
index
int64 0
0
| repo_id
stringclasses 179
values | file_path
stringlengths 26
186
| content
stringlengths 1
2.1M
| __index_level_0__
int64 0
9
|
|---|---|---|---|---|
0 | hf_public_repos/candle/candle-pyo3/py_src/candle | hf_public_repos/candle/candle-pyo3/py_src/candle/nn/normalization.py | import candle
from candle import Tensor
from .module import Module
from typing import Union, List, Tuple, Optional, Any
_shape_t = Union[int, List[int]]
import numbers
class LayerNorm(Module):
r"""Applies Layer Normalization over a mini-batch of inputs as described in
the paper `Layer Normalization <https://arxiv.org/abs/1607.06450>`
math::
y = \frac{x - \mathrm{E}[x]}{ \sqrt{\mathrm{Var}[x] + \epsilon}} * \gamma + \beta
"""
__constants__ = ["normalized_shape", "eps"]
normalized_shape: Tuple[int, ...]
eps: float
def __init__(
self,
normalized_shape: _shape_t,
eps: float = 1e-5,
bias: bool = True,
device=None,
dtype=None,
) -> None:
factory_kwargs = {"device": device, "dtype": dtype}
super().__init__()
if isinstance(normalized_shape, numbers.Integral):
normalized_shape = (normalized_shape,)
self.normalized_shape = tuple(normalized_shape)
self.eps = eps
self.weight = candle.ones(normalized_shape, **factory_kwargs)
if bias:
self.bias = candle.zeros(normalized_shape, **factory_kwargs)
else:
self.bias = None
def forward(self, input: Tensor) -> Tensor:
mean_x = input.sum_keepdim(2) / float(self.normalized_shape[-1])
x = input.broadcast_sub(mean_x)
norm_x = x.sqr().sum_keepdim(2) / float(self.normalized_shape[-1])
x_normed = x.broadcast_div((norm_x + self.eps).sqrt())
x = x_normed.broadcast_mul(self.weight)
if self.bias:
x = x.broadcast_add(self.bias)
return x
def extra_repr(self) -> str:
return "{normalized_shape}, eps={eps}, " "elementwise_affine={elementwise_affine}".format(**self.__dict__)
| 0 |
0 | hf_public_repos/candle/candle-pyo3/py_src/candle | hf_public_repos/candle/candle-pyo3/py_src/candle/nn/__init__.py | from .module import Module
from .container import Sequential, ModuleList, ModuleDict
from .sparse import Embedding
from .normalization import LayerNorm
from .linear import Linear
| 1 |
0 | hf_public_repos/candle/candle-pyo3/py_src/candle | hf_public_repos/candle/candle-pyo3/py_src/candle/nn/sparse.py | from .module import Module
from typing import Optional, Tuple, Any
from candle import Tensor
import candle
class Embedding(Module):
"""A simple lookup table that stores embeddings of a fixed dictionary and size.
This module is often used to store word embeddings and retrieve them using indices.
The input to the module is a list of indices, and the output is the corresponding
word embeddings.
Args:
num_embeddings (int): size of the dictionary of embeddings
embedding_dim (int): the size of each embedding vector
Attributes:
weight (Tensor): the learnable weights of the module of shape (num_embeddings, embedding_dim)
initialized from :math:`\mathcal{N}(0, 1)`
Shape:
- Input: :math:`(*)`, IntTensor or LongTensor of arbitrary shape containing the indices to extract
- Output: :math:`(*, H)`, where `*` is the input shape and :math:`H=\text{embedding\_dim}`
"""
def __init__(self, num_embeddings: int, embedding_dim: int, device=None) -> None:
factory_kwargs = {"device": device}
super().__init__()
self.num_embeddings = num_embeddings
self.embedding_dim = embedding_dim
self.weight = candle.randn((num_embeddings, embedding_dim), **factory_kwargs)
def forward(self, indexes: Tensor) -> Tensor:
final_dims = list(indexes.shape)
final_dims.append(self.embedding_dim)
indexes = indexes.flatten_all()
values = self.weight.index_select(indexes, 0)
return values.reshape(final_dims)
| 2 |
0 | hf_public_repos/candle/candle-pyo3/py_src/candle | hf_public_repos/candle/candle-pyo3/py_src/candle/nn/container.py | # see https://github.com/pytorch/pytorch/blob/main/torch/nn/modules/container.py
from .module import Module
from typing import (
Any,
Dict,
Iterable,
Iterator,
Mapping,
Optional,
overload,
Tuple,
TypeVar,
Union,
)
from collections import OrderedDict, abc as container_abcs
import operator
from itertools import chain, islice
__all__ = ["Sequential", "ModuleList", "ModuleDict"]
T = TypeVar("T", bound=Module)
def _addindent(s_: str, numSpaces: int):
s = s_.split("\n")
# don't do anything for single-line stuff
if len(s) == 1:
return s_
first = s.pop(0)
s = [(numSpaces * " ") + line for line in s]
s = "\n".join(s)
s = first + "\n" + s
return s
class Sequential(Module):
r"""A sequential container.
Modules will be added to it in the order they are passed in the
constructor. Alternatively, an ``OrderedDict`` of modules can be
passed in. The ``forward()`` method of ``Sequential`` accepts any
input and forwards it to the first module it contains. It then
"chains" outputs to inputs sequentially for each subsequent module,
finally returning the output of the last module.
The value a ``Sequential`` provides over manually calling a sequence
of modules is that it allows treating the whole container as a
single module, such that performing a transformation on the
``Sequential`` applies to each of the modules it stores (which are
each a registered submodule of the ``Sequential``).
What's the difference between a ``Sequential`` and a
:class:`candle.nn.ModuleList`? A ``ModuleList`` is exactly what it
sounds like--a list for storing ``Module`` s! On the other hand,
the layers in a ``Sequential`` are connected in a cascading way.
"""
_modules: Dict[str, Module] # type: ignore[assignment]
@overload
def __init__(self, *args: Module) -> None: ...
@overload
def __init__(self, arg: "OrderedDict[str, Module]") -> None: ...
def __init__(self, *args):
super().__init__()
if len(args) == 1 and isinstance(args[0], OrderedDict):
for key, module in args[0].items():
self.add_module(key, module)
else:
for idx, module in enumerate(args):
self.add_module(str(idx), module)
def _get_item_by_idx(self, iterator, idx) -> T:
"""Get the idx-th item of the iterator"""
size = len(self)
idx = operator.index(idx)
if not -size <= idx < size:
raise IndexError("index {} is out of range".format(idx))
idx %= size
return next(islice(iterator, idx, None))
def __getitem__(self, idx: Union[slice, int]) -> Union["Sequential", T]:
if isinstance(idx, slice):
return self.__class__(OrderedDict(list(self._modules.items())[idx]))
else:
return self._get_item_by_idx(self._modules.values(), idx)
def __setitem__(self, idx: int, module: Module) -> None:
key: str = self._get_item_by_idx(self._modules.keys(), idx)
return setattr(self, key, module)
def __delitem__(self, idx: Union[slice, int]) -> None:
if isinstance(idx, slice):
for key in list(self._modules.keys())[idx]:
delattr(self, key)
else:
key = self._get_item_by_idx(self._modules.keys(), idx)
delattr(self, key)
# To preserve numbering
str_indices = [str(i) for i in range(len(self._modules))]
self._modules = OrderedDict(list(zip(str_indices, self._modules.values())))
def __len__(self) -> int:
return len(self._modules)
def __add__(self, other) -> "Sequential":
if isinstance(other, Sequential):
ret = Sequential()
for layer in self:
ret.append(layer)
for layer in other:
ret.append(layer)
return ret
else:
raise ValueError(
"add operator supports only objects " "of Sequential class, but {} is given.".format(str(type(other)))
)
def pop(self, key: Union[int, slice]) -> Module:
v = self[key]
del self[key]
return v
def __iadd__(self, other) -> "Sequential":
if isinstance(other, Sequential):
offset = len(self)
for i, module in enumerate(other):
self.add_module(str(i + offset), module)
return self
else:
raise ValueError(
"add operator supports only objects " "of Sequential class, but {} is given.".format(str(type(other)))
)
def __mul__(self, other: int) -> "Sequential":
if not isinstance(other, int):
raise TypeError(f"unsupported operand type(s) for *: {type(self)} and {type(other)}")
elif other <= 0:
raise ValueError(f"Non-positive multiplication factor {other} for {type(self)}")
else:
combined = Sequential()
offset = 0
for _ in range(other):
for module in self:
combined.add_module(str(offset), module)
offset += 1
return combined
def __rmul__(self, other: int) -> "Sequential":
return self.__mul__(other)
def __imul__(self, other: int) -> "Sequential":
if not isinstance(other, int):
raise TypeError(f"unsupported operand type(s) for *: {type(self)} and {type(other)}")
elif other <= 0:
raise ValueError(f"Non-positive multiplication factor {other} for {type(self)}")
else:
len_original = len(self)
offset = len(self)
for _ in range(other - 1):
for i in range(len_original):
self.add_module(str(i + offset), self._modules[str(i)])
offset += len_original
return self
def __dir__(self):
keys = super().__dir__()
keys = [key for key in keys if not key.isdigit()]
return keys
def __iter__(self) -> Iterator[Module]:
return iter(self._modules.values())
# NB: We can't really type check this function as the type of input
# may change dynamically (as is tested in
# TestScript.test_sequential_intermediary_types). Cannot annotate
# with Any as TorchScript expects a more precise type
def forward(self, input):
for module in self:
input = module(input)
return input
def append(self, module: Module) -> "Sequential":
r"""Appends a given module to the end.
Args:
module (nn.Module): module to append
"""
self.add_module(str(len(self)), module)
return self
def insert(self, index: int, module: Module) -> "Sequential":
if not isinstance(module, Module):
raise AssertionError("module should be of type: {}".format(Module))
n = len(self._modules)
if not (-n <= index <= n):
raise IndexError("Index out of range: {}".format(index))
if index < 0:
index += n
for i in range(n, index, -1):
self._modules[str(i)] = self._modules[str(i - 1)]
self._modules[str(index)] = module
return self
def extend(self, sequential) -> "Sequential":
for layer in sequential:
self.append(layer)
return self
class ModuleList(Module):
r"""Holds submodules in a list.
:class:`~candle.nn.ModuleList` can be indexed like a regular Python list, but
modules it contains are properly registered, and will be visible by all
:class:`~candle.nn.Module` methods.
Args:
modules (iterable, optional): an iterable of modules to add
Example::
class MyModule(nn.Module):
def __init__(self):
super().__init__()
self.linears = nn.ModuleList([nn.Linear(10, 10) for i in range(10)])
def forward(self, x):
# ModuleList can act as an iterable, or be indexed using ints
for i, l in enumerate(self.linears):
x = self.linears[i // 2](x) + l(x)
return x
"""
_modules: Dict[str, Module] # type: ignore[assignment]
def __init__(self, modules: Optional[Iterable[Module]] = None) -> None:
super().__init__()
if modules is not None:
self += modules
def _get_abs_string_index(self, idx):
"""Get the absolute index for the list of modules"""
idx = operator.index(idx)
if not (-len(self) <= idx < len(self)):
raise IndexError("index {} is out of range".format(idx))
if idx < 0:
idx += len(self)
return str(idx)
def __getitem__(self, idx: Union[int, slice]) -> Union[Module, "ModuleList"]:
if isinstance(idx, slice):
return self.__class__(list(self._modules.values())[idx])
else:
return self._modules[self._get_abs_string_index(idx)]
def __setitem__(self, idx: int, module: Module) -> None:
idx = self._get_abs_string_index(idx)
return setattr(self, str(idx), module)
def __delitem__(self, idx: Union[int, slice]) -> None:
if isinstance(idx, slice):
for k in range(len(self._modules))[idx]:
delattr(self, str(k))
else:
delattr(self, self._get_abs_string_index(idx))
# To preserve numbering, self._modules is being reconstructed with modules after deletion
str_indices = [str(i) for i in range(len(self._modules))]
self._modules = OrderedDict(list(zip(str_indices, self._modules.values())))
def __len__(self) -> int:
return len(self._modules)
def __iter__(self) -> Iterator[Module]:
return iter(self._modules.values())
def __iadd__(self, modules: Iterable[Module]) -> "ModuleList":
return self.extend(modules)
def __add__(self, other: Iterable[Module]) -> "ModuleList":
combined = ModuleList()
for i, module in enumerate(chain(self, other)):
combined.add_module(str(i), module)
return combined
def __repr__(self):
"""A custom repr for ModuleList that compresses repeated module representations"""
list_of_reprs = [repr(item) for item in self]
if len(list_of_reprs) == 0:
return self._get_name() + "()"
start_end_indices = [[0, 0]]
repeated_blocks = [list_of_reprs[0]]
for i, r in enumerate(list_of_reprs[1:], 1):
if r == repeated_blocks[-1]:
start_end_indices[-1][1] += 1
continue
start_end_indices.append([i, i])
repeated_blocks.append(r)
lines = []
main_str = self._get_name() + "("
for (start_id, end_id), b in zip(start_end_indices, repeated_blocks):
local_repr = f"({start_id}): {b}" # default repr
if start_id != end_id:
n = end_id - start_id + 1
local_repr = f"({start_id}-{end_id}): {n} x {b}"
local_repr = _addindent(local_repr, 2)
lines.append(local_repr)
main_str += "\n " + "\n ".join(lines) + "\n"
main_str += ")"
return main_str
def __dir__(self):
keys = super().__dir__()
keys = [key for key in keys if not key.isdigit()]
return keys
def insert(self, index: int, module: Module) -> None:
r"""Insert a given module before a given index in the list.
Args:
index (int): index to insert.
module (nn.Module): module to insert
"""
for i in range(len(self._modules), index, -1):
self._modules[str(i)] = self._modules[str(i - 1)]
self._modules[str(index)] = module
def append(self, module: Module) -> "ModuleList":
r"""Appends a given module to the end of the list.
Args:
module (nn.Module): module to append
"""
self.add_module(str(len(self)), module)
return self
def pop(self, key: Union[int, slice]) -> Module:
v = self[key]
del self[key]
return v
def extend(self, modules: Iterable[Module]) -> "ModuleList":
r"""Appends modules from a Python iterable to the end of the list.
Args:
modules (iterable): iterable of modules to append
"""
if not isinstance(modules, container_abcs.Iterable):
raise TypeError(
"ModuleList.extend should be called with an " "iterable, but got " + type(modules).__name__
)
offset = len(self)
for i, module in enumerate(modules):
self.add_module(str(offset + i), module)
return self
# remove forward altogether to fallback on Module's _forward_unimplemented
class ModuleDict(Module):
r"""Holds submodules in a dictionary.
:class:`~candle.nn.ModuleDict` can be indexed like a regular Python dictionary,
but modules it contains are properly registered, and will be visible by all
:class:`~candle.nn.Module` methods.
:class:`~candle.nn.ModuleDict` is an **ordered** dictionary that respects
* the order of insertion, and
* in :meth:`~candle.nn.ModuleDict.update`, the order of the merged
``OrderedDict``, ``dict`` (started from Python 3.6) or another
:class:`~candle.nn.ModuleDict` (the argument to
:meth:`~candle.nn.ModuleDict.update`).
Note that :meth:`~candle.nn.ModuleDict.update` with other unordered mapping
types (e.g., Python's plain ``dict`` before Python version 3.6) does not
preserve the order of the merged mapping.
Args:
modules (iterable, optional): a mapping (dictionary) of (string: module)
or an iterable of key-value pairs of type (string, module)
"""
_modules: Dict[str, Module] # type: ignore[assignment]
def __init__(self, modules: Optional[Mapping[str, Module]] = None) -> None:
super().__init__()
if modules is not None:
self.update(modules)
def __getitem__(self, key: str) -> Module:
return self._modules[key]
def __setitem__(self, key: str, module: Module) -> None:
self.add_module(key, module)
def __delitem__(self, key: str) -> None:
del self._modules[key]
def __len__(self) -> int:
return len(self._modules)
def __iter__(self) -> Iterator[str]:
return iter(self._modules)
def __contains__(self, key: str) -> bool:
return key in self._modules
def clear(self) -> None:
"""Remove all items from the ModuleDict."""
self._modules.clear()
def pop(self, key: str) -> Module:
r"""Remove key from the ModuleDict and return its module.
Args:
key (str): key to pop from the ModuleDict
"""
v = self[key]
del self[key]
return v
def keys(self) -> Iterable[str]:
r"""Return an iterable of the ModuleDict keys."""
return self._modules.keys()
def items(self) -> Iterable[Tuple[str, Module]]:
r"""Return an iterable of the ModuleDict key/value pairs."""
return self._modules.items()
def values(self) -> Iterable[Module]:
r"""Return an iterable of the ModuleDict values."""
return self._modules.values()
def update(self, modules: Mapping[str, Module]) -> None:
r"""Update the :class:`~candle.nn.ModuleDict` with the key-value pairs from a
mapping or an iterable, overwriting existing keys.
.. note::
If :attr:`modules` is an ``OrderedDict``, a :class:`~candle.nn.ModuleDict`, or
an iterable of key-value pairs, the order of new elements in it is preserved.
Args:
modules (iterable): a mapping (dictionary) from string to :class:`~candle.nn.Module`,
or an iterable of key-value pairs of type (string, :class:`~candle.nn.Module`)
"""
if not isinstance(modules, container_abcs.Iterable):
raise TypeError(
"ModuleDict.update should be called with an "
"iterable of key/value pairs, but got " + type(modules).__name__
)
if isinstance(modules, (OrderedDict, ModuleDict, container_abcs.Mapping)):
for key, module in modules.items():
self[key] = module
else:
# modules here can be a list with two items
for j, m in enumerate(modules):
if not isinstance(m, container_abcs.Iterable):
raise TypeError(
"ModuleDict update sequence element "
"#" + str(j) + " should be Iterable; is" + type(m).__name__
)
if not len(m) == 2:
raise ValueError(
"ModuleDict update sequence element "
"#" + str(j) + " has length " + str(len(m)) + "; 2 is required"
)
# modules can be Mapping (what it's typed at), or a list: [(name1, module1), (name2, module2)]
# that's too cumbersome to type correctly with overloads, so we add an ignore here
self[m[0]] = m[1] # type: ignore[assignment]
# remove forward altogether to fallback on Module's _forward_unimplemented
| 3 |
0 | hf_public_repos/candle/candle-pyo3/py_src/candle | hf_public_repos/candle/candle-pyo3/py_src/candle/models/llama.py | import candle
from typing import Dict, Tuple, Any
from candle import Tensor, QTensor, utils, nn
from candle.nn import Module, ModuleList
def masked_fill(on_false: Tensor, mask: Tensor, on_true: Tensor):
shape = mask.shape
on_true = candle.tensor(on_true).broadcast_as(shape)
return mask.where_cond(on_true, on_false)
def precompute_freqs_cis(hparams: Dict[str, Any], freq_base: float, max_seq_len: int):
head_dim = hparams["n_embd"] // hparams["n_head"]
theta = [1.0 / freq_base ** (i / head_dim) for i in range(0, head_dim, 2)]
theta = candle.tensor(theta)
idx_theta = [float(i) for i in range(max_seq_len)]
idx_theta = candle.tensor(idx_theta).reshape((max_seq_len, 1))
m = idx_theta.matmul(theta.unsqueeze(0))
return (m.cos(), m.sin())
class RmsNorm(Module):
def __init__(self, qtensor: QTensor):
super().__init__()
self.weight = qtensor.dequantize()
def forward(self, x: Tensor) -> Tensor:
b_size, seq_len, hidden_size = x.shape
norm_x = x.sqr().sum_keepdim(2) / hidden_size
x_normed = x.broadcast_div((norm_x + 1e-5).sqrt())
return x_normed.broadcast_mul(self.weight)
class QuantizedLayer(Module):
def __init__(
self,
layer_idx: int,
hparams: Dict[str, Any],
all_tensors: Dict[str, QTensor],
cos_sin: Tuple[Tensor, Tensor],
):
super().__init__()
p = f"layers.{layer_idx}"
self.attention_wq = all_tensors[f"{p}.attention.wq.weight"]
self.attention_wk = all_tensors[f"{p}.attention.wk.weight"]
self.attention_wv = all_tensors[f"{p}.attention.wv.weight"]
self.attention_wo = all_tensors[f"{p}.attention.wo.weight"]
self.ffw1 = all_tensors[f"{p}.feed_forward.w1.weight"]
self.ffw2 = all_tensors[f"{p}.feed_forward.w2.weight"]
self.ffw3 = all_tensors[f"{p}.feed_forward.w3.weight"]
self.attn_norm = RmsNorm(all_tensors[f"{p}.attention_norm.weight"])
self.ffn_norm = RmsNorm(all_tensors[f"{p}.ffn_norm.weight"])
self.n_head = hparams["n_head"]
self.n_kv_head = self.n_head
self.head_dim = hparams["n_embd"] // self.n_head
self.kv_cache = None
self.cos = cos_sin[0]
self.sin = cos_sin[1]
self._non_persistent_buffers_set.add("cos")
self._non_persistent_buffers_set.add("sin")
def forward(self, x: Tensor, mask: Tensor, index_pos: int) -> Tensor:
residual = x
x = self.attn_norm(x)
attn = self.forward_attn(x, mask, index_pos)
x = attn + residual
residual = x
x = self.ffn_norm(x)
w1 = self.ffw1.matmul_t(x)
w3 = self.ffw3.matmul_t(x)
mlp = self.ffw2.matmul_t(nn.silu(w1) * w3)
return mlp + residual
def forward_attn(self, x: Tensor, mask: Tensor, index_pos: int):
b_size, seq_len, n_embd = x.shape
q = self.attention_wq.matmul_t(x)
k = self.attention_wk.matmul_t(x)
v = self.attention_wv.matmul_t(x)
q = q.reshape((b_size, seq_len, self.n_head, self.head_dim)).transpose(1, 2)
k = k.reshape((b_size, seq_len, self.n_kv_head, self.head_dim)).transpose(1, 2)
v = v.reshape((b_size, seq_len, self.n_kv_head, self.head_dim)).transpose(1, 2)
q = self.apply_rotary_emb(q, index_pos)
k = self.apply_rotary_emb(k, index_pos)
if self.kv_cache is not None and index_pos > 0:
prev_k, prev_v = self.kv_cache
k = candle.cat([prev_k, k], 2).contiguous()
v = candle.cat([prev_v, v], 2).contiguous()
self.kv_cache = (k, v)
# TODO: maybe repeat k/v here if we start supporting MQA.
att = q.matmul(k.t()) / self.head_dim**0.5
mask = mask.broadcast_as(att.shape)
att = masked_fill(att, mask, float("-inf"))
att = nn.softmax(att, -1)
y = att.matmul(v.contiguous())
y = y.transpose(1, 2).reshape((b_size, seq_len, n_embd))
return self.attention_wo.matmul_t(y)
def apply_rotary_emb(self, x: Tensor, index_pos: int):
b_size, n_head, seq_len, n_embd = x.shape
cos = self.cos.narrow(0, index_pos, seq_len).reshape((seq_len, n_embd // 2, 1))
sin = self.sin.narrow(0, index_pos, seq_len).reshape((seq_len, n_embd // 2, 1))
x = x.reshape((b_size, n_head, seq_len, n_embd // 2, 2))
x0 = x.narrow(-1, 0, 1)
x1 = x.narrow(-1, 1, 1)
y0 = x0.broadcast_mul(cos) - x1.broadcast_mul(sin)
y1 = x0.broadcast_mul(sin) + x1.broadcast_mul(cos)
rope = candle.cat([y0, y1], -1)
return rope.flatten_from(-2)
class QuantizedLlama(Module):
def __init__(self, hparams: Dict[str, Any], all_tensors: Dict[str, QTensor]):
super().__init__()
self.tok_embeddings = all_tensors["tok_embeddings.weight"].dequantize()
self.norm = RmsNorm(all_tensors["norm.weight"])
self.output = all_tensors["output.weight"]
self.layers = ModuleList()
rope_freq = hparams.get("rope_freq", 10000.0)
cos_sin = precompute_freqs_cis(hparams, rope_freq, hparams["context_length"])
for layer_idx in range(hparams["n_layer"]):
layer = QuantizedLayer(layer_idx, hparams, all_tensors, cos_sin)
self.layers.append(layer)
def forward(self, token: Tensor, index_pos: int) -> Tensor:
b_size, seq_len = token.shape
vocab_size, hidden_size = self.tok_embeddings.shape
token = token.reshape((b_size * seq_len,))
x = self.tok_embeddings.index_select(token, 0)
x = x.reshape((b_size, seq_len, hidden_size))
mask = [int(j > i) for j in range(seq_len) for i in range(seq_len)]
mask = candle.tensor(mask).reshape((seq_len, seq_len))
for layer in self.layers:
x = layer(x, mask, index_pos)
x = self.norm(x)
x = x.narrow(1, -1, 1).squeeze(1)
x = self.output.matmul_t(x)
return x
| 4 |
0 | hf_public_repos/candle/candle-pyo3/py_src/candle | hf_public_repos/candle/candle-pyo3/py_src/candle/models/bert.py | from dataclasses import dataclass
from typing import Optional
from candle.nn import Module, Embedding, LayerNorm, Linear, ModuleList
from candle import Tensor
import candle
import candle.functional as F
from typing import Tuple, Optional
@dataclass
class Config:
vocab_size: int = 30522
hidden_size: int = 768
num_hidden_layers: int = 12
num_attention_heads: int = 12
intermediate_size: int = 3072
hidden_act: str = "gelu"
hidden_dropout_prob: float = 0.1
max_position_embeddings: int = 512
type_vocab_size: int = 2
initializer_range: float = 0.02
layer_norm_eps: float = 1e-12
pad_token_id: int = 0
position_embedding_type: str = "absolute"
use_cache: bool = True
classifier_dropout: Optional[float] = None
model_type: Optional[str] = "bert"
class BertSelfAttention(Module):
def __init__(self, config: Config) -> None:
super().__init__()
self.num_attention_heads = config.num_attention_heads
self.attention_head_size = int(config.hidden_size / self.num_attention_heads)
all_head_size = int(config.num_attention_heads * self.attention_head_size)
hidden_size = config.hidden_size
self.query = Linear(hidden_size, all_head_size)
self.key = Linear(hidden_size, all_head_size)
self.value = Linear(hidden_size, all_head_size)
def transpose_for_scores(self, x: Tensor) -> Tensor:
new_x_shape = x.shape[:-1] + (
self.num_attention_heads,
self.attention_head_size,
)
x = x.reshape(new_x_shape).transpose(1, 2)
return x.contiguous()
def forward(self, hidden_states: Tensor, attention_mask=None) -> Tensor:
query = self.query.forward(hidden_states)
key = self.key.forward(hidden_states)
value = self.value.forward(hidden_states)
query = self.transpose_for_scores(query)
key = self.transpose_for_scores(key)
value = self.transpose_for_scores(value)
attention_scores = query.matmul(key.t())
attention_scores = attention_scores / float(self.attention_head_size) ** 0.5
if attention_mask is not None:
b_size, _, _, last_dim = attention_scores.shape
attention_scores = attention_scores.broadcast_add(attention_mask.reshape((b_size, 1, 1, last_dim)))
attention_probs = F.softmax(attention_scores, dim=-1)
context_layer = attention_probs.matmul(value)
context_layer = context_layer.transpose(1, 2).contiguous()
context_layer = context_layer.flatten_from(-2)
return context_layer
class BertSelfOutput(Module):
def __init__(self, config: Config) -> None:
super().__init__()
self.dense = Linear(config.hidden_size, config.hidden_size)
self.LayerNorm = LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
def forward(self, hidden_states: Tensor, input_tensor: Tensor) -> Tensor:
hidden_states = self.dense.forward(hidden_states)
return self.LayerNorm.forward(hidden_states + input_tensor)
class BertAttention(Module):
def __init__(self, config: Config) -> None:
super().__init__()
self.self = BertSelfAttention(config)
self.output = BertSelfOutput(config)
def forward(self, hidden_states: Tensor, attention_mask: None) -> Tensor:
self_outputs = self.self.forward(hidden_states, attention_mask=attention_mask)
attention_output = self.output.forward(self_outputs, hidden_states)
return attention_output
class BertIntermediate(Module):
def __init__(self, config: Config) -> None:
super().__init__()
self.dense = Linear(config.hidden_size, config.intermediate_size)
self.act = F.gelu if config.hidden_act == "gelu" else F.relu
def forward(self, hidden_states: Tensor) -> Tensor:
hidden_states = self.dense.forward(hidden_states)
return self.act(hidden_states)
class BertOutput(Module):
def __init__(self, config: Config) -> None:
super().__init__()
self.dense = Linear(config.intermediate_size, config.hidden_size)
self.LayerNorm = LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
def forward(self, hidden_states: Tensor, input_tensor: Tensor) -> Tensor:
hidden_states = self.dense.forward(hidden_states)
return self.LayerNorm.forward(hidden_states + input_tensor)
class BertLayer(Module):
def __init__(self, config: Config) -> None:
super().__init__()
self.attention = BertAttention(config)
self.intermediate = BertIntermediate(config)
self.output = BertOutput(config)
def forward(self, hidden_states: Tensor, attention_mask=None) -> Tensor:
attention_output = self.attention.forward(hidden_states, attention_mask=attention_mask)
# TODO: Support cross-attention?
# https://github.com/huggingface/transformers/blob/6eedfa6dd15dc1e22a55ae036f681914e5a0d9a1/src/transformers/models/bert/modeling_bert.py#L523
# TODO: Support something similar to `apply_chunking_to_forward`?
intermediate_output = self.intermediate.forward(attention_output)
layer_output = self.output.forward(intermediate_output, attention_output)
return layer_output
class BertEncoder(Module):
def __init__(self, config: Config) -> None:
super().__init__()
self.layer = ModuleList()
for _ in range(config.num_hidden_layers):
self.layer.append(BertLayer(config))
def forward(self, hidden_states: Tensor, attention_mask=None) -> Tensor:
for l in self.layer:
hidden_states = l.forward(hidden_states, attention_mask=attention_mask)
return hidden_states
class BertEmbeddings(Module):
def __init__(self, config: Config) -> None:
super().__init__()
self.word_embeddings = Embedding(config.vocab_size, config.hidden_size)
self.position_embeddings = Embedding(config.max_position_embeddings, config.hidden_size)
self.token_type_embeddings = Embedding(config.type_vocab_size, config.hidden_size)
self.LayerNorm = LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
self.position_ids = candle.Tensor(list(range(config.max_position_embeddings))).reshape(
(1, config.max_position_embeddings)
)
def forward(self, input_ids: Tensor, token_type_ids: Tensor) -> Tensor:
(_batch_size, seq_len) = input_ids.shape
input_embeddings = self.word_embeddings.forward(input_ids)
token_type_embeddings = self.token_type_embeddings.forward(token_type_ids)
embeddings: Tensor = input_embeddings + token_type_embeddings
position_ids = list(range(seq_len))
position_ids = Tensor(position_ids).to_dtype(input_ids.dtype).to_device(input_ids.device)
embeddings = embeddings.broadcast_add(self.position_embeddings.forward(position_ids))
embeddings = self.LayerNorm(embeddings)
return embeddings
class BertPooler(Module):
def __init__(self, config: Config) -> None:
super().__init__()
self.dense = Linear(config.hidden_size, config.hidden_size)
self.activation = F.tanh
def forward(self, hidden_states: Tensor) -> Tensor:
first_token_tensor = hidden_states[:, 0]
pooled_output = self.dense.forward(first_token_tensor)
pooled_output = self.activation(pooled_output)
return pooled_output
def masked_fill(on_false: float, mask: Tensor, on_true: float):
shape = mask.shape
on_true = candle.tensor(on_true).broadcast_as(shape)
on_false = candle.tensor(on_false).broadcast_as(shape)
return mask.where_cond(on_true, on_false)
# https://github.com/huggingface/transformers/blob/6eedfa6dd15dc1e22a55ae036f681914e5a0d9a1/src/transformers/models/bert/modeling_bert.py#L874
class BertModel(Module):
def __init__(self, config: Config, add_pooling_layer=True) -> None:
super().__init__()
self.config = config
self.embeddings = BertEmbeddings(config)
self.encoder = BertEncoder(config)
self.pooler = BertPooler(config) if add_pooling_layer else None
def forward(
self, input_ids: Tensor, token_type_ids: Tensor, attention_mask=None
) -> Tuple[Tensor, Optional[Tensor]]:
if attention_mask is not None:
# Replace 0s with -inf, and 1s with 0s.
attention_mask = masked_fill(float("-inf"), attention_mask, 1.0)
embeddings = self.embeddings.forward(input_ids, token_type_ids)
encoder_out = self.encoder.forward(embeddings, attention_mask=attention_mask)
pooled_output = self.pooler(encoder_out) if self.pooler is not None else None
return encoder_out, pooled_output
| 5 |
0 | hf_public_repos/candle/candle-pyo3/py_src/candle | hf_public_repos/candle/candle-pyo3/py_src/candle/utils/__init__.pyi | # Generated content DO NOT EDIT
from typing import Any, Callable, Dict, List, Optional, Tuple, Union, Sequence
from os import PathLike
from candle.typing import _ArrayLike, Device, Scalar, Index, Shape
from candle import Tensor, DType, QTensor
@staticmethod
def cuda_is_available() -> bool:
"""
Returns true if the 'cuda' backend is available.
"""
pass
@staticmethod
def get_num_threads() -> int:
"""
Returns the number of threads used by the candle.
"""
pass
@staticmethod
def has_accelerate() -> bool:
"""
Returns true if candle was compiled with 'accelerate' support.
"""
pass
@staticmethod
def has_mkl() -> bool:
"""
Returns true if candle was compiled with MKL support.
"""
pass
@staticmethod
def load_ggml(path, device=None) -> Tuple[Dict[str, QTensor], Dict[str, Any], List[str]]:
"""
Load a GGML file. Returns a tuple of three objects: a dictionary mapping tensor names to tensors,
a dictionary mapping hyperparameter names to hyperparameter values, and a vocabulary.
"""
pass
@staticmethod
def load_gguf(path, device=None) -> Tuple[Dict[str, QTensor], Dict[str, Any]]:
"""
Loads a GGUF file. Returns a tuple of two dictionaries: the first maps tensor names to tensors,
and the second maps metadata keys to metadata values.
"""
pass
@staticmethod
def load_safetensors(path: Union[str, PathLike]) -> Dict[str, Tensor]:
"""
Loads a safetensors file. Returns a dictionary mapping tensor names to tensors.
"""
pass
@staticmethod
def save_gguf(path, tensors, metadata):
"""
Save quanitzed tensors and metadata to a GGUF file.
"""
pass
@staticmethod
def save_safetensors(path: Union[str, PathLike], tensors: Dict[str, Tensor]) -> None:
"""
Saves a dictionary of tensors to a safetensors file.
"""
pass
| 6 |
0 | hf_public_repos/candle/candle-pyo3/py_src/candle | hf_public_repos/candle/candle-pyo3/py_src/candle/utils/__init__.py | # Generated content DO NOT EDIT
from .. import utils
cuda_is_available = utils.cuda_is_available
get_num_threads = utils.get_num_threads
has_accelerate = utils.has_accelerate
has_mkl = utils.has_mkl
load_ggml = utils.load_ggml
load_gguf = utils.load_gguf
load_safetensors = utils.load_safetensors
save_gguf = utils.save_gguf
save_safetensors = utils.save_safetensors
| 7 |
0 | hf_public_repos/candle/candle-pyo3 | hf_public_repos/candle/candle-pyo3/_additional_typing/__init__.py | from typing import Union, Sequence
class Tensor:
"""
This contains the type hints for the magic methodes of the `candle.Tensor` class.
"""
def __add__(self, rhs: Union["Tensor", "Scalar"]) -> "Tensor":
"""
Add a scalar to a tensor or two tensors together.
"""
pass
def __radd__(self, rhs: Union["Tensor", "Scalar"]) -> "Tensor":
"""
Add a scalar to a tensor or two tensors together.
"""
pass
def __sub__(self, rhs: Union["Tensor", "Scalar"]) -> "Tensor":
"""
Subtract a scalar from a tensor or one tensor from another.
"""
pass
def __truediv__(self, rhs: Union["Tensor", "Scalar"]) -> "Tensor":
"""
Divide a tensor by a scalar or one tensor by another.
"""
pass
def __mul__(self, rhs: Union["Tensor", "Scalar"]) -> "Tensor":
"""
Multiply a tensor by a scalar or one tensor by another.
"""
pass
def __rmul__(self, rhs: Union["Tensor", "Scalar"]) -> "Tensor":
"""
Multiply a tensor by a scalar or one tensor by another.
"""
pass
def __richcmp__(self, rhs: Union["Tensor", "Scalar"], op) -> "Tensor":
"""
Compare a tensor with a scalar or one tensor with another.
"""
pass
def __getitem__(self, index: Union["Index", "Tensor", Sequence["Index"]]) -> "Tensor":
"""
Return a slice of a tensor.
"""
pass
def __eq__(self, rhs: Union["Tensor", "Scalar"]) -> "Tensor":
"""
Compare a tensor with a scalar or one tensor with another.
"""
pass
def __ne__(self, rhs: Union["Tensor", "Scalar"]) -> "Tensor":
"""
Compare a tensor with a scalar or one tensor with another.
"""
pass
def __lt__(self, rhs: Union["Tensor", "Scalar"]) -> "Tensor":
"""
Compare a tensor with a scalar or one tensor with another.
"""
pass
def __le__(self, rhs: Union["Tensor", "Scalar"]) -> "Tensor":
"""
Compare a tensor with a scalar or one tensor with another.
"""
pass
def __gt__(self, rhs: Union["Tensor", "Scalar"]) -> "Tensor":
"""
Compare a tensor with a scalar or one tensor with another.
"""
pass
def __ge__(self, rhs: Union["Tensor", "Scalar"]) -> "Tensor":
"""
Compare a tensor with a scalar or one tensor with another.
"""
pass
| 8 |
0 | hf_public_repos/candle/candle-pyo3 | hf_public_repos/candle/candle-pyo3/_additional_typing/README.md | This python module contains external typehinting for certain `candle` classes. This is only necessary for `magic` methodes e.g. `__add__` as their text signature cant be set via pyo3.
The classes in this module will be parsed by the `stub.py` script and interleafed with the signatures of the actual pyo3 `candle.candle` module. | 9 |
0 | hf_public_repos/alignment-handbook/recipes/gpt2-nl | hf_public_repos/alignment-handbook/recipes/gpt2-nl/cpt/config_full.yaml | # Model arguments
model_name_or_path: gpt2
model_revision: main
torch_dtype: bfloat16
# Data training arguments
dataset_mixer:
yhavinga/mc4_nl_cleaned: 1.0
dataset_splits:
- train
dataset_configs:
- tiny
preprocessing_num_workers: 12
# SFT trainer config
bf16: true
do_eval: False
eval_strategy: "no"
gradient_accumulation_steps: 1
gradient_checkpointing: true
gradient_checkpointing_kwargs:
use_reentrant: False
hub_model_id: gpt2-cpt-dutch
hub_strategy: every_save
learning_rate: 2.0e-04
log_level: info
logging_steps: 5
logging_strategy: steps
lr_scheduler_type: cosine
max_seq_length: 1024
max_steps: -1
num_train_epochs: 1
output_dir: data/gpt2-cpt-dutch
overwrite_output_dir: true
per_device_eval_batch_size: 8
per_device_train_batch_size: 16
push_to_hub: true
remove_unused_columns: true
report_to:
- wandb
save_strategy: "steps"
save_steps: 100
save_total_limit: 1
seed: 42
warmup_ratio: 0.1
| 0 |
0 | hf_public_repos/alignment-handbook/recipes/gpt2-nl | hf_public_repos/alignment-handbook/recipes/gpt2-nl/sft/config_full.yaml | # Model arguments
model_name_or_path: BramVanroy/gpt2-cpt-dutch
model_revision: main
torch_dtype: bfloat16
# Data training arguments
chat_template: "{% for message in messages %}\n{% if message['role'] == 'user' %}\n{{ '<|user|>\n' + message['content'] + eos_token }}\n{% elif message['role'] == 'system' %}\n{{ '<|system|>\n' + message['content'] + eos_token }}\n{% elif message['role'] == 'assistant' %}\n{{ '<|assistant|>\n' + message['content'] + eos_token }}\n{% endif %}\n{% if loop.last and add_generation_prompt %}\n{{ '<|assistant|>' }}\n{% endif %}\n{% endfor %}"
dataset_mixer:
BramVanroy/ultrachat_200k_dutch: 1.0
dataset_splits:
- train_sft
- test_sft
preprocessing_num_workers: 12
# SFT trainer config
bf16: true
do_eval: true
eval_strategy: epoch
gradient_accumulation_steps: 1
gradient_checkpointing: true
gradient_checkpointing_kwargs:
use_reentrant: False
hub_model_id: gpt2-sft-dutch
hub_strategy: every_save
learning_rate: 2.0e-05
log_level: info
logging_steps: 5
logging_strategy: steps
lr_scheduler_type: cosine
max_seq_length: 1024
max_steps: -1
num_train_epochs: 1
output_dir: data/gpt2-sft-dutch
overwrite_output_dir: true
per_device_eval_batch_size: 8
per_device_train_batch_size: 8
push_to_hub: true
remove_unused_columns: true
report_to:
- wandb
save_strategy: "steps"
save_steps: 100
save_total_limit: 1
seed: 42
warmup_ratio: 0.1
| 1 |
0 | hf_public_repos/alignment-handbook/recipes | hf_public_repos/alignment-handbook/recipes/accelerate_configs/fsdp_qlora.yaml | compute_environment: LOCAL_MACHINE
debug: false
distributed_type: FSDP
downcast_bf16: 'no'
fsdp_config:
fsdp_auto_wrap_policy: TRANSFORMER_BASED_WRAP
fsdp_backward_prefetch: BACKWARD_PRE
fsdp_cpu_ram_efficient_loading: true
fsdp_forward_prefetch: false
fsdp_offload_params: true
fsdp_sharding_strategy: FULL_SHARD
fsdp_state_dict_type: SHARDED_STATE_DICT
fsdp_sync_module_states: true
fsdp_use_orig_params: false
machine_rank: 0
main_training_function: main
mixed_precision: 'no'
num_machines: 1
num_processes: 2
rdzv_backend: static
same_network: true
tpu_env: []
tpu_use_cluster: false
tpu_use_sudo: false
use_cpu: false | 2 |
0 | hf_public_repos/alignment-handbook/recipes | hf_public_repos/alignment-handbook/recipes/accelerate_configs/deepspeed_zero3.yaml | compute_environment: LOCAL_MACHINE
debug: false
deepspeed_config:
deepspeed_multinode_launcher: standard
offload_optimizer_device: none
offload_param_device: none
zero3_init_flag: true
zero3_save_16bit_model: true
zero_stage: 3
distributed_type: DEEPSPEED
downcast_bf16: 'no'
machine_rank: 0
main_training_function: main
mixed_precision: bf16
num_machines: 1
num_processes: 8
rdzv_backend: static
same_network: true
tpu_env: []
tpu_use_cluster: false
tpu_use_sudo: false
use_cpu: false
| 3 |
0 | hf_public_repos/alignment-handbook/recipes | hf_public_repos/alignment-handbook/recipes/accelerate_configs/multi_gpu.yaml | compute_environment: LOCAL_MACHINE
debug: false
distributed_type: MULTI_GPU
downcast_bf16: 'no'
gpu_ids: all
machine_rank: 0
main_training_function: main
mixed_precision: bf16
num_machines: 1
num_processes: 8
rdzv_backend: static
same_network: true
tpu_env: []
tpu_use_cluster: false
tpu_use_sudo: false
use_cpu: false
| 4 |
0 | hf_public_repos/alignment-handbook/recipes | hf_public_repos/alignment-handbook/recipes/accelerate_configs/fsdp.yaml | compute_environment: LOCAL_MACHINE
debug: false
distributed_type: FSDP
downcast_bf16: 'no'
enable_cpu_affinity: false
fsdp_config:
fsdp_auto_wrap_policy: TRANSFORMER_BASED_WRAP
fsdp_backward_prefetch: BACKWARD_PRE
fsdp_cpu_ram_efficient_loading: true
fsdp_forward_prefetch: true
fsdp_offload_params: false
fsdp_sharding_strategy: FULL_SHARD
fsdp_state_dict_type: SHARDED_STATE_DICT
fsdp_sync_module_states: true
fsdp_use_orig_params: true
machine_rank: 0
main_training_function: main
mixed_precision: bf16
num_machines: 1
num_processes: 8
rdzv_backend: static
same_network: true
tpu_env: []
tpu_use_cluster: false
tpu_use_sudo: false
use_cpu: false
| 5 |
0 | hf_public_repos/alignment-handbook/recipes | hf_public_repos/alignment-handbook/recipes/constitutional-ai/README.md | # Constitutional AI
This repo includes the recipe for training the following models:
* https://huggingface.co/HuggingFaceH4/mistral-7b-anthropic
* https://huggingface.co/HuggingFaceH4/mistral-7b-grok
## Full training examples
You will require 8 GPUs (80GB of VRAM) to train the full model.
```shell
# Step 1 - SFT
ACCELERATE_LOG_LEVEL=info accelerate launch --config_file recipes/accelerate_configs/deepspeed_zero3.yaml scripts/run_sft.py recipes/constitutional-ai/sft/config_{grok,anthropic}.yaml
# Step 2 - DPO
ACCELERATE_LOG_LEVEL=info accelerate launch --config_file recipes/accelerate_configs/deepspeed_zero3.yaml scripts/run_dpo.py recipes/constitutional-ai/dpo/config_anthropic.yaml
# Note that we did not include the DPO recipe for grok, as that model's seems overtrained and too snarky.
```
## Advanced: generating you own dataset
To generate the constitutional AI dataset, see https://github.com/huggingface/llm-swarm/tree/main/examples/constitutional-ai for detailed instructions if you want to build or customize the dataset.
| 6 |
0 | hf_public_repos/alignment-handbook/recipes/constitutional-ai | hf_public_repos/alignment-handbook/recipes/constitutional-ai/dpo/config_anthropic.yaml | # Model arguments
model_name_or_path: alignment-handbook/mistral-7b-sft-constitutional-ai
torch_dtype: null
# Data training arguments
# For definitions, see: src/h4/training/config.py
dataset_mixer:
HuggingFaceH4/ultrafeedback_binarized: 1.0
HuggingFaceH4/cai-conversation-harmless: 1.0
dataset_splits:
- train_prefs
- test_prefs
preprocessing_num_workers: 12
# DPOTrainer arguments
bf16: true
beta: 0.1
do_eval: true
do_train: true
eval_strategy: steps
eval_steps: 1000
gradient_accumulation_steps: 1
gradient_checkpointing: true
hub_model_id: mistral-7b-dpo-constitutional-ai
learning_rate: 5.0e-7
log_level: info
logging_steps: 10
lr_scheduler_type: linear
max_length: 1024
max_prompt_length: 512
num_train_epochs: 3
optim: rmsprop
output_dir: data/mistral-7b-dpo-constitutional-ai
per_device_train_batch_size: 2
per_device_eval_batch_size: 8
push_to_hub: true
save_strategy: "steps"
save_steps: 100
save_total_limit: 1
seed: 42
warmup_ratio: 0.1 | 7 |
0 | hf_public_repos/alignment-handbook/recipes/constitutional-ai | hf_public_repos/alignment-handbook/recipes/constitutional-ai/sft/config_grok.yaml | # Model arguments
model_name_or_path: mistralai/Mistral-7B-v0.1
model_revision: main
torch_dtype: bfloat16
attn_implementation: flash_attention_2
# Data training arguments
chat_template: "{% for message in messages %}\n{% if message['role'] == 'user' %}\n{{ '<|user|>\n' + message['content'] + eos_token }}\n{% elif message['role'] == 'system' %}\n{{ '<|system|>\n' + message['content'] + eos_token }}\n{% elif message['role'] == 'assistant' %}\n{{ '<|assistant|>\n' + message['content'] + eos_token }}\n{% endif %}\n{% if loop.last and add_generation_prompt %}\n{{ '<|assistant|>' }}\n{% endif %}\n{% endfor %}"
dataset_mixer:
HuggingFaceH4/grok-conversation-harmless: 0.15
HuggingFaceH4/ultrachat_200k: 1.0
dataset_splits:
- train_sft
- test_sft
preprocessing_num_workers: 12
# SFT trainer config
bf16: true
do_eval: true
do_train: true
eval_strategy: epoch # One of ["no", "steps", "epoch"]
gradient_accumulation_steps: 4
gradient_checkpointing: true
gradient_checkpointing_kwargs:
use_reentrant: False
hub_model_id: mistral-7b-sft-constitutional-ai
hub_strategy: every_save
learning_rate: 2.0e-05
log_level: info
logging_steps: 5
logging_strategy: steps
lr_scheduler_type: cosine
max_seq_length: 2048
max_steps: -1
num_train_epochs: 1
output_dir: data/mistral-7b-sft-constitutional-ai
overwrite_output_dir: true
per_device_eval_batch_size: 8
per_device_train_batch_size: 8
push_to_hub: true
remove_unused_columns: true
report_to:
- tensorboard
save_strategy: "steps"
save_steps: 100
save_total_limit: 1
seed: 42
warmup_ratio: 0.1 | 8 |
0 | hf_public_repos/alignment-handbook/recipes/constitutional-ai | hf_public_repos/alignment-handbook/recipes/constitutional-ai/sft/config_anthropic.yaml | # Model arguments
model_name_or_path: mistralai/Mistral-7B-v0.1
model_revision: main
torch_dtype: bfloat16
attn_implementation: flash_attention_2
# Data training arguments
chat_template: "{% for message in messages %}\n{% if message['role'] == 'user' %}\n{{ '<|user|>\n' + message['content'] + eos_token }}\n{% elif message['role'] == 'system' %}\n{{ '<|system|>\n' + message['content'] + eos_token }}\n{% elif message['role'] == 'assistant' %}\n{{ '<|assistant|>\n' + message['content'] + eos_token }}\n{% endif %}\n{% if loop.last and add_generation_prompt %}\n{{ '<|assistant|>' }}\n{% endif %}\n{% endfor %}"
dataset_mixer:
HuggingFaceH4/cai-conversation-harmless: 1.0
HuggingFaceH4/ultrachat_200k: 1.0
dataset_splits:
- train_sft
- test_sft
preprocessing_num_workers: 12
# SFT trainer config
bf16: true
do_eval: true
do_train: true
eval_strategy: epoch # One of ["no", "steps", "epoch"]
gradient_accumulation_steps: 4
gradient_checkpointing: true
gradient_checkpointing_kwargs:
use_reentrant: False
hub_model_id: mistral-7b-sft-constitutional-ai
hub_strategy: every_save
learning_rate: 2.0e-05
log_level: info
logging_steps: 5
logging_strategy: steps
lr_scheduler_type: cosine
max_seq_length: 2048
max_steps: -1
num_train_epochs: 1
output_dir: data/mistral-7b-sft-constitutional-ai
overwrite_output_dir: true
per_device_eval_batch_size: 8
per_device_train_batch_size: 8
push_to_hub: true
remove_unused_columns: true
report_to:
- tensorboard
save_strategy: "steps"
save_steps: 100
save_total_limit: 1
seed: 42
warmup_ratio: 0.1 | 9 |
0 | hf_public_repos/autotrain-advanced/src/autotrain | hf_public_repos/autotrain-advanced/src/autotrain/backends/nvcf.py | import os
import threading
import time
from types import SimpleNamespace
import requests
from autotrain import logger
from autotrain.backends.base import BaseBackend
NVCF_API = "https://huggingface.co/api/integrations/dgx/v1"
class NVCFRunner(BaseBackend):
"""
NVCFRunner is a backend class responsible for managing and executing NVIDIA NVCF jobs.
Methods
-------
_convert_dict_to_object(dictionary):
Recursively converts a dictionary to an object using SimpleNamespace.
_conf_nvcf(token, nvcf_type, url, job_name, method="POST", payload=None):
Configures and submits an NVCF job using the specified parameters.
_poll_nvcf(url, token, job_name, method="get", timeout=86400, interval=30, op="poll"):
Polls the status of an NVCF job until completion or timeout.
create():
Initiates the creation and polling of an NVCF job.
"""
def _convert_dict_to_object(self, dictionary):
if isinstance(dictionary, dict):
for key, value in dictionary.items():
dictionary[key] = self._convert_dict_to_object(value)
return SimpleNamespace(**dictionary)
elif isinstance(dictionary, list):
return [self._convert_dict_to_object(item) for item in dictionary]
else:
return dictionary
def _conf_nvcf(self, token, nvcf_type, url, job_name, method="POST", payload=None):
logger.info(f"{job_name}: {method} - Configuring NVCF {nvcf_type}.")
headers = {"Content-Type": "application/json", "Authorization": f"Bearer {token}"}
try:
if method.upper() == "POST":
response = requests.post(url, headers=headers, json=payload, timeout=30)
else:
raise ValueError(f"Unsupported HTTP method: {method}")
response.raise_for_status()
if response.status_code == 202:
logger.info(f"{job_name}: {method} - Successfully submitted NVCF job. Polling reqId for completion")
response_data = response.json()
nvcf_reqid = response_data.get("nvcfRequestId")
if nvcf_reqid:
logger.info(f"{job_name}: nvcfRequestId: {nvcf_reqid}")
return nvcf_reqid
logger.warning(f"{job_name}: nvcfRequestId key is missing in the response body")
return None
result = response.json()
result_obj = self._convert_dict_to_object(result)
logger.info(f"{job_name}: {method} - Successfully processed NVCF {nvcf_type}.")
return result_obj
except requests.HTTPError as http_err:
# Log the response body for more context
error_message = http_err.response.text if http_err.response else "No additional error information."
logger.error(
f"{job_name}: HTTP error occurred processing NVCF {nvcf_type} with {method} request: {http_err}. "
f"Error details: {error_message}"
)
raise Exception(f"HTTP Error {http_err.response.status_code}: {http_err}. Details: {error_message}")
except (requests.Timeout, ConnectionError) as err:
logger.error(f"{job_name}: Failed to process NVCF {nvcf_type} with {method} request - {repr(err)}")
raise Exception(f"Unreachable, please try again later: {err}")
def _poll_nvcf(self, url, token, job_name, method="get", timeout=86400, interval=30, op="poll"):
timeout = float(timeout)
interval = float(interval)
start_time = time.time()
success = False
last_full_log = ""
while time.time() - start_time < timeout:
try:
headers = {"Content-Type": "application/json", "Authorization": f"Bearer {token}"}
if method.upper() == "GET":
response = requests.get(url, headers=headers)
else:
raise ValueError(f"Unsupported HTTP method: {method}")
if response.status_code == 404 and success:
break
response.raise_for_status()
try:
data = response.json()
except ValueError:
logger.error("Failed to parse JSON from response")
continue
if response.status_code == 500:
logger.error("Training failed")
if "detail" in data:
detail_message = data["detail"]
for line in detail_message.split("\n"):
if line.strip():
print(line)
break
if response.status_code in [200, 202]:
logger.info(
f"{job_name}: {method} - {response.status_code} - {'Polling completed' if response.status_code == 200 else 'Polling reqId for completion'}"
)
if "log" in data:
current_full_log = data["log"]
if current_full_log != last_full_log:
new_log_content = current_full_log[len(last_full_log) :]
for line in new_log_content.split("\n"):
if line.strip():
print(line)
last_full_log = current_full_log
if response.status_code == 200:
success = True
except requests.HTTPError as http_err:
if not (http_err.response.status_code == 404 and success):
logger.error(f"HTTP error occurred: {http_err}")
except (requests.ConnectionError, ValueError) as err:
logger.error(f"Error while handling request: {err}")
time.sleep(interval)
if not success:
raise TimeoutError(f"Operation '{op}' did not complete successfully within the timeout period.")
def create(self):
hf_token = self.env_vars["HF_TOKEN"]
job_name = f"{self.username}-{self.params.project_name}"
logger.info("Starting NVCF training")
logger.info(f"job_name: {job_name}")
logger.info(f"backend: {self.backend}")
nvcf_url_submit = f"{NVCF_API}/invoke/{self.available_hardware[self.backend]['id']}"
org_name = os.environ.get("SPACE_ID")
if org_name is None:
raise ValueError("SPACE_ID environment variable is not set")
org_name = org_name.split("/")[0]
nvcf_fr_payload = {
"cmd": [
"conda",
"run",
"--no-capture-output",
"-p",
"/app/env",
"python",
"-u",
"-m",
"uvicorn",
"autotrain.app.training_api:api",
"--host",
"0.0.0.0",
"--port",
"7860",
],
"env": {key: value for key, value in self.env_vars.items()},
"ORG_NAME": org_name,
}
nvcf_fn_req = self._conf_nvcf(
token=hf_token,
nvcf_type="job_submit",
url=nvcf_url_submit,
job_name=job_name,
method="POST",
payload=nvcf_fr_payload,
)
nvcf_url_reqpoll = f"{NVCF_API}/status/{nvcf_fn_req}"
logger.info(f"{job_name}: Polling : {nvcf_url_reqpoll}")
poll_thread = threading.Thread(
target=self._poll_nvcf,
kwargs={
"url": nvcf_url_reqpoll,
"token": hf_token,
"job_name": job_name,
"method": "GET",
"timeout": 172800,
"interval": 20,
},
)
poll_thread.start()
return nvcf_fn_req
| 0 |
0 | hf_public_repos/autotrain-advanced/src/autotrain | hf_public_repos/autotrain-advanced/src/autotrain/backends/endpoints.py | import requests
from autotrain.backends.base import BaseBackend
ENDPOINTS_URL = "https://api.endpoints.huggingface.cloud/v2/endpoint/"
class EndpointsRunner(BaseBackend):
"""
EndpointsRunner is responsible for creating and managing endpoint instances.
Methods
-------
create():
Creates an endpoint instance with the specified hardware and model parameters.
create() Method
---------------
Creates an endpoint instance with the specified hardware and model parameters.
Parameters
----------
None
Returns
-------
str
The name of the created endpoint instance.
Raises
------
requests.exceptions.RequestException
If there is an issue with the HTTP request.
"""
def create(self):
hardware = self.available_hardware[self.backend]
accelerator = hardware.split("_")[2]
instance_size = hardware.split("_")[3]
region = hardware.split("_")[1]
vendor = hardware.split("_")[0]
instance_type = hardware.split("_")[4]
payload = {
"accountId": self.username,
"compute": {
"accelerator": accelerator,
"instanceSize": instance_size,
"instanceType": instance_type,
"scaling": {"maxReplica": 1, "minReplica": 1},
},
"model": {
"framework": "custom",
"image": {
"custom": {
"env": {
"HF_TOKEN": self.params.token,
"AUTOTRAIN_USERNAME": self.username,
"PROJECT_NAME": self.params.project_name,
"PARAMS": self.params.model_dump_json(),
"DATA_PATH": self.params.data_path,
"TASK_ID": str(self.task_id),
"MODEL": self.params.model,
"ENDPOINT_ID": f"{self.username}/{self.params.project_name}",
},
"health_route": "/",
"port": 7860,
"url": "public.ecr.aws/z4c3o6n6/autotrain-api:latest",
}
},
"repository": "autotrain-projects/autotrain-advanced",
"revision": "main",
"task": "custom",
},
"name": self.params.project_name,
"provider": {"region": region, "vendor": vendor},
"type": "protected",
}
headers = {"Authorization": f"Bearer {self.params.token}"}
r = requests.post(
ENDPOINTS_URL + self.username,
json=payload,
headers=headers,
timeout=120,
)
return r.json()["name"]
| 1 |
0 | hf_public_repos/autotrain-advanced/src/autotrain | hf_public_repos/autotrain-advanced/src/autotrain/backends/base.py | import json
from dataclasses import dataclass
from typing import Union
from autotrain.trainers.clm.params import LLMTrainingParams
from autotrain.trainers.extractive_question_answering.params import ExtractiveQuestionAnsweringParams
from autotrain.trainers.generic.params import GenericParams
from autotrain.trainers.image_classification.params import ImageClassificationParams
from autotrain.trainers.image_regression.params import ImageRegressionParams
from autotrain.trainers.object_detection.params import ObjectDetectionParams
from autotrain.trainers.sent_transformers.params import SentenceTransformersParams
from autotrain.trainers.seq2seq.params import Seq2SeqParams
from autotrain.trainers.tabular.params import TabularParams
from autotrain.trainers.text_classification.params import TextClassificationParams
from autotrain.trainers.text_regression.params import TextRegressionParams
from autotrain.trainers.token_classification.params import TokenClassificationParams
from autotrain.trainers.vlm.params import VLMTrainingParams
AVAILABLE_HARDWARE = {
# hugging face spaces
"spaces-a10g-large": "a10g-large",
"spaces-a10g-small": "a10g-small",
"spaces-a100-large": "a100-large",
"spaces-t4-medium": "t4-medium",
"spaces-t4-small": "t4-small",
"spaces-cpu-upgrade": "cpu-upgrade",
"spaces-cpu-basic": "cpu-basic",
"spaces-l4x1": "l4x1",
"spaces-l4x4": "l4x4",
"spaces-l40sx1": "l40sx1",
"spaces-l40sx4": "l40sx4",
"spaces-l40sx8": "l40sx8",
"spaces-a10g-largex2": "a10g-largex2",
"spaces-a10g-largex4": "a10g-largex4",
# ngc
"dgx-a100": "dgxa100.80g.1.norm",
"dgx-2a100": "dgxa100.80g.2.norm",
"dgx-4a100": "dgxa100.80g.4.norm",
"dgx-8a100": "dgxa100.80g.8.norm",
# hugging face endpoints
"ep-aws-useast1-s": "aws_us-east-1_gpu_small_g4dn.xlarge",
"ep-aws-useast1-m": "aws_us-east-1_gpu_medium_g5.2xlarge",
"ep-aws-useast1-l": "aws_us-east-1_gpu_large_g4dn.12xlarge",
"ep-aws-useast1-xl": "aws_us-east-1_gpu_xlarge_p4de",
"ep-aws-useast1-2xl": "aws_us-east-1_gpu_2xlarge_p4de",
"ep-aws-useast1-4xl": "aws_us-east-1_gpu_4xlarge_p4de",
"ep-aws-useast1-8xl": "aws_us-east-1_gpu_8xlarge_p4de",
# nvcf
"nvcf-l40sx1": {"id": "67bb8939-c932-429a-a446-8ae898311856"},
"nvcf-h100x1": {"id": "848348f8-a4e2-4242-bce9-6baa1bd70a66"},
"nvcf-h100x2": {"id": "fb006a89-451e-4d9c-82b5-33eff257e0bf"},
"nvcf-h100x4": {"id": "21bae5af-87e5-4132-8fc0-bf3084e59a57"},
"nvcf-h100x8": {"id": "6e0c2af6-5368-47e0-b15e-c070c2c92018"},
# local
"local-ui": "local",
"local": "local",
"local-cli": "local",
}
@dataclass
class BaseBackend:
"""
BaseBackend class is responsible for initializing and validating backend configurations
for various training parameters. It supports multiple types of training parameters
including text classification, image classification, LLM training, and more.
Attributes:
params (Union[TextClassificationParams, ImageClassificationParams, LLMTrainingParams,
GenericParams, TabularParams, Seq2SeqParams,
TokenClassificationParams, TextRegressionParams, ObjectDetectionParams,
SentenceTransformersParams, ImageRegressionParams, VLMTrainingParams,
ExtractiveQuestionAnsweringParams]): Training parameters.
backend (str): Backend type.
Methods:
__post_init__(): Initializes the backend configuration, validates parameters,
sets task IDs, and prepares environment variables.
"""
params: Union[
TextClassificationParams,
ImageClassificationParams,
LLMTrainingParams,
GenericParams,
TabularParams,
Seq2SeqParams,
TokenClassificationParams,
TextRegressionParams,
ObjectDetectionParams,
SentenceTransformersParams,
ImageRegressionParams,
VLMTrainingParams,
ExtractiveQuestionAnsweringParams,
]
backend: str
def __post_init__(self):
self.username = None
if isinstance(self.params, GenericParams) and self.backend.startswith("local"):
raise ValueError("Local backend is not supported for GenericParams")
if (
self.backend.startswith("spaces-")
or self.backend.startswith("ep-")
or self.backend.startswith("ngc-")
or self.backend.startswith("nvcf-")
):
if self.params.username is not None:
self.username = self.params.username
else:
raise ValueError("Must provide username")
if isinstance(self.params, LLMTrainingParams):
self.task_id = 9
elif isinstance(self.params, TextClassificationParams):
self.task_id = 2
elif isinstance(self.params, TabularParams):
self.task_id = 26
elif isinstance(self.params, GenericParams):
self.task_id = 27
elif isinstance(self.params, Seq2SeqParams):
self.task_id = 28
elif isinstance(self.params, ImageClassificationParams):
self.task_id = 18
elif isinstance(self.params, TokenClassificationParams):
self.task_id = 4
elif isinstance(self.params, TextRegressionParams):
self.task_id = 10
elif isinstance(self.params, ObjectDetectionParams):
self.task_id = 29
elif isinstance(self.params, SentenceTransformersParams):
self.task_id = 30
elif isinstance(self.params, ImageRegressionParams):
self.task_id = 24
elif isinstance(self.params, VLMTrainingParams):
self.task_id = 31
elif isinstance(self.params, ExtractiveQuestionAnsweringParams):
self.task_id = 5
else:
raise NotImplementedError
self.available_hardware = AVAILABLE_HARDWARE
self.wait = False
if self.backend == "local-ui":
self.wait = False
if self.backend in ("local", "local-cli"):
self.wait = True
self.env_vars = {
"HF_TOKEN": self.params.token,
"AUTOTRAIN_USERNAME": self.username,
"PROJECT_NAME": self.params.project_name,
"TASK_ID": str(self.task_id),
"PARAMS": json.dumps(self.params.model_dump_json()),
}
self.env_vars["DATA_PATH"] = self.params.data_path
if not isinstance(self.params, GenericParams):
self.env_vars["MODEL"] = self.params.model
| 2 |
0 | hf_public_repos/autotrain-advanced/src/autotrain | hf_public_repos/autotrain-advanced/src/autotrain/backends/ngc.py | import base64
import json
import os
import requests
from requests.exceptions import HTTPError
from autotrain import logger
from autotrain.backends.base import BaseBackend
NGC_API = os.environ.get("NGC_API", "https://api.ngc.nvidia.com/v2/org")
NGC_AUTH = os.environ.get("NGC_AUTH", "https://authn.nvidia.com")
NGC_ACE = os.environ.get("NGC_ACE")
NGC_ORG = os.environ.get("NGC_ORG")
NGC_API_KEY = os.environ.get("NGC_CLI_API_KEY")
NGC_TEAM = os.environ.get("NGC_TEAM")
class NGCRunner(BaseBackend):
"""
NGCRunner class for managing NGC backend trainings.
Methods:
_user_authentication_ngc():
Authenticates the user with NGC and retrieves an authentication token.
Returns:
str: The authentication token.
Raises:
Exception: If an HTTP error or connection error occurs during the request.
_create_ngc_job(token, url, payload):
Creates a job on NGC using the provided token, URL, and payload.
Args:
token (str): The authentication token.
url (str): The URL for the NGC API endpoint.
payload (dict): The payload containing job details.
Returns:
str: The ID of the created job.
Raises:
Exception: If an HTTP error or connection error occurs during the request.
create():
Creates a job on NGC with the specified parameters.
Returns:
str: The ID of the created job.
"""
def _user_authentication_ngc(self):
logger.info("Authenticating NGC user...")
scope = "group/ngc"
querystring = {"service": "ngc", "scope": scope}
auth = f"$oauthtoken:{NGC_API_KEY}"
headers = {
"Authorization": f"Basic {base64.b64encode(auth.encode('utf-8')).decode('utf-8')}",
"Content-Type": "application/json",
"Cache-Control": "no-cache",
}
try:
response = requests.get(NGC_AUTH + "/token", headers=headers, params=querystring, timeout=30)
except HTTPError as http_err:
logger.error(f"HTTP error occurred: {http_err}")
raise Exception("HTTP Error %d: from '%s'" % (response.status_code, NGC_AUTH))
except (requests.Timeout, ConnectionError) as err:
logger.error(f"Failed to request NGC token - {repr(err)}")
raise Exception("%s is unreachable, please try again later." % NGC_AUTH)
return json.loads(response.text.encode("utf8"))["token"]
def _create_ngc_job(self, token, url, payload):
logger.info("Creating NGC Job")
headers = {"Content-Type": "application/json", "Authorization": f"Bearer {token}"}
try:
response = requests.post(NGC_API + url + "/jobs", headers=headers, json=payload, timeout=30)
result = response.json()
logger.info(
f"NGC Job ID: {result.get('job', {}).get('id')}, Job Status History: {result.get('jobStatusHistory')}"
)
return result.get("job", {}).get("id")
except HTTPError as http_err:
logger.error(f"HTTP error occurred: {http_err}")
raise Exception(f"HTTP Error {response.status_code}: {http_err}")
except (requests.Timeout, ConnectionError) as err:
logger.error(f"Failed to create NGC job - {repr(err)}")
raise Exception(f"Unreachable, please try again later: {err}")
def create(self):
job_name = f"{self.username}-{self.params.project_name}"
ngc_url = f"/{NGC_ORG}/team/{NGC_TEAM}"
ngc_cmd = "set -x; conda run --no-capture-output -p /app/env autotrain api --port 7860 --host 0.0.0.0"
ngc_payload = {
"name": job_name,
"aceName": NGC_ACE,
"aceInstance": self.available_hardware[self.backend],
"dockerImageName": f"{NGC_ORG}/autotrain-advanced:latest",
"command": ngc_cmd,
"envs": [{"name": key, "value": value} for key, value in self.env_vars.items()],
"jobOrder": 50,
"jobPriority": "NORMAL",
"portMappings": [{"containerPort": 7860, "protocol": "HTTPS"}],
"resultContainerMountPoint": "/results",
"runPolicy": {"preemptClass": "RUNONCE", "totalRuntimeSeconds": 259200},
}
ngc_token = self._user_authentication_ngc()
job_id = self._create_ngc_job(ngc_token, ngc_url, ngc_payload)
return job_id
| 3 |
0 | hf_public_repos/autotrain-advanced/src/autotrain | hf_public_repos/autotrain-advanced/src/autotrain/backends/local.py | from autotrain import logger
from autotrain.backends.base import BaseBackend
from autotrain.utils import run_training
class LocalRunner(BaseBackend):
"""
LocalRunner is a class that inherits from BaseBackend and is responsible for managing local training tasks.
Methods:
create():
Starts the local training process by retrieving parameters and task ID from environment variables.
Logs the start of the training process.
Runs the training with the specified parameters and task ID.
If the `wait` attribute is False, logs the training process ID (PID).
Returns the training process ID (PID).
"""
def create(self):
logger.info("Starting local training...")
params = self.env_vars["PARAMS"]
task_id = int(self.env_vars["TASK_ID"])
training_pid = run_training(params, task_id, local=True, wait=self.wait)
if not self.wait:
logger.info(f"Training PID: {training_pid}")
return training_pid
| 4 |
0 | hf_public_repos/autotrain-advanced/src/autotrain | hf_public_repos/autotrain-advanced/src/autotrain/backends/spaces.py | import io
from huggingface_hub import HfApi
from autotrain.backends.base import BaseBackend
from autotrain.trainers.generic.params import GenericParams
_DOCKERFILE = """
FROM huggingface/autotrain-advanced:latest
CMD pip uninstall -y autotrain-advanced && pip install -U autotrain-advanced && autotrain api --port 7860 --host 0.0.0.0
"""
# format _DOCKERFILE
_DOCKERFILE = _DOCKERFILE.replace("\n", " ").replace(" ", "\n").strip()
class SpaceRunner(BaseBackend):
"""
SpaceRunner is a backend class responsible for creating and managing training jobs on Hugging Face Spaces.
Methods
-------
_create_readme():
Creates a README.md file content for the space.
_add_secrets(api, space_id):
Adds necessary secrets to the space repository.
create():
Creates a new space repository, adds secrets, and uploads necessary files.
"""
