别。
**Q2**: 为什么使用这个特定的 checkpoint?
如前所述,我们使用特定的数据集来构建系统。因此,与其使用通用模型 (例如 在 [ImageNet-1k 数据集上训练的模型](https://huggingface.co/models?dataset=dataset:imagenet-1k&sort=downloads)),不如使用使用已针对所用数据集微调过的模型。这样,模型能更好地理解输入图像。
**注意** 你还可以使用通过自监督预训练获得的 checkpoint, 不必得由有监督学习训练而得。事实上,如果预训练得当,自监督模型可以 [获得](https://ai.facebook.com/blog/dino-paws-computer-vision-with-self-supervised-transformers-and-10x-more-efficient-training/) 令人印象深刻的检索性能。
现在我们有了一个用于计算嵌入的模型,我们需要一些候选图像来被查询。
## 加载候选图像数据集
后面,我们会构建将候选图像映射到哈希值的哈希表。在查询时,我们会使用到这些哈希表,详细讨论的讨论稍后进行。现在,我们先使用 [`beans` 数据集](https://huggingface.co/datasets/beans) 中的训练集来获取一组候选图像。
```py
from datasets import load_dataset
dataset = load_dataset("beans")
```
This is how a single sample from the training split looks like:
<div align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/image_similarity/beans.png" width=600/>
</div>
该数据集的三个 `features` 如下:
```py
dataset["train"].features
>>> {'image_file_path': Value(dtype='string', id=None),
'image': Image(decode=True, id=None),
'labels': ClassLabel(names=['angular_leaf_spot', 'bean_rust', 'healthy'], id=None)}
```
为了使图像相似性系统可演示,系统的总体运行时间需要比较短,因此我们这里只使用候选图像数据集中的 100 张图像。
```py
num_samples = 100
seed = 42
candidate_subset = dataset["train"].shuffle(seed=seed).select(range(num_samples))
```
## 寻找相似图片的过程
下图展示了获取相似图像的基本过程。
<div align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/image_similarity/fetch-similar-process.png">
</div>
稍微拆解一下上图,我们分为 4 步走:
1. 从候选图像 (`candidate_subset`) 中提取嵌入,将它们存储在一个矩阵中。
2. 获取查询图像并提取其嵌入。
3. 遍历嵌入矩阵 (步骤 1 中得到的) 并计算查询嵌入和当前候选嵌入之间的相似度得分。我们通常维护一个类似字典的映射,来维护候选图像的 ID 与相似性分数之间的对应关系。
4. 根据相似度得分进行排序并返回相应的图像 ID。最后,使用这些 ID 来获取候选图像。
我们可以编写一个简单的工具函数用于计算嵌入并使用 `map()` 方法将其作用于候选图像数据集的每张图像,以有效地计算嵌入。
```py
import torch
def extract_embeddings(model: torch.nn.Module):
"""Utility to compute embeddings."""
device = model.device
def pp(batch):
images = batch["image"]
# `transformation_chain` is a compostion of preprocessing
# transformations we apply to the input images to prepare them
# for the model. For more details, check out the accompanying Colab Notebook.
image_batch_transformed = torch.stack(
[transformation_chain(image) for image in images]
)
new_batch = {"pixel_values": image_batch_transformed.to(device)}
with torch.no_grad():
embeddings = model(**new_batch).last_hidden_state[:, 0].cpu()
return {"embeddings": embeddings}
return pp
```
我们可以像这样映射 `extract_embeddings()`:
```py
device = "cuda" if torch.cuda.is_available() else "cpu"
extract_fn = extract_embeddings(model.to(device))
candidate_subset_emb = candidate_subset.map(extract_fn, batched=True, batch_size=batch_size)
```
接下来,为方便起见,我们创建一个候选图像 ID 的列表。
```py
candidate_ids = []
for id in tqdm(range(len(candidate_subset_emb))):
label = candidate_subset_emb[id]["labels"]
# Create a unique indentifier.
entry = str(id) + "_" + str(label)
candidate_ids.append(entry)
```
我们用包含所有候选图像的嵌入矩阵来计算与查询图像的相似度分数。我们之前已经计算了候选图像嵌入,在这里我们只是将它们集中到一个矩阵中。
```py
all_candidate_embeddings = np.array(candidate_subset_emb["embeddings"])
all_candidate_embeddings = torch.from_numpy(all_candidate_embeddings)
```
我们将使用余弦相似度来计算两个嵌入向量之间的 [相似度分数](https://en.wikipedia.org/wiki/Cosine_similarity)。然后,我们用它来获取给定查询图像的相似候选图像。
```py
def compute_scores(emb_one, emb_two):
"""Computes cosine similarity between two vectors."""
scores = torch.nn.functional.cosine_similarity(emb_one, emb_two)
return scores.numpy().tolist()
def fetch_similar(image, top_k=5):
"""Fetches the `top_k` similar images with `image` as the query."""
# Prepare the input query image for embedding computation.
image_transformed = transformation_chain(image).unsqueeze(0)
new_batch = {"pixel_values": image_transformed.to(device)}
# Comute the embedding.
with torch.no_grad():
query_embeddings = model(**new_batch).last_hidden_state[:, 0].cpu()
# Compute similarity scores with all the candidate images at one go.
# We also create a mapping between the candidate image identifiers
# and their similarity scores with the query image.
sim_scores = compute_scores(all_candidate_embeddings, query_embeddings)
similarity_mapping = dict(zip(candidate_ids, sim_scores))
# Sort the mapping dictionary and return `top_k` candidates.
similarity_mapping_sorted = dict(
sorted(similarity_mapping.items(), key=lambda x: x[1], reverse=True)
)
id_entries = list(similarity_mapping_sorted.keys())[:top_k]
ids = list(map(lambda x: int(x.split("_")[0]), id_entries))
labels = list(map(lambda x: int(x.split("_")[-1]), id_entries))
return ids, labels
```
## 执行查询
经过以上准备,我们可以进行相似性搜索了。我们从 `beans` 数据集的测试集中选取一张查询图像来搜索:
```py
test_idx = np.random.choice(len(dataset["test"]))
test_sample = dataset["test"][test_idx]["image"]
test_label = dataset["test"][test_idx]["labels"]
sim_ids, sim_labels = fetch_similar(test_sample)
print(f"Query label: {test_label}")
print(f"Top 5 candidate labels: {sim_labels}")
```
结果为:
```
Query label: 0
Top 5 candidate labels: [0, 0, 0, 0, 0]
```
看起来我们的系统得到了一组正确的相似图像。将结果可视化,如下:
<div align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/image_similarity/results_one.png">
</div>
## 进一步扩展与结论
现在,我们有了一个可用的图像相似度系统。但实际系统需要处理比这多得多的候选图像。考虑到这一点,我们目前的程序有不少缺点:
* 如果我们按原样存储嵌入,内存需求会迅速增加,尤其是在处理数百万张候选图像时。在我们的例子中嵌入是 768 维,这即使对大规模系统而言可能也是相对比较高的维度。
* 高维的嵌入对检索部分涉及的后续计算有直接影响。
如果我们能以某种方式降低嵌入的维度而不影响它们的意义,我们仍然可以在速度和检索质量之间保持良好的折衷。本文 [附带的 Colab Notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_similarity.ipynb) 实现并演示了如何通过随机投影 (random projection) 和位置敏感哈希 (locality-sensitive hashing,LSH) 这两种方法来取得折衷。
🤗 Datasets 提供与 [FAISS](https://github.com/facebookresearch/faiss) 的直接集成,进一步简化了构建相似性系统的过程。假设你已经提取了候选图像的嵌入 (beans 数据集) 并把他们存储在称为 embedding 的 feature 中。你现在可以轻松地使用 dataset 的 [`add_faiss_index()`](https://huggingface.co/docs/datasets/v2.7.1/en/package_reference/main_classes#datasets.Dataset.add_faiss_index) 方法来构建稠密索引:
```py
dataset_with_embeddings.add_faiss_index(column="embeddings")
```
建立索引后,可以使用 `dataset_with_embeddings` 模块的 [`get_nearest_examples()`](https://huggingface.co/docs/datasets/v2.7.1/en/package_reference/main_classes#datasets.Dataset.get_nearest_examples) 方法为给定查询嵌入检索最近邻:
```py
scores, retrieved_examples = dataset_with_embeddings.get_nearest_examples(
"embeddings", qi_embedding, k=top_k
)
```
该方法返回检索分数及其对应的图像。要了解更多信息,你可以查看 [官方文档](https://huggingface.co/docs/datasets/faiss_es) 和 [这个 Notebook](https://colab.research.google.com/gist/sayakpaul/5b5b5a9deabd3c5d8cb5ef8c7b4bb536/image_similarity_faiss.ipynb)。
最后,你可以试试下面的 Hugging Face Space,这是一个简单的图片相似度应用:
<script type="module" src="https://gradio.s3-us-west-2.amazonaws.com/3.12.0/gradio.js"></script>
<gradio-app theme_mode="light" space="sayakpaul/fetch-similar-images"></gradio-app>
在本文中,我们快速入门并构建了一个图像相似度系统。如果你觉得这篇文章很有趣,我们强烈建议你基于我们讨论的概念继续构建你的系统,这样你就可以更加熟悉内部工作原理。
还想了解更多吗?以下是一些可能对你有用的其他资源:
* [Faiss: 高效相似性搜索库](https://engineering.fb.com/2017/03/29/data-infrastructure/faiss-a-library-for-efficient-similarity-search/)
* [ScaNN: 高效向量相似性搜索](http://ai.googleblog.com/2020/07/announcing-scann-efficient-vector.html)
* [在移动应用程序中集成图像搜索引擎](https://www.tensorflow.org/lite/inference_with_metadata/task_library/image_searcher)
| 7 |
0 | hf_public_repos/blog | hf_public_repos/blog/zh/rwkv.md | ---
title: "RWKV -- transformer 与 RNN 的强强联合"
thumbnail: /blog/assets/142_rwkv/rwkv_thumbnail.png
authors:
- user: BLinkDL
- user: Hazzzardous
- user: sgugger
- user: RWKV
translators:
- user: SuSung-boy
- user: zhongdongy
proofreader: true
---
# RWKV – transformer 与 RNN 的强强联合
在 NLP (Natural Language Processing, 自然语言处理) 领域,ChatGPT 和其他的聊天机器人应用引起了极大的关注。每个社区为构建自己的应用,也都在持续地寻求强大、可靠的开源模型。自 Vaswani 等人于 2017 年首次提出 [Attention Is All You Need](https://arxiv.org/abs/1706.03762) 之后,基于 transformer 的强大的模型一直在不断地涌现,它们在 NLP 相关任务上的表现远远超过基于 RNN (Recurrent Neural Networks, 递归神经网络) 的 SoTA 模型,甚至多数认为 RNN 已死。而本文将介绍一个集 RNN 和 transformer 两者的优势于一身的全新网络架构 –RWKV!现已在 HuggingFace [transformers](https://github.com/huggingface/transformers) 库中支持。
### RWKV 项目概览
RWKV 项目已经启动,由 [Bo Peng](https://github.com/BlinkDL) 主导、贡献和维护。同时项目成员在官方 Discord 也开设了不同主题的讨论频道: 如性能 (RWKV.cpp、量化等),扩展性 (数据集收集和处理),相关研究 (chat 微调、多模态微调等)。该项目中训练 RWKV 模型所需的 GPU 资源由 Stability AI 提供。
读者可以加入 [官方 discord 频道](https://discord.gg/qt9egFA7ve) 了解详情或者参与讨论。如想了解 RWKV 背后的思想,可以参考这两篇博文:
- https://johanwind.github.io/2023/03/23/rwkv_overview.html
- https://johanwind.github.io/2023/03/23/rwkv_details.html
### Transformer 与 RNN 架构对比
RNN 架构是最早广泛用于处理序列数据的神经网络架构之一。与接收固定输入尺寸的经典架构不同,RNN 接收当前时刻的 “token”(即数据流中的当前数据点) 和先前时刻的 “状态” 作为输入,通过网络预测输出下一时刻的 “token” 和 “状态”,同时输出的 “状态” 还能继续用到后续的预测中去,一直到序列末尾。RNN 还可以用于不同的 “模式”,适用于多种不同的场景。参考 [Andrej Karpathy 的博客](https://karpathy.github.io/2015/05/21/rnn-effectiveness/),RNN 可以用于: 一对一 (图像分类),一对多 (图像描述),多对一 (序列分类),多对多 (序列生成),等等。
| 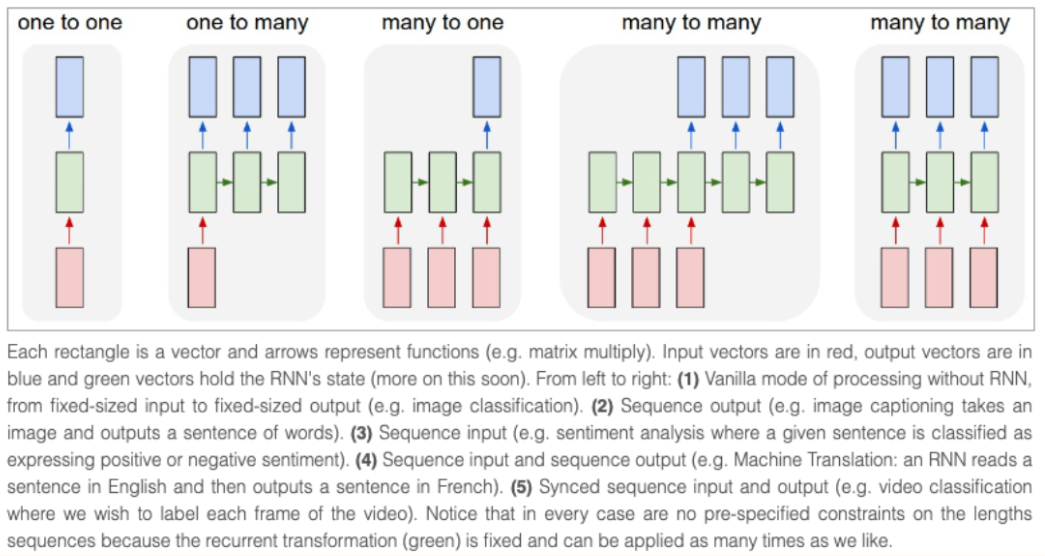 |
| :-: |
| <b>RNN 在不同场景下 RNN 的网络配置简图。图片来源:<a href="https://karpathy.github.io/2015/05/21/rnn-effectiveness/" rel="noopener" target="_blank">Andrej Karpathy 的博文</a></b> |
由于 RNN 在计算每一时刻的预测值时使用的都是同一组网络权重,因此 RNN 很难解决长距离序列信息的记忆问题,这一定程度上也是训练过程中梯度消失导致的。为解决这个问题,相继有新的网络架构被提出,如 LSTM 或者 GRU,其中 transformer 是已被证实最有效的架构。
在 transformer 架构中,不同时刻的输入 token 可以在 self-attention 模块中并行处理。首先 token 经过 Q、K、V 权重矩阵做线性变换投影到不同的空间,得到的 Q、K 矩阵用于计算注意力分数 (通过 softmax,如下图所示),然后乘以 V 的隐状态得到最终的隐状态,这种架构设计可以有效缓解长距离序列问题,同时具有比 RNN 更快的训练和推理速度。
| 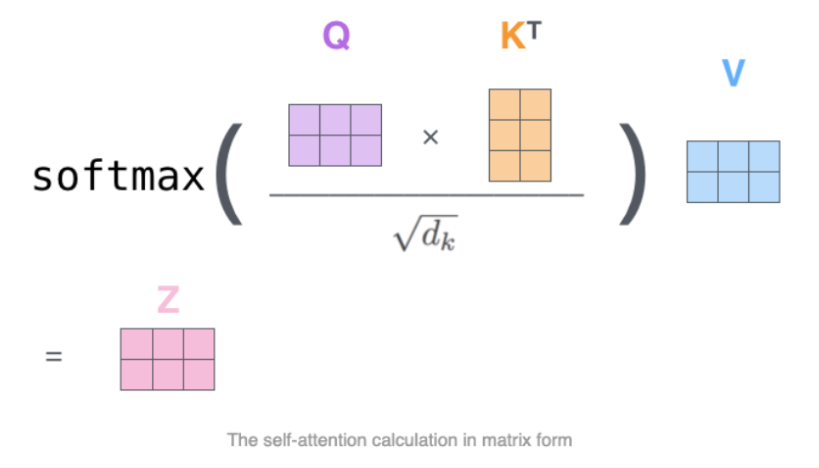 |
| :-: |
| <b>transformer 模型中的注意力分数计算公式。图片来源:<a href="https://jalammar.github.io/illustrated-transformer/" rel="noopener" target="_blank" >Jay Alammar 的博文</a></b> |
|  |
| :-: |
| <b>RWKV 模型中的注意力分数计算公式。来源:<a href="https://raw.githubusercontent.com/BlinkDL/RWKV-LM/main/RWKV-formula.png" rel="noopener" target="_blank" >RWKV 博文</a></b> |
在训练过程中,Transformer 架构相比于传统的 RNN 和 CNN 有多个优势,最突出的优势是它能够学到上下文特征表达。不同于每次仅处理输入序列中一个 token 的 RNN 和 CNN,transformer 可以单次处理整个输入序列,这种特性也使得 transformer 可以很好地应对长距离序列 token 依赖问题,因此 transformer 在语言翻译和问答等多种任务中表现非常亮眼。
在推理过程中,RNN 架构在推理速度和内存效率方面会具有一些优势。例如计算简单 (只需矩阵 - 向量运算) 、内存友好 (内存不会随着推理阶段的进行而增加),速度稳定 (与上下文窗口长度一致,因为 RNN 只关注当前时刻的 token 和状态)。
## RWKV 架构
RWKV 的灵感来自于 Apple 公司的 [Attention Free Transformer](https://machinelearning.apple.com/research/attention-free-transformer)。RWKV 该架构经过精心简化和优化,可以转换为 RNN。除此此外,为使 RWKV 性能媲美 GPT,还额外使用了许多技巧,例如 `TokenShift` 和 `SmallInitEmb` (使用的完整技巧列表在 [官方 GitHub 仓库的 README 中](https://github.com/BlinkDL/RWKV-LM/blob/main/README.md#how-it-works) 说明)。对于 RWKV 的训练,现有的项目仓库可以将参数量扩展到 14B,并且迭代修了 RWKV-4 的一些训练问题,例如数值不稳定性等。
### RWKV 是 RNN 和 Transformer 的强强联合
如何把 transformer 和 RNN 优势结合起来?基于 transformer 的模型的主要缺点是,在接收超出上下文长度预设值的输入时,推理结果可能会出现潜在的风险,因为注意力分数是针对训练时的预设值来同时计算整个序列的。
RNN 本身支持非常长的上下文长度。即使在训练时接收的上下文长度有限,RNN 也可以通过精心的编码,来得到数百万长度的推理结果。目前,RWKV 模型使用上下文长度上为 8192 ( `ctx8192`) 和 `ctx1024` 时的训练速度和内存需求均相同。
传统 RNN 模型的主要缺陷,以及 RWKV 是如何避免的:
1. 传统的 RNN 模型无法利用很长距离的上下文信息 (LSTM 用作语言模型时也只能有效处理约 100 个 token),而 RWKV 可以处理数千个甚至更多的 token,如下图所示:
|  |
| :-: |
| <b>LM Loss 在不同上下文长度和模型大小的曲线。图片来源:<a href="https://raw.githubusercontent.com/BlinkDL/RWKV-LM/main/RWKV-ctxlen.png" rel="noopener" target="_blank">RWKV 原始仓库</a></b> |
1. 传统的 RNN 模型无法并行训练,而 RWKV 更像一个 “线性 GPT”,因此比 GPT 训练得更快。
通过将这两个优势强强联合,希望 RWKV 可以实现 “1 + 1 > 2” 的效果。
### RWKV 注意力公式
RWKV 模型架构与经典的 transformer 模型架构非常相似 (例如也包含 embedding 层、Layer Normalization、用于预测下一 token 的因果语言模型头、以及多个完全相同的网络层等),唯一的区别在于注意力层,它与传统的 transformer 模型架构完全不同,因此 RWKV 的注意力计算公式也不一样。
本文不会对注意力层过多的介绍,这里推荐一篇 [Johan Sokrates Wind 的博文](https://johanwind.github.io/2023/03/23/rwkv_details.html),里面有对注意力层的分数计算公式等更全面的解释。
### 现有检查点
#### 纯语言模型: RWKV-4 模型
大多数采用 RWKV 架构的语言模型参数量范围从 170M 到 14B 不等。 据 [RWKV 概述博文](https://johanwind.github.io/2023/03/23/rwkv_overview.html) 介绍,这些模型已经在 Pile 数据集上完成训练,并进行了多项不同的基准测试,取得了与其他 SoTA 模型表现相当的性能结果。
|  |
| :-: |
| <b>RWKV-4 与其他常见架构的性能对比。图片来源:<a href="https://johanwind.github.io/2023/03/23/rwkv_overview.html" rel="noopener" target="_blank" >Johan Wind 的博文</a></b> |
#### 指令微调/Chat 版: RWKV-4 Raven
Bo 还训练了 RWKV 架构的 “chat” 版本: RWKV-4 Raven 模型。RWKV-4 Raven 是一个在 Pile 数据集上预训练的模型,并在 ALPACA、CodeAlpaca、Guanaco、GPT4All、ShareGPT 等上进行了微调。RWKV-4 Raven 模型有多个版本,如不同语言 (仅英文、英文 + 中文 + 日文、英文 + 日文等) 和不同大小 (1.5B 参数、7B 参数、14B 参数) 等。
所有 HF 版的模型都可以在 Hugging Face Hub 的 [RWKV 社区主页](https://huggingface.co/RWKV) 找到。
## 集成 🤗 Transformers 库
感谢这个 [Pull Request](https://github.com/huggingface/transformers/pull/22797) 的贡献,RWKV 架构现已集成到 🤗 transformers 库中。在作者撰写本文之时,您已经可以通过从源代码安装 `transformers` 库,或者使用其 `main` 分支。RWKV 架构也会与 transformers 库一起更新,您可以像使用任何其他架构一样使用它。
下面让我们来看一些使用示例。
### 文本生成示例
要在给定 prompt 的情况下生成文本,您可以使用 `pipeline`:
```python
from transformers import pipeline
model_id = "RWKV/rwkv-4-169m-pile"
prompt = "\nIn a shocking finding, scientist discovered a herd of dragons living in a remote, previously unexplored valley, in Tibet. Even more surprising to the researchers was the fact that the dragons spoke perfect Chinese."
pipe = pipeline("text-generation", model=model_id)
print(pipe(prompt, max_new_tokens=20))
>>> [{'generated_text': '\nIn a shocking finding, scientist discovered a herd of dragons living in a remote, previously unexplored valley, in Tibet. Even more surprising to the researchers was the fact that the dragons spoke perfect Chinese.\n\nThe researchers found that the dragons were able to communicate with each other, and that they were'}]
```
或者可以运行下面的代码片段:
```python
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained("RWKV/rwkv-4-169m-pile")
tokenizer = AutoTokenizer.from_pretrained("RWKV/rwkv-4-169m-pile")
prompt = "\nIn a shocking finding, scientist discovered a herd of dragons living in a remote, previously unexplored valley, in Tibet. Even more surprising to the researchers was the fact that the dragons spoke perfect Chinese."
inputs = tokenizer(prompt, return_tensors="pt")
output = model.generate(inputs["input_ids"], max_new_tokens=20)
print(tokenizer.decode(output[0].tolist()))
>>> In a shocking finding, scientist discovered a herd of dragons living in a remote, previously unexplored valley, in Tibet. Even more surprising to the researchers was the fact that the dragons spoke perfect Chinese.\n\nThe researchers found that the dragons were able to communicate with each other, and that they were
```
### 使用 Raven 模型 (chat 模型) 示例
您可以以 alpaca 风格使用提示 chat 版模型,示例如下:
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
model_id = "RWKV/rwkv-raven-1b5"
model = AutoModelForCausalLM.from_pretrained(model_id).to(0)
tokenizer = AutoTokenizer.from_pretrained(model_id)
question = "Tell me about ravens"
prompt = f"### Instruction: {question}\n### Response:"
inputs = tokenizer(prompt, return_tensors="pt").to(0)
output = model.generate(inputs["input_ids"], max_new_tokens=100)
print(tokenizer.decode(output[0].tolist(), skip_special_tokens=True))
>>> ### Instruction: Tell me about ravens
### Response: RAVENS are a type of bird that is native to the Middle East and North Africa. They are known for their intelligence, adaptability, and their ability to live in a variety of environments. RAVENS are known for their intelligence, adaptability, and their ability to live in a variety of environments. They are known for their intelligence, adaptability, and their ability to live in a variety of environments.
```
据 Bo 所述,[这条 discord 消息 (访问超链接时请确保已加入 discord 频道) ](https://discord.com/channels/992359628979568762/1083107245971226685/1098533896355848283) 中有更详细的书写指令技巧。
|  |
### 权重转换
任何用户都可以使用 `transformers` 库中提供的转换脚本轻松地将原始 RWKV 模型权重转换为 HF 格式。具体步骤为: 首先,将 “原始” 权重 push 到 Hugging Face Hub (假定目标仓库为 `RAW_HUB_REPO`,目标权重文件为 `RAW_FILE`),然后运行以下转换脚本:
```bash
python convert_rwkv_checkpoint_to_hf.py --repo_id RAW_HUB_REPO --checkpoint_file RAW_FILE --output_dir OUTPUT_DIR
```
如果您想将转换后的模型 push 到 Hub 上 (假定推送目录为 `dummy_user/converted-rwkv`),首先请确保在 push 模型之前使用 `huggingface-cli login` 登录 HF 账号,然后运行:
```bash
python convert_rwkv_checkpoint_to_hf.py --repo_id RAW_HUB_REPO --checkpoint_file RAW_FILE --output_dir OUTPUT_DIR --push_to_hub --model_name dummy_user/converted-rwkv
```
## 未来工作
### 多语言 RWKV
Bo 目前正在研究在多语言语料库上训练 RWKV 模型,最近发布了一个新的 [多语言分词器](https://twitter.com/BlinkDL_AI/status/1649839897208045573)。
### 社区后续研究方向
RWKV 社区非常活跃,致力于几个后续研究方向。项目清单可以在 RWKV 的 [discord 专用频道中找到 (访问超链接时请确保已加入 discord 频道)](https://discord.com/channels/992359628979568762/1068563033510653992)。欢迎加入这个 RWKV 研究频道,以及对 RWKV 的积极贡献!
### 模型压缩与加速
由于只需要矩阵 - 向量运算,对于非标准化和实验性的计算硬件,RWKV 是一个非常理想的架构选择,例如光子处理器/加速器。
因此自然地,RWKV 架构也可以使用经典的加速和压缩技术 (如 [ONNX](https://github.com/harrisonvanderbyl/rwkv-onnx)、4 位/8 位量化等)。我们希望集成了 transformer 的 RWKV 架构能够使更多开发者和从业者受益。
在不久的将来,RWKV 还可以使用 [optimum](https://github.com/huggingface/optimum) 库提出的加速技术。[rwkv.cpp](https://github.com/saharNooby/rwkv.cpp) 或 [rwkv-cpp-cuda](https://github.com/harrisonvanderbyl/rwkv-cpp-cuda) 仓库涉及的其中一些技术在库中已标明。
### 致谢
我们 Hugging Face 团队非常感谢 Bo 和 RWKV 社区抽出宝贵时间来回答关于架构的问题,以及非常感谢他们的帮助和支持。我们很期待在 HF 生态中看到更多 RWKV 模型的应用。我们还要感谢 [Johan Wind](https://twitter.com/johanwind) 发布的关于 RWKV 的博文,这对我们理解架构本身和其潜力有很大帮助。最后,我们着重感谢 [ArEnSc](https://github.com/ArEnSc) 开启 RWKV 集成到 `transformers` 库的 PR 所做的工作,以及感谢 [Merve Noyan](https://huggingface.co/merve)、[Maria Khalusova](https://huggingface.co/MariaK) 和 [Pedro Cuenca](https://huggingface.co/pcuenq) 审阅和校对本篇文章!
### 引用
如果您希望在工作中使用 RWKV,请使用此 [cff 引用](https://github.com/BlinkDL/RWKV-LM/blob/main/CITATION.cff)。
| 8 |
0 | hf_public_repos/blog | hf_public_repos/blog/zh/ml-for-games-4.md | ---
title: "制作 2D 素材|基于 AI 5 天创建一个农场游戏,第 4 天"
thumbnail: /blog/assets/124_ml-for-games/thumbnail4.png
authors:
- user: dylanebert
translators:
- user: SuSung-boy
- user: zhongdongy
proofreader: true
---
# 制作 2D 素材|基于 AI 5 天创建一个农场游戏,第 4 天
**欢迎使用 AI 进行游戏开发!** 在本系列中,我们将使用 AI 工具在 5 天内创建一个功能完备的农场游戏。到本系列结束时,您将了解到如何将多种 AI 工具整合到游戏开发流程中。本系列文章将向您展示如何将 AI 工具用于:
1. 美术风格
2. 游戏设计
3. 3D 素材
4. 2D 素材
5. 剧情
想快速观看视频的版本?你可以在 [这里](https://www.tiktok.com/@individualkex/video/7192994527312137518) 观看。不过如果你想要了解技术细节,请继续阅读吧!
**注意:** 本教程面向熟悉 Unity 开发和 C# 语言的读者。如果您不熟悉这些技术,请先查看 [Unity for Beginners](https://www.tiktok.com/@individualkex/video/7086863567412038954) 系列后再继续阅读。
## 第 4 天:2D 素材
本教程系列的 [第 3 部分](https://huggingface.co/blog/zh/ml-for-games-3) 讨论到现阶段 **文本-3D** 技术应用到游戏开发中并不可行。不过对于 2D 来说,情况就大相径庭了。
在这一部分中,我们将探讨如何使用 AI 制作 2D 素材。
### 前言
本部分教程将介绍如何将 Stable Diffusion 工具嵌入到传统 2D 素材制作流程中,来帮助从业者使用 AI 制作 2D 素材。此教程适用于具有一定图片编辑和 2D 游戏素材制作知识基础的读者,同时对游戏或者 AI 领域的初学者和资深从业者也会有所帮助。
必要条件:
- 图片编辑软件。可以根据您的使用习惯偏好选择,如 [Photoshop](https://www.adobe.com/products/photoshop.html) 或 [GIMP](https://www.gimp.org/) (免费)。
- Stable Diffusion。可以参照 [第 1 部分](https://huggingface.co/blog/ml-for-games-1#setting-up-stable-diffusion) 的说明设置 Stable Diffusion。
### Image2Image
诸如 [Diffusion models](https://en.wikipedia.org/wiki/Diffusion_model) 之类的扩散模型生成图片的过程是从初始噪声开始,通过不断去噪来重建图片,同时在去噪过程中可以添加额外的指导条件来引导生成图片的某种特性,这个条件可以是文本、轮廓、位置等。基于扩散模型的 Image2Image 生成图片的过程也一样,但并非从初始噪声开始,而是输入真实图片,这样最终生成的图片将会与输入图片有一定的相似性。
Image2Image 中的一个比较重要的参数是 **去噪强度** (denoising strength),它可以控制生成图片与输入图片的差异程度。去噪强度为 0 会生成与输入图片完全一致的图片,去噪强度为 1 则截然不同。去噪强度也可以理解为 **创造性**。例如:给定一张圆形图案的输入图片,添加文本提示语 “月亮”,对去噪强度设置不同的参数值,Image2Image 可以生成不同创造性的图片,示意图如下。
<div align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/124_ml-for-games/moons.png" alt="Denoising Strength 示例">
</div>
基于 Stable Diffusion 的 Image2Image 方法并非代替了传统美术作品绘图流程,而是作为一种工具辅助使用。具体来说,您可以先手动绘制图片,然后将其输入给 Image2Image,调整相关参数后得到生成图片,然后继续将生成的图片输入给 Image2Image 进行多次迭代,直到生成一张满意的图片。以本系列的农场游戏为例,我会在接下来的部分说明具体细节。
### 示例:玉米
在这一小节中,我会介绍使用 Image2Image 为农场游戏的农作物玉米生成图标的完整流程。首先需要确定整体构图,我简单勾勒了一张非常粗糙的玉米图标草图。
<div align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/124_ml-for-games/corn1.png" alt="Corn 1">
</div>
接下来,我输入以下提示语:
> corn, james gilleard, atey ghailan, pixar concept artists, stardew valley, animal crossing
>
> 注:corn:玉米;james gilleard:未来主义插画艺术家;atey ghailan:现拳头游戏概念艺术家;pixar concept artists:皮克斯动画概念艺术;stardew valley:星露谷物语,一款像素风农场游戏;animal crossing:动物之森,任天堂游戏
同时设置去噪强度为 0.8,确保扩散模型生成的图片在保持原始构图的同时兼顾更多的创造性。从多次随机生成的图片中,我挑选了一张喜欢的,如下所示。
<div align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/124_ml-for-games/corn2.png" alt="Corn 2">
</div>
生成的图片不需要很完美,因为通常会多次迭代来不断修复不完美的部分。对于上面挑选的图片,我觉得整体风格很不错,不过玉米叶部分稍微有些复杂,所以我使用 PhotoShop 做了一些修改。
<div align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/124_ml-for-games/corn3.png" alt="Corn 3">
</div>
请注意,这里我仅在 PhotoShop 中用笔刷非常粗略地涂掉了要改的部分,然后把它输入到 Image2Image 中,让 Stable Diffusion 自行填充这部分的细节。由于这次输入图片的大部分信息需要被保留下来,因此我设置去噪强度为 0.6,得到了一张 *还不错* 的图片。
<div align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/124_ml-for-games/corn4.png" alt="Corn 4">
</div>
接着我在 PhotoShop 中又做了一些修改:简化了底部的线条以及去除了顶部的新芽,再一次输入 Stable Diffusion 迭代,并且删除了背景,最终的玉米图标如下图所示。
<div align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/124_ml-for-games/corn5.png" alt="Corn 5">
</div>
瞧!不到 10 分钟,一个玉米图标游戏素材就制作完成了!其实您可以花更多时间来打磨一个更好的作品。如想了解如何制作更加精致的游戏素材,可以前往观看详细演示视频。
### 示例:镰刀
很多时候,您可能需要对扩散模型进行 负面引导 才能生成期望的图片。下图毫无疑问可以用作镰刀图标,但这些简单的图片却需要大量迭代次数才能生成。
<div align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/124_ml-for-games/scythe.png" alt="Scythe">
</div>
原因可能是这样:扩散模型使用的训练图片基本都是网络上的,而网络上关于镰刀的图片大部分是 **武器**,只有小部分是 *农具*,这就导致模型生成的镰刀图片会偏离 农具。一种解决方法是改善提示语:以增加 负面提示语 的方式引导模型避开相应的结果。上述示例中,除了输入 **镰刀,农具** 之外,在负面提示语一栏输入 **武器** 就能奏效。当然,也不只有这一种解决方法。
[Dreambooth](https://dreambooth.github.io/)、[textual inversion](https://textual-inversion.github.io/) 和 [LoRA](https://huggingface.co/blog/lora) 技术用于定制个人专属的扩散模型,可以使模型生成更加明确的图片。在 2D 生成领域,这些技术会越来越重要,不过具体技术细节不在本教程范围之内,这里就不展开了。
[layer.ai](https://layer.ai/) 和 [scenario.gg](https://www.scenario.gg/) 等是专门提供游戏素材生成的服务商,可以使游戏从业者在游戏开发过程中生成的游戏素材保持风格一致,他们的底层技术很可能就是 dreambooth 或 textual inversion。在新兴的开发游戏素材生成工具包赛道,是这些技术成为主流?还是会再出现其他技术?让我们拭目以待!
如果您对 Dreambooth 的工作流程细节感兴趣,可以查看 [博客文章](https://huggingface.co/blog/dreambooth) 阅读相关信息,也可以进入 Hugging Face 的 Dreambooth Training [Space](https://huggingface.co/spaces/multimodalart/dreambooth-training) 应用体验整个流程。
点击 [这里](https://huggingface.co/blog/zh/ml-for-games-5) 继续阅读第五部分,我们一起进入 **AI 设计游戏剧情**。
| 9 |
0 | hf_public_repos/api-inference-community/docker_images/allennlp/app | hf_public_repos/api-inference-community/docker_images/allennlp/app/pipelines/__init__.py | from app.pipelines.base import Pipeline, PipelineException # isort:skip
from app.pipelines.question_answering import QuestionAnsweringPipeline
| 0 |
0 | hf_public_repos/api-inference-community/docker_images/allennlp/app | hf_public_repos/api-inference-community/docker_images/allennlp/app/pipelines/question_answering.py | import os
import shutil
from typing import Any, Dict
# Even though it is not imported, it is actually required, it downloads some stuff.
import allennlp_models # noqa: F401
from allennlp.predictors.predictor import Predictor
from app.pipelines import Pipeline
class QuestionAnsweringPipeline(Pipeline):
def __init__(
self,
model_id: str,
):
try:
self.predictor = Predictor.from_path("hf://" + model_id)
except (IOError, OSError):
nltk = os.getenv("NLTK_DATA")
if nltk is None:
raise
directory = os.path.join(nltk, "corpora")
shutil.rmtree(directory)
self.predictor = Predictor.from_path("hf://" + model_id)
def __call__(self, inputs: Dict[str, str]) -> Dict[str, Any]:
"""
Args:
inputs (:obj:`dict`):
a dictionary containing two keys, 'question' being the question being asked and 'context' being some text containing the answer.
Return:
A :obj:`dict`:. The object return should be like {"answer": "XXX", "start": 3, "end": 6, "score": 0.82} containing :
- "answer": the extracted answer from the `context`.
- "start": the offset within `context` leading to `answer`. context[start:stop] == answer
- "end": the ending offset within `context` leading to `answer`. context[start:stop] === answer
- "score": A score between 0 and 1 describing how confident the model is for this answer.
"""
allenlp_input = {"passage": inputs["context"], "question": inputs["question"]}
predictions = self.predictor.predict_json(allenlp_input)
start_token_idx, end_token_idx = predictions["best_span"]
start = predictions["token_offsets"][start_token_idx][0]
end = predictions["token_offsets"][end_token_idx][1]
score = (
predictions["span_end_probs"][end_token_idx]
* predictions["span_start_probs"][start_token_idx]
)
return {
"answer": predictions["best_span_str"],
"start": start,
"end": end,
"score": score,
}
| 1 |
0 | hf_public_repos/api-inference-community/docker_images/allennlp | hf_public_repos/api-inference-community/docker_images/allennlp/tests/test_docker_build.py | import os
import subprocess
from unittest import TestCase
class cd:
"""Context manager for changing the current working directory"""
def __init__(self, newPath):
self.newPath = os.path.expanduser(newPath)
def __enter__(self):
self.savedPath = os.getcwd()
os.chdir(self.newPath)
def __exit__(self, etype, value, traceback):
os.chdir(self.savedPath)
class DockerBuildTestCase(TestCase):
def test_can_build_docker_image(self):
with cd(os.path.dirname(os.path.dirname(__file__))):
subprocess.check_output(["docker", "build", "."])
| 2 |
0 | hf_public_repos/api-inference-community/docker_images/allennlp | hf_public_repos/api-inference-community/docker_images/allennlp/tests/test_api.py | import os
from typing import Dict
from unittest import TestCase, skipIf
from app.main import ALLOWED_TASKS, get_pipeline
# Must contain at least one example of each implemented pipeline
# Tests do not check the actual values of the model output, so small dummy
# models are recommended for faster tests.
TESTABLE_MODELS: Dict[str, str] = {
"question-answering": "lysandre/bidaf-elmo-model-2020.03.19"
}
ALL_TASKS = {
"automatic-speech-recognition",
"audio-source-separation",
"image-classification",
"question-answering",
"text-generation",
"text-to-speech",
}
class PipelineTestCase(TestCase):
@skipIf(
os.path.dirname(os.path.dirname(__file__)).endswith("common"),
"common is a special case",
)
def test_has_at_least_one_task_enabled(self):
self.assertGreater(
len(ALLOWED_TASKS.keys()), 0, "You need to implement at least one task"
)
def test_unsupported_tasks(self):
unsupported_tasks = ALL_TASKS - ALLOWED_TASKS.keys()
for unsupported_task in unsupported_tasks:
with self.subTest(msg=unsupported_task, task=unsupported_task):
with self.assertRaises(EnvironmentError):
get_pipeline(unsupported_task, model_id="XX")
| 3 |
0 | hf_public_repos/api-inference-community/docker_images/allennlp | hf_public_repos/api-inference-community/docker_images/allennlp/tests/test_api_question_answering.py | import json
import os
from unittest import TestCase, skipIf
from app.main import ALLOWED_TASKS
from starlette.testclient import TestClient
from tests.test_api import TESTABLE_MODELS
@skipIf(
"question-answering" not in ALLOWED_TASKS,
"question-answering not implemented",
)
class QuestionAnsweringTestCase(TestCase):
def setUp(self):
model_id = TESTABLE_MODELS["question-answering"]
self.old_model_id = os.getenv("MODEL_ID")
self.old_task = os.getenv("TASK")
os.environ["MODEL_ID"] = model_id
os.environ["TASK"] = "question-answering"
from app.main import app
self.app = app
def tearDown(self):
if self.old_model_id is not None:
os.environ["MODEL_ID"] = self.old_model_id
else:
del os.environ["MODEL_ID"]
if self.old_task is not None:
os.environ["TASK"] = self.old_task
else:
del os.environ["TASK"]
def test_simple(self):
inputs = {"question": "Where do I live ?", "context": "I live in New-York"}
with TestClient(self.app) as client:
response = client.post("/", json={"inputs": inputs})
self.assertEqual(
response.status_code,
200,
)
content = json.loads(response.content)
self.assertEqual(set(content.keys()), {"answer", "start", "end", "score"})
with TestClient(self.app) as client:
response = client.post("/", json=inputs)
self.assertEqual(
response.status_code,
200,
)
content = json.loads(response.content)
self.assertEqual(set(content.keys()), {"answer", "start", "end", "score"})
def test_malformed_question(self):
with TestClient(self.app) as client:
response = client.post("/", data=b"Where do I live ?")
self.assertEqual(response.status_code, 400, response.content)
content = json.loads(response.content)
self.assertEqual(set(content.keys()), {"error"})
| 4 |
0 | hf_public_repos/api-inference-community/docker_images | hf_public_repos/api-inference-community/docker_images/sentence_transformers/requirements.txt | starlette==0.27.0
api-inference-community==0.0.32
sentence-transformers==3.0.1
transformers==4.41.1
tokenizers==0.19.1
protobuf==3.18.3
huggingface_hub==0.23.3
sacremoses==0.0.53
# dummy.
| 5 |
0 | hf_public_repos/api-inference-community/docker_images | hf_public_repos/api-inference-community/docker_images/sentence_transformers/Dockerfile | FROM tiangolo/uvicorn-gunicorn:python3.8
LABEL maintainer="Omar <[email protected]>"
# Add any system dependency here
# RUN apt-get update -y && apt-get install libXXX -y
RUN pip3 install --no-cache-dir torch==1.13.0
COPY ./requirements.txt /app
RUN pip install --no-cache-dir -r requirements.txt
COPY ./prestart.sh /app/
# Most DL models are quite large in terms of memory, using workers is a HUGE
# slowdown because of the fork and GIL with python.
# Using multiple pods seems like a better default strategy.
# Feel free to override if it does not make sense for your library.
ARG max_workers=1
ENV MAX_WORKERS=$max_workers
ENV HUGGINGFACE_HUB_CACHE=/data
ENV SENTENCE_TRANSFORMERS_HOME=/data
ENV TRANSFORMERS_CACHE=/data
# Necessary on GPU environment docker.
# TIMEOUT env variable is used by nvcr.io/nvidia/pytorch:xx for another purpose
# rendering TIMEOUT defined by uvicorn impossible to use correctly
# We're overriding it to be renamed UVICORN_TIMEOUT
# UVICORN_TIMEOUT is a useful variable for very large models that take more
# than 30s (the default) to load in memory.
# If UVICORN_TIMEOUT is too low, uvicorn will simply never loads as it will
# kill workers all the time before they finish.
RUN sed -i 's/TIMEOUT/UVICORN_TIMEOUT/g' /gunicorn_conf.py
COPY ./app /app/app
| 6 |
0 | hf_public_repos/api-inference-community/docker_images | hf_public_repos/api-inference-community/docker_images/sentence_transformers/prestart.sh | python app/main.py
| 7 |
0 | hf_public_repos/api-inference-community/docker_images/sentence_transformers | hf_public_repos/api-inference-community/docker_images/sentence_transformers/app/main.py | import functools
import logging
import os
from typing import Dict, Type
from api_inference_community.routes import pipeline_route, status_ok
from app.pipelines import (
FeatureExtractionPipeline,
Pipeline,
SentenceSimilarityPipeline,
)
from starlette.applications import Starlette
from starlette.middleware import Middleware
from starlette.middleware.gzip import GZipMiddleware
from starlette.routing import Route
TASK = os.getenv("TASK")
MODEL_ID = os.getenv("MODEL_ID")
logger = logging.getLogger(__name__)
# Add the allowed tasks
# Supported tasks are:
# - text-generation
# - text-classification
# - token-classification
# - translation
# - summarization
# - automatic-speech-recognition
# - ...
# For instance
# from app.pipelines import AutomaticSpeechRecognitionPipeline
# ALLOWED_TASKS = {"automatic-speech-recognition": AutomaticSpeechRecognitionPipeline}
# You can check the requirements and expectations of each pipelines in their respective
# directories. Implement directly within the directories.
ALLOWED_TASKS: Dict[str, Type[Pipeline]] = {
"feature-extraction": FeatureExtractionPipeline,
"sentence-similarity": SentenceSimilarityPipeline,
}
@functools.lru_cache()
def get_pipeline() -> Pipeline:
task = os.environ["TASK"]
model_id = os.environ["MODEL_ID"]
if task not in ALLOWED_TASKS:
raise EnvironmentError(f"{task} is not a valid pipeline for model : {model_id}")
return ALLOWED_TASKS[task](model_id)
routes = [
Route("/{whatever:path}", status_ok),
Route("/{whatever:path}", pipeline_route, methods=["POST"]),
]
middleware = [Middleware(GZipMiddleware, minimum_size=1000)]
if os.environ.get("DEBUG", "") == "1":
from starlette.middleware.cors import CORSMiddleware
middleware.append(
Middleware(
CORSMiddleware,
allow_origins=["*"],
allow_headers=["*"],
allow_methods=["*"],
)
)
app = Starlette(routes=routes, middleware=middleware)
@app.on_event("startup")
async def startup_event():
logger = logging.getLogger("uvicorn.access")
handler = logging.StreamHandler()
handler.setFormatter(logging.Formatter("%(asctime)s - %(levelname)s - %(message)s"))
logger.handlers = [handler]
# Link between `api-inference-community` and framework code.
app.get_pipeline = get_pipeline
try:
get_pipeline()
except Exception:
# We can fail so we can show exception later.
pass
if __name__ == "__main__":
try:
get_pipeline()
except Exception:
# We can fail so we can show exception later.
pass
| 8 |
0 | hf_public_repos/api-inference-community/docker_images/sentence_transformers/app | hf_public_repos/api-inference-community/docker_images/sentence_transformers/app/pipelines/sentence_similarity.py | import os
from typing import Dict, List, Union
from app.pipelines import Pipeline
from sentence_transformers import SentenceTransformer, util
class SentenceSimilarityPipeline(Pipeline):
def __init__(
self,
model_id: str,
):
self.model = SentenceTransformer(
model_id, use_auth_token=os.getenv("HF_API_TOKEN")
)
def __call__(self, inputs: Dict[str, Union[str, List[str]]]) -> List[float]:
"""
Args:
inputs (:obj:`dict`):
a dictionary containing two keys, 'source_sentence' mapping
to the sentence that will be compared against all the others,
and 'sentences', mapping to a list of strings to which the
source will be compared.
Return:
A :obj:`list` of floats: Cosine similarity between `source_sentence` and each sentence from `sentences`.
"""
embeddings1 = self.model.encode(
inputs["source_sentence"], convert_to_tensor=True
)
embeddings2 = self.model.encode(inputs["sentences"], convert_to_tensor=True)
similarities = util.pytorch_cos_sim(embeddings1, embeddings2).tolist()[0]
return similarities
| 9 |
0 | hf_public_repos/autotrain-advanced/configs | hf_public_repos/autotrain-advanced/configs/extractive_question_answering/local_dataset.yml | task: extractive-qa
base_model: google-bert/bert-base-uncased
project_name: autotrain-bert-ex-qa2
log: tensorboard
backend: local
data:
path: data/ # this must be the path to the directory containing the train and valid files
train_split: train # this must be either train.csv or train.json
valid_split: valid # this must be either valid.csv or valid.json
column_mapping:
text_column: context
question_column: question
answer_column: answers
params:
max_seq_length: 512
max_doc_stride: 128
epochs: 3
batch_size: 4
lr: 2e-5
optimizer: adamw_torch
scheduler: linear
gradient_accumulation: 1
mixed_precision: fp16
hub:
username: ${HF_USERNAME}
token: ${HF_TOKEN}
push_to_hub: true | 0 |
0 | hf_public_repos/autotrain-advanced/configs | hf_public_repos/autotrain-advanced/configs/extractive_question_answering/hub_dataset.yml | task: extractive-qa
base_model: google-bert/bert-base-uncased
project_name: autotrain-bert-ex-qa1
log: tensorboard
backend: local
data:
path: lhoestq/squad
train_split: train
valid_split: validation
column_mapping:
text_column: context
question_column: question
answer_column: answers
params:
max_seq_length: 512
max_doc_stride: 128
epochs: 3
batch_size: 4
lr: 2e-5
optimizer: adamw_torch
scheduler: linear
gradient_accumulation: 1
mixed_precision: fp16
hub:
username: ${HF_USERNAME}
token: ${HF_TOKEN}
push_to_hub: true | 1 |
0 | hf_public_repos/autotrain-advanced/configs | hf_public_repos/autotrain-advanced/configs/text_classification/local_dataset.yml | task: text_classification
base_model: google-bert/bert-base-uncased
project_name: autotrain-bert-imdb-finetuned
log: tensorboard
backend: local
data:
path: data/ # this must be the path to the directory containing the train and valid files
train_split: train # this must be either train.csv or train.json
valid_split: valid # this must be either valid.csv or valid.json
column_mapping:
text_column: text # this must be the name of the column containing the text
target_column: label # this must be the name of the column containing the target
params:
max_seq_length: 512
epochs: 3
batch_size: 4
lr: 2e-5
optimizer: adamw_torch
scheduler: linear
gradient_accumulation: 1
mixed_precision: fp16
hub:
username: ${HF_USERNAME}
token: ${HF_TOKEN}
push_to_hub: true | 2 |
0 | hf_public_repos/autotrain-advanced/configs | hf_public_repos/autotrain-advanced/configs/text_classification/hub_dataset.yml | task: text_classification
base_model: google-bert/bert-base-uncased
project_name: autotrain-bert-imdb-finetuned
log: tensorboard
backend: local
data:
path: stanfordnlp/imdb
train_split: train
valid_split: test
column_mapping:
text_column: text
target_column: label
params:
max_seq_length: 512
epochs: 3
batch_size: 4
lr: 2e-5
optimizer: adamw_torch
scheduler: linear
gradient_accumulation: 1
mixed_precision: fp16
hub:
username: ${HF_USERNAME}
token: ${HF_TOKEN}
push_to_hub: true | 3 |
0 | hf_public_repos/autotrain-advanced | hf_public_repos/autotrain-advanced/docs/README.md | # Generating the documentation
To generate the documentation, you have to build it. Several packages are necessary to build the doc.
First, you need to install the project itself by running the following command at the root of the code repository:
```bash
pip install -e .
```
You also need to install 2 extra packages:
```bash
# `hf-doc-builder` to build the docs
pip install git+https://github.com/huggingface/doc-builder@main
# `watchdog` for live reloads
pip install watchdog
```
---
**NOTE**
You only need to generate the documentation to inspect it locally (if you're planning changes and want to
check how they look before committing for instance). You don't have to commit the built documentation.
---
## Building the documentation
Once you have setup the `doc-builder` and additional packages with the pip install command above,
you can generate the documentation by typing the following command:
```bash
doc-builder build autotrain docs/source/ --build_dir ~/tmp/test-build
```
You can adapt the `--build_dir` to set any temporary folder that you prefer. This command will create it and generate
the MDX files that will be rendered as the documentation on the main website. You can inspect them in your favorite
Markdown editor.
## Previewing the documentation
To preview the docs, run the following command:
```bash
doc-builder preview autotrain docs/source/
```
The docs will be viewable at [http://localhost:5173](http://localhost:5173). You can also preview the docs once you
have opened a PR. You will see a bot add a comment to a link where the documentation with your changes lives.
---
**NOTE**
The `preview` command only works with existing doc files. When you add a completely new file, you need to update
`_toctree.yml` & restart `preview` command (`ctrl-c` to stop it & call `doc-builder preview ...` again).
--- | 4 |
0 | hf_public_repos/autotrain-advanced/docs | hf_public_repos/autotrain-advanced/docs/source/autotrain_api.mdx | # AutoTrain API
With AutoTrain API, you can run your own instance of AutoTrain and use it to
train models on Hugging Face Spaces infrastructure (local training coming soon).
This API is designed to be used with autotrain compatible models and datasets, and it provides a simple interface to
train models with minimal configuration.
## Getting Started
To get started with AutoTrain API, all you need to do is install `autotrain-advanced`
as discussed in running locally section and run the autotrain app command:
```bash
$ autotrain app --port 8000 --host 127.0.0.1
```
You can then access the API reference at `http://127.0.0.1:8000/docs`.
## Example Usage
```bash
curl -X POST "http://127.0.0.1:8000/api/create_project" \
-H "Content-Type: application/json" \
-H "Authorization: Bearer hf_XXXXX" \
-d '{
"username": "abhishek",
"project_name": "my-autotrain-api-model",
"task": "llm:orpo",
"base_model": "meta-llama/Meta-Llama-3-8B-Instruct",
"hub_dataset": "argilla/distilabel-capybara-dpo-7k-binarized",
"train_split": "train",
"hardware": "spaces-a10g-large",
"column_mapping": {
"text_column": "chosen",
"rejected_text_column": "rejected",
"prompt_text_column": "prompt"
},
"params": {
"block_size": 1024,
"model_max_length": 4096,
"max_prompt_length": 512,
"epochs": 1,
"batch_size": 2,
"lr": 0.00003,
"peft": true,
"quantization": "int4",
"target_modules": "all-linear",
"padding": "right",
"optimizer": "adamw_torch",
"scheduler": "linear",
"gradient_accumulation": 4,
"mixed_precision": "fp16",
"chat_template": "chatml"
}
}'
```
| 5 |
0 | hf_public_repos/autotrain-advanced/docs | hf_public_repos/autotrain-advanced/docs/source/getting_started.bck | # Installation
There is no installation required! AutoTrain Advanced runs on Hugging Face Spaces. All you need to do is create a new space with the AutoTrain Advanced template: https://huggingface.co/new-space?template=autotrain-projects/autotrain-advanced. Please make sure you keep the space private.
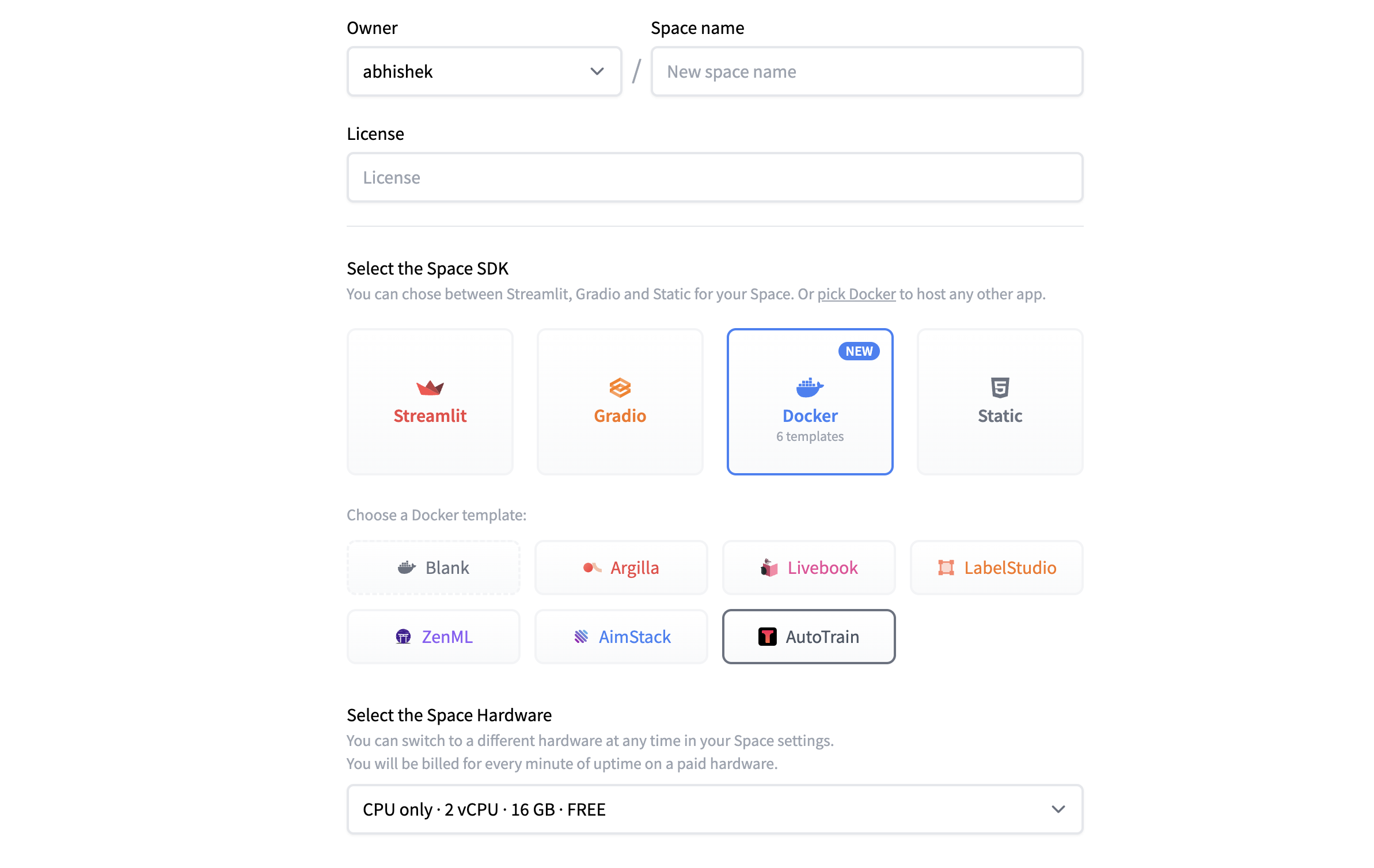
Once you have selected Docker > AutoTrain template and an appropriate hardware, you can click on "Create Space" and you will be redirected to your new space.
