
index
int64 0
0
| repo_id
stringclasses 179
values | file_path
stringlengths 26
186
| content
stringlengths 1
2.1M
| __index_level_0__
int64 0
9
|
|---|---|---|---|---|
0 | hf_public_repos/candle/candle-wasm-examples | hf_public_repos/candle/candle-wasm-examples/blip/blipWorker.js | import init, { Model } from "./build/m.js";
async function fetchArrayBuffer(url, cacheFile = true) {
if (!cacheFile) return new Uint8Array(await (await fetch(url)).arrayBuffer());
const cacheName = "blip-candle-cache";
const cache = await caches.open(cacheName);
const cachedResponse = await cache.match(url);
if (cachedResponse) {
const data = await cachedResponse.arrayBuffer();
return new Uint8Array(data);
}
const res = await fetch(url, { cache: "force-cache" });
cache.put(url, res.clone());
return new Uint8Array(await res.arrayBuffer());
}
class Blip {
static instance = {};
static async getInstance(
weightsURL,
tokenizerURL,
configURL,
modelID,
quantized
) {
if (!this.instance[modelID]) {
await init();
self.postMessage({ status: "loading", message: "Loading Model" });
const [weightsArrayU8, tokenizerArrayU8, configArrayU8] =
await Promise.all([
fetchArrayBuffer(weightsURL),
fetchArrayBuffer(tokenizerURL),
fetchArrayBuffer(configURL),
]);
this.instance[modelID] = new Model(
weightsArrayU8,
tokenizerArrayU8,
configArrayU8,
quantized
);
} else {
self.postMessage({ status: "ready", message: "Model Already Loaded" });
}
return this.instance[modelID];
}
}
self.addEventListener("message", async (event) => {
const { weightsURL, tokenizerURL, configURL, modelID, imageURL, quantized } =
event.data;
try {
self.postMessage({ status: "status", message: "Loading Blip Model..." });
const model = await Blip.getInstance(
weightsURL,
tokenizerURL,
configURL,
modelID,
quantized
);
self.postMessage({
status: "status",
message: "Running Blip Inference...",
});
const imageArrayU8 = await fetchArrayBuffer(imageURL, false);
const output = model.generate_caption_from_image(imageArrayU8);
self.postMessage({
status: "complete",
message: "complete",
output: output,
});
} catch (e) {
self.postMessage({ error: e });
}
});
| 0 |
0 | hf_public_repos/candle/candle-wasm-examples | hf_public_repos/candle/candle-wasm-examples/blip/build-lib.sh | cargo build --target wasm32-unknown-unknown --release
wasm-bindgen ../../target/wasm32-unknown-unknown/release/m.wasm --out-dir build --target web | 1 |
0 | hf_public_repos/candle/candle-wasm-examples | hf_public_repos/candle/candle-wasm-examples/blip/README.md | ## Running [BLIP Image Captioning](https://huggingface.co/Salesforce/blip-image-captioning-large) Example
### Vanilla JS and WebWorkers
To build and test the UI made in Vanilla JS and WebWorkers, first we need to build the WASM library:
```bash
sh build-lib.sh
```
This will bundle the library under `./build` and we can import it inside our WebWorker like a normal JS module:
```js
import init, { Model } from "./build/m.js";
```
The full example can be found under `./index.html`. All needed assets are fetched from the web, so no need to download anything.
Finally, you can preview the example by running a local HTTP server. For example:
```bash
python -m http.server
```
Then open `http://localhost:8000/index.html` in your browser.
| 2 |
0 | hf_public_repos/candle/candle-wasm-examples/blip | hf_public_repos/candle/candle-wasm-examples/blip/src/lib.rs | use wasm_bindgen::prelude::*;
pub mod token_output_stream;
#[wasm_bindgen]
extern "C" {
// Use `js_namespace` here to bind `console.log(..)` instead of just
// `log(..)`
#[wasm_bindgen(js_namespace = console)]
pub fn log(s: &str);
}
#[macro_export]
macro_rules! console_log {
// Note that this is using the `log` function imported above during
// `bare_bones`
($($t:tt)*) => ($crate::log(&format_args!($($t)*).to_string()))
}
| 3 |
0 | hf_public_repos/candle/candle-wasm-examples/blip | hf_public_repos/candle/candle-wasm-examples/blip/src/token_output_stream.rs | use candle::Result;
/// This is a wrapper around a tokenizer to ensure that tokens can be returned to the user in a
/// streaming way rather than having to wait for the full decoding.
pub struct TokenOutputStream {
tokenizer: tokenizers::Tokenizer,
tokens: Vec<u32>,
prev_index: usize,
current_index: usize,
}
impl TokenOutputStream {
pub fn new(tokenizer: tokenizers::Tokenizer) -> Self {
Self {
tokenizer,
tokens: Vec::new(),
prev_index: 0,
current_index: 0,
}
}
pub fn into_inner(self) -> tokenizers::Tokenizer {
self.tokenizer
}
fn decode(&self, tokens: &[u32]) -> Result<String> {
match self.tokenizer.decode(tokens, true) {
Ok(str) => Ok(str),
Err(err) => candle::bail!("cannot decode: {err}"),
}
}
// https://github.com/huggingface/text-generation-inference/blob/5ba53d44a18983a4de32d122f4cb46f4a17d9ef6/server/text_generation_server/models/model.py#L68
pub fn next_token(&mut self, token: u32) -> Result<Option<String>> {
let prev_text = if self.tokens.is_empty() {
String::new()
} else {
let tokens = &self.tokens[self.prev_index..self.current_index];
self.decode(tokens)?
};
self.tokens.push(token);
let text = self.decode(&self.tokens[self.prev_index..])?;
if text.len() > prev_text.len() && text.chars().last().unwrap().is_ascii() {
let text = text.split_at(prev_text.len());
self.prev_index = self.current_index;
self.current_index = self.tokens.len();
Ok(Some(text.1.to_string()))
} else {
Ok(None)
}
}
pub fn decode_rest(&self) -> Result<Option<String>> {
let prev_text = if self.tokens.is_empty() {
String::new()
} else {
let tokens = &self.tokens[self.prev_index..self.current_index];
self.decode(tokens)?
};
let text = self.decode(&self.tokens[self.prev_index..])?;
if text.len() > prev_text.len() {
let text = text.split_at(prev_text.len());
Ok(Some(text.1.to_string()))
} else {
Ok(None)
}
}
pub fn decode_all(&self) -> Result<String> {
self.decode(&self.tokens)
}
pub fn get_token(&self, token_s: &str) -> Option<u32> {
self.tokenizer.get_vocab(true).get(token_s).copied()
}
pub fn tokenizer(&self) -> &tokenizers::Tokenizer {
&self.tokenizer
}
pub fn clear(&mut self) {
self.tokens.clear();
self.prev_index = 0;
self.current_index = 0;
}
}
| 4 |
0 | hf_public_repos/candle/candle-wasm-examples/blip/src | hf_public_repos/candle/candle-wasm-examples/blip/src/bin/m.rs | use candle::{DType, Device, Tensor};
use candle_nn::VarBuilder;
use candle_transformers::generation::LogitsProcessor;
use candle_transformers::models::blip;
use candle_transformers::models::quantized_blip;
use candle_wasm_example_blip::console_log;
use candle_wasm_example_blip::token_output_stream::TokenOutputStream;
use js_sys::Date;
use tokenizers::Tokenizer;
use wasm_bindgen::prelude::*;
enum SelectedModel {
M(blip::BlipForConditionalGeneration),
Q(quantized_blip::BlipForConditionalGeneration),
}
impl SelectedModel {
fn text_decoder_forward(&mut self, xs: &Tensor, img_xs: &Tensor) -> Result<Tensor, JsError> {
match self {
Self::M(m) => m
.text_decoder()
.forward(xs, img_xs)
.map_err(|e| JsError::new(&e.to_string())),
Self::Q(m) => m
.text_decoder()
.forward(xs, img_xs)
.map_err(|e| JsError::new(&e.to_string())),
}
}
fn reset_kv_cache(&mut self) {
match self {
Self::M(m) => m.reset_kv_cache(),
Self::Q(m) => m.reset_kv_cache(),
}
}
}
#[wasm_bindgen]
pub struct Model {
model: SelectedModel,
tokenizer: TokenOutputStream,
}
const SEP_TOKEN_ID: u32 = 102;
#[wasm_bindgen]
impl Model {
#[wasm_bindgen(constructor)]
pub fn load(
weights: Vec<u8>,
tokenizer: Vec<u8>,
config: Vec<u8>,
quantized: bool,
) -> Result<Model, JsError> {
console_error_panic_hook::set_once();
console_log!("loading model");
let tokenizer =
Tokenizer::from_bytes(&tokenizer).map_err(|m| JsError::new(&m.to_string()))?;
let tokenizer = TokenOutputStream::new(tokenizer);
let config: blip::Config = serde_json::from_slice(&config)?;
let device = Device::Cpu;
let start = Date::now();
let model: SelectedModel = if quantized {
let vb = quantized_blip::VarBuilder::from_gguf_buffer(&weights, &device)?;
let model = quantized_blip::BlipForConditionalGeneration::new(&config, vb)?;
SelectedModel::Q(model)
} else {
let vb = VarBuilder::from_buffered_safetensors(weights, DType::F32, &device)?;
let model = blip::BlipForConditionalGeneration::new(&config, vb)?;
SelectedModel::M(model)
};
console_log!("model loaded in {:?}s", (Date::now() - start) / 1000.);
Ok(Self { model, tokenizer })
}
#[wasm_bindgen]
pub fn generate_caption_from_image(&mut self, image: Vec<u8>) -> Result<String, JsError> {
self.model.reset_kv_cache();
let device = Device::Cpu;
console_log!("loading image as tensor");
let start = Date::now();
let image: Tensor = self.load_image(image)?.to_device(&device)?;
console_log!("image loaded in {:?}s", (Date::now() - start) / 1000.);
let start = Date::now();
let image_embeds: Tensor = match &mut self.model {
SelectedModel::M(m) => image.unsqueeze(0)?.apply(m.vision_model())?,
SelectedModel::Q(m) => image.unsqueeze(0)?.apply(m.vision_model())?,
};
console_log!("image embedded in {:?}s", (Date::now() - start) / 1000.);
let mut logits_processor = LogitsProcessor::new(299792458, None, None);
let mut token_ids = vec![30522u32];
let mut text: String = "".to_string();
let start = Date::now();
for index in 0..1000 {
let context_size = if index > 0 { 1 } else { token_ids.len() };
let start_pos = token_ids.len().saturating_sub(context_size);
let input_ids = Tensor::new(&token_ids[start_pos..], &device)?.unsqueeze(0)?;
let logits = self.model.text_decoder_forward(&input_ids, &image_embeds)?;
let logits = logits.squeeze(0)?;
let logits = logits.get(logits.dim(0)? - 1)?;
let token = logits_processor.sample(&logits)?;
if token == SEP_TOKEN_ID {
break;
}
token_ids.push(token);
if let Some(t) = self.tokenizer.next_token(token)? {
text.push_str(&t);
}
}
if let Some(rest) = self
.tokenizer
.decode_rest()
.map_err(|m| JsError::new(&m.to_string()))?
{
text.push_str(&rest);
}
console_log!("caption generated in {:?}s", (Date::now() - start) / 1000.);
Ok(text)
}
}
impl Model {
fn load_image(&self, image: Vec<u8>) -> Result<Tensor, JsError> {
let device = &Device::Cpu;
let img = image::ImageReader::new(std::io::Cursor::new(image))
.with_guessed_format()?
.decode()
.map_err(|e| JsError::new(&e.to_string()))?
.resize_to_fill(384, 384, image::imageops::FilterType::Triangle);
let img = img.to_rgb8();
let data = img.into_raw();
let data = Tensor::from_vec(data, (384, 384, 3), device)?.permute((2, 0, 1))?;
let mean =
Tensor::new(&[0.48145466f32, 0.4578275, 0.40821073], device)?.reshape((3, 1, 1))?;
let std =
Tensor::new(&[0.26862954f32, 0.261_302_6, 0.275_777_1], device)?.reshape((3, 1, 1))?;
(data.to_dtype(candle::DType::F32)? / 255.)?
.broadcast_sub(&mean)?
.broadcast_div(&std)
.map_err(|e| JsError::new(&e.to_string()))
}
}
fn main() {
console_error_panic_hook::set_once();
}
| 5 |
0 | hf_public_repos/candle/candle-wasm-examples | hf_public_repos/candle/candle-wasm-examples/whisper/index.html | <!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8" />
<title>Welcome to Candle!</title>
<link data-trunk rel="copy-file" href="mel_filters.safetensors" />
<!-- samples -->
<link data-trunk rel="copy-dir" href="audios" />
<!-- tiny.en -->
<link data-trunk rel="copy-dir" href="whisper-tiny.en" />
<!-- tiny -->
<link data-trunk rel="copy-dir" href="whisper-tiny" />
<!-- quantized -->
<link data-trunk rel="copy-dir" href="quantized" />
<link
data-trunk
rel="rust"
href="Cargo.toml"
data-bin="app"
data-type="main" />
<link
data-trunk
rel="rust"
href="Cargo.toml"
data-bin="worker"
data-type="worker" />
<link
rel="stylesheet"
href="https://fonts.googleapis.com/css?family=Roboto:300,300italic,700,700italic" />
<link
rel="stylesheet"
href="https://cdnjs.cloudflare.com/ajax/libs/normalize/8.0.1/normalize.css" />
<link
rel="stylesheet"
href="https://cdnjs.cloudflare.com/ajax/libs/milligram/1.4.1/milligram.css" />
</head>
<body></body>
</html>
| 6 |
0 | hf_public_repos/candle/candle-wasm-examples | hf_public_repos/candle/candle-wasm-examples/whisper/Cargo.toml | [package]
name = "candle-wasm-example-whisper"
version.workspace = true
edition.workspace = true
description.workspace = true
repository.workspace = true
keywords.workspace = true
categories.workspace = true
license.workspace = true
[dependencies]
candle = { workspace = true }
candle-nn = { workspace = true }
candle-transformers = { workspace = true }
num-traits = { workspace = true }
tokenizers = { workspace = true, features = ["unstable_wasm"] }
# App crates.
anyhow = { workspace = true }
log = { workspace = true }
rand = { workspace = true }
serde = { workspace = true }
serde_json = { workspace = true }
hound = { workspace = true }
safetensors = { workspace = true }
# Wasm specific crates.
getrandom = { version = "0.2", features = ["js"] }
gloo = "0.11"
js-sys = "0.3.64"
wasm-bindgen = "0.2.87"
wasm-bindgen-futures = "0.4.37"
wasm-logger = "0.2"
yew-agent = "0.2.0"
yew = { version = "0.20.0", features = ["csr"] }
[dependencies.web-sys]
version = "0.3.70"
features = [
'Blob',
'Document',
'Element',
'HtmlElement',
'Node',
'Window',
'Request',
'RequestCache',
'RequestInit',
'RequestMode',
'Response',
'Performance',
]
| 7 |
0 | hf_public_repos/candle/candle-wasm-examples | hf_public_repos/candle/candle-wasm-examples/whisper/build-lib.sh | cargo build --target wasm32-unknown-unknown --release
wasm-bindgen ../../target/wasm32-unknown-unknown/release/m.wasm --out-dir build --target web
| 8 |
0 | hf_public_repos/candle/candle-wasm-examples | hf_public_repos/candle/candle-wasm-examples/whisper/lib-example.html | <html>
<head>
<meta content="text/html;charset=utf-8" http-equiv="Content-Type" />
<title>Candle Whisper Rust/WASM</title>
</head>
<body></body>
</html>
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<style>
@import url("https://fonts.googleapis.com/css2?family=Source+Code+Pro:wght@200;300;400&family=Source+Sans+3:wght@100;200;300;400;500;600;700;800;900&display=swap");
html,
body {
font-family: "Source Sans 3", sans-serif;
}
</style>
<script src="https://cdn.tailwindcss.com"></script>
<script type="module">
// base url for audio examples
const AUDIO_BASE_URL =
"https://huggingface.co/datasets/Narsil/candle-examples/resolve/main/";
// models base url
const MODELS = {
tiny_multilingual: {
base_url: "https://huggingface.co/openai/whisper-tiny/resolve/main/",
model: "model.safetensors",
tokenizer: "tokenizer.json",
config: "config.json",
size: "151 MB",
},
tiny_en: {
base_url:
"https://huggingface.co/openai/whisper-tiny.en/resolve/main/",
model: "model.safetensors",
tokenizer: "tokenizer.json",
config: "config.json",
size: "151 MB",
},
tiny_quantized_multilingual_q80: {
base_url: "https://huggingface.co/lmz/candle-whisper/resolve/main/",
model: "model-tiny-q80.gguf",
tokenizer: "tokenizer-tiny.json",
config: "config-tiny.json",
size: "41.5 MB",
},
tiny_en_quantized_q80: {
base_url: "https://huggingface.co/lmz/candle-whisper/resolve/main/",
model: "model-tiny-q80.gguf",
tokenizer: "tokenizer-tiny-en.json",
config: "config-tiny-en.json",
size: "41.8 MB",
},
distil_medium_en: {
base_url:
"https://huggingface.co/distil-whisper/distil-medium.en/resolve/main/",
model: "model.safetensors",
tokenizer: "tokenizer.json",
config: "config.json",
size: "789 MB",
},
};
const modelEl = document.querySelector("#model");
Object.keys(MODELS).forEach((modelID) => {
const model = MODELS[modelID];
const option = document.createElement("option");
option.value = modelID;
option.textContent = `${modelID} (${model.size})`;
modelEl.appendChild(option);
});
const whisperWorker = new Worker("./whisperWorker.js", {
type: "module",
});
async function classifyAudio(
weightsURL, // URL to the weights file
modelID, // model ID
tokenizerURL, // URL to the tokenizer file
configURL, // model config URL
mel_filtersURL, // URL to the mel filters file
audioURL, // URL to the audio file
updateStatus // function to update the status
) {
return new Promise((resolve, reject) => {
whisperWorker.postMessage({
weightsURL,
modelID,
tokenizerURL,
configURL,
mel_filtersURL,
audioURL,
});
function messageHandler(event) {
console.log(event.data);
if ("status" in event.data) {
updateStatus(event.data);
}
if ("error" in event.data) {
whisperWorker.removeEventListener("message", messageHandler);
reject(new Error(event.data.error));
}
if (event.data.status === "complete") {
whisperWorker.removeEventListener("message", messageHandler);
resolve(event.data);
}
}
whisperWorker.addEventListener("message", messageHandler);
});
}
// keep track of the audio URL
let audioURL = null;
function setAudio(src) {
const audio = document.querySelector("#audio");
audio.src = src;
audio.controls = true;
audio.hidden = false;
document.querySelector("#detect").disabled = false;
audioURL = src;
}
// add event listener to audio buttons
document.querySelectorAll("#audios-select > button").forEach((target) => {
target.addEventListener("click", (e) => {
const value = target.dataset.value;
const href = AUDIO_BASE_URL + value;
setAudio(href);
});
});
//add event listener to file input
document.querySelector("#file-upload").addEventListener("change", (e) => {
const target = e.target;
if (target.files.length > 0) {
const href = URL.createObjectURL(target.files[0]);
setAudio(href);
}
});
// add event listener to drop-area
const dropArea = document.querySelector("#drop-area");
dropArea.addEventListener("dragenter", (e) => {
e.preventDefault();
dropArea.classList.add("border-blue-700");
});
dropArea.addEventListener("dragleave", (e) => {
e.preventDefault();
dropArea.classList.remove("border-blue-700");
});
dropArea.addEventListener("dragover", (e) => {
e.preventDefault();
dropArea.classList.add("border-blue-700");
});
dropArea.addEventListener("drop", (e) => {
e.preventDefault();
dropArea.classList.remove("border-blue-700");
const url = e.dataTransfer.getData("text/uri-list");
const files = e.dataTransfer.files;
if (files.length > 0) {
const href = URL.createObjectURL(files[0]);
setAudio(href);
} else if (url) {
setAudio(url);
}
});
// add event listener to detect button
document.querySelector("#detect").addEventListener("click", async () => {
if (audioURL === null) {
return;
}
const modelID = modelEl.value;
const model = MODELS[modelID];
const modelURL = model.base_url + model.model;
const tokenizerURL = model.base_url + model.tokenizer;
const configURL = model.base_url + model.config;
classifyAudio(
modelURL,
modelID,
tokenizerURL,
configURL,
"mel_filters.safetensors",
audioURL,
updateStatus
)
.then((result) => {
console.log("RESULT", result);
const { output } = result;
const text = output.map((segment) => segment.dr.text).join(" ");
console.log(text);
document.querySelector("#output-status").hidden = true;
document.querySelector("#output-generation").hidden = false;
document.querySelector("#output-generation").textContent = text;
})
.catch((error) => {
console.error(error);
});
});
function updateStatus(data) {
const { status, message } = data;
const button = document.querySelector("#detect");
if (status === "decoding" || status === "loading") {
button.disabled = true;
button.textContent = message;
} else if (status === "complete") {
button.disabled = false;
button.textContent = "Transcribe Audio";
}
}
</script>
</head>
<body class="container max-w-4xl mx-auto p-4">
<main class="grid grid-cols-1 gap-8 relative">
<span class="absolute text-5xl -ml-[1em]"> 🕯️ </span>
<div>
<h1 class="text-5xl font-bold">Candle Whisper</h1>
<h2 class="text-2xl font-bold">Rust/WASM Demo</h2>
<p class="max-w-lg">
Transcribe audio in the browser using rust/wasm with an audio file.
This demo uses the
<a
href="https://huggingface.co/openai/"
target="_blank"
class="underline hover:text-blue-500 hover:no-underline">
OpenAI Whisper models
</a>
and WASM runtime built with
<a
href="https://github.com/huggingface/candle/"
target="_blank"
class="underline hover:text-blue-500 hover:no-underline"
>Candle
</a>
</p>
</div>
<div>
<label for="model" class="font-medium">Models Options: </label>
<select
id="model"
class="border-2 border-gray-500 rounded-md font-light">
</select>
</div>
<!-- drag and drop area -->
<div class="relative">
<div
id="drop-area"
class="flex flex-col items-center justify-center border-2 border-gray-300 border-dashed rounded-xl relative h-48 w-full overflow-hidden">
<div
class="flex flex-col items-center justify-center space-y-1 text-center">
<svg
width="25"
height="25"
viewBox="0 0 25 25"
fill="none"
xmlns="http://www.w3.org/2000/svg">
<path
d="M3.5 24.3a3 3 0 0 1-1.9-.8c-.5-.5-.8-1.2-.8-1.9V2.9c0-.7.3-1.3.8-1.9.6-.5 1.2-.7 2-.7h18.6c.7 0 1.3.2 1.9.7.5.6.7 1.2.7 2v18.6c0 .7-.2 1.4-.7 1.9a3 3 0 0 1-2 .8H3.6Zm0-2.7h18.7V2.9H3.5v18.7Zm2.7-2.7h13.3c.3 0 .5 0 .6-.3v-.7l-3.7-5a.6.6 0 0 0-.6-.2c-.2 0-.4 0-.5.3l-3.5 4.6-2.4-3.3a.6.6 0 0 0-.6-.3c-.2 0-.4.1-.5.3l-2.7 3.6c-.1.2-.2.4 0 .7.1.2.3.3.6.3Z"
fill="#000" />
</svg>
<div class="flex text-sm text-gray-600">
<label
for="file-upload"
class="relative cursor-pointer bg-white rounded-md font-medium text-blue-950 hover:text-blue-700">
<span>Drag and drop your audio here</span>
<span class="block text-xs">or</span>
<span class="block text-xs">Click to upload</span>
</label>
</div>
<input
id="file-upload"
name="file-upload"
type="file"
accept="audio/*"
class="sr-only" />
</div>
<audio
id="audio"
hidden
controls
class="w-full p-2 select-none"></audio>
</div>
</div>
<div>
<div class="flex flex-wrap gap-3 items-center" id="audios-select">
<h3 class="font-medium">Examples:</h3>
<button
data-value="samples_jfk.wav"
class="text-gray-500 border border-gray-500 rounded-md p-2 underline hover:no-underline">
<span>jfk.wav</span>
<span class="text-xs block"> (352 kB)</span>
</button>
<button
data-value="samples_a13.wav"
class="text-gray-500 border border-gray-500 rounded-md p-2 underline hover:no-underline">
<span>a13.wav</span>
<span class="text-xs block"> (960 kB)</span>
</button>
<button
data-value="samples_mm0.wav"
class="text-gray-500 border border-gray-500 rounded-md p-2 underline hover:no-underline">
<span>mm0.wav</span>
<span class="text-xs block new"> (957 kB)</span>
</button>
<button
data-value="samples_gb0.wav"
class="text-gray-500 border border-gray-500 rounded-md p-2 underline hover:no-underline">
<span>gb0.wav </span>
<span class="text-xs block">(4.08 MB)</span>
</button>
<button
data-value="samples_gb1.wav"
class="text-gray-500 border border-gray-500 rounded-md p-2 underline hover:no-underline">
<span>gb1.wav </span>
<span class="text-xs block">(6.36 MB)</span>
</button>
<button
data-value="samples_hp0.wav"
class="text-gray-500 border border-gray-500 rounded-md p-2 underline hover:no-underline">
<span>hp0.wav </span>
<span class="text-xs block">(8.75 MB)</span>
</button>
</div>
</div>
<div>
<button
id="detect"
disabled
class="bg-gray-700 hover:bg-gray-800 text-white font-normal py-2 px-4 rounded disabled:bg-gray-300 disabled:cursor-not-allowed">
Transcribe Audio
</button>
</div>
<div>
<h3 class="font-medium">Transcription:</h3>
<div
class="min-h-[250px] bg-slate-100 text-gray-500 p-4 rounded-md flex flex-col gap-2">
<p hidden id="output-generation" class="grid-rows-2"></p>
<span id="output-status" class="m-auto font-light"
>No transcription results yet</span
>
</div>
</div>
</main>
</body>
</html>
| 9 |
0 | hf_public_repos/accelerate | hf_public_repos/accelerate/tests/test_memory_utils.py | # Copyright 2022 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import unittest
from torch import nn
from accelerate.test_utils import memory_allocated_func, require_non_cpu, require_non_torch_xla, torch_device
from accelerate.utils.memory import find_executable_batch_size, release_memory
def raise_fake_out_of_memory():
raise RuntimeError("CUDA out of memory.")
class ModelForTest(nn.Module):
def __init__(self):
super().__init__()
self.linear1 = nn.Linear(3, 4)
self.batchnorm = nn.BatchNorm1d(4)
self.linear2 = nn.Linear(4, 5)
def forward(self, x):
return self.linear2(self.batchnorm(self.linear1(x)))
class MemoryTest(unittest.TestCase):
def test_memory_implicit(self):
batch_sizes = []
@find_executable_batch_size(starting_batch_size=128)
def mock_training_loop_function(batch_size):
nonlocal batch_sizes
batch_sizes.append(batch_size)
if batch_size != 8:
raise_fake_out_of_memory()
mock_training_loop_function()
assert batch_sizes == [128, 64, 32, 16, 8]
def test_memory_explicit(self):
batch_sizes = []
@find_executable_batch_size(starting_batch_size=128)
def mock_training_loop_function(batch_size, arg1):
nonlocal batch_sizes
batch_sizes.append(batch_size)
if batch_size != 8:
raise_fake_out_of_memory()
return batch_size, arg1
bs, arg1 = mock_training_loop_function("hello")
assert batch_sizes == [128, 64, 32, 16, 8]
assert [bs, arg1] == [8, "hello"]
def test_start_zero(self):
@find_executable_batch_size(starting_batch_size=0)
def mock_training_loop_function(batch_size):
pass
with self.assertRaises(RuntimeError) as cm:
mock_training_loop_function()
assert "No executable batch size found, reached zero." in cm.exception.args[0]
def test_approach_zero(self):
@find_executable_batch_size(starting_batch_size=16)
def mock_training_loop_function(batch_size):
if batch_size > 0:
raise_fake_out_of_memory()
pass
with self.assertRaises(RuntimeError) as cm:
mock_training_loop_function()
assert "No executable batch size found, reached zero." in cm.exception.args[0]
def test_verbose_guard(self):
@find_executable_batch_size(starting_batch_size=128)
def mock_training_loop_function(batch_size, arg1, arg2):
if batch_size != 8:
raise raise_fake_out_of_memory()
with self.assertRaises(TypeError) as cm:
mock_training_loop_function(128, "hello", "world")
assert "Batch size was passed into `f`" in cm.exception.args[0]
assert "`f(arg1='hello', arg2='world')" in cm.exception.args[0]
def test_any_other_error(self):
@find_executable_batch_size(starting_batch_size=16)
def mock_training_loop_function(batch_size):
raise ValueError("Oops, we had an error!")
with self.assertRaises(ValueError) as cm:
mock_training_loop_function()
assert "Oops, we had an error!" in cm.exception.args[0]
@require_non_cpu
@require_non_torch_xla
def test_release_memory(self):
starting_memory = memory_allocated_func()
model = ModelForTest()
model.to(torch_device)
assert memory_allocated_func() > starting_memory
model = release_memory(model)
assert memory_allocated_func() == starting_memory
| 0 |
0 | hf_public_repos/accelerate | hf_public_repos/accelerate/tests/test_imports.py | # Copyright 2024 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import subprocess
import sys
from accelerate.test_utils import require_transformer_engine
from accelerate.test_utils.testing import TempDirTestCase, require_import_timer
from accelerate.utils import is_import_timer_available
if is_import_timer_available():
from import_timer import calculate_total_time, read_import_profile
from import_timer.core import get_paths_above_threshold, sort_nodes_by_total_time
def convert_list_to_string(data):
end_result = ""
arrow_right = "->"
for path in data:
end_result += f"{arrow_right.join(path[0])} {path[1]:.3f}s\n"
return end_result
def run_import_time(command: str):
output = subprocess.run([sys.executable, "-X", "importtime", "-c", command], capture_output=True, text=True)
return output.stderr
@require_import_timer
class ImportSpeedTester(TempDirTestCase):
"""
Test suite which checks if imports have seen slowdowns
based on a particular baseline.
If the error messages are not clear enough to get a
full view of what is slowing things down (or to
figure out how deep the initial depth should be),
please view the profile with the `tuna` framework:
`tuna import.log`.
"""
clear_on_setup = False
@classmethod
def setUpClass(cls):
super().setUpClass()
output = run_import_time("import torch")
data = read_import_profile(output)
total_time = calculate_total_time(data)
cls.pytorch_time = total_time
def test_base_import(self):
output = run_import_time("import accelerate")
data = read_import_profile(output)
total_time = calculate_total_time(data)
pct_more = (total_time - self.pytorch_time) / self.pytorch_time * 100
# Base import should never be more than 20% slower than raw torch import
err_msg = f"Base import is more than 20% slower than raw torch import ({pct_more:.2f}%), please check the attached `tuna` profile:\n"
sorted_data = sort_nodes_by_total_time(data)
paths_above_threshold = get_paths_above_threshold(sorted_data, 0.05, max_depth=7)
err_msg += f"\n{convert_list_to_string(paths_above_threshold)}"
self.assertLess(pct_more, 20, err_msg)
def test_cli_import(self):
output = run_import_time("from accelerate.commands.launch import launch_command_parser")
data = read_import_profile(output)
total_time = calculate_total_time(data)
pct_more = (total_time - self.pytorch_time) / self.pytorch_time * 100
# Base import should never be more than 20% slower than raw torch import
err_msg = f"Base import is more than 20% slower than raw torch import ({pct_more:.2f}%), please check the attached `tuna` profile:\n"
sorted_data = sort_nodes_by_total_time(data)
paths_above_threshold = get_paths_above_threshold(sorted_data, 0.05, max_depth=7)
err_msg += f"\n{convert_list_to_string(paths_above_threshold)}"
self.assertLess(pct_more, 20, err_msg)
@require_transformer_engine
class LazyImportTester(TempDirTestCase):
"""
Test suite which checks if specific packages are lazy-loaded.
Eager-import will trigger circular import in some case,
e.g. in huggingface/accelerate#3056.
"""
def test_te_import(self):
output = run_import_time("import accelerate, accelerate.utils.transformer_engine")
self.assertFalse(" transformer_engine" in output, "`transformer_engine` should not be imported on import")
| 1 |
0 | hf_public_repos/accelerate | hf_public_repos/accelerate/tests/xla_spawn.py | # Copyright 2021 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""
A simple launcher script for TPU training
Inspired by https://github.com/pytorch/pytorch/blob/master/torch/distributed/launch.py
::
>>> python xla_spawn.py --num_cores=NUM_CORES_YOU_HAVE
YOUR_TRAINING_SCRIPT.py (--arg1 --arg2 --arg3 and all other
arguments of your training script)
"""
import importlib
import sys
from argparse import REMAINDER, ArgumentParser
from pathlib import Path
import torch_xla.distributed.xla_multiprocessing as xmp
def parse_args():
"""
Helper function parsing the command line options
@retval ArgumentParser
"""
parser = ArgumentParser(
description=(
"PyTorch TPU distributed training launch "
"helper utility that will spawn up "
"multiple distributed processes"
)
)
# Optional arguments for the launch helper
parser.add_argument("--num_cores", type=int, default=1, help="Number of TPU cores to use (1 or 8).")
# positional
parser.add_argument(
"training_script",
type=str,
help=(
"The full path to the single TPU training "
"program/script to be launched in parallel, "
"followed by all the arguments for the "
"training script"
),
)
# rest from the training program
parser.add_argument("training_script_args", nargs=REMAINDER)
return parser.parse_args()
def main():
args = parse_args()
# Import training_script as a module.
script_fpath = Path(args.training_script)
sys.path.append(str(script_fpath.parent.resolve()))
mod_name = script_fpath.stem
mod = importlib.import_module(mod_name)
# Patch sys.argv
sys.argv = [args.training_script] + args.training_script_args + ["--tpu_num_cores", str(args.num_cores)]
xmp.spawn(mod._mp_fn, args=(), nprocs=args.num_cores)
if __name__ == "__main__":
main()
| 2 |
0 | hf_public_repos/accelerate | hf_public_repos/accelerate/tests/test_multigpu.py | # Copyright 2021 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import inspect
import unittest
import torch
from accelerate import Accelerator
from accelerate.big_modeling import dispatch_model
from accelerate.test_utils import (
DEFAULT_LAUNCH_COMMAND,
assert_exception,
device_count,
execute_subprocess_async,
get_launch_command,
path_in_accelerate_package,
require_huggingface_suite,
require_multi_device,
require_multi_gpu,
require_non_torch_xla,
require_non_xpu,
require_pippy,
require_torchvision,
torch_device,
)
from accelerate.utils import patch_environment
class MultiDeviceTester(unittest.TestCase):
test_file_path = path_in_accelerate_package("test_utils", "scripts", "test_script.py")
data_loop_file_path = path_in_accelerate_package("test_utils", "scripts", "test_distributed_data_loop.py")
operation_file_path = path_in_accelerate_package("test_utils", "scripts", "test_ops.py")
pippy_file_path = path_in_accelerate_package("test_utils", "scripts", "external_deps", "test_pippy.py")
merge_weights_file_path = path_in_accelerate_package("test_utils", "scripts", "test_merge_weights.py")
@require_multi_device
def test_multi_device(self):
print(f"Found {device_count} devices.")
cmd = DEFAULT_LAUNCH_COMMAND + [self.test_file_path]
with patch_environment(omp_num_threads=1):
execute_subprocess_async(cmd)
@require_multi_device
def test_multi_device_ops(self):
print(f"Found {device_count} devices.")
cmd = DEFAULT_LAUNCH_COMMAND + [self.operation_file_path]
with patch_environment(omp_num_threads=1):
execute_subprocess_async(cmd)
@require_multi_device
def test_pad_across_processes(self):
print(f"Found {device_count} devices.")
cmd = DEFAULT_LAUNCH_COMMAND + [inspect.getfile(self.__class__)]
with patch_environment(omp_num_threads=1):
execute_subprocess_async(cmd)
@require_multi_device
def test_multi_device_merge_fsdp_weights(self):
print(f"Found {device_count} devices.")
cmd = DEFAULT_LAUNCH_COMMAND + [self.merge_weights_file_path]
with patch_environment(omp_num_threads=1):
execute_subprocess_async(cmd)
@require_non_torch_xla
@require_multi_device
def test_distributed_data_loop(self):
"""
This TestCase checks the behaviour that occurs during distributed training or evaluation,
when the batch size does not evenly divide the dataset size.
"""
print(f"Found {device_count} devices, using 2 devices only")
cmd = get_launch_command(num_processes=2) + [self.data_loop_file_path]
env_kwargs = dict(omp_num_threads=1)
if torch_device == "xpu":
env_kwargs.update(ze_affinity_mask="0,1")
elif torch_device == "npu":
env_kwargs.update(ascend_rt_visible_devices="0,1")
elif torch_device == "mlu":
env_kwargs.update(mlu_visible_devices="0,1")
else:
env_kwargs.update(cuda_visible_devices="0,1")
with patch_environment(**env_kwargs):
execute_subprocess_async(cmd)
@require_non_xpu
@require_multi_gpu
@require_pippy
@require_torchvision
@require_huggingface_suite
def test_pippy(self):
"""
Checks the integration with the pippy framework
"""
print(f"Found {device_count} devices")
cmd = get_launch_command(multi_gpu=True, num_processes=device_count) + [self.pippy_file_path]
with patch_environment(omp_num_threads=1):
execute_subprocess_async(cmd)
if __name__ == "__main__":
accelerator = Accelerator()
shape = (accelerator.state.process_index + 2, 10)
tensor = torch.randint(0, 10, shape).to(accelerator.device)
error_msg = ""
tensor1 = accelerator.pad_across_processes(tensor)
if tensor1.shape[0] != accelerator.state.num_processes + 1:
error_msg += f"Found shape {tensor1.shape} but should have {accelerator.state.num_processes + 1} at dim 0."
if not torch.equal(tensor1[: accelerator.state.process_index + 2], tensor):
error_msg += "Tensors have different values."
if not torch.all(tensor1[accelerator.state.process_index + 2 :] == 0):
error_msg += "Padding was not done with the right value (0)."
tensor2 = accelerator.pad_across_processes(tensor, pad_first=True)
if tensor2.shape[0] != accelerator.state.num_processes + 1:
error_msg += f"Found shape {tensor2.shape} but should have {accelerator.state.num_processes + 1} at dim 0."
index = accelerator.state.num_processes - accelerator.state.process_index - 1
if not torch.equal(tensor2[index:], tensor):
error_msg += "Tensors have different values."
if not torch.all(tensor2[:index] == 0):
error_msg += "Padding was not done with the right value (0)."
# Raise error at the end to make sure we don't stop at the first failure.
if len(error_msg) > 0:
raise ValueError(error_msg)
# Check device_map
accelerator.print("Test `device_map` cannot be prepared.")
class ModelForTest(torch.nn.Module):
def __init__(self):
super().__init__()
self.linear1 = torch.nn.Linear(3, 4)
self.batchnorm = torch.nn.BatchNorm1d(4)
self.linear2 = torch.nn.Linear(4, 5)
def forward(self, x):
return self.linear2(self.batchnorm(self.linear1(x)))
device_map = {"linear1": 0, "batchnorm": "cpu", "linear2": 1}
model = ModelForTest()
dispatch_model(model, device_map=device_map)
with assert_exception(ValueError, "You can't train a model that has been loaded with"):
model = accelerator.prepare_model(model)
| 3 |
0 | hf_public_repos/accelerate | hf_public_repos/accelerate/tests/test_data_loader.py | # Copyright 2021 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import random
import unittest
import pytest
import torch
from parameterized import parameterized
from torch.utils.data import BatchSampler, DataLoader, IterableDataset
from accelerate import Accelerator, PartialState
from accelerate.data_loader import (
BatchSamplerShard,
DataLoaderDispatcher,
DataLoaderShard,
DataLoaderStateMixin,
IterableDatasetShard,
SkipBatchSampler,
SkipDataLoader,
prepare_data_loader,
skip_first_batches,
)
from accelerate.state import GradientState
from accelerate.test_utils.testing import require_torchdata_stateful_dataloader
from accelerate.utils import is_torchdata_stateful_dataloader_available
if is_torchdata_stateful_dataloader_available():
from torchdata.stateful_dataloader import (
StatefulDataLoader,
)
def parameterized_custom_name_func(func, param_num, param):
# customize the test name generator function as we want both params to appear in the sub-test
# name, as by default it shows only the first param
param_based_name = f"num_workers_{param.args[0]}"
return f"{func.__name__}_{param_based_name}"
class RandomIterableDataset(IterableDataset):
# For testing, an iterable dataset of random length
def __init__(self, p_stop=0.01, max_length=1000):
self.p_stop = p_stop
self.max_length = max_length
def __iter__(self):
count = 0
stop = False
while not stop and count < self.max_length:
yield count
count += 1
stop = random.random() < self.p_stop
class SimpleIterableDataset(IterableDataset):
def __init__(self, num_samples=1000):
self.num_samples = num_samples
def __iter__(self):
for _ in range(self.num_samples):
yield torch.rand(1)
def __len__(self):
return self.num_samples
def set_epoch(self, epoch):
self.epoch = epoch
class SimpleBatchSampler(BatchSampler):
def __init__(self, sampler, batch_size, drop_last, generator, seed):
super().__init__(sampler, batch_size, drop_last)
self.generator = generator
self.seed = seed
self.epoch = 0
def __iter__(self):
self.generator.manual_seed(self.seed + self.epoch)
return super().__iter__()
def set_epoch(self, epoch):
self.epoch = epoch
class DataLoaderTester(unittest.TestCase):
def check_batch_sampler_shards(self, batch_sampler, expected, split_batches=False, even_batches=True):
batch_sampler_shards = [
BatchSamplerShard(batch_sampler, 2, i, split_batches=split_batches, even_batches=even_batches)
for i in range(2)
]
batch_sampler_lists = [list(batch_sampler_shard) for batch_sampler_shard in batch_sampler_shards]
if not split_batches:
assert [len(shard) for shard in batch_sampler_shards] == [len(e) for e in expected]
assert batch_sampler_lists == expected
def test_batch_sampler_shards_with_no_splits(self):
# Check the shards when the dataset is a round multiple of total batch size.
batch_sampler = BatchSampler(range(24), batch_size=3, drop_last=False)
expected = [
[[0, 1, 2], [6, 7, 8], [12, 13, 14], [18, 19, 20]],
[[3, 4, 5], [9, 10, 11], [15, 16, 17], [21, 22, 23]],
]
self.check_batch_sampler_shards(batch_sampler, expected)
batch_sampler = BatchSampler(range(24), batch_size=3, drop_last=True)
# Expected shouldn't change
self.check_batch_sampler_shards(batch_sampler, expected)
# Check the shards when the dataset is a round multiple of batch size but not total batch size.
batch_sampler = BatchSampler(range(21), batch_size=3, drop_last=False)
expected = [
[[0, 1, 2], [6, 7, 8], [12, 13, 14], [18, 19, 20]],
[[3, 4, 5], [9, 10, 11], [15, 16, 17], [0, 1, 2]],
]
self.check_batch_sampler_shards(batch_sampler, expected)
batch_sampler = BatchSampler(range(21), batch_size=3, drop_last=True)
expected = [
[[0, 1, 2], [6, 7, 8], [12, 13, 14]],
[[3, 4, 5], [9, 10, 11], [15, 16, 17]],
]
self.check_batch_sampler_shards(batch_sampler, expected)
# Check the shards when the dataset is not a round multiple of batch size but has a multiple of
# num_processes batch.
batch_sampler = BatchSampler(range(22), batch_size=3, drop_last=False)
expected = [
[[0, 1, 2], [6, 7, 8], [12, 13, 14], [18, 19, 20]],
[[3, 4, 5], [9, 10, 11], [15, 16, 17], [21, 0, 1]],
]
self.check_batch_sampler_shards(batch_sampler, expected)
batch_sampler = BatchSampler(range(22), batch_size=3, drop_last=True)
expected = [
[[0, 1, 2], [6, 7, 8], [12, 13, 14]],
[[3, 4, 5], [9, 10, 11], [15, 16, 17]],
]
self.check_batch_sampler_shards(batch_sampler, expected)
# Check the shards when the dataset is not a round multiple of batch size but and has not a multiple of
# num_processes batch.
batch_sampler = BatchSampler(range(20), batch_size=3, drop_last=False)
expected = [
[[0, 1, 2], [6, 7, 8], [12, 13, 14], [18, 19, 0]],
[[3, 4, 5], [9, 10, 11], [15, 16, 17], [1, 2, 3]],
]
self.check_batch_sampler_shards(batch_sampler, expected)
batch_sampler = BatchSampler(range(20), batch_size=3, drop_last=True)
expected = [
[[0, 1, 2], [6, 7, 8], [12, 13, 14]],
[[3, 4, 5], [9, 10, 11], [15, 16, 17]],
]
self.check_batch_sampler_shards(batch_sampler, expected)
# Check the shards when the dataset is very small.
batch_sampler = BatchSampler(range(2), batch_size=3, drop_last=False)
expected = [[[0, 1, 0]], [[1, 0, 1]]]
self.check_batch_sampler_shards(batch_sampler, expected)
batch_sampler = BatchSampler(range(2), batch_size=3, drop_last=True)
expected = [[], []]
self.check_batch_sampler_shards(batch_sampler, expected)
def test_batch_sampler_shards_with_splits(self):
# Check the shards when the dataset is a round multiple of batch size.
batch_sampler = BatchSampler(range(24), batch_size=4, drop_last=False)
expected = [
[[0, 1], [4, 5], [8, 9], [12, 13], [16, 17], [20, 21]],
[[2, 3], [6, 7], [10, 11], [14, 15], [18, 19], [22, 23]],
]
self.check_batch_sampler_shards(batch_sampler, expected, split_batches=True)
batch_sampler = BatchSampler(range(24), batch_size=4, drop_last=True)
# Expected shouldn't change
self.check_batch_sampler_shards(batch_sampler, expected, split_batches=True)
# Check the shards when the dataset is not a round multiple of batch size.
batch_sampler = BatchSampler(range(22), batch_size=4, drop_last=False)
expected = [
[[0, 1], [4, 5], [8, 9], [12, 13], [16, 17], [20, 21]],
[[2, 3], [6, 7], [10, 11], [14, 15], [18, 19], [0, 1]],
]
self.check_batch_sampler_shards(batch_sampler, expected, split_batches=True)
batch_sampler = BatchSampler(range(22), batch_size=4, drop_last=True)
expected = [
[[0, 1], [4, 5], [8, 9], [12, 13], [16, 17]],
[[2, 3], [6, 7], [10, 11], [14, 15], [18, 19]],
]
self.check_batch_sampler_shards(batch_sampler, expected, split_batches=True)
# Check the shards when the dataset is not a round multiple of batch size or num_processes.
batch_sampler = BatchSampler(range(21), batch_size=4, drop_last=False)
expected = [
[[0, 1], [4, 5], [8, 9], [12, 13], [16, 17], [20, 0]],
[[2, 3], [6, 7], [10, 11], [14, 15], [18, 19], [1, 2]],
]
self.check_batch_sampler_shards(batch_sampler, expected, split_batches=True)
batch_sampler = BatchSampler(range(21), batch_size=4, drop_last=True)
expected = [
[[0, 1], [4, 5], [8, 9], [12, 13], [16, 17]],
[[2, 3], [6, 7], [10, 11], [14, 15], [18, 19]],
]
self.check_batch_sampler_shards(batch_sampler, expected, split_batches=True)
# Check the shards when the dataset is very small.
batch_sampler = BatchSampler(range(2), batch_size=4, drop_last=False)
expected = [[[0, 1]], [[0, 1]]]
self.check_batch_sampler_shards(batch_sampler, expected, split_batches=True)
batch_sampler = BatchSampler(range(2), batch_size=4, drop_last=True)
expected = [[], []]
self.check_batch_sampler_shards(batch_sampler, expected, split_batches=True)
def test_batch_sampler_shards_with_no_splits_no_even(self):
# Check the shards when the dataset is a round multiple of total batch size.
batch_sampler = BatchSampler(range(24), batch_size=3, drop_last=False)
expected = [
[[0, 1, 2], [6, 7, 8], [12, 13, 14], [18, 19, 20]],
[[3, 4, 5], [9, 10, 11], [15, 16, 17], [21, 22, 23]],
]
self.check_batch_sampler_shards(batch_sampler, expected, even_batches=False)
batch_sampler = BatchSampler(range(24), batch_size=3, drop_last=True)
# Expected shouldn't change
self.check_batch_sampler_shards(batch_sampler, expected, even_batches=False)
# Check the shards when the dataset is a round multiple of batch size but not total batch size.
batch_sampler = BatchSampler(range(21), batch_size=3, drop_last=False)
expected = [
[[0, 1, 2], [6, 7, 8], [12, 13, 14], [18, 19, 20]],
[[3, 4, 5], [9, 10, 11], [15, 16, 17]],
]
self.check_batch_sampler_shards(batch_sampler, expected, even_batches=False)
batch_sampler = BatchSampler(range(21), batch_size=3, drop_last=True)
expected = [
[[0, 1, 2], [6, 7, 8], [12, 13, 14]],
[[3, 4, 5], [9, 10, 11], [15, 16, 17]],
]
self.check_batch_sampler_shards(batch_sampler, expected, even_batches=False)
# Check the shards when the dataset is not a round multiple of batch size but has a multiple of
# num_processes batch.
batch_sampler = BatchSampler(range(22), batch_size=3, drop_last=False)
expected = [
[[0, 1, 2], [6, 7, 8], [12, 13, 14], [18, 19, 20]],
[[3, 4, 5], [9, 10, 11], [15, 16, 17], [21]],
]
self.check_batch_sampler_shards(batch_sampler, expected, even_batches=False)
batch_sampler = BatchSampler(range(22), batch_size=3, drop_last=True)
expected = [
[[0, 1, 2], [6, 7, 8], [12, 13, 14]],
[[3, 4, 5], [9, 10, 11], [15, 16, 17]],
]
self.check_batch_sampler_shards(batch_sampler, expected, even_batches=False)
# Check the shards when the dataset is not a round multiple of batch size but and has not a multiple of
# num_processes batch.
batch_sampler = BatchSampler(range(20), batch_size=3, drop_last=False)
expected = [
[[0, 1, 2], [6, 7, 8], [12, 13, 14], [18, 19]],
[[3, 4, 5], [9, 10, 11], [15, 16, 17]],
]
self.check_batch_sampler_shards(batch_sampler, expected, even_batches=False)
batch_sampler = BatchSampler(range(20), batch_size=3, drop_last=True)
expected = [
[[0, 1, 2], [6, 7, 8], [12, 13, 14]],
[[3, 4, 5], [9, 10, 11], [15, 16, 17]],
]
self.check_batch_sampler_shards(batch_sampler, expected, even_batches=False)
# Check the shards when the dataset is very small.
batch_sampler = BatchSampler(range(2), batch_size=3, drop_last=False)
expected = [[[0, 1]], []]
self.check_batch_sampler_shards(batch_sampler, expected, even_batches=False)
batch_sampler = BatchSampler(range(2), batch_size=3, drop_last=True)
expected = [[], []]
self.check_batch_sampler_shards(batch_sampler, expected, even_batches=False)
def test_batch_sampler_shards_with_splits_no_even(self):
# Check the shards when the dataset is a round multiple of batch size.
batch_sampler = BatchSampler(range(24), batch_size=4, drop_last=False)
expected = [
[[0, 1], [4, 5], [8, 9], [12, 13], [16, 17], [20, 21]],
[[2, 3], [6, 7], [10, 11], [14, 15], [18, 19], [22, 23]],
]
self.check_batch_sampler_shards(batch_sampler, expected, split_batches=True, even_batches=False)
batch_sampler = BatchSampler(range(24), batch_size=4, drop_last=True)
# Expected shouldn't change
self.check_batch_sampler_shards(batch_sampler, expected, split_batches=True, even_batches=False)
# Check the shards when the dataset is not a round multiple of batch size.
batch_sampler = BatchSampler(range(22), batch_size=4, drop_last=False)
expected = [
[[0, 1], [4, 5], [8, 9], [12, 13], [16, 17], [20, 21]],
[[2, 3], [6, 7], [10, 11], [14, 15], [18, 19]],
]
self.check_batch_sampler_shards(batch_sampler, expected, split_batches=True, even_batches=False)
batch_sampler = BatchSampler(range(22), batch_size=4, drop_last=True)
expected = [
[[0, 1], [4, 5], [8, 9], [12, 13], [16, 17]],
[[2, 3], [6, 7], [10, 11], [14, 15], [18, 19]],
]
self.check_batch_sampler_shards(batch_sampler, expected, split_batches=True, even_batches=False)
# Check the shards when the dataset is not a round multiple of batch size or num_processes.
batch_sampler = BatchSampler(range(21), batch_size=4, drop_last=False)
expected = [
[[0, 1], [4, 5], [8, 9], [12, 13], [16, 17], [20]],
[[2, 3], [6, 7], [10, 11], [14, 15], [18, 19]],
]
self.check_batch_sampler_shards(batch_sampler, expected, split_batches=True, even_batches=False)
batch_sampler = BatchSampler(range(21), batch_size=4, drop_last=True)
expected = [
[[0, 1], [4, 5], [8, 9], [12, 13], [16, 17]],
[[2, 3], [6, 7], [10, 11], [14, 15], [18, 19]],
]
self.check_batch_sampler_shards(batch_sampler, expected, split_batches=True, even_batches=False)
# Check the shards when the dataset is very small.
batch_sampler = BatchSampler(range(2), batch_size=4, drop_last=False)
expected = [[[0, 1]], []]
self.check_batch_sampler_shards(batch_sampler, expected, split_batches=True, even_batches=False)
batch_sampler = BatchSampler(range(2), batch_size=4, drop_last=True)
expected = [[], []]
self.check_batch_sampler_shards(batch_sampler, expected, split_batches=True, even_batches=False)
def test_batch_sampler_with_varying_batch_size(self):
batch_sampler = [[0, 1, 2], [3, 4], [5, 6, 7, 8], [9, 10, 11], [12, 13]]
batch_sampler_shards = [BatchSamplerShard(batch_sampler, 2, i, even_batches=False) for i in range(2)]
assert len(batch_sampler_shards[0]) == 3
assert len(batch_sampler_shards[1]) == 2
assert list(batch_sampler_shards[0]) == [[0, 1, 2], [5, 6, 7, 8], [12, 13]]
assert list(batch_sampler_shards[1]) == [[3, 4], [9, 10, 11]]
def check_iterable_dataset_shards(
self, dataset, seed, batch_size, drop_last=False, num_processes=2, split_batches=False
):
random.seed(seed)
reference = list(dataset)
iterable_dataset_shards = [
IterableDatasetShard(
dataset,
batch_size=batch_size,
drop_last=drop_last,
num_processes=num_processes,
process_index=i,
split_batches=split_batches,
)
for i in range(num_processes)
]
iterable_dataset_lists = []
for iterable_dataset_shard in iterable_dataset_shards:
# Since our random iterable dataset will be... random... we need to use a seed to get reproducible results.
random.seed(seed)
iterable_dataset_lists.append(list(iterable_dataset_shard))
shard_batch_size = batch_size // num_processes if split_batches else batch_size
# All iterable dataset shard should have the same length, a round multiple of shard_batch_size
first_list = iterable_dataset_lists[0]
for l in iterable_dataset_lists[1:]:
assert len(l) == len(first_list)
assert (len(l) % shard_batch_size) == 0
observed = []
for idx in range(0, len(first_list), shard_batch_size):
for l in iterable_dataset_lists:
observed += l[idx : idx + shard_batch_size]
if not drop_last:
while len(reference) < len(observed):
reference += reference
assert observed == reference[: len(observed)]
def test_iterable_dataset_shard(self):
seed = 42
dataset = RandomIterableDataset()
self.check_iterable_dataset_shards(dataset, seed, batch_size=4, drop_last=False, split_batches=False)
self.check_iterable_dataset_shards(dataset, seed, batch_size=4, drop_last=True, split_batches=False)
self.check_iterable_dataset_shards(dataset, seed, batch_size=4, drop_last=False, split_batches=True)
self.check_iterable_dataset_shards(dataset, seed, batch_size=4, drop_last=True, split_batches=True)
# Edge case with a very small dataset
dataset = RandomIterableDataset(max_length=2)
self.check_iterable_dataset_shards(dataset, seed, batch_size=4, drop_last=False, split_batches=False)
self.check_iterable_dataset_shards(dataset, seed, batch_size=4, drop_last=True, split_batches=False)
self.check_iterable_dataset_shards(dataset, seed, batch_size=4, drop_last=False, split_batches=True)
self.check_iterable_dataset_shards(dataset, seed, batch_size=4, drop_last=True, split_batches=True)
def test_iterable_dataset_using_none_batch_size(self):
dataset = SimpleIterableDataset(100)
dataloader = DataLoader(dataset, batch_size=None)
dataloader = prepare_data_loader(dataloader)
for d in dataloader:
assert isinstance(d, torch.Tensor)
def test_skip_batch_sampler(self):
batch_sampler = BatchSampler(range(16), batch_size=4, drop_last=False)
new_batch_sampler = SkipBatchSampler(batch_sampler, 2)
assert list(new_batch_sampler) == [[8, 9, 10, 11], [12, 13, 14, 15]]
def test_dataloader_inheritance(self):
"""
`DataLoaderAdapter`'s parent classes are dynamically constructed, assert that subclasses of DataLoaderAdapter
are instances of DataLoader and DataLoaderStateMixin.
"""
skip_dl = SkipDataLoader(range(16), batch_size=4, skip_batches=2)
dl_shard = DataLoaderShard(range(16), batch_size=4)
dl_dispatcher = DataLoaderDispatcher(range(16), batch_size=4)
# Test dataloaders are instances of instantiated classes
# These asserts look redundant, but it's worth checking since we are doing magic tricks such as dynamically overriding __class__
assert isinstance(skip_dl, SkipDataLoader)
assert isinstance(dl_shard, DataLoaderShard)
assert isinstance(dl_dispatcher, DataLoaderDispatcher)
# Test dataloaders are instances of base classes
assert isinstance(skip_dl, DataLoader)
assert isinstance(dl_shard, DataLoader)
assert isinstance(dl_dispatcher, DataLoader)
assert isinstance(dl_shard, DataLoaderStateMixin)
assert isinstance(dl_dispatcher, DataLoaderStateMixin)
assert isinstance(skip_dl.base_dataloader, DataLoader)
assert isinstance(dl_shard.base_dataloader, DataLoader)
assert isinstance(dl_dispatcher.base_dataloader, DataLoader)
with pytest.raises(AttributeError):
_ = DataLoaderShard.base_dataloader
def test_skip_data_loader(self):
dataloader = SkipDataLoader(list(range(16)), batch_size=4, skip_batches=2)
assert [t.tolist() for t in dataloader] == [[8, 9, 10, 11], [12, 13, 14, 15]]
def test_skip_first_batches(self):
dataloader = DataLoader(list(range(16)), batch_size=4)
new_dataloader = skip_first_batches(dataloader, num_batches=2)
assert [t.tolist() for t in new_dataloader] == [[8, 9, 10, 11], [12, 13, 14, 15]]
def test_end_of_dataloader(self):
dataloader = DataLoaderShard(list(range(16)), batch_size=4)
for idx, _ in enumerate(dataloader):
assert dataloader.end_of_dataloader == (idx == 3)
# Test it also works on the second iteration
for idx, _ in enumerate(dataloader):
assert dataloader.end_of_dataloader == (idx == 3)
def test_end_of_dataloader_dispatcher(self):
dataloader = DataLoaderDispatcher(range(16), batch_size=4)
for idx, _ in enumerate(dataloader):
assert dataloader.end_of_dataloader == (idx == 3)
# Test it also works on the second iteration
for idx, _ in enumerate(dataloader):
assert dataloader.end_of_dataloader == (idx == 3)
def test_set_epoch_in_batch_sampler(self):
# Ensure that set_epoch gets propagated to custom batch samplers that accept it
dataset = list(range(16))
generator = torch.Generator()
batch_sampler = SimpleBatchSampler(dataset, batch_size=4, drop_last=False, generator=generator, seed=12)
dataloader = DataLoader(dataset, batch_sampler=batch_sampler)
accelerator = Accelerator()
dataloader = accelerator.prepare_data_loader(dataloader)
assert batch_sampler.epoch == 0
dataloader.set_epoch(1)
assert batch_sampler.epoch == 1
class StatefulDataLoaderTester(unittest.TestCase):
@require_torchdata_stateful_dataloader
def test_skip_data_loader(self):
dataloader = SkipDataLoader(list(range(16)), batch_size=4, skip_batches=2, use_stateful_dataloader=True)
assert isinstance(dataloader, StatefulDataLoader)
assert [t.tolist() for t in dataloader] == [[8, 9, 10, 11], [12, 13, 14, 15]]
@require_torchdata_stateful_dataloader
def test_end_of_dataloader(self):
dataloader = DataLoaderShard(list(range(16)), batch_size=4, use_stateful_dataloader=True)
assert dataloader.use_stateful_dataloader
assert isinstance(dataloader, StatefulDataLoader)
for idx, _ in enumerate(dataloader):
assert dataloader.end_of_dataloader == (idx == 3)
# Test it also works on the second iteration
for idx, _ in enumerate(dataloader):
assert dataloader.end_of_dataloader == (idx == 3)
@require_torchdata_stateful_dataloader
def test_end_of_dataloader_dispatcher(self):
dataloader = DataLoaderDispatcher(range(16), batch_size=4, use_stateful_dataloader=True)
assert isinstance(dataloader, StatefulDataLoader)
for idx, _ in enumerate(dataloader):
assert dataloader.end_of_dataloader == (idx == 3)
# Test it also works on the second iteration
for idx, _ in enumerate(dataloader):
assert dataloader.end_of_dataloader == (idx == 3)
@parameterized.expand([0, 2], name_func=parameterized_custom_name_func)
@require_torchdata_stateful_dataloader
def test_dataloader_state_dict(self, num_workers):
"""
Test that saving a stateful dataloader's state, then loading it back, gives the same results.
"""
dataset = list(range(16))
dataloader = DataLoaderShard(dataset, batch_size=4, use_stateful_dataloader=True, num_workers=num_workers)
assert dataloader.use_stateful_dataloader
assert isinstance(dataloader, StatefulDataLoader)
vals = []
for idx, val in enumerate(dataloader):
vals.append(val)
if idx == 1:
sd = dataloader.state_dict()
assert len(vals) == 4
dataloader2 = DataLoaderShard(dataset, batch_size=4, use_stateful_dataloader=True, num_workers=num_workers)
dataloader2.load_state_dict(sd)
data1 = vals[2:]
data2 = list(dataloader2)
assert len(data1) == len(data2)
for d1, d2 in zip(data1, data2):
assert torch.allclose(d1, d2)
@parameterized.expand([0, 2], name_func=parameterized_custom_name_func)
@require_torchdata_stateful_dataloader
def test_dataloader_dispatcher_state_dict(self, num_workers):
"""
Test that saving a stateful dataloader's state, then loading it back, gives the same results.
"""
dataset = list(range(16))
dataloader = DataLoaderDispatcher(dataset, batch_size=4, use_stateful_dataloader=True, num_workers=num_workers)
assert dataloader.use_stateful_dataloader
assert isinstance(dataloader, StatefulDataLoader)
vals = []
for idx, val in enumerate(dataloader):
vals.append(val)
if idx == 1:
sd = dataloader.state_dict()
assert len(vals) == 4
dataloader2 = DataLoaderDispatcher(
dataset, batch_size=4, use_stateful_dataloader=True, num_workers=num_workers
)
dataloader2.load_state_dict(sd)
data1 = vals[2:]
data2 = list(dataloader2)
assert len(data1) == len(data2)
for d1, d2 in zip(data1, data2):
assert torch.allclose(d1, d2)
@require_torchdata_stateful_dataloader
def test_dataloader_inheritance(self):
"""
`DataLoaderAdapter`'s parent classes are dynamically constructed, assert that if use_stateful_dataloader=True,
subclasses of DataLoaderAdapter are instances of StatefulDataLoader and DataLoaderStateMixin.
"""
skip_dl = SkipDataLoader(range(16), batch_size=4, skip_batches=2, use_stateful_dataloader=True)
dl_shard = DataLoaderShard(range(16), batch_size=4, use_stateful_dataloader=True)
dl_dispatcher = DataLoaderDispatcher(range(16), batch_size=4, use_stateful_dataloader=True)
# Test dataloaders are instances of instantiated classes
# These asserts look redundant, but it's worth checking since we are doing magic tricks such as dynamically overriding __class__
assert isinstance(skip_dl, SkipDataLoader)
assert isinstance(dl_shard, DataLoaderShard)
assert isinstance(dl_dispatcher, DataLoaderDispatcher)
assert isinstance(skip_dl, StatefulDataLoader)
assert isinstance(dl_shard, StatefulDataLoader)
assert isinstance(dl_dispatcher, StatefulDataLoader)
assert isinstance(dl_shard, DataLoaderStateMixin)
assert isinstance(dl_dispatcher, DataLoaderStateMixin)
assert isinstance(skip_dl.base_dataloader, StatefulDataLoader)
assert isinstance(dl_shard.base_dataloader, StatefulDataLoader)
assert isinstance(dl_dispatcher.base_dataloader, StatefulDataLoader)
@parameterized.expand([0, 2], name_func=parameterized_custom_name_func)
@require_torchdata_stateful_dataloader
def test_stateful_dataloader_adapter_equivalent_to_torchdata_stateful_dataloader(self, num_workers):
"""
Assert that `state_dict()` and `load_state_dict()` for derived subclasses of `DataLoaderAdapter` produce
the same behavior as `state_dict()` and `load_state_dict()` for `StatefulDataLoader`.
"""
dataset = list(range(64))
# Set the seed for reproducibility
def g():
return torch.Generator().manual_seed(42)
accelerator = Accelerator()
stateful_dl = StatefulDataLoader(dataset, batch_size=4, num_workers=num_workers, generator=g())
skip_dl = SkipDataLoader(
dataset, batch_size=4, num_workers=num_workers, generator=g(), use_stateful_dataloader=True
)
dl_shard = DataLoaderShard(
dataset, batch_size=4, num_workers=num_workers, generator=g(), use_stateful_dataloader=True
)
dl_dispatcher = DataLoaderDispatcher(
dataset, batch_size=4, num_workers=num_workers, generator=g(), use_stateful_dataloader=True
)
dataloaders_under_test = [skip_dl, dl_shard, dl_dispatcher]
num_batches_to_skip = 8
def get_first_n_batches(dl, n, device):
"""
Iterate over the first `n` batches of a dataloader then break, returning the batches in a list.
"""
batches = []
for idx, batch in enumerate(dl):
if idx == n - 1:
if hasattr(dl, "end"):
dl.end()
break
batches.append(batch.to(device))
return batches
# Iterate over all of the dataloaders identically, expect the same values
expected_batches = get_first_n_batches(stateful_dl, num_batches_to_skip, accelerator.device)
batches_from_dataloaders = [
get_first_n_batches(dl, num_batches_to_skip, accelerator.device) for dl in dataloaders_under_test
]
for dl_batches in batches_from_dataloaders:
for expected, actual in zip(expected_batches, dl_batches):
assert torch.allclose(expected, actual)
# The adapters should all produce the same state_dict as the reference stateful dataloader
expected_state_dict = stateful_dl.state_dict()
skip_dl_state_dict = skip_dl.state_dict()
dl_shard_state_dict = dl_shard.state_dict()
dl_dispatcher_state_dict = dl_dispatcher.state_dict()
assert expected_state_dict == skip_dl_state_dict
assert expected_state_dict == dl_shard_state_dict
assert expected_state_dict == dl_dispatcher_state_dict
# Load the state dict into new dataloaders
manual_skip_dl = SkipDataLoader(
dataset,
batch_size=4,
num_workers=num_workers,
generator=g(),
skip_batches=num_batches_to_skip,
use_stateful_dataloader=True,
)
loaded_stateful_dl = StatefulDataLoader(dataset, batch_size=4, num_workers=num_workers, generator=g())
loaded_stateful_dl.load_state_dict(expected_state_dict)
loaded_skip_dl = SkipDataLoader(
dataset, batch_size=4, num_workers=num_workers, generator=g(), use_stateful_dataloader=True
)
loaded_skip_dl.load_state_dict(expected_state_dict)
loaded_dl_shard = DataLoaderShard(
dataset, batch_size=4, num_workers=num_workers, generator=g(), use_stateful_dataloader=True
)
loaded_dl_shard.load_state_dict(expected_state_dict)
loaded_dl_dispatcher = DataLoaderDispatcher(
dataset, batch_size=4, num_workers=num_workers, generator=g(), use_stateful_dataloader=True
)
loaded_dl_dispatcher.load_state_dict(expected_state_dict)
# Continue the iteration, expecting identical behavior across the board
def get_all_batches(dl, device):
"""
Iterate over all batches of a dataloader, returning (batches, num_batches_yielded)
"""
batches = []
num_batches_yielded = 0
for batch in dl:
batches.append(batch.to(device))
num_batches_yielded += 1
return (batches, num_batches_yielded)
expected_batch_results = get_all_batches(loaded_stateful_dl, accelerator.device)
dataloader_batch_results = [
get_all_batches(dl, accelerator.device)
for dl in [manual_skip_dl, loaded_skip_dl, loaded_dl_shard, loaded_dl_dispatcher]
]
for dl_results in dataloader_batch_results:
for expected, actual in zip(expected_batches, dl_batches):
assert torch.allclose(expected[0], actual[0])
assert expected_batch_results[1] == dl_results[1]
assert accelerator.gradient_state.active_dataloader is None
@parameterized.expand([0, 2], name_func=parameterized_custom_name_func)
@require_torchdata_stateful_dataloader
def test_decoupled_stateful_dataloader_adapter_equivalent_to_torchdata_stateful_dataloader(self, num_workers):
"""
Assert that `state_dict()` and `load_state_dict()` for derived subclasses of `DataLoaderAdapter` produce
the same behavior as `state_dict()` and `load_state_dict()` for `StatefulDataLoader` when *not* using
Accelerator (and instead using the decoupled `PartialState` workflow).
"""
dataset = list(range(64))
# Set the seed for reproducibility
def g():
return torch.Generator().manual_seed(42)
state = PartialState()
stateful_dl = StatefulDataLoader(dataset, batch_size=4, num_workers=num_workers, generator=g())
skip_dl = SkipDataLoader(
dataset, batch_size=4, num_workers=num_workers, generator=g(), use_stateful_dataloader=True
)
dl_shard = DataLoaderShard(
dataset, batch_size=4, num_workers=num_workers, generator=g(), use_stateful_dataloader=True
)
dl_dispatcher = DataLoaderDispatcher(
dataset, batch_size=4, num_workers=num_workers, generator=g(), use_stateful_dataloader=True
)
dataloaders_under_test = [skip_dl, dl_shard, dl_dispatcher]
num_batches_to_skip = 8
def get_first_n_batches(dl, n, device):
"""
Iterate over the first `n` batches of a dataloader then break, returning the batches in a list.
"""
batches = []
for idx, batch in enumerate(dl):
if idx == n - 1:
if hasattr(dl, "end"):
dl.end()
break
batches.append(batch.to(device))
return batches
# Iterate over all of the dataloaders identically, expect the same values
expected_batches = get_first_n_batches(stateful_dl, num_batches_to_skip, state.device)
batches_from_dataloaders = [
get_first_n_batches(dl, num_batches_to_skip, state.device) for dl in dataloaders_under_test
]
for dl_batches in batches_from_dataloaders:
for expected, actual in zip(expected_batches, dl_batches):
assert torch.allclose(expected, actual)
# The adapters should all produce the same state_dict as the reference stateful dataloader
expected_state_dict = stateful_dl.state_dict()
skip_dl_state_dict = skip_dl.state_dict()
dl_shard_state_dict = dl_shard.state_dict()
dl_dispatcher_state_dict = dl_dispatcher.state_dict()
assert expected_state_dict == skip_dl_state_dict
assert expected_state_dict == dl_shard_state_dict
assert expected_state_dict == dl_dispatcher_state_dict
# Load the state dict into new dataloaders
manual_skip_dl = SkipDataLoader(
dataset,
batch_size=4,
num_workers=num_workers,
generator=g(),
skip_batches=num_batches_to_skip,
use_stateful_dataloader=True,
)
loaded_stateful_dl = StatefulDataLoader(dataset, batch_size=4, num_workers=num_workers, generator=g())
loaded_stateful_dl.load_state_dict(expected_state_dict)
loaded_skip_dl = SkipDataLoader(
dataset, batch_size=4, num_workers=num_workers, generator=g(), use_stateful_dataloader=True
)
loaded_skip_dl.load_state_dict(expected_state_dict)
loaded_dl_shard = DataLoaderShard(
dataset, batch_size=4, num_workers=num_workers, generator=g(), use_stateful_dataloader=True
)
loaded_dl_shard.load_state_dict(expected_state_dict)
loaded_dl_dispatcher = DataLoaderDispatcher(
dataset, batch_size=4, num_workers=num_workers, generator=g(), use_stateful_dataloader=True
)
loaded_dl_dispatcher.load_state_dict(expected_state_dict)
# Continue the iteration, expecting identical behavior across the board
def get_all_batches(dl, device):
"""
Iterate over all batches of a dataloader, returning (batches, num_batches_yielded)
"""
batches = []
num_batches_yielded = 0
for batch in dl:
batches.append(batch.to(device))
num_batches_yielded += 1
return (batches, num_batches_yielded)
expected_batch_results = get_all_batches(loaded_stateful_dl, state.device)
dataloader_batch_results = [
get_all_batches(dl, state.device)
for dl in [manual_skip_dl, loaded_skip_dl, loaded_dl_shard, loaded_dl_dispatcher]
]
for dl_results in dataloader_batch_results:
for expected, actual in zip(expected_batches, dl_batches):
assert torch.allclose(expected[0], actual[0])
assert expected_batch_results[1] == dl_results[1]
# Using the decoupled (`PartialState`) workflow, GradientState should be automatically initialized (with
# default parameters) by `DataLoaderDispatcher`
assert GradientState._shared_state != {}, "GradientState should already be initialized!"
gradient_state = GradientState()
assert gradient_state.active_dataloader is None
| 4 |
0 | hf_public_repos/accelerate | hf_public_repos/accelerate/tests/test_tpu.py | # Copyright 2021 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import os
import sys
import unittest
from accelerate.test_utils import execute_subprocess_async, path_in_accelerate_package, require_tpu
class MultiTPUTester(unittest.TestCase):
test_file_path = path_in_accelerate_package("test_utils", "scripts", "test_script.py")
test_dir = os.path.dirname(__file__)
@require_tpu
def test_tpu(self):
distributed_args = f"""
{self.test_dir}/xla_spawn.py
--num_cores 8
{self.test_file_path}
""".split()
cmd = [sys.executable] + distributed_args
execute_subprocess_async(cmd)
| 5 |
0 | hf_public_repos/accelerate | hf_public_repos/accelerate/tests/test_state_checkpointing.py | # Copyright 2022 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import inspect
import logging
import os
import random
import shutil
import tempfile
import unittest
import uuid
from contextlib import contextmanager
import pytest
import torch
from parameterized import parameterized_class
from torch import nn
from torch.utils.data import DataLoader, TensorDataset
from accelerate import Accelerator
from accelerate.test_utils import (
DEFAULT_LAUNCH_COMMAND,
execute_subprocess_async,
require_non_cpu,
require_non_torch_xla,
)
from accelerate.utils import DistributedType, ProjectConfiguration, set_seed
logger = logging.getLogger(__name__)
def dummy_dataloaders(a=2, b=3, batch_size=16, n_train_batches: int = 10, n_valid_batches: int = 2):
"Generates a tuple of dummy DataLoaders to test with"
def get_dataset(n_batches):
x = torch.randn(batch_size * n_batches, 1)
return TensorDataset(x, a * x + b + 0.1 * torch.randn(batch_size * n_batches, 1))
train_dataset = get_dataset(n_train_batches)
valid_dataset = get_dataset(n_valid_batches)
train_dataloader = DataLoader(train_dataset, shuffle=True, batch_size=batch_size, num_workers=4)
valid_dataloader = DataLoader(valid_dataset, shuffle=False, batch_size=batch_size, num_workers=4)
return (train_dataloader, valid_dataloader)
def train(num_epochs, model, dataloader, optimizer, accelerator, scheduler=None):
"Trains for `num_epochs`"
rands = []
for epoch in range(num_epochs):
# Train quickly
model.train()
for batch in dataloader:
x, y = batch
outputs = model(x)
loss = torch.nn.functional.mse_loss(outputs, y)
accelerator.backward(loss)
optimizer.step()
optimizer.zero_grad()
rands.append(random.random()) # Introduce some randomness
if scheduler is not None:
scheduler.step()
return rands
class DummyModel(nn.Module):
"Simple model to do y=mx+b"
def __init__(self):
super().__init__()
self.a = nn.Parameter(torch.randn(1))
self.b = nn.Parameter(torch.randn(1))
def forward(self, x):
return x * self.a + self.b
def parameterized_custom_name_func(func, param_num, param):
# customize the test name generator function as we want both params to appear in the sub-test
# name, as by default it shows only the first param
param_based_name = "use_safetensors" if param["use_safetensors"] is True else "use_pytorch"
return f"{func.__name__}_{param_based_name}"
@parameterized_class(("use_safetensors",), [[True], [False]], class_name_func=parameterized_custom_name_func)
class CheckpointTest(unittest.TestCase):
def check_adam_state(self, state1, state2, distributed_type):
# For DistributedType.XLA, the `accelerator.save_state` function calls `xm._maybe_convert_to_cpu` before saving.
# As a result, all tuple values are converted to lists. Therefore, we need to convert them back here.
# Remove this code once Torch XLA fixes this issue.
if distributed_type == DistributedType.XLA:
state1["param_groups"][0]["betas"] = tuple(state1["param_groups"][0]["betas"])
state2["param_groups"][0]["betas"] = tuple(state2["param_groups"][0]["betas"])
assert state1 == state2
def test_with_save_limit(self):
with tempfile.TemporaryDirectory() as tmpdir:
set_seed(42)
model = DummyModel()
optimizer = torch.optim.Adam(params=model.parameters(), lr=1e-3)
train_dataloader, valid_dataloader = dummy_dataloaders()
project_config = ProjectConfiguration(total_limit=1, project_dir=tmpdir, automatic_checkpoint_naming=True)
# Train baseline
accelerator = Accelerator(project_config=project_config)
model, optimizer, train_dataloader, valid_dataloader = accelerator.prepare(
model, optimizer, train_dataloader, valid_dataloader
)
# Save initial
accelerator.save_state(safe_serialization=self.use_safetensors)
# Save second state
accelerator.save_state(safe_serialization=self.use_safetensors)
assert len(os.listdir(accelerator.project_dir)) == 1
def test_can_resume_training_with_folder(self):
with tempfile.TemporaryDirectory() as tmpdir:
set_seed(42)
model = DummyModel()
optimizer = torch.optim.Adam(params=model.parameters(), lr=1e-3)
train_dataloader, valid_dataloader = dummy_dataloaders()
# Train baseline
accelerator = Accelerator()
model, optimizer, train_dataloader, valid_dataloader = accelerator.prepare(
model, optimizer, train_dataloader, valid_dataloader
)
# Save initial
initial = os.path.join(tmpdir, "initial")
accelerator.save_state(initial, safe_serialization=self.use_safetensors)
(a, b) = model.a.item(), model.b.item()
opt_state = optimizer.state_dict()
ground_truth_rands = train(3, model, train_dataloader, optimizer, accelerator)
(a1, b1) = model.a.item(), model.b.item()
opt_state1 = optimizer.state_dict()
# Train partially
set_seed(42)
model = DummyModel()
optimizer = torch.optim.Adam(params=model.parameters(), lr=1e-3)
train_dataloader, valid_dataloader = dummy_dataloaders()
accelerator = Accelerator()
model, optimizer, train_dataloader, valid_dataloader = accelerator.prepare(
model, optimizer, train_dataloader, valid_dataloader
)
accelerator.load_state(initial)
(a2, b2) = model.a.item(), model.b.item()
opt_state2 = optimizer.state_dict()
self.assertEqual(a, a2)
self.assertEqual(b, b2)
assert a == a2
assert b == b2
self.check_adam_state(opt_state, opt_state2, accelerator.distributed_type)
test_rands = train(2, model, train_dataloader, optimizer, accelerator)
# Save everything
checkpoint = os.path.join(tmpdir, "checkpoint")
accelerator.save_state(checkpoint, safe_serialization=self.use_safetensors)
# Load everything back in and make sure all states work
accelerator.load_state(checkpoint)
test_rands += train(1, model, train_dataloader, optimizer, accelerator)
(a3, b3) = model.a.item(), model.b.item()
opt_state3 = optimizer.state_dict()
assert a1 == a3
assert b1 == b3
self.check_adam_state(opt_state1, opt_state3, accelerator.distributed_type)
assert ground_truth_rands == test_rands
def test_can_resume_training(self):
with tempfile.TemporaryDirectory() as tmpdir:
set_seed(42)
model = DummyModel()
optimizer = torch.optim.Adam(params=model.parameters(), lr=1e-3)
train_dataloader, valid_dataloader = dummy_dataloaders()
project_config = ProjectConfiguration(automatic_checkpoint_naming=True)
# Train baseline
accelerator = Accelerator(project_dir=tmpdir, project_config=project_config)
model, optimizer, train_dataloader, valid_dataloader = accelerator.prepare(
model, optimizer, train_dataloader, valid_dataloader
)
# Save initial
accelerator.save_state(safe_serialization=self.use_safetensors)
(a, b) = model.a.item(), model.b.item()
opt_state = optimizer.state_dict()
ground_truth_rands = train(3, model, train_dataloader, optimizer, accelerator)
(a1, b1) = model.a.item(), model.b.item()
opt_state1 = optimizer.state_dict()
# Train partially
set_seed(42)
model = DummyModel()
optimizer = torch.optim.Adam(params=model.parameters(), lr=1e-3)
train_dataloader, valid_dataloader = dummy_dataloaders()
project_config = ProjectConfiguration(iteration=1, automatic_checkpoint_naming=True)
accelerator = Accelerator(project_dir=tmpdir, project_config=project_config)
model, optimizer, train_dataloader, valid_dataloader = accelerator.prepare(
model, optimizer, train_dataloader, valid_dataloader
)
accelerator.load_state(os.path.join(tmpdir, "checkpoints", "checkpoint_0"))
(a2, b2) = model.a.item(), model.b.item()
opt_state2 = optimizer.state_dict()
assert a == a2
assert b == b2
self.check_adam_state(opt_state, opt_state2, accelerator.distributed_type)
test_rands = train(2, model, train_dataloader, optimizer, accelerator)
# Save everything
accelerator.save_state(safe_serialization=self.use_safetensors)
# Load everything back in and make sure all states work
accelerator.load_state(os.path.join(tmpdir, "checkpoints", "checkpoint_1"))
test_rands += train(1, model, train_dataloader, optimizer, accelerator)
(a3, b3) = model.a.item(), model.b.item()
opt_state3 = optimizer.state_dict()
assert a1 == a3
assert b1 == b3
self.check_adam_state(opt_state1, opt_state3, accelerator.distributed_type)
assert ground_truth_rands == test_rands
def test_can_resume_training_checkpoints_relative_path(self):
# See #1983
# This test is like test_can_resume_training but uses a relative path for the checkpoint and automatically
# infers the checkpoint path when loading.
@contextmanager
def temporary_relative_directory():
# This is equivalent to tempfile.TemporaryDirectory() except that it returns a relative path
rand_dir = f"test_path_{uuid.uuid4()}"
os.mkdir(rand_dir)
try:
yield rand_dir
finally:
shutil.rmtree(rand_dir)
with temporary_relative_directory() as tmpdir:
set_seed(42)
model = DummyModel()
optimizer = torch.optim.Adam(params=model.parameters(), lr=1e-3)
train_dataloader, valid_dataloader = dummy_dataloaders()
project_config = ProjectConfiguration(automatic_checkpoint_naming=True)
# Train baseline
accelerator = Accelerator(project_dir=tmpdir, project_config=project_config)
model, optimizer, train_dataloader, valid_dataloader = accelerator.prepare(
model, optimizer, train_dataloader, valid_dataloader
)
# Save initial
accelerator.save_state(safe_serialization=self.use_safetensors)
(a, b) = model.a.item(), model.b.item()
opt_state = optimizer.state_dict()
ground_truth_rands = train(3, model, train_dataloader, optimizer, accelerator)
(a1, b1) = model.a.item(), model.b.item()
opt_state1 = optimizer.state_dict()
# Train partially
set_seed(42)
model = DummyModel()
optimizer = torch.optim.Adam(params=model.parameters(), lr=1e-3)
train_dataloader, valid_dataloader = dummy_dataloaders()
project_config = ProjectConfiguration(iteration=1, automatic_checkpoint_naming=True)
accelerator = Accelerator(project_dir=tmpdir, project_config=project_config)
model, optimizer, train_dataloader, valid_dataloader = accelerator.prepare(
model, optimizer, train_dataloader, valid_dataloader
)
accelerator.load_state() # <= infer the directory automatically
(a2, b2) = model.a.item(), model.b.item()
opt_state2 = optimizer.state_dict()
assert a == a2
assert b == b2
self.check_adam_state(opt_state, opt_state2, accelerator.distributed_type)
assert opt_state == opt_state2
test_rands = train(2, model, train_dataloader, optimizer, accelerator)
# Save everything
accelerator.save_state(safe_serialization=self.use_safetensors)
# Load everything back in and make sure all states work
accelerator.load_state(os.path.join(tmpdir, "checkpoints", "checkpoint_1"))
test_rands += train(1, model, train_dataloader, optimizer, accelerator)
(a3, b3) = model.a.item(), model.b.item()
opt_state3 = optimizer.state_dict()
assert a1 == a3
assert b1 == b3
self.check_adam_state(opt_state1, opt_state3, accelerator.distributed_type)
assert ground_truth_rands == test_rands
def test_invalid_registration(self):
t = torch.tensor([1, 2, 3])
t1 = torch.tensor([2, 3, 4])
net = DummyModel()
opt = torch.optim.Adam(net.parameters())
accelerator = Accelerator()
with self.assertRaises(ValueError) as ve:
accelerator.register_for_checkpointing(t, t1, net, opt)
message = str(ve.exception)
assert "Item at index 0" in message
assert "Item at index 1" in message
assert "Item at index 2" not in message
assert "Item at index 3" not in message
def test_with_scheduler(self):
with tempfile.TemporaryDirectory() as tmpdir:
set_seed(42)
model = DummyModel()
optimizer = torch.optim.Adam(params=model.parameters(), lr=1e-3)
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=1, gamma=0.99)
train_dataloader, valid_dataloader = dummy_dataloaders()
project_config = ProjectConfiguration(automatic_checkpoint_naming=True)
# Train baseline
accelerator = Accelerator(project_dir=tmpdir, project_config=project_config)
model, optimizer, train_dataloader, valid_dataloader, scheduler = accelerator.prepare(
model, optimizer, train_dataloader, valid_dataloader, scheduler
)
# Save initial
accelerator.save_state(safe_serialization=self.use_safetensors)
scheduler_state = scheduler.state_dict()
train(3, model, train_dataloader, optimizer, accelerator, scheduler)
assert scheduler_state != scheduler.state_dict()
# Load everything back in and make sure all states work
accelerator.load_state(os.path.join(tmpdir, "checkpoints", "checkpoint_0"))
assert scheduler_state == scheduler.state_dict()
def test_automatic_loading(self):
with tempfile.TemporaryDirectory() as tmpdir:
set_seed(42)
model = DummyModel()
optimizer = torch.optim.Adam(params=model.parameters(), lr=1e-3)
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=1, gamma=0.99)
train_dataloader, valid_dataloader = dummy_dataloaders()
project_config = ProjectConfiguration(automatic_checkpoint_naming=True)
# Train baseline
accelerator = Accelerator(project_dir=tmpdir, project_config=project_config)
model, optimizer, train_dataloader, valid_dataloader, scheduler = accelerator.prepare(
model, optimizer, train_dataloader, valid_dataloader, scheduler
)
# Save initial
accelerator.save_state(safe_serialization=self.use_safetensors)
train(2, model, train_dataloader, optimizer, accelerator, scheduler)
(a2, b2) = model.a.item(), model.b.item()
# Save a first time
accelerator.save_state(safe_serialization=self.use_safetensors)
train(1, model, train_dataloader, optimizer, accelerator, scheduler)
(a3, b3) = model.a.item(), model.b.item()
# Load back in the last saved checkpoint, should point to a2, b2
accelerator.load_state()
assert a3 != model.a.item()
assert b3 != model.b.item()
assert a2 == model.a.item()
assert b2 == model.b.item()
def test_checkpoint_deletion(self):
with tempfile.TemporaryDirectory() as tmpdir:
set_seed(42)
model = DummyModel()
project_config = ProjectConfiguration(automatic_checkpoint_naming=True, total_limit=2)
# Train baseline
accelerator = Accelerator(project_dir=tmpdir, project_config=project_config)
model = accelerator.prepare(model)
# Save 3 states:
for _ in range(11):
accelerator.save_state(safe_serialization=self.use_safetensors)
assert not os.path.exists(os.path.join(tmpdir, "checkpoints", "checkpoint_0"))
assert os.path.exists(os.path.join(tmpdir, "checkpoints", "checkpoint_9"))
assert os.path.exists(os.path.join(tmpdir, "checkpoints", "checkpoint_10"))
@require_non_cpu
@require_non_torch_xla
def test_map_location(self):
cmd = DEFAULT_LAUNCH_COMMAND + [inspect.getfile(self.__class__)]
execute_subprocess_async(
cmd,
env={
**os.environ,
"USE_SAFETENSORS": str(self.use_safetensors),
"OMP_NUM_THREADS": "1",
},
)
if __name__ == "__main__":
use_safetensors = os.environ.get("USE_SAFETENSORS", "False") == "True"
savedir = "/tmp/accelerate/state_checkpointing"
model = DummyModel()
optimizer = torch.optim.Adam(params=model.parameters(), lr=1e-3)
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=1, gamma=0.99)
train_dataloader, valid_dataloader = dummy_dataloaders()
project_config = ProjectConfiguration(automatic_checkpoint_naming=True)
# Train baseline
accelerator = Accelerator(project_dir=savedir, project_config=project_config, mixed_precision="no")
if accelerator.process_index == 0:
if os.path.exists(savedir):
shutil.rmtree(savedir)
os.makedirs(savedir)
model, optimizer, train_dataloader, valid_dataloader, scheduler = accelerator.prepare(
model, optimizer, train_dataloader, valid_dataloader, scheduler
)
model, optimizer = accelerator.prepare(model, optimizer)
train(3, model, train_dataloader, optimizer, accelerator, scheduler)
# Check that the intial optimizer is loaded on the GPU
for group in optimizer.param_groups:
param_device = group["params"][0].device
break
assert param_device.type == accelerator.device.type
model = model.cpu()
accelerator.wait_for_everyone()
accelerator.save_state(safe_serialization=use_safetensors)
accelerator.wait_for_everyone()
# Check CPU state
accelerator.load_state(os.path.join(savedir, "checkpoints", "checkpoint_0"), map_location="cpu")
for group in optimizer.param_groups:
param_device = group["params"][0].device
break
assert (
param_device.type == torch.device("cpu").type
), f"Loaded optimizer states did not match, expected to be loaded on the CPU but got {param_device}"
# Check device state
model.to(accelerator.device)
accelerator.load_state(os.path.join(savedir, "checkpoints", "checkpoint_0"), map_location="on_device")
for group in optimizer.param_groups:
param_device = group["params"][0].device
break
assert (
param_device.type == accelerator.device.type
), f"Loaded optimizer states did not match, expected to be loaded on {accelerator.device} but got {param_device}"
# Check error
with pytest.raises(TypeError, match="Unsupported optimizer map location passed"):
accelerator.load_state(os.path.join(savedir, "checkpoints", "checkpoint_0"), map_location="invalid")
accelerator.wait_for_everyone()
if accelerator.process_index == 0:
shutil.rmtree(savedir)
accelerator.wait_for_everyone()
| 6 |
0 | hf_public_repos/accelerate | hf_public_repos/accelerate/tests/test_sagemaker.py | # Copyright 2021 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import unittest
from dataclasses import dataclass
import pytest
from accelerate.commands.config.config_args import SageMakerConfig
from accelerate.utils import ComputeEnvironment
from accelerate.utils.launch import _convert_nargs_to_dict
@dataclass
class MockLaunchConfig(SageMakerConfig):
compute_environment = ComputeEnvironment.AMAZON_SAGEMAKER
fp16 = True
ec2_instance_type = "ml.p3.2xlarge"
iam_role_name = "accelerate_sagemaker_execution_role"
profile = "hf-sm"
region = "us-east-1"
num_machines = 1
base_job_name = "accelerate-sagemaker-1"
pytorch_version = "1.6"
transformers_version = "4.4"
training_script = "train.py"
success_training_script_args = [
"--model_name_or_path",
"bert",
"--do_train",
"False",
"--epochs",
"3",
"--learning_rate",
"5e-5",
"--max_steps",
"50.5",
]
fail_training_script_args = [
"--model_name_or_path",
"bert",
"--do_train",
"--do_test",
"False",
"--do_predict",
"--epochs",
"3",
"--learning_rate",
"5e-5",
"--max_steps",
"50.5",
]
class SageMakerLaunch(unittest.TestCase):
def test_args_convert(self):
# If no defaults are changed, `to_kwargs` returns an empty dict.
converted_args = _convert_nargs_to_dict(MockLaunchConfig.success_training_script_args)
assert isinstance(converted_args["model_name_or_path"], str)
assert isinstance(converted_args["do_train"], bool)
assert isinstance(converted_args["epochs"], int)
assert isinstance(converted_args["learning_rate"], float)
assert isinstance(converted_args["max_steps"], float)
with pytest.raises(ValueError):
_convert_nargs_to_dict(MockLaunchConfig.fail_training_script_args)
| 7 |
0 | hf_public_repos/accelerate | hf_public_repos/accelerate/tests/test_optimizer.py | # Copyright 2022 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import pickle
import unittest
import torch
from accelerate import Accelerator
from accelerate.state import AcceleratorState
from accelerate.test_utils import require_cpu, require_non_cpu, require_non_xpu
@require_cpu
class CPUOptimizerTester(unittest.TestCase):
def test_accelerated_optimizer_pickling(self):
model = torch.nn.Linear(10, 10)
optimizer = torch.optim.SGD(model.parameters(), 0.1)
accelerator = Accelerator()
optimizer = accelerator.prepare(optimizer)
try:
pickle.loads(pickle.dumps(optimizer))
except Exception as e:
self.fail(f"Accelerated optimizer pickling failed with {e}")
AcceleratorState._reset_state()
@require_non_cpu
@require_non_xpu
class OptimizerTester(unittest.TestCase):
def test_accelerated_optimizer_step_was_skipped(self):
model = torch.nn.Linear(5, 5)
optimizer = torch.optim.SGD(model.parameters(), 0.1)
accelerator = Accelerator(mixed_precision="fp16")
model, optimizer = accelerator.prepare(model, optimizer)
loss = model(torch.randn(2, 5, device=accelerator.device)).sum()
accelerator.backward(loss)
for p in model.parameters():
# Fake the gradients, as if there's no overflow
p.grad.fill_(0.01)
optimizer.step()
assert optimizer.step_was_skipped is False
loss = model(torch.randn(2, 5, device=accelerator.device)).sum()
accelerator.backward(loss)
for p in model.parameters():
p.grad.fill_(0.01)
# Manually set the gradients to be NaN, as if there's an overflow
p.grad[0] = torch.tensor(float("nan"))
optimizer.step()
assert optimizer.step_was_skipped is True
loss = model(torch.randn(2, 5, device=accelerator.device)).sum()
accelerator.backward(loss)
for p in model.parameters():
p.grad.fill_(0.01)
# Manually set the gradients to be NaN, as if there's an overflow
p.grad[0] = torch.tensor(float("nan"))
optimizer.step()
assert optimizer.step_was_skipped is True
loss = model(torch.randn(2, 5, device=accelerator.device)).sum()
accelerator.backward(loss)
for p in model.parameters():
# Fake the gradients, as if there's no overflow
p.grad.fill_(0.01)
optimizer.step()
assert optimizer.step_was_skipped is False
AcceleratorState._reset_state()
| 8 |
0 | hf_public_repos/accelerate | hf_public_repos/accelerate/tests/test_hooks.py | # Copyright 2022 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import inspect
import unittest
import torch
import torch.nn as nn
from torch.fx import symbolic_trace
from accelerate.hooks import (
AlignDevicesHook,
ModelHook,
SequentialHook,
add_hook_to_module,
attach_align_device_hook,
remove_hook_from_module,
remove_hook_from_submodules,
)
from accelerate.test_utils import require_multi_device, torch_device
torch_device = f"{torch_device}:0" if torch_device != "cpu" else "cpu"
class ModelForTest(nn.Module):
def __init__(self):
super().__init__()
self.linear1 = nn.Linear(3, 4)
self.batchnorm = nn.BatchNorm1d(4)
self.linear2 = nn.Linear(4, 5)
def forward(self, x):
return self.linear2(self.batchnorm(self.linear1(x)))
class PreForwardHook(ModelHook):
def pre_forward(self, module, *args, **kwargs):
return (args[0] + 1,) + args[1:], kwargs
class PostForwardHook(ModelHook):
def post_forward(self, module, output):
return output + 1
class HooksModelTester(unittest.TestCase):
def test_add_and_remove_hooks(self):
test_model = ModelForTest()
test_hook = ModelHook()
add_hook_to_module(test_model, test_hook)
assert test_model._hf_hook == test_hook
assert hasattr(test_model, "_old_forward")
# Check adding the hook did not change the name or the signature
assert test_model.forward.__name__ == "forward"
assert list(inspect.signature(test_model.forward).parameters) == ["x"]
remove_hook_from_module(test_model)
assert not hasattr(test_model, "_hf_hook")
assert not hasattr(test_model, "_old_forward")
def test_append_and_remove_hooks(self):
test_model = ModelForTest()
test_hook = ModelHook()
add_hook_to_module(test_model, test_hook)
add_hook_to_module(test_model, test_hook, append=True)
assert isinstance(test_model._hf_hook, SequentialHook) is True
assert len(test_model._hf_hook.hooks) == 2
assert hasattr(test_model, "_old_forward")
# Check adding the hook did not change the name or the signature
assert test_model.forward.__name__ == "forward"
assert list(inspect.signature(test_model.forward).parameters) == ["x"]
remove_hook_from_module(test_model)
assert not hasattr(test_model, "_hf_hook")
assert not hasattr(test_model, "_old_forward")
def test_pre_forward_hook_is_executed(self):
test_model = ModelForTest()
x = torch.randn(2, 3)
expected = test_model(x + 1)
expected2 = test_model(x + 2)
test_hook = PreForwardHook()
add_hook_to_module(test_model, test_hook)
output1 = test_model(x)
assert torch.allclose(output1, expected, atol=1e-5)
# Attaching a hook to a model when it already has one replaces, does not chain
test_hook = PreForwardHook()
add_hook_to_module(test_model, test_hook)
output1 = test_model(x)
assert torch.allclose(output1, expected, atol=1e-5)
# You need to use the sequential hook to chain two or more hooks
test_hook = SequentialHook(PreForwardHook(), PreForwardHook())
add_hook_to_module(test_model, test_hook)
output2 = test_model(x)
assert torch.allclose(output2, expected2, atol=1e-5)
def test_post_forward_hook_is_executed(self):
test_model = ModelForTest()
x = torch.randn(2, 3)
output = test_model(x)
test_hook = PostForwardHook()
add_hook_to_module(test_model, test_hook)
output1 = test_model(x)
assert torch.allclose(output1, (output + 1), atol=1e-5)
# Attaching a hook to a model when it already has one replaces, does not chain
test_hook = PostForwardHook()
add_hook_to_module(test_model, test_hook)
output1 = test_model(x)
assert torch.allclose(output1, (output + 1), atol=1e-5)
# You need to use the sequential hook to chain two or more hooks
test_hook = SequentialHook(PostForwardHook(), PostForwardHook())
add_hook_to_module(test_model, test_hook)
output2 = test_model(x)
assert torch.allclose(output2, output + 2, atol=1e-5)
def test_no_grad_in_hook(self):
test_model = ModelForTest()
x = torch.randn(2, 3)
output = test_model(x)
test_hook = PostForwardHook()
add_hook_to_module(test_model, test_hook)
output1 = test_model(x)
assert torch.allclose(output1, (output + 1))
assert output1.requires_grad
test_hook.no_grad = True
output1 = test_model(x)
assert not output1.requires_grad
@require_multi_device
def test_align_devices_as_model_parallelism(self):
model = ModelForTest()
# Everything is on CPU
assert model.linear1.weight.device == torch.device("cpu")
assert model.batchnorm.weight.device == torch.device("cpu")
assert model.linear2.weight.device == torch.device("cpu")
# This will move each submodule on different devices
add_hook_to_module(model.linear1, AlignDevicesHook(execution_device=0))
add_hook_to_module(model.batchnorm, AlignDevicesHook(execution_device=0))
add_hook_to_module(model.linear2, AlignDevicesHook(execution_device=1))
assert model.linear1.weight.device == torch.device(torch_device)
assert model.batchnorm.weight.device == torch.device(torch_device)
assert model.batchnorm.running_mean.device == torch.device(torch_device)
assert model.linear2.weight.device == torch.device(torch_device.replace(":0", ":1"))
# We can still make a forward pass. The input does not need to be on any particular device
x = torch.randn(2, 3)
output = model(x)
assert output.device == torch.device(torch_device.replace(":0", ":1"))
# We can add a general hook to put back output on same device as input.
add_hook_to_module(model, AlignDevicesHook(io_same_device=True))
x = torch.randn(2, 3).to(torch_device)
output = model(x)
assert output.device == torch.device(torch_device)
def test_align_devices_as_cpu_offload(self):
model = ModelForTest()
# Everything is on CPU
assert model.linear1.weight.device == torch.device("cpu")
assert model.batchnorm.weight.device == torch.device("cpu")
assert model.linear2.weight.device == torch.device("cpu")
# This will move each submodule on different devices
hook_kwargs = {"execution_device": torch_device, "offload": True}
add_hook_to_module(model.linear1, AlignDevicesHook(**hook_kwargs))
add_hook_to_module(model.batchnorm, AlignDevicesHook(**hook_kwargs))
add_hook_to_module(model.linear2, AlignDevicesHook(**hook_kwargs))
# Parameters have been offloaded, so on the meta device
assert model.linear1.weight.device == torch.device("meta")
assert model.batchnorm.weight.device == torch.device("meta")
assert model.linear2.weight.device == torch.device("meta")
# Buffers are not included in the offload by default, so are on the execution device
device = torch.device(hook_kwargs["execution_device"])
assert model.batchnorm.running_mean.device == device
x = torch.randn(2, 3)
output = model(x)
assert output.device == device
# Removing hooks loads back the weights in the model.
remove_hook_from_module(model.linear1)
remove_hook_from_module(model.batchnorm)
remove_hook_from_module(model.linear2)
assert model.linear1.weight.device == torch.device("cpu")
assert model.batchnorm.weight.device == torch.device("cpu")
assert model.linear2.weight.device == torch.device("cpu")
# Now test with buffers included in the offload
hook_kwargs = {
"execution_device": torch_device,
"offload": True,
"offload_buffers": True,
}
add_hook_to_module(model.linear1, AlignDevicesHook(**hook_kwargs))
add_hook_to_module(model.batchnorm, AlignDevicesHook(**hook_kwargs))
add_hook_to_module(model.linear2, AlignDevicesHook(**hook_kwargs))
# Parameters have been offloaded, so on the meta device, buffers included
assert model.linear1.weight.device == torch.device("meta")
assert model.batchnorm.weight.device == torch.device("meta")
assert model.linear2.weight.device == torch.device("meta")
assert model.batchnorm.running_mean.device == torch.device("meta")
x = torch.randn(2, 3)
output = model(x)
assert output.device == device
# Removing hooks loads back the weights in the model.
remove_hook_from_module(model.linear1)
remove_hook_from_module(model.batchnorm)
remove_hook_from_module(model.linear2)
assert model.linear1.weight.device == torch.device("cpu")
assert model.batchnorm.weight.device == torch.device("cpu")
assert model.linear2.weight.device == torch.device("cpu")
def test_attach_align_device_hook_as_cpu_offload(self):
model = ModelForTest()
# Everything is on CPU
assert model.linear1.weight.device == torch.device("cpu")
assert model.batchnorm.weight.device == torch.device("cpu")
assert model.linear2.weight.device == torch.device("cpu")
# This will move each submodule on different devices
execution_device = torch_device
attach_align_device_hook(model, execution_device=execution_device, offload=True)
# Parameters have been offloaded, so on the meta device
assert model.linear1.weight.device == torch.device("meta")
assert model.batchnorm.weight.device == torch.device("meta")
assert model.linear2.weight.device == torch.device("meta")
# Buffers are not included in the offload by default, so are on the execution device
device = torch.device(execution_device)
assert model.batchnorm.running_mean.device == device
x = torch.randn(2, 3)
output = model(x)
assert output.device == device
# Removing hooks loads back the weights in the model.
remove_hook_from_submodules(model)
assert model.linear1.weight.device == torch.device("cpu")
assert model.batchnorm.weight.device == torch.device("cpu")
assert model.linear2.weight.device == torch.device("cpu")
# Now test with buffers included in the offload
attach_align_device_hook(model, execution_device=execution_device, offload=True, offload_buffers=True)
# Parameters have been offloaded, so on the meta device, buffers included
assert model.linear1.weight.device == torch.device("meta")
assert model.batchnorm.weight.device == torch.device("meta")
assert model.linear2.weight.device == torch.device("meta")
assert model.batchnorm.running_mean.device == torch.device("meta")
x = torch.randn(2, 3)
output = model(x)
assert output.device == device
# Removing hooks loads back the weights in the model.
remove_hook_from_submodules(model)
assert model.linear1.weight.device == torch.device("cpu")
assert model.batchnorm.weight.device == torch.device("cpu")
assert model.linear2.weight.device == torch.device("cpu")
def test_attach_align_device_hook_as_cpu_offload_with_weight_map(self):
model = ModelForTest()
# Everything is on CPU
assert model.linear1.weight.device == torch.device("cpu")
assert model.batchnorm.weight.device == torch.device("cpu")
assert model.linear2.weight.device == torch.device("cpu")
# This will move each submodule on different devices
execution_device = torch_device
attach_align_device_hook(
model, execution_device=execution_device, offload=True, weights_map=model.state_dict()
)
# Parameters have been offloaded, so on the meta device
assert model.linear1.weight.device == torch.device("meta")
assert model.batchnorm.weight.device == torch.device("meta")
assert model.linear2.weight.device == torch.device("meta")
# Buffers are not included in the offload by default, so are on the execution device
device = torch.device(execution_device)
assert model.batchnorm.running_mean.device == device
x = torch.randn(2, 3)
output = model(x)
assert output.device == device
# Removing hooks loads back the weights in the model.
remove_hook_from_submodules(model)
assert model.linear1.weight.device == torch.device("cpu")
assert model.batchnorm.weight.device == torch.device("cpu")
assert model.linear2.weight.device == torch.device("cpu")
# Now test with buffers included in the offload
attach_align_device_hook(
model,
execution_device=execution_device,
offload=True,
weights_map=model.state_dict(),
offload_buffers=True,
)
# Parameters have been offloaded, so on the meta device, buffers included
assert model.linear1.weight.device == torch.device("meta")
assert model.batchnorm.weight.device == torch.device("meta")
assert model.linear2.weight.device == torch.device("meta")
assert model.batchnorm.running_mean.device == torch.device("meta")
x = torch.randn(2, 3)
output = model(x)
assert output.device == device
# Removing hooks loads back the weights in the model.
remove_hook_from_submodules(model)
assert model.linear1.weight.device == torch.device("cpu")
assert model.batchnorm.weight.device == torch.device("cpu")
assert model.linear2.weight.device == torch.device("cpu")
def test_add_remove_hook_fx_graph_module(self):
with torch.no_grad():
test_model = ModelForTest()
test_hook = ModelHook()
x = torch.randn(2, 3)
output1 = test_model(x)
graph_model = symbolic_trace(test_model)
output2 = graph_model(x)
assert torch.allclose(output1, output2)
add_hook_to_module(graph_model, test_hook)
remove_hook_from_module(graph_model, recurse=True)
# We want to make sure that `add_hook_to_module` and `remove_hook_from_module` yields back an fx.GraphModule
# that behaves correctly (for example that is not frozen, see https://github.com/huggingface/accelerate/pull/2369).
# For that, we add a sigmoid node to the FX graph and make sure that the new output (output3 below) is different than
# the original model's output.
linear2_node = None
for node in graph_model.graph.nodes:
if node.name == "linear2":
linear2_node = node
assert linear2_node is not None
graph_model.graph.inserting_after(linear2_node)
new_node = graph_model.graph.create_node(
op="call_function", target=torch.sigmoid, args=(linear2_node,), name="relu"
)
output_node = None
for node in graph_model.graph.nodes:
if node.name == "output":
output_node = node
assert output_node is not None
output_node.replace_input_with(linear2_node, new_node)
graph_model.graph.lint()
graph_model.recompile()
output3 = graph_model(x)
# Now the output is expected to be different since we modified the graph.
assert not torch.allclose(output1, output3)
| 9 |
0 | hf_public_repos/alignment-handbook/recipes | hf_public_repos/alignment-handbook/recipes/pref_align_scan/README.md | # Comparing Preference Alignment Algorithms
This directory contains various comparisons for three algorithms: DPO, IPO, and KTO. Each algorithm has been run in different hyperparameter configurations to study their performance. Two different models and datasets have been used to compare the performance of each algorithm:
- zephyr-beta-sft and Ultrafeedback
- OpenHermes-2.5 and the OpenOrca datasets
We release a collection containing the datasets and models used for these experiments, if you require the other trained models, we can release them on request.
You can find a longer description of these results in our [blogpost](https://huggingface.co/blog/pref-tuning)
## Comparisons
For each algorithm, we aim to tune the beta parameter for a fixed learning rate. We vary beta from 0.1-0.9 in steps of 0.1, we have also found that in certain configurations a tiny value of beta, 0.01, can be effective. So we have included this smaller value in all our comparisons.
## Usage
The experiments can be launched with the following bash script:
```bash
#!/bin/bash
# Define an array containing the base configs we wish to fine tune
configs=("zephyr" "openhermes")
# Define an array of loss types
loss_types=("sigmoid" "kto_pair" "ipo")
# Define an array of beta values
betas=("0.01" "0.1" "0.2" "0.3" "0.4" "0.5" "0.6" "0.7" "0.8" "0.9")
# Outer loop for loss types
for config in "${configs[@]}"; do
for loss_type in "${loss_types[@]}"; do
# Inner loop for beta values
for beta in "${betas[@]}"; do
# Determine the job name and model revision based on loss type
job_name="$config_${loss_type}_beta_${beta}"
model_revision="${loss_type}-${beta}"
# Submit the job
sbatch --job-name=${job_name} recipes/launch.slurm pref_align_scan dpo $config deepspeed_zero3 \
"--beta=${beta} --loss_type=${loss_type} --output_dir=data/$config-7b-align-scan-${loss_type}-beta-${beta} --hub_model_revision=${model_revision}"
done
done
done
```
| 0 |
0 | hf_public_repos/alignment-handbook/recipes/pref_align_scan | hf_public_repos/alignment-handbook/recipes/pref_align_scan/dpo/config_openhermes.yaml | # Model arguments
model_name_or_path: teknium/OpenHermes-2.5-Mistral-7B
torch_dtype: null
# Data training arguments
dataset_mixer:
HuggingFaceH4/orca_dpo_pairs: 1.0
dataset_splits:
- train_prefs
- test_prefs
preprocessing_num_workers: 12
# Training arguments with sensible defaults
bf16: true
beta: 0.01
loss_type: sigmoid
do_eval: true
do_train: true
eval_strategy: steps
eval_steps: 100
gradient_accumulation_steps: 2
gradient_checkpointing: true
gradient_checkpointing_kwargs:
use_reentrant: False
hub_model_id: HuggingFaceH4/openhermes-2.5-mistral-7b-dpo
hub_model_revision: v1.0
learning_rate: 5.0e-7
logging_steps: 10
lr_scheduler_type: cosine
max_prompt_length: 512
num_train_epochs: 1
optim: adamw_torch
output_dir: data/openhermes-2.5-mistral-7b-dpo-v1.0
per_device_train_batch_size: 8
per_device_eval_batch_size: 8
save_strategy: "steps"
save_steps: 100
save_total_limit: 1
seed: 42
warmup_ratio: 0.1 | 1 |
0 | hf_public_repos/alignment-handbook/recipes/pref_align_scan | hf_public_repos/alignment-handbook/recipes/pref_align_scan/dpo/config_zephyr.yaml | # Model arguments
model_name_or_path: alignment-handbook/zephyr-7b-sft-full
torch_dtype: null
# Data training arguments
dataset_mixer:
HuggingFaceH4/ultrafeedback_binarized: 1.0
dataset_splits:
- train_prefs
- test_prefs
preprocessing_num_workers: 12
# Training arguments with sensible defaults
bf16: true
beta: 0.01
loss_type: sigmoid
do_eval: true
eval_strategy: steps
eval_steps: 100
gradient_accumulation_steps: 2
gradient_checkpointing: true
gradient_checkpointing_kwargs:
use_reentrant: False
hub_model_id: zephyr-7b-align-scan
hub_model_revision: dpo-beta-0.01
learning_rate: 5.0e-7
logging_steps: 10
lr_scheduler_type: cosine
max_prompt_length: 512
num_train_epochs: 1
optim: adamw_torch
output_dir: data/zephyr-7b-align-scan-dpo-beta-0.01
per_device_train_batch_size: 8
per_device_eval_batch_size: 8
save_strategy: "steps"
save_steps: 100
save_total_limit: 1
seed: 42
warmup_ratio: 0.1 | 2 |
0 | hf_public_repos/alignment-handbook/recipes | hf_public_repos/alignment-handbook/recipes/smollm2/README.md |
# Instructions to train SmolLM2-1.7B-Instruct
We build the [SmolLM2-Instruct](https://huggingface.co/collections/HuggingFaceTB/smollm2-6723884218bcda64b34d7db9) by doing SFT on [SmolTalk](https://huggingface.co/datasets/HuggingFaceTB/smoltalk) and then DPO on [UltraFeedBack](https://huggingface.co/datasets/HuggingFaceH4/ultrafeedback_binarized).
## Setup
Follow the installation instructions in https://github.com/huggingface/alignment-handbook/tree/main?tab=readme-ov-file#installation-instructions
## Training
We train the 1.7B on 8 GPUs using the following command:
```shell
# SFT
ACCELERATE_LOG_LEVEL=info accelerate launch --config_file recipes/accelerate_configs/deepspeed_zero3.yaml scripts/run_sft.py recipes/smollm2/sft/config.yaml
# DPO
ACCELERATE_LOG_LEVEL=info accelerate launch --config_file recipes/accelerate_configs/deepspeed_zero3.yaml scripts/run_dpo.py recipes/smollm2/dpo/config.yaml
```
For the 135M and 360M we use [smol-smoltalk](https://huggingface.co/datasets/HuggingFaceTB/smol-smoltalk) dataset for SFT and UltraFeedback for DPO:
```shell
# SFT
ACCELERATE_LOG_LEVEL=info accelerate launch --config_file recipes/accelerate_configs/deepspeed_zero3.yaml scripts/run_sft.py recipes/smollm2/sft/config_smol.yaml
# DPO
ACCELERATE_LOG_LEVEL=info accelerate launch --config_file recipes/accelerate_configs/deepspeed_zero3.yaml scripts/run_dpo.py recipes/smollm2/dpo/config_smol.yaml
``` | 3 |
0 | hf_public_repos/alignment-handbook/recipes/smollm2 | hf_public_repos/alignment-handbook/recipes/smollm2/dpo/config_smol.yaml | # Model arguments
model_name_or_path: loubnabnl/smollm2-360M-sft # we use this script for the 135M model too
torch_dtype: bfloat16
# Data training arguments
dataset_mixer:
HuggingFaceH4/ultrafeedback_binarized: 1.0
dataset_splits:
- train_prefs
- test_prefs
preprocessing_num_workers: 12
# DPOTrainer arguments
bf16: true
beta: 0.5
do_eval: true
hub_private_repo: true
eval_strategy: steps
eval_steps: 100
gradient_accumulation_steps: 8
gradient_checkpointing: true
gradient_checkpointing_kwargs:
use_reentrant: False
hub_model_id: smollm2-360M-dpo
learning_rate: 1.0e-6
log_level: info
logging_steps: 10
lr_scheduler_type: cosine
max_length: 1024
max_prompt_length: 512
num_train_epochs: 2
optim: adamw_torch
output_dir: data/smollm2-360M-dpo
per_device_train_batch_size: 2
per_device_eval_batch_size: 4
push_to_hub: true
report_to:
- tensorboard
- wandb
save_strategy: "no"
seed: 42
warmup_ratio: 0.1 | 4 |
0 | hf_public_repos/alignment-handbook/recipes/smollm2 | hf_public_repos/alignment-handbook/recipes/smollm2/dpo/config.yaml | # Model arguments
model_name_or_path: loubnabnl/smollm2-1.7B-sft
torch_dtype: bfloat16
# Data training arguments
dataset_mixer:
HuggingFaceH4/ultrafeedback_binarized: 1.0
dataset_splits:
- train_prefs
- test_prefs
preprocessing_num_workers: 12
# DPOTrainer arguments
bf16: true
beta: 0.5
do_eval: true
hub_private_repo: true
eval_strategy: steps
eval_steps: 100
gradient_accumulation_steps: 8
gradient_checkpointing: true
gradient_checkpointing_kwargs:
use_reentrant: False
hub_model_id: smollm2-1.7B-dpo
learning_rate: 1.0e-6
log_level: info
logging_steps: 10
lr_scheduler_type: cosine
max_length: 1024
max_prompt_length: 512
num_train_epochs: 3
optim: adamw_torch
output_dir: data/smollm2-1.7B-dpo
per_device_train_batch_size: 2
per_device_eval_batch_size: 4
push_to_hub: true
report_to:
- tensorboard
- wandb
save_strategy: "no"
seed: 42
warmup_ratio: 0.1 | 5 |
0 | hf_public_repos/alignment-handbook/recipes/smollm2 | hf_public_repos/alignment-handbook/recipes/smollm2/sft/config_smol.yaml | # Model arguments
model_name_or_path: HuggingFaceTB/SmolLM2-360M # we use this script for the 135M model too
model_revision: main
tokenizer_name_or_path: HuggingFaceTB/SmolLM2-360M-Instruct # Custom tokenizer with <|im_start|> and <|im_end|> tokens
torch_dtype: bfloat16
use_flash_attention_2: true
# Data training arguments
dataset_mixer:
HuggingFaceTB/smol-smoltalk: 1.0
dataset_splits:
- train
- test
preprocessing_num_workers: 36
# SFT trainer config
bf16: true
do_eval: true
evaluation_strategy: epoch
gradient_accumulation_steps: 4
gradient_checkpointing: true
gradient_checkpointing_kwargs:
use_reentrant: false
hub_model_id: smollm2-360M-sft
hub_strategy: every_save
learning_rate: 1.0e-03 # 3e-4
log_level: info
logging_steps: 5
logging_strategy: steps
lr_scheduler_type: cosine
max_seq_length: 8192
max_steps: -1
num_train_epochs: 2
output_dir: data/smollm2-360M-sft
overwrite_output_dir: true
per_device_eval_batch_size: 4
per_device_train_batch_size: 4
push_to_hub: true
remove_unused_columns: true
report_to:
- tensorboard
- wandb
save_strategy: "no"
seed: 42
warmup_ratio: 0.1 | 6 |
0 | hf_public_repos/alignment-handbook/recipes/smollm2 | hf_public_repos/alignment-handbook/recipes/smollm2/sft/config.yaml | # Model arguments
model_name_or_path: HuggingFaceTB/SmolLM2-1.7B
model_revision: main
tokenizer_name_or_path: HuggingFaceTB/SmolLM2-1.7B-Instruct # Custom tokenizer with <|im_start|> and <|im_end|> tokens
torch_dtype: bfloat16
use_flash_attention_2: true
# Data training arguments
dataset_mixer:
HuggingFaceTB/smoltalk: 1.0
dataset_configs:
- all
dataset_splits:
- train
- test
preprocessing_num_workers: 36
# SFT trainer config
bf16: true
do_eval: true
evaluation_strategy: epoch
gradient_accumulation_steps: 4
gradient_checkpointing: true
gradient_checkpointing_kwargs:
use_reentrant: false
hub_model_id: smollm2-1.7B-sft
hub_strategy: every_save
learning_rate: 3.0e-04
log_level: info
logging_steps: 5
logging_strategy: steps
lr_scheduler_type: cosine
max_seq_length: 8192
max_steps: -1
num_train_epochs: 2
output_dir: data/smollm2-1.7B-sft
overwrite_output_dir: true
per_device_eval_batch_size: 4
per_device_train_batch_size: 4
push_to_hub: true
remove_unused_columns: true
report_to:
- tensorboard
- wandb
save_strategy: "no"
seed: 42
warmup_ratio: 0.1 | 7 |
0 | hf_public_repos/alignment-handbook/recipes | hf_public_repos/alignment-handbook/recipes/gpt2-nl/README.md | # Language Adaptation through Continued Pretraining
This directory shows a base example of how to use continued pretraining and further tuning to adapt a language model to new data (e.g. a new language or domain).
Three steps are needed: continued pretraining (`cpt`), supervised finetuning (`sft`), and direct preference optimisation (`dpo`). In this dummy example, we'll continue pretraining gpt2 on Dutch raw data, then sft-tuning it, and finally aligning it with DPO. Note that no extensive hyperparameters were tested in this example and that the output models are bad - it is just to show you how you can use the scripts for LM adaptation. The scripts work on 4x 3090s (24GB VRAM). If you have less powerful hardware you may need to reduce the batch size.
## Continued pretraining
This step will further pretrain the original `gpt2` model on plain Dutch text. Note that the script will by default use the `text` column in the dataset but you can change that by specifying `text_column` in the yaml file or on the command-line.
```shell
ACCELERATE_LOG_LEVEL=info accelerate launch \
--config_file recipes/accelerate_configs/multi_gpu.yaml \
--num_processes 4 \
scripts/run_cpt.py \
recipes/gpt2-nl/cpt/config_full.yaml
```
## Supervised finetuning
As other recipes, such as the famous zephyr-7b-beta recipe, have shown, we can then teach our model how to hold a conversation by finetuning it on chat-formatted data. As a base model, we'll make use of the output of the previous step.
```shell
ACCELERATE_LOG_LEVEL=info accelerate launch \
--config_file recipes/accelerate_configs/multi_gpu.yaml \
--num_processes 4 \
scripts/run_sft.py recipes/gpt2-nl/sft/config_full.yaml
```
## Direct preference optimisation
Finally, to align the model better with feedback, we can finetune the SFT output with the DPO algorithm. This should improve the quality of the chat capabilities of the model.
```shell
ACCELERATE_LOG_LEVEL=info accelerate launch \
--config_file recipes/accelerate_configs/multi_gpu.yaml \
--num_processes 4 \
scripts/run_dpo.py recipes/gpt2-nl/dpo/config_full.yaml
```
## Conclusion
With the steps above you can adapt an LM to a new domain, more data, or even a different language. Then, with sft and dpo, you can end up building a powerful chatbot, too! All within just three simple commands. It should be obvious that all of these follow a very similar approach, which makes them suitable to apply in parameterized slurm jobs. The neat part is that you can easily overwrite arguments in the yaml files by specifying the overwriting argument as a command-line argument, so the adaptability is also great.
| 8 |
0 | hf_public_repos/alignment-handbook/recipes/gpt2-nl | hf_public_repos/alignment-handbook/recipes/gpt2-nl/dpo/config_full.yaml | # Model arguments
model_name_or_path: BramVanroy/gpt2-sft-dutch
model_revision: main
torch_dtype: bfloat16
# Data training arguments
# For definitions, see: src/h4/training/config.py
dataset_mixer:
BramVanroy/ultra_feedback_dutch: 1.0
dataset_splits:
- train_prefs
- test_prefs
preprocessing_num_workers: 12
# DPOTrainer arguments
bf16: true
beta: 0.1
do_eval: true
eval_strategy: steps
eval_steps: 100
gradient_accumulation_steps: 8
gradient_checkpointing: true
gradient_checkpointing_kwargs:
use_reentrant: False
hub_model_id: gpt2-dpo-dutch
learning_rate: 5.0e-7
log_level: info
logging_steps: 10
lr_scheduler_type: cosine
max_length: 1024
max_prompt_length: 512
num_train_epochs: 1
optim: adamw_torch
output_dir: data/gpt2-dpo-dutch
per_device_train_batch_size: 8
per_device_eval_batch_size: 8
push_to_hub: true
save_strategy: "steps"
save_steps: 100
save_total_limit: 1
seed: 42
warmup_ratio: 0.1
report_to:
- wandb
| 9 |
0 | hf_public_repos/candle/candle-wasm-examples | hf_public_repos/candle/candle-wasm-examples/segment-anything/samWorker.js | //load the candle SAM Model wasm module
import init, { Model } from "./build/m.js";
async function fetchArrayBuffer(url, cacheModel = true) {
if (!cacheModel)
return new Uint8Array(await (await fetch(url)).arrayBuffer());
const cacheName = "sam-candle-cache";
const cache = await caches.open(cacheName);
const cachedResponse = await cache.match(url);
if (cachedResponse) {
const data = await cachedResponse.arrayBuffer();
return new Uint8Array(data);
}
const res = await fetch(url, { cache: "force-cache" });
cache.put(url, res.clone());
return new Uint8Array(await res.arrayBuffer());
}
class SAMModel {
static instance = {};
// keep current image embeddings state
static imageArrayHash = {};
// Add a new property to hold the current modelID
static currentModelID = null;
static async getInstance(modelURL, modelID) {
if (!this.instance[modelID]) {
await init();
self.postMessage({
status: "loading",
message: `Loading Model ${modelID}`,
});
const weightsArrayU8 = await fetchArrayBuffer(modelURL);
this.instance[modelID] = new Model(
weightsArrayU8,
/tiny|mobile/.test(modelID)
);
} else {
self.postMessage({ status: "loading", message: "Model Already Loaded" });
}
// Set the current modelID to the modelID that was passed in
this.currentModelID = modelID;
return this.instance[modelID];
}
// Remove the modelID parameter from setImageEmbeddings
static setImageEmbeddings(imageArrayU8) {
// check if image embeddings are already set for this image and model
const imageArrayHash = this.getSimpleHash(imageArrayU8);
if (
this.imageArrayHash[this.currentModelID] === imageArrayHash &&
this.instance[this.currentModelID]
) {
self.postMessage({
status: "embedding",
message: "Embeddings Already Set",
});
return;
}
this.imageArrayHash[this.currentModelID] = imageArrayHash;
this.instance[this.currentModelID].set_image_embeddings(imageArrayU8);
self.postMessage({ status: "embedding", message: "Embeddings Set" });
}
static getSimpleHash(imageArrayU8) {
// get simple hash of imageArrayU8
let imageArrayHash = 0;
for (let i = 0; i < imageArrayU8.length; i += 100) {
imageArrayHash ^= imageArrayU8[i];
}
return imageArrayHash.toString(16);
}
}
async function createImageCanvas(
{ mask_shape, mask_data }, // mask
{ original_width, original_height, width, height } // original image
) {
const [_, __, shape_width, shape_height] = mask_shape;
const maskCanvas = new OffscreenCanvas(shape_width, shape_height); // canvas for mask
const maskCtx = maskCanvas.getContext("2d");
const canvas = new OffscreenCanvas(original_width, original_height); // canvas for creating mask with original image size
const ctx = canvas.getContext("2d");
const imageData = maskCtx.createImageData(
maskCanvas.width,
maskCanvas.height
);
const data = imageData.data;
for (let p = 0; p < data.length; p += 4) {
data[p] = 0;
data[p + 1] = 0;
data[p + 2] = 0;
data[p + 3] = mask_data[p / 4] * 255;
}
maskCtx.putImageData(imageData, 0, 0);
let sx, sy;
if (original_height < original_width) {
sy = original_height / original_width;
sx = 1;
} else {
sy = 1;
sx = original_width / original_height;
}
ctx.drawImage(
maskCanvas,
0,
0,
maskCanvas.width * sx,
maskCanvas.height * sy,
0,
0,
original_width,
original_height
);
const blob = await canvas.convertToBlob();
return URL.createObjectURL(blob);
}
self.addEventListener("message", async (event) => {
const { modelURL, modelID, imageURL, points } = event.data;
try {
self.postMessage({ status: "loading", message: "Starting SAM" });
const sam = await SAMModel.getInstance(modelURL, modelID);
self.postMessage({ status: "loading", message: "Loading Image" });
const imageArrayU8 = await fetchArrayBuffer(imageURL, false);
self.postMessage({ status: "embedding", message: "Creating Embeddings" });
SAMModel.setImageEmbeddings(imageArrayU8);
if (!points) {
// no points only do the embeddings
self.postMessage({
status: "complete-embedding",
message: "Embeddings Complete",
});
return;
}
self.postMessage({ status: "segmenting", message: "Segmenting" });
const { mask, image } = sam.mask_for_point({ points });
const maskDataURL = await createImageCanvas(mask, image);
// Send the segment back to the main thread as JSON
self.postMessage({
status: "complete",
message: "Segmentation Complete",
output: { maskURL: maskDataURL },
});
} catch (e) {
self.postMessage({ error: e });
}
});
| 0 |
0 | hf_public_repos/candle/candle-wasm-examples | hf_public_repos/candle/candle-wasm-examples/segment-anything/Cargo.toml | [package]
name = "candle-wasm-example-sam"
version.workspace = true
edition.workspace = true
description.workspace = true
repository.workspace = true
keywords.workspace = true
categories.workspace = true
license.workspace = true
[dependencies]
candle = { workspace = true }
candle-nn = { workspace = true }
candle-transformers = { workspace = true }
num-traits = { workspace = true }
# App crates.
anyhow = { workspace = true }
byteorder = { workspace = true }
getrandom = { version = "0.2", features = ["js"] }
image = { workspace = true }
log = { workspace = true }
safetensors = { workspace = true }
serde = { workspace = true }
serde_json = { workspace = true }
# Wasm specific crates.
console_error_panic_hook = "0.1.7"
wasm-bindgen = "0.2.87"
serde-wasm-bindgen = "0.6.0"
| 1 |
0 | hf_public_repos/candle/candle-wasm-examples | hf_public_repos/candle/candle-wasm-examples/segment-anything/build-lib.sh | cargo build --target wasm32-unknown-unknown --release
wasm-bindgen ../../target/wasm32-unknown-unknown/release/m.wasm --out-dir build --target web
| 2 |
0 | hf_public_repos/candle/candle-wasm-examples | hf_public_repos/candle/candle-wasm-examples/segment-anything/lib-example.html | <html>
<head>
<meta content="text/html;charset=utf-8" http-equiv="Content-Type" />
<title>Candle Segment Anything Model (SAM) Rust/WASM</title>
</head>
<body></body>
</html>
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<style>
@import url("https://fonts.googleapis.com/css2?family=Source+Code+Pro:wght@200;300;400&family=Source+Sans+3:wght@100;200;300;400;500;600;700;800;900&display=swap");
html,
body {
font-family: "Source Sans 3", sans-serif;
}
</style>
<script src="https://cdn.tailwindcss.com"></script>
<script type="module">
// base url for image examples
const MODEL_BASEURL =
"https://huggingface.co/lmz/candle-sam/resolve/main/";
// models base url
const MODELS = {
sam_mobile_tiny: {
url: "mobile_sam-tiny-vitt.safetensors",
},
sam_base: {
url: "sam_vit_b_01ec64.safetensors",
},
};
const samWorker = new Worker("./samWorker.js", { type: "module" });
async function segmentPoints(
modelURL, // URL to the weights file
modelID, // model ID
imageURL, // URL to the image file
points // {x, y} points to prompt image
) {
return new Promise((resolve, reject) => {
function messageHandler(event) {
console.log(event.data);
if ("status" in event.data) {
updateStatus(event.data);
}
if ("error" in event.data) {
samWorker.removeEventListener("message", messageHandler);
reject(new Error(event.data.error));
}
if (event.data.status === "complete-embedding") {
samWorker.removeEventListener("message", messageHandler);
resolve();
}
if (event.data.status === "complete") {
samWorker.removeEventListener("message", messageHandler);
resolve(event.data.output);
}
}
samWorker.addEventListener("message", messageHandler);
samWorker.postMessage({
modelURL,
modelID,
imageURL,
points,
});
});
}
function updateStatus(statusMessage) {
statusOutput.innerText = event.data.message;
}
let copyMaskURL = null;
let copyImageURL = null;
const clearBtn = document.querySelector("#clear-btn");
const maskBtn = document.querySelector("#mask-btn");
const undoBtn = document.querySelector("#undo-btn");
const downloadBtn = document.querySelector("#download-btn");
const canvas = document.querySelector("#canvas");
const mask = document.querySelector("#mask");
const ctxCanvas = canvas.getContext("2d");
const ctxMask = mask.getContext("2d");
const fileUpload = document.querySelector("#file-upload");
const dropArea = document.querySelector("#drop-area");
const dropButtons = document.querySelector("#drop-buttons");
const imagesExamples = document.querySelector("#image-select");
const modelSelection = document.querySelector("#model");
const statusOutput = document.querySelector("#output-status");
//add event listener to file input
fileUpload.addEventListener("input", (e) => {
const target = e.target;
if (target.files.length > 0) {
const href = URL.createObjectURL(target.files[0]);
clearImageCanvas();
copyImageURL = href;
drawImageCanvas(href);
setImageEmbeddings(href);
togglePointMode(false);
}
});
// add event listener to drop-area
dropArea.addEventListener("dragenter", (e) => {
e.preventDefault();
dropArea.classList.add("border-blue-700");
});
dropArea.addEventListener("dragleave", (e) => {
e.preventDefault();
dropArea.classList.remove("border-blue-700");
});
dropArea.addEventListener("dragover", (e) => {
e.preventDefault();
});
dropArea.addEventListener("drop", (e) => {
e.preventDefault();
dropArea.classList.remove("border-blue-700");
const url = e.dataTransfer.getData("text/uri-list");
const files = e.dataTransfer.files;
if (files.length > 0) {
const href = URL.createObjectURL(files[0]);
clearImageCanvas();
copyImageURL = href;
drawImageCanvas(href);
setImageEmbeddings(href);
togglePointMode(false);
} else if (url) {
clearImageCanvas();
copyImageURL = url;
drawImageCanvas(url);
setImageEmbeddings(url);
togglePointMode(false);
}
});
let hasImage = false;
let isSegmenting = false;
let isEmbedding = false;
let currentImageURL = "";
let pointArr = [];
let bgPointMode = false;
//add event listener to image examples
imagesExamples.addEventListener("click", (e) => {
if (isEmbedding || isSegmenting) {
return;
}
const target = e.target;
if (target.nodeName === "IMG") {
const href = target.src;
clearImageCanvas();
copyImageURL = href;
drawImageCanvas(href);
setImageEmbeddings(href);
}
});
//add event listener to mask button
maskBtn.addEventListener("click", () => {
togglePointMode();
});
//add event listener to clear button
clearBtn.addEventListener("click", () => {
clearImageCanvas();
togglePointMode(false);
pointArr = [];
});
//add event listener to undo button
undoBtn.addEventListener("click", () => {
undoPoint();
});
// add event to download btn
downloadBtn.addEventListener("click", async () => {
// Function to load image blobs as Image elements asynchronously
const loadImageAsync = (imageURL) => {
return new Promise((resolve) => {
const img = new Image();
img.onload = () => {
resolve(img);
};
img.crossOrigin = "anonymous";
img.src = imageURL;
});
};
const originalImage = await loadImageAsync(copyImageURL);
const maskImage = await loadImageAsync(copyMaskURL);
// create main a board to draw
const canvas = document.createElement("canvas");
const ctx = canvas.getContext("2d");
canvas.width = originalImage.width;
canvas.height = originalImage.height;
// Perform the mask operation
ctx.drawImage(maskImage, 0, 0);
ctx.globalCompositeOperation = "source-in";
ctx.drawImage(originalImage, 0, 0);
// to blob
const blobPromise = new Promise((resolve) => {
canvas.toBlob(resolve);
});
const blob = await blobPromise;
const resultURL = URL.createObjectURL(blob);
// download
const link = document.createElement("a");
link.href = resultURL;
link.download = "cutout.png";
link.click();
});
//add click event to canvas
canvas.addEventListener("click", async (event) => {
if (!hasImage || isEmbedding || isSegmenting) {
return;
}
const backgroundMode = event.shiftKey ? bgPointMode^event.shiftKey : bgPointMode;
const targetBox = event.target.getBoundingClientRect();
const x = (event.clientX - targetBox.left) / targetBox.width;
const y = (event.clientY - targetBox.top) / targetBox.height;
const ptsToRemove = [];
for (const [idx, pts] of pointArr.entries()) {
const d = Math.sqrt((pts[0] - x) ** 2 + (pts[1] - y) ** 2);
if (d < 6 / targetBox.width) {
ptsToRemove.push(idx);
}
}
if (ptsToRemove.length > 0) {
pointArr = pointArr.filter((_, idx) => !ptsToRemove.includes(idx));
} else {
pointArr = [...pointArr, [x, y, !backgroundMode]];
}
undoBtn.disabled = false;
downloadBtn.disabled = false;
if (pointArr.length == 0) {
ctxMask.clearRect(0, 0, canvas.width, canvas.height);
undoBtn.disabled = true;
downloadBtn.disabled = true;
return;
}
isSegmenting = true;
const { maskURL } = await getSegmentationMask(pointArr);
isSegmenting = false;
copyMaskURL = maskURL;
drawMask(maskURL, pointArr);
});
async function undoPoint() {
if (!hasImage || isEmbedding || isSegmenting) {
return;
}
if (pointArr.length === 0) {
return;
}
pointArr.pop();
if (pointArr.length === 0) {
ctxMask.clearRect(0, 0, canvas.width, canvas.height);
undoBtn.disabled = true;
return;
}
isSegmenting = true;
const { maskURL } = await getSegmentationMask(pointArr);
isSegmenting = false;
copyMaskURL = maskURL;
drawMask(maskURL, pointArr);
}
function togglePointMode(mode) {
bgPointMode = mode === undefined ? !bgPointMode : mode;
maskBtn.querySelector("span").innerText = bgPointMode
? "Background Point"
: "Mask Point";
if (bgPointMode) {
maskBtn.querySelector("#mask-circle").setAttribute("hidden", "");
maskBtn.querySelector("#unmask-circle").removeAttribute("hidden");
} else {
maskBtn.querySelector("#mask-circle").removeAttribute("hidden");
maskBtn.querySelector("#unmask-circle").setAttribute("hidden", "");
}
}
async function getSegmentationMask(points) {
const modelID = modelSelection.value;
const modelURL = MODEL_BASEURL + MODELS[modelID].url;
const imageURL = currentImageURL;
const { maskURL } = await segmentPoints(
modelURL,
modelID,
imageURL,
points
);
return { maskURL };
}
async function setImageEmbeddings(imageURL) {
if (isEmbedding) {
return;
}
canvas.classList.remove("cursor-pointer");
canvas.classList.add("cursor-wait");
clearBtn.disabled = true;
const modelID = modelSelection.value;
const modelURL = MODEL_BASEURL + MODELS[modelID].url;
isEmbedding = true;
await segmentPoints(modelURL, modelID, imageURL);
canvas.classList.remove("cursor-wait");
canvas.classList.add("cursor-pointer");
clearBtn.disabled = false;
isEmbedding = false;
currentImageURL = imageURL;
}
function clearImageCanvas() {
ctxCanvas.clearRect(0, 0, canvas.width, canvas.height);
ctxMask.clearRect(0, 0, canvas.width, canvas.height);
hasImage = false;
isEmbedding = false;
isSegmenting = false;
currentImageURL = "";
pointArr = [];
clearBtn.disabled = true;
canvas.parentElement.style.height = "auto";
dropButtons.classList.remove("invisible");
}
function drawMask(maskURL, points) {
if (!maskURL) {
throw new Error("No mask URL provided");
}
const img = new Image();
img.crossOrigin = "anonymous";
img.onload = () => {
mask.width = canvas.width;
mask.height = canvas.height;
ctxMask.save();
ctxMask.drawImage(canvas, 0, 0);
ctxMask.globalCompositeOperation = "source-atop";
ctxMask.fillStyle = "rgba(255, 0, 0, 0.6)";
ctxMask.fillRect(0, 0, canvas.width, canvas.height);
ctxMask.globalCompositeOperation = "destination-in";
ctxMask.drawImage(img, 0, 0);
ctxMask.globalCompositeOperation = "source-over";
for (const pt of points) {
if (pt[2]) {
ctxMask.fillStyle = "rgba(0, 255, 255, 1)";
} else {
ctxMask.fillStyle = "rgba(255, 255, 0, 1)";
}
ctxMask.beginPath();
ctxMask.arc(
pt[0] * canvas.width,
pt[1] * canvas.height,
3,
0,
2 * Math.PI
);
ctxMask.fill();
}
ctxMask.restore();
};
img.src = maskURL;
}
function drawImageCanvas(imgURL) {
if (!imgURL) {
throw new Error("No image URL provided");
}
ctxCanvas.clearRect(0, 0, canvas.width, canvas.height);
ctxCanvas.clearRect(0, 0, canvas.width, canvas.height);
const img = new Image();
img.crossOrigin = "anonymous";
img.onload = () => {
canvas.width = img.width;
canvas.height = img.height;
ctxCanvas.drawImage(img, 0, 0);
canvas.parentElement.style.height = canvas.offsetHeight + "px";
hasImage = true;
clearBtn.disabled = false;
dropButtons.classList.add("invisible");
};
img.src = imgURL;
}
const observer = new ResizeObserver((entries) => {
for (let entry of entries) {
if (entry.target === canvas) {
canvas.parentElement.style.height = canvas.offsetHeight + "px";
}
}
});
observer.observe(canvas);
</script>
</head>
<body class="container max-w-4xl mx-auto p-4">
<main class="grid grid-cols-1 gap-8 relative">
<span class="absolute text-5xl -ml-[1em]">🕯️</span>
<div>
<h1 class="text-5xl font-bold">Candle Segment Anything</h1>
<h2 class="text-2xl font-bold">Rust/WASM Demo</h2>
<p class="max-w-lg">
Zero-shot image segmentation with
<a
href="https://segment-anything.com"
class="underline hover:text-blue-500 hover:no-underline"
target="_blank"
>Segment Anything Model (SAM)</a
>
and
<a
href="https://github.com/ChaoningZhang/MobileSAM"
class="underline hover:text-blue-500 hover:no-underline"
target="_blank"
>MobileSAM </a
>. It runs in the browser with a WASM runtime built with
<a
href="https://github.com/huggingface/candle/"
target="_blank"
class="underline hover:text-blue-500 hover:no-underline"
>Candle
</a>
</p>
</div>
<div>
<label for="model" class="font-medium">Models Options: </label>
<select
id="model"
class="border-2 border-gray-500 rounded-md font-light">
<option value="sam_mobile_tiny" selected>
Mobile SAM Tiny (40.6 MB)
</option>
<option value="sam_base">SAM Base (375 MB)</option>
</select>
</div>
<div>
<p class="text-xs italic max-w-lg">
<b>Note:</b>
The model's first run may take a few seconds as it loads and caches
the model in the browser, and then creates the image embeddings. Any
subsequent clicks on points will be significantly faster.
</p>
</div>
<div class="relative max-w-2xl">
<div class="flex justify-between items-center">
<div class="px-2 rounded-md inline text-xs">
<span id="output-status" class="m-auto font-light"></span>
</div>
<div class="flex gap-2">
<button
id="mask-btn"
title="Toggle Mask Point and Background Point"
class="text-xs bg-white rounded-md disabled:opacity-50 flex gap-1 items-center">
<span>Mask Point</span>
<svg
xmlns="http://www.w3.org/2000/svg"
height="1em"
viewBox="0 0 512 512">
<path
id="mask-circle"
d="M256 512a256 256 0 1 0 0-512 256 256 0 1 0 0 512z" />
<path
id="unmask-circle"
hidden
d="M464 256a208 208 0 1 0-416 0 208 208 0 1 0 416 0zM0 256a256 256 0 1 1 512 0 256 256 0 1 1-512 0z" />
</svg>
</button>
<button
id="undo-btn"
disabled
title="Undo Last Point"
class="text-xs bg-white rounded-md disabled:opacity-50 flex gap-1 items-center">
<svg
xmlns="http://www.w3.org/2000/svg"
height="1em"
viewBox="0 0 512 512">
<path
d="M48.5 224H40a24 24 0 0 1-24-24V72a24 24 0 0 1 41-17l41.6 41.6a224 224 0 1 1-1 317.8 32 32 0 0 1 45.3-45.3 160 160 0 1 0 1-227.3L185 183a24 24 0 0 1-17 41H48.5z" />
</svg>
</button>
<button
id="clear-btn"
disabled
title="Clear Image"
class="text-xs bg-white rounded-md disabled:opacity-50 flex gap-1 items-center">
<svg
class=""
xmlns="http://www.w3.org/2000/svg"
viewBox="0 0 13 12"
height="1em">
<path
d="M1.6.7 12 11.1M12 .7 1.6 11.1"
stroke="#2E3036"
stroke-width="2" />
</svg>
</button>
</div>
</div>
<div
id="drop-area"
class="flex flex-col items-center justify-center border-2 border-gray-300 border-dashed rounded-xl relative p-20 w-full overflow-hidden">
<div
id="drop-buttons"
class="flex flex-col items-center justify-center space-y-1 text-center relative z-10">
<svg
width="25"
height="25"
viewBox="0 0 25 25"
fill="none"
xmlns="http://www.w3.org/2000/svg">
<path
d="M3.5 24.3a3 3 0 0 1-1.9-.8c-.5-.5-.8-1.2-.8-1.9V2.9c0-.7.3-1.3.8-1.9.6-.5 1.2-.7 2-.7h18.6c.7 0 1.3.2 1.9.7.5.6.7 1.2.7 2v18.6c0 .7-.2 1.4-.7 1.9a3 3 0 0 1-2 .8H3.6Zm0-2.7h18.7V2.9H3.5v18.7Zm2.7-2.7h13.3c.3 0 .5 0 .6-.3v-.7l-3.7-5a.6.6 0 0 0-.6-.2c-.2 0-.4 0-.5.3l-3.5 4.6-2.4-3.3a.6.6 0 0 0-.6-.3c-.2 0-.4.1-.5.3l-2.7 3.6c-.1.2-.2.4 0 .7.1.2.3.3.6.3Z"
fill="#000" />
</svg>
<div class="flex text-sm text-gray-600">
<label
for="file-upload"
class="relative cursor-pointer bg-white rounded-md font-medium text-blue-950 hover:text-blue-700">
<span>Drag and drop your image here</span>
<span class="block text-xs">or</span>
<span class="block text-xs">Click to upload</span>
</label>
</div>
<input
id="file-upload"
name="file-upload"
type="file"
class="sr-only" />
</div>
<canvas id="canvas" class="absolute w-full"></canvas>
<canvas
id="mask"
class="pointer-events-none absolute w-full"></canvas>
</div>
<div class="text-right py-2">
<button
id="share-btn"
class="bg-white rounded-md hover:outline outline-orange-200 disabled:opacity-50 invisible">
<img
src="https://huggingface.co/datasets/huggingface/badges/raw/main/share-to-community-sm.svg" />
</button>
<button
id="download-btn"
title="Copy result (.png)"
disabled
class="p-1 px-2 text-xs font-medium bg-white rounded-2xl outline outline-gray-200 hover:outline-orange-200 disabled:opacity-50"
>
Download Cut-Out
</button>
</div>
</div>
<div>
<div
class="flex gap-3 items-center overflow-x-scroll"
id="image-select">
<h3 class="font-medium">Examples:</h3>
<img
src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/candle/examples/sf.jpg"
class="cursor-pointer w-24 h-24 object-cover" />
<img
src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/candle/examples/bike.jpeg"
class="cursor-pointer w-24 h-24 object-cover" />
<img
src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/candle/examples/000000000077.jpg"
class="cursor-pointer w-24 h-24 object-cover" />
</div>
</div>
</main>
</body>
</html>
| 3 |
0 | hf_public_repos/candle/candle-wasm-examples | hf_public_repos/candle/candle-wasm-examples/segment-anything/README.md | ## Running Segment Anything Example
Here, we provide an example showing how to run the Segment Anything model in the
browser.
### Vanilla JS and WebWorkers
To build and test the UI made in Vanilla JS and WebWorkers, first we need to build the WASM library:
```bash
sh build-lib.sh
```
This will bundle the library under `./build` and we can import it inside our WebWorker like a normal JS module:
```js
import init, { Model } from "./build/m.js";
```
The full example can be found under `./lib-example.html`. All needed assets are fetched from the web, so no need to download anything.
Finally, you can preview the example by running a local HTTP server. For example:
```bash
python -m http.server
```
Then open `http://localhost:8000/lib-example.html` in your browser.
| 4 |
0 | hf_public_repos/candle/candle-wasm-examples/segment-anything | hf_public_repos/candle/candle-wasm-examples/segment-anything/src/lib.rs | use candle_transformers::models::segment_anything::sam;
use wasm_bindgen::prelude::*;
pub use sam::{Sam, IMAGE_SIZE};
#[wasm_bindgen]
extern "C" {
// Use `js_namespace` here to bind `console.log(..)` instead of just
// `log(..)`
#[wasm_bindgen(js_namespace = console)]
pub fn log(s: &str);
}
#[macro_export]
macro_rules! console_log {
// Note that this is using the `log` function imported above during
// `bare_bones`
($($t:tt)*) => ($crate::log(&format_args!($($t)*).to_string()))
}
| 5 |
0 | hf_public_repos/candle/candle-wasm-examples/segment-anything/src | hf_public_repos/candle/candle-wasm-examples/segment-anything/src/bin/m.rs | use candle::{DType, Device, Tensor};
use candle_nn::VarBuilder;
use candle_wasm_example_sam as sam;
use wasm_bindgen::prelude::*;
struct Embeddings {
original_width: u32,
original_height: u32,
width: u32,
height: u32,
data: Tensor,
}
#[wasm_bindgen]
pub struct Model {
sam: sam::Sam,
embeddings: Option<Embeddings>,
}
#[wasm_bindgen]
impl Model {
#[wasm_bindgen(constructor)]
pub fn new(weights: Vec<u8>, use_tiny: bool) -> Result<Model, JsError> {
console_error_panic_hook::set_once();
let dev = &Device::Cpu;
let vb = VarBuilder::from_buffered_safetensors(weights, DType::F32, dev)?;
let sam = if use_tiny {
sam::Sam::new_tiny(vb)? // tiny vit_t
} else {
sam::Sam::new(768, 12, 12, &[2, 5, 8, 11], vb)? // sam_vit_b
};
Ok(Self {
sam,
embeddings: None,
})
}
pub fn set_image_embeddings(&mut self, image_data: Vec<u8>) -> Result<(), JsError> {
sam::console_log!("image data: {}", image_data.len());
let image_data = std::io::Cursor::new(image_data);
let image = image::ImageReader::new(image_data)
.with_guessed_format()?
.decode()
.map_err(candle::Error::wrap)?;
let (original_height, original_width) = (image.height(), image.width());
let (height, width) = (original_height, original_width);
let resize_longest = sam::IMAGE_SIZE as u32;
let (height, width) = if height < width {
let h = (resize_longest * height) / width;
(h, resize_longest)
} else {
let w = (resize_longest * width) / height;
(resize_longest, w)
};
let image_t = {
let img = image.resize_exact(width, height, image::imageops::FilterType::CatmullRom);
let data = img.to_rgb8().into_raw();
Tensor::from_vec(
data,
(img.height() as usize, img.width() as usize, 3),
&Device::Cpu,
)?
.permute((2, 0, 1))?
};
let data = self.sam.embeddings(&image_t)?;
self.embeddings = Some(Embeddings {
original_width,
original_height,
width,
height,
data,
});
Ok(())
}
pub fn mask_for_point(&self, input: JsValue) -> Result<JsValue, JsError> {
let input: PointsInput =
serde_wasm_bindgen::from_value(input).map_err(|m| JsError::new(&m.to_string()))?;
let transformed_points = input.points;
for &(x, y, _bool) in &transformed_points {
if !(0.0..=1.0).contains(&x) {
return Err(JsError::new(&format!(
"x has to be between 0 and 1, got {}",
x
)));
}
if !(0.0..=1.0).contains(&y) {
return Err(JsError::new(&format!(
"y has to be between 0 and 1, got {}",
y
)));
}
}
let embeddings = match &self.embeddings {
None => Err(JsError::new("image embeddings have not been set"))?,
Some(embeddings) => embeddings,
};
let (mask, iou_predictions) = self.sam.forward_for_embeddings(
&embeddings.data,
embeddings.height as usize,
embeddings.width as usize,
&transformed_points,
false,
)?;
let iou = iou_predictions.flatten(0, 1)?.to_vec1::<f32>()?[0];
let mask_shape = mask.dims().to_vec();
let mask_data = mask.ge(0f32)?.flatten_all()?.to_vec1::<u8>()?;
let mask = Mask {
iou,
mask_shape,
mask_data,
};
let image = Image {
original_width: embeddings.original_width,
original_height: embeddings.original_height,
width: embeddings.width,
height: embeddings.height,
};
Ok(serde_wasm_bindgen::to_value(&MaskImage { mask, image })?)
}
}
#[derive(serde::Serialize, serde::Deserialize)]
struct Mask {
iou: f32,
mask_shape: Vec<usize>,
mask_data: Vec<u8>,
}
#[derive(serde::Serialize, serde::Deserialize)]
struct Image {
original_width: u32,
original_height: u32,
width: u32,
height: u32,
}
#[derive(serde::Serialize, serde::Deserialize)]
struct MaskImage {
mask: Mask,
image: Image,
}
#[derive(serde::Serialize, serde::Deserialize)]
struct PointsInput {
points: Vec<(f64, f64, bool)>,
}
fn main() {
console_error_panic_hook::set_once();
}
| 6 |
0 | hf_public_repos/candle/candle-wasm-examples | hf_public_repos/candle/candle-wasm-examples/phi/index.html | <html>
<head>
<meta content="text/html;charset=utf-8" http-equiv="Content-Type" />
<title>Candle Phi 1.5 / Phi 2.0 Rust/WASM</title>
</head>
<body></body>
</html>
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<link
rel="stylesheet"
href="https://cdn.jsdelivr.net/gh/highlightjs/[email protected]/build/styles/default.min.css"
/>
<style>
@import url("https://fonts.googleapis.com/css2?family=Source+Code+Pro:wght@200;300;400&family=Source+Sans+3:wght@100;200;300;400;500;600;700;800;900&display=swap");
html,
body {
font-family: "Source Sans 3", sans-serif;
}
code,
output,
select,
pre {
font-family: "Source Code Pro", monospace;
}
</style>
<style type="text/tailwindcss">
.link {
@apply underline hover:text-blue-500 hover:no-underline;
}
</style>
<script src="https://cdn.tailwindcss.com"></script>
<script type="module">
import snarkdown from "https://cdn.skypack.dev/snarkdown";
import hljs from "https://cdn.skypack.dev/highlight.js";
// models base url
const MODELS = {
phi_1_5_q4k: {
base_url:
"https://huggingface.co/lmz/candle-quantized-phi/resolve/main/",
model: "model-q4k.gguf",
tokenizer: "tokenizer.json",
config: "phi-1_5.json",
quantized: true,
seq_len: 2048,
size: "800 MB",
},
phi_1_5_q80: {
base_url:
"https://huggingface.co/lmz/candle-quantized-phi/resolve/main/",
model: "model-q80.gguf",
tokenizer: "tokenizer.json",
config: "phi-1_5.json",
quantized: true,
seq_len: 2048,
size: "1.51 GB",
},
phi_2_0_q4k: {
base_url:
"https://huggingface.co/radames/phi-2-quantized/resolve/main/",
model: [
"model-v2-q4k.gguf_aa.part",
"model-v2-q4k.gguf_ab.part",
"model-v2-q4k.gguf_ac.part",
],
tokenizer: "tokenizer.json",
config: "config.json",
quantized: true,
seq_len: 2048,
size: "1.57GB",
},
puffin_phi_v2_q4k: {
base_url:
"https://huggingface.co/lmz/candle-quantized-phi/resolve/main/",
model: "model-puffin-phi-v2-q4k.gguf",
tokenizer: "tokenizer-puffin-phi-v2.json",
config: "puffin-phi-v2.json",
quantized: true,
seq_len: 2048,
size: "798 MB",
},
puffin_phi_v2_q80: {
base_url:
"https://huggingface.co/lmz/candle-quantized-phi/resolve/main/",
model: "model-puffin-phi-v2-q80.gguf",
tokenizer: "tokenizer-puffin-phi-v2.json",
config: "puffin-phi-v2.json",
quantized: true,
seq_len: 2048,
size: "1.50 GB",
},
};
const TEMPLATES = [
{
title: "Simple prompt",
prompt: `Sebastien is in London today, it’s the middle of July yet it’s raining, so Sebastien is feeling gloomy. He`,
},
{
title: "Think step by step",
prompt: `Suppose Alice originally had 3 apples, then Bob gave Alice 7 apples, then Alice gave Cook 5 apples, and then Tim gave Alice 3x the amount of apples Alice had. How many apples does Alice have now?
Let’s think step by step.`,
},
{
title: "Explaing a code snippet",
prompt: `What does this script do?
\`\`\`python
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
s.bind(('', 0))
s.listen(1)
conn, addr = s.accept()
print('Connected by', addr)
return conn.getsockname()[1]
\`\`\`
Let’s think step by step.`,
},
{
title: "Question answering",
prompt: `Instruct: What is the capital of France?
Output:`,
},
{
title: "Chat mode",
prompt: `Alice: Can you tell me how to create a python application to go through all the files
in one directory where the file’s name DOES NOT end with '.json'?
Bob:`,
},
{
title: "Python code completion",
prompt: `"""write a python function called batch(function, list) which call function(x) for x in
list in parallel"""
Solution:`,
},
{
title: "Python Sample",
prompt: `"""Can you make sure those histograms appear side by side on the same plot:
\`\`\`python
plt.hist(intreps_retrained[0][1].view(64,-1).norm(dim=1).detach().cpu().numpy(), bins = 20)
plt.hist(intreps_pretrained[0][1].view(64,-1).norm(dim=1).detach().cpu().numpy(), bins = 20)
\`\`\`
"""`,
},
{
title: "Write a Twitter post",
prompt: `Write a twitter post for the discovery of gravitational wave.
Twitter Post:`,
},
{
title: "Write a review",
prompt: `Write a polite review complaining that the video game 'Random Game' was too badly optimized and it burned my laptop.
Very polite review:`,
},
];
const phiWorker = new Worker("./phiWorker.js", {
type: "module",
});
async function generateSequence(controller) {
const getValue = (id) => document.querySelector(`#${id}`).value;
const modelID = getValue("model");
const model = MODELS[modelID];
const weightsURL =
model.model instanceof Array
? model.model.map((m) => model.base_url + m)
: model.base_url + model.model;
const tokenizerURL = model.base_url + model.tokenizer;
const configURL = model.base_url + model.config;
const prompt = getValue("prompt").trim();
const temperature = getValue("temperature");
const topP = getValue("top-p");
const repeatPenalty = getValue("repeat_penalty");
const seed = getValue("seed");
const maxSeqLen = getValue("max-seq");
function updateStatus(data) {
const outStatus = document.querySelector("#output-status");
const outGen = document.querySelector("#output-generation");
const outCounter = document.querySelector("#output-counter");
switch (data.status) {
case "loading":
outStatus.hidden = false;
outStatus.textContent = data.message;
outGen.hidden = true;
outCounter.hidden = true;
break;
case "generating":
const { message, prompt, sentence, tokensSec, totalTime } = data;
outStatus.hidden = true;
outCounter.hidden = false;
outGen.hidden = false;
outGen.innerHTML = snarkdown(prompt + sentence);
outCounter.innerHTML = `${(totalTime / 1000).toFixed(
2
)}s (${tokensSec.toFixed(2)} tok/s)`;
hljs.highlightAll();
break;
case "complete":
outStatus.hidden = true;
outGen.hidden = false;
break;
}
}
return new Promise((resolve, reject) => {
phiWorker.postMessage({
weightsURL,
modelID,
tokenizerURL,
configURL,
quantized: model.quantized,
prompt,
temp: temperature,
top_p: topP,
repeatPenalty,
seed: seed,
maxSeqLen,
command: "start",
});
const handleAbort = () => {
phiWorker.postMessage({ command: "abort" });
};
const handleMessage = (event) => {
const { status, error, message, prompt, sentence } = event.data;
if (status) updateStatus(event.data);
if (error) {
phiWorker.removeEventListener("message", handleMessage);
reject(new Error(error));
}
if (status === "aborted") {
phiWorker.removeEventListener("message", handleMessage);
resolve(event.data);
}
if (status === "complete") {
phiWorker.removeEventListener("message", handleMessage);
resolve(event.data);
}
};
controller.signal.addEventListener("abort", handleAbort);
phiWorker.addEventListener("message", handleMessage);
});
}
const form = document.querySelector("#form");
const prompt = document.querySelector("#prompt");
const clearBtn = document.querySelector("#clear-btn");
const runBtn = document.querySelector("#run");
const modelSelect = document.querySelector("#model");
const promptTemplates = document.querySelector("#prompt-templates");
let runController = new AbortController();
let isRunning = false;
document.addEventListener("DOMContentLoaded", () => {
for (const [id, model] of Object.entries(MODELS)) {
const option = document.createElement("option");
option.value = id;
option.innerText = `${id} (${model.size})`;
modelSelect.appendChild(option);
}
const query = new URLSearchParams(window.location.search);
const modelID = query.get("model");
if (modelID) {
modelSelect.value = modelID;
} else {
modelSelect.value = "phi_1_5_q4k";
}
for (const [i, { title, prompt }] of TEMPLATES.entries()) {
const div = document.createElement("div");
const input = document.createElement("input");
input.type = "radio";
input.name = "task";
input.id = `templates-${i}`;
input.classList.add("font-light", "cursor-pointer");
input.value = prompt;
const label = document.createElement("label");
label.htmlFor = `templates-${i}`;
label.classList.add("cursor-pointer");
label.innerText = title;
div.appendChild(input);
div.appendChild(label);
promptTemplates.appendChild(div);
}
});
promptTemplates.addEventListener("change", (e) => {
const template = e.target.value;
prompt.value = template;
prompt.style.height = "auto";
prompt.style.height = prompt.scrollHeight + "px";
runBtn.disabled = false;
clearBtn.classList.remove("invisible");
});
modelSelect.addEventListener("change", (e) => {
const query = new URLSearchParams(window.location.search);
query.set("model", e.target.value);
window.history.replaceState(
{},
"",
`${window.location.pathname}?${query}`
);
window.parent.postMessage({ queryString: "?" + query }, "*");
const model = MODELS[e.target.value];
document.querySelector("#max-seq").max = model.seq_len;
document.querySelector("#max-seq").nextElementSibling.value = 200;
});
form.addEventListener("submit", async (e) => {
e.preventDefault();
if (isRunning) {
stopRunning();
} else {
startRunning();
await generateSequence(runController);
stopRunning();
}
});
function startRunning() {
isRunning = true;
runBtn.textContent = "Stop";
}
function stopRunning() {
runController.abort();
runController = new AbortController();
runBtn.textContent = "Run";
isRunning = false;
}
clearBtn.addEventListener("click", (e) => {
e.preventDefault();
prompt.value = "";
clearBtn.classList.add("invisible");
runBtn.disabled = true;
stopRunning();
});
prompt.addEventListener("input", (e) => {
runBtn.disabled = false;
if (e.target.value.length > 0) {
clearBtn.classList.remove("invisible");
} else {
clearBtn.classList.add("invisible");
}
});
</script>
</head>
<body class="container max-w-4xl mx-auto p-4 text-gray-800">
<main class="grid grid-cols-1 gap-8 relative">
<span class="absolute text-5xl -ml-[1em]"> 🕯️ </span>
<div>
<h1 class="text-5xl font-bold">Candle Phi 1.5 / Phi 2.0</h1>
<h2 class="text-2xl font-bold">Rust/WASM Demo</h2>
<p class="max-w-lg">
The
<a
href="https://huggingface.co/microsoft/phi-1_5"
class="link"
target="_blank"
>Phi-1.5</a
>
and
<a
href="https://huggingface.co/microsoft/phi-2"
class="link"
target="_blank"
>Phi-2</a
>
models achieve state-of-the-art performance with only 1.3 billion and
2.7 billion parameters, compared to larger models with up to 13
billion parameters. Here you can try the quantized versions.
Additional prompt examples are available in the
<a
href="https://arxiv.org/pdf/2309.05463.pdf#page=8"
class="link"
target="_blank"
>
technical report </a
>.
</p>
<p class="max-w-lg">
You can also try
<a
href="https://huggingface.co/teknium/Puffin-Phi-v2"
class="link"
target="_blank"
>Puffin-Phi V2
</a>
quantized version, a fine-tuned version of Phi-1.5 on the
<a
href="https://huggingface.co/datasets/LDJnr/Puffin"
class="link"
target="_blank"
>Puffin dataset
</a>
</p>
</div>
<div>
<p class="text-xs italic max-w-lg">
<b>Note:</b>
When first run, the app will download and cache the model, which could
take a few minutes. The models are <b>~800MB</b> or <b>~1.57GB</b> in
size.
</p>
</div>
<div>
<label for="model" class="font-medium">Models Options: </label>
<select
id="model"
class="border-2 border-gray-500 rounded-md font-light"
></select>
</div>
<div>
<details>
<summary class="font-medium cursor-pointer">Prompt Templates</summary>
<form
id="prompt-templates"
class="grid grid-cols-1 sm:grid-cols-2 gap-1 my-2"
></form>
</details>
</div>
<form
id="form"
class="flex text-normal px-1 py-1 border border-gray-700 rounded-md items-center"
>
<input type="submit" hidden />
<textarea
type="text"
id="prompt"
class="font-light text-lg w-full px-3 py-2 mx-1 resize-none outline-none"
oninput="this.style.height = 0;this.style.height = this.scrollHeight + 'px'"
placeholder="Add your prompt here..."
>
Instruct: Write a detailed analogy between mathematics and a lighthouse.
Output:</textarea
>
<button id="clear-btn">
<svg
fill="none"
xmlns="http://www.w3.org/2000/svg"
width="40"
viewBox="0 0 70 40"
>
<path opacity=".5" d="M39 .2v40.2" stroke="#1F2937" />
<path
d="M1.5 11.5 19 29.1m0-17.6L1.5 29.1"
opacity=".5"
stroke="#1F2937"
stroke-width="2"
/>
</svg>
</button>
<button
id="run"
class="bg-gray-700 hover:bg-gray-800 text-white font-normal py-2 w-16 rounded disabled:bg-gray-300 disabled:cursor-not-allowed"
>
Run
</button>
</form>
<details>
<summary class="font-medium cursor-pointer">Advanced Options</summary>
<div class="grid grid-cols-3 max-w-md items-center gap-3 py-3">
<label class="text-sm font-medium" for="max-seq"
>Maximum length
</label>
<input
type="range"
id="max-seq"
name="max-seq"
min="1"
max="2048"
step="1"
value="200"
oninput="this.nextElementSibling.value = Number(this.value)"
/>
<output
class="text-xs w-[50px] text-center font-light px-1 py-1 border border-gray-700 rounded-md"
>
200</output
>
<label class="text-sm font-medium" for="temperature"
>Temperature</label
>
<input
type="range"
id="temperature"
name="temperature"
min="0"
max="2"
step="0.01"
value="0.00"
oninput="this.nextElementSibling.value = Number(this.value).toFixed(2)"
/>
<output
class="text-xs w-[50px] text-center font-light px-1 py-1 border border-gray-700 rounded-md"
>
0.00</output
>
<label class="text-sm font-medium" for="top-p">Top-p</label>
<input
type="range"
id="top-p"
name="top-p"
min="0"
max="1"
step="0.01"
value="1.00"
oninput="this.nextElementSibling.value = Number(this.value).toFixed(2)"
/>
<output
class="text-xs w-[50px] text-center font-light px-1 py-1 border border-gray-700 rounded-md"
>
1.00</output
>
<label class="text-sm font-medium" for="repeat_penalty"
>Repeat Penalty</label
>
<input
type="range"
id="repeat_penalty"
name="repeat_penalty"
min="1"
max="2"
step="0.01"
value="1.10"
oninput="this.nextElementSibling.value = Number(this.value).toFixed(2)"
/>
<output
class="text-xs w-[50px] text-center font-light px-1 py-1 border border-gray-700 rounded-md"
>1.10</output
>
<label class="text-sm font-medium" for="seed">Seed</label>
<input
type="number"
id="seed"
name="seed"
value="299792458"
class="font-light border border-gray-700 text-right rounded-md p-2"
/>
<button
id="run"
onclick="document.querySelector('#seed').value = Math.floor(Math.random() * Number.MAX_SAFE_INTEGER)"
class="bg-gray-700 hover:bg-gray-800 text-white font-normal py-1 w-[50px] rounded disabled:bg-gray-300 disabled:cursor-not-allowed text-sm"
>
Rand
</button>
</div>
</details>
<div>
<h3 class="font-medium">Generation:</h3>
<div
class="min-h-[250px] bg-slate-100 text-gray-500 p-4 rounded-md flex flex-col gap-2"
>
<div
id="output-counter"
hidden
class="ml-auto font-semibold grid-rows-1"
></div>
<p hidden id="output-generation" class="grid-rows-2 text-lg"></p>
<span id="output-status" class="m-auto font-light"
>No output yet</span
>
</div>
</div>
</main>
</body>
</html>
| 7 |
0 | hf_public_repos/candle/candle-wasm-examples | hf_public_repos/candle/candle-wasm-examples/phi/Cargo.toml | [package]
name = "candle-wasm-example-phi"
version.workspace = true
edition.workspace = true
description.workspace = true
repository.workspace = true
keywords.workspace = true
categories.workspace = true
license.workspace = true
[dependencies]
candle = { workspace = true }
candle-nn = { workspace = true }
candle-transformers = { workspace = true }
tokenizers = { workspace = true, features = ["unstable_wasm"] }
num-traits = { workspace = true }
# App crates.
anyhow = { workspace = true }
byteorder = { workspace = true }
getrandom = { version = "0.2", features = ["js"] }
image = { workspace = true }
log = { workspace = true }
safetensors = { workspace = true }
serde = { workspace = true }
serde_json = { workspace = true }
# Wasm specific crates.
console_error_panic_hook = "0.1.7"
wasm-bindgen = "0.2.87"
js-sys = "0.3.64"
| 8 |
0 | hf_public_repos/candle/candle-wasm-examples | hf_public_repos/candle/candle-wasm-examples/phi/build-lib.sh | cargo build --target wasm32-unknown-unknown --release
wasm-bindgen ../../target/wasm32-unknown-unknown/release/m.wasm --out-dir build --target web
| 9 |
0 | hf_public_repos/blog | hf_public_repos/blog/zh/watermarking.md | ---
title: "人工智能水印技术入门:工具与技巧"
thumbnail: /blog/assets/watermarking/thumbnail.png
authors:
- user: sasha
- user: yjernite
- user: derek-thomas
- user: EmilyWitko
- user: Ezi
- user: JJoe206
- user: reach-vb
- user: BrigitteTousi
- user: meg
translators:
- user: AdinaY
---
# 人工智能水印技术入门:工具与技巧
近几个月来,我们看到了多起关于“深度伪造 (deepfakes)”或人工智能生成内容的新闻报道:从 [泰勒·斯威夫特的图片](https://www.npr.org/2024/01/26/1227091070/deepfakes-taylor-swift-images-regulation)、[汤姆·汉克斯的视频](https://www.theguardian.com/film/2023/oct/02/tom-hanks-dental-ad-ai-version-fake) 到 [美国总统乔·拜登的录音](https://www.bbc.com/news/world-us-canada-68064247)。这些深度伪造内容被用于各种目的,如销售产品、未经授权操纵人物形象、钓鱼获取私人信息,甚至制作误导选民的虚假资料,它们在社交媒体平台的迅速传播,使其具有更广泛的影响力,从而可能造成持久的伤害。
在本篇博文中,我们将介绍 AI 生成内容加水印的方法,讨论其优缺点,并展示 Hugging Face Hub 上一些可用于添加/检测水印的工具。
## 什么是水印以及它是如何工作的?
<figure class="image text-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/watermarking/fig1.png" alt="Dall-E 2 watermark">
<figcaption> 图 1: OpenAI 的 Dall-E 2 在右下角加入了由 5 块不同颜色组成的可见水印。来源: instagram.com/dailydall.e </figcaption>
</figure>
水印是一种标记内容以传递额外信息(如内容的真实性)的方法。在 AI 生成的内容中,水印既可以是完全可见的(如图 1 所示),也可以是完全不可见的(如图 2 所示)。具体来说,在 AI 领域,水印指的是在数字内容(例如图片)中加入特定模式,用以标示内容的来源;这些模式之后可以被人类或通过算法识别。
<figure class="image text-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/watermarking/fig2.png" alt="Invisible watermark">
<figcaption> 图 2: 例如 Imatag 和 Truepic 等公司已开发出将不可察觉的水印嵌入 AI 生成图像的技术。 </figcaption>
</figure>
AI 生成内容的水印主要有两种方法:第一种是在内容创作过程中加入,这需要访问模型本身,但因为它是生成过程的一部分,所以 [更为稳固](https://huggingface.co/blog/imatag-vch/stable-signature-bzh)。第二种方法是在内容生成后应用,可以用于闭源和专有模型生成的内容,但可能不适用于所有类型的内容(如文本)。
### 数据投毒与签名技术
除了水印,还有几种相关技术可以限制未经同意的图像操纵。有些技术通过微妙地改变在线分享的图像来防止 AI 算法正确处理这些图像。尽管人类可以正常查看这些图像,但 AI 算法则无法访问类似内容,从而无法创建新图像。这类技术包括 Glaze 和 Photoguard。还有一些工具通过“投毒”图像来破坏 AI 算法训练中的固有假设,使得 AI 系统无法根据在线分享的图像学习人们的外貌——这让这些系统更难以生成假人物图像。这类工具包括 [Nightshade](https://nightshade.cs.uchicago.edu/whatis.html) 和 [Fawkes](http://sandlab.cs.uchicago.edu/fawkes/)。
通过使用“签名”技术,也可以维护内容的真实性和可靠性,这些技术将内容与其来源的元数据链接起来,如 [Truepic](https://truepic.com/) 的工作,它嵌入了 [遵循 C2PA 标准的元数据](https://huggingface.co/spaces/Truepic/ai-content-credentials)。图像签名有助于了解图像的来源。虽然元数据可以被编辑,但像 Truepic 这样的系统通过 1) 提供认证以确保可以验证元数据的有效性;以及 2) 与水印技术整合,使得删除信息更加困难,来克服这一限制。
### 开放与封闭的水印
为公众提供对水印器和检测器不同级别的访问权有其优点和缺点。开放性有助于促进创新,开发者可以在关键思想上进行迭代,创造出越来越好的系统。然而,这需要与防止恶意使用进行权衡。如果 AI 流程中的开放代码调用了水印器,去除水印步骤变得很简单。即使水印部分是封闭的,如果水印已知且水印代码开放,恶意行为者可能会阅读代码找到方法编辑生成的内容,使水印失效。如果还可以访问检测器,就可能继续编辑合成内容,直到检测器显示低置信度,从而无效化水印。存在一些直接解决这些问题的混合开放-封闭方法。例如,Truepic 的水印代码是封闭的,但他们提供了一个可以验证内容凭证的公共 JavaScript 库。IMATAG 的调用水印器代码是开放的,但[实际的水印器和检测器是私有的](https://huggingface.co/blog/imatag-vch/stable-signature-bzh)。
## 对不同数据类型进行水印
虽然水印是跨多种模态(音频、图像、文本等)的重要工具,但每种模态都带来其独特的挑战和考量。水印的意图也不尽相同,无论是为了防止*训练数据*被用于训练模型、防止内容被操纵、标记模型的*输出*,还是*检测* AI 生成的数据。在本节中,我们将探讨不同的数据模态、它们在水印方面的挑战,以及 Hugging Face Hub 上存在的用于实施不同类型水印的开源工具。
### 图像水印
可能最为人熟知的水印类型(无论是人类创作还是 AI 生成的内容)是对图像的水印。已经提出了不同的方法来标记训练数据,以影响基于它训练的模型的输出:这种“图像隐身”方法最著名的是 [“Nightshade”](https://arxiv.org/abs/2310.13828),它对图像进行微小的修改,这些修改对人眼来说几乎不可察觉,但会影响基于被污染数据训练的模型的质量。Hub 上也有类似的图像隐身工具——例如,由开发 Nightshade 的相同实验室开发的 [Fawkes](https://huggingface.co/spaces/derek-thomas/fawkes),专门针对人物图像,目的是阻挠面部识别系统。同样,还有 [Photoguard](https://huggingface.co/spaces/hadisalman/photoguard),旨在保护图像不被用于生成 AI 工具(例如,基于它们创建深度伪造)的操纵。
关于水印输出图像,Hub 上提供了两种互补的方法:[IMATAG](https://huggingface.co/spaces/imatag/stable-signature-bzh)(见图 2),它通过利用修改过的流行模型(如 [Stable Diffusion XL Turbo](https://huggingface.co/stabilityai/sdxl-turbo))在内容生成过程中实施水印;以及 [Truepic](https://huggingface.co/spaces/Truepic/watermarked-content-credentials),它在图像生成后添加不可见的内容凭证。
TruePic 还将 C2PA 内容凭证嵌入图像中,允许在图像本身中存储有关图像来源和生成的元数据。IMATAG 和 TruePic Spaces 还允许检测由它们系统水印的图像。这两种检测工具都是方法特定的。Hub 上已有一个现有的通用 [深度伪造检测的 Space 应用 ](https://huggingface.co/spaces/Wvolf/CNN_Deepfake_Image_Detection),但根据我们的经验,这些解决方案的性能取决于图像的质量和使用的模型。
### 文本水印
虽然给 AI 生成的图像加水印似乎更直观——考虑到这种内容的强烈视觉特性——但文本是另一个完全不同的故事……你如何在文字和数字(令牌)中添加水印呢?当前的水印方法依赖于基于之前文本推广子词汇表。让我们深入了解这对于 LLM 生成的文本来说意味着什么。
在生成过程中,LLM 在执行采样或贪婪解码之前输出[下一个令牌的 logits 列表](https://huggingface.co/docs/transformers/main_classes/output#transformers.modeling_outputs.CausalLMOutput.logits)。基于之前生成的文本,大多数方法将所有候选令牌分为两组——称它们为“红色”和“绿色”。“红色”令牌将被限制,而“绿色”组将被推广。这可以通过完全禁止红色组令牌(硬水印)或通过增加绿色组的概率(软水印)来实现。我们对原始概率的更改越多,我们的水印强度就越高。[WaterBench](https://huggingface.co/papers/2311.07138) 创建了一个基准数据集,以便在控制水印强度进行苹果与苹果的比较时,促进跨水印算法的性能比较。
检测工作通过确定每个令牌的“颜色”,然后计算输入文本来自于讨论的模型的概率。值得注意的是,较短的文本因为令牌较少,因此置信度较低。
<figure class="image text-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/watermarking/fig3.png" alt="Text watermark">
<figcaption> 图 3: <a href="https://huggingface.co/spaces/tomg-group-umd/lm-watermarking">LLM 水印 Space</a> 显示了合成文本上的红色和绿色令牌,代表这些是 AI 生成的概率。 </figcaption>
</figure>
你可以在 Hugging Face Hub 上轻松实现 LLM 的水印。[LLM 水印 Space](https://huggingface.co/spaces/tomg-group-umd/lm-watermarking)(见图 3)演示了这一点,使用了 [LLM 水印方法](https://huggingface.co/papers/2301.10226) 对模型如 OPT 和 Flan-T5 进行了应用。对于生产级工作负载,你可以使用我们的 [文本生成推理工具包](https://huggingface.co/docs/text-generation-inference/index),它实现了相同的水印算法,并设置了 [相应的参数](https://huggingface.co/docs/text-generation-inference/main/en/basic_tutorials/launcher#watermarkgamma),可以与最新模型一起使用!
与 AI 生成图像的通用水印类似,是否可以普遍水印文本尚未得到证明。诸如 [GLTR](http://gltr.io/) 之类的方法旨在对任何可访问的语言模型(鉴于它们依赖于将生成文本的 logits 与不同模型的 logits 进行比较)都具有鲁棒性。在没有访问该模型(无论是因为它是闭源的还是因为你不知道哪个模型被用来生成文本)的情况下,检测给定文本是否使用语言模型生成目前是不可能的。
正如我们上面讨论的,检测生成文本的方法需要大量文本才能可靠。即使如此,检测器也可能有高误报率,错误地将人们写的文本标记为合成。实际上,[OpenAI 在 2023 年因低准确率而悄悄关闭了他们的内部检测工具](https://www.pcmag.com/news/openai-quietly-shuts-down-ai-text-detection-tool-over-inaccuracies),这在教师用它来判断学生提交的作业是否使用 ChatGPT 生成时带来了 [意想不到的后果](https://www.rollingstone.com/culture/culture-features/texas-am-chatgpt-ai-professor-flunks-students-false-claims-1234736601/)。
### 音频水印
从个人声音中提取的数据(声纹)通常被用作生物安全认证机制来识别个体。虽然通常与 PIN 或密码等其他安全因素结合使用,但这种生物识别数据的泄露仍然存在风险,可以被用来获得访问权限,例如银行账户,鉴于许多银行使用声音识别技术通过电话验证客户。随着声音变得更容易用 AI 复制,我们也必须改进验证声音音频真实性的技术。水印音频内容类似于水印图像,因为它有一个多维输出空间,可以用来注入有关来源的元数据。在音频的情况下,水印通常在人耳无法察觉的频率上进行(低于约 20 或高于约 20,000 Hz),然后可以使用 AI 驱动的方法进行检测。
鉴于音频输出的高风险性质,水印音频内容是一个活跃的研究领域,过去几年提出了多种方法(例如,[WaveFuzz](https://arxiv.org/abs/2203.13497),[Venomave](https://ieeexplore.ieee.org/abstract/document/10136135))。
<figure class="image text-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/watermarking/fig4.png" alt="AudioSeal watermarking approach.">
<figcaption> 图 4 - AudioSeal 水印和检测的流程图。来源:<a href="https://github.com/facebookresearch/audioseal">GitHub (AudioSeal)</a> </figcaption>
</figure>
AudioSeal 也被用于发布 [SeamlessExpressive](https://huggingface.co/spaces/facebook/seamless-expressive) 和 [SeamlessStreaming](https://huggingface.co/spaces/facebook/seamless-streaming) 演示,带有安全机制。
## 结论
面对虚假信息、被错误地指控生产合成内容,以及未经本人同意就使用其形象,都是既困难又耗时的问题;在可以进行更正和澄清之前,大部分损害已经造成。因此,作为我们使好的机器学习普惠化的使命的一部分,我们相信,拥有快速和系统地识别 AI 生成内容的机制是至关重要的。AI 水印虽不是万能的,但在对抗恶意和误导性 AI 使用方面,它是一个强有力的工具。
# 相关新闻报道
- [It Doesn't End With Taylor Swift: How to Protect Against AI Deepfakes and Sexual Harassment | PopSugar](https://www.popsugar.com/tech/ai-deepfakes-taylor-swift-sexual-harassment-49334216) (@meg)
- [Three ways we can fight deepfake porn | MIT Technology Review ](https://www.technologyreview.com/2024/01/29/1087325/three-ways-we-can-fight-deepfake-porn-taylors-version/) (@sasha)
- [Gun violence killed them. Now, their voices will lobby Congress to do more using AI | NPR](https://www.npr.org/2024/02/14/1231264701/gun-violence-parkland-anniversary-ai-generated-voices-congress) (@irenesolaiman)
- [Google DeepMind has launched a watermarking tool for AI-generated images | MIT Technology Review](https://www.technologyreview.com/2023/08/29/1078620/google-deepmind-has-launched-a-watermarking-tool-for-ai-generated-images/) (@sasha)
- [Invisible AI watermarks won’t stop bad actors. But they are a ‘really big deal’ for good ones | VentureBeat](https://venturebeat.com/ai/invisible-ai-watermarks-wont-stop-bad-actors-but-they-are-a-really-big-deal-for-good-ones/) (@meg)
- [A watermark for chatbots can expose text written by an AI | MIT Technology Review](https://www.technologyreview.com/2023/01/27/1067338/a-watermark-for-chatbots-can-spot-text-written-by-an-ai/) (@irenesolaiman)
- [Hugging Face empowers users with deepfake detection tools | Mashable](https://mashable.com/article/hugging-face-empowers-users-ai-deepfake-detetection-tools) (@meg)
| 0 |
0 | hf_public_repos/blog | hf_public_repos/blog/zh/bloom-inference-optimization.md | ---
title: "优化故事: BLOOM 模型推理"
thumbnail: /blog/assets/bloom-inference-pytorch-scripts/thumbnail.png
authors:
- user: Narsil
translators:
- user: MatrixYao
---
# 优化故事: BLOOM 模型推理
<!-- 经过“九九八十一难”,大模型终于炼成。下一步就是架设服务,准备开门营业了。真这么简单?恐怕未必!行百里者半九十,推理优化又是新的雄关漫道。如何进行延迟优化?如何进行成本优化(别忘了 OpenAI 8K 上下文的 GPT-4 模型,提示每 1000 词元只需 0.03 美金,补全每 1000 词元只需 0.06 美金)?如何在延迟和吞吐量之间折衷?如何处理大模型特有的分布式推理后端和网络服务前端的协作问题?...... 要不动手之前还是先看看 BLOOM 推理服务踩过的坑吧!-->
本文介绍了我们在实现 [BLOOM](https://huggingface.co/bigscience/bloom) 模型高效推理服务的过程中发生的幕后故事。
在短短数周内,我们把推理延迟降低了 5 倍(同时,吞吐量增加了 50 倍)。我们将分享我们为达成这一性能改进而经历的所有斗争和史诗般的胜利。
在此过程中,不同的人参与了不同的阶段,尝试了各种不同的优化手段,我们无法一一罗列,还请多多包涵。如果你发现本文中某些内容可能已过时甚至完全错误,这也不奇怪,因为一方面对于如何优化超大模型性能我们仍在努力学习中,另一方面,市面上新硬件功能和新优化技巧也层出不穷。
如果本文没有讨论你最中意的优化技巧,或者我们对某些方法表述有误,我们很抱歉,请告诉我们,我们非常乐意尝试新东西并纠正错误。
# 训练 BLOOM
这是不言而喻的,如果不先获取到大模型,那推理优化就无从谈起。大模型训练是一项由很多不同的人共同领导的超级工程。
为了最大化 GPU 的利用率,我们探索了多种训练方案。最后,我们选择了 [Megatron-Deepspeed](https://github.com/bigscience-workshop/Megatron-DeepSpeed) 来训练最终模型。这意味着训练代码与 `transformers` 库并不完全兼容。
# 移植至 transformers
由于上文提及的原因,我们第一件事是将现有模型移植到 `transformers` 上。我们需要从训练代码中提取相关代码并将其实现至 `transformers` 里。[Younes](/ybelkada) 负责完成了这项工作。这个工作量绝对不小,我们大概花了将近一个月的时间,进行了 [200 次提交](https://github.com/huggingface/transformers/pull/17474/commits) 才最终完成。
有几点需要注意,我们后面还会提到:
小版的模型,如 [bigscience/bigscience-small-testing](https://huggingface.co/bigscience/bigscience-small-testing) 和 [bigscience/bloom-560m](https://huggingface.co/bigscience/bloom-560m) 非常重要。因为模型结构与大版的一样但尺寸更小,所以在它们上面一切工作(如调试、测试等)都更快。
首先,你必须放弃那种最终你会得到比特级一致的 `logits` 结果的幻想。不同的 PyTorch 版本间的算子核函数更改都会引入细微差别,更不用说不同的硬件可能会因为体系架构不同而产生不同的结果(而出于成本原因,你可能并不能一直在 A100 GPU 上开发)。
***一个好的严格的测试套件对所有模型都非常重要***
我们发现,最佳的测试方式是使用一组固定的提示。从测试角度,你知道提示(prompt),而且你想要为每个提示生成确定性的补全(completion),所以解码器用贪心搜索就好了。如果两次测试生成的补全是相同的,你基本上可以无视 logits 上的小差异。每当你看到生成的补全发生漂移时,就需要调查原因。可能是你的代码没有做它应该做的事;也有可能是你的提示不在该模型的知识域内[译者注:即模型的训练数据中并不包含提示所涉及的话题],所以它对噪声更敏感。如果你有多个提示且提示足够长,不太可能每个提示都触发上述不在知识域的问题。因此,提示越多越好,越长越好。
第一个模型(small-testing)和大 BLOOM 一样,精度是 `bfloat16` 的。我们原以为两者应该非常相似,但由于小模型没有经过太多训练或者单纯只是性能差,最终表现出来的结果是它的输出波动很大。这意味着我们用它进行生成测试会有问题。第二个模型更稳定,但模型数据精度是 `float16` 而不是 `bfloat16`,因此两者间的误差空间更大。
公平地说,推理时将 `bfloat16` 模型转换为 `float16` 似乎问题不大(`bfloat16` 的存在主要是为了处理大梯度,而推理中不存在大梯度)。
在此步骤中,我们发现并实现了一个重要的折衷。因为 BLOOM 是在分布式环境中训练的,所以部分代码会对 Linear 层作张量并行,这意味着在单GPU上运行相同的操作会得到[不同的数值结果](https://github.com/huggingface/transformers/blob/main/src/transformers/models/bloom/modeling_bloom.py#L350)。我们花了一段时间才查明这个问题。这个问题没办法彻底解决,要么我们追求 100% 的数值一致性而牺牲模型运行速度,要么我们接受每次生成时都会出现一些小的差异但运行速度更快,代码更简单。我们为此设了一个标志位供用户自己配置。
# 首次推理(PP + Accelerate)
```
注意:这里,流水线并行 (Pipeline Parallelism, PP) 意味着每个 GPU 将分得模型的一些层,因此每个 GPU 将完成一部分操作,然后再将其结果交给下一个 GPU。
```
现在我们有了一个能支持 BLOOM 的 `transformers`,我们可以开始跑了。
BLOOM 是一个 352GB(176B bf16 参数)的模型,我们至少需要那么多显存才能放下它。我们花了一点时间试了试在小显存的 GPU 上使用 CPU 卸载的方式来推理,但是推理速度慢了几个数量级,所以我们很快放弃了它。
然后,我们转而想使用 `transformers` 的 [pipeline](https://huggingface.co/docs/transformers/v4.22.2/en/pipeline_tutorial#pipeline-usage) API,吃一下这个 API 的狗粮。然而,`pipeline` 不是分布式感知的(这不是它的设计目标)。
经过短暂的技术方案讨论,我们最终使用了 [accelerate](https://github.com/huggingface/accelerate/) 的新功能 `device_map="auto` 来管理模型的分片。我们不得不解决一些 `accelerate` 以及 `transformers` 的 bug,才使得这一方案能正常工作。
它的工作原理是将 transformer 模型按层进行切分,每个 GPU 分到一些层。真正运行时,是 GPU0 先开始工作,然后将结果交给 GPU1,依次下去。
最后,在前端架一个小型 HTTP 服务器,我们就可以开始提供 BLOOM(大模型)推理服务了!!
# 起点
至此,我们甚至还没有开始讨论优化!
我们其实做了不少优化,这一切过程有点像纸牌叠城堡游戏。在优化期间,我们将对底层代码进行修改,所以一定要确保我们不会以任何方式破坏模型,这一点非常重要,而且其实比想象中更容易做到。
优化的第一步是测量性能。在整个优化过程中,性能测量贯穿始终。所以,首先需要考虑我们需要测量什么,也即我们关心的是什么。对于一个支持多种选项的开放式推理服务而言,用户会向该服务发送各种不同的查询请求,我们关心的是:
1. 我们可以同时服务的用户数是多少(吞吐量)?
2. 我们平均为每个用户服务的时间是多少(延迟)?
我们用 [locust](https://locust.io/) 做了一个测试脚本,如下:
```python
from locust import HttpUser, between, task
from random import randrange, random
class QuickstartUser(HttpUser):
wait_time = between(1, 5)
@task
def bloom_small(self):
sentence = "Translate to chinese. EN: I like soup. CN: "
self.client.post(
"/generate",
json={
"inputs": sentence[: randrange(1, len(sentence))],
"parameters": {"max_new_tokens": 20, "seed": random()},
},
)
@task
def bloom_small(self):
sentence = "Translate to chinese. EN: I like soup. CN: "
self.client.post(
"/generate",
json={
"inputs": sentence[: randrange(1, len(sentence))],
"parameters": {
"max_new_tokens": 20,
"do_sample": True,
"top_p": 0.9,
"seed": random(),
},
},
)
```
**注意:这不是我们最佳的也不是唯一的负载测试,但始终是我们第一个运行的负载测试,因此它可用于公平地比较不同方案。在此基准测试表现最好并不意味着它绝对是最好的解决方案。我们还需要使用其他更复杂的测试场景来模拟真实场景的真实性能。**
我们想观察各种实现方案部署时如何爬坡,并确保在熔断时适当地降低服务器负载。熔断意味着原本能(快速)响应你的请求的服务不再响应你的请求,因为同一时间有太多人想要使用它。避免`死亡之拥(hug of death)` 是极其重要的。[译者注:死亡之拥是一个互联网领域的隐喻,意指由于极端峰值流量而导致互联网服务宕机]
在上述基准测试中,我们得到的初始性能是(使用 GCP 上的 16xA100 40G 环境测得,本文后续所有测试都基于该环境):
每秒处理请求数(吞吐量):0.3
每词元延迟:350ms
这两个值并不是很好。在正式开始工作之前,我们可以预估一下我们能得到的最好结果。BLOOM 模型所需的计算量公式为 $24Bsh^2 + 4Bs^2h * 24Bsh^2 + 4Bs^2h$,其中 `B` 是 batch size,`s` 是序列长度,`h` 是隐含层维度。
让我们算一下,一次前向传播需要 `17 TFlop`。A100 的 [规格](https://www.nvidia.com/en-us/data-center/a100/)为单卡 `312 TFLOPS`。这意味着单个 GPU 最多能达到 `17 / 312 = 54毫秒/词元` 的延迟。我们用了 16 个 GPU,因此可得 `3毫秒/词元`。这只是个上限,我们永远不可能达到这个值,况且现实中卡的性能很少能达到其规格所宣称的数字。此外,如果你的模型并不受限于计算[译者注:如受限于内存带宽、受限于 IO 带宽等],那么这个值你也达不到。知道理想值,只是为了让我们对优化目标心里有个数。在这里,我们到目前为止与理想值差 2 个数量级。此外,这个估计假设你将所有算力都用于延迟型服务,这意味着一次只能执行一个请求(没关系,因为你正在最大化你的机器利用率,所以没有太多其他事情要做;但另一个思路是,我们可以牺牲一点延迟,通过批处理方式来获得更高的吞吐量)。
# 探索多条路线
```
注意:这里,张量并行(Tensor Parallelism,TP) 意味着每个 GPU 将拥有部分权重,因此所有 GPU 始终处于工作状态,专注于分给它的部分工作。通常这会带来非常轻微的开销,因为会有一些工作是重复的,更重要的是,GPU 必须定期相互通信交流它们的结果,然后再继续计算。
```
现在我们已经比较清楚地了解了我们的处境,是时候开始工作了。
我们根据我们自己及其他人的各种经验和知识尝试了各种方法。
每次尝试都值得写一篇专门的博文,由于篇幅所限,在这里我们仅将它们列出来,并只深入解释并研究那些最终应用到当前服务中去的技术的细节。从流水线并行 (PP) 切换到张量并行 (TP) 是延迟优化的一个重要一步。每个 GPU 将拥有部分参数,并且所有 GPU 将同时工作,所以延迟应该会迅速下降。但是付出的代价是通信开销,因为它们的中间结果需要经常互相通信。
需要注意的是,这里涉及的方法相当广泛。我们会有意识地学习更多关于每个工具的知识,以及在后续优化中如何使用它。
## 将代码移植到 JAX/Flax 中以在 TPU 上运行
- 并行方案的选择更加容易。因此 TP 的测试会更方便,这是 JAX 的设计带来的好处之一。
- 对硬件的限制更多,JAX 上 TPU 的性能可能比 GPU 更好,但 TPU 比 GPU 更难获取(只在 GCP 上有,数量也没有 GPU 多)。
- 缺点:需要移植工作。但无论如何,把它集成到我们的库里面这件事肯定是受欢迎的。
结果:
- 移植比较麻烦,因为某些条件语句和核函数很难准确复制,但尚可勉力为之。
- 一旦移植完后,测试各种并行方案就比较方便。感谢 JAX,没有食言。
- 事实证明,在 Ray 集群里与 TPU worker 通信对我们来讲真的太痛苦了。
不知道是工具原因还是网络的原因,或者仅仅是因为我们不太懂,但这事实上减慢了我们的实验速度,而且需要的工作比我们预期的要多得多。
我们启动一个需要 5 分钟时间运行的实验,等了 5 分钟没有发生任何事情,10 分钟之后仍然没有任何事情发生,结果发现是一些 TPU worker 宕机了或者是没有响应。我们不得不手动登进去看,弄清楚发生了什么,修复它,重启一些东西,最后再重新启动实验,就这样半小时过去了。几次下来,几天就没了。我们再强调一下,这未必真的是我们使用的工具的问题,但我们的主观体验确实如此。
- 无法控制编译
我们运行起来后,就尝试了几种设置,想找出最适合我们心目中想要的推理性能的设置,结果证明很难从这些实验中推测出延迟/吞吐量的规律。例如,在 batch_size=1 时吞吐量有 0.3 RPS(Requests Per Second, RPS)(此时每个请求/用户都是独立的),延迟为 15毫秒/词元(不要与本文中的其他数字进行太多比较,TPU 机器与 GPU 机器大不相同),延迟很好,但是总吞吐量跟之前差不多。所以我们决定引入批处理,在 batch_size=2 的情况下,延迟增加到原来的 5 倍,而吞吐量只提高到原来的 2 倍…… 经过进一步调查,我们发现一直到 batch_size=16,每个 batch_size 之间的延迟都差不多。
因此,我们可以以 5 倍的延迟为代价获得 16 倍的吞吐量。看上去挺不错的,但我们更希望对延迟有更细粒度的控制,从而使得延迟能满足 [100ms, 1s, 10s, 1mn](https://www.nngroup.com/articles/response-times-3-important-limits/) 规则中的各档。
## 使用 ONNX/TRT 或其他编译方法
- 它们应该能处理大部分优化工作
- 缺点:通常需要手动处理并行性
结果:
- 事实证明,为了能够 trace/jit/export 模型,我们需要重写 PyTorch 相关的一部分代码,使其能够很容易与纯 PyTorch 方法相融合。总体来讲,我们发现我们可以通过留在 PyTorch 中获得我们想要的大部分优化,使我们能够保持灵活性而无需进行太多编码工作。另一件值得注意的事情是,因为我们在 GPU 上运行,而文本生成有很多轮前向过程,所以我们需要张量留在 GPU 上,有时很难将你的张量输给某个库,返回结果,计算 logits(如 argmax 或采样),再回输给那个库。
将循环放在外部库里面意味着像 JAX 一样失去灵活性,这不是我们设想的推理服务应用场景的使用方法。
## DeepSpeed
- 这是我们训练 BLOOM 时使用的技术,所以用它来推理也很公平
- 缺点:DeepSpeed 之前从未用于推理,其设计也没准备用于推理
结果:
- 我们很快就得到了很不错的结果,这个结果与我们现行方案的上一版性能大致相同。
- 我们必须想出一种方法,在多进程上架设用于处理并发请求网络服务,因为现在一个推理任务是由多个 DeepSpeed 进程完成的(每个 GPU 一个进程),。有一个优秀的库 [Mii](https://github.com/microsoft/DeepSpeed-MII) 可供使用,它虽然还达不到我们所设想的极致灵活的目标,但我们现在可以在它之上开始我们的工作。(当前的解决方案稍后讨论)。
- 我们在使用 DeepSpeed 时遇到的最大问题是缺乏稳定性。
我们在 CUDA 11.4 上运行基于 11.6 编译的代码时遇到了问题。而其中一个由来已久的、我们永远无法真正解决的问题是:经常会发生核函数崩溃(CUDA 非法访问、尺寸不匹配等)。我们修复了其中一些问题,但在压测我们的网络服务时,我们永远无法完全实现稳定性。尽管如此,我想向帮助过我们的 Microsoft 人员说,感谢那些非常愉快的交流,它们提高了我们对正在发生的事情的理解,并为我们的后续工作提供了真知灼见。
- 另一个痛点是我们的团队主要在欧洲,而微软在加利福尼亚,所以合作时间很棘手,我们因此损失了大量时间。这与技术部分无关,但我们确实认识到合作的组织部分也非常重要。
- 另一件需要注意的事情是,DeepSpeed 依赖于 `transformers` 来注入其优化,并且由于我们一直在更新我们的代码,这使得 DeepSpeed 团队很难在我们的主分支上工作。很抱歉让它变得困难,这也可能是 `transformers` 被称为技术最前沿的原因。
## 有关 Web 服务的想法
- 鉴于我们准备运行一个免费服务,支持用户向该服务发送长短不一的文本,并要求获取短至几个词,长至如整个食谱那么长的回应,每个请求的参数也可以各不相同,web服务需要做点什么来支持这个需求。
结果:
- 我们使用绑定库 [tch-rs](https://github.com/LaurentMazare/tch-rs) 在 `Rust` 中重写了所有代码。Rust 的目标不是提高性能,而是对并行性(线程/进程)以及 web 服务和 PyTorch 的并发性进行更细粒度的控制。由于 [GIL](https://realpython.com/python-gil/)的存在,Python 很难处理这些底层细节。
- 结果表明,大部分的痛苦来自于移植工作,移植完后,实验就轻而易举了。我们认为,通过对循环进行精确的控制,即使在具有大量不同属性的请求的场景中,我们也可以为每个请求提供出色的性能。如果你感兴趣的话,可以查看[代码](https://github.com/Narsil/bloomserver),但这份代码没有任何支持,也没有好的文档。
- Rust web 服务投入生产了几周,因为它对并行性的支持更宽松,我们可以更有效地使用 GPU(如使用 GPU0 处理请求 1,而 GPU1 处理请求 0)。在保持延迟不变的情况下,我们把吞吐从 0.3 RPS 提高到了 ~2.5 RPS。虽然在最理想情况下,我们能将吞吐提高到 16 倍。但实际工作负载上的测出来能到 8 倍左右的话也还算不错。
## 纯 PyTorch
- 纯粹修改现有代码,通过删除诸如 `reshape` 之类的操作、使用更优化的核函数等方法来使其运行速度更快。
- 缺点:我们必须自己编写 TP 代码,并且我们还有一个限制,即修改后代码最好仍然适合我们的库(至少大部分)。
结果
- 在下一章详述。
# 最终路线:PyTorch + TP + 1 个自定义内核 + torch.jit.script
## 编写更高效的 PyTorch
第一件事是在代码中删除不必要的操作。可以通过代码走查并找出明显可被删除的某些操作:
- Alibi 在 BLOOM 中用于添加位置嵌入(position embeddings),源代码中计算Alibi的地方太多,每次都重新计算一次,我们优化成只计算一次,这样效率更高。
旧代码:[链接](https://github.com/huggingface/transformers/blob/ca2a55e9dfb245527b5e1c954fec6ffbb7aef07b/src/transformers/models/bloom/modeling_bloom.py#L94-L132)
新代码:[链接](https://github.com/huggingface/transformers/blob/main/src/transformers/models/bloom/modeling_bloom.py#L86-L127)
这个改动获得了 10 倍的加速,最新版本还增加了对填充(padding)的支持!
由于此步骤仅计算一次,因此在这里,运算本身实际速度并不重要,而总体上减少操作和张量创建的次数更重要。
当你开始 [剖析](https://pytorch.org/tutorials/recipes/recipes/profiler_recipe.html) 代码性能时,其他部分会越来越清晰,我们大量地使用了 [tensorboard](https://pytorch.org/tutorials/intermediate/tensorboard_profiler_tutorial.html) 来帮助我们进行性能剖析。它提供了如下图所示的这类图像,可以提供有关性能的洞见:
<img src="/blog/assets/bloom-inference-optimization/profiler_simple.png">
注意力层占用了很多时间,注意这是一个CPU视图,所以条形很长并不意味着核函数执行时间很长,它只意味着 CPU 正在等待上一步的 GPU 结果。
<img src="/blog/assets/bloom-inference-optimization/profiler.png">
我们还在 `baddbmm` 操作之前看到许多 `cat` 操作。
再举个例子,在删除大量 `reshape`/`transpose` 后,我们在 tensorboard 中发现:
- 注意力是性能热点(这是预期的,但能够通过测量数据来验证总是好的)。
- 在注意力中,由于大量的reshape,很多核函数其实是显存拷贝函数。
- 我们**可以**通过修改权重和 `past_key_values` 的内存布局来移除 `reshape`。这个改动有点大,但性能确实有一定的提高!
## 支持 TP
好了,我们已经拿到了大部分唾手可得的成果,现在我们的 PP 版本的延迟从大约 350 毫秒/词元降低到 300 毫秒/词元。延迟降低了 15%,实际情况收益更大,但由于我们最初的测量并不是非常严格,所以就用这个数吧。
然后我们继续实现一个 TP 版。进度比我们预期的要快得多,一个(有经验的)开发人员仅花了半天时间就实现出来了,代码见[此处](https://github.com/huggingface/transformers/tree/thomas/dirty_bloom_tp/src/transformers/models/bloom)。在此过程中,我们还重用了一些其他项目的代码,这对我们很有帮助。
延迟从 300 毫秒/词元直接变为 91 毫秒/词元,这是用户体验的巨大改进。
一个简单的 20 个词元的请求延迟从 6 秒变成了 2 秒,用户体验直接从“慢”变成了轻微延迟。
此外,吞吐量上升了很多,达到 10 RPS。 batch_size=1 和 batch_size=32 延迟基本相同,因此,从这种意义上来讲,在相同的延迟下,吞吐量的上升基本上是*免费*的。
## 唾手可得的果实
现在我们有了一个 TP 版本的实现,我们可以再次开始进行性能剖析和优化。因为并行方案发生了改变,我们有必要再从头开始分析一遍。
首先,同步 (`ncclAllReduce`) 开始成为主要热点,这符合我们的预期,同步需要花时间。但我们不打算优化这一部分,因为它已经使用了 `nccl`。虽然可能还有一些改进空间,但我们认为我们很难做得更好。
第二个是 `Gelu` 算子,我们可以看到它启动了许多 `element-wise` 类的核函数,总体而言它占用的计算份额比我们预期的要大。
我们对 `Gelu` 作了如下修改:
从
```python
def bloom_gelu_forward(x):
return x * 0.5 * (1.0 + torch.tanh(0.79788456 * x * (1 + 0.044715 * x * x)))
```
改成了
```python
@torch.jit.script
def bloom_gelu_forward(x):
return x * 0.5 * (1.0 + torch.tanh(0.79788456 * x * (1 + 0.044715 * x * x)))
```
我们使用 `jit` 将许多小的 `element-wise` 核函数融合成了一个核函数,从而节省了核函数启动开销和内存拷贝开销。
该优化降低了 10% 的延迟,从 91 毫秒/词元到 81 毫秒/词元,搞定!
不过要小心,这种方法可不是任何时候都有效,算子融合不一定每次都会发生。另外如果原来的算子实现已经非常高效了,就算融合了也不能带来很多的增益。
我们发现它在下面几个场合有用:
- 你有很多小的、`element-wise` 的操作
- 你的性能热点里有一些难以去除的 `reshape` 算子,这些算子一般就是拷贝
- 算子能融合时
## 滑铁卢
在测试期间,有一段时间,我们观察到 Rust 服务的延迟比 Python 服务低 25%。这很奇怪,但因为它们的测试环境是一致的,而且去除了核函数后我们还是能测到这个速度增益,我们开始感觉,也许降低 Python 开销可以带来不错的性能提升。
我们开始了为期 3 天的重新实现 `torch.distributed` 部分代码的工作,以便在 Rust 里运行 [nccl-rs](https://github.com/Narsil/nccl-rs)。代码能工作,但生成的句子与 Python 版有些不一样,于是我们开始调查这些问题,就在这个过程中,我们发现......**在测量 PyTorch 版性能时,我们忘记删除 PyTorch 里的 profiler 代码了**......
我们遭遇了滑铁卢,删除 profiler 代码后延迟降低了 25%,两份代码延迟一样了。其实我们最初也是这么想的,Python 一定不会影响性能,因为模型运行时运行的主要还是 torch cpp 的代码。虽然 3 天其实也不算啥,但发生这样的事还是挺糟糕的。
针对错误的或不具代表性的测量数据进行优化,这很常见,优化结果最终会令人失望甚至对整个产品带来反效果。这就是为什么`小步快走`以及`设立正确预期`有助于控制这种风险。
另一个我们必须格外小心的地方是产生第一个新词的前向过程[译者注:第一个新词`past_key_values`为`None`]和产生后续新词的前向过程[译者注:此时`past_key_values`不为空] 是不一样的。如果你只针对第一个词优化,你反而会拖慢后续的那些更重要并且占大部分运行时间的词的生成时间。
另一个很常见的罪魁祸首是测量时间,它测量的是 CPU 时间,而不是实际的 CUDA 时间,因此运行时需要用 `torch.cuda.synchronize()` 来确保 GPU 执行完成。
## 定制核函数
到目前为止,我们已经实现了接近 DeepSpeed 的性能,而无需任何自定义代码!很简约。我们也不必在推理 batch size 的灵活性上做出任何妥协!
但根据 DeepSpeed 的经验,我们也想尝试编写一个自定义核函数,以对 `torch.jit.script` 无法完成融合的一些操作进行融合。主要就是下面两行:
```python
attn_weights = attention_scores.masked_fill_(attention_mask, torch.finfo(attention_scores.dtype).min)
attention_probs = F.softmax(attn_weights, dim=-1, dtype=torch.float32).to(input_dtype)
```
第一个 `masked_fill_` 是创建一个新的张量,这里只是告诉 softmax 运算符忽略这些值。此外,softmax 需要在 float32 上计算(为了数值稳定性),但在自定义核函数中,我们可以减少向上数据类型转换的次数,仅在求和及累加时转换。
你可以在[此处](https://github.com/huggingface/transformers/blob/thomas/add_custom_kernels/src/transformers/models/bloom/custom_kernels/fused_bloom_attention_cuda.cu) 找到我们的代码。
请记住,我们的优化只针对一个特定的 GPU 架构(即 A100),所以该核函数不适用于其他 GPU 架构;同时我们也不是编写核函数的专家,因此很有可能有更好的实现方法。
这个自定义核函数又提供了 10% 的延迟提升,延迟从 81 毫秒/词元降低到 71 毫秒/词元。同时,我们继续保持了灵活性。
在那之后,我们调查、探索了更多优化手段,比如融合更多的算子来删除剩下的 `reshape` 等等。但还没有哪个手段能产生足够大的提升而值得被放入最终版本。
## Web 服务部分
就像我们在 Rust 里做的一样,我们必须实现对具有不同参数的请求的批处理。由于我们处于 `PyTorch` 世界中,我们几乎可以完全控制正在发生的事情。
而又由于我们处于 `Python` 世界中,我们有一个限制因素,即 `torch.distributed` 需要多进程而不是多线程运行,这意味着进程之间的通信有点麻烦。最后,我们选择通过 Redis 发布/订阅来传递原始字符串,以便同时将请求分发给所有进程。因为我们处于不同的进程中,所以这样做比进行张量通信更容易、通信量也很小。
然后我们不得不放弃使用 [generate](https://huggingface.co/docs/transformers/v4.22.2/en/main_classes/text_generation#transformers.generation_utils.GenerationMixin.generate) 函数,因为这会将参数应用于batch中所有的序列,而实际上每个序列的参数可能各不相同。值得庆幸的是,我们可以重用较底层的 API ,如 [LogitsProcessor](https://huggingface.co/docs/transformers/internal/generation_utils#transformers.LogitsProcessor),以节省大量工作。因此,我们重构了一个 `generate` 函数,它接受一个参数列表并将列表中的参数分别应用于 batch 中的各个序列。
最终用户体验主要还是看延迟。由于我们支持不同的请求有不同的参数,因此可能出现这样的情况:一个请求想要生成 20 个词元,而另一个请求想要生成 250 个词元。由于每个词元需要 75 毫秒的延迟,因此一个请求需要 1.5 秒,而另一个需要 18 秒。如果我们一直进行批处理的话,我们会让第一个用户等待 18 秒,因此看起来好像我们正在以 900 毫秒/词元的速度运行,太慢了!
由于我们处于具有极大灵活性的 PyTorch 世界中,我们可以做的是在生成前 20 个词元后立即从批处理中提取第一个请求,并在 1.5 秒内返回给该用户!这同时也节省了 230 个词元的计算量。
因此,**灵活性**对于获得最佳延迟非常重要。
# 最后的笔记和疯狂的想法
优化是一项永无止境的工作,与任何其他项目一样,20% 的工作通常会产生 80% 的结果。
从某个时间点开始,我们开始制定一个小的测试策略来确定我们的某个想法的潜在收益,如果测试没有产生显著的结果,我们就会放弃这个想法。1 天增加 10% 足够有价值,2 周增加 10 倍也足够有价值。2 周提高 10% 就算了吧。
## 你试过 ...... 吗?
由于各种原因,有些方法我们知道但我们没使用的。可能原因有:感觉它不适合我们的场景、工作量太大、收益潜力不够大、或者甚至仅仅是因为我们有太多的选择要试而时间不够所以就放弃了一些。以下排名不分先后:
- [CUDA graphs](https://developer.nvidia.com/blog/cuda-graphs/)
- [nvFuser](https://pytorch.org/tutorials/intermediate/nvfuser_intro_tutorial.html) (它是 `torch.jit.script` 的后端,所以从这个角度来讲,我们也算用了它。)
- [FasterTransformer](https://github.com/NVIDIA/FasterTransformer)
- [Nvidia's Triton](https://developer.nvidia.com/nvidia-triton-inference-server)
- [XLA](https://www.tensorflow.org/xla) (JAX 也使用 XLA!)
- [torch.fx](https://pytorch.org/docs/stable/fx.html)
- [TensorRT](https://developer.nvidia.com/blog/accelerating-inference-up-to-6x-faster-in-pytorch-with-torch-tensorrt/)
如果你最喜欢的工具没有列在这儿,或者你认为我们错过了一些可能有用的重要工具,请随时与我们联系!
## [Flash attention](https://github.com/HazyResearch/flash-attention)
我们简单集成过 flash attention,虽然它在生成第一个词元(没有 `past_key_values`)时表现非常好,但在有了 `past_key_values` 后,它并没有产生太大的改进。而且如果我们要用上它,我们需要对其进行调整以支持 `alibi` 张量的计算。因此我们决定暂时不做这项工作。
## [OpenAI Triton](https://openai.com/blog/triton/)
[Triton](https://github.com/openai/triton) 是一个用于在 Python 中构建定制核函数的出色框架。我们后面打算多用它,但到目前为止我们还没有。我们很想知道它的性能是否优于我们手写的 CUDA 核函数。当时,在做方案选择时,我们认为直接用 CUDA 编写似乎是实现目标的最短路径。
## 填充和 `reshape`
正如本文通篇所提到的,每次张量拷贝都有成本,而生产环境中运行时的另一个隐藏成本是填充。当两个查询的长度不同时,你必须使用填充(使用虚拟标记)以使它们等长。这可能会导致很多不必要的计算。[更多信息](https://huggingface.co/docs/transformers/v4.22.2/en/main_classes/pipelines#pipeline-batching)。
理想情况下,我们可以永远*不*做这些计算,永远不做 `reshape`。
TensorFlow 有 [RaggedTensor](https://www.tensorflow.org/guide/ragged_tensor) 而 PyTorch 也有[嵌套张量](https://pytorch.org/docs/stable/nested.html) 的概念。这两者似乎都不像常规张量那样精简,但能使我们的计算更好,这对我们有好处。
理想的情况下,整个推理过程都可以用 CUDA 或纯 GPU 代码来实现。考虑到我们在融合算子时看到性能改进,这种方法看起来很诱人。但我们不知道性能提升能到什么程度。如果有更聪明的GPU专家知道,我们洗耳恭听!
# 致谢
所有这些工作都是许多 HF 团队成员合作的结果。以下排名不分先后, [@ThomasWang](https://huggingface.co/TimeRobber) [@stas](https://huggingface.co/stas)
[@Nouamane](https://huggingface.co/nouamanetazi) [@Suraj](https://huggingface.co/valhalla)
[@Sanchit](https://huggingface.co/sanchit-gandhi) [@Patrick](https://huggingface.co/patrickvonplaten)
[@Younes](/ybelkada) [@Sylvain](https://huggingface.co/sgugger)
[@Jeff (Microsoft)](https://github.com/jeffra) [@Reza](https://github.com/RezaYazdaniAminabadi)
以及 [BigScience](https://huggingface.co/bigscience) 项目中的所有人。
| 1 |
0 | hf_public_repos/blog | hf_public_repos/blog/zh/synthetic-data-save-costs.md | ---
title: "合成数据:利用开源技术节约资金、时间和减少碳排放"
thumbnail: /blog/assets/176_synthetic-data-save-costs/thumbnail.png
authors:
- user: MoritzLaurer
translators:
- user: innovation64
- user: zhongdongy
proofreader: true
---
# 合成数据: 利用开源技术节约资金、时间和减少碳排放 <!-- omit in toc -->
## 简单概括 <!-- omit in toc -->
你应该使用自己的模型,还是使用 LLM API?创建你自己的模型可以让你完全控制,但需要数据收集、训练和部署方面的专业知识。LLM API 使用起来更简单,但会将数据发送给第三方,并对提供商有强烈依赖。这篇博客让你可以将 LLM 的便利性与定制模型的控制性和效率相结合。
在一个关于识别新闻报道中投资者情绪的案例研究中,我们展示了如何使用开源 LLM 创建合成数据,并在几个步骤中训练你的定制模型。我们定制的 RoBERTa 模型可以分析大型新闻数据集,与 GPT4 相比性能一致都是 (94% acc 和 0.94 的 F1 macro),我们只需 2.7 美元,排碳 0.12kg,延迟 0.13s ; 而 GPT4 要费 3061 美元,排碳约 735 到 1100 kg ,延迟多秒。这里提供了 [notebooks](https://github.com/MoritzLaurer/synthetic-data-blog/tree/main) 方便你用于自己的研究。
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/176_synthetic-data-save-costs/table_pros_cons.png" alt="table_pros_cons" width=95%>
</p>
## 目录 <!-- omit in toc -->
- [1. 问题:你的使用案例没有数据](#1-问题-你的使用案例没有数据)
- [2. 解决方案:合成数据来高效蒸馏学生模型](#2-解决方案-合成数据来高效蒸馏学生模型)
- [3. 案例分析:监控金融情绪 ](#3-案例分析-监控金融情绪 )
- [3.1 给 LLM 提示来标注你的数据](#31-给-LLM-提示来标注你的数据)
- [3.2 将开源模型与专有模型进行比较](#32-将开源模型与专有模型进行比较)
- [3.3 理解并验证你合成的数据](#33-理解并验证你合成的数据)
- [3.4 使用 AutoTrain 调整你高效、专业的模型](#34-使用-AutoTrain-调整你高效、专业的模型)
- [3.5 不同方法的利弊](#35-不同方法的利弊)
- [结论](#结论)
## 1. 问题: 你的使用案例没有数据
想象一下你的老板让你去建一个你公司的情感分析系统。你可以在 Hugging Face Hub 上找到 100,000+ 个数据集,这其中包含标题含有 “sentiment” 的字段的数据集, Twitter 上的情感数据集、诗歌中的情感或以希伯来语的情感数据集。这很好,但比如你在一家金融机构工作并且你追踪你投资组合中特定品牌的市场情绪,那么你可能会发现上面这些数据集没有一个有用的。虽然机器学习需要处理数百万的任务公司,但正巧别人已经收集并发布你公司的这个案例的数据集的可能性机会几乎为零。
由于对特定领域的数据集和模型的缺失,许多人尝试用更加通用的 LLM。这些模型都非常大和通用,以至于它们可以开箱即用,并实现令人印象深刻的准确度。它们的易于使用的 API 消除了对微调和对部署的专业知识的需求。但他们最主要的缺点是大小和可控性: 大小超过十亿到万亿的参数运行在计算集群中,控制权只在少数的几家公司手中。
## 2. 解决方案: 合成数据来高效蒸馏学生模型
在 2023 年,一个东西根本的改变了机器学习的蓝图,LLM 开始达到和人类数据标注者相同的水平。现在有大量的证据表明,最好的 LLM 比众包工人更胜一筹,并且在创建高质量 (合成的) 数据中部分达到了专家水平 (例如 [Zheng et al. 2023](https://arxiv.org/pdf/2306.05685.pdf), [Gilardi et al. 2023](https://arxiv.org/pdf/2303.15056.pdf), [He et al. 2023](https://arxiv.org/pdf/2303.16854.pdf))。这一进展的重要性怎么强调都不为过。创建定制模型的关键瓶颈在于招募和协调人工工作者以创造定制训练数据的资金、时间和专业知识需求。随着大型语言模型 (LLMs) 开始达到人类水平,高质量的数据标注现在可以通过 API 获得; 可复制的注释指令可以作为提示 prompt 发送; 合成数据几乎可以立即返回,唯一的瓶颈就剩计算能力了。
在 2024 年,这种方法将变得具有商业可行性,并提升开源对大中小企业的重要性。在 2023 年的大部分时间里,由于 LLM API 提供商的限制性商业条款,LLMs 的商业用途在标注数据方面被阻止。随着像 [Mistral](https://mistral.ai/) 的 [Mixtral-8x7B-Instruct-v0.1](https://huggingface.co/mistralai/Mixtral-8x7B-Instruct-v0.1) 这样的模型的推出,LLM 数据标注和合成数据现在对商业用途开放。[Mixtral 的表现与 GPT3.5 相当](https://huggingface.co/spaces/lmsys/chatbot-arena-leaderboard),并且由于它的 Apache 2.0 许可证,其合成数据输出可以作为商业用例中较小、专业化的模型 (“学生”) 的训练数据。这篇博客提供了一个示例,这将显著加快你自己的定制模型的创建速度,同时大幅降低长期推理成本。
## 3. 案例分析: 监控金融情绪
想象你是一个数据科学家,正在为一家大型投资公司工作。你的任务是监控经济新闻情绪,以帮助公司做出投资决策。最近,你有两个主要选择:
1. 你可以微调你自己的模型。这需要编写标注指令,创建标注接口,招人,引入质量保证措施以处理低质量数据,在这个数据上微调模型,并部署。
2. 或者,你可以按照指令将数据发送到 LLM API。你完全跳过微调和部署步骤,将数据分析过程简化为编写指令 (提示),然后发送给 API 背后的“LLM 标注器”。在这种情况下,LLM API 就是你的最终推理解决方案,你直接使用 LLM 的输出进行分析。
尽管选项 2 在推理时间上更贵,并且需要你发送敏感数据到第三方,但选项 2 比选项 1 更容易设置,因此被许多开发人员使用。
在 2024 年,合成数据将提供第三个选项: 结合选项 1 的成本效益与选项 2 的简易性。你可以使用一个 LLM (老师模型) 去标注一个你的小数据样本,并在这个数据集上微调一个小的,高效的语言模型 (学生模型)。这种方法可以在几步内执行完成。
### 3.1 给 LLM 提示来标注你的数据
我们使用 [financial_phrasebank](https://huggingface.co/datasets/financial_phrasebank) 情感数据集作为示例,但你可以将代码适配到任何其他用例。financial_phrasebank 任务是一个 3 类分类任务,其中 16 位专家从投资者视角对芬兰公司金融新闻中的句子进行“积极”/“消极”/“中性”标注 ( [Malo et al. 2013](https://arxiv.org/pdf/1307.5336.pdf) )。例如,数据集中包含这样一句话: “对于 2010 年最后一个季度,Componenta 的净销售额翻倍,达到 1.31 亿欧元,而去年同期为 7600 万欧元”,标注者从投资者视角将其归类为“积极”。
我们首先安装一些必需的库。
```python
!pip install datasets # for loading the example dataset
!pip install huggingface_hub # for secure token handling
!pip install requests # for making API requests
!pip install scikit-learn # for evaluation metrics
!pip install pandas # for post-processing some data
!pip install tqdm # for progress bars
```
然后,我们可以下载带有专家标注的示例数据集。
```python
from datasets import load_dataset
dataset = load_dataset("financial_phrasebank", "sentences_allagree", split='train')
# create a new column with the numeric label verbalised as label_text (e.g. "positive" instead of "0")
label_map = {
i: label_text
for i, label_text in enumerate(dataset.features["label"].names)
}
def add_label_text(example):
example["label_text"] = label_map[example["label"]]
return example
dataset = dataset.map(add_label_text)
print(dataset)
# Dataset({
# features: ['sentence', 'label', 'label_text'],
# num_rows: 2264
#})
```
现在我们写一个短的标注指令,针对 `financial_phrasebank` 任务,并将其格式化为一个 LLM 提示。这个提示类似于你通常提供给众包工人的指令。
```python
prompt_financial_sentiment = """\
You are a highly qualified expert trained to annotate machine learning training data.
Your task is to analyze the sentiment in the TEXT below from an investor perspective and label it with only one the three labels:
positive, negative, or neutral.
Base your label decision only on the TEXT and do not speculate e.g. based on prior knowledge about a company.
Do not provide any explanations and only respond with one of the labels as one word: negative, positive, or neutral
Examples:
Text: Operating profit increased, from EUR 7m to 9m compared to the previous reporting period.
Label: positive
Text: The company generated net sales of 11.3 million euro this year.
Label: neutral
Text: Profit before taxes decreased to EUR 14m, compared to EUR 19m in the previous period.
Label: negative
Your TEXT to analyse:
TEXT: {text}
Label: """
```
这个标注指令现在可以被传递给 LLM API。对于这个例子,我们使用免费 Hugging Face [无服务的推理 API](https://huggingface.co/docs/api-inference/index)。这个 API 是测试流行模型的理想选择。请注意,如果你发送次数过多,尤其是分享给过多用户,你可能会遇到速率限制。对于更大的工作流,我们推荐创建一个 [专用推理端点](https://huggingface.co/docs/inference-endpoints/index)。专用推理端点对于你自己的付费 API 尤为重要,特别是你可以灵活的控制开和关。
我们登录 `huggingface_hub` 库,简单安全的填入我们的 API token。或者,你也可以定义你自己的 token 作为环境变量。(详情可以参考 [文档](https://huggingface.co/docs/huggingface_hub/quick-start#authentication))。
```python
# you need a huggingface account and create a token here: https://huggingface.co/settings/tokens
# we can then safely call on the token with huggingface_hub.get_token()
import huggingface_hub
huggingface_hub.login()
```
我么定义一个简单的 `generate_text` 函数,用于发送我们的提示 prompt 和数据到 API。
```python
import os
import requests
# Choose your LLM annotator
# to find available LLMs see: https://huggingface.co/docs/huggingface_hub/main/en/package_reference/inference_client#huggingface_hub.InferenceClient.list_deployed_models
API_URL = "https://api-inference.huggingface.co/models/mistralai/Mixtral-8x7B-Instruct-v0.1"
# docs on different parameters: https://huggingface.co/docs/api-inference/detailed_parameters#text-generation-task
generation_params = dict(
top_p=0.90,
temperature=0.8,
max_new_tokens=128,
return_full_text=False,
use_cache=False
)
def generate_text(prompt=None, generation_params=None):
payload = {
"inputs": prompt,
"parameters": {**generation_params}
}
response = requests.post(
API_URL,
headers={"Authorization": f"Bearer {huggingface_hub.get_token()}"},
json=payload
)
return response.json()[0]["generated_text"]
```
作为 LLM 可能不会总是返回标签相同的标准化格式,我们还可以定义一个短 `clean_output` 函数,将 LLM 从字符串输出映射到我们的三个可能标签。
```python
labels = ["positive", "negative", "neutral"]
def clean_output(string, random_choice=True):
for category in labels:
if category.lower() in string.lower():
return category
# if the output string cannot be mapped to one of the categories, we either return "FAIL" or choose a random label
if random_choice:
return random.choice(labels)
else:
return "FAIL"
```
我们现在可以将我们的文本发送给 LLM 进行标注。下面的代码将每一段文本发送到 LLM API,并将文本输出映射到我们的三个清晰类别。注意: 在实际操作中,逐个文本迭代并将它们分别发送到 API 是非常低效的。API 可以同时处理多个文本,你可以异步地批量向 API 发送文本来显著加快 API 调用速度。你可以在本博客的 [复现仓库](https://github.com/MoritzLaurer/synthetic-data-blog/tree/main) 中找到优化后的代码。
```python
output_simple = []
for text in dataset["sentence"]:
# add text into the prompt template
prompt_formatted = prompt_financial_sentiment.format(text=text)
# send text to API
output = generate_text(
prompt=prompt_formatted, generation_params=generation_params
)
# clean output
output_cl = clean_output(output, random_choice=True)
output_simple.append(output_cl)
```
基于这个输出,我么可以计算指标来查看模型在不对其进行训练的情况下是否准确地完成了任务。
```python
from sklearn.metrics import classification_report
def compute_metrics(label_experts, label_pred):
# classification report gives us both aggregate and per-class metrics
metrics_report = classification_report(
label_experts, label_pred, digits=2, output_dict=True, zero_division='warn'
)
return metrics_report
label_experts = dataset["label_text"]
label_pred = output_simple
metrics = compute_metrics(label_experts, label_pred)
```
基于简单的提示 prompt,LLM 正确分类了 91.6% 的文本 (0.916 准确率和 0.916 F1 macro)。考虑到它没有训练来完成这个具体任务,这相当不错。
我们通过使用两个简单的提示 Prompt 技巧来进一步提升精度: 思维链 COT 和 自我一致 SC。CoT 要求模型首先对正确的标签进行推理,然后再做出标注决策,而不是立即决定正确的标签。SC 意味着多次向同一个 LLM 发送相同文本的相同提示。SC 有效地为 LLM 提供了针对每段文本的多条不同的推理路径,如果 LLM 回应“积极”两次和“中性”一次,我们选择多数 (“积极”) 作为正确的标签。这是我们为 CoT 和 SC 更新的提示:
```python
prompt_financial_sentiment_cot = """\
You are a highly qualified expert trained to annotate machine learning training data.
Your task is to briefly analyze the sentiment in the TEXT below from an investor perspective and then label it with only one the three labels:
positive, negative, neutral.
Base your label decision only on the TEXT and do not speculate e.g. based on prior knowledge about a company.
You first reason step by step about the correct label and then return your label.
You ALWAYS respond only in the following JSON format: {{"reason": "...", "label": "..."}}
You only respond with one single JSON response.
Examples:
Text: Operating profit increased, from EUR 7m to 9m compared to the previous reporting period.
JSON response: {{"reason": "An increase in operating profit is positive for investors", "label": "positive"}}
Text: The company generated net sales of 11.3 million euro this year.
JSON response: {{"reason": "The text only mentions financials without indication if they are better or worse than before", "label": "neutral"}}
Text: Profit before taxes decreased to EUR 14m, compared to EUR 19m in the previous period.
JSON response: {{"reason": "A decrease in profit is negative for investors", "label": "negative"}}
Your TEXT to analyse:
TEXT: {text}
JSON response: """
```
这是一个 JSON 提示,我们要求 LLM 返回一个结构化的 JSON 字符串,其中 “reason” 作为一个键,“label” 作为另一个键。JSON 的主要优点是我们可以将其解析为 Python 字典,然后提取 “label” 。如果我们想了解 LLM 选择这个标签的原因,我们也可以提取 “reason”。
`process_output_cot` 函数解析 LLM 返回的 JSON 字符串,并且如果 LLM 没有返回有效的 JSON,它会尝试使用上面定义的 `clean_output` 函数通过简单的字符串匹配来识别标签。
```python
import ast
def process_output_cot(output):
try:
output_dic = ast.literal_eval(output)
return output_dic
except Exception as e:
# if json/dict parse fails, do simple search for occurance of first label term
print(f"Parsing failed for output: {output}, Error: {e}")
output_cl = clean_output(output, random_choice=False)
output_dic = {"reason": "FAIL", "label": output_cl}
return output_dic
```
现在,我们可以使用上面新的提示重复使用我们的 `generate_text` 函数,用 `process_output_cot` 处理 JSON 的 COT 输出,并且为了 SC 多次发送每个提示。
```python
self_consistency_iterations = 3
output_cot_multiple = []
for _ in range(self_consistency_iterations):
output_lst_step = []
for text in tqdm(dataset["sentence"]):
prompt_formatted = prompt_financial_sentiment_cot.format(text=text)
output = generate_text(
prompt=prompt_formatted, generation_params=generation_params
)
output_dic = process_output_cot(output)
output_lst_step.append(output_dic["label"])
output_cot_multiple.append(output_lst_step)
```
对于每段文本,我们现在的 LLM 标注器有了三次尝试来识别正确标签,并采用了三种不同的推理路径。下面的代码从这三条路径中选择了多数标签。
```python
import pandas as pd
from collections import Counter
def find_majority(row):
# Count occurrences
count = Counter(row)
# Find majority
majority = count.most_common(1)[0]
# Check if it's a real majority or if all labels are equally frequent
if majority[1] > 1:
return majority[0]
else: # in case all labels appear with equal frequency
return random.choice(labels)
df_output = pd.DataFrame(data=output_cot_multiple).T
df_output['label_pred_cot_multiple'] = df_output.apply(find_majority, axis=1)
```
现在,我们可以比较我们的改进的 LLM 标签与专家标签,并计算指标。
```python
label_experts = dataset["label_text"]
label_pred_cot_multiple = df_output['label_pred_cot_multiple']
metrics_cot_multiple = compute_metrics(label_experts, label_pred_cot_multiple)
```
CoT 和 SC 将性能提升到了 94.0% 的准确率和 0.94 的 F1 macro。通过给模型时间来考虑其标签决策,并给予它多次尝试,我们提升了性能。请注意,CoT 和 SC 需要额外的计算资源。我们本质上是在用计算资源购买标注的准确性。
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/176_synthetic-data-save-costs/fig_mixtral.png" alt="fig_mixtral" width=95%>
</p>
现在,我们通过这些简单的 LLM API 调用创建了一个合成训练数据集。我们在做出标签决策之前,让 LLM 尝试了三种不同的推理路径来标注每段文本。结果是,这些标签与人类专家的高度一致,并且我们得到了一个高质量的数据集,可以用来训练更高效、更专业的模型。
```python
df_train = pd.DataFrame({
"text": dataset["sentence"],
"labels": df_output['label_pred_cot_multiple']
})
df_train.to_csv("df_train.csv")
```
请注意,在这篇博客文章的 [完整复现脚本](https://github.com/MoritzLaurer/synthetic-data-blog/tree/main) 中,我们还将仅基于专家标注创建一个测试集,以评估所有模型的质量。所有指标始终基于这个人类专家测试集。
### 3.2 将开源模型与专有模型进行比较
使用开源的 Mixtral 模型创建的这种数据的主要优势在于,这些数据在商业上完全可用,且没有法律上的不确定性。例如,使用 OpenAI API 创建的数据受 [OpenAI 商业条款](https://openai.com/policies/business-terms) 的约束,这些条款明确禁止将模型输出用于训练与他们的产品和服务竞争的模型。这些条款的法律价值和意义尚不明确,但它们为使用 OpenAI 模型合成的数据训练模型的商业使用引入了法律上的不确定性。任何使用合成数据训练的更小、更高效的模型都可能被视为竞争者,因为它减少了对 API 服务的依赖。
开源的 Mistral 的 `Mixtral-8x7B-Instruct-v0.1` 与 OpenAI 的 GPT3.5 和 GPT4 之间合成的数据质量如何比较呢?我们使用 `gpt-3.5-turbo-0613` 和 `gpt-4-0125-preview` 运行了上述相同的流程和提示,并在下表中报告了结果。我们看到,Mixtral 在这个任务上的表现优于 GPT3.5,并且与 GPT4 相当,这取决于提示类型。(我们没有显示新版本的 gpt-3.5-turbo-0125 的结果,因为不知何故,这个模型的表现比旧版本的默认 gpt-3.5-turbo-0613 要差)。
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/176_synthetic-data-save-costs/fig_mixtral_gpt.png" alt="fig_mixtral_gpt" width=95%>
</p>
请注意,这并不意味着 Mixtral 总是比 GPT3.5 更好,与 GPT4 相当。GPT4 在多个基准测试上的表现更好。主要想表达的是,开源模型现在可以创建高质量的合成数据。
### 3.3 理解并验证你合成的数据
所有这些在实践中意味着什么呢?到目前为止,结果只是由一些黑盒 LLM 标注的数据。我们只能计算指标,因为我们有来自示例数据集的专家标注的参考数据。如果在真实世界的场景中没有专家标注,我们如何信任 LLM 的标注呢?
在实践中,无论你使用哪种标注器 (人类标注或 LLM ),你只能信任你自己验证过的数据。指令/提示总是包含一定程度的模糊性。即使是一个完美智能的标注也可能犯错误,并且在面对通常模糊的现实世界数据时,必须做出不明确的决定。
幸运的是,随着近年来开源工具的出现,数据验证变得更加简单: [Argilla](https://argilla.io/) 提供了一个免费的界面,用于验证和清理非结构化的 LLM 输出; [LabelStudio](https://labelstud.io/) 使你能够以多种方式标注数据; [CleanLab](https://cleanlab.ai/) 提供了一个用于标注和自动清理结构化数据的界面; 对于快速和简单的验证,仅在简单的 Excel 文件中标注也可能是可以的。
花些时间标注文本,以了解数据和其模糊性,这是非常重要的。你会很快发现模型犯了一些错误,但也会有几个例子,正确的标签是不明确的,有些文本你更同意 LLM 的决定,而不是创建数据集的专家。这些错误和模糊性是数据集创建的正常部分。实际上,只有极少数现实世界的任务中,人类专家的基线是完全一致的。这是一个古老的见解,最近被机器学习文献“重新发现”,即人类数据是一个有缺陷的金标准 ([Krippendorf 2004](https://books.google.de/books/about/Content_Analysis.html?id=q657o3M3C8cC&redir_esc=y), [Hosking et al. 2024](https://arxiv.org/pdf/2309.16349.pdf))。
在标注界面不到一个小时的时间里,我们更好地了解了我们的数据并纠正了一些错误。然而,为了可复现性,以及展示纯粹合成数据的质量,我们在下一步继续使用未清理的 LLM 标注。
### 3.4 使用 AutoTrain 调整你高效、专业的模型
到目前为止,我们已经经历了一个标准的流程,即通过 API 提示 LLM 并验证输出。现在,进入一个额外的步骤,以实现显著的资源节约: 我们将在 LLM 的合成数据上微调一个更小、更高效和专业化的 LM。这个过程也被称为“蒸馏”,其中较大模型的输出 (“教师”) 用于训练一个较小的模型 (“学生”)。虽然这听起来很复杂,但它本质上只意味着我们使用数据集中的原始 `text` ,并将 LLM 的预测作为我们微调的 `labels` 。如果你以前训练过分类器,你知道,使用 `transformers` 、 `sklearn` 或其他库,你只需要这两个列来训练一个分类器。
我们使用 Hugging Face 的 [AutoTrain](https://huggingface.co/autotrain) 解决方案使这个过程更加简单。AutoTrain 是一个无代码界面,它使你能够上传一个带有标记数据的 `.csv` 文件,该服务然后使用它为你自动微调模型。这消除了为训练你自己的模型编写代码或深入微调专业知识的需求。
在 Hugging Face 网站上,我们首先在顶部点击 “Spaces”,然后点击 “Create new Space”。然后选择 “Docker”>“AutoTrain” 并选择一个小型 A10G GPU,每小时成本为 $1.05。AutoTrain 的空间将然后初始化。然后,我们可以通过界面上传我们的合成训练数据和专家测试数据,并调整不同的字段,如下面的截图所示。填写所有内容后,我们可以点击 “Start Training”,并在 Space 的日志中跟踪训练过程。仅在 1811 个数据点上训练一个小型的 RoBERTa-base 模型 (~0.13 B 参数) 非常快,可能不需要超过几分钟。一旦训练完成,模型将自动上传到你的 HF 个人资料。一旦训练完成,space 就会停止,整个过程最多应该需要 15 分钟,成本不到 $1。
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/176_synthetic-data-save-costs/autotrain.png" alt="autotrain" width=95%>
</p>
如果你愿意,你也可以完全在你自己的硬件上本地使用 AutoTrain,请参阅我们的 [文档](https://huggingface.co/docs/autotrain/index)。高级用户当然总是可以编写自己的训练脚本,但对于这些默认的超参数,AutoTrain 的结果对于许多分类任务来说应该足够了。
我们最终微调的约 0.13B 参数的 RoBERTa-base 模型与更大的 LLM 相比表现如何?下图显示,在 1811 个文本上微调的自定义模型达到了 94% 的准确率,与它的老师 Mixtral 和 GPT4 一样!一个小型模型当然无法与一个更大型的 LLM 出厂即战,但通过在一些高质量数据上进行微调,它可以达到在它所专长的任务上与大型 LLM 相同的性能水平。
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/176_synthetic-data-save-costs/fig_mixtral_gpt_roberta.png" alt="fig_mixtral_gpt_roberta" width=95%>
</p>
### 3.5 不同方法的利弊
我们在开始时讨论的三种方法的总体优缺点是什么:(1) 手动创建你自己的数据和模型,(2) 仅使用 LLM API,或者 (3) 使用 LLM API 创建用于专业模型的合成数据?下面的表格显示了不同因素之间的权衡,我们将在下面根据我们的示例数据集讨论不同的指标。
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/176_synthetic-data-save-costs/table_pros_cons.png" alt="table_pros_cons" width=95%>
</p>
让我们从任务性能开始。如上所示,专业模型与更大型的 LLM 表现相当。微调后的模型只能执行我们训练它执行的特定任务,但它在执行这个特定任务方面表现非常好。要创建更多训练数据来将模型适应到新的领域或更复杂的任务是轻而易举的。多亏了 LLM 的合成数据,由于缺乏专业数据而导致的低性能不再是问题。
其次,计算成本和推理速度。实际中的主要计算成本将是推理,即在训练后运行模型。假设在你的生产用例中,你需要在给定时间段内处理 100 万句话。我们的微调 RoBERTa-base 模型在一个带有 16GB RAM 的小型 T4 GPU 上运行效率很高,在 [推理端点](https://ui.endpoints.huggingface.co/) 上的成本为每小时 $0.6。它具有 0.13s 的延迟和每秒 61 句话的吞吐量 ( `batch_size=8` )。这使得处理 100 万句话的总成本为 $2.7。
使用 GPT 模型,我们可以通过计算 token 来计算推理成本。处理 100 万句话的 toekn 将花费 GPT3.5 约 $153,GPT4 约 $3061。这些模型的延迟和吞吐量更加复杂,因为它们根据一天中的当前服务器负载而变化。任何使用 GPT4 的人都清楚,延迟通常可以是多秒,并且受到速率限制。请注意,速度是任何 LLM (API) 的问题,包括开源 LLM。许多生成型 LLM 由于过大而无法快速运行。
训练计算成本往往不太相关,因为 LLM 可以不经过微调直接使用,且小型模型的微调成本相对较小 (微调 RoBERTa-base 的成本不到 $1)。只有在需要将大型生成型 LLM 专门化以执行特定生成任务时,才需要投资从头开始预训练模型。当微调一个更大的生成型 LLM 以使其适应特定生成任务时,训练成本可能变得相关。
第三,在时间和专业知识方面的投资。这是 LLM API 的主要优势。与手动收集数据、微调定制模型和部署相比,向 API 发送指令要容易得多。这正是使用 LLM API 创建合成数据变得重要的地方。创建良好的训练数据变得显著更容易。然后,微调和部署可以由 AutoTrain 等服务和专业推理端点处理。
第四,控制。这可能是 LLM API 的主要缺点。按设计,LLM API 使你依赖于 LLM API 提供商。你需要将敏感数据发送到别人的服务器,并且你无法控制系统的可靠性和速度。自己训练模型可以让你选择如何和在哪里部署它。
最后,环境影响。由于缺乏有关模型架构和硬件基础设施的信息,很难估计 GPT4 等封闭模型的能源消耗和二氧化碳排放。我们找到的 [最佳 (但非常粗略) 估计](https://towardsdatascience.com/chatgpts-energy-use-per-query-9383b8654487) 显示,GPT4 查询的能源消耗约为 0.0017 至 0.0026 千瓦时。这将是分析 100 万句话的大致 1700 至 2600 千瓦时。根据 [EPA 二氧化碳当量计算器](https://www.epa.gov/energy/greenhouse-gas-equivalencies-calculator),这相当于 0.735 至 1.1 公吨二氧化碳,或平均汽车行驶 1885 至 2883 英里。请注意,实际二氧化碳排放可以根据 LLM 特定计算区域的能源混合而有很大差异。与我们的自定义模型相比,这个估计要容易得多。使用自定义模型分析 100 万句话,在一个 T4 GPU 上大约需要 4.52 小时,在 US East N. Virginia 的 AWS 服务器上,这相当于大约 0.12 公斤二氧化碳 (见 [ML CO2 Impact calculator](https://mlco2.github.io/impact/))。与具有 (据称) 8x220B 参数的通用 LLM 相比,运行一个专门化的模型 (约 0.13B 参数) 的效率低下得多。
## 结论
我们已经展示了使用 LLM 创建合成数据来训练一个更小、更高效的模型的巨大好处。虽然这个例子只处理了投资者情绪分类,但同样的流程可以应用于许多其他任务,从其他分类任务 (例如,客户意图检测或有害内容检测),到 token 分类 (例如,命名实体识别或 PII 检测),或生成任务 (例如,总结或问答)。
在 2024 年,公司创建自己的高效模型、控制自己的数据和基础设施、减少二氧化碳排放、节省计算成本和时间,而不必妥协准确性的难度从未如此之低。
现在,亲自动手尝试一下!你可以在本博客文章中找到所有数字的完整复现代码,以及更高效的异步函数和批量 API 调用的代码,在 [复现仓库](https://github.com/MoritzLaurer/synthetic-data-blog/tree/main) 中。我们邀请你复制并适配我们的代码以应用于你的用例! | 2 |
0 | hf_public_repos/blog | hf_public_repos/blog/zh/train-dgx-cloud.md | ---
title: "在 NVIDIA DGX Cloud上使用 H100 GPU 轻松训练模型"
thumbnail: /blog/assets/train-dgx-cloud/thumbnail.jpg
authors:
- user: philschmid
- user: jeffboudier
- user: rafaelpierrehf
- user: abhishek
translators:
- user: chenglu
---
# 在 NVIDIA DGX Cloud上使用 H100 GPU 轻松训练模型
今天,我们正式宣布推出 **DGX 云端训练 (Train on DGX Cloud)** 服务,这是 Hugging Face Hub 上针对企业 Hub 组织的全新服务。
通过在 DGX 云端训练,你可以轻松借助 NVIDIA DGX Cloud的高速计算基础设施来使用开放的模型。这项服务旨在让企业 Hub 的用户能够通过几次点击,就在 [Hugging Face Hub](https://huggingface.co/models) 中轻松访问最新的 NVIDIA H100 Tensor Core GPU,并微调如 Llama、Mistral 和 Stable Diffusion 这样的流行生成式 AI (Generative AI) 模型。
<div align="center">
<img src="/blog/assets/train-dgx-cloud/thumbnail.jpg" alt="Thumbnail">
</div>
## GPU 不再是稀缺资源
这一新体验基于我们去年宣布的[战略合作](https://nvidianews.nvidia.com/news/nvidia-and-hugging-face-to-connect-millions-of-developers-to-generative-ai-supercomputing),旨在简化 NVIDIA 加速计算平台上开放生成式 AI 模型的训练和部署。开发者和机构面临的主要挑战之一是 GPU 资源稀缺,以及编写、测试和调试 AI 模型训练脚本的工作繁琐。在 DGX 云上训练为这些挑战提供了简便的解决方案,提供了对 NVIDIA GPUs 的即时访问,从 NVIDIA DGX Cloud上的 H100 开始。此外,该服务还提供了一个简洁的无代码训练任务创建体验,由 Hugging Face AutoTrain 和 Hugging Face Spaces 驱动。
通过 [企业版的 HF Hub](https://huggingface.co/enterprise),组织能够为其团队提供强大 NVIDIA GPU 的即时访问权限,只需按照训练任务所用的计算实例分钟数付费。
> 在 DGX 云端训练是目前训练生成式 AI 模型最简单、最快速、最便捷的方式,它结合了强大 GPU 的即时访问、按需付费和无代码训练,这对全球的数据科学家来说将是一次变革性的进步!
>
> —— Abhishek Thakur, Hugging Face AutoTrain 团队创始人
> 今天发布的 Hugging Face Autotrain,得益于 DGX 云的支持,标志着简化 AI 模型训练过程向前迈出了重要一步,通过将 NVIDIA 的云端 AI 超级计算机与 Hugging Face 的友好界面结合起来,我们正在帮助各个组织加速他们的 AI 创新步伐。
>
> —— Alexis Bjorlin, NVIDIA DGX Cloud 副总裁
## 操作指南
在 NVIDIA DGX Cloud 上训练 Hugging Face 模型变得非常简单。以下是针对如何微调 Mistral 7B 的分步教程。
> 注意:你需要访问一个拥有 [企业版的 HF Hub](https://huggingface.co/enterprise) 订阅的组织账户,才能使用在 DGX 云端训练的服务
你可以在支持的生成式 AI 模型的模型页面上找到在 DGX 云端训练的选项。目前,它支持以下模型架构:Llama、Falcon、Mistral、Mixtral、T5、Gemma、Stable Diffusion 和 Stable Diffusion XL。
<div align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/autotrain-dgx-cloud/01%20model%20card.png" alt="Model Card">
</div>
点击“训练 (Train)”菜单,并选择“NVIDIA DGX Cloud”选项,这将打开一个页面,让你可以选择你的企业组织。
<div align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/autotrain-dgx-cloud/02%20select%20organization.png" alt="Organization Selection">
</div>
接下来,点击“Create new Space”。当你首次使用在 DGX 云端训练时,系统将在你的组织内创建一个新的 Hugging Face 空间,使你可以利用 AutoTrain 创建将在 NVIDIA DGX Cloud上执行的训练任务。当你日后需要创建更多训练任务时,系统将自动将你重定向到已存在的 AutoTrain Space 应用。
进入 AutoTrain Space 应用后,你可以通过配置硬件、基础模型、任务和训练参数来设置你的训练任务。
<div align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/autotrain-dgx-cloud/03%20start.png" alt="Create AutoTrain Job">
</div>
在硬件选择方面,你可以选择 NVIDIA H100 GPU,提供 1x、2x、4x 和 8x 实例,或即将推出的 L40S GPUs。训练数据集需要直接上传至“上传训练文件”区域,目前支持 CSV 和 JSON 文件格式。请确保根据以下示例正确设置列映射。对于训练参数,你可以直接在右侧的 JSON 配置中进行编辑,例如,将训练周期数从 3 调整为 2。
一切设置完成后,点击“开始训练”即可启动你的训练任务。AutoTrain 将验证你的数据集,并请求你确认开始训练。
<div align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/autotrain-dgx-cloud/04%20success.png" alt="Launched Training Job">
</div>
你可以通过查看这个 Space 应用的“Logs 日志”来查看训练进度。
<div align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/autotrain-dgx-cloud/05%20logs.png" alt="Training Logs">
</div>
训练完成后,你微调后的模型将上传到 Hugging Face Hub 上你所选择的命名空间内的一个新的私有仓库中。
从今天起,所有企业 Hub 组织都可以使用在 DGX 云端训练的服务了!欢迎尝试并分享你的反馈!
## DGX 云端训练的定价
使用在 DGX 云端训练服务,将根据你训练任务期间使用的 GPU 实例分钟数来计费。当前的训练作业价格为:H100 实例每 GPU 小时 8.25 美元,L40S 实例每 GPU 小时 2.75 美元。作业完成后,费用将累加到你企业 Hub 组织当前的月度账单中。你可以随时查看企业 Hub 组织的计费设置中的当前和历史使用情况。
<table>
<tr>
<td>NVIDIA GPU
</td>
<td>GPU 显存
</td>
<td>按需计费价格(每小时)
</td>
</tr>
<tr>
<td><a href="https://www.nvidia.com/en-us/data-center/l40/">NVIDIA L40S</a>
</td>
<td>48GB
</td>
<td>$2.75
</td>
</tr>
<tr>
<td><a href="https://www.nvidia.com/de-de/data-center/h100/">NVIDIA H100</a>
</td>
<td>80 GB
</td>
<td>$8.25
</td>
</tr>
</table>
例如,微调 1500 个样本的 Mistral 7B 在一台 NVIDIA L40S 上大约需要 10 分钟,成本约为 0.45 美元。
## 我们的旅程刚刚开始
我们很高兴能与 NVIDIA 合作,推动加速机器学习在开放科学、开源和云服务领域的普惠化。
通过 [BigCode](https://huggingface.co/bigcode) 项目的合作,我们训练了 [StarCoder 2 15B](https://huggingface.co/bigcode/starcoder2-15b),这是一个基于超过 600 种编程语言训练的全开放、最先进的代码大语言模型(LLM)。
我们在开源方面的合作推动了新的 [optimum-nvidia 库](https://github.com/huggingface/optimum-nvidia) 的开发,加速了最新 NVIDIA GPUs 上大语言模型的推理,已经达到了 Llama 2 每秒 1200 Tokens 的推理速度。
我们在云服务方面的合作促成了今天的在 DGX 云端训练服务。我们还在与 NVIDIA 合作优化推理过程,并使加速计算对 Hugging Face 社区更容易受益。此外,Hugging Face 上一些最受欢迎的开放模型将出现在今天 GTC 上宣布的 [NVIDIA NIM 微服务](https://developer.nvidia.cn/zh-cn/blog/nvidia-nim-offers-optimized-inference-microservices-for-deploying-ai-models-at-scale/) 上。
本周参加 GTC 的朋友们,请不要错过周三 3/20 下午 3 点 PT 的会议 [S63149](https://www.nvidia.com/gtc/session-catalog/?tab.allsessions=1700692987788001F1cG&search=S63149#/session/1704937870817001eXsB),[Jeff](https://huggingface.co/jeffboudier) 将带你深入了解在 DGX 云端训练等更多内容。另外,不要错过下一期 Hugging Cast,在那里我们将现场演示在 DGX 云端训练,并且你可以直接向 [Abhishek](https://huggingface.co/abhishek) 和 [Rafael](https://huggingface.co/rafaelpierrehf) 提问,时间是周四 3/21 上午 9 点 PT / 中午 12 点 ET / 17h CET - [请在此注册](https://streamyard.com/watch/YfEj26jJJg2w)。 | 3 |
0 | hf_public_repos/blog | hf_public_repos/blog/zh/open-llm-leaderboard-drop.md | ---
title: "开放 LLM 排行榜:深入研究 DROP"
thumbnail: /blog/assets/evaluating-mmlu-leaderboard/thumbnail.png
authors:
- user: clefourrier
- user: cabreraalex
guest: true
- user: stellaathena
guest: true
- user: SaylorTwift
- user: thomwolf
translators:
- user: MatrixYao
- user: zhongdongy
proofreader: true
---
# 开放 LLM 排行榜: 深入研究 DROP
最近,[开放 LLM 排行榜](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard) 迎来了 [3 个新成员](https://twitter.com/clefourrier/status/1722555555338956840): Winogrande、GSM8k 以及 DROP,它们都使用了 [EleutherAI Harness](https://github.com/EleutherAI/lm-evaluation-harness/) 的原始实现。一眼望去,我们就会发现 DROP 的分数有点古怪: 绝大多数模型的 F1 分数都低于 10 分 (满分 100 分)!我们对此进行了深入调查以一探究竟,请随我们一起踏上发现之旅吧!
## 初步观察
在 DROP (Discrete Reasoning Over Paragraphs,段落级离散推理) 评估中,模型需要先从英文文段中提取相关信息,然后再对其执行离散推理 (例如,对目标对象进行排序或计数以得出正确答案,如下图中的例子)。其使用的指标是自定义 F1 以及精确匹配分数。
<div align="center">
<figure class="image table text-center m-0 w-full">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/open-llm-leaderboard/drop/drop_example.png" width="500" />
<figcaption>基于文段的推理示例</figcaption>
</figure>
</div>
三周前,我们将 DROP 添加至开放 LLM 排行榜中,然后我们观察到预训练模型的 DROP F1 分数有个奇怪的趋势: 当我们把排行榜所有原始基准 (ARC、HellaSwag、TruthfulQA 和 MMLU) 的平均分 (我们认为其一定程度上代表了模型的总体性能) 和 DROP 分数作为两个轴绘制散点图时,我们本来希望看到 DROP 分数与原始均分呈正相关的关系 (即原始均值高的模型,DROP 分数也应更高)。然而,事实证明只有少数模型符合这一预期,其他大多数模型的 DROP F1 分数都非常低,低于 10。
<div align="center">
<figure class="image table text-center m-0 w-full">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/open-llm-leaderboard/drop/drop_bimodal.png" width="500" />
<figcaption> 该图展现了两类趋势: 少部分模型 DROP 分数与原始均分正相关 (对角线那几个点),大多数模型则不管原始均分多少,DROP 分数统一集中在 5 左右 (图左侧的垂直线)。</figcaption>
</figure>
</div>
## 文本规范化的锅
第一站,我们观察到文本规范化的结果与预期不符: 在某些情况下,当正确的数字答案后面直接跟有除空格之外的其他空白字符 (如: 换行符) 时,规范化操作导致即使答案正确也无法匹配。举个例子,假设生成的文本是 `10\n\nPassage: The 2011 census recorded a population of 1,001,360` ,而对应的标准答案为 `10` 。
测试基准会先对生成文本和标准答案文本都进行文本规范化,整个过程分为多个步骤:
1) **按分隔符 (`|` 、`-` 或 ` ` ) 分词**
生成文本的开头 `10\n\nPassage:` 并不包含分隔符,因此会被放进同一个词元 (即第一个词元) ;
2) **删除标点符号**
删除标点后,第一个词元会变为 `10\n\nPassage` (`:` 被删除);
3) **数字均质化**
每个可以转换为浮点数的字符串都会被视为数字并转换为浮点数,然后再重新转回字符串。 `10\n\nPassage` 保持不变,因为它不能被转换为浮点数,而标准答案的 `10` 变成了 `10.0` 。
4) **其他步骤**
随后继续执行其他规范化步骤 (如删除冠词、删除其他空格等),最终得到的规范化文本是: `10 passage 2011.0 census recorded population of 1001360.0` 。
最终得分并不是根据字符串计算而得,而是根据从字符串中提取的词袋 (bag of words,BOW) 计算而得。仍用上例,规范化后的生成文本词袋为 `{'recorded', 'population', 'passage', 'census', '2011.0', ' 1001360.0', '10'}` ,而规范化后的标准答案词袋为 `{10.0}` ,两者求交,正如你所看到的,即使模型生成了正确答案,两者交集也为 0!
总之,如果一个数字后面跟着除标准空格字符外的任何其它表示空格的字符,目前的文本规范化实现就不会对该数字进行规范化,因此如果此时标准答案也是一个数字,那么两者就永远无法匹配了!这个问题可能给最终分数带来严重影响,但显然这并是导致 DROP 分数如此低的唯一罪魁祸首。我们决定继续调查。
## 对结果进行深入研究
我们在 [Zeno](https://zenoml.com) 的朋友加入了调查并对结果 [进行了更深入的探索](https://hub.zenoml.com/report/1255/DROP%20Benchmark%20Exploration),他们选择了 5 个有代表性的模型进行深入分析: falcon-180B 和 mistra-7B 表现低于预期,Yi-34B 和 Tigerbot-70B 的 DROP 分数与原始均分正相关,而 facebook/xglm-7.5B 则落在中间。
如果你有兴趣的话,也可以试试在 [这个 Zeno 项目](https://hub.zenoml.com/project/2f5dec90-df5e-4e3e-a4d1-37faf814c5ae/OpenLLM%20Leaderboard%20DROP%20Comparison/explore?params=eyJtb2RlbCI6ImZhY2Vib29rX194Z2xtLTcuNUIiLCJtZXRyaWMiOnsiaWQiOjk1NjUsIm5hbWUiOiJmMSIsInR5cGUiOiJtZWFuIiwiY29sdW1ucyI6WyJmMSJdfSwiY29tcGFyaXNvbk1vZGVsIjoiVGlnZXJSZXNlYXJjaF9fdGlnZXJib3QtNzBiLWNoYXQiLCJjb21wYXJpc29uQ29sdW1uIjp7ImlkIjoiYzJmNTY1Y2EtYjJjZC00MDkwLWIwYzctYTNiNTNkZmViM2RiIiwibmFtZSI6ImVtIiwiY29sdW1uVHlwZSI6IkZFQVRVUkUiLCJkYXRhVHlwZSI6IkNPTlRJTlVPVVMiLCJtb2RlbCI6ImZhY2Vib29rX194Z2xtLTcuNUIifSwiY29tcGFyZVNvcnQiOltudWxsLHRydWVdLCJtZXRyaWNSYW5nZSI6W251bGwsbnVsbF0sInNlbGVjdGlvbnMiOnsic2xpY2VzIjpbXSwibWV0YWRhdGEiOnt9LCJ0YWdzIjpbXX19) 上分析一把。
Zeno 团队发现了两件更麻烦的事情:
1) 如果答案是浮点数,没有一个模型的结果是正确的
2) 擅长生成长答案的高质量模型 F1 分数反而更低
最后,我们认为这两件事情实际上是同一个根因引起的,即: 使用 `.` 作为停止词 (以结束生成):
1) 浮点数答案在生成过程中直接被截断了 [译者注: 小数点被当成句号直接中断输出了。]
2) 更高质量的模型,为了尝试匹配少样本提示格式,其生成会像这样 `Answer\n\nPlausible prompt for the next question.` ,而按照当前停止词的设定,该行为仅会在结果生成后且遇到第一个 `.` 停止,因此模型会生成太多多余的单词从而导致糟糕的 F1 分数。
我们假设这两个问题都可以通过使用 `\n` 而不是 `.` 来充当停止词而得到解决。
## 更改生成停止词
我们对此进行了初步实验!我们试验了在现有的生成文本上使用 `\n` 作为结束符。如果生成的答案中有 `\n` ,我们就在遇到第一个 `\n` 时截断文本,并基于截断文本重新计算分数。
_请注意,这只能近似正确结果,因为它不会修复由于 `.` 而过早截断的答案 (如浮点数答案)。但同时,它也不会给任何模型带来不公平的优势,因为所有模型都受这个问题的影响。因此,这是我们在不重新运行模型的情况下 (因为我们希望尽快向社区发布进展) 能做的最好的事情了。_
结果如下。使用 `\n` 作为停止词后,DROP 分数与原始均分的相关度提高不少,因此模型的 DROP 分数与模型原始的总体表现相关度也变高了。
<div align="center">
<figure class="image table text-center m-0 w-full">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/open-llm-leaderboard/drop/drop_partial_fix.png" width="500" />
<figcaption>我们可以看到橙色部分表示在处理后的新答案上计算的分数,其与模型原始均分的相关性更好。</figcaption>
</figure>
</div>
## 那下一步咋整
快速估算一下,重新对所有模型运行完整评估的成本相当高 (全部更新需花 8 个 GPU 年,DROP 占用了其中的很大一部分)。因此,我们对仅重新运行失败的例子所需要的成本进行了估算。
有 10% 样本的标准答案是浮点数 (如 `12.25` ),且模型输出以正确答案开头 (本例中为 `12` ),但在 `.` 处被截断 - 这种情况如果继续生成的话,有可能答案是正确的,因此我们肯定要重新运行!但这 10% 尚不包括以数字结尾的句子,这类句子也可能会被不当截断 (在剩下的 90% 中占 40%),也不包括被规范化操作搞乱掉的情况。
因此,为了获得正确的结果,我们需要重新运行超过 50% 的样本,这需要大量的 GPU 时!我们需要确保这次要运行的代码是正确的。
于是,我们与 EleutherAI 团队通过 [GitHub](https://github.com/EleutherAI/lm-evaluation-harness/issues/978) 及内部渠道进行了广泛的讨论,他们指导我们理解代码并帮助我们进行调查,很明显,LM Eval Harness 的实现严格遵循了“官方 DROP 代码”的实现,因此这不是 LM Eval Harness 的 bug,而是需要开发 DROP 基准评估的新版本!
**因此,我们决定暂时从 Open LLM 排行榜中删除 DROP,直到新版本出现为止。**
从本次调查中我们学到的一点是,通过社区协作对基准测试进行检阅,能发现以前遗漏的错误,这一点很有价值。开源、社区和开放式研发的力量再次闪耀,有了这些,我们甚至可以透明地调查一个已经存在数年的基准上的问题并找到根因。
我们希望有兴趣的社区成员与发明 DROP 评估的学者联手,以解决其在评分及文本规范化上的问题。我们希望能再次使用它,因为数据集本身非常有趣而且很酷。如国你对如何评估 DROP 有任何见解,请不要犹豫,[告诉我们](https://github.com/EleutherAI/lm-evaluation-harness/issues/1050)。
感谢众多社区成员指出 DROP 分数的问题,也非常感谢 EleutherAI Harness 和 Zeno 团队在此问题上的大力协助。
| 4 |
0 | hf_public_repos/blog | hf_public_repos/blog/zh/zero-shot-vqa-docmatix.md | ---
title: "LAVE:使用 LLM 对 Docmatix 进行零样本 VQA 评估 - 我们还需要微调吗?"
thumbnail: /blog/assets/184_zero_shot_docmatix/thumb.001.jpeg
authors:
- user: danaaubakirova
- user: andito
translators:
- user: MatrixYao
- user: zhongdongy
proofreader: true
---
# LAVE: 使用 LLM 对 Docmatix 进行零样本 VQA 评估 - 我们还需要微调吗?
在开发 Docmatix 时,我们发现经其微调的 Florence-2 在 DocVQA 任务上表现出色,但在基准测试中得分仍比较低。为了提高基准测试得分,我们必须在 DocVQA 数据集上进一步对模型进行微调,以学习该基准测试的语法风格。有意思的是,人类评估者认为经额外微调后,模型的表现似乎反而不如仅在 Docmatix 上微调那么好,因此我们最后决定仅将额外微调后的模型用于消融实验,而公开发布的还是仅在 Docmatix 上微调的模型。
尽管模型生成的答案在语义上与参考答案一致 (如图 1 所示),但基准测试的得分却较低。这就引出了一个问题: 我们应该微调模型以改进在既有指标上的表现,还是应该开发与人类感知更相符的新指标?
<div align="center">
<img src="https://cdn-uploads.huggingface.co/production/uploads/640e21ef3c82bd463ee5a76d/RaQZkkcnTAcS80pPyt55J.png" alt="VQA 评估 " style="width: 55%; border: none;">
</div>
<p align="center">
<em>图 1: Docmatix 数据集微调模型零样本生成的答案与参考答案之间的 t-SNE 图</em>
</p>
## 背景
社区最近很关注分布外 (out-of-distribution,OOD) 评估,即利用诸如零样本之类的方法将模型的能力迁移至未见过的 VQA 任务抑或是对一个 VQA 数据集进行微调并在另一个 VQA 数据集上进行评估。这一转变与用于微调视觉语言模型 (VLM) 的合成数据集 (例如 Docmatix、SciGraphQA、SimVQA) 的日渐兴起紧密相关。
一直以来,VQA 准确度一直是评估模型性能的主要指标,其方法是计算模型预测答案与人工标注的一组参考答案之间的精确字符串匹配率。因为传统的 VQA 评估遵循独立同分布 (independent and identically distributed,IID) 范式,其训练数据和测试数据分布相似,而传统的模型训练是遵循此假设的,所以此时该指标的效果很好,详情请参阅 [此处](https://arxiv.org/pdf/2205.12191)。
但在 OOD 场景下,由于格式、专业度以及表达等方面的差异,生成的答案尽管正确,但可能与参考答案不尽匹配。图 1 完美地展示了这种情况,图中我们将零样本生成的文本描述与合成数据集中的参考文本描述进行了比较。指令生成的数据集与人工标注的数据集之间的差异尤甚。目前已有一些 [方法](https://proceedings.mlr.press/v202/li23q.html) 试图将生成的答案格式对齐至参考答案格式,但这只是治标之策,并未改变评估指标有缺陷的根本症结。虽然也可以采用人工评估的方式,结果会比较可靠,但其成本高昂且不可扩展,所以当务之急还是设计与人类判断更相符的新指标。
## 方法
[Docmatix](https://huggingface.co/blog/docmatix) 是当前最大的 DocVQA 合成数据集,它是基于精选文档数据集 [PDFA](https://huggingface.co/datasets/pixparse/pdfa-eng-wds) 生成的。它比之前市面上的数据集大 100 倍。其对标的是人工标注数据集 DocVQA,DocVQA 目前被普遍用作文档理解类 VQA 模型的评估基准。本文中,我们使用的是 **Docmatix 的子集**,它包含大约 200 个测试样本,你可于此处下载 [Docmatix-zero-shot-exp](https://huggingface.co/datasets/HuggingFaceM4/Docmatix/viewer/zero-shot-exp)。
<div style="display: flex; justify-content: center; align-items: center; gap: 0px; width: 100%; margin: 0 auto;">
<img src="https://cdn-uploads.huggingface.co/production/uploads/640e21ef3c82bd463ee5a76d/feXi3iSLo8hBXTh2y8NnR.png" alt="Image 1" style="width: 45%; height: auto; object-fit: cover;">
<img src="https://cdn-uploads.huggingface.co/production/uploads/640e21ef3c82bd463ee5a76d/2X4KdrTi6M8VYU6hOdmk1.png" alt="Image 2" style="width: 45%; height: auto; object-fit: cover;">
</div>
<p align="center">
<em>图 2: 来自 Docmatix 和 DocVQA 测试集的问答对示例。注: 此处未显示相应的图像。</em>
</p>
尽管 Docmatix 和 DocVQA 中问答对的内容相似,但它们的风格却有着显著差异。此时,CIDER、ANLS 以及 BLEU 等传统指标对于零样本评估而言可能过于严格。鉴于从 t-SNE 中观察到的嵌入的相似性 (图 1),我们决定使用一个不同于以往的新评估指标: LAVE (LLM-Assisted VQA Evaluation,LLM 辅助 VQA 评估),以期更好地评估模型在未见但语义相似的数据集上的泛化能力。
<div style="display: flex; justify-content: center; align-items: center; gap: 10px; width: 100%; margin: 0 auto;">
<img src="https://cdn-uploads.huggingface.co/production/uploads/640e21ef3c82bd463ee5a76d/C4twDu9D6cw0XHdA57Spe.png" alt="Image 1" style="width: 30%; height: auto; object-fit: cover;">
<img src="https://cdn-uploads.huggingface.co/production/uploads/640e21ef3c82bd463ee5a76d/pYsiOyToOXzRitmRidejW.png" alt="Image 2" style="width: 30%; height: auto; object-fit: cover;">
<img src="https://cdn-uploads.huggingface.co/production/uploads/640e21ef3c82bd463ee5a76d/uM6IPAAvjyiYTPJXdB10w.png" alt="Image 3" style="width: 30%; height: auto; object-fit: cover;">
</div>
<p align="center">
<em>图 3: Docmatix 和 DocVQA 数据集中的问题、答案以及图像特征的 t-SNE 图</em>
</p>
评估时,我们选择 [MPLUGDocOwl1.5](https://arxiv.org/pdf/2403.12895) 作为基线模型。该模型在原始 DocVQA 数据集的测试子集上 ANLS 得分为 84%。然后,我们在 Docmatix 的一个子集 (含 200 张图像) 上运行零样本生成。我们使用 [Llama-2-Chat-7b](https://huggingface.co/meta-llama/Llama-2-7b-chat-hf) 对答案进行评分。
## 关于 LAVE
我们遵循 [本篇论文](https://arxiv.org/html/2310.02567v2) 中的步骤,将 VQA 评估设计为一个基于 LLM 上下文学习的答案评分任务。我们将分数设在 1 到 3 之间并考虑了问题不明晰或答案不完整的情况。LLM 的提示词包含任务描述、几个输入/输出演示以及待测样本的输入。
我们撰写了任务描述并在其后加上了指令 **“在评分之前给出理由”** 以要求 LLM 给出评分理由。每个演示都包含一个问题、一组参考答案、候选答案、答案得分及其理由。在提示中,我们还要求 **“仅提供一个评分”** 以避免因逐句分析带来的多个评分。
```py
task_description = """You are given a question, a set of gold-standard reference answers written by
experts, and a candidate answer. Please rate the accuracy of the candidate answer for the question
considering the reference answers. Use a scale of 1-3, with 1 indicating an incorrect or irrelevant
answer, 2 indicating an ambiguous or incomplete answer, and 3 indicating a correct answer.
Give the rationale before rating. Provide only one rating.
THIS IS VERY IMPORTANT:
A binary question should only be answered with 'yes' or 'no',
otherwise the candidate answer is incorrect."""
demonstrations = [
{
"question": "What's the weather like?",
"reference_answer": ["sunny", "clear", "bright", "sunny", "sunny"],
"generated_answer": "cloudy"
}
]
```
#### 评分函数
给定 LLM 为测试样本生成的提示,我们从最后一个字符 (为 1、2 或 3) 中提取评分,并将其缩放至 `[0, 1]` 范围内: $s = \frac{r - 1}{2}$,以获取最终评分。
#### 结果
各指标得分如下:
<table style="border-collapse: collapse; width: 50%; margin: auto;">
<tr>
<th style="border: 1px solid black; padding: 8px; text-align: center;"> 指标 </th>
<th style="border: 1px solid black; padding: 8px; text-align: center;">CIDER</th>
<th style="border: 1px solid black; padding: 8px; text-align: center;">BLEU</th>
<th style="border: 1px solid black; padding: 8px; text-align: center;">ANLS</th>
<th style="border: 1px solid black; padding: 8px; text-align: center;">LAVE</th>
</tr>
<tr>
<td style="border: 1px solid black; padding: 8px; text-align: center;"> 得分 </td>
<td style="border: 1px solid black; padding: 8px; text-align: center;">0.1411</td>
<td style="border: 1px solid black; padding: 8px; text-align: center;">0.0032</td>
<td style="border: 1px solid black; padding: 8px; text-align: center;">0.002</td>
<td style="border: 1px solid black; padding: 8px; text-align: center;">0.58</td>
</tr>
</table>
## 几个生成案例
<div align="center">
<img src="https://cdn-uploads.huggingface.co/production/uploads/640e21ef3c82bd463ee5a76d/5ljrlVqrHHB4VGRek7hJv.png" alt="VQA Evaluation" style="width:120%, border: none;">
</div>
<p align="center">
<em>图 4: Docmatix 测试子集中的一个问题、参考答案、模型生成的答案以及 Llama 给出的评分及理由。</em>
</p>
<div align="center">
<img src="https://cdn-uploads.huggingface.co/production/uploads/640e21ef3c82bd463ee5a76d/scly6WR_2Wvrk5qd05cx4.png" alt="VQA Evaluation" style="width:120%, border: none;">
</div>
<p align="center">
<em>图 5: Docmatix 测试子集中的一个问题、参考答案、模型生成的答案以及 Llama 给出的评分及理由。</em>
</p>
## 现有的 VQA 系统评估标准是否过于僵化了?我们还需要微调吗?
当使用 LLM 来评估答案时,我们答案的准确率提高了大约 50%,这表明虽未遵循严格的格式,答案也可能是正确的。这表明我们目前的评估指标可能过于僵化。值得注意的是,本文并不是一篇全面的研究论文,因此需要更多的消融实验来充分了解不同指标对合成数据集零样本性能评估的有效性。我们希望社区能够以我们的工作为起点,继续深化拓展下去,从而改进合成数据集背景下的零样本视觉语言模型评估工作,并探索能够超越提示学习的其它更有效的方法。
## 参考文献
```
@inproceedings{cascante2022simvqa,
title={Simvqa: Exploring simulated environments for visual question answering},
author={Cascante-Bonilla, Paola and Wu, Hui and Wang, Letao and Feris, Rogerio S and Ordonez, Vicente},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
pages={5056--5066},
year={2022}
}
@article{hu2024mplug,
title={mplug-docowl 1.5: Unified structure learning for ocr-free document understanding},
author={Hu, Anwen and Xu, Haiyang and Ye, Jiabo and Yan, Ming and Zhang, Liang and Zhang, Bo and Li, Chen and Zhang, Ji and Jin, Qin and Huang, Fei and others},
journal={arXiv preprint arXiv:2403.12895},
year={2024}
}
@article{agrawal2022reassessing,
title={Reassessing evaluation practices in visual question answering: A case study on out-of-distribution generalization},
author={Agrawal, Aishwarya and Kaji{\'c}, Ivana and Bugliarello, Emanuele and Davoodi, Elnaz and Gergely, Anita and Blunsom, Phil and Nematzadeh, Aida},
journal={arXiv preprint arXiv:2205.12191},
year={2022}
}
@inproceedings{li2023blip,
title={Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models},
author={Li, Junnan and Li, Dongxu and Savarese, Silvio and Hoi, Steven},
booktitle={International conference on machine learning},
pages={19730--19742},
year={2023},
organization={PMLR}
}
@inproceedings{manas2024improving,
title={Improving automatic vqa evaluation using large language models},
author={Ma{\~n}as, Oscar and Krojer, Benno and Agrawal, Aishwarya},
booktitle={Proceedings of the AAAI Conference on Artificial Intelligence},
volume={38},
number={5},
pages={4171--4179},
year={2024}
}
@article{li2023scigraphqa,
title={Scigraphqa: A large-scale synthetic multi-turn question-answering dataset for scientific graphs},
author={Li, Shengzhi and Tajbakhsh, Nima},
journal={arXiv preprint arXiv:2308.03349},
year={2023}
}
``` | 5 |
0 | hf_public_repos/blog | hf_public_repos/blog/zh/mms_adapters.md | ---
title: "微调用于多语言 ASR 的 MMS 适配器模型"
thumbnail: /blog/assets/151_mms/mms_map.png
authors:
- user: patrickvonplaten
translators:
- user: innovation64
- user: zhongdongy
proofreader: true
---
# **微调用于多语言 ASR 的 MMS 适配器模型**
<a target="_blank" href="https://colab.research.google.com/github/patrickvonplaten/notebooks/blob/master/Fine_Tune_MMS_on_Common_Voice.ipynb">
<img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/>
</a>
**新内容 (06/2023)**: 这篇博文受到 [“在多语言 ASR 上微调 XLS-R”](https://huggingface.co/blog/zh/fine-tune-xlsr-wav2vec2) 的强烈启发,可以看作是它的改进版本。
**Wav2Vec2** 是自动语音识别 (ASR) 的预训练模型,由 _Alexei Baevski、Michael Auli_ 和 _Alex Conneau_ 于 [2020 年 9 月](https://ai.facebook.com/blog/wav2vec-20-learning-the-structure-of-speech-from-raw-audio/) 发布。其在最流行的 ASR 英语数据集之一 [LibriSpeech](https://huggingface.co/datasets/librispeech_asr) 上展示了 Wav2Vec2 的强大性能后不久, _Facebook AI_ 就推出了 Wav2Vec2 的两个多语言版本,称为 [XLSR](https://arxiv.org/abs/2006.13979) 和 [XLM-R](https://ai.facebook.com/blog/-xlm-r-state-of-the-art-cross-lingual-understanding-through-self-supervision/),能够识别多达 128 种语言的语音。XLSR 代表 _跨语言语音表示_ ,指的是模型学习跨多种语言有用的语音表示的能力。
Meta AI 的最新版本,[**大规模多语言语音 (MMS)**](https://ai.facebook.com/blog/multilingual-model-speech-recognition/),由 _Vineel Pratap、Andros Tjandra、Bowen Shi_ 等人编写。将多语言语音表示提升到一个新的水平。通过发布的各种 [语言识别、语音识别和文本转语音检查点](https://huggingface.co/models?other=mms),可以识别、转录和生成超过 1,100 多种口语。
在这篇博文中,我们展示了 MMS 的适配器训练如何在短短 10-20 分钟的微调后实现惊人的低单词错误率。
对于资源匮乏的语言,我们 **强烈** 建议使用 MMS 的适配器训练,而不是像 [“在多语言 ASR 上微调 XLS-R”](https://huggingface.co/blog/zh/fine-tune-xlsr-wav2vec2) 中那样微调整个模型。
在我们的实验中,MMS 的适配器训练不仅内存效率更高、更稳健,而且对于低资源语言也能产生更好的性能。对于中到高资源语言,微调整个检查点而不是使用适配器层仍然是有利的。

