
index
int64 0
0
| repo_id
stringclasses 179
values | file_path
stringlengths 26
186
| content
stringlengths 1
2.1M
| __index_level_0__
int64 0
9
|
|---|---|---|---|---|
0 | hf_public_repos/accelerate | hf_public_repos/accelerate/examples/README.md | <!---
Copyright 2021 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
-->
# In this folder we showcase various full examples using 🤗 Accelerate
## Simple NLP example
The [nlp_example.py](./nlp_example.py) script is a simple example to train a Bert model on a classification task ([GLUE's MRPC](https://www.microsoft.com/en-us/download/details.aspx?id=52398)).
Prior to running it you should install 🤗 Dataset and 🤗 Transformers:
```bash
pip install datasets evaluate transformers
```
The same script can be run in any of the following configurations:
- single CPU or single GPU
- multi CPUs
- multi GPUs (using PyTorch distributed mode)
- (multi) TPUs
- fp16 (mixed-precision) or fp32 (normal precision)
To run it in each of these various modes, use the following commands:
- single CPU:
* from a server without GPU
```bash
python ./nlp_example.py
```
* from any server by passing `cpu=True` to the `Accelerator`.
```bash
python ./nlp_example.py --cpu
```
* from any server with Accelerate launcher
```bash
accelerate launch --cpu ./nlp_example.py
```
- single GPU:
```bash
python ./nlp_example.py # from a server with a GPU
```
- with fp16 (mixed-precision)
* from any server by passing `mixed_precison=fp16` to the `Accelerator`.
```bash
python ./nlp_example.py --mixed_precision fp16
```
* from any server with Accelerate launcher
```bash
accelerate launch --mixed_precision fp16 ./nlp_example.py
- multi CPUs (requires Open MPI, Intel MPI, or MVAPICH)
* With Accelerate config and launcher, execute the following from node 0:
```bash
accelerate config # Select to have accelerate launch mpirun
accelerate launch ./nlp_example.py # This will run the script on each server
```
* With Intel MPI:
```bash
export CCL_WORKER_COUNT=1
export MASTER_ADDR=xxx.xxx.xxx.xxx #node0 ip
mpirun -f hostfile -n 16 -ppn 4 python ./nlp_example.py
```
- multi GPUs (using PyTorch distributed mode)
* With Accelerate config and launcher
```bash
accelerate config # This will create a config file on your server
accelerate launch ./nlp_example.py # This will run the script on your server
```
* With traditional PyTorch launcher (`python -m torch.distributed.run` can be used instead of `torchrun`)
```bash
torchrun --nproc_per_node 2 ./nlp_example.py
```
- multi GPUs, multi node (several machines, using PyTorch distributed mode)
* With Accelerate config and launcher, on each machine:
```bash
accelerate config # This will create a config file on each server
accelerate launch ./nlp_example.py # This will run the script on each server
```
* With PyTorch launcher only (`python -m torch.distributed.run` can be used instead of `torchrun`). Run this command on each node:
```bash
torchrun \ # python -m torch.distributed.run
--nproc_per_node 2 \
--nnodes 2 \
--rdzv_id 2299 \ # A unique job id
--rdzv_backend c10d \
--rdzv_endpoint master_node_ip_address:29500 \
./nlp_example.py
```
- (multi) TPUs
* With Accelerate config and launcher
```bash
accelerate config # This will create a config file on your TPU server
accelerate launch ./nlp_example.py # This will run the script on each server
```
* In PyTorch:
Add an `xmp.spawn` line in your script as you usually do.
## Simple vision example
The [cv_example.py](./cv_example.py) script is a simple example to fine-tune a ResNet-50 on a classification task ([Ofxord-IIT Pet Dataset](https://www.robots.ox.ac.uk/~vgg/data/pets/)).
The same script can be run in any of the following configurations:
- single CPU or single GPU
- multi CPUs
- multi GPUs (using PyTorch distributed mode)
- (multi) TPUs
- fp16 (mixed-precision) or fp32 (normal precision)
Prior to running it you should install timm and torchvision:
```bash
pip install timm torchvision
```
and you should download the data with the following commands:
```bash
wget https://www.robots.ox.ac.uk/~vgg/data/pets/data/images.tar.gz
tar -xzf images.tar.gz
```
To run it in each of these various modes, use the following commands:
- single CPU:
* from a server without GPU
```bash
python ./cv_example.py --data_dir path_to_data
```
* from any server by passing `cpu=True` to the `Accelerator`.
```bash
python ./cv_example.py --data_dir path_to_data --cpu
```
* from any server with Accelerate launcher
```bash
accelerate launch --cpu ./cv_example.py --data_dir path_to_data
```
- single GPU:
```bash
python ./cv_example.py # from a server with a GPU
```
- with fp16 (mixed-precision)
* from any server by passing `mixed_precison=fp16` to the `Accelerator`.
```bash
python ./cv_example.py --data_dir path_to_data --mixed_precison fp16
```
* from any server with Accelerate launcher
```bash
accelerate launch --mixed_precison fp16 ./cv_example.py --data_dir path_to_data
- multi CPUs (requires Open MPI, Intel MPI, or MVAPICH)
* With Accelerate config and launcher, run the following from node 0:
```bash
accelerate config --config_file config.yaml # Select to have accelerate launch mpirun
accelerate launch ./cv_example.py --data_dir path_to_data # This will run the script on each server
```
* With Intel MPI, execute mpirun from node 0:
```bash
export CCL_WORKER_COUNT=1
export MASTER_ADDR=xxx.xxx.xxx.xxx #node0 ip
mpirun -f hostfile -n 16 -ppn 4 python ./cv_example.py --data_dir path_to_data
```
- multi GPUs (using PyTorch distributed mode)
* With Accelerate config and launcher
```bash
accelerate config --config_file config.yaml # This will create a config file on your server to `config.yaml`
accelerate launch --config_file config.yaml ./cv_example.py --data_dir path_to_data # This will run the script on your server
```
* With traditional PyTorch launcher (`python -m torch.distributed.run` can be used instead of `torchrun`)
```bash
torchrun --nproc_per_node 2 ./cv_example.py --data_dir path_to_data
```
- multi GPUs, multi node (several machines, using PyTorch distributed mode)
* With Accelerate config and launcher, on each machine:
```bash
accelerate config --config_file config.yaml # This will create a config file on your server to `config.yaml`
accelerate launch --config_file config.yaml ./cv_example.py --data_dir path_to_data # This will run the script on each server
```
* With PyTorch launcher only (`python -m torch.distributed.run` can be used instead of `torchrun`). Run this command on each node:
```bash
torchrun \ # python -m torch.distributed.run
--nproc_per_node 2 \
--nnodes 2 \
--rdzv_id 2299 \ # A unique job id
--rdzv_backend c10d \
--rdzv_endpoint master_node_ip_address:29500 \
./cv_example.py --data_dir path_to_data
```
- (multi) TPUs
* With Accelerate config and launcher
```bash
accelerate config --config_file config.yaml # This will create a config file on your server to `config.yaml`
accelerate launch --config_file config.yaml ./cv_example.py --data_dir path_to_data # This will run the script on each server
```
* In PyTorch:
Add an `xmp.spawn` line in your script as you usually do.
### Simple vision example (GANs)
- [huggan project](https://github.com/huggingface/community-events/tree/main/huggan)
### Using AWS SageMaker integration
- [Examples showcasing AWS SageMaker integration of 🤗 Accelerate.](https://github.com/pacman100/accelerate-aws-sagemaker)
## Configuration zoo
In [/config_yaml_templates](./config_yaml_templates/) we have a variety of *minimal* `config.yaml` templates and examples to help you learn
how to create your own configuration files depending on the scenario.
## SLURM Scripts
In [/slurm/submit_multigpu.sh](./slurm/submit_multigpu.sh) and [/slurm/submit_multinode.sh](./slurm/submit_multinode.sh) we present two scripts for running the examples on a machine with [SLURM](https://slurm.schedmd.com/documentation.html) workload manager.
In [/slurm/submit_multigpu.sh](./slurm/submit_multigpu.sh) the only parameter in the launcher that needs to be modified is `--num_processes`, which determines the number of GPUs we will use. In this case, using the environment variable `$SLURM_GPUS`, we indicate that we want to utilize all the GPUs available on the node we have requested.
In [/slurm/submit_multinode.sh](./slurm/submit_multinode.sh) we must specify the number of nodes that will be part of the training (`--num_machines`), how many GPUs we will use in total (`--num_processes`), the [`backend`](https://pytorch.org/docs/stable/elastic/run.html#note-on-rendezvous-backend), `--main_process_ip` which will be the address the master node and the `--main_process_port`.
In [/slurm/submit_multicpu.sh](./slurm/submit_multicpu.sh) we must specify the number of nodes that will be part of the training (`--num_machines`), how many CPU processes we will use in total (`--num_processes`), the [`backend`](https://pytorch.org/docs/stable/elastic/run.html#note-on-rendezvous-backend), `--main_process_ip` which will be the address the master node and the `--main_process_port`. `mpirun_hostfile` specifies to run the job using MPIRun.
In both scripts, we run `activateEnviroment.sh` at the beginning. This script should contain the necessary instructions to initialize the environment for execution. Below, we show an example that loads the necessary libraries ([Environment modules](https://github.com/cea-hpc/modules)), activates the Python environment, and sets up various environment variables, most of them to run the scripts in offline mode in case we don't have internet connection from the cluster.
```bash
# activateEnvironment.sh
module purge
module load anaconda3/2020.02 cuda/10.2 cudnn/8.0.5 nccl/2.9.9 arrow/7.0.0 openmpi
source activate /home/nct01/nct01328/pytorch_antoni_local
export HF_HOME=/gpfs/projects/nct01/nct01328/
export HF_LOCAL_HOME=/gpfs/projects/nct01/nct01328/HF_LOCAL
export HF_DATASETS_OFFLINE=1
export TRANSFORMERS_OFFLINE=1
export PYTHONPATH=/home/nct01/nct01328/transformers-in-supercomputers:$PYTHONPATH
export GPUS_PER_NODE=4
```
## Simple Multi-GPU Hardware Launcher (using an external platform)
[multigpu_remote_launcher.py](./multigpu_remote_launcher.py) is a minimal script that demonstrates launching accelerate
on multiple remote GPUs, and with automatic hardware environment and dependency setup for reproducibility. You can
easily customize the training function used, training arguments, hyperparameters, and type of compute hardware, and then
run the script to automatically launch multi GPU training on remote hardware.
This script uses [Runhouse](https://github.com/run-house/runhouse) to launch on self-hosted hardware (e.g. in your own
cloud account or on-premise cluster) but there are other options for running remotely as well. Runhouse can be installed
with `pip install runhouse`, and you can refer to
[hardware setup](https://runhouse-docs.readthedocs-hosted.com/en/latest/api/python/cluster.html#hardware-setup)
for hardware setup instructions, or this
[Colab tutorial](https://colab.research.google.com/drive/1qVwYyLTCPYPSdz9ZX7BZl9Qm0A3j7RJe) for a more in-depth walkthrough.
## Finer Examples
While the first two scripts are extremely barebones when it comes to what you can do with accelerate, more advanced features are documented in two other locations.
### `by_feature` examples
These scripts are *individual* examples highlighting one particular feature or use-case within Accelerate. They all stem from the [nlp_example.py](./nlp_example.py) script, and any changes or modifications is denoted with a `# New Code #` comment.
Read the README.md file located in the `by_feature` folder for more information.
### `complete_*` examples
These two scripts contain *every* single feature currently available in Accelerate in one place, as one giant script.
New arguments that can be passed include:
- `checkpointing_steps`, whether the various states should be saved at the end of every `n` steps, or `"epoch"` for each epoch. States are then saved to folders named `step_{n}` or `epoch_{n}`
- `resume_from_checkpoint`, should be used if you want to resume training off of a previous call to the script and passed a `checkpointing_steps` to it.
- `with_tracking`, should be used if you want to log the training run using all available experiment trackers in your environment. Currently supported trackers include TensorBoard, Weights and Biases, and CometML.
| 0 |
0 | hf_public_repos/accelerate/examples/inference | hf_public_repos/accelerate/examples/inference/distributed/stable_diffusion.py | # Copyright 2024 The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import torch
from diffusers import DiffusionPipeline
from accelerate import PartialState # Can also be Accelerator or AcceleratorState
pipe = DiffusionPipeline.from_pretrained("runwayml/stable-diffusion-v1-5", torch_dtype=torch.float16)
distributed_state = PartialState()
pipe.to(distributed_state.device)
# Assume two processes
# On the first GPU, the prompts will be ["a dog", "a cat"],
# and on the second GPU it will be ["a chicken", "a chicken"].
# Make sure to drop the final sample, as it will be a duplicate of the previous one.
with distributed_state.split_between_processes(["a dog", "a cat", "a chicken"], apply_padding=True) as prompt:
result = pipe(prompt).images
| 1 |
0 | hf_public_repos/accelerate/examples/inference | hf_public_repos/accelerate/examples/inference/distributed/phi2.py | # Copyright 2024 The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
from accelerate import PartialState
from accelerate.utils import gather_object
# Start up the distributed environment without needing the Accelerator.
distributed_state = PartialState()
# You can change the model to any LLM such as mistralai/Mistral-7B-v0.1 or meta-llama/Llama-2-7b-chat-hf
model_name = "microsoft/phi-2"
model = AutoModelForCausalLM.from_pretrained(
model_name, device_map=distributed_state.device, torch_dtype=torch.float16
)
tokenizer = AutoTokenizer.from_pretrained(model_name)
# Need to set the padding token to the eos token for generation
tokenizer.pad_token = tokenizer.eos_token
prompts = [
"I would like to",
"hello how are you",
"what is going on",
"roses are red and",
"welcome to the hotel",
]
# You can change the batch size depending on your GPU RAM
batch_size = 2
# We set it to 8 since it is better for some hardware. More information here https://github.com/huggingface/tokenizers/issues/991
pad_to_multiple_of = 8
# Split into batches
# We will get the following results:
# [ ["I would like to", "hello how are you"], [ "what is going on", "roses are red and"], [ "welcome to the hotel"] ]
formatted_prompts = [prompts[i : i + batch_size] for i in range(0, len(prompts), batch_size)]
# Apply padding on the left since we are doing generation
padding_side_default = tokenizer.padding_side
tokenizer.padding_side = "left"
# Tokenize each batch
tokenized_prompts = [
tokenizer(formatted_prompt, padding=True, pad_to_multiple_of=pad_to_multiple_of, return_tensors="pt")
for formatted_prompt in formatted_prompts
]
# Put back the original padding behavior
tokenizer.padding_side = padding_side_default
completions_per_process = []
# We automatically split the batched data we passed to it across all the processes. We also set apply_padding=True
# so that the GPUs will have the same number of prompts, and you can then gather the results.
# For example, if we have 2 gpus, the distribution will be:
# GPU 0: ["I would like to", "hello how are you"], "what is going on", "roses are red and"]
# GPU 1: ["welcome to the hotel"], ["welcome to the hotel"] -> this prompt is duplicated to ensure that all gpus have the same number of prompts
with distributed_state.split_between_processes(tokenized_prompts, apply_padding=True) as batched_prompts:
for batch in batched_prompts:
# Move the batch to the device
batch = batch.to(distributed_state.device)
# We generate the text, decode it and add it to the list completions_per_process
outputs = model.generate(**batch, max_new_tokens=20)
generated_text = tokenizer.batch_decode(outputs, skip_special_tokens=True)
completions_per_process.extend(generated_text)
# We are gathering string, so we need to use gather_object.
# If you need to gather tensors, you can use gather from accelerate.utils
completions_gather = gather_object(completions_per_process)
# Drop duplicates produced by apply_padding in split_between_processes
completions = completions_gather[: len(prompts)]
distributed_state.print(completions)
| 2 |
0 | hf_public_repos/accelerate/examples/inference | hf_public_repos/accelerate/examples/inference/distributed/florence2.py | # Copyright 2024 The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import json
import os
import pathlib
import queue
from concurrent.futures import ThreadPoolExecutor
from functools import partial
from typing import Union
import fire
import torch
import webdataset as wds
from huggingface_hub.utils import insecure_hashlib
from PIL import Image
from tqdm import tqdm
from transformers import AutoModelForCausalLM, AutoProcessor
from accelerate import PartialState
"""
Additional requirements: flash_attn einops timm webdataset fire tqdm huggingface_hub
pip install flash_attn einops timm webdataset fire tqdm huggingface_hub
Example:
accelerate launch --num_processes=2 florence2.py --data_path "https://huggingface.co/datasets/pixparse/cc3m-wds/resolve/main/cc3m-train-0000.tar" --output_path outputs --batch_size 12 --num_workers 1 --prompt "<CAPTION>"
"""
def main(
data_path: str,
output_path: str,
batch_size: int,
num_workers: int,
prompt: str = "<MORE_DETAILED_CAPTION>",
model_name: str = "microsoft/Florence-2-large",
max_new_tokens: int = 1024,
num_beams: int = 3,
):
output_dir = pathlib.Path(output_path)
distributed_state = PartialState()
if distributed_state.is_main_process:
output_dir.mkdir(exist_ok=True)
model = AutoModelForCausalLM.from_pretrained(
model_name,
device_map=distributed_state.device,
torch_dtype=torch.float16,
trust_remote_code=True,
)
processor = AutoProcessor.from_pretrained(model_name, trust_remote_code=True, clean_up_tokenization_spaces=True)
class ExistsFilter:
def __init__(self, output_dir: Union[pathlib.Path, str]):
current_training_img_hashes = [f.split(".jpg")[0] for f in os.listdir(output_dir) if f.endswith(".jpg")]
self.current_training_img_hashes = set(current_training_img_hashes)
if distributed_state.is_main_process:
print(f"Existing images found: {len(self.current_training_img_hashes)}.")
def __call__(self, x):
if len(self.current_training_img_hashes) > 0:
if x["img_hash"] in self.current_training_img_hashes:
return False
else:
return True
else:
return True
def preprocess_fn(sample, processor):
image: Image.Image = sample["jpg"].convert("RGB")
img_hash = insecure_hashlib.sha1(image.tobytes()).hexdigest()
inputs = processor(
text=prompt,
images=image,
return_tensors="pt",
)
return {
"input_ids": inputs["input_ids"],
"pixel_values": inputs["pixel_values"],
"image": image,
"img_hash": img_hash,
"original_caption": sample["txt"],
}
def collate_fn(examples):
input_ids = torch.cat([example["input_ids"] for example in examples])
pixel_values = torch.cat([example["pixel_values"] for example in examples])
images = [example["image"] for example in examples]
img_hashes = [example["img_hash"] for example in examples]
captions = [example["original_caption"] for example in examples]
return {
"input_ids": input_ids,
"pixel_values": pixel_values,
"images": images,
"img_hashes": img_hashes,
"original_captions": captions,
}
exist_filter = ExistsFilter(output_dir)
dataset = (
wds.WebDataset(
data_path,
handler=wds.warn_and_continue,
nodesplitter=None,
shardshuffle=False,
empty_check=False,
)
.decode("pil", handler=wds.warn_and_continue)
.map(partial(preprocess_fn, processor=processor), handler=wds.warn_and_continue)
)
if len(exist_filter.current_training_img_hashes) > 0:
dataset = dataset.select(exist_filter)
dataset = dataset.batched(
batch_size,
partial=False,
collation_fn=collate_fn,
)
dataloader = wds.WebLoader(
dataset,
batch_size=None,
num_workers=num_workers,
pin_memory=True,
persistent_workers=True,
)
def save_results(output_queue: queue.Queue, output_dir: pathlib.Path, processor):
while True:
try:
item = output_queue.get(timeout=5)
if item is None:
break
original_captions, predictions, images, img_hashes = item
predicted_captions = processor.batch_decode(
predictions,
skip_special_tokens=False,
)
for caption, pred_caption, image, img_hash in zip(
original_captions, predicted_captions, images, img_hashes
):
processed_caption = processor.post_process_generation(
pred_caption, task=prompt, image_size=(image.width, image.height)
)[prompt]
img_path = output_dir.joinpath(f"{img_hash}.jpg")
image.save(img_path)
caption_dict = {"original": caption, "predicted": processed_caption}
with output_dir.joinpath(f"{img_hash}_caption.json").open("w") as f:
json.dump(caption_dict, f, indent=4)
except queue.Empty:
continue
output_queue = queue.Queue()
save_thread = ThreadPoolExecutor(max_workers=num_workers)
save_future = save_thread.submit(save_results, output_queue, output_dir, processor)
try:
for _, batch_raw in tqdm(
enumerate(dataloader),
disable=not distributed_state.is_main_process,
):
with distributed_state.split_between_processes(batch_raw) as batch:
outputs = model.generate(
input_ids=batch["input_ids"].to(distributed_state.device),
pixel_values=batch["pixel_values"].to(distributed_state.device, model.dtype),
max_new_tokens=max_new_tokens,
num_beams=num_beams,
)
output_queue.put(
(
batch["original_captions"],
outputs,
batch["images"],
batch["img_hashes"],
)
)
finally:
output_queue.put(None)
save_thread.shutdown(wait=True)
save_future.result()
if __name__ == "__main__":
fire.Fire(main)
| 3 |
0 | hf_public_repos/accelerate/examples/inference | hf_public_repos/accelerate/examples/inference/distributed/distributed_image_generation.py | # Copyright 2024 The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""
Originally by jiwooya1000, put together together by sayakpaul.
Documentation: https://huggingface.co/docs/diffusers/main/en/training/distributed_inference
Run:
accelerate launch distributed_image_generation.py --batch_size 8
# Enable memory optimizations for large models like SD3
accelerate launch distributed_image_generation.py --batch_size 8 --low_mem
"""
import os
import time
import fire
import torch
from datasets import load_dataset
from diffusers import DiffusionPipeline
from tqdm import tqdm
from accelerate import PartialState
from accelerate.utils import gather_object
START_TIME = time.strftime("%Y%m%d_%H%M%S")
DTYPE_MAP = {"fp32": torch.float32, "fp16": torch.float16, "bf16": torch.bfloat16}
def get_batches(items, batch_size):
num_batches = (len(items) + batch_size - 1) // batch_size
batches = []
for i in range(num_batches):
start_index = i * batch_size
end_index = min((i + 1) * batch_size, len(items))
batch = items[start_index:end_index]
batches.append(batch)
return batches
def main(
ckpt_id: str = "PixArt-alpha/PixArt-Sigma-XL-2-1024-MS",
save_dir: str = "./evaluation/examples",
seed: int = 1,
batch_size: int = 4,
num_inference_steps: int = 20,
guidance_scale: float = 4.5,
dtype: str = "fp16",
low_mem: bool = False,
):
pipeline = DiffusionPipeline.from_pretrained(ckpt_id, torch_dtype=DTYPE_MAP[dtype])
save_dir = save_dir + f"_{START_TIME}"
parti_prompts = load_dataset("nateraw/parti-prompts", split="train")
data_loader = get_batches(items=parti_prompts["Prompt"], batch_size=batch_size)
distributed_state = PartialState()
if low_mem:
pipeline.enable_model_cpu_offload(gpu_id=distributed_state.device.index)
else:
pipeline = pipeline.to(distributed_state.device)
if distributed_state.is_main_process:
if not os.path.exists(save_dir):
os.makedirs(save_dir)
print(f"Directory '{save_dir}' created successfully.")
else:
print(f"Directory '{save_dir}' already exists.")
count = 0
for _, prompts_raw in tqdm(enumerate(data_loader), total=len(data_loader)):
input_prompts = []
with distributed_state.split_between_processes(prompts_raw) as prompts:
generator = torch.manual_seed(seed)
images = pipeline(
prompts, num_inference_steps=num_inference_steps, guidance_scale=guidance_scale, generator=generator
).images
input_prompts.extend(prompts)
distributed_state.wait_for_everyone()
images = gather_object(images)
input_prompts = gather_object(input_prompts)
if distributed_state.is_main_process:
for image, prompt in zip(images, input_prompts):
count += 1
temp_dir = os.path.join(save_dir, f"example_{count}")
os.makedirs(temp_dir)
prompt = "_".join(prompt.split())
image.save(f"image_{prompt}.png")
if distributed_state.is_main_process:
print(f">>> Image Generation Finished. Saved in {save_dir}")
if __name__ == "__main__":
fire.Fire(main)
| 4 |
0 | hf_public_repos/accelerate/examples/inference | hf_public_repos/accelerate/examples/inference/distributed/distributed_speech_generation.py | # Copyright 2024 The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import json
import os
import pathlib
import queue
from concurrent.futures import ThreadPoolExecutor
from typing import Union
import fire
import scipy.io.wavfile
import torch
from datasets import load_dataset
from transformers import AutoTokenizer, VitsModel
from accelerate import PartialState
from accelerate.utils import tqdm
"""
Requirements: transformers accelerate fire scipy datasets
pip install transformers accelerate fire scipy datasets
Example usage:
accelerate launch distributed_speech_generation.py --output_path outputs --batch_size 8 --num_workers 2 --dataset_split train
"""
"""
To run the speech generation
import scipy.io.wavfile
import numpy as np
from IPython.display import Audio
sample_rate, audio_data = scipy.io.wavfile.read('path_to_you_wav_file.wav')
audio_data = audio_data.astype(np.float32) / 32762.0
Audio(audio_data, rate=sample_rate)
"""
def load_pokemon_data(split: str, max_text_length: int):
"""Load Pokemon descriptions from the dataset"""
ds = load_dataset("svjack/pokemon-blip-captions-en-zh", split=split)
# Create dataset of dictionaries
dataset = []
for idx, text in enumerate(ds["en_text"]):
if len(text.strip()) > 0: # Skip empty descriptions
dataset.append(
{
"id": f"pokemon_{idx:06d}",
"text": text.strip()[:max_text_length], # Truncate long descriptions
"original_text": text.strip(), # Keep original for metadata
}
)
return dataset
class ExistsFilter:
def __init__(self, output_dir: Union[pathlib.Path, str]):
current_files = [f.split(".wav")[0] for f in os.listdir(output_dir) if f.endswith(".wav")]
self.processed_files = set(current_files)
print(f"Existing audio files found: {len(self.processed_files)}.")
def __call__(self, x):
return x["id"] not in self.processed_files
def preprocess_fn(sample, tokenizer, max_text_length: int):
inputs = tokenizer(sample["text"], padding=False, truncation=True, max_length=max_text_length, return_tensors="pt")
return {
"input_ids": inputs["input_ids"][0].tolist(),
"attention_mask": inputs["attention_mask"][0].tolist(),
"id": sample["id"],
"text": sample["text"],
"original_text": sample["original_text"],
}
def collate_fn(examples, tokenizer):
"""Collate batch of examples with proper padding"""
# Find max length in this batch
max_length = max(len(example["input_ids"]) for example in examples)
# Pad sequences to max_length
input_ids_list = []
attention_mask_list = []
for example in examples:
# Get current lengths
curr_len = len(example["input_ids"])
padding_length = max_length - curr_len
# Pad sequences
padded_input_ids = example["input_ids"] + [tokenizer.pad_token_id] * padding_length
padded_attention_mask = example["attention_mask"] + [0] * padding_length
input_ids_list.append(padded_input_ids)
attention_mask_list.append(padded_attention_mask)
# Convert to tensors
input_ids = torch.tensor(input_ids_list, dtype=torch.long)
attention_mask = torch.tensor(attention_mask_list, dtype=torch.long)
ids = [example["id"] for example in examples]
texts = [example["text"] for example in examples]
original_texts = [example["original_text"] for example in examples]
return {
"input_ids": input_ids,
"attention_mask": attention_mask,
"ids": ids,
"texts": texts,
"original_texts": original_texts,
}
def create_dataloader(dataset, batch_size, distributed_state, tokenizer):
"""Create dataloader with preprocessing"""
processed_dataset = [preprocess_fn(item, tokenizer, max_text_length=200) for item in dataset]
# Split dataset for distributed processing
if distributed_state.num_processes > 1:
chunk_size = len(processed_dataset) // distributed_state.num_processes
start_idx = distributed_state.process_index * chunk_size
end_idx = (
start_idx + chunk_size
if distributed_state.process_index < distributed_state.num_processes - 1
else len(processed_dataset)
)
processed_dataset = processed_dataset[start_idx:end_idx]
# Create batches
batches = []
for i in range(0, len(processed_dataset), batch_size):
batch = processed_dataset[i : i + batch_size]
batches.append(collate_fn(batch, tokenizer))
return batches
def save_results(output_queue: queue.Queue, output_dir: pathlib.Path, sampling_rate: int):
while True:
try:
item = output_queue.get(timeout=5)
if item is None:
break
waveforms, ids, texts, original_texts = item
# Save each audio file and its metadata
for waveform, file_id, text, original_text in zip(waveforms, ids, texts, original_texts):
# Save audio
wav_path = output_dir / f"{file_id}.wav"
scipy.io.wavfile.write(wav_path, rate=sampling_rate, data=waveform.cpu().float().numpy())
# Save metadata with both truncated and original text
metadata = {
"text_used": text,
"original_text": original_text,
"model": "facebook/mms-tts-eng",
"sampling_rate": sampling_rate,
}
metadata_path = output_dir / f"{file_id}_metadata.json"
with metadata_path.open("w") as f:
json.dump(metadata, f, indent=4)
except queue.Empty:
continue
def main(
output_path: str = "speech_data",
batch_size: int = 8,
num_workers: int = 2,
dataset_split: str = "train",
model_name: str = "facebook/mms-tts-eng",
max_text_length: int = 200,
):
output_dir = pathlib.Path(output_path)
output_dir.mkdir(parents=True, exist_ok=True)
distributed_state = PartialState()
# Load model and tokenizer
model = VitsModel.from_pretrained(
model_name,
device_map=distributed_state.device,
torch_dtype=torch.float32,
)
tokenizer = AutoTokenizer.from_pretrained(model_name)
# Load and filter data
dataset = load_pokemon_data(dataset_split, max_text_length)
exist_filter = ExistsFilter(output_dir)
dataset = [item for item in dataset if exist_filter(item)]
distributed_state.print(f"Processing {len(dataset)} Pokemon descriptions")
# Create dataloader
batches = create_dataloader(dataset, batch_size, distributed_state, tokenizer)
# Setup output queue and save thread
output_queue = queue.Queue()
save_thread = ThreadPoolExecutor(max_workers=num_workers)
save_future = save_thread.submit(save_results, output_queue, output_dir, model.config.sampling_rate)
try:
for batch in tqdm(batches, desc="Generating Pokemon descriptions"):
with torch.no_grad():
outputs = model(
input_ids=batch["input_ids"].to(distributed_state.device, dtype=torch.long),
attention_mask=batch["attention_mask"].to(distributed_state.device, dtype=torch.long),
).waveform
output_queue.put((outputs, batch["ids"], batch["texts"], batch["original_texts"]))
finally:
output_queue.put(None)
save_thread.shutdown(wait=True)
save_future.result()
if __name__ == "__main__":
fire.Fire(main)
| 5 |
0 | hf_public_repos/accelerate/examples/inference | hf_public_repos/accelerate/examples/inference/distributed/README.md | # Distributed inference examples
This folder contains a variety of tutorials for running distributed inference with the following strategy:
Load an entire model onto each GPU and sending chunks of a batch through each GPU’s model copy at a time
## Installation
```bash
pip install accelerate torch
```
## Running code
You can either use `torchrun` or the recommended way of `accelerate launch` (without needing to run `accelerate config`) on each script:
```bash
accelerate launch --num_processes {NUM_GPUS} phi2.py
```
Or:
```bash
torchrun --nproc-per-node {NUM_GPUS} phi2.py
```
| 6 |
0 | hf_public_repos/accelerate/examples/inference | hf_public_repos/accelerate/examples/inference/pippy/llama.py | # Copyright 2024 The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
from accelerate import PartialState, prepare_pippy
# sdpa implementation which is the default torch>2.1.2 fails with the tracing + attention mask kwarg
# with attn_implementation="eager" mode, the forward is very slow for some reason
model = AutoModelForCausalLM.from_pretrained(
"meta-llama/Llama-2-7b-chat-hf", low_cpu_mem_usage=True, attn_implementation="sdpa"
)
model.eval()
# Input configs
# Create example inputs for the model
tokenizer = AutoTokenizer.from_pretrained("meta-llama/Llama-2-7b-chat-hf")
prompts = ("I would like to", "I really like to") # bs = 2, sending 2 per process
tokenizer.pad_token = tokenizer.eos_token
inputs = tokenizer(prompts, return_tensors="pt", padding=True)
# Create a pipeline stage from the model
# Using `auto` is equivalent to letting `device_map="auto"` figure
# out device mapping and will also split the model according to the
# number of total GPUs available if it fits on one GPU
model = prepare_pippy(model, split_points="auto", example_kwargs=inputs)
# You can pass `gather_output=True` to have the output from the model
# available on all GPUs
# model = prepare_pippy(model, split_points="auto", example_args=(input,), gather_output=True)
# currently we don't support `model.generate`
# output = model.generate(**inputs, max_new_tokens=1)
prompts = ("I would like to", "I really like to", "The weather is pretty") # bs = 3
inputs = tokenizer(prompts, return_tensors="pt", padding=True)
inputs = inputs.to(0)
with torch.no_grad():
output = model(**inputs)
# The outputs are only on the final process by default
if PartialState().is_last_process:
next_token_logits = output[0][:, -1, :]
next_token = torch.argmax(next_token_logits, dim=-1)
print(tokenizer.batch_decode(next_token))
PartialState().destroy_process_group()
| 7 |
0 | hf_public_repos/accelerate/examples/inference | hf_public_repos/accelerate/examples/inference/pippy/requirements.txt | accelerate
pippy>=0.2.0 | 8 |
0 | hf_public_repos/accelerate/examples/inference | hf_public_repos/accelerate/examples/inference/pippy/bert.py | # Copyright 2024 The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import time
import torch
from transformers import AutoModelForMaskedLM
from accelerate import PartialState, prepare_pippy
from accelerate.utils import set_seed
# Set the random seed to have reproducable outputs
set_seed(42)
# Create an example model
model = AutoModelForMaskedLM.from_pretrained("bert-base-uncased")
model.eval()
# Input configs
# Create example inputs for the model
input = torch.randint(
low=0,
high=model.config.vocab_size,
size=(1, 512), # bs x seq_len
device="cpu",
dtype=torch.int64,
requires_grad=False,
)
# Create a pipeline stage from the model
# Using `auto` is equivalent to letting `device_map="auto"` figure
# out device mapping and will also split the model according to the
# number of total GPUs available if it fits on one GPU
model = prepare_pippy(model, split_points="auto", example_args=(input,))
# You can pass `gather_output=True` to have the output from the model
# available on all GPUs
# model = prepare_pippy(model, split_points="auto", example_args=(input,), gather_output=True)
# Create new inputs of the expected size (n_processes)
input = torch.randint(
low=0,
high=model.config.vocab_size,
size=(2, 512), # bs x seq_len
device="cpu",
dtype=torch.int64,
requires_grad=False,
)
# Move the inputs to the first device
input = input.to("cuda:0")
# Take an average of 5 times
# Measure first batch
torch.cuda.synchronize()
start_time = time.time()
with torch.no_grad():
output = model(input)
torch.cuda.synchronize()
end_time = time.time()
first_batch = end_time - start_time
# Now that CUDA is init, measure after
torch.cuda.synchronize()
start_time = time.time()
for i in range(5):
with torch.no_grad():
output = model(input)
torch.cuda.synchronize()
end_time = time.time()
# The outputs are only on the final process by default
if PartialState().is_last_process:
output = torch.stack(tuple(output[0]))
print(f"Time of first pass: {first_batch}")
print(f"Average time per batch: {(end_time - start_time) / 5}")
PartialState().destroy_process_group()
| 9 |
0 | hf_public_repos/candle/candle-transformers/src | hf_public_repos/candle/candle-transformers/src/models/falcon.rs | //! Falcon language model inference implementation
//!
//! See ["Falcon: a new approach to large language models"](https://huggingface.co/blog/falcon)
//!
//! Based on implementation from [Huggingface Transformers](https://github.com/huggingface/transformers/blob/main/src/transformers/models/falcon)
use candle::{DType, Device, Result, Tensor, D};
use candle_nn::{embedding, linear_b as linear, Embedding, LayerNorm, Linear, Module, VarBuilder};
use serde::Deserialize;
const MAX_SEQ_LEN: usize = 5000;
fn layer_norm(size: usize, eps: f64, vb: VarBuilder) -> Result<LayerNorm> {
let (weight, bias) = match (vb.get(size, "weight"), vb.get(size, "bias")) {
(Ok(weight), Ok(bias)) => (weight, bias),
(Err(err), _) | (_, Err(err)) => {
if let (Ok(weight), Ok(bias)) = (vb.get(size, "gamma"), vb.get(size, "beta")) {
(weight, bias)
} else {
return Err(err);
}
}
};
Ok(LayerNorm::new(weight, bias, eps))
}
// https://raw.githubusercontent.com/huggingface/transformers/030c863aaa0165e98352b61697430bf69bf33755/src/transformers/models/falcon/configuration_falcon.py
#[derive(Clone, Debug, Deserialize)]
pub struct Config {
pub vocab_size: usize,
pub hidden_size: usize,
pub num_hidden_layers: usize,
pub num_attention_heads: usize,
pub layer_norm_epsilon: f64,
pub initializer_range: f64,
pub use_cache: bool,
pub bos_token_id: u32,
pub eos_token_id: u32,
pub hidden_dropout: f64,
pub attention_dropout: f64,
pub n_head_kv: Option<usize>,
pub alibi: bool,
pub new_decoder_architecture: bool,
pub multi_query: bool,
pub parallel_attn: bool,
pub bias: bool,
}
impl Default for Config {
fn default() -> Self {
Self {
vocab_size: 65024,
hidden_size: 4544,
num_hidden_layers: 32,
num_attention_heads: 71,
layer_norm_epsilon: 1e-5,
initializer_range: 0.02,
use_cache: true,
bos_token_id: 11,
eos_token_id: 11,
hidden_dropout: 0.0,
attention_dropout: 0.0,
n_head_kv: None,
alibi: false,
new_decoder_architecture: false,
multi_query: true,
parallel_attn: true,
bias: false,
}
}
}
impl Config {
pub fn validate(&self) -> Result<()> {
if self.alibi {
candle::bail!("alibi is not supported");
}
if self.new_decoder_architecture {
candle::bail!("new_decoder_architecture is not supported");
}
if self.n_head_kv.is_some() {
candle::bail!("n_head_kv is not supported");
}
Ok(())
}
// https://huggingface.co/tiiuae/falcon-7b/blob/main/config.json
pub fn falcon7b() -> Self {
// This is currently on par with the defaults, the defaults come from the Python default
// arguments for the config initialization whereas the following come from the json config.
Self {
vocab_size: 65024,
hidden_size: 4544,
num_hidden_layers: 32,
num_attention_heads: 71,
layer_norm_epsilon: 1e-5,
initializer_range: 0.02,
use_cache: true,
bos_token_id: 11,
eos_token_id: 11,
hidden_dropout: 0.,
attention_dropout: 0.,
n_head_kv: None,
alibi: false,
new_decoder_architecture: false,
multi_query: true,
parallel_attn: true,
bias: false,
}
}
fn head_dim(&self) -> usize {
self.hidden_size / self.num_attention_heads
}
fn rotary(&self) -> bool {
!self.alibi
}
}
fn rotate_half(x: &Tensor) -> Result<Tensor> {
let l = x.dim(D::Minus1)?;
let x1 = x.narrow(D::Minus1, 0, l / 2)?;
let x2 = x.narrow(D::Minus1, l / 2, l - l / 2)?;
let x21 = Tensor::cat(&[&x2.neg()?, &x1], D::Minus1)?;
Ok(x21)
}
#[derive(Debug, Clone)]
struct FalconRotaryEmbedding {
inv_freq: Tensor,
cache: Option<(usize, Tensor, Tensor)>,
}
impl FalconRotaryEmbedding {
fn load(device: &Device, cfg: &Config) -> Result<Self> {
let head_dim = cfg.head_dim();
let inv_freq: Vec<_> = (0..head_dim)
.step_by(2)
.map(|i| 1f32 / 10000f32.powf(i as f32 / head_dim as f32))
.collect();
Ok(Self {
inv_freq: Tensor::new(inv_freq.as_slice(), device)?,
cache: None,
})
}
fn cos_sin(
&mut self,
seq_len: usize,
device: &Device,
dtype: DType,
) -> Result<(Tensor, Tensor)> {
match &self.cache {
Some((s, cos, sin)) if *s == seq_len => {
return Ok((cos.clone(), sin.clone()));
}
_ => {}
}
let t = Tensor::arange(0, seq_len as u32, device)?.to_dtype(dtype)?;
let inv_freq = self.inv_freq.to_dtype(dtype)?;
let freqs = t.unsqueeze(1)?.matmul(&inv_freq.unsqueeze(0)?)?;
let emb = Tensor::cat(&[&freqs, &freqs], D::Minus1)?;
let cos = emb.cos()?;
let sin = emb.sin()?;
self.cache = Some((seq_len, cos.clone(), sin.clone()));
Ok((cos, sin))
}
fn forward(
&mut self,
query: &Tensor,
key: &Tensor,
past_kv_len: usize,
) -> Result<(Tensor, Tensor)> {
let (_batch, seq_len, _head_dim) = query.dims3()?;
let (cos, sin) = self.cos_sin(MAX_SEQ_LEN, query.device(), query.dtype())?;
let cos = cos.narrow(0, past_kv_len, seq_len)?;
let sin = sin.narrow(0, past_kv_len, seq_len)?;
let qs = (query.broadcast_mul(&cos)? + &rotate_half(query)?.broadcast_mul(&sin)?)?;
let ks = (key.broadcast_mul(&cos)? + &rotate_half(key)?.broadcast_mul(&sin)?)?;
Ok((qs, ks))
}
}
fn masked_fill(on_false: &Tensor, mask: &Tensor, on_true: f32) -> Result<Tensor> {
let shape = mask.shape();
let on_true = Tensor::new(on_true, on_false.device())?
.to_dtype(on_false.dtype())?
.broadcast_as(shape.dims())?;
let m = mask.where_cond(&on_true, on_false)?;
Ok(m)
}
#[derive(Debug, Clone)]
struct FalconAttention {
query_key_value: Linear,
dense: Linear,
maybe_rotary: Option<FalconRotaryEmbedding>,
kv_cache: Option<(Tensor, Tensor)>,
inv_norm_factor: f64,
multi_query: bool,
use_cache: bool,
num_heads: usize,
head_dim: usize,
n_head_kv: usize,
}
impl FalconAttention {
fn load(vb: VarBuilder, cfg: &Config) -> Result<Self> {
let maybe_rotary = if cfg.rotary() {
let rotary = FalconRotaryEmbedding::load(vb.device(), cfg)?;
Some(rotary)
} else {
None
};
let head_dim = cfg.head_dim();
let hidden_size = cfg.hidden_size;
let qkv_out_dim = if cfg.multi_query {
hidden_size + 2 * head_dim
} else {
3 * hidden_size
};
let query_key_value = linear(hidden_size, qkv_out_dim, cfg.bias, vb.pp("query_key_value"))?;
let dense = linear(hidden_size, hidden_size, cfg.bias, vb.pp("dense"))?;
Ok(Self {
query_key_value,
dense,
maybe_rotary,
kv_cache: None,
inv_norm_factor: 1. / (head_dim as f64).sqrt(),
multi_query: cfg.multi_query,
use_cache: cfg.use_cache,
num_heads: cfg.num_attention_heads,
n_head_kv: cfg.n_head_kv.unwrap_or(1),
head_dim,
})
}
fn split_heads(&self, fused_qkv: &Tensor) -> Result<(Tensor, Tensor, Tensor)> {
let (b_sz, seq_len, _) = fused_qkv.dims3()?;
if !self.multi_query {
let fused_qkv = fused_qkv.reshape((b_sz, seq_len, self.num_heads, 3, self.head_dim))?;
let q = fused_qkv.narrow(D::Minus2, 0, 1)?.squeeze(D::Minus2)?;
let k = fused_qkv.narrow(D::Minus2, 1, 1)?.squeeze(D::Minus2)?;
let v = fused_qkv.narrow(D::Minus2, 2, 1)?.squeeze(D::Minus2)?;
Ok((q, k, v))
} else {
let fused_qkv =
fused_qkv.reshape((b_sz, seq_len, self.num_heads + 2, self.head_dim))?;
let d = fused_qkv.dim(D::Minus2)?;
let q = fused_qkv.narrow(D::Minus2, 0, d - 2)?;
let k = fused_qkv.narrow(D::Minus2, d - 2, 1)?;
let v = fused_qkv.narrow(D::Minus2, d - 1, 1)?;
Ok((q, k, v))
}
}
fn forward(&mut self, x: &Tensor, mask: Option<&Tensor>, past_kv_len: usize) -> Result<Tensor> {
let fused_qkv = self.query_key_value.forward(x)?;
let head_dim = self.head_dim;
let (query, key, value) = self.split_heads(&fused_qkv)?;
let (b_sz, seq_len, _, _) = query.dims4()?;
let query = query
.transpose(1, 2)?
.reshape((b_sz * self.num_heads, seq_len, head_dim))?;
let key = key
.transpose(1, 2)?
.reshape((b_sz * self.n_head_kv, seq_len, head_dim))?;
let value = value
.transpose(1, 2)?
.reshape((b_sz * self.n_head_kv, seq_len, head_dim))?;
let (query, key) = if let Some(r) = &mut self.maybe_rotary {
r.forward(&query, &key, past_kv_len)?
} else {
(query, key)
};
let (mut key, mut value) = (key, value);
if self.use_cache {
if let Some((cache_k, cache_v)) = &self.kv_cache {
// TODO: we could trim the tensors to MAX_SEQ_LEN so that this would work for
// arbitrarily large sizes.
key = Tensor::cat(&[cache_k, &key], 1)?.contiguous()?;
value = Tensor::cat(&[cache_v, &value], 1)?.contiguous()?;
}
self.kv_cache = Some((key.clone(), value.clone()))
}
let query = query.reshape((b_sz * self.num_heads, seq_len, head_dim))?;
let all_len = past_kv_len + seq_len;
let key = key.reshape((b_sz * self.n_head_kv, all_len, head_dim))?;
let value = value.reshape((b_sz * self.n_head_kv, all_len, head_dim))?;
let (key, value) = if self.n_head_kv == 1 {
(
key.broadcast_as((b_sz * self.num_heads, all_len, head_dim))?,
value.broadcast_as((b_sz * self.num_heads, all_len, head_dim))?,
)
} else {
(key, value)
};
// Only handle the case where alibi is None here, and non-flash attention.
let attention_scores = (query.matmul(&key.t()?)? * self.inv_norm_factor)?;
let attention_scores = match mask {
None => attention_scores,
Some(mask) => {
let mask = masked_fill(&mask.to_dtype(DType::F32)?, mask, -1e9)?
.to_dtype(query.dtype())?;
attention_scores.broadcast_add(&mask.squeeze(1)?)?
}
};
let attention_scores =
candle_nn::ops::softmax(&attention_scores.to_dtype(DType::F32)?, D::Minus1)?
.to_dtype(x.dtype())?;
let attn_output = attention_scores
.matmul(&value)?
.reshape((b_sz, self.num_heads, seq_len, head_dim))?
.transpose(1, 2)?
.reshape((b_sz, seq_len, self.num_heads * head_dim))?;
let attn_output = self.dense.forward(&attn_output)?;
Ok(attn_output)
}
fn clear_kv_cache(&mut self) {
self.kv_cache = None
}
}
#[derive(Debug, Clone)]
struct FalconMlp {
dense_h_to_4h: Linear,
dense_4h_to_h: Linear,
}
impl FalconMlp {
fn load(vb: VarBuilder, cfg: &Config) -> Result<Self> {
let h = cfg.hidden_size;
let b = cfg.bias;
let dense_h_to_4h = linear(h, 4 * h, b, vb.pp("dense_h_to_4h"))?;
let dense_4h_to_h = linear(4 * h, h, b, vb.pp("dense_4h_to_h"))?;
Ok(Self {
dense_h_to_4h,
dense_4h_to_h,
})
}
fn forward(&self, x: &Tensor) -> Result<Tensor> {
let x = self.dense_h_to_4h.forward(x)?.gelu()?;
let x = self.dense_4h_to_h.forward(&x)?;
Ok(x)
}
}
#[derive(Debug, Clone)]
struct FalconDecoderLayer {
inp_layernorm: LayerNorm,
self_attention: FalconAttention,
post_attention_layernorm: Option<LayerNorm>,
mlp: FalconMlp,
parallel_attn: bool,
}
impl FalconDecoderLayer {
fn load(vb: VarBuilder, cfg: &Config) -> Result<Self> {
let mlp = FalconMlp::load(vb.pp("mlp"), cfg)?;
let inp_layernorm = layer_norm(
cfg.hidden_size,
cfg.layer_norm_epsilon,
vb.pp("input_layernorm"),
)?;
let self_attention = FalconAttention::load(vb.pp("self_attention"), cfg)?;
let post_attention_layernorm = if cfg.parallel_attn {
None
} else {
let ln = layer_norm(
cfg.hidden_size,
cfg.layer_norm_epsilon,
vb.pp("post_attention_layernorm"),
)?;
Some(ln)
};
Ok(Self {
inp_layernorm,
self_attention,
post_attention_layernorm,
mlp,
parallel_attn: cfg.parallel_attn,
})
}
fn forward(&mut self, x: &Tensor, mask: Option<&Tensor>, past_kv_len: usize) -> Result<Tensor> {
let residual = x.clone();
let ln_attn = self.inp_layernorm.forward(x)?;
let attn_output = self.self_attention.forward(&ln_attn, mask, past_kv_len)?;
let (residual, ln_mlp) = match &self.post_attention_layernorm {
None => (residual, ln_attn),
Some(pal) => {
// This should include some dropout.
let residual = (&attn_output + &residual)?;
let ln_mlp = pal.forward(&residual)?;
(residual, ln_mlp)
}
};
let mlp_output = self.mlp.forward(&ln_mlp)?;
let mlp_output = if self.parallel_attn {
(mlp_output + attn_output)?
} else {
mlp_output
};
let output = (mlp_output + residual)?;
Ok(output)
}
pub fn clear_kv_cache(&mut self) {
self.self_attention.clear_kv_cache()
}
}
#[derive(Debug, Clone)]
pub struct Falcon {
word_embeddings: Embedding,
blocks: Vec<FalconDecoderLayer>,
ln_f: LayerNorm,
lm_head: Linear,
config: Config,
}
fn make_causal_mask(t: usize) -> Result<Tensor> {
let mask: Vec<_> = (0..t)
.flat_map(|i| (0..t).map(move |j| u8::from(j > i)))
.collect();
let mask = Tensor::from_slice(&mask, (t, t), &Device::Cpu)?;
Ok(mask)
}
fn prepare_attn_mask(b_sz: usize, seq_len: usize) -> Result<Tensor> {
// let mask = Tensor::ones((b_sz, seq_len), DType::U32, &Device::Cpu)?;
let mask = make_causal_mask(seq_len)?;
let mask = mask.broadcast_as((b_sz, 1, seq_len, seq_len))?;
Ok(mask)
}
impl Falcon {
pub fn config(&self) -> &Config {
&self.config
}
pub fn load(vb: VarBuilder, cfg: Config) -> Result<Self> {
let word_embeddings = embedding(
cfg.vocab_size,
cfg.hidden_size,
vb.pp("transformer.word_embeddings"),
)?;
let blocks = (0..cfg.num_hidden_layers)
.map(|i| FalconDecoderLayer::load(vb.pp(format!("transformer.h.{i}")), &cfg))
.collect::<Result<Vec<_>>>()?;
let ln_f = layer_norm(
cfg.hidden_size,
cfg.layer_norm_epsilon,
vb.pp("transformer.ln_f"),
)?;
let lm_head = linear(cfg.hidden_size, cfg.vocab_size, false, vb.pp("lm_head"))?;
Ok(Self {
word_embeddings,
blocks,
ln_f,
lm_head,
config: cfg,
})
}
pub fn forward(&mut self, input_ids: &Tensor) -> Result<Tensor> {
let (b_sz, seq_len) = input_ids.dims2()?;
let mut hidden_state = self.word_embeddings.forward(input_ids)?;
let past_kv_len = match &self.blocks[0].self_attention.kv_cache {
Some((k, _)) => k.dim(1)?,
None => 0,
};
let causal_mask = if seq_len <= 1 {
None
} else {
Some(prepare_attn_mask(b_sz, seq_len)?.to_device(input_ids.device())?)
};
for block in self.blocks.iter_mut() {
hidden_state = block.forward(&hidden_state, causal_mask.as_ref(), past_kv_len)?;
}
let hidden_state = self.ln_f.forward(&hidden_state)?;
let hidden_state = hidden_state.narrow(1, seq_len - 1, 1)?;
let logits = self.lm_head.forward(&hidden_state)?.squeeze(1)?;
Ok(logits)
}
pub fn clear_kv_cache(&mut self) {
for block in self.blocks.iter_mut() {
block.clear_kv_cache()
}
}
}
| 0 |
0 | hf_public_repos/candle/candle-transformers/src | hf_public_repos/candle/candle-transformers/src/models/dinov2.rs | //! Implementation of the DINOv2 models from Meta Research.
//!
//! This module implements the DINOv2 vision transformer model from Meta AI Research.
//! DINOv2 is a self-supervised learning model that can learn visual features
//! without using any labeled data. See: ["DINOv2: Learning Robust Visual Features without Supervision"](https://github.com/facebookresearch/dinov2)
//!
//! ## Running an example with color map and CUDA
//!
//! ```bash
//! cargo run \
//! --features cuda,depth_anything_v2 \
//! --package candle-examples \
//! --example depth_anything_v2 \
//! -- --color-map \
//! --image candle-examples/examples/yolo-v8/assets/bike.jpg
//! ```
//!
//! ## Running as an ImageNet classifier
//!
//! The model returns the probability for the image to belong to each of the 1000 ImageNet categories.
//!
//! <div align=center>
//! <img src="https://github.com/huggingface/candle/raw/main/candle-examples/examples/yolo-v8/assets/bike.jpg" alt="" width=640>
//! </div>
//!
//! ```bash
//! cargo run \
//! --example dinov2 \
//! --release \
//! -- --image candle-examples/examples/yolo-v8/assets/bike.jpg
//!
//! > mountain bike, all-terrain bike, off-roader: 43.67%
//! > bicycle-built-for-two, tandem bicycle, tandem: 33.20%
//! > crash helmet : 13.23%
//! > unicycle, monocycle : 2.44%
//! > maillot : 2.42%
//! ```
//!
use candle::{IndexOp, Result, Tensor, D};
use candle_nn::{layer_norm, LayerNorm, Linear, Module, VarBuilder};
const IMG_SIZE: usize = 518;
const PATCH_SIZE: usize = 14;
const NUM_CLASSES: usize = 1000;
fn linear(vb: VarBuilder, in_dim: usize, out_dim: usize, bias: bool) -> Result<Linear> {
if bias {
candle_nn::linear(in_dim, out_dim, vb)
} else {
candle_nn::linear_no_bias(in_dim, out_dim, vb)
}
}
#[derive(Debug)]
struct Attention {
qkv: Linear,
proj: Linear,
num_heads: usize,
scale: f64,
}
impl Attention {
fn new(
vb: VarBuilder,
dim: usize,
num_heads: usize,
qkv_bias: bool,
proj_bias: bool,
) -> Result<Self> {
let qkv = linear(vb.pp("qkv"), dim, dim * 3, qkv_bias)?;
let proj = linear(vb.pp("proj"), dim, dim, proj_bias)?;
let scale = 1. / ((dim / num_heads) as f64).sqrt();
Ok(Self {
qkv,
proj,
num_heads,
scale,
})
}
}
impl Module for Attention {
fn forward(&self, xs: &Tensor) -> Result<Tensor> {
let (b, n, c) = xs.dims3()?;
let qkv = self
.qkv
.forward(xs)?
.reshape((b, n, 3, self.num_heads, c / self.num_heads))?
.transpose(1, 2)? // 02134
.transpose(0, 1)? // 20134
.transpose(2, 3)?; // 20314
let q = (qkv.i(0)? * self.scale)?;
let k = qkv.i(1)?.contiguous()?;
let v = qkv.i(2)?.contiguous()?;
let attn = candle_nn::ops::softmax(&q.matmul(&k.t()?)?, D::Minus1)?;
let attn = attn.matmul(&v)?.transpose(1, 2)?.reshape((b, n, c))?;
self.proj.forward(&attn)
}
}
#[derive(Debug)]
struct LayerScale {
gamma: Tensor,
}
impl LayerScale {
fn new(vb: VarBuilder, dim: usize) -> Result<Self> {
let gamma = vb.get(dim, "gamma")?;
Ok(Self { gamma })
}
}
impl Module for LayerScale {
fn forward(&self, xs: &Tensor) -> Result<Tensor> {
xs.broadcast_mul(&self.gamma)
}
}
#[derive(Debug)]
struct Mlp {
fc1: Linear,
fc2: Linear,
}
impl Mlp {
fn new(vb: VarBuilder, in_features: usize, hidden_features: usize, bias: bool) -> Result<Self> {
let out_features = in_features;
let fc1 = linear(vb.pp("fc1"), in_features, hidden_features, bias)?;
let fc2 = linear(vb.pp("fc2"), hidden_features, out_features, bias)?;
Ok(Self { fc1, fc2 })
}
}
impl Module for Mlp {
fn forward(&self, xs: &Tensor) -> Result<Tensor> {
let xs = self.fc1.forward(xs)?.gelu()?;
self.fc2.forward(&xs)
}
}
#[derive(Debug)]
struct Block {
norm1: LayerNorm,
attn: Attention,
ls1: LayerScale,
norm2: LayerNorm,
mlp: Mlp,
ls2: LayerScale,
}
impl Block {
fn new(vb: VarBuilder, dim: usize, num_heads: usize) -> Result<Self> {
let norm1 = layer_norm(dim, 1e-5, vb.pp("norm1"))?;
let attn = Attention::new(vb.pp("attn"), dim, num_heads, true, true)?;
let ls1 = LayerScale::new(vb.pp("ls1"), dim)?;
let norm2 = layer_norm(dim, 1e-5, vb.pp("norm2"))?;
let mlp = Mlp::new(vb.pp("mlp"), dim, dim * 4, true)?;
let ls2 = LayerScale::new(vb.pp("ls2"), dim)?;
Ok(Self {
norm1,
attn,
ls1,
norm2,
mlp,
ls2,
})
}
}
impl Module for Block {
fn forward(&self, xs: &Tensor) -> Result<Tensor> {
let residual = xs;
let xs = self
.ls1
.forward(&self.attn.forward(&self.norm1.forward(xs)?)?)?;
let xs = (xs + residual)?;
let residual = &xs;
let xs = self
.ls2
.forward(&self.mlp.forward(&self.norm2.forward(&xs)?)?)?;
xs + residual
}
}
#[derive(Debug)]
struct PatchEmbed {
proj: candle_nn::Conv2d,
patch_size: (usize, usize),
num_patches: usize,
}
impl PatchEmbed {
fn new(
vb: VarBuilder,
img_size: usize,
patch_size: usize,
in_chans: usize,
embed_dim: usize,
) -> Result<Self> {
let config = candle_nn::Conv2dConfig {
stride: patch_size,
..Default::default()
};
let proj = candle_nn::conv2d(in_chans, embed_dim, patch_size, config, vb.pp("proj"))?;
let num_patches = (img_size / patch_size) * (img_size / patch_size);
Ok(Self {
proj,
patch_size: (patch_size, patch_size),
num_patches,
})
}
}
impl Module for PatchEmbed {
fn forward(&self, xs: &Tensor) -> Result<Tensor> {
let (_b, _c, h, w) = xs.dims4()?;
let (patch_h, patch_w) = self.patch_size;
if (h % patch_h) != 0 {
candle::bail!("image height {h} is not a multiple of patch height {patch_h}")
}
if (w % patch_w) != 0 {
candle::bail!("image width {w} is not a multiple of patch width {patch_w}")
}
let xs = self.proj.forward(xs)?;
let (b, c, h, w) = xs.dims4()?;
// flatten embeddings.
xs.reshape((b, c, h * w))?.transpose(1, 2)
}
}
#[derive(Debug)]
pub struct DinoVisionTransformer {
patch_embed: PatchEmbed,
cls_token: Tensor,
pos_embed: Tensor,
blocks: Vec<Block>,
norm: LayerNorm,
head: Linear,
}
impl DinoVisionTransformer {
pub fn new(vb: VarBuilder, depth: usize, embed_dim: usize, num_heads: usize) -> Result<Self> {
let patch_embed =
PatchEmbed::new(vb.pp("patch_embed"), IMG_SIZE, PATCH_SIZE, 3, embed_dim)?;
let cls_token = vb.get((1, 1, embed_dim), "cls_token")?;
let num_tokens = 1;
let pos_embed = vb.get(
(1, patch_embed.num_patches + num_tokens, embed_dim),
"pos_embed",
)?;
let head = linear(vb.pp("head"), 2 * embed_dim, NUM_CLASSES, true)?;
let norm = layer_norm(embed_dim, 1e-5, vb.pp("norm"))?;
let vb_b = vb.pp("blocks");
let blocks = (0..depth)
.map(|i| Block::new(vb_b.pp(i.to_string()), embed_dim, num_heads))
.collect::<Result<Vec<_>>>()?;
Ok(Self {
patch_embed,
cls_token,
pos_embed,
blocks,
norm,
head,
})
}
fn interpolate_pos_encoding(&self, xs: &Tensor, w: usize, h: usize) -> Result<Tensor> {
let npatch = xs.dim(1)? - 1;
let n = self.pos_embed.dim(1)? - 1;
let sqrt_n = (n as f64).sqrt();
if npatch == n && w == h {
return Ok(xs.clone());
}
let class_pos_embed = self.pos_embed.i((.., ..1))?;
let patch_pos_embed = self.pos_embed.i((.., 1..))?;
let dim = xs.dim(D::Minus1)?;
let (w0, h0) = ((w / PATCH_SIZE) as f64 + 0.1, (h / PATCH_SIZE) as f64 + 0.1);
let patch_pos_embed = patch_pos_embed
.reshape((1, sqrt_n as usize, sqrt_n as usize, dim))?
.transpose(2, 3)?
.transpose(1, 2)?;
// This uses bicubic interpolation in the original implementation.
let patch_pos_embed = patch_pos_embed.upsample_nearest2d(h0 as usize, w0 as usize)?;
let el_count = patch_pos_embed.shape().elem_count();
let patch_pos_embed =
patch_pos_embed
.transpose(1, 2)?
.transpose(2, 3)?
.reshape((1, el_count / dim, dim))?;
Tensor::cat(&[&class_pos_embed, &patch_pos_embed], 1)
}
fn prepare_tokens_with_mask(&self, xs: &Tensor) -> Result<Tensor> {
let (_b, _nc, w, h) = xs.dims4()?;
let xs = self.patch_embed.forward(xs)?;
let xs = Tensor::cat(&[&self.cls_token, &xs], 1)?;
&xs + &self.interpolate_pos_encoding(&xs, w, h)?
}
fn get_intermediate_layers_not_chunked(
&self,
xs: &Tensor,
blocks_to_take: &[usize],
) -> Result<Vec<Tensor>> {
let mut xs = self.prepare_tokens_with_mask(xs)?;
let mut output = Vec::new();
for (i, blk) in self.blocks.iter().enumerate() {
xs = blk.forward(&xs)?;
if blocks_to_take.contains(&i) {
output.push(xs.clone());
}
}
if output.len() != blocks_to_take.len() {
candle::bail!(
"only {} / {} blocks found",
output.len(),
blocks_to_take.len()
);
}
Ok(output)
}
pub fn get_intermediate_layers(
&self,
xs: &Tensor,
blocks_to_take: &[usize],
reshape: bool,
return_class_token: bool,
norm: bool,
) -> Result<Tensor> {
let outputs = self.get_intermediate_layers_not_chunked(xs, blocks_to_take)?;
let outputs = if norm {
outputs
.iter()
.map(|out| self.norm.forward(out))
.collect::<Result<Vec<_>>>()?
} else {
outputs
};
let class_tokens = outputs
.iter()
.map(|out| out.i((.., 0)))
.collect::<Result<Vec<_>>>()?;
let outputs = outputs
.iter()
.map(|out| out.i((.., 1..)))
.collect::<Result<Vec<_>>>()?;
let outputs = if reshape {
let (b, _c, w, h) = xs.dims4()?;
let patch_size = self.patch_embed.patch_size.0;
let num_channels = outputs[0].elem_count() / (b * (w / patch_size) * (h / patch_size));
outputs
.iter()
.map(|out| {
out.reshape((b, w / patch_size, h / patch_size, num_channels))?
.transpose(2, 3)?
.transpose(1, 2)
})
.collect::<Result<Vec<_>>>()?
} else {
outputs
};
let outputs = if return_class_token {
outputs
.iter()
.zip(class_tokens.iter())
.map(|(out, class_token)| Tensor::cat(&[out, class_token], D::Minus1))
.collect::<Result<Vec<_>>>()?
} else {
outputs
};
Tensor::stack(&outputs[..], 0)
}
}
impl Module for DinoVisionTransformer {
fn forward(&self, xs: &Tensor) -> Result<Tensor> {
let mut xs = self.prepare_tokens_with_mask(xs)?;
for blk in self.blocks.iter() {
xs = blk.forward(&xs)?
}
let xs = self.norm.forward(&xs)?;
let xs_norm_clstoken = xs.i((.., 0))?;
let xs_norm_patchtokens = xs.i((.., 1..))?.mean(1)?;
let xs = Tensor::cat(&[xs_norm_clstoken, xs_norm_patchtokens], D::Minus1)?;
self.head.forward(&xs)
}
}
pub fn vit_small(vb: VarBuilder) -> Result<DinoVisionTransformer> {
DinoVisionTransformer::new(vb, 12, 384, 6)
}
| 1 |
0 | hf_public_repos/candle/candle-transformers/src | hf_public_repos/candle/candle-transformers/src/models/starcoder2.rs | //! StarCoder model implementation with quantization support.
//!
//! StarCoder is a large language model optimized for code generation.
//! This implementation provides quantization for reduced memory and compute.
//!
//! Key characteristics:
//! - Causal self-attention mechanism
//! - Multi-query attention (MQA)
//! - LayerNorm for normalization
//! - Absolute positional embeddings
//! - Support for 8-bit quantization
//!
//! References:
//! - 📝 [StarCoder Paper](https://arxiv.org/abs/2305.06161)
//! - 🤗 [Model Card](https://huggingface.co/bigcode/starcoder)
//!
use candle::{DType, Device, Module, Result, Tensor, D};
use candle_nn::{layer_norm, linear_b, LayerNorm, Linear, VarBuilder};
use std::sync::Arc;
#[derive(Debug, Clone, serde::Deserialize)]
pub struct Config {
vocab_size: usize,
hidden_size: usize,
intermediate_size: usize,
num_hidden_layers: usize,
num_attention_heads: usize,
num_key_value_heads: usize,
hidden_act: candle_nn::Activation,
max_position_embeddings: usize,
norm_epsilon: f64,
rope_theta: f64,
use_bias: bool,
sliding_window: Option<usize>,
}
#[derive(Debug, Clone)]
struct RotaryEmbedding {
sin: Tensor,
cos: Tensor,
}
fn rotate_half(xs: &Tensor) -> Result<Tensor> {
let last_dim = xs.dim(D::Minus1)?;
let xs1 = xs.narrow(D::Minus1, 0, last_dim / 2)?;
let xs2 = xs.narrow(D::Minus1, last_dim / 2, last_dim - last_dim / 2)?;
Tensor::cat(&[&xs2.neg()?, &xs1], D::Minus1)
}
impl RotaryEmbedding {
fn new(dtype: DType, cfg: &Config, dev: &Device) -> Result<Self> {
let dim = cfg.hidden_size / cfg.num_attention_heads;
let max_seq_len = cfg.max_position_embeddings;
let inv_freq: Vec<_> = (0..dim)
.step_by(2)
.map(|i| 1f32 / cfg.rope_theta.powf(i as f64 / dim as f64) as f32)
.collect();
let inv_freq_len = inv_freq.len();
let inv_freq = Tensor::from_vec(inv_freq, (1, inv_freq_len), dev)?.to_dtype(dtype)?;
let t = Tensor::arange(0u32, max_seq_len as u32, dev)?
.to_dtype(dtype)?
.reshape((max_seq_len, 1))?;
let freqs = t.matmul(&inv_freq)?;
let freqs = Tensor::cat(&[&freqs, &freqs], D::Minus1)?;
Ok(Self {
sin: freqs.sin()?,
cos: freqs.cos()?,
})
}
fn apply_rotary_emb_qkv(
&self,
q: &Tensor,
k: &Tensor,
seqlen_offset: usize,
) -> Result<(Tensor, Tensor)> {
let (_b_sz, _h, seq_len, _n_embd) = q.dims4()?;
let cos = self.cos.narrow(0, seqlen_offset, seq_len)?;
let sin = self.sin.narrow(0, seqlen_offset, seq_len)?;
let cos = cos.unsqueeze(0)?.unsqueeze(0)?; // (1, 1, seq_len, dim)
let sin = sin.unsqueeze(0)?.unsqueeze(0)?; // (1, 1, seq_len, dim)
let q_embed = (q.broadcast_mul(&cos)? + rotate_half(q)?.broadcast_mul(&sin))?;
let k_embed = (k.broadcast_mul(&cos)? + rotate_half(k)?.broadcast_mul(&sin))?;
Ok((q_embed, k_embed))
}
}
#[derive(Debug, Clone)]
#[allow(clippy::upper_case_acronyms)]
struct MLP {
c_fc: Linear,
c_proj: Linear,
act: candle_nn::Activation,
}
impl MLP {
fn new(cfg: &Config, vb: VarBuilder) -> Result<Self> {
let (h_size, i_size) = (cfg.hidden_size, cfg.intermediate_size);
let c_fc = linear_b(h_size, i_size, cfg.use_bias, vb.pp("c_fc"))?;
let c_proj = linear_b(i_size, h_size, cfg.use_bias, vb.pp("c_proj"))?;
Ok(Self {
c_fc,
c_proj,
act: cfg.hidden_act,
})
}
}
impl Module for MLP {
fn forward(&self, xs: &Tensor) -> Result<Tensor> {
xs.apply(&self.c_fc)?.apply(&self.act)?.apply(&self.c_proj)
}
}
#[derive(Debug, Clone)]
struct Attention {
q_proj: Linear,
k_proj: Linear,
v_proj: Linear,
o_proj: Linear,
num_heads: usize,
num_kv_heads: usize,
num_kv_groups: usize,
head_dim: usize,
hidden_size: usize,
rotary_emb: Arc<RotaryEmbedding>,
kv_cache: Option<(Tensor, Tensor)>,
}
impl Attention {
fn new(rotary_emb: Arc<RotaryEmbedding>, cfg: &Config, vb: VarBuilder) -> Result<Self> {
let hidden_sz = cfg.hidden_size;
let num_heads = cfg.num_attention_heads;
let num_kv_heads = cfg.num_key_value_heads;
let num_kv_groups = num_heads / num_kv_heads;
let head_dim = hidden_sz / num_heads;
let b = cfg.use_bias;
let q_proj = linear_b(hidden_sz, num_heads * head_dim, b, vb.pp("q_proj"))?;
let k_proj = linear_b(hidden_sz, num_kv_heads * head_dim, b, vb.pp("k_proj"))?;
let v_proj = linear_b(hidden_sz, num_kv_heads * head_dim, b, vb.pp("v_proj"))?;
let o_proj = linear_b(num_heads * head_dim, hidden_sz, b, vb.pp("o_proj"))?;
Ok(Self {
q_proj,
k_proj,
v_proj,
o_proj,
num_heads,
num_kv_heads,
num_kv_groups,
head_dim,
hidden_size: hidden_sz,
rotary_emb,
kv_cache: None,
})
}
fn forward(
&mut self,
xs: &Tensor,
attention_mask: Option<&Tensor>,
seqlen_offset: usize,
) -> Result<Tensor> {
let (b_sz, q_len, _) = xs.dims3()?;
let query_states = self.q_proj.forward(xs)?;
let key_states = self.k_proj.forward(xs)?;
let value_states = self.v_proj.forward(xs)?;
let query_states = query_states
.reshape((b_sz, q_len, self.num_heads, self.head_dim))?
.transpose(1, 2)?;
let key_states = key_states
.reshape((b_sz, q_len, self.num_kv_heads, self.head_dim))?
.transpose(1, 2)?;
let value_states = value_states
.reshape((b_sz, q_len, self.num_kv_heads, self.head_dim))?
.transpose(1, 2)?;
let (query_states, key_states) =
self.rotary_emb
.apply_rotary_emb_qkv(&query_states, &key_states, seqlen_offset)?;
let (key_states, value_states) = match &self.kv_cache {
None => (key_states, value_states),
Some((prev_k, prev_v)) => {
let key_states = Tensor::cat(&[prev_k, &key_states], 2)?;
let value_states = Tensor::cat(&[prev_v, &value_states], 2)?;
(key_states, value_states)
}
};
self.kv_cache = Some((key_states.clone(), value_states.clone()));
let key_states = crate::utils::repeat_kv(key_states, self.num_kv_groups)?;
let value_states = crate::utils::repeat_kv(value_states, self.num_kv_groups)?;
let scale = 1f64 / f64::sqrt(self.head_dim as f64);
let attn_weights = (query_states.matmul(&key_states.transpose(2, 3)?)? * scale)?;
let attn_weights = match attention_mask {
None => attn_weights,
Some(mask) => attn_weights.broadcast_add(mask)?,
};
let attn_weights = candle_nn::ops::softmax_last_dim(&attn_weights)?;
let attn_output = attn_weights.matmul(&value_states)?;
attn_output
.transpose(1, 2)?
.reshape((b_sz, q_len, self.hidden_size))?
.apply(&self.o_proj)
}
fn clear_kv_cache(&mut self) {
self.kv_cache = None
}
}
#[derive(Debug, Clone)]
struct DecoderLayer {
self_attn: Attention,
mlp: MLP,
input_layernorm: LayerNorm,
post_attention_layernorm: LayerNorm,
}
impl DecoderLayer {
fn new(rotary_emb: Arc<RotaryEmbedding>, cfg: &Config, vb: VarBuilder) -> Result<Self> {
let self_attn = Attention::new(rotary_emb, cfg, vb.pp("self_attn"))?;
let mlp = MLP::new(cfg, vb.pp("mlp"))?;
let input_layernorm =
layer_norm(cfg.hidden_size, cfg.norm_epsilon, vb.pp("input_layernorm"))?;
let post_attention_layernorm = layer_norm(
cfg.hidden_size,
cfg.norm_epsilon,
vb.pp("post_attention_layernorm"),
)?;
Ok(Self {
self_attn,
mlp,
input_layernorm,
post_attention_layernorm,
})
}
fn forward(
&mut self,
xs: &Tensor,
attention_mask: Option<&Tensor>,
seqlen_offset: usize,
) -> Result<Tensor> {
let residual = xs;
let xs = self.input_layernorm.forward(xs)?;
let xs = self.self_attn.forward(&xs, attention_mask, seqlen_offset)?;
let xs = (xs + residual)?;
let residual = &xs;
let xs = xs.apply(&self.post_attention_layernorm)?.apply(&self.mlp)?;
residual + xs
}
fn clear_kv_cache(&mut self) {
self.self_attn.clear_kv_cache()
}
}
#[derive(Debug, Clone)]
pub struct Model {
embed_tokens: candle_nn::Embedding,
layers: Vec<DecoderLayer>,
norm: LayerNorm,
lm_head: Linear,
sliding_window: Option<usize>,
device: Device,
dtype: DType,
}
impl Model {
pub fn new(cfg: &Config, vb: VarBuilder) -> Result<Self> {
let vb_m = vb.pp("model");
let embed_tokens =
candle_nn::embedding(cfg.vocab_size, cfg.hidden_size, vb_m.pp("embed_tokens"))?;
let rotary_emb = Arc::new(RotaryEmbedding::new(vb.dtype(), cfg, vb_m.device())?);
let mut layers = Vec::with_capacity(cfg.num_hidden_layers);
let vb_l = vb_m.pp("layers");
for layer_idx in 0..cfg.num_hidden_layers {
let layer = DecoderLayer::new(rotary_emb.clone(), cfg, vb_l.pp(layer_idx))?;
layers.push(layer)
}
let norm = layer_norm(cfg.hidden_size, cfg.norm_epsilon, vb_m.pp("norm"))?;
let lm_head = candle_nn::Linear::new(embed_tokens.embeddings().clone(), None);
Ok(Self {
embed_tokens,
layers,
norm,
lm_head,
sliding_window: cfg.sliding_window,
device: vb.device().clone(),
dtype: vb.dtype(),
})
}
fn prepare_decoder_attention_mask(
&self,
b_size: usize,
tgt_len: usize,
seqlen_offset: usize,
) -> Result<Tensor> {
let sliding_window = self.sliding_window.unwrap_or(tgt_len + 42);
let mask: Vec<_> = (0..tgt_len)
.flat_map(|i| {
(0..tgt_len).map(move |j| {
if i < j || j + sliding_window < i {
f32::NEG_INFINITY
} else {
0.
}
})
})
.collect();
let mask = Tensor::from_slice(&mask, (tgt_len, tgt_len), &self.device)?;
let mask = if seqlen_offset > 0 {
let mask0 = Tensor::zeros((tgt_len, seqlen_offset), DType::F32, &self.device)?;
Tensor::cat(&[&mask0, &mask], D::Minus1)?
} else {
mask
};
mask.expand((b_size, 1, tgt_len, tgt_len + seqlen_offset))?
.to_dtype(self.dtype)
}
pub fn forward(&mut self, input_ids: &Tensor, seqlen_offset: usize) -> Result<Tensor> {
let (b_size, seq_len) = input_ids.dims2()?;
let attention_mask = if seq_len <= 1 {
None
} else {
let mask = self.prepare_decoder_attention_mask(b_size, seq_len, seqlen_offset)?;
Some(mask)
};
let mut xs = self.embed_tokens.forward(input_ids)?;
for layer in self.layers.iter_mut() {
xs = layer.forward(&xs, attention_mask.as_ref(), seqlen_offset)?
}
xs.narrow(1, seq_len - 1, 1)?
.apply(&self.norm)?
.apply(&self.lm_head)
}
pub fn clear_kv_cache(&mut self) {
for layer in self.layers.iter_mut() {
layer.clear_kv_cache()
}
}
}
| 2 |
0 | hf_public_repos/candle/candle-transformers/src | hf_public_repos/candle/candle-transformers/src/models/beit.rs | //! Based on the BEIT vision-language model.
//!
//! See "BEIT: BERT Pre-Training of Image Transformers", Bao et al. 2021
//! - [Arxiv](https://arxiv.org/abs/2106.08254)
//! - [Github](https://github.com/microsoft/unilm/tree/master/beit)
//!
use candle::{DType, Device, IndexOp, Result, Tensor, D};
use candle_nn::{layer_norm, LayerNorm, Linear, Module, VarBuilder};
const IMG_SIZE: usize = 384;
const PATCH_SIZE: usize = 16;
const NUM_CLASSES: usize = 1000;
const WINDOW_SIZE: usize = IMG_SIZE / PATCH_SIZE; // 384 / 16 = 24
const NB_TOKENS: usize = WINDOW_SIZE * WINDOW_SIZE + 1; // 24 * 24 + 1 = 577
fn linear(vb: VarBuilder, in_dim: usize, out_dim: usize, bias: bool) -> Result<Linear> {
if bias {
candle_nn::linear(in_dim, out_dim, vb)
} else {
candle_nn::linear_no_bias(in_dim, out_dim, vb)
}
}
#[derive(Debug)]
struct Attention {
qkv: Linear,
proj: Linear,
relative_position_bias_table: Tensor,
relative_position_index: Tensor,
num_heads: usize,
scale: f64,
}
impl Attention {
fn new(
vb: VarBuilder,
dim: usize,
num_heads: usize,
qkv_bias: bool,
proj_bias: bool,
) -> Result<Self> {
let qkv = linear(vb.pp("qkv"), dim, dim * 3, qkv_bias)?;
let proj = linear(vb.pp("proj"), dim, dim, proj_bias)?;
// num_relative_distance = token-token(47x47) + token-CLS(1) + CLS-token(1) + CLS-CLS(1) = 2212
let num_relative_distance = (2 * WINDOW_SIZE - 1) * (2 * WINDOW_SIZE - 1) + 3;
let relative_position_bias_table = vb.get(
(num_relative_distance, num_heads),
"relative_position_bias_table",
)?;
let relative_position_index =
Self::gen_relative_position_index(relative_position_bias_table.device())?;
let scale = 1. / ((dim / num_heads) as f64).sqrt();
Ok(Self {
qkv,
proj,
relative_position_bias_table,
relative_position_index,
num_heads,
scale,
})
}
}
impl Attention {
// See: https://github.com/huggingface/pytorch-image-models/blob/main/timm/models/beit.py#L61
fn gen_relative_position_index(device: &Device) -> Result<Tensor> {
let num_relative_distance = (2 * WINDOW_SIZE - 1) * (2 * WINDOW_SIZE - 1) + 3;
let w_area = WINDOW_SIZE * WINDOW_SIZE;
let t_arange: Tensor = Tensor::arange(0, WINDOW_SIZE as u32, device)?;
let t_ndgrid = Tensor::meshgrid(&[&t_arange, &t_arange], false)?;
let coords_flatten = Tensor::stack(&t_ndgrid, 0)?.flatten(1, 2)?;
let tmp1 = coords_flatten
.unsqueeze(2)?
.broadcast_as((2, w_area, w_area))?
.to_dtype(DType::I64)?;
let tmp2 = coords_flatten
.unsqueeze(1)?
.broadcast_as((2, w_area, w_area))?
.to_dtype(DType::I64)?;
let relative_coords = (tmp1 - tmp2)?
.transpose(0, 1)? // 102
.transpose(1, 2)? // 120
.contiguous()?;
let relative_coords = relative_coords.slice_assign(
&[0..w_area, 0..w_area, 0..1],
&(relative_coords.i((0..w_area, 0..w_area, 0..1))? + (WINDOW_SIZE - 1) as f64)?,
)?;
let relative_coords = relative_coords.slice_assign(
&[0..w_area, 0..w_area, 1..2],
&(relative_coords.i((0..w_area, 0..w_area, 1..2))? + (WINDOW_SIZE - 1) as f64)?,
)?;
let relative_coords = relative_coords.slice_assign(
&[0..w_area, 0..w_area, 0..1],
&(relative_coords.i((.., .., 0..1))? * (2. * (WINDOW_SIZE as f64) - 1.))?,
)?;
Tensor::zeros((w_area + 1, w_area + 1), DType::I64, device)?
.slice_assign(&[1.., 1..], &relative_coords.sum(2)?)?
.slice_assign(
&[0..1, 0..(w_area + 1)],
&(Tensor::ones((1, w_area + 1), DType::I64, device)?
* ((num_relative_distance - 3) as f64))?
.to_dtype(DType::I64)?,
)?
.slice_assign(
&[0..(w_area + 1), 0..1],
&(Tensor::ones((w_area + 1, 1), DType::I64, device)?
* ((num_relative_distance - 2) as f64))?
.to_dtype(DType::I64)?,
)?
.slice_assign(
&[0..1, 0..1],
&(Tensor::ones((1, 1), DType::I64, device)?
* ((num_relative_distance - 1) as f64))?
.to_dtype(DType::I64)?,
)
}
fn _get_rel_pos_bias(&self) -> Result<Tensor> {
self.relative_position_bias_table
.index_select(
&self
.relative_position_index
.flatten_all()?
.to_dtype(DType::U32)?,
0,
)?
.reshape((NB_TOKENS, NB_TOKENS, ()))?
.transpose(0, 1)? // 102
.transpose(0, 2)? // 201
.contiguous()?
.unsqueeze(0)
}
}
impl Module for Attention {
fn forward(&self, xs: &Tensor) -> Result<Tensor> {
let (b, n, c) = xs.dims3()?;
let qkv = self
.qkv
.forward(xs)?
.reshape((b, n, 3, self.num_heads, c / self.num_heads))?
.transpose(1, 2)? // 02134
.transpose(0, 1)? // 20134
.transpose(2, 3)?; // 20314
let q = (qkv.i(0)? * self.scale)?;
let k = qkv.i(1)?.contiguous()?;
let v = qkv.i(2)?.contiguous()?;
let attn = (&q.matmul(&k.t()?)? + self._get_rel_pos_bias())?;
let attn = candle_nn::ops::softmax(&attn, D::Minus1)?;
let attn = attn.matmul(&v)?.transpose(1, 2)?.reshape((b, n, c))?;
self.proj.forward(&attn)
}
}
#[derive(Debug)]
struct LayerScale {
gamma: Tensor,
}
impl LayerScale {
fn new(vb: VarBuilder, dim: usize) -> Result<Self> {
let gamma = vb.get(dim, "gamma")?;
Ok(Self { gamma })
}
}
impl Module for LayerScale {
fn forward(&self, xs: &Tensor) -> Result<Tensor> {
xs.broadcast_mul(&self.gamma)
}
}
#[derive(Debug)]
struct Mlp {
fc1: Linear,
fc2: Linear,
}
impl Mlp {
fn new(vb: VarBuilder, in_features: usize, hidden_features: usize, bias: bool) -> Result<Self> {
let out_features = in_features;
let fc1 = linear(vb.pp("fc1"), in_features, hidden_features, bias)?;
let fc2 = linear(vb.pp("fc2"), hidden_features, out_features, bias)?;
Ok(Self { fc1, fc2 })
}
}
impl Module for Mlp {
fn forward(&self, xs: &Tensor) -> Result<Tensor> {
let xs = self.fc1.forward(xs)?.gelu()?;
self.fc2.forward(&xs)
}
}
#[derive(Debug)]
struct Block {
norm1: LayerNorm,
attn: Attention,
ls1: LayerScale,
norm2: LayerNorm,
mlp: Mlp,
ls2: LayerScale,
}
impl Block {
fn new(vb: VarBuilder, dim: usize, num_heads: usize) -> Result<Self> {
let norm1 = layer_norm(dim, 1e-6, vb.pp("norm1"))?;
let attn = Attention::new(vb.pp("attn"), dim, num_heads, true, true)?;
let ls1 = LayerScale::new(vb.pp("ls1"), dim)?;
let norm2 = layer_norm(dim, 1e-6, vb.pp("norm2"))?;
let mlp = Mlp::new(vb.pp("mlp"), dim, dim * 4, true)?;
let ls2 = LayerScale::new(vb.pp("ls2"), dim)?;
Ok(Self {
norm1,
attn,
ls1,
norm2,
mlp,
ls2,
})
}
}
impl Module for Block {
fn forward(&self, xs: &Tensor) -> Result<Tensor> {
let residual = xs;
let xs = self
.ls1
.forward(&self.attn.forward(&self.norm1.forward(xs)?)?)?;
let xs = (xs + residual)?;
let residual = &xs;
let xs = self
.ls2
.forward(&self.mlp.forward(&self.norm2.forward(&xs)?)?)?;
xs + residual
}
}
#[derive(Debug)]
struct PatchEmbed {
proj: candle_nn::Conv2d,
patch_size: (usize, usize),
}
impl PatchEmbed {
fn new(vb: VarBuilder, patch_size: usize, in_chans: usize, embed_dim: usize) -> Result<Self> {
let config = candle_nn::Conv2dConfig {
stride: patch_size,
..Default::default()
};
let proj = candle_nn::conv2d(in_chans, embed_dim, patch_size, config, vb.pp("proj"))?;
Ok(Self {
proj,
patch_size: (patch_size, patch_size),
})
}
}
impl Module for PatchEmbed {
fn forward(&self, xs: &Tensor) -> Result<Tensor> {
let (_b, _c, h, w) = xs.dims4()?;
let (patch_h, patch_w) = self.patch_size;
if (h % patch_h) != 0 {
candle::bail!("image height {h} is not a multiple of patch height {patch_h}")
}
if (w % patch_w) != 0 {
candle::bail!("image width {w} is not a multiple of patch width {patch_w}")
}
let xs = self.proj.forward(xs)?;
let (b, c, h, w) = xs.dims4()?;
// flatten embeddings.
xs.reshape((b, c, h * w))?.transpose(1, 2)
}
}
#[derive(Debug)]
pub struct BeitVisionTransformer {
patch_embed: PatchEmbed,
cls_token: Tensor,
blocks: Vec<Block>,
norm: LayerNorm,
head: Linear,
}
impl BeitVisionTransformer {
pub fn new(vb: VarBuilder, depth: usize, embed_dim: usize, num_heads: usize) -> Result<Self> {
let patch_embed = PatchEmbed::new(vb.pp("patch_embed"), PATCH_SIZE, 3, embed_dim)?;
let cls_token = vb.get((1, 1, embed_dim), "cls_token")?;
let head = linear(vb.pp("head"), embed_dim, NUM_CLASSES, true)?;
let norm = layer_norm(embed_dim, 1e-6, vb.pp("norm"))?;
let vb_b = vb.pp("blocks");
let blocks = (0..depth)
.map(|i| Block::new(vb_b.pp(i.to_string()), embed_dim, num_heads))
.collect::<Result<Vec<_>>>()?;
Ok(Self {
patch_embed,
cls_token,
blocks,
norm,
head,
})
}
fn prepare_tokens_with_mask(&self, xs: &Tensor) -> Result<Tensor> {
let xs = self.patch_embed.forward(xs)?;
Tensor::cat(&[&self.cls_token, &xs], 1)
}
fn get_intermediate_layers_not_chunked(
&self,
xs: &Tensor,
blocks_to_take: &[usize],
) -> Result<Vec<Tensor>> {
let mut xs = self.prepare_tokens_with_mask(xs)?;
let mut output = Vec::new();
for (i, blk) in self.blocks.iter().enumerate() {
xs = blk.forward(&xs)?;
if blocks_to_take.contains(&i) {
output.push(xs.clone());
}
}
if output.len() != blocks_to_take.len() {
candle::bail!(
"only {} / {} blocks found",
output.len(),
blocks_to_take.len()
);
}
Ok(output)
}
pub fn get_intermediate_layers(
&self,
xs: &Tensor,
blocks_to_take: &[usize],
reshape: bool,
return_class_token: bool,
norm: bool,
) -> Result<Tensor> {
let outputs = self.get_intermediate_layers_not_chunked(xs, blocks_to_take)?;
let outputs = if norm {
outputs
.iter()
.map(|out| self.norm.forward(out))
.collect::<Result<Vec<_>>>()?
} else {
outputs
};
let class_tokens = outputs
.iter()
.map(|out| out.i((.., 0)))
.collect::<Result<Vec<_>>>()?;
let outputs = outputs
.iter()
.map(|out| out.i((.., 1..)))
.collect::<Result<Vec<_>>>()?;
let outputs = if reshape {
let (b, _c, w, h) = xs.dims4()?;
let patch_size = self.patch_embed.patch_size.0;
let num_channels = outputs[0].elem_count() / (b * (w / patch_size) * (h / patch_size));
outputs
.iter()
.map(|out| {
out.reshape((b, w / patch_size, h / patch_size, num_channels))?
.transpose(2, 3)?
.transpose(1, 2)
})
.collect::<Result<Vec<_>>>()?
} else {
outputs
};
let outputs = if return_class_token {
outputs
.iter()
.zip(class_tokens.iter())
.map(|(out, class_token)| Tensor::cat(&[out, class_token], D::Minus1))
.collect::<Result<Vec<_>>>()?
} else {
outputs
};
Tensor::stack(&outputs[..], 0)
}
}
impl Module for BeitVisionTransformer {
fn forward(&self, xs: &Tensor) -> Result<Tensor> {
let mut xs = self.prepare_tokens_with_mask(xs)?;
for blk in self.blocks.iter() {
xs = blk.forward(&xs)?
}
let xs_moy_local_tokens = xs.i((.., 1..))?.mean(1)?;
let xs_norm = self.norm.forward(&xs_moy_local_tokens)?;
self.head.forward(&xs_norm)
}
}
pub fn vit_base(vb: VarBuilder) -> Result<BeitVisionTransformer> {
BeitVisionTransformer::new(vb, 12, 768, 12)
}
pub fn vit_large(vb: VarBuilder) -> Result<BeitVisionTransformer> {
BeitVisionTransformer::new(vb, 24, 1024, 16)
}
| 3 |
0 | hf_public_repos/candle/candle-transformers/src | hf_public_repos/candle/candle-transformers/src/models/quantized_blip.rs | //! BLIP model implementation with quantization support.
//!
//! BLIP is a vision-language model for image understanding and generation tasks.
//! This implementation provides quantization for reduced memory and compute.
//!
//! Key characteristics:
//! - Vision encoder using ViT architecture
//! - Text decoder using BERT-style transformer
//! - Cross-attention between vision and text features
//! - Support for 8-bit quantization
//!
//! References:
//! - [BLIP Paper](https://arxiv.org/abs/2201.12086)
//! - [Hugging Face Implementation](https://huggingface.co/docs/transformers/model_doc/blip)
//!
use super::quantized_blip_text as blip_text;
use crate::quantized_nn::{layer_norm, linear, Linear};
pub use crate::quantized_var_builder::VarBuilder;
use candle::{Module, Result, Tensor, D};
use candle_nn::{Conv2d, Conv2dConfig, LayerNorm};
pub type VisionConfig = super::blip::VisionConfig;
pub type Config = super::blip::Config;
#[derive(Debug, Clone)]
struct VisionEmbeddings {
class_embedding: Tensor,
patch_embedding: Conv2d,
position_embedding: Tensor,
}
impl VisionEmbeddings {
fn new(cfg: &VisionConfig, vb: VarBuilder) -> Result<Self> {
let class_embedding = vb
.get((1, 1, cfg.hidden_size), "class_embedding")?
.dequantize(vb.device())?;
let conv_cfg = Conv2dConfig {
stride: cfg.patch_size,
..Default::default()
};
let pe_vb = vb.pp("patch_embedding");
let pe_weight = pe_vb
.get(
(cfg.hidden_size, 3, cfg.patch_size, cfg.patch_size),
"weight",
)?
.dequantize(vb.device())?;
let pe_bias = pe_vb
.get(cfg.hidden_size, "bias")?
.dequantize(vb.device())?;
let patch_embedding = Conv2d::new(pe_weight, Some(pe_bias), conv_cfg);
let num_patches1 = cfg.image_size / cfg.patch_size;
let num_patches = num_patches1 * num_patches1;
let num_positions = num_patches + 1;
let position_embedding = vb
.get((1, num_positions, cfg.hidden_size), "position_embedding")?
.dequantize(vb.device())?;
Ok(Self {
class_embedding,
patch_embedding,
position_embedding,
})
}
}
impl Module for VisionEmbeddings {
fn forward(&self, xs: &Tensor) -> Result<Tensor> {
let target_dtype = xs.dtype();
let b_size = xs.dim(0)?;
let patch_embeds = xs.apply(&self.patch_embedding)?.flatten_from(2)?.t()?;
let d = self.class_embedding.dim(D::Minus1)?;
let class_embeds = self
.class_embedding
.broadcast_as((b_size, 1, d))?
.to_dtype(target_dtype)?;
let embeddings = Tensor::cat(&[&class_embeds, &patch_embeds], 1)?;
let position_embedding = self.position_embedding.narrow(1, 0, embeddings.dim(1)?)?;
embeddings.broadcast_add(&position_embedding)
}
}
#[derive(Debug, Clone)]
struct Attention {
qkv: Linear,
projection: Linear,
scale: f64,
num_heads: usize,
}
impl Attention {
fn new(cfg: &VisionConfig, vb: VarBuilder) -> Result<Self> {
let embed_dim = cfg.hidden_size;
let num_heads = cfg.num_attention_heads;
let head_dim = embed_dim / num_heads;
let scale = 1f64 / (head_dim as f64).sqrt();
let qkv = linear(embed_dim, 3 * embed_dim, vb.pp("qkv"))?;
let projection = linear(embed_dim, embed_dim, vb.pp("projection"))?;
Ok(Self {
qkv,
projection,
scale,
num_heads,
})
}
fn forward(&self, xs: &Tensor, attn_mask: Option<&Tensor>) -> Result<Tensor> {
let (b_sz, tgt_len, embed_dim) = xs.dims3()?;
let mixed_qkv = xs
.apply(&self.qkv)?
.reshape((b_sz, tgt_len, 3, self.num_heads, embed_dim / self.num_heads))?
.permute((2, 0, 3, 1, 4))?;
let query = mixed_qkv.get(0)?;
let key = mixed_qkv.get(1)?;
let value = mixed_qkv.get(2)?;
let attention_scores = query.matmul(&key.t()?)?;
let attention_scores = (attention_scores * self.scale)?;
let attention_probs = candle_nn::ops::softmax_last_dim(&attention_scores)?;
let attention_probs = match attn_mask {
None => attention_probs,
Some(attn_mask) => (attention_probs * attn_mask)?,
};
attention_probs
.matmul(&value)?
.permute((0, 2, 1, 3))?
.flatten_from(D::Minus2)?
.apply(&self.projection)
}
}
#[derive(Debug, Clone)]
#[allow(clippy::upper_case_acronyms)]
struct MLP {
activation_fn: candle_nn::Activation,
fc1: Linear,
fc2: Linear,
}
impl MLP {
fn new(cfg: &VisionConfig, vb: VarBuilder) -> Result<Self> {
let fc1 = linear(cfg.hidden_size, cfg.intermediate_size, vb.pp("fc1"))?;
let fc2 = linear(cfg.intermediate_size, cfg.hidden_size, vb.pp("fc2"))?;
Ok(Self {
activation_fn: cfg.hidden_act,
fc1,
fc2,
})
}
}
impl Module for MLP {
fn forward(&self, xs: &Tensor) -> Result<Tensor> {
xs.apply(&self.fc1)?
.apply(&self.activation_fn)?
.apply(&self.fc2)
}
}
#[derive(Debug, Clone)]
struct EncoderLayer {
self_attn: Attention,
layer_norm1: LayerNorm,
mlp: MLP,
layer_norm2: LayerNorm,
}
impl EncoderLayer {
fn new(cfg: &VisionConfig, vb: VarBuilder) -> Result<Self> {
let embed_dim = cfg.hidden_size;
let self_attn = Attention::new(cfg, vb.pp("self_attn"))?;
let layer_norm1 = layer_norm(embed_dim, cfg.layer_norm_eps, vb.pp("layer_norm1"))?;
let layer_norm2 = layer_norm(embed_dim, cfg.layer_norm_eps, vb.pp("layer_norm2"))?;
let mlp = MLP::new(cfg, vb.pp("mlp"))?;
Ok(Self {
self_attn,
layer_norm1,
mlp,
layer_norm2,
})
}
fn forward(&self, xs: &Tensor, attention_mask: Option<&Tensor>) -> Result<Tensor> {
let residual = xs;
let xs = xs.apply(&self.layer_norm1)?;
let xs = self.self_attn.forward(&xs, attention_mask)?;
let xs = (xs + residual)?;
let residual = &xs;
let xs = xs.apply(&self.layer_norm2)?.apply(&self.mlp)?;
xs + residual
}
}
#[derive(Debug, Clone)]
struct Encoder {
layers: Vec<EncoderLayer>,
}
impl Encoder {
fn new(cfg: &VisionConfig, vb: VarBuilder) -> Result<Self> {
let mut layers = Vec::with_capacity(cfg.num_hidden_layers);
let vb = vb.pp("layers");
for i in 0..cfg.num_hidden_layers {
let layer = EncoderLayer::new(cfg, vb.pp(i))?;
layers.push(layer)
}
Ok(Self { layers })
}
fn forward(&self, xs: &Tensor, attention_mask: Option<&Tensor>) -> Result<Tensor> {
let mut xs = xs.clone();
for layer in self.layers.iter() {
xs = layer.forward(&xs, attention_mask)?
}
Ok(xs)
}
}
#[derive(Debug, Clone)]
pub struct VisionModel {
embeddings: VisionEmbeddings,
encoder: Encoder,
post_layernorm: LayerNorm,
}
impl VisionModel {
fn new(cfg: &VisionConfig, vb: VarBuilder) -> Result<Self> {
let embeddings = VisionEmbeddings::new(cfg, vb.pp("embeddings"))?;
let encoder = Encoder::new(cfg, vb.pp("encoder"))?;
let post_layernorm =
layer_norm(cfg.hidden_size, cfg.layer_norm_eps, vb.pp("post_layernorm"))?;
Ok(Self {
embeddings,
encoder,
post_layernorm,
})
}
}
impl Module for VisionModel {
fn forward(&self, xs: &Tensor) -> Result<Tensor> {
let xs = xs.apply(&self.embeddings)?;
let encoder_outputs = self.encoder.forward(&xs, None)?;
// Return the last hidden state rather than pooled outputs.
encoder_outputs.apply(&self.post_layernorm)
}
}
#[derive(Debug, Clone)]
pub struct BlipForConditionalGeneration {
vision_model: VisionModel,
text_decoder: blip_text::TextLMHeadModel,
}
impl BlipForConditionalGeneration {
pub fn new(cfg: &Config, vb: VarBuilder) -> Result<Self> {
let vision_model = VisionModel::new(&cfg.vision_config, vb.pp("vision_model"))?;
let text_decoder =
blip_text::TextLMHeadModel::new(&cfg.text_config, vb.pp("text_decoder"))?;
Ok(Self {
vision_model,
text_decoder,
})
}
pub fn vision_model(&self) -> &VisionModel {
&self.vision_model
}
pub fn text_decoder(&mut self) -> &mut blip_text::TextLMHeadModel {
&mut self.text_decoder
}
pub fn reset_kv_cache(&mut self) {
self.text_decoder.reset_kv_cache();
}
}
| 4 |
0 | hf_public_repos/candle/candle-transformers/src | hf_public_repos/candle/candle-transformers/src/models/dinov2reg4.rs | //! Implementation of the DINOv2 revision (4 regularization)
//!
//! The DINOv2-reg4 model is a variant of DINOv2 that adds 4 regularization tokens to the
//! original architecture. This implementation is specifically trained for plant species
//! classification on the PlantCLEF2024 dataset with 7,806 classes.
//!
//! - [Paper](https://arxiv.org/abs/2309.16588). DINOv2: Learning Robust Visual Features without Supervision
//! - [GH Repo](https://github.com/facebookresearch/dinov2)
//!
//! # Example
//!
//! ```bash
//! # Download classes names and a plant picture to identify
//! # see candle/examples/dinov2reg4 for full code.
//!
//! # Perform inference
//! cargo run \
//! --example dinov2reg4 \
//! --release -- \
//! --image <orchid-file>
//!
//! > Orchis simia Lam. : 45.55%
//! > Orchis × bergonii Nanteuil: 9.80%
//! > Orchis italica Poir. : 9.66%
//! > Orchis × angusticruris Franch.: 2.76%
//! > Orchis × bivonae Tod. : 2.54%
//! ```
//!
//! <div align=center>
//! <img src="https://bs.plantnet.org/image/o/bd2d3830ac3270218ba82fd24e2290becd01317c" alt="" width=320>
//! </div>
//!
use candle::{IndexOp, Result, Tensor, D};
use candle_nn::{layer_norm, LayerNorm, Linear, Module, VarBuilder};
const IMG_SIZE: usize = 518;
const PATCH_SIZE: usize = 14;
const NUM_CLASSES: usize = 7806; // PlantCLEF2024 DINOv2 (https://zenodo.org/records/10848263)
fn linear(vb: VarBuilder, in_dim: usize, out_dim: usize, bias: bool) -> Result<Linear> {
if bias {
candle_nn::linear(in_dim, out_dim, vb)
} else {
candle_nn::linear_no_bias(in_dim, out_dim, vb)
}
}
#[derive(Debug)]
struct Attention {
qkv: Linear,
proj: Linear,
num_heads: usize,
scale: f64,
}
impl Attention {
fn new(
vb: VarBuilder,
dim: usize,
num_heads: usize,
qkv_bias: bool,
proj_bias: bool,
) -> Result<Self> {
let qkv = linear(vb.pp("qkv"), dim, dim * 3, qkv_bias)?;
let proj = linear(vb.pp("proj"), dim, dim, proj_bias)?;
let scale = 1. / ((dim / num_heads) as f64).sqrt();
Ok(Self {
qkv,
proj,
num_heads,
scale,
})
}
}
impl Module for Attention {
fn forward(&self, xs: &Tensor) -> Result<Tensor> {
let (b, n, c) = xs.dims3()?;
let qkv = self
.qkv
.forward(xs)?
.reshape((b, n, 3, self.num_heads, c / self.num_heads))?
.transpose(1, 2)? // 02134
.transpose(0, 1)? // 20134
.transpose(2, 3)?; // 20314
let q = (qkv.i(0)? * self.scale)?;
let k = qkv.i(1)?.contiguous()?;
let v = qkv.i(2)?.contiguous()?;
let attn = candle_nn::ops::softmax(&q.matmul(&k.t()?)?, D::Minus1)?;
let attn = attn.matmul(&v)?.transpose(1, 2)?.reshape((b, n, c))?;
self.proj.forward(&attn)
}
}
#[derive(Debug)]
struct LayerScale {
gamma: Tensor,
}
impl LayerScale {
fn new(vb: VarBuilder, dim: usize) -> Result<Self> {
let gamma = vb.get(dim, "gamma")?;
Ok(Self { gamma })
}
}
impl Module for LayerScale {
fn forward(&self, xs: &Tensor) -> Result<Tensor> {
xs.broadcast_mul(&self.gamma)
}
}
#[derive(Debug)]
struct Mlp {
fc1: Linear,
fc2: Linear,
}
impl Mlp {
fn new(vb: VarBuilder, in_features: usize, hidden_features: usize, bias: bool) -> Result<Self> {
let out_features = in_features;
let fc1 = linear(vb.pp("fc1"), in_features, hidden_features, bias)?;
let fc2 = linear(vb.pp("fc2"), hidden_features, out_features, bias)?;
Ok(Self { fc1, fc2 })
}
}
impl Module for Mlp {
fn forward(&self, xs: &Tensor) -> Result<Tensor> {
let xs = self.fc1.forward(xs)?.gelu()?;
self.fc2.forward(&xs)
}
}
#[derive(Debug)]
struct Block {
norm1: LayerNorm,
attn: Attention,
ls1: LayerScale,
norm2: LayerNorm,
mlp: Mlp,
ls2: LayerScale,
}
impl Block {
fn new(vb: VarBuilder, dim: usize, num_heads: usize) -> Result<Self> {
let norm1 = layer_norm(dim, 1e-6, vb.pp("norm1"))?;
let attn = Attention::new(vb.pp("attn"), dim, num_heads, true, true)?;
let ls1 = LayerScale::new(vb.pp("ls1"), dim)?;
let norm2 = layer_norm(dim, 1e-6, vb.pp("norm2"))?;
let mlp = Mlp::new(vb.pp("mlp"), dim, dim * 4, true)?;
let ls2 = LayerScale::new(vb.pp("ls2"), dim)?;
Ok(Self {
norm1,
attn,
ls1,
norm2,
mlp,
ls2,
})
}
}
impl Module for Block {
fn forward(&self, xs: &Tensor) -> Result<Tensor> {
let residual = xs;
let xs = self
.ls1
.forward(&self.attn.forward(&self.norm1.forward(xs)?)?)?;
let xs = (xs + residual)?;
let residual = &xs;
let xs = self
.ls2
.forward(&self.mlp.forward(&self.norm2.forward(&xs)?)?)?;
xs + residual
}
}
#[derive(Debug)]
struct PatchEmbed {
proj: candle_nn::Conv2d,
patch_size: (usize, usize),
num_patches: usize,
}
impl PatchEmbed {
fn new(
vb: VarBuilder,
img_size: usize,
patch_size: usize,
in_chans: usize,
embed_dim: usize,
) -> Result<Self> {
let config = candle_nn::Conv2dConfig {
stride: patch_size,
..Default::default()
};
let proj = candle_nn::conv2d(in_chans, embed_dim, patch_size, config, vb.pp("proj"))?;
let num_patches = (img_size / patch_size) * (img_size / patch_size);
Ok(Self {
proj,
patch_size: (patch_size, patch_size),
num_patches,
})
}
}
impl Module for PatchEmbed {
fn forward(&self, xs: &Tensor) -> Result<Tensor> {
let (_b, _c, h, w) = xs.dims4()?;
let (patch_h, patch_w) = self.patch_size;
if (h % patch_h) != 0 {
candle::bail!("image height {h} is not a multiple of patch height {patch_h}")
}
if (w % patch_w) != 0 {
candle::bail!("image width {w} is not a multiple of patch width {patch_w}")
}
let xs = self.proj.forward(xs)?;
let (b, c, h, w) = xs.dims4()?;
// flatten embeddings.
xs.reshape((b, c, h * w))?.transpose(1, 2)
}
}
#[derive(Debug)]
pub struct DinoVisionTransformer {
patch_embed: PatchEmbed,
cls_token: Tensor,
reg_token: Tensor,
pos_embed: Tensor,
blocks: Vec<Block>,
norm: LayerNorm,
head: Linear,
}
impl DinoVisionTransformer {
pub fn new(vb: VarBuilder, depth: usize, embed_dim: usize, num_heads: usize) -> Result<Self> {
let patch_embed =
PatchEmbed::new(vb.pp("patch_embed"), IMG_SIZE, PATCH_SIZE, 3, embed_dim)?;
let cls_token = vb.get((1, 1, embed_dim), "cls_token")?;
let reg_token = vb.get((1, 4, embed_dim), "reg_token")?;
let pos_embed = vb.get((1, patch_embed.num_patches, embed_dim), "pos_embed")?;
let head = linear(vb.pp("head"), embed_dim, NUM_CLASSES, true)?;
let norm = layer_norm(embed_dim, 1e-6, vb.pp("norm"))?;
let vb_b = vb.pp("blocks");
let blocks = (0..depth)
.map(|i| Block::new(vb_b.pp(i.to_string()), embed_dim, num_heads))
.collect::<Result<Vec<_>>>()?;
Ok(Self {
patch_embed,
cls_token,
reg_token,
pos_embed,
blocks,
norm,
head,
})
}
fn interpolate_pos_encoding(&self, xs: &Tensor, w: usize, h: usize) -> Result<Tensor> {
let npatch = xs.dim(1)? - 1;
let n = self.pos_embed.dim(1)? - 1;
let sqrt_n = (n as f64).sqrt();
if npatch == n && w == h {
return Ok(self.pos_embed.clone());
}
let patch_pos_embed = &self.pos_embed;
let dim = xs.dim(D::Minus1)?;
let (w0, h0) = ((w / PATCH_SIZE) as f64 + 0.1, (h / PATCH_SIZE) as f64 + 0.1);
let patch_pos_embed = patch_pos_embed
.reshape((1, sqrt_n as usize, sqrt_n as usize, dim))?
.transpose(2, 3)?
.transpose(1, 2)?;
// This uses bicubic interpolation in the original implementation.
let patch_pos_embed = patch_pos_embed.upsample_nearest2d(h0 as usize, w0 as usize)?;
let el_count = patch_pos_embed.shape().elem_count();
patch_pos_embed
.transpose(1, 2)?
.transpose(2, 3)?
.reshape((1, el_count / dim, dim))
}
fn prepare_tokens_with_mask(&self, xs: &Tensor) -> Result<Tensor> {
let (_b, _nc, w, h) = xs.dims4()?;
if (w != IMG_SIZE) || (h != IMG_SIZE) {
panic!("Error: The input tensor should have the shape: Bx3x518x518.");
}
let xs = self.patch_embed.forward(xs)?;
let xs = (&xs + &self.interpolate_pos_encoding(&xs, w, h)?)?;
let xs = Tensor::cat(&[&self.cls_token, &self.reg_token, &xs], 1)?;
Ok(xs)
}
}
impl Module for DinoVisionTransformer {
fn forward(&self, xs: &Tensor) -> Result<Tensor> {
let mut xs = self.prepare_tokens_with_mask(xs)?;
for blk in self.blocks.iter() {
xs = blk.forward(&xs)?
}
let xs = self.norm.forward(&xs)?;
let xs_norm_clstoken = xs.i((.., 0))?;
self.head.forward(&xs_norm_clstoken)
}
}
pub fn vit_small(vb: VarBuilder) -> Result<DinoVisionTransformer> {
DinoVisionTransformer::new(vb, 12, 384, 6)
}
pub fn vit_base(vb: VarBuilder) -> Result<DinoVisionTransformer> {
DinoVisionTransformer::new(vb, 12, 768, 12)
}
| 5 |
0 | hf_public_repos/candle/candle-transformers/src | hf_public_repos/candle/candle-transformers/src/models/trocr.rs | //! TrOCR model implementation.
//!
//! TrOCR is a Transformer-based OCR model that uses a Vision Transformer encoder
//! and a BART-like decoder for optical character recognition.
//!
//! Key characteristics:
//! - Vision Transformer encoder for image processing
//! - BART-style decoder for text generation
//! - Learned positional embeddings
//! - Layer normalization and self-attention
//!
//! References:
//! - [Paper](https://arxiv.org/abs/2109.10282)
//! - [Model Card](https://huggingface.co/microsoft/trocr-base-handwritten)
//!
use crate::models::vit::{Config, Embeddings, Encoder};
use candle::{DType, Result, Tensor};
use candle_nn::{
embedding, layer_norm, linear_no_bias, Embedding, LayerNorm, Linear, Module, VarBuilder,
};
fn default_tie_word_embeddings() -> bool {
true
}
fn default_use_learned_position_embeddings() -> bool {
true
}
#[derive(Debug, Clone, PartialEq, serde::Deserialize)]
pub struct TrOCRConfig {
pub vocab_size: usize,
pub d_model: usize,
pub cross_attention_hidden_size: usize,
pub decoder_layers: usize,
pub decoder_attention_heads: usize,
pub decoder_ffn_dim: usize,
pub activation_function: candle_nn::Activation,
pub max_position_embeddings: usize,
pub dropout: f64,
pub attention_dropout: f64,
pub activation_dropout: f64,
pub decoder_start_token_id: u32,
pub init_std: f64,
pub decoder_layerdrop: f64,
pub use_cache: bool,
pub scale_embedding: bool,
pub pad_token_id: usize,
pub bos_token_id: usize,
pub eos_token_id: u32,
pub decoder_vocab_size: Option<usize>,
#[serde(default = "default_use_learned_position_embeddings")]
pub use_learned_position_embeddings: bool,
#[serde(default = "default_tie_word_embeddings")]
pub tie_word_embeddings: bool,
}
impl Default for TrOCRConfig {
fn default() -> Self {
Self {
vocab_size: 50265,
d_model: 1024,
cross_attention_hidden_size: 768,
decoder_layers: 12,
decoder_attention_heads: 16,
decoder_ffn_dim: 4096,
activation_function: candle_nn::Activation::Gelu,
max_position_embeddings: 512,
dropout: 0.1,
attention_dropout: 0.0,
activation_dropout: 0.0,
decoder_start_token_id: 2,
init_std: 0.02,
decoder_layerdrop: 0.0,
use_cache: true,
scale_embedding: false,
pad_token_id: 1,
bos_token_id: 0,
eos_token_id: 2,
decoder_vocab_size: Some(50265),
use_learned_position_embeddings: true,
tie_word_embeddings: true,
}
}
}
#[derive(Debug, Clone)]
struct TrOCRLearnedPositionalEmbedding {
offset: usize,
weights: Embedding,
}
impl TrOCRLearnedPositionalEmbedding {
fn load(vb: VarBuilder, cfg: &TrOCRConfig) -> Result<Self> {
let offset: usize = 2;
let num_embeddings = cfg.max_position_embeddings;
let embedding_dim = cfg.d_model;
let weights = embedding(num_embeddings + offset, embedding_dim, vb)?;
Ok(Self { offset, weights })
}
fn new_sinusoidal(vb: VarBuilder, cfg: &TrOCRConfig) -> Result<Self> {
// https://github.com/huggingface/transformers/blob/58e3d23e97078f361a533b9ec4a6a2de674ea52a/src/transformers/models/trocr/modeling_trocr.py#L81
let embedding_dim = cfg.d_model;
let half_dim = embedding_dim / 2;
let num_positions = cfg.max_position_embeddings + cfg.pad_token_id + 1;
let dev = vb.device();
let inv_freq: Vec<_> = (0..half_dim)
.map(|i| 1f32 / 10000f32.powf(i as f32 / (half_dim - 1) as f32))
.collect();
let inv_freq_len = inv_freq.len();
let inv_freq = Tensor::from_vec(inv_freq, (1, inv_freq_len), dev)?;
let t = Tensor::arange(0u32, num_positions as u32, dev)?
.to_dtype(DType::F32)?
.reshape((num_positions, 1))?;
let freqs = t.matmul(&inv_freq)?;
let emb = Tensor::cat(&[freqs.sin()?, freqs.cos()?], 1)?;
let emb = Tensor::cat(
&[
emb.narrow(0, 0, cfg.pad_token_id)?,
Tensor::zeros((1, embedding_dim), DType::F32, dev)?,
emb.narrow(0, cfg.pad_token_id + 1, cfg.max_position_embeddings)?,
],
0,
)?
.contiguous()?;
let emb = Embedding::new(emb, embedding_dim);
Ok(Self {
offset: cfg.pad_token_id + 1,
weights: emb,
})
}
fn forward(&mut self, input_ids: &Tensor, past_key_values_length: u32) -> Result<Tensor> {
let (b_sz, seq_len) = input_ids.dims2()?;
let positions = Tensor::arange(
past_key_values_length,
seq_len as u32 + past_key_values_length,
input_ids.device(),
)?
.expand((b_sz, seq_len))?;
let positions =
positions.broadcast_add(&Tensor::new(self.offset as u32, input_ids.device())?)?;
self.weights.forward(&positions)
}
}
#[derive(Debug, Clone)]
struct TrOCRAttention {
head_dim: usize,
num_heads: usize,
is_decoder: bool,
scaling: f64,
k_proj: Linear,
v_proj: Linear,
q_proj: Linear,
out_proj: Linear,
kv_cache: Option<(Tensor, Tensor)>,
}
impl TrOCRAttention {
fn load(
vb: VarBuilder,
cfg: &TrOCRConfig,
kdim: Option<usize>,
vdim: Option<usize>,
) -> Result<Self> {
let embed_dim = cfg.d_model;
let num_heads = cfg.decoder_attention_heads;
let head_dim = embed_dim / num_heads;
let kdim = kdim.unwrap_or(embed_dim);
let vdim = vdim.unwrap_or(embed_dim);
let k_proj = linear_no_bias(kdim, embed_dim, vb.pp("k_proj"))?;
let v_proj = linear_no_bias(vdim, embed_dim, vb.pp("v_proj"))?;
let q_proj = linear_no_bias(embed_dim, embed_dim, vb.pp("q_proj"))?;
let out_proj = linear_no_bias(embed_dim, embed_dim, vb.pp("out_proj"))?;
Ok(Self {
head_dim,
num_heads,
is_decoder: true,
scaling: 1. / (head_dim as f64).sqrt(),
k_proj,
v_proj,
q_proj,
out_proj,
kv_cache: None,
})
}
fn reset_kv_cache(&mut self) {
self.kv_cache = None
}
fn _shape(&self, tensor: &Tensor, bsz: usize) -> Result<Tensor> {
tensor
.reshape((bsz, (), self.num_heads, self.head_dim))?
.transpose(1, 2)?
.contiguous()
}
fn forward(
&mut self,
xs: &Tensor,
kv_states: Option<&Tensor>,
attn_mask: Option<&Tensor>,
) -> Result<Tensor> {
let (b_sz, tgt_len, _) = xs.dims3()?;
let query_states = (xs.apply(&self.q_proj)? * self.scaling)?;
let (key_states, value_states) = match kv_states {
None => {
let key_states = self._shape(&xs.apply(&self.k_proj)?, b_sz)?;
let value_states = self._shape(&xs.apply(&self.v_proj)?, b_sz)?;
if self.is_decoder {
let kv_states = match &self.kv_cache {
None => (key_states, value_states),
Some((p_key_states, p_value_states)) => {
let key_states = Tensor::cat(&[p_key_states, &key_states], 2)?;
let value_states = Tensor::cat(&[p_value_states, &value_states], 2)?;
(key_states, value_states)
}
};
self.kv_cache = Some(kv_states.clone());
kv_states
} else {
(key_states, value_states)
}
}
Some(kv_states) => {
let key_states = self._shape(&kv_states.apply(&self.k_proj)?, b_sz)?;
let value_states = self._shape(&kv_states.apply(&self.v_proj)?, b_sz)?;
(key_states, value_states)
}
};
let proj_shape = (b_sz * self.num_heads, (), self.head_dim);
let query_states = self._shape(&query_states, b_sz)?.reshape(proj_shape)?;
let key_states = key_states.reshape(proj_shape)?;
let value_states = value_states.reshape(proj_shape)?;
let attn_weights = query_states.matmul(&key_states.transpose(1, 2)?)?;
let attn_weights = match attn_mask {
None => attn_weights,
Some(attn_mask) => attn_weights.broadcast_add(attn_mask)?,
};
let attn_probs = candle_nn::ops::softmax_last_dim(&attn_weights)?;
let attn_output = attn_probs.matmul(&value_states)?;
attn_output
.reshape((b_sz, self.num_heads, tgt_len, self.head_dim))?
.transpose(1, 2)?
.reshape((b_sz, tgt_len, self.head_dim * self.num_heads))?
.apply(&self.out_proj)
}
}
#[derive(Debug, Clone)]
struct TrOCRDecoderLayer {
self_attn: TrOCRAttention,
activation_fn: candle_nn::Activation,
self_attn_layer_norm: LayerNorm,
encoder_attn: TrOCRAttention,
encoder_attn_layer_norm: LayerNorm,
fc1: Linear,
fc2: Linear,
final_layer_norm: LayerNorm,
}
impl TrOCRDecoderLayer {
fn load(vb: VarBuilder, cfg: &TrOCRConfig) -> Result<Self> {
let embed_dim = cfg.d_model;
let self_attn = TrOCRAttention::load(vb.pp("self_attn"), cfg, None, None)?;
let self_attn_layer_norm = layer_norm(embed_dim, 1e-5, vb.pp("self_attn_layer_norm"))?;
let encoder_attn = TrOCRAttention::load(
vb.pp("encoder_attn"),
cfg,
Some(cfg.cross_attention_hidden_size),
Some(cfg.cross_attention_hidden_size),
)?;
let encoder_attn_layer_norm =
layer_norm(embed_dim, 1e-5, vb.pp("encoder_attn_layer_norm"))?;
let fc1 = linear_no_bias(embed_dim, cfg.decoder_ffn_dim, vb.pp("fc1"))?;
let fc2 = linear_no_bias(cfg.decoder_ffn_dim, embed_dim, vb.pp("fc2"))?;
let final_layer_norm = layer_norm(embed_dim, 1e-5, vb.pp("final_layer_norm"))?;
Ok(Self {
self_attn,
activation_fn: cfg.activation_function,
self_attn_layer_norm,
encoder_attn,
encoder_attn_layer_norm,
fc1,
fc2,
final_layer_norm,
})
}
fn reset_kv_cache(&mut self) {
self.self_attn.reset_kv_cache();
}
fn forward(
&mut self,
xs: &Tensor,
attention_mask: &Tensor,
encoder_hidden_states: Option<&Tensor>,
) -> Result<Tensor> {
let residual = xs.clone();
let xs = self.self_attn.forward(xs, None, Some(attention_mask))?;
let xs = (xs + residual)?;
let mut xs = self.self_attn_layer_norm.forward(&xs)?;
if let Some(encoder_hidden_states) = &encoder_hidden_states {
let residual = xs.clone();
let encoder_attention_mask = attention_mask.clone(); // TODO
xs = self.encoder_attn.forward(
&xs,
Some(encoder_hidden_states),
Some(&encoder_attention_mask),
)?;
xs = (xs + residual)?;
xs = self.encoder_attn_layer_norm.forward(&xs)?
}
let residual = xs.clone();
let xs = self.fc1.forward(&xs)?;
let xs = self.activation_fn.forward(&xs)?;
let xs = self.fc2.forward(&xs)?;
let xs = (xs + residual)?;
let xs = self.final_layer_norm.forward(&xs)?;
Ok(xs)
}
}
#[derive(Debug, Clone)]
pub struct TrOCRDecoder {
layers: Vec<TrOCRDecoderLayer>,
embed_scale: Option<f64>,
embed_tokens: Embedding,
embed_positions: TrOCRLearnedPositionalEmbedding,
}
impl TrOCRDecoder {
fn new(cfg: &TrOCRConfig, vb: VarBuilder) -> Result<Self> {
let vb = vb.pp("decoder.model.decoder");
let embed_tokens = embedding(cfg.vocab_size, cfg.d_model, vb.pp("embed_tokens"))?;
let embed_positions = if cfg.use_learned_position_embeddings {
TrOCRLearnedPositionalEmbedding::load(vb.pp("embed_positions"), cfg)?
} else {
TrOCRLearnedPositionalEmbedding::new_sinusoidal(vb.pp("embed_positions"), cfg)?
};
let mut layers = Vec::with_capacity(cfg.decoder_layers);
let vb_l = vb.pp("layers");
for idx in 0..cfg.decoder_layers {
let layer = TrOCRDecoderLayer::load(vb_l.pp(idx), cfg)?;
layers.push(layer)
}
let embed_scale = if cfg.scale_embedding {
Some((cfg.d_model as f64).sqrt())
} else {
None
};
Ok(Self {
layers,
embed_scale,
embed_tokens,
embed_positions,
})
}
fn reset_kv_cache(&mut self) {
self.layers.iter_mut().for_each(|l| l.reset_kv_cache())
}
pub fn forward(
&mut self,
xs: &Tensor,
encoder_xs: Option<&Tensor>,
past_kv_len: usize,
attn_mask: &Tensor,
) -> Result<Tensor> {
let embed_pos = self.embed_positions.forward(xs, past_kv_len as u32)?;
let xs = xs.apply(&self.embed_tokens)?;
let xs = match self.embed_scale {
None => xs,
Some(scale) => (xs * scale)?,
};
let mut xs = xs.broadcast_add(&embed_pos)?;
for layer in self.layers.iter_mut() {
xs = layer.forward(&xs, attn_mask, encoder_xs)?;
}
Ok(xs)
}
}
#[derive(Debug, Clone)]
pub struct TrOCREncoder {
embeddings: Embeddings,
encoder: Encoder,
layernorm: LayerNorm,
}
impl TrOCREncoder {
pub fn new(cfg: &Config, vb: VarBuilder) -> Result<Self> {
let vb_v = vb.pp("encoder");
let embeddings = Embeddings::new(cfg, false, vb_v.pp("embeddings"))?;
let encoder = Encoder::new(cfg, vb_v.pp("encoder"))?;
let layernorm = layer_norm(cfg.hidden_size, cfg.layer_norm_eps, vb_v.pp("layernorm"))?;
Ok(Self {
embeddings,
encoder,
layernorm,
})
}
pub fn forward(&self, xs: &Tensor) -> Result<Tensor> {
let embedding_output = self.embeddings.forward(xs, None, false)?;
let encoder_outputs = self.encoder.forward(&embedding_output)?;
self.layernorm.forward(&encoder_outputs)
}
}
#[derive(Debug, Clone)]
pub struct TrOCRForCausalLM {
decoder: TrOCRDecoder,
output_projection: Linear,
}
impl TrOCRForCausalLM {
pub fn new(decoder_cfg: &TrOCRConfig, vb: VarBuilder) -> Result<Self> {
let decoder = TrOCRDecoder::new(decoder_cfg, vb.clone())?;
let output_projection = if decoder_cfg.tie_word_embeddings {
candle_nn::Linear::new(decoder.embed_tokens.embeddings().clone(), None)
} else {
candle_nn::linear_no_bias(
decoder_cfg.d_model,
decoder_cfg.vocab_size,
vb.pp("decoder.output_projection"),
)?
};
Ok(Self {
decoder,
output_projection,
})
}
pub fn forward(
&mut self,
xs: &Tensor,
encoder_xs: Option<&Tensor>,
past_kv_len: usize,
attn_mask: &Tensor,
) -> Result<Tensor> {
let xs = self
.decoder
.forward(xs, encoder_xs, past_kv_len, attn_mask)?;
let xs = xs.apply(&self.output_projection)?;
Ok(xs)
}
fn reset_kv_cache(&mut self) {
self.decoder.reset_kv_cache();
}
}
#[derive(Debug, Clone)]
pub struct TrOCRModel {
encoder: TrOCREncoder,
decoder: TrOCRForCausalLM,
}
impl TrOCRModel {
pub fn new(encoder_cfg: &Config, decoder_cfg: &TrOCRConfig, vb: VarBuilder) -> Result<Self> {
let encoder = TrOCREncoder::new(encoder_cfg, vb.clone())?;
let decoder = TrOCRForCausalLM::new(decoder_cfg, vb)?;
Ok(Self { encoder, decoder })
}
pub fn encoder(&mut self) -> &mut TrOCREncoder {
&mut self.encoder
}
pub fn decoder(&mut self) -> &mut TrOCRForCausalLM {
&mut self.decoder
}
pub fn decode(
&mut self,
xs: &Tensor,
encoder_xs: &Tensor,
past_kv_len: usize,
) -> Result<Tensor> {
let seq_len = xs.dim(1)?;
let mask: Vec<_> = (0..seq_len)
.flat_map(|i| (0..seq_len).map(move |j| if j > i { f32::NEG_INFINITY } else { 0f32 }))
.collect();
let mask = Tensor::from_vec(mask, (seq_len, seq_len), xs.device())?;
self.decoder
.forward(xs, Some(encoder_xs), past_kv_len, &mask)
}
pub fn reset_kv_cache(&mut self) {
self.decoder.reset_kv_cache();
}
}
| 6 |
0 | hf_public_repos/candle/candle-transformers/src | hf_public_repos/candle/candle-transformers/src/models/repvgg.rs | //! RepVGG inference implementation
//!
//! Key characteristics:
//! - Efficient inference architecture through structural reparameterization
//! - Single 3x3 conv layer after fusing 3x3 branch, 1x1 branch and identity branch
//! - Different configurations including a0-a2, b0-b3 and variants with group convolutions
//! - High accuracy with VGG-like plain architecture and training
//!
//! References:
//! - [RepVGG Paper](https://arxiv.org/abs/2101.03697). RepVGG: Making VGG-style ConvNets Great Again
//! - [Official Implementation](https://github.com/DingXiaoH/RepVGG)
//!
use candle::{Result, Tensor, D};
use candle_nn::{
batch_norm, conv2d_no_bias, linear, BatchNorm, Conv2d, Conv2dConfig, Func, VarBuilder,
};
const CHANNELS_PER_STAGE: [usize; 5] = [64, 64, 128, 256, 512];
#[derive(Clone)]
pub struct Config {
a: f32,
b: f32,
groups: usize,
stages: [usize; 4],
}
impl Config {
pub fn a0() -> Self {
Self {
a: 0.75,
b: 2.5,
groups: 1,
stages: [2, 4, 14, 1],
}
}
pub fn a1() -> Self {
Self {
a: 1.0,
b: 2.5,
groups: 1,
stages: [2, 4, 14, 1],
}
}
pub fn a2() -> Self {
Self {
a: 1.5,
b: 2.75,
groups: 1,
stages: [2, 4, 14, 1],
}
}
pub fn b0() -> Self {
Self {
a: 1.0,
b: 2.5,
groups: 1,
stages: [4, 6, 16, 1],
}
}
pub fn b1() -> Self {
Self {
a: 2.0,
b: 4.0,
groups: 1,
stages: [4, 6, 16, 1],
}
}
pub fn b2() -> Self {
Self {
a: 2.5,
b: 5.0,
groups: 1,
stages: [4, 6, 16, 1],
}
}
pub fn b3() -> Self {
Self {
a: 3.0,
b: 5.0,
groups: 1,
stages: [4, 6, 16, 1],
}
}
pub fn b1g4() -> Self {
Self {
a: 2.0,
b: 4.0,
groups: 4,
stages: [4, 6, 16, 1],
}
}
pub fn b2g4() -> Self {
Self {
a: 2.5,
b: 5.0,
groups: 4,
stages: [4, 6, 16, 1],
}
}
pub fn b3g4() -> Self {
Self {
a: 3.0,
b: 5.0,
groups: 4,
stages: [4, 6, 16, 1],
}
}
}
// fuses a convolutional kernel and a batchnorm layer into a convolutional layer
// based on the _fuse_bn_tensor method in timm