def _create_readme(self):
_readme = "---\n"
_readme += f"title: {self.params.project_name}\n"
_readme += "emoji: 🚀\n"
_readme += "colorFrom: green\n"
_readme += "colorTo: indigo\n"
_readme += "sdk: docker\n"
_readme += "pinned: false\n"
_readme += "tags:\n"
_readme += "- autotrain\n"
_readme += "duplicated_from: autotrain-projects/autotrain-advanced\n"
_readme += "---\n"
_readme = io.BytesIO(_readme.encode())
return _readme
def _add_secrets(self, api, space_id):
if isinstance(self.params, GenericParams):
for k, v in self.params.env.items():
api.add_space_secret(repo_id=space_id, key=k, value=v)
self.params.env = {}
api.add_space_secret(repo_id=space_id, key="HF_TOKEN", value=self.params.token)
api.add_space_secret(repo_id=space_id, key="AUTOTRAIN_USERNAME", value=self.username)
api.add_space_secret(repo_id=space_id, key="PROJECT_NAME", value=self.params.project_name)
api.add_space_secret(repo_id=space_id, key="TASK_ID", value=str(self.task_id))
api.add_space_secret(repo_id=space_id, key="PARAMS", value=self.params.model_dump_json())
api.add_space_secret(repo_id=space_id, key="DATA_PATH", value=self.params.data_path)
if not isinstance(self.params, GenericParams):
api.add_space_secret(repo_id=space_id, key="MODEL", value=self.params.model)
def create(self):
api = HfApi(token=self.params.token)
space_id = f"{self.username}/autotrain-{self.params.project_name}"
api.create_repo(
repo_id=space_id,
repo_type="space",
space_sdk="docker",
space_hardware=self.available_hardware[self.backend],
private=True,
)
self._add_secrets(api, space_id)
api.set_space_sleep_time(repo_id=space_id, sleep_time=604800)
readme = self._create_readme()
api.upload_file(
path_or_fileobj=readme,
path_in_repo="README.md",
repo_id=space_id,
repo_type="space",
)
_dockerfile = io.BytesIO(_DOCKERFILE.encode())
api.upload_file(
path_or_fileobj=_dockerfile,
path_in_repo="Dockerfile",
repo_id=space_id,
repo_type="space",
)
return space_id
| 5 |
0 | hf_public_repos/autotrain-advanced/src/autotrain | hf_public_repos/autotrain-advanced/src/autotrain/cli/run_app.py | import os
import signal
import subprocess
import sys
import threading
from argparse import ArgumentParser
from autotrain import logger
from . import BaseAutoTrainCommand
def handle_output(stream, log_file):
"""
Continuously reads lines from a given stream and writes them to both
standard output and a log file until the stream is exhausted.
Args:
stream (io.TextIOBase): The input stream to read lines from.
log_file (io.TextIOBase): The log file to write lines to.
Returns:
None
"""
while True:
line = stream.readline()
if not line:
break
sys.stdout.write(line)
sys.stdout.flush()
log_file.write(line)
log_file.flush()
def run_app_command_factory(args):
return RunAutoTrainAppCommand(args.port, args.host, args.share, args.workers, args.colab)
class RunAutoTrainAppCommand(BaseAutoTrainCommand):
"""
Command to run the AutoTrain application.
This command sets up and runs the AutoTrain application with the specified
configuration options such as port, host, number of workers, and sharing options.
Methods
-------
register_subcommand(parser: ArgumentParser):
Registers the subcommand and its arguments to the provided parser.
__init__(port: int, host: str, share: bool, workers: int, colab: bool):
Initializes the command with the specified parameters.
run():
Executes the command to run the AutoTrain application. Handles different
modes such as running in Colab or sharing via ngrok.
"""
@staticmethod
def register_subcommand(parser: ArgumentParser):
run_app_parser = parser.add_parser(
"app",
description="✨ Run AutoTrain app",
)
run_app_parser.add_argument(
"--port",
type=int,
default=7860,
help="Port to run the app on",
required=False,
)
run_app_parser.add_argument(
"--host",
type=str,
default="127.0.0.1",
help="Host to run the app on",
required=False,
)
run_app_parser.add_argument(
"--workers",
type=int,
default=1,
help="Number of workers to run the app with",
required=False,
)
run_app_parser.add_argument(
"--share",
action="store_true",
help="Share the app on ngrok",
required=False,
)
run_app_parser.add_argument(
"--colab",
action="store_true",
help="Use app in colab",
required=False,
)
run_app_parser.set_defaults(func=run_app_command_factory)
def __init__(self, port, host, share, workers, colab):
self.port = port
self.host = host
self.share = share
self.workers = workers
self.colab = colab
def run(self):
if self.colab:
from IPython.display import display
from autotrain.app.colab import colab_app
elements = colab_app()
display(elements)
return
if self.share:
from pyngrok import ngrok
os.system(f"fuser -n tcp -k {self.port}")
authtoken = os.environ.get("NGROK_AUTH_TOKEN", "")
if authtoken.strip() == "":
logger.info("NGROK_AUTH_TOKEN not set")
raise ValueError("NGROK_AUTH_TOKEN not set. Please set it!")
ngrok.set_auth_token(authtoken)
active_tunnels = ngrok.get_tunnels()
for tunnel in active_tunnels:
public_url = tunnel.public_url
ngrok.disconnect(public_url)
url = ngrok.connect(addr=self.port, bind_tls=True)
logger.info(f"AutoTrain Public URL: {url}")
logger.info("Please wait for the app to load...")
command = f"uvicorn autotrain.app.app:app --host {self.host} --port {self.port}"
command += f" --workers {self.workers}"
with open("autotrain.log", "w", encoding="utf-8") as log_file:
if sys.platform == "win32":
process = subprocess.Popen(
command, stdout=subprocess.PIPE, stderr=subprocess.STDOUT, shell=True, text=True, bufsize=1
)
else:
process = subprocess.Popen(
command,
stdout=subprocess.PIPE,
stderr=subprocess.STDOUT,
shell=True,
text=True,
bufsize=1,
preexec_fn=os.setsid,
)
output_thread = threading.Thread(target=handle_output, args=(process.stdout, log_file))
output_thread.start()
try:
process.wait()
output_thread.join()
except KeyboardInterrupt:
logger.warning("Attempting to terminate the process...")
if sys.platform == "win32":
process.terminate()
else:
# If user cancels (Ctrl+C), terminate the subprocess
# Use os.killpg to send SIGTERM to the process group, ensuring all child processes are killed
os.killpg(os.getpgid(process.pid), signal.SIGTERM)
logger.info("Process terminated by user")
| 6 |
0 | hf_public_repos/autotrain-advanced/src/autotrain | hf_public_repos/autotrain-advanced/src/autotrain/cli/utils.py | from typing import Any, Type
from autotrain.backends.base import AVAILABLE_HARDWARE
def common_args():
args = [
{
"arg": "--train",
"help": "Command to train the model",
"required": False,
"action": "store_true",
},
{
"arg": "--deploy",
"help": "Command to deploy the model (limited availability)",
"required": False,
"action": "store_true",
},
{
"arg": "--inference",
"help": "Command to run inference (limited availability)",
"required": False,
"action": "store_true",
},
{
"arg": "--username",
"help": "Hugging Face Hub Username",
"required": False,
"type": str,
},
{
"arg": "--backend",
"help": "Backend to use: default or spaces. Spaces backend requires push_to_hub & username. Advanced users only.",
"required": False,
"type": str,
"default": "local",
"choices": AVAILABLE_HARDWARE.keys(),
},
{
"arg": "--token",
"help": "Your Hugging Face API token. Token must have write access to the model hub.",
"required": False,
"type": str,
},
{
"arg": "--push-to-hub",
"help": "Push to hub after training will push the trained model to the Hugging Face model hub.",
"required": False,
"action": "store_true",
},
{
"arg": "--model",
"help": "Base model to use for training",
"required": True,
"type": str,
},
{
"arg": "--project-name",
"help": "Output directory / repo id for trained model (must be unique on hub)",
"required": True,
"type": str,
},
{
"arg": "--data-path",
"help": "Train dataset to use. When using cli, this should be a directory path containing training and validation data in appropriate formats",
"required": False,
"type": str,
},
{
"arg": "--train-split",
"help": "Train dataset split to use",
"required": False,
"type": str,
"default": "train",
},
{
"arg": "--valid-split",
"help": "Validation dataset split to use",
"required": False,
"type": str,
"default": None,
},
{
"arg": "--batch-size",
"help": "Training batch size to use",
"required": False,
"type": int,
"default": 2,
"alias": ["--train-batch-size"],
},
{
"arg": "--seed",
"help": "Random seed for reproducibility",
"required": False,
"default": 42,
"type": int,
},
{
"arg": "--epochs",
"help": "Number of training epochs",
"required": False,
"default": 1,
"type": int,
},
{
"arg": "--gradient-accumulation",
"help": "Gradient accumulation steps",
"required": False,
"default": 1,
"type": int,
"alias": ["--gradient-accumulation"],
},
{
"arg": "--disable-gradient-checkpointing",
"help": "Disable gradient checkpointing",
"required": False,
"action": "store_true",
"alias": ["--disable-gradient-checkpointing", "--disable-gc"],
},
{
"arg": "--lr",
"help": "Learning rate",
"required": False,
"default": 5e-4,
"type": float,
},
{
"arg": "--log",
"help": "Use experiment tracking",
"required": False,
"type": str,
"default": "none",
"choices": ["none", "wandb", "tensorboard"],
},
]
return args
def python_type_from_schema_field(field_data: dict) -> Type:
"""Converts JSON schema field types to Python types."""
type_map = {
"string": str,
"number": float,
"integer": int,
"boolean": bool,
}
field_type = field_data.get("type")
if field_type:
return type_map.get(field_type, str)
elif "anyOf" in field_data:
for type_option in field_data["anyOf"]:
if type_option["type"] != "null":
return type_map.get(type_option["type"], str)
return str
def get_default_value(field_data: dict) -> Any:
return field_data["default"]
def get_field_info(params_class):
schema = params_class.model_json_schema()
properties = schema.get("properties", {})
field_info = []
for field_name, field_data in properties.items():
temp_info = {
"arg": f"--{field_name.replace('_', '-')}",
"alias": [f"--{field_name}", f"--{field_name.replace('_', '-')}"],
"type": python_type_from_schema_field(field_data),
"help": field_data.get("title", ""),
"default": get_default_value(field_data),
}
if temp_info["type"] == bool:
temp_info["action"] = "store_true"
field_info.append(temp_info)
return field_info
| 7 |
0 | hf_public_repos/autotrain-advanced/src/autotrain | hf_public_repos/autotrain-advanced/src/autotrain/cli/run_image_classification.py | from argparse import ArgumentParser
from autotrain import logger
from autotrain.cli.utils import get_field_info
from autotrain.project import AutoTrainProject
from autotrain.trainers.image_classification.params import ImageClassificationParams
from . import BaseAutoTrainCommand
def run_image_classification_command_factory(args):
return RunAutoTrainImageClassificationCommand(args)
class RunAutoTrainImageClassificationCommand(BaseAutoTrainCommand):
@staticmethod
def register_subcommand(parser: ArgumentParser):
arg_list = get_field_info(ImageClassificationParams)
arg_list = [
{
"arg": "--train",
"help": "Command to train the model",
"required": False,
"action": "store_true",
},
{
"arg": "--deploy",
"help": "Command to deploy the model (limited availability)",
"required": False,
"action": "store_true",
},
{
"arg": "--inference",
"help": "Command to run inference (limited availability)",
"required": False,
"action": "store_true",
},
{
"arg": "--backend",
"help": "Backend",
"required": False,
"type": str,
"default": "local",
},
] + arg_list
run_image_classification_parser = parser.add_parser(
"image-classification", description="✨ Run AutoTrain Image Classification"
)
for arg in arg_list:
names = [arg["arg"]] + arg.get("alias", [])
if "action" in arg:
run_image_classification_parser.add_argument(
*names,
dest=arg["arg"].replace("--", "").replace("-", "_"),
help=arg["help"],
required=arg.get("required", False),
action=arg.get("action"),
default=arg.get("default"),
)
else:
run_image_classification_parser.add_argument(
*names,
dest=arg["arg"].replace("--", "").replace("-", "_"),
help=arg["help"],
required=arg.get("required", False),
type=arg.get("type"),
default=arg.get("default"),
choices=arg.get("choices"),
)
run_image_classification_parser.set_defaults(func=run_image_classification_command_factory)
def __init__(self, args):
self.args = args
store_true_arg_names = [
"train",
"deploy",
"inference",
"auto_find_batch_size",
"push_to_hub",
]
for arg_name in store_true_arg_names:
if getattr(self.args, arg_name) is None:
setattr(self.args, arg_name, False)
if self.args.train:
if self.args.project_name is None:
raise ValueError("Project name must be specified")
if self.args.data_path is None:
raise ValueError("Data path must be specified")
if self.args.model is None:
raise ValueError("Model must be specified")
if self.args.push_to_hub:
if self.args.username is None:
raise ValueError("Username must be specified for push to hub")
else:
raise ValueError("Must specify --train, --deploy or --inference")
if self.args.backend.startswith("spaces") or self.args.backend.startswith("ep-"):
if not self.args.push_to_hub:
raise ValueError("Push to hub must be specified for spaces backend")
if self.args.username is None:
raise ValueError("Username must be specified for spaces backend")
if self.args.token is None:
raise ValueError("Token must be specified for spaces backend")
def run(self):
logger.info("Running Image Classification")
if self.args.train:
params = ImageClassificationParams(**vars(self.args))
project = AutoTrainProject(params=params, backend=self.args.backend, process=True)
job_id = project.create()
logger.info(f"Job ID: {job_id}")
| 8 |
0 | hf_public_repos/autotrain-advanced/src/autotrain | hf_public_repos/autotrain-advanced/src/autotrain/cli/run_text_regression.py | from argparse import ArgumentParser
from autotrain import logger
from autotrain.cli.utils import get_field_info
from autotrain.project import AutoTrainProject
from autotrain.trainers.text_regression.params import TextRegressionParams
from . import BaseAutoTrainCommand
def run_text_regression_command_factory(args):
return RunAutoTrainTextRegressionCommand(args)
class RunAutoTrainTextRegressionCommand(BaseAutoTrainCommand):
@staticmethod
def register_subcommand(parser: ArgumentParser):
arg_list = get_field_info(TextRegressionParams)
arg_list = [
{
"arg": "--train",
"help": "Command to train the model",
"required": False,
"action": "store_true",
},
{
"arg": "--deploy",
"help": "Command to deploy the model (limited availability)",
"required": False,
"action": "store_true",
},
{
"arg": "--inference",
"help": "Command to run inference (limited availability)",
"required": False,
"action": "store_true",
},
{
"arg": "--backend",
"help": "Backend",
"required": False,
"type": str,
"default": "local",
},
] + arg_list
arg_list = [arg for arg in arg_list if arg["arg"] != "--disable-gradient-checkpointing"]
run_text_regression_parser = parser.add_parser(
"text-regression", description="✨ Run AutoTrain Text Regression"
)
for arg in arg_list:
names = [arg["arg"]] + arg.get("alias", [])
if "action" in arg:
run_text_regression_parser.add_argument(
*names,
dest=arg["arg"].replace("--", "").replace("-", "_"),
help=arg["help"],
required=arg.get("required", False),
action=arg.get("action"),
default=arg.get("default"),
)
else:
run_text_regression_parser.add_argument(
*names,
dest=arg["arg"].replace("--", "").replace("-", "_"),
help=arg["help"],
required=arg.get("required", False),
type=arg.get("type"),
default=arg.get("default"),
choices=arg.get("choices"),
)
run_text_regression_parser.set_defaults(func=run_text_regression_command_factory)
def __init__(self, args):
self.args = args
store_true_arg_names = [
"train",
"deploy",
"inference",
"auto_find_batch_size",
"push_to_hub",
]
for arg_name in store_true_arg_names:
if getattr(self.args, arg_name) is None:
setattr(self.args, arg_name, False)
if self.args.train:
if self.args.project_name is None:
raise ValueError("Project name must be specified")
if self.args.data_path is None:
raise ValueError("Data path must be specified")
if self.args.model is None:
raise ValueError("Model must be specified")
if self.args.push_to_hub:
if self.args.username is None:
raise ValueError("Username must be specified for push to hub")
else:
raise ValueError("Must specify --train, --deploy or --inference")
def run(self):
logger.info("Running Text Regression")
if self.args.train:
params = TextRegressionParams(**vars(self.args))
project = AutoTrainProject(params=params, backend=self.args.backend, process=True)
job_id = project.create()
logger.info(f"Job ID: {job_id}")
| 9 |
0 | hf_public_repos/candle/candle-transformers/src | hf_public_repos/candle/candle-transformers/src/models/quantized_rwkv_v5.rs | //! RWKV v5 model implementation with quantization support.
//!
//! RWKV v5 is an attention-free language model optimized for efficiency.
//! This implementation provides quantization for reduced memory and compute.
//!
//! Key characteristics:
//! - Linear attention mechanism
//! - GroupNorm layer normalization
//! - Time-mixing layers
//! - State-based sequential processing
//! - Support for 8-bit quantization
//!
//! References:
//! - [RWKV Model](https://github.com/BlinkDL/RWKV-LM)
//! - [RWKV v5 Architecture](https://www.rwkv.com/v5)
//!
use crate::{
quantized_nn::{layer_norm, linear_no_bias as linear, Embedding, Linear},
quantized_var_builder::VarBuilder,
};
use candle::{IndexOp, Result, Tensor};
use candle_nn::{GroupNorm, LayerNorm, Module};
pub use crate::models::rwkv_v5::{Config, State, Tokenizer};
#[derive(Debug, Clone)]
struct SelfAttention {
key: Linear,
receptance: Linear,
value: Linear,
gate: Linear,
output: Linear,
ln_x: candle_nn::GroupNorm,
time_mix_key: Tensor,
time_mix_value: Tensor,
time_mix_receptance: Tensor,
time_decay: Tensor,
time_faaaa: Tensor,
time_mix_gate: Tensor,
layer_id: usize,
n_attn_heads: usize,
}
impl SelfAttention {
fn new(layer_id: usize, cfg: &Config, vb: VarBuilder) -> Result<Self> {
let hidden_size = cfg.hidden_size;
let attn_hidden_size = cfg.attention_hidden_size;
let key = linear(hidden_size, attn_hidden_size, vb.pp("key"))?;
let receptance = linear(hidden_size, attn_hidden_size, vb.pp("receptance"))?;
let value = linear(hidden_size, attn_hidden_size, vb.pp("value"))?;
let gate = linear(hidden_size, attn_hidden_size, vb.pp("gate"))?;
let output = linear(attn_hidden_size, hidden_size, vb.pp("output"))?;
let vb_x = vb.pp("ln_x");
let ln_x_weight = vb_x.get(hidden_size, "weight")?.dequantize(vb.device())?;
let ln_x_bias = vb_x.get(hidden_size, "bias")?.dequantize(vb.device())?;
let ln_x = GroupNorm::new(
ln_x_weight,
ln_x_bias,
hidden_size,
hidden_size / cfg.head_size,
1e-5,
)?;
let time_mix_key = vb
.get((1, 1, cfg.hidden_size), "time_mix_key")?
.dequantize(vb.device())?;
let time_mix_value = vb
.get((1, 1, cfg.hidden_size), "time_mix_value")?
.dequantize(vb.device())?;
let time_mix_receptance = vb
.get((1, 1, cfg.hidden_size), "time_mix_receptance")?
.dequantize(vb.device())?;
let n_attn_heads = cfg.hidden_size / cfg.head_size;
let time_decay = vb
.get((n_attn_heads, cfg.head_size), "time_decay")?
.dequantize(vb.device())?;
let time_faaaa = vb
.get((n_attn_heads, cfg.head_size), "time_faaaa")?
.dequantize(vb.device())?;
let time_mix_gate = vb
.get((1, 1, cfg.hidden_size), "time_mix_gate")?
.dequantize(vb.device())?;
Ok(Self {
key,
value,
receptance,
gate,
output,
ln_x,
time_mix_key,
time_mix_value,
time_mix_receptance,
time_decay,
time_faaaa,
time_mix_gate,
layer_id,
n_attn_heads,
})
}
pub fn forward(&self, xs: &Tensor, state: &mut State) -> Result<Tensor> {
let h = self.time_decay.dim(0)?;
let (b, t, s) = xs.dims3()?;
let s = s / h;
let (receptance, key, value, gate) = {
// extract key-value
let shifted = state.per_layer[self.layer_id].extract_key_value.clone();
let shifted = if shifted.rank() == 2 {
shifted.unsqueeze(1)?
} else {
shifted
};
let key = ((xs * &self.time_mix_key)? + &shifted * (1.0 - &self.time_mix_key)?)?;
let value = ((xs * &self.time_mix_value)? + &shifted * (1.0 - &self.time_mix_value)?)?;
let receptance = ((xs * &self.time_mix_receptance)?
+ &shifted * (1.0 - &self.time_mix_receptance)?)?;
let gate = ((xs * &self.time_mix_gate)? + &shifted * (1.0 - &self.time_mix_gate)?)?;
let key = self.key.forward(&key)?;
let value = self.value.forward(&value)?;
let receptance = self.receptance.forward(&receptance)?;
let gate = candle_nn::ops::silu(&self.gate.forward(&gate)?)?;
state.per_layer[self.layer_id].extract_key_value = xs.i((.., t - 1))?;
(receptance, key, value, gate)
};
// linear attention
let mut state_ = state.per_layer[self.layer_id].linear_attention.clone();
let key = key.reshape((b, t, h, s))?.permute((0, 2, 3, 1))?;
let value = value.reshape((b, t, h, s))?.transpose(1, 2)?;
let receptance = receptance.reshape((b, t, h, s))?.transpose(1, 2)?;
let time_decay = self
.time_decay
.exp()?
.neg()?
.exp()?
.reshape(((), 1, 1))?
.reshape((self.n_attn_heads, (), 1))?;
let time_faaaa =
self.time_faaaa
.reshape(((), 1, 1))?
.reshape((self.n_attn_heads, (), 1))?;
let mut out: Vec<Tensor> = Vec::with_capacity(t);
for t_ in 0..t {
let rt = receptance.i((.., .., t_..t_ + 1))?.contiguous()?;
let kt = key.i((.., .., .., t_..t_ + 1))?.contiguous()?;
let vt = value.i((.., .., t_..t_ + 1))?.contiguous()?;
let at = kt.matmul(&vt)?;
let rhs = (time_faaaa.broadcast_mul(&at)? + &state_)?;
let out_ = rt.matmul(&rhs)?.squeeze(2)?;
state_ = (&at + time_decay.broadcast_mul(&state_))?;
out.push(out_)
}
let out = Tensor::cat(&out, 1)?.reshape((b * t, h * s, 1))?;
let out = out.apply(&self.ln_x)?.reshape((b, t, h * s))?;
let out = (out * gate)?.apply(&self.output)?;
state.per_layer[self.layer_id].linear_attention = state_;
Ok(out)
}
}
#[derive(Debug, Clone)]
struct FeedForward {
time_mix_key: Tensor,
time_mix_receptance: Tensor,
key: Linear,
receptance: Linear,
value: Linear,
layer_id: usize,
}
impl FeedForward {
fn new(layer_id: usize, cfg: &Config, vb: VarBuilder) -> Result<Self> {
let int_size = cfg
.intermediate_size
.unwrap_or(((cfg.hidden_size as f64 * 3.5) as usize) / 32 * 32);
let key = linear(cfg.hidden_size, int_size, vb.pp("key"))?;
let receptance = linear(cfg.hidden_size, cfg.hidden_size, vb.pp("receptance"))?;
let value = linear(int_size, cfg.hidden_size, vb.pp("value"))?;
let time_mix_key = vb
.get((1, 1, cfg.hidden_size), "time_mix_key")?
.dequantize(vb.device())?;
let time_mix_receptance = vb
.get((1, 1, cfg.hidden_size), "time_mix_receptance")?
.dequantize(vb.device())?;
Ok(Self {
key,
receptance,
value,
time_mix_key,
time_mix_receptance,
layer_id,
})
}
fn forward(&self, xs: &Tensor, state: &mut State) -> Result<Tensor> {
let shifted = &state.per_layer[self.layer_id].feed_forward;
let key = (xs.broadcast_mul(&self.time_mix_key)?
+ shifted.broadcast_mul(&(1.0 - &self.time_mix_key)?)?)?;
let receptance = (xs.broadcast_mul(&self.time_mix_receptance)?
+ shifted.broadcast_mul(&(1.0 - &self.time_mix_receptance)?)?)?;
let key = key.apply(&self.key)?.relu()?.sqr()?;
let value = key.apply(&self.value)?;
let receptance = candle_nn::ops::sigmoid(&receptance.apply(&self.receptance)?)?;
state.per_layer[self.layer_id].feed_forward = xs.i((.., xs.dim(1)? - 1))?;
let xs = (receptance * value)?;
Ok(xs)
}
}
#[derive(Debug, Clone)]
struct Block {
pre_ln: Option<LayerNorm>,
ln1: LayerNorm,
ln2: LayerNorm,
attention: SelfAttention,
feed_forward: FeedForward,
}
impl Block {
fn new(layer_id: usize, cfg: &Config, vb: VarBuilder) -> Result<Self> {
let ln1 = layer_norm(cfg.hidden_size, cfg.layer_norm_epsilon, vb.pp("ln1"))?;
let ln2 = layer_norm(cfg.hidden_size, cfg.layer_norm_epsilon, vb.pp("ln2"))?;
let pre_ln = if layer_id == 0 {
let ln = layer_norm(cfg.hidden_size, cfg.layer_norm_epsilon, vb.pp("pre_ln"))?;
Some(ln)
} else {
None
};
let attention = SelfAttention::new(layer_id, cfg, vb.pp("attention"))?;
let feed_forward = FeedForward::new(layer_id, cfg, vb.pp("feed_forward"))?;
Ok(Self {
pre_ln,
ln1,
ln2,
attention,
feed_forward,
})
}
fn forward(&self, xs: &Tensor, state: &mut State) -> Result<Tensor> {
let xs = match self.pre_ln.as_ref() {
None => xs.clone(),
Some(pre_ln) => xs.apply(pre_ln)?,
};
let attention = self.attention.forward(&xs.apply(&self.ln1)?, state)?;
let xs = (xs + attention)?;
let feed_forward = self.feed_forward.forward(&xs.apply(&self.ln2)?, state)?;
let xs = (xs + feed_forward)?;
Ok(xs)
}
}
#[derive(Debug, Clone)]
pub struct Model {
embeddings: Embedding,
blocks: Vec<Block>,
ln_out: LayerNorm,
head: Linear,
rescale_every: usize,
layers_are_rescaled: bool,
}
impl Model {
pub fn new(cfg: &Config, vb: VarBuilder) -> Result<Self> {
let vb_m = vb.pp("rwkv");
let embeddings = Embedding::new(cfg.vocab_size, cfg.hidden_size, vb_m.pp("embeddings"))?;
let mut blocks = Vec::with_capacity(cfg.num_hidden_layers);
let vb_b = vb_m.pp("blocks");
for block_index in 0..cfg.num_hidden_layers {
let block = Block::new(block_index, cfg, vb_b.pp(block_index))?;
blocks.push(block)
}
let ln_out = layer_norm(cfg.hidden_size, 1e-5, vb_m.pp("ln_out"))?;
let head = linear(cfg.hidden_size, cfg.vocab_size, vb.pp("head"))?;
Ok(Self {
embeddings,
blocks,
ln_out,
head,
rescale_every: cfg.rescale_every,
layers_are_rescaled: false, // This seem to only happen for the f16/bf16 dtypes.
})
}
pub fn forward(&self, xs: &Tensor, state: &mut State) -> Result<Tensor> {
let (_b_size, _seq_len) = xs.dims2()?;
let mut xs = xs.apply(&self.embeddings)?;
for (block_idx, block) in self.blocks.iter().enumerate() {
xs = block.forward(&xs, state)?;
if self.layers_are_rescaled && (block_idx + 1) % self.rescale_every == 0 {
xs = (xs / 2.)?
}
}
let xs = xs.apply(&self.ln_out)?.apply(&self.head)?;
state.pos += 1;
Ok(xs)
}
}
| 0 |
0 | hf_public_repos/candle/candle-transformers/src | hf_public_repos/candle/candle-transformers/src/models/segformer.rs | //! Segformer model implementation for semantic segmentation and image classification.
//!
//! Segformer is a transformer-based model designed for vision tasks. It uses a hierarchical
//! structure that progressively generates features at different scales.
//!
//! Key characteristics:
//! - Efficient self-attention with sequence reduction
//! - Hierarchical feature generation
//! - Mix-FFN for local and global feature interaction
//! - Lightweight all-MLP decode head
//!
//! References:
//! - [SegFormer Paper](https://arxiv.org/abs/2105.15203)
//! - [Model Card](https://huggingface.co/nvidia/mit-b0)
//!
use crate::models::with_tracing::{conv2d, linear, Conv2d, Linear};
use candle::{Module, ModuleT, Result, Tensor, D};
use candle_nn::{conv2d_no_bias, layer_norm, Activation, Conv2dConfig, VarBuilder};
use serde::Deserialize;
use std::collections::HashMap;
// https://github.com/huggingface/transformers/blob/main/src/transformers/models/segformer/configuration_segformer.py
#[derive(Debug, Clone, PartialEq, Deserialize)]
pub struct Config {
#[serde(default)]
pub id2label: HashMap<String, String>,
pub num_channels: usize,
pub num_encoder_blocks: usize,
pub depths: Vec<usize>,
pub sr_ratios: Vec<usize>,
pub hidden_sizes: Vec<usize>,
pub patch_sizes: Vec<usize>,
pub strides: Vec<usize>,
pub num_attention_heads: Vec<usize>,
pub mlp_ratios: Vec<usize>,
pub hidden_act: candle_nn::Activation,
pub layer_norm_eps: f64,
pub decoder_hidden_size: usize,
}
#[derive(Debug, Clone)]
struct SegformerOverlapPatchEmbeddings {
projection: Conv2d,
layer_norm: candle_nn::LayerNorm,
}
impl SegformerOverlapPatchEmbeddings {
fn new(
config: &Config,
patch_size: usize,
stride: usize,
num_channels: usize,
hidden_size: usize,
vb: VarBuilder,
) -> Result<Self> {
let projection = conv2d(
num_channels,
hidden_size,
patch_size,
Conv2dConfig {
stride,
padding: patch_size / 2,
..Default::default()
},
vb.pp("proj"),
)?;
let layer_norm =
candle_nn::layer_norm(hidden_size, config.layer_norm_eps, vb.pp("layer_norm"))?;
Ok(Self {
projection,
layer_norm,
})
}
}
impl Module for SegformerOverlapPatchEmbeddings {
fn forward(&self, x: &Tensor) -> Result<Tensor> {
let embeddings = self.projection.forward(x)?;
let shape = embeddings.shape();
// [B, C, H, W] -> [B, H * W, C]
let embeddings = embeddings.flatten_from(2)?.transpose(1, 2)?;
let embeddings = self.layer_norm.forward(&embeddings)?;
// [B, H * W, C] -> [B, C, H, W]
let embeddings = embeddings.transpose(1, 2)?.reshape(shape)?;
Ok(embeddings)
}
}
#[derive(Debug, Clone)]
struct SegformerEfficientSelfAttention {
num_attention_heads: usize,
attention_head_size: usize,
query: Linear,
key: Linear,
value: Linear,
sr: Option<Conv2d>,
layer_norm: Option<layer_norm::LayerNorm>,
}
impl SegformerEfficientSelfAttention {
fn new(
config: &Config,
hidden_size: usize,
num_attention_heads: usize,
sequence_reduction_ratio: usize,
vb: VarBuilder,
) -> Result<Self> {
if hidden_size % num_attention_heads != 0 {
candle::bail!(
"The hidden size {} is not a multiple of the number of attention heads {}",
hidden_size,
num_attention_heads
)
}
let attention_head_size = hidden_size / num_attention_heads;
let all_head_size = num_attention_heads * attention_head_size;
let query = linear(hidden_size, all_head_size, vb.pp("query"))?;
let key = linear(hidden_size, all_head_size, vb.pp("key"))?;
let value = linear(hidden_size, all_head_size, vb.pp("value"))?;
let (sr, layer_norm) = if sequence_reduction_ratio > 1 {
(
Some(conv2d(
hidden_size,
hidden_size,
sequence_reduction_ratio,
Conv2dConfig {
stride: sequence_reduction_ratio,
..Default::default()
},
vb.pp("sr"),
)?),
Some(candle_nn::layer_norm(
hidden_size,
config.layer_norm_eps,
vb.pp("layer_norm"),
)?),
)
} else {
(None, None)
};
Ok(Self {
num_attention_heads,
attention_head_size,
query,
key,
value,
sr,
layer_norm,
})
}
fn transpose_for_scores(&self, hidden_states: Tensor) -> Result<Tensor> {
let (batch, seq_length, _) = hidden_states.shape().dims3()?;
let new_shape = &[
batch,
seq_length,
self.num_attention_heads,
self.attention_head_size,
];
let hidden_states = hidden_states.reshape(new_shape)?;
let hidden_states = hidden_states.permute((0, 2, 1, 3))?;
Ok(hidden_states)
}
}
impl Module for SegformerEfficientSelfAttention {
fn forward(&self, x: &Tensor) -> Result<Tensor> {
// [B, C, H, W] -> [B, H * W, C]
let hidden_states = x.flatten_from(2)?.permute((0, 2, 1))?;
let query = self
.transpose_for_scores(self.query.forward(&hidden_states)?)?
.contiguous()?;
let hidden_states = if let (Some(sr), Some(layer_norm)) = (&self.sr, &self.layer_norm) {
let hidden_states = sr.forward(x)?;
// [B, C, H, W] -> [B, H * W, C]
let hidden_states = hidden_states.flatten_from(2)?.permute((0, 2, 1))?;
layer_norm.forward(&hidden_states)?
} else {
// already [B, H * W, C]
hidden_states
};
// standard self-attention
let key = self
.transpose_for_scores(self.key.forward(&hidden_states)?)?
.contiguous()?;
let value = self
.transpose_for_scores(self.value.forward(&hidden_states)?)?
.contiguous()?;
let attention_scores =
(query.matmul(&key.t()?)? / f64::sqrt(self.attention_head_size as f64))?;
let attention_scores = candle_nn::ops::softmax_last_dim(&attention_scores)?;
let result = attention_scores.matmul(&value)?;
let result = result.permute((0, 2, 1, 3))?.contiguous()?;
result.flatten_from(D::Minus2)
}
}
#[derive(Debug, Clone)]
struct SegformerSelfOutput {
dense: Linear,
}
impl SegformerSelfOutput {
fn new(hidden_size: usize, vb: VarBuilder) -> Result<Self> {
let dense = linear(hidden_size, hidden_size, vb.pp("dense"))?;
Ok(Self { dense })
}
}
impl Module for SegformerSelfOutput {
fn forward(&self, x: &Tensor) -> Result<Tensor> {
self.dense.forward(x)
}
}
#[derive(Debug, Clone)]
struct SegformerAttention {
attention: SegformerEfficientSelfAttention,
output: SegformerSelfOutput,
}
impl SegformerAttention {
fn new(
config: &Config,
hidden_size: usize,
num_attention_heads: usize,
sequence_reduction_ratio: usize,
vb: VarBuilder,
) -> Result<Self> {
let attention = SegformerEfficientSelfAttention::new(
config,
hidden_size,
num_attention_heads,
sequence_reduction_ratio,
vb.pp("self"),
)?;
let output = SegformerSelfOutput::new(hidden_size, vb.pp("output"))?;
Ok(Self { attention, output })
}
}
impl Module for SegformerAttention {
fn forward(&self, x: &Tensor) -> Result<Tensor> {
let attention_output = self.attention.forward(x)?;
self.output.forward(&attention_output)
}
}
#[derive(Debug, Clone)]
struct SegformerDWConv {
dw_conv: Conv2d,
}
impl SegformerDWConv {
fn new(dim: usize, vb: VarBuilder) -> Result<Self> {
let dw_conv = conv2d(
dim,
dim,
3,
Conv2dConfig {
stride: 1,
padding: 1,
groups: dim,
..Default::default()
},
vb.pp("dwconv"),
)?;
Ok(Self { dw_conv })
}
}
impl Module for SegformerDWConv {
fn forward(&self, x: &Tensor) -> Result<Tensor> {
self.dw_conv.forward(x)
}
}
#[derive(Debug, Clone)]
struct SegformerMixFFN {
dense1: Linear,
dw_conv: SegformerDWConv,
act: Activation,
dense2: Linear,
}
impl SegformerMixFFN {
fn new(
config: &Config,
in_features: usize,
hidden_features: usize,
out_features: usize,
vb: VarBuilder,
) -> Result<Self> {
let dense1 = linear(in_features, hidden_features, vb.pp("dense1"))?;
let dw_conv = SegformerDWConv::new(hidden_features, vb.pp("dwconv"))?;
let act = config.hidden_act;
let dense2 = linear(hidden_features, out_features, vb.pp("dense2"))?;
Ok(Self {
dense1,
dw_conv,
act,
dense2,
})
}
}
impl Module for SegformerMixFFN {
fn forward(&self, x: &Tensor) -> Result<Tensor> {
let (batch, _, height, width) = x.shape().dims4()?;
let hidden_states = self
.dense1
.forward(&x.flatten_from(2)?.permute((0, 2, 1))?)?;
let channels = hidden_states.dim(2)?;
let hidden_states = self.dw_conv.forward(
&hidden_states
.permute((0, 2, 1))?
.reshape((batch, channels, height, width))?,
)?;
let hidden_states = self.act.forward(&hidden_states)?;
let hidden_states = self
.dense2
.forward(&hidden_states.flatten_from(2)?.permute((0, 2, 1))?)?;
let channels = hidden_states.dim(2)?;
hidden_states
.permute((0, 2, 1))?
.reshape((batch, channels, height, width))
}
}
#[derive(Debug, Clone)]
struct SegformerLayer {
layer_norm_1: candle_nn::LayerNorm,
attention: SegformerAttention,
layer_norm_2: candle_nn::LayerNorm,
mlp: SegformerMixFFN,
}
impl SegformerLayer {
fn new(
config: &Config,
hidden_size: usize,
num_attention_heads: usize,
sequence_reduction_ratio: usize,
mlp_ratio: usize,
vb: VarBuilder,
) -> Result<Self> {
let layer_norm_1 = layer_norm(hidden_size, config.layer_norm_eps, vb.pp("layer_norm_1"))?;
let attention = SegformerAttention::new(
config,
hidden_size,
num_attention_heads,
sequence_reduction_ratio,
vb.pp("attention"),
)?;
let layer_norm_2 = layer_norm(hidden_size, config.layer_norm_eps, vb.pp("layer_norm_2"))?;
let mlp = SegformerMixFFN::new(
config,
hidden_size,
hidden_size * mlp_ratio,
hidden_size,
vb.pp("mlp"),
)?;
Ok(Self {
layer_norm_1,
attention,
layer_norm_2,
mlp,
})
}
}
impl Module for SegformerLayer {
fn forward(&self, x: &Tensor) -> Result<Tensor> {
let shape = x.shape().dims4()?;
// [B, C, H, W] -> [B, H * W, C]
let hidden_states = x.flatten_from(2)?.permute((0, 2, 1))?;
let layer_norm_output = self.layer_norm_1.forward(&hidden_states)?;
let layer_norm_output = layer_norm_output.permute((0, 2, 1))?.reshape(shape)?;
// attention takes in [B, C, H, W] in order to properly do conv2d (and output [B, H * W, C])
let attention_output = self.attention.forward(&layer_norm_output)?;
let hidden_states = (attention_output + hidden_states)?;
let layer_norm_output = self.layer_norm_2.forward(&hidden_states)?;
let mlp_output = self
.mlp
.forward(&layer_norm_output.permute((0, 2, 1))?.reshape(shape)?)?;
hidden_states.permute((0, 2, 1))?.reshape(shape)? + mlp_output
}
}
#[derive(Debug, Clone)]
struct SegformerEncoder {
/// config file
config: Config,
/// a list of embeddings
patch_embeddings: Vec<SegformerOverlapPatchEmbeddings>,
/// a list of attention blocks, each consisting of layers
blocks: Vec<Vec<SegformerLayer>>,
/// a final list of layer norms
layer_norms: Vec<candle_nn::LayerNorm>,
}
impl SegformerEncoder {
fn new(config: Config, vb: VarBuilder) -> Result<Self> {
let mut patch_embeddings = Vec::with_capacity(config.num_encoder_blocks);
let mut blocks = Vec::with_capacity(config.num_encoder_blocks);
let mut layer_norms = Vec::with_capacity(config.num_encoder_blocks);
for i in 0..config.num_encoder_blocks {
let patch_size = config.patch_sizes[i];
let stride = config.strides[i];
let hidden_size = config.hidden_sizes[i];
let num_channels = if i == 0 {
config.num_channels
} else {
config.hidden_sizes[i - 1]
};
patch_embeddings.push(SegformerOverlapPatchEmbeddings::new(
&config,
patch_size,
stride,
num_channels,
hidden_size,
vb.pp(format!("patch_embeddings.{}", i)),
)?);
let mut layers = Vec::with_capacity(config.depths[i]);
for j in 0..config.depths[i] {
let sequence_reduction_ratio = config.sr_ratios[i];
let num_attention_heads = config.num_attention_heads[i];
let mlp_ratio = config.mlp_ratios[i];
layers.push(SegformerLayer::new(
&config,
hidden_size,
num_attention_heads,
sequence_reduction_ratio,
mlp_ratio,
vb.pp(format!("block.{}.{}", i, j)),
)?);
}
blocks.push(layers);
layer_norms.push(layer_norm(
hidden_size,
config.layer_norm_eps,
vb.pp(format!("layer_norm.{}", i)),
)?);
}
Ok(Self {
config,
patch_embeddings,
blocks,
layer_norms,
})
}
}
impl ModuleWithHiddenStates for SegformerEncoder {
fn forward(&self, x: &Tensor) -> Result<Vec<Tensor>> {
let mut all_hidden_states = Vec::with_capacity(self.config.num_encoder_blocks);
let mut hidden_states = x.clone();
for i in 0..self.config.num_encoder_blocks {
hidden_states = self.patch_embeddings[i].forward(&hidden_states)?;
for layer in &self.blocks[i] {
hidden_states = layer.forward(&hidden_states)?;
}
let shape = hidden_states.shape().dims4()?;
hidden_states =
self.layer_norms[i].forward(&hidden_states.flatten_from(2)?.permute((0, 2, 1))?)?;
hidden_states = hidden_states.permute((0, 2, 1))?.reshape(shape)?;
all_hidden_states.push(hidden_states.clone());
}
Ok(all_hidden_states)
}
}
#[derive(Debug, Clone)]
struct SegformerModel {
encoder: SegformerEncoder,
}
impl SegformerModel {
fn new(config: &Config, vb: VarBuilder) -> Result<Self> {
let encoder = SegformerEncoder::new(config.clone(), vb.pp("encoder"))?;
Ok(Self { encoder })
}
}
impl ModuleWithHiddenStates for SegformerModel {
fn forward(&self, x: &Tensor) -> Result<Vec<Tensor>> {
self.encoder.forward(x)
}
}
#[derive(Debug, Clone)]
struct SegformerMLP {
proj: Linear,
}
impl SegformerMLP {
fn new(config: &Config, input_dim: usize, vb: VarBuilder) -> Result<Self> {
let proj = linear(input_dim, config.decoder_hidden_size, vb.pp("proj"))?;
Ok(Self { proj })
}
}
impl Module for SegformerMLP {
fn forward(&self, x: &Tensor) -> Result<Tensor> {
self.proj.forward(x)
}
}
#[derive(Debug, Clone)]
struct SegformerDecodeHead {
linear_c: Vec<SegformerMLP>,
linear_fuse: candle_nn::Conv2d,
batch_norm: candle_nn::BatchNorm,
classifier: candle_nn::Conv2d,
}
impl SegformerDecodeHead {
fn new(config: &Config, num_labels: usize, vb: VarBuilder) -> Result<Self> {
let mut linear_c = Vec::with_capacity(config.num_encoder_blocks);
for i in 0..config.num_encoder_blocks {
let hidden_size = config.hidden_sizes[i];
linear_c.push(SegformerMLP::new(
config,
hidden_size,
vb.pp(format!("linear_c.{}", i)),
)?);
}
let linear_fuse = conv2d_no_bias(
config.decoder_hidden_size * config.num_encoder_blocks,
config.decoder_hidden_size,
1,
Conv2dConfig::default(),
vb.pp("linear_fuse"),
)?;
let batch_norm = candle_nn::batch_norm(
config.decoder_hidden_size,
config.layer_norm_eps,
vb.pp("batch_norm"),
)?;
let classifier = conv2d_no_bias(
config.decoder_hidden_size,
num_labels,
1,
Conv2dConfig::default(),
vb.pp("classifier"),
)?;
Ok(Self {
linear_c,
linear_fuse,
batch_norm,
classifier,
})
}
fn forward(&self, encoder_hidden_states: &[Tensor]) -> Result<Tensor> {
if encoder_hidden_states.len() != self.linear_c.len() {
candle::bail!(
"The number of encoder hidden states {} is not equal to the number of linear layers {}",
encoder_hidden_states.len(),
self.linear_c.len()
)
}
// most fine layer
let (_, _, upsample_height, upsample_width) = encoder_hidden_states[0].shape().dims4()?;
let mut hidden_states = Vec::with_capacity(self.linear_c.len());
for (hidden_state, mlp) in encoder_hidden_states.iter().zip(&self.linear_c) {
let (batch, _, height, width) = hidden_state.shape().dims4()?;
let hidden_state = mlp.forward(&hidden_state.flatten_from(2)?.permute((0, 2, 1))?)?;
let hidden_state = hidden_state.permute((0, 2, 1))?.reshape((
batch,
hidden_state.dim(2)?,
height,
width,
))?;
let hidden_state = hidden_state.upsample_nearest2d(upsample_height, upsample_width)?;
hidden_states.push(hidden_state);
}
hidden_states.reverse();
let hidden_states = Tensor::cat(&hidden_states, 1)?;
let hidden_states = self.linear_fuse.forward(&hidden_states)?;
let hidden_states = self.batch_norm.forward_t(&hidden_states, false)?;
let hidden_states = hidden_states.relu()?;
self.classifier.forward(&hidden_states)
}
}
trait ModuleWithHiddenStates {
fn forward(&self, xs: &Tensor) -> Result<Vec<Tensor>>;
}
#[derive(Debug, Clone)]
pub struct SemanticSegmentationModel {
segformer: SegformerModel,
decode_head: SegformerDecodeHead,
}
impl SemanticSegmentationModel {
pub fn new(config: &Config, num_labels: usize, vb: VarBuilder) -> Result<Self> {
let segformer = SegformerModel::new(config, vb.pp("segformer"))?;
let decode_head = SegformerDecodeHead::new(config, num_labels, vb.pp("decode_head"))?;
Ok(Self {
segformer,
decode_head,
})
}
}
impl Module for SemanticSegmentationModel {
fn forward(&self, x: &Tensor) -> Result<Tensor> {
let hidden_states = self.segformer.forward(x)?;
self.decode_head.forward(&hidden_states)
}
}
#[derive(Debug, Clone)]
pub struct ImageClassificationModel {
segformer: SegformerModel,
classifier: Linear,
}
impl ImageClassificationModel {
pub fn new(config: &Config, num_labels: usize, vb: VarBuilder) -> Result<Self> {
let segformer = SegformerModel::new(config, vb.pp("segformer"))?;
let classifier = linear(config.decoder_hidden_size, num_labels, vb.pp("classifier"))?;
Ok(Self {
segformer,
classifier,
})
}
}
impl Module for ImageClassificationModel {
fn forward(&self, x: &Tensor) -> Result<Tensor> {
let all_hidden_states = self.segformer.forward(x)?;
let hidden_states = all_hidden_states.last().unwrap();
let hidden_states = hidden_states.flatten_from(2)?.permute((0, 2, 1))?;
let mean = hidden_states.mean(1)?;
self.classifier.forward(&mean)
}
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn test_config_json_load() {
let raw_json = r#"{
"architectures": [
"SegformerForImageClassification"
],
"attention_probs_dropout_prob": 0.0,
"classifier_dropout_prob": 0.1,
"decoder_hidden_size": 256,
"depths": [
2,
2,
2,
2
],
"downsampling_rates": [
1,
4,
8,
16
],
"drop_path_rate": 0.1,
"hidden_act": "gelu",
"hidden_dropout_prob": 0.0,
"hidden_sizes": [
32,
64,
160,
256
],
"image_size": 224,
"initializer_range": 0.02,
"layer_norm_eps": 1e-06,
"mlp_ratios": [
4,
4,
4,
4
],
"model_type": "segformer",
"num_attention_heads": [
1,
2,
5,
8
],
"num_channels": 3,
"num_encoder_blocks": 4,
"patch_sizes": [
7,
3,
3,
3
],
"sr_ratios": [
8,
4,
2,
1
],
"strides": [
4,
2,
2,
2
],
"torch_dtype": "float32",
"transformers_version": "4.12.0.dev0"
}"#;
let config: Config = serde_json::from_str(raw_json).unwrap();
assert_eq!(vec![4, 2, 2, 2], config.strides);
assert_eq!(1e-6, config.layer_norm_eps);
}
}
| 1 |
0 | hf_public_repos/candle/candle-transformers/src | hf_public_repos/candle/candle-transformers/src/models/persimmon.rs | //! Persimmon Model
//!
//! A transformer language model for efficient inference and general-purpose tasks. The model uses a standard transformer architecture with:
//! - Layer normalization for Q/K attention
//! - RoPE embeddings with partial rotary factor
//! - ReLU activation
//! - Separate number of attention heads and KV heads
//!
//! References:
//! - 💻 [Hugging Face Implementation](https://github.com/huggingface/transformers/blob/main/src/transformers/models/persimmon/modeling_persimmon.py)
//! - 💻 [Persimmon Config](https://github.com/huggingface/transformers/blob/main/src/transformers/models/persimmon/configuration_persimmon.py)
//! - 🤗 [Hugging Face](https://huggingface.co/adept/persimmon-8b-base)
//!
use candle::DType;
use serde::Deserialize;
pub const DTYPE: DType = DType::F32;
#[derive(Debug, Clone, Copy, PartialEq, Eq, Deserialize)]
#[serde(rename_all = "lowercase")]
pub enum PositionEmbeddingType {
Absolute,
Alibi,
}
// https://github.com/huggingface/transformers/blob/main/src/transformers/models/persimmon/configuration_persimmon.py
#[derive(Debug, Clone, PartialEq, Deserialize)]
pub struct Config {
pub vocab_size: usize,
pub hidden_size: usize,
pub intermediate_size: usize,
pub num_hidden_layers: usize,
pub num_attention_heads: usize,
pub num_key_value_heads: usize,
pub hidden_act: candle_nn::Activation,
pub max_position_embeddings: usize,
pub initializer_range: f64,
pub layer_norm_eps: f64,
pub rms_norm_eps: f64,
pub use_cache: bool,
pub tie_word_embeddings: bool,
pub rope_theta: f64,
pub qk_layernorm: bool,
pub partial_rotary_factor: f64,
}
impl Config {
pub fn base_8b() -> Self {
// https://huggingface.co/adept/persimmon-8b-base/blob/main/config.json
Self {
hidden_act: candle_nn::Activation::Relu,
hidden_size: 4096,
initializer_range: 0.02,
intermediate_size: 16384,
layer_norm_eps: 1e-05,
max_position_embeddings: 16384,
num_attention_heads: 64,
num_hidden_layers: 36,
num_key_value_heads: 64,
qk_layernorm: true,
rms_norm_eps: 1e-06,
rope_theta: 25000.0,
tie_word_embeddings: false,
use_cache: true,
vocab_size: 262144,
partial_rotary_factor: 0.5,
}
}
}
| 2 |
0 | hf_public_repos/candle/candle-transformers/src | hf_public_repos/candle/candle-transformers/src/models/llama2_c.rs | //! Llama2 inference implementation.
//!
//! See ["LLaMA 2: Open Foundation and Fine-Tuned Chat Models"](https://arxiv.org/abs/2307.09288)
//!
//! - ⚡ [Interactive Wasm Example](https://huggingface.co/spaces/lmz/candle-llama2)
//! - 💻 llama2.c [GH Link](https://github.com/karpathy/llama2.c)
//!
use candle::{DType, Device, IndexOp, Result, Tensor, D};
use candle_nn::linear_no_bias as linear;
use candle_nn::{embedding, rms_norm, Embedding, Linear, Module, RmsNorm, VarBuilder};
use std::collections::HashMap;
#[derive(Debug, Clone)]
pub struct Config {
pub dim: usize, // transformer dimension
pub hidden_dim: usize, // for ffn layers
pub n_layers: usize, // number of layers
pub n_heads: usize, // number of query heads
pub n_kv_heads: usize, // number of key/value heads (can be < query heads because of multiquery)
pub vocab_size: usize, // vocabulary size, usually 256 (byte-level)
pub seq_len: usize, // max sequence length
pub norm_eps: f64,
}
impl Config {
pub fn tiny_260k() -> Self {
Self {
dim: 64,
hidden_dim: 768,
n_layers: 5,
n_heads: 8,
n_kv_heads: 4,
vocab_size: 32000,
seq_len: 512,
norm_eps: 1e-5,
}
}
pub fn tiny_15m() -> Self {
Self {
dim: 288,
hidden_dim: 768,
n_layers: 6,
n_heads: 6,
n_kv_heads: 6,
vocab_size: 32000,
seq_len: 256,
norm_eps: 1e-5,
}
}
pub fn tiny_42m() -> Self {
Self {
dim: 512,
hidden_dim: 768,
n_layers: 8,
n_heads: 8,
n_kv_heads: 8,
vocab_size: 32000,
seq_len: 1024,
norm_eps: 1e-5,
}
}
pub fn tiny_110m() -> Self {
Self {
dim: 768,
hidden_dim: 768,
n_layers: 12,
n_heads: 12,
n_kv_heads: 12,
vocab_size: 32000,
seq_len: 1024,
norm_eps: 1e-5,
}
}
}
#[derive(Debug, Clone)]
pub struct Cache {
masks: HashMap<usize, Tensor>,
pub use_kv_cache: bool,
pub kvs: Vec<Option<(Tensor, Tensor)>>,
pub cos: Tensor,
pub sin: Tensor,
device: Device,
}
impl Cache {
pub fn new(use_kv_cache: bool, cfg: &Config, vb: VarBuilder) -> Result<Self> {
let n_elem = cfg.dim / cfg.n_heads;
let theta: Vec<_> = (0..n_elem)
.step_by(2)
.map(|i| 1f32 / 10000f32.powf(i as f32 / n_elem as f32))
.collect();
let theta = Tensor::new(theta.as_slice(), vb.device())?;
let idx_theta = Tensor::arange(0, cfg.seq_len as u32, vb.device())?
.to_dtype(DType::F32)?
.reshape((cfg.seq_len, 1))?
.matmul(&theta.reshape((1, theta.elem_count()))?)?;
let precomputed_cos = idx_theta.cos()?;
let precomputed_sin = idx_theta.sin()?;
let freq_cis_real = vb
.get((cfg.seq_len, cfg.head_size() / 2), "freq_cis_real")
.unwrap_or(precomputed_cos);
let freq_cis_imag = vb
.get((cfg.seq_len, cfg.head_size() / 2), "freq_cis_imag")
.unwrap_or(precomputed_sin);
let cos = freq_cis_real.reshape((cfg.seq_len, cfg.head_size() / 2, 1))?;
let sin = freq_cis_imag.reshape((cfg.seq_len, cfg.head_size() / 2, 1))?;
Ok(Self {
masks: HashMap::new(),
use_kv_cache,
kvs: vec![None; cfg.n_layers],
cos,
sin,
device: vb.device().clone(),
})
}
pub fn mask(&mut self, t: usize) -> Result<Tensor> {
if let Some(mask) = self.masks.get(&t) {
Ok(mask.clone())
} else {
let mask: Vec<_> = (0..t)
.flat_map(|i| (0..t).map(move |j| u8::from(j > i)))
.collect();
let mask = Tensor::from_slice(&mask, (t, t), &self.device)?;
self.masks.insert(t, mask.clone());
Ok(mask)
}
}
}
fn silu(xs: &Tensor) -> Result<Tensor> {
xs / (xs.neg()?.exp()? + 1.0)?
}
#[derive(Debug, Clone)]
struct CausalSelfAttention {
q_proj: Linear,
k_proj: Linear,
v_proj: Linear,
o_proj: Linear,
n_head: usize,
n_key_value_head: usize,
head_dim: usize,
}
impl CausalSelfAttention {
fn apply_rotary_emb(&self, x: &Tensor, index_pos: usize, cache: &Cache) -> Result<Tensor> {
let (b_sz, seq_len, h, n_embd) = x.dims4()?;
let cos = cache.cos.i(index_pos..index_pos + seq_len)?;
let sin = cache.sin.i(index_pos..index_pos + seq_len)?;
let cos = cos.unsqueeze(1)?;
let sin = sin.unsqueeze(1)?;
let cos = cos.broadcast_as((b_sz, seq_len, 1, n_embd / 2, 1))?;
let sin = sin.broadcast_as((b_sz, seq_len, 1, n_embd / 2, 1))?;
let x = x.reshape((b_sz, seq_len, h, n_embd / 2, 2))?;
let x0 = x.narrow(D::Minus1, 0, 1)?;
let x1 = x.narrow(D::Minus1, 1, 1)?;
let dst0 = (x0.broadcast_mul(&cos)? - x1.broadcast_mul(&sin)?)?;
let dst1 = (x0.broadcast_mul(&sin)? + x1.broadcast_mul(&cos)?)?;
let rope = Tensor::cat(&[&dst0, &dst1], D::Minus1)?.reshape((b_sz, seq_len, h, n_embd))?;
Ok(rope)
}
fn forward(
&self,
x: &Tensor,
index_pos: usize,
block_idx: usize,
cache: &mut Cache,
) -> Result<Tensor> {
let (b_sz, seq_len, n_embd) = x.dims3()?;
let q = self.q_proj.forward(x)?;
let k = self.k_proj.forward(x)?;
let v = self.v_proj.forward(x)?;
let q = q.reshape((b_sz, seq_len, self.n_head, self.head_dim))?;
let k = k.reshape((b_sz, seq_len, self.n_key_value_head, self.head_dim))?;
let mut v = v.reshape((b_sz, seq_len, self.n_key_value_head, self.head_dim))?;
let q = self.apply_rotary_emb(&q, index_pos, cache)?;
let mut k = self.apply_rotary_emb(&k, index_pos, cache)?;
if cache.use_kv_cache {
if let Some((cache_k, cache_v)) = &cache.kvs[block_idx] {
k = Tensor::cat(&[cache_k, &k], 1)?.contiguous()?;
v = Tensor::cat(&[cache_v, &v], 1)?.contiguous()?;
}
cache.kvs[block_idx] = Some((k.clone(), v.clone()))
}
let k = self.repeat_kv(k)?;
let v = self.repeat_kv(v)?;
let q = q.transpose(1, 2)?.contiguous()?;
let k = k.transpose(1, 2)?.contiguous()?;
let v = v.transpose(1, 2)?.contiguous()?;
let att = (q.matmul(&k.t()?)? / (self.head_dim as f64).sqrt())?;
let att = if seq_len <= 1 {
att
} else {
let mask = cache.mask(seq_len)?.broadcast_as(att.shape())?;
masked_fill(&att, &mask, f32::NEG_INFINITY)?
};
let att = candle_nn::ops::softmax(&att, D::Minus1)?;
// Convert to contiguous as matmul doesn't support strided vs for now.
let y = att.matmul(&v.contiguous()?)?;
let y = y.transpose(1, 2)?.reshape(&[b_sz, seq_len, n_embd])?;
let y = self.o_proj.forward(&y)?;
Ok(y)
}
fn repeat_kv(&self, x: Tensor) -> Result<Tensor> {
let n_rep = self.n_head / self.n_key_value_head;
if n_rep == 1 {
Ok(x)
} else {
let (b_sz, seq_len, n_kv_head, head_dim) = x.dims4()?;
let x = x
.unsqueeze(3)?
.expand((b_sz, seq_len, n_kv_head, n_rep, head_dim))?
.reshape((b_sz, seq_len, n_kv_head * n_rep, head_dim))?;
Ok(x)
}
}
fn load(vb: VarBuilder, cfg: &Config) -> Result<Self> {
let size_in = cfg.dim;
let size_q = (cfg.dim / cfg.n_heads) * cfg.n_heads;
let size_kv = (cfg.dim / cfg.n_heads) * cfg.n_kv_heads;
let q_proj = linear(size_in, size_q, vb.pp("q_proj"))?;
let k_proj = linear(size_in, size_kv, vb.pp("k_proj"))?;
let v_proj = linear(size_in, size_kv, vb.pp("v_proj"))?;
let o_proj = linear(size_q, size_in, vb.pp("o_proj"))?;
Ok(Self {
q_proj,
k_proj,
v_proj,
o_proj,
n_head: cfg.n_heads,
n_key_value_head: cfg.n_kv_heads,
head_dim: cfg.dim / cfg.n_heads,
})
}
}
fn masked_fill(on_false: &Tensor, mask: &Tensor, on_true: f32) -> Result<Tensor> {
let shape = mask.shape();
let on_true = Tensor::new(on_true, on_false.device())?.broadcast_as(shape.dims())?;
let m = mask.where_cond(&on_true, on_false)?;
Ok(m)
}
#[derive(Debug, Clone)]
struct Mlp {
c_fc1: Linear,
c_fc2: Linear,
c_proj: Linear,
}
impl Mlp {
fn new(c_fc1: Linear, c_fc2: Linear, c_proj: Linear) -> Self {
Self {
c_fc1,
c_fc2,
c_proj,
}
}
fn forward(&self, x: &Tensor) -> Result<Tensor> {
let x = (silu(&self.c_fc1.forward(x)?)? * self.c_fc2.forward(x)?)?;
self.c_proj.forward(&x)
}
fn load(vb: VarBuilder, cfg: &Config) -> Result<Self> {
let h_size = cfg.dim;
let i_size = cfg.hidden_dim;
let c_fc1 = linear(h_size, i_size, vb.pp("gate_proj"))?;
let c_fc2 = linear(h_size, i_size, vb.pp("up_proj"))?;
let c_proj = linear(i_size, h_size, vb.pp("down_proj"))?;
Ok(Self::new(c_fc1, c_fc2, c_proj))
}
}
#[derive(Debug, Clone)]
struct Block {
rms_1: RmsNorm,
attn: CausalSelfAttention,
rms_2: RmsNorm,
mlp: Mlp,
}
impl Block {
fn new(rms_1: RmsNorm, attn: CausalSelfAttention, rms_2: RmsNorm, mlp: Mlp) -> Self {
Self {
rms_1,
attn,
rms_2,
mlp,
}
}
fn forward(
&self,
x: &Tensor,
index_pos: usize,
block_idx: usize,
cache: &mut Cache,
) -> Result<Tensor> {
let residual = x;
let x = self.rms_1.forward(x)?;
let x = (self.attn.forward(&x, index_pos, block_idx, cache)? + residual)?;
let residual = &x;
let x = (self.mlp.forward(&self.rms_2.forward(&x)?)? + residual)?;
Ok(x)
}
fn load(vb: VarBuilder, cfg: &Config) -> Result<Self> {
let attn = CausalSelfAttention::load(vb.pp("self_attn"), cfg)?;
let mlp = Mlp::load(vb.pp("mlp"), cfg)?;
let input_layernorm = rms_norm(cfg.dim, cfg.norm_eps, vb.pp("input_layernorm"))?;
let post_attention_layernorm =
rms_norm(cfg.dim, cfg.norm_eps, vb.pp("post_attention_layernorm"))?;
Ok(Self::new(
input_layernorm,
attn,
post_attention_layernorm,
mlp,
))
}
}
#[derive(Debug, Clone)]
pub struct Llama {
wte: Embedding,
blocks: Vec<Block>,
ln_f: RmsNorm,
lm_head: Linear,
pub config: Config,
}
impl Llama {
pub fn forward(&self, x: &Tensor, index_pos: usize, cache: &mut Cache) -> Result<Tensor> {
let (_b_sz, _seq_len) = x.dims2()?;
let mut x = self.wte.forward(x)?;
for (block_idx, block) in self.blocks.iter().enumerate() {
x = block.forward(&x, index_pos, block_idx, cache)?;
}
let x = self.ln_f.forward(&x)?;
let logits = self.lm_head.forward(&x)?;
logits.to_dtype(DType::F32)
}
pub fn load(vb: VarBuilder, cfg: Config) -> Result<Self> {
let wte = embedding(cfg.vocab_size, cfg.dim, vb.pp("model.embed_tokens"))?;
let lm_head = linear(cfg.dim, cfg.vocab_size, vb.pp("lm_head"))?;
let ln_f = rms_norm(cfg.dim, cfg.norm_eps, vb.pp("model.norm"))?;
let blocks: Vec<_> = (0..cfg.n_layers)
.map(|i| Block::load(vb.pp(format!("model.layers.{i}")), &cfg).unwrap())
.collect();
Ok(Self {
wte,
blocks,
ln_f,
lm_head,
config: cfg,
})
}
}
| 3 |
0 | hf_public_repos/candle/candle-transformers/src | hf_public_repos/candle/candle-transformers/src/models/mistral.rs | //! Mixtral Model, based on the Mistral architecture
//!
//! See Mistral and Mixtral at:
//! - [Hugging Face](https://huggingface.co/docs/transformers/model_doc/mixtral)
//! - [Github](https://github.com/mistralai/mistral-src)
//!
use crate::models::with_tracing::{linear_no_bias, Linear, RmsNorm};
/// Mistral LLM, https://github.com/mistralai/mistral-src
use candle::{DType, Device, Module, Result, Tensor, D};
use candle_nn::{Activation, VarBuilder};
use std::sync::Arc;
fn default_num_attention_heads() -> usize {
32
}
fn default_use_flash_attn() -> bool {
false
}
fn default_hidden_act() -> candle_nn::Activation {
candle_nn::Activation::Silu
}
#[derive(Debug, Clone, PartialEq, serde::Deserialize)]
pub struct Config {
pub vocab_size: usize,
pub hidden_size: usize,
pub intermediate_size: usize,
pub num_hidden_layers: usize,
#[serde(default = "default_num_attention_heads")]
pub num_attention_heads: usize,
pub head_dim: Option<usize>,
pub num_key_value_heads: usize,
#[serde(default = "default_hidden_act")]
pub hidden_act: Activation,
pub max_position_embeddings: usize,
pub rms_norm_eps: f64,
pub rope_theta: f64,
pub sliding_window: Option<usize>,
#[serde(default = "default_use_flash_attn")]
pub use_flash_attn: bool,
}
impl Config {
// https://huggingface.co/mistralai/Mistral-7B-v0.1/blob/main/config.json
pub fn config_7b_v0_1(use_flash_attn: bool) -> Self {
Self {
vocab_size: 32000,
hidden_size: 4096,
intermediate_size: 14336,
num_hidden_layers: 32,
num_attention_heads: 32,
head_dim: None,
num_key_value_heads: 8,
hidden_act: Activation::Silu,
max_position_embeddings: 32768,
rms_norm_eps: 1e-5,
rope_theta: 10_000.,
sliding_window: Some(4096),
use_flash_attn,
}
}
// https://huggingface.co/Open-Orca/Mistral-7B-OpenOrca/blob/main/config.json
// https://huggingface.co/teknium/OpenHermes-2.5-Mistral-7B/blob/main/config.json
pub fn config_chat_ml(use_flash_attn: bool) -> Self {
Self {
vocab_size: 32002,
hidden_size: 4096,
intermediate_size: 14336,
num_hidden_layers: 32,
num_attention_heads: 32,
head_dim: None,
num_key_value_heads: 8,
hidden_act: Activation::Silu,
max_position_embeddings: 32768,
rms_norm_eps: 1e-5,
rope_theta: 10_000.,
sliding_window: Some(4096),
use_flash_attn,
}
}
// https://huggingface.co/amazon/MistralLite/blob/main/config.json
pub fn config_amazon_mistral_lite(use_flash_attn: bool) -> Self {
Self {
vocab_size: 32003,
hidden_size: 4096,
intermediate_size: 14336,
num_hidden_layers: 32,
num_attention_heads: 32,
head_dim: None,
num_key_value_heads: 8,
hidden_act: Activation::Silu,
max_position_embeddings: 32768,
rms_norm_eps: 1e-5,
rope_theta: 10_000.,
sliding_window: Some(4096),
use_flash_attn,
}
}
fn head_dim(&self) -> usize {
self.head_dim
.unwrap_or(self.hidden_size / self.num_attention_heads)
}
}
#[derive(Debug, Clone)]
struct RotaryEmbedding {
sin: Tensor,
cos: Tensor,
}
impl RotaryEmbedding {
fn new(dtype: DType, cfg: &Config, dev: &Device) -> Result<Self> {
let rope_theta = cfg.rope_theta as f32;
let dim = cfg.head_dim();
let max_seq_len = cfg.max_position_embeddings;
let inv_freq: Vec<_> = (0..dim)
.step_by(2)
.map(|i| 1f32 / rope_theta.powf(i as f32 / dim as f32))
.collect();
let inv_freq_len = inv_freq.len();
let inv_freq = Tensor::from_vec(inv_freq, (1, inv_freq_len), dev)?.to_dtype(DType::F32)?;
let t = Tensor::arange(0u32, max_seq_len as u32, dev)?
.to_dtype(DType::F32)?
.reshape((max_seq_len, 1))?;
let freqs = t.matmul(&inv_freq)?;
Ok(Self {
sin: freqs.sin()?.to_dtype(dtype)?,
cos: freqs.cos()?.to_dtype(dtype)?,
})
}
fn apply_rotary_emb_qkv(
&self,
q: &Tensor,
k: &Tensor,
seqlen_offset: usize,
) -> Result<(Tensor, Tensor)> {
let (_b_sz, _h, seq_len, _n_embd) = q.dims4()?;
let cos = self.cos.narrow(0, seqlen_offset, seq_len)?;
let sin = self.sin.narrow(0, seqlen_offset, seq_len)?;
let q_embed = candle_nn::rotary_emb::rope(q, &cos, &sin)?;
let k_embed = candle_nn::rotary_emb::rope(k, &cos, &sin)?;
Ok((q_embed, k_embed))
}
}
#[derive(Debug, Clone)]
#[allow(clippy::upper_case_acronyms)]
struct MLP {
gate_proj: Linear,
up_proj: Linear,
down_proj: Linear,
act_fn: Activation,
}
impl MLP {
fn new(cfg: &Config, vb: VarBuilder) -> Result<Self> {
let hidden_sz = cfg.hidden_size;
let intermediate_sz = cfg.intermediate_size;
let gate_proj = linear_no_bias(hidden_sz, intermediate_sz, vb.pp("gate_proj"))?;
let up_proj = linear_no_bias(hidden_sz, intermediate_sz, vb.pp("up_proj"))?;
let down_proj = linear_no_bias(intermediate_sz, hidden_sz, vb.pp("down_proj"))?;
Ok(Self {
gate_proj,
up_proj,
down_proj,
act_fn: cfg.hidden_act,
})
}
}
impl Module for MLP {
fn forward(&self, xs: &Tensor) -> Result<Tensor> {
let lhs = xs.apply(&self.gate_proj)?.apply(&self.act_fn)?;
let rhs = xs.apply(&self.up_proj)?;
(lhs * rhs)?.apply(&self.down_proj)
}
}
#[cfg(feature = "flash-attn")]
fn flash_attn(
q: &Tensor,
k: &Tensor,
v: &Tensor,
softmax_scale: f32,
causal: bool,
) -> Result<Tensor> {
candle_flash_attn::flash_attn(q, k, v, softmax_scale, causal)
}
#[cfg(not(feature = "flash-attn"))]
fn flash_attn(_: &Tensor, _: &Tensor, _: &Tensor, _: f32, _: bool) -> Result<Tensor> {
unimplemented!("compile with '--features flash-attn'")
}
#[derive(Debug, Clone)]
struct Attention {
q_proj: Linear,
k_proj: Linear,
v_proj: Linear,
o_proj: Linear,
num_heads: usize,
num_kv_heads: usize,
num_kv_groups: usize,
head_dim: usize,
rotary_emb: Arc<RotaryEmbedding>,
kv_cache: Option<(Tensor, Tensor)>,
use_flash_attn: bool,
}
impl Attention {
fn new(rotary_emb: Arc<RotaryEmbedding>, cfg: &Config, vb: VarBuilder) -> Result<Self> {
let hidden_sz = cfg.hidden_size;
let num_heads = cfg.num_attention_heads;
let num_kv_heads = cfg.num_key_value_heads;
let num_kv_groups = num_heads / num_kv_heads;
let head_dim = cfg.head_dim();
let q_proj = linear_no_bias(hidden_sz, num_heads * head_dim, vb.pp("q_proj"))?;
let k_proj = linear_no_bias(hidden_sz, num_kv_heads * head_dim, vb.pp("k_proj"))?;
let v_proj = linear_no_bias(hidden_sz, num_kv_heads * head_dim, vb.pp("v_proj"))?;
let o_proj = linear_no_bias(num_heads * head_dim, hidden_sz, vb.pp("o_proj"))?;
Ok(Self {
q_proj,
k_proj,
v_proj,
o_proj,
num_heads,
num_kv_heads,
num_kv_groups,
head_dim,
rotary_emb,
kv_cache: None,
use_flash_attn: cfg.use_flash_attn,
})
}
fn forward(
&mut self,
xs: &Tensor,
attention_mask: Option<&Tensor>,
seqlen_offset: usize,
) -> Result<Tensor> {
let (b_sz, q_len, _) = xs.dims3()?;
let query_states = self.q_proj.forward(xs)?;
let key_states = self.k_proj.forward(xs)?;
let value_states = self.v_proj.forward(xs)?;
let query_states = query_states
.reshape((b_sz, q_len, self.num_heads, self.head_dim))?
.transpose(1, 2)?
.contiguous()?;
let key_states = key_states
.reshape((b_sz, q_len, self.num_kv_heads, self.head_dim))?
.transpose(1, 2)?
.contiguous()?;
let value_states = value_states
.reshape((b_sz, q_len, self.num_kv_heads, self.head_dim))?
.transpose(1, 2)?;
let (query_states, key_states) =
self.rotary_emb
.apply_rotary_emb_qkv(&query_states, &key_states, seqlen_offset)?;
let (key_states, value_states) = match &self.kv_cache {
None => (key_states, value_states),
Some((prev_k, prev_v)) => {
let key_states = Tensor::cat(&[prev_k, &key_states], 2)?;
let value_states = Tensor::cat(&[prev_v, &value_states], 2)?;
(key_states, value_states)
}
};
self.kv_cache = Some((key_states.clone(), value_states.clone()));
let key_states = crate::utils::repeat_kv(key_states, self.num_kv_groups)?;
let value_states = crate::utils::repeat_kv(value_states, self.num_kv_groups)?;
let attn_output = if self.use_flash_attn {
// flash-attn expects (b_sz, seq_len, nheads, head_dim)
let q = query_states.transpose(1, 2)?;
let k = key_states.transpose(1, 2)?;
let v = value_states.transpose(1, 2)?;
let softmax_scale = 1f32 / (self.head_dim as f32).sqrt();
flash_attn(&q, &k, &v, softmax_scale, q_len > 1)?.transpose(1, 2)?
} else {
let scale = 1f64 / f64::sqrt(self.head_dim as f64);
let attn_weights = (query_states.matmul(&key_states.transpose(2, 3)?)? * scale)?;
let attn_weights = match attention_mask {
None => attn_weights,
Some(mask) => attn_weights.broadcast_add(mask)?,
};
let attn_weights = candle_nn::ops::softmax_last_dim(&attn_weights)?;
attn_weights.matmul(&value_states)?
};
attn_output
.transpose(1, 2)?
.reshape((b_sz, q_len, self.num_heads * self.head_dim))?
.apply(&self.o_proj)
}
fn clear_kv_cache(&mut self) {
self.kv_cache = None
}
}
#[derive(Debug, Clone)]
struct DecoderLayer {
self_attn: Attention,
mlp: MLP,
input_layernorm: RmsNorm,
post_attention_layernorm: RmsNorm,
}
impl DecoderLayer {
fn new(rotary_emb: Arc<RotaryEmbedding>, cfg: &Config, vb: VarBuilder) -> Result<Self> {
let self_attn = Attention::new(rotary_emb, cfg, vb.pp("self_attn"))?;
let mlp = MLP::new(cfg, vb.pp("mlp"))?;
let input_layernorm =
RmsNorm::new(cfg.hidden_size, cfg.rms_norm_eps, vb.pp("input_layernorm"))?;
let post_attention_layernorm = RmsNorm::new(
cfg.hidden_size,
cfg.rms_norm_eps,
vb.pp("post_attention_layernorm"),
)?;
Ok(Self {
self_attn,
mlp,
input_layernorm,
post_attention_layernorm,
})
}
fn forward(
&mut self,
xs: &Tensor,
attention_mask: Option<&Tensor>,
seqlen_offset: usize,
) -> Result<Tensor> {
let residual = xs;
let xs = self.input_layernorm.forward(xs)?;
let xs = self.self_attn.forward(&xs, attention_mask, seqlen_offset)?;
let xs = (xs + residual)?;
let residual = &xs;
let xs = xs.apply(&self.post_attention_layernorm)?.apply(&self.mlp)?;
residual + xs
}
fn clear_kv_cache(&mut self) {
self.self_attn.clear_kv_cache()
}
}
#[derive(Debug, Clone)]
pub struct Model {
embed_tokens: candle_nn::Embedding,
layers: Vec<DecoderLayer>,
norm: RmsNorm,
lm_head: Linear,
sliding_window: Option<usize>,
device: Device,
dtype: DType,
}
impl Model {
pub fn new(cfg: &Config, vb: VarBuilder) -> Result<Self> {
let vb_m = vb.pp("model");
let embed_tokens =
candle_nn::embedding(cfg.vocab_size, cfg.hidden_size, vb_m.pp("embed_tokens"))?;
let rotary_emb = Arc::new(RotaryEmbedding::new(vb.dtype(), cfg, vb_m.device())?);
let mut layers = Vec::with_capacity(cfg.num_hidden_layers);
let vb_l = vb_m.pp("layers");
for layer_idx in 0..cfg.num_hidden_layers {
let layer = DecoderLayer::new(rotary_emb.clone(), cfg, vb_l.pp(layer_idx))?;
layers.push(layer)
}
let norm = RmsNorm::new(cfg.hidden_size, cfg.rms_norm_eps, vb_m.pp("norm"))?;
let lm_head = linear_no_bias(cfg.hidden_size, cfg.vocab_size, vb.pp("lm_head"))?;
Ok(Self {
embed_tokens,
layers,
norm,
lm_head,
sliding_window: cfg.sliding_window,
device: vb.device().clone(),
dtype: vb.dtype(),
})
}
fn prepare_decoder_attention_mask(
&self,
tgt_len: usize,
seqlen_offset: usize,
) -> Result<Tensor> {
let sliding_window = self.sliding_window.unwrap_or(tgt_len + 1);
let mask: Vec<_> = (0..tgt_len)
.flat_map(|i| {
(0..tgt_len).map(move |j| {
if i < j || j + sliding_window < i {
f32::NEG_INFINITY
} else {
0.
}
})
})
.collect();
let mask = Tensor::from_slice(&mask, (tgt_len, tgt_len), &self.device)?;
let mask = if seqlen_offset > 0 {
let mask0 = Tensor::zeros((tgt_len, seqlen_offset), DType::F32, &self.device)?;
Tensor::cat(&[&mask0, &mask], D::Minus1)?
} else {
mask
};
mask.expand((1, 1, tgt_len, tgt_len + seqlen_offset))?
.to_dtype(self.dtype)
}
pub fn embed_tokens(&self) -> &candle_nn::Embedding {
&self.embed_tokens
}
pub fn forward(&mut self, input_ids: &Tensor, seqlen_offset: usize) -> Result<Tensor> {