## **保护世界语言多样性**
根据 https://www.ethnologue.com/ 的数据,大约 3000 种语言 (即所有“现存”语言的 40%) 由于母语人士越来越少而濒临灭绝。这种趋势只会在日益全球化的世界中持续下去。
**MMS** 能够转录许多濒临灭绝的语言,例如 _Ari_ 或 _Kaivi_ 。未来,MMS 可以通过帮助剩余的使用者创建书面记录并用母语进行交流,这在保持语言活力方面发挥至关重要的作用。
为了适应 1000 多个不同的词汇表,**MMS** 使用适配器 (Adapters) - 一种仅训练一小部分模型权重的训练方法。
适配器层就像语言桥梁一样,使模型能够在解读另一种语言时利用一种语言的知识。
## **微调 MMS**
**MMS** 无监督检查点使用 **1,400** 多种语言的超过 **50 万** 小时的音频进行了预训练,参数范围从 3 亿到 10 亿不等。
你可以在 🤗 Hub 上找到 3 亿个参数 (300M) 和 10 亿个参数 (1B) 模型大小的仅预训练检查点:
- [**`mms-300m`**](https://huggingface.co/facebook/mms-300m)
- [**`mms-1b`**](https://huggingface.co/facebook/mms-1b)
_注意_ : 如果你想微调基本模型,可以按照 [“在多语言 ASR 上微调 XLS-R”](https://huggingface.co/blog/zh/fine-tune-xlsr-wav2vec2) 中所示的完全相同的方式进行操作。
与 [BERT 的掩码语言建模目标](http://jalammar.github.io/illustrated-bert/) 类似,MMS 通过随机遮蔽特征向量来学习上下文语音表示,然后在自监督预训练期间将其传递到 Transformer 网络。
对于 ASR,预训练 [MMS-1B 检查点](https://huggingface.co/facebook/mms-1b) 通过联合词汇输出层以监督方式对 1000 多种语言进行了进一步微调。最后一步,联合词汇输出层被丢弃,并保留特定于语言的适配器层。每个适配器层 **仅** 包含约 2.5M 权重,由每个注意力块的小型线性投影层以及特定于语言的词汇输出层组成。
已发布针对语音识别 (ASR) 进行微调的三个 **MMS** 检查点。它们分别包括 102、1107 和 1162 个适配器权重 (每种语言一个):
- [**`mms-1b-fl102`**](https://huggingface.co/facebook/mms-1b-fl102)
- [**`mms-1b-l1107`**](https://huggingface.co/facebook/mms-1b-l1107)
- [**`mms-1b-all`**](https://huggingface.co/facebook/mms-1b-all)
你可以看到基本模型 (像往常一样) 保存为文件 [`model.safetensors`](https://huggingface.co/facebook/mms-1b-all/blob/main/model.safetensors),但此外这些存储库还存储了许多适配器权重, _例如_ 针对法国的 [`adapter.fra.safetensors`](https://huggingface.co/facebook/mms-1b-all/blob/main/adapter.fra.safetensors)。
Hugging Face 文档很好地 [解释了如何使用此类检查点进行推理](https://huggingface.co/docs/transformers/main/en/model_doc/mms#loading),因此在这篇博文中,我们将重点学习如何基于任何已发布的 ASR 检查点有效地训练高性能适配器模型。
## 训练自适应权重
在机器学习中,适配器是一种用于微调预训练模型同时保持原始模型参数不变的方法。他们通过在模型的现有层之间插入小型可训练模块 (称为 [适配器层](https://arxiv.org/pdf/1902.00751.pdf)) 来实现此目的,然后使模型适应特定任务,而无需进行大量的重新训练。
适配器在语音识别,尤其是 **说话人识别** 方面有着悠久的历史。在说话人识别中,适配器已被有效地用于调整预先存在的模型,以识别单个说话人的特质,正如 [Gales 和 Woodland (1996)](https://www.isca-speech.org/archive_v0/archive_papers/icslp_1996/i96_1832.pdf) 以及 [Miao 等人 (2014)](https://www.cs.cmu.edu/~ymiao/pub/tasl_sat.pdf) 的工作中所强调的那样。与训练完整模型相比,这种方法不仅大大降低了计算要求,而且使得特定于说话者的调整更好、更灵活。
**MMS** 中完成的工作利用了跨不同语言的语音识别适配器的想法。对少量适配器权重进行了微调,以掌握每种目标语言独特的语音和语法特征。因此,MMS 使单个大型基础模型 (_例如_ [**mms-1b-all**](https://huggingface.co/facebook/mms-1b-all) 模型检查点) 和 1000 多个小型适配器层 (每个 2.5M 权重 **mms-1b-all**) 能够理解和转录多种语言。这极大地减少了为每种语言开发不同模型的计算需求。
棒极了!现在我们了解其动机和理论,下面让我们研究一下 **mms-1b-all** 🔥的适配器权重微调
## Notebook 设置
正如之前在 [“多语言 ASR 上微调 XLS-R”](https://huggingface.co/blog/zh/fine-tune-xlsr-wav2vec2) 博客文章中所做的那样,我们在 [Common Voice](https://huggingface.co/datasets/common_voice) 的低资源 ASR 数据集上微调模型,该数据集仅包含 _ca._ 4 小时经过验证的训练数据。
就像 Wav2Vec2 或 XLS-R 一样,MMS 使用连接时序分类 (CTC) 进行微调,CTC 是一种用于训练神经网络解决序列到序列问题 (例如 ASR 和手写识别) 的算法。
有关 CTC 算法的更多详细信息,我强烈建议阅读 Awni Hannun 的写得很好的一篇博客文章 [_Sequence Modeling with CTC (2017)_](https://distill.pub/2017/ctc/)。
在我们开始之前,让我们安装 `datasets` 和 `transformers`。此外,我们需要 `torchaudio` 来加载音频文件,以及使用 [字错误率 (WER)](https://huggingface.co/metrics/wer) 指标 \( {}^1 \) 评估我们微调后的模型,因此也需要安装 `jiwer`。
```bash
%%capture
!pip install --upgrade pip
!pip install datasets[audio]
!pip install evaluate
!pip install git+https://github.com/huggingface/transformers.git
!pip install jiwer
!pip install accelerate
```
我们强烈建议你在训练时将训练检查点直接上传到 [🤗 Hub](https://huggingface.co/)。Hub 存储库内置了版本控制,因此你可以确保在训练期间不会丢失任何模型检查点。
为此,你必须存储来自 Hugging Face 网站的身份验证令牌 (如果你还没有注册,请在 [此处](https://huggingface.co/join) 注册!)
```python
from huggingface_hub import notebook_login
notebook_login()
```
## 准备数据、分词器、特征提取器
ASR 模型将语音转录为文本,这意味着我们需要一个将语音信号处理为模型输入格式 (例如特征向量) 的特征提取器,以及一个将模型输出格式处理为文本的分词器。
在🤗 Transformers 中,MMS 模型同时伴随着一个名为 [Wav2Vec2FeatureExtractor](https://huggingface.co/transformers/master/model_doc/wav2vec2.html#wav2vec2featureextractor) 的特征提取器和一个名为 [Wav2Vec2CTCTokenizer](https://huggingface.co/transformers/master/model_doc/wav2vec2.html#wav2vec2ctctokenizer) 的分词器。
我们首先创建标记生成器,将预测的输出类解码为输出转录。
### 创建 `Wav2Vec2CTCTokenizer`
微调的 MMS 模型,例如 [**mms-1b-all**](https://huggingface.co/facebook/mms-1b-all) 已经有一个伴随模型检查点的 [分词器](https://huggingface.co/facebook/mms-1b-all/blob/main/tokenizer_config.json)。然而,由于我们想要在某种语言的特定低资源数据上微调模型,因此建议完全删除分词器和词汇输出层,并根据训练数据本身创建新的。
在 CTC 上微调的类似 Wav2Vec2 的模型通过一次前向传递来转录音频文件,首先将音频输入处理为一系列经过处理的上下文表示,然后使用最终的词汇输出层将每个上下文表示分类为表示该字符的字符转录。
该层的输出大小对应于词汇表中的标记数量,我们将从用于微调的标记数据集中提取该词汇表。因此,第一步,我们将查看所选的 Common Voice 数据集,并根据转录定义词汇表。
对于本 notebook,我们将使用 [Common Voice](https://huggingface.co/datasets/mozilla-foundation/common_voice_6_1) 的 6.1 土耳其语数据集。土耳其语对应于语言代码 `"tr"`。
太好了,现在我们可以使用 🤗 Datasets 的简单 API 来下载数据了。数据集名称是 `"mozilla-foundation/common_voice_6_1"`,配置名称对应于语言代码,在我们的例子中是 `"tr"`。
**注意**: 在下载数据集之前,你必须登录你的 Hugging Face 帐户,进入 [数据集存储库页](https://huggingface.co/datasets/mozilla-foundation/common_voice_6_1) 面并单击“同意并访问存储库”来访问它
Common Voice 有许多不同的分割,其中包括 `invalidated`,它指的是未被评为“足够干净”而被认为有用的数据。在此 notebook 中,我们将仅使用拆分的 `"train"`, `"validation"` 和 `"test"` 。
```python
from datasets import load_dataset, load_metric, Audio
common_voice_train = load_dataset("mozilla-foundation/common_voice_6_1", "tr", split="train+validation", use_auth_token=True)
common_voice_test = load_dataset("mozilla-foundation/common_voice_6_1", "tr", split="test", use_auth_token=True)
```
许多 ASR 数据集仅提供每个音频数组 (`'audio'`) 和文件 (`'path'`) 的目标文本 (`'sentence'`)。实际上,Common Voice 提供了关于每个音频文件的更多信息,例如 `'accent'` 等。为了使 notebook 尽可能通用,我们仅考虑用于微调的转录文本。
```python
common_voice_train = common_voice_train.remove_columns(["accent", "age", "client_id", "down_votes", "gender", "locale", "segment", "up_votes"])
common_voice_test = common_voice_test.remove_columns(["accent", "age", "client_id", "down_votes", "gender", "locale", "segment", "up_votes"])
```
让我们编写一个简短的函数来显示数据集的一些随机样本,并运行它几次以了解转录的感觉。
```python
from datasets import ClassLabel
import random
import pandas as pd
from IPython.display import display, HTML
def show_random_elements(dataset, num_examples=10):
assert num_examples <= len(dataset), "Can't pick more elements than there are in the dataset."
picks = []
for _ in range(num_examples):
pick = random.randint(0, len(dataset)-1)
while pick in picks:
pick = random.randint(0, len(dataset)-1)
picks.append(pick)
df = pd.DataFrame(dataset[picks])
display(HTML(df.to_html()))
```
```python
show_random_elements(common_voice_train.remove_columns(["path", "audio"]), num_examples=10)
```
```bash
Oylar teker teker elle sayılacak.
Son olaylar endişe seviyesini yükseltti.
Tek bir kart hepsinin kapılarını açıyor.
Blogcular da tam bundan bahsetmek istiyor.
Bu Aralık iki bin onda oldu.
Fiyatın altmış altı milyon avro olduğu bildirildi.
Ardından da silahlı çatışmalar çıktı.
"Romanya'da kurumlar gelir vergisi oranı yüzde on altı."
Bu konuda neden bu kadar az şey söylendiğini açıklayabilir misiniz?
```
好吧!转录看起来相当干净。翻译完转录的句子后,这种语言似乎更多地对应于书面文本,而不是嘈杂的对话。考虑到 [Common Voice](https://huggingface.co/datasets/common_voice) 是一个众包阅读语音语料库,这也解释的通。
我们可以看到,转录文本中包含一些特殊字符,如 `,.?!;:`。没有语言模型,要将语音块分类为这些特殊字符就更难了,因为它们并不真正对应于一个特征性的声音单元。例如,字母 `"s"` 有一个或多或少清晰的声音,而特殊字符 `"."` 则没有。此外,为了理解语音信号的含义,通常不需要在转录中包含特殊字符。
让我们简单地删除所有对单词的含义没有贡献并且不能真正用声音表示的字符,并对文本进行规范化。
```python
import re
chars_to_remove_regex = '[\,\?\.\!\-\;\:\"\“\%\‘\”\�\']'
def remove_special_characters(batch):
batch["sentence"] = re.sub(chars_to_remove_regex, '', batch["sentence"]).lower()
return batch
```
```python
common_voice_train = common_voice_train.map(remove_special_characters)
common_voice_test = common_voice_test.map(remove_special_characters)
```
我们再看看处理后的文本标签。
```python
show_random_elements(common_voice_train.remove_columns(["path","audio"]))
```
```bash
i̇kinci tur müzakereler eylül ayında başlayacak
jani ve babası bu düşüncelerinde yalnız değil
onurun gözlerindeki büyü
bandiç oyların yüzde kırk sekiz virgül elli dördünü topladı
bu imkansız
bu konu açık değildir
cinayet kamuoyunu şiddetle sarstı
kentin sokakları iki metre su altında kaldı
muhalefet partileri hükümete karşı ciddi bir mücadele ortaya koyabiliyorlar mı
festivale tüm dünyadan elli film katılıyor
```
好!这看起来更好了。我们已经从转录中删除了大多数特殊字符,并将它们规范化为仅小写。
在完成预处理之前,咨询目标语言的母语人士总是有益的,以查看文本是否可以进一步简化。
对于这篇博客文章,[Merve](https://twitter.com/mervenoyann) 很友好地快速查看了一下,并指出带帽子的字符 (如 `â`) 在土耳其语中已经不再使用,可以用它们的无帽子等效物 (例如 `a`) 替换。
这意味着我们应该将像 `"yargı sistemi hâlâ sağlıksız"` 这样的句子替换为 `"yargı sistemi hala sağlıksız"`。
让我们再写一个简短的映射函数来进一步简化文本标签。记住 - 文本标签越简单,模型学习预测这些标签就越容易。
```python
def replace_hatted_characters(batch):
batch["sentence"] = re.sub('[â]', 'a', batch["sentence"])
batch["sentence"] = re.sub('[î]', 'i', batch["sentence"])
batch["sentence"] = re.sub('[ô]', 'o', batch["sentence"])
batch["sentence"] = re.sub('[û]', 'u', batch["sentence"])
return batch
```
```python
common_voice_train = common_voice_train.map(replace_hatted_characters)
common_voice_test = common_voice_test.map(replace_hatted_characters)
```
在 CTC 中,将语音块分类为字母是很常见的,所以我们在这里也做同样的事情。让我们提取训练和测试数据中所有不同的字母,并从这组字母中构建我们的词汇表。
我们编写一个映射函数,将所有转录连接成一个长转录,然后将字符串转换为一组字符。将参数传递 `batched=True` 给 `map(...)` 函数非常重要,以便映射函数可以立即访问所有转录。
```python
def extract_all_chars(batch):
all_text = " ".join(batch["sentence"])
vocab = list(set(all_text))
return {"vocab": [vocab], "all_text": [all_text]}
```
```python
vocab_train = common_voice_train.map(extract_all_chars, batched=True, batch_size=-1, keep_in_memory=True, remove_columns=common_voice_train.column_names)
vocab_test = common_voice_test.map(extract_all_chars, batched=True, batch_size=-1, keep_in_memory=True, remove_columns=common_voice_test.column_names)
```
现在,我们创建训练数据集和测试数据集中所有不同字母的并集,并将结果列表转换为枚举字典。
```python
vocab_list = list(set(vocab_train["vocab"][0]) | set(vocab_test["vocab"][0]))
```
```python
vocab_dict = {v: k for k, v in enumerate(sorted(vocab_list))}
vocab_dict
```
```bash
{' ': 0,
'a': 1,
'b': 2,
'c': 3,
'd': 4,
'e': 5,
'f': 6,
'g': 7,
'h': 8,
'i': 9,
'j': 10,
'k': 11,
'l': 12,
'm': 13,
'n': 14,
'o': 15,
'p': 16,
'q': 17,
'r': 18,
's': 19,
't': 20,
'u': 21,
'v': 22,
'w': 23,
'x': 24,
'y': 25,
'z': 26,
'ç': 27,
'ë': 28,
'ö': 29,
'ü': 30,
'ğ': 31,
'ı': 32,
'ş': 33,
'̇': 34}
```
很酷,我们看到字母表中的所有字母都出现在数据集中 (这并不令人惊讶),我们还提取了特殊字符 `""` 和 `'`。请注意,我们没有排除这些特殊字符,因为模型必须学会预测单词何时结束,否则预测将始终是一系列字母,这将使得不可能将单词彼此分开。
人们应该始终记住,在训练模型之前,预处理是一个非常重要的步骤。例如,我们不希望我们的模型仅仅因为我们忘记规范化数据而区分 `a` 和 `A`。`a` 和 `A` 之间的区别根本不取决于字母的“声音”,而更多地取决于语法规则 - 例如,在句子开头使用大写字母。因此,删除大写字母和非大写字母之间的差异是明智的,这样模型在学习转录语音时就更容易了。
为了更清楚地表明 `" "` 具有自己的标记类别,我们给它一个更明显的字符 `|`。此外,我们还添加了一个“未知”标记,以便模型以后能够处理 Common Voice 训练集中未遇到的字符。
```python
vocab_dict["|"] = vocab_dict[" "]
del vocab_dict[" "]
```
最后,我们还添加了一个对应于 CTC 的“空白标记”的填充标记。 “空白标记”是 CTC 算法的核心组成部分。欲了解更多信息,请查看 [此处](https://distill.pub/2017/ctc/) 的“对齐”部分。
```python
vocab_dict["[UNK]"] = len(vocab_dict)
vocab_dict["[PAD]"] = len(vocab_dict)
len(vocab_dict)
```
```bash
37
```
很酷,现在我们的词汇表已经完成,包含 37 个标记,这意味着我们将作为适配器权重的一部分添加在预训练的 MMS 检查点顶部的线性层将具有 37 的输出维度。
由于单个 MMS 检查点可以为多种语言提供定制权重,因此分词器也可以包含多个词汇表。因此,我们需要嵌套我们的 `vocab_dict`,以便将来可能向词汇表中添加更多语言。字典应该嵌套使用适配器权重的名称,并在分词器配置中以 [`target_lang`](https://huggingface.co/docs/transformers/model_doc/wav2vec2#transformers.Wav2Vec2CTCTokenizer.target_lang) 的名称保存。
让我们像原始的 [**`mms-1b-all`**](https://huggingface.co/facebook/mms-1b-all) 检查点一样使用 ISO-639-3 语言代码。
```python
target_lang = "tur"
```
让我们定义一个空字典,我们可以在其中添加刚刚创建的词汇表
```python
new_vocab_dict = {target_lang: vocab_dict}
```
**注意**: 如果你想使用此 notebook 将新的适配器层添加到 _现有模型仓库_ ,请确保 **不要** 创建一个空的新词汇表,而是重用已经存在的词汇表。为此,你应该取消注释以下单元格,并将 `"patrickvonplaten/wav2vec2-large-mms-1b-turkish-colab"` 替换为你要添加适配器权重的模型仓库 ID。
```python
# from transformers import Wav2Vec2CTCTokenizer
# mms_adapter_repo = "patrickvonplaten/wav2vec2-large-mms-1b-turkish-colab" # make sure to replace this path with a repo to which you want to add your new adapter weights
# tokenizer = Wav2Vec2CTCTokenizer.from_pretrained(mms_adapter_repo)
# new_vocab = tokenizer.vocab
# new_vocab[target_lang] = vocab_dict
```
现在让我们将词汇表保存为 json 文件。
```python
import json
with open('vocab.json', 'w') as vocab_file:
json.dump(new_vocab_dict, vocab_file)
```
最后一步,我们使用 json 文件将词汇表加载到类的实例中 `Wav2Vec2CTCTokenizer`。
```python
from transformers import Wav2Vec2CTCTokenizer
tokenizer = Wav2Vec2CTCTokenizer.from_pretrained("./", unk_token="[UNK]", pad_token="[PAD]", word_delimiter_token="|", target_lang=target_lang)
```
如果想要在本 notebook 的微调模型中重用刚刚创建的分词器,强烈建议将 `tokenizer` 上传到 [🤗 Hub](https://huggingface.co/)。让我们将上传文件的仓库命名为 `"wav2vec2-large-mms-1b-turkish-colab"`:
```python
repo_name = "wav2vec2-large-mms-1b-turkish-colab"
```
并将分词器上传到 [🤗 Hub](https://huggingface.co/)。
```python
tokenizer.push_to_hub(repo_name)
```
```bash
CommitInfo(commit_url='https://huggingface.co/patrickvonplaten/wav2vec2-large-mms-1b-turkish-colab/commit/48cccbfd6059aa6ce655e9d94b8358ba39536cb7', commit_message='Upload tokenizer', commit_description='', oid='48cccbfd6059aa6ce655e9d94b8358ba39536cb7', pr_url=None, pr_revision=None, pr_num=None)
```
太好了,你可以在下面看到刚刚创建的存储库 `https://huggingface.co/<your-username>/wav2vec2-large-mms-1b-tr-colab`
### 创建 `Wav2Vec2FeatureExtractor`
语音是一个连续的信号,要被计算机处理,首先必须离散化,这通常被称为 **采样**。采样率在这里起着重要的作用,它定义了每秒测量语音信号的数据点数。因此,采用更高的采样率采样会更好地近似 _真实_ 语音信号,但也需要每秒更多的值。
预训练检查点期望其输入数据与其训练数据的分布大致相同。两个不同采样率采样的相同语音信号具有非常不同的分布,例如,将采样率加倍会导致数据点数量加倍。因此,在微调 ASR 模型的预训练检查点之前,必须验证用于预训练模型的数据的采样率与用于微调模型的数据集的采样率是否匹配。 `Wav2Vec2FeatureExtractor` 对象需要以下参数才能实例化:
- `feature_size`: 语音模型以特征向量序列作为输入。虽然这个序列的长度显然会变化,但特征大小不应该变化。在 Wav2Vec2 的情况下,特征大小为 1,因为该模型是在原始语音信号上训练的 \( {}^2 \)。
- `sampling_rate`: 模型训练时使用的采样率。
- `padding_value`: 对于批量推理,较短的输入需要用特定值填充
- `do_normalize`: 输入是否应该进行 _零均值单位方差_ 归一化。通常,语音模型在归一化输入时表现更好
- `return_attention_mask`: 模型是否应该使用 `attention_mask` 进行批量推理。通常情况下,XLS-R 模型检查点应该 **始终** 使用 `attention_mask`
```python
from transformers import Wav2Vec2FeatureExtractor
feature_extractor = Wav2Vec2FeatureExtractor(feature_size=1, sampling_rate=16000, padding_value=0.0, do_normalize=True, return_attention_mask=True)
```
太好了,MMS 的特征提取管道已经完全定义!
为了提高用户友好性,特征提取器和分词器被 _封装_ 到一个 `Wav2Vec2Processor` 类中,这样只需要一个 `model` 和 `processor` 对象。
```python
from transformers import Wav2Vec2Processor
processor = Wav2Vec2Processor(feature_extractor=feature_extractor, tokenizer=tokenizer)
```
接下来,我们可以准备数据集。
### 预处理数据
到目前为止,我们还没有看过语音信号的实际值,只看过转录。除了 `sentence`,我们的数据集还包括另外两个列名 `path` 和 `audio`。 `path` 表示音频文件的绝对路径, `audio` 表示已经加载的音频数据。MMS 期望输入格式为 16kHz 的一维数组。这意味着音频文件必须加载并重新采样。
值得庆幸的是,当列名为 `audio` 时, `datasets` 会自动完成这一操作。让我们试试。
```python
common_voice_train[0]["audio"]
```
```bash
{'path': '/root/.cache/huggingface/datasets/downloads/extracted/71ba9bd154da9d8c769b736301417178729d2b87b9e00cda59f6450f742ed778/cv-corpus-6.1-2020-12-11/tr/clips/common_voice_tr_17346025.mp3',
'array': array([ 0.00000000e+00, -2.98378618e-13, -1.59835903e-13, ...,
-2.01663317e-12, -1.87991593e-12, -1.17969588e-12]),
'sampling_rate': 48000}
```
在上面的示例中,我们可以看到音频数据以 48kHz 的采样率加载,而模型期望的是 16kHz,正如我们所见。我们可以通过使用 [`cast_column`](https://huggingface.co/docs/datasets/package_reference/main_classes.html?highlight=cast_column#datasets.DatasetDict.cast_column) 将音频特征设置为正确的采样率:
```python
common_voice_train = common_voice_train.cast_column("audio", Audio(sampling_rate=16_000))
common_voice_test = common_voice_test.cast_column("audio", Audio(sampling_rate=16_000))
```
我们再来看一下 `"audio"`。
```python
common_voice_train[0]["audio"]
```
```
{'path': '/root/.cache/huggingface/datasets/downloads/extracted/71ba9bd154da9d8c769b736301417178729d2b87b9e00cda59f6450f742ed778/cv-corpus-6.1-2020-12-11/tr/clips/common_voice_tr_17346025.mp3',
'array': array([ 9.09494702e-13, -6.13908924e-12, -1.09139364e-11, ...,
1.81898940e-12, 4.54747351e-13, 3.63797881e-12]),
'sampling_rate': 16000}
```
这似乎奏效了!让我们通过打印语音输入的形状、转录内容和相应的采样率来最后检查数据是否准备正确。
```python
rand_int = random.randint(0, len(common_voice_train)-1)
print("Target text:", common_voice_train[rand_int]["sentence"])
print("Input array shape:", common_voice_train[rand_int]["audio"]["array"].shape)
print("Sampling rate:", common_voice_train[rand_int]["audio"]["sampling_rate"])
```
```bash
Target text: bağış anlaşması bir ağustosta imzalandı
Input array shape:(70656,)
Sampling rate: 16000
```
很好!一切看起来都很棒 - 数据是一维数组,采样率始终对应于 16kHz,并且目标文本已标准化。
最后,我们可以利用 `Wav2Vec2Processor` 将数据处理成 `Wav2Vec2ForCTC` 训练所需的格式。为此,让我们利用 Dataset 的 [`map(...)`](https://huggingface.co/docs/datasets/package_reference/main_classes.html?highlight=map#datasets.DatasetDict.map) 函数。
首先,我们通过调用 `batch["audio"]` 来加载并重新采样音频数据。
其次,我们从加载的音频文件中提取 `input_values`。在我们的情况下, `Wav2Vec2Processor` 只规范化数据。然而,对于其他语音模型,这一步可能包括更复杂的特征提取,例如 [Log-Mel 特征提取](https://en.wikipedia.org/wiki/Mel-frequency_cepstrum)。
第三,我们将转录编码为标签 id。
**注意**: 这个映射函数是一个很好的例子,说明了如何使用 `Wav2Vec2Processor` 类。在“正常”情况下,调用 `processor(...)` 会重定向到 `Wav2Vec2FeatureExtractor` 的调用方法。然而,当将处理器封装到 `as_target_processor` 上下文中时,同一个方法会重定向到 `Wav2Vec2CTCTokenizer` 的调用方法。
欲了解更多信息,请查看 [文档](https://huggingface.co/transformers/master/model_doc/wav2vec2.html#transformers.Wav2Vec2Processor.__call__)。
```python
def prepare_dataset(batch):
audio = batch["audio"]
# batched output is "un-batched"
batch["input_values"] = processor(audio["array"], sampling_rate=audio["sampling_rate"]).input_values[0]
batch["input_length"] = len(batch["input_values"])
batch["labels"] = processor(text=batch["sentence"]).input_ids
return batch
```
让我们将数据准备功能应用到所有示例中。
```python
common_voice_train = common_voice_train.map(prepare_dataset, remove_columns=common_voice_train.column_names)
common_voice_test = common_voice_test.map(prepare_dataset, remove_columns=common_voice_test.column_names)
```
**注意**: `datasets` 自动处理音频加载和重新采样。如果你希望实现自己的定制数据加载/采样,请随意使用该 `"path"` 列并忽略该 `"audio"` 列。
太棒了,现在我们准备开始训练了!
## 训练
数据已经处理好,我们准备开始设置训练流程。我们将使用 🤗 的 [Trainer](https://huggingface.co/transformers/master/main_classes/trainer.html?highlight=trainer),为此我们基本上需要做以下几件事:
- 定义一个数据整理器。与大多数 NLP 模型不同,MMS 的输入长度比输出长度大得多。例如,输入长度为 50000 的样本的输出长度不超过 100。鉴于输入大小较大,动态填充训练批次更为高效,这意味着所有训练样本只应填充到其批次中最长的样本,而不是整体最长的样本。因此,微调 MMS 需要一个特殊的填充数据整理器,我们将在下面定义它
- 评估指标。在训练过程中,模型应该根据字错误率进行评估。我们应该相应地定义一个 `compute_metrics` 函数
- 加载预训练检查点。我们需要加载预训练检查点并正确配置它进行训练。
- 定义训练配置。
在微调模型之后,我们将正确地在测试数据上评估它,并验证它是否确实学会了正确转录语音。
### 设置 Trainer
让我们从定义数据整理器开始。数据整理器的代码是从 [这个示例](https://github.com/huggingface/transformers/blob/7e61d56a45c19284cfda0cee8995fb552f6b1f4e/examples/pytorch/speech-recognition/run_speech_recognition_ctc.py#L219) 中复制的。
不详细讲述,与常见的数据整理器不同,这个数据整理器分别对待 `input_values` 和 `labels`,因此对它们应用两个单独的填充函数 (再次利用 MMS 处理器的上下文管理器)。这是必要的,因为在语音识别中,输入和输出属于不同的模态,因此它们不应该被相同的填充函数处理。
与常见的数据整理器类似,标签中的填充标记用 `-100` 填充,以便在计算损失时 **不** 考虑这些标记。
```python
import torch
from dataclasses import dataclass, field
from typing import Any, Dict, List, Optional, Union
@dataclass
class DataCollatorCTCWithPadding:
"""
Data collator that will dynamically pad the inputs received.
Args:
processor (:class:`~transformers.Wav2Vec2Processor`)
The processor used for proccessing the data.
padding (:obj:`bool`, :obj:`str` or :class:`~transformers.tokenization_utils_base.PaddingStrategy`, `optional`, defaults to :obj:`True`):
Select a strategy to pad the returned sequences (according to the model's padding side and padding index)
among:
*:obj:`True` or :obj:`'longest'`: Pad to the longest sequence in the batch (or no padding if only a single
sequence if provided).
*:obj:`'max_length'`: Pad to a maximum length specified with the argument :obj:`max_length` or to the
maximum acceptable input length for the model if that argument is not provided.
*:obj:`False` or :obj:`'do_not_pad'` (default): No padding (i.e., can output a batch with sequences of
different lengths).
"""
processor: Wav2Vec2Processor
padding: Union[bool, str] = True
def __call__(self, features: List[Dict[str, Union[List[int], torch.Tensor]]]) -> Dict[str, torch.Tensor]:
# split inputs and labels since they have to be of different lenghts and need
# different padding methods
input_features = [{"input_values": feature["input_values"]} for feature in features]
label_features = [{"input_ids": feature["labels"]} for feature in features]
batch = self.processor.pad(
input_features,
padding=self.padding,
return_tensors="pt",
)
labels_batch = self.processor.pad(
labels=label_features,
padding=self.padding,
return_tensors="pt",
)
# replace padding with -100 to ignore loss correctly
labels = labels_batch["input_ids"].masked_fill(labels_batch.attention_mask.ne(1), -100)
batch["labels"] = labels
return batch
```
```python
data_collator = DataCollatorCTCWithPadding(processor=processor, padding=True)
```
接下来,定义评估指标。如前所述,ASR 中的主要指标是单词错误率 (WER),因此我们也将在本 notebook 中使用它。
```python
from evaluate import load
wer_metric = load("wer")
```
模型将返回一系列 logit 向量:
\( \mathbf{y}_1, \ldots, \mathbf{y}_m \) 其中 \( \mathbf{y} _1 = f_{\theta}(x_1, \ldots, x_n)[0] \) 且 \( n >> m \)。
logit 向量 \( \mathbf{y}_1 \) 包含我们前面定义的词汇表中每个单词的对数几率,因此 \( \text{len}(\mathbf{y}_i) = \) `config.vocab_size`。我们对模型最可能的预测感兴趣,因此取 logits 的 `argmax(...)`。此外,我们通过将 `-100` 替换为 `pad_token_id` 并解码 id,同时确保连续标记 **不** 以 CTC 风格分组到同一标记 \( {}^1 \),将编码后的标签转换回原始字符串。
```python
def compute_metrics(pred):
pred_logits = pred.predictions
pred_ids = np.argmax(pred_logits, axis=-1)
pred.label_ids[pred.label_ids == -100] = processor.tokenizer.pad_token_id
pred_str = processor.batch_decode(pred_ids)
# we do not want to group tokens when computing the metrics
label_str = processor.batch_decode(pred.label_ids, group_tokens=False)
wer = wer_metric.compute(predictions=pred_str, references=label_str)
return {"wer": wer}
```
现在,我们可以加载预训练的 [`mms-1b-all`](https://huggingface.co/facebook/mms-1b-all) 检查点。分词器的 `pad_token_id` 必须定义模型的 `pad_token_id`,或者在 `Wav2Vec2ForCTC` 的情况下也是 CTC 的 _空白标记_ \( {}^2 \)。
由于我们只训练一小部分权重,模型不容易过拟合。因此,我们确保禁用所有 dropout 层。
**注意**: 当使用本笔记本在 Common Voice 的另一种语言上训练 MMS 时,这些超参数设置可能不会很好地工作。根据你的用例,随意调整这些设置。
```python
from transformers import Wav2Vec2ForCTC
model = Wav2Vec2ForCTC.from_pretrained(
"facebook/mms-1b-all",
attention_dropout=0.0,
hidden_dropout=0.0,
feat_proj_dropout=0.0,
layerdrop=0.0,
ctc_loss_reduction="mean",
pad_token_id=processor.tokenizer.pad_token_id,
vocab_size=len(processor.tokenizer),
ignore_mismatched_sizes=True,
)
```
```bash
Some weights of Wav2Vec2ForCTC were not initialized from the model checkpoint at facebook/mms-1b-all and are newly initialized because the shapes did not match:
- lm_head.bias: found shape torch.Size([154]) in the checkpoint and torch.Size([39]) in the model instantiated
- lm_head.weight: found shape torch.Size([154, 1280]) in the checkpoint and torch.Size([39, 1280]) in the model instantiated
You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
```
**注意**: 预计一些权重将被重新初始化。这些权重对应于新初始化的词汇输出层。
我们现在希望确保只有适配器权重将被训练,而模型的其余部分保持冻结。
首先,我们重新初始化所有适配器权重,这可以通过方便的 `init_adapter_layers` 方法完成。也可以不重新初始化适配器权重并继续微调,但在这种情况下,在训练之前应该通过 [`load_adapter(...)` 方法](https://huggingface.co/docs/transformers/main/en/model_doc/wav2vec2#transformers.Wav2Vec2ForCTC.load_adapter) 加载合适的适配器权重。然而,词汇表通常仍然不会很好地匹配自定义训练数据,因此通常更容易重新初始化所有适配器层,以便它们可以轻松地进行微调。
```python
model.init_adapter_layers()
```
接下来,我们冻结 **除** 适配器层之外的所有权重。
```python
model.freeze_base_model()
adapter_weights = model._get_adapters()
for param in adapter_weights.values():
param.requires_grad = True
```
最后一步,我们定义与训练相关的所有参数。
对一些参数进行更多解释:
- `group_by_length` 通过将输入长度相似的训练样本分组到一个批次中,使训练更加高效。这可以通过大大减少通过模型传递的无用填充标记的总数,从而显著加快训练时间
- `learning_rate` 被选择为 1e-3,这是使用 Adam 训练的常用默认值。其他学习率可能同样有效。
有关其他参数的更多解释,可以查看 [文档](https://huggingface.co/transformers/master/main_classes/trainer.html?highlight=trainer#trainingarguments)。为了节省 GPU 内存,我们启用 PyTorch 的 [梯度检查点](https://pytorch.org/docs/stable/checkpoint.html),并将损失减少设置为“ _mean_ ”。MMS 适配器微调非常快地收敛到非常好的性能,因此即使对于像 4 小时这样小的数据集,我们也只会训练 4 个周期。在训练过程中,每 200 个训练步骤将异步上传一个检查点到 hub。它允许你在模型仍在训练时也可以使用演示小部件玩耍。
**注意**: 如果不想将模型检查点上传到 hub,只需将 `push_to_hub=False` 即可。
```python
from transformers import TrainingArguments
training_args = TrainingArguments(
output_dir=repo_name,
group_by_length=True,
per_device_train_batch_size=32,
evaluation_strategy="steps",
num_train_epochs=4,
gradient_checkpointing=True,
fp16=True,
save_steps=200,
eval_steps=100,
logging_steps=100,
learning_rate=1e-3,
warmup_steps=100,
save_total_limit=2,
push_to_hub=True,
)
```
现在,所有实例都可以传递给 Trainer,我们准备开始训练!
```python
from transformers import Trainer
trainer = Trainer(
model=model,
data_collator=data_collator,
args=training_args,
compute_metrics=compute_metrics,
train_dataset=common_voice_train,
eval_dataset=common_voice_test,
tokenizer=processor.feature_extractor,
)
```
---
\( {}^1 \) 为了使模型独立于说话人速率,在 CTC 中,相同的连续标记简单地分组为单个标记。然而,在解码时不应该对编码的标签进行分组,因为它们不对应于模型的预测标记,这就是为什么必须传递 `group_tokens=False` 参数。如果我们不传递这个参数,像 `"hello"` 这样的单词会被错误地编码,并解码为 `"helo"`。
\( {}^2 \) 空白标记允许模型通过强制在两个 l 之间插入空白标记来预测一个词,例如 `"hello"`。我们模型的 CTC 符合预测 `"hello"` 将是 `[PAD] [PAD]"h" "e" "e" "l" "l" [PAD]"l" "o" "o" [PAD]`。
### 训练
训练时间应该少于 30 分钟,具体取决于所使用的 GPU。
```python
trainer.train()
```
| 训练损失 | 训练步数 | 验证损失 | Wer |
| :-: | :-: | :-: | :-: |
| 4.905 | 100 | 0.215 | 0.280 |
| 0.290 | 200 | 0.167 | 0.232 |
| 0.2659 | 300 | 0.161 | 0.229 |
| 0.2398 | 400 | 0.156 | 0.223 |
训练损失和验证 WER 都很好地下降。
我们看到,仅微调 `mms-1b-all` 的适配器层 100 步就大大超过了 [这里](https://huggingface.co/blog/zh/fine-tune-xlsr-wav2vec2#training-1) 显示的微调整个 `xls-r-300m` 检查点。
从 [官方论文](https://scontent-cdg4-3.xx.fbcdn.net/v/t39.8562-6/348827959_6967534189927933_6819186233244071998_n.pdf?_nc_cat=104&ccb=1-7&_nc_sid=ad8a9d&_nc_ohc=fSo3qQ7uxr0AX8EWnWl&_nc_ht=scontent-cdg4-3.xx&oh=00_AfBL34K0MAAPb0CgnthjbHfiB6pSnnwbn5esj9DZVPvyoA&oe=6495E802) 和这个快速比较中可以清楚地看出, `mms-1b-all` 具有更高的将知识转移到低资源语言的能力,应该优先于 `xls-r-300m`。此外,训练也更节省内存,因为只训练了一小部分层。
适配器权重将作为模型检查点的一部分上传,但我们也希望确保单独保存它们,以便它们可以轻松地上下线。
让我们将所有适配器层保存到训练输出目录中,以便它能够正确上传到 Hub。
```python
from safetensors.torch import save_file as safe_save_file
from transformers.models.wav2vec2.modeling_wav2vec2 import WAV2VEC2_ADAPTER_SAFE_FILE
import os
adapter_file = WAV2VEC2_ADAPTER_SAFE_FILE.format(target_lang)
adapter_file = os.path.join(training_args.output_dir, adapter_file)
safe_save_file(model._get_adapters(), adapter_file, metadata={"format": "pt"})
```
最后,你可以将训练结果上传到🤗 Hub。
```python
trainer.push_to_hub()
```
适配器权重训练的主要优点之一是“基础”模型 (约占模型权重的 99%) 保持不变,只需共享一个小的 [2.5M 适配器检查点](https://huggingface.co/patrickvonplaten/wav2vec2-large-mms-1b-turkish-colab/blob/main/adapter.tur.safetensors) 即可使用训练好的检查点。
这使得训练额外的适配器层并将它们添加到你的仓库变得非常简单。
你可以通过简单地重新运行此脚本并将你想要训练的语言更改为另一种语言来轻松实现,例如 `swe` 表示瑞典语。此外,你应该确保词汇表不会被完全覆盖,而是新语言词汇表应该像上面注释掉的单元格中所述那样 **附加** 到现有词汇表中。
为了演示如何加载不同的适配器层,我还训练并上传了一个瑞典语适配器层,其 iso 语言代码为 `swe`,如 [此处](https://huggingface.co/patrickvonplaten/wav2vec2-large-mms-1b-turkish-colab/blob/main/adapter.swe.safetensors) 所示
你可以像往常一样使用 `from_pretrained(...)` 加载微调后的检查点,但应确保在方法中添加 `target_lang="<your-lang-code>"`,以便加载正确的适配器。你还应该为分词器正确设置目标语言。
让我们看看如何首先加载土耳其检查点。
```python
model_id = "patrickvonplaten/wav2vec2-large-mms-1b-turkish-colab"
model = Wav2Vec2ForCTC.from_pretrained(model_id, target_lang="tur").to("cuda")
processor = Wav2Vec2Processor.from_pretrained(model_id)
processor.tokenizer.set_target_lang("tur")
```
让我们检查模型是否可以正确转录土耳其语
```python
from datasets import Audio
common_voice_test_tr = load_dataset("mozilla-foundation/common_voice_6_1", "tr", data_dir="./cv-corpus-6.1-2020-12-11", split="test", use_auth_token=True)
common_voice_test_tr = common_voice_test_tr.cast_column("audio", Audio(sampling_rate=16_000))
```
让我们处理音频,运行前向传递并预测 ids
```python
input_dict = processor(common_voice_test_tr[0]["audio"]["array"], sampling_rate=16_000, return_tensors="pt", padding=True)
logits = model(input_dict.input_values.to("cuda")).logits
pred_ids = torch.argmax(logits, dim=-1)[0]
```
最后,我们可以解码该示例。
```python
print("Prediction:")
print(processor.decode(pred_ids))
print("\nReference:")
print(common_voice_test_tr[0]["sentence"].lower())
```
**输出**:
```bash
Prediction:
pekçoğuda roman toplumundan geliyor
Reference:
pek çoğu da roman toplumundan geliyor.
```
这看起来几乎完全正确,只是第一个单词中应该添加两个空格。
现在,通过调用 [`model.load_adapter(...)`](mozilla-foundation/common_voice_6_1) 并将分词器更改为瑞典语,可以非常简单地将适配器更改为瑞典语。
```python
model.load_adapter("swe")
processor.tokenizer.set_target_lang("swe")
```
我们再次从普通语音加载瑞典语测试集
```python
common_voice_test_swe = load_dataset("mozilla-foundation/common_voice_6_1", "sv-SE", data_dir="./cv-corpus-6.1-2020-12-11", split="test", use_auth_token=True)
common_voice_test_swe = common_voice_test_swe.cast_column("audio", Audio(sampling_rate=16_000))
```
并转录一个样本:
```python
input_dict = processor(common_voice_test_swe[0]["audio"]["array"], sampling_rate=16_000, return_tensors="pt", padding=True)
logits = model(input_dict.input_values.to("cuda")).logits
pred_ids = torch.argmax(logits, dim=-1)[0]
print("Prediction:")
print(processor.decode(pred_ids))
print("\nReference:")
print(common_voice_test_swe[0]["sentence"].lower())
```
**输出**:
```bash
Prediction:
jag lämnade grovjobbet åt honom
Reference:
jag lämnade grovjobbet åt honom.
```
太好了,这看起来像是一个完美的转录!
我们在这篇博客文章中展示了 MMS 适配器权重微调不仅在低资源语言上提供了最先进的性能,而且还显著缩短了训练时间,并允许轻松构建定制的适配器权重集合。
_相关帖子和附加链接列在这里:_
- [**官方论文**](https://huggingface.co/papers/2305.13516)
- [**原始 cobebase**](https://github.com/facebookresearch/fairseq/tree/main/examples/mms/asr)
- [**官方演示**](https://huggingface.co/spaces/facebook/MMS)
- [**Transformers 文档**](https://huggingface.co/docs/transformers/index)
- [**相关 XLS-R 博客文章**](https://huggingface.co/blog/zh/fine-tune-xlsr-wav2vec2)
- [**Hub 上的模型**](https://huggingface.co/models?other=mms) | 6 |
0 | hf_public_repos/blog | hf_public_repos/blog/zh/transformers-design-philosophy.md | ---
title: "〜不要〜重复自己"
thumbnail: /blog/assets/59_transformers_philosophy/transformers.png
authors:
- user: patrickvonplaten
translators:
- user: MatrixYao
- user: zhongdongy
proofreader: true
---
# ~~不要~~ 重复自己*
##### *如何为现代机器学习设计开源库*
## 🤗 Transformers 设计理念
_“不要重复自己 (Don’t Repeat Yourself)”_ ,或 **DRY**,是广为人知的软件开发原则。该原则出自《程序员修炼之道: 从小工到专家》 (英文名为 The pragmatic programmer),这是代码设计领域迄今为止阅读量最大的一本书。该原则言简意赅,即: 重用而不要重写其他地方已有的逻辑。这可以确保代码保持同步,使其更易于维护且更健壮。该做法使得对公共代码逻辑的任何更改都会统一地影响所有依赖该公共代码逻辑的代码。
乍一看,Hugging Face transformers 库的设计与 DRY 原则背道而驰。注意力机制的代码被复制到不同的模型文件里不下 50 次。有时整个 BERT 模型的代码都会被复制到其他模型文件中。贡献者在添加新模型时,如果新模型用到了现有的某个模型,我们经常强制要求他们把该现有模型的所有代码复制到新模型代码中,连一个小小的逻辑调整也不例外。我们为什么要这么做?是因为我们太懒抑或是因为我们无力承担将所有公共逻辑集中到一个地方所带来的工作量?
不,我们并不懒 —— 不在 transformers 库中使用 DRY 原则是有意之举。我们决定采用一种与 DRY 不同的设计原则,我们称之为 _**单模型文件**_ 策略 (single model file policy)。 _单一模型文件_ 策略要求,任何模型的所有代码都只应该放在一个文件中,这个文件就是该模型自己的模型文件。如果读者想了解 BERT 如何是进行推理的,他/她只需要阅读 BERT 的 `modeling_bert.py` 文件即可。通常情况下,我们拒绝任何将不同模型的相同子模块抽象并集中到一个新文件中的尝试。我们不想要一个包含所有可能的注意力机制的 `attention_layer.py` 。
我们为何作出这样的设计呢?我们将原因概括如下:
- **1. Transformers 生于开源,服务开源**
- **2. 我们的产品是模型,我们的客户是那些阅读或修改模型代码的用户。**
- **3. 机器学习领域发展极其迅速。**
- **4. 机器学习模型是静态的。**
### 1. 生于开源,服务开源
Transformers 积极鼓励来自外部的贡献。贡献一般有错误修复和新模型添加两类。如果有人发现了某个模型文件中的错误,我们希望他/她很容易就能修复它。没有什么比修复了一个 bug 却发现它导致了其他模型上的 100 个 bug 更令人沮丧的了。
因为每个模型代码相互独立,所以对于只了解他/她正在用的那个模型的人来说,修复它会轻松很多。同样,如果只添加一个新的模型文件,添加新的模型代码以及 review 相应的 PR 会更容易。贡献者不必弄清楚如何在不破坏现有模型的情况下向公共的注意力机制代码添加新功能,代码评审者也缺省地知道这个 PR 不会破坏任何一个现有模型。
### 2. 模型代码即产品
我们假设 transformers 库的很多用户不仅会阅读文档,而且会查看实际模型代码并有可能对其进行修改。鉴于 transformers 库被 fork 了 1 万多次,我们的 transformers 论文被引用了 1 千多次,这个假设应该是站得住脚的。
因此,最重要的是让第一次阅读 transformers 模型代码的人能够轻松理解并修改它。在单个模型文件中囊括该模型的所有必要逻辑组件有助于提高可读性和可修改性。处于同样的目的,我们也非常关注变量及方法命名的合理性,我们更喜欢表达力强/可读性强的代码,而不盲目追求短代码。
### 3. 机器学习正以惊人的速度发展
机器学习领域,尤其是神经网络领域的研究发展非常迅速。一年前最先进的模型今天可能已经过时了。我们甚至不知道明年会流行哪一种注意力机制、位置嵌入或架构。因此,我们无法定义适用于所有模型的标准模板。
例如,两年前,人们可能将 BERT 的自注意力层定义为所有 transformer 模型的标准注意力层。从逻辑上讲,“标准”注意力函数可以移到一个集中性的 `attention.py` 文件中。但是随后出现了在每层中添加相对位置嵌入的注意力层 (如 T5),多种不同形式的分块注意力层 (Reformer,Longformer,BigBird),以及将位置嵌入和词嵌入分离的注意力机制 (DeBERTa) …… 每当发生这类事情时,我们都不得不问自己是否应该调整“标准”注意力函数,还是说向 `attention.py` 添加一个新的注意力函数更好。但如果要添加新的注意力函数,我们该如何命名呢? `attention_with_positional_embd` , `reformer_attention` 还有 `deberta_attention` ?
给机器学习模型的组件起通用的名字是危险的,因为关于名字意义的解释可能会很快改变或过时。例如,分块注意力指的是 GPTNeo 的分块注意力,还是 Reformer 的分块注意力,抑或是 BigBird 的分块注意力?注意层是自注意层、交叉注意层,还是两者都包含?如果我们最终决定用模型名称来命名注意力层,我们何不直接把这个注意力函数放在相应的模型文件中?
### 4. 机器学习模型是静态的
Transformers 库是不同研究团队创建的统一且完善的机器学习模型的集合。每个机器学习模型通常都对应一篇论文及其官方 GitHub 存储库。机器学习模型一旦发布,后面就很少会对其进行调整或更改。
相反,研究团队倾向于发布基于之前模型构建的新模型,而很少对已发布的代码进行重大更改。在决定 transformers 库的设计原则时,这是一个重要的认知。这意味着一旦将模型架构添加到 transformers 中,模型的基本组件就不会再改变。有可能会发现并修复一些错误,有可能会重命名方法或变量,也有可能对模型的输出或输入格式进行微调,但一般不会改动模型的核心组件。因此,对 transformers 中的所有模型进行大的全局性改动的需求大大减少,这使得每个逻辑模块只存在一次这件事情变得不那么重要,因为我们很少改动它。
第二个认知是模型之间 **不** 存在双向依赖。新发布的模型可能依赖于现存模型,但很明显,现存模型在逻辑上并不依赖于其前面的模型。例如,T5 部分建立在 BERT 之上,因此 T5 的模型代码在逻辑上可能依赖于 BERT 的模型代码,但 BERT 在逻辑上绝不可能依赖于 T5。因此,重构 BERT 的注意力功能以使其满足 T5 的要求这件事在逻辑上不合理 —— 阅读 BERT 的注意力层代码的人不需要对 T5 有任何了解。同样,这也促使我们不要将注意力层等组件集中到所有模型都可以访问的公共模块中。
另一方面,新模型的代码在逻辑上可能对其前面的模型有一定的依赖性。例如,DeBERTa-v2 的代码确实在某种程度上依赖于 DeBERTa 的代码。通过确保 DeBERTa-v2 的模型代码与 DeBERTa 的保持同步,可以显著提高可维护性。理论上来讲,修复 DeBERTa 中的 bug 的同时也应该修复 DeBERTa-v2 中的相同 bug。我们如何在确保新模型与其依赖的模型保持同步的同时维持 _单模型文件_ 策略?
现在,我们解释一下为什么我们在 _“重复自己”_ 之后加上星号$ {}^{\textbf{*}} $。我们不会无脑复制粘贴现有模型的相应代码,即使看上去我们好像就是这么做的。 Transformers 的核心维护者之一 [Sylvain Gugger](https://github.com/sgugger) 发现了一种既尊重 _单文件策略_ 又将可维护性成本控制在一定范围内的好机制。该机制,我们暂且称其为 _“复制机制”_ ,允许我们使用 `#Copied from <predecessor_model>.<function>` 语句标记某些逻辑组件 (如注意力层函数),从而强制被标记的当前代码与 `<predecessor_model>` 的 `<function>` 相同。例如,[DeBERTa-v2 类](https://github.com/huggingface/transformers/blob/21decb7731e998d3d208ec33e5b249b0a84c0a02/src/transformers/models/deberta_v2/modeling_deberta_v2.py#L325) 里的这行代码强制整个 `DebertaV2Layer` 类除了类名前缀 `DeBERTav2` 之外须与 [DebertaLayer 类](https://github.com/huggingface/transformers/blob/21decb7731e998d3d208ec33e5b249b0a84c0a02/src/transformers/models/deberta/modeling_deberta.py#L336) 相同。如此可以看到,复制机制使模型代码非常容易理解,同时又显著减少了维护成本。如果有人改动了某个模型的某个函数,则我们可以使用一个自动化工具来更正依赖于这个模型的这个函数的所有其他模型的相应代码。
### 缺点
显然,单文件策略也有缺点,我们在这里简单提两个。
Transformers 的一个主要目标是为所有模型的推理和训练提供统一的 API,以便用户可以在不同模型之间快速切换。但是,如果不允许模型文件使用抽象这一设计模式,则确保跨模型的统一 API 会困难得多。我们通过运行 **大量** 测试 (截至本文撰写时,每天需要运行大约 2 万次测试) 来解决这个问题,以确保模型遵循一致的 API。在这种情况下,单文件策略要求我们在评审新模型和新测例时非常严格。
其次,有很多研究仅针对机器学习模型的单个组件。 _例如_ ,有研究团队会致力于研究一种适用于所有现有预训练模型的注意力机制的新形式,如 [Rethinking Attention with Performers](https://arxiv.org/abs/2009.14794) 一文所做的。我们应该如何将此类研究纳入 transformers 库?确实不好弄。我们应该改变所有现有模型吗?这将违背上文中的第 3 点和第 4 点。还是我们应该添加 100 多个新的模型文件,每个文件都以 `Performer...` 为前缀?这也很荒谬。遗憾的是,对此类情况我们还没有好的解决方案,我们只能选择不将该论文的成果集成到 transformers 中。等这篇论文获得更多关注并有了性能强大的预训练 checkpoint,我们可能会为其中最重要的模型添加一个新的模型文件,例如目前我们已有 `modeling_performer_bert.py` 。
### 总结
总而言之,在 🤗 Hugging Face,我们坚信 _单文件策略_ 是适合 transformers 的代码设计理念。
你的想法如何?我们很想听听你的意见!如果你有话要说,欢迎到这个 [帖子](https://discuss.huggingface.co/t/repeat-yourself-transformers-design-philosophy/16483) 下留言。 | 7 |
0 | hf_public_repos/blog | hf_public_repos/blog/zh/constrained-beam-search.md | ---
title: 在 🤗 Transformers 中使用约束波束搜索引导文本生成
thumbnail: /blog/assets/53_constrained_beam_search/thumbnail.png
authors:
- user: cwkeam
guest: true
translators:
- user: MatrixYao
- user: zhongdongy
proofreader: true
---
# 在 🤗 Transformers 中使用约束波束搜索引导文本生成
<a target="_blank" href="https://colab.research.google.com/github/huggingface/blog/blob/main/notebooks/53_constrained_beam_search.ipynb">
<img src="https://colab.research.google.com/assets/colab-badge.svg" alt=" 在 Colab 中打开 "/>
</a>
## **引言**
本文假设读者已经熟悉文本生成领域波束搜索相关的背景知识,具体可参见博文 [如何生成文本: 通过 Transformers 用不同的解码方法生成文本](https://huggingface.co/blog/zh/how-to-generate)。
与普通的波束搜索不同,**约束** 波束搜索允许我们控制所生成的文本。这很有用,因为有时我们确切地知道输出中需要包含什么。例如,在机器翻译任务中,我们可能通过查字典已经知道哪些词必须包含在最终的译文中; 而在某些特定的场合中,虽然某几个词对于语言模型而言差不多,但对最终用户而言可能却相差很大。这两种情况都可以通过允许用户告诉模型最终输出中必须包含哪些词来解决。
### **这事儿为什么这么难**
然而,这个事情操作起来并不容易,它要求我们在生成过程中的 _某个时刻_ 在输出文本的 _某个位置_ 强制生成某些特定子序列。
假设我们要生成一个句子 `S`,它必须按照先 $t_1$ 再 $t_2$ 的顺序包含短语 $p_1={ t_1, t_2 }$。以下定义了我们希望生成的句子 $S$:
$$ S_{期望} = { s_1, s_2, …, s_k, t_1, t_2, s_{k+1}, …, s_n } $$
问题是波束搜索是逐词输出文本的。我们可以大致将波束搜索视为函数 $B(\mathbf{s}_{0:i}) = s_{i+1}$,它根据当前生成的序列 $\mathbf{s}_{0:i}$ 预测下一时刻 $i+1$ 的输出。但是这个函数在任意时刻 $i < k$ 怎么知道,未来的某个时刻 $k$ 必须生成某个指定词?或者当它在时刻 $i=k$ 时,它如何确定当前那个指定词的最佳位置,而不是未来的某一时刻 $i>k$?
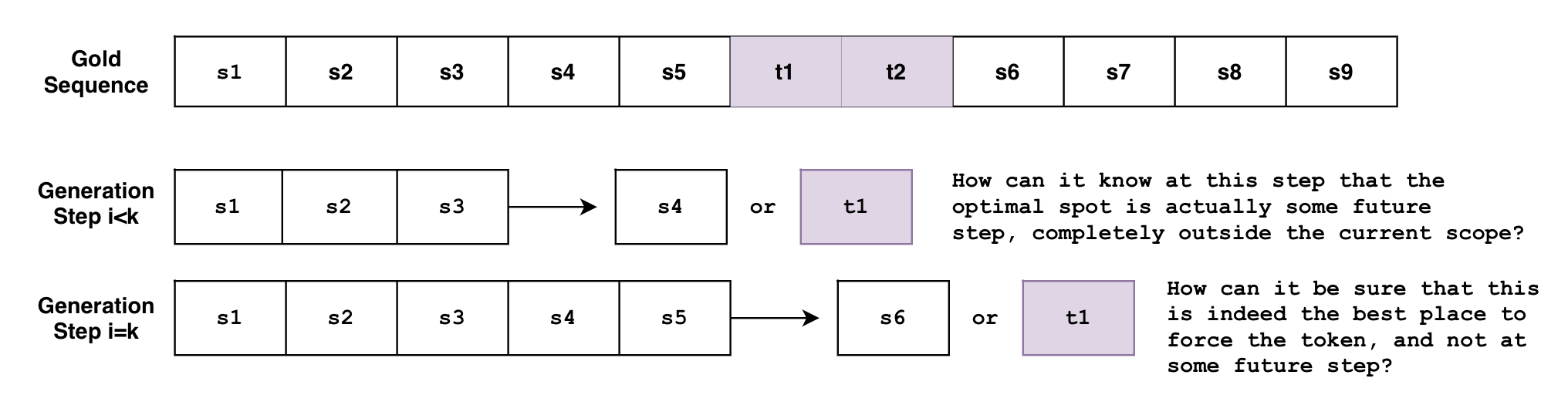
如果你同时有多个不同的约束怎么办?如果你想同时指定使用短语 $p_1={t_1, t_2}$ _和_ 短语 $p_2={ t_3, t_4, t_5, t_6}$ 怎么办?如果你希望模型在两个短语之间 **任选一个** 怎么办?如果你想同时指定使用短语 $p_1$ 以及短语列表 ${p_{21}, p_{22}, p_{23}}$ 中的任一短语怎么办?
上述需求在实际场景中是很合理的需求,下文介绍的新的约束波束搜索功能可以满足所有这些需求!
我们会先简要介绍一下新的 _**约束波束搜索**_ 可以做些什么,然后再深入介绍其原理。
## **例 1: 指定包含某词**
假设我们要将 `"How old are you?"` 翻译成德语。它对应两种德语表达,其中 `"Wie alt bist du?"` 是非正式场合的表达,而 `"Wie alt sind Sie?"` 是正式场合的表达。
不同的场合,我们可能倾向于不同的表达,但我们如何告诉模型呢?
### **使用传统波束搜索**
我们先看下如何使用 _**传统波束搜索**_ 来完成翻译。
```
!pip install -q git+https://github.com/huggingface/transformers.git
```
```python
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
tokenizer = AutoTokenizer.from_pretrained("t5-base")
model = AutoModelForSeq2SeqLM.from_pretrained("t5-base")
encoder_input_str = "translate English to German: How old are you?"
input_ids = tokenizer(encoder_input_str, return_tensors="pt").input_ids
outputs = model.generate(
input_ids,
num_beams=10,
num_return_sequences=1,
no_repeat_ngram_size=1,
remove_invalid_values=True,
)
print("Output:\n" + 100 *'-')
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
```
Output:
----------------------------------------------------------------------------------------------------
Wie alt bist du?
### **使用约束波束搜索**
但是如果我们想要一个正式的表达而不是非正式的表达呢?如果我们已经先验地知道输出中必须包含什么,我们该如何 _将其_ 注入到输出中呢?
我们可以通过 `model.generate()` 的 `force_words_ids` 参数来实现这一功能,代码如下:
```python
tokenizer = AutoTokenizer.from_pretrained("t5-base")
model = AutoModelForSeq2SeqLM.from_pretrained("t5-base")
encoder_input_str = "translate English to German: How old are you?"
force_words = ["Sie"]
input_ids = tokenizer(encoder_input_str, return_tensors="pt").input_ids
force_words_ids = tokenizer(force_words, add_special_tokens=False).input_ids
outputs = model.generate(
input_ids,
force_words_ids=force_words_ids,
num_beams=5,
num_return_sequences=1,
no_repeat_ngram_size=1,
remove_invalid_values=True,
)
print("Output:\n" + 100 *'-')
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
```
Output:
----------------------------------------------------------------------------------------------------
Wie alt sind Sie?
如你所见,现在我们能用我们对输出的先验知识来指导文本的生成。以前我们必须先生成一堆候选输出,然后手动从中挑选出符合我们要求的输出。现在我们可以直接在生成阶段做到这一点。
## **例 2: 析取式约束**
在上面的例子中,我们知道需要在最终输出中包含哪些单词。这方面的一个例子可能是在神经机器翻译过程中结合使用字典。
但是,如果我们不知道要使用哪种 _词形_呢,我们可能希望使用单词 `rain` 但对其不同的词性没有偏好,即 `["raining", "rained", "rains", ...]` 是等概的。更一般地,很多情况下,我们可能并不刻板地希望 _逐字母一致_ ,此时我们希望划定一个范围由模型去从中选择最合适的。
支持这种行为的约束叫 _**析取式约束 (Disjunctive Constraints)**_ ,其允许用户输入一个单词列表来引导文本生成,最终输出中仅须包含该列表中的 _至少一个_ 词即可。
下面是一个混合使用上述两类约束的例子:
```python
from transformers import GPT2LMHeadModel, GPT2Tokenizer
model = GPT2LMHeadModel.from_pretrained("gpt2")
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
force_word = "scared"
force_flexible = ["scream", "screams", "screaming", "screamed"]
force_words_ids = [
tokenizer([force_word], add_prefix_space=True, add_special_tokens=False).input_ids,
tokenizer(force_flexible, add_prefix_space=True, add_special_tokens=False).input_ids,
]
starting_text = ["The soldiers", "The child"]
input_ids = tokenizer(starting_text, return_tensors="pt").input_ids
outputs = model.generate(
input_ids,
force_words_ids=force_words_ids,
num_beams=10,
num_return_sequences=1,
no_repeat_ngram_size=1,
remove_invalid_values=True,
)
print("Output:\n" + 100 *'-')
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
print(tokenizer.decode(outputs[1], skip_special_tokens=True))
```
Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation.
Output:
----------------------------------------------------------------------------------------------------
The soldiers, who were all scared and screaming at each other as they tried to get out of the
The child was taken to a local hospital where she screamed and scared for her life, police said.
如你所见,第一个输出里有 `"screaming"` ,第二个输出里有 `"screamed"` ,同时它们都原原本本地包含了 `"scared"` 。注意,其实 `["screaming", "screamed", ...]` 列表中不必一定是同一单词的不同词形,它可以是任何单词。使用这种方式,可以满足我们只需要从候选单词列表中选择一个单词的应用场景。
## **传统波束搜索**
以下是传统 **波束搜索** 的一个例子,摘自之前的 [博文](https://huggingface.co/blog/zh/how-to-generate):
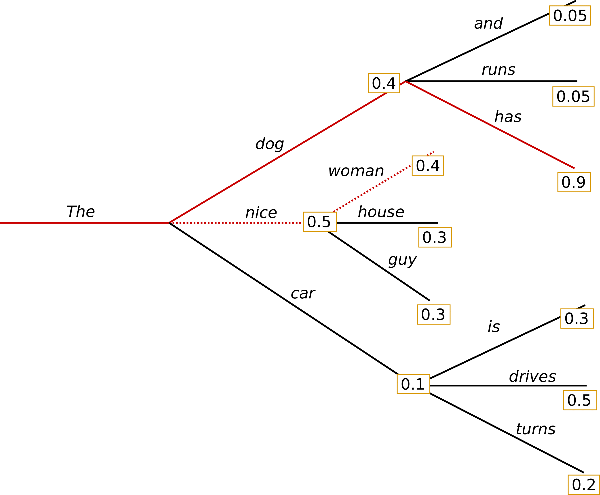
与贪心搜索不同,波束搜索会保留更多的候选词。上图中,我们每一步都展示了 3 个最可能的预测词。
在 `num_beams=3` 时,我们可以将第 1 步波束搜索表示成下图:
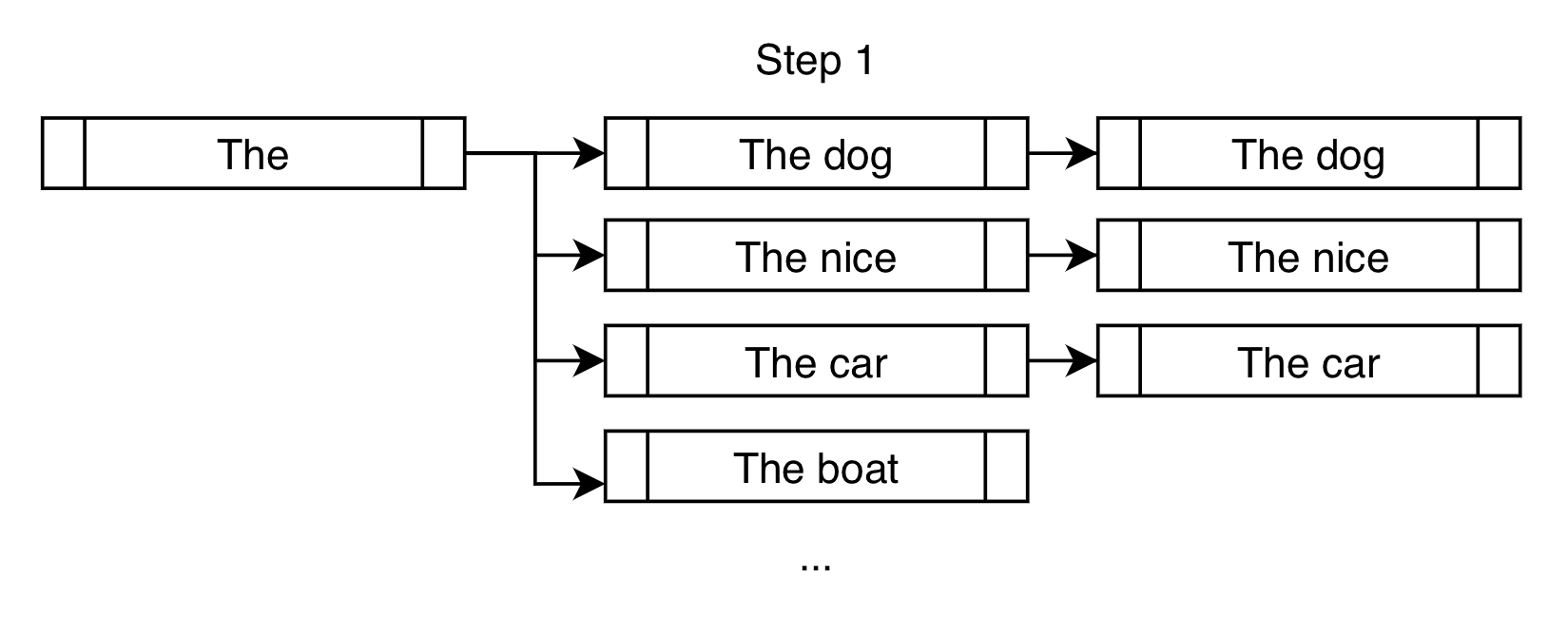
波束搜索不像贪心搜索那样只选择 `"The dog"` ,而是允许将 `"The nice"` 和 `"The car"` _留待进一步考虑_ 。
下一步,我们会为上一步创建的三个分支分别预测可能的下一个词。
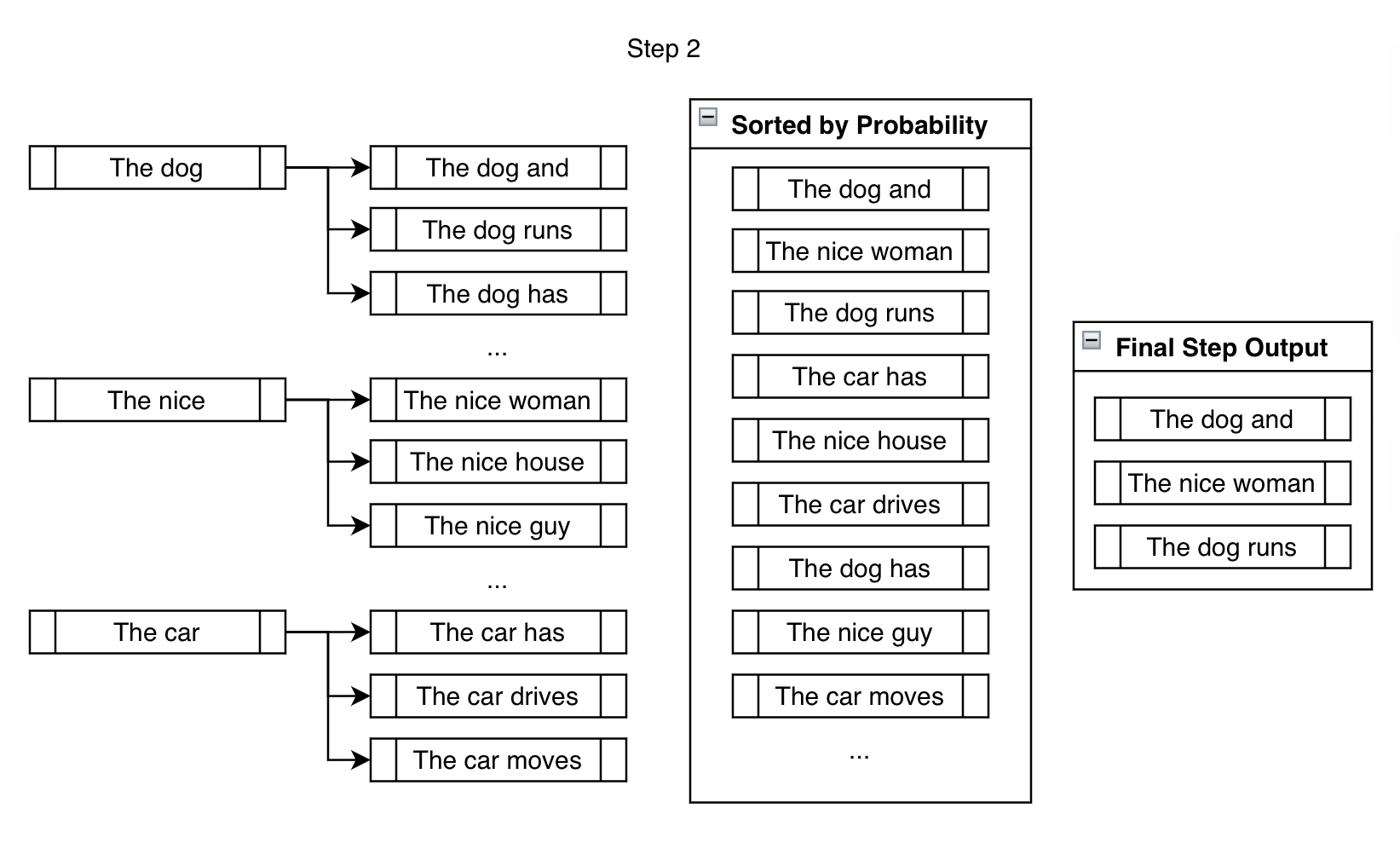
虽然我们 _考查_ 了明显多于 `num_beams` 个候选词,但在每步结束时,我们只会输出 `num_beams` 个最终候选词。我们不能一直分叉,那样的话, `beams` 的数目将在 $n$ 步后变成 $\text{beams}^{n}$ 个,最终变成指数级的增长 (当波束数为 $10$ 时,在 $10$ 步之后就会变成 $10,000,000,000$ 个分支!)。
接着,我们重复上述步骤,直到满足中止条件,如生成 `<eos>` 标记或达到 `max_length` 。整个过程可以总结为: 分叉、排序、剪枝,如此往复。
## **约束波束搜索**
约束波束搜索试图通过在每一步生成过程中 _注入_所需词来满足约束。
假设我们试图指定输出中须包含短语 `"is fast"` 。
在传统波束搜索中,我们在每个分支中找到 `k` 个概率最高的候选词,以供下一步使用。在约束波束搜索中,除了执行与传统波束搜索相同的操作外,我们还会试着把约束词加进去,以 _看看我们是否能尽量满足约束_。图示如下:
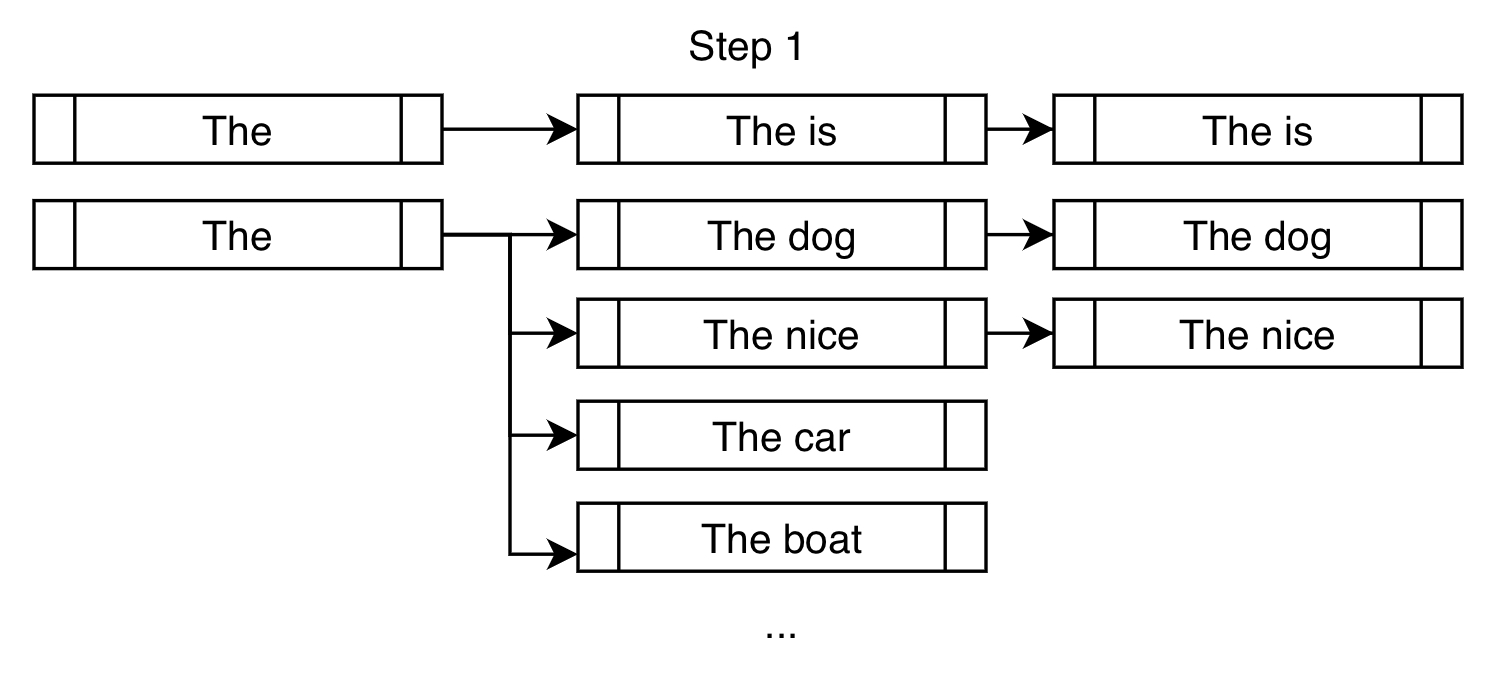
上图中,我们最终候选词除了包括像 `"dog"` 和 `"nice"` 这样的高概率词之外,我们还把 `"is"` 塞了进去,以尽量满足生成的句子中须含 `"is fast"` 的约束。
第二步,每个分支的候选词选择与传统的波束搜索大部分类似。唯一的不同是,与上面第一步一样,约束波束搜索会在每个新分叉上继续强加约束,把满足约束的候选词强加进来,如下图所示:
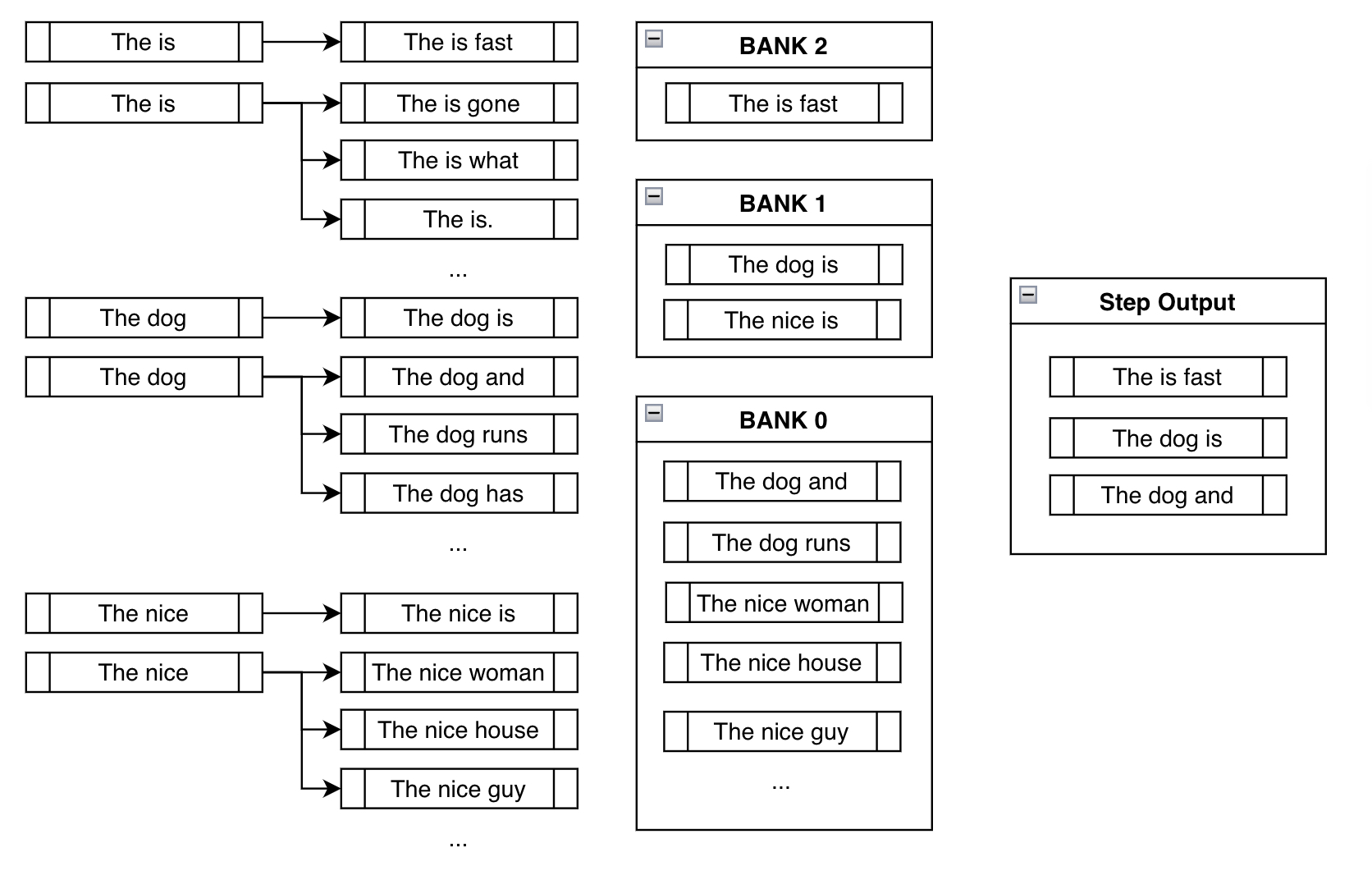
### **组 (Banks)**
在讨论下一步之前,我们停下来思考一下上述方法的缺陷。
在输出中野蛮地强制插入约束短语 `is fast` 的问题在于,大多数情况下,你最终会得到像上面的 `The is fast` 这样的无意义输出。我们需要解决这个问题。你可以从 `huggingface/transformers` 代码库中的这个 [问题](https://github.com/huggingface/transformers/issues/14081#issuecomment-1004479944) 中了解更多有关这个问题及其复杂性的深入讨论。
组方法通过在满足约束和产生合理输出两者之间取得平衡来解决这个问题。
我们把所有候选波束按照其 `满足了多少步约束`分到不同的组中,其中组 $n$ 里包含的是 _**满足了 $n$ 步约束的波束列表**_ 。然后我们按照顺序轮流选择各组的候选波束。在上图中,我们先从组 2 (Bank 2) 中选择概率最大的输出,然后从组 1 (Bank 1) 中选择概率最大的输出,最后从组 0 (Bank 0) 中选择最大的输出; 接着我们从组 2 (Bank 2) 中选择概率次大的输出,从组 1 (Bank 1) 中选择概率次大的输出,依此类推。因为我们使用的是 `num_beams=3`,所以我们只需执行上述过程三次,就可以得到 `["The is fast", "The dog is", "The dog and"]`。
这样,即使我们 _强制_ 模型考虑我们手动添加的约束词分支,我们依然会跟踪其他可能更有意义的高概率序列。尽管 `The is fast` 完全满足约束,但这并不是一个有意义的短语。幸运的是,我们有 `"The dog is"` 和 `"The dog and"` 可以在未来的步骤中使用,希望在将来这会产生更有意义的输出。
图示如下 (以上例的第 3 步为例):
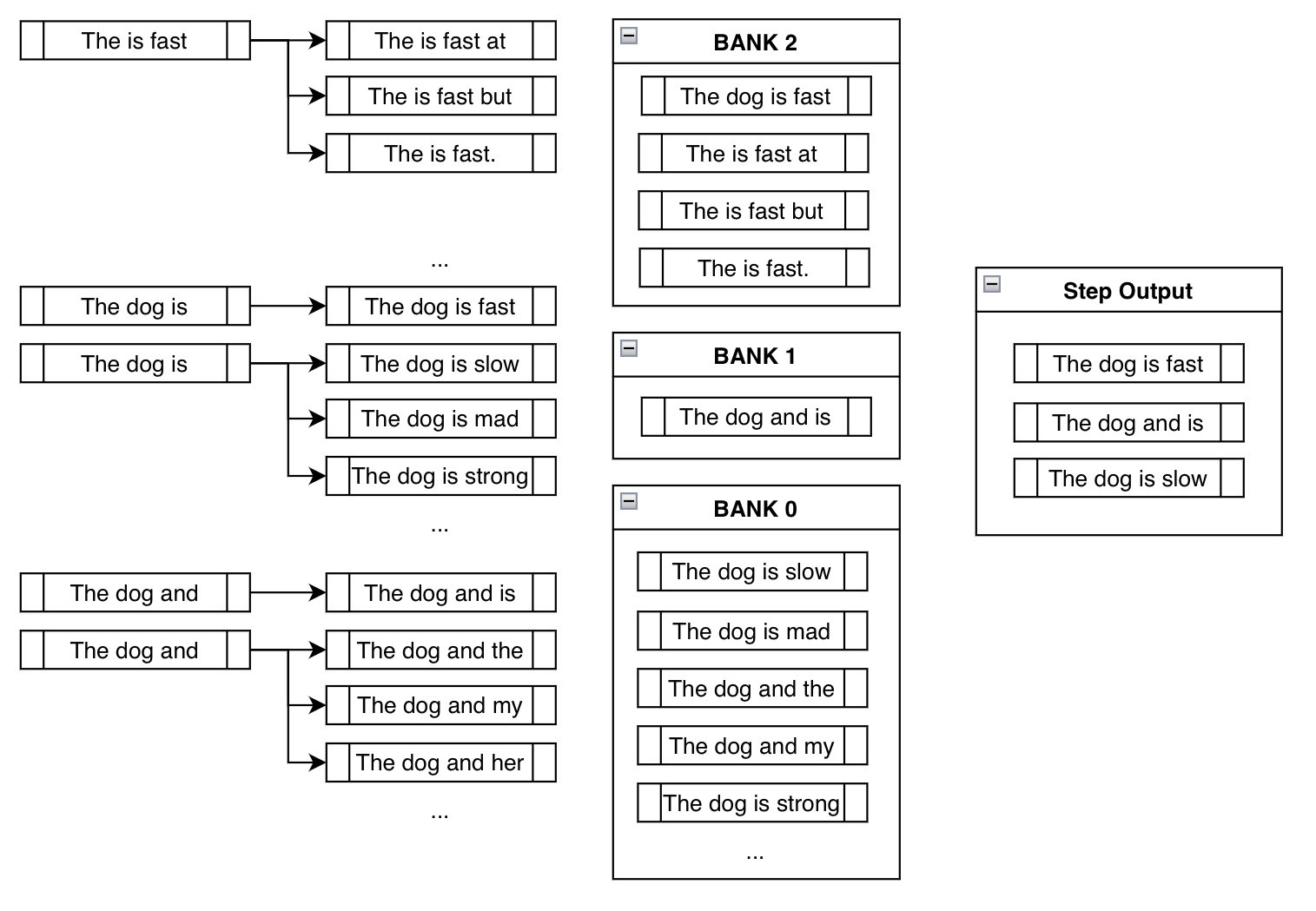
请注意,上图中不需要强制添加 `"The is fast"`,因为它已经被包含在概率排序中了。另外,请注意像 `"The dog is slow"` 或 `"The dog is mad"` 这样的波束实际上是属于组 0 (Bank 0) 的,为什么呢?因为尽管它包含词 `"is"` ,但它不可用于生成 `"is fast"` ,因为 `fast` 的位子已经被 `slow` 或 `mad` 占掉了,也就杜绝了后续能生成 `"is fast"` 的可能性。从另一个角度讲,因为 `slow` 这样的词的加入,该分支 _满足约束的进度_ 被重置成了 0。
最后请注意,我们最终生成了包含约束短语的合理输出: `"The dog is fast"` !
起初我们很担心,因为盲目地添加约束词会导致出现诸如 `"The is fast"` 之类的无意义短语。然而,使用基于组的轮流选择方法,我们最终隐式地摆脱了无意义的输出,优先选择了更合理的输出。
## **关于 `Constraint` 类的更多信息及自定义约束**
我们总结下要点。每一步,我们都不断地纠缠模型,强制添加约束词,同时也跟踪不满足约束的分支,直到最终生成包含所需短语的合理的高概率序列。
在实现时,我们的主要方法是将每个约束表示为一个 `Constraint` 对象,其目的是跟踪满足约束的进度并告诉波束搜索接下来要生成哪些词。尽管我们可以使用 `model.generate()` 的关键字参数 `force_words_ids` ,但使用该参数时后端实际发生的情况如下:
```python
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM, PhrasalConstraint
tokenizer = AutoTokenizer.from_pretrained("t5-base")
model = AutoModelForSeq2SeqLM.from_pretrained("t5-base")
encoder_input_str = "translate English to German: How old are you?"
constraints = [
PhrasalConstraint(
tokenizer("Sie", add_special_tokens=False).input_ids
)
]
input_ids = tokenizer(encoder_input_str, return_tensors="pt").input_ids
outputs = model.generate(
input_ids,
constraints=constraints,
num_beams=10,
num_return_sequences=1,
no_repeat_ngram_size=1,
remove_invalid_values=True,
)
print("Output:\n" + 100 *'-')
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
```
Output:
----------------------------------------------------------------------------------------------------
Wie alt sind Sie?
你甚至可以定义一个自己的约束并将其通过 `constraints` 参数输入给 `model.generate()` 。此时,你只需要创建 `Constraint` 抽象接口类的子类并遵循其要求即可。你可以在 [此处](https://github.com/huggingface/transformers/blob/main/src/transformers/generation/beam_constraints.py) 的 `Constraint` 定义中找到更多信息。
我们还可以尝试其他一些有意思的约束 (尚未实现,也许你可以试一试!) 如 `OrderedConstraints` 、 `TemplateConstraints` 等。目前,在最终输出中约束短语间是无序的。例如,前面的例子一个输出中的约束短语顺序为 `scared -> screaming` ,而另一个输出中的约束短语顺序为 `screamed -> scared` 。 如果有了 `OrderedConstraints`, 我们就可以允许用户指定约束短语的顺序。 `TemplateConstraints` 的功能更小众,其约束可以像这样:
```python
starting_text = "The woman"
template = ["the", "", "School of", "", "in"]
possible_outputs == [
"The woman attended the Ross School of Business in Michigan.",
"The woman was the administrator for the Harvard School of Business in MA."
]
```
或是这样:
```python
starting_text = "The woman"
template = ["the", "", "", "University", "", "in"]
possible_outputs == [
"The woman attended the Carnegie Mellon University in Pittsburgh.",
]
impossible_outputs == [
"The woman attended the Harvard University in MA."
]
```
或者,如果用户不关心两个词之间应该隔多少个词,那仅用 `OrderedConstraint` 就可以了。
## **总结**
约束波束搜索为我们提供了一种将外部知识和需求注入文本生成过程的灵活方法。以前,没有一个简单的方法可用于告诉模型 1. 输出中需要包含某列表中的词或短语,其中 2. 其中有一些是可选的,有些必须包含的,这样 3. 它们可以最终生成至在合理的位置。现在,我们可以通过综合使用 `Constraint` 的不同子类来完全控制我们的生成!
该新特性主要基于以下论文:
- [Guided Open Vocabulary Image Captioning with Constrained Beam Search](https://arxiv.org/pdf/1612.00576.pdf)
- [Fast Lexically Constrained Decoding with Dynamic Beam Allocation for Neural Machine Translation](https://arxiv.org/abs/1804.06609)
- [Improved Lexically Constrained Decoding for Translation and Monolingual Rewriting](https://aclanthology.org/N19-1090/)
- [Guided Generation of Cause and Effect](https://arxiv.org/pdf/2107.09846.pdf)
与上述这些工作一样,还有许多新的研究正在探索如何使用外部知识 (例如 KG (Knowledge Graph) 、KB (Knowledge Base) ) 来指导大型深度学习模型输出。我们希望约束波束搜索功能成为实现此目的的有效方法之一。
感谢所有为此功能提供指导的人: Patrick von Platen 参与了从 [初始问题](https://github.com/huggingface/transformers/issues/14081) 讨论到 [最终 PR](https://github.com/huggingface/transformers/pull/15761) 的全过程,还有 Narsil Patry,他们二位对代码进行了详细的反馈。
_本文使用的图标来自于 <a href="https://www.flaticon.com/free-icons/shorthand" title="shorthand icons">Freepik - Flaticon</a>。_ | 8 |
0 | hf_public_repos/blog | hf_public_repos/blog/zh/if.md | ---
title: "在免费版 Google Colab 上使用 🧨 diffusers 运行 IF"
thumbnail: /blog/assets/if/thumbnail.jpg
authors:
- user: shonenkov
guest: true
- user: Gugutse
guest: true
- user: ZeroShot-AI
guest: true
- user: williamberman
- user: patrickvonplaten
- user: multimodalart
translators:
- user: SuSung-boy
---
# 在免费版 Google Colab 上使用 🧨 diffusers 运行 IF
<a target="_blank" href="https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/deepfloyd_if_free_tier_google_colab.ipynb">
<img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/>
</a>
**本文简介**: 本文展示了如何在免费版 Google Colab 上使用 🧨 diffusers 运行最强大的开源文本生成图片模型之一 **IF**。
您也可以直接访问 IF 的 [Hugging Face Space](https://huggingface.co/spaces/DeepFloyd/IF) 页面来探索模型强大的性能。
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/if/nabla.jpg" alt="if-collage"><br>
<em>压缩的生成图片样例,选自官方 <a href="https://github.com/deep-floyd/IF/blob/release/pics/nabla.jpg">IF GitHub 库</a></em>
</p>
## 介绍
IF 是一类像素级的文生图模型,由 [DeepFloyd](https://github.com/deep-floyd/IF) 于 2023 年 4 月下旬发布。IF 的模型架构受 Google 的闭源模型 [Imagen](https://imagen.research.google/) 的强烈启发。
与现有的文本生成图片模型(如 Stable Diffusion)相比,IF 有两个明显的优势:
- IF 模型直接在 “像素空间”(即未降维、未压缩的图片)中计算生成,而非需要迭代去噪的隐空间(如 [Stable Diffusion](http://hf.co/blog/stable_diffusion))。
- IF 模型基于 [T5-XXL](https://huggingface.co/google/t5-v1_1-xxl) 文本编码器的输出进行训练。T5-XXL 是一个比 Stable DIffusion 中的 [CLIP](https://openai.com/research/clip) 更强大的文本编码器。
因此,IF 更擅长生成具有高频细节(例如人脸和手部)的图片,并且 IF 是 **第一个能够在图片中生成可靠文字** 的开源图片生成模型。
不过,在具有上述两个优势(像素空间计算、使用更优文本编码器)的同时,IF 模型也存在明显的不足,那就是参数量更加庞大。IF 模型的文本编码器 T5、文本生成图片网络 UNet、超分辨率模型 upscaler UNet 的参数量分别为 4.5B、4.3B、1.2B,而 [Stable Diffusion v2.1](https://huggingface.co/stabilityai/stable-diffusion-2-1) 模型的文本编码器 CLIP 和去噪网络 UNet 的参数量仅为 400M 和 900M。
尽管如此,我们仍然可以在消费级 GPU 上运行 IF 模型,不过这需要一些优化技巧来降低显存占用。不用担心,我们将在本篇博客中详细介绍如何使用 🧨 diffusers 库来实现这些技巧。
在本文后面的 1.) 中,我们将介绍如何使用 IF 模型进行文本生成图片;在 2.) 和 3.) 中,我们将介绍 IF 模型的 Img2Img 和 Inpainting (图片修复) 能力。
💡 **注意**:本文为保证 IF 模型可以在免费版 Google Colab 上成功运行,采用了多模型组件顺序在 GPU 上加载卸载的技巧,以放慢生成速度为代价换取显存占用降低。如果您有条件使用更高端的 GPU 如 A100,我们建议您把所有的模型组件都加载并保留在 GPU 上,以获得最快的图片生成速度,代码详情见 [IF 的官方示例](https://huggingface.co/spaces/DeepFloyd/IF)。
💡 **注意**:本文为保证读者在阅读时图片加载得更快,对文中的一些高分辨率图片进行了压缩。在您自行使用官方模型尝试生成时,图片质量将会更高!
让我们开始 IF 之旅吧!🚀
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/if/meme.png"><br>
<em>IF 模型生成含文字的图片的强大能力</em>
</p>
## 本文目录
* [接受许可证](#接受许可证)
* [优化 IF 模型以在有限的硬件条件下运行](#优化-if-模型以在有限的硬件条件下运行)
* [可用资源](#可用资源)
* [安装依赖](#安装依赖)
* [文本生成图片](#1-文本生成图片)
* [Img2Img](#2-img2img)
* [Inpainting](#3-inpainting)
## 接受许可证
在您使用 IF 模型之前,您需要接受它的使用条件。 为此:
- 1. 确保已开通 [Hugging Face 帐户](https://huggingface.co/join) 并登录
- 2. 接受 [DeepFloyd/IF-I-XL-v1.0](https://huggingface.co/DeepFloyd/IF-I-XL-v1.0) 模型卡的许可证。在 Stage1 模型卡上接受许可证会自动接受其他 IF 模型许可证。
- 3. 确保在本地已安装 `huggingface_hub` 库并登录
```sh
pip install huggingface_hub --upgrade
```
在 Python shell 中运行登录函数
```py
from huggingface_hub import login
login()
```
输入您的 [Hugging Face Hub 访问令牌](https://huggingface.co/docs/hub/security-tokens#what-are-user-access-tokens)。
## 优化 IF 模型以在有限的硬件条件下运行
**最先进的机器学习技术不应该只掌握在少数精英手里。** 要使机器学习更 “普惠大众” 就意味着模型能够在消费级硬件上运行,而不是仅支持在最新型最高端的硬件上运行。
深度学习开放社区创造了众多世界一流的工具,来支持在消费级硬件上运行资源密集型模型。例如:
- [🤗 accelerate](https://github.com/huggingface/accelerate) 提供用于处理 [大模型](https://huggingface.co/docs/accelerate/usage_guides/big_modeling) 的实用工具。
- [🤗 safetensors](https://github.com/huggingface/safetensors) 在保证模型保存的安全性的同时,还能显著加快大模型的加载速度。
- [bitsandbytes](https://github.com/TimDettmers/bitsandbytes) 使所有的 PyTorch 模型都可以采用 8 位量化。
Diffusers 库无缝集成了上述库,只需调用一个简单的 API 即可实现大模型的优化。
免费版 Google Colab 既受 CPU RAM 限制(13GB RAM),又受 GPU VRAM 限制(免费版 T4 为 15GB RAM),无法直接运行整个 IF 模型(>10B)。
我们先来看看运行完整 float32 精度的 IF 模型时,各个组件所需的内存占用:
- [T5-XXL 文本编码器](https://huggingface.co/DeepFloyd/IF-I-XL-v1.0/tree/main/text_encoder): 20GB
- [Stage1 UNet](https://huggingface.co/DeepFloyd/IF-I-XL-v1.0/tree/main/unet): 17.2GB
- [Stage2 超分辨率 UNet](https://huggingface.co/DeepFloyd/IF-II-L-v1.0/blob/main/pytorch_model.bin): 2.5 GB
- [Stage 3 x4-upscaler 超分辨率模型](https://huggingface.co/stabilityai/stable-diffusion-x4-upscaler): 3.4GB
可见我们无法以 float32 精度运行 IF 模型,因为 T5 和 Stage1 UNet 权重所需的内存占用均超出了免费版 CPU RAM 的可用范围。
很容易想到,我们可以通过降低模型运行的位精度来减少内存占用。如果以 float16 精度来运行 IF 模型,则 T5、Stage1 UNet、Stage2 UNet 所需的内存占用分别下降至 11GB、8.6GB、1.25GB。对于免费版 GPU 的 15GB RAM 限制,float16 精度已经满足运行条件,不过在实际加载 T5 模型时,我们很可能仍然会遇到 CPU 内存溢出错误,因为 CPU 的一部分内存会被其他进程占用。
因此我们继续降低位精度,实际上仅降低 T5 的精度就可以了。这里我们使用 `bitsandbytes` 库将 T5 量化到 8 位精度,最终可以将 T5 权重的内存占用降低至 [8GB](https://huggingface.co/DeepFloyd/IF-I-XL-v1.0/blob/main/text_encoder/model.8bit.safetensors)。
好了,现在 IF 模型的每个组件的 CPU 和 GPU 内存占用都各自符合免费版 Google Colab 的限制,接下来我们只需要确保在运行每个组件的时候,CPU 和 GPU 内存不会被其他组件或者进程占用就可以了。
Diffusers 库支持模块化地独立加载单个组件,也就是说我们可以只加载文本编码器 T5,而不加载文本生成图片模型 UNet,反之亦然。这种模块化加载的技巧可以确保在运行多个组件的管线时,每个组件仅在需要计算时才被加载,可以有效避免同时加载时导致的 CPU 和 GPU 内存溢出。
来实操代码试一试吧!🚀