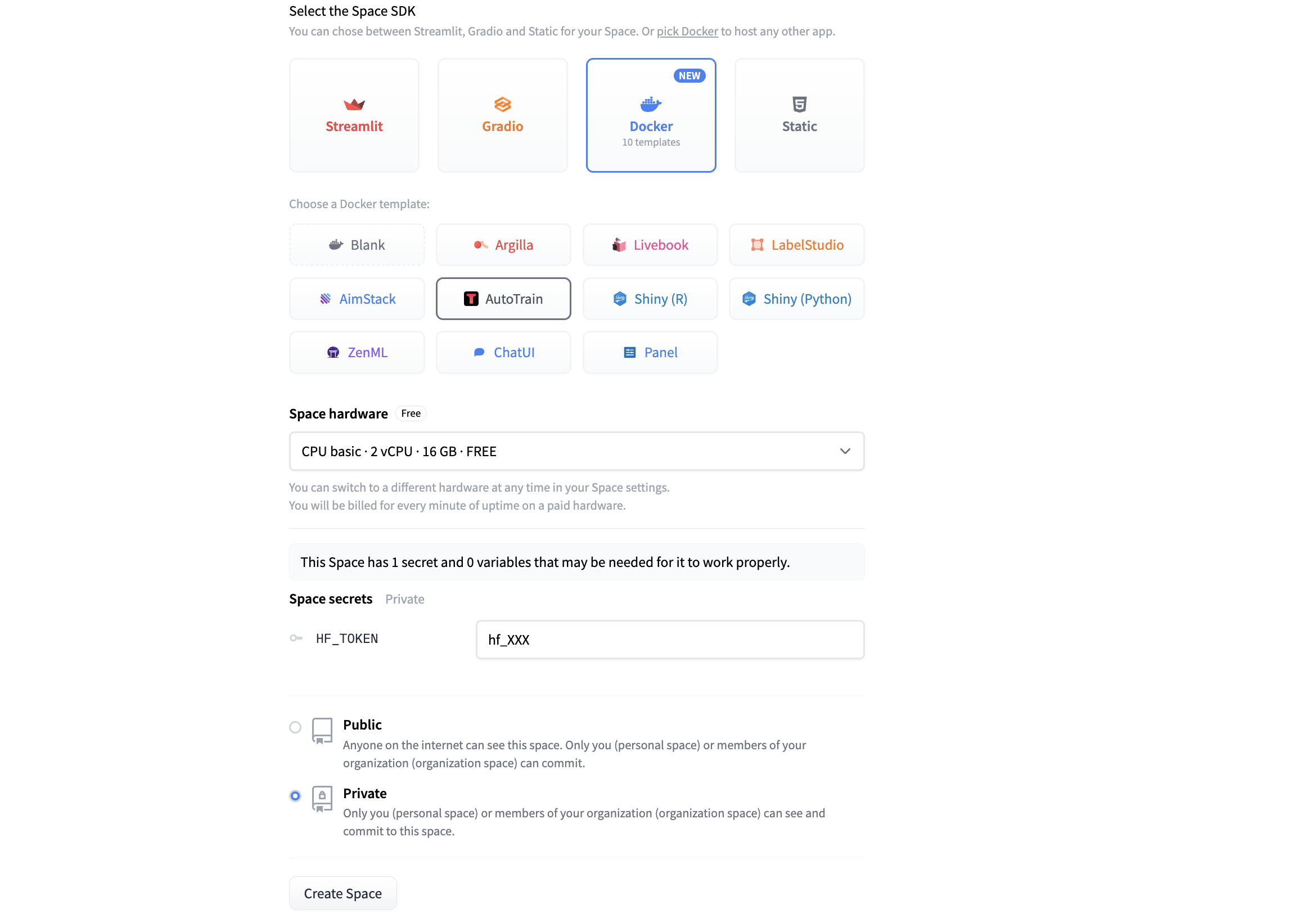
Make sure to use a write token and keep the space private for any unauthorized access.
# Updating AutoTrain Advanced to Latest Version
We are constantly adding new features and tasks to AutoTrain Advanced. Its always a good idea to update your space to the latest version before starting a new project. An up-to-date version of AutoTrain Advanced will have the latest tasks, features and bug fixes! Updating is as easy as clicking on the "Factory reboot" button in the setting page of your space.
Please note that "restarting" a space will not update it to the latest version. You need to "Factory reboot" the space to update it to the latest version.
And now we are all set and we can start with our first project!
# Understanding the UI
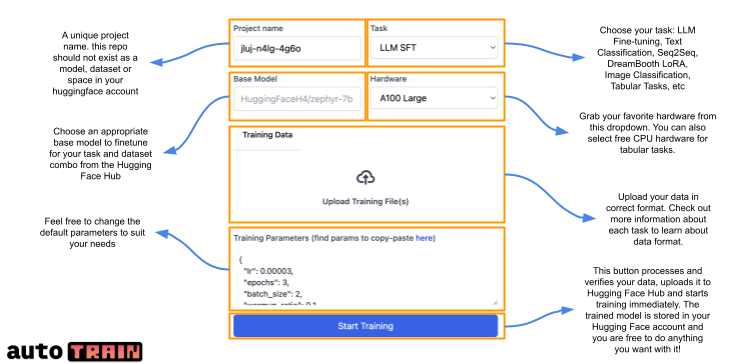
| 6 |
0 | hf_public_repos/autotrain-advanced/docs | hf_public_repos/autotrain-advanced/docs/source/quickstart_spaces.mdx | # Quickstart Guide to AutoTrain on Hugging Face Spaces
AutoTrain on Hugging Face Spaces is the preferred choice for a streamlined experience in
model training. This platform is optimized for ease of use, with pre-installed dependencies
and managed hardware resources. AutoTrain on Hugging Face Spaces can be used both by
no-code users and developers, making it versatile for various levels of expertise.
## Creating a New AutoTrain Space
Getting started with AutoTrain is straightforward. Here’s how you can create your new space:
1. **Visit the AutoTrain Page**: To create a new space with AutoTrain Docker image, all you need to do is go
to [AutoTrain Homepage](https://hf.co/autotrain) and click on "Create new project".
2. **Log In or View the Setup Screen**: If not logged in, you'll be prompted to do so. Then, you’ll see a screen similar to this:
3. **Set Up Your Space**:
- **Choose a Space Name**: Name your space something relevant to your project.
- **Allocate Hardware Resources**: Select the necessary computational resources based on your project needs.
- **Duplicate Space**: Click on "Duplicate Space" to initiate your AutoTrain space with the Docker image.
4. **Configuration Options**:
- PAUSE_ON_FAILURE: Set this to 0 if you prefer the space not to pause on training failures, useful for running continuous experiments. This option can also be used if you continuously want to perfom many experiments in the same space.
5. **Launch and Train**:
- Once done, in a few seconds, the AutoTrain Space will be up and running and you will be presented with the following screen:
- From here, you can select tasks, upload datasets, choose models, adjust hyperparameters (if needed),
and start the training process directly within the space.
- The space will manage its own activity, shutting down post-training unless configured
otherwise based on the `PAUSE_ON_FAILURE` setting.
6. **Monitoring Progress**:
- All training logs and progress can be monitored via TensorBoard, accessible under
`username/project_name` on the Hugging Face Hub.
- Once training concludes successfully, you’ll find the model files in the same repository.
7. **Navigating the UI**:
- If you need help understanding any UI elements, click on the small (i) information icons for detailed descriptions.
If you are confused about the UI elements, click on the small (i) information icon to get more information about the UI element.
For data formats and detailed parameter information, please see the Data Formats and Parameters section where we provide
example datasets and detailed information about the parameters for each task supported by AutoTrain.
## Ensuring Your AutoTrain is Up-to-Date
We are constantly adding new features and tasks to AutoTrain Advanced. To benefit from the latest features, tasks, and bug fixes, update your AutoTrain space regularly:
- *Factory Reboot*: Navigate to the settings page of your space and click on "Factory reboot" to upgrade to the latest version of AutoTrain Advanced.

- *Note*: Simply "restarting" the space does not update it; a factory reboot is necessary for a complete update.
For additional details on data formats and specific parameters, refer to the
'Data Formats and Parameters' section where we provide example datasets and extensive
parameter information for each supported task by AutoTrain.
With these steps, you can effortlessly initiate and manage your AutoTrain projects on
Hugging Face Spaces, leveraging the platform's robust capabilities for your machine learning and AI
needs.
| 7 |
0 | hf_public_repos/autotrain-advanced/docs | hf_public_repos/autotrain-advanced/docs/source/config.mdx | # AutoTrain Configs
AutoTrain Configs are the way to use and train models using AutoTrain locally.
Once you have installed AutoTrain Advanced, you can use the following command to train models using AutoTrain config files:
```bash
$ export HF_USERNAME=your_hugging_face_username
$ export HF_TOKEN=your_hugging_face_write_token
$ autotrain --config path/to/config.yaml
```
Example configurations for all tasks can be found in the `configs` directory of
the [AutoTrain Advanced GitHub repository](https://github.com/huggingface/autotrain-advanced).
Here is an example of an AutoTrain config file:
```yaml
task: llm
base_model: meta-llama/Meta-Llama-3-8B-Instruct
project_name: autotrain-llama3-8b-orpo
log: tensorboard
backend: local
data:
path: argilla/distilabel-capybara-dpo-7k-binarized
train_split: train
valid_split: null
chat_template: chatml
column_mapping:
text_column: chosen
rejected_text_column: rejected
params:
trainer: orpo
block_size: 1024
model_max_length: 2048
max_prompt_length: 512
epochs: 3
batch_size: 2
lr: 3e-5
peft: true
quantization: int4
target_modules: all-linear
padding: right
optimizer: adamw_torch
scheduler: linear
gradient_accumulation: 4
mixed_precision: bf16
hub:
username: ${HF_USERNAME}
token: ${HF_TOKEN}
push_to_hub: true
```
In this config, we are finetuning the `meta-llama/Meta-Llama-3-8B-Instruct` model
on the `argilla/distilabel-capybara-dpo-7k-binarized` dataset using the `orpo`
trainer for 3 epochs with a batch size of 2 and a learning rate of `3e-5`.
More information on the available parameters can be found in the *Data Formats and Parameters* section.
In case you dont want to push the model to hub, you can set `push_to_hub` to `false` in the config file.
If not pushing the model to hub username and token are not required. Note: they may still be needed
if you are trying to access gated models or datasets. | 8 |
0 | hf_public_repos/autotrain-advanced/docs | hf_public_repos/autotrain-advanced/docs/source/faq.mdx | # Frequently Asked Questions
## Are my data and models secure?
Yes, your data and models are secure. AutoTrain uses the Hugging Face Hub to store your data and models.
All your data and models are uploaded to your Hugging Face account as private repositories and are only accessible by you.
Read more about security [here](https://huggingface.co/docs/hub/en/security).
## Do you upload my data to the Hugging Face Hub?
AutoTrain will not upload your dataset to the Hub if you are using the local backend or training in the same space.
AutoTrain will push your dataset to the Hub if you are using features like: DGX Cloud
or using local CLI to train on Hugging Face's infrastructure.
You can safely remove the dataset from the Hub after training is complete.
If uploaded, the dataset will be stored in your Hugging Face account as a private repository and will only be accessible by you
and the training process. It is not used once the training is complete.
## My training space paused for no reason mid-training
AutoTrain Training Spaces will pause itself after training is done (or failed). This is done to save resources and costs.
If your training failed, you can still see the space logs and find out what went wrong. Note: you won't be able to retrive the logs if you restart the space.
Another reason for the space to pause is if the space is space's sleep time kicking in. If you have a long running training job, you must set the sleep time to a much higher value.
The space will anyways pause itself after the training is done thus saving you costs.
## I get error `Your installed package nvidia-ml-py is corrupted. Skip patch functions`
This error can be safely ignored. It is a warning from the `nvitop` library and does not affect the functionality of AutoTrain.
## I get 409 conflict error when using the UI
This error occurs when you try to create a project with the same name as an existing project.
To resolve this error, you can either delete the existing project or create a new project
with a different name.
This error can also occur when you are trying to train a model while a model is already training in the same space or locally.
## The model I want to use doesn't show up in the model selection dropdown.
If the model you want to use is not available in the model selection dropdown,
you can add it in the environment variable `AUTOTRAIN_CUSTOM_MODELS` in the space settings.
For example, if you want to add the `xxx/yyy` model, go to space settings, create a variable named `AUTOTRAIN_CUSTOM_MODELS`
and set the value to `xxx/yyy`.
You can also pass the model name as query parameter in the URL. For example, if you want to use the `xxx/yyy` model,
you can use the URL `https://huggingface.co/spaces/your_autotrain_space?custom_models=xxx/yyy`.
## How do I use AutoTrain locally?
AutoTrain can be used locally by installing the AutoTrain Advanced pypi package.
You can read more in *Use AutoTrain Locally* section.
## Can I run AutoTrain on Colab?
To start the UI on Colab, you can simply click on the following link:
[](https://colab.research.google.com/github/huggingface/autotrain-advanced/blob/main/colabs/AutoTrain.ipynb)
Please note, to run the app on Colab, you will need an ngrok token. You can get one by signing up for free on [ngrok](https://ngrok.com/).
This is because Colab does not allow exposing ports to the internet directly.
To use the CLI instead on Colab, you can follow the same instructions as for using AutoTrain locally.
## Does AutoTrain have a docker image?
Yes, AutoTrain has a docker image.
You can find the docker image on Docker Hub [here](https://hub.docker.com/r/huggingface/autotrain-advanced).
## Is windows supported?
Unfortunately, AutoTrain does not officially support Windows at the moment.
You can try using WSL (Windows Subsystem for Linux) to run AutoTrain on Windows or the docker image.
## "--project-name" argument can not be set as a directory
`--project-name` argument should not be a path. it will be created where autotrain command is run.
This parameter must be alphanumeric and can contain hypens.
## I am getting `config.json` not found error
This means you have trained an adapter model (peft=true) which doesnt generate config.json.
It doesnt matter though, the model can still be loaded with AutoModelForCausalLM or with Inference endpoints.
If you want to merge weights with base models, you can use `autotrain tools`. Please read about it in miscelleneous section.
## Does autotrain support multi-gpu training?
Yes, autotrain supports multi-gpu training.
AutoTrain will determine on its own if the user is running the command on a multi-gpu setup and will use
multi-gpu ddp if number of gpus is greater than 1 and less than 4 and deepspeed if number of gpus is greater than or equal to 4.
## How can i use a hub dataset with multiple configs?
If your hub dataset has multiple configs, you can use `train_split` parameter to specify the both the config and the split.
For example, in this dataset [here](https://huggingface.co/datasets/timdettmers/openassistant-guanaco),
there are multiple configs: `pair`, `pair-class`, `pair-score` and `triplet`.
If i want to use `train` split of `pair-class` config, i can use write `pair-class:train` as `train_split` in the UI or the CLI / config.
An example config is shown below:
```yaml
data:
path: sentence-transformers/all-nli
train_split: pair-class:train
valid_split: pair-class:test
column_mapping:
sentence1_column: premise
sentence2_column: hypothesis
target_column: label
``` | 9 |
0 | hf_public_repos/api-inference-community/docker_images/diffusers/app | hf_public_repos/api-inference-community/docker_images/diffusers/app/pipelines/text_to_image.py | import importlib
import json
import logging
import os
from typing import TYPE_CHECKING
import torch
from app import idle, lora, offline, timing, validation
from app.pipelines import Pipeline
from diffusers import (
AutoencoderKL,
AutoPipelineForText2Image,
DiffusionPipeline,
EulerAncestralDiscreteScheduler,
)
from diffusers.schedulers.scheduling_utils import KarrasDiffusionSchedulers
logger = logging.getLogger(__name__)
if TYPE_CHECKING:
from PIL import Image
class TextToImagePipeline(
Pipeline, lora.LoRAPipelineMixin, offline.OfflineBestEffortMixin
):
def __init__(self, model_id: str):
self.current_lora_adapter = None
self.model_id = None
self.current_tokens_loaded = 0
self.use_auth_token = os.getenv("HF_API_TOKEN")
# This should allow us to make the image work with private models when no token is provided, if the said model
# is already in local cache
self.offline_preferred = validation.str_to_bool(os.getenv("OFFLINE_PREFERRED"))
model_data = self._hub_model_info(model_id)
kwargs = (
{"safety_checker": None}
if model_id.startswith("hf-internal-testing/")
else {}
)
env_dtype = os.getenv("TORCH_DTYPE")
if env_dtype:
kwargs["torch_dtype"] = getattr(torch, env_dtype)
elif torch.cuda.is_available():
kwargs["torch_dtype"] = torch.float16
has_model_index = any(
file.rfilename == "model_index.json" for file in model_data.siblings
)
if self._is_lora(model_data):
model_type = "LoraModel"
elif has_model_index:
config_file = self._hub_repo_file(model_id, "model_index.json")
with open(config_file, "r") as f:
config_dict = json.load(f)
model_type = config_dict.get("_class_name", None)
else:
raise ValueError("Model type not found")
if model_type == "LoraModel":
model_to_load = model_data.cardData["base_model"]
self.model_id = model_to_load
if not model_to_load:
raise ValueError(
"No `base_model` found. Please include a `base_model` on your README.md tags"
)
self._load_sd_with_sdxl_fix(model_to_load, **kwargs)
# The lora will actually be lazily loaded on the fly per request
self.current_lora_adapter = None
else:
if model_id == "stabilityai/stable-diffusion-xl-base-1.0":
self._load_sd_with_sdxl_fix(model_id, **kwargs)
else:
self.ldm = AutoPipelineForText2Image.from_pretrained(
model_id, use_auth_token=self.use_auth_token, **kwargs
)
self.model_id = model_id
self.is_karras_compatible = (
self.ldm.__class__.__init__.__annotations__.get("scheduler", None)
== KarrasDiffusionSchedulers
)
if self.is_karras_compatible:
self.ldm.scheduler = EulerAncestralDiscreteScheduler.from_config(
self.ldm.scheduler.config
)
self.default_scheduler = self.ldm.scheduler
if not idle.UNLOAD_IDLE:
self._model_to_gpu()
def _load_sd_with_sdxl_fix(self, model_id, **kwargs):
if model_id == "stabilityai/stable-diffusion-xl-base-1.0":
vae = AutoencoderKL.from_pretrained(
"madebyollin/sdxl-vae-fp16-fix",
torch_dtype=torch.float16, # load fp16 fix VAE
)
kwargs["vae"] = vae
kwargs["variant"] = "fp16"
self.ldm = DiffusionPipeline.from_pretrained(
model_id, use_auth_token=self.use_auth_token, **kwargs
)
@timing.timing
def _model_to_gpu(self):
if torch.cuda.is_available():
self.ldm.to("cuda")
def __call__(self, inputs: str, **kwargs) -> "Image.Image":
"""
Args:
inputs (:obj:`str`):
a string containing some text
Return:
A :obj:`PIL.Image.Image` with the raw image representation as PIL.
"""
# Check if users set a custom scheduler and pop if from the kwargs if so
custom_scheduler = None
if "scheduler" in kwargs:
custom_scheduler = kwargs["scheduler"]
kwargs.pop("scheduler")
if custom_scheduler:
compatibles = self.ldm.scheduler.compatibles
# Check if the scheduler is compatible
is_compatible_scheduler = [
cls for cls in compatibles if cls.__name__ == custom_scheduler
]
# In case of a compatible scheduler, swap to that for inference
if is_compatible_scheduler:
# Import the scheduler dynamically
SchedulerClass = getattr(
importlib.import_module("diffusers.schedulers"), custom_scheduler
)
self.ldm.scheduler = SchedulerClass.from_config(
self.ldm.scheduler.config
)
else:
logger.info("%s scheduler not loaded: incompatible", custom_scheduler)
self.ldm.scheduler = self.default_scheduler
else:
self.ldm.scheduler = self.default_scheduler
self._load_lora_adapter(kwargs)
if idle.UNLOAD_IDLE:
with idle.request_witnesses():
self._model_to_gpu()
resp = self._process_req(inputs, **kwargs)
else:
resp = self._process_req(inputs, **kwargs)
return resp
def _process_req(self, inputs, **kwargs):
# only one image per prompt is supported
kwargs["num_images_per_prompt"] = 1
if "num_inference_steps" not in kwargs:
default_num_steps = os.getenv("DEFAULT_NUM_INFERENCE_STEPS")
if default_num_steps:
kwargs["num_inference_steps"] = int(default_num_steps)
elif self.is_karras_compatible:
kwargs["num_inference_steps"] = 20
# Else, don't specify anything, leave the default behaviour
if "guidance_scale" not in kwargs:
default_guidance_scale = os.getenv("DEFAULT_GUIDANCE_SCALE")
if default_guidance_scale is not None:
kwargs["guidance_scale"] = float(default_guidance_scale)
# Else, don't specify anything, leave the default behaviour
if "seed" in kwargs:
seed = int(kwargs["seed"])
generator = torch.Generator().manual_seed(seed)
kwargs["generator"] = generator
kwargs.pop("seed")
images = self.ldm(inputs, **kwargs)["images"]
return images[0]
| 0 |
0 | hf_public_repos/api-inference-community/docker_images/diffusers/app | hf_public_repos/api-inference-community/docker_images/diffusers/app/pipelines/base.py | from abc import ABC, abstractmethod
from typing import Any
class Pipeline(ABC):
@abstractmethod
def __init__(self, model_id: str):
raise NotImplementedError("Pipelines should implement an __init__ method")
@abstractmethod
def __call__(self, inputs: Any) -> Any:
raise NotImplementedError("Pipelines should implement a __call__ method")
class PipelineException(Exception):
pass
| 1 |
0 | hf_public_repos/api-inference-community/docker_images/diffusers/app | hf_public_repos/api-inference-community/docker_images/diffusers/app/pipelines/__init__.py | from app.pipelines.base import Pipeline, PipelineException # isort:skip
from app.pipelines.image_to_image import ImageToImagePipeline
from app.pipelines.text_to_image import TextToImagePipeline
| 2 |
0 | hf_public_repos/api-inference-community/docker_images/diffusers/app | hf_public_repos/api-inference-community/docker_images/diffusers/app/pipelines/image_to_image.py | import json
import logging
import os
import torch
from app import idle, offline, timing, validation
from app.pipelines import Pipeline
from diffusers import (
AltDiffusionImg2ImgPipeline,
AltDiffusionPipeline,
AutoPipelineForImage2Image,
ControlNetModel,
DiffusionPipeline,
DPMSolverMultistepScheduler,
KandinskyImg2ImgPipeline,
KandinskyPriorPipeline,
StableDiffusionControlNetPipeline,
StableDiffusionDepth2ImgPipeline,
StableDiffusionImageVariationPipeline,
StableDiffusionImg2ImgPipeline,
StableDiffusionInstructPix2PixPipeline,
StableDiffusionLatentUpscalePipeline,
StableDiffusionPipeline,
StableDiffusionUpscalePipeline,
StableDiffusionXLImg2ImgPipeline,
StableUnCLIPImg2ImgPipeline,
StableUnCLIPPipeline,
)
from PIL import Image
logger = logging.getLogger(__name__)
class ImageToImagePipeline(Pipeline, offline.OfflineBestEffortMixin):
def __init__(self, model_id: str):
use_auth_token = os.getenv("HF_API_TOKEN")
self.use_auth_token = use_auth_token
# This should allow us to make the image work with private models when no token is provided, if the said model
# is already in local cache
self.offline_preferred = validation.str_to_bool(os.getenv("OFFLINE_PREFERRED"))
model_data = self._hub_model_info(model_id)
kwargs = (
{"safety_checker": None}
if model_id.startswith("hf-internal-testing/")
else {}
)
env_dtype = os.getenv("TORCH_DTYPE")
if env_dtype:
kwargs["torch_dtype"] = getattr(torch, env_dtype)
elif torch.cuda.is_available():
kwargs["torch_dtype"] = torch.float16
if model_id == "stabilityai/stable-diffusion-xl-refiner-1.0":
kwargs["variant"] = "fp16"
# check if is controlnet or SD/AD
config_file_name = None
for file_name in ("config.json", "model_index.json"):
if any(file.rfilename == file_name for file in model_data.siblings):
config_file_name = file_name
break
if config_file_name:
config_file = self._hub_repo_file(model_id, config_file_name)
with open(config_file, "r") as f:
config_dict = json.load(f)
model_type = config_dict.get("_class_name", None)
else:
raise ValueError("Model type not found")
# load according to model type
if model_type == "ControlNetModel":
model_to_load = (
model_data.cardData["base_model"]
if "base_model" in model_data.cardData
else "runwayml/stable-diffusion-v1-5"
)
controlnet = ControlNetModel.from_pretrained(
model_id, use_auth_token=use_auth_token, **kwargs
)
self.ldm = StableDiffusionControlNetPipeline.from_pretrained(
model_to_load,
controlnet=controlnet,
use_auth_token=use_auth_token,
**kwargs,
)
elif model_type in ["AltDiffusionPipeline", "AltDiffusionImg2ImgPipeline"]:
self.ldm = AltDiffusionImg2ImgPipeline.from_pretrained(
model_id, use_auth_token=use_auth_token, **kwargs
)
elif model_type in [
"StableDiffusionPipeline",
"StableDiffusionImg2ImgPipeline",
]:
self.ldm = StableDiffusionImg2ImgPipeline.from_pretrained(
model_id, use_auth_token=use_auth_token, **kwargs
)
elif model_type in ["StableUnCLIPPipeline", "StableUnCLIPImg2ImgPipeline"]:
self.ldm = StableUnCLIPImg2ImgPipeline.from_pretrained(
model_id, use_auth_token=use_auth_token, **kwargs
)
elif model_type in [
"StableDiffusionImageVariationPipeline",
"StableDiffusionInstructPix2PixPipeline",
"StableDiffusionUpscalePipeline",
"StableDiffusionLatentUpscalePipeline",
"StableDiffusionDepth2ImgPipeline",
]:
self.ldm = DiffusionPipeline.from_pretrained(
model_id, use_auth_token=use_auth_token, **kwargs
)
elif model_type in ["KandinskyImg2ImgPipeline", "KandinskyPipeline"]:
model_to_load = "kandinsky-community/kandinsky-2-1-prior"
self.ldm = KandinskyImg2ImgPipeline.from_pretrained(
model_id, use_auth_token=use_auth_token, **kwargs
)
self.prior = KandinskyPriorPipeline.from_pretrained(
model_to_load, use_auth_token=use_auth_token, **kwargs
)
else:
logger.debug("Falling back to generic auto pipeline loader")
self.ldm = AutoPipelineForImage2Image.from_pretrained(
model_id, use_auth_token=use_auth_token, **kwargs
)
if isinstance(
self.ldm,
(
StableUnCLIPImg2ImgPipeline,
StableUnCLIPPipeline,
StableDiffusionPipeline,
StableDiffusionImg2ImgPipeline,
AltDiffusionPipeline,
AltDiffusionImg2ImgPipeline,
StableDiffusionControlNetPipeline,
StableDiffusionInstructPix2PixPipeline,
StableDiffusionImageVariationPipeline,
StableDiffusionDepth2ImgPipeline,
),
):
self.ldm.scheduler = DPMSolverMultistepScheduler.from_config(
self.ldm.scheduler.config
)
if not idle.UNLOAD_IDLE:
self._model_to_gpu()
@timing.timing
def _model_to_gpu(self):
if torch.cuda.is_available():
self.ldm.to("cuda")
if isinstance(self.ldm, (KandinskyImg2ImgPipeline)):
self.prior.to("cuda")
def __call__(self, image: Image.Image, prompt: str = "", **kwargs) -> "Image.Image":
"""
Args:
prompt (:obj:`str`):
a string containing some text
image (:obj:`PIL.Image.Image`):
a condition image
Return:
A :obj:`PIL.Image.Image` with the raw image representation as PIL.
"""
if idle.UNLOAD_IDLE:
with idle.request_witnesses():
self._model_to_gpu()
resp = self._process_req(image, prompt)
else:
resp = self._process_req(image, prompt)
return resp
def _process_req(self, image, prompt, **kwargs):
# only one image per prompt is supported
kwargs["num_images_per_prompt"] = 1
if isinstance(
self.ldm,
(
StableDiffusionPipeline,
StableDiffusionImg2ImgPipeline,
AltDiffusionPipeline,
AltDiffusionImg2ImgPipeline,
StableDiffusionControlNetPipeline,
StableDiffusionInstructPix2PixPipeline,
StableDiffusionUpscalePipeline,
StableDiffusionLatentUpscalePipeline,
StableDiffusionDepth2ImgPipeline,
),
):
if "num_inference_steps" not in kwargs:
kwargs["num_inference_steps"] = int(
os.getenv("DEFAULT_NUM_INFERENCE_STEPS", "25")
)
images = self.ldm(prompt, image, **kwargs)["images"]
return images[0]
elif isinstance(self.ldm, StableDiffusionXLImg2ImgPipeline):
if "num_inference_steps" not in kwargs:
kwargs["num_inference_steps"] = int(
os.getenv("DEFAULT_NUM_INFERENCE_STEPS", "25")
)
image = image.convert("RGB")
images = self.ldm(prompt, image=image, **kwargs)["images"]
return images[0]
elif isinstance(self.ldm, (StableUnCLIPImg2ImgPipeline, StableUnCLIPPipeline)):
if "num_inference_steps" not in kwargs:
kwargs["num_inference_steps"] = int(
os.getenv("DEFAULT_NUM_INFERENCE_STEPS", "25")
)
# image comes first
images = self.ldm(image, prompt, **kwargs)["images"]
return images[0]
elif isinstance(self.ldm, StableDiffusionImageVariationPipeline):
if "num_inference_steps" not in kwargs:
kwargs["num_inference_steps"] = int(
os.getenv("DEFAULT_NUM_INFERENCE_STEPS", "25")
)
# only image is needed
images = self.ldm(image, **kwargs)["images"]
return images[0]
elif isinstance(self.ldm, (KandinskyImg2ImgPipeline)):
if "num_inference_steps" not in kwargs:
kwargs["num_inference_steps"] = int(
os.getenv("DEFAULT_NUM_INFERENCE_STEPS", "100")
)
# not all args are supported by the prior
prior_args = {
"num_inference_steps": kwargs["num_inference_steps"],
"num_images_per_prompt": kwargs["num_images_per_prompt"],
"negative_prompt": kwargs.get("negative_prompt", None),
"guidance_scale": kwargs.get("guidance_scale", 7),
}
if "guidance_scale" not in kwargs:
default_guidance_scale = os.getenv("DEFAULT_GUIDANCE_SCALE")
if default_guidance_scale is not None:
kwargs["guidance_scale"] = float(default_guidance_scale)
prior_args["guidance_scale"] = float(default_guidance_scale)
# Else, don't specify anything, leave the default behaviour
image_emb, zero_image_emb = self.prior(prompt, **prior_args).to_tuple()
images = self.ldm(
prompt,
image=image,
image_embeds=image_emb,
negative_image_embeds=zero_image_emb,
**kwargs,
)["images"]
return images[0]
else:
raise ValueError("Model type not found or pipeline not implemented")
| 3 |
0 | hf_public_repos/api-inference-community/docker_images/diffusers | hf_public_repos/api-inference-community/docker_images/diffusers/tests/test_docker_build.py | import os
import subprocess
from unittest import TestCase
class cd:
"""Context manager for changing the current working directory"""
def __init__(self, newPath):
self.newPath = os.path.expanduser(newPath)
def __enter__(self):
self.savedPath = os.getcwd()
os.chdir(self.newPath)
def __exit__(self, etype, value, traceback):
os.chdir(self.savedPath)
class DockerBuildTestCase(TestCase):
def test_can_build_docker_image(self):
with cd(os.path.dirname(os.path.dirname(__file__))):
subprocess.check_output(["docker", "build", "."])
| 4 |
0 | hf_public_repos/api-inference-community/docker_images/diffusers | hf_public_repos/api-inference-community/docker_images/diffusers/tests/test_api.py | import os
from typing import Dict, List
from unittest import TestCase, skipIf
from app.main import ALLOWED_TASKS, get_pipeline
# Must contain at least one example of each implemented pipeline
# Tests do not check the actual values of the model output, so small dummy
# models are recommended for faster tests.
TESTABLE_MODELS: Dict[str, List[str]] = {
"text-to-image": ["hf-internal-testing/tiny-stable-diffusion-pipe-no-safety"],
"image-to-image": [
"hf-internal-testing/tiny-controlnet",
"hf-internal-testing/tiny-stable-diffusion-pix2pix",
],
}
ALL_TASKS = {
"audio-classification",
"audio-to-audio",
"automatic-speech-recognition",
"feature-extraction",
"image-classification",
"question-answering",
"sentence-similarity",
"speech-segmentation",
"tabular-classification",
"tabular-regression",
"text-classification",
"text-to-image",
"text-to-speech",
"token-classification",
"conversational",
"feature-extraction",
"question-answering",
"sentence-similarity",
"fill-mask",
"table-question-answering",
"summarization",
"text2text-generation",
"text-classification",
"text-to-image",
"text-to-speech",
"token-classification",
"zero-shot-classification",
}
class PipelineTestCase(TestCase):
@skipIf(
os.path.dirname(os.path.dirname(__file__)).endswith("common"),
"common is a special case",
)
def test_has_at_least_one_task_enabled(self):
self.assertGreater(
len(ALLOWED_TASKS.keys()), 0, "You need to implement at least one task"
)
def test_unsupported_tasks(self):
unsupported_tasks = ALL_TASKS - ALLOWED_TASKS.keys()
for unsupported_task in unsupported_tasks:
with self.subTest(msg=unsupported_task, task=unsupported_task):
os.environ["TASK"] = unsupported_task
os.environ["MODEL_ID"] = "XX"
with self.assertRaises(EnvironmentError):
get_pipeline()
| 5 |
0 | hf_public_repos/api-inference-community/docker_images/diffusers | hf_public_repos/api-inference-community/docker_images/diffusers/tests/test_api_text_to_image.py | import os
from io import BytesIO
from unittest import TestCase, skipIf
import PIL
from app.main import ALLOWED_TASKS
from parameterized import parameterized_class
from starlette.testclient import TestClient
from tests.test_api import TESTABLE_MODELS
@skipIf(
"text-to-image" not in ALLOWED_TASKS,
"text-to-image not implemented",
)
@parameterized_class(
[{"model_id": model_id} for model_id in TESTABLE_MODELS["text-to-image"]]
)
class TextToImageTestCase(TestCase):
def setUp(self):
self.old_model_id = os.getenv("MODEL_ID")
self.old_task = os.getenv("TASK")
os.environ["MODEL_ID"] = self.model_id
os.environ["TASK"] = "text-to-image"
from app.main import app
self.app = app
@classmethod
def setUpClass(cls):
from app.main import get_pipeline
get_pipeline.cache_clear()
def tearDown(self):
if self.old_model_id is not None:
os.environ["MODEL_ID"] = self.old_model_id
else:
del os.environ["MODEL_ID"]
if self.old_task is not None:
os.environ["TASK"] = self.old_task
else:
del os.environ["TASK"]
def test_simple(self):
inputs = "soap bubble"
with TestClient(self.app) as client:
response = client.post("/", json={"inputs": inputs})
self.assertEqual(
response.status_code,
200,
)
image = PIL.Image.open(BytesIO(response.content))
self.assertTrue(isinstance(image, PIL.Image.Image))
def test_malformed_input(self):
with TestClient(self.app) as client:
response = client.post("/", data=b"\xc3\x28")
self.assertEqual(
response.status_code,
400,
)
self.assertEqual(
response.content,
b'{"error":"\'utf-8\' codec can\'t decode byte 0xc3 in position 0: invalid continuation byte"}',
)
| 6 |
0 | hf_public_repos/api-inference-community/docker_images/diffusers | hf_public_repos/api-inference-community/docker_images/diffusers/tests/test_api_image_to_image.py | import base64
import os
from io import BytesIO
from unittest import TestCase, skipIf
import PIL
from app.main import ALLOWED_TASKS
from parameterized import parameterized_class
from starlette.testclient import TestClient
from tests.test_api import TESTABLE_MODELS
@skipIf(
"image-to-image" not in ALLOWED_TASKS,
"image-to-image not implemented",
)
@parameterized_class(
[{"model_id": model_id} for model_id in TESTABLE_MODELS["image-to-image"]]
)
class ImageToImageTestCase(TestCase):
def setUp(self):
self.old_model_id = os.getenv("MODEL_ID")
self.old_task = os.getenv("TASK")
os.environ["MODEL_ID"] = self.model_id
os.environ["TASK"] = "image-to-image"
from app.main import app
self.app = app
@classmethod
def setUpClass(cls):
from app.main import get_pipeline
get_pipeline.cache_clear()
def tearDown(self):
if self.old_model_id is not None:
os.environ["MODEL_ID"] = self.old_model_id
else:
del os.environ["MODEL_ID"]
if self.old_task is not None:
os.environ["TASK"] = self.old_task
else:
del os.environ["TASK"]
def test_simple(self):
image = PIL.Image.new("RGB", (64, 64))
image_bytes = BytesIO()
image.save(image_bytes, format="JPEG")
image_bytes.seek(0)
parameters = {"prompt": "soap bubble"}
with TestClient(self.app) as client:
response = client.post(
"/",
json={
"image": base64.b64encode(image_bytes.read()).decode("utf-8"),
"parameters": parameters,
},
)
self.assertEqual(
response.status_code,
200,
)
image = PIL.Image.open(BytesIO(response.content))
self.assertTrue(isinstance(image, PIL.Image.Image))
def test_malformed_input(self):
with TestClient(self.app) as client:
response = client.post("/", data=b"\xc3\x28")
self.assertEqual(
response.status_code,
400,
)
self.assertTrue(
b'{"error":"cannot identify image file <_io.BytesIO object at'
in response.content
)
| 7 |
0 | hf_public_repos/api-inference-community/docker_images | hf_public_repos/api-inference-community/docker_images/espnet/requirements.txt | api-inference-community==0.0.32
huggingface_hub==0.18.0
espnet==202310
torch<2.0.1
torchaudio
torch_optimizer
espnet_model_zoo==0.1.7
| 8 |
0 | hf_public_repos/api-inference-community/docker_images | hf_public_repos/api-inference-community/docker_images/espnet/Dockerfile | FROM tiangolo/uvicorn-gunicorn:python3.8
LABEL maintainer="me <[email protected]>"
# Add any system dependency here
# RUN apt-get update -y && apt-get install libXXX -y
RUN apt-get update -y && apt-get install ffmpeg -y
COPY ./requirements.txt /app
RUN pip install --no-cache-dir -r requirements.txt
COPY ./prestart.sh /app/
# Most DL models are quite large in terms of memory, using workers is a HUGE
# slowdown because of the fork and GIL with python.
# Using multiple pods seems like a better default strategy.
# Feel free to override if it does not make sense for your library.
ARG max_workers=1
ENV MAX_WORKERS=$max_workers
ENV HUGGINGFACE_HUB_CACHE=/data
# Necessary on GPU environment docker.
# TIMEOUT env variable is used by nvcr.io/nvidia/pytorch:xx for another purpose
# rendering TIMEOUT defined by uvicorn impossible to use correctly
# We're overriding it to be renamed UVICORN_TIMEOUT
# UVICORN_TIMEOUT is a useful variable for very large models that take more
# than 30s (the default) to load in memory.
# If UVICORN_TIMEOUT is too low, uvicorn will simply never loads as it will
# kill workers all the time before they finish.
RUN sed -i 's/TIMEOUT/UVICORN_TIMEOUT/g' /gunicorn_conf.py
COPY ./app /app/app
| 9 |
0 | hf_public_repos | hf_public_repos/blog/ram-efficient-pytorch-fsdp.md | ---
title: "Fine-tuning Llama 2 70B using PyTorch FSDP"
thumbnail: /blog/assets/160_fsdp_llama/thumbnail.jpg
authors:
- user: smangrul
- user: sgugger
- user: lewtun
- user: philschmid
---
# Fine-tuning Llama 2 70B using PyTorch FSDP
## Introduction
In this blog post, we will look at how to fine-tune Llama 2 70B using PyTorch FSDP and related best practices. We will be leveraging Hugging Face Transformers, Accelerate and TRL. We will also learn how to use Accelerate with SLURM.
Fully Sharded Data Parallelism (FSDP) is a paradigm in which the optimizer states, gradients and parameters are sharded across devices. During the forward pass, each FSDP unit performs an _all-gather operation_ to get the complete weights, computation is performed followed by discarding the shards from other devices. After the forward pass, the loss is computed followed by the backward pass. In the backward pass, each FSDP unit performs an all-gather operation to get the complete weights, with computation performed to get the local gradients. These local gradients are averaged and sharded across the devices via a _reduce-scatter operation_ so that each device can update the parameters of its shard. For more information on what PyTorch FSDP is, please refer to this blog post: [Accelerate Large Model Training using PyTorch Fully Sharded Data Parallel](https://huggingface.co/blog/pytorch-fsdp).

(Source: [link](https://pytorch.org/blog/introducing-pytorch-fully-sharded-data-parallel-api/))
## Hardware Used
Number of nodes: 2. Minimum required is 1.
Number of GPUs per node: 8
GPU type: A100
GPU memory: 80GB
intra-node connection: NVLink
RAM per node: 1TB
CPU cores per node: 96
inter-node connection: Elastic Fabric Adapter
## Challenges with fine-tuning LLaMa 70B
We encountered three main challenges when trying to fine-tune LLaMa 70B with FSDP:
1. FSDP wraps the model after loading the pre-trained model. If each process/rank within a node loads the Llama-70B model, it would require 70\*4\*8 GB ~ 2TB of CPU RAM, where 4 is the number of bytes per parameter and 8 is the number of GPUs on each node. This would result in the CPU RAM getting out of memory leading to processes being terminated.
2. Saving entire intermediate checkpoints using `FULL_STATE_DICT` with CPU offloading on rank 0 takes a lot of time and often results in NCCL Timeout errors due to indefinite hanging during broadcasting. However, at the end of training, we want the whole model state dict instead of the sharded state dict which is only compatible with FSDP.
3. We need to improve the speed and reduce the VRAM usage to train faster and save compute costs.
Let’s look at how to solve the above challenges and fine-tune a 70B model!
Before we get started, here's all the required resources to reproduce our results:
1. Codebase:
https://github.com/pacman100/DHS-LLM-Workshop/tree/main/chat_assistant/sft/training with flash-attn V2
2. FSDP config: https://github.com/pacman100/DHS-LLM-Workshop/blob/main/chat_assistant/training/configs/fsdp_config.yaml
3. SLURM script `launch.slurm`: https://gist.github.com/pacman100/1cb1f17b2f1b3139a63b764263e70b25
4. Model: `meta-llama/Llama-2-70b-chat-hf`
5. Dataset: [smangrul/code-chat-assistant-v1](https://huggingface.co/datasets/smangrul/code-chat-assistant-v1) (mix of LIMA+GUANACO with proper formatting in a ready-to-train format)
### Pre-requisites
First follow these steps to install Flash Attention V2: Dao-AILab/flash-attention: Fast and memory-efficient exact attention (github.com). Install the latest nightlies of PyTorch with CUDA ≥11.8. Install the remaining requirements as per DHS-LLM-Workshop/code_assistant/training/requirements.txt. Here, we will be installing 🤗 Accelerate and 🤗 Transformers from the main branch.
## Fine-Tuning
### Addressing Challenge 1
PRs [huggingface/transformers#25107](https://github.com/huggingface/transformers/pull/25107) and [huggingface/accelerate#1777](https://github.com/huggingface/accelerate/pull/1777) solve the first challenge and requires no code changes from user side. It does the following:
1. Create the model with no weights on all ranks (using the `meta` device).
2. Load the state dict only on rank==0 and set the model weights with that state dict on rank 0
3. For all other ranks, do `torch.empty(*param.size(), dtype=dtype)` for every parameter on `meta` device
4. So, rank==0 will have loaded the model with correct state dict while all other ranks will have random weights.
5. Set `sync_module_states=True` so that FSDP object takes care of broadcasting them to all the ranks before training starts.
Below is the output snippet on a 7B model on 2 GPUs measuring the memory consumed and model parameters at various stages. We can observe that during loading the pre-trained model rank 0 & rank 1 have CPU total peak memory of `32744 MB` and `1506 MB` , respectively. Therefore, only rank 0 is loading the pre-trained model leading to efficient usage of CPU RAM. The whole logs at be found [here](https://gist.github.com/pacman100/2fbda8eb4526443a73c1455de43e20f9)
```bash
accelerator.process_index=0 GPU Memory before entering the loading : 0
accelerator.process_index=0 GPU Memory consumed at the end of the loading (end-begin): 0
accelerator.process_index=0 GPU Peak Memory consumed during the loading (max-begin): 0
accelerator.process_index=0 GPU Total Peak Memory consumed during the loading (max): 0
accelerator.process_index=0 CPU Memory before entering the loading : 926
accelerator.process_index=0 CPU Memory consumed at the end of the loading (end-begin): 26415
accelerator.process_index=0 CPU Peak Memory consumed during the loading (max-begin): 31818
accelerator.process_index=0 CPU Total Peak Memory consumed during the loading (max): 32744
accelerator.process_index=1 GPU Memory before entering the loading : 0
accelerator.process_index=1 GPU Memory consumed at the end of the loading (end-begin): 0
accelerator.process_index=1 GPU Peak Memory consumed during the loading (max-begin): 0
accelerator.process_index=1 GPU Total Peak Memory consumed during the loading (max): 0
accelerator.process_index=1 CPU Memory before entering the loading : 933
accelerator.process_index=1 CPU Memory consumed at the end of the loading (end-begin): 10
accelerator.process_index=1 CPU Peak Memory consumed during the loading (max-begin): 573
accelerator.process_index=1 CPU Total Peak Memory consumed during the loading (max): 1506
```
### Addressing Challenge 2
It is addressed via choosing `SHARDED_STATE_DICT` state dict type when creating FSDP config. `SHARDED_STATE_DICT` saves shard per GPU separately which makes it quick to save or resume training from intermediate checkpoint. When `FULL_STATE_DICT` is used, first process (rank 0) gathers the whole model on CPU and then saving it in a standard format.
Let’s create the accelerate config via below command:
```
accelerate config --config_file "fsdp_config.yaml"
```
The resulting config is available here: [fsdp_config.yaml](https://github.com/pacman100/DHS-LLM-Workshop/blob/main/chat_assistant/training/configs/fsdp_config.yaml). Here, the sharding strategy is `FULL_SHARD`. We are using `TRANSFORMER_BASED_WRAP` for auto wrap policy and it uses `_no_split_module` to find the Transformer block name for nested FSDP auto wrap. We use `SHARDED_STATE_DICT` to save the intermediate checkpoints and optimizer states in this format recommended by the PyTorch team. Make sure to enable broadcasting module parameters from rank 0 at the start as mentioned in the above paragraph on addressing Challenge 1. We are enabling `bf16` mixed precision training.
For final checkpoint being the whole model state dict, below code snippet is used:
```python
if trainer.is_fsdp_enabled:
trainer.accelerator.state.fsdp_plugin.set_state_dict_type("FULL_STATE_DICT")
trainer.save_model(script_args.output_dir) # alternatively, trainer.push_to_hub() if the whole ckpt is below 50GB as the LFS limit per file is 50GB
```
### Addressing Challenge 3
Flash Attention and enabling gradient checkpointing are required for faster training and reducing VRAM usage to enable fine-tuning and save compute costs. The codebase currently uses monkey patching and the implementation is at [chat_assistant/training/llama_flash_attn_monkey_patch.py](https://github.com/pacman100/DHS-LLM-Workshop/blob/main/chat_assistant/training/llama_flash_attn_monkey_patch.py).
[FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness](https://arxiv.org/pdf/2205.14135.pdf) introduces a way to compute exact attention while being faster and memory-efficient by leveraging the knowledge of the memory hierarchy of the underlying hardware/GPUs - The higher the bandwidth/speed of the memory, the smaller its capacity as it becomes more expensive.
If we follow the blog [Making Deep Learning Go Brrrr From First Principles](https://horace.io/brrr_intro.html), we can figure out that `Attention` module on current hardware is `memory-bound/bandwidth-bound`. The reason being that Attention **mostly consists of elementwise operations** as shown below on the left hand side. We can observe that masking, softmax and dropout operations take up the bulk of the time instead of matrix multiplications which consists of the bulk of FLOPs.
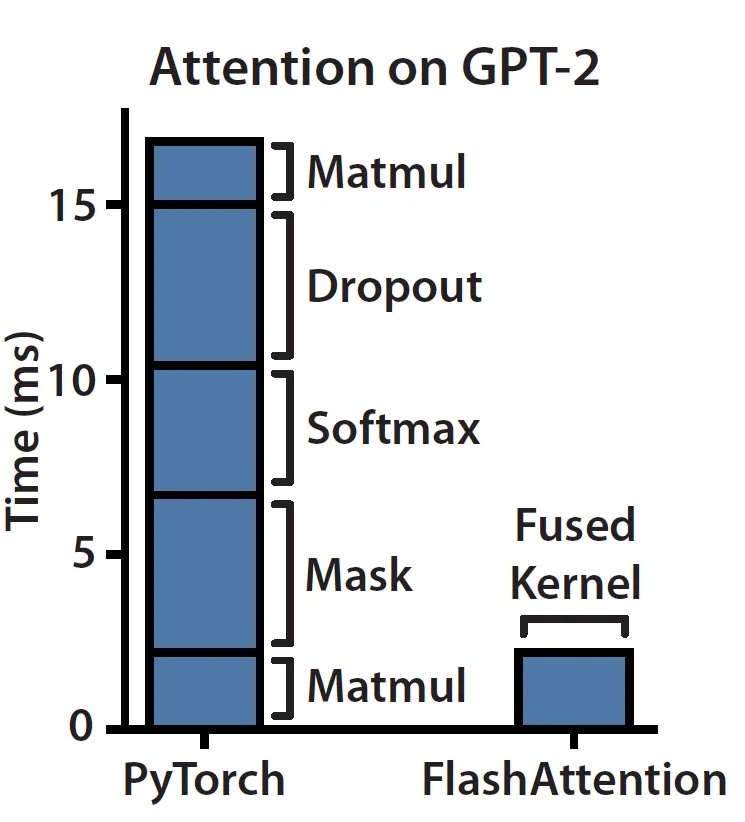
(Source: [link](https://arxiv.org/pdf/2205.14135.pdf))
This is precisely the problem that Flash Attention addresses. The idea is to **remove redundant HBM reads/writes.** It does so by keeping everything in SRAM, perform all the intermediate steps and only then write the final result back to HBM, also known as **Kernel Fusion**. Below is an illustration of how this overcomes the memory-bound bottleneck.
(Source: [link](https://gordicaleksa.medium.com/eli5-flash-attention-5c44017022ad))
**Tiling** is used during forward and backward passes to chunk the NxN softmax/scores computation into blocks to overcome the limitation of SRAM memory size. To enable tiling, online softmax algorithm is used. **Recomputation** is used during backward pass in order to avoid storing the entire NxN softmax/score matrix during forward pass. This greatly reduces the memory consumption.
For a simplified and in depth understanding of Flash Attention, please refer the blog posts [ELI5: FlashAttention](https://gordicaleksa.medium.com/eli5-flash-attention-5c44017022ad) and [Making Deep Learning Go Brrrr From First Principles](https://horace.io/brrr_intro.html) along with the original paper [FlashAttention: Fast and Memory-Efficient Exact Attention
with IO-Awareness](https://arxiv.org/pdf/2205.14135.pdf).
## Bringing it all-together
To run the training using `Accelerate` launcher with SLURM, refer this gist [launch.slurm](https://gist.github.com/pacman100/1cb1f17b2f1b3139a63b764263e70b25). Below is an equivalent command showcasing how to use `Accelerate` launcher to run the training. Notice that we are overriding `main_process_ip` , `main_process_port` , `machine_rank` , `num_processes` and `num_machines` values of the `fsdp_config.yaml`. Here, another important point to note is that the storage is stored between all the nodes.
```
accelerate launch \
--config_file configs/fsdp_config.yaml \
--main_process_ip $MASTER_ADDR \
--main_process_port $MASTER_PORT \
--machine_rank \$MACHINE_RANK \
--num_processes 16 \
--num_machines 2 \
train.py \
--seed 100 \
--model_name "meta-llama/Llama-2-70b-chat-hf" \
--dataset_name "smangrul/code-chat-assistant-v1" \
--chat_template_format "none" \
--add_special_tokens False \
--append_concat_token False \
--splits "train,test" \
--max_seq_len 2048 \
--max_steps 500 \
--logging_steps 25 \
--log_level "info" \
--eval_steps 100 \
--save_steps 250 \
--logging_strategy "steps" \
--evaluation_strategy "steps" \
--save_strategy "steps" \
--push_to_hub \
--hub_private_repo True \
--hub_strategy "every_save" \
--bf16 True \
--packing True \
--learning_rate 5e-5 \
--lr_scheduler_type "cosine" \
--weight_decay 0.01 \
--warmup_ratio 0.03 \
--max_grad_norm 1.0 \
--output_dir "/shared_storage/sourab/experiments/full-finetune-llama-chat-asst" \
--per_device_train_batch_size 1 \
--per_device_eval_batch_size 1 \
--gradient_accumulation_steps 1 \
--gradient_checkpointing True \
--use_reentrant False \
--dataset_text_field "content" \
--use_flash_attn True \
--ddp_timeout 5400 \
--optim paged_adamw_32bit
```
Fine-tuning completed in ~13.5 hours and below is the training loss plot.
**Important Note**:
Here, if you are using only a single node with 8 A100 80GB GPUs, then `paged_adamw_32bit` optimizer from `bitsandbytes` is required. For more information about paged optimizers, please refer https://huggingface.co/docs/bitsandbytes/main/en/optimizers#paged-optimizers.
Below is an example conversation using the above model:
```diff
System Prompt: You are a helpful, respectful and honest assistant. Always answer as helpfully \
as possible, while being safe. Your answers should not include any harmful, \
unethical, racist, sexist, toxic, dangerous, or illegal content. Please ensure that \
your responses are socially unbiased and positive in nature.
If a question does not make any sense, or is not factually coherent, explain why \
instead of answering something not correct. If you don’t know the answer to a \
question, please don’t share false information.
- Human: What is Deep Learning? Explain like a Pirate.
+ Assistant: Arrr Grumete! Are ye lookin' fer a proper explanation o' Deep Learnin'?
+ Alright then, listen up me hearty! Deep Learnin' be a type o' machine learnin' that uses artificial neural networks to analyze data.
+ Aye, ye heard that right, mateys! Artificial neural networks be models o' the human brain, but instead o' using neurons, they use interconnected nodes or "artificial neurons" to process information.
+ These nodes work together to form layers o' processing units that can learn from large amounts o' data.
+ The more data these systems receive, the better they get at recognizing patterns and makin' decisions on their own.
+ So hoist the sails and set course for adventure with deep learnin', me hearties! It's a treasure trove o' knowledge just waitin' to be discovered.
+ Fair winds and following seas!
- Human: Now explain it like a chef.
+ Assistant: Certainly! Here's an explanation of deep learning from a culinary perspective:
+ Think of a recipe as a sequence of steps used to transform raw ingredients into a delicious dish.
+ Similarly, in deep learning, there are multiple layers of "ingredients" (or features) that are combined and transformed through various operations to produce a final output or prediction.
+ Each layer builds upon the previous one, refining and enhancing the representation of the input data until it reaches the desired outcome.
+ Just as different spices enhance the flavors of food, each layer adds depth and complexity to the model's understanding of the input, allowing it to make more accurate predictions.
+ And much like how chefs must carefully balance the amount of salt, sugar, and other seasonings in a recipe, the training process in deep learning involves adjusting the weights and biases of the network to achieve the perfect blend of accuracy and efficiency.
+ With enough practice and experimentation, anyone can become a master chef... I mean, a master of deep learning! Bon appétit!
```
The whole conversation is formatted as below:
```
<|system|> system message <|endoftext|> <|prompter|> Q1 <|endoftext|> <|assistant|> A1 <|endoftext|> ...
```
## Conclusion
We successfully fine-tuned 70B Llama model using PyTorch FSDP in a multi-node multi-gpu setting while addressing various challenges. We saw how 🤗 Transformers and 🤗 Accelerates now supports efficient way of initializing large models when using FSDP to overcome CPU RAM getting out of memory. This was followed by recommended practices for saving/loading intermediate checkpoints and how to save the final model in a way to readily use it. To enable faster training and reducing GPU memory usage, we outlined the importance of Flash Attention and Gradient Checkpointing. Overall, we can see how a simple config using 🤗 Accelerate enables finetuning of such large models in a multi-node multi-gpu setting. | 0 |
0 | hf_public_repos | hf_public_repos/blog/optimizing-bark.md | ---
title: "Optimizing Bark using 🤗 Transformers"
thumbnail: /blog/assets/bark_optimization/thumbnail.png
authors:
- user: ylacombe
---
# Optimizing a Text-To-Speech model using 🤗 Transformers
<a target="_blank" href="https://colab.research.google.com/github/ylacombe/notebooks/blob/main/Benchmark_Bark_HuggingFace.ipynb">
<img src="https://colab.research.google.com/assets/colab-badge.svg"/>
</a>
🤗 Transformers provides many of the latest state-of-the-art (SoTA) models across domains and tasks. To get the best performance from these models, they need to be optimized for inference speed and memory usage.
The 🤗 Hugging Face ecosystem offers precisely such ready & easy to use optimization tools that can be applied across the board to all the models in the library. This makes it easy to **reduce memory footprint** and **improve inference** with just a few extra lines of code.
In this hands-on tutorial, I'll demonstrate how you can optimize [Bark](https://huggingface.co/docs/transformers/main/en/model_doc/bark#overview), a Text-To-Speech (TTS) model supported by 🤗 Transformers, based on three simple optimizations. These optimizations rely solely on the [Transformers](https://github.com/huggingface/transformers), [Optimum](https://github.com/huggingface/optimum) and [Accelerate](https://github.com/huggingface/accelerate) libraries from the 🤗 ecosystem.
This tutorial is also a demonstration of how one can benchmark a non-optimized model and its varying optimizations.
For a more streamlined version of the tutorial
with fewer explanations but all the code, see the accompanying [Google Colab](https://colab.research.google.com/github/ylacombe/notebooks/blob/main/Benchmark_Bark_HuggingFace.ipynb).
This blog post is organized as follows:
## Table of Contents
1. A [reminder](#bark-architecture) of Bark architecture
2. An [overview](#optimization-techniques) of different optimization techniques and their advantages
3. A [presentation](#benchmark-results) of benchmark results
## Bark Architecture
**Bark** is a transformer-based text-to-speech model proposed by Suno AI in [suno-ai/bark](https://github.com/suno-ai/bark). It is capable of generating a wide range of audio outputs, including speech, music, background noise, and simple sound effects. Additionally, it can produce nonverbal communication sounds such as laughter, sighs, and sobs.
Bark has been available in 🤗 Transformers since v4.31.0 onwards!
You can play around with Bark and discover it's abilities [here](https://colab.research.google.com/github/ylacombe/notebooks/blob/main/Bark_HuggingFace_Demo.ipynb).
Bark is made of 4 main models:
- `BarkSemanticModel` (also referred to as the 'text' model): a causal auto-regressive transformer model that takes as input tokenized text, and predicts semantic text tokens that capture the meaning of the text.
- `BarkCoarseModel` (also referred to as the 'coarse acoustics' model): a causal autoregressive transformer, that takes as input the results of the `BarkSemanticModel` model. It aims at predicting the first two audio codebooks necessary for EnCodec.
- `BarkFineModel` (the 'fine acoustics' model), this time a non-causal autoencoder transformer, which iteratively predicts the last codebooks based on the sum of the previous codebooks embeddings.
- having predicted all the codebook channels from the [`EncodecModel`](https://huggingface.co/docs/transformers/v4.31.0/model_doc/encodec), Bark uses it to decode the output audio array.
At the time of writing, two Bark checkpoints are available, a [smaller](https://huggingface.co/suno/bark-small) and a [larger](https://huggingface.co/suno/bark) version.
### Load the Model and its Processor
The pre-trained Bark small and large checkpoints can be loaded from the [pre-trained weights](https://huggingface.co/suno/bark) on the Hugging Face Hub. You can change the repo-id with the checkpoint size that you wish to use.
We'll default to the small checkpoint, to keep it fast. But you can try the large checkpoint by using `"suno/bark"` instead of `"suno/bark-small"`.
```python
from transformers import BarkModel
model = BarkModel.from_pretrained("suno/bark-small")
```
Place the model to an accelerator device to get the most of the optimization techniques:
```python
import torch
device = "cuda:0" if torch.cuda.is_available() else "cpu"
model = model.to(device)
```
Load the processor, which will take care of tokenization and optional speaker embeddings.
```python
from transformers import AutoProcessor
processor = AutoProcessor.from_pretrained("suno/bark-small")
```
## Optimization techniques
In this section, we'll explore how to use off-the-shelf features from the 🤗 Optimum and 🤗 Accelerate libraries to optimize the Bark model, with minimal changes to the code.
### Some set-ups
Let's prepare the inputs and define a function to measure the latency and GPU memory footprint of the Bark generation method.