let (_b_size, seq_len) = input_ids.dims2()?;
let attention_mask = if seq_len <= 1 {
None
} else {
let mask = self.prepare_decoder_attention_mask(seq_len, seqlen_offset)?;
Some(mask)
};
let mut xs = self.embed_tokens.forward(input_ids)?;
for layer in self.layers.iter_mut() {
xs = layer.forward(&xs, attention_mask.as_ref(), seqlen_offset)?
}
xs.narrow(1, seq_len - 1, 1)?
.apply(&self.norm)?
.apply(&self.lm_head)
}
pub fn forward_embeds(
&mut self,
xs: &Tensor,
attn_mask: Option<&Tensor>,
seqlen_offset: usize,
) -> Result<Tensor> {
let (_b_size, seq_len, _) = xs.dims3()?;
let mut xs = xs.clone();
for layer in self.layers.iter_mut() {
xs = layer.forward(&xs, attn_mask, seqlen_offset)?
}
xs.narrow(1, seq_len - 1, 1)?
.apply(&self.norm)?
.apply(&self.lm_head)
}
pub fn clear_kv_cache(&mut self) {
for layer in self.layers.iter_mut() {
layer.clear_kv_cache()
}
}
}
| 4 |
0 | hf_public_repos/candle/candle-transformers/src | hf_public_repos/candle/candle-transformers/src/models/quantized_llama2_c.rs | //! Quantized Llama2 model implementation.
//!
//! This provides an 8-bit quantized implementation of Meta's LLaMA2 language model
//! for reduced memory usage and faster inference.
//!
//! Key characteristics:
//! - Decoder-only transformer architecture
//! - RoPE position embeddings
//! - Grouped Query Attention
//! - 8-bit quantization of weights
//!
//! References:
//! - [LLaMA2 Paper](https://arxiv.org/abs/2307.09288)
//! - [LLaMA2 Technical Report](https://ai.meta.com/research/publications/llama-2-open-foundation-and-fine-tuned-chat-models/)
//!
use super::llama2_c::{Cache, Config};
use crate::quantized_nn::{linear_no_bias as linear, Embedding, Linear, RmsNorm};
pub use crate::quantized_var_builder::VarBuilder;
use candle::{DType, IndexOp, Module, Result, Tensor, D};
fn silu(xs: &Tensor) -> Result<Tensor> {
xs / (xs.neg()?.exp()? + 1.0)?
}
#[derive(Debug, Clone)]
struct CausalSelfAttention {
q_proj: Linear,
k_proj: Linear,
v_proj: Linear,
o_proj: Linear,
n_head: usize,
n_key_value_head: usize,
head_dim: usize,
}
impl CausalSelfAttention {
fn apply_rotary_emb(&self, x: &Tensor, index_pos: usize, cache: &Cache) -> Result<Tensor> {
let (b_sz, seq_len, h, n_embd) = x.dims4()?;
let cos = cache.cos.i(index_pos..index_pos + seq_len)?;
let sin = cache.sin.i(index_pos..index_pos + seq_len)?;
let cos = cos.unsqueeze(1)?;
let sin = sin.unsqueeze(1)?;
let cos = cos.broadcast_as((b_sz, seq_len, 1, n_embd / 2, 1))?;
let sin = sin.broadcast_as((b_sz, seq_len, 1, n_embd / 2, 1))?;
let x = x.reshape((b_sz, seq_len, h, n_embd / 2, 2))?;
let x0 = x.narrow(D::Minus1, 0, 1)?;
let x1 = x.narrow(D::Minus1, 1, 1)?;
let dst0 = (x0.broadcast_mul(&cos)? - x1.broadcast_mul(&sin)?)?;
let dst1 = (x0.broadcast_mul(&sin)? + x1.broadcast_mul(&cos)?)?;
let rope = Tensor::cat(&[&dst0, &dst1], D::Minus1)?.reshape((b_sz, seq_len, h, n_embd))?;
Ok(rope)
}
fn forward(
&self,
x: &Tensor,
index_pos: usize,
block_idx: usize,
cache: &mut Cache,
) -> Result<Tensor> {
let (b_sz, seq_len, n_embd) = x.dims3()?;
let q = self.q_proj.forward(x)?;
let k = self.k_proj.forward(x)?;
let v = self.v_proj.forward(x)?;
let q = q.reshape((b_sz, seq_len, self.n_head, self.head_dim))?;
let k = k.reshape((b_sz, seq_len, self.n_key_value_head, self.head_dim))?;
let mut v = v.reshape((b_sz, seq_len, self.n_key_value_head, self.head_dim))?;
let q = self.apply_rotary_emb(&q, index_pos, cache)?;
let mut k = self.apply_rotary_emb(&k, index_pos, cache)?;
if cache.use_kv_cache {
if let Some((cache_k, cache_v)) = &cache.kvs[block_idx] {
k = Tensor::cat(&[cache_k, &k], 1)?.contiguous()?;
v = Tensor::cat(&[cache_v, &v], 1)?.contiguous()?;
}
cache.kvs[block_idx] = Some((k.clone(), v.clone()))
}
let k = self.repeat_kv(k)?;
let v = self.repeat_kv(v)?;
let q = q.transpose(1, 2)?.contiguous()?;
let k = k.transpose(1, 2)?.contiguous()?;
let v = v.transpose(1, 2)?.contiguous()?;
let att = (q.matmul(&k.t()?)? / (self.head_dim as f64).sqrt())?;
let att = if seq_len <= 1 {
att
} else {
let mask = cache.mask(seq_len)?.broadcast_as(att.shape())?;
masked_fill(&att, &mask, f32::NEG_INFINITY)?
};
let att = candle_nn::ops::softmax(&att, D::Minus1)?;
// Convert to contiguous as matmul doesn't support strided vs for now.
let y = att.matmul(&v.contiguous()?)?;
let y = y.transpose(1, 2)?.reshape(&[b_sz, seq_len, n_embd])?;
let y = self.o_proj.forward(&y)?;
Ok(y)
}
fn repeat_kv(&self, x: Tensor) -> Result<Tensor> {
let n_rep = self.n_head / self.n_key_value_head;
if n_rep == 1 {
Ok(x)
} else {
let (b_sz, seq_len, n_kv_head, head_dim) = x.dims4()?;
let x = x
.unsqueeze(3)?
.expand((b_sz, seq_len, n_kv_head, n_rep, head_dim))?
.reshape((b_sz, seq_len, n_kv_head * n_rep, head_dim))?;
Ok(x)
}
}
fn load(vb: VarBuilder, cfg: &Config) -> Result<Self> {
let size_in = cfg.dim;
let size_q = (cfg.dim / cfg.n_heads) * cfg.n_heads;
let size_kv = (cfg.dim / cfg.n_heads) * cfg.n_kv_heads;
let q_proj = linear(size_in, size_q, vb.pp("q_proj"))?;
let k_proj = linear(size_in, size_kv, vb.pp("k_proj"))?;
let v_proj = linear(size_in, size_kv, vb.pp("v_proj"))?;
let o_proj = linear(size_q, size_in, vb.pp("o_proj"))?;
Ok(Self {
q_proj,
k_proj,
v_proj,
o_proj,
n_head: cfg.n_heads,
n_key_value_head: cfg.n_kv_heads,
head_dim: cfg.dim / cfg.n_heads,
})
}
}
fn masked_fill(on_false: &Tensor, mask: &Tensor, on_true: f32) -> Result<Tensor> {
let shape = mask.shape();
let on_true = Tensor::new(on_true, on_false.device())?.broadcast_as(shape.dims())?;
let m = mask.where_cond(&on_true, on_false)?;
Ok(m)
}
#[derive(Debug, Clone)]
struct Mlp {
c_fc1: Linear,
c_fc2: Linear,
c_proj: Linear,
}
impl Mlp {
fn new(c_fc1: Linear, c_fc2: Linear, c_proj: Linear) -> Self {
Self {
c_fc1,
c_fc2,
c_proj,
}
}
fn forward(&self, x: &Tensor) -> Result<Tensor> {
let x = (silu(&self.c_fc1.forward(x)?)? * self.c_fc2.forward(x)?)?;
self.c_proj.forward(&x)
}
fn load(vb: VarBuilder, cfg: &Config) -> Result<Self> {
let h_size = cfg.dim;
let i_size = cfg.hidden_dim;
let c_fc1 = linear(h_size, i_size, vb.pp("gate_proj"))?;
let c_fc2 = linear(h_size, i_size, vb.pp("up_proj"))?;
let c_proj = linear(i_size, h_size, vb.pp("down_proj"))?;
Ok(Self::new(c_fc1, c_fc2, c_proj))
}
}
#[derive(Debug, Clone)]
struct Block {
rms_1: RmsNorm,
attn: CausalSelfAttention,
rms_2: RmsNorm,
mlp: Mlp,
}
impl Block {
fn new(rms_1: RmsNorm, attn: CausalSelfAttention, rms_2: RmsNorm, mlp: Mlp) -> Self {
Self {
rms_1,
attn,
rms_2,
mlp,
}
}
fn forward(
&self,
x: &Tensor,
index_pos: usize,
block_idx: usize,
cache: &mut Cache,
) -> Result<Tensor> {
let residual = x;
let x = self.rms_1.forward(x)?;
let x = (self.attn.forward(&x, index_pos, block_idx, cache)? + residual)?;
let residual = &x;
let x = (self.mlp.forward(&self.rms_2.forward(&x)?)? + residual)?;
Ok(x)
}
fn load(vb: VarBuilder, cfg: &Config) -> Result<Self> {
let attn = CausalSelfAttention::load(vb.pp("self_attn"), cfg)?;
let mlp = Mlp::load(vb.pp("mlp"), cfg)?;
let input_layernorm = RmsNorm::new(cfg.dim, cfg.norm_eps, vb.pp("input_layernorm"))?;
let post_attention_layernorm =
RmsNorm::new(cfg.dim, cfg.norm_eps, vb.pp("post_attention_layernorm"))?;
Ok(Self::new(
input_layernorm,
attn,
post_attention_layernorm,
mlp,
))
}
}
#[derive(Debug, Clone)]
pub struct QLlama {
wte: Embedding,
blocks: Vec<Block>,
ln_f: RmsNorm,
lm_head: Linear,
pub config: Config,
}
impl QLlama {
pub fn forward(&self, x: &Tensor, index_pos: usize, cache: &mut Cache) -> Result<Tensor> {
let (_b_sz, _seq_len) = x.dims2()?;
let mut x = self.wte.forward(x)?;
for (block_idx, block) in self.blocks.iter().enumerate() {
x = block.forward(&x, index_pos, block_idx, cache)?;
}
let x = self.ln_f.forward(&x)?;
let logits = self.lm_head.forward(&x)?;
logits.to_dtype(DType::F32)
}
pub fn load(vb: VarBuilder, cfg: Config) -> Result<Self> {
let wte = Embedding::new(cfg.vocab_size, cfg.dim, vb.pp("model.embed_tokens"))?;
let lm_head = linear(cfg.dim, cfg.vocab_size, vb.pp("lm_head"))?;
let ln_f = RmsNorm::new(cfg.dim, cfg.norm_eps, vb.pp("model.norm"))?;
let blocks: Vec<_> = (0..cfg.n_layers)
.map(|i| Block::load(vb.pp(format!("model.layers.{i}")), &cfg).unwrap())
.collect();
Ok(Self {
wte,
blocks,
ln_f,
lm_head,
config: cfg,
})
}
}
| 5 |
0 | hf_public_repos/candle/candle-transformers/src | hf_public_repos/candle/candle-transformers/src/models/mpt.rs | //! Module implementing the MPT (Multi-Purpose Transformer) model
//!
//! References:
//! - [MPT Model used by replit-code-v1_5-3b](https://huggingface.co/replit/replit-code-v1_5-3b/blob/main/modeling_mpt.py)
//! - [Configuration](https://huggingface.co/replit/replit-code-v1_5-3b/blob/main/configuration_mpt.py)
//!
//! The model uses grouped query attention and alibi positional embeddings.
use crate::models::with_tracing::{linear_no_bias, Embedding, Linear};
/// MPT model used by replit-code-v1_5-3b
/// https://huggingface.co/replit/replit-code-v1_5-3b/blob/main/modeling_mpt.py
use candle::{DType, Device, IndexOp, Module, Result, Tensor, D};
use candle_nn::{layer_norm, LayerNorm, VarBuilder};
// https://huggingface.co/replit/replit-code-v1_5-3b/blob/main/configuration_mpt.py
#[derive(Debug, Clone, PartialEq)]
pub struct Config {
pub(crate) d_model: usize,
pub(crate) n_heads: usize,
pub(crate) n_layers: usize,
pub(crate) expansion_ratio: usize,
pub(crate) max_seq_len: usize,
pub(crate) vocab_size: usize,
pub(crate) kv_n_heads: usize,
pub(crate) attn_prefix_lm: bool,
pub(crate) attn_alibi: bool,
pub(crate) attn_alibi_bias_max: usize,
}
impl Config {
pub fn replit_code_v1_5_3b() -> Self {
Self {
d_model: 3072,
n_heads: 24,
n_layers: 32,
expansion_ratio: 4,
max_seq_len: 4096,
vocab_size: 32768,
kv_n_heads: 8,
attn_prefix_lm: false,
attn_alibi: true,
attn_alibi_bias_max: 8,
}
}
pub fn is_causal(&self) -> bool {
!self.attn_prefix_lm
}
}
#[derive(Debug, Clone)]
struct GroupedQueryAttention {
wqkv: Linear,
out_proj: Linear,
kv_cache: Option<(Tensor, Tensor)>,
softmax_scale: f64,
head_dim: usize,
d_model: usize,
n_heads: usize,
kv_n_heads: usize,
attn_bias: Tensor,
span: tracing::Span,
}
impl GroupedQueryAttention {
fn new(cfg: &Config, vb: VarBuilder) -> Result<Self> {
let head_dim = cfg.d_model / cfg.n_heads;
let wqkv_size = cfg.d_model + 2 * cfg.kv_n_heads * head_dim;
let wqkv = linear_no_bias(cfg.d_model, wqkv_size, vb.pp("Wqkv"))?;
let softmax_scale = 1f64 / (head_dim as f64).sqrt();
let out_proj = linear_no_bias(cfg.d_model, cfg.d_model, vb.pp("out_proj"))?;
let attn_bias = build_alibi_bias(cfg)?.to_device(vb.device())?;
Ok(Self {
wqkv,
out_proj,
kv_cache: None,
softmax_scale,
head_dim,
d_model: cfg.d_model,
n_heads: cfg.n_heads,
kv_n_heads: cfg.kv_n_heads,
attn_bias,
span: tracing::span!(tracing::Level::TRACE, "gqa"),
})
}
fn forward(&mut self, xs: &Tensor, mask: Option<&Tensor>) -> Result<Tensor> {
let _enter = self.span.enter();
let (b_size, seq_len, _n_embd) = xs.dims3()?;
let qkv = self.wqkv.forward(xs)?;
let query = qkv.narrow(2, 0, self.d_model)?;
let kv_size = self.kv_n_heads * self.head_dim;
let key = qkv.narrow(2, self.d_model, kv_size)?;
let value = qkv.narrow(2, self.d_model + kv_size, kv_size)?;
// scaled_multihead_dot_product_attention
let query = query
.reshape((b_size, seq_len, self.n_heads, ()))?
.transpose(1, 2)?; // b,h,s,d
let key = key
.reshape((b_size, seq_len, self.kv_n_heads, ()))?
.permute((0, 2, 3, 1))?; // b,h,d,s
let value = value
.reshape((b_size, seq_len, self.kv_n_heads, ()))?
.transpose(1, 2)?; // b,h,s,d
let (key, value) = match &self.kv_cache {
None => (key, value),
Some((prev_k, prev_v)) => {
let k = Tensor::cat(&[prev_k, &key], 3)?;
let v = Tensor::cat(&[prev_v, &value], 2)?;
(k, v)
}
};
self.kv_cache = Some((key.clone(), value.clone()));
let query = query.contiguous()?;
let key = crate::utils::repeat_kv(key, self.n_heads / self.kv_n_heads)?.contiguous()?;
let value = crate::utils::repeat_kv(value, self.n_heads / self.kv_n_heads)?.contiguous()?;
let attn_weights = (query.matmul(&key)? * self.softmax_scale)?;
let attn_bias = {
let s_q = query.dim(D::Minus2)?;
let s_k = key.dim(D::Minus1)?;
let (_, _, a_q, a_k) = self.attn_bias.dims4()?;
let start_q = a_q.saturating_sub(s_q);
let start_k = a_k.saturating_sub(s_k);
self.attn_bias.i((.., .., start_q.., start_k..))?
};
let attn_weights = attn_weights.broadcast_add(&attn_bias)?;
let attn_weights = match mask {
None => attn_weights,
Some(mask) => masked_fill(
&attn_weights,
&mask.broadcast_as(attn_weights.shape())?,
f32::NEG_INFINITY,
)?,
};
let attn_weights = candle_nn::ops::softmax_last_dim(&attn_weights)?;
let attn_output = attn_weights
.matmul(&value)?
.transpose(1, 2)?
.flatten_from(D::Minus2)?;
let out = attn_output.apply(&self.out_proj)?;
Ok(out)
}
}
#[derive(Debug, Clone)]
struct Ffn {
up_proj: Linear,
down_proj: Linear,
}
impl Ffn {
fn new(cfg: &Config, vb: VarBuilder) -> Result<Self> {
let hidden = cfg.d_model * cfg.expansion_ratio;
let up_proj = linear_no_bias(cfg.d_model, hidden, vb.pp("up_proj"))?;
let down_proj = linear_no_bias(hidden, cfg.d_model, vb.pp("down_proj"))?;
Ok(Self { up_proj, down_proj })
}
}
impl Module for Ffn {
fn forward(&self, xs: &Tensor) -> Result<Tensor> {
xs.apply(&self.up_proj)?.gelu_erf()?.apply(&self.down_proj)
}
}
#[derive(Debug, Clone)]
struct MPTBlock {
norm1: LayerNorm, // Do we need the low-precision variant?
attn: GroupedQueryAttention,
norm2: LayerNorm,
ffn: Ffn,
}
impl MPTBlock {
fn new(cfg: &Config, vb: VarBuilder) -> Result<Self> {
let ln_cfg = candle_nn::LayerNormConfig {
affine: false,
..Default::default()
};
let norm1 = layer_norm(cfg.d_model, ln_cfg, vb.pp("norm_1"))?;
let norm2 = layer_norm(cfg.d_model, ln_cfg, vb.pp("norm_2"))?;
let attn = GroupedQueryAttention::new(cfg, vb.pp("attn"))?;
let ffn = Ffn::new(cfg, vb.pp("ffn"))?;
Ok(Self {
norm1,
attn,
norm2,
ffn,
})
}
fn forward(&mut self, xs: &Tensor, mask: Option<&Tensor>) -> Result<Tensor> {
let residual = xs;
let xs = xs.apply(&self.norm1)?;
let xs = self.attn.forward(&xs, mask)?;
let xs = (xs + residual)?;
let residual = &xs;
let xs = xs.apply(&self.norm2)?.apply(&self.ffn)?;
xs + residual
}
}
pub(crate) fn build_alibi_bias(cfg: &Config) -> Result<Tensor> {
let full = !cfg.is_causal();
let seq_len = cfg.max_seq_len;
let alibi_bias = Tensor::arange(1 - seq_len as i64, 1, &Device::Cpu)?;
let alibi_bias = if full {
let a1 = alibi_bias.reshape((1, 1, 1, seq_len))?;
let a2 = alibi_bias.reshape((1, 1, seq_len, 1))?;
a1.broadcast_sub(&a2)?.abs()?.neg()?
} else {
alibi_bias.reshape((1, 1, 1, seq_len))?
};
let mut n_heads2 = 1;
while n_heads2 < cfg.n_heads {
n_heads2 *= 2
}
let slopes = (1..=n_heads2)
.map(|v| 1f32 / 2f32.powf((v * cfg.attn_alibi_bias_max) as f32 / n_heads2 as f32))
.collect::<Vec<_>>();
let slopes = if n_heads2 == cfg.n_heads {
slopes
} else {
slopes
.iter()
.skip(1)
.step_by(2)
.chain(slopes.iter().step_by(2))
.take(cfg.n_heads)
.cloned()
.collect::<Vec<f32>>()
};
let slopes = Tensor::new(slopes, &Device::Cpu)?.reshape((1, (), 1, 1))?;
alibi_bias.to_dtype(DType::F32)?.broadcast_mul(&slopes)
}
#[derive(Debug, Clone)]
pub struct Model {
wte: Embedding,
blocks: Vec<MPTBlock>,
norm_f: LayerNorm,
}
impl Model {
pub fn new(cfg: &Config, vb: VarBuilder) -> Result<Self> {
let wte = Embedding::new(cfg.vocab_size, cfg.d_model, vb.pp("wte"))?;
let vb_b = vb.pp("blocks");
let mut blocks = Vec::with_capacity(cfg.n_layers);
for i in 0..cfg.n_layers {
let block = MPTBlock::new(cfg, vb_b.pp(i))?;
blocks.push(block)
}
let ln_cfg = candle_nn::LayerNormConfig {
affine: false,
..Default::default()
};
let norm_f = candle_nn::layer_norm(cfg.d_model, ln_cfg, vb.pp("norm_f"))?;
Ok(Self {
wte,
blocks,
norm_f,
})
}
pub fn forward(&mut self, xs: &Tensor) -> Result<Tensor> {
let (_b_size, seq_len) = xs.dims2()?;
let mut xs = xs.apply(&self.wte)?;
let mask = if seq_len <= 1 {
None
} else {
Some(get_mask(seq_len, xs.device())?)
};
for block in self.blocks.iter_mut() {
xs = block.forward(&xs, mask.as_ref())?;
}
let xs = xs.apply(&self.norm_f)?;
let logits = xs
.narrow(1, seq_len - 1, 1)?
.squeeze(1)?
.matmul(&self.wte.embeddings().t()?)?
.squeeze(1)?;
Ok(logits)
}
}
pub(crate) fn get_mask(size: usize, device: &Device) -> Result<Tensor> {
let mask: Vec<_> = (0..size)
.flat_map(|i| (0..size).map(move |j| u8::from(j > i)))
.collect();
Tensor::from_slice(&mask, (size, size), device)
}
pub(crate) fn masked_fill(on_false: &Tensor, mask: &Tensor, on_true: f32) -> Result<Tensor> {
let shape = mask.shape();
let on_true = Tensor::new(on_true, on_false.device())?.broadcast_as(shape.dims())?;
let m = mask.where_cond(&on_true, on_false)?;
Ok(m)
}
| 6 |
0 | hf_public_repos/candle/candle-transformers/src | hf_public_repos/candle/candle-transformers/src/models/mobileone.rs | //! # MobileOne
//!
//! MobileOne inference implementation based on timm and candle-repvgg
//!
//! See ["MobileOne: An Improved One millisecond Mobile Backbone"](https://arxiv.org/abs/2206.04040)
use candle::{DType, Result, Tensor, D};
use candle_nn::{
batch_norm, conv2d, conv2d_no_bias, linear, ops::sigmoid, BatchNorm, Conv2d, Conv2dConfig,
Func, VarBuilder,
};
struct StageConfig {
blocks: usize,
channels: usize,
}
// The architecture in the paper has 6 stages. The timm implementation uses an equivalent form
// by concatenating the 5th stage (starts with stride 1) to the previous one.
const STAGES: [StageConfig; 5] = [
StageConfig {
blocks: 1,
channels: 64,
},
StageConfig {
blocks: 2,
channels: 64,
},
StageConfig {
blocks: 8,
channels: 128,
},
StageConfig {
blocks: 10,
channels: 256,
},
StageConfig {
blocks: 1,
channels: 512,
},
];
#[derive(Clone)]
pub struct Config {
/// overparameterization factor
k: usize,
/// per-stage channel number multipliers
alphas: [f32; 5],
}
impl Config {
pub fn s0() -> Self {
Self {
k: 4,
alphas: [0.75, 0.75, 1.0, 1.0, 2.0],
}
}
pub fn s1() -> Self {
Self {
k: 1,
alphas: [1.5, 1.5, 1.5, 2.0, 2.5],
}
}
pub fn s2() -> Self {
Self {
k: 1,
alphas: [1.5, 1.5, 2.0, 2.5, 4.0],
}
}
pub fn s3() -> Self {
Self {
k: 1,
alphas: [2.0, 2.0, 2.5, 3.0, 4.0],
}
}
pub fn s4() -> Self {
Self {
k: 1,
alphas: [3.0, 3.0, 3.5, 3.5, 4.0],
}
}
}
// SE blocks are used in the last stages of the s4 variant.
fn squeeze_and_excitation(
in_channels: usize,
squeeze_channels: usize,
vb: VarBuilder,
) -> Result<Func<'static>> {
let conv2d_cfg = Conv2dConfig {
..Default::default()
};
let fc1 = conv2d(in_channels, squeeze_channels, 1, conv2d_cfg, vb.pp("fc1"))?;
let fc2 = conv2d(squeeze_channels, in_channels, 1, conv2d_cfg, vb.pp("fc2"))?;
Ok(Func::new(move |xs| {
let residual = xs;
let xs = xs.mean_keepdim(D::Minus2)?.mean_keepdim(D::Minus1)?;
let xs = sigmoid(&xs.apply(&fc1)?.relu()?.apply(&fc2)?)?;
residual.broadcast_mul(&xs)
}))
}
// fuses a convolutional kernel and a batchnorm layer into a convolutional layer
// based on the _fuse_bn_tensor method in timm
// see https://github.com/huggingface/pytorch-image-models/blob/main/timm/models/byobnet.py#L602
fn fuse_conv_bn(weights: &Tensor, bn: BatchNorm) -> Result<(Tensor, Tensor)> {
let (gamma, beta) = bn.weight_and_bias().unwrap();
let mu = bn.running_mean();
let sigma = (bn.running_var() + bn.eps())?.sqrt();
let gps = (gamma / sigma)?;
let bias = (beta - mu * &gps)?;
let weights = weights.broadcast_mul(&gps.reshape(((), 1, 1, 1))?)?;
Ok((weights, bias))
}
// A mobileone block has a different training time and inference time architecture.
// The latter is a simple and efficient equivalent transformation of the former
// realized by a structural reparameterization technique, where convolutions
// along with identity branches and batchnorm layers are fused into a single convolution.
#[allow(clippy::too_many_arguments)]
fn mobileone_block(
has_identity: bool,
k: usize,
dim: usize,
stride: usize,
padding: usize,
groups: usize,
kernel: usize,
in_channels: usize,
out_channels: usize,
vb: VarBuilder,
) -> Result<Func<'static>> {
let conv2d_cfg = Conv2dConfig {
stride,
padding,
groups,
..Default::default()
};
let mut w = Tensor::zeros(
(out_channels, in_channels / groups, kernel, kernel),
DType::F32,
vb.device(),
)?;
let mut b = Tensor::zeros(dim, DType::F32, vb.device())?;
// k is the training-time overparameterization factor, larger than 1 only in the s0 variant
for i in 0..k {
let conv_kxk_bn = batch_norm(dim, 1e-5, vb.pp(format!("conv_kxk.{i}.bn")))?;
let conv_kxk = conv2d_no_bias(
in_channels,
out_channels,
kernel,
conv2d_cfg,
vb.pp(format!("conv_kxk.{i}.conv")),
)?;
let (wk, bk) = fuse_conv_bn(conv_kxk.weight(), conv_kxk_bn)?;
w = (w + wk)?;
b = (b + bk)?;
}
if kernel > 1 {
let conv_scale_bn = batch_norm(dim, 1e-5, vb.pp("conv_scale.bn"))?;
let conv_scale = conv2d_no_bias(
in_channels,
out_channels,
1,
conv2d_cfg,
vb.pp("conv_scale.conv"),
)?;
let (mut ws, bs) = fuse_conv_bn(conv_scale.weight(), conv_scale_bn)?;
// resize to 3x3
ws = ws.pad_with_zeros(D::Minus1, 1, 1)?;
ws = ws.pad_with_zeros(D::Minus2, 1, 1)?;
w = (w + ws)?;
b = (b + bs)?;
}
// Use SE blocks if present (last layers of the s4 variant)
let se = squeeze_and_excitation(out_channels, out_channels / 16, vb.pp("attn"));
// read and reparameterize the identity bn into wi and bi
if has_identity {
let identity_bn = batch_norm(dim, 1e-5, vb.pp("identity"))?;
let mut weights: Vec<f32> = vec![0.0; w.elem_count()];
let id = in_channels / groups;
// See https://github.com/huggingface/pytorch-image-models/blob/main/timm/models/byobnet.py#L809
for i in 0..in_channels {
if kernel > 1 {
weights[i * kernel * kernel + 4] = 1.0;
} else {
weights[i * (id + 1)] = 1.0;
}
}
let weights = &Tensor::from_vec(weights, w.shape(), w.device())?;
let (wi, bi) = fuse_conv_bn(weights, identity_bn)?;
w = (w + wi)?;
b = (b + bi)?;
}
let reparam_conv = Conv2d::new(w, Some(b), conv2d_cfg);
Ok(Func::new(move |xs| {
let mut xs = xs.apply(&reparam_conv)?;
if let Ok(f) = &se {
xs = xs.apply(f)?;
}
xs = xs.relu()?;
Ok(xs)
}))
}
// Get the number of output channels per stage taking into account the multipliers
fn output_channels_per_stage(cfg: &Config, stage: usize) -> usize {
let channels = STAGES[stage].channels as f32;
let alpha = cfg.alphas[stage];
match stage {
0 => std::cmp::min(64, (channels * alpha) as usize),
_ => (channels * alpha) as usize,
}
}
// Each stage is made of blocks. The first layer always downsamples with stride 2.
// All but the first block have a residual connection.
fn mobileone_stage(cfg: &Config, idx: usize, vb: VarBuilder) -> Result<Func<'static>> {
let nblocks = STAGES[idx].blocks;
let mut blocks = Vec::with_capacity(nblocks);
let mut in_channels = output_channels_per_stage(cfg, idx - 1);
for block_idx in 0..nblocks {
let out_channels = output_channels_per_stage(cfg, idx);
let (has_identity, stride) = if block_idx == 0 {
(false, 2)
} else {
(true, 1)
};
// depthwise convolution layer
blocks.push(mobileone_block(
has_identity,
cfg.k,
in_channels,
stride,
1,
in_channels,
3,
in_channels,
in_channels,
vb.pp(block_idx * 2),
)?);
// pointwise convolution layer
blocks.push(mobileone_block(
has_identity,
cfg.k,
out_channels,
1, // stride
0, // padding
1, // groups
1, // kernel
in_channels,
out_channels,
vb.pp(block_idx * 2 + 1),
)?);
in_channels = out_channels;
}
Ok(Func::new(move |xs| {
let mut xs = xs.clone();
for block in blocks.iter() {
xs = xs.apply(block)?
}
Ok(xs)
}))
}
// Build a mobileone model for a given configuration.
fn mobileone_model(
config: &Config,
nclasses: Option<usize>,
vb: VarBuilder,
) -> Result<Func<'static>> {
let cls = match nclasses {
None => None,
Some(nclasses) => {
let outputs = output_channels_per_stage(config, 4);
let linear = linear(outputs, nclasses, vb.pp("head.fc"))?;
Some(linear)
}
};
let stem_dim = output_channels_per_stage(config, 0);
let stem = mobileone_block(false, 1, stem_dim, 2, 1, 1, 3, 3, stem_dim, vb.pp("stem"))?;
let vb = vb.pp("stages");
let stage1 = mobileone_stage(config, 1, vb.pp(0))?;
let stage2 = mobileone_stage(config, 2, vb.pp(1))?;
let stage3 = mobileone_stage(config, 3, vb.pp(2))?;
let stage4 = mobileone_stage(config, 4, vb.pp(3))?;
Ok(Func::new(move |xs| {
let xs = xs
.apply(&stem)?
.apply(&stage1)?
.apply(&stage2)?
.apply(&stage3)?
.apply(&stage4)?
.mean(D::Minus2)?
.mean(D::Minus1)?;
match &cls {
None => Ok(xs),
Some(cls) => xs.apply(cls),
}
}))
}
pub fn mobileone(cfg: &Config, nclasses: usize, vb: VarBuilder) -> Result<Func<'static>> {
mobileone_model(cfg, Some(nclasses), vb)
}
pub fn mobileone_no_final_layer(cfg: &Config, vb: VarBuilder) -> Result<Func<'static>> {
mobileone_model(cfg, None, vb)
}
| 7 |
0 | hf_public_repos/candle/candle-transformers/src | hf_public_repos/candle/candle-transformers/src/models/quantized_llama.rs | //! Quantized llama model implementation.
//!
//! This provides a quantized implementation of the llama language model architecture.
//! The model implements parameter efficient quantization for reduced memory usage
//! while maintaining model quality.
//!
//! Key characteristics:
//! - Transformer decoder architecture
//! - Support for 2/3/4/8-bit quantization
//! - Optimized memory usage through quantization
//! - Configurable model sizes and parameter counts
//!
//! - 💻 [GH Link](https://github.com/facebookresearch/llama)
//! - 📝 [Paper](https://arxiv.org/abs/2302.13971)
//!
//! 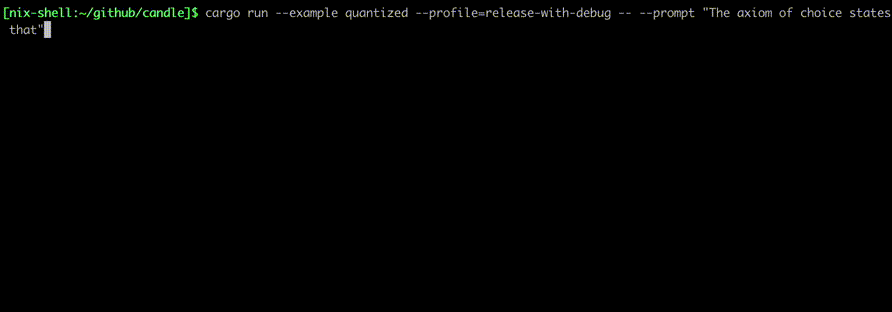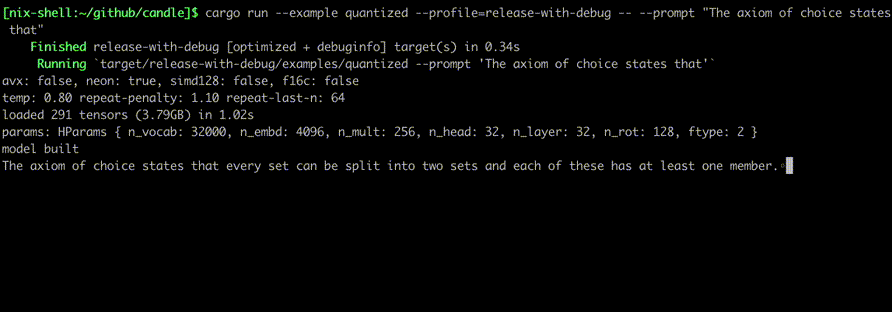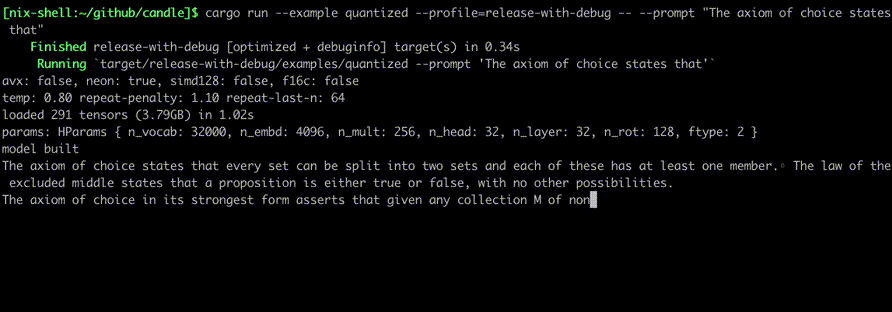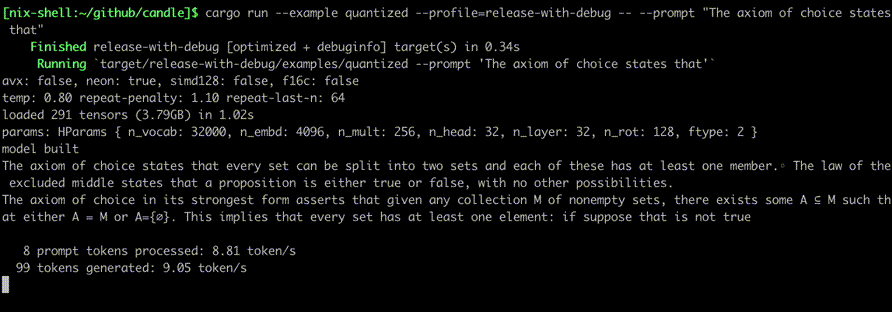
//!
use std::collections::HashMap;
use crate::quantized_nn::RmsNorm;
use candle::quantized::QTensor;
use candle::quantized::{ggml_file, gguf_file};
use candle::{DType, Device, IndexOp, Result, Tensor};
use candle_nn::{Embedding, Module};
pub const MAX_SEQ_LEN: usize = 4096;
// QMatMul wrapper adding some tracing.
#[derive(Debug, Clone)]
struct QMatMul {
inner: candle::quantized::QMatMul,
span: tracing::Span,
}
impl QMatMul {
fn from_qtensor(qtensor: QTensor) -> Result<Self> {
let inner = candle::quantized::QMatMul::from_qtensor(qtensor)?;
let span = tracing::span!(tracing::Level::TRACE, "qmatmul");
Ok(Self { inner, span })
}
fn forward(&self, xs: &Tensor) -> Result<Tensor> {
let _enter = self.span.enter();
self.inner.forward(xs)
}
}
#[derive(Debug, Clone)]
struct Mlp {
feed_forward_w1: QMatMul,
feed_forward_w2: QMatMul,
feed_forward_w3: QMatMul,
}
impl Module for Mlp {
fn forward(&self, xs: &Tensor) -> Result<Tensor> {
let w1 = self.feed_forward_w1.forward(xs)?;
let w3 = self.feed_forward_w3.forward(xs)?;
self.feed_forward_w2
.forward(&(candle_nn::ops::silu(&w1)? * w3)?)
}
}
#[derive(Debug, Clone)]
enum MlpOrMoe {
Mlp(Mlp),
MoE {
n_expert_used: usize,
feed_forward_gate_inp: QMatMul,
experts: Vec<Mlp>,
},
}
impl Module for MlpOrMoe {
fn forward(&self, xs: &Tensor) -> Result<Tensor> {
match self {
Self::MoE {
feed_forward_gate_inp,
experts,
n_expert_used,
} => {
let (b_size, seq_len, hidden_dim) = xs.dims3()?;
let xs = xs.reshape(((), hidden_dim))?;
let router_logits = feed_forward_gate_inp.forward(&xs)?;
let routing_weights = candle_nn::ops::softmax_last_dim(&router_logits)?;
// In order to extract topk, we extract the data from the tensor and manipulate it
// directly. Maybe we will want to use some custom ops instead at some point.
let routing_weights = routing_weights.to_dtype(DType::F32)?.to_vec2::<f32>()?;
// routing_weights, selected_experts = torch.topk(routing_weights, self.top_k, dim=-1)
// top_x contains the row indexes to evaluate for each expert.
let mut top_x = vec![vec![]; experts.len()];
let mut selected_rws = vec![vec![]; experts.len()];
for (row_idx, rw) in routing_weights.iter().enumerate() {
let mut dst = (0..rw.len() as u32).collect::<Vec<u32>>();
dst.sort_by(|&i, &j| rw[j as usize].total_cmp(&rw[i as usize]));
let mut sum_routing_weights = 0f32;
for &expert_idx in dst.iter().take(*n_expert_used) {
let expert_idx = expert_idx as usize;
let routing_weight = rw[expert_idx];
sum_routing_weights += routing_weight;
top_x[expert_idx].push(row_idx as u32);
}
for &expert_idx in dst.iter().take(*n_expert_used) {
let expert_idx = expert_idx as usize;
let routing_weight = rw[expert_idx];
selected_rws[expert_idx].push(routing_weight / sum_routing_weights)
}
}
// routing_weights /= routing_weights.sum(dim=-1, keepdim=True)
// expert_mask = torch.nn.functional.one_hot(selected_experts, num_classes=self.num_experts).permute(2, 1, 0)
let mut ys = xs.zeros_like()?;
for (expert_idx, expert_layer) in experts.iter().enumerate() {
let top_x = &top_x[expert_idx];
if top_x.is_empty() {
continue;
}
let top_x = Tensor::new(top_x.as_slice(), xs.device())?;
let selected_rws =
Tensor::new(selected_rws[expert_idx].as_slice(), xs.device())?
.reshape(((), 1))?;
// Index the correct hidden states and compute the expert hidden state for
// the current expert. We need to make sure to multiply the output hidden
// states by `routing_weights` on the corresponding tokens (top-1 and top-2)
let current_state = xs.index_select(&top_x, 0)?.reshape(((), hidden_dim))?;
// current_hidden_states = expert_layer(current_state, routing_weights[top_x_list, idx_list, None])
let current_hidden_states = expert_layer.forward(¤t_state)?;
let current_hidden_states =
current_hidden_states.broadcast_mul(&selected_rws)?;
ys = ys.index_add(&top_x, ¤t_hidden_states, 0)?;
}
let ys = ys.reshape((b_size, seq_len, hidden_dim))?;
Ok(ys)
}
Self::Mlp(mlp) => mlp.forward(xs),
}
}
}
#[derive(Debug, Clone)]
struct LayerWeights {
attention_wq: QMatMul,
attention_wk: QMatMul,
attention_wv: QMatMul,
attention_wo: QMatMul,
attention_norm: RmsNorm,
mlp_or_moe: MlpOrMoe,
ffn_norm: RmsNorm,
n_head: usize,
n_kv_head: usize,
head_dim: usize,
cos: Tensor,
sin: Tensor,
neg_inf: Tensor,
kv_cache: Option<(Tensor, Tensor)>,
span_attn: tracing::Span,
span_rot: tracing::Span,
span_mlp: tracing::Span,
}
fn masked_fill(on_false: &Tensor, mask: &Tensor, on_true: &Tensor) -> Result<Tensor> {
let shape = mask.shape();
let m = mask.where_cond(&on_true.broadcast_as(shape.dims())?, on_false)?;
Ok(m)
}
impl LayerWeights {
fn apply_rotary_emb(&self, x: &Tensor, index_pos: usize) -> Result<Tensor> {
let _enter = self.span_rot.enter();
let (_b_sz, _n_head, seq_len, _n_embd) = x.dims4()?;
let cos = self.cos.narrow(0, index_pos, seq_len)?;
let sin = self.sin.narrow(0, index_pos, seq_len)?;
// The call to contiguous below is only necessary when processing the prompt.
// When the seq_len is 1 in the inference loop, this is a no-op.
candle_nn::rotary_emb::rope_i(&x.contiguous()?, &cos, &sin)
}
fn forward_attn(
&mut self,
x: &Tensor,
mask: Option<&Tensor>,
index_pos: usize,
) -> Result<Tensor> {
let _enter = self.span_attn.enter();
let (b_sz, seq_len, n_embd) = x.dims3()?;
let q = self.attention_wq.forward(x)?;
let k = self.attention_wk.forward(x)?;
let v = self.attention_wv.forward(x)?;
let q = q
.reshape((b_sz, seq_len, self.n_head, self.head_dim))?
.transpose(1, 2)?;
let k = k
.reshape((b_sz, seq_len, self.n_kv_head, self.head_dim))?
.transpose(1, 2)?;
let v = v
.reshape((b_sz, seq_len, self.n_kv_head, self.head_dim))?
.transpose(1, 2)?
// This call to contiguous ensures that the fast kernel can be called below. It's
// actually a no-op except when processing the initial prompt so has no significant
// impact on performance.
.contiguous()?;
let q = self.apply_rotary_emb(&q, index_pos)?;
let k = self.apply_rotary_emb(&k, index_pos)?;
let (k, v) = match &self.kv_cache {
None => (k, v),
Some((k_cache, v_cache)) => {
if index_pos == 0 {
(k, v)
} else {
let k = Tensor::cat(&[k_cache, &k], 2)?;
let v = Tensor::cat(&[v_cache, &v], 2)?;
(k, v)
}
}
};
self.kv_cache = Some((k.clone(), v.clone()));
let y = if q.device().is_metal() && seq_len == 1 {
// SDPA will do MQA for us
candle_nn::ops::sdpa(&q, &k, &v, 1. / (self.head_dim as f32).sqrt(), 1.)?
} else {
// Support for MQA, useful for 70B models and mistral.
let k = crate::utils::repeat_kv(k, self.n_head / self.n_kv_head)?;
let v = crate::utils::repeat_kv(v, self.n_head / self.n_kv_head)?;
let att = (q.matmul(&k.t()?)? / (self.head_dim as f64).sqrt())?;
let att = match mask {
None => att,
Some(mask) => {
let mask = mask.broadcast_as(att.shape())?;
masked_fill(&att, &mask, &self.neg_inf)?
}
};
let att = candle_nn::ops::softmax_last_dim(&att)?;
// Convert to contiguous as matmul doesn't support strided vs for now.
att.matmul(&v.contiguous()?)?
};
let y = y.transpose(1, 2)?.reshape(&[b_sz, seq_len, n_embd])?;
let y = self.attention_wo.forward(&y)?;
Ok(y)
}
}
#[derive(Debug, Clone)]
pub struct ModelWeights {
tok_embeddings: Embedding,
layers: Vec<LayerWeights>,
norm: RmsNorm,
output: QMatMul,
masks: HashMap<usize, Tensor>,
span: tracing::Span,
span_output: tracing::Span,
}
fn precomput_freqs_cis(
head_dim: usize,
freq_base: f32,
device: &Device,
) -> Result<(Tensor, Tensor)> {
let theta: Vec<_> = (0..head_dim)
.step_by(2)
.map(|i| 1f32 / freq_base.powf(i as f32 / head_dim as f32))
.collect();
let theta = Tensor::new(theta.as_slice(), device)?;
let idx_theta = Tensor::arange(0, MAX_SEQ_LEN as u32, device)?
.to_dtype(DType::F32)?
.reshape((MAX_SEQ_LEN, 1))?
.matmul(&theta.reshape((1, theta.elem_count()))?)?;
let cos = idx_theta.cos()?;
let sin = idx_theta.sin()?;
Ok((cos, sin))
}
impl ModelWeights {
pub fn from_ggml(mut ct: ggml_file::Content, gqa: usize) -> Result<Self> {
let head_dim = (ct.hparams.n_embd / ct.hparams.n_head) as usize;
let (cos, sin) = precomput_freqs_cis(head_dim, 10000., &ct.device)?;
let neg_inf = Tensor::new(f32::NEG_INFINITY, &ct.device)?;
let tok_embeddings = ct.remove("tok_embeddings.weight")?;
let tok_embeddings = tok_embeddings.dequantize(&ct.device)?;
let norm = RmsNorm::from_qtensor(ct.remove("norm.weight")?, 1e-5)?;
let output = ct.remove("output.weight")?;
let mut layers = Vec::with_capacity(ct.hparams.n_layer as usize);
for layer_idx in 0..ct.hparams.n_layer {
let prefix = format!("layers.{layer_idx}");
let attention_wq = ct.remove(&format!("{prefix}.attention.wq.weight"))?;
let attention_wk = ct.remove(&format!("{prefix}.attention.wk.weight"))?;
let attention_wv = ct.remove(&format!("{prefix}.attention.wv.weight"))?;
let attention_wo = ct.remove(&format!("{prefix}.attention.wo.weight"))?;
let mlp_or_moe = {
let feed_forward_w1 = ct.remove(&format!("{prefix}.feed_forward.w1.weight"))?;
let feed_forward_w2 = ct.remove(&format!("{prefix}.feed_forward.w2.weight"))?;
let feed_forward_w3 = ct.remove(&format!("{prefix}.feed_forward.w3.weight"))?;
MlpOrMoe::Mlp(Mlp {
feed_forward_w1: QMatMul::from_qtensor(feed_forward_w1)?,
feed_forward_w2: QMatMul::from_qtensor(feed_forward_w2)?,
feed_forward_w3: QMatMul::from_qtensor(feed_forward_w3)?,
})
};
let attention_norm = ct.remove(&format!("{prefix}.attention_norm.weight"))?;
let ffn_norm = ct.remove(&format!("{prefix}.ffn_norm.weight"))?;
let span_attn = tracing::span!(tracing::Level::TRACE, "attn");
let span_rot = tracing::span!(tracing::Level::TRACE, "attn-rot");
let span_mlp = tracing::span!(tracing::Level::TRACE, "attn-mlp");
layers.push(LayerWeights {
attention_wq: QMatMul::from_qtensor(attention_wq)?,
attention_wk: QMatMul::from_qtensor(attention_wk)?,
attention_wv: QMatMul::from_qtensor(attention_wv)?,
attention_wo: QMatMul::from_qtensor(attention_wo)?,
attention_norm: RmsNorm::from_qtensor(attention_norm, 1e-5)?,
mlp_or_moe,
ffn_norm: RmsNorm::from_qtensor(ffn_norm, 1e-5)?,
n_head: ct.hparams.n_head as usize,
n_kv_head: ct.hparams.n_head as usize / gqa,
head_dim: (ct.hparams.n_embd / ct.hparams.n_head) as usize,
cos: cos.clone(),
sin: sin.clone(),
neg_inf: neg_inf.clone(),
kv_cache: None,
span_attn,
span_rot,
span_mlp,
})
}
let span = tracing::span!(tracing::Level::TRACE, "model");
let span_output = tracing::span!(tracing::Level::TRACE, "output");
Ok(Self {
tok_embeddings: Embedding::new(tok_embeddings, ct.hparams.n_embd as usize),
layers,
norm,
output: QMatMul::from_qtensor(output)?,
masks: HashMap::new(),
span,
span_output,
})
}
pub fn from_gguf<R: std::io::Seek + std::io::Read>(
ct: gguf_file::Content,
reader: &mut R,
device: &Device,
) -> Result<Self> {
let md_get = |s: &str| match ct.metadata.get(s) {
None => candle::bail!("cannot find {s} in metadata"),
Some(v) => Ok(v),
};
// Parameter extraction from metadata.
let n_expert = md_get("llama.expert_count")
.and_then(|v| v.to_u32())
.unwrap_or(0) as usize;
let n_expert_used = md_get("llama.expert_used_count")
.and_then(|v| v.to_u32())
.unwrap_or(0) as usize;
let head_count = md_get("llama.attention.head_count")?.to_u32()? as usize;
let head_count_kv = md_get("llama.attention.head_count_kv")?.to_u32()? as usize;
let block_count = md_get("llama.block_count")?.to_u32()? as usize;
let embedding_length = md_get("llama.embedding_length")?.to_u32()? as usize;
let rope_dim = md_get("llama.rope.dimension_count")?.to_u32()? as usize;
// Strangely this value is generally 1e-6 in GGUF file but used to be 1e-5 by default.
let rms_norm_eps = md_get("llama.attention.layer_norm_rms_epsilon")?.to_f32()? as f64;
let rope_freq_base = md_get("llama.rope.freq_base")
.and_then(|m| m.to_f32())
.unwrap_or(10000f32);
let (cos, sin) = precomput_freqs_cis(rope_dim, rope_freq_base, device)?;
let neg_inf = Tensor::new(f32::NEG_INFINITY, device)?;
let tok_embeddings_q = ct.tensor(reader, "token_embd.weight", device)?;
let tok_embeddings = tok_embeddings_q.dequantize(device)?;
let norm = RmsNorm::from_qtensor(
ct.tensor(reader, "output_norm.weight", device)?,
rms_norm_eps,
)?;
let output = match ct.tensor(reader, "output.weight", device) {
Ok(tensor) => tensor,
Err(_) => tok_embeddings_q,
};
let mut layers = Vec::with_capacity(block_count);
for layer_idx in 0..block_count {
let prefix = format!("blk.{layer_idx}");
let attention_wq = ct.tensor(reader, &format!("{prefix}.attn_q.weight"), device)?;
let attention_wk = ct.tensor(reader, &format!("{prefix}.attn_k.weight"), device)?;
let attention_wv = ct.tensor(reader, &format!("{prefix}.attn_v.weight"), device)?;
let attention_wo =
ct.tensor(reader, &format!("{prefix}.attn_output.weight"), device)?;
let mlp_or_moe = if n_expert <= 1 {
let feed_forward_w1 =
ct.tensor(reader, &format!("{prefix}.ffn_gate.weight"), device)?;
let feed_forward_w2 =
ct.tensor(reader, &format!("{prefix}.ffn_down.weight"), device)?;
let feed_forward_w3 =
ct.tensor(reader, &format!("{prefix}.ffn_up.weight"), device)?;
MlpOrMoe::Mlp(Mlp {
feed_forward_w1: QMatMul::from_qtensor(feed_forward_w1)?,
feed_forward_w2: QMatMul::from_qtensor(feed_forward_w2)?,
feed_forward_w3: QMatMul::from_qtensor(feed_forward_w3)?,
})
} else {
let feed_forward_gate_inp =
ct.tensor(reader, &format!("{prefix}.ffn_gate_inp.weight"), device)?;
let mut experts = Vec::with_capacity(n_expert);
for i in 0..n_expert {
let feed_forward_w1 =
ct.tensor(reader, &format!("{prefix}.ffn_gate.{i}.weight"), device)?;
let feed_forward_w2 =
ct.tensor(reader, &format!("{prefix}.ffn_down.{i}.weight"), device)?;
let feed_forward_w3 =
ct.tensor(reader, &format!("{prefix}.ffn_up.{i}.weight"), device)?;
experts.push(Mlp {
feed_forward_w1: QMatMul::from_qtensor(feed_forward_w1)?,
feed_forward_w2: QMatMul::from_qtensor(feed_forward_w2)?,
feed_forward_w3: QMatMul::from_qtensor(feed_forward_w3)?,
})
}
MlpOrMoe::MoE {
n_expert_used,
feed_forward_gate_inp: QMatMul::from_qtensor(feed_forward_gate_inp)?,
experts,
}
};
let attention_norm =
ct.tensor(reader, &format!("{prefix}.attn_norm.weight"), device)?;
let ffn_norm = ct.tensor(reader, &format!("{prefix}.ffn_norm.weight"), device)?;
let span_attn = tracing::span!(tracing::Level::TRACE, "attn");
let span_rot = tracing::span!(tracing::Level::TRACE, "attn-rot");
let span_mlp = tracing::span!(tracing::Level::TRACE, "attn-mlp");
layers.push(LayerWeights {
attention_wq: QMatMul::from_qtensor(attention_wq)?,
attention_wk: QMatMul::from_qtensor(attention_wk)?,
attention_wv: QMatMul::from_qtensor(attention_wv)?,
attention_wo: QMatMul::from_qtensor(attention_wo)?,
attention_norm: RmsNorm::from_qtensor(attention_norm, rms_norm_eps)?,
mlp_or_moe,
ffn_norm: RmsNorm::from_qtensor(ffn_norm, rms_norm_eps)?,
n_head: head_count,
n_kv_head: head_count_kv,
head_dim: embedding_length / head_count,
cos: cos.clone(),
sin: sin.clone(),
neg_inf: neg_inf.clone(),
kv_cache: None,
span_attn,
span_rot,
span_mlp,
})
}
let span = tracing::span!(tracing::Level::TRACE, "model");
let span_output = tracing::span!(tracing::Level::TRACE, "output");
Ok(Self {
tok_embeddings: Embedding::new(tok_embeddings, embedding_length),
layers,
norm,
output: QMatMul::from_qtensor(output)?,
masks: HashMap::new(),
span,
span_output,
})
}
fn mask(&mut self, t: usize, device: &Device) -> Result<Tensor> {
if let Some(mask) = self.masks.get(&t) {
Ok(mask.clone())
} else {
let mask: Vec<_> = (0..t)
.flat_map(|i| (0..t).map(move |j| u8::from(j > i)))
.collect();
let mask = Tensor::from_slice(&mask, (t, t), device)?;
self.masks.insert(t, mask.clone());
Ok(mask)
}
}
pub fn forward(&mut self, x: &Tensor, index_pos: usize) -> Result<Tensor> {
let (_b_sz, seq_len) = x.dims2()?;
let mask = if seq_len == 1 {
None
} else {
Some(self.mask(seq_len, x.device())?)
};
let _enter = self.span.enter();
let mut layer_in = self.tok_embeddings.forward(x)?;
for layer in self.layers.iter_mut() {
let x = layer_in;
let residual = &x;
let x = layer.attention_norm.forward(&x)?;
let attn = layer.forward_attn(&x, mask.as_ref(), index_pos)?;
let x = (attn + residual)?;
// MLP
let _enter = layer.span_mlp.enter();
let residual = &x;
let x = layer.ffn_norm.forward(&x)?;
let x = layer.mlp_or_moe.forward(&x)?;
let x = (x + residual)?;
layer_in = x
}
let x = self.norm.forward(&layer_in)?;
let x = x.i((.., seq_len - 1, ..))?;
let _enter = self.span_output.enter();
self.output.forward(&x)
}
}
| 8 |
0 | hf_public_repos/candle/candle-transformers/src | hf_public_repos/candle/candle-transformers/src/models/encodec.rs | //! EnCodec neural audio codec based on the Encodec implementation.
//!
//! See ["High Fidelity Neural Audio Compression"](https://arxiv.org/abs/2210.13438)
//!
//! Based on implementation from [huggingface/transformers](https://github.com/huggingface/transformers/blob/main/src/transformers/models/encodec/modeling_encodec.py)
use candle::{DType, IndexOp, Layout, Module, Result, Shape, Tensor, D};
use candle_nn::{conv1d, Conv1d, ConvTranspose1d, VarBuilder};
// Encodec Model
// https://github.com/huggingface/transformers/blob/main/src/transformers/models/encodec/modeling_encodec.py
#[derive(Debug, Copy, Clone, PartialEq, Eq, serde::Deserialize)]
pub enum NormType {
WeightNorm,
TimeGroupNorm,
None,
}
#[derive(Debug, Copy, Clone, PartialEq, Eq, serde::Deserialize)]
pub enum PadMode {
Constant,
Reflect,
Replicate,
}
#[derive(Debug, Clone, PartialEq, serde::Deserialize)]
pub struct Config {
pub target_bandwidths: Vec<f64>,
pub sampling_rate: usize,
pub audio_channels: usize,
pub normalize: bool,
pub chunk_length_s: Option<usize>,
pub overlap: Option<usize>,
pub hidden_size: usize,
pub num_filters: usize,
pub num_residual_layers: usize,
pub upsampling_ratios: Vec<usize>,
pub norm_type: NormType,
pub kernel_size: usize,
pub last_kernel_size: usize,
pub residual_kernel_size: usize,
pub dilation_growth_rate: usize,
pub use_causal_conv: bool,
pub pad_mode: PadMode,
pub compress: usize,
pub num_lstm_layers: usize,
pub trim_right_ratio: f64,
pub codebook_size: usize,
pub codebook_dim: Option<usize>,
pub use_conv_shortcut: bool,
}
impl Default for Config {
fn default() -> Self {
Self {
target_bandwidths: vec![1.5, 3.0, 6.0, 12.0, 24.0],
sampling_rate: 24_000,
audio_channels: 1,
normalize: false,
chunk_length_s: None,
overlap: None,
hidden_size: 128,
num_filters: 32,
num_residual_layers: 1,
upsampling_ratios: vec![8, 5, 4, 2],
norm_type: NormType::WeightNorm,
kernel_size: 7,
last_kernel_size: 7,
residual_kernel_size: 3,
dilation_growth_rate: 2,
use_causal_conv: true,
// This should be PadMode::Reflect which is currently unsupported in candle.
pad_mode: PadMode::Replicate,
compress: 2,
num_lstm_layers: 2,
trim_right_ratio: 1.0,
codebook_size: 1024,
codebook_dim: None,
use_conv_shortcut: true,
}
}
}
impl Config {
fn codebook_dim(&self) -> usize {
self.codebook_dim.unwrap_or(self.hidden_size)
}
fn frame_rate(&self) -> usize {
let hop_length: usize = self.upsampling_ratios.iter().product();
self.sampling_rate.div_ceil(hop_length)
}
fn num_quantizers(&self) -> usize {
let num = 1000f64
* self
.target_bandwidths
.last()
.expect("empty target_bandwidths");
(num as usize) / (self.frame_rate() * 10)
}
}
fn get_extra_padding_for_conv1d(
xs: &Tensor,
k_size: usize,
stride: usize,
padding_total: usize,
) -> Result<usize> {
let len = xs.dim(D::Minus1)?;
let n_frames = (len + padding_total).saturating_sub(k_size) as f64 / stride as f64 + 1.0;
let ideal_len =
((n_frames.ceil() as usize - 1) * stride + k_size).saturating_sub(padding_total);
Ok(ideal_len.saturating_sub(len))
}
fn pad1d(xs: &Tensor, pad_l: usize, pad_r: usize, mode: PadMode) -> Result<Tensor> {
match mode {
PadMode::Constant => xs.pad_with_zeros(D::Minus1, pad_l, pad_r),
PadMode::Reflect => candle::bail!("pad-mode 'reflect' is not supported"),
PadMode::Replicate => xs.pad_with_same(D::Minus1, pad_l, pad_r),
}
}
// Applies weight norm for inference by recomputing the weight tensor. This
// does not apply to training.
// https://pytorch.org/docs/stable/generated/torch.nn.utils.weight_norm.html
pub fn conv1d_weight_norm(
in_c: usize,
out_c: usize,
kernel_size: usize,
config: candle_nn::Conv1dConfig,
vb: VarBuilder,
) -> Result<Conv1d> {
let weight_g = vb.get((out_c, 1, 1), "weight_g")?;
let weight_v = vb.get((out_c, in_c, kernel_size), "weight_v")?;
let norm_v = weight_v.sqr()?.sum_keepdim((1, 2))?.sqrt()?;
let weight = weight_v.broadcast_mul(&weight_g)?.broadcast_div(&norm_v)?;
let bias = vb.get(out_c, "bias")?;
Ok(Conv1d::new(weight, Some(bias), config))
}
pub fn conv_transpose1d_weight_norm(
in_c: usize,
out_c: usize,
kernel_size: usize,
bias: bool,
config: candle_nn::ConvTranspose1dConfig,
vb: VarBuilder,
) -> Result<ConvTranspose1d> {
let weight_g = vb.get((in_c, 1, 1), "weight_g")?;
let weight_v = vb.get((in_c, out_c, kernel_size), "weight_v")?;
let norm_v = weight_v.sqr()?.sum_keepdim((1, 2))?.sqrt()?;
let weight = weight_v.broadcast_mul(&weight_g)?.broadcast_div(&norm_v)?;
let bias = if bias {
Some(vb.get(out_c, "bias")?)
} else {
None
};
Ok(ConvTranspose1d::new(weight, bias, config))
}
struct CodebookEncode;
impl candle::CustomOp2 for CodebookEncode {
fn name(&self) -> &'static str {
"cb"
}
fn cpu_fwd(
&self,
lhs_storage: &candle::CpuStorage,
lhs_layout: &Layout,
rhs_storage: &candle::CpuStorage,
rhs_layout: &Layout,
) -> Result<(candle::CpuStorage, Shape)> {
use rayon::prelude::*;
let (lhs_dim1, lhs_dim2) = lhs_layout.shape().dims2()?;
let (rhs_dim1, rhs_dim2) = rhs_layout.shape().dims2()?;
if lhs_dim2 != rhs_dim2 {
candle::bail!("CodebookEncode, mismatch on last dim, {lhs_layout:?} {rhs_layout:?}");
}
if lhs_dim2 == 0 {
candle::bail!("CodebookEncode, empty last dim {lhs_layout:?}")
}
let lhs = match lhs_layout.contiguous_offsets() {
None => candle::bail!("CodebookEncode, lhs has to be contiguous, got {lhs_layout:?}"),
Some((o1, o2)) => {
let slice = lhs_storage.as_slice::<f32>()?;
&slice[o1..o2]
}
};
let rhs = match rhs_layout.contiguous_offsets() {
None => candle::bail!("CodebookEncode, rhs has to be contiguous, got {rhs_layout:?}"),
Some((o1, o2)) => {
let slice = rhs_storage.as_slice::<f32>()?;
&slice[o1..o2]
}
};
let dst = (0..lhs_dim1)
.into_par_iter()
.map(|idx1| {
let mut where_min = 0;
let mut min_dist = f32::INFINITY;
let lhs = &lhs[idx1 * lhs_dim2..(idx1 + 1) * lhs_dim2];
for idx2 in 0..rhs_dim1 {
let rhs = &rhs[idx2 * rhs_dim2..(idx2 + 1) * rhs_dim2];
let mut dist = 0f32;
for (a, b) in lhs.iter().zip(rhs.iter()) {
dist += (a - b) * (a - b)
}
if dist < min_dist {
min_dist = dist;
where_min = idx2;
}
}
where_min as u32
})
.collect();
let storage = candle::WithDType::to_cpu_storage_owned(dst);
Ok((storage, (lhs_dim1,).into()))
}
}
// https://github.com/huggingface/transformers/blob/abaca9f9432a84cfaa95531de4c72334f38a42f2/src/transformers/models/encodec/modeling_encodec.py#L340
#[allow(unused)]
#[derive(Clone, Debug)]
pub struct EuclideanCodebook {
inited: Tensor,
cluster_size: Tensor,
embed: candle_nn::Embedding,
embed_avg: Tensor,
c2: Tensor,
}
impl EuclideanCodebook {
pub fn new(cfg: &Config, vb: VarBuilder) -> Result<Self> {
let inited = vb.get(1, "inited")?;
let cluster_size = vb.get(cfg.codebook_size, "cluster_size")?;
let e_shape = (cfg.codebook_size, cfg.codebook_dim());
let embed = vb.get(e_shape, "embed")?;
let c2 = ((&embed * &embed)?.sum(D::Minus1)? / 2.0)?;
let embed_avg = vb.get(e_shape, "embed_avg")?;
Ok(Self {
inited,
cluster_size,
embed: candle_nn::Embedding::new(embed, cfg.codebook_dim()),
embed_avg,
c2,
})
}
pub fn encode_slow(&self, xs: &Tensor) -> Result<Tensor> {
let mut target_shape = xs.dims().to_vec();
target_shape.pop();
let xs = xs.flatten_to(D::Minus2)?;
let _ = xs.dims2()?;
let dot_prod = xs.matmul(&self.embed.embeddings().t()?)?;
let codes = self.c2.broadcast_sub(&dot_prod)?.argmin(D::Minus1)?;
codes.reshape(target_shape)
}
pub fn encode(&self, xs: &Tensor) -> Result<Tensor> {
let mut target_shape = xs.dims().to_vec();
target_shape.pop();
let xs = xs.flatten_to(D::Minus2)?;
let _ = xs.dims2()?;
let codes = Tensor::apply_op2(&xs, self.embed.embeddings(), CodebookEncode)?;
codes.reshape(target_shape)
}
pub fn decode(&self, embed_ind: &Tensor) -> Result<Tensor> {
let quantize = self.embed.forward(embed_ind)?;
Ok(quantize)
}
}
#[derive(Clone, Debug)]
pub struct VectorQuantization {
codebook: EuclideanCodebook,
}
impl VectorQuantization {
pub fn new(cfg: &Config, vb: VarBuilder) -> Result<Self> {
let codebook = EuclideanCodebook::new(cfg, vb.pp("codebook"))?;
Ok(Self { codebook })
}
pub fn encode(&self, xs: &Tensor) -> Result<Tensor> {
let xs = xs.transpose(1, 2)?;
self.codebook.encode_slow(&xs)
}
pub fn decode(&self, embed_ind: &Tensor) -> Result<Tensor> {
let quantize = self.codebook.decode(embed_ind)?;
let quantize = quantize.transpose(1, 2)?;
Ok(quantize)
}
}
#[derive(Clone, Debug)]
pub struct ResidualVectorQuantizer {
layers: Vec<VectorQuantization>,
dtype: DType,
}
impl ResidualVectorQuantizer {
pub fn new(cfg: &Config, vb: VarBuilder) -> Result<Self> {
let vb = &vb.pp("layers");
let layers = (0..cfg.num_quantizers())
.map(|i| VectorQuantization::new(cfg, vb.pp(i)))
.collect::<Result<Vec<_>>>()?;
Ok(Self {
layers,
dtype: vb.dtype(),
})
}
pub fn encode(&self, xs: &Tensor) -> Result<Tensor> {
let mut codes = Vec::with_capacity(self.layers.len());
let mut residual = xs.clone();
for layer in self.layers.iter() {
let indices = layer.encode(&residual)?;
let quantized = layer.decode(&indices)?;
residual = (residual - quantized)?;
codes.push(indices)
}
Tensor::stack(&codes, 0)
}
pub fn decode(&self, codes: &Tensor) -> Result<Tensor> {
let mut quantized_out = Tensor::zeros((), self.dtype, codes.device())?;
let ncodes = codes.dim(0)?;
if ncodes > self.layers.len() {
candle::bail!(
"codes shape {:?} does not match the number of quantization layers {}",
codes.shape(),
self.layers.len()
)
}
for (i, layer) in self.layers.iter().take(ncodes).enumerate() {
let quantized = layer.decode(&codes.i(i)?)?;
quantized_out = quantized.broadcast_add(&quantized_out)?;
}
Ok(quantized_out)
}
}
// https://github.com/huggingface/transformers/blob/abaca9f9432a84cfaa95531de4c72334f38a42f2/src/transformers/models/encodec/modeling_encodec.py#L226
#[derive(Clone, Debug)]
pub struct EncodecLSTM {
layers: Vec<candle_nn::LSTM>,
}
impl EncodecLSTM {
pub fn new(dim: usize, cfg: &Config, vb: VarBuilder) -> Result<Self> {
let vb = &vb.pp("lstm");
let mut layers = vec![];
for layer_idx in 0..cfg.num_lstm_layers {
let config = candle_nn::LSTMConfig {
layer_idx,
..Default::default()
};
let lstm = candle_nn::lstm(dim, dim, config, vb.clone())?;
layers.push(lstm)
}
Ok(Self { layers })
}
}
impl Module for EncodecLSTM {
fn forward(&self, xs: &Tensor) -> Result<Tensor> {
use candle_nn::RNN;
// This is different from the Python transformers version as candle LSTM is batch first.
let xs = xs.t()?;
let residual = &xs;
let mut xs = xs.clone();
for layer in self.layers.iter() {
let states = layer.seq(&xs)?;
xs = layer.states_to_tensor(&states)?;
}
let xs = (xs + residual)?.t()?;
Ok(xs)
}
}
#[derive(Clone, Debug)]
pub struct EncodecConvTranspose1d {
conv: ConvTranspose1d,
}
impl EncodecConvTranspose1d {
fn new(
in_c: usize,
out_c: usize,
k: usize,
stride: usize,
_cfg: &Config,
vb: VarBuilder,
) -> Result<Self> {
let cfg = candle_nn::ConvTranspose1dConfig {
stride,
..Default::default()
};
let conv = conv_transpose1d_weight_norm(in_c, out_c, k, true, cfg, vb.pp("conv"))?;
Ok(Self { conv })
}
}
impl Module for EncodecConvTranspose1d {
fn forward(&self, xs: &Tensor) -> Result<Tensor> {
xs.apply(&self.conv)
}
}
#[derive(Clone, Debug)]
pub struct EncodecConv1d {
causal: bool,
conv: Conv1d,
norm: Option<candle_nn::GroupNorm>,
pad_mode: PadMode,
}
impl EncodecConv1d {
pub fn new(
in_c: usize,
out_c: usize,
kernel_size: usize,
stride: usize,
dilation: usize,
cfg: &Config,
vb: VarBuilder,
) -> Result<Self> {
let conv = match cfg.norm_type {
NormType::WeightNorm => conv1d_weight_norm(
in_c,
out_c,
kernel_size,
candle_nn::Conv1dConfig {
stride,
dilation,
..Default::default()
},
vb.pp("conv"),
)?,
NormType::None | NormType::TimeGroupNorm => conv1d(
in_c,
out_c,
kernel_size,
candle_nn::Conv1dConfig {
padding: 0,
stride,
groups: 1,
dilation: 1,
},
vb.pp("conv"),
)?,
};
let norm = match cfg.norm_type {
NormType::None | NormType::WeightNorm => None,
NormType::TimeGroupNorm => {
let gn = candle_nn::group_norm(1, out_c, 1e-5, vb.pp("norm"))?;
Some(gn)
}
};
Ok(Self {
causal: cfg.use_causal_conv,
conv,
norm,
pad_mode: cfg.pad_mode,
})
}
}
impl Module for EncodecConv1d {
fn forward(&self, xs: &Tensor) -> Result<Tensor> {
let (_b, _t, _c) = xs.dims3()?;
let k_size = self.conv.weight().dim(D::Minus1)?;
let conv_cfg = self.conv.config();
// Effective kernel size with dilations.
let k_size = (k_size - 1) * conv_cfg.dilation + 1;
let padding_total = k_size - conv_cfg.stride;
let extra_padding =
get_extra_padding_for_conv1d(xs, k_size, conv_cfg.stride, padding_total)?;
let xs = if self.causal {
pad1d(xs, padding_total, extra_padding, self.pad_mode)?
} else {
let padding_right = padding_total / 2;
let padding_left = padding_total - padding_right;
pad1d(
xs,
padding_left,
padding_right + extra_padding,
self.pad_mode,
)?
};
let xs = self.conv.forward(&xs)?;
match &self.norm {
None => Ok(xs),
Some(norm) => xs.apply(norm),
}
}
}
#[derive(Clone, Debug)]
pub struct EncodecResnetBlock {
block_conv1: EncodecConv1d,
block_conv2: EncodecConv1d,
shortcut: Option<EncodecConv1d>,
}
impl EncodecResnetBlock {
pub fn new(
dim: usize,
(dilation1, dilation2): (usize, usize),
cfg: &Config,
vb: VarBuilder,
) -> Result<Self> {
let h = dim / cfg.compress;
let mut layer = Layer::new(vb.pp("block"));
// TODO: Apply dilations!
layer.inc();
let block_conv1 = EncodecConv1d::new(
dim,
h,
cfg.residual_kernel_size,
1,
dilation1,
cfg,
layer.next(),
)?;
layer.inc();
let block_conv2 = EncodecConv1d::new(h, dim, 1, 1, dilation2, cfg, layer.next())?;
let shortcut = if cfg.use_conv_shortcut {
let conv = EncodecConv1d::new(dim, dim, 1, 1, 1, cfg, vb.pp("shortcut"))?;
Some(conv)
} else {
None
};
Ok(Self {
block_conv1,
block_conv2,
shortcut,
})
}
}
impl Module for EncodecResnetBlock {
fn forward(&self, xs: &Tensor) -> Result<Tensor> {
let residual = xs.clone();
let xs = xs.elu(1.)?;
let xs = self.block_conv1.forward(&xs)?;
let xs = xs.elu(1.)?;
let xs = self.block_conv2.forward(&xs)?;
let xs = match &self.shortcut {
None => (xs + residual)?,
Some(shortcut) => xs.add(&shortcut.forward(&residual)?)?,
};
Ok(xs)
}
}
struct Layer<'a> {
vb: VarBuilder<'a>,
cnt: usize,
}
impl<'a> Layer<'a> {
fn new(vb: VarBuilder<'a>) -> Self {
Self { vb, cnt: 0 }
}
fn inc(&mut self) {
self.cnt += 1;
}
fn next(&mut self) -> VarBuilder {
let vb = self.vb.pp(self.cnt.to_string());
self.cnt += 1;
vb
}
}
#[derive(Clone, Debug)]
pub struct Encoder {
init_conv: EncodecConv1d,
sampling_layers: Vec<(Vec<EncodecResnetBlock>, EncodecConv1d)>,
final_lstm: EncodecLSTM,
final_conv: EncodecConv1d,
}
impl Encoder {
pub fn new(cfg: &Config, vb: VarBuilder) -> Result<Self> {
let mut layer = Layer::new(vb.pp("layers"));
let init_conv = EncodecConv1d::new(
cfg.audio_channels,
cfg.num_filters,
cfg.kernel_size,
1,
1,
cfg,
layer.next(),
)?;
let mut sampling_layers = vec![];
let mut scaling = 1;
for &ratio in cfg.upsampling_ratios.iter().rev() {
let current_scale = scaling * cfg.num_filters;
let mut resnets = vec![];
for j in 0..(cfg.num_residual_layers as u32) {
let resnet = EncodecResnetBlock::new(
current_scale,
(cfg.dilation_growth_rate.pow(j), 1),
cfg,
layer.next(),
)?;
resnets.push(resnet)
}
layer.inc(); // ELU
let conv1d = EncodecConv1d::new(
current_scale,
current_scale * 2,
ratio * 2,
ratio,
1,
cfg,
layer.next(),
)?;
sampling_layers.push((resnets, conv1d));
scaling *= 2;
}
let final_lstm = EncodecLSTM::new(cfg.num_filters * scaling, cfg, layer.next())?;
layer.inc(); // ELU
let final_conv = EncodecConv1d::new(
cfg.num_filters * scaling,
cfg.hidden_size,
cfg.last_kernel_size,
1,
1,
cfg,
layer.next(),
)?;
Ok(Self {
init_conv,
sampling_layers,
final_conv,
final_lstm,
})
}
}
impl Module for Encoder {
fn forward(&self, xs: &Tensor) -> Result<Tensor> {
let mut xs = xs.apply(&self.init_conv)?;
for (resnets, conv) in self.sampling_layers.iter() {
for resnet in resnets.iter() {
xs = xs.apply(resnet)?;
}
xs = xs.elu(1.0)?.apply(conv)?;
}
xs.apply(&self.final_lstm)?
.elu(1.0)?
.apply(&self.final_conv)
}
}
#[derive(Clone, Debug)]
pub struct Decoder {
init_conv: EncodecConv1d,
init_lstm: EncodecLSTM,
sampling_layers: Vec<(EncodecConvTranspose1d, Vec<EncodecResnetBlock>)>,
final_conv: EncodecConv1d,
}
impl Decoder {
pub fn new(cfg: &Config, vb: VarBuilder) -> Result<Self> {
let mut layer = Layer::new(vb.pp("layers"));
let mut scaling = usize::pow(2, cfg.upsampling_ratios.len() as u32);
let init_conv = EncodecConv1d::new(
cfg.hidden_size,
cfg.num_filters * scaling,
cfg.last_kernel_size,
1,
1,
cfg,
layer.next(),
)?;
let init_lstm = EncodecLSTM::new(cfg.num_filters * scaling, cfg, layer.next())?;
let mut sampling_layers = vec![];
for &ratio in cfg.upsampling_ratios.iter() {
let current_scale = scaling * cfg.num_filters;
layer.inc(); // ELU
let conv1d = EncodecConvTranspose1d::new(
current_scale,
current_scale / 2,
ratio * 2,
ratio,
cfg,
layer.next(),
)?;
let mut resnets = vec![];
for j in 0..(cfg.num_residual_layers as u32) {
let resnet = EncodecResnetBlock::new(
current_scale / 2,
(cfg.dilation_growth_rate.pow(j), 1),
cfg,
layer.next(),
)?;
resnets.push(resnet)
}
sampling_layers.push((conv1d, resnets));
scaling /= 2;
}
layer.inc(); // ELU
let final_conv = EncodecConv1d::new(
cfg.num_filters,
cfg.audio_channels,
cfg.last_kernel_size,
1,
1,
cfg,
layer.next(),
)?;
Ok(Self {
init_conv,
init_lstm,
sampling_layers,
final_conv,
})
}
}
impl Module for Decoder {
fn forward(&self, xs: &Tensor) -> Result<Tensor> {
let mut xs = xs.apply(&self.init_conv)?.apply(&self.init_lstm)?;
for (conv, resnets) in self.sampling_layers.iter() {
xs = xs.elu(1.)?.apply(conv)?;
for resnet in resnets.iter() {
xs = xs.apply(resnet)?
}
}
xs.elu(1.)?.apply(&self.final_conv)
}
}
#[derive(Debug)]
pub struct Model {
encoder: Encoder,
decoder: Decoder,
quantizer: ResidualVectorQuantizer,
}
impl Model {
pub fn new(cfg: &Config, vb: VarBuilder) -> Result<Self> {
let encoder = Encoder::new(cfg, vb.pp("encoder"))?;
let decoder = Decoder::new(cfg, vb.pp("decoder"))?;
let quantizer = ResidualVectorQuantizer::new(cfg, vb.pp("quantizer"))?;
Ok(Self {
encoder,
decoder,
quantizer,
})
}
pub fn encode(&self, xs: &Tensor) -> Result<Tensor> {
let xs = self.encoder.forward(xs)?;
let codes = self.quantizer.encode(&xs)?;
codes.transpose(0, 1)
}
pub fn decode(&self, codes: &Tensor) -> Result<Tensor> {
let (_b_sz, _codebooks, _seqlen) = codes.dims3()?;
let codes = codes.transpose(0, 1)?;
let embeddings = self.quantizer.decode(&codes)?;
let outputs = self.decoder.forward(&embeddings)?;
Ok(outputs)
}
}
| 9 |
0 | hf_public_repos/candle/candle-examples/examples | hf_public_repos/candle/candle-examples/examples/segment-anything/main.rs | //! SAM: Segment Anything Model
//! https://github.com/facebookresearch/segment-anything
#[cfg(feature = "mkl")]
extern crate intel_mkl_src;
#[cfg(feature = "accelerate")]
extern crate accelerate_src;
use candle::DType;
use candle_nn::VarBuilder;
use candle_transformers::models::segment_anything::sam;
use clap::Parser;
#[derive(Parser)]
struct Args {
#[arg(long)]
model: Option<String>,
#[arg(long)]
image: String,
/// Run on CPU rather than on GPU.
#[arg(long)]
cpu: bool,
#[arg(long)]
generate_masks: bool,
/// List of x,y coordinates, between 0 and 1 (0.5 is at the middle of the image). These points
/// should be part of the generated mask.
#[arg(long)]
point: Vec<String>,
/// List of x,y coordinates, between 0 and 1 (0.5 is at the middle of the image). These points
/// should not be part of the generated mask and should be part of the background instead.
#[arg(long)]
neg_point: Vec<String>,
/// The detection threshold for the mask, 0 is the default value, negative values mean a larger
/// mask, positive makes the mask more selective.
#[arg(long, allow_hyphen_values = true, default_value_t = 0.)]
threshold: f32,
/// Enable tracing (generates a trace-timestamp.json file).
#[arg(long)]
tracing: bool,
/// Use the TinyViT based models from MobileSAM
#[arg(long)]
use_tiny: bool,
}
pub fn main() -> anyhow::Result<()> {
use tracing_chrome::ChromeLayerBuilder;
use tracing_subscriber::prelude::*;
let args = Args::parse();
let _guard = if args.tracing {
let (chrome_layer, guard) = ChromeLayerBuilder::new().build();
tracing_subscriber::registry().with(chrome_layer).init();
Some(guard)
} else {
None
};
let device = candle_examples::device(args.cpu)?;
let (image, initial_h, initial_w) =
candle_examples::load_image(&args.image, Some(sam::IMAGE_SIZE))?;
let image = image.to_device(&device)?;
println!("loaded image {image:?}");
let model = match args.model {
Some(model) => std::path::PathBuf::from(model),
None => {
let api = hf_hub::api::sync::Api::new()?;
let api = api.model("lmz/candle-sam".to_string());
let filename = if args.use_tiny {
"mobile_sam-tiny-vitt.safetensors"
} else {
"sam_vit_b_01ec64.safetensors"
};
api.get(filename)?
}
};
let vb = unsafe { VarBuilder::from_mmaped_safetensors(&[model], DType::F32, &device)? };
let sam = if args.use_tiny {
sam::Sam::new_tiny(vb)? // tiny vit_t
} else {
sam::Sam::new(768, 12, 12, &[2, 5, 8, 11], vb)? // sam_vit_b
};
if args.generate_masks {
// Default options similar to the Python version.
let bboxes = sam.generate_masks(
&image,
/* points_per_side */ 32,
/* crop_n_layer */ 0,
/* crop_overlap_ratio */ 512. / 1500.,
/* crop_n_points_downscale_factor */ 1,
)?;
for (idx, bbox) in bboxes.iter().enumerate() {
println!("{idx} {bbox:?}");
let mask = (&bbox.data.to_dtype(DType::U8)? * 255.)?;
let (h, w) = mask.dims2()?;
let mask = mask.broadcast_as((3, h, w))?;
candle_examples::save_image_resize(
&mask,
format!("sam_mask{idx}.png"),
initial_h,
initial_w,
)?;
}
} else {
let iter_points = args.point.iter().map(|p| (p, true));
let iter_neg_points = args.neg_point.iter().map(|p| (p, false));
let points = iter_points
.chain(iter_neg_points)
.map(|(point, b)| {
use std::str::FromStr;
let xy = point.split(',').collect::<Vec<_>>();
if xy.len() != 2 {
anyhow::bail!("expected format for points is 0.4,0.2")
}
Ok((f64::from_str(xy[0])?, f64::from_str(xy[1])?, b))
})
.collect::<anyhow::Result<Vec<_>>>()?;
let start_time = std::time::Instant::now();
let (mask, iou_predictions) = sam.forward(&image, &points, false)?;
println!(
"mask generated in {:.2}s",
start_time.elapsed().as_secs_f32()
);
println!("mask:\n{mask}");
println!("iou_predictions: {iou_predictions}");
let mask = (mask.ge(args.threshold)? * 255.)?;
let (_one, h, w) = mask.dims3()?;
let mask = mask.expand((3, h, w))?;
let mut img = image::ImageReader::open(&args.image)?
.decode()
.map_err(candle::Error::wrap)?;
let mask_pixels = mask.permute((1, 2, 0))?.flatten_all()?.to_vec1::<u8>()?;
let mask_img: image::ImageBuffer<image::Rgb<u8>, Vec<u8>> =
match image::ImageBuffer::from_raw(w as u32, h as u32, mask_pixels) {
Some(image) => image,
None => anyhow::bail!("error saving merged image"),
};
let mask_img = image::DynamicImage::from(mask_img).resize_to_fill(
img.width(),
img.height(),
image::imageops::FilterType::CatmullRom,
);
for x in 0..img.width() {
for y in 0..img.height() {
let mask_p = imageproc::drawing::Canvas::get_pixel(&mask_img, x, y);
if mask_p.0[0] > 100 {
let mut img_p = imageproc::drawing::Canvas::get_pixel(&img, x, y);
img_p.0[2] = 255 - (255 - img_p.0[2]) / 2;
img_p.0[1] /= 2;
img_p.0[0] /= 2;
imageproc::drawing::Canvas::draw_pixel(&mut img, x, y, img_p)
}
}
}
for (x, y, b) in points {
let x = (x * img.width() as f64) as i32;
let y = (y * img.height() as f64) as i32;
let color = if b {
image::Rgba([255, 0, 0, 200])
} else {
image::Rgba([0, 255, 0, 200])
};
imageproc::drawing::draw_filled_circle_mut(&mut img, (x, y), 3, color);
}
img.save("sam_merged.jpg")?
}
Ok(())
}
| 0 |
0 | hf_public_repos/candle/candle-examples/examples | hf_public_repos/candle/candle-examples/examples/segment-anything/README.md | # candle-segment-anything: Segment-Anything Model
This example is based on Meta AI [Segment-Anything
Model](https://github.com/facebookresearch/segment-anything). This model
provides a robust and fast image segmentation pipeline that can be tweaked via
some prompting (requesting some points to be in the target mask, requesting some
points to be part of the background so _not_ in the target mask, specifying some
bounding box).
The default backbone can be replaced by the smaller and faster TinyViT model
based on [MobileSAM](https://github.com/ChaoningZhang/MobileSAM).
## Running some example.
```bash
cargo run --example segment-anything --release -- \
--image candle-examples/examples/yolo-v8/assets/bike.jpg
--use-tiny
--point 0.6,0.6 --point 0.6,0.55
```
Running this command generates a `sam_merged.jpg` file containing the original
image with a blue overlay of the selected mask. The red dots represent the prompt
specified by `--point 0.6,0.6 --point 0.6,0.55`, this prompt is assumed to be part
of the target mask.
The values used for `--point` should be a comma delimited pair of float values.
They are proportional to the image dimension, i.e. use 0.5 for the image center.
Original image:

Segment results by prompting with a single point `--point 0.6,0.55`:

Segment results by prompting with multiple points `--point 0.6,0.6 --point 0.6,0.55`:

### Command-line flags
- `--use-tiny`: use the TinyViT based MobileSAM backbone rather than the default
one.
- `--point`: specifies the location of the target points.
- `--threshold`: sets the threshold value to be part of the mask, a negative
value results in a larger mask and can be specified via `--threshold=-1.2`.
| 1 |
0 | hf_public_repos/candle/candle-examples/examples | hf_public_repos/candle/candle-examples/examples/encodec/main.rs | #[cfg(feature = "mkl")]
extern crate intel_mkl_src;
#[cfg(feature = "accelerate")]
extern crate accelerate_src;
use anyhow::Result;
use candle::{DType, IndexOp, Tensor};
use candle_nn::VarBuilder;
use candle_transformers::models::encodec::{Config, Model};
use clap::{Parser, ValueEnum};
use hf_hub::api::sync::Api;
mod audio_io;
#[derive(Clone, Debug, Copy, PartialEq, Eq, ValueEnum)]
enum Action {
AudioToAudio,
AudioToCode,
CodeToAudio,
}
#[derive(Parser, Debug)]
#[command(author, version, about, long_about = None)]
struct Args {
/// The action to be performed, specifies the format for the input and output data.
action: Action,
/// The input file, either an audio file or some encodec tokens stored as safetensors.
in_file: String,
/// The output file, either a wave audio file or some encodec tokens stored as safetensors.
out_file: String,
/// Run on CPU rather than on GPU.
#[arg(long)]
cpu: bool,
/// The model weight file, in safetensor format.
#[arg(long)]
model: Option<String>,
}
fn main() -> Result<()> {
let args = Args::parse();
let device = candle_examples::device(args.cpu)?;
let model = match args.model {
Some(model) => std::path::PathBuf::from(model),
None => Api::new()?
.model("facebook/encodec_24khz".to_string())
.get("model.safetensors")?,
};
let vb = unsafe { VarBuilder::from_mmaped_safetensors(&[model], DType::F32, &device)? };
let config = Config::default();
let model = Model::new(&config, vb)?;
let codes = match args.action {
Action::CodeToAudio => {
let codes = candle::safetensors::load(args.in_file, &device)?;
codes.get("codes").expect("no codes in input file").clone()
}
Action::AudioToCode | Action::AudioToAudio => {
let pcm = if args.in_file == "-" {
println!(">>>> RECORDING AUDIO, PRESS ENTER ONCE DONE <<<<");
let (stream, input_audio) = audio_io::setup_input_stream()?;
let mut pcms = vec![];
let stdin = std::thread::spawn(|| {
let mut s = String::new();
std::io::stdin().read_line(&mut s)
});
while !stdin.is_finished() {
let input = input_audio.lock().unwrap().take_all();
if input.is_empty() {
std::thread::sleep(std::time::Duration::from_millis(100));
continue;
}
pcms.push(input)
}
drop(stream);
pcms.concat()
} else {
let (pcm, sample_rate) = audio_io::pcm_decode(args.in_file)?;
if sample_rate != 24_000 {
println!("WARNING: encodec uses a 24khz sample rate, input uses {sample_rate}, resampling...");
audio_io::resample(&pcm, sample_rate as usize, 24_000)?
} else {
pcm
}
};
let pcm_len = pcm.len();
let pcm = Tensor::from_vec(pcm, (1, 1, pcm_len), &device)?;
println!("input pcm shape: {:?}", pcm.shape());
model.encode(&pcm)?
}
};
println!("codes shape: {:?}", codes.shape());
match args.action {
Action::AudioToCode => {
codes.save_safetensors("codes", &args.out_file)?;
}
Action::AudioToAudio | Action::CodeToAudio => {
let pcm = model.decode(&codes)?;
println!("output pcm shape: {:?}", pcm.shape());
let pcm = pcm.i(0)?.i(0)?;
let pcm = candle_examples::audio::normalize_loudness(&pcm, 24_000, true)?;
let pcm = pcm.to_vec1::<f32>()?;
if args.out_file == "-" {
let (stream, ad) = audio_io::setup_output_stream()?;
{
let mut ad = ad.lock().unwrap();
ad.push_samples(&pcm)?;
}
loop {
let ad = ad.lock().unwrap();
if ad.is_empty() {
break;
}
// That's very weird, calling thread::sleep here triggers the stream to stop
// playing (the callback doesn't seem to be called anymore).
// std::thread::sleep(std::time::Duration::from_millis(100));
}
drop(stream)
} else {
let mut output = std::fs::File::create(&args.out_file)?;
candle_examples::wav::write_pcm_as_wav(&mut output, &pcm, 24_000)?;
}
}
}
Ok(())
}
| 2 |
0 | hf_public_repos/candle/candle-examples/examples | hf_public_repos/candle/candle-examples/examples/encodec/audio_io.rs | use anyhow::{Context, Result};
use std::sync::{Arc, Mutex};
pub const SAMPLE_RATE: usize = 24_000;
pub(crate) struct AudioOutputData_ {
resampled_data: std::collections::VecDeque<f32>,
resampler: rubato::FastFixedIn<f32>,
output_buffer: Vec<f32>,
input_buffer: Vec<f32>,
input_len: usize,
}
impl AudioOutputData_ {
pub(crate) fn new(input_sample_rate: usize, output_sample_rate: usize) -> Result<Self> {
use rubato::Resampler;
let resampled_data = std::collections::VecDeque::with_capacity(output_sample_rate * 10);
let resample_ratio = output_sample_rate as f64 / input_sample_rate as f64;
let resampler = rubato::FastFixedIn::new(
resample_ratio,
f64::max(resample_ratio, 1.0),
rubato::PolynomialDegree::Septic,
1024,
1,
)?;
let input_buffer = resampler.input_buffer_allocate(true).remove(0);
let output_buffer = resampler.output_buffer_allocate(true).remove(0);
Ok(Self {
resampled_data,
resampler,
input_buffer,
output_buffer,
input_len: 0,
})
}
pub fn reset(&mut self) {
use rubato::Resampler;
self.output_buffer.fill(0.);
self.input_buffer.fill(0.);
self.resampler.reset();
self.resampled_data.clear();
}
pub(crate) fn take_all(&mut self) -> Vec<f32> {
let mut data = Vec::with_capacity(self.resampled_data.len());
while let Some(elem) = self.resampled_data.pop_back() {
data.push(elem);
}
data
}
pub(crate) fn is_empty(&self) -> bool {
self.resampled_data.is_empty()
}
// Assumes that the input buffer is large enough.
fn push_input_buffer(&mut self, samples: &[f32]) {
self.input_buffer[self.input_len..self.input_len + samples.len()].copy_from_slice(samples);
self.input_len += samples.len()
}
pub(crate) fn push_samples(&mut self, samples: &[f32]) -> Result<()> {
use rubato::Resampler;
let mut pos_in = 0;
loop {
let rem = self.input_buffer.len() - self.input_len;
let pos_end = usize::min(pos_in + rem, samples.len());
self.push_input_buffer(&samples[pos_in..pos_end]);
pos_in = pos_end;
if self.input_len < self.input_buffer.len() {
break;
}
let (_, out_len) = self.resampler.process_into_buffer(
&[&self.input_buffer],
&mut [&mut self.output_buffer],
None,
)?;
for &elem in self.output_buffer[..out_len].iter() {
self.resampled_data.push_front(elem)
}
self.input_len = 0;
}
Ok(())
}
}
type AudioOutputData = Arc<Mutex<AudioOutputData_>>;
pub(crate) fn setup_output_stream() -> Result<(cpal::Stream, AudioOutputData)> {
use cpal::traits::{DeviceTrait, HostTrait, StreamTrait};
println!("Setup audio output stream!");
let host = cpal::default_host();
let device = host
.default_output_device()
.context("no output device available")?;
let mut supported_configs_range = device.supported_output_configs()?;
let config_range = match supported_configs_range.find(|c| c.channels() == 1) {
// On macOS, it's commonly the case that there are only stereo outputs.
None => device
.supported_output_configs()?
.next()
.context("no audio output available")?,
Some(config_range) => config_range,
};
let sample_rate = cpal::SampleRate(SAMPLE_RATE as u32).clamp(
config_range.min_sample_rate(),
config_range.max_sample_rate(),
);
let config: cpal::StreamConfig = config_range.with_sample_rate(sample_rate).into();
let channels = config.channels as usize;
println!(
"cpal device: {} {} {config:?}",
device.name().unwrap_or_else(|_| "unk".to_string()),
config.sample_rate.0
);
let audio_data = Arc::new(Mutex::new(AudioOutputData_::new(
SAMPLE_RATE,
config.sample_rate.0 as usize,
)?));
let ad = audio_data.clone();
let stream = device.build_output_stream(
&config,
move |data: &mut [f32], _: &cpal::OutputCallbackInfo| {
data.fill(0.);
let mut ad = ad.lock().unwrap();
let mut last_elem = 0f32;
for (idx, elem) in data.iter_mut().enumerate() {
if idx % channels == 0 {
match ad.resampled_data.pop_back() {
None => break,
Some(v) => {
last_elem = v;
*elem = v
}
}
} else {
*elem = last_elem
}
}
},
move |err| eprintln!("cpal error: {err}"),
None, // None=blocking, Some(Duration)=timeout
)?;
stream.play()?;
Ok((stream, audio_data))
}
pub(crate) fn setup_input_stream() -> Result<(cpal::Stream, AudioOutputData)> {
use cpal::traits::{DeviceTrait, HostTrait, StreamTrait};
println!("Setup audio input stream!");
let host = cpal::default_host();
let device = host
.default_input_device()
.context("no input device available")?;
let mut supported_configs_range = device.supported_input_configs()?;
let config_range = supported_configs_range
.find(|c| c.channels() == 1)
.context("no audio input available")?;
let sample_rate = cpal::SampleRate(SAMPLE_RATE as u32).clamp(
config_range.min_sample_rate(),
config_range.max_sample_rate(),
);
let config: cpal::StreamConfig = config_range.with_sample_rate(sample_rate).into();
println!(
"cpal device: {} {} {config:?}",
device.name().unwrap_or_else(|_| "unk".to_string()),
config.sample_rate.0
);
let audio_data = Arc::new(Mutex::new(AudioOutputData_::new(
config.sample_rate.0 as usize,
SAMPLE_RATE,
)?));
let ad = audio_data.clone();
let stream = device.build_input_stream(
&config,
move |data: &[f32], _: &cpal::InputCallbackInfo| {
let mut ad = ad.lock().unwrap();
if let Err(err) = ad.push_samples(data) {
eprintln!("error processing audio input {err:?}")
}
},
move |err| eprintln!("cpal error: {err}"),
None, // None=blocking, Some(Duration)=timeout
)?;
stream.play()?;
Ok((stream, audio_data))
}
fn conv<T>(samples: &mut Vec<f32>, data: std::borrow::Cow<symphonia::core::audio::AudioBuffer<T>>)
where
T: symphonia::core::sample::Sample,
f32: symphonia::core::conv::FromSample<T>,
{
use symphonia::core::audio::Signal;
use symphonia::core::conv::FromSample;
samples.extend(data.chan(0).iter().map(|v| f32::from_sample(*v)))
}
pub(crate) fn pcm_decode<P: AsRef<std::path::Path>>(path: P) -> Result<(Vec<f32>, u32)> {
use symphonia::core::audio::{AudioBufferRef, Signal};
let src = std::fs::File::open(path)?;
let mss = symphonia::core::io::MediaSourceStream::new(Box::new(src), Default::default());
let hint = symphonia::core::probe::Hint::new();
let meta_opts: symphonia::core::meta::MetadataOptions = Default::default();
let fmt_opts: symphonia::core::formats::FormatOptions = Default::default();
let probed = symphonia::default::get_probe().format(&hint, mss, &fmt_opts, &meta_opts)?;
let mut format = probed.format;
let track = format
.tracks()
.iter()
.find(|t| t.codec_params.codec != symphonia::core::codecs::CODEC_TYPE_NULL)
.expect("no supported audio tracks");
let mut decoder = symphonia::default::get_codecs()
.make(&track.codec_params, &Default::default())
.expect("unsupported codec");
let track_id = track.id;
let sample_rate = track.codec_params.sample_rate.unwrap_or(0);
let mut pcm_data = Vec::new();
while let Ok(packet) = format.next_packet() {
while !format.metadata().is_latest() {
format.metadata().pop();
}
if packet.track_id() != track_id {
continue;
}
match decoder.decode(&packet)? {
AudioBufferRef::F32(buf) => pcm_data.extend(buf.chan(0)),
AudioBufferRef::U8(data) => conv(&mut pcm_data, data),
AudioBufferRef::U16(data) => conv(&mut pcm_data, data),
AudioBufferRef::U24(data) => conv(&mut pcm_data, data),
AudioBufferRef::U32(data) => conv(&mut pcm_data, data),
AudioBufferRef::S8(data) => conv(&mut pcm_data, data),
AudioBufferRef::S16(data) => conv(&mut pcm_data, data),
AudioBufferRef::S24(data) => conv(&mut pcm_data, data),
AudioBufferRef::S32(data) => conv(&mut pcm_data, data),
AudioBufferRef::F64(data) => conv(&mut pcm_data, data),
}
}
Ok((pcm_data, sample_rate))
}
pub(crate) fn resample(pcm_in: &[f32], sr_in: usize, sr_out: usize) -> Result<Vec<f32>> {
use rubato::Resampler;
let mut pcm_out =
Vec::with_capacity((pcm_in.len() as f64 * sr_out as f64 / sr_in as f64) as usize + 1024);
let mut resampler = rubato::FftFixedInOut::<f32>::new(sr_in, sr_out, 1024, 1)?;
let mut output_buffer = resampler.output_buffer_allocate(true);
let mut pos_in = 0;
while pos_in + resampler.input_frames_next() < pcm_in.len() {
let (in_len, out_len) =
resampler.process_into_buffer(&[&pcm_in[pos_in..]], &mut output_buffer, None)?;
pos_in += in_len;
pcm_out.extend_from_slice(&output_buffer[0][..out_len]);
}
if pos_in < pcm_in.len() {
let (_in_len, out_len) = resampler.process_partial_into_buffer(
Some(&[&pcm_in[pos_in..]]),
&mut output_buffer,
None,
)?;
pcm_out.extend_from_slice(&output_buffer[0][..out_len]);
}
Ok(pcm_out)
}
| 3 |
0 | hf_public_repos/candle/candle-examples/examples | hf_public_repos/candle/candle-examples/examples/encodec/README.md | # candle-endocec
[EnCodec](https://huggingface.co/facebook/encodec_24khz) is a high-quality audio
compression model using an encoder/decoder architecture with residual vector
quantization.
## Running one example
```bash
cargo run --example encodec --features encodec --release -- code-to-audio \
candle-examples/examples/encodec/jfk-codes.safetensors \
jfk.wav
```
This decodes the EnCodec tokens stored in `jfk-codes.safetensors` and generates
an output wav file containing the audio data.
Instead of `code-to-audio` one can use:
- `audio-to-audio in.mp3 out.wav`: encodes the input audio file then decodes it to a wav file.
- `audio-to-code in.mp3 out.safetensors`: generates a safetensors file
containing EnCodec tokens for the input audio file.
If the audio output file name is set to `-`, the audio content directly gets
played on default audio output device. If the audio input file is set to `-`, the audio
gets recorded from the default audio input.
| 4 |
0 | hf_public_repos/candle/candle-examples/examples | hf_public_repos/candle/candle-examples/examples/mistral/main.rs | #[cfg(feature = "mkl")]
extern crate intel_mkl_src;
#[cfg(feature = "accelerate")]
extern crate accelerate_src;
use anyhow::{Error as E, Result};
use clap::Parser;
use candle_transformers::models::mistral::{Config, Model as Mistral};
use candle_transformers::models::quantized_mistral::Model as QMistral;
use candle::{DType, Device, Tensor};
use candle_examples::token_output_stream::TokenOutputStream;
use candle_nn::VarBuilder;
use candle_transformers::generation::{LogitsProcessor, Sampling};
use hf_hub::{api::sync::Api, Repo, RepoType};
use tokenizers::Tokenizer;
enum Model {
Mistral(Mistral),
Quantized(QMistral),
}
struct TextGeneration {
model: Model,
device: Device,
tokenizer: TokenOutputStream,
logits_processor: LogitsProcessor,
repeat_penalty: f32,
repeat_last_n: usize,
}
impl TextGeneration {
#[allow(clippy::too_many_arguments)]
fn new(
model: Model,
tokenizer: Tokenizer,
seed: u64,
temp: Option<f64>,
top_p: Option<f64>,
top_k: Option<usize>,
repeat_penalty: f32,
repeat_last_n: usize,
device: &Device,
) -> Self {
let logits_processor = {
let temperature = temp.unwrap_or(0.);
let sampling = if temperature <= 0. {
Sampling::ArgMax
} else {
match (top_k, top_p) {
(None, None) => Sampling::All { temperature },
(Some(k), None) => Sampling::TopK { k, temperature },
(None, Some(p)) => Sampling::TopP { p, temperature },
(Some(k), Some(p)) => Sampling::TopKThenTopP { k, p, temperature },
}
};
LogitsProcessor::from_sampling(seed, sampling)
};
Self {
model,
tokenizer: TokenOutputStream::new(tokenizer),
logits_processor,
repeat_penalty,
repeat_last_n,
device: device.clone(),
}
}
fn run(&mut self, prompt: &str, sample_len: usize) -> Result<()> {
use std::io::Write;
self.tokenizer.clear();
let mut tokens = self
.tokenizer
.tokenizer()
.encode(prompt, true)
.map_err(E::msg)?
.get_ids()
.to_vec();
for &t in tokens.iter() {
if let Some(t) = self.tokenizer.next_token(t)? {
print!("{t}")
}
}
std::io::stdout().flush()?;
let mut generated_tokens = 0usize;
let eos_token = match self.tokenizer.get_token("</s>") {
Some(token) => token,
None => anyhow::bail!("cannot find the </s> token"),
};
let start_gen = std::time::Instant::now();
for index in 0..sample_len {
let context_size = if index > 0 { 1 } else { tokens.len() };
let start_pos = tokens.len().saturating_sub(context_size);
let ctxt = &tokens[start_pos..];
let input = Tensor::new(ctxt, &self.device)?.unsqueeze(0)?;
let logits = match &mut self.model {
Model::Mistral(m) => m.forward(&input, start_pos)?,
Model::Quantized(m) => m.forward(&input, start_pos)?,
};
let logits = logits.squeeze(0)?.squeeze(0)?.to_dtype(DType::F32)?;
let logits = if self.repeat_penalty == 1. {
logits
} else {
let start_at = tokens.len().saturating_sub(self.repeat_last_n);
candle_transformers::utils::apply_repeat_penalty(
&logits,
self.repeat_penalty,
&tokens[start_at..],
)?
};
let next_token = self.logits_processor.sample(&logits)?;
tokens.push(next_token);
generated_tokens += 1;
if next_token == eos_token {
break;
}
if let Some(t) = self.tokenizer.next_token(next_token)? {
print!("{t}");
std::io::stdout().flush()?;
}
}
let dt = start_gen.elapsed();
if let Some(rest) = self.tokenizer.decode_rest().map_err(E::msg)? {
print!("{rest}");
}
std::io::stdout().flush()?;
println!(
"\n{generated_tokens} tokens generated ({:.2} token/s)",
generated_tokens as f64 / dt.as_secs_f64(),
);
Ok(())
}
}
#[derive(Clone, Debug, Copy, PartialEq, Eq, clap::ValueEnum)]
enum Which {
#[value(name = "7b-v0.1")]
Mistral7bV01,
#[value(name = "7b-v0.2")]
Mistral7bV02,
#[value(name = "7b-instruct-v0.1")]
Mistral7bInstructV01,
#[value(name = "7b-instruct-v0.2")]
Mistral7bInstructV02,
#[value(name = "7b-maths-v0.1")]
Mathstral7bV01,
#[value(name = "nemo-2407")]
MistralNemo2407,
#[value(name = "nemo-instruct-2407")]
MistralNemoInstruct2407,
}
#[derive(Parser, Debug)]
#[command(author, version, about, long_about = None)]
struct Args {
/// Run on CPU rather than on GPU.
#[arg(long)]
cpu: bool,
/// Enable tracing (generates a trace-timestamp.json file).
#[arg(long)]
tracing: bool,
#[arg(long)]
use_flash_attn: bool,
#[arg(long)]
prompt: String,
/// The temperature used to generate samples.
#[arg(long)]
temperature: Option<f64>,
/// Nucleus sampling probability cutoff.
#[arg(long)]
top_p: Option<f64>,
/// Only sample among the top K samples.
#[arg(long)]
top_k: Option<usize>,
/// The seed to use when generating random samples.
#[arg(long, default_value_t = 299792458)]
seed: u64,
/// The length of the sample to generate (in tokens).
#[arg(long, short = 'n', default_value_t = 10000)]
sample_len: usize,
/// The model size to use.
#[arg(long, default_value = "7b-v0.1")]
which: Which,
#[arg(long)]
model_id: Option<String>,
#[arg(long, default_value = "main")]
revision: String,
#[arg(long)]
tokenizer_file: Option<String>,
#[arg(long)]
config_file: Option<String>,
#[arg(long)]
weight_files: Option<String>,
#[arg(long)]
quantized: bool,
/// Penalty to be applied for repeating tokens, 1. means no penalty.
#[arg(long, default_value_t = 1.1)]
repeat_penalty: f32,
/// The context size to consider for the repeat penalty.
#[arg(long, default_value_t = 64)]
repeat_last_n: usize,
/// Use the slower dmmv cuda kernel.
#[arg(long)]
force_dmmv: bool,
}
fn main() -> Result<()> {
use tracing_chrome::ChromeLayerBuilder;
use tracing_subscriber::prelude::*;
let args = Args::parse();
#[cfg(feature = "cuda")]
candle::quantized::cuda::set_force_dmmv(args.force_dmmv);
let _guard = if args.tracing {
let (chrome_layer, guard) = ChromeLayerBuilder::new().build();
tracing_subscriber::registry().with(chrome_layer).init();
Some(guard)
} else {
None
};
println!(
"avx: {}, neon: {}, simd128: {}, f16c: {}",
candle::utils::with_avx(),
candle::utils::with_neon(),
candle::utils::with_simd128(),
candle::utils::with_f16c()
);
println!(
"temp: {:.2} repeat-penalty: {:.2} repeat-last-n: {}",
args.temperature.unwrap_or(0.),
args.repeat_penalty,
args.repeat_last_n
);
let start = std::time::Instant::now();
let api = Api::new()?;
let model_id = match args.model_id {
Some(model_id) => model_id,
None => {
if args.quantized {
if args.which != Which::Mistral7bV01 {
anyhow::bail!("only 7b-v0.1 is available as a quantized model for now")
}
"lmz/candle-mistral".to_string()
} else {
let name = match args.which {
Which::Mistral7bV01 => "mistralai/Mistral-7B-v0.1",
Which::Mistral7bV02 => "mistralai/Mistral-7B-v0.2",
Which::Mistral7bInstructV01 => "mistralai/Mistral-7B-Instruct-v0.1",
Which::Mistral7bInstructV02 => "mistralai/Mistral-7B-Instruct-v0.2",
Which::Mathstral7bV01 => "mistralai/mathstral-7B-v0.1",
Which::MistralNemo2407 => "mistralai/Mistral-Nemo-Base-2407",
Which::MistralNemoInstruct2407 => "mistralai/Mistral-Nemo-Instruct-2407",
};
name.to_string()
}
}
};
let repo = api.repo(Repo::with_revision(
model_id,
RepoType::Model,
args.revision,
));
let tokenizer_filename = match args.tokenizer_file {
Some(file) => std::path::PathBuf::from(file),
None => repo.get("tokenizer.json")?,
};
let filenames = match args.weight_files {
Some(files) => files
.split(',')
.map(std::path::PathBuf::from)
.collect::<Vec<_>>(),
None => {
if args.quantized {
vec![repo.get("model-q4k.gguf")?]
} else {
candle_examples::hub_load_safetensors(&repo, "model.safetensors.index.json")?
}
}
};
println!("retrieved the files in {:?}", start.elapsed());
let tokenizer = Tokenizer::from_file(tokenizer_filename).map_err(E::msg)?;
let start = std::time::Instant::now();
let config = match args.config_file {
Some(config_file) => serde_json::from_slice(&std::fs::read(config_file)?)?,
None => {
if args.quantized {
Config::config_7b_v0_1(args.use_flash_attn)
} else {
let config_file = repo.get("config.json")?;
serde_json::from_slice(&std::fs::read(config_file)?)?
}
}
};
let device = candle_examples::device(args.cpu)?;
let (model, device) = if args.quantized {
let filename = &filenames[0];
let vb =
candle_transformers::quantized_var_builder::VarBuilder::from_gguf(filename, &device)?;
let model = QMistral::new(&config, vb)?;
(Model::Quantized(model), device)
} else {
let dtype = if device.is_cuda() {
DType::BF16
} else {
DType::F32
};
let vb = unsafe { VarBuilder::from_mmaped_safetensors(&filenames, dtype, &device)? };
let model = Mistral::new(&config, vb)?;
(Model::Mistral(model), device)
};
println!("loaded the model in {:?}", start.elapsed());
let mut pipeline = TextGeneration::new(
model,
tokenizer,
args.seed,
args.temperature,
args.top_p,
args.top_k,
args.repeat_penalty,
args.repeat_last_n,
&device,
);
pipeline.run(&args.prompt, args.sample_len)?;
Ok(())
}
| 5 |
0 | hf_public_repos/candle/candle-examples/examples | hf_public_repos/candle/candle-examples/examples/mistral/README.md | # candle-mistral: 7b LLM with Apache 2.0 licensed weights
Mistral-7B-v0.1 is a pretrained generative LLM with 7 billion parameters. It outperforms all the publicly available 13b models
as of 2023-09-28. Weights (and the original Python model code) are released under the permissive Apache 2.0 license.
- [Blog post](https://mistral.ai/news/announcing-mistral-7b/) from Mistral announcing the model release.
- [Model card](https://huggingface.co/mistralai/Mistral-7B-v0.1) on the
HuggingFace Hub.
This example supports the initial model as well as a quantized variant.
## Running the example
```bash
$ cargo run --example mistral --release --features cuda -- --prompt 'Write helloworld code in Rust' --sample-len 150
Generated text:
Write helloworld code in Rust
=============================
This is a simple example of how to write "Hello, world!" program in Rust.
## Compile and run
``bash
$ cargo build --release
Compiling hello-world v0.1.0 (/home/user/rust/hello-world)
Finished release [optimized] target(s) in 0.26s
$ ./target/release/hello-world
Hello, world!
``
## Source code
``rust
fn main() {
println!("Hello, world!");
}
``
## License
This example is released under the terms
```
## Running the quantized version of the model
```bash
$ cargo run --example mistral --features accelerate --release -- \
$ --prompt "Here is a sample quick sort implementation in rust " --quantized -n 400
avx: false, neon: true, simd128: false, f16c: false
temp: 0.00 repeat-penalty: 1.10 repeat-last-n: 64
retrieved the files in 562.292µs
loaded the model in 1.100323667s
Here is a sample quick sort implementation in rust
``rust
fn quick_sort(arr: &mut [i32]) {
if arr.len() <= 1 {
return;
}
let pivot = arr[0];
let mut left = vec![];
let mut right = vec![];
for i in 1..arr.len() {
if arr[i] < pivot {
left.push(arr[i]);
} else {
right.push(arr[i]);
}
}
quick_sort(&mut left);
quick_sort(&mut right);
let mut i = 0;
for _ in &left {
arr[i] = left.pop().unwrap();
i += 1;
}
for _ in &right {
arr[i] = right.pop().unwrap();
i += 1;
}
}
``
226 tokens generated (10.91 token/s)
```
| 6 |
0 | hf_public_repos/candle/candle-examples/examples | hf_public_repos/candle/candle-examples/examples/llava/readme.md | # candle-llava
LLaVA (Large Language-and-Vision Assistant) is an end-to-end trained large
multimodal model. This example is from [candle-llava](https://github.com/chenwanqq/candle-llava)
The code is based on [https://github.com/haotian-liu/LLaVA](https://github.com/haotian-liu/LLaVA), Hence the llava-hf version of config may perform differently.
## model zoo
* [liuhaotian/LLaVA](https://huggingface.co/liuhaotian)
* [llava-hf](https://huggingface.co/llava-hf)
Right now this has been tested on `liuhaotian/llava-v1.6-vicuna-7b` and
`llava-hf/llava-v1.6-vicuna-7b-hf`. Memory usage might have room for optimization.
## Tokenizer Setup
The llava-hf models contain a `tokenizer.json` file so can be used directly with
the `-hf` command line flag.
For the original llava models, you can use the following code to generate the `tokenizer.json` file.
```bash
conda create -n llava python=3.10
pip install transformers protobuf
conda activate llava
python -c "from transformers import AutoTokenizer;tokenizer=AutoTokenizer.from_pretrained('liuhaotian/llava-v1.6-vicuna-7b');tokenizer.save_pretrained('tokenizer')"
```
Then the `tokenizer.json` file should be in `tokenizer/tokenizer.json` (which is the default path).
## eval
```bash
cargo run --example llava --features cuda -- --image-file "llava_logo.png" --prompt "is this a cat?" --hf # default args, use llava-hf/llava-v1.6-vicuna-7b-hf. image-file is required^_^
cargo run --example llava --features cuda -- --model-path liuhaotian/llava-v1.6-vicuna-7b --image-file "llava_logo.png" --prompt "is this a cat?" # use liuhaotian/llava-v1.6-vicuna-7b, tokenizer setup should be done
```
## Major Limitations
1. Currently only support llama-2/vicuna llm. Haven't supoort Mistral yet.
2. There are some ops like split, nonzero and where are not supported by candle.
3. Lack of quantization and LoRA support.
| 7 |
0 | hf_public_repos/candle/candle-examples/examples | hf_public_repos/candle/candle-examples/examples/llava/main.rs | pub mod constants;
pub mod conversation;
pub mod image_processor;
use candle_transformers::generation::{LogitsProcessor, Sampling};
use candle_transformers::models::llama::Cache;
use anyhow::{bail, Error as E, Result};
use candle::{DType, Device, IndexOp, Tensor};
use candle_nn::VarBuilder;
use candle_transformers::models::llava::config::{
HFGenerationConfig, HFLLaVAConfig, HFPreProcessorConfig,
};
use candle_transformers::models::llava::{config::LLaVAConfig, LLaVA};
use clap::Parser;
use constants::*;
use conversation::Conversation;
use hf_hub::api::sync::Api;
use image_processor::{process_image, ImageProcessor};
use std::io::Write;
use tokenizers::Tokenizer;
#[derive(Parser, Debug)]
#[command(author, version, about,long_about=None)]
struct Args {
#[arg(long, default_value = "llava-hf/llava-v1.6-vicuna-7b-hf")]
model_path: String,
#[arg(long, default_value = "tokenizer/tokenizer.json")]
tokenizer_path: String,
#[arg(long)]
model_base: Option<String>,
#[arg(long)]
image_file: String, // Required
#[arg(long)]
conv_mode: Option<String>,
#[arg(long, default_value_t = 0.2)]
temperature: f32,
#[arg(long, default_value_t = 512)]
max_new_tokens: usize,
#[arg(long, action)]
hf: bool,
#[arg(long, action)]
cpu: bool,
#[arg(long, action)]
no_kv_cache: bool,
#[arg(long)]
prompt: String,
/// The seed to use when generating random samples. Copy from candle llama. Not exist in python llava.
#[arg(long, default_value_t = 299792458)]
seed: u64,
}
//from https://github.com/huggingface/candle/blob/main/candle-examples/examples/clip/main.rs
fn load_image<T: AsRef<std::path::Path>>(
path: T,
processor: &ImageProcessor,
llava_config: &LLaVAConfig,
dtype: DType,
) -> Result<((u32, u32), Tensor)> {
let img = image::ImageReader::open(path)?.decode()?;
let img_tensor = process_image(&img, processor, llava_config)?;
Ok(((img.width(), img.height()), img_tensor.to_dtype(dtype)?))
}
fn get_model_name_from_path(model_path: &str) -> String {
let model_paths: Vec<String> = model_path
.trim_matches('/')
.split('/')
.map(|s| s.to_string())
.collect();
if model_paths.last().unwrap().starts_with("checkpoint-") {
format!(
"{}_{}",
model_paths[model_paths.len() - 2],
model_paths.last().unwrap()
)
} else {
model_paths.last().unwrap().to_string()
}
}
fn duplicate_vec<T>(vec: &[T], n: usize) -> Vec<T>
where
T: Clone,
{
let mut res = Vec::new();
for _ in 0..n {
res.extend(vec.to_owned());
}
res
}
fn insert_separator<T>(x: Vec<Vec<T>>, sep: Vec<T>) -> Vec<Vec<T>>
where
T: Clone,
{
let sep = vec![sep];
let sep = duplicate_vec(&sep, x.len());
let mut res = x
.iter()
.zip(sep.iter())
.flat_map(|(x, y)| vec![x.clone(), y.clone()])
.collect::<Vec<Vec<T>>>();
res.pop();
res
}
fn tokenizer_image_token(
prompt: &str,
tokenizer: &Tokenizer,
image_token_index: i64,
llava_config: &LLaVAConfig,
) -> Result<Tensor> {
let prompt_chunks = prompt
.split("<image>")
.map(|s| {
tokenizer
.encode(s, true)
.unwrap()
.get_ids()
.to_vec()
.iter()
.map(|x| *x as i64)
.collect()
})
.collect::<Vec<Vec<i64>>>();
let mut input_ids = Vec::new();
let mut offset = 0;
if !prompt_chunks.is_empty()
&& !prompt_chunks[0].is_empty()
&& prompt_chunks[0][0] == llava_config.bos_token_id as i64
{
offset = 1;
input_ids.push(prompt_chunks[0][0]);
}
for x in insert_separator(
prompt_chunks,
duplicate_vec(&[image_token_index], offset + 1),
)
.iter()
{
input_ids.extend(x[1..].to_vec())
}
let input_len = input_ids.len();
Tensor::from_vec(input_ids, (1, input_len), &Device::Cpu).map_err(E::msg)
}
fn main() -> Result<()> {
let mut args = Args::parse();
let device = candle_examples::device(args.cpu)?;
println!("Start loading model");
let api = Api::new()?;
let api = api.model(args.model_path.clone());
let (llava_config, tokenizer, clip_vision_config, image_processor) = if args.hf {
let config_filename = api.get("config.json")?;
let hf_llava_config: HFLLaVAConfig =
serde_json::from_slice(&std::fs::read(config_filename)?)?;
let generation_config_filename = api.get("generation_config.json")?;
let generation_config: HFGenerationConfig =
serde_json::from_slice(&std::fs::read(generation_config_filename)?)?;
let preprocessor_config_filename = api.get("preprocessor_config.json")?;
let preprocessor_config: HFPreProcessorConfig =
serde_json::from_slice(&std::fs::read(preprocessor_config_filename)?)?;
let llava_config =
hf_llava_config.to_llava_config(&generation_config, &preprocessor_config);
let tokenizer_filename = api.get("tokenizer.json")?;
let tokenizer = Tokenizer::from_file(tokenizer_filename).map_err(E::msg)?;
let clip_vision_config = hf_llava_config.to_clip_vision_config();
(
llava_config,
tokenizer,
Some(clip_vision_config),
ImageProcessor::from_hf_preprocessor_config(&preprocessor_config),
)
} else {
let config_filename = api.get("config.json")?;
let llava_config: LLaVAConfig = serde_json::from_slice(&std::fs::read(config_filename)?)?;
let tokenizer = Tokenizer::from_file(&args.tokenizer_path)
.map_err(|e| E::msg(format!("Error loading {}: {}", &args.tokenizer_path, e)))?;
(
llava_config.clone(),
tokenizer,
None,
ImageProcessor::from_pretrained(&llava_config.mm_vision_tower.unwrap())?,
)
};
let llama_config = llava_config.to_llama_config();
let dtype: DType = match llava_config.torch_dtype.as_str() {
"float16" => DType::F16,
"bfloat16" => DType::BF16,
_ => bail!("unsupported dtype"),
};
let eos_token_id = llava_config.eos_token_id;
println!("setting kv cache");
let mut cache = Cache::new(!args.no_kv_cache, dtype, &llama_config, &device)?;
println!("loading model weights");
let weight_filenames =
candle_examples::hub_load_safetensors(&api, "model.safetensors.index.json")?;
let vb = unsafe { VarBuilder::from_mmaped_safetensors(&weight_filenames, dtype, &device)? };
let llava: LLaVA = LLaVA::load(vb, &llava_config, clip_vision_config)?;
println!("generating conv template");
let image_token_se = format!(
"{}{}{}",
DEFAULT_IM_START_TOKEN, DEFAULT_IMAGE_TOKEN, DEFAULT_IM_END_TOKEN
);
let qs = if args.prompt.contains(IMAGE_PLACEHOLDER) {
if llava_config.mm_use_im_start_end {
args.prompt.replace(IMAGE_PLACEHOLDER, &image_token_se)
} else {
args.prompt.replace(IMAGE_PLACEHOLDER, DEFAULT_IMAGE_TOKEN)
}
} else if llava_config.mm_use_im_start_end {
format!("{}\n{}", image_token_se, args.prompt)
} else {
format!("{}\n{}", DEFAULT_IMAGE_TOKEN, args.prompt)
};
let model_name = get_model_name_from_path(&args.model_path).to_lowercase();
let conv_mode = if model_name.contains("llama-2") {
"llava_llama_2"
} else if model_name.contains("mistral") {
"mistral_instruct"
} else if model_name.contains("v1.6-34b") {
"chatml_direct"
} else if model_name.contains("v1") {
"llava_v1"
} else if model_name.contains("mpt") {
"mpt"
} else {
"llava_v0"
};
if args.conv_mode.is_some() && args.conv_mode.as_deref() != Some(conv_mode) {
println!(
"Warning: the model is trained with {}, but you are using {}",
conv_mode,
args.conv_mode.as_deref().unwrap()
);
} else {
args.conv_mode = Some(conv_mode.to_string());
}
let mut conv = match args.conv_mode {
Some(conv_mode) => match conv_mode.as_str() {
"chatml_direct" => Conversation::conv_chatml_direct(),
"llava_v1" => Conversation::conv_llava_v1(),
_ => todo!("not implement yet"),
},
None => bail!("conv_mode is required"),
};
conv.append_user_message(Some(&qs));
conv.append_assistant_message(None);
let prompt = conv.get_prompt();
println!("loading image");
let (image_size, image_tensor) =
load_image(&args.image_file, &image_processor, &llava_config, dtype)
.map_err(|e| E::msg(format!("Error loading {}: {}", &args.image_file, e)))?;
let image_tensor = image_tensor.to_device(&device)?;
let mut logits_processor = {
let temperature = f64::from(args.temperature);
let sampling = if temperature <= 0. {
Sampling::ArgMax
} else {
Sampling::All { temperature }
};
LogitsProcessor::from_sampling(args.seed, sampling)
};
// get input tokens
let tokens = tokenizer_image_token(
&prompt,
&tokenizer,
llava_config.image_token_index as i64,
&llava_config,
)?;
let mut input_embeds =
llava.prepare_inputs_labels_for_multimodal(&tokens, &[image_tensor], &[image_size])?;
//inference loop, based on https://github.com/huggingface/candle/blob/main/candle-examples/examples/llama/main.rs
let mut tokenizer = candle_examples::token_output_stream::TokenOutputStream::new(tokenizer);
let mut index_pos = 0;
for index in 0..args.max_new_tokens {
let (_, input_embeds_len, _) = input_embeds.dims3()?;
let (context_size, context_index) = if cache.use_kv_cache && index > 0 {
(1, index_pos)
} else {
(input_embeds_len, 0)
};
let input = input_embeds.i((.., input_embeds_len.saturating_sub(context_size).., ..))?;
let logits = llava.forward(&input, context_index, &mut cache)?; //[1,32000]
let logits = logits.squeeze(0)?;
let (_, input_len, _) = input.dims3()?;
index_pos += input_len;
let next_token = logits_processor.sample(&logits)?;
let next_token_tensor = Tensor::from_vec(vec![next_token], 1, &device)?;
let next_embeds = llava.llama.embed(&next_token_tensor)?.unsqueeze(0)?;
input_embeds = Tensor::cat(&[input_embeds, next_embeds], 1)?;
if next_token == eos_token_id as u32 {
break;
}
if let Some(t) = tokenizer.next_token(next_token)? {
print!("{t}");
std::io::stdout().flush()?;
}
}
if let Some(rest) = tokenizer.decode_rest().map_err(E::msg)? {
print!("{rest}");
}
Ok(())
}
| 8 |
0 | hf_public_repos/candle/candle-examples/examples | hf_public_repos/candle/candle-examples/examples/llava/conversation.rs | pub enum SeparatorStyle {
Two,
Mpt,
}
pub struct Conversation {
pub system: String,
pub roles: Vec<String>,
pub messages: Vec<(String, Option<String>)>,
pub offset: i32,
pub sep_style: SeparatorStyle,
pub sep: String,
pub sep2: Option<String>,
pub version: String,
}
impl Conversation {
pub fn new(
system: &str,
roles: &[String],
offset: i32,
sep_style: SeparatorStyle,
sep: &str,
sep2: Option<&str>,
version: &str,
) -> Self {
Conversation {
system: system.to_string(),
roles: roles.to_vec(),
messages: Vec::new(),
offset,
sep_style,
sep: sep.to_string(),
sep2: sep2.map(|s| s.to_string()),
version: version.to_string(),
}
}
pub fn conv_chatml_direct() -> Self {
Conversation::new(
"<|im_start|>system\nAnswer the questions.",
&[
"<|im_start|>user\n".to_string(),
"<|im_start|>assistant\n".to_string(),
],
0,
SeparatorStyle::Mpt,
"<|im_end|>",
None,
"mpt",
)
}
pub fn conv_llava_v1() -> Self {
Conversation::new(
"A chat between a curious human and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the human's questions.",
&[
"USER".to_string(),
"ASSISTANT".to_string(),
],
0,
SeparatorStyle::Two,
" ",
Some("</s>"),
"v1"
)
}
pub fn append_message(&mut self, role: String, message: Option<&str>) {
self.messages.push((role, message.map(|s| s.to_string())))
}
pub fn append_user_message(&mut self, message: Option<&str>) {
self.append_message(self.roles[0].clone(), message);
}
pub fn append_assistant_message(&mut self, message: Option<&str>) {
self.append_message(self.roles[1].clone(), message);
}
pub fn get_prompt(&self) -> String {
match self.sep_style {
SeparatorStyle::Mpt => {
let mut ret = String::new();
ret.push_str(&self.system);
ret.push_str(&self.sep);
for (role, message) in &self.messages {
ret.push_str(role);
if let Some(message) = message {
ret.push_str(message);
};
ret.push_str(&self.sep);
}
ret
}
SeparatorStyle::Two => {
let seps = [self.sep.clone(), self.sep2.clone().unwrap()];
let mut ret = String::new();
ret.push_str(&self.system);
ret.push_str(&seps[0]);
for (i, (role, message)) in self.messages.iter().enumerate() {
ret.push_str(role);
if let Some(message) = message {
ret.push_str(": "); // strictly follow the python implementation, otherwise it will cause some minor difference between tokens ^_^
ret.push_str(message);
ret.push_str(&seps[i % 2]);
} else {
ret.push(':')
}
}
ret
}
}
}
}
| 9 |
0 | hf_public_repos/candle/candle-flash-attn | hf_public_repos/candle/candle-flash-attn/kernels/flash_fwd_hdim32_bf16_sm80.cu | // Copyright (c) 2023, Tri Dao.
// Splitting the different head dimensions to different files to speed up compilation.
// This file is auto-generated. See "generate_kernels.py"
#include "flash_fwd_launch_template.h"
template<>
void run_mha_fwd_<cutlass::bfloat16_t, 32, false>(Flash_fwd_params ¶ms, cudaStream_t stream) {
run_mha_fwd_hdim32<cutlass::bfloat16_t, false>(params, stream);
}
| 0 |
0 | hf_public_repos/candle/candle-flash-attn | hf_public_repos/candle/candle-flash-attn/kernels/flash_fwd_hdim128_fp16_causal_sm80.cu | // Copyright (c) 2023, Tri Dao.
// Splitting the different head dimensions to different files to speed up compilation.
// This file is auto-generated. See "generate_kernels.py"
#include "flash_fwd_launch_template.h"
template<>
void run_mha_fwd_<cutlass::half_t, 128, true>(Flash_fwd_params ¶ms, cudaStream_t stream) {
run_mha_fwd_hdim128<cutlass::half_t, true>(params, stream);
}
| 1 |
0 | hf_public_repos/candle/candle-flash-attn | hf_public_repos/candle/candle-flash-attn/kernels/flash_fwd_hdim32_fp16_causal_sm80.cu | // Copyright (c) 2023, Tri Dao.
// Splitting the different head dimensions to different files to speed up compilation.
// This file is auto-generated. See "generate_kernels.py"
#include "flash_fwd_launch_template.h"
template<>
void run_mha_fwd_<cutlass::half_t, 32, true>(Flash_fwd_params ¶ms, cudaStream_t stream) {
run_mha_fwd_hdim32<cutlass::half_t, true>(params, stream);
}
| 2 |
0 | hf_public_repos/candle/candle-flash-attn | hf_public_repos/candle/candle-flash-attn/kernels/flash_fwd_hdim224_bf16_causal_sm80.cu | // Copyright (c) 2023, Tri Dao.
// Splitting the different head dimensions to different files to speed up compilation.
// This file is auto-generated. See "generate_kernels.py"
#include "flash_fwd_launch_template.h"
template<>
void run_mha_fwd_<cutlass::bfloat16_t, 224, true>(Flash_fwd_params ¶ms, cudaStream_t stream) {
run_mha_fwd_hdim224<cutlass::bfloat16_t, true>(params, stream);
}
| 3 |
0 | hf_public_repos/candle/candle-flash-attn | hf_public_repos/candle/candle-flash-attn/kernels/flash_fwd_hdim96_bf16_causal_sm80.cu | // Copyright (c) 2023, Tri Dao.
// Splitting the different head dimensions to different files to speed up compilation.
// This file is auto-generated. See "generate_kernels.py"
#include "flash_fwd_launch_template.h"
template<>
void run_mha_fwd_<cutlass::bfloat16_t, 96, true>(Flash_fwd_params ¶ms, cudaStream_t stream) {
run_mha_fwd_hdim96<cutlass::bfloat16_t, true>(params, stream);
}
| 4 |
0 | hf_public_repos/candle/candle-flash-attn | hf_public_repos/candle/candle-flash-attn/kernels/kernels.h | #ifndef _GPU_OPS_KERNELS_H_
#define _GPU_OPS_KERNELS_H_
#include <cuda_runtime_api.h>
#include <cstddef>
#include <cstdint>
#include<stdlib.h>
#include<stdint.h>
namespace gpu_ops {
struct MHAParams {
uint32_t q_batch_stride;
uint32_t k_batch_stride;
uint32_t v_batch_stride;
uint32_t o_batch_stride;
uint32_t q_row_stride;
uint32_t k_row_stride;
uint32_t v_row_stride;
uint32_t o_row_stride;
uint32_t q_head_stride;
uint32_t k_head_stride;
uint32_t v_head_stride;
uint32_t o_head_stride;
uint32_t b;
uint32_t h;
uint32_t h_k;
uint32_t d;
uint32_t d_rounded;
float softmax_scale;
float softcap;
uint32_t seqlen_q;
uint32_t seqlen_k;
uint32_t seqlen_q_rounded;
uint32_t seqlen_k_rounded;
int window_size_left;
int window_size_right;
int is_causal;
int is_bf16;
};
void run_mha_fwd_j(cudaStream_t stream, void **buffers,
const char *opaque,
std::size_t opaque_len);
void run_mha_bwd_j(cudaStream_t stream, void **buffers,
const char *opaque,
std::size_t opaque_len);
}
#endif
| 5 |
0 | hf_public_repos/candle/candle-flash-attn | hf_public_repos/candle/candle-flash-attn/kernels/flash.h | /******************************************************************************
* Copyright (c) 2023, Tri Dao.
******************************************************************************/
#pragma once
#include <cuda.h>
#include <vector>
// #ifdef OLD_GENERATOR_PATH
// #include <ATen/CUDAGeneratorImpl.h>
// #else
// #include <ATen/cuda/CUDAGeneratorImpl.h>
// #endif
//
// #include <ATen/cuda/CUDAGraphsUtils.cuh> // For at::cuda::philox::unpack
constexpr int TOTAL_DIM = 0;
constexpr int H_DIM = 1;
constexpr int D_DIM = 2;
////////////////////////////////////////////////////////////////////////////////////////////////////
struct Qkv_params {
using index_t = int64_t;
// The QKV matrices.
void *__restrict__ q_ptr;
void *__restrict__ k_ptr;
void *__restrict__ v_ptr;
// The stride between rows of the Q, K and V matrices.
index_t q_batch_stride;
index_t k_batch_stride;
index_t v_batch_stride;
index_t q_row_stride;
index_t k_row_stride;
index_t v_row_stride;
index_t q_head_stride;
index_t k_head_stride;
index_t v_head_stride;
// The number of heads.
int h, h_k;
// In the case of multi-query and grouped-query attention (MQA/GQA), nheads_k could be
// different from nheads (query).
int h_h_k_ratio; // precompute h / h_k,
};
////////////////////////////////////////////////////////////////////////////////////////////////////
struct Flash_fwd_params : public Qkv_params {
// The O matrix (output).
void * __restrict__ o_ptr;
void * __restrict__ oaccum_ptr;
// The stride between rows of O.
index_t o_batch_stride;
index_t o_row_stride;
index_t o_head_stride;
// The pointer to the P matrix.
void * __restrict__ p_ptr;
// The pointer to the softmax sum.
void * __restrict__ softmax_lse_ptr;
void * __restrict__ softmax_lseaccum_ptr;
// The dimensions.
int b, seqlen_q, seqlen_k, seqlen_knew, d, seqlen_q_rounded, seqlen_k_rounded, d_rounded, rotary_dim, total_q;
// The scaling factors for the kernel.
float scale_softmax;
float scale_softmax_log2;
// array of length b+1 holding starting offset of each sequence.
int * __restrict__ cu_seqlens_q;
int * __restrict__ cu_seqlens_k;
// If provided, the actual length of each k sequence.
int * __restrict__ seqused_k;
int *__restrict__ blockmask;
// The K_new and V_new matrices.
void * __restrict__ knew_ptr;
void * __restrict__ vnew_ptr;
// The stride between rows of the Q, K and V matrices.
index_t knew_batch_stride;
index_t vnew_batch_stride;
index_t knew_row_stride;
index_t vnew_row_stride;
index_t knew_head_stride;
index_t vnew_head_stride;
// The cos and sin matrices for rotary embedding.
void * __restrict__ rotary_cos_ptr;
void * __restrict__ rotary_sin_ptr;
// The indices to index into the KV cache.
int * __restrict__ cache_batch_idx;
// Paged KV cache
int * __restrict__ block_table;
index_t block_table_batch_stride;
int page_block_size;
// The dropout probability (probability of keeping an activation).
float p_dropout;
// uint32_t p_dropout_in_uint;
// uint16_t p_dropout_in_uint16_t;
uint8_t p_dropout_in_uint8_t;
// Scale factor of 1 / (1 - p_dropout).
float rp_dropout;
float scale_softmax_rp_dropout;
// Local window size
int window_size_left, window_size_right;
float softcap;
// Random state.
// at::PhiloxCudaState philox_args;
// Pointer to the RNG seed (idx 0) and offset (idx 1).
uint64_t * rng_state;
bool is_bf16;
bool is_causal;
// If is_seqlens_k_cumulative, then seqlen_k is cu_seqlens_k[bidb + 1] - cu_seqlens_k[bidb].
// Otherwise it's cu_seqlens_k[bidb], i.e., we use cu_seqlens_k to store the sequence lengths of K.
bool is_seqlens_k_cumulative;
bool is_rotary_interleaved;
int num_splits; // For split-KV version
void * __restrict__ alibi_slopes_ptr;
index_t alibi_slopes_batch_stride;
bool unpadded_lse; // For varlen paths: LSE is in [nheads, total_seqlen_q] format instead of [b, nheads, seqlen_q].
bool seqlenq_ngroups_swapped; // q has been transposed from (b, 1, (nheads_kv ngroups), d) to (b, ngroups, nheads_kv, d).
};
////////////////////////////////////////////////////////////////////////////////////////////////////
struct Flash_bwd_params : public Flash_fwd_params {
// The dO and dQKV matrices.
void *__restrict__ do_ptr;
void *__restrict__ dq_ptr;
void *__restrict__ dk_ptr;
void *__restrict__ dv_ptr;
// To accumulate dQ
void *__restrict__ dq_accum_ptr;
void *__restrict__ dk_accum_ptr;
void *__restrict__ dv_accum_ptr;
// // To accumulate dK and dV in case we're splitting the bwd along seqlen_q
// dimension void *__restrict__ dk_accum_ptr; void *__restrict__
// dv_accum_ptr;
// The stride between rows of the dO, dQ, dK and dV matrices.
// TD [2022-04-16]: We're using 32-bit indexing to save registers.
// The code probably won't work for arrays larger than 2GB.
index_t do_batch_stride;
index_t do_row_stride;
index_t do_head_stride;
index_t dq_batch_stride;
index_t dk_batch_stride;
index_t dv_batch_stride;
index_t dq_row_stride;
index_t dk_row_stride;
index_t dv_row_stride;
index_t dq_head_stride;
index_t dk_head_stride;
index_t dv_head_stride;
// The pointer to the softmax d sum.
void *__restrict__ dsoftmax_sum;
bool deterministic;
index_t dq_accum_split_stride;
};
////////////////////////////////////////////////////////////////////////////////////////////////////
template<typename T, int Headdim, bool Is_causal> void run_mha_fwd_(Flash_fwd_params ¶ms, cudaStream_t stream);
template<typename T, int Headdim, bool Is_causal> void run_mha_fwd_splitkv_dispatch(Flash_fwd_params ¶ms, cudaStream_t stream);
template<typename T, int Headdim> void run_mha_bwd_(Flash_bwd_params ¶ms, cudaStream_t stream);
| 6 |
0 | hf_public_repos/candle/candle-flash-attn | hf_public_repos/candle/candle-flash-attn/kernels/flash_api.cu | #include "kernels.h"
#include "kernel_helpers.h"
#include "flash_fwd_launch_template.h"
void run_mha_fwd(Flash_fwd_params ¶ms, cudaStream_t stream) {
FP16_SWITCH(!params.is_bf16, [&] {
HEADDIM_SWITCH(params.d, [&] {
BOOL_SWITCH(params.is_causal, Is_causal, [&] {
run_mha_fwd_<elem_type, kHeadDim, Is_causal>(params, stream);
});
});
});
}
extern "C" void run_mha(
void *q_ptr,
void *k_ptr,
void *v_ptr,
void *o_ptr,
void *softmax_lse_ptr,
void *alibi_slopes_ptr,
int32_t *cu_seqlens_q_ptr,
int32_t *cu_seqlens_k_ptr,
uint32_t q_batch_stride,
uint32_t k_batch_stride,
uint32_t v_batch_stride,
uint32_t o_batch_stride,
uint32_t alibi_slopes_batch_stride,
uint32_t q_row_stride,
uint32_t k_row_stride,
uint32_t v_row_stride,
uint32_t o_row_stride,
uint32_t q_head_stride,
uint32_t k_head_stride,
uint32_t v_head_stride,
uint32_t o_head_stride,
uint32_t b,
uint32_t h,
uint32_t h_k,
uint32_t d,
uint32_t d_rounded,
float softmax_scale,
uint32_t seqlen_q,
uint32_t seqlen_k,
uint32_t seqlen_q_rounded,
uint32_t seqlen_k_rounded,
int is_bf16,
int is_causal,
int window_size_left,
int window_size_right
) {
Flash_fwd_params params;
// Reset the parameters
memset(¶ms, 0, sizeof(params));
// Set the pointers and strides.
params.q_ptr = q_ptr;
params.k_ptr = k_ptr;
params.v_ptr = v_ptr;
params.o_ptr = o_ptr;
params.softmax_lse_ptr = softmax_lse_ptr;
params.alibi_slopes_ptr = alibi_slopes_ptr;
// All stride are in elements, not bytes.
params.q_batch_stride = q_batch_stride;
params.k_batch_stride = k_batch_stride;
params.v_batch_stride = v_batch_stride;
params.o_batch_stride = o_batch_stride;
params.alibi_slopes_batch_stride = alibi_slopes_batch_stride;
params.q_row_stride = q_row_stride;
params.k_row_stride = k_row_stride;
params.v_row_stride = v_row_stride;
params.o_row_stride = o_row_stride;
params.q_head_stride = q_head_stride;
params.k_head_stride = k_head_stride;
params.v_head_stride = v_head_stride;
params.o_head_stride = o_head_stride;
// Set the dimensions.
params.b = b;
params.h = h;
params.h_k = h_k;
params.h_h_k_ratio = h / h_k;
params.seqlen_q = seqlen_q;
params.seqlen_k = seqlen_k;
params.seqlen_q_rounded = seqlen_q_rounded;
params.seqlen_k_rounded = seqlen_k_rounded;
params.d = d;
params.d_rounded = d_rounded;
// Set the different scale values.
params.scale_softmax = softmax_scale;
params.scale_softmax_log2 = softmax_scale * M_LOG2E;
params.p_dropout = 1.; // probability to keep
params.p_dropout_in_uint8_t = uint8_t(std::floor(params.p_dropout * 255.0));
params.rp_dropout = 1.f / params.p_dropout;
params.scale_softmax_rp_dropout = params.rp_dropout * params.scale_softmax;
params.is_bf16 = is_bf16;
params.cu_seqlens_q = cu_seqlens_q_ptr;
params.cu_seqlens_k = cu_seqlens_k_ptr;
params.p_ptr = nullptr; // used for `return_softmax`.
params.seqused_k = nullptr;
params.is_causal = is_causal;
params.window_size_left = window_size_left;
params.window_size_right = window_size_right;
params.is_seqlens_k_cumulative = true;
params.num_splits = 1;
cudaStream_t stream = 0; // Use the default stream.
run_mha_fwd(params, stream);
}
| 7 |
0 | hf_public_repos/candle/candle-flash-attn | hf_public_repos/candle/candle-flash-attn/kernels/block_info.h | /******************************************************************************
* Copyright (c) 2023, Tri Dao.
******************************************************************************/
#pragma once
namespace flash {
////////////////////////////////////////////////////////////////////////////////////////////////////
template<bool Varlen=true>
struct BlockInfo {
template<typename Params>
__device__ BlockInfo(const Params ¶ms, const int bidb)
: sum_s_q(!Varlen || params.cu_seqlens_q == nullptr ? -1 : params.cu_seqlens_q[bidb])
, sum_s_k(!Varlen || params.cu_seqlens_k == nullptr || !params.is_seqlens_k_cumulative ? -1 : params.cu_seqlens_k[bidb])
, actual_seqlen_q(!Varlen || params.cu_seqlens_q == nullptr ? params.seqlen_q : params.cu_seqlens_q[bidb + 1] - sum_s_q)
// If is_seqlens_k_cumulative, then seqlen_k is cu_seqlens_k[bidb + 1] - cu_seqlens_k[bidb].
// Otherwise it's cu_seqlens_k[bidb], i.e., we use cu_seqlens_k to store the sequence lengths of K.
, seqlen_k_cache(!Varlen || params.cu_seqlens_k == nullptr ? params.seqlen_k : (params.is_seqlens_k_cumulative ? params.cu_seqlens_k[bidb + 1] - sum_s_k : params.cu_seqlens_k[bidb]))
, actual_seqlen_k(params.seqused_k ? params.seqused_k[bidb] : seqlen_k_cache + (params.knew_ptr == nullptr ? 0 : params.seqlen_knew))
{
}
template <typename index_t>
__forceinline__ __device__ index_t q_offset(const index_t batch_stride, const index_t row_stride, const int bidb) const {
return sum_s_q == -1 ? bidb * batch_stride : uint32_t(sum_s_q) * row_stride;
}
template <typename index_t>
__forceinline__ __device__ index_t k_offset(const index_t batch_stride, const index_t row_stride, const int bidb) const {
return sum_s_k == -1 ? bidb * batch_stride : uint32_t(sum_s_k) * row_stride;
}
const int sum_s_q;
const int sum_s_k;
const int actual_seqlen_q;
// We have to have seqlen_k_cache declared before actual_seqlen_k, otherwise actual_seqlen_k is set to 0.
const int seqlen_k_cache;
const int actual_seqlen_k;
};
////////////////////////////////////////////////////////////////////////////////////////////////////
} // namespace flash
| 8 |
0 | hf_public_repos/candle/candle-flash-attn | hf_public_repos/candle/candle-flash-attn/kernels/static_switch.h | // Inspired by
// https://github.com/NVIDIA/DALI/blob/main/include/dali/core/static_switch.h
// and https://github.com/pytorch/pytorch/blob/master/aten/src/ATen/Dispatch.h
#pragma once
/// @param COND - a boolean expression to switch by
/// @param CONST_NAME - a name given for the constexpr bool variable.
/// @param ... - code to execute for true and false
///
/// Usage:
/// ```
/// BOOL_SWITCH(flag, BoolConst, [&] {
/// some_function<BoolConst>(...);
/// });
/// ```
#define BOOL_SWITCH(COND, CONST_NAME, ...) \
[&] { \
if (COND) { \
constexpr static bool CONST_NAME = true; \
return __VA_ARGS__(); \
} else { \
constexpr static bool CONST_NAME = false; \
return __VA_ARGS__(); \
} \
}()
#ifdef FLASHATTENTION_DISABLE_DROPOUT
#define DROPOUT_SWITCH(COND, CONST_NAME, ...) \
[&] { \
constexpr static bool CONST_NAME = false; \
return __VA_ARGS__(); \
}()
#else
#define DROPOUT_SWITCH BOOL_SWITCH
#endif
#ifdef FLASHATTENTION_DISABLE_ALIBI
#define ALIBI_SWITCH(COND, CONST_NAME, ...) \
[&] { \
constexpr static bool CONST_NAME = false; \
return __VA_ARGS__(); \
}()
#else
#define ALIBI_SWITCH BOOL_SWITCH
#endif
#ifdef FLASHATTENTION_DISABLE_UNEVEN_K
#define EVENK_SWITCH(COND, CONST_NAME, ...) \
[&] { \
constexpr static bool CONST_NAME = true; \
return __VA_ARGS__(); \
}()
#else
#define EVENK_SWITCH BOOL_SWITCH
#endif
#ifdef FLASHATTENTION_DISABLE_SOFTCAP
#define SOFTCAP_SWITCH(COND, CONST_NAME, ...) \
[&] { \
constexpr static bool CONST_NAME = false; \
return __VA_ARGS__(); \
}()
#else
#define SOFTCAP_SWITCH BOOL_SWITCH
#endif
#ifdef FLASHATTENTION_DISABLE_LOCAL
#define LOCAL_SWITCH(COND, CONST_NAME, ...) \
[&] { \
constexpr static bool CONST_NAME = false; \
return __VA_ARGS__(); \
}()
#else
#define LOCAL_SWITCH BOOL_SWITCH
#endif
#define FP16_SWITCH(COND, ...) \
[&] { \
if (COND) { \
using elem_type = cutlass::half_t; \
return __VA_ARGS__(); \
} else { \
using elem_type = cutlass::bfloat16_t; \
return __VA_ARGS__(); \
} \
}()
#define HEADDIM_SWITCH(HEADDIM, ...) \
[&] { \
if (HEADDIM <= 32) { \
constexpr static int kHeadDim = 32; \
return __VA_ARGS__(); \
} else if (HEADDIM <= 64) { \
constexpr static int kHeadDim = 64; \
return __VA_ARGS__(); \
} else if (HEADDIM <= 96) { \
constexpr static int kHeadDim = 96; \
return __VA_ARGS__(); \
} else if (HEADDIM <= 128) { \
constexpr static int kHeadDim = 128; \
return __VA_ARGS__(); \
} else if (HEADDIM <= 160) { \
constexpr static int kHeadDim = 160; \
return __VA_ARGS__(); \
} else if (HEADDIM <= 192) { \
constexpr static int kHeadDim = 192; \
return __VA_ARGS__(); \
} else if (HEADDIM <= 224) { \
constexpr static int kHeadDim = 224; \
return __VA_ARGS__(); \
} else if (HEADDIM <= 256) { \
constexpr static int kHeadDim = 256; \
return __VA_ARGS__(); \
} \
}()
| 9 |
0 | hf_public_repos | hf_public_repos/blog/ml-for-games-1.md | ---
title: "AI for Game Development: Creating a Farming Game in 5 Days. Part 1"
thumbnail: /blog/assets/124_ml-for-games/thumbnail.png
authors:
- user: dylanebert
---
# AI for Game Development: Creating a Farming Game in 5 Days. Part 1
**Welcome to AI for Game Development!** In this series, we'll be using AI tools to create a fully functional farming game in just 5 days. By the end of this series, you will have learned how you can incorporate a variety of AI tools into your game development workflow. I will show you how you can use AI tools for:
1. Art Style
2. Game Design
3. 3D Assets
4. 2D Assets
5. Story
Want the quick video version? You can watch it [here](https://www.tiktok.com/@individualkex/video/7184106492180630827). Otherwise, if you want the technical details, keep reading!
**Note:** This tutorial is intended for readers who are familiar with Unity development and C#. If you're new to these technologies, check out the [Unity for Beginners](https://www.tiktok.com/@individualkex/video/7086863567412038954?is_from_webapp=1&sender_device=pc&web_id=7043883634428052997) series before continuing.
## Day 1: Art Style
The first step in our game development process **is deciding on the art style**. To decide on the art style for our farming game, we'll be using a tool called Stable Diffusion. Stable Diffusion is an open-source model that generates images based on text descriptions. We'll use this tool to create a visual style for our game.
### Setting up Stable Diffusion
There are a couple options for running Stable Diffusion: *locally* or *online*. If you're on a desktop with a decent GPU and want the fully-featured toolset, I recommend <a href="#locally">locally</a>. Otherwise, you can run an <a href="#online">online</a> solution.
#### Locally <a name="locally"></a>
We'll be running Stable Diffusion locally using the [Automatic1111 WebUI](https://github.com/AUTOMATIC1111/stable-diffusion-webui). This is a popular solution for running Stable Diffusion locally, but it does require some technical knowledge to set up. If you're on Windows and have an Nvidia GPU with at least 8 gigabytes in memory, continue with the instructions below. Otherwise, you can find instructions for other platforms on the [GitHub repository README](https://github.com/AUTOMATIC1111/stable-diffusion-webui), or may opt instead for an <a href="#online">online</a> solution.
##### Installation on Windows:
**Requirements**: An Nvidia GPU with at least 8 gigabytes of memory.
1. Install [Python 3.10.6](https://www.python.org/downloads/windows/). **Be sure to check "Add Python to PATH" during installation.**
2. Install [git](https://git-scm.com/download/win).
3. Clone the repository by typing the following in the Command Prompt:
```
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git
```
4. Download the [Stable Diffusion 1.5 weights](https://huggingface.co/runwayml/stable-diffusion-v1-5). Place them in the `models` directory of the cloned repository.
5. Run the WebUI by running `webui-user.bat` in the cloned repository.
6. Navigate to `localhost://7860` to use the WebUI. If everything is working correctly, it should look something like this:
<figure class="image text-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/124_ml-for-games/webui.png" alt="Stable Diffusion WebUI">
</figure>
#### Online <a name="online"></a>
If you don't meet the requirements to run Stable Diffusion locally, or prefer a more streamlined solution, there are many ways to run Stable Diffusion online.
Free solutions include many [spaces](https://huggingface.co/spaces) here on 🤗 Hugging Face, such as the [Stable Diffusion 2.1 Demo](https://huggingface.co/spaces/stabilityai/stable-diffusion) or the [camemduru webui](https://huggingface.co/spaces/camenduru/webui). You can find a list of additional online services [here](https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki/Online-Services). You can even use 🤗 [Diffusers](https://huggingface.co/docs/diffusers/index) to write your own free solution! You can find a simple code example to get started [here](https://colab.research.google.com/drive/1HebngGyjKj7nLdXfj6Qi0N1nh7WvD74z?usp=sharing).
*Note:* Parts of this series will use advanced features such as image2image, which may not be available on all online services.
### Generating Concept Art <a name="generating"></a>
Let's generate some concept art. The steps are simple:
1. Type what you want.
2. Click generate.
<figure class="image text-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/124_ml-for-games/sd-demo.png" alt="Stable Diffusion Demo Space">
</figure>
But, how do you get the results you actually want? Prompting can be an art by itself, so it's ok if the first images you generate are not great. There are many amazing resources out there to improve your prompting. I made a [20-second video](https://youtube.com/shorts/8PGucf999nI?feature=share) on the topic. You can also find this more extensive [written guide](https://www.reddit.com/r/StableDiffusion/comments/x41n87/how_to_get_images_that_dont_suck_a/).
The shared point of emphasis of these is to use a source such as [lexica.art](https://lexica.art/) to see what others have generated with Stable Diffusion. Look for images that are similar to the style you want, and get inspired. There is no right or wrong answer here, but here are some tips when generating concept art with Stable Diffusion 1.5:
- Constrain the *form* of the output with words like *isometric, simple, solid shapes*. This produces styles that are easier to reproduce in-game.
- Some keywords, like *low poly*, while on-topic, tend to produce lower-quality results. Try to find alternate keywords that don't degrade results.
- Using names of specific artists is a powerful way to guide the model toward specific styles with higher-quality results.
I settled on the prompt: *isometric render of a farm by a river, simple, solid shapes, james gilleard, atey ghailan*. Here's the result:
<figure class="image text-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/124_ml-for-games/concept.png" alt="Stable Diffusion Concept Art">
</figure>
### Bringing it to Unity
Now, how do we make this concept art into a game? We'll be using [Unity](https://unity.com/), a popular game engine, to bring our game to life.
1. Create a Unity project using [Unity 2021.9.3f1](https://unity.com/releases/editor/whats-new/2021.3.9) with the [Universal Render Pipeline](https://docs.unity3d.com/Packages/[email protected]/manual/index.html).
2. Block out the scene using basic shapes. For example, to add a cube, *Right Click -> 3D Object -> Cube*.
<figure class="image text-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/124_ml-for-games/gray.png" alt="Gray Scene">
</figure>
3. Set up your [Materials](https://docs.unity3d.com/Manual/Materials.html), using the concept art as a reference. I'm using the basic built-in materials.
<figure class="image text-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/124_ml-for-games/color.png" alt="Scene with Materials">
</figure>
4. Set up your [Lighting](https://docs.unity3d.com/Manual/Lighting.html). I'm using a warm sun (#FFE08C, intensity 1.25) with soft ambient lighting (#B3AF91).
<figure class="image text-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/124_ml-for-games/lighting.png" alt="Scene with Lighting">
</figure>
5. Set up your [Camera](https://docs.unity3d.com/ScriptReference/Camera.html) **using an orthographic projection** to match the projection of the concept art.
<figure class="image text-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/124_ml-for-games/camera.png" alt="Scene with Camera">
</figure>
6. Add some water. I'm using the [Stylized Water Shader](https://assetstore.unity.com/packages/vfx/shaders/stylized-water-shader-71207) from the Unity asset store.
<figure class="image text-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/124_ml-for-games/water.png" alt="Scene with Water">
</figure>
7. Finally, set up [Post-processing](https://docs.unity3d.com/Packages/[email protected]/manual/integration-with-post-processing.html). I'm using ACES tonemapping and +0.2 exposure.
<figure class="image text-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/124_ml-for-games/post-processing.png" alt="Final Result">
</figure>
That's it! A simple but appealing scene, made in less than a day! Have questions? Want to get more involved? Join the [Hugging Face Discord](https://t.co/1n75wi976V?amp=1)!
Click [here](https://huggingface.co/blog/ml-for-games-2) to read Part 2, where we use **AI for Game Design**. | 0 |
0 | hf_public_repos | hf_public_repos/blog/password-git-deprecation.md | ---
title: Deprecation of Git Authentication using password
thumbnail: /blog/assets/password-git-deprecation/thumbnail.png
authors:
- user: Sylvestre
- user: pierric
- user: sbrandeis
---
# Hugging Face Hub: Important Git Authentication Changes
Because we are committed to improving the security of our services, we are making changes to the way you authenticate when interacting with the Hugging Face Hub through Git.
Starting from **October 1st, 2023**, we will no longer accept passwords as a way to authenticate your command-line Git operations. Instead, we recommend using more secure authentication methods, such as replacing the password with a personal access token or using an SSH key.
## Background
In recent months, we have implemented various security enhancements, including sign-in alerts and support for SSH keys in Git. However, users have still been able to authenticate Git operations using their username and password. To further improve security, we are now transitioning to token-based or SSH key authentication.
Token-based and SSH key authentication offer several advantages over traditional password authentication, including unique, revocable, and random features that enhance security and control.
## Action Required Today
If you currently use your HF account password to authenticate with Git, please switch to using a personal access token or SSH keys before **October 1st, 2023**.
### Switching to personal access token
You will need to generate an access token for your account; you can follow https://huggingface.co/docs/hub/security-tokens#user-access-tokens to generate one.
After generating your access token, you can update your Git repository using the following commands:
```bash
$: git remote set-url origin https://<user_name>:<token>@huggingface.co/<repo_path>
$: git pull origin
```
where `<repo_path>` is in the form of:
- `<user_name>/<repo_name>` for models
- `datasets/<user_name>/<repo_name>` for datasets
- `spaces/<user_name>/<repo_name>` for Spaces
If you clone a new repo, you can just input a token in place of your password when your Git credential manager asks you for your authentication credentials.
### Switching to SSH keys
Follow our guide to generate an SSH key and add it to your account: https://huggingface.co/docs/hub/security-git-ssh
Then you'll be able to update your Git repository using:
```bash
$: git remote set-url origin [email protected]:<repo_path> # see above for the format of the repo path
```
## Timeline
Here's what you can expect in the coming weeks:
- Today: Users relying on passwords for Git authentication may receive emails urging them to update their authentication method.
- October 1st: Personal access tokens or SSH keys will be mandatory for all Git operations.
For more details, reach out to HF Support to address any questions or concerns at [email protected]
| 1 |
0 | hf_public_repos | hf_public_repos/blog/_events.yml | # "date" attribute should be end date of an event in `Mon DD, YYYY` format (e.g. Feb 3, 2014)
# "date_formatted" attribute is optional if you want to control the format/look of "date" on hf.co
# (e.g. specifying event date range like Jan 24 to Feb 7, 2022)
# pro tip: put strings e.g. name or description in "quotes" or do not include special characters incl. ':' '['
- name: "Hugging Face Open Source community event 🥐 Paris"
link: https://partiful.com/e/oWOMGoPxB5D37qw5F8yN
date: October 5, 2023
description: "Hugging Face Community event in Paris is here! Join the space with an amazing intersection between researchers, machine learning engineers, artists, and enthusiasts."
- name: "The Race to Open-Source ChatGPT"
link: https://us06web.zoom.us/webinar/register/WN_Veu65U_zQryiN0E8DNkzUA?t=1693401002754
date: September 1, 2023
description: "Join Lewis Tunstall at FlowGPT's PromptCon for a talk on the exciting developments around open-source chatbots."
- name: "Hugging Cast v4 - Live AI News and Demos"
link: https://streamyard.com/watch/ujrA4pG3ixAm
date: July 27, 2023
description: "Join our live show - we'll discuss LLaMa 2 with our special guest Omar, and demo how to deploy it!"
- name: "Free Workshop: Text and Image Generation with Inferentia2"
link: https://aws-startup-lofts.com/amer/loft/new-york/e/af1cc/ml-workshop-text-and-image-generation-with-hugging-face-and-aws-inferentia
date: Jul 25, 2023
description: "[New York] Learn how to save money deploying text and image Generative AI models on AWS Inferentia2!"
- name: "Hugging Cast v3 - Live AI News and Demos"
link: https://streamyard.com/watch/6k35DN7h5n64
date: June 29, 2023
description: "Join our live show - we'll discuss Falcon, and demo how to deploy it on SageMaker"
- name: "Deploying Generative AI Models"
link: https://lu.ma/ijcugt4n
date: June 10, 2023
description: "This meetup caters to all AI enthusiasts, from beginners in model training to deployment experts and researchers."
- name: "Hugging Cast v2 - Live AI News and Demos"
link: https://streamyard.com/watch/GJkVxAWR76k2
date: May 26, 2023
description: "Join our live show - we'll discuss StarCoder, Transformer Agents and our latest benchmarks!"
- name: "Free Panel – The Linux Moment of AI: Open Sourced AI Stack"
link: https://future.snorkel.ai/agenda/
date: June 7, 2023
description: "In this virtual panel, experts, including Hugging Face Chief Evangelist, will delve into how open-source models and tools can revolutionize AI."
- name: "Free Workshop: Save money with Inferentia2"
link: https://aws-startup-lofts.com/amer/loft/san-francisco/e/c1621/ml-startup-workshop-deploying-text-summarization-and-image-generation-applications-with-hugging-face-and-aws-inferentia2
date: May 11, 2023
description: "[San Francisco] Learn how to save money deploying text and image Generative AI models on AWS Inferentia2!"
- name: Meet-up on Generative AI
link: https://sites.google.com/huggingface.co/generative-ai-meetup
date: Apr 29, 2023
description: Free meet-up in collaboration with NVIDIA to discuss the bleeding egde from the world of Generative AI.
- name: "Hugging Cast v1 - Live AI News and Demos"
link: https://streamyard.com/watch/zWBsznmYH5fP
date: Apr 27, 2023
description: "Join us for the premiere of Hugging Cast, our new live show about open source AI!"
- name: Diffusers/JAX Community Sprint
link: https://github.com/huggingface/community-events/tree/main/jax-controlnet-sprint
date: Mar 29 to May 8, 2023
description: This is a community event to develop applications with 🧨 diffusers and JAX using TPUs.
- name: Scikit-learn Documentation Sprint
link: https://github.com/huggingface/community-events/blob/main/sklearn-sprint/guidelines.md
date: Apr 14 to May 1, 2023
description: This is a community event to develop applications for examples in scikit-learn documentation using Gradio.
- name: (IRL San Francisco) Open Source AI meetup with 🤗 CEO
link: https://partiful.com/e/fE0XH0PrSOZB9ezYuFbW
date: Mar 31, 2023
description: 🤗 CEO Clement Delangue & team members are heading to San Francisco to celebrate the open-source AI community.
- name: Keras DreamBooth Community Sprint
link: https://huggingface.co/keras-dreambooth
date: Mar 6 to Apr 1, 2023
description: A community sprint on fine-tuning Stable Diffusion using DreamBooth technique on Keras library.
- name: How to build Machine Learning apps with Hugging Face
link: https://www.eventbrite.com/e/building-machine-learning-apps-with-hugging-facellms-to-diffusion-modeling-tickets-565837343727?aff=HF
date: Mar 23, 2023
description: Free workshop hosted by DeepLearning.AI for developers learn how to build with ML without the Ops.
- name: "Ethics & Society: Making Intellicence – Ethical Values in ML Benchmarks"
link: https://hf.co/ethics
date: Mar 13, 2023
description: A Discord Q&A with Leif Hancox-Li, PhD and Borhane Blili-Hamelin, PhD!
- name: (IRL San Francisco) Building Generative AI Products with AWS and HuggingFace
link: https://aws-startup-lofts.com/amer/loft/san-francisco/e/c77d4/ml-startup-tech-talk-building-generative-ai-products
date: Mar 8, 2023
description: Free event in downtown SF hosted by AWS to learn how to use Hugging Face with SageMaker
- name: Keras Dreambooth Event Kick-off Session with talks on diffusers & KerasCV
link: https://www.youtube.com/watch?v=Njt8BuSW-TQ&ab_channel=HuggingFace
date: Mar 5, 2023
description: Free talks with Francois Chollet, Nataniel Ruiz, Apolinario Passos and Merve Noyan.
- name: How Witty Works leverages Hugging Face to scale inclusive language?
link: https://www.eventbrite.com/e/how-witty-works-leverages-hugging-face-to-scale-inclusive-language-tickets-503429429977
date: Feb 16, 2023
description: This webinar will teach you how Witty Works leverages Hugging Face for text classification use cases.
- name: NLP with Transformers Reading Group
link: https://discord.gg/fabCGvFq?event=1050810825335644243
date: Dec 15, 2022
description: Want to learn how to apply transformers to your use-cases and how to contribute to open-source projects? Join our reading group!
- name: Few-Shot Learning in Production
link: https://discord.gg/fabCGvFq?event=1049707836755693628
date: Dec 14, 2022
description: Join researchers from Hugging Face and Intel Labs for a workshop about training and deploying few-shot language models.
- name: Reinforcement Learning from Human Feedback From Zero to ChatGPT
link: https://youtu.be/EAd4oQtEJOM
date: Dec 13, 2022
description: We will cover the basics of Reinforcement Learning from Human Feedback (RLHF) and how this technology is being used to enable state-of-the-art ML tools like ChatGPT
- name: Whisper Fine Tuning Sprint
link: https://discuss.huggingface.co/t/open-to-the-community-whisper-fine-tuning-event/26681
date: Dec 5, 2022
description: Help us bring SoTA Whisper architecture to 70+ languages. Join our Whisper fin-tuning sprint from Dec 5th - 19th!
- name: NLP with Transformers Reading Group
link: https://discord.com/events/879548962464493619/1042396704802091048
date: Dec 1, 2022
description: Want to learn how to apply transformers to your use-cases and how to contribute to open-source projects? Join our reading group!
- name: Diffusion Models Live Event 🧨
link: https://www.youtube.com/watch?v=5gPS_Tn9rlg
date: Nov 30, 2022
description: Live talks from the creators of Stable Diffusion and many more!
- name: NLP with Transformers Reading Group
link: https://discord.com/events/879548962464493619/1039565337420648458
date: Nov 17, 2022
description: Want to learn how to apply transformers to your use-cases and how to contribute to open-source projects? Join our reading group!
- name: NLP with Transformers Reading Group
link: https://discord.com/events/879548962464493619/1029013213318217848
date: Oct 20, 2022
description: Want to learn how to apply transformers to your use-cases and how to contribute to open-source projects? Join our reading group!
- name: Efficient Few-Shot Learning with Sentence Transformers
link: https://discord.com/events/879548962464493619/1027893081741201508
date: Oct 18, 2022
description: Join researchers from Hugging Face and Intel Labs for a presentation about their recent work on SetFit, a new framework for few-shot learning with language models.
- name: Hugging Face Inference Endpoints | 🤗 Announcement and demo
link: https://app.livestorm.co/hugging-face/hugging-face-inference-endpoints?type=detailed
date: Sep 27, 2022
description: "Transformers in production: SOLVED ✅"
- name: How Synapse Medicine leverages Hugging Face to improve medication safety
link: https://www.eventbrite.com/e/how-synapse-medicine-leverages-hugging-face-to-improve-medication-safety-tickets-328906848237
date: Sep 20, 2022
description: Learn how Synapse Medicine leverages Hugging Face to improve medication safety!
- name: Hugging Face AI Hardware Summit Workshop
link: https://www.kisacoresearch.com/ai-hardware-summit-agenda
date: Sep 13, 2022
description: Learn from Hugging Face experts how to use Graphcore IPUs, Habana Gaudi AI Hardware Accelerators with Optimum!
- name: fastai X Hugging Face Group 2022
link: https://huggingface.co/hugginglearners
date: Jul 15, 2022
date_formatted: Jun 15 to Jul 15, 2022
description: Share Vision and Text pre-trained fastai Learners with the community.
- name: Twitter Space with ONNX RunTime
link: https://twitter.com/i/spaces/1jMJgeQZjrYKL
date: Jun 22, 2022
description: Join our live discussion with the ONNX RunTime team about accelerating Transformers with Optimum!
- name: Data2vec Reading Group
link: https://huggingface.co/join/discord
date: Jun 22, 2022
description: Join us to talk about data2vec, a model that works across different modalities - text, audio, and images.
- name: Hugging Face VIP Party at the AI Summit London
link: https://www.addevent.com/event/Rt13780880
date: Jun 15, 2022
description: Come meet Hugging Face at the Skylight Bar on the roof of Tobacco Dock during AI Summit London! 6pm-9pm
- name: Masader Hackathon
link: https://docs.google.com/document/d/1Oc-UhWByRnrPk4Orh2bVenV9PzxkGRjkML9ebBqn9hU/edit?usp=sharing
date: Jun 10, 2022
description: A sprint to add 125 Arabic NLP datasets to Masader, https://arbml.github.io/masader/, 5pm-7pm Saudi Arabia time.
- name: Introduction to Hugging Face Ecosystem at PyData Paris
link: https://www.meetup.com/PyData-Paris/events/286206845/
date: June 9, 2022
description: An extensive introduction to the open-source ecosystem in Hugging Face.
- name: Computer Vision with Hugging Face
link: https://youtu.be/oL-xmufhZM8
date: June 8, 2022
description: In this session, Niels Rogge walks us through the tools and architectures used to train computer vision models using Hugging Face.
- name: How to Teach Open-Source Machine Learning Tools
link: https://www.eventbrite.com/e/how-to-teach-open-source-machine-learning-tools-tickets-310980931337
date: Jun 6, 2022
description: Learn how the open-source ecosystem can be used in your machine learning and data science classes.
- name: Accelerate BERT Inference with Knowledge Distillation & AWS Inferentia
link: https://app.livestorm.co/hugging-face/accelerate-bert-inference-with-knowledge-distillation-and-aws-inferentia?type=detailed
date: Apr 13, 2022
description: Accelerate BERT Inference with knowledge distillation & compiling using Hugging Face Transformers, Amazon SageMaker & AWS Inferentia.
- name: Computer Vision Study Group Paper Reading Session on "How Do Vision Transformers Work?"
link: https://discord.gg/EmEpESpn?event=957940949261115402
date: Apr 5, 2022
description: Discussion on paper "How Do Vision Transformers Work?".
- name: NLP in Spanish Hackathon
link: https://www.eventbrite.com/e/registro-hackathon-de-pln-en-espanol-273014111557
date: Mar 31, 2022
date_formatted: Mar 14 to Mar 31, 2022
description: Largest Hackathon ever of NLP in Spanish.
- name: Chasing the wrong benchmarks in Machine Learning, How it will fail in production
link: https://eveeno.com/ai-academy-kickoff
date: Mar 22, 2022
description: Niels Reimers will present his view on chasing wrong benchmarks in ML and how they will fail in production.
- name: NLP with TF Keras and HF Transformers with Merve Noyan
link: https://www.youtube.com/watch?v=IBaDGxgY3Po&ab_channel=Weights%26Biases
date: Feb 16, 2022
description: Learn about how NLP can be done with TensorFlow and Transformers.
- name: Robust Speech Recognition Challenge
link: https://discuss.huggingface.co/t/open-to-the-community-robust-speech-recognition-challenge/13614
date: Feb 7, 2022
date_formatted: Jan 24 to Feb 7, 2022
description: Community event in which robust speech recognition systems in many languages are created.
- name: Hub Featureton
link: https://www.youtube.com/watch?v=gAEeiFR7O0Q&ab_channel=HuggingFace
date: Feb 3, 2022
description: Would you like to know all the things you can do with the Hub? This event is for you! During the webinar, we'll go through some amazing features the Hugging Face team has been working on.
- name: XLS-R, Large-Scale Cross-lingual Speech Representation Learning on 128 Languages
link: https://www.youtube.com/watch?v=ic_J7ZCROBM&ab_channel=HuggingFace
date: Jan 21, 2022
description: Changan Wang, from Meta AI Research, is one of the authors of the XLS-R, a large-scale model for cross-lingual speech representation learning based on wav2vec.
- name: The Common Voice Dataset
link: https://www.youtube.com/watch?v=Vvn984QmAVg&ab_channel=HuggingFace
date: Jan 21, 2022
description: Gabriel Habayeb, from Mozilla Common Voice, will join us to speak about the Common Voice Dataset.
- name: ML for Audio Study Group - ML4Audio - pyctcdecode, A simple and fast speech-to-text prediction decoding algorithm
link: https://www.youtube.com/watch?v=CDuvVL0z_xk&ab_channel=HuggingFace
date: Jan 19, 2022
description: Watch a presentation about pyctcdecode, a fast and feature-rich CTC beam search decoder for speech recognition.
- name: Intro to Transfer Learning, end-to-end deployment with TFX, and demo with Streamlit
link: https://www.youtube.com/watch?v=y9qy7lxXl-c&ab_channel=TensorFlowUserGroupCasablanca
date: Jan 8, 2022
date_formatted: Jan 7 & 8, 2022
description: Are you a TF user and would like to learn about Transformers and building cool demos? This is for you!
- name: ML for Audio Study Group - Text to Speech Deep Dive
link: https://www.youtube.com/watch?v=aLBedWj-5CQ&ab_channel=HuggingFace
date: Jan 4, 2022
description: Vatsal and VB provide a high level overview of how TTS is solved and share more about the history of the domain.
- name: ML for Audio Study Group - Intro to Audio and ASR Deep Dive
link: https://www.youtube.com/watch?v=D-MH6YjuIlE&ab_channel=HuggingFace
date: Dec 21, 2021
description: Watch a high level overview of audio data and its challenges and learn about transcribing audio files.
- name: GDG Cloud San Francisco DevFest - BigScience
link: https://youtu.be/-euoEOpfUIk?t=5695
date: Dec 18, 2021
description: Learn about the BigScience project, a one year research workshop on large multilingual datasets and language models.
- name: Pretraining Language Models & CodeParrot
link: https://www.youtube.com/watch?v=ExUR7w6xe94&ab_channel=HuggingFace
date: Dec 17, 2021
description: Leandro and Merve explain how to pre-train language models and Code Parrot, a model that can write code.
- name: ML for Audio Study Group - Kick Off
link: https://www.youtube.com/watch?v=cAviRhkqdnc&ab_channel=HuggingFace
date: Dec 14, 2021
description: Intro to ML for Audio. Learn about Automatic Speech Recognition and Text to Speech.
- name: Question Answering workshop
link: https://www.youtube.com/watch?v=Ihgk8kGLpIE&ab_channel=HuggingFace
date: Dec 10, 2021
description: Course special session where Lewis and Merve will go through notebooks, course material and answer your questions.
- name: On Sentiments and Biases
link: https://www.youtube.com/watch?v=0K5ybetv-dA&ab_channel=HuggingFace
date: Dec 8, 2021
description: Join Merve & Vincent in this talk on Sentiments and Biases in Hugging Face models!
- name: Implementing DietNeRF with JAX and Flax.
link: https://www.youtube.com/watch?v=A9iefUXkvQU&t=1s&ab_channel=HuggingFace
date: Nov 30, 2021
description: Learn about NeRF, JAX+Flax, 3D reconstruction, HF Spaces, and more!
- name: Course launch event!
link: https://www.youtube.com/playlist?list=PLo2EIpI_JMQvcXKx5RFReyg6Qd2UICAif
date: Nov 15, 2021
description: Talks from Thom Wolf, Margaret Mitchell, Jay Alammar, and many more!
- name: Open Source Office Hours
link: https://www.youtube.com/watch?v=VWOHu_Hg0Pc
date: Nov 8, 2021
description: In this 30 minutes session the team will share the latest updates from our open source tools and answer questions from the community.
- name: T0 Discussion with Victor Sanh
link: https://www.youtube.com/watch?v=Oy49SCW_Xpw&ab_channel=HuggingFace
date: Nov 5, 2021
description: Learn about the T0, a model for zero-show task generalization
- name: NLP with Transformers and the Hugging Face Ecosystem 🤗
link: https://www.mlt.ai/hands-on-transformers-workshop
date: Oct 22, 2021
description: In this workshop, learn the core concepts behind Transformers and how to train these models in the Hugging Face ecosystem.
| 2 |
0 | hf_public_repos | hf_public_repos/blog/how-to-train.md | ---
title: How to train a new language model from scratch using Transformers and Tokenizers
thumbnail: /blog/assets/01_how-to-train/how-to-train_blogpost.png
authors:
- user: julien-c
---
# How to train a new language model from scratch using Transformers and Tokenizers
<a target="_blank" href="https://colab.research.google.com/github/huggingface/blog/blob/main/notebooks/01_how_to_train.ipynb">
<img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab">
</a>
Over the past few months, we made several improvements to our [`transformers`](https://github.com/huggingface/transformers) and [`tokenizers`](https://github.com/huggingface/tokenizers) libraries, with the goal of making it easier than ever to **train a new language model from scratch**.
In this post we’ll demo how to train a “small” model (84 M parameters = 6 layers, 768 hidden size, 12 attention heads) – that’s the same number of layers & heads as DistilBERT – on **Esperanto**. We’ll then fine-tune the model on a downstream task of part-of-speech tagging.
Esperanto is a *constructed language* with a goal of being easy to learn. We pick it for this demo for several reasons:
- it is a relatively low-resource language (even though it’s spoken by ~2 million people) so this demo is less boring than training one more English model 😁
- its grammar is highly regular (e.g. all common nouns end in -o, all adjectives in -a) so we should get interesting linguistic results even on a small dataset.
- finally, the overarching goal at the foundation of the language is to bring people closer (fostering world peace and international understanding) which one could argue is aligned with the goal of the NLP community 💚
> N.B. You won’t need to understand Esperanto to understand this post, but if you do want to learn it, [Duolingo](https://www.duolingo.com/enroll/eo/en/Learn-Esperanto) has a nice course with 280k active learners.
Our model is going to be called… wait for it… **EsperBERTo** 😂
<img src="/blog/assets/01_how-to-train/eo.svg" alt="Esperanto flag" style="margin: auto; display: block; width: 260px;">
## 1. Find a dataset
First, let us find a corpus of text in Esperanto. Here we’ll use the Esperanto portion of the [OSCAR corpus](https://traces1.inria.fr/oscar/) from INRIA.
OSCAR is a huge multilingual corpus obtained by language classification and filtering of [Common Crawl](https://commoncrawl.org/) dumps of the Web.
<img src="/blog/assets/01_how-to-train/oscar.png" style="margin: auto; display: block; width: 260px;">
The Esperanto portion of the dataset is only 299M, so we’ll concatenate with the Esperanto sub-corpus of the [Leipzig Corpora Collection](https://wortschatz.uni-leipzig.de/en/download), which is comprised of text from diverse sources like news, literature, and wikipedia.
The final training corpus has a size of 3 GB, which is still small – for your model, you will get better results the more data you can get to pretrain on.
## 2. Train a tokenizer
We choose to train a byte-level Byte-pair encoding tokenizer (the same as GPT-2), with the same special tokens as RoBERTa. Let’s arbitrarily pick its size to be 52,000.
We recommend training a byte-level BPE (rather than let’s say, a WordPiece tokenizer like BERT) because it will start building its vocabulary from an alphabet of single bytes, so all words will be decomposable into tokens (no more `<unk>` tokens!).
```python
#! pip install tokenizers
from pathlib import Path
from tokenizers import ByteLevelBPETokenizer
paths = [str(x) for x in Path("./eo_data/").glob("**/*.txt")]
# Initialize a tokenizer
tokenizer = ByteLevelBPETokenizer()
# Customize training
tokenizer.train(files=paths, vocab_size=52_000, min_frequency=2, special_tokens=[
"<s>",
"<pad>",
"</s>",
"<unk>",
"<mask>",
])
# Save files to disk
tokenizer.save_model(".", "esperberto")
```
And here’s a slightly accelerated capture of the output:

<small>On our dataset, training took about ~5 minutes.</small>
🔥🔥 Wow, that was fast! ⚡️🔥
We now have both a `vocab.json`, which is a list of the most frequent tokens ranked by frequency, and a `merges.txt` list of merges.
```json
{
"<s>": 0,
"<pad>": 1,
"</s>": 2,
"<unk>": 3,
"<mask>": 4,
"!": 5,
"\"": 6,
"#": 7,
"$": 8,
"%": 9,
"&": 10,
"'": 11,
"(": 12,
")": 13,
# ...
}
# merges.txt
l a
Ġ k
o n
Ġ la
t a
Ġ e
Ġ d
Ġ p
# ...
```
What is great is that our tokenizer is optimized for Esperanto. Compared to a generic tokenizer trained for English, more native words are represented by a single, unsplit token. Diacritics, i.e. accented characters used in Esperanto – `ĉ`, `ĝ`, `ĥ`, `ĵ`, `ŝ`, and `ŭ` – are encoded natively. We also represent sequences in a more efficient manner. Here on this corpus, the average length of encoded sequences is ~30% smaller as when using the pretrained GPT-2 tokenizer.
Here’s how you can use it in `tokenizers`, including handling the RoBERTa special tokens – of course, you’ll also be able to use it directly from `transformers`.
```python
from tokenizers.implementations import ByteLevelBPETokenizer
from tokenizers.processors import BertProcessing
tokenizer = ByteLevelBPETokenizer(
"./models/EsperBERTo-small/vocab.json",
"./models/EsperBERTo-small/merges.txt",
)
tokenizer._tokenizer.post_processor = BertProcessing(
("</s>", tokenizer.token_to_id("</s>")),
("<s>", tokenizer.token_to_id("<s>")),
)
tokenizer.enable_truncation(max_length=512)
print(
tokenizer.encode("Mi estas Julien.")
)
# Encoding(num_tokens=7, ...)
# tokens: ['<s>', 'Mi', 'Ġestas', 'ĠJuli', 'en', '.', '</s>']
```
## 3. Train a language model from scratch
**Update:** The associated Colab notebook uses our new [`Trainer`](https://github.com/huggingface/transformers/blob/master/src/transformers/trainer.py) directly, instead of through a script. Feel free to pick the approach you like best.
We will now train our language model using the [`run_language_modeling.py`](https://github.com/huggingface/transformers/blob/main/examples/legacy/run_language_modeling.py) script from `transformers` (newly renamed from `run_lm_finetuning.py` as it now supports training from scratch more seamlessly). Just remember to leave `--model_name_or_path` to `None` to train from scratch vs. from an existing model or checkpoint.
> We’ll train a RoBERTa-like model, which is a BERT-like with a couple of changes (check the [documentation](https://huggingface.co/transformers/model_doc/roberta.html) for more details).
As the model is BERT-like, we’ll train it on a task of *Masked language modeling*, i.e. the predict how to fill arbitrary tokens that we randomly mask in the dataset. This is taken care of by the example script.
We just need to do two things:
- implement a simple subclass of `Dataset` that loads data from our text files
- Depending on your use case, you might not even need to write your own subclass of Dataset, if one of the provided examples (`TextDataset` and `LineByLineTextDataset`) works – but there are lots of custom tweaks that you might want to add based on what your corpus looks like.
- Choose and experiment with different sets of hyperparameters.
Here’s a simple version of our EsperantoDataset.
```python
from torch.utils.data import Dataset
class EsperantoDataset(Dataset):
def __init__(self, evaluate: bool = False):
tokenizer = ByteLevelBPETokenizer(
"./models/EsperBERTo-small/vocab.json",
"./models/EsperBERTo-small/merges.txt",
)
tokenizer._tokenizer.post_processor = BertProcessing(
("</s>", tokenizer.token_to_id("</s>")),
("<s>", tokenizer.token_to_id("<s>")),
)
tokenizer.enable_truncation(max_length=512)
# or use the RobertaTokenizer from `transformers` directly.
self.examples = []
src_files = Path("./data/").glob("*-eval.txt") if evaluate else Path("./data/").glob("*-train.txt")
for src_file in src_files:
print("🔥", src_file)
lines = src_file.read_text(encoding="utf-8").splitlines()
self.examples += [x.ids for x in tokenizer.encode_batch(lines)]
def __len__(self):
return len(self.examples)
def __getitem__(self, i):
# We’ll pad at the batch level.
return torch.tensor(self.examples[i])
```
If your dataset is very large, you can opt to load and tokenize examples on the fly, rather than as a preprocessing step.
Here is one specific set of **hyper-parameters and arguments** we pass to the script:
```
--output_dir ./models/EsperBERTo-small-v1
--model_type roberta
--mlm
--config_name ./models/EsperBERTo-small
--tokenizer_name ./models/EsperBERTo-small
--do_train
--do_eval
--learning_rate 1e-4
--num_train_epochs 5
--save_total_limit 2
--save_steps 2000
--per_gpu_train_batch_size 16
--evaluate_during_training
--seed 42
```
As usual, pick the largest batch size you can fit on your GPU(s).
**🔥🔥🔥 Let’s start training!! 🔥🔥🔥**
Here you can check our Tensorboard for [one particular set of hyper-parameters](https://tensorboard.dev/experiment/8AjtzdgPR1qG6bDIe1eKfw/#scalars):
[](https://tensorboard.dev/experiment/8AjtzdgPR1qG6bDIe1eKfw/#scalars)
> Our example scripts log into the Tensorboard format by default, under `runs/`. Then to view your board just run `tensorboard dev upload --logdir runs` – this will set up [tensorboard.dev](https://tensorboard.dev/), a Google-managed hosted version that lets you share your ML experiment with anyone.
## 4. Check that the LM actually trained
Aside from looking at the training and eval losses going down, the easiest way to check whether our language model is learning anything interesting is via the `FillMaskPipeline`.
Pipelines are simple wrappers around tokenizers and models, and the 'fill-mask' one will let you input a sequence containing a masked token (here, `<mask>`) and return a list of the most probable filled sequences, with their probabilities.
```python
from transformers import pipeline
fill_mask = pipeline(
"fill-mask",
model="./models/EsperBERTo-small",
tokenizer="./models/EsperBERTo-small"
)
# The sun <mask>.
# =>
result = fill_mask("La suno <mask>.")
# {'score': 0.2526160776615143, 'sequence': '<s> La suno brilis.</s>', 'token': 10820}
# {'score': 0.0999930202960968, 'sequence': '<s> La suno lumis.</s>', 'token': 23833}
# {'score': 0.04382849484682083, 'sequence': '<s> La suno brilas.</s>', 'token': 15006}
# {'score': 0.026011141017079353, 'sequence': '<s> La suno falas.</s>', 'token': 7392}
# {'score': 0.016859788447618484, 'sequence': '<s> La suno pasis.</s>', 'token': 4552}
```
Ok, simple syntax/grammar works. Let’s try a slightly more interesting prompt:
```python
fill_mask("Jen la komenco de bela <mask>.")
# This is the beginning of a beautiful <mask>.
# =>
# {
# 'score':0.06502299010753632
# 'sequence':'<s> Jen la komenco de bela vivo.</s>'
# 'token':1099
# }
# {
# 'score':0.0421181358397007
# 'sequence':'<s> Jen la komenco de bela vespero.</s>'
# 'token':5100
# }
# {
# 'score':0.024884626269340515
# 'sequence':'<s> Jen la komenco de bela laboro.</s>'
# 'token':1570
# }
# {
# 'score':0.02324388362467289
# 'sequence':'<s> Jen la komenco de bela tago.</s>'
# 'token':1688
# }
# {
# 'score':0.020378097891807556
# 'sequence':'<s> Jen la komenco de bela festo.</s>'
# 'token':4580
# }
```
> “**Jen la komenco de bela tago**”, indeed!
With more complex prompts, you can probe whether your language model captured more semantic knowledge or even some sort of (statistical) common sense reasoning.
## 5. Fine-tune your LM on a downstream task
We now can fine-tune our new Esperanto language model on a downstream task of **Part-of-speech tagging.**
As mentioned before, Esperanto is a highly regular language where word endings typically condition the grammatical part of speech. Using a dataset of annotated Esperanto POS tags formatted in the CoNLL-2003 format (see example below), we can use the [`run_ner.py`](https://github.com/huggingface/transformers/blob/main/examples/pytorch/token-classification/run_ner.py) script from `transformers`.
> POS tagging is a token classification task just as NER so we can just use the exact same script.

Again, here’s the hosted **[Tensorboard](https://tensorboard.dev/experiment/lOZn2wOWQo6ixpwtWyyDfQ/#scalars)** for this fine-tuning. We train for 3 epochs using a batch size of 64 per GPU.
Training and eval losses converge to small residual values as the task is rather easy (the language is regular) – it’s still fun to be able to train it end-to-end 😃.
This time, let’s use a `TokenClassificationPipeline`:
```python
from transformers import TokenClassificationPipeline, pipeline
MODEL_PATH = "./models/EsperBERTo-small-pos/"
nlp = pipeline(
"ner",
model=MODEL_PATH,
tokenizer=MODEL_PATH,
)
# or instantiate a TokenClassificationPipeline directly.
nlp("Mi estas viro kej estas tago varma.")
# {'entity': 'PRON', 'score': 0.9979867339134216, 'word': ' Mi'}
# {'entity': 'VERB', 'score': 0.9683094620704651, 'word': ' estas'}
# {'entity': 'VERB', 'score': 0.9797462821006775, 'word': ' estas'}
# {'entity': 'NOUN', 'score': 0.8509314060211182, 'word': ' tago'}
# {'entity': 'ADJ', 'score': 0.9996201395988464, 'word': ' varma'}
```
**Looks like it worked! 🔥**
<small>For a more challenging dataset for NER, <a href="https://github.com/stefan-it">@stefan-it</a> recommended that we could train on the silver standard dataset from WikiANN</small>
## 6. Share your model 🎉
Finally, when you have a nice model, please think about sharing it with the community:
- upload your model using the CLI: `transformers-cli upload`
- write a README.md model card and add it to the repository under `model_cards/`. Your model card should ideally include:
- a model description,
- training params (dataset, preprocessing, hyperparameters),
- evaluation results,
- intended uses & limitations
- whatever else is helpful! 🤓
### **TADA!**
➡️ Your model has a page on https://huggingface.co/models and everyone can load it using `AutoModel.from_pretrained("username/model_name")`.
[](https://huggingface.co/julien-c/EsperBERTo-small)
If you want to take a look at models in different languages, check https://huggingface.co/models
[](https://huggingface.co/models)
## Thank you!

| 3 |
0 | hf_public_repos | hf_public_repos/blog/wuerstchen.md | ---
title: "Introducing Würstchen: Fast Diffusion for Image Generation"
thumbnail: /blog/assets/wuerstchen/thumbnail.jpg
authors:
- user: dome272
guest: true
- user: babbleberns
guest: true
- user: kashif
- user: sayakpaul
- user: pcuenq
---
# Introducing Würstchen: Fast Diffusion for Image Generation

## What is Würstchen?
Würstchen is a diffusion model, whose text-conditional component works in a highly compressed latent space of images. Why is this important? Compressing data can reduce computational costs for both training and inference by orders of magnitude. Training on 1024×1024 images is way more expensive than training on 32×32. Usually, other works make use of a relatively small compression, in the range of 4x - 8x spatial compression. Würstchen takes this to an extreme. Through its novel design, it achieves a 42x spatial compression! This had never been seen before, because common methods fail to faithfully reconstruct detailed images after 16x spatial compression. Würstchen employs a two-stage compression, what we call Stage A and Stage B. Stage A is a VQGAN, and Stage B is a Diffusion Autoencoder (more details can be found in the **[paper](https://arxiv.org/abs/2306.00637)**). Together Stage A and B are called the *Decoder*, because they decode the compressed images back into pixel space. A third model, Stage C, is learned in that highly compressed latent space. This training requires fractions of the compute used for current top-performing models, while also allowing cheaper and faster inference. We refer to Stage C as the *Prior*.

## Why another text-to-image model?
Well, this one is pretty fast and efficient. Würstchen’s biggest benefits come from the fact that it can generate images much faster than models like Stable Diffusion XL, while using a lot less memory! So for all of us who don’t have A100s lying around, this will come in handy. Here is a comparison with SDXL over different batch sizes:
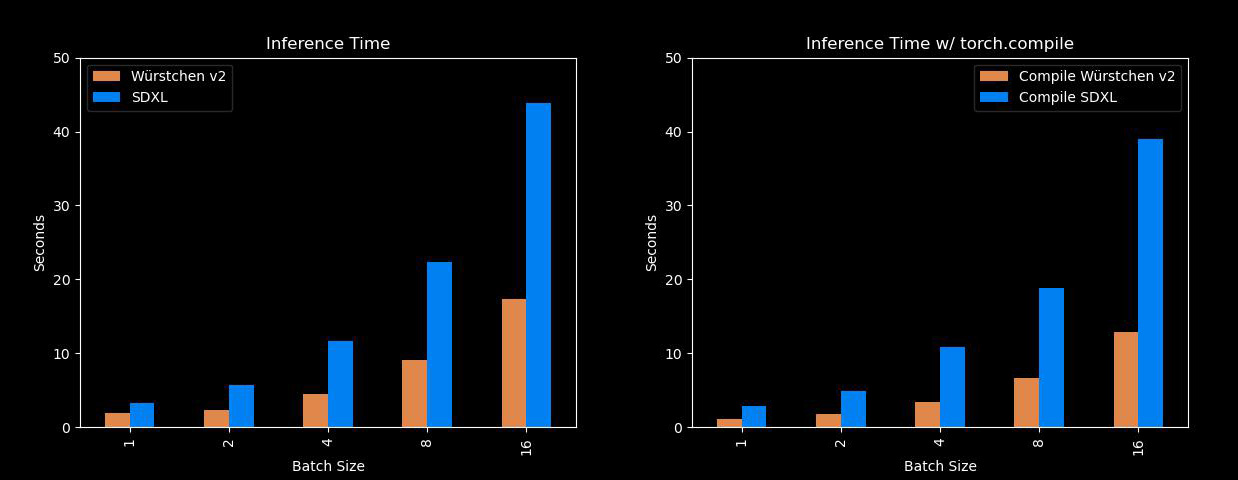
In addition to that, another greatly significant benefit of Würstchen comes with the reduced training costs. Würstchen v1, which works at 512x512, required only 9,000 GPU hours of training. Comparing this to the 150,000 GPU hours spent on Stable Diffusion 1.4 suggests that this 16x reduction in cost not only benefits researchers when conducting new experiments, but it also opens the door for more organizations to train such models. Würstchen v2 used 24,602 GPU hours. With resolutions going up to 1536, this is still 6x cheaper than SD1.4, which was only trained at 512x512.
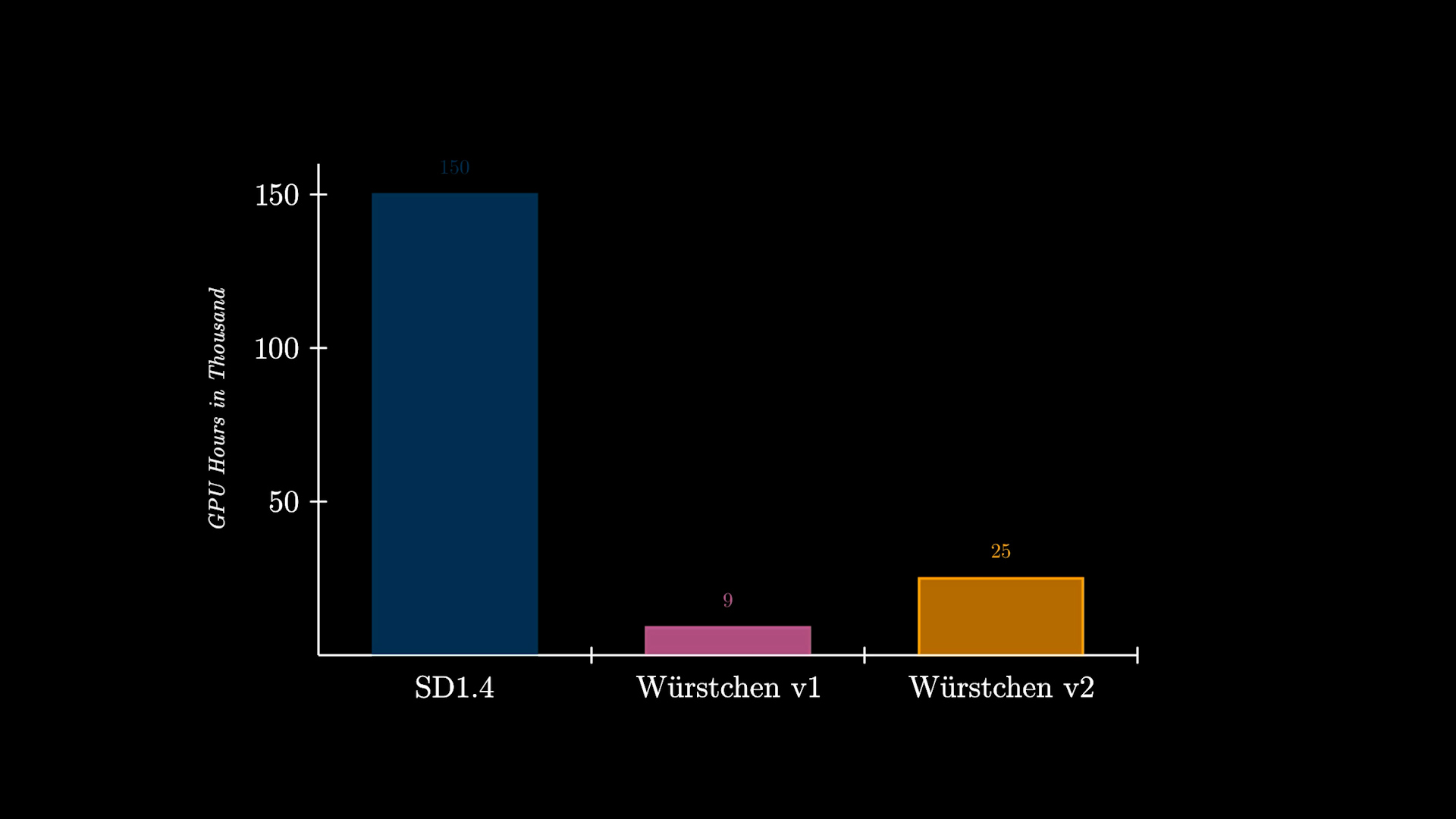
You can also find a detailed explanation video here:
<iframe width="708" height="398" src="https://www.youtube.com/embed/ogJsCPqgFMk" title="Efficient Text-to-Image Training (16x cheaper than Stable Diffusion) | Paper Explained" frameborder="0" allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture; web-share" allowfullscreen></iframe>
## How to use Würstchen?
You can either try it using the Demo here:
<script type="module" src="https://gradio.s3-us-west-2.amazonaws.com/3.44.2/gradio.js"> </script>
<gradio-app theme_mode="light" space="warp-ai/Wuerstchen"></gradio-app>
Otherwise, the model is available through the Diffusers Library, so you can use the interface you are already familiar with. For example, this is how to run inference using the `AutoPipeline`:
```Python
import torch
from diffusers import AutoPipelineForText2Image
from diffusers.pipelines.wuerstchen import DEFAULT_STAGE_C_TIMESTEPS
pipeline = AutoPipelineForText2Image.from_pretrained("warp-ai/wuerstchen", torch_dtype=torch.float16).to("cuda")
caption = "Anthropomorphic cat dressed as a firefighter"
images = pipeline(
caption,
height=1024,
width=1536,
prior_timesteps=DEFAULT_STAGE_C_TIMESTEPS,
prior_guidance_scale=4.0,
num_images_per_prompt=4,
).images
```

### What image sizes does Würstchen work on?
Würstchen was trained on image resolutions between 1024x1024 & 1536x1536. We sometimes also observe good outputs at resolutions like 1024x2048. Feel free to try it out.
We also observed that the Prior (Stage C) adapts extremely fast to new resolutions. So finetuning it at 2048x2048 should be computationally cheap.
<img src="https://cdn-uploads.huggingface.co/production/uploads/634cb5eefb80cc6bcaf63c3e/5pA5KUfGmvsObqiIjdGY1.jpeg" width=1000>
### Models on the Hub
All checkpoints can also be seen on the [Huggingface Hub](https://huggingface.co/warp-ai). Multiple checkpoints, as well as future demos and model weights can be found there. Right now there are 3 checkpoints for the Prior available and 1 checkpoint for the Decoder.
Take a look at the [documentation](https://huggingface.co/docs/diffusers/main/en/api/pipelines/wuerstchen) where the checkpoints are explained and what the different Prior models are and can be used for.
### Diffusers integration
Because Würstchen is fully integrated in `diffusers`, it automatically comes with various goodies and optimizations out of the box. These include:
- Automatic use of [PyTorch 2 `SDPA`](https://huggingface.co/docs/diffusers/optimization/torch2.0) accelerated attention, as described below.
- Support for the [xFormers flash attention](https://huggingface.co/docs/diffusers/optimization/xformers) implementation, if you need to use PyTorch 1.x instead of 2.
- [Model offload](https://huggingface.co/docs/diffusers/optimization/fp16#model-offloading-for-fast-inference-and-memory-savings), to move unused components to CPU while they are not in use. This saves memory with negligible performance impact.
- [Sequential CPU offload](https://huggingface.co/docs/diffusers/optimization/fp16#offloading-to-cpu-with-accelerate-for-memory-savings), for situations where memory is really precious. Memory use will be minimized, at the cost of slower inference.
- [Prompt weighting](https://huggingface.co/docs/diffusers/using-diffusers/weighted_prompts) with the [Compel](https://github.com/damian0815/compel) library.
- Support for the [`mps` device](https://huggingface.co/docs/diffusers/optimization/mps) on Apple Silicon macs.
- Use of generators for [reproducibility](https://huggingface.co/docs/diffusers/using-diffusers/reproducibility).
- Sensible defaults for inference to produce high-quality results in most situations. Of course you can tweak all parameters as you wish!
## Optimisation Technique 1: Flash Attention
Starting from version 2.0, PyTorch has integrated a highly optimised and resource-friendly version of the attention mechanism called [`torch.nn.functional.scaled_dot_product_attention`](https://pytorch.org/docs/master/generated/torch.nn.functional.scaled_dot_product_attention) or SDPA. Depending on the nature of the input, this function taps into multiple underlying optimisations. Its performance and memory efficiency outshine the traditional attention model. Remarkably, the SDPA function mirrors the characteristics of the *flash attention* technique, as highlighted in the research paper [Fast and Memory-Efficient Exact Attention with IO-Awareness](https://arxiv.org/abs/2205.14135) penned by Dao and team.
If you're using Diffusers with PyTorch 2.0 or a later version, and the SDPA function is accessible, these enhancements are automatically applied. Get started by setting up torch 2.0 or a newer version using the [official guidelines](https://pytorch.org/get-started/locally/)!
```python
images = pipeline(caption, height=1024, width=1536, prior_timesteps=DEFAULT_STAGE_C_TIMESTEPS, prior_guidance_scale=4.0, num_images_per_prompt=4).images
```
For an in-depth look at how `diffusers` leverages SDPA, check out the [documentation](https://huggingface.co/docs/diffusers/optimization/torch2.0).
If you're on a version of Pytorch earlier than 2.0, you can still achieve memory-efficient attention using the [xFormers](https://facebookresearch.github.io/xformers/) library:
```Python
pipeline.enable_xformers_memory_efficient_attention()
```
## Optimisation Technique 2: Torch Compile
If you're on the hunt for an extra performance boost, you can make use of `torch.compile`. It is best to apply it to both the prior's
and decoder's main model for the biggest increase in performance.
```python
pipeline.prior_prior = torch.compile(pipeline.prior_prior , mode="reduce-overhead", fullgraph=True)
pipeline.decoder = torch.compile(pipeline.decoder, mode="reduce-overhead", fullgraph=True)
```
Bear in mind that the initial inference step will take a long time (up to 2 minutes) while the models are being compiled. After that you can just normally run inference:
```python
images = pipeline(caption, height=1024, width=1536, prior_timesteps=DEFAULT_STAGE_C_TIMESTEPS, prior_guidance_scale=4.0, num_images_per_prompt=4).images
```
And the good news is that this compilation is a one-time execution. Post that, you're set to experience faster inferences consistently for the same image resolutions. The initial time investment in compilation is quickly offset by the subsequent speed benefits. For a deeper dive into `torch.compile` and its nuances, check out the [official documentation](https://pytorch.org/tutorials/intermediate/torch_compile_tutorial.html).
## How was the model trained?
The ability to train this model was only possible through compute resources provided by [Stability AI](https://stability.ai/).
We wanna say a special thank you to Stability for giving us the possibility to pursue this kind of research, with the chance
to make it accessible to so many more people!
## Resources
* Further information about this model can be found in the official diffusers [documentation](https://huggingface.co/docs/diffusers/main/en/api/pipelines/wuerstchen).
* All the checkpoints can be found on the [hub](https://huggingface.co/warp-ai)
* You can try out the [demo here](https://huggingface.co/spaces/warp-ai/Wuerstchen).
* Join our [Discord](https://discord.com/invite/BTUAzb8vFY) if you want to discuss future projects or even contribute with your own ideas!
* Training code and more can be found in the official [GitHub repository](https://github.com/dome272/wuerstchen/)
| 4 |
0 | hf_public_repos | hf_public_repos/blog/codellama.md | ---
title: "Code Llama: Llama 2 learns to code"
thumbnail: /blog/assets/160_codellama/thumbnail.jpg
authors:
- user: philschmid
- user: osanseviero
- user: pcuenq
- user: lewtun
- user: lvwerra
- user: loubnabnl
- user: ArthurZ
- user: joaogante
---
# Code Llama: Llama 2 learns to code
## Introduction
Code Llama is a family of state-of-the-art, open-access versions of [Llama 2](https://huggingface.co/blog/llama2) specialized on code tasks, and we’re excited to release integration in the Hugging Face ecosystem! Code Llama has been released with the same permissive community license as Llama 2 and is available for commercial use.
Today, we’re excited to release:
- Models on the Hub with their model cards and license
- Transformers integration
- Integration with Text Generation Inference for fast and efficient production-ready inference
- Integration with Inference Endpoints
- Integration with VS Code extension
- Code benchmarks
Code LLMs are an exciting development for software engineers because they can boost productivity through code completion in IDEs, take care of repetitive or annoying tasks like writing docstrings, or create unit tests.
## Table of Contents
- [Introduction](#introduction)
- [Table of Contents](#table-of-contents)
- [What’s Code Llama?](#whats-code-llama)
- [How to use Code Llama?](#how-to-use-code-llama)
- [Demo](#demo)
- [Transformers](#transformers)
- [A Note on dtypes](#a-note-on-dtypes)
- [Code Completion](#code-completion)
- [Code Infilling](#code-infilling)
- [Conversational Instructions](#conversational-instructions)
- [4-bit Loading](#4-bit-loading)
- [Using text-generation-inference and Inference Endpoints](#using-text-generation-inference-and-inference-endpoints)
- [Using VS Code extension](#using-vs-code-extension)
- [Evaluation](#evaluation)
- [Additional Resources](#additional-resources)
## What’s Code Llama?
The Code Llama release introduces a family of models of 7, 13, and 34 billion parameters. The base models are initialized from Llama 2 and then trained on 500 billion tokens of code data. Meta fine-tuned those base models for two different flavors: a Python specialist (100 billion additional tokens) and an instruction fine-tuned version, which can understand natural language instructions.
The models show state-of-the-art performance in Python, C++, Java, PHP, C#, TypeScript, and Bash. The 7B and 13B base and instruct variants support infilling based on surrounding content, making them ideal for use as code assistants.
Code Llama was trained on a 16k context window. In addition, the three model variants had additional long-context fine-tuning, allowing them to manage a context window of up to 100,000 tokens.
Increasing Llama 2’s 4k context window to Code Llama’s 16k (that can extrapolate up to 100k) was possible due to recent developments in RoPE scaling. The community found that Llama’s position embeddings can be interpolated linearly or in the frequency domain, which eases the transition to a larger context window through fine-tuning. In the case of Code Llama, the frequency domain scaling is done with a slack: the fine-tuning length is a fraction of the scaled pretrained length, giving the model powerful extrapolation capabilities.