## 可用资源
免费版 Google Colab 的 CPU RAM 可用资源约 13GB:
``` python
!grep MemTotal /proc/meminfo
```
```bash
MemTotal: 13297192 kB
```
免费版 GPU 型号为 NVIDIA T4,其 VRAM 可用资源约 15GB:
``` python
!nvidia-smi
```
```bash
Sun Apr 23 23:14:19 2023
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 525.85.12 Driver Version: 525.85.12 CUDA Version: 12.0 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 Tesla T4 Off | 00000000:00:04.0 Off | 0 |
| N/A 72C P0 32W / 70W | 1335MiB / 15360MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
+-----------------------------------------------------------------------------+
```
## 安装依赖
本文使用的优化技巧需要安装最新版本的依赖项。如果您在运行代码时遇到问题,请首先仔细检查依赖项的安装版本。
``` python
! pip install --upgrade \
diffusers~=0.16 \
transformers~=4.28 \
safetensors~=0.3 \
sentencepiece~=0.1 \
accelerate~=0.18 \
bitsandbytes~=0.38 \
torch~=2.0 -q
```
## 1. 文本生成图片
这一部分我们将分步介绍如何使用 Diffusers 运行 IF 模型来完成文本到图片的生成。对于接下来使用的 API 和优化技巧,文中仅作简要的解释,如果您想深入了解更多原理或者细节,可以前往 [Diffusers](https://huggingface.co/docs/diffusers/index),[Transformers](https://huggingface.co/docs/transformers/index),[Accelerate](https://huggingface.co/docs/accelerate/index),以及 [bitsandbytes](https://github.com/TimDettmers/bitsandbytes) 的官方文档查看。
### 1.1 加载文本编码器
首先我们使用 Transformers 库加载 8 位量化后的文本编码器 T5。Transformers 库直接支持 [bitsandbytes](https://huggingface.co/docs/transformers/main/en/main_classes/quantization#load-a-large-model-in-8bit) 量化,可以通过 `load_in_8bit` 参数来标识是否加载 8 位量化模型。
设置参数 `variant="8bit"` 来下载预量化版的权重。
Transformers 还支持模块化地独立加载单个模型的某些层!`device_map` 参数可以指定单个模型的权重在不同 GPU 设备上加载或者卸载的映射策略,在不需要参与计算时甚至可以卸载到 CPU 或者磁盘上。这里我们设置 `device_map` 参数为 `"auto"`,让 transformers 库自动创建设备映射。更多相关信息,请查看 [transformers 文档](https://huggingface.co/docs/accelerate/usage_guides/big_modeling#designing-a-device-map)。
``` python
from transformers import T5EncoderModel
text_encoder = T5EncoderModel.from_pretrained(
"DeepFloyd/IF-I-XL-v1.0",
subfolder="text_encoder",
device_map="auto",
load_in_8bit=True,
variant="8bit"
)
```
### 1.2 创建 prompt embeddings
Diffusers API 中的 `DiffusionPipeline` 类及其子类专门用于访问扩散模型。`DiffusionPipeline` 中的每个实例都包含一套独立的方法和默认的模型。我们可以通过 `from_pretrained` 方法来覆盖默认实例中的模型,只需将目标模型实例作为关键字参数传给 `from_pretrained`。
上文说过,我们在加载文本编码器 T5 的时候无需加载扩散模型组件 UNet,因此这里我们需要用 `None` 来覆盖 `DiffusionPipeline` 的实例中的 UNet 部分,此时将 `from_pretrained` 方法的 `unet` 参数设为 `None` 即可实现。
``` python
from diffusers import DiffusionPipeline
pipe = DiffusionPipeline.from_pretrained(
"DeepFloyd/IF-I-XL-v1.0",
text_encoder=text_encoder, # 传入前面加载的 8 位量化文本编码器实例
unet=None,
device_map="auto"
)
```
IF 模型还有一个超分辨率管线。为了后面能够方便地加载运行,我们这里把 prompt embeddings 保存下来,后面就可以直接输入给超分辨率管线,而不需要再经过文本编码器了。
接下来就可以开始输入 prompt 了。为了凸显 IF 模型能够生成带文字的图片的优势,这里要在 Stable Diffusion 中生成 [宇航员骑马](https://huggingface.co/blog/stable_diffusion) (an astronaut just riding a
horse) 的图片示例的基础上, 增加一个带有文字的指示牌!
我们给出一个合适的 prompt:
``` python
prompt = "a photograph of an astronaut riding a horse holding a sign that says Pixel's in space"
```
然后输入给 8 位量化的 T5 模型,生成 prompt 的 embeddings:
``` python
prompt_embeds, negative_embeds = pipe.encode_prompt(prompt)
```
### 1.3 释放内存
当 prompt embeddings 创建完成之后,我们就不再需要文本编码器了。但目前 T5 仍然存在于 GPU 内存中,因此我们需要释放 T5 占用的内存,以便加载 UNet。
释放 PyTorch 内存并非易事。我们必须对所有指向实际分配到 GPU 上的 Python 对象实施垃圾回收。
为此,我们首先使用 Python 关键字 `del` 来删除掉所有引用的已分配到 GPU 内存上的 Python 对象。
``` python
del text_encoder
del pipe
```
不过仅删除 Python 对象仍然不够,因为垃圾回收机制实际上是在释放 GPU 完成之后才完成的。
然后,我们调用 `torch.cuda.empty_cache()` 方法来释放缓存。实际上该方法也并非绝对必要,因为缓存中的 cuda 内存也能够立即用于进一步分配,不过它可以帮我们在 Colab UI 中验证是否有足够的内存可用。
这里我们编写一个辅助函数 `flush()` 来刷新内存。
``` python
import gc
import torch
def flush():
gc.collect()
torch.cuda.empty_cache()
```
运行 `flush()`。
``` python
flush()
```
### 1.4 Stage1:核心扩散过程
好了,现在已经有足够的 GPU 内存可用,我们就能重新加载一个只包含 UNet 部分的 `DiffusionPipeline` 了,因为接下来我们只需要运行核心扩散过程部分。
按照上文中对 UNet 内存占用的计算,IF 模型的 UNet 部分权重能够以 float16 精度加载,设置 `variant` 和 `torch_dtype` 参数即可实现。
``` python
pipe = DiffusionPipeline.from_pretrained(
"DeepFloyd/IF-I-XL-v1.0",
text_encoder=None,
variant="fp16",
torch_dtype=torch.float16,
device_map="auto"
)
```
一般情况下,我们会直接将 prompt 传入 `DiffusionPipeline.__call__` 函数。不过我们这里已经计算出了 prompt embeddings,因此只需传入 embeddings 即可。
Stage1 的 UNet 接收 embeddings 作为输入运行完成后,我们还需要继续运行 Stage2 的超分辨率组件,因此我们需要保存模型的原始输出 (即 PyTorch tensors) 来输入到 Stage2,而不是 PIL 图片。这里设置参数 `output_type="pt"` 可以将 Stage1 输出的 PyTorch tensors 保留在 GPU 上。
我们来定义一个随机生成器,并运行 Stage1 的扩散过程。
``` python
generator = torch.Generator().manual_seed(1)
image = pipe(
prompt_embeds=prompt_embeds,
negative_prompt_embeds=negative_embeds,
output_type="pt",
generator=generator,
).images
```
虽然运行结果是原始的 PyTorch tensors,我们仍然可以手动将其转换为 PIL 图片,起码先瞧一瞧生成图片的大概样子嘛。Stage1 的输出可以转换为一张 64x64 的图片。
``` python
from diffusers.utils import pt_to_pil
pil_image = pt_to_pil(image)
pipe.watermarker.apply_watermark(pil_image, pipe.unet.config.sample_size)
pil_image[0]
```