```python
text_prompt = "Let's try generating speech, with Bark, a text-to-speech model"
inputs = processor(text_prompt).to(device)
```
Measuring the latency and GPU memory footprint requires the use of specific CUDA methods. We define a utility function that measures both the latency and GPU memory footprint of the model at inference time. To ensure we get an accurate picture of these metrics, we average over a specified number of runs `nb_loops`:
```python
import torch
from transformers import set_seed
def measure_latency_and_memory_use(model, inputs, nb_loops = 5):
# define Events that measure start and end of the generate pass
start_event = torch.cuda.Event(enable_timing=True)
end_event = torch.cuda.Event(enable_timing=True)
# reset cuda memory stats and empty cache
torch.cuda.reset_peak_memory_stats(device)
torch.cuda.empty_cache()
torch.cuda.synchronize()
# get the start time
start_event.record()
# actually generate
for _ in range(nb_loops):
# set seed for reproducibility
set_seed(0)
output = model.generate(**inputs, do_sample = True, fine_temperature = 0.4, coarse_temperature = 0.8)
# get the end time
end_event.record()
torch.cuda.synchronize()
# measure memory footprint and elapsed time
max_memory = torch.cuda.max_memory_allocated(device)
elapsed_time = start_event.elapsed_time(end_event) * 1.0e-3
print('Execution time:', elapsed_time/nb_loops, 'seconds')
print('Max memory footprint', max_memory*1e-9, ' GB')
return output
```
### Base case
Before incorporating any optimizations, let's measure the performance of the baseline model and listen to a generated example. We'll benchmark the model over five iterations and report an average of the metrics:
```python
with torch.inference_mode():
speech_output = measure_latency_and_memory_use(model, inputs, nb_loops = 5)
```
**Output:**
```
Execution time: 9.3841625 seconds
Max memory footprint 1.914612224 GB
```
Now, listen to the output:
```python
from IPython.display import Audio
# now, listen to the output
sampling_rate = model.generation_config.sample_rate
Audio(speech_output[0].cpu().numpy(), rate=sampling_rate)
```
The output sounds like this ([download audio](https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/bark_optimization/audio_sample_base.wav)):
<audio controls>
<source src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/bark_optimization/audio_sample_base.wav" type="audio/wav">
Your browser does not support the audio element.
</audio>
#### Important note:
Here, the number of iterations is actually quite low. To accurately measure and compare results, one should increase it to at least 100.
One of the main reasons for the importance of increasing `nb_loops` is that the speech lengths generated vary greatly between different iterations, even with a fixed input.
One consequence of this is that the latency measured by `measure_latency_and_memory_use` may not actually reflect the actual performance of optimization techniques! The benchmark at the end of the blog post reports the results averaged over 100 iterations, which gives a true indication of the performance of the model.
### 1. 🤗 Better Transformer
Better Transformer is an 🤗 Optimum feature that performs kernel fusion under the hood. This means that certain model operations will be better optimized on the GPU and that the model will ultimately be faster.
To be more specific, most models supported by 🤗 Transformers rely on attention, which allows them to selectively focus on certain parts of the input when generating output. This enables the models to effectively handle long-range dependencies and capture complex contextual relationships in the data.
The naive attention technique can be greatly optimized via a technique called [Flash Attention](https://arxiv.org/abs/2205.14135), proposed by the authors Dao et. al. in 2022.
Flash Attention is a faster and more efficient algorithm for attention computations that combines traditional methods (such as tiling and recomputation) to minimize memory usage and increase speed. Unlike previous algorithms, Flash Attention reduces memory usage from quadratic to linear in sequence length, making it particularly useful for applications where memory efficiency is important.
Turns out that Flash Attention is supported by 🤗 Better Transformer out of the box! It requires one line of code to export the model to 🤗 Better Transformer and enable Flash Attention:
```python
model = model.to_bettertransformer()
with torch.inference_mode():
speech_output = measure_latency_and_memory_use(model, inputs, nb_loops = 5)
```
**Output:**
```
Execution time: 5.43284375 seconds
Max memory footprint 1.9151841280000002 GB
```
The output sounds like this ([download audio](https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/bark_optimization/audio_sample_bettertransformer.wav)):
<audio controls>
<source src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/bark_optimization/audio_sample_bettertransformer.wav" type="audio/wav">
Your browser does not support the audio element.
</audio>
**What does it bring to the table?**
There's no performance degradation, which means you can get exactly the same result as without this function, while gaining 20% to 30% in speed! Want to know more? See this [blog post](https://pytorch.org/blog/out-of-the-box-acceleration/).
### 2. Half-precision
Most AI models typically use a storage format called single-precision floating point, i.e. `fp32`. What does it mean in practice? Each number is stored using 32 bits.
You can thus choose to encode the numbers using 16 bits, with what is called half-precision floating point, i.e. `fp16`, and use half as much storage as before! More than that, you also get inference speed-up!
Of course, it also comes with small performance degradation since operations inside the model won't be as precise as using `fp32`.
You can load a 🤗 Transformers model with half-precision by simpling adding `torch_dtype=torch.float16` to the `BarkModel.from_pretrained(...)` line!
In other words:
```python
model = BarkModel.from_pretrained("suno/bark-small", torch_dtype=torch.float16).to(device)
with torch.inference_mode():
speech_output = measure_latency_and_memory_use(model, inputs, nb_loops = 5)
```
**Output:**
```
Execution time: 7.00045390625 seconds
Max memory footprint 2.7436124160000004 GB
```
The output sounds like this ([download audio](https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/bark_optimization/audio_sample_fp16.wav)):
<audio controls>
<source src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/bark_optimization/audio_sample_fp16.wav" type="audio/wav">
Your browser does not support the audio element.
</audio>
**What does it bring to the table?**
With a slight degradation in performance, you benefit from a memory footprint reduced by 50% and a speed gain of 5%.
### 3. CPU offload
As mentioned in the first section of this booklet, Bark comprises 4 sub-models, which are called up sequentially during audio generation. **In other words, while one sub-model is in use, the other sub-models are idle.**
Why is this a problem? GPU memory is precious in AI, because it's where operations are fastest, and it's often a bottleneck.
A simple solution is to unload sub-models from the GPU when inactive. This operation is called CPU offload.
**Good news:** CPU offload for Bark was integrated into 🤗 Transformers and you can use it with only one line of code.
You only need to make sure 🤗 Accelerate is installed!
```python
model = BarkModel.from_pretrained("suno/bark-small")
# Enable CPU offload
model.enable_cpu_offload()
with torch.inference_mode():
speech_output = measure_latency_and_memory_use(model, inputs, nb_loops = 5)
```
**Output:**
```
Execution time: 8.97633828125 seconds
Max memory footprint 1.3231160320000002 GB
```
The output sounds like this ([download audio](https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/bark_optimization/audio_sample_cpu_offload.wav)):
<audio controls>
<source src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/bark_optimization/audio_sample_cpu_offload.wav" type="audio/wav">
Your browser does not support the audio element.
</audio>
**What does it bring to the table?**
With a slight degradation in speed (10%), you benefit from a huge memory footprint reduction (60% 🤯).
With this feature enabled, `bark-large` footprint is now only 2GB instead of 5GB.
That's the same memory footprint as `bark-small`!
Want more? With `fp16` enabled, it's even down to 1GB. We'll see this in practice in the next section!
### 4. Combine
Let's bring it all together. The good news is that you can combine optimization techniques, which means you can use CPU offload, as well as half-precision and 🤗 Better Transformer!
```python
# load in fp16
model = BarkModel.from_pretrained("suno/bark-small", torch_dtype=torch.float16).to(device)
# convert to bettertransformer
model = BetterTransformer.transform(model, keep_original_model=False)
# enable CPU offload
model.enable_cpu_offload()
with torch.inference_mode():
speech_output = measure_latency_and_memory_use(model, inputs, nb_loops = 5)
```
**Output:**
```
Execution time: 7.4496484375000005 seconds
Max memory footprint 0.46871091200000004 GB
```
The output sounds like this ([download audio](https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/bark_optimization/audio_sample_cpu_offload.wav)):
<audio controls>
<source src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/bark_optimization/audio_sample_optimized.wav" type="audio/wav">
Your browser does not support the audio element.
</audio>
**What does it bring to the table?**
Ultimately, you get a 23% speed-up and a huge 80% memory saving!
### Using batching
Want more?
Altogether, the 3 optimization techniques bring even better results when batching.
Batching means combining operations for multiple samples to bring the overall time spent generating the samples lower than generating sample per sample.
Here is a quick example of how you can use it:
```python
text_prompt = [
"Let's try generating speech, with Bark, a text-to-speech model",
"Wow, batching is so great!",
"I love Hugging Face, it's so cool."]
inputs = processor(text_prompt).to(device)
with torch.inference_mode():
# samples are generated all at once
speech_output = model.generate(**inputs, do_sample = True, fine_temperature = 0.4, coarse_temperature = 0.8)
```
The output sounds like this (download [first](https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/bark_optimization/audio_sample_batch_0.wav), [second](https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/bark_optimization/audio_sample_batch_1.wav), and [last](https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/bark_optimization/audio_sample_batch_2.wav) audio):
<audio controls>
<source src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/bark_optimization/audio_sample_batch_0.wav" type="audio/wav">
Your browser does not support the audio element.
</audio>
<audio controls>
<source src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/bark_optimization/audio_sample_batch_1.wav" type="audio/wav">
Your browser does not support the audio element.
</audio>
<audio controls>
<source src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/bark_optimization/audio_sample_batch_2.wav" type="audio/wav">
Your browser does not support the audio element.
</audio>
## Benchmark results
As mentioned above, the little experiment we've carried out is an exercise in thinking and needs to be extended for a better measure of performance. One also needs to warm up the GPU with a few blank iterations before properly measuring performance.
Here are the results of a 100-sample benchmark extending the measurements, **using the large version of Bark**.
The benchmark was run on an NVIDIA TITAN RTX 24GB with a maximum of 256 new tokens.
### How to read the results?
#### Latency
It measures the duration of a single call to the generation method, regardless of batch size.
In other words, it's equal to \\(\frac{elapsedTime}{nbLoops}\\).
**A lower latency is preferred.**
#### Maximum memory footprint
It measures the maximum memory used during a single call to the generation method.
**A lower footprint is preferred.**
#### Throughput
It measures the number of samples generated per second. This time, the batch size is taken into account.
In other words, it's equal to \\(\frac{nbLoops*batchSize}{elapsedTime}\\).
**A higher throughput is preferred.**
### No batching
Here are the results with `batch_size=1`.
| Absolute values | Latency | Memory |
|-----------------------------|---------|---------|
| no optimization | 10.48 | 5025.0M |
| bettertransformer only | 7.70 | 4974.3M |
| offload + bettertransformer | 8.90 | 2040.7M |
| offload + bettertransformer + fp16 | 8.10 | 1010.4M |
| Relative value | Latency | Memory |
|-----------------------------|---------|--------|
| no optimization | 0% | 0% |
| bettertransformer only | -27% | -1% |
| offload + bettertransformer | -15% | -59% |
| offload + bettertransformer + fp16 | -23% | -80% |
#### Comment
As expected, CPU offload greatly reduces memory footprint while slightly increasing latency.
However, combined with bettertransformer and `fp16`, we get the best of both worlds, huge latency and memory decrease!
### Batch size set to 8
And here are the benchmark results but with `batch_size=8` and throughput measurement.
Note that since `bettertransformer` is a free optimization because it does exactly the same operation and has the same memory footprint as the non-optimized model while being faster, the benchmark was run with **this optimization enabled by default**.
| absolute values | Latency | Memory | Throghput |
|-------------------------------|---------|---------|-----------|
| base case (bettertransformer) | 19.26 | 8329.2M | 0.42 |
| + fp16 | 10.32 | 4198.8M | 0.78 |
| + offload | 20.46 | 5172.1M | 0.39 |
| + offload + fp16 | 10.91 | 2619.5M | 0.73 |
| Relative value | Latency | Memory | Throughput |
|-------------------------------|---------|--------|------------|
| + base case (bettertransformer) | 0% | 0% | 0% |
| + fp16 | -46% | -50% | 87% |
| + offload | 6% | -38% | -6% |
| + offload + fp16 | -43% | -69% | 77% |
#### Comment
This is where we can see the potential of combining all three optimization features!
The impact of `fp16` on latency is less marked with `batch_size = 1`, but here it is of enormous interest as it can reduce latency by almost half, and almost double throughput!
## Concluding remarks
This blog post showcased a few simple optimization tricks bundled in the 🤗 ecosystem. Using anyone of these techniques, or a combination of all three, can greatly improve Bark inference speed and memory footprint.
* You can use the large version of Bark without any performance degradation and a footprint of just 2GB instead of 5GB, 15% faster, **using 🤗 Better Transformer and CPU offload**.
* Do you prefer high throughput? **Batch by 8 with 🤗 Better Transformer and half-precision**.
* You can get the best of both worlds by using **fp16, 🤗 Better Transformer and CPU offload**!
| 1 |
0 | hf_public_repos | hf_public_repos/blog/segmoe.md | ---
title: "SegMoE: Segmind Mixture of Diffusion Experts"
thumbnail: /blog/assets/segmoe/thumbnail.png
authors:
- user: Warlord-K
guest: true
- user: Icar
guest: true
- user: harishp
guest: true
---
# SegMoE: Segmind Mixture of Diffusion Experts
SegMoE is an exciting framework for creating Mixture-of-Experts Diffusion models from scratch! SegMoE is comprehensively integrated within the Hugging Face ecosystem and comes supported with `diffusers` 🔥!
Among the features and integrations being released today:
- [Models on the Hub](https://huggingface.co/models?search=segmind/SegMoE), with their model cards and licenses (Apache 2.0)
- [Github Repository](https://github.com/segmind/segmoe) to create your own MoE-style models.
## Table of Contents
- [What is SegMoE](#what-is-segmoe)
- [About the name](#about-the-name)
- [Inference](#inference)
- [Samples](#Samples)
- [Using 🤗 Diffusers](#using-🤗-diffusers)
- [Using a Local Model](#using-a-local-model)
- [Comparison](#comparison)
- [Creating your Own SegMoE](#creating-your-own-segmoe)
- [Disclaimers and ongoing work](#disclaimers-and-ongoing-work)
- [Additional Resources](#additional-resources)
- [Conclusion](#conclusion)
## What is SegMoE?
SegMoE models follow the same architecture as Stable Diffusion. Like [Mixtral 8x7b](https://huggingface.co/blog/mixtral), a SegMoE model comes with multiple models in one. The way this works is by replacing some Feed-Forward layers with a sparse MoE layer. A MoE layer contains a router network to select which experts process which tokens most efficiently.
You can use the `segmoe` package to create your own MoE models! The process takes just a few minutes. For further information, please visit [the Github Repository](https://github.com/segmind/segmoe). We take inspiration from the popular library [`mergekit`](https://github.com/arcee-ai/mergekit) to design `segmoe`. We thank the contributors of `mergekit` for such a useful library.
For more details on MoEs, see the Hugging Face 🤗 post: [hf.co/blog/moe](https://huggingface.co/blog/moe).
**SegMoE release TL;DR;**
- Release of SegMoE-4x2, SegMoE-2x1 and SegMoE-SD4x2 versions
- Release of custom MoE-making code
### About the name
The SegMoE MoEs are called **SegMoE-AxB**, where `A` refers to the number of expert models MoE-d together, while the second number refers to the number of experts involved in the generation of each image. Only some layers of the model (the feed-forward blocks, attentions, or all) are replicated depending on the configuration settings; the rest of the parameters are the same as in a Stable Diffusion model. For more details about how MoEs work, please refer to [the "Mixture of Experts Explained" post](https://huggingface.co/blog/moe).
## Inference
We release 3 merges on the Hub:
1. [SegMoE 2x1](https://huggingface.co/segmind/SegMoE-2x1-v0) has two expert models.
2. [SegMoE 4x2](https://huggingface.co/segmind/SegMoE-4x2-v0) has four expert models.
3. [SegMoE SD 4x2](https://huggingface.co/segmind/SegMoE-SD-4x2-v0) has four Stable Diffusion 1.5 expert models.
### Samples
Images generated using [SegMoE 4x2](https://huggingface.co/segmind/SegMoE-4x2-v0)

Images generated using [SegMoE 2x1](https://huggingface.co/segmind/SegMoE-2x1-v0):

Images generated using [SegMoE SD 4x2](https://huggingface.co/segmind/SegMoE-SD-4x2-v0)

### Using 🤗 Diffusers
Please, run the following command to install the `segmoe` package. Make sure you have the latest version of `diffusers` and `transformers` installed.
```bash
pip install -U segmoe diffusers transformers
```
The following loads up the second model ("SegMoE 4x2") from the list above, and runs generation on it.
```python
from segmoe import SegMoEPipeline
pipeline = SegMoEPipeline("segmind/SegMoE-4x2-v0", device="cuda")
prompt = "cosmic canvas, orange city background, painting of a chubby cat"
negative_prompt = "nsfw, bad quality, worse quality"
img = pipeline(
prompt=prompt,
negative_prompt=negative_prompt,
height=1024,
width=1024,
num_inference_steps=25,
guidance_scale=7.5,
).images[0]
img.save("image.png")
```

### Using a Local Model
Alternatively, a local model can also be loaded up, here `segmoe_v0` is the path to the directory containing the local SegMoE model. Checkout [Creating your Own SegMoE](#creating-your-own-segmoe) to learn how to build your own!
```python
from segmoe import SegMoEPipeline
pipeline = SegMoEPipeline("segmoe_v0", device="cuda")
prompt = "cosmic canvas, orange city background, painting of a chubby cat"
negative_prompt = "nsfw, bad quality, worse quality"
img = pipeline(
prompt=prompt,
negative_prompt=negative_prompt,
height=1024,
width=1024,
num_inference_steps=25,
guidance_scale=7.5,
).images[0]
img.save("image.png")
```
## Comparison
Prompt understanding seems to improve, as shown in the images below. Each image shows the following models left to right: [SegMoE-2x1-v0](https://huggingface.co/segmind/SegMoE-2x1-v0), [SegMoE-4x2-v0](https://huggingface.co/segmind/SegMoE-4x2-v0), Base Model ([RealVisXL_V3.0](https://huggingface.co/SG161222/RealVisXL_V3.0))

<div align="center">three green glass bottles</div>
<br>

<div align="center">panda bear with aviator glasses on its head</div>
<br>

<div align="center">the statue of Liberty next to the Washington Monument</div>

<div align="center">Taj Mahal with its reflection. detailed charcoal sketch.</div>
## Creating your Own SegMoE
Simply prepare a `config.yaml` file, with the following structure:
```yaml
base_model: Base Model Path, Model Card or CivitAI Download Link
num_experts: Number of experts to use
moe_layers: Type of Layers to Mix (can be "ff", "attn" or "all"). Defaults to "attn"
num_experts_per_tok: Number of Experts to use
experts:
- source_model: Expert 1 Path, Model Card or CivitAI Download Link
positive_prompt: Positive Prompt for computing gate weights
negative_prompt: Negative Prompt for computing gate weights
- source_model: Expert 2 Path, Model Card or CivitAI Download Link
positive_prompt: Positive Prompt for computing gate weights
negative_prompt: Negative Prompt for computing gate weights
- source_model: Expert 3 Path, Model Card or CivitAI Download Link
positive_prompt: Positive Prompt for computing gate weights
negative_prompt: Negative Prompt for computing gate weights
- source_model: Expert 4 Path, Model Card or CivitAI Download Link
positive_prompt: Positive Prompt for computing gate weights
negative_prompt: Negative Prompt for computing gate weights
```
Any number of models can be combined. For detailed information on how to create a config file, please refer to the [github repository](https://github.com/segmind/segmoe)
**Note**
Both Hugging Face and CivitAI models are supported. For CivitAI models, paste the download link of the model, for example: "https://civitai.com/api/download/models/239306"
Then run the following command:
```bash
segmoe config.yaml segmoe_v0
```
This will create a folder called `segmoe_v0` with the following structure:
```bash
├── model_index.json
├── scheduler
│ └── scheduler_config.json
├── text_encoder
│ ├── config.json
│ └── model.safetensors
├── text_encoder_2
│ ├── config.json
│ └── model.safetensors
├── tokenizer
│ ├── merges.txt
│ ├── special_tokens_map.json
│ ├── tokenizer_config.json
│ └── vocab.json
├── tokenizer_2
│ ├── merges.txt
│ ├── special_tokens_map.json
│ ├── tokenizer_config.json
│ └── vocab.json
├── unet
│ ├── config.json
│ └── diffusion_pytorch_model.safetensors
└──vae
├── config.json
└── diffusion_pytorch_model.safetensors
```
Alternatively, you can also use the Python API to create a mixture of experts model:
```python
from segmoe import SegMoEPipeline
pipeline = SegMoEPipeline("config.yaml", device="cuda")
pipeline.save_pretrained("segmoe_v0")
```
### Push to Hub
The Model can be pushed to the hub via the huggingface-cli
```bash
huggingface-cli upload segmind/segmoe_v0 ./segmoe_v0
```
The model can also be pushed to the Hub directly from Python:
```python
from huggingface_hub import create_repo, upload_folder
model_id = "segmind/SegMoE-v0"
repo_id = create_repo(repo_id=model_id, exist_ok=True).repo_id
upload_folder(
repo_id=repo_id,
folder_path="segmoe_v0",
commit_message="Inital Commit",
ignore_patterns=["step_*", "epoch_*"],
)
```
Detailed usage can be found [here](https://huggingface.co/docs/huggingface_hub/guides/upload)
## Disclaimers and ongoing work
- **Slower Speed**: If the number of experts per token is larger than 1, the MoE performs computation across several expert models. This makes it slower than a single SD 1.5 or SDXL model.
- **High VRAM usage**: MoEs run inference very quickly but still need a large amount of VRAM (and hence an expensive GPU). This makes it challenging to use them in local setups, but they are great for deployments with multiple GPUs. As a reference point, SegMoE-4x2 requires 24GB of VRAM in half-precision.
## Conclusion
We built SegMoE to provide the community a new tool that can potentially create SOTA Diffusion Models with ease, just by combining pretrained models while keeping inference times low. We're excited to see what you can build with it!
## Additional Resources
- [Mixture of Experts Explained](https://huggingface.co/blog/moe)
- [Mixture of Experts Models on Hugging Face](https://huggingface.co/models?other=moe)
| 2 |
0 | hf_public_repos | hf_public_repos/blog/galore.md | ---
title: "GaLore: Advancing Large Model Training on Consumer-grade Hardware"
authors:
- user: Titus-von-Koeller
- user: jiaweizhao
guest: true
- user: mdouglas
guest: true
- user: hiyouga
guest: true
- user: ybelkada
- user: muellerzr
- user: amyeroberts
- user: smangrul
- user: BenjaminB
---
# GaLore: Advancing Large Model Training on Consumer-grade Hardware
The integration of GaLore into the training of large language models (LLMs) marks a significant advancement in the field of deep learning, particularly in terms of memory efficiency and the democratization of AI research. By allowing for the training of billion-parameter models on consumer-grade hardware, reducing memory footprint in optimizer states, and leveraging advanced projection matrix techniques, GaLore opens new horizons for researchers and practitioners with limited access to high-end computational resources.
## Scaling LLMs with Consumer-Grade Hardware
The capability of GaLore to facilitate the training of models with up to 7 billion parameters, such as those based on the Llama architecture, on consumer GPUs like the NVIDIA RTX 4090, is groundbreaking. This is achieved by significantly reducing the memory requirements traditionally associated with optimizer states and gradients during the training process. The approach leverages the inherent low-rank structure of gradients in deep neural networks, applying a projection that reduces the dimensionality of the data that needs to be stored and manipulated.
## Memory Efficiency in Optimizer States
The optimizer state, especially in adaptive optimization algorithms like Adam, represents a significant portion of the memory footprint during model training. GaLore addresses this by projecting the gradients into a lower-dimensional subspace before they are processed by the optimizer. This not only reduces the memory required to store these states but also maintains the effectiveness of the optimization process.
The memory savings are substantial, with [the authors reporting](https://x.com/AnimaAnandkumar/status/1765613815146893348?s=20) “more than **82.5% reduction in memory for storing optimizer states during training**”, making it feasible to train larger models or use larger batch sizes within the same memory constraints. When combined with 8-bit precision optimizers, these savings can be even more pronounced.
## Subspace Switching and Advanced Projection Techniques
A critical component of GaLore's effectiveness is its dynamic subspace switching mechanism, which allows the model to navigate through different low-rank subspaces throughout the training process. This ensures that the model is not confined to a limited portion of the parameter space, thus preserving the capacity for full-parameter learning. The decision on when and how to switch subspaces is pivotal, with the frequency of these switches being a balance between maintaining a consistent optimization trajectory and adapting to the evolving landscape of the gradient's low-rank structure.
The ability to dynamically adjust these projections in response to changes in the gradient structure is a potent tool in the GaLore arsenal, allowing for more nuanced control over the memory-optimization trade-offs inherent in training large models.
## Combining GaLore with 8-bit Optimizers
The combination of GaLore with 8-bit precision optimizers represents a synergy that maximizes memory efficiency while maintaining the integrity and performance of the training process. 8-bit optimizers reduce the memory footprint by quantizing the optimizer states. When used in conjunction with GaLore's projection mechanism, the result is a highly memory-efficient training regime that does not compromise on model accuracy or convergence speed.
This combination is particularly effective in scenarios where memory is a critical bottleneck, such as training large models on consumer-grade hardware or deploying models in memory-constrained environments. It enables the use of more complex models and larger datasets within the same hardware constraints, pushing the boundaries of what can be achieved with limited resources.
## Implementation Details
Integrating 8-bit optimizers with GaLore for training large language models (LLMs) involves quantizing the gradients, weights, and optimizer states to 8-bit representations. This quantization process significantly reduces the memory footprint, enabling the training of larger models or the use of larger batch sizes within the same memory constraints. The algorithmic details of this integration involve several key steps, some of which would benefit significantly from native CUDA implementation for efficiency gains. GaLore opens new possibilities to integrate these techniques even more tightly with quantization and specialized parameterization of the matrices, which can lead to further reductions in memory usage. We are currently exploring this direction in the bitsandbytes library.
### Algorithmic Overview of 8-bit Optimization with GaLore
**Gradient Projection**: GaLore projects the full-precision gradients into a low-rank subspace using projection matrices. This step reduces the dimensionality of the gradients, which are then quantized to 8-bit format.
**Quantization**: The projected gradients, along with the model weights and optimizer states (such as the moving averages in Adam), are quantized from 32-bit floating-point to 8-bit integer representations. This involves scaling the floating-point values to the 8-bit range and rounding them to the nearest integer.
**Optimizer Update**: The 8-bit quantized gradients are used to update the model weights. This step involves de-quantizing the gradients back to floating-point format, applying the optimizer's update rule (e.g., Adam's moment update and parameter adjustment), and then quantizing the updated optimizer states back to 8-bit for storage.
**De-quantization and Weight Update**: The 8-bit quantized weights undergo de-quantization to a floating-point representation for processing, albeit retaining the 8-bit precision inherent to their quantized form due to the limited range of values. This step is needed because standard operations in frameworks like PyTorch do not support 8-bit integers, and such integer weights cannot accommodate gradients. While this approach does not inherently enhance accuracy, it facilitates the practical application and gradient computation of quantized weights within the constraints of current deep learning libraries. Note that after de-quantization and before applying the weight update, GaLore employs one more projection that projects de-quantized low-rank updates back to the original space.
## Use it with Hugging Face Transformers
To use GaLore optimizers with the Hugging Face transformers library, you first need to update it to a version that supports GaLore optimizers, by either installing the latest update, i.e. `pip install transformers>=4.39.0` or installing transformers from source.
Then install the galore-torch library with `pip install galore-torch`. Below is a full working example of GaLore with transformers, for pretraining Mistral-7B on the imdb dataset:
```python
import torch
import datasets
from transformers import TrainingArguments, AutoConfig, AutoTokenizer, AutoModelForCausalLM
import trl
train_dataset = datasets.load_dataset('imdb', split='train')
args = TrainingArguments(
output_dir="./test-galore",
max_steps=100,
per_device_train_batch_size=2,
optim="galore_adamw",
optim_target_modules=["attn", "mlp"]
)
model_id = "mistralai/Mistral-7B-v0.1"
config = AutoConfig.from_pretrained(model_id)
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_config(config).to(0)
trainer = trl.SFTTrainer(
model=model,
args=args,
train_dataset=train_dataset,
dataset_text_field='text',
max_seq_length=512,
)
trainer.train()
```
`TrainingArguments`: Simply pass a valid `optim_target_modules` (it supports a single string, regex, or a list of strings or regexes) as well as, for `optim`, a valid GaLore optimizer, such as `galore_adamw`, `galore_adamw_8bit`, `galore_adafactor` – and you’re good to go!
### Layer-wise Updates
Another important point to mention are the _layer-wise_ optimizers (i.e. updating weights one layer at a time). Typically, the optimizer performs a single weight update for all layers after backpropagation. This is done by storing the entire weight gradients in memory. By adopting layer-wise weight updates, we can further reduce the memory footprint during training. Under the hood, this is implemented with PyTorch post-accumulation hooks on the layers the users want to update.
To use this feature, simply append `_layerwise` to the optimizer names, for example `galore_adamw_layerwise`.
## Conclusion
GaLore, with its innovative approach to leveraging the low-rank structure of gradients, represents a significant step forward in the memory-efficient training of LLMs. By enabling the training of billion-parameter models on consumer-grade hardware, reducing the memory footprint of optimizer states through projection techniques, and allowing for dynamic subspace switching, GaLore democratizes access to large-scale model training. The compatibility of GaLore with 8-bit precision optimizers further enhances its utility, offering a pathway to training larger and more complex models without the need for specialized computational resources. This opens up new possibilities for research and application in AI, making it an exciting time for practitioners and researchers alike.
## Resources
Please refer to [the original paper](https://arxiv.org/pdf/2403.03507.pdf). Twitter references: [1](https://twitter.com/AnimaAnandkumar/status/1765613815146893348) [2](https://x.com/_akhaliq/status/1765598376312152538?s=20) [3](https://x.com/tydsh/status/1765628222308491418?s=20). The paper also draws comparisons between GaLore and ReLoRA, which might be of interest to some readers. For readers with questions that remain unanswered, especially after review of the paper, or who would like to constructively discuss the results, please feel free to [join the author’s Slack community](https://galore-social.slack.com/join/shared_invite/zt-2ev152px0-DguuQ5WRTLQjtq2C88HBvQ#/shared-invite/email). For those interested in further releases along these lines, please follow [Jiawei Zhao](https://twitter.com/jiawzhao) and [Titus von Koeller](https://twitter.com/Titus_vK) (for information on the latest `bitsandbytes` releases) as well as [Younes Belkada](https://twitter.com/younesbelkada) for the latest and greatest infos on quantization-related topics within and around the Hugging Face ecosystem.
| 3 |
0 | hf_public_repos | hf_public_repos/blog/ml-for-games-5.md | ---
title: "Generating Stories: AI for Game Development #5"
thumbnail: /blog/assets/124_ml-for-games/thumbnail5.png
authors:
- user: dylanebert
---
# Generating Stories: AI for Game Development #5
**Welcome to AI for Game Development!** In this series, we'll be using AI tools to create a fully functional farming game in just 5 days. By the end of this series, you will have learned how you can incorporate a variety of AI tools into your game development workflow. I will show you how you can use AI tools for:
1. Art Style
2. Game Design
3. 3D Assets
4. 2D Assets
5. Story
Want the quick video version? You can watch it [here](https://www.tiktok.com/@individualkex/video/7197505390353960235). Otherwise, if you want the technical details, keep reading!
**Note:** This post makes several references to [Part 2](https://huggingface.co/blog/ml-for-games-2), where we used ChatGPT for Game Design. Read Part 2 for additional context on how ChatGPT works, including a brief overview of language models and their limitations.
## Day 5: Story
In [Part 4](https://huggingface.co/blog/ml-for-games-4) of this tutorial series, we talked about how you can use Stable Diffusion and Image2Image as a tool in your 2D Asset workflow.
In this final part, we'll be using AI for Story. First, I'll walk through my [process](#process) for the farming game, calling attention to ⚠️ **Limitations** to watch out for. Then, I'll talk about relevant technologies and [where we're headed](#where-were-headed) in the context of game development. Finally, I'll [conclude](#conclusion) with the final game.
### Process
**Requirements:** I'm using [ChatGPT](https://openai.com/blog/chatgpt/) throughout this process. For more information on ChatGPT and language modeling in general, I recommend reading [Part 2](https://huggingface.co/blog/ml-for-games-2) of the series. ChatGPT isn't the only viable solution, with many emerging competitors, including open-source dialog agents. Read ahead to learn more about [the emerging landscape](#the-emerging-landscape) of dialog agents.
1. **Ask ChatGPT to write a story.** I provide plenty of context about my game, then ask ChatGPT to write a story summary.
<div align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/124_ml-for-games/chatgpt1.png" alt="ChatGPT for Story #1">
</div>
ChatGPT then responds with a story summary that is extremely similar to the story of the game [Stardew Valley](https://www.stardewvalley.net/).
> ⚠️ **Limitation:** Language models are susceptible to reproducing existing stories.
This highlights the importance of using language models as a tool, rather than as a replacement for human creativity. In this case, relying solely on ChatGPT would result in a very unoriginal story.
2. **Refine the results.** As with Image2Image in [Part 4](https://huggingface.co/blog/ml-for-games-4), the real power of these tools comes from back-and-forth collaboration. So, I ask ChatGPT directly to be more original.
<div align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/124_ml-for-games/chatgpt2.png" alt="ChatGPT for Story #2">
</div>
This is already much better. I continue to refine the result, such as asking to remove elements of magic since the game doesn't contain magic. After a few rounds of back-and-forth, I reach a description I'm happy with. Then, it's a matter of generating the actual content that tells this story.
3. **Write the content.** Once I'm happy with the story summary, I ask ChatGPT to write the in-game story content. In the case of this farming game, the only written content is the description of the game, and the description of the items in the shop.
<div align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/124_ml-for-games/chatgpt3.png" alt="ChatGPT for Story #3">
</div>
Not bad. However, there is definitely no help from experienced farmers in the game, nor challenges or adventures to discover.
4. **Refine the content.** I continue to refine the generated content to better fit the game.
<div align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/124_ml-for-games/chatgpt4.png" alt="ChatGPT for Story #4">
</div>
I'm happy with this result. So, should I use it directly? Maybe. Since this is a free game being developed for an AI tutorial, probably. However, it may not be straightforward for commercial products, having potential unintended legal, ethical, and commercial ramifications.
> ⚠️ **Limitation:** Using outputs from language models directly may have unintended legal, ethical, and commercial ramifications.
Some potential unintended ramifications of using outputs directly are as follows:
- <u>Legal:</u> The legal landscape surrounding Generative AI is currently very unclear, with several ongoing lawsuits.
- <u>Ethical:</u> Language models can produce plagiarized or biased outputs. For more information, check out the [Ethics and Society Newsletter](https://huggingface.co/blog/ethics-soc-2).
- <u>Commercial:</u> [Some](https://www.searchenginejournal.com/google-says-ai-generated-content-is-against-guidelines/444916/) sources have stated that AI-generated content may be deprioritized by search engines. This [may not](https://seo.ai/blog/google-is-not-against-ai-content) be the case for most non-spam content, but is worth considering. Tools such as [AI Content Detector](https://writer.com/ai-content-detector/) can be used to check whether content may be detected as AI-generated. There is ongoing research on language model [watermarking](https://arxiv.org/abs/2301.10226) which may mark text as AI-generated.
Given these limitations, the safest approach may be to use language models like ChatGPT for brainstorming but write the final content by hand.
5. **Scale the content.** I continue to use ChatGPT to flesh out descriptions for the items in the store.
<div align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/124_ml-for-games/chatgpt5.png" alt="ChatGPT for Story #5">
</div>
For my simple farming game, this may be an effective approach to producing all the story content for the game. However, this may quickly run into scaling limitations. ChatGPT isn't well-suited to very long cohesive storytelling. Even after generating a few item descriptions for the farming game, the results begin to drift in quality and fall into repetition.
> ⚠️ **Limitation:** Language models are susceptible to repetition.
To wrap up this section, here are some tips from my own experience that may help with using AI for Story:
- **Ask for outlines.** As mentioned, quality may deteriorate with long-form content. Developing high-level story outlines tends to work much better.
- **Brainstorm small ideas.** Use language models to help flesh out ideas that don't require the full story context. For example, describe a character and use the AI to help brainstorm details about that character.
- **Refine content.** Write your actual story content, and ask for suggestions on ways to improve that content. Even if you don't use the result, it may give you ideas on how to improve the content.
Despite the limitations I've discussed, dialog agents are an incredibly useful tool for game development, and it's only the beginning. Let's talk about the emerging landscape of dialog agents and their potential impact on game development.
### Where We're Headed
#### The Emerging Landscape
My [process](#process) focused on how ChatGPT can be used for story. However, ChatGPT isn't the only solution available. [Character.AI](https://beta.character.ai/) provides access to dialog agents that are customized to characters with different personalities, including an [agent](https://beta.character.ai/chat?char=9ZSDyg3OuPbFgDqGwy3RpsXqJblE4S1fKA_oU3yvfTM) that is specialized for creative writing.
There are many other models which are not yet publicly accessible. Check out [this](https://huggingface.co/blog/dialog-agents) recent blog post on dialog agents, including a comparison with other existing models. These include:
- [Google's LaMDA](https://arxiv.org/abs/2201.08239) and [Bard](https://blog.google/technology/ai/bard-google-ai-search-updates/)
- [Meta's BlenderBot](https://arxiv.org/abs/2208.03188)
- [DeepMind's Sparrow](https://arxiv.org/abs/2209.14375)
- [Anthropic's Assistant](https://arxiv.org/abs/2204.05862).
While many prevalent contenders are closed-source, there are also open-source dialog agent efforts, such as [LAION's OpenAssistant](https://github.com/LAION-AI/Open-Assistant), reported efforts from [CarperAI](https://carper.ai), and the open source release of [Google's FLAN-T5 XXL](https://huggingface.co/google/flan-t5-xxl). These can be combined with open-source tools like [LangChain](https://github.com/hwchase17/langchain), which allow language model inputs and outputs to be chained, helping to work toward open dialog agents.
Just as the open-source release of Stable Diffusion has rapidly risen to a wide variety of innovations that have inspired this series, the open-source community will be key to exciting language-centric applications in game development that are yet to be seen. To keep up with these developments, feel free to follow me on [Twitter](https://twitter.com/dylan_ebert_). In the meantime, let's discuss some of these potential developments.
#### In-Game Development
**NPCs:** Aside from the clear uses of language models and dialog agents in the game development workflow, there is an exciting in-game potential for this technology that has not yet been realized. The most clear case of this is AI-powered NPCs. There are already startups built around the idea. Personally, I don't quite see how language models, as they currently are, can be applied to create compelling NPCs. However, I definitely don't think it's far off. I'll let you know.
**Controls.** What if you could control a game by talking to it? This is actually not too hard to do right now, though it hasn't been put into common practice. Would you be interested in learning how to do this? Stay tuned.
### Conclusion
Want to play the final farming game? Check it out [here](https://huggingface.co/spaces/dylanebert/FarmingGame) or on [itch.io](https://individualkex.itch.io/farming-game).
<div align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/124_ml-for-games/game.png" alt="Final Farming Game">
</div>
Thank you for reading the AI for Game Development series! This series is only the beginning of AI for Game Development at Hugging Face, with more to come. Have questions? Want to get more involved? Join the [Hugging Face Discord](https://hf.co/join/discord)! | 4 |
0 | hf_public_repos | hf_public_repos/blog/bert-cpu-scaling-part-2.md | ---
title: "Scaling up BERT-like model Inference on modern CPU - Part 2"
authors:
- user: echarlaix
- user: jeffboudier
- user: mfuntowicz
- user: michaelbenayoun
---
# Scaling up BERT-like model Inference on modern CPU - Part 2
<script async defer src="https://unpkg.com/medium-zoom-element@0/dist/medium-zoom-element.min.js"></script>
## Introduction: Using Intel Software to Optimize AI Efficiency on CPU
As we detailed in our [previous blog post](https://huggingface.co/blog/bert-cpu-scaling-part-1), Intel Xeon CPUs provide a set of features especially designed for AI workloads such as AVX512 or VNNI (Vector Neural Network Instructions)
for efficient inference using integer quantized neural network for inference along with additional system tools to ensure the work is being done in the most efficient way.
In this blog post, we will focus on software optimizations and give you a sense of the performances of the new Ice Lake generation of Xeon CPUs from Intel. Our goal is to give you a full picture of what’s available on the software side to make the most out of your Intel hardware.
As in the previous blog post, we show the performance with benchmark results and charts, along with new tools to make all these knobs and features easy to use.
Back in April, Intel launched its [latest generation of Intel Xeon processors](https://www.intel.com/content/www/us/en/products/details/processors/xeon/scalable.html), codename Ice Lake, targeting more efficient and performant AI workloads.
More precisely, Ice Lake Xeon CPUs can achieve up to 75% faster inference on a variety of NLP tasks when comparing against the previous generation of Cascade Lake Xeon processors.
This is achieved by a combination of both hardware and software improvements, [such as new instructions](https://en.wikichip.org/wiki/x86/avx512_vnni) and PCIe 4.0 featured on the new Sunny Cove architecture to supports Machine Learning and Deep Learning workloads.
Last but not least, Intel worked on dedicated optimizations for various frameworks which now come with Intel’s flavors like
[Intel’s Extension for Scikit Learn](https://intel.github.io/scikit-learn-intelex/),
[Intel TensorFlow](https://www.intel.com/content/www/us/en/developer/articles/guide/optimization-for-tensorflow-installation-guide.html) and
[Intel PyTorch Extension](https://www.intel.com/content/www/us/en/developer/articles/containers/pytorch-extension.html).
All these features are very low-level in the stack of what Data Scientists and Machine Learning Engineers use in their day-to-day toolset.
In a vast majority of situations, it is more common to rely on higher level frameworks and libraries to handle multi-dimensional arrays manipulation such as
[PyTorch](https://pytorch.org) and [TensorFlow](https://www.tensorflow.org/) and make use of highly tuned mathematical operators such as [BLAS (Basic Linear Algebra Subroutines)](http://www.netlib.org/blas/) for the computational part.
In this area, Intel plays an essential role by providing software components under the oneAPI umbrella which makes it very easy to use highly efficient linear algebra routines through
Intel [oneMKL (Math Kernel Library)](https://www.intel.com/content/www/us/en/develop/documentation/oneapi-programming-guide/top/api-based-programming/intel-oneapi-math-kernel-library-onemkl.html),
higher-level parallelization framework with Intel OpenMP or the [Threading Building Blocks (oneTBB)](https://www.intel.com/content/www/us/en/developer/tools/oneapi/onetbb.html).
Also, oneAPI provides some domain-specific libraries such as Intel [oneDNN](https://www.intel.com/content/www/us/en/developer/tools/oneapi/onednn.html) for deep neural network primitives (ReLU, fully-connected, etc.) or
[oneCCL](https://www.intel.com/content/www/us/en/developer/tools/oneapi/oneccl.html) for collective communication especially useful when using distributed setups to access efficient all-reduce operations over multiple hosts.
Some of these libraries, especially MKL or oneDNN, are natively included in frameworks such as PyTorch and TensorFlow ([since 2.5.0](https://medium.com/intel-analytics-software/leverage-intel-deep-learning-optimizations-in-tensorflow-129faa80ee07)) to bring all the performance improvements to the end user out of the box.
When one would like to target very specific hardware features, Intel provides custom versions of the most common software, especially optimized for the Intel platform.
This is for instance the case with TensorFlow, [for which Intel provides custom, highly tuned and optimized versions of the framework](https://www.intel.com/content/www/us/en/developer/articles/guide/optimization-for-tensorflow-installation-guide.html),
or with the Intel PyTorch Extension (IPEX) framework which can be considered as a feature laboratory before upstreaming to PyTorch.
## Deep Dive: Leveraging advanced Intel features to improve AI performances
### Performance tuning knobs
As highlighted above, we are going to cover a new set of tunable items to improve the performance of our AI application. From a high-level point of view, every machine learning and deep learning framework is made of the same ingredients:
1. A structural way of representing data in memory (vector, matrices, etc.)
2. Implementation of mathematical operators
3. Efficient parallelization of the computations on the target hardware
_In addition to the points listed above, deep learning frameworks provide ways to represent data flow and dependencies to compute gradients.
This falls out of the scope of this blog post, and it leverages the same components as the ones listed above!_
<br>
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="Intel libraries overview under the oneAPI umbrella" src="assets/35_bert_cpu_scaling_part_2/oneapi.jpg"></medium-zoom>
<figcaption>Figure 1. Intel libraries overview under the oneAPI umbrella</figcaption>
</figure>
<br>
### 1. Memory allocation and management libraries
This blog post will deliberately skip the first point about the data representation as it is something rather framework specific.
For reference, PyTorch uses its very own implementation, called [ATen](https://github.com/pytorch/pytorch/tree/master/aten/src),
while TensorFlow relies on the open source library [Eigen](https://eigen.tuxfamily.org/index.php?title=Main_Page) for this purpose.
While it’s very complex to apply generic optimizations to different object structures and layouts, there is one area where we can have an impact: Memory Allocation.
As a short reminder, memory allocation here refers to the process of programmatically asking the operating system a dynamic (unknown beforehand) area on the system where we will be able to store items into, such as the malloc and derived in C or the new operator in C++.
Memory efficiency, both in terms of speed but also in terms of fragmentation, is a vast scientific and engineering subject with multiple solutions depending on the task and underlying hardware.
Over the past years we saw more and more work in this area, with notably:
- [jemalloc](http://jemalloc.net/) (Facebook - 2005)
- [mimalloc](https://microsoft.github.io/mimalloc/) (Microsoft - 2019)
- [tcmalloc](https://abseil.io/blog/20200212-tcmalloc) (Google - 2020)
Each pushes forward different approaches to improve aspects of the memory allocation and management on various software.
### 2. Efficient parallelization of computations
Now that we have an efficient way to represent our data, we need a way to take the most out of the computational hardware at our disposal.
Interestingly, when it comes to inference, CPUs have a potential advantage over GPUs in the sense they are everywhere, and they do not require specific application components and administration staff to operate them.
Modern CPUs come with many cores and complex mechanisms to increase the general performances of software.
Yet, as we highlighted on [the first blog post](https://hf.co/blog/bert-cpu-scaling-part-1), they also have features which can be tweaked depending on the kind of workload (CPU or I/O bound) you target, to further improve performances for your application.
Still, implementing parallel algorithms might not be as simple as throwing more cores to do the work.
Many factors, such as data structures used, concurrent data access, CPU caches invalidation - all of which might prevent your algorithm from being effectively faster.
As a reference talk, we recommend the talk from [**Scott Meyers: CPU Caches and Why You Care**](https://www.youtube.com/watch?v=WDIkqP4JbkE) if you are interested in diving more into the subject.
Thankfully, there are libraries which make the development process of such parallel algorithms easier and less error-prone.
Among the most common parallel libraries we can mention OpenMP and TBB (Threading Building Blocks), which work at various levels, from programming API in C/C++ to environment variable tuning and dynamic scheduling.
On Intel hardware, it is advised to use the Intel implementation of the OpenMP specification often referred as "IOMP" available as part of the [Intel oneAPI toolkit](https://www.intel.com/content/www/us/en/developer/tools/oneapi/overview.html).
<br>
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="Code snippet showing parallel computation done through OpenMP" src="assets/35_bert_cpu_scaling_part_2/openmp.png"></medium-zoom>
<figcaption>Figure 2. Code snippet showing parallel computation done through OpenMP</figcaption>
</figure>
[comment]: <> (<br>)
### 3. Optimized mathematical operators
Now that we covered the necessary building blocks for designing efficient data structures and parallel algorithms, the last remaining piece is the one running the computation,
the one implementing the variety of mathematical operators and neural network layers to do what we love most, designing neural networks! 😊
In every programmer toolkit, there are multiple levels which can bring mathematical operations support, which can then be optimized differently depending on various factors such as the data storage layout
being used (Contiguous memory, Chunked, Packed, etc.), the data format representing each scalar element (Float32, Integer, Long, Bfloat16, etc.) and of course the various instructions being supported by your processor.
Nowadays, almost all processors support basic mathematical operations on scalar items (one single item at time) or in vectorized mode (meaning they operate on multiple items within the same CPU instructions, referred as SIMD “Single Instruction Multiple Data”).
Famous sets of SIMD instructions are SSE2, AVX, AVX2 and the AVX-512 present on the latest generations of Intel CPUs being able to operate over 16 bytes of content within a single CPU clock.
Most of the time, one doesn't have to worry too much about the actual assembly being generated to execute a simple element-wise addition between two vectors, but if you do,
again there are some libraries which allow you to go one level higher than writing code calling CPU specific intrinsic to implement efficient mathematical kernels.
This is for instance what Intel’s MKL “Math Kernel Library” provides, along with the famous BLAS “Basic Linear Algebra Subroutines” interface to implement all the basic operations for linear algebra.
Finally, on top of this, one can find some domain specific libraries such as Intel's oneDNN which brings all the most common and essential building blocks required to implement neural network layers.
Intel MKL and oneDNN are natively integrated within the PyTorch framework, where it can enable some performance speedup for certain operations such as Linear + ReLU or Convolution.
On the TensorFlow side, oneDNN can be enabled by setting the environment variable `TF_ENABLE_ONEDNN_OPTS=1` (_TensorFlow >= 2.5.0_) to achieve similar machinery under the hood.
## More Efficient AI Processing on latest Intel Ice Lake CPUs
In order to report the performances of the Ice Lake product lineup we will closely follow [the methodology we used for the first blog](https://hf.co/blog/bert-cpu-scaling-part-1#2-benchmarking-methodology) post of this series. As a reminder, we will adopt the exact same schema to benchmark the various setups we will highlight through this second blog post. More precisely, the results presented in the following sections are based on:
- PyTorch: 1.9.0
- TensorFlow: 2.5.0
- Batch Sizes: 1, 4, 8, 16, 32, 128
- Sequence Lengths: 8, 16, 32, 64, 128, 384, 512
We will present the results through metrics accepted by the field to establish the performances of the proposed optimizations:
- Latency: Time it takes to execute a single inference request (i.e., “forward call”) through the model, expressed in millisecond.
- Throughput: Number of inference requests (i.e., “forward calls”) the system can sustain within a defined period, expressed in call/sec.
We will also provide an initial baseline showing out-of-the-box results and a second baseline applying all the different optimizations we highlighted in the first blogpost.
Everything was run on an Intel provided cloud instance featuring the [Ice Lake Xeon Platinum 8380](https://ark.intel.com/content/www/fr/fr/ark/products/205684/intel-xeon-platinum-8380hl-processor-38-5m-cache-2-90-ghz.html) CPU operating on Ubuntu 20.04.2 LTS.
You can find the same processors on the various cloud providers:
- [AWS m6i / c6i instances](https://aws.amazon.com/fr/blogs/aws/new-amazon-ec2-c6i-instances-powered-by-the-latest-generation-intel-xeon-scalable-processors/)
- [Azure Ev5 / Dv5 series](https://azure.microsoft.com/en-us/blog/upgrade-your-infrastructure-with-the-latest-dv5ev5-azure-vms-in-preview/)
<br>
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="Intel Ice Lake Xeon 8380 Specifications" src="assets/35_bert_cpu_scaling_part_2/intel_xeon_8380_specs.svg"></medium-zoom>
<figcaption>Figure 3. Intel Ice Lake Xeon 8380 Specifications</figcaption>
</figure>
<br>
### Establishing the baseline
As mentioned previously, the baselines will be composed of two different setups:
- Out-of-the-box: We are running the workloads as-is, without any tuning
- Optimized: We apply the various knobs present in [Blog #1](https://hf.co/blog/bert-cpu-scaling-part-1#2-benchmarking-methodology)
Also, from the comments we had about the previous blog post, we wanted to change the way we present the framework within the resulting benchmarks.
As such, through the rest of this second blog post, we will split framework benchmarking results according to the following:
- Frameworks using “eager” mode for computations (PyTorch, TensorFlow)
- Frameworks using “graph” mode for computations (TorchScript, TensorFlow Graph, Intel Tensorflow)
#### Baseline: Eager frameworks latencies
Frameworks operating in eager mode usually discover the actual graph while executing it.
More precisely, the actual computation graph is not known beforehand and you gradually (_eagerly_) execute one operator
which will become the input of the next one, etc. until you reach leaf nodes (outputs).
These frameworks usually provide more flexibility in the algorithm you implement at the cost of increased runtime overhead
and slightly potential more memory usage to keep track of all the required elements for the backward pass.
Last but not least, it is usually harder through these frameworks to enable graph optimizations such as operator fusion.
For instance, many deep learning libraries such as oneDNN have optimized kernels for Convolution + ReLU but you actually need
to know before executing the graph that this pattern will occur within the sequence of operation, which is, by design, not
something possible within eager frameworks.
<br>
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="PyTorch latencies with respect to the number of cores involved" src="assets/35_bert_cpu_scaling_part_2/baselines/eager_mode_pytorch_baseline.svg"></medium-zoom>
<figcaption>Figure 4. PyTorch latencies with respect to the number of cores involved</figcaption>
</figure>
<br>
<br>
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="Google's TensorFlow latencies with respect to the number of cores involved" src="assets/35_bert_cpu_scaling_part_2/baselines/eager_mode_tensorflow_baseline.svg"></medium-zoom>
<figcaption> Figure 5. Google's TensorFlow latencies with respect to the number of cores involved</figcaption>
</figure>
<br>
<br>
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="Google's TensorFlow with oneDNN enabled latencies with respect to the number of cores involved" src="assets/35_bert_cpu_scaling_part_2/baselines/eager_mode_tensorflow_onednn_baseline.svg"></medium-zoom>
<figcaption>Figure 6. Google's TensorFlow with oneDNN enabled latencies with respect to the number of cores involved</figcaption>
</figure>
<br>
<br>
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="Intel TensorFlow latencies with respect to the number of cores involved" src="assets/35_bert_cpu_scaling_part_2/baselines/eager_mode_intel_tensorflow_baseline.svg"></medium-zoom>
<figcaption>Figure 7. Intel TensorFlow latencies with respect to the number of cores involved</figcaption>
</figure>
<br>
The global trend highlights the positive impact of the number of cores on the observed latencies.
In most of the cases, increasing the number of cores reduces the computation time across the different workload sizes.
Still, putting more cores to the task doesn't result in monotonic latency reductions, there is always a trade-off between the workload’s size and the number of resources you allocate to execute the job.
As you can see on the charts above, one very common pattern tends to arise from using all the cores available on systems with more than one CPU (more than one socket).
The inter-socket communication introduces a significant latency overhead and results in very little improvement to increased latency overall.
Also, this inter-socket communication overhead tends to be less and less perceptive as the workload becomes larger,
meaning the usage of all computational resources benefits from using all the available cores.
In this domain, it seems PyTorch (Figure 1.) and Intel TensorFlow (Figure 4.) seem to have slightly better parallelism support,
as showed on the sequence length 384 and 512 for which using all the cores still reduces the observed latency.
#### Baseline: Graph frameworks latencies
This time we compare performance when using frameworks in “Graph” mode, where the graph is fully known beforehand,
and all the allocations and optimizations such as graph pruning and operators fusing can be made.
<br>
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="TorchScript latencies with respect to the number of cores involved" src="assets/35_bert_cpu_scaling_part_2/baselines/graph_mode_torchscript_baseline.svg"></medium-zoom>
<figcaption>Figure 8. TorchScript latencies with respect to the number of cores involved</figcaption>
</figure>
<br>
<br>
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="Google's TensorFlow latencies with respect to the number of cores involved" src="assets/35_bert_cpu_scaling_part_2/baselines/graph_mode_tensorflow_baseline.svg"></medium-zoom>
<figcaption>Figure 9. Google's TensorFlow latencies with respect to the number of cores involved</figcaption>
</figure>
<br>
<br>
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="Google's TensorFlow with oneDNN enabled latencies with respect to the number of cores involved" src="assets/35_bert_cpu_scaling_part_2/baselines/graph_mode_tensorflow_onednn_baseline.svg"></medium-zoom>
<figcaption>Figure 10. Google's TensorFlow with oneDNN enabled latencies with respect to the number of cores involved</figcaption>
</figure>
<br>
<br>
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="Intel TensorFlow latencies with respect to the number of cores involved" src="assets/35_bert_cpu_scaling_part_2/baselines/graph_mode_intel_tensorflow_baseline.svg"></medium-zoom>
<figcaption>Figure 11. Intel TensorFlow latencies with respect to the number of cores involved</figcaption>
</figure>
<br>
This is often referred to as “tracing” the graph and, as you can see here, the results are not that different from TorchScript (Graph execution mode from PyTorch) vs TensorFlow(s).
All TensorFlow implementations seem to perform better than TorchScript when the parallelization is limited (low number of cores involved in the intra operation computations) but this seems not to scale efficiently
as we increase the computation resources, whereas TorchScript seems to be able to better leverage the power of modern CPUs.
Still, the margin between all these frameworks in most cases very limited.
### Tuning the Memory Allocator: Can this impact the latencies observed?
One crucial component every program dynamically allocating memory relies on is the memory allocator.
If you are familiar with C/C++ programming this component provides the low bits to malloc/free or new/delete.
Most of the time you don’t have to worry too much about it and the default ones (glibc for instance on most Linux distributions) will provide great performances out of the box.
Still, in some situations it might not provide the most efficient performances, as these default allocators are most of the time designed to be “good” most of the time,
and not fine-tuned for specific workloads or parallelism.
So, what are the alternatives, and when are they more suitable than the default ones? Well, again, it depends on the kind of context around your software.
Possible situations are a heavy number of allocations/de-allocations causing fragmentation over time,
specific hardware and/or architecture you’re executing your software on and finally the level of parallelism of your application.
Do you see where this is going? Deep learning and by extension all the applications doing heavy computations are heavily multi-threaded,
that’s also the case for software libraries such as PyTorch, TensorFlow and any other frameworks targeting Machine Learning workloads.
The default memory allocator strategies often rely on global memory pools which require the usage of synchronization primitives to operate,
increasing the overall pressure on the system, reducing the performance of your application.
Some recent works by companies such as Google, Facebook and Microsoft provided alternative memory allocation strategies implemented in custom memory allocator libraries
one can easily integrate directly within its software components or use dynamic shared library preload to swap the library being used to achieve the allocation/de-allocation.
Among these libraries, we can cite a few of them such as [tcmalloc](), [jemalloc]() and [mimalloc]().
<br>
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="Legend - Various allocator benchmarked on different tasks" src="assets/35_bert_cpu_scaling_part_2/allocator_benchmark_legend.png"></medium-zoom>
</figure>
<br>
<br>
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="Various allocator benchmarked on different tasks" src="assets/35_bert_cpu_scaling_part_2/allocator_benchmark.png"></medium-zoom>
<figcaption>Figure 12. Various memory allocators benchmarked on different tasks</figcaption>
</figure>
<br>
Through this blog post we will only focus on benchmarking tcmalloc and jemalloc as potential memory allocators drop-in candidates.
To be fully transparent, for the scope of the results below we used tcmalloc as part of the gperftools package available on Ubuntu distributions version 2.9 and jemalloc 5.1.0-1.
#### Memory allocator benchmarks
Again, we first compare performance against frameworks executing in an eager fashion.
This is potentially the use case where the allocator can play the biggest role: As the graph is unknown before its execution, each framework must manage the memory required for each operation when it meets the actual execution of the above node, no planning ahead possible.
In this context, the allocator is a major component due to all the system calls to allocate and reclaim memory.
<br>
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="PyTorch memory allocator and cores scaling latencies" src="assets/35_bert_cpu_scaling_part_2/allocators/allocator_and_cores_pytorch_latency.svg"></medium-zoom>
<figcaption>Figure 13. PyTorch memory allocator and cores scaling latencies</figcaption>
</figure>
<br>
<br>
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="Google's TensorFlow memory allocator and cores scaling latencies" src="assets/35_bert_cpu_scaling_part_2/allocators/allocator_and_cores_tensorflow_latency.svg"></medium-zoom>
<figcaption>Figure 14. Google's TensorFlow memory allocator and cores scaling latencies</figcaption>
</figure>
<br>
<br>
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="Google's TensorFlow with oneDNN enabled memory allocator and cores scaling latencies" src="assets/35_bert_cpu_scaling_part_2/allocators/allocator_and_cores_tensorflow_onednn_latency.svg"></medium-zoom>
<figcaption>Figure 15. Google's TensorFlow with oneDNN enabled memory allocator and cores scaling latencies</figcaption>
</figure>
<br>
<br>
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="Intel TensorFlow memory allocator and cores scaling latencies" src="assets/35_bert_cpu_scaling_part_2/allocators/allocator_and_cores_intel_tensorflow_latency.svg"></medium-zoom>
<figcaption>Figure 16. Intel TensorFlow memory allocator and cores scaling latencies</figcaption>
</figure>
<br>
As per the graph above, you can notice that the standard library allocator (glibc) is often behind performance-wise but provides reasonable performance.