// see https://github.com/huggingface/pytorch-image-models/blob/main/timm/models/byobnet.py#L602
fn fuse_conv_bn(weights: &Tensor, bn: BatchNorm) -> Result<(Tensor, Tensor)> {
let (gamma, beta) = bn.weight_and_bias().unwrap();
let mu = bn.running_mean();
let sigma = (bn.running_var() + bn.eps())?.sqrt();
let gps = (gamma / sigma)?;
let bias = (beta - mu * &gps)?;
let weights = weights.broadcast_mul(&gps.reshape(((), 1, 1, 1))?)?;
Ok((weights, bias))
}
// A RepVGG layer has a different training time and inference time architecture.
// The latter is a simple and efficient equivalent transformation of the former
// realized by a structural reparameterization technique, where 3x3 and 1x1 convolutions
// along with identity branches and batchnorm layers are fused into a single 3x3 convolution.
fn repvgg_layer(
has_identity: bool,
dim: usize,
stride: usize,
in_channels: usize,
out_channels: usize,
groups: usize,
vb: VarBuilder,
) -> Result<Func<'static>> {
let conv2d_cfg = Conv2dConfig {
stride,
groups,
padding: 1,
..Default::default()
};
// read and reparameterize the 1x1 conv and bn into w1 and b1
// based on https://github.com/huggingface/pytorch-image-models/blob/main/timm/models/byobnet.py#L543
let conv1x1_bn = batch_norm(dim, 1e-5, vb.pp("conv_1x1.bn"))?;
let conv1x1 = conv2d_no_bias(
in_channels,
out_channels,
1,
conv2d_cfg,
vb.pp("conv_1x1.conv"),
)?;
let (mut w1, b1) = fuse_conv_bn(conv1x1.weight(), conv1x1_bn)?;
// resize to 3x3
w1 = w1.pad_with_zeros(D::Minus1, 1, 1)?;
w1 = w1.pad_with_zeros(D::Minus2, 1, 1)?;
// read and reparameterize the 3x3 conv and bn into w3 and b3
let convkxk_bn = batch_norm(dim, 1e-5, vb.pp("conv_kxk.bn"))?;
let conv3x3 = conv2d_no_bias(
in_channels,
out_channels,
3,
conv2d_cfg,
vb.pp("conv_kxk.conv"),
)?;
let (w3, b3) = fuse_conv_bn(conv3x3.weight(), convkxk_bn)?;
let mut w = (w1 + w3)?;
let mut b = (b1 + b3)?;
// read and reparameterize the identity bn into wi and bi
if has_identity {
let identity_bn = batch_norm(dim, 1e-5, vb.pp("identity"))?;
// create a 3x3 convolution equivalent to the identity branch
let mut weights: Vec<f32> = vec![0.0; conv3x3.weight().elem_count()];
// https://github.com/huggingface/pytorch-image-models/blob/main/timm/models/byobnet.py#L620
let in_dim = in_channels / groups;
for i in 0..in_channels {
weights[i * in_dim * 3 * 3 + (i % in_dim) * 3 * 3 + 4] = 1.0;
}
let weights = &Tensor::from_vec(weights, w.shape(), w.device())?;
let (wi, bi) = fuse_conv_bn(weights, identity_bn)?;
w = (w + wi)?;
b = (b + bi)?;
}
// create the 3x3 conv equivalent to the sum of 3x3, 1x1 and identity branches
let reparam_conv = Conv2d::new(w, Some(b), conv2d_cfg);
Ok(Func::new(move |xs| {
let xs = xs.apply(&reparam_conv)?.relu()?;
Ok(xs)
}))
}
// Get the number of output channels per stage taking into account the multipliers
fn output_channels_per_stage(a: f32, b: f32, stage: usize) -> usize {
let channels = CHANNELS_PER_STAGE[stage] as f32;
match stage {
0 => std::cmp::min(64, (channels * a) as usize),
4 => (channels * b) as usize,
_ => (channels * a) as usize,
}
}
// Each stage is made of layers. The first layer always downsamples with stride 2.
// All but the first layer have a residual connection.
// The G4 variants have a groupwise convolution instead of a dense one on odd layers
// counted across stage boundaries, so we keep track of which layer we are in the
// full model.
fn repvgg_stage(cfg: &Config, idx: usize, vb: VarBuilder) -> Result<Func<'static>> {
let nlayers = cfg.stages[idx - 1];
let mut layers = Vec::with_capacity(nlayers);
let prev_layers: usize = cfg.stages[..idx - 1].iter().sum();
let out_channels_prev = output_channels_per_stage(cfg.a, cfg.b, idx - 1);
let out_channels = output_channels_per_stage(cfg.a, cfg.b, idx);
for layer_idx in 0..nlayers {
let (has_identity, stride, in_channels) = if layer_idx == 0 {
(false, 2, out_channels_prev)
} else {
(true, 1, out_channels)
};
let groups = if (prev_layers + layer_idx) % 2 == 1 {
cfg.groups
} else {
1
};
layers.push(repvgg_layer(
has_identity,
out_channels,
stride,
in_channels,
out_channels,
groups,
vb.pp(layer_idx),
)?)
}
Ok(Func::new(move |xs| {
let mut xs = xs.clone();
for layer in layers.iter() {
xs = xs.apply(layer)?
}
Ok(xs)
}))
}
// Build a RepVGG model for a given configuration.
fn repvgg_model(config: &Config, nclasses: Option<usize>, vb: VarBuilder) -> Result<Func<'static>> {
let cls = match nclasses {
None => None,
Some(nclasses) => {
let outputs = output_channels_per_stage(config.a, config.b, 4);
let linear = linear(outputs, nclasses, vb.pp("head.fc"))?;
Some(linear)
}
};
let stem_dim = output_channels_per_stage(config.a, config.b, 0);
let stem = repvgg_layer(false, stem_dim, 2, 3, stem_dim, 1, vb.pp("stem"))?;
let vb = vb.pp("stages");
let stage1 = repvgg_stage(config, 1, vb.pp(0))?;
let stage2 = repvgg_stage(config, 2, vb.pp(1))?;
let stage3 = repvgg_stage(config, 3, vb.pp(2))?;
let stage4 = repvgg_stage(config, 4, vb.pp(3))?;
Ok(Func::new(move |xs| {
let xs = xs
.apply(&stem)?
.apply(&stage1)?
.apply(&stage2)?
.apply(&stage3)?
.apply(&stage4)?
.mean(D::Minus1)?
.mean(D::Minus1)?;
match &cls {
None => Ok(xs),
Some(cls) => xs.apply(cls),
}
}))
}
pub fn repvgg(cfg: &Config, nclasses: usize, vb: VarBuilder) -> Result<Func<'static>> {
repvgg_model(cfg, Some(nclasses), vb)
}
pub fn repvgg_no_final_layer(cfg: &Config, vb: VarBuilder) -> Result<Func<'static>> {
repvgg_model(cfg, None, vb)
}
| 7 |
0 | hf_public_repos/candle/candle-transformers/src | hf_public_repos/candle/candle-transformers/src/models/llama2_c_weights.rs | //! Llama2 inference implementation.
//!
//! See ["LLaMA 2: Open Foundation and Fine-Tuned Chat Models"](https://arxiv.org/abs/2307.09288)
//!
//! Based on the [llama2.c](https://github.com/karpathy/llama2.c) implementation
use byteorder::{LittleEndian, ReadBytesExt};
use candle::{DType, Device, IndexOp, Result, Shape, Tensor};
use candle_nn::VarBuilder;
use super::llama2_c::Config;
pub struct TransformerWeights {
// token embedding table
token_embedding_table: Tensor, // (vocab_size, dim)
// weights for rmsnorms
rms_att_weight: Tensor, // (layer, dim) rmsnorm weights
rms_ffn_weight: Tensor, // (layer, dim)
// weights for matmuls
wq: Tensor, // (layer, dim, dim)
wk: Tensor, // (layer, dim, dim)
wv: Tensor, // (layer, dim, dim)
wo: Tensor, // (layer, dim, dim)
// weights for ffn
w1: Tensor, // (layer, hidden_dim, dim)
w2: Tensor, // (layer, dim, hidden_dim)
w3: Tensor, // (layer, hidden_dim, dim)
// final rmsnorm
rms_final_weight: Tensor, // (dim,)
// freq_cis for RoPE relatively positional embeddings
freq_cis_real: Tensor, // (seq_len, head_size/2)
freq_cis_imag: Tensor, // (seq_len, head_size/2)
}
fn read_i32<R: std::io::Read>(r: &mut R) -> Result<i32> {
let mut buf = [0u8; 4];
r.read_exact(&mut buf)?;
Ok(i32::from_le_bytes(buf))
}
fn read_tensor<R: std::io::Read, S: Into<Shape>>(
r: &mut R,
shape: S,
dev: &Device,
) -> Result<Tensor> {
let shape = shape.into();
let mut data_t = vec![0f32; shape.elem_count()];
r.read_f32_into::<LittleEndian>(&mut data_t)?;
let tensor = Tensor::from_vec(data_t, shape, dev)?;
Ok(tensor)
}
impl Config {
pub fn from_reader<R: std::io::Read>(r: &mut R) -> Result<Self> {
let dim = read_i32(r)? as usize;
let hidden_dim = read_i32(r)? as usize;
let n_layers = read_i32(r)? as usize;
let n_heads = read_i32(r)? as usize;
let n_kv_heads = read_i32(r)? as usize;
let vocab_size = read_i32(r)? as usize;
let seq_len = read_i32(r)? as usize;
Ok(Self {
dim,
hidden_dim,
n_layers,
n_heads,
n_kv_heads,
vocab_size,
seq_len,
norm_eps: 1e-5,
})
}
pub fn head_size(&self) -> usize {
self.dim / self.n_heads
}
}
impl TransformerWeights {
pub fn from_reader<R: std::io::Read>(r: &mut R, c: &Config, dev: &Device) -> Result<Self> {
let token_embedding_table = read_tensor(r, (c.vocab_size, c.dim), dev)?;
let rms_att_weight = read_tensor(r, (c.n_layers, c.dim), dev)?;
let wq = read_tensor(r, (c.n_layers, c.dim, c.dim), dev)?;
let wk = read_tensor(r, (c.n_layers, c.dim, c.dim), dev)?;
let wv = read_tensor(r, (c.n_layers, c.dim, c.dim), dev)?;
let wo = read_tensor(r, (c.n_layers, c.dim, c.dim), dev)?;
let rms_ffn_weight = read_tensor(r, (c.n_layers, c.dim), dev)?;
let w1 = read_tensor(r, (c.n_layers, c.hidden_dim, c.dim), dev)?;
let w2 = read_tensor(r, (c.n_layers, c.dim, c.hidden_dim), dev)?;
let w3 = read_tensor(r, (c.n_layers, c.hidden_dim, c.dim), dev)?;
let rms_final_weight = read_tensor(r, c.dim, dev)?;
let head_size = c.head_size();
let freq_cis_real = read_tensor(r, (c.seq_len, head_size / 2), dev)?;
let freq_cis_imag = read_tensor(r, (c.seq_len, head_size / 2), dev)?;
Ok(Self {
token_embedding_table,
rms_att_weight,
wq,
wk,
wv,
wo,
rms_ffn_weight,
w1,
w2,
w3,
rms_final_weight,
freq_cis_real,
freq_cis_imag,
})
}
pub fn var_builder(&self, cfg: &Config, device: &Device) -> Result<VarBuilder<'static>> {
// TODO: As of 2023-08-04, gemm is slower than expected when multiplying a matrix of
// size (1, k) with the transpose of a matrix of size (k, n) as it ends up transposing the
// second matrix back. We detect this case here and as a temporary hack make the weight
// matrix column major rather than row major. This ends up speeding up text generation from
// 120 token/s to 220 token/s on a Ryzen 2600X.
let tr = device.is_cpu() && !candle::utils::has_mkl();
let tr = |x: Tensor| if tr { x.t()?.contiguous()?.t() } else { Ok(x) };
let mut ws = std::collections::HashMap::new();
let mut insert = |name: &str, t: Tensor| {
ws.insert(name.to_string(), t);
};
insert("rot.freq_cis_real", self.freq_cis_real.clone());
insert("rot.freq_cis_imag", self.freq_cis_imag.clone());
insert(
"model.embed_tokens.weight",
self.token_embedding_table.clone(),
);
insert("lm_head.weight", tr(self.token_embedding_table.clone())?);
insert("model.norm.weight", self.rms_final_weight.clone());
for layer in 0..cfg.n_layers {
ws.insert(
format!("model.layers.{layer}.self_attn.q_proj.weight"),
tr(self.wq.i(layer)?)?,
);
ws.insert(
format!("model.layers.{layer}.self_attn.k_proj.weight"),
tr(self.wk.i(layer)?)?,
);
ws.insert(
format!("model.layers.{layer}.self_attn.v_proj.weight"),
tr(self.wv.i(layer)?)?,
);
ws.insert(
format!("model.layers.{layer}.self_attn.o_proj.weight"),
tr(self.wo.i(layer)?)?,
);
ws.insert(
format!("model.layers.{layer}.mlp.gate_proj.weight"),
tr(self.w1.i(layer)?)?,
);
ws.insert(
format!("model.layers.{layer}.mlp.down_proj.weight"),
tr(self.w2.i(layer)?)?,
);
ws.insert(
format!("model.layers.{layer}.mlp.up_proj.weight"),
tr(self.w3.i(layer)?)?,
);
ws.insert(
format!("model.layers.{layer}.input_layernorm.weight"),
self.rms_att_weight.i(layer)?,
);
ws.insert(
format!("model.layers.{layer}.post_attention_layernorm.weight"),
self.rms_ffn_weight.i(layer)?,
);
}
let vb = VarBuilder::from_tensors(ws, DType::F32, device);
Ok(vb)
}
}
| 8 |
0 | hf_public_repos/candle/candle-transformers/src | hf_public_repos/candle/candle-transformers/src/models/quantized_phi.rs | //! Phi2 model implementation with quantization support.
//!
//! Phi2 is a 2.7B parameter language model using scaled-up Transformer decoder architecture.
//! This implementation provides quantization for reduced memory and compute usage.
//!
//! Key characteristics:
//! - Partial attention with learned mixing to reduce quadratic costs
//! - Layer reuse for improved inference efficiency
//! - Linear transformations with scalar mixing
//! - Rotary positional embeddings (RoPE)
//! - Support for 8-bit quantization
//!
//! References:
//! - [Phi2 Paper](https://arxiv.org/abs/2309.05463)
//! - [Model Card](https://huggingface.co/microsoft/phi-2)
//!
use std::collections::HashMap;
use candle::quantized::gguf_file;
use candle::quantized::QTensor;
use candle::{DType, Device, IndexOp, Module, Result, Tensor, D};
use candle_nn::{Embedding, LayerNorm};
pub const MAX_SEQ_LEN: usize = 4096;
#[derive(Debug, Clone)]
struct QLinear {
inner: candle::quantized::QMatMul,
bias: Tensor,
span: tracing::Span,
}
impl QLinear {
fn new<R: std::io::Read + std::io::Seek>(
ct: &gguf_file::Content,
r: &mut R,
name: &str,
device: &Device,
) -> Result<Self> {
let span = tracing::span!(tracing::Level::TRACE, "qmatmul");
let w = ct.tensor(r, &format!("{name}.weight"), device)?;
let b = ct.tensor(r, &format!("{name}.bias"), device)?;
let inner = candle::quantized::QMatMul::from_qtensor(w)?;
let bias = b.dequantize(device)?;
Ok(Self { inner, bias, span })
}
}
impl Module for QLinear {
fn forward(&self, xs: &Tensor) -> Result<Tensor> {
let _enter = self.span.enter();
self.inner.forward(xs)?.broadcast_add(&self.bias)
}
}
#[derive(Debug, Clone)]
struct Mlp {
ffn_up: QLinear,
ffn_down: QLinear,
}
impl Module for Mlp {
fn forward(&self, xs: &Tensor) -> Result<Tensor> {
xs.apply(&self.ffn_up)?.gelu()?.apply(&self.ffn_down)
}
}
#[derive(Debug, Clone)]
struct LayerWeights {
attn_qkv: QLinear,
attn_output: QLinear,
attn_norm: LayerNorm,
mlp: Mlp,
n_head: usize,
n_kv_head: usize,
head_dim: usize,
cos: Tensor,
sin: Tensor,
rope_dim: usize,
neg_inf: Tensor,
kv_cache: Option<(Tensor, Tensor)>,
span_attn: tracing::Span,
span_rot: tracing::Span,
}
fn masked_fill(on_false: &Tensor, mask: &Tensor, on_true: &Tensor) -> Result<Tensor> {
let shape = mask.shape();
let m = mask.where_cond(&on_true.broadcast_as(shape.dims())?, on_false)?;
Ok(m)
}
impl LayerWeights {
fn apply_rotary_emb(&self, xs: &Tensor, index_pos: usize) -> Result<Tensor> {
let _enter = self.span_rot.enter();
let (_b_sz, _n_head, seq_len, _n_embd) = xs.dims4()?;
let xs_rot = xs.i((.., .., .., ..self.rope_dim))?;
let xs_pass = xs.i((.., .., .., self.rope_dim..))?;
let cos = self.cos.narrow(0, index_pos, seq_len)?;
let sin = self.sin.narrow(0, index_pos, seq_len)?;
let xs_rot = candle_nn::rotary_emb::rope(&xs_rot.contiguous()?, &cos, &sin)?;
Tensor::cat(&[&xs_rot, &xs_pass], D::Minus1)
}
fn forward_attn(
&mut self,
x: &Tensor,
mask: Option<&Tensor>,
index_pos: usize,
) -> Result<Tensor> {
let _enter = self.span_attn.enter();
let (b_sz, seq_len, n_embd) = x.dims3()?;
let qkv =
self.attn_qkv
.forward(x)?
.reshape((b_sz, seq_len, 3, self.n_head, self.head_dim))?;
let q = qkv.i((.., .., 0))?.transpose(1, 2)?;
let k = qkv.i((.., .., 1))?.transpose(1, 2)?;
let v = qkv.i((.., .., 2))?.transpose(1, 2)?;
// This call to contiguous ensures that the fast kernel can be called below. It's
// actually a no-op except when processing the initial prompt so has no significant
// impact on performance.
let v = v.contiguous()?;
let q = self.apply_rotary_emb(&q, index_pos)?.contiguous()?;
let k = self.apply_rotary_emb(&k, index_pos)?;
let (k, v) = match &self.kv_cache {
None => (k.contiguous()?, v.contiguous()?),
Some((k_cache, v_cache)) => {
if index_pos == 0 {
(k.contiguous()?, v.contiguous()?)
} else {
let k = Tensor::cat(&[k_cache, &k], 2)?;
let v = Tensor::cat(&[v_cache, &v], 2)?;
(k.contiguous()?, v.contiguous()?)
}
}
};
self.kv_cache = Some((k.clone(), v.clone()));
let k = crate::utils::repeat_kv(k, self.n_head / self.n_kv_head)?;
let v = crate::utils::repeat_kv(v, self.n_head / self.n_kv_head)?;
let att = (q.matmul(&k.t()?)? / (self.head_dim as f64).sqrt())?;
let att = match mask {
None => att,
Some(mask) => {
let mask = mask.broadcast_as(att.shape())?;
masked_fill(&att, &mask, &self.neg_inf)?
}
};
let att = candle_nn::ops::softmax_last_dim(&att)?;
// Convert to contiguous as matmul doesn't support strided vs for now.
let y = att.matmul(&v.contiguous()?)?;
let y = y.transpose(1, 2)?.reshape(&[b_sz, seq_len, n_embd])?;
let y = self.attn_output.forward(&y)?;
Ok(y)
}
}
#[derive(Debug, Clone)]
pub struct ModelWeights {
tok_embeddings: Embedding,
layers: Vec<LayerWeights>,
output_norm: LayerNorm,
output: QLinear,
masks: HashMap<usize, Tensor>,
span: tracing::Span,
span_output: tracing::Span,
}
fn precomput_freqs_cis(
head_dim: usize,
freq_base: f32,
device: &Device,
) -> Result<(Tensor, Tensor)> {
let theta: Vec<_> = (0..head_dim)
.step_by(2)
.map(|i| 1f32 / freq_base.powf(i as f32 / head_dim as f32))
.collect();
let theta = Tensor::new(theta.as_slice(), device)?;
let idx_theta = Tensor::arange(0, MAX_SEQ_LEN as u32, device)?
.to_dtype(DType::F32)?
.reshape((MAX_SEQ_LEN, 1))?
.matmul(&theta.reshape((1, theta.elem_count()))?)?;
let cos = idx_theta.cos()?;
let sin = idx_theta.sin()?;
Ok((cos, sin))
}
fn layer_norm(w: QTensor, b: QTensor, eps: f64) -> Result<LayerNorm> {
let w = w.dequantize(&w.device())?;
let b = b.dequantize(&b.device())?;
let ln = LayerNorm::new(w, b, eps);
Ok(ln)
}
impl ModelWeights {
pub fn from_gguf<R: std::io::Seek + std::io::Read>(
ct: gguf_file::Content,
reader: &mut R,
device: &Device,
) -> Result<Self> {
let md_get = |s: &str| match ct.metadata.get(s) {
None => candle::bail!("cannot find {s} in metadata"),
Some(v) => Ok(v),
};
// Parameter extraction from metadata.
let head_count = md_get("phi2.attention.head_count")?.to_u32()? as usize;
let head_count_kv = md_get("phi2.attention.head_count_kv")?.to_u32()? as usize;
let block_count = md_get("phi2.block_count")?.to_u32()? as usize;
let embedding_length = md_get("phi2.embedding_length")?.to_u32()? as usize;
let rope_dim = md_get("phi2.rope.dimension_count")?.to_u32()? as usize;
let ln_eps = md_get("phi2.attention.layer_norm_epsilon")?.to_f32()? as f64;
let (cos, sin) = precomput_freqs_cis(rope_dim, 10_000., device)?;
let neg_inf = Tensor::new(f32::NEG_INFINITY, device)?;
let tok_embeddings = ct.tensor(reader, "token_embd.weight", device)?;
let tok_embeddings = tok_embeddings.dequantize(device)?;
let output_norm = layer_norm(
ct.tensor(reader, "output_norm.weight", device)?,
ct.tensor(reader, "output_norm.bias", device)?,
ln_eps,
)?;
let output = QLinear::new(&ct, reader, "output", device)?;
let mut layers = Vec::with_capacity(block_count);
for layer_idx in 0..block_count {
let prefix = format!("blk.{layer_idx}");
let ffn_up = QLinear::new(&ct, reader, &format!("{prefix}.ffn_up"), device)?;
let ffn_down = QLinear::new(&ct, reader, &format!("{prefix}.ffn_down"), device)?;
let mlp = Mlp { ffn_up, ffn_down };
let attn_norm = layer_norm(
ct.tensor(reader, &format!("{prefix}.attn_norm.weight"), device)?,
ct.tensor(reader, &format!("{prefix}.attn_norm.bias"), device)?,
ln_eps,
)?;
let span_attn = tracing::span!(tracing::Level::TRACE, "attn");
let span_rot = tracing::span!(tracing::Level::TRACE, "attn-rot");
layers.push(LayerWeights {
attn_qkv: QLinear::new(&ct, reader, &format!("{prefix}.attn_qkv"), device)?,
attn_output: QLinear::new(&ct, reader, &format!("{prefix}.attn_output"), device)?,
attn_norm,
mlp,
n_head: head_count,
n_kv_head: head_count_kv,
head_dim: embedding_length / head_count,
cos: cos.clone(),
sin: sin.clone(),
rope_dim,
neg_inf: neg_inf.clone(),
kv_cache: None,
span_attn,
span_rot,
})
}
let span = tracing::span!(tracing::Level::TRACE, "model");
let span_output = tracing::span!(tracing::Level::TRACE, "output");
Ok(Self {
tok_embeddings: Embedding::new(tok_embeddings, embedding_length),
layers,
output_norm,
output,
masks: HashMap::new(),
span,
span_output,
})
}
fn mask(&mut self, t: usize, device: &Device) -> Result<Tensor> {
if let Some(mask) = self.masks.get(&t) {
Ok(mask.clone())
} else {
let mask: Vec<_> = (0..t)
.flat_map(|i| (0..t).map(move |j| u8::from(j > i)))
.collect();
let mask = Tensor::from_slice(&mask, (t, t), device)?;
self.masks.insert(t, mask.clone());
Ok(mask)
}
}
pub fn forward(&mut self, xs: &Tensor, index_pos: usize) -> Result<Tensor> {
let (_b_sz, seq_len) = xs.dims2()?;
let mask = if seq_len == 1 {
None
} else {
Some(self.mask(seq_len, xs.device())?)
};
let _enter = self.span.enter();
let mut xs = self.tok_embeddings.forward(xs)?;
for layer in self.layers.iter_mut() {
let residual = &xs;
let xs_norm = xs.apply(&layer.attn_norm)?;
let attn_outputs = layer.forward_attn(&xs_norm, mask.as_ref(), index_pos)?;
let feed_forward_hidden_states = layer.mlp.forward(&xs_norm)?;
xs = (attn_outputs + feed_forward_hidden_states + residual)?
}
let xs = xs.apply(&self.output_norm)?.i((.., seq_len - 1, ..))?;
let _enter = self.span_output.enter();
self.output.forward(&xs)
}
}
| 9 |
0 | hf_public_repos/autotrain-advanced/src/autotrain/trainers | hf_public_repos/autotrain-advanced/src/autotrain/trainers/clm/callbacks.py | import os
import torch
from peft import set_peft_model_state_dict
from transformers import TrainerCallback, TrainerControl, TrainerState, TrainingArguments
from transformers.trainer_utils import PREFIX_CHECKPOINT_DIR
class SavePeftModelCallback(TrainerCallback):
def on_save(
self,
args: TrainingArguments,
state: TrainerState,
control: TrainerControl,
**kwargs,
):
checkpoint_folder = os.path.join(args.output_dir, f"{PREFIX_CHECKPOINT_DIR}-{state.global_step}")
kwargs["model"].save_pretrained(checkpoint_folder)
pytorch_model_path = os.path.join(checkpoint_folder, "pytorch_model.bin")
torch.save({}, pytorch_model_path)
return control
class LoadBestPeftModelCallback(TrainerCallback):
def on_train_end(
self,
args: TrainingArguments,
state: TrainerState,
control: TrainerControl,
**kwargs,
):
print(f"Loading best peft model from {state.best_model_checkpoint} (score: {state.best_metric}).")
best_model_path = os.path.join(state.best_model_checkpoint, "adapter_model.bin")
adapters_weights = torch.load(best_model_path)
model = kwargs["model"]
set_peft_model_state_dict(model, adapters_weights)
return control
class SaveDeepSpeedPeftModelCallback(TrainerCallback):
def __init__(self, trainer, save_steps=500):
self.trainer = trainer
self.save_steps = save_steps
def on_step_end(
self,
args: TrainingArguments,
state: TrainerState,
control: TrainerControl,
**kwargs,
):
if (state.global_step + 1) % self.save_steps == 0:
self.trainer.accelerator.wait_for_everyone()
state_dict = self.trainer.accelerator.get_state_dict(self.trainer.deepspeed)
unwrapped_model = self.trainer.accelerator.unwrap_model(self.trainer.deepspeed)
if self.trainer.accelerator.is_main_process:
unwrapped_model.save_pretrained(args.output_dir, state_dict=state_dict)
self.trainer.accelerator.wait_for_everyone()
return control
| 0 |
0 | hf_public_repos/autotrain-advanced/src/autotrain/trainers | hf_public_repos/autotrain-advanced/src/autotrain/trainers/clm/params.py | from typing import List, Optional, Union
from pydantic import Field
from autotrain.trainers.common import AutoTrainParams
class LLMTrainingParams(AutoTrainParams):
"""
LLMTrainingParams: Parameters for training a language model using the autotrain library.
Attributes:
model (str): Model name to be used for training. Default is "gpt2".
project_name (str): Name of the project and output directory. Default is "project-name".
data_path (str): Path to the dataset. Default is "data".
train_split (str): Configuration for the training data split. Default is "train".
valid_split (Optional[str]): Configuration for the validation data split. Default is None.
add_eos_token (bool): Whether to add an EOS token at the end of sequences. Default is True.
block_size (Union[int, List[int]]): Size of the blocks for training, can be a single integer or a list of integers. Default is -1.
model_max_length (int): Maximum length of the model input. Default is 2048.
padding (Optional[str]): Side on which to pad sequences (left or right). Default is "right".
trainer (str): Type of trainer to use. Default is "default".
use_flash_attention_2 (bool): Whether to use flash attention version 2. Default is False.
log (str): Logging method for experiment tracking. Default is "none".
disable_gradient_checkpointing (bool): Whether to disable gradient checkpointing. Default is False.
logging_steps (int): Number of steps between logging events. Default is -1.
eval_strategy (str): Strategy for evaluation (e.g., 'epoch'). Default is "epoch".
save_total_limit (int): Maximum number of checkpoints to keep. Default is 1.
auto_find_batch_size (bool): Whether to automatically find the optimal batch size. Default is False.
mixed_precision (Optional[str]): Type of mixed precision to use (e.g., 'fp16', 'bf16', or None). Default is None.
lr (float): Learning rate for training. Default is 3e-5.
epochs (int): Number of training epochs. Default is 1.
batch_size (int): Batch size for training. Default is 2.
warmup_ratio (float): Proportion of training to perform learning rate warmup. Default is 0.1.
gradient_accumulation (int): Number of steps to accumulate gradients before updating. Default is 4.
optimizer (str): Optimizer to use for training. Default is "adamw_torch".
scheduler (str): Learning rate scheduler to use. Default is "linear".
weight_decay (float): Weight decay to apply to the optimizer. Default is 0.0.
max_grad_norm (float): Maximum norm for gradient clipping. Default is 1.0.
seed (int): Random seed for reproducibility. Default is 42.
chat_template (Optional[str]): Template for chat-based models, options include: None, zephyr, chatml, or tokenizer. Default is None.
quantization (Optional[str]): Quantization method to use (e.g., 'int4', 'int8', or None). Default is "int4".
target_modules (Optional[str]): Target modules for quantization or fine-tuning. Default is "all-linear".
merge_adapter (bool): Whether to merge the adapter layers. Default is False.
peft (bool): Whether to use Parameter-Efficient Fine-Tuning (PEFT). Default is False.
lora_r (int): Rank of the LoRA matrices. Default is 16.
lora_alpha (int): Alpha parameter for LoRA. Default is 32.
lora_dropout (float): Dropout rate for LoRA. Default is 0.05.
model_ref (Optional[str]): Reference model for DPO trainer. Default is None.
dpo_beta (float): Beta parameter for DPO trainer. Default is 0.1.
max_prompt_length (int): Maximum length of the prompt. Default is 128.
max_completion_length (Optional[int]): Maximum length of the completion. Default is None.
prompt_text_column (Optional[str]): Column name for the prompt text. Default is None.
text_column (str): Column name for the text data. Default is "text".
rejected_text_column (Optional[str]): Column name for the rejected text data. Default is None.
push_to_hub (bool): Whether to push the model to the Hugging Face Hub. Default is False.
username (Optional[str]): Hugging Face username for authentication. Default is None.
token (Optional[str]): Hugging Face token for authentication. Default is None.
unsloth (bool): Whether to use the unsloth library. Default is False.
distributed_backend (Optional[str]): Backend to use for distributed training. Default is None.
"""
model: str = Field("gpt2", title="Model name to be used for training")
project_name: str = Field("project-name", title="Name of the project and output directory")
# data params
data_path: str = Field("data", title="Path to the dataset")
train_split: str = Field("train", title="Configuration for the training data split")
valid_split: Optional[str] = Field(None, title="Configuration for the validation data split")
add_eos_token: bool = Field(True, title="Whether to add an EOS token at the end of sequences")
block_size: Union[int, List[int]] = Field(
-1, title="Size of the blocks for training, can be a single integer or a list of integers"
)
model_max_length: int = Field(2048, title="Maximum length of the model input")
padding: Optional[str] = Field("right", title="Side on which to pad sequences (left or right)")
# trainer params
trainer: str = Field("default", title="Type of trainer to use")
use_flash_attention_2: bool = Field(False, title="Whether to use flash attention version 2")
log: str = Field("none", title="Logging method for experiment tracking")
disable_gradient_checkpointing: bool = Field(False, title="Whether to disable gradient checkpointing")
logging_steps: int = Field(-1, title="Number of steps between logging events")
eval_strategy: str = Field("epoch", title="Strategy for evaluation (e.g., 'epoch')")
save_total_limit: int = Field(1, title="Maximum number of checkpoints to keep")
auto_find_batch_size: bool = Field(False, title="Whether to automatically find the optimal batch size")
mixed_precision: Optional[str] = Field(
None, title="Type of mixed precision to use (e.g., 'fp16', 'bf16', or None)"
)
lr: float = Field(3e-5, title="Learning rate for training")
epochs: int = Field(1, title="Number of training epochs")
batch_size: int = Field(2, title="Batch size for training")
warmup_ratio: float = Field(0.1, title="Proportion of training to perform learning rate warmup")
gradient_accumulation: int = Field(4, title="Number of steps to accumulate gradients before updating")
optimizer: str = Field("adamw_torch", title="Optimizer to use for training")
scheduler: str = Field("linear", title="Learning rate scheduler to use")
weight_decay: float = Field(0.0, title="Weight decay to apply to the optimizer")
max_grad_norm: float = Field(1.0, title="Maximum norm for gradient clipping")
seed: int = Field(42, title="Random seed for reproducibility")
chat_template: Optional[str] = Field(
None, title="Template for chat-based models, options include: None, zephyr, chatml, or tokenizer"
)
# peft
quantization: Optional[str] = Field("int4", title="Quantization method to use (e.g., 'int4', 'int8', or None)")
target_modules: Optional[str] = Field("all-linear", title="Target modules for quantization or fine-tuning")
merge_adapter: bool = Field(False, title="Whether to merge the adapter layers")
peft: bool = Field(False, title="Whether to use Parameter-Efficient Fine-Tuning (PEFT)")
lora_r: int = Field(16, title="Rank of the LoRA matrices")
lora_alpha: int = Field(32, title="Alpha parameter for LoRA")
lora_dropout: float = Field(0.05, title="Dropout rate for LoRA")
# dpo
model_ref: Optional[str] = Field(None, title="Reference model for DPO trainer")
dpo_beta: float = Field(0.1, title="Beta parameter for DPO trainer")
# orpo + dpo
max_prompt_length: int = Field(128, title="Maximum length of the prompt")
max_completion_length: Optional[int] = Field(None, title="Maximum length of the completion")
# column mappings
prompt_text_column: Optional[str] = Field(None, title="Column name for the prompt text")
text_column: str = Field("text", title="Column name for the text data")
rejected_text_column: Optional[str] = Field(None, title="Column name for the rejected text data")
# push to hub
push_to_hub: bool = Field(False, title="Whether to push the model to the Hugging Face Hub")
username: Optional[str] = Field(None, title="Hugging Face username for authentication")
token: Optional[str] = Field(None, title="Hugging Face token for authentication")
# unsloth
unsloth: bool = Field(False, title="Whether to use the unsloth library")
distributed_backend: Optional[str] = Field(None, title="Backend to use for distributed training")
| 1 |
0 | hf_public_repos/autotrain-advanced/src/autotrain/trainers | hf_public_repos/autotrain-advanced/src/autotrain/trainers/clm/train_clm_default.py | from functools import partial
import torch
from datasets import Dataset
from peft.tuners.lora import LoraLayer
from transformers import Trainer, TrainingArguments, default_data_collator
from transformers.trainer_callback import PrinterCallback
from autotrain import logger
from autotrain.trainers.clm import utils
from autotrain.trainers.clm.params import LLMTrainingParams
def process_data(data, tokenizer, config):
data = data.to_pandas()
data = data.fillna("")
data = data[[config.text_column]]
if config.add_eos_token:
data[config.text_column] = data[config.text_column] + tokenizer.eos_token
data = Dataset.from_pandas(data)
return data
def train(config):
logger.info("Starting default/generic CLM training...")
if isinstance(config, dict):
config = LLMTrainingParams(**config)
train_data, valid_data = utils.process_input_data(config)
tokenizer = utils.get_tokenizer(config)
train_data, valid_data = utils.process_data_with_chat_template(config, tokenizer, train_data, valid_data)
train_data = process_data(
data=train_data,
tokenizer=tokenizer,
config=config,
)
if config.valid_split is not None:
valid_data = process_data(
data=valid_data,
tokenizer=tokenizer,
config=config,
)
logging_steps = utils.configure_logging_steps(config, train_data, valid_data)
training_args = utils.configure_training_args(config, logging_steps)
config = utils.configure_block_size(config, tokenizer)
args = TrainingArguments(**training_args)
model = utils.get_model(config, tokenizer)
tokenize_fn = partial(utils.tokenize, tokenizer=tokenizer, config=config)
group_texts_fn = partial(utils.group_texts, config=config)
train_data = train_data.map(
tokenize_fn,
batched=True,
num_proc=1,
remove_columns=list(train_data.features),
desc="Running tokenizer on train dataset",
)
if config.valid_split is not None:
valid_data = valid_data.map(
tokenize_fn,
batched=True,
num_proc=1,
remove_columns=list(valid_data.features),
desc="Running tokenizer on validation dataset",
)
train_data = train_data.map(
group_texts_fn,
batched=True,
num_proc=4,
desc=f"Grouping texts in chunks of {config.block_size}",
)
if config.valid_split is not None:
valid_data = valid_data.map(
group_texts_fn,
batched=True,
num_proc=4,
desc=f"Grouping texts in chunks of {config.block_size}",
)
logger.info("creating trainer")
callbacks = utils.get_callbacks(config)
trainer_args = dict(
args=args,
model=model,
callbacks=callbacks,
)
trainer = Trainer(
**trainer_args,
train_dataset=train_data,
eval_dataset=valid_data if config.valid_split is not None else None,
tokenizer=tokenizer,
data_collator=default_data_collator,
)
for name, module in trainer.model.named_modules():
if isinstance(module, LoraLayer):
if config.mixed_precision == "bf16":
module = module.to(torch.bfloat16)
if "norm" in name:
module = module.to(torch.float32)
if any(x in name for x in ["lm_head", "embed_tokens", "wte", "wpe"]):
if hasattr(module, "weight"):
if config.mixed_precision == "bf16" and module.weight.dtype == torch.float32:
module = module.to(torch.bfloat16)
trainer.remove_callback(PrinterCallback)
trainer.train()
utils.post_training_steps(config, trainer)
| 2 |
0 | hf_public_repos/autotrain-advanced/src/autotrain/trainers | hf_public_repos/autotrain-advanced/src/autotrain/trainers/clm/train_clm_dpo.py | import torch
from peft import LoraConfig
from transformers import AutoConfig, AutoModelForCausalLM, BitsAndBytesConfig
from transformers.trainer_callback import PrinterCallback
from trl import DPOConfig, DPOTrainer
from autotrain import logger
from autotrain.trainers.clm import utils
from autotrain.trainers.clm.params import LLMTrainingParams
from autotrain.trainers.common import ALLOW_REMOTE_CODE
def train(config):
logger.info("Starting DPO training...")
if isinstance(config, dict):
config = LLMTrainingParams(**config)
train_data, valid_data = utils.process_input_data(config)
tokenizer = utils.get_tokenizer(config)
train_data, valid_data = utils.process_data_with_chat_template(config, tokenizer, train_data, valid_data)
logging_steps = utils.configure_logging_steps(config, train_data, valid_data)
training_args = utils.configure_training_args(config, logging_steps)
config = utils.configure_block_size(config, tokenizer)
training_args["max_length"] = config.block_size
training_args["max_prompt_length"] = config.max_prompt_length
training_args["max_target_length"] = config.max_completion_length
training_args["beta"] = config.dpo_beta
args = DPOConfig(**training_args)
logger.info("loading model config...")
model_config = AutoConfig.from_pretrained(
config.model,
token=config.token,
trust_remote_code=ALLOW_REMOTE_CODE,
use_cache=config.disable_gradient_checkpointing,
)
logger.info("loading model...")
if config.peft:
if config.quantization == "int4":
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.float16,
bnb_4bit_use_double_quant=False,
)
elif config.quantization == "int8":
bnb_config = BitsAndBytesConfig(load_in_8bit=True)
else:
bnb_config = None
model = AutoModelForCausalLM.from_pretrained(
config.model,
config=model_config,
token=config.token,
quantization_config=bnb_config,
trust_remote_code=ALLOW_REMOTE_CODE,
use_flash_attention_2=config.use_flash_attention_2,
)
logger.info("Using PEFT, model_ref will be set to None")
model_ref = None
else:
model = AutoModelForCausalLM.from_pretrained(
config.model,
config=model_config,
token=config.token,
trust_remote_code=ALLOW_REMOTE_CODE,
use_flash_attention_2=config.use_flash_attention_2,
)
if config.model_ref is not None:
model_ref = AutoModelForCausalLM.from_pretrained(
config.model_ref,
config=model_config,
token=config.token,
trust_remote_code=ALLOW_REMOTE_CODE,
use_flash_attention_2=config.use_flash_attention_2,
)
else:
model_ref = None
logger.info(f"model dtype: {model.dtype}")
model.resize_token_embeddings(len(tokenizer))
if model_ref is not None:
logger.info(f"model_ref dtype: {model_ref.dtype}")
model_ref.resize_token_embeddings(len(tokenizer))
if config.peft:
peft_config = LoraConfig(
r=config.lora_r,
lora_alpha=config.lora_alpha,
lora_dropout=config.lora_dropout,
bias="none",
task_type="CAUSAL_LM",
target_modules=utils.get_target_modules(config),
)
logger.info("creating trainer")
callbacks = utils.get_callbacks(config)
trainer_args = dict(
args=args,
model=model,
callbacks=callbacks,
)
trainer = DPOTrainer(
**trainer_args,
ref_model=model_ref,
train_dataset=train_data,
eval_dataset=valid_data if config.valid_split is not None else None,
processing_class=tokenizer,
peft_config=peft_config if config.peft else None,
)
trainer.remove_callback(PrinterCallback)
trainer.train()
utils.post_training_steps(config, trainer)
| 3 |
0 | hf_public_repos/autotrain-advanced/src/autotrain/trainers | hf_public_repos/autotrain-advanced/src/autotrain/trainers/vlm/utils.py | import os
import torch
from accelerate import PartialState
from huggingface_hub import HfApi
from peft import LoraConfig, PeftModel, get_peft_model, prepare_model_for_kbit_training
from transformers import AutoConfig, BitsAndBytesConfig, PaliGemmaForConditionalGeneration
from autotrain import logger
from autotrain.trainers.common import (
ALLOW_REMOTE_CODE,
LossLoggingCallback,
TrainStartCallback,
UploadLogs,
pause_space,
remove_autotrain_data,
save_training_params,
)
TARGET_MODULES = {}
SUPPORTED_MODELS = [
"PaliGemmaForConditionalGeneration",
# "Florence2ForConditionalGeneration", support later
]
MODEL_CARD = """
---
tags:
- autotrain
- text-generation-inference
- image-text-to-text
- text-generation{peft}
library_name: transformers{base_model}
license: other{dataset_tag}
---
# Model Trained Using AutoTrain
This model was trained using AutoTrain. For more information, please visit [AutoTrain](https://hf.co/docs/autotrain).
# Usage
```python
# you will need to adjust code if you didnt use peft
from PIL import Image
from transformers import PaliGemmaForConditionalGeneration, PaliGemmaProcessor
import torch
import requests
from peft import PeftModel
base_model_id = BASE_MODEL_ID
peft_model_id = THIS_MODEL_ID
max_new_tokens = 100
text = "Whats on the flower?"
img_url = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/tasks/bee.JPG?download=true"
image = Image.open(requests.get(img_url, stream=True).raw)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
base_model = PaliGemmaForConditionalGeneration.from_pretrained(base_model_id)
processor = PaliGemmaProcessor.from_pretrained(base_model_id)
model = PeftModel.from_pretrained(base_model, peft_model_id)
model.merge_and_unload()
model = model.eval().to(device)
inputs = processor(text=text, images=image, return_tensors="pt").to(device)
with torch.inference_mode():
generated_ids = model.generate(
**inputs,
max_new_tokens=max_new_tokens,
do_sample=False,
)
result = processor.batch_decode(generated_ids, skip_special_tokens=True)
print(result)
```
"""
def get_target_modules(config):
if config.target_modules is None:
return TARGET_MODULES.get(config.model)
if config.target_modules.strip() == "":
return TARGET_MODULES.get(config.model)
if config.target_modules.strip().lower() == "all-linear":
return "all-linear"
return config.target_modules.split(",")
def create_model_card(config):
if config.peft:
peft = "\n- peft"
else:
peft = ""
if config.data_path == f"{config.project_name}/autotrain-data" or os.path.isdir(config.data_path):
dataset_tag = ""
else:
dataset_tag = f"\ndatasets:\n- {config.data_path}"
if os.path.isdir(config.model):
base_model = ""
else:
base_model = f"\nbase_model: {config.model}"
model_card = MODEL_CARD.format(
dataset_tag=dataset_tag,
peft=peft,
base_model=base_model,
)
return model_card.strip()
def check_model_support(config):
api = HfApi(token=config.token)
model_info = api.model_info(config.model)
architectures = model_info.config.get("architectures", [])
for arch in architectures:
if arch in SUPPORTED_MODELS:
return True
return False
def configure_logging_steps(config, train_data, valid_data):
logger.info("configuring logging steps")
if config.logging_steps == -1:
if config.valid_split is not None:
logging_steps = int(0.2 * len(valid_data) / config.batch_size)
else:
logging_steps = int(0.2 * len(train_data) / config.batch_size)
if logging_steps == 0:
logging_steps = 1
if logging_steps > 25:
logging_steps = 25
config.logging_steps = logging_steps
else:
logging_steps = config.logging_steps
logger.info(f"Logging steps: {logging_steps}")
return logging_steps
def configure_training_args(config, logging_steps):
logger.info("configuring training args")
training_args = dict(
output_dir=config.project_name,
per_device_train_batch_size=config.batch_size,
per_device_eval_batch_size=config.batch_size,
learning_rate=config.lr,
num_train_epochs=config.epochs,
eval_strategy=config.eval_strategy if config.valid_split is not None else "no",
logging_steps=logging_steps,
save_total_limit=config.save_total_limit,
save_strategy=config.eval_strategy if config.valid_split is not None else "no",
gradient_accumulation_steps=config.gradient_accumulation,
report_to=config.log,
auto_find_batch_size=config.auto_find_batch_size,
lr_scheduler_type=config.scheduler,
optim=config.optimizer,
warmup_ratio=config.warmup_ratio,
weight_decay=config.weight_decay,
max_grad_norm=config.max_grad_norm,
push_to_hub=False,
load_best_model_at_end=True if config.valid_split is not None else False,
ddp_find_unused_parameters=False,
gradient_checkpointing=not config.disable_gradient_checkpointing,
remove_unused_columns=False,
)
if not config.disable_gradient_checkpointing:
if config.peft and config.quantization in ("int4", "int8"):
training_args["gradient_checkpointing_kwargs"] = {"use_reentrant": True}
else:
training_args["gradient_checkpointing_kwargs"] = {"use_reentrant": False}
if config.mixed_precision == "fp16":
training_args["fp16"] = True
if config.mixed_precision == "bf16":
training_args["bf16"] = True
return training_args
def get_callbacks(config):
callbacks = [UploadLogs(config=config), LossLoggingCallback(), TrainStartCallback()]
return callbacks
def get_model(config):
logger.info("loading model config...")
model_config = AutoConfig.from_pretrained(
config.model,
token=config.token,
trust_remote_code=ALLOW_REMOTE_CODE,
use_cache=config.disable_gradient_checkpointing,
)
logger.info("loading model...")
if config.peft:
if config.quantization == "int4":
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.float16,
bnb_4bit_use_double_quant=False,
)
elif config.quantization == "int8":
bnb_config = BitsAndBytesConfig(load_in_8bit=True)
else:
bnb_config = None
model = PaliGemmaForConditionalGeneration.from_pretrained(
config.model,
config=model_config,
token=config.token,
quantization_config=bnb_config,
trust_remote_code=ALLOW_REMOTE_CODE,
)
else:
model = PaliGemmaForConditionalGeneration.from_pretrained(
config.model,
config=model_config,
token=config.token,
trust_remote_code=ALLOW_REMOTE_CODE,
)
logger.info(f"model dtype: {model.dtype}")
if config.peft:
logger.info("preparing peft model...")
if config.quantization is not None:
gradient_checkpointing_kwargs = {}
if not config.disable_gradient_checkpointing:
if config.quantization in ("int4", "int8"):
gradient_checkpointing_kwargs = {"use_reentrant": True}
else:
gradient_checkpointing_kwargs = {"use_reentrant": False}
model = prepare_model_for_kbit_training(
model,
use_gradient_checkpointing=not config.disable_gradient_checkpointing,
gradient_checkpointing_kwargs=gradient_checkpointing_kwargs,
)
else:
model.enable_input_require_grads()
peft_config = LoraConfig(
r=config.lora_r,
lora_alpha=config.lora_alpha,
lora_dropout=config.lora_dropout,
bias="none",
task_type="CAUSAL_LM",
target_modules=get_target_modules(config),
)
model = get_peft_model(model, peft_config)
for param in model.vision_tower.parameters():
param.requires_grad = False
for param in model.multi_modal_projector.parameters():
param.requires_grad = False
return model
def merge_adapter(base_model_path, target_model_path, adapter_path):
logger.info("Loading adapter...")
model = PaliGemmaForConditionalGeneration.from_pretrained(
base_model_path,
torch_dtype=torch.float16,
low_cpu_mem_usage=True,
trust_remote_code=ALLOW_REMOTE_CODE,
)
model = PeftModel.from_pretrained(model, adapter_path)
model = model.merge_and_unload()
logger.info("Saving target model...")
model.save_pretrained(target_model_path)
def post_training_steps(config, trainer):
logger.info("Finished training, saving model...")
trainer.model.config.use_cache = True
trainer.save_model(config.project_name)
model_card = create_model_card(config)
# save model card to output directory as README.md
with open(f"{config.project_name}/README.md", "w", encoding="utf-8") as f:
f.write(model_card)
if config.peft and config.merge_adapter:
logger.info("Merging adapter weights...")
try:
del trainer
torch.cuda.empty_cache()
merge_adapter(
base_model_path=config.model,
target_model_path=config.project_name,
adapter_path=config.project_name,
)
# remove adapter weights: adapter_*
for file in os.listdir(config.project_name):
if file.startswith("adapter_"):
os.remove(f"{config.project_name}/{file}")
except Exception as e:
logger.warning(f"Failed to merge adapter weights: {e}")
logger.warning("Skipping adapter merge. Only adapter weights will be saved.")
if config.push_to_hub:
if PartialState().process_index == 0:
# remove data folder
remove_autotrain_data(config)
logger.info("Pushing model to hub...")
save_training_params(config)
api = HfApi(token=config.token)
api.create_repo(
repo_id=f"{config.username}/{config.project_name}", repo_type="model", private=True, exist_ok=True
)
api.upload_folder(
folder_path=config.project_name,
repo_id=f"{config.username}/{config.project_name}",
repo_type="model",
)
if PartialState().process_index == 0:
pause_space(config)
| 4 |
0 | hf_public_repos/autotrain-advanced/src/autotrain/trainers | hf_public_repos/autotrain-advanced/src/autotrain/trainers/vlm/train_vlm_generic.py | from functools import partial
from datasets import load_dataset, load_from_disk
from transformers import AutoProcessor, Trainer, TrainingArguments
from transformers.trainer_callback import PrinterCallback
from autotrain import logger
from autotrain.trainers.common import ALLOW_REMOTE_CODE
from autotrain.trainers.vlm import utils
def collate_fn(examples, config, processor):
prompts = ["answer " + example[config.prompt_text_column] for example in examples]
labels = [example[config.text_column] for example in examples]
images = [example[config.image_column].convert("RGB") for example in examples]
tokens = processor(
text=prompts,
images=images,
suffix=labels,
return_tensors="pt",
padding="longest",
tokenize_newline_separately=False,
)
return tokens
def train(config):
valid_data = None
if config.data_path == f"{config.project_name}/autotrain-data":
train_data = load_from_disk(config.data_path)[config.train_split]
else:
if ":" in config.train_split:
dataset_config_name, split = config.train_split.split(":")
train_data = load_dataset(
config.data_path,
name=dataset_config_name,
split=split,
token=config.token,
)
else:
train_data = load_dataset(
config.data_path,
split=config.train_split,
token=config.token,
)
if config.valid_split is not None:
if config.data_path == f"{config.project_name}/autotrain-data":
valid_data = load_from_disk(config.data_path)[config.valid_split]
else:
if ":" in config.valid_split:
dataset_config_name, split = config.valid_split.split(":")
valid_data = load_dataset(
config.data_path,
name=dataset_config_name,
split=split,
token=config.token,
)
else:
valid_data = load_dataset(
config.data_path,
split=config.valid_split,
token=config.token,
)
logger.info(f"Train data: {train_data}")
logger.info(f"Valid data: {valid_data}")
if config.trainer == "captioning":
config.prompt_text_column = "caption"
processor = AutoProcessor.from_pretrained(config.model, token=config.token, trust_remote_code=ALLOW_REMOTE_CODE)
logging_steps = utils.configure_logging_steps(config, train_data, valid_data)
training_args = utils.configure_training_args(config, logging_steps)
args = TrainingArguments(**training_args)
model = utils.get_model(config)
logger.info("creating trainer")
callbacks = utils.get_callbacks(config)
trainer_args = dict(
args=args,
model=model,
callbacks=callbacks,
)
col_fn = partial(collate_fn, config=config, processor=processor)
trainer = Trainer(
**trainer_args,
train_dataset=train_data,
eval_dataset=valid_data if valid_data is not None else None,
data_collator=col_fn,
)
trainer.remove_callback(PrinterCallback)
trainer.train()
utils.post_training_steps(config, trainer)
| 5 |
0 | hf_public_repos/autotrain-advanced/src/autotrain/trainers | hf_public_repos/autotrain-advanced/src/autotrain/trainers/vlm/__main__.py | import argparse
import json
from autotrain.trainers.common import monitor
from autotrain.trainers.vlm import utils
from autotrain.trainers.vlm.params import VLMTrainingParams
def parse_args():
# get training_config.json from the end user
parser = argparse.ArgumentParser()
parser.add_argument("--training_config", type=str, required=True)
return parser.parse_args()
@monitor
def train(config):
if isinstance(config, dict):
config = VLMTrainingParams(**config)
if not utils.check_model_support(config):
raise ValueError(f"model `{config.model}` not supported")
if config.trainer in ("vqa", "captioning"):
from autotrain.trainers.vlm.train_vlm_generic import train as train_generic
train_generic(config)
else:
raise ValueError(f"trainer `{config.trainer}` not supported")
if __name__ == "__main__":
_args = parse_args()
training_config = json.load(open(_args.training_config))
_config = VLMTrainingParams(**training_config)
train(_config)
| 6 |
0 | hf_public_repos/autotrain-advanced/src/autotrain/trainers | hf_public_repos/autotrain-advanced/src/autotrain/trainers/vlm/params.py | from typing import Optional
from pydantic import Field
from autotrain.trainers.common import AutoTrainParams
class VLMTrainingParams(AutoTrainParams):
"""
VLMTrainingParams
Attributes:
model (str): Model name. Default is "google/paligemma-3b-pt-224".
project_name (str): Output directory. Default is "project-name".
data_path (str): Data path. Default is "data".
train_split (str): Train data config. Default is "train".
valid_split (Optional[str]): Validation data config. Default is None.
trainer (str): Trainer type (captioning, vqa, segmentation, detection). Default is "vqa".
log (str): Logging using experiment tracking. Default is "none".
disable_gradient_checkpointing (bool): Gradient checkpointing. Default is False.
logging_steps (int): Logging steps. Default is -1.
eval_strategy (str): Evaluation strategy. Default is "epoch".
save_total_limit (int): Save total limit. Default is 1.
auto_find_batch_size (bool): Auto find batch size. Default is False.
mixed_precision (Optional[str]): Mixed precision (fp16, bf16, or None). Default is None.
lr (float): Learning rate. Default is 3e-5.
epochs (int): Number of training epochs. Default is 1.
batch_size (int): Training batch size. Default is 2.
warmup_ratio (float): Warmup proportion. Default is 0.1.
gradient_accumulation (int): Gradient accumulation steps. Default is 4.
optimizer (str): Optimizer. Default is "adamw_torch".
scheduler (str): Scheduler. Default is "linear".
weight_decay (float): Weight decay. Default is 0.0.
max_grad_norm (float): Max gradient norm. Default is 1.0.
seed (int): Seed. Default is 42.
quantization (Optional[str]): Quantization (int4, int8, or None). Default is "int4".
target_modules (Optional[str]): Target modules. Default is "all-linear".
merge_adapter (bool): Merge adapter. Default is False.
peft (bool): Use PEFT. Default is False.
lora_r (int): Lora r. Default is 16.
lora_alpha (int): Lora alpha. Default is 32.
lora_dropout (float): Lora dropout. Default is 0.05.
image_column (Optional[str]): Image column. Default is "image".
text_column (str): Text (answer) column. Default is "text".
prompt_text_column (Optional[str]): Prompt (prefix) column. Default is "prompt".
push_to_hub (bool): Push to hub. Default is False.
username (Optional[str]): Hugging Face Username. Default is None.
token (Optional[str]): Huggingface token. Default is None.
"""
model: str = Field("google/paligemma-3b-pt-224", title="Model name")
project_name: str = Field("project-name", title="Output directory")
# data params
data_path: str = Field("data", title="Data path")
train_split: str = Field("train", title="Train data config")
valid_split: Optional[str] = Field(None, title="Validation data config")
# trainer params
trainer: str = Field("vqa", title="Trainer type") # captioning, vqa, segmentation, detection
log: str = Field("none", title="Logging using experiment tracking")
disable_gradient_checkpointing: bool = Field(False, title="Gradient checkpointing")
logging_steps: int = Field(-1, title="Logging steps")
eval_strategy: str = Field("epoch", title="Evaluation strategy")
save_total_limit: int = Field(1, title="Save total limit")
auto_find_batch_size: bool = Field(False, title="Auto find batch size")
mixed_precision: Optional[str] = Field(None, title="fp16, bf16, or None")
lr: float = Field(3e-5, title="Learning rate")
epochs: int = Field(1, title="Number of training epochs")
batch_size: int = Field(2, title="Training batch size")
warmup_ratio: float = Field(0.1, title="Warmup proportion")
gradient_accumulation: int = Field(4, title="Gradient accumulation steps")
optimizer: str = Field("adamw_torch", title="Optimizer")
scheduler: str = Field("linear", title="Scheduler")
weight_decay: float = Field(0.0, title="Weight decay")
max_grad_norm: float = Field(1.0, title="Max gradient norm")
seed: int = Field(42, title="Seed")
# peft
quantization: Optional[str] = Field("int4", title="int4, int8, or None")
target_modules: Optional[str] = Field("all-linear", title="Target modules")
merge_adapter: bool = Field(False, title="Merge adapter")
peft: bool = Field(False, title="Use PEFT")
lora_r: int = Field(16, title="Lora r")
lora_alpha: int = Field(32, title="Lora alpha")
lora_dropout: float = Field(0.05, title="Lora dropout")
# column mappings
image_column: Optional[str] = Field("image", title="Image column")
text_column: str = Field("text", title="Text (answer) column")
prompt_text_column: Optional[str] = Field("prompt", title="Prompt (prefix) column")
# push to hub
push_to_hub: bool = Field(False, title="Push to hub")
username: Optional[str] = Field(None, title="Hugging Face Username")
token: Optional[str] = Field(None, title="Huggingface token")
| 7 |
0 | hf_public_repos/autotrain-advanced/src/autotrain/trainers | hf_public_repos/autotrain-advanced/src/autotrain/trainers/image_classification/utils.py | import os
import albumentations as A
import numpy as np
from sklearn import metrics
from autotrain.trainers.image_classification.dataset import ImageClassificationDataset
BINARY_CLASSIFICATION_EVAL_METRICS = (
"eval_loss",
"eval_accuracy",
"eval_f1",
"eval_auc",
"eval_precision",
"eval_recall",
)
MULTI_CLASS_CLASSIFICATION_EVAL_METRICS = (
"eval_loss",
"eval_accuracy",
"eval_f1_macro",
"eval_f1_micro",
"eval_f1_weighted",
"eval_precision_macro",
"eval_precision_micro",
"eval_precision_weighted",
"eval_recall_macro",
"eval_recall_micro",
"eval_recall_weighted",
)
MODEL_CARD = """
---
tags:
- autotrain
- image-classification{base_model}
widget:
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/tiger.jpg
example_title: Tiger
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/teapot.jpg
example_title: Teapot
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/palace.jpg
example_title: Palace{dataset_tag}
---
# Model Trained Using AutoTrain
- Problem type: Image Classification
## Validation Metrics
{validation_metrics}
"""
def _binary_classification_metrics(pred):
"""
Computes various binary classification metrics given the predictions and labels.
Args:
pred (tuple): A tuple containing raw predictions and true labels.
raw_predictions (numpy.ndarray): The raw prediction scores from the model.
labels (numpy.ndarray): The true labels.
Returns:
dict: A dictionary containing the following metrics:
- f1 (float): The F1 score.
- precision (float): The precision score.
- recall (float): The recall score.
- auc (float): The Area Under the ROC Curve (AUC) score.
- accuracy (float): The accuracy score.
"""
raw_predictions, labels = pred
predictions = np.argmax(raw_predictions, axis=1)
result = {
"f1": metrics.f1_score(labels, predictions),
"precision": metrics.precision_score(labels, predictions),
"recall": metrics.recall_score(labels, predictions),
"auc": metrics.roc_auc_score(labels, raw_predictions[:, 1]),
"accuracy": metrics.accuracy_score(labels, predictions),
}
return result
def _multi_class_classification_metrics(pred):
"""
Compute various classification metrics for multi-class classification.
Args:
pred (tuple): A tuple containing raw predictions and true labels.
- raw_predictions (numpy.ndarray): The raw prediction scores for each class.
- labels (numpy.ndarray): The true labels.
Returns:
dict: A dictionary containing the following metrics:
- "f1_macro": F1 score with macro averaging.
- "f1_micro": F1 score with micro averaging.
- "f1_weighted": F1 score with weighted averaging.
- "precision_macro": Precision score with macro averaging.
- "precision_micro": Precision score with micro averaging.
- "precision_weighted": Precision score with weighted averaging.
- "recall_macro": Recall score with macro averaging.
- "recall_micro": Recall score with micro averaging.
- "recall_weighted": Recall score with weighted averaging.
- "accuracy": Accuracy score.
"""
raw_predictions, labels = pred
predictions = np.argmax(raw_predictions, axis=1)
results = {
"f1_macro": metrics.f1_score(labels, predictions, average="macro"),
"f1_micro": metrics.f1_score(labels, predictions, average="micro"),
"f1_weighted": metrics.f1_score(labels, predictions, average="weighted"),
"precision_macro": metrics.precision_score(labels, predictions, average="macro"),
"precision_micro": metrics.precision_score(labels, predictions, average="micro"),
"precision_weighted": metrics.precision_score(labels, predictions, average="weighted"),
"recall_macro": metrics.recall_score(labels, predictions, average="macro"),
"recall_micro": metrics.recall_score(labels, predictions, average="micro"),
"recall_weighted": metrics.recall_score(labels, predictions, average="weighted"),
"accuracy": metrics.accuracy_score(labels, predictions),
}
return results
def process_data(train_data, valid_data, image_processor, config):
"""
Processes training and validation data for image classification.
Args:
train_data (Dataset): The training dataset.
valid_data (Dataset or None): The validation dataset. Can be None if no validation data is provided.
image_processor (ImageProcessor): An object containing image processing parameters such as size, mean, and std.
config (dict): Configuration dictionary containing additional parameters for dataset processing.
Returns:
tuple: A tuple containing the processed training dataset and the processed validation dataset (or None if no validation data is provided).
"""
if "shortest_edge" in image_processor.size:
size = image_processor.size["shortest_edge"]
else:
size = (image_processor.size["height"], image_processor.size["width"])
try:
height, width = size
except TypeError:
height = size
width = size
train_transforms = A.Compose(
[
A.RandomResizedCrop(height=height, width=width),
A.RandomRotate90(),
A.HorizontalFlip(p=0.5),
A.RandomBrightnessContrast(p=0.2),
A.Normalize(mean=image_processor.image_mean, std=image_processor.image_std),
]
)
val_transforms = A.Compose(
[
A.Resize(height=height, width=width),
A.Normalize(mean=image_processor.image_mean, std=image_processor.image_std),
]
)
train_data = ImageClassificationDataset(train_data, train_transforms, config)
if valid_data is not None:
valid_data = ImageClassificationDataset(valid_data, val_transforms, config)
return train_data, valid_data
return train_data, None
def create_model_card(config, trainer, num_classes):
"""
Generates a model card for the given configuration and trainer.
Args:
config (object): Configuration object containing various settings.
trainer (object): Trainer object used for model training and evaluation.
num_classes (int): Number of classes in the classification task.
Returns:
str: A formatted string representing the model card.
The function evaluates the model if a validation split is provided in the config.
It then formats the evaluation scores based on whether the task is binary or multi-class classification.
If no validation split is provided, it notes that no validation metrics are available.
The function also checks the data path and model path in the config to determine if they are directories.
Based on these checks, it formats the dataset tag and base model information accordingly.
Finally, it uses the formatted information to create and return the model card string.
"""
if config.valid_split is not None:
eval_scores = trainer.evaluate()
valid_metrics = (
BINARY_CLASSIFICATION_EVAL_METRICS if num_classes == 2 else MULTI_CLASS_CLASSIFICATION_EVAL_METRICS
)
eval_scores = [f"{k[len('eval_'):]}: {v}" for k, v in eval_scores.items() if k in valid_metrics]
eval_scores = "\n\n".join(eval_scores)
else:
eval_scores = "No validation metrics available"
if config.data_path == f"{config.project_name}/autotrain-data" or os.path.isdir(config.data_path):
dataset_tag = ""
else:
dataset_tag = f"\ndatasets:\n- {config.data_path}"
if os.path.isdir(config.model):
base_model = ""
else:
base_model = f"\nbase_model: {config.model}"
model_card = MODEL_CARD.format(
dataset_tag=dataset_tag,
validation_metrics=eval_scores,
base_model=base_model,
)
return model_card
| 8 |
0 | hf_public_repos/autotrain-advanced/src/autotrain/trainers | hf_public_repos/autotrain-advanced/src/autotrain/trainers/image_classification/__main__.py | import argparse
import json
from accelerate.state import PartialState
from datasets import load_dataset, load_from_disk
from huggingface_hub import HfApi
from transformers import (
AutoConfig,
AutoImageProcessor,
AutoModelForImageClassification,
EarlyStoppingCallback,
Trainer,
TrainingArguments,
)
from transformers.trainer_callback import PrinterCallback
from autotrain import logger
from autotrain.trainers.common import (
ALLOW_REMOTE_CODE,
LossLoggingCallback,
TrainStartCallback,
UploadLogs,
monitor,
pause_space,
remove_autotrain_data,
save_training_params,
)
from autotrain.trainers.image_classification import utils
from autotrain.trainers.image_classification.params import ImageClassificationParams
def parse_args():
# get training_config.json from the end user
parser = argparse.ArgumentParser()
parser.add_argument("--training_config", type=str, required=True)
return parser.parse_args()
@monitor
def train(config):
if isinstance(config, dict):
config = ImageClassificationParams(**config)
valid_data = None
if config.data_path == f"{config.project_name}/autotrain-data":
train_data = load_from_disk(config.data_path)[config.train_split]
else:
if ":" in config.train_split:
dataset_config_name, split = config.train_split.split(":")
train_data = load_dataset(
config.data_path,
name=dataset_config_name,
split=split,
token=config.token,
trust_remote_code=ALLOW_REMOTE_CODE,
)
else:
train_data = load_dataset(
config.data_path,
split=config.train_split,
token=config.token,
trust_remote_code=ALLOW_REMOTE_CODE,
)
if config.valid_split is not None:
if config.data_path == f"{config.project_name}/autotrain-data":
valid_data = load_from_disk(config.data_path)[config.valid_split]
else:
if ":" in config.valid_split:
dataset_config_name, split = config.valid_split.split(":")
valid_data = load_dataset(
config.data_path,
name=dataset_config_name,
split=split,
token=config.token,
trust_remote_code=ALLOW_REMOTE_CODE,
)
else:
valid_data = load_dataset(
config.data_path,
split=config.valid_split,
token=config.token,
trust_remote_code=ALLOW_REMOTE_CODE,
)
logger.info(f"Train data: {train_data}")
logger.info(f"Valid data: {valid_data}")
classes = train_data.features[config.target_column].names
logger.info(f"Classes: {classes}")
label2id = {c: i for i, c in enumerate(classes)}
num_classes = len(classes)
if num_classes < 2:
raise ValueError("Invalid number of classes. Must be greater than 1.")
if config.valid_split is not None:
num_classes_valid = len(valid_data.unique(config.target_column))
if num_classes_valid != num_classes:
raise ValueError(
f"Number of classes in train and valid are not the same. Training has {num_classes} and valid has {num_classes_valid}"
)
model_config = AutoConfig.from_pretrained(
config.model,
num_labels=num_classes,
trust_remote_code=ALLOW_REMOTE_CODE,
token=config.token,
)
model_config._num_labels = len(label2id)
model_config.label2id = label2id
model_config.id2label = {v: k for k, v in label2id.items()}
try:
model = AutoModelForImageClassification.from_pretrained(
config.model,
config=model_config,
trust_remote_code=ALLOW_REMOTE_CODE,
token=config.token,
ignore_mismatched_sizes=True,
)
except OSError:
model = AutoModelForImageClassification.from_pretrained(
config.model,
config=model_config,
from_tf=True,
trust_remote_code=ALLOW_REMOTE_CODE,
token=config.token,
ignore_mismatched_sizes=True,
)
image_processor = AutoImageProcessor.from_pretrained(
config.model,
token=config.token,
trust_remote_code=ALLOW_REMOTE_CODE,
)
train_data, valid_data = utils.process_data(train_data, valid_data, image_processor, config)
if config.logging_steps == -1:
if config.valid_split is not None:
logging_steps = int(0.2 * len(valid_data) / config.batch_size)
else:
logging_steps = int(0.2 * len(train_data) / config.batch_size)
if logging_steps == 0:
logging_steps = 1
if logging_steps > 25:
logging_steps = 25
config.logging_steps = logging_steps
else:
logging_steps = config.logging_steps
logger.info(f"Logging steps: {logging_steps}")
training_args = dict(
output_dir=config.project_name,
per_device_train_batch_size=config.batch_size,
per_device_eval_batch_size=2 * config.batch_size,
learning_rate=config.lr,
num_train_epochs=config.epochs,
eval_strategy=config.eval_strategy if config.valid_split is not None else "no",
logging_steps=logging_steps,
save_total_limit=config.save_total_limit,
save_strategy=config.eval_strategy if config.valid_split is not None else "no",
gradient_accumulation_steps=config.gradient_accumulation,
report_to=config.log,
auto_find_batch_size=config.auto_find_batch_size,
lr_scheduler_type=config.scheduler,
optim=config.optimizer,
warmup_ratio=config.warmup_ratio,
weight_decay=config.weight_decay,
max_grad_norm=config.max_grad_norm,
push_to_hub=False,
load_best_model_at_end=True if config.valid_split is not None else False,
ddp_find_unused_parameters=False,
)
if config.mixed_precision == "fp16":
training_args["fp16"] = True
if config.mixed_precision == "bf16":
training_args["bf16"] = True
if config.valid_split is not None:
early_stop = EarlyStoppingCallback(
early_stopping_patience=config.early_stopping_patience,
early_stopping_threshold=config.early_stopping_threshold,
)
callbacks_to_use = [early_stop]
else:
callbacks_to_use = []
callbacks_to_use.extend([UploadLogs(config=config), LossLoggingCallback(), TrainStartCallback()])
args = TrainingArguments(**training_args)
trainer_args = dict(
args=args,
model=model,
callbacks=callbacks_to_use,
compute_metrics=(
utils._binary_classification_metrics if num_classes == 2 else utils._multi_class_classification_metrics
),
)
trainer = Trainer(
**trainer_args,
train_dataset=train_data,
eval_dataset=valid_data,
)
trainer.remove_callback(PrinterCallback)
trainer.train()
logger.info("Finished training, saving model...")
trainer.save_model(config.project_name)
image_processor.save_pretrained(config.project_name)
model_card = utils.create_model_card(config, trainer, num_classes)
# save model card to output directory as README.md
with open(f"{config.project_name}/README.md", "w") as f:
f.write(model_card)
if config.push_to_hub:
if PartialState().process_index == 0:
remove_autotrain_data(config)
save_training_params(config)
logger.info("Pushing model to hub...")
api = HfApi(token=config.token)
api.create_repo(
repo_id=f"{config.username}/{config.project_name}", repo_type="model", private=True, exist_ok=True
)
api.upload_folder(
folder_path=config.project_name, repo_id=f"{config.username}/{config.project_name}", repo_type="model"
)
if PartialState().process_index == 0:
pause_space(config)
if __name__ == "__main__":
_args = parse_args()
training_config = json.load(open(_args.training_config))
_config = ImageClassificationParams(**training_config)
train(_config)
| 9 |
0 | hf_public_repos/accelerate/examples | hf_public_repos/accelerate/examples/deepspeed_config_templates/zero_stage2_offload_config.json | {
"fp16": {
"enabled": true,
"loss_scale": 0,
"loss_scale_window": 1000,
"initial_scale_power": 16,
"hysteresis": 2,
"min_loss_scale": 1
},
"optimizer": {
"type": "AdamW",
"params": {
"lr": "auto",
"weight_decay": "auto",
"torch_adam": true,
"adam_w_mode": true
}
},
"scheduler": {
"type": "WarmupDecayLR",
"params": {
"warmup_min_lr": "auto",
"warmup_max_lr": "auto",
"warmup_num_steps": "auto",
"total_num_steps": "auto"
}
},
"zero_optimization": {
"stage": 2,
"offload_optimizer": {
"device": "cpu",
"pin_memory": true
},
"allgather_partitions": true,
"allgather_bucket_size": 2e8,
"overlap_comm": true,
"reduce_scatter": true,
"reduce_bucket_size": "auto",
"contiguous_gradients": true
},
"gradient_accumulation_steps": 1,
"gradient_clipping": "auto",
"steps_per_print": 2000,
"train_batch_size": "auto",
"train_micro_batch_size_per_gpu": "auto",
"wall_clock_breakdown": false
} | 0 |
0 | hf_public_repos/accelerate/examples | hf_public_repos/accelerate/examples/deepspeed_config_templates/zero_stage3_offload_config.json | {
"fp16": {
"enabled": true,
"loss_scale": 0,
"loss_scale_window": 1000,
"initial_scale_power": 16,
"hysteresis": 2,
"min_loss_scale": 1
},
"optimizer": {
"type": "AdamW",
"params": {
"lr": "auto",
"weight_decay": "auto"
}
},
"scheduler": {
"type": "WarmupDecayLR",
"params": {
"warmup_min_lr": "auto",
"warmup_max_lr": "auto",
"warmup_num_steps": "auto",
"total_num_steps": "auto"
}
},
"zero_optimization": {
"stage": 3,
"offload_optimizer": {
"device": "cpu",
"pin_memory": true
},
"offload_param": {
"device": "cpu",
"pin_memory": true
},
"overlap_comm": true,
"contiguous_gradients": true,
"reduce_bucket_size": "auto",
"stage3_prefetch_bucket_size": "auto",
"stage3_param_persistence_threshold": "auto",
"sub_group_size": 1e9,
"stage3_max_live_parameters": 1e9,
"stage3_max_reuse_distance": 1e9,
"stage3_gather_16bit_weights_on_model_save": "auto"
},
"gradient_accumulation_steps": 1,
"gradient_clipping": "auto",
"steps_per_print": 2000,
"train_batch_size": "auto",
"train_micro_batch_size_per_gpu": "auto",
"wall_clock_breakdown": false
} | 1 |
0 | hf_public_repos/accelerate/examples | hf_public_repos/accelerate/examples/slurm/submit_multicpu.sh | #!/bin/bash -l
#SBATCH --job-name=multicpu
#SBATCH --nodes=2 # number of Nodes
#SBATCH --ntasks-per-node=1 # number of MP tasks
#SBATCH --exclusive
#SBATCH --output=O-%x.%j
#SBATCH --error=E-%x.%j
######################
### Set enviroment ###
######################
source activateEnvironment.sh
######################
#### Set network #####
######################
head_node_ip=$(scontrol show hostnames $SLURM_JOB_NODELIST | head -n 1)
######################
# Setup env variables for distributed jobs
export MASTER_PORT="${MASTER_PORT:-29555 }"
echo "head_node_ip=${head_node_ip}"
echo "MASTER_PORT=${MASTER_PORT}"
INSTANCES_PER_NODE="${INSTANCES_PER_NODE:-1}"
if [[ $SLURM_NNODES == 1 ]] && [[ $INSTANCES_PER_NODE == 1 ]]; then
export CCL_WORKER_COUNT=0
LAUNCHER=""
else
# Setup env variables for distributed jobs
export CCL_WORKER_COUNT="${CCL_WORKER_COUNT:-2}"
echo "CCL_WORKER_COUNT=${CCL_WORKER_COUNT}"
# Write hostfile
HOSTFILE_PATH=hostfile
scontrol show hostname $SLURM_JOB_NODELIST | perl -ne 'chomb; print "$_"x1'> ${HOSTFILE_PATH}
export LAUNCHER="accelerate launch \
--num_processes $((SLURM_NNODES * ${INSTANCES_PER_NODE})) \
--num_machines $SLURM_NNODES \
--rdzv_backend c10d \
--main_process_ip $head_node_ip \
--main_process_port $MASTER_PORT \
--mpirun_hostfile $HOSTFILE_PATH \
--mpirun_ccl $CCL_WORKER_COUNT"
fi
# This step is necessary because accelerate launch does not handle multiline arguments properly
export ACCELERATE_DIR="${ACCELERATE_DIR:-/accelerate}"
export SCRIPT="${ACCELERATE_DIR}/examples/complete_nlp_example.py"
export SCRIPT_ARGS=" \
--cpu \
--output_dir ${ACCELERATE_DIR}/examples/output \
"
# This step is necessary because accelerate launch does not handle multiline arguments properly
export CMD="$LAUNCHER $SCRIPT $SCRIPT_ARGS"
# Print the command
echo $CMD
echo ""
# Run the command
eval $CMD | 2 |
0 | hf_public_repos/accelerate/examples | hf_public_repos/accelerate/examples/slurm/submit_multinode.sh | #!/bin/bash
#SBATCH --job-name=multinode
#SBATCH -D .
#SBATCH --output=O-%x.%j
#SBATCH --error=E-%x.%j
#SBATCH --nodes=4 # number of nodes
#SBATCH --ntasks-per-node=1 # number of MP tasks
#SBATCH --gres=gpu:4 # number of GPUs per node
#SBATCH --cpus-per-task=160 # number of cores per tasks
#SBATCH --time=01:59:00 # maximum execution time (HH:MM:SS)
######################
### Set enviroment ###
######################
source activateEnvironment.sh
export GPUS_PER_NODE=4
######################
######################
#### Set network #####
######################
head_node_ip=$(scontrol show hostnames $SLURM_JOB_NODELIST | head -n 1)
######################
export LAUNCHER="accelerate launch \
--num_processes $((SLURM_NNODES * GPUS_PER_NODE)) \
--num_machines $SLURM_NNODES \
--rdzv_backend c10d \
--main_process_ip $head_node_ip \
--main_process_port 29500 \
"
export ACCELERATE_DIR="${ACCELERATE_DIR:-/accelerate}"
export SCRIPT="${ACCELERATE_DIR}/examples/complete_nlp_example.py"
export SCRIPT_ARGS=" \
--mixed_precision fp16 \
--output_dir ${ACCELERATE_DIR}/examples/output \
"
# This step is necessary because accelerate launch does not handle multiline arguments properly
export CMD="$LAUNCHER $PYTHON_FILE $ARGS"
srun $CMD | 3 |
0 | hf_public_repos/accelerate/examples | hf_public_repos/accelerate/examples/slurm/fsdp_config.yaml | distributed_type: FSDP
fsdp_config:
fsdp_activation_checkpointing: false
fsdp_auto_wrap_policy: TRANSFORMER_BASED_WRAP
fsdp_backward_prefetch: BACKWARD_PRE
fsdp_cpu_ram_efficient_loading: true
fsdp_forward_prefetch: false
fsdp_offload_params: false
fsdp_sharding_strategy: FULL_SHARD
fsdp_state_dict_type: SHARDED_STATE_DICT
fsdp_sync_module_states: true
fsdp_use_orig_params: true
| 4 |
0 | hf_public_repos/accelerate/examples | hf_public_repos/accelerate/examples/slurm/submit_multinode_fsdp.sh | #!/bin/bash
#SBATCH --job-name=multinode
#SBATCH -D .
#SBATCH --output=O-%x.%j
#SBATCH --error=E-%x.%j
#SBATCH --nodes=4 # number of nodes
#SBATCH --ntasks-per-node=1 # number of MP tasks
#SBATCH --gres=gpu:4 # number of GPUs per node
#SBATCH --cpus-per-task=160 # number of cores per tasks
#SBATCH --time=01:59:00 # maximum execution time (HH:MM:SS)
######################
### Set enviroment ###
######################
source activateEnvironment.sh
export GPUS_PER_NODE=4
######################
######################
#### Set network #####
######################
head_node_ip=$(scontrol show hostnames $SLURM_JOB_NODELIST | head -n 1)
######################
export ACCELERATE_DIR="${ACCELERATE_DIR:-/accelerate}"
export LAUNCHER="accelerate launch \
--config ${ACCELERATE_DIR}/examples/slurm/fsdp_config.yaml \
--num_processes $((SLURM_NNODES * GPUS_PER_NODE)) \
--num_machines $SLURM_NNODES \
--rdzv_backend c10d \
--main_process_ip $head_node_ip \
--main_process_port 29500 \
"
export SCRIPT="${ACCELERATE_DIR}/examples/complete_nlp_example.py"
export SCRIPT_ARGS=" \
--mixed_precision fp16 \
--output_dir ${ACCELERATE_DIR}/examples/output \
"
# This step is necessary because accelerate launch does not handle multiline arguments properly
export CMD="$LAUNCHER $SCRIPT $SCRIPT_ARGS"
srun $CMD | 5 |
0 | hf_public_repos/accelerate/examples | hf_public_repos/accelerate/examples/slurm/submit_multigpu.sh | #!/bin/bash
#SBATCH --job-name=multigpu
#SBATCH -D .
#SBATCH --output=O-%x.%j
#SBATCH --error=E-%x.%j
#SBATCH --nodes=1
#SBATCH --ntasks-per-node=1 # number of MP tasks
#SBATCH --gres=gpu:4 # number of GPUs per node
#SBATCH --cpus-per-task=160 # number of cores per tasks
#SBATCH --time=01:59:00 # maximum execution time (HH:MM:SS)
######################
### Set enviroment ###
######################
source activateEnvironment.sh
export GPUS_PER_NODE=4
######################
export ACCELERATE_DIR="${ACCELERATE_DIR:-/accelerate}"
export SCRIPT="${ACCELERATE_DIR}/examples/complete_nlp_example.py"
export SCRIPT_ARGS=" \
--mixed_precision fp16 \
--output_dir ${ACCELERATE_DIR}/examples/output \
--with_tracking \
"
accelerate launch --num_processes $GPUS_PER_NODE $SCRIPT $SCRIPT_ARGS | 6 |
0 | hf_public_repos/accelerate | hf_public_repos/accelerate/docker/README.md | <!---
Copyright 2024 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
-->
# Official Hugging Face Accelerate Docker Images
Accelerate publishes a variety of docker versions as part of our CI that users can also use. These are stable images that Accelerate can run off of which comes with a variety of different setup configurations, all of which are officially hosted on [Docker Hub](https://hub.docker.com/r/huggingface/accelerate).
A breakdown of each are given below
## Naming Conventions
Accelerate docker images follow a tagging convention of:
```bash
huggingface/accelerate:{accelerator}-{nightly,release}
```
`accelerator` in this instance is one of many applical pre-configured backend supports:
* `gpu`: Comes compiled off of the `nvidia/cuda` image and includes core parts like `bitsandbytes`. Runs off python 3.9.
* `cpu`: Comes compiled off of `python:3.9-slim` and is designed for non-CUDA based workloads.
* More to come soon
* `gpu-deepspeed`: Comes compiled off of the `nvidia/cuda` image and includes core parts like `bitsandbytes` as well as the latest `deepspeed` version. Runs off python 3.10.
* `gpu-fp8-transformerengine`: Comes compiled off of `nvcr.io/nvidia/pytorch` and is specifically for running the `benchmarks/fp8` scripts on devices which support FP8 operations using the `TransformerEngine` library (RTX 4090, H100, etc)
## Nightlies vs Releases
Each release a new build is pushed with a version number included in the name. For a GPU-supported image of version 0.28.0 for instance, it would look like the following:
```bash
huggingface/accelerate:gpu-release-0.28.0
```
Nightlies contain two different image tags. There is a general `nightly` tag which is built each night, and a `nightly-YYYY-MM-DD` which corresponds to a build from a particular date.
For instance, here is an example nightly CPU image from 3/14/2024
```bash
huggingface/accelerate:cpu-nightly-2024-03-14
```
## Running the images
Each image comes compiled with `conda` and an `accelerate` environment contains all of the installed dependencies.
To pull down the latest nightly run:
```bash
docker pull huggingface/accelerate:gpu-nightly
```
To then run it in interactive mode with GPU-memory available, run:
```bash
docker container run --gpus all -it huggingface/accelerate:gpu-nightly
```
## DEPRECATED IMAGES
CPU and GPU docker images were hosted at `huggingface/accelerate-gpu` and `huggingface/accelerate-cpu`. These builds are now outdated and will not receive updates.
The builds at the corresponding `huggingface/accelerate:{gpu,cpu}` contain the same `Dockerfile`, so it's as simple as changing the docker image to the desired ones from above. We will not be deleting these images for posterity, but they will not be receiving updates going forward. | 7 |
0 | hf_public_repos/accelerate/docker | hf_public_repos/accelerate/docker/accelerate-gpu/Dockerfile | # Builds GPU docker image of PyTorch specifically
# Uses multi-staged approach to reduce size
# Stage 1
# Use base conda image to reduce time
FROM continuumio/miniconda3:latest AS compile-image
# Specify py version
ENV PYTHON_VERSION=3.9
# Install apt libs
RUN apt-get update && \
apt-get install -y curl git wget && \
apt-get clean && \
rm -rf /var/lib/apt/lists*
# Create our conda env
RUN conda create --name accelerate python=${PYTHON_VERSION} ipython jupyter pip
# We don't install pytorch here yet since CUDA isn't available
# instead we use the direct torch wheel
ENV PATH /opt/conda/envs/accelerate/bin:$PATH
# Activate our bash shell
RUN chsh -s /bin/bash
SHELL ["/bin/bash", "-c"]
# Activate the conda env, install mpy4pi, and install torch + accelerate
RUN source activate accelerate && conda install -c conda-forge mpi4py
RUN source activate accelerate && \
python3 -m pip install --no-cache-dir \
git+https://github.com/huggingface/accelerate#egg=accelerate[testing,test_trackers] \
--extra-index-url https://download.pytorch.org/whl/cu117
RUN python3 -m pip install --no-cache-dir bitsandbytes
# Stage 2
FROM nvidia/cuda:12.1.0-cudnn8-devel-ubuntu20.04 AS build-image
COPY --from=compile-image /opt/conda /opt/conda
ENV PATH /opt/conda/bin:$PATH
# Install apt libs
RUN apt-get update && \
apt-get install -y curl git wget && \
apt-get clean && \
rm -rf /var/lib/apt/lists*
RUN echo "source activate accelerate" >> ~/.profile
# Activate the virtualenv
CMD ["/bin/bash"] | 8 |
0 | hf_public_repos/accelerate/docker | hf_public_repos/accelerate/docker/accelerate-gpu-deepspeed/Dockerfile | # Builds GPU docker image of PyTorch specifically
# Uses multi-staged approach to reduce size
# Stage 1
# Use base conda image to reduce time
FROM continuumio/miniconda3:latest AS compile-image
# Specify py version
# Note: DeepSpeed beyond v0.12.6 requires py 3.10
ENV PYTHON_VERSION=3.10
# Install apt libs
RUN apt-get update && \
apt-get install -y curl git wget && \
apt-get clean && \
rm -rf /var/lib/apt/lists*
# Create our conda env
RUN conda create --name accelerate python=${PYTHON_VERSION} ipython jupyter pip
# We don't install pytorch here yet since CUDA isn't available
# instead we use the direct torch wheel
ENV PATH /opt/conda/envs/accelerate/bin:$PATH
# Activate our bash shell
RUN chsh -s /bin/bash
SHELL ["/bin/bash", "-c"]
# Activate the conda env, install mpy4pi, and install torch + accelerate
RUN source activate accelerate && conda install -c conda-forge mpi4py
RUN source activate accelerate && \
python3 -m pip install --no-cache-dir \
git+https://github.com/huggingface/accelerate#egg=accelerate[testing,test_trackers,deepspeed] \
--extra-index-url https://download.pytorch.org/whl/cu117
RUN python3 -m pip install --no-cache-dir bitsandbytes
# Stage 2
FROM nvidia/cuda:12.1.0-cudnn8-devel-ubuntu20.04 AS build-image
COPY --from=compile-image /opt/conda /opt/conda
ENV PATH /opt/conda/bin:$PATH
# Install apt libs
RUN apt-get update && \
apt-get install -y curl git wget && \
apt-get clean && \
rm -rf /var/lib/apt/lists*
RUN echo "source activate accelerate" >> ~/.profile
# Activate the virtualenv
CMD ["/bin/bash"] | 9 |
0 | hf_public_repos/candle/candle-wasm-tests | hf_public_repos/candle/candle-wasm-tests/src/lib.rs | pub fn add(left: usize, right: usize) -> usize {
left + right
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn it_works() {
let result = add(2, 2);
assert_eq!(result, 4);
}
}
| 0 |
0 | hf_public_repos/candle/candle-wasm-tests | hf_public_repos/candle/candle-wasm-tests/tests/quantized_tests.rs | #![allow(unused)]
use candle::{
quantized::{self, k_quants, GgmlDType, GgmlType},
test_utils::to_vec2_round,
Device, Module, Result, Tensor,
};
use wasm_bindgen_test::*;
wasm_bindgen_test_configure!(run_in_browser);
#[wasm_bindgen_test]
fn quantized_matmul_neg() -> Result<()> {
let cpu = &Device::Cpu;
let (m, k, n) = (3, 64, 4);
let lhs = (0..(m * k))
.map(|v| v as f32 - (m * k) as f32 / 2.0)
.collect::<Vec<_>>();
let tensor_lhs = Tensor::from_slice(&lhs, (m, k), cpu)?;
let mut dst = vec![42.; 3 * 4];
let mut rhs_t = vec![k_quants::BlockQ4_0::zeros(); 8];
let rhs = (0..k * n)
.map(|v| v as f32 - (k * n) as f32 / 3.0)
.collect::<Vec<_>>();
let tensor_rhs = Tensor::from_slice(&rhs, (n, k), cpu)?.t()?;
k_quants::BlockQ4_0::from_float(&rhs, &mut rhs_t)?;
k_quants::matmul((m, k, n), &lhs, &rhs_t, &mut dst)?;
assert_eq!(
dst.iter().map(|x| x.round()).collect::<Vec<_>>(),
&[
243524.0, -19596.0, -285051.0, -549815.0, 23777.0, 21651.0, 19398.0, 18367.0,
-196472.0, 63012.0, 324585.0, 587902.0
]
);
let mm = tensor_lhs.matmul(&tensor_rhs)?;
assert_eq!(
to_vec2_round(&mm, 0)?,
&[
[244064.0, -20128.0, -284320.0, -548512.0],
[23563.0, 21515.0, 19467.0, 17419.0],
[-196939.0, 63157.0, 323253.0, 583349.0]
]
);
let qtensor = quantized::QTensor::new(quantized::QStorage::Cpu(Box::new(rhs_t)), (4, 64))?;
let matmul = quantized::QMatMul::from_qtensor(qtensor)?;
let res = matmul.forward(&tensor_lhs)?;
assert_eq!(
to_vec2_round(&res, 0)?,
&[
[243524.0, -19596.0, -285051.0, -549815.0],
[23777.0, 21651.0, 19398.0, 18367.0],
[-196472.0, 63012.0, 324585.0, 587902.0]
]
);
Ok(())
}
/// Creates a vector similarly to the one used in GGML unit tests: https://github.com/ggerganov/llama.cpp/blob/master/tests/test-quantize-fns.cpp#L26-L30
fn create_ggml_like_vector(offset: f32) -> Vec<f32> {
const GGML_TEST_SIZE: usize = 32 * 128;
(0..GGML_TEST_SIZE)
.map(|i| 0.1 + 2.0 * (i as f32 + offset).cos())
.collect()
}
/// Very simple dot product implementation
fn vec_dot_reference(a: &[f32], b: &[f32]) -> f32 {
a.iter().zip(b).map(|(a, b)| a * b).sum()
}
/// Returns the error achieved by the GGML matmul unit test.
fn ggml_reference_matmul_error(dtype: GgmlDType) -> Result<f32> {
let err = match dtype {
GgmlDType::F16 => 0.000010,
GgmlDType::Q2K => 0.004086,
GgmlDType::Q3K => 0.016148,
GgmlDType::Q4K => 0.002425,
GgmlDType::Q5K => 0.000740,
GgmlDType::Q6K => 0.000952,
GgmlDType::Q4_0 => 0.001143,
GgmlDType::Q4_1 => 0.007784,
GgmlDType::Q5_0 => 0.001353,
GgmlDType::Q5_1 => 0.001363,
GgmlDType::Q8_0 => 0.000092,
// Not from the ggml repo.
GgmlDType::Q8K => 0.00065,
_ => candle::bail!("No GGML results for quantization type {dtype:?}",),
};
Ok(err)
}
/// Mirrores the GGML matmul unit test: https://github.com/ggerganov/llama.cpp/blob/master/tests/test-quantize-fns.cpp#L76-L91
fn ggml_matmul_error_test<T: GgmlType>() -> Result<()> {
const GGML_MAX_DOT_PRODUCT_ERROR: f32 = 0.02;
let a = create_ggml_like_vector(0.0);
let b = create_ggml_like_vector(1.0);
let length = a.len();
let mut a_quant = vec![T::zeros(); length / T::BLCK_SIZE];
let mut b_quant = vec![T::VecDotType::zeros(); length / T::VecDotType::BLCK_SIZE];
T::from_float(&a, &mut a_quant)?;
T::VecDotType::from_float(&b, &mut b_quant)?;
let result = T::vec_dot(length, &a_quant, &b_quant)?;
let result_unopt = T::vec_dot_unopt(length, &a_quant, &b_quant)?;
let reference_result = vec_dot_reference(&a, &b);
if (result - result_unopt).abs() / length as f32 > 1e-6 {
candle::bail!(
"the opt and unopt vec-dot returned different values, opt {result}, unopt {result_unopt}"
)
}
let error = (result - reference_result).abs() / length as f32;
let ggml_error = ggml_reference_matmul_error(T::DTYPE)?;
if !error.is_finite() || error > GGML_MAX_DOT_PRODUCT_ERROR {
candle::bail!(
"Dot product error {} exceeds max error {}",
error,
GGML_MAX_DOT_PRODUCT_ERROR
);
}
// We diverge slightly due to different rounding behavior / f16 to f32 conversions in GGML
// => we use a slightly higher error threshold
const ERROR_LENIENCY: f32 = 0.00001;
if error - ERROR_LENIENCY > ggml_error {
candle::bail!(
"Dot product error {} exceeds ggml reference error {}",
error,
ggml_error
);
}
Ok(())
}
#[wasm_bindgen_test]
fn quantized_matmul_q40() -> Result<()> {
ggml_matmul_error_test::<candle::quantized::k_quants::BlockQ4_0>()?;
Ok(())
}
#[wasm_bindgen_test]
fn quantized_matmul_q50() -> Result<()> {
ggml_matmul_error_test::<candle::quantized::k_quants::BlockQ5_0>()?;
Ok(())
}
#[wasm_bindgen_test]
fn quantized_matmul_q80() -> Result<()> {
ggml_matmul_error_test::<candle::quantized::k_quants::BlockQ8_0>()?;
Ok(())
}
#[wasm_bindgen_test]
fn quantized_matmul_q2k() -> Result<()> {
ggml_matmul_error_test::<candle::quantized::k_quants::BlockQ2K>()?;
Ok(())
}
#[wasm_bindgen_test]
fn quantized_matmul_q3k() -> Result<()> {
ggml_matmul_error_test::<candle::quantized::k_quants::BlockQ3K>()?;
Ok(())
}
#[wasm_bindgen_test]
fn quantized_matmul_q4k() -> Result<()> {
ggml_matmul_error_test::<candle::quantized::k_quants::BlockQ4K>()?;
Ok(())
}
#[wasm_bindgen_test]
fn quantized_matmul_q5k() -> Result<()> {
ggml_matmul_error_test::<candle::quantized::k_quants::BlockQ5K>()?;
Ok(())
}
#[wasm_bindgen_test]
fn quantized_matmul_q6k() -> Result<()> {
ggml_matmul_error_test::<candle::quantized::k_quants::BlockQ6K>()?;
Ok(())
}
#[wasm_bindgen_test]
fn quantized_matmul_q8k() -> Result<()> {
ggml_matmul_error_test::<candle::quantized::k_quants::BlockQ8K>()?;
Ok(())
}
| 1 |
0 | hf_public_repos/candle | hf_public_repos/candle/candle-book/Cargo.toml | [package]
name = "candle-book"
version.workspace = true
edition.workspace = true
description.workspace = true
repository.workspace = true
keywords.workspace = true
categories.workspace = true
license.workspace = true
readme = "README.md"
[dependencies]
accelerate-src = { workspace = true, optional = true }
candle = { workspace = true }
candle-datasets = { workspace = true }
candle-nn = { workspace = true }
candle-transformers = { workspace = true }
candle-flash-attn = { workspace = true, optional = true }
safetensors = { workspace = true }
serde = { workspace = true }
serde_json = { workspace = true }
num-traits = { workspace = true }
intel-mkl-src = { workspace = true, optional = true }
cudarc = { workspace = true, optional = true }
half = { workspace = true, optional = true }
image = { workspace = true, optional = true }
anyhow = { workspace = true }
tokio = "1.29.1"
[dev-dependencies]
byteorder = { workspace = true }
hf-hub = { workspace = true, features=["tokio"]}
clap = { workspace = true }
memmap2 = { workspace = true }
rand = { workspace = true }
tokenizers = { workspace = true, features = ["onig"] }
tracing = { workspace = true }
tracing-chrome = { workspace = true }
tracing-subscriber = { workspace = true }
# Necessary to disambiguate with tokio in wasm examples which are 1.28.1
parquet = { workspace = true }
image = { workspace = true }
[build-dependencies]
anyhow = { workspace = true }
[features]
default = []
| 2 |
0 | hf_public_repos/candle | hf_public_repos/candle/candle-book/book.toml | [book]
authors = ["Nicolas Patry"]
language = "en"
multilingual = false
src = "src"
title = "Candle Documentation"
| 3 |
0 | hf_public_repos/candle/candle-book | hf_public_repos/candle/candle-book/src/lib.rs | #[cfg(test)]
pub mod simplified;
#[cfg(test)]
mod tests {
use anyhow::Result;
use candle::{DType, Device, Tensor};
use parquet::file::reader::SerializedFileReader;
// NOTE: Waiting on https://github.com/rust-lang/mdBook/pull/1856
#[rustfmt::skip]
#[tokio::test]
async fn book_hub_1() {
// ANCHOR: book_hub_1
use candle::Device;
use hf_hub::api::tokio::Api;
let api = Api::new().unwrap();
let repo = api.model("bert-base-uncased".to_string());
let weights_filename = repo.get("model.safetensors").await.unwrap();
let weights = candle::safetensors::load(weights_filename, &Device::Cpu).unwrap();
// ANCHOR_END: book_hub_1
assert_eq!(weights.len(), 206);
}
#[rustfmt::skip]
#[test]
fn book_hub_2() {
{
// ANCHOR: book_hub_2
use candle::Device;
use hf_hub::api::sync::Api;
use memmap2::Mmap;
use std::fs;
let api = Api::new().unwrap();
let repo = api.model("bert-base-uncased".to_string());
let weights_filename = repo.get("model.safetensors").unwrap();
let file = fs::File::open(weights_filename).unwrap();
let mmap = unsafe { Mmap::map(&file).unwrap() };
let weights = candle::safetensors::load_buffer(&mmap[..], &Device::Cpu).unwrap();
// ANCHOR_END: book_hub_2
assert_eq!(weights.len(), 206);
}
// #[rustfmt::skip]
// #[test]
// fn book_hub_3() {
{
// ANCHOR: book_hub_3
use candle::{DType, Device, Tensor};
use hf_hub::api::sync::Api;
use memmap2::Mmap;
use safetensors::slice::IndexOp;
use safetensors::SafeTensors;
use std::fs;
let api = Api::new().unwrap();
let repo = api.model("bert-base-uncased".to_string());
let weights_filename = repo.get("model.safetensors").unwrap();
let file = fs::File::open(weights_filename).unwrap();
let mmap = unsafe { Mmap::map(&file).unwrap() };
// Use safetensors directly
let tensors = SafeTensors::deserialize(&mmap[..]).unwrap();
let view = tensors
.tensor("bert.encoder.layer.0.attention.self.query.weight")
.unwrap();
// We're going to load shard with rank 1, within a world_size of 4
// We're going to split along dimension 0 doing VIEW[start..stop, :]
let rank = 1;
let world_size = 4;
let dim = 0;
let dtype = view.dtype();
let mut tp_shape = view.shape().to_vec();
let size = tp_shape[0];
if size % world_size != 0 {
panic!("The dimension is not divisible by `world_size`");
}
let block_size = size / world_size;
let start = rank * block_size;
let stop = (rank + 1) * block_size;
// Everything is expressed in tensor dimension
// bytes offsets is handled automatically for safetensors.
let iterator = view.slice(start..stop).unwrap();
tp_shape[dim] = block_size;
// Convert safetensors Dtype to candle DType
let dtype: DType = dtype.try_into().unwrap();
// TODO: Implement from_buffer_iterator so we can skip the extra CPU alloc.
let raw: Vec<u8> = iterator.into_iter().flatten().cloned().collect();
let tp_tensor = Tensor::from_raw_buffer(&raw, dtype, &tp_shape, &Device::Cpu).unwrap();
// ANCHOR_END: book_hub_3
assert_eq!(view.shape(), &[768, 768]);
assert_eq!(tp_tensor.dims(), &[192, 768]);
}
}
#[allow(unused)]
#[rustfmt::skip]
fn book_training_1() -> Result<()>{
// ANCHOR: book_training_1
use hf_hub::{api::sync::Api, Repo, RepoType};
let dataset_id = "mnist".to_string();
let api = Api::new()?;
let repo = Repo::with_revision(
dataset_id,
RepoType::Dataset,
"refs/convert/parquet".to_string(),
);
let repo = api.repo(repo);
let test_parquet_filename = repo.get("mnist/test/0000.parquet")?;
let train_parquet_filename = repo.get("mnist/train/0000.parquet")?;
let test_parquet = SerializedFileReader::new(std::fs::File::open(test_parquet_filename)?)?;
let train_parquet = SerializedFileReader::new(std::fs::File::open(train_parquet_filename)?)?;
// ANCHOR_END: book_training_1
// Ignore unused
let _train = train_parquet;
// ANCHOR: book_training_2
for row in test_parquet {
for (idx, (name, field)) in row?.get_column_iter().enumerate() {
println!("Column id {idx}, name {name}, value {field}");
}
}
// ANCHOR_END: book_training_2
let test_parquet_filename = repo.get("mnist/test/0000.parquet")?;
let train_parquet_filename = repo.get("mnist/train/0000.parquet")?;
let test_parquet = SerializedFileReader::new(std::fs::File::open(test_parquet_filename)?)?;
let train_parquet = SerializedFileReader::new(std::fs::File::open(train_parquet_filename)?)?;
// ANCHOR: book_training_3
let test_samples = 10_000;
let mut test_buffer_images: Vec<u8> = Vec::with_capacity(test_samples * 784);
let mut test_buffer_labels: Vec<u8> = Vec::with_capacity(test_samples);
for row in test_parquet{
for (_name, field) in row?.get_column_iter() {
if let parquet::record::Field::Group(subrow) = field {
for (_name, field) in subrow.get_column_iter() {
if let parquet::record::Field::Bytes(value) = field {
let image = image::load_from_memory(value.data()).unwrap();
test_buffer_images.extend(image.to_luma8().as_raw());
}
}
}else if let parquet::record::Field::Long(label) = field {
test_buffer_labels.push(*label as u8);
}
}
}
let test_images = (Tensor::from_vec(test_buffer_images, (test_samples, 784), &Device::Cpu)?.to_dtype(DType::F32)? / 255.)?;
let test_labels = Tensor::from_vec(test_buffer_labels, (test_samples, ), &Device::Cpu)?;
let train_samples = 60_000;
let mut train_buffer_images: Vec<u8> = Vec::with_capacity(train_samples * 784);
let mut train_buffer_labels: Vec<u8> = Vec::with_capacity(train_samples);
for row in train_parquet{
for (_name, field) in row?.get_column_iter() {
if let parquet::record::Field::Group(subrow) = field {
for (_name, field) in subrow.get_column_iter() {
if let parquet::record::Field::Bytes(value) = field {
let image = image::load_from_memory(value.data()).unwrap();
train_buffer_images.extend(image.to_luma8().as_raw());
}
}
}else if let parquet::record::Field::Long(label) = field {
train_buffer_labels.push(*label as u8);
}
}
}
let train_images = (Tensor::from_vec(train_buffer_images, (train_samples, 784), &Device::Cpu)?.to_dtype(DType::F32)? / 255.)?;
let train_labels = Tensor::from_vec(train_buffer_labels, (train_samples, ), &Device::Cpu)?;
let mnist = candle_datasets::vision::Dataset {
train_images,
train_labels,
test_images,
test_labels,
labels: 10,
};
// ANCHOR_END: book_training_3
assert_eq!(mnist.test_images.dims(), &[10_000, 784]);
assert_eq!(mnist.test_labels.dims(), &[10_000]);
assert_eq!(mnist.train_images.dims(), &[60_000, 784]);
assert_eq!(mnist.train_labels.dims(), &[60_000]);
Ok(())
}
}
| 4 |
0 | hf_public_repos/candle/candle-book | hf_public_repos/candle/candle-book/src/chapter_1.md | # Chapter 1
| 5 |
0 | hf_public_repos/candle/candle-book | hf_public_repos/candle/candle-book/src/simplified.rs | //! #A simplified example in Rust of training a neural network and then using it based on the Candle Framework by Hugging Face.
//! Author: Evgeny Igumnov 2023 [email protected]
//! This program implements a neural network to predict the winner of the second round of elections based on the results of the first round.
//!
//! ##Basic moments:
//!
//! A multilayer perceptron with two hidden layers is used. The first hidden layer has 4 neurons, the second has 2 neurons.
//! The input is a vector of 2 numbers - the percentage of votes for the first and second candidates in the first stage.
//! The output is the number 0 or 1, where 1 means that the first candidate will win in the second stage, 0 means that he will lose.
//! For training, samples with real data on the results of the first and second stages of different elections are used.
//! The model is trained by backpropagation using gradient descent and the cross-entropy loss function.
//! Model parameters (weights of neurons) are initialized randomly, then optimized during training.
//! After training, the model is tested on a deferred sample to evaluate the accuracy.
//! If the accuracy on the test set is below 100%, the model is considered underfit and the learning process is repeated.
//! Thus, this neural network learns to find hidden relationships between the results of the first and second rounds of voting in order to make predictions for new data.
#[rustfmt::skip]
mod tests {
use candle::{DType, Result, Tensor, D, Device};
use candle_nn::{loss, ops, Linear, Module, VarBuilder, VarMap, Optimizer};
// ANCHOR: book_training_simplified1
const VOTE_DIM: usize = 2;
const RESULTS: usize = 1;
const EPOCHS: usize = 10;
const LAYER1_OUT_SIZE: usize = 4;
const LAYER2_OUT_SIZE: usize = 2;
const LEARNING_RATE: f64 = 0.05;
#[derive(Clone)]
pub struct Dataset {
pub train_votes: Tensor,
pub train_results: Tensor,
pub test_votes: Tensor,
pub test_results: Tensor,
}
struct MultiLevelPerceptron {
ln1: Linear,
ln2: Linear,
ln3: Linear,
}
impl MultiLevelPerceptron {
fn new(vs: VarBuilder) -> Result<Self> {
let ln1 = candle_nn::linear(VOTE_DIM, LAYER1_OUT_SIZE, vs.pp("ln1"))?;
let ln2 = candle_nn::linear(LAYER1_OUT_SIZE, LAYER2_OUT_SIZE, vs.pp("ln2"))?;
let ln3 = candle_nn::linear(LAYER2_OUT_SIZE, RESULTS + 1, vs.pp("ln3"))?;
Ok(Self { ln1, ln2, ln3 })
}
fn forward(&self, xs: &Tensor) -> Result<Tensor> {
let xs = self.ln1.forward(xs)?;
let xs = xs.relu()?;
let xs = self.ln2.forward(&xs)?;
let xs = xs.relu()?;
self.ln3.forward(&xs)
}
}
// ANCHOR_END: book_training_simplified1
// ANCHOR: book_training_simplified3
#[tokio::test]
async fn simplified() -> anyhow::Result<()> {
let dev = Device::cuda_if_available(0)?;
let train_votes_vec: Vec<u32> = vec![
15, 10,
10, 15,
5, 12,
30, 20,
16, 12,
13, 25,
6, 14,
31, 21,
];
let train_votes_tensor = Tensor::from_vec(train_votes_vec.clone(), (train_votes_vec.len() / VOTE_DIM, VOTE_DIM), &dev)?.to_dtype(DType::F32)?;
let train_results_vec: Vec<u32> = vec![
1,
0,
0,
1,
1,
0,
0,
1,
];
let train_results_tensor = Tensor::from_vec(train_results_vec, train_votes_vec.len() / VOTE_DIM, &dev)?;
let test_votes_vec: Vec<u32> = vec![
13, 9,
8, 14,
3, 10,
];
let test_votes_tensor = Tensor::from_vec(test_votes_vec.clone(), (test_votes_vec.len() / VOTE_DIM, VOTE_DIM), &dev)?.to_dtype(DType::F32)?;
let test_results_vec: Vec<u32> = vec![
1,
0,
0,
];
let test_results_tensor = Tensor::from_vec(test_results_vec.clone(), test_results_vec.len(), &dev)?;
let m = Dataset {
train_votes: train_votes_tensor,
train_results: train_results_tensor,
test_votes: test_votes_tensor,
test_results: test_results_tensor,
};
let trained_model: MultiLevelPerceptron;
loop {
println!("Trying to train neural network.");
match train(m.clone(), &dev) {
Ok(model) => {
trained_model = model;
break;
},
Err(e) => {
println!("Error: {}", e);
continue;
}
}
}
let real_world_votes: Vec<u32> = vec![
13, 22,
];
let tensor_test_votes = Tensor::from_vec(real_world_votes.clone(), (1, VOTE_DIM), &dev)?.to_dtype(DType::F32)?;
let final_result = trained_model.forward(&tensor_test_votes)?;
let result = final_result
.argmax(D::Minus1)?
.to_dtype(DType::F32)?
.get(0).map(|x| x.to_scalar::<f32>())??;
println!("real_life_votes: {:?}", real_world_votes);
println!("neural_network_prediction_result: {:?}", result);
Ok(())
}
// ANCHOR_END: book_training_simplified3
// ANCHOR: book_training_simplified2
fn train(m: Dataset, dev: &Device) -> anyhow::Result<MultiLevelPerceptron> {
let train_results = m.train_results.to_device(dev)?;
let train_votes = m.train_votes.to_device(dev)?;
let varmap = VarMap::new();
let vs = VarBuilder::from_varmap(&varmap, DType::F32, dev);
let model = MultiLevelPerceptron::new(vs.clone())?;
let mut sgd = candle_nn::SGD::new(varmap.all_vars(), LEARNING_RATE)?;
let test_votes = m.test_votes.to_device(dev)?;
let test_results = m.test_results.to_device(dev)?;
let mut final_accuracy: f32 = 0.0;
for epoch in 1..EPOCHS + 1 {
let logits = model.forward(&train_votes)?;
let log_sm = ops::log_softmax(&logits, D::Minus1)?;
let loss = loss::nll(&log_sm, &train_results)?;
sgd.backward_step(&loss)?;
let test_logits = model.forward(&test_votes)?;
let sum_ok = test_logits
.argmax(D::Minus1)?
.eq(&test_results)?
.to_dtype(DType::F32)?
.sum_all()?
.to_scalar::<f32>()?;
let test_accuracy = sum_ok / test_results.dims1()? as f32;
final_accuracy = 100. * test_accuracy;
println!("Epoch: {epoch:3} Train loss: {:8.5} Test accuracy: {:5.2}%",
loss.to_scalar::<f32>()?,
final_accuracy
);
if final_accuracy == 100.0 {
break;
}
}
if final_accuracy < 100.0 {
Err(anyhow::Error::msg("The model is not trained well enough."))
} else {
Ok(model)
}
}
// ANCHOR_END: book_training_simplified2
}
| 6 |
0 | hf_public_repos/candle/candle-book | hf_public_repos/candle/candle-book/src/SUMMARY.md | # Summary
[Introduction](README.md)
# User Guide
- [Installation](guide/installation.md)
- [Hello World - MNIST](guide/hello_world.md)
- [PyTorch cheatsheet](guide/cheatsheet.md)
# Reference Guide
- [Running a model](inference/inference.md)
- [Using the hub](inference/hub.md)
- [Error management](error_manage.md)
- [Training](training/training.md)
- [Simplified](training/simplified.md)
- [MNIST](training/mnist.md)
- [Fine-tuning]()
- [Serialization]()
- [Advanced Cuda usage]()
- [Writing a custom kernel]()
- [Porting a custom kernel]()
- [Using MKL]()
- [Creating apps]()
- [Creating a WASM app]()
- [Creating a REST api webserver]()
- [Creating a desktop Tauri app]()
| 7 |
0 | hf_public_repos/candle/candle-book | hf_public_repos/candle/candle-book/src/error_manage.md | # Error management
You might have seen in the code base a lot of `.unwrap()` or `?`.
If you're unfamiliar with Rust check out the [Rust book](https://doc.rust-lang.org/book/ch09-02-recoverable-errors-with-result.html)
for more information.
What's important to know though, is that if you want to know *where* a particular operation failed
You can simply use `RUST_BACKTRACE=1` to get the location of where the model actually failed.
Let's see on failing code:
```rust,ignore
let x = Tensor::zeros((1, 784), DType::F32, &device)?;
let y = Tensor::zeros((1, 784), DType::F32, &device)?;
let z = x.matmul(&y)?;
```
Will print at runtime:
```bash
Error: ShapeMismatchBinaryOp { lhs: [1, 784], rhs: [1, 784], op: "matmul" }
```
After adding `RUST_BACKTRACE=1`:
```bash
Error: WithBacktrace { inner: ShapeMismatchBinaryOp { lhs: [1, 784], rhs: [1, 784], op: "matmul" }, backtrace: Backtrace [{ fn: "candle::error::Error::bt", file: "/home/nicolas/.cargo/git/checkouts/candle-5bb8ef7e0626d693/f291065/candle-core/src/error.rs", line: 200 }, { fn: "candle::tensor::Tensor::matmul", file: "/home/nicolas/.cargo/git/checkouts/candle-5bb8ef7e0626d693/f291065/candle-core/src/tensor.rs", line: 816 }, { fn: "myapp::main", file: "./src/main.rs", line: 29 }, { fn: "core::ops::function::FnOnce::call_once", file: "/rustc/8ede3aae28fe6e4d52b38157d7bfe0d3bceef225/library/core/src/ops/function.rs", line: 250 }, { fn: "std::sys_common::backtrace::__rust_begin_short_backtrace", file: "/rustc/8ede3aae28fe6e4d52b38157d7bfe0d3bceef225/library/std/src/sys_common/backtrace.rs", line: 135 }, { fn: "std::rt::lang_start::{{closure}}", file: "/rustc/8ede3aae28fe6e4d52b38157d7bfe0d3bceef225/library/std/src/rt.rs", line: 166 }, { fn: "core::ops::function::impls::<impl core::ops::function::FnOnce<A> for &F>::call_once", file: "/rustc/8ede3aae28fe6e4d52b38157d7bfe0d3bceef225/library/core/src/ops/function.rs", line: 284 }, { fn: "std::panicking::try::do_call", file: "/rustc/8ede3aae28fe6e4d52b38157d7bfe0d3bceef225/library/std/src/panicking.rs", line: 500 }, { fn: "std::panicking::try", file: "/rustc/8ede3aae28fe6e4d52b38157d7bfe0d3bceef225/library/std/src/panicking.rs", line: 464 }, { fn: "std::panic::catch_unwind", file: "/rustc/8ede3aae28fe6e4d52b38157d7bfe0d3bceef225/library/std/src/panic.rs", line: 142 }, { fn: "std::rt::lang_start_internal::{{closure}}", file: "/rustc/8ede3aae28fe6e4d52b38157d7bfe0d3bceef225/library/std/src/rt.rs", line: 148 }, { fn: "std::panicking::try::do_call", file: "/rustc/8ede3aae28fe6e4d52b38157d7bfe0d3bceef225/library/std/src/panicking.rs", line: 500 }, { fn: "std::panicking::try", file: "/rustc/8ede3aae28fe6e4d52b38157d7bfe0d3bceef225/library/std/src/panicking.rs", line: 464 }, { fn: "std::panic::catch_unwind", file: "/rustc/8ede3aae28fe6e4d52b38157d7bfe0d3bceef225/library/std/src/panic.rs", line: 142 }, { fn: "std::rt::lang_start_internal", file: "/rustc/8ede3aae28fe6e4d52b38157d7bfe0d3bceef225/library/std/src/rt.rs", line: 148 }, { fn: "std::rt::lang_start", file: "/rustc/8ede3aae28fe6e4d52b38157d7bfe0d3bceef225/library/std/src/rt.rs", line: 165 }, { fn: "main" }, { fn: "__libc_start_main" }, { fn: "_start" }] }
```
Not super pretty at the moment, but we can see error occurred on `{ fn: "myapp::main", file: "./src/main.rs", line: 29 }`
Another thing to note, is that since Rust is compiled it is not necessarily as easy to recover proper stacktraces
especially in release builds. We're using [`anyhow`](https://docs.rs/anyhow/latest/anyhow/) for that.
The library is still young, please [report](https://github.com/LaurentMazare/candle/issues) any issues detecting where an error is coming from.
## Cuda error management
When running a model on Cuda, you might get a stacktrace not really representing the error.
The reason is that CUDA is async by nature, and therefore the error might be caught while you were sending totally different kernels.
One way to avoid this is to use `CUDA_LAUNCH_BLOCKING=1` as an environment variable. This will force every kernel to be launched sequentially.
You might still however see the error happening on other kernels as the faulty kernel might exit without an error but spoiling some pointer for which the error will happen when dropping the `CudaSlice` only.
If this occurs, you can use [`compute-sanitizer`](https://docs.nvidia.com/compute-sanitizer/ComputeSanitizer/index.html)
This tool is like `valgrind` but for cuda. It will help locate the errors in the kernels.
| 8 |
0 | hf_public_repos/candle/candle-book | hf_public_repos/candle/candle-book/src/README.md | # Introduction
{{#include ../../README.md:features}}
This book will introduce step by step how to use `candle`.
| 9 |
0 | hf_public_repos/api-inference-community/docker_images/peft/app | hf_public_repos/api-inference-community/docker_images/peft/app/pipelines/text_generation.py | import logging
import os
import torch
from app import idle, timing
from app.pipelines import Pipeline
from huggingface_hub import model_info
from peft import PeftModel
from transformers import AutoModelForCausalLM, AutoTokenizer
logger = logging.getLogger(__name__)
class TextGenerationPipeline(Pipeline):
def __init__(self, model_id: str):
use_auth_token = os.getenv("HF_API_TOKEN")
model_data = model_info(model_id, token=use_auth_token)
config_dict = model_data.config.get("peft")
if config_dict:
base_model_id = config_dict["base_model_name_or_path"]
if base_model_id:
self.tokenizer = AutoTokenizer.from_pretrained(base_model_id)
model = AutoModelForCausalLM.from_pretrained(
base_model_id, device_map="auto"
)
# wrap base model with peft
self.model = PeftModel.from_pretrained(model, model_id)
else:
raise ValueError("There's no base model ID in configuration file.")
else:
raise ValueError("Config file for this model does not exist or is invalid.")
def __call__(self, inputs: str, **kwargs) -> str:
"""
Args:
inputs (:obj:`str`):
a string for text to be completed
Returns:
A string of completed text.
"""
if idle.UNLOAD_IDLE:
with idle.request_witnesses():
self._model_to_gpu()
resp = self._process_req(inputs, **kwargs)
else:
resp = self._process_req(inputs, **kwargs)
return [{"generated_text": resp[0]}]
@timing.timing
def _model_to_gpu(self):
if torch.cuda.is_available():
self.model.to("cuda")
def _process_req(self, inputs: str, **kwargs) -> str:
"""
Args:
inputs (:obj:`str`):
a string for text to be completed
Returns:
A string of completed text.
"""
tokenized_inputs = self.tokenizer(inputs, return_tensors="pt")