Stage1 完成之后,我们同样删除 Python 指针,释放 CPU 和 GPU 内存。
``` python
del pipe
flush()
```
### 1.5 Stage2:超分辨率 64x64 到 256x256
IF 模型包含多个独立的超分辨率组件。
对于每个超分辨率扩散过程组件,我们都使用单独的管线来运行。
在加载超分辨率管线时需要传入文本参数。如果需要,它也是可以同时加载文本编码器,来从 prompt 开始运行的。不过更一般的做法是从第一个 IF 管线中计算得到的 prompt embeddings 开始,此时要把 `text_encoder` 参数设为 `None`。
创建一个超分辨率 UNet 管线。
``` python
pipe = DiffusionPipeline.from_pretrained(
"DeepFloyd/IF-II-L-v1.0",
text_encoder=None, # 未用到文本编码器 => 节省内存!
variant="fp16",
torch_dtype=torch.float16,
device_map="auto"
)
```
将 Stage1 输出的 Pytorch tensors 和 T5 输出的 embeddings 输入给 Stage2 并运行。
``` python
image = pipe(
image=image,
prompt_embeds=prompt_embeds,
negative_prompt_embeds=negative_embeds,
output_type="pt",
generator=generator,
).images
```
我们同样可以转换为 PIL 图片来查看中间结果。
``` python
pil_image = pt_to_pil(image)
pipe.watermarker.apply_watermark(pil_image, pipe.unet.config.sample_size)
pil_image[0]
```

再一次,删除 Python 指针,释放内存。
``` python
del pipe
flush()
```
### 1.6 Stage3:超分辨率 256x256 到 1024x1024
IF 模型的第 2 个超分辨率组件是 Stability AI 之前发布的 [x4 Upscaler](https://huggingface.co/stabilityai/stable-diffusion-x4-upscaler)。
我们创建相应的管线,并设置参数 `device_map="auto"` 直接加载到 GPU 上。
``` python
pipe = DiffusionPipeline.from_pretrained(
"stabilityai/stable-diffusion-x4-upscaler",
torch_dtype=torch.float16,
device_map="auto"
)
```
🧨 diffusers 可以使得独立开发的扩散模型非常简便地组合使用,因为 diffusers 中的管线可以链接在一起。比如这里我们可以设置参数 `image=image` 来将先前输出的 PyTorch tensors 输入给 Stage3 管线。
💡 **注意**:x4 Upscaler 并非使用 T5,而使用它 [自己的文本编码器](https://huggingface.co/stabilityai/stable-diffusion-x4-upscaler/tree/main/text_encoder)。因此,我们不能使用 1.2 中创建的 prompt embeddings,必须传入原始 prompt。
``` python
pil_image = pipe(prompt, generator=generator, image=image).images
```
IF 模型管线在生成图片时默认会在右下角添加 IF 水印。由于 Stage3 使用的 x4 upscaler 管线并非属于 IF (实际上属于 Stable Diffusion),因此经过超分辨率生成的图片也不会带有 IF 水印。
不过我们可以手动添加水印。
``` python
from diffusers.pipelines.deepfloyd_if import IFWatermarker
watermarker = IFWatermarker.from_pretrained("DeepFloyd/IF-I-XL-v1.0", subfolder="watermarker")
watermarker.apply_watermark(pil_image, pipe.unet.config.sample_size)
```
查看 Stage3 的输出图片。
``` python
pil_image[0]
```