Jemalloc allocator is sometimes the fastest around but in very specific situations, where the concurrency is not that high, this can be explained by the underlying structure jemalloc uses
internally which is out of the scope of this blog, but you can read the [Facebook Engineering blog](https://engineering.fb.com/2011/01/03/core-data/scalable-memory-allocation-using-jemalloc/) if you want to know more about it.
Finally, tcmalloc seems to be the one providing generally best performances across all the workloads benchmarked here.
Again, tcmalloc has a different approach than Jemalloc in the way it allocates resources, especially tcmalloc maintains a pool of memory segments locally for each thread, which reduces the necessity to have global, exclusive, critical paths.
Again, for more details, I invite you to read the full [blog by Google Abseil team](https://abseil.io/blog/20200212-tcmalloc).
Now, back to the graph mode where we benchmark framework having an omniscient representation of the overall computation graph.
<br>
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="TorchScript memory allocator and cores scaling latencies" src="assets/35_bert_cpu_scaling_part_2/allocators/allocator_and_cores_torchscript_latency.svg"></medium-zoom>
<figcaption>Figure 17. TorchScript memory allocator and cores scaling latencies</figcaption>
</figure>
<br>
<br>
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="Google's TensorFlow memory allocator and cores scaling latencies" src="assets/35_bert_cpu_scaling_part_2/allocators/allocator_and_cores_tensorflow_graph_latency.svg"></medium-zoom>
<figcaption>Figure 18. Google's TensorFlow memory allocator and cores scaling latencies</figcaption>
</figure>
<br>
<br>
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="Google's TensorFlow with oneDNN enabled memory allocator and cores scaling latencies" src="assets/35_bert_cpu_scaling_part_2/allocators/allocator_and_cores_tensorflow_onednn_graph_latency.svg"></medium-zoom>
<figcaption>Figure 19. Google's TensorFlow with oneDNN enabled memory allocator and cores scaling latencies</figcaption>
</figure>
<br>
<br>
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="Intel TensorFlow memory allocator and cores scaling latencies" src="assets/35_bert_cpu_scaling_part_2/allocators/allocator_and_cores_intel_tensorflow_graph_latency.svg"></medium-zoom>
<figcaption>Figure 20. Intel TensorFlow memory allocator and cores scaling latencies</figcaption>
</figure>
<br>
This time, by knowing the underlying structure of the operator flows and matrix shapes involved then the framework can plan and reserve the required resources beforehand.
In this context, and as it is shown in the chart above, the difference between framework is very small and there is no clear winner between jemalloc and tcmalloc.
Of course, glibc is still slightly behind as a general-purpose memory allocator, but the margin is less significant than in the eager setup.
To sum it up, tuning the memory allocator can provide an interesting item to grab the last milliseconds' improvement at the end of the optimization process, especially if you are already using traced computation graphs.
### OpenMP
In the previous section we talked about the memory management within machine learning software involving mostly CPU-bound workloads.
Such software often relies on intermediary frameworks such as PyTorch or TensorFlow for Deep Learning which commonly abstract away all the underlying, highly parallelized, operator implementations.
Writing such highly parallel and optimized algorithms is a real engineering challenge, and it requires a very low-level understanding of all the actual elements coming into play
operated by the CPU (synchronization, memory cache, cache validity, etc.).
In this context, it is very important to be able to leverage primitives to implement such powerful algorithms, reducing the delivery time and computation time by a large margin
compared to implementing everything from scratch.
There are many libraries available which provide such higher-level features to accelerate the development of algorithms.
Among the most common, one can look at OpenMP, Thread Building Blocks and directly from the C++ when targeting a recent version of the standard.
In the following part of this blog post, we will restrict ourselves to OpenMP and especially comparing the GNU, open source and community-based implementation, to the Intel OpenMP one.
The latter especially targets Intel CPUs and is optimized to provide best of class performances when used as a drop-in replacement against the GNU OpenMP one.
OpenMP exposes [many environment variables](https://www.openmp.org/spec-html/5.0/openmpch6.html) to automatically configure the underlying resources which will be involved in the computations,
such as the number of threads to use to dispatch computation to (intra-op threads), the way the system scheduler should bind each of these threads with respect to the CPU resources (threads, cores, sockets)
and some other variables which bring further control to the user.
Intel OpenMP exposes [more of these environment variables](https://www.intel.com/content/www/us/en/develop/documentation/cpp-compiler-developer-guide-and-reference/top/compilation/supported-environment-variables.html) to provide the user even more flexibility to adjust the performance of its software.
<br>
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="OpenMP vs Intel OpenMP latencies running PyTorch" src="assets/35_bert_cpu_scaling_part_2/openmp/openmp_pytorch_latencies.svg"></medium-zoom>
<figcaption>Figure 21. OpenMP vs Intel OpenMP latencies running PyTorch</figcaption>
</figure>
<br>
<br>
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="OpenMP vs Intel OpenMP latencies running PyTorch" src="assets/35_bert_cpu_scaling_part_2/openmp/openmp_torchscript_latency.svg"></medium-zoom>
<figcaption>Figure 22. OpenMP vs Intel OpenMP latencies running PyTorch</figcaption>
</figure>
<br>
As stated above, tuning OpenMP is something you can start to tweak when you tried all the other, system related, tuning knobs.
It can bring a final speed up to you model with just a single environment variable to set.
Also, it is important to note that tuning OpenMP library will only work within software that uses the OpenMP API internally.
More specially, now only PyTorch and TorchScript really make usage of OpenMP and thus benefit from OpenMP backend tuning.
This also explains why we reported latencies only for these two frameworks.
## Automatic Performances Tuning: Bayesian Optimization with Intel SigOpt
As mentioned above, many knobs can be tweaked to improve latency and throughput on Intel CPUs, but because there are many, tuning all of them to get optimal performance can be cumbersome.
For instance, in our experiments, the following knobs were tuned:
- The number of cores: although using as many cores as you have is often a good idea, it does not always provide the best performance because it also means more communication between the different threads. On top of that, having better performance with fewer cores can be very useful as it allows to run multiple instances at the same time, resulting in both better latency and throughput.
- The memory allocator: which memory allocator out of the default malloc, Google's tcmalloc and Facebook's jemalloc provides the best performance?
- The parallelism library: which parallelism library out of GNU OpenMP and Intel OpenMP provides the best performance?
- Transparent Huge Pages: does enabling Transparent Huge Pages (THP) on the system provide better performance?
- KMP block time parameter: sets the time, in milliseconds, that a thread should wait, after completing the execution of a parallel region, before sleeping.
Of course, the brute force approach, consisting of trying out all the possibilities will provide the best knob values to use to get optimal performance but,
the size of the search space being `N x 3 x 2 x 2 x 2 = 24N`, it can take a lot of time: on a machine with 80 physical cores, this means trying out at most `24 x 80 = 1920` different setups! 😱
Fortunately, Intel's [SigOpt](https://sigopt.com/), through Bayesian optimization, allows us to make these tuning experiments both faster and more convenient to analyse, while providing similar performance than the brute force approach.
When we analyse the relative difference between the absolute best latency and what SigOpt provides, we observe that although it is often not as good as brute force (except for sequence length = 512 in that specific case),
it gives very close performance, with **8.6%** being the biggest gap on this figure.
<table class="block mx-auto">
<tr>
<td>
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="Absolute best latency found by SigOpt automatic tuning vs brute force" src="assets/35_bert_cpu_scaling_part_2/sigopt/Intel%20Ice%20lake%20Xeon%208380%20-%20TorchScript%20-%20Batch%20Size%201%20-%20Absolute%20Best%20Latency%20vs%20SigOpt%20Best%20Latency.svg"></medium-zoom>
<figcaption>Figure 23. Absolute best latency found by SigOpt automatic tuning vs brute force</figcaption>
</figure>
</td>
<td>
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="Relative best latency found by SigOpt automatic tuning vs brute force" src="assets/35_bert_cpu_scaling_part_2/sigopt/Intel%20Ice%20lake%20Xeon%208380%20-%20TorchScript%20-%20Batch%20Size%201%20-%20Relative%20Difference%20Absolute%20Best%20Latency%20vs%20SigOpt%20Best%20Latency.svg"></medium-zoom>
<figcaption>Figure 24. Relative best latency found by SigOpt automatic tuning vs brute force</figcaption>
</figure>
</td>
</tr>
</table>
SigOpt is also very useful for analysis: it provides a lot of figures and valuable information.
First, it gives the best value it was able to find, the corresponding knobs, and the history of trials and how it improved as trials went, for example, with sequence length = 20:
<table>
<tr>
<td>
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="SigOpt best value display" src="assets/35_bert_cpu_scaling_part_2/sigopt/sigopt_best_value.png"></medium-zoom>
<figcaption>Figure 25. SigOpt best value reporting</figcaption>
</figure>
</td>
<td>
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="SigOpt best value display" src="assets/35_bert_cpu_scaling_part_2/sigopt/sigopt_improvements_over_time.png"></medium-zoom>
<figcaption>Figure 26. SigOpt best value reporting</figcaption>
</figure>
</td>
</tr>
</table>
In this specific setup, 16 cores along with the other knobs were able to give the best results, that is very important to know, because as mentioned before,
that means that multiple instances of the model can be run in parallel while still having the best latency for each.
It also shows that it had converged at roughly 20 trials, meaning that maybe 25 trials instead of 40 would have been enough.
A wide range of other valuable information is available, such as Parameter Importance:
As expected, the number of cores is, by far, the most important parameter, but the others play a part too, and it is very experiment dependent.
For instance, for the sequence length = 512 experiment, this was the Parameter Importance:
<table>
<tr>
<td>
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="SigOpt best value for Batch Size = 1, Sequence Length = 20" src="assets/35_bert_cpu_scaling_part_2/sigopt/sigopt_parameters_importance_seq_20.png"></medium-zoom>
<figcaption>Figure 27. SigOpt best value for Batch Size = 1, Sequence Length = 20</figcaption>
</figure>
</td>
<td>
<figure class="image table text-center m-0 w-full"`>
<medium-zoom background="rgba(0,0,0,.7)" alt="SigOpt best value for Batch Size = 1, Sequence Length = 512" src="assets/35_bert_cpu_scaling_part_2/sigopt/sigopt_parameters_importance_seq_512.png"></medium-zoom>
<figcaption>Figure 28. SigOpt best value for Batch Size = 1, Sequence Length = 512</figcaption>
</figure>
</td>
</tr>
</table>
Here not only the impact of using OpenMP vs Intel OpenMP was bigger than the impact of the allocator, the relative importance of each knob is more balanced than in the sequence length = 20 experiment.
And many more figures, often interactive, are available on SigOpt such as:
- 2D experiment history, allowing to compare knobs vs knobs or knobs vs objectives
- 3D experiment history, allowing to do the same thing as the 2D experiment history with one more knob / objective.
## Conclusion - Accelerating Transformers for Production
In this post, we showed how the new Intel Ice Lake Xeon CPUs are suitable for running AI workloads at scale along with the software elements you can swap and tune in order to exploit the full potential of the hardware.
All these items are to be considered after setting-up the various lower-level knobs detailed in [the previous blog](https://huggingface.co/blog/bert-cpu-scaling-part-1) to maximize the usage of all the cores and resources.
At Hugging Face, we are on a mission to democratize state-of-the-art Machine Learning, and a critical part of our work is to make these state-of-the-art models as efficient as possible, to use less energy and memory at scale, and to be more affordable to run by companies of all sizes.
Our collaboration with Intel through the 🤗 [Hardware Partner Program](https://huggingface.co/hardware) enables us to make advanced efficiency and optimization techniques easily available to the community, through our new 🤗 [Optimum open source library](https://github.com/huggingface/optimum) dedicated to production performance.
For companies looking to accelerate their Transformer models inference, our new 🤗 [Infinity product offers a plug-and-play containerized solution](https://huggingface.co/infinity), achieving down to 1ms latency on GPU and 2ms on Intel Xeon Ice Lake CPUs.
If you found this post interesting or useful to your work, please consider giving Optimum a star. And if this post was music to your ears, consider [joining our Machine Learning Optimization team](https://apply.workable.com/huggingface/)!
| 5 |
0 | hf_public_repos | hf_public_repos/blog/paligemma.md | ---
title: "PaliGemma – Google's Cutting-Edge Open Vision Language Model"
thumbnail: /blog/assets/paligemma/Paligemma.png
authors:
- user: merve
- user: andsteing
guest: true
org: google
- user: pcuenq
---
# PaliGemma – Google's Cutting-Edge Open Vision Language Model
Updated on 23-05-2024: We have introduced a few changes to the transformers PaliGemma implementation around fine-tuning, which you can find in this [notebook](https://github.com/merveenoyan/smol-vision/blob/main/Fine_tune_PaliGemma.ipynb).
PaliGemma is a new family of vision language models from Google. PaliGemma can take in an image and a text and output text.
The team at Google has released three types of models: the pretrained (pt) models, the mix models, and the fine-tuned (ft) models, each with different resolutions and available in multiple precisions for convenience.
All models are released in the Hugging Face Hub model repositories with their model cards and licenses and have transformers integration.
## What is PaliGemma?
PaliGemma ([Github](https://github.com/google-research/big_vision/blob/main/big_vision/configs/proj/paligemma/README.md)) is a family of vision-language models with an architecture consisting of [SigLIP-So400m](https://huggingface.co/google/siglip-so400m-patch14-384) as the image encoder and [Gemma-2B](https://huggingface.co/google/gemma-2b) as text decoder. SigLIP is a state-of-the-art model that can understand both images and text. Like CLIP, it consists of an image and text encoder trained jointly. Similar to [PaLI-3](https://arxiv.org/abs/2310.09199), the combined PaliGemma model is pre-trained on image-text data and can then easily be fine-tuned on downstream tasks, such as captioning, or referring segmentation. [Gemma](https://huggingface.co/blog/gemma) is a decoder-only model for text generation. Combining the image encoder of SigLIP with Gemma using a linear adapter makes PaliGemma a powerful vision language model.

The PaliGemma release comes with three types of models:
- PT checkpoints: Pretrained models that can be fine-tuned to downstream tasks.
- Mix checkpoints: PT models fine-tuned to a mixture of tasks. They are suitable for general-purpose inference with free-text prompts, and can be used for research purposes only.
- FT checkpoints: A set of fine-tuned models, each one specialized on a different academic benchmark. They are available in various resolutions and are intended for research purposes only.
The models come in three different resolutions (`224x224`, `448x448`, `896x896`) and three different precisions (`bfloat16`, `float16`, and `float32`). Each repository contains the checkpoints for a given resolution and task, with three revisions for each of the available precisions. The `main` branch of each repository contains `float32` checkpoints, where as the `bfloat16` and `float16` revisions contain the corresponding precisions. There are separate repositories for models compatible with 🤗 transformers, and with the original JAX implementation.
As explained in detail further down, the high-resolution models require a lot more memory to run, because the input sequences are much longer. They may help with fine-grained tasks such as OCR, but the quality increase is small for most tasks. The 224 versions are perfectly fine for most purposes.
You can find all the models and Spaces in this [collection](https://huggingface.co/collections/google/paligemma-release-6643a9ffbf57de2ae0448dda).
## Model Capabilities
PaliGemma is a single-turn vision language model not meant for conversational use, and it works best when fine-tuning to a specific use case.
You can configure which task the model will solve by conditioning it with task prefixes, such as “detect” or “segment”. The pretrained models were trained in this fashion to imbue them with a rich set of capabilities (question answering, captioning, segmentation, etc.). However, they are not designed to be used directly, but to be transferred (by fine-tuning) to specific tasks using a similar prompt structure. For interactive testing, you can use the "mix" family of models, which have been fine-tuned on a mixture of tasks.
The examples below use the mix checkpoints to demonstrate some of the capabilities.
### Image Captioning
PaliGemma can caption images when prompted to. You can try various captioning prompts with the mix checkpoints to see how they respond.

### Visual Question Answering
PaliGemma can answer questions about an image, simply pass your question along with the image to do so.

### Detection
PaliGemma can detect entities in an image using the `detect [entity]` prompt. It will output the location for the bounding box coordinates in the form of special `<loc[value]>` tokens, where `value` is a number that represents a normalized coordinate. Each detection is represented by four location coordinates in the order _y_min, x_min, y_max, x_max_, followed by the label that was detected in that box. To convert values to coordinates, you first need to divide the numbers by 1024, then multiply `y` by the image height and `x` by its width. This will give you the coordinates of the bounding boxes, relative to the original image size.

### Referring Expression Segmentation
PaliGemma mix checkpoints can also segment entities in an image when given the `segment [entity]` prompt. This is called referring expression segmentation, because we refer to the entities of interest using natural language descriptions. The output is a sequence of location and segmentation tokens. The location tokens represent a bounding box as described above. The segmentation tokens can be further processed to generate segmentation masks.

### Document Understanding
PaliGemma mix checkpoints have great document understanding and reasoning capabilities.

### Mix Benchmarks
Below you can find the scores for mix checkpoints.
| Model | MMVP Accuracy | POPE Accuracy (random/popular/adversarial) |
|---------|---------------|--------------------------------------------|
| mix-224 | 46.00 | 88.00 86.63 85.67 |
| mix-448 | 45.33 | 89.37 88.40 87.47 |
## Fine-tuned Checkpoints
In addition to the pretrained and mix models, Google has released models already transferred to various tasks. They correspond to academic benchmarks that can be used by the research community to compare how they perform. Below, you can find a selected few. These models also come in different resolutions. You can check out the model card of any model for all metrics.
| Model Name | Dataset/Task | Score in Transferred Task |
|-------------------------------------------|--------------------------------------------------------|---------------------------------------------------------------------------------|
| [paligemma-3b-ft-vqav2-448](https://hf.co/google/paligemma-3b-ft-vqav2-448)| Diagram Understanding | 85.64 Accuracy on VQAV2 |
| [paligemma-3b-ft-cococap-448](https://hf.co/google/paligemma-3b-ft-cococap-448)| COCO Captions | 144.6 CIDEr |
| [paligemma-3b-ft-science-qa-448](https://hf.co/google/paligemma-3b-ft-science-qa-448)| Science Question Answering | 95.93 Accuracy on ScienceQA Img subset with no CoT |
| [paligemma-3b-ft-refcoco-seg-896](https://hf.co/google/paligemma-3b-ft-refcoco-seg-896)| Understanding References to Specific Objects in Images | 76.94 Mean IoU on refcoco 72.18 Mean IoU on refcoco+ 72.22 Mean IoU on refcocog |
| [paligemma-3b-ft-rsvqa-hr-224](https://hf.co/google/paligemma-3b-ft-rsvqa-hr-224)| Remote Sensing Visual Question Answering | 92.61 Accuracy on test 90.58 Accuracy on test2 |
## Demo
As part of this release we have a [demo](https://huggingface.co/spaces/google/paligemma) that wraps the reference implementation in the [big_vision repository](https://github.com/google-research/big_vision) and provides an easy way to play around with the mix models.
We also have a version of the [demo compatible with Transformers](https://huggingface.co/spaces/google/paligemma-hf), to show how to use the PaliGemma transformers API.
<figure class="image flex flex-col items-center text-center m-0 w-full">
<video alt="paligemma.mp4" autoplay loop autobuffer muted playsinline>
<source src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/paligemma/paligemma.mp4" type="video/mp4">
</video>
<figcaption></figcaption>
</figure>
## How to Run Inference
To obtain access to the PaliGemma models, you need to accept the Gemma license terms and conditions. If you already have access to other Gemma models in Hugging Face, you’re good to go. Otherwise, please visit any of the PaliGemma models, and accept the license if you agree with it. Once you have access, you need to authenticate either through [notebook_login](https://huggingface.co/docs/huggingface_hub/v0.21.2/en/package_reference/login#huggingface_hub.notebook_login) or [huggingface-cli login](https://huggingface.co/docs/huggingface_hub/en/guides/cli#huggingface-cli-login). After logging in, you’ll be good to go!
You can also try inference [in this notebook](https://colab.research.google.com/drive/1gOhRCFyt9yIoasJkd4VoaHcIqJPdJnlg?usp=sharing) right away.
### Using Transformers
You can use the `PaliGemmaForConditionalGeneration` class to infer with any of the released models. Simply preprocess the prompt and the image with the built-in processor, and then pass the preprocessed inputs for generation.
```python
from transformers import AutoProcessor, PaliGemmaForConditionalGeneration
model_id = "google/paligemma-3b-mix-224"
model = PaliGemmaForConditionalGeneration.from_pretrained(model_id)
processor = AutoProcessor.from_pretrained(model_id)
prompt = "What is on the flower?"
image_file = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/bee.jpg?download=true"
raw_image = Image.open(requests.get(image_file, stream=True).raw)
inputs = processor(prompt, raw_image, return_tensors="pt")
output = model.generate(**inputs, max_new_tokens=20)
print(processor.decode(output[0], skip_special_tokens=True)[len(prompt):])
# bee
```
You can also load the model in 4-bit as follows.
```python
from transformers import BitsAndBytesConfig
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16
)
model = PaligemmaForConditionalGeneration.from_pretrained(
model_id,
quantization_config=bnb_config,
device_map={"":0}
)
```
In addition to 4-bit (or 8-bit) loading, the transformers integration allows you to leverage other tools in the Hugging Face ecosystem, such as:
- Training and inference scripts and examples
- Serialization to safe files ([safetensors](https://huggingface.co/docs/safetensors/en/index))
- Integrations with tools such as [PEFT (parameter efficient fine-tuning)](https://huggingface.co/docs/peft/en/index)
- [Utilities and helpers](https://huggingface.co/docs/transformers/v4.34.0/en/internal/generation_utils) to run generation with the model
## Detailed Inference Process
If you want to write your own pre-processing or training code or would like to understand in more detail how PaliGemma works, these are the steps that the input image and text go through.
The input text is tokenized normally. A `<bos>` token is added at the beginning, and an additional newline token (`\n`) is appended. This newline token is an essential part of the input prompt the model was trained with, so adding it explicitly ensures it's always there. The tokenized text is also prefixed with a fixed number of `<image>` tokens. How many? It depends on the input image resolution and the patch size used by the SigLIP model. PaliGemma models are pre-trained on one of three square sizes (224x224, 448x448, or 896x896), and always use a patch size of 14. Therefore, the number of `<image>` tokens to prepend is 256 for the 224 models (`224/14 * 224/14`), 1024 for the 448 models, and 4096 for the 896 models.
Note that larger images result in much longer input sequences, and therefore require a lot more memory to go through the language portion of the model. Keep this in mind when considering what model to use. For finer-grained tasks, such as OCR, larger images may help achieve better results, but the incremental quality is small for the vast majority of tasks. Do test on your tasks before deciding to move to a larger resolution!
This complete "prompt" goes through the text embeddings layer of the language model and generates token embeddings with 2048 dimensions per token.
In parallel with this, the input image is resized, using bicubic resampling, to the required input size (224x224 for the smallest-resolution models). Then it goes through the SigLIP Image Encoder to generate image embeddings with 1152 dimensions per patch. This is where the linear projector comes into play: the image embeddings are projected to obtain representations with 2048 dimensions per patch, same as the ones obtained from the text tokens. The final image embeddings are then merged with the `<image>` text embeddings, and this is the final input that is used for autoregressive text generation. Generation works normally in autoregressive mode. It uses full block attention for the complete input (`image + bos + prompt + \n`), and a causal attention mask for the generated text.
All of these details are taken care of automatically in the processor and model classes, so inference can be performed using the familiar high-level transformers API shown in the previous examples.
## Fine-tuning
### Using big_vision
PaliGemma was trained in the [big_vision](https://github.com/google-research/big_vision) codebase. The same codebase was already used to develop models like BiT, the original ViT, LiT, CapPa, SigLIP, and many more.
The project config folder [configs/proj/paligemma/](https://github.com/google-research/big_vision/blob/main/big_vision/configs/proj/paligemma/) contains a `README.md`. The pretrained model can be transferred by running config files in the [transfers/](https://github.com/google-research/big_vision/blob/main/big_vision/configs/proj/paligemma/transfers/) subfolder, and all our transfer results were obtained by running the configs provided therein. If you want to transfer your own model, fork the example config [transfers/forkme.py](https://github.com/google-research/big_vision/blob/main/big_vision/configs/proj/paligemma/transfers/forkme.py) and follow the instructions in the comments to adapt it to your usecase.
There is also a Colab [`finetune_paligemma.ipynb`](https://colab.research.google.com/github/google-research/big_vision/blob/main/big_vision/configs/proj/paligemma/finetune_paligemma.ipynb) that runs a *simplified fine-tuning* that works on a free T4 GPU runtime. To fit on the limited host and GPU memory, the code in the Colab only updates the weights in the attention layers (170M params) and uses SGD (instead of Adam).
### Using transformers
Fine-tuning PaliGemma is very easy, thanks to transformers. One can also do QLoRA or LoRA fine-tuning. In this example, we will briefly fine-tune the decoder, and then show how to switch to QLoRA fine-tuning.
We will install the latest version of the transformers library.
```bash
pip install transformers
```
Just like on the inference section, we will authenticate to access the model using `notebook_login()`.
```python
from huggingface_hub import notebook_login
notebook_login()
```
For this example, we will use the VQAv2 dataset, and fine-tune the model to answer questions about images. Let’s load the dataset. We will only use the columns question, multiple_choice_answer and image, so let’s remove the rest of the columns as well. We will also split the dataset.
```python
from datasets import load_dataset
ds = load_dataset('HuggingFaceM4/VQAv2', split="train")
cols_remove = ["question_type", "answers", "answer_type", "image_id", "question_id"]
ds = ds.remove_columns(cols_remove)
ds = ds.train_test_split(test_size=0.1)
train_ds = ds["train"]
val_ds = ds["test"]
```
We will now load the processor, which contains the image processing and tokenization part, and preprocess our dataset.
```python
from transformers import PaliGemmaProcessor
model_id = "google/paligemma-3b-pt-224"
processor = PaliGemmaProcessor.from_pretrained(model_id)
```
We will create a prompt template to condition PaliGemma to answer visual questions. Since the tokenizer pads the inputs, we need to set the pads in our labels to something other than the pad token in the tokenizer, as well as the image token.
```python
import torch
device = "cuda"
image_token = processor.tokenizer.convert_tokens_to_ids("<image>")
def collate_fn(examples):
texts = ["answer " + example["question"] for example in examples]
labels= [example['multiple_choice_answer'] for example in examples]
images = [example["image"].convert("RGB") for example in examples]
tokens = processor(text=texts, images=images, suffix=labels,
return_tensors="pt", padding="longest")
tokens = tokens.to(torch.bfloat16).to(device)
return tokens
```
You can either load the model directly or load the model in 4-bit for QLoRA. Below you can see how to load the model directly. We will load the model, and freeze the image encoder and the projector, and only fine-tune the decoder. If your images are within a particular domain, which might not be in the dataset the model was pre-trained with, you might want to skip freezing the image encoder.
```python
model = PaliGemmaForConditionalGeneration.from_pretrained(model_id, torch_dtype=torch.bfloat16).to(device)
for param in model.vision_tower.parameters():
param.requires_grad = False
for param in model.multi_modal_projector.parameters():
param.requires_grad = True
```
If you want to load model in 4-bit for QLoRA, you can add the following changes below.
```python
from transformers import BitsAndBytesConfig
from peft import get_peft_model, LoraConfig
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_type=torch.bfloat16
)
lora_config = LoraConfig(
r=8,
target_modules=["q_proj", "o_proj", "k_proj", "v_proj", "gate_proj", "up_proj", "down_proj"],
task_type="CAUSAL_LM",
)
model = PaliGemmaForConditionalGeneration.from_pretrained(model_id, quantization_config=bnb_config, device_map={"":0})
model = get_peft_model(model, lora_config)
model.print_trainable_parameters()
#trainable params: 11,298,816 || all params: 2,934,634,224 || trainable%: 0.38501616002417344
```
We will now initialize the Trainer and TrainingArguments. If you will do QLoRA fine-tuning, set the optimizer to `paged_adamw_8bit` instead.
```python
from transformers import TrainingArguments
args=TrainingArguments(
num_train_epochs=2,
remove_unused_columns=False,
per_device_train_batch_size=16,
gradient_accumulation_steps=4,
warmup_steps=2,
learning_rate=2e-5,
weight_decay=1e-6,
adam_beta2=0.999,
logging_steps=100,
optim="adamw_hf",
save_strategy="steps",
save_steps=1000,
push_to_hub=True,
save_total_limit=1,
bf16=True,
report_to=["tensorboard"],
dataloader_pin_memory=False
)
```
Initialize `Trainer`, pass in the datasets, data collating function and training arguments, and call `train()` to start training.
```python
trainer = Trainer(
model=model,
train_dataset=train_ds,
eval_dataset=val_ds,
data_collator=collate_fn,
args=args
)
trainer.train()
```
## Additional Resources
- [Vision Language Models Explained](https://huggingface.co/blog/vlms)
- [Model docs](https://huggingface.co/docs/transformers/model_doc/paligemma)
- [Notebook for inference](https://colab.research.google.com/drive/1gOhRCFyt9yIoasJkd4VoaHcIqJPdJnlg?usp=sharing)
- [Big vision PaliGemma demo](https://huggingface.co/spaces/google/paligemma)
- [🤗 transformers PaliGemma demo](https://huggingface.co/spaces/google/paligemma-hf)
- [Collection for all PaliGemma models](https://huggingface.co/collections/google/paligemma-release-6643a9ffbf57de2ae0448dda)
- [Collection for all PaliGemma fine-tuned models](https://huggingface.co/collections/google/paligemma-ft-models-6643b03efb769dad650d2dda)
- [Original Implementation](https://github.com/google-research/big_vision/blob/main/big_vision/models/proj/paligemma/paligemma.py)
We would like to thank [Omar Sanseviero](osanseviero), [Lucas Beyer](https://huggingface.co/giffmana), [Xiaohua Zhai](https://huggingface.co/xiaohuazhai) and [Matthias Minderer](https://huggingface.co/mjlm) for their thorough reviews on this blog post. We would like to thank [Peter Robicheaux](https://github.com/probicheaux) for their help with fine-tuning changes in transformers.
| 6 |
0 | hf_public_repos | hf_public_repos/blog/sasha-luccioni-interview.md | ---
title: "Machine Learning Experts - Sasha Luccioni"
thumbnail: /blog/assets/69_sasha_luccioni_interview/thumbnail.png
authors:
- user: britneymuller
---
# Machine Learning Experts - Sasha Luccioni
## 🤗 Welcome to Machine Learning Experts - Sasha Luccioni
🚀 _If you're interested in learning how ML Experts, like Sasha, can help accelerate your ML roadmap visit: <a href="https://huggingface.co/support?utm_source=blog&utm_medium=blog&utm_campaign=ml_experts&utm_content=sasha_interview_article">hf.co/support.</a>_
Hey friends! Welcome to Machine Learning Experts. I'm your host, Britney Muller and today’s guest is [Sasha Luccioni](https://twitter.com/SashaMTL). Sasha is a Research Scientist at Hugging Face where she works on the ethical and societal impacts of Machine Learning models and datasets.
Sasha is also a co-chair of the Carbon Footprint WG of the [Big Science Workshop](https://bigscience.huggingface.co), on the Board of [WiML](https://wimlworkshop.org), and a founding member of the [Climate Change AI (CCAI)](https://www.climatechange.ai) organization which catalyzes impactful work applying machine learning to the climate crisis.
You’ll hear Sasha talk about how she measures the carbon footprint of an email, how she helped a local soup kitchen leverage the power of ML, and how meaning and creativity fuel her work.
Very excited to introduce this brilliant episode to you! Here’s my conversation with Sasha Luccioni:
<iframe width="100%" style="aspect-ratio: 16 / 9;"src="https://www.youtube.com/embed/AQRkcMr0Zk0" title="YouTube video player" frameborder="0" allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture" allowfullscreen></iframe>
*Note: Transcription has been slightly modified/reformatted to deliver the highest-quality reading experience.*
### Thank you so much for joining us today, we are so excited to have you on!
**Sasha:** I'm really excited to be here.
### Diving right in, can you speak to your background and what led you to Hugging Face?
**Sasha:** Yeah, I mean if we go all the way back, I started studying linguistics. I was super into languages and both of my parents were mathematicians. But I thought, I don't want to do math, I want to do language. I started doing NLP, natural language processing, during my undergrad and got super into it.
My Ph.D. was in computer science, but I maintained a linguistic angle. I started out in humanities and then got into computer science. Then after my Ph.D., I spent a couple of years working in applied AI research. My last job was in finance, and then one day I decided that I wanted to do good and socially positive AI research, so I quit my job. I decided that no amount of money was worth working on AI for AI's sake, I wanted to do more. So I spent a couple of years working with Yoshua Bengio, meanwhile working on AI for good projects, AI for climate change projects, and then I was looking for my next role.
I wanted to be in a place that I trusted was doing the right things and going in the right direction. When I met Thom and Clem, I knew that Hugging Face was a place for me and that it would be exactly what I was looking for.
### Love that you wanted to something that felt meaningful!
**Sasha:** Yeah, when I hear people on Sunday evening being like “Monday's tomorrow…” I'm like “Tomorrow's Monday! That's great!” And it's not that I'm a workaholic, I definitely do other stuff, and have a family and everything, but I'm literally excited to go to work to do really cool stuff. Think that's important. I know people can live without it, but I can't.
### What are you most excited about that you're working on now?
**Sasha:** I think the [Big Science](https://bigscience.huggingface.co/) project is definitely super inspiring. For the last couple of years, I've been seeing these large language models, and I was always like, but how do they work? And where's the code, where's their data, and what's going on in there? How are they developed and who was involved? It was all like a black box thing, and I'm so happy that we're finally making it a glass box. And there are so many people involved and so many really interesting perspectives.
And I'm chairing the carbon footprint working group, so we're working on different aspects of environmental impacts and above and beyond just counting CO2 emissions, but other things like the manufacturing costs. At some point, we even consider how much CO2 an email generates, things like that, so we're definitely thinking of different perspectives.
Also about the data, I'm involved in a lot of the data working groups at Big Science, and it's really interesting because typically it’s been like we're gonna get the most data we can, stuff it in a language model and it's gonna be great. And it's gonna learn all this stuff, but what's actually in there, there's so much weird stuff on the internet, and things that you don't necessarily want your model to be seeing. So we're really looking into mindfulness, data curation, and multilingualism as well to make sure that it's not just a hundred percent English or 99% English. So it's such a great initiative, and it makes me excited to be involved.
### Love the idea of evaluating the carbon footprint of an email!?
**Sasha:** Yeah, people did it, depending on the attachment or not, but it was just because we found this article of, I think it was a theoretical physics project and they did that, they did everything. They did video calls, travel commutes, emails, and the actual experiments as well. And they made this pie chart and it was cool because there were 37 categories in the pie chart, and we really wanted to do that. But I don't know if we want to go into that level of detail, but we were going to do a survey and ask participants on average, how many hours did they spend working on Big Science or training in language models and things like that. So we didn’t want just the number of GPU hours for training the model, but also people's implication and participation in the project.
### Can you speak a little bit more about the environmental impact of AI?
**Sasha:** Yeah, it's a topic I got involved in three years ago now. The first article that came out was by [Emma Strubell and her colleagues](https://arxiv.org/pdf/1906.02243.pdf) and they essentially trained a large language model with hyperparameter tuning. So essentially looking at all the different configurations and then the figure they got was like that AI model emitted as much carbon as five cars in their lifetimes. Which includes gas and everything, like the average kind of consumption. And with my colleagues we were like, well that doesn't sound right, it can't be all models, right? And so we really went off the deep end into figuring out what has an impact on emissions, and how we can measure emissions.
So first we just [created this online calculator](https://mlco2.github.io/impact/) where someone could enter what hardware they use, how long they trained for, and where on their location or a cloud computing instance. And then it would give them an estimate of the carbon involved that they admitted. Essentially that was our first attempt, a calculator, and then we helped create a package called code carbon which actually does that in real-time. So it's gonna run in parallel to whatever you're doing training a model and then at the end spit out an estimate of the carbon emissions.
Lately we've been going further and further. I just had an article that I was a co-author on that got accepted, about how to proactively reduce emissions. For example, by anticipating times when servers are not as used as other times, like doing either time delaying or picking the right region because if you train in, I don't know, Australia, it's gonna be a coal-based grid, and so it's gonna be highly polluting. Whereas in Quebec or Montreal where I'm based, it's a hundred percent hydroelectricity. So just by making that choice, you can reduce your emissions by around a hundredfold. And so just small things like that, like above and beyond estimating, we also want people to start reducing their emissions. It's the next step.
### It’s never crossed my mind that geographically where you compute has a different emissions cost.
**Sasha:** Oh yeah, and I'm so into energy grids now. Every time I go somewhere I'm like, so what's the energy coming from? How are you generating it? And so it's really interesting, there are a lot of historical factors and a lot of cultural factors.
For example; France is mostly nuclear, mostly energy, and Canada has a lot of hydroelectric energy. Some places have a lot of wind or tidal, and so it's really interesting just to understand when you turn on a lamp, where that electricity is coming from and at what cost to the environment. Because when I was growing up, I would always turn off the lights, and unplug whatever but not anything more than that. It was just good best practices. You turn off the light when you're not in a room, but after that, you can really go deeper depending on where you live, your energy's coming from different sources. And there is more or less pollution, but we just don't see that we don't see how energy is produced, we just see the light and we're like oh, this is my lamp. So it's really important to start thinking about that.
### It's so easy not to think about that stuff, which I could see being a barrier for machine learning engineers who might not have that general awareness.
**Sasha:** Yeah, exactly. And I mean usually, it's just by habit, right? I think there's a default option when you're using cloud instances, often it's like the closest one to you or the one with the most GPUs available or whatever. There's a default option, and people are like okay, fine, whatever and click the default. It's this nudge theory aspect.
I did a master's in cognitive science and just by changing the default option, you can change people's behavior to an incredible degree. So whether you put apples or chocolate bars near the cash register, or small stuff like that. And so if the default option, all of a sudden was the low carbon one, we could save so many emissions just because people are just like okay, fine, I'm gonna train a model in Montreal, I don't care. It doesn't matter, as long as you have access to the hardware you need, you don't care where it is. But in the long run, it really adds up.
### What are some of the ways that machine learning teams and engineers could be a bit more proactive in aspects like that?
**Sasha:** So I've noticed that a lot of people are really environmentally conscious. Like they'll bike to work or they'll eat less meat and things like that. They'll have this kind of environmental awareness, but then disassociate it from their work because we're not aware of our impact as machine learning researchers or engineers on the environment. And without sharing it necessarily, just starting to measure, for example, carbon emissions. And starting to look at what instances you're picking, if you have a choice. For example, I know that Google Cloud and AWS have started putting low carbon as a little tag so you can pick it because the information is there. And starting to make these little steps, and connecting the dots between environment and tech. These are dots that are not often connected because tech is so like the cloud, it's nice to be distributed, and you don't really see it. And so by grounding it more, you see the impact it can have on the environment.
### That's a great point. And I've listened to a couple talks and podcasts of yours, where you've mentioned how machine learning can be used to help offset the environmental impact of models.
**Sasha:** Yeah, we wrote a paper a couple of years ago that was a cool experience. It's almost a hundred pages, it's called [Tackling Climate Change with Machine Learning](https://dl.acm.org/doi/10.1145/3485128). And there are like 25 authors, but there are all these different sections ranging from electricity to city planning to transportation to forestry and agriculture. We essentially have these chapters of the paper where we talk about the problems that exist. For example, renewable energy is variable in a lot of cases. So if you have solar panels, they won't produce energy at night. That's kind of like a given. And then wind power is dependent on the wind. And so a big challenge in implementing renewable energy is that you have to respond to the demand. You need to be able to give people power at night, even if you're on solar energy. And so typically you have either diesel generators or this backup system that often cancels out the environmental effect, like the emissions that you're saving, but what machine learning can do, you're essentially predicting how much energy will be needed. So based on previous days, based on the temperature, based on events that happen, you can start being like okay, well we're gonna be predicting half an hour out or an hour out or 6 hours or 24 hours. And you can start having different horizons and doing time series prediction.
Then instead of powering up a diesel generator which is cool because you can just power them up, and in a couple of seconds they're up and running. What you can also do is have batteries, but batteries you need to start charging them ahead of time. So say you're six hours out, you start charging your batteries, knowing that either there's a cloud coming or that night's gonna fall, so you need that energy stored ahead. And so there are things that you could do that are proactive that can make a huge difference. And then machine learning is good at that, it’s good at predicting the future, it’s good at finding the right features, and things like that. So that's one of the go-to examples. Another one is remote sensing. So we have a lot of satellite data about the planet and see either deforestation or tracking wildfires. In a lot of cases, you can detect wildfires automatically based on satellite imagery and deploy people right away. Because they're often in remote places that you don't necessarily have people living in. And so there are all these different cases in which machine learning could be super useful. We have the data, we have the need, and so this paper is all about how to get involved and whatever you're good at, whatever you like doing, and how to apply machine learning and use it in the fight against climate change.
### For people listening that are interested in this effort, but perhaps work at an organization where it's not prioritized, what tips do you have to help incentivize teams to prioritize environmental impact?
**Sasha:** So it's always a question of cost and benefit or time, you know, the time that you need to put in. And sometimes people just don't know that there are different tools that exist or approaches. And so if people are interested or even curious to learn about it. I think that's the first up because even when I first started thinking of what I can do, I didn't know that all these things existed. People have been working on this for like a fairly long time using different data science techniques.
For example, we created a website called [climatechange.ai](http://climatechange.ai), and we have interactive summaries that you can read about how climate change can help and detect methane or whatever. And I think that just by sprinkling this knowledge can help trigger some interesting thought processes or discussions. I've participated in several round tables at companies that are not traditionally climate change-oriented but are starting to think about it. And they're like okay well we put a composting bin in the kitchen, or we did this and we did that. So then from the tech side, what can we do? It's really interesting because there are a lot of low-hanging fruits that you just need to learn about. And then it's like oh well, I can do that, I can by default use this cloud computing instance and that's not gonna cost me anything. And you need to change a parameter somewhere.
### What are some of the more common mistakes you see machine learning engineers or teams make when it comes to implementing these improvements?
**Sasha:** Actually, machine learning people or AI people, in general, have this stereotype from other communities that we think AI's gonna solve everything. We just arrived and we're like oh, we're gonna do AI. And it's gonna solve all your problems no matter what you guys have been doing for 50 years, AI's gonna do it. And I haven't seen that attitude that much, but we know what AI can do, we know what machine learning can do, and we have a certain kind of worldview. It's like when you have a hammer, everything's a nail, so it’s kind of something like that. And I participated in a couple of hackathons and just like in general, people want to make stuff or do stuff to fight climate change. It's often like oh, this sounds like a great thing AI can do, and we're gonna do it without thinking of how it's gonna be used or how it's gonna be useful or how it's gonna be. Because it's like yeah, sure, AI can do all this stuff, but then at the end of the day, someone's gonna use it.
For example, if you create something for scanning satellite imagery and detecting wildfire, the information that your model outputs has to be interpretable. Or you need to add that little extra step of sending a new email or whatever it is. Otherwise, we train a model, it's great, it's super accurate, but then at the end of the day, nobody's gonna use it just because it's missing a tiny little connection to the real world or the way that people will use it. And that's not sexy, people are like yeah, whatever, I don't even know how to write a script that sends an email. I don't either. But still, just doing that little extra step, that's so much less technologically complex than what you've done so far. Just adding that little thing will make a big difference and it can be in terms of UI, or it can be in terms of creating an app. It's like the machine learning stuff that's actually crucial for your project to be used.
And I've participated in organizing workshops where people submit ideas that are super great on paper that have great accuracy rates, but then they just stagnate in paper form or article form because you still need to have that next step. I remember this one presentation of a machine learning algorithm that could reduce flight emissions of airplanes by 3 to 7% by calculating the wind speed, etc. Of course, that person should have done a startup or a product or pitched this to Boeing or whatever, otherwise it was just a paper that they published in this workshop that I was organizing, and then that was it. And scientists or engineers don't necessarily have those skills necessary to go see an airplane manufacturer with this thing, but it's frustrating. And at the end of the day, to see these great ideas, this great tech that just fizzles.
### So sad. That's such a great story though and how there are opportunities like that.
**Sasha:** Yeah, and I think scientists, so often, don't necessarily want to make money, they just want to solve problems often. And so you don't necessarily even need to start a startup, you could just talk to someone or pitch this to someone, but you have to get out of your comfort zone. And the academic conferences you go to, you need to go to a networking event in the aviation industry and that's scary, right? And so there are often these barriers between disciplines that I find very sad. I actually like going to a business or random industry networking event because this is where connections can get made, that can make the biggest changes. It's not in the industry-specific conferences because everyone's talking about the same technical style that of course, they're making progress and making innovations. But then if you're the only machine learning expert in a room full of aviation experts, you can do so much. You can spark all these little sparks, and after you're gonna have people reducing emissions of flights.
### That's powerful. Wondering if you could add some more context as to why finding meaning in your work is so important?
**Sasha:** Yeah, there's this concept that my mom read about in some magazine ages ago when I was a kid. It's called [Ikigai](https://en.wikipedia.org/wiki/Ikigai), and it's a Japanese concept, it's like how to find the reason or the meaning of life. It's kind of how to find your place in the universe. And it was like you need to find something that has these four elements. Like what you love doing, what you're good at, what the world needs and then what can be a career. I was always like this is my career, but she was always like no because even if you love doing this, but you can't get paid for it, then it's a hard life as well. And so she always asked me this when I was picking my courses at university or even my degree, she'll always be like okay, well is that aligned with things you love and things you're good at? And some things she'd be like yeah, but you're not good at that though. I mean you could really want to do this, but maybe this is not what you're good at.
So I think that it's always been my driving factor in my career. And I feel that it helps feel that you're useful and you're like a positive force in the world. For example, when I was working at Morgan Stanley, I felt that there were interesting problems like I was doing really well, no questions asked, the salary was amazing. No complaints there, but there was missing this what the world needs aspect that was kind of like this itch I couldn’t scratch essentially. But given this framing, this itchy guy, I was like oh, that's what's missing in my life. And so I think that people in general, not only in machine learning, it's good to think about not only what you're good at, but also what you love doing, what motivates you, why you would get out of bed in the morning and of course having this aspect of what the world needs. And it doesn't have to be like solving world hunger, it can be on a much smaller scale or on a much more conceptual scale.
For example, what I feel like we're doing at Hugging Face is really that machine learning needs more open source code, more model sharing, but not because it's gonna solve any one particular problem, because it can contribute to a spectrum of problems. Anything from reproducibility to compatibility to product, but there's like the world needs this to some extent. And so I think that really helped me converge on Hugging Face as being maybe the world doesn't necessarily need better social networks because a lot of people doing AI research in the context of social media or these big tech companies. Maybe the world doesn't necessarily need that, maybe not right now, maybe what the world needs is something different. And so this kind of four-part framing really helped me find meaning in my career and my life in general, trying to find all these four elements.
### What other examples or applications do you find and see potential meaning in AI machine learning?
**Sasha:** I think that an often overlooked aspect is accessibility and I guess democratization, but like making AI easier for non-specialists. Because can you imagine if I don't know anyone like a journalist or a doctor or any profession you can think of could easily train or use an AI model. Because I feel like yeah, for sure we do AI in medicine and healthcare, but it's from a very AI machine learning angle. But if we had more doctors who were empowered to create more tools or any profession like a baker… I actually have a friend who has a bakery here in Montreal and he was like yeah, well can AI help me make better bread? And I was like probably, yeah. I'm sure that if you do some kind of experimentation and he's like oh, I can install a camera in my oven. And I was like oh yeah, you could do that I guess. I mean we were talking about it and you know, actually, bread is pretty fickle, you need the right humidity, and it actually takes a lot of experimentation and a lot of know-how from ‘boulangers’ [‘bakers’]. And the same thing for croissants, his croissants are so good and he's like yeah, well you need to really know the right butter, etc. And he was like I want to make an AI model that will help bake bread. And I was like I don't even know how to help you start, like where do you start doing that?
So accessibility is such an important part. For example, the internet has become so accessible nowadays. Anyone can navigate, and initially, it was a lot less so I think that AI still has some road to travel in order to become a more accessible and democratic tool.
### And you've talked before about the power of data and how it's not talked about enough.
**Sasha:** Yeah, four or five years ago, I went to Costa Rica with my husband on a trip. We were just looking on a map and then I found this research center that was at the edge of the world. It was like being in the middle of nowhere. We had to take a car on a dirt road, then a first boat then a second boat to get there. And they're in the middle of the jungle and they essentially study the jungle and they have all these camera traps that are automatically activated, that are all over the jungle. And then every couple of days they have to hike from camera to camera to switch out the SD cards. And then they take these SD cards back to the station and then they have a laptop and they have to go through every picture it took. And of course, there are a lot of false positives because of wind or whatever, like an animal moving really fast, so there's literally maybe like 5% of actual good images. And I was like why aren't they using it to track biodiversity? And they'd no, we saw a Jaguar on blah, blah, blah at this location because they have a bunch of them.
Then they would try to track if a Jaguar or another animal got killed, if it had babies, or if it looked injured; like all of these different things. And then I was like, I'm sure a part of that could be automated, at least the filtering process of taking out the images that are essentially not useful, but they had graduate students or whatever doing it. But still, there are so many examples like this domain in all areas. And just having these little tools, I'm not saying that because I think we're not there yet, completely replacing scientists in this kind of task, but just small components that are annoying and time-consuming, then machine learning can help bridge that gap.
### Wow. That is so interesting!
**Sasha:** It's actually really, camera trap data is a really huge part of tracking biodiversity. It's used for birds and other animals. It's used in a lot of cases and actually, there's been Kaggle competitions for the last couple of years around camera trap data. And essentially during the year, they have camera traps in different places like Kenya has a bunch and Tanzania as well. And then at the end of the year, they have this big Kaggle competition of recognizing different species of animals. Then after that they deployed the models, and then they update them every year.
So it's picking up, but there's just a lot of data, as you said. So each ecosystem is unique and so you need a model that's gonna be trained on exactly. You can't take a model from Kenya and make it work in Costa Rica, that's not gonna work. You need data, you need experts to train the model, and so there are a lot of elements that need to converge in order for you to be able to do this. Kind of like AutoTrain, Hugging Face has one, but even simpler where biodiversity researchers in Costa Rica could be like these are my images, help me figure out which ones are good quality and the types of animals that are on them. And they could just drag and drop the images like a web UI or something. And then they had this model that's like, here are the 12 images of Jaguars, this one is injured, this one has a baby, etc.
### Do you have insights for teams that are trying to solve for things like this with machine learning, but just lack the necessary data?
**Sasha:** Yeah, I guess another anecdote, I have a lot of these anecdotes, but at some point we wanted to organize an AI for social good hackathon here in Montreal like three or three or four years ago. And then we were gonna contact all these NGOs, like soup kitchens, homeless shelters in Montreal. And we started going to these places and then we're like okay, where's your data? And they're like, “What data?” I'm like, “Well don't you keep track of how many people you have in your homeless shelter or if they come back,” and they're like “No.” And then they're like, “But on the other hand, we have these problems of either people disappearing and we don't know where they are or people staying for a long time. And then at a certain point we're supposed to not let them stand.” They had a lot of issues, for example, in the food kitchen, they had a lot of wasted food because they had trouble predicting how many people would arrive. And sometimes they're like yeah, we noticed that in October, usually there are fewer people, but we don't really have any data to support that.
So we completely canceled the hackathon, then instead we did, I think we call them data literacy or digital literacy workshops. So essentially we went to these places if they were interested and we gave one or two-hour workshops about how to use a spreadsheet and figure out what they wanted to track. Because sometimes they didn't even know what kind of things they wanted to save or wanted to really have a trace of. So we did a couple of them in some places like we would come back every couple of months and check in. And then a year later we had a couple, especially a food kitchen, we actually managed to make a connection between them, and I don't remember what the company name was anymore, but they essentially did this supply chain management software thing. And so the kitchen was actually able to implement a system where they would track like we got 10 pounds of tomatoes, this many people showed up today, and this is the waste of food we have. Then a year later we were able to do a hackathon to help them reduce food waste.
So that was really cool because we really saw a year and some before they had no trace of anything, they just had intuitions, which were useful, but weren't formal. And then a year later we were able to get data and integrate it into their app, and then they would have a thing saying be careful, your tomatoes are gonna go bad soon because it's been three days since you had them. Or in cases where it's like pasta, it would be six months or a year, and so we implemented a system that would actually give alerts to them. And it was super simple in terms of technology, there was not even much AI in there, but just something that would help them keep track of different categories of food. And so it was a really interesting experience because I realized that yeah, you can come in and be like we're gonna help you do whatever, but if you don't have much data, what are you gonna do?
### Exactly, that's so interesting. That's so amazing that you were able to jump in there and provide that first step; the educational piece of that puzzle to get them set up on something like that.
**Sasha:** Yeah, it's been a while since I organized any hackathons. But I think these community involvement events are really important because they help people learn stuff like we learn that you can't just like barge in and use AI, digital literacy is so much more important and they just never really put the effort into collecting the data, even if they needed it. Or they didn't know what could be done and things like that. So taking this effort or five steps back and helping improve tech skills, generally speaking, is a really useful contribution that people don't really realize is an option, I guess.
### What industries are you most excited to see machine learning be applied to?
**Sasha:** Climate change! Yeah, the environment is kind of my number one. Education has always been something that I've really been interested in and I've kind of always been waiting. I did my Ph.D. in education and AI, like how AI can be used in education. I keep waiting for it to finally hit a certain peak, but I guess there are a lot of contextual elements and stuff like that, but I think AI, machine learning, and education can be used in so many different ways.
For example, what I was working on during my Ph.D. was how to help pick activities, like learning activities and exercises that are best suited for learners. Instead of giving all kids or adults or whatever the same exercise to help them focus on their weak knowledge points, weak skills, and focusing on those. So instead of like a one size fits all approach. And not replacing the teacher, but tutoring more, like okay, you learn a concept in school, and help you work on it. And you have someone figure this one out really fast and they don't need those exercises, but someone else could need more time to practice. And I think that there is so much that can be done, but I still don't see it really being used, but I think it's potentially really impactful.
### All right, so we're going to dive into rapid-fire questions. If you could go back and do one thing differently at the start of your machine learning career, what would it be?
**Sasha:** I would spend more time focusing on math. So as I said, my parents are mathematicians and they would always give me extra math exercises. And they would always be like math is universal, math, math, math. So when you get force-fed things in your childhood, you don't necessarily appreciate them later, and so I was like no, languages. And so for a good part of my university studies, I was like no math, only humanities. And so I feel like if I had been a bit more open from the beginning and realized the potential of math, even in linguistics or a lot of things, I think I would've come to where I'm at much faster than spending three years being like no math, no math.
I remember in grade 12, my final year of high school, my parents made me sign up for a math competition, like an Olympiad and I won it. Then I remember I had a medal and I put it on my mom and I'm like “Now leave me alone, I'm not gonna do any more math in my life.” And she was like “Yeah, yeah.” And then after that, when I was picking my Ph.D. program, she's like “Oh I see there are math classes, eh? because you're doing machine learning, eh?”, and I was like “No,” but yeah, I should have gotten over my initial distaste for math a lot quicker.
### That's so funny, and it’s interesting to hear that because I often hear people say you need to know less and less math, the more advanced some of these ML libraries and programs get.
**Sasha:** Definitely, but I think having a good base, I'm not saying you have to be a super genius, but having this intuition. Like when I was working with Yoshua for example, he's a total math genius and just the facility of interpreting results or understanding behaviors of a machine learning model just because math is so second nature. Whereas for me I have to be like, okay, so I'm gonna write this equation with the loss function. I'm gonna try to understand the consequences, etc., and it's a bit less automatic, but it's a skill that you can develop. It's not necessarily theoretical, it could also be experimental knowledge. But just having this really solid math background helps you get there quicker, you couldn't really skip a few steps.
### That was brilliant. And you can ask your parents for help?
**Sasha:** No, I refuse to ask my parents for help, no way. Plus since they're like theoretical mathematicians, they think machine learning is just for people who aren't good at math and who are lazy or whatever. And so depending on whatever area you're in, there's pure mathematicians, theoretical mathematics, applied mathematicians, there's like statisticians, and there are all these different camps.
And so I remember my little brother also was thinking of going to machine learning, and my dad was like no, stay in theoretical math, that's where all the geniuses are. He was like “No, machine learning is where math goes to die,” and I was like “Dad, I’m here!” And he was like “Well I'd rather your brother stayed in something more refined,” and I was like “That's not fair.”
So yeah, there are a lot of empirical aspects in machine learning, and a lot of trial and error, like you're tuning hyperparameters and you don't really know why. And so I think formal mathematicians, unless there's like a formula, they don't think ML is real or legit.
### So besides maybe a mathematical foundation, what advice would you give to someone looking to get into machine learning?
**Sasha:** I think getting your hands dirty and starting out with I don't know, Jupyter Notebooks or coding exercises, things like that. Especially if you do have specific angles or problems you want to get into or just ideas in general, and so starting to try. I remember I did a summer school in machine learning when I was at the beginning of my Ph.D., I think. And then it was really interesting, but then all these examples were so disconnected. I don't remember what the data was, like cats versus dogs, I don't know, but like, why am I gonna use that? And then they're like part of the exercise was to find something that you want to use, like a classifier essentially to do.
Then I remember I got pictures of flowers or something, and I got super into it. I was like yeah, see, it confuses this flower and that flower because they're kind of similar. I understand I need more images, and I got super into it and that's when it clicked in my head, it's not only this super abstract classification. Or like oh yeah, I remember we were using this data app called [MNIST](https://huggingface.co/datasets/mnist) which is super popular because it's like handwritten digits and they're really small, and the network goes fast. So people use it a lot in the beginning of machine learning courses. And I was like who cares, I don't want to classify digits, like whatever, right? And then when they let us pick our own images, all of a sudden it gets a lot more personal, interesting, and captivating. So I think that if people are stuck in a rut, they can really focus on things that interest them. For example, get some climate change data and start playing around with it and it really makes the process more pleasant.
### I love that, find something that you're interested in.
**Sasha:** Exactly. And one of my favorite projects I worked on was classifying butterflies. We trained neural networks to classify butterflies based on pictures people took and it was so much fun. You learn so much, and then you're also solving a problem that you understand how it's gonna be used, and so it was such a great thing to be involved in. And I wish that everyone had found this kind of interest in the work they do because you really feel like you're making a difference, and it's cool, it's fun and it's interesting, and you want to do more. For example, this project was done in partnership with the Montreal insectarium, which is a museum for insects. And I kept in touch with a lot of these people and then they just renovated the insectarium and they're opening it after like three years of renovation this weekend.
They also invited me and my family to the opening, and I'm so excited to go there. You could actually handle insects, they’re going to have stick bugs, and they're gonna have a big greenhouse where there are butterflies everywhere. And in that greenhouse, I mean you have to install the app, but you can take pictures of butterflies, then it uses our AI network to identify them. And I'm so excited to go there to use the app and to see my kids using it and to see this whole thing. Because of the old version, they would give you this little pamphlet with pictures of butterflies and you have to go find them. I just can't wait to see the difference between that static representation and this actual app that you could use to take pictures of butterflies.
### Oh my gosh. And how cool to see something that you created being used like that.
**Sasha:** Exactly. And even if it's not like fighting climate change, I think it can make a big difference in helping people appreciate nature and biodiversity and taking things from something that's so abstract and two-dimensional to something that you can really get involved in and take pictures of. I think that makes a huge difference in terms of our perception and our connection. It helps you make a connection between yourself and nature, for example.
### So should people be afraid of AI taking over the world?
**Sasha:** I think that we're really far from it. I guess it depends on what you mean by taking over the world, but I think that we should be a lot more mindful of what's going on right now. Instead of thinking to the future and being like oh terminator, whatever, and to kind of be aware of how AI's being used in our phones and our lives, and to be more cognizant of that.
Technology or events in general, we have more influence on them than we think by using Alexa, for example, we're giving agency, we're giving not only material or funds to this technology. And we can also participate in it, for example, oh well I'm gonna opt out of my data being used for whatever if I am using this technology. Or I'm gonna read the fine print and figure out what it is that AI is doing in this case, and being more involved in general.
So I think that people are really seeing AI as a very distant potential mega threat, but it's actually a current threat, but on a different scale. It's like a different perception. It's like instead of thinking of this AGI or whatever, start thinking about the small things in our lives that AI is being used for, and then engage with them. And then there's gonna be less chance that AGI is gonna take over the world if you make the more mindful choices about data sharing, about consent, about using technology in certain ways. Like if you find out that your police force in your city is using facial recognition technology, you can speak up about that. That's part of your rights as a citizen in many places. And so it's by engaging yourself, you can have an influence on the future by engaging in the present.