self._model_to_gpu()
if torch.cuda.is_available():
device = "cuda"
tokenized_inputs = {
"input_ids": tokenized_inputs["input_ids"].to(device),
"attention_mask": tokenized_inputs["attention_mask"].to(device),
}
with torch.no_grad():
outputs = self.model.generate(
input_ids=tokenized_inputs["input_ids"],
attention_mask=tokenized_inputs["attention_mask"],
max_new_tokens=10,
eos_token_id=3,
)
return self.tokenizer.batch_decode(outputs, skip_special_tokens=True)
| 0 |
0 | hf_public_repos/api-inference-community/docker_images/peft/app | hf_public_repos/api-inference-community/docker_images/peft/app/pipelines/base.py | from abc import ABC, abstractmethod
from typing import Any
class Pipeline(ABC):
@abstractmethod
def __init__(self, model_id: str):
raise NotImplementedError("Pipelines should implement an __init__ method")
@abstractmethod
def __call__(self, inputs: Any) -> Any:
raise NotImplementedError("Pipelines should implement a __call__ method")
class PipelineException(Exception):
pass
| 1 |
0 | hf_public_repos/api-inference-community/docker_images/peft/app | hf_public_repos/api-inference-community/docker_images/peft/app/pipelines/__init__.py | from app.pipelines.base import Pipeline, PipelineException # isort:skip
from app.pipelines.text_generation import TextGenerationPipeline
| 2 |
0 | hf_public_repos/api-inference-community/docker_images/peft | hf_public_repos/api-inference-community/docker_images/peft/tests/test_api.py | import os
from typing import Dict
from unittest import TestCase, skipIf
from app.main import ALLOWED_TASKS, get_pipeline
# Must contain at least one example of each implemented pipeline
# Tests do not check the actual values of the model output, so small dummy
# models are recommended for faster tests.
TESTABLE_MODELS: Dict[str, str] = {
"text-generation": "merve/peft-test-3",
}
ALL_TASKS = {
"audio-classification",
"audio-to-audio",
"automatic-speech-recognition",
"feature-extraction",
"image-classification",
"question-answering",
"sentence-similarity",
"speech-segmentation",
"tabular-classification",
"tabular-regression",
"text-to-image",
"text-to-speech",
"token-classification",
"conversational",
"feature-extraction",
"sentence-similarity",
"fill-mask",
"table-question-answering",
"summarization",
"text2text-generation",
"text-classification",
"zero-shot-classification",
}
class PipelineTestCase(TestCase):
@skipIf(
os.path.dirname(os.path.dirname(__file__)).endswith("common"),
"common is a special case",
)
def test_has_at_least_one_task_enabled(self):
self.assertGreater(
len(ALLOWED_TASKS.keys()), 0, "You need to implement at least one task"
)
def test_unsupported_tasks(self):
unsupported_tasks = ALL_TASKS - ALLOWED_TASKS.keys()
for unsupported_task in unsupported_tasks:
with self.subTest(msg=unsupported_task, task=unsupported_task):
os.environ["TASK"] = unsupported_task
os.environ["MODEL_ID"] = "XX"
with self.assertRaises(EnvironmentError):
get_pipeline()
| 3 |
0 | hf_public_repos/api-inference-community/docker_images/peft | hf_public_repos/api-inference-community/docker_images/peft/tests/test_api_text_generation.py | import json
import os
from unittest import TestCase, skipIf
from app.main import ALLOWED_TASKS
from starlette.testclient import TestClient
from tests.test_api import TESTABLE_MODELS
@skipIf(
"text-generation" not in ALLOWED_TASKS,
"text-generation not implemented",
)
class TextGenerationTestCase(TestCase):
def setUp(self):
model_id = TESTABLE_MODELS["text-generation"]
self.old_model_id = os.getenv("MODEL_ID")
self.old_task = os.getenv("TASK")
os.environ["MODEL_ID"] = model_id
os.environ["TASK"] = "text-generation"
from app.main import app
self.app = app
@classmethod
def setUpClass(cls):
from app.main import get_pipeline
get_pipeline.cache_clear()
def tearDown(self):
if self.old_model_id is not None:
os.environ["MODEL_ID"] = self.old_model_id
else:
del os.environ["MODEL_ID"]
if self.old_task is not None:
os.environ["TASK"] = self.old_task
else:
del os.environ["TASK"]
def test_simple(self):
inputs = "It is a beautiful day outside"
with TestClient(self.app) as client:
response = client.post("/", json={"inputs": inputs})
self.assertEqual(
response.status_code,
200,
)
content = json.loads(response.content)
self.assertEqual(type(content), str)
with TestClient(self.app) as client:
response = client.post("/", json=inputs)
self.assertEqual(
response.status_code,
200,
)
content = json.loads(response.content)
self.assertEqual(type(content), list)
self.assertEqual(type(content[0]["generated_text"]), str)
def test_malformed_question(self):
with TestClient(self.app) as client:
response = client.post("/", data=b"\xc3\x28")
self.assertEqual(
response.status_code,
400,
)
self.assertEqual(
response.content,
b'{"error":"\'utf-8\' codec can\'t decode byte 0xc3 in position 0: invalid continuation byte"}',
)
| 4 |
0 | hf_public_repos/api-inference-community/docker_images | hf_public_repos/api-inference-community/docker_images/sklearn/requirements.txt | starlette>=0.14.2
api-inference-community>=0.0.25
huggingface_hub>=0.5.1
scikit-learn
joblib>=1.0.1
# Dummy changes.
| 5 |
0 | hf_public_repos/api-inference-community/docker_images | hf_public_repos/api-inference-community/docker_images/sklearn/run_app.sh | #!/bin/bash --login
# This file creates an environment with all required dependencies for the given
# model, and then runs the start command.
# This makes it easy to see in logs what exactly is being run.
set -xe
get_requirements() {
requirements="pandas uvicorn gunicorn api-inference-community skops"
# this next command is needed to run the while loop in the same process and
# therefore modify the same $requirements variable. Otherwise the loop would be
# a separate process and the variable wouldn't be accessible from this parent
# process.
shopt -s lastpipe
jq '.sklearn.environment' /tmp/config.json | jq '.[]' | while read r; do
requirements+=" $r"
done
# not sure why these are required. But if they're not here, the string passed
# to micromamba is kinda not parsable by it.
requirements=$(echo "$requirements" | sed "s/'//g")
requirements=$(echo "$requirements" | sed "s/\"//g")
echo $requirements
}
# We download only the config file and use `jq` to extract the requirements. If
# the download fails, we use a default set of dependencies. We need to capture
# the output of `curl` here so that if it fails, it doesn't make the whole
# script to exit, which it would do due to the -e flag we've set above the
# script.
response="$(curl https://huggingface.co/$MODEL_ID/raw/main/config.json -f --output /tmp/config.json)" || response=$?
if [ -z $response ]; then
requirements=$(get_requirements)
else
# if the curl command is not successful, we use a default set of
# dependencies, and use the latest scikit-learn version. This is to allow
# users for a basic usage if they haven't put the config.json file in their
# repository.
requirements="pandas uvicorn gunicorn api-inference-community scikit-learn"
fi
micromamba create -c conda-forge -y -q --name=api-inference-model-env $requirements
micromamba activate api-inference-model-env
# start.sh file is not in our repo, rather taken from the
# `uvicorn-gunicorn-docker` repo. You can check the Dockerfile to see where
# exactly it is coming from.
/start.sh
| 6 |
0 | hf_public_repos/api-inference-community/docker_images | hf_public_repos/api-inference-community/docker_images/sklearn/Dockerfile | FROM mambaorg/micromamba
LABEL maintainer="Adrin Jalali [email protected]"
# micromamba comes with a default non-root user. But we need root to install
# our required system packages.
USER root
RUN apt-get update && apt-get install -y curl jq
USER $MAMBAUSER
# Most our dockerfiles start from tiangolo/uvicorn-gunicorn:python3.8, but
# since here we'd like to start from micromamba, we copy necessary files from
# the uvicorn docker image using `COPY --from=...` commands. These steps are
# taken from:
# https://github.com/tiangolo/uvicorn-gunicorn-docker/blob/master/docker-images/python3.8-slim.dockerfile
COPY --from=tiangolo/uvicorn-gunicorn:python3.8 /start.sh /start.sh
RUN chmod +x /start.sh
COPY --from=tiangolo/uvicorn-gunicorn:python3.8 /gunicorn_conf.py /gunicorn_conf.py
COPY --from=tiangolo/uvicorn-gunicorn:python3.8 /start-reload.sh /start-reload.sh
RUN chmod +x /start-reload.sh
COPY --from=tiangolo/uvicorn-gunicorn:python3.8 /app /app
WORKDIR /app/
ENV PYTHONPATH=/app
EXPOSE 80
# This part is new and only specific to scikit-learn image.
ENV HUGGINGFACE_HUB_CACHE=/data
COPY ./app /app/app
COPY run_app.sh /run_app.sh
RUN chmod +x /run_app.sh
CMD /run_app.sh
| 7 |
0 | hf_public_repos/api-inference-community/docker_images | hf_public_repos/api-inference-community/docker_images/sklearn/prestart.sh | python app/main.py
| 8 |
0 | hf_public_repos/api-inference-community/docker_images | hf_public_repos/api-inference-community/docker_images/sklearn/README.md | ## Tests
### Test setup
The tests require certain repositories with certain requirements to exist on HF
Hub and certain output files to be created.
You can make sure those repos and files are up to date by running the
`docker_images/sklearn/tests/generators/run.sh` script. The script creates
required conda environments, updates them if necessary, and runs scripts inside
those environments. You should also give it a valid token with access to the
`skops-tests` org:
```bash
# from the project root
SKOPS_TESTS_TOKEN=your_secret_token docker_images/sklearn/tests/generators/run.sh
```
This script needs to be run _only once_ when you first start developing, or each
time a new scikit-learn version is released.
The created model repositories are also used for common tests of this package,
see `tests/test_dockers.py` > `test_sklearn`.
Note that a working [mamba
installation](https://mamba.readthedocs.io/en/latest/installation.html) is
required for this step
### Test environment
Create a new Python environment and install the test dependencies:
```bash
# with pip
python -m pip install -r docker_images/sklearn/requirements.txt
# with conda/mamba
conda install --file docker_images/sklearn/requirements.txt
```
### Running the tests
From within the Python environment, run:
```
pytest -sv --rootdir docker_images/sklearn/ docker_images/sklearn/
```
You will see many tests being skipped. If the message is "Skipping test because
requirements are not met.", it means that the test was intended to be skipped,
so you don't need to do anything about it. When adding a new test, make sure
that at least one of the parametrized settings is not skipped for that test.
### Adding a new task
When adding tests for a new task, certain artifacts like HF Hub repositories,
model inputs, and model outputs need to be generated first using the `run.sh`
script, as explained above. For the new task, those have to be implemented
first. For this, visit `docker_images/sklearn/tests/generators/generate.py` and
extend the script to include the new task. Most notably, visit the "CONSTANTS"
section and extend the constants defined there to include your task. This will
make it obvious which extra functions you need to write.
| 9 |
0 | hf_public_repos/audio-transformers-course/chapters/ru | hf_public_repos/audio-transformers-course/chapters/ru/chapter7/hands-on.mdx | # Практическое занятие
В этом разделе мы объединили материал, рассмотренный в предыдущих шести разделах курса, для создания трех интегрированных
аудио приложений. Как вы убедились, создание более сложных аудио инструментов вполне достижимо при использовании базовых навыков работы
приобретенных в рамках данного курса.
В практическом занятии используется одно из приложений, рассматриваемых в данном разделе, которое расширяется с помощью нескольких многоязычных
функций 🌍. Ваша задача - взять [каскадный перевод речи в речь из Gradio демо](https://huggingface.co/spaces/course-demos/speech-to-speech-translation)
из первого урока данного раздела и модернизировать его для перевода на любой **неанглийский** язык. То есть демо
должно принимать речь на языке X и переводить ее в речь на языке Y, где целевой язык Y не является английским.
Начать следует с [дублирования](https://huggingface.co/spaces/course-demos/speech-to-speech-translation?duplicate=true) шаблона в вашем пространстве
имен Hugging Face. Нет необходимости использовать GPU-ускоритель - бесплатный уровень подписки с CPU отлично справится с этой задачей 🤗.
Однако следует убедиться, что видимость вашего демо установлена в **public**. Это необходимо для того, чтобы ваше демо было доступно для нас
и могло быть проверено на корректность.
Советы по обновлению функции перевода речи для выполнения многоязычного перевода приведены в разделе [перевод речи в речь](speech-to-speech).
Следуя этим инструкциям, вы сможете обновить демо версию для перевода с речи на языке X в текст на языке Y, а это уже половина задачи!
Для синтеза из текста на языке Y в речь на языке Y, где Y - многоязычный язык, вам потребуется [NL] использовать контрольную точку многоязычной модели TTS.
Для этого можно использовать либо контрольную точку SpeechT5 TTS, которую вы дообучали на предыдущем практическом занятии, либо предварительно
обученную контрольную точку многоязычной TTS. Существует два варианта предварительно обученных контрольных точек: либо контрольная точка
[sanchit-gandhi/speecht5_tts_vox_nl](https://huggingface.co/sanchit-gandhi/speecht5_tts_vox_nl), которая представляет собой контрольную точку SpeechT5,
дообученную на голландском фрагменте набора данных [VoxPopuli](https://huggingface.co/datasets/facebook/voxpopuli) [NL], либо контрольная точка MMS TTS
(смотрите раздел [предварительно обученные модели text-to-speech](../chapter6/pre-trained_models)).
<Tip>
По нашему опыту экспериментов с голландским языком, использование контрольной точки MMS TTS дает лучшую производительность, чем
с дообученной SpeechT5, но вы можете обнаружить, что ваша дообученная контрольная точка TTS предпочтительнее для вашего языка.
Если вы решили использовать контрольную точку MMS TTS, вам необходимо обновить <a href="https://huggingface.co/spaces/course-demos/speech-to-speech-translation/blob/a03175878f522df7445290d5508bfb5c5178f787/requirements.txt#L2">requirements.txt</a>
файл вашей демонстрации для установки <code>transformers</code> из ветки PR:
<p><code>git+https://github.com/hollance/transformers.git@6900e8ba6532162a8613d2270ec2286c3f58f57b</code></p>
</Tip>
Ваше демо должно принимать на вход аудиофайл, а на выходе возвращать другой аудиофайл, соответствующий сигнатуре функции
[`speech_to_speech_translation`](https://huggingface.co/spaces/course-demos/speech-to-speech-translation/blob/3946ba6705a6632a63de8672ac52a482ab74b3fc/app.py#L35) [NL] в шаблоне демо.
Поэтому мы рекомендуем оставить основную функцию `speech_to_speech_translation` как есть, и обновлять лишь функции [`translate`](https://huggingface.co/spaces/course-demos/speech-to-speech-translation/blob/a03175878f522df7445290d5508bfb5c5178f787/app.py#L24)
и [`synthesise`](https://huggingface.co/spaces/course-demos/speech-to-speech-translation/blob/a03175878f522df7445290d5508bfb5c5178f787/app.py#L29) по мере необходимости.
После того как вы создали своё демо в виде приложения Gradio на Hugging Face Hub, вы можете отправить его на оценку. Перейдите в пространство
[audio-course-u7-assessment](https://huggingface.co/spaces/huggingface-course/audio-course-u7-assessment) и при появлении запроса укажите идентификатор репозитория вашего демо.
Этот пространство проверяет правильность сборки демо-версии, посылая [NL] образец аудиофайла в демо и проверяя, что возвращаемый аудиофайл действительно неанглийский.
Если ваше демо работает корректно, вы получите зеленую галочку рядом с вашим именем в общем [пространстве прогресса](https://huggingface.co/spaces/MariaK/Check-my-progress-Audio-Course) ✅.
| 0 |
0 | hf_public_repos/audio-transformers-course/chapters/ru | hf_public_repos/audio-transformers-course/chapters/ru/chapter6/evaluation.mdx | # Оценка моделей text-to-speech
В процессе обучения модели преобразования текста в речь оптимизируются по среднеквадратичной ошибке (mean-square error, MSE) (или средней абсолютной ошибке (mean absolute error, MAE)) между
спрогнозированными значениями спектрограмм и сгенерированными. Как MSE, так и MAE способствуют минимизации разности
между прогнозируемой и целевой спектрограммами. Однако, поскольку TTS - это проблема отображения "один ко многим", т.е. выходная спектрограмма для данного текста может быть представлена множеством
различных способов, оценка полученных моделей преобразования текста в речь (TTS) значительно сложнее.
В отличие от многих других вычислительных задач, которые могут быть объективно измерены с помощью количественных показателей,
таких как accuracy или precision, оценка TTS в значительной степени зависит от субъективного человеческого анализа.
Одним из наиболее часто используемых методов оценки систем TTS является качественная оценка с использованием cредней экспертной оценки (Mean Opinion Scores, MOS).
MOS - это субъективная система оценки, которая позволяет людям оценить качество синтезированной речи [NL] по шкале от 1 до 5.
Эти оценки обычно собираются с помощью тестов на прослушивание, в которых участники-люди [NL] прослушивают и оценивают синтезированные образцы речи.
Одной из основных причин, по которой трудно разработать объективные метрики для оценки TTS, является субъективный характер восприятия
речи. Слушатели имеют различные предпочтения и чувствительность к различным аспектам речи, включая произношение, интонацию, естественность и ясность.
Учесть все эти нюансы восприятия с помощью одного числового значения - сложная задача.
В то же время субъективность человеческой оценки затрудняет сравнение и сопоставление различных систем TTS.
Кроме того, при такой оценке могут быть упущены некоторые важные аспекты синтеза речи, такие как естественность, выразительность и эмоциональное воздействие.
Эти качества трудно поддаются объективной количественной оценке, но очень важны в приложениях, где синтезированная речь должна передавать человекоподобные качества и вызывать соответствующие эмоциональные реакции.
В итоге, можно сказать, что оценка моделей преобразования текста в речь является сложной задачей из-за отсутствия единой действительно объективной метрики. Наиболее распространенный метод оценки,
средняя экспертная оценка (MOS), опирается на субъективный человеческий анализ. Хотя MOS дает ценные сведения о качестве синтезированной речи, она также вносит вариативность и субъективность.
| 1 |
0 | hf_public_repos/audio-transformers-course/chapters/ru | hf_public_repos/audio-transformers-course/chapters/ru/chapter6/supplemental_reading.mdx | # Дополнительные материалы и ресурсы
В этом разделе была представлена задача преобразования текста в речь.
Хотите узнать больше? Здесь вы найдете дополнительные ресурсы, которые помогут вам углубить понимание рассматриваемых тем
и повысить эффективность обучения.
* [HiFi-GAN: генеративные состязательные сети для эффективного и высококачественного синтеза речи](https://arxiv.org/pdf/2010.05646.pdf): статья, в которой представлена HiFi-GAN для синтеза речи.
* [Х-Векторы: Надежные DNN-Эмбединги для распознавания дикторов](https://www.danielpovey.com/files/2018_icassp_xvectors.pdf): статья, в которой представлен метод Х-Векторов для эмбеддингов дикторов.
* [FastSpeech 2: быстрое и высококачественное преобразование текста в речь](https://arxiv.org/pdf/2006.04558.pdf): статья, в которой представлена FastSpeech 2 - еще одна популярная модель преобразования текста в речь, использующая неавторегрессионный TTS метод.
* [Векторно-квантованный подход для синтеза текста в речь на основе спонтанной речи в реальном мире](https://arxiv.org/pdf/2302.04215v1.pdf): статья, посвященная MQTTS - авторегрессионной системе TTS, в которой мел-спектрограммы заменены квантованным дискретным представлением.
| 2 |
0 | hf_public_repos/audio-transformers-course/chapters/ru | hf_public_repos/audio-transformers-course/chapters/ru/chapter6/pre-trained_models.mdx | # Предварительно обученные модели text-to-speech
По сравнению с задачами ASR (автоматическое распознавание речи) и классификации звука, здесь значительно меньше предварительно обученных
контрольных точек. На 🤗 Hub вы найдете около 300 подходящих контрольных точек. Среди
этих предварительно обученных моделей мы остановимся на двух архитектурах, которые легко доступны для вас в библиотеке
🤗 Transformers - SpeechT5 и Massive Multilingual Speech (MMS).
В этом разделе мы рассмотрим, как использовать эти предварительно обученные модели в библиотеке Transformers для TTS.
## SpeechT5
[SpeechT5](https://arxiv.org/abs/2110.07205) - это модель, опубликованная Джуньи Ао и другими специалистами компании Microsoft, которая способна
решать целый ряд речевых задач. Несмотря на то, что в данном разделе мы сосредоточились на аспекте преобразования текста в речь,
эта модель может быть адаптирована как для задач преобразования речи в текст (автоматическое распознавание речи или идентификация диктора),
так и для задач преобразования речи в речь (например, улучшение речи или преобразование между различными голосами). Это обусловлено тем, как эта модель
была спроектирована и предварительно обучена.
В основе SpeechT5 лежит обычная модель трансформера энкодер-декодер. Как и любой другой трансформер, модель энкодер-декодер
осуществляет преобразование последовательности в последовательность с использованием скрытых представлений. Эта основа трансформера
одинакова для всех задач, поддерживаемых SpeechT5.
Этот трансформер дополнен шестью модально-специфическими (речь/текст) _пред-сетями_ и _пост-сетями_. Входная речь или текст
(в зависимости от задачи) предварительно обрабатывается через соответствующую предварительную сеть для получения скрытых представлений, которые может использовать трансформер.
Выходные данные трансформера передаются в пост-сеть, которая использует их для генерации вывода в целевой модальности.
Вот как выглядит архитектура (изображение из оригинальной статьи):
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/speecht5/architecture.jpg" alt="SpeechT5 architecture from the original paper">
</div>
SpeechT5 сначала проходит предварительное обучение на больших объемах немаркированных речевых и текстовых данных, чтобы получить единое представление
различных модальностей. На этапе предварительного обучения все предварительные и последующие сети используются одновременно.
После предварительного обучения вся структура энкодера-декодера настраивается для каждой конкретной задачи. На этом этапе используются только те
пред-сети и пост-сети, которые имеют отношение к конкретной задаче. Например, чтобы использовать SpeechT5 для преобразования текста в речь, необходимо
использовать предварительную сеть энкодера текста для текстовых входов и предварительную и пост-сети декодера речи для речевых выходов.
Такой подход позволяет получить несколько моделей, дообученных для различных речевых задач, все они выигрывают от первоначального
предварительного обучения на немаркированных данных.
<Tip>
Несмотря на то что в начале работы дообученные модели используют один и тот же набор весов из общей предварительно обученной модели, конечные версии
в итоге оказываются совершенно разными. Например, вы не можете взять дообученную ASR-модель и поменять местами пред-сети и пост-сети,
чтобы получить рабочую TTS-модель. SpeechT5 гибкая, но не настолько ;)
</Tip>
Посмотрим, какие пред- и пост-сети использует SpeechT5 для решения задачи TTS:
* Предварительная сеть энкодера текста: Слой эмбедингов текста, который сопоставляет текстовые токены со скрытыми представлениями, ожидаемыми энкодером. Это аналогично тому, что происходит в NLP-модели, такой как BERT.
* Предварительная сеть декодера речи: На вход подается лог мел спектрограммы, и с помощью последовательности линейных слоев спектрограмма сжимается в скрытые представления.
* Пост-сеть декодера речи: Здесь прогнозируется остаток, который добавляется к выходной спектрограмме и используется для уточнения результатов.
В совокупности именно так выглядит архитектура SpeechT5 для преобразования текста в речь:
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/speecht5/tts.jpg" alt="SpeechT5 architecture for TTS">
</div>
Как видите, на выходе получается лог-мел спектрограмма, а не конечная форма волны. Если вы помните, мы вкратце касались
этой темы в [Разделе 3](../chapter3/introduction#spectrogram-output). Обычно модели, генерирующие звук, выдают
лог мел спектограмму, которой необходимо преобразовать в форму волны с помощью дополнительной нейронной сети, называемой вокодером.
Давайте посмотрим, как это можно сделать.
Сначала загрузим из 🤗 Hub настроенную TTS-модель SpeechT5, а также объект процессора, используемый для токенизации
и извлечения признаков:
```python
from transformers import SpeechT5Processor, SpeechT5ForTextToSpeech
processor = SpeechT5Processor.from_pretrained("microsoft/speecht5_tts")
model = SpeechT5ForTextToSpeech.from_pretrained("microsoft/speecht5_tts")
```
Далее необходимо выполнить токенизацию входного текста.
```python
inputs = processor(text="Don't count the days, make the days count.", return_tensors="pt")
```
Модель SpeechT5 TTS не ограничивается созданием речи для одного диктора. Вместо этого она использует так называемые эмбединги диктора,
которые фиксируют голосовые характеристики конкретного диктора.
<Tip>
Эмбеддинги диктора - это метод компактного представления личности диктора в виде вектора
фиксированного размера, независимо от длины высказывания. Эти эмбеддинги фиксируют важную информацию о голосе,
акценте, интонации и других уникальных характеристиках, отличающих одного диктора от другого. Такие эмбеддинги могут быть
использованы для верификации диктора, диаризации, идентификации диктора и т.д.
Наиболее распространенными методами генерации эмбеддингов диктора являются:
* I-векторы (I-Vectors): I-векторы (векторы идентичности) основаны на смешанной модели Гаусса (Gaussian mixture model, GMM). Они представляют говорящих в виде низкоразмерных векторов фиксированной длины, полученных на основе статистики GMM, специфичной для конкретного говорящего, и получаются неконтролируемым (unsupervised) способом.
* X-векторы (X-Vectors): X-векторы создаются с помощью глубоких нейронных сетей (DNN) и захватывают информацию о дикторе на уровне фрейма с учетом временного контекста.
[X-Vectors](https://www.danielpovey.com/files/2018_icassp_xvectors.pdf) это современный метод, который показывает более высокую эффективность
на оценочных наборах данных по сравнению с I-векторами. Для получения X-векторов используется глубокая нейронная сеть: она обучается различать
дикторов и сопоставляет высказывания переменной длины с эмбеддингами фиксированной размерности. Также можно загрузить X-вектор заранее вычисленных эмбеддингов диктора, в котором будут заключены речевые характеристики конкретного диктора.
</Tip>
Загрузим такие эмбединги диктора из набора датсета в Hub. Эмбединги были получены из [датасета CMU ARCTIC](http://www.festvox.org/cmu_arctic/) с помощью
[этого скрипта](https://huggingface.co/mechanicalsea/speecht5-vc/blob/main/manifest/utils/prep_cmu_arctic_spkemb.py), но любой Х-вектор эмбединг должен работать.
```python
from datasets import load_dataset
embeddings_dataset = load_dataset("Matthijs/cmu-arctic-xvectors", split="validation")
import torch
speaker_embeddings = torch.tensor(embeddings_dataset[7306]["xvector"]).unsqueeze(0)
```
Эмбеддинг диктора представляет собой тензор формы (1, 512). Данный эмбеддинг диктора описывает женский голос.
На данном этапе у нас уже достаточно входных данных, чтобы сгенерировать на выходе лог-мел спектрограмму, это можно сделать следующим образом:
```python
spectrogram = model.generate_speech(inputs["input_ids"], speaker_embeddings)
```
В результате получается тензор формы (140, 80), содержащий лог-мел спектрограмму. Первое измерение - длина последовательности, и
она может изменяться между запусками, так как предварительная сеть декодер речи всегда применяет исключение (dropout) к входной последовательности. Это вносит некоторую
случайную вариативность в генерируемую речь.
Однако если мы хотим генерировать форму волны речи, нам необходимо указать вокодер, который будет использоваться для преобразования спектрограммы в форму волны.
Теоретически можно использовать любой вокодер, работающий с 80-биновыми мел-спектрограммами. Удобно, что 🤗 Transformers предлагает вокодер,
основанный на HiFi-GAN. Его весовые коэффициенты были любезно предоставлены авторами SpeechT5.
<Tip>
[HiFi-GAN](https://arxiv.org/pdf/2010.05646v2.pdf) представляет собой современную генеративную состязательную сеть (generative adversarial network, GAN), разработанную
для высокоточного синтеза речи. Она способна генерировать высококачественные и реалистичные формы волны звука на основе спектрограмм.
В общем случае HiFi-GAN состоит из одного генератора и двух дискриминаторов. Генератор представляет собой полностью сверточную
нейронную сеть, которая принимает на вход mel-спектрограмму и учится генерировать исходные аудиосигналы. Роль дискриминаторов
заключается в том, чтобы различать реальный и сгенерированный звук. Оба дискриминатора фокусируются на различных аспектах звука.
HiFi-GAN обучается на большом наборе данных высококачественных аудиозаписей. В нем используется так называемое <em>состязательное обучение</em>,
при котором сети генератора и дискриминатора соревнуются друг с другом. Вначале генератор выдает низкокачественный звук и дискриминатор легко
отличает его от реального звука. В ходе обучения генератор улучшает свой выход, пытаясь обмануть дискриминатор. Дискриминатор, в свою очередь,
становится более точным в различении реального и сгенерированного звука. Такая состязательная обратная связь помогает обеим сетям совершенствоваться
с течением времени. В конечном итоге HiFi-GAN учится генерировать звук высокой достоверности, близкий по характеристикам к обучающим данным.
</Tip>
Загрузить вокодер так же просто, как и любую другую модель 🤗 Transformers.
```python
from transformers import SpeechT5HifiGan
vocoder = SpeechT5HifiGan.from_pretrained("microsoft/speecht5_hifigan")
```
Теперь достаточно передать его в качестве аргумента при генерации речи, и выходные данные будут автоматически преобразованы в форму волны речи.
```python
speech = model.generate_speech(inputs["input_ids"], speaker_embeddings, vocoder=vocoder)
```
Давайте послушаем результат. Частота дискретизации, используемая SpeechT5, всегда равна 16 кГц.
```python
from IPython.display import Audio
Audio(speech, rate=16000)
```
Отлично!
Не стесняйтесь пользоваться демонстрационной версией SpeechT5, изучайте другие голоса, экспериментируйте с вводом. Обратите внимание, что эта
предварительно обученная контрольная точка поддерживает только английский язык:
<iframe
src="https://matthijs-speecht5-tts-demo.hf.space"
frameborder="0"
width="850"
height="450">
</iframe>
## Bark
Bark - это модель преобразования текста в речь на основе трансформера, предложенная компанией Suno AI в [suno-ai/bark](https://github.com/suno-ai/bark).
В отличие от SpeechT5, Bark генерирует непосредственно "сырые" формы волны речи, что избавляет от необходимости использования отдельного вокодера при инференсе - он уже интегрирован. Такая эффективность достигается за счет использования [`Encodec`](https://huggingface.co/docs/transformers/main/en/model_doc/encodec), который служит одновременно и кодеком, и инструментом сжатия.
С помощью `Encodec` можно сжимать звук в облегченный формат для уменьшения занимаемой памяти и впоследствии распаковывать его для восстановления исходного звучания. Процесс сжатия осуществляется с помощью 8 кодовых книг (codebook), каждая из которых состоит из целочисленных векторов. Эти кодовые книги можно рассматривать как представления или эмбеддинги звука в целочисленной форме. Важно отметить, что каждая последующая кодовая книга улучшает качество восстановления звука из предыдущих кодовых книг. Поскольку кодовые книги являются целочисленными векторами, они могут быть выучены с помощью трансформерных моделей, которые очень эффективно справляются с этой задачей. Именно для этого и был специально обучен Bark.
Если говорить более конкретно, то Bark состоит из 4 основных моделей:
- `BarkSemanticModel` (также называемая 'текстовой' моделью): каузальная авторегрессионная трансформерная модель, принимающая на вход токены из текста и предсказывающая семантические токены, отражающие смысл текста.
- `BarkCoarseModel` (также называемая моделью 'грубой акустики'): каузальный авторегрессионный трансформер, принимающий на вход результаты работы модели `BarkSemanticModel`. Его цель - предсказать первые две кодовые книги, необходимые для работы [EnCodec](https://github.com/facebookresearch/encodec).
- `BarkFineModel` (модель 'тонкой акустики'), на этот раз некаузальный автоэнкодерный трансформер, который итеративно предсказывает последние кодовые книги на основе суммы эбеддингов предыдущих кодовых книг.
- спрогнозировав все каналы кодовой книги из `EncodecModel`, Bark использует ее для декодирования выходного звукового массива.
Следует отметить, что каждый из первых трех модулей может поддерживать условные эмбеддинги диктора, обусловливающие выходной звук в соответствии с определенным заранее заданным голосом.
Bark - это высокоуправляемая модель преобразования текста в речь, то есть ее можно использовать с различными настройками, в чем мы сейчас убедимся.
Прежде всего, загрузите модель и ее процессор.
Роль процессора здесь двухсторонняя:
1. Он используется для токенизации входного текста, т.е. для разбиения его на небольшие фрагменты, понятные модели.
2. В нем хранятся эбеддинги дикторов, т.е. голосовые предустановки, которые могут обуславливать генерацию.
```python
from transformers import BarkModel, BarkProcessor
model = BarkModel.from_pretrained("suno/bark-small")
processor = BarkProcessor.from_pretrained("suno/bark-small")
```
Bark очень универсален и может генерировать звук, обусловленный [библиотекой эбеддингов дикторов](https://suno-ai.notion.site/8b8e8749ed514b0cbf3f699013548683?v=bc67cff786b04b50b3ceb756fd05f68c) которая может быть загружена через процессор.
```python
# add a speaker embedding
inputs = processor("This is a test!", voice_preset="v2/en_speaker_3")
speech_output = model.generate(**inputs).cpu().numpy()
```
<audio controls>
<source src="https://huggingface.co/datasets/ylacombe/hf-course-audio-files/resolve/main/first_sample.wav" type="audio/wav">
Your browser does not support the audio element.
</audio>
Он также может генерировать готовую многоязычную речь, например, на французском и китайском языках. Список поддерживаемых языков можно найти [здесь](https://huggingface.co/suno/bark). В отличие от MMS, о котором речь пойдет ниже, здесь не нужно указывать используемый язык, а достаточно просто адаптировать входной текст к соответствующему языку.
```python
# try it in French, let's also add a French speaker embedding
inputs = processor("C'est un test!", voice_preset="v2/fr_speaker_1")
speech_output = model.generate(**inputs).cpu().numpy()
```
<audio controls>
<source src="https://huggingface.co/datasets/ylacombe/hf-course-audio-files/resolve/main/second_sample.wav" type="audio/wav">
Your browser does not support the audio element.
</audio>
Модель также может генерировать **невербальные коммуникации**, такие как смех, вздох и плач. Для этого достаточно модифицировать входной текст соответствующими подсказками, такими как `[clears throat]`, `[laughter]` или `...`.
```python
inputs = processor(
"[clears throat] This is a test ... and I just took a long pause.",
voice_preset="v2/fr_speaker_1",
)
speech_output = model.generate(**inputs).cpu().numpy()
```
<audio controls>
<source src="https://huggingface.co/datasets/ylacombe/hf-course-audio-files/resolve/main/third_sample.wav" type="audio/wav">
Your browser does not support the audio element.
</audio>
Bark может даже генерировать музыку. Вы можете помочь, добавив ♪ музыкальные ноты ♪ вокруг ваших слов.
```python
inputs = processor(
"♪ In the mighty jungle, I'm trying to generate barks.",
)
speech_output = model.generate(**inputs).cpu().numpy()
```
<audio controls>
<source src="https://huggingface.co/datasets/ylacombe/hf-course-audio-files/resolve/main/fourth_sample.wav" type="audio/wav">
Your browser does not support the audio element.
</audio>
В отличие от SpeechT5, Bark напрямую генерирует форму волны сырой речи. Это означает, что для инференса не нужно добавлять вокодер, он уже "встроен".
Кроме того, Bark поддерживает пакетную обработку, то есть можно одновременно обрабатывать несколько текстовых записей за счет более интенсивных вычислений.
На некоторых аппаратных средствах, таких как GPU, пакетная обработка позволяет ускорить общую генерацию, что означает, что генерация всех образцов одновременно может быть быстрее, чем генерация их по одному.
Попробуем сгенерировать несколько примеров:
```python
input_list = [
"[clears throat] Hello uh ..., my dog is cute [laughter]",
"Let's try generating speech, with Bark, a text-to-speech model",
"♪ In the jungle, the mighty jungle, the lion barks tonight ♪",
]
# также добавляем эмбеддинги диктора
inputs = processor(input_list, voice_preset="v2/en_speaker_3")
speech_output = model.generate(**inputs).cpu().numpy()
```
Давайте прослушаем выводы по очереди.
Первый:
```python
from IPython.display import Audio
sampling_rate = model.generation_config.sample_rate
Audio(speech_output[0], rate=sampling_rate)
```
<audio controls>
<source src="https://huggingface.co/datasets/ylacombe/hf-course-audio-files/resolve/main/batch_1.wav" type="audio/wav">
Your browser does not support the audio element.
</audio>
Второй:
```python
Audio(speech_output[1], rate=sampling_rate)
```
<audio controls>
<source src="https://huggingface.co/datasets/ylacombe/hf-course-audio-files/resolve/main/batch_2.wav" type="audio/wav">
Your browser does not support the audio element.
</audio>
Третий:
```python
Audio(speech_output[2], rate=sampling_rate)
```
<audio controls>
<source src="https://huggingface.co/datasets/ylacombe/hf-course-audio-files/resolve/main/batch_3.wav" type="audio/wav">
Your browser does not support the audio element.
</audio>
<Tip>
Bark, как и другие 🤗 модели трансформеров, могут быть оптимизированы всего в нескольких строках кода в отношении скорости и потребления памяти. Чтобы узнать, как это сделать, нажмите на [этот демонстрационный блокнот Colab](https://colab.research.google.com/github/ylacombe/notebooks/blob/main/Benchmark_Bark_HuggingFace.ipynb).
</Tip>
## Massive Multilingual Speech (MMS)
Что делать, если вам нужна предварительно обученная модель на языке, отличном от английского? Массивная многоязыковая речь (Massive Multilingual Speech, MMS) - это
еще одна модель, которая охватывает целый ряд речевых задач, но при этом поддерживает большое количество языков. Например, она может
синтезировать речь на более чем 1100 языках.
MMS для преобразования текста в речь базируется на технологии описанной в [статье VITS написанной Kim и другими специалистами в 2021 году]((https://arxiv.org/pdf/2106.06103.pdf)),
которая является одним из современных подходов в TTS.
VITS - это сеть генерации речи, преобразующая текст в сырую форму волны речи. Он работает как условный вариационный
автокодер, вычисляя звуковые признаки из входного текста. Сначала генерируются акустические признаки, представленные
в виде спектрограмм. Затем форма сигнала декодируется с помощью транспонированных сверточных слоев, адаптированных из HiFi-GAN.
В процессе инференса кодировки текста подвергаются апсемплингу и преобразуются в волновые формы с помощью потокового модуля и декодера HiFi-GAN.
Это означает, что не нужно добавлять вокодер для инференса, он уже "встроен".
<Tip warning={true}>
Модель MMS была добавлена в 🤗 Transformers совсем недавно, поэтому ее API может немного измениться. На момент выхода этого раздела
MMS для TTS планируется интегрировать в Transformers `main` через пару дней.
После слияния вам придется установить библиотеку из исходного кода. Тем временем, если вы хотите попробовать следующий пример инференса,
вы можете установить модель из ветки PR:
```bash
pip install git+https://github.com/hollance/transformers.git@6900e8ba6532162a8613d2270ec2286c3f58f57b
```
</Tip>
Давайте попробуем использовать MMS и посмотрим, как можно синтезировать речь на языке, отличном от английского, например, на немецком.
Сначала загрузим контрольную точку модели и токенизатор для нужного языка:
```python
from transformers import VitsModel, VitsTokenizer
model = VitsModel.from_pretrained("facebook/mms-tts-deu")
tokenizer = VitsTokenizer.from_pretrained("facebook/mms-tts-deu")
```
Вы можете заметить, что для загрузки модели MMS необходимо использовать `VitsModel` и `VitsTokenizer`. Это связано с тем, что MMS для преобразования текста в речь
основана на модели VITS, о которой говорилось выше.
Возьмем для примера текст на немецком языке, например, эти две первые строчки из детской песенки:
```python
text_example = (
"Ich bin Schnappi das kleine Krokodil, komm aus Ägypten das liegt direkt am Nil."
)
```
Для генерации выходной волновой формы необходимо предварительно обработать текст с помощью токенизатора и передать его в модель:
```python
import torch
inputs = tokenizer(text_example, return_tensors="pt")
input_ids = inputs["input_ids"]
with torch.no_grad():
outputs = model(input_ids)
speech = outputs.audio[0]
```
Давайте послушаем:
```python
from IPython.display import Audio
Audio(speech, rate=16000)
```
Замечательно! Если вы хотите попробовать MMS на другом языке, найдите другие подходящие контрольные точки `vits` [в 🤗 Hub](https://huggingface.co/models?filter=vits).
Теперь давайте посмотрим, как можно самостоятельно дообучить модель TTS!
| 3 |
0 | hf_public_repos/audio-transformers-course/chapters/ru | hf_public_repos/audio-transformers-course/chapters/ru/chapter6/tts_datasets.mdx | # Наборах данных Text-to-speech
Задача преобразования текста в речь (называемая также _синтезом речи_) сопряжена с целым рядом трудностей.
Во-первых, как и в ранее рассмотренном случае автоматического распознавания речи, согласование текста и речи может быть затруднено.
Однако, в отличие от ASR, TTS - это проблема отображения **одного ко многим**, т.е. один и тот же текст может быть синтезирован множеством различных способов. Подумайте о разнообразии голосов и стилей речи,
которые вы слышите ежедневно - каждый человек по-своему произносит одно и то же предложение, но все они правильные и верные! Даже разные выходные данные (спектрограммы или формы волны звука)
могут соответствовать одной и той же истине. Модель должна научиться генерировать правильную длительность и время для каждой фонемы, слова или предложения, что может оказаться непростой задачей,
особенно для длинных и сложных предложений.
Далее, существует проблема дальних зависимостей: язык имеет временной аспект, и понимание смысла предложения
часто требует учета контекста окружающих слов. Убедиться в том, что модель TTS улавливает и сохраняет контекстную информацию
в длинных последовательностях, очень важно для создания связной и естественно звучащей речи.
Наконец, для обучения TTS-моделей обычно требуются пары из текста и соответствующих записей речи. Кроме того, для того чтобы
модель могла генерировать речь, звучащую естественно для различных дикторов и стилей речи, данные должны содержать разнообразные и
репрезентативные образцы речи от различных дикторов. Сбор таких данных является дорогостоящим, трудоемким и для некоторых языков
нецелесообразным. Вы можете подумать, почему бы просто не взять набор данных, предназначенный для ASR (автоматического распознавания речи), и не использовать его для
обучения модели TTS? К сожалению, наборы данных автоматического распознавания речи (ASR) - не самый лучший вариант. Особенности, которые
делают его полезным для ASR, например, чрезмерный фоновый шум, обычно нежелательны в TTS. Очень хорошо, если вы можете
выделить речь из шумной уличной записи, но не очень хорошо, если ваш голосовой помощник отвечает вам на фоне гудка машин
и бурного строительства на заднем плане. Тем не менее, некоторые наборы данных ASR иногда могут быть полезны для дообучения,
так как найти высококачественные, многоязычные и многоголосые наборы данных TTS может быть довольно сложно.
Рассмотрим несколько наборов данных, подходящих для TTS, которые можно найти на 🤗 Hub.
## LJSpeech
[LJSpeech](https://huggingface.co/datasets/lj_speech) представляет собой набор данных, состоящий из 13 100 англоязычных аудиоклипов,
сопоставленных с соответствующими транскрипциями. Набор содержит запись чтения одним диктором предложений
из 7 нехудожественных книг на английском языке. LJSpeech часто используется в качестве эталона для оценки моделей TTS
благодаря высокому качеству звука и разнообразию лингвистического контента.
## Multilingual LibriSpeech
[Multilingual LibriSpeech](https://huggingface.co/datasets/facebook/multilingual_librispeech) является многоязычным расширением
набора данных LibriSpeech, представляющего собой крупномасштабную коллекцию прочитанных англоязычных аудиокниг. Многоязычный LibriSpeech
расширяется за счет включения дополнительных языков, таких как немецкий, голландский, испанский, французский, итальянский, португальский и польский.
Он предлагает аудиозаписи вместе с выверенными транскрипциями для каждого языка. Этот набор данных представляет собой ценный ресурс
для разработки многоязычных систем TTS и изучения методов межъязыкового синтеза речи.
## VCTK (Voice Cloning Toolkit)
[VCTK](https://huggingface.co/datasets/vctk) - это набор данных, специально разработанный для исследований и разработок в области преобразования текста в речь.
Он содержит аудиозаписи 110 дикторов английского языка с различными акцентами. Каждый диктор зачитывает около 400 предложений,
которые были выбраны из газеты, [радужного отрывка](https://www.dialectsarchive.com/the-rainbow-passage)* и элективного абзаца, использованного для архива акцентов речи.
VCTK представляет собой ценный ресурс для обучения TTS-моделей с различными голосами и акцентами, что позволяет осуществлять более естественный и разнообразный
синтез речи.
## Libri-TTS/ LibriTTS-R
[Libri-TTS/ LibriTTS-R](https://huggingface.co/datasets/cdminix/libritts-r-aligned) это многоголосный корпус английской речи,
включающий около 585 часов чтения английской речи с частотой дискретизации 24 кГц, подготовленный компанией Heiga Zen при содействии членов команд Google Speech
и Google Brain. Корпус LibriTTS предназначен для исследования TTS. Он создан на основе оригинальных материалов
(аудиофайлов mp3 из LibriVox и текстовых файлов из Project Gutenberg) корпуса LibriSpeech. Основные отличия
от корпуса LibriSpeech перечислены ниже:
* Аудиофайлы имеют частоту дискретизации 24 кГц.
* Речь разбита на фрагменты.
* Включены как оригинальные, так и нормализованные тексты.
* Контекстная информация (например, соседние предложения) может быть извлечена.
* Исключены фразы со значительным фоновым шумом.
Собрать хороший набор данных для TTS - задача не из легких, поскольку такой набор должен обладать несколькими ключевыми характеристиками:
* Качественные и разнообразные записи, охватывающие широкий спектр речевых паттернов, акцентов, языков и эмоций. Записи должны быть чистыми, без фоновых шумов и демонстрировать естественные характеристики речи.
* Транскрипция: Каждая аудиозапись должна сопровождаться соответствующей текстовой транскрипцией.
* Разнообразие лингвистического контента: Набор данных должен содержать разнообразный лингвистический контент, включая различные типы предложений, фраз и слов. Он должен охватывать различные темы, жанры и области,
чтобы обеспечить способность модели работать с различными языковыми контекстами.
Хорошая новость заключается в том, что вряд ли вам придется обучать TTS-модель с нуля. В следующем разделе мы рассмотрим
предварительно обученные модели, доступные на 🤗 Hub.
-----
* - радужный отрывок - это конкретный фрагмент текста, который часто используется в англоязычных исследованиях речи и голоса для оценки различных аспектов речи. Он включает в себя различные фонетические звуки и лингвистические паттерны, которые могут помочь исследователям понять,
как звуки речи произносятся людьми с различными акцентами или особенностями речи.
| 4 |
0 | hf_public_repos/audio-transformers-course/chapters/ru | hf_public_repos/audio-transformers-course/chapters/ru/chapter6/introduction.mdx | # Раздел 6. От текста к речи
В предыдущем разделе вы узнали, как использовать трансформеры для преобразования устной речи в текст. Теперь давайте перевернем сценарий
и посмотрим, как можно преобразовать заданный входной текст в аудио вывод, звучащий как человеческая речь.
Задача, которую мы будем изучать в этом блоке, называется "Преобразование текста в речь " (Text-to-speech, TTS). Модели, способные преобразовывать текст в слышимую
человеческую речь, имеют широкий спектр потенциальных применений:
* Вспомогательные приложения: подумайте об инструментах, которые могут использовать эти модели для обеспечения доступа людей с ослабленным зрением к цифровому контенту с помощью звука.
* Озвучивание аудиокниг: перевод письменных книг в аудиоформат делает литературу более доступной для тех, кто предпочитает слушать или испытывает трудности с чтением.
* Виртуальные помощники: TTS-модели являются фундаментальным компонентом виртуальных помощников, таких как Siri, Google Assistant или Amazon Alexa. После того как они с помощью классификационной модели поймали слово "пробуждение" и использовали ASR-модель для обработки запроса, они могут использовать TTS-модель для ответа на ваш запрос.
* Развлечения, игры и изучение языков: озвучивайте персонажей NPC, рассказывайте об игровых событиях или помогайте изучающим язык примерами правильного произношения и интонации слов и фраз.
Это лишь некоторые примеры, и я уверен, что вы можете придумать множество других! Однако с такой мощью приходит и ответственность
,важно подчеркнуть, что модели TTS потенциально могут быть использованы в злонамеренных целях.
Например, имея достаточное количество образцов голоса, злоумышленники могут создавать убедительные поддельные аудиозаписи, что приводит к
несанкционированному использованию голоса человека в мошеннических целях или для манипуляций. Если вы планируете собирать данные для дообучения
собственных систем, тщательно продумайте вопросы конфиденциальности и информационного согласия. Получение голосовых данных должно осуществляться с явного согласия
людей, при этом они должны понимать цель, объем и потенциальные риски, связанные с использованием их голоса
в системе TTS. Пожалуйста, используйте преобразование текста в речь ответственно.
## Чему вы научитесь и что создадите
В этом разделе мы поговорим о:
* [Наборах данных, пригодных для обучения Text-to-speech](tts_datasets)
* [Предварительно обученных моделях для преобразования текста в речь](pre-trained_models)
* [Дообучение SpeechT5 на новом языке](fine-tuning)
* [Оценке моделей TTS](evaluation)
| 5 |
0 | hf_public_repos/audio-transformers-course/chapters/ru | hf_public_repos/audio-transformers-course/chapters/ru/chapter6/fine-tuning.mdx | # Дообучение SpeechT5
Теперь, когда вы знакомы с задачей преобразования текста в речь и внутренним устройством модели SpeechT5, которая была предварительно обучена
на англоязычных данных, давайте посмотрим, как мы можем дообучить ее для другого языка.
## House-keeping
Если вы хотите воспроизвести этот пример, убедитесь, что у вас есть графический процессор. В блокноте это можно проверить с помощью следующей команды:
```bash
nvidia-smi
```
<Tip warning={true}>
В нашем примере мы будем использовать около 40 часов обучающих данных. Если вы хотите повторить этот процесс, используя бесплатный тарифный план Google Colab,
необходимо уменьшить объем обучающих данных примерно до 10-15 часов и сократить количество шагов обучения.
</Tip>
Вам также понадобятся некоторые дополнительные зависимости:
```bash
pip install transformers datasets soundfile speechbrain accelerate
```
Наконец, не забудьте войти в свою учетную запись Hugging Face, чтобы загрузить свою модель и поделиться ею с сообществом:
```py
from huggingface_hub import notebook_login
notebook_login()
```
## Набор данных
В данном примере мы возьмем подмножество голландского (`nl`) языка из датасета [VoxPopuli](https://huggingface.co/datasets/facebook/voxpopuli).
[VoxPopuli](https://huggingface.co/datasets/facebook/voxpopuli) - это обширный многоязычный речевой корпус, состоящий из данных,
полученных из записей мероприятий Европейского парламента 2009-2020 гг. Он содержит маркированные данные аудио-транскрипций для 15 европейских языков.
Хотя мы будем использовать подмножество голландского языка, вы можете выбрать другое подмножество.
Это набор данных автоматического распознавания речи (ASR), поэтому, как уже говорилось, он не является наиболее подходящим
вариантом для обучения TTS-моделей. Однако для данного упражнения этого будет вполне достаточно.
Давайте загрузим данные:
```python
from datasets import load_dataset, Audio
dataset = load_dataset("facebook/voxpopuli", "nl", split="train")
len(dataset)
```
**Output:**
```out
20968
```
20968 примеров должно быть достаточно для дообучения. Для SpeechT5 требуется, чтобы частота дискретизации аудиоданных составляла 16 кГц, поэтому
убедимся, что примеры в наборе данных соответствуют этому требованию:
```python
dataset = dataset.cast_column("audio", Audio(sampling_rate=16000))
```
## Препроцессинг данных
Начнем с определения используемой контрольной точки модели и загрузки соответствующего процессора, содержащего как токенизатор,
так и экстрактор признаков, которые понадобятся нам для подготовки данных к обучению:
```py
from transformers import SpeechT5Processor
checkpoint = "microsoft/speecht5_tts"
processor = SpeechT5Processor.from_pretrained(checkpoint)
```
### Очистка текста для токенизации SpeechT5
Во-первых, для подготовки текста нам понадобится часть процессора - токенизатор, поэтому возьмем его:
```py
tokenizer = processor.tokenizer
```
Рассмотрим пример:
```python
dataset[0]
```
**Output:**
```out
{'audio_id': '20100210-0900-PLENARY-3-nl_20100210-09:06:43_4',
'language': 9,
'audio': {'path': '/root/.cache/huggingface/datasets/downloads/extracted/02ec6a19d5b97c03e1379250378454dbf3fa2972943504a91c7da5045aa26a89/train_part_0/20100210-0900-PLENARY-3-nl_20100210-09:06:43_4.wav',
'array': array([ 4.27246094e-04, 1.31225586e-03, 1.03759766e-03, ...,
-9.15527344e-05, 7.62939453e-04, -2.44140625e-04]),
'sampling_rate': 16000},
'raw_text': 'Dat kan naar mijn gevoel alleen met een brede meerderheid die wij samen zoeken.',
'normalized_text': 'dat kan naar mijn gevoel alleen met een brede meerderheid die wij samen zoeken.',
'gender': 'female',
'speaker_id': '1122',
'is_gold_transcript': True,
'accent': 'None'}
```
Можно заметить, что примеры из датасета содержат признаки `raw_text` и `normalized_text`. При выборе признака
в качестве входного текста важно знать, что в токенизаторе SpeechT5 нет токенов для чисел. В `normalized_text`
числа записываются в виде текста. Таким образом, он лучше подходит, и в качестве входного текста следует использовать `normalized_text`.
Поскольку SpeechT5 обучалась на английском языке, она может не распознать некоторые символы в голландском наборе данных. Если
оставить все как есть, то эти символы будут преобразованы в токены `<unk>`. Однако в голландском языке некоторые символы, например `à`, используются
для выделения слогов. Чтобы сохранить смысл текста, можно заменить этот символ на обычное `a`.
Чтобы выявить неподдерживаемые токены, извлечем все уникальные символы из датасета с помощью `SpeechT5Tokenizer`, который
работает с символами как с токенами. Для этого напишем функцию отображения `extract_all_chars`, которая объединяет
транскрипции из всех примеров в одну строку и преобразует ее в набор символов. [NL]
Обязательно задайте `batched=True` и `batch_size=-1` в `dataset.map()`, чтобы все транскрипции были доступны сразу для
функции отображения.
```py
def extract_all_chars(batch):
all_text = " ".join(batch["normalized_text"])
vocab = list(set(all_text))
return {"vocab": [vocab], "all_text": [all_text]}
vocabs = dataset.map(
extract_all_chars,
batched=True,
batch_size=-1,
keep_in_memory=True,
remove_columns=dataset.column_names,
)
dataset_vocab = set(vocabs["vocab"][0])
tokenizer_vocab = {k for k, _ in tokenizer.get_vocab().items()}
```
Теперь у вас есть два набора символов: один со словарем из датасета, другой - со словарем из токенизатора.
Для выявления неподдерживаемых символов в наборе данных можно взять разность между этими двумя наборами. Полученный набор
будет содержать символы, которые есть в наборе данных, но отсутствуют в токенизаторе.
```py
dataset_vocab - tokenizer_vocab
```
**Output:**
```out
{' ', 'à', 'ç', 'è', 'ë', 'í', 'ï', 'ö', 'ü'}
```
Для работы с неподдерживаемыми символами, выявленными на предыдущем этапе, можно определить функцию, которая сопоставляет эти символы с допустимыми токенами.
Заметим, что пробелы уже заменены на `▁` в токенизаторе и не нуждаются в отдельной обработке.
```py
replacements = [
("à", "a"),
("ç", "c"),
("è", "e"),
("ë", "e"),
("í", "i"),
("ï", "i"),
("ö", "o"),
("ü", "u"),
]
def cleanup_text(inputs):
for src, dst in replacements:
inputs["normalized_text"] = inputs["normalized_text"].replace(src, dst)
return inputs
dataset = dataset.map(cleanup_text)
```
Теперь, когда мы разобрались со специальными символами в тексте, пришло время переключить внимание на аудио данные.
### Дикторы
Набор данных VoxPopuli включает речь нескольких дикторов, но сколько дикторов представлено в наборе? Чтобы
определить это, мы можем подсчитать количество уникальных дикторов и количество примеров, которые каждый диктор вносит в набор данных.
Учитывая, что всего в наборе данных 20 968 примеров, эта информация позволит нам лучше понять распределение
дикторов и примеров в данных.
```py
from collections import defaultdict
speaker_counts = defaultdict(int)
for speaker_id in dataset["speaker_id"]:
speaker_counts[speaker_id] += 1
```
Построив гистограмму, можно получить представление о том, сколько данных имеется для каждого диктора.
```py
import matplotlib.pyplot as plt
plt.figure()
plt.hist(speaker_counts.values(), bins=20)
plt.ylabel("Speakers")
plt.xlabel("Examples")
plt.show()
```
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/tasks/tts_speakers_histogram.png" alt="Speakers histogram"/>
</div>
Гистограмма показывает, что примерно треть дикторов в наборе данных имеет менее 100 примеров, в то время как
около десяти дикторов имеют более 500 примеров. Чтобы повысить эффективность обучения и сбалансировать набор данных, мы можем ограничить
данные дикторами, имеющими от 100 до 400 примеров.
```py
def select_speaker(speaker_id):
return 100 <= speaker_counts[speaker_id] <= 400
dataset = dataset.filter(select_speaker, input_columns=["speaker_id"])
```
Проверим, сколько осталось дикторов:
```py
len(set(dataset["speaker_id"]))
```
**Output:**
```out
42
```
Посмотрим, сколько осталось примеров:
```py
len(dataset)
```
**Output:**
```out
9973
```
В результате вы получаете чуть менее 10 000 примеров из примерно 40 уникальных дикторов, что должно быть вполне достаточно.
Отметим, что некоторые дикторы с небольшим количеством примеров могут иметь больше аудиофайлов, если примеры длинные. Однако
определение общего объема аудиозаписей для каждого диктора требует сканирования всего датасета, что является
трудоемким процессом, включающим загрузку и декодирование каждого аудиофайла. Поэтому в данном случае мы решили пропустить этот этап.
### Эмбеддинги диктора
Для того чтобы модель TTS могла различать несколько дикторов, необходимо создать эмбеддинги диктора для каждого примера.
Эмбеддинги дикторов - это дополнительный вход для модели, который фиксирует характеристики голоса конкретного диктора.
Для создания эмбеддингов диктора используется предварительно обученная модель [spkrec-xvect-voxceleb](https://huggingface.co/speechbrain/spkrec-xvect-voxceleb)
от SpeechBrain.
Создадим функцию `create_speaker_embedding()`, которая принимает входную волновую форму звука и выдает 512-элементный вектор,
содержащий соответствующие эмбеддинги диктора.
```py
import os
import torch
from speechbrain.pretrained import EncoderClassifier
spk_model_name = "speechbrain/spkrec-xvect-voxceleb"
device = "cuda" if torch.cuda.is_available() else "cpu"
speaker_model = EncoderClassifier.from_hparams(
source=spk_model_name,
run_opts={"device": device},
savedir=os.path.join("/tmp", spk_model_name),
)
def create_speaker_embedding(waveform):
with torch.no_grad():
speaker_embeddings = speaker_model.encode_batch(torch.tensor(waveform))
speaker_embeddings = torch.nn.functional.normalize(speaker_embeddings, dim=2)
speaker_embeddings = speaker_embeddings.squeeze().cpu().numpy()
return speaker_embeddings
```
Важно отметить, что модель `speechbrain/spkrec-xvect-voxceleb` была обучена на английской речи из датасета VoxCeleb,
в то время как учебные примеры в данном руководстве представлены на голландском языке. Хотя мы считаем, что данная модель все равно будет генерировать разумные эмбеддинги диктора
для нашего голландского датасета, это предположение может быть справедливо не во всех случаях.
Для получения оптимальных результатов необходимо сначала обучить модель X-вектора на целевой речи. Это позволит модели
лучше улавливать уникальные речевые особенности, присущие голландскому языку. Если вы хотите обучить свою собственную X-векторную модель,
то в качестве примера можно использовать [этот скрипт](https://huggingface.co/mechanicalsea/speecht5-vc/blob/main/manifest/utils/prep_cmu_arctic_spkemb.py).
### Обработка датасета
Наконец, обработаем данные в тот формат, который ожидает модель. Создадим функцию `prepare_dataset`, которая принимает
один пример и использует объект `SpeechT5Processor` для токенизации входного текста и загрузки целевого аудио в лог-мел спектрограмму.
Она также должна добавлять эмбеддинги диктора в качестве дополнительного входного сигнала.
```py
def prepare_dataset(example):
audio = example["audio"]
example = processor(
text=example["normalized_text"],
audio_target=audio["array"],
sampling_rate=audio["sampling_rate"],
return_attention_mask=False,
)
# strip off the batch dimension
example["labels"] = example["labels"][0]
# use SpeechBrain to obtain x-vector
example["speaker_embeddings"] = create_speaker_embedding(audio["array"])
return example
```
Проверить правильность обработки можно на одном из примеров:
```py
processed_example = prepare_dataset(dataset[0])
list(processed_example.keys())
```
**Output:**
```out
['input_ids', 'labels', 'stop_labels', 'speaker_embeddings']
```
Эмбеддинги диктора должны представлять собой 512-элементный вектор:
```py
processed_example["speaker_embeddings"].shape
```
**Output:**
```out
(512,)
```
Метки должны представлять собой лог-мел спектрограмму с 80 мел бинами.
```py
import matplotlib.pyplot as plt
plt.figure()
plt.imshow(processed_example["labels"].T)
plt.show()
```
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/tasks/tts_logmelspectrogram_1.png" alt="Log-mel spectrogram with 80 mel bins"/>
</div>
Примечание: Если данная спектрограмма кажется вам непонятной, то это может быть связано с тем, что вы привыкли располагать низкие частоты
внизу, а высокие - вверху графика. Однако при построении спектрограмм в виде изображения с помощью библиотеки matplotlib ось y
переворачивается, и спектрограммы выглядят перевернутыми.
Теперь необходимо применить функцию препроцессинга ко всему набору данных. Это займет от 5 до 10 минут.
```py
dataset = dataset.map(prepare_dataset, remove_columns=dataset.column_names)
```
Появится предупреждение о том, что длина некоторых примеров в датасете превышает максимальную длину входных данных, которую может обработать модель (600 лексем).
Удалите эти примеры из датасета. Здесь мы идем еще дальше и для того, чтобы увеличить размер батча, удаляем все, что превышает 200 токенов.
```py
def is_not_too_long(input_ids):
input_length = len(input_ids)
return input_length < 200
dataset = dataset.filter(is_not_too_long, input_columns=["input_ids"])
len(dataset)
```
**Output:**
```out
8259
```
Затем создадим базовое разделение на тренировочную и тестовую части:
```py
dataset = dataset.train_test_split(test_size=0.1)
```
### Коллатор данных
Для того чтобы объединить несколько примеров в батч, необходимо определить пользовательский коллатор данных. Этот коллатор будет дополнять более короткие последовательности токенами,
гарантируя, что все примеры будут иметь одинаковую длину. Для меток спектрограммы дополняемая части заменяются на специальное значение `-100`.
Это специальное значение указывает модели игнорировать эту часть спектрограммы при расчете потерь спектрограммы.
```py
from dataclasses import dataclass
from typing import Any, Dict, List, Union
@dataclass
class TTSDataCollatorWithPadding:
processor: Any
def __call__(
self, features: List[Dict[str, Union[List[int], torch.Tensor]]]
) -> Dict[str, torch.Tensor]:
input_ids = [{"input_ids": feature["input_ids"]} for feature in features]
label_features = [{"input_values": feature["labels"]} for feature in features]
speaker_features = [feature["speaker_embeddings"] for feature in features]
# collate the inputs and targets into a batch
batch = processor.pad(
input_ids=input_ids, labels=label_features, return_tensors="pt"
)
# replace padding with -100 to ignore loss correctly
batch["labels"] = batch["labels"].masked_fill(
batch.decoder_attention_mask.unsqueeze(-1).ne(1), -100
)
# not used during fine-tuning
del batch["decoder_attention_mask"]
# round down target lengths to multiple of reduction factor
if model.config.reduction_factor > 1:
target_lengths = torch.tensor(
[len(feature["input_values"]) for feature in label_features]
)
target_lengths = target_lengths.new(
[
length - length % model.config.reduction_factor
for length in target_lengths
]
)
max_length = max(target_lengths)
batch["labels"] = batch["labels"][:, :max_length]
# also add in the speaker embeddings
batch["speaker_embeddings"] = torch.tensor(speaker_features)
return batch
```
В SpeechT5 входная информация для декодера уменьшается в 2 раза. Другими словами, отбрасывается каждый второй
временной шаг из целевой последовательности.Затем декодер предсказывает последовательность, которая в два раза длиннее. Поскольку исходная длина
целевой последовательности [NL] может быть нечетной, коллатор данных обязательно округляет максимальную длину батча до значения [NL], кратного 2.
```py
data_collator = TTSDataCollatorWithPadding(processor=processor)
```
## Обучение модели
Загрузите предварительно обученную модель из той же контрольной точки, которая использовалась для загрузки процессора:
```py
from transformers import SpeechT5ForTextToSpeech
model = SpeechT5ForTextToSpeech.from_pretrained(checkpoint)
```
Опция `use_cache=True` несовместима с использованием градиентных контрольных точек. Отключите ее для обучения и снова включите кэш для генерации,
чтобы ускорить инференс:
```py
from functools import partial
# отключить кэш во время обучения, так как он несовместим с градиентными контрольными точками
model.config.use_cache = False
# заданим язык и задачу для генерации и снова включим кэш
model.generate = partial(model.generate, use_cache=True)
```
Определим аргументы обучения. Здесь мы не вычисляем никаких оценочных метрик в процессе обучения,
мы поговорим об оценке позже в этой главе. Вместо этого мы будем рассматривать только потери:
```python
from transformers import Seq2SeqTrainingArguments
training_args = Seq2SeqTrainingArguments(
output_dir="speecht5_finetuned_voxpopuli_nl", # change to a repo name of your choice
per_device_train_batch_size=4,
gradient_accumulation_steps=8,
learning_rate=1e-5,
warmup_steps=500,
max_steps=4000,
gradient_checkpointing=True,
fp16=True,
evaluation_strategy="steps",
per_device_eval_batch_size=2,
save_steps=1000,
eval_steps=1000,
logging_steps=25,
report_to=["tensorboard"],
load_best_model_at_end=True,
greater_is_better=False,
label_names=["labels"],
push_to_hub=True,
)
```
Инстанцируем объект `Trainer` и передаем ему модель, набор данных и коллатор данных.
```py
from transformers import Seq2SeqTrainer
trainer = Seq2SeqTrainer(
args=training_args,
model=model,
train_dataset=dataset["train"],
eval_dataset=dataset["test"],
data_collator=data_collator,
tokenizer=processor,
)
```
И с этим мы готовы приступить к обучению! Обучение займет несколько часов. В зависимости от используемого GPU
возможно, что при начале обучения возникнет ошибка CUDA "out-of-memory". В этом случае можно уменьшить
размер `per_device_train_batch_size` постепенно в 2 раза и увеличить `gradient_accumulation_steps` в 2 раза, чтобы компенсировать это.
```py
trainer.train()
```
Push the final model to the 🤗 Hub:
```py
trainer.push_to_hub()
```
## Инференс
После того как модель дообучена, ее можно использовать для инференса! Загрузите модель из 🤗 Hub (убедитесь, что в
следующем фрагменте кода используется имя вашей учетной записи):
```py
model = SpeechT5ForTextToSpeech.from_pretrained(
"YOUR_ACCOUNT/speecht5_finetuned_voxpopuli_nl"
)
```
Выберем пример, здесь мы возьмем пример из тестового набора данных. Получаем эмбеддинги диктора.
```py
example = dataset["test"][304]
speaker_embeddings = torch.tensor(example["speaker_embeddings"]).unsqueeze(0)
```
Определим некоторый входной текст и токенизируем его.
```py
text = "hallo allemaal, ik praat nederlands. groetjes aan iedereen!"
```
Выполним препроцессинг входного текста:
```py
inputs = processor(text=text, return_tensors="pt")
```
Инстанцируем вокодер и сгенерируем речь:
```py
from transformers import SpeechT5HifiGan
vocoder = SpeechT5HifiGan.from_pretrained("microsoft/speecht5_hifigan")
speech = model.generate_speech(inputs["input_ids"], speaker_embeddings, vocoder=vocoder)
```
Готовы послушать результат?
```py
from IPython.display import Audio
Audio(speech.numpy(), rate=16000)
```
Получение удовлетворительных результатов с помощью этой модели на новом языке может оказаться непростой задачей. Качество эмбеддингов диктора
может быть существенным фактором. Поскольку SpeechT5 была предварительно обучена на английских x-векторах, она показывает наилучшие результаты
при использовании эмбеддингов английских дикторов. Если синтезированная речь звучит плохо, попробуйте использовать другие эмбеддинги диктора.
Увеличение продолжительности обучения, вероятно, также повысит качество результатов. Несмотря на это, речь явно голландская, а не английская, и в ней
передаются особенности голоса говорящего (сравните с оригинальным аудио в примере).
Еще один момент, с которым можно поэкспериментировать, - это настройка модели. Например, попробуйте использовать `config.reduction_factor = 1`, чтобы
посмотреть, улучшит ли это результаты.
В следующем разделе мы расскажем о том, как мы оцениваем модели преобразования текста в речь.
| 6 |
0 | hf_public_repos/audio-transformers-course/chapters/ru | hf_public_repos/audio-transformers-course/chapters/ru/chapter6/hands_on.mdx | # Практическое занятие
В этом разделе мы рассмотрели аудиозадачу преобразования текста в речь, рассказали о существующих наборах данных, предварительно обученных
моделях и нюансах дообучения SpeechT5 для нового языка.
Как вы убедились, дообучение моделей для задач преобразования текста в речь может быть сложной задачей в условиях ограниченных ресурсов. В то же время
оценивать модели преобразования текста в речь также нелегко.
По этим причинам данное практическое занятие будет направлено на отработку навыков, а не на достижение определенного значения метрики.
Ваша задача - провести дообучение SpeechT5 на выбранном вами наборе данных. Вы можете выбрать
другой язык из того же набора данных `voxpopuli`, либо выбрать любой другой набор данных, приведенный в этом разделе.
Помните о размере обучающих данных! Для обучения на GPU бесплатного уровня в Google Colab мы рекомендуем ограничить объем обучающих
данных примерно до 10-15 часов.
После завершения процесса дообучения поделитесь своей моделью, загрузив ее в Hub. Обязательно пометьте модель
как модель `text-to-speech` либо соответствующими параметрами kwargs, либо через графический интерфейс Hub.
Помните, что основная цель этого упражнения - предоставить вам обширную практику, которая позволит вам отточить свои навыки и
получить более глубокое представление об аудиозадачах преобразования текста в речь.
| 7 |
0 | hf_public_repos/audio-transformers-course/chapters | hf_public_repos/audio-transformers-course/chapters/bn/_toctree.yml | - title: অধ্যায় 0. পাঠক্রমে স্বাগতম !
sections:
- local: chapter0/introduction
title: এই পাঠক্রম থেকে কি কি আসা করা যাই?
- local: chapter0/get_ready
title: প্রস্তুতি পর্ব -
- local: chapter0/community
title: কি করে 🤗 সম্প্রদায়ের অংশ হবো?
- title: অধ্যায় ১. অডিও ডাটার সাথে কাজ করার পদ্ধতিসমূহ
sections:
- local: chapter1/introduction
title: এই অধ্যায় থেকে তুমি কি কি শিখবে?
- local: chapter1/audio_data
title: অডিও ডাটার সাথে পরিচয়
- local: chapter1/load_and_explore
title: অডিও ডাটাসেটকে লোড এবং বিশ্লেষণ করা
- local: chapter1/preprocessing
title: অডিও ডাটা প্রক্রিয়াকরণ
- local: chapter1/streaming
title: অডিও ডাটা স্ট্রিমিং
- local: chapter1/quiz
title: প্রতিযোগিতা
প্রতিযোগিতা: ১
- local: chapter1/supplemental_reading
title: পরিপূরক পাঠ এবং সংস্থান
- title: অধ্যায় ২. অডিও অ্যাপ্লিকেশনের সূচনা
sections:
- local: chapter2/introduction
title: অডিও অ্যাপ্লিকেশন এর পরিদর্শন
- local: chapter2/audio_classification_pipeline
title: Pipeline এর মাদ্ধমে Audio classification
- local: chapter2/asr_pipeline
title: pipeline এর মাদ্ধমে Automatic speech recognition
- local: chapter2/hands_on
title: হাতে-করি অনুশীলন
#- title: অধ্যায় ৩. Transformer architectures for audio
# sections:
# - local: chapter3/introduction
# title: Transformer মডেলস এর যাচাই
# - local: chapter3/ctc
# title: CTC মডেলস এর নির্মাণকৌশল
# - local: chapter3/seq2seq
# title: Seq2Seq মডেলস এর নির্মাণকৌশল
# - local: chapter3/classification
# title: Audio classification মডেলস এর নির্মাণকৌশল
# - local: chapter3/quiz
# title: প্রতিযোগিতা
# প্রতিযোগিতা: ৩
# - local: chapter3/supplemental_reading
# title: পরিপূরক পাঠ এবং সংস্থান
#
#- title: অধ্যায় ৪. Build a music genre classifier
# sections:
# - local: chapter4/introduction
# title: এই অধ্যায় থেকে তুমি কি কি শিখবে এবং কি কি তৈরী করবে?
# - local: chapter4/classification_models
# title: Audio classification এর জন্যে Pre-trained মডেলস.
# - local: chapter4/fine-tuning
# title: Music classification এর জন্যে মডেল Fine-tuninging.
# - local: chapter4/demo
# title: Gradio এর মাদ্ধমে ডেমো তৈরী
# - local: chapter4/hands_on
# title: হাতে-করি অনুশীলন
#
#- title: অধ্যায় ৫. একটি মিটিং রেকর্ডিং এর প্রতিলিপি
# sections:
# - local: chapter5/introduction
# title: এই অধ্যায় থেকে তুমি কি কি শিখবে এবং কি কি তৈরী করবে?
# - local: chapter5/choosing_dataset
# title: Dataset নির্বাচন করা
# - local: chapter5/asr_models
# title: Automatic speech recognition এর জন্যে Pre-trained মডেলস
# - local: chapter5/preprocessing_data
# title: ডাটা লোডিং এবং প্রক্রিয়াকরণ
# - local: chapter5/evaluation
# title: ASR এর মূল্যায়নের প্রক্রিয়াসমূহ
# - local: chapter5/fine-tuning
# title: ASR মডেল এর Fine-tuning
# - local: chapter5/speaker_diarization
# title: Speaker diarization এর সাথে Automatic speech recognition
# - local: chapter5/quiz
# title: প্রতিযোগিতা
# প্রতিযোগিতা: ৫
# - local: chapter5/hands_on
# title: হাতে-করি অনুশীলন
# - local: chapter5/supplemental_reading
# title: পরিপূরক পাঠ এবং সংস্থান
#
#- title: অধ্যায় ৬. text থেকে speech এ রূপান্তর
# sections:
# - local: chapter6/introduction
# title: এই অধ্যায় থেকে তুমি কি কি শিখবে এবং কি কি তৈরী করবে?
# - local: chapter6/overview
# title: কিভাবে human speech থেকে text এ সংশ্লেষিত করবো?
# - local: chapter6/choosing_dataset
# title: ডাটাসেট নির্বাচন করা
# - local: chapter6/preprocessing
# title: ডাটা লোডিং এবং প্রক্রিয়াকরণ
# - local: chapter6/pre-trained_models
# title: Text-To-Speech এর জন্যে Pre-trained মডেলস.
# - local: chapter6/evaluation
# title: Text-To-Speech এর মূল্যায়নের প্রক্রিয়াসমূহ
# - local: chapter6/fine-tuning
# title: SpeechT5 কে Fine-tuning করা
# - local: chapter6/quiz
# title: প্রতিযোগিতা
# প্রতিযোগিতা: ৬
# - local: chapter6/hands_on
# title: হাতে-করি অনুশীলন
# - local: chapter6/supplemental_reading
# title: পরিপূরক পাঠ এবং সংস্থান
#
#- title: অধ্যায় ৭. Audio to audio
# sections:
# - local: chapter7/introduction
# title: এই অধ্যায় থেকে তুমি কি কি শিখবে এবং কি কি তৈরী করবে?
# - local: chapter7/tasks
# title: Audio-To-Audio এর উদাহরণ
# - local: chapter7/choosing_dataset
# title: ডাটাসেট নির্বাচন করা
# - local: chapter7/preprocessing
# title: ডাটা লোডিং এবং প্রক্রিয়াকরণ
# - local: chapter7/evaluation
# title: Audio-To-Audio এর মূল্যায়নের প্রক্রিয়াসমূহ
# - local: chapter7/fine-tuning
# title: মডেল Fine-tune করো
# - local: chapter7/quiz
# title: প্রতিযোগিতা
# প্রতিযোগিতা: ৭
# - local: chapter7/hands_on
# title: হাতে-করি অনুশীলন
# - local: chapter7/supplemental_reading
# title: পরিপূরক পাঠ এবং সংস্থান
#
#- title: অধ্যায় ৮. শেষ অধ্যায়
# sections:
# - local: chapter8/introduction
# title: অভিনন্দন!
# - local: chapter8/certification
# title: সার্টিফিকেট সংগ্রহ করে নাও
# - local: chapter8/stay_in_touch
# title: সাথে থাকুন
#
#- title: বোনাস অধ্যায়. Audio এর জন্য Diffusion models
# sections:
# - local: chapter9/introduction
# title: পরিদর্শন
# - local: chapter9/music_generation
# title: Music generation
# - local: chapter9/riffusion
# title: Riffusion
# - local: chapter9/audioldm
# title: AudioLDM
# - local: chapter9/dance_diffusion
# title: Dance Diffusion
- title: পাঠক্রম এর ঘটনাবলী
sections:
- local: events/introduction
title: লাইভ সেশন এবং কর্মশালা | 8 |
0 | hf_public_repos/audio-transformers-course/chapters/bn | hf_public_repos/audio-transformers-course/chapters/bn/chapter0/get_ready.mdx | # প্রস্তুতি পর্ব
আমরা আশা করি আপনি পাঠক্রমটি শুরু করতে উত্তেজিত, এবং আমরা এই পৃষ্ঠাটি আপনার প্রস্তুতির শুরু করার জন্যে ডিজাইন করেছি!
## পদক্ষেপ ১. Sign up
সমস্ত আপডেট এবং বিশেষ সামাজিক ইভেন্টগুলির সাথে আপ টু ডেট থাকতে, কোর্সে Sign Up করুন ৷
[👉 SIGN UP](http://eepurl.com/insvcI)
## পদক্ষেপ ২. 🤗 account তৈরী করুন
আপনার যদি এখনও একটি 🤗 account না থাকে, একটি 🤗 account তৈরি করুন (এটি বিনামূল্যে)। হাতে-কলমে কাজগুলি সম্পূর্ণ করার জন্য আপনার এটির
প্রয়োজন হব। এছাড়াও এটি আপনার সমাপ্তির শংসাপত্র গ্রহণ করতে, pre-trained models গুলি অন্বেষণ করতে, ডেটাসেটগুলি অ্যাক্সেস করতে এবং আরও
অনেক কিছু করতে সাহায্য করবে ।
[👉 🤗 account তৈরি করুন](https://huggingface.co/join)
## পদক্ষেপ ৩. Transformer models এর যাচাই করে নিন (আপনার যদি প্রয়োজন পরে তবেই)
আমরা অনুমান করি যে আপনার Deep Learning এর সাথে পরিচয় আছে এবং Transformers models এর সাথে সাধারণ পরিচিতি রয়েছে।
আপনার যদি Transformers models এর ব্যাপারে যাচাই করার প্রয়োজন পরে তাহলে আমাদের [NLP Course](https://huggingface.co/course/chapter1/1) এর সাহায্য নিতে পারেন।
## পদক্ষেপ ৪. আপনার সেটআপ চেক করুন
আপনার যা যা প্রয়োজন হবে:
- ইন্টারনেট সংযোগ সহ একটি কম্পিউটার
- [Google Colab](https://colab.research.google.com) এর প্রয়োজন হবে হাতে-করি অনুশীলনীর জন্যে। বিনামূল্যের সংস্করণটি যথেষ্ট.
আপনি যদি আগে কখনো Google Colab ব্যবহার না করে থাকেন তাহলে এটি দেখুন - [official introduction notebook](https://colab.research.google.com/notebooks/intro.ipynb).
## পদক্ষেপ ৫. 🤗 সম্প্রদায় যোগদান করুন
আমাদের Discord সার্ভারে Sign Up করুন, সেই জায়গা যেখানে আপনি আপনার সহপাঠীদের সাথে ধারনা এবং তথ্য বিনিময় করতে পারেন এবং আমাদের সাথে যোগাযোগ করতে পারেন (🤗 Team)।
[👉 🤗 সম্প্রদায় যোগদান করুন](http://hf.co/join/discord)
আমাদের সম্প্রদায়ের সম্পর্কে আরো জানতে পরের [পাতায় যান](community)।
| 9 |
0 | hf_public_repos/blog | hf_public_repos/blog/zh/ram-efficient-pytorch-fsdp.md | ---
title: "使用 PyTorch FSDP 微调 Llama 2 70B"
thumbnail: /blog/assets/160_fsdp_llama/thumbnail.jpg
authors:
- user: smangrul
- user: sgugger
- user: lewtun
- user: philschmid
translators:
- user: MatrixYao
- user: zhongdongy
proofreader: true
---
# 使用 PyTorch FSDP 微调 Llama 2 70B
## 引言
通过本文,你将了解如何使用 PyTorch FSDP 及相关最佳实践微调 Llama 2 70B。在此过程中,我们主要会用到 Hugging Face Transformers、Accelerate 和 TRL 库。我们还将展示如何在 SLURM 中使用 Accelerate。
完全分片数据并行 (Fully Sharded Data Parallelism,FSDP) 是一种训练范式,在该范式中优化器状态、梯度和模型参数都会被跨设备分片。前向传播时,每个 FSDP 单元执行 _all gather_ 以获取完整的权重,然后用它们进行计算并在计算后丢弃掉其他设备的分片。随后是反向传播,然后就是损失计算。反向传播时,每个 FSDP 单元执行 _all gather_ 操作以获取完整的权重,并执行计算以获得本地 batch 的梯度。这些梯度通过 _reduce scatter_ 在设备上进行均值计算并分片,这样每个设备都可以更新其对应分片的参数。有关 PyTorch FSDP 的更多信息,请参阅此博文: [使用 PyTorch 完全分片数据并行技术加速大模型训练](https://huggingface.co/blog/zh/pytorch-fsdp)。
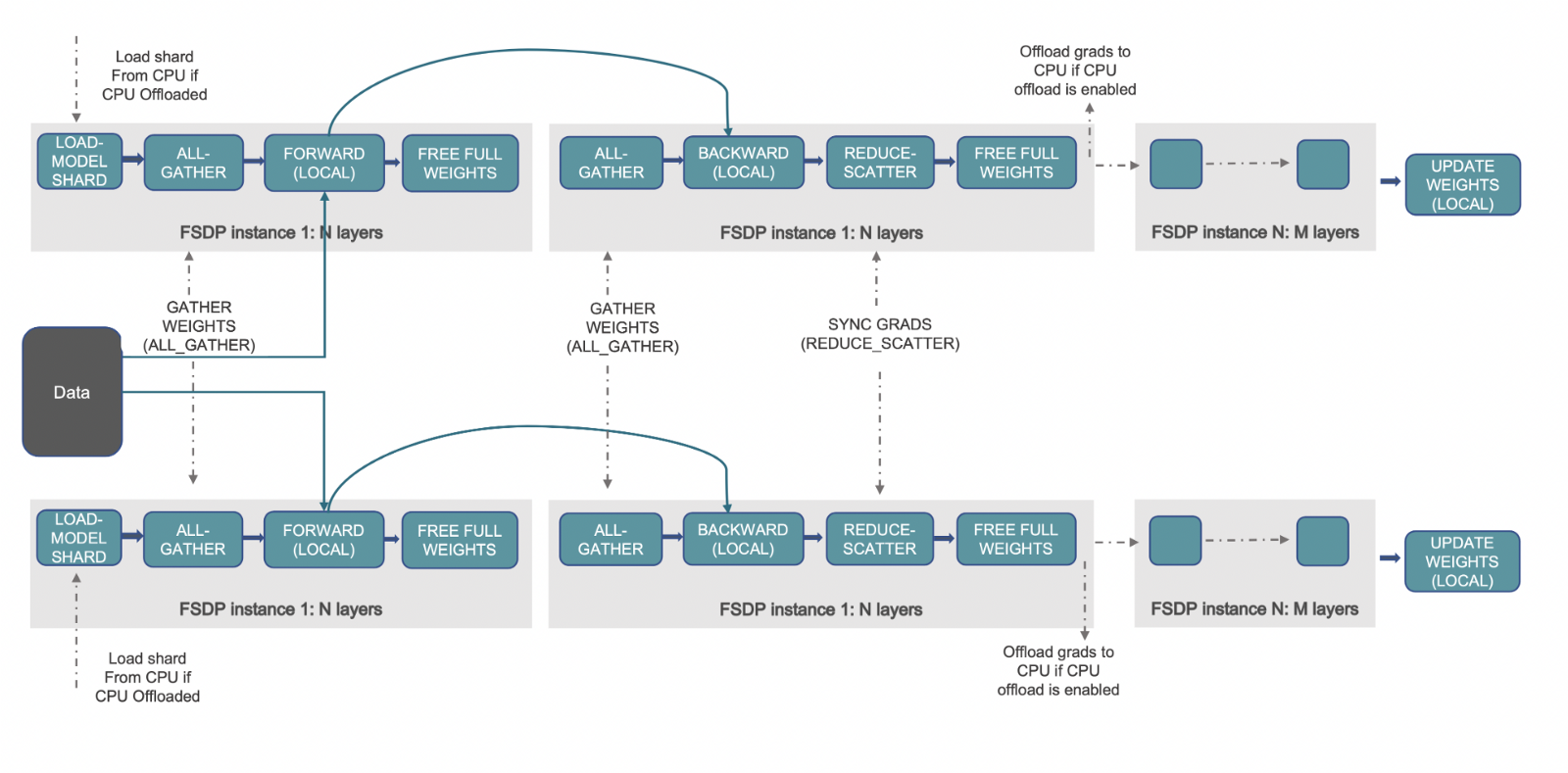
(图源: [链接](https://pytorch.org/blog/introducing-pytorch-fully-sharded-data-parallel-api/))
## 使用的硬件
节点数: 2,至少 1 个节点
每节点 GPU 数: 8
GPU 类型: A100
GPU 显存: 80GB
节点内互联: NVLink
每节点内存: 1TB
每节点 CPU 核数: 96
节点间互联: AWS 的 Elastic Fabric Adapter (EFA)
## 微调 LLaMa 2 70B 面临的挑战
在尝试使用 FSDP 微调 LLaMa 2 70B 时,我们主要遇到了三个挑战:
1. FSDP 会先加载整个预训练模型,然后再对模型进行分片。这样就意味着节点内的每个进程 (即 rank) 都会加载整个 Llama-70B 模型,因此需要 70*4*8 GB ~ 2TB 的 CPU 内存,这个算式中 4 是每个参数所需字节数,8 是每个节点的 GPU 数。这会导致 CPU 内存不足,进而导致进程终止。
2. 使用 `FULL_STATE_DICT` 来保存完整中间检查点并将其卸载至 rank 0 的 CPU 内存中需要花费大量时间,且由于在此期间通信库需要无限期挂起等待保存完成,因此经常会导致 NCCL 超时错误。然而,完全关掉这个选项也不好,因为在训练结束时我们需要保存完整的模型状态字典,而不是 FSDP 式分片的状态字典。
3. 我们需要提高速度并减少显存使用,以加快训练并节约计算成本。
下文,我们主要讨论如何一一解决上述挑战,最终微调出一个 70B 的模型!
先列出重现结果所需的所有资源:
1. 代码库: <url>https://github.com/pacman100/DHS-LLM-Workshop/tree/main/chat_assistant/training</url>,代码中包含了使能 flash 注意力 V2 的热补丁
2. FSDP 配置文件: <url>https://github.com/pacman100/DHS-LLM-Workshop/blob/main/chat_assistant/training/configs/fsdp_config.yaml</url>
3. SLURM 启动脚本 - `launch.slurm` : <url>https://gist.github.com/pacman100/1cb1f17b2f1b3139a63b764263e70b25</url>
4. 模型: `meta-llama/Llama-2-70b-chat-hf`
5. 数据集: [smangrul/code-chat-assistant-v1](https://huggingface.co/datasets/smangrul/code-chat-assistant-v1) (混合了 LIMA 和 GUANACO 数据集,且已转换为训练所需的格式)
### 准备工作
首先按照 [此步骤](https://github.com/Dao-AILab/flash-attention) 安装 Flash Attention V2。然后,安装最新的 PyTorch nightly (CUDA ≥11.8)。接着,根据 [此文件](https://github.com/pacman100/DHS-LLM-Workshop/blob/main/personal_copilot/training/requirements.txt) 安装其余依赖软件。在本文中,我们是从主分支安装 🤗 Accelerate 和 🤗 Transformers 的。
## 微调
### 应对挑战 1
PR [25107](https://github.com/huggingface/transformers/pull/25107) 和 PR [1777](https://github.com/huggingface/accelerate/pull/1777) 解决了第一个挑战,且无需用户侧更改任何代码。主要做的事情如下:
1. 在所有 rank 上创建无权重的空模型 (使用 `meta` 设备)
2. 仅在 rank 0 上将状态字典加载至模型
3. 其他 rank 仅对 `meta` 设备上的参数执行 `torch.empty(*param.size(), dtype=dtype)`
4. 因此,只有 rank 0 上加载了完整的模型及权重,而所有其他 rank 上的权重是空的
5. 设置 `sync_module_states=True` ,以便 FSDP 实例在训练开始之前将权重广播到各 rank
下面是在 2 个 GPU 上加载 7B 模型的输出日志片段,它测量了各个阶段内存的消耗及其加载的模型参数量。我们可以观察到,在加载预训练模型时,rank 0 和 rank 1 的 CPU 峰值内存分别为 `32744 MB` 和 `1506 MB` 。因此可知,仅有 rank 0 加载了预训练模型,这就实现了 CPU 内存的有效利用。你可在 [此处](https://gist.github.com/pacman100/2fbda8eb4526443a73c1455de43e20f9) 找到完整日志。
```bash
accelerator.process_index=0 GPU Memory before entering the loading : 0
accelerator.process_index=0 GPU Memory consumed at the end of the loading (end-begin): 0
accelerator.process_index=0 GPU Peak Memory consumed during the loading (max-begin): 0
accelerator.process_index=0 GPU Total Peak Memory consumed during the loading (max): 0
accelerator.process_index=0 CPU Memory before entering the loading : 926
accelerator.process_index=0 CPU Memory consumed at the end of the loading (end-begin): 26415
accelerator.process_index=0 CPU Peak Memory consumed during the loading (max-begin): 31818
accelerator.process_index=0 CPU Total Peak Memory consumed during the loading (max): 32744
accelerator.process_index=1 GPU Memory before entering the loading : 0
accelerator.process_index=1 GPU Memory consumed at the end of the loading (end-begin): 0
accelerator.process_index=1 GPU Peak Memory consumed during the loading (max-begin): 0
accelerator.process_index=1 GPU Total Peak Memory consumed during the loading (max): 0
accelerator.process_index=1 CPU Memory before entering the loading : 933
accelerator.process_index=1 CPU Memory consumed at the end of the loading (end-begin): 10
accelerator.process_index=1 CPU Peak Memory consumed during the loading (max-begin): 573
accelerator.process_index=1 CPU Total Peak Memory consumed during the loading (max): 1506
```
### 应对挑战 2
该挑战可以通过在配置 FSDP 时将状态字典类型设为 `SHARDED_STATE_DICT` 来解决。设为 `SHARDED_STATE_DICT` 后,每个 rank 各自保存各自 GPU 所需要的分片,这使得用户可以快速保存中间检查点并快速从其恢复训练。而当使用 `FULL_STATE_DICT` 时,第一个进程 (rank 0) 会用 CPU 收集整个模型,然后将其保存为标准格式。
我们可以用以下命令创建相应的 accelerte 配置文件:
```
accelerate config --config_file "fsdp_config.yaml"
```
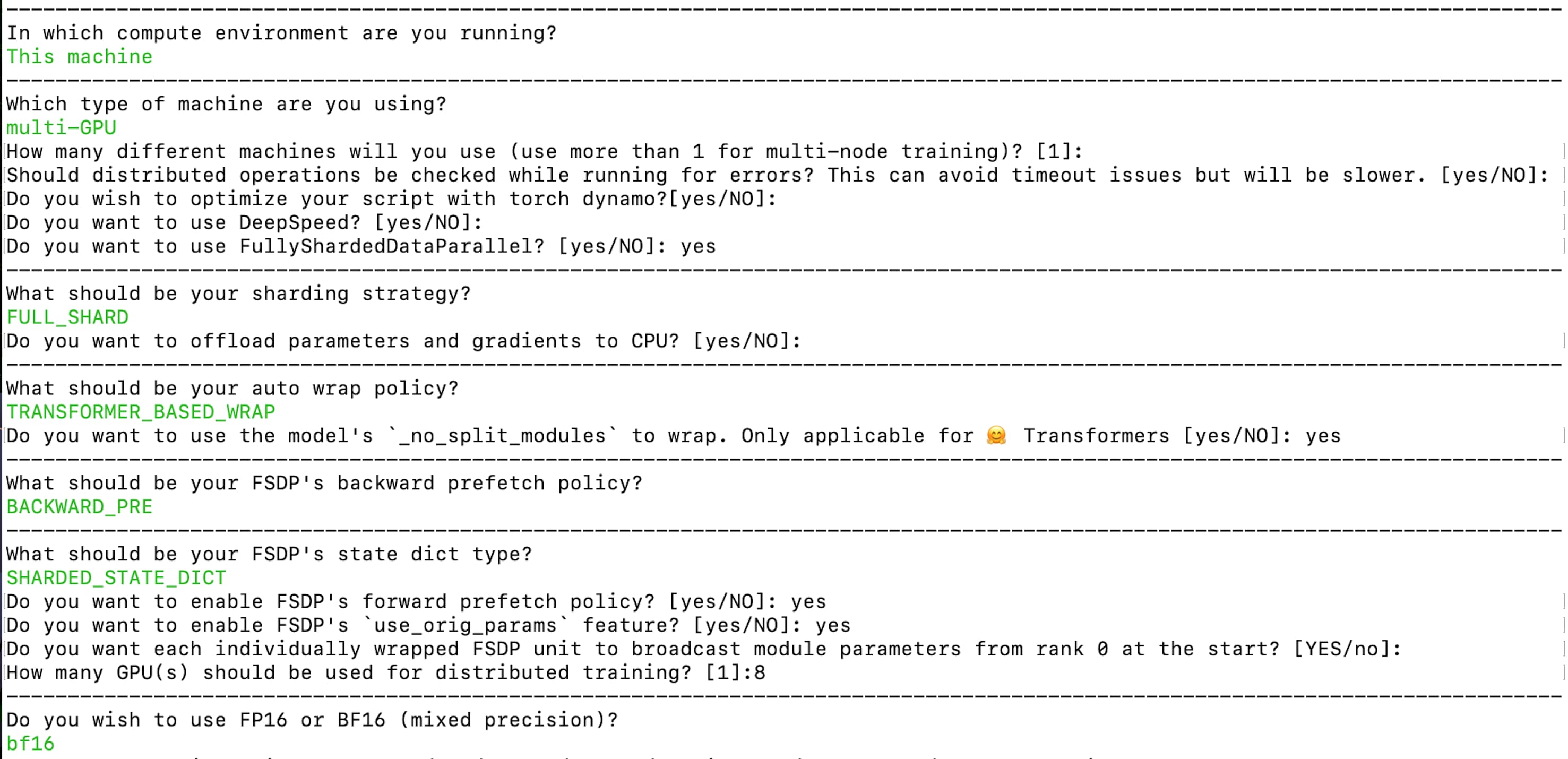
你可以从此处获取生成的配置文件: [fsdp_config.yaml](https://github.com/pacman100/DHS-LLM-Workshop/blob/main/chat_assistant/training/configs/fsdp_config.yaml)。在该配置文件中,分片策略是 `FULL_SHARD` 。我们使用 `TRANSFORMER_BASED_WRAP` 作为自动模型包装策略,它使用 `_no_split_module` 来搜索 transformer 块名并自动进行嵌套 FSDP 包装。我们使用 `SHAARDED_STATE_DICT` 把中间检查点和优化器状态保存为 PyTorch 官方推荐的格式。同时,如上一节 `应对挑战 1` 中所述,我们还需要确保训练开始时用 rank 0 来广播参数。从配置文件中你还可以看到我们用的是 `bf16` 混合精度训练。
那么,在保存最终检查点时,如果将其保存成单个文件呢?我们使用的是以下代码段:
```python
if trainer.is_fsdp_enabled:
trainer.accelerator.state.fsdp_plugin.set_state_dict_type("FULL_STATE_DICT")
trainer.save_model(script_args.output_dir) # 或者 , 如果整个模型小于 50 GB (即 LFS 单文件的最大尺寸),你还可以使用 trainer.push_to_hub() 把模型推到 hub 上去。
```
### 应对挑战 3
为了加快训练速度并减少显存占用,我们可以使用 flash 注意力并开启梯度检查点优化,从而在微调的同时节省计算成本。当前,我们用了一个热补丁来实现 flash 注意力,具体代码可见 [这儿](https://github.com/pacman100/DHS-LLM-Workshop/blob/main/chat_assistant/training/llama_flash_attn_monkey_patch.py)。
[FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness](https://arxiv.org/pdf/2205.14135.pdf) 一文基于对底层硬件 (即 GPU) 的内存层次结构的深刻理解而引入了一种更快、更节省内存的无损注意力加速算法。底层硬件在设计内存层次结构时,遵循的实践原则是: 带宽/速度越高的内存,其容量越小,因为它更贵。
根据博文 [根据第一性原理让深度学习性能起飞](https://horace.io/brrr_intro.html),我们可以发现,当前硬件上的注意力模块是 `内存带宽受限` 的。原因是注意力机制 **主要由逐元素操作** 组成,如下左图所示。我们可以观察到,掩码、softmax 和 dropout 操作占用了大部分时间,而非需要大量 FLOP 的矩阵乘法。
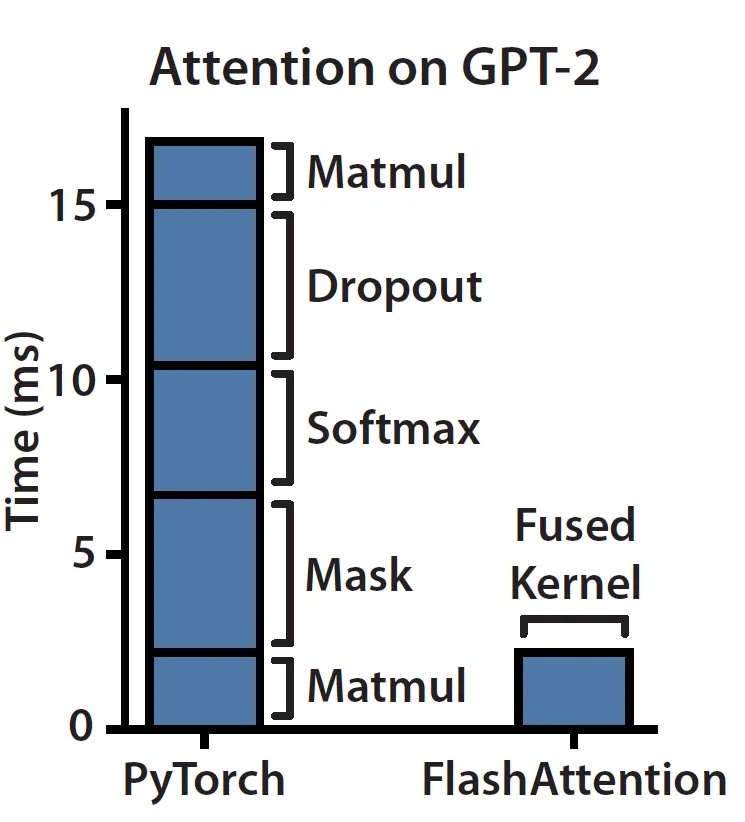
(图源: [链接](https://arxiv.org/pdf/2205.14135.pdf))
这正是 flash 注意力解决的问题,其想法是 **去除冗余的 HBM 读/写操作**。该算法通过将所有内容保留在 SRAM 中,待执行完所有中间步骤后再将最终结果写回到 HBM,即 **算子融合** 来实现这一目的。下图简要描述了算子融合是如何克服内存瓶颈的。
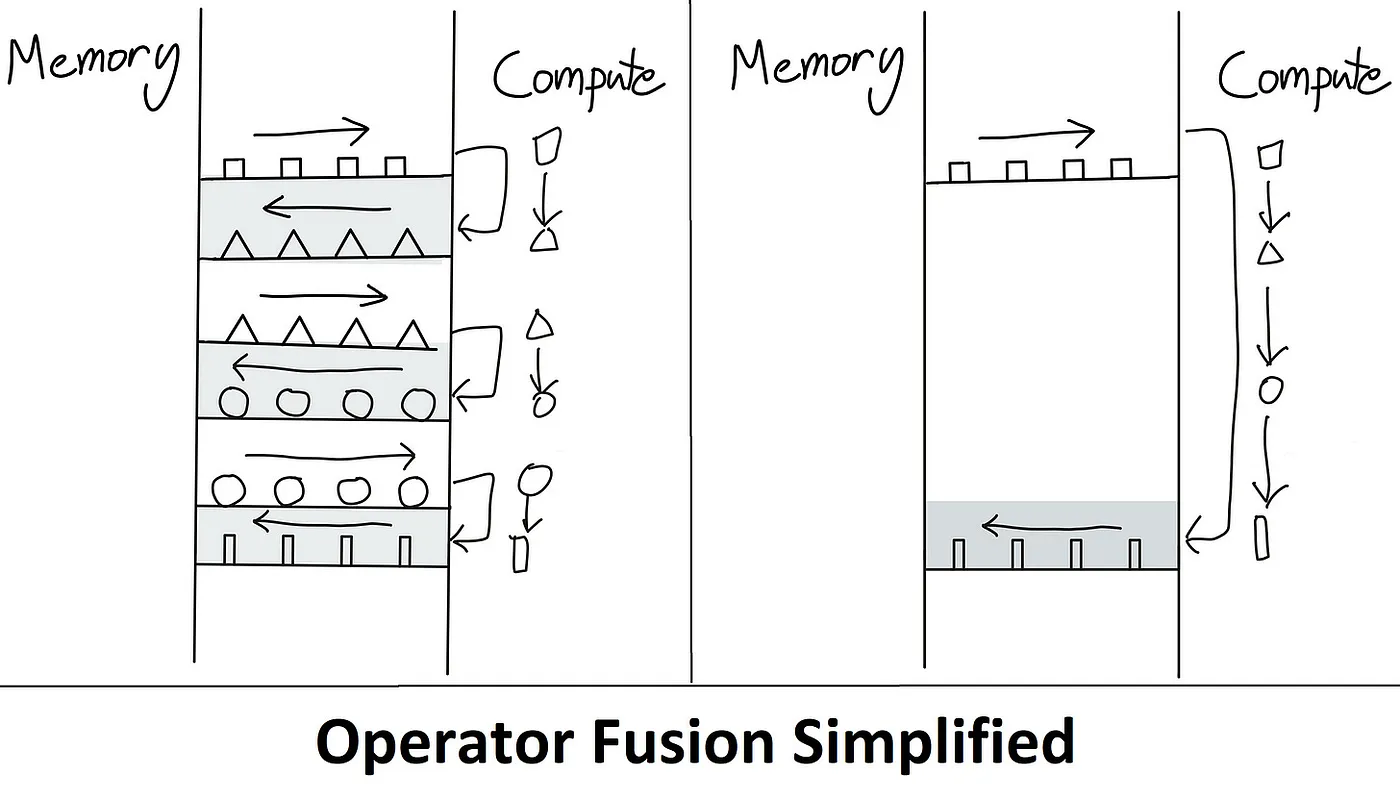
(图源: [链接](https://gordicaleksa.medium.com/eli5-flash-attention-5c44017022ad))
在前向和反向传播过程中我们还使用了 **平铺 (Tiling)** 优化技巧,将 NxN 大小的 softmax 分数计算切成块,以克服 SRAM 内存大小的限制。在使用平铺技巧时,我们会使用在线 softmax 算法。同时,我们还在反向传播中使用了 **重计算** 技巧,以大大降低在前向传播过程中存储整个 NxN softmax 分数矩阵所带来的内存消耗。
如欲深入理解 flash 注意力,请参考博文 [ELI5: FlashAttention](https://gordicaleksa.medium.com/eli5-flash-attention-5c44017022ad)、[根据第一性原理让深度学习性能起飞](https://horace.io/brrr_intro.html) 以及原始论文 [FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness](https://arxiv.org/pdf/2205.14135.pdf)。
## 综合运用所有手段
你可参考 [此脚本]((https://gist.github.com/pacman100/1cb1f17b2f1b3139a63b764263e70b25)),以在 SLURM 中用 `Accelerate` 启动器运行训练。下面还给出了一个等效命令,展示了如何使用 `Accelerate` 启动器来运行训练。请注意,该命令会覆盖 `fsdp_config.yaml` 中的 `main_process_ip` 、 `main_process_port` 、 `machine_rank` 、 `num_processes` 以及 `num_machines` 配置。另一个需要重点注意的是,这里的存储是所有节点共享的。
```
accelerate launch \
--config_file configs/fsdp_config.yaml \
--main_process_ip $MASTER_ADDR \
--main_process_port $MASTER_PORT \
--machine_rank \$MACHINE_RANK \
--num_processes 16 \
--num_machines 2 \
train.py \
--model_name "meta-llama/Llama-2-70b-chat-hf" \
--dataset_name "smangrul/code-chat-assistant-v1" \
--max_seq_len 2048 \
--max_steps 500 \
--logging_steps 25 \
--eval_steps 100 \
--save_steps 250 \
--bf16 True \
--packing True \
--output_dir "/shared_storage/sourab/experiments/full-finetune-llama-chat-asst" \
--per_device_train_batch_size 1 \
--gradient_accumulation_steps 1 \
--dataset_text_field "content" \
--use_gradient_checkpointing True \
--learning_rate 5e-5 \
--lr_scheduler_type "cosine" \
--weight_decay 0.01 \
--warmup_ratio 0.03 \
--use_flash_attn True
```
整个微调过程需要约 13.5 小时,下图给出了训练损失曲线。
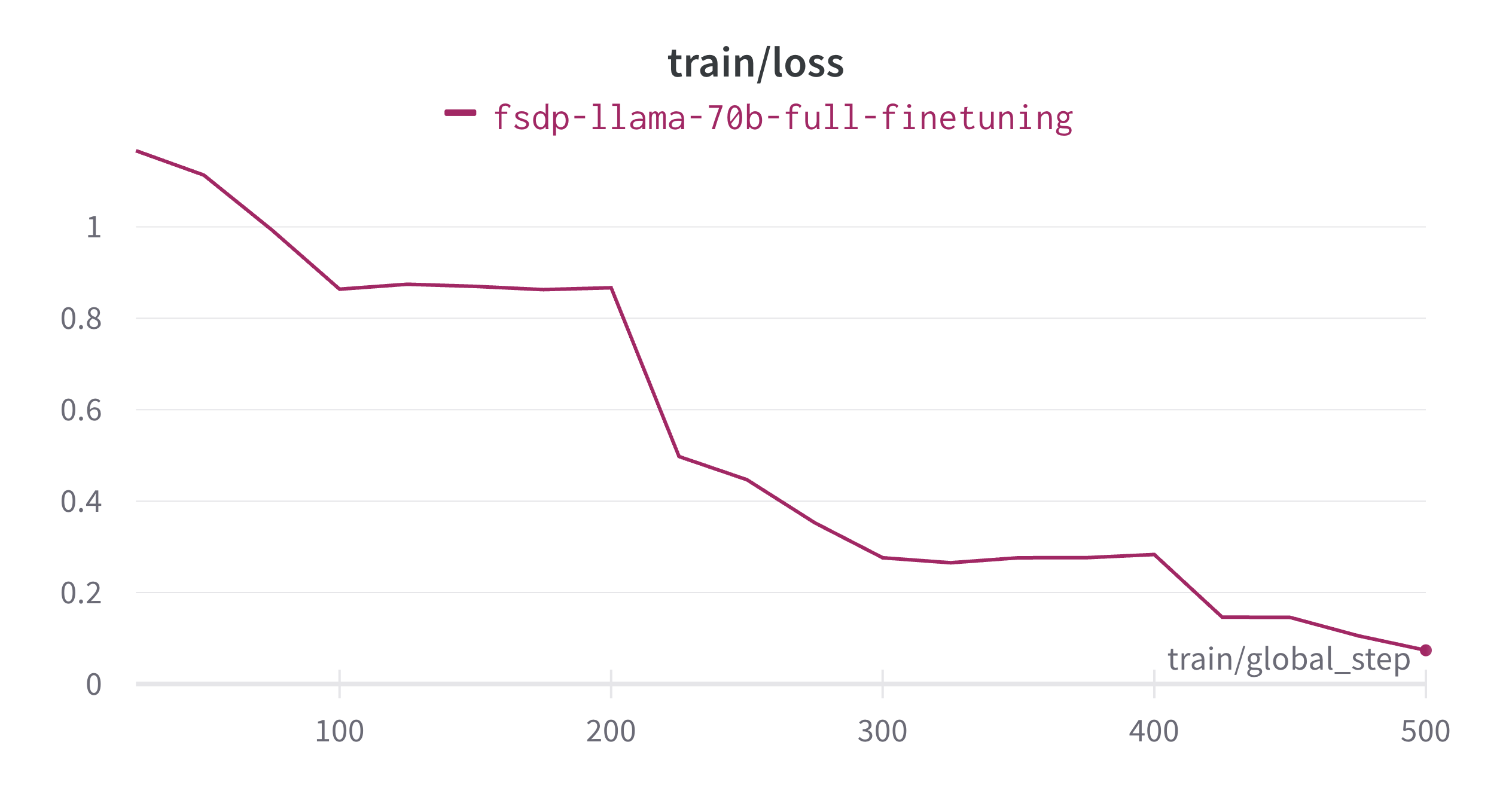
下例给出了使用上述模型完成的一段对话:
```diff
System Prompt: You are a helpful, respectful and honest assistant. Always answer as helpfully \
as possible, while being safe. Your answers should not include any harmful, \
unethical, racist, sexist, toxic, dangerous, or illegal content. Please ensure that \
your responses are socially unbiased and positive in nature.
If a question does not make any sense, or is not factually coherent, explain why \
instead of answering something not correct. If you don’t know the answer to a \
question, please don’t share false information.
- Human: What is Deep Learning? Explain like a Pirate.
+ Assistant: Arrr Grumete! Are ye lookin' fer a proper explanation o' Deep Learnin'?
+ Alright then, listen up me hearty! Deep Learnin' be a type o' machine learnin' that uses artificial neural networks to analyze data.
+ Aye, ye heard that right, mateys! Artificial neural networks be models o' the human brain, but instead o' using neurons, they use interconnected nodes or "artificial neurons" to process information.
+ These nodes work together to form layers o' processing units that can learn from large amounts o' data.
+ The more data these systems receive, the better they get at recognizing patterns and makin' decisions on their own.
+ So hoist the sails and set course for adventure with deep learnin', me hearties! It's a treasure trove o' knowledge just waitin' to be discovered.
+ Fair winds and following seas!
- Human: Now explain it like a chef.
+ Assistant: Certainly! Here's an explanation of deep learning from a culinary perspective:
+ Think of a recipe as a sequence of steps used to transform raw ingredients into a delicious dish.
+ Similarly, in deep learning, there are multiple layers of "ingredients" (or features) that are combined and transformed through various operations to produce a final output or prediction.
+ Each layer builds upon the previous one, refining and enhancing the representation of the input data until it reaches the desired outcome.
+ Just as different spices enhance the flavors of food, each layer adds depth and complexity to the model's understanding of the input, allowing it to make more accurate predictions.
+ And much like how chefs must carefully balance the amount of salt, sugar, and other seasonings in a recipe, the training process in deep learning involves adjusting the weights and biases of the network to achieve the perfect blend of accuracy and efficiency.
+ With enough practice and experimentation, anyone can become a master chef... I mean, a master of deep learning! Bon appétit!
```
整个对话使用的格式如下:
```
<|system|> system message <|endoftext|> <|prompter|> Q1 <|endoftext|> <|assistant|> A1 <|endoftext|> ...
```
## 总结
我们在多节点多 GPU 上使用 PyTorch FSDP 成功微调了一个 70B Llama 模型,并在此过程中解决了各种挑战。我们看到了当前在 🤗 Transformers 和 🤗 Accelerates 中应如何初始化大模型从而有效克服 CPU 内存不足的问题。我们还给出了如何高效地保存/加载中间检查点,同时又能以易于使用的方式保存最终模型的最佳实践。为了加速训练并减少 GPU 显存使用,我们还强调了 flash 注意力和梯度检查点机制的重要性。最后,我们向大家展示了在 🤗 Accelerate 上仅需要简单的配置就可以在多节点多 GPU 上微调大模型。 | 0 |
0 | hf_public_repos/blog | hf_public_repos/blog/zh/optimizing-bark.md | ---
title: "使用 🤗 Transformers 优化 Bark"
thumbnail: /blog/assets/bark_optimization/thumbnail.png
authors:
- user: ylacombe
translators:
- user: MatrixYao
- user: zhongdongy
proofreader: true
---
# 使用 🤗 Transformers 优化文本转语音模型 Bark
<a target="_blank" href="https://colab.research.google.com/github/ylacombe/notebooks/blob/main/Benchmark_Bark_HuggingFace.ipynb">
<img src="https://colab.research.google.com/assets/colab-badge.svg"/>
</a>
🤗 Transformers 提供了许多最新最先进 (state-of-the-art,SoTA) 的模型,这些模型横跨多个领域及任务。为了使这些模型能以最佳性能运行,我们需要优化其推理速度及内存使用。
🤗 Hugging Face 生态系统为满足上述需求提供了现成且易于使用的优化工具,这些工具可应用于库中的所有模型。用户只需添加几行代码就可以轻松 **减少内存占用** 并 **提高推理速度**。
在本实战教程中,我将演示如何用三个简单的优化技巧来优化 [Bark](https://huggingface.co/docs/transformers/main/en/model_doc/bark#overview) 模型。Bark 是🤗 Transformers 支持的一个文本转语音 (Text-To-Speech,TTS) 模型。所有优化仅依赖于 [Transformers](https://github.com/huggingface/transformers)、[Optimum](https://github.com/huggingface/optimum) 以及 [Accelerate](https://github.com/huggingface/accelerate) 这三个 🤗 生态系统库。
本教程还演示了如何对模型及其不同的优化方案进行性能基准测试。
本文对应的 Google Colab 在 [此](https://colab.research.google.com/github/ylacombe/notebooks/blob/main/Benchmark_Bark_HuggingFace.ipynb)。
本文结构如下:
## 目录
1. Bark 模型 [简介](#bark-模型架构)
2. 不同优化技巧及其优点 [概述](#优化技术)
3. 基准测试结果 [展示](#基准测试结果)
# Bark 模型架构
**Bark** 是 Suno AI 提出的基于 transformer 的 TTS 模型,其原始代码库为 [suno-ai/bark](https://github.com/suno-ai/bark)。该模型能够生成各种音频输出,包括语音、音乐、背景噪音以及简单的音效。此外,它还可以产生非语言语音,如笑声、叹息声和抽泣声等。
自 v4.31.0 起,Bark 已集成入 🤗 Transformers!
你可以通过 [这个 notebook](https://colab.research.google.com/github/ylacombe/notebooks/blob/main/Bark_HuggingFace_Demo.ipynb) 试试 Bark 并探索其功能。
Bark 主要由 4 个模型组成:
- `BarkSemanticModel` (也称为 **文本** 模型): 一个因果自回归 transformer 模型,其输入为分词后的词元序列,并输出能捕获文义的语义词元。
- `BarkCoarseModel` (也称为 **粗声学** 模型): 一个因果自回归 transformer 模型,其接收 `BarkSemanticModel` 模型的输出,并据此预测 EnCodec 所需的前两个音频码本。
- `BarkFineModel` (也称为 **细声学** 模型),这次是个非因果自编码器 transformer 模型,它对 _先前码本的嵌入和_ 进行迭代,从而生成最后一个码本。
- 在 [`EncodecModel`](https://huggingface.co/docs/transformers/v4.31.0/model_doc/encodec) 的编码器部分预测出所有码本通道后,Bark 继续用其解码器来解码并输出音频序列。
截至本文撰写时,共有两个 Bark checkpoint 可用,其中一个是 [小版](https://huggingface.co/suno/bark-small),一个是 [大版](https://huggingface.co/suno/bark)。
## 加载模型及其处理器
预训练的 Bark [小 checkpoint](https://huggingface.co/suno/bark-small) 和 [大 checkpoint]((https://huggingface.co/suno/bark)) 均可从 Hugging Face Hub 上加载。你可根据实际需要加载相应的 repo-id。
为了使实验运行起来快点,我们默认使用小 checkpoint,即 `“suno/bark-small”` 。但你可以随意改成 `“suno/bark”` 来尝试大 checkpoint。
```python
from transformers import BarkModel
model = BarkModel.from_pretrained("suno/bark-small")
```
将模型放到加速器上以优化其速度:
```python
import torch
device = "cuda:0" if torch.cuda.is_available() else "cpu"
model = model.to(device)
```
加载处理器,它主要处理分词以及说话人嵌入 (若有)。
```python
from transformers import AutoProcessor
processor = AutoProcessor.from_pretrained("suno/bark-small")
```
# 优化技巧
本节,我们将探索如何使用 🤗 Optimum 和 🤗 Accelerate 库中的现成功能来以最少的代码改动达到优化 Bark 模型的目的。
## 设置实验环境
首先,我们准备一个输入文本并定义一个函数来测量 Bark 生成过程的延迟及其 GPU 显存占用情况。
```python
text_prompt = "Let's try generating speech, with Bark, a text-to-speech model"
inputs = processor(text_prompt).to(device)
```
测量延迟和 GPU 内存占用需要使用特定的 CUDA 函数。我们实现了一个工具函数,用于测量模型的推理延迟及 GPU 内存占用。为了确保结果的准确性,每次测量我们会运行 `nb_loops` 次求均值:
```python
import torch
from transformers import set_seed
def measure_latency_and_memory_use(model, inputs, nb_loops = 5):
# define Events that measure start and end of the generate pass
start_event = torch.cuda.Event(enable_timing=True)
end_event = torch.cuda.Event(enable_timing=True)
# reset cuda memory stats and empty cache
torch.cuda.reset_peak_memory_stats(device)
torch.cuda.empty_cache()
torch.cuda.synchronize()
# get the start time
start_event.record()
# actually generate
for _ in range(nb_loops):
# set seed for reproducibility
set_seed(0)
output = model.generate(**inputs, do_sample = True, fine_temperature = 0.4, coarse_temperature = 0.8)
# get the end time
end_event.record()
torch.cuda.synchronize()
# measure memory footprint and elapsed time
max_memory = torch.cuda.max_memory_allocated(device)
elapsed_time = start_event.elapsed_time(end_event)* 1.0e-3
print('Execution time:', elapsed_time/nb_loops, 'seconds')
print('Max memory footprint', max_memory*1e-9, ' GB')
return output
```
## 基线
在优化之前,我们先测量下模型的基线性能并听一下生成的音频,我们测量五次并求均值:
```python
with torch.inference_mode():
speech_output = measure_latency_and_memory_use(model, inputs, nb_loops = 5)
```
**输出:**
```
Execution time: 9.3841625 seconds
Max memory footprint 1.914612224 GB
```
现在,我们可以播放一下输出音频:
```python
from IPython.display import Audio
# now, listen to the output
sampling_rate = model.generation_config.sample_rate
Audio(speech_output[0].cpu().numpy(), rate=sampling_rate)
```
按下面的播放键听一下吧 ([下载该音频文件](https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/bark_optimization/audio_sample_base.wav)):
<audio controls>
<source src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/bark_optimization/audio_sample_base.wav" type="audio/wav">
当前浏览器不支持音频元素。
</audio>
### 重要说明
上例中运行次数较少。为了测量和后续对比的准确性,运行次数需要增加到至少 100。
增加 `nb_loops` 一个主要原因是,同一输入的多次运行所生成的语音长度差异也很大。因此当运行次数较少时,有可能通过 `measure_latency_and_memory_use` 测出的延迟并不能反映出优化方法的实际性能!文末的基准测试取的是 100 次运行的均值,用以逼近模型的真实性能。
## 1. 🤗 Better Transformer
Better Transformer 是 🤗 Optimum 的一个功能,它可以帮助在后台执行算子融合。这意味着模型的某些操作在 GPU 上的性能将会得到进一步优化,从而加速模型的最终运行速度。
再具体一点,🤗 Transformers 支持的大多数模型都依赖于注意力,这使得模型在生成输出时可以选择性地关注输入的某些部分,因而能够有效地处理远程依赖关系并捕获数据中复杂的上下文关系。
Dao 等人于 2022 年提出了一项名为 [Flash Attention](https://arxiv.org/abs/2205.14135) 的技术,极大地优化了朴素注意力的性能。
Flash Attention 是一种更快、更高效的注意力算法,它巧妙地结合了一些传统方法 (如平铺和重计算),以最大限度地减少内存使用并提高速度。与之前的算法不同,Flash Attention 将内存使用量从与序列长度呈平方关系降低到线性关系,这对关注内存效率的应用尤其重要。
🤗 Better Transformer 可以开箱即用地支持 Flash Attention!只需一行代码即可将模型导出到 🤗 Better Transformer 并启用 Flash Attention:
```python
model = model.to_bettertransformer()
with torch.inference_mode():
speech_output = measure_latency_and_memory_use(model, inputs, nb_loops = 5)
```
**输出:**
```
Execution time: 5.43284375 seconds
Max memory footprint 1.9151841280000002 GB
```
按下面的播放键听一下输出吧 ([下载该音频文件](https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/bark_optimization/audio_sample_bettertransformer.wav)):
<audio controls>
<source src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/bark_optimization/audio_sample_bettertransformer.wav" type="audio/wav">
当前浏览器不支持音频元素。
</audio>
**利弊**
效果不会下降,这意味着你可以获得与基线版本完全相同的结果,同时提速 20% 到 30%!想要了解更多有关 Better Transformer 的详细信息,请参阅此 [博文](https://pytorch.org/blog/out-of-the-box-acceleration/)。
## 2. 半精度
大多数人工智能模型通常使用称为单精度浮点的存储格式,即 `fp32` ,这在实践中意味着每个数都用 32 比特来存储。
你也可以选择使用 16 比特对每个数进行编码,即所谓的半精度浮点,即 `fp16` (译者注: 或 `bf16` ),这时每个数占用的存储空间就变成了原来的一半!除此以外,你还可以获得计算上的加速!
但天下没有免费的午餐,半精度会带来较小的效果下降,因为模型内部的操作不如 `fp32` 精确了。
你可以通过简单地在 `BarkModel.from_pretrained(...)` 的入参中添加 `torch_dtype=torch.float16` 来将 Transformers 模型加载为半精度!
代码如下:
```python
model = BarkModel.from_pretrained("suno/bark-small", torch_dtype=torch.float16).to(device)
with torch.inference_mode():
speech_output = measure_latency_and_memory_use(model, inputs, nb_loops = 5)
```
**输出:**
```
Execution time: 7.00045390625 seconds
Max memory footprint 2.7436124160000004 GB
```
照例,按下面的播放键听一下输出吧 ([下载该音频文件](https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/bark_optimization/audio_sample_fp16.wav)):
<audio controls>
<source src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/bark_optimization/audio_sample_fp16.wav" type="audio/wav">
当前浏览器不支持音频元素。
</audio>
**利弊**
虽然效果略有下降,但内存占用量减少了 50%,速度提高了 5%。
## 3. CPU 卸载
正如本文第一部分所述,Bark 包含 4 个子模型,这些子模型在音频生成过程中按序调用。 **换句话说,当一个子模型正在使用时,其他子模型处于空闲状态。**
为什么要讨论这个问题呢? 因为 GPU 显存在 AI 工作负载中非常宝贵,显存中的运算速度是最快的,而很多情况下显存不足是推理速度的瓶颈。
一个简单的解决方案是将空闲子模型从 GPU 显存中卸载至 CPU 内存,该操作称为 CPU 卸载。
**好消息: ** Bark 的 CPU 卸载已集成至 🤗 Transformers 中,只需一行代码即可使能。唯一条件是,仅需确保安装了 🤗 Accelerate 即可!
```python
model = BarkModel.from_pretrained("suno/bark-small")
# Enable CPU offload
model.enable_cpu_offload()
with torch.inference_mode():
speech_output = measure_latency_and_memory_use(model, inputs, nb_loops = 5)
```
**输出:**
```
Execution time: 8.97633828125 seconds
Max memory footprint 1.3231160320000002 GB
```
按下面的播放键听一下输出吧 ([下载该音频文件](https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/bark_optimization/audio_sample_cpu_offload.wav)):
<audio controls>
<source src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/bark_optimization/audio_sample_cpu_offload.wav" type="audio/wav">
当前浏览器不支持音频元素。
</audio>
**利弊**
速度略有下降 (10%),换得内存占用的巨大降低 (60% 🤯)。
启用此功能后, `bark-large` 占用空间从原先的 5GB 降至 2GB,与 `bark-small` 的内存占用相同!
如果你还想要降更多的话,可以试试启用 `fp16` ,内存占用甚至可以降至 1GB。具体可以参见下一节的数据。
## 4. 组合优化
我们把上述所有优化组合到一起,这意味着你可以合并 CPU 卸载、半精度以及 🤗 Better Transformer 带来的收益!
```python
# load in fp16
model = BarkModel.from_pretrained("suno/bark-small", torch_dtype=torch.float16).to(device)
# convert to bettertransformer
model = BetterTransformer.transform(model, keep_original_model=False)
# enable CPU offload
model.enable_cpu_offload()
with torch.inference_mode():
speech_output = measure_latency_and_memory_use(model, inputs, nb_loops = 5)
```
**输出:**
```
Execution time: 7.4496484375000005 seconds
Max memory footprint 0.46871091200000004 GB
```
按下面的播放键听一下输出吧 ([下载该音频文件](https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/bark_optimization/audio_sample_optimized.wav)):
<audio controls>
<source src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/bark_optimization/audio_sample_optimized.wav" type="audio/wav">
当前浏览器不支持音频元素。
</audio>
**利弊**
最终,你将获得 23% 的加速并节约 80% 的内存!
## 批处理
得陇望蜀?
加个批处理吧,上述 3 种优化技巧加上批处理可以进一步提升速度。批处理即将多个样本组合起来一起推理,这样会使这些样本的总生成时间低于逐样本生成时的总生成时间。
下面给出了一个批处理的简单代码:
```python
text_prompt = [
"Let's try generating speech, with Bark, a text-to-speech model",
"Wow, batching is so great!",
"I love Hugging Face, it's so cool."]
inputs = processor(text_prompt).to(device)
with torch.inference_mode():
# samples are generated all at once
speech_output = model.generate(**inputs, do_sample = True, fine_temperature = 0.4, coarse_temperature = 0.8)
```
输出音频如下 (下载 [第一个](https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/bark_optimization/audio_sample_batch_0.wav)、[第二个](https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/bark_optimization/audio_sample_batch_1.wav) 以及 [第三个](https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/bark_optimization/audio_sample_batch_2.wav) 音频文件):
<audio controls>
<source src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/bark_optimization/audio_sample_batch_0.wav" type="audio/wav">
当前浏览器不支持音频元素。
</audio>
<audio controls>
<source src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/bark_optimization/audio_sample_batch_1.wav" type="audio/wav">
当前浏览器不支持音频元素。
</audio>
<audio controls>
<source src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/bark_optimization/audio_sample_batch_2.wav" type="audio/wav">
当前浏览器不支持音频元素。
</audio>
# 基准测试结果
上文我们进行的这些小实验更多是想法验证,我们需要将其扩展以更准确地衡量性能。另外,在每次正式测量性能之前,还需要先跑几轮以预热 GPU。
以下是扩展至 100 个样本的基准测量的结果,使用的模型为 **大 Bark**。
该基准测试在 NVIDIA TITAN RTX 24GB 上运行,最大词元数为 256。
## 如何解读结果?
### 延迟
该指标主要测量每次调用生成函数的平均时间,无论 batch size 如何。
换句话说,它等于 $\frac{elapsedTime}{nbLoops}$。
**延迟越小越好。**
### 最大内存占用
它主要测量生成函数在每次调用期间使用的最大内存。
**内存占用越小越好。**
### 吞吐量
它测量每秒生成的样本数。这次,batch size 的因素已被考虑在内。
换句话说,它等于 $\frac{nbLoops*batchSize}{elapsedTime}$。
**吞吐量越高越好。**
## 单样本推理
下表为 `batch_size=1` 的结果。
| 绝对性能 | 延迟 | 内存占用 |
|-----------------------------|---------|---------|
| 无优化 | 10.48 | 5025.0M |
| 仅 bettertransformer | 7.70 | 4974.3M |
| CPU 卸载 + bettertransformer | 8.90 | 2040.7M |
| CPU 卸载 + bettertransformer + fp16 | 8.10 | 1010.4M |
| 相对性能 | 延迟 | 内存占用 |
|-----------------------------|---------|--------|
| 无优化 | 0% | 0% |
| 仅 bettertransformer | -27% | -1% |
| CPU 卸载 + bettertransformer | -15% | -59% |
| CPU 卸载 + bettertransformer + fp16 | -23% | -80% |
### 点评
不出所料,CPU 卸载极大地减少了内存占用,同时略微增加了延迟。
然而,结合 bettertransformer 和 `fp16` ,我们得到了两全其美的效果,巨大的延迟和内存降低!
## batch size 为 8
以下是 `batch_size=8` 时的吞吐量基准测试结果。
请注意,由于 `bettertransformer` 是一种免费优化,它执行与非优化模型完全相同的操作并具有相同的内存占用,同时速度更快,因此所有的基准测试均 **默认开启此优化**。
| 绝对性能 | 延迟 | 内存占用 | 吞吐量 |
|-------------------------------|---------|---------|-----------|
| 基线 (bettertransformer) | 19.26 | 8329.2M | 0.42 |
| + fp16 | 10.32 | 4198.8M | 0.78 |
| + CPU 卸载 | 20.46 | 5172.1M | 0.39 |
| + CPU 卸载 + fp16 | 10.91 | 2619.5M | 0.73 |
| 相对性能 | 延迟 | 内存占用 | 吞吐量 |
|-------------------------------|---------|--------|------------|
| + 基线 (bettertransformer) | 0% | 0% | 0% |
| + fp16 | -46% | -50% | 87% |
| + CPU 卸载 | 6% | -38% | -6% |
| + CPU 卸载 + fp16 | -43% | -69% | 77% |
### 点评
这里,我们看到了组合所有三个优化技巧后的性能潜力!
`fp16` 对延迟的影响在 `batch_size = 1` 时不太明显,但在 `batch_size = 1` 时的表现非常有趣,它可以将延迟减少近一半,吞吐量几乎翻倍!
# 结束语
本文展示了 🤗 生态系统中的一些现成的、简单的优化技巧。使用这些技巧中的任何一种或全部三种都可以极大地改善 Bark 的推理速度和内存占用。
- **使用🤗 Better Transformer 和 CPU 卸载**,你可以对大 Bark 模型进行推理,而不会出现任何性能下降,占用空间仅为 2GB (而不是 5GB),同时速度提高 15%。
- 如果你钟情于高吞吐,可以 **把 batch size 打到 8,并利用 🤗 Better Transformer 和 fp16**。
- 如果你“既要,又要,还要”,试试 **fp16、🤗 Better Transformer 加 CPU 卸载** 组合优化吧! | 1 |
0 | hf_public_repos/blog | hf_public_repos/blog/zh/ml-for-games-5.md | ---
title: "ChatGPT 设计游戏剧情 | 基于 AI 5 天创建一个农场游戏,完结篇!"
thumbnail: /blog/assets/124_ml-for-games/thumbnail5.png
authors:
- user: dylanebert
translators:
- user: SuSung-boy
---
# ChatGPT 设计游戏剧情 | 基于 AI 5 天创建一个农场游戏,完结篇!
**欢迎使用 AI 进行游戏开发!** 在本系列中,我们将使用 AI 工具在 5 天内创建一个功能完备的农场游戏。到本系列结束时,您将了解到如何将多种 AI 工具整合到游戏开发流程中。本文将向您展示如何将 AI 工具用于:
1. 美术风格
2. 游戏设计
3. 3D 素材
4. 2D 素材
5. 剧情
想快速观看视频的版本?你可以在 [这里](https://www.tiktok.com/@individualkex/video/7197505390353960235) 观看。不过如果你想要了解技术细节,请继续阅读吧!
**注意:** 此篇文章多次引用 第 2 部分 相关内容。简单来说,[第 2 部分](https://huggingface.co/blog/zh/ml-for-games-2) 使用了 ChatGPT 进行游戏设计; 更具体地,介绍了 ChatGPT 的工作原理、语言模型及其局限性。如果您还没有阅读过,可以跳转阅读更多信息。
## 第 5 天: 剧情
在本教程系列的 [第 4 部分](https://huggingface.co/blog/zh/ml-for-games-4) 中,我们介绍了如何将 Stable Diffusion 和 Image2Image 工具嵌入到传统 2D 素材制作流程中,来帮助从业者使用 AI 制作 2D 游戏素材。
本文是该系列的最后一部分,我们将使用 AI 设计游戏剧情。首先,我会介绍使用语言模型为农场游戏生成 [剧情的设计流程](#剧情设计流程),请注意带有 ⚠️ **局限性** 标识的段落。其次,我会具体阐述涉及到的相关技术,以及它们在游戏开发方面的 [发展方向](#发展方向)。最后,我会对本系列做一个 [总结](#结语)。
### 剧情设计流程
**必要条件:** [ChatGPT](https://openai.com/blog/chatgpt/)。ChatGPT 会贯穿整个剧情设计流程。可以跳转 [第 2 部分](https://huggingface.co/blog/zh/ml-for-games-2) 阅读更多相关信息。实际上 ChatGPT 并不是唯一的可行方案,有许多竞争对手正在涌现,包括一些开源的对话代理 (dialog agent)。我会在后面的部分详细介绍对话代理 [新兴领域](#新兴领域)。
1. **让 ChatGPT 写剧情概要。** 我给 ChatGPT 提供了大量农场游戏相关信息,让它写一个剧情概要。
<div align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/124_ml-for-games/chatgpt1.png" alt="ChatGPT for Story #1">
</div>
ChatGPT 回答的剧情概要与 [星露谷物语](https://www.stardewvalley.net/) 极其相似。
> ⚠️ **局限性:** 由于训练语料库的原因,语言模型倾向于生成现有的剧情。
这说明了不能完全依赖语言模型代替人工,而应该把语言模型作为激发创意的工具。例如上文中 ChatGPT 生成了与星露谷物语相似的剧情,完全不具备原创性。
2. **优化概要。** 与 [第 4 部分](https://huggingface.co/blog/zh/ml-for-games-4) 中的 Image2Image 相同,这类工具在工作流程中需要反复迭代多次才能发挥潜力。接下里,我继续询求 ChatGPT 更具原创性的结果。
<div align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/124_ml-for-games/chatgpt2.png" alt="ChatGPT for Story #2">
</div>
这次的回答好多了。我继续优化结果,例如要求移除农场游戏中不必要的魔法元素。经过几次迭代,我得到了一份满意的剧情概要。接下来就是生成游戏剧情的具体细节了。
3. **让 ChatGPT 写剧情细节。** 剧情概要基本确定之后,我继续询求 ChatGPT 补充游戏剧情细节信息。就该系列的农场游戏而言,唯一需要补充的是游戏介绍和农作物简介。
<div align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/124_ml-for-games/chatgpt3.png" alt="ChatGPT for Story #3">
</div>
得到的回答还不错。不过我在第 1~4 部分中开发的游戏内容里,并没有经验丰富的农夫提供帮助这一特性,也没有新的冒险和挑战系统。
4. **优化细节。** 同样地,我继续迭代优化剧情细节。
<div align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/124_ml-for-games/chatgpt4.png" alt="ChatGPT for Story #4">
</div>
我对这个回答很满意。那么新的问题来了,我可以直接把这段内容应用到我的游戏中吗?对于此系列的农场游戏而言,或许可以,因为这是一款为 AI 教程开发的免费游戏。但是对于商业产品而言,最好不要,它很可能会导致潜在的法律、道德和商业后果。
> ⚠️ **局限性:** 直接将语言模型的生成内容拿来自行使用,很可能会导致潜在的法律、道德和商业后果。
潜在的后果如下:
- <u>法律:</u> 目前围绕生成式 AI 的法律环境非常不明朗,有几起存在争议的诉讼正在进行中。
- <u>道德:</u> 语言模型生成的内容可能包含抄袭和偏见。详情请见 [道德与社会新闻稿](https://huggingface.co/blog/zh/ethics-soc-2)。
- <u>商业:</u> [一些消息](https://www.searchenginejournal.com/google-says-ai-generated-content-is-against-guidelines/444916/) 来源显示,AI 生成的内容可能会被搜索引擎降低优先级。SEO (Search Engine Optimization,搜索引擎优化,是一项优化搜索引擎排名的技术) 指出,[不同于](https://seo.ai/blog/google-is-not-against-ai-content) 垃圾邮件需要被搜索引擎排除,AI 生成的内容对搜索引擎具有一定的价值,但并不需要太高的优先级。同时,一些 [AI 内容检测](https://writer.com/ai-content-detector/) 工具可以检查搜索到的内容是否为 AI 生成的,例如正在研究的语言模型 [watermarking](https://arxiv.org/abs/2301.10226) 可以给 AI 生成内容增加 隐式水印,以使更容易地被 AI 内容检测工具捕捉。
考虑到这些局限性,最安全的方法可能是: 仅使用 ChatGPT 等语言模型进行头脑风暴,获取灵感后手动完成最终内容。
5. **细化描述。** 我继续询求 ChatGPT 对农作物商品的细致描述。
<div align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/124_ml-for-games/chatgpt5.png" alt="ChatGPT for Story #5">
</div>
由于此系列的农场游戏剧情简短,使用 ChatGPT 生成全部剧情内容非常有效。但是当生成的剧情越来越长,局限性就会越加明显: ChatGPT 不太适合生成长篇连贯剧情。即使仅仅是询求 ChatGPT 为农作物生成简短的描述句子,几次询求之后生成的内容质量也开始下降并且陷入重复。
> ⚠️ **局限性:** 语言模型生成的内容重复性高。
最后,我总结了使用 AI 设计游戏剧情的整体流程,以下是我个人经验的一些技巧:
- **询求剧情概要。** 语言模型生成的长篇内容质量可能较低,生成高抽象度的剧情概要往往效果更好。
- **头脑风暴。** 语言模型生成的内容不连贯,用在某个点上激发创意比较好。例如先设计一个角色基本框架,再使用 AI 来头脑风暴角色的具体细节。
- **优化内容。** 写下设计的剧情内容,并询求语言模型如何改进。即使生成内容不被采用,它也可能激发您改进相关的创意。
尽管语言模型有以上种种局限性,但对游戏开发而言,对话代理仍然是一个非常有用的工具。而这仅仅是个开始,接下来我会探讨对话代理的新兴领域及其对游戏开发的潜在影响。
### 发展方向
#### 新兴领域
我在 [剧情设计流程](#剧情设计流程) 部分介绍了如何使用 ChatGPT 辅助设计,也提到 ChatGPT 并不是唯一的可行方案。[Character.AI](https://beta.character.ai/) 是一个提供多种极具个性的角色定制化对话代理服务 (例如您可以跟 “埃隆·马斯克” 和 “迈克尔·杰克逊” 对话) 的网站,同时它也提供专门的 [创意写作对话代理](https://beta.character.ai/chat?char=9ZSDyg3OuPbFgDqGwy3RpsXqJblE4S1fKA_oU3yvfTM) 服务。
除此之外,还有许多尚未公开的对话代理模型。可以在 [这篇文章](https://huggingface.co/blog/zh/dialog-agents) 查看这些模型的异同以及更多对话代理相关信息,其中涉及到的模型主要包括:
- [Google's LaMDA](https://arxiv.org/abs/2201.08239) 和 [Bard](https://blog.google/technology/ai/bard-google-ai-search-updates/)
- [Meta's BlenderBot](https://arxiv.org/abs/2208.03188)
- [DeepMind's Sparrow](https://arxiv.org/abs/2209.14375)
- [Anthropic's Assistant](https://arxiv.org/abs/2204.05862).
上面提到的 ChatGPT 的竞争对手都是闭源的。此外也有一些对话代理的开源工作,例如 [LAION 的 OpenAssistant](https://github.com/LAION-AI/Open-Assistant),[CarperAI](https://carper.ai) 的开源报告,以及 [谷歌的 FLAN-T5 XXL](https://huggingface.co/google/flan-t5-xxl) 的开源版本,这些与 [LangChain](https://github.com/hwchase17/langchain) 等开源工具结合使用,可以将语言模型的输入和输出连接起来,有助于开放式对话代理的开发工作。
前段时间,Stable Diffusion 开源版本的出现激发了很多领域爆发式革新,农场游戏系列教程的灵感也来源于此。语言模型也相同,要在游戏开发中加入语言类的 AI 应用,开源社区将成为未来的关键一环。如果您想跟上最新进展,可以在 [Twitter](https://twitter.com/dylan_ebert_) 上关注我,随时与我联系,我们一起探讨语言模型的发展潜力。
#### 游戏内开发方向
**NPCs:** 除了在游戏开发流程中使用语言模型和对话代理帮助设计游戏剧情等之外,在游戏内还有一个令人兴奋的开发潜力尚未实现,最明显的例子是 AI 驱动的 NPC。实际上已经出现了一些基于此想法的初创公司。就我个人而言,我目前还不清楚如何使用语言模型开发一个智能 NPC。但我认为 AI-NPC 就在不远的未来,请持续关注我的最新进展。
**控制系统:** 想象一下,如果不需要键盘、手柄等控制器,而用对话的方式来控制游戏会怎么样?尽管现在还没有游戏实现这种功能,但它并不是一件困难的事。如果您对此有兴趣,也请持续关注我。
### 结语
至此,5 天创建一个农场游戏系列就结束了。那么,想看最终游戏的样子,或者想亲自试玩一下吗?来 [Hugging Face Space 应用](https://huggingface.co/spaces/dylanebert/FarmingGame) 或 [itch.io](https://individualkex.itch.io/farming-game) 吧!
<div align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/124_ml-for-games/game.png" alt="Final Farming Game">
</div>
感谢您阅读 基于 AI 进行游戏开发 系列文章!本系列仅仅是 Hugging Face AI 开发游戏的开始,未来还会有更多内容!如果您有任何问题,或者想了解更多相关内容,现在来加入 Hugging Face 官方 [Discord 频道](https://hf.co/join/discord) 与我们交流吧!
| 2 |
0 | hf_public_repos/blog | hf_public_repos/blog/zh/paligemma.md | ---
title: "PaliGemma 正式发布 — Google 最新发布的前沿开放视觉语言模型"
thumbnail: /blog/assets/paligemma/Paligemma.png
authors:
- user: merve
- user: andsteing
guest: true
org: google
- user: pcuenq
translators:
- user: chenglu
---
# PaliGemma 正式发布 — Google 最新发布的前沿开放视觉语言模型
PaliGemma 是 Google 推出的新一代视觉语言模型家族,能够接收图像与文本输入并生成文本输出。
Google 团队已推出三种类型的模型:预训练(PT)模型、混合模型和微调(FT)模型,这些模型分辨率各异,提供多种精度以便使用。
所有模型均在 Hugging Face Hub 的模型库中发布,配备了模型说明和许可证,并且支持 transformers 集成。
## PaliGemma 是什么?
PaliGemma([Github](https://github.com/google-research/big_vision/blob/main/big_vision/configs/proj/paligemma/README.md))是一系列具有视觉和语言处理能力的模型,由 [SigLIP-So400m](https://huggingface.co/google/siglip-so400m-patch14-384) 作为图像编码器和 [Gemma-2B](https://huggingface.co/google/gemma-2b) 作为文本解码器构成。SigLIP 是一个顶尖的模型,可以同时解析图像和文本。它的工作方式类似于 CLIP,包括图像和文本编码器的联合训练。与 [PaLI-3](https://arxiv.org/abs/2310.09199)相似,PaliGemma 模型在图像-文本数据上进行预训练后,可轻松针对下游任务(如图像标题生成或指代分割)进行微调。[Gemma](https://huggingface.co/blog/gemma)是一个专为文本生成设计的解码器模型。通过线性适配器将 SigLIP 的图像编码功能与 Gemma 结合,使 PaliGemma 成为一个功能强大的视觉语言模型。