All models were initially trained with 500 billion tokens on a near-deduplicated dataset of publicly available code. The dataset also contains some natural language datasets, such as discussions about code and code snippets. Unfortunately, there is not more information about the dataset.
For the instruction model, they used two datasets: the instruction tuning dataset collected for Llama 2 Chat and a self-instruct dataset. The self-instruct dataset was created by using Llama 2 to create interview programming questions and then using Code Llama to generate unit tests and solutions, which are later evaluated by executing the tests.
## How to use Code Llama?
Code Llama is available in the Hugging Face ecosystem, starting with `transformers` version 4.33.
### Demo
You can easily try the Code Llama Model (13 billion parameters!) in **[this Space](https://huggingface.co/spaces/codellama/codellama-playground)** or in the playground embedded below:
<script type="module" src="https://gradio.s3-us-west-2.amazonaws.com/3.28.3/gradio.js"> </script>
<gradio-app theme_mode="light" space="codellama/codellama-playground"></gradio-app>
Under the hood, this playground uses Hugging Face's [Text Generation Inference](https://github.com/huggingface/text-generation-inference), the same technology that powers [HuggingChat](https://huggingface.co/chat/), and we'll share more in the following sections.
If you want to try out the bigger instruct-tuned 34B model, it is now available on **HuggingChat**! You can try it out here: [hf.co/chat](https://hf.co/chat). Make sure to specify the Code Llama model. You can also check [this chat-based demo](https://huggingface.co/spaces/codellama/codellama-13b-chat) and duplicate it for your use – it's self-contained, so you can examine the source code and adapt it as you wish!
### Transformers
Starting with `transformers` 4.33, you can use Code Llama and leverage all the tools within the HF ecosystem, such as:
- training and inference scripts and examples
- safe file format (`safetensors`)
- integrations with tools such as `bitsandbytes` (4-bit quantization) and PEFT (parameter efficient fine-tuning)
- utilities and helpers to run generation with the model
- mechanisms to export the models to deploy
```bash
!pip install --upgrade transformers
```
#### A Note on dtypes
When using models like Code Llama, it's important to take a look at the data types of the models.
* 32-bit floating point (`float32`): PyTorch convention on model initialization is to load models in `float32`, no matter with which precision the model weights were stored. `transformers` also follows this convention for consistency with PyTorch.
* 16-bit Brain floating point (`bfloat16`): Code Llama was trained with this precision, so we recommend using it for further training or fine-tuning.
* 16-bit floating point (`float16`): We recommend running inference using this precision, as it's usually faster than `bfloat16`, and evaluation metrics show no discernible degradation with respect to `bfloat16`. You can also run inference using `bfloat16`, and we recommend you check inference results with both `float16` and `bfloat16` after fine-tuning.
As mentioned above, `transformers` loads weights using `float32` (no matter with which precision the models are stored), so it's important to specify the desired `dtype` when loading the models. If you want to fine-tune Code Llama, it's recommended to use `bfloat16`, as using `float16` can lead to overflows and NaNs. If you run inference, we recommend using `float16` because `bfloat16` can be slower.
#### Code Completion
The 7B and 13B models can be used for text/code completion or infilling. The following code snippet uses the `pipeline` interface to demonstrate text completion. It runs on the free tier of Colab, as long as you select a GPU runtime.
```python
from transformers import AutoTokenizer
import transformers
import torch
tokenizer = AutoTokenizer.from_pretrained("codellama/CodeLlama-7b-hf")
pipeline = transformers.pipeline(
"text-generation",
model="codellama/CodeLlama-7b-hf",
torch_dtype=torch.float16,
device_map="auto",
)
sequences = pipeline(
'def fibonacci(',
do_sample=True,
temperature=0.2,
top_p=0.9,
num_return_sequences=1,
eos_token_id=tokenizer.eos_token_id,
max_length=100,
)
for seq in sequences:
print(f"Result: {seq['generated_text']}")
```
This may produce output like the following:
```python
Result: def fibonacci(n):
if n == 0:
return 0
elif n == 1:
return 1
else:
return fibonacci(n-1) + fibonacci(n-2)
def fibonacci_memo(n, memo={}):
if n == 0:
return 0
elif n == 1:
return
```
Code Llama is specialized in code understanding, but it's a language model in its own right. You can use the same generation strategy to autocomplete comments or general text.
#### Code Infilling
This is a specialized task particular to code models. The model is trained to generate the code (including comments) that best matches an existing prefix and suffix. This is the strategy typically used by code assistants: they are asked to fill the current cursor position, considering the contents that appear before and after it.
This task is available in the **base** and **instruction** variants of the 7B and 13B models. It is _not_ available for any of the 34B models or the Python versions.
To use this feature successfully, you need to pay close attention to the format used to train the model for this task, as it uses special separators to identify the different parts of the prompt. Fortunately, transformers' `CodeLlamaTokenizer` makes this very easy, as demonstrated below:
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
import transformers
import torch
model_id = "codellama/CodeLlama-7b-hf"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.float16
).to("cuda")
prompt = '''def remove_non_ascii(s: str) -> str:
""" <FILL_ME>
return result
'''
input_ids = tokenizer(prompt, return_tensors="pt")["input_ids"].to("cuda")
output = model.generate(
input_ids,
max_new_tokens=200,
)
output = output[0].to("cpu")
filling = tokenizer.decode(output[input_ids.shape[1]:], skip_special_tokens=True)
print(prompt.replace("<FILL_ME>", filling))
```
```Python
def remove_non_ascii(s: str) -> str:
""" Remove non-ASCII characters from a string.
Args:
s: The string to remove non-ASCII characters from.
Returns:
The string with non-ASCII characters removed.
"""
result = ""
for c in s:
if ord(c) < 128:
result += c
return result
```
Under the hood, the tokenizer [automatically splits by `<FILL_ME>`](https://huggingface.co/docs/transformers/main/model_doc/code_llama#transformers.CodeLlamaTokenizer.fill_token) to create a formatted input string that follows [the original training pattern](https://github.com/facebookresearch/codellama/blob/cb51c14ec761370ba2e2bc351374a79265d0465e/llama/generation.py#L402). This is more robust than preparing the pattern yourself: it avoids pitfalls, such as token glueing, that are very hard to debug.
#### Conversational Instructions
The base model can be used for both completion and infilling, as described. The Code Llama release also includes an instruction fine-tuned model that can be used in conversational interfaces.
To prepare inputs for this task we have to use a prompt template like the one described in our [Llama 2 blog post](https://huggingface.co/blog/llama2#how-to-prompt-llama-2), which we reproduce again here:
```
<s>[INST] <<SYS>>
{{ system_prompt }}
<</SYS>>
{{ user_msg_1 }} [/INST] {{ model_answer_1 }} </s><s>[INST] {{ user_msg_2 }} [/INST]
```
Note that the system prompt is optional - the model will work without it, but you can use it to further configure its behavior or style. For example, if you'd always like to get answers in JavaScript, you could state that here. After the system prompt, you need to provide all the previous interactions in the conversation: what was asked by the user and what was answered by the model. As in the infilling case, you need to pay attention to the delimiters used. The final component of the input must always be a new user instruction, which will be the signal for the model to provide an answer.
The following code snippets demonstrate how the template works in practice.
1. **First user query, no system prompt**
```python
user = 'In Bash, how do I list all text files in the current directory (excluding subdirectories) that have been modified in the last month?'
prompt = f"<s>[INST] {user.strip()} [/INST]"
inputs = tokenizer(prompt, return_tensors="pt", add_special_tokens=False).to("cuda")
```
2. **First user query with system prompt**
```python
system = "Provide answers in JavaScript"
user = "Write a function that computes the set of sums of all contiguous sublists of a given list."
prompt = f"<s>[INST] <<SYS>>\\n{system}\\n<</SYS>>\\n\\n{user}[/INST]"
inputs = tokenizer(prompt, return_tensors="pt", add_special_tokens=False).to("cuda")
```
3. **On-going conversation with previous answers**
The process is the same as in [Llama 2](https://huggingface.co/blog/llama2#how-to-prompt-llama-2). We haven’t used loops or generalized this example code for maximum clarity:
```python
system = "System prompt"
user_1 = "user_prompt_1"
answer_1 = "answer_1"
user_2 = "user_prompt_2"
answer_2 = "answer_2"
user_3 = "user_prompt_3"
prompt = f"<<SYS>>\n{system}\n<</SYS>>\n\n{user_1}"
prompt = f"<s>[INST] {prompt.strip()} [/INST] {answer_1.strip()} </s>"
prompt += f"<s>[INST] {user_2.strip()} [/INST] {answer_2.strip()} </s>"
prompt += f"<s>[INST] {user_3.strip()} [/INST]"
inputs = tokenizer(prompt, return_tensors="pt", add_special_tokens=False).to("cuda")
```
#### 4-bit Loading
Integration of Code Llama in Transformers means that you get immediate support for advanced features like 4-bit loading. This allows you to run the big 32B parameter models on consumer GPUs like nvidia 3090 cards!
Here's how you can run inference in 4-bit mode:
```Python
from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig
import torch
model_id = "codellama/CodeLlama-34b-hf"
quantization_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_compute_dtype=torch.float16
)
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
quantization_config=quantization_config,
device_map="auto",
)
prompt = 'def remove_non_ascii(s: str) -> str:\n """ '
inputs = tokenizer(prompt, return_tensors="pt").to("cuda")
output = model.generate(
inputs["input_ids"],
max_new_tokens=200,
do_sample=True,
top_p=0.9,
temperature=0.1,
)
output = output[0].to("cpu")
print(tokenizer.decode(output))
```
### Using text-generation-inference and Inference Endpoints
[Text Generation Inference](https://github.com/huggingface/text-generation-inference) is a production-ready inference container developed by Hugging Face to enable easy deployment of large language models. It has features such as continuous batching, token streaming, tensor parallelism for fast inference on multiple GPUs, and production-ready logging and tracing.
You can try out Text Generation Inference on your own infrastructure, or you can use Hugging Face's [Inference Endpoints](https://huggingface.co/inference-endpoints). To deploy a Codellama 2 model, go to the [model page](https://huggingface.co/codellama) and click on the [Deploy -> Inference Endpoints](https://huggingface.co/codellama/CodeLlama-7b-hf) widget.
- For 7B models, we advise you to select "GPU [medium] - 1x Nvidia A10G".
- For 13B models, we advise you to select "GPU [xlarge] - 1x Nvidia A100".
- For 34B models, we advise you to select "GPU [1xlarge] - 1x Nvidia A100" with `bitsandbytes` quantization enabled or "GPU [2xlarge] - 2x Nvidia A100"
*Note: You might need to request a quota upgrade via email to **[[email protected]](mailto:[email protected])** to access A100s*
You can learn more on how to [Deploy LLMs with Hugging Face Inference Endpoints in our blog](https://huggingface.co/blog/inference-endpoints-llm). The [blog](https://huggingface.co/blog/inference-endpoints-llm) includes information about supported hyperparameters and how to stream your response using Python and Javascript.
### Using VS Code extension
[HF Code Autocomplete](https://marketplace.visualstudio.com/items?itemName=HuggingFace.huggingface-vscode) is a VS Code extension for testing open source code completion models. The extension was developed as part of [StarCoder project](/blog/starcoder#tools--demos) and was updated to support the medium-sized base model, [Code Llama 13B](/codellama/CodeLlama-13b-hf). Find more [here](https://github.com/huggingface/huggingface-vscode#code-llama) on how to install and run the extension with Code Llama.

## Evaluation
Language models for code are typically benchmarked on datasets such as HumanEval. It consists of programming challenges where the model is presented with a function signature and a docstring and is tasked to complete the function body. The proposed solution is then verified by running a set of predefined unit tests. Finally, a pass rate is reported which describes how many solutions passed all tests. The pass@1 rate describes how often the model generates a passing solution when having one shot whereas pass@10 describes how often at least one solution passes out of 10 proposed candidates.
While HumanEval is a Python benchmark there have been significant efforts to translate it to more programming languages and thus enable a more holistic evaluation. One such approach is [MultiPL-E](https://github.com/nuprl/MultiPL-E) which translates HumanEval to over a dozen languages. We are hosting a [multilingual code leaderboard](https://huggingface.co/spaces/bigcode/multilingual-code-evals) based on it to allow the community to compare models across different languages to evaluate which model fits their use-case best.
| Model | License | Dataset known | Commercial use? | Pretraining length [tokens] | Python | JavaScript | Leaderboard Avg Score |
| ---------------------- | ------------------ | ------------- | --------------- | --------------------------- | ------ | ---------- | --------------------- |
| CodeLlaMa-34B | Llama 2 license | ❌ | ✅ | 2,500B | 45.11 | 41.66 | 33.89 |
| CodeLlaMa-13B | Llama 2 license | ❌ | ✅ | 2,500B | 35.07 | 38.26 | 28.35 |
| CodeLlaMa-7B | Llama 2 license | ❌ | ✅ | 2,500B | 29.98 | 31.8 | 24.36 |
| CodeLlaMa-34B-Python | Llama 2 license | ❌ | ✅ | 2,620B | 53.29 | 44.72 | 33.87 |
| CodeLlaMa-13B-Python | Llama 2 license | ❌ | ✅ | 2,620B | 42.89 | 40.66 | 28.67 |
| CodeLlaMa-7B-Python | Llama 2 license | ❌ | ✅ | 2,620B | 40.48 | 36.34 | 23.5 |
| CodeLlaMa-34B-Instruct | Llama 2 license | ❌ | ✅ | 2,620B | 50.79 | 45.85 | 35.09 |
| CodeLlaMa-13B-Instruct | Llama 2 license | ❌ | ✅ | 2,620B | 50.6 | 40.91 | 31.29 |
| CodeLlaMa-7B-Instruct | Llama 2 license | ❌ | ✅ | 2,620B | 45.65 | 33.11 | 26.45 |
| StarCoder-15B | BigCode-OpenRail-M | ✅ | ✅ | 1,035B | 33.57 | 30.79 | 22.74 |
| StarCoderBase-15B | BigCode-OpenRail-M | ✅ | ✅ | 1,000B | 30.35 | 31.7 | 22.4 |
| WizardCoder-15B | BigCode-OpenRail-M | ❌ | ✅ | 1,035B | 58.12 | 41.91 | 32.07 |
| OctoCoder-15B | BigCode-OpenRail-M | ✅ | ✅ | 1,000B | 45.3 | 32.8 | 24.01 |
| CodeGeeX-2-6B | CodeGeeX License | ❌ | ❌ | 2,000B | 33.49 | 29.9 | 21.23 |
| CodeGen-2.5-7B-Mono | Apache-2.0 | ✅ | ✅ | 1400B | 45.65 | 23.22 | 12.1 |
| CodeGen-2.5-7B-Multi | Apache-2.0 | ✅ | ✅ | 1400B | 28.7 | 26.27 | 20.04 |
**Note:** The scores presented in the table above were sourced from our code leaderboard at the time of publication. Scores change as new models are released, because models are compared against one another. For more details, please refer to the [leaderboard](https://huggingface.co/spaces/bigcode/multilingual-code-evals).
## Additional Resources
- [Models on the Hub](https://huggingface.co/codellama)
- [Paper Page](https://huggingface.co/papers/2308.12950)
- [Official Meta announcement](https://ai.meta.com/blog/code-llama-large-language-model-coding/)
- [Responsible Use Guide](https://ai.meta.com/llama/responsible-use-guide/)
- [Demo (code completion, streaming server)](https://huggingface.co/spaces/codellama/codellama-playground)
- [Demo (instruction fine-tuned, self-contained & clonable)](https://huggingface.co/spaces/codellama/codellama-13b-chat)
| 5 |
0 | hf_public_repos | hf_public_repos/blog/huggingface-and-ibm.md | ---
title: "Hugging Face and IBM partner on watsonx.ai, the next-generation enterprise studio for AI builders"
thumbnail: /blog/assets/144_ibm/01.png
authors:
- user: juliensimon
---
# Hugging Face and IBM partner on watsonx.ai, the next-generation enterprise studio for AI builders
<kbd>
<img src="assets/144_ibm/01.png">
</kbd>
All hype aside, it's hard to deny the profound impact that AI is having on society and businesses. From startups to enterprises to the public sector, every customer we talk to is busy experimenting with large language models and generative AI, identifying the most promising use cases, and gradually bringing them to production.
The #1 comment we get from customers is that no single model will rule them all. They understand the value of building the best model for each use case to maximize its relevance on company data while optimizing the compute budget. Of course, privacy and intellectual property are also top concerns, and customers want to ensure they maintain complete control.
As AI finds its way into every department and business unit, customers also realize the need to train and deploy many different models. In a large multinational organization, this could mean running hundreds, even thousands, of models at any time. Given the pace of AI innovation, newer and higher-performance model architectures will also lead customers to replace their models quicker than expected, reinforcing the need to train and deploy new models in production quickly and seamlessly.
All of this will only happen with standardization and automation. Organizations can't afford to build models, tools, and infrastructure from scratch for new projects. Fortunately, the last few years have seen some very positive developments:
1. **Model standardization**: the [Transformer](https://arxiv.org/abs/1706.03762) architecture is now the de facto standard for Deep Learning applications like Natural Language Processing, Computer Vision, Audio, Speech, and more. It’s now easier to build tools and workflows that perform well across many use cases.
2. **Pre-trained models**: [hundreds of thousands](https://huggingface.co/models) of pre-trained models are just a click away. You can discover and test them directly on [Hugging Face](https://huggingface.co) and quickly shortlist the promising ones for your projects.
3. **Open-source libraries**: the Hugging Face [libraries](https://huggingface.co/docs) let you download pre-trained models with a single line of code, and you can start experimenting with your data in minutes. From training to deployment to hardware optimization, customers can rely on a consistent set of community-driven tools that work the same everywhere, from their laptops to their production environment.
In addition, our cloud partnerships let customers use Hugging Face models and libraries at any scale without worrying about provisioning infrastructure and building technical environments. This makes it much easier to get high-quality models out the door at a rapid pace without having to reinvent the wheel.
Following up on our collaboration with AWS on Amazon SageMaker and Microsoft on Azure Machine Learning, we're thrilled to work with none other than IBM on their new AI studio, [watsonx.ai](https://www.ibm.com/products/watsonx-ai). [watsonx.ai](http://watsonx.ai) is the next-generation enterprise studio for AI builders to train, validate, tune, and deploy both traditional ML and new generative AI capabilities, powered by foundation models.
IBM decided that open source should be at the core of watsonx.ai. We couldn't agree more! Built on [RedHat OpenShift](https://www.redhat.com/en/technologies/cloud-computing/openshift), watsonx.ai will be available in the cloud and on-premise. This is excellent news for customers who cannot use the cloud because of strict compliance rules or are more comfortable working with their confidential data on their infrastructure. Until now, these customers often had to build their in-house ML platform. They now have an open-source off-the-shelf alternative deployed and managed using standard DevOps tools.
Under the hood, watsonx.ai also integrates many Hugging Face open-source libraries, such as [transformers](https://github.com/huggingface/transformers) (100k+ GitHub stars!), [accelerate](https://github.com/huggingface/accelerate), [peft](https://github.com/huggingface/peft) and our [Text Generation Inference](https://github.com/huggingface/text-generation-inference) server, to name a few. We're happy to partner with IBM and to collaborate on the watsonx AI and data platform so that Hugging Face customers can work natively with their Hugging Face models and datasets to multiply the impact of AI across businesses.
In addition, IBM has also developed its own collection of Large Language Models, and we will work with their team to open-source them and make them easily available in the Hugging Face Hub.
To learn more, watch Dr. Darío Gil, SVP and Director of IBM Research, and our CEO Clem Delangue, [announce our collaboration](https://youtu.be/FrDnPTPgEmk?t=1077), [walk through the watsonx platform](https://youtu.be/FrDnPTPgEmk?t=283), and present IBM’s [suite of Large Language Models](https://youtu.be/FrDnPTPgEmk?t=586) in an IBM THINK 2023 keynote.
Our joint team is hard at work at the moment. We can't wait to show you what we've been up to! The most iconic of technology companies joining forces with an up-and-coming startup to tackle AI in the Enterprise... who would have thought?
Fascinating times. Stay tuned!
| 6 |
0 | hf_public_repos | hf_public_repos/blog/eval-on-the-hub.md | ---
title: "Announcing Evaluation on the Hub"
thumbnail: /blog/assets/82_eval_on_the_hub/thumbnail.png
authors:
- user: lewtun
- user: abhishek
- user: Tristan
- user: sasha
- user: lvwerra
- user: nazneen
- user: ola13
- user: osanseviero
- user: douwekiela
---
# Announcing Evaluation on the Hub
<br>
<div style="background-color: #e6f9e6; padding: 16px 32px; outline: 2px solid; border-radius: 10px;">
November 2023 Update:
This project has been archived. If you want to evaluate LLMs on the Hub, check out [this collection of leaderboards](https://huggingface.co/collections/clefourrier/llm-leaderboards-and-benchmarks-✨-64f99d2e11e92ca5568a7cce).
</div>
<em>TL;DR</em>: Today we introduce [Evaluation on the Hub](https://huggingface.co/spaces/autoevaluate/model-evaluator), a new tool powered by [AutoTrain](https://huggingface.co/autotrain) that lets you evaluate any model on any dataset on the Hub without writing a single line of code!
<figure class="image table text-center m-0">
<video
alt="Evaluating models from the Hugging Face Hub"
style="max-width: 70%; margin: auto;"
autoplay loop autobuffer muted playsinline
>
<source src="/blog/assets/82_eval_on_the_hub/autoeval-demo.mp4" type="video/mp4">
</video>
<figcaption>Evaluate all the models 🔥🔥🔥!</figcaption>
</figure>
Progress in AI has been nothing short of amazing, to the point where some people are now seriously debating whether AI models may be better than humans at certain tasks. However, that progress has not at all been even: to a machine learner from several decades ago, modern hardware and algorithms might look incredible, as might the sheer quantity of data and compute at our disposal, but the way we evaluate these models has stayed roughly the same.
However, it is no exaggeration to say that modern AI is in an evaluation crisis. Proper evaluation these days involves measuring many models, often on many datasets and with multiple metrics. But doing so is unnecessarily cumbersome. This is especially the case if we care about reproducibility, since self-reported results may have suffered from inadvertent bugs, subtle differences in implementation, or worse.
We believe that better evaluation can happen, if we - the community - establish a better set of best practices and try to remove the hurdles. Over the past few months, we've been hard at work on [Evaluation on the Hub](https://huggingface.co/spaces/autoevaluate/model-evaluator): evaluate any model on any dataset using any metric, at the click of a button. To get started, we evaluated hundreds models on several key datasets, and using the nifty new [Pull Request feature](https://huggingface.co/blog/community-update) on the Hub, opened up loads of PRs on model cards to display their verified performance. Evaluation results are encoded directly in the model card metadata, following [a format](https://huggingface.co/docs/hub/models-cards) for all models on the Hub. Check out the model card for [DistilBERT](https://huggingface.co/distilbert-base-uncased-finetuned-sst-2-english/blob/main/README.md#L7-L42) to see how it looks!
## On the Hub
Evaluation on the Hub opens the door to so many interesting use cases. From the data scientist or executive who needs to decide which model to deploy, to the academic trying to reproduce a paper’s results on a new dataset, to the ethicist who wants to better understand risks of deployment. If we have to single out three primary initial use case scenarios, they are these:
**Finding the best model for your task**<br/>
Suppose you know exactly what your task is and you want to find the right model for the job. You can check out the leaderboard for a dataset representative of your task, which aggregates all the results. That’s great! And what if that fancy new model you’re interested in isn’t on the [leaderboard](https://huggingface.co/spaces/autoevaluate/leaderboards) yet for that dataset? Simply run an evaluation for it, without leaving the Hub.
**Evaluating models on your brand new dataset**<br/>
Now what if you have a brand spanking new dataset that you want to run baselines on? You can upload it to the Hub and evaluate as many models on it as you like. No code required. What’s more, you can be sure that the way you are evaluating these models on your dataset is exactly the same as how they’ve been evaluated on other datasets.
**Evaluating your model on many other related datasets**<br/>
Or suppose you have a brand new question answering model, trained on SQuAD? There are hundreds of different question answering datasets to evaluate on :scream: You can pick the ones you are interested in and evaluate your model, directly from the Hub.
## Ecosystem
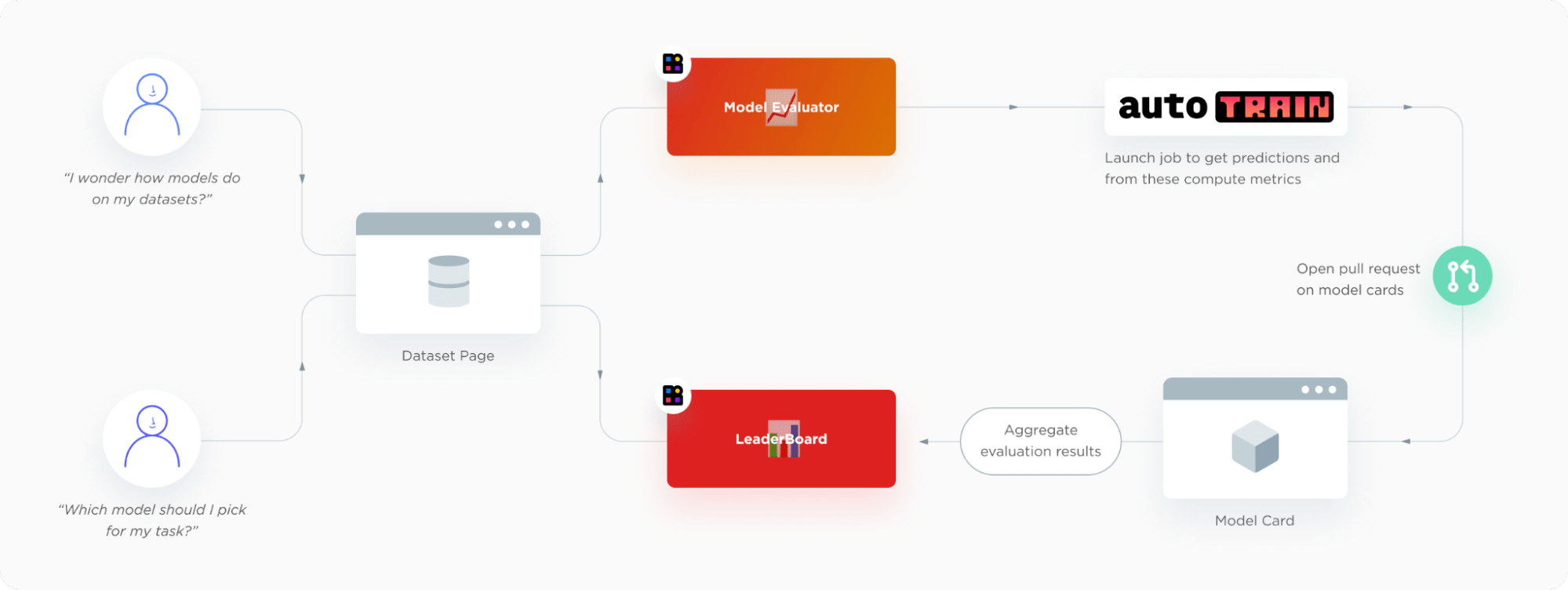
<figcaption><center><i>Evaluation on the Hub fits neatly into the Hugging Face ecosystem.</i></center></figcaption>
Evaluation on the Hub is meant to make your life easier. But of course, there’s a lot happening in the background. What we really like about Evaluation on the Hub: it fits so neatly into the existing Hugging Face ecosystem, we almost had to do it. Users start on dataset pages, from where they can launch evaluations or see leaderboards. The model evaluation submission interface and the leaderboards are regular Hugging Face Spaces. The evaluation backend is powered by AutoTrain, which opens up a PR on the Hub for the given model’s model card.
## DogFood - Distinguishing Dogs, Muffins and Fried Chicken
So what does it look like in practice? Let’s run through an example. Suppose you are in the business of telling apart dogs, muffins and fried chicken (a.k.a. dogfooding!).

<figcaption><center><i>Example images of dogs and food (muffins and fried chicken). <a href="https://github.com/qw2243c/Image-Recognition-Dogs-Fried-Chicken-or-Blueberry-Muffins-/">Source</a> / <a href="https://twitter.com/teenybiscuit/status/667777205397680129?s=20&t=wPgYJMp-JPwRsNAOMvEbxg">Original source</a>.</i></center></figcaption>
As the above image shows, to solve this problem, you’ll need:
* A dataset of dog, muffin, and fried chicken images
* Image classifiers that have been trained on these images
Fortunately, your data science team has uploaded [a dataset](https://huggingface.co/datasets/lewtun/dog_food) to the Hugging Face Hub and trained [a few different models on it](https://huggingface.co/models?datasets=lewtun/dog_food). So now you just need to pick the best one - let’s use Evaluation on the Hub to see how well they perform on the test set!
### Configuring an evaluation job
To get started, head over to the [`model-evaluator` Space](https://huggingface.co/spaces/autoevaluate/model-evaluator) and select the dataset you want to evaluate models on. For our dataset of dog and food images, you’ll see something like the image below:
Now, many datasets on the Hub contain metadata that specifies how an evaluation should be configured (check out [acronym_identification](https://huggingface.co/datasets/acronym_identification/blob/main/README.md#L22-L30) for an example). This allows you to evaluate models with a single click, but in our case we’ll show you how to configure the evaluation manually.
Clicking on the <em>Advanced configuration</em> button will show you the various settings to choose from:
* The task, dataset, and split configuration
* The mapping of the dataset columns to a standard format
* The choice of metrics
As shown in the image below, configuring the task, dataset, and split to evaluate on is straightforward:

The next step is to define which dataset columns contain the images, and which ones contain the labels:
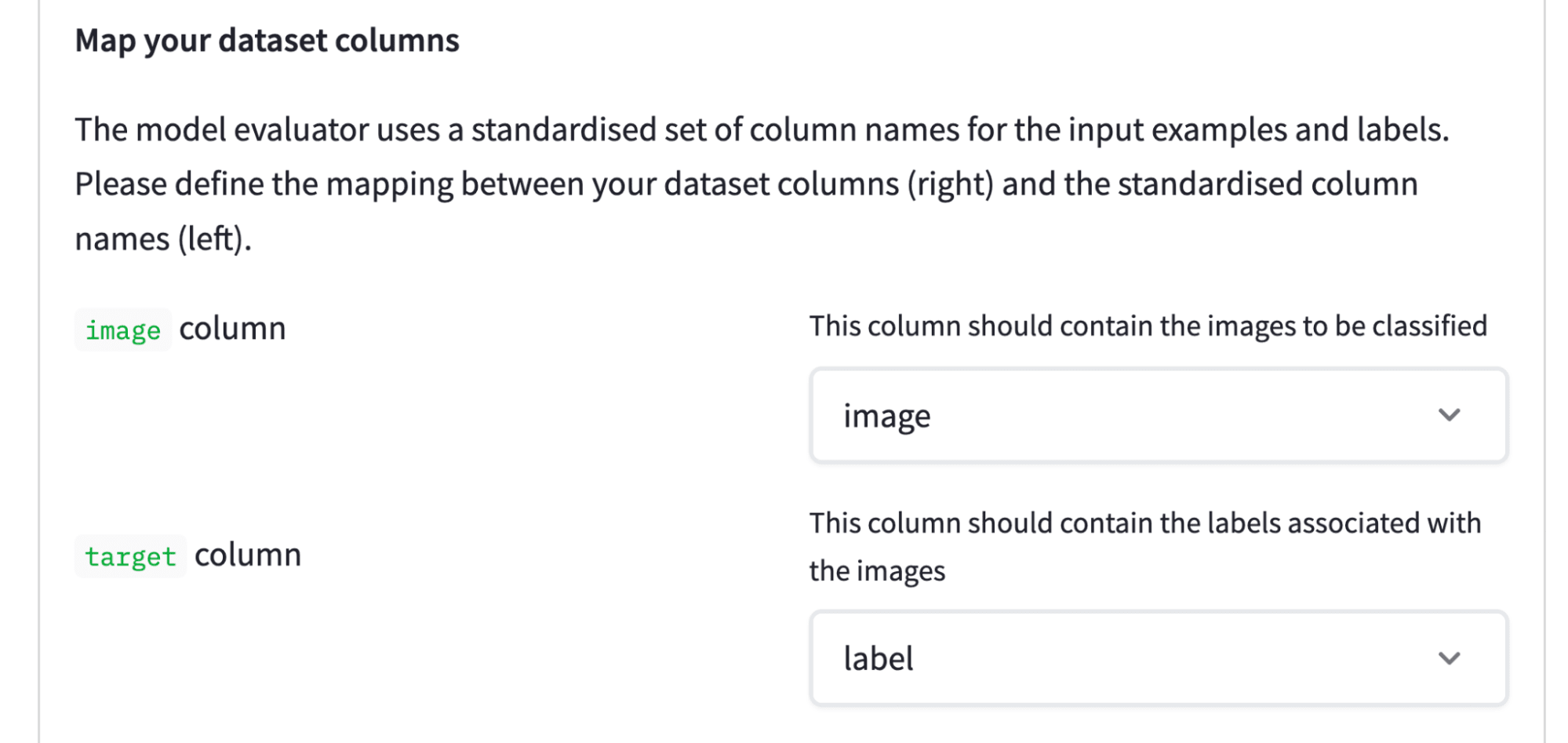
Now that the task and dataset are configured, the final (optional) step is to select the metrics to evaluate with. Each task is associated with a set of default metrics. For example, the image below shows that F1 score, accuracy etc will be computed automatically. To spice things up, we’ll also calculate the [Matthew’s correlation coefficient](https://huggingface.co/spaces/evaluate-metric/matthews_correlation), which provides a balanced measure of classifier performance:
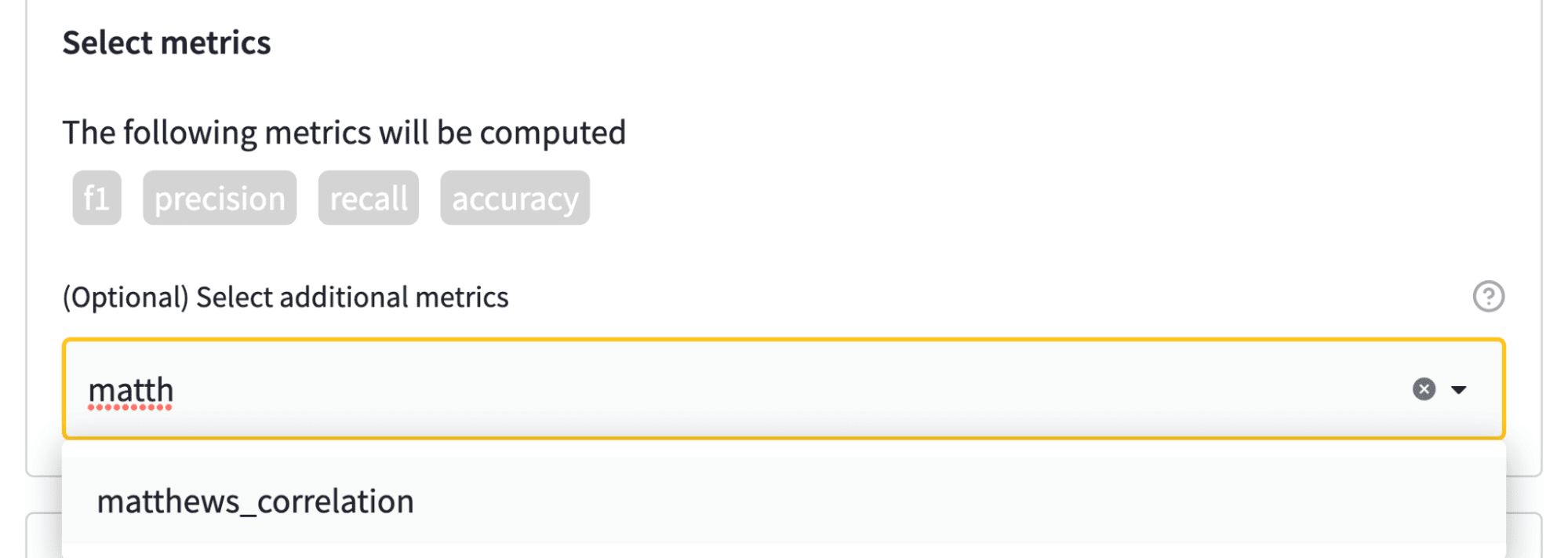
And that’s all it takes to configure an evaluation job! Now we just need to pick some models to evaluate - let’s take a look.
### Selecting models to evaluate
Evaluation on the Hub links datasets and models via tags in the model card metadata. In our example, we have three models to choose from, so let’s select them all!
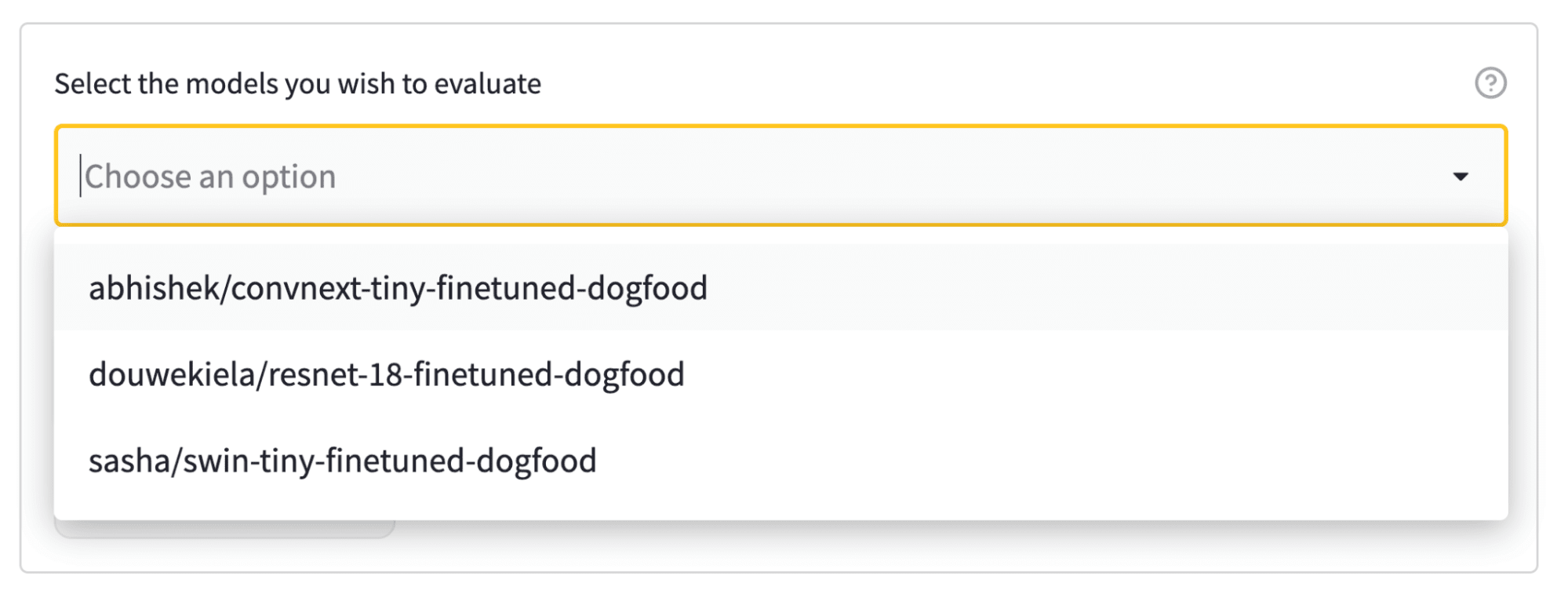
Once the models are selected, simply enter your Hugging Face Hub username (to be notified when the evaluation is complete) and hit the big <em>Evaluate models</em> button:
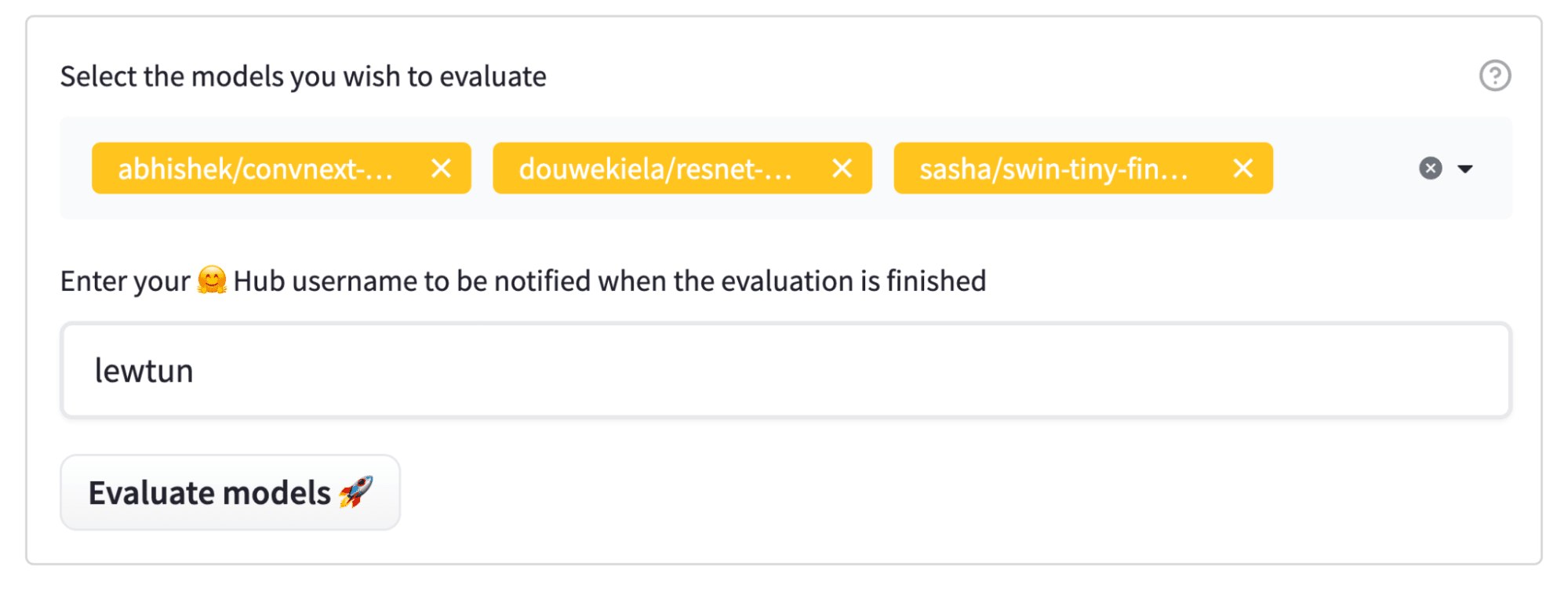
Once a job is submitted, the models will be automatically evaluated and a Hub pull request will be opened with the evaluation results:
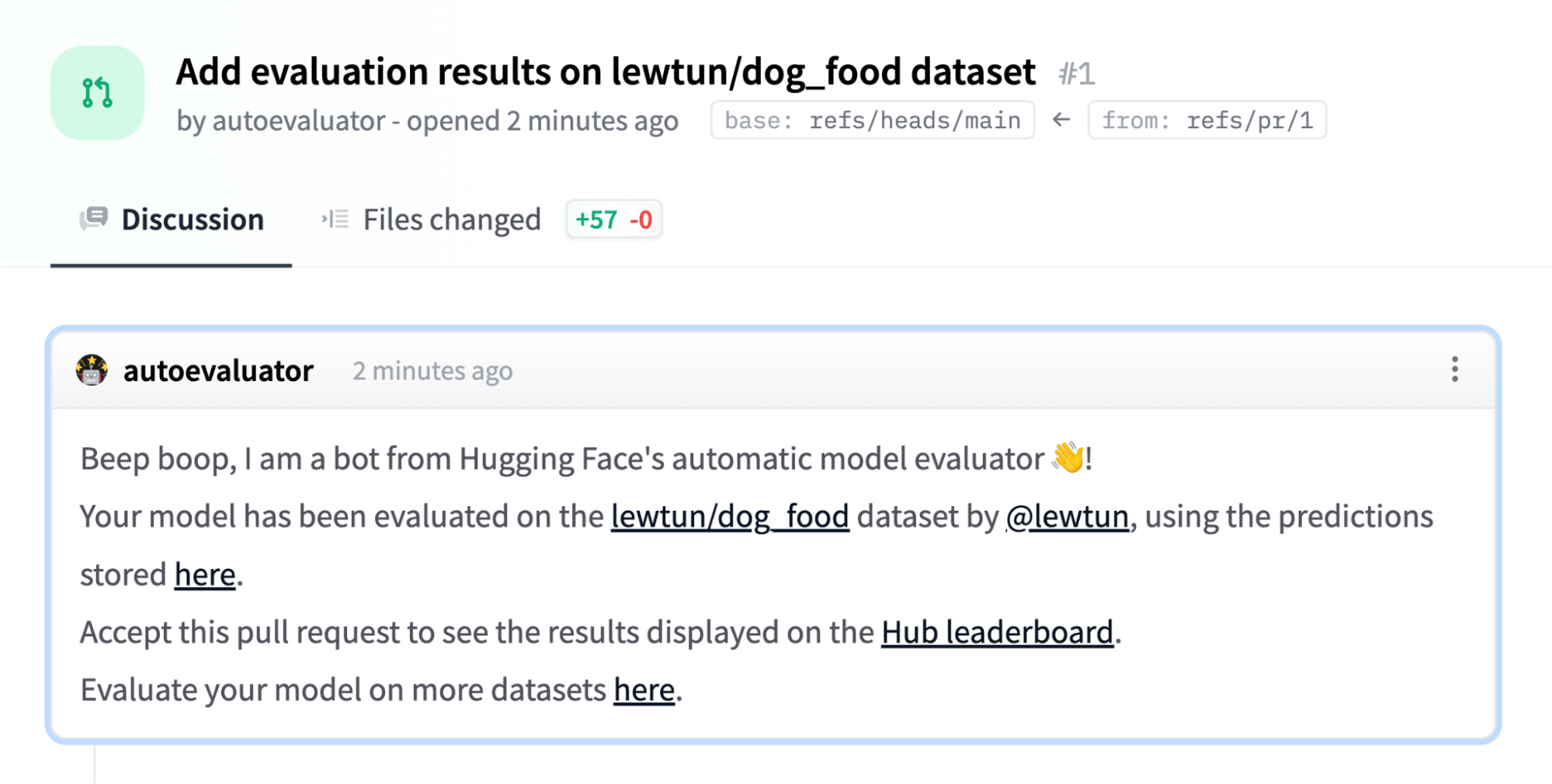
You can also copy-paste the evaluation metadata into the dataset card so that you and the community can skip the manual configuration next time!
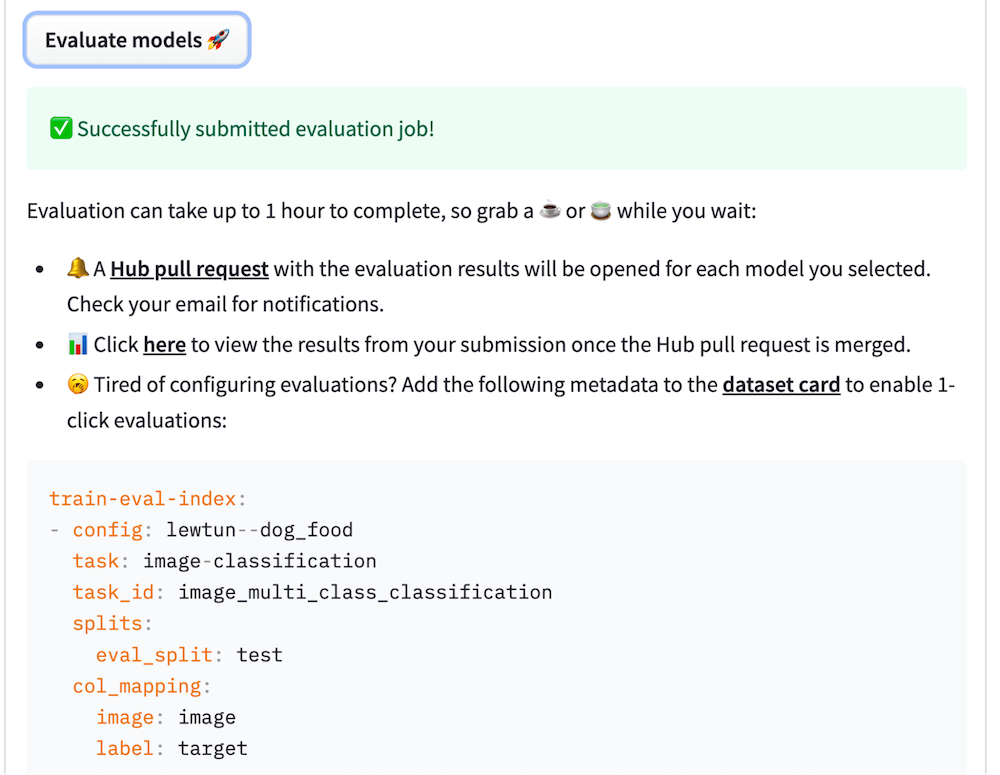
### Check out the leaderboard
To facilitate the comparison of models, Evaluation on the Hub also provides leaderboards that allow you to examine which models perform best on which split and metric:
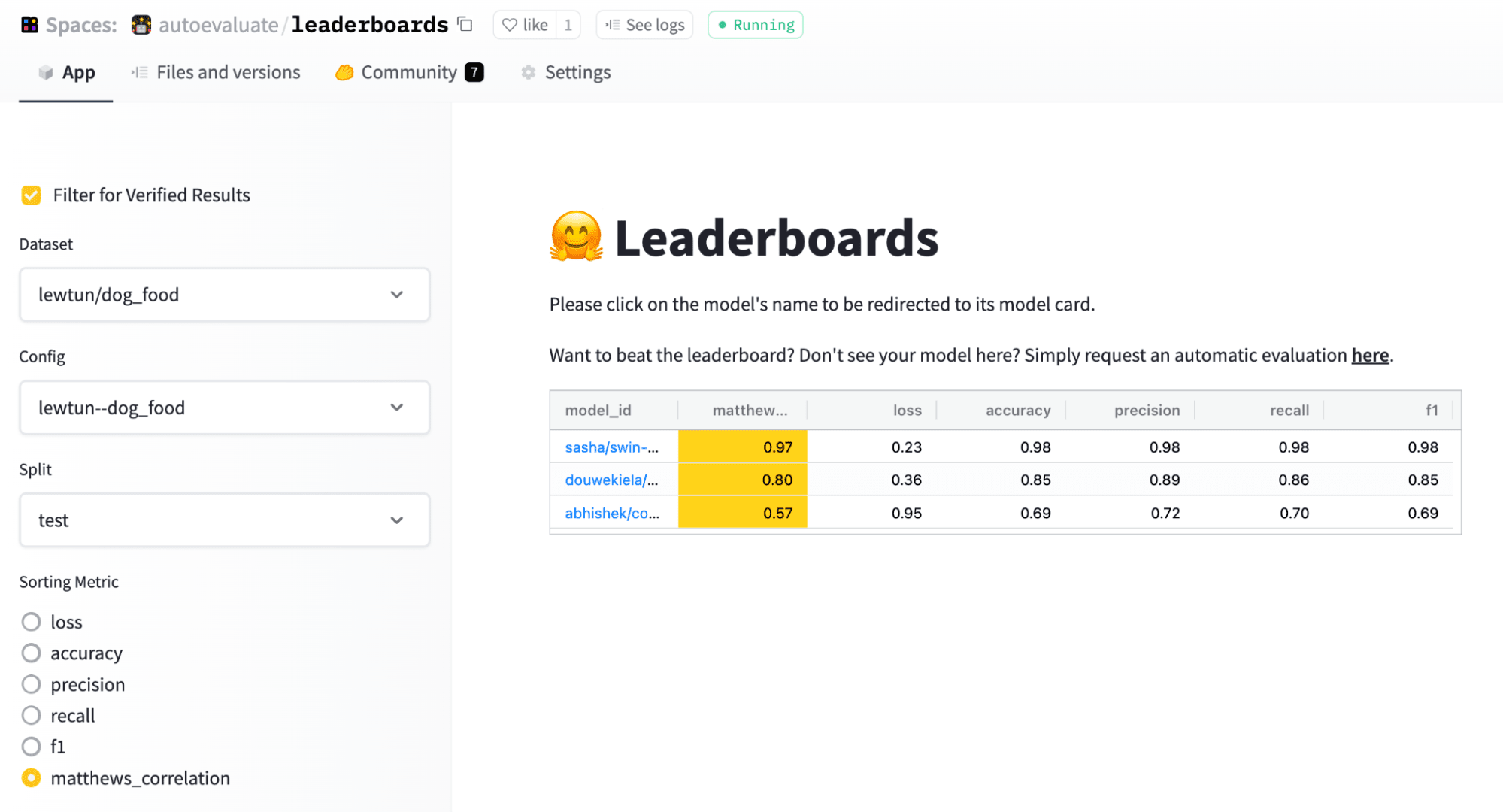
Looks like the Swin Transformer came out on top!
### Try it yourself!
If you’d like to evaluate your own choice of models, give Evaluation on the Hub a spin by checking out these popular datasets:
* [Emotion](https://huggingface.co/spaces/autoevaluate/model-evaluator?dataset=emotion) for text classification
* [MasakhaNER](https://huggingface.co/spaces/autoevaluate/model-evaluator?dataset=masakhaner) for named entity recognition
* [SAMSum](https://huggingface.co/spaces/autoevaluate/model-evaluator?dataset=samsum) for text summarization
## The Bigger Picture
Since the dawn of machine learning, we've evaluated models by computing some form of accuracy on a held-out test set that is assumed to be independent and identically distributed. Under the pressures of modern AI, that paradigm is now starting to show serious cracks.
Benchmarks are saturating, meaning that machines outperform humans on certain test sets, almost faster than we can come up with new ones. Yet, AI systems are known to be brittle and suffer from, or even worse amplify, severe malicious biases. Reproducibility is lacking. Openness is an afterthought. While people fixate on leaderboards, practical considerations for deploying models, such as efficiency and fairness, are often glossed over. The hugely important role data plays in model development is still not taken seriously enough. What is more, the practices of pretraining and prompt-based in-context learning have blurred what it means to be “in distribution” in the first place. Machine learning is slowly catching up to these things, and we hope to help the field move forward with our work.
## Next Steps
A few weeks ago, we launched the Hugging Face [Evaluate library](https://github.com/huggingface/evaluate), aimed at lowering barriers to the best practices of machine learning evaluation. We have also been hosting benchmarks, like [RAFT](https://huggingface.co/spaces/ought/raft-leaderboard) and [GEM](https://huggingface.co/spaces/GEM/submission-form). Evaluation on the Hub is a logical next step in our efforts to enable a future where models are evaluated in a more holistic fashion, along many axes of evaluation, in a trustable and guaranteeably reproducible manner. Stay tuned for more launches soon, including more tasks, and a new and improved [data measurements tool](https://huggingface.co/spaces/huggingface/data-measurements-tool)!
We’re excited to see where the community will take this! If you'd like to help out, evaluate as many models on as many datasets as you like. And as always, please give us lots of feedback, either on the [Community tabs](https://huggingface.co/spaces/autoevaluate/model-evaluator/discussions) or the [forums](https://discuss.huggingface.co/)!
| 7 |
0 | hf_public_repos | hf_public_repos/blog/the-partnership-amazon-sagemaker-and-hugging-face.md | ---
title: 'The Partnership: Amazon SageMaker and Hugging Face'
thumbnail: /blog/assets/17_the_partnership_amazon_sagemaker_and_hugging_face/thumbnail.png
---
<img src="/blog/assets/17_the_partnership_amazon_sagemaker_and_hugging_face/cover.png" alt="hugging-face-and-aws-logo" class="w-full">
> Look at these smiles!
# **The Partnership: Amazon SageMaker and Hugging Face**
Today, we announce a strategic partnership between Hugging Face and [Amazon](https://huggingface.co/amazon) to make it easier for companies to leverage State of the Art Machine Learning models, and ship cutting-edge NLP features faster.
Through this partnership, Hugging Face is leveraging Amazon Web Services as its Preferred Cloud Provider to deliver services to its customers.
As a first step to enable our common customers, Hugging Face and Amazon are introducing new Hugging Face Deep Learning Containers (DLCs) to make it easier than ever to train Hugging Face Transformer models in [Amazon SageMaker](https://aws.amazon.com/sagemaker/).
To learn how to access and use the new Hugging Face DLCs with the Amazon SageMaker Python SDK, check out the guides and resources below.
> _On July 8th, 2021 we extended the Amazon SageMaker integration to add easy deployment and inference of Transformers models. If you want to learn how you can [deploy Hugging Face models easily with Amazon SageMaker](https://huggingface.co/blog/deploy-hugging-face-models-easily-with-amazon-sagemaker) take a look at the [new blog post](https://huggingface.co/blog/deploy-hugging-face-models-easily-with-amazon-sagemaker) and the [documentation](https://huggingface.co/docs/sagemaker/inference)._
---
## **Features & Benefits 🔥**
## One Command is All you Need
With the new Hugging Face Deep Learning Containers available in Amazon SageMaker, training cutting-edge Transformers-based NLP models has never been simpler. There are variants specially optimized for TensorFlow and PyTorch, for single-GPU, single-node multi-GPU and multi-node clusters.
## Accelerating Machine Learning from Science to Production
In addition to Hugging Face DLCs, we created a first-class Hugging Face extension to the SageMaker Python-sdk to accelerate data science teams, reducing the time required to set up and run experiments from days to minutes.
You can use the Hugging Face DLCs with the Automatic Model Tuning capability of Amazon SageMaker, in order to automatically optimize your training hyperparameters and quickly increase the accuracy of your models.
Thanks to the SageMaker Studio web-based Integrated Development Environment (IDE), you can easily track and compare your experiments and your training artifacts.
## Built-in Performance
With the Hugging Face DLCs, SageMaker customers will benefit from built-in performance optimizations for PyTorch or TensorFlow, to train NLP models faster, and with the flexibility to choose the training infrastructure with the best price/performance ratio for your workload.
The Hugging Face DLCs are fully integrated with the [SageMaker distributed training libraries](https://docs.aws.amazon.com/sagemaker/latest/dg/distributed-training.html), to train models faster than was ever possible before, using the latest generation of instances available on Amazon EC2.
---
## **Resources, Documentation & Samples 📄**
Below you can find all the important resources to all published blog posts, videos, documentation, and sample Notebooks/scripts.
## Blog/Video
- [AWS: Embracing natural language processing with Hugging Face](https://aws.amazon.com/de/blogs/opensource/embracing-natural-language-processing-with-hugging-face/)
- [Deploy Hugging Face models easily with Amazon SageMaker](https://huggingface.co/blog/deploy-hugging-face-models-easily-with-amazon-sagemaker)
- [AWS and Hugging Face collaborate to simplify and accelerate adoption of natural language processing models](https://aws.amazon.com/blogs/machine-learning/aws-and-hugging-face-collaborate-to-simplify-and-accelerate-adoption-of-natural-language-processing-models/)
- [Walkthrough: End-to-End Text Classification](https://youtu.be/ok3hetb42gU)
- [Working with Hugging Face models on Amazon SageMaker](https://youtu.be/leyrCgLAGjMn)
- [Distributed Training: Train BART/T5 for Summarization using 🤗 Transformers and Amazon SageMaker](https://huggingface.co/blog/sagemaker-distributed-training-seq2seq)
- [Deploy a Hugging Face Transformers Model from S3 to Amazon SageMaker](https://youtu.be/pfBGgSGnYLs)
- [Deploy a Hugging Face Transformers Model from the Model Hub to Amazon SageMaker](https://youtu.be/l9QZuazbzWM)
## Documentation
- [Hugging Face documentation for Amazon SageMaker](https://huggingface.co/docs/sagemaker/main)
- [Run training on Amazon SageMaker](https://huggingface.co/docs/sagemaker/train)
- [Deploy models to Amazon SageMaker](https://huggingface.co/docs/sagemaker/inference)
- [Frequently Asked Questions](https://huggingface.co/docs/sagemaker/faq)
- [Amazon SageMaker documentation for Hugging Face](https://docs.aws.amazon.com/sagemaker/latest/dg/hugging-face.html)
- [Python SDK SageMaker documentation for Hugging Face](https://sagemaker.readthedocs.io/en/stable/frameworks/huggingface/index.html)
- [Deep Learning Container](https://github.com/aws/deep-learning-containers/blob/master/available_images.md#huggingface-training-containers)
- [SageMaker's Distributed Data Parallel Library](https://docs.aws.amazon.com/sagemaker/latest/dg/data-parallel.html)
- [SageMaker's Distributed Model Parallel Library](https://docs.aws.amazon.com/sagemaker/latest/dg/model-parallel.html)
## Sample Notebook
- [all Notebooks](https://github.com/huggingface/notebooks/tree/master/sagemaker)
- [Getting Started Pytorch](https://github.com/huggingface/notebooks/blob/master/sagemaker/01_getting_started_pytorch/sagemaker-notebook.ipynb)
- [Getting Started Tensorflow](https://github.com/huggingface/notebooks/blob/master/sagemaker/02_getting_started_tensorflow/sagemaker-notebook.ipynb)
- [Distributed Training Data Parallelism](https://github.com/huggingface/notebooks/blob/master/sagemaker/03_distributed_training_data_parallelism/sagemaker-notebook.ipynb)
- [Distributed Training Model Parallelism](https://github.com/huggingface/notebooks/blob/master/sagemaker/04_distributed_training_model_parallelism/sagemaker-notebook.ipynb)
- [Spot Instances and continue training](https://github.com/huggingface/notebooks/blob/master/sagemaker/05_spot_instances/sagemaker-notebook.ipynb)
- [SageMaker Metrics](https://github.com/huggingface/notebooks/blob/master/sagemaker/06_sagemaker_metrics/sagemaker-notebook.ipynb)
- [Distributed Training Data Parallelism Tensorflow](https://github.com/huggingface/notebooks/blob/master/sagemaker/07_tensorflow_distributed_training_data_parallelism/sagemaker-notebook.ipynb)
- [Distributed Training Summarization](https://github.com/huggingface/notebooks/blob/master/sagemaker/08_distributed_summarization_bart_t5/sagemaker-notebook.ipynb)
- [Image Classification with Vision Transformer](https://github.com/huggingface/notebooks/blob/master/sagemaker/09_image_classification_vision_transformer/sagemaker-notebook.ipynb)
- [Deploy one of the 10,000+ Hugging Face Transformers to Amazon SageMaker for Inference](https://github.com/huggingface/notebooks/blob/master/sagemaker/11_deploy_model_from_hf_hub/deploy_transformer_model_from_hf_hub.ipynb)
- [Deploy a Hugging Face Transformer model from S3 to SageMaker for inference](https://github.com/huggingface/notebooks/blob/master/sagemaker/10_deploy_model_from_s3/deploy_transformer_model_from_s3.ipynb)
---
## **Getting started: End-to-End Text Classification 🧭**
In this getting started guide, we will use the new Hugging Face DLCs and Amazon SageMaker extension to train a transformer model on binary text classification using the transformers and datasets libraries.
We will use an Amazon SageMaker Notebook Instance for the example. You can learn [here how to set up a Notebook Instance](https://docs.aws.amazon.com/sagemaker/latest/dg/nbi.html).
**What are we going to do:**
- set up a development environment and install sagemaker
- create the training script `train.py`
- preprocess our data and upload it to [Amazon S3](https://docs.aws.amazon.com/AmazonS3/latest/userguide/Welcome.html)
- create a [HuggingFace Estimator](https://huggingface.co/transformers/sagemaker.html) and train our model
## Set up a development environment and install sagemaker
As mentioned above we are going to use SageMaker Notebook Instances for this. To get started you need to jump into your Jupyer Notebook or JupyterLab and create a new Notebook with the conda_pytorch_p36 kernel.
_**Note:** The use of Jupyter is optional: We could also launch SageMaker Training jobs from anywhere we have an SDK installed, connectivity to the cloud and appropriate permissions, such as a Laptop, another IDE or a task scheduler like Airflow or AWS Step Functions._
After that we can install the required dependencies
```bash
pip install "sagemaker>=2.31.0" "transformers==4.6.1" "datasets[s3]==1.6.2" --upgrade
```
To run training on SageMaker we need to create a sagemaker Session and provide an IAM role with the right permission. This IAM role will be later attached to the TrainingJob enabling it to download data, e.g. from Amazon S3.
```python
import sagemaker
sess = sagemaker.Session()
# sagemaker session bucket -> used for uploading data, models and logs
# sagemaker will automatically create this bucket if it not exists
sagemaker_session_bucket=None
if sagemaker_session_bucket is None and sess is not None:
# set to default bucket if a bucket name is not given
sagemaker_session_bucket = sess.default_bucket()
role = sagemaker.get_execution_role()
sess = sagemaker.Session(default_bucket=sagemaker_session_bucket)
print(f"sagemaker role arn: {role}")
print(f"sagemaker bucket: {sess.default_bucket()}")
print(f"sagemaker session region: {sess.boto_region_name}")
```
## Create the training script `train.py`
In a SageMaker `TrainingJob` we are executing a python script with named arguments. In this example, we use PyTorch together with transformers. The script will
- pass the incoming parameters (hyperparameters from HuggingFace Estimator)
- load our dataset
- define our compute metrics function
- set up our `Trainer`
- run training with `trainer.train()`
- evaluate the training and save our model at the end to S3.
```bash
from transformers import AutoModelForSequenceClassification, Trainer, TrainingArguments
from sklearn.metrics import accuracy_score, precision_recall_fscore_support
from datasets import load_from_disk
import random
import logging
import sys
import argparse
import os
import torch
if __name__ == "__main__":
parser = argparse.ArgumentParser()
# hyperparameters sent by the client are passed as command-line arguments to the script.
parser.add_argument("--epochs", type=int, default=3)
parser.add_argument("--train-batch-size", type=int, default=32)
parser.add_argument("--eval-batch-size", type=int, default=64)
parser.add_argument("--warmup_steps", type=int, default=500)
parser.add_argument("--model_name", type=str)
parser.add_argument("--learning_rate", type=str, default=5e-5)
# Data, model, and output directories
parser.add_argument("--output-data-dir", type=str, default=os.environ["SM_OUTPUT_DATA_DIR"])
parser.add_argument("--model-dir", type=str, default=os.environ["SM_MODEL_DIR"])
parser.add_argument("--n_gpus", type=str, default=os.environ["SM_NUM_GPUS"])
parser.add_argument("--training_dir", type=str, default=os.environ["SM_CHANNEL_TRAIN"])
parser.add_argument("--test_dir", type=str, default=os.environ["SM_CHANNEL_TEST"])
args, _ = parser.parse_known_args()
# Set up logging
logger = logging.getLogger(__name__)
logging.basicConfig(
level=logging.getLevelName("INFO"),
handlers=[logging.StreamHandler(sys.stdout)],
format="%(asctime)s - %(name)s - %(levelname)s - %(message)s",
)
# load datasets
train_dataset = load_from_disk(args.training_dir)
test_dataset = load_from_disk(args.test_dir)
logger.info(f" loaded train_dataset length is: {len(train_dataset)}")
logger.info(f" loaded test_dataset length is: {len(test_dataset)}")
# compute metrics function for binary classification
def compute_metrics(pred):
labels = pred.label_ids
preds = pred.predictions.argmax(-1)
precision, recall, f1, _ = precision_recall_fscore_support(labels, preds, average="binary")
acc = accuracy_score(labels, preds)
return {"accuracy": acc, "f1": f1, "precision": precision, "recall": recall}
# download model from model hub
model = AutoModelForSequenceClassification.from_pretrained(args.model_name)
# define training args
training_args = TrainingArguments(
output_dir=args.model_dir,
num_train_epochs=args.epochs,
per_device_train_batch_size=args.train_batch_size,
per_device_eval_batch_size=args.eval_batch_size,
warmup_steps=args.warmup_steps,
evaluation_strategy="epoch",
logging_dir=f"{args.output_data_dir}/logs",
learning_rate=float(args.learning_rate),
)
# create Trainer instance
trainer = Trainer(
model=model,
args=training_args,
compute_metrics=compute_metrics,
train_dataset=train_dataset,
eval_dataset=test_dataset,
)
# train model
trainer.train()
# evaluate model
eval_result = trainer.evaluate(eval_dataset=test_dataset)
# writes eval result to file which can be accessed later in s3 output
with open(os.path.join(args.output_data_dir, "eval_results.txt"), "w") as writer:
print(f"***** Eval results *****")
for key, value in sorted(eval_result.items()):
writer.write(f"{key} = {value}\\n")
# Saves the model to s3; default is /opt/ml/model which SageMaker sends to S3
trainer.save_model(args.model_dir)
```
## Preprocess our data and upload it to s3
We use the `datasets` library to download and preprocess our `imdb` dataset. After preprocessing, the dataset will be uploaded to the current session’s default s3 bucket `sess.default_bucket()` used within our training job. The `imdb` dataset consists of 25000 training and 25000 testing highly polar movie reviews.
```python
import botocore
from datasets import load_dataset
from transformers import AutoTokenizer
from datasets.filesystems import S3FileSystem
# tokenizer used in preprocessing
tokenizer_name = 'distilbert-base-uncased'
# filesystem client for s3
s3 = S3FileSystem()
# dataset used
dataset_name = 'imdb'
# s3 key prefix for the data
s3_prefix = 'datasets/imdb'
# load dataset
dataset = load_dataset(dataset_name)
# download tokenizer
tokenizer = AutoTokenizer.from_pretrained(tokenizer_name)
# tokenizer helper function
def tokenize(batch):
return tokenizer(batch['text'], padding='max_length', truncation=True)
# load dataset
train_dataset, test_dataset = load_dataset('imdb', split=['train', 'test'])
test_dataset = test_dataset.shuffle().select(range(10000)) # smaller the size for test dataset to 10k
# tokenize dataset
train_dataset = train_dataset.map(tokenize, batched=True, batch_size=len(train_dataset))
test_dataset = test_dataset.map(tokenize, batched=True, batch_size=len(test_dataset))
# set format for pytorch
train_dataset = train_dataset.rename_column("label", "labels")
train_dataset.set_format('torch', columns=['input_ids', 'attention_mask', 'labels'])
test_dataset = test_dataset.rename_column("label", "labels")
test_dataset.set_format('torch', columns=['input_ids', 'attention_mask', 'labels'])
# save train_dataset to s3
training_input_path = f's3://{sess.default_bucket()}/{s3_prefix}/train'
train_dataset.save_to_disk(training_input_path,fs=s3)
# save test_dataset to s3
test_input_path = f's3://{sess.default_bucket()}/{s3_prefix}/test'
test_dataset.save_to_disk(test_input_path,fs=s3)
```
## Create a HuggingFace Estimator and train our model
In order to create a SageMaker `Trainingjob` we can use a HuggingFace Estimator. The Estimator handles the end-to-end Amazon SageMaker training. In an Estimator, we define which fine-tuning script should be used as `entry_point`, which `instance_type` should be used, which hyperparameters are passed in. In addition to this, a number of advanced controls are available, such as customizing the output and checkpointing locations, specifying the local storage size or network configuration.
SageMaker takes care of starting and managing all the required Amazon EC2 instances for us with the Hugging Face DLC, it uploads the provided fine-tuning script, for example, our `train.py`, then downloads the data from the S3 bucket, `sess.default_bucket()`, into the container. Once the data is ready, the training job will start automatically by running.
```bash
/opt/conda/bin/python train.py --epochs 1 --model_name distilbert-base-uncased --train_batch_size 32
```
The hyperparameters you define in the HuggingFace Estimator are passed in as named arguments.
```python
from sagemaker.huggingface import HuggingFace
# hyperparameters, which are passed into the training job
hyperparameters={'epochs': 1,
'train_batch_size': 32,
'model_name':'distilbert-base-uncased'
}
# create the Estimator
huggingface_estimator = HuggingFace(
entry_point='train.py',
source_dir='./scripts',
instance_type='ml.p3.2xlarge',
instance_count=1,
role=role,
transformers_version='4.6',
pytorch_version='1.7',
py_version='py36',
hyperparameters = hyperparameters
)
```
To start our training we call the .fit() method and pass our S3 uri as input.
```python
# starting the train job with our uploaded datasets as input
huggingface_estimator.fit({'train': training_input_path, 'test': test_input_path})
```
---
## **Additional Features 🚀**
In addition to the Deep Learning Container and the SageMaker SDK, we have implemented other additional features.
## Distributed Training: Data-Parallel
You can use [SageMaker Data Parallelism Library](https://aws.amazon.com/blogs/aws/managed-data-parallelism-in-amazon-sagemaker-simplifies-training-on-large-datasets/) out of the box for distributed training. We added the functionality of Data Parallelism directly into the Trainer. If your train.py uses the Trainer API you only need to define the distribution parameter in the HuggingFace Estimator.
- [Example Notebook PyTorch](https://github.com/huggingface/notebooks/blob/master/sagemaker/04_distributed_training_model_parallelism/sagemaker-notebook.ipynb)
- [Example Notebook TensorFlow](https://github.com/huggingface/notebooks/blob/master/sagemaker/07_tensorflow_distributed_training_data_parallelism/sagemaker-notebook.ipynb)
```python
# configuration for running training on smdistributed Data Parallel
distribution = {'smdistributed':{'dataparallel':{ 'enabled': True }}}
# create the Estimator
huggingface_estimator = HuggingFace(
entry_point='train.py',
source_dir='./scripts',
instance_type='ml.p3dn.24xlarge',
instance_count=2,
role=role,
transformers_version='4.4.2',
pytorch_version='1.6.0',
py_version='py36',
hyperparameters = hyperparameters
distribution = distribution
)
```
The "Getting started: End-to-End Text Classification 🧭" example can be used for distributed training without any changes.
## Distributed Training: Model Parallel
You can use [SageMaker Model Parallelism Library](https://aws.amazon.com/blogs/aws/amazon-sagemaker-simplifies-training-deep-learning-models-with-billions-of-parameters/) out of the box for distributed training. We added the functionality of Model Parallelism directly into the [Trainer](https://huggingface.co/transformers/main_classes/trainer.html). If your `train.py` uses the [Trainer](https://huggingface.co/transformers/main_classes/trainer.html) API you only need to define the distribution parameter in the HuggingFace Estimator.
For detailed information about the adjustments take a look [here](https://sagemaker.readthedocs.io/en/stable/api/training/smd_model_parallel_general.html?highlight=modelparallel#required-sagemaker-python-sdk-parameters).
- [Example Notebook](https://github.com/huggingface/notebooks/blob/master/sagemaker/04_distributed_training_model_parallelism/sagemaker-notebook.ipynb)
```python
# configuration for running training on smdistributed Model Parallel
mpi_options = {
"enabled" : True,
"processes_per_host" : 8
}
smp_options = {
"enabled":True,
"parameters": {
"microbatches": 4,
"placement_strategy": "spread",
"pipeline": "interleaved",
"optimize": "speed",
"partitions": 4,
"ddp": True,
}
}
distribution={
"smdistributed": {"modelparallel": smp_options},
"mpi": mpi_options
}
# create the Estimator
huggingface_estimator = HuggingFace(
entry_point='train.py',
source_dir='./scripts',
instance_type='ml.p3dn.24xlarge',
instance_count=2,
role=role,
transformers_version='4.4.2',
pytorch_version='1.6.0',
py_version='py36',
hyperparameters = hyperparameters,
distribution = distribution
)
```
## Spot instances
With the creation of HuggingFace Framework extension for the SageMaker Python SDK we can also leverage the benefit of [fully-managed EC2 spot instances](https://docs.aws.amazon.com/sagemaker/latest/dg/model-managed-spot-training.html) and save up to 90% of our training cost.
_Note: Unless your training job will complete quickly, we recommend you use [checkpointing](https://docs.aws.amazon.com/sagemaker/latest/dg/model-checkpoints.html) with managed spot training, therefore you need to define the `checkpoint_s3_uri`._
To use spot instances with the `HuggingFace` Estimator we have to set the `use_spot_instances` parameter to `True` and define your `max_wait` and `max_run` time. You can read more about [the managed spot training lifecycle here](https://docs.aws.amazon.com/sagemaker/latest/dg/model-managed-spot-training.html).
- [Example Notebook](https://github.com/huggingface/notebooks/blob/master/sagemaker/05_spot_instances/sagemaker-notebook.ipynb)
```python
# hyperparameters, which are passed into the training job
hyperparameters={'epochs': 1,
'train_batch_size': 32,
'model_name':'distilbert-base-uncased',
'output_dir':'/opt/ml/checkpoints'
}
# create the Estimator
huggingface_estimator = HuggingFace(
entry_point='train.py',
source_dir='./scripts',
instance_type='ml.p3.2xlarge',
instance_count=1,
checkpoint_s3_uri=f's3://{sess.default_bucket()}/checkpoints'
use_spot_instances=True,
max_wait=3600, # This should be equal to or greater than max_run in seconds'
max_run=1000,
role=role,
transformers_version='4.4',
pytorch_version='1.6',
py_version='py36',
hyperparameters = hyperparameters
)
# Training seconds: 874
# Billable seconds: 105
# Managed Spot Training savings: 88.0%
```
## Git Repositories
When you create an `HuggingFace` Estimator, you can specify a [training script that is stored in a GitHub](https://sagemaker.readthedocs.io/en/stable/overview.html#use-scripts-stored-in-a-git-repository) repository as the entry point for the estimator, so that you don’t have to download the scripts locally. If Git support is enabled, then `entry_point` and `source_dir` should be relative paths in the Git repo if provided.
As an example to use `git_config` with an [example script from the transformers repository](https://github.com/huggingface/transformers/tree/master/examples/text-classification).
_Be aware that you need to define `output_dir` as a hyperparameter for the script to save your model to S3 after training. Suggestion: define output_dir as `/opt/ml/model` since it is the default `SM_MODEL_DIR` and will be uploaded to S3._
- [Example Notebook](https://github.com/huggingface/notebooks/blob/master/sagemaker/02_getting_started_tensorflow/sagemaker-notebook.ipynb)
```python
# configure git settings
git_config = {'repo': 'https://github.com/huggingface/transformers.git','branch': 'master'}
# create the Estimator
huggingface_estimator = HuggingFace(
entry_point='run_glue.py',
source_dir='./examples/text-classification',
git_config=git_config,
instance_type='ml.p3.2xlarge',
instance_count=1,
role=role,
transformers_version='4.4',
pytorch_version='1.6',
py_version='py36',
hyperparameters=hyperparameters
)
```
## SageMaker Metrics
[SageMaker Metrics](https://docs.aws.amazon.com/sagemaker/latest/dg/training-metrics.html#define-train-metrics) can automatically parse the logs for metrics and send those metrics to CloudWatch. If you want SageMaker to parse logs you have to specify the metrics that you want SageMaker to send to CloudWatch when you configure the training job. You specify the name of the metrics that you want to send and the regular expressions that SageMaker uses to parse the logs that your algorithm emits to find those metrics.
- [Example Notebook](https://github.com/huggingface/notebooks/blob/master/sagemaker/06_sagemaker_metrics/sagemaker-notebook.ipynb)
```python
# define metrics definitions
metric_definitions = [
{"Name": "train_runtime", "Regex": "train_runtime.*=\D*(.*?)$"},
{"Name": "eval_accuracy", "Regex": "eval_accuracy.*=\D*(.*?)$"},
{"Name": "eval_loss", "Regex": "eval_loss.*=\D*(.*?)$"},
]
# create the Estimator
huggingface_estimator = HuggingFace(
entry_point='train.py',
source_dir='./scripts',
instance_type='ml.p3.2xlarge',
instance_count=1,
role=role,
transformers_version='4.4',
pytorch_version='1.6',
py_version='py36',
metric_definitions=metric_definitions,
hyperparameters = hyperparameters
)
```
---
## **FAQ 🎯**
You can find the complete [Frequently Asked Questions](https://huggingface.co/docs/sagemaker/faq) in the [documentation](https://huggingface.co/docs/sagemaker/faq).
_Q: What are Deep Learning Containers?_
A: Deep Learning Containers (DLCs) are Docker images pre-installed with deep learning frameworks and libraries (e.g. transformers, datasets, tokenizers) to make it easy to train models by letting you skip the complicated process of building and optimizing your environments from scratch.
_Q: Do I have to use the SageMaker Python SDK to use the Hugging Face Deep Learning Containers?_
A: You can use the HF DLC without the SageMaker Python SDK and launch SageMaker Training jobs with other SDKs, such as the [AWS CLI](https://docs.aws.amazon.com/cli/latest/reference/sagemaker/create-training-job.html) or [boto3](https://boto3.amazonaws.com/v1/documentation/api/latest/reference/services/sagemaker.html#SageMaker.Client.create_training_job). The DLCs are also available through Amazon ECR and can be pulled and used in any environment of choice.
_Q: Why should I use the Hugging Face Deep Learning Containers?_
A: The DLCs are fully tested, maintained, optimized deep learning environments that require no installation, configuration, or maintenance.
_Q: Why should I use SageMaker Training to train Hugging Face models?_
A: SageMaker Training provides numerous benefits that will boost your productivity with Hugging Face : (1) first it is cost-effective: the training instances live only for the duration of your job and are paid per second. No risk anymore to leave GPU instances up all night: the training cluster stops right at the end of your job! It also supports EC2 Spot capacity, which enables up to 90% cost reduction. (2) SageMaker also comes with a lot of built-in automation that facilitates teamwork and MLOps: training metadata and logs are automatically persisted to a serverless managed metastore, and I/O with S3 (for datasets, checkpoints and model artifacts) is fully managed. Finally, SageMaker also allows to drastically scale up and out: you can launch multiple training jobs in parallel, but also launch large-scale distributed training jobs
_Q: Once I've trained my model with Amazon SageMaker, can I use it with 🤗/Transformers ?_
A: Yes, you can download your trained model from S3 and directly use it with transformers or upload it to the [Hugging Face Model Hub](https://huggingface.co/models).
_Q: How is my data and code secured by Amazon SageMaker?_
A: Amazon SageMaker provides numerous security mechanisms including [encryption at rest](https://docs.aws.amazon.com/sagemaker/latest/dg/encryption-at-rest-nbi.html) and [in transit](https://docs.aws.amazon.com/sagemaker/latest/dg/encryption-in-transit.html), [Virtual Private Cloud (VPC) connectivity](https://docs.aws.amazon.com/sagemaker/latest/dg/interface-vpc-endpoint.html) and [Identity and Access Management (IAM)](https://docs.aws.amazon.com/sagemaker/latest/dg/security_iam_service-with-iam.html). To learn more about security in the AWS cloud and with Amazon SageMaker, you can visit [Security in Amazon SageMaker](https://docs.aws.amazon.com/sagemaker/latest/dg/security_iam_service-with-iam.html) and [AWS Cloud Security](https://docs.aws.amazon.com/sagemaker/latest/dg/security_iam_service-with-iam.html).
_Q: Is this available in my region?_
A: For a list of the supported regions, please visit the [AWS region table](https://aws.amazon.com/about-aws/global-infrastructure/regional-product-services/) for all AWS global infrastructure.
_Q: Do I need to pay for a license from Hugging Face to use the DLCs?_
A: No - the Hugging Face DLCs are open source and licensed under Apache 2.0.
_Q: How can I run inference on my trained models?_
A: You have multiple options to run inference on your trained models. One option is to use Hugging Face [Accelerated Inference-API](https://api-inference.huggingface.co/docs/python/html/index.html) hosted service: start by [uploading the trained models to your Hugging Face account](https://huggingface.co/new) to deploy them publicly, or privately. Another great option is to use [SageMaker Inference](https://docs.aws.amazon.com/sagemaker/latest/dg/your-algorithms-inference-main.html) to run your own inference code in Amazon SageMaker. We are working on offering an integrated solution for Amazon SageMaker with Hugging Face Inference DLCs in the future - stay tuned!
_Q: Do you offer premium support or support SLAs for this solution?_
A: AWS Technical Support tiers are available from AWS and cover development and production issues for AWS products and services - please refer to AWS Support for specifics and scope.
If you have questions which the Hugging Face community can help answer and/or benefit from, please [post them in the Hugging Face forum](https://discuss.huggingface.co/c/sagemaker/17).
If you need premium support from the Hugging Face team to accelerate your NLP roadmap, our Expert Acceleration Program offers direct guidance from our open source, science and ML Engineering team - [contact us to learn more](mailto:[email protected]).
_Q: What are you planning next through this partnership?_
A: Our common goal is to democratize state of the art Machine Learning. We will continue to innovate to make it easier for researchers, data scientists and ML practitioners to manage, train and run state of the art models. If you have feature requests for integration in AWS with Hugging Face, please [let us know in the Hugging Face community forum](https://discuss.huggingface.co/c/sagemaker/17).
_Q: I use Hugging Face with Azure Machine Learning or Google Cloud Platform, what does this partnership mean for me?_
A: A foundational goal for Hugging Face is to make the latest AI accessible to as many people as possible, whichever framework or development environment they work in. While we are focusing integration efforts with Amazon Web Services as our Preferred Cloud Provider, we will continue to work hard to serve all Hugging Face users and customers, no matter what compute environment they run on.
| 8 |
0 | hf_public_repos | hf_public_repos/blog/aws-marketplace.md | ---
title: "Hugging Face Hub on the AWS Marketplace: Pay with your AWS Account"
thumbnail: /blog/assets/158_aws_marketplace/thumbnail.jpg
authors:
- user: philschmid
- user: sbrandeis
- user: jeffboudier
---
# Hugging Face Hub on the AWS Marketplace: Pay with your AWS Account
The [Hugging Face Hub](https://aws.amazon.com/marketplace/pp/prodview-n6vsyhdjkfng2) has landed on the AWS Marketplace. Starting today, you can subscribe to the Hugging Face Hub through AWS Marketplace to pay for your Hugging Face usage directly with your AWS account. This new integrated billing method makes it easy to manage payment for usage of all our managed services by all members of your organization, including Inference Endpoints, Spaces Hardware Upgrades, and AutoTrain to easily train, test and deploy the most popular machine learning models like Llama 2, StarCoder, or BERT.
By making [Hugging Face available on AWS Marketplace](https://aws.amazon.com/marketplace/pp/prodview-n6vsyhdjkfng2), we are removing barriers to adopting AI and making it easier for companies to leverage large language models. Now with just a few clicks, AWS customers can subscribe and connect their Hugging Face Account with their AWS account.
By subscribing through AWS Marketplace, Hugging Face organization usage charges for services like Inference Endpoints will automatically appear on your AWS bill, instead of being charged by Hugging Face to the credit card on file for your organization.
We are excited about this launch as it will bring our technology to more developers who rely on AWS, and make it easier for businesses to consume Hugging Face services.
## Getting Started
Before you can connect your AWS Account with your Hugging Face account, you need to fulfill the following prerequisites:
- Have access to an active AWS account with access to subscribe to products on the AWS Marketplace.
- Create a [Hugging Face organization account](https://huggingface.co/organizations/new) with a registered and confirmed email. (You cannot connect user accounts)
- Be a member of the Hugging Face organization you want to connect with the [“admin” role](https://huggingface.co/docs/hub/organizations-security).
- Logged into the Hugging Face Hub.
Once you meet these requirements, you can proceed with connecting your AWS and Hugging Face accounts.
### 1. Subscribe to the Hugging Face Hub
The first step is to go to the [AWS Marketplace offering](https://aws.amazon.com/marketplace/pp/prodview-n6vsyhdjkfng2) and subscribe to the Hugging Face Platform. There you open the [offer](https://aws.amazon.com/marketplace/pp/prodview-n6vsyhdjkfng2) and then click on “View purchase options” at the top right screen.

You are now on the “subscribe” page, where you can see the summary of pricing and where you can subscribe. To subscribe to the offer, click “Subscribe”.

After you successfully subscribe, you should see a green banner at the top with a button “Set up your account”. You need to click on “Set up your account” to connect your Hugging Face Account with your AWS account.

After clicking the button, you will be redirected to the Hugging Face Hub, where you can select the Hugging Face organization account you want to link to your AWS account. After selecting your account, click “Submit”

After clicking "Submit", you will be redirected to the Billings settings of the Hugging Face organization, where you can see the current state of your subscription, which should be `subscribe-pending`.

After a few minutes you should receive 2 emails: 1 from AWS confirming your subscription, and 1 from Hugging Face, which should look like the image below:

If you have received this, your AWS Account and Hugging Face organization account are now successfully connected!
To confirm it, you can open the Billing settings for [your organization account](https://huggingface.co/settings/organizations), where you should now see a `subscribe-success` status.

Congratulations! 🥳 All members of your organization can now start using Hugging Face premium services with billing directly managed by your AWS account:
- [Inference Endpoints Deploy models in minutes](https://ui.endpoints.huggingface.co/)
- [AutoTrain creates ML models without code](https://huggingface.co/autotrain)
- [Spaces Hardware upgrades](https://huggingface.co/docs/hub/spaces-gpus)
With one more [step](https://huggingface.co/enterprise-hub-aws-marketplace), you can enable Enterprise Hub and upgrade your free Hugging Face organization with advanced security features, access controls, collaboration tools and compute options. With Enterprise Hub, companies can build AI privately and securely within our GDPR compliant and SOC2 Type 2 certified platform (more details [here](https://huggingface.co/enterprise-hub-aws-marketplace)).
Pricing for Hugging Face Hub through the AWS marketplace offer is identical to the [public Hugging Face pricing](https://huggingface.co/pricing), but will be billed through your AWS Account. You can monitor the usage and billing of your organization at any time within the Billing section of your [organization settings](https://huggingface.co/settings/organizations).
---
Thanks for reading! If you have any questions, feel free to contact us at [[email protected]](mailto:[email protected]).
| 9 |
0 | hf_public_repos | hf_public_repos/blog/introduction-to-ggml.md | ---
title: "Introduction to ggml"
thumbnail: /blog/assets/introduction-to-ggml/cover.jpg
authors:
- user: ngxson
- user: ggerganov
guest: true
org: ggml-org
- user: slaren
guest: true
org: ggml-org
---
# Introduction to ggml
[ggml](https://github.com/ggerganov/ggml) is a machine learning (ML) library written in C and C++ with a focus on Transformer inference. The project is open-source and is being actively developed by a growing community. ggml is similar to ML libraries such as PyTorch and TensorFlow, though it is still in its early stages of development and some of its fundamentals are still changing rapidly.
Over time, ggml has gained popularity alongside other projects like [llama.cpp](https://github.com/ggerganov/llama.cpp) and [whisper.cpp](https://github.com/ggerganov/whisper.cpp). Many other projects also use ggml under the hood to enable on-device LLM, including [ollama](https://github.com/ollama/ollama), [jan](https://github.com/janhq/jan), [LM Studio](https://github.com/lmstudio-ai), [GPT4All](https://github.com/nomic-ai/gpt4all).
The main reasons people choose to use ggml over other libraries are:
1. **Minimalism**: The core library is self-contained in less than 5 files. While you may want to include additional files for GPU support, it's optional.
2. **Easy compilation**: You don't need fancy build tools. Without GPU support, you only need GCC or Clang!
3. **Lightweight**: The compiled binary size is less than 1MB, which is tiny compared to PyTorch (which usually takes hundreds of MB).
4. **Good compatibility**: It supports many types of hardware, including x86_64, ARM, Apple Silicon, CUDA, etc.
5. **Support for quantized tensors**: Tensors can be quantized to save memory (similar to JPEG compression) and in certain cases to improve performance.
6. **Extremely memory efficient**: Overhead for storing tensors and performing computations is minimal.
However, ggml also comes with some disadvantages that you need to keep in mind when using it (this list may change in future versions of ggml):
- Not all tensor operations are supported on all backends. For example, some may work on CPU but won't work on CUDA.
- Development with ggml may not be straightforward and may require deep knowledge of low-level programming.
- The project is in active development, so breaking changes are expected.
In this article, we will focus on the fundamentals of ggml for developers looking to get started with the library. We do not cover higher-level tasks such as LLM inference with llama.cpp, which builds upon ggml. Instead, we'll explore the core concepts and basic usage of ggml to provide a solid foundation for further learning and development.
## Getting started
Great, so how do you start?
For simplicity, this guide will show you how to compile ggml on **Ubuntu**. In reality, you can compile ggml on virtually any platform (including Windows, macOS, and BSD).
```sh
# Start by installing build dependencies
# "gdb" is optional, but is recommended
sudo apt install build-essential cmake git gdb
# Then, clone the repository
git clone https://github.com/ggerganov/ggml.git
cd ggml
# Try compiling one of the examples
cmake -B build
cmake --build build --config Release --target simple-ctx
# Run the example
./build/bin/simple-ctx
```
Expected output:
```
mul mat (4 x 3) (transposed result):
[ 60.00 55.00 50.00 110.00
90.00 54.00 54.00 126.00
42.00 29.00 28.00 64.00 ]
```
If you see the expected result, that means we're good to go!
## Terminology and concepts
Before diving deep into ggml, we should understand some key concepts. If you're coming from high-level libraries like PyTorch or TensorFlow, these may seem challenging to grasp. However, keep in mind that ggml is a **low-level** library. Understanding these terms can give you much more control over performance:
- [ggml_context](https://github.com/ggerganov/ggml/blob/18703ad600cc68dbdb04d57434c876989a841d12/include/ggml.h#L355): A "container" that holds objects such as tensors, graphs, and optionally data
- [ggml_cgraph](https://github.com/ggerganov/ggml/blob/18703ad600cc68dbdb04d57434c876989a841d12/include/ggml.h#L652): Represents a computational graph. Think of it as the "order of computation" that will be transferred to the backend.
- [ggml_backend](https://github.com/ggerganov/ggml/blob/18703ad600cc68dbdb04d57434c876989a841d12/src/ggml-backend-impl.h#L80): Represents an interface for executing computation graphs. There are many types of backends: CPU (default), CUDA, Metal (Apple Silicon), Vulkan, RPC, etc.
- [ggml_backend_buffer_type](https://github.com/ggerganov/ggml/blob/18703ad600cc68dbdb04d57434c876989a841d12/src/ggml-backend-impl.h#L18): Represents a buffer type. Think of it as a "memory allocator" connected to each `ggml_backend`. For example, if you want to perform calculations on a GPU, you need to allocate memory on the GPU via `buffer_type` (usually abbreviated as `buft`).
- [ggml_backend_buffer](https://github.com/ggerganov/ggml/blob/18703ad600cc68dbdb04d57434c876989a841d12/src/ggml-backend-impl.h#L52): Represents a buffer allocated by `buffer_type`. Remember: a buffer can hold the data of multiple tensors.
- [ggml_gallocr](https://github.com/ggerganov/ggml/blob/18703ad600cc68dbdb04d57434c876989a841d12/include/ggml-alloc.h#L46): Represents a graph memory allocator, used to allocate efficiently the tensors used in a computation graph.
- [ggml_backend_sched](https://github.com/ggerganov/ggml/blob/18703ad600cc68dbdb04d57434c876989a841d12/include/ggml-backend.h#L169): A scheduler that enables concurrent use of multiple backends. It can distribute computations across different hardware (e.g., GPU and CPU) when dealing with large models or multiple GPUs. The scheduler can also automatically assign GPU-unsupported operations to the CPU, ensuring optimal resource utilization and compatibility.
## Simple example
In this example, we'll go through the steps to replicate the code we ran in [Getting Started](#getting-started). We need to create 2 matrices, multiply them and get the result. Using PyTorch, the code looks like this:
```py
import torch
# Create two matrices
matrix1 = torch.tensor([
[2, 8],
[5, 1],
[4, 2],
[8, 6],
])
matrix2 = torch.tensor([
[10, 5],
[9, 9],
[5, 4],
])
# Perform matrix multiplication
result = torch.matmul(matrix1, matrix2.T)
print(result.T)
```
With ggml, the following steps must be done to achieve the same result:
1. Allocate `ggml_context` to store tensor data
2. Create tensors and set data
3. Create a `ggml_cgraph` for mul_mat operation
4. Run the computation
5. Retrieve results (output tensors)
6. Free memory and exit
**NOTE**: In this example, we will allocate the tensor data **inside** the `ggml_context` for simplicity. In practice, memory should be allocated as a device buffer, as we'll see in the next section.
To get started, let's create a new directory `examples/demo`
```sh
cd ggml # make sure you're in the project root
# create C source and CMakeLists file
touch examples/demo/demo.c
touch examples/demo/CMakeLists.txt
```
The code for this example is based on [simple-ctx.cpp](https://github.com/ggerganov/ggml/blob/6c71d5a071d842118fb04c03c4b15116dff09621/examples/simple/simple-ctx.cpp)
Edit `examples/demo/demo.c` with the content below:
```c
#include "ggml.h"
#include "ggml-cpu.h"
#include <string.h>
#include <stdio.h>
int main(void) {
// initialize data of matrices to perform matrix multiplication
const int rows_A = 4, cols_A = 2;
float matrix_A[rows_A * cols_A] = {
2, 8,
5, 1,
4, 2,
8, 6
};
const int rows_B = 3, cols_B = 2;
float matrix_B[rows_B * cols_B] = {
10, 5,
9, 9,
5, 4
};
// 1. Allocate `ggml_context` to store tensor data
// Calculate the size needed to allocate
size_t ctx_size = 0;
ctx_size += rows_A * cols_A * ggml_type_size(GGML_TYPE_F32); // tensor a
ctx_size += rows_B * cols_B * ggml_type_size(GGML_TYPE_F32); // tensor b
ctx_size += rows_A * rows_B * ggml_type_size(GGML_TYPE_F32); // result
ctx_size += 3 * ggml_tensor_overhead(); // metadata for 3 tensors
ctx_size += ggml_graph_overhead(); // compute graph
ctx_size += 1024; // some overhead (exact calculation omitted for simplicity)
// Allocate `ggml_context` to store tensor data
struct ggml_init_params params = {
/*.mem_size =*/ ctx_size,
/*.mem_buffer =*/ NULL,
/*.no_alloc =*/ false,
};
struct ggml_context * ctx = ggml_init(params);
// 2. Create tensors and set data
struct ggml_tensor * tensor_a = ggml_new_tensor_2d(ctx, GGML_TYPE_F32, cols_A, rows_A);
struct ggml_tensor * tensor_b = ggml_new_tensor_2d(ctx, GGML_TYPE_F32, cols_B, rows_B);
memcpy(tensor_a->data, matrix_A, ggml_nbytes(tensor_a));
memcpy(tensor_b->data, matrix_B, ggml_nbytes(tensor_b));
// 3. Create a `ggml_cgraph` for mul_mat operation
struct ggml_cgraph * gf = ggml_new_graph(ctx);
// result = a*b^T
// Pay attention: ggml_mul_mat(A, B) ==> B will be transposed internally
// the result is transposed
struct ggml_tensor * result = ggml_mul_mat(ctx, tensor_a, tensor_b);
// Mark the "result" tensor to be computed
ggml_build_forward_expand(gf, result);
// 4. Run the computation
int n_threads = 1; // Optional: number of threads to perform some operations with multi-threading
ggml_graph_compute_with_ctx(ctx, gf, n_threads);
// 5. Retrieve results (output tensors)
float * result_data = (float *) result->data;
printf("mul mat (%d x %d) (transposed result):\n[", (int) result->ne[0], (int) result->ne[1]);
for (int j = 0; j < result->ne[1] /* rows */; j++) {
if (j > 0) {
printf("\n");
}
for (int i = 0; i < result->ne[0] /* cols */; i++) {
printf(" %.2f", result_data[j * result->ne[0] + i]);
}
}
printf(" ]\n");
// 6. Free memory and exit
ggml_free(ctx);
return 0;
}
```
Write these lines in the `examples/demo/CMakeLists.txt` file you created:
```
set(TEST_TARGET demo)
add_executable(${TEST_TARGET} demo)
target_link_libraries(${TEST_TARGET} PRIVATE ggml)
```
Edit `examples/CMakeLists.txt`, add this line at the end:
```
add_subdirectory(demo)
```
Compile and run it:
```sh
cmake -B build
cmake --build build --config Release --target demo
# Run it
./build/bin/demo
```
Expected result:
```
mul mat (4 x 3) (transposed result):
[ 60.00 55.00 50.00 110.00
90.00 54.00 54.00 126.00
42.00 29.00 28.00 64.00 ]
```
## Example with a backend
"Backend" in ggml refers to an interface that can handle tensor operations. Backend can be CPU, CUDA, Vulkan, etc.
The backend abstracts the execution of the computation graphs. Once defined, a graph can be computed with the available hardware by using the respective backend implementation. Note that ggml will automatically reserve memory for any intermediate tensors necessary for the computation and will optimize the memory usage based on the lifetime of these intermediate results.
When doing a computation or inference with backend, common steps that need to be done are:
1. Initialize `ggml_backend`
2. Allocate `ggml_context` to store tensor metadata (we **don't need** to allocate tensor data right away)
3. Create tensors metadata (only their shapes and data types)
4. Allocate a `ggml_backend_buffer` to store all tensors
5. Copy tensor data from main memory (RAM) to backend buffer
6. Create a `ggml_cgraph` for mul_mat operation
7. Create a `ggml_gallocr` for cgraph allocation
8. Optionally: schedule the cgraph using `ggml_backend_sched`
9. Run the computation
10. Retrieve results (output tensors)
11. Free memory and exit
The code for this example is based on [simple-backend.cpp](https://github.com/ggerganov/ggml/blob/6c71d5a071d842118fb04c03c4b15116dff09621/examples/simple/simple-backend.cpp)
```cpp
#include "ggml.h"
#include "ggml-alloc.h"
#include "ggml-backend.h"
#ifdef GGML_USE_CUDA
#include "ggml-cuda.h"
#endif
#include <stdlib.h>
#include <string.h>
#include <stdio.h>
int main(void) {
// initialize data of matrices to perform matrix multiplication
const int rows_A = 4, cols_A = 2;
float matrix_A[rows_A * cols_A] = {
2, 8,
5, 1,
4, 2,
8, 6
};
const int rows_B = 3, cols_B = 2;
float matrix_B[rows_B * cols_B] = {
10, 5,
9, 9,
5, 4
};
// 1. Initialize backend
ggml_backend_t backend = NULL;
#ifdef GGML_USE_CUDA
fprintf(stderr, "%s: using CUDA backend\n", __func__);
backend = ggml_backend_cuda_init(0); // init device 0
if (!backend) {
fprintf(stderr, "%s: ggml_backend_cuda_init() failed\n", __func__);
}
#endif
// if there aren't GPU Backends fallback to CPU backend
if (!backend) {
backend = ggml_backend_cpu_init();
}
// Calculate the size needed to allocate
size_t ctx_size = 0;
ctx_size += 2 * ggml_tensor_overhead(); // tensors
// no need to allocate anything else!
// 2. Allocate `ggml_context` to store tensor data
struct ggml_init_params params = {
/*.mem_size =*/ ctx_size,
/*.mem_buffer =*/ NULL,
/*.no_alloc =*/ true, // the tensors will be allocated later by ggml_backend_alloc_ctx_tensors()
};
struct ggml_context * ctx = ggml_init(params);
// Create tensors metadata (only there shapes and data type)
struct ggml_tensor * tensor_a = ggml_new_tensor_2d(ctx, GGML_TYPE_F32, cols_A, rows_A);
struct ggml_tensor * tensor_b = ggml_new_tensor_2d(ctx, GGML_TYPE_F32, cols_B, rows_B);
// 4. Allocate a `ggml_backend_buffer` to store all tensors
ggml_backend_buffer_t buffer = ggml_backend_alloc_ctx_tensors(ctx, backend);
// 5. Copy tensor data from main memory (RAM) to backend buffer
ggml_backend_tensor_set(tensor_a, matrix_A, 0, ggml_nbytes(tensor_a));
ggml_backend_tensor_set(tensor_b, matrix_B, 0, ggml_nbytes(tensor_b));
// 6. Create a `ggml_cgraph` for mul_mat operation
struct ggml_cgraph * gf = NULL;
struct ggml_context * ctx_cgraph = NULL;
{
// create a temporally context to build the graph
struct ggml_init_params params0 = {
/*.mem_size =*/ ggml_tensor_overhead()*GGML_DEFAULT_GRAPH_SIZE + ggml_graph_overhead(),
/*.mem_buffer =*/ NULL,
/*.no_alloc =*/ true, // the tensors will be allocated later by ggml_gallocr_alloc_graph()
};
ctx_cgraph = ggml_init(params0);
gf = ggml_new_graph(ctx_cgraph);
// result = a*b^T
// Pay attention: ggml_mul_mat(A, B) ==> B will be transposed internally
// the result is transposed
struct ggml_tensor * result0 = ggml_mul_mat(ctx_cgraph, tensor_a, tensor_b);
// Add "result" tensor and all of its dependencies to the cgraph
ggml_build_forward_expand(gf, result0);
}
// 7. Create a `ggml_gallocr` for cgraph computation
ggml_gallocr_t allocr = ggml_gallocr_new(ggml_backend_get_default_buffer_type(backend));
ggml_gallocr_alloc_graph(allocr, gf);
// (we skip step 8. Optionally: schedule the cgraph using `ggml_backend_sched`)
// 9. Run the computation
int n_threads = 1; // Optional: number of threads to perform some operations with multi-threading
if (ggml_backend_is_cpu(backend)) {
ggml_backend_cpu_set_n_threads(backend, n_threads);
}
ggml_backend_graph_compute(backend, gf);
// 10. Retrieve results (output tensors)
// in this example, output tensor is always the last tensor in the graph
struct ggml_tensor * result = gf->nodes[gf->n_nodes - 1];
float * result_data = malloc(ggml_nbytes(result));
// because the tensor data is stored in device buffer, we need to copy it back to RAM
ggml_backend_tensor_get(result, result_data, 0, ggml_nbytes(result));
printf("mul mat (%d x %d) (transposed result):\n[", (int) result->ne[0], (int) result->ne[1]);
for (int j = 0; j < result->ne[1] /* rows */; j++) {
if (j > 0) {
printf("\n");
}
for (int i = 0; i < result->ne[0] /* cols */; i++) {
printf(" %.2f", result_data[j * result->ne[0] + i]);
}
}
printf(" ]\n");
free(result_data);
// 11. Free memory and exit
ggml_free(ctx_cgraph);
ggml_gallocr_free(allocr);
ggml_free(ctx);
ggml_backend_buffer_free(buffer);
ggml_backend_free(backend);
return 0;
}
```
Compile and run it, you should get the same result as the last example:
```sh
cmake -B build
cmake --build build --config Release --target demo
# Run it
./build/bin/demo
```
Expected result:
```
mul mat (4 x 3) (transposed result):
[ 60.00 55.00 50.00 110.00
90.00 54.00 54.00 126.00
42.00 29.00 28.00 64.00 ]
```
## Printing the computational graph
The `ggml_cgraph` represents the computational graph, which defines the order of operations that will be executed by the backend. Printing the graph can be a helpful debugging tool, especially when working with more complex models and computations.
You can add `ggml_graph_print` to print the cgraph:
```cpp
...
// Mark the "result" tensor to be computed
ggml_build_forward_expand(gf, result0);
// Print the cgraph
ggml_graph_print(gf);
```
Run it:
```
=== GRAPH ===
n_nodes = 1
- 0: [ 4, 3, 1] MUL_MAT
n_leafs = 2
- 0: [ 2, 4] NONE leaf_0
- 1: [ 2, 3] NONE leaf_1
========================================
```
Additionally, you can draw the cgraph as graphviz dot format:
```cpp
ggml_graph_dump_dot(gf, NULL, "debug.dot");
```
You can use the `dot` command or this [online website](https://dreampuf.github.io/GraphvizOnline) to render `debug.dot` into a final image:

## Conclusion
This article has provided an introductory overview of ggml, covering the key concepts, a simple usage example, and an example using a backend. While we've covered the basics, there is much more to explore when it comes to ggml.
In upcoming articles, we'll dive deeper into other ggml-related subjects, such as the GGUF format, quantization, and how the different backends are organized and utilized. Additionally, you can visit the [ggml examples directory](https://github.com/ggerganov/ggml/tree/master/examples) to see more advanced use cases and sample code. Stay tuned for more ggml content in the future!
| 0 |
0 | hf_public_repos | hf_public_repos/blog/diffusion-models-event.md | ---
title: "Diffusion Models Live Event"
thumbnail: /blog/assets/diffusion-models-event/thumbnail.png
authors:
- user: lewtun
- user: johnowhitaker
---
# Diffusion Models Live Event
We are excited to share that the [Diffusion Models Class](https://github.com/huggingface/diffusion-models-class) with Hugging Face and Jonathan Whitaker will be **released on November 28th** 🥳! In this free course, you will learn all about the theory and application of diffusion models -- one of the most exciting developments in deep learning this year. If you've never heard of diffusion models, here's a demo to give you a taste of what they can do:
<script type="module" src="https://gradio.s3-us-west-2.amazonaws.com/3.6/gradio.js "></script>
<gradio-app theme_mode="light" space="runwayml/stable-diffusion-v1-5"></gradio-app>
To go with this release, we are organising a **live community event on November 30th** to which you are invited! The program includes exciting talks from the creators of Stable Diffusion, researchers at Stability AI and Meta, and more!
To register, please fill out [this form](http://eepurl.com/icSzXv). More details on the speakers and talks are provided below.
## Live Talks
The talks will focus on a high-level presentation of diffusion models and the tools we can use to build applications with them.
<div
class="container md:grid md:grid-cols-2 gap-2 max-w-7xl"
>
<div class="text-center flex flex-col items-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/diffusion-models-event/david-ha.png" width=50% style="border-radius: 50%;">
<p><strong>David Ha: <em>Collective Intelligence and Creative AI</em></strong></p>
<p>David Ha is the Head of Strategy at Stability AI. He previously worked as a Research Scientist at Google, working in the Brain team in Japan. His research interests include complex systems, self-organization, and creative applications of machine learning. Prior to joining Google, He worked at Goldman Sachs as a Managing Director, where he co-ran the fixed-income trading business in Japan. He obtained undergraduate and masters degrees from the University of Toronto, and a PhD from the University of Tokyo.</p>
</div>
<div class="text-center flex flex-col items-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/diffusion-models-event/devi-parikh.png" width=50% style="border-radius: 50%;">
<p><strong>Devi Parikh: <em>Make-A-Video: Diffusion Models for Text-to-Video Generation without Text-Video Data</em></strong></p>
<p>Devi Parikh is a Research Director at the Fundamental AI Research (FAIR) lab at Meta, and an Associate Professor in the School of Interactive Computing at Georgia Tech. She has held visiting positions at Cornell University, University of Texas at Austin, Microsoft Research, MIT, Carnegie Mellon University, and Facebook AI Research. She received her M.S. and Ph.D. degrees from the Electrical and Computer Engineering department at Carnegie Mellon University in 2007 and 2009 respectively. Her research interests are in computer vision, natural language processing, embodied AI, human-AI collaboration, and AI for creativity.</p>
</div>
<div class="text-center flex flex-col items-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/diffusion-models-event/patrick-esser.png" width=50% style="border-radius: 50%;">
<p><strong>Patrick Esser: <em>Food for Diffusion</em></strong></p>
<p>Patrick Esser is a Principal Research Scientist at Runway, leading applied research efforts including the core model behind Stable Diffusion, otherwise known as High-Resolution Image Synthesis with Latent Diffusion Models.</p>
</div>
<div class="text-center flex flex-col items-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/diffusion-models-event/justin-pinkey.png" width=50% style="border-radius: 50%;">
<p><strong>Justin Pinkney: <em>Beyond text - giving Stable Diffusion new abilities</em></strong></p>
<p>Justin is a Senior Machine Learning Researcher at Lambda Labs working on image generation and editing, particularly for artistic and creative applications. He loves to play and tweak pre-trained models to add new capabilities to them, and is probably best known for models like: Toonify, Stable Diffusion Image Variations, and Text-to-Pokemon.</p>
</div>
<div class="text-center flex flex-col items-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/diffusion-models-event/poli.png" width=50% style="border-radius: 50%;">
<p><strong>Apolinário Passos: <em>DALL-E 2 is cool but... what will come after the generative media hype?</em></strong></p>
<p>Apolinário Passos is a Machine Learning Art Engineer at Hugging Face and an artist who focuses on generative art and generative media. He founded the platform multimodal.art and the corresponding Twitter account, and works on the organization, aggregation, and platformization of open-source generative media machine learning models.</p>
</div>
</div>
| 1 |
0 | hf_public_repos | hf_public_repos/blog/noob_intro_transformers.md | ---
title: "Total noob’s intro to Hugging Face Transformers"
thumbnail: /blog/assets/78_ml_director_insights/guide.png
authors:
- user: 2legit2overfit
---
# Total noob’s intro to Hugging Face Transformers
Welcome to "A Total Noob’s Introduction to Hugging Face Transformers," a guide designed specifically for those looking to understand the bare basics of using open-source ML. Our goal is to demystify what Hugging Face Transformers is and how it works, not to turn you into a machine learning practitioner, but to enable better understanding of and collaboration with those who are. That being said, the best way to learn is by doing, so we'll walk through a simple worked example of running Microsoft’s Phi-2 LLM in a notebook on a Hugging Face space.
You might wonder, with the abundance of tutorials on Hugging Face already available, why create another? The answer lies in accessibility: most existing resources assume some technical background, including Python proficiency, which can prevent non-technical individuals from grasping ML fundamentals. As someone who came from the business side of AI, I recognize that the learning curve presents a barrier and wanted to offer a more approachable path for like-minded learners.
Therefore, this guide is tailored for a non-technical audience keen to better understand open-source machine learning without having to learn Python from scratch. We assume no prior knowledge and will explain concepts from the ground up to ensure clarity. If you're an engineer, you’ll find this guide a bit basic, but for beginners, it's an ideal starting point.
Let’s get stuck in… but first some context.
## What is Hugging Face Transformers?
Hugging Face Transformers is an open-source Python library that provides access to thousands of pre-trained Transformers models for natural language processing (NLP), computer vision, audio tasks, and more. It simplifies the process of implementing Transformer models by abstracting away the complexity of training or deploying models in lower level ML frameworks like PyTorch, TensorFlow and JAX.
## What is a library?
A library is just a collection of reusable pieces of code that can be integrated into projects to implement functionality more efficiently without the need to write your own code from scratch.
Notably, the Transformers library provides re-usable code for implementing models in common frameworks like PyTorch, TensorFlow and JAX. This re-usable code can be accessed by calling upon functions (also known as methods) within the library.
## What is the Hugging Face Hub?
The Hugging Face Hub is a collaboration platform that hosts a huge collection of open-source models and datasets for machine learning, think of it being like Github for ML. The hub facilitates sharing and collaborating by making it easy for you to discover, learn, and interact with useful ML assets from the open-source community. The hub integrates with, and is used in conjunction with the Transformers library, as models deployed using the Transformers library are downloaded from the hub.
## What are Hugging Face Spaces?
Spaces from Hugging Face is a service available on the Hugging Face Hub that provides an easy to use GUI for building and deploying web hosted ML demos and apps. The service allows you to quickly build ML demos, upload your own apps to be hosted, or even select a number of pre-configured ML applications to deploy instantly.
In the tutorial we’ll be deploying one of the pre-configured ML applications, a JupyterLab notebook, by selecting the corresponding docker container.
## What is a notebook?
Notebooks are interactive applications that allow you to write and share live executable code interwoven with complementary narrative text. Notebooks are especially useful for Data Scientists and Machine Learning Engineers as they allow you to experiment with code in realtime and easily review and share the results.
1. Create a Hugging Face account
- Go to [hf.co](https://hf.co), click “Sign Up” and create an account if you don’t already have one
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/llama2-non-engineers/guide1.png"><br>
</p>
2. Add your billing information
- Within your HF account go to Settings > Billing, add your credit card to the payment information section
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/llama2-non-engineers/guide2.png"><br>
</p>
## Why do we need your credit card?
In order to run most LLMs you'll need a GPU, which unfortunately aren’t free, you can however rent these from Hugging Face. Don’t worry, it shouldn’t cost you much. The GPU required for this tutorial, an NVIDIA A10G, only costs a couple of dollars per hour.
3. Create a Space to host your notebook
- On [hf.co](https://hf.co) go to Spaces > Create New
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/llama2-non-engineers/guide3.png"><br>
</p>
4. Configure your Space
- Set your preferred space name
- Select Docker > JupyterLab to select the pre-configured notebook app
- Select Space Hardware as “Nvidia A10G Small”
- Everything else can be left as default
- Select “Create Space”
## What is a docker template?
A Docker template is a predefined blueprint for a software environment that includes the necessary software and configurations, enabling developers to easily and rapidly deploy applications in a consistent and isolated way.
## Why do I need to select a GPU Space Hardware?
By default, our Space comes with a complimentary CPU, which is fine for some applications. However, the many computations required by LLMs benefit significantly from being run in parallel to improve speed, which is something GPUs are great at.
It's also important to choose a GPU with enough memory to store the model and providing spare working memory. In our case, an A10G Small with 24GB is enough for Phi-2.
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/llama2-non-engineers/guide4.png"><br>
</p>
5. Login to JupyterLab
- After the Space has finished building, you will see a log in screen. If you left the token as default in the template, you can log in with “huggingface”. Otherwise, just use the token you set
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/llama2-non-engineers/guide5.png"><br>
</p>
6. Create a new notebook
- Within the “Launcher” tab, select the top “Python 3” square under the “Notebook” heading, this will create a new notebook environment that has Python already installed
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/llama2-non-engineers/guide6.png"><br>
</p>
7. Install required packages
- In your new notebook you’ll need to install the PyTorch and Transformers libraries, as they do not come pre-installed in the environment .
- This can be done by entering the !pip command + library name in your notebook. Click the play button to execute the code and watch as the libraries are installed (Alternatively: Hit CMD + Return / CTRL + Enter)
```python
!pip install torch
!pip install transformers
```
## What is !pip install?
`!pip` is a command that installs Python packages from the Python Package Index ([PyPI](https://pypi.org/)) a web repository of libraries available for use in a Python environment. It allows us to extend the functionality of Python applications by incorporating a wide range of third-party add-ons.
## If we are using Transformers, why do we need Pytorch too?
Hugging Face is a library that is built on top of other frameworks like Pytorch, Tensorflow and JAX. In this case we are using Transformers with Pytorch and so need to install it to access it’s functionality.
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/llama2-non-engineers/guide7.png"><br>
</p>
8. Import the AutoTokenizer and AutoModelForCausalLM classes from Transformers
- Enter the following code on a new line and run it
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
```
## What is a Class?
Think of Classes as code recipes for creating these things called Objects. They are useful because they allow us to save Objects with a combination of properties and functions. This in turn simplifies coding as all of the information and operations needed for particular topics are accessible from the same place. We’ll be using these Classes to create two Objects: a `model` and a `tokenizer` Object.
## Why do I need to import the Class again after installing Transformers?
Although Transformers is already installed, the specific Classes within Transformers are not automatically available for use in your environment. Python requires us to explicitly import individual Classes as it helps avoid naming conflicts and ensures that only the necessary parts of a library are loaded into your current working context.
9. Define which model you want to run
- To detail the model you want to download and run from the Hugging Face Hub, you need to specify the name of the model repo in your code
- We do this by setting a variable equal to the model name, in this case we decide to call the variable `model_id`
- We’ll use Microsoft's Phi-2, a small but surprisingly capable model which can be found at https://huggingface.co/microsoft/phi-2. Note: Phi-2 is a base not an instruction tuned model and so will respond unusually if you try to use it for chat
```python
model_id = "microsoft/phi-2"
```
## What is an instruction tuned model?
An instruction-tuned language model is a type of model that has been further trained from its base version to understand and respond to commands or prompts given by a user, improving its ability to follow instructions. Base models are able to autocomplete text, but often don’t respond to commands in a useful way. We'll see this later when we try to prompt Phi.
10. Create a model object and load the model
- To load the model from the Hugging Face Hub into our local environment we need to instantiate the model object. We do this by passing the “model_id” which we defined in the last step into the argument of the “.from_pretrained” method on the AutoModelForCausalLM Class.
- Run your code and grab a drink, the model may take a few minutes to download
```python
model = AutoModelForCausalLM.from_pretrained(model_id)
```
## What is an argument?
An argument is input information that is passed to a function in order for it to compute an output. We pass an argument into a function by placing it between the function brackets. In this case the model ID is the sole argument, although functions can have multiple arguments, or none.
## What is a Method?
A Method is another name for a function that specifically uses information from a particular Object or Class. In this case the `.from_pretrained` method uses information from the Class and the `model_id` to create a new `model` object.
11. Create a tokenizer object and load the tokenizer
- To load the tokenizer you now need to create a tokenizer object. To do this again pass the `model_id` as an argument into the `.from_pretrained` method on the AutoTokenizer Class.
- Note there are some additional arguments, for the purposes of this example they aren’t important to understand so we won’t explain them.
```python
tokenizer = AutoTokenizer.from_pretrained(model_id, add_eos_token=True, padding_side='left')
```
## What is a tokenizer?
A tokenizer is a tool that splits sentences into smaller pieces of text (tokens) and assigns each token a numeric value called an input id. This is needed because our model only understands numbers, so we first must convert (a.k.a encode) the text into a format the model can understand. Each model has it’s own tokenizer vocabulary, it’s important to use the same tokenizer that the model was trained on or it will misinterpret the text.
12. Create the inputs for the model to process
- Define a new variable `input_text` that will take the prompt you want to give the model. In this case I asked "Who are you?" but you can choose whatever you prefer.
- Pass the new variable as an argument to the tokenizer object to create the `input_ids`
- Pass a second argument to the tokenizer object, `return_tensors="pt"`, this ensures the token_id is represented as the correct kind of vector for the model version we are using (i.e. in Pytorch not Tensorflow)
```python
input_text = "Who are you?"
input_ids = tokenizer(input_text, return_tensors="pt")
```
13. Run generation and decode the output
- Now the input in the right format we need to pass it into the model, we do this by calling the `.generate` method on the `model object` passing the `input_ids` as an argument and assigning it to a new variable `outputs`. We also set a second argument `max_new_tokens` equal to 100, this limts the number of tokens the model will generate.
- The outputs are not human readable yet, to return them to text we must decode the output. We can do this with the `.decode` method and saving that to the variable `decoded_outputs`
- Finally, passing the `decoded_output` variable into the print function allows us to see the model output in our notebook.
- Optional: Pass the `outputs` variable into the print function to see how they compare to the `decoded outputs`
```python
outputs = model.generate(input_ids["input_ids"], max_new_tokens=100)
decoded_outputs = tokenizer.decode(outputs[0])
print(decoded_outputs)
```
## Why do I need to decode?
Models only understand numbers, so when we provided our `input_ids` as vectors it returned an output in the same format. To return those outputs to text we need to reverse the initial encoding we did using the tokenizer.
## Why does the output read like a story?
Remember that Phi-2 is a base model that hasn't been instruction tuned for conversational uses, as such it's effectively a massive auto-complete model. Based on your input it is predicting what it thinks is most likely to come next based on all the web pages, books and other content it has seen previously.
Congratulations, you've run inference on your very first LLM!
I hope that working through this example helped you to better understand the world of open-source ML. If you want to continue your ML learning journey, I recommend the recent [Hugging Face course](https://www.deeplearning.ai/short-courses/open-source-models-hugging-face/) we released in partnership with DeepLearning AI.
| 2 |
0 | hf_public_repos | hf_public_repos/blog/sdxl_jax.md | ---
title: 🧨 Accelerating Stable Diffusion XL Inference with JAX on Cloud TPU v5e
thumbnail: /blog/assets/sdxl-jax/thumbnail.jpg
authors:
- user: pcuenq
- user: jffacevedo
guest: true
- user: alexspiridonov
guest: true
- user: pmotter
guest: true
- user: yyetim
guest: true
- user: svaibhav
guest: true
- user: vjsingh
guest: true
- user: patrickvonplaten
---
# Accelerating Stable Diffusion XL Inference with JAX on Cloud TPU v5e
Generative AI models, such as Stable Diffusion XL (SDXL), enable the creation of high-quality, realistic content with wide-ranging applications. However, harnessing the power of such models presents significant challenges and computational costs. SDXL is a large image generation model whose UNet component is about three times as large as the one in the previous version of the model. Deploying a model like this in production is challenging due to the increased memory requirements, as well as increased inference times. Today, we are thrilled to announce that Hugging Face Diffusers now supports serving SDXL using JAX on Cloud TPUs, enabling high-performance, cost-efficient inference.
[Google Cloud TPUs](https://cloud.google.com/tpu) are custom-designed AI accelerators, which are optimized for training and inference of large AI models, including state-of-the-art LLMs and generative AI models such as SDXL. The new [Cloud TPU v5e](https://cloud.google.com/blog/products/compute/announcing-cloud-tpu-v5e-and-a3-gpus-in-ga) is purpose-built to bring the cost-efficiency and performance required for large-scale AI [training](https://cloud.google.com/blog/products/compute/using-cloud-tpu-multislice-to-scale-ai-workloads) and [inference](https://cloud.google.com/blog/products/compute/how-cloud-tpu-v5e-accelerates-large-scale-ai-inference). At less than half the cost of TPU v4, TPU v5e makes it possible for more organizations to train and deploy AI models.
🧨 Diffusers JAX integration offers a convenient way to run SDXL on TPU via [XLA](https://github.com/openxla/xla), and we built a demo to showcase it. You can try it out in [this Space](https://huggingface.co/spaces/google/sdxl) or in the playground embedded below:
<script type="module" src="https://gradio.s3-us-west-2.amazonaws.com/3.45.1/gradio.js"> </script>
<gradio-app theme_mode="light" space="google/sdxl"></gradio-app>
Under the hood, this demo runs on several TPU v5e-4 instances (each instance has 4 TPU chips) and takes advantage of parallelization to serve four large 1024×1024 images in about 4 seconds. This time includes format conversions, communications time, and frontend processing; the actual generation time is about 2.3s, as we'll see below!
In this blog post,
1. [We describe why JAX + TPU + Diffusers is a powerful framework to run SDXL](#why-jax--tpu-v5e-for-sdxl)
2. [Explain how you can write a simple image generation pipeline with Diffusers and JAX](#how-to-write-an-image-generation-pipeline-in-jax)
3. [Show benchmarks comparing different TPU settings](#benchmark)
## Why JAX + TPU v5e for SDXL?
Serving SDXL with JAX on Cloud TPU v5e with high performance and cost-efficiency is possible thanks to the combination of purpose-built TPU hardware and a software stack optimized for performance. Below we highlight two key factors: JAX just-in-time (jit) compilation and XLA compiler-driven parallelism with JAX pmap.
#### JIT compilation
A notable feature of JAX is its [just-in-time (jit) compilation](https://jax.readthedocs.io/en/latest/jax-101/02-jitting.html). The JIT compiler traces code during the first run and generates highly optimized TPU binaries that are re-used in subsequent calls.
The catch of this process is that it requires all input, intermediate, and output shapes to be **static**, meaning that they must be known in advance. Every time we change the shapes
a new and costly compilation process will be triggered again. JIT compilation is ideal for services that can be designed around static shapes: compilation runs once, and then we take advantage of super-fast inference times.
Image generation is well-suited for JIT compilation. If we always generate the same number of images and they have the same size, then the output shapes are constant and known in advance. The text inputs are also constant: by design, Stable Diffusion and SDXL use fixed-shape embedding vectors (with padding) to represent the prompts typed by the user. Therefore, we can write JAX code that relies on fixed shapes, and that can be greatly optimized!
#### High-performance throughput for high batch sizes
Workloads can be scaled across multiple devices using JAX's [pmap](https://jax.readthedocs.io/en/latest/_autosummary/jax.pmap.html), which expresses single-program multiple-data (SPMD) programs. Applying pmap to a function will compile a function with XLA, then execute it in parallel on various XLA devices.
For text-to-image generation workloads this means that increasing the number of images rendered simultaneously is straightforward to implement and doesn't compromise performance. For example, running SDXL on a TPU with 8 chips will generate 8 images in the same time it takes for 1 chip to create a single image.
TPU v5e instances come in multiple shapes, including 1, 4 and 8-chip shapes, all the way up to 256 chips (a full TPU v5e pod), with ultra-fast ICI links between chips. This allows you to choose the TPU shape that best suits your use case and easily take advantage of the parallelism that JAX and TPUs provide.
## How to write an image generation pipeline in JAX
We'll go step by step over the code you need to write to run inference super-fast using JAX! First, let's import the dependencies.
```python
# Show best practices for SDXL JAX
import jax
import jax.numpy as jnp
import numpy as np
from flax.jax_utils import replicate
from diffusers import FlaxStableDiffusionXLPipeline
import time
```
We'll now load the base SDXL model and the rest of the components required for inference. The diffusers pipeline takes care of downloading and caching everything for us. Adhering to JAX's functional approach, the model's parameters are returned separately and will have to be passed to the pipeline during inference:
```python
pipeline, params = FlaxStableDiffusionXLPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0", split_head_dim=True
)
```
Model parameters are downloaded in 32-bit precision by default. To save memory and run computation faster we'll convert them to `bfloat16`, an efficient 16-bit representation. However, there's a caveat: for best results, we have to keep the _scheduler state_ in `float32`, otherwise precision errors accumulate and result in low-quality or even black images.
```python
scheduler_state = params.pop("scheduler")
params = jax.tree_util.tree_map(lambda x: x.astype(jnp.bfloat16), params)
params["scheduler"] = scheduler_state
```
We are now ready to set up our prompt and the rest of the pipeline inputs.
```python
default_prompt = "high-quality photo of a baby dolphin playing in a pool and wearing a party hat"
default_neg_prompt = "illustration, low-quality"
default_seed = 33
default_guidance_scale = 5.0
default_num_steps = 25
```
The prompts have to be supplied as tensors to the pipeline, and they always have to have the same dimensions across invocations. This allows the inference call to be compiled. The pipeline `prepare_inputs` method performs all the necessary steps for us, so we'll create a helper function to prepare both our prompt and negative prompt as tensors. We'll use it later from our `generate` function:
```python
def tokenize_prompt(prompt, neg_prompt):
prompt_ids = pipeline.prepare_inputs(prompt)
neg_prompt_ids = pipeline.prepare_inputs(neg_prompt)
return prompt_ids, neg_prompt_ids
```
To take advantage of parallelization, we'll replicate the inputs across devices. A Cloud TPU v5e-4 has 4 chips, so by replicating the inputs we get each chip to generate a different image, in parallel. We need to be careful to supply a different random seed to each chip so the 4 images are different:
```python
NUM_DEVICES = jax.device_count()
# Model parameters don't change during inference,
# so we only need to replicate them once.
p_params = replicate(params)
def replicate_all(prompt_ids, neg_prompt_ids, seed):
p_prompt_ids = replicate(prompt_ids)
p_neg_prompt_ids = replicate(neg_prompt_ids)
rng = jax.random.PRNGKey(seed)
rng = jax.random.split(rng, NUM_DEVICES)
return p_prompt_ids, p_neg_prompt_ids, rng
```
We are now ready to put everything together in a generate function:
```python
def generate(
prompt,
negative_prompt,
seed=default_seed,
guidance_scale=default_guidance_scale,
num_inference_steps=default_num_steps,
):
prompt_ids, neg_prompt_ids = tokenize_prompt(prompt, negative_prompt)
prompt_ids, neg_prompt_ids, rng = replicate_all(prompt_ids, neg_prompt_ids, seed)
images = pipeline(
prompt_ids,
p_params,
rng,
num_inference_steps=num_inference_steps,
neg_prompt_ids=neg_prompt_ids,
guidance_scale=guidance_scale,
jit=True,
).images
# convert the images to PIL
images = images.reshape((images.shape[0] * images.shape[1], ) + images.shape[-3:])
return pipeline.numpy_to_pil(np.array(images))
```
`jit=True` indicates that we want the pipeline call to be compiled. This will happen the first time we call `generate`, and it will be very slow – JAX needs to trace the operations, optimize them, and convert them to low-level primitives. We'll run a first generation to complete this process and warm things up:
```python
start = time.time()
print(f"Compiling ...")
generate(default_prompt, default_neg_prompt)
print(f"Compiled in {time.time() - start}")
```
This took about three minutes the first time we ran it.
But once the code has been compiled, inference will be super fast. Let's try again!
```python
start = time.time()
prompt = "llama in ancient Greece, oil on canvas"
neg_prompt = "cartoon, illustration, animation"
images = generate(prompt, neg_prompt)
print(f"Inference in {time.time() - start}")
```
It now took about 2s to generate the 4 images!
## Benchmark
The following measures were obtained running SDXL 1.0 base for 20 steps, with the default Euler Discrete scheduler. We compare Cloud TPU v5e with TPUv4 for the same batch sizes. Do note that, due to parallelism, a TPU v5e-4 like the ones we use in our demo will generate **4 images** when using a batch size of 1 (or 8 images with a batch size of 2). Similarly, a TPU v5e-8 will generate 8 images when using a batch size of 1.
The Cloud TPU tests were run using Python 3.10 and jax version 0.4.16. These are the same specs used in our [demo Space](https://huggingface.co/spaces/google/sdxl).
| | Batch Size | Latency | Perf/$ |
|-----------------|------------|:--------:|--------|
| TPU v5e-4 (JAX) | 4 | 2.33s | 21.46 |
| | 8 | 4.99s | 20.04 |
| TPU v4-8 (JAX) | 4 | 2.16s | 9.05 |
| | 8 | 4.17 | 8.98 |
TPU v5e achieves up to 2.4x greater perf/$ on SDXL compared to TPU v4, demonstrating the cost-efficiency of the latest TPU generation.
To measure inference performance, we use the industry-standard metric of throughput. First, we measure latency per image when the model has been compiled and loaded. Then, we calculate throughput by dividing batch size over latency per chip. As a result, throughput measures how the model is performing in production environments regardless of how many chips are used. We then divide throughput by the list price to get performance per dollar.
## How does the demo work?
The [demo we showed before](https://huggingface.co/spaces/google/sdxl) was built using a script that essentially follows the code we posted in this blog post. It runs on a few Cloud TPU v5e devices with 4 chips each, and there's a simple load-balancing server that routes user requests to backend servers randomly. When you enter a prompt in the demo, your request will be assigned to one of the backend servers, and you'll receive the 4 images it generates.
This is a simple solution based on several pre-allocated TPU instances. In a future post, we'll cover how to create dynamic solutions that adapt to load using GKE.
All the code for the demo is open-source and available in Hugging Face Diffusers today. We are excited to see what you build with Diffusers + JAX + Cloud TPUs!
| 3 |
0 | hf_public_repos | hf_public_repos/blog/microsoft-collaboration.md | ---
title: "From cloud to developers: Hugging Face and Microsoft Deepen Collaboration"
thumbnail: /blog/assets/microsoft-collaboration/thumbnail.jpg
authors:
- user: jeffboudier
- user: philschmid
---
# From cloud to developers: Hugging Face and Microsoft Deepen Collaboration
Today at Microsoft Build we are happy to announce a broad set of new features and collaborations as Microsoft and Hugging Face deepen their strategic collaboration to make open models and open source AI easier to use everywhere. Together, we will work to enable AI builders across open science, open source, cloud, hardware and developer experiences - read on for announcements today on all fronts!