看!免费版 Google Colab 上运行 IF 模型生成精美的 1024x1024 图片了!
至此,我们已经展示了使用 🧨 diffusers 来分解和模块化加载资源密集型扩散模型的全部内容,是不是非常简单!
💡 **注意**:我们不建议在生产流程中使用上述以放慢推理速度为代价来换取低内存消耗的设置:8 位量化、模型权重的解耦和重分配、磁盘卸载等,尤其是需要重复使用某个扩散模型组件的时候。在实际生产中,我们还是建议您使用 40GB VRAM 的 A100,以确保所有的模型组件可以同时加载到 GPU 上。如果您条件满足,可以参考 Hugging Face 上的 [**官方 IF 示例**](https://huggingface.co/spaces/DeepFloyd/IF) 设置。
## 2. Img2Img
在 1.) 中加载的文本生成图片的 IF 模型各个组件的预训练权重,也同样可用于文本引导的图片生成图片,也叫 Img2Img,还能用于 Inpainting (图片修复),我们将在 3.) 中介绍。Img2Img 和 Inpainting 的核心扩散过程,除了初始噪声是图片之外,其余均与文本生成图片的扩散过程相同。
这里我们创建 Img2Img 管线 `IFImg2ImgPipeline` 和超分辨率管线
`IFImg2ImgSuperResolution`,并加载和 1.) 中各个组件相同的预训练权重。
内存优化的 API 也都相同!
同样地释放内存。
``` python
del pipe
flush()
```
对于 Img2Img,我们需要一张初始图片。
这一部分,我们将使用在外网著名的 “Slaps Roof of Car” meme (可以理解为汽车推销员表情包制作模板)。首先从网上下载这张图片。
``` python
import requests
url = "https://i.kym-cdn.com/entries/icons/original/000/026/561/car.jpg"
response = requests.get(url)
```
然后使用 PIL 图像库加载图片。
``` python
from PIL import Image
from io import BytesIO
original_image = Image.open(BytesIO(response.content)).convert("RGB")
original_image = original_image.resize((768, 512))
original_image
```

Img2Img 管线可以接收 PIL 图像对象或原始 tensors 对象作为输入。点击 [此处](https://huggingface.co/docs/diffusers/v0.16.0/en/api/pipelines/if#diffusers.IFImg2ImgPipeline.__call__) 可跳转文档页面查看更详细的输入参数说明。
### 2.1 文本编码器
Img2Img 可以由文本引导。这里我们也尝试给出一个合适的 prompt 并使用文本编码器 T5 创建其 embeddings。
首先再次加载 8 位量化的文本编码器。
``` python
from transformers import T5EncoderModel
text_encoder = T5EncoderModel.from_pretrained(
"DeepFloyd/IF-I-XL-v1.0",
subfolder="text_encoder",
device_map="auto",
load_in_8bit=True,
variant="8bit"
)
```
对于 Img2Img,我们需要使用 [`IFImg2ImgPipeline`](https://huggingface.co/docs/diffusers/v0.16.0/en/api/pipelines/if#diffusers.IFImg2ImgPipeline) 类来加载预训练权重,而不能使用 1.) 中的 `DiffusionPipeline` 类。这是因为当使用 `from_pretrained()` 方法加载 IF 模型(或其他扩散模型)的预训练权重时,会返回 **默认的文本生成图片** 管线 [`IFPipeline`](https://huggingface.co/docs/diffusers/v0.16.0/en/api/pipelines/if#diffusers.IFPipeline)。因此,要加载 Img2Img 或 Depth2Img 等非默认形式的管线,必须指定明确的类名。
``` python
from diffusers import IFImg2ImgPipeline
pipe = IFImg2ImgPipeline.from_pretrained(
"DeepFloyd/IF-I-XL-v1.0",
text_encoder=text_encoder,
unet=None,
device_map="auto"
)
```
我们来把汽车推销员变得动漫风一些,对应的 prompt 为:
``` python
prompt = "anime style"
```
同样地,使用 T5 来创建 prompt embeddings。
``` python
prompt_embeds, negative_embeds = pipe.encode_prompt(prompt)
```
释放 CPU 和 GPU 内存。
同样先删除 Python 指针,
``` python
del text_encoder
del pipe
```
再刷新内存。
``` python
flush()
```
### 2.2 Stage1:核心扩散过程
接下来也是一样,我们在管线中只加载 Stage1 UNet 部分权重。
``` python
pipe = IFImg2ImgPipeline.from_pretrained(
"DeepFloyd/IF-I-XL-v1.0",
text_encoder=None,
variant="fp16",
torch_dtype=torch.float16,
device_map="auto"
)
```
运行 Img2Img Stage1 管线需要原始图片和 prompt embeddings 作为输入。
我们可以选择使用 `strength` 参数来配置 Img2Img 的变化程度。`strength` 参数直接控制了添加的噪声强度,该值越高,生成图片偏离原始图片的程度就越大。
``` python
generator = torch.Generator().manual_seed(0)
image = pipe(
image=original_image,
prompt_embeds=prompt_embeds,
negative_prompt_embeds=negative_embeds,
output_type="pt",
generator=generator,
).images
```
我们再次查看一下生成的 64x64 图片。
``` python
pil_image = pt_to_pil(image)
pipe.watermarker.apply_watermark(pil_image, pipe.unet.config.sample_size)
pil_image[0]
```

看起来不错!我们可以继续释放内存,并进行超分辨率放大图片了。
``` python
del pipe
flush()
```
### 2.3 Stage2: 超分辨率
对于超分辨率,我们使用 `IFImg2ImgSuperResolutionPipeline` 类,并加载与 1.5 中相同的预训练权重。
``` python
from diffusers import IFImg2ImgSuperResolutionPipeline
pipe = IFImg2ImgSuperResolutionPipeline.from_pretrained(
"DeepFloyd/IF-II-L-v1.0",
text_encoder=None,
variant="fp16",
torch_dtype=torch.float16,
device_map="auto"
)
```
💡 **注意**:Img2Img 超分辨率管线不仅需要 Stage1 输出的生成图片,还需要原始图片作为输入。
实际上我们还可以在 Stage2 输出的图片基础上继续使用 Stable Diffusion x4 upscaler 进行二次超分辨率。不过这里没有展示,如果需要,请使用 1.6 中的代码片段进行尝试。
``` python
image = pipe(
image=image,
original_image=original_image,
prompt_embeds=prompt_embeds,
negative_prompt_embeds=negative_embeds,
generator=generator,
).images[0]
image
```

好了!Img2Img 的全部内容也介绍完毕。我们继续释放内存,然后介绍最后一个 Inpainting 管线。
``` python
del pipe
flush()
```
## 3. Inpainting
IF 模型的 Inpainting 管线大体上与 Img2Img 相同,只不过仅对图片的部分指定区域进行去噪和生成。
我们首先用图片 mask 来指定一个待修复区域。
让我们来展示一下 IF 模型 “生成带文字的图片” 这项令人惊叹的能力!我们来找一张带标语的图片,然后用 IF 模型替换标语的文字内容。
首先下载图片
``` python
import requests
url = "https://i.imgflip.com/5j6x75.jpg"
response = requests.get(url)
```
并将其转换为 PIL 图片对象。
``` python
from PIL import Image
from io import BytesIO
original_image = Image.open(BytesIO(response.content)).convert("RGB")
original_image = original_image.resize((512, 768))
original_image
```

我们指定标语牌区域为 mask 待修复区域,让 IF 模型替换该区域的文字内容。
为方便起见,我们已经预生成了 mask 图片并将其加载到 HF 数据集中了。
下载 mask 图片。
``` python
from huggingface_hub import hf_hub_download
mask_image = hf_hub_download("diffusers/docs-images", repo_type="dataset", filename="if/sign_man_mask.png")
mask_image = Image.open(mask_image)
mask_image
```

💡 **注意**:您也可以自行手动创建灰度 mask 图片。下面是一个创建 mask 图片的代码例子。
``` python
from PIL import Image
import numpy as np
height = 64
width = 64
example_mask = np.zeros((height, width), dtype=np.int8)
# 设置待修复区域的 mask 像素值为 255
example_mask[20:30, 30:40] = 255
# 确保 PIL 的 mask 图片模式为 'L'
# 'L' 代表单通道灰度图
example_mask = Image.fromarray(example_mask, mode='L')
example_mask
```

好了,我们可以开始修复图片了🎨🖌
### 3.1. 文本编码器
我们同样先加载文本编码器。
``` python
from transformers import T5EncoderModel
text_encoder = T5EncoderModel.from_pretrained(
"DeepFloyd/IF-I-XL-v1.0",
subfolder="text_encoder",
device_map="auto",
load_in_8bit=True,
variant="8bit"
)
```
再创建一个 inpainting 管线,这次使用 `IFInpaintingPipeline` 类并初始化文本编码器预训练权重。
``` python
from diffusers import IFInpaintingPipeline
pipe = IFInpaintingPipeline.from_pretrained(
"DeepFloyd/IF-I-XL-v1.0",
text_encoder=text_encoder,
unet=None,
device_map="auto"
)
```
我们来让图片中的这位男士为 “just stack more layers” 作个代言!
*注:外网中的一个梗,每当现有神经网络解决不了现有问题时,就会有 Just Stack More Layers! ......*
``` python
prompt = 'the text, "just stack more layers"'
```
给定 prompt 之后,接着创建 embeddings。
``` python
prompt_embeds, negative_embeds = pipe.encode_prompt(prompt)
```
然后再次释放内存。
``` python
del text_encoder
del pipe
flush()
```
### 3.2 Stage1: 核心扩散过程
同样地,我们只加载 Stage1 UNet 的预训练权重。
``` python
pipe = IFInpaintingPipeline.from_pretrained(
"DeepFloyd/IF-I-XL-v1.0",
text_encoder=None,
variant="fp16",
torch_dtype=torch.float16,
device_map="auto"
)
```
这里,我们需要传入原始图片、mask 图片和 prompt embeddings。
``` python
image = pipe(
image=original_image,
mask_image=mask_image,
prompt_embeds=prompt_embeds,
negative_prompt_embeds=negative_embeds,
output_type="pt",
generator=generator,
).images
```
可视化查看一下中间输出。
``` python
pil_image = pt_to_pil(image)
pipe.watermarker.apply_watermark(pil_image, pipe.unet.config.sample_size)
pil_image[0]
```

看起来不错!标语牌上的文字内容非常连贯!
我们继续释放内存,做超分辨率放大图片。
``` python
del pipe
flush()
```
### 3.3 Stage2: 超分辨率
对于超分辨率,使用 `IFInpaintingSuperResolutionPipeline` 类来加载预训练权重。
``` python
from diffusers import IFInpaintingSuperResolutionPipeline
pipe = IFInpaintingSuperResolutionPipeline.from_pretrained(
"DeepFloyd/IF-II-L-v1.0",
text_encoder=None,
variant="fp16",
torch_dtype=torch.float16,
device_map="auto"
)
```
IF 模型的 inpainting 超分辨率管线需要接收 Stage1 输出的图片、原始图片、mask 图片、以及 prompt embeddings 作为输入。
让我们运行最后的超分辨率管线。
``` python
image = pipe(
image=image,
original_image=original_image,
mask_image=mask_image,
prompt_embeds=prompt_embeds,
negative_prompt_embeds=negative_embeds,
generator=generator,
).images[0]
image
```