PaliGemma 的发布包括三种模型类型:
- PT 检查点:预训练模型,可用于下游任务的微调;
- 混合检查点:已针对任务混合进行微调的PT模型,适合使用自由文本提示进行通用推理,仅限研究使用;
- FT 检查点:针对不同学术基准进行微调的模型,提供多种分辨率,仅限研究使用。
这些模型提供三种分辨率(`224x224`、`448x448`、`896x896`)和三种精度(`bfloat16`、`float16`、`float32`)。每个版本都包含给定分辨率和任务的检查点,每种精度有三个版本。每个版本的`main`分支包含`float32`检查点,而`bfloat16`和`float16`版本则包含相应精度的检查点。同时提供了与 transformers 兼容的模型,以及原始 JAX 实现的版本。
正如后续详细说明的,高分辨率模型因输入序列较长而需要更多内存。虽然它们可能有助于执行细粒度任务,如 OCR,但对大多数任务的质量提升较小。224 版本已足够应对大多数场景。
你可以在这个 Hugging Face [合集](https://huggingface.co/collections/google/paligemma-release-6643a9ffbf57de2ae0448dda) 中找到所有相关模型和 Space 应用。
## 模型功能
PaliGemma 是一个单轮视觉语言模型,不适用于对话场景,最佳应用是针对特定用例进行微调。
你可以通过设置任务前缀,如“detect”或“segment”,来配置模型解决的任务。预训练模型即是通过这种方式训练的,赋予其丰富的功能(问题回答、图像标题生成、图像分割等)。然而,这些模型并非设计为直接使用,而是通过微调以适应特定任务,使用类似的提示结构。对于交互式测试,你可以使用已对多任务进行微调的“mix”系列模型。
以下是使用混合检查点展示的一些功能示例。
### 图像标题生成
当被提示时,PaliGemma 能够为图像生成标题。你可以尝试使用混合检查点进行各种标题生成提示,看看它们如何反应。