### What are you interested in right now? It could be anything, a movie, a recipe, a podcast, etc.?
**Sasha:** So during the pandemic, or the lockdowns and stuff like that, I got super into plants. I bought so many plants and now we're preparing a garden with my children. So this is the first time I've done this, we've planted seeds like tomatoes, peppers, and cucumbers. I usually just buy them at the groceries when they're already ready, but this time around I was like, no, I want to teach my kids. But I also want to learn what the whole process is. And so we planted them maybe 10 days ago and they're starting to grow. And we're watering them every day, and I think that this is also part of this process of learning more about nature and the conditions that can help plants thrive and stuff like that. So last summer already, we built not just a square essentially that we fill in with dirt, but this year we're trying to make it better. I want to have several levels and stuff like that, so I'm really looking forward to learning more about growing your own food.
### That is so cool. I feel like that's such a grounding activity.
**Sasha:** Yeah, and it's like the polar opposite of what I do. It's great not doing something on my computer, but just going outside and having dirty fingernails. I remember being like who would want to do gardening, it’s so boring, now I'm super into gardening. I can't wait for the weekend to go gardening.
### Yeah, that's great. There's something so rewarding about creating something that you can see touch, feel, and smell as opposed to pushing pixels.
**Sasha:** Exactly, sometimes you spend a whole day grappling with this program that has bugs in it and it's not working. You're so frustrating, and then you go outside and you're like, but I have cherry tomatoes, it's all good.
### What are some of your favorite machine learning papers?
**Sasha:** My favorite currently, papers by a researcher or by [Abeba Birhane](https://twitter.com/Abebab) who's a researcher in AI ethics. It's like a completely different way of looking at things. So for example, she wrote [a paper](https://arxiv.org/abs/2106.15590) that just got accepted to [FAcct](https://facctconference.org/), which is fairness in ethics conference in AI. Which was about values and how the way we do machine learning research is actually driven by the things that we value and the things that, for example, if I value a network that has high accuracy, for example, performance, I might be less willing to focus on efficiency. So for example, I'll train a model for a long time, just because I want it to be really accurate. Or like if I want to have something new, like this novelty value, I'm not gonna read the literature and see what people have been doing for whatever 10 years, I'm gonna be like I'm gonna reinvent this.
So she and her co-authors write this really interesting paper about the connection between values that are theoretical, like a kind of metaphysical, and the way that they're instantiated in machine learning. And I found that it was really interesting because typically we don't see it that way. Typically it's like oh, well we have to establish state-of-the-art, we have to establish accuracy and do this and that, and then like site-related work, but it's like a checkbox, you just have to do it. And then they think a lot more in-depth about why we're doing this, and then what are some ultra ways of doing things. For example, doing a trade off between efficiency and accuracy, like if you have a model that's slightly less accurate, but that's a lot more efficient and trains faster, that could be a good way of democratizing AI because people need less computational resources to train a model. And so there are all these different connections that they make that I find it really cool.
### Wow, we'll definitely be linking to that paper as well, so people can check that out. Yeah, very cool. Anything else you'd like to share? Maybe things you're working on or that you would like people to know about?
**Sasha:** Yeah, something I'm working on outside of Big Science is on evaluation and how we evaluate models. Well kind of to what Ababa talks about in her paper, but even from just a pure machine learning perspective, what are the different ways that we can evaluate models and compare them on different aspects, I guess. Not only accuracy but efficiency and carbon emissions and things like that. So there's a project that started a month or ago on how to evaluate in a way that's not only performance-driven, but takes into account different aspects essentially. And I think that this has been a really overlooked aspect of machine learning, like people typically just once again and just check off like oh, you have to evaluate this and that and that, and then submit the paper. There are also these interesting trade-offs that we could be doing and things that we could be measuring that we're not.
For example, if you have a data set and you have an average accuracy, is the accuracy the same again in different subsets of the data set, like are there for example, patterns that you can pick up on that will help you improve your model, but also make it fairer? I guess the typical example is like image recognition, does it do the same in different… Well the famous [Gender Shades](http://gendershades.org/) paper about the algorithm did better on white men than African American women, but you could do that about anything. Not only gender and race, but you could do that for images, color or types of objects or angles. Like is it good for images from above or images from street level. There are all these different ways of analyzing accuracy or performance that we haven't really looked at because it's typically more time-consuming. And so we want to make tools to help people delve deeper into the results and understand their models better.
### Where can people find you online?
**Sasha:** I'm on [Twitter @SashaMTL](https://twitter.com/SashaMTL), and that's about it. I have a [website](https://www.sashaluccioni.com/), I don't update it enough, but Twitter I think is the best.
### Perfect. We can link to that too. Sasha, thank you so much for joining me today, this has been so insightful and amazing. I really appreciate it.
**Sasha:** Thanks, Britney.
### Thank you for listening to Machine Learning Experts!
_If you or someone you know is interested in direct access to leading ML experts like Sasha who are ready to help accelerate your ML project, go to <a href="https://huggingface.co/support?utm_source=blog&utm_medium=blog&utm_campaign=ml_experts&utm_content=sasha_interview_article">hf.co/support</a> to learn more._ ❤️
| 7 |
0 | hf_public_repos | hf_public_repos/blog/us-national-ai-research-resource.md | ---
title: "Comments on U.S. National AI Research Resource Interim Report"
thumbnail: /blog/assets/92_us_national_ai_research_resource/nairr_thumbnail.png
authors:
- user: irenesolaiman
---
# AI Policy @🤗: Comments on U.S. National AI Research Resource Interim Report
In late June 2022, Hugging Face submitted a response to the White House Office of Science and Technology Policy and National Science Foundation’s Request for Information on a roadmap for implementing the National Artificial Intelligence Research Resource (NAIRR) Task Force’s interim report findings. As a platform working to democratize machine learning by empowering all backgrounds to contribute to AI, we strongly support NAIRR’s efforts.
In our response, we encourage the Task Force to:
- Appoint Technical and Ethical Experts as Advisors
- Technical experts with a track record of ethical innovation should be prioritized as advisors; they can calibrate NAIRR on not only what is technically feasible, implementable, and necessary for AI systems, but also on how to avoid exacerbating harmful biases and other malicious uses of AI systems. [Dr. Margaret Mitchell](https://www.m-mitchell.com/), one of the most prominent technical experts and ethics practitioners in the AI field and Hugging Face’s Chief Ethics Scientist, is a natural example of an external advisor.
- Resource (Model and Data) Documentation Standards
- NAIRR-provided standards and templates for system and dataset documentation will ease accessibility and function as a checklist. This standardization should ensure readability across audiences and backgrounds. [Model Cards](https://huggingface.co/docs/hub/models-cards) are a vastly adopted structure for documentation that can be a strong template for AI models.
- Make ML Accessible to Interdisciplinary, Non-Technical Experts
- NAIRR should provide education resources as well as easily understandable interfaces and low- or no-code tools for all relevant experts to conduct complex tasks, such as training an AI model. For example, Hugging Face’s [AutoTrain](https://huggingface.co/autotrain) empowers anyone regardless of technical skill to train, evaluate, and deploy a natural language processing (NLP) model.
- Monitor for Open-Source and Open-Science for High Misuse and Malicious Use Potential
- Harm must be defined by NAIRR and advisors and continually updated, but should encompass egregious and harmful biases, political disinformation, and hate speech. NAIRR should also invest in legal expertise to craft [Responsible AI Licenses](https://bigscience.huggingface.co/blog/the-bigscience-rail-license) to take action should an actor misuse resources.
- Empower Diverse Researcher Perspectives via Accessible Tooling and Resources
- Tooling and resources must be available and accessible to different disciplines as well as the many languages and perspectives needed to drive responsible innovation. This means at minimum providing resources in multiple languages, which can be based on the most spoken languages in the U.S. The [BigScience Research Workshop](https://bigscience.huggingface.co/), a community of over 1000 researchers from different disciplines hosted by Hugging Face and the French government, is a good example of empowering perspectives from over 60 countries to build one of the most powerful open-source multilingual language models.
Our <a href="/blog/assets/92_us_national_ai_research_resource/Hugging_Face_NAIRR_RFI_2022.pdf">memo</a> goes into further detail for each recommendation. We are eager for more resources to make AI broadly accessible in a responsible manner.
| 8 |
0 | hf_public_repos | hf_public_repos/blog/llama32.md | ---
title: "Llama can now see and run on your device - welcome Llama 3.2"
thumbnail: /blog/assets/llama32/thumbnail.jpg
authors:
- user: merve
- user: philschmid
- user: osanseviero
- user: reach-vb
- user: lewtun
- user: ariG23498
- user: pcuenq
---
# Llama can now see and run on your device - welcome Llama 3.2
Llama 3.2 is out! Today, we welcome the next iteration of the [Llama collection](https://huggingface.co/collections/meta-llama/llama-32-66f448ffc8c32f949b04c8cf) to Hugging Face. This time, we’re excited to collaborate with Meta on the release of multimodal and small models. Ten open-weight models (5 multimodal models and 5 text-only ones) are available on the Hub.
Llama 3.2 Vision comes in two sizes: 11B for efficient deployment and development on consumer-size GPU, and 90B for large-scale applications. Both versions come in base and instruction-tuned variants. In addition to the four multimodal models, Meta released a new version of Llama Guard with vision support. Llama Guard 3 is a safeguard model that can classify model inputs and generations, including detecting harmful multimodal prompts or assistant responses.
Llama 3.2 also includes small text-only language models that can run on-device. They come in two new sizes (1B and 3B) with base and instruct variants, and they have strong capabilities for their sizes. There’s also a small 1B version of Llama Guard that can be deployed alongside these or the larger text models in production use cases.
Among the features and integrations being released, we have:
- [Model checkpoints on the Hub](https://huggingface.co/collections/meta-llama/llama-32-66f448ffc8c32f949b04c8cf)
- [Hugging Face Transformers](https://huggingface.co/docs/transformers/v4.45.1/en/model_doc/mllama) and TGI integration for the Vision models
- Inference & Deployment Integration with Inference Endpoints, Google Cloud, Amazon SageMaker & DELL Enterprise Hub
- Fine-tuning Llama 3.2 11B Vision on a single GPU with [transformers🤗](https://github.com/huggingface/huggingface-llama-recipes/blob/main/fine_tune/Llama-Vision%20FT.ipynb) and [TRL](https://github.com/huggingface/huggingface-llama-recipes/blob/main/fine_tune/sft_vlm.py)
## Table of contents
- [What is Llama 3.2 Vision?](#what-is-llama-32-vision)
- [Llama 3.2 license changes. Sorry, EU :(](#llama-32-license-changes-sorry-eu-)
- [What is special about Llama 3.2 1B and 3B?](#what-is-special-about-llama-32-1b-and-3b)
- [Demo](#demo)
- [Using Hugging Face Transformers](#using-hugging-face-transformers)
- [Llama 3.2 1B & 3B Language Models](#llama-32-1b--3b-language-models)
- [Llama 3.2 Vision](#llama-32-vision)
- [On-device](#on-device)
- [Llama.cpp & Llama-cpp-python](#llamacpp--llama-cpp-python)
- [Transformers.js](#transformersjs)
- [Fine-tuning Llama 3.2](#fine-tuning-llama-32)
- [Hugging Face Partner Integrations](#hugging-face-partner-integrations)
- [Additional Resources](#additional-resources)
- [Acknowledgements](#acknowledgements)
## What is Llama 3.2 Vision?
Llama 3.2 Vision is the most powerful open multimodal model released by Meta. It has great visual understanding and reasoning capabilities and can be used to accomplish a variety of tasks, including visual reasoning and grounding, document question answering, and image-text retrieval. Chain of Thought (CoT) answers are often very good, which makes visual reasoning particularly powerful.
Llama 3.2 Vision can be used to process text and an image as well as only text. With image-text prompting, the model can take English inputs, while for text-only prompting, the model can handle multiple languages.
The full list of languages in text-only mode is:
- English
- German
- French
- Italian
- Portuguese
- Hindi
- Spanish
- Thai
The architecture of these models is based on the combination of Llama 3.1 LLMs combined with a vision tower and an image adapter. The text models used are Llama 3.1 8B for the Llama 3.2 11B Vision model, and Llama 3.1 70B for the 3.2 90B Vision model. To the best of our understanding, the text models were frozen during the training of the vision models to preserve text-only performance.
Below you can find some inference examples from the 11B instruction-tuned model that showcase real world knowledge, document reasoning and infographics understanding capabilities.
<table><thead><tr><th>Input Image</th><th>Input Prompt</th><th>Answer</th></tr></thead><tbody><tr>
<tr>
<td style="vertical-align: middle;"><img src="https://huggingface.co/datasets/huggingface/release-assets/resolve/main/wat_arun.jpg" width="300"/></td>
<td style="vertical-align: middle;">
<strong>Where is this located in? What are other attractions nearby?</strong>
</td>
<td style="vertical-align: middle;">
The image depicts the Grand Palace in Bangkok, Thailand. The Grand Palace is a complex of buildings that served as the official residence of the King of Siam and the administrative seat of government for 150 years. It is one of the most popular tourist attractions in Bangkok and a must-see for anyone visiting the city.<br><br>
Some other attractions near the Grand Palace include:<br>
* Wat Phra Kaew: This temple is located within the Grand Palace complex and is home to the famous Emerald Buddha statue.<br>
* Wat Arun: This temple is located on the west bank of the Chao Phraya River and is known for its stunning architecture and beautiful views of the city.<br>
* Wat Pho: This temple is located near the Grand Palace and is home to a large reclining Buddha statue.<br>
</td>
</tr>
<tr>
<td style="vertical-align: middle;"><img src="https://huggingface.co/datasets/huggingface/release-assets/resolve/main/weather_events.png" width="300"/></td>
<td style="vertical-align: middle;">
<strong>Where do the droughts happen according to this diagram?</strong>
</td>
<td style="vertical-align: middle;">
<strong>Drought Regions in 2016</strong><br>According to the diagram, droughts occurred in two distinct regions in 2016:<br>
* <strong>Eastern and Southern Africa:</strong> This region experienced severe droughts.<br>
* <strong>Chile:</strong> Chile was the driest in January in over 50 years. These areas faced significant water scarcity issues during that period.
</td>
</tr>
<tr>
<td style="vertical-align: middle;"><img src="https://huggingface.co/datasets/huggingface/release-assets/resolve/main/invoice.png" width="300"/></td>
<td style="vertical-align: middle;">
<strong>How long does it take from invoice date to due date? Be short and concise.</strong>
</td>
<td style="vertical-align: middle;">
<strong>Invoice Date:</strong> 11/02/2019<br>
<strong>Due Date:</strong> 26/02/2019<br>
<strong>Time Difference Calculation:</strong><br>
26/02/2019 - 11/02/2019 = 15 days<br>
The time difference between the invoice date and the due date is <strong>15 days.</strong>
</td>
</tr>
</table>
Vision models have a context length of 128k tokens, which allows for multiple-turn conversations that may contain images. However, the model works best when attending to a single image, so the `transformers` implementation only attends to the last image provided in the input. This preserves quality and saves memory.
The 11B base model supports tile sizes of 448, while the instruct version and the 90B models all use tile sizes of 560. The models were trained on a massive dataset of 6 billion image-text pairs with a diverse data mixture. This makes them excellent candidates for fine-tuning on downstream tasks. For reference, you can see below how the 11B, 90B and their instruction fine-tuned versions compare in some benchmarks, as reported by Meta. Please, refer to the model cards for additional benchmarks and details.
| | 11B | 11B (instruction-tuned) | 90B | 90B (instruction-tuned) | Metric |
|------------|-------------------|-----------------|-------------------|------------------|------------------|
| MMMU (val) | 41.7 | 50.7 (CoT) | 49.3 (zero-shot) | 60.3 (CoT) | Micro Average Accuracy |
| VQAv2 | 66.8 (val) | 75.2 (test) | 73.6 (val) | 78.1 (test) | Accuracy |
| DocVQA | 62.3 (val) | 88.4 (test) | 70.7 (val) | 90.1 (test) | ANLS |
| AI2D | 62.4 | 91.1 | 75.3 | 92.3 | Accuracy |
We expect the text capabilities of these models to be on par with the 8B and 70B Llama 3.1 models, respectively, as our understanding is that the text models were frozen during the training of the Vision models. Hence, text benchmarks should be consistent with 8B and 70B.
## Llama 3.2 license changes. Sorry, EU :(

Regarding the licensing terms, Llama 3.2 comes with a very similar license to Llama 3.1, with one key difference in the acceptable use policy: any individual domiciled in, or a company with a principal place of business in, the European Union is not being granted the license rights to use multimodal models included in Llama 3.2. This restriction does not apply to end users of a product or service that incorporates any such multimodal models, so people can still build global products with the vision variants.
For full details, please make sure to read [the official license](https://huggingface.co/meta-llama/Llama-3.2-1B/blob/main/LICENSE.txt) and [acceptable use policy](https://huggingface.co/meta-llama/Llama-3.2-1B/blob/main/USE_POLICY.md).
## What is special about Llama 3.2 1B and 3B?
The Llama 3.2 collection includes 1B and 3B text models. These models are designed for on-device use cases, such as prompt rewriting, multilingual knowledge retrieval, summarization tasks, tool usage, and locally running assistants. They outperform many of the available open-access models at these sizes and compete with models that are many times larger. In a later section, we’ll show you how to run these models offline.
The models follow the same architecture as Llama 3.1. They were trained with up to 9 trillion tokens and still support the long context length of 128k tokens. The models are multilingual, supporting English, German, French, Italian, Portuguese, Hindi, Spanish, and Thai.
There is also a new small version of Llama Guard, Llama Guard 3 1B, that can be deployed with these models to evaluate the last user or assistant responses in a multi-turn conversation. It uses a set of pre-defined categories which (new to this version) can be customized or excluded to account for the developer’s use case. For more details on the use of Llama Guard, please refer to the model card.
Bonus: Llama 3.2 has been exposed to a broader collection of languages than the 8 supported languages mentioned above. Developers are encouraged to fine-tune Llama 3.2 models for their specific language use cases.
We ran the base models through the Open LLM Leaderboard evaluation suite, while the instruct models were evaluated across three popular benchmarks that measure instruction-following and correlate well with the LMSYS Chatbot Arena: [IFEval](https://arxiv.org/abs/2311.07911), [AlpacaEval](https://arxiv.org/abs/2404.04475), and [MixEval-Hard](https://arxiv.org/abs/2406.06565). These are the results for the base models, with Llama-3.1-8B included as a reference:
| Model | BBH | MATH Lvl 5 | GPQA | MUSR | MMLU-PRO | Average |
|----------------------|-------|------------|-------|-------|----------|---------|
| Meta-Llama-3.2-1B | 4.37 | 0.23 | 0.00 | 2.56 | 2.26 | 1.88 |
| Meta-Llama-3.2-3B | 14.73 | 1.28 | 4.03 | 3.39 | 16.57 | 8.00 |
| Meta-Llama-3.1-8B | 25.29 | 4.61 | 6.15 | 8.98 | 24.95 | 14.00 |
And here are the results for the instruct models, with Llama-3.1-8B-Instruct included as a reference:
| Model | AlpacaEval (LC) | IFEval | MixEval-Hard | Average |
|-----------------------------|-----------------|--------|--------------|---------|
| Meta-Llama-3.2-1B-Instruct | 7.17 | 58.92 | 26.10 | 30.73 |
| Meta-Llama-3.2-3B-Instruct | 20.88 | 77.01 | 31.80 | 43.23 |
| Meta-Llama-3.1-8B-Instruct | 25.74 | 76.49 | 44.10 | 48.78 |
Remarkably, the 3B model is as strong as the 8B one on IFEval! This makes the model well-suited for agentic applications, where following instructions is crucial for improving reliability. This high IFEval score is very impressive for a model of this size.
Tool use is supported in both the 1B and 3B instruction-tuned models. Tools are specified by the user in a zero-shot setting (the model has no previous information about the tools developers will use). Thus, the built-in tools that were part of the Llama 3.1 models (`brave_search` and `wolfram_alpha`) are no longer available.
Due to their size, these small models can be used as assistants for bigger models and perform [assisted generation](https://huggingface.co/blog/assisted-generation) (also known as speculative decoding). [Here](https://github.com/huggingface/huggingface-llama-recipes/blob/main/assisted_decoding/assisted_decoding_8B_1B.ipynb) is an example of using the Llama 3.2 1B model as an assistant to the Llama 3.1 8B model. For offline use cases, please check the [on-device section](#on-device) later in the post.
## Demo
You can experiment with the three Instruct models in the following demos:
- [Gradio Space with Llama 3.2 11B Vision Instruct](https://huggingface.co/spaces/huggingface-projects/llama-3.2-vision-11B)
- [Gradio-powered Space with Llama 3.2 3B](https://huggingface.co/spaces/huggingface-projects/llama-3.2-3B-Instruct)
- [Llama 3.2 3B running on WebGPU](https://huggingface.co/spaces/webml-community/llama-3.2-webgpu)
- [WebGPU Llama 3.2 3B powered by MLC Web-LLM](https://huggingface.co/spaces/cfahlgren1/webllm-llama-3.2)

## Using Hugging Face Transformers
The text-only checkpoints have the same architecture as previous releases, so there is no need to update your environment. However, given the new architecture, Llama 3.2 Vision requires an update to Transformers. Please make sure to upgrade your installation to release 4.45.0 or later.
```bash
pip install "transformers>=4.45.0" --upgrade
```
Once upgraded, you can use the new Llama 3.2 models and leverage all the tools of the Hugging Face ecosystem.
## Llama 3.2 1B & 3B Language Models
You can run the 1B and 3B Text model checkpoints in just a couple of lines with Transformers. The model checkpoints are uploaded in `bfloat16` precision, but you can also use float16 or quantized weights. Memory requirements depend on the model size and the precision of the weights. Here's a table showing the approximate memory required for inference using different configurations:
| Model Size | BF16/FP16 | FP8 | INT4 |
|------------|--------|---------|---------|
| 3B | 6.5 GB | 3.2 GB | 1.75 GB |
| 1B | 2.5 GB | 1.25 GB | 0.75 GB |
```python
from transformers import pipeline
import torch
model_id = "meta-llama/Llama-3.2-3B-Instruct"
pipe = pipeline(
"text-generation",
model=model_id,
torch_dtype=torch.bfloat16,
device_map="auto",
)
messages = [
{"role": "user", "content": "Who are you? Please, answer in pirate-speak."},
]
outputs = pipe(
messages,
max_new_tokens=256,
)
response = outputs[0]["generated_text"][-1]["content"]
print(response)
# Arrrr, me hearty! Yer lookin' fer a bit o' information about meself, eh? Alright then, matey! I be a language-generatin' swashbuckler, a digital buccaneer with a penchant fer spinnin' words into gold doubloons o' knowledge! Me name be... (dramatic pause)...Assistant! Aye, that be me name, and I be here to help ye navigate the seven seas o' questions and find the hidden treasure o' answers! So hoist the sails and set course fer adventure, me hearty! What be yer first question?
```
A couple of details:
- We load the model in `bfloat16`. As mentioned above, this is the type used by the original checkpoint published by Meta, so it’s the recommended way to run to ensure the best precision or conduct evaluations. Depending on your hardware, float16 might be faster.
- By default, transformers uses the same sampling parameters (temperature=0.6 and top_p=0.9) as the original meta codebase. We haven’t conducted extensive tests yet, feel free to explore!
## Llama 3.2 Vision
The Vision models are larger, so they require more memory to run than the small text models. For reference, the 11B Vision model takes about 10 GB of GPU RAM during inference, in 4-bit mode.
The easiest way to infer with the instruction-tuned Llama Vision model is to use the built-in chat template. The inputs have `user` and `assistant` roles to indicate the conversation turns. One difference with respect to the text models is that the system role is not supported. User turns may include image-text or text-only inputs. To indicate that the input contains an image, add `{"type": "image"}` to the content part of the input and then pass the image data to the `processor`:
```python
import requests
import torch
from PIL import Image
from transformers import MllamaForConditionalGeneration, AutoProcessor
model_id = "meta-llama/Llama-3.2-11B-Vision-Instruct"
model = MllamaForConditionalGeneration.from_pretrained(
model_id,
torch_dtype=torch.bfloat16,
device="cuda",
)
processor = AutoProcessor.from_pretrained(model_id)
url = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/0052a70beed5bf71b92610a43a52df6d286cd5f3/diffusers/rabbit.jpg"
image = Image.open(requests.get(url, stream=True).raw)
messages = [
{"role": "user", "content": [
{"type": "image"},
{"type": "text", "text": "Can you please describe this image in just one sentence?"}
]}
]
input_text = processor.apply_chat_template(
messages, add_generation_prompt=True,
)
inputs = processor(
image,
input_text,
add_special_tokens=False,
return_tensors="pt",
).to(model.device)
output = model.generate(**inputs, max_new_tokens=70)
print(processor.decode(output[0][inputs["input_ids"].shape[-1]:]))
## The image depicts a rabbit dressed in a blue coat and brown vest, standing on a dirt road in front of a stone house.
```
You can continue the conversation about the image. Remember, however, that if you provide a new image in a new user turn, the model will refer to the new image from that moment on. You can’t query about two different images at the same time. This is an example of the previous conversation continued, where we add the assistant turn to the conversation and ask for some more details:
```python
messages = [
{"role": "user", "content": [
{"type": "image"},
{"type": "text", "text": "Can you please describe this image in just one sentence?"}
]},
{"role": "assistant", "content": "The image depicts a rabbit dressed in a blue coat and brown vest, standing on a dirt road in front of a stone house."},
{"role": "user", "content": "What is in the background?"}
]
input_text = processor.apply_chat_template(
messages,
add_generation_prompt=True,
)
inputs = processor(image, input_text, return_tensors="pt").to(model.device)
output = model.generate(**inputs, max_new_tokens=70)
print(processor.decode(output[0][inputs["input_ids"].shape[-1]:]))
```
And this is the response we got:
```
In the background, there is a stone house with a thatched roof, a dirt road, a field of flowers, and rolling hills.
```
You can also automatically quantize the model, loading it in 8-bit or even 4-bit mode with the `bitsandbytes` library. This is how you’d load the generation pipeline in 4-bit:
```diff
import torch
from transformers import MllamaForConditionalGeneration, AutoProcessor
+from transformers import BitsAndBytesConfig
+bnb_config = BitsAndBytesConfig(
+ load_in_4bit=True,
+ bnb_4bit_quant_type="nf4",
+ bnb_4bit_compute_dtype=torch.bfloat16
)
model = MllamaForConditionalGeneration.from_pretrained(
model_id,
- torch_dtype=torch.bfloat16,
- device="cuda",
+ quantization_config=bnb_config,
)
```
You can then apply the chat template, use the processor, and call the model just like you did before.
## On-device
You can run both Llama 3.2 1B and 3B directly on your device's CPU/ GPU/ Browser using several open-source libraries like the following.
### Llama.cpp & Llama-cpp-python
[Llama.cpp](https://github.com/ggerganov/llama.cpp) is the go-to framework for all things cross-platform on-device ML inference. We provide quantized 4-bit & 8-bit weights for both 1B & 3B models in this collection. We expect the community to embrace these models and create additional quantizations and fine-tunes. You can find all the quantized Llama 3.2 models [here](https://huggingface.co/models?search=hugging-quants/Llama-3.2-).
Here’s how you can use these checkpoints directly with llama.cpp.
Install llama.cpp through brew (works on Mac and Linux).
```bash
brew install llama.cpp
```
You can use the CLI to run a single generation or invoke the llama.cpp server, which is compatible with the Open AI messages specification.
You’d run the CLI using a command like this:
```bash
llama-cli --hf-repo hugging-quants/Llama-3.2-3B-Instruct-Q8_0-GGUF --hf-file llama-3.2-3b-instruct-q8_0.gguf -p "The meaning to life and the universe is"
```
And you’d fire up the server like this:
```bash
llama-server --hf-repo hugging-quants/Llama-3.2-3B-Instruct-Q8_0-GGUF --hf-file llama-3.2-3b-instruct-q8_0.gguf -c 2048
```
You can also use [llama-cpp-python](https://github.com/abetlen/llama-cpp-python) to access these models programmatically in Python. Pip install the library from [PyPI](https://pypi.org/project/llama-cpp-python/) using:
```bash
pip install llama-cpp-python
```
Then, you can run the model as follows:
```python
from llama_cpp import Llama
llm = Llama.from_pretrained(
repo_id="hugging-quants/Llama-3.2-3B-Instruct-Q8_0-GGUF",
filename="*q8_0.gguf",
)
output = llm.create_chat_completion(
messages = [
{
"role": "user",
"content": "What is the capital of France?"
}
]
)
print(output)
```
### Transformers.js
You can even run Llama 3.2 in your browser (or any JavaScript runtime like Node.js, Deno, or Bun) using [Transformers.js](https://huggingface.co/docs/transformers.js). You can find the [ONNX model](https://huggingface.co/onnx-community/Llama-3.2-1B-Instruct) on the Hub. If you haven't already, you can install the library from [NPM](https://www.npmjs.com/package/@huggingface/transformers) using:
```bash
npm i @huggingface/transformers
```
Then, you can run the model as follows:
```js
import { pipeline } from "@huggingface/transformers";
// Create a text generation pipeline
const generator = await pipeline("text-generation", "onnx-community/Llama-3.2-1B-Instruct");
// Define the list of messages
const messages = [
{ role: "system", content: "You are a helpful assistant." },
{ role: "user", content: "Tell me a joke." },
];
// Generate a response
const output = await generator(messages, { max_new_tokens: 128 });
console.log(output[0].generated_text.at(-1).content);
```
<details>
<summary>Example output</summary>
```
Here's a joke for you:
What do you call a fake noodle?
An impasta!
I hope that made you laugh! Do you want to hear another one?
```
</details>
### MLC.ai Web-LLM
MLC.ai Web-LLM is a high-performance in-browser LLM inference engine that brings language model inference directly onto web browsers with hardware acceleration. Everything runs inside the browser with no server support and is accelerated with WebGPU.
WebLLM is fully compatible with OpenAI API. That is, you can use the same OpenAI API on any open-source models locally, with functionalities including streaming, JSON-mode, function-calling, etc.
You can install Web-LLM from npm
```bash
npm install @mlc/web-llm
```
Then, you can run the model as follows:
```js
// Import everything
import * as webllm from "@mlc-ai/web-llm";
// Or only import what you need
import { CreateMLCEngine } from "@mlc-ai/web-llm";
// Callback function to update model loading progress
const initProgressCallback = (initProgress) => {
console.log(initProgress);
}
const selectedModel = "Llama-3.2-3B-Instruct-q4f32_1-MLC";
const engine = await CreateMLCEngine(
selectedModel,
{ initProgressCallback: initProgressCallback }, // engineConfig
);
```
After successfully initializing the engine, you can now invoke chat completions using OpenAI style chat APIs through the `engine.chat.completions` interface.
```js
const messages = [
{ role: "system", content: "You are a helpful AI assistant." },
{ role: "user", content: "Explain the meaning of life as a pirate!" },
]
const reply = await engine.chat.completions.create({
messages,
});
console.log(reply.choices[0].message);
console.log(reply.usage);
```
## Fine-tuning Llama 3.2
TRL supports chatting and fine-tuning with the Llama 3.2 text models out of the box:
```bash
# Chat
trl chat --model_name_or_path meta-llama/Llama-3.2-3B
# Fine-tune
trl sft --model_name_or_path meta-llama/Llama-3.2-3B \
--dataset_name HuggingFaceH4/no_robots \
--output_dir Llama-3.2-3B-Instruct-sft \
--gradient_checkpointing
```
Support for fine tuning Llama 3.2 Vision is also available in TRL with [this script](https://github.com/huggingface/trl/tree/main/examples/scripts/sft_vlm.py).
```bash
# Tested on 8x H100 GPUs
accelerate launch --config_file=examples/accelerate_configs/deepspeed_zero3.yaml \
examples/scripts/sft_vlm.py \
--dataset_name HuggingFaceH4/llava-instruct-mix-vsft \
--model_name_or_path meta-llama/Llama-3.2-11B-Vision-Instruct \
--per_device_train_batch_size 8 \
--gradient_accumulation_steps 8 \
--output_dir Llama-3.2-11B-Vision-Instruct-sft \
--bf16 \
--torch_dtype bfloat16 \
--gradient_checkpointing
```
You can also check out [this notebook](https://github.com/huggingface/huggingface-llama-recipes/blob/main/fine_tune/Llama-Vision%20FT.ipynb) for LoRA fine-tuning using transformers and PEFT.
## Hugging Face Partner Integrations
We are currently working with our partners at AWS, Google Cloud, Microsoft Azure and DELL on adding Llama 3.2 11B, 90B to Amazon SageMaker, Google Kubernetes Engine, Vertex AI Model Catalog, Azure AI Studio, DELL Enterprise Hub. We will update this section as soon as the containers are available, and you can subscribe to [Hugging Squad](https://mailchi.mp/huggingface/squad) for email updates.
## Additional Resources
- [Models on the Hub](https://huggingface.co/collections/meta-llama/llama-32-66f448ffc8c32f949b04c8cf)
- [Hugging Face Llama Recipes](https://github.com/huggingface/huggingface-llama-recipes)
- [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)
- [Meta Blog](https://ai.meta.com/blog/llama-3-2-connect-2024-vision-edge-mobile-devices/)
- [Evaluation datasets](https://huggingface.co/collections/meta-llama/llama-32-evals-66f44b3d2df1c7b136d821f0)
## Acknowledgements
Releasing such models with support and evaluations in the ecosystem would not be possible without the contributions of thousands of community members who have contributed to transformers, text-generation-inference, vllm, pytorch, LM Eval Harness, and many other projects. Hat tip to the VLLM team for their help in testing and reporting issues. This release couldn't have happened without all the support of Clémentine, Alina, Elie, and Loubna for LLM evaluations, Nicolas Patry, Olivier Dehaene, and Daniël de Kok for Text Generation Inference; Lysandre, Arthur, Pavel, Edward Beeching, Amy, Benjamin, Joao, Pablo, Raushan Turganbay, Matthew Carrigan, and Joshua Lochner for transformers, transformers.js, TRL, and PEFT support; Nathan Sarrazin and Victor for making Llama 3.2 available in Hugging Chat; Brigitte Tousignant and Florent Daudens for communication; Julien, Simon, Pierric, Eliott, Lucain, Alvaro, Caleb, and Mishig from the Hub team for Hub development and features for launch.
And big thanks to the Meta Team for releasing Llama 3.2 and making it available to the open AI community!
| 9 |
0 | hf_public_repos | hf_public_repos/blog/ml-for-games-4.md | ---
title: "2D Asset Generation: AI for Game Development #4"
thumbnail: /blog/assets/124_ml-for-games/thumbnail4.png
authors:
- user: dylanebert
---
# 2D Asset Generation: AI for Game Development #4
**Welcome to AI for Game Development!** In this series, we'll be using AI tools to create a fully functional farming game in just 5 days. By the end of this series, you will have learned how you can incorporate a variety of AI tools into your game development workflow. I will show you how you can use AI tools for:
1. Art Style
2. Game Design
3. 3D Assets
4. 2D Assets
5. Story
Want the quick video version? You can watch it [here](https://www.tiktok.com/@individualkex/video/7192994527312137518). Otherwise, if you want the technical details, keep reading!
**Note:** This tutorial is intended for readers who are familiar with Unity development and C#. If you're new to these technologies, check out the [Unity for Beginners](https://www.tiktok.com/@individualkex/video/7086863567412038954) series before continuing.
## Day 4: 2D Assets
In [Part 3](https://huggingface.co/blog/ml-for-games-3) of this tutorial series, we discussed how **text-to-3D** isn't quite ready yet. However, the story is much different for 2D.
In this part, we'll talk about how you can use AI to generate 2D Assets.
### Preface
This tutorial describes a collaborative process for generating 2D Assets, where Stable Diffusion is incorporated as a tool in a conventional 2D workflow. This is intended for readers with some knowledge of image editing and 2D asset creation but may otherwise be helpful for beginners and experts alike.
Requirements:
- Your preferred image-editing software, such as [Photoshop](https://www.adobe.com/products/photoshop.html) or [GIMP](https://www.gimp.org/) (free).
- Stable Diffusion. For instructions on setting up Stable Diffusion, refer to [Part 1](https://huggingface.co/blog/ml-for-games-1#setting-up-stable-diffusion).
### Image2Image
[Diffusion models](https://en.wikipedia.org/wiki/Diffusion_model) such as Stable Diffusion work by reconstructing images from noise, guided by text. Image2Image uses the same process but starts with real images as input rather than noise. This means that the outputs will, to some extent, resemble the input image.
An important parameter in Image2Image is **denoising strength**. This controls the extent to which the model changes the input. A denoising strength of 0 will reproduce the input image exactly, while a denoising strength of 1 will generate a very different image. Another way to think about denoising strength is **creativity**. The image below demonstrates image-to-image with an input image of a circle and the prompt "moon", at various denoising strengths.
<div align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/124_ml-for-games/moons.png" alt="Denoising Strength Example">
</div>
Image2Image allows Stable Diffusion to be used as a tool, rather than as a replacement for the conventional artistic workflow. That is, you can pass your own handmade assets to Image2Image, iterate back on the result by hand, and so on. Let's take an example for the farming game.
### Example: Corn
In this section, I'll walk through how I generated a corn icon for the farming game. As a starting point, I sketched a very rough corn icon, intended to lay out the composition of the image.
<div align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/124_ml-for-games/corn1.png" alt="Corn 1">
</div>
Next, I used Image2Image to generate some icons using the following prompt:
> corn, james gilleard, atey ghailan, pixar concept artists, stardew valley, animal crossing
I used a denoising strength of 0.8, to encourage the model to be more creative. After generating several times, I found a result I liked.
<div align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/124_ml-for-games/corn2.png" alt="Corn 2">
</div>
The image doesn't need to be perfect, just in the direction you're going for, since we'll keep iterating. In my case, I liked the style that was produced, but thought the stalk was a bit too intricate. So, I made some modifications in photoshop.
<div align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/124_ml-for-games/corn3.png" alt="Corn 3">
</div>
Notice that I roughly painted over the parts I wanted to change, allowing Stable Diffusion to fill the details in. I dropped my modified image back into Image2Image, this time using a lower denoising strength of 0.6 since I didn't want to deviate too far from the input. This resulted in an icon I was *almost* happy with.
<div align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/124_ml-for-games/corn4.png" alt="Corn 4">
</div>
The base of the corn stalk was just a bit too painterly for me, and there was a sprout coming out of the top. So, I painted over these in photoshop, made one more pass in Stable Diffusion, and removed the background.
<div align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/124_ml-for-games/corn5.png" alt="Corn 5">
</div>
Voilà, a game-ready corn icon in less than 10 minutes. However, you could spend much more time to get a better result. I recommend [this video](https://youtu.be/blXnuyVgA_Y) for a more detailed walkthrough of making a more intricate asset.
### Example: Scythe
In many cases, you may need to fight Stable Diffusion a bit to get the result you're going for. For me, this was definitely the case for the scythe icon, which required a lot of iteration to get in the direction I was going for.
<div align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/124_ml-for-games/scythe.png" alt="Scythe">
</div>
The issue likely lies in the fact that there are way more images online of scythes as *weapons* rather than as *farming tools*. One way around this is prompt engineering, or fiddling with the prompt to try to push it in the right direction, i.e. writing **scythe, scythe tool** in the prompt or **weapon** in the negative prompt. However, this isn't the only solution.
[Dreambooth](https://dreambooth.github.io/), [textual inversion](https://textual-inversion.github.io/), and [LoRA](https://huggingface.co/blog/lora) are techniques for customizing diffusion models, making them capable of producing results much more specific to what you're going for. These are outside the scope of this tutorial, but are worth mentioning, as they're becoming increasingly prominent in the area of 2D Asset generation.
Generative services such as [layer.ai](https://layer.ai/) and [scenario.gg](https://www.scenario.gg/) are specifically targeted toward game asset generation, likely using techniques such as dreambooth and textual inversion to allow game developers to generate style-consistent assets. However, it remains to be seen which approaches will rise to the top in the emerging generative game development toolkit.
If you're interested in diving deeper into these advanced workflows, check out this [blog post](https://huggingface.co/blog/dreambooth) and [space](https://huggingface.co/spaces/multimodalart/dreambooth-training) on Dreambooth training.
Click [here](https://huggingface.co/blog/ml-for-games-5) to read Part 5, where we use **AI for Story**.
| 0 |
0 | hf_public_repos | hf_public_repos/blog/long-range-transformers.md | ---
title: "Hugging Face Reads, Feb. 2021 - Long-range Transformers"
thumbnail: /blog/assets/14_long_range_transformers/EfficientTransformerTaxonomy.png
authors:
- user: VictorSanh
---
<figure>
<img src="/blog/assets/14_long_range_transformers/EfficientTransformerTaxonomy.png" alt="Efficient Transformers taxonomy"/>
<figcaption>Efficient Transformers taxonomy from Efficient Transformers: a Survey by Tay et al.</figcaption>
</figure>
# Hugging Face Reads, Feb. 2021 - Long-range Transformers
Co-written by Teven Le Scao, Patrick Von Platen, Suraj Patil, Yacine Jernite and Victor Sanh.
> Each month, we will choose a topic to focus on, reading a set of four papers recently published on the subject. We will then write a short blog post summarizing their findings and the common trends between them, and questions we had for follow-up work after reading them. The first topic for January 2021 was [Sparsity and Pruning](https://discuss.huggingface.co/t/hugging-face-reads-01-2021-sparsity-and-pruning/3144), in February 2021 we addressed Long-Range Attention in Transformers.
## Introduction
After the rise of large transformer models in 2018 and 2019, two trends have quickly emerged to bring their compute requirements down. First, conditional computation, quantization, distillation, and pruning have unlocked inference of large models in compute-constrained environments; we’ve already touched upon this in part in our [last reading group post](https://discuss.huggingface.co/t/hugging-face-reads-01-2021-sparsity-and-pruning/3144). The research community then moved to reduce the cost of pre-training.
In particular, one issue has been at the center of the efforts: the quadratic cost in memory and time of transformer models with regard to the sequence length. In order to allow efficient training of very large models, 2020 saw an onslaught of papers to address that bottleneck and scale transformers beyond the usual 512- or 1024- sequence lengths that were the default in NLP at the start of the year.
This topic has been a key part of our research discussions from the start, and our own Patrick Von Platen has already dedicated [a 4-part series to Reformer](https://huggingface.co/blog/reformer). In this reading group, rather than trying to cover every approach (there are so many!), we’ll focus on four main ideas:
* Custom attention patterns (with [Longformer](https://arxiv.org/abs/2004.05150))
* Recurrence (with [Compressive Transformer](https://arxiv.org/abs/1911.05507))
* Low-rank approximations (with [Linformer](https://arxiv.org/abs/2006.04768))
* Kernel approximations (with [Performer](https://arxiv.org/abs/2009.14794))
For exhaustive views of the subject, check out [Efficient Transfomers: A Survey](https://arxiv.org/abs/2009.06732) and [Long Range Arena](https://arxiv.org/abs/2011.04006).
## Summaries
### [Longformer - The Long-Document Transformer](https://arxiv.org/abs/2004.05150)
Iz Beltagy, Matthew E. Peters, Arman Cohan
Longformer addresses the memory bottleneck of transformers by replacing conventional self-attention with a combination of windowed/local/sparse (cf. [Sparse Transformers (2019)](https://arxiv.org/abs/1904.10509)) attention and global attention that scales linearly with the sequence length. As opposed to previous long-range transformer models (e.g. [Transformer-XL (2019)](https://arxiv.org/abs/1901.02860), [Reformer (2020)](https://arxiv.org/abs/2001.04451), [Adaptive Attention Span (2019)](https://arxiv.org/abs/1905.07799)), Longformer’s self-attention layer is designed as a drop-in replacement for the standard self-attention, thus making it possible to leverage pre-trained checkpoints for further pre-training and/or fine-tuning on long sequence tasks.
The standard self-attention matrix (Figure a) scales quadratically with the input length:
<figure>
<img src="/blog/assets/14_long_range_transformers/Longformer.png" alt="Longformer attention"/>
<figcaption>Figure taken from Longformer</figcaption>
</figure>
Longformer uses different attention patterns for autoregressive language modeling, encoder pre-training & fine-tuning, and sequence-to-sequence tasks.
* For autoregressive language modeling, the strongest results are obtained by replacing causal self-attention (a la GPT2) with dilated windowed self-attention (Figure c). With \\(n\\) being the sequence length and \\(w\\) being the window length, this attention pattern reduces the memory consumption from \\(n^2\\) to \\(wn\\), which under the assumption that \\(w << n\\), scales linearly with the sequence length.
* For encoder pre-training, Longformer replaces the bi-directional self-attention (a la BERT) with a combination of local windowed and global bi-directional self-attention (Figure d). This reduces the memory consumption from \\(n^2\\) to \\(w n + g n\\) with \\(g\\) being the number of tokens that are attended to globally, which again scales linearly with the sequence length.
* For sequence-to-sequence models, only the encoder layers (a la BART) are replaced with a combination of local and global bi-directional self-attention (Figure d) because for most seq2seq tasks, only the encoder processes very large inputs (e.g. summarization). The memory consumption is thus reduced from \\(n_s^2+ n_s n_t +n_t^2\\) to \\(w n_s +gn_s +n_s n_t +n_t^2\\) with \\(n_s\\) and \\(n_t\\) being the source (encoder input) and target (decoder input) lengths respectively. For Longformer Encoder-Decoder to be efficient, it is assumed that \\(n_s\\) is much bigger than \\(n_t\\).
#### Main findings
* The authors proposed the dilated windowed self-attention (Figure c) and showed that it yields better results on language modeling compared to just windowed/sparse self-attention (Figure b). The window sizes are increased through the layers. This pattern further outperforms previous architectures (such as Transformer-XL, or adaptive span attention) on downstream benchmarks.
* Global attention allows the information to flow through the whole sequence and applying the global attention to task-motivated tokens (such as the tokens of the question in QA, CLS token for sentence classification) leads to stronger performance on downstream tasks. Using this global pattern, Longformer can be successfully applied to document-level NLP tasks in the transfer learning setting.
* Standard pre-trained models can be adapted to long-range inputs by simply replacing the standard self-attention with the long-range self-attention proposed in this paper and then fine-tuning on the downstream task. This avoids costly pre-training specific to long-range inputs.
#### Follow-up questions
* The increasing size (throughout the layers) of the dilated windowed self-attention echoes findings in computer vision on increasing the receptive field of stacked CNN. How do these two findings relate? What are the transposable learnings?
* Longformer’s Encoder-Decoder architecture works well for tasks that do not require a long target length (e.g. summarization). However, how would it work for long-range seq2seq tasks which require a long target length (e.g. document translation, speech recognition, etc.) especially considering the cross-attention layer of encoder-decoder’s models?
* In practice, the sliding window self-attention relies on many indexing operations to ensure a symmetric query-key weights matrix. Those operations are very slow on TPUs which highlights the question of the applicability of such patterns on other hardware.
### [Compressive Transformers for Long-Range Sequence Modelling](https://arxiv.org/abs/1911.05507)
Jack W. Rae, Anna Potapenko, Siddhant M. Jayakumar, Timothy P. Lillicrap
[Transformer-XL (2019)](https://arxiv.org/abs/1901.02860) showed that caching previously computed layer activations in a memory can boost performance on language modeling tasks (such as *enwik8*). Instead of just attending the current \\(n\\) input tokens, the model can also attend to the past \\(n_m\\) tokens, with \\(n_m\\) being the memory size of the model. Transformer-XL has a memory complexity of \\(O(n^2+ n n_m)\\), which shows that memory cost can increase significantly for very large \\(n_m\\). Hence, Transformer-XL has to eventually discard past activations from the memory when the number of cached activations gets larger than \\(n_m\\). Compressive Transformer addresses this problem by adding an additional compressed memory to efficiently cache past activations that would have otherwise eventually been discarded. This way the model can learn better long-range sequence dependencies having access to significantly more past activations.
<figure>
<img src="/blog/assets/14_long_range_transformers/CompressiveTransformer.png" alt="Compressive Tranformer recurrence"/>
<figcaption>Figure taken from Compressive Transfomer</figcaption>
</figure>
A compression factor \\(c\\) (equal to 3 in the illustration) is chosen to decide the rate at which past activations are compressed. The authors experiment with different compression functions \\(f_c\\) such as max/mean pooling (parameter-free) and 1D convolution (trainable layer). The compression function is trained with backpropagation through time or local auxiliary compression losses. In addition to the current input of length \\(n\\), the model attends to \\(n_m\\) cached activations in the regular memory and \\(n_{cm}\\) compressed memory activations allowing a long temporal dependency of \\(l × (n_m + c n_{cm})\\), with \\(l\\) being the number of attention layers. This increases Transformer-XL’s range by additional \\(l × c × n_{cm}\\) tokens and the memory cost amounts to \\(O(n^2+ n n_m+ n n_{cm})\\). Experiments are conducted on Reinforcement learning, audio generation, and natural language processing. The authors also introduce a new long-range language modeling benchmark called [PG19](https://huggingface.co/datasets/pg19).
#### Main findings
* Compressive Transformer significantly outperforms the state-of-the-art perplexity on language modeling, namely on the enwik8 and WikiText-103 datasets. In particular, compressed memory plays a crucial role in modeling rare words occurring on long sequences.
* The authors show that the model learns to preserve salient information by increasingly attending the compressed memory instead of the regular memory, which goes against the trend of older memories being accessed less frequently.
* All compression functions (average pooling, max pooling, 1D convolution) yield similar results confirming that memory compression is an effective way to store past information.
#### Follow-up questions
* Compressive Transformer requires a special optimization schedule in which the effective batch size is progressively increased to avoid significant performance degradation for lower learning rates. This effect is not well understood and calls into more analysis.
* The Compressive Transformer has many more hyperparameters compared to a simple model like BERT or GPT2: the compression rate, the compression function and loss, the regular and compressed memory sizes, etc. It is not clear whether those parameters generalize well across different tasks (other than language modeling) or similar to the learning rate, make the training also very brittle.
* It would be interesting to probe the regular memory and compressed memory to analyze what kind of information is memorized through the long sequences. Shedding light on the most salient pieces of information can inform methods such as [Funnel Transformer](https://arxiv.org/abs/2006.03236) which reduces the redundancy in maintaining a full-length token-level sequence.
### [Linformer: Self-Attention with Linear Complexity](https://arxiv.org/abs/2006.04768)
Sinong Wang, Belinda Z. Li, Madian Khabsa, Han Fang, Hao Ma
The goal is to reduce the complexity of the self-attention with respect to the sequence length \\(n\\)) from quadratic to linear. This paper makes the observation that the attention matrices are low rank (i.e. they don’t contain \\(n × n\\) worth of information) and explores the possibility of using high-dimensional data compression techniques to build more memory efficient transformers.
The theoretical foundations of the proposed approach are based on the Johnson-Lindenstrauss lemma. Let’s consider \\(m\\)) points in a high-dimensional space. We want to project them to a low-dimensional space while preserving the structure of the dataset (i.e. the mutual distances between points) with a margin of error \\(\varepsilon\\). The Johnson-Lindenstrauss lemma states we can choose a small dimension \\(k \sim 8 \log(m) / \varepsilon^2\\) and find a suitable projection into Rk in polynomial time by simply trying random orthogonal projections.
Linformer projects the sequence length into a smaller dimension by learning a low-rank decomposition of the attention context matrix. The matrix multiplication of the self-attention can be then cleverly re-written such that no matrix of size \\(n × n\\) needs to be ever computed and stored.
Standard transformer:
$$\text{Attention}(Q, K, V) = \text{softmax}(Q * K) * V$$
(n * h) (n * n) (n * h)
Linformer:
$$\text{LinAttention}(Q, K, V) = \text{softmax}(Q * K * W^K) * W^V * V$$
(n * h) (n * d) (d * n) (n * h)
#### Main findings
* The self-attention matrix is low-rank which implies that most of its information can be recovered by its first few highest eigenvalues and can be approximated by a low-rank matrix.
* Lot of works focus on reducing the dimensionality of the hidden states. This paper shows that reducing the sequence length with learned projections can be a strong alternative while shrinking the memory complexity of the self-attention from quadratic to linear.
* Increasing the sequence length doesn’t affect the inference speed (time-clock) of Linformer, when transformers have a linear increase. Moreover, the convergence speed (number of updates) is not impacted by Linformer's self-attention.
<figure>
<img src="/blog/assets/14_long_range_transformers/Linformer.png" alt="Linformer performance"/>
<figcaption>Figure taken from Linformer</figcaption>
</figure>
#### Follow-up questions
* Even though the projections matrices are shared between layers, the approach presented here comes in contrast with the Johnson-Lindenstrauss that states that random orthogonal projections are sufficient (in polynomial time). Would random projections have worked here? This is reminiscent of Reformer which uses random projections in locally sensitive hashing to reduce the memory complexity of the self-attention.
### [Rethinking Attention with Performers](https://arxiv.org/abs/2009.14794)
Krzysztof Choromanski, Valerii Likhosherstov, David Dohan, Xingyou Song, Andreea Gane, Tamas Sarlos, Peter Hawkins, Jared Davis, Afroz Mohiuddin, Lukasz Kaiser, David Belanger, Lucy Colwell, Adrian Weller
The goal is (again!) to reduce the complexity of the self-attention with respect to the sequence length \\(n\\)) from quadratic to linear. In contrast to other papers, the authors note that the sparsity and low-rankness priors of the self-attention may not hold in other modalities (speech, protein sequence modeling). Thus the paper explores methods to reduce the memory burden of the self-attention without any priors on the attention matrix.
The authors observe that if we could perform the matrix multiplication \\(K × V\\) through the softmax ( \\(\text{softmax}(Q × K) × V\\) ), we wouldn’t have to compute the \\(Q x K\\) matrix of size \\(n x n\\) which is the memory bottleneck. They use random feature maps (aka random projections) to approximate the softmax by:
$$\text{softmax}(Q * K) \sim Q’ * K’ = \phi(Q) * \phi(K)$$
, where \\(phi\\) is a non-linear suitable function. And then:
$$\text{Attention}(Q, K, V) \sim \phi(Q) * (\phi(K) * V)$$
Taking inspiration from machine learning papers from the early 2000s, the authors introduce **FAVOR+** (**F**ast **A**ttention **V**ia **O**rthogonal **R**andom positive (**+**) **F**eatures) a procedure to find unbiased or nearly-unbiased estimations of the self-attention matrix, with uniform convergence and low estimation variance.
#### Main findings
* The FAVOR+ procedure can be used to approximate self-attention matrices with high accuracy, without any priors on the form of the attention matrix, making it applicable as a drop-in replacement of standard self-attention and leading to strong performances in multiple applications and modalities.
* The very thorough mathematical investigation of how-to and not-to approximate softmax highlights the relevance of principled methods developed in the early 2000s even in the deep learning era.
* FAVOR+ can also be applied to efficiently model other kernelizable attention mechanisms beyond softmax.
#### Follow-up questions
* Even if the approximation of the attention mechanism is tight, small errors propagate through the transformer layers. This raises the question of the convergence and stability of fine-tuning a pre-trained network with FAVOR+ as an approximation of self-attention.
* The FAVOR+ algorithm is the combination of multiple components. It is not clear which of these components have the most empirical impact on the performance, especially in view of the variety of modalities considered in this work.
## Reading group discussion
The developments in pre-trained transformer-based language models for natural language understanding and generation are impressive. Making these systems efficient for production purposes has become a very active research area. This emphasizes that we still have much to learn and build both on the methodological and practical sides to enable efficient and general deep learning based systems, in particular for applications that require modeling long-range inputs.
The four papers above offer different ways to deal with the quadratic memory complexity of the self-attention mechanism, usually by reducing it to linear complexity. Linformer and Longformer both rely on the observation that the self-attention matrix does not contain \\(n × n\\) worth of information (the attention matrix is low-rank and sparse). Performer gives a principled method to approximate the softmax-attention kernel (and any kernelizable attention mechanisms beyond softmax). Compressive Transformer offers an orthogonal approach to model long range dependencies based on recurrence.
These different inductive biases have implications in terms of computational speed and generalization beyond the training setup. In particular, Linformer and Longformer lead to different trade-offs: Longformer explicitly designs the sparse attention patterns of the self-attention (fixed patterns) while Linformer learns the low-rank matrix factorization of the self-attention matrix. In our experiments, Longformer is less efficient than Linformer, and is currently highly dependent on implementation details. On the other hand, Linformer’s decomposition only works for fixed context length (fixed at training) and cannot generalize to longer sequences without specific adaptation. Moreover, it cannot cache previous activations which can be extremely useful in the generative setup. Interestingly, Performer is conceptually different: it learns to approximate the softmax attention kernel without relying on any sparsity or low-rank assumption. The question of how these inductive biases compare to each other for varying quantities of training data remains.
All these works highlight the importance of long-range inputs modeling in natural language. In the industry, it is common to encounter use-cases such as document translation, document classification or document summarization which require modeling very long sequences in an efficient and robust way. Recently, zero-shot examples priming (a la GPT3) has also emerged as a promising alternative to standard fine-tuning, and increasing the number of priming examples (and thus the context size) steadily increases the performance and robustness. Finally, it is common in other modalities such as speech or protein modeling to encounter long sequences beyond the standard 512 time steps.
Modeling long inputs is not antithetical to modeling short inputs but instead should be thought from the perspective of a continuum from shorter to longer sequences. [Shortformer](https://arxiv.org/abs/2012.15832), Longformer and BERT provide evidence that training the model on short sequences and gradually increasing sequence lengths lead to an accelerated training and stronger downstream performance. This observation is coherent with the intuition that the long-range dependencies acquired when little data is available can rely on spurious correlations instead of robust language understanding. This echoes some experiments Teven Le Scao has run on language modeling: LSTMs are stronger learners in the low data regime compared to transformers and give better perplexities on small-scale language modeling benchmarks such as Penn Treebank.
From a practical point of view, the question of positional embeddings is also a crucial methodological aspect with computational efficiency trade-offs. Relative positional embeddings (introduced in Transformer-XL and used in Compressive Transformers) are appealing because they can easily be extended to yet-unseen sequence lengths, but at the same time, relative positional embeddings are computationally expensive. On the other side, absolute positional embeddings (used in Longformer and Linformer) are less flexible for sequences longer than the ones seen during training, but are computationally more efficient. Interestingly, [Shortformer](https://arxiv.org/abs/2012.15832) introduces a simple alternative by adding the positional information to the queries and keys of the self-attention mechanism instead of adding it to the token embeddings. The method is called position-infused attention and is shown to be very efficient while producing strong results.
## @Hugging Face 🤗: Long-range modeling
The Longformer implementation and the associated open-source checkpoints are available through the Transformers library and the [model hub](https://huggingface.co/models?search=longformer). Performer and Big Bird, which is a long-range model based on sparse attention, are currently in the works as part of our [call for models](https://twitter.com/huggingface/status/1359903233976762368), an effort involving the community in order to promote open-source contributions. We would be pumped to hear from you if you’ve wondered how to contribute to `transformers` but did not know where to start!
For further reading, we recommend checking Patrick Platen’s blog on [Reformer](https://arxiv.org/abs/2001.04451), Teven Le Scao’s post on [Johnson-Lindenstrauss approximation](https://tevenlescao.github.io/blog/fastpages/jupyter/2020/06/18/JL-Lemma-+-Linformer.html), [Efficient Transfomers: A Survey](https://arxiv.org/abs/2009.06732), and [Long Range Arena: A Benchmark for Efficient Transformers](https://arxiv.org/abs/2011.04006).
Next month, we'll cover self-training methods and applications. See you in March!
| 1 |
0 | hf_public_repos | hf_public_repos/blog/mteb.md | ---
title: "MTEB: Massive Text Embedding Benchmark"
thumbnail: /blog/assets/110_mteb/thumbnail.png
authors:
- user: Muennighoff
---
# MTEB: Massive Text Embedding Benchmark
MTEB is a massive benchmark for measuring the performance of text embedding models on diverse embedding tasks.
The 🥇 [leaderboard](https://huggingface.co/spaces/mteb/leaderboard) provides a holistic view of the best text embedding models out there on a variety of tasks.
The 📝 [paper](https://arxiv.org/abs/2210.07316) gives background on the tasks and datasets in MTEB and analyzes leaderboard results!