非常好!IF 模型生成的单词没有出现任何拼写错误!
## 总结
运行完整的 float32 精度的 IF 模型共需要至少 40GB 内存。本文展示了如何仅使用开源库来使 IF 模型能够在免费版 Google Colab 上运行并生成图片。
机器学习领域的生态如此壮大主要受益于各种工具和模型的开源共享。本文涉及到的模型来自于 DeepFloyd, StabilityAI, 以及 [Google](https://huggingface.co/google),涉及到的库有 Diffusers, Transformers, Accelerate, 和 bitsandbytes 等,它们同样来自于不同组织的无数贡献者。
非常感谢 DeepFloyd 团队创建和开源 IF 模型,以及为良好的机器学习生态做出的贡献🤗。
| 9 |
0 | hf_public_repos/accelerate | hf_public_repos/accelerate/tests/test_tracking.py | # Copyright 2022 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import csv
import json
import logging
import os
import re
import subprocess
import tempfile
import unittest
import zipfile
from pathlib import Path
from typing import Optional
from unittest import mock
import numpy as np
import torch
from packaging import version
# We use TF to parse the logs
from accelerate import Accelerator
from accelerate.test_utils.testing import (
MockingTestCase,
TempDirTestCase,
require_clearml,
require_comet_ml,
require_dvclive,
require_pandas,
require_tensorboard,
require_wandb,
skip,
)
from accelerate.tracking import CometMLTracker, GeneralTracker
from accelerate.utils import (
ProjectConfiguration,
is_comet_ml_available,
is_dvclive_available,
is_tensorboard_available,
)
if is_comet_ml_available():
from comet_ml import OfflineExperiment
if is_tensorboard_available():
import struct
import tensorboard.compat.proto.event_pb2 as event_pb2
if is_dvclive_available():
from dvclive.plots.metric import Metric
from dvclive.serialize import load_yaml
from dvclive.utils import parse_metrics
logger = logging.getLogger(__name__)
@require_tensorboard
class TensorBoardTrackingTest(unittest.TestCase):
@unittest.skipIf(version.parse(np.__version__) >= version.parse("2.0"), "TB doesn't support numpy 2.0")
def test_init_trackers(self):
project_name = "test_project_with_config"
with tempfile.TemporaryDirectory() as dirpath:
accelerator = Accelerator(log_with="tensorboard", project_dir=dirpath)
config = {"num_iterations": 12, "learning_rate": 1e-2, "some_boolean": False, "some_string": "some_value"}
accelerator.init_trackers(project_name, config)
accelerator.end_training()
for child in Path(f"{dirpath}/{project_name}").glob("*/**"):
log = list(filter(lambda x: x.is_file(), child.iterdir()))[0]
assert str(log) != ""
def test_log(self):
project_name = "test_project_with_log"
with tempfile.TemporaryDirectory() as dirpath:
accelerator = Accelerator(log_with="tensorboard", project_dir=dirpath)
accelerator.init_trackers(project_name)
values = {"total_loss": 0.1, "iteration": 1, "my_text": "some_value"}
accelerator.log(values, step=0)
accelerator.end_training()
# Logged values are stored in the outermost-tfevents file and can be read in as a TFRecord
# Names are randomly generated each time
log = list(filter(lambda x: x.is_file(), Path(f"{dirpath}/{project_name}").iterdir()))[0]
assert str(log) != ""
def test_log_with_tensor(self):
project_name = "test_project_with_log"
with tempfile.TemporaryDirectory() as dirpath:
accelerator = Accelerator(log_with="tensorboard", project_dir=dirpath)
accelerator.init_trackers(project_name)
values = {"tensor": torch.tensor(1)}
accelerator.log(values, step=0)
accelerator.end_training()
# Logged values are stored in the outermost-tfevents file and can be read in as a TFRecord
# Names are randomly generated each time
log = list(filter(lambda x: x.is_file(), Path(f"{dirpath}/{project_name}").iterdir()))[0]
# Reading implementation based on https://github.com/pytorch/pytorch/issues/45327#issuecomment-703757685
with open(log, "rb") as f:
data = f.read()
found_tensor = False
while data:
header = struct.unpack("Q", data[:8])
event_str = data[12 : 12 + int(header[0])] # 8+4
data = data[12 + int(header[0]) + 4 :]
event = event_pb2.Event()
event.ParseFromString(event_str)
if event.HasField("summary"):
for value in event.summary.value:
if value.simple_value == 1.0 and value.tag == "tensor":
found_tensor = True
assert found_tensor, "Converted tensor was not found in the log file!"
def test_project_dir(self):
with self.assertRaisesRegex(ValueError, "Logging with `tensorboard` requires a `logging_dir`"):
_ = Accelerator(log_with="tensorboard")
with tempfile.TemporaryDirectory() as dirpath:
_ = Accelerator(log_with="tensorboard", project_dir=dirpath)
def test_project_dir_with_config(self):
config = ProjectConfiguration(total_limit=30)
with tempfile.TemporaryDirectory() as dirpath:
_ = Accelerator(log_with="tensorboard", project_dir=dirpath, project_config=config)
@require_wandb
@mock.patch.dict(os.environ, {"WANDB_MODE": "offline"})
class WandBTrackingTest(TempDirTestCase, MockingTestCase):
def setUp(self):
super().setUp()
# wandb let's us override where logs are stored to via the WANDB_DIR env var
self.add_mocks(mock.patch.dict(os.environ, {"WANDB_DIR": self.tmpdir}))
@staticmethod
def parse_log(log: str, section: str, record: bool = True):
"""
Parses wandb log for `section` and returns a dictionary of
all items in that section. Section names are based on the
output of `wandb sync --view --verbose` and items starting
with "Record" in that result
"""
# Big thanks to the W&B team for helping us parse their logs
pattern = rf"{section} ([\S\s]*?)\n\n"
if record:
pattern = rf"Record: {pattern}"
cleaned_record = re.findall(pattern, log)[0]
# A config
if section == "config" or section == "history":
cleaned_record = re.findall(r'"([a-zA-Z0-9_.,]+)', cleaned_record)
return {key: val for key, val in zip(cleaned_record[0::2], cleaned_record[1::2])}
# Everything else
else:
return dict(re.findall(r'(\w+): "([^\s]+)"', cleaned_record))
@skip
def test_wandb(self):
project_name = "test_project_with_config"
accelerator = Accelerator(log_with="wandb")
config = {"num_iterations": 12, "learning_rate": 1e-2, "some_boolean": False, "some_string": "some_value"}
kwargs = {"wandb": {"tags": ["my_tag"]}}
accelerator.init_trackers(project_name, config, kwargs)
values = {"total_loss": 0.1, "iteration": 1, "my_text": "some_value"}
accelerator.log(values, step=0)
accelerator.end_training()
# The latest offline log is stored at wandb/latest-run/*.wandb
for child in Path(f"{self.tmpdir}/wandb/latest-run").glob("*"):
if child.is_file() and child.suffix == ".wandb":
cmd = ["wandb", "sync", "--view", "--verbose", str(child)]
content = subprocess.check_output(cmd, encoding="utf8", errors="ignore")
break
# Check HPS through careful parsing and cleaning
logged_items = self.parse_log(content, "config")
assert logged_items["num_iterations"] == "12"
assert logged_items["learning_rate"] == "0.01"
assert logged_items["some_boolean"] == "false"
assert logged_items["some_string"] == "some_value"
assert logged_items["some_string"] == "some_value"
# Run tags
logged_items = self.parse_log(content, "run", False)
assert logged_items["tags"] == "my_tag"
# Actual logging
logged_items = self.parse_log(content, "history")
assert logged_items["total_loss"] == "0.1"
assert logged_items["iteration"] == "1"
assert logged_items["my_text"] == "some_value"
assert logged_items["_step"] == "0"
# Comet has a special `OfflineExperiment` we need to use for testing
def offline_init(self, run_name: str, tmpdir: str):
self.run_name = run_name
self.writer = OfflineExperiment(project_name=run_name, offline_directory=tmpdir)
logger.info(f"Initialized offline CometML project {self.run_name}")
logger.info("Make sure to log any initial configurations with `self.store_init_configuration` before training!")
@require_comet_ml
@mock.patch.object(CometMLTracker, "__init__", offline_init)
class CometMLTest(unittest.TestCase):
@staticmethod
def get_value_from_key(log_list, key: str, is_param: bool = False):
"Extracts `key` from Comet `log`"
for log in log_list:
j = json.loads(log)["payload"]
if is_param and "param" in j.keys():
if j["param"]["paramName"] == key:
return j["param"]["paramValue"]
if "log_other" in j.keys():
if j["log_other"]["key"] == key:
return j["log_other"]["val"]
if "metric" in j.keys():
if j["metric"]["metricName"] == key:
return j["metric"]["metricValue"]
if j.get("key", None) == key:
return j["value"]
def test_init_trackers(self):
with tempfile.TemporaryDirectory() as d:
tracker = CometMLTracker("test_project_with_config", d)
accelerator = Accelerator(log_with=tracker)
config = {"num_iterations": 12, "learning_rate": 1e-2, "some_boolean": False, "some_string": "some_value"}
accelerator.init_trackers(None, config)
accelerator.end_training()
log = os.listdir(d)[0] # Comet is nice, it's just a zip file here
# We parse the raw logs
p = os.path.join(d, log)
archive = zipfile.ZipFile(p, "r")
log = archive.open("messages.json").read().decode("utf-8")
list_of_json = log.split("\n")[:-1]
assert self.get_value_from_key(list_of_json, "num_iterations", True) == 12
assert self.get_value_from_key(list_of_json, "learning_rate", True) == 0.01
assert self.get_value_from_key(list_of_json, "some_boolean", True) is False
assert self.get_value_from_key(list_of_json, "some_string", True) == "some_value"
def test_log(self):
with tempfile.TemporaryDirectory() as d:
tracker = CometMLTracker("test_project_with_config", d)
accelerator = Accelerator(log_with=tracker)
accelerator.init_trackers(None)
values = {"total_loss": 0.1, "iteration": 1, "my_text": "some_value"}
accelerator.log(values, step=0)
accelerator.end_training()
log = os.listdir(d)[0] # Comet is nice, it's just a zip file here
# We parse the raw logs
p = os.path.join(d, log)
archive = zipfile.ZipFile(p, "r")
log = archive.open("messages.json").read().decode("utf-8")
list_of_json = log.split("\n")[:-1]
assert self.get_value_from_key(list_of_json, "curr_step", True) == 0
assert self.get_value_from_key(list_of_json, "total_loss") == 0.1
assert self.get_value_from_key(list_of_json, "iteration") == 1
assert self.get_value_from_key(list_of_json, "my_text") == "some_value"
@require_clearml
class ClearMLTest(TempDirTestCase, MockingTestCase):
def setUp(self):
super().setUp()
# ClearML offline session location is stored in CLEARML_CACHE_DIR
self.add_mocks(mock.patch.dict(os.environ, {"CLEARML_CACHE_DIR": str(self.tmpdir)}))
@staticmethod
def _get_offline_dir(accelerator):
from clearml.config import get_offline_dir
return get_offline_dir(task_id=accelerator.get_tracker("clearml", unwrap=True).id)
@staticmethod
def _get_metrics(offline_dir):
metrics = []
with open(os.path.join(offline_dir, "metrics.jsonl")) as f:
json_lines = f.readlines()
for json_line in json_lines:
metrics.extend(json.loads(json_line))
return metrics
def test_init_trackers(self):
from clearml import Task
from clearml.utilities.config import text_to_config_dict
Task.set_offline(True)
accelerator = Accelerator(log_with="clearml")
config = {"num_iterations": 12, "learning_rate": 1e-2, "some_boolean": False, "some_string": "some_value"}
accelerator.init_trackers("test_project_with_config", config)
offline_dir = ClearMLTest._get_offline_dir(accelerator)
accelerator.end_training()
with open(os.path.join(offline_dir, "task.json")) as f:
offline_session = json.load(f)
clearml_offline_config = text_to_config_dict(offline_session["configuration"]["General"]["value"])
assert config == clearml_offline_config
def test_log(self):
from clearml import Task
Task.set_offline(True)
accelerator = Accelerator(log_with="clearml")
accelerator.init_trackers("test_project_with_log")
values_with_iteration = {"should_be_under_train": 1, "eval_value": 2, "test_value": 3.1, "train_value": 4.1}
accelerator.log(values_with_iteration, step=1)
single_values = {"single_value_1": 1.1, "single_value_2": 2.2}
accelerator.log(single_values)
offline_dir = ClearMLTest._get_offline_dir(accelerator)
accelerator.end_training()
metrics = ClearMLTest._get_metrics(offline_dir)
assert (len(values_with_iteration) + len(single_values)) == len(metrics)
for metric in metrics:
if metric["metric"] == "Summary":
assert metric["variant"] in single_values
assert metric["value"] == single_values[metric["variant"]]
elif metric["metric"] == "should_be_under_train":
assert metric["variant"] == "train"
assert metric["iter"] == 1
assert metric["value"] == values_with_iteration["should_be_under_train"]
else:
values_with_iteration_key = metric["variant"] + "_" + metric["metric"]
assert values_with_iteration_key in values_with_iteration
assert metric["iter"] == 1
assert metric["value"] == values_with_iteration[values_with_iteration_key]
def test_log_images(self):
from clearml import Task
Task.set_offline(True)
accelerator = Accelerator(log_with="clearml")
accelerator.init_trackers("test_project_with_log_images")
base_image = np.eye(256, 256, dtype=np.uint8) * 255
base_image_3d = np.concatenate((np.atleast_3d(base_image), np.zeros((256, 256, 2), dtype=np.uint8)), axis=2)
images = {
"base_image": base_image,
"base_image_3d": base_image_3d,
}
accelerator.get_tracker("clearml").log_images(images, step=1)
offline_dir = ClearMLTest._get_offline_dir(accelerator)
accelerator.end_training()
images_saved = Path(os.path.join(offline_dir, "data")).rglob("*.jpeg")
assert len(list(images_saved)) == len(images)
def test_log_table(self):
from clearml import Task
Task.set_offline(True)
accelerator = Accelerator(log_with="clearml")
accelerator.init_trackers("test_project_with_log_table")
accelerator.get_tracker("clearml").log_table(
"from lists with columns", columns=["A", "B", "C"], data=[[1, 3, 5], [2, 4, 6]]
)
accelerator.get_tracker("clearml").log_table("from lists", data=[["A2", "B2", "C2"], [7, 9, 11], [8, 10, 12]])
offline_dir = ClearMLTest._get_offline_dir(accelerator)
accelerator.end_training()
metrics = ClearMLTest._get_metrics(offline_dir)
assert len(metrics) == 2
for metric in metrics:
assert metric["metric"] in ("from lists", "from lists with columns")
plot = json.loads(metric["plot_str"])
if metric["metric"] == "from lists with columns":
print(plot["data"][0])
self.assertCountEqual(plot["data"][0]["header"]["values"], ["A", "B", "C"])
self.assertCountEqual(plot["data"][0]["cells"]["values"], [[1, 2], [3, 4], [5, 6]])
else:
self.assertCountEqual(plot["data"][0]["header"]["values"], ["A2", "B2", "C2"])
self.assertCountEqual(plot["data"][0]["cells"]["values"], [[7, 8], [9, 10], [11, 12]])
@require_pandas
def test_log_table_pandas(self):
import pandas as pd
from clearml import Task
Task.set_offline(True)
accelerator = Accelerator(log_with="clearml")
accelerator.init_trackers("test_project_with_log_table_pandas")
accelerator.get_tracker("clearml").log_table(
"from df", dataframe=pd.DataFrame({"A": [1, 2], "B": [3, 4], "C": [5, 6]}), step=1
)
offline_dir = ClearMLTest._get_offline_dir(accelerator)
accelerator.end_training()
metrics = ClearMLTest._get_metrics(offline_dir)
assert len(metrics) == 1
assert metrics[0]["metric"] == "from df"
plot = json.loads(metrics[0]["plot_str"])
self.assertCountEqual(plot["data"][0]["header"]["values"], [["A"], ["B"], ["C"]])
self.assertCountEqual(plot["data"][0]["cells"]["values"], [[1, 2], [3, 4], [5, 6]])
class MyCustomTracker(GeneralTracker):
"Basic tracker that writes to a csv for testing"
_col_names = [
"total_loss",
"iteration",
"my_text",
"learning_rate",
"num_iterations",
"some_boolean",
"some_string",
]
name = "my_custom_tracker"
requires_logging_directory = False
def __init__(self, dir: str):
self.f = open(f"{dir}/log.csv", "w+")
self.writer = csv.DictWriter(self.f, fieldnames=self._col_names)
self.writer.writeheader()
@property
def tracker(self):
return self.writer
def store_init_configuration(self, values: dict):
logger.info("Call init")
self.writer.writerow(values)
def log(self, values: dict, step: Optional[int]):
logger.info("Call log")
self.writer.writerow(values)
def finish(self):
self.f.close()
class CustomTrackerTestCase(unittest.TestCase):
def test_init_trackers(self):
with tempfile.TemporaryDirectory() as d:
tracker = MyCustomTracker(d)
accelerator = Accelerator(log_with=tracker)
config = {"num_iterations": 12, "learning_rate": 1e-2, "some_boolean": False, "some_string": "some_value"}
accelerator.init_trackers("Some name", config)
accelerator.end_training()
with open(f"{d}/log.csv") as f:
data = csv.DictReader(f)
data = next(data)
truth = {
"total_loss": "",
"iteration": "",
"my_text": "",
"learning_rate": "0.01",
"num_iterations": "12",
"some_boolean": "False",
"some_string": "some_value",
}
assert data == truth
def test_log(self):
with tempfile.TemporaryDirectory() as d:
tracker = MyCustomTracker(d)
accelerator = Accelerator(log_with=tracker)
accelerator.init_trackers("Some name")
values = {"total_loss": 0.1, "iteration": 1, "my_text": "some_value"}
accelerator.log(values, step=0)
accelerator.end_training()
with open(f"{d}/log.csv") as f:
data = csv.DictReader(f)
data = next(data)
truth = {
"total_loss": "0.1",
"iteration": "1",
"my_text": "some_value",
"learning_rate": "",
"num_iterations": "",
"some_boolean": "",
"some_string": "",
}
assert data == truth
@require_dvclive
@mock.patch("dvclive.live.get_dvc_repo", return_value=None)
class DVCLiveTrackingTest(unittest.TestCase):
def test_init_trackers(self, mock_repo):
project_name = "test_project_with_config"
with tempfile.TemporaryDirectory() as dirpath:
accelerator = Accelerator(log_with="dvclive")
config = {
"num_iterations": 12,
"learning_rate": 1e-2,
"some_boolean": False,
"some_string": "some_value",
}
init_kwargs = {"dvclive": {"dir": dirpath, "save_dvc_exp": False, "dvcyaml": None}}
accelerator.init_trackers(project_name, config, init_kwargs)
accelerator.end_training()
live = accelerator.trackers[0].live
params = load_yaml(live.params_file)
assert params == config
def test_log(self, mock_repo):
project_name = "test_project_with_log"
with tempfile.TemporaryDirectory() as dirpath:
accelerator = Accelerator(log_with="dvclive", project_dir=dirpath)
init_kwargs = {"dvclive": {"dir": dirpath, "save_dvc_exp": False, "dvcyaml": None}}
accelerator.init_trackers(project_name, init_kwargs=init_kwargs)
values = {"total_loss": 0.1, "iteration": 1, "my_text": "some_value"}
# Log step 0
accelerator.log(values)
# Log step 1
accelerator.log(values)
# Log step 3 (skip step 2)
accelerator.log(values, step=3)
accelerator.end_training()
live = accelerator.trackers[0].live
logs, latest = parse_metrics(live)
assert latest.pop("step") == 3
assert latest == values
scalars = os.path.join(live.plots_dir, Metric.subfolder)
for val in values.keys():
val_path = os.path.join(scalars, f"{val}.tsv")
steps = [int(row["step"]) for row in logs[val_path]]
assert steps == [0, 1, 3]
| 0 |
0 | hf_public_repos/accelerate | hf_public_repos/accelerate/tests/test_kwargs_handlers.py | # Copyright 2021 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import inspect
import os
import unittest
from dataclasses import dataclass
import torch
from accelerate import Accelerator, DistributedDataParallelKwargs, GradScalerKwargs
from accelerate.state import AcceleratorState
from accelerate.test_utils import (
DEFAULT_LAUNCH_COMMAND,
execute_subprocess_async,
path_in_accelerate_package,
require_multi_device,
require_non_cpu,
require_non_xpu,
)
from accelerate.test_utils.testing import slow
from accelerate.utils import AutocastKwargs, KwargsHandler, ProfileKwargs, TorchDynamoPlugin, clear_environment
from accelerate.utils.dataclasses import DistributedType
@dataclass
class MockClass(KwargsHandler):
a: int = 0
b: bool = False
c: float = 3.0
class KwargsHandlerTester(unittest.TestCase):
def test_kwargs_handler(self):
# If no defaults are changed, `to_kwargs` returns an empty dict.
assert MockClass().to_kwargs() == {}
assert MockClass(a=2).to_kwargs() == {"a": 2}
assert MockClass(a=2, b=True).to_kwargs() == {"a": 2, "b": True}
assert MockClass(a=2, c=2.25).to_kwargs() == {"a": 2, "c": 2.25}
@require_non_cpu
@require_non_xpu
def test_grad_scaler_kwargs(self):
# If no defaults are changed, `to_kwargs` returns an empty dict.
scaler_handler = GradScalerKwargs(init_scale=1024, growth_factor=2)
AcceleratorState._reset_state()
accelerator = Accelerator(mixed_precision="fp16", kwargs_handlers=[scaler_handler])
assert accelerator.mixed_precision == "fp16"
scaler = accelerator.scaler
# Check the kwargs have been applied
assert scaler._init_scale == 1024.0
assert scaler._growth_factor == 2.0
# Check the other values are at the default
assert scaler._backoff_factor == 0.5
assert scaler._growth_interval == 2000
assert scaler._enabled is True
@require_multi_device
def test_ddp_kwargs(self):
cmd = DEFAULT_LAUNCH_COMMAND + [inspect.getfile(self.__class__)]
execute_subprocess_async(cmd)
@require_non_cpu
def test_autocast_kwargs(self):
kwargs = AutocastKwargs(enabled=False)
AcceleratorState._reset_state()
accelerator = Accelerator(mixed_precision="fp16")
a_float32 = torch.rand((8, 8), device=accelerator.device)
b_float32 = torch.rand((8, 8), device=accelerator.device)
c_float32 = torch.rand((8, 8), device=accelerator.device)
d_float32 = torch.rand((8, 8), device=accelerator.device)
with accelerator.autocast():
e_float16 = torch.mm(a_float32, b_float32)
assert e_float16.dtype == torch.float16
with accelerator.autocast(autocast_handler=kwargs):
# Convert e_float16 to float32
f_float32 = torch.mm(c_float32, e_float16.float())
assert f_float32.dtype == torch.float32
g_float16 = torch.mm(d_float32, f_float32)
# We should be back in fp16
assert g_float16.dtype == torch.float16
@slow
def test_profile_kwargs(self):
# Arrange
schedule_options = [
dict(wait=1, warmup=1, active=2, repeat=1),
dict(wait=2, warmup=2, active=2, repeat=2),
dict(wait=0, warmup=1, active=3, repeat=3, skip_first=1),
dict(wait=3, warmup=2, active=1, repeat=1, skip_first=2),
dict(wait=1, warmup=0, active=1, repeat=5),
]
total_steps = 100
for option in schedule_options:
count = 0
table_outputs = []
steps_per_cycle = option["wait"] + option["warmup"] + option["active"]
effective_steps = max(0, total_steps - option.get("skip_first", 0))
cycles = effective_steps // steps_per_cycle
if option["repeat"] > 0:
expected_count = min(cycles, option["repeat"])
else:
expected_count = cycles
def on_trace_ready(prof):
nonlocal count
nonlocal table_outputs
count += 1
table_outputs.append(prof.key_averages().table(sort_by="cpu_time_total", row_limit=-1))
kwargs = ProfileKwargs(activities=["cpu"], on_trace_ready=on_trace_ready, schedule_option=option)
accelerator = Accelerator(kwargs_handlers=[kwargs])
# Act
with accelerator.profile() as prof:
for _ in range(total_steps):
prof.step()
torch.tensor([1, 2, 3, 4, 5], device=accelerator.device)
# Assert
assert isinstance(prof, torch.profiler.profile)
assert count == expected_count, f"Option: {option}, Expected count: {expected_count}, but got {count}"
for output in table_outputs:
self.assertIn("CPU time total:", output)
def test_torch_dynamo_plugin(self):
with clear_environment():
prefix = "ACCELERATE_DYNAMO_"
# nvfuser's dynamo backend name is "nvprims_nvfuser"
# use "nvfuser" here to cause exception if this test causes os.environ changed permanently
os.environ[prefix + "BACKEND"] = "aot_ts_nvfuser"
os.environ[prefix + "MODE"] = "reduce-overhead"
dynamo_plugin_kwargs = TorchDynamoPlugin().to_kwargs()
assert dynamo_plugin_kwargs == {"backend": "aot_ts_nvfuser", "mode": "reduce-overhead"}
assert os.environ.get(prefix + "BACKEND") != "aot_ts_nvfuser"
@require_multi_device
def test_ddp_comm_hook(self):
cmd = DEFAULT_LAUNCH_COMMAND + [path_in_accelerate_package("test_utils", "scripts", "test_ddp_comm_hook.py")]
execute_subprocess_async(cmd)
def main():
ddp_scaler = DistributedDataParallelKwargs(bucket_cap_mb=15, find_unused_parameters=True)
accelerator = Accelerator(kwargs_handlers=[ddp_scaler])
# Skip this test due to TorchXLA not using torch.nn.parallel.DistributedDataParallel for model wrapping.
if accelerator.distributed_type == DistributedType.XLA:
return
model = torch.nn.Linear(100, 200)
model = accelerator.prepare(model)
# Check the values changed in kwargs
error_msg = ""
observed_bucket_cap_map = model.bucket_bytes_cap // (1024 * 1024)
if observed_bucket_cap_map != 15:
error_msg += f"Kwargs badly passed, should have `15` but found {observed_bucket_cap_map}.\n"
if model.find_unused_parameters is not True:
error_msg += f"Kwargs badly passed, should have `True` but found {model.find_unused_parameters}.\n"
# Check the values of the defaults
if model.dim != 0:
error_msg += f"Default value not respected, should have `0` but found {model.dim}.\n"
if model.broadcast_buffers is not True:
error_msg += f"Default value not respected, should have `True` but found {model.broadcast_buffers}.\n"
if model.gradient_as_bucket_view is not False:
error_msg += f"Default value not respected, should have `False` but found {model.gradient_as_bucket_view}.\n"
# Raise error at the end to make sure we don't stop at the first failure.
if len(error_msg) > 0:
raise ValueError(error_msg)
if __name__ == "__main__":
main()
| 1 |
0 | hf_public_repos/accelerate | hf_public_repos/accelerate/tests/test_modeling_utils.py | # Copyright 2022 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import json
import os
import tempfile
import unittest
import warnings
from collections import OrderedDict
from typing import Dict, Optional
import torch
import torch.nn as nn
from parameterized import parameterized
from safetensors.torch import save_file
from accelerate import init_empty_weights
from accelerate.big_modeling import cpu_offload
from accelerate.test_utils import (
require_cuda,
require_huggingface_suite,
require_multi_device,
require_non_cpu,
torch_device,
)
from accelerate.utils.modeling import (
align_module_device,
check_device_map,
clean_device_map,
compute_module_sizes,
compute_module_total_buffer_size,
convert_file_size_to_int,
find_tied_parameters,
get_balanced_memory,
get_state_dict_offloaded_model,
infer_auto_device_map,
load_checkpoint_in_model,
load_state_dict,
named_module_tensors,
retie_parameters,
set_module_tensor_to_device,
)
torch_device = f"{torch_device}:0" if torch_device != "cpu" else "cpu"
class ModelForTest(nn.Module):
def __init__(self):
super().__init__()
self.linear1 = nn.Linear(3, 4)
self.batchnorm = nn.BatchNorm1d(4)
self.linear2 = nn.Linear(4, 5)
def forward(self, x):
return self.linear2(self.batchnorm(self.linear1(x)))
class NestedModelForTest(nn.Module):
def __init__(self):
super().__init__()
self.model = ModelForTest()
def forward(self, x):
return self.model(x)
class LinearWithNonPersistentBuffers(nn.Module):
def __init__(self, in_features: int, out_features: int, bias: bool = True, device=None, dtype=None) -> None:
factory_kwargs = {"device": device, "dtype": dtype}
super().__init__()
self.in_features = in_features
self.out_features = out_features
self.register_buffer("weight", torch.empty((out_features, in_features), **factory_kwargs))
if bias:
self.register_buffer("bias", torch.empty(out_features, **factory_kwargs), persistent=False)
else:
self.register_buffer("bias", None)
def forward(self, input: torch.Tensor) -> torch.Tensor:
return torch.nn.functional.linear(input, self.weight, self.bias)
class ModelSeveralDtypes(nn.Module):
def __init__(self):
super().__init__()
self.register_buffer("int_param", torch.randint(high=10, size=(15, 30)))
self.register_parameter("float_param", torch.nn.Parameter(torch.rand(10, 5)))
def forward(self, x):
return x + 2
def sequential_model(num_layers):
layers = OrderedDict([(f"linear{i}", nn.Linear(1000, 1000)) for i in range(1, num_layers + 1)])
return nn.Sequential(layers)
class ModelingUtilsTester(unittest.TestCase):
def check_set_module_tensor_for_device(self, model, device1, device2):
assert model.linear1.weight.device == torch.device(device1)
with self.subTest("Access by submodule and direct name for a parameter"):
set_module_tensor_to_device(model.linear1, "weight", device2)
assert model.linear1.weight.device == torch.device(device2)
if torch.device(device2) == torch.device("meta"):
with self.assertRaises(ValueError):
# We need a `value` to set the weight back on device1
set_module_tensor_to_device(model.linear1, "weight", device1)
set_module_tensor_to_device(model.linear1, "weight", device1, value=torch.randn(4, 3))
else:
set_module_tensor_to_device(model.linear1, "weight", device1)
assert model.linear1.weight.device == torch.device(device1)
with self.subTest("Access by module and full name for a parameter"):
set_module_tensor_to_device(model, "linear1.weight", device2)
assert model.linear1.weight.device == torch.device(device2)
if torch.device(device2) == torch.device("meta"):
with self.assertRaises(ValueError):
# We need a `value` to set the weight back on device1
set_module_tensor_to_device(model, "linear1.weight", device1)
set_module_tensor_to_device(model, "linear1.weight", device1, value=torch.randn(4, 3))
else:
set_module_tensor_to_device(model, "linear1.weight", device1)
assert model.linear1.weight.device == torch.device(device1)
assert model.batchnorm.running_mean.device == torch.device(device1)
with self.subTest("Access by submodule and direct name for a buffer"):
set_module_tensor_to_device(model.batchnorm, "running_mean", device2)
assert model.batchnorm.running_mean.device == torch.device(device2)
if torch.device(device2) == torch.device("meta"):
with self.assertRaises(ValueError):
# We need a `value` to set the weight back on device1
set_module_tensor_to_device(model.batchnorm, "running_mean", device1)
set_module_tensor_to_device(model.batchnorm, "running_mean", device1, value=torch.randn(4))
else:
set_module_tensor_to_device(model.batchnorm, "running_mean", device1)
assert model.batchnorm.running_mean.device == torch.device(device1)
with self.subTest("Access by module and full name for a parameter"):
set_module_tensor_to_device(model, "batchnorm.running_mean", device2)
assert model.batchnorm.running_mean.device == torch.device(device2)
if torch.device(device2) == torch.device("meta"):
with self.assertRaises(ValueError):
# We need a `value` to set the weight back on CPU
set_module_tensor_to_device(model, "batchnorm.running_mean", device1)
set_module_tensor_to_device(model, "batchnorm.running_mean", device1, value=torch.randn(4))
else:
set_module_tensor_to_device(model, "batchnorm.running_mean", device1)
assert model.batchnorm.running_mean.device == torch.device(device1)
def test_set_module_tensor_to_meta_and_cpu(self):
model = ModelForTest()
self.check_set_module_tensor_for_device(model, "cpu", "meta")
@require_non_cpu
def test_set_module_tensor_to_cpu_and_gpu(self):
model = ModelForTest()
self.check_set_module_tensor_for_device(model, "cpu", torch_device)
@require_non_cpu
def test_set_module_tensor_to_meta_and_gpu(self):
model = ModelForTest().to(torch_device)
self.check_set_module_tensor_for_device(model, torch_device, "meta")
@require_multi_device
def test_set_module_tensor_between_gpus(self):
model = ModelForTest().to(torch_device)
self.check_set_module_tensor_for_device(model, torch_device, torch_device.replace("0", "1"))
def test_set_module_tensor_sets_dtype(self):
model = ModelForTest()
set_module_tensor_to_device(model, "linear1.weight", "cpu", value=model.linear1.weight, dtype=torch.float16)
assert model.linear1.weight.dtype == torch.float16
def test_set_module_tensor_checks_shape(self):
model = ModelForTest()
tensor = torch.zeros((2, 2))
with self.assertRaises(ValueError) as cm:
set_module_tensor_to_device(model, "linear1.weight", "cpu", value=tensor)
assert (
str(cm.exception)
== 'Trying to set a tensor of shape torch.Size([2, 2]) in "weight" (which has shape torch.Size([4, 3])), this looks incorrect.'
)
def test_named_tensors(self):
model = nn.BatchNorm1d(4)
named_tensors = named_module_tensors(model)
assert [name for name, _ in named_tensors] == [
"weight",
"bias",
"running_mean",
"running_var",
"num_batches_tracked",
]
named_tensors = named_module_tensors(model, include_buffers=False)
assert [name for name, _ in named_tensors] == ["weight", "bias"]
model = ModelForTest()
named_tensors = named_module_tensors(model)
assert [name for name, _ in named_tensors] == []
named_tensors = named_module_tensors(model, recurse=True)
assert [name for name, _ in named_tensors] == [
"linear1.weight",
"linear1.bias",
"batchnorm.weight",
"batchnorm.bias",
"linear2.weight",
"linear2.bias",
"batchnorm.running_mean",
"batchnorm.running_var",
"batchnorm.num_batches_tracked",
]
named_tensors = named_module_tensors(model, include_buffers=False, recurse=True)
assert [name for name, _ in named_tensors] == [
"linear1.weight",
"linear1.bias",
"batchnorm.weight",
"batchnorm.bias",
"linear2.weight",
"linear2.bias",
]
model = LinearWithNonPersistentBuffers(10, 10)
named_tensors = named_module_tensors(model, include_buffers=True, remove_non_persistent=False)
assert [name for name, _ in named_tensors] == ["weight", "bias"]
named_tensors = named_module_tensors(model, include_buffers=True, remove_non_persistent=True)
assert [name for name, _ in named_tensors] == ["weight"]
def test_find_tied_parameters(self):
model = sequential_model(4)
assert find_tied_parameters(model) == []
model.linear2.weight = model.linear1.weight
assert find_tied_parameters(model) == [["linear1.weight", "linear2.weight"]]
model.linear4.weight = model.linear1.weight
assert find_tied_parameters(model) == [["linear1.weight", "linear2.weight", "linear4.weight"]]
model = sequential_model(5)
model.linear1.weight = model.linear4.weight
model.linear2.weight = model.linear3.weight
model.linear5.weight = model.linear2.weight
tied_params = sorted(find_tied_parameters(model), key=lambda x: len(x))
assert tied_params == [
["linear1.weight", "linear4.weight"],
["linear2.weight", "linear3.weight", "linear5.weight"],
]
model = nn.Sequential(OrderedDict([("block1", sequential_model(4)), ("block2", sequential_model(4))]))
model.block1.linear1.weight = model.block2.linear1.weight
assert find_tied_parameters(model) == [["block1.linear1.weight", "block2.linear1.weight"]]
layer = nn.Linear(10, 10)
model = nn.Sequential(layer, layer)
tied_params = find_tied_parameters(model)
assert sorted(tied_params) == [["0.bias", "1.bias"], ["0.weight", "1.weight"]]
def test_retie_parameters(self):
model = sequential_model(2)
retie_parameters(model, [["linear1.weight", "linear2.weight"]])
assert model.linear1.weight is model.linear2.weight
model = sequential_model(3)
retie_parameters(model, [["linear1.weight", "linear2.weight", "linear3.weight"]])
assert model.linear1.weight is model.linear2.weight
assert model.linear1.weight is model.linear3.weight
model = sequential_model(5)
retie_parameters(
model, [["linear1.weight", "linear4.weight"], ["linear2.weight", "linear3.weight", "linear5.weight"]]
)
assert model.linear1.weight is model.linear4.weight
assert model.linear2.weight is model.linear3.weight
assert model.linear2.weight is model.linear5.weight
model = nn.Sequential(OrderedDict([("block1", sequential_model(4)), ("block2", sequential_model(4))]))
retie_parameters(model, [["block1.linear1.weight", "block2.linear1.weight"]])
assert model.block1.linear1.weight is model.block2.linear1.weight
def test_compute_module_sizes(self):
model = ModelForTest()
expected_sizes = {"": 236, "linear1": 64, "linear1.weight": 48, "linear1.bias": 16}
expected_sizes.update({"linear2": 100, "linear2.weight": 80, "linear2.bias": 20})
expected_sizes.update({"batchnorm": 72, "batchnorm.weight": 16, "batchnorm.bias": 16})
expected_sizes.update(
{"batchnorm.running_mean": 16, "batchnorm.running_var": 16, "batchnorm.num_batches_tracked": 8}
)
module_sizes = compute_module_sizes(model)
assert module_sizes == expected_sizes
model.half()
expected_sizes = {k: s // 2 for k, s in expected_sizes.items()}
# This one is not converted to half.
expected_sizes["batchnorm.num_batches_tracked"] = 8
# This impacts batchnorm and total
expected_sizes["batchnorm"] += 4
expected_sizes[""] += 4
module_sizes = compute_module_sizes(model)
assert module_sizes == expected_sizes
def test_compute_module_total_buffer_size(self):
model = ModelForTest()
model.linear1.register_buffer("test_buffer", torch.zeros(10, 10))
model.register_buffer("test_buffer2", torch.zeros(20, 10))
buffer_size = compute_module_total_buffer_size(model)
assert buffer_size == 1240
model.half()
buffer_size = compute_module_total_buffer_size(model)
assert buffer_size == 624
def test_check_device_map(self):
model = ModelForTest()
check_device_map(model, {"": 0})
with self.assertRaises(ValueError):
check_device_map(model, {"linear1": 0, "linear2": 1})
check_device_map(model, {"linear1": 0, "linear2": 1, "batchnorm": 1})
def shard_test_model(self, model, tmp_dir):
module_index = {
"linear1": "checkpoint_part1.bin",
"batchnorm": "checkpoint_part2.bin",
"linear2": "checkpoint_part3.bin",
}
index = {}
for name, _ in model.state_dict().items():
module = name.split(".")[0]
index[name] = module_index[module]
with open(os.path.join(tmp_dir, "weight_map.index.json"), "w") as f:
json.dump(index, f)
for module, fname in module_index.items():
state_dict = {k: v for k, v in model.state_dict().items() if k.startswith(module)}
full_fname = os.path.join(tmp_dir, fname)
torch.save(state_dict, full_fname)
def test_load_checkpoint_in_model(self):
# Check with whole checkpoint
model = ModelForTest()
with tempfile.TemporaryDirectory() as tmp_dir:
fname = os.path.join(tmp_dir, "pt_model.bin")
torch.save(model.state_dict(), fname)
load_checkpoint_in_model(model, fname)
# Check with sharded index
model = ModelForTest()
with tempfile.TemporaryDirectory() as tmp_dir:
self.shard_test_model(model, tmp_dir)
index_file = os.path.join(tmp_dir, "weight_map.index.json")
load_checkpoint_in_model(model, index_file)
# Check with sharded checkpoint
model = ModelForTest()
with tempfile.TemporaryDirectory() as tmp_dir:
self.shard_test_model(model, tmp_dir)
load_checkpoint_in_model(model, tmp_dir)
@require_non_cpu
def test_load_checkpoint_in_model_one_gpu(self):
device_map = {"linear1": 0, "batchnorm": "cpu", "linear2": "cpu"}
# Check with whole checkpoint
model = ModelForTest()
with tempfile.TemporaryDirectory() as tmp_dir:
fname = os.path.join(tmp_dir, "pt_model.bin")
torch.save(model.state_dict(), fname)
load_checkpoint_in_model(model, fname, device_map=device_map)
assert model.linear1.weight.device == torch.device(torch_device)
assert model.batchnorm.weight.device == torch.device("cpu")
assert model.linear2.weight.device == torch.device("cpu")
# Check with sharded index
model = ModelForTest()
with tempfile.TemporaryDirectory() as tmp_dir:
self.shard_test_model(model, tmp_dir)
index_file = os.path.join(tmp_dir, "weight_map.index.json")
load_checkpoint_in_model(model, index_file, device_map=device_map)
assert model.linear1.weight.device == torch.device(torch_device)
assert model.batchnorm.weight.device == torch.device("cpu")
assert model.linear2.weight.device == torch.device("cpu")
# Check with sharded checkpoint folder
model = ModelForTest()
with tempfile.TemporaryDirectory() as tmp_dir:
self.shard_test_model(model, tmp_dir)
load_checkpoint_in_model(model, tmp_dir, device_map=device_map)
assert model.linear1.weight.device == torch.device(torch_device)
assert model.batchnorm.weight.device == torch.device("cpu")
assert model.linear2.weight.device == torch.device("cpu")
@require_non_cpu
def test_load_checkpoint_in_model_disk_offload(self):
device_map = {"linear1": "cpu", "batchnorm": "disk", "linear2": "cpu"}
model = ModelForTest()
with tempfile.TemporaryDirectory() as tmp_dir:
fname = os.path.join(tmp_dir, "pt_model.bin")
torch.save(model.state_dict(), fname)
load_checkpoint_in_model(model, fname, device_map=device_map, offload_folder=tmp_dir)
assert model.linear1.weight.device == torch.device("cpu")
assert model.batchnorm.weight.device == torch.device("meta")
# Buffers are not offloaded by default
assert model.batchnorm.running_mean.device == torch.device("cpu")
assert model.linear2.weight.device == torch.device("cpu")
model = ModelForTest()
with tempfile.TemporaryDirectory() as tmp_dir:
fname = os.path.join(tmp_dir, "pt_model.bin")
torch.save(model.state_dict(), fname)
load_checkpoint_in_model(model, fname, device_map=device_map, offload_folder=tmp_dir, offload_buffers=True)
assert model.linear1.weight.device == torch.device("cpu")
assert model.batchnorm.weight.device == torch.device("meta")
assert model.batchnorm.running_mean.device == torch.device("meta")
assert model.linear2.weight.device == torch.device("cpu")
@require_multi_device
def test_load_checkpoint_in_model_two_gpu(self):
device_map = {"linear1": 0, "batchnorm": "cpu", "linear2": 1}
# Check with whole checkpoint
model = ModelForTest()
with tempfile.TemporaryDirectory() as tmp_dir:
fname = os.path.join(tmp_dir, "pt_model.bin")
torch.save(model.state_dict(), fname)
load_checkpoint_in_model(model, fname, device_map=device_map)
assert model.linear1.weight.device == torch.device(torch_device)
assert model.batchnorm.weight.device == torch.device("cpu")
assert model.linear2.weight.device == torch.device(torch_device.replace("0", "1"))
# Check with sharded index
model = ModelForTest()
with tempfile.TemporaryDirectory() as tmp_dir:
self.shard_test_model(model, tmp_dir)
index_file = os.path.join(tmp_dir, "weight_map.index.json")
load_checkpoint_in_model(model, index_file, device_map=device_map)
assert model.linear1.weight.device == torch.device(torch_device)
assert model.batchnorm.weight.device == torch.device("cpu")
assert model.linear2.weight.device == torch.device(torch_device.replace("0", "1"))
# Check with sharded checkpoint
model = ModelForTest()
with tempfile.TemporaryDirectory() as tmp_dir:
self.shard_test_model(model, tmp_dir)
load_checkpoint_in_model(model, tmp_dir, device_map=device_map)
assert model.linear1.weight.device == torch.device(torch_device)
assert model.batchnorm.weight.device == torch.device("cpu")
assert model.linear2.weight.device == torch.device(torch_device.replace("0", "1"))
def test_load_checkpoint_in_model_dtype(self):
with tempfile.NamedTemporaryFile(suffix=".pt") as tmpfile:
model = ModelSeveralDtypes()
torch.save(model.state_dict(), tmpfile.name)
new_model = ModelSeveralDtypes()
load_checkpoint_in_model(
new_model, tmpfile.name, offload_state_dict=True, dtype=torch.float16, device_map={"": "cpu"}
)
assert new_model.int_param.dtype == torch.int64
assert new_model.float_param.dtype == torch.float16
@parameterized.expand([(None,), ({"": "cpu"},)])
def test_load_checkpoint_in_model_unexpected_keys(self, device_map: Optional[Dict]):
model = ModelForTest()
state_dict = model.state_dict()
state_dict["foo"] = torch.rand(4, 5)
with tempfile.NamedTemporaryFile(suffix=".pt") as tmpfile:
torch.save(state_dict, tmpfile)
model = ModelForTest()
with self.assertLogs() as cm:
load_checkpoint_in_model(model, tmpfile.name, device_map=device_map)
self.assertTrue(any("were not used when" in out for out in cm.output))
with self.assertRaises((ValueError, RuntimeError)):
load_checkpoint_in_model(model, tmpfile.name, device_map=device_map, strict=True)
def test_clean_device_map(self):
# Regroup everything if all is on the same device
assert clean_device_map({"a": 0, "b": 0, "c": 0}) == {"": 0}
# Regroups children of level 1 on the same device
assert clean_device_map({"a.x": 0, "a.y": 0, "b.x": 1, "b.y": 1, "c": 1}) == {"a": 0, "b": 1, "c": 1}
# Regroups children of level 2 on the same device
assert clean_device_map({"a.x": 0, "a.y": 0, "b.x.0": 1, "b.x.1": 1, "b.y.0": 2, "b.y.1": 2, "c": 2}) == {
"a": 0,
"b.x": 1,
"b.y": 2,
"c": 2,
}
def test_infer_auto_device_map(self):
model = ModelForTest()
# model has size 236: linear1 64, batchnorm 72, linear2 100
try:
with self.assertLogs() as cm:
device_map = infer_auto_device_map(model, max_memory={0: 200, 1: 200})
self.assertFalse(any("insufficient memory" in out for out in cm.output))
except AssertionError:
# No logs exist; test passes implicitly
pass
# only linear1 fits on device 0 as we keep memory available for the maximum layer in case of offload
assert device_map == {"linear1": 0, "batchnorm": 1, "linear2": 1}
device_map = infer_auto_device_map(model, max_memory={0: 200, 1: 172, 2: 200})
# On device 1, we don't care about keeping size available for the max layer, so even if there is just the
# size available for batchnorm + linear2, they fit here.
assert device_map == {"linear1": 0, "batchnorm": 1, "linear2": 1}
model.linear1.weight = model.linear2.weight
device_map = infer_auto_device_map(model, max_memory={0: 200, 1: 200})
# By tying weights, the whole model fits on device 0
assert device_map == {"": 0}
# When splitting a bigger model, the split is done at the layer level
model = nn.Sequential(ModelForTest(), ModelForTest(), ModelForTest())
device_map = infer_auto_device_map(model, max_memory={0: 500, 1: 500})
assert device_map == {"0": 0, "1.linear1": 0, "1.batchnorm": 0, "1.linear2": 1, "2": 1}
# With no_split_module_classes, it's done at that module level
model = nn.Sequential(ModelForTest(), ModelForTest(), ModelForTest())
device_map = infer_auto_device_map(
model, max_memory={0: 500, 1: 500}, no_split_module_classes=["ModelForTest"]
)
assert device_map == {"0": 0, "1": 1, "2": 1}
def test_infer_auto_device_map_with_tied_weights(self):
model = nn.Sequential(
OrderedDict([("layer1", ModelForTest()), ("layer2", ModelForTest()), ("layer3", ModelForTest())])
)
model.layer3.linear2.weight = model.layer1.linear2.weight
device_map = infer_auto_device_map(model, max_memory={0: 400, 1: 500})
expected = {"layer1": 0, "layer3.linear2": 0, "layer2": 1, "layer3.linear1": 1, "layer3.batchnorm": 1}
assert device_map == expected
# With three weights tied together
model.layer2.linear2.weight = model.layer1.linear2.weight
device_map = infer_auto_device_map(model, max_memory={0: 400, 1: 500})
expected = {
"layer1": 0,
"layer2.linear2": 0,
"layer3.linear2": 0,
"layer2.linear1": 1,
"layer2.batchnorm": 1,
"layer3.linear1": 1,
"layer3.batchnorm": 1,
}
assert device_map == expected
# With two groups of weights tied together
model.layer2.linear1.weight = model.layer1.linear1.weight
device_map = infer_auto_device_map(model, max_memory={0: 400, 1: 500})
expected = {
"layer1": 0,
"layer2.linear1": 0,
"layer2.linear2": 0,
"layer3.linear2": 0,
"layer2.batchnorm": 1,
"layer3.linear1": 1,
"layer3.batchnorm": 1,
}
assert device_map == expected
# With weights ties in the same module
model = nn.Sequential(
OrderedDict(
[
("linear1", nn.Linear(4, 4)),
("linear2", nn.Linear(6, 6)),
("linear3", nn.Linear(4, 4)),
("linear4", nn.Linear(6, 6)),
]
)
)
model.linear3.weight = model.linear1.weight
model.linear3.bias = model.linear1.bias
device_map = infer_auto_device_map(model, max_memory={0: 250, 1: 400})
expected = {"linear1": 0, "linear2": 1, "linear3": 0, "linear4": 1}
assert device_map == expected
# With tied weights sharing a same prefix name (`compute.weight` vs `compute.weight_submodule.parameter`)
class SubModule(torch.nn.Module):
def __init__(self, ref_to_parameter):
super().__init__()
self.parameter = ref_to_parameter
def forward(self, x):
return self.x + torch.max(self.parameter)
class LinearModuleAndSubModule(torch.nn.Linear):
def __init__(self, in_features, out_features):
super().__init__(in_features, out_features)
self.weight_submodule = SubModule(self.weight)
def forward(self, x):
return torch.nn.functional.linear(self.weight_submodule(x), self.weight)
class Model(torch.nn.Module):
def __init__(self):
super().__init__()
self.compute = LinearModuleAndSubModule(3, 8)
def forward(self, x):
return self.compute(x)
model = Model()
device_memory = {0: 4, "cpu": 96000} # Low memory device, just to force splitting and trigger the error
infer_auto_device_map(model, device_memory)
@require_huggingface_suite
def test_infer_auto_device_map_on_t0pp(self):
from transformers import AutoConfig, AutoModelForSeq2SeqLM
config = AutoConfig.from_pretrained("bigscience/T0pp")
with init_empty_weights():
model = AutoModelForSeq2SeqLM.from_config(config)
model.tie_weights()
special_dtypes = {n: torch.float32 for n, _ in model.named_parameters() if "wo" in n}
max_memory = {0: 10**10, 1: 10**10, "cpu": 10**10}
device_map = infer_auto_device_map(
model,
no_split_module_classes=["T5Block"],
dtype=torch.float16,
max_memory=max_memory,
special_dtypes=special_dtypes,
)
# The 3 tied weights should all be on device 0
assert device_map["shared"] == 0
assert device_map["encoder.embed_tokens"] == 0
assert device_map["decoder.embed_tokens"] == 0
def test_infer_auto_device_map_with_buffer_check(self):
model = ModelForTest()
model.linear1.register_buffer("test_buffer1", torch.zeros(10, 2))
model.batchnorm.register_buffer("test_buffer2", torch.zeros(10, 3))
model.linear2.register_buffer("test_buffer3", torch.zeros(10, 3))
# model has size 236(parameters) + 360(buffers): linear1 64 + 80, batchnorm 72 + 160, linear2 100 + 120
# Only linear1 (144) fits on device 0, and remaining buffers (batchnorm's 160 + linear2's 120 = 280) won't fit
# device 0, because they will also be loaded to device 0 all at once when inferencing without offload_buffers
# Should print a warning as intended in such case
with self.assertWarns(Warning):
device_map = infer_auto_device_map(model, max_memory={0: 400, "cpu": "1GB"})
assert device_map == {"linear1": 0, "batchnorm": "cpu", "linear2": "cpu"}
# Only linear1 (144) fits on device 0, and remaining buffers (batchnorm's 160 + linear2's 120 = 280) won't fit
# device 0, but with offload_buffers they won't be loaded to device 0 all at once, so it's ok now
# Should NOT print a warning in such case
with warnings.catch_warnings(record=True) as w:
warnings.simplefilter("always")
device_map = infer_auto_device_map(model, max_memory={0: 400, "cpu": "1GB"}, offload_buffers=True)
assert len(w) == 0
assert device_map == {"linear1": 0, "batchnorm": "cpu", "linear2": "cpu"}
def test_infer_auto_device_map_with_buffer_check_and_multi_devices(self):
model = ModelForTest()
model.linear1.register_buffer("test_buffer1", torch.zeros(10, 2))
model.batchnorm.register_buffer("test_buffer2", torch.zeros(10, 3))
model.linear2.register_buffer("test_buffer3", torch.zeros(10, 3))
model.linear3 = nn.Linear(4, 5)
model.linear3.register_buffer("test_buffer4", torch.zeros(10, 2))
# model has size 336(parameters) + 440(buffers): linear1 64 + 80, batchnorm 72 + 160, linear2 100 + 120,
# linear3 100 + 80
# Now we have two devices, linear1 will fit on device 0, batchnorm will fit on device 1, and the second device
# can hold all remaining buffers
# Should NOT print a warning in such case
with warnings.catch_warnings(record=True) as w:
warnings.simplefilter("always")
device_map = infer_auto_device_map(model, max_memory={0: 400, 1: 400, "cpu": "1GB"})
assert len(w) == 0
assert device_map == {"linear1": 0, "batchnorm": 1, "linear2": "cpu", "linear3": "cpu"}
# Now we have two devices, but neither the first nor the second device can hold all remaining buffers
# Should print a warning as intended in such case
with self.assertWarns(Warning):
device_map = infer_auto_device_map(model, max_memory={0: 400, 1: 200, "cpu": "1GB"})
assert device_map == {"linear1": 0, "batchnorm": 1, "linear2": "cpu", "linear3": "cpu"}
# Now we have two devices, neither can hold all the buffers, but we are using the offload_buffers=True
# Should NOT print a warning in such case
with warnings.catch_warnings(record=True) as w:
warnings.simplefilter("always")
device_map = infer_auto_device_map(model, max_memory={0: 400, 1: 200, "cpu": "1GB"}, offload_buffers=True)
assert len(w) == 0
assert device_map == {"linear1": 0, "batchnorm": 1, "linear2": "cpu", "linear3": "cpu"}
def test_infer_auto_device_map_with_fallback_allocation(self):
# Create a model where modules cannot be allocated without fallback_allocation
# Define the inner module with its layers
inner_module = nn.Sequential(
OrderedDict([("linear1", nn.Linear(10, 4)), ("linear2", nn.Linear(4, 4)), ("linear3", nn.Linear(4, 8))])
)
# Wrap the inner module in another module
model = nn.Sequential(OrderedDict([("module", inner_module)]))
max_memory = {0: 256}
# Without fallback_allocation
with self.assertLogs() as cm:
device_map = infer_auto_device_map(model, max_memory=max_memory, fallback_allocation=False)
# No module should be assigned to device 0
assert all(device != 0 for device in device_map.values())
# Check for warning about insufficient memory
self.assertTrue(any("insufficient memory" in out for out in cm.output))
# With fallback_allocation
try:
with self.assertLogs() as cm:
device_map = infer_auto_device_map(model, max_memory=max_memory, fallback_allocation=True)
self.assertFalse(any("insufficient memory" in out for out in cm.output))
except AssertionError:
# No logs exist; test passes implicitly
pass
# At least one submodule should be assigned to device 0
assert any(device == 0 for device in device_map.values())
expected_device_map = {"module.linear1": "disk", "module.linear2": 0, "module.linear3": "disk"}
assert device_map == expected_device_map
def test_infer_auto_device_map_with_fallback_allocation_no_fit(self):
# Create a model where even the smallest submodules cannot fit
inner_module = nn.Sequential(
OrderedDict(
[("linear1", nn.Linear(10, 10)), ("linear2", nn.Linear(10, 10)), ("linear3", nn.Linear(10, 10))]
)
)
# Wrap the inner module in another module
model = nn.Sequential(OrderedDict([("module", inner_module)]))
max_memory = {0: 30}
# With fallback_allocation
try:
with self.assertLogs() as cm:
device_map = infer_auto_device_map(model, max_memory=max_memory, fallback_allocation=True)
# No module should be assigned to device 0
assert all(device != 0 for device in device_map.values())
# Check for warning about insufficient memory
self.assertTrue(any("insufficient memory" in out for out in cm.output))
except AssertionError:
# No logs exist; test passes implicitly
pass
def test_infer_auto_device_map_with_fallback_allocation_partial_fit(self):
# Create a model with deeper hierarchy
class CustomModule(nn.Module):
def __init__(self):
super().__init__()
self.submodule1 = nn.Linear(20, 20)
self.submodule2 = nn.Linear(20, 20)
model = nn.Sequential(
OrderedDict([("module1", CustomModule()), ("module2", CustomModule()), ("module3", CustomModule())])
)
max_memory = {0: 5000}
# With fallback_allocation
device_map = infer_auto_device_map(model, max_memory=max_memory, fallback_allocation=True)
# Check that at least some parameters are assigned to device 0
assigned_to_device_0 = [name for name, device in device_map.items() if device == 0]
assert len(assigned_to_device_0) > 0
def test_infer_auto_device_map_with_fallback_allocation_tied_weights(self):
# Create a model with tied weights
class TiedWeightsModel(nn.Module):
def __init__(self):
super().__init__()
self.linear1 = nn.Linear(10, 10)
self.linear2 = nn.Linear(10, 10)
self.linear2.weight = self.linear1.weight
model = TiedWeightsModel()
max_memory = {0: 600}
# With fallback_allocation
device_map = infer_auto_device_map(model, max_memory=max_memory, fallback_allocation=True)
# Check that tied modules are assigned correctly
expected_device_map = {"": 0}
assert device_map == expected_device_map
def test_infer_auto_device_map_with_fallback_allocation_and_buffers(self):
# Create a model with buffers
model = nn.Sequential(
OrderedDict(
[("linear1", nn.Linear(10, 10)), ("batchnorm", nn.BatchNorm1d(10)), ("linear2", nn.Linear(10, 10))]
)
)
model.linear1.register_buffer("buffer1", torch.zeros(5))
model.batchnorm.register_buffer("buffer2", torch.zeros(5))
model.linear2.register_buffer("buffer3", torch.zeros(5))
max_memory = {0: 678}
# With fallback_allocation and offload_buffers=False
with self.assertWarns(Warning) as cm:
device_map = infer_auto_device_map(
model, max_memory=max_memory, fallback_allocation=True, offload_buffers=False
)
# Check that the warning contains the expected message
warning_message = str(cm.warning)
assert "offload_buffers" in warning_message or "Current model requires" in warning_message
# Verify that the entire model is assigned to device 0
expected_device_map = {"batchnorm": 0, "linear1": "disk", "linear2": "disk"}
assert device_map == expected_device_map
@require_cuda
def test_get_balanced_memory(self):
model = ModelForTest()
# model has size 236: linear1 64, batchnorm 72, linear2 100
max_memory = get_balanced_memory(model, max_memory={0: 200, 1: 200})
assert {0: 200, 1: 200} == max_memory
# We should be able to set models on a non-contiguous sub-set of
max_memory = get_balanced_memory(model, max_memory={0: 200, 2: 200})
assert {0: 200, 2: 200} == max_memory
max_memory = get_balanced_memory(model, max_memory={0: 300, 1: 300})
assert {0: 215, 1: 300} == max_memory
# Last device always get max memory to give more buffer and avoid accidental CPU offload
max_memory = get_balanced_memory(model, max_memory={0: 300, 1: 500})
assert {0: 215, 1: 500} == max_memory
# Last device always get max memory to give more buffer, even if CPU is provided
max_memory = get_balanced_memory(model, max_memory={0: 300, "cpu": 1000})
assert {0: 300, "cpu": 1000} == max_memory
# If we set a device to 0, it's not counted.
max_memory = get_balanced_memory(model, max_memory={0: 0, 1: 300, 2: 300})
assert {0: 0, 1: 215, 2: 300} == max_memory
# If we set a device to 0, it's not counted.
max_memory = get_balanced_memory(model, max_memory={0: 0, "cpu": 100})
assert {0: 0, "cpu": 100} == max_memory
@require_non_cpu
def test_load_state_dict(self):
state_dict = {k: torch.randn(4, 5) for k in ["a", "b", "c"]}
device_maps = [{"a": "cpu", "b": 0, "c": "disk"}, {"a": 0, "b": 0, "c": "disk"}, {"a": 0, "b": 0, "c": 0}]
for device_map in device_maps:
with tempfile.TemporaryDirectory() as tmp_dir:
checkpoint_file = os.path.join(tmp_dir, "model.safetensors")
save_file(state_dict, checkpoint_file, metadata={"format": "pt"})
loaded_state_dict = load_state_dict(checkpoint_file, device_map=device_map)
for param, device in device_map.items():
device = device if device != "disk" else "cpu"
assert loaded_state_dict[param].device == torch.device(device)
def test_convert_file_size(self):
result = convert_file_size_to_int("0MB")
assert result == 0
result = convert_file_size_to_int("100MB")
assert result == (100 * (10**6))
result = convert_file_size_to_int("2GiB")
assert result == (2 * (2**30))
result = convert_file_size_to_int("512KiB")
assert result == (512 * (2**10))
result = convert_file_size_to_int("1.5GB")
assert result == (1.5 * (10**9))
result = convert_file_size_to_int("100KB")
assert result == (100 * (10**3))
result = convert_file_size_to_int(500)
assert result == 500
with self.assertRaises(ValueError):
convert_file_size_to_int("5MBB")
with self.assertRaises(ValueError):
convert_file_size_to_int("5k0MB")
with self.assertRaises(ValueError):
convert_file_size_to_int("-1GB")
def test_get_state_dict_offloaded_model(self):
for model_cls in (ModelForTest, NestedModelForTest):
model = model_cls()
execution_device = torch.device(torch_device)
original_state_dict = model.state_dict()
cpu_offload(model, execution_device=execution_device)
state_dict = get_state_dict_offloaded_model(model)
assert original_state_dict.keys() == state_dict.keys()
for key in original_state_dict:
assert torch.equal(original_state_dict[key], state_dict[key])
def test_align_module_device_simple(self):
model = ModelForTest()
execution_device = torch.device(torch_device)
model_device = torch.device("cpu")
# test default execution device
with align_module_device(model.batchnorm):
assert model.linear1.weight.device == model_device
assert model.batchnorm.weight.device == model_device
assert model.linear2.weight.device == model_device
assert model.linear1.weight.device == model_device
assert model.batchnorm.weight.device == model_device
assert model.linear2.weight.device == model_device
# test with explicit execution device
with align_module_device(model.batchnorm, execution_device=execution_device):
assert model.linear1.weight.device == model_device
assert model.batchnorm.weight.device == execution_device
assert model.linear2.weight.device == model_device
assert model.linear1.weight.device == model_device
assert model.batchnorm.weight.device == model_device
assert model.linear2.weight.device == model_device
def test_align_module_device_offloaded(self):
model = ModelForTest()
execution_device = torch.device(torch_device)
offload_device = torch.device("meta")
cpu_offload(model, execution_device=execution_device)
# test default execution device
with align_module_device(model.batchnorm):
assert model.linear1.weight.device == offload_device
assert model.batchnorm.weight.device == execution_device
assert model.linear2.weight.device == offload_device
assert model.linear1.weight.device == offload_device
assert model.batchnorm.weight.device == offload_device
assert model.linear2.weight.device == offload_device
# test with explicit execution device
with align_module_device(model.batchnorm, execution_device="cpu"):
assert model.linear1.weight.device == offload_device
assert model.batchnorm.weight.device == torch.device("cpu")
assert model.linear2.weight.device == offload_device
assert model.linear1.weight.device == offload_device
assert model.batchnorm.weight.device == offload_device
assert model.linear2.weight.device == offload_device
def test_align_module_device_offloaded_nested(self):
model = NestedModelForTest()
execution_device = torch.device(torch_device)
align_device = torch.device("cpu")
cpu_offload(model, execution_device=execution_device)
for module in model.modules():
with align_module_device(module, align_device):
for param in model.parameters(recurse=False):
assert param.device == align_device
| 2 |
0 | hf_public_repos/accelerate/tests | hf_public_repos/accelerate/tests/deepspeed/ds_config_zero2_model_only.json | {
"fp16": {
"enabled": "auto",
"loss_scale": 0,
"loss_scale_window": 1000,
"initial_scale_power": 16,
"hysteresis": 2,
"min_loss_scale": 1
},
"bf16": {
"enabled": "auto"
},
"zero_optimization": {
"stage": 2,
"offload_optimizer": {
"device": "cpu",
"pin_memory": true
},
"allgather_partitions": true,
"allgather_bucket_size": 2e8,
"overlap_comm": true,
"reduce_scatter": true,
"reduce_bucket_size": "auto",
"contiguous_gradients": true
},
"gradient_accumulation_steps": 1,
"gradient_clipping": "auto",
"steps_per_print": 2000,
"train_batch_size": "auto",
"train_micro_batch_size_per_gpu": "auto",
"wall_clock_breakdown": false
} | 3 |
0 | hf_public_repos/accelerate/tests | hf_public_repos/accelerate/tests/deepspeed/test_deepspeed_multiple_model.py | # Copyright 2024 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import inspect
import json
from functools import partial
from pathlib import Path
import torch
from transformers import AutoModelForCausalLM
from accelerate import Accelerator, DeepSpeedPlugin
from accelerate.commands.launch import launch_command, launch_command_parser
from accelerate.test_utils.testing import (
AccelerateTestCase,
path_in_accelerate_package,
require_deepspeed,
require_huggingface_suite,
require_multi_device,
require_non_cpu,
slow,
)
from accelerate.test_utils.training import RegressionDataset
from accelerate.utils import patch_environment
from accelerate.utils.deepspeed import DummyOptim, DummyScheduler, get_active_deepspeed_plugin
GPT2_TINY = "hf-internal-testing/tiny-random-gpt2"
@require_deepspeed
@require_non_cpu
class DeepSpeedConfigIntegration(AccelerateTestCase):
parser = launch_command_parser()
test_scripts_folder = path_in_accelerate_package("test_utils", "scripts", "external_deps")
def setUp(self):
super().setUp()
self.dist_env = dict(
ACCELERATE_USE_DEEPSPEED="true",
MASTER_ADDR="localhost",
MASTER_PORT="10999",
RANK="0",
LOCAL_RANK="0",
WORLD_SIZE="1",
)
self._test_file_path = inspect.getfile(self.__class__)
path = Path(self._test_file_path).resolve()
self.test_file_dir_str = str(path.parents[0])
self.ds_config_file = dict(
zero2=f"{self.test_file_dir_str}/ds_config_zero2.json",
zero3_inference=f"{self.test_file_dir_str}/ds_config_zero3_model_only.json",
zero3_training=f"{self.test_file_dir_str}/ds_config_zero3.json",
)
with open(self.ds_config_file["zero2"], encoding="utf-8") as f:
self.config_zero2 = json.load(f)
with open(self.ds_config_file["zero3_training"], encoding="utf-8") as f:
self.config_zero3 = json.load(f)
with open(self.ds_config_file["zero3_inference"], encoding="utf-8") as f:
self.config_zero3_inference = json.load(f)
self.model_init = partial(AutoModelForCausalLM.from_pretrained, GPT2_TINY)
def get_ds_plugins(self, zero3_inference=False):
ds_zero2 = DeepSpeedPlugin(
hf_ds_config=self.config_zero2,
)
ds_zero3 = DeepSpeedPlugin(
hf_ds_config=self.config_zero3 if not zero3_inference else self.config_zero3_inference,
)
return {"zero2": ds_zero2, "zero3": ds_zero3}
def test_select_plugin(self):
ds_plugins = self.get_ds_plugins()
ds_zero2, ds_zero3 = ds_plugins.values()
accelerator = Accelerator(
deepspeed_plugin=ds_plugins,
)
# Accelerator's constructor should automatically enable the first plugin
assert ds_zero2.selected
assert not ds_zero3.selected
assert get_active_deepspeed_plugin(accelerator.state) == ds_zero2
assert accelerator.deepspeed_plugin == ds_zero2
assert accelerator.state.get_deepspeed_plugin("zero2") == ds_zero2
accelerator.state.select_deepspeed_plugin("zero3")
assert not ds_zero2.selected
assert ds_zero3.selected
assert get_active_deepspeed_plugin(accelerator.state) == ds_zero3
assert accelerator.deepspeed_plugin == ds_zero3
assert accelerator.state.get_deepspeed_plugin("zero3") == ds_zero3
accelerator.state.select_deepspeed_plugin("zero2")
assert not ds_zero3.selected
assert ds_zero2.selected
assert get_active_deepspeed_plugin(accelerator.state) == ds_zero2
assert accelerator.deepspeed_plugin == ds_zero2
assert accelerator.state.get_deepspeed_plugin("zero2") == ds_zero2
@require_huggingface_suite
def test_config_reference_update(self):
# Make sure that the transformers weakref is updating when we update the config
ds_plugins = self.get_ds_plugins(zero3_inference=True)
zero2, zero3 = ds_plugins.values()
accelerator = Accelerator(deepspeed_plugin=ds_plugins)
from transformers.integrations.deepspeed import deepspeed_config
# Note that these have `auto` values being set so we need to adjust
assert accelerator.deepspeed_plugin is zero2
zero2.deepspeed_config["train_micro_batch_size_per_gpu"] = 1
zero2.deepspeed_config.pop("train_batch_size")
assert deepspeed_config() == accelerator.deepspeed_plugin.hf_ds_config.config
accelerator.state.select_deepspeed_plugin("zero3")
assert accelerator.deepspeed_plugin is zero3
assert deepspeed_config() == accelerator.deepspeed_plugin.hf_ds_config.config
def test_enable_disable_manually_set(self):
ds_plugins = self.get_ds_plugins()
ds_zero2, _ = ds_plugins.values()
with self.assertRaises(ValueError):
ds_zero2.select()
accelerator = Accelerator(deepspeed_plugin=ds_plugins)
accelerator.state.select_deepspeed_plugin("zero2")
with self.assertRaises(NotImplementedError):
ds_zero2.selected = False
assert ds_zero2.selected
def test_multiple_accelerators(self):
ds_plugins = self.get_ds_plugins()
ds_zero2, ds_zero3 = ds_plugins.values()
_ = Accelerator(
deepspeed_plugin=ds_zero2,
)
with self.assertRaises(NotImplementedError):
_ = Accelerator(deepspeed_plugin=ds_zero3)
def test_prepare_multiple_models_zero3_inference(self):
with patch_environment(**self.dist_env):
ds_plugins = self.get_ds_plugins(zero3_inference=True)
accelerator = Accelerator(deepspeed_plugin=ds_plugins)
# Using Zero-2 first
model1 = self.model_init()
optimizer = DummyOptim(model1.parameters())
scheduler = DummyScheduler(optimizer)
dataset = RegressionDataset()
dataloader = torch.utils.data.DataLoader(dataset, batch_size=1)
model1, optimizer, scheduler, dataloader = accelerator.prepare(model1, optimizer, scheduler, dataloader)
accelerator.state.select_deepspeed_plugin("zero3")
model2 = self.model_init()
with self.assertLogs(level="WARNING") as captured:
model2 = accelerator.prepare(model2)
self.assertIn(
"A wrapped DeepSpeed engine reference is currently tied for this `Accelerator()` instance.",
captured.output[0],
)
assert accelerator.deepspeed_engine_wrapped.engine is model1
@require_huggingface_suite
@require_multi_device
@slow
def test_train_multiple_models(self):
self.test_file_path = self.test_scripts_folder / "test_ds_multiple_model.py"
args = ["--num_processes=2", "--num_machines=1", "--main_process_port=0", str(self.test_file_path)]
args = self.parser.parse_args(args)
launch_command(args)
| 4 |
0 | hf_public_repos/accelerate/tests | hf_public_repos/accelerate/tests/deepspeed/ds_config_zero2.json | {
"fp16": {
"enabled": "auto",
"loss_scale": 0,
"loss_scale_window": 1000,
"initial_scale_power": 16,
"hysteresis": 2,
"min_loss_scale": 1
},
"bf16": {
"enabled": "auto"
},
"optimizer": {
"type": "AdamW",
"params": {
"lr": "auto",
"weight_decay": "auto",
"torch_adam": true,
"adam_w_mode": true
}
},
"scheduler": {
"type": "WarmupLR",
"params": {
"warmup_min_lr": "auto",
"warmup_max_lr": "auto",
"warmup_num_steps": "auto"
}
},
"zero_optimization": {
"stage": 2,
"offload_optimizer": {
"device": "cpu",
"pin_memory": true
},
"allgather_partitions": true,
"allgather_bucket_size": 2e8,
"overlap_comm": true,
"reduce_scatter": true,
"reduce_bucket_size": "auto",
"contiguous_gradients": true
},
"gradient_accumulation_steps": 1,
"gradient_clipping": "auto",
"steps_per_print": 2000,
"train_batch_size": "auto",
"train_micro_batch_size_per_gpu": "auto",
"wall_clock_breakdown": false
} | 5 |
0 | hf_public_repos/accelerate/tests | hf_public_repos/accelerate/tests/deepspeed/ds_config_zero3_model_only.json | {
"fp16": {
"enabled": "auto",
"loss_scale": 0,
"loss_scale_window": 1000,
"initial_scale_power": 16,
"hysteresis": 2,
"min_loss_scale": 1
},
"bf16": {
"enabled": "auto"
},
"zero_optimization": {
"stage": 3,
"offload_param": {
"device": "cpu",
"pin_memory": true
},
"overlap_comm": true,
"sub_group_size": 1e9,
"reduce_bucket_size": 1e9,
"stage3_prefetch_bucket_size": 1e9,
"stage3_param_persistence_threshold": 1e9,
"stage3_max_live_parameters": 1e9,
"stage3_max_reuse_distance": 1e9,
"stage3_gather_16bit_weights_on_model_save": true
},
"train_micro_batch_size_per_gpu": 1
} | 6 |
0 | hf_public_repos/accelerate/tests | hf_public_repos/accelerate/tests/deepspeed/ds_config_zero3.json | {
"fp16": {
"enabled": "auto",
"loss_scale": 0,
"loss_scale_window": 1000,
"initial_scale_power": 16,
"hysteresis": 2,
"min_loss_scale": 1
},
"bf16": {
"enabled": "auto"
},
"optimizer": {
"type": "AdamW",
"params": {
"lr": "auto",
"weight_decay": "auto",
"torch_adam": true,
"adam_w_mode": true
}
},
"scheduler": {
"type": "WarmupLR",
"params": {
"warmup_min_lr": "auto",
"warmup_max_lr": "auto",
"warmup_num_steps": "auto"
}
},
"zero_optimization": {
"stage": 3,
"offload_optimizer": {
"device": "cpu",
"pin_memory": true
},
"offload_param": {
"device": "cpu",
"pin_memory": true
},
"overlap_comm": true,
"contiguous_gradients": true,
"sub_group_size": 1e9,
"reduce_bucket_size": "auto",
"stage3_prefetch_bucket_size": "auto",
"stage3_param_persistence_threshold": "auto",
"stage3_max_live_parameters": 1e9,
"stage3_max_reuse_distance": 1e9,
"stage3_gather_16bit_weights_on_model_save": "auto"
},
"gradient_accumulation_steps": 1,
"gradient_clipping": "auto",
"steps_per_print": 2000,
"train_batch_size": "auto",
"train_micro_batch_size_per_gpu": "auto",
"wall_clock_breakdown": false
} | 7 |
0 | hf_public_repos/accelerate/tests | hf_public_repos/accelerate/tests/deepspeed/test_deepspeed.py | # Copyright 2022 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import inspect
import itertools
import json
import os
import tempfile
from copy import deepcopy
from pathlib import Path
import torch
from parameterized import parameterized
from torch.utils.data import BatchSampler, DataLoader, RandomSampler, SequentialSampler
from transformers import AutoConfig, AutoModel, AutoModelForCausalLM, get_scheduler
from transformers.testing_utils import mockenv_context
from transformers.trainer_utils import set_seed
from transformers.utils import is_torch_bf16_available
from accelerate.accelerator import Accelerator
from accelerate.scheduler import AcceleratedScheduler
from accelerate.state import AcceleratorState
from accelerate.test_utils.testing import (
AccelerateTestCase,
TempDirTestCase,
execute_subprocess_async,
path_in_accelerate_package,
require_deepspeed,
require_huggingface_suite,
require_multi_device,
require_non_cpu,
slow,
)
from accelerate.test_utils.training import RegressionDataset, RegressionModel
from accelerate.utils import patch_environment
from accelerate.utils.dataclasses import DeepSpeedPlugin
from accelerate.utils.deepspeed import (
DeepSpeedEngineWrapper,
DeepSpeedOptimizerWrapper,
DeepSpeedSchedulerWrapper,
DummyOptim,
DummyScheduler,
)
from accelerate.utils.versions import compare_versions
set_seed(42)
GPT2_TINY = "sshleifer/tiny-gpt2"
MOBILEVIT = "apple/mobilevit-xx-small"
QWEN_MOE = "peft-internal-testing/tiny-random-qwen-1.5-MoE"
ZERO2 = "zero2"
ZERO3 = "zero3"
FP16 = "fp16"
BF16 = "bf16"
CUSTOM_OPTIMIZER = "custom_optimizer"
CUSTOM_SCHEDULER = "custom_scheduler"
DS_OPTIMIZER = "deepspeed_optimizer"
DS_SCHEDULER = "deepspeed_scheduler"
NO_CONFIG = "no_config"
CONFIG_WITH_NO_HIDDEN_SIZE = "config_with_no_hidden_size"
CONFIG_WITH_HIDDEN_SIZE = "config_with_hidden_size"
CONFIG_WITH_HIDDEN_SIZES = "config_with_hidden_sizes"
stages = [ZERO2, ZERO3]
optims = [CUSTOM_OPTIMIZER, DS_OPTIMIZER]
schedulers = [CUSTOM_SCHEDULER, DS_SCHEDULER]
model_types = [NO_CONFIG, CONFIG_WITH_NO_HIDDEN_SIZE, CONFIG_WITH_HIDDEN_SIZE, CONFIG_WITH_HIDDEN_SIZES]
if is_torch_bf16_available():
dtypes = [FP16, BF16]
else:
dtypes = [FP16]
def parameterized_custom_name_func(func, param_num, param):
# customize the test name generator function as we want both params to appear in the sub-test
# name, as by default it shows only the first param
param_based_name = parameterized.to_safe_name("_".join(str(x) for x in param.args))
return f"{func.__name__}_{param_based_name}"
# Cartesian-product of zero stages with models to test
params = list(itertools.product(stages, dtypes))
optim_scheduler_params = list(itertools.product(optims, schedulers))
class DummyConfig:
def __init__(self):
self._name_or_path = "dummy"
@require_deepspeed
@require_non_cpu
class DeepSpeedConfigIntegration(AccelerateTestCase):
def setUp(self):
super().setUp()
self._test_file_path = inspect.getfile(self.__class__)
path = Path(self._test_file_path).resolve()
self.test_file_dir_str = str(path.parents[0])
self.ds_config_file = dict(
zero2=f"{self.test_file_dir_str}/ds_config_zero2.json",
zero3=f"{self.test_file_dir_str}/ds_config_zero3.json",
)
# use self.get_config_dict(stage) to use these to ensure the original is not modified
with open(self.ds_config_file[ZERO2], encoding="utf-8") as f:
config_zero2 = json.load(f)
with open(self.ds_config_file[ZERO3], encoding="utf-8") as f:
config_zero3 = json.load(f)
# The following setting slows things down, so don't enable it by default unless needed by a test.
# It's in the file as a demo for users since we want everything to work out of the box even if slower.
config_zero3["zero_optimization"]["stage3_gather_16bit_weights_on_model_save"] = False
self.ds_config_dict = dict(zero2=config_zero2, zero3=config_zero3)
self.dist_env = dict(
ACCELERATE_USE_DEEPSPEED="true",
MASTER_ADDR="localhost",
MASTER_PORT="10999",
RANK="0",
LOCAL_RANK="0",
WORLD_SIZE="1",
)
def get_config_dict(self, stage):
# As some tests modify the dict, always make a copy
return deepcopy(self.ds_config_dict[stage])
@parameterized.expand(stages, name_func=parameterized_custom_name_func)
def test_deepspeed_plugin(self, stage):
# Test zero3_init_flag will be set to False when ZeRO stage != 3
deepspeed_plugin = DeepSpeedPlugin(
gradient_accumulation_steps=1,
gradient_clipping=1.0,
zero_stage=2,
offload_optimizer_device="cpu",
offload_param_device="cpu",
zero3_save_16bit_model=True,
zero3_init_flag=True,
)
assert not deepspeed_plugin.zero3_init_flag
deepspeed_plugin.deepspeed_config = None
# Test zero3_init_flag will be set to True only when ZeRO stage == 3
deepspeed_plugin = DeepSpeedPlugin(
gradient_accumulation_steps=1,
gradient_clipping=1.0,
zero_stage=3,
offload_optimizer_device="cpu",
offload_param_device="cpu",
zero3_save_16bit_model=True,
zero3_init_flag=True,
)
assert deepspeed_plugin.zero3_init_flag
deepspeed_plugin.deepspeed_config = None
# Test config files are loaded correctly
deepspeed_plugin = DeepSpeedPlugin(hf_ds_config=self.ds_config_file[stage], zero3_init_flag=True)
if stage == ZERO2:
assert not deepspeed_plugin.zero3_init_flag
elif stage == ZERO3:
assert deepspeed_plugin.zero3_init_flag
# Test `gradient_accumulation_steps` is set to 1 if unavailable in config file
with tempfile.TemporaryDirectory() as dirpath:
ds_config = self.get_config_dict(stage)
del ds_config["gradient_accumulation_steps"]
with open(os.path.join(dirpath, "ds_config.json"), "w") as out_file:
json.dump(ds_config, out_file)
deepspeed_plugin = DeepSpeedPlugin(hf_ds_config=os.path.join(dirpath, "ds_config.json"))
assert deepspeed_plugin.deepspeed_config["gradient_accumulation_steps"] == 1
deepspeed_plugin.deepspeed_config = None
# Test `ValueError` is raised if `zero_optimization` is unavailable in config file
with tempfile.TemporaryDirectory() as dirpath:
ds_config = self.get_config_dict(stage)
del ds_config["zero_optimization"]
with open(os.path.join(dirpath, "ds_config.json"), "w") as out_file:
json.dump(ds_config, out_file)
with self.assertRaises(ValueError) as cm:
deepspeed_plugin = DeepSpeedPlugin(hf_ds_config=os.path.join(dirpath, "ds_config.json"))
assert "Please specify the ZeRO optimization config in the DeepSpeed config." in str(cm.exception)
deepspeed_plugin.deepspeed_config = None
# Test `deepspeed_config_process`
deepspeed_plugin = DeepSpeedPlugin(hf_ds_config=self.ds_config_file[stage])
kwargs = {
"fp16.enabled": True,
"bf16.enabled": False,
"optimizer.params.lr": 5e-5,
"optimizer.params.weight_decay": 0.0,
"scheduler.params.warmup_min_lr": 0.0,
"scheduler.params.warmup_max_lr": 5e-5,
"scheduler.params.warmup_num_steps": 0,
"train_micro_batch_size_per_gpu": 16,
"gradient_clipping": 1.0,
"train_batch_size": 16,
"zero_optimization.reduce_bucket_size": 5e5,
"zero_optimization.stage3_prefetch_bucket_size": 5e5,
"zero_optimization.stage3_param_persistence_threshold": 5e5,
"zero_optimization.stage3_gather_16bit_weights_on_model_save": False,
}
deepspeed_plugin.deepspeed_config_process(**kwargs)
for ds_key_long, value in kwargs.items():
config, ds_key = deepspeed_plugin.hf_ds_config.find_config_node(ds_key_long)
if config.get(ds_key) is not None:
assert config.get(ds_key) == value
# Test mismatches
mismatches = {
"optimizer.params.lr": 1e-5,
"optimizer.params.weight_decay": 1e-5,
"gradient_accumulation_steps": 2,
}
with self.assertRaises(ValueError) as cm:
new_kwargs = deepcopy(kwargs)
new_kwargs.update(mismatches)
deepspeed_plugin.deepspeed_config_process(**new_kwargs)
for key in mismatches.keys():
assert key in str(cm.exception), f"{key} is not in the exception message: {cm.exception}"
# Test `ValueError` is raised if some config file fields with `auto` value is missing in `kwargs`
deepspeed_plugin.deepspeed_config["optimizer"]["params"]["lr"] = "auto"
with self.assertRaises(ValueError) as cm:
del kwargs["optimizer.params.lr"]
deepspeed_plugin.deepspeed_config_process(**kwargs)
assert "`optimizer.params.lr` not found in kwargs." in str(cm.exception)
@parameterized.expand([FP16, BF16], name_func=parameterized_custom_name_func)
def test_accelerate_state_deepspeed(self, dtype):
AcceleratorState._reset_state(True)
deepspeed_plugin = DeepSpeedPlugin(
gradient_accumulation_steps=1,
gradient_clipping=1.0,
zero_stage=ZERO2,
offload_optimizer_device="cpu",
offload_param_device="cpu",
zero3_save_16bit_model=True,
zero3_init_flag=True,
)
with mockenv_context(**self.dist_env):
state = Accelerator(mixed_precision=dtype, deepspeed_plugin=deepspeed_plugin).state
assert state.deepspeed_plugin.deepspeed_config[dtype]["enabled"]
def test_init_zero3(self):
deepspeed_plugin = DeepSpeedPlugin(
gradient_accumulation_steps=1,
gradient_clipping=1.0,
zero_stage=3,
offload_optimizer_device="cpu",
offload_param_device="cpu",
zero3_save_16bit_model=True,
zero3_init_flag=True,
)
with mockenv_context(**self.dist_env):
accelerator = Accelerator(deepspeed_plugin=deepspeed_plugin) # noqa: F841
from transformers.integrations import is_deepspeed_zero3_enabled
assert is_deepspeed_zero3_enabled()
@parameterized.expand(optim_scheduler_params, name_func=parameterized_custom_name_func)
def test_prepare_deepspeed(self, optim_type, scheduler_type):
# 1. Testing with one of the ZeRO Stages is enough to test the `_prepare_deepspeed` function.
# Here we test using ZeRO Stage 2 with FP16 enabled.
from deepspeed.runtime.engine import DeepSpeedEngine
kwargs = {
"optimizer.params.lr": 5e-5,
"optimizer.params.weight_decay": 0.0,
"scheduler.params.warmup_min_lr": 0.0,
"scheduler.params.warmup_max_lr": 5e-5,
"scheduler.params.warmup_num_steps": 0,
"train_micro_batch_size_per_gpu": 16,
"gradient_clipping": 1.0,
"train_batch_size": 16,
"zero_optimization.reduce_bucket_size": 5e5,
"zero_optimization.stage3_prefetch_bucket_size": 5e5,
"zero_optimization.stage3_param_persistence_threshold": 5e5,
"zero_optimization.stage3_gather_16bit_weights_on_model_save": False,
}
if optim_type == CUSTOM_OPTIMIZER and scheduler_type == CUSTOM_SCHEDULER:
# Test custom optimizer + custom scheduler
deepspeed_plugin = DeepSpeedPlugin(
gradient_accumulation_steps=1,
gradient_clipping=1.0,
zero_stage=2,
offload_optimizer_device="cpu",
offload_param_device="cpu",
zero3_save_16bit_model=False,
zero3_init_flag=False,
)
with mockenv_context(**self.dist_env):
accelerator = Accelerator(mixed_precision="fp16", deepspeed_plugin=deepspeed_plugin)
train_set = RegressionDataset(length=80)
eval_set = RegressionDataset(length=20)
train_dataloader = DataLoader(train_set, batch_size=16, shuffle=True)
eval_dataloader = DataLoader(eval_set, batch_size=32, shuffle=False)
model = AutoModel.from_pretrained(GPT2_TINY)
optimizer = torch.optim.AdamW(model.parameters(), lr=5e-5)
lr_scheduler = get_scheduler(
name="linear",
optimizer=optimizer,
num_warmup_steps=0,
num_training_steps=1000,
)
dummy_optimizer = DummyOptim(params=model.parameters())
dummy_lr_scheduler = DummyScheduler(dummy_optimizer)
with self.assertRaises(ValueError) as cm:
model, optimizer, train_dataloader, eval_dataloader, lr_scheduler = accelerator.prepare(
model, dummy_optimizer, train_dataloader, eval_dataloader, lr_scheduler
)
assert "You cannot create a `DummyOptim` without specifying an optimizer in the config file." in str(
cm.exception
)
with self.assertRaises(ValueError) as cm:
model, optimizer, train_dataloader, eval_dataloader, lr_scheduler = accelerator.prepare(
model, optimizer, train_dataloader, eval_dataloader, dummy_lr_scheduler
)
assert (
"Either specify a scheduler in the config file or "
"pass in the `lr_scheduler_callable` parameter when using `accelerate.utils.DummyScheduler`."
in str(cm.exception)
)
with self.assertRaises(ValueError) as cm:
model, optimizer, lr_scheduler = accelerator.prepare(model, optimizer, lr_scheduler)
assert (
"When using DeepSpeed, `accelerate.prepare()` requires you to pass at least one of training or evaluation dataloaders "
"with `batch_size` attribute returning an integer value "
"or alternatively set an integer value in `train_micro_batch_size_per_gpu` in the deepspeed config file "
"or assign integer value to `AcceleratorState().deepspeed_plugin.deepspeed_config['train_micro_batch_size_per_gpu']`."
in str(cm.exception)
)
model, optimizer, train_dataloader, eval_dataloader, lr_scheduler = accelerator.prepare(
model, optimizer, train_dataloader, eval_dataloader, lr_scheduler
)
assert accelerator.deepspeed_config["zero_allow_untested_optimizer"]
assert accelerator.deepspeed_config["train_batch_size"], 16
assert type(model) is DeepSpeedEngine
assert type(optimizer) is DeepSpeedOptimizerWrapper
assert type(lr_scheduler) is AcceleratedScheduler
assert type(accelerator.deepspeed_engine_wrapped) is DeepSpeedEngineWrapper
elif optim_type == DS_OPTIMIZER and scheduler_type == DS_SCHEDULER:
# Test DeepSpeed optimizer + DeepSpeed scheduler
deepspeed_plugin = DeepSpeedPlugin(hf_ds_config=self.ds_config_file[ZERO2])
with mockenv_context(**self.dist_env):
accelerator = Accelerator(deepspeed_plugin=deepspeed_plugin, mixed_precision="fp16")
train_set = RegressionDataset(length=80)
eval_set = RegressionDataset(length=20)
train_dataloader = DataLoader(train_set, batch_size=10, shuffle=True)
eval_dataloader = DataLoader(eval_set, batch_size=5, shuffle=False)
model = AutoModel.from_pretrained(GPT2_TINY)
optimizer = torch.optim.AdamW(model.parameters(), lr=5e-5)
lr_scheduler = get_scheduler(
name="linear",
optimizer=optimizer,
num_warmup_steps=0,
num_training_steps=1000,
)
dummy_optimizer = DummyOptim(params=model.parameters())
dummy_lr_scheduler = DummyScheduler(dummy_optimizer)
kwargs["train_batch_size"] = (
kwargs["train_micro_batch_size_per_gpu"]
* deepspeed_plugin.deepspeed_config["gradient_accumulation_steps"]
* accelerator.num_processes
)
accelerator.state.deepspeed_plugin.deepspeed_config_process(**kwargs)
with self.assertRaises(ValueError) as cm:
model, optimizer, train_dataloader, eval_dataloader, lr_scheduler = accelerator.prepare(
model, optimizer, train_dataloader, eval_dataloader, dummy_lr_scheduler
)
assert "You cannot specify an optimizer in the config file and in the code at the same time" in str(
cm.exception
)
with self.assertRaises(ValueError) as cm:
model, optimizer, train_dataloader, eval_dataloader, lr_scheduler = accelerator.prepare(
model, dummy_optimizer, train_dataloader, eval_dataloader, lr_scheduler
)
assert "You cannot specify a scheduler in the config file and in the code at the same time" in str(
cm.exception
)
with self.assertRaises(ValueError) as cm:
model, optimizer, train_dataloader, eval_dataloader, lr_scheduler = accelerator.prepare(
model, dummy_optimizer, train_dataloader, eval_dataloader, lr_scheduler
)
assert "You cannot specify a scheduler in the config file and in the code at the same time" in str(
cm.exception
)
model, optimizer, train_dataloader, eval_dataloader, lr_scheduler = accelerator.prepare(
model, dummy_optimizer, train_dataloader, eval_dataloader, dummy_lr_scheduler
)
assert type(model) is DeepSpeedEngine
assert type(optimizer) is DeepSpeedOptimizerWrapper
assert type(lr_scheduler) is DeepSpeedSchedulerWrapper
assert type(accelerator.deepspeed_engine_wrapped) is DeepSpeedEngineWrapper
elif optim_type == CUSTOM_OPTIMIZER and scheduler_type == DS_SCHEDULER:
# Test custom optimizer + DeepSpeed scheduler
deepspeed_plugin = DeepSpeedPlugin(hf_ds_config=self.ds_config_file[ZERO2])
with mockenv_context(**self.dist_env):
accelerator = Accelerator(deepspeed_plugin=deepspeed_plugin, mixed_precision="fp16")
train_set = RegressionDataset(length=80)
eval_set = RegressionDataset(length=20)
train_dataloader = DataLoader(train_set, batch_size=10, shuffle=True)
eval_dataloader = DataLoader(eval_set, batch_size=5, shuffle=False)
model = AutoModel.from_pretrained(GPT2_TINY)
optimizer = torch.optim.AdamW(model.parameters(), lr=5e-5)
lr_scheduler = get_scheduler(
name="linear",
optimizer=optimizer,
num_warmup_steps=0,
num_training_steps=1000,
)
dummy_optimizer = DummyOptim(params=model.parameters())
dummy_lr_scheduler = DummyScheduler(dummy_optimizer)
kwargs["train_batch_size"] = (
kwargs["train_micro_batch_size_per_gpu"]
* deepspeed_plugin.deepspeed_config["gradient_accumulation_steps"]
* accelerator.num_processes
)
accelerator.state.deepspeed_plugin.deepspeed_config_process(**kwargs)
del accelerator.state.deepspeed_plugin.deepspeed_config["optimizer"]
model, optimizer, train_dataloader, eval_dataloader, lr_scheduler = accelerator.prepare(
model, optimizer, train_dataloader, eval_dataloader, dummy_lr_scheduler
)
assert type(model) is DeepSpeedEngine
assert type(optimizer) is DeepSpeedOptimizerWrapper
assert type(lr_scheduler) is DeepSpeedSchedulerWrapper
assert type(accelerator.deepspeed_engine_wrapped) is DeepSpeedEngineWrapper
elif optim_type == DS_OPTIMIZER and scheduler_type is CUSTOM_SCHEDULER:
# Test deepspeed optimizer + custom scheduler
deepspeed_plugin = DeepSpeedPlugin(hf_ds_config=self.ds_config_file[ZERO2])
with mockenv_context(**self.dist_env):
accelerator = Accelerator(deepspeed_plugin=deepspeed_plugin, mixed_precision="fp16")
train_set = RegressionDataset(length=80)
eval_set = RegressionDataset(length=20)
train_dataloader = DataLoader(train_set, batch_size=10, shuffle=True)
eval_dataloader = DataLoader(eval_set, batch_size=5, shuffle=False)
model = AutoModel.from_pretrained(GPT2_TINY)
optimizer = torch.optim.AdamW(model.parameters(), lr=5e-5)
lr_scheduler = get_scheduler(
name="linear",
optimizer=optimizer,
num_warmup_steps=0,
num_training_steps=1000,
)
dummy_optimizer = DummyOptim(params=model.parameters())
dummy_lr_scheduler = DummyScheduler(dummy_optimizer)
kwargs["train_batch_size"] = (
kwargs["train_micro_batch_size_per_gpu"]
* deepspeed_plugin.deepspeed_config["gradient_accumulation_steps"]
* accelerator.num_processes
)
accelerator.state.deepspeed_plugin.deepspeed_config_process(**kwargs)
del accelerator.state.deepspeed_plugin.deepspeed_config["scheduler"]
with self.assertRaises(ValueError) as cm:
model, optimizer, train_dataloader, eval_dataloader, lr_scheduler = accelerator.prepare(
model, dummy_optimizer, train_dataloader, eval_dataloader, lr_scheduler
)
assert (
"You can only specify `accelerate.utils.DummyScheduler` in the code when using `accelerate.utils.DummyOptim`."
in str(cm.exception)
)
# passing `DummyScheduler` without `lr_scheduler_callable` should fail
with self.assertRaises(ValueError) as cm:
model, optimizer, train_dataloader, eval_dataloader, lr_scheduler = accelerator.prepare(
model, dummy_optimizer, train_dataloader, eval_dataloader, dummy_lr_scheduler
)
assert (
"Either specify a scheduler in the config file or "
"pass in the `lr_scheduler_callable` parameter when using `accelerate.utils.DummyScheduler`."
in str(cm.exception)
)
# passing `lr_scheduler_callable` to DummyScheduler should enable DS Optim + Custom Scheduler
def _lr_scheduler_callable(optimizer):
return get_scheduler(
name="linear",
optimizer=optimizer,
num_warmup_steps=0,
num_training_steps=1000,
)
dummy_lr_scheduler = DummyScheduler(dummy_optimizer, lr_scheduler_callable=_lr_scheduler_callable)
model, optimizer, train_dataloader, eval_dataloader, lr_scheduler = accelerator.prepare(
model, dummy_optimizer, train_dataloader, eval_dataloader, dummy_lr_scheduler
)
def test_dataloader_with_batch_sampler(self):
deepspeed_plugin = DeepSpeedPlugin(
gradient_accumulation_steps=1,
gradient_clipping=1.0,
zero_stage=2,
offload_optimizer_device="cpu",
offload_param_device="cpu",
zero3_save_16bit_model=False,
zero3_init_flag=False,
)
with mockenv_context(**self.dist_env):
accelerator = Accelerator(mixed_precision="fp16", deepspeed_plugin=deepspeed_plugin)
train_set = RegressionDataset(length=80)
eval_set = RegressionDataset(length=20)
train_dataloader = DataLoader(
train_set, batch_sampler=BatchSampler(RandomSampler(train_set), batch_size=10, drop_last=False)
)
eval_dataloader = DataLoader(
eval_set, batch_sampler=BatchSampler(SequentialSampler(eval_set), batch_size=10, drop_last=False)
)
model = AutoModel.from_pretrained(GPT2_TINY)
optimizer = torch.optim.AdamW(model.parameters(), lr=5e-5)
lr_scheduler = get_scheduler(
name="linear",
optimizer=optimizer,
num_warmup_steps=0,
num_training_steps=1000,
)
with self.assertRaises(ValueError) as cm:
model, optimizer, train_dataloader, eval_dataloader, lr_scheduler = accelerator.prepare(
model, optimizer, train_dataloader, eval_dataloader, lr_scheduler
)
assert (
"At least one of the dataloaders passed to `accelerate.prepare()` has `None` as batch size. "
"Please set an integer value in `train_micro_batch_size_per_gpu` in the deepspeed config file "
"or assign integer value to `AcceleratorState().deepspeed_plugin.deepspeed_config['train_micro_batch_size_per_gpu']`."
in str(cm.exception)
)
def test_save_checkpoints(self):
deepspeed_plugin = DeepSpeedPlugin(
hf_ds_config=self.ds_config_file[ZERO3],
zero3_init_flag=True,
)
del deepspeed_plugin.deepspeed_config["bf16"]
kwargs = {
"optimizer.params.lr": 5e-5,
"optimizer.params.weight_decay": 0.0,
"scheduler.params.warmup_min_lr": 0.0,
"scheduler.params.warmup_max_lr": 5e-5,
"scheduler.params.warmup_num_steps": 0,
"train_micro_batch_size_per_gpu": 16,
"gradient_clipping": 1.0,
"train_batch_size": 16,
"zero_optimization.reduce_bucket_size": 5e5,
"zero_optimization.stage3_prefetch_bucket_size": 5e5,
"zero_optimization.stage3_param_persistence_threshold": 5e5,
"zero_optimization.stage3_gather_16bit_weights_on_model_save": False,
}
with mockenv_context(**self.dist_env):
accelerator = Accelerator(deepspeed_plugin=deepspeed_plugin, mixed_precision="fp16")
kwargs["train_batch_size"] = (
kwargs["train_micro_batch_size_per_gpu"]
* deepspeed_plugin.deepspeed_config["gradient_accumulation_steps"]
* accelerator.num_processes
)
accelerator.state.deepspeed_plugin.deepspeed_config_process(**kwargs)
train_set = RegressionDataset(length=80)
eval_set = RegressionDataset(length=20)
train_dataloader = DataLoader(train_set, batch_size=16, shuffle=True)
eval_dataloader = DataLoader(eval_set, batch_size=32, shuffle=False)
model = AutoModelForCausalLM.from_pretrained("gpt2")
dummy_optimizer = DummyOptim(params=model.parameters())
dummy_lr_scheduler = DummyScheduler(dummy_optimizer)
model, _, train_dataloader, eval_dataloader, _ = accelerator.prepare(
model, dummy_optimizer, train_dataloader, eval_dataloader, dummy_lr_scheduler
)
with self.assertRaises(ValueError) as cm:
accelerator.get_state_dict(model)
msg = (
"Cannot get 16bit model weights because `stage3_gather_16bit_weights_on_model_save` in DeepSpeed config is False. "
"To save the model weights in 16bit, set `stage3_gather_16bit_weights_on_model_save` to True in DeepSpeed config file or "
"set `zero3_save_16bit_model` to True when using `accelerate config`. "
"To save the full checkpoint, run `model.save_checkpoint(save_dir)` and use `zero_to_fp32.py` to recover weights."
)
assert msg in str(cm.exception)
def test_autofill_dsconfig(self):
deepspeed_plugin = DeepSpeedPlugin(
hf_ds_config=self.ds_config_file[ZERO3],
zero3_init_flag=True,
)
del deepspeed_plugin.deepspeed_config["bf16"]
del deepspeed_plugin.deepspeed_config["fp16"]
with mockenv_context(**self.dist_env):
accelerator = Accelerator(deepspeed_plugin=deepspeed_plugin)
train_set = RegressionDataset(length=80)
eval_set = RegressionDataset(length=20)
train_dataloader = DataLoader(train_set, batch_size=16, shuffle=True)
eval_dataloader = DataLoader(eval_set, batch_size=32, shuffle=False)
model = AutoModelForCausalLM.from_pretrained("gpt2")
dummy_optimizer = DummyOptim(params=model.parameters(), lr=5e-5, weight_decay=1e-4)
dummy_lr_scheduler = DummyScheduler(dummy_optimizer, warmup_num_steps=10, total_num_steps=1000)
hidden_size = model.config.hidden_size
model, _, train_dataloader, eval_dataloader, _ = accelerator.prepare(
model, dummy_optimizer, train_dataloader, eval_dataloader, dummy_lr_scheduler
)
config = accelerator.deepspeed_config
assert config["train_micro_batch_size_per_gpu"] == 16
assert config["train_batch_size"] == 16
assert config["optimizer"]["params"]["lr"] == 5e-05
assert config["optimizer"]["params"]["weight_decay"] == 1e-4
assert config["scheduler"]["params"]["warmup_min_lr"] == 0.0
assert config["scheduler"]["params"]["warmup_max_lr"] == 5e-05
assert config["scheduler"]["params"]["warmup_num_steps"] == 10
assert config["gradient_clipping"] == 1.0
assert config["zero_optimization"]["reduce_bucket_size"] == (hidden_size * hidden_size)
assert config["zero_optimization"]["stage3_prefetch_bucket_size"] == int((0.9 * hidden_size) * hidden_size)
assert config["zero_optimization"]["stage3_param_persistence_threshold"] == (10 * hidden_size)
assert not config["zero_optimization"]["stage3_gather_16bit_weights_on_model_save"]
@parameterized.expand(model_types, name_func=parameterized_custom_name_func)
def test_autofill_comm_buffers_dsconfig(self, model_type):
deepspeed_plugin = DeepSpeedPlugin(
hf_ds_config=self.ds_config_file[ZERO3],
zero3_init_flag=True,
)
del deepspeed_plugin.deepspeed_config["bf16"]
del deepspeed_plugin.deepspeed_config["fp16"]
del deepspeed_plugin.deepspeed_config["optimizer"]
del deepspeed_plugin.deepspeed_config["scheduler"]
with mockenv_context(**self.dist_env):
accelerator = Accelerator(mixed_precision="fp16", deepspeed_plugin=deepspeed_plugin)
train_set = RegressionDataset(length=80)
eval_set = RegressionDataset(length=20)
train_dataloader = DataLoader(train_set, batch_size=16, shuffle=True)
eval_dataloader = DataLoader(eval_set, batch_size=32, shuffle=False)
model = RegressionModel()
if model_type == CONFIG_WITH_NO_HIDDEN_SIZE:
model.config = DummyConfig()
elif model_type == CONFIG_WITH_HIDDEN_SIZE:
model.config = AutoConfig.from_pretrained(GPT2_TINY)
hidden_size = model.config.hidden_size
elif model_type == CONFIG_WITH_HIDDEN_SIZES:
model.config = AutoConfig.from_pretrained(MOBILEVIT)
hidden_size = max(model.config.hidden_sizes)
optimizer = torch.optim.AdamW(model.parameters(), lr=5e-5)
lr_scheduler = get_scheduler(
name="linear",
optimizer=optimizer,
num_warmup_steps=0,
num_training_steps=1000,
)
if model_type == NO_CONFIG:
with self.assertRaises(ValueError) as cm:
model, optimizer, train_dataloader, eval_dataloader, lr_scheduler = accelerator.prepare(
model, optimizer, train_dataloader, eval_dataloader, lr_scheduler
)
msg = "Can't find `model.config` entry"
assert msg in str(cm.exception)
elif model_type == CONFIG_WITH_NO_HIDDEN_SIZE:
with self.assertRaises(ValueError) as cm:
model, optimizer, train_dataloader, eval_dataloader, lr_scheduler = accelerator.prepare(
model, optimizer, train_dataloader, eval_dataloader, lr_scheduler
)
msg = "Can find neither `model.config.hidden_size` nor `model.config.hidden_sizes`"
assert msg in str(cm.exception)
else:
model, optimizer, train_dataloader, eval_dataloader, lr_scheduler = accelerator.prepare(
model, optimizer, train_dataloader, eval_dataloader, lr_scheduler
)
zero_opt = accelerator.deepspeed_config["zero_optimization"]
assert zero_opt["reduce_bucket_size"] == (hidden_size * hidden_size)
assert zero_opt["stage3_prefetch_bucket_size"] == int((0.9 * hidden_size) * hidden_size)
assert zero_opt["stage3_param_persistence_threshold"] == (10 * hidden_size)
@parameterized.expand([FP16, BF16], name_func=parameterized_custom_name_func)
def test_autofill_dsconfig_from_ds_plugin(self, dtype):
ds_config = self.ds_config_dict["zero3"]
if dtype == BF16:
del ds_config["fp16"]
else:
del ds_config["bf16"]
ds_config[dtype]["enabled"] = "auto"
ds_config["zero_optimization"]["stage"] = "auto"
ds_config["zero_optimization"]["stage3_gather_16bit_weights_on_model_save"] = "auto"
ds_config["zero_optimization"]["offload_optimizer"]["device"] = "auto"
ds_config["zero_optimization"]["offload_param"]["device"] = "auto"
ds_config["gradient_accumulation_steps"] = "auto"
ds_config["gradient_clipping"] = "auto"
deepspeed_plugin = DeepSpeedPlugin(
hf_ds_config=ds_config,
zero3_init_flag=True,
gradient_accumulation_steps=2,
gradient_clipping=1.0,
zero_stage=2,
offload_optimizer_device="cpu",
offload_param_device="cpu",
zero3_save_16bit_model=True,
)
with mockenv_context(**self.dist_env):
accelerator = Accelerator(deepspeed_plugin=deepspeed_plugin, mixed_precision=dtype)
config = accelerator.state.deepspeed_plugin.deepspeed_config
assert config["gradient_clipping"] == 1.0
assert config["gradient_accumulation_steps"] == 2
assert config["zero_optimization"]["stage"] == 2
assert config["zero_optimization"]["offload_optimizer"]["device"] == "cpu"
assert config["zero_optimization"]["offload_param"]["device"] == "cpu"
assert config["zero_optimization"]["stage3_gather_16bit_weights_on_model_save"]
assert config[dtype]["enabled"]
AcceleratorState._reset_state(True)
diff_dtype = "bf16" if dtype == "fp16" else "fp16"
with mockenv_context(**self.dist_env):
with self.assertRaises(ValueError) as cm:
accelerator = Accelerator(deepspeed_plugin=deepspeed_plugin, mixed_precision=diff_dtype)
assert (
f"`--mixed_precision` arg cannot be set to `{diff_dtype}` when `{dtype}` is set in the DeepSpeed config file."
in str(cm.exception)
)
# base case of passing in `gradient_accumulation_steps` to `DeepSpeedPlugin`
AcceleratorState._reset_state(True)
deepspeed_plugin = DeepSpeedPlugin(zero_stage=2, gradient_accumulation_steps=4)
with mockenv_context(**self.dist_env):
accelerator = Accelerator(deepspeed_plugin=deepspeed_plugin, mixed_precision=dtype)
deepspeed_plugin = accelerator.state.deepspeed_plugin
assert deepspeed_plugin.deepspeed_config["gradient_accumulation_steps"] == 4
# filling the `auto` gradient_accumulation_steps via Accelerator's value
AcceleratorState._reset_state(True)
deepspeed_plugin = DeepSpeedPlugin(
hf_ds_config=ds_config,
zero3_init_flag=True,
gradient_clipping=1.0,
zero_stage=2,
offload_optimizer_device="cpu",
offload_param_device="cpu",
zero3_save_16bit_model=True,
)
with mockenv_context(**self.dist_env):
accelerator = Accelerator(
deepspeed_plugin=deepspeed_plugin, mixed_precision=dtype, gradient_accumulation_steps=8
)
train_set = RegressionDataset(length=80)
eval_set = RegressionDataset(length=20)
train_dataloader = DataLoader(train_set, batch_size=16, shuffle=True)
eval_dataloader = DataLoader(eval_set, batch_size=32, shuffle=False)
model = AutoModelForCausalLM.from_pretrained("gpt2")
dummy_optimizer = DummyOptim(params=model.parameters(), lr=5e-5, weight_decay=1e-4)
dummy_lr_scheduler = DummyScheduler(dummy_optimizer, warmup_num_steps=10, total_num_steps=1000)
model, _, train_dataloader, eval_dataloader, _ = accelerator.prepare(
model, dummy_optimizer, train_dataloader, eval_dataloader, dummy_lr_scheduler
)
deepspeed_plugin = accelerator.state.deepspeed_plugin
assert deepspeed_plugin.deepspeed_config["gradient_accumulation_steps"] == 8
def test_ds_config_assertions(self):
ambiguous_env = self.dist_env.copy()
ambiguous_env["ACCELERATE_CONFIG_DS_FIELDS"] = (
"gradient_accumulation_steps,gradient_clipping,zero_stage,offload_optimizer_device,offload_param_device,zero3_save_16bit_model,mixed_precision"
)
with mockenv_context(**ambiguous_env):
with self.assertRaises(ValueError) as cm:
deepspeed_plugin = DeepSpeedPlugin(
hf_ds_config=self.ds_config_file[ZERO3],
zero3_init_flag=True,
gradient_accumulation_steps=1,
gradient_clipping=1.0,
zero_stage=ZERO2,
offload_optimizer_device="cpu",
offload_param_device="cpu",
zero3_save_16bit_model=True,
)
_ = Accelerator(deepspeed_plugin=deepspeed_plugin, mixed_precision=FP16)
assert (
"If you are using an accelerate config file, remove others config variables mentioned in the above specified list."
in str(cm.exception)
)
def test_ds_zero3_no_init_autofill(self):
ds_config = {
"bf16": {"enabled": True},
"zero_optimization": {
"stage": 3,
"allgather_partitions": True,
"allgather_bucket_size": 5e8,
"overlap_comm": True,
"reduce_scatter": True,
"reduce_bucket_size": "auto",
"contiguous_gradients": True,
"stage3_gather_16bit_weights_on_model_save": False,
"offload_optimizer": {"device": "none"},
"offload_param": {"device": "none"},
},
"gradient_clipping": 1.0,
"gradient_accumulation_steps": 1,
"train_batch_size": "auto",
"train_micro_batch_size_per_gpu": "auto",
"steps_per_print": 2000000,
}
deepspeed_plugin = DeepSpeedPlugin(
hf_ds_config=ds_config,
zero3_init_flag=False,
)
with mockenv_context(**self.dist_env):
_ = Accelerator(deepspeed_plugin=deepspeed_plugin)
_ = AutoModelForCausalLM.from_pretrained("gpt2")
@parameterized.expand(stages, name_func=parameterized_custom_name_func)
def test_ds_config(self, stage):
deepspeed_plugin = DeepSpeedPlugin(
hf_ds_config=self.ds_config_file[stage],
zero3_init_flag=True,
)
assert deepspeed_plugin.zero_stage == int(stage.replace("zero", ""))
def test_prepare_deepspeed_prepare_moe(self):
if compare_versions("transformers", "<", "4.40") and compare_versions("deepspeed", "<", "0.14"):
return
deepspeed_plugin = DeepSpeedPlugin(
zero3_init_flag=True,
gradient_accumulation_steps=1,
gradient_clipping=1.0,
zero_stage=3,
offload_optimizer_device="none",
offload_param_device="none",
zero3_save_16bit_model=True,
transformer_moe_cls_names="Qwen2MoeSparseMoeBlock",
)
with mockenv_context(**self.dist_env):
accelerator = Accelerator(mixed_precision="fp16", deepspeed_plugin=deepspeed_plugin)
accelerator.state.deepspeed_plugin.deepspeed_config["train_micro_batch_size_per_gpu"] = 1
model = AutoModelForCausalLM.from_pretrained(QWEN_MOE)
model = accelerator.prepare(model)
from transformers.models.qwen2_moe.modeling_qwen2_moe import Qwen2MoeSparseMoeBlock
for module in model.modules():
if isinstance(module, Qwen2MoeSparseMoeBlock):
assert hasattr(module, "_z3_leaf") and module._z3_leaf
def test_basic_run(self):
test_file_path = path_in_accelerate_package("test_utils", "scripts", "external_deps", "test_performance.py")
with tempfile.TemporaryDirectory() as dirpath:
cmd = [
"accelerate",
"launch",
"--num_processes=1",
"--num_machines=1",
"--machine_rank=0",
"--mixed_precision=fp16",
"--use_deepspeed",
"--gradient_accumulation_steps=1",
"--zero_stage=2",
"--offload_optimizer_device=none",
"--offload_param_device=none",
test_file_path,
"--model_name_or_path=distilbert-base-uncased",
"--num_epochs=1",
f"--output_dir={dirpath}",
]
with patch_environment(omp_num_threads=1):
execute_subprocess_async(cmd)
@require_deepspeed
@require_multi_device
@slow
class DeepSpeedIntegrationTest(TempDirTestCase):
test_scripts_folder = path_in_accelerate_package("test_utils", "scripts", "external_deps")
def setUp(self):
super().setUp()
self._test_file_path = inspect.getfile(self.__class__)
path = Path(self._test_file_path).resolve()
self.test_file_dir_str = str(path.parents[0])
self.ds_config_file = dict(
zero2=f"{self.test_file_dir_str}/ds_config_zero2.json",
zero3=f"{self.test_file_dir_str}/ds_config_zero3.json",
)
self.stages = [1, 2, 3]
self.zero3_offload_config = False
self.performance_lower_bound = 0.82
self.peak_memory_usage_upper_bound = {
"multi_gpu_fp16": 3200,
"deepspeed_stage_1_fp16": 1600,
"deepspeed_stage_2_fp16": 2500,
"deepspeed_stage_3_zero_init_fp16": 2800,
# Disabling below test as it overwhelms the RAM memory usage
# on CI self-hosted runner leading to tests getting killed.
# "deepspeed_stage_3_cpu_offload_fp16": 1900,
}
self.n_train = 160
self.n_val = 160
def test_performance(self):
self.test_file_path = self.test_scripts_folder / "test_performance.py"
cmd = [
"accelerate",
"launch",
"--num_processes=2",
"--num_machines=1",
"--machine_rank=0",
"--mixed_precision=fp16",
"--use_deepspeed",
"--gradient_accumulation_steps=1",
"--gradient_clipping=1",
"--zero3_init_flag=True",
"--zero3_save_16bit_model=True",
]
for stage in self.stages:
if stage == 1:
continue
cmd_stage = cmd.copy()
cmd_stage.extend([f"--zero_stage={stage}"])
cmd_stage.extend(["--offload_optimizer_device=none", "--offload_param_device=none"])
if self.zero3_offload_config:
with open(self.ds_config_file[ZERO3], encoding="utf-8") as f:
ds_config = json.load(f)
del ds_config["bf16"]
del ds_config["optimizer"]["params"]["torch_adam"]
del ds_config["optimizer"]["params"]["adam_w_mode"]
ds_config["fp16"]["enabled"] = True
ds_config_path = os.path.join(self.tmpdir, "ds_config.json")
with open(ds_config_path, "w") as out_file:
json.dump(ds_config, out_file)
cmd_stage.extend([f"--deepspeed_config_file={ds_config_path}"])
cmd_stage.extend(
[
self.test_file_path,
f"--output_dir={self.tmpdir}",
f"--performance_lower_bound={self.performance_lower_bound}",
]
)
with patch_environment(omp_num_threads=1):
execute_subprocess_async(cmd_stage)
def test_checkpointing(self):
self.test_file_path = self.test_scripts_folder / "test_checkpointing.py"
cmd = [
"accelerate",
"launch",
"--num_processes=2",
"--num_machines=1",
"--machine_rank=0",
"--mixed_precision=fp16",
"--use_deepspeed",
"--gradient_accumulation_steps=1",
"--gradient_clipping=1",
"--zero3_init_flag=True",
"--zero3_save_16bit_model=True",
]
for stage in self.stages:
if stage == 1:
continue
cmd_stage = cmd.copy()
cmd_stage.extend([f"--zero_stage={stage}"])
cmd_stage.extend(["--offload_optimizer_device=none", "--offload_param_device=none"])
if self.zero3_offload_config:
with open(self.ds_config_file[ZERO3], encoding="utf-8") as f:
ds_config = json.load(f)
del ds_config["bf16"]
del ds_config["optimizer"]["params"]["torch_adam"]
del ds_config["optimizer"]["params"]["adam_w_mode"]
ds_config["fp16"]["enabled"] = True
ds_config_path = os.path.join(self.tmpdir, "ds_config.json")
with open(ds_config_path, "w") as out_file:
json.dump(ds_config, out_file)
cmd_stage.extend([f"--deepspeed_config_file={ds_config_path}"])
cmd_stage.extend(
[
self.test_file_path,
f"--output_dir={self.tmpdir}",
"--partial_train_epoch=1",
]
)
with patch_environment(omp_num_threads=1):
execute_subprocess_async(cmd_stage)
cmd_stage = cmd_stage[:-1]
resume_from_checkpoint = os.path.join(self.tmpdir, "epoch_0")
cmd_stage.extend(
[
f"--resume_from_checkpoint={resume_from_checkpoint}",
]
)
with patch_environment(omp_num_threads=1):
execute_subprocess_async(cmd_stage)
def test_peak_memory_usage(self):
if compare_versions("deepspeed", ">", "0.12.6"):
self.skipTest(
"The test fails when deepspeed>0.12.6. This is something that needs to be fixed on deepspeed library"
)
self.test_file_path = self.test_scripts_folder / "test_peak_memory_usage.py"
cmd = [
"accelerate",
"launch",
"--num_processes=2",
"--num_machines=1",
"--machine_rank=0",
]
for spec, peak_mem_upper_bound in self.peak_memory_usage_upper_bound.items():
cmd_stage = cmd.copy()
if "fp16" in spec:
cmd_stage.extend(["--mixed_precision=fp16"])
if "multi_gpu" in spec:
continue
else:
cmd_stage.extend(
[
"--use_deepspeed",
"--gradient_accumulation_steps=1",
"--gradient_clipping=1",
"--zero3_init_flag=True",
"--zero3_save_16bit_model=True",
]
)
for i in range(3):
if f"stage_{i + 1}" in spec:
cmd_stage.extend([f"--zero_stage={i + 1}"])
break
cmd_stage.extend(
[
"--offload_optimizer_device=none",
"--offload_param_device=none",
"--offload_optimizer_nvme_path=none",
"--offload_param_nvme_path=none",
]
)
if "cpu_offload" in spec:
with open(self.ds_config_file[ZERO3], encoding="utf-8") as f:
ds_config = json.load(f)
del ds_config["bf16"]
del ds_config["fp16"]
del ds_config["optimizer"]["params"]["torch_adam"]
del ds_config["optimizer"]["params"]["adam_w_mode"]
ds_config_path = os.path.join(self.tmpdir, "ds_config.json")
with open(ds_config_path, "w") as out_file:
json.dump(ds_config, out_file)
cmd_stage.extend([f"--deepspeed_config_file={ds_config_path}"])
cmd_stage.extend(
[
self.test_file_path,
f"--output_dir={self.tmpdir}",
f"--peak_memory_upper_bound={peak_mem_upper_bound}",
f"--n_train={self.n_train}",
f"--n_val={self.n_val}",
]
)
with patch_environment(omp_num_threads=1):
execute_subprocess_async(cmd_stage)
def test_lr_scheduler(self):
self.test_file_path = self.test_scripts_folder / "test_performance.py"
cmd = [
"accelerate",
"launch",
"--num_processes=2",
"--num_machines=1",
"--machine_rank=0",
"--mixed_precision=no",
"--use_deepspeed",
"--gradient_accumulation_steps=1",
"--gradient_clipping=1",
"--zero3_init_flag=True",
"--zero3_save_16bit_model=True",
"--zero_stage=3",
"--offload_optimizer_device=none",
"--offload_param_device=none",
self.test_file_path,
f"--output_dir={self.tmpdir}",
f"--performance_lower_bound={self.performance_lower_bound}",
]
with patch_environment(omp_num_threads=1):
execute_subprocess_async(cmd)
@require_huggingface_suite
def test_zero3_integration(self):
self.test_file_path = self.test_scripts_folder / "test_zero3_integration.py"
cmd = ["accelerate", "launch", "--num_processes=2", "--num_machines=1", self.test_file_path]
with patch_environment(omp_num_threads=1):
execute_subprocess_async(cmd)
| 8 |
0 | hf_public_repos/accelerate/tests | hf_public_repos/accelerate/tests/test_samples/test_command_file.sh | echo "hello world"
echo "this is a second command" | 9 |
0 | hf_public_repos/accelerate/benchmarks/fp8 | hf_public_repos/accelerate/benchmarks/fp8/transformer_engine/distrib_deepspeed.py | # Copyright 2024 The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""
This script tests to ensure that `accelerate` performs at the same level as raw `TransformersEngine`.
This particular script verifies this for DDP training.
"""
from unittest.mock import patch
import deepspeed
import evaluate
import torch
import transformer_engine.common.recipe as te_recipe
import transformer_engine.pytorch as te
from fp8_utils import evaluate_model, get_named_parameters, get_training_utilities
from transformer_engine.common.recipe import DelayedScaling
from accelerate import Accelerator, DeepSpeedPlugin
from accelerate.state import AcceleratorState
from accelerate.utils import FP8RecipeKwargs, set_seed
from accelerate.utils.transformer_engine import convert_model
MODEL_NAME = "bert-base-cased"
METRIC = evaluate.load("glue", "mrpc")
def train_baseline(zero_stage: int = 1):
# This forces transformers to think Zero-3 Init should be used
with patch("transformers.integrations.deepspeed.is_deepspeed_zero3_enabled") as mock:
mock.return_value = zero_stage == 3
set_seed(42)
accelerator = Accelerator()
model, optimizer, train_dataloader, eval_dataloader, lr_scheduler = get_training_utilities(
MODEL_NAME, accelerator=accelerator
)
# Convert the model to TE
old_named_params = get_named_parameters(model)
with torch.no_grad():
convert_model(model)
new_named_params = get_named_parameters(model)
mapping = {p: new_named_params[n] for n, p in old_named_params.items()}
for param_group in optimizer.param_groups:
param_group["params"] = [mapping[p] for p in param_group["params"]]
FP8_RECIPE_KWARGS = {"fp8_format": te_recipe.Format.HYBRID, "amax_history_len": 32, "amax_compute_algo": "max"}
fp8_recipe = DelayedScaling(**FP8_RECIPE_KWARGS)
import numpy as np
config = {
"train_batch_size": 32,
"train_micro_batch_size_per_gpu": 16,
"gradient_accumulation_steps": 1,
"zero_optimization": {
"stage": zero_stage,
"offload_optimizer": {"device": "none", "nvme_path": None},
"offload_param": {"device": "none", "nvme_path": None},
"stage3_gather_16bit_weights_on_model_save": False,
},
"gradient_clipping": 1.0,
"steps_per_print": np.inf,
"bf16": {"enabled": True},
"fp16": {"enabled": False},
"zero_allow_untested_optimizer": True,
}
(
model,
optimizer,
_,
_,
) = deepspeed.initialize(
model=model,
optimizer=optimizer,
config_params=config,
)
base_model_results = evaluate_model(model, eval_dataloader, METRIC, accelerator=accelerator)
model.train()
model_outputs = []
data = []
for _ in range(2):
for batch in train_dataloader:
with te.fp8_autocast(enabled=True, fp8_recipe=fp8_recipe):
outputs = model(**batch)
data.append(batch.to("cpu"))
model_outputs.append(outputs.logits.to("cpu"))
loss = outputs.loss
model.backward(loss)
model.step()
for _ in range(accelerator.num_processes):
lr_scheduler.step()
trained_model_results = evaluate_model(model, eval_dataloader, METRIC, accelerator=accelerator)
model.destroy()
assert (
trained_model_results["accuracy"] > base_model_results["accuracy"]
), f'Accuracy should be higher for the trained model: {trained_model_results["accuracy"]} > {base_model_results["accuracy"]}'
assert (
trained_model_results["f1"] > base_model_results["f1"]
), f'F1 score should be higher for the trained model: {trained_model_results["f1"]} > {base_model_results["f1"]}'
return base_model_results, trained_model_results, model_outputs, data
def train_integration(zero_stage: int = 1):
set_seed(42)
FP8_RECIPE_KWARGS = {"fp8_format": "HYBRID", "amax_history_len": 32, "amax_compute_algo": "max"}
kwargs_handlers = [FP8RecipeKwargs(backend="TE", **FP8_RECIPE_KWARGS)]
AcceleratorState()._reset_state(True)
deepspeed_plugin = DeepSpeedPlugin(
zero_stage=zero_stage,
zero3_init_flag=zero_stage == 3,
)
accelerator = Accelerator(
mixed_precision="fp8", kwargs_handlers=kwargs_handlers, deepspeed_plugin=deepspeed_plugin
)
accelerator.state.deepspeed_plugin.deepspeed_config["train_micro_batch_size_per_gpu"] = 16
model, optimizer, train_dataloader, eval_dataloader, lr_scheduler = get_training_utilities(
MODEL_NAME, accelerator=accelerator
)
model, optimizer, lr_scheduler = accelerator.prepare(model, optimizer, lr_scheduler)
base_model_results = evaluate_model(model, eval_dataloader, METRIC, accelerator=accelerator)
model.train()
model_outputs = []
data = []
for _ in range(2):
for batch in train_dataloader:
outputs = model(**batch)
data.append(batch.to("cpu"))
model_outputs.append(outputs.logits.to("cpu"))
loss = outputs.loss
accelerator.backward(loss)
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad()
trained_model_results = evaluate_model(model, eval_dataloader, METRIC, accelerator=accelerator)
model.destroy()
assert (
trained_model_results["accuracy"] > base_model_results["accuracy"]
), f'Accuracy should be higher for the trained model: {trained_model_results["accuracy"]} > {base_model_results["accuracy"]}'
assert (
trained_model_results["f1"] > base_model_results["f1"]
), f'F1 score should be higher for the trained model: {trained_model_results["f1"]} > {base_model_results["f1"]}'
return base_model_results, trained_model_results, model_outputs, data
if __name__ == "__main__":
# for zero_stage in [1, 2, 3]:
zero_stage = 1
baseline_not_trained, baseline_trained, baseline_outputs, baseline_data = train_baseline(zero_stage)
accelerator_not_trained, accelerator_trained, accelerator_outputs, accelerator_data = train_integration(zero_stage)
assert (
baseline_not_trained["accuracy"] == accelerator_not_trained["accuracy"]
), f'ZERO stage {zero_stage}: Accuracy should be the same for the baseline and accelerator: {baseline_not_trained["accuracy"]} == {accelerator_not_trained["accuracy"]}'
assert (
baseline_not_trained["f1"] == accelerator_not_trained["f1"]
), f'ZERO stage {zero_stage}: F1 score should be the same for the baseline and accelerator: {baseline_not_trained["f1"]} == {accelerator_not_trained["f1"]}'
assert (
baseline_trained["accuracy"] == accelerator_trained["accuracy"]
), f'ZERO stage {zero_stage}: Accuracy should be the same for the baseline and accelerator: {baseline_trained["accuracy"]} == {accelerator_trained["accuracy"]}'
assert (
baseline_trained["f1"] == accelerator_trained["f1"]
), f'ZERO stage {zero_stage}: F1 score should be the same for the baseline and accelerator: {baseline_trained["f1"]} == {accelerator_trained["f1"]}'
torch.distributed.destroy_process_group()
| 0 |
0 | hf_public_repos/accelerate/benchmarks/fp8 | hf_public_repos/accelerate/benchmarks/fp8/transformer_engine/README.md | # FP8 Benchmarks
Comparing and running [TransformerEngine](https://github.com/NVIDIA/TransformerEngine) FP8 with accelerate
## Overview
This repo provides scripts which compare native TransformerEngine model training against `accelerate`'s own integration. Each modeling type is segmented out via a script, supporting the following:
* Single GPU training (`non_distributed.py`)
* Multi-GPU training via DistributedDataParallelism (`ddp.py`)
* Fully Sharded Data Parallelism (`fsdp.py`)
* DeepSpeed ZeRO 1-3 (`deepspeed.py`)
To run them, it's recommended to use a docker image (see the attached `Dockerfile`) and not install `TransformerEngine` manually.
## Running:
There are official Docker images located at `huggingface/accelerate:gpu-fp8-transformerengine-nightly` which can be used.
You can run all scripts using the core `accelerate launch` command without any `accelerate config` being needed.
For single GPU, run it via `python`:
```bash
python non_distributed.py
```
For the rest, run it via `accelerate launch`:
```bash
accelerate launch ddp.py # or distrib_deepspeed.py, ddp.py
``` | 1 |
0 | hf_public_repos/accelerate/benchmarks/fp8 | hf_public_repos/accelerate/benchmarks/fp8/transformer_engine/non_distributed.py | # Copyright 2024 The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""
This script tests to ensure that `accelerate` performs at the same level as raw `TransformersEngine`.
This particular script verifies this for single GPU training.
"""
import evaluate
import torch
import transformer_engine.common.recipe as te_recipe
import transformer_engine.pytorch as te
from fp8_utils import evaluate_model, get_named_parameters, get_training_utilities
from transformer_engine.common.recipe import DelayedScaling
from accelerate import Accelerator
from accelerate.state import AcceleratorState
from accelerate.utils import FP8RecipeKwargs, set_seed
from accelerate.utils.transformer_engine import convert_model
MODEL_NAME = "bert-base-cased"
METRIC = evaluate.load("glue", "mrpc")
def train_baseline():
set_seed(42)
model, optimizer, train_dataloader, eval_dataloader, lr_scheduler = get_training_utilities(MODEL_NAME)
# Convert the model to TE
old_named_params = get_named_parameters(model)
with torch.no_grad():
convert_model(model)
new_named_params = get_named_parameters(model)
mapping = {p: new_named_params[n] for n, p in old_named_params.items()}
for param_group in optimizer.param_groups:
param_group["params"] = [mapping[p] for p in param_group["params"]]
FP8_RECIPE_KWARGS = {"fp8_format": te_recipe.Format.HYBRID, "amax_history_len": 32, "amax_compute_algo": "max"}
fp8_recipe = DelayedScaling(**FP8_RECIPE_KWARGS)
model.to("cuda")
base_model_results = evaluate_model(model, eval_dataloader, METRIC)
model.train()
for batch in train_dataloader:
with te.fp8_autocast(enabled=True, fp8_recipe=fp8_recipe):
with torch.autocast(device_type="cuda", dtype=torch.bfloat16):
batch = batch.to("cuda")
outputs = model(**batch)
loss = outputs.loss
loss.backward()
optimizer.step()
optimizer.zero_grad()
lr_scheduler.step()
trained_model_results = evaluate_model(model, eval_dataloader, METRIC)
assert (
trained_model_results["accuracy"] > base_model_results["accuracy"]
), f'Accuracy should be higher for the trained model: {trained_model_results["accuracy"]} > {base_model_results["accuracy"]}'
assert (
trained_model_results["f1"] > base_model_results["f1"]
), f'F1 score should be higher for the trained model: {trained_model_results["f1"]} > {base_model_results["f1"]}'
return base_model_results, trained_model_results
def train_integration():
FP8_RECIPE_KWARGS = {"fp8_format": "HYBRID", "amax_history_len": 32, "amax_compute_algo": "max"}
kwargs_handlers = [FP8RecipeKwargs(backend="TE", **FP8_RECIPE_KWARGS)]
AcceleratorState()._reset_state(True)
accelerator = Accelerator(mixed_precision="fp8", kwargs_handlers=kwargs_handlers)
set_seed(42)
model, optimizer, train_dataloader, eval_dataloader, lr_scheduler = get_training_utilities(
MODEL_NAME, accelerator=accelerator
)
model, optimizer, lr_scheduler = accelerator.prepare(model, optimizer, lr_scheduler)
base_model_results = evaluate_model(model, eval_dataloader, METRIC)
model.train()
for batch in train_dataloader:
outputs = model(**batch)
loss = outputs.loss
accelerator.backward(loss)
optimizer.step()
optimizer.zero_grad()
lr_scheduler.step()
trained_model_results = evaluate_model(model, eval_dataloader, METRIC)
assert (
trained_model_results["accuracy"] > base_model_results["accuracy"]
), f'Accuracy should be higher for the trained model: {trained_model_results["accuracy"]} > {base_model_results["accuracy"]}'
assert (
trained_model_results["f1"] > base_model_results["f1"]
), f'F1 score should be higher for the trained model: {trained_model_results["f1"]} > {base_model_results["f1"]}'
return base_model_results, trained_model_results
if __name__ == "__main__":
baseline_not_trained, baseline_trained = train_baseline()
accelerator_not_trained, accelerator_trained = train_integration()
assert (
baseline_not_trained["accuracy"] == accelerator_not_trained["accuracy"]
), f'Accuracy should be the same for the baseline and accelerator: {baseline_not_trained["accuracy"]} == {accelerator_not_trained["accuracy"]}'
assert (
baseline_not_trained["f1"] == accelerator_not_trained["f1"]
), f'F1 score should be the same for the baseline and accelerator: {baseline_not_trained["f1"]} == {accelerator_not_trained["f1"]}'
assert (
baseline_trained["accuracy"] == accelerator_trained["accuracy"]
), f'Accuracy should be the same for the baseline and accelerator: {baseline_trained["accuracy"]} == {accelerator_trained["accuracy"]}'
assert (
baseline_trained["f1"] == accelerator_trained["f1"]
), f'F1 score should be the same for the baseline and accelerator: {baseline_trained["f1"]} == {accelerator_trained["f1"]}'
| 2 |
0 | hf_public_repos/accelerate/benchmarks/fp8 | hf_public_repos/accelerate/benchmarks/fp8/ms_amp/Dockerfile | FROM ghcr.io/azure/msamp
RUN pip install transformers evaluate datasets
RUN git clone https://github.com/huggingface/accelerate
RUN cd accelerate && \
pip install -e . && \
cd benchmarks/fp8
CMD ["bash"]
| 3 |
0 | hf_public_repos/accelerate/benchmarks/fp8 | hf_public_repos/accelerate/benchmarks/fp8/ms_amp/ddp.py | # Copyright 2024 The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""
This script tests to ensure that `accelerate` performs at the same level as raw `MS-AMP`.
This particular script verifies this for DDP training.
"""
import evaluate
import msamp
import torch
from fp8_utils import evaluate_model, get_training_utilities
from torch.nn.parallel import DistributedDataParallel as DDP
from accelerate import Accelerator
from accelerate.state import AcceleratorState
from accelerate.utils import FP8RecipeKwargs, get_grad_scaler, set_seed
MODEL_NAME = "bert-base-cased"
METRIC = evaluate.load("glue", "mrpc")
def train_baseline(opt_level="O2"):
set_seed(42)
scaler = get_grad_scaler()
model, optimizer, train_dataloader, eval_dataloader, lr_scheduler = get_training_utilities(MODEL_NAME)
accelerator = Accelerator()
device = accelerator.device
model, optimizer = msamp.initialize(model, optimizer, opt_level=opt_level)
model.to(device)
# Convert the model to DDP
device_ids, output_device = [accelerator.local_process_index], accelerator.local_process_index
model = DDP(model, device_ids=device_ids, output_device=output_device)
base_model_results = evaluate_model(model, eval_dataloader, METRIC, accelerator=accelerator)
model.train()
for i, batch in enumerate(train_dataloader):
with torch.autocast(device_type="cuda", dtype=torch.bfloat16):
outputs = model(**batch)
loss = outputs.loss
scaler.scale(loss).backward()
optimizer.step()
optimizer.zero_grad()
lr_scheduler.step()
trained_model_results = evaluate_model(model, eval_dataloader, METRIC, accelerator=accelerator)
assert (
trained_model_results["accuracy"] > base_model_results["accuracy"]
), f'Accuracy should be higher for the trained model: {trained_model_results["accuracy"]} > {base_model_results["accuracy"]}'
assert (
trained_model_results["f1"] > base_model_results["f1"]
), f'F1 score should be higher for the trained model: {trained_model_results["f1"]} > {base_model_results["f1"]}'
return base_model_results, trained_model_results
def train_integration(opt_level="O2"):
kwargs_handlers = [FP8RecipeKwargs(backend="msamp", opt_level=opt_level)]
AcceleratorState()._reset_state(True)
accelerator = Accelerator(mixed_precision="fp8", kwargs_handlers=kwargs_handlers)
set_seed(42)
model, optimizer, train_dataloader, eval_dataloader, lr_scheduler = get_training_utilities(
MODEL_NAME, accelerator=accelerator
)
model, optimizer = accelerator.prepare(model, optimizer)
base_model_results = evaluate_model(model, eval_dataloader, METRIC, accelerator=accelerator)
model.train()
for i, batch in enumerate(train_dataloader):
with torch.autocast(device_type="cuda", dtype=torch.bfloat16):
outputs = model(**batch)
loss = outputs.loss
accelerator.backward(loss)
optimizer.step()
optimizer.zero_grad()
lr_scheduler.step()
trained_model_results = evaluate_model(model, eval_dataloader, METRIC, accelerator=accelerator)
assert (
trained_model_results["accuracy"] > base_model_results["accuracy"]
), f'Accuracy should be higher for the trained model: {trained_model_results["accuracy"]} > {base_model_results["accuracy"]}'
assert (
trained_model_results["f1"] > base_model_results["f1"]
), f'F1 score should be higher for the trained model: {trained_model_results["f1"]} > {base_model_results["f1"]}'
return base_model_results, trained_model_results
if __name__ == "__main__":
for opt_level in ["O1", "O2"]:
baseline_not_trained, baseline_trained = train_baseline(opt_level)
accelerator_not_trained, accelerator_trained = train_integration(opt_level)
assert (
baseline_not_trained["accuracy"] == accelerator_not_trained["accuracy"]
), f'Accuracy not the same for untrained baseline and accelerator using opt_level={opt_level}: {baseline_not_trained["accuracy"]} == {accelerator_not_trained["accuracy"]}'
assert (
baseline_not_trained["f1"] == accelerator_not_trained["f1"]
), f'F1 not the same for untrained baseline and accelerator using opt_level={opt_level}: {baseline_not_trained["f1"]} == {accelerator_not_trained["f1"]}'
assert (
baseline_trained["accuracy"] == accelerator_trained["accuracy"]
), f'Accuracy not the same for trained baseline and accelerator using opt_level={opt_level}: {baseline_trained["accuracy"]} == {accelerator_trained["accuracy"]}'
assert (
baseline_trained["f1"] == accelerator_trained["f1"]
), f'F1 not the same for trained baseline and accelerator using opt_level={opt_level}: {baseline_trained["f1"]} == {accelerator_trained["f1"]}'
| 4 |
0 | hf_public_repos/accelerate/benchmarks/fp8 | hf_public_repos/accelerate/benchmarks/fp8/ms_amp/fp8_utils.py | # Copyright 2024 The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import torch
def get_dataloaders(model_name: str, batch_size: int = 16):
from datasets import load_dataset
from torch.utils.data import DataLoader
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained(model_name)
datasets = load_dataset("glue", "mrpc")
def tokenize_function(examples):
# max_length=None => use the model max length (it's actually the default)
outputs = tokenizer(examples["sentence1"], examples["sentence2"], truncation=True, max_length=None)
return outputs
# Apply the method we just defined to all the examples in all the splits of the dataset
# starting with the main process first:
tokenized_datasets = datasets.map(
tokenize_function,
batched=True,
remove_columns=["idx", "sentence1", "sentence2"],
)
# We also rename the 'label' column to 'labels' which is the expected name for labels by the models of the
# transformers library
tokenized_datasets = tokenized_datasets.rename_column("label", "labels")
def collate_fn(examples):
return tokenizer.pad(
examples,
padding="longest",
pad_to_multiple_of=16, # Specific for FP8
return_tensors="pt",
)
# Instantiate dataloaders.
train_dataloader = DataLoader(
tokenized_datasets["train"], shuffle=True, collate_fn=collate_fn, batch_size=batch_size, drop_last=True
)
eval_dataloader = DataLoader(
tokenized_datasets["validation"],
shuffle=False,
collate_fn=collate_fn,
batch_size=16,
drop_last=True,
)
return train_dataloader, eval_dataloader
def get_training_utilities(model_name: str, batch_size: int = 16, accelerator=None):
"""
Returns a tuple of:
- Model
- Optimizer
- Train dataloader (prepared)
- Eval dataloader (prepared)
- LR Scheduler
Suitable for training on the MRPC dataset
"""
from torch.optim import AdamW
from transformers import AutoModelForSequenceClassification, get_linear_schedule_with_warmup
from accelerate import Accelerator
if accelerator is None:
accelerator = Accelerator()
model = AutoModelForSequenceClassification.from_pretrained(model_name)
train_dataloader, eval_dataloader = get_dataloaders(model_name, batch_size)
optimizer = AdamW(model.parameters(), lr=0.0001)
lr_scheduler = get_linear_schedule_with_warmup(
optimizer=optimizer,
num_warmup_steps=100,
num_training_steps=len(train_dataloader) * 2,
)
train_dataloader, eval_dataloader = accelerator.prepare(train_dataloader, eval_dataloader)
return model, optimizer, train_dataloader, eval_dataloader, lr_scheduler
def get_named_parameters(model):
"""
Same thing as `Accelerator.get_named_parameters` Returns a list of the named parameters of the model (extracted
from parallel)
"""
from accelerate.utils import extract_model_from_parallel
model = extract_model_from_parallel(model)
return {n: p for n, p in model.named_parameters()}
def evaluate_model(model, dataloader, metric, accelerator=None):
"Turns model to .eval(), runs dataloader, calculates metric, then turns eval back on"
model.eval()
for step, batch in enumerate(dataloader):
with torch.no_grad():
# W/ MS-AMP, we need to cast while evaluating
with torch.autocast(device_type="cuda", dtype=torch.bfloat16):
outputs = model(**batch)
predictions = outputs.logits.argmax(dim=-1)
references = batch["labels"]
if accelerator is not None and accelerator.num_processes > 1:
predictions, references = accelerator.gather_for_metrics((predictions, references))
metric.add_batch(predictions=predictions, references=references)
return metric.compute()
| 5 |
0 | hf_public_repos/accelerate/benchmarks/fp8 | hf_public_repos/accelerate/benchmarks/fp8/ms_amp/distrib_deepspeed.py | # Copyright 2024 The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""
This script tests to ensure that `accelerate` performs at the same level as raw `MS-AMP`.
This particular script verifies this for DeepSpeed training.
NOTE: MS-AMP does *not* support ZeRO-3.
"""
# import msamp.deepspeed as msamp_deepspeed
import evaluate
import torch
from fp8_utils import evaluate_model, get_training_utilities
from msamp import deepspeed as msamp_deepspeed
from accelerate import Accelerator, DeepSpeedPlugin
from accelerate.state import AcceleratorState
from accelerate.utils import set_seed
MODEL_NAME = "bert-base-cased"
METRIC = evaluate.load("glue", "mrpc")
def train_baseline(zero_stage: int = 1, opt_level: str = "O1"):
set_seed(42)
accelerator = Accelerator()
model, optimizer, train_dataloader, eval_dataloader, lr_scheduler = get_training_utilities(
MODEL_NAME, accelerator=accelerator
)
import numpy as np
config = {
"train_batch_size": 32,
"train_micro_batch_size_per_gpu": 16,
"gradient_accumulation_steps": 1,
"zero_optimization": {
"stage": zero_stage,
"offload_optimizer": {"device": "none", "nvme_path": None},
"offload_param": {"device": "none", "nvme_path": None},
},
"gradient_clipping": 1.0,
"steps_per_print": np.inf,
"bf16": {"enabled": True},
"fp16": {"enabled": False},
"zero_allow_untested_optimizer": True,
"msamp": {
"enabled": True,
"opt_level": opt_level,
},
}
(
model,
optimizer,
_,
_,
) = msamp_deepspeed.initialize(
model=model,
optimizer=optimizer,
config_params=config,
)
base_model_results = evaluate_model(model, eval_dataloader, METRIC, accelerator=accelerator)
model.train()
for _ in range(2):
for batch in train_dataloader:
outputs = model(**batch)
loss = outputs.loss
model.backward(loss)
model.step()
for _ in range(accelerator.num_processes):
lr_scheduler.step()
trained_model_results = evaluate_model(model, eval_dataloader, METRIC, accelerator=accelerator)
model.destroy()
torch.cuda.empty_cache()
AcceleratorState()._reset_state(True)
assert (
trained_model_results["accuracy"] > base_model_results["accuracy"]
), f'Accuracy should be higher for the trained model: {trained_model_results["accuracy"]} > {base_model_results["accuracy"]}'
assert (
trained_model_results["f1"] > base_model_results["f1"]
), f'F1 score should be higher for the trained model: {trained_model_results["f1"]} > {base_model_results["f1"]}'
return base_model_results, trained_model_results
def train_integration(zero_stage: int = 1, opt_level: str = "O1"):
set_seed(42)
deepspeed_plugin = DeepSpeedPlugin(
zero_stage=zero_stage,
enable_msamp=True,
msamp_opt_level=opt_level,
)
accelerator = Accelerator(mixed_precision="fp8", deepspeed_plugin=deepspeed_plugin)
accelerator.state.deepspeed_plugin.deepspeed_config["train_micro_batch_size_per_gpu"] = 16
model, optimizer, train_dataloader, eval_dataloader, lr_scheduler = get_training_utilities(
MODEL_NAME, accelerator=accelerator
)
model, optimizer, lr_scheduler = accelerator.prepare(model, optimizer, lr_scheduler)
base_model_results = evaluate_model(model, eval_dataloader, METRIC, accelerator=accelerator)
model.train()
for _ in range(2):
for batch in train_dataloader:
outputs = model(**batch)
loss = outputs.loss
accelerator.backward(loss)
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad()
trained_model_results = evaluate_model(model, eval_dataloader, METRIC, accelerator=accelerator)
model.destroy()
torch.cuda.empty_cache()
assert (
trained_model_results["accuracy"] > base_model_results["accuracy"]
), f'Accuracy should be higher for the trained model: {trained_model_results["accuracy"]} > {base_model_results["accuracy"]}'
assert (
trained_model_results["f1"] > base_model_results["f1"]
), f'F1 score should be higher for the trained model: {trained_model_results["f1"]} > {base_model_results["f1"]}'
AcceleratorState()._reset_state(True)
return base_model_results, trained_model_results
if __name__ == "__main__":
for zero_stage in [1, 2]:
for opt_level in ["O1", "O2", "O3"]:
baseline_not_trained, baseline_trained = train_baseline(zero_stage, opt_level)
accelerator_not_trained, accelerator_trained = train_integration(zero_stage, opt_level)
assert (
baseline_not_trained["accuracy"] == accelerator_not_trained["accuracy"]
), f'ZERO stage {zero_stage}, opt_level={opt_level}:\nAccuracy should be the same for the baseline and accelerator: {baseline_not_trained["accuracy"]} == {accelerator_not_trained["accuracy"]}'
assert (
baseline_not_trained["f1"] == accelerator_not_trained["f1"]
), f'ZERO stage {zero_stage}, opt_level={opt_level}:\nF1 score should be the same for the baseline and accelerator: {baseline_not_trained["f1"]} == {accelerator_not_trained["f1"]}'
assert (
baseline_trained["accuracy"] == accelerator_trained["accuracy"]
), f'ZERO stage {zero_stage}, opt_level={opt_level}:\nAccuracy should be the same for the baseline and accelerator: {baseline_trained["accuracy"]} == {accelerator_trained["accuracy"]}'
assert (
baseline_trained["f1"] == accelerator_trained["f1"]
), f'ZERO stage {zero_stage}, opt_level={opt_level}:\nF1 score should be the same for the baseline and accelerator: {baseline_trained["f1"]} == {accelerator_trained["f1"]}'
torch.distributed.destroy_process_group()
| 6 |
0 | hf_public_repos/accelerate/benchmarks/fp8 | hf_public_repos/accelerate/benchmarks/fp8/ms_amp/non_distributed.py | # Copyright 2024 The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""
This script tests to ensure that `accelerate` performs at the same level as raw `MS-AMP`.
This particular script verifies this for single GPU training.
"""
import evaluate
import msamp
import torch
from fp8_utils import evaluate_model, get_training_utilities
from accelerate import Accelerator
from accelerate.state import AcceleratorState
from accelerate.utils import FP8RecipeKwargs, get_grad_scaler, set_seed
MODEL_NAME = "bert-base-cased"
METRIC = evaluate.load("glue", "mrpc")
def train_baseline(opt_level="O2"):
set_seed(42)
model, optimizer, train_dataloader, eval_dataloader, lr_scheduler = get_training_utilities(MODEL_NAME)
model, optimizer = msamp.initialize(model, optimizer, opt_level=opt_level)
model.to("cuda")
base_model_results = evaluate_model(model, eval_dataloader, METRIC)
model.train()
scaler = get_grad_scaler()
for batch in train_dataloader:
batch = batch.to("cuda")
with torch.autocast(device_type="cuda", dtype=torch.bfloat16):
outputs = model(**batch)
loss = outputs.loss
loss = scaler.scale(loss)
loss.backward()
optimizer.step()
optimizer.zero_grad()
lr_scheduler.step()
trained_model_results = evaluate_model(model, eval_dataloader, METRIC)
assert (
trained_model_results["accuracy"] > base_model_results["accuracy"]
), f'Accuracy should be higher for the trained model: {trained_model_results["accuracy"]} > {base_model_results["accuracy"]}'
assert (
trained_model_results["f1"] > base_model_results["f1"]
), f'F1 score should be higher for the trained model: {trained_model_results["f1"]} > {base_model_results["f1"]}'
return base_model_results, trained_model_results
def train_integration(opt_level="O2"):
kwargs_handlers = [FP8RecipeKwargs(backend="msamp", opt_level=opt_level)]
AcceleratorState()._reset_state(True)
accelerator = Accelerator(mixed_precision="fp8", kwargs_handlers=kwargs_handlers)
set_seed(42)
model, optimizer, train_dataloader, eval_dataloader, lr_scheduler = get_training_utilities(
MODEL_NAME, accelerator=accelerator
)
model, optimizer, lr_scheduler = accelerator.prepare(model, optimizer, lr_scheduler)
base_model_results = evaluate_model(model, eval_dataloader, METRIC)
model.train()
for batch in train_dataloader:
outputs = model(**batch)
loss = outputs.loss
accelerator.backward(loss)
optimizer.step()
optimizer.zero_grad()
lr_scheduler.step()
trained_model_results = evaluate_model(model, eval_dataloader, METRIC)
assert (
trained_model_results["accuracy"] > base_model_results["accuracy"]
), f'Accuracy should be higher for the trained model: {trained_model_results["accuracy"]} > {base_model_results["accuracy"]}'
assert (
trained_model_results["f1"] > base_model_results["f1"]
), f'F1 score should be higher for the trained model: {trained_model_results["f1"]} > {base_model_results["f1"]}'
return base_model_results, trained_model_results
if __name__ == "__main__":
for opt_level in ["O1", "O2"]:
baseline_not_trained, baseline_trained = train_baseline(opt_level)
accelerator_not_trained, accelerator_trained = train_integration(opt_level)
assert (
baseline_not_trained["accuracy"] == accelerator_not_trained["accuracy"]
), f'Accuracy should be the same for the baseline and accelerator: {baseline_not_trained["accuracy"]} == {accelerator_not_trained["accuracy"]}'
assert (
baseline_not_trained["f1"] == accelerator_not_trained["f1"]
), f'F1 score should be the same for the baseline and accelerator: {baseline_not_trained["f1"]} == {accelerator_not_trained["f1"]}'
assert (
baseline_trained["accuracy"] == accelerator_trained["accuracy"]
), f'Accuracy should be the same for the baseline and accelerator: {baseline_trained["accuracy"]} == {accelerator_trained["accuracy"]}'
assert (
baseline_trained["f1"] == accelerator_trained["f1"]
), f'F1 score should be the same for the baseline and accelerator: {baseline_trained["f1"]} == {accelerator_trained["f1"]}'
| 7 |
0 | hf_public_repos/accelerate | hf_public_repos/accelerate/tests/test_examples.py | # Copyright 2022 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import ast
import os
import re
import shutil
import tempfile
import unittest
from pathlib import Path
from unittest import mock, skip
import torch
from accelerate.test_utils.examples import compare_against_test
from accelerate.test_utils.testing import (
TempDirTestCase,
get_launch_command,
require_huggingface_suite,
require_multi_device,
require_multi_gpu,
require_non_xpu,
require_pippy,
require_schedulefree,
require_trackers,
run_command,
slow,
)
from accelerate.utils import write_basic_config
# DataLoaders built from `test_samples/MRPC` for quick testing
# Should mock `{script_name}.get_dataloaders` via:
# @mock.patch("{script_name}.get_dataloaders", mocked_dataloaders)
EXCLUDE_EXAMPLES = [
"cross_validation.py",
"checkpointing.py",
"gradient_accumulation.py",
"local_sgd.py",
"multi_process_metrics.py",
"memory.py",
"schedule_free.py",
"tracking.py",
"automatic_gradient_accumulation.py",
"fsdp_with_peak_mem_tracking.py",
"deepspeed_with_config_support.py",
"megatron_lm_gpt_pretraining.py",
"early_stopping.py",
"ddp_comm_hook.py",
"profiler.py",
]
class ExampleDifferenceTests(unittest.TestCase):
"""
This TestCase checks that all of the `complete_*` scripts contain all of the
information found in the `by_feature` scripts, line for line. If one fails,
then a complete example does not contain all of the features in the features
scripts, and should be updated.
Each example script should be a single test (such as `test_nlp_example`),
and should run `one_complete_example` twice: once with `parser_only=True`,
and the other with `parser_only=False`. This is so that when the test
failures are returned to the user, they understand if the discrepancy lies in
the `main` function, or the `training_loop` function. Otherwise it will be
unclear.
Also, if there are any expected differences between the base script used and
`complete_nlp_example.py` (the canonical base script), these should be included in
`special_strings`. These would be differences in how something is logged, print statements,
etc (such as calls to `Accelerate.log()`)
"""
by_feature_path = Path("examples", "by_feature").resolve()
examples_path = Path("examples").resolve()
def one_complete_example(
self, complete_file_name: str, parser_only: bool, secondary_filename: str = None, special_strings: list = None
):
"""
Tests a single `complete` example against all of the implemented `by_feature` scripts
Args:
complete_file_name (`str`):
The filename of a complete example
parser_only (`bool`):
Whether to look at the main training function, or the argument parser
secondary_filename (`str`, *optional*):
A potential secondary base file to strip all script information not relevant for checking,
such as "cv_example.py" when testing "complete_cv_example.py"
special_strings (`list`, *optional*):
A list of strings to potentially remove before checking no differences are left. These should be
diffs that are file specific, such as different logging variations between files.
"""
self.maxDiff = None
for item in os.listdir(self.by_feature_path):
if item not in EXCLUDE_EXAMPLES:
item_path = self.by_feature_path / item
if item_path.is_file() and item_path.suffix == ".py":
with self.subTest(
tested_script=complete_file_name,
feature_script=item,
tested_section="main()" if parser_only else "training_function()",
):
diff = compare_against_test(
self.examples_path / complete_file_name, item_path, parser_only, secondary_filename
)
diff = "\n".join(diff)
if special_strings is not None:
for string in special_strings:
diff = diff.replace(string, "")
assert diff == ""
def test_nlp_examples(self):
self.one_complete_example("complete_nlp_example.py", True)
self.one_complete_example("complete_nlp_example.py", False)
def test_cv_examples(self):
cv_path = (self.examples_path / "cv_example.py").resolve()
special_strings = [
" " * 16 + "{\n\n",
" " * 20 + '"accuracy": eval_metric["accuracy"],\n\n',
" " * 20 + '"f1": eval_metric["f1"],\n\n',
" " * 20 + '"train_loss": total_loss.item() / len(train_dataloader),\n\n',
" " * 20 + '"epoch": epoch,\n\n',
" " * 16 + "},\n\n",
" " * 16 + "step=epoch,\n",
" " * 12,
" " * 8 + "for step, batch in enumerate(active_dataloader):\n",
]
self.one_complete_example("complete_cv_example.py", True, cv_path, special_strings)
self.one_complete_example("complete_cv_example.py", False, cv_path, special_strings)
@mock.patch.dict(os.environ, {"TESTING_MOCKED_DATALOADERS": "1"})
@require_huggingface_suite
class FeatureExamplesTests(TempDirTestCase):
clear_on_setup = False
@classmethod
def setUpClass(cls):
super().setUpClass()
cls._tmpdir = tempfile.mkdtemp()
cls.config_file = Path(cls._tmpdir) / "default_config.yml"
write_basic_config(save_location=cls.config_file)
cls.launch_args = get_launch_command(config_file=cls.config_file)
@classmethod
def tearDownClass(cls):
super().tearDownClass()
shutil.rmtree(cls._tmpdir)
def test_checkpointing_by_epoch(self):
testargs = f"""
examples/by_feature/checkpointing.py
--checkpointing_steps epoch
--output_dir {self.tmpdir}
""".split()
run_command(self.launch_args + testargs)
assert (self.tmpdir / "epoch_0").exists()
def test_checkpointing_by_steps(self):
testargs = f"""
examples/by_feature/checkpointing.py
--checkpointing_steps 1
--output_dir {self.tmpdir}
""".split()
_ = run_command(self.launch_args + testargs)
assert (self.tmpdir / "step_2").exists()
def test_load_states_by_epoch(self):
testargs = f"""
examples/by_feature/checkpointing.py
--resume_from_checkpoint {self.tmpdir / "epoch_0"}
""".split()
output = run_command(self.launch_args + testargs, return_stdout=True)
assert "epoch 0:" not in output
assert "epoch 1:" in output
def test_load_states_by_steps(self):
testargs = f"""
examples/by_feature/checkpointing.py
--resume_from_checkpoint {self.tmpdir / "step_2"}
""".split()
output = run_command(self.launch_args + testargs, return_stdout=True)
if torch.cuda.is_available():
num_processes = torch.cuda.device_count()
else:
num_processes = 1
if num_processes > 1:
assert "epoch 0:" not in output
assert "epoch 1:" in output
else:
assert "epoch 0:" in output
assert "epoch 1:" in output
@slow
def test_cross_validation(self):
testargs = """
examples/by_feature/cross_validation.py
--num_folds 2
""".split()
with mock.patch.dict(os.environ, {"TESTING_MOCKED_DATALOADERS": "0"}):
output = run_command(self.launch_args + testargs, return_stdout=True)
results = re.findall("({.+})", output)
results = [r for r in results if "accuracy" in r][-1]
results = ast.literal_eval(results)
assert results["accuracy"] >= 0.75
def test_multi_process_metrics(self):
testargs = ["examples/by_feature/multi_process_metrics.py"]
run_command(self.launch_args + testargs)
@require_schedulefree
def test_schedulefree(self):
testargs = ["examples/by_feature/schedule_free.py"]
run_command(self.launch_args + testargs)
@require_trackers
@mock.patch.dict(os.environ, {"WANDB_MODE": "offline", "DVCLIVE_TEST": "true"})
def test_tracking(self):
with tempfile.TemporaryDirectory() as tmpdir:
testargs = f"""
examples/by_feature/tracking.py
--with_tracking
--project_dir {tmpdir}
""".split()
run_command(self.launch_args + testargs)
assert os.path.exists(os.path.join(tmpdir, "tracking"))
def test_gradient_accumulation(self):
testargs = ["examples/by_feature/gradient_accumulation.py"]
run_command(self.launch_args + testargs)
def test_local_sgd(self):
testargs = ["examples/by_feature/local_sgd.py"]
run_command(self.launch_args + testargs)
def test_early_stopping(self):
testargs = ["examples/by_feature/early_stopping.py"]
run_command(self.launch_args + testargs)
def test_profiler(self):
testargs = ["examples/by_feature/profiler.py"]
run_command(self.launch_args + testargs)
@require_multi_device
def test_ddp_comm_hook(self):
testargs = ["examples/by_feature/ddp_comm_hook.py", "--ddp_comm_hook", "fp16"]
run_command(self.launch_args + testargs)
@skip(
reason="stable-diffusion-v1-5 is no longer available. Potentially `Comfy-Org/stable-diffusion-v1-5-archive` once diffusers support is added."
)
@require_multi_device
def test_distributed_inference_examples_stable_diffusion(self):
testargs = ["examples/inference/distributed/stable_diffusion.py"]
run_command(self.launch_args + testargs)
@require_multi_device
def test_distributed_inference_examples_phi2(self):
testargs = ["examples/inference/distributed/phi2.py"]
run_command(self.launch_args + testargs)
@require_non_xpu
@require_pippy
@require_multi_gpu
def test_pippy_examples_bert(self):
testargs = ["examples/inference/pippy/bert.py"]
run_command(self.launch_args + testargs)
@require_non_xpu
@require_pippy
@require_multi_gpu
def test_pippy_examples_gpt2(self):
testargs = ["examples/inference/pippy/gpt2.py"]
run_command(self.launch_args + testargs)
| 8 |
0 | hf_public_repos/accelerate | hf_public_repos/accelerate/tests/test_scheduler.py | # Copyright 2021 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import unittest
from functools import partial
import torch
from accelerate import Accelerator, debug_launcher
from accelerate.state import AcceleratorState, GradientState
from accelerate.test_utils import require_cpu, require_huggingface_suite
from accelerate.utils import GradientAccumulationPlugin
def one_cycle_test(num_processes=2, step_scheduler_with_optimizer=True, split_batches=False):
accelerator = Accelerator(step_scheduler_with_optimizer=step_scheduler_with_optimizer, split_batches=split_batches)
model = torch.nn.Linear(2, 4)
optimizer = torch.optim.AdamW(model.parameters(), lr=1.0)
scheduler = torch.optim.lr_scheduler.OneCycleLR(optimizer, max_lr=0.01, steps_per_epoch=2, epochs=1)
model, optimizer, scheduler = accelerator.prepare(model, optimizer, scheduler)
# Optimizer has stepped
scheduler.step()
if step_scheduler_with_optimizer or (num_processes == 1):
assert (
scheduler.scheduler.last_epoch == num_processes
), f"Last Epoch ({scheduler.scheduler.last_epoch}) != Num Processes ({num_processes})"
else:
assert (
scheduler.scheduler.last_epoch != num_processes
), f"Last Epoch ({scheduler.scheduler.last_epoch}) == Num Processes ({num_processes})"
def lambda_test(num_processes=2, step_scheduler_with_optimizer=True, split_batches=False):
accelerator = Accelerator(step_scheduler_with_optimizer=step_scheduler_with_optimizer, split_batches=split_batches)
model = torch.nn.Linear(2, 4)
optimizer = torch.optim.AdamW(model.parameters(), lr=1.0)
scheduler = torch.optim.lr_scheduler.LambdaLR(optimizer, lr_lambda=lambda n: 1 - n / 10)
model, optimizer, scheduler = accelerator.prepare(model, optimizer, scheduler)
# Optimizer has stepped
optimizer._is_overflow = False
scheduler.step()
expected_lr = 1 - (num_processes if (step_scheduler_with_optimizer and not split_batches) else 1) / 10
assert (
scheduler.get_last_lr()[0] == expected_lr
), f"Wrong lr found at first step, expected {expected_lr}, got {scheduler.get_last_lr()[0]}"
# Optimizer has not stepped
optimizer._is_overflow = True
scheduler.step()
if not step_scheduler_with_optimizer:
expected_lr = 1 - 2 / 10
assert (
scheduler.get_last_lr()[0] == expected_lr
), f"Wrong lr found at second step, expected {expected_lr}, got {scheduler.get_last_lr()[0]}"
def accumulation_test(num_processes: int = 2):
"""
With this test, an observed batch size of 64 should result in neglible
differences in the scheduler after going through the correct number of steps.
Uses single, two, and four steps to test.
"""
from transformers import get_linear_schedule_with_warmup
steps = [1, 2, 4]
for num_steps in steps:
plugin = GradientAccumulationPlugin(num_steps=num_steps, adjust_scheduler=num_steps > 1)
accelerator = Accelerator(gradient_accumulation_plugin=plugin)
model = torch.nn.Linear(2, 4)
optimizer = torch.optim.AdamW(model.parameters(), lr=10.0)
scheduler = get_linear_schedule_with_warmup(optimizer=optimizer, num_warmup_steps=0, num_training_steps=20)
model, optimizer, scheduler = accelerator.prepare(model, optimizer, scheduler)
for i in range(10 * num_steps):
with accelerator.accumulate(model):
optimizer.step()
scheduler.step()
if i == (10 * num_steps - 2):
assert (
scheduler.get_last_lr()[0] != 0
), f"Wrong lr found at second-to-last step, expected non-zero, got {scheduler.get_last_lr()[0]}. num_steps: {num_steps}"
assert (
scheduler.get_last_lr()[0] == 0
), f"Wrong lr found at last step, expected 0, got {scheduler.get_last_lr()[0]}"
GradientState._reset_state()
@require_cpu
class SchedulerTester(unittest.TestCase):
def test_lambda_scheduler_steps_with_optimizer_single_process(self):
debug_launcher(partial(lambda_test, num_processes=1), num_processes=1)
debug_launcher(partial(lambda_test, num_processes=1, split_batches=True), num_processes=1)
def test_one_cycle_scheduler_steps_with_optimizer_single_process(self):
debug_launcher(partial(one_cycle_test, num_processes=1), num_processes=1)
debug_launcher(partial(one_cycle_test, num_processes=1, split_batches=True), num_processes=1)
def test_lambda_scheduler_not_step_with_optimizer_single_process(self):
debug_launcher(partial(lambda_test, num_processes=1, step_scheduler_with_optimizer=False), num_processes=1)
def test_one_cycle_scheduler_not_step_with_optimizer_single_process(self):
debug_launcher(partial(one_cycle_test, num_processes=1, step_scheduler_with_optimizer=False), num_processes=1)
def test_lambda_scheduler_steps_with_optimizer_multiprocess(self):
AcceleratorState._reset_state(True)
debug_launcher(lambda_test)
debug_launcher(partial(lambda_test, num_processes=1, split_batches=True), num_processes=1)
def test_one_cycle_scheduler_steps_with_optimizer_multiprocess(self):
AcceleratorState._reset_state(True)
debug_launcher(one_cycle_test)
debug_launcher(partial(one_cycle_test, num_processes=1, split_batches=True), num_processes=1)
def test_lambda_scheduler_not_step_with_optimizer_multiprocess(self):
AcceleratorState._reset_state(True)
debug_launcher(partial(lambda_test, step_scheduler_with_optimizer=False))
def test_one_cycle_scheduler_not_step_with_optimizer_multiprocess(self):
AcceleratorState._reset_state(True)
debug_launcher(partial(one_cycle_test, step_scheduler_with_optimizer=False))
@require_huggingface_suite
def test_accumulation(self):
AcceleratorState._reset_state(True)
debug_launcher(partial(accumulation_test, num_processes=1))
debug_launcher(accumulation_test)
| 9 |
0 | hf_public_repos/candle/candle-examples/examples | hf_public_repos/candle/candle-examples/examples/yolo-v8/main.rs | #[cfg(feature = "mkl")]
extern crate intel_mkl_src;
#[cfg(feature = "accelerate")]
extern crate accelerate_src;
mod model;
use model::{Multiples, YoloV8, YoloV8Pose};
use candle::{DType, Device, IndexOp, Result, Tensor};
use candle_nn::{Module, VarBuilder};
use candle_transformers::object_detection::{non_maximum_suppression, Bbox, KeyPoint};
use clap::{Parser, ValueEnum};
use image::DynamicImage;
// Keypoints as reported by ChatGPT :)
// Nose
// Left Eye
// Right Eye
// Left Ear
// Right Ear
// Left Shoulder
// Right Shoulder
// Left Elbow
// Right Elbow
// Left Wrist
// Right Wrist
// Left Hip
// Right Hip
// Left Knee
// Right Knee
// Left Ankle
// Right Ankle
const KP_CONNECTIONS: [(usize, usize); 16] = [
(0, 1),
(0, 2),
(1, 3),
(2, 4),
(5, 6),
(5, 11),
(6, 12),
(11, 12),
(5, 7),
(6, 8),
(7, 9),
(8, 10),
(11, 13),
(12, 14),
(13, 15),
(14, 16),
];
// Model architecture from https://github.com/ultralytics/ultralytics/issues/189
// https://github.com/tinygrad/tinygrad/blob/master/examples/yolov8.py
pub fn report_detect(
pred: &Tensor,
img: DynamicImage,
w: usize,
h: usize,
confidence_threshold: f32,
nms_threshold: f32,
legend_size: u32,
) -> Result<DynamicImage> {
let pred = pred.to_device(&Device::Cpu)?;
let (pred_size, npreds) = pred.dims2()?;
let nclasses = pred_size - 4;
// The bounding boxes grouped by (maximum) class index.
let mut bboxes: Vec<Vec<Bbox<Vec<KeyPoint>>>> = (0..nclasses).map(|_| vec![]).collect();
// Extract the bounding boxes for which confidence is above the threshold.
for index in 0..npreds {
let pred = Vec::<f32>::try_from(pred.i((.., index))?)?;
let confidence = *pred[4..].iter().max_by(|x, y| x.total_cmp(y)).unwrap();
if confidence > confidence_threshold {
let mut class_index = 0;
for i in 0..nclasses {
if pred[4 + i] > pred[4 + class_index] {
class_index = i
}
}
if pred[class_index + 4] > 0. {
let bbox = Bbox {
xmin: pred[0] - pred[2] / 2.,
ymin: pred[1] - pred[3] / 2.,
xmax: pred[0] + pred[2] / 2.,
ymax: pred[1] + pred[3] / 2.,
confidence,
data: vec![],
};
bboxes[class_index].push(bbox)
}
}
}
non_maximum_suppression(&mut bboxes, nms_threshold);
// Annotate the original image and print boxes information.
let (initial_h, initial_w) = (img.height(), img.width());
let w_ratio = initial_w as f32 / w as f32;
let h_ratio = initial_h as f32 / h as f32;
let mut img = img.to_rgb8();
let font = Vec::from(include_bytes!("roboto-mono-stripped.ttf") as &[u8]);
let font = ab_glyph::FontRef::try_from_slice(&font).map_err(candle::Error::wrap)?;
for (class_index, bboxes_for_class) in bboxes.iter().enumerate() {
for b in bboxes_for_class.iter() {
println!(
"{}: {:?}",
candle_examples::coco_classes::NAMES[class_index],
b
);
let xmin = (b.xmin * w_ratio) as i32;
let ymin = (b.ymin * h_ratio) as i32;
let dx = (b.xmax - b.xmin) * w_ratio;
let dy = (b.ymax - b.ymin) * h_ratio;
if dx >= 0. && dy >= 0. {
imageproc::drawing::draw_hollow_rect_mut(
&mut img,
imageproc::rect::Rect::at(xmin, ymin).of_size(dx as u32, dy as u32),
image::Rgb([255, 0, 0]),
);
}
if legend_size > 0 {
imageproc::drawing::draw_filled_rect_mut(
&mut img,
imageproc::rect::Rect::at(xmin, ymin).of_size(dx as u32, legend_size),
image::Rgb([170, 0, 0]),
);
let legend = format!(
"{} {:.0}%",
candle_examples::coco_classes::NAMES[class_index],
100. * b.confidence
);
imageproc::drawing::draw_text_mut(
&mut img,
image::Rgb([255, 255, 255]),
xmin,
ymin,
ab_glyph::PxScale {
x: legend_size as f32 - 1.,
y: legend_size as f32 - 1.,
},
&font,
&legend,
)
}
}
}
Ok(DynamicImage::ImageRgb8(img))
}
pub fn report_pose(
pred: &Tensor,
img: DynamicImage,
w: usize,
h: usize,
confidence_threshold: f32,
nms_threshold: f32,
) -> Result<DynamicImage> {
let pred = pred.to_device(&Device::Cpu)?;
let (pred_size, npreds) = pred.dims2()?;
if pred_size != 17 * 3 + 4 + 1 {
candle::bail!("unexpected pred-size {pred_size}");
}
let mut bboxes = vec![];
// Extract the bounding boxes for which confidence is above the threshold.
for index in 0..npreds {
let pred = Vec::<f32>::try_from(pred.i((.., index))?)?;
let confidence = pred[4];
if confidence > confidence_threshold {
let keypoints = (0..17)
.map(|i| KeyPoint {
x: pred[3 * i + 5],
y: pred[3 * i + 6],
mask: pred[3 * i + 7],
})
.collect::<Vec<_>>();
let bbox = Bbox {
xmin: pred[0] - pred[2] / 2.,
ymin: pred[1] - pred[3] / 2.,
xmax: pred[0] + pred[2] / 2.,
ymax: pred[1] + pred[3] / 2.,
confidence,
data: keypoints,
};
bboxes.push(bbox)
}
}
let mut bboxes = vec![bboxes];
non_maximum_suppression(&mut bboxes, nms_threshold);
let bboxes = &bboxes[0];
// Annotate the original image and print boxes information.
let (initial_h, initial_w) = (img.height(), img.width());
let w_ratio = initial_w as f32 / w as f32;
let h_ratio = initial_h as f32 / h as f32;
let mut img = img.to_rgb8();
for b in bboxes.iter() {
println!("{b:?}");
let xmin = (b.xmin * w_ratio) as i32;
let ymin = (b.ymin * h_ratio) as i32;
let dx = (b.xmax - b.xmin) * w_ratio;
let dy = (b.ymax - b.ymin) * h_ratio;
if dx >= 0. && dy >= 0. {
imageproc::drawing::draw_hollow_rect_mut(
&mut img,
imageproc::rect::Rect::at(xmin, ymin).of_size(dx as u32, dy as u32),
image::Rgb([255, 0, 0]),
);
}
for kp in b.data.iter() {
if kp.mask < 0.6 {
continue;
}
let x = (kp.x * w_ratio) as i32;
let y = (kp.y * h_ratio) as i32;
imageproc::drawing::draw_filled_circle_mut(
&mut img,
(x, y),
2,
image::Rgb([0, 255, 0]),
);
}
for &(idx1, idx2) in KP_CONNECTIONS.iter() {
let kp1 = &b.data[idx1];
let kp2 = &b.data[idx2];
if kp1.mask < 0.6 || kp2.mask < 0.6 {
continue;
}
imageproc::drawing::draw_line_segment_mut(
&mut img,
(kp1.x * w_ratio, kp1.y * h_ratio),
(kp2.x * w_ratio, kp2.y * h_ratio),
image::Rgb([255, 255, 0]),
);
}
}
Ok(DynamicImage::ImageRgb8(img))
}
#[derive(Clone, Copy, ValueEnum, Debug)]
enum Which {
N,
S,
M,
L,
X,
}
#[derive(Clone, Copy, ValueEnum, Debug)]
enum YoloTask {
Detect,
Pose,
}
#[derive(Parser, Debug)]
#[command(author, version, about, long_about = None)]
pub struct Args {
/// Run on CPU rather than on GPU.
#[arg(long)]
cpu: bool,
/// Enable tracing (generates a trace-timestamp.json file).
#[arg(long)]
tracing: bool,
/// Model weights, in safetensors format.
#[arg(long)]
model: Option<String>,
/// Which model variant to use.
#[arg(long, value_enum, default_value_t = Which::S)]
which: Which,
images: Vec<String>,
/// Threshold for the model confidence level.
#[arg(long, default_value_t = 0.25)]
confidence_threshold: f32,
/// Threshold for non-maximum suppression.
#[arg(long, default_value_t = 0.45)]
nms_threshold: f32,
/// The task to be run.
#[arg(long, default_value = "detect")]
task: YoloTask,
/// The size for the legend, 0 means no legend.
#[arg(long, default_value_t = 14)]
legend_size: u32,
}
impl Args {
fn model(&self) -> anyhow::Result<std::path::PathBuf> {
let path = match &self.model {
Some(model) => std::path::PathBuf::from(model),
None => {
let api = hf_hub::api::sync::Api::new()?;
let api = api.model("lmz/candle-yolo-v8".to_string());
let size = match self.which {
Which::N => "n",
Which::S => "s",
Which::M => "m",
Which::L => "l",
Which::X => "x",
};
let task = match self.task {
YoloTask::Pose => "-pose",
YoloTask::Detect => "",
};
api.get(&format!("yolov8{size}{task}.safetensors"))?
}
};
Ok(path)
}
}
pub trait Task: Module + Sized {
fn load(vb: VarBuilder, multiples: Multiples) -> Result<Self>;
fn report(
pred: &Tensor,
img: DynamicImage,
w: usize,
h: usize,
confidence_threshold: f32,
nms_threshold: f32,
legend_size: u32,
) -> Result<DynamicImage>;
}
impl Task for YoloV8 {
fn load(vb: VarBuilder, multiples: Multiples) -> Result<Self> {
YoloV8::load(vb, multiples, /* num_classes=*/ 80)
}
fn report(
pred: &Tensor,
img: DynamicImage,
w: usize,
h: usize,
confidence_threshold: f32,
nms_threshold: f32,
legend_size: u32,
) -> Result<DynamicImage> {
report_detect(
pred,
img,
w,
h,
confidence_threshold,
nms_threshold,
legend_size,
)
}
}
impl Task for YoloV8Pose {
fn load(vb: VarBuilder, multiples: Multiples) -> Result<Self> {
YoloV8Pose::load(vb, multiples, /* num_classes=*/ 1, (17, 3))
}
fn report(
pred: &Tensor,
img: DynamicImage,
w: usize,
h: usize,
confidence_threshold: f32,
nms_threshold: f32,
_legend_size: u32,
) -> Result<DynamicImage> {
report_pose(pred, img, w, h, confidence_threshold, nms_threshold)
}
}
pub fn run<T: Task>(args: Args) -> anyhow::Result<()> {
let device = candle_examples::device(args.cpu)?;
// Create the model and load the weights from the file.
let multiples = match args.which {
Which::N => Multiples::n(),
Which::S => Multiples::s(),
Which::M => Multiples::m(),
Which::L => Multiples::l(),
Which::X => Multiples::x(),
};
let model = args.model()?;
let vb = unsafe { VarBuilder::from_mmaped_safetensors(&[model], DType::F32, &device)? };
let model = T::load(vb, multiples)?;
println!("model loaded");
for image_name in args.images.iter() {
println!("processing {image_name}");
let mut image_name = std::path::PathBuf::from(image_name);
let original_image = image::ImageReader::open(&image_name)?
.decode()
.map_err(candle::Error::wrap)?;
let (width, height) = {
let w = original_image.width() as usize;
let h = original_image.height() as usize;
if w < h {
let w = w * 640 / h;
// Sizes have to be divisible by 32.
(w / 32 * 32, 640)
} else {
let h = h * 640 / w;
(640, h / 32 * 32)
}
};
let image_t = {
let img = original_image.resize_exact(
width as u32,
height as u32,
image::imageops::FilterType::CatmullRom,
);
let data = img.to_rgb8().into_raw();
Tensor::from_vec(
data,
(img.height() as usize, img.width() as usize, 3),
&device,
)?
.permute((2, 0, 1))?
};
let image_t = (image_t.unsqueeze(0)?.to_dtype(DType::F32)? * (1. / 255.))?;
let predictions = model.forward(&image_t)?.squeeze(0)?;
println!("generated predictions {predictions:?}");
let image_t = T::report(
&predictions,
original_image,
width,
height,
args.confidence_threshold,
args.nms_threshold,
args.legend_size,
)?;
image_name.set_extension("pp.jpg");
println!("writing {image_name:?}");
image_t.save(image_name)?
}
Ok(())
}
pub fn main() -> anyhow::Result<()> {
use tracing_chrome::ChromeLayerBuilder;
use tracing_subscriber::prelude::*;
let args = Args::parse();
let _guard = if args.tracing {
let (chrome_layer, guard) = ChromeLayerBuilder::new().build();
tracing_subscriber::registry().with(chrome_layer).init();
Some(guard)
} else {
None
};
match args.task {
YoloTask::Detect => run::<YoloV8>(args)?,
YoloTask::Pose => run::<YoloV8Pose>(args)?,
}
Ok(())
}
| 0 |
0 | hf_public_repos/candle/candle-examples/examples | hf_public_repos/candle/candle-examples/examples/yolo-v8/model.rs | use candle::{DType, IndexOp, Result, Tensor, D};
use candle_nn::{batch_norm, conv2d, conv2d_no_bias, Conv2d, Conv2dConfig, Module, VarBuilder};
#[derive(Clone, Copy, PartialEq, Debug)]
pub struct Multiples {
depth: f64,
width: f64,
ratio: f64,
}
impl Multiples {
pub fn n() -> Self {
Self {
depth: 0.33,
width: 0.25,
ratio: 2.0,
}
}
pub fn s() -> Self {
Self {
depth: 0.33,
width: 0.50,
ratio: 2.0,
}
}
pub fn m() -> Self {
Self {
depth: 0.67,
width: 0.75,
ratio: 1.5,
}
}
pub fn l() -> Self {
Self {
depth: 1.00,
width: 1.00,
ratio: 1.0,
}
}
pub fn x() -> Self {
Self {
depth: 1.00,
width: 1.25,
ratio: 1.0,
}
}
fn filters(&self) -> (usize, usize, usize) {
let f1 = (256. * self.width) as usize;
let f2 = (512. * self.width) as usize;
let f3 = (512. * self.width * self.ratio) as usize;
(f1, f2, f3)
}
}
#[derive(Debug)]
struct Upsample {
scale_factor: usize,
}
impl Upsample {
fn new(scale_factor: usize) -> Result<Self> {
Ok(Upsample { scale_factor })
}
}
impl Module for Upsample {
fn forward(&self, xs: &Tensor) -> candle::Result<Tensor> {
let (_b_size, _channels, h, w) = xs.dims4()?;
xs.upsample_nearest2d(self.scale_factor * h, self.scale_factor * w)
}
}
#[derive(Debug)]
struct ConvBlock {
conv: Conv2d,
span: tracing::Span,
}
impl ConvBlock {
fn load(
vb: VarBuilder,
c1: usize,
c2: usize,
k: usize,
stride: usize,
padding: Option<usize>,
) -> Result<Self> {
let padding = padding.unwrap_or(k / 2);
let cfg = Conv2dConfig {
padding,
stride,
groups: 1,
dilation: 1,
};
let bn = batch_norm(c2, 1e-3, vb.pp("bn"))?;
let conv = conv2d_no_bias(c1, c2, k, cfg, vb.pp("conv"))?.absorb_bn(&bn)?;
Ok(Self {
conv,
span: tracing::span!(tracing::Level::TRACE, "conv-block"),
})
}
}
impl Module for ConvBlock {
fn forward(&self, xs: &Tensor) -> Result<Tensor> {
let _enter = self.span.enter();
let xs = self.conv.forward(xs)?;
candle_nn::ops::silu(&xs)
}
}
#[derive(Debug)]
struct Bottleneck {
cv1: ConvBlock,
cv2: ConvBlock,
residual: bool,
span: tracing::Span,
}
impl Bottleneck {
fn load(vb: VarBuilder, c1: usize, c2: usize, shortcut: bool) -> Result<Self> {
let channel_factor = 1.;
let c_ = (c2 as f64 * channel_factor) as usize;
let cv1 = ConvBlock::load(vb.pp("cv1"), c1, c_, 3, 1, None)?;
let cv2 = ConvBlock::load(vb.pp("cv2"), c_, c2, 3, 1, None)?;
let residual = c1 == c2 && shortcut;
Ok(Self {
cv1,
cv2,
residual,
span: tracing::span!(tracing::Level::TRACE, "bottleneck"),
})
}
}
impl Module for Bottleneck {
fn forward(&self, xs: &Tensor) -> Result<Tensor> {
let _enter = self.span.enter();
let ys = self.cv2.forward(&self.cv1.forward(xs)?)?;
if self.residual {
xs + ys
} else {
Ok(ys)
}
}
}
#[derive(Debug)]
struct C2f {
cv1: ConvBlock,
cv2: ConvBlock,
bottleneck: Vec<Bottleneck>,
span: tracing::Span,
}
impl C2f {
fn load(vb: VarBuilder, c1: usize, c2: usize, n: usize, shortcut: bool) -> Result<Self> {
let c = (c2 as f64 * 0.5) as usize;
let cv1 = ConvBlock::load(vb.pp("cv1"), c1, 2 * c, 1, 1, None)?;
let cv2 = ConvBlock::load(vb.pp("cv2"), (2 + n) * c, c2, 1, 1, None)?;
let mut bottleneck = Vec::with_capacity(n);
for idx in 0..n {
let b = Bottleneck::load(vb.pp(format!("bottleneck.{idx}")), c, c, shortcut)?;
bottleneck.push(b)
}
Ok(Self {
cv1,
cv2,
bottleneck,
span: tracing::span!(tracing::Level::TRACE, "c2f"),
})
}
}
impl Module for C2f {
fn forward(&self, xs: &Tensor) -> Result<Tensor> {
let _enter = self.span.enter();
let ys = self.cv1.forward(xs)?;
let mut ys = ys.chunk(2, 1)?;
for m in self.bottleneck.iter() {
ys.push(m.forward(ys.last().unwrap())?)
}
let zs = Tensor::cat(ys.as_slice(), 1)?;
self.cv2.forward(&zs)
}
}
#[derive(Debug)]
struct Sppf {
cv1: ConvBlock,
cv2: ConvBlock,
k: usize,
span: tracing::Span,
}
impl Sppf {
fn load(vb: VarBuilder, c1: usize, c2: usize, k: usize) -> Result<Self> {
let c_ = c1 / 2;
let cv1 = ConvBlock::load(vb.pp("cv1"), c1, c_, 1, 1, None)?;
let cv2 = ConvBlock::load(vb.pp("cv2"), c_ * 4, c2, 1, 1, None)?;
Ok(Self {
cv1,
cv2,
k,
span: tracing::span!(tracing::Level::TRACE, "sppf"),
})
}
}
impl Module for Sppf {
fn forward(&self, xs: &Tensor) -> Result<Tensor> {
let _enter = self.span.enter();
let (_, _, _, _) = xs.dims4()?;
let xs = self.cv1.forward(xs)?;
let xs2 = xs
.pad_with_zeros(2, self.k / 2, self.k / 2)?
.pad_with_zeros(3, self.k / 2, self.k / 2)?
.max_pool2d_with_stride(self.k, 1)?;
let xs3 = xs2
.pad_with_zeros(2, self.k / 2, self.k / 2)?
.pad_with_zeros(3, self.k / 2, self.k / 2)?
.max_pool2d_with_stride(self.k, 1)?;
let xs4 = xs3
.pad_with_zeros(2, self.k / 2, self.k / 2)?
.pad_with_zeros(3, self.k / 2, self.k / 2)?
.max_pool2d_with_stride(self.k, 1)?;
self.cv2.forward(&Tensor::cat(&[&xs, &xs2, &xs3, &xs4], 1)?)
}
}
#[derive(Debug)]
struct Dfl {
conv: Conv2d,
num_classes: usize,
span: tracing::Span,
}
impl Dfl {
fn load(vb: VarBuilder, num_classes: usize) -> Result<Self> {
let conv = conv2d_no_bias(num_classes, 1, 1, Default::default(), vb.pp("conv"))?;
Ok(Self {
conv,
num_classes,
span: tracing::span!(tracing::Level::TRACE, "dfl"),
})
}
}
impl Module for Dfl {
fn forward(&self, xs: &Tensor) -> Result<Tensor> {
let _enter = self.span.enter();
let (b_sz, _channels, anchors) = xs.dims3()?;
let xs = xs
.reshape((b_sz, 4, self.num_classes, anchors))?
.transpose(2, 1)?;
let xs = candle_nn::ops::softmax(&xs, 1)?;
self.conv.forward(&xs)?.reshape((b_sz, 4, anchors))
}
}
#[derive(Debug)]
struct DarkNet {
b1_0: ConvBlock,
b1_1: ConvBlock,
b2_0: C2f,
b2_1: ConvBlock,
b2_2: C2f,
b3_0: ConvBlock,
b3_1: C2f,
b4_0: ConvBlock,
b4_1: C2f,
b5: Sppf,
span: tracing::Span,
}
impl DarkNet {
fn load(vb: VarBuilder, m: Multiples) -> Result<Self> {
let (w, r, d) = (m.width, m.ratio, m.depth);
let b1_0 = ConvBlock::load(vb.pp("b1.0"), 3, (64. * w) as usize, 3, 2, Some(1))?;
let b1_1 = ConvBlock::load(
vb.pp("b1.1"),
(64. * w) as usize,
(128. * w) as usize,
3,
2,
Some(1),
)?;
let b2_0 = C2f::load(
vb.pp("b2.0"),
(128. * w) as usize,
(128. * w) as usize,
(3. * d).round() as usize,
true,
)?;
let b2_1 = ConvBlock::load(
vb.pp("b2.1"),
(128. * w) as usize,
(256. * w) as usize,
3,
2,
Some(1),
)?;
let b2_2 = C2f::load(
vb.pp("b2.2"),
(256. * w) as usize,
(256. * w) as usize,
(6. * d).round() as usize,
true,
)?;
let b3_0 = ConvBlock::load(
vb.pp("b3.0"),
(256. * w) as usize,
(512. * w) as usize,
3,
2,
Some(1),
)?;
let b3_1 = C2f::load(
vb.pp("b3.1"),
(512. * w) as usize,
(512. * w) as usize,
(6. * d).round() as usize,
true,
)?;
let b4_0 = ConvBlock::load(
vb.pp("b4.0"),
(512. * w) as usize,
(512. * w * r) as usize,
3,
2,
Some(1),
)?;
let b4_1 = C2f::load(
vb.pp("b4.1"),
(512. * w * r) as usize,
(512. * w * r) as usize,
(3. * d).round() as usize,
true,
)?;
let b5 = Sppf::load(
vb.pp("b5.0"),
(512. * w * r) as usize,
(512. * w * r) as usize,
5,
)?;
Ok(Self {
b1_0,
b1_1,
b2_0,
b2_1,
b2_2,
b3_0,
b3_1,
b4_0,
b4_1,
b5,
span: tracing::span!(tracing::Level::TRACE, "darknet"),
})
}
fn forward(&self, xs: &Tensor) -> Result<(Tensor, Tensor, Tensor)> {
let _enter = self.span.enter();
let x1 = self.b1_1.forward(&self.b1_0.forward(xs)?)?;
let x2 = self
.b2_2
.forward(&self.b2_1.forward(&self.b2_0.forward(&x1)?)?)?;
let x3 = self.b3_1.forward(&self.b3_0.forward(&x2)?)?;
let x4 = self.b4_1.forward(&self.b4_0.forward(&x3)?)?;
let x5 = self.b5.forward(&x4)?;
Ok((x2, x3, x5))
}
}
#[derive(Debug)]
struct YoloV8Neck {
up: Upsample,
n1: C2f,
n2: C2f,
n3: ConvBlock,
n4: C2f,
n5: ConvBlock,
n6: C2f,
span: tracing::Span,
}
impl YoloV8Neck {
fn load(vb: VarBuilder, m: Multiples) -> Result<Self> {
let up = Upsample::new(2)?;
let (w, r, d) = (m.width, m.ratio, m.depth);
let n = (3. * d).round() as usize;
let n1 = C2f::load(
vb.pp("n1"),
(512. * w * (1. + r)) as usize,
(512. * w) as usize,
n,
false,
)?;
let n2 = C2f::load(
vb.pp("n2"),
(768. * w) as usize,
(256. * w) as usize,
n,
false,
)?;
let n3 = ConvBlock::load(
vb.pp("n3"),
(256. * w) as usize,
(256. * w) as usize,
3,
2,
Some(1),
)?;
let n4 = C2f::load(
vb.pp("n4"),
(768. * w) as usize,
(512. * w) as usize,
n,
false,
)?;
let n5 = ConvBlock::load(
vb.pp("n5"),
(512. * w) as usize,
(512. * w) as usize,
3,
2,
Some(1),
)?;
let n6 = C2f::load(
vb.pp("n6"),
(512. * w * (1. + r)) as usize,
(512. * w * r) as usize,
n,
false,
)?;
Ok(Self {
up,
n1,
n2,
n3,
n4,
n5,
n6,
span: tracing::span!(tracing::Level::TRACE, "neck"),
})
}
fn forward(&self, p3: &Tensor, p4: &Tensor, p5: &Tensor) -> Result<(Tensor, Tensor, Tensor)> {
let _enter = self.span.enter();
let x = self
.n1
.forward(&Tensor::cat(&[&self.up.forward(p5)?, p4], 1)?)?;
let head_1 = self
.n2
.forward(&Tensor::cat(&[&self.up.forward(&x)?, p3], 1)?)?;
let head_2 = self
.n4
.forward(&Tensor::cat(&[&self.n3.forward(&head_1)?, &x], 1)?)?;
let head_3 = self
.n6
.forward(&Tensor::cat(&[&self.n5.forward(&head_2)?, p5], 1)?)?;
Ok((head_1, head_2, head_3))
}
}
#[derive(Debug)]
struct DetectionHead {
dfl: Dfl,
cv2: [(ConvBlock, ConvBlock, Conv2d); 3],
cv3: [(ConvBlock, ConvBlock, Conv2d); 3],
ch: usize,
no: usize,
span: tracing::Span,
}
#[derive(Debug)]
struct PoseHead {
detect: DetectionHead,
cv4: [(ConvBlock, ConvBlock, Conv2d); 3],
kpt: (usize, usize),
span: tracing::Span,
}
fn make_anchors(
xs0: &Tensor,
xs1: &Tensor,
xs2: &Tensor,
(s0, s1, s2): (usize, usize, usize),
grid_cell_offset: f64,
) -> Result<(Tensor, Tensor)> {
let dev = xs0.device();
let mut anchor_points = vec![];
let mut stride_tensor = vec![];
for (xs, stride) in [(xs0, s0), (xs1, s1), (xs2, s2)] {
// xs is only used to extract the h and w dimensions.
let (_, _, h, w) = xs.dims4()?;
let sx = (Tensor::arange(0, w as u32, dev)?.to_dtype(DType::F32)? + grid_cell_offset)?;
let sy = (Tensor::arange(0, h as u32, dev)?.to_dtype(DType::F32)? + grid_cell_offset)?;
let sx = sx
.reshape((1, sx.elem_count()))?
.repeat((h, 1))?
.flatten_all()?;
let sy = sy
.reshape((sy.elem_count(), 1))?
.repeat((1, w))?
.flatten_all()?;
anchor_points.push(Tensor::stack(&[&sx, &sy], D::Minus1)?);
stride_tensor.push((Tensor::ones(h * w, DType::F32, dev)? * stride as f64)?);
}
let anchor_points = Tensor::cat(anchor_points.as_slice(), 0)?;
let stride_tensor = Tensor::cat(stride_tensor.as_slice(), 0)?.unsqueeze(1)?;
Ok((anchor_points, stride_tensor))
}
fn dist2bbox(distance: &Tensor, anchor_points: &Tensor) -> Result<Tensor> {
let chunks = distance.chunk(2, 1)?;
let lt = &chunks[0];
let rb = &chunks[1];
let x1y1 = anchor_points.sub(lt)?;
let x2y2 = anchor_points.add(rb)?;
let c_xy = ((&x1y1 + &x2y2)? * 0.5)?;
let wh = (&x2y2 - &x1y1)?;
Tensor::cat(&[c_xy, wh], 1)
}
struct DetectionHeadOut {
pred: Tensor,
anchors: Tensor,
strides: Tensor,
}
impl DetectionHead {
fn load(vb: VarBuilder, nc: usize, filters: (usize, usize, usize)) -> Result<Self> {
let ch = 16;
let dfl = Dfl::load(vb.pp("dfl"), ch)?;
let c1 = usize::max(filters.0, nc);
let c2 = usize::max(filters.0 / 4, ch * 4);
let cv3 = [
Self::load_cv3(vb.pp("cv3.0"), c1, nc, filters.0)?,
Self::load_cv3(vb.pp("cv3.1"), c1, nc, filters.1)?,
Self::load_cv3(vb.pp("cv3.2"), c1, nc, filters.2)?,
];
let cv2 = [
Self::load_cv2(vb.pp("cv2.0"), c2, ch, filters.0)?,
Self::load_cv2(vb.pp("cv2.1"), c2, ch, filters.1)?,
Self::load_cv2(vb.pp("cv2.2"), c2, ch, filters.2)?,
];
let no = nc + ch * 4;
Ok(Self {
dfl,
cv2,
cv3,
ch,
no,
span: tracing::span!(tracing::Level::TRACE, "detection-head"),
})
}
fn load_cv3(
vb: VarBuilder,
c1: usize,
nc: usize,
filter: usize,
) -> Result<(ConvBlock, ConvBlock, Conv2d)> {
let block0 = ConvBlock::load(vb.pp("0"), filter, c1, 3, 1, None)?;
let block1 = ConvBlock::load(vb.pp("1"), c1, c1, 3, 1, None)?;
let conv = conv2d(c1, nc, 1, Default::default(), vb.pp("2"))?;
Ok((block0, block1, conv))
}
fn load_cv2(
vb: VarBuilder,
c2: usize,
ch: usize,
filter: usize,
) -> Result<(ConvBlock, ConvBlock, Conv2d)> {
let block0 = ConvBlock::load(vb.pp("0"), filter, c2, 3, 1, None)?;
let block1 = ConvBlock::load(vb.pp("1"), c2, c2, 3, 1, None)?;
let conv = conv2d(c2, 4 * ch, 1, Default::default(), vb.pp("2"))?;
Ok((block0, block1, conv))
}
fn forward(&self, xs0: &Tensor, xs1: &Tensor, xs2: &Tensor) -> Result<DetectionHeadOut> {
let _enter = self.span.enter();
let forward_cv = |xs, i: usize| {
let xs_2 = self.cv2[i].0.forward(xs)?;
let xs_2 = self.cv2[i].1.forward(&xs_2)?;
let xs_2 = self.cv2[i].2.forward(&xs_2)?;
let xs_3 = self.cv3[i].0.forward(xs)?;
let xs_3 = self.cv3[i].1.forward(&xs_3)?;
let xs_3 = self.cv3[i].2.forward(&xs_3)?;
Tensor::cat(&[&xs_2, &xs_3], 1)
};
let xs0 = forward_cv(xs0, 0)?;
let xs1 = forward_cv(xs1, 1)?;
let xs2 = forward_cv(xs2, 2)?;
let (anchors, strides) = make_anchors(&xs0, &xs1, &xs2, (8, 16, 32), 0.5)?;
let anchors = anchors.transpose(0, 1)?.unsqueeze(0)?;
let strides = strides.transpose(0, 1)?;
let reshape = |xs: &Tensor| {
let d = xs.dim(0)?;
let el = xs.elem_count();
xs.reshape((d, self.no, el / (d * self.no)))
};
let ys0 = reshape(&xs0)?;
let ys1 = reshape(&xs1)?;
let ys2 = reshape(&xs2)?;
let x_cat = Tensor::cat(&[ys0, ys1, ys2], 2)?;
let box_ = x_cat.i((.., ..self.ch * 4))?;
let cls = x_cat.i((.., self.ch * 4..))?;
let dbox = dist2bbox(&self.dfl.forward(&box_)?, &anchors)?;
let dbox = dbox.broadcast_mul(&strides)?;
let pred = Tensor::cat(&[dbox, candle_nn::ops::sigmoid(&cls)?], 1)?;
Ok(DetectionHeadOut {
pred,
anchors,
strides,
})
}
}
impl PoseHead {
// kpt: keypoints, (17, 3)
// nc: num-classes, 80
fn load(
vb: VarBuilder,
nc: usize,
kpt: (usize, usize),
filters: (usize, usize, usize),
) -> Result<Self> {
let detect = DetectionHead::load(vb.clone(), nc, filters)?;
let nk = kpt.0 * kpt.1;
let c4 = usize::max(filters.0 / 4, nk);
let cv4 = [
Self::load_cv4(vb.pp("cv4.0"), c4, nk, filters.0)?,
Self::load_cv4(vb.pp("cv4.1"), c4, nk, filters.1)?,
Self::load_cv4(vb.pp("cv4.2"), c4, nk, filters.2)?,
];
Ok(Self {
detect,
cv4,
kpt,
span: tracing::span!(tracing::Level::TRACE, "pose-head"),
})
}
fn load_cv4(
vb: VarBuilder,
c1: usize,
nc: usize,
filter: usize,
) -> Result<(ConvBlock, ConvBlock, Conv2d)> {
let block0 = ConvBlock::load(vb.pp("0"), filter, c1, 3, 1, None)?;
let block1 = ConvBlock::load(vb.pp("1"), c1, c1, 3, 1, None)?;
let conv = conv2d(c1, nc, 1, Default::default(), vb.pp("2"))?;
Ok((block0, block1, conv))
}
fn forward(&self, xs0: &Tensor, xs1: &Tensor, xs2: &Tensor) -> Result<Tensor> {
let _enter = self.span.enter();
let d = self.detect.forward(xs0, xs1, xs2)?;
let forward_cv = |xs: &Tensor, i: usize| {
let (b_sz, _, h, w) = xs.dims4()?;
let xs = self.cv4[i].0.forward(xs)?;
let xs = self.cv4[i].1.forward(&xs)?;
let xs = self.cv4[i].2.forward(&xs)?;
xs.reshape((b_sz, self.kpt.0 * self.kpt.1, h * w))
};
let xs0 = forward_cv(xs0, 0)?;
let xs1 = forward_cv(xs1, 1)?;
let xs2 = forward_cv(xs2, 2)?;
let xs = Tensor::cat(&[xs0, xs1, xs2], D::Minus1)?;
let (b_sz, _nk, hw) = xs.dims3()?;
let xs = xs.reshape((b_sz, self.kpt.0, self.kpt.1, hw))?;
let ys01 = ((xs.i((.., .., 0..2))? * 2.)?.broadcast_add(&d.anchors)? - 0.5)?
.broadcast_mul(&d.strides)?;
let ys2 = candle_nn::ops::sigmoid(&xs.i((.., .., 2..3))?)?;
let ys = Tensor::cat(&[ys01, ys2], 2)?.flatten(1, 2)?;
Tensor::cat(&[d.pred, ys], 1)
}
}
#[derive(Debug)]
pub struct YoloV8 {
net: DarkNet,
fpn: YoloV8Neck,
head: DetectionHead,
span: tracing::Span,
}
impl YoloV8 {
pub fn load(vb: VarBuilder, m: Multiples, num_classes: usize) -> Result<Self> {
let net = DarkNet::load(vb.pp("net"), m)?;
let fpn = YoloV8Neck::load(vb.pp("fpn"), m)?;
let head = DetectionHead::load(vb.pp("head"), num_classes, m.filters())?;
Ok(Self {
net,
fpn,
head,
span: tracing::span!(tracing::Level::TRACE, "yolo-v8"),
})
}
}
impl Module for YoloV8 {
fn forward(&self, xs: &Tensor) -> Result<Tensor> {
let _enter = self.span.enter();
let (xs1, xs2, xs3) = self.net.forward(xs)?;
let (xs1, xs2, xs3) = self.fpn.forward(&xs1, &xs2, &xs3)?;
Ok(self.head.forward(&xs1, &xs2, &xs3)?.pred)
}
}
#[derive(Debug)]
pub struct YoloV8Pose {
net: DarkNet,
fpn: YoloV8Neck,
head: PoseHead,
span: tracing::Span,
}
impl YoloV8Pose {
pub fn load(
vb: VarBuilder,
m: Multiples,
num_classes: usize,
kpt: (usize, usize),
) -> Result<Self> {
let net = DarkNet::load(vb.pp("net"), m)?;
let fpn = YoloV8Neck::load(vb.pp("fpn"), m)?;
let head = PoseHead::load(vb.pp("head"), num_classes, kpt, m.filters())?;
Ok(Self {
net,
fpn,
head,
span: tracing::span!(tracing::Level::TRACE, "yolo-v8-pose"),
})
}
}
impl Module for YoloV8Pose {
fn forward(&self, xs: &Tensor) -> Result<Tensor> {
let _enter = self.span.enter();
let (xs1, xs2, xs3) = self.net.forward(xs)?;
let (xs1, xs2, xs3) = self.fpn.forward(&xs1, &xs2, &xs3)?;
self.head.forward(&xs1, &xs2, &xs3)
}
}
| 1 |
0 | hf_public_repos/candle/candle-examples/examples | hf_public_repos/candle/candle-examples/examples/yolo-v8/README.md | # candle-yolo-v8: Object Detection and Pose Estimation
This is a port of [Ultralytics
YOLOv8](https://github.com/ultralytics/ultralytics). The implementation is based
on the [tinygrad
version](https://github.com/tinygrad/tinygrad/blob/master/examples/yolov8.py)
and on the model architecture described in this
[issue](https://github.com/ultralytics/ultralytics/issues/189). The supported
tasks are object detection and pose estimation.
You can try this model online on the [Candle YOLOv8
Space](https://huggingface.co/spaces/lmz/candle-yolo). The model then fully runs
in your browser using WebAssembly - if you use a custom image it will never
leave your phone/computer!
## Running some example
### Object Detection
```bash
cargo run --example yolo-v8 --release -- candle-examples/examples/yolo-v8/assets/bike.jpg
```
This prints details about the detected objects and generates a `bike.pp.jpg` file.