### 视觉问题回答
PaliGemma 能够回答关于图像的问题,只需将你的问题连同图像一起传入即可。

### 检测
PaliGemma 可以使用`detect [entity]`提示来检测图像中的实体。它会以特殊的`<loc[value]>`令牌形式输出边界框坐标的位置,其中`value`是一个表示归一化坐标的数字。每次检测都由四个位置坐标代表——_y_min, x_min, y_max, x_max_,后跟检测到的框中的标签。要将这些值转换为坐标,你需要首先将数字除以1024,然后将`y`乘以图像高度,`x`乘以宽度。这将给你提供相对于原始图像大小的边界框坐标。

### 指代表达分割
PaliGemma 混合检查点也能够在给定`segment [entity]`提示时对图像中的实体进行分割。这称为指代表达分割,因为我们使用自然语言描述来引用感兴趣的实体。输出是位置和分割标记的序列。位置标记代表如上所述的一个边界框。分割标记可以进一步处理,生成分割掩模。

### 文档理解
PaliGemma 混合检查点具备出色的文档理解与推理能力。

### 混合基准
以下是混合检查点的得分数据。
| 模型 | MMVP准确率 | POPE准确率(随机/流行/对抗) |
|---------|-------------|----------------------------|
| mix-224 | 46.00 | 88.00 86.63 85.67 |
| mix-448 | 45.33 | 89.37 88.40 87.47 |
## 微调检查点
除了预训练和混合模型之外,Google 还发布了已针对各种任务进行微调的模型。这些模型对应于研究社区可用于比较性能的学术基准。以下是一些选定的模型,这些模型也提供了不同的分辨率。你可以查看任何一个模型的模型卡以获取所有度量指标。
| 模型名称 | 数据集/任务 | 转移任务中的得分 |
|------------------------------------------------|---------------------------------------------|----------------------------------------|
| [paligemma-3b-ft-vqav2-448](https://hf.co/google/paligemma-3b-ft-vqav2-448)| 图解理解 | 在 VQAV2 上的准确率为 85.64 |
| [paligemma-3b-ft-cococap-448](https://hf.co/google/paligemma-3b-ft-cococap-448)| COCO 标题 | CIDEr 为 144.6 |
| [paligemma-3b-ft-science-qa-448](https://hf.co/google/paligemma-3b-ft-science-qa-448)| 科学问题回答 | 在没有 CoT 的 ScienceQA Img 子集上的准确率为 95.93 |
| [paligemma-3b-ft-refcoco-seg-896](https://hf.co/google/paligemma-3b-ft-refcoco-seg-896)| 图像中特定对象的理解 | 在 refcoco 上的平均 IoU 为 76.94,在 refcoco+ 上为 72.18,在 refcocog 上为 72.22 |
| [paligemma-3b-ft-rsvqa-hr-224](https://hf.co/google/paligemma-3b-ft-rsvqa-hr-224)| 遥感视觉问题回答 | 在 test 上的准确率为 92.61,在 test2 上为 90.58 |
## 演示
作为此次发布的一部分,我们提供了一个 [Space 应用](https://huggingface.co/spaces/google/paligemma),直接用 [big_vision 仓库](https://github.com/google-research/big_vision) 中的参考实现,并提供了一个简便的方式来使用混合模型。
我们还有一个与 Transformers 兼容的[演示版本](https://huggingface.co/spaces/google/paligemma-hf),展示了如何使用 PaliGemma transformers API。
<figure class="image flex flex-col items-center text-center m-0 w-full">
<video alt="paligemma.mp4" autoplay loop autobuffer muted playsinline>
<source src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/paligemma/paligemma.mp4" type="video/mp4">
</video>
<figcaption></figcaption>
</figure>
## 如何运行推理
要获取 PaliGemma 模型的访问权限,你需要接受 Gemma 许可条款和条件。如果你已经可以访问 Hugging Face 中的其他 Gemma 模型,那么你已经准备好了。否则,请访问任何一个 PaliGemma 模型,并在你同意许可时接受它。一旦你获得了访问权限,你需要通过 [notebook_login](https://huggingface.co/docs/huggingface_hub/v0.21.2/en/package_reference/login#huggingface_hub.notebook_login) 或 [huggingface-cli login](https://huggingface.co/docs/huggingface_hub/en/guides/cli#huggingface-cli-login) 进行认证。登录后,你就可以开始了!
你还可以立即在 [此notebook](https://colab.research.google.com/drive/1gOhRCFyt9yIoasJkd4VoaHcIqJPdJnlg?usp=sharing) 中尝试运行推理。
### 使用 Transformers
你可以使用`PaliGemmaForConditionalGeneration`类来推断任何已发布的模型。只需使用内置的处理器预处理提示和图像,然后传递预处理输入进行生成。
```python
from transformers import AutoProcessor, PaliGemmaForConditionalGeneration
model_id = "google/paligemma-3b-mix-224"
model = PaliGemmaForConditionalGeneration.from_pretrained(model_id)
processor = AutoProcessor.from_pretrained(model_id)
prompt = "What is on the flower?"
image_file = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/bee.jpg?download=true"
raw_image = Image.open(requests.get(image_file, stream=True).raw)
inputs = processor(prompt, raw_image, return_tensors="pt")
output = model.generate(**inputs, max_new_tokens=20)
print(processor.decode(output[0], skip_special_tokens=True)[len(prompt):])
# bee
```
你还可以按以下方式加载 4 位模型。
```python
from transformers import BitsAndBytesConfig
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16
)
model = PaligemmaForConditionalGeneration.from_pretrained(
model_id,
quantization_config=bnb_config,
device_map={"":0}
)
```
除了 4 位(或 8 位)加载,transformers 集成还允许你利用 Hugging Face 生态系统中的其他工具,例如:
- 训练和推理脚本以及示例
- 序列化到安全文件([safetensors](https://huggingface.co/docs/safetensors/en/index))
- 与工具集成,如 [PEFT(参数效率微调)](https://huggingface.co/docs/peft/en/index)
- [实用工具和助手](https://huggingface.co/docs/transformers/v4.34.0/en/internal/generation_utils)来运行模型生成
## 详细推理过程
如果你想编写自己的预处理或训练代码,或想更详细地了解 PaliGemma 如何工作,以下是输入图像和文本的处理步骤:
输入文本会正常进行标记化。会在开头添加一个`<bos>`标记,并附加一个额外的换行标记(`\n`)。这个换行标记是模型训练中输入提示的重要部分,因此明确添加它以确保它始终存在。标记化的文本还以固定数量的`<image>`标记为前缀。需要多少个?这取决于输入图像的分辨率和 SigLIP 模型使用的贴片大小。PaliGemma 模型预先训练在三种正方形大小(224x224、448x448 或 896x896)之一,并始终使用 14 的贴片大小。因此,要添加的`<image>`标记数量是 224 模型的 256(`224/14 * 224/14`),448 模型的 1024,896 模型的 4096。
更大的图像导致输入序列显著增长,因此需要更多的内存。在考虑使用哪种模型时,请记住这一点。对于细粒度任务,如 OCR,使用较大图像可能有助于实现更好的结果,但对于大多数任务,质量提升不大。在决定升级到更高分辨率之前,请先在你的任务上进行测试!
这个完整的“提示”通过语言模型的文本嵌入层,并生成每个标记2048维的标记嵌入。
与此同时,输入图像经过调整大小,使用双三次重采样至所需的输入大小(对于最小分辨率模型为 224x224)。然后,它通过 SigLIP 图像编码器生成每个贴片 1152 维的图像嵌入。这里线性投影器发挥作用:将图像嵌入投影以获取 2048 维每贴片的表示,与文本标记获得的表示相同。最终的图像嵌入然后与`<image>`文本嵌入合并,这是用于自回归文本生成的最终输入。生成在自回归模式下正常工作,对整个输入(`image + bos + prompt + \n`)使用完整块注意力,并对生成的文本使用因果注意力掩码。
所有这些细节都在处理器和模型类中自动处理,因此可以使用前面示例中所示的熟悉的高级 transformers API 进行推理。
## 微调
### 使用 big_vision
PaliGemma 是在 [big_vision](https://github.com/google-research/big_vision)代码库中训练的。该代码库已用于开发如 BiT、原始 ViT、LiT、CapPa、SigLIP 等模型。
项目配置文件夹 [configs/proj/paligemma/](https://github.com/google-research/big_vision/blob/main/big_vision/configs/proj/paligemma/)包含一个`README.md`。预训练模型可以通过运行 [transfers/](https://github.com/google-research/big_vision/blob/main/big_vision/configs/proj/paligemma/transfers/) 子文件夹中的配置文件进行转移,我们的所有转移结果都是通过运行其中提供的配置文件获得的。如果你想转移自己的模型,可以复制示例配置 [transfers/forkme.py](https://github.com/google-research/big_vision/blob/main/big_vision/configs/proj/paligemma/transfers/forkme.py) 并按照注释中的说明调整它以适应你的用例。
还有一个 Colab: [`finetune_paligemma.ipynb`](https://colab.research.google.com/github/google-research/big_vision/blob/main/big_vision/configs/proj/paligemma/finetune_paligemma.ipynb),它运行一个**简化的微调**,可在免费 T4 GPU 运行时上运行。为了适应有限的主机和 GPU 内存,Colab 中的代码仅更新注意力层中的权重(170M 参数),并使用 SGD(而不是 Adam)。
### 使用 transformers
通过 transformers 进行 PaliGemma 的微调非常简单,也还可以进行 QLoRA 或 LoRA 微调。在这个例子中,我们将简要微调解码器,然后展示如何切换到 QLoRA 微调。
我们将安装 transformers 库的最新版本。
```bash
pip install git+https://github.com/huggingface/transformers.git
```
就像在推理部分一样,我们将进行身份验证以访问模型,使用`notebook_login()`。
```python
from huggingface_hub import notebook_login
notebook_login()
```
对于这个例子,我们将使用 VQAv2 数据集,并微调模型以回答有关图像的问题。让我们加载数据集。我们只会使用 question、multiple_choice_answer 和 image 列,所以让我们删除其他列。我们还将拆分数据集。
```python
from datasets import load_dataset
ds = load_dataset('HuggingFaceM4/VQAv2', split="train")
cols_remove = ["question_type", "answers", "answer_type", "image_id", "question_id"]
ds = ds.remove_columns(cols_remove)
ds = ds.train_test_split(test_size=0.1)
train_ds = ds["train"]
val_ds = ds["test"]
```
我们现在将加载处理器,其中包含图像处理和标记化部分,并预处理我们的数据集。
```python
from transformers import PaliGemmaProcessor
model_id = "google/paligemma-3b-pt-224"
processor = PaliGemmaProcessor(model_id)
```
我们将创建一个提示模板,以调整 PaliGemma 回答视觉问题。由于标记器填充输入,我们需要将我们标签中的填充设置为与标记器中的填充标记不同,以及图像标记。
注意:在标记化部分,我们传递一个`tokenize_newline_separately`标志,因为换行用于提示条件,必须单独标记化。在推理期间,默认为`True`。
```python
device = "cuda"
image_token = processor.tokenizer.convert_tokens_to_ids("<image>")
def collate_fn(examples):
texts = ["answer " + example["question"] + "\n" + example['multiple_choice_answer'] for example in examples]
images = [example["image"].convert("RGB") for example in examples]
tokens = processor(text=texts, images=images,
return_tensors="pt", padding="longest",
tokenize_newline_separately=False)
labels = tokens["input_ids"].clone()
labels[labels == processor.tokenizer.pad_token_id] = -100
labels[labels == image_token] = -100
tokens["labels"] = labels
tokens = tokens.to(torch.bfloat16).to(device)
return tokens
```
你可以直接加载模型,或者为 QLoRA 加载 4 位模型。以下是如何直接加载模型。我们将加载模型,并冻结图像编码器和投影器,仅微调解码器。如果你的图像属于特定领域,这些领域可能不在模型预训练的数据集中,你可能想跳过
冻结图像编码器。
```python
model = PaliGemmaForConditionalGeneration.from_pretrained(model_id, torch_dtype=torch.bfloat16).to(device)
for param in model.vision_tower.parameters():
param.requires_grad = False
for param in model.multi_modal_projector.parameters():
param.requires_grad = True
```
如果你想为 QLoRA 加载 4 位模型,你可以添加以下更改:
```python
from transformers import BitsAndBytesConfig
from peft import get_peft_model, LoraConfig
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_type=torch.bfloat16
)
lora_config = LoraConfig(
r=8,
target_modules=["q_proj", "o_proj", "k_proj", "v_proj", "gate_proj", "up_proj", "down_proj"],
task_type="CAUSAL_LM",
)
model = PaliGemmaForConditionalGeneration.from_pretrained(model_id, quantization_config=bnb_config, device_map={"":0})
model = get_peft_model(model, lora_config)
model.print_trainable_parameters()
#trainable params: 11,298,816 || all params: 2,934,634,224 || trainable%: 0.38501616002417344
```
我们将初始化 Trainer 和 TrainingArguments。如果你将进行 QLoRA 微调,请将优化器设置为`paged_adamw_8bit`。
```python
from transformers import TrainingArguments
args=TrainingArguments(
num_train_epochs=2,
remove_unused_columns=False,
per_device_train_batch_size=16,
gradient_accumulation_steps=4,
warmup_steps=2,
learning_rate=2e-5,
weight_decay=1e-6,
adam_beta2=0.999,
logging_steps=100,
optim="adamw_hf",
save_strategy="steps",
save_steps=1000,
push_to_hub=True,
save_total_limit=1,
bf16=True,
report_to=["tensorboard"],
dataloader_pin_memory=False
)
```
初始化`Trainer`,传入数据集、数据整合函数和训练参数,并调用`train()`开始训练。
```python
from transformers import Trainer
trainer = Trainer(
model=model,
train_dataset=train_ds,
eval_dataset=val_ds,
data_collator=collate_fn,
args=args
)
trainer.train()
```
## 额外资源
- [视觉语言模型解析](https://huggingface.co/blog/vlms)
- [模型文档](https://huggingface.co/docs/transformers/model_doc/paligemma)
- [推理笔记本](https://colab.research.google.com/drive/1gOhRCFyt9yIoasJkd4VoaHcIqJPdJnlg?usp=sharing)
- [Big vision PaliGemma 演示](https://huggingface.co/spaces/google/paligemma)
- [🤗 transformers PaliGemma 演示](https://huggingface.co/spaces/google/paligemma-hf)
- [所有 PaliGemma 模型的集合](https://huggingface.co/collections/google/paligemma-release-6643a9ffbf57de2ae0448dda)
- [所有 PaliGemma 微调模型的集合](https://huggingface.co/collections/google/paligemma-ft-models-6643b03efb769dad650d2dda)
- [原始实现](https://github.com/google-research/big_vision/blob/main/big_vision/models/proj/paligemma/paligemma.py)
感谢 [Omar Sanseviero](osanseviero)、[Lucas Beyer](https://huggingface.co/giffmana)、[Xiaohua Zhai](https://huggingface.co/xiaohuazhai)和 [Matthias Minderer](https://huggingface.co/mjlm) 对本博客文章的全面审校。
| 3 |
0 | hf_public_repos/blog | hf_public_repos/blog/zh/llama32.md | ---
title: "现在 Llama 具备视觉能力并可以在你的设备上运行 - 欢迎使用 Llama 3.2"
thumbnail: /blog/assets/llama32/thumbnail.jpg
authors:
- user: merve
- user: philschmid
- user: osanseviero
- user: reach-vb
- user: lewtun
- user: ariG23498
- user: pcuenq
translators:
- user: cheninwang
- user: roseking
- user: zhongdongy
proofreader: true
---
# 现在 Llama 具备视觉能力并可以在你的设备上运行 - 欢迎使用 Llama 3.2
Llama 3.2 来了!今天,我们欢迎 Llama 系列的下一个版本加入 Hugging Face。这次,我们很高兴与 Meta 合作发布多模态和小型模型。在 Hub 上提供了十个开源模型 (5 个多模态模型和 5 个仅文本模型)。
Llama 3.2 Vision 有两种尺寸: 11B 适用于在消费级 GPU 上的高效部署和开发,90B 适用于大规模应用。两种版本都有基础版和指令微调版。除了这四个多模态模型外,Meta 还发布了支持视觉的新版 Llama Guard。Llama Guard 3 是一个安全模型,可以分类模型输入和生成内容,包括检测有害的多模态提示或助手响应。
Llama 3.2 还包括可以在设备上运行的小型仅文本语言模型。它们有两种新大小 (1B 和 3B),并提供基础版和指令版,具有强大的能力。还有一个小型 1B 版本的 Llama Guard,可以与这些或更大的文本模型一起部署在生产用例中。
在发布的功能和集成中,我们有:
- [Hub 上的模型检查点](https://huggingface.co/collections/meta-llama/llama-32-66f448ffc8c32f949b04c8cf)
- Hugging Face Transformers 和 TGI 对视觉模型的集成
- 在 Google Cloud、Amazon SageMaker 和 DELL 企业中心的推理与部署集成
- 使用 [transformers🤗](https://github.com/huggingface/huggingface-llama-recipes/tree/main/Llama-Vision%20FT.ipynb) 和 [TRL](https://github.com/huggingface/trl/tree/main/examples/scripts/sft_vlm.py) 在单个 GPU 上微调 Llama 3.2 11B 视觉模型
## 目录
- [什么是 Llama 3.2 视觉模型?](# 什么是Llama32-Vision-模型)
- [Llama 3.2 许可变更。抱歉,欧盟](#Llama-32-许可变更-抱歉-欧盟用户)
- [Llama 3.2 1B 和 3B 的特别之处?](#Llama-32-1B-和-3B-有什么特别之处)
- [演示](#演示)
- [使用 Hugging Face Transformers](#使用-Hugging-Face-Transformers)
- [Llama 3.2 1B 和 3B 语言模型](#Llama-32-1B-和-3B-语言模型)
- [Llama 3.2 视觉模型](#Llama-32-视觉模型)
- [设备端部署](#设备端部署)
- [Llama.cpp 和 Llama-cpp-python](#llamacpp--llama-cpp-python)
- [Transformers.js](#transformersjs)
- [微调 Llama 3.2](#微调-llama-32)
- [Hugging Face 合作伙伴集成](#Hugging-Face-合作伙伴集成)
- [其他资源](#额外资源)
- [致谢](#鸣谢)
## 什么是 Llama3.2 Vision 模型?
Llama 3.2 Vision 是 Meta 发布的最强大的开源多模态模型。它具有出色的视觉理解和推理能力,可以用于完成各种任务,包括视觉推理与定位、文档问答和图像 - 文本检索。思维链 (Chain of Thought, CoT) 答案通常非常好,这使得视觉推理特别强大。
Llama 3.2 Vision 可以处理文本和图像,也可以仅处理文本。对于图像 - 文本提示,模型可以接受英文输入,而对于仅文本提示,模型可以处理多种语言。在仅文本模式下,支持的完整语言列表包括英语、德语、法语、意大利语、葡萄牙语、印地语、西班牙语和泰语。
这些模型的架构基于 Llama 3.1 LLM 与视觉塔和图像适配器的组合。用于 Llama 3.2 11B Vision 的文本模型是 Llama 3.1 8B,而 Llama 3.2 90B Vision 则使用 Llama 3.1 70B。根据我们的了解,文本模型在视觉模型训练期间是冻结的,以保持仅文本的性能。
下面是一些来自 11B 指令调优模型的推理示例,展示了真实世界知识、文档推理和信息图理解能力。
<table>
<tr>
<td style="vertical-align: middle;"><img src="https://huggingface.co/datasets/huggingface/release-assets/resolve/main/wat_arun.jpg" width="300"/></td>
<td style="vertical-align: middle;">
<strong> 这张图片位于哪里?附近还有哪些景点?</strong><br>
图片描绘的是泰国曼谷的大皇宫。大皇宫是一个建筑群,曾作为暹罗国王的官方住所,并作为政府的行政中心达 150 年之久。它是曼谷最受欢迎的旅游景点之一,是任何访问该市的人必去之地。<br><br>
大皇宫附近的一些其他景点包括: <br>
* 玉佛寺 (Wat Phra Kaew): 这座寺庙位于大皇宫复合区内,拥有著名的玉佛像。<br>
* 郑王庙 (Wat Arun): 这座寺庙位于湄南河的西岸,以其惊艳的建筑和美丽的城市景观而闻名。<br>
* 卧佛寺 (Wat Pho): 这座寺庙靠近大皇宫,拥有一尊巨大的卧佛像。<br>
* 隆比尼公园 (Lumpini Park): 这个公园位于曼谷中心,提供了一个远离城市喧嚣的宁静避风港。<br>
* 吉姆·汤普森故居 (Jim Thompson House): 这座博物馆展示了美国商人吉姆·汤普森的生活和工作,他在 20 世纪 50 年代和 60 年代帮助振兴了泰国丝绸产业。
</td>
</tr>
<tr>
<td style="vertical-align: middle;"><img src="https://huggingface.co/datasets/huggingface/release-assets/resolve/main/weather_events.png" width="300"/></td>
<td style="vertical-align: middle;">
<strong> 根据这张图表,干旱发生在什么地方?</strong><br>
<strong>2016 年干旱区域: </strong> 根据图表,2016 年发生干旱的地区有两个: <br>
* <strong> 东非和南非: </strong> 该地区经历了严重的干旱。<br>
* <strong> 智利: </strong> 智利在 1 月份经历了 50 多年来最干燥的天气。这些地区在那段时间面临严重的水资源短缺问题。
</td>
</tr>
<tr>
<td style="vertical-align: middle;"><img src="https://huggingface.co/datasets/huggingface/release-assets/resolve/main/invoice.png" width="300"/></td>
<td style="vertical-align: middle;">
<strong> 从发票日期到到期日期需要多长时间?请简洁明了。</strong><br>
<strong> 发票日期: </strong>2019 年 2 月 11 日 <br>
<strong> 到期日期: </strong>2019 年 2 月 26 日 <br>
<strong> 时间差计算: </strong><br>
2019 年 2 月 26 日 - 2019 年 2 月 11 日 = 15 天 <br><br>
发票日期与到期日期之间的时间差为**15 天**。
</td>
</tr>
</table>
Vision 模型的上下文长度为 128k 个token,这允许包含图像的多轮对话。然而,该模型在关注单一图像时效果最佳,因此`transformers`实现仅关注输入中的最后一张图像。这可以保持质量并节省内存。
11B 基础模型支持 448 的分块尺寸,而指令微调版本和 90B 模型都使用 560 的分块尺寸。这些模型在一个包含 60 亿图文对的海量数据集上进行了训练,数据来源非常多样化。这使得它们成为下游任务微调的极佳候选模型。下表展示了 11B、90B 模型及其指令微调版本在一些基准测试中的表现,数据来自 Meta。请参阅模型卡片以获取更多基准测试和详细信息。
Vision 模型的上下文长度为 128k 个 token,这允许包含图像的多轮对话。然而,该模型在关注单一图像时效果最佳,因此 `transformers` 实现仅关注输入中的最后一张图像。这可以保持质量并节省内存。
11B 基础模型支持 448 的分块尺寸,而指令微调版本和 90B 模型都使用 560 的分块尺寸。这些模型在一个包含 60 亿图文对的海量数据集上进行了训练,数据来源非常多样化。这使得它们成为下游任务微调的极佳候选模型。下表展示了 11B、90B 模型及其指令微调版本在一些基准测试中的表现,数据来自 Meta。请参阅模型卡片以获取更多基准测试和详细信息。
| 模型 | 11B | 11B (指令微调) | 90B | 90B (指令微调) | 指标 |
|------------|-------------------|-----------------|-------------------|------------------|------------------|
| MMMU (val) | 41.7 | 50.7 (CoT) | 49.3 (zero-shot) | 60.3 (CoT) | Micro Average Accuracy |
| VQAv2 | 66.8 (val) | 75.2 (test) | 73.6 (val) | 78.1 (test) | Accuracy |
| DocVQA | 62.3 (val) | 88.4 (test) | 70.7 (val) | 90.1 (test) | ANLS |
| AI2D | 62.4 | 91.1 | 75.3 | 92.3 | Accuracy |
我们预计这些模型的文本能力将与 8B 和 70B 的 Llama 3.1 模型相当,因为我们的理解是文本模型在 Vision 模型训练期间是冻结的。因此,文本基准测试应该与 8B 和 70B 一致。
## Llama 3.2 许可证变更。对不起,欧盟 :(