The 💻 [Github repo](https://github.com/embeddings-benchmark/mteb) contains the code for benchmarking and submitting any model of your choice to the leaderboard.
<p align="center">
<a href="https://huggingface.co/spaces/mteb/leaderboard"><img src="assets/110_mteb/leaderboard.png" alt="MTEB Leaderboard"></a>
</p>
## Why Text Embeddings?
Text Embeddings are vector representations of text that encode semantic information. As machines require numerical inputs to perform computations, text embeddings are a crucial component of many downstream NLP applications. For example, Google uses text embeddings to [power their search engine](https://cloud.google.com/blog/topics/developers-practitioners/find-anything-blazingly-fast-googles-vector-search-technology). Text Embeddings can also be used for finding [patterns in large amount of text via clustering](https://txt.cohere.ai/combing-for-insight-in-10-000-hacker-news-posts-with-text-clustering/) or as inputs to text classification models, such as in our recent [SetFit](https://huggingface.co/blog/setfit) work. The quality of text embeddings, however, is highly dependent on the embedding model used. MTEB is designed to help you find the best embedding model out there for a variety of tasks!
## MTEB
🐋 **Massive**: MTEB includes 56 datasets across 8 tasks and currently summarizes >2000 results on the [leaderboard](https://huggingface.co/spaces/mteb/leaderboard).
🌎 **Multilingual**: MTEB contains up to 112 different languages! We have benchmarked several multilingual models on Bitext Mining, Classification, and STS.
🦚 **Extensible**: Be it new tasks, datasets, metrics, or leaderboard additions, any contribution is very welcome. Check out the GitHub repository to [submit to the leaderboard](https://github.com/embeddings-benchmark/mteb#leaderboard) or [solve open issues](https://github.com/embeddings-benchmark/mteb/issues). We hope you join us on the journey of finding the best text embedding model!
<p align="center">
<img src="assets/110_mteb/mteb_diagram_white_background.png" alt="MTEB Taxonomy">
</p>
<p align="center">
<em>Overview of tasks and datasets in MTEB. Multilingual datasets are marked with a purple shade.</em>
</p>
## Models
For the initial benchmarking of MTEB, we focused on models claiming state-of-the-art results and popular models on the Hub. This led to a high representation of transformers. 🤖
<p align="center">
<img src="assets/110_mteb/benchmark.png" alt="MTEB Speed Benchmark">
</p>
<p align="center">
<em>Models by average English MTEB score (y) vs speed (x) vs embedding size (circle size).</em>
</p>
We grouped models into the following three attributes to simplify finding the best model for your task:
**🏎 Maximum speed** Models like [Glove](https://huggingface.co/sentence-transformers/average_word_embeddings_glove.6B.300d) offer high speed, but suffer from a lack of context awareness resulting in low average MTEB scores.
**⚖️ Speed and performance** Slightly slower, but significantly stronger, [all-mpnet-base-v2](https://huggingface.co/sentence-transformers/all-mpnet-base-v2) or [all-MiniLM-L6-v2](https://huggingface.co/sentence-transformers/all-MiniLM-L6-v2) provide a good balance between speed and performance.
**💪 Maximum performance** Multi-billion parameter models like [ST5-XXL](https://huggingface.co/sentence-transformers/sentence-t5-xxl), [GTR-XXL](https://huggingface.co/sentence-transformers/gtr-t5-xxl) or [SGPT-5.8B-msmarco](https://huggingface.co/Muennighoff/SGPT-5.8B-weightedmean-msmarco-specb-bitfit) dominate on MTEB. They tend to also produce bigger embeddings like [SGPT-5.8B-msmarco](https://huggingface.co/Muennighoff/SGPT-5.8B-weightedmean-msmarco-specb-bitfit) which produces 4096 dimensional embeddings requiring more storage!
Model performance varies a lot depending on the task and dataset, so we recommend checking the various tabs of the [leaderboard](https://huggingface.co/spaces/mteb/leaderboard) before deciding which model to use!
## Benchmark your model
Using the [MTEB library](https://github.com/embeddings-benchmark/mteb), you can benchmark any model that produces embeddings and add its results to the public leaderboard. Let's run through a quick example!
First, install the library:
```sh
pip install mteb
```
Next, benchmark a model on a dataset, for example [komninos word embeddings](https://huggingface.co/sentence-transformers/average_word_embeddings_komninos) on [Banking77](https://huggingface.co/datasets/mteb/banking77).
```python
from mteb import MTEB
from sentence_transformers import SentenceTransformer
model_name = "average_word_embeddings_komninos"
model = SentenceTransformer(model_name)
evaluation = MTEB(tasks=["Banking77Classification"])
results = evaluation.run(model, output_folder=f"results/{model_name}")
```
This should produce a `results/average_word_embeddings_komninos/Banking77Classification.json` file!
Now you can submit the results to the leaderboard by adding it to the metadata of the `README.md` of any model on the Hub.
Run our [automatic script](https://github.com/embeddings-benchmark/mteb/blob/main/scripts/mteb_meta.py) to generate the metadata:
```sh
python mteb_meta.py results/average_word_embeddings_komninos
```
The script will produce a `mteb_metadata.md` file that looks like this:
```sh
---
tags:
- mteb
model-index:
- name: average_word_embeddings_komninos
results:
- task:
type: Classification
dataset:
type: mteb/banking77
name: MTEB Banking77Classification
config: default
split: test
revision: 0fd18e25b25c072e09e0d92ab615fda904d66300
metrics:
- type: accuracy
value: 66.76623376623377
- type: f1
value: 66.59096432882667
---
```
Now add the metadata to the top of a `README.md` of any model on the Hub, like this [SGPT-5.8B-msmarco](https://huggingface.co/Muennighoff/SGPT-5.8B-weightedmean-msmarco-specb-bitfit/blob/main/README.md) model, and it will show up on the [leaderboard](https://huggingface.co/spaces/mteb/leaderboard) after refreshing!
## Next steps
Go out there and benchmark any model you like! Let us know if you have questions or feedback by opening an issue on our [GitHub repo](https://github.com/embeddings-benchmark/mteb) or the [leaderboard community tab](https://huggingface.co/spaces/mteb/leaderboard/discussions) 🤗
Happy embedding!
## Credits
Huge thanks to the following who contributed to the article or to the MTEB codebase (listed in alphabetical order): Steven Liu, Loïc Magne, Nils Reimers and Nouamane Tazi.
| 2 |
0 | hf_public_repos | hf_public_repos/blog/falconmamba.md | ---
title: "Welcome Falcon Mamba: The first strong attention-free 7B model"
thumbnail: /blog/assets/falconmamba/thumbnail.png
authors:
- user: JingweiZuo
guest: true
org: tiiuae
- user: yellowvm
guest: true
org: tiiuae
- user: DhiyaEddine
guest: true
org: tiiuae
- user: IChahed
guest: true
org: tiiuae
- user: ybelkada
guest: true
org: tiiuae
- user: Gkunsch
guest: true
org: tiiuae
---
[Falcon Mamba](https://falconllm.tii.ae/tii-releases-first-sslm-with-falcon-mamba-7b.html) is a new model by [Technology Innovation Institute (TII)](https://www.tii.ae/ai-and-digital-science) in Abu Dhabi released under the [TII Falcon Mamba 7B License 1.0](https://falconllm.tii.ae/falcon-mamba-7b-terms-and-conditions.html). The model is open access and available within the Hugging Face ecosystem [here](https://huggingface.co/tiiuae/falcon-mamba-7b) for anyone to use for their research or application purposes.
In this blog, we will go through the design decisions behind the model, how the model is competitive with respect to other existing SoTA models, and how to use it within the Hugging Face ecosystem.
## First general purpose large-scale pure Mamba model
Transformers, based on the attention mechanism, are the dominant architecture used in all the strongest large language models today. Yet, the attention mechanism is fundamentally limited in processing large sequences due to the increase in compute and memory costs with sequence length. Various alternative architectures, in particular State Space Language Models (SSLMs), tried to address the sequence scaling limitation but fell back in performance compared to SoTA transformers.
With Falcon Mamba, we demonstrate that sequence scaling limitation can indeed be overcome without loss in performance. Falcon Mamba is based on the original Mamba architecture, proposed in [*Mamba: Linear-Time Sequence Modeling with Selective State Spaces*](https://arxiv.org/abs/2312.00752), with the addition of extra RMS normalization layers to ensure stable training at scale. This choice of architecture ensures that Falcon Mamba:
* can process sequences of arbitrary length without any increase in memory storage, in particular, fitting on a single A10 24GB GPU.
* takes a constant amount of time to generate a new token, regardless of the size of the context (see this [section](#hardware-performance))
## Model training
Falcon Mamba was trained with ~ 5500GT of data, mainly composed of RefinedWeb data with addition of high-quality technical data and code data from public sources. We used constant learning rate for the most of the training, followed by a relatively short learning rate decay stage. In this last stage, we also added a small portion of high-quality curated data to further enhance model performance.
## Evaluations
We evaluate our model on all benchmarks of the new leaderboard's version using the `lm-evaluation-harness` package and then normalize the evaluation results with Hugging Face score normalization.
| `model name` |`IFEval`| `BBH` |`MATH LvL5`| `GPQA`| `MUSR`|`MMLU-PRO`|`Average`|
|:--------------------------|:------:|:-----:|:---------:|:-----:|:-----:|:--------:|:-------:|
| ***Pure SSM models*** | | | | | | | |
| `Falcon Mamba-7B` | 33.36 | 19.88 | 3.63 | 8.05 | 10.86 | 14.47 |**15.04**|
| `TRI-ML/mamba-7b-rw`<sup>*</sup>| 22.46 | 6.71 | 0.45 | 1.12 | 5.51 | 1.69 | 6.25 |
|***Hybrid SSM-attention models*** | | | | | | |
|`recurrentgemma-9b` | 30.76 | 14.80 | 4.83 | 4.70 | 6.60 | 17.88 | 13.20 |
| `Zyphra/Zamba-7B-v1`<sup>*</sup> | 24.06 | 21.12 | 3.32 | 3.03 | 7.74 | 16.02 | 12.55 |
|***Transformer models*** | | | | | | | |
| `Falcon2-11B` | 32.61 | 21.94 | 2.34 | 2.80 | 7.53 | 15.44 | 13.78 |
| `Meta-Llama-3-8B` | 14.55 | 24.50 | 3.25 | 7.38 | 6.24 | 24.55 | 13.41 |
| `Meta-Llama-3.1-8B` | 12.70 | 25.29 | 4.61 | 6.15 | 8.98 | 24.95 | 13.78 |
| `Mistral-7B-v0.1` | 23.86 | 22.02 | 2.49 | 5.59 | 10.68 | 22.36 | 14.50 |
| `Mistral-Nemo-Base-2407 (12B)` | 16.83 | 29.37 | 4.98 | 5.82 | 6.52 | 27.46 | 15.08 |
| `gemma-7B` | 26.59 | 21.12 | 6.42 | 4.92 | 10.98 | 21.64 |**15.28**|
Also, we evaluate our model on the benchmarks of the first version of the LLM Leaderboard using `lighteval`.
| `model name` |`ARC`|`HellaSwag` |`MMLU` |`Winogrande`|`TruthfulQA`|`GSM8K`|`Average` |
|:-----------------------------|:------:|:---------:|:-----:|:----------:|:----------:|:-----:|:----------------:|
| ***Pure SSM models*** | | | | | | | |
| `Falcon Mamba-7B`<sup>*</sup> |62.03 | 80.82 | 62.11 | 73.64 | 53.42 | 52.54 | **64.09** |
| `TRI-ML/mamba-7b-rw`<sup>*</sup> | 51.25 | 80.85 | 33.41 | 71.11 | 32.08 | 4.70 | 45.52 |
|***Hybrid SSM-attention models***| | | | | | | |
| `recurrentgemma-9b`<sup>**</sup> |52.00 | 80.40 | 60.50 | 73.60 | 38.60 | 42.60 | 57.95 |
| `Zyphra/Zamba-7B-v1`<sup>*</sup> | 56.14 | 82.23 | 58.11 | 79.87 | 52.88 | 30.78 | 60.00 |
|***Transformer models*** | | | | | | | |
| `Falcon2-11B` | 59.73 | 82.91 | 58.37 | 78.30 | 52.56 | 53.83 | **64.28** |
| `Meta-Llama-3-8B` | 60.24 | 82.23 | 66.70 | 78.45 | 42.93 | 45.19 | 62.62 |
| `Meta-Llama-3.1-8B` | 58.53 | 82.13 | 66.43 | 74.35 | 44.29 | 47.92 | 62.28 |
| `Mistral-7B-v0.1` | 59.98 | 83.31 | 64.16 | 78.37 | 42.15 | 37.83 | 60.97 |
| `gemma-7B` | 61.09 | 82.20 | 64.56 | 79.01 | 44.79 | 50.87 | 63.75 |
For the models marked by *star*, we evaluated the tasks internally, while for the models marked by two *stars*, the results were taken from paper or model card.
## Processing large sequences
Following theoretical efficiency SSM models in processing large sequences, we perform a comparison of memory usage and generation throughput between Falcon Mamba and popular transfomer models using the
[optimum-benchmark](https://github.com/huggingface/optimum-benchmark) library. For a fair comparison, we rescaled the vocabulary size of all transformer models to match Falcon Mamba since it has a big impact on the memory requirements of the model.
Before going to the results, let's first discuss the difference between the prompt (prefill) and generated (decode) parts of the sequence. As we will see, the details of prefill are more important for state space models than for transformer models. When a transformer generates the next token, it needs to attend to the keys and values of all previous tokens in the context. This implies linear scaling of both memory requirements and generation time with context length. A state space model attends to and stores only its recurrent state and, therefore, doesn't need additional memory or time to generate large sequences. While this explains the claimed advantage of SSMs over transformers in the decode stage, the prefill stage requires additional effort to fully utilize SSM architecture.
A standard approach for prefill is to process the whole prompt in parallel to fully utilize GPU. This approach is used in [optimum-benchmark](https://github.com/huggingface/optimum-benchmark) library and we will refer to it as parallel prefill. Parallel prefill needs to store in memory the hidden states of each token in the prompt. For transformers, this additional memory is dominated by the memory of stored KV caches. For SSM models, no caching is required, and the memory for storing hidden states becomes the only component proportional to the prompt length. As a result, the memory requirement will scale with prompt length, and SSM models will lose the ability to process arbitrary long sequences, similar to transformers.
An alternative to parallel prefill is to process the prompt token by token, which we will refer to as *sequential prefill*. Akin to sequence parallelism, it can also be done on larger chunks of the prompt instead of individual tokens for better GPU usage. While sequential prefill makes little sense for transformers, it brings back the possibility of processing arbitrary long prompts by SSM models.
With these remarks in mind, we first test the largest sequence length that can fit on a single 24 GB A10 GPU, putting the results on the [figure](#max-length) below. The batch size is fixed at 1, and we are using float32 precision. Even for parallel prefill, Falcon Mamba can fit larger sequences than a transformer, while in sequential prefill, it unlocks its full potential and can process arbitrary long prompt
<a id="max-length"></a>

Next, we measure the generation throughput in a setting with a prompt of length 1 and up to 130k generated tokens, using batch size 1 and H100 GPU. The results are reported in the [figure](#throughput) below. We observe that our Falcon Mamba is generating all the tokens at constant throughput and without any increase in CUDA peak memory. For the transformer model, the peak memory grows, and generation speed slows down as the number of generated tokens grows.
<a id="throughput"></a>

## How to use it within Hugging Face transformers?
The Falcon Mamba architecture will be available in the next release of the Hugging Face transformers library (>4.45.0). To use the model, make sure to install the latest version of Hugging Face transformers or install the library from the source.
Falcon Mamba is compatible with most of the APIs Hugging Face offers, which you are familiar with, such as `AutoModelForCausalLM` or `pipeline` :
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
model_id = "tiiuae/falcon-mamba-7b"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(model_id, torch_dtype="auto", device_map="auto")
inputs = tokenizer("Hello world, today", return_tensors="pt").to(0)
output = model.generate(**inputs, max_new_tokens=100, do_sample=True)
print(tokenizer.decode(Output[0], skip_special_tokens=True))
```
As the model is large, it also supports features such as `bitsandbytes` quantization to run the model on smaller GPU memory constraints, e.g.:
```python
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
model_id = "tiiuae/falcon-mamba-7b"
tokenizer = AutoTokenizer.from_pretrained(model_id)
quantization_config = BitsAndBytesConfig(load_in_4bit=True)
model = AutoModelForCausalLM.from_pretrained(model_id, quantization_config=quantization_config)
inputs = tokenizer("Hello world, today", return_tensors="pt").to(0)
output = model.generate(**inputs, max_new_tokens=100, do_sample=True)
print(tokenizer.decode(output[0], skip_special_tokens=True))
```
We are also pleased to introduce the instruction-tuned version of Falcon Mamba, which has been fine-tuned with an additional 5 billion tokens of supervised fine-tuning (SFT) data. This extended training enhances the model's ability to perform instructional tasks with better precision and effectiveness. You can experience the capabilities of the instruct model through our demo, available [here](https://huggingface.co/spaces/tiiuae/falcon-mamba-playground). For the chat template we use the following format:
```bash
<|im_start|>user
prompt<|im_end|>
<|im_start|>assistant
```
You can also directly use the 4-bit converted version of both the [base model](https://huggingface.co/tiiuae/falcon-mamba-7b-4bit) and the [instruct model](https://huggingface.co/tiiuae/falcon-mamba-7b-instruct-4bit). Make sure to have access to a GPU that is compatible with `bitsandbytes` library to run the quantized model.
You can also benefit from faster inference using `torch.compile`; simply call `model = torch.compile(model)` once you have loaded the model.
## Acknowledgments
The authors of this blog post would like to thank the Hugging Face team for their smooth support and integration within their ecosystem, in particular
- [Alina Lozovskaya](https://huggingface.co/alozowski) and [Clementine Fourrier](https://huggingface.co/clefourrier) for helping us evaluating the model on the leaderboard
- [Arthur Zucker](https://huggingface.co/ArthurZ) for the transformers integration
- [Vaibhav Srivastav](https://huggingface.co/reach-vb), [hysts](https://huggingface.co/hysts) and [Omar Sanseviero](https://huggingface.co/osanseviero) for their support with questions related to Hub
The authors would also like to thank Tri Dao and Albert Gu for implementing and open-sourcing Mamba architecture to the community.
| 3 |
0 | hf_public_repos | hf_public_repos/blog/cinepile2.md | ---
title: "CinePile 2.0 - making stronger datasets with adversarial refinement"
thumbnail: /blog/assets/188_cinepile2/thumbnail.png
authors:
- user: RuchitRawal
guest: true
org: UMD
- user: mfarre
- user: somepago
guest: true
org: UMD
- user: lvwerra
---
# CinePile 2.0 - making stronger datasets with adversarial refinement
In this blog post we share the journey of releasing [CinePile 2.0](https://huggingface.co/datasets/tomg-group-umd/cinepile), a significantly improved version of our long video QA dataset. The improvements in the new dataset rely on a new approach that we coined adversarial dataset refinement.
We're excited to share both CinePile 2.0 and our adversarial refinement method implementation, which we believe can strengthen many existing datasets and directly be part of future dataset creation pipelines.
<a name="adv_ref_pipe"></a> 
If you are mainly interested in the adversarial refinement method, you can [jump directly to the Adversarial Refinement section](#adversarial-refinement).
## Wait. What is CinePile?
In May 2024, we launched CinePile, a long video QA dataset with about 300,000 training samples and 5,000 test samples.
The first release stood out from other datasets in two aspects:
* Question diversity: It covers temporal understanding, plot analysis, character dynamics, setting, and themes.
* Question difficulty: In our benchmark, humans outperformed the best commercial vision models by 25% and open-source ones by 65%.
### Taking a look at a data sample
Part of the secret sauce behind it is that it relies on movie clips from YouTube and Q&A distilled from precise audio descriptions designed for visually impaired audiences. These descriptions offer rich context beyond basic visuals (e.g., "What color is the car?"), helping us create more complex questions.
<div style="display: flex; gap: 20px; align-items: center;">
<div style="flex: 1;">
<iframe width="100%" height="200" src="https://www.youtube.com/embed/Z4DDrBjEBHE" frameborder="0" allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture" allowfullscreen></iframe>
</div>
<div style="flex: 2;">
<a name="teaser"></a>
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/cinepile2/teaser_figure.png" alt="Sample Scene" style="width: 100%; height: auto;">
</div>
</div>
### Tell me more. How did you put together the original dataset?
To automate question creation, we first built question templates by inspecting existing datasets like MovieQA and TVQA. We clustered the questions in these datasets using a textual similarity model [WhereIsAI/UAE-Large-V1](https://huggingface.co/WhereIsAI/UAE-Large-V1) and then prompted GPT-4 with 10 random examples from each cluster to generate a question template and a prototypical question for each:
| Category | Question template | Prototypical question |
|----------|------------------|----------------------|
| Character and Relationship Dynamics (CRD) | Interpersonal Dynamics | What changes occur in the relationship between person A and person B following a shared experience or actions? |
| Character and Relationship Dynamics (CRD) | Decision Justification | What reasons did the character give for making their decision? |
| Narrative and Plot Analysis (NPA) | Crisis Event | What major event leads to the character's drastic action? |
| Narrative and Plot Analysis (NPA) | Mysteries Unveiled | What secret does character A reveal about event B? |
| Setting and Technical Analysis (STA) | Physical Possessions | What is [Character Name] holding? |
| Setting and Technical Analysis (STA) | Environmental Details | What does the [setting/location] look like [during/at] [specific time/place/event]? |
| Temporal (TEMP) | Critical Time-Sensitive Actions | What must [Character] do quickly, and what are the consequences otherwise? |
| Temporal (Temp) | Frequency | How many times does a character attempt [action A]? |
| Thematic Exploration (TH) | Symbolism and Motif Tracking | Are there any symbols or motifs introduced in Scene A that reappear or evolve in Scene B, and what do they signify? |
| Thematic Exploration (TH) | Thematic Parallels | What does the chaos in the scene parallel in terms of the movie's themes? |
Since templates aren't always relevant to every movie clip, we used Gemini 1.0 Pro to select the most appropriate ones for each scene. Next, we feed a language model the scene's text, selected template names (e.g., "Physical Possession"), sample questions, and a system prompt to create scene-specific questions. A well-designed prompt helps the model focus on the entire scene, generating deeper questions while avoiding superficial ones. We found that:
* Providing prototypical examples and including timestamps for dialogues and visual descriptions prevents GPT-4 from hallucinating
* This approach leads to more plausible multiple-choice question (MCQ) distractors
* Asking the model to provide a rationale for its answers improves the quality of the questions
Using this approach, we generate approximately 32 questions per video.
Prior to releasing CinePile, we implemented several mechanisms to ensure the quality of the dataset/benchmark that we cover in the next section.
### Inspecting the quality of the first results
While our process typically generates well-formed, answerable questions, some turn out to be trivial or rely on basic concepts that don't require watching the clip. To address this, we used several large language models (LLMs) to identify and filter three types of issues:
1. **Degeneracy Issues**
* A question is considered "degenerate" if its answer is obvious from the question itself (e.g., "What is the color of the pink house?")
* These comprised only a small portion of our dataset
* Since manual review wasn't feasible at our scale, we employed three LLMs—Gemini, GPT-3.5, and Phi-1.5—for automated detection
* Questions were excluded from the evaluation set if all three models answered correctly without any context
2. **Vision Reliance Issues**
* Some multiple-choice questions could be answered using dialogue alone, without requiring visual information
* We used the Gemini model to determine if questions could be answered using only dialogue
* Questions received a binary score: 0 if answerable without visuals, 1 if visual information was required
3. **Difficulty Assessment**
* To evaluate question difficulty, we tested whether models could answer correctly even when given full context (both visual descriptions and subtitles)
Through continued use of the benchmark by our team and the broader community, we identified several areas for improvement that drove us to consider CinePile 2.0.
## CinePile 2.0
For CinePile's second release, we worked together with Hugging Face (following their successful experimentation with fine-tuning [Video Llava 7B on CinePile](https://huggingface.co/mfarre/Video-LLaVA-7B-hf-CinePile)) to identify and prioritize several areas of improvement.
### Issues in CinePile 1.0
While the degeneracy filtering was useful in CinePile 1.0, it had several limitations:
* Some questions could be answered using just the Q&A pairs, without requiring transcripts or visual content
* Many flagged questions contained valuable insights from the video - rather than discarding them, they could have been rephrased to better capture their value
* Degeneracy checks were limited to the test set: running multiple models—especially proprietary ones—was too expensive at scale for CinePile 1.0's training set
To address these issues, we introduced a new *Adversarial Refinement* pipeline that helps improve weak questions rather than simply discarding them. This approach can be more easily applied at scale. Throughout this post, we'll refer to the model(s) that identify degenerate questions (using only the question and answer choices, without visual or dialogue information) as the "Deaf-Blind LLM."
### Adversarial Refinement
<a name="adv_ref_pipe"></a> 
The *Adversarial Refinement* pipeline aims to modify questions or answers until a Deaf-Blind LLM cannot easily predict the correct answer. Here's how it works:
1. The Deaf-Blind LLM provides both an answer and a rationale explaining its choice based solely on the question
2. These rationales help identify implicit cues or biases embedded in the question
3. Our question-generation model uses this rationale to modify the question and/or answer choices, removing implicit clues
4. This process repeats up to five times per question until the Deaf-Blind LLM's performance drops to random chance
<div style="display: flex; gap: 20px; align-items: center;">
<div style="flex: 1;">
<iframe width="100%" height="200" src="https://www.youtube.com/embed/kD0zHgK3BJ8" frameborder="0" allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture" allowfullscreen></iframe>
</div>
<div style="flex: 2;">
<a name="teaser"></a>
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/cinepile2/cinepile_refine_ques.png" alt="Generated to Refined QA Example" style="width: 100%; height: auto;">
</div>
</div>
Given the computational demands of this iterative process, we needed a powerful yet accessible LLM that could run locally to avoid API usage limits, delays, and cloud service costs. We chose:
* LLaMA 3.1 70B (open-source model) as the Deaf-Blind LLM
* GPT-4 for question modification generation
To account for random chance, we:
* Tested all five permutations of answer choice order
* Marked a question as degenerate if the model answered correctly in three out of five attempts
#### Results of the adversarial refinement
Briefly, this was the impact of running adversarial refinement in CinePile:
* Successfully modified 90.24% of degenerate Q&A pairs in the test set
* Manually reviewed unfixable Q&A pairs (~80 out of 800)
* Modified when possible
* Otherwise excluded from evaluation split
* Corrected 90.94% of weak pairs in the training set
* Retained unfixable ones as they don't negatively impact performance
#### Implementation
In this release, we're publishing both our adversarial refinement pipeline and the code for identifying weak questions. The complete implementation, including all prompts, is available in our [public repository](https://github.com/JARVVVIS/Adversarial-Refinement).
### Evaluations
After testing both previously evaluated models and 16 new Video-LLMs on the modified test set, we’ve highlighted the top performers in the figure below. Here’s what the results show:
* **Gemini 1.5 Pro** led among commercial Vision Language Models (VLMs)
* Excelled particularly in "Setting and Technical Analysis"
* Best performance on visually-driven questions about movie environments and character interactions
* **GPT-based models** showed competitive performance
* Strong in "Narrative and Plot Analysis"
* Performed well on questions about storylines and character interactions
* **Gemini 1.5 Flash**, a lighter version of Gemini 1.5 Pro
* Achieved 58.75% overall accuracy
* Performed particularly well in "Setting and Technical Analysis"
<a name="acc_cats"></a> 
#### Open Source models
The open-source video-LLM community has made significant progress from the first to the current release of CinePile. This is what we learned:
* **LLaVa-One Vision** leads open-source models
* Achieved 49.34% accuracy
* A dramatic improvement from CinePile 1.0's best performer (Video LLaVA at 22.51%)
* **Smaller models showed competitive performance**
* LLaVa-OV (7B parameters)
* MiniCPM-V 2.6 (8B parameters)
* Both outperformed InternVL2 (26B parameters)
* **There is room to improve**
* Nearly all models showed 15-20% accuracy drop on the hard-split
* Indicates significant room for improvement
#### Hard Split
The hard-split results in CinePile clearly demonstrate that current models still lag far behind human capability in understanding visual narratives and story elements. This gap highlights the value of CinePile's new release as a benchmark for measuring progress toward more sophisticated visual understanding.
<a name="avg_v_hard"></a> 
### Leaderboard
We've launched a new [CinePile Leaderboard](https://huggingface.co/spaces/tomg-group-umd/CinePileLeaderboard) that will be continuously updated as new models emerge. Visit the space to learn how to submit your own models for evaluation. | 4 |
0 | hf_public_repos | hf_public_repos/blog/layerskip.md | ---
title: "Faster Text Generation with Self-Speculative Decoding"
thumbnail: /blog/assets/layerskip/thumbnail.png
authors:
- user: ariG23498
- user: melhoushi
guest: true
org: facebook
- user: pcuenq
- user: reach-vb
---
# Faster Text Generation with Self-Speculative Decoding
Self-speculative decoding, proposed in
[LayerSkip: Enabling Early Exit Inference and Self-Speculative Decoding](https://arxiv.org/abs/2404.16710)
is a novel approach to text generation. It combines the strengths of speculative decoding with early
exiting from a large language model (LLM). This method allows for efficient generation
by using the *same model's* early layers for drafting tokens, and later layers for verification.
This technique not only speeds up text generation, but it also achieves significant
memory savings and reduces computational latency. In order to obtain an end-to-end speedup, the
output of the earlier layers need to be close enough to the last layer. This is achieved by a
training recipe which, as described in the paper, can be applied during pretraining,
and also while fine-tuning on a specific domain. Self-speculative decoding is
especially efficient for real-world applications, enabling deployment on smaller GPUs and lowering
the overall hardware footprint needed for **large-scale inference**.
In this blog post, we explore the concept of self-speculative decoding, its implementation,
and practical applications using the 🤗 transformers library. You’ll learn about the
technical underpinnings, including **early exit layers**, **unembedding**, and **training modifications**.
To ground these concepts in practice, we offer code examples, benchmark comparisons with traditional
speculative decoding, and insights into performance trade-offs.
Dive straight into the following Hugging Face artifacts to know more about the method
and try it out yourself:
1. [Hugging Face Paper Discussion Forum](https://huggingface.co/papers/2404.16710)
2. [LayerSkip Model Collections](https://huggingface.co/collections/facebook/layerskip-666b25c50c8ae90e1965727a)
3. [Colab Notebook showcasing the in-depth working of self-speculative decoding](https://huggingface.co/datasets/ariG23498/layer-skip-assets/blob/main/early_exit_self_speculative_decoding.ipynb)
## Speculative Decoding and Self-Speculative Decoding

*Illustration of LayerSkip inference on [`facebook/layerskip-llama2-7B`](https://huggingface.co/facebook/layerskip-llama2-7B)
(Llama2 7B continually pretrained with the LayerSkip recipe).*
[Traditional speculative decoding](https://huggingface.co/blog/assisted-generation) uses **two** models:
a smaller one (draft model) to generate a sequence of draft tokens, and a larger one
(verification model) to verify the draft’s accuracy. The smaller model performs a significant
portion of the generation, while the larger model refines the results. This increases text
generation speed since the larger model verifies full sequences at once, instead of generating
one draft at a time.
In self-speculative decoding, the authors build on this concept but use the early layers of a
large model to generate draft tokens that are then verified by the model's deeper layers.
This "self" aspect of speculative decoding, which requires specific training,
allows the model to perform both drafting and verification. This, in turn, improves speed and
reduces computational costs compared to the traditional speculative decoding.
## Usage with `transformers`
In order to enable early-exit self-speculative decoding in the
[🤗 transformers library](https://github.com/huggingface/transformers), we
just need to add the `assistant_early_exit` argument to the `generate()` function.
Here is a simple code snippet showcasing the functionality.
```sh
pip install transformers
```
```py
from transformers import AutoTokenizer, AutoModelForCausalLM
early_exit_layer = 4
prompt = "Alice and Bob"
checkpoint = "facebook/layerskip-llama2-7B"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
inputs = tokenizer(prompt, return_tensors="pt").to("cuda")
model = AutoModelForCausalLM.from_pretrained(checkpoint).to("cuda")
outputs = model.generate(**inputs, assistant_early_exit=early_exit_layer)
```
> **Note:** While the `assistant_early_exit` argument can potentially enable early-exit
self-speculative decoding for any decoder-only transformer, the logits from the intermediate layers
cannot be **unembedded** (process of decoding through LM Head, described later in the blog post)
unless the model is specifically trained for that. You will also **only obtain speedups** for
a checkpoint that was trained in such a way to increase the accuracy of earlier layers.
The [LayerSkip paper](https://arxiv.org/abs/2404.16710) proposes a training recipe to achieve that
(namely, applying early exit loss, and progressively increasing layer dropout rates). A collection
of Llama2, Llama3, and Code Llama checkpoints that have been continually pretrained with the
LayerSkip training recipe are provided [here](https://huggingface.co/collections/facebook/layerskip-666b25c50c8ae90e1965727a).
### Benchmarking
We ran an extensive list of benchmarks to measure the speedup of LayerSkip’s self-speculative
decoding with respect to autoregressive decoding on various models. We also compare self-speculative
decoding (based on early exiting) with standrad speculative decoding techniques. To reproduce the
results, you may find the code [here](https://github.com/gante/huggingface-demos/pull/1)
and the command to run each experiment in this
[spreadsheet](https://huggingface.co/datasets/ariG23498/layer-skip-assets/blob/main/LayerSkip%20HuggingFace%20Benchmarking%20-%20summarization.csv).
All the experiments were ran on a single 80GB A100 GPU, except for Llama2 70B experiments that
ran on a node of 8 A100 GPUs.
#### Llama3.2 1B
| Model Variant | Layers | Assistant Model | Assistant Layers | Task | Total Layers | FLOPs/Input (G) | Time/Input (s) | FLOPs/Output (G) | Time/Output (s) | Efficiency |
| :--: | :--: | :--: | :--: | :--: | :--: | :--: | :--: | :--: | :--: | :--: |
| **facebook/layerskip-llama3.2-1B** | **1** | **Early Exit @ Layer 4** | | **summarization** | **1** | **1195.28** | **9.96** | **2147.7** | **17.9** | **1.80** |
#### Llama3 8B
| Model Variant | Layers | Assistant Model | Assistant Layers | Task | Total Layers | FLOPs/Input (G) | Time/Input (s) | FLOPs/Output (G) | Time/Output (s) | Efficiency |
| :--: | :--: | :--: | :--: | :--: | :--: | :--: | :--: | :--: | :--: | :--: |
| meta-llama/Meta-Llama-3-8B | 8 | meta-llama/Llama-3.2-1B | 1 | summarization | 9 | 1872.46 | 19.04 | 2859.35 | 29.08 | 1.53 |
| meta-llama/Meta-Llama-3-8B | 8 | meta-llama/Llama-3.2-3B | 3 | summarization | 11 | 2814.82 | 28.63 | 2825.36 | 28.73 | 1.00 |
| **facebook/layerskip-llama3-8B** | **8** | **Early Exit @ Layer 4** | | **summarization** | **8** | **1949.02** | **15.75** | **3571.81** | **28.87** | **1.83** |
#### Llama2 70B
| Model Variant | Layers | Assistant Model | Assistant Layers | Task | Total Layers | FLOPs/Input (G) | Time/Input (s) | FLOPs/Output (G) | Time/Output (s) | Efficiency |
| :--: | :--: | :--: | :--: | :--: | :--: | :--: | :--: | :--: | :--: | :--: |
| meta-llama/Llama-2-70b-hf | 70 | meta-llama/Llama-2-13b-hf | 13 | summarization | 83 | 5036.54 | 46.3 | 12289.01 | 112.97 | 2.44 |
| meta-llama/Llama-2-70b-hf | 70 | meta-llama/Llama-2-7b-hf | 7 | summarization | 77 | 4357.55 | 40.06 | 12324.19 | 113.3 | 2.83 |
| meta-llama/Llama-2-70b-hf | 70 | TinyLlama/TinyLlama_v1.1 | 1 | summarization | 71 | 4356.21 | 40.05 | 12363.22 | 113.66 | 2.84 |
| **facebook/layerskip-llama2-70B** | **70** | **Early Exit @ Layer 10** | | **summarization** | **70** | **6012.04** | **54.96** | **1283.34** | **113.2** | **2.06** |
#### Llama2 13B
| Model Variant | Layers | Assistant Model | Assistant Layers | Task | Total Layers | FLOPs/Input (G) | Time/Input (s) | FLOPs/Output (G) | Time/Output (s) | Efficiency |
| :--: | :--: | :--: | :--: | :--: | :--: | :--: | :--: | :--: | :--: | :--: |
| meta-llama/Llama-2-13b-hf | 13 | meta-llama/Llama-2-7b-hf | 7 | summarization | 20 | 3557.07 | 27.79 | 4088.48 | 31.94 | 1.15 |
| meta-llama/Llama-2-13b-hf | 13 | TinyLlama/TinyLlama_v1.1 | 1 | summarization | 14 | 2901.92 | 22.67 | 4190.42 | 32.74 | 1.44 |
| meta-llama/Llama-2-13b-hf | 13 | apple/OpenELM-270M | 0.27 | summarization | 13.27 | 2883.33 | 22.53 | 4521.12 | 35.32 | 1.57 |
| meta-llama/Llama-2-13b-hf | 13 | apple/OpenELM-450M | 0.45 | summarization | 13.45 | 3267.69 | 25.53 | 4321.75 | 33.76 | 1.32 |
| **facebook/layerskip-llama2-13B** | **13** | **Early Exit @ Layer 4** | | **summarization** | **13** | **4238.45** | **33.11** | **4217.78** | **32.95** | **0.995** |
| **facebook/layerskip-llama2-13B** | **13** | **Early Exit @ Layer 8** | | **summarization** | **13** | **2459.61** | **19.22** | **4294.98** | **33.55** | **1.746** |
#### Llama2 7B
| Model Variant | Layers | Assistant Model | Assistant Layers | Task | Total Layers | FLOPs/Input (G) | Time/Input (s) | FLOPs/Output (G) | Time/Output (s) | Efficiency |
| :--: | :--: | :--: | :--: | :--: | :--: | :--: | :--: | :--: | :--: | :--: |
| meta-llama/Llama-2-7b-hf | 7 | TinyLlama/TinyLlama_v1.1 | 1 | summarization | 8 | 2771.54 | 21.65 | 3368.48 | 26.32 | 1.22 |
| meta-llama/Llama-2-7b-hf | 7 | apple/OpenELM-270M | 0.27 | summarization | 7.27 | 2607.82 | 20.37 | 4221.14 | 32.98 | 1.62 |
| meta-llama/Llama-2-7b-hf | 7 | apple/OpenELM-450M | 0.45 | summarization | 7.45 | 3324.68 | 25.97 | 4178.66 | 32.65 | 1.26 |
| **facebook/layerskip-llama2-7B** | **7** | **Early Exit @ Layer 4** | | **summarization** | **7** | **2548.4** | **19.91** | **3306.73** | **25.83** | **1.297** |
Some observations we can make from the results:
* As seen in the **Total Number of Parameters** column, self-speculative decoding consumes less memory
because it does not require a separate draft model and weights for the draft stage layers are re-used.
* For all model sizes and generations except Llama2 70B, the early-exit self-speculative decoding
is faster than the regular two-model speculative decoding.
There could be different reasons for the relatively limited speedups of self-speculative decoding
on Llama2 70B compared to other models, e.g., the LayerSkip checkpoint of Llama2 70B was continually
pretrained with fewer tokens (328 M tokens for Llama2 70B compared to 52B tokens for Llama2 7B).
But this is an area of improvement to investigate for future research. Nevertheless,
self-speculative decoding for 70B is significantly faster than autoregressive decoding.
## Early Exit and Unembedding
One key technique in self-speculative decoding is early exit, where the generation process can halt
at a pre specified layer. To accomplish this, we **unembed** the logits from these layers by projecting
them onto the language model (LM) head to predict the next token. This allows the model to skip
subsequent layers and improve inference time.
Unembedding can be performed at any transformer layer, turning early-exit into an efficient
token-prediction mechanism. A natural question arises: how can the LM head be adapted to unembed
logits from earlier layers when it was initially trained to work with the final layer only? This
is where the training modifications come into play.
## Training Modifications: *Layer Dropout* and *Early Exit Loss*
In the training phase, we introduce **layer dropout**,
which allows the model to skip certain layers during training. The dropout rate increases
progressively in deeper layers, making the model less reliant on its later layers, as well as
enhancing the model's generalization and speeding up training.
In addition to layer dropout, **early exit loss** is applied to ensure the LM head learns to
unembed different layers. The total loss function for training the model with early exits is
given by a summation of normalized loss from each exit (intermediate layers). This technique enables
efficient training by distributing the learning task across all layers.
## Self-Drafting and Self-Verification
Once training is complete, we can apply self-speculative decoding during inference.
[The process](https://huggingface.co/docs/transformers/v4.46.3/en/llm_optims#speculative-decoding)
begins with **self-drafting**, where tokens are generated by exiting early from some intermediate
layer. The number of speculative tokens defines how many draft tokens are produced during
this stage, and the layer we exit at defines how large and accurate is the draft stage.
Both parameters can be specified at inference based on a
[trade-off between speed and accuracy of the draft stage](https://huggingface.co/blog/assisted-generation).
The next stage is **self-verification**, where the full model is used to verify the draft tokens.
The verification model reuses the portion of cache from the draft model. If the draft tokens align
with the verified tokens, they are added to the final output, resulting in a better usage of the
memory bandwidth in our system, because it’s much more expensive to generate a sequence of tokens
with the full model than verifying a draft, as long as several of the tokens match.
In the self-verification stage, only the remaining layers are computed for verification, because
the results from the early layers are cached during the drafting phase.
## Optimizations: Shared Weights, Shared KV Cache, and Shared Compute
Self-speculative decoding benefits significantly from cache reuse, particularly the **KV cache**,
which stores key-value pairs computed during the drafting stage. This cache allows the model to skip
redundant calculations, as both the draft and verification stages use the same early layers.
Additionally, the **exit query cache** stores the query vector from the exit layer, allowing
verification to continue seamlessly from the draft stage.
Compared to traditional two-model speculative decoding, early-exit self-speculative decoding can
benefit from the following savings:
* **Shared Weights**: Reuses the weights from the first \\( E \\) layers for both drafting and verification.
* **Shared KV Cache**: Reuses key-value pairs from the first \\( E \\) layers for both drafting and verification.
* **Shared Compute**: Reuses the compute of the first \\( E \\) layers by using a
**Exit Query Cache** that saves only the query vector of the exit layer \\(E-1\\) so that the
verification process won’t need to compute layers \\( 0 \\) to \\( E-1 \\).
The combination of KV and exit query caches, known as the **KVQ cache**, reduces memory
overhead and improves inference latency.
So far, the 🤗 transformers library has implemented the first optimization (Shared Weights) in this
[pull request](https://github.com/huggingface/transformers/pull/34240). As the number of models
that use this method increases, we'll consider the additional optimizations.
Feel free to open a PR if you're interested!
## How Early Can We Exit?
The early exit layer of the draft stage is a hyperparameter that we can tune or modify during inference:
* The earlier we exit, the faster the generation of draft tokens are but the less accurate they will be.
* The later we exit, the more accurate the draft tokens generated are but the slower their generation will be.
We wrote [a script](https://gist.github.com/mostafaelhoushi/1dd2781b896504bf0569a3ae4b8f9ecf)
to sweep across different early exit layers and measure the tokens per second on A100 GPUs.
In the Tables below we plot the tokens per second versus the early exit layer for different
Llama models for both LayerSkip and baseline checkpoints (you can view the full logs
[here](https://drive.google.com/drive/folders/145CUq-P_6tbPkmArL7qsjxUihjDgLnzX?usp=sharing)).
#### Llama3.2 1B
| Normal | LayerSkip |
| :--: | :--: |
|  |  |
#### Llama3 8B
| Normal | LayerSkip |
| :--: | :--: |
|  |  |
#### Code Llama3 34B
| Normal | LayerSkip |
| :--: | :--: |
|  |  |
#### Code Llama3 7B
| Normal | LayerSkip |
| :--: | :--: |
|  |  |
#### Llama2 70B
| Normal | LayerSkip |
| :--: | :--: |
|  |  |
#### Llama2 13B
| Normal | LayerSkip |
| :--: | :--: |
|  |  |
#### Llama2 7B
| Normal | LayerSkip |
| :--: | :--: |
|  |  |
We can observe the following:
* For the baseline checkpoints that have not been pretrained or continually pretrained with the
LayerSkip training recipe, early exit self-speculative decoding is slower than autoregressive decoding.
This is because during training of most LLMs, earlier layers are not motivated to learn to predict
the output, and hence generating tokens using earlier layers will have a very low acceptance rate.
* On the other hand, for the Llama checkpoints that were continually pre-trained with the LayerSkip
training, early exit self-speculative decoding has higher speedup than autoregressive decoding for
at least a subset of the layers.
* For most models, except Llama3.2 1B, we notice a regular pattern when we traverse across
layers: speedup starts low for the first few layers, increases gradually to a sweet spot, and
then decreases again.
* The early exit layer sweet spot is when we have the optimal tradeoff between high accuracy of
predictions and low overhead of generating tokens. This sweet spot depends on each model,
and may also depend on the prompt or domain of the prompt.
These observations present intriguing opportunities for further experimentation and exploration.
We encourage readers to build upon these ideas, test variations, and pursue their own research.
Such efforts can lead to valuable insights and contribute meaningfully to the field.
## Conclusion
LayerSkip leverages the synergy between early exit, layer dropout, and cache reuse to create a fast
and efficient text generation pipeline. By training the model to unembed outputs from different
layers and optimizing the verification process with caches, this approach strikes a balance between
speed and accuracy. As a result, it significantly improves inference times in large language models
while maintaining high-quality outputs. It also reduces memory compared to traditional speculative
decoding techniques due to a single model used as both the draft and verification model.
Self-speculation is an exciting field where the same LLM can create draft tokens and fix itself. Other
self-speculation approaches include:
* [Draft & Verify](https://aclanthology.org/2024.acl-long.607/): where the draft stage involves
skipping pre-determined attention and feed forward layers.
* [MagicDec](https://arxiv.org/abs/2408.11049): where the draft stage uses a subset of the KV cache,
which is useful for long context inputs.
* [Jacobi Decoding](https://arxiv.org/abs/2305.10427) and [Lookahead Decoding](https://arxiv.org/abs/2402.02057):
Where the draft stage are a series of “guess tokens” that could be either random or obtained from a n-gram lookup table. | 5 |
0 | hf_public_repos | hf_public_repos/blog/gradio-lite.md | ---
title: "Gradio-Lite: Serverless Gradio Running Entirely in Your Browser"
thumbnail: /blog/assets/167_gradio_lite/thumbnail.png
authors:
- user: abidlabs
- user: whitphx
- user: aliabd
---
# Gradio-Lite: Serverless Gradio Running Entirely in Your Browser
Gradio is a popular Python library for creating interactive machine learning apps. Traditionally, Gradio applications have relied on server-side infrastructure to run, which can be a hurdle for developers who need to host their applications.
Enter Gradio-lite (`@gradio/lite`): a library that leverages [Pyodide](https://pyodide.org/en/stable/) to bring Gradio directly to your browser. In this blog post, we'll explore what `@gradio/lite` is, go over example code, and discuss the benefits it offers for running Gradio applications.
## What is `@gradio/lite`?
`@gradio/lite` is a JavaScript library that enables you to run Gradio applications directly within your web browser. It achieves this by utilizing Pyodide, a Python runtime for WebAssembly, which allows Python code to be executed in the browser environment. With `@gradio/lite`, you can **write regular Python code for your Gradio applications**, and they will **run seamlessly in the browser** without the need for server-side infrastructure.
## Getting Started
Let's build a "Hello World" Gradio app in `@gradio/lite`
### 1. Import JS and CSS
Start by creating a new HTML file, if you don't have one already. Importing the JavaScript and CSS corresponding to the `@gradio/lite` package by using the following code:
```html
<html>
<head>
<script type="module" crossorigin src="https://cdn.jsdelivr.net/npm/@gradio/lite/dist/lite.js"></script>
<link rel="stylesheet" href="https://cdn.jsdelivr.net/npm/@gradio/lite/dist/lite.css" />
</head>
</html>
```
Note that you should generally use the latest version of `@gradio/lite` that is available. You can see the [versions available here](https://www.jsdelivr.com/package/npm/@gradio/lite?tab=files).
### 2. Create the `<gradio-lite>` tags
Somewhere in the body of your HTML page (wherever you'd like the Gradio app to be rendered), create opening and closing `<gradio-lite>` tags.
```html
<html>
<head>
<script type="module" crossorigin src="https://cdn.jsdelivr.net/npm/@gradio/lite/dist/lite.js"></script>
<link rel="stylesheet" href="https://cdn.jsdelivr.net/npm/@gradio/lite/dist/lite.css" />
</head>
<body>
<gradio-lite>
</gradio-lite>
</body>
</html>
```
Note: you can add the `theme` attribute to the `<gradio-lite>` tag to force the theme to be dark or light (by default, it respects the system theme). E.g.
```html
<gradio-lite theme="dark">
...
</gradio-lite>
```
### 3. Write your Gradio app inside of the tags
Now, write your Gradio app as you would normally, in Python! Keep in mind that since this is Python, whitespace and indentations matter.
```html
<html>
<head>
<script type="module" crossorigin src="https://cdn.jsdelivr.net/npm/@gradio/lite/dist/lite.js"></script>
<link rel="stylesheet" href="https://cdn.jsdelivr.net/npm/@gradio/lite/dist/lite.css" />
</head>
<body>
<gradio-lite>
import gradio as gr
def greet(name):
return "Hello, " + name + "!"
gr.Interface(greet, "textbox", "textbox").launch()
</gradio-lite>
</body>
</html>
```
And that's it! You should now be able to open your HTML page in the browser and see the Gradio app rendered! Note that it may take a little while for the Gradio app to load initially since Pyodide can take a while to install in your browser.
**Note on debugging**: to see any errors in your Gradio-lite application, open the inspector in your web browser. All errors (including Python errors) will be printed there.
## More Examples: Adding Additional Files and Requirements
What if you want to create a Gradio app that spans multiple files? Or that has custom Python requirements? Both are possible with `@gradio/lite`!
### Multiple Files
Adding multiple files within a `@gradio/lite` app is very straightforward: use the `<gradio-file>` tag. You can have as many `<gradio-file>` tags as you want, but each one needs to have a `name` attribute and the entry point to your Gradio app should have the `entrypoint` attribute.
Here's an example:
```html
<gradio-lite>
<gradio-file name="app.py" entrypoint>
import gradio as gr
from utils import add
demo = gr.Interface(fn=add, inputs=["number", "number"], outputs="number")
demo.launch()
</gradio-file>
<gradio-file name="utils.py" >
def add(a, b):
return a + b
</gradio-file>
</gradio-lite>
```
### Additional Requirements
If your Gradio app has additional requirements, it is usually possible to [install them in the browser using micropip](https://pyodide.org/en/stable/usage/loading-packages.html#loading-packages). We've created a wrapper to make this paticularly convenient: simply list your requirements in the same syntax as a `requirements.txt` and enclose them with `<gradio-requirements>` tags.
Here, we install `transformers_js_py` to run a text classification model directly in the browser!
```html
<gradio-lite>
<gradio-requirements>
transformers_js_py
</gradio-requirements>
<gradio-file name="app.py" entrypoint>
from transformers_js import import_transformers_js
import gradio as gr
transformers = await import_transformers_js()
pipeline = transformers.pipeline
pipe = await pipeline('sentiment-analysis')
async def classify(text):
return await pipe(text)
demo = gr.Interface(classify, "textbox", "json")
demo.launch()
</gradio-file>
</gradio-lite>
```
**Try it out**: You can see this example running in [this Hugging Face Static Space](https://huggingface.co/spaces/abidlabs/gradio-lite-classify), which lets you host static (serverless) web applications for free. Visit the page and you'll be able to run a machine learning model without internet access!
## Benefits of Using `@gradio/lite`
### 1. Serverless Deployment
The primary advantage of @gradio/lite is that it eliminates the need for server infrastructure. This simplifies deployment, reduces server-related costs, and makes it easier to share your Gradio applications with others.
### 2. Low Latency
By running in the browser, @gradio/lite offers low-latency interactions for users. There's no need for data to travel to and from a server, resulting in faster responses and a smoother user experience.
### 3. Privacy and Security
Since all processing occurs within the user's browser, `@gradio/lite` enhances privacy and security. User data remains on their device, providing peace of mind regarding data handling.
### Limitations
* Currently, the biggest limitation in using `@gradio/lite` is that your Gradio apps will generally take more time (usually 5-15 seconds) to load initially in the browser. This is because the browser needs to load the Pyodide runtime before it can render Python code.
* Not every Python package is supported by Pyodide. While `gradio` and many other popular packages (including `numpy`, `scikit-learn`, and `transformers-js`) can be installed in Pyodide, if your app has many dependencies, its worth checking whether the dependencies are included in Pyodide, or can be [installed with `micropip`](https://micropip.pyodide.org/en/v0.2.2/project/api.html#micropip.install).
## Try it out!
You can immediately try out `@gradio/lite` by copying and pasting this code in a local `index.html` file and opening it with your browser:
```html
<html>
<head>
<script type="module" crossorigin src="https://cdn.jsdelivr.net/npm/@gradio/lite/dist/lite.js"></script>
<link rel="stylesheet" href="https://cdn.jsdelivr.net/npm/@gradio/lite/dist/lite.css" />
</head>
<body>
<gradio-lite>
import gradio as gr
def greet(name):
return "Hello, " + name + "!"
gr.Interface(greet, "textbox", "textbox").launch()
</gradio-lite>
</body>
</html>
```
We've also created a playground on the Gradio website that allows you to interactively edit code and see the results immediately!
Playground: https://www.gradio.app/playground
| 6 |
0 | hf_public_repos | hf_public_repos/blog/llama-sagemaker-benchmark.md | ---
title: "Llama 2 on Amazon SageMaker a Benchmark"
thumbnail: /blog/assets/llama_sagemaker_benchmark/thumbnail.jpg
authors:
- user: philschmid
---
# Llama 2 on Amazon SageMaker a Benchmark

Deploying large language models (LLMs) and other generative AI models can be challenging due to their computational requirements and latency needs. To provide useful recommendations to companies looking to deploy Llama 2 on Amazon SageMaker with the [Hugging Face LLM Inference Container](https://huggingface.co/blog/sagemaker-huggingface-llm), we created a comprehensive benchmark analyzing over 60 different deployment configurations for Llama 2.
In this benchmark, we evaluated varying sizes of Llama 2 on a range of Amazon EC2 instance types with different load levels. Our goal was to measure latency (ms per token), and throughput (tokens per second) to find the optimal deployment strategies for three common use cases:
- Most Cost-Effective Deployment: For users looking for good performance at low cost
- Best Latency Deployment: Minimizing latency for real-time services
- Best Throughput Deployment: Maximizing tokens processed per second
To keep this benchmark fair, transparent, and reproducible, we share all of the assets, code, and data we used and collected:
- [GitHub Repository](https://github.com/philschmid/text-generation-inference-tests/tree/master/sagemaker_llm_container)
- [Raw Data](https://github.com/philschmid/text-generation-inference-tests/tree/master/results/sagemaker)
- [Spreadsheet with processed data](https://docs.google.com/spreadsheets/d/1PBjw6aG3gPaoxd53vp7ZtCdPngExi2vWPC0kPZXaKlw/edit?usp=sharing)
We hope to enable customers to use LLMs and Llama 2 efficiently and optimally for their use case. Before we get into the benchmark and data, let's look at the technologies and methods we used.
- [Llama 2 on Amazon SageMaker a Benchmark](#llama-2-on-amazon-sagemaker-a-benchmark)
- [What is the Hugging Face LLM Inference Container?](#what-is-the-hugging-face-llm-inference-container)
- [What is Llama 2?](#what-is-llama-2)
- [What is GPTQ?](#what-is-gptq)
- [Benchmark](#benchmark)
- [Recommendations \& Insights](#recommendations--insights)
- [Most Cost-Effective Deployment](#most-cost-effective-deployment)
- [Best Throughput Deployment](#best-throughput-deployment)
- [Best Latency Deployment](#best-latency-deployment)
- [Conclusions](#conclusions)
### What is the Hugging Face LLM Inference Container?
[Hugging Face LLM DLC](https://huggingface.co/blog/sagemaker-huggingface-llm) is a purpose-built Inference Container to easily deploy LLMs in a secure and managed environment. The DLC is powered by [Text Generation Inference (TGI)](https://github.com/huggingface/text-generation-inference), an open-source, purpose-built solution for deploying and serving LLMs. TGI enables high-performance text generation using Tensor Parallelism and dynamic batching for the most popular open-source LLMs, including StarCoder, BLOOM, GPT-NeoX, Falcon, Llama, and T5. VMware, IBM, Grammarly, Open-Assistant, Uber, Scale AI, and many more already use Text Generation Inference.
### What is Llama 2?
Llama 2 is a family of LLMs from Meta, trained on 2 trillion tokens. Llama 2 comes in three sizes - 7B, 13B, and 70B parameters - and introduces key improvements like longer context length, commercial licensing, and optimized chat abilities through reinforcement learning compared to Llama (1). If you want to learn more about Llama 2 check out this [blog post](https://huggingface.co/blog/llama2).
### What is GPTQ?
GPTQ is a post-training quantziation method to compress LLMs, like GPT. GPTQ compresses GPT (decoder) models by reducing the number of bits needed to store each weight in the model, from 32 bits down to just 3-4 bits. This means the model takes up much less memory and can run on less Hardware, e.g. Single GPU for 13B Llama2 models. GPTQ analyzes each layer of the model separately and approximates the weights to preserve the overall accuracy. If you want to learn more and how to use it, check out [Optimize open LLMs using GPTQ and Hugging Face Optimum](https://www.philschmid.de/gptq-llama).
## Benchmark
To benchmark the real-world performance of Llama 2, we tested 3 model sizes (7B, 13B, 70B parameters) on four different instance types with four different load levels, resulting in 60 different configurations:
- Models: We evaluated all currently available model sizes, including 7B, 13B, and 70B.
- Concurrent Requests: We tested configurations with 1, 5, 10, and 20 concurrent requests to determine the performance on different usage scenarios.
- Instance Types: We evaluated different GPU instances, including g5.2xlarge, g5.12xlarge, g5.48xlarge powered by NVIDIA A10G GPUs, and p4d.24xlarge powered by NVIDIA A100 40GB GPU.
- Quantization: We compared performance with and without quantization. We used GPTQ 4-bit as a quantization technique.
As metrics, we used Throughput and Latency defined as:
- Throughput (tokens/sec): Number of tokens being generated per second.
- Latency (ms/token): Time it takes to generate a single token
We used those to evaluate the performance of Llama across the different setups to understand the benefits and tradeoffs. If you want to run the benchmark yourself, we created a [Github repository](https://github.com/philschmid/text-generation-inference-tests/tree/master/sagemaker_llm_container).
You can find the full data of the benchmark in the [Amazon SageMaker Benchmark: TGI 1.0.3 Llama 2](https://docs.google.com/spreadsheets/d/1PBjw6aG3gPaoxd53vp7ZtCdPngExi2vWPC0kPZXaKlw/edit#gid=0) sheet. The raw data is available on [GitHub](https://github.com/philschmid/text-generation-inference-tests/tree/master/results/sagemaker).
If you are interested in all of the details, we recommend you to dive deep into the provided raw data.
## Recommendations & Insights
Based on the benchmark, we provide specific recommendations for optimal LLM deployment depending on your priorities between cost, throughput, and latency for all Llama 2 model sizes.