Image source:
[wikimedia](https://commons.wikimedia.org/wiki/File:Leading_group,_Giro_d%27Italia_2021,_Stage_15.jpg).

### Pose Estimation
```bash
cargo run --example yolo-v8 --release -- \
candle-examples/examples/yolo-v8/assets/bike.jpg --task pose
```

### Command-line flags
- `--which`: select the model variant to be used, `n`, `s` , `m`, `l`, or `x` by
increasing size and quality.
- `--task`: `detect` for object detection and `pose` for pose estimation.
- `--legend-size`: the size of the characters to print.
- `--model`: use a local model file rather than downloading it from the hub.
| 2 |
0 | hf_public_repos/candle/candle-examples/examples | hf_public_repos/candle/candle-examples/examples/musicgen/musicgen_model.rs | use candle::{DType, Device, Result, Tensor, D};
use candle_nn::{
embedding, layer_norm, linear_no_bias, Activation, Embedding, LayerNorm, Linear, Module,
VarBuilder,
};
use candle_transformers::models::{encodec, t5};
// https://github.com/huggingface/transformers/blob/cd4584e3c809bb9e1392ccd3fe38b40daba5519a/src/transformers/models/musicgen/configuration_musicgen.py#L83
#[derive(Debug, Clone, PartialEq)]
pub struct Config {
vocab_size: usize,
max_position_embeddings: usize,
num_hidden_layers: usize,
ffn_dim: usize,
num_attention_heads: usize,
layerdrop: f64,
use_cache: bool,
activation_function: Activation,
hidden_size: usize,
dropout: f64,
attention_dropout: f64,
activation_dropout: f64,
initializer_factor: f64,
scale_embedding: bool,
num_codebooks: usize,
pad_token_id: usize,
bos_token_id: usize,
eos_token_id: Option<usize>,
tie_word_embeddings: bool,
}
impl Default for Config {
fn default() -> Self {
Self {
vocab_size: 2048,
max_position_embeddings: 2048,
num_hidden_layers: 24,
ffn_dim: 4096,
num_attention_heads: 16,
layerdrop: 0.0,
use_cache: true,
activation_function: Activation::Gelu,
hidden_size: 1024,
dropout: 0.1,
attention_dropout: 0.0,
activation_dropout: 0.0,
initializer_factor: 0.02,
scale_embedding: false,
num_codebooks: 4,
pad_token_id: 2048,
bos_token_id: 2048,
eos_token_id: None,
tie_word_embeddings: false,
}
}
}
impl Config {
fn musicgen_small() -> Self {
Self {
vocab_size: 2048,
max_position_embeddings: 2048,
num_hidden_layers: 24,
ffn_dim: 4096,
num_attention_heads: 16,
layerdrop: 0.0,
use_cache: true,
activation_function: Activation::Gelu,
hidden_size: 1024,
dropout: 0.1,
attention_dropout: 0.0,
activation_dropout: 0.0,
initializer_factor: 0.02,
scale_embedding: false,
num_codebooks: 4,
pad_token_id: 2048,
bos_token_id: 2048,
eos_token_id: None,
tie_word_embeddings: false,
}
}
}
fn get_embedding(num_embeddings: usize, embedding_dim: usize) -> Result<Tensor> {
let half_dim = embedding_dim / 2;
let emb = f64::ln(10000.) / (half_dim - 1) as f64;
let xs: Vec<_> = (0..num_embeddings).map(|v| v as f32).collect();
let xs = Tensor::from_vec(xs, (num_embeddings, 1), &Device::Cpu)?;
let ys: Vec<_> = (0..half_dim)
.map(|v| f64::exp(v as f64 * -emb) as f32)
.collect();
let ys = Tensor::from_vec(ys, (1, half_dim), &Device::Cpu)?;
let shape = (num_embeddings, half_dim);
let emb = (xs.broadcast_as(shape)? * ys.broadcast_as(shape)?)?;
let emb =
Tensor::cat(&[&emb.cos()?, &emb.sin()?], 1)?.reshape((num_embeddings, 2 * half_dim))?;
let emb = if embedding_dim % 2 == 1 {
let zeros = Tensor::zeros((num_embeddings, 1), DType::F32, &Device::Cpu)?;
Tensor::cat(&[&emb, &zeros], 1)?
} else {
emb
};
Ok(emb)
}
#[derive(Debug)]
struct MusicgenSinusoidalPositionalEmbedding {
num_positions: usize,
embedding_dim: usize,
weights: Tensor,
}
impl MusicgenSinusoidalPositionalEmbedding {
fn load(_vb: VarBuilder, cfg: &Config) -> Result<Self> {
let num_positions = cfg.max_position_embeddings;
let embedding_dim = cfg.hidden_size;
let weights = get_embedding(num_positions, embedding_dim)?;
Ok(Self {
num_positions,
embedding_dim,
weights,
})
}
fn forward(&mut self, input_ids: &Tensor) -> Result<Tensor> {
let (_b_sz, _codebooks, seq_len) = input_ids.dims3()?;
if seq_len > self.weights.dim(0)? {
self.weights = get_embedding(seq_len, self.embedding_dim)?
}
self.weights.narrow(0, 0, seq_len)
}
}
#[derive(Debug)]
struct MusicgenAttention {
scaling: f64,
is_decoder: bool,
num_heads: usize,
head_dim: usize,
k_proj: Linear,
v_proj: Linear,
q_proj: Linear,
out_proj: Linear,
}
impl MusicgenAttention {
fn load(vb: VarBuilder, cfg: &Config) -> Result<Self> {
let h = cfg.hidden_size;
let num_heads = cfg.num_attention_heads;
let head_dim = h / num_heads;
let k_proj = linear_no_bias(h, h, vb.pp("k_proj"))?;
let v_proj = linear_no_bias(h, h, vb.pp("v_proj"))?;
let q_proj = linear_no_bias(h, h, vb.pp("q_proj"))?;
let out_proj = linear_no_bias(h, h, vb.pp("out_proj"))?;
Ok(Self {
scaling: 1. / (head_dim as f64).sqrt(),
is_decoder: true,
num_heads,
head_dim,
k_proj,
v_proj,
q_proj,
out_proj,
})
}
fn forward(
&mut self,
xs: &Tensor,
kv_states: Option<&Tensor>,
attention_mask: &Tensor,
) -> Result<Tensor> {
let (b_sz, tgt_len, _) = xs.dims3()?;
let query_states = (self.q_proj.forward(xs)? * self.scaling)?;
let kv_states = kv_states.unwrap_or(xs);
let key_states = self.k_proj.forward(kv_states)?;
let value_states = self.v_proj.forward(kv_states)?;
let tgt = (b_sz, tgt_len, self.num_heads, self.head_dim);
let query_states = query_states.reshape(tgt)?.transpose(1, 2)?.contiguous()?;
let key_states = key_states.reshape(tgt)?.transpose(1, 2)?.contiguous()?;
let value_states = value_states.reshape(tgt)?.transpose(1, 2)?.contiguous()?;
let src_len = key_states.dim(1)?;
let attn_weights = query_states.matmul(&key_states.transpose(1, 2)?)?;
let attn_weights = attn_weights
.reshape((b_sz, self.num_heads, tgt_len, src_len))?
.broadcast_add(attention_mask)?;
let attn_weights = candle_nn::ops::softmax(&attn_weights, D::Minus1)?;
// TODO: layer_head_mask?
let attn_output = attn_weights
.matmul(&value_states)?
.reshape((b_sz, self.num_heads, tgt_len, self.head_dim))?
.transpose(1, 2)?
.reshape((b_sz, tgt_len, self.num_heads * self.head_dim))?;
let attn_output = self.out_proj.forward(&attn_output)?;
Ok(attn_output)
}
}
#[derive(Debug)]
struct MusicgenDecoderLayer {
self_attn: MusicgenAttention,
self_attn_layer_norm: LayerNorm,
encoder_attn: MusicgenAttention,
encoder_attn_layer_norm: LayerNorm,
fc1: Linear,
fc2: Linear,
final_layer_norm: LayerNorm,
activation_fn: Activation,
}
impl MusicgenDecoderLayer {
fn load(vb: VarBuilder, cfg: &Config) -> Result<Self> {
let h = cfg.hidden_size;
let self_attn = MusicgenAttention::load(vb.pp("self_attn"), cfg)?;
let self_attn_layer_norm = layer_norm(h, 1e-5, vb.pp("self_attn_layer_norm"))?;
let encoder_attn = MusicgenAttention::load(vb.pp("encoder_attn"), cfg)?;
let encoder_attn_layer_norm = layer_norm(h, 1e-5, vb.pp("encoder_attn_layer_norm"))?;
let fc1 = linear_no_bias(h, cfg.ffn_dim, vb.pp("fc1"))?;
let fc2 = linear_no_bias(cfg.ffn_dim, h, vb.pp("fc2"))?;
let final_layer_norm = layer_norm(h, 1e-5, vb.pp("final_layer_norm"))?;
Ok(Self {
self_attn,
self_attn_layer_norm,
encoder_attn,
encoder_attn_layer_norm,
fc1,
fc2,
final_layer_norm,
activation_fn: cfg.activation_function,
})
}
fn forward(
&mut self,
xs: &Tensor,
attention_mask: &Tensor,
encoder_hidden_states: Option<&Tensor>,
) -> Result<Tensor> {
let residual = xs.clone();
let xs = self.self_attn_layer_norm.forward(xs)?;
let xs = self.self_attn.forward(&xs, None, attention_mask)?;
let mut xs = (xs + residual)?;
if let Some(encoder_hidden_states) = &encoder_hidden_states {
let residual = xs.clone();
let encoder_attention_mask = attention_mask.clone(); // TODO
xs = self.encoder_attn.forward(
&xs,
Some(encoder_hidden_states),
&encoder_attention_mask,
)?;
xs = (xs + residual)?
}
let residual = xs.clone();
let xs = self.final_layer_norm.forward(&xs)?;
let xs = self.fc1.forward(&xs)?;
let xs = self.activation_fn.forward(&xs)?;
let xs = self.fc2.forward(&xs)?;
let xs = (xs + residual)?;
Ok(xs)
}
}
#[derive(Debug)]
struct MusicgenDecoder {
embed_tokens: Vec<Embedding>,
embed_positions: MusicgenSinusoidalPositionalEmbedding,
layers: Vec<MusicgenDecoderLayer>,
layer_norm: LayerNorm,
embed_scale: f64,
num_codebooks: usize,
d_model: usize,
}
impl MusicgenDecoder {
fn load(vb: VarBuilder, cfg: &Config) -> Result<Self> {
let h = cfg.hidden_size;
let embed_scale = if cfg.scale_embedding {
(h as f64).sqrt()
} else {
1.
};
let embed_dim = cfg.vocab_size + 1;
let embed_tokens = (0..cfg.num_codebooks)
.map(|i| embedding(embed_dim, h, vb.pp(format!("embed_tokens.{i}"))))
.collect::<Result<Vec<_>>>()?;
let embed_positions = MusicgenSinusoidalPositionalEmbedding::load(vb.clone(), cfg)?;
let layers = (0..cfg.num_hidden_layers)
.map(|i| MusicgenDecoderLayer::load(vb.pp(format!("layers.{i}")), cfg))
.collect::<Result<Vec<_>>>()?;
let layer_norm = layer_norm(h, 1e-5, vb.pp("layer_norm"))?;
Ok(Self {
embed_tokens,
embed_positions,
layers,
layer_norm,
embed_scale,
num_codebooks: cfg.num_codebooks,
d_model: cfg.hidden_size,
})
}
fn prepare_decoder_attention_mask(&self, _b_sz: usize, _seq_len: usize) -> Result<Tensor> {
todo!()
}
fn forward(&mut self, input_ids: &Tensor) -> Result<Tensor> {
let dev = input_ids.device();
let (b_sz_times_codebooks, seq_len) = input_ids.dims2()?;
let b_sz = b_sz_times_codebooks / self.num_codebooks;
let input = input_ids.reshape((b_sz, self.num_codebooks, seq_len))?;
let mut inputs_embeds = Tensor::zeros((b_sz, seq_len, self.d_model), DType::F32, dev)?;
for (idx, codebook) in self.embed_tokens.iter().enumerate() {
let inp = input.narrow(1, idx, 1)?.squeeze(1)?;
inputs_embeds = (inputs_embeds + codebook.forward(&inp)?)?
}
let inputs_embeds = inputs_embeds;
let positions = self.embed_positions.forward(&input)?.to_device(dev)?;
let mut xs = inputs_embeds.broadcast_add(&positions)?;
let attention_mask = self.prepare_decoder_attention_mask(b_sz, seq_len)?;
for decoder_layer in self.layers.iter_mut() {
xs = decoder_layer.forward(&xs, &attention_mask, None)?;
}
let xs = self.layer_norm.forward(&xs)?;
Ok(xs)
}
}
#[derive(Debug)]
pub struct MusicgenForCausalLM {
decoder: MusicgenDecoder,
lm_heads: Vec<Linear>,
num_codebooks: usize,
vocab_size: usize,
}
impl MusicgenForCausalLM {
pub fn load(vb: VarBuilder, cfg: &Config) -> Result<Self> {
let h = cfg.hidden_size;
let decoder = MusicgenDecoder::load(vb.pp("model.decoder"), cfg)?;
let lm_heads = (0..cfg.num_codebooks)
.map(|i| linear_no_bias(h, cfg.vocab_size, vb.pp(format!("lm_heads.{i}"))))
.collect::<Result<Vec<_>>>()?;
Ok(Self {
decoder,
lm_heads,
num_codebooks: cfg.num_codebooks,
vocab_size: cfg.vocab_size,
})
}
pub fn forward(&mut self, input_ids: &Tensor) -> Result<Tensor> {
let (b_sz, seq_len) = input_ids.dims2()?;
let hidden_states = self.decoder.forward(input_ids)?;
let lm_logits = self
.lm_heads
.iter()
.map(|h| h.forward(&hidden_states))
.collect::<Result<Vec<_>>>()?;
let lm_logits = Tensor::stack(&lm_logits, 1)?.reshape((
b_sz * self.num_codebooks,
seq_len,
self.vocab_size,
))?;
Ok(lm_logits)
}
}
#[derive(Debug)]
pub struct MusicgenForConditionalGeneration {
pub text_encoder: t5::T5EncoderModel,
pub audio_encoder: encodec::Model,
pub decoder: MusicgenForCausalLM,
cfg: GenConfig,
}
#[derive(Debug, Clone, PartialEq)]
pub struct GenConfig {
musicgen: Config,
t5: t5::Config,
encodec: encodec::Config,
}
impl GenConfig {
pub fn small() -> Self {
// https://huggingface.co/facebook/musicgen-small/blob/495da4ad086b3416a27c6187f9239f9fd96f3962/config.json#L6
let encodec = encodec::Config {
audio_channels: 1,
chunk_length_s: None,
codebook_dim: Some(128),
codebook_size: 2048,
compress: 2,
dilation_growth_rate: 2,
hidden_size: 128,
kernel_size: 7,
last_kernel_size: 7,
norm_type: encodec::NormType::WeightNorm,
normalize: false,
num_filters: 64,
num_lstm_layers: 2,
num_residual_layers: 1,
overlap: None,
// This should be Reflect and not Replicate but Reflect does not work yet.
pad_mode: encodec::PadMode::Replicate,
residual_kernel_size: 3,
sampling_rate: 32_000,
target_bandwidths: vec![2.2],
trim_right_ratio: 1.0,
upsampling_ratios: vec![8, 5, 4, 4],
use_causal_conv: false,
use_conv_shortcut: false,
};
Self {
musicgen: Config::musicgen_small(),
t5: t5::Config::musicgen_small(),
encodec,
}
}
}
impl MusicgenForConditionalGeneration {
pub fn config(&self) -> &GenConfig {
&self.cfg
}
pub fn load(vb: VarBuilder, cfg: GenConfig) -> Result<Self> {
let text_encoder = t5::T5EncoderModel::load(vb.pp("text_encoder"), &cfg.t5)?;
let audio_encoder = encodec::Model::new(&cfg.encodec, vb.pp("audio_encoder"))?;
let decoder = MusicgenForCausalLM::load(vb.pp("decoder"), &cfg.musicgen)?;
Ok(Self {
text_encoder,
audio_encoder,
decoder,
cfg,
})
}
}
| 3 |
0 | hf_public_repos/candle/candle-examples/examples | hf_public_repos/candle/candle-examples/examples/musicgen/main.rs | #![allow(dead_code)]
// https://huggingface.co/facebook/musicgen-small/tree/main
// https://github.com/huggingface/transformers/blob/cd4584e3c809bb9e1392ccd3fe38b40daba5519a/src/transformers/models/musicgen/modeling_musicgen.py
// TODO: Add an offline mode.
// TODO: Add a KV cache.
#[cfg(feature = "mkl")]
extern crate intel_mkl_src;
#[cfg(feature = "accelerate")]
extern crate accelerate_src;
mod musicgen_model;
use musicgen_model::{GenConfig, MusicgenForConditionalGeneration};
use anyhow::{Error as E, Result};
use candle::{DType, Tensor};
use candle_nn::VarBuilder;
use clap::Parser;
use hf_hub::{api::sync::Api, Repo, RepoType};
const DTYPE: DType = DType::F32;
#[derive(Parser, Debug)]
#[command(author, version, about, long_about = None)]
struct Args {
/// Run on CPU rather than on GPU.
#[arg(long)]
cpu: bool,
/// The model weight file, in safetensor format.
#[arg(long)]
model: Option<String>,
/// The tokenizer config.
#[arg(long)]
tokenizer: Option<String>,
#[arg(
long,
default_value = "90s rock song with loud guitars and heavy drums"
)]
prompt: String,
}
fn main() -> Result<()> {
use tokenizers::Tokenizer;
let args = Args::parse();
let device = candle_examples::device(args.cpu)?;
let tokenizer = match args.tokenizer {
Some(tokenizer) => std::path::PathBuf::from(tokenizer),
None => Api::new()?
.model("facebook/musicgen-small".to_string())
.get("tokenizer.json")?,
};
let mut tokenizer = Tokenizer::from_file(tokenizer).map_err(E::msg)?;
let tokenizer = tokenizer
.with_padding(None)
.with_truncation(None)
.map_err(E::msg)?;
let model = match args.model {
Some(model) => std::path::PathBuf::from(model),
None => Api::new()?
.repo(Repo::with_revision(
"facebook/musicgen-small".to_string(),
RepoType::Model,
"refs/pr/13".to_string(),
))
.get("model.safetensors")?,
};
let vb = unsafe { VarBuilder::from_mmaped_safetensors(&[model], DTYPE, &device)? };
let config = GenConfig::small();
let mut model = MusicgenForConditionalGeneration::load(vb, config)?;
let tokens = tokenizer
.encode(args.prompt.as_str(), true)
.map_err(E::msg)?
.get_ids()
.to_vec();
println!("tokens: {tokens:?}");
let tokens = Tensor::new(tokens.as_slice(), &device)?.unsqueeze(0)?;
println!("{tokens:?}");
let embeds = model.text_encoder.forward(&tokens)?;
println!("{embeds}");
Ok(())
}
| 4 |
0 | hf_public_repos/candle/candle-examples/examples | hf_public_repos/candle/candle-examples/examples/mamba-minimal/main.rs | #[cfg(feature = "mkl")]
extern crate intel_mkl_src;
#[cfg(feature = "accelerate")]
extern crate accelerate_src;
use anyhow::{Error as E, Result};
use clap::{Parser, ValueEnum};
mod model;
use model::{Config, Model};
use candle::{DType, Device, Module, Tensor};
use candle_examples::token_output_stream::TokenOutputStream;
use candle_nn::VarBuilder;
use candle_transformers::generation::LogitsProcessor;
use hf_hub::{api::sync::Api, Repo, RepoType};
use tokenizers::Tokenizer;
struct TextGeneration {
model: Model,
device: Device,
tokenizer: TokenOutputStream,
logits_processor: LogitsProcessor,
repeat_penalty: f32,
repeat_last_n: usize,
}
impl TextGeneration {
#[allow(clippy::too_many_arguments)]
fn new(
model: Model,
tokenizer: Tokenizer,
seed: u64,
temp: Option<f64>,
top_p: Option<f64>,
repeat_penalty: f32,
repeat_last_n: usize,
device: &Device,
) -> Self {
let logits_processor = LogitsProcessor::new(seed, temp, top_p);
Self {
model,
tokenizer: TokenOutputStream::new(tokenizer),
logits_processor,
repeat_penalty,
repeat_last_n,
device: device.clone(),
}
}
fn run(&mut self, prompt: &str, sample_len: usize) -> Result<()> {
use std::io::Write;
self.tokenizer.clear();
let mut tokens = self
.tokenizer
.tokenizer()
.encode(prompt, true)
.map_err(E::msg)?
.get_ids()
.to_vec();
for &t in tokens.iter() {
if let Some(t) = self.tokenizer.next_token(t)? {
print!("{t}")
}
}
std::io::stdout().flush()?;
let mut generated_tokens = 0usize;
let eos_token = match self.tokenizer.get_token("<|endoftext|>") {
Some(token) => token,
None => anyhow::bail!("cannot find the </s> token"),
};
let start_gen = std::time::Instant::now();
for _ in 0..sample_len {
let input = Tensor::new(tokens.as_slice(), &self.device)?.unsqueeze(0)?;
let logits = self.model.forward(&input)?;
let logits = logits.squeeze(0)?.squeeze(0)?.to_dtype(DType::F32)?;
let logits = if self.repeat_penalty == 1. {
logits
} else {
let start_at = tokens.len().saturating_sub(self.repeat_last_n);
candle_transformers::utils::apply_repeat_penalty(
&logits,
self.repeat_penalty,
&tokens[start_at..],
)?
};
let next_token = self.logits_processor.sample(&logits)?;
tokens.push(next_token);
generated_tokens += 1;
if next_token == eos_token {
break;
}
if let Some(t) = self.tokenizer.next_token(next_token)? {
print!("{t}");
std::io::stdout().flush()?;
}
}
let dt = start_gen.elapsed();
if let Some(rest) = self.tokenizer.decode_rest().map_err(E::msg)? {
print!("{rest}");
}
std::io::stdout().flush()?;
println!(
"\n{generated_tokens} tokens generated ({:.2} token/s)",
generated_tokens as f64 / dt.as_secs_f64(),
);
Ok(())
}
}
#[derive(Parser, ValueEnum, Clone, Copy, PartialEq, Eq, Debug)]
enum Which {
Mamba130m,
Mamba370m,
Mamba790m,
Mamba1_4b,
Mamba2_8b,
Mamba2_8bSlimPj,
}
impl std::fmt::Display for Which {
fn fmt(&self, f: &mut std::fmt::Formatter<'_>) -> std::fmt::Result {
write!(f, "{:?}", self)
}
}
impl Which {
fn model_id(&self) -> &'static str {
match self {
Self::Mamba130m => "state-spaces/mamba-130m",
Self::Mamba370m => "state-spaces/mamba-370m",
Self::Mamba790m => "state-spaces/mamba-790m",
Self::Mamba1_4b => "state-spaces/mamba-1.4b",
Self::Mamba2_8b => "state-spaces/mamba-2.8b",
Self::Mamba2_8bSlimPj => "state-spaces/mamba-2.8b-slimpj'",
}
}
fn revision(&self) -> &'static str {
match self {
Self::Mamba130m
| Self::Mamba370m
| Self::Mamba790m
| Self::Mamba1_4b
| Self::Mamba2_8bSlimPj => "refs/pr/1",
Self::Mamba2_8b => "refs/pr/4",
}
}
}
#[derive(Parser, Debug)]
#[command(author, version, about, long_about = None)]
struct Args {
/// Run on CPU rather than on GPU.
#[arg(long)]
cpu: bool,
/// Enable tracing (generates a trace-timestamp.json file).
#[arg(long)]
tracing: bool,
#[arg(long)]
prompt: String,
/// The temperature used to generate samples.
#[arg(long)]
temperature: Option<f64>,
/// Nucleus sampling probability cutoff.
#[arg(long)]
top_p: Option<f64>,
/// The seed to use when generating random samples.
#[arg(long, default_value_t = 299792458)]
seed: u64,
/// The length of the sample to generate (in tokens).
#[arg(long, short = 'n', default_value_t = 5000)]
sample_len: usize,
#[arg(long, default_value = "mamba130m")]
which: Which,
#[arg(long)]
model_id: Option<String>,
#[arg(long)]
revision: Option<String>,
#[arg(long)]
tokenizer_file: Option<String>,
#[arg(long)]
weight_files: Option<String>,
#[arg(long)]
config_file: Option<String>,
/// Penalty to be applied for repeating tokens, 1. means no penalty.
#[arg(long, default_value_t = 1.1)]
repeat_penalty: f32,
/// The context size to consider for the repeat penalty.
#[arg(long, default_value_t = 64)]
repeat_last_n: usize,
}
fn main() -> Result<()> {
use tracing_chrome::ChromeLayerBuilder;
use tracing_subscriber::prelude::*;
let args = Args::parse();
let _guard = if args.tracing {
let (chrome_layer, guard) = ChromeLayerBuilder::new().build();
tracing_subscriber::registry().with(chrome_layer).init();
Some(guard)
} else {
None
};
println!(
"avx: {}, neon: {}, simd128: {}, f16c: {}",
candle::utils::with_avx(),
candle::utils::with_neon(),
candle::utils::with_simd128(),
candle::utils::with_f16c()
);
println!(
"temp: {:.2} repeat-penalty: {:.2} repeat-last-n: {}",
args.temperature.unwrap_or(0.),
args.repeat_penalty,
args.repeat_last_n
);
let start = std::time::Instant::now();
let api = Api::new()?;
let repo = api.repo(Repo::with_revision(
args.model_id
.unwrap_or_else(|| args.which.model_id().to_string()),
RepoType::Model,
args.revision
.unwrap_or_else(|| args.which.revision().to_string()),
));
let tokenizer_filename = match args.tokenizer_file {
Some(file) => std::path::PathBuf::from(file),
None => api
.model("EleutherAI/gpt-neox-20b".to_string())
.get("tokenizer.json")?,
};
let config_filename = match args.config_file {
Some(file) => std::path::PathBuf::from(file),
None => repo.get("config.json")?,
};
let filenames = match args.weight_files {
Some(files) => files
.split(',')
.map(std::path::PathBuf::from)
.collect::<Vec<_>>(),
None => {
vec![repo.get("model.safetensors")?]
}
};
println!("retrieved the files in {:?}", start.elapsed());
let tokenizer = Tokenizer::from_file(tokenizer_filename).map_err(E::msg)?;
let start = std::time::Instant::now();
let config: Config = serde_json::from_slice(&std::fs::read(config_filename)?)?;
let device = candle_examples::device(args.cpu)?;
let vb = unsafe { VarBuilder::from_mmaped_safetensors(&filenames, DType::F32, &device)? };
let model = Model::new(&config, vb.pp("backbone"))?;
println!("loaded the model in {:?}", start.elapsed());
let mut pipeline = TextGeneration::new(
model,
tokenizer,
args.seed,
args.temperature,
args.top_p,
args.repeat_penalty,
args.repeat_last_n,
&device,
);
pipeline.run(&args.prompt, args.sample_len)?;
Ok(())
}
| 5 |
0 | hf_public_repos/candle/candle-examples/examples | hf_public_repos/candle/candle-examples/examples/mamba-minimal/model.rs | /// This follows the lines of:
/// https://github.com/johnma2006/mamba-minimal/blob/master/model.py
/// Simple, minimal implementation of Mamba in one file of PyTorch.
use candle::{IndexOp, Module, Result, Tensor, D};
use candle_nn::{RmsNorm, VarBuilder};
use candle_transformers::models::with_tracing::{linear, linear_no_bias, Linear};
#[derive(Debug, Clone, serde::Deserialize)]
pub struct Config {
d_model: usize,
n_layer: usize,
vocab_size: usize,
pad_vocab_size_multiple: usize,
}
impl Config {
fn vocab_size(&self) -> usize {
let pad = self.pad_vocab_size_multiple;
self.vocab_size.div_ceil(pad) * pad
}
fn dt_rank(&self) -> usize {
(self.d_model + 15) / 16
}
fn d_conv(&self) -> usize {
4
}
fn d_state(&self) -> usize {
16
}
fn d_inner(&self) -> usize {
self.d_model * 2
}
}
// https://github.com/johnma2006/mamba-minimal/blob/61f01953ca153f8c4a850d7111beecbf4be9cee1/model.py#L177
#[derive(Clone, Debug)]
pub struct MambaBlock {
in_proj: Linear,
conv1d: candle_nn::Conv1d,
x_proj: Linear,
dt_proj: Linear,
a_log: Tensor,
d: Tensor,
out_proj: Linear,
dt_rank: usize,
}
impl MambaBlock {
pub fn new(cfg: &Config, vb: VarBuilder) -> Result<Self> {
let d_inner = cfg.d_inner();
let d_conv = cfg.d_conv();
let d_state = cfg.d_state();
let dt_rank = cfg.dt_rank();
let in_proj = linear_no_bias(cfg.d_model, d_inner * 2, vb.pp("in_proj"))?;
let conv_cfg = candle_nn::Conv1dConfig {
groups: d_inner,
padding: d_conv - 1,
..Default::default()
};
let conv1d = candle_nn::conv1d(d_inner, d_inner, d_conv, conv_cfg, vb.pp("conv1d"))?;
let x_proj = linear_no_bias(d_inner, dt_rank + d_state * 2, vb.pp("x_proj"))?;
let dt_proj = linear(dt_rank, d_inner, vb.pp("dt_proj"))?;
let a_log = vb.get((d_inner, d_state), "A_log")?;
let d = vb.get(d_inner, "D")?;
let out_proj = linear_no_bias(d_inner, cfg.d_model, vb.pp("out_proj"))?;
Ok(Self {
in_proj,
conv1d,
x_proj,
dt_proj,
a_log,
d,
out_proj,
dt_rank,
})
}
fn ssm(&self, xs: &Tensor) -> Result<Tensor> {
let (_d_in, n) = self.a_log.dims2()?;
let a = self.a_log.to_dtype(candle::DType::F32)?.exp()?.neg()?;
let d = self.d.to_dtype(candle::DType::F32)?;
let x_dbl = xs.apply(&self.x_proj)?;
let delta = x_dbl.narrow(D::Minus1, 0, self.dt_rank)?;
let b = x_dbl.narrow(D::Minus1, self.dt_rank, n)?;
let c = x_dbl.narrow(D::Minus1, self.dt_rank + n, n)?;
let delta = delta.contiguous()?.apply(&self.dt_proj)?;
// softplus without threshold
let delta = (delta.exp()? + 1.)?.log()?;
let ss = selective_scan(xs, &delta, &a, &b, &c, &d)?;
Ok(ss)
}
}
// https://github.com/johnma2006/mamba-minimal/blob/61f01953ca153f8c4a850d7111beecbf4be9cee1/model.py#L275
fn selective_scan(
u: &Tensor,
delta: &Tensor,
a: &Tensor,
b: &Tensor,
c: &Tensor,
d: &Tensor,
) -> Result<Tensor> {
let (b_sz, l, d_in) = u.dims3()?;
let n = a.dim(1)?;
let delta = delta.t()?.reshape((b_sz, d_in, l, 1))?; // b d_in l 1
let delta_a = delta.broadcast_mul(&a.reshape((1, d_in, 1, n))?)?.exp()?;
let delta_b_u = delta
.broadcast_mul(&b.reshape((b_sz, 1, l, n))?)?
.broadcast_mul(&u.t()?.reshape((b_sz, d_in, l, 1))?)?;
let mut xs = Tensor::zeros((b_sz, d_in, n), delta_a.dtype(), delta_a.device())?;
let mut ys = Vec::with_capacity(l);
for i in 0..l {
xs = ((delta_a.i((.., .., i))? * xs)? + delta_b_u.i((.., .., i))?)?;
let y = xs.matmul(&c.i((.., i, ..))?.unsqueeze(2)?)?.squeeze(2)?;
ys.push(y)
}
let ys = Tensor::stack(ys.as_slice(), 1)?;
ys + u.broadcast_mul(d)
}
impl Module for MambaBlock {
// https://github.com/johnma2006/mamba-minimal/blob/61f01953ca153f8c4a850d7111beecbf4be9cee1/model.py#L206
fn forward(&self, xs: &Tensor) -> Result<Tensor> {
let (_b_sz, seq_len, _dim) = xs.dims3()?;
let xs_and_res = xs.apply(&self.in_proj)?.chunk(2, D::Minus1)?;
let (xs, res) = (&xs_and_res[0], &xs_and_res[1]);
let xs = xs
.t()?
.apply(&self.conv1d)?
.narrow(D::Minus1, 0, seq_len)?
.t()?;
let xs = candle_nn::ops::silu(&xs)?;
let ys = (self.ssm(&xs)? * candle_nn::ops::silu(res))?;
ys.apply(&self.out_proj)
}
}
// https://github.com/johnma2006/mamba-minimal/blob/61f01953ca153f8c4a850d7111beecbf4be9cee1/model.py#L143
#[derive(Clone, Debug)]
pub struct ResidualBlock {
mixer: MambaBlock,
norm: RmsNorm,
}
impl ResidualBlock {
pub fn new(cfg: &Config, vb: VarBuilder) -> Result<Self> {
let norm = candle_nn::rms_norm(cfg.d_model, 1e-5, vb.pp("norm"))?;
let mixer = MambaBlock::new(cfg, vb.pp("mixer"))?;
Ok(Self { mixer, norm })
}
}
impl Module for ResidualBlock {
fn forward(&self, xs: &Tensor) -> Result<Tensor> {
xs.apply(&self.norm)?.apply(&self.mixer)? + xs
}
}
// https://github.com/johnma2006/mamba-minimal/blob/61f01953ca153f8c4a850d7111beecbf4be9cee1/model.py#L56
#[derive(Clone, Debug)]
pub struct Model {
embedding: candle_nn::Embedding,
layers: Vec<ResidualBlock>,
norm_f: RmsNorm,
lm_head: Linear,
}
impl Model {
pub fn new(cfg: &Config, vb: VarBuilder) -> Result<Self> {
let embedding = candle_nn::embedding(cfg.vocab_size(), cfg.d_model, vb.pp("embedding"))?;
let mut layers = Vec::with_capacity(cfg.n_layer);
let vb_l = vb.pp("layers");
for layer_idx in 0..cfg.n_layer {
let layer = ResidualBlock::new(cfg, vb_l.pp(layer_idx))?;
layers.push(layer)
}
let norm_f = candle_nn::rms_norm(cfg.d_model, 1e-5, vb.pp("norm_f"))?;
let lm_head = Linear::from_weights(embedding.embeddings().clone(), None);
Ok(Self {
embedding,
layers,
norm_f,
lm_head,
})
}
}
impl Module for Model {
fn forward(&self, input_ids: &Tensor) -> Result<Tensor> {
let (_b_size, seq_len) = input_ids.dims2()?;
let mut xs = self.embedding.forward(input_ids)?;
for layer in self.layers.iter() {
xs = layer.forward(&xs)?
}
xs.narrow(1, seq_len - 1, 1)?
.apply(&self.norm_f)?
.apply(&self.lm_head)
}
}
| 6 |
0 | hf_public_repos/candle/candle-examples/examples | hf_public_repos/candle/candle-examples/examples/mamba-minimal/README.md | # candle-mamba-minimal: minimal implementation of Mamba
This is based on [mamba-minimal](https://github.com/johnma2006/mamba-minimal).
Compared to the mamba example, this version can handle training but is much
slower.
## Running the example
```bash
$ cargo run --example mamba-minimal --release -- --prompt "Mamba is the"
Mamba is the most popular and best-selling game in the world. It has been downloaded more than 1,000 times by over 1 million people worldwide since its release on March 18th 2016.
The Mamba series of games are a collection that combines elements from all genres including action, adventure, strategy & puzzle games with some unique gameplay features such as stealth and survival. The game is also known for its innovative graphics and the ability to play in a variety of different modes like single player or multiplayer.
```
| 7 |
0 | hf_public_repos/candle/candle-examples/examples | hf_public_repos/candle/candle-examples/examples/recurrent-gemma/main.rs | #[cfg(feature = "mkl")]
extern crate intel_mkl_src;
#[cfg(feature = "accelerate")]
extern crate accelerate_src;
use anyhow::{Error as E, Result};
use clap::Parser;
use candle_transformers::models::quantized_recurrent_gemma::Model as QModel;
use candle_transformers::models::recurrent_gemma::{Config, Model as BModel};
use candle::{DType, Device, Tensor};
use candle_examples::token_output_stream::TokenOutputStream;
use candle_nn::VarBuilder;
use candle_transformers::generation::LogitsProcessor;
use hf_hub::{api::sync::Api, Repo, RepoType};
use tokenizers::Tokenizer;
enum Model {
B(BModel),
Q(QModel),
}
impl Model {
fn forward(&mut self, xs: &Tensor, pos: usize) -> candle::Result<Tensor> {
match self {
Self::B(m) => m.forward(xs, pos),
Self::Q(m) => m.forward(xs, pos),
}
}
}
#[derive(Clone, Debug, Copy, PartialEq, Eq, clap::ValueEnum)]
enum Which {
#[value(name = "2b")]
Base2B,
#[value(name = "2b-it")]
Instruct2B,
}
struct TextGeneration {
model: Model,
device: Device,
tokenizer: TokenOutputStream,
logits_processor: LogitsProcessor,
repeat_penalty: f32,
repeat_last_n: usize,
}
impl TextGeneration {
#[allow(clippy::too_many_arguments)]
fn new(
model: Model,
tokenizer: Tokenizer,
seed: u64,
temp: Option<f64>,
top_p: Option<f64>,
top_k: usize,
repeat_penalty: f32,
repeat_last_n: usize,
device: &Device,
) -> Self {
let sampling = match temp {
None => candle_transformers::generation::Sampling::ArgMax,
Some(temperature) => match top_p {
None => candle_transformers::generation::Sampling::TopK {
temperature,
k: top_k,
},
Some(top_p) => candle_transformers::generation::Sampling::TopKThenTopP {
temperature,
k: top_k,
p: top_p,
},
},
};
let logits_processor = LogitsProcessor::from_sampling(seed, sampling);
Self {
model,
tokenizer: TokenOutputStream::new(tokenizer),
logits_processor,
repeat_penalty,
repeat_last_n,
device: device.clone(),
}
}
fn run(&mut self, prompt: &str, sample_len: usize) -> Result<()> {
use std::io::Write;
self.tokenizer.clear();
let mut tokens = self
.tokenizer
.tokenizer()
.encode(prompt, true)
.map_err(E::msg)?
.get_ids()
.to_vec();
for &t in tokens.iter() {
if let Some(t) = self.tokenizer.next_token(t)? {
print!("{t}")
}
}
std::io::stdout().flush()?;
let mut generated_tokens = 0usize;
let eos_token = match self.tokenizer.get_token("<eos>") {
Some(token) => token,
None => anyhow::bail!("cannot find the <eos> token"),
};
let start_gen = std::time::Instant::now();
for index in 0..sample_len {
let context_size = if index > 0 { 1 } else { tokens.len() };
let start_pos = tokens.len().saturating_sub(context_size);
let ctxt = &tokens[start_pos..];
let input = Tensor::new(ctxt, &self.device)?.unsqueeze(0)?;
let logits = self.model.forward(&input, start_pos)?;
let logits = logits.squeeze(0)?.squeeze(0)?.to_dtype(DType::F32)?;
let logits = if self.repeat_penalty == 1. {
logits
} else {
let start_at = tokens.len().saturating_sub(self.repeat_last_n);
candle_transformers::utils::apply_repeat_penalty(
&logits,
self.repeat_penalty,
&tokens[start_at..],
)?
};
let next_token = self.logits_processor.sample(&logits)?;
tokens.push(next_token);
generated_tokens += 1;
if next_token == eos_token {
break;
}
if let Some(t) = self.tokenizer.next_token(next_token)? {
print!("{t}");
std::io::stdout().flush()?;
}
}
let dt = start_gen.elapsed();
if let Some(rest) = self.tokenizer.decode_rest().map_err(E::msg)? {
print!("{rest}");
}
std::io::stdout().flush()?;
println!(
"\n{generated_tokens} tokens generated ({:.2} token/s)",
generated_tokens as f64 / dt.as_secs_f64(),
);
Ok(())
}
}
#[derive(Parser, Debug)]
#[command(author, version, about, long_about = None)]
struct Args {
/// Run on CPU rather than on GPU.
#[arg(long)]
cpu: bool,
/// Enable tracing (generates a trace-timestamp.json file).
#[arg(long)]
tracing: bool,
#[arg(long)]
prompt: String,
/// The temperature used to generate samples.
#[arg(long)]
temperature: Option<f64>,
/// Nucleus sampling probability cutoff.
#[arg(long)]
top_p: Option<f64>,
#[arg(long, default_value_t = 250)]
top_k: usize,
/// The seed to use when generating random samples.
#[arg(long, default_value_t = 299792458)]
seed: u64,
/// The length of the sample to generate (in tokens).
#[arg(long, short = 'n', default_value_t = 8000)]
sample_len: usize,
#[arg(long)]
model_id: Option<String>,
#[arg(long, default_value = "main")]
revision: String,
#[arg(long)]
tokenizer_file: Option<String>,
#[arg(long)]
config_file: Option<String>,
#[arg(long)]
weight_files: Option<String>,
/// Penalty to be applied for repeating tokens, 1. means no penalty.
#[arg(long, default_value_t = 1.1)]
repeat_penalty: f32,
/// The context size to consider for the repeat penalty.
#[arg(long, default_value_t = 64)]
repeat_last_n: usize,
/// The model to use.
#[arg(long, default_value = "2b")]
which: Which,
#[arg(long)]
quantized: bool,
}
fn main() -> Result<()> {
use tracing_chrome::ChromeLayerBuilder;
use tracing_subscriber::prelude::*;
let args = Args::parse();
let _guard = if args.tracing {
let (chrome_layer, guard) = ChromeLayerBuilder::new().build();
tracing_subscriber::registry().with(chrome_layer).init();
Some(guard)
} else {
None
};
println!(
"avx: {}, neon: {}, simd128: {}, f16c: {}",
candle::utils::with_avx(),
candle::utils::with_neon(),
candle::utils::with_simd128(),
candle::utils::with_f16c()
);
println!(
"temp: {:.2} repeat-penalty: {:.2} repeat-last-n: {}",
args.temperature.unwrap_or(0.),
args.repeat_penalty,
args.repeat_last_n
);
let start = std::time::Instant::now();
let api = Api::new()?;
let model_id = match &args.model_id {
Some(model_id) => model_id.to_string(),
None => match args.which {
Which::Base2B => "google/recurrentgemma-2b".to_string(),
Which::Instruct2B => "google/recurrentgemma-2b-it".to_string(),
},
};
let repo = api.repo(Repo::with_revision(
model_id,
RepoType::Model,
args.revision,
));
let tokenizer_filename = match args.tokenizer_file {
Some(file) => std::path::PathBuf::from(file),
None => repo.get("tokenizer.json")?,
};
let config_filename = match args.config_file {
Some(file) => std::path::PathBuf::from(file),
None => repo.get("config.json")?,
};
let filenames = match args.weight_files {
Some(files) => files
.split(',')
.map(std::path::PathBuf::from)
.collect::<Vec<_>>(),
None => {
if args.quantized {
let filename = match args.which {
Which::Base2B => "recurrent-gemma-2b-q4k.gguf",
Which::Instruct2B => "recurrent-gemma-7b-q4k.gguf",
};
let filename = api.model("lmz/candle-gemma".to_string()).get(filename)?;
vec![filename]
} else {
candle_examples::hub_load_safetensors(&repo, "model.safetensors.index.json")?
}
}
};
println!("retrieved the files in {:?}", start.elapsed());
let tokenizer = Tokenizer::from_file(tokenizer_filename).map_err(E::msg)?;
let config: Config = serde_json::from_reader(std::fs::File::open(config_filename)?)?;
let start = std::time::Instant::now();
let device = candle_examples::device(args.cpu)?;
let dtype = if device.is_cuda() {
DType::BF16
} else {
DType::F32
};
let model = if args.quantized {
let vb = candle_transformers::quantized_var_builder::VarBuilder::from_gguf(
&filenames[0],
&device,
)?;
Model::Q(QModel::new(&config, vb.pp("model"))?)
} else {
let vb = unsafe { VarBuilder::from_mmaped_safetensors(&filenames, dtype, &device)? };
Model::B(BModel::new(&config, vb.pp("model"))?)
};
println!("loaded the model in {:?}", start.elapsed());
let mut pipeline = TextGeneration::new(
model,
tokenizer,
args.seed,
args.temperature,
args.top_p,
args.top_k,
args.repeat_penalty,
args.repeat_last_n,
&device,
);
pipeline.run(&args.prompt, args.sample_len)?;
Ok(())
}
| 8 |
0 | hf_public_repos/candle/candle-examples/examples | hf_public_repos/candle/candle-examples/examples/recurrent-gemma/README.md | # candle-recurrent-gemma
This model card corresponds to the 2B base version of the RecurrentGemma model
[huggingface model card](https://huggingface.co/google/recurrentgemma-2b).
```bash
cargo run --features cuda -r --example recurrent-gemma -- \
--prompt "Write me a poem about Machine Learning."
```
| 9 |
0 | hf_public_repos | hf_public_repos/blog/fhe-endpoints.md | ---
title: "Running Privacy-Preserving Inferences on Hugging Face Endpoints"
thumbnail: /blog/assets/fhe-endpoints/thumbnail.png
authors:
- user: binoua
guest: true
org: zama-fhe
---
# Running Privacy-Preserving Inferences on Hugging Face Endpoints
> [!NOTE] This is a guest blog post by the Zama team. Zama is an open source cryptography company building state-of-the-art FHE solutions for blockchain and AI.
Eighteen months ago, Zama started [Concrete ML](https://github.com/zama-ai/concrete-ml), a privacy-preserving ML framework with bindings to traditional ML frameworks such as scikit-learn, ONNX, PyTorch, and TensorFlow. To ensure privacy for users' data, Zama uses Fully Homomorphic Encryption (FHE), a cryptographic tool that allows to make direct computations over encrypted data, without ever knowing the private key.
From the start, we wanted to pre-compile some FHE-friendly networks and make them available somewhere on the internet, allowing users to use them trivially. We are ready today! And not in a random place on the internet, but directly on Hugging Face.
More precisely, we use Hugging Face [Endpoints](https://huggingface.co/docs/inference-endpoints/en/index) and [custom inference handlers](https://huggingface.co/docs/inference-endpoints/en/guides/custom_handler), to be able to store our Concrete ML models and let users deploy on HF machines in one click. At the end of this blog post, you will understand how to use pre-compiled models and how to prepare yours. This blog can also be considered as another tutorial for custom inference handlers.
## Deploying a pre-compiled model
Let's start with deploying an FHE-friendly model (prepared by Zama or third parties - see [Preparing your pre-compiled model](#preparing-your-pre-compiled-model) section below for learning how to prepare yours).
First, look for the model you want to deploy: We have pre-compiled a [bunch of models](https://huggingface.co/zama-fhe?#models) on Zama's HF page (or you can [find them](https://huggingface.co/models?other=concrete-ml) with tags). Let's suppose you have chosen [concrete-ml-encrypted-decisiontree](https://huggingface.co/zama-fhe/concrete-ml-encrypted-decisiontree): As explained in the description, this pre-compiled model allows you to detect spam without looking at the message content in the clear.
Like with any other model available on the Hugging Face platform, select _Deploy_ and then _Inference Endpoint (dedicated)_:
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/fhe-endpoints/inference_endpoint.png" alt="Inference Endpoint (dedicated)" style="width: 20%; height: auto;"><be>
<em>Inference Endpoint (dedicated)</em>
</p>
Next, choose the Endpoint name or the region, and most importantly, the CPU (Concrete ML models do not use GPUs for now; we are [working](https://www.zama.ai/post/tfhe-rs-v0-5) on it) as well as the best machine available - in the example below we chose eight vCPU. Now click on _Create Endpoint_ and wait for the initialization to finish.
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/fhe-endpoints/create_endpoint.png" alt="Create Endpoint" style="width: 90%; height: auto;"><be>
<em>Create Endpoint</em>
</p>
After a few seconds, the Endpoint is deployed, and your privacy-preserving model is ready to operate.
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/fhe-endpoints/endpoint_is_created.png" alt="Endpoint is created" style="width: 90%; height: auto;"><be>
<em>Endpoint is created</em>
</p>
> [!NOTE]: Don’t forget to delete the Endpoint (or at least pause it) when you are no longer using it, or else it will cost more than anticipated.
## Using the Endpoint
### Installing the client side
The goal is not only to deploy your Endpoint but also to let your users play with it. For that, they need to clone the repository on their computer. This is done by selecting _Clone Repository_, in the dropdown menu:
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/fhe-endpoints/clone_repository.png" alt="Clone Repository" style="width: 12%; height: auto;"><be>
<em>Clone Repository</em>
</p>
They will be given a small command line that they can run in their terminal:
```bash
git clone https://huggingface.co/zama-fhe/concrete-ml-encrypted-decisiontree
```
Once the command is done, they go to the `concrete-ml-encrypted-decisiontree` directory and open `play_with_endpoint.py` with their editor. Here, they will find the line with `API_URL = …` and should replace it with the new URL of the Endpoint created in the previous section.
```bash
API_URL = "https://vtx9w974oxrq54ff.us-east-1.aws.endpoints.huggingface.cloud"
```
Of course, fill it in with with _your_ Entrypoint’s URL. Also, define an [access token](https://huggingface.co/docs/hub/en/security-tokens) and store it in an environment variable:
```bash
export HF_TOKEN=[your token hf_XX..XX]
```
Lastly, your user machines need to have Concrete ML installed locally: Make a virtual environment, source it, and install the necessary dependencies:
```bash
python3.10 -m venv .venv
source .venv/bin/activate
pip install -U setuptools pip wheel
pip install -r requirements.txt
```
> [!NOTE] Remark that we currently force the use of Python 3.10 (which is also the default python version used in Hugging Face Endpoints). This is because our development files currently depend on the Python version. We are working on making them independent. This should be available in a further version.
### Running inferences
Now, your users can run inference on the Endpoint launching the script:
```bash
python play_with_endpoint.py
```
It should generate some logs similar to the following:
```bash
Sending 0-th piece of the key (remaining size is 71984.14 kbytes)
Storing the key in the database under uid=3307376977
Sending 1-th piece of the key (remaining size is 0.02 kbytes)
Size of the payload: 0.23 kilobytes
for 0-th input, prediction=0 with expected 0 in 3.242 seconds
for 1-th input, prediction=0 with expected 0 in 3.612 seconds
for 2-th input, prediction=0 with expected 0 in 4.765 seconds
(...)
for 688-th input, prediction=0 with expected 1 in 3.176 seconds
for 689-th input, prediction=1 with expected 1 in 4.027 seconds
for 690-th input, prediction=0 with expected 0 in 4.329 seconds
Accuracy on 691 samples is 0.8958031837916064
Total time: 2873.860 seconds
Duration per inference: 4.123 seconds
```
### Adapting to your application or needs
If you edit `play_with_endpoint.py`, you'll see that we iterate over different samples of the test dataset and run encrypted inferences directly on the Endpoint.
```python
for i in range(nb_samples):
# Quantize the input and encrypt it
encrypted_inputs = fhemodel_client.quantize_encrypt_serialize(X_test[i].reshape(1, -1))
# Prepare the payload
payload = {
"inputs": "fake",
"encrypted_inputs": to_json(encrypted_inputs),
"method": "inference",
"uid": uid,
}
if is_first:
print(f"Size of the payload: {sys.getsizeof(payload) / 1024:.2f} kilobytes")
is_first = False
# Run the inference on HF servers
duration -= time.time()
duration_inference = -time.time()
encrypted_prediction = query(payload)
duration += time.time()
duration_inference += time.time()
encrypted_prediction = from_json(encrypted_prediction)
# Decrypt the result and dequantize
prediction_proba = fhemodel_client.deserialize_decrypt_dequantize(encrypted_prediction)[0]
prediction = np.argmax(prediction_proba)
if verbose:
print(
f"for {i}-th input, {prediction=} with expected {Y_test[i]} in {duration_inference:.3f} seconds"
)
# Measure accuracy
nb_good += Y_test[i] == prediction
```
Of course, this is just an example of the Entrypoint's usage. Developers are encouraged to adapt this example to their own use-case or application.
### Under the hood
Please note that all of this is done thanks to the flexibility of [custom handlers](https://huggingface.co/docs/inference-endpoints/en/guides/custom_handler), and we express our gratitude to the Hugging Face developers for offering such flexibility. The mechanism is defined in `handler.py`. As explained in the Hugging Face documentation, you can define the `__call__` method of `EndpointHandler` pretty much as you want: In our case, we have defined a `method` parameter, which can be `save_key` (to save FHE evaluation keys), `append_key` (to save FHE evaluation keys piece by piece if the key is too large to be sent in one single call) and finally `inference` (to run FHE inferences). These methods are used to set the evaluation key once and then run all the inferences, one by one, as seen in `play_with_endpoint.py`.
### Limits
One can remark, however, that keys are stored in the RAM of the Endpoint, which is not convenient for a production environment: At each restart, the keys are lost and need to be re-sent. Plus, when you have several machines to handle massive traffic, this RAM is not shared between the machines. Finally, the available CPU machines only provide eight vCPUs at most for Endpoints, which could be a limit for high-load applications.
## Preparing your pre-compiled model
Now that you know how easy it is to deploy a pre-compiled model, you may want to prepare yours. For this, you can fork [one of the repositories we have prepared](https://huggingface.co/zama-fhe?#models). All the model categories supported by Concrete ML ([linear](https://docs.zama.ai/concrete-ml/built-in-models/linear) models, [tree-based](https://docs.zama.ai/concrete-ml/built-in-models/tree) models, built-in [MLP](https://docs.zama.ai/concrete-ml/built-in-models/neural-networks), [PyTorch](https://docs.zama.ai/concrete-ml/deep-learning/torch_support) models) have at least one example, that can be used as a template for new pre-compiled models.
Then, edit `creating_models.py`, and change the ML task to be the one you want to tackle in your pre-compiled model: For example, if you started with [concrete-ml-encrypted-decisiontree](https://huggingface.co/zama-fhe/concrete-ml-encrypted-decisiontree), change the dataset and the model kind.
As explained earlier, you must have installed Concrete ML to prepare your pre-compiled model. Remark that you may have to use the same python version than Hugging Face use by default (3.10 when this blog is written), or your models may need people to use a container with your python during the deployment.
Now you can launch `python creating_models.py`. This will train the model and create the necessary development files (`client.zip`, `server.zip`, and `versions.json`) in the `compiled_model` directory. As explained in the [documentation](https://docs.zama.ai/concrete-ml/deployment/client_server), these files contain your pre-compiled model. If you have any issues, you can get support on the [fhe.org discord](http://discord.fhe.org).
The last step is to modify `play_with_endpoint.py` to also deal with the same ML task as in `creating_models.py`: Set the dataset accordingly.
Now, you can save this directory with the `compiled_model` directory and files, as well as your modifications in `creating_models.py` and `play_with_endpoint.py` on Hugging Face models. Certainly, you will need to run some tests and make slight adjustments for it to work. Do not forget to add a `concrete-ml` and `FHE` tag, such that your pre-compiled model appears easily in [searches](https://huggingface.co/models?other=concrete-ml).
## Pre-compiled models available today
For now, we have prepared a few pre-compiled models as examples, hoping the community will extend this soon. Pre-compiled models can be found by searching for the [concrete-ml](https://huggingface.co/models?other=concrete-ml) or [FHE](https://huggingface.co/models?other=FHE) tags.
| Model kind | Dataset | Execution time on HF Endpoint |
|---|---|---|
| [Logistic Regression](https://huggingface.co/zama-fhe/concrete-ml-encrypted-logreg) | Synthetic | 0.4 sec |
[DecisionTree](https://huggingface.co/zama-fhe/concrete-ml-encrypted-decisiontree) | Spam | 2.0 sec
[QNN](https://huggingface.co/zama-fhe/concrete-ml-encrypted-qnn) | Iris | 3.7 sec
[CNN](https://huggingface.co/zama-fhe/concrete-ml-encrypted-deeplearning) | MNIST | 24 sec
Keep in mind that there's a limited set of configuration options in Hugging Face for CPU-backed Endpoints (up to 8 vCPU with 16 GB of RAM today). Depending on your production requirements and model characteristics, execution times could be faster on more powerful cloud instances. Hopefully, more powerful machines will soon be available on Hugging Face Endpoints to improve these timings.
## Additional resources
- Check out Zama libraries [Concrete](https://github.com/zama-ai/concrete) and [Concrete-ML](https://github.com/zama-ai/concrete-ml) and start using FHE in your own applications.
- Check out [Zama's Hugging Face profile](https://huggingface.co/zama-fhe) to read more blog posts and try practical FHE demos.
- Check out [@zama_fhe](https://twitter.com/zama_fhe) on twitter to get our latest updates.
## Conclusion and next steps
In this blog post, we have shown that custom Endpoints are pretty easy yet powerful to use. What we do in Concrete ML is pretty different from the regular workflow of ML practitioners, but we are still able to accommodate the custom Endpoints to deal with most of our needs. Kudos to Hugging Face engineers for developing such a generic solution.
We explained how:
- Developers can create their own pre-compiled models and make them available on Hugging Face models.
- Companies can deploy developers' pre-compiled models and make them available to their users via HF Endpoints.
- Final users can use these Endpoints to run their ML tasks over encrypted data.
To go further, it would be useful to have more powerful machines available on Hugging Face Endpoints to make inferences faster. Also, we could imagine that Concrete ML becomes more integrated into Hugging Face's interface and has a _Private-Preserving Inference Endpoint_ button, simplifying developers' lives even more. Finally, for integration in several server machines, it could be helpful to have a way to share a state between machines and keep this state non-volatile (FHE inference keys would be stored there).
| 0 |
0 | hf_public_repos | hf_public_repos/blog/tgi-benchmarking.md | ---
title: "Benchmarking Text Generation Inference"
thumbnail: /blog/assets/tgi-benchmarking/tgi-benchmarking-thumbnail.png
authors:
- user: derek-thomas
---
# Benchmarking Text Generation Inference
In this blog we will be exploring [Text Generation Inference’s](https://github.com/huggingface/text-generation-inference) (TGI) little brother, the [TGI Benchmarking tool](https://github.com/huggingface/text-generation-inference/blob/main/benchmark/README.md). It will help us understand how to profile TGI beyond simple throughput to better understand the tradeoffs to make decisions on how to tune your deployment for your needs. If you have ever felt like LLM deployments cost too much or if you want to tune your deployment to improve performance this blog is for you!
I’ll show you how to do this in a convenient [Hugging Face Space](https://huggingface.co/spaces). You can take the results and use it on an [Inference Endpoint](https://huggingface.co/inference-endpoints/dedicated) or other copy of the same hardware.
## Motivation
To get a better understanding of the need to profile, let's discuss some background information first.
Large Language Models (LLMs) are fundamentally inefficient. Based on [the way decoders work](https://huggingface.co/learn/nlp-course/chapter1/6?fw=pt), generation requires a new forward pass for each decoded token. As LLMs increase in size, and [adoption rates surge](https://a16z.com/generative-ai-enterprise-2024/) across enterprises, the AI industry has done a great job of creating new optimizations and performance enhancing techniques.
There have been dozens of improvements in many aspects of serving LLMs. We have seen [Flash Attention](https://huggingface.co/docs/text-generation-inference/en/conceptual/flash_attention), [Paged Attention](https://huggingface.co/docs/text-generation-inference/en/conceptual/paged_attention), [streaming responses](https://huggingface.co/docs/text-generation-inference/en/conceptual/streaming), [improvements in batching](https://huggingface.co/docs/text-generation-inference/en/basic_tutorials/launcher#maxwaitingtokens), [speculation](https://huggingface.co/docs/text-generation-inference/en/conceptual/speculation), [quantization](https://huggingface.co/docs/text-generation-inference/en/conceptual/quantization) of many kinds, [improvements in web servers](https://github.com/huggingface/text-generation-inference?tab=readme-ov-file#architecture), adoptions of [faster languages](https://github.com/search?q=repo%3Ahuggingface%2Ftext-generation-inference++language%3ARust&type=code) (sorry python 🐍), and many more. There are also use-case improvements like [structured generation](https://huggingface.co/docs/text-generation-inference/en/conceptual/guidance) and [watermarking](https://huggingface.co/blog/watermarking) that now have a place in the LLM inference world. The problem is that fast and efficient implementations require more and more niche skills to implement [[1]](#1).
[Text Generation Inference](https://github.com/huggingface/text-generation-inference) is a high-performance LLM inference server from Hugging Face designed to embrace and develop the latest techniques in improving the deployment and consumption of LLMs. Due to Hugging Face’s open-source partnerships, most (if not all) major Open Source LLMs are available in TGI on release day.
Oftentimes users will have very different needs depending on their use-case requirements. Consider prompt and generation in a **RAG use-case**:
* Instructions/formatting
* usually short, <200 tokens
* The user query
* usually short, <200 tokens
* Multiple documents
* medium-sized, 500-1000 tokens per document,
* N documents where N<10
* An answer in the output
* medium-sized ~500-1000 tokens
In RAG it's important to have the right document to get a quality response, you increase this chance by increasing N which includes more documents. This means that RAG will often try to max out an LLM’s context window to increase task performance. In contrast, think about basic chat. Typical **chat scenarios** have significantly fewer tokens than RAG:
* Multiple turns
* 2xTx50-200 tokens, for T turns
* The 2x is for both User and Assistant
Given that we have such different scenarios, we need to make sure that we configure our LLM server accordingly depending on which one is more relevant. Hugging Face has a [benchmarking tool](https://github.com/huggingface/text-generation-inference/blob/main/benchmark/README.md) that can help us explore what configurations make the most sense and I'll explain how you can do this on a [Hugging Face Space](https://huggingface.co/docs/hub/en/spaces-overview).
## Pre-requisites
Let’s make sure we have a common understanding of a few key concepts before we dive into the tool.
### Latency vs Throughput
<video style="width: auto; height: auto;" controls autoplay muted loop>
<source src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/tgi-benchmarking/LatencyThroughputVisualization.webm" type="video/webm">
Your browser does not support the video tag.
</video>
| |
|-------------------------------------------------|
| *Figure 1: Latency vs Throughput Visualization* |
* Token Latency – The amount of time it takes 1 token to be processed and sent to a user
* Request Latency – The amount of time it takes to fully respond to a request
* Time to First Token - The amount of time from the initial request to the first token returning to the user. This is a combination of the amount of time to process the prefill input and a single generated token
* Throughput – The number of tokens the server can return in a set amount of time (4 tokens per second in this case)
Latency is a tricky measurement because it doesn’t tell you the whole picture. You might have a long generation or a short one which won't tell you much regarding your actual server performance.
It’s important to understand that Throughput and Latency are orthogonal measurements, and depending on how we configure our server, we can optimize for one or the other. Our benchmarking tool will help us understand the trade-off via a data visualization.
### Pre-filling and Decoding
||
|:--:|
|*Figure 2: Prefilling vs Decoding inspired by [[2]](#2)*|
Here is a simplified view of how an LLM generates text. The model (typically) generates a single token for each forward pass. For the **pre-filling stage** in orange, the full prompt (What is.. of the US?) is sent to the model and one token (Washington) is generated. In the **decoding stage** in blue, the generated token is appended to the previous input and then this (... the capital of the US? Washington) is sent through the model for another forward pass. Until the model generates the end-of-sequence-token (\<EOS\>), this process will continue: send input through the model, generate a token, append the token to input.
<br>
<div style="background-color: #e6f9e6; padding: 16px 32px; outline: 2px solid; border-radius: 10px;">
Thinking Question: Why does pre-filling only take 1 pass when we are submitting multiple unseen tokens as input?
<details>
<summary>Click to reveal the answer</summary>
We don’t need to generate what comes after “What is the”. We know its “capital” from the user.
</details>
</div>
I only included a short example for illustration purposes, but consider that pre-filling only needs 1 forward pass through the model, but decoding can take hundreds or more. Even in our short example we can see more blue arrows than orange. We can see now why it takes so much time to get output from an LLM! Decoding is usually where we spend more time thinking through due to the many passes.
## Benchmarking Tool
### Motivation
We have all seen comparisons of tools, new algorithms, or models that show throughput. While this is an important part of the LLM inference story, it's missing some key information. At a minimum (you can of course go more in-depth) we need to know what the throughput AND what the latency is to make good decisions. One of the primary benefits of the TGI benchmarking tool is that it has this capability.
Another important line of thought is considering what experience you want the user to have. Do you care more about serving to many users, or do you want each user once engaged with your system to have a fast response? Do you want to have a better Time To First Token (TTFT) or do you want blazing fast tokens to appear once they get their first token even if the first one is delayed?
Here are some ideas on how that can play out. Remember there is no free lunch. But with enough GPUs and a proper configuration, you can have almost any meal you want.
<table>
<tr>
<td><strong>I care about…</strong>
</td>
<td><strong>I should focus on…</strong>
</td>
</tr>
<tr>
<td>Handling more users
</td>
<td>Maximizing Throughput
</td>
</tr>
<tr>
<td>People not navigating away from my page/app
</td>
<td>Minimizing TTFT
</td>
</tr>
<tr>
<td>User Experience for a moderate amount of users
</td>
<td>Minimizing Latency
</td>
</tr>
<tr>
<td>Well rounded experience
</td>
<td>Capping latency and maximizing throughput
</td>
</tr>
</table>
### Setup
The benchmarking tool is installed with TGI, but you need access to the server to run it. With that in mind I’ve provided this space [derek-thomas/tgi-benchmark-space](https://huggingface.co/spaces/derek-thomas/tgi-benchmark-space) to combine a TGI docker image (pinned to latest) and a jupyter lab working space. It's designed to be duplicated, so dont be alarmed if it's sleeping. It will allow us to deploy a model of our choosing and easily run the benchmarking tool via a CLI. I’ve added some notebooks that will allow you to easily follow along. Feel free to dive into the [Dockerfile](https://huggingface.co/spaces/derek-thomas/tgi-benchmark-space/blob/main/Dockerfile) to get a feel for how it’s built, especially if you want to tweak it.
### Getting Started
Please note that it's much better to run the benchmarking tool in a jupyter lab terminal rather than a notebook due to its interactive nature, but I'll put the commands in a notebook so I can annotate and it's easy to follow along.
1. Click: <a class="duplicate-button" style="display:inline-block" target="_blank" href="https://huggingface.co/spaces/derek-thomas/tgi-benchmark-space?duplicate=true"><img style="margin-top:0;margin-bottom:0" src="https://huggingface.co/datasets/huggingface/badges/raw/main/duplicate-this-space-sm.svg" alt="Duplicate Space"></a>
* Set your default password in the `JUPYTER_TOKEN` [space secret](https://huggingface.co/docs/hub/spaces-sdks-docker#secrets) (it should prompt you upon duplication)
* Choose your HW, note that it should mirror the HW you want to deploy on
2. Go to your space and login with your password
3. Launch `01_1_TGI-launcher.ipynb`
* This will launch TGI with default settings using the jupyter notebook
4. Launch `01_2_TGI-benchmark.ipynb`
* This will launch the TGI benchmarking tool with some demo settings
### Main Components
||
|:--:|
|*Figure 3: Benchmarking Tool Components*|
* **Component 1**: Batch Selector and other information.
* Use your arrows to select different batches
* **Component 2** and **Component 4**: Pre-fill stats and histogram
* The calculated stats/histogram are based on how many `--runs`
* **Component 3** and **Component 5**: Pre-fill Throughput vs Latency Scatter Plot
* X-axis is latency (small is good)
* Y-axis is throughput (large is good)
* The legend shows us our batch-size
* An “*ideal*” point would be in the top left corner (low latency and high throughput)
### Understanding the Benchmarking tool
||
|:--:|
|*Figure 4: Benchmarking Tool Charts*|
If you used the same HW and settings I did, you should have a really similar chart to Figure 4. The benchmarking tool is showing us the throughput and latency for different batch sizes (amounts of user requests, slightly different than the language when we are launching TGI) for the current settings and HW given when we launched TGI. This is important to understand as we should update the settings in how we launch TGI based on our findings with the benchmarking tool.
The chart in **Component 3** tends to be more interesting as we get longer pre-fills like in RAG. It does impact TTFT (shown on the X-axis) which is a big part of the user experience. Remember we get to push our input tokens through in one forward pass even if we do have to build the KV cache from scratch. So it does tend to be faster in many cases per token than decoding.
The chart in **Component 5** is when we are decoding. Let's take a look at the shape the data points make. We can see that for batch sizes of 1-32 the shape is mostly vertical at ~5.3s. This is really good. This means that for no degradation in latency we can improve throughput significantly! What happens at 64 and 128? We can see that while our throughput is increasing, we are starting to tradeoff latency.
For these same values let's check out what is happening on the chart in **Component 3**. For batch size 32 we can see that we are still about 1 second for our TTFT. But we do start to see linear growth from 32 -> 64 -> 128, 2x the batch size has 2x the latency. Further there is no throughput gain! This means that we don't really get much benefit from the tradeoff.
<br>
<div style="background-color: #e6f9e6; padding: 16px 32px; outline: 2px solid; border-radius: 10px;">
Thinking Questions:
<ul>
<li>What types of shapes do you expect these curves to take if we add more points?</li>
<li>How would you expect these curves to change if you have more tokens (pre-fill or decoding)?</li>
</ul>
</div>
If your batch size is in a vertical area, this is great, you can get more throughput and handle more users for free. If your batch size is in a horizontal area, this means you are compute bound and increasing users just delays everyone with no benefit of throughput. You should improve your TGI configuration or scale your hardware.
Now that we learned a bit about TGI’s behavior in various scenarios we can try different settings for TGI and benchmark again. It's good to go through this cycle a few times before deciding on a good configuration. If there is enough interest maybe we can have a part 2 which dives into the optimization for a use-case like chat or RAG.
### Winding Down
It's important to keep track of actual user behavior. When we estimate user behavior we have to start somewhere and make educated guesses. These number choices will make a big impact on how we are able to profile. Luckily TGI can tell us this information in the logs, so be sure to check that out as well.
Once you are done with your exploration, be sure to stop running everything so you won't incur further charges.
* Kill the running cell in the `TGI-launcher.ipynb` jupyter notebook
* Hit `q` in the terminal to stop the profiling tool.
* Hit pause in the settings of the space
## Conclusion
LLMs are bulky and expensive, but there are a number of ways to reduce that cost. LLM inference servers like TGI have done most of the work for us as long as we leverage their capabilities properly. The first step is to understand what is going on and what trade-offs you can make. We’ve seen how to do that with the TGI Benchmarking tool. We can take these results and use them on any equivalent HW in AWS, GCP, or Inference Endpoints.
Thanks to Nicolas Patry and Olivier Dehaene for creating [TGI](https://github.com/huggingface/text-generation-inference) and its [benchmarking tool](https://github.com/huggingface/text-generation-inference/blob/main/benchmark/README.md). Also special thanks to Nicholas Patry, Moritz Laurer, Nicholas Broad, Diego Maniloff, and Erik Rignér for their very helpful proofreading.
## References
<a id="1">[1]</a> : Sara Hooker, [The Hardware Lottery](https://arxiv.org/abs/1911.05248), 2020
<a id="2">[2]</a> : Pierre Lienhart, [LLM Inference Series: 2. The two-phase process behind LLMs’ responses](https://medium.com/@plienhar/llm-inference-series-2-the-two-phase-process-behind-llms-responses-1ff1ff021cd5), 2023
| 1 |
0 | hf_public_repos | hf_public_repos/blog/ml-director-insights-3.md | ---
title: "Director of Machine Learning Insights [Part 3: Finance Edition]"
thumbnail: /blog/assets/78_ml_director_insights/thumbnail.png
authors:
- user: britneymuller
---
# Director of Machine Learning Insights [Part 3: Finance Edition]
_If you're interested in building ML solutions faster visit [hf.co/support](https://huggingface.co/support?utm_source=article&utm_medium=blog&utm_campaign=ml_director_insights_3) today!_
👋 Welcome back to our Director of ML Insights Series, Finance Edition! If you missed earlier Editions you can find them here:
- [Director of Machine Learning Insights [Part 1]](https://huggingface.co/blog/ml-director-insights)
- [Director of Machine Learning Insights [Part 2 : SaaS Edition]](https://huggingface.co/blog/ml-director-insights-2)
Machine Learning Directors within finance face the unique challenges of navigating legacy systems, deploying interpretable models, and maintaining customer trust, all while being highly regulated (with lots of government oversight). Each of these challenges requires deep industry knowledge and technical expertise to pilot effectively. The following experts from U.S. Bank, the Royal Bank of Canada, Moody's Analytics and ex Research Scientist at Bloomberg AI all help uncover unique gems within the Machine Learning x Finance sector.
You’ll hear from a juniors Greek National Tennis Champion, a published author with over 100+ patents, and a cycle polo player who regularly played at the world’s oldest polo club (the Calcutta Polo Club). All turned financial ML experts.
🚀 Buckle up Goose, here are the top insights from financial ML Mavericks:
_Disclaimer: All views are from individuals and not from any past or current employers._
<img class="mx-auto" style="float: left;" padding="5px" width="200" src="/blog/assets/78_ml_director_insights/Ioannis-Bakagiannis.jpeg"></a>
### [Ioannis Bakagiannis](https://www.linkedin.com/in/bakagiannisioannis//) - Director of Machine Learning, Marketing Science at [RBC](https://www.rbcroyalbank.com/personal.html)
**Background:** Passionate Machine Learning Expert with experience in delivering scalable, production-grade, and state-of-the-art Machine Learning solutions. Ioannis is also the Host of [Bak Up Podcast](https://www.youtube.com/channel/UCHK-YMcyzw2TwKonKoFtiug) and seeks to make an impact on the world through AI.
**Fun Fact:** Ioannis was a juniors Greek national tennis champion.🏆
**RBC:** The world’s leading organizations look to RBC Capital Markets as an innovative, trusted partner in capital markets, banking and finance.
#### **1. How has ML made a positive impact on finance?**
We all know that ML is a disrupting force in all industries while continuously creating new business opportunities. Many financial products have been created or altered due to ML such as personalized insurance and targeted marketing.
Disruptions and profit are great but my favorite financial impact has been the ML-initiated conversation around trust in financial decision making.
In the past, financial decisions like loan approval, rate determination, portfolio management, etc. have all been done by humans with relevant expertise. Essentially, people trusted “other people” or “experts” for financial decisions (and often without question).
When ML attempted to automate that decision-making process, people asked, “Why should we trust a model?”. Models appeared to be black boxes of doom coming to replace honest working people. But that argument has initiated the conversation of trust in financial decision-making and ethics, regardless of who or what is involved.
As an industry, we are still defining this conversation but with more transparency, thanks to ML in finance.
#### **2. What are the biggest ML challenges within finance?**
I can’t speak for companies but established financial institutions experience one continuous struggle, like all long-lived organizations: Legacy Systems.
Financial organizations have been around for a while and they have evolved over time but today they have found themselves somehow as ‘tech companies’. Such organizations need to be part of cutting-edge technologies so they can compete with newcomer rivals but at the same time maintain the robustness that makes our financial world work.
This internal battle is skewed by the risk appetite of the institutions. Financial risk increases linearly (usually) with the scale of the solution you provide since we are talking about money. But on top of that, there are other forms of risk that a system failure will incur such as Regulatory and Reputational risk. This compounded risk along with the complexity of migrating a huge, mature system to a new tech stack is, at least in my opinion, the biggest challenge in adopting cutting-edge technologies such as ML.
#### **3. What’s a common mistake you see people make trying to integrate ML into financial applications?**
ML, even with all its recent attention, is still a relatively new field in software engineering. The deployment of ML applications is often not a well-defined process. The artist/engineer can deliver an ML application but the world around it is still not familiar with the technical process. At that intersection of technical and non-technical worlds, I have seen the most “mistakes”.
It is hard to optimize for the right Business and ML KPIs and define the right objective function or the desired labels. I have seen applications go to waste due to undesired prediction windows or because they predict the wrong labels.
The worst outcome comes when the misalignment is not uncovered in the development step and makes it into production.
Then applications can create unwanted user behavior or simply measure/predict the wrong thing. Unfortunately, we tend to equip the ML teams with tools and computing but not with solid processes and communication buffers. And mistakes at the beginning of an ill-defined process grow with every step.
#### **4. What excites you most about the future of ML?**
It is difficult not to get excited with everything new that comes out of ML. The field changes so frequently that it’s refreshing.
Currently, we are good at solving individual problems: computer vision, the next word prediction, data point generation, etc, but we haven’t been able to address multiple problems at the same time. I’m excited to see how we can model such behaviors in mathematical expressions that currently seem to contradict each other. Hope we get there soon!
<img class="mx-auto" style="float: left;" padding="5px" width="200" src="/blog/assets/78_ml_director_insights/Debanjan-Mahata.jpeg"></a>
### [Debanjan Mahata](https://www.linkedin.com/in/debanjanmahata/) - Director of AI & ML at [Moody's Analytics](https://www.moodysanalytics.com/) / Ex Research Scientist @ Bloomberg AI
**Background:** Debanjan is Director of Machine Learning in the AI Team at Moody's Analytics and also serves as an Adjunct Faculty at IIIT-Delhi, India. He is an active researcher and is currently interested in various information extraction problems and domain adaptation techniques in NLP. He has a track record of formulating and applying machine learning to various use cases. He actively participates in the program committee of different top tier conference venues in machine learning.
**Fun Fact:** Debanjan played cycle polo at the world's oldest polo club (the Calcutta Polo Club) when he was a kid.
**Moody's Analytics:** Provides financial intelligence and analytical tools supporting our clients’ growth, efficiency and risk management objectives.
#### **1. How has ML made a positive impact on finance?**
Machine learning (ML) has made a significant positive impact in the finance industry in many ways. For example, it has helped in combating financial crimes and identifying fraudulent transactions. Machine learning has been a crucial tool in applications such as Know Your Customer (KYC) screening and Anti Money Laundering (AML). With an increase in AML fines by financial institutions worldwide, ever changing realm of sanctions, and greater complexity in money laundering, banks are increasing their investments in KYC and AML technologies, many of which are powered by ML. ML is revolutionizing multiple facets of this sector, especially bringing huge efficiency gains by automating various processes and assisting analysts to do their jobs more efficiently and accurately.
One of the key useful traits of ML is that it can learn from and find hidden patterns in large volumes of data. With a focus on digitization, the financial sector is producing digital data more than ever, which makes it challenging for humans to comprehend, process and make decisions. ML is enabling humans in making sense of the data, glean information from them, and make well-informed decisions. At Moody's Analytics, we are using ML and helping our clients to better manage risk and meet business and industry demands.
#### **2. What are the biggest ML challenges within finance?**
1. Reducing the False Positives without impacting the True Positives - A number of applications using ML in the regtech space rely on alerts. With strict regulatory measures and big financial implications of a wrong decision, human investigations can be time consuming and demanding. ML certainly helps in these scenarios in assisting human analysts to arrive at the right decisions. But if a ML system results in a lot of False Positives, it makes an analysts' job harder. Coming up with the right balance is an important challenge for ML in finance.
2. Gap between ML in basic research and education and ML in finance - Due to the regulated nature of the finance industry, we see limited exchange of ideas, data, and resources between the basic research and the finance sector, in the area of ML. There are few exceptions of course. This has led to scarcity of developing ML research that cater to the needs of the finance industry. I think more efforts must be made to decrease this gap. Otherwise, it will be increasingly challenging for the finance industry to leverage the latest ML advances.
3. Legacy infrastructure and databases - Many financial institutions still carry legacy infrastructure with them which makes it challenging for applying modern ML technologies and especially to integrate them. The finance industry would benefit from borrowing key ideas, culture and best practices from the tech industry when it comes to developing new infrastructure and enabling the ML professionals to innovate and make more impact. There are certainly challenges related to operationalizing ML across the industry.
4. Data and model governance - More data and model governance efforts need to be made in this sector. As we collect more and more data there should be more increase in the efforts to collect high quality data and the right data. Extra precautions need to be taken when ML models are involved in decisioning. Proper model governance measures and frameworks needs to be developed for different financial applications. A big challenge in this space is the lack of tools and technologies to operationalize data and model governance that are often needed for ML systems operating in this sector. More efforts should also be made in understanding bias in the data that train the models and how to make it a common practice to mitigate them in the overall process. Ensuring auditability, model and data lineage has been challenging for ML teams.
5. Explainability and Interpretability - Developing models which are highly accurate as well as interpretable and explainable is a big challenge. Modern deep learning models often outperform more traditional models; however, they lack explainability and interpretability. Most of the applications in finance demands explainability. Adopting the latest developments in this area and ensuring the development of interpretable models with explainable predictions have been a challenge.
#### **3. What’s a common mistake you see people make trying to integrate ML into financial applications?**
- Not understanding the data well and the raw predictions made by the ML models trained on them.
- Not analyzing failed efforts and learning from them.
- Not understanding the end application and how it will be used.
- Trying complex techniques when simpler solutions might suffice.
#### **4. What excites you most about the future of ML?**
I am really blown away by how modern ML models have been learning rich representations of text, audio, images, videos, code and so on using self-supervised learning on large amounts of data. The future is certainly multi-modal and there has been consistent progress in understanding multi-modal content through the lens of ML. I think this is going to play a crucial role in the near future and I am excited by it and looking forward to being a part of these advances.
<img class="mx-auto" style="float: left;" padding="5px" width="200" src="/blog/assets/78_ml_director_insights/Soumitri-Kolavennu.jpeg"></a>
### [Soumitri Kolavennu](https://www.linkedin.com/in/soumitri-kolavennu-2b47376/) - Artificial Intelligence Leader - Enterprise Analytics & AI at [U.S. Bank](https://www.usbank.com/index.html)
**Background:** Soumitri Kolavennu is a SVP and head of AI research in U.S. Bank’s enterprise analytics and AI organization. He is currently focused on deep learning based NLP, vision & audio analytics, graph neural networks, sensor/knowledge fusion, time-series data with application to automation, information extraction, fraud detection and anti-money laundering in financial systems.
Previously, he held the position of Fellows Leader & Senior Fellow, while working at Honeywell International Inc. where he had worked on IoT and control systems applied to smart home, smart cities, industrial and automotive systems.
**Fun Fact:** Soumitri is a prolific inventor with 100+ issued U.S. patents in varied fields including control systems, Internet of Things, wireless networking, optimization, turbocharging, speech recognition, machine learning and AI. He also has around 30 publications, [authored a book](https://www.elsevier.com/books/industrial-wireless-sensor-networks/budampati/978-1-78242-230-3), book chapters and was elected member of NIST’s smart grid committee.
**U.S. Bank:** The largest regional bank in the United States, U.S. Bank blends its relationship teams, branches and ATM networks with digital tools that allow customers to bank when, where and how they prefer.
#### **1. How has ML made a positive impact on finance?**
Machine learning and artificial intelligence have made a profound and positive impact on finance in general and banking in particular. There are many applications in banking where many factors (features) are to be considered when making a decision and ML has traditionally helped in this respect. For example, the credit score we all universally rely on is derived from a machine learning algorithm.
Over the years ML has interestingly also helped remove human bias from decisions and provided a consistent algorithmic approach to decisions. For example, in credit card/loan underwriting and mortgages, modern AI techniques can take more factors (free form text, behavioral trends, social and financial interactions) into account for decisions while also detecting fraud.
#### **2. What are the biggest ML challenges within finance?**
The finance and banking industry brings a lot of challenges due to the nature of the industry. First of all, it is a highly regulated industry with government oversight in many aspects. The data that is often used is very personal and identifiable data (social security numbers, bank statements, tax records, etc). Hence there is a lot of care taken to create machine learning and AI models that are private and unbiased. Many government regulations require any models to be explainable. For example, if a loan is denied, there is a fundamental need to explain why it is denied.
The data on the other hand, which may be scarce in other industries is abundant in the financial industry. (Mortgage records have to be kept for 30 years for example). The current trend for digitization of data and the explosion of more sophisticated AI/ML techniques has created a unique opportunity for the application of these advances.
#### **3. What’s a common mistake you see people make trying to integrate ML into financial applications?**
One of the most common mistakes people make is to use a model or a technique without understanding the underlying working principles, advantages, and shortcomings of the model. People tend to think of AI/ML models as a ‘black box’. In finance, it is especially important to understand the model and to be able to explain its’ output. Another mistake is not comprehensively testing the model on a representative input space. Model performance, validation, inference capacities, and model monitoring (retraining intervals) are all important to consider when choosing a model.
#### **4. What excites you most about the future of ML?**
Now is a great time to be in applied ML and AI. The techniques in AI/ML are certainly refining if not redefining many scientific disciplines. I am very excited about how all the developments that are currently underway will reshape the future.
When I first started working in NLP, I was in awe of the ability of neural networks/language models to generate a number or vector (which we now call embeddings) that represents a word, a sentence with the associated grammar, or even a paragraph. We are constantly in search of more and more appropriate and contextual embeddings.
We have advanced far beyond a “simple” embedding for a text to “multimodal” embeddings that are even more awe-inspiring to me. I am most excited and look forward to generating and playing with these new embeddings enabling more exciting applications in the future.
---
🤗 Thank you for joining us in this third installment of ML Director Insights. Stay tuned for more insights from ML Directors.
Big thanks to Soumitri Kolavennu, Debanjan Mahata, and Ioannis Bakagiannis for their brilliant insights and participation in this piece. We look forward to watching your continued success and will be cheering you on each step of the way. 🎉
If you're' interested in accelerating your ML roadmap with Hugging Face Experts please visit [hf.co/support](https://huggingface.co/support?utm_source=article&utm_medium=blog&utm_campaign=ml_director_insights_3) to learn more.
| 2 |
0 | hf_public_repos | hf_public_repos/blog/intel-protein-language-model-protst.md | ---
title: "Accelerating Protein Language Model ProtST on Intel Gaudi 2"
thumbnail: /blog/assets/intel-protein-language-model-protst/01.jpeg
authors:
- user: juliensimon
- user: Jiqing
guest: true
org: Intel
- user: Santiago Miret
guest: true
- user: katarinayuan
guest: true
- user: sywangyi
guest: true
org: Intel
- user: MatrixYao
guest: true
org: Intel
- user: ChrisAllenMing
guest: true
- user: kding1
guest: true
org: Intel
---
# Accelerating Protein Language Model ProtST on Intel Gaudi 2
<p align="center">
<img src="assets/intel-protein-language-model-protst/01.jpeg" alt="A teenage scientist creating molecules with computers and artificial intelligence" width="512"><br>
</p>
## Introduction
Protein Language Models (PLMs) have emerged as potent tools for predicting and designing protein structure and function. At the International Conference on Machine Learning 2023 (ICML), MILA and Intel Labs released [ProtST](https://proceedings.mlr.press/v202/xu23t.html), a pioneering multi-modal language model for protein design based on text prompts. Since then, ProtST has been well-received in the research community, accumulating more than 40 citations in less than a year, showing the scientific strength of the work.
One of PLM's most popular tasks is predicting the subcellular location of an amino acid sequence. In this task, users feed an amino acid sequence into the model, and the model outputs a label indicating the subcellular location of this sequence. Out of the box, zero-shot ProtST-ESM-1b outperforms state-of-the-art few-shot classifiers.
<kbd>
<img src="assets/intel-protein-language-model-protst/02.png">
</kbd>
To make ProtST more accessible, Intel and MILA have re-architected and shared the model on the Hugging Face Hub. You can download the models and datasets [here](https://huggingface.co/mila-intel).
This post will show you how to run ProtST inference efficiently and fine-tune it with Intel Gaudi 2 accelerators and the Optimum for Intel Gaudi open-source library. [Intel Gaudi 2](https://habana.ai/products/gaudi2/) is the second-generation AI accelerator that Intel designed. Check out our [previous blog post](https://huggingface.co/blog/habana-gaudi-2-bloom#habana-gaudi2) for an in-depth introduction and a guide to accessing it through the [Intel Developer Cloud](https://cloud.intel.com). Thanks to the [Optimum for Intel Gaudi library](https://github.com/huggingface/optimum-habana), you can port your transformers-based scripts to Gaudi 2 with minimal code changes.
## Inference with ProtST
Common subcellular locations include the nucleus, cell membrane, cytoplasm, mitochondria, and others as described in [this dataset](https://huggingface.co/datasets/mila-intel/subloc_template) in greater detail.
We compare ProtST's inference performance on NVIDIA A100 80GB PCIe and Gaudi 2 accelerator using the test split of the ProtST-SubcellularLocalization dataset. This test set contains 2772 amino acid sequences, with variable sequence lengths ranging from 79 to 1999.
You can reproduce our experiment using [this script](https://github.com/huggingface/optimum-habana/tree/main/examples/protein-folding#single-hpu-inference-for-zero-shot-evaluation), where we run the model in full bfloat16 precision with batch size 1. We get an identical accuracy of 0.44 on the Nvidia A100 and Intel Gaudi 2, with Gaudi2 delivering 1.76x faster inferencing speed than the A100. The wall time for a single A100 and a single Gaudi 2 is shown in the figure below.
<kbd>
<img src="assets/intel-protein-language-model-protst/03.png">
</kbd>
## Fine-tuning ProtST
Fine-tuning the ProtST model on downstream tasks is an easy and established way to improve modeling accuracy. In this experiment, we specialize the model for binary location, a simpler version of subcellular localization, with binary labels indicating whether a protein is membrane-bound or soluble.
You can reproduce our experiment using [this script](https://github.com/huggingface/optimum-habana/tree/main/examples/protein-folding#multi-hpu-finetune-for-sequence-classification-task). Here, we fine-tune the [ProtST-ESM1b-for-sequential-classification](https://huggingface.co/mila-intel/protst-esm1b-for-sequential-classification) model in bfloat16 precision on the [ProtST-BinaryLocalization](https://huggingface.co/datasets/mila-intel/ProtST-BinaryLocalization) dataset. The table below shows model accuracy on the test split with different training hardware setups, and they closely match the results published in the paper (around 92.5% accuracy).
<kbd>
<img src="assets/intel-protein-language-model-protst/04.png">
</kbd>
The figure below shows fine-tuning time. A single Gaudi 2 is 2.92x faster than a single A100. The figure also shows how distributed training scales near-linearly with 4 or 8 Gaudi 2 accelerators.
<kbd>
<img src="assets/intel-protein-language-model-protst/05.png">
</kbd>
## Conclusion
In this blog post, we have demonstrated the ease of deploying ProtST inference and fine-tuning on Gaudi 2 based on Optimum for Intel Gaudi Accelerators. In addition, our results show competitive performance against A100, with a 1.76x speedup for inference and a 2.92x speedup for fine-tuning.
The following resources will help you get started with your models on the Intel Gaudi 2 accelerator:
* Optimum for Intel Gaudi Accelerators [repository](https://github.com/huggingface/optimum-habana)
* Intel Gaudi [documentation](https://docs.habana.ai/en/latest/index.html)
Thank you for reading! We look forward to seeing your innovations built on top of ProtST with Intel Gaudi 2 accelerator capabilities.
| 3 |
0 | hf_public_repos | hf_public_repos/blog/fine-tune-xlsr-wav2vec2.md | ---
title: "Fine-Tune XLSR-Wav2Vec2 for low-resource ASR with 🤗 Transformers"
thumbnail: /blog/assets/xlsr_wav2vec2.png
authors:
- user: patrickvonplaten
---
# Fine-tuning XLS-R for Multi-Lingual ASR with 🤗 Transformers
<a target="_blank" href="https://colab.research.google.com/github/patrickvonplaten/notebooks/blob/master/Fine_Tune_XLS_R_on_Common_Voice.ipynb">
<img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/>
</a>
***New (11/2021)***: *This blog post has been updated to feature XLSR\'s
successor, called [XLS-R](https://huggingface.co/models?other=xls_r)*.
**Wav2Vec2** is a pretrained model for Automatic Speech Recognition
(ASR) and was released in [September
2020](https://ai.facebook.com/blog/wav2vec-20-learning-the-structure-of-speech-from-raw-audio/)
by *Alexei Baevski, Michael Auli, and Alex Conneau*. Soon after the
superior performance of Wav2Vec2 was demonstrated on one of the most
popular English datasets for ASR, called
[LibriSpeech](https://huggingface.co/datasets/librispeech_asr),
*Facebook AI* presented a multi-lingual version of Wav2Vec2, called
[XLSR](https://arxiv.org/abs/2006.13979). XLSR stands for *cross-lingual
speech representations* and refers to model\'s ability to learn speech
representations that are useful across multiple languages.
XLSR\'s successor, simply called **XLS-R** (refering to the
[*\'\'XLM-R*](https://ai.facebook.com/blog/-xlm-r-state-of-the-art-cross-lingual-understanding-through-self-supervision/)
*for Speech\'\'*), was released in [November 2021](https://ai.facebook.com/blog/xls-r-self-supervised-speech-processing-for-128-languages) by *Arun
Babu, Changhan Wang, Andros Tjandra, et al.* XLS-R used almost **half a
million** hours of audio data in 128 languages for self-supervised
pre-training and comes in sizes ranging from 300 milion up to **two
billion** parameters. You can find the pretrained checkpoints on the 🤗
Hub:
- [**Wav2Vec2-XLS-R-300M**](https://huggingface.co/facebook/wav2vec2-xls-r-300m)
- [**Wav2Vec2-XLS-R-1B**](https://huggingface.co/facebook/wav2vec2-xls-r-1b)
- [**Wav2Vec2-XLS-R-2B**](https://huggingface.co/facebook/wav2vec2-xls-r-2b)
Similar to [BERT\'s masked language modeling
objective](http://jalammar.github.io/illustrated-bert/), XLS-R learns
contextualized speech representations by randomly masking feature
vectors before passing them to a transformer network during
self-supervised pre-training (*i.e.* diagram on the left below).
For fine-tuning, a single linear layer is added on top of the
pre-trained network to train the model on labeled data of audio
downstream tasks such as speech recognition, speech translation and
audio classification (*i.e.* diagram on the right below).