关于许可条款,Llama 3.2 的许可与 Llama 3.1 非常相似,唯一的关键区别在于可接受使用政策: 任何居住在欧盟的个人或在欧盟有主要营业地点的公司不被授予使用 Llama 3.2 中包含的多模态模型的许可权。这一限制不适用于集成了任何此类多模态模型的产品或服务的最终用户,因此人们仍然可以构建全球产品与视觉变体。
有关完整详情,请务必阅读 [官方许可证](https://huggingface.co/meta-llama/Llama-3.2-1B/blob/main/LICENSE.txt) 和 [可接受的使用政策](https://huggingface.co/meta-llama/Llama-3.2-1B/blob/main/USE_POLICY.md)。
## Llama 3.2 1B 和 3B 有什么特别之处?
Llama 3.2 系列包括 1B 和 3B 文本模型。这些模型旨在用于设备上的使用案例,如提示重写、多语言知识检索、摘要任务、工具使用和本地运行的助手。它们在这些规模上超过了许多可用的开放访问模型,并与大得多的模型竞争。在后面的部分中,我们将展示如何离线运行这些模型。
这些模型遵循与 Llama 3.1 相同的架构。它们使用高达 9 万亿个 token 进行训练,并仍然支持长上下文长度的 128k 个 token。模型是多语言的,支持英语、德语、法语、意大利语、葡萄牙语、印地语、西班牙语和泰语。
还有一个新的 Llama Guard 小版本,Llama Guard 3 1B,可以与这些模型一起部署,以评估多轮对话中最后一次用户或助手的响应。它使用一组预定义的类别 (在此版本中新增),可以根据开发者的用例进行自定义或排除。有关使用 Llama Guard 的更多详细信息,请参考模型卡。
额外提示: Llama 3.2 接触了比上述 8 种语言更广泛的语言集合。鼓励开发者针对特定语言用例微调 Llama 3.2 模型。
我们通过 Open LLM Leaderboard 评估套件对基础模型进行了测试,而指令模型则在三个流行的基准上进行了评估,这些基准衡量遵循指令的能力,并与 LMSYS Chatbot Arena 高度相关: [IFEval](https://arxiv.org/abs/2311.07911)、[AlpacaEval](https://arxiv.org/abs/2404.04475) 和 [MixEval-Hard](https://arxiv.org/abs/2406.06565)。以下是基础模型的结果,其中包括 Llama-3.1-8B 作为参考:
| 模型 | BBH | MATH Lvl 5 | GPQA | MUSR | MMLU-PRO | 平均 |
|----------------------|-------|------------|-------|-------|----------|---------|
| Meta-Llama-3.2-1B | 4.37 | 0.23 | 0.00 | 2.56 | 2.26 | 1.88 |
| Meta-Llama-3.2-3B | 14.73 | 1.28 | 4.03 | 3.39 | 16.57 | 8.00 |
| Meta-Llama-3.1-8B | 25.29 | 4.61 | 6.15 | 8.98 | 24.95 | 14.00 |
以下是指令模型的结果,以Llama-3.1-8B-Instruct 作为参考:
| 模型 | AlpacaEval (LC) | IFEval | MixEval-Hard | 平均 |
|-----------------------------|-----------------|--------|--------------|---------|
| Meta-Llama-3.2-1B-Instruct | 7.17 | 58.92 | 26.10 | 30.73 |
| Meta-Llama-3.2-3B-Instruct | 20.88 | 77.01 | 31.80 | 43.23 |
| Meta-Llama-3.1-8B-Instruct | 25.74 | 76.49 | 44.10 | 48.78 |
值得注意的是,3B 模型在 IFEval 上的表现与 8B 模型相当!这使得该模型非常适合代理应用,在这些应用中,遵循指令对于提高可靠性至关重要。这个高 IFEval 分数对于这个规模的模型来说非常令人印象深刻。
1B 和 3B 的指令调优模型均支持工具使用。用户在 0-shot 环境中指定工具 (模型之前没有关于开发者将使用的工具的信息)。因此,Llama 3.1 模型中包含的内置工具 ( `brave_search` 和 `wolfram_alpha` ) 不再可用。
由于其体积小,这些小模型可以作为更大模型的助手,执行 [辅助生成](https://huggingface.co/blog/assisted-generation) (也称为推测解码)。[这里](https://github.com/huggingface/huggingface-llama-recipes/tree/main) 是一个使用 Llama 3.2 1B 模型作为 Llama 3.1 8B 模型助手的示例。有关离线使用案例,请查看后面的设备上运行部分。
## 演示
你可以在以下演示中体验这三种指令模型:
- [Gradio 空间中的 Llama 3.2 11B 视觉指令](https://huggingface.co/spaces/huggingface-projects/llama-3.2-vision-11B)
- [Gradio 驱动的空间中的 Llama 3.2 3B](https://huggingface.co/spaces/huggingface-projects/llama-3.2-3B-Instruct)
- Llama 3.2 3B 在 WebGPU 上运行

## 使用 Hugging Face Transformers
仅文本检查点具有与之前版本相同的架构,因此无需更新你的环境。然而,由于新的架构,Llama 3.2 Vision 需要更新 Transformers。请确保将你的安装升级到 4.45.0 或更高版本。
```bash
pip install "transformers>=4.45.0" --upgrade
```
升级后,你可以使用新的 Llama 3.2 模型,并利用 Hugging Face 生态系统的所有工具。
## Llama 3.2 1B 和 3B 语言模型
你可以仅用几行代码通过 Transformers 运行 1B 和 3B 文本模型检查点。模型检查点以 `bfloat16` 精度上传,但你也可以使用 float16 或量化权重。内存要求取决于模型大小和权重精度。以下是一个表格,显示使用不同配置进行推理时所需的大致内存:
| Model Size | BF16/FP16 | FP8 | INT4 |
|------------|--------|---------|---------|
| 3B | 6.5 GB | 3.2 GB | 1.75 GB |
| 1B | 2.5 GB | 1.25 GB | 0.75 GB |
```python
from transformers import pipeline
import torch
model_id = "meta-llama/Llama-3.2-3B-Instruct"
pipe = pipeline(
"text-generation",
model=model_id,
torch_dtype=torch.bfloat16,
device_map="auto",
)
messages = [
{"role": "user", "content": "Who are you? Please, answer in pirate-speak."},
]
outputs = pipe(
messages,
max_new_tokens=256,
)
response = outputs[0]["generated_text"][-1]["content"]
print(response)
# Arrrr, me hearty! Yer lookin' fer a bit o' information about meself, eh? Alright then, matey! I be a language-generatin' swashbuckler, a digital buccaneer with a penchant fer spinnin' words into gold doubloons o' knowledge! Me name be... (dramatic pause)...Assistant! Aye, that be me name, and I be here to help ye navigate the seven seas o' questions and find the hidden treasure o' answers! So hoist the sails and set course fer adventure, me hearty! What be yer first question?
```
一些细节:
- 我们使用 `bfloat16` 加载模型。如上所述,这是 Meta 发布的原始检查点所使用的类型,因此建议以确保最佳精度或进行评估。根据你的硬件,float16 可能会更快。
- 默认情况下,transformers 使用与原始 Meta 代码库相同的采样参数 (temperature=0.6 和 top_p=0.9)。我们尚未进行广泛测试,请随意探索!
## Llama 3.2 Vision 模型
Vision 模型更大,因此比小型文本模型需要更多的内存来运行。作为参考,11B Vision 模型在 4 位模式下进行推理大约需要 10 GB 的 GPU RAM。
使用指令调优的 Llama 视觉模型进行推理的最简单方法是使用内置的聊天模板。输入具有 `user` 和 `assistant` 角色,以指示对话的轮次。与文本模型的一个区别是不支持系统角色。用户轮次可以包括图像 - 文本或仅文本输入。要指示输入包含图像,请在输入的内容部分添加 `{"type": "image"}` ,然后将图像数据传递给 `processor` :
```python
import requests
import torch
from PIL import Image
from transformers import MllamaForConditionalGeneration, AutoProcessor
model_id = "meta-llama/Llama-3.2-11B-Vision-Instruct"
model = MllamaForConditionalGeneration.from_pretrained(
model_id,
torch_dtype=torch.bfloat16,
device="cuda",
)
processor = AutoProcessor.from_pretrained(model_id)
url = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/0052a70beed5bf71b92610a43a52df6d286cd5f3/diffusers/rabbit.jpg"
image = Image.open(requests.get(url, stream=True).raw)
messages = [
{"role": "user", "content": [
{"type": "image"},
{"type": "text", "text": "Can you please describe this image in just one sentence?"}
]}
]
input_text = processor.apply_chat_template(
messages, add_generation_prompt=True,
)
inputs = processor(
image, input_text, return_tensors="pt"
).to(model.device)
output = model.generate(**inputs, max_new_tokens=70)
print(processor.decode(output[0][inputs["input_ids"].shape[-1]:]))
## The image depicts a rabbit dressed in a blue coat and brown vest, standing on a dirt road in front of a stone house.
```
你可以继续关于图像的对话。请记住,如果你在新用户轮次中提供新图像,模型将从那时起引用新图像。你不能同时查询两幅不同的图像。这是继续之前对话的一个示例,我们在对话中添加助手轮次,并询问一些更多的细节:
```python
messages = [
{"role": "user", "content": [
{"type": "image"},
{"type": "text", "text": "Can you please describe this image in just one sentence?"}
]},
{"role": "assistant", "content": "The image depicts a rabbit dressed in a blue coat and brown vest, standing on a dirt road in front of a stone house."},
{"role": "user", "content": "What is in the background?"}
]
input_text = processor.apply_chat_template(
messages,
add_generation_prompt=True,
)
inputs = processor(image, input_text, return_tensors="pt").to(model.device)
output = model.generate(**inputs, max_new_tokens=70)
print(processor.decode(output[0][inputs["input_ids"].shape[-1]:]))
```
这是我们得到的回复:
```
In the background, there is a stone house with a thatched roof, a dirt road, a field of flowers, and rolling hills.
```
你还可以使用 `bitsandbytes` 库自动量化模型,以 8-bit 或甚至 4-bit 模式加载。以下是如何在 4-bit 模式下加载生成管道的示例:
```diff
import torch
from transformers import MllamaForConditionalGeneration, AutoProcessor
+from transformers import BitsAndBytesConfig
+bnb_config = BitsAndBytesConfig(
+ load_in_4bit=True,
+ bnb_4bit_quant_type="nf4",
+ bnb_4bit_compute_dtype=torch.bfloat16
)
model = MllamaForConditionalGeneration.from_pretrained(
model_id,
- torch_dtype=torch.bfloat16,
- device="cuda",
+ quantization_config=bnb_config,
)
```
然后,你可以应用聊天模板,使用 `processor` ,并像以前一样调用模型。
## 设备端部署
你可以直接在设备的 CPU/GPU/浏览器上运行 Llama 3.2 1B 和 3B,使用多个开源库,如下所示。
### Llama.cpp & Llama-cpp-python
[Llama.cpp](https://github.com/ggerganov/llama.cpp) 是进行跨平台设备上机器学习推理的首选框架。我们为 1B 和 3B 模型提供了 4-bit 和 8-bit 的量化权重。我们希望社区能够采用这些模型,并创建其他量化和微调。你可以在 [这里](https://huggingface.co/models?search=hugging-quants/Llama-3.2-) 找到所有量化的 Llama 3.2 模型。
以下是如何直接使用 llama.cpp 运行这些检查点的方法。
通过 brew 安装 llama.cpp (适用于 Mac 和 Linux)。
```bash
brew install llama.cpp
```
你可以使用 CLI 运行单次生成或调用兼容 Open AI 消息规范的 llama.cpp 服务器。
你可以使用如下命令运行 CLI:
```bash
llama-cli --hf-repo hugging-quants/Llama-3.2-3B-Instruct-Q8_0-GGUF --hf-file llama-3.2-3b-instruct-q8_0.gguf -p " 生命和宇宙的意义是 "
```
你可以这样启动服务器:
```bash
llama-server --hf-repo hugging-quants/Llama-3.2-3B-Instruct-Q8_0-GGUF --hf-file llama-3.2-3b-instruct-q8_0.gguf -c 2048
```
你还可以使用 [llama-cpp-python](https://github.com/abetlen/llama-cpp-python) 在 Python 中以编程方式访问这些模型。
```python
from llama_cpp import Llama
llm = Llama.from_pretrained(
repo_id="hugging-quants/Llama-3.2-3B-Instruct-Q8_0-GGUF",
filename="*q8_0.gguf",
)
llm.create_chat_completion(
messages = [
{
"role": "user",
"content": "What is the capital of France?"
}
]
)
```
### Transformers.js
你甚至可以在浏览器 (或任何 JavaScript 运行时,如 Node.js、Deno 或 Bun) 中使用 [Transformers.js](https://huggingface.co/docs/transformers.js) 运行 Llama 3.2。你可以在 Hub 上找到 [ONNX 模型](https://huggingface.co/onnx-community/Llama-3.2-1B-Instruct)。如果你还没有安装该库,可以通过 [NPM](https://www.npmjs.com/package/@huggingface/transformers) 使用以下命令安装:
```bash
npm i @huggingface/transformers
```
然后,你可以按照以下方式运行模型:
```js
import { pipeline } from "@huggingface/transformers";
// Create a text generation pipeline
const generator = await pipeline("text-generation", "onnx-community/Llama-3.2-1B-Instruct");
// Define the list of messages
const messages = [
{ role: "system", content: "You are a helpful assistant." },
{ role: "user", content: "Tell me a joke." },
];
// Generate a response
const output = await generator(messages, { max_new_tokens: 128 });
console.log(output[0].generated_text.at(-1).content);
```
<details>
<summary>Example output</summary>
```
Here's a joke for you:
What do you call a fake noodle?
An impasta!
I hope that made you laugh! Do you want to hear another one?
```
</details>
## 微调 Llama 3.2
TRL 支持直接对 Llama 3.2 文本模型进行聊天和微调:
```bash
# Chat
trl chat --model_name_or_path meta-llama/Llama-3.2-3B
# Fine-tune
trl sft --model_name_or_path meta-llama/Llama-3.2-3B \
--dataset_name HuggingFaceH4/no_robots \
--output_dir Llama-3.2-3B-Instruct-sft \
--gradient_checkpointing
```
TRL 还支持使用 [这个脚本](https://github.com/huggingface/trl/tree/main/examples/scripts/sft_vlm.py) 微调 Llama 3.2 Vision。
```bash
# Tested on 8x H100 GPUs
accelerate launch --config_file=examples/accelerate_configs/deepspeed_zero3.yaml \
examples/scripts/sft_vlm.py \
--dataset_name HuggingFaceH4/llava-instruct-mix-vsft \
--model_name_or_path meta-llama/Llama-3.2-11B-Vision-Instruct \
--per_device_train_batch_size 8 \
--gradient_accumulation_steps 8 \
--output_dir Llama-3.2-11B-Vision-Instruct-sft \
--bf16 \
--torch_dtype bfloat16 \
--gradient_checkpointing
```
你还可以查看 [笔记本](https://github.com/huggingface/huggingface-llama-recipes/blob/main/Llama-Vision%20FT.ipynb),了解如何使用 Transformers 和 PEFT 进行 LoRA 微调。
## Hugging Face 合作伙伴集成
我们目前正在与 AWS、Google Cloud、Microsoft Azure 和 DELL 的合作伙伴合作,正在将 Llama 3.2 11B 和 90B 模型添加到 Amazon SageMaker、Google Kubernetes Engine、Vertex AI Model Catalog、Azure AI Studio 和 DELL Enterprise Hub 中。我们会在这些容器可用时更新本节内容,你可以订阅 [Hugging Squad](https://mailchi.mp/huggingface/squad) 获取电子邮件更新。
## 额外资源
- [Hub 上的模型](https://huggingface.co/collections/meta-llama/llama-32-66f448ffc8c32f949b04c8cf)
- [Hugging Face Llama Recipes](https://github.com/huggingface/huggingface-llama-recipes)
- [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)
- [Meta Blog](https://ai.meta.com/blog/llama-3-2-connect-2024-vision-edge-mobile-devices/)
- [评估数据集](https://huggingface.co/collections/meta-llama/llama-32-evals-66f44b3d2df1c7b136d821f0)
## 鸣谢
没有成千上万社区成员的贡献,这种模型的发布以及生态系统中的支持和评估将无法实现,他们为 transformers、text-generation-inference、vllm、pytorch、LM Eval Harness 以及其他众多项目作出了贡献。特别感谢 VLLM 团队的测试和问题报告支持。这次发布的顺利进行离不开 Clémentine、Alina、Elie 和 Loubna 对 LLM 评估的支持,Nicolas Patry、Olivier Dehaene 和 Daniël de Kok 对文本生成推理的贡献; Lysandre、Arthur、Pavel、Edward Beeching、Amy、Benjamin、Joao、Pablo、Raushan Turganbay、Matthew Carrigan 和 Joshua Lochner 对 transformers、transformers.js、TRL 和 PEFT 的支持; Nathan Sarrazin 和 Victor 让 Llama 3.2 在 Hugging Chat 上可用; Brigitte Tousignant 和 Florent Daudens 的沟通支持; Julien、Simon、Pierric、Eliott、Lucain、Alvaro、Caleb 和 Mishig 来自 Hub 团队的开发和功能发布支持。
特别感谢 Meta 团队发布 Llama 3.2 并使其开放给 AI 社区!
| 4 |
0 | hf_public_repos/blog | hf_public_repos/blog/zh/os-llms.md | ---
title: "Hugging Face 的文本生成和大语言模型的开源生态"
thumbnail: /blog/assets/os_llms/thumbnail.png
authors:
- user: merve
translators:
- user: vermillionde
- user: zhongdongy
proofreader: true
---
# Hugging Face 的文本生成和大语言模型的开源生态
[更新于 2023 年 7 月 23 日: 添加 Llama 2。]
文本生成和对话技术已经出现多年了。早期的挑战在于通过设置参数和分辨偏差,同时控制好文本忠实性和多样性。更忠实的输出一般更缺少创造性,并且和原始训练数据更加接近,也更不像人话。最近的研究克服了这些困难,并且友好的交互页面能让每个人尝试这些模型。如 ChatGPT 的服务,已经把亮点放在强大的模型如 GPT-4,并且引发了爆发式的开源替代品变成主流如 Llama。我们认为这些技术将持续很长一段时间,并且会越来越集成到日常产品中。
这篇博客分成一下几个部分:
1. [文本生成的简明背景](#文本生成的简明背景)
2. [许可证](#许可证)
3. [Hugging Face 的生态中面向大语言模型的服务](#Hugging-Face-的生态中面向大语言模型的服务)
4. [参数高效的微调](#参数高效的微调)
## 文本生成的简明背景
文本生成模型本质上是以补全文本或者根据提示词生成文本为目的训练的。补全文本的模型被称之为条件语言模型 (Causal Language Models),有著名的例子比如 OpenAI 的 GPT-3 和 Meta AI 的 [Llama](https://ai.meta.com/blog/large-language-model-Llama-meta-ai/)。
下面你最好要了解型微调,这是把一个大语言模型中的知识迁移到另外的应用场景的过程,我们称之为一个 _下游任务_ 。这些任务的形式可以是根据提示的。模型越大,就越能泛化到预训练数据中不存在,但是可以在微调中学习到的提示词上。
条件语言模型有采用基于人类反馈的强化学习 (Reinforcement Learning from Human Feedback, RLHF)。这个优化过程主要基于答复文本的自然性和忠实性,而不是答复的检验值。解释 RLHF 的工作原理超出了本博客的范围,但是你可以在 [这里](https://huggingface.co/blog/rlhf) 了解。
举例而言,GPT-3 是一个条件 _基本_ 语言模型,作为 ChatGPT 的后端,通过 RLHF 在对话和提示文本上做微调。最好对这些模型做区分。
在 Hugging Face Hub 上,你可以同时找到条件语言模型和在提示文本上微调过的条件语言模型 (这篇博客后面会给出链接)。Llama 是最早开源,并且能超过闭源模型的大语言模型之一。一个由 Together 领导的研究团队已经复线了 Llama 的数据集,称之为 Red Pajama,并且已经在上面训练和微调了大语言模型。你可以在 [这里](https://www.together.xyz/blog/redpajama) 了解。以及在 Hugging Face Hub 上找到 [模型](https://huggingface.co/models?sort=trending&search=togethercomputer%2Fredpajama)。截止本博客写好的时候,三个最大的开源语言模型和其许可证分别为 [MosaicML 的 MPT-30B](https://huggingface.co/mosaicml/mpt-30b),[Salesforce 的 XGen](https://huggingface.co/Salesforce/xgen-7b-8k-base) 和 [TII UAE 的 Falcon](https://huggingface.co/tiiuae/falcon-40b),全都已经在 Hugging Face Hub 上开源了。
最近,Meta 开放了 [Llama 2](https://ai.meta.com/Llama/),其许可证允许商业用途。截止目前 Llama 2 能在各种指标上超过任何其他开源模型。[Llama 2 在 Hugging Face Hub 上的 checkpoint](https://huggingface.co/meta-Llama) 在 transformers 上兼容,并且最大的 checkpoint 人们都可以在 [HuggingChat](https://huggingface.co/chat/) 上尝试。你可以通过 [这篇博客](https://huggingface.co/blog/Llama2) 学习到如何在 Llama 2 上微调,部署和做提示词。
第二种文本生成模型通常称之为文本到文本的生成模型。这些模型在文本对的数据集上训练,这些数据集或者是问答形式,或者是提示和反馈的形式。最受欢迎的是 T5 和 BART (目前为止以及不是最新的技术了)。Google 最近发布了 FLAN-T5 系列的模型。FLAN 是最近为提示任务设计的技术,而 FLAN-T5 便是完全由 T5 用 FLAN 微调得到的模型。目前为止,FLAN-T5 系列的模型是最新的技术,并且开源,可以在 [Hugging Face Hub](https://huggingface.co/models?search=google/flan) 上看到。注意这和用条件语言模型在提示任务的微调下是不一样的,尽管其输入和输出形式类似。下面你能看到这些模型的原理。
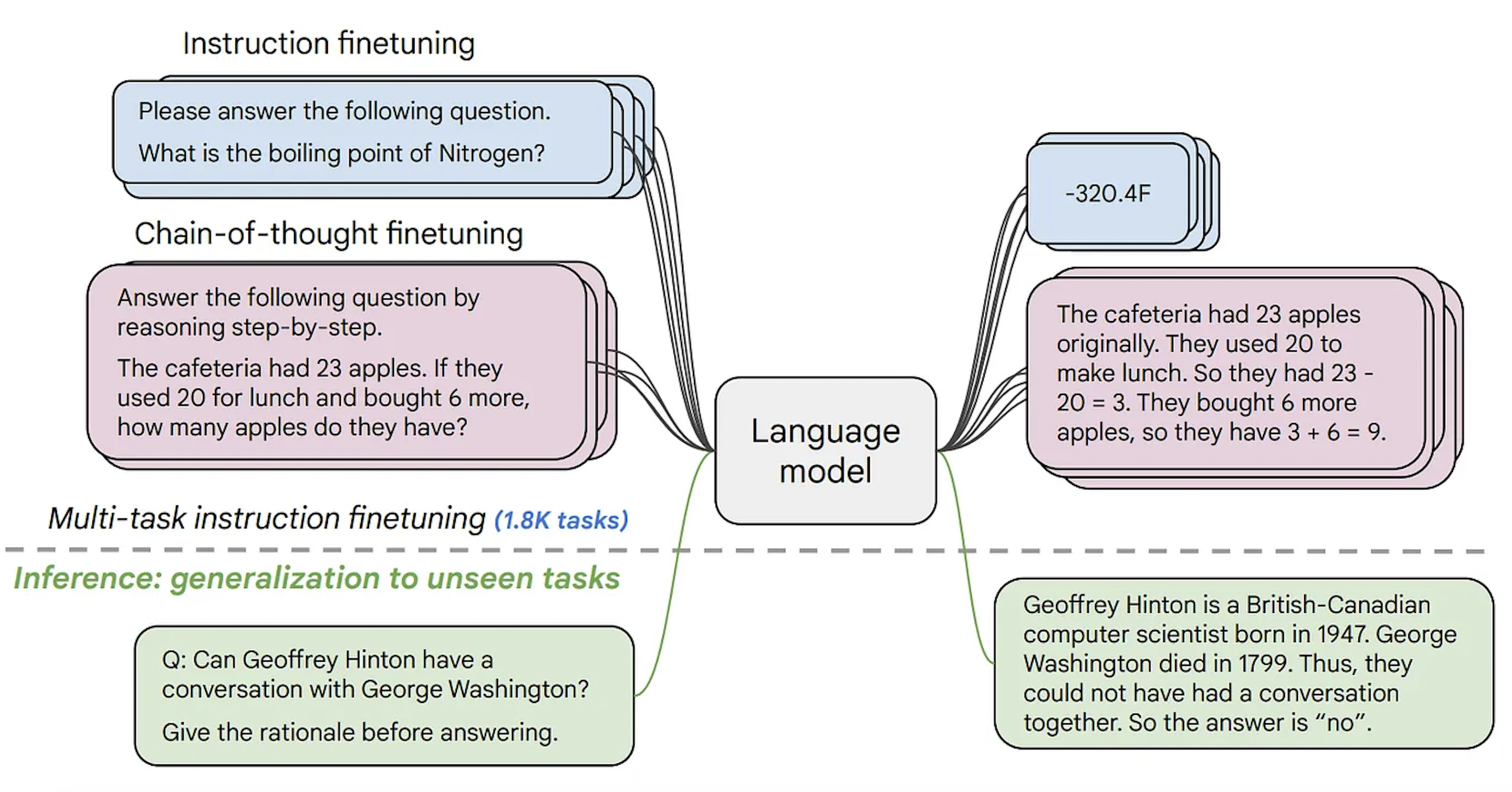
拥有更多开源的文本生成模型能让公司保证其数据隐私,部署下游更快,并且减少购买闭源 API 的支出。Hugging Face Hub 上所有开源的条件语言模型都能在 [这里](https://huggingface.co/models?pipeline_tag=text-generation) 找到,并且文本到文本的生成模型都能在 [这里](https://huggingface.co/models?pipeline_tag=text2text-generation&sort=trending) 找到。
### Hugging Face 用爱和 BigScience 与 BigCode 创造的模型 💗
Hugging Face 引领了两家科研初创 BigScience 和 BigCode。它们分别创造了两个大语言模型 [BLOOM](https://huggingface.co/bigscience/bloom) 🌸 和 [StarCoder](https://huggingface.co/bigcode/starcoder) 🌟。
BLOOM 是一个以 46 种自然语言和 13 种编程语言训练的条件语言模型,是第一个比 GPT-3 有更多参数量的开源模型。你能在 [BLOOM 的文档](https://huggingface.co/docs/transformers/model_doc/bloom) 上下载所需的所有 checkpoint。
StarCoder 是一个以 GitHub 上可访问的代码作为数据集,以 Fill-in-the-Middle 形式训练的语言模型。它不是以提示文本来微调的,所以它更适合对给定代码做补全任务,比如把 Python 翻译到 C++,解释概念 (什么是递归),或者假扮终端。你可以在 [这里](https://huggingface.co/spaces/bigcode/bigcode-playground) 找到 StarCoder 所有的 checkpoints。它也有对应的 [VSCode 扩展](https://marketplace.visualstudio.com/items?itemName=HuggingFace.huggingface-vscode)。
本博客中提及的模型,使用代码段都或者在模型主页,或者在该类模型的文档中。
## 许可证
许多文本生成模型,要么是闭源的,要么是许可证限制商业使用。幸运的是,开源模型开始出现,并且受社区青睐,用于进一步开发、微调、部署到项目中。下面你能找到一些完全开源的大型条件语言模型。
- [Falcon 40B](https://huggingface.co/tiiuae/falcon-40b)
- [XGen](https://huggingface.co/tiiuae/falcon-40b)
- [MPT-30B](https://huggingface.co/mosaicml/mpt-30b)
- [Pythia-12B](https://huggingface.co/EleutherAI/pythia-12b)
- [RedPajama-INCITE-7B](https://huggingface.co/togethercomputer/RedPajama-INCITE-7B-Base)
- [OpenAssistant (Falcon variant)](https://huggingface.co/OpenAssistant/falcon-40b-sft-mix-1226)
有两个代码生成模型,[BigCode 的 StarCoder](https://huggingface.co/models?sort=trending&search=bigcode%2Fstarcoder) 和 [Salesforce 的 Codegen](https://huggingface.co/models?sort=trending&search=salesforce%2Fcodegen)。它们提供了不同大小的模型 checkpoint。除了 [在提示文本上微调的 Codegen](https://huggingface.co/Salesforce/codegen25-7b-instruct) 之外,使用了开源或者 [open RAIL](https://huggingface.co/blog/open_rail) 许可证。
Hugging Face Hub 也有许多为提示文本或聊天微调的模型,根据你的需求不同,可以选择不同风格和大小。
- [MPT-30B-Chat](https://huggingface.co/mosaicml/mpt-30b-chat),Mosaic ML,使用 CC-BY-NC-SA 许可证,不允许商业用途。但是,[MPT-30B-Instruct](https://huggingface.co/mosaicml/mpt-30b-instruct) 使用 CC-BY-SA 3.0 许可证,允许商业使用。
- [Falcon-40B-Instruct](https://huggingface.co/tiiuae/falcon-40b-instruct) 和 [Falcon-7B-Instruct](https://huggingface.co/tiiuae/falcon-7b-instruct) 都使用 Apache 2.0 许可证,所以允许商业使用。
- 另外一系列受欢迎的模型是 OpenAssistant,部分是在 Meta 的 Llama 使用个性化的提示文本微调得到的。因为原本的 Llama 只允许研究用途,OpenAssistant 中使用 Llama 的部分不能完全开源。但是,也有 OpenAssistant 模型建立在完全开源的模型之上,比如 [Falcon](https://huggingface.co/models?search=openassistant/falcon) 或者 [pythia](https://huggingface.co/models?search=openassistant/pythia)。
- [StarChat Beta](https://huggingface.co/HuggingFaceH4/starchat-beta) 是 StarCoder 通过提示文本微调的版本,使用 BigCode Open RAIL-M v1 许可证,允许商用。Salesforce 的用提示文本微调的模型, [XGen model](https://huggingface.co/Salesforce/xgen-7b-8k-inst),只允许研究用途。
如果你想要用一个现成的提示文本数据集微调模型,你需要知道它是怎么来的。一些现成的提示文本数据集要么是由大量人工编写,要么是现有的模型的输出 (比如 ChatGPT 背后的模型)。Stanford 的 [ALPACA](https://crfm.stanford.edu/2023/03/13/alpaca.html) 数据集由 ChatGPT 背后的数据集的输出组成。另外,不少人工编写的数据集是开源的,比如 [oasst1](https://huggingface.co/datasets/OpenAssistant/oasst1) (由数千名志愿者输出!) 或者 [databricks/databricks-dolly-15k](https://huggingface.co/datasets/databricks/databricks-dolly-15k)。如果你想自己创建数据集,那你可以看 [the dataset card of Dolly](https://huggingface.co/datasets/databricks/databricks-dolly-15k#sources) 来学习创建提示文本数据集。模型在数据集上微调的过程可以分布式进行。
你可以通过如下表格了解一些开源或者开放的模型。
| Model | Dataset | License | Use |
|------------------------------------------------------------------------------------------|---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|--------------------|-------------------------|
| [Falcon 40B](https://huggingface.co/tiiuae/falcon-40b) | [Falcon RefinedWeb](https://huggingface.co/datasets/tiiuae/falcon-refinedweb) | Apache-2.0 | 文本生成 |
| [SalesForce XGen 7B](https://huggingface.co/Salesforce/xgen-7b-8k-base) | 由 C4, RedPajama 和其他数据集混合 | Apache-2.0 | 文本生成 |
| [MPT-30B](https://huggingface.co/mosaicml/mpt-30b) | 由 C4, RedPajama 和其他数据集混合 | Apache-2.0 | 文本生成 |
| [Pythia-12B](https://huggingface.co/EleutherAI/pythia-12b) | [Pile](https://huggingface.co/datasets/EleutherAI/pile) | Apache-2.0 | 文本生成 |
| [RedPajama INCITE 7B](https://huggingface.co/togethercomputer/RedPajama-INCITE-7B-Base) | [RedPajama](https://huggingface.co/togethercomputer/RedPajama-INCITE-7B-Base) | Apache-2.0 | 文本生成 |
| [OpenAssistant Falcon 40B](https://huggingface.co/OpenAssistant/falcon-40b-sft-mix-1226) | [oasst1](https://huggingface.co/datasets/OpenAssistant/oasst1) 和 [Dolly](https://huggingface.co/datasets/databricks/databricks-dolly-15k) | Apache-2.0 | 文本生成 |
| [StarCoder](https://huggingface.co/bigcode/starcoder) | [The Stack](https://huggingface.co/datasets/bigcode/the-stack-dedup) | BigCode OpenRAIL-M | 代码生成 |
| [Salesforce CodeGen](https://huggingface.co/Salesforce/codegen25-7b-multi) | [Starcoder Data](https://huggingface.co/datasets/bigcode/starcoderdata) | Apache-2.0 | 代码生成 |
| [FLAN-T5-XXL](https://huggingface.co/google/flan-t5-xxl) | [gsm8k](https://huggingface.co/datasets/gsm8k), [lambada](https://huggingface.co/datasets/lambada), 和 [esnli](https://huggingface.co/datasets/esnli) | Apache-2.0 | 文本到文本生成 |
| [MPT-30B Chat](https://huggingface.co/mosaicml/mpt-30b-chat) | [ShareGPT-Vicuna](https://huggingface.co/datasets/anon8231489123/ShareGPT_Vicuna_unfiltered), [OpenAssistant Guanaco](https://huggingface.co/datasets/timdettmers/openassistant-guanaco) 和更多 | CC-By-NC-SA-4.0 | 聊天 |
| [MPT-30B Instruct](https://huggingface.co/mosaicml/mpt-30b-instruct) | [duorc](https://huggingface.co/datasets/duorc), [competition_math](https://huggingface.co/datasets/competition_math), [dolly_hhrlhf](https://huggingface.co/datasets/mosaicml/dolly_hhrlhf) | CC-By-SA-3.0 | 提示任务 |
| [Falcon 40B Instruct](https://huggingface.co/tiiuae/falcon-40b-instruct) | [baize](https://github.com/project-baize/baize-chatbot) | Apache-2.0 | 提示任务 |
| [Dolly v2](https://huggingface.co/databricks/dolly-v2-12b) | [Dolly](https://huggingface.co/datasets/databricks/databricks-dolly-15k) | MIT | 文本生成 |
| [StarChat-β](https://huggingface.co/HuggingFaceH4/starchat-beta) | [OpenAssistant Guanaco](https://huggingface.co/datasets/timdettmers/openassistant-guanaco) | BigCode OpenRAIL-M | 代码提示任务 |
| [Llama 2](https://huggingface.co/meta-Llama/Llama-2-70b-hf) | 非公开的数据集 | Custom Meta License (允许商用) | 文本生成 |
## Hugging Face 的生态中面向大语言模型的服务
### 文本生成推理
使用这些大模型为多用户提供并发服务时,想要降低响应时间和延迟是一个巨大的挑战。为了解决这个问题,Hugging Face 发布了 [text-generation-inference](https://github.com/huggingface/text-generation-inference) (TGI),这是一个开源的大语言模型部署解决方案,它使用了 Rust、Python 和 gRPC。TGI 被整合到了 Hugging Face 的推理解决方案中,包括 [Inference Endpoints](https://huggingface.co/inference-endpoints) 和 [Inference API](https://huggingface.co/inference-api),所以你能通过简单几次点击创建优化过的服务接入点,或是向 Hugging Face 的推理 API 发送请求,而不是直接将 TGI 整合到你的平台里。
当前 TGI 助力实现了 [HuggingChat](https://huggingface.co/chat/),这是 Hugging Face 的开源 LLM 聊天界面。目前这项服务背后是来自 OpenAssistant 的模型。你可以随意和 HuggingChat 聊天,并且使用网页搜索功能来检索当前网页的内容。你还可以为每次响应提供反馈,供模型的作者进行优化训练。HuggingChat 的界面同样也是 [开源](https://github.com/huggingface/chat-ui) 的,我们正持续不断完善它,争取加入更多功能,比如在聊天过程中生成图片。
最近,Hugging Face Spaces 上发布了用于 HuggingChat 的 Docker 模板。这样一来每个人都可以轻松部署和自定义自己的 HuggingChat 实例了。你可以在 [这里](https://huggingface.co/new-space?template=huggingchat/chat-ui-template) 基于众多大语言模型 (包括 Llama 2) 创建自己的实例。
### 如何寻找最佳模型?
Hugging Face 设立了一个 [大语言模型排名](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)。该排名是通过社区提交的模型在不同指标上的测试结果在 Hugging Face 的集群上的表现评估的。如果你无法找到你想要的模型或者方向,你可以在 [这里](https://huggingface.co/models?pipeline_tag=text-generation&sort=downloads) 设置过滤条件。
你也能找到 [大语言模型的表现排名](https://huggingface.co/spaces/optimum/llm-perf-leaderboard),它评估了 Hugging Face Hub 上大语言模型输出的中间值。
## 参数高效的微调 (PEFT)
如果你想用你自己的数据集来微调一个模型,在客户端硬件上微调并部署基本是不可能的 (因为提示模型和原本模型的大小一样)。[PEFT](https://huggingface.co/docs/peft/index) 是一个实现参数高效的微调技术的库。这意味着,不需要训练整个模型,你只需要训练少量参数,允许更快速的训练而只有非常小的性能损失。通过 PEFT,你可以使用 LoRA,prefix tuning, prompt tuning 和 p-tuning。
以下更多资源可以帮助你了解和文本生成有关的更多信息。
**更多资源**
- 我们和 AWS 一起发布了基于 TGI 的 LLM 开发的深度学习容器,称之为 LLM Inference Containers。戳 [这里](https://aws.amazon.com/tr/blogs/machine-learning/announcing-the-launch-of-new-hugging-face-llm-inference-containers-on-amazon-sagemaker/) 了解。
- [文本生成任务页面](https://huggingface.co/tasks/text-generation)。
- PEFT 发布的 [博客](https://huggingface.co/blog/peft)。
- 阅读了解 [Inference Endpoints 如何使用 TGI](https://huggingface.co/blog/inference-endpoints-llm)。
- 阅读 [如何用 Transformers,PEFT 和提示词微调 Llama 2](https://huggingface.co/blog/Llama2)。 | 5 |
0 | hf_public_repos/blog | hf_public_repos/blog/zh/unity-in-spaces.md | ---
title: "如何在 🤗 Space 上托管 Unity 游戏"
thumbnail: /blog/assets/124_ml-for-games/unity-in-spaces-thumbnail.png
authors:
- user: dylanebert
translators:
- user: SuSung-boy
- user: zhongdongy
proofreader: true
---
# 如何在 🤗 Space 上托管 Unity 游戏
你知道吗?Hugging Face Space 可以托管自己开发的 Unity 游戏!惊不惊喜,意不意外?来了解一下吧!
Hugging Face Space 是一个能够以简单的方式来构建、托管和分享项目或应用样例的平台。虽然通常更多地是应用在机器学习样例中,不过实际上 Space 还可以用来托管 Unity 游戏,并且支持点击即玩。这里有一些游戏的 Space 示例:
- [Huggy](https://huggingface.co/spaces/ThomasSimonini/Huggy)。Huggy 是一个基于强化学习构建的简易游戏,玩家可以点击鼠标扔出小木棍,来教宠物狗把木棍捡回来
- [农场游戏](https://huggingface.co/spaces/dylanebert/FarmingGame)。农场游戏是我们在 [<五天创建一个农场游戏>](https://huggingface.co/blog/zh/ml-for-games-1) 系列中完成的游戏,玩家可以通过种植、收获和升级农作物来打造一个自己的繁荣农场
- [Unity API Demo](https://huggingface.co/spaces/dylanebert/UnityDemo)。一个 Unity 样例
本文将详细介绍如何在 🤗 Space 上托管自己的 Unity 游戏。
## 第 1 步: 使用静态 HTML 模板创建 Space 应用
首先,导航至 [Hugging Face Spaces](https://huggingface.co/new-space) 页面,创建一个新的 Space 应用。
<figure class="image text-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/124_ml-for-games/games-in-spaces/1.png">
</figure>
选择 “静态 HTML” 模板,并为该 Space 取个名字,然后点击创建 Space。
<figure class="image text-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/124_ml-for-games/games-in-spaces/2.png">
</figure>
## 第 2 步: 使用 Git 克隆 Space 库到本地
使用 Git 将上一步创建的 Space 库克隆到本地。克隆命令如下:
```
git clone https://huggingface.co/spaces/{your-username}/{your-space-name}
```
## 第 3 步: 打开 Unity 项目
打开你希望在 🤗 Space 上托管的 Unity 项目
<figure class="image text-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/124_ml-for-games/games-in-spaces/3.png">
</figure>
## 第 4 步: 将构建目标切换为 WebGL
点击菜单栏的 `File > Build Settings`,将构建目标切换为 WebGL。
<figure class="image text-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/124_ml-for-games/games-in-spaces/4.png">
</figure>
## 第 5 步: 打开 Player Settings 面板
在上一步打开的 Build Settings 窗口中,点击左下角的 “Player Settings” 按钮,打开 Player Settings 面板。
<figure class="image text-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/124_ml-for-games/games-in-spaces/5.png">
</figure>
## 第 6 步:(可选) 下载 Hugging Face Unity WebGL 模板
Hugging Face Unity WebGL 模板可以使得你制作的游戏在 🤗 Space 上展示地更加美观。可以点击 [此处](https://github.com/huggingface/Unity-WebGL-template-for-Hugging-Face-Spaces) 下载模板库,并将其放到你的游戏项目目录,然后在 Player Settings 面板中将 WebGL 模板切换为 Hugging Face 即可。
如下图所示,在 Player Settings 面板中点击 “Resolution and Presentation”,然后选择 Hugging Face WebGL 模板。
<figure class="image text-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/124_ml-for-games/games-in-spaces/6.png">
</figure>
## 第 7 步: 禁用压缩
在 Player Settings 面板中点击 “Publishing Settings”,将 Compression Format 改为 “Disabled” 来禁用压缩。
<figure class="image text-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/124_ml-for-games/games-in-spaces/7.png">
</figure>
## 第 8 步: 构建游戏项目
返回 Build Settings 窗口,并点击 “Build” 按钮,选择一个本地目录来保存构建的游戏项目文件。按照前几步的设置,Unity 将会把项目构建为 WebGL。
<figure class="image text-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/124_ml-for-games/games-in-spaces/8.png">
</figure>
## 第 9 步: 将构建完成的文件复制到 Space 库
构建过程完成之后,打开上一步中项目保存的本地目录,将该目录下的文件复制到 [第 2 步](#第-2-步-使用-git-克隆-space-库到本地) 中克隆的 Space 库里。
<figure class="image text-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/124_ml-for-games/games-in-spaces/9.png">
</figure>
## 第 10 步: 为大文件存储启用 Git-LFS
打开 Space 库, 在该目录执行以下命令来追踪构建的大型文件。
```
git lfs install
git track Build/*
```
## 第 11 步: Push 到 Hugging Face Space
最后,将本地的 Space 库的所有改动推送到 Hugging Face Space 上。执行以下 Git 命令即可完成推送:
```
git add .
git commit -m "Add Unity WebGL build files"
git push
```
## 完成!
至此,在 🤗 Space 上托管 Unity 游戏的所有步骤就都完成了。恭喜!现在请刷新你的 Space 页面,你就可以在 Space 上玩游戏了!
希望本教程对你有所帮助。如果你有任何疑问,或想更多地参与到 Hugging Face 游戏相关的应用中,可以加入 Hugging Face 的官方 [Discord](https://hf.co/join/discord) 频道来与我们取得联系! | 6 |
0 | hf_public_repos/blog | hf_public_repos/blog/zh/document-ai.md | ---
title: "加速 Document AI (文档智能) 发展"
thumbnail: /blog/assets/112_document-ai/thumbnail.png
authors:
- user: rajistics
- user: nielsr
- user: florentgbelidji
- user: nbroad
translators:
- user: Johnson817
---
# 加速 Document AI (文档智能) 发展
在企业的数字工作流中充满了各种文档,包括信件、发票、表格、报告、收据等,我们无法自动提取它们的知识。如今随着文本、视觉和多模态人工智能的进步,我们有可能解锁这些知识,这篇文章向你展示了你的团队该如何使用开源模型来构建免费的定制化解决方案。
Document AI 包括了许多数据科学的任务,包括 [图像分类](https://huggingface.co/tasks/image-classification)、[图像转文本](https://huggingface.co/tasks/image-to-text) (image to text)、[文档回答](https://huggingface.co/tasks/document-question-answering) (document question answering) 、[表格回答](https://huggingface.co/tasks/table-question-answering) (table question answering) 以及 [视觉回答](https://huggingface.co/tasks/visual-question-answering) (visual question answering) 。
本文将向大家介绍 Document AI 中的六种不同使用场景,以及它们的最佳开源模型,之后重点分三个方面介绍了许可、数据准备和建模问题,在文章中,有一些 Web 演示、文档和模型的链接。
## 六大使用场景
构建 Document AI 解决方案至少有六个使用场景,这些使用场景在文档输入和输出的数据结构上有所不同,在解决具体的企业 Document AI 问题时,往往需要综合各种方法。
### 1. 光学字符识别 (OCR)
将打字、手写或打印的文本变成机器编码的文本,这一过程被称为光学字符识别 (OCR)。这是一个被广泛研究的问题,有许多成熟的开源和商业产品,图中展示了一个将手写文字转换为文本的案例:

OCR 是 Document AI 使用场景的支柱,它对于将文本转化为计算机可读的东西至关重要,一些广泛使用的模型是 [EasyOCR](https://huggingface.co/spaces/tomofi/EasyOCR) 或 [PaddleOCR](https://huggingface.co/spaces/PaddlePaddle/PaddleOCR) ,它们在文档层面上运行。还有一些模型在单行文本图像上运行,比如 [TrOCR:基于转化器的光学字符识别与预训练模型](https://huggingface.co/docs/transformers/model_doc/trocr),这个模型与 CRAFT 这样的文本检测模型一起工作,它首先以边界框的形式识别文档中的单个文本「片断」。
OCR 的相关指标是字符错误率 ( CER ) 和 word-level 精度、召回率和 F1。在 [这个空间](https://huggingface.co/spaces/tomofi/CRAFT-TrOCR) 可以看到 CRAFT 和 TrOCR 的演示。
### 2. 文档图像分类
将文档归入适当的类别,如表格、发票或信件,被称为文档图像分类。
分类的对象可以选择文档的图像和文本中的一种或两种,最近,出现了一些更为先进的采用视觉结构和底层文本的多模态模型,它们的加入极大地提高了分类器的性能。
一个基本的方法是在文档图像上应用 OCR,然后使用类似 BERT 的模型进行分类,然而,[BERT](https://huggingface.co/docs/transformers/model_doc/bert) 模型并不能考虑到任何布局或视觉信息,同时参考 [RVL-CDIP](https://huggingface.co/datasets/rvl_cdip) 数据集的图,我们可以看到不同文档类型的视觉结构是不同的:

这就是 [LayoutLM](https://huggingface.co/docs/transformers/model_doc/layoutlmv3) 和 [Donut](https://huggingface.co/docs/transformers/model_doc/donut) 等多模态模型发挥作用的地方,由于同时纳入了文本和视觉信息,这些模型可以极大地提高准确性,在 [RVL-CDIP](https://huggingface.co/datasets/rvl_cdip) (文档图像分类的一个重要基准数据集) 上:
* 基于 BERT 的模型仅使用文本,实现了 89% 的准确率;
* [DiT](https://huggingface.co/docs/transformers/main/en/model_doc/dit) (Document image Transformer) 仅使用视觉,可以达到 92% 的准确率;
* 而像 LayoutLMv3 和 Donut 这样使用多模态 Transformer 将文本和视觉信息结合起来的模型,可以达到 95% 的准确率,它们正在改变从业者解决 Document AI 问题的方法。
### 3. 文档布局分析 (Document layout analysis)
文档布局分析是确定文档物理结构的任务,即确定构成文档的各个组成部分,如文本段落、标题和表格
这项任务通常是通过将其作为一个图像分割 (image segmentation) 、物体检测 (object detection) 问题来解决,该模型的输出为一组分割掩码 / 边界框,以及类别名称。
目前最先进的文档布局分析模型是 [LayoutLMv3](https://huggingface.co/docs/transformers/model_doc/layoutlmv3) 和 [DiT](https://huggingface.co/docs/transformers/model_doc/dit) (Document image Transformer) 。这两种模型都使用经典的 [Mask R-CNN](https://arxiv.org/abs/1703.06870) 框架作为对象检测的骨架。这个 [文档布局分析](https://huggingface.co/spaces/nielsr/dit-document-layout-analysis) 空间说明了 [DiT](https://github.com/microsoft/unilm/tree/master/dit) 模型如何被用来识别文档中的文本段、标题和表格。这里展示了一个使用 DiT 检测文档不同部分的例子:

文档布局分析通常使用 mAP (平均精度) 指标来评估对象检测模型,使用 [PubLayNet](https://github.com/ibm-aur-nlp/PubLayNet) 数据集作为重要基准,截至本文写作,最先进的模型是 [LayoutLMv3](https://huggingface.co/docs/transformers/main/en/model_doc/layoutlmv3),其总体 mAP 得分为 0.951 ([点击](https://paperswithcode.com/sota/document-layout-analysis-on-publaynet-val) 查看各模型精度对比) 。
### 4. 文档解析
比布局分析更进一步的是文档解析,文档解析的目标是识别和提取文档中的关键信息,比如识别发票表格中的名称、项目和总数,点击 [LayoutLMv2 Space](https://huggingface.co/spaces/nielsr/LayoutLMv2-FUNSD) Space 可以了解如何解析文档,识别问题、答案和标题。
LayoutLM 的第一个版本 (现在称为 LayoutLMv1) 于 2020 年发布,显著提高了当时存在的基准,如今它仍然是 Hugging Face Hub 上最受欢迎的模型之一,用于 Document AI。[LayoutLMv2](https://huggingface.co/docs/transformers/main/en/model_doc/layoutlmv2) 和 [LayoutLMv3](https://huggingface.co/docs/transformers/main/en/model_doc/layoutlmv3) 在预训练期间纳入了视觉特征,相比于第一代提供了一个改进。LayoutLM 系列让 Document AI 的性能方面产生了阶梯式的变化。例如,在 [FUNSD](https://guillaumejaume.github.io/FUNSD/) 基准数据集上,BERT 模型的 F1 指标层面得分是 60%,但使用 LayoutLM,就有可能达到 90%!
LayoutLMv1 现在有许多继承者:
* Donut 建立在 LayoutLM 的基础上,但可以把图像作为输入,所以它不需要一个单独的 OCR 引擎;
* [ERNIE-Layout](https://arxiv.org/abs/2210.06155) 最近被发布了,并取得了令人鼓舞的成果,请看 [Space](https://huggingface.co/spaces/PaddlePaddle/ERNIE-Layout)
对于多语言的使用情况,LayoutLM 有一些多语言的变种,比如 [LayoutXLM](https://huggingface.co/docs/transformers/model_doc/layoutxlm) 和 [LiLT](https://huggingface.co/docs/transformers/main/en/model_doc/lilt),这张来自 LayoutLM 论文的图展示了 LayoutLM 对一些不同文档的分析:

虽然数据科学家发现文档布局分析和提取是企业的关键使用场景,但由于大多数企业数据在内容和结构上的多样性,现有的通用商业解决方案通常无法处理。因此,数据科学团队通常可以微调自己的模型来超越现有的商业工具。
### 5. 表格检测、内容提取和结构识别
文档通常包含表格,而大多数 OCR 工具在表格数据上的工作效果并不十分理想,无法做到开箱即用,这就需要表格的检测,内容提取和结构识别工作。
检测的任务是识别表格的位置,提取则是对该信息进行结构化表示,结构识别是识别构成表格的各个部分的任务,如行、列和单元。更进一步表格功能分析 (Functional Analysis) 是识别表的键 (key) 和值 (value) 的任务,下图 [Table transformer](https://github.com/microsoft/table-transformer) 的图说明了各个子任务之间的区别。

表格检测和结构识别的方法与文档布局分析类似,使用对象检测模型,输出为一组边界框和相应的类。最新的方法,如 Table Transformer ,可以用同一个模型实现表的检测和表的结构识别。
[Table Transformer](https://huggingface.co/docs/transformers/main/en/model_doc/table-transformer) 是一个类似 [DETR](https://huggingface.co/docs/transformers/model_doc/detr) 的对象检测模型,在 PubTables-1M (由一百万张表组成的数据集) 上进行训练。表的检测和识别的评估通常采用平均精度 (AP) 指标。据报告,在 [PubTables-1M](https://arxiv.org/abs/2110.00061) 数据集上, Table Transformer 的性能在表检测方面的 AP 为 0.966,在表结构识别 + 功能分析方面的 AP 为 0.912。
虽然表格检测和提取有了一个令人兴奋的方法,但在你的数据上,结果可能是不同的,根据我们的经验,不同表格的质量和格式差别很大,这会影响模型的表现,所以在一些自定义的数据上进行额外的微调将大大改善性能。
### 6. 文档回答 (DocVQA)
文档上的问题回答 ( Question Answering) 已经极大地改变了人们与人工智能的交互方式,最近的进展使得要求模型回答关于图像的问题成为可能 —— 这被称为文档视觉回答,或简称 [DocVQA dataset](https://rrc.cvc.uab.es/?ch=17) 。
在得到一个问题后,模型会分析图像,并回答一个答案,下图是 DocVQA 数据集 的一个例子:
* 用户问道:"提到写的邮政编码吗?"
* 模型回答说:" 是的。

在过去,建立一个 DocVQA 系统往往需要多个模型一起工作,比如用单独的模型来分析文档布局、执行 OCR 、提取实体,然后再使用一个模型回答问题。而最新的 DocVQA 模型能够以端到端的方式进行问题回答,只需要一个 (多模态) 模型。
DocVQA 通常使用平均归一化列文斯坦相似度 ( ANLS ) 指标进行评估,关于这个指标的更多细节,我们可以参考 [这个指南](https://rrc.cvc.uab.es/?ch=11&com=tasks)。
在 DocVQA 基准上,目前最先进的是 [LayoutLMv3](https://huggingface.co/docs/transformers/model_doc/layoutlmv3),这个模型由 OCR + 多模态 Transformer 组成,它的 ANLS 得分达到了 83.37;
而使用单一的编码器 - 解码器 Transformer 以端到端的方式解决任务的 [Donut](https://huggingface.co/docs/transformers/model_doc/donut) 模型没有提供最先进的准确性,只是展示了使用类似 T5 的生成模型的端到端方法的巨大潜力;
Impira 开发了一个令人兴奋的 [space](https://huggingface.co/spaces/impira/docquery),说明了 DocVQA 的 LayoutLM 和 Donut。
虽然视觉回答是是可信的,但若要成功地使用它,有许多注意事项,需要团队拥有准确的训练数据、评估指标和后处理过程。
还要注意 DocVQA 的正常工作也可能出问题:在某些情况下,回答可能是不可预测的,模型可能会出现 "幻觉",给出一个不在文档中出现的答案,以及视觉回答模型可以继承数据中的偏见,从而引发道德问题,所以要建立一个成功的 DocVQA 解决方案,确保正确的模型设置和后处理十分必要。
## Document AI 中的许可 (License) 问题
工业界和学术界为推进 Document AI 做出了巨大贡献,有各种各样的模型和数据集可供数据科学家使用。然而,对于建立一个企业解决方案来说,许可证可能是一个不小的问题,一些著名的模型会有限制性许可,它们无法商用,比如最值得警惕的:微软的 [LayoutLMv2](https://huggingface.co/docs/transformers/main/en/model_doc/layoutlmv2) 和 [LayoutLMv3](https://huggingface.co/docs/transformers/main/en/model_doc/layoutlmv3) 的 checkpoints。
当你开始一个项目时,应该仔细评估潜在的模型的许可证情况,在一开始就知道你想使用哪些模型,因为这会影响数据的收集和注释,本文末尾有一个流行模型的表格,其中有它们的许可授权相关信息。
## Document AI 中的数据准备问题
Document AI 的数据准备很关键,并具有一定挑战性,需要有正确注释的数据,以下是我们在数据准备方面学到的一些经验和方法:
1. 机器学习取决于你的数据规模和质量,如果你文档里面的图像质量很差,你不能指望人工智能能够神奇地阅读这些文档,同样地,如果你的训练数据很小,且有很多不同数据类型,模型的表现可能会很差,Document AI 就像机器学习中的其他问题一样,数据越大,性能越好。
2. 在方法上要灵活,你可能需要测试几种不同的方法来找到最佳解决方案。一个很好的例子是 OCR ,你可以使用像 Tesseract 这样的开源产品、像 Cloud Vision API 这样的商业解决方案,或者像 [Donut](https://huggingface.co/docs/transformers/model_doc/donut) 这样的开源多模态模型内部的 OCR 能力。
3. 从小处开始,仔细评估你的表现。根据我们的经验,你可以通过几百个文档获得良好的结果,所以先注释少量数据 (annotating data) ,并明智地选择模型工具。缩小了整体方法,就可以开始扩大数据的规模,最大限度地提高你的预测准确性。在注释时,记住一些任务,如布局识别和文档提取,需要识别文档中的特定区域,要确保注释工具支持它的边界框 (bounding boxes) 。
## Document AI 中的模型构建
构建模型的灵活性为数据科学家带来了许多选择,我们强烈建议团队从预训练的开源模型开始,根据你的具体文档微调模型,这通常是获得好模型的最快途径。对于考虑建立自己的预训练模型的团队,请注意这可能涉及到数百万的文档,并且很容易耗费几周的时间来训练一个模型。建立一个预训练的模型需要很大的努力,不建议大多数数据科学团队使用。
如果选择从微调一个模型开始,首先要问自己这些问题:
1. 你想让模型来处理 OCR 吗?例如,Donut 不需要对文档进行 OCR 处理,直接在全分辨率的图像上工作,所以在建模之前不需要 OCR 。当然,根据你的问题设置,单独获取 OCR 可能更简单。
2. 你应该使用更高分辨率的图像吗?当使用 [LayoutLMv2](https://huggingface.co/docs/transformers/main/en/model_doc/layoutlmv2) 的图像时,它将图像缩减为 224 乘 224,而 [Donut]() 则使用完整的高分辨率图像。然而,使用完整的高分辨率图像会极大地增加训练和推理所需的内存。
3. 你是如何评估这个模型的?注意错位的边界框,确保 OCR 引擎提供的边界框与模型处理器相一致。其次,让你的项目要求指导你的评估指标。例如,在一些任务中,如标记分类或问题回答,100% 的匹配可能不是最好的衡量标准,像部分匹配这样的指标可以让更多的潜在标记得到考虑,比如 "Acme" 和 "internal Acme" 可以作为匹配。最后,在评估过程中要考虑道德问题,因为这些模型可能是在使用有偏见的数据,或提供不稳定的结果,可能对某些人群有偏见。
### 接下来的步骤
你是否看到了 Document AI 的无限可能性?我们每天都在利用最先进的视觉和语言模型释放有价值的数据帮助企业,我们在这篇文章中包含了各种 demo 的链接,所以可以把它们作为一个起点。这篇文章的最后一节包含了开始编写你自己的模型的资源,例如视觉回答模型,一旦你准备好开始建立你的解决方案,[Hugging Face 模型中心](https://huggingface.co/models) 是一个不错的起点,它托管了大量的 Document AI 模型。
如果你想加速 Document AI 工作,Hugging Face 可以帮助你:通过我们的 [企业加速计划](https://huggingface.co/support),我们与企业合作,为人工智能使用场景提供指导,对于 Document AI ,我们会帮助您建立一个预训练模型,提高微调任务的准确性,或为你的第一个 Document AI 案例提供总体指导。我们还可以提供计算积分,以便您大规模地使用我们的训练 (AutoTrain) 或推理 (Spaces 或 Inference Endpoints) 产品。
### 资源
许多 Document AI 模型的笔记本和教程可以在以下网站找到。
- Niels' [Transformers-Tutorials](https://github.com/NielsRogge/Transformers-Tutorials)
- Philipp's [Document AI with Hugging Face Transformers](https://github.com/philschmid/document-ai-transformers)
我们还整理了 Document AI 最流行的开源模型以及其指标:
| model | paper | license | checkpoints |
| --- | --- | --- | --- |
| [Donut](https://huggingface.co/docs/transformers/main/en/model_doc/donut#overview) | [arxiv](https://arxiv.org/abs/2111.15664) | [MIT](https://github.com/clovaai/donut#license) | [huggingface](https://huggingface.co/models?other=donut) |
| [LayoutLM](https://huggingface.co/docs/transformers/model_doc/layoutlm) | [arxiv](https://arxiv.org/abs/1912.13318) | [MIT](https://github.com/microsoft/unilm/blob/master/LICENSE) | [huggingface](https://huggingface.co/models?other=layoutlm) |
| [LayoutXLM](https://huggingface.co/docs/transformers/model_doc/layoutxlm) | [arxiv](https://arxiv.org/abs/2104.08836) | [CC BY-NC-SA 4.0](https://github.com/microsoft/unilm/tree/master/layoutxlm) | [huggingface](https://huggingface.co/microsoft/layoutxlm-base) |
| [LayoutLMv2](https://huggingface.co/docs/transformers/main/en/model_doc/layoutlmv2) | [arxiv](https://arxiv.org/abs/2012.14740) | [CC BY-NC-SA 4.0](https://github.com/microsoft/unilm/tree/master/layoutlmv2) | [huggingface](https://huggingface.co/models?other=layoutlmv2) |
| [LayoutLMv3](https://huggingface.co/docs/transformers/main/en/model_doc/layoutlmv3) | [arxiv](https://arxiv.org/abs/2204.08387) | [CC BY-NC-SA 4.0](https://github.com/microsoft/unilm/tree/master/layoutlmv3) | [huggingface](https://huggingface.co/models?other=layoutlmv3) |
| [DiT](https://huggingface.co/docs/transformers/model_doc/dit) | [arxiv](https://arxiv.org/abs/2203.02378) | [CC BY-NC-SA 4.0](https://github.com/microsoft/unilm/tree/master/dit) | [huggingface](https://huggingface.co/models?other=dit) |
| [TrOCR](https://huggingface.co/docs/transformers/main/en/model_doc/trocr) | [arxiv](https://arxiv.org/abs/2109.10282) | [MIT](https://github.com/microsoft/unilm/blob/master/LICENSE) | [huggingface](https://huggingface.co/models?search=trocr) |
| [Table Transformer](https://huggingface.co/docs/transformers/main/en/model_doc/table-transformer) | [arxiv](https://arxiv.org/abs/2110.00061) | [MIT](https://github.com/microsoft/table-transformer/blob/main/LICENSE) | [huggingface](https://huggingface.co/models?other=table-transformer) |
| [LiLT](https://huggingface.co/docs/transformers/main/en/model_doc/lilt) | [arxiv](https://arxiv.org/abs/2202.13669) | [MIT](https://github.com/jpWang/LiLT/blob/main/LICENSE) | [huggingface](https://huggingface.co/models?other=lilt) |
以及基准数据集:
| task | typical metrics | benchmark datasets |
| --- | --- | --- |
| Optical Character Recognition | Character Error Rate (CER) | |
| Document Image Classification | Accuracy, F1 | [RVL-CDIP](https://huggingface.co/datasets/rvl_cdip) |
| Document layout analysis | mAP (mean average precision) | [PubLayNet](https://github.com/ibm-aur-nlp/PubLayNet), [XFUND](https://github.com/doc-analysis/XFUND)(Forms) |
| Document parsing | Accuracy, F1 | [FUNSD](https://guillaumejaume.github.io/FUNSD/), [SROIE](https://huggingface.co/datasets/darentang/sroie/), [CORD](https://github.com/clovaai/cord) |
| Table Detection and Extraction | mAP (mean average precision) | [PubTables-1M](https://arxiv.org/abs/2110.00061) |
| Document visual question answering | Average Normalized Levenshtein Similarity (ANLS) | [DocVQA](https://rrc.cvc.uab.es/?ch=17) |
| 7 |
0 | hf_public_repos/blog | hf_public_repos/blog/zh/stable_diffusion.md | ---
title: 使用Diffusers来实现Stable Diffusion 🧨
thumbnail: /blog/assets/98_stable_diffusion/thumbnail.png
authors:
- user: valhalla
- user: pcuenq
- user: natolambert
- user: patrickvonplaten
translators:
- user: tunglinwu
---
# 使用Diffusers来实现Stable Diffusion 🧨
<a target="_blank" href="https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_diffusion.ipynb">
<img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/>
</a>
**实现Stable Diffusion的效果** 🎨 *...借由 🧨 Diffusers*
Stable Diffusion 是一种文本到图像的潜在扩散模型,由 [CompVis](https://github.com/CompVis)、[Stability AI](https://stability.ai/) 和 [LAION](https://laion.ai/) 的研究人员和工程师创建。它是在 [LAION-5B](https://laion.ai/blog/laion-5b/) 数据库的一个子集上使用 512x512 图像训练的。*LAION-5B* 是目前存在的最大、可自由访问的多模态数据集。
在这篇文章中,我们将展示如何使用 [🧨 Diffusers 库](https://github.com/huggingface/diffusers)中的 Stable Diffusion 模型,解释模型的工作原理,并深入探讨 `diffusers` 如何让用户定制图像生成流水线。
**注意**: 强烈建议您对扩散模型有基本的了解。如果您对扩散模型完全陌生,我们建议阅读以下博客文章之一:
- [The Annotated Diffusion Model](https://huggingface.co/blog/annotated-diffusion)
- [Getting started with 🧨 Diffusers](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/diffusers_intro.ipynb)
现在,让我们开始生成一些图像吧 🎨。
## 运行 Stable Diffusion
### 许可证
在使用模型之前,您需要接受该模型的[许可证](https://huggingface.co/spaces/CompVis/stable-diffusion-license),以便下载和使用权重。**注意:现在不再需要通过 UI 显式接受许可证**。
该许可证旨在减轻如此强大的机器学习系统可能带来的潜在有害影响。我们请求用户**完整且仔细地阅读许可证**。以下是摘要:
1. 您不能故意使用模型生成或分享非法或有害的输出或内容。
2. 我们对您生成的输出不主张任何权利,您可以自由使用这些输出,并对其使用负责,且不得违反许可证中规定的条款。
3. 您可以重新分发权重,并将模型用于商业用途和/或作为服务使用。如果这样做,请注意,您必须包括与许可证中相同的使用限制,并向所有用户提供 CreativeML OpenRAIL-M 的副本。
### 使用方法
首先,您应该安装 `diffusers==0.10.2` 以运行以下代码片段:
```bash
pip install diffusers==0.10.2 transformers scipy ftfy accelerate
```
在这篇文章中,我们将使用模型版本 [`v1-4`](https://huggingface.co/CompVis/stable-diffusion-v1-4),但您也可以使用其他版本的模型,如 1.5、2 和 2.1,只需做最小的代码修改。
Stable Diffusion 模型可以使用 [`StableDiffusionPipeline`](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion.py) 流水线在推理中运行,仅需几行代码即可。流水线设置了从文本生成图像所需的一切,只需一个简单的 `from_pretrained` 函数调用。
```python
from diffusers import StableDiffusionPipeline
pipe = StableDiffusionPipeline.from_pretrained("CompVis/stable-diffusion-v1-4")
```
如果有 GPU 可用,咱们把它移过去吧!
```python
pipe.to("cuda")
```
**注意**: 如果您受限于 GPU 内存且 GPU RAM 少于 10GB,请确保加载 `StableDiffusionPipeline` 时使用 float16 精度,而不是上述的默认 float32 精度。
您可以通过加载 `fp16` 分支的权重并告诉 `diffusers` 权重为 float16 精度来实现:
```python
import torch
from diffusers import StableDiffusionPipeline
pipe = StableDiffusionPipeline.from_pretrained("CompVis/stable-diffusion-v1-4", revision="fp16", torch_dtype=torch.float16)
```
要运行流水线,只需定义提示词并调用 `pipe`。
```python
prompt = "a photograph of an astronaut riding a horse"
image = pipe(prompt).images[0]
# 您可以用以下代码保存图像
# image.save(f"astronaut_rides_horse.png")
```
结果如下所示

每次运行上面的代码都会生成不同的图像。
如果您某个时候得到了黑色图像,可能是因为模型内置的内容过滤器可能检测到不适合的内容。如果您认为不该是这样,可以尝试调整提示词或使用不同的种子。事实上,模型预测结果中包含是否检测到不适合内容的信息。让我们看看它们是什么样子:
```python
result = pipe(prompt)
print(result)
```
```json
{
'images': [<PIL.Image.Image image mode=RGB size=512x512>],
'nsfw_content_detected': [False]
}
```
如果您想要确定性的输出,可以设定一个随机种子并将生成器传递给流水线。每次使用相同种子的生成器时,您将得到相同的图像输出。
```python
import torch
generator = torch.Generator("cuda").manual_seed(1024)
image = pipe(prompt, guidance_scale=7.5, generator=generator).images[0]
# 您可以用以下代码保存图像
# image.save(f"astronaut_rides_horse.png")
```
结果如下所示

您可以使用 `num_inference_steps` 参数更改推理步骤的数量。
通常,步骤越多,结果越好,但是步骤越多,生成所需的时间也越长。Stable Diffusion 在相对较少的步骤下表现得很好,所以我们建议使用默认的 `50` 步推理步骤。如果您想要更快的结果,可以使用更少的步骤。如果您想要可能更高质量的结果,可以使用更大的步骤数。
让我们尝试以更少的去噪步骤运行流水线。
```python
import torch
generator = torch.Generator("cuda").manual_seed(1024)
image = pipe(prompt, guidance_scale=7.5, num_inference_steps=15, generator=generator).images[0]
# 您可以用以下代码保存图像
# image.save(f"astronaut_rides_horse.png")
```

注意图像的结构虽然相同,但宇航员的宇航服和马的整体形态出现了问题。这表明,仅使用15次去噪步骤显著降低了生成结果的质量。正如之前提到的,通常50次去噪步骤足以生成高质量图像。
除了`num_inference_steps`参数之外,我们在之前的所有示例中还使用了另一个名为`guidance_scale`的函数参数。`guidance_scale`是一种增强生成结果与条件信号(在本例中为文本)的符合度以及整体样本质量的方法。它也被称为[无分类器指导](https://arxiv.org/abs/2207.12598),简单来说,它强制生成结果更好地匹配提示词,可能会以图像质量或多样性为代价。对于稳定扩散,`7`到`8.5`之间的值通常是较好的选择。默认情况下,管道使用`guidance_scale`为7.5。
如果使用非常大的值,图像可能看起来很好,但多样性会减少。你可以在本文的[此部分](#writing-your-own-inference-pipeline)了解此参数的技术细节。
接下来,我们看看如何一次生成同一提示的多张图像。首先,我们将创建一个`image_grid`函数,以帮助我们在网格中将它们美观地可视化。
```python
from PIL import Image
def image_grid(imgs, rows, cols):
assert len(imgs) == rows*cols
w, h = imgs[0].size
grid = Image.new('RGB', size=(cols*w, rows*h))
grid_w, grid_h = grid.size
for i, img in enumerate(imgs):
grid.paste(img, box=(i%cols*w, i//cols*h))
return grid
```
我们可以通过使用一个包含重复多次的相同提示词的列表来生成多张图像。我们将这个列表传递给管道,而不是之前使用的字符串。
```python
num_images = 3
prompt = ["a photograph of an astronaut riding a horse"] * num_images
images = pipe(prompt).images
grid = image_grid(images, rows=1, cols=3)
# 您可以用以下代码保存图像
# grid.save(f"astronaut_rides_horse.png")
```

默认情况下,Stable Diffusion生成的图像为`512 × 512`像素。通过使用`height`和`width`参数,非常容易覆盖默认值以创建纵向或横向比例的矩形图像。
在选择图像尺寸时,我们建议以下几点:
- 确保`height`和`width`都是8的倍数。
- 尺寸低于512可能会导致图像质量降低。
- 在两个方向上超过512会导致图像区域重复(全局一致性丧失)。
- 创建非正方形图像的最佳方法是一个维度使用`512`,另一个维度使用大于`512`的值。
让我们运行一个示例:
```python
prompt = "a photograph of an astronaut riding a horse"
image = pipe(prompt, height=512, width=768).images[0]
# 您可以用以下代码保存图像
# image.save(f"astronaut_rides_horse.png")
```