## A collaboration for Cloud AI Builders
we are excited to announce two major new experiences to build AI with open models on Microsoft Azure.
### Expanded HF Collection in Azure Model Catalog
A year ago, Hugging Face and Microsoft [unveiled the Hugging Face Collection in the Azure Model Catalog](https://huggingface.co/blog/hugging-face-endpoints-on-azure). The Hugging Face Collection has been used by hundreds of Azure AI customers, with over a thousand open models available since its introduction. Today, we are adding some of the most popular open Large Language Models to the Hugging Face Collection to enable direct, 1-click deployment from Azure AI Studio.
The new models include [Llama 3 from Meta](https://huggingface.co/meta-llama/Meta-Llama-3-70B-Instruct), [Mistral 7B from Mistral AI](https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.2), [Command R Plus from Cohere for AI](https://huggingface.co/CohereForAI/c4ai-command-r-plus), [Qwen 1.5 110B from Qwen](https://huggingface.co/Qwen/Qwen1.5-110B-Chat), and some of the highest performing fine-tuned models on the [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard) from the Hugging Face community.
To deploy the models in your own Azure account, you can start from the model card on the Hugging Face Hub, selecting the “Deploy on Azure” option:

Or you can find model directly in [Azure AI Studio](https://ai.azure.com) within the Hugging Face Collection, and click “Deploy”

### Build AI with the new AMD MI300X on Azure
Today, Microsoft made new [Azure ND MI300X virtual machines](https://techcommunity.microsoft.com/t5/azure-high-performance-computing/azure-announces-new-ai-optimized-vm-series-featuring-amd-s/ba-p/3980770) (VMs) generally available on Azure, based on the latest AMD Instinct MI300 GPUs. Hugging Face collaborated with AMD and Microsoft to achieve amazing performance and cost/performance for Hugging Face models on the new virtual machines.
This work leverages our [deep collaboration with AMD](https://huggingface.co/blog/huggingface-and-optimum-amd) and our open source library [Optimum-AMD](https://github.com/huggingface/optimum-amd), with optimization, ROCm integrations and continuous testing of Hugging Face open source libraries and models on AMD Instinct GPUs.
## A Collaboration for Open Science
Microsoft has been releasing some of the most popular open models on Hugging Face, with close to 300 models currently available in the [Microsoft organization on the Hugging Face Hub](https://huggingface.co/microsoft).
This includes the recent [Phi-3 family of models](https://huggingface.co/collections/microsoft/phi-3-6626e15e9585a200d2d761e3), which are permissibly licensed under MIT, and offer performance way above their weight class. For instance, with only 3.8 billion parameters, Phi-3 mini outperforms many of the larger 7 to 10 billion parameter large language models, which makes the models excellent candidates for on-device applications.
To demonstrate the capabilities of Phi-3, Hugging Face [deployed Phi-3 mini in Hugging Chat](https://huggingface.co/chat/models/microsoft/Phi-3-mini-4k-instruct), its free consumer application to chat with the greatest open models and create assistants.
## A Collaboration for Open Source
Hugging Face and Microsoft have been collaborating for 3 years to make it easy to [export and use Hugging Face models with ONNX Runtime](https://huggingface.co/docs/optimum/onnxruntime/overview), through the [optimum open source library](https://github.com/huggingface/optimum).
Recently, Hugging Face and Microsoft have been focusing on enabling local inference through WebGPU, leveraging [Transformers.js](https://github.com/xenova/transformers.js) and [ONNX Runtime Web](https://onnxruntime.ai/docs/get-started/with-javascript/web.html). Read more about the collaboration in this [community article](https://huggingface.co/blog/Emma-N/enjoy-the-power-of-phi-3-with-onnx-runtime) by the ONNX Runtime team.
To see the power of WebGPU in action, consider this [demo of Phi-3](https://x.com/xenovacom/status/1792661746269692412) generating over 70 tokens per second locally in the browser!
<video class="w-full" autoplay loop muted>
<source src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/microsoft-collaboration/phi-3-webgpu.mp4" type="video/mp4">
Your browser does not support playing the video.
</video>
## A Collaboration for Developers
Last but not least, today we are unveiling a new integration that makes it easier than ever for developers to build AI applications with Hugging Face Spaces and VS Code!
The Hugging Face community has created over 500,000 AI demo applications on the Hub with Hugging Face Spaces. With the new Spaces Dev Mode, Hugging Face users can easily connect their Space to their local VS Code, or spin up a web hosted VS Code environment.

Spaces Dev Mode is currently in beta, and available to [PRO subscribers](https://huggingface.co/pricing#pro). To learn more about Spaces Dev Mode, check out [Introducing Spaces Dev mode for a seamless developer experience](https://huggingface.co/blog/spaces-dev-mode) or [documentation](https://huggingface.co/dev-mode-explorers).
## What’s Next
We are excited to deepen our strategic collaboration with Microsoft, to make open-source AI more accessible everywhere. Stay tuned as we enable more models in the Azure AI Studio model catalog and introduce new features and experiences in the months to come.
| 4 |
0 | hf_public_repos | hf_public_repos/blog/swift-coreml-llm.md | ---
title: "Releasing Swift Transformers: Run On-Device LLMs in Apple Devices"
thumbnail: /blog/assets/swift-coreml-llm/thumbnail.png
authors:
- user: pcuenq
---
# Releasing Swift Transformers: Run On-Device LLMs in Apple Devices
I have a lot of respect for iOS/Mac developers. I started writing apps for iPhones in 2007, when not even APIs or documentation existed. The new devices adopted some unfamiliar decisions in the constraint space, with a combination of power, screen real estate, UI idioms, network access, persistence, and latency that was different to what we were used to before. Yet, this community soon managed to create top-notch applications that felt at home with the new paradigm.
I believe that ML is a new way to build software, and I know that many Swift developers want to incorporate AI features in their apps. The ML ecosystem has matured a lot, with thousands of models that solve a wide variety of problems. Moreover, LLMs have recently emerged as almost general-purpose tools – they can be adapted to new domains as long as we can model our task to work on text or text-like data. We are witnessing a defining moment in computing history, where LLMs are going out of research labs and becoming computing tools for everybody.
However, using an LLM model such as Llama in an app involves several tasks which many people face and solve alone. We have been exploring this space and would love to continue working on it with the community. We aim to create a set of tools and building blocks that help developers build faster.
Today, we are publishing this guide to go through the steps required to run a model such as Llama 2 on your Mac using Core ML. We are also releasing alpha libraries and tools to support developers in the journey. We are calling all Swift developers interested in ML – is that _all_ Swift developers? – to contribute with PRs, bug reports, or opinions to improve this together.
Let's go!
<p align="center">
<video controls title="Llama 2 (7B) chat model running on an M1 MacBook Pro with Core ML">
<source src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/swift-transformers/llama-2-7b-chat.mp4" type="video/mp4">
<em>Video: Llama 2 (7B) chat model running on an M1 MacBook Pro with Core ML.</em>
</p>
## Released Today
- [`swift-transformers`](https://github.com/huggingface/swift-transformers), an in-development Swift package to implement a transformers-like API in Swift focused on text generation. It is an evolution of [`swift-coreml-transformers`](https://github.com/huggingface/swift-coreml-transformers) with broader goals: Hub integration, arbitrary tokenizer support, and pluggable models.
- [`swift-chat`](https://github.com/huggingface/swift-chat), a simple app demonstrating how to use the package.
- An updated version of [`exporters`](https://github.com/huggingface/exporters), a Core ML conversion package for transformers models.
- An updated version of [`transformers-to-coreml`](https://huggingface.co/spaces/coreml-projects/transformers-to-coreml), a no-code Core ML conversion tool built on `exporters`.
- Some converted models, such as [Llama 2 7B](https://huggingface.co/coreml-projects/Llama-2-7b-chat-coreml) or [Falcon 7B](https://huggingface.co/tiiuae/falcon-7b-instruct/tree/main/coreml), ready for use with these text generation tools.
## Tasks Overview
When I published tweets showing [Falcon](https://twitter.com/pcuenq/status/1664605575882366980) or [Llama 2](https://twitter.com/pcuenq/status/1681404748904431616) running on my Mac, I got many questions from other developers asking how to convert those models to Core ML, because they want to use them in their apps as well. Conversion is a crucial step, but it's just the first piece of the puzzle. The real reason I write those apps is to face the same problems that any other developer would and identify areas where we can help. We'll go through some of these tasks in the rest of this post, explaining where (and where not) we have tools to help.
- [Conversion to Core ML](#conversion-to-core-ml). We'll use Llama 2 as a real-life example.
- [Optimization](#optimization) techniques to make your model (and app) run fast and consume as little memory as possible. This is an area that permeates across the project and there's no silver-bullet solution you can apply.
- [`swift-transformers`](#swift-transformers), our new library to help with some common tasks.
- [Tokenizers](#tokenizers). Tokenization is the way to convert text input to the actual set of numbers that are processed by the model (and back to text from the generated predictions). This is a lot more involved than it sounds, as there are many different options and strategies.
- [Model and Hub wrappers](#model-and-hub-wrappers). If we want to support the wide variety of models on the Hub, we can't afford to hardcode model settings. We created a simple `LanguageModel` abstraction and various utilities to download model and tokenizer configuration files from the Hub.
- [Generation Algorithms](#generation-algorithms). Language models are trained to predict a probability distribution for the next token that may appear after a sequence of text. We need to call the model multiple times to generate text output and select a token at each step. There are many ways to decide which token we should choose next.
- [Supported Models](#supported-models). Not all model families are supported (yet).
- [`swift-chat`](#swift-chat). This is a small app that simply shows how to use `swift-transformers` in a project.
- [Missing Parts / Coming Next](#missing-parts--coming-next). Some stuff that's important but not yet available, as directions for future work.
- [Resources](#resources). Links to all the projects and tools.
## Conversion to Core ML
Core ML is Apple's native framework for Machine Learning, and also the name of the file format it uses. After you convert a model from (for example) PyTorch to Core ML, you can use it in your Swift apps. The Core ML framework automatically selects the best hardware to run your model on: the CPU, the GPU, or a specialized tensor unit called the Neural Engine. A combination of several of these compute units is also possible, depending on the characteristics of your system and the model details.
To see what it looks like to convert a model in real life, we'll look at converting the recently-released Llama 2 model. The process can sometimes be convoluted, but we offer some tools to help. These tools won't always work, as new models are being introduced all the time, and we need to make adjustments and modifications.
Our recommended approach is:
1. Use the [`transformers-to-coreml`](https://huggingface.co/spaces/coreml-projects/transformers-to-coreml) conversion Space:
This is an automated tool built on top of `exporters` (see below) that either works for your model, or doesn't. It requires no coding: enter the Hub model identifier, select the task you plan to use the model for, and click apply. If the conversion succeeds, you can push the converted Core ML weights to the Hub, and you are done!
You can [visit the Space](https://huggingface.co/spaces/coreml-projects/transformers-to-coreml) or use it directly here:
<script type="module" src="https://gradio.s3-us-west-2.amazonaws.com/3.23.0/gradio.js"></script>
<gradio-app theme_mode="light" space="coreml-projects/transformers-to-coreml"></gradio-app>
2. Use [`exporters`](https://github.com/huggingface/exporters), a Python conversion package built on top of Apple's `coremltools` (see below).
This library gives you a lot more options to configure the conversion task. In addition, it lets you create your own [conversion configuration class](https://github.com/huggingface/exporters#overriding-default-choices-in-the-configuration-object), which you may use for additional control or to work around conversion issues.
3. Use [`coremltools`](https://github.com/apple/coremltools), Apple's conversion package.
This is the lowest-level approach and therefore provides maximum control. It can still fail for some models (especially new ones), but you always have the option to dive inside the source code and try to figure out why.
The good news about Llama 2 is that we did the legwork and the conversion process works using any of these methods. The bad news is that it _failed to convert_ when it was released, and we had to do some fixing to support it. We briefly look at what happened in [the appendix](#appendix-converting-llama-2-the-hard-way) so you can get a taste of what to do when things go wrong.
### Important lessons learned
I've followed the conversion process for some recent models (Llama 2, Falcon, StarCoder), and I've applied what I learned to both `exporters` and the `transformers-to-coreml` Space. This is a summary of some takeaways:
- If you have to use `coremltools`, use the latest version: `7.0b1`. Despite technically being a beta, I've been using it for weeks and it's really good: stable, includes a lot of fixes, supports PyTorch 2, and has new features like advanced quantization tools.
- `exporters` no longer applies a softmax to outputs when converting text generation tasks. We realized this was necessary for some generation algorithms.
- `exporters` now defaults to using fixed sequence lengths for text models. Core ML has a way to specify "flexible shapes", such that your input sequence may have any length between 1 and, say, 4096 tokens. We discovered that flexible inputs only run on CPU, but not on GPU or the Neural Engine. More investigation coming soon!
We'll keep adding best practices to our tools so you don't have to discover the same issues again.
## Optimization
There's no point in converting models if they don't run fast on your target hardware and respect system resources. The models mentioned in this post are pretty big for local use, and we are consciously using them to stretch the limits of what's possible with current technology and understand where the bottlenecks are.
There are a few key optimization areas we've identified. They are a very important topic for us and the subject of current and upcoming work. Some of them include:
- Cache attention keys and values from previous generations, just like the transformers models do in the PyTorch implementation. The computation of attention scores needs to run on the whole sequence generated so far, but all the past key-value pairs were already computed in previous runs. We are currently _not_ using any caching mechanism for Core ML models, but are planning to do so!
- Use discrete shapes instead of a small fixed sequence length. The main reason not to use flexible shapes is that they are not compatible with the GPU or the Neural Engine. A secondary reason is that generation would become slower as the sequence length grows, because of the absence of caching as mentioned above. Using a discrete set of fixed shapes, coupled with caching key-value pairs should allow for larger context sizes and a more natural chat experience.
- Quantization techniques. We've already explored them in the context of Stable Diffusion models, and are really excited about the options they'd bring. For example, [6-bit palettization](https://huggingface.co/blog/fast-diffusers-coreml) decreases model size and is efficient with resources. [Mixed-bit quantization](https://huggingface.co/blog/stable-diffusion-xl-coreml), a new technique, can achieve 4-bit quantization (on average) with low impact on model quality. We are planning to work on these topics for language models too!
For production applications, consider iterating with smaller models, especially during development, and then apply optimization techniques to select the smallest model you can afford for your use case.
## `swift-transformers`
[`swift-transformers`](https://github.com/huggingface/swift-transformers) is an in-progress Swift package that aims to provide a transformers-like API to Swift developers. Let's see what it has and what's missing.
### Tokenizers
Tokenization solves two complementary tasks: adapt text input to the tensor format used by the model and convert results from the model back to text. The process is nuanced, for example:
- Do we use words, characters, groups of characters or bytes?
- How should we deal with lowercase vs uppercase letters? Should we even deal with the difference?
- Should we remove repeated characters, such as spaces, or are they important?
- How do we deal with words that are not in the model's vocabulary?
There are a few general tokenization algorithms, and a lot of different normalization and pre-processing steps that are crucial to using the model effectively. The transformers library made the decision to abstract all those operations in the same library (`tokenizers`), and represent the decisions as configuration files that are stored in the Hub alongside the model. For example, this is an excerpt from the configuration of the Llama 2 tokenizer that describes _just the normalization step_:
```
"normalizer": {
"type": "Sequence",
"normalizers": [
{
"type": "Prepend",
"prepend": "▁"
},
{
"type": "Replace",
"pattern": {
"String": " "
},
"content": "▁"
}
]
},
```
It reads like this: normalization is a sequence of operations applied in order. First, we `Prepend` character `_` to the input string. Then we replace all spaces with `_`. There's a huge list of potential operations, they can be applied to regular expression matches, and they have to be performed in a very specific order. The code in the `tokenizers` library takes care of all these details for all the models in the Hub.
In contrast, projects that use language models in other domains, such as Swift apps, usually resort to hardcoding these decisions as part of the app's source code. This is fine for a couple of models, but then it's difficult to replace a model with a different one, and it's easy to make mistakes.
What we are doing in `swift-transformers` is replicate those abstractions in Swift, so we write them once and everybody can use them in their apps. We are just getting started, so coverage is still small. Feel free to open issues in the repo or contribute your own!
Specifically, we currently support BPE (Byte-Pair Encoding) tokenizers, one of the three main families in use today. The GPT models, Falcon and Llama, all use this method. Support for Unigram and WordPiece tokenizers will come later. We haven't ported all the possible normalizers, pre-tokenizers and post-processors - just the ones we encountered during our conversions of Llama 2, Falcon and GPT models.
This is how to use the `Tokenizers` module in Swift:
```swift
import Tokenizers
func testTokenizer() async throws {
let tokenizer = try await AutoTokenizer.from(pretrained: "pcuenq/Llama-2-7b-chat-coreml")
let inputIds = tokenizer("Today she took a train to the West")
assert(inputIds == [1, 20628, 1183, 3614, 263, 7945, 304, 278, 3122])
}
```
However, you don't usually need to tokenize the input text yourself - the [`Generation` code](https://github.com/huggingface/swift-transformers/blob/17d4bfae3598482fc7ecf1a621aa77ab586d379a/Sources/Generation/Generation.swift#L82) will take care of it.
### Model and Hub wrappers
As explained above, `transformers` heavily use configuration files stored in the Hub. We prepared a simple `Hub` module to download configuration files from the Hub, which is used to instantiate the tokenizer and retrieve metadata about the model.
Regarding models, we created a simple `LanguageModel` type as a wrapper for a Core ML model, focusing on the text generation task. Using protocols, we can query any model with the same API.
To retrieve the appropriate metadata for the model you use, `swift-transformers` relies on a few custom metadata fields that must be added to the Core ML file when converting it. `swift-transformers` will use this information to download all the necessary configuration files from the Hub. These are the fields we use, as presented in Xcode's model preview:

`exporters` and `transformers-to-coreml` will automatically add these fields for you. Please, make sure you add them yourself if you use `coremltools` manually.
### Generation Algorithms
Language models are trained to predict a probability distribution of the next token that may appear as a continuation to an input sequence. In order to compose a response, we need to call the model multiple times until it produces a special _termination_ token, or we reach the length we desire. There are many ways to decide what's the next best token to use. We currently support two of them:
- Greedy decoding. This is the obvious algorithm: select the token with the highest probability, append it to the sequence, and repeat. This will always produce the same result for the same input sequence.
- top-k sampling. Select the `top-k` (where `k` is a parameter) most probable tokens, and then randomly _sample_ from them using parameters such as `temperature`, which will increase variability at the expense of potentially causing the model to go on tangents and lose track of the content.
Additional methods such as "nucleus sampling" will come later. We recommend [this blog post](https://huggingface.co/blog/how-to-generate) (updated recently) for an excellent overview of generation methods and how they work. Sophisticated methods such as [assisted generation](https://huggingface.co/blog/assisted-generation) can also be very useful for optimization!
### Supported Models
So far, we've tested `swift-transformers` with a handful of models to validate the main design decisions. We are looking forward to trying many more!
- Llama 2.
- Falcon.
- StarCoder models, based on a variant of the GPT architecture.
- GPT family, including GPT2, distilgpt, GPT-NeoX, GPT-J.
## `swift-chat`
`swift-chat` is a simple demo app built on `swift-transformers`. Its main purpose is to show how to use `swift-transformers` in your code, but it can also be used as a model tester tool.
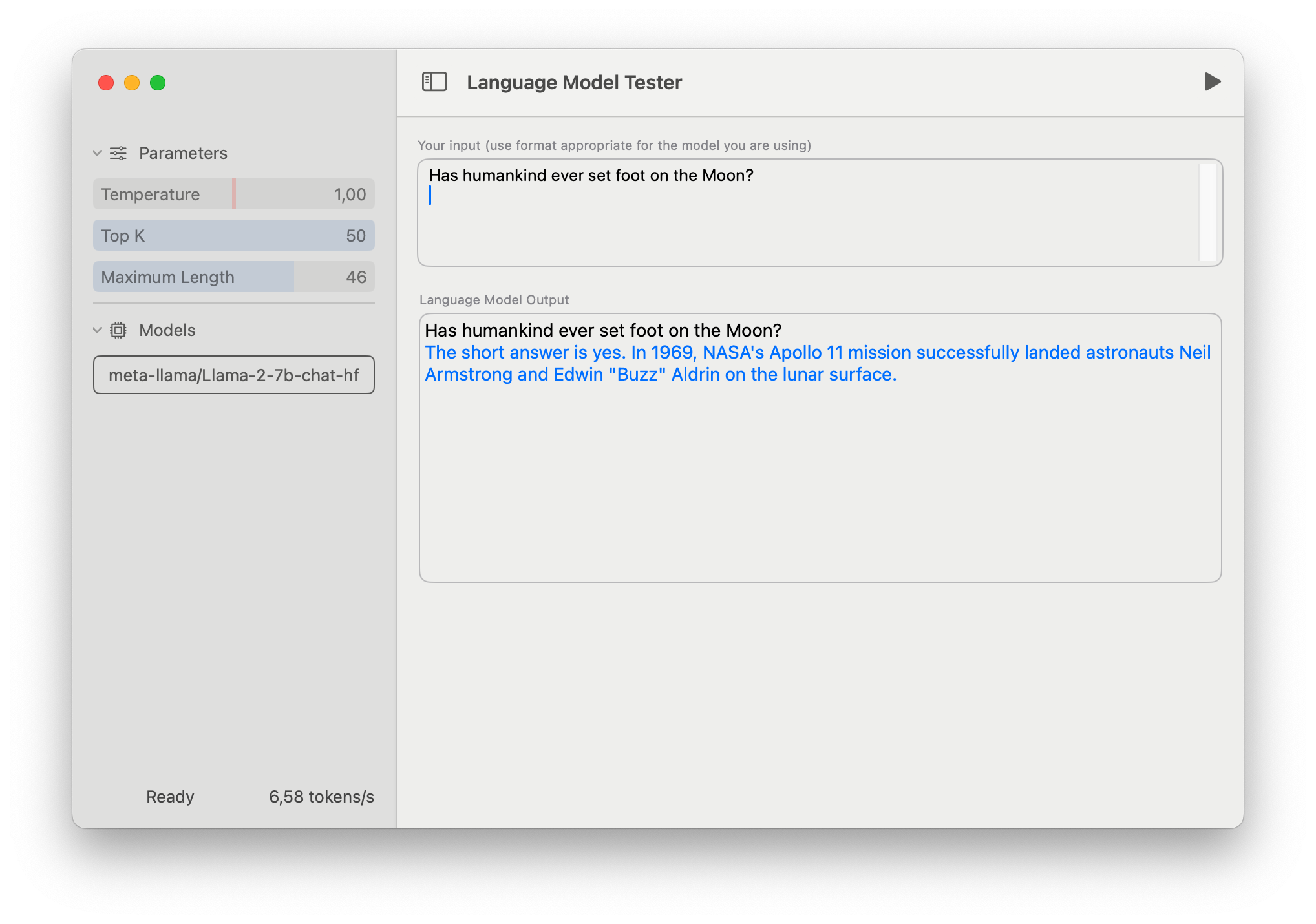
To use it, download a Core ML model from the Hub or create your own, and select it from the UI. All the relevant model configuration files will be downloaded from the Hub, using the metadata information to identify what model type this is.
The first time you load a new model, it will take some time to prepare it. In this phase, the CoreML framework will compile the model and decide what compute devices to run it on, based on your machine specs and the model's structure. This information is cached and reused in future runs.
The app is intentionally simple to make it readable and concise. It also lacks a few features, primarily because of the current limitations in model context size. For example, it does not have any provision for "system prompts", which are [useful for specifying the behaviour of your language model](https://huggingface.co/blog/llama2#how-to-prompt-llama-2) and even its personality.
## Missing Parts / Coming Next
As stated, we are just getting started! Our upcoming priorities include:
- Encoder-decoder models such as T5 and Flan.
- More tokenizers: support for Unigram and WordPiece.
- Additional generation algorithms.
- Support key-value caching for optimization.
- Use discrete sequence shapes for conversion. Together with key-value caching this will allow for larger contexts.
Let us know what you think we should work on next, or head over to the repos for [Good First Issues](https://github.com/huggingface/swift-transformers/issues?q=is%3Aissue+is%3Aopen+label%3A%22good+first+issue%22) to try your hand on!
## Conclusion
We introduced a set of tools to help Swift developers incorporate language models in their apps. I can't wait to see what you create with them, and I look forward to improving them with the community's help! Don't hesitate to get in touch :)
### _Appendix: Converting Llama 2 the Hard Way_
You can safely ignore this section unless you've experienced Core ML conversion issues and are ready to fight :)
In my experience, there are two frequent reasons why PyTorch models fail to convert to Core ML using `coremltools`:
- Unsupported PyTorch operations or operation variants
PyTorch has _a lot_ of operations, and all of them have to be mapped to an intermediate representation ([MIL](https://apple.github.io/coremltools/source/coremltools.converters.mil.mil.ops.defs.html), for _Model Intermediate Language_), which in turn is converted to native Core ML instructions. The set of PyTorch operations is not static, so new ones have to be added to `coremltools` too. In addition, some operations are really complex and can work on exotic combinations of their arguments. An example of a recently-added, very complex op, was _scaled dot-product attention_, introduced in PyTorch 2. An example of a partially supported op is `einsum`: not all possible equations are translated to MIL.
- Edge cases and type mismatches
Even for supported PyTorch operations, it's very difficult to ensure that the translation process works on all possible inputs across all the different input types. Keep in mind that a single PyTorch op can have multiple backend implementations for different devices (cpu, CUDA), input types (integer, float), or precision (float16, float32). The product of all combinations is staggering, and sometimes the way a model uses PyTorch code triggers a translation path that may have not been considered or tested.
This is what happened when I first tried to convert Llama 2 using `coremltools`:
By comparing different versions of transformers, I could see the problem started happening when [this line of code](https://github.com/huggingface/transformers/blob/d114a6b71f243054db333dc5a3f55816161eb7ea/src/transformers/models/llama/modeling_llama.py#L52C5-L52C6) was introduced. It's part of a recent `transformers` refactor to better deal with causal masks in _all_ models that use them, so this would be a big problem for other models, not just Llama.
What the error screenshot is telling us is that there's a type mismatch trying to fill the mask tensor. It comes from the `0` in the line: it's interpreted as an `int`, but the tensor to be filled contains `floats`, and using different types was rejected by the translation process. In this particular case, I came up with a [patch for `coremltools`](https://github.com/apple/coremltools/pull/1915), but fortunately this is rarely necessary. In many cases, you can patch your code (a `0.0` in a local copy of `transformers` would have worked), or create a "special operation" to deal with the exceptional case. Our `exporters` library has very good support for custom, special operations. See [this example](https://github.com/huggingface/exporters/blob/f134e5ceca05409ea8abcecc3df1c39b53d911fe/src/exporters/coreml/models.py#L139C9-L139C18) for a missing `einsum` equation, or [this one](https://github.com/huggingface/exporters/blob/f134e5ceca05409ea8abcecc3df1c39b53d911fe/src/exporters/coreml/models.py#L208C9-L208C18) for a workaround to make `StarCoder` models work until a new version of `coremltools` is released.
Fortunately, `coremltools` coverage for new operations is good and the team reacts very fast.
## Resources
- [`swift-transformers`](https://github.com/huggingface/swift-transformers).
- [`swift-chat`](https://github.com/huggingface/swift-chat).
- [`exporters`](https://github.com/huggingface/exporters).
- [`transformers-to-coreml`](https://huggingface.co/spaces/coreml-projects/transformers-to-coreml).
- Some Core ML models for text generation:
- [Llama-2-7b-chat-coreml](https://huggingface.co/coreml-projects/Llama-2-7b-chat-coreml)
- [Falcon-7b-instruct](https://huggingface.co/tiiuae/falcon-7b-instruct/tree/main/coreml)
| 5 |
0 | hf_public_repos | hf_public_repos/blog/dell-enterprise-hub.md | ---
title: "Build AI on premise with Dell Enterprise Hub"
thumbnail: /blog/assets/dell-enterprise-hub/thumbnail.jpg
authors:
- user: jeffboudier
- user: philschmid
- user: balaatdell
guest: true
org: DellTechnologies
- user: ianr007
guest: true
org: DellTechnologies
---
# Build AI on premise with Dell Enterprise Hub

Today we announce the Dell Enterprise Hub, a new experience on Hugging Face to easily train and deploy open models on-premise using Dell platforms.
Try it out at [dell.huggingface.co](https://dell.huggingface.co)
## Enterprises need to build AI with open models
When building AI systems, open models is the best solution to meet security, compliance and privacy requirements of enterprises:
* Building upon open models allows companies to understand, own and control their AI features,
* Open models can be hosted within enterprises secure IT environment,
* Training and deploying open models on-premises protects customers data.
But working with large language models (LLMs) within on-premises infrastructure often requires weeks of trial and error, dealing with containers, parallelism, quantization and out of memory errors.
With the Dell Enterprise Hub, we make it easy to train and deploy LLMs on premise using Dell platforms, reducing weeks of engineering work into minutes.
## Dell Enterprise Hub: On-Premise LLMs made easy
The Dell Enterprise Hub offers a curated list of the most advanced open models available today, including [Llama 3 from Meta](https://huggingface.co/meta-llama/Meta-Llama-3-70B-Instruct), [Mixtral from Mistral AI](https://huggingface.co/mistralai/Mixtral-8x22B-Instruct-v0.1), [Gemma from Google](https://huggingface.co/google/gemma-7b) and more.
To access Dell Enterprise Hub, all you need is a Hugging Face account.

The Dell Enterprise Hub is designed from the ground up for enterprises, and optimized for Dell Platforms.
You can easily filter available models by their license or model size.

Once you’ve selected a model, you can review a comprehensive model card designed for enterprise use. At a glance you see key information about the model, its size, and which Dell platforms support it well.
Many models from Meta, Mistral and Google require authorization to get access to the model weights. Because Dell Enterprise Hub is built upon Hugging Face user accounts, your account entitlements transfer over to Dell Enterprise Hub, and you only need to get permission once.
## Deploy open models with Dell Enterprise Hub
Once you’ve selected a deployable model, deploying it in your Dell environment is really easy. Just select a supported Dell platform, and the number of GPUs you want to use for your deployment.

When you paste the provided script in your Dell environment terminal or server, everything happens automagically to make your model available as an API endpoint hosted on your Dell platform. Hugging Face optimized deployment configurations for each Dell platform, taking into account the available hardware, memory and connectivity capabilities, and regularly tests them on Dell infrastructure to offer the best results out of the box.
## Train open models with Dell Enterprise Hub
Fine-tuning models improves their performance on specific domains and use cases by updating the model weights based on company-specific training data. Fine-tuned open models have been shown to outperform the best available closed models like GPT-4, providing more efficient and performant models to power specific AI features. Because the company-specific training data often includes confidential information, intellectual property and customer data, it is important for enterprise compliance to do the fine-tuning on-premises, so the data never leaves the company secure IT environment.
Fine-tuning open models on premises with Dell Enterprise Hub is just as easy as deploying a model. The main additional parameters are to provide the optimized training container with the Dell environment local path where the training dataset is hosted, and where to upload the fine-tuned model when done. Training datasets can be provided as CSV or JSONL formatted files, following [this specification](https://dell.huggingface.co/faq#how-should-my-dataset-look).

## Bring your Own Model with Dell Enterprise Hub
What if you want to deploy on-premises your own model without it ever leaving your secure environment?
With the Dell Enterprise Hub, once you’ve trained a model it will be hosted in your local secure environment at the path you selected. Deploying it is just another simple step by selecting the tab “Deploy Fine-Tuned”.
And if you trained your model on your own using one of the model architectures supported by Dell Enterprise Hub, you can deploy it the exact same way.
Just set the local path to where you stored the model weights in the environment you will run the provided code snippet.