*Note: The recommendations are based on the configuration we tested. In the future, other environments or hardware offerings, such as Inferentia2, may be even more cost-efficient.*
### Most Cost-Effective Deployment
The most cost-effective configuration focuses on the right balance between performance (latency and throughput) and cost. Maximizing the output per dollar spent is the goal. We looked at the performance during 5 concurrent requests. We can see that GPTQ offers the best cost-effectiveness, allowing customers to deploy Llama 2 13B on a single GPU.
| Model | Quantization | Instance | concurrent requests | Latency (ms/token) median | Throughput (tokens/second) | On-demand cost ($/h) in us-west-2 | Time to generate 1 M tokens (minutes) | cost to generate 1M tokens ($) |
| ----------- | ------------ | -------------- | ------------------- | ------------------------- | -------------------------- | --------------------------------- | ------------------------------------- | ------------------------------ |
| Llama 2 7B | GPTQ | g5.2xlarge | 5 | 34.245736 | 120.0941633 | $1.52 | 138.78 | $3.50 |
| Llama 2 13B | GPTQ | g5.2xlarge | 5 | 56.237484 | 71.70560104 | $1.52 | 232.43 | $5.87 |
| Llama 2 70B | GPTQ | ml.g5.12xlarge | 5 | 138.347928 | 33.33372399 | $7.09 | 499.99 | $59.08 |
### Best Throughput Deployment
The Best Throughput configuration maximizes the number of tokens that are generated per second. This might come with some reduction in overall latency since you process more tokens simultaneously. We looked at the highest tokens per second performance during twenty concurrent requests, with some respect to the cost of the instance. The highest throughput was for Llama 2 13B on the ml.p4d.24xlarge instance with 688 tokens/sec.
| Model | Quantization | Instance | concurrent requests | Latency (ms/token) median | Throughput (tokens/second) | On-demand cost ($/h) in us-west-2 | Time to generate 1 M tokens (minutes) | cost to generate 1M tokens ($) |
| ----------- | ------------ | --------------- | ------------------- | ------------------------- | -------------------------- | --------------------------------- | ------------------------------------- | ------------------------------ |
| Llama 2 7B | None | ml.g5.12xlarge | 20 | 43.99524 | 449.9423027 | $7.09 | 33.59 | $3.97 |
| Llama 2 13B | None | ml.p4d.12xlarge | 20 | 67.4027465 | 668.0204881 | $37.69 | 24.95 | $15.67 |
| Llama 2 70B | None | ml.p4d.24xlarge | 20 | 59.798591 | 321.5369158 | $37.69 | 51.83 | $32.56 |
### Best Latency Deployment
The Best Latency configuration minimizes the time it takes to generate one token. Low latency is important for real-time use cases and providing a good experience to the customer, e.g. Chat applications. We looked at the lowest median for milliseconds per token during 1 concurrent request. The lowest overall latency was for Llama 2 7B on the ml.g5.12xlarge instance with 16.8ms/token.
| Model | Quantization | Instance | concurrent requests | Latency (ms/token) median | Thorughput (tokens/second) | On-demand cost ($/h) in us-west-2 | Time to generate 1 M tokens (minutes) | cost to generate 1M tokens ($) |
| ----------- | ------------ | --------------- | ------------------- | ------------------------- | -------------------------- | --------------------------------- | ------------------------------------- | ------------------------------ |
| Llama 2 7B | None | ml.g5.12xlarge | 1 | 16.812526 | 61.45733054 | $7.09 | 271.19 | $32.05 |
| Llama 2 13B | None | ml.g5.12xlarge | 1 | 21.002715 | 47.15736567 | $7.09 | 353.43 | $41.76 |
| Llama 2 70B | None | ml.p4d.24xlarge | 1 | 41.348543 | 24.5142928 | $37.69 | 679.88 | $427.05 |
## Conclusions
In this benchmark, we tested 60 configurations of Llama 2 on Amazon SageMaker. For cost-effective deployments, we found 13B Llama 2 with GPTQ on g5.2xlarge delivers 71 tokens/sec at an hourly cost of $1.55. For max throughput, 13B Llama 2 reached 296 tokens/sec on ml.g5.12xlarge at $2.21 per 1M tokens. And for minimum latency, 7B Llama 2 achieved 16ms per token on ml.g5.12xlarge.
We hope the benchmark will help companies deploy Llama 2 optimally based on their needs. If you want to get started deploying Llama 2 on Amazon SageMaker, check out [Introducing the Hugging Face LLM Inference Container for Amazon SageMaker](https://huggingface.co/blog/sagemaker-huggingface-llm) and [Deploy Llama 2 7B/13B/70B on Amazon SageMaker](https://www.philschmid.de/sagemaker-llama-llm) blog posts.
---
Thanks for reading! If you have any questions, feel free to contact me on [Twitter](https://twitter.com/_philschmid) or [LinkedIn](https://www.linkedin.com/in/philipp-schmid-a6a2bb196/).
| 7 |
0 | hf_public_repos | hf_public_repos/blog/arena-tts.md | ---
title: "TTS Arena: Benchmarking Text-to-Speech Models in the Wild"
thumbnail: /blog/assets/arenas-on-the-hub/thumbnail.png
authors:
- user: mrfakename
guest: true
- user: reach-vb
- user: clefourrier
- user: Wauplin
- user: ylacombe
- user: main-horse
guest: true
- user: sanchit-gandhi
---
# TTS Arena: Benchmarking Text-to-Speech Models in the Wild
Automated measurement of the quality of text-to-speech (TTS) models is very difficult. Assessing the naturalness and inflection of a voice is a trivial task for humans, but it is much more difficult for AI. This is why today, we’re thrilled to announce the TTS Arena. Inspired by [LMSys](https://lmsys.org/)'s [Chatbot Arena](https://huggingface.co/spaces/lmsys/chatbot-arena-leaderboard) for LLMs, we developed a tool that allows anyone to easily compare TTS models side-by-side. Just submit some text, listen to two different models speak it out, and vote on which model you think is the best. The results will be organized into a leaderboard that displays the community’s highest-rated models.
<script type="module" src="https://gradio.s3-us-west-2.amazonaws.com/4.19.2/gradio.js"> </script>
<gradio-app theme_mode="light" space="TTS-AGI/TTS-Arena"></gradio-app>
## Motivation
The field of speech synthesis has long lacked an accurate method to measure the quality of different models. Objective metrics like WER (word error rate) are unreliable measures of model quality, and subjective measures such as MOS (mean opinion score) are typically small-scale experiments conducted with few listeners. As a result, these measurements are generally not useful for comparing two models of roughly similar quality. To address these drawbacks, we are inviting the community to rank models in an easy-to-use interface. By opening this tool and disseminating results to the public, we aim to democratize how models are ranked and to make model comparison and selection accessible to everyone.
## The TTS Arena
Human ranking for AI systems is not a novel approach. Recently, LMSys applied this method in their [Chatbot Arena](https://arena.lmsys.org/) with great results, collecting over 300,000 rankings so far. Because of its success, we adopted a similar framework for our leaderboard, inviting any person to rank synthesized audio.
The leaderboard allows a user to enter text, which will be synthesized by two models. After listening to each sample, the user will vote on which model sounds more natural. Due to the risks of human bias and abuse, model names will be revealed only after a vote is submitted.
## Selected Models
We selected several SOTA (State of the Art) models for our leaderboard. While most are open-source models, we also included several proprietary models to allow developers to compare the state of open-source development with proprietary models.
The models available at launch are:
- ElevenLabs (proprietary)
- MetaVoice
- OpenVoice
- Pheme
- WhisperSpeech
- XTTS
Although there are many other open and closed source models available, we chose these because they are generally accepted as the highest-quality publicly available models.
## The TTS Leaderboard
The results from Arena voting will be made publicly available in a dedicated leaderboard. Note that it will be initially empty until sufficient votes are accumulated, then models will gradually appear. As raters submit new votes, the leaderboard will automatically update.
Similar to the Chatbot Arena, models will be ranked using an algorithm similar to the [Elo rating system](https://en.wikipedia.org/wiki/Elo_rating_system), commonly used in chess and other games.
## Conclusion
We hope the [TTS Arena](https://huggingface.co/spaces/TTS-AGI/TTS-Arena) proves to be a helpful resource for all developers. We'd love to hear your feedback! Please do not hesitate to let us know if you have any questions or suggestions by sending us an [X/Twitter DM](https://twitter.com/realmrfakename), or by opening a discussion in [the community tab of the Space](https://huggingface.co/spaces/TTS-AGI/TTS-Arena/discussions).
## Credits
Special thanks to all the people who helped make this possible, including [Clémentine Fourrier](https://twitter.com/clefourrier), [Lucian Pouget](https://twitter.com/wauplin), [Yoach Lacombe](https://twitter.com/yoachlacombe), [Main Horse](https://twitter.com/main_horse), and the Hugging Face team. In particular, I’d like to thank [VB](https://twitter.com/reach_vb) for his time and technical assistance. I’d also like to thank [Sanchit Gandhi](https://twitter.com/sanchitgandhi99) and [Apolinário Passos](https://twitter.com/multimodalart) for their feedback and support during the development process.
| 8 |
0 | hf_public_repos | hf_public_repos/blog/tf-serving.md | ---
title: Faster TensorFlow models in Hugging Face Transformers
thumbnail: /blog/assets/10_tf-serving/thumbnail.png
authors:
- user: jplu
---
# Faster TensorFlow models in Hugging Face Transformers
<a target="_blank" href="https://colab.research.google.com/github/huggingface/blog/blob/main/notebooks/10_tf_serving.ipynb">
<img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab">
</a>
In the last few months, the Hugging Face team has been working hard on improving Transformers’ TensorFlow models to make them more robust and faster. The recent improvements are mainly focused on two aspects:
1. Computational performance: BERT, RoBERTa, ELECTRA and MPNet have been improved in order to have a much faster computation time. This gain of computational performance is noticeable for all the computational aspects: graph/eager mode, TF Serving and for CPU/GPU/TPU devices.
2. TensorFlow Serving: each of these TensorFlow model can be deployed with TensorFlow Serving to benefit of this gain of computational performance for inference.
## Computational Performance
To demonstrate the computational performance improvements, we have done a thorough benchmark where we compare BERT's performance with TensorFlow Serving of v4.2.0 to the official implementation from [Google](https://github.com/tensorflow/models/tree/master/official/nlp/bert). The benchmark has been run on a GPU V100 using a sequence length of 128 (times are in millisecond):
| Batch size | Google implementation | v4.2.0 implementation | Relative difference Google/v4.2.0 implem |
|:----------:|:---------------------:|:---------------------:|:----------------------------------------:|
| 1 | 6.7 | 6.26 | 6.79% |
| 2 | 9.4 | 8.68 | 7.96% |
| 4 | 14.4 | 13.1 | 9.45% |
| 8 | 24 | 21.5 | 10.99% |
| 16 | 46.6 | 42.3 | 9.67% |
| 32 | 83.9 | 80.4 | 4.26% |
| 64 | 171.5 | 156 | 9.47% |
| 128 | 338.5 | 309 | 9.11% |
The current implementation of Bert in v4.2.0 is faster than the Google implementation by up to ~10%. Apart from that it is also twice as fast as the implementations in the 4.1.1 release.
## TensorFlow Serving
The previous section demonstrates that the brand new Bert model got a dramatic increase in computational performance in the last version of Transformers. In this section, we will show you step-by-step how to deploy a Bert model with TensorFlow Serving to benefit from the increase in computational performance in a production environment.
### What is TensorFlow Serving?
TensorFlow Serving belongs to the set of tools provided by [TensorFlow Extended (TFX)](https://www.tensorflow.org/tfx/guide/serving) that makes the task of deploying a model to a server easier than ever. TensorFlow Serving provides two APIs, one that can be called upon using HTTP requests and another one using gRPC to run inference on the server.
### What is a SavedModel?
A SavedModel contains a standalone TensorFlow model, including its weights and its architecture. It does not require the original source of the model to be run, which makes it useful for sharing or deploying with any backend that supports reading a SavedModel such as Java, Go, C++ or JavaScript among others. The internal structure of a SavedModel is represented as such:
```
savedmodel
/assets
-> here the needed assets by the model (if any)
/variables
-> here the model checkpoints that contains the weights
saved_model.pb -> protobuf file representing the model graph
```
### How to install TensorFlow Serving?
There are three ways to install and use TensorFlow Serving:
- through a Docker container,
- through an apt package,
- or using [pip](https://pypi.org/project/pip/).
To make things easier and compliant with all the existing OS, we will use Docker in this tutorial.
### How to create a SavedModel?
SavedModel is the format expected by TensorFlow Serving. Since Transformers v4.2.0, creating a SavedModel has three additional features:
1. The sequence length can be modified freely between runs.
2. All model inputs are available for inference.
3. `hidden states` or `attention` are now grouped into a single output when returning them with `output_hidden_states=True` or `output_attentions=True`.
Below, you can find the inputs and outputs representations of a `TFBertForSequenceClassification` saved as a TensorFlow SavedModel:
```
The given SavedModel SignatureDef contains the following input(s):
inputs['attention_mask'] tensor_info:
dtype: DT_INT32
shape: (-1, -1)
name: serving_default_attention_mask:0
inputs['input_ids'] tensor_info:
dtype: DT_INT32
shape: (-1, -1)
name: serving_default_input_ids:0
inputs['token_type_ids'] tensor_info:
dtype: DT_INT32
shape: (-1, -1)
name: serving_default_token_type_ids:0
The given SavedModel SignatureDef contains the following output(s):
outputs['attentions'] tensor_info:
dtype: DT_FLOAT
shape: (12, -1, 12, -1, -1)
name: StatefulPartitionedCall:0
outputs['logits'] tensor_info:
dtype: DT_FLOAT
shape: (-1, 2)
name: StatefulPartitionedCall:1
Method name is: tensorflow/serving/predict
```
To directly pass `inputs_embeds` (the token embeddings) instead of `input_ids` (the token IDs) as input, we need to subclass the model to have a new serving signature. The following snippet of code shows how to do so:
```python
from transformers import TFBertForSequenceClassification
import tensorflow as tf
# Creation of a subclass in order to define a new serving signature
class MyOwnModel(TFBertForSequenceClassification):
# Decorate the serving method with the new input_signature
# an input_signature represents the name, the data type and the shape of an expected input
@tf.function(input_signature=[{
"inputs_embeds": tf.TensorSpec((None, None, 768), tf.float32, name="inputs_embeds"),
"attention_mask": tf.TensorSpec((None, None), tf.int32, name="attention_mask"),
"token_type_ids": tf.TensorSpec((None, None), tf.int32, name="token_type_ids"),
}])
def serving(self, inputs):
# call the model to process the inputs
output = self.call(inputs)
# return the formated output
return self.serving_output(output)
# Instantiate the model with the new serving method
model = MyOwnModel.from_pretrained("bert-base-cased")
# save it with saved_model=True in order to have a SavedModel version along with the h5 weights.
model.save_pretrained("my_model", saved_model=True)
```
The serving method has to be overridden by the new `input_signature` argument of the `tf.function` decorator. See the [official documentation](https://www.tensorflow.org/api_docs/python/tf/function#args_1) to know more about the `input_signature` argument. The `serving` method is used to define how will behave a SavedModel when deployed with TensorFlow Serving. Now the SavedModel looks like as expected, see the new `inputs_embeds` input:
```
The given SavedModel SignatureDef contains the following input(s):
inputs['attention_mask'] tensor_info:
dtype: DT_INT32
shape: (-1, -1)
name: serving_default_attention_mask:0
inputs['inputs_embeds'] tensor_info:
dtype: DT_FLOAT
shape: (-1, -1, 768)
name: serving_default_inputs_embeds:0
inputs['token_type_ids'] tensor_info:
dtype: DT_INT32
shape: (-1, -1)
name: serving_default_token_type_ids:0
The given SavedModel SignatureDef contains the following output(s):
outputs['attentions'] tensor_info:
dtype: DT_FLOAT
shape: (12, -1, 12, -1, -1)
name: StatefulPartitionedCall:0
outputs['logits'] tensor_info:
dtype: DT_FLOAT
shape: (-1, 2)
name: StatefulPartitionedCall:1
Method name is: tensorflow/serving/predict
```
## How to deploy and use a SavedModel?
Let’s see step by step how to deploy and use a BERT model for sentiment classification.
### Step 1
Create a SavedModel. To create a SavedModel, the Transformers library lets you load a PyTorch model called `nateraw/bert-base-uncased-imdb` trained on the IMDB dataset and convert it to a TensorFlow Keras model for you:
```python
from transformers import TFBertForSequenceClassification
model = TFBertForSequenceClassification.from_pretrained("nateraw/bert-base-uncased-imdb", from_pt=True)
# the saved_model parameter is a flag to create a SavedModel version of the model in same time than the h5 weights
model.save_pretrained("my_model", saved_model=True)
```
### Step 2
Create a Docker container with the SavedModel and run it. First, pull the TensorFlow Serving Docker image for CPU (for GPU replace serving by serving:latest-gpu):
```
docker pull tensorflow/serving
```
Next, run a serving image as a daemon named serving_base:
```
docker run -d --name serving_base tensorflow/serving
```
copy the newly created SavedModel into the serving_base container's models folder:
```
docker cp my_model/saved_model serving_base:/models/bert
```
commit the container that serves the model by changing MODEL_NAME to match the model's name (here `bert`), the name (`bert`) corresponds to the name we want to give to our SavedModel:
```
docker commit --change "ENV MODEL_NAME bert" serving_base my_bert_model
```
and kill the serving_base image ran as a daemon because we don't need it anymore:
```
docker kill serving_base
```
Finally, Run the image to serve our SavedModel as a daemon and we map the ports 8501 (REST API), and 8500 (gRPC API) in the container to the host and we name the the container `bert`.
```
docker run -d -p 8501:8501 -p 8500:8500 --name bert my_bert_model
```
### Step 3
Query the model through the REST API:
```python
from transformers import BertTokenizerFast, BertConfig
import requests
import json
import numpy as np
sentence = "I love the new TensorFlow update in transformers."
# Load the corresponding tokenizer of our SavedModel
tokenizer = BertTokenizerFast.from_pretrained("nateraw/bert-base-uncased-imdb")
# Load the model config of our SavedModel
config = BertConfig.from_pretrained("nateraw/bert-base-uncased-imdb")
# Tokenize the sentence
batch = tokenizer(sentence)
# Convert the batch into a proper dict
batch = dict(batch)
# Put the example into a list of size 1, that corresponds to the batch size
batch = [batch]
# The REST API needs a JSON that contains the key instances to declare the examples to process
input_data = {"instances": batch}
# Query the REST API, the path corresponds to http://host:port/model_version/models_root_folder/model_name:method
r = requests.post("http://localhost:8501/v1/models/bert:predict", data=json.dumps(input_data))
# Parse the JSON result. The results are contained in a list with a root key called "predictions"
# and as there is only one example, takes the first element of the list
result = json.loads(r.text)["predictions"][0]
# The returned results are probabilities, that can be positive or negative hence we take their absolute value
abs_scores = np.abs(result)
# Take the argmax that correspond to the index of the max probability.
label_id = np.argmax(abs_scores)
# Print the proper LABEL with its index
print(config.id2label[label_id])
```
This should return POSITIVE. It is also possible to pass by the gRPC (google Remote Procedure Call) API to get the same result:
```python
from transformers import BertTokenizerFast, BertConfig
import numpy as np
import tensorflow as tf
from tensorflow_serving.apis import predict_pb2
from tensorflow_serving.apis import prediction_service_pb2_grpc
import grpc
sentence = "I love the new TensorFlow update in transformers."
tokenizer = BertTokenizerFast.from_pretrained("nateraw/bert-base-uncased-imdb")
config = BertConfig.from_pretrained("nateraw/bert-base-uncased-imdb")
# Tokenize the sentence but this time with TensorFlow tensors as output already batch sized to 1. Ex:
# {
# 'input_ids': <tf.Tensor: shape=(1, 3), dtype=int32, numpy=array([[ 101, 19082, 102]])>,
# 'token_type_ids': <tf.Tensor: shape=(1, 3), dtype=int32, numpy=array([[0, 0, 0]])>,
# 'attention_mask': <tf.Tensor: shape=(1, 3), dtype=int32, numpy=array([[1, 1, 1]])>
# }
batch = tokenizer(sentence, return_tensors="tf")
# Create a channel that will be connected to the gRPC port of the container
channel = grpc.insecure_channel("localhost:8500")
# Create a stub made for prediction. This stub will be used to send the gRPC request to the TF Server.
stub = prediction_service_pb2_grpc.PredictionServiceStub(channel)
# Create a gRPC request made for prediction
request = predict_pb2.PredictRequest()
# Set the name of the model, for this use case it is bert
request.model_spec.name = "bert"
# Set which signature is used to format the gRPC query, here the default one
request.model_spec.signature_name = "serving_default"
# Set the input_ids input from the input_ids given by the tokenizer
# tf.make_tensor_proto turns a TensorFlow tensor into a Protobuf tensor
request.inputs["input_ids"].CopyFrom(tf.make_tensor_proto(batch["input_ids"]))
# Same with attention mask
request.inputs["attention_mask"].CopyFrom(tf.make_tensor_proto(batch["attention_mask"]))
# Same with token type ids
request.inputs["token_type_ids"].CopyFrom(tf.make_tensor_proto(batch["token_type_ids"]))
# Send the gRPC request to the TF Server
result = stub.Predict(request)
# The output is a protobuf where the only one output is a list of probabilities
# assigned to the key logits. As the probabilities as in float, the list is
# converted into a numpy array of floats with .float_val
output = result.outputs["logits"].float_val
# Print the proper LABEL with its index
print(config.id2label[np.argmax(np.abs(output))])
```
## Conclusion
Thanks to the last updates applied on the TensorFlow models in transformers, one can now easily deploy its models in production using TensorFlow Serving. One of the next steps we are thinking about is to directly integrate the preprocessing part inside the SavedModel to make things even easier.
| 9 |
0 | hf_public_repos/block_movement_pruning | hf_public_repos/block_movement_pruning/block_movement_pruning/counts_parameters.py | # Copyright 2020-present, the HuggingFace Inc. team.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""
Count remaining (non-zero) weights in the encoder (i.e. the transformer layers).
Sparsity and remaining weights levels are equivalent: sparsity % = 100 - remaining weights %.
"""
import argparse
import os
import torch
from emmental.modules import MaskedLinear
def expand_mask(mask, args):
mask_block_rows = args.mask_block_rows
mask_block_cols = args.mask_block_cols
mask = torch.repeat_interleave(mask, mask_block_rows, dim=0)
mask = torch.repeat_interleave(mask, mask_block_cols, dim=1)
return mask
def main(args):
serialization_dir = args.serialization_dir
pruning_method = args.pruning_method
threshold = args.threshold
ampere_pruning_method = args.ampere_pruning_method
st = torch.load(os.path.join(serialization_dir, "pytorch_model.bin"), map_location="cuda")
remaining_count = 0 # Number of remaining (not pruned) params in the encoder
encoder_count = 0 # Number of params in the encoder
print("name".ljust(60, " "), "Remaining Weights %", "Remaining Weight")
for name, param in st.items():
if "encoder" not in name:
continue
if name.endswith(".weight"):
weights = MaskedLinear.masked_weights_from_state_dict(st,
name,
pruning_method,
threshold,
ampere_pruning_method)
mask_ones = (weights != 0).sum().item()
print(name.ljust(60, " "), str(round(100 * mask_ones / param.numel(), 3)).ljust(20, " "), str(mask_ones))
remaining_count += mask_ones
elif MaskedLinear.check_name(name):
pass
else:
encoder_count += param.numel()
if name.endswith(".weight") and ".".join(name.split(".")[:-1] + ["mask_scores"]) in st:
pass
else:
remaining_count += param.numel()
print("")
print("Remaining Weights (global) %: ", 100 * remaining_count / encoder_count)
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument(
"--pruning_method",
choices=["l0", "topK", "sigmoied_threshold"],
type=str,
required=True,
help="Pruning Method (l0 = L0 regularization, topK = Movement pruning, sigmoied_threshold = Soft movement pruning)",
)
parser.add_argument(
"--threshold",
type=float,
required=False,
help="For `topK`, it is the level of remaining weights (in %) in the fine-pruned model."
"For `sigmoied_threshold`, it is the threshold \tau against which the (sigmoied) scores are compared."
"Not needed for `l0`",
)
parser.add_argument(
"--serialization_dir",
type=str,
required=True,
help="Folder containing the model that was previously fine-pruned",
)
parser.add_argument(
"--mask_block_rows",
default=1,
type=int,
help="Block row size for masks. Default is 1 -> general sparsity, not block sparsity.",
)
parser.add_argument(
"--mask_block_cols",
default=1,
type=int,
help="Block row size for masks. Default is 1 -> general sparsity, not block sparsity.",
)
args = parser.parse_args()
main(args)
| 0 |
0 | hf_public_repos/block_movement_pruning | hf_public_repos/block_movement_pruning/block_movement_pruning/bertarize.py | # Copyright 2020-present, the HuggingFace Inc. team.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""
Once a model has been fine-pruned, the weights that are masked during the forward pass can be pruned once for all.
For instance, once the a model from the :class:`~emmental.MaskedBertForSequenceClassification` is trained, it can be saved (and then loaded)
as a standard :class:`~transformers.BertForSequenceClassification`.
"""
import argparse
import os
import shutil
import torch
from emmental.modules import MaskedLinear
def expand_mask(mask, args):
mask_block_rows = args.mask_block_rows
mask_block_cols = args.mask_block_cols
mask = torch.repeat_interleave(mask, mask_block_rows, dim=0)
mask = torch.repeat_interleave(mask, mask_block_cols, dim=1)
return mask
def main(args):
pruning_method = args.pruning_method
ampere_pruning_method = args.ampere_pruning_method
threshold = args.threshold
model_name_or_path = args.model_name_or_path.rstrip("/")
target_model_path = args.target_model_path
print(f"Load fine-pruned model from {model_name_or_path}")
model = torch.load(os.path.join(model_name_or_path, "pytorch_model.bin"))
pruned_model = {}
for name, tensor in model.items():
if "embeddings" in name or "LayerNorm" in name or "pooler" in name:
pruned_model[name] = tensor
print(f"Copied layer {name}")
elif "classifier" in name or "qa_output" in name:
pruned_model[name] = tensor
print(f"Copied layer {name}")
elif "bias" in name:
pruned_model[name] = tensor
print(f"Copied layer {name}")
else:
if name.endswith(".weight"):
pruned_model[name] = MaskedLinear.masked_weights_from_state_dict(model, name, pruning_method, threshold, ampere_pruning_method)
else:
assert(MaskedLinear.check_name(name))
if target_model_path is None:
target_model_path = os.path.join(
os.path.dirname(model_name_or_path), f"bertarized_{os.path.basename(model_name_or_path)}"
)
if not os.path.isdir(target_model_path):
shutil.copytree(model_name_or_path, target_model_path)
print(f"\nCreated folder {target_model_path}")
torch.save(pruned_model, os.path.join(target_model_path, "pytorch_model.bin"))
print("\nPruned model saved! See you later!")
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument(
"--pruning_method",
choices=["l0", "magnitude", "topK", "sigmoied_threshold"],
type=str,
required=True,
help="Pruning Method (l0 = L0 regularization, magnitude = Magnitude pruning, topK = Movement pruning, sigmoied_threshold = Soft movement pruning)",
)
parser.add_argument(
"--threshold",
type=float,
required=False,
help="For `magnitude` and `topK`, it is the level of remaining weights (in %) in the fine-pruned model."
"For `sigmoied_threshold`, it is the threshold \tau against which the (sigmoied) scores are compared."
"Not needed for `l0`",
)
parser.add_argument(
"--model_name_or_path",
type=str,
required=True,
help="Folder containing the model that was previously fine-pruned",
)
parser.add_argument(
"--target_model_path",
default=None,
type=str,
required=False,
help="Folder containing the model that was previously fine-pruned",
)
parser.add_argument(
"--mask_block_rows",
default=1,
type=int,
help="Block row size for masks. Default is 1 -> general sparsity, not block sparsity.",
)
parser.add_argument(
"--mask_block_cols",
default=1,
type=int,
help="Block row size for masks. Default is 1 -> general sparsity, not block sparsity.",
)
args = parser.parse_args()
main(args)
| 1 |
0 | hf_public_repos/block_movement_pruning | hf_public_repos/block_movement_pruning/block_movement_pruning/command_line.py | import click
@click.group()
@click.pass_context
def cli(ctx):
ctx.obj = {}
@cli.command()
@click.pass_context
@click.argument('path', default = None, type=click.Path(exists = True, resolve_path = True))
@click.argument('output', default = None, type=click.Path(resolve_path = True))
@click.option('--arg', '-a', is_flag = True)
def command1(ctx, path, output, arg):
click.echo(click.style("Running !", fg="red"))
#print(path + ":" + main(path, output))
def train_command():
pass | 2 |
0 | hf_public_repos/block_movement_pruning | hf_public_repos/block_movement_pruning/block_movement_pruning/masked_run_squad.py | # coding=utf-8
# Copyright 2018 The Google AI Language Team Authors and The HuggingFace Inc. team.
# Copyright (c) 2018, NVIDIA CORPORATION. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
""" Fine-pruning Masked BERT for question-answering on SQuAD."""
import argparse
import copy
import glob
import logging
import os
import random
import timeit
import shutil
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.utils.data import DataLoader, RandomSampler, SequentialSampler
from torch.utils.data.distributed import DistributedSampler
from tqdm import tqdm, trange
from emmental import MaskedBertConfig, MaskedBertForQuestionAnswering
from transformers import (
WEIGHTS_NAME,
AdamW,
BertConfig,
BertForQuestionAnswering,
BertTokenizer,
get_linear_schedule_with_warmup,
squad_convert_examples_to_features,
)
from transformers.data.metrics.squad_metrics import (
compute_predictions_log_probs,
compute_predictions_logits,
squad_evaluate,
)
from transformers.data.processors.squad import SquadResult, SquadV1Processor, SquadV2Processor
from transformers.utils.hp_naming import TrialShortNamer
try:
from torch.utils.tensorboard import SummaryWriter
except ImportError:
from tensorboardX import SummaryWriter
logger = logging.getLogger(__name__)
MODEL_CLASSES = {
"bert": (BertConfig, BertForQuestionAnswering, BertTokenizer),
"masked_bert": (MaskedBertConfig, MaskedBertForQuestionAnswering, BertTokenizer),
}
def set_seed(args):
random.seed(args.seed)
np.random.seed(args.seed)
torch.manual_seed(args.seed)
if args.n_gpu > 0:
torch.cuda.manual_seed_all(args.seed)
def schedule_threshold(
step: int,
total_step: int,
warmup_steps: int,
initial_threshold: float,
final_threshold: float,
initial_warmup: int,
final_warmup: int,
final_lambda: float,
initial_ampere_temperature:float,
final_ampere_temperature:float,
initial_shuffling_temperature: float,
final_shuffling_temperature: float,
):
if step <= initial_warmup * warmup_steps:
threshold = initial_threshold
ampere_temperature = initial_ampere_temperature
shuffling_temperature = initial_shuffling_temperature
elif step > (total_step - final_warmup * warmup_steps):
threshold = final_threshold
ampere_temperature = final_ampere_temperature
shuffling_temperature = final_shuffling_temperature
else:
spars_warmup_steps = initial_warmup * warmup_steps
spars_schedu_steps = (final_warmup + initial_warmup) * warmup_steps
mul_coeff = 1 - (step - spars_warmup_steps) / (total_step - spars_schedu_steps)
threshold = final_threshold + (initial_threshold - final_threshold) * (mul_coeff ** 3)
ampere_temperature = final_ampere_temperature + (initial_ampere_temperature - final_ampere_temperature) * (mul_coeff ** 3)
shuffling_temperature = final_shuffling_temperature + (initial_shuffling_temperature - final_shuffling_temperature) * (mul_coeff ** 3)
regu_lambda = final_lambda * threshold / final_threshold
return threshold, regu_lambda, ampere_temperature, shuffling_temperature
def regularization(model: nn.Module, mode: str):
regu, counter = 0, 0
for name, param in model.named_parameters():
if "mask_scores" in name:
if mode == "l1":
regu += torch.norm(torch.sigmoid(param), p=1) / param.numel()
elif mode == "l0":
regu += torch.sigmoid(param - 2 / 3 * np.log(0.1 / 1.1)).sum() / param.numel()
else:
ValueError("Don't know this mode.")
counter += 1
return regu / counter
def to_list(tensor):
return tensor.detach().cpu().tolist()
def train(args, train_dataset, model, tokenizer, teacher=None):
""" Train the model """
if args.local_rank in [-1, 0]:
tb_writer = SummaryWriter(log_dir=args.output_dir)
args.train_batch_size = args.per_gpu_train_batch_size * max(1, args.n_gpu)
train_sampler = RandomSampler(train_dataset) if args.local_rank == -1 else DistributedSampler(train_dataset)
train_dataloader = DataLoader(train_dataset, sampler=train_sampler, batch_size=args.train_batch_size)
if args.max_steps > 0:
t_total = args.max_steps
args.num_train_epochs = args.max_steps // (len(train_dataloader) // args.gradient_accumulation_steps) + 1
else:
t_total = len(train_dataloader) // args.gradient_accumulation_steps * args.num_train_epochs
# Prepare optimizer and schedule (linear warmup and decay)
no_decay = ["bias", "LayerNorm.weight"]
optimizer_grouped_parameters = [
{
"params": [p for n, p in model.named_parameters() if "mask_score" in n and p.requires_grad],
"lr": args.mask_scores_learning_rate,
},
{
"params": [p for n, p in model.named_parameters() if "ampere_permut_scores" in n and p.requires_grad],
"lr": args.ampere_learning_rate,
},
{
"params": [p for n, p in model.named_parameters() if "permutation_scores" in n and p.requires_grad],
"lr": args.shuffling_learning_rate,
},
{
"params": [
p
for n, p in model.named_parameters()
if "mask_score" not in n and "ampere_permut_scores" not in n and "permutation_scores" not in n and p.requires_grad and not any(nd in n for nd in no_decay)
],
"lr": args.learning_rate,
"weight_decay": args.weight_decay,
},
{
"params": [
p
for n, p in model.named_parameters()
if "mask_score" not in n and "ampere_permut_scores" not in n and "permutation_scores" not in n and p.requires_grad and any(nd in n for nd in no_decay)
],
"lr": args.learning_rate,
"weight_decay": 0.0,
},
]
optimizer = AdamW(optimizer_grouped_parameters, lr=args.learning_rate, eps=args.adam_epsilon)
scheduler = get_linear_schedule_with_warmup(
optimizer, num_warmup_steps=args.warmup_steps, num_training_steps=t_total
)
# Check if saved optimizer or scheduler states exist
if os.path.isfile(os.path.join(args.model_name_or_path, "optimizer.pt")) and os.path.isfile(
os.path.join(args.model_name_or_path, "scheduler.pt")
):
# Load in optimizer and scheduler states
optimizer.load_state_dict(torch.load(os.path.join(args.model_name_or_path, "optimizer.pt")))
scheduler.load_state_dict(torch.load(os.path.join(args.model_name_or_path, "scheduler.pt")))
if args.fp16:
try:
from apex import amp
except ImportError:
raise ImportError("Please install apex from https://www.github.com/nvidia/apex to use fp16 training.")
model, optimizer = amp.initialize(model, optimizer, opt_level=args.fp16_opt_level)
# multi-gpu training (should be after apex fp16 initialization)
if args.n_gpu > 1:
model = torch.nn.DataParallel(model)
# Distributed training (should be after apex fp16 initialization)
if args.local_rank != -1:
model = torch.nn.parallel.DistributedDataParallel(
model,
device_ids=[args.local_rank],
output_device=args.local_rank,
find_unused_parameters=True,
)
# Train!
logger.info("***** Running training *****")
logger.info(" Num examples = %d", len(train_dataset))
logger.info(" Num Epochs = %d", args.num_train_epochs)
logger.info(" Instantaneous batch size per GPU = %d", args.per_gpu_train_batch_size)
logger.info(
" Total train batch size (w. parallel, distributed & accumulation) = %d",
args.train_batch_size
* args.gradient_accumulation_steps
* (torch.distributed.get_world_size() if args.local_rank != -1 else 1),
)
logger.info(" Gradient Accumulation steps = %d", args.gradient_accumulation_steps)
logger.info(" Total optimization steps = %d", t_total)
# Distillation
if teacher is not None:
logger.info(" Training with distillation")
global_step = 1
# Global TopK
if args.global_topk:
threshold_mem = None
epochs_trained = 0
steps_trained_in_current_epoch = 0
# Check if continuing training from a checkpoint
if os.path.exists(args.model_name_or_path):
# set global_step to global_step of last saved checkpoint from model path
try:
checkpoint_suffix = args.model_name_or_path.split("-")[-1].split("/")[0]
global_step = int(checkpoint_suffix)
epochs_trained = global_step // (len(train_dataloader) // args.gradient_accumulation_steps)
steps_trained_in_current_epoch = global_step % (len(train_dataloader) // args.gradient_accumulation_steps)
logger.info(" Continuing training from checkpoint, will skip to saved global_step")
logger.info(" Continuing training from epoch %d", epochs_trained)
logger.info(" Continuing training from global step %d", global_step)
logger.info(" Will skip the first %d steps in the first epoch", steps_trained_in_current_epoch)
except ValueError:
logger.info(" Starting fine-tuning.")
tr_loss, logging_loss = 0.0, 0.0
model.zero_grad()
train_iterator = trange(
epochs_trained, int(args.num_train_epochs), desc="Epoch", disable=args.local_rank not in [-1, 0]
)
# Added here for reproducibility
set_seed(args)
for _ in train_iterator:
epoch_iterator = tqdm(train_dataloader, desc="Iteration", disable=args.local_rank not in [-1, 0])
for step, batch in enumerate(epoch_iterator):
# Skip past any already trained steps if resuming training
if steps_trained_in_current_epoch > 0:
steps_trained_in_current_epoch -= 1
continue
model.train()
batch = tuple(t.to(args.device) for t in batch)
threshold, regu_lambda, ampere_temperature, shuffling_temperature = schedule_threshold(
step=global_step,
total_step=t_total,
warmup_steps=args.warmup_steps,
final_threshold=args.final_threshold,
initial_threshold=args.initial_threshold,
final_warmup=args.final_warmup,
initial_warmup=args.initial_warmup,
final_lambda=args.final_lambda,
initial_ampere_temperature=args.initial_ampere_temperature,
final_ampere_temperature=args.final_ampere_temperature,
initial_shuffling_temperature=args.initial_shuffling_temperature,
final_shuffling_temperature=args.final_shuffling_temperature,
)
# Global TopK
if args.global_topk:
if threshold == 1.0:
threshold = -1e2 # Or an indefinitely low quantity
else:
if (threshold_mem is None) or (global_step % args.global_topk_frequency_compute == 0):
# Sort all the values to get the global topK
concat = torch.cat(
[param.view(-1) for name, param in model.named_parameters() if "mask_scores" in name]
)
n = concat.numel()
kth = max(n - (int(n * threshold) + 1), 1)
threshold_mem = concat.kthvalue(kth).values.item()
threshold = threshold_mem
else:
threshold = threshold_mem
inputs = {
"input_ids": batch[0],
"attention_mask": batch[1],
"token_type_ids": batch[2],
"start_positions": batch[3],
"end_positions": batch[4],
}
if args.model_type in ["xlm", "roberta", "distilbert", "camembert"]:
del inputs["token_type_ids"]
if args.model_type in ["xlnet", "xlm"]:
inputs.update({"cls_index": batch[5], "p_mask": batch[6]})
if args.version_2_with_negative:
inputs.update({"is_impossible": batch[7]})
if hasattr(model, "config") and hasattr(model.config, "lang2id"):
inputs.update(
{"langs": (torch.ones(batch[0].shape, dtype=torch.int64) * args.lang_id).to(args.device)}
)
if "masked" in args.model_type:
current_config = dict(threshold = threshold,
ampere_temperature=ampere_temperature,
shuffling_temperature=shuffling_temperature)
inputs["current_config"] = current_config
outputs = model(**inputs)
# model outputs are always tuple in transformers (see doc)
loss, start_logits_stu, end_logits_stu = outputs
# Distillation loss
if teacher is not None:
with torch.no_grad():
start_logits_tea, end_logits_tea = teacher(
input_ids=inputs["input_ids"],
token_type_ids=inputs["token_type_ids"],
attention_mask=inputs["attention_mask"],
)
loss_start = (
F.kl_div(
input=F.log_softmax(start_logits_stu / args.temperature, dim=-1),
target=F.softmax(start_logits_tea / args.temperature, dim=-1),
reduction="batchmean",
)
* (args.temperature ** 2)
)
loss_end = (
F.kl_div(
input=F.log_softmax(end_logits_stu / args.temperature, dim=-1),
target=F.softmax(end_logits_tea / args.temperature, dim=-1),
reduction="batchmean",
)
* (args.temperature ** 2)
)
loss_logits = (loss_start + loss_end) / 2.0
loss = args.alpha_distil * loss_logits + args.alpha_ce * loss
# Regularization
if args.regularization is not None:
regu_ = regularization(model=model, mode=args.regularization)
loss = loss + regu_lambda * regu_
if args.n_gpu > 1:
loss = loss.mean() # mean() to average on multi-gpu parallel training
if args.gradient_accumulation_steps > 1:
loss = loss / args.gradient_accumulation_steps
if args.fp16:
with amp.scale_loss(loss, optimizer) as scaled_loss:
scaled_loss.backward()
else:
loss.backward()
tr_loss += loss.item()
if (step + 1) % args.gradient_accumulation_steps == 0:
if args.fp16:
torch.nn.utils.clip_grad_norm_(amp.master_params(optimizer), args.max_grad_norm)
else:
torch.nn.utils.clip_grad_norm_(model.parameters(), args.max_grad_norm)
if args.local_rank in [-1, 0] and args.logging_steps > 0 and global_step % args.logging_steps == 0:
tb_writer.add_scalar("threshold", threshold, global_step)
for name, param in model.named_parameters():
try:
if not param.requires_grad:
continue
tb_writer.add_scalar("parameter_mean/" + name, param.data.mean(), global_step)
tb_writer.add_scalar("parameter_std/" + name, param.data.std(), global_step)
tb_writer.add_scalar("parameter_min/" + name, param.data.min(), global_step)
tb_writer.add_scalar("parameter_max/" + name, param.data.max(), global_step)
if "pooler" in name:
continue
tb_writer.add_scalar("grad_mean/" + name, param.grad.data.mean(), global_step)
tb_writer.add_scalar("grad_std/" + name, param.grad.data.std(), global_step)
if args.regularization is not None and "mask_scores" in name:
if args.regularization == "l1":
perc = (torch.sigmoid(param) > threshold).sum().item() / param.numel()
elif args.regularization == "l0":
perc = (torch.sigmoid(param - 2 / 3 * np.log(0.1 / 1.1))).sum().item() / param.numel()
tb_writer.add_scalar("retained_weights_perc/" + name, perc, global_step)
except AttributeError as e:
print(f"name error with {name}", e)
optimizer.step()
scheduler.step() # Update learning rate schedule
model.zero_grad()
global_step += 1
# Log metrics
if args.local_rank in [-1, 0] and args.logging_steps > 0 and global_step % args.logging_steps == 0:
# Only evaluate when single GPU otherwise metrics may not average well
if args.local_rank == -1 and args.evaluate_during_training:
results = evaluate(args, model, tokenizer)
for key, value in results.items():
tb_writer.add_scalar("eval/{}".format(key), value, global_step)
learning_rate_scalar = scheduler.get_lr()
tb_writer.add_scalar("lr", learning_rate_scalar[0], global_step)
if len(learning_rate_scalar) > 1:
for idx, lr in enumerate(learning_rate_scalar[1:]):
tb_writer.add_scalar(f"lr/{idx+1}", lr, global_step)
tb_writer.add_scalar("loss", (tr_loss - logging_loss) / args.logging_steps, global_step)
if teacher is not None:
tb_writer.add_scalar("loss/distil", loss_logits.item(), global_step)
if args.regularization is not None:
tb_writer.add_scalar("loss/regularization", regu_.item(), global_step)
if (teacher is not None) or (args.regularization is not None):
if (teacher is not None) and (args.regularization is not None):
tb_writer.add_scalar(
"loss/instant_ce",
(loss.item() - regu_lambda * regu_.item() - args.alpha_distil * loss_logits.item())
/ args.alpha_ce,
global_step,
)
elif teacher is not None:
tb_writer.add_scalar(
"loss/instant_ce",
(loss.item() - args.alpha_distil * loss_logits.item()) / args.alpha_ce,
global_step,
)
else:
tb_writer.add_scalar(
"loss/instant_ce", loss.item() - regu_lambda * regu_.item(), global_step
)
logging_loss = tr_loss
# Save model checkpoint
if args.local_rank in [-1, 0] and args.save_steps > 0 and global_step % args.save_steps == 0:
output_dir = os.path.join(args.output_dir, "checkpoint-{}".format(global_step))
if not os.path.exists(output_dir):
os.makedirs(output_dir)
# Take care of distributed/parallel training
model_to_save = model.module if hasattr(model, "module") else model
model_to_save.save_pretrained(output_dir)
tokenizer.save_pretrained(output_dir)
torch.save(args, os.path.join(output_dir, "training_args.bin"))
logger.info("Saving model checkpoint to %s", output_dir)
torch.save(optimizer.state_dict(), os.path.join(output_dir, "optimizer.pt"))
torch.save(scheduler.state_dict(), os.path.join(output_dir, "scheduler.pt"))
logger.info("Saving optimizer and scheduler states to %s", output_dir)
# Log metrics
if args.eval_all_checkpoints:
results = evaluate(args, model, tokenizer)
for key, value in results.items():
tb_writer.add_scalar("eval/{}".format(key), value, global_step)
if args.max_steps > 0 and global_step > args.max_steps:
epoch_iterator.close()
break
if args.max_steps > 0 and global_step > args.max_steps:
train_iterator.close()
break
if args.local_rank in [-1, 0]:
tb_writer.close()
return global_step, tr_loss / global_step
def evaluate(args, model, tokenizer, prefix=""):
dataset, examples, features = load_and_cache_examples(args, tokenizer, evaluate=True, output_examples=True)
if not os.path.exists(args.output_dir) and args.local_rank in [-1, 0]:
os.makedirs(args.output_dir)
args.eval_batch_size = args.per_gpu_eval_batch_size * max(1, args.n_gpu)
# Note that DistributedSampler samples randomly
eval_sampler = SequentialSampler(dataset)
eval_dataloader = DataLoader(dataset, sampler=eval_sampler, batch_size=args.eval_batch_size)
# multi-gpu eval
if args.n_gpu > 1 and not isinstance(model, torch.nn.DataParallel):
model = torch.nn.DataParallel(model)
# Eval!
logger.info("***** Running evaluation {} *****".format(prefix))
logger.info(" Num examples = %d", len(dataset))
logger.info(" Batch size = %d", args.eval_batch_size)
all_results = []
start_time = timeit.default_timer()
# Global TopK
if args.global_topk:
threshold_mem = None
for batch in tqdm(eval_dataloader, desc="Evaluating"):
model.eval()
batch = tuple(t.to(args.device) for t in batch)
with torch.no_grad():
inputs = {
"input_ids": batch[0],
"attention_mask": batch[1],
"token_type_ids": batch[2],
}
if args.model_type in ["xlm", "roberta", "distilbert", "camembert"]:
del inputs["token_type_ids"]
example_indices = batch[3]
# XLNet and XLM use more arguments for their predictions
if args.model_type in ["xlnet", "xlm"]:
inputs.update({"cls_index": batch[4], "p_mask": batch[5]})
# for lang_id-sensitive xlm models
if hasattr(model, "config") and hasattr(model.config, "lang2id"):
inputs.update(
{"langs": (torch.ones(batch[0].shape, dtype=torch.int64) * args.lang_id).to(args.device)}
)
if "masked" in args.model_type:
inputs["current_config"] = {}
inputs["current_config"]["threshold"] = args.final_threshold
inputs["current_config"]["ampere_temperature"] = args.final_ampere_temperature
inputs["current_config"]["shuffling_temperature"] = args.final_shuffling_temperature
if args.global_topk:
if threshold_mem is None:
concat = torch.cat(
[param.view(-1) for name, param in model.named_parameters() if "mask_scores" in name]
)
n = concat.numel()
kth = max(n - (int(n * args.final_threshold) + 1), 1)
threshold_mem = concat.kthvalue(kth).values.item()
inputs["current_config"]["threshold"] = threshold_mem
outputs = model(**inputs)
for i, example_index in enumerate(example_indices):
eval_feature = features[example_index.item()]
unique_id = int(eval_feature.unique_id)
output = [to_list(output[i]) for output in outputs]
# Some models (XLNet, XLM) use 5 arguments for their predictions, while the other "simpler"
# models only use two.
if len(output) >= 5:
start_logits = output[0]
start_top_index = output[1]
end_logits = output[2]
end_top_index = output[3]
cls_logits = output[4]
result = SquadResult(
unique_id,
start_logits,
end_logits,
start_top_index=start_top_index,
end_top_index=end_top_index,
cls_logits=cls_logits,
)
else:
start_logits, end_logits = output
result = SquadResult(unique_id, start_logits, end_logits)
all_results.append(result)
evalTime = timeit.default_timer() - start_time
logger.info(" Evaluation done in total %f secs (%f sec per example)", evalTime, evalTime / len(dataset))
# Compute predictions
output_prediction_file = os.path.join(args.output_dir, "predictions_{}.json".format(prefix))
output_nbest_file = os.path.join(args.output_dir, "nbest_predictions_{}.json".format(prefix))
if args.version_2_with_negative:
output_null_log_odds_file = os.path.join(args.output_dir, "null_odds_{}.json".format(prefix))
else:
output_null_log_odds_file = None
# XLNet and XLM use a more complex post-processing procedure
if args.model_type in ["xlnet", "xlm"]:
start_n_top = model.config.start_n_top if hasattr(model, "config") else model.module.config.start_n_top
end_n_top = model.config.end_n_top if hasattr(model, "config") else model.module.config.end_n_top
predictions = compute_predictions_log_probs(
examples,
features,
all_results,
args.n_best_size,
args.max_answer_length,
output_prediction_file,
output_nbest_file,
output_null_log_odds_file,
start_n_top,
end_n_top,
args.version_2_with_negative,
tokenizer,
args.verbose_logging,
)
else:
predictions = compute_predictions_logits(
examples,
features,
all_results,
args.n_best_size,
args.max_answer_length,
args.do_lower_case,
output_prediction_file,
output_nbest_file,
output_null_log_odds_file,
args.verbose_logging,
args.version_2_with_negative,
args.null_score_diff_threshold,
tokenizer,
)
# Compute the F1 and exact scores.
results = squad_evaluate(examples, predictions)
return results
def load_and_cache_examples(args, tokenizer, evaluate=False, output_examples=False):
if args.local_rank not in [-1, 0] and not evaluate:
# Make sure only the first process in distributed training process the dataset, and the others will use the cache
torch.distributed.barrier()
# Load data features from cache or dataset file
input_dir = args.data_dir if args.data_dir else "."
cached_features_file = os.path.join(
input_dir,
"cached_{}_{}_{}_{}".format(
"dev" if evaluate else "train",
args.tokenizer_name
if args.tokenizer_name
else list(filter(None, args.model_name_or_path.split("/"))).pop(),
str(args.max_seq_length),
list(filter(None, args.predict_file.split("/"))).pop()
if evaluate
else list(filter(None, args.train_file.split("/"))).pop(),
),
)
if args.truncate_train_examples != -1:
cached_features_file = cached_features_file[: -len(".json")] + f"_truncate_{args.truncate_train_examples}.json"
# Init features and dataset from cache if it exists
if os.path.exists(cached_features_file) and not args.overwrite_cache:
logger.info("Loading features from cached file %s", cached_features_file)
features_and_dataset = torch.load(cached_features_file)
features, dataset, examples = (
features_and_dataset["features"],
features_and_dataset["dataset"],
features_and_dataset["examples"],
)
else:
logger.info("Creating features from dataset file at %s", input_dir)
if not args.data_dir and ((evaluate and not args.predict_file) or (not evaluate and not args.train_file)):
try:
import tensorflow_datasets as tfds
except ImportError:
raise ImportError("If not data_dir is specified, tensorflow_datasets needs to be installed.")
if args.version_2_with_negative:
logger.warn("tensorflow_datasets does not handle version 2 of SQuAD.")
tfds_examples = tfds.load("squad")
examples = SquadV1Processor().get_examples_from_dataset(tfds_examples, evaluate=evaluate)
else:
processor = SquadV2Processor() if args.version_2_with_negative else SquadV1Processor()
if evaluate:
examples = processor.get_dev_examples(args.data_dir, filename=args.predict_file)
else:
examples = processor.get_train_examples(args.data_dir, filename=args.train_file)
if args.truncate_train_examples != -1:
examples = examples[: args.truncate_train_examples]
features, dataset = squad_convert_examples_to_features(
examples=examples,
tokenizer=tokenizer,
max_seq_length=args.max_seq_length,
doc_stride=args.doc_stride,
max_query_length=args.max_query_length,
is_training=not evaluate,
return_dataset="pt",
threads=args.threads,
)
if args.local_rank in [-1, 0]:
logger.info("Saving features into cached file %s", cached_features_file)
torch.save({"features": features, "dataset": dataset, "examples": examples}, cached_features_file)
if args.local_rank == 0 and not evaluate:
# Make sure only the first process in distributed training process the dataset, and the others will use the cache
torch.distributed.barrier()
if output_examples:
return dataset, examples, features
return dataset
def create_parser():
parser = argparse.ArgumentParser()
# Required parameters
parser.add_argument(
"--model_type",
default=None,
type=str,
required=True,
help="Model type selected in the list: " + ", ".join(MODEL_CLASSES.keys()),
)
parser.add_argument(
"--model_name_or_path",
default=None,
type=str,
required=True,
help="Path to pretrained model or model identifier from huggingface.co/models",
)
parser.add_argument(
"--output_dir",
default=None,
type=str,
required=True,
help="The output directory where the model checkpoints and predictions will be written.",
)
# Other parameters
parser.add_argument(
"--data_dir",
default=None,
type=str,
help="The input data dir. Should contain the .json files for the task."
+ "If no data dir or train/predict files are specified, will run with tensorflow_datasets.",
)
parser.add_argument(
"--train_file",
default=None,
type=str,
help="The input training file. If a data dir is specified, will look for the file there"
+ "If no data dir or train/predict files are specified, will run with tensorflow_datasets.",
)
parser.add_argument(
"--predict_file",
default=None,
type=str,
help="The input evaluation file. If a data dir is specified, will look for the file there"
+ "If no data dir or train/predict files are specified, will run with tensorflow_datasets.",
)
parser.add_argument(
"--config_name", default="", type=str, help="Pretrained config name or path if not the same as model_name"
)
parser.add_argument(
"--tokenizer_name",
default="",
type=str,
help="Pretrained tokenizer name or path if not the same as model_name",
)
parser.add_argument(
"--cache_dir",
default="",
type=str,
help="Where do you want to store the pre-trained models downloaded from s3",
)
parser.add_argument(
"--version_2_with_negative",
action="store_true",
help="If true, the SQuAD examples contain some that do not have an answer.",
)
parser.add_argument(
"--null_score_diff_threshold",
type=float,
default=0.0,
help="If null_score - best_non_null is greater than the threshold predict null.",
)
parser.add_argument(
"--max_seq_length",
default=384,
type=int,
help="The maximum total input sequence length after WordPiece tokenization. Sequences "
"longer than this will be truncated, and sequences shorter than this will be padded.",
)
parser.add_argument(
"--doc_stride",
default=128,
type=int,
help="When splitting up a long document into chunks, how much stride to take between chunks.",
)
parser.add_argument(
"--max_query_length",
default=64,
type=int,
help="The maximum number of tokens for the question. Questions longer than this will "
"be truncated to this length.",
)
parser.add_argument("--do_train", action="store_true", help="Whether to run training.")
parser.add_argument("--do_eval", action="store_true", help="Whether to run eval on the dev set.")
parser.add_argument(
"--evaluate_during_training", action="store_true", help="Run evaluation during training at each logging step."
)
parser.add_argument(
"--do_lower_case", action="store_true", help="Set this flag if you are using an uncased model."
)
parser.add_argument("--per_gpu_train_batch_size", default=8, type=int, help="Batch size per GPU/CPU for training.")
parser.add_argument(
"--per_gpu_eval_batch_size", default=8, type=int, help="Batch size per GPU/CPU for evaluation."
)
parser.add_argument("--learning_rate", default=5e-5, type=float, help="The initial learning rate for Adam.")
# Pruning parameters
parser.add_argument(
"--mask_scores_learning_rate",
default=1e-2,
type=float,
help="The Adam initial learning rate of the mask scores.",
)
# Pruning parameters
parser.add_argument(
"--ampere_learning_rate",
default=1e-2,
type=float,
help="The Adam initial learning rate of the mask scores.",
)
# Pruning parameters
parser.add_argument(
"--shuffling_learning_rate",
default=1e-3,
type=float,
help="The Adam initial learning rate of the mask scores.",
)
parser.add_argument(
"--initial_threshold", default=1.0, type=float, help="Initial value of the threshold (for scheduling)."
)
parser.add_argument(
"--final_threshold", default=0.7, type=float, help="Final value of the threshold (for scheduling)."
)
parser.add_argument(
"--initial_ampere_temperature", default=0.0, type=float, help="Initial value of the ampere temperature (for scheduling)."
)
parser.add_argument(
"--final_ampere_temperature", default=20, type=float, help="Final value of the ampere temperature (for scheduling)."
)
parser.add_argument(
"--initial_shuffling_temperature", default=0.1, type=float, help="Initial value of the shuffling temperature (for scheduling)."
)
parser.add_argument(
"--final_shuffling_temperature", default=20, type=float, help="Final value of the shuffling temperature (for scheduling)."
)
parser.add_argument(
"--initial_warmup",
default=1,
type=int,
help="Run `initial_warmup` * `warmup_steps` steps of threshold warmup during which threshold stays"
"at its `initial_threshold` value (sparsity schedule).",
)
parser.add_argument(
"--final_warmup",
default=2,
type=int,
help="Run `final_warmup` * `warmup_steps` steps of threshold cool-down during which threshold stays"
"at its final_threshold value (sparsity schedule).",
)
parser.add_argument(
"--pruning_method",
default="topK",
type=str,
help="Pruning Method (l0 = L0 regularization, magnitude = Magnitude pruning, topK = Movement pruning, sigmoied_threshold = Soft movement pruning).",
)
parser.add_argument(
"--mask_init",
default="constant",
type=str,
help="Initialization method for the mask scores. Choices: constant, uniform, kaiming.",
)
parser.add_argument(
"--mask_scale", default=0.0, type=float, help="Initialization parameter for the chosen initialization method."
)
parser.add_argument(
"--mask_block_rows",
default=1,
type=int,
help="Block row size for masks. Default is 1 -> general sparsity, not block sparsity.",
)
parser.add_argument(
"--mask_block_cols",
default=1,
type=int,
help="Block row size for masks. Default is 1 -> general sparsity, not block sparsity.",
)
parser.add_argument(
"--ampere_pruning_method",
default="disabled",
type=str,
help="Pruning Method (annealing: softmaxing mask values with temperature).",
)
parser.add_argument(
"--ampere_mask_init",
default="constant",
type=str,
help="Initialization method for the ampere mask scores"
)
parser.add_argument(
"--ampere_mask_scale", default=0.0, type=float,
help="Initialization parameter for the chosen ampere mask initialization method."
)
parser.add_argument(
"--shuffling_method",
default="disabled",
type=str,
help="Shuffling Method (annealing: softmaxing permutation scores with temperature).",
)
parser.add_argument(
"--in_shuffling_group",
default="4",
type=int,
help="Shuffling group size for matrix input (with shuffling_method == annealing).",
)
parser.add_argument(
"--out_shuffling_group",
default="4",
type=int,
help="Shuffling group size for matrix output (with shuffling_method == annealing).",
)
parser.add_argument("--regularization", default=None, help="Add L0 or L1 regularization to the mask scores.")
parser.add_argument(
"--final_lambda",
default=0.0,
type=float,
help="Regularization intensity (used in conjunction with `regularization`.",
)
parser.add_argument("--global_topk", action="store_true", help="Global TopK on the Scores.")
parser.add_argument(
"--global_topk_frequency_compute",
default=25,
type=int,
help="Frequency at which we compute the TopK global threshold.",
)
# Distillation parameters (optional)
parser.add_argument(
"--teacher_type",
default=None,
type=str,
help="Teacher type. Teacher tokenizer and student (model) tokenizer must output the same tokenization. Only for distillation.",
)
parser.add_argument(
"--teacher_name_or_path",
default=None,
type=str,
help="Path to the already SQuAD fine-tuned teacher model. Only for distillation.",
)
parser.add_argument(
"--alpha_ce", default=0.5, type=float, help="Cross entropy loss linear weight. Only for distillation."
)
parser.add_argument(
"--alpha_distil", default=0.5, type=float, help="Distillation loss linear weight. Only for distillation."
)
parser.add_argument(
"--temperature", default=2.0, type=float, help="Distillation temperature. Only for distillation."