## Stable Diffusion 是如何工作的?
在看到Stable Diffusion可以生成的高质量图像后,让我们尝试更好地理解模型的工作原理。
Stable Diffusion基于一种特殊类型的扩散模型,称为**潜在扩散(Latent Diffusion)**,该模型在[基于潜在扩散模型的高分辨率图像合成](https://arxiv.org/abs/2112.10752)中提出。
一般来说,扩散模型是通过一步步去噪高斯噪声,从而得到目标样本(例如*图像*)的机器学习系统。有关它们如何工作的更详细概述,请查看[此Colab](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/diffusers_intro.ipynb)。
扩散模型已被证明在生成图像数据方面达到了最先进的水平。但扩散模型的一个缺点是逆向去噪过程非常慢,因为它是重复的、序列化的。此外,这些模型消耗大量内存,因为它们在像素空间中操作,而在生成高分辨率图像时,像素空间变得非常庞大。因此,训练这些模型和进行推理都非常具有挑战性。
潜在扩散通过在低维的*潜在*空间上应用扩散过程来减少内存和计算复杂度,而不是使用实际的像素空间。这是标准扩散模型与潜在扩散模型之间的关键区别:**在潜在扩散中,模型被训练生成图像的潜在(压缩)表示。**
潜在扩散中有三个主要组件:
1. 一个自编码器(VAE)。
2. 一个[U-Net](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/diffusers_intro.ipynb#scrollTo=wW8o1Wp0zRkq)。
3. 一个文本编码器,例如[CLIP的文本编码器](https://huggingface.co/docs/transformers/model_doc/clip#transformers.CLIPTextModel)。
**1. 自编码器(VAE)**
VAE模型有两个部分,一个编码器和一个解码器。编码器用于将图像转换为低维的潜在表示,这将作为*U-Net*模型的输入。
解码器则将潜在表示转化为图像。
在潜在扩散*训练*期间,编码器用于获取图像的潜在表示(_潜在变量_),用于正向扩散过程,在每一步中加入更多的噪声。在*推理*期间,通过逆向扩散过程生成的去噪潜在变量由VAE解码器转换回图像。正如我们将看到的,在推理期间我们**只需要VAE解码器**。
**2. U-Net**
U-Net的结构包括一个编码器部分和一个解码器部分,两者都由ResNet块组成。
编码器将图像表示压缩为较低分辨率的图像表示,而解码器将较低分辨率的图像表示解码回原始的较高分辨率图像表示,假定其噪声较少。
更具体地说,U-Net的输出预测了可以用来计算预测的去噪图像表示的噪声残差。
为了防止U-Net在下采样时丢失重要信息,通常会在编码器的下采样ResNet块和解码器的上采样ResNet块之间添加捷径连接。
此外,Stable Diffusion的U-Net能够通过交叉注意力层将其输出与文本嵌入进行条件化。交叉注意力层通常在编码器和解码器部分的ResNet块之间添加。
**3. 文本编码器**
文本编码器负责将输入提示,例如"An astronaut riding a horse"转换为U-Net可以理解的嵌入空间。它通常是一个简单的*基于变换器(transformer-based)的*编码器,用于将输入标记序列映射为一系列潜在的文本嵌入。
受[Imagen](https://imagen.research.google/)启发,Stable Diffusion在训练期间**不会**训练文本编码器,而是直接使用已经训练好的CLIP文本编码器,[CLIPTextModel](https://huggingface.co/docs/transformers/model_doc/clip#transformers.CLIPTextModel)。
**为什么潜在扩散快且高效?**
由于潜在扩散在低维空间中操作,相比于像素空间的扩散模型,它极大地减少了内存和计算需求。例如,Stable Diffusion中使用的自编码器的缩减因子为8。这意味着形状为`(3, 512, 512)`的图像在潜在空间中变为`(4, 64, 64)`,这意味着空间压缩比为`8 × 8 = 64`。
这就是为什么即使在16GB的Colab GPU上,也能如此快速地生成`512 × 512`的图像的原因!
**推理中的稳定扩散**
将所有部分结合起来,我们现在来仔细看看模型在推理中的工作原理,并通过展示逻辑流程来进行说明
<p align="center">
<img src="https://raw.githubusercontent.com/patrickvonplaten/scientific_images/master/stable_diffusion.png" alt="sd-pipeline" width="500"/>
</p>
稳定扩散模型同时接受一个潜在种子和文本提示作为输入。然后使用潜在种子生成大小为\\( 64 \times 64 \\)的随机潜在图像表示,而文本提示则通过CLIP的文本编码器转换为大小为\\( 77 \times 768 \\)的文本嵌入。
接下来,U-Net模型在文本嵌入的条件下,逐步对随机潜在图像表示进行*去噪*。U-Net的输出——即噪声残差——通过调度算法计算出去噪后的潜在图像表示。可以使用多种不同的调度算法来进行此计算,每种算法各有优缺点。对于稳定扩散,我们推荐使用以下几种调度器之一:
- [PNDM调度器](https://github.com/huggingface/diffusers/blob/main/src/diffusers/schedulers/scheduling_pndm.py)(默认使用)
- [DDIM调度器](https://github.com/huggingface/diffusers/blob/main/src/diffusers/schedulers/scheduling_ddim.py)
- [K-LMS调度器](https://github.com/huggingface/diffusers/blob/main/src/diffusers/schedulers/scheduling_lms_discrete.py)
关于调度算法如何工作的理论超出了本笔记本的范围,但简而言之,应该记住它们是根据前一个噪声表示和预测的噪声残差来计算预测的去噪图像表示的。有关更多信息,我们建议参考[Elucidating the Design Space of Diffusion-Based Generative Models](https://arxiv.org/abs/2206.00364)。
*去噪*过程重复*约*50次,以逐步获得更好的潜在图像表示。
一旦完成,潜在图像表示将由变分自动编码器的解码器部分进行解码。
在对潜在扩散和稳定扩散进行简要介绍后,我们来看如何高级使用🤗 Hugging Face `diffusers`库!
## 编写自己的推理管道
最后,我们展示如何使用`diffusers`创建自定义的扩散管道。
编写自定义推理管道是`diffusers`库的高级用法,可以用于替换某些组件,例如上面提到的VAE或调度器。
例如,我们将展示如何使用不同的调度器,即[Katherine Crowson's](https://github.com/crowsonkb) K-LMS调度器,该调度器已在[此PR](https://github.com/huggingface/diffusers/pull/185)中添加。
[预训练模型](https://huggingface.co/CompVis/stable-diffusion-v1-4/tree/main)包含设置完整扩散管道所需的所有组件。它们存储在以下文件夹中:
- `text_encoder`: 稳定扩散使用CLIP,但其他扩散模型可能使用其他编码器,如`BERT`。
- `tokenizer`: 必须与`text_encoder`模型所使用的分词器相匹配。
- `scheduler`: 在训练期间用于逐渐向图像添加噪声的调度算法。
- `unet`: 用于生成输入的潜在表示的模型。
- `vae`: 我们将用来将潜在表示解码为真实图像的自动编码器模块。
我们可以通过引用保存它们的文件夹来加载组件,使用`from_pretrained`中的`subfolder`参数。
```python
from transformers import CLIPTextModel, CLIPTokenizer
from diffusers import AutoencoderKL, UNet2DConditionModel, PNDMScheduler
# 1. 加载自动编码器模型,将用来将潜在表示解码为图像空间。
vae = AutoencoderKL.from_pretrained("CompVis/stable-diffusion-v1-4", subfolder="vae")
# 2. 加载分词器和文本编码器,以对文本进行分词和编码。
tokenizer = CLIPTokenizer.from_pretrained("openai/clip-vit-large-patch14")
text_encoder = CLIPTextModel.from_pretrained("openai/clip-vit-large-patch14")
# 3. 用于生成潜在变量的UNet模型。
unet = UNet2DConditionModel.from_pretrained("CompVis/stable-diffusion-v1-4", subfolder="unet")
```
我们加载带有适配参数的[K-LMS调度器](https://github.com/huggingface/diffusers/blob/71ba8aec55b52a7ba5a1ff1db1265ffdd3c65ea2/src/diffusers/schedulers/scheduling_lms_discrete.py#L26)而不是加载预定义的调度器。
```python
from diffusers import LMSDiscreteScheduler
scheduler = LMSDiscreteScheduler(beta_start=0.00085, beta_end=0.012, beta_schedule="scaled_linear", num_train_timesteps=1000)
```
接下来,将模型移动到GPU上。
```python
torch_device = "cuda"
vae.to(torch_device)
text_encoder.to(torch_device)
unet.to(torch_device)
```
现在我们定义生成图像时要使用的参数。
请注意,`guidance_scale`与[Imagen论文](https://arxiv.org/pdf/2205.11487.pdf)中的方程(2)中的指导权重`w`类似。`guidance_scale == 1`表示不进行分类器自由指导。这里我们将其设置为7.5,就像之前一样。
与之前的例子相比,我们将`num_inference_steps`设置为100,以获得更清晰的图像。
```python
prompt = ["a photograph of an astronaut riding a horse"]
height = 512 # 稳定扩散的默认高度
width = 512 # 稳定扩散的默认宽度
num_inference_steps = 100 # 去噪步骤数
guidance_scale = 7.5 # 分类器自由指导的比例
generator = torch.manual_seed(0) # 用于创建初始潜在噪声的种子生成器
batch_size = len(prompt)
```
首先,我们为传递的提示获取`text_embeddings`。这些嵌入将用于条件UNet模型,并引导图像生成接近输入提示。
```python
text_input = tokenizer(prompt, padding="max_length", max_length=tokenizer.model_max_length, truncation=True, return_tensors="pt")
text_embeddings = text_encoder(text_input.input_ids.to(torch_device))[0]
```
我们还将为分类器自由指导获取无条件的文本嵌入,即填充标记(空文本)的嵌入。它们需要具有与条件`text_embeddings`相同的形状(`batch_size`和`seq_length`)。
```python
max_length = text_input.input_ids.shape[-1]
uncond_input = tokenizer(
[""] * batch_size, padding="max_length", max_length=max_length, return_tensors="pt"
)
uncond_embeddings = text_encoder(uncond_input.input_ids.to(torch_device))[0]
```
对于分类器自由指导,我们需要执行两次前向传递:一次使用条件输入(`text_embeddings`),另一次使用无条件嵌入(`uncond_embeddings`)。实际上,我们可以将两者连接成一个批次,以避免进行两次前向传递。
```python
text_embeddings = torch.cat([uncond_embeddings, text_embeddings])
```
接下来,生成初始随机噪声。
```python
latents = torch.randn(
(batch_size, unet.in_channels, height // 8, width // 8),
generator=generator,
)
latents = latents.to(torch_device)
```
如果此时检查`latents`,我们会发现它们的形状为`torch.Size([1, 4, 64, 64])`,比我们要生成的图像小得多。稍后模型将把这种潜在表示(纯噪声)转换为`512 × 512`图像。
接下来,我们使用所选的`num_inference_steps`初始化调度器。
这将计算去噪过程中使用的`sigma`和确切时间步值。
```python
scheduler.set_timesteps(num_inference_steps)
```
K-LMS调度器需要将`latents`乘以其`sigma`值。让我们在此进行操作:
```python
latents = latents * scheduler.init_noise_sigma
```
我们已准备好编写去噪循环。
```python
from tqdm.auto import tqdm
scheduler.set_timesteps(num_inference_steps)
for t in tqdm(scheduler.timesteps):
# 如果我们正在进行分类器自由指导,则扩展潜在变量,以避免进行两次前向传递。
latent_model_input = torch.cat([latents] * 2)
latent_model_input = scheduler.scale_model_input(latent_model_input, timestep=t)
# 预测噪声残差
with torch.no_grad():
noise_pred = unet(latent_model_input, t, encoder_hidden_states=text_embeddings).sample
# 进行分类器自由指导
noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
# 计算去噪图像的隐空间表示
latents = scheduler.step(noise_pred, t, latents).prev_sample
```
代码执行后,潜在变量`latents`应该不再只是噪声,而是去噪后潜在图像的表示。
在去噪循环中,我们需要从潜在空间解码图像。
```python
# 将潜在变量缩放回去。
latents = 1 / 0.18215 * latents
with torch.no_grad():
image = vae.decode(latents).sample
```
最后,将解码的图像转换为像素值,并显示它们。
```python
image = (image / 2 + 0.5).clamp(0, 1)
image = image.detach().cpu().permute(0, 2, 3, 1).numpy()
images = (image * 255).round().astype("uint8")
pil_images = [Image.fromarray(image) for image in images]
pil_images[0]
```

我们已经从使用 🤗 Hugging Face Diffusers 的 Stable Diffusion 基础应用,逐步深入到了更高级的用法,并尝试介绍现代扩散系统的各个组成部分。如果你对这个主题感兴趣并想了解更多内容,我们推荐以下资源:
- 我们的 [Colab notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_diffusion.ipynb) 提供了有关 Stable Diffusion 的实践练习。
- [Diffusers 入门指南](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/diffusers_intro.ipynb) 的 notebook,概述了扩散系统的基本知识。
- [Annotated Diffusion Model](https://huggingface.co/blog/annotated-diffusion) 博客文章。
- 我们的 [GitHub 代码](https://github.com/huggingface/diffusers),如果你觉得 `diffusers` 对你有帮助,我们会很高兴收到你的 ⭐ !
### Citation:
```
@article{patil2022stable,
author = {Patil, Suraj and Cuenca, Pedro and Lambert, Nathan and von Platen, Patrick},
title = {Stable Diffusion with 🧨 Diffusers},
journal = {Hugging Face Blog},
year = {2022},
note = {[https://huggingface.co/blog/rlhf](https://huggingface.co/blog/stable_diffusion)},
}
```
| 8 |
0 | hf_public_repos/blog | hf_public_repos/blog/zh/open-llm-leaderboard-rlhf.md | ---
title: "基础大模型能像人类一样标注数据吗?"
thumbnail: /blog/assets/llm-leaderboard/leaderboard-thumbnail.png
authors:
- user: nazneen
- user: natolambert
- user: sheonhan
- user: wangjean
guest: true
- user: OsvaldN97
guest: true
- user: edbeeching
- user: lewtun
- user: slippylolo
- user: thomwolf
translators:
- user: hugging-hoi2022
- user: zhongdongy
proofreader: true
---
# 基础大模型能像人类一样标注数据吗?
自从 ChatGPT 出现以来,我们见证了大语言模型 (LLM) 领域前所未有的发展,尤其是对话类模型,经过微调以后可以根据给出的提示语 (prompt) 来完成相关要求和命令。然而,直到如今我们也无法对比这些大模型的性能,因为缺乏一个统一的基准,难以严谨地去测试它们各自的性能。评测我们发给它们的指令以及对话模型本身,从本质上来讲就很困难,毕竟用户的评价标准都是围绕对回答的质量的主观感受; 而现有的自然语言处理任务的性能评价标准,却大多局限于特定指标和某些定量标准。
在这一领域,通常当一个新的大语言模型发布时,都会这么宣传: 我们的模型比在百分之多少的情况下优于 ChatGPT。这句话的潜在意思是,模型使用某些基于 GPT-4 的评价标准,在百分之多少的情况下优于 ChatGPT。这些分数实际想表达的是一种不同评价标准的代替方案: 由人类打标者提供的分数。利用人类反馈的强化学习 (RLHF) 大量提供了对比两个模型的接口和数据。这些从 RLHF 而来的数据被用来训练一个奖励模型,用以评判哪个回答是更好的,但为模型输出结果进行打分和排名的这一思想已经演变成了一种更通用的模型评测工具。
这里我们展示一些示例,分别来自我们的盲测数据中的 `instruct` 和 `code-instruct` 两个子集合。

从迭代速度来讲,使用一个语言模型去评测模型输出已经十分高效了,但这里遗漏了一个大问题: **有没有调研这个下游的快捷工具是否针对原有的评测形式进行了校准对齐**。在本文中,我们将会详细了解: 通过扩展 Open LLM Leaderboard 评测体系,哪些时候你需要相信或不相信你从你选择的大语言模型中得到的数据标签。
现如今,各种排行榜已经开始涌现,比如 [LMSYS](https://leaderboard.lmsys.org/) 以及 [nomic / GPT4All](https://gpt4all.io/index.html) 等,用以从各种角度对比模型。但我们仍需要一个更完整的资源,用以对比模型性能。有些人会使用现有的 NLP 测试基准,看一看提问回答的能力; 还有些人会用一些众包的、开放式问答的排行榜。为了为大家提供一个更全面通用的评测方法,我们扩展了 [Hugging Face Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?tab=evaluation),囊括了各个自动化的学术评测基准、专业人员的打标,以及 GPT-4 相关的评测方法。
---
## 目录
- [评估开源模型的偏好](#评估开源模型的偏好)
- [相关工作](#相关工作)
- [GPT-4 评测样例](#GPT-4 评测样例)
- [更多实验](#更多实验)
- [要点和讨论](#要点和讨论)
- [资源和引用](#资源和引用)
## 评估开源模型的偏好
在训练阶段的任何时间点,人工组织数据的需求从内在来看都是成本很高的。迄今为止,在这一领域仅存在少量人工标注的偏好数据集可以用来训练大模型,例如 [Anthropic’s HHH data](https://huggingface.co/datasets/Anthropic/hh-rlhf)、[OpenAssistant’s dialogue rankings](https://huggingface.co/datasets/OpenAssistant/oasst1) 或是 OpenAI 的 [Learning to Summarize](https://huggingface.co/datasets/openai/summarize_from_feedback) / [WebGPT](https://huggingface.co/datasets/openai/webgpt_comparisons) 数据集。相同的偏好标签也可以用模型输出获取,用以构建两两模型间的 Elo 排序 ([Elo 排序](https://en.wikipedia.org/wiki/Elo_rating_system) 是常用于象棋或游戏中的一种通过两两对比构建全局排行榜的方法,排名越高越好)。当给到标注者的文本源是由我们关注的模型生成时,数据就变得很有趣了。
训练模型的过程会发生很多意想不到的趣事,所以我们需要对各个开源模型做一个更严格的对照实验,看看偏好收集过程如何转化为当今盛行的 GPT-4/ChatGPT 偏好评估,以及与它们的差异对比。
为了这一目的,我们组织了一个指令提示语的集合,以及对应的一系列由开源模型 ( [Koala 13b](https://huggingface.co/young-geng/koala)、[Vicuna 13b](https://huggingface.co/lmsys/vicuna-13b-delta-v1.1)、[OpenAssistant 12b](https://huggingface.co/OpenAssistant/oasst-sft-1-pythia-12b)、[Dolly 12b](https://huggingface.co/databricks/dolly-v2-12b)) 完成的补全。