Once deployed, the model is available as an API endpoint that is easy to call by sending requests following the OpenAI-compatible [Messages API](https://huggingface.co/docs/text-generation-inference/en/messages_api). This makes it super easy to transition a prototype built with OpenAI to a secure on-premises deployment set up with Dell Enterprise Hub.
## We’re just getting started
Today we are very excited to release the Dell Enterprise Hub, with many models available as ready-to-use containers optimized for many platforms, 6 months after [announcing our collaboration with Dell Technologies](https://www.dell.com/en-us/dt/corporate/newsroom/announcements/detailpage.press-releases~usa~2023~11~20231114-dell-technologies-and-hugging-face-to-simplify-generative-ai-with-on-premises-it.htm#/filter-on/Country:en-us).
Dell offers many platforms built upon AI hardware accelerators from NVIDIA, AMD, and Intel Gaudi. Hugging Face engineering collaborations with NVIDIA ([optimum-nvidia](https://github.com/huggingface/optimum-nvidia)), AMD ([optimum-amd](https://github.com/huggingface/optimum-amd)) and Intel ([optimum-intel](https://github.com/huggingface/optimum-intel) and [optimum-habana](https://github.com/huggingface/optimum-habana)) will allow us to offer ever more optimized containers for deployment and training of open models on all Dell platform configurations. We are excited to bring support to more state-of-the-art open models, and enable them on more Dell platforms - we’re just getting started! | 6 |
0 | hf_public_repos | hf_public_repos/blog/fine-tune-clip-rsicd.md | ---
title: Fine tuning CLIP with Remote Sensing (Satellite) images and captions
thumbnail: /blog/assets/30_clip_rsicd/clip_schematic.png
authors:
- user: arampacha
guest: true
- user: devv
guest: true
- user: goutham794
guest: true
- user: cataluna84
guest: true
- user: ghosh-r
guest: true
- user: sujitpal
guest: true
---
# Fine tuning CLIP with Remote Sensing (Satellite) images and captions
## Fine tuning CLIP with Remote Sensing (Satellite) images and captions
<img src="/blog/assets/30_clip_rsicd/clip-rsicd-header-image.png"/>
In July this year, [Hugging Face](https://huggingface.co/) organized a [Flax/JAX Community Week](https://github.com/huggingface/transformers/blob/master/examples/research_projects/jax-projects/README.md), and invited the community to submit projects to train Hugging Face [transformers](https://github.com/huggingface/transformers) models in the areas of Natural Language Processing (NLP) and Computer Vision (CV).
Participants used Tensor Processing Units (TPUs) with [Flax](https://github.com/google/flax) and [JAX](https://github.com/google/jax). JAX is a linear algebra library (like `numpy`) that can do automatic differentiation ([Autograd](https://github.com/hips/autograd)) and compile down to [XLA](https://www.tensorflow.org/xla), and Flax is a neural network library and ecosystem for JAX. TPU compute time was provided free by [Google Cloud](https://cloud.google.com/), who co-sponsored the event.
Over the next two weeks, teams participated in lectures from Hugging Face and Google, trained one or more models using JAX/Flax, shared them with the community, and provided a [Hugging Face Spaces](https://huggingface.co/spaces) demo showcasing the capabilities of their model. Approximately 100 teams participated in the event, and it resulted in 170 models and 36 demos.
Our team, like probably many others, is a distributed one, spanning 12 time zones. Our common thread is that we all belong to the [TWIML Slack Channel](https://twimlai.slack.com/), where we came together based on a shared interest in Artificial Intelligence (AI) and Machine Learning (ML) topics.
We fine-tuned the [CLIP Network from OpenAI](https://openai.comclip/) with satellite images and captions from the [RSICD dataset](https://github.com/201528014227051/RSICD_optimal). The CLIP network learns visual concepts by being trained with image and caption pairs in a self-supervised manner, by using text paired with images found across the Internet. During inference, the model can predict the most relevant image given a text description or the most relevant text description given an image. CLIP is powerful enough to be used in zero-shot manner on everyday images. However, we felt that satellite images were sufficiently different from everyday images that it would be useful to fine-tune CLIP with them. Our intuition turned out to be correct, as the evaluation results (described below) shows. In this post, we describe details of our training and evaluation process, and our plans for future work on this project.
The goal of our project was to provide a useful service and demonstrate how to use CLIP for practical use cases. Our model can be used by applications to search through large collections of satellite images using textual queries. Such queries could describe the image in totality (for example, beach, mountain, airport, baseball field, etc) or search or mention specific geographic or man-made features within these images. CLIP can similarly be fine-tuned for other domains as well, as shown by the [medclip-demo team](https://huggingface.co/spaces/flax-community/medclip-demo) for medical images.
The ability to search through large collections of images using text queries is an immensely powerful feature, and can be used as much for social good as for malign purposes. Possible applications include national defense and anti-terrorism activities, the ability to spot and address effects of climate change before they become unmanageable, etc. Unfortunately, this power can also be misused, such as for military and police surveillance by authoritarian nation-states, so it does raise some ethical questions as well.
You can read about the project on our [project page](https://github.com/arampacha/CLIP-rsicd), download our [trained model](https://huggingface.co/flax-community/clip-rsicd-v2) to use for inference on your own data, or see it in action on our [demo](https://huggingface.co/spaces/sujitpal/clip-rsicd-demo).
### Training
#### Dataset
We fine-tuned the CLIP model primarily with the [RSICD dataset](https://github.com/201528014227051/RSICD_optimal). This dataset consists of about 10,000 images collected from Google Earth, Baidu Map, MapABC, and Tianditu. It is provided freely to the research community to advance remote sensing captioning via [Exploring Models and Data for Remote Sensing Image Caption Generation](https://arxiv.org/abs/1712.0783) (Lu et al, 2017). The images are (224, 224) RGB images at various resolutions, and each image has up to 5 captions associated with it.
<img src="/blog/assets/30_clip_rsicd/rsicd-images-sampling.png"/>
<center><i>Some examples of images from the RSICD dataset</i></center>
In addition, we used the [UCM Dataset](https://mega.nz/folder/wCpSzSoS#RXzIlrv--TDt3ENZdKN8JA) and the [Sydney dataset](https://mega.nz/folder/pG4yTYYA#4c4buNFLibryZnlujsrwEQ) for training, The UCM dataset is based on the UC Merced Land Use dataset. It consists of 2100 images belonging to 21 classes (100 images per class), and each image has 5 captions. The Sydney dataset contains images of Sydney, Australia from Google Earth. It contains 613 images belonging to 7 classes. Images are (500, 500) RGB and provides 5 captions for each image. We used these additional datasets because we were not sure if the RSICD dataset would be large enough to fine-tune CLIP.
#### Model
Our model is just the fine-tuned version of the original CLIP model shown below. Inputs to the model are a batch of captions and a batch of images passed through the CLIP text encoder and image encoder respectively. The training process uses [contrastive learning](https://towardsdatascience.com/understanding-contrastive-learning-d5b19fd96607) to learn a joint embedding representation of image and captions. In this embedding space, images and their respective captions are pushed close together, as are similar images and similar captions. Conversely, images and captions for different images, or dissimilar images and captions, are likely to be pushed further apart.
<img src="/blog/assets/30_clip_rsicd/clip_schematic.png"/>
<center><i>CLIP Training and Inference (Image Credit: CLIP: Connecting Text and Images (https://openai.comclip/))</i></center>
#### Data Augmentation
In order to regularize our dataset and prevent overfitting due to the size of the dataset, we used both image and text augmentation.
Image augmentation was done inline using built-in transforms from Pytorch's [Torchvision](https://pytorch.org/vision/stable/index.html) package. The transformations used were Random Cropping, Random Resizing and Cropping, Color Jitter, and Random Horizontal and Vertical flipping.
We augmented the text with backtranslation to generate captions for images with less than 5 unique captions per image. The [Marian MT]((https://huggingface.co/transformers/model_doc/marian.html)) family of models from Hugging Face was used to translate the existing captions into French, Spanish, Italian, and Portuguese and back to English to fill out the captions for these images.
As shown in these loss plots below, image augmentation reduced overfitting significantly, and text and image augmentation reduced overfitting even further.
<img src="/blog/assets/30_clip_rsicd/image-augment-loss.png"/>
<img src="/blog/assets/30_clip_rsicd/image-text-aug-loss.png"/>
<center><i>Evaluation and Training loss plots comparing (top) no augmentation vs image augmentation, and (bottom) image augmentation vs text+image augmentation</i></center>
### Evaluation
#### Metrics
A subset of the RSICD test set was used for evaluation. We found 30 categories of images in this subset. The evaluation was done by comparing each image with a set of 30 caption sentences of the form `"An aerial photograph of {category}"`. The model produced a ranked list of the 30 captions, from most relevant to least relevant. Categories corresponding to captions with the top k scores (for k=1, 3, 5, and 10) were compared with the category provided via the image file name. The scores are averaged over the entire set of images used for evaluation and reported for various values of k, as shown below.
The `baseline` model represents the pre-trained `openai/clip-vit-base-path32` CLIP model. This model was fine-tuned with captions and images from the RSICD dataset, which resulted in a significant performance boost, as shown below.
Our best model was trained with image and text augmentation, with batch size 1024 (128 on each of the 8 TPU cores), and the Adam optimizer with learning rate 5e-6. We trained our second base model with the same hyperparameters, except that we used the Adafactor optimizer with learning rate 1e-4. You can download either model from their model repos linked to in the table below.
| Model-name | k=1 | k=3 | k=5 | k=10 |
| ---------------------------------------- | ----- | ----- | ----- | ----- |
| baseline | 0.572 | 0.745 | 0.837 | 0.939 |
| bs128x8-lr1e-4-augs/ckpt-2 | 0.819 | 0.950 | 0.974 | 0.994 |
| bs128x8-lr1e-4-imgaugs/ckpt-2 | 0.812 | 0.942 | 0.970 | 0.991 |
| [bs128x8-lr1e-4-imgaugs-textaugs/ckpt-4](https://huggingface.co/flax-community/clip-rsicd)<sup>2</sup> | 0.843 | 0.958 | 0.977 | 0.993 |
| bs128x8-lr5e-5-imgaugs-textaugs/ckpt-8 | 0.831 | 0.959 | 0.977 | 0.994 |
| bs128x8-lr5e-5-imgaugs/ckpt-4 | 0.746 | 0.906 | 0.956 | 0.989 |
| bs128x8-lr5e-5-imgaugs-textaugs-2/ckpt-4 | 0.811 | 0.945 | 0.972 | 0.993 |
| bs128x8-lr5e-5-imgaugs-textaugs-3/ckpt-5 | 0.823 | 0.946 | 0.971 | 0.992 |
| bs128x8-lr5e-5-wd02/ckpt-4 | 0.820 | 0.946 | 0.965 | 0.990 |
| [bs128x8-lr5e-6-adam/ckpt-1](https://huggingface.co/flax-community/clip-rsicd-v2)<sup>1</sup> | **0.883** | **0.968** | **0.982** | **0.998** |
_1 - our best model, 2 - our second best model_
#### Demo
You can access the [CLIP-RSICD Demo](https://huggingface.co/spaces/sujitpal/clip-rsicd-demo) here. It uses our fine-tuned CLIP model to provide the following functionality:
* Text to Image search
* Image to Image search
* Find text feature in image
The first two functionalities use the RSICD test set as its image corpus. They are encoded using our best fine-tuned CLIP model and stored in a [NMSLib](https://github.com/nmslib/nmslib) index which allows Approximate Nearest Neighbor based retrieval. For text-to-image and image-to-image search respectively, the query text or image are encoded with our model and matched against the image vectors in the corpus. For the third functionality, we divide the incoming image into patches and encode them, encode the queried text feature, match the text vector with each image patch vector, and return the probability of finding the feature in each patch.
### Future Work
We are grateful that we have been given an opportunity to further refine our model. Some ideas we have for future work are as follows:
1. Construct a sequence to sequence model using a CLIP encoder and a GPT-3 decoder and train it for image captioning.
2. Fine-tune the model on more image caption pairs from other datasets and investigate if we can improve its performance.
3. Investigate how fine-tuning affects the performance of model on non-RSICD image caption pairs.
4. Investigate the capability of the fine-tuned model to classify outside the categories it has been fine-tuned on.
5. Evaluate the model using other criteria such as image classification.
| 7 |
0 | hf_public_repos | hf_public_repos/blog/openvino.md | ---
title: "Accelerate your models with 🤗 Optimum Intel and OpenVINO"
thumbnail: /blog/assets/113_openvino/thumbnail.png
authors:
- user: echarlaix
- user: juliensimon
---
# Accelerate your models with 🤗 Optimum Intel and OpenVINO

Last July, we [announced](https://huggingface.co/blog/intel) that Intel and Hugging Face would collaborate on building state-of-the-art yet simple hardware acceleration tools for Transformer models.
Today, we are very happy to announce that we added Intel [OpenVINO](https://docs.openvino.ai/latest/index.html) to [Optimum Intel](https://github.com/huggingface/optimum-intel). You can now easily perform inference with OpenVINO Runtime on a variety of Intel processors ([see](https://docs.openvino.ai/latest/openvino_docs_OV_UG_supported_plugins_Supported_Devices.html) the full list of supported devices) using Transformers models which can be hosted either on the Hugging Face hub or locally. You can also quantize your model with the OpenVINO Neural Network Compression Framework ([NNCF](https://github.com/openvinotoolkit/nncf)), and reduce its size and prediction latency in near minutes.
This first release is based on OpenVINO 2022.2 and enables inference for a large quantity of PyTorch models using our [`OVModels`](https://huggingface.co/docs/optimum/intel/inference). Post-training static quantization and quantization aware training can be applied on many encoder models (BERT, DistilBERT, etc.). More encoder models will be supported in the upcoming OpenVINO release. Currently the quantization of Encoder Decoder models is not enabled, however this restriction should be lifted with our integration of the next OpenVINO release.
Let us show you how to get started in minutes!
## Quantizing a Vision Transformer with Optimum Intel and OpenVINO
In this example, we will run post-training static quantization on a Vision Transformer (ViT) [model](https://huggingface.co/juliensimon/autotrain-food101-1471154050) fine-tuned for image classification on the [food101](https://huggingface.co/datasets/food101) dataset.
Quantization is a process that lowers memory and compute requirements by reducing the bit width of model parameters. Reducing the number of bits means that the resulting model requires less memory at inference time, and that operations like matrix multiplication can be performed faster thanks to integer arithmetic.
First, let's create a virtual environment and install all dependencies.
```bash
virtualenv openvino
source openvino/bin/activate
pip install pip --upgrade
pip install optimum[openvino,nncf] torchvision evaluate
```
Next, moving to a Python environment, we import the appropriate modules and download the original model as well as its processor.
```python
from transformers import AutoImageProcessor, AutoModelForImageClassification
model_id = "juliensimon/autotrain-food101-1471154050"
model = AutoModelForImageClassification.from_pretrained(model_id)
processor = AutoImageProcessor.from_pretrained(model_id)
```
Post-training static quantization requires a calibration step where data is fed through the network in order to compute the quantized activation parameters. Here, we take 300 samples from the original dataset to build the calibration dataset.
```python
from optimum.intel.openvino import OVQuantizer
quantizer = OVQuantizer.from_pretrained(model)
calibration_dataset = quantizer.get_calibration_dataset(
"food101",
num_samples=300,
dataset_split="train",
)
```
As usual with image datasets, we need to apply the same image transformations that were used at training time. We use the preprocessing defined in the processor. We also define a data collation function to feed the model batches of properly formatted tensors.
```python
import torch
from torchvision.transforms import (
CenterCrop,
Compose,
Normalize,
Resize,
ToTensor,
)
normalize = Normalize(mean=processor.image_mean, std=processor.image_std)
size = processor.size["height"]
_val_transforms = Compose(
[
Resize(size),
CenterCrop(size),
ToTensor(),
normalize,
]
)
def val_transforms(example_batch):
example_batch["pixel_values"] = [_val_transforms(pil_img.convert("RGB")) for pil_img in example_batch["image"]]
return example_batch
calibration_dataset.set_transform(val_transforms)
def collate_fn(examples):
pixel_values = torch.stack([example["pixel_values"] for example in examples])
labels = torch.tensor([example["label"] for example in examples])
return {"pixel_values": pixel_values, "labels": labels}
```
For our first attempt, we use the default configuration for quantization. You can also specify the number of samples to use during the calibration step, which is by default 300.
```python
from optimum.intel.openvino import OVConfig
quantization_config = OVConfig()
quantization_config.compression["initializer"]["range"]["num_init_samples"] = 300
```
We're now ready to quantize the model. The `OVQuantizer.quantize()` method quantizes the model and exports it to the OpenVINO format. The resulting graph is represented with two files: an XML file describing the network topology and a binary file describing the weights. The resulting model can run on any target Intel® device.
```python
save_dir = "quantized_model"
# Apply static quantization and export the resulting quantized model to OpenVINO IR format
quantizer.quantize(
quantization_config=quantization_config,
calibration_dataset=calibration_dataset,
data_collator=collate_fn,
remove_unused_columns=False,
save_directory=save_dir,
)
processor.save_pretrained(save_dir)
```
A minute or two later, the model has been quantized. We can then easily load it with our [`OVModelForXxx`](https://huggingface.co/docs/optimum/intel/inference) classes, the equivalent of the Transformers [`AutoModelForXxx`](https://huggingface.co/docs/transformers/main/en/autoclass_tutorial#automodel) classes found in the `transformers` library. Likewise, we can create [pipelines](https://huggingface.co/docs/transformers/main/en/main_classes/pipelines) and run inference with [OpenVINO Runtime](https://docs.openvino.ai/latest/openvino_docs_OV_UG_OV_Runtime_User_Guide.html).
```python
from transformers import pipeline
from optimum.intel.openvino import OVModelForImageClassification
ov_model = OVModelForImageClassification.from_pretrained(save_dir)
ov_pipe = pipeline("image-classification", model=ov_model, image_processor=processor)
outputs = ov_pipe("http://farm2.staticflickr.com/1375/1394861946_171ea43524_z.jpg")
print(outputs)
```
To verify that quantization did not have a negative impact on accuracy, we applied an evaluation step to compare the accuracy of the original model with its quantized counterpart. We evaluate both models on a subset of the dataset (taking only 20% of the evaluation dataset). We observed little to no loss in accuracy with both models having an accuracy of **87.6**.
```python
from datasets import load_dataset
from evaluate import evaluator
# We run the evaluation step on 20% of the evaluation dataset
eval_dataset = load_dataset("food101", split="validation").select(range(5050))
task_evaluator = evaluator("image-classification")
ov_eval_results = task_evaluator.compute(
model_or_pipeline=ov_pipe,
data=eval_dataset,
metric="accuracy",
label_mapping=ov_pipe.model.config.label2id,
)
trfs_pipe = pipeline("image-classification", model=model, image_processor=processor)
trfs_eval_results = task_evaluator.compute(
model_or_pipeline=trfs_pipe,
data=eval_dataset,
metric="accuracy",
label_mapping=trfs_pipe.model.config.label2id,
)
print(trfs_eval_results, ov_eval_results)
```
Looking at the quantized model, we see that its memory size decreased by **3.8x** from 344MB to 90MB. Running a quick benchmark on 5050 image predictions, we also notice a speedup in latency of **2.4x**, from 98ms to 41ms per sample. That's not bad for a few lines of code!
⚠️ An important thing to mention is that the model is compiled just before the first inference, which will inflate the latency of the first inference. So before doing your own benchmark, make sure to first warmup your model by doing at least one prediction.
You can find the resulting [model](https://huggingface.co/echarlaix/vit-food101-int8) hosted on the Hugging Face hub. To load it, you can easily do as follows:
```python
from optimum.intel.openvino import OVModelForImageClassification
ov_model = OVModelForImageClassification.from_pretrained("echarlaix/vit-food101-int8")
```
## Now it's your turn
As you can see, it's pretty easy to accelerate your models with 🤗 Optimum Intel and OpenVINO. If you'd like to get started, please visit the [Optimum Intel](https://github.com/huggingface/optimum-intel) repository, and don't forget to give it a star ⭐. You'll also find additional examples [there](https://huggingface.co/docs/optimum/intel/optimization_ov). If you'd like to dive deeper into OpenVINO, the Intel [documentation](https://docs.openvino.ai/latest/index.html) has you covered.
Give it a try and let us know what you think. We'd love to hear your feedback on the Hugging Face [forum](https://discuss.huggingface.co/c/optimum), and please feel free to request features or file issues on [Github](https://github.com/huggingface/optimum-intel).
Have fun with 🤗 Optimum Intel, and thank you for reading.
| 8 |
0 | hf_public_repos | hf_public_repos/blog/trufflesecurity-partnership.md | ---
title: Hugging Face partners with TruffleHog to Scan for Secrets
thumbnail: /blog/assets/trufflesecurity-partnership/thumbnail.png
authors:
- user: mcpotato
---
# Hugging Face partners with TruffleHog to Scan for Secrets
We're excited to announce our partnership and integration with Truffle Security, bringing TruffleHog's powerful secret scanning features to our platform as part of [our ongoing commitment to security](https://huggingface.co/blog/2024-security-features).
<img class="block" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/trufflesecurity-partnership/truffle_security_landing_page.png"/>
TruffleHog is an open-source tool that detects and verifies secret leaks in code. With a wide range of detectors for popular SaaS and cloud providers, it scans files and repositories for sensitive information like credentials, tokens, and encryption keys.
Accidentally committing secrets to code repositories can have serious consequences. By scanning repositories for secrets, TruffleHog helps developers catch and remove this sensitive information before it becomes a problem, protecting data and preventing costly security incidents.
To combat secret leakage in public and private repositories, we worked with the TruffleHog team on two different initiatives:
Enhancing our automated scanning pipeline with TruffleHog
Creating a native Hugging Face scanner in TruffleHog
## Enhancing our automated scanning pipeline with TruffleHog
At Hugging Face, we are committed to protecting our users' sensitive information. This is why we've implemented an automated security scanning pipeline that scans all repos and commits. We have extended our automated scanning pipeline to include TruffleHog, which means there are now three types of scans:
- malware scanning: scans for known malware signatures with [ClamAV](https://www.clamav.net/)
- pickle scanning: scans pickle files for malicious executable code with [picklescan](https://github.com/mmaitre314/picklescan)
- secret scanning: scans for passwords, tokens and API keys with [TruffleHog](https://github.com/trufflesecurity/trufflehog)
We run the `trufflehog filesystem` command on every new or modified file on each push to a repository, scanning for potential secrets. If and when a verified secret is detected, we notify the user via email, empowering them to take corrective action.
Verified secrets are the ones that have been confirmed to work for authentication against their respective providers. Note, however, that unverified secrets are not necessarily harmless or invalid: verification can fail due to technical reasons, such as in the case of down time from the provider.
It will always be valuable to run trufflehog on your repositories yourself, even when we do it for you. For instance, you could have rotated the secrets that were leaked and want to make sure they come up as “unverified”, or you’d like to manually check if unverified secrets still pose a threat.
We will eventually migrate to the `trufflehog huggingface` command, the native Hugging Face scanner, once support for LFS lands.
<img class="block" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/token-leak-email-example.png"/>
## TruffleHog Native Hugging Face Scanner
The goal for creating a native Hugging Face scanner in TruffleHog is to empower our users (and the security teams protecting them) to proactively scan their own account data for leaked secrets.
TruffleHog’s new open-source Hugging Face integration can scan models, datasets and Spaces, as well as any relevant PRs or Discussions. The only limitation is TruffleHog will not currently scan files stored in LFS. Their team is looking to address this for all of their `git` sources soon.
To scan all of your, or your organization’s Hugging Face models, datasets, and Spaces for secrets using TruffleHog, run the following command(s):
```sh
# For your user
trufflehog huggingface --user <username>
# For your organization
trufflehog huggingface --org <orgname>
# Or both
trufflehog huggingface --user <username> --org <orgname>
```
You can optionally include the (`--include-discussions`) and PRs (`--include-prs`) flags to scan Hugging Face discussion and PR comments.
If you’d like to scan just one model, dataset or Space, TruffleHog has specific flags for each of those.
```sh
# Scan one model
trufflehog huggingface --model <model_id>
# Scan one dataset
trufflehog huggingface --dataset <dataset_id>
# Scan one Space
trufflehog huggingface --space <space_id>
```
If you need to pass in an authentication token, you can do so using the --token flag or by setting a HUGGINGFACE_TOKEN environment variable.
Here is an example of TruffleHog’s output when run on [mcpotato/42-eicar-street](https://huggingface.co/mcpotato/42-eicar-street):
```
trufflehog huggingface --model mcpotato/42-eicar-street
🐷🔑🐷 TruffleHog. Unearth your secrets. 🐷🔑🐷
2024-09-02T16:39:30+02:00 info-0 trufflehog running source {"source_manager_worker_id": "3KRwu", "with_units": false, "target_count": 0, "source_manager_units_configurable": true}
2024-09-02T16:39:30+02:00 info-0 trufflehog Completed enumeration {"num_models": 1, "num_spaces": 0, "num_datasets": 0}
2024-09-02T16:39:32+02:00 info-0 trufflehog scanning repo {"source_manager_worker_id": "3KRwu", "model": "https://huggingface.co/mcpotato/42-eicar-street.git", "repo": "https://huggingface.co/mcpotato/42-eicar-street.git"}
Found unverified result 🐷🔑❓
Detector Type: HuggingFace
Decoder Type: PLAIN
Raw result: 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
Commit: 9cb322a7c2b4ec7c9f18045f0fa05015b831f256
Email: Luc Georges <[email protected]>
File: token_leak.yml
Line: 1
Link: https://huggingface.co/mcpotato/42-eicar-street/blob/9cb322a7c2b4ec7c9f18045f0fa05015b831f256/token_leak.yml#L1
Repository: https://huggingface.co/mcpotato/42-eicar-street.git
Resource_type: model
Timestamp: 2024-06-17 13:11:50 +0000
2024-09-02T16:39:32+02:00 info-0 trufflehog finished scanning {"chunks": 19, "bytes": 2933, "verified_secrets": 0, "unverified_secrets": 1, "scan_duration": "2.176551292s", "trufflehog_version": "3.81.10"}
```
Kudos to the TruffleHog team for offering such a great tool to make our community safe! Stay tuned for more features as we continue to collaborate to make the Hub more secure for everyone.
| 9 |
0 | hf_public_repos/amused | hf_public_repos/amused/training/generate_images.py | import argparse
import logging
from diffusers import AmusedPipeline
import os
from peft import PeftModel
from diffusers import UVit2DModel
logger = logging.getLogger(__name__)
def parse_args():
parser = argparse.ArgumentParser()
parser.add_argument(
"--pretrained_model_name_or_path",
type=str,
default=None,
required=True,
help="Path to pretrained model or model identifier from huggingface.co/models.",
)
parser.add_argument(
"--revision",
type=str,
default=None,
required=False,
help="Revision of pretrained model identifier from huggingface.co/models.",
)
parser.add_argument(
"--variant",
type=str,
default=None,
help="Variant of the model files of the pretrained model identifier from huggingface.co/models, 'e.g.' fp16",
)
parser.add_argument("--style_descriptor", type=str, default="[V]")
parser.add_argument(
"--load_transformer_from",
type=str,
required=False,
default=None,
)
parser.add_argument(
"--load_transformer_lora_from",
type=str,
required=False,
default=None,
)
parser.add_argument("--device", type=str, default='cuda')
parser.add_argument("--batch_size", type=int, default=1)
parser.add_argument("--write_images_to", type=str, required=True)
args = parser.parse_args()
return args
def main(args):
prompts = [
f"A chihuahua in {args.style_descriptor} style",
f"A tabby cat in {args.style_descriptor} style",
f"A portrait of chihuahua in {args.style_descriptor} style",
f"An apple on the table in {args.style_descriptor} style",
f"A banana on the table in {args.style_descriptor} style",
f"A church on the street in {args.style_descriptor} style",
f"A church in the mountain in {args.style_descriptor} style",
f"A church in the field in {args.style_descriptor} style",
f"A church on the beach in {args.style_descriptor} style",
f"A chihuahua walking on the street in {args.style_descriptor} style",
f"A tabby cat walking on the street in {args.style_descriptor} style",
f"A portrait of tabby cat in {args.style_descriptor} style",
f"An apple on the dish in {args.style_descriptor} style",
f"A banana on the dish in {args.style_descriptor} style",
f"A human walking on the street in {args.style_descriptor} style",
f"A temple on the street in {args.style_descriptor} style",
f"A temple in the mountain in {args.style_descriptor} style",
f"A temple in the field in {args.style_descriptor} style",
f"A temple on the beach in {args.style_descriptor} style",
f"A chihuahua walking in the forest in {args.style_descriptor} style",
f"A tabby cat walking in the forest in {args.style_descriptor} style",
f"A portrait of human face in {args.style_descriptor} style",
f"An apple on the ground in {args.style_descriptor} style",
f"A banana on the ground in {args.style_descriptor} style",
f"A human walking in the forest in {args.style_descriptor} style",
f"A cabin on the street in {args.style_descriptor} style",
f"A cabin in the mountain in {args.style_descriptor} style",
f"A cabin in the field in {args.style_descriptor} style",
f"A cabin on the beach in {args.style_descriptor} style"
]
logger.warning(f"generating image for {prompts}")
logger.warning(f"loading models")
pipe_args = {}
if args.load_transformer_from is not None:
pipe_args["transformer"] = UVit2DModel.from_pretrained(args.load_transformer_from)
pipe = AmusedPipeline.from_pretrained(
pretrained_model_name_or_path=args.pretrained_model_name_or_path,
revision=args.revision,
variant=args.variant,
**pipe_args
)
if args.load_transformer_lora_from is not None:
pipe.transformer = PeftModel.from_pretrained(
pipe.transformer, os.path.join(args.load_transformer_from), is_trainable=False
)
pipe.to(args.device)
logger.warning(f"generating images")
os.makedirs(args.write_images_to, exist_ok=True)
for prompt_idx in range(0, len(prompts), args.batch_size):
images = pipe(prompts[prompt_idx:prompt_idx+args.batch_size]).images
for image_idx, image in enumerate(images):
prompt = prompts[prompt_idx+image_idx]
image.save(os.path.join(args.write_images_to, prompt + ".png"))
if __name__ == "__main__":
main(parse_args()) | 0 |
0 | hf_public_repos | hf_public_repos/audio-transformers-course/LICENSE | Apache License
Version 2.0, January 2004
http://www.apache.org/licenses/
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
1. Definitions.
"License" shall mean the terms and conditions for use, reproduction,
and distribution as defined by Sections 1 through 9 of this document.
"Licensor" shall mean the copyright owner or entity authorized by
the copyright owner that is granting the License.
"Legal Entity" shall mean the union of the acting entity and all
other entities that control, are controlled by, or are under common
control with that entity. For the purposes of this definition,
"control" means (i) the power, direct or indirect, to cause the
direction or management of such entity, whether by contract or
otherwise, or (ii) ownership of fifty percent (50%) or more of the
outstanding shares, or (iii) beneficial ownership of such entity.
"You" (or "Your") shall mean an individual or Legal Entity
exercising permissions granted by this License.
"Source" form shall mean the preferred form for making modifications,
including but not limited to software source code, documentation
source, and configuration files.
"Object" form shall mean any form resulting from mechanical
transformation or translation of a Source form, including but
not limited to compiled object code, generated documentation,
and conversions to other media types.
"Work" shall mean the work of authorship, whether in Source or
Object form, made available under the License, as indicated by a
copyright notice that is included in or attached to the work
(an example is provided in the Appendix below).
"Derivative Works" shall mean any work, whether in Source or Object
form, that is based on (or derived from) the Work and for which the
editorial revisions, annotations, elaborations, or other modifications
represent, as a whole, an original work of authorship. For the purposes
of this License, Derivative Works shall not include works that remain
separable from, or merely link (or bind by name) to the interfaces of,
the Work and Derivative Works thereof.
"Contribution" shall mean any work of authorship, including
the original version of the Work and any modifications or additions
to that Work or Derivative Works thereof, that is intentionally
submitted to Licensor for inclusion in the Work by the copyright owner
or by an individual or Legal Entity authorized to submit on behalf of
the copyright owner. For the purposes of this definition, "submitted"
means any form of electronic, verbal, or written communication sent
to the Licensor or its representatives, including but not limited to
communication on electronic mailing lists, source code control systems,
and issue tracking systems that are managed by, or on behalf of, the
Licensor for the purpose of discussing and improving the Work, but
excluding communication that is conspicuously marked or otherwise
designated in writing by the copyright owner as "Not a Contribution."
"Contributor" shall mean Licensor and any individual or Legal Entity
on behalf of whom a Contribution has been received by Licensor and
subsequently incorporated within the Work.
2. Grant of Copyright License. Subject to the terms and conditions of
this License, each Contributor hereby grants to You a perpetual,
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
copyright license to reproduce, prepare Derivative Works of,
publicly display, publicly perform, sublicense, and distribute the
Work and such Derivative Works in Source or Object form.
3. Grant of Patent License. Subject to the terms and conditions of
this License, each Contributor hereby grants to You a perpetual,
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
(except as stated in this section) patent license to make, have made,
use, offer to sell, sell, import, and otherwise transfer the Work,
where such license applies only to those patent claims licensable
by such Contributor that are necessarily infringed by their
Contribution(s) alone or by combination of their Contribution(s)
with the Work to which such Contribution(s) was submitted. If You
institute patent litigation against any entity (including a
cross-claim or counterclaim in a lawsuit) alleging that the Work
or a Contribution incorporated within the Work constitutes direct
or contributory patent infringement, then any patent licenses
granted to You under this License for that Work shall terminate
as of the date such litigation is filed.
4. Redistribution. You may reproduce and distribute copies of the
Work or Derivative Works thereof in any medium, with or without
modifications, and in Source or Object form, provided that You
meet the following conditions:
(a) You must give any other recipients of the Work or
Derivative Works a copy of this License; and
(b) You must cause any modified files to carry prominent notices
stating that You changed the files; and
(c) You must retain, in the Source form of any Derivative Works
that You distribute, all copyright, patent, trademark, and
attribution notices from the Source form of the Work,
excluding those notices that do not pertain to any part of
the Derivative Works; and
(d) If the Work includes a "NOTICE" text file as part of its
distribution, then any Derivative Works that You distribute must
include a readable copy of the attribution notices contained
within such NOTICE file, excluding those notices that do not
pertain to any part of the Derivative Works, in at least one
of the following places: within a NOTICE text file distributed
as part of the Derivative Works; within the Source form or
documentation, if provided along with the Derivative Works; or,
within a display generated by the Derivative Works, if and
wherever such third-party notices normally appear. The contents
of the NOTICE file are for informational purposes only and
do not modify the License. You may add Your own attribution
notices within Derivative Works that You distribute, alongside
or as an addendum to the NOTICE text from the Work, provided
that such additional attribution notices cannot be construed
as modifying the License.
You may add Your own copyright statement to Your modifications and
may provide additional or different license terms and conditions
for use, reproduction, or distribution of Your modifications, or
for any such Derivative Works as a whole, provided Your use,
reproduction, and distribution of the Work otherwise complies with
the conditions stated in this License.
5. Submission of Contributions. Unless You explicitly state otherwise,
any Contribution intentionally submitted for inclusion in the Work
by You to the Licensor shall be under the terms and conditions of
this License, without any additional terms or conditions.
Notwithstanding the above, nothing herein shall supersede or modify
the terms of any separate license agreement you may have executed
with Licensor regarding such Contributions.
6. Trademarks. This License does not grant permission to use the trade
names, trademarks, service marks, or product names of the Licensor,
except as required for reasonable and customary use in describing the
origin of the Work and reproducing the content of the NOTICE file.
7. Disclaimer of Warranty. Unless required by applicable law or
agreed to in writing, Licensor provides the Work (and each
Contributor provides its Contributions) on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
implied, including, without limitation, any warranties or conditions
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
PARTICULAR PURPOSE. You are solely responsible for determining the
appropriateness of using or redistributing the Work and assume any
risks associated with Your exercise of permissions under this License.
8. Limitation of Liability. In no event and under no legal theory,
whether in tort (including negligence), contract, or otherwise,
unless required by applicable law (such as deliberate and grossly
negligent acts) or agreed to in writing, shall any Contributor be
liable to You for damages, including any direct, indirect, special,
incidental, or consequential damages of any character arising as a
result of this License or out of the use or inability to use the
Work (including but not limited to damages for loss of goodwill,
work stoppage, computer failure or malfunction, or any and all
other commercial damages or losses), even if such Contributor
has been advised of the possibility of such damages.
9. Accepting Warranty or Additional Liability. While redistributing
the Work or Derivative Works thereof, You may choose to offer,
and charge a fee for, acceptance of support, warranty, indemnity,
or other liability obligations and/or rights consistent with this
License. However, in accepting such obligations, You may act only
on Your own behalf and on Your sole responsibility, not on behalf
of any other Contributor, and only if You agree to indemnify,
defend, and hold each Contributor harmless for any liability
incurred by, or claims asserted against, such Contributor by reason
of your accepting any such warranty or additional liability.
END OF TERMS AND CONDITIONS
APPENDIX: How to apply the Apache License to your work.
To apply the Apache License to your work, attach the following
boilerplate notice, with the fields enclosed by brackets "[]"
replaced with your own identifying information. (Don't include
the brackets!) The text should be enclosed in the appropriate
comment syntax for the file format. We also recommend that a
file or class name and description of purpose be included on the
same "printed page" as the copyright notice for easier
identification within third-party archives.
Copyright [yyyy] [name of copyright owner]
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
| 1 |
0 | hf_public_repos | hf_public_repos/audio-transformers-course/Makefile | .PHONY: quality style
# Check code formatting
quality:
python utils/code_formatter.py --check_only
# Format code samples automatically and check is there are any problems left that need manual fixing
style:
python utils/code_formatter.py
| 2 |
0 | hf_public_repos | hf_public_repos/audio-transformers-course/requirements.txt | nbformat>=5.1.3
PyYAML>=5.4.1
black>=22.3.0 | 3 |
0 | hf_public_repos | hf_public_repos/audio-transformers-course/README.md | # The Audio Transformers Course
This repo contains the content that's used to create [Hugging Face's Audio Transformers Course](https://huggingface.co/learn/audio-course/).
The course teaches you about applying Transformers to various tasks in audio and speech processing.It's completely free and open-source!
## 🌎 Languages and translations
| Language | Source | Authors |
|:------------------------------------------------------------------------------|:-----------------------------------------------------------------------------------|:---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| [Bengali](https://huggingface.co/learn/audio-course/bn/chapter0/introduction) | [`chapters/bn`](https://github.com/huggingface/audio-transformers-course/tree/main/chapters/bn) | |
| [English](https://huggingface.co/learn/audio-course/chapter0/introduction) | [`chapters/en`](https://github.com/huggingface/audio-transformers-course/tree/main/chapters/en) | |
| [Spanish](https://huggingface.co/learn/audio-course/es/chapter0/introduction) | [`chapters/es`](https://github.com/huggingface/audio-transformers-course/tree/main/chapters/es) | |
| [French](https://huggingface.co/learn/audio-course/fr/chapter0/introduction) | [`chapters/fr`](https://github.com/huggingface/audio-transformers-course/tree/main/chapters/fr) | |
| [Korean](https://huggingface.co/learn/audio-course/ko/chapter0/introduction) | [`chapters/ko`](https://github.com/huggingface/audio-transformers-course/tree/main/chapters/ko) | |
| [Russian](https://huggingface.co/learn/audio-course/ru/chapter0/introduction) | [`chapters/ru`](https://github.com/huggingface/audio-transformers-course/tree/main/chapters/ru) | [@blademoon](https://github.com/blademoon), [@Lightmourne](https://github.com/Lightmourne) |
| [Turkish](https://huggingface.co/learn/audio-course/tr/chapter0/introduction) | [`chapters/tr`](https://github.com/huggingface/audio-transformers-course/tree/main/chapters/tr) | |
| [Chinese (simplified)](https://huggingface.co/learn/audio-course/zh-CN/chapter0/introduction) | [`chapters/zh-CN`](https://github.com/huggingface/audio-transformers-course/tree/main/chapters/zh-CN) | |
### Translating the course into your language
As part of our mission to democratise machine learning, we'd love to have the course available in many more languages!
Please follow the steps below if you'd like to help translate the course into your language 🙏.
**🗞️ Open an issue**
To get started, navigate to the [_Issues_](https://github.com/huggingface/audio-transformers-course/issues) page of
this repo and check if anyone else has opened an issue for your language. If not, open a new issue by selecting
the _Translation template_ from the _New issue_ button.
Once an issue is created, post a comment to indicate which chapters you'd like to work on and we'll add your name to the list.
**🗣 Join our Discord**
Since it can be difficult to discuss translation details quickly over GitHub issues, we have created dedicated channels
for each language on our Discord server. Join here 👉: [http://hf.co/join/discord](http://hf.co/join/discord)
**🍴 Fork the repository**
Next, you'll need to [fork this repo](https://docs.github.com/en/get-started/quickstart/fork-a-repo). You can do this
by clicking on the **Fork** button on the top-right corner of this repo's page.
Once you've forked the repo, you'll want to get the files on your local machine for editing. You can do that by cloning the fork with Git as follows:
```bash
git clone https://github.com/YOUR-USERNAME/audio-transformers-course
```
**📋 Copy-paste the English files with a new language code**
The course files are organised under a main directory:
* [`chapters`](https://github.com/huggingface/audio-transformers-course/tree/main/chapters): all the text and code snippets associated with the course.
You'll only need to copy the files in the [`chapters/en`](https://github.com/huggingface/audio-transformers-course/tree/main/chapters/en)
directory, so first navigate to your fork of the repo and run the following:
```bash
cd ~/path/to/audio-transformers-course
cp -r chapters/en/CHAPTER-NUMBER chapters/LANG-ID/CHAPTER-NUMBER
```
Here, `CHAPTER-NUMBER` refers to the chapter you'd like to work on and `LANG-ID` should be ISO 639-1 (two lower case letters)
language code -- see [here](https://www.loc.gov/standards/iso639-2/php/code_list.php) for a handy table.
Alternatively, {two lowercase letters}-{two uppercase letters} format is also supported, e.g. `zh-CN`, here's
an [example](https://huggingface.co/learn/nlp-course/zh-CN/chapter1/1).
**✍️ Start translating**
Now comes the fun part - translating the text! The first thing we recommend is translating the part of the `_toctree.yml` file that corresponds to your chapter. This file is used to render the table of contents on the website and provide the links to the Colab notebooks. The only fields you should change are the `title`, ones -- for example, here are the parts of `_toctree.yml` that we'd translate for [Chapter 0 of the NLP course](https://huggingface.co/course/chapter0/1?fw=pt):
```yaml
- title: 0. Setup # Translate this!
sections:
- local: chapter0/1 # Do not change this!
title: Introduction # Translate this!
```
> 🚨 Make sure the `_toctree.yml` file only contains the sections that have been translated! Otherwise you won't be able to build the content on the website or locally (see below how).
Once you have translated the `_toctree.yml` file, you can start translating the [MDX](https://mdxjs.com/) files associated with your chapter.
> 🙋 If the `_toctree.yml` file doesn't yet exist for your language, you can simply create one by copy-pasting from the English version and deleting the sections that aren't related to your chapter. Just make sure it exists in the `chapters/LANG-ID/` directory!
**👷♂️ Build the course locally**
Once you're happy with your changes, you can preview how they'll look by first installing the [`doc-builder`](https://github.com/huggingface/doc-builder) tool that we use for building all documentation at Hugging Face:
```shell
python -m pip install hf-doc-builder
```
```shell
doc-builder preview audio-transformers-course ../audio-transformers-course/chapters/LANG-ID --not_python_module
```
This will build and render the course on [http://localhost:3000/](http://localhost:3000/). Although the content looks much nicer on the Hugging Face website, this step will still allow you to check that everything is formatted correctly.
**🚀 Submit a pull request**
If the translations look good locally, the final step is to prepare the content for a pull request. Here, the first think to check is that the files are formatted correctly. For that you can run:
```
pip install -r requirements.txt
make style
```
Once that's run, commit any changes, open a pull request, and wait for a review. Congratulations, you've now completed your first translation 🥳!
> 🚨 To build the course on the website, double-check your language code exists in `languages` field of the `build_documentation.yml` and `build_pr_documentation.yml` files in the `.github` folder. If not, just add them in their alphabetical order.
## 📔 Jupyter notebooks
The Jupyter notebooks containing all the code from the course are hosted on the [`huggingface/notebooks`](https://github.com/huggingface/notebooks) repo. If you wish to generate them locally, first install the required dependencies:
```bash
python -m pip install -r requirements.txt
```
Then run the following script:
```bash
python utils/generate_notebooks.py --output_dir nbs
```
This script extracts all the code snippets from the chapters and stores them as notebooks in the `nbs` folder (which is ignored by Git by default).
## ✍️ Contributing a new chapter
> Note: we are not currently accepting community contributions for new chapters. These instructions are for the Hugging Face authors.
Adding a new chapter to the course is quite simple:
1. Create a new directory under `chapters/en/chapterX`, where `chapterX` is the chapter you'd like to add.
2. Add numbered MDX files `sectionX.mdx` for each section.
3. Update the `_toctree.yml` file to include your chapter sections -- this information will render the table of contents on the website. If your section involves both the PyTorch and TensorFlow APIs of `transformers`, make sure you include links to both Colabs in the `colab` field.
If you get stuck, check out one of the existing chapters -- this will often show you the expected syntax.
Once you are happy with the content, open a pull request and wait for a review. We recommend adding the first chapter draft as a single pull request -- the team will then provide feedback internally to iterate on the content 🤗!
## 🙌 Acknowledgements
The structure of this repo and README are inspired by the wonderful [Advanced NLP with spaCy](https://github.com/ines/spacy-course) course.
| 4 |
0 | hf_public_repos/audio-transformers-course/chapters | hf_public_repos/audio-transformers-course/chapters/zh-CN/_toctree.yml | - title: 第0单元:欢迎来到Hugging Face音频课程!
sections:
- local: chapter0/introduction
title: 课堂目标
- local: chapter0/get_ready
title: 准备工作
- local: chapter0/community
title: 加入社区
- title: 第1单元:音频数据处理
sections:
- local: chapter1/introduction
title: 单元简介
- local: chapter1/audio_data
title: 音频数据处理入门
- local: chapter1/load_and_explore
title: 加载音频数据集
- local: chapter1/preprocessing
title: 音频数据集的预处理
- local: chapter1/streaming
title: 音频数据的流式加载
- local: chapter1/quiz
title: 习题
quiz: 1
- local: chapter1/supplemental_reading
title: 补充阅读
- title: 第2单元:音频应用的入门介绍
sections:
- local: chapter2/introduction
title: 音频应用概览
- local: chapter2/audio_classification_pipeline
title: 利用pipeline进行音频分类
- local: chapter2/asr_pipeline
title: 利用pipeline进行自动语音识别
- local: chapter2/hands_on
title: 实战练习
- title: 第3单元:音频Transformer结构
sections:
- local: chapter3/introduction
title: Transformer模型回顾
- local: chapter3/ctc
title: CTC结构
- local: chapter3/seq2seq
title: Seq2Seq结构
- local: chapter3/classification
title: 音频分类结构
- local: chapter3/quiz
title: 习题
quiz: 3
- local: chapter3/supplemental_reading
title: 补充阅读
#- title: 第4单元:构建音乐风格分类器
# sections:
# - local: chapter4/introduction
# title: 单元简介
# - local: chapter4/classification_models
# title: 音频分类的预训练模型
# - local: chapter4/fine-tuning
# title: 针对音乐分类进行微调
# - local: chapter4/demo
# title: 使用Gradio构建demo
# - local: chapter4/hands_on
# title: 实战练习
#
- title: 第5单元:自动语音识别 (ASR)
sections:
- local: chapter5/introduction
title: 单元简介
- local: chapter5/asr_models
title: 语音识别的预训练模型
- local: chapter5/choosing_dataset
title: 选择数据集
- local: chapter5/evaluation
title: 语音识别的评价指标
- local: chapter5/fine-tuning
title: 微调语音识别模型
- local: chapter5/demo
title: 创建 demo
- local: chapter5/hands_on
title: 实战练习
- local: chapter5/supplemental_reading
title: 补充阅读
- title: 第六单元:从文本到语音
sections:
- local: chapter6/introduction
title: 单元简介
- local: chapter6/tts_datasets
title: 语音合成数据集
- local: chapter6/pre-trained_models
title: 语音合成的预训练模型
- local: chapter6/fine-tuning
title: 微调 SpeechT5
- local: chapter6/evaluation
title: 评估语音合成模型
- local: chapter6/hands_on
title: 实战练习
- local: chapter6/supplemental_reading
title: 补充阅读
#
#- title: 第7单元:音频到音频合成(ATA)
# sections:
# - local: chapter7/introduction
# title: 单元简介
# - local: chapter7/tasks
# title: 音频到音频合成(ATA)任务实例
# - local: chapter7/choosing_dataset
# title: 数据集选择
# - local: chapter7/preprocessing
# title: 数据加载和预处理
# - local: chapter7/evaluation
# title: 音频到音频合成(ATA)的评价指标
# - local: chapter7/fine-tuning
# title: 模型微调
# - local: chapter7/quiz
# title: 习题
# quiz: 7
# - local: chapter7/hands_on
# title: 实战练习
# - local: chapter7/supplemental_reading
# title: 补充阅读
#
#- title: 第8单元:终点线
# sections:
# - local: chapter8/introduction
# title: Congratulations!
# - local: chapter8/certification
# title: Get your certification of completion
# - local: chapter8/stay_in_touch
# title: Stay in touch
#
#- title: 附加单元:音频扩散模型
# sections:
# - local: chapter9/introduction
# title: 单元简介
# - local: chapter9/music_generation
# title: 音乐生成
# - local: chapter9/riffusion
# title: Riffusion模型
# - local: chapter9/audioldm
# title: AudioLDM模型
# - local: chapter9/dance_diffusion
# title: Dance Diffusion模型
#- title: 课程活动
# sections:
# - local: events/introduction
# title: 直播录像
| 5 |
0 | hf_public_repos/audio-transformers-course/chapters/zh-CN | hf_public_repos/audio-transformers-course/chapters/zh-CN/chapter0/get_ready.mdx | # 课程准备工作
希望你已经做好准备开始学习了!这一节中我们会确保你做好了所有开始学习前的准备工作。
## 第1步:注册课程
注册课程以获取内容更新和特殊活动的通知:
[👉 注册课程(仅英文)](http://eepurl.com/insvcI)
## 第2步:创建Hugging Face 账号
如果你还没有Hugging Face 账号,我们推荐你现在进行免费注册。实战练习需要使用你的个人Hugging Face 账号来探索预训练模型、获取数据集和更多资源。
[👉 创建Hugging Face 账号(仅英文)](https://huggingface.co/join)
## 第3步:复习基础内容(如需要)
本课程针对熟悉深度学习基础知识并对Transformer架构有一定了解的同学而设计。如果你需要复习Transformer架构的基础内容,可以参考我们的[自然语言处理课程](https://huggingface.co/learn/nlp-course/chapter0/1)。
## 第4步:检查你的环境
学习本课程需要以下资源:
- 一台联网的电脑
- 使用[Google Colab](https://colab.research.google.com)进行实战练习。免费版本即可。
如果你没有使用过Google Colab,可以参考这个[官方介绍笔记本(仅英文)](https://colab.research.google.com/notebooks/intro.ipynb).
## 第5步:加入社区
加入我们的Discord频道,与同学们和Hugging Face 团队交流你的想法。
[👉 加入DISCORD社区(仅英文)](http://hf.co/join/discord)
想了解更多关于社区的内容并更好地利用它,请参考[下一小节](community).
| 6 |
0 | hf_public_repos/audio-transformers-course/chapters/zh-CN | hf_public_repos/audio-transformers-course/chapters/zh-CN/chapter0/introduction.mdx | # 欢迎来到Hugging Face 音频课程!
屏幕前的同学,
欢迎来到本课!我们将为你介绍Transformer模型在音频领域的应用。Transformer模型已经多次证明了自己是最强大、多功能的深度学习模型之一,并在自然语言处理(Natural Language Processing, NLP)、机器视觉(Computer Vision, CV)、和最近的音频处理等等任务上取得了最佳成绩。
在本课中,我们会学习如何将Trasnfromer结构应用到音频数据上。你会学到如何使用Transformer解决各种各样与音频有关的任务。无论你是对自动语音识别(Automatic Speech Recognition, ASR)、音频分类(Audio CLassification)、或是由文字生成语音(Text-to-Speech synthesis, TTS)感兴趣,本课和Transformer都会成为你的得力助手。
让我们直观地感受一下这些模型的威力吧!在下面的demo里随便说些什么,然后看看我们的模型是如何实时地将语音记录成文字的(仅支持英语):
<iframe
src="https://openai-whisper.hf.space"
frameborder="0"
width="850"
height="450">
</iframe>
在本课中,你会学习到针对音频数据的特殊处理方法、各种不同的Transformer架构、以及使用强大的预训练模型来训练你自己的音频Transformer。
本课是为有一定深度学习基础,并对Transformer有一些初步了解的同学而设计。你不需要对音频数据处理有任何经验。如果你需要加强自己对Transformer结构的基础了解,请参考我们的[自然语言处理课程](https://huggingface.co/learn/nlp-course/zh-CN/chapter1/1)。这门课程包含了Transformer结构的基础知识和更多细节。
## 关于作者
**Sanchit Gandhi, Hugging Face机器学习科研工程师**
嗨! 我是Sanchit,来自Hugging Face🤗开源组的的音频机器学习研发工程师。我的主要方向是自动语音识别和(automatic speech recognition,ASR)和自动语音翻译。我现在的工作方向是构建更快、更轻、更易用的语音模型。
**Matthijs Hollemans, Hugging Face机器学习工程师**
我是Matthijs, Hugging Face开源组的音频机器学习工程师。我也是《how to write sound synthesizers》(如何编写音频合成器)一书的作者。我喜欢在业余时间编写音频插件。
**Maria Khalusova, Hugging Face文档和课程经理**
我是Maria,我的主要工作是制作教学内容和文档,使我们的Transformers库和其他开源工具更加易用。我会解构复杂的技术概念,并且帮助大家从零开始理解最前沿的技术。
**Vaibhav Srivastav, Hugging Face机器学习开发者大使**
我是Vaibhav (VB),Hugging Face开源组的开发者大使(Developer Advocate)。我的研究方向是低资源TTS以及尖端语音研究的大众化推进。
## 课程结构
本课程被分为多个单元,涵盖了众多方向的深度议题:
* 第1单元:学习音频数据的特殊性,包括音频信号处理技巧和数据预处理。
* 第2单元:了解音频机器学习的应用,使用🤗Transformers pipelines实现不同任务,包括音频分类(Audio classification)和语音识别(speech recognition)。
* 第3单元:探索各种音频Transformer架构,了解他们的区别和各自的优势任务。
* 第4单元:学习如何构建你自己的音乐风格分类器(music genre classifier)
* 第5单元:深入学习语音识别(speech recognition),搭建一个会议转录模型。
* 第6单元:学习如何从文字生成语音。
* 第7单元:学习利用Transformer进行音频到音频转换(audio to audio)。
每个单元都包含了理论部分,对模型背后的概念和技巧做了深入的极少。本课程的各个章节都包含了课后习题,用来测试和强化你的学习成果。部分单元还包含了实战练习。
完成本课程的学习后,你会在Transformer和音频数据上拥有一个扎实的基础,并且会学习到针对多种音频相关任务的工具,帮助你快速开发应用。
本课程的各个单元会按照如下的时间表发布:(译注:此表为英文版课程发布时间)
| 单元 | 发布日期 |
|---|-----------------|
| 第0、1、2单元 | 2023年6月14日 |
| 第3、4单元 | 2023年6月21日 |
| 第5单元 | 2023年6月28日 |
| 第6单元 | 2023年7月5日 |
| 第7、8单元 | 2023年7月12日 |
[//]: # (| 额外单元 | 未定 |)
## 学习方法和证书
你可以用任何方式来利用这门课程。本课程的所有内容均为100%免费、公开且开源。你可以按照自己喜欢的节奏来学习本课程,不过我们建议按照顺序来阅读各个单元。
如果你想要获取结课证明,我们提供两种不同的选项:
| 证书类别 | 要求 |
|---|------------------------------------------------------------------------------------------------|
| 结课证书 | 在2023年7月底前,根据指引完成80%的实战练习内容。 |
| 荣誉证书 | 在2023年7月底前,根据指引完成100%的实战练习内容。 |
每个单元的实战练习内容均有各自的完成标准。当你完成了任意类别的证书要求后,请按照最后一个单元的指引来获取你的结课证明。祝你好运!
## 注册本课程
本课程的不同单元会在数周内逐渐更新。我们建议你注册课程更新通知,以防错过新内容的更新。注册课程的同学还能第一时间了解到我们举办的特殊活动。
[注册链接(仅英文)](http://eepurl.com/insvcI)
祝你学习愉快! | 7 |
0 | hf_public_repos/audio-transformers-course/chapters/zh-CN | hf_public_repos/audio-transformers-course/chapters/zh-CN/chapter0/community.mdx | # 加入社区!
我们邀请你 [加入我们充满活力和乐于助人的Discord社区(仅英文)](http://hf.co/join/discord)。在这里,你将有机会认识同温层的同学、与他们交流想法,并且获得关于实战练习的宝贵反馈。你可以在这里提问、分享资源、与他人合作。
我们的团队也会在Discord中和大家交流,并且为大家提供支持和指引。加入社区可以帮助你保持学习动力、增加参与感、加强练习。我们欢迎你成为社区的一员!
## Discord是什么?
Discord是一个免费的聊天平台。如果你使用过Slack,那么Discord也与之类似。我们的Hugging Face Discord频道已经有超过18000名用户,包括了AI专家、AI学习者和AI爱好者。我们邀请你参与到讨论中来!
## 使用Discord
在你注册并加入我们的Discord服务器之后,你可以在界面左侧点击`#role-assignment`来添加你感兴趣的话题。你可以选择任意数量的话题。想要加入本课程的讨论组,请点击"ML for Audio and Speech"标签。我们也欢迎你在`#introduce-yourself`标签中分享关于你自己的内容。
## 音频课程频道
我们的Discord服务器中有针对许多不同方向的频道。大家可以在不同的频道中讨论论文、组织活动、分享自己的项目的调子、头脑风暴、等等。作为音频课程的同学,你可以关注以下频道的相关内容:
* `#audio-announcements`: 课程内容的更新、Hugging Face所有音频相关内容的新闻、活动通知等。
* `#audio-study-group`: 交流想法、提问和交流课程相关内容的频道。
* `#audio-discuss`: 任何音频相关内容的讨论。
除了加入`#audio-study-group`频道之外,你也可以创建自己的学习小组。一起学习总是更加轻松!
| 8 |
0 | hf_public_repos/audio-transformers-course/chapters/zh-CN | hf_public_repos/audio-transformers-course/chapters/zh-CN/chapter5/choosing_dataset.mdx | # 选择数据集
就像在其他机器学习问题中一样,我们的模型最多只能表现得与我们用来训练它的数据一样好。
语音识别数据集在组织方式和覆盖的领域方面有很大的不同,我们需要查看它们提供的特征,选出最符合我们标准的数据集。
所以在选择数据集之前,我们首先需要了解特征的定义。
## 语音数据集的特征
### 1. 小时数
简单来说,训练小时数体现了数据集的大小,类似 NLP 数据集中的训练样例数量。然而,更大的数据集不一定更好。
如果我们想要一个泛化能力强的模型,就需要一个具有许多不同发言者、领域和发言风格的**多样化**数据集。
### 2. 领域
领域(domain)包括数据的来源,比如有声读物、播客、YouTube 还是金融会议。每个领域的数据分布都不同,
例如有声读物在高质量的录音室条件下录制(没有背景噪音),并且文本取自书面文学。而对于 YouTube,音频可能包含更多背景噪音和更非正式的语音风格。
我们需要保证选择的领域与推理时的条件相匹配。例如,如果我们在有声读物上训练我们的模型,就不能期望它在嘈杂的环境中表现良好。
### 3. 说话风格
说话风格(speaking style)分为两类:
* 叙述性(Narrated):按照给定的文本朗读
* 自发性(Spontaneous):没有固定剧本的对话
音频和文本数据反映了说话的风格。由于叙述文本是有剧本的,它表达得会比较清晰,没有任何错误:
```
“Consider the task of training a model on a speech recognition dataset”
```
而自发性言语使用更口语化的说话风格,包括重复、犹豫和错误:
```
“Let's uhh let's take a look at how you'd go about training a model on uhm a sp- speech recognition dataset”
```
### 4. 转写风格
转写风格指的是目标文本是否有标点、区分大小写等。如果我们希望系统生成可用于出版物或会议转写的完全格式化文本,我们需要带有标点和大小写的训练数据。
如果我们只需要未格式化结构的口头言语,那么标点和大小写都不是必需的。在这种情况下,我们可以选择一个没有标点或大小写的数据集,或者选择一个有标点和大小写的数据集,然后通过预处理从目标文本中去除它们。
## Hub 上数据集的汇总
以下是 Hugging Face Hub 上最受欢迎的英语语音识别数据集,作为您根据自己的标准选择数据集的参考:
| 数据集 | 训练小时数 | 领域 | 说话风格 | 大小写 | 标点 | 许可证 | 推荐用途 |
|---------------------------------------------------------------------------------------------|---------|--------------------------|----------------|--------|------|------------------|----------------------|
| [LibriSpeech](https://huggingface.co/datasets/librispeech_asr) | 960 | 有声读物 | 叙述性 | ❌ | ❌ | CC-BY-4.0 | 学术基准测试 |
| [Common Voice 11](https://huggingface.co/datasets/mozilla-foundation/common_voice_11_0) | 3000 | 维基百科 | 叙述性 | ✅ | ✅ | CC0-1.0 | 非母语发言者 |
| [VoxPopuli](https://huggingface.co/datasets/facebook/voxpopuli) | 540 | 欧洲议会 | 演讲式 | ❌ | ✅ | CC0 | 非母语发言者 |
| [TED-LIUM](https://huggingface.co/datasets/LIUM/tedlium) | 450 | TED 演讲 | 演讲式 | ❌ | ❌ | CC-BY-NC-ND 3.0 | 技术主题 |
| [GigaSpeech](https://huggingface.co/datasets/speechcolab/gigaspeech) | 10000 | 有声读物、播客、YouTube | 叙述性、自发性 | ❌ | ✅ | apache-2.0 | 多领域鲁棒性 |
| [SPGISpeech](https://huggingface.co/datasets/kensho/spgispeech) | 5000 | 金融会议 | 演讲式、自发性 | ✅ | ✅ | User Agreement | 完全格式化的转写 |
| [Earnings-22](https://huggingface.co/datasets/revdotcom/earnings22) | 119 | 金融会议 | 演讲式、自发性 | ✅ | ✅ | CC-BY-SA-4.0 | 口音多样性 |
| [AMI](https://huggingface.co/datasets/edinburghcstr/ami) | 100 | 会议 | 自发性 | ✅ | ✅ | CC-BY-4.0 | 嘈杂语音环境 |
以下是多语言语音识别数据集的表格,请注意,我们省略了训练小时数列(因为这取决于每个数据集有哪些语言,占比多少),改成了每个数据集的语言数量:
| 数据集 | 语言数量 | 领域 | 说话风格 | 大小写 | 标点 | 许可证 | 推荐用途 |
|------------------------------------------------------------------------------------------------|--------|---------------------------|---------|-------|-------|-----------|------------------|
| [Multilingual LibriSpeech](https://huggingface.co/datasets/facebook/multilingual_librispeech) | 6 | 有声读物 | 叙述性 | ❌ | ❌ | CC-BY-4.0 | 学术基准测试 |
| [Common Voice 13](https://huggingface.co/datasets/mozilla-foundation/common_voice_13_0) | 108 | 维基百科文本和众筹的言语 | 叙述性 | ✅ | ✅ | CC0-1.0 | 多样化的发言者集合 |
| [VoxPopuli](https://huggingface.co/datasets/facebook/voxpopuli) | 15 | 欧洲议会 | 自发性 | ❌ | ✅ | CC0 | 欧洲语言 |
| [FLEURS](https://huggingface.co/datasets/google/fleurs) | 101 | 欧洲议会 | 自发性 | ❌ | ❌ | CC-BY-4.0 | 多语言评估 |
有关两个表中涵盖的音频数据集的详细分析,请参阅博文 [音频数据集完全指南](https://huggingface.co/blog/audio-datasets#a-tour-of-audio-datasets-on-the-hub)。
虽然 Hub 上有超过 180 个语音识别数据集,但可能没有一个数据集符合您的需求。在这种情况下,也可以通过 🤗 Datasets 库来使用您自己的音频数据。要创建自定义音频数据集,请参考指南 [创建音频数据集](https://huggingface.co/docs/datasets/audio_dataset)。
自定义音频数据集时,请考虑在 Hub 上分享最终构建出的数据集,以便社区中的其他人可以从您的成果中受益——音频社区包容且广大,您感谢其他人的贡献,其他人会像一样感谢您的贡献。
好了!既然我们已经了解了选择 ASR 数据集的所有标准,那么我们为这个教程选择一个吧。我们知道 Whisper 已经在高资源语言(如英语和西班牙语)上做得很好了,
所以我们将专注于低资源的多语言转写。我们想保留 Whisper 预测标点和大小写的能力,所以从第二张表来看,Common Voice 13 是一个很好的候选数据集!
## Common Voice 13
Common Voice 13 是一个众筹的数据集,发言者用不同语言朗读并录制维基百科的文本。它是由 Mozilla 基金会发布的一系列 Common Voice 数据集之一。
在撰写本文时,Common Voice 13 是最新版的数据集,拥有迄今为止任何版本中最多的语言和每种语言最多的小时数。
我们可以通过查看 Hub 上的数据集页面来获取 Common Voice 13 数据集的全部语言列表:[mozilla-foundation/common_voice_13_0](https://huggingface.co/datasets/mozilla-foundation/common_voice_13_0)。
您第一次查看此页面时会被要求接受使用条款,之后您将获得完全访问数据集的权限。
一旦我们提交了使用数据集的认证信息,我们将看到数据集预览。数据集预览向我们展示了每种语言数据集的前 100 个样本。更重要的是,它已加载了可播放的音频样本。
对于这个单元,我们将选择 [_Dhivehi_](https://en.wikipedia.org/wiki/Maldivian_language)(或 _迪维希语_),一种在南亚岛国马尔代夫使用的印度-雅利安语。
虽然我们在本教程中只示范了迪维希语,但这里介绍的步骤适用于 Common Voice 13 数据集中 108 种语言的任何一种,以及 Hugging Face Hub 上 180 多个音频数据集的任何一个,没有语言或方言的限制。
我们可以通过使用下拉菜单将子集设置为 `dv` 来选择 Common Voice 13 的 Dhivehi 子集(`dv` 是迪维希语的语言代码):
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface-course/audio-course-images/resolve/main/cv_13_dv_selection.png" alt="从数据集预览中选择 Dhivehi 集">
</div>
如果我们点击第一个样本上的播放按钮,我们可以听到音频并查看相应的文本。浏览训练和测试集的样本,以更好地了解我们正在处理的音频和文本数据。
从语调和风格上可以看出,录音来自叙述性言语。您可能会注意到每条数据的发言者和录音质量的有很大不同,这是众筹数据的一个共同特征。
数据集预览是在开始大规模使用之前感性认知音频数据集的绝佳方式。您可以选择 Hub 上的任何数据集,浏览样本并播放不同子集的音频,评估它是否适合您的需求。选择了一个数据集后,加载数据并开始使用就非常简单了。
目前我个人不会说迪维希语,而且估计绝大多数读者也不会!为了知道我们微调后的模型是否有效,我们需要一种严格的方法来**评估**它对未见过的数据的转写准确性。我们将在下一节中详细介绍这一点!
| 9 |
0 | hf_public_repos/api-inference-community/docker_images/adapter_transformers | hf_public_repos/api-inference-community/docker_images/adapter_transformers/tests/test_api_token_classification.py | import json
import os
from unittest import TestCase, skipIf
from app.main import ALLOWED_TASKS
from starlette.testclient import TestClient
from tests.test_api import TESTABLE_MODELS
@skipIf(
"token-classification" not in ALLOWED_TASKS,
"token-classification not implemented",
)
class TokenClassificationTestCase(TestCase):
def setUp(self):
model_id = TESTABLE_MODELS["token-classification"]
self.old_model_id = os.getenv("MODEL_ID")
self.old_task = os.getenv("TASK")
os.environ["MODEL_ID"] = model_id
os.environ["TASK"] = "token-classification"
from app.main import app
self.app = app
@classmethod
def setUpClass(cls):
from app.main import get_pipeline
get_pipeline.cache_clear()
def tearDown(self):
if self.old_model_id is not None:
os.environ["MODEL_ID"] = self.old_model_id
else:
del os.environ["MODEL_ID"]
if self.old_task is not None:
os.environ["TASK"] = self.old_task
else:
del os.environ["TASK"]
def test_simple(self):
inputs = "Hello, my name is John and I live in New York"
with TestClient(self.app) as client:
response = client.post("/", json={"inputs": inputs})
self.assertEqual(
response.status_code,
200,
)
content = json.loads(response.content)
self.assertEqual(type(content), list)
self.assertEqual(
set(k for el in content for k in el.keys()),
{"entity_group", "word", "start", "end", "score"},
)
with TestClient(self.app) as client:
response = client.post("/", json=inputs)
self.assertEqual(
response.status_code,
200,
)
content = json.loads(response.content)
self.assertEqual(type(content), list)
self.assertEqual(
set(k for el in content for k in el.keys()),
{"entity_group", "word", "start", "end", "score"},
)
def test_malformed_question(self):
with TestClient(self.app) as client:
response = client.post("/", data=b"\xc3\x28")
self.assertEqual(
response.status_code,
400,
)
self.assertEqual(
response.content,
b'{"error":"\'utf-8\' codec can\'t decode byte 0xc3 in position 0: invalid continuation byte"}',
)
| 0 |
0 | hf_public_repos/api-inference-community/docker_images/adapter_transformers | hf_public_repos/api-inference-community/docker_images/adapter_transformers/tests/test_api_summarization.py | import json
import os
from unittest import TestCase, skipIf
from app.main import ALLOWED_TASKS
from starlette.testclient import TestClient
from tests.test_api import TESTABLE_MODELS
@skipIf(
"summarization" not in ALLOWED_TASKS,
"summarization not implemented",
)
class SummarizationTestCase(TestCase):
def setUp(self):
model_id = TESTABLE_MODELS["summarization"]
self.old_model_id = os.getenv("MODEL_ID")
self.old_task = os.getenv("TASK")
os.environ["MODEL_ID"] = model_id
os.environ["TASK"] = "summarization"
from app.main import app
self.app = app
@classmethod
def setUpClass(cls):
from app.main import get_pipeline
get_pipeline.cache_clear()
def tearDown(self):
if self.old_model_id is not None:
os.environ["MODEL_ID"] = self.old_model_id
else:
del os.environ["MODEL_ID"]
if self.old_task is not None:
os.environ["TASK"] = self.old_task
else:
del os.environ["TASK"]
def test_simple(self):
inputs = "The weather is nice today."
with TestClient(self.app) as client:
response = client.post("/", json={"inputs": inputs})
self.assertEqual(
response.status_code,
200,
)
content = json.loads(response.content)
self.assertEqual(type(content), list)
self.assertEqual(type(content[0]["summary_text"]), str)
with TestClient(self.app) as client:
response = client.post("/", json=inputs)
self.assertEqual(
response.status_code,
200,
)
content = json.loads(response.content)
self.assertEqual(type(content), list)
self.assertEqual(type(content[0]["summary_text"]), str)
def test_malformed_question(self):
with TestClient(self.app) as client:
response = client.post("/", data=b"\xc3\x28")
self.assertEqual(
response.status_code,
400,
)
content = json.loads(response.content)
self.assertEqual(set(content.keys()), {"error"})
| 1 |
0 | hf_public_repos/api-inference-community/docker_images/adapter_transformers | hf_public_repos/api-inference-community/docker_images/adapter_transformers/tests/test_api_question_answering.py | import json
import os
from unittest import TestCase, skipIf
from app.main import ALLOWED_TASKS
from starlette.testclient import TestClient
from tests.test_api import TESTABLE_MODELS
@skipIf(
"question-answering" not in ALLOWED_TASKS,
"question-answering not implemented",
)
class QuestionAnsweringTestCase(TestCase):
def setUp(self):
model_id = TESTABLE_MODELS["question-answering"]
self.old_model_id = os.getenv("MODEL_ID")
self.old_task = os.getenv("TASK")
os.environ["MODEL_ID"] = model_id
os.environ["TASK"] = "question-answering"
from app.main import app
self.app = app
@classmethod
def setUpClass(cls):
from app.main import get_pipeline
get_pipeline.cache_clear()
def tearDown(self):
if self.old_model_id is not None:
os.environ["MODEL_ID"] = self.old_model_id
else:
del os.environ["MODEL_ID"]
if self.old_task is not None:
os.environ["TASK"] = self.old_task
else:
del os.environ["TASK"]
def test_simple(self):
inputs = {"question": "Where do I live ?", "context": "I live in New-York"}
with TestClient(self.app) as client:
response = client.post("/", json={"inputs": inputs})
self.assertEqual(
response.status_code,
200,
)
content = json.loads(response.content)
self.assertEqual(set(content.keys()), {"answer", "start", "end", "score"})
with TestClient(self.app) as client:
response = client.post("/", json=inputs)
self.assertEqual(
response.status_code,
200,
)
content = json.loads(response.content)
self.assertEqual(set(content.keys()), {"answer", "start", "end", "score"})
def test_malformed_question(self):
with TestClient(self.app) as client:
response = client.post("/", data=b"Where do I live ?")
self.assertEqual(
response.status_code,
400,
)
content = json.loads(response.content)
self.assertEqual(set(content.keys()), {"error"})
| 2 |
0 | hf_public_repos/api-inference-community/docker_images/adapter_transformers | hf_public_repos/api-inference-community/docker_images/adapter_transformers/tests/test_api_text_classification.py | import json
import os
from unittest import TestCase, skipIf
from app.main import ALLOWED_TASKS
from starlette.testclient import TestClient
from tests.test_api import TESTABLE_MODELS
@skipIf(
"text-classification" not in ALLOWED_TASKS,
"text-classification not implemented",
)
class TextClassificationTestCase(TestCase):
def setUp(self):
model_id = TESTABLE_MODELS["text-classification"]
self.old_model_id = os.getenv("MODEL_ID")
self.old_task = os.getenv("TASK")
os.environ["MODEL_ID"] = model_id
os.environ["TASK"] = "text-classification"
from app.main import app
self.app = app
@classmethod
def setUpClass(cls):
from app.main import get_pipeline
get_pipeline.cache_clear()
def tearDown(self):
if self.old_model_id is not None:
os.environ["MODEL_ID"] = self.old_model_id
else:
del os.environ["MODEL_ID"]
if self.old_task is not None:
os.environ["TASK"] = self.old_task
else:
del os.environ["TASK"]
def test_simple(self):
inputs = "It is a beautiful day outside"
with TestClient(self.app) as client:
response = client.post("/", json={"inputs": inputs})
self.assertEqual(
response.status_code,
200,
)
content = json.loads(response.content)
self.assertEqual(type(content), list)
self.assertEqual(len(content), 1)
self.assertEqual(type(content[0]), list)
self.assertEqual(
set(k for el in content[0] for k in el.keys()),
{"label", "score"},
)
with TestClient(self.app) as client:
response = client.post("/", json=inputs)
self.assertEqual(
response.status_code,
200,
)
content = json.loads(response.content)
self.assertEqual(type(content), list)
self.assertEqual(len(content), 1)
self.assertEqual(type(content[0]), list)
self.assertEqual(
set(k for el in content[0] for k in el.keys()),
{"label", "score"},
)
def test_malformed_question(self):
with TestClient(self.app) as client:
response = client.post("/", data=b"\xc3\x28")
self.assertEqual(
response.status_code,
400,
)
self.assertEqual(
response.content,
b'{"error":"\'utf-8\' codec can\'t decode byte 0xc3 in position 0: invalid continuation byte"}',
)
| 3 |
0 | hf_public_repos/api-inference-community/docker_images/adapter_transformers | hf_public_repos/api-inference-community/docker_images/adapter_transformers/tests/test_api_text_generation.py | import json
import os
from unittest import TestCase, skipIf
from app.main import ALLOWED_TASKS
from starlette.testclient import TestClient
from tests.test_api import TESTABLE_MODELS
@skipIf(
"text-generation" not in ALLOWED_TASKS,
"text-generation not implemented",
)
class TextGenerationTestCase(TestCase):
def setUp(self):
model_id = TESTABLE_MODELS["text-generation"]
self.old_model_id = os.getenv("MODEL_ID")
self.old_task = os.getenv("TASK")
os.environ["MODEL_ID"] = model_id
os.environ["TASK"] = "text-generation"
from app.main import app
self.app = app
@classmethod
def setUpClass(cls):
from app.main import get_pipeline
get_pipeline.cache_clear()
def tearDown(self):
if self.old_model_id is not None:
os.environ["MODEL_ID"] = self.old_model_id
else:
del os.environ["MODEL_ID"]
if self.old_task is not None:
os.environ["TASK"] = self.old_task
else:
del os.environ["TASK"]
def test_simple(self):
inputs = "The weather is nice today."
with TestClient(self.app) as client:
response = client.post("/", json={"inputs": inputs})
self.assertEqual(
response.status_code,
200,
)
content = json.loads(response.content)
self.assertEqual(type(content), list)
with TestClient(self.app) as client:
response = client.post("/", json=inputs)
self.assertEqual(
response.status_code,
200,
)
content = json.loads(response.content)
self.assertEqual(type(content), list)
self.assertEqual(type(content[0]["generated_text"]), str)
def test_malformed_question(self):
with TestClient(self.app) as client:
response = client.post("/", data=b"\xc3\x28")
self.assertEqual(
response.status_code,
400,
)
content = json.loads(response.content)
self.assertEqual(set(content.keys()), {"error"})
| 4 |
0 | hf_public_repos/api-inference-community/docker_images | hf_public_repos/api-inference-community/docker_images/paddlenlp/requirements.txt | starlette==0.27.0
api-inference-community==0.0.27
huggingface_hub>=0.10.1
paddlepaddle==2.5.0
paddlenlp>=2.5.0
#Dummy
| 5 |
0 | hf_public_repos/api-inference-community/docker_images | hf_public_repos/api-inference-community/docker_images/paddlenlp/Dockerfile | FROM tiangolo/uvicorn-gunicorn:python3.8
LABEL maintainer="PaddleNLP <[email protected]>"
# Add any system dependency here
# RUN apt-get update -y && apt-get install libXXX -y
COPY ./requirements.txt /app
RUN pip install --no-cache-dir -r requirements.txt
COPY ./prestart.sh /app/
# Most DL models are quite large in terms of memory, using workers is a HUGE
# slowdown because of the fork and GIL with python.
# Using multiple pods seems like a better default strategy.
# Feel free to override if it does not make sense for your library.
ARG max_workers=1
ENV MAX_WORKERS=$max_workers
ENV HUGGINGFACE_HUB_CACHE=/data
# Necessary on GPU environment docker.
# TIMEOUT env variable is used by nvcr.io/nvidia/pytorch:xx for another purpose
# rendering TIMEOUT defined by uvicorn impossible to use correctly
# We're overriding it to be renamed UVICORN_TIMEOUT
# UVICORN_TIMEOUT is a useful variable for very large models that take more
# than 30s (the default) to load in memory.
# If UVICORN_TIMEOUT is too low, uvicorn will simply never loads as it will
# kill workers all the time before they finish.
RUN sed -i 's/TIMEOUT/UVICORN_TIMEOUT/g' /gunicorn_conf.py
COPY ./app /app/app
| 6 |
0 | hf_public_repos/api-inference-community/docker_images | hf_public_repos/api-inference-community/docker_images/paddlenlp/prestart.sh | python app/main.py
| 7 |
0 | hf_public_repos/api-inference-community/docker_images/paddlenlp | hf_public_repos/api-inference-community/docker_images/paddlenlp/app/main.py | import functools
import logging
import os
from typing import Dict, Type
from api_inference_community.routes import pipeline_route, status_ok
from app.pipelines import (
ConversationalPipeline,
FillMaskPipeline,
Pipeline,
SummarizationPipeline,
ZeroShotClassificationPipeline,
)
from starlette.applications import Starlette
from starlette.middleware import Middleware
from starlette.middleware.gzip import GZipMiddleware
from starlette.routing import Route
TASK = os.getenv("TASK")
MODEL_ID = os.getenv("MODEL_ID")
logger = logging.getLogger(__name__)
# Add the allowed tasks
# Supported tasks are:
# - text-generation
# - text-classification
# - token-classification
# - translation
# - summarization
# - automatic-speech-recognition
# - ...
# For instance
# from app.pipelines import AutomaticSpeechRecognitionPipeline
# ALLOWED_TASKS = {"automatic-speech-recognition": AutomaticSpeechRecognitionPipeline}
# You can check the requirements and expectations of each pipelines in their respective
# directories. Implement directly within the directories.
ALLOWED_TASKS: Dict[str, Type[Pipeline]] = {
"conversational": ConversationalPipeline,
"fill-mask": FillMaskPipeline,
"summarization": SummarizationPipeline,
"zero-shot-classification": ZeroShotClassificationPipeline,
}
@functools.lru_cache()
def get_pipeline() -> Pipeline:
task = os.environ["TASK"]
model_id = os.environ["MODEL_ID"]
if task not in ALLOWED_TASKS:
raise EnvironmentError(f"{task} is not a valid pipeline for model : {model_id}")
return ALLOWED_TASKS[task](model_id)
routes = [
Route("/{whatever:path}", status_ok),
Route("/{whatever:path}", pipeline_route, methods=["POST"]),
]
middleware = [Middleware(GZipMiddleware, minimum_size=1000)]
if os.environ.get("DEBUG", "") == "1":
from starlette.middleware.cors import CORSMiddleware
middleware.append(
Middleware(
CORSMiddleware,
allow_origins=["*"],
allow_headers=["*"],
allow_methods=["*"],
)
)
app = Starlette(routes=routes, middleware=middleware)
@app.on_event("startup")
async def startup_event():
logger = logging.getLogger("uvicorn.access")
handler = logging.StreamHandler()
handler.setFormatter(logging.Formatter("%(asctime)s - %(levelname)s - %(message)s"))
logger.handlers = [handler]
# Link between `api-inference-community` and framework code.
app.get_pipeline = get_pipeline
try:
get_pipeline()
except Exception:
# We can fail so we can show exception later.
pass
if __name__ == "__main__":
try:
get_pipeline()
except Exception:
# We can fail so we can show exception later.
pass
| 8 |
0 | hf_public_repos/api-inference-community/docker_images/paddlenlp/app | hf_public_repos/api-inference-community/docker_images/paddlenlp/app/pipelines/conversational.py | from typing import Any, Dict, List, Union
from app.pipelines import Pipeline
from paddlenlp.taskflow import Taskflow
class ConversationalPipeline(Pipeline):
def __init__(self, model_id: str):
self.pipeline = Taskflow("dialogue", task_path=model_id, from_hf_hub=True)
def __call__(self, inputs: Dict[str, Union[str, List[str]]]) -> Dict[str, Any]:
"""
Args:
inputs (:obj:`dict`): a dictionary containing the following key values:
text (`str`, *optional*):
The initial user input to start the conversation
past_user_inputs (`List[str]`, *optional*):
Eventual past history of the conversation of the user. You don't need to pass it manually if you use the
pipeline interactively but if you want to recreate history you need to set both `past_user_inputs` and
`generated_responses` with equal length lists of strings
generated_responses (`List[str]`, *optional*):
Eventual past history of the conversation of the model. You don't need to pass it manually if you use the
pipeline interactively but if you want to recreate history you need to set both `past_user_inputs` and
`generated_responses` with equal length lists of strings
Return:
A :obj:`dict`: a dictionary containing the following key values:
generated_text (`str`):
The answer of the bot
conversation (`Dict[str, List[str]]`):
A facility dictionary to send back for the next input (with the new user input addition).
past_user_inputs (`List[str]`)
List of strings. The last inputs from the user in the conversation, after the model has run.
generated_responses (`List[str]`)
List of strings. The last outputs from the model in the conversation, after the model has run.
"""
text = inputs["text"]
past_user_inputs = inputs.get("past_user_inputs", [])
generated_responses = inputs.get("generated_responses", [])
complete_message_history = []
for user_input, responses in zip(past_user_inputs, generated_responses):
complete_message_history.extend([user_input, responses])
complete_message_history.append(text)
cur_response = self.pipeline(complete_message_history)[0]
past_user_inputs.append(text)
generated_responses.append(cur_response)
return {
"generated_text": cur_response,
"conversation": {
"generated_responses": generated_responses,
"past_user_inputs": past_user_inputs,
},
}
| 9 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.