)
parser.add_argument(
"--gradient_accumulation_steps",
type=int,
default=1,
help="Number of updates steps to accumulate before performing a backward/update pass.",
)
parser.add_argument("--weight_decay", default=0.0, type=float, help="Weight decay if we apply some.")
parser.add_argument("--adam_epsilon", default=1e-8, type=float, help="Epsilon for Adam optimizer.")
parser.add_argument("--max_grad_norm", default=1.0, type=float, help="Max gradient norm.")
parser.add_argument(
"--num_train_epochs",
default=3.0,
type=float,
help="Total number of training epochs to perform.",
)
parser.add_argument(
"--max_steps",
default=-1,
type=int,
help="If > 0: set total number of training steps to perform. Override num_train_epochs.",
)
parser.add_argument("--warmup_steps", default=0, type=int, help="Linear warmup over warmup_steps.")
parser.add_argument(
"--n_best_size",
default=20,
type=int,
help="The total number of n-best predictions to generate in the nbest_predictions.json output file.",
)
parser.add_argument(
"--max_answer_length",
default=30,
type=int,
help="The maximum length of an answer that can be generated. This is needed because the start "
"and end predictions are not conditioned on one another.",
)
parser.add_argument(
"--verbose_logging",
action="store_true",
help="If true, all of the warnings related to data processing will be printed. "
"A number of warnings are expected for a normal SQuAD evaluation.",
)
parser.add_argument(
"--lang_id",
default=0,
type=int,
help="language id of input for language-specific xlm models (see tokenization_xlm.PRETRAINED_INIT_CONFIGURATION)",
)
parser.add_argument("--logging_steps", type=int, default=500, help="Log every X updates steps.")
parser.add_argument("--save_steps", type=int, default=500, help="Save checkpoint every X updates steps.")
parser.add_argument(
"--eval_all_checkpoints",
action="store_true",
help="Evaluate all checkpoints starting with the same prefix as model_name ending and ending with step number",
)
parser.add_argument("--no_cuda", action="store_true", help="Whether not to use CUDA when available")
parser.add_argument(
"--overwrite_output_dir", action="store_true", help="Overwrite the content of the output directory"
)
parser.add_argument(
"--overwrite_cache", action="store_true", help="Overwrite the cached training and evaluation sets"
)
parser.add_argument("--seed", type=int, default=42, help="random seed for initialization")
parser.add_argument("--local_rank", type=int, default=-1, help="local_rank for distributed training on gpus")
parser.add_argument(
"--fp16",
action="store_true",
help="Whether to use 16-bit (mixed) precision (through NVIDIA apex) instead of 32-bit",
)
parser.add_argument(
"--fp16_opt_level",
type=str,
default="O1",
help="For fp16: Apex AMP optimization level selected in ['O0', 'O1', 'O2', and 'O3']."
"See details at https://nvidia.github.io/apex/amp.html",
)
parser.add_argument("--server_ip", type=str, default="", help="Can be used for distant debugging.")
parser.add_argument("--server_port", type=str, default="", help="Can be used for distant debugging.")
parser.add_argument("--threads", type=int, default=1, help="multiple threads for converting example to features")
parser.add_argument(
"--truncate_train_examples",
type=int,
default=-1,
help="Only keep first train examples, for development purpose for example.",
)
return parser
class ShortNamer(TrialShortNamer):
DEFAULTS = dict(
adam_epsilon=1e-08,
alpha_ce=0.5,
alpha_distil=0.5,
cache_dir="",
config_name="",
data_dir="squad_data",
do_eval=True,
do_lower_case=True,
do_train=True,
doc_stride=128,
eval_all_checkpoints=True,
evaluate_during_training=False,
final_lambda=0.0,
final_threshold=0.1,
final_warmup=2,
fp16=False,
fp16_opt_level="O1",
global_topk=False,
global_topk_frequency_compute=25,
gradient_accumulation_steps=1,
initial_threshold=1.0,
initial_warmup=1,
lang_id=0,
learning_rate=3e-05,
local_rank=-1,
logging_steps=1000,
mask_init="constant",
mask_scale=0.0,
mask_scores_learning_rate=0.01,
ampere_learning_rate=0.01,
shuffling_learning_rate=0.001,
mask_block_rows=1,
mask_block_cols=1,
max_answer_length=30,
max_grad_norm=1.0,
max_query_length=64,
max_seq_length=384,
max_steps=-1,
model_name_or_path="bert-base-uncased",
model_type="masked_bert",
n_best_size=20,
no_cuda=False,
null_score_diff_threshold=0.0,
num_train_epochs=10.0,
output_dir="block_movement_pruning/output",
overwrite_cache=False,
overwrite_output_dir=True,
per_gpu_eval_batch_size=16,
per_gpu_train_batch_size=16,
predict_file="dev-v1.1.json",
pruning_method="topK",
regularization=None,
save_steps=5000,
seed=42,
server_ip="",
server_port="",
teacher_name_or_path=None,
teacher_type=None,
temperature=2.0,
threads=8,
tokenizer_name="",
train_file="train-v1.1.json",
truncate_train_examples=-1,
verbose_logging=False,
version_2_with_negative=False,
warmup_steps=5400,
weight_decay=0.0,
ampere_mask_init='constant',
ampere_mask_scale=0.0,
ampere_pruning_method='disabled',
initial_ampere_temperature=0.0,
final_ampere_temperature=20,
shuffling_method="disabled",
in_shuffling_group=4,
out_shuffling_group=4,
initial_shuffling_temperature=0.1,
final_shuffling_temperature=20,
)
def main_single(args):
short_name = ShortNamer.shortname(args.__dict__)
print(f"HP NAME {short_name}")
args.output_dir = os.path.join(args.output_dir, short_name)
if args.doc_stride >= args.max_seq_length - args.max_query_length:
logger.warning(
"WARNING - You've set a doc stride which may be superior to the document length in some "
"examples. This could result in errors when building features from the examples. Please reduce the doc "
"stride or increase the maximum length to ensure the features are correctly built."
)
if (
os.path.exists(args.output_dir)
and os.listdir(args.output_dir)
and args.do_train
and not args.overwrite_output_dir
):
raise ValueError(
"Output directory ({}) already exists and is not empty. Use --overwrite_output_dir to overcome.".format(
args.output_dir
)
)
if args.overwrite_output_dir:
shutil.rmtree(args.output_dir, ignore_errors=True)
os.makedirs(args.output_dir)
# Setup distant debugging if needed
if args.server_ip and args.server_port:
# Distant debugging - see https://code.visualstudio.com/docs/python/debugging#_attach-to-a-local-script
import ptvsd
print("Waiting for debugger attach")
ptvsd.enable_attach(address=(args.server_ip, args.server_port), redirect_output=True)
ptvsd.wait_for_attach()
# Setup CUDA, GPU & distributed training
if args.local_rank == -1 or args.no_cuda:
device = torch.device("cuda" if torch.cuda.is_available() and not args.no_cuda else "cpu")
args.n_gpu = 0 if args.no_cuda else torch.cuda.device_count()
else: # Initializes the distributed backend which will take care of synchronizing nodes/GPUs
torch.cuda.set_device(args.local_rank)
device = torch.device("cuda", args.local_rank)
torch.distributed.init_process_group(backend="nccl")
args.n_gpu = 1
args.device = device
# Setup logging
logging.basicConfig(
format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
datefmt="%m/%d/%Y %H:%M:%S",
level=logging.INFO if args.local_rank in [-1, 0] else logging.WARN,
)
logger.warning(
"Process rank: %s, device: %s, n_gpu: %s, distributed training: %s, 16-bits training: %s",
args.local_rank,
device,
args.n_gpu,
bool(args.local_rank != -1),
args.fp16,
)
# Set seed
set_seed(args)
# Load pretrained model and tokenizer
if args.local_rank not in [-1, 0]:
# Make sure only the first process in distributed training will download model & vocab
torch.distributed.barrier()
args.model_type = args.model_type.lower()
config_class, model_class, tokenizer_class = MODEL_CLASSES[args.model_type]
config = config_class.from_pretrained(
args.config_name if args.config_name else args.model_name_or_path,
cache_dir=args.cache_dir if args.cache_dir else None,
pruning_method=args.pruning_method,
mask_init=args.mask_init,
mask_scale=args.mask_scale,
mask_block_rows=args.mask_block_rows,
mask_block_cols=args.mask_block_cols,
ampere_pruning_method=args.ampere_pruning_method,
ampere_mask_init=args.ampere_mask_init,
ampere_mask_scale=args.ampere_mask_scale,
shuffling_method=args.shuffling_method,
in_shuffling_group=args.in_shuffling_group,
out_shuffling_group=args.out_shuffling_group,
)
tokenizer = tokenizer_class.from_pretrained(
args.tokenizer_name if args.tokenizer_name else args.model_name_or_path,
do_lower_case=args.do_lower_case,
cache_dir=args.cache_dir if args.cache_dir else None,
)
model = model_class.from_pretrained(
args.model_name_or_path,
from_tf=bool(".ckpt" in args.model_name_or_path),
config=config,
cache_dir=args.cache_dir if args.cache_dir else None,
)
if args.teacher_type is not None:
assert args.teacher_name_or_path is not None
assert args.alpha_distil > 0.0
assert args.alpha_distil + args.alpha_ce > 0.0
teacher_config_class, teacher_model_class, _ = MODEL_CLASSES[args.teacher_type]
teacher_config = teacher_config_class.from_pretrained(args.teacher_name_or_path)
teacher = teacher_model_class.from_pretrained(
args.teacher_name_or_path,
from_tf=False,
config=teacher_config,
cache_dir=args.cache_dir if args.cache_dir else None,
)
teacher.to(args.device)
else:
teacher = None
if args.local_rank == 0:
# Make sure only the first process in distributed training will download model & vocab
torch.distributed.barrier()
model.to(args.device)
logger.info("Training/evaluation parameters %s", args)
# Before we do anything with models, we want to ensure that we get fp16 execution of torch.einsum if args.fp16 is set.
# Otherwise it'll default to "promote" mode, and we'll get fp32 operations. Note that running `--fp16_opt_level="O2"` will
# remove the need for this code, but it is still valid.
if args.fp16:
try:
import apex
apex.amp.register_half_function(torch, "einsum")
except ImportError:
raise ImportError("Please install apex from https://www.github.com/nvidia/apex to use fp16 training.")
# Training
if args.do_train:
train_dataset = load_and_cache_examples(args, tokenizer, evaluate=False, output_examples=False)
global_step, tr_loss = train(args, train_dataset, model, tokenizer, teacher=teacher)
logger.info(" global_step = %s, average loss = %s", global_step, tr_loss)
# Save the trained model and the tokenizer
if args.do_train and (args.local_rank == -1 or torch.distributed.get_rank() == 0):
logger.info("Saving model checkpoint to %s", args.output_dir)
# Save a trained model, configuration and tokenizer using `save_pretrained()`.
# They can then be reloaded using `from_pretrained()`
# Take care of distributed/parallel training
model_to_save = model.module if hasattr(model, "module") else model
model_to_save.save_pretrained(args.output_dir)
tokenizer.save_pretrained(args.output_dir)
# Good practice: save your training arguments together with the trained model
torch.save(args, os.path.join(args.output_dir, "training_args.bin"))
# Load a trained model and vocabulary that you have fine-tuned
model = model_class.from_pretrained(args.output_dir) # , force_download=True)
tokenizer = tokenizer_class.from_pretrained(args.output_dir, do_lower_case=args.do_lower_case)
model.to(args.device)
# Evaluation - we can ask to evaluate all the checkpoints (sub-directories) in a directory
results = {}
if args.do_eval and args.local_rank in [-1, 0]:
if args.do_train:
logger.info("Loading checkpoints saved during training for evaluation")
checkpoints = [args.output_dir]
else:
logger.info("Loading checkpoint %s for evaluation", args.model_name_or_path)
checkpoints = [args.model_name_or_path]
logger.info("Evaluate the following checkpoints: %s", checkpoints)
for checkpoint in checkpoints:
# Reload the model
global_step = checkpoint.split("-")[-1] if len(checkpoints) > 1 else ""
model = model_class.from_pretrained(checkpoint) # , force_download=True)
model.to(args.device)
# Evaluate
result = evaluate(args, model, tokenizer, prefix=global_step)
result = dict((k + ("_{}".format(global_step) if global_step else ""), v) for k, v in result.items())
results.update(result)
logger.info("Results: {}".format(results))
predict_file = list(filter(None, args.predict_file.split("/"))).pop()
if not os.path.exists(os.path.join(args.output_dir, predict_file)):
os.makedirs(os.path.join(args.output_dir, predict_file))
output_eval_file = os.path.join(args.output_dir, predict_file, "eval_results.txt")
with open(output_eval_file, "w") as writer:
for key in sorted(results.keys()):
writer.write("%s = %s\n" % (key, str(results[key])))
return results
def main():
parser = create_parser()
args = parser.parse_args()
# Regularization
if args.regularization == "null":
args.regularization = None
sizes = [(2, 1), (8, 1), (32, 1), (128, 1), (4, 4), (8, 8), (32, 32), (1, 2), (1, 8), (1, 32), (1, 128)][::]
sizes = [(32,32), (16,16), (64,64)]
for size in sizes:
single_args = copy.deepcopy(args)
single_args.mask_block_rows = size[0]
single_args.mask_block_cols = size[1]
#try:
main_single(single_args)
#except Exception as e:
# print(e)
if __name__ == "__main__":
main()
| 3 |
0 | hf_public_repos/block_movement_pruning/block_movement_pruning | hf_public_repos/block_movement_pruning/block_movement_pruning/tests/test_fun.py | import unittest
from unittest import TestCase
class TestFun(TestCase):
def test_basic(self):
pass
if __name__ == '__main__':
unittest.main() | 4 |
0 | hf_public_repos/block_movement_pruning/block_movement_pruning | hf_public_repos/block_movement_pruning/block_movement_pruning/emmental/configuration_bert_masked.py | # coding=utf-8
# Copyright 2018 The Google AI Language Team Authors and The HuggingFace Inc. team.
# Copyright (c) 2018, NVIDIA CORPORATION. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
""" Masked BERT model configuration. It replicates the class `~transformers.BertConfig`
and adapts it to the specificities of MaskedBert (`pruning_method`, `mask_init` and `mask_scale`."""
import logging
from transformers.configuration_utils import PretrainedConfig
logger = logging.getLogger(__name__)
class MaskedBertConfig(PretrainedConfig):
"""
A class replicating the `~transformers.BertConfig` with additional parameters for pruning/masking configuration.
"""
model_type = "masked_bert"
def __init__(
self,
vocab_size=30522,
hidden_size=768,
num_hidden_layers=12,
num_attention_heads=12,
intermediate_size=3072,
hidden_act="gelu",
hidden_dropout_prob=0.1,
attention_probs_dropout_prob=0.1,
max_position_embeddings=512,
type_vocab_size=2,
initializer_range=0.02,
layer_norm_eps=1e-12,
pad_token_id=0,
pruning_method="topK",
mask_init="constant",
mask_scale=0.0,
mask_block_rows=1,
mask_block_cols=1,
ampere_pruning_method: str = None,
ampere_mask_init: str = "constant",
ampere_mask_scale: float = 0.0,
shuffling_method: str = None,
in_shuffling_group: int = 4,
out_shuffling_group: int = 4,
**kwargs
):
super().__init__(pad_token_id=pad_token_id, **kwargs)
self.vocab_size = vocab_size
self.hidden_size = hidden_size
self.num_hidden_layers = num_hidden_layers
self.num_attention_heads = num_attention_heads
self.hidden_act = hidden_act
self.intermediate_size = intermediate_size
self.hidden_dropout_prob = hidden_dropout_prob
self.attention_probs_dropout_prob = attention_probs_dropout_prob
self.max_position_embeddings = max_position_embeddings
self.type_vocab_size = type_vocab_size
self.initializer_range = initializer_range
self.layer_norm_eps = layer_norm_eps
self.pruning_method = pruning_method
self.mask_init = mask_init
self.mask_scale = mask_scale
self.mask_block_rows = mask_block_rows
self.mask_block_cols = mask_block_cols
self.ampere_pruning_method = ampere_pruning_method
self.ampere_mask_init = ampere_mask_init
self.ampere_mask_scale = ampere_mask_scale
self.shuffling_method = shuffling_method
self.in_shuffling_group = in_shuffling_group
self.out_shuffling_group = out_shuffling_group
| 5 |
0 | hf_public_repos/block_movement_pruning/block_movement_pruning | hf_public_repos/block_movement_pruning/block_movement_pruning/emmental/modeling_bert_masked.py | # coding=utf-8
# Copyright 2018 The Google AI Language Team Authors and The HuggingFace Inc. team.
# Copyright (c) 2018, NVIDIA CORPORATION. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""Masked Version of BERT. It replaces the `torch.nn.Linear` layers with
:class:`~emmental.MaskedLinear` and add an additional parameters in the forward pass to
compute the adaptive mask.
Built on top of `transformers.modeling_bert`"""
import logging
import math
import torch
from torch import nn
from torch.nn import CrossEntropyLoss, MSELoss
from transformers.file_utils import add_start_docstrings, add_start_docstrings_to_model_forward
from transformers.modeling_bert import ACT2FN, load_tf_weights_in_bert
from transformers.modeling_utils import PreTrainedModel, prune_linear_layer
from emmental import MaskedBertConfig
from emmental.modules import MaskedLinear
BertLayerNorm = torch.nn.LayerNorm
logger = logging.getLogger(__name__)
def create_masked_linear(in_features, out_features, config, bias=True):
ret = MaskedLinear(in_features=in_features,
out_features=out_features,
pruning_method=config.pruning_method,
mask_init=config.mask_init,
mask_scale=config.mask_scale,
mask_block_rows=config.mask_block_rows,
mask_block_cols=config.mask_block_cols,
ampere_pruning_method=config.ampere_pruning_method,
ampere_mask_init=config.ampere_mask_init,
ampere_mask_scale=config.ampere_mask_scale,
shuffling_method = config.shuffling_method,
in_shuffling_group = config.in_shuffling_group,
out_shuffling_group = config.out_shuffling_group,
)
return ret
class BertEmbeddings(nn.Module):
"""Construct the embeddings from word, position and token_type embeddings."""
def __init__(self, config):
super().__init__()
self.word_embeddings = nn.Embedding(config.vocab_size, config.hidden_size, padding_idx=0)
self.position_embeddings = nn.Embedding(config.max_position_embeddings, config.hidden_size)
self.token_type_embeddings = nn.Embedding(config.type_vocab_size, config.hidden_size)
# self.LayerNorm is not snake-cased to stick with TensorFlow model variable name and be able to load
# any TensorFlow checkpoint file
self.LayerNorm = BertLayerNorm(config.hidden_size, eps=config.layer_norm_eps)
self.dropout = nn.Dropout(config.hidden_dropout_prob)
def forward(self, input_ids=None, token_type_ids=None, position_ids=None, inputs_embeds=None):
if input_ids is not None:
input_shape = input_ids.size()
else:
input_shape = inputs_embeds.size()[:-1]
seq_length = input_shape[1]
device = input_ids.device if input_ids is not None else inputs_embeds.device
if position_ids is None:
position_ids = torch.arange(seq_length, dtype=torch.long, device=device)
position_ids = position_ids.unsqueeze(0).expand(input_shape)
if token_type_ids is None:
token_type_ids = torch.zeros(input_shape, dtype=torch.long, device=device)
if inputs_embeds is None:
inputs_embeds = self.word_embeddings(input_ids)
position_embeddings = self.position_embeddings(position_ids)
token_type_embeddings = self.token_type_embeddings(token_type_ids)
embeddings = inputs_embeds + position_embeddings + token_type_embeddings
embeddings = self.LayerNorm(embeddings)
embeddings = self.dropout(embeddings)
return embeddings
class BertSelfAttention(nn.Module):
def __init__(self, config):
super().__init__()
if config.hidden_size % config.num_attention_heads != 0 and not hasattr(config, "embedding_size"):
raise ValueError(
"The hidden size (%d) is not a multiple of the number of attention "
"heads (%d)" % (config.hidden_size, config.num_attention_heads)
)
self.output_attentions = config.output_attentions
self.num_attention_heads = config.num_attention_heads
self.attention_head_size = int(config.hidden_size / config.num_attention_heads)
self.all_head_size = self.num_attention_heads * self.attention_head_size
self.query = create_masked_linear(config.hidden_size, self.all_head_size, config)
self.key = create_masked_linear(config.hidden_size, self.all_head_size, config)
self.value = create_masked_linear(config.hidden_size, self.all_head_size, config)
self.dropout = nn.Dropout(config.attention_probs_dropout_prob)
def transpose_for_scores(self, x):
new_x_shape = x.size()[:-1] + (self.num_attention_heads, self.attention_head_size)
x = x.view(*new_x_shape)
return x.permute(0, 2, 1, 3)
def forward(
self,
hidden_states,
attention_mask=None,
head_mask=None,
encoder_hidden_states=None,
encoder_attention_mask=None,
current_config=None,
):
mixed_query_layer = self.query(hidden_states, current_config=current_config)
# If this is instantiated as a cross-attention module, the keys
# and values come from an encoder; the attention mask needs to be
# such that the encoder's padding tokens are not attended to.
if encoder_hidden_states is not None:
mixed_key_layer = self.key(encoder_hidden_states, current_config=current_config)
mixed_value_layer = self.value(encoder_hidden_states, current_config=current_config)
attention_mask = encoder_attention_mask
else:
mixed_key_layer = self.key(hidden_states, current_config=current_config)
mixed_value_layer = self.value(hidden_states, current_config=current_config)
query_layer = self.transpose_for_scores(mixed_query_layer)
key_layer = self.transpose_for_scores(mixed_key_layer)
value_layer = self.transpose_for_scores(mixed_value_layer)
# Take the dot product between "query" and "key" to get the raw attention scores.
attention_scores = torch.matmul(query_layer, key_layer.transpose(-1, -2))
attention_scores = attention_scores / math.sqrt(self.attention_head_size)
if attention_mask is not None:
# Apply the attention mask is (precomputed for all layers in BertModel forward() function)
attention_scores = attention_scores + attention_mask
# Normalize the attention scores to probabilities.
attention_probs = nn.Softmax(dim=-1)(attention_scores)
# This is actually dropping out entire tokens to attend to, which might
# seem a bit unusual, but is taken from the original Transformer paper.
attention_probs = self.dropout(attention_probs)
# Mask heads if we want to
if head_mask is not None:
attention_probs = attention_probs * head_mask
context_layer = torch.matmul(attention_probs, value_layer)
context_layer = context_layer.permute(0, 2, 1, 3).contiguous()
new_context_layer_shape = context_layer.size()[:-2] + (self.all_head_size,)
context_layer = context_layer.view(*new_context_layer_shape)
outputs = (context_layer, attention_probs) if self.output_attentions else (context_layer,)
return outputs
class BertSelfOutput(nn.Module):
def __init__(self, config):
super().__init__()
self.dense = create_masked_linear(config.hidden_size, config.hidden_size, config)
self.LayerNorm = BertLayerNorm(config.hidden_size, eps=config.layer_norm_eps)
self.dropout = nn.Dropout(config.hidden_dropout_prob)
def forward(self, hidden_states, input_tensor, current_config):
hidden_states = self.dense(hidden_states, current_config=current_config)
hidden_states = self.dropout(hidden_states)
hidden_states = self.LayerNorm(hidden_states + input_tensor)
return hidden_states
class BertAttention(nn.Module):
def __init__(self, config):
super().__init__()
self.self = BertSelfAttention(config)
self.output = BertSelfOutput(config)
self.pruned_heads = set()
def prune_heads(self, heads):
if len(heads) == 0:
return
mask = torch.ones(self.self.num_attention_heads, self.self.attention_head_size)
heads = set(heads) - self.pruned_heads # Convert to set and remove already pruned heads
for head in heads:
# Compute how many pruned heads are before the head and move the index accordingly
head = head - sum(1 if h < head else 0 for h in self.pruned_heads)
mask[head] = 0
mask = mask.view(-1).contiguous().eq(1)
index = torch.arange(len(mask))[mask].long()
# Prune linear layers
self.self.query = prune_linear_layer(self.self.query, index)
self.self.key = prune_linear_layer(self.self.key, index)
self.self.value = prune_linear_layer(self.self.value, index)
self.output.dense = prune_linear_layer(self.output.dense, index, dim=1)
# Update hyper params and store pruned heads
self.self.num_attention_heads = self.self.num_attention_heads - len(heads)
self.self.all_head_size = self.self.attention_head_size * self.self.num_attention_heads
self.pruned_heads = self.pruned_heads.union(heads)
def forward(
self,
hidden_states,
attention_mask=None,
head_mask=None,
encoder_hidden_states=None,
encoder_attention_mask=None,
current_config=None,
):
self_outputs = self.self(
hidden_states,
attention_mask,
head_mask,
encoder_hidden_states,
encoder_attention_mask,
current_config=current_config,
)
attention_output = self.output(self_outputs[0], hidden_states, current_config=current_config)
outputs = (attention_output,) + self_outputs[1:] # add attentions if we output them
return outputs
class BertIntermediate(nn.Module):
def __init__(self, config):
super().__init__()
self.dense = create_masked_linear(config.hidden_size, config.intermediate_size, config)
if isinstance(config.hidden_act, str):
self.intermediate_act_fn = ACT2FN[config.hidden_act]
else:
self.intermediate_act_fn = config.hidden_act
def forward(self, hidden_states, current_config):
hidden_states = self.dense(hidden_states, current_config=current_config)
hidden_states = self.intermediate_act_fn(hidden_states)
return hidden_states
class BertOutput(nn.Module):
def __init__(self, config):
super().__init__()
self.dense = create_masked_linear(config.intermediate_size, config.hidden_size, config)
self.LayerNorm = BertLayerNorm(config.hidden_size, eps=config.layer_norm_eps)
self.dropout = nn.Dropout(config.hidden_dropout_prob)
def forward(self, hidden_states, input_tensor, current_config):
hidden_states = self.dense(hidden_states, current_config=current_config)
hidden_states = self.dropout(hidden_states)
hidden_states = self.LayerNorm(hidden_states + input_tensor)
return hidden_states
class BertLayer(nn.Module):
def __init__(self, config):
super().__init__()
self.attention = BertAttention(config)
self.is_decoder = config.is_decoder
if self.is_decoder:
self.crossattention = BertAttention(config)
self.intermediate = BertIntermediate(config)
self.output = BertOutput(config)
def forward(
self,
hidden_states,
attention_mask=None,
head_mask=None,
encoder_hidden_states=None,
encoder_attention_mask=None,
current_config=None,
):
self_attention_outputs = self.attention(hidden_states, attention_mask, head_mask, current_config=current_config)
attention_output = self_attention_outputs[0]
outputs = self_attention_outputs[1:] # add self attentions if we output attention weights
if self.is_decoder and encoder_hidden_states is not None:
cross_attention_outputs = self.crossattention(
attention_output, attention_mask, head_mask, encoder_hidden_states, encoder_attention_mask
)
attention_output = cross_attention_outputs[0]
outputs = outputs + cross_attention_outputs[1:] # add cross attentions if we output attention weights
intermediate_output = self.intermediate(attention_output, current_config=current_config)
layer_output = self.output(intermediate_output, attention_output, current_config=current_config)
outputs = (layer_output,) + outputs
return outputs
class BertEncoder(nn.Module):
def __init__(self, config):
super().__init__()
self.output_attentions = config.output_attentions
self.output_hidden_states = config.output_hidden_states
self.layer = nn.ModuleList([BertLayer(config) for _ in range(config.num_hidden_layers)])
def forward(
self,
hidden_states,
attention_mask=None,
head_mask=None,
encoder_hidden_states=None,
encoder_attention_mask=None,
current_config=None,
):
all_hidden_states = ()
all_attentions = ()
for i, layer_module in enumerate(self.layer):
if self.output_hidden_states:
all_hidden_states = all_hidden_states + (hidden_states,)
layer_outputs = layer_module(
hidden_states,
attention_mask,
head_mask[i],
encoder_hidden_states,
encoder_attention_mask,
current_config=current_config,
)
hidden_states = layer_outputs[0]
if self.output_attentions:
all_attentions = all_attentions + (layer_outputs[1],)
# Add last layer
if self.output_hidden_states:
all_hidden_states = all_hidden_states + (hidden_states,)
outputs = (hidden_states,)
if self.output_hidden_states:
outputs = outputs + (all_hidden_states,)
if self.output_attentions:
outputs = outputs + (all_attentions,)
return outputs # last-layer hidden state, (all hidden states), (all attentions)
class BertPooler(nn.Module):
def __init__(self, config):
super().__init__()
self.dense = nn.Linear(config.hidden_size, config.hidden_size)
self.activation = nn.Tanh()
def forward(self, hidden_states):
# We "pool" the model by simply taking the hidden state corresponding
# to the first token.
first_token_tensor = hidden_states[:, 0]
pooled_output = self.dense(first_token_tensor)
pooled_output = self.activation(pooled_output)
return pooled_output
class MaskedBertPreTrainedModel(PreTrainedModel):
"""An abstract class to handle weights initialization and
a simple interface for downloading and loading pretrained models.
"""
config_class = MaskedBertConfig
load_tf_weights = load_tf_weights_in_bert
base_model_prefix = "bert"
def _init_weights(self, module):
""" Initialize the weights """
if isinstance(module, (nn.Linear, nn.Embedding)):
# Slightly different from the TF version which uses truncated_normal for initialization
# cf https://github.com/pytorch/pytorch/pull/5617
module.weight.data.normal_(mean=0.0, std=self.config.initializer_range)
elif isinstance(module, BertLayerNorm):
module.bias.data.zero_()
module.weight.data.fill_(1.0)
if isinstance(module, nn.Linear) and module.bias is not None:
module.bias.data.zero_()
MASKED_BERT_START_DOCSTRING = r"""
This model is a PyTorch `torch.nn.Module <https://pytorch.org/docs/stable/nn.html#torch.nn.Module>`_ sub-class.
Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general
usage and behavior.
Parameters:
config (:class:`~emmental.MaskedBertConfig`): Model configuration class with all the parameters of the model.
Initializing with a config file does not load the weights associated with the model, only the configuration.
Check out the :meth:`~transformers.PreTrainedModel.from_pretrained` method to load the model weights.
"""
MASKED_BERT_INPUTS_DOCSTRING = r"""
Args:
input_ids (:obj:`torch.LongTensor` of shape :obj:`(batch_size, sequence_length)`):
Indices of input sequence tokens in the vocabulary.
Indices can be obtained using :class:`transformers.BertTokenizer`.
See :func:`transformers.PreTrainedTokenizer.encode` and
:func:`transformers.PreTrainedTokenizer.__call__` for details.
`What are input IDs? <../glossary.html#input-ids>`__
attention_mask (:obj:`torch.FloatTensor` of shape :obj:`(batch_size, sequence_length)`, `optional`):
Mask to avoid performing attention on padding token indices.
Mask values selected in ``[0, 1]``:
``1`` for tokens that are NOT MASKED, ``0`` for MASKED tokens.
`What are attention masks? <../glossary.html#attention-mask>`__
token_type_ids (:obj:`torch.LongTensor` of shape :obj:`(batch_size, sequence_length)`, `optional`):
Segment token indices to indicate first and second portions of the inputs.
Indices are selected in ``[0, 1]``: ``0`` corresponds to a `sentence A` token, ``1``
corresponds to a `sentence B` token
`What are token type IDs? <../glossary.html#token-type-ids>`_
position_ids (:obj:`torch.LongTensor` of shape :obj:`(batch_size, sequence_length)`, `optional`):
Indices of positions of each input sequence tokens in the position embeddings.
Selected in the range ``[0, config.max_position_embeddings - 1]``.
`What are position IDs? <../glossary.html#position-ids>`_
head_mask (:obj:`torch.FloatTensor` of shape :obj:`(num_heads,)` or :obj:`(num_layers, num_heads)`, `optional`):
Mask to nullify selected heads of the self-attention modules.
Mask values selected in ``[0, 1]``:
:obj:`1` indicates the head is **not masked**, :obj:`0` indicates the head is **masked**.
inputs_embeds (:obj:`torch.FloatTensor` of shape :obj:`(batch_size, sequence_length, hidden_size)`, `optional`):
Optionally, instead of passing :obj:`input_ids` you can choose to directly pass an embedded representation.
This is useful if you want more control over how to convert `input_ids` indices into associated vectors
than the model's internal embedding lookup matrix.
encoder_hidden_states (:obj:`torch.FloatTensor` of shape :obj:`(batch_size, sequence_length, hidden_size)`, `optional`):
Sequence of hidden-states at the output of the last layer of the encoder. Used in the cross-attention
if the model is configured as a decoder.
encoder_attention_mask (:obj:`torch.FloatTensor` of shape :obj:`(batch_size, sequence_length)`, `optional`):
Mask to avoid performing attention on the padding token indices of the encoder input. This mask
is used in the cross-attention if the model is configured as a decoder.
Mask values selected in ``[0, 1]``:
``1`` for tokens that are NOT MASKED, ``0`` for MASKED tokens.
"""
@add_start_docstrings(
"The bare Masked Bert Model transformer outputting raw hidden-states without any specific head on top.",
MASKED_BERT_START_DOCSTRING,
)
class MaskedBertModel(MaskedBertPreTrainedModel):
"""
The `MaskedBertModel` class replicates the :class:`~transformers.BertModel` class
and adds specific inputs to compute the adaptive mask on the fly.
Note that we freeze the embeddings modules from their pre-trained values.
"""
def __init__(self, config):
super().__init__(config)
self.config = config
self.embeddings = BertEmbeddings(config)
self.embeddings.requires_grad_(requires_grad=False)
self.encoder = BertEncoder(config)
self.pooler = BertPooler(config)
self.init_weights()
def get_input_embeddings(self):
return self.embeddings.word_embeddings
def set_input_embeddings(self, value):
self.embeddings.word_embeddings = value
def _prune_heads(self, heads_to_prune):
"""Prunes heads of the model.
heads_to_prune: dict of {layer_num: list of heads to prune in this layer}
See base class PreTrainedModel
"""
for layer, heads in heads_to_prune.items():
self.encoder.layer[layer].attention.prune_heads(heads)
@add_start_docstrings_to_model_forward(MASKED_BERT_INPUTS_DOCSTRING)
def forward(
self,
input_ids=None,
attention_mask=None,
token_type_ids=None,
position_ids=None,
head_mask=None,
inputs_embeds=None,
encoder_hidden_states=None,
encoder_attention_mask=None,
current_config=None,
):
r"""
current_config dict
current_config dict (see :class:`emmental.MaskedLinear`).
Return:
:obj:`tuple(torch.FloatTensor)` comprising various elements depending on the configuration (:class:`~emmental.MaskedBertConfig`) and inputs:
last_hidden_state (:obj:`torch.FloatTensor` of shape :obj:`(batch_size, sequence_length, hidden_size)`):
Sequence of hidden-states at the output of the last layer of the model.
pooler_output (:obj:`torch.FloatTensor`: of shape :obj:`(batch_size, hidden_size)`):
Last layer hidden-state of the first token of the sequence (classification token)
further processed by a Linear layer and a Tanh activation function. The Linear
layer weights are trained from the next sentence prediction (classification)
objective during pre-training.
This output is usually *not* a good summary
of the semantic content of the input, you're often better with averaging or pooling
the sequence of hidden-states for the whole input sequence.
hidden_states (:obj:`tuple(torch.FloatTensor)`, `optional`, returned when ``config.output_hidden_states=True``):
Tuple of :obj:`torch.FloatTensor` (one for the output of the embeddings + one for the output of each layer)
of shape :obj:`(batch_size, sequence_length, hidden_size)`.
Hidden-states of the model at the output of each layer plus the initial embedding outputs.
attentions (:obj:`tuple(torch.FloatTensor)`, `optional`, returned when ``config.output_attentions=True``):
Tuple of :obj:`torch.FloatTensor` (one for each layer) of shape
:obj:`(batch_size, num_heads, sequence_length, sequence_length)`.
Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
heads.
"""
if input_ids is not None and inputs_embeds is not None:
raise ValueError("You cannot specify both input_ids and inputs_embeds at the same time")
elif input_ids is not None:
input_shape = input_ids.size()
elif inputs_embeds is not None:
input_shape = inputs_embeds.size()[:-1]
else:
raise ValueError("You have to specify either input_ids or inputs_embeds")
device = input_ids.device if input_ids is not None else inputs_embeds.device
if attention_mask is None:
attention_mask = torch.ones(input_shape, device=device)
if token_type_ids is None:
token_type_ids = torch.zeros(input_shape, dtype=torch.long, device=device)
# We can provide a self-attention mask of dimensions [batch_size, from_seq_length, to_seq_length]
# ourselves in which case we just need to make it broadcastable to all heads.
if attention_mask.dim() == 3:
extended_attention_mask = attention_mask[:, None, :, :]
elif attention_mask.dim() == 2:
# Provided a padding mask of dimensions [batch_size, seq_length]
# - if the model is a decoder, apply a causal mask in addition to the padding mask
# - if the model is an encoder, make the mask broadcastable to [batch_size, num_heads, seq_length, seq_length]
if self.config.is_decoder:
batch_size, seq_length = input_shape
seq_ids = torch.arange(seq_length, device=device)
causal_mask = seq_ids[None, None, :].repeat(batch_size, seq_length, 1) <= seq_ids[None, :, None]
causal_mask = causal_mask.to(
attention_mask.dtype
) # causal and attention masks must have same type with pytorch version < 1.3
extended_attention_mask = causal_mask[:, None, :, :] * attention_mask[:, None, None, :]
else:
extended_attention_mask = attention_mask[:, None, None, :]
else:
raise ValueError(
"Wrong shape for input_ids (shape {}) or attention_mask (shape {})".format(
input_shape, attention_mask.shape
)
)
# Since attention_mask is 1.0 for positions we want to attend and 0.0 for
# masked positions, this operation will create a tensor which is 0.0 for
# positions we want to attend and -10000.0 for masked positions.
# Since we are adding it to the raw scores before the softmax, this is
# effectively the same as removing these entirely.
extended_attention_mask = extended_attention_mask.to(dtype=next(self.parameters()).dtype) # fp16 compatibility
extended_attention_mask = (1.0 - extended_attention_mask) * -10000.0
# If a 2D ou 3D attention mask is provided for the cross-attention
# we need to make broadcastable to [batch_size, num_heads, seq_length, seq_length]
if self.config.is_decoder and encoder_hidden_states is not None:
encoder_batch_size, encoder_sequence_length, _ = encoder_hidden_states.size()
encoder_hidden_shape = (encoder_batch_size, encoder_sequence_length)
if encoder_attention_mask is None:
encoder_attention_mask = torch.ones(encoder_hidden_shape, device=device)
if encoder_attention_mask.dim() == 3:
encoder_extended_attention_mask = encoder_attention_mask[:, None, :, :]
elif encoder_attention_mask.dim() == 2:
encoder_extended_attention_mask = encoder_attention_mask[:, None, None, :]
else:
raise ValueError(
"Wrong shape for encoder_hidden_shape (shape {}) or encoder_attention_mask (shape {})".format(
encoder_hidden_shape, encoder_attention_mask.shape
)
)
encoder_extended_attention_mask = encoder_extended_attention_mask.to(
dtype=next(self.parameters()).dtype
) # fp16 compatibility
encoder_extended_attention_mask = (1.0 - encoder_extended_attention_mask) * -10000.0
else:
encoder_extended_attention_mask = None
# Prepare head mask if needed
# 1.0 in head_mask indicate we keep the head
# attention_probs has shape bsz x n_heads x N x N
# input head_mask has shape [num_heads] or [num_hidden_layers x num_heads]
# and head_mask is converted to shape [num_hidden_layers x batch x num_heads x seq_length x seq_length]
if head_mask is not None:
if head_mask.dim() == 1:
head_mask = head_mask.unsqueeze(0).unsqueeze(0).unsqueeze(-1).unsqueeze(-1)
head_mask = head_mask.expand(self.config.num_hidden_layers, -1, -1, -1, -1)
elif head_mask.dim() == 2:
head_mask = (
head_mask.unsqueeze(1).unsqueeze(-1).unsqueeze(-1)
) # We can specify head_mask for each layer
head_mask = head_mask.to(
dtype=next(self.parameters()).dtype
) # switch to float if need + fp16 compatibility
else:
head_mask = [None] * self.config.num_hidden_layers
embedding_output = self.embeddings(
input_ids=input_ids, position_ids=position_ids, token_type_ids=token_type_ids, inputs_embeds=inputs_embeds
)
encoder_outputs = self.encoder(
embedding_output,
attention_mask=extended_attention_mask,
head_mask=head_mask,
encoder_hidden_states=encoder_hidden_states,
encoder_attention_mask=encoder_extended_attention_mask,
current_config=current_config,
)
sequence_output = encoder_outputs[0]
pooled_output = self.pooler(sequence_output)
outputs = (sequence_output, pooled_output,) + encoder_outputs[
1:
] # add hidden_states and attentions if they are here
return outputs # sequence_output, pooled_output, (hidden_states), (attentions)
@add_start_docstrings(
"""Masked Bert Model transformer with a sequence classification/regression head on top (a linear layer on top of
the pooled output) e.g. for GLUE tasks. """,
MASKED_BERT_START_DOCSTRING,
)
class MaskedBertForSequenceClassification(MaskedBertPreTrainedModel):
def __init__(self, config):
super().__init__(config)
self.num_labels = config.num_labels
self.bert = MaskedBertModel(config)
self.dropout = nn.Dropout(config.hidden_dropout_prob)
self.classifier = nn.Linear(config.hidden_size, self.config.num_labels)
self.init_weights()
@add_start_docstrings_to_model_forward(MASKED_BERT_INPUTS_DOCSTRING)
def forward(
self,
input_ids=None,
attention_mask=None,
token_type_ids=None,
position_ids=None,
head_mask=None,
inputs_embeds=None,
labels=None,
current_config=None,
):
r"""
labels (:obj:`torch.LongTensor` of shape :obj:`(batch_size,)`, `optional`):
Labels for computing the sequence classification/regression loss.
Indices should be in :obj:`[0, ..., config.num_labels - 1]`.
If :obj:`config.num_labels == 1` a regression loss is computed (Mean-Square loss),
If :obj:`config.num_labels > 1` a classification loss is computed (Cross-Entropy).
current_config dict
current_config dict (see :class:`emmental.MaskedLinear`).
Returns:
:obj:`tuple(torch.FloatTensor)` comprising various elements depending on the configuration (:class:`~emmental.MaskedBertConfig`) and inputs:
loss (:obj:`torch.FloatTensor` of shape :obj:`(1,)`, `optional`, returned when :obj:`label` is provided):
Classification (or regression if config.num_labels==1) loss.
logits (:obj:`torch.FloatTensor` of shape :obj:`(batch_size, config.num_labels)`):
Classification (or regression if config.num_labels==1) scores (before SoftMax).
hidden_states (:obj:`tuple(torch.FloatTensor)`, `optional`, returned when ``config.output_hidden_states=True``):
Tuple of :obj:`torch.FloatTensor` (one for the output of the embeddings + one for the output of each layer)
of shape :obj:`(batch_size, sequence_length, hidden_size)`.
Hidden-states of the model at the output of each layer plus the initial embedding outputs.
attentions (:obj:`tuple(torch.FloatTensor)`, `optional`, returned when ``config.output_attentions=True``):
Tuple of :obj:`torch.FloatTensor` (one for each layer) of shape
:obj:`(batch_size, num_heads, sequence_length, sequence_length)`.
Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
heads.
"""
outputs = self.bert(
input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids,
position_ids=position_ids,
head_mask=head_mask,
inputs_embeds=inputs_embeds,
current_config=current_config,
)
pooled_output = outputs[1]
pooled_output = self.dropout(pooled_output)
logits = self.classifier(pooled_output)
outputs = (logits,) + outputs[2:] # add hidden states and attention if they are here
if labels is not None:
if self.num_labels == 1:
# We are doing regression
loss_fct = MSELoss()
loss = loss_fct(logits.view(-1), labels.view(-1))
else:
loss_fct = CrossEntropyLoss()
loss = loss_fct(logits.view(-1, self.num_labels), labels.view(-1))
outputs = (loss,) + outputs
return outputs # (loss), logits, (hidden_states), (attentions)
@add_start_docstrings(
"""Masked Bert Model with a multiple choice classification head on top (a linear layer on top of
the pooled output and a softmax) e.g. for RocStories/SWAG tasks. """,
MASKED_BERT_START_DOCSTRING,
)
class MaskedBertForMultipleChoice(MaskedBertPreTrainedModel):
def __init__(self, config):
super().__init__(config)
self.bert = MaskedBertModel(config)
self.dropout = nn.Dropout(config.hidden_dropout_prob)
self.classifier = nn.Linear(config.hidden_size, 1)
self.init_weights()
@add_start_docstrings_to_model_forward(MASKED_BERT_INPUTS_DOCSTRING)
def forward(
self,
input_ids=None,
attention_mask=None,
token_type_ids=None,
position_ids=None,
head_mask=None,
inputs_embeds=None,
labels=None,
current_config=None,
):
r"""
labels (:obj:`torch.LongTensor` of shape :obj:`(batch_size,)`, `optional`):
Labels for computing the multiple choice classification loss.
Indices should be in ``[0, ..., num_choices]`` where `num_choices` is the size of the second dimension
of the input tensors. (see `input_ids` above)
current_config dict
current_config dict (see :class:`emmental.MaskedLinear`).
Returns:
:obj:`tuple(torch.FloatTensor)` comprising various elements depending on the configuration (:class:`~emmental.MaskedBertConfig`) and inputs:
loss (:obj:`torch.FloatTensor` of shape `(1,)`, `optional`, returned when :obj:`labels` is provided):
Classification loss.
classification_scores (:obj:`torch.FloatTensor` of shape :obj:`(batch_size, num_choices)`):
`num_choices` is the second dimension of the input tensors. (see `input_ids` above).
Classification scores (before SoftMax).
hidden_states (:obj:`tuple(torch.FloatTensor)`, `optional`, returned when ``config.output_hidden_states=True``):
Tuple of :obj:`torch.FloatTensor` (one for the output of the embeddings + one for the output of each layer)
of shape :obj:`(batch_size, sequence_length, hidden_size)`.
Hidden-states of the model at the output of each layer plus the initial embedding outputs.
attentions (:obj:`tuple(torch.FloatTensor)`, `optional`, returned when ``config.output_attentions=True``):
Tuple of :obj:`torch.FloatTensor` (one for each layer) of shape
:obj:`(batch_size, num_heads, sequence_length, sequence_length)`.
Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
heads.
"""
num_choices = input_ids.shape[1]
input_ids = input_ids.view(-1, input_ids.size(-1))
attention_mask = attention_mask.view(-1, attention_mask.size(-1)) if attention_mask is not None else None
token_type_ids = token_type_ids.view(-1, token_type_ids.size(-1)) if token_type_ids is not None else None
position_ids = position_ids.view(-1, position_ids.size(-1)) if position_ids is not None else None
outputs = self.bert(
input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids,
position_ids=position_ids,
head_mask=head_mask,
inputs_embeds=inputs_embeds,
current_config=current_config,
)
pooled_output = outputs[1]
pooled_output = self.dropout(pooled_output)
logits = self.classifier(pooled_output)
reshaped_logits = logits.view(-1, num_choices)
outputs = (reshaped_logits,) + outputs[2:] # add hidden states and attention if they are here
if labels is not None:
loss_fct = CrossEntropyLoss()
loss = loss_fct(reshaped_logits, labels)
outputs = (loss,) + outputs
return outputs # (loss), reshaped_logits, (hidden_states), (attentions)
@add_start_docstrings(
"""Masked Bert Model with a token classification head on top (a linear layer on top of
the hidden-states output) e.g. for Named-Entity-Recognition (NER) tasks. """,
MASKED_BERT_START_DOCSTRING,
)
class MaskedBertForTokenClassification(MaskedBertPreTrainedModel):
def __init__(self, config):
super().__init__(config)
self.num_labels = config.num_labels
self.bert = MaskedBertModel(config)
self.dropout = nn.Dropout(config.hidden_dropout_prob)
self.classifier = nn.Linear(config.hidden_size, config.num_labels)
self.init_weights()
@add_start_docstrings_to_model_forward(MASKED_BERT_INPUTS_DOCSTRING)
def forward(
self,
input_ids=None,
attention_mask=None,
token_type_ids=None,
position_ids=None,
head_mask=None,
inputs_embeds=None,
labels=None,
current_config=None,
):
r"""
labels (:obj:`torch.LongTensor` of shape :obj:`(batch_size, sequence_length)`, `optional`):
Labels for computing the token classification loss.
Indices should be in ``[0, ..., config.num_labels - 1]``.
current_config dict
current_config dict (see :class:`emmental.MaskedLinear`).
Returns:
:obj:`tuple(torch.FloatTensor)` comprising various elements depending on the configuration (:class:`~emmental.MaskedBertConfig`) and inputs:
loss (:obj:`torch.FloatTensor` of shape :obj:`(1,)`, `optional`, returned when ``labels`` is provided) :
Classification loss.
scores (:obj:`torch.FloatTensor` of shape :obj:`(batch_size, sequence_length, config.num_labels)`)
Classification scores (before SoftMax).
hidden_states (:obj:`tuple(torch.FloatTensor)`, `optional`, returned when ``config.output_hidden_states=True``):
Tuple of :obj:`torch.FloatTensor` (one for the output of the embeddings + one for the output of each layer)
of shape :obj:`(batch_size, sequence_length, hidden_size)`.
Hidden-states of the model at the output of each layer plus the initial embedding outputs.
attentions (:obj:`tuple(torch.FloatTensor)`, `optional`, returned when ``config.output_attentions=True``):
Tuple of :obj:`torch.FloatTensor` (one for each layer) of shape
:obj:`(batch_size, num_heads, sequence_length, sequence_length)`.
Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
heads.
"""
outputs = self.bert(
input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids,
position_ids=position_ids,
head_mask=head_mask,
inputs_embeds=inputs_embeds,
current_config=current_config,
)
sequence_output = outputs[0]
sequence_output = self.dropout(sequence_output)
logits = self.classifier(sequence_output)
outputs = (logits,) + outputs[2:] # add hidden states and attention if they are here
if labels is not None:
loss_fct = CrossEntropyLoss()
# Only keep active parts of the loss
if attention_mask is not None:
active_loss = attention_mask.view(-1) == 1
active_logits = logits.view(-1, self.num_labels)
active_labels = torch.where(
active_loss, labels.view(-1), torch.tensor(loss_fct.ignore_index).type_as(labels)
)
loss = loss_fct(active_logits, active_labels)
else:
loss = loss_fct(logits.view(-1, self.num_labels), labels.view(-1))
outputs = (loss,) + outputs
return outputs # (loss), scores, (hidden_states), (attentions)
@add_start_docstrings(
"""Masked Bert Model with a span classification head on top for extractive question-answering tasks like SQuAD (a linear
layers on top of the hidden-states output to compute `span start logits` and `span end logits`). """,
MASKED_BERT_START_DOCSTRING,
)
class MaskedBertForQuestionAnswering(MaskedBertPreTrainedModel):
def __init__(self, config):
super().__init__(config)
self.num_labels = config.num_labels
self.bert = MaskedBertModel(config)
self.qa_outputs = nn.Linear(config.hidden_size, config.num_labels)
self.init_weights()
@add_start_docstrings_to_model_forward(MASKED_BERT_INPUTS_DOCSTRING)
def forward(
self,
input_ids=None,
attention_mask=None,
token_type_ids=None,
position_ids=None,
head_mask=None,
inputs_embeds=None,
start_positions=None,
end_positions=None,
current_config=None,
):
r"""
start_positions (:obj:`torch.LongTensor` of shape :obj:`(batch_size,)`, `optional`):
Labels for position (index) of the start of the labelled span for computing the token classification loss.
Positions are clamped to the length of the sequence (`sequence_length`).
Position outside of the sequence are not taken into account for computing the loss.
end_positions (:obj:`torch.LongTensor` of shape :obj:`(batch_size,)`, `optional`):
Labels for position (index) of the end of the labelled span for computing the token classification loss.
Positions are clamped to the length of the sequence (`sequence_length`).
Position outside of the sequence are not taken into account for computing the loss.
current_config dict
current_config dict (see :class:`emmental.MaskedLinear`).
Returns:
:obj:`tuple(torch.FloatTensor)` comprising various elements depending on the configuration (:class:`~emmental.MaskedBertConfig`) and inputs:
loss (:obj:`torch.FloatTensor` of shape :obj:`(1,)`, `optional`, returned when :obj:`labels` is provided):
Total span extraction loss is the sum of a Cross-Entropy for the start and end positions.
start_scores (:obj:`torch.FloatTensor` of shape :obj:`(batch_size, sequence_length,)`):
Span-start scores (before SoftMax).
end_scores (:obj:`torch.FloatTensor` of shape :obj:`(batch_size, sequence_length,)`):
Span-end scores (before SoftMax).
hidden_states (:obj:`tuple(torch.FloatTensor)`, `optional`, returned when ``config.output_hidden_states=True``):
Tuple of :obj:`torch.FloatTensor` (one for the output of the embeddings + one for the output of each layer)
of shape :obj:`(batch_size, sequence_length, hidden_size)`.
Hidden-states of the model at the output of each layer plus the initial embedding outputs.
attentions (:obj:`tuple(torch.FloatTensor)`, `optional`, returned when ``config.output_attentions=True``):
Tuple of :obj:`torch.FloatTensor` (one for each layer) of shape
:obj:`(batch_size, num_heads, sequence_length, sequence_length)`.
Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
heads.
"""
outputs = self.bert(
input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids,
position_ids=position_ids,
head_mask=head_mask,
inputs_embeds=inputs_embeds,
current_config=current_config,
)
sequence_output = outputs[0]
logits = self.qa_outputs(sequence_output)
start_logits, end_logits = logits.split(1, dim=-1)
start_logits = start_logits.squeeze(-1)
end_logits = end_logits.squeeze(-1)
outputs = (
start_logits,
end_logits,
) + outputs[2:]
if start_positions is not None and end_positions is not None:
# If we are on multi-GPU, split add a dimension
if len(start_positions.size()) > 1:
start_positions = start_positions.squeeze(-1)
if len(end_positions.size()) > 1:
end_positions = end_positions.squeeze(-1)
# sometimes the start/end positions are outside our model inputs, we ignore these terms
ignored_index = start_logits.size(1)
start_positions.clamp_(0, ignored_index)
end_positions.clamp_(0, ignored_index)
loss_fct = CrossEntropyLoss(ignore_index=ignored_index)
start_loss = loss_fct(start_logits, start_positions)
end_loss = loss_fct(end_logits, end_positions)
total_loss = (start_loss + end_loss) / 2
outputs = (total_loss,) + outputs
return outputs # (loss), start_logits, end_logits, (hidden_states), (attentions)
| 6 |
0 | hf_public_repos/block_movement_pruning/block_movement_pruning | hf_public_repos/block_movement_pruning/block_movement_pruning/emmental/__init__.py | # flake8: noqa
from .configuration_bert_masked import MaskedBertConfig
from .modeling_bert_masked import (
MaskedBertForMultipleChoice,
MaskedBertForQuestionAnswering,
MaskedBertForSequenceClassification,
MaskedBertForTokenClassification,
MaskedBertModel,
)
from .modules import *
| 7 |
0 | hf_public_repos/block_movement_pruning/block_movement_pruning/emmental | hf_public_repos/block_movement_pruning/block_movement_pruning/emmental/modules/binarizer.py | # coding=utf-8
# Copyright 2020-present, AllenAI Authors, University of Illinois Urbana-Champaign,
# Intel Nervana Systems and the HuggingFace Inc. team.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""
Binarizers take a (real value) matrice as input and produce a binary (values in {0,1}) mask of the same shape.
"""
import torch
from torch import autograd
class ThresholdBinarizer(autograd.Function):
"""
Threshold binarizer.
Computes a binary mask M from a real value matrix S such that `M_{i,j} = 1` if and only if `S_{i,j} > \tau`
where `\tau` is a real value threshold.
Implementation is inspired from:
https://github.com/arunmallya/piggyback
Piggyback: Adapting a Single Network to Multiple Tasks by Learning to Mask Weights
Arun Mallya, Dillon Davis, Svetlana Lazebnik
"""
@staticmethod
def forward(ctx, inputs: torch.tensor, threshold: float, sigmoid: bool):
"""
Args:
inputs (`torch.FloatTensor`)
The input matrix from which the binarizer computes the binary mask.
threshold (`float`)
The threshold value (in R).
sigmoid (`bool`)
If set to ``True``, we apply the sigmoid function to the `inputs` matrix before comparing to `threshold`.
In this case, `threshold` should be a value between 0 and 1.
Returns:
mask (`torch.FloatTensor`)
Binary matrix of the same size as `inputs` acting as a mask (1 - the associated weight is
retained, 0 - the associated weight is pruned).
"""
nb_elems = inputs.numel()
nb_min = int(0.005 * nb_elems) + 1
if sigmoid:
mask = (torch.sigmoid(inputs) > threshold).type(inputs.type())
else:
mask = (inputs > threshold).type(inputs.type())
if mask.sum() < nb_min:
# We limit the pruning so that at least 0.5% (half a percent) of the weights are remaining
k_threshold = inputs.flatten().kthvalue(max(nb_elems - nb_min, 1)).values
mask = (inputs > k_threshold).type(inputs.type())
return mask
@staticmethod
def backward(ctx, gradOutput):
return gradOutput, None, None
class TopKBinarizer(autograd.Function):
"""
Top-k Binarizer.
Computes a binary mask M from a real value matrix S such that `M_{i,j} = 1` if and only if `S_{i,j}`
is among the k% highest values of S.
Implementation is inspired from:
https://github.com/allenai/hidden-networks
What's hidden in a randomly weighted neural network?
Vivek Ramanujan*, Mitchell Wortsman*, Aniruddha Kembhavi, Ali Farhadi, Mohammad Rastegari
"""
@staticmethod
def forward(ctx, inputs: torch.tensor, threshold: float):
"""
Args:
inputs (`torch.FloatTensor`)
The input matrix from which the binarizer computes the binary mask.
threshold (`float`)
The percentage of weights to keep (the rest is pruned).
`threshold` is a float between 0 and 1.
Returns:
mask (`torch.FloatTensor`)
Binary matrix of the same size as `inputs` acting as a mask (1 - the associated weight is
retained, 0 - the associated weight is pruned).
"""
# Get the subnetwork by sorting the inputs and using the top threshold %
mask = inputs.clone()
_, idx = inputs.flatten().sort(descending=True)
j = int(threshold * inputs.numel())
# flat_out and mask access the same memory.
flat_out = mask.flatten()
flat_out[idx[j:]] = 0
flat_out[idx[:j]] = 1
return mask
@staticmethod
def backward(ctx, gradOutput):
return gradOutput, None
class MagnitudeBinarizer(object):
"""
Magnitude Binarizer.
Computes a binary mask M from a real value matrix S such that `M_{i,j} = 1` if and only if `S_{i,j}`
is among the k% highest values of |S| (absolute value).
Implementation is inspired from https://github.com/NervanaSystems/distiller/blob/2291fdcc2ea642a98d4e20629acb5a9e2e04b4e6/distiller/pruning/automated_gradual_pruner.py#L24
"""
@staticmethod
def apply(inputs: torch.tensor, threshold: float):
"""
Args:
inputs (`torch.FloatTensor`)
The input matrix from which the binarizer computes the binary mask.
This input marix is typically the weight matrix.
threshold (`float`)
The percentage of weights to keep (the rest is pruned).
`threshold` is a float between 0 and 1.
Returns:
mask (`torch.FloatTensor`)
Binary matrix of the same size as `inputs` acting as a mask (1 - the associated weight is
retained, 0 - the associated weight is pruned).
"""
# Get the subnetwork by sorting the inputs and using the top threshold %
mask = inputs.clone()
_, idx = inputs.abs().flatten().sort(descending=True)
j = int(threshold * inputs.numel())
# flat_out and mask access the same memory.
flat_out = mask.flatten()
flat_out[idx[j:]] = 0
flat_out[idx[:j]] = 1
return mask
| 8 |
0 | hf_public_repos/block_movement_pruning/block_movement_pruning/emmental | hf_public_repos/block_movement_pruning/block_movement_pruning/emmental/modules/__init__.py | # flake8: noqa
from .binarizer import MagnitudeBinarizer, ThresholdBinarizer, TopKBinarizer
from .masked_nn import MaskedLinear
| 9 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.