我们从 [Self-Instruct](https://arxiv.org/abs/2212.10560) 评测集中收集了一系列高质量、由人编写的提示语,同时也从数据商那里收集了一些早期的讨论类对话数据,涵盖了生成、头脑风暴、问答、总结、常识、编程等各种任务类别。总共有 327 条覆盖这些任务类型的提示语,其中 25 条是编程相关的。
这里我们列出一些提示语相关的数据统计,包括其句子长度。
| | prompt | completions |
| --- | --- | --- |
| count | 327 | 327 |
| length (mean ± std. dev.) in tokens | 24 ± 38 | 69 ± 79 |
| min. length | 3 | 1 |
| 25% percentile length | 10 | 18 |
| 50% percentile length | 15 | 42 |
| 75% percentile length | 23 | 83 |
| max | 381 | 546 |
借助这些数据,我们开始使用 Scale AI 和 GPT-4 去评估模型质量。我们针对偏好模型使用 Antropic 的方法,并要求打分者去依照利克特 (Likert) 量表打 1 到 8 分。在这个范围内,1 分代表打分者相比第一个模型,对当前模型有强烈偏好; 4 分表示基本与第一个模型持平; 8 分则代表评价者的观点与 1 分完全相反。
### 人工 Elo 结果
我们与 Scale AI 合作,为一些开源的指令调教的模型基于我们的盲测集收集了高质量的人工标注。我们要求标注者以一种两两对比的形式,针对有用性和真实性对模型的回答打分。为此,我们为每个提示语生成了 $ n \choose 2 $ 个组合对,其中 $n$ 是我们要评测的模型的数量。下图就是一个为人工标注者提供的打分页面,其中包含了给标注者发出的任务指示 (相关工具由 Scale AI 提供)。
使用这一数据,我们依据两两模型间的胜率“自举地”估算出了 Elo 排序结果。如果读者对 Elo 的过程感兴趣,可以阅读 LMSYS 的这篇 [notebook](https://colab.research.google.com/drive/17L9uCiAivzWfzOxo2Tb9RMauT7vS6nVU?usp=sharing),我们盲测集上的 Elo 分数也在 [leaderboard]() 上有列出。
在本文中,我们会展示“自举”估算 Elo 的方法以及其中的错误估算。下表列出了依据我们盲测集和标注人员的排行榜:
****************不含平局的 Elo 排序 (由 1000 轮采样的对局自举计算而来)** **************
| Model | Elo ranking (median) | 5th and 95th percentiles |
| --- | --- | --- |
| Vicuna-13B | 1140 | 1061 ↔ 1219 |
| Koala-13B | 1073 | 999 ↔ 1147 |
| Oasst-12B | 986 | 913 ↔ 1061 |
| Dolly-12B | 802 | 730 ↔ 878 |
针对利克特量表,打分打到 4 或 5 分是否构成一场胜利也很有争议。所以我们也计算了一个当 4 或 5 分表示平局时的 Elo 排序。但基于这一改变,我们并没有观察到模型间相互胜负的太大变化。平局的计数 (每对模型间对局 327 次) 和新的 Elo 排序如下图所示。每格的数字代表两个模型的平局数,比如,Koala-13B 和 Vicuna-13B 之间由最多的平局 (96 次),说明它们可能性能非常相近。
_注意这张表的读法: 选取一行,如 `oasst-12b` ,然后横向看这个模型和其它各个模型分别有多少场平局。_
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/llm-leaderboard/tie_counts.png" width="600" />
</p>
****************包含平局的 Elo 排序 (由 1000 轮采样的对局自举计算而来)** **************
| Model | Elo ranking (median) | 5th and 95th percentiles |
| --- | --- | --- |
| Vicuna-13B | 1130 | 1066 ↔ 1192 |
| Koala-13B | 1061 | 998 ↔ 1128 |
| Oasst-12B | 988 | 918 ↔ 1051 |
| Dolly-12B | 820 | 760 ↔ 890 |
下图统计了打分的分布情况,数据来自 Scale AI taskforce。
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/llm-leaderboard/human-hist.png" width="600" />
</p>
在本文接下来内容中,你还会看到基于不同数据生成准测的相似分析流程。
### GPT-4 的 Elo 结果
接下来我们来看看 GPT-4 如何对比结果。几个待评测模型的顺序不变,但相对的间隔变了。
**不含平局的 Elo 排序 (由 1000 轮采样的对局自举计算而来)**
| Model | Elo ranking (median) | 2.5th and 97.5th percentiles |
| --- | --- | --- |
| vicuna-13b | 1134 | 1036 ↔ 1222 |
| koala-13b | 1082 | 989 ↔ 1169 |
| oasst-12b | 972 | 874 ↔ 1062 |
| dolly-12b | 812 | 723 ↔ 909 |
**包含平局的 Elo 排序 (由 1000 轮采样的对局自举计算而来)**
_提醒一下,利克特 1 到 8 分量表中,4 或 5 分代表平局_
| Model | Elo ranking (median) | 2.5th and 97.5th percentiles |
| --- | --- | --- |
| vicuna-13b | 1114 | 1033 ↔ 1194 |
| koala-13b | 1082 | 995 ↔ 1172 |
| oasst-12b | 973 | 885 ↔ 1054 |
| dolly-12b | 831 | 742 ↔ 919 |
为此,我们使用了一个由 [FastChat evaluation prompts](https://github.com/lm-sys/FastChat/blob/main/fastchat/eval/table/prompt.jsonl) 改编而来的提示语,以便用较短的句子长度来获得更快和更低成本的生成结果 (比如解释性的话语大多数时间都舍弃掉了)。
```
### Question
{question}
### The Start of Assistant 1's Answer
{answer_1}
### The End of Assistant 1's Answer
### The Start of Assistant 2's Answer
{answer_2}
### The End of Assistant 2's Answer
### System
We would like to request your feedback on the performance of two AI assistants in response to the user question displayed above.
Please compare the helpfulness, relevance, accuracy, level of details of their responses.
The rating should be from the set of 1, 2, 3, 4, 5, 6, 7, or 8, where higher numbers indicated that Assistant 2 was better than Assistant 1.
Please first output a single line containing only one value indicating the preference between Assistant 1 and 2.
In the subsequent line, please provide a brief explanation of your evaluation, avoiding any potential bias and ensuring that the order in which the responses were presented does not affect your judgment.
```
下面基于 GPT-4 关于回答的柱状图开始显示一个基于大语言模型评测的明显问题了: 位置偏差 ( **positional bias** )。哪个模型对应上面的 `answer_1` 是完全随机的。
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/llm-leaderboard/gpt4-hist.png" width="600" />
</p>
鉴于 GPT-4 评价的不确定性,我们决定加上一个新的评测基准: 高度训练过的人类打标者的补全。我们希望知道人类给出的 Elo 排序会是什么样的。
### GPT-4 Elo 结果及展示
最终,人类给出的 Elo 排序看上去非常令人困惑。很多假设可以解释这一点,但它最终指向了一个潜在的风格优势,这种优势存在于在大语言模型的输出数据上训练的那些模型上 (当我们拿 Dolly 做对比时)。这是由于训练和评测方法是并行开发的,导致了两者之间的“非故意掺杂”( _****unintentional doping****_ )。
**不含平局的 Elo 排序 (由 1000 轮采样的对局自举计算而来)**
| Model | Elo ranking (median) | 2.5th and 975th percentiles |
| --- | --- | --- |
| Vicuna-13b | 1148 | 1049 ↔ 1239 |
| koala-13b | 1097 | 1002 ↔ 1197 |
| Oasst-12b | 985 | 896 ↔ 1081 |
| human | 940 | 840 ↔ 1034 |
| dolly-12b | 824 | 730 ↔ 922 |
## 相关工作
我们不是唯一指出 GPT-4 不一定是个完美的训练和测评 LLM 的工具的。两篇最近的论文也调研了通过 OpenAI 的模型输出进行指令调校 (instruction tuning) 的影响,以及这样做为什么会影响模型对比性评估 (即你训练的模型输出拿来和 ChatGPT 或 GPT-4 的输出做对比)。最引人注目的一篇论文 _[How Far Can Camels Go?](https://arxiv.org/abs/2306.04751)_ (来自 Allen AI) 展示了导致 GPT-4 过高打分的潜在迹象: 多样性和回答的长度。这些关联是令人吃惊的,因为它在鼓励模型去说更多的话,即使这个任务并没有希望它这么做。下图中,作者们就展示了胜率和分词数量的关联关系。
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/llm-leaderboard/camel-fig.png" width="600" />
</p>
另一篇伯克利的论文 *[The False Promise of Imitating Proprietary LLMs](https://arxiv.org/abs/2305.15717)* 展示了使用更多数据训练反而降低了对比结果的情况。针对本文作者实验时用的模型规模,看起来还是需要更多的研究才能更全面地了解这些结果。但这篇文章指向了一个很清晰的方向: 使用其它 LLM 训练和评测时需要格外谨慎。下图就是论文中演示这一现象的图表:
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/llm-leaderboard/false-promise-fig.png" width="600" />
</p>
## GPT-4 评测样例
下面我们展示了一些样例,用以展示评测是如何进行的,让你能感觉到 GPT-4 是如何挑选答案的:
---
**Question:**
Indicate the genre of the book to which it belongs.\n Input: Love in the Time of Cholera.
**Model response (koala)**:
The genre of "Love in the Time of Cholera" is a romance novel with elements of magical realism and historical fiction.
It tells the story of two men, Fermina Daza and Florentino Ariza, who are both deeply in love with her but cannot be together due to various circumstances.
Throughout their lives, they encounter obstacles that prevent them from being reunited, including war, illness, and societal pressure.
However, their love for each other never fades away, and they continue to hold onto hope that one day they will be able to be together again.
This combination of romantic elements and historical context makes this book fall under the category of romance novels with magical realistic and historical fictional elements.
**Human response:**
Fiction
**GPT-4 rating: 1** (model greatly better)
Assistant 1 provided a more detailed and accurate answer, discussing the elements of romance, magical realism, and historical fiction present in the novel.
Assistant 2's answer was too brief and did not provide sufficient information about the genre of the book.
---
**Question:**
Write a LinkedIn post to announce that you have accepted a new job offer.\n Input:
**Model response (koala)**:
Exciting news! I am thrilled to announce that I have officially accepted an exciting new job opportunity as [Job Title] at [Company Name]. This role will allow me to leverage my skills and experience in [industry/field of expertise], while also providing opportunities for personal and professional growth.
I want to take this moment to express my gratitude to everyone who has supported me throughout the hiring process, including [previous employer name(s) or individuals who provided guidance/advice/references]. Your support means the world to me and I couldn't be more grateful for your help.
I am excited about what lies ahead and can't wait to join the team at [Company Name]. Thank you again for all your support!
**Human response:**
I’m excited beyond words to share with you my decision to accept the role of Marketing Director at the XYZ Company!
I couldn’t have had this opportunity if not for the help of my friend, [name], who shared this job opportunity with me, and my former boss, [boss’s name], for her stellar recommendation and guidance.
I happily look forward to starting this new journey and growing professionally with my new family—the marketing rock stars of XYZ Company.
**GPT-4 rating: 6** (model better)
Both assistants provided helpful and relevant responses for a LinkedIn post announcing a new job offer.
However, Assistant 2's answer was more detailed and included placeholders for specific information, making it easier for the user to customize the post.
Assistant 1's response was also good, but slightly less structured and detailed compared to Assistant 2's response.
---
**Question:**
You are given a search query and a document. Classify whether the document is relevant to the search query or not relevant.
Input: Search: why sky is blue
Document: The Short Answer: Sunlight reaches Earth's atmosphere and is scattered in all directions by all the gases and particles in the air. Blue light is scattered more than the other colors because it travels as shorter, smaller waves. This is why we see a blue sky most of the time
**Model response (dolly)**:
The provided example search "why sky is blue" is related to the input document which explains the reason for blue color of the sky.
Advantages
This answer only takes up 34 characters compared to longer explanations like sunlight reaching earth due to its speed through space etc.. which would take up 80 characters. Hence this answer is highly relevant and useful to many users.
Disadvantage
Now if the question was about reasons behind changes in the weather one could think of many documents relating to climate change, pollution, static charges in the air etc., these documents might be relevant to the user but taking up lots of additional real-estate makes them less relevant compared to the above mentioned answer.
**Human response:**
relevant
**GPT-4 rating: 5** (model slightly better)
Both assistants provided relevant answers to the question, but Assistant 1’s answer was more detailed and explained the reason behind the sky’s blue color, while Assistant 2’s answer was concise but not as informative. Assistant 1’s answer is more helpful for users who want to understand the phenomenon, while Assistant 2’s answer is suitable for users who only want a quick confirmation.
---
## 更多实验
### 人工打标和 GPT-4 打标的相关性分析
这里我们选出一些类别,展示在哪一部分 GPT-4 可能稍微表现得更好。我们发现,对比于事实类的任务,在需要创造性的任务中,相关性更高。这表明人类在察觉模型的不准确性上做得更好,而这是我们期待模型有的能力。
| Category | Correlation: GPT-4 to Human Labels |
| --- | --- |
| Brainstorm | 0.60 |
| Creative generation | 0.55 |
| Commonsense reasoning | 0.46 |
| Question answering | 0.44 |
| Summarization | 0.40 |
| Natural language to code | 0.33 |
### 对比实验
**GPT-4 的 Elo 实验: 使用分数而不是排名**
有些评测基准使用一个排名系统去对比模型——让 GPT-4 去返回两个分数并解释原因。我们希望对比这些结果,即使情理上讲者并不符合 RLHF 的训练范式 (分数还不能训练可靠的偏好模型,而对比结果则可以)。
使用排名的方式展示了潜在的位置偏差的减少。具体可见下表中的中位数 Elo 估算数据 (不含平局):
| Model | Elo ranking (median) |
| --- | --- |
| Vicuna-13b | 1136 |
| koala-13b | 1081 |
| Oasst-12b | 961 |
| human | 958 |
| dolly-12b | 862 |
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/llm-leaderboard/gpt4-score-hist.png" width="600" />
</p>
**GPT-4 的 Elo 实验: 要求去除偏差**
我们已经认识到的位置偏差的影响,如果我们在提示语中要求 LLM 去除位置偏差,会是怎么样?就像下面描述中这样提问:
```latex
Be aware that LLMs like yourself are extremely prone to positional bias and tend to return 1, can you please try to remove this bias so our data is fair?
```
下面的柱状图展示了这样设置带来的新结果,偏差被改变了 (但并没有完全解决问题)。另外,有些时候 GPT-4 会返回要求的打分区间外的整数分数。
下面,你可以看看更新过的评分分布,以及相应的无平局的 Elo 估计 (这些结果很相近)。
| Model | Elo ranking (median) |
| --- | --- |
| koala-13b | 1105 |
| Oasst-12b | 1075 |
| Vicuna-13b | 1066 |
| human | 916 |
| dolly-12b | 835 |
这里我们还做了实验,改变模型的顺序结果会是怎样 (含有平局的情况):
| Model | Elo ranking (median) |
| --- | --- |
| Vicuna-13b | 1110 |
| koala-13b | 1085 |
| Oasst-12b | 1075 |
| human | 923 |
| dolly-12b | 804 |
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/llm-leaderboard/gpt4-debias-hist.png" width="600" />
</p>
## 要点和讨论
总结我们实验的几个重要发现:
- GPT-4 存在位置偏差,当我们使用 1 到 8 分 范围,两两对比模型偏差时,GPT-4 倾向于给第一个模型更高分。
- 在提示语中要求 GPT-4 不要保留这种位置偏差,会导致模型偏向另一边,但不会像上述情况那么差。
- 针对事实性和有用性的回答上,GPT-4 更倾向于偏好那些用 InstructGPT、GPT-4、ChatGPT 生成的数据训练的模型。比如,在人类手写的输出方面,GPT-4 更倾向 Vicuna 和 Alpaca。
- GPT-4 和人工评价者在评价非编程任务时,有着 0.5 左右的正相关性; 而对于编程任务,仍保持正相关,但数值远没有那么高。
- 如果我们按任务类型看,人类和 GPT-4 的相关性在”高熵“任务 (如头脑风暴和生成类任务) 中相关性最高,而在编程类任务中相关性低。
这一领域的工作还是很新的,所以
- **利克特 vs 评分**: 在我们的评测过程中,我们使用了利克特量表作为评测工具——如何收集偏好数据来使用 RLHF 去训练模型。在这里,我们反复展示了,使用打出来的分数去训练一个偏好模型并不能产出有用的训练信息 (相比于相对性的排名来说)。类似地,我们也发现在分数上评测也不太可能生成出长期有效的训练信号。
此外,值得注意的是,ChatGPT (性能稍低点的模型) 实际上难以返回一个符合利克特量表定义的分数,但有的时候可以多少可靠地做出排名。这暗示着这些模型其实才刚刚开始学习格式方面的信息,来符合我们的评测框架; 这个能力的获取距离它成为一个有用的评测工具还有较长的距离。
- 为评测做提示语: 在我们的实验中,我们看到了 GPT-4 评测时潜在的位置偏差。但仍有很多其它因素,可能影响提示语的质量。在最近的一个 [podcast](https://thegradientpub.substack.com/p/riley-goodside-the-art-and-craft#details) 中,Riley Goodside 描述了 LLM 输出时每个分词的信息量极限,所以在提示语中首先输出分数可能会限制像 GPT-4 这样的模型能力,使得它不能充分阐述缘由。
- 打分和排名的范围: 我们还不清楚打分或利克特排名的真正合理范围是多少。LLM 习惯去看到训练数据中的某种组合 (如 1 到 5 星),这可能会让模型打分数产生偏差。给定特定的 token 让模型去返回,而不是让模型直接输出一个分数,可能会降低这样的偏差。
- 句子长度的偏差: ChatGPT 受欢迎的一个原因也在于它可以输出有趣的、很长的回答。我们可以看到,在使用 GPT-4 评测时,GPT-4 非常不喜欢简介而正确的回答,仅仅是因为另一个模型喜欢持续输出更长的回答。
- 正确的生成参数: 在我们早期实验中,我们需要花费大量时间获取各个模型正确的对话格式 (可参考 [FastChat 的 `conversation.py`](https://github.com/lm-sys/FastChat/blob/main/fastchat/conversation.py))。这可能使得模型仅仅获得 70-90% 的的潜在能力。剩下的部分需要通过调生成参数来获取 (如 temperature 或 top-p 等),但我们仍缺少可信的评测基准,迄今也没有一个公平的方法去做这个。针对我们的实验,我们设置 temperature 为 0.5,top-k 为 50 以及 top-p 为 0.95 (针对生成,OpenAI 的评测还需要别的参数)。
### 资源和引用
- 更多关于针对标注的指示信息可以查看 [这里](https://docs.google.com/document/d/1c5-96Lj-UH4lzKjLvJ_MRQaVMjtoEXTYA4dvoAYVCHc/edit?usp=sharing).
如果你有一个模型需要 GPT-4 或人工标注者去评测,可以在 [the leaderboard discussions](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard_internal/discussions) 留言。
```
@article{rajani2023llm_labels,
author = {Rajani, Nazneen, and Lambert, Nathan and Han, Sheon and Wang, Jean and Nitski, Osvald and Beeching, Edward and Tunstall, Lewis},
title = {Can foundation models label data like humans?},
journal = {Hugging Face Blog},
year = {2023},
note = {https://huggingface.co/blog/llm-v-human-data},
}
```
_感谢 [Joao](https://twitter.com/_joaogui1) 指出我们表格中一个拼写错误_
| 9 |
0 | hf_public_repos/candle/candle-datasets | hf_public_repos/candle/candle-datasets/src/hub.rs | use hf_hub::{
api::sync::{Api, ApiRepo},
Repo, RepoType,
};
use parquet::file::reader::SerializedFileReader;
use std::fs::File;
#[derive(thiserror::Error, Debug)]
pub enum Error {
#[error("ApiError : {0}")]
ApiError(#[from] hf_hub::api::sync::ApiError),
#[error("IoError : {0}")]
IoError(#[from] std::io::Error),
#[error("ParquetError : {0}")]
ParquetError(#[from] parquet::errors::ParquetError),
}
fn sibling_to_parquet(
rfilename: &str,
repo: &ApiRepo,
) -> Result<SerializedFileReader<File>, Error> {
let local = repo.get(rfilename)?;
let file = File::open(local)?;
let reader = SerializedFileReader::new(file)?;
Ok(reader)
}
pub fn from_hub(api: &Api, dataset_id: String) -> Result<Vec<SerializedFileReader<File>>, Error> {
let repo = Repo::with_revision(
dataset_id,
RepoType::Dataset,
"refs/convert/parquet".to_string(),
);
let repo = api.repo(repo);
let info = repo.info()?;
let files: Result<Vec<_>, _> = info
.siblings
.into_iter()
.filter_map(|s| -> Option<Result<_, _>> {
let filename = s.rfilename;
if filename.ends_with(".parquet") {
let reader_result = sibling_to_parquet(&filename, &repo);
Some(reader_result)
} else {
None
}
})
.collect();
let files = files?;
Ok(files)
}
#[cfg(test)]
mod tests {
use super::*;
use parquet::file::reader::FileReader;
#[test]
fn test_dataset() {
let api = Api::new().unwrap();
let files = from_hub(
&api,
"hf-internal-testing/dummy_image_text_data".to_string(),
)
.unwrap();
assert_eq!(files.len(), 1);
assert_eq!(files[0].metadata().file_metadata().num_rows(), 20);
}
}
| 0 |
0 | hf_public_repos/candle/candle-datasets | hf_public_repos/candle/candle-datasets/src/batcher.rs | use candle::{Result, Tensor};
pub struct Batcher<I> {
inner: I,
batch_size: usize,
return_last_incomplete_batch: bool,
}
impl<I> Batcher<I> {
fn new(inner: I) -> Self {
Self {
inner,
batch_size: 16,
return_last_incomplete_batch: false,
}
}
pub fn batch_size(mut self, batch_size: usize) -> Self {
self.batch_size = batch_size;
self
}
pub fn return_last_incomplete_batch(mut self, r: bool) -> Self {
self.return_last_incomplete_batch = r;
self
}
}
pub struct Iter1<I: Iterator<Item = Tensor>> {
inner: I,
}
pub struct Iter2<I: Iterator<Item = (Tensor, Tensor)>> {
inner: I,
}
impl<I: Iterator<Item = Tensor>> Batcher<Iter1<I>> {
pub fn new1(inner: I) -> Self {
Self::new(Iter1 { inner })
}
}
impl<I: Iterator<Item = (Tensor, Tensor)>> Batcher<Iter2<I>> {
pub fn new2(inner: I) -> Self {
Self::new(Iter2 { inner })
}
}
pub struct IterResult1<I: Iterator<Item = Result<Tensor>>> {
inner: I,
}
pub struct IterResult2<I: Iterator<Item = Result<(Tensor, Tensor)>>> {
inner: I,
}
impl<I: Iterator<Item = Result<Tensor>>> Batcher<IterResult1<I>> {
pub fn new_r1(inner: I) -> Self {
Self::new(IterResult1 { inner })
}
}
impl<I: Iterator<Item = Result<(Tensor, Tensor)>>> Batcher<IterResult2<I>> {
pub fn new_r2(inner: I) -> Self {
Self::new(IterResult2 { inner })
}
}
impl<I: Iterator<Item = Tensor>> Iterator for Batcher<Iter1<I>> {
type Item = Result<Tensor>;
fn next(&mut self) -> Option<Self::Item> {
let mut items = Vec::with_capacity(self.batch_size);
for _i in 0..self.batch_size {
// We have two levels of inner here so that we can have two implementations of the
// Iterator trait that are different for Iter1 and Iter2. If rust gets better
// specialization at some point we can get rid of this.
match self.inner.inner.next() {
Some(item) => items.push(item),
None => {
if self.return_last_incomplete_batch {
break;
}
return None;
}
}
}
Some(Tensor::stack(&items, 0))
}
}
impl<I: Iterator<Item = (Tensor, Tensor)>> Iterator for Batcher<Iter2<I>> {
type Item = Result<(Tensor, Tensor)>;
fn next(&mut self) -> Option<Self::Item> {
let mut xs = Vec::with_capacity(self.batch_size);
let mut ys = Vec::with_capacity(self.batch_size);
for _i in 0..self.batch_size {
match self.inner.inner.next() {
Some((x, y)) => {
xs.push(x);
ys.push(y)
}
None => {
if self.return_last_incomplete_batch {
break;
}
return None;
}
}
}
let xs = Tensor::stack(&xs, 0);
let ys = Tensor::stack(&ys, 0);
Some(xs.and_then(|xs| ys.map(|ys| (xs, ys))))
}
}
impl<I: Iterator<Item = Result<Tensor>>> Iterator for Batcher<IterResult1<I>> {
type Item = Result<Tensor>;
fn next(&mut self) -> Option<Self::Item> {
let mut items = Vec::with_capacity(self.batch_size);
for _i in 0..self.batch_size {
// We have two levels of inner here so that we can have two implementations of the
// Iterator trait that are different for Iter1 and Iter2. If rust gets better
// specialization at some point we can get rid of this.
match self.inner.inner.next() {
Some(item) => items.push(item),
None => {
if self.return_last_incomplete_batch {
break;
}
return None;
}
}
}
let items = items.into_iter().collect::<Result<Vec<Tensor>>>();
Some(items.and_then(|items| Tensor::stack(&items, 0)))
}
}
impl<I: Iterator<Item = Result<(Tensor, Tensor)>>> Iterator for Batcher<IterResult2<I>> {
type Item = Result<(Tensor, Tensor)>;
fn next(&mut self) -> Option<Self::Item> {
let mut xs = Vec::with_capacity(self.batch_size);
let mut ys = Vec::with_capacity(self.batch_size);
let mut errs = vec![];
for _i in 0..self.batch_size {
match self.inner.inner.next() {
Some(Ok((x, y))) => {
xs.push(x);
ys.push(y)
}
Some(Err(err)) => errs.push(err),
None => {
if self.return_last_incomplete_batch {
break;
}
return None;
}
}
}
if !errs.is_empty() {
return Some(Err(errs.swap_remove(0)));
}
let xs = Tensor::stack(&xs, 0);
let ys = Tensor::stack(&ys, 0);
Some(xs.and_then(|xs| ys.map(|ys| (xs, ys))))
}
}
| 1 |
0 | hf_public_repos/candle/candle-datasets/src | hf_public_repos/candle/candle-datasets/src/nlp/tinystories.rs | //! Helper functions for the tinystories dataset. This uses the pre-tokenized version as generated
//! by the tools from https://github.com/karpathy/llama2.c
use candle::{Device, Result, Tensor};
pub struct Dataset {
valid_tokens: Vec<memmap2::Mmap>,
train_tokens: Vec<memmap2::Mmap>,
}
fn mmap_file(p: &std::path::PathBuf) -> Result<memmap2::Mmap> {
let file = std::fs::File::open(p)?;
let mmap = unsafe { memmap2::MmapOptions::new().map(&file)? };
Ok(mmap)
}
impl Dataset {
pub fn new<P: AsRef<std::path::Path>>(dir: P) -> Result<Self> {
let dir = dir.as_ref();
let mut bin_files = vec![];
for file in std::fs::read_dir(dir)?.flatten() {
let file = file.path();
if let Some(extension) = file.extension() {
if extension == "bin" {
bin_files.push(file)
}
}
}
if bin_files.len() < 2 {
candle::bail!("found less than two bin files in {:?}", dir)
}
bin_files.sort();
let valid_tokens = mmap_file(&bin_files[0])?;
let train_tokens = bin_files[1..]
.iter()
.map(mmap_file)
.collect::<Result<Vec<_>>>()?;
Ok(Self {
valid_tokens: vec![valid_tokens],
train_tokens,
})
}
pub fn train_tokens(&self) -> usize {
self.train_tokens.len()
}
pub fn valid_tokens(&self) -> usize {
self.valid_tokens.len()
}
}
pub struct DatasetRandomIter<'a> {
all_tokens: &'a [memmap2::Mmap],
tokens: Vec<&'a memmap2::Mmap>,
current_tokens: &'a memmap2::Mmap,
indexes_in_bytes: Vec<usize>,
seq_len: usize,
device: Device,
}
impl<'a> DatasetRandomIter<'a> {
pub fn new(ds: &'a Dataset, valid: bool, seq_len: usize, device: Device) -> Self {
use rand::seq::SliceRandom;
use rand::thread_rng;
let all_tokens = if valid {
&ds.valid_tokens
} else {
&ds.train_tokens
};
let mut tokens = all_tokens.iter().collect::<Vec<_>>();
tokens.shuffle(&mut thread_rng());
let current_tokens = tokens.pop().unwrap();
let seq_len_in_bytes = seq_len * 2;
let mut indexes_in_bytes = (0..current_tokens.len() - seq_len_in_bytes)
.step_by(seq_len_in_bytes)
.collect::<Vec<_>>();
indexes_in_bytes.shuffle(&mut thread_rng());
Self {
all_tokens,
tokens,
current_tokens,
indexes_in_bytes,
seq_len,
device,
}
}
}
impl Iterator for DatasetRandomIter<'_> {
type Item = Result<(Tensor, Tensor)>;
fn next(&mut self) -> Option<Self::Item> {
use byteorder::{LittleEndian, ReadBytesExt};
use rand::seq::SliceRandom;
use rand::thread_rng;
let seq_len = self.seq_len;
if self.indexes_in_bytes.is_empty() {
if self.tokens.is_empty() {
self.tokens = self.all_tokens.iter().collect();
self.tokens.shuffle(&mut thread_rng());
}
self.current_tokens = self.tokens.pop().unwrap();
let seq_len_in_bytes = self.seq_len * 2;
self.indexes_in_bytes = (0..self.current_tokens.len() - seq_len_in_bytes)
.step_by(seq_len_in_bytes)
.collect::<Vec<_>>();
self.indexes_in_bytes.shuffle(&mut thread_rng());
}
let start_idx = self.indexes_in_bytes.pop().unwrap();
let bytes = &self.current_tokens[start_idx..start_idx + 2 * (seq_len + 1)];
let mut tokens = vec![0u16; bytes.len() / 2];
if let Err(err) = std::io::Cursor::new(bytes).read_u16_into::<LittleEndian>(&mut tokens) {
return Some(Err(err.into()));
}
let tokens = tokens.into_iter().map(|v| v as u32).collect::<Vec<_>>();
let inputs = Tensor::new(&tokens[..seq_len], &self.device);
let targets = Tensor::new(&tokens[1..], &self.device);
Some(candle::error::zip(inputs, targets))
}
}
| 2 |
0 | hf_public_repos/candle/candle-datasets/src | hf_public_repos/candle/candle-datasets/src/nlp/mod.rs | pub mod tinystories;
| 3 |
0 | hf_public_repos/candle/candle-datasets/src | hf_public_repos/candle/candle-datasets/src/vision/mod.rs | use candle::Tensor;
pub struct Dataset {
pub train_images: Tensor,
pub train_labels: Tensor,
pub test_images: Tensor,
pub test_labels: Tensor,
pub labels: usize,
}
pub mod cifar;
pub mod mnist;
| 4 |
0 | hf_public_repos/candle/candle-datasets/src | hf_public_repos/candle/candle-datasets/src/vision/cifar.rs | //! The CIFAR-10 dataset.
//!
//! The files can be downloaded from the following page:
//! <https://www.cs.toronto.edu/~kriz/cifar.html>
//! The binary version of the dataset is used.
use crate::vision::Dataset;
use candle::{DType, Device, Error, Result, Tensor};
use hf_hub::{api::sync::Api, Repo, RepoType};
use parquet::file::reader::{FileReader, SerializedFileReader};
use std::fs::File;
use std::io::{BufReader, Read};
const W: usize = 32;
const H: usize = 32;
const C: usize = 3;
const BYTES_PER_IMAGE: usize = W * H * C + 1;
const SAMPLES_PER_FILE: usize = 10000;
fn read_file(filename: &std::path::Path) -> Result<(Tensor, Tensor)> {
let mut buf_reader = BufReader::new(File::open(filename)?);
let mut data = vec![0u8; SAMPLES_PER_FILE * BYTES_PER_IMAGE];
buf_reader.read_exact(&mut data)?;
let mut images = vec![];
let mut labels = vec![];
for index in 0..SAMPLES_PER_FILE {
let content_offset = BYTES_PER_IMAGE * index;
labels.push(data[content_offset]);
images.push(&data[1 + content_offset..content_offset + BYTES_PER_IMAGE]);
}
let images: Vec<u8> = images
.iter()
.copied()
.flatten()
.copied()
.collect::<Vec<_>>();
let labels = Tensor::from_vec(labels, SAMPLES_PER_FILE, &Device::Cpu)?;
let images = Tensor::from_vec(images, (SAMPLES_PER_FILE, C, H, W), &Device::Cpu)?;
let images = (images.to_dtype(DType::F32)? / 255.)?;
Ok((images, labels))
}
pub fn load_dir<T: AsRef<std::path::Path>>(dir: T) -> Result<Dataset> {
let dir = dir.as_ref();
let (test_images, test_labels) = read_file(&dir.join("test_batch.bin"))?;
let train_images_and_labels = [
"data_batch_1.bin",
"data_batch_2.bin",
"data_batch_3.bin",
"data_batch_4.bin",
"data_batch_5.bin",
]
.iter()
.map(|x| read_file(&dir.join(x)))
.collect::<Result<Vec<_>>>()?;
let (train_images, train_labels): (Vec<_>, Vec<_>) =
train_images_and_labels.into_iter().unzip();
Ok(Dataset {
train_images: Tensor::cat(&train_images, 0)?,
train_labels: Tensor::cat(&train_labels, 0)?,
test_images,
test_labels,
labels: 10,
})
}
fn load_parquet(parquet: SerializedFileReader<std::fs::File>) -> Result<(Tensor, Tensor)> {
let samples = parquet.metadata().file_metadata().num_rows() as usize;
let mut buffer_images: Vec<u8> = Vec::with_capacity(samples * 1_024);
let mut buffer_labels: Vec<u8> = Vec::with_capacity(samples);
for row in parquet.into_iter().flatten() {
for (_name, field) in row.get_column_iter() {
if let parquet::record::Field::Group(subrow) = field {
for (_name, field) in subrow.get_column_iter() {
if let parquet::record::Field::Bytes(value) = field {
let image = image::load_from_memory(value.data()).unwrap();
buffer_images.extend(image.to_rgb8().as_raw());
}
}
} else if let parquet::record::Field::Long(label) = field {
buffer_labels.push(*label as u8);
}
}
}
let images = (Tensor::from_vec(buffer_images, (samples, 3, 32, 32), &Device::Cpu)?
.to_dtype(DType::U8)?
/ 255.)?;
let labels = Tensor::from_vec(buffer_labels, (samples,), &Device::Cpu)?;
Ok((images, labels))
}
pub fn load() -> Result<Dataset> {
let api = Api::new().map_err(|e| Error::Msg(format!("Api error: {e}")))?;
let dataset_id = "cifar10".to_string();
let repo = Repo::with_revision(
dataset_id,
RepoType::Dataset,
"refs/convert/parquet".to_string(),
);
let repo = api.repo(repo);
let test_parquet_filename = repo
.get("plain_text/test/0000.parquet")
.map_err(|e| Error::Msg(format!("Api error: {e}")))?;
let train_parquet_filename = repo
.get("plain_text/train/0000.parquet")
.map_err(|e| Error::Msg(format!("Api error: {e}")))?;
let test_parquet = SerializedFileReader::new(std::fs::File::open(test_parquet_filename)?)
.map_err(|e| Error::Msg(format!("Parquet error: {e}")))?;
let train_parquet = SerializedFileReader::new(std::fs::File::open(train_parquet_filename)?)
.map_err(|e| Error::Msg(format!("Parquet error: {e}")))?;
let (test_images, test_labels) = load_parquet(test_parquet)?;
let (train_images, train_labels) = load_parquet(train_parquet)?;
Ok(crate::vision::Dataset {
train_images,
train_labels,
test_images,
test_labels,
labels: 10,
})
}
| 5 |
0 | hf_public_repos/candle/candle-datasets/src | hf_public_repos/candle/candle-datasets/src/vision/mnist.rs | //! The MNIST hand-written digit dataset.
//!
//! The files can be obtained from the following link:
//! <http://yann.lecun.com/exdb/mnist/>
use candle::{DType, Device, Error, Result, Tensor};
use hf_hub::{api::sync::Api, Repo, RepoType};
use parquet::file::reader::{FileReader, SerializedFileReader};
use std::fs::File;
use std::io::{self, BufReader, Read};
fn read_u32<T: Read>(reader: &mut T) -> std::io::Result<u32> {
use byteorder::ReadBytesExt;
reader.read_u32::<byteorder::BigEndian>()
}
fn check_magic_number<T: Read>(reader: &mut T, expected: u32) -> Result<()> {
let magic_number = read_u32(reader)?;
if magic_number != expected {
Err(io::Error::new(
io::ErrorKind::Other,
format!("incorrect magic number {magic_number} != {expected}"),
))?;
}
Ok(())
}
fn read_labels(filename: &std::path::Path) -> Result<Tensor> {
let mut buf_reader = BufReader::new(File::open(filename)?);
check_magic_number(&mut buf_reader, 2049)?;
let samples = read_u32(&mut buf_reader)?;
let mut data = vec![0u8; samples as usize];
buf_reader.read_exact(&mut data)?;
let samples = data.len();
Tensor::from_vec(data, samples, &Device::Cpu)
}
fn read_images(filename: &std::path::Path) -> Result<Tensor> {
let mut buf_reader = BufReader::new(File::open(filename)?);
check_magic_number(&mut buf_reader, 2051)?;
let samples = read_u32(&mut buf_reader)? as usize;
let rows = read_u32(&mut buf_reader)? as usize;
let cols = read_u32(&mut buf_reader)? as usize;
let data_len = samples * rows * cols;
let mut data = vec![0u8; data_len];
buf_reader.read_exact(&mut data)?;
let tensor = Tensor::from_vec(data, (samples, rows * cols), &Device::Cpu)?;
tensor.to_dtype(DType::F32)? / 255.
}
pub fn load_dir<T: AsRef<std::path::Path>>(dir: T) -> Result<crate::vision::Dataset> {
let dir = dir.as_ref();
let train_images = read_images(&dir.join("train-images-idx3-ubyte"))?;
let train_labels = read_labels(&dir.join("train-labels-idx1-ubyte"))?;
let test_images = read_images(&dir.join("t10k-images-idx3-ubyte"))?;
let test_labels = read_labels(&dir.join("t10k-labels-idx1-ubyte"))?;
Ok(crate::vision::Dataset {
train_images,
train_labels,
test_images,
test_labels,
labels: 10,
})
}
fn load_parquet(parquet: SerializedFileReader<std::fs::File>) -> Result<(Tensor, Tensor)> {
let samples = parquet.metadata().file_metadata().num_rows() as usize;
let mut buffer_images: Vec<u8> = Vec::with_capacity(samples * 784);
let mut buffer_labels: Vec<u8> = Vec::with_capacity(samples);
for row in parquet.into_iter().flatten() {
for (_name, field) in row.get_column_iter() {
if let parquet::record::Field::Group(subrow) = field {
for (_name, field) in subrow.get_column_iter() {
if let parquet::record::Field::Bytes(value) = field {
let image = image::load_from_memory(value.data()).unwrap();
buffer_images.extend(image.to_luma8().as_raw());
}
}
} else if let parquet::record::Field::Long(label) = field {
buffer_labels.push(*label as u8);
}
}
}
let images = (Tensor::from_vec(buffer_images, (samples, 784), &Device::Cpu)?
.to_dtype(DType::F32)?
/ 255.)?;
let labels = Tensor::from_vec(buffer_labels, (samples,), &Device::Cpu)?;
Ok((images, labels))
}
pub fn load() -> Result<crate::vision::Dataset> {
let api = Api::new().map_err(|e| Error::Msg(format!("Api error: {e}")))?;
let dataset_id = "ylecun/mnist".to_string();
let repo = Repo::with_revision(
dataset_id,
RepoType::Dataset,
"refs/convert/parquet".to_string(),
);
let repo = api.repo(repo);
let test_parquet_filename = repo
.get("mnist/test/0000.parquet")
.map_err(|e| Error::Msg(format!("Api error: {e}")))?;
let train_parquet_filename = repo
.get("mnist/train/0000.parquet")
.map_err(|e| Error::Msg(format!("Api error: {e}")))?;
let test_parquet = SerializedFileReader::new(std::fs::File::open(test_parquet_filename)?)
.map_err(|e| Error::Msg(format!("Parquet error: {e}")))?;
let train_parquet = SerializedFileReader::new(std::fs::File::open(train_parquet_filename)?)
.map_err(|e| Error::Msg(format!("Parquet error: {e}")))?;
let (test_images, test_labels) = load_parquet(test_parquet)?;
let (train_images, train_labels) = load_parquet(train_parquet)?;
Ok(crate::vision::Dataset {
train_images,
train_labels,
test_images,
test_labels,
labels: 10,
})
}
| 6 |
0 | hf_public_repos/candle | hf_public_repos/candle/candle-nn/Cargo.toml | [package]
name = "candle-nn"
version.workspace = true
edition.workspace = true
description.workspace = true
repository.workspace = true
keywords.workspace = true
categories.workspace = true
license.workspace = true
readme = "README.md"
[dependencies]
accelerate-src = { workspace = true, optional = true }
candle = { workspace = true }
half = { workspace = true }
thiserror = { workspace = true }
intel-mkl-src = { workspace = true, optional = true }
num-traits = { workspace = true }
rayon = { workspace = true }
safetensors = { workspace = true }
serde = { workspace = true }
metal = { workspace = true, optional = true }
candle-metal-kernels = { workspace = true, optional = true }
[dev-dependencies]
anyhow = { workspace = true }
clap = { workspace = true }
rand = { workspace = true }
criterion = { workspace = true }
[features]
default = []
accelerate = ["dep:accelerate-src", "candle/accelerate"]
cuda = ["candle/cuda"]
mkl = ["dep:intel-mkl-src", "candle/mkl"]
metal = ["candle/metal", "dep:candle-metal-kernels", "dep:metal"]
[[bench]]
name = "bench_main"
harness = false | 7 |
0 | hf_public_repos/candle | hf_public_repos/candle/candle-nn/README.md | # candle-nn
| 8 |
0 | hf_public_repos/candle/candle-nn | hf_public_repos/candle/candle-nn/src/embedding.rs | //! Embedding Layer.
use candle::{Result, Tensor};
#[derive(Clone, Debug)]
pub struct Embedding {
embeddings: Tensor,
hidden_size: usize,
}
impl Embedding {
pub fn new(embeddings: Tensor, hidden_size: usize) -> Self {
Self {
embeddings,
hidden_size,
}
}
pub fn embeddings(&self) -> &Tensor {
&self.embeddings
}
/// Get the hidden size of the embedding matrix
pub fn hidden_size(&self) -> usize {
self.hidden_size
}
}
impl crate::Module for Embedding {
fn forward(&self, indexes: &Tensor) -> Result<Tensor> {
let mut final_dims = indexes.dims().to_vec();
final_dims.push(self.hidden_size);
let indexes = indexes.flatten_all()?;
let values = self.embeddings.index_select(&indexes, 0)?;
let values = values.reshape(final_dims)?;
Ok(values)
}
}
pub fn embedding(in_size: usize, out_size: usize, vb: crate::VarBuilder) -> Result<Embedding> {
let embeddings = vb.get_with_hints(
(in_size, out_size),
"weight",
crate::Init::Randn {
mean: 0.,
stdev: 1.,
},
)?;
Ok(Embedding::new(embeddings, out_size))
}
| 9 |
0 | hf_public_repos/accelerate/examples | hf_public_repos/accelerate/examples/config_yaml_templates/single_gpu.yaml | # Since this is single GPU, we don't need distributed training
distributed_type: "NO"
# Can be one of "no", "fp16", or "bf16" (see `transformer_engine.yaml` for `fp8`)
mixed_precision: "bf16" | 0 |
0 | hf_public_repos/accelerate/examples | hf_public_repos/accelerate/examples/by_feature/deepspeed_with_config_support.py | #!/usr/bin/env python
# Copyright 2022 The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""
Fine-tuning the library models for causal language modeling (GPT, GPT-2, CTRL, ...)
on a text file or a dataset without using HuggingFace Trainer.
Here is the full list of checkpoints on the hub that can be fine-tuned by this script:
https://huggingface.co/models?filter=text-generation
"""
# You can also adapt this script on your own causal language modeling task. Pointers for this are left as comments.
import argparse
import json
import logging
import math
import os
import random
from itertools import chain
from pathlib import Path
import datasets
import torch
import transformers
from datasets import load_dataset
from huggingface_hub import HfApi
from torch.utils.data import DataLoader
from tqdm.auto import tqdm
from transformers import (
CONFIG_MAPPING,
MODEL_MAPPING,
AutoConfig,
AutoModelForCausalLM,
AutoTokenizer,
SchedulerType,
default_data_collator,
get_scheduler,
)
from transformers.utils.versions import require_version
from accelerate import Accelerator, DistributedType
from accelerate.logging import get_logger
from accelerate.utils import DummyOptim, DummyScheduler, set_seed
logger = get_logger(__name__)
require_version("datasets>=1.8.0", "To fix: pip install -r examples/pytorch/language-modeling/requirements.txt")
MODEL_CONFIG_CLASSES = list(MODEL_MAPPING.keys())
MODEL_TYPES = tuple(conf.model_type for conf in MODEL_CONFIG_CLASSES)
def parse_args():
parser = argparse.ArgumentParser(description="Finetune a transformers model on a causal language modeling task")
parser.add_argument(
"--dataset_name",
type=str,
default=None,
help="The name of the dataset to use (via the datasets library).",
)
parser.add_argument(
"--dataset_config_name",
type=str,
default=None,
help="The configuration name of the dataset to use (via the datasets library).",
)
parser.add_argument(
"--train_file", type=str, default=None, help="A csv or a json file containing the training data."
)
parser.add_argument(
"--validation_file", type=str, default=None, help="A csv or a json file containing the validation data."
)
parser.add_argument(
"--validation_split_percentage",
default=5,
help="The percentage of the train set used as validation set in case there's no validation split",
)
parser.add_argument(
"--model_name_or_path",
type=str,
help="Path to pretrained model or model identifier from huggingface.co/models.",
required=False,
)
parser.add_argument(
"--config_name",
type=str,
default=None,
help="Pretrained config name or path if not the same as model_name",
)
parser.add_argument(
"--tokenizer_name",
type=str,
default=None,
help="Pretrained tokenizer name or path if not the same as model_name",
)
parser.add_argument(
"--use_slow_tokenizer",
action="store_true",
help="If passed, will use a slow tokenizer (not backed by the 🤗 Tokenizers library).",
)
parser.add_argument(
"--per_device_train_batch_size",
type=int,
default=8,
help="Batch size (per device) for the training dataloader.",
)
parser.add_argument(
"--per_device_eval_batch_size",
type=int,
default=8,
help="Batch size (per device) for the evaluation dataloader.",
)
parser.add_argument(
"--learning_rate",
type=float,
default=5e-5,
help="Initial learning rate (after the potential warmup period) to use.",
)
parser.add_argument("--weight_decay", type=float, default=0.0, help="Weight decay to use.")
parser.add_argument("--num_train_epochs", type=int, default=3, help="Total number of training epochs to perform.")
parser.add_argument(
"--max_train_steps",
type=int,
default=None,
help="Total number of training steps to perform. If provided, overrides num_train_epochs.",
)
parser.add_argument(
"--gradient_accumulation_steps",
type=int,
default=1,
help="Number of updates steps to accumulate before performing a backward/update pass.",
)
parser.add_argument(
"--lr_scheduler_type",
type=SchedulerType,
default="linear",
help="The scheduler type to use.",
choices=["linear", "cosine", "cosine_with_restarts", "polynomial", "constant", "constant_with_warmup"],
)
parser.add_argument(
"--num_warmup_steps", type=int, default=0, help="Number of steps for the warmup in the lr scheduler."
)
parser.add_argument("--output_dir", type=str, default=None, help="Where to store the final model.")
parser.add_argument("--seed", type=int, default=None, help="A seed for reproducible training.")
parser.add_argument(
"--model_type",
type=str,
default=None,
help="Model type to use if training from scratch.",
choices=MODEL_TYPES,
)
parser.add_argument(
"--block_size",
type=int,
default=None,
help=(
"Optional input sequence length after tokenization. The training dataset will be truncated in block of"
" this size for training. Default to the model max input length for single sentence inputs (take into"
" account special tokens)."
),
)
parser.add_argument(
"--preprocessing_num_workers",
type=int,
default=None,
help="The number of processes to use for the preprocessing.",
)
parser.add_argument(
"--overwrite_cache", type=bool, default=False, help="Overwrite the cached training and evaluation sets"
)
parser.add_argument(
"--no_keep_linebreaks", action="store_true", help="Do not keep line breaks when using TXT files."
)
parser.add_argument("--push_to_hub", action="store_true", help="Whether or not to push the model to the Hub.")
parser.add_argument(
"--hub_model_id", type=str, help="The name of the repository to keep in sync with the local `output_dir`."
)
parser.add_argument("--hub_token", type=str, help="The token to use to push to the Model Hub.")
parser.add_argument(
"--checkpointing_steps",
type=str,
default=None,
help="Whether the various states should be saved at the end of every n steps, or 'epoch' for each epoch.",
)
parser.add_argument(
"--resume_from_checkpoint",
type=str,
default=None,
help="If the training should continue from a checkpoint folder.",
)
# New Code #
# Whether to load the best model at the end of training
parser.add_argument(
"--load_best_model",
action="store_true",
help="Whether to load the best model at the end of training",
)
parser.add_argument(
"--with_tracking",
action="store_true",
help="Whether to enable experiment trackers for logging.",
)
parser.add_argument(
"--report_to",
type=str,
default="all",
help=(
'The integration to report the results and logs to. Supported platforms are `"tensorboard"`,'
' `"wandb"`, `"comet_ml"`, and `"dvclive"`. Use `"all"` (default) to report to all integrations.'
"Only applicable when `--with_tracking` is passed."
),
)
args = parser.parse_args()
# Sanity checks
if args.dataset_name is None and args.train_file is None and args.validation_file is None:
raise ValueError("Need either a dataset name or a training/validation file.")
else:
if args.train_file is not None:
extension = args.train_file.split(".")[-1]
assert extension in ["csv", "json", "txt"], "`train_file` should be a csv, json or txt file."
if args.validation_file is not None:
extension = args.validation_file.split(".")[-1]
assert extension in ["csv", "json", "txt"], "`validation_file` should be a csv, json or txt file."
if args.push_to_hub:
assert args.output_dir is not None, "Need an `output_dir` to create a repo when `--push_to_hub` is passed."
return args
# New Code #
def evaluate(args, model, eval_dataloader, accelerator, eval_dataset):
model.eval()
losses = []
for step, batch in enumerate(eval_dataloader):
with torch.no_grad():
outputs = model(**batch)
loss = outputs.loss
losses.append(accelerator.gather_for_metrics(loss.repeat(args.per_device_eval_batch_size)))
losses = torch.cat(losses)
try:
eval_loss = torch.mean(losses)
perplexity = math.exp(eval_loss)
except OverflowError:
perplexity = float("inf")
return perplexity, eval_loss
def main():
args = parse_args()
# Initialize the accelerator. We will let the accelerator handle device placement for us in this example.
# If we're using tracking, we also need to initialize it here and it will by default pick up all supported trackers
# in the environment
# when using DeepSpeed, the `gradient_accumulation_steps` is properly set from the DeepSpeed plugin/config
# or from `accelerate launch` via `--gradient_accumulation_steps` else
# defaulting to the passed `args.gradient_accumulation_steps`
accelerator = (
Accelerator(
log_with=args.report_to,
project_dir=args.output_dir,
gradient_accumulation_steps=args.gradient_accumulation_steps,
)
if args.with_tracking
else Accelerator(gradient_accumulation_steps=args.gradient_accumulation_steps)
)
# Make one log on every process with the configuration for debugging.
logging.basicConfig(
format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
datefmt="%m/%d/%Y %H:%M:%S",
level=logging.INFO,
)
logger.info(accelerator.state, main_process_only=False)
if accelerator.is_local_main_process:
datasets.utils.logging.set_verbosity_warning()
transformers.utils.logging.set_verbosity_info()
else:
datasets.utils.logging.set_verbosity_error()
transformers.utils.logging.set_verbosity_error()
# If passed along, set the training seed now.
if args.seed is not None:
set_seed(args.seed)
# Handle the repository creation
if accelerator.is_main_process:
if args.push_to_hub:
api = HfApi(token=args.hub_token)
# Create repo (repo_name from args or inferred)
repo_name = args.hub_model_id
if repo_name is None:
repo_name = Path(args.output_dir).absolute().name
repo_id = api.create_repo(repo_name, exist_ok=True).repo_id
with open(os.path.join(args.output_dir, ".gitignore"), "w+") as gitignore:
if "step_*" not in gitignore:
gitignore.write("step_*\n")
if "epoch_*" not in gitignore:
gitignore.write("epoch_*\n")
elif args.output_dir is not None:
os.makedirs(args.output_dir, exist_ok=True)
accelerator.wait_for_everyone()
# Get the datasets: you can either provide your own CSV/JSON/TXT training and evaluation files (see below)
# or just provide the name of one of the public datasets available on the hub at https://huggingface.co/datasets/
# (the dataset will be downloaded automatically from the datasets Hub).
#
# For CSV/JSON files, this script will use the column called 'text' or the first column if no column called
# 'text' is found. You can easily tweak this behavior (see below).
#
# In distributed training, the load_dataset function guarantee that only one local process can concurrently
# download the dataset.
if args.dataset_name is not None:
# Downloading and loading a dataset from the hub.
raw_datasets = load_dataset(args.dataset_name, args.dataset_config_name)
if "validation" not in raw_datasets.keys():
raw_datasets["validation"] = load_dataset(
args.dataset_name,
args.dataset_config_name,
split=f"train[:{args.validation_split_percentage}%]",
)
raw_datasets["train"] = load_dataset(
args.dataset_name,
args.dataset_config_name,
split=f"train[{args.validation_split_percentage}%:]",
)
else:
data_files = {}
dataset_args = {}
if args.train_file is not None:
data_files["train"] = args.train_file
if args.validation_file is not None:
data_files["validation"] = args.validation_file
extension = args.train_file.split(".")[-1]
if extension == "txt":
extension = "text"
dataset_args["keep_linebreaks"] = not args.no_keep_linebreaks
raw_datasets = load_dataset(extension, data_files=data_files, **dataset_args)
# If no validation data is there, validation_split_percentage will be used to divide the dataset.
if "validation" not in raw_datasets.keys():
raw_datasets["validation"] = load_dataset(
extension,
data_files=data_files,
split=f"train[:{args.validation_split_percentage}%]",
**dataset_args,
)
raw_datasets["train"] = load_dataset(
extension,
data_files=data_files,
split=f"train[{args.validation_split_percentage}%:]",
**dataset_args,
)
# See more about loading any type of standard or custom dataset (from files, python dict, pandas DataFrame, etc) at
# https://huggingface.co/docs/datasets/loading_datasets.html.
# Load pretrained model and tokenizer
#
# In distributed training, the .from_pretrained methods guarantee that only one local process can concurrently
# download model & vocab.
if args.config_name:
config = AutoConfig.from_pretrained(args.config_name)
elif args.model_name_or_path:
config = AutoConfig.from_pretrained(args.model_name_or_path)
else:
config = CONFIG_MAPPING[args.model_type]()
logger.warning("You are instantiating a new config instance from scratch.")
if args.tokenizer_name:
tokenizer = AutoTokenizer.from_pretrained(args.tokenizer_name, use_fast=not args.use_slow_tokenizer)
elif args.model_name_or_path:
tokenizer = AutoTokenizer.from_pretrained(args.model_name_or_path, use_fast=not args.use_slow_tokenizer)
else:
raise ValueError(
"You are instantiating a new tokenizer from scratch. This is not supported by this script."
"You can do it from another script, save it, and load it from here, using --tokenizer_name."
)
if args.model_name_or_path:
model = AutoModelForCausalLM.from_pretrained(
args.model_name_or_path,
from_tf=bool(".ckpt" in args.model_name_or_path),
config=config,
)
else:
logger.info("Training new model from scratch")
model = AutoModelForCausalLM.from_config(config)
model.resize_token_embeddings(len(tokenizer))
# Preprocessing the datasets.
# First we tokenize all the texts.
column_names = raw_datasets["train"].column_names
text_column_name = "text" if "text" in column_names else column_names[0]
def tokenize_function(examples):
return tokenizer(examples[text_column_name])
with accelerator.main_process_first():
tokenized_datasets = raw_datasets.map(
tokenize_function,
batched=True,
num_proc=args.preprocessing_num_workers,
remove_columns=column_names,
load_from_cache_file=not args.overwrite_cache,
desc="Running tokenizer on dataset",
)
if args.block_size is None:
block_size = tokenizer.model_max_length
if block_size > 1024:
logger.warning(
f"The tokenizer picked seems to have a very large `model_max_length` ({tokenizer.model_max_length}). "
"Picking 1024 instead. You can change that default value by passing --block_size xxx."
)
block_size = 1024
else:
if args.block_size > tokenizer.model_max_length:
logger.warning(
f"The block_size passed ({args.block_size}) is larger than the maximum length for the model"
f"({tokenizer.model_max_length}). Using block_size={tokenizer.model_max_length}."
)
block_size = min(args.block_size, tokenizer.model_max_length)
# Main data processing function that will concatenate all texts from our dataset and generate chunks of block_size.
def group_texts(examples):
# Concatenate all texts.
concatenated_examples = {k: list(chain(*examples[k])) for k in examples.keys()}
total_length = len(concatenated_examples[list(examples.keys())[0]])
# We drop the small remainder, we could add padding if the model supported it instead of this drop, you can
# customize this part to your needs.
if total_length >= block_size:
total_length = (total_length // block_size) * block_size
# Split by chunks of max_len.
result = {
k: [t[i : i + block_size] for i in range(0, total_length, block_size)]
for k, t in concatenated_examples.items()
}
result["labels"] = result["input_ids"].copy()
return result
# Note that with `batched=True`, this map processes 1,000 texts together, so group_texts throws away a remainder
# for each of those groups of 1,000 texts. You can adjust that batch_size here but a higher value might be slower
# to preprocess.
#
# To speed up this part, we use multiprocessing. See the documentation of the map method for more information:
# https://huggingface.co/docs/datasets/package_reference/main_classes.html#datasets.Dataset.map
with accelerator.main_process_first():
lm_datasets = tokenized_datasets.map(
group_texts,
batched=True,
num_proc=args.preprocessing_num_workers,
load_from_cache_file=not args.overwrite_cache,
desc=f"Grouping texts in chunks of {block_size}",
)
train_dataset = lm_datasets["train"]
eval_dataset = lm_datasets["validation"]
# Log a few random samples from the training set:
for index in random.sample(range(len(train_dataset)), 3):
logger.info(f"Sample {index} of the training set: {train_dataset[index]}.")
# DataLoaders creation:
train_dataloader = DataLoader(
train_dataset, shuffle=True, collate_fn=default_data_collator, batch_size=args.per_device_train_batch_size
)
eval_dataloader = DataLoader(
eval_dataset, collate_fn=default_data_collator, batch_size=args.per_device_eval_batch_size
)
# Optimizer
# Split weights in two groups, one with weight decay and the other not.
no_decay = ["bias", "LayerNorm.weight"]
optimizer_grouped_parameters = [
{
"params": [p for n, p in model.named_parameters() if not any(nd in n for nd in no_decay)],
"weight_decay": args.weight_decay,
},
{
"params": [p for n, p in model.named_parameters() if any(nd in n for nd in no_decay)],
"weight_decay": 0.0,
},
]
# New Code #
# Creates Dummy Optimizer if `optimizer` was specified in the config file else creates Adam Optimizer
optimizer_cls = (
torch.optim.AdamW
if accelerator.state.deepspeed_plugin is None
or "optimizer" not in accelerator.state.deepspeed_plugin.deepspeed_config
else DummyOptim
)
optimizer = optimizer_cls(optimizer_grouped_parameters, lr=args.learning_rate)
# On TPU, the tie weights in our model have been disconnected, so we need to restore the ties.
if accelerator.distributed_type == DistributedType.XLA:
model.tie_weights()
# Scheduler and math around the number of training steps.
num_update_steps_per_epoch = math.ceil(len(train_dataloader) / accelerator.gradient_accumulation_steps)
overrode_max_train_steps = False
if args.max_train_steps is None:
args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
overrode_max_train_steps = True
else:
args.num_train_epochs = math.ceil(args.max_train_steps / num_update_steps_per_epoch)
# New Code #
# Creates Dummy Scheduler if `scheduler` was specified in the config file else creates `args.lr_scheduler_type` Scheduler
if (
accelerator.state.deepspeed_plugin is None
or "scheduler" not in accelerator.state.deepspeed_plugin.deepspeed_config
):
lr_scheduler = get_scheduler(
name=args.lr_scheduler_type,
optimizer=optimizer,
num_warmup_steps=args.num_warmup_steps,
num_training_steps=args.max_train_steps,
)
else:
lr_scheduler = DummyScheduler(
optimizer, total_num_steps=args.max_train_steps, warmup_num_steps=args.num_warmup_steps
)
# Prepare everything with our `accelerator`.
model, optimizer, train_dataloader, eval_dataloader, lr_scheduler = accelerator.prepare(
model, optimizer, train_dataloader, eval_dataloader, lr_scheduler
)
# We need to recalculate our total training steps as the size of the training dataloader may have changed.
num_update_steps_per_epoch = math.ceil(len(train_dataloader) / accelerator.gradient_accumulation_steps)
if overrode_max_train_steps:
args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
# Afterwards we recalculate our number of training epochs
args.num_train_epochs = math.ceil(args.max_train_steps / num_update_steps_per_epoch)
# Figure out how many steps we should save the Accelerator states
checkpointing_steps = args.checkpointing_steps
if checkpointing_steps is not None and checkpointing_steps.isdigit():
checkpointing_steps = int(checkpointing_steps)
# We need to initialize the trackers we use, and also store our configuration.
# The trackers initializes automatically on the main process.
if args.with_tracking:
experiment_config = vars(args)
# TensorBoard cannot log Enums, need the raw value
experiment_config["lr_scheduler_type"] = experiment_config["lr_scheduler_type"].value
accelerator.init_trackers("clm_no_trainer", experiment_config)
# Train!
total_batch_size = (
args.per_device_train_batch_size * accelerator.num_processes * accelerator.gradient_accumulation_steps
)
logger.info("***** Running training *****")
logger.info(f" Num examples = {len(train_dataset)}")
logger.info(f" Num Epochs = {args.num_train_epochs}")
logger.info(f" Instantaneous batch size per device = {args.per_device_train_batch_size}")
logger.info(f" Total train batch size (w. parallel, distributed & accumulation) = {total_batch_size}")
logger.info(f" Gradient Accumulation steps = {accelerator.gradient_accumulation_steps}")
logger.info(f" Total optimization steps = {args.max_train_steps}")
# Only show the progress bar once on each machine.
progress_bar = tqdm(range(args.max_train_steps), disable=not accelerator.is_local_main_process)
completed_steps = 0
starting_epoch = 0
best_metric = None
best_metric_checkpoint = None
# Potentially load in the weights and states from a previous save
if args.resume_from_checkpoint:
accelerator.load_state(args.resume_from_checkpoint)
accelerator.print(f"Resumed from checkpoint: {args.resume_from_checkpoint}")
path = os.path.basename(args.resume_from_checkpoint)
training_difference = os.path.splitext(path)[0]
if "epoch" in training_difference:
starting_epoch = int(training_difference.replace("epoch_", "")) + 1
resume_step = None
completed_steps = starting_epoch * num_update_steps_per_epoch
else:
resume_step = int(training_difference.replace("step_", ""))
starting_epoch = resume_step // num_update_steps_per_epoch
resume_step -= starting_epoch * num_update_steps_per_epoch
completed_steps = resume_step
# update progress bar if resumed from checkpoint
progress_bar.update(completed_steps)
for epoch in range(starting_epoch, args.num_train_epochs):
model.train()
if args.with_tracking:
total_loss = 0
# skip new `skip_first_batches` to skip the batches when resuming from ckpt
if args.resume_from_checkpoint and epoch == starting_epoch and resume_step is not None:
# We need to skip steps until we reach the resumed step
active_dataloader = accelerator.skip_first_batches(train_dataloader, resume_step)
else:
# After the first iteration though, we need to go back to the original dataloader
active_dataloader = train_dataloader
for step, batch in enumerate(active_dataloader):
# In particular, DeepSpeed handles `gradient_accumulation` via `DeepSpeedEngine`.
# Below, we use `accelerator.accumulate` if the user
# wants to switch to other approaches such as plain DDP, PyTorch FSDP ...
# This avoids having to change any code as things are all handled across different distributed setups.
with accelerator.accumulate(model):
outputs = model(**batch)
loss = outputs.loss
accelerator.backward(loss)
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad()
if accelerator.sync_gradients:
progress_bar.update(1)
completed_steps += 1
# We keep track of the loss at each epoch
if args.with_tracking:
step_loss = accelerator.reduce(loss.detach().clone()).item()
total_loss += step_loss
if isinstance(checkpointing_steps, int):
if completed_steps % checkpointing_steps == 0:
output_dir = f"step_{completed_steps}"
if args.output_dir is not None:
output_dir = os.path.join(args.output_dir, output_dir)
accelerator.save_state(output_dir)
if completed_steps >= args.max_train_steps:
break
perplexity, eval_loss = evaluate(args, model, eval_dataloader, accelerator, eval_dataset)
logger.info(f"epoch {epoch}: perplexity: {perplexity} eval_loss: {eval_loss}")
if args.with_tracking:
accelerator.log(
{
"perplexity": perplexity,
"eval_loss": eval_loss,
"train_loss": total_loss / len(train_dataloader),
"epoch": epoch,
"step": completed_steps,
},
step=completed_steps,
)
if isinstance(checkpointing_steps, str) and checkpointing_steps == "epoch":
accelerator.save_state(os.path.join(args.output_dir, f"epoch_{epoch}"))
# New Code #
# Tracks the best checkpoint and best metric
if best_metric is None or best_metric > perplexity:
best_metric = perplexity
best_metric_checkpoint = os.path.join(args.output_dir, "best_checkpoint")
accelerator.save_state(best_metric_checkpoint)
accelerator.print(f"New best metric: {best_metric} at epoch {epoch}")
accelerator.print(f"best_metric_checkpoint: {best_metric_checkpoint}")
# New Code #
# Loads the best checkpoint after the training is finished
if args.load_best_model:
accelerator.load_state(best_metric_checkpoint)
# New Code #
# Evaluates using the best checkpoint
perplexity, eval_loss = evaluate(args, model, eval_dataloader, accelerator, eval_dataset)
logger.info(f"Best model metrics: perplexity: {perplexity} eval_loss: {eval_loss}")
if perplexity != best_metric:
raise AssertionError(
f"Best metric {best_metric} does not match the metric {perplexity} of the loaded best model."
)
if args.output_dir is not None:
accelerator.wait_for_everyone()
unwrapped_model = accelerator.unwrap_model(model)
# New Code #
# Saves the whole/unpartitioned fp16 model when in ZeRO Stage-3 to the output directory if
# `stage3_gather_16bit_weights_on_model_save` is True in DeepSpeed Config file or
# `zero3_save_16bit_model` is True in DeepSpeed Plugin.
# For Zero Stages 1 and 2, models are saved as usual in the output directory.
# The model name saved is `pytorch_model.bin`
unwrapped_model.save_pretrained(
args.output_dir,
is_main_process=accelerator.is_main_process,
save_function=accelerator.save,
state_dict=accelerator.get_state_dict(model),
)
if accelerator.is_main_process:
tokenizer.save_pretrained(args.output_dir)
if args.push_to_hub:
api.upload_folder(
repo_id=repo_id,
folder_path=args.output_dir,
commit_message="End of training",
)
with open(os.path.join(args.output_dir, "all_results.json"), "w") as f:
json.dump({"perplexity": perplexity, "eval_loss": eval_loss.item()}, f)
accelerator.end_training()
if __name__ == "__main__":
main()
| 1 |
0 | hf_public_repos/accelerate/examples | hf_public_repos/accelerate/examples/by_feature/multi_process_metrics.py | # Copyright 2022 The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import argparse
import os
import evaluate
import torch
from datasets import load_dataset
from torch.optim import AdamW
from torch.utils.data import DataLoader
from transformers import AutoModelForSequenceClassification, AutoTokenizer, get_linear_schedule_with_warmup, set_seed
from accelerate import Accelerator, DistributedType
########################################################################
# This is a fully working simple example to use Accelerate,
# specifically showcasing how to properly calculate the metrics on the
# validation dataset when in a distributed system, and builds off the
# `nlp_example.py` script.
#
# This example trains a Bert base model on GLUE MRPC
# in any of the following settings (with the same script):
# - single CPU or single GPU
# - multi GPUS (using PyTorch distributed mode)
# - (multi) TPUs
# - fp16 (mixed-precision) or fp32 (normal precision)
#
# To help focus on the differences in the code, building `DataLoaders`
# was refactored into its own function.
# New additions from the base script can be found quickly by
# looking for the # New Code # tags
#
# To run it in each of these various modes, follow the instructions
# in the readme for examples:
# https://github.com/huggingface/accelerate/tree/main/examples
#
########################################################################
MAX_GPU_BATCH_SIZE = 16
EVAL_BATCH_SIZE = 32
def get_dataloaders(accelerator: Accelerator, batch_size: int = 16):
"""
Creates a set of `DataLoader`s for the `glue` dataset,
using "bert-base-cased" as the tokenizer.
Args:
accelerator (`Accelerator`):
An `Accelerator` object
batch_size (`int`, *optional*):
The batch size for the train and validation DataLoaders.
"""
tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
datasets = load_dataset("glue", "mrpc")
def tokenize_function(examples):
# max_length=None => use the model max length (it's actually the default)
outputs = tokenizer(examples["sentence1"], examples["sentence2"], truncation=True, max_length=None)
return outputs
# Apply the method we just defined to all the examples in all the splits of the dataset
# starting with the main process first:
with accelerator.main_process_first():
tokenized_datasets = datasets.map(
tokenize_function,
batched=True,
remove_columns=["idx", "sentence1", "sentence2"],
)
# We also rename the 'label' column to 'labels' which is the expected name for labels by the models of the
# transformers library
tokenized_datasets = tokenized_datasets.rename_column("label", "labels")
def collate_fn(examples):
# On TPU it's best to pad everything to the same length or training will be very slow.
max_length = 128 if accelerator.distributed_type == DistributedType.XLA else None
# When using mixed precision we want round multiples of 8/16
if accelerator.mixed_precision == "fp8":
pad_to_multiple_of = 16
elif accelerator.mixed_precision != "no":
pad_to_multiple_of = 8
else:
pad_to_multiple_of = None
return tokenizer.pad(
examples,
padding="longest",
max_length=max_length,
pad_to_multiple_of=pad_to_multiple_of,
return_tensors="pt",
)
# Instantiate dataloaders.
train_dataloader = DataLoader(
tokenized_datasets["train"], shuffle=True, collate_fn=collate_fn, batch_size=batch_size
)
eval_dataloader = DataLoader(
tokenized_datasets["validation"], shuffle=False, collate_fn=collate_fn, batch_size=EVAL_BATCH_SIZE
)
return train_dataloader, eval_dataloader
# For testing only
if os.environ.get("TESTING_MOCKED_DATALOADERS", None) == "1":
from accelerate.test_utils.training import mocked_dataloaders
get_dataloaders = mocked_dataloaders # noqa: F811
def training_function(config, args):
# For testing only
if os.environ.get("TESTING_MOCKED_DATALOADERS", None) == "1":
config["num_epochs"] = 2
# Initialize accelerator
accelerator = Accelerator(cpu=args.cpu, mixed_precision=args.mixed_precision)
# Sample hyper-parameters for learning rate, batch size, seed and a few other HPs
lr = config["lr"]
num_epochs = int(config["num_epochs"])
seed = int(config["seed"])
batch_size = int(config["batch_size"])
metric = evaluate.load("glue", "mrpc")
# If the batch size is too big we use gradient accumulation
gradient_accumulation_steps = 1
if batch_size > MAX_GPU_BATCH_SIZE and accelerator.distributed_type != DistributedType.XLA:
gradient_accumulation_steps = batch_size // MAX_GPU_BATCH_SIZE
batch_size = MAX_GPU_BATCH_SIZE
set_seed(seed)
train_dataloader, eval_dataloader = get_dataloaders(accelerator, batch_size)
# Instantiate the model (we build the model here so that the seed also control new weights initialization)
model = AutoModelForSequenceClassification.from_pretrained("bert-base-cased", return_dict=True)
# We could avoid this line since the accelerator is set with `device_placement=True` (default value).
# Note that if you are placing tensors on devices manually, this line absolutely needs to be before the optimizer
# creation otherwise training will not work on TPU (`accelerate` will kindly throw an error to make us aware of that).
model = model.to(accelerator.device)
# Instantiate optimizer
optimizer = AdamW(params=model.parameters(), lr=lr)
# Instantiate scheduler
lr_scheduler = get_linear_schedule_with_warmup(
optimizer=optimizer,
num_warmup_steps=100,
num_training_steps=(len(train_dataloader) * num_epochs) // gradient_accumulation_steps,
)
# Prepare everything
# There is no specific order to remember, we just need to unpack the objects in the same order we gave them to the
# prepare method.
model, optimizer, train_dataloader, eval_dataloader, lr_scheduler = accelerator.prepare(
model, optimizer, train_dataloader, eval_dataloader, lr_scheduler
)
# Now we train the model
for epoch in range(num_epochs):
model.train()
for step, batch in enumerate(train_dataloader):
# We could avoid this line since we set the accelerator with `device_placement=True`.
batch.to(accelerator.device)
outputs = model(**batch)
loss = outputs.loss
loss = loss / gradient_accumulation_steps
accelerator.backward(loss)
if step % gradient_accumulation_steps == 0:
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad()
model.eval()
samples_seen = 0
for step, batch in enumerate(eval_dataloader):
# We could avoid this line since we set the accelerator with `device_placement=True`.
batch.to(accelerator.device)
with torch.no_grad():
outputs = model(**batch)
predictions = outputs.logits.argmax(dim=-1)
predictions, references = accelerator.gather((predictions, batch["labels"]))
# New Code #
# First we check if it's a distributed system
if accelerator.use_distributed:
# Then see if we're on the last batch of our eval dataloader
if step == len(eval_dataloader) - 1:
# Last batch needs to be truncated on distributed systems as it contains additional samples
predictions = predictions[: len(eval_dataloader.dataset) - samples_seen]
references = references[: len(eval_dataloader.dataset) - samples_seen]
else:
# Otherwise we add the number of samples seen
samples_seen += references.shape[0]
# All of this can be avoided if you use `Accelerator.gather_for_metrics` instead of `Accelerator.gather`:
# accelerator.gather_for_metrics((predictions, batch["labels"]))
metric.add_batch(
predictions=predictions,
references=references,
)
eval_metric = metric.compute()
# Use accelerator.print to print only on the main process.
accelerator.print(f"epoch {epoch}:", eval_metric)
accelerator.end_training()
def main():
parser = argparse.ArgumentParser(description="Simple example of training script.")
parser.add_argument(
"--mixed_precision",
type=str,
default=None,
choices=["no", "fp16", "bf16", "fp8"],
help="Whether to use mixed precision. Choose"
"between fp16 and bf16 (bfloat16). Bf16 requires PyTorch >= 1.10."
"and an Nvidia Ampere GPU.",
)
parser.add_argument("--cpu", action="store_true", help="If passed, will train on the CPU.")
args = parser.parse_args()
config = {"lr": 2e-5, "num_epochs": 3, "seed": 42, "batch_size": 16}
training_function(config, args)
if __name__ == "__main__":
main()
| 2 |
0 | hf_public_repos/accelerate/examples | hf_public_repos/accelerate/examples/by_feature/ddp_comm_hook.py | # Copyright 2021 The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import argparse
import os
import evaluate
import torch
from datasets import load_dataset
from torch.optim import AdamW
from torch.utils.data import DataLoader
from transformers import AutoModelForSequenceClassification, AutoTokenizer, get_linear_schedule_with_warmup, set_seed
from accelerate import Accelerator, DistributedType
from accelerate.utils import DDPCommunicationHookType, DistributedDataParallelKwargs
########################################################################
# This is a fully working simple example to use Accelerate
# and perform ddp communication hook
#
# This example trains a Bert base model on GLUE MRPC
# in any of the following settings (with the same script):
# - single CPU or single GPU
# - multi GPUS (using PyTorch distributed mode)
# - (multi) TPUs
# - fp16 (mixed-precision) or fp32 (normal precision)
#
# To run it in each of these various modes, follow the instructions
# in the readme for examples:
# https://github.com/huggingface/accelerate/tree/main/examples
#
########################################################################
MAX_GPU_BATCH_SIZE = 16
EVAL_BATCH_SIZE = 32
def get_dataloaders(accelerator: Accelerator, batch_size: int = 16):
"""
Creates a set of `DataLoader`s for the `glue` dataset,
using "bert-base-cased" as the tokenizer.
Args:
accelerator (`Accelerator`):
An `Accelerator` object
batch_size (`int`, *optional*):
The batch size for the train and validation DataLoaders.
"""
tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
datasets = load_dataset("glue", "mrpc")
def tokenize_function(examples):
# max_length=None => use the model max length (it's actually the default)
outputs = tokenizer(examples["sentence1"], examples["sentence2"], truncation=True, max_length=None)
return outputs
# Apply the method we just defined to all the examples in all the splits of the dataset
# starting with the main process first:
with accelerator.main_process_first():
tokenized_datasets = datasets.map(
tokenize_function,
batched=True,
remove_columns=["idx", "sentence1", "sentence2"],
)
# We also rename the 'label' column to 'labels' which is the expected name for labels by the models of the
# transformers library
tokenized_datasets = tokenized_datasets.rename_column("label", "labels")
def collate_fn(examples):
# On TPU it's best to pad everything to the same length or training will be very slow.
max_length = 128 if accelerator.distributed_type == DistributedType.XLA else None
# When using mixed precision we want round multiples of 8/16
if accelerator.mixed_precision == "fp8":
pad_to_multiple_of = 16
elif accelerator.mixed_precision != "no":
pad_to_multiple_of = 8
else:
pad_to_multiple_of = None
return tokenizer.pad(
examples,
padding="longest",
max_length=max_length,
pad_to_multiple_of=pad_to_multiple_of,
return_tensors="pt",
)
# Instantiate dataloaders.
train_dataloader = DataLoader(
tokenized_datasets["train"], shuffle=True, collate_fn=collate_fn, batch_size=batch_size
)
eval_dataloader = DataLoader(
tokenized_datasets["validation"], shuffle=False, collate_fn=collate_fn, batch_size=EVAL_BATCH_SIZE
)
return train_dataloader, eval_dataloader
# For testing only
if os.environ.get("TESTING_MOCKED_DATALOADERS", None) == "1":
from accelerate.test_utils.training import mocked_dataloaders
get_dataloaders = mocked_dataloaders # noqa: F811
def training_function(config, args):
# For testing only
if os.environ.get("TESTING_MOCKED_DATALOADERS", None) == "1":
config["num_epochs"] = 2
# New Code #
ddp_comm_hook_type = DDPCommunicationHookType(args.ddp_comm_hook)
ddp_comm_wrapper = DDPCommunicationHookType(args.ddp_comm_wrapper)
ddp_kwargs = DistributedDataParallelKwargs(comm_hook=ddp_comm_hook_type, comm_wrapper=ddp_comm_wrapper)
# Initialize accelerator
accelerator = Accelerator(cpu=args.cpu, mixed_precision=args.mixed_precision, kwargs_handlers=[ddp_kwargs])
# Sample hyper-parameters for learning rate, batch size, seed and a few other HPs
lr = config["lr"]
num_epochs = int(config["num_epochs"])
seed = int(config["seed"])
batch_size = int(config["batch_size"])
metric = evaluate.load("glue", "mrpc")
set_seed(seed)
train_dataloader, eval_dataloader = get_dataloaders(accelerator, batch_size)
# Instantiate the model (we build the model here so that the seed also control new weights initialization)
model = AutoModelForSequenceClassification.from_pretrained("bert-base-cased", return_dict=True)
# We could avoid this line since the accelerator is set with `device_placement=True` (default value).
# Note that if you are placing tensors on devices manually, this line absolutely needs to be before the optimizer
# creation otherwise training will not work on TPU (`accelerate` will kindly throw an error to make us aware of that).
model = model.to(accelerator.device)
# Instantiate optimizer
optimizer = AdamW(params=model.parameters(), lr=lr)
# Instantiate scheduler
lr_scheduler = get_linear_schedule_with_warmup(
optimizer=optimizer,
num_warmup_steps=100,
num_training_steps=(len(train_dataloader) * num_epochs),
)
# Prepare everything
# There is no specific order to remember, we just need to unpack the objects in the same order we gave them to the
# prepare method.
model, optimizer, train_dataloader, eval_dataloader, lr_scheduler = accelerator.prepare(
model, optimizer, train_dataloader, eval_dataloader, lr_scheduler
)
# Now we train the model
for epoch in range(num_epochs):
model.train()
for step, batch in enumerate(train_dataloader):
# We could avoid this line since we set the accelerator with `device_placement=True`.
batch.to(accelerator.device)
# We use the new `accumulate` context manager to perform gradient accumulation
with accelerator.accumulate(model):
output = model(**batch)
loss = output.loss
accelerator.backward(loss)
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad()
model.eval()
for step, batch in enumerate(eval_dataloader):
# We could avoid this line since we set the accelerator with `device_placement=True`.
batch.to(accelerator.device)
with torch.no_grad():
outputs = model(**batch)
predictions = outputs.logits.argmax(dim=-1)
predictions, references = accelerator.gather_for_metrics((predictions, batch["labels"]))
metric.add_batch(
predictions=predictions,
references=references,
)
eval_metric = metric.compute()
# Use accelerator.print to print only on the main process.
accelerator.print(f"epoch {epoch}:", eval_metric)
accelerator.end_training()
def main():
parser = argparse.ArgumentParser(description="Simple example of training script.")
parser.add_argument(
"--mixed_precision",
type=str,
default=None,
choices=["no", "fp16", "bf16", "fp8"],
help="Whether to use mixed precision. Choose"
"between fp16 and bf16 (bfloat16). Bf16 requires PyTorch >= 1.10."
"and an Nvidia Ampere GPU.",
)
# New Code #
parser.add_argument(
"--ddp_comm_hook",
type=str,
default="no",
choices=["no", "fp16", "bf16", "power_sgd", "batched_power_sgd"],
help="DDP Communication hook to use. Choose between `no`, `fp16`, `bf16`, `power_sgd`, and `batched_power_sgd`.",
)
# New Code #
parser.add_argument(
"--ddp_comm_wrapper",
type=str,
default="no",
choices=["no", "fp16", "bf16"],
help="DDP Communication wrapper to use. Choose between `no`, `fp16`, and `bf16`.",
)
parser.add_argument("--cpu", action="store_true", help="If passed, will train on the CPU.")
args = parser.parse_args()
config = {"lr": 2e-5, "num_epochs": 3, "seed": 42, "batch_size": 16}
training_function(config, args)
if __name__ == "__main__":
main()
| 3 |
0 | hf_public_repos/accelerate/examples | hf_public_repos/accelerate/examples/by_feature/cross_validation.py | # Copyright 2022 The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import argparse
from typing import List
import evaluate
import numpy as np
import torch
from datasets import DatasetDict, load_dataset
# New Code #
# We'll be using StratifiedKFold for this example
from sklearn.model_selection import StratifiedKFold
from torch.optim import AdamW
from torch.utils.data import DataLoader
from transformers import AutoModelForSequenceClassification, AutoTokenizer, get_linear_schedule_with_warmup, set_seed
from accelerate import Accelerator, DistributedType
########################################################################
# This is a fully working simple example to use Accelerate,
# specifically showcasing how to perform Cross Validation,
# and builds off the `nlp_example.py` script.
#
# This example trains a Bert base model on GLUE MRPC
# in any of the following settings (with the same script):
# - single CPU or single GPU
# - multi GPUS (using PyTorch distributed mode)
# - (multi) TPUs
# - fp16 (mixed-precision) or fp32 (normal precision)
#
# To help focus on the differences in the code, building `DataLoaders`
# was refactored into its own function.
# New additions from the base script can be found quickly by
# looking for the # New Code # tags
#
# To run it in each of these various modes, follow the instructions
# in the readme for examples:
# https://github.com/huggingface/accelerate/tree/main/examples
#
########################################################################
MAX_GPU_BATCH_SIZE = 16
EVAL_BATCH_SIZE = 32
# New Code #
# We need a different `get_dataloaders` function that will build dataloaders by index
def get_fold_dataloaders(
accelerator: Accelerator, dataset: DatasetDict, train_idxs: List[int], valid_idxs: List[int], batch_size: int = 16
):
"""
Gets a set of train, valid, and test dataloaders for a particular fold
Args:
accelerator (`Accelerator`):
The main `Accelerator` object
train_idxs (list of `int`):
The split indices for the training dataset
valid_idxs (list of `int`):
The split indices for the validation dataset
batch_size (`int`):
The size of the minibatch. Default is 16
"""
tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
datasets = DatasetDict(
{
"train": dataset["train"].select(train_idxs),
"validation": dataset["train"].select(valid_idxs),
"test": dataset["validation"],
}
)
def tokenize_function(examples):
# max_length=None => use the model max length (it's actually the default)
outputs = tokenizer(examples["sentence1"], examples["sentence2"], truncation=True, max_length=None)
return outputs
# Apply the method we just defined to all the examples in all the splits of the dataset
# starting with the main process first:
with accelerator.main_process_first():
tokenized_datasets = datasets.map(
tokenize_function,
batched=True,
remove_columns=["idx", "sentence1", "sentence2"],
)
# We also rename the 'label' column to 'labels' which is the expected name for labels by the models of the
# transformers library
tokenized_datasets = tokenized_datasets.rename_column("label", "labels")
def collate_fn(examples):
# On TPU it's best to pad everything to the same length or training will be very slow.
max_length = 128 if accelerator.distributed_type == DistributedType.XLA else None
# When using mixed precision we want round multiples of 8/16
if accelerator.mixed_precision == "fp8":
pad_to_multiple_of = 16
elif accelerator.mixed_precision != "no":
pad_to_multiple_of = 8
else:
pad_to_multiple_of = None
return tokenizer.pad(
examples,
padding="longest",
max_length=max_length,
pad_to_multiple_of=pad_to_multiple_of,
return_tensors="pt",
)
# Instantiate dataloaders.
train_dataloader = DataLoader(
tokenized_datasets["train"], shuffle=True, collate_fn=collate_fn, batch_size=batch_size
)
eval_dataloader = DataLoader(
tokenized_datasets["validation"], shuffle=False, collate_fn=collate_fn, batch_size=EVAL_BATCH_SIZE
)
test_dataloader = DataLoader(
tokenized_datasets["test"], shuffle=False, collate_fn=collate_fn, batch_size=EVAL_BATCH_SIZE
)
return train_dataloader, eval_dataloader, test_dataloader
def training_function(config, args):
# New Code #
test_predictions = []
# Download the dataset
datasets = load_dataset("glue", "mrpc")
# Create our splits
kfold = StratifiedKFold(n_splits=int(args.num_folds))
# Initialize accelerator
accelerator = Accelerator(cpu=args.cpu, mixed_precision=args.mixed_precision)
# Sample hyper-parameters for learning rate, batch size, seed and a few other HPs
lr = config["lr"]
num_epochs = int(config["num_epochs"])
seed = int(config["seed"])
batch_size = int(config["batch_size"])
metric = evaluate.load("glue", "mrpc")
# If the batch size is too big we use gradient accumulation
gradient_accumulation_steps = 1
if batch_size > MAX_GPU_BATCH_SIZE and accelerator.distributed_type != DistributedType.XLA:
gradient_accumulation_steps = batch_size // MAX_GPU_BATCH_SIZE
batch_size = MAX_GPU_BATCH_SIZE
set_seed(seed)
# New Code #
# Create our folds:
folds = kfold.split(np.zeros(datasets["train"].num_rows), datasets["train"]["label"])
test_references = []
# Iterate over them
for i, (train_idxs, valid_idxs) in enumerate(folds):
train_dataloader, eval_dataloader, test_dataloader = get_fold_dataloaders(
accelerator,
datasets,
train_idxs,
valid_idxs,
)
# Instantiate the model (we build the model here so that the seed also control new weights initialization)
model = AutoModelForSequenceClassification.from_pretrained("bert-base-cased", return_dict=True)
# We could avoid this line since the accelerator is set with `device_placement=True` (default value).
# Note that if you are placing tensors on devices manually, this line absolutely needs to be before the optimizer
# creation otherwise training will not work on TPU (`accelerate` will kindly throw an error to make us aware of that).
model = model.to(accelerator.device)
# Instantiate optimizer
optimizer = AdamW(params=model.parameters(), lr=lr)
# Instantiate scheduler
lr_scheduler = get_linear_schedule_with_warmup(
optimizer=optimizer,
num_warmup_steps=100,
num_training_steps=(len(train_dataloader) * num_epochs) // gradient_accumulation_steps,
)
# Prepare everything
# There is no specific order to remember, we just need to unpack the objects in the same order we gave them to the
# prepare method.
model, optimizer, train_dataloader, eval_dataloader, lr_scheduler = accelerator.prepare(
model, optimizer, train_dataloader, eval_dataloader, lr_scheduler
)
# Now we train the model
for epoch in range(num_epochs):
model.train()
for step, batch in enumerate(train_dataloader):
# We could avoid this line since we set the accelerator with `device_placement=True`.
batch.to(accelerator.device)
outputs = model(**batch)
loss = outputs.loss
loss = loss / gradient_accumulation_steps
accelerator.backward(loss)
if step % gradient_accumulation_steps == 0:
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad()
model.eval()
for step, batch in enumerate(eval_dataloader):
# We could avoid this line since we set the accelerator with `device_placement=True`.
batch.to(accelerator.device)
with torch.no_grad():
outputs = model(**batch)
predictions = outputs.logits.argmax(dim=-1)
predictions, references = accelerator.gather_for_metrics((predictions, batch["labels"]))
metric.add_batch(
predictions=predictions,
references=references,
)
eval_metric = metric.compute()
# Use accelerator.print to print only on the main process.
accelerator.print(f"epoch {epoch}:", eval_metric)
# New Code #
# We also run predictions on the test set at the very end
fold_predictions = []
for step, batch in enumerate(test_dataloader):
# We could avoid this line since we set the accelerator with `device_placement=True`.
batch.to(accelerator.device)
with torch.no_grad():
outputs = model(**batch)
predictions = outputs.logits
predictions, references = accelerator.gather_for_metrics((predictions, batch["labels"]))
fold_predictions.append(predictions.cpu())
if i == 0:
# We need all of the test predictions
test_references.append(references.cpu())
# Use accelerator.print to print only on the main process.
test_predictions.append(torch.cat(fold_predictions, dim=0))
# We now need to release all our memory and get rid of the current model, optimizer, etc
model, optimizer = accelerator.free_memory(model, optimizer)
# New Code #
# Finally we check the accuracy of our folded results:
test_references = torch.cat(test_references, dim=0)
preds = torch.stack(test_predictions, dim=0).sum(dim=0).div(int(args.num_folds)).argmax(dim=-1)
test_metric = metric.compute(predictions=preds, references=test_references)
accelerator.print("Average test metrics from all folds:", test_metric)
accelerator.end_training()
def main():
parser = argparse.ArgumentParser(description="Simple example of training script.")
parser.add_argument(
"--mixed_precision",
type=str,
default=None,
choices=["no", "fp16", "bf16", "fp8"],
help="Whether to use mixed precision. Choose"
"between fp16 and bf16 (bfloat16). Bf16 requires PyTorch >= 1.10."
"and an Nvidia Ampere GPU.",
)
parser.add_argument("--cpu", action="store_true", help="If passed, will train on the CPU.")
# New Code #
parser.add_argument("--num_folds", type=int, default=3, help="The number of splits to perform across the dataset")
args = parser.parse_args()
config = {"lr": 2e-5, "num_epochs": 3, "seed": 42, "batch_size": 16}
training_function(config, args)
if __name__ == "__main__":
main()
| 4 |
0 | hf_public_repos/accelerate/examples | hf_public_repos/accelerate/examples/by_feature/schedule_free.py | # Copyright 2024 The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import argparse
import os
import evaluate
import torch
from datasets import load_dataset
from torch.utils.data import DataLoader
from transformers import AutoModelForSequenceClassification, AutoTokenizer, set_seed
from accelerate import Accelerator, DistributedType
from accelerate.utils import is_schedulefree_available
if is_schedulefree_available():
import schedulefree
else:
raise ImportError(
"This example requires the `schedulefree` library. Please install it with `pip install schedulefree`"
)
########################################################################
# This is a fully working simple example to use Accelerate and Facebook's
# scheduler-free optimizer: https://github.com/facebookresearch/schedule_free/
#
# This example trains a Bert base model on GLUE MRPC
# in any of the following settings (with the same script):
# - single CPU or single GPU
# - multi GPUS (using PyTorch distributed mode)
# - (multi) TPUs
# - fp16 (mixed-precision) or fp32 (normal precision)
#
# To run it in each of these various modes, follow the instructions
# in the readme for examples:
# https://github.com/huggingface/accelerate/tree/main/examples
#
########################################################################
MAX_GPU_BATCH_SIZE = 16
EVAL_BATCH_SIZE = 32
def get_dataloaders(accelerator: Accelerator, batch_size: int = 16):
"""
Creates a set of `DataLoader`s for the `glue` dataset,
using "bert-base-cased" as the tokenizer.
Args:
accelerator (`Accelerator`):
An `Accelerator` object
batch_size (`int`, *optional*):
The batch size for the train and validation DataLoaders.
"""
tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
datasets = load_dataset("glue", "mrpc")
def tokenize_function(examples):
# max_length=None => use the model max length (it's actually the default)
outputs = tokenizer(examples["sentence1"], examples["sentence2"], truncation=True, max_length=None)
return outputs
# Apply the method we just defined to all the examples in all the splits of the dataset
# starting with the main process first:
with accelerator.main_process_first():
tokenized_datasets = datasets.map(
tokenize_function,
batched=True,
remove_columns=["idx", "sentence1", "sentence2"],
)
# We also rename the 'label' column to 'labels' which is the expected name for labels by the models of the
# transformers library
tokenized_datasets = tokenized_datasets.rename_column("label", "labels")
def collate_fn(examples):
# For Torchxla, it's best to pad everything to the same length or training will be very slow.
max_length = 128 if accelerator.distributed_type == DistributedType.XLA else None
# When using mixed precision we want round multiples of 8/16
if accelerator.mixed_precision == "fp8":
pad_to_multiple_of = 16
elif accelerator.mixed_precision != "no":
pad_to_multiple_of = 8
else:
pad_to_multiple_of = None
return tokenizer.pad(
examples,
padding="longest",
max_length=max_length,
pad_to_multiple_of=pad_to_multiple_of,
return_tensors="pt",
)
# Instantiate dataloaders.
train_dataloader = DataLoader(
tokenized_datasets["train"], shuffle=True, collate_fn=collate_fn, batch_size=batch_size, drop_last=True
)
eval_dataloader = DataLoader(
tokenized_datasets["validation"],
shuffle=False,
collate_fn=collate_fn,
batch_size=EVAL_BATCH_SIZE,
drop_last=(accelerator.mixed_precision == "fp8"),
)
return train_dataloader, eval_dataloader
# For testing only
if os.environ.get("TESTING_MOCKED_DATALOADERS", None) == "1":
from accelerate.test_utils.training import mocked_dataloaders
get_dataloaders = mocked_dataloaders # noqa: F811
def training_function(config, args):
# Initialize accelerator
accelerator = Accelerator(cpu=args.cpu, mixed_precision=args.mixed_precision)
# Sample hyper-parameters for learning rate, batch size, seed and a few other HPs
lr = config["lr"]
num_epochs = int(config["num_epochs"])
seed = int(config["seed"])
batch_size = int(config["batch_size"])
metric = evaluate.load("glue", "mrpc")
# If the batch size is too big we use gradient accumulation
gradient_accumulation_steps = 1
if batch_size > MAX_GPU_BATCH_SIZE and accelerator.distributed_type != DistributedType.XLA:
gradient_accumulation_steps = batch_size // MAX_GPU_BATCH_SIZE
batch_size = MAX_GPU_BATCH_SIZE
set_seed(seed)
train_dataloader, eval_dataloader = get_dataloaders(accelerator, batch_size)
# Instantiate the model (we build the model here so that the seed also control new weights initialization)
model = AutoModelForSequenceClassification.from_pretrained("bert-base-cased", return_dict=True)
# We could avoid this line since the accelerator is set with `device_placement=True` (default value).
# Note that if you are placing tensors on devices manually, this line absolutely needs to be before the optimizer
# creation otherwise training will not work on TPU (`accelerate` will kindly throw an error to make us aware of that).
model = model.to(accelerator.device)
# Instantiate optimizer with warmup steps
optimizer = schedulefree.AdamWScheduleFree(
model.parameters(),
lr=lr,
warmup_steps=100,
)
# Prepare everything
# There is no specific order to remember, we just need to unpack the objects in the same order we gave them to the
# prepare method.
model, optimizer, train_dataloader, eval_dataloader = accelerator.prepare(
model, optimizer, train_dataloader, eval_dataloader
)
# Now we train the model
for epoch in range(num_epochs):
model.train()
optimizer.train()
for step, batch in enumerate(train_dataloader):
# We could avoid this line since we set the accelerator with `device_placement=True`.
batch.to(accelerator.device)
outputs = model(**batch)
loss = outputs.loss
loss = loss / gradient_accumulation_steps
accelerator.backward(loss)
if step % gradient_accumulation_steps == 0:
optimizer.step()
optimizer.zero_grad()
model.eval()
optimizer.eval()
for step, batch in enumerate(eval_dataloader):
# We could avoid this line since we set the accelerator with `device_placement=True`.
batch.to(accelerator.device)
with torch.no_grad():
outputs = model(**batch)
predictions = outputs.logits.argmax(dim=-1)
predictions, references = accelerator.gather_for_metrics((predictions, batch["labels"]))
metric.add_batch(
predictions=predictions,
references=references,
)
eval_metric = metric.compute()
# Use accelerator.print to print only on the main process.
accelerator.print(f"epoch {epoch}:", eval_metric)
accelerator.end_training()
def main():
parser = argparse.ArgumentParser(description="Simple example of training script.")
parser.add_argument(
"--mixed_precision",
type=str,
default=None,
choices=["no", "fp16", "bf16", "fp8"],
help="Whether to use mixed precision. Choose"
"between fp16 and bf16 (bfloat16). Bf16 requires PyTorch >= 1.10."
"and an Nvidia Ampere GPU.",
)
parser.add_argument("--cpu", action="store_true", help="If passed, will train on the CPU.")
args = parser.parse_args()
config = {"lr": 2e-5, "num_epochs": 3, "seed": 42, "batch_size": 16}
training_function(config, args)
if __name__ == "__main__":
main()
| 5 |
0 | hf_public_repos/accelerate/examples | hf_public_repos/accelerate/examples/by_feature/early_stopping.py | # Copyright 2021 The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import argparse
import evaluate
import torch
from datasets import load_dataset
from torch.optim import AdamW
from torch.utils.data import DataLoader
from transformers import AutoModelForSequenceClassification, AutoTokenizer, get_linear_schedule_with_warmup, set_seed
from accelerate import Accelerator, DistributedType
########################################################################
# This is a fully working simple example to use Accelerate
# specifically showcasing how to perform early stopping,
# and builds off the `nlp_example.py` script
#
# This example trains a Bert base model on GLUE MRPC
# in any of the following settings (with the same script):
# - single CPU or single GPU
# - multi GPUS (using PyTorch distributed mode)
# - (multi) TPUs
# - fp16 (mixed-precision) or fp32 (normal precision)
#
# To run it in each of these various modes, follow the instructions
# in the readme for examples:
# https://github.com/huggingface/accelerate/tree/main/examples
#
########################################################################
MAX_GPU_BATCH_SIZE = 16
EVAL_BATCH_SIZE = 32
def get_dataloaders(accelerator: Accelerator, batch_size: int = 16):
"""
Creates a set of `DataLoader`s for the `glue` dataset,
using "bert-base-cased" as the tokenizer.
Args:
accelerator (`Accelerator`):
An `Accelerator` object
batch_size (`int`, *optional*):
The batch size for the train and validation DataLoaders.
"""
tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
datasets = load_dataset("glue", "mrpc")
def tokenize_function(examples):
# max_length=None => use the model max length (it's actually the default)
outputs = tokenizer(examples["sentence1"], examples["sentence2"], truncation=True, max_length=None)
return outputs
# Apply the method we just defined to all the examples in all the splits of the dataset
# starting with the main process first:
with accelerator.main_process_first():
tokenized_datasets = datasets.map(
tokenize_function,
batched=True,
remove_columns=["idx", "sentence1", "sentence2"],
)
# We also rename the 'label' column to 'labels' which is the expected name for labels by the models of the
# transformers library
tokenized_datasets = tokenized_datasets.rename_column("label", "labels")
def collate_fn(examples):
# On TPU it's best to pad everything to the same length or training will be very slow.
max_length = 128 if accelerator.distributed_type == DistributedType.XLA else None
# When using mixed precision we want round multiples of 8/16
if accelerator.mixed_precision == "fp8":
pad_to_multiple_of = 16
elif accelerator.mixed_precision != "no":
pad_to_multiple_of = 8
else:
pad_to_multiple_of = None
return tokenizer.pad(
examples,
padding="longest",
max_length=max_length,
pad_to_multiple_of=pad_to_multiple_of,
return_tensors="pt",
)
# Instantiate dataloaders.
train_dataloader = DataLoader(
tokenized_datasets["train"], shuffle=True, collate_fn=collate_fn, batch_size=batch_size, drop_last=True
)
eval_dataloader = DataLoader(
tokenized_datasets["validation"],
shuffle=False,
collate_fn=collate_fn,
batch_size=EVAL_BATCH_SIZE,
drop_last=(accelerator.mixed_precision == "fp8"),
)
return train_dataloader, eval_dataloader
# New code
class EarlyStoppingCallback:
"A callback class that helps with early stopping"
def __init__(self, min_delta=0, patience=5):
self.min_delta = min_delta
self.patience = patience
self.counter = 0
self.lowest_loss = float("inf")
def check_early_stopping(self, eval_loss):
delta = self.lowest_loss - eval_loss
if delta >= self.min_delta:
self.lowest_loss = eval_loss
self.counter = 0
else:
self.counter += 1
if self.counter >= self.patience:
return True
return False
callback = EarlyStoppingCallback()
def training_function(config, args):
# Initialize accelerator
accelerator = Accelerator(cpu=args.cpu, mixed_precision=args.mixed_precision)
# Sample hyper-parameters for learning rate, batch size, seed and a few other HPs
lr = config["lr"]
num_epochs = int(config["num_epochs"])
seed = int(config["seed"])
batch_size = int(config["batch_size"])
metric = evaluate.load("glue", "mrpc")
# If the batch size is too big we use gradient accumulation
gradient_accumulation_steps = 1
if batch_size > MAX_GPU_BATCH_SIZE and accelerator.distributed_type != DistributedType.XLA:
gradient_accumulation_steps = batch_size // MAX_GPU_BATCH_SIZE
batch_size = MAX_GPU_BATCH_SIZE
set_seed(seed)
train_dataloader, eval_dataloader = get_dataloaders(accelerator, batch_size)
# Instantiate the model (we build the model here so that the seed also control new weights initialization)
model = AutoModelForSequenceClassification.from_pretrained("bert-base-cased", return_dict=True)
# We could avoid this line since the accelerator is set with `device_placement=True` (default value).
# Note that if you are placing tensors on devices manually, this line absolutely needs to be before the optimizer
# creation otherwise training will not work on TPU (`accelerate` will kindly throw an error to make us aware of that).
model = model.to(accelerator.device)
# Instantiate optimizer
optimizer = AdamW(params=model.parameters(), lr=lr)
# Instantiate scheduler
lr_scheduler = get_linear_schedule_with_warmup(
optimizer=optimizer,
num_warmup_steps=100,
num_training_steps=(len(train_dataloader) * num_epochs) // gradient_accumulation_steps,
)
# Prepare everything
# There is no specific order to remember, we just need to unpack the objects in the same order we gave them to the
# prepare method.
model, optimizer, train_dataloader, eval_dataloader, lr_scheduler = accelerator.prepare(
model, optimizer, train_dataloader, eval_dataloader, lr_scheduler
)
# Now we train the model
for epoch in range(num_epochs):
model.train()
for step, batch in enumerate(train_dataloader):
# We could avoid this line since we set the accelerator with `device_placement=True`.
batch.to(accelerator.device)
outputs = model(**batch)
loss = outputs.loss
loss = loss / gradient_accumulation_steps
accelerator.backward(loss)
if step % gradient_accumulation_steps == 0:
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad()
# New code
# Check if we should stop the training on any processes
if callback.check_early_stopping(loss.item()):
accelerator.set_trigger()
# If so, we break the loop
if accelerator.check_trigger():
break
model.eval()
for step, batch in enumerate(eval_dataloader):
# We could avoid this line since we set the accelerator with `device_placement=True`.
batch.to(accelerator.device)
with torch.no_grad():
outputs = model(**batch)
predictions = outputs.logits.argmax(dim=-1)
predictions, references = accelerator.gather_for_metrics((predictions, batch["labels"]))
metric.add_batch(
predictions=predictions,
references=references,
)
eval_metric = metric.compute()
# Use accelerator.print to print only on the main process.
accelerator.print(f"epoch {epoch}:", eval_metric)
accelerator.end_training()
def main():
parser = argparse.ArgumentParser(description="Simple example of training script.")
parser.add_argument(
"--mixed_precision",
type=str,
default=None,
choices=["no", "fp16", "bf16", "fp8"],
help="Whether to use mixed precision. Choose"
"between fp16 and bf16 (bfloat16). Bf16 requires PyTorch >= 1.10."
"and an Nvidia Ampere GPU.",
)
parser.add_argument("--cpu", action="store_true", help="If passed, will train on the CPU.")
args = parser.parse_args()
config = {"lr": 2e-5, "num_epochs": 3, "seed": 42, "batch_size": 16}
training_function(config, args)
if __name__ == "__main__":
main()
| 6 |
0 | hf_public_repos/accelerate/examples | hf_public_repos/accelerate/examples/by_feature/automatic_gradient_accumulation.py | # Copyright 2022 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import argparse
import os
# New Code #
import evaluate
import torch
from datasets import load_dataset
from torch.optim import AdamW
from torch.utils.data import DataLoader
from transformers import AutoModelForSequenceClassification, AutoTokenizer, get_linear_schedule_with_warmup, set_seed
from accelerate import Accelerator
from accelerate.utils import find_executable_batch_size
########################################################################
# This is a fully working simple example to use Accelerate,
# specifically showcasing how to combine both the gradient accumulation
# and automatic batch size finder utilities of Accelerate to perfrom
# automatic gradient accumulation
#
# This example trains a Bert base model on GLUE MRPC
# in any of the following settings (with the same script):
# - single CPU or single GPU
# - multi GPUS (using PyTorch distributed mode)
# - (multi) TPUs
# - fp16 (mixed-precision) or fp32 (normal precision)
#
# New additions from the base script can be found quickly by
# looking for the # New Code # tags
#
# To run it in each of these various modes, follow the instructions
# in the readme for examples:
# https://github.com/huggingface/accelerate/tree/main/examples
#
########################################################################
EVAL_BATCH_SIZE = 32
def get_dataloaders(accelerator: Accelerator, batch_size: int = 16):
"""
Creates a set of `DataLoader`s for the `glue` dataset,
using "bert-base-cased" as the tokenizer.
Args:
accelerator (`Accelerator`):
An `Accelerator` object
batch_size (`int`, *optional*):
The batch size for the train and validation DataLoaders.
"""
tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
datasets = load_dataset("glue", "mrpc")
def tokenize_function(examples):
# max_length=None => use the model max length (it's actually the default)
outputs = tokenizer(examples["sentence1"], examples["sentence2"], truncation=True, max_length=None)
return outputs
# Apply the method we just defined to all the examples in all the splits of the dataset
# starting with the main process first:
with accelerator.main_process_first():
tokenized_datasets = datasets.map(
tokenize_function,
batched=True,
remove_columns=["idx", "sentence1", "sentence2"],
)
# We also rename the 'label' column to 'labels' which is the expected name for labels by the models of the
# transformers library
tokenized_datasets = tokenized_datasets.rename_column("label", "labels")
def collate_fn(examples):
# When using mixed precision we want round multiples of 8/16
if accelerator.mixed_precision == "fp8":
pad_to_multiple_of = 16
elif accelerator.mixed_precision != "no":
pad_to_multiple_of = 8
else:
pad_to_multiple_of = None
return tokenizer.pad(
examples,
padding="longest",
pad_to_multiple_of=pad_to_multiple_of,
return_tensors="pt",
)
# Instantiate dataloaders.
train_dataloader = DataLoader(
tokenized_datasets["train"], shuffle=True, collate_fn=collate_fn, batch_size=batch_size
)
eval_dataloader = DataLoader(
tokenized_datasets["validation"], shuffle=False, collate_fn=collate_fn, batch_size=EVAL_BATCH_SIZE
)
return train_dataloader, eval_dataloader
# For testing only
if os.environ.get("TESTING_MOCKED_DATALOADERS", None) == "1":
from accelerate.test_utils.training import mocked_dataloaders
get_dataloaders = mocked_dataloaders # noqa: F811
def training_function(config, args):
# For testing only
if os.environ.get("TESTING_MOCKED_DATALOADERS", None) == "1":
config["num_epochs"] = 2
# Initialize accelerator
accelerator = Accelerator(cpu=args.cpu, mixed_precision=args.mixed_precision)
# Sample hyper-parameters for learning rate, batch size, seed and a few other HPs
lr = config["lr"]
num_epochs = int(config["num_epochs"])
seed = int(config["seed"])
observed_batch_size = int(config["batch_size"])
metric = evaluate.load("glue", "mrpc")
# New Code #
# We use the `find_executable_batch_size` decorator, passing in the desired observed batch size
# to train on. If a CUDA OOM error occurs, it will retry this loop cutting the batch size in
# half each time. From this, we can calculate the number of gradient accumulation steps needed
# and modify the Accelerator object as a result
@find_executable_batch_size(starting_batch_size=int(observed_batch_size))
def inner_training_loop(batch_size):
# Since we need to modify the outside accelerator object, we need to bring it
# to the local scope
nonlocal accelerator
# We can calculate the number of gradient accumulation steps based on the current
# batch size vs the starting batch size
num_gradient_accumulation_steps = observed_batch_size // batch_size
# And then set it in the Accelerator directly:
accelerator.gradient_accumulation_steps = num_gradient_accumulation_steps
# Next we need to free all of the stored model references in the Accelerator each time
accelerator.free_memory()
# And set the seed so our results are reproducable each reset
set_seed(seed)
# Instantiate the model (we build the model here so that the seed also control new weights initialization)
model = AutoModelForSequenceClassification.from_pretrained("bert-base-cased", return_dict=True)
# We could avoid this line since the accelerator is set with `device_placement=True` (default value).
# Note that if you are placing tensors on devices manually, this line absolutely needs to be before the optimizer
# creation otherwise training will not work on TPU (`accelerate` will kindly throw an error to make us aware of that).
model = model.to(accelerator.device)
# Instantiate optimizer
optimizer = AdamW(params=model.parameters(), lr=lr)
train_dataloader, eval_dataloader = get_dataloaders(accelerator, batch_size)
# Instantiate scheduler
lr_scheduler = get_linear_schedule_with_warmup(
optimizer=optimizer,
num_warmup_steps=100,
num_training_steps=(len(train_dataloader) * num_epochs),
)
# Prepare everything
# There is no specific order to remember, we just need to unpack the objects in the same order we gave them to the
# prepare method.
model, optimizer, train_dataloader, eval_dataloader, lr_scheduler = accelerator.prepare(
model, optimizer, train_dataloader, eval_dataloader, lr_scheduler
)
# Now we train the model
for epoch in range(num_epochs):
model.train()
for step, batch in enumerate(train_dataloader):
# And perform gradient accumulation
with accelerator.accumulate(model):
# We could avoid this line since we set the accelerator with `device_placement=True`.
batch.to(accelerator.device)
outputs = model(**batch)
loss = outputs.loss
accelerator.backward(loss)
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad()
model.eval()
for step, batch in enumerate(eval_dataloader):
# We could avoid this line since we set the accelerator with `device_placement=True`.
batch.to(accelerator.device)
with torch.no_grad():
outputs = model(**batch)
predictions = outputs.logits.argmax(dim=-1)
predictions, references = accelerator.gather_for_metrics((predictions, batch["labels"]))
metric.add_batch(
predictions=predictions,
references=references,
)
eval_metric = metric.compute()
# Use accelerator.print to print only on the main process.
accelerator.print(f"epoch {epoch}:", eval_metric)
# New Code #
# And call it at the end with no arguments
# Note: You could also refactor this outside of your training loop function
inner_training_loop()
accelerator.end_training()
def main():
parser = argparse.ArgumentParser(description="Simple example of training script.")
parser.add_argument(
"--mixed_precision",
type=str,
default=None,
choices=["no", "fp16", "bf16", "fp8"],
help="Whether to use mixed precision. Choose"
"between fp16 and bf16 (bfloat16). Bf16 requires PyTorch >= 1.10."
"and an Nvidia Ampere GPU.",
)
parser.add_argument("--cpu", action="store_true", help="If passed, will train on the CPU.")
args = parser.parse_args()
# New Code #
# We modify the starting batch size to be an observed batch size of 256, to guarentee an initial CUDA OOM
config = {"lr": 2e-5, "num_epochs": 3, "seed": 42, "batch_size": 256}
training_function(config, args)
if __name__ == "__main__":
main()
| 7 |
0 | hf_public_repos/accelerate/examples | hf_public_repos/accelerate/examples/by_feature/megatron_lm_gpt_pretraining.py | #!/usr/bin/env python
# Copyright 2021 The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""
Fine-tuning the library models for causal language modeling (GPT, GPT-2, CTRL, ...)
on a text file or a dataset without using HuggingFace Trainer.
Here is the full list of checkpoints on the hub that can be fine-tuned by this script:
https://huggingface.co/models?filter=text-generation
"""
# You can also adapt this script on your own causal language modeling task. Pointers for this are left as comments.
import argparse
import json
import logging
import math
import os
import random
from itertools import chain
from pathlib import Path
import datasets
import torch
import transformers
from datasets import load_dataset
from huggingface_hub import HfApi
from torch.utils.data import DataLoader
from tqdm.auto import tqdm
from transformers import (
CONFIG_MAPPING,
MODEL_MAPPING,
AutoConfig,
AutoModelForCausalLM,
AutoTokenizer,
SchedulerType,
default_data_collator,
get_scheduler,
)
from transformers.utils import check_min_version, send_example_telemetry
from transformers.utils.versions import require_version
from accelerate import Accelerator, DistributedType
from accelerate.logging import get_logger
from accelerate.utils import MegatronLMDummyScheduler, set_seed
# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
check_min_version("4.23.0.dev0")
logger = get_logger(__name__)
require_version("datasets>=1.8.0", "To fix: pip install -r examples/pytorch/language-modeling/requirements.txt")
MODEL_CONFIG_CLASSES = list(MODEL_MAPPING.keys())
MODEL_TYPES = tuple(conf.model_type for conf in MODEL_CONFIG_CLASSES)
def parse_args():
parser = argparse.ArgumentParser(description="Finetune a transformers model on a causal language modeling task")
parser.add_argument(
"--dataset_name",
type=str,
default=None,
help="The name of the dataset to use (via the datasets library).",
)
parser.add_argument(
"--dataset_config_name",
type=str,
default=None,
help="The configuration name of the dataset to use (via the datasets library).",
)
parser.add_argument(
"--train_file", type=str, default=None, help="A csv or a json file containing the training data."
)
parser.add_argument(
"--validation_file", type=str, default=None, help="A csv or a json file containing the validation data."
)
parser.add_argument(
"--validation_split_percentage",
default=5,
help="The percentage of the train set used as validation set in case there's no validation split",
)
parser.add_argument(
"--model_name_or_path",
type=str,
help="Path to pretrained model or model identifier from huggingface.co/models.",
required=False,
)
parser.add_argument(
"--config_name",
type=str,
default=None,
help="Pretrained config name or path if not the same as model_name",
)
parser.add_argument(
"--tokenizer_name",
type=str,
default=None,
help="Pretrained tokenizer name or path if not the same as model_name",
)
parser.add_argument(
"--use_slow_tokenizer",
action="store_true",
help="If passed, will use a slow tokenizer (not backed by the 🤗 Tokenizers library).",
)
parser.add_argument(
"--per_device_train_batch_size",
type=int,
default=8,
help="Batch size (per device) for the training dataloader.",
)
parser.add_argument(
"--per_device_eval_batch_size",
type=int,
default=8,
help="Batch size (per device) for the evaluation dataloader.",
)
parser.add_argument(
"--learning_rate",
type=float,
default=5e-5,
help="Initial learning rate (after the potential warmup period) to use.",
)
parser.add_argument("--weight_decay", type=float, default=0.0, help="Weight decay to use.")
parser.add_argument("--num_train_epochs", type=int, default=3, help="Total number of training epochs to perform.")
parser.add_argument(
"--max_train_steps",
type=int,
default=None,
help="Total number of training steps to perform. If provided, overrides num_train_epochs.",
)
parser.add_argument(
"--gradient_accumulation_steps",
type=int,
default=1,
help="Number of updates steps to accumulate before performing a backward/update pass.",
)
parser.add_argument(
"--lr_scheduler_type",
type=SchedulerType,
default="linear",
help="The scheduler type to use.",
choices=["linear", "cosine", "cosine_with_restarts", "polynomial", "constant", "constant_with_warmup"],
)
parser.add_argument(
"--num_warmup_steps", type=int, default=0, help="Number of steps for the warmup in the lr scheduler."
)
parser.add_argument("--output_dir", type=str, default=None, help="Where to store the final model.")
parser.add_argument("--seed", type=int, default=None, help="A seed for reproducible training.")
parser.add_argument(
"--model_type",
type=str,
default=None,
help="Model type to use if training from scratch.",
choices=MODEL_TYPES,
)
parser.add_argument(
"--block_size",
type=int,
default=None,
help=(
"Optional input sequence length after tokenization. The training dataset will be truncated in block of"
" this size for training. Default to the model max input length for single sentence inputs (take into"
" account special tokens)."
),
)
parser.add_argument(
"--preprocessing_num_workers",
type=int,
default=None,
help="The number of processes to use for the preprocessing.",
)
parser.add_argument(
"--overwrite_cache", action="store_true", help="Overwrite the cached training and evaluation sets"
)
parser.add_argument(
"--no_keep_linebreaks", action="store_true", help="Do not keep line breaks when using TXT files."
)
parser.add_argument("--push_to_hub", action="store_true", help="Whether or not to push the model to the Hub.")
parser.add_argument(
"--hub_model_id", type=str, help="The name of the repository to keep in sync with the local `output_dir`."
)
parser.add_argument("--hub_token", type=str, help="The token to use to push to the Model Hub.")
parser.add_argument(
"--checkpointing_steps",
type=str,
default=None,
help="Whether the various states should be saved at the end of every n steps, or 'epoch' for each epoch.",
)
parser.add_argument(
"--resume_from_checkpoint",
type=str,
default=None,
help="If the training should continue from a checkpoint folder.",
)
parser.add_argument(
"--with_tracking",
action="store_true",
help="Whether to enable experiment trackers for logging.",
)
parser.add_argument(
"--report_to",
type=str,
default="all",
help=(
'The integration to report the results and logs to. Supported platforms are `"tensorboard"`,'
' `"wandb"`, `"comet_ml"`, and `"dvclive"`. Use `"all"` (default) to report to all integrations.'
"Only applicable when `--with_tracking` is passed."
),
)
args = parser.parse_args()
# Sanity checks
if args.dataset_name is None and args.train_file is None and args.validation_file is None:
raise ValueError("Need either a dataset name or a training/validation file.")
else:
if args.train_file is not None:
extension = args.train_file.split(".")[-1]
assert extension in ["csv", "json", "txt"], "`train_file` should be a csv, json or txt file."
if args.validation_file is not None:
extension = args.validation_file.split(".")[-1]
assert extension in ["csv", "json", "txt"], "`validation_file` should be a csv, json or txt file."
if args.push_to_hub:
assert args.output_dir is not None, "Need an `output_dir` to create a repo when `--push_to_hub` is passed."
return args
def main():
args = parse_args()
# Sending telemetry. Tracking the example usage helps us better allocate resources to maintain them. The
# information sent is the one passed as arguments along with your Python/PyTorch versions.
send_example_telemetry("run_clm_no_trainer", args)
# Initialize the accelerator. We will let the accelerator handle device placement for us in this example.
# If we're using tracking, we also need to initialize it here and it will by default pick up all supported trackers
# in the environment
accelerator_log_kwargs = {}
if args.with_tracking:
accelerator_log_kwargs["log_with"] = args.report_to
accelerator_log_kwargs["logging_dir"] = args.output_dir
accelerator = Accelerator(gradient_accumulation_steps=args.gradient_accumulation_steps, **accelerator_log_kwargs)
# Make one log on every process with the configuration for debugging.
logging.basicConfig(
format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
datefmt="%m/%d/%Y %H:%M:%S",
level=logging.INFO,
)
logger.info(accelerator.state, main_process_only=False)
if accelerator.is_local_main_process:
datasets.utils.logging.set_verbosity_warning()
transformers.utils.logging.set_verbosity_info()
else:
datasets.utils.logging.set_verbosity_error()
transformers.utils.logging.set_verbosity_error()
# If passed along, set the training seed now.
if args.seed is not None:
set_seed(args.seed)
# Handle the repository creation
if accelerator.is_main_process:
if args.push_to_hub:
api = HfApi(token=args.hub_token)
# Create repo (repo_name from args or inferred)
repo_name = args.hub_model_id
if repo_name is None:
repo_name = Path(args.output_dir).absolute().name
repo_id = api.create_repo(repo_name, exist_ok=True).repo_id
with open(os.path.join(args.output_dir, ".gitignore"), "w+") as gitignore:
if "step_*" not in gitignore:
gitignore.write("step_*\n")
if "epoch_*" not in gitignore:
gitignore.write("epoch_*\n")
elif args.output_dir is not None:
os.makedirs(args.output_dir, exist_ok=True)
accelerator.wait_for_everyone()
# Get the datasets: you can either provide your own CSV/JSON/TXT training and evaluation files (see below)
# or just provide the name of one of the public datasets available on the hub at https://huggingface.co/datasets/
# (the dataset will be downloaded automatically from the datasets Hub).
#
# For CSV/JSON files, this script will use the column called 'text' or the first column if no column called
# 'text' is found. You can easily tweak this behavior (see below).
#
# In distributed training, the load_dataset function guarantee that only one local process can concurrently
# download the dataset.
if args.dataset_name is not None:
# Downloading and loading a dataset from the hub.
raw_datasets = load_dataset(args.dataset_name, args.dataset_config_name)
if "validation" not in raw_datasets.keys():
raw_datasets["validation"] = load_dataset(
args.dataset_name,
args.dataset_config_name,
split=f"train[:{args.validation_split_percentage}%]",
)
raw_datasets["train"] = load_dataset(
args.dataset_name,
args.dataset_config_name,
split=f"train[{args.validation_split_percentage}%:]",
)
else:
data_files = {}
dataset_args = {}
if args.train_file is not None:
data_files["train"] = args.train_file
if args.validation_file is not None:
data_files["validation"] = args.validation_file
extension = args.train_file.split(".")[-1]
if extension == "txt":
extension = "text"
dataset_args["keep_linebreaks"] = not args.no_keep_linebreaks
raw_datasets = load_dataset(extension, data_files=data_files, **dataset_args)
# If no validation data is there, validation_split_percentage will be used to divide the dataset.
if "validation" not in raw_datasets.keys():
raw_datasets["validation"] = load_dataset(
extension,
data_files=data_files,
split=f"train[:{args.validation_split_percentage}%]",
**dataset_args,
)
raw_datasets["train"] = load_dataset(
extension,
data_files=data_files,
split=f"train[{args.validation_split_percentage}%:]",
**dataset_args,
)
# See more about loading any type of standard or custom dataset (from files, python dict, pandas DataFrame, etc) at
# https://huggingface.co/docs/datasets/loading_datasets.html.
# Load pretrained model and tokenizer
#
# In distributed training, the .from_pretrained methods guarantee that only one local process can concurrently
# download model & vocab.
if args.config_name:
config = AutoConfig.from_pretrained(args.config_name)
elif args.model_name_or_path:
config = AutoConfig.from_pretrained(args.model_name_or_path)
else:
config = CONFIG_MAPPING[args.model_type]()
logger.warning("You are instantiating a new config instance from scratch.")
if args.tokenizer_name:
tokenizer = AutoTokenizer.from_pretrained(args.tokenizer_name, use_fast=not args.use_slow_tokenizer)
elif args.model_name_or_path:
tokenizer = AutoTokenizer.from_pretrained(args.model_name_or_path, use_fast=not args.use_slow_tokenizer)
else:
raise ValueError(
"You are instantiating a new tokenizer from scratch. This is not supported by this script."
"You can do it from another script, save it, and load it from here, using --tokenizer_name."
)
if args.model_name_or_path:
model = AutoModelForCausalLM.from_pretrained(
args.model_name_or_path,
from_tf=bool(".ckpt" in args.model_name_or_path),
config=config,
)
else:
logger.info("Training new model from scratch")
model = AutoModelForCausalLM.from_config(config)
model.resize_token_embeddings(len(tokenizer))
# Preprocessing the datasets.
# First we tokenize all the texts.
column_names = raw_datasets["train"].column_names
text_column_name = "text" if "text" in column_names else column_names[0]
def tokenize_function(examples):
return tokenizer(examples[text_column_name])
with accelerator.main_process_first():
tokenized_datasets = raw_datasets.map(
tokenize_function,
batched=True,
num_proc=args.preprocessing_num_workers,
remove_columns=column_names,
load_from_cache_file=not args.overwrite_cache,
desc="Running tokenizer on dataset",
)
if args.block_size is None:
block_size = tokenizer.model_max_length
if block_size > 1024:
logger.warning(
f"The tokenizer picked seems to have a very large `model_max_length` ({tokenizer.model_max_length}). "
"Picking 1024 instead. You can change that default value by passing --block_size xxx."
)
block_size = 1024
else:
if args.block_size > tokenizer.model_max_length:
logger.warning(
f"The block_size passed ({args.block_size}) is larger than the maximum length for the model"
f"({tokenizer.model_max_length}). Using block_size={tokenizer.model_max_length}."
)
block_size = min(args.block_size, tokenizer.model_max_length)
# Main data processing function that will concatenate all texts from our dataset and generate chunks of block_size.
def group_texts(examples):
# Concatenate all texts.
concatenated_examples = {k: list(chain(*examples[k])) for k in examples.keys()}
total_length = len(concatenated_examples[list(examples.keys())[0]])
# We drop the small remainder, we could add padding if the model supported it instead of this drop, you can
# customize this part to your needs.
if total_length >= block_size:
total_length = (total_length // block_size) * block_size
# Split by chunks of max_len.
result = {
k: [t[i : i + block_size] for i in range(0, total_length, block_size)]
for k, t in concatenated_examples.items()
}
result["labels"] = result["input_ids"].copy()
return result
# Note that with `batched=True`, this map processes 1,000 texts together, so group_texts throws away a remainder
# for each of those groups of 1,000 texts. You can adjust that batch_size here but a higher value might be slower
# to preprocess.
#
# To speed up this part, we use multiprocessing. See the documentation of the map method for more information:
# https://huggingface.co/docs/datasets/package_reference/main_classes.html#datasets.Dataset.map
with accelerator.main_process_first():
lm_datasets = tokenized_datasets.map(
group_texts,
batched=True,
num_proc=args.preprocessing_num_workers,
load_from_cache_file=not args.overwrite_cache,
desc=f"Grouping texts in chunks of {block_size}",
)
train_dataset = lm_datasets["train"]
eval_dataset = lm_datasets["validation"]
# Log a few random samples from the training set:
for index in random.sample(range(len(train_dataset)), 3):
logger.info(f"Sample {index} of the training set: {train_dataset[index]}.")
# DataLoaders creation:
train_dataloader = DataLoader(
train_dataset, shuffle=True, collate_fn=default_data_collator, batch_size=args.per_device_train_batch_size
)
eval_dataloader = DataLoader(
eval_dataset, collate_fn=default_data_collator, batch_size=args.per_device_eval_batch_size
)
# Optimizer
# Split weights in two groups, one with weight decay and the other not.
no_decay = ["bias", "layer_norm.weight"]
optimizer_grouped_parameters = [
{
"params": [p for n, p in model.named_parameters() if not any(nd in n for nd in no_decay)],
"weight_decay": args.weight_decay,
},
{
"params": [p for n, p in model.named_parameters() if any(nd in n for nd in no_decay)],
"weight_decay": 0.0,
},
]
optimizer = torch.optim.AdamW(optimizer_grouped_parameters, lr=args.learning_rate)
# Scheduler and math around the number of training steps.
overrode_max_train_steps = False
num_update_steps_per_epoch = math.ceil(len(train_dataloader) / args.gradient_accumulation_steps)
if args.max_train_steps is None:
args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
overrode_max_train_steps = True
# New Code
# For Megatron-LM, we need to use `MegatronLMDummyScheduler` instead of regular schedulers
if accelerator.distributed_type == DistributedType.MEGATRON_LM:
lr_scheduler = MegatronLMDummyScheduler(
optimizer=optimizer,
total_num_steps=args.max_train_steps,
warmup_num_steps=args.num_warmup_steps,
)
else:
lr_scheduler = get_scheduler(
name=args.lr_scheduler_type,
optimizer=optimizer,
num_warmup_steps=args.num_warmup_steps * args.gradient_accumulation_steps,
num_training_steps=args.max_train_steps * args.gradient_accumulation_steps,
)
# Prepare everything with our `accelerator`.
model, optimizer, train_dataloader, eval_dataloader, lr_scheduler = accelerator.prepare(
model, optimizer, train_dataloader, eval_dataloader, lr_scheduler
)
# On TPU, the tie weights in our model have been disconnected, so we need to restore the ties.
if accelerator.distributed_type == DistributedType.XLA:
model.tie_weights()
# We need to recalculate our total training steps as the size of the training dataloader may have changed.
num_update_steps_per_epoch = math.ceil(len(train_dataloader) / args.gradient_accumulation_steps)
if overrode_max_train_steps:
args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
# Afterwards we recalculate our number of training epochs
args.num_train_epochs = math.ceil(args.max_train_steps / num_update_steps_per_epoch)
# Figure out how many steps we should save the Accelerator states
checkpointing_steps = args.checkpointing_steps
if checkpointing_steps is not None and checkpointing_steps.isdigit():
checkpointing_steps = int(checkpointing_steps)
# We need to initialize the trackers we use, and also store our configuration.
# The trackers initializes automatically on the main process.
if args.with_tracking:
experiment_config = vars(args)
# TensorBoard cannot log Enums, need the raw value
experiment_config["lr_scheduler_type"] = experiment_config["lr_scheduler_type"].value
accelerator.init_trackers("clm_no_trainer", experiment_config)
# Train!
# New Code
# For Megatron-LM, we need to get `global_batch_size` from megatron_lm_plugin
# as it handles the specifics related to data parallelism, tensor model parallelism and pipeline parallelism
if accelerator.distributed_type == DistributedType.MEGATRON_LM:
total_batch_size = accelerator.state.megatron_lm_plugin.global_batch_size
else:
total_batch_size = (
args.per_device_train_batch_size * accelerator.num_processes * args.gradient_accumulation_steps
)
logger.info("***** Running training *****")
logger.info(f" Num examples = {len(train_dataset)}")
logger.info(f" Num Epochs = {args.num_train_epochs}")
logger.info(f" Instantaneous batch size per device = {args.per_device_train_batch_size}")
logger.info(f" Total train batch size (w. parallel, distributed & accumulation) = {total_batch_size}")
logger.info(f" Gradient Accumulation steps = {args.gradient_accumulation_steps}")
logger.info(f" Total optimization steps = {args.max_train_steps}")
# Only show the progress bar once on each machine.
progress_bar = tqdm(range(args.max_train_steps), disable=not accelerator.is_local_main_process)
completed_steps = 0
starting_epoch = 0
# Potentially load in the weights and states from a previous save
if args.resume_from_checkpoint:
if args.resume_from_checkpoint is not None or args.resume_from_checkpoint != "":
accelerator.print(f"Resumed from checkpoint: {args.resume_from_checkpoint}")
accelerator.load_state(args.resume_from_checkpoint)
path = os.path.basename(args.resume_from_checkpoint)
else:
# Get the most recent checkpoint
dirs = [f.name for f in os.scandir(os.getcwd()) if f.is_dir()]
dirs.sort(key=os.path.getctime)
path = dirs[-1] # Sorts folders by date modified, most recent checkpoint is the last
# Extract `epoch_{i}` or `step_{i}`
training_difference = os.path.splitext(path)[0]
if "epoch" in training_difference:
starting_epoch = int(training_difference.replace("epoch_", "")) + 1
resume_step = None
else:
# need to multiply `gradient_accumulation_steps` to reflect real steps
resume_step = int(training_difference.replace("step_", "")) * args.gradient_accumulation_steps
starting_epoch = resume_step // len(train_dataloader)
resume_step -= starting_epoch * len(train_dataloader)
# update the progress_bar if load from checkpoint
progress_bar.update(starting_epoch * num_update_steps_per_epoch)
completed_steps = starting_epoch * num_update_steps_per_epoch
for epoch in range(starting_epoch, args.num_train_epochs):
model.train()
if args.with_tracking:
total_loss = 0
for step, batch in enumerate(train_dataloader):
# We need to skip steps until we reach the resumed step
if args.resume_from_checkpoint and epoch == starting_epoch:
if resume_step is not None and step < resume_step:
if step % args.gradient_accumulation_steps == 0:
progress_bar.update(1)
completed_steps += 1
continue
with accelerator.accumulate(model):
outputs = model(**batch)
loss = outputs.loss
# We keep track of the loss at each epoch
if args.with_tracking:
total_loss += loss.detach().float()
accelerator.backward(loss)
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad()
# Checks if the accelerator has performed an optimization step behind the scenes
if accelerator.sync_gradients:
progress_bar.update(1)
completed_steps += 1
if isinstance(checkpointing_steps, int):
if completed_steps % checkpointing_steps == 0:
output_dir = f"step_{completed_steps }"
if args.output_dir is not None:
output_dir = os.path.join(args.output_dir, output_dir)
accelerator.save_state(output_dir)
if completed_steps >= args.max_train_steps:
break
model.eval()
losses = []
for step, batch in enumerate(eval_dataloader):
with torch.no_grad():
outputs = model(**batch)
loss = outputs.loss
# New Code
# For Megatron-LM, the losses are already averaged across the data parallel group
if accelerator.distributed_type == DistributedType.MEGATRON_LM:
losses.append(loss)
else:
losses.append(accelerator.gather_for_metrics(loss.repeat(args.per_device_eval_batch_size)))
try:
if accelerator.distributed_type == DistributedType.MEGATRON_LM:
losses = torch.tensor(losses)
else:
losses = torch.cat(losses)
eval_loss = torch.mean(losses)
perplexity = math.exp(eval_loss)
except OverflowError:
perplexity = float("inf")
logger.info(f"epoch {epoch}: perplexity: {perplexity} eval_loss: {eval_loss}")
if args.with_tracking:
accelerator.log(
{
"perplexity": perplexity,
"eval_loss": eval_loss,
"train_loss": total_loss.item() / len(train_dataloader),
"epoch": epoch,
"step": completed_steps,
},
step=completed_steps,
)
if args.push_to_hub and epoch < args.num_train_epochs - 1:
accelerator.wait_for_everyone()
unwrapped_model = accelerator.unwrap_model(model)
unwrapped_model.save_pretrained(
args.output_dir, is_main_process=accelerator.is_main_process, save_function=accelerator.save
)
if accelerator.is_main_process:
tokenizer.save_pretrained(args.output_dir)
api.upload_folder(
repo_id=repo_id,
folder_path=args.output_dir,
commit_message=f"Training in progress epoch {epoch}",
run_as_future=True,
)
if args.checkpointing_steps == "epoch":
output_dir = f"epoch_{epoch}"
if args.output_dir is not None:
output_dir = os.path.join(args.output_dir, output_dir)
accelerator.save_state(output_dir)
# this is causing some issue with Megatron-LM when using `wandb` at the end of the main function.
# Everything works fine inspite of commenting this out. (wandb finishes/closes the run without error)
# if args.with_tracking:
# accelerator.end_training()
if args.output_dir is not None:
accelerator.wait_for_everyone()
# New Code
# For Megatron-LM, we need to save the model using `accelerator.save_state`
if accelerator.distributed_type == DistributedType.MEGATRON_LM:
accelerator.save_state(args.output_dir)
else:
unwrapped_model = accelerator.unwrap_model(model)
unwrapped_model.save_pretrained(
args.output_dir, is_main_process=accelerator.is_main_process, save_function=accelerator.save
)
if accelerator.is_main_process:
tokenizer.save_pretrained(args.output_dir)
if args.push_to_hub:
api.upload_folder(
repo_id=repo_id,
folder_path=args.output_dir,
commit_message="End of training",
)
with open(os.path.join(args.output_dir, "all_results.json"), "w") as f:
json.dump({"perplexity": perplexity}, f)
accelerator.end_training()
if __name__ == "__main__":
main()
| 8 |
0 | hf_public_repos/accelerate/examples | hf_public_repos/accelerate/examples/by_feature/checkpointing.py | # Copyright 2021 The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import argparse
import os
import evaluate
import torch
from datasets import load_dataset
from torch.optim import AdamW
from torch.utils.data import DataLoader
from transformers import AutoModelForSequenceClassification, AutoTokenizer, get_linear_schedule_with_warmup
from accelerate import Accelerator, DataLoaderConfiguration, DistributedType
from accelerate.utils import set_seed
########################################################################
# This is a fully working simple example to use Accelerate,
# specifically showcasing the checkpointing capability,
# and builds off the `nlp_example.py` script.
#
# This example trains a Bert base model on GLUE MRPC
# in any of the following settings (with the same script):
# - single CPU or single GPU
# - multi GPUS (using PyTorch distributed mode)
# - (multi) TPUs
# - fp16 (mixed-precision) or fp32 (normal precision)
#
# To help focus on the differences in the code, building `DataLoaders`
# was refactored into its own function.
# New additions from the base script can be found quickly by
# looking for the # New Code # tags
#
# To run it in each of these various modes, follow the instructions
# in the readme for examples:
# https://github.com/huggingface/accelerate/tree/main/examples
#
########################################################################
MAX_GPU_BATCH_SIZE = 16
EVAL_BATCH_SIZE = 32
def get_dataloaders(accelerator: Accelerator, batch_size: int = 16):
"""
Creates a set of `DataLoader`s for the `glue` dataset,
using "bert-base-cased" as the tokenizer.
Args:
accelerator (`Accelerator`):
An `Accelerator` object
batch_size (`int`, *optional*):
The batch size for the train and validation DataLoaders.
"""
tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
datasets = load_dataset("glue", "mrpc")
def tokenize_function(examples):
# max_length=None => use the model max length (it's actually the default)
outputs = tokenizer(examples["sentence1"], examples["sentence2"], truncation=True, max_length=None)
return outputs
# Apply the method we just defined to all the examples in all the splits of the dataset
# starting with the main process first:
with accelerator.main_process_first():
tokenized_datasets = datasets.map(
tokenize_function,
batched=True,
remove_columns=["idx", "sentence1", "sentence2"],
)
# We also rename the 'label' column to 'labels' which is the expected name for labels by the models of the
# transformers library
tokenized_datasets = tokenized_datasets.rename_column("label", "labels")
def collate_fn(examples):
# On TPU it's best to pad everything to the same length or training will be very slow.
max_length = 128 if accelerator.distributed_type == DistributedType.XLA else None
# When using mixed precision we want round multiples of 8/16
if accelerator.mixed_precision == "fp8":
pad_to_multiple_of = 16
elif accelerator.mixed_precision != "no":
pad_to_multiple_of = 8
else:
pad_to_multiple_of = None
return tokenizer.pad(
examples,
padding="longest",
max_length=max_length,
pad_to_multiple_of=pad_to_multiple_of,
return_tensors="pt",
)
# Instantiate dataloaders.
train_dataloader = DataLoader(
tokenized_datasets["train"], shuffle=True, collate_fn=collate_fn, batch_size=batch_size
)
eval_dataloader = DataLoader(
tokenized_datasets["validation"], shuffle=False, collate_fn=collate_fn, batch_size=EVAL_BATCH_SIZE
)
return train_dataloader, eval_dataloader
# For testing only
if os.environ.get("TESTING_MOCKED_DATALOADERS", None) == "1":
from accelerate.test_utils.training import mocked_dataloaders
get_dataloaders = mocked_dataloaders # noqa: F811
def training_function(config, args):
# For testing only
if os.environ.get("TESTING_MOCKED_DATALOADERS", None) == "1":
config["num_epochs"] = 2
# Initialize accelerator
dataloader_config = DataLoaderConfiguration(use_stateful_dataloader=args.use_stateful_dataloader)
accelerator = Accelerator(cpu=args.cpu, mixed_precision=args.mixed_precision, dataloader_config=dataloader_config)
# Sample hyper-parameters for learning rate, batch size, seed and a few other HPs
lr = config["lr"]
num_epochs = int(config["num_epochs"])
seed = int(config["seed"])
batch_size = int(config["batch_size"])
# New Code #
# Parse out whether we are saving every epoch or after a certain number of batches
if hasattr(args.checkpointing_steps, "isdigit"):
if args.checkpointing_steps == "epoch":
checkpointing_steps = args.checkpointing_steps
elif args.checkpointing_steps.isdigit():
checkpointing_steps = int(args.checkpointing_steps)
else:
raise ValueError(
f"Argument `checkpointing_steps` must be either a number or `epoch`. `{args.checkpointing_steps}` passed."
)
else:
checkpointing_steps = None
set_seed(seed)
train_dataloader, eval_dataloader = get_dataloaders(accelerator, batch_size)
metric = evaluate.load("glue", "mrpc")
# If the batch size is too big we use gradient accumulation
gradient_accumulation_steps = 1
if batch_size > MAX_GPU_BATCH_SIZE and accelerator.distributed_type != DistributedType.XLA:
gradient_accumulation_steps = batch_size // MAX_GPU_BATCH_SIZE
batch_size = MAX_GPU_BATCH_SIZE
# Instantiate the model (we build the model here so that the seed also control new weights initialization)
model = AutoModelForSequenceClassification.from_pretrained("bert-base-cased", return_dict=True)
# We could avoid this line since the accelerator is set with `device_placement=True` (default value).
# Note that if you are placing tensors on devices manually, this line absolutely needs to be before the optimizer
# creation otherwise training will not work on TPU (`accelerate` will kindly throw an error to make us aware of that).
model = model.to(accelerator.device)
# Instantiate optimizer
optimizer = AdamW(params=model.parameters(), lr=lr)
# Instantiate scheduler
lr_scheduler = get_linear_schedule_with_warmup(
optimizer=optimizer,
num_warmup_steps=100,
num_training_steps=(len(train_dataloader) * num_epochs) // gradient_accumulation_steps,
)
# Prepare everything
# There is no specific order to remember, we just need to unpack the objects in the same order we gave them to the
# prepare method.
model, optimizer, train_dataloader, eval_dataloader, lr_scheduler = accelerator.prepare(
model, optimizer, train_dataloader, eval_dataloader, lr_scheduler
)
# New Code #
# We need to keep track of how many total steps we have iterated over
overall_step = 0
# We also need to keep track of the stating epoch so files are named properly
starting_epoch = 0
# We need to load the checkpoint back in before training here with `load_state`
# The total number of epochs is adjusted based on where the state is being loaded from,
# as we assume continuation of the same training script
if args.resume_from_checkpoint:
if args.resume_from_checkpoint is not None or args.resume_from_checkpoint != "":
accelerator.print(f"Resumed from checkpoint: {args.resume_from_checkpoint}")
accelerator.load_state(args.resume_from_checkpoint)
path = os.path.basename(args.resume_from_checkpoint)
else:
# Get the most recent checkpoint
dirs = [f.name for f in os.scandir(os.getcwd()) if f.is_dir()]
dirs.sort(key=os.path.getctime)
path = dirs[-1] # Sorts folders by date modified, most recent checkpoint is the last
# Extract `epoch_{i}` or `step_{i}`
training_difference = os.path.splitext(path)[0]
if "epoch" in training_difference:
starting_epoch = int(training_difference.replace("epoch_", "")) + 1
resume_step = None
else:
resume_step = int(training_difference.replace("step_", ""))
starting_epoch = resume_step // len(train_dataloader)
resume_step -= starting_epoch * len(train_dataloader)
# Now we train the model
for epoch in range(starting_epoch, num_epochs):
model.train()
# New Code #
if args.resume_from_checkpoint and epoch == starting_epoch and resume_step is not None:
# We need to skip steps until we reach the resumed step only if we are not using a stateful dataloader
if not args.use_stateful_dataloader:
active_dataloader = accelerator.skip_first_batches(train_dataloader, resume_step)
else:
active_dataloader = train_dataloader
overall_step += resume_step
else:
# After the first iteration though, we need to go back to the original dataloader
active_dataloader = train_dataloader
for step, batch in enumerate(active_dataloader):
# We could avoid this line since we set the accelerator with `device_placement=True`.
batch.to(accelerator.device)
outputs = model(**batch)
loss = outputs.loss
loss = loss / gradient_accumulation_steps
accelerator.backward(loss)
if step % gradient_accumulation_steps == 0:
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad()
# New Code #
overall_step += 1
# New Code #
# We save the model, optimizer, lr_scheduler, and seed states by calling `save_state`
# These are saved to folders named `step_{overall_step}`
# Will contain files: "pytorch_model.bin", "optimizer.bin", "scheduler.bin", and "random_states.pkl"
# If mixed precision was used, will also save a "scalar.bin" file
if isinstance(checkpointing_steps, int):
output_dir = f"step_{overall_step}"
if overall_step % checkpointing_steps == 0:
if args.output_dir is not None:
output_dir = os.path.join(args.output_dir, output_dir)
accelerator.save_state(output_dir)
model.eval()
for step, batch in enumerate(eval_dataloader):
# We could avoid this line since we set the accelerator with `device_placement=True` (the default).
batch.to(accelerator.device)
with torch.no_grad():
outputs = model(**batch)
predictions = outputs.logits.argmax(dim=-1)
predictions, references = accelerator.gather_for_metrics((predictions, batch["labels"]))
metric.add_batch(
predictions=predictions,
references=references,
)
eval_metric = metric.compute()
# Use accelerator.print to print only on the main process.
accelerator.print(f"epoch {epoch}:", eval_metric)
# New Code #
# We save the model, optimizer, lr_scheduler, and seed states by calling `save_state`
# These are saved to folders named `epoch_{epoch}`
# Will contain files: "pytorch_model.bin", "optimizer.bin", "scheduler.bin", and "random_states.pkl"
# If mixed precision was used, will also save a "scalar.bin" file
if checkpointing_steps == "epoch":
output_dir = f"epoch_{epoch}"
if args.output_dir is not None:
output_dir = os.path.join(args.output_dir, output_dir)
accelerator.save_state(output_dir)
accelerator.end_training()
def main():
parser = argparse.ArgumentParser(description="Simple example of training script.")
parser.add_argument(
"--mixed_precision",
type=str,
default=None,
choices=["no", "fp16", "bf16", "fp8"],
help="Whether to use mixed precision. Choose"
"between fp16 and bf16 (bfloat16). Bf16 requires PyTorch >= 1.10."
"and an Nvidia Ampere GPU.",
)
parser.add_argument("--cpu", action="store_true", help="If passed, will train on the CPU.")
parser.add_argument(
"--checkpointing_steps",
type=str,
default=None,
help="Whether the various states should be saved at the end of every n steps, or 'epoch' for each epoch.",
)
parser.add_argument(
"--output_dir",
type=str,
default=".",
help="Optional save directory where all checkpoint folders will be stored. Default is the current working directory.",
)
parser.add_argument(
"--resume_from_checkpoint",
type=str,
default=None,
help="If the training should continue from a checkpoint folder.",
)
parser.add_argument(
"--use_stateful_dataloader",
action="store_true",
help="If the dataloader should be a resumable stateful dataloader.",
)
args = parser.parse_args()
config = {"lr": 2e-5, "num_epochs": 3, "seed": 42, "batch_size": 16}
training_function(config, args)
if __name__ == "__main__":
main()
| 9 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.