XLS-R shows impressive improvements over previous state-of-the-art
results on both speech recognition, speech translation and
speaker/language identification, *cf.* with Table 3-6, Table 7-10, and
Table 11-12 respectively of the official [paper](https://ai.facebook.com/blog/xls-r-self-supervised-speech-processing-for-128-languages).
Setup
--------------
In this blog, we will give an in-detail explanation of how XLS-R -
more specifically the pre-trained checkpoint
[**Wav2Vec2-XLS-R-300M**](https://huggingface.co/facebook/wav2vec2-xls-r-300m) - can be fine-tuned for ASR.
For demonstration purposes, we fine-tune the model on the low resource
ASR dataset of [Common
Voice](https://huggingface.co/datasets/common_voice) that contains only
*ca.* 4h of validated training data.
XLS-R is fine-tuned using Connectionist Temporal Classification (CTC),
which is an algorithm that is used to train neural networks for
sequence-to-sequence problems, such as ASR and handwriting recognition.
I highly recommend reading the well-written blog post [*Sequence
Modeling with CTC (2017)*](https://distill.pub/2017/ctc/) by Awni
Hannun.
Before we start, let\'s install `datasets` and `transformers`. Also, we
need the `torchaudio` to load audio files and `jiwer` to evaluate our
fine-tuned model using the [word error rate
(WER)](https://huggingface.co/metrics/wer) metric \\( {}^1 \\).
```python
!pip install datasets==1.18.3
!pip install transformers==4.11.3
!pip install huggingface_hub==0.1
!pip install torchaudio
!pip install librosa
!pip install jiwer
```
We strongly suggest to upload your training checkpoints directly to the
[Hugging Face Hub](https://huggingface.co/) while training. The [Hugging Face
Hub](https://huggingface.co/) has integrated version control so you can
be sure that no model checkpoint is getting lost during training.
To do so you have to store your authentication token from the Hugging
Face website (sign up [here](https://huggingface.co/join) if you
haven\'t already!)
```python
from huggingface_hub import notebook_login
notebook_login()
```
**Print Output:**
```bash
Login successful
Your token has been saved to /root/.huggingface/token
```
Then you need to install Git-LFS to upload your model checkpoints:
```bash
apt install git-lfs
```
------------------------------------------------------------------------
\\( {}^1 \\) In the [paper](https://arxiv.org/pdf/2006.13979.pdf), the model
was evaluated using the phoneme error rate (PER), but by far the most
common metric in ASR is the word error rate (WER). To keep this notebook
as general as possible we decided to evaluate the model using WER.
Prepare Data, Tokenizer, Feature Extractor
------------------------------------------
ASR models transcribe speech to text, which means that we both need a
feature extractor that processes the speech signal to the model\'s input
format, *e.g.* a feature vector, and a tokenizer that processes the
model\'s output format to text.
In 🤗 Transformers, the XLS-R model is thus accompanied by both a
tokenizer, called
[Wav2Vec2CTCTokenizer](https://huggingface.co/transformers/master/model_doc/wav2vec2.html#wav2vec2ctctokenizer),
and a feature extractor, called
[Wav2Vec2FeatureExtractor](https://huggingface.co/transformers/master/model_doc/wav2vec2.html#wav2vec2featureextractor).
Let\'s start by creating the tokenizer to decode the predicted output
classes to the output transcription.
### Create `Wav2Vec2CTCTokenizer`
A pre-trained XLS-R model maps the speech signal to a sequence of
context representations as illustrated in the figure above. However, for
speech recognition the model has to to map this sequence of context
representations to its corresponding transcription which means that a
linear layer has to be added on top of the transformer block (shown in
yellow in the diagram above). This linear layer is used to classify
each context representation to a token class analogous to how
a linear layer is added on top of BERT\'s embeddings
for further classification after pre-training (*cf.* with *\'BERT\'* section of the following [blog
post](https://huggingface.co/blog/warm-starting-encoder-decoder)).
after pretraining a linear layer is added on top of BERT\'s embeddings
for further classification - *cf.* with *\'BERT\'* section of this [blog
post](https://huggingface.co/blog/warm-starting-encoder-decoder).
The output size of this layer corresponds to the number of tokens in the
vocabulary, which does **not** depend on XLS-R\'s pretraining task, but
only on the labeled dataset used for fine-tuning. So in the first step,
we will take a look at the chosen dataset of Common Voice and define a
vocabulary based on the transcriptions.
First, let\'s go to Common Voice [official
website](https://commonvoice.mozilla.org/en/datasets) and pick a
language to fine-tune XLS-R on. For this notebook, we will use Turkish.
For each language-specific dataset, you can find a language code
corresponding to your chosen language. On [Common
Voice](https://commonvoice.mozilla.org/en/datasets), look for the field
\"Version\". The language code then corresponds to the prefix before the
underscore. For Turkish, *e.g.* the language code is `"tr"`.
Great, now we can use 🤗 Datasets\' simple API to download the data. The
dataset name is `"common_voice"`, the configuration name corresponds to
the language code, which is `"tr"` in our case.
Common Voice has many different splits including `invalidated`, which
refers to data that was not rated as \"clean enough\" to be considered
useful. In this notebook, we will only make use of the splits `"train"`,
`"validation"` and `"test"`.
Because the Turkish dataset is so small, we will merge both the
validation and training data into a training dataset and only use the
test data for validation.
```python
from datasets import load_dataset, load_metric, Audio
common_voice_train = load_dataset("common_voice", "tr", split="train+validation")
common_voice_test = load_dataset("common_voice", "tr", split="test")
```
Many ASR datasets only provide the target text, `'sentence'` for each
audio array `'audio'` and file `'path'`. Common Voice actually provides
much more information about each audio file, such as the `'accent'`,
etc. Keeping the notebook as general as possible, we only consider the
transcribed text for fine-tuning.
```python
common_voice_train = common_voice_train.remove_columns(["accent", "age", "client_id", "down_votes", "gender", "locale", "segment", "up_votes"])
common_voice_test = common_voice_test.remove_columns(["accent", "age", "client_id", "down_votes", "gender", "locale", "segment", "up_votes"])
```
Let\'s write a short function to display some random samples of the
dataset and run it a couple of times to get a feeling for the
transcriptions.
```python
from datasets import ClassLabel
import random
import pandas as pd
from IPython.display import display, HTML
def show_random_elements(dataset, num_examples=10):
assert num_examples <= len(dataset), "Can't pick more elements than there are in the dataset."
picks = []
for _ in range(num_examples):
pick = random.randint(0, len(dataset)-1)
while pick in picks:
pick = random.randint(0, len(dataset)-1)
picks.append(pick)
df = pd.DataFrame(dataset[picks])
display(HTML(df.to_html()))
```
**Print Output:**
| Idx | Sentence |
|----------|:-------------:|
| 1 | Jonuz, kısa süreli görevi kabul eden tek adaydı. |
| 2 | Biz umudumuzu bu mücadeleden almaktayız. |
| 3 | Sergide beş Hırvat yeniliği sergilendi. |
| 4 | Herşey adıyla bilinmeli. |
| 5 | Kuruluş özelleştirmeye hazır. |
| 6 | Yerleşim yerlerinin manzarası harika. |
| 7 | Olayların failleri bulunamadı. |
| 8 | Fakat bu çabalar boşa çıktı. |
| 9 | Projenin değeri iki virgül yetmiş yedi milyon avro. |
| 10 | Büyük yeniden yapım projesi dört aşamaya bölündü. |
Alright! The transcriptions look fairly clean. Having translated the
transcribed sentences, it seems that the language corresponds more to
written-out text than noisy dialogue. This makes sense considering that
[Common Voice](https://huggingface.co/datasets/common_voice) is a
crowd-sourced read speech corpus.
We can see that the transcriptions contain some special characters, such
as `,.?!;:`. Without a language model, it is much harder to classify
speech chunks to such special characters because they don\'t really
correspond to a characteristic sound unit. *E.g.*, the letter `"s"` has
a more or less clear sound, whereas the special character `"."` does
not. Also in order to understand the meaning of a speech signal, it is
usually not necessary to include special characters in the
transcription.
Let\'s simply remove all characters that don\'t contribute to the
meaning of a word and cannot really be represented by an acoustic sound
and normalize the text.
```python
import re
chars_to_remove_regex = '[\,\?\.\!\-\;\:\"\“\%\‘\”\�\']'
def remove_special_characters(batch):
batch["sentence"] = re.sub(chars_to_remove_regex, '', batch["sentence"]).lower()
return batch
```
```python
common_voice_train = common_voice_train.map(remove_special_characters)
common_voice_test = common_voice_test.map(remove_special_characters)
```
Let\'s look at the processed text labels again.
```python
show_random_elements(common_voice_train.remove_columns(["path","audio"]))
```
**Print Output:**
| Idx | Transcription |
|----------|:-------------:|
| 1 | birisi beyazlar için dediler |
| 2 | maktouf'un cezası haziran ayında sona erdi |
| 3 | orijinalin aksine kıyafetler çıkarılmadı |
| 4 | bunların toplam değeri yüz milyon avroyu buluyor |
| 5 | masada en az iki seçenek bulunuyor |
| 6 | bu hiç de haksız bir heveslilik değil |
| 7 | bu durum bin dokuz yüz doksanlarda ülkenin bölünmesiyle değişti |
| 8 | söz konusu süre altı ay |
| 9 | ancak bedel çok daha yüksek olabilir |
| 10 | başkent fira bir tepenin üzerinde yer alıyor |
Good! This looks better. We have removed most special characters from
transcriptions and normalized them to lower-case only.
Before finalizing the pre-processing, it is always advantageous to
consult a native speaker of the target language to see whether the text
can be further simplified. For this blog post,
[Merve](https://twitter.com/mervenoyann) was kind enough to take a quick
look and noted that \"hatted\" characters - like `â` - aren\'t really
used anymore in Turkish and can be replaced by their \"un-hatted\"
equivalent, *e.g.* `a`.
This means that we should replace a sentence like
`"yargı sistemi hâlâ sağlıksız"` to `"yargı sistemi hala sağlıksız"`.
Let\'s write another short mapping function to further simplify the text
labels. Remember, the simpler the text labels, the easier it is for the
model to learn to predict those labels.
```python
def replace_hatted_characters(batch):
batch["sentence"] = re.sub('[â]', 'a', batch["sentence"])
batch["sentence"] = re.sub('[î]', 'i', batch["sentence"])
batch["sentence"] = re.sub('[ô]', 'o', batch["sentence"])
batch["sentence"] = re.sub('[û]', 'u', batch["sentence"])
return batch
```
```python
common_voice_train = common_voice_train.map(replace_hatted_characters)
common_voice_test = common_voice_test.map(replace_hatted_characters)
```
In CTC, it is common to classify speech chunks into letters, so we will
do the same here. Let\'s extract all distinct letters of the training
and test data and build our vocabulary from this set of letters.
We write a mapping function that concatenates all transcriptions into
one long transcription and then transforms the string into a set of
chars. It is important to pass the argument `batched=True` to the
`map(...)` function so that the mapping function has access to all
transcriptions at once.
```python
def extract_all_chars(batch):
all_text = " ".join(batch["sentence"])
vocab = list(set(all_text))
return {"vocab": [vocab], "all_text": [all_text]}
```
```python
vocab_train = common_voice_train.map(extract_all_chars, batched=True, batch_size=-1, keep_in_memory=True, remove_columns=common_voice_train.column_names)
vocab_test = common_voice_test.map(extract_all_chars, batched=True, batch_size=-1, keep_in_memory=True, remove_columns=common_voice_test.column_names)
```
Now, we create the union of all distinct letters in the training dataset
and test dataset and convert the resulting list into an enumerated
dictionary.
```python
vocab_list = list(set(vocab_train["vocab"][0]) | set(vocab_test["vocab"][0]))
```
```python
vocab_dict = {v: k for k, v in enumerate(sorted(vocab_list))}
vocab_dict
```
**Print Output:**
```bash
{
' ': 0,
'a': 1,
'b': 2,
'c': 3,
'd': 4,
'e': 5,
'f': 6,
'g': 7,
'h': 8,
'i': 9,
'j': 10,
'k': 11,
'l': 12,
'm': 13,
'n': 14,
'o': 15,
'p': 16,
'q': 17,
'r': 18,
's': 19,
't': 20,
'u': 21,
'v': 22,
'w': 23,
'x': 24,
'y': 25,
'z': 26,
'ç': 27,
'ë': 28,
'ö': 29,
'ü': 30,
'ğ': 31,
'ı': 32,
'ş': 33,
'̇': 34
}
```
Cool, we see that all letters of the alphabet occur in the dataset
(which is not really surprising) and we also extracted the special
characters `""` and `'`. Note that we did not exclude those special
characters because:
The model has to learn to predict when a word is finished or else the
model prediction would always be a sequence of chars which would make it
impossible to separate words from each other.
One should always keep in mind that pre-processing is a very important
step before training your model. E.g., we don\'t want our model to
differentiate between `a` and `A` just because we forgot to normalize
the data. The difference between `a` and `A` does not depend on the
\"sound\" of the letter at all, but more on grammatical rules - *e.g.*
use a capitalized letter at the beginning of the sentence. So it is
sensible to remove the difference between capitalized and
non-capitalized letters so that the model has an easier time learning to
transcribe speech.
To make it clearer that `" "` has its own token class, we give it a more
visible character `|`. In addition, we also add an \"unknown\" token so
that the model can later deal with characters not encountered in Common
Voice\'s training set.
```python
vocab_dict["|"] = vocab_dict[" "]
del vocab_dict[" "]
```
Finally, we also add a padding token that corresponds to CTC\'s \"*blank
token*\". The \"blank token\" is a core component of the CTC algorithm.
For more information, please take a look at the \"Alignment\" section
[here](https://distill.pub/2017/ctc/).
```python
vocab_dict["[UNK]"] = len(vocab_dict)
vocab_dict["[PAD]"] = len(vocab_dict)
len(vocab_dict)
```
Cool, now our vocabulary is complete and consists of 39 tokens, which
means that the linear layer that we will add on top of the pretrained
XLS-R checkpoint will have an output dimension of 39.
Let\'s now save the vocabulary as a json file.
```python
import json
with open('vocab.json', 'w') as vocab_file:
json.dump(vocab_dict, vocab_file)
```
In a final step, we use the json file to load the vocabulary into an
instance of the `Wav2Vec2CTCTokenizer` class.
```python
from transformers import Wav2Vec2CTCTokenizer
tokenizer = Wav2Vec2CTCTokenizer.from_pretrained("./", unk_token="[UNK]", pad_token="[PAD]", word_delimiter_token="|")
```
If one wants to re-use the just created tokenizer with the fine-tuned
model of this notebook, it is strongly advised to upload the `tokenizer`
to the [Hugging Face Hub](https://huggingface.co/). Let\'s call the repo to which
we will upload the files `"wav2vec2-large-xlsr-turkish-demo-colab"`:
```python
repo_name = "wav2vec2-large-xls-r-300m-tr-colab"
```
and upload the tokenizer to the [🤗 Hub](https://huggingface.co/).
```python
tokenizer.push_to_hub(repo_name)
```
Great, you can see the just created repository under
`https://huggingface.co/<your-username>/wav2vec2-large-xls-r-300m-tr-colab`
### Create `Wav2Vec2FeatureExtractor`
Speech is a continuous signal, and, to be treated by computers, it first
has to be discretized, which is usually called **sampling**. The
sampling rate hereby plays an important role since it defines how many
data points of the speech signal are measured per second. Therefore,
sampling with a higher sampling rate results in a better approximation
of the *real* speech signal but also necessitates more values per
second.
A pretrained checkpoint expects its input data to have been sampled more
or less from the same distribution as the data it was trained on. The
same speech signals sampled at two different rates have a very different
distribution. For example, doubling the sampling rate results in data points
being twice as long. Thus, before fine-tuning a pretrained checkpoint of
an ASR model, it is crucial to verify that the sampling rate of the data
that was used to pretrain the model matches the sampling rate of the
dataset used to fine-tune the model.
XLS-R was pretrained on audio data of
[Babel](http://www.reading.ac.uk/AcaDepts/ll/speechlab/babel/r),
[Multilingual LibriSpeech
(MLS)](https://huggingface.co/datasets/multilingual_librispeech),
[Common Voice](https://huggingface.co/datasets/common_voice),
[VoxPopuli](https://arxiv.org/abs/2101.00390), and
[VoxLingua107](https://arxiv.org/abs/2011.12998) at a sampling rate of
16kHz. Common Voice, in its original form, has a sampling rate of 48kHz,
thus we will have to downsample the fine-tuning data to 16kHz in the
following.
A `Wav2Vec2FeatureExtractor` object requires the following parameters to
be instantiated:
- `feature_size`: Speech models take a sequence of feature vectors as
an input. While the length of this sequence obviously varies, the
feature size should not. In the case of Wav2Vec2, the feature size
is 1 because the model was trained on the raw speech signal \\( {}^2 \\).
- `sampling_rate`: The sampling rate at which the model is trained on.
- `padding_value`: For batched inference, shorter inputs need to be
padded with a specific value
- `do_normalize`: Whether the input should be
*zero-mean-unit-variance* normalized or not. Usually, speech models
perform better when normalizing the input
- `return_attention_mask`: Whether the model should make use of an
`attention_mask` for batched inference. In general, XLS-R models
checkpoints should **always** use the `attention_mask`.
```python
from transformers import Wav2Vec2FeatureExtractor
feature_extractor = Wav2Vec2FeatureExtractor(feature_size=1, sampling_rate=16000, padding_value=0.0, do_normalize=True, return_attention_mask=True)
```
Great, XLS-R\'s feature extraction pipeline is thereby fully defined!
For improved user-friendliness, the feature extractor and tokenizer are
*wrapped* into a single `Wav2Vec2Processor` class so that one only needs
a `model` and `processor` object.
```python
from transformers import Wav2Vec2Processor
processor = Wav2Vec2Processor(feature_extractor=feature_extractor, tokenizer=tokenizer)
```
Next, we can prepare the dataset.
### Preprocess Data
So far, we have not looked at the actual values of the speech signal but
just the transcription. In addition to `sentence`, our datasets include
two more column names `path` and `audio`. `path` states the absolute
path of the audio file. Let\'s take a look.
```python
common_voice_train[0]["path"]
```
XLS-R expects the input in the format of a 1-dimensional array of 16
kHz. This means that the audio file has to be loaded and resampled.
Thankfully, `datasets` does this automatically by calling the other
column `audio`. Let try it out.
```python
common_voice_train[0]["audio"]
```
```bash
{'array': array([ 0.0000000e+00, 0.0000000e+00, 0.0000000e+00, ...,
-8.8930130e-05, -3.8027763e-05, -2.9146671e-05], dtype=float32),
'path': '/root/.cache/huggingface/datasets/downloads/extracted/05be0c29807a73c9b099873d2f5975dae6d05e9f7d577458a2466ecb9a2b0c6b/cv-corpus-6.1-2020-12-11/tr/clips/common_voice_tr_21921195.mp3',
'sampling_rate': 48000}
```
Great, we can see that the audio file has automatically been loaded.
This is thanks to the new [`"Audio"`
feature](https://huggingface.co/docs/datasets/package_reference/main_classes.html?highlight=audio#datasets.Audio)
introduced in `datasets == 1.18.3`, which loads and resamples audio
files on-the-fly upon calling.
In the example above we can see that the audio data is loaded with a
sampling rate of 48kHz whereas 16kHz are expected by the model. We can
set the audio feature to the correct sampling rate by making use of
[`cast_column`](https://huggingface.co/docs/datasets/package_reference/main_classes.html?highlight=cast_column#datasets.DatasetDict.cast_column):
```python
common_voice_train = common_voice_train.cast_column("audio", Audio(sampling_rate=16_000))
common_voice_test = common_voice_test.cast_column("audio", Audio(sampling_rate=16_000))
```
Let\'s take a look at `"audio"` again.
```python
common_voice_train[0]["audio"]
```
```bash
{'array': array([ 0.0000000e+00, 0.0000000e+00, 0.0000000e+00, ...,
-7.4556941e-05, -1.4621433e-05, -5.7861507e-05], dtype=float32),
'path': '/root/.cache/huggingface/datasets/downloads/extracted/05be0c29807a73c9b099873d2f5975dae6d05e9f7d577458a2466ecb9a2b0c6b/cv-corpus-6.1-2020-12-11/tr/clips/common_voice_tr_21921195.mp3',
'sampling_rate': 16000}
```
This seemed to have worked! Let\'s listen to a couple of audio files to
better understand the dataset and verify that the audio was correctly
loaded.
```python
import IPython.display as ipd
import numpy as np
import random
rand_int = random.randint(0, len(common_voice_train)-1)
print(common_voice_train[rand_int]["sentence"])
ipd.Audio(data=common_voice_train[rand_int]["audio"]["array"], autoplay=True, rate=16000)
```
**Print Output:**
```bash
sunulan bütün teklifler i̇ngilizce idi
```
It seems like the data is now correctly loaded and resampled.
It can be heard, that the speakers change along with their speaking
rate, accent, and background environment, etc. Overall, the recordings
sound acceptably clear though, which is to be expected from a
crowd-sourced read speech corpus.
Let\'s do a final check that the data is correctly prepared, by printing
the shape of the speech input, its transcription, and the corresponding
sampling rate.
```python
rand_int = random.randint(0, len(common_voice_train)-1)
print("Target text:", common_voice_train[rand_int]["sentence"])
print("Input array shape:", common_voice_train[rand_int]["audio"]["array"].shape)
print("Sampling rate:", common_voice_train[rand_int]["audio"]["sampling_rate"])
```
**Print Output:**
```bash
Target text: makedonya bu yıl otuz adet tyetmiş iki tankı aldı
Input array shape: (71040,)
Sampling rate: 16000
```
Good! Everything looks fine - the data is a 1-dimensional array, the
sampling rate always corresponds to 16kHz, and the target text is
normalized.
Finally, we can leverage `Wav2Vec2Processor` to process the data to the
format expected by `Wav2Vec2ForCTC` for training. To do so let\'s make
use of Dataset\'s
[`map(...)`](https://huggingface.co/docs/datasets/package_reference/main_classes.html?highlight=map#datasets.DatasetDict.map)
function.
First, we load and resample the audio data, simply by calling
`batch["audio"]`. Second, we extract the `input_values` from the loaded
audio file. In our case, the `Wav2Vec2Processor` only normalizes the
data. For other speech models, however, this step can include more
complex feature extraction, such as [Log-Mel feature
extraction](https://en.wikipedia.org/wiki/Mel-frequency_cepstrum).
Third, we encode the transcriptions to label ids.
**Note**: This mapping function is a good example of how the
`Wav2Vec2Processor` class should be used. In \"normal\" context, calling
`processor(...)` is redirected to `Wav2Vec2FeatureExtractor`\'s call
method. When wrapping the processor into the `as_target_processor`
context, however, the same method is redirected to
`Wav2Vec2CTCTokenizer`\'s call method. For more information please check
the
[docs](https://huggingface.co/transformers/master/model_doc/wav2vec2.html#transformers.Wav2Vec2Processor.__call__).
```python
def prepare_dataset(batch):
audio = batch["audio"]
# batched output is "un-batched"
batch["input_values"] = processor(audio["array"], sampling_rate=audio["sampling_rate"]).input_values[0]
batch["input_length"] = len(batch["input_values"])
with processor.as_target_processor():
batch["labels"] = processor(batch["sentence"]).input_ids
return batch
```
Let\'s apply the data preparation function to all examples.
```python
common_voice_train = common_voice_train.map(prepare_dataset, remove_columns=common_voice_train.column_names)
common_voice_test = common_voice_test.map(prepare_dataset, remove_columns=common_voice_test.column_names)
```
**Note**: Currently `datasets` make use of
[`torchaudio`](https://pytorch.org/audio/stable/index.html) and
[`librosa`](https://librosa.org/doc/latest/index.html) for audio loading
and resampling. If you wish to implement your own costumized data
loading/sampling, feel free to just make use of the `"path"` column
instead and disregard the `"audio"` column.
Long input sequences require a lot of memory. XLS-R is based on
`self-attention`. The memory requirement scales quadratically with the
input length for long input sequences (*cf.* with
[this](https://www.reddit.com/r/MachineLearning/comments/genjvb/d_why_is_the_maximum_input_sequence_length_of/)
reddit post). In case this demo crashes with an \"Out-of-memory\" error
for you, you might want to uncomment the following lines to filter all
sequences that are longer than 5 seconds for training.
```python
#max_input_length_in_sec = 5.0
#common_voice_train = common_voice_train.filter(lambda x: x < max_input_length_in_sec * processor.feature_extractor.sampling_rate, input_columns=["input_length"])
```
Awesome, now we are ready to start training!
Training
--------
The data is processed so that we are ready to start setting up the
training pipeline. We will make use of 🤗\'s
[Trainer](https://huggingface.co/transformers/master/main_classes/trainer.html?highlight=trainer)
for which we essentially need to do the following:
- Define a data collator. In contrast to most NLP models, XLS-R has a
much larger input length than output length. *E.g.*, a sample of
input length 50000 has an output length of no more than 100. Given
the large input sizes, it is much more efficient to pad the training
batches dynamically meaning that all training samples should only be
padded to the longest sample in their batch and not the overall
longest sample. Therefore, fine-tuning XLS-R requires a special
padding data collator, which we will define below
- Evaluation metric. During training, the model should be evaluated on
the word error rate. We should define a `compute_metrics` function
accordingly
- Load a pretrained checkpoint. We need to load a pretrained
checkpoint and configure it correctly for training.
- Define the training configuration.
After having fine-tuned the model, we will correctly evaluate it on the
test data and verify that it has indeed learned to correctly transcribe
speech.
### Set-up Trainer
Let\'s start by defining the data collator. The code for the data
collator was copied from [this
example](https://github.com/huggingface/transformers/blob/7e61d56a45c19284cfda0cee8995fb552f6b1f4e/examples/pytorch/speech-recognition/run_speech_recognition_ctc.py#L219).
Without going into too many details, in contrast to the common data
collators, this data collator treats the `input_values` and `labels`
differently and thus applies to separate padding functions on them
(again making use of XLS-R processor\'s context manager). This is
necessary because in speech input and output are of different modalities
meaning that they should not be treated by the same padding function.
Analogous to the common data collators, the padding tokens in the labels
with `-100` so that those tokens are **not** taken into account when
computing the loss.
```python
import torch
from dataclasses import dataclass, field
from typing import Any, Dict, List, Optional, Union
@dataclass
class DataCollatorCTCWithPadding:
"""
Data collator that will dynamically pad the inputs received.
Args:
processor (:class:`~transformers.Wav2Vec2Processor`)
The processor used for proccessing the data.
padding (:obj:`bool`, :obj:`str` or :class:`~transformers.tokenization_utils_base.PaddingStrategy`, `optional`, defaults to :obj:`True`):
Select a strategy to pad the returned sequences (according to the model's padding side and padding index)
among:
* :obj:`True` or :obj:`'longest'`: Pad to the longest sequence in the batch (or no padding if only a single
sequence if provided).
* :obj:`'max_length'`: Pad to a maximum length specified with the argument :obj:`max_length` or to the
maximum acceptable input length for the model if that argument is not provided.
* :obj:`False` or :obj:`'do_not_pad'` (default): No padding (i.e., can output a batch with sequences of
different lengths).
"""
processor: Wav2Vec2Processor
padding: Union[bool, str] = True
def __call__(self, features: List[Dict[str, Union[List[int], torch.Tensor]]]) -> Dict[str, torch.Tensor]:
# split inputs and labels since they have to be of different lengths and need
# different padding methods
input_features = [{"input_values": feature["input_values"]} for feature in features]
label_features = [{"input_ids": feature["labels"]} for feature in features]
batch = self.processor.pad(
input_features,
padding=self.padding,
return_tensors="pt",
)
with self.processor.as_target_processor():
labels_batch = self.processor.pad(
label_features,
padding=self.padding,
return_tensors="pt",
)
# replace padding with -100 to ignore loss correctly
labels = labels_batch["input_ids"].masked_fill(labels_batch.attention_mask.ne(1), -100)
batch["labels"] = labels
return batch
```
```python
data_collator = DataCollatorCTCWithPadding(processor=processor, padding=True)
```
Next, the evaluation metric is defined. As mentioned earlier, the
predominant metric in ASR is the word error rate (WER), hence we will
use it in this notebook as well.
```python
wer_metric = load_metric("wer")
```
The model will return a sequence of logit vectors:
\\( \mathbf{y}_1, \ldots, \mathbf{y}_m \\) with
\\( \mathbf{y}_1 = f_{\theta}(x_1, \ldots, x_n)[0] \\) and \\( n >> m \\).
A logit vector \\( \mathbf{y}_1 \\) contains the log-odds for each word in the
vocabulary we defined earlier, thus \\( \text{len}(\mathbf{y}_i) = \\)
`config.vocab_size`. We are interested in the most likely prediction of
the model and thus take the `argmax(...)` of the logits. Also, we
transform the encoded labels back to the original string by replacing
`-100` with the `pad_token_id` and decoding the ids while making sure
that consecutive tokens are **not** grouped to the same token in CTC
style \\( {}^1 \\).
```python
def compute_metrics(pred):
pred_logits = pred.predictions
pred_ids = np.argmax(pred_logits, axis=-1)
pred.label_ids[pred.label_ids == -100] = processor.tokenizer.pad_token_id
pred_str = processor.batch_decode(pred_ids)
# we do not want to group tokens when computing the metrics
label_str = processor.batch_decode(pred.label_ids, group_tokens=False)
wer = wer_metric.compute(predictions=pred_str, references=label_str)
return {"wer": wer}
```
Now, we can load the pretrained checkpoint of
[Wav2Vec2-XLS-R-300M](https://huggingface.co/facebook/wav2vec2-xls-r-300m).
The tokenizer\'s `pad_token_id` must be to define the model\'s
`pad_token_id` or in the case of `Wav2Vec2ForCTC` also CTC\'s *blank
token* \\( {}^2 \\). To save GPU memory, we enable PyTorch\'s [gradient
checkpointing](https://pytorch.org/docs/stable/checkpoint.html) and also
set the loss reduction to \"*mean*\".
Because the dataset is quite small (\~6h of training data) and because
Common Voice is quite noisy, fine-tuning Facebook\'s
[wav2vec2-xls-r-300m checkpoint](FILL%20ME) seems to require some
hyper-parameter tuning. Therefore, I had to play around a bit with
different values for dropout,
[SpecAugment](https://arxiv.org/abs/1904.08779)\'s masking dropout rate,
layer dropout, and the learning rate until training seemed to be stable
enough.
**Note**: When using this notebook to train XLS-R on another language of
Common Voice those hyper-parameter settings might not work very well.
Feel free to adapt those depending on your use case.
```python
from transformers import Wav2Vec2ForCTC
model = Wav2Vec2ForCTC.from_pretrained(
"facebook/wav2vec2-xls-r-300m",
attention_dropout=0.0,
hidden_dropout=0.0,
feat_proj_dropout=0.0,
mask_time_prob=0.05,
layerdrop=0.0,
ctc_loss_reduction="mean",
pad_token_id=processor.tokenizer.pad_token_id,
vocab_size=len(processor.tokenizer),
)
```
The first component of XLS-R consists of a stack of CNN layers that are
used to extract acoustically meaningful - but contextually independent -
features from the raw speech signal. This part of the model has already
been sufficiently trained during pretraining and as stated in the
[paper](https://arxiv.org/pdf/2006.13979.pdf) does not need to be
fine-tuned anymore. Thus, we can set the `requires_grad` to `False` for
all parameters of the *feature extraction* part.
```python
model.freeze_feature_extractor()
```
In a final step, we define all parameters related to training. To give
more explanation on some of the parameters:
- `group_by_length` makes training more efficient by grouping training
samples of similar input length into one batch. This can
significantly speed up training time by heavily reducing the overall
number of useless padding tokens that are passed through the model
- `learning_rate` and `weight_decay` were heuristically tuned until
fine-tuning has become stable. Note that those parameters strongly
depend on the Common Voice dataset and might be suboptimal for other
speech datasets.
For more explanations on other parameters, one can take a look at the
[docs](https://huggingface.co/transformers/master/main_classes/trainer.html?highlight=trainer#trainingarguments).
During training, a checkpoint will be uploaded asynchronously to the Hub
every 400 training steps. It allows you to also play around with the
demo widget even while your model is still training.
**Note**: If one does not want to upload the model checkpoints to the
Hub, simply set `push_to_hub=False`.
```python
from transformers import TrainingArguments
training_args = TrainingArguments(
output_dir=repo_name,
group_by_length=True,
per_device_train_batch_size=16,
gradient_accumulation_steps=2,
evaluation_strategy="steps",
num_train_epochs=30,
gradient_checkpointing=True,
fp16=True,
save_steps=400,
eval_steps=400,
logging_steps=400,
learning_rate=3e-4,
warmup_steps=500,
save_total_limit=2,
push_to_hub=True,
)
```
Now, all instances can be passed to Trainer and we are ready to start
training!
```python
from transformers import Trainer
trainer = Trainer(
model=model,
data_collator=data_collator,
args=training_args,
compute_metrics=compute_metrics,
train_dataset=common_voice_train,
eval_dataset=common_voice_test,
tokenizer=processor.feature_extractor,
)
```
------------------------------------------------------------------------
\\( {}^1 \\) To allow models to become independent of the speaker rate, in
CTC, consecutive tokens that are identical are simply grouped as a
single token. However, the encoded labels should not be grouped when
decoding since they don\'t correspond to the predicted tokens of the
model, which is why the `group_tokens=False` parameter has to be passed.
If we wouldn\'t pass this parameter a word like `"hello"` would
incorrectly be encoded, and decoded as `"helo"`.
\\( {}^2 \\) The blank token allows the model to predict a word, such as
`"hello"` by forcing it to insert the blank token between the two l\'s.
A CTC-conform prediction of `"hello"` of our model would be
`[PAD] [PAD] "h" "e" "e" "l" "l" [PAD] "l" "o" "o" [PAD]`.
### Training
Training will take multiple hours depending on the GPU allocated to this
notebook. While the trained model yields somewhat satisfying results on
*Common Voice*\'s test data of Turkish, it is by no means an optimally
fine-tuned model. The purpose of this notebook is just to demonstrate
how to fine-tune XLS-R XLSR-Wav2Vec2\'s on an ASR dataset.
Depending on what GPU was allocated to your google colab it might be
possible that you are seeing an `"out-of-memory"` error here. In this
case, it\'s probably best to reduce `per_device_train_batch_size` to 8
or even less and increase
[`gradient_accumulation`](https://huggingface.co/transformers/master/main_classes/trainer.html#trainingarguments).
```python
trainer.train()
```
**Print Output:**
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 3.8842 | 3.67 | 400 | 0.6794 | 0.7000 |
| 0.4115 | 7.34 | 800 | 0.4304 | 0.4548 |
| 0.1946 | 11.01 | 1200 | 0.4466 | 0.4216 |
| 0.1308 | 14.68 | 1600 | 0.4526 | 0.3961 |
| 0.0997 | 18.35 | 2000 | 0.4567 | 0.3696 |
| 0.0784 | 22.02 | 2400 | 0.4193 | 0.3442 |
| 0.0633 | 25.69 | 2800 | 0.4153 | 0.3347 |
| 0.0498 | 29.36 | 3200 | 0.4077 | 0.3195 |
The training loss and validation WER go down nicely.
You can now upload the result of the training to the Hub, just execute
this instruction:
```python
trainer.push_to_hub()
```
You can now share this model with all your friends, family, favorite
pets: they can all load it with the identifier
\"your-username/the-name-you-picked\" so for instance:
```python
from transformers import AutoModelForCTC, Wav2Vec2Processor
model = AutoModelForCTC.from_pretrained("patrickvonplaten/wav2vec2-large-xls-r-300m-tr-colab")
processor = Wav2Vec2Processor.from_pretrained("patrickvonplaten/wav2vec2-large-xls-r-300m-tr-colab")
```
For more examples of how XLS-R can be fine-tuned, please take a look at the official
[🤗 Transformers examples](https://github.com/huggingface/transformers/tree/master/examples/pytorch/speech-recognition#examples).
### Evaluation
As a final check, let\'s load the model and verify that it indeed has
learned to transcribe Turkish speech.
Let\'s first load the pretrained checkpoint.
```python
model = Wav2Vec2ForCTC.from_pretrained(repo_name).to("cuda")
processor = Wav2Vec2Processor.from_pretrained(repo_name)
```
Now, we will just take the first example of the test set, run it through
the model and take the `argmax(...)` of the logits to retrieve the
predicted token ids.
```python
input_dict = processor(common_voice_test[0]["input_values"], return_tensors="pt", padding=True)
logits = model(input_dict.input_values.to("cuda")).logits
pred_ids = torch.argmax(logits, dim=-1)[0]
```
It is strongly recommended to pass the ``sampling_rate`` argument to this function.Failing to do so can result in silent errors that might be hard to debug.
We adapted `common_voice_test` quite a bit so that the dataset instance
does not contain the original sentence label anymore. Thus, we re-use
the original dataset to get the label of the first example.
```python
common_voice_test_transcription = load_dataset("common_voice", "tr", data_dir="./cv-corpus-6.1-2020-12-11", split="test")
```
Finally, we can decode the example.
```python
print("Prediction:")
print(processor.decode(pred_ids))
print("\nReference:")
print(common_voice_test_transcription[0]["sentence"].lower())
```
**Print Output:**
| pred_str | target_text |
|----------|:-------------:|
| hatta küçük şeyleri için bir büyt bir şeyleri kolluyor veyınıki çuk şeyler için bir bir mizi inciltiyoruz | hayatta küçük şeyleri kovalıyor ve yine küçük şeyler için birbirimizi incitiyoruz. |
Alright! The transcription can definitely be recognized from our
prediction, but it is not perfect yet. Training the model a bit longer,
spending more time on the data preprocessing, and especially using a
language model for decoding would certainly improve the model\'s overall
performance.
For a demonstration model on a low-resource language, the results are
quite acceptable however 🤗.
| 4 |
0 | hf_public_repos | hf_public_repos/blog/bert-inferentia-sagemaker.md | ---
title: "Accelerate BERT inference with Hugging Face Transformers and AWS Inferentia"
thumbnail: /blog//assets/55_bert_inferentia_sagemaker/thumbnail.png
authors:
- user: philschmid
---
# Accelerate BERT inference with Hugging Face Transformers and AWS Inferentia
<script async defer src="https://unpkg.com/medium-zoom-element@0/dist/medium-zoom-element.min.js"></script>
notebook: [sagemaker/18_inferentia_inference](https://github.com/huggingface/notebooks/blob/master/sagemaker/18_inferentia_inference/sagemaker-notebook.ipynb)
The adoption of [BERT](https://huggingface.co/blog/bert-101) and [Transformers](https://huggingface.co/docs/transformers/index) continues to grow. Transformer-based models are now not only achieving state-of-the-art performance in Natural Language Processing but also for [Computer Vision](https://arxiv.org/abs/2010.11929), [Speech](https://arxiv.org/abs/2006.11477), and [Time-Series](https://arxiv.org/abs/2002.06103). 💬 🖼 🎤 ⏳
Companies are now slowly moving from the experimentation and research phase to the production phase in order to use transformer models for large-scale workloads. But by default BERT and its friends are relatively slow, big, and complex models compared to the traditional Machine Learning algorithms. Accelerating Transformers and BERT is and will become an interesting challenge to solve in the future.
AWS's take to solve this challenge was to design a custom machine learning chip designed for optimized inference workload called [AWS Inferentia](https://aws.amazon.com/machine-learning/inferentia/?nc1=h_ls). AWS says that AWS Inferentia *“delivers up to 80% lower cost per inference and up to 2.3X higher throughput than comparable current generation GPU-based Amazon EC2 instances.”*
The real value of AWS Inferentia instances compared to GPU comes through the multiple Neuron Cores available on each device. A Neuron Core is the custom accelerator inside AWS Inferentia. Each Inferentia chip comes with 4x Neuron Cores. This enables you to either load 1 model on each core (for high throughput) or 1 model across all cores (for lower latency).
## Tutorial
In this end-to-end tutorial, you will learn how to speed up BERT inference for text classification with Hugging Face Transformers, Amazon SageMaker, and AWS Inferentia.
You can find the notebook here: [sagemaker/18_inferentia_inference](https://github.com/huggingface/notebooks/blob/master/sagemaker/18_inferentia_inference/sagemaker-notebook.ipynb)
You will learn how to:
- [1. Convert your Hugging Face Transformer to AWS Neuron](#1-convert-your-hugging-face-transformer-to-aws-neuron)
- [2. Create a custom `inference.py` script for `text-classification`](#2-create-a-custom-inferencepy-script-for-text-classification)
- [3. Create and upload the neuron model and inference script to Amazon S3](#3-create-and-upload-the-neuron-model-and-inference-script-to-amazon-s3)
- [4. Deploy a Real-time Inference Endpoint on Amazon SageMaker](#4-deploy-a-real-time-inference-endpoint-on-amazon-sagemaker)
- [5. Run and evaluate Inference performance of BERT on Inferentia](#5-run-and-evaluate-inference-performance-of-bert-on-inferentia)
Let's get started! 🚀
---
*If you are going to use Sagemaker in a local environment (not SageMaker Studio or Notebook Instances), you need access to an IAM Role with the required permissions for Sagemaker. You can find [here](https://docs.aws.amazon.com/sagemaker/latest/dg/sagemaker-roles.html) more about it.*
## 1. Convert your Hugging Face Transformer to AWS Neuron
We are going to use the [AWS Neuron SDK for AWS Inferentia](https://awsdocs-neuron.readthedocs-hosted.com/en/latest/index.html). The Neuron SDK includes a deep learning compiler, runtime, and tools for converting and compiling PyTorch and TensorFlow models to neuron compatible models, which can be run on [EC2 Inf1 instances](https://aws.amazon.com/ec2/instance-types/inf1/).
As a first step, we need to install the [Neuron SDK](https://awsdocs-neuron.readthedocs-hosted.com/en/latest/neuron-intro/neuron-install-guide.html) and the required packages.
*Tip: If you are using Amazon SageMaker Notebook Instances or Studio you can go with the `conda_python3` conda kernel.*
```python
# Set Pip repository to point to the Neuron repository
!pip config set global.extra-index-url https://pip.repos.neuron.amazonaws.com
# Install Neuron PyTorch
!pip install torch-neuron==1.9.1.* neuron-cc[tensorflow] sagemaker>=2.79.0 transformers==4.12.3 --upgrade
```
After we have installed the Neuron SDK we can load and convert our model. Neuron models are converted using `torch_neuron` with its `trace` method similar to `torchscript`. You can find more information in our [documentation](https://huggingface.co/docs/transformers/serialization#torchscript).
To be able to convert our model we first need to select the model we want to use for our text classification pipeline from [hf.co/models](http://hf.co/models). For this example, let's go with [distilbert-base-uncased-finetuned-sst-2-english](https://huggingface.co/distilbert-base-uncased-finetuned-sst-2-english) but this can be easily adjusted with other BERT-like models.
```python
model_id = "distilbert-base-uncased-finetuned-sst-2-english"
```
At the time of writing, the [AWS Neuron SDK does not support dynamic shapes](https://awsdocs-neuron.readthedocs-hosted.com/en/latest/neuron-guide/models/models-inferentia.html#dynamic-shapes), which means that the input size needs to be static for compiling and inference.
In simpler terms, this means that when the model is compiled with e.g. an input of batch size 1 and sequence length of 16, the model can only run inference on inputs with that same shape.
*When using a `t2.medium` instance the compilation takes around 3 minutes*
```python
import os
import tensorflow # to workaround a protobuf version conflict issue
import torch
import torch.neuron
from transformers import AutoTokenizer, AutoModelForSequenceClassification
# load tokenizer and model
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForSequenceClassification.from_pretrained(model_id, torchscript=True)
# create dummy input for max length 128
dummy_input = "dummy input which will be padded later"
max_length = 128
embeddings = tokenizer(dummy_input, max_length=max_length, padding="max_length",return_tensors="pt")
neuron_inputs = tuple(embeddings.values())
# compile model with torch.neuron.trace and update config
model_neuron = torch.neuron.trace(model, neuron_inputs)
model.config.update({"traced_sequence_length": max_length})
# save tokenizer, neuron model and config for later use
save_dir="tmp"
os.makedirs("tmp",exist_ok=True)
model_neuron.save(os.path.join(save_dir,"neuron_model.pt"))
tokenizer.save_pretrained(save_dir)
model.config.save_pretrained(save_dir)
```
## 2. Create a custom `inference.py` script for `text-classification`
The [Hugging Face Inference Toolkit](https://github.com/aws/sagemaker-huggingface-inference-toolkit) supports zero-code deployments on top of the [pipeline feature](https://huggingface.co/transformers/main_classes/pipelines.html) from 🤗 Transformers. This allows users to deploy Hugging Face transformers without an inference script [[Example](https://github.com/huggingface/notebooks/blob/master/sagemaker/11_deploy_model_from_hf_hub/deploy_transformer_model_from_hf_hub.ipynb)].
Currently, this feature is not supported with AWS Inferentia, which means we need to provide an `inference.py` script for running inference.
*If you would be interested in support for zero-code deployments for Inferentia let us know on the [forum](https://discuss.huggingface.co/c/sagemaker/17).*
---
To use the inference script, we need to create an `inference.py` script. In our example, we are going to overwrite the `model_fn` to load our neuron model and the `predict_fn` to create a text-classification pipeline.
If you want to know more about the `inference.py` script check out this [example](https://github.com/huggingface/notebooks/blob/master/sagemaker/17_custom_inference_script/sagemaker-notebook.ipynb). It explains amongst other things what `model_fn` and `predict_fn` are.
```python
!mkdir code
```
We are using the `NEURON_RT_NUM_CORES=1` to make sure that each HTTP worker uses 1 Neuron core to maximize throughput.
```python
%%writefile code/inference.py
import os
from transformers import AutoConfig, AutoTokenizer
import torch
import torch.neuron
# To use one neuron core per worker
os.environ["NEURON_RT_NUM_CORES"] = "1"
# saved weights name
AWS_NEURON_TRACED_WEIGHTS_NAME = "neuron_model.pt"
def model_fn(model_dir):
# load tokenizer and neuron model from model_dir
tokenizer = AutoTokenizer.from_pretrained(model_dir)
model = torch.jit.load(os.path.join(model_dir, AWS_NEURON_TRACED_WEIGHTS_NAME))
model_config = AutoConfig.from_pretrained(model_dir)
return model, tokenizer, model_config
def predict_fn(data, model_tokenizer_model_config):
# destruct model, tokenizer and model config
model, tokenizer, model_config = model_tokenizer_model_config
# create embeddings for inputs
inputs = data.pop("inputs", data)
embeddings = tokenizer(
inputs,
return_tensors="pt",
max_length=model_config.traced_sequence_length,
padding="max_length",
truncation=True,
)
# convert to tuple for neuron model
neuron_inputs = tuple(embeddings.values())
# run prediciton
with torch.no_grad():
predictions = model(*neuron_inputs)[0]
scores = torch.nn.Softmax(dim=1)(predictions)
# return dictonary, which will be json serializable
return [{"label": model_config.id2label[item.argmax().item()], "score": item.max().item()} for item in scores]
```
## 3. Create and upload the neuron model and inference script to Amazon S3
Before we can deploy our neuron model to Amazon SageMaker we need to create a `model.tar.gz` archive with all our model artifacts saved into `tmp/`, e.g. `neuron_model.pt` and upload this to Amazon S3.
To do this we need to set up our permissions.
```python
import sagemaker
import boto3
sess = sagemaker.Session()
# sagemaker session bucket -> used for uploading data, models and logs
# sagemaker will automatically create this bucket if it not exists
sagemaker_session_bucket=None
if sagemaker_session_bucket is None and sess is not None:
# set to default bucket if a bucket name is not given
sagemaker_session_bucket = sess.default_bucket()
try:
role = sagemaker.get_execution_role()
except ValueError:
iam = boto3.client('iam')
role = iam.get_role(RoleName='sagemaker_execution_role')['Role']['Arn']
sess = sagemaker.Session(default_bucket=sagemaker_session_bucket)
print(f"sagemaker role arn: {role}")
print(f"sagemaker bucket: {sess.default_bucket()}")
print(f"sagemaker session region: {sess.boto_region_name}")
```
Next, we create our `model.tar.gz`. The `inference.py` script will be placed into a `code/` folder.
```python
# copy inference.py into the code/ directory of the model directory.
!cp -r code/ tmp/code/
# create a model.tar.gz archive with all the model artifacts and the inference.py script.
%cd tmp
!tar zcvf model.tar.gz *
%cd ..
```
Now we can upload our `model.tar.gz` to our session S3 bucket with `sagemaker`.
```python
from sagemaker.s3 import S3Uploader
# create s3 uri
s3_model_path = f"s3://{sess.default_bucket()}/{model_id}"
# upload model.tar.gz
s3_model_uri = S3Uploader.upload(local_path="tmp/model.tar.gz",desired_s3_uri=s3_model_path)
print(f"model artifcats uploaded to {s3_model_uri}")
```
## 4. Deploy a Real-time Inference Endpoint on Amazon SageMaker
After we have uploaded our `model.tar.gz` to Amazon S3 can we create a custom `HuggingfaceModel`. This class will be used to create and deploy our real-time inference endpoint on Amazon SageMaker.
```python
from sagemaker.huggingface.model import HuggingFaceModel
# create Hugging Face Model Class
huggingface_model = HuggingFaceModel(
model_data=s3_model_uri, # path to your model and script
role=role, # iam role with permissions to create an Endpoint
transformers_version="4.12", # transformers version used
pytorch_version="1.9", # pytorch version used
py_version='py37', # python version used
)
# Let SageMaker know that we've already compiled the model via neuron-cc
huggingface_model._is_compiled_model = True
# deploy the endpoint endpoint
predictor = huggingface_model.deploy(
initial_instance_count=1, # number of instances
instance_type="ml.inf1.xlarge" # AWS Inferentia Instance
)
```
## 5. Run and evaluate Inference performance of BERT on Inferentia
The `.deploy()` returns an `HuggingFacePredictor` object which can be used to request inference.
```python
data = {
"inputs": "the mesmerizing performances of the leads keep the film grounded and keep the audience riveted .",
}
res = predictor.predict(data=data)
res
```
We managed to deploy our neuron compiled BERT to AWS Inferentia on Amazon SageMaker. Now, let's test its performance. As a dummy load test, we will loop and send 10,000 synchronous requests to our endpoint.
```python
# send 10000 requests
for i in range(10000):
resp = predictor.predict(
data={"inputs": "it 's a charming and often affecting journey ."}
)
```
Let's inspect the performance in cloudwatch.
```python
print(f"https://console.aws.amazon.com/cloudwatch/home?region={sess.boto_region_name}#metricsV2:graph=~(metrics~(~(~'AWS*2fSageMaker~'ModelLatency~'EndpointName~'{predictor.endpoint_name}~'VariantName~'AllTraffic))~view~'timeSeries~stacked~false~region~'{sess.boto_region_name}~start~'-PT5M~end~'P0D~stat~'Average~period~30);query=~'*7bAWS*2fSageMaker*2cEndpointName*2cVariantName*7d*20{predictor.endpoint_name}")
```
The average latency for our BERT model is `5-6ms` for a sequence length of 128.
<br>
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="Model Latency in Cloudwatch" src="assets/55_bert_inferentia_sagemaker/cloudwatch_metrics_bert.png"></medium-zoom>
<figcaption>Figure 1. Model Latency</figcaption>
</figure>
<br>
### Delete model and endpoint
To clean up, we can delete the model and endpoint.
```python
predictor.delete_model()
predictor.delete_endpoint()
```
## Conclusion
We successfully managed to compile a vanilla Hugging Face Transformers model to an AWS Inferentia compatible Neuron Model. After that we deployed our Neuron model to Amazon SageMaker using the new Hugging Face Inference DLC. We managed to achieve `5-6ms` latency per neuron core, which is faster than CPU in terms of latency, and achieves a higher throughput than GPUs since we ran 4 models in parallel.
If you or you company are currently using a BERT-like Transformer for encoder tasks (text-classification, token-classification, question-answering etc.), and the latency meets your requirements you should switch to AWS Inferentia. This will not only save costs, but can also increase efficiency and performance for your models.
We are planning to do a more detailed case study on cost-performance of transformers in the future, so stay tuned!
Also if you want to learn more about accelerating transformers you should also check out Hugging Face [optimum](https://github.com/huggingface/optimum).
---
Thanks for reading! If you have any questions, feel free to contact me, through [Github](https://github.com/huggingface/transformers), or on the [forum](https://discuss.huggingface.co/c/sagemaker/17). You can also connect with me on [Twitter](https://twitter.com/_philschmid) or [LinkedIn](https://www.linkedin.com/in/philipp-schmid-a6a2bb196/).
| 5 |
0 | hf_public_repos | hf_public_repos/blog/ryght-case-study.md | ---
title: "Ryght’s Journey to Empower Healthcare and Life Sciences with Expert Support from Hugging Face"
thumbnail: /blog/assets/ryght-case-study/thumbnail.png
authors:
- user: andrewrreed
- user: johnnybio
guest: true
org: RyghtAI
---
# Ryght’s Journey to Empower Healthcare and Life Sciences with Expert Support from Hugging Face
> [!NOTE] This is a guest blog post by the Ryght team.
## Who is Ryght?
Ryght is building an enterprise-grade generative AI platform tailored for the healthcare and life sciences sectors. Today is their official launch of [Ryght Preview](https://www.ryght.ai/signup?utm_campaign=Preview%20Launch%20April%2016%2C%2024&utm_source=Huggging%20Face%20Blog%20-%20Preview%20Launch%20Sign%20Up), now publicly available for all.
Life science companies are amassing a wealth of data from diverse sources (lab data, EMR, genomics, claims, pharmacy, clinical, etc.), but analysis of that data is archaic, requiring large teams for everything from simple queries to developing useful ML models. There is huge demand for actionable knowledge to drive drug development, clinical trials, and commercial activity, and the rise of precision medicine is only accelerating this demand.
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/ryght-case-study/click-through.gif" alt="Ryght Laptop" style="width: 90%; height: auto;"><br>
</p>
[Ryght’s](https://hubs.li/Q02sLGKL0) goal is to empower life science professionals to get the insights they need swiftly and securely. To do so, they’re building a SaaS platform that offers industry-specific AI copilots and custom built solutions for professionals and organizations to accelerate their research, analysis, and documentation across a variety of complex data sources.
Recognizing how fast paced and ever changing the AI landscape is, Ryght sought out Hugging Face as a technical advisory partner early in their journey via the [Expert Support Program](https://huggingface.co/support).
## Overcoming challenges, together
> ##### *Our partnership with Hugging Face's expert support has played a crucial role in expediting the development of our generative AI platform. The rapidly evolving landscape of AI has the potential to revolutionize our industry, and Hugging Face’s highly performant and enterprise-ready Text Generation Inference (TGI) and Text Embeddings Inference (TEI) services are game changers in their own right. - [Johnny Crupi, CTO](https://www.linkedin.com/in/johncrupi/) at [Ryght](http://www.ryght.ai/?utm_campaign=hf&utm_source=hf_blog)*
Ryght faced several challenges as they set out to build their generative AI platform.
### 1. The need to quickly upskill a team and stay informed in a highly dynamic environment
With AI and ML technologies advancing so quickly, ensuring that the team remains abreast of the latest techniques, tools, and best practices is critical. This continuous learning curve is steep and requires a concerted effort to stay informed.
Having access to Hugging Face’s team of experts who operate at the center of the AI ecosystem helps Ryght keep up with the latest developments and models that are relevant to their domain. This is achieved through open, asynchronous channels of communication, regular advisory meetings, and dedicated technical workshops.
### 2. Identifying the most [cost] effective ML approaches amidst the noisy sea of options
The AI field is bustling with innovation, leading to an abundance of tools, libraries, models, and methodologies. For a startup like Ryght, it's imperative to cut through this noise and identify which ML strategies are most applicable to their unique use cases in the life sciences sector. This involves not just understanding the current state of the art, but also looking ahead to which technologies will remain relevant and scalable for the future.
Hugging Face serves as a partner to Ryght’s technical team – assisting in solution design, proof-of-concept development, and production workload optimization. This includes tailored recommendations on libraries, frameworks, and models best fit for Ryght’s specific needs, along with demonstrable examples of how to use them. This guidance ultimately streamlines the decision-making process and reduces the time to development.
### 3. Requirement to develop performant solutions that emphasize security, privacy, and flexibility
Given the focus on enterprise-level solutions, Ryght prioritizes security, privacy, and governance. This necessitates a flexible architecture capable of interfacing with various large language models (LLMs) in real-time, a crucial feature for their life science-specific content generation and query handling.
Understanding the rapid innovation within the open-source community, especially regarding medical LLMs, they embraced an architectural approach that supports "pluggable" LLMs. This design choice allows them to seamlessly evaluate and integrate new or specialized medical LLMs as they emerge.
In Ryght’s platform, each LLM is registered and linked to one or more, customer-specific inference endpoints. This setup not only secures the connections, but also provides the ability to switch between different LLMs, offering unparalleled flexibility – a design choice that is made possible by the adoption of Hugging Face’s [Text Generation Inference (TGI)](https://huggingface.co/docs/text-generation-inference/index) and [Inference Endpoints](https://huggingface.co/inference-endpoints/dedicated).
In addition to TGI, Ryght has also integrated [Text Embeddings Inference (TEI)](https://huggingface.co/docs/text-embeddings-inference/en/index) into their ML platform. Serving open-source embedding models with TEI marks a significant improvement over relying solely on proprietary embeddings – enabling Ryght to benefit from faster inference speeds, the elimination of rate limit worries, and the flexibility to serve their own fine-tuned models, tailored to the unique requirements of the life sciences domain.
Catering to multiple customers simultaneously, their system is designed to handle high volumes of concurrent requests while maintaining low latency. Their embedding and inference services go beyond simple model invocation and encompass a suite of services adept at batching, queuing, and distributing model processing across GPUs. This infrastructure is critical to avoiding performance bottlenecks and ensuring users do not experience delays, thereby maintaining an optimal system response time.
## Conclusion
Ryght's strategic partnership with and integration of Hugging Face's ML services underscores their commitment to delivering cutting-edge solutions in healthcare and life sciences. By embracing a flexible, secure, and scalable architecture, they ensure that their platform remains at the forefront of innovation, offering their clients unparalleled service and expertise in navigating the complexities of modern medical domains.
[Sign up for Ryght Preview](https://hubs.li/Q02sLFl_0), now publicly available to life sciences knowledge workers as a free, secure platform with frictionless onboarding. Ryght’s copilot library consists of a diverse collection of tools to accelerate information retrieval, synthesis and structuring of complex unstructured data, and document builders, taking what might have taken weeks to complete down to days or hours. To inquire about custom building and collaborations, [contact their team](https://hubs.li/Q02sLG9V0) of AI experts to discuss Ryght for Enterprise.
If you’re interested to know more about Hugging Face Expert Support, please [contact us here](https://huggingface.co/contact/sales?from=support) - our team will reach out to discuss your requirements! | 6 |
0 | hf_public_repos | hf_public_repos/blog/panel-on-hugging-face.md | ---
title: "Panel on Hugging Face"
thumbnail: /blog/assets/panel-on-hugging-face/thumbnail.png
authors:
- user: philippjfr
guest: true
- user: sophiamyang
guest: true
---
# Panel on Hugging Face
We are thrilled to announce the collaboration between Panel and Hugging Face! 🎉 We have integrated a Panel template in Hugging Face Spaces to help you get started building Panel apps and deploy them on Hugging Face effortlessly.
<a href="https://huggingface.co/new-space?template=Panel-Org/panel-template"> <img src="https://huggingface.co/datasets/huggingface/badges/raw/main/deploy-to-spaces-lg.svg"/> </a>
## What does Panel offer?
[Panel](https://panel.holoviz.org/) is an open-source Python library that lets you easily build powerful tools, dashboards and complex applications entirely in Python. It has a batteries-included philosophy, putting the PyData ecosystem, powerful data tables and much more at your fingertips. High-level reactive APIs and lower-level callback based APIs ensure you can quickly build exploratory applications, but you aren’t limited if you build complex, multi-page apps with rich interactivity. Panel is a member of the [HoloViz](https://holoviz.org/) ecosystem, your gateway into a connected ecosystem of data exploration tools. Panel, like the other HoloViz tools, is a NumFocus-sponsored project, with support from Anaconda and Blackstone.
Here are some notable features of Panel that our users find valuable.
- Panel provides extensive support for various plotting libraries, such as Matplotlib, Seaborn, Altair, Plotly, Bokeh, PyDeck,Vizzu, and more.
- All interactivity works the same in Jupyter and in a standalone deployment. Panel allows seamless integration of components from a Jupyter notebook into a dashboard, enabling smooth transitions between data exploration and sharing results.
- Panel empowers users to build complex multi-page applications, advanced interactive features, visualize large datasets, and stream real-time data.
- Integration with Pyodide and WebAssembly enables seamless execution of Panel applications in web browsers.
Ready to build Panel apps on Hugging Face? Check out our [Hugging Face deployment docs](https://panel.holoviz.org/how_to/deployment/huggingface.html#hugging-face), click this button, and begin your journey:
<a href="https://huggingface.co/new-space?template=Panel-Org/panel-template"> <img src="https://huggingface.co/datasets/huggingface/badges/raw/main/deploy-to-spaces-lg.svg"/> </a>
<a href="https://huggingface.co/new-space?template=Panel-Org/panel-template">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/spaces-panel.png" style="width:70%"> </a>
## 🌐 Join Our Community
The Panel community is vibrant and supportive, with experienced developers and data scientists eager to help and share their knowledge. Join us and connect with us:
- [Discord](https://discord.gg/aRFhC3Dz9w)
- [Discourse](https://discourse.holoviz.org/)
- [Twitter](https://twitter.com/Panel_Org)
- [LinkedIn](https://www.linkedin.com/company/panel-org)
- [Github](https://github.com/holoviz/panel)
| 7 |
0 | hf_public_repos | hf_public_repos/blog/leaderboard-nphardeval.md | ---
title: "NPHardEval Leaderboard: Unveiling the Reasoning Abilities of Large Language Models through Complexity Classes and Dynamic Updates"
thumbnail: /blog/assets/leaderboards-on-the-hub/thumbnail_nphardeval.png
authors:
- user: lizhouf
guest: true
- user: wenyueH
guest: true
- user: hyfrankl
guest: true
- user: clefourrier
---
# NPHardEval Leaderboard: Unveiling the Reasoning Abilities of Large Language Models through Complexity Classes and Dynamic Updates
We're happy to introduce the [NPHardEval leaderboard](https://huggingface.co/spaces/NPHardEval/NPHardEval-leaderboard), using [NPHardEval](https://arxiv.org/abs/2312.14890), a cutting-edge benchmark developed by researchers from the University of Michigan and Rutgers University.
NPHardEval introduces a dynamic, complexity-based framework for assessing Large Language Models' (LLMs) reasoning abilities. It poses 900 algorithmic questions spanning the NP-Hard complexity class and lower, designed to rigorously test LLMs, and is updated on a monthly basis to prevent overfitting!
<script type="module" src="https://gradio.s3-us-west-2.amazonaws.com/3.45.1/gradio.js"> </script>
<gradio-app theme_mode="light" space="NPHardEval/NPHardEval-leaderboard"></gradio-app>
## A Unique Approach to LLM Evaluation
[NPHardEval](https://arxiv.org/abs/2312.14890) stands apart by employing computational complexity classes, offering a quantifiable and robust measure of LLM reasoning skills. The benchmark's tasks mirror real-world decision-making challenges, enhancing its relevance and applicability. Regular monthly updates of the benchmark data points mitigate the risk of model overfitting, ensuring a reliable evaluation.
The major contributions of NPHardEval are new using new benchmarking strategies (proposing an automatic and dynamic benchmark), and introducing a new way to evaluate LLM reasoning.
Regarding benchmarking strategies, NPHardEval uses an **automated mechanism**, both to generate and check questions in the benchmark. Since they are based on algorithmically computable problems, human intervention is not required to determine the correctness of the responses from LLMs. This also allows NPHardEval to be a **dynamic benchmark**: since questions can be automatically generated, the benchmark can be updated on a monthly basis. This monthly-refreshed benchmark helps prevent model overfitting as we can always generate novel questions with varying difficulty levels for evaluation.
The questions themselves use a new system to evaluate LLM Reasoning. The questions in the benchmark are grounded in the computational complexity hierarchy, a well-established concept extensively studied in theoretical computer science. This foundation enables us to leverage existing research to rigorously and quantitatively measure an LLM's logical reasoning extent, by **defining reasoning via complexity classes**. The benchmark also deliberatley excludes numerical computation from the questions, since it is a notoriously difficult task for LLMs. **Focusing on logical questions** allows for a more accurate evaluation of an LLM's pure logical reasoning ability, as numerical questions can obscure this assessment.
## Data Synthesis
NPHardEval uses 100 questions for each of 9 different algorithms, with 10 difficulty levels, resulting in 900 questions across complexity and difficulty. The 9 algorithms, including 3 P, 3 NP-complete, and 3 NP-hard questions, are characterized according to the computing theory. The 900 questions are all synthesized and updated monthly.
<div align="center">
<img src="https://github.com/casmlab/NPHardEval/raw/main/figure/questions_blog.png" alt="Tasks in NPHardEval" style="width:80%">
</div>
More background and insights are available in [these slides](https://docs.google.com/presentation/d/1VYBrCw5BqxuCCwlHeVn_UlhFj6zw04uETJzufw6spA8/edit?usp=sharing).
## Evaluation Metrics
We use two metrics to evaluate the reasoning ability of LLMs: Weighted Accuracy and Failure Rate.
### Weighted Accuracy (WA)
**Weighted Accuracy (WA)** is used to evaluate problem-solving accuracy. This method is applied to each problem, either through comparison with a correct answer or via step-by-step result checking for problems without a singular answer. To reflect comparative accuracy more effectively, we assign weights to different difficulty levels. Each level's weight corresponds to its relative importance or challenge, with higher difficulty levels receiving more weight in a linear progression (for instance, level 1 has weight 1, level 2 has weight 2, and so on).
The formula for Weighted Accuracy is as follows:
<div align="center">
\\( WA = \frac{\sum\limits_{i=1}^{10} (w_i \times A_i)}{\sum\limits_{i=1}^{10} w_i} \\)
</div>
In this equation, \\(w_i\\) represents the weight assigned to difficulty level \\(i\\) (ranging from 1 to 10), and \\(A_i\\) is the accuracy at that level.
### Failure Rate (FR)
Another critical metric we consider is the **Failure Rate (FR)**. This measure helps assess the frequency of unsuccessful outcomes across different problems and difficulty levels. It's particularly useful for identifying instances where an LLM's result does not match the expected output format.
The Failure Rate is calculated by considering the proportion of failed attempts relative to the total number of attempts for each difficulty level. An attempt is counted as failed if the model generates results that cannot be successfully parsed in all endpoint calls. We set the maximum number of tries as 10. For each problem, the Failure Rate is then aggregated across all difficulty levels, considering the total of 10 attempts at each level.
The formal definition of Failure Rate is:
<div align="center">
\\( FR = \frac{\sum\limits_{i=1}^{10} F_i}{100} \\)
</div>
Here, \\( F_i \\) denotes the number of failed attempts at difficulty level \\( i \\).
## Experimentation and Insights
The benchmark includes comprehensive experiments to analyze LLMs across various complexity classes and difficulty levels. It delves into the nuances of LLM performance, providing valuable insights into their reasoning strengths and limitations. In general:
- Closed-source models generally perform better than open-source models, with GPT 4 Turbo performing the best overall.
- Models generally perform better on less-complex questions, i.e. easier complexity classes, while not always linearly decrease on complexity levels. Models such as Claude 2 perform the best on NP-complete (middle-complexity) questions.
- Some open-source models can outperform close-source models on specific questions. Leading open-source models include Yi-34b, Qwen-14b, Phi-2, and Mistral-7b.
<div align="center">
<img src="https://github.com/casmlab/NPHardEval/raw/main/figure/weighted_accuracy_failed.png" alt="Weighted Accuracy and Failure Rate" style="width:80%">
</div>
<div align="center">
<img src="https://github.com/casmlab/NPHardEval/raw/main/figure/zeroshot_heatmap.png" alt="Zeroshot Heatmap" style="width:60%">
</div>
## Reproducing NPHardEval Benchmark results on your machine
To set up the NPHardEval Benchmark, you need to follow a few steps:
1. Environment setup: after cloning the repository to your local machine, install the required python library with `conda`.
```bash
conda create --name llm_reason python==3.10
conda activate llm_reason
git clone https://github.com/casmlab/NPHardEval.git
pip install -r requirements.txt
```
2. Set-up API keys: fetch API keys and change the corresponding entries in `secrets.txt`.
3. Example Commands: evaluate your model with the NPHardEval benchmark!
For example, to use the GPT 4 Turbo model (GPT-4-1106-preview) and the edit distance problem (EDP) for evaluation:
- For its zeroshot experiment, we can use:
```
cd Close/run
python run_p_EDP.py gpt-4-1106-preview
```
- For its fewshot experiment,
```
cd Close/run
python run_p_EDP_few.py gpt-4-1106-preview self
```
We currently support fewshot examples from the same question (self), and may support examples from other questions (other) in the future.
## Join the Conversation
[The NPHardEval leaderboard](https://huggingface.co/spaces/NPHardEval/NPHardEval-leaderboard), [dataset](https://huggingface.co/datasets/NPHardEval/NPHardEval-results) and [code](https://github.com/casmlab/NPHardEval) are available on Github and Hugging Face for community access and contributions.
We'll love to see community contributions and interest on the NPHardEval [GitHub Repository](https://github.com/casmlab/NPHardEval) and [Hugging Face Leaderboard](https://huggingface.co/spaces/NPHardEval/NPHardEval-leaderboard).
| 8 |
0 | hf_public_repos | hf_public_repos/blog/designing-positional-encoding.md | ---
title: "You could have designed state of the art positional encoding"
thumbnail: /blog/assets/designing-positional-encoding/thumbnail_posenc.png
authors:
- user: FL33TW00D-HF
---
> **Gall's Law** \
> A complex system that works is invariably found to have evolved from a simple
> system that worked \
> John Gall
This post walks you through the step-by-step discovery of state-of-the-art positional encoding in transformer models. We will achieve
this by iteratively improving our approach to encoding position, arriving at **Ro**tary **P**ostional **E**ncoding (RoPE) used in the latest [LLama 3.2](https://ai.meta.com/blog/llama-3-2-connect-2024-vision-edge-mobile-devices/) release and most modern transformers. This post intends to limit the mathematical knowledge required to follow along, but some basic linear algebra, trigonometry and understanding of self attention is expected.
## Problem Statement
> You shall know a word by the company it keeps \
> John Rupert Firth
As with all problems, it is best to first start with understanding **exactly** what we are trying to achieve. The self attention mechanism in transformers is utilized to understand relationships
between tokens in a sequence. Self attention is a **set** operation, which
means it is **permutation equivariant**. If we do not
enrich self attention with positional information, many important relationships are
**incapable of being determined**.
This is best demonstrated by example.
## Motivating Example
Consider this sentence with the same word in different positions:
$$
\text{The dog chased another dog}
$$
Intuitively, "dog" refers to two different entities. Let's see what happens if we first tokenize them, map to the real token embeddings of **Llama 3.2 1B** and pass them through [torch.nn.MultiheadAttention](https://pytorch.org/docs/stable/generated/torch.nn.MultiheadAttention.html).
```python
import torch
import torch.nn as nn
from transformers import AutoTokenizer, AutoModel
model_id = "meta-llama/Llama-3.2-1B"
tok = AutoTokenizer.from_pretrained(model_id)
model = AutoModel.from_pretrained(model_id)
text = "The dog chased another dog"
tokens = tok(text, return_tensors="pt")["input_ids"]
embeddings = model.embed_tokens(tokens)
hdim = embeddings.shape[-1]
W_q = nn.Linear(hdim, hdim, bias=False)
W_k = nn.Linear(hdim, hdim, bias=False)
W_v = nn.Linear(hdim, hdim, bias=False)
mha = nn.MultiheadAttention(embed_dim=hdim, num_heads=4, batch_first=True)
with torch.no_grad():
for param in mha.parameters():
nn.init.normal_(param, std=0.1) # Initialize weights to be non-negligible
output, _ = mha(W_q(embeddings), W_k(embeddings), W_v(embeddings))
dog1_out = output[0, 2]
dog2_out = output[0, 5]
print(f"Dog output identical?: {torch.allclose(dog1_out, dog2_out, atol=1e-6)}") #True
```
As we can see, without any positional information, the output of a (multi
headed) self attention operation is **identical for the same token in
different positions**, despite the tokens clearly representing distinct entities. Let's begin designing a method of enhancing self attention with positional information, such that it can determine relationships between words encoded by
their positions.
How should an ideal positional encoding scheme behave?
## Desirable Properties
Let's try and define some desirable properties that will make the optimization
process as easy as possible.
#### Property 1 - Unique encoding for each position (across sequences)
Each position needs a unique encoding that remains consistent regardless of sequence length - a token at position 5 should have the same encoding whether the current sequence is of length 10 or 10,000.
#### Property 2 - Linear relation between two encoded positions
The relationship between positions should be mathematically simple. If we know the encoding for position \\(p\\), it should be straightforward to compute the encoding for position \\(p+k\\), making it easier for the model to learn positional patterns.
If you think about how we represent numbers on a number line, it's easy to understand that 5 is 2 steps away from 3, or that 10 is 5 steps from 15. The same intuitive relationship should exist in our encodings.
#### Property 3 - Generalizes to longer sequences than those encountered in training
To increase our models' utility in the real world, they should generalize outside
their training distribution. Therefore, our encoding scheme needs to be
adaptable enough to handle unexpected input lengths, without
violating any of our other desirable properties.
#### Property 4 - Generated by a deterministic process the model can learn
It would be ideal if our positional encodings could be drawn from a
deterministic process. This should allow the model to learn the mechanism
behind our encoding scheme efficiently.
#### Property 5 - Extensible to multiple dimensions
With multimodal models becoming the norm, it is crucial that our positional
encoding scheme can naturally extend from \\(1D\\) to \\(nD\\). This will allow models to consume data like images or brain scans, which are \\(2D\\) and \\(4D\\)
respectively.
Now we know the ideal properties (henceforth referred to as \\(Pr_n\\)), let's start designing and iterating on our encoding scheme.
## Integer Position Encoding
The first approach that may jump to mind is simply to add the integer value of the token position to each component of the token embedding, with values ranging from \\(0 \rightarrow L\\) where \\(L\\) is the
length of our current sequence.
<figure class="image flex flex-col items-center text-center m-0 w-full">
<video alt="IntegerEncoding.mp4" autoplay loop autobuffer muted playsinline>
<source src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/you-could-have-designed-SOTA-positional-encoding/IntegerEncoding.mp4" type="video/mp4">
</video>
<figcaption></figcaption>
</figure>
In the above animation, we create our positional encoding vector for the token \\(\color{#699C52}\text{chased}\\) from the index and add it to our token embedding. The embedding values here are a subset of the real values from **Llama 3.2 1B**. We can observe that they're clustered around 0. This
is desirable to avoid [vanishing or exploding gradients](https://www.cs.toronto.edu/~rgrosse/courses/csc321_2017/readings/L15%20Exploding%20and%20Vanishing%20Gradients.pdf) during training and therefore is something we'd like to maintain throughout the model.
It's clear that our current naïve approach is going to cause problems. The magnitude of the position value
vastly exceeds the actual values of our input. This means the signal-to-noise
ratio is very low, and it's hard for the model to separate the semantic
information from the positional information.
With this new knowledge, a natural follow on might be to normalize the position value by \\(\frac{1}{N}\\). This constrains the values between 0 and 1, but introduces another problem. If we choose \\(N\\) to be the length of the current sequence, then the position values will be completely different for each sequence of differing lengths, violating \\(Pr_1\\).
Is there a better way to ensure our numbers are between 0 and 1?
If we thought really hard about this for a while, we might come up with switching
from decimal to binary numbers.
## Binary Position Encoding
Instead of adding our (potentially normalized) integer position to each
component of the embedding, we could instead convert it into its binary
representation and *s t r e t c h* our value out to match our embedding dimension, as demonstrated below.
<figure class="image flex flex-col items-center text-center m-0 w-full">
<video alt="BinaryEncoding.mp4" autoplay loop autobuffer muted playsinline>
<source src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/you-could-have-designed-SOTA-positional-encoding/BinaryEncoding.mp4" type="video/mp4">
</video>
<figcaption></figcaption>
</figure>
We've converted the position of interest (252) into its binary representation
(11111100) and added each bit to the corresponding component of the
token embedding. The least significant bit (LSB) will cycle between 0 and 1 for every
subsequent token, whilst the most significant bit (MSB) will cycle every
\\(2^{n-1}\\) tokens where \\(n\\) is the number of bits.
You can see the positional encoding vector for different indices in the animation below \\([^1]\\).
<figure class="image flex flex-col items-center text-center m-0 w-full">
<video alt="BinaryPositionalEncodingPlot.mp4" autoplay loop autobuffer muted playsinline>
<source src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/you-could-have-designed-SOTA-positional-encoding/BinaryPositionalEncodingPlot.mp4" type="video/mp4">
</video>
<figcaption></figcaption>
</figure>
We've solved the value range problem, and we now have unique encodings that are
consistent across different sequence lengths. What happens if we plot a low dimensional version of our token embedding and visualize the addition of our binary positional vector for different values.
<figure class="image flex flex-col items-center text-center m-0 w-full">
<video alt="BinaryVector3D.mp4" autoplay loop autobuffer muted playsinline>
<source src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/you-could-have-designed-SOTA-positional-encoding/BinaryVector3D.mp4" type="video/mp4">
</video>
<figcaption></figcaption>
</figure>
We can see that the result is very "jumpy" (as we might expect from the
discrete nature of binary). The optimization process likes smooth, continuous and
predictable changes. Do we know any functions with similar value ranges that are smooth and continuous?
If we looked around a little, we might notice that both \\(\sin\\) and \\(\cos\\) fit the bill!
## Sinusoidal positional encoding
<figure class="image flex flex-col items-center text-center m-0 w-full">
<video alt="SteppedPositionalEncodingPlot.mp4" autoplay loop autobuffer muted playsinline>
<source src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/you-could-have-designed-SOTA-positional-encoding/SteppedPositionalEncodingPlot.mp4" type="video/mp4">
</video>
<figcaption></figcaption>
</figure>
The above animation visualizes our position embedding if each component is
alternatively drawn from \\(\sin\\) and \\(\cos\\) with gradually increasing
wavelengths. If you compare it with the previous animation, you'll notice a striking similarity!
We've now arrived at Sinusoidal embeddings; originally defined in the [Attention is all you need](https://arxiv.org/abs/1706.03762) paper.
Let's look at the equations:
$$
PE_{(pos,2i)} = \color{#58C4DD}\sin\left(\color{black}\frac{pos}{10000^{2i/d}}\color{#58C4DD}\right)\color{black} \\
\quad \\
PE_{(pos,2i+1)} = \color{#FC6255}\cos\left(\color{black}\frac{pos}{10000^{2i/d}}\color{#FC6255}\right)\color{black} \\
$$
where \\(pos\\) is the tokens position index, \\(i\\) is the component index
in the positional encoding vector, and \\(d\\) is the model dimension. \\(10,000\\) is the **base wavelength** (henceforth referred to as
\\(\theta\\)), which we stretch or compress as a function of the component index. I encourage you to plug in some realistic values to get a feel for this
geometric progression.
There's a few parts of this equation that are confusing at first glance. How did the
authors choose \\(10,000\\)? Why are we using \\(\sin\\) **and** \\(\cos\\) for even and odd positions respectively?
It seems that using \\(10,000\\) for the base wavelength was determined experimentally \\([^2]\\). Deciphering the usage of both \\(\sin\\) and \\(\cos\\) is more involved, but crucial
for our iterative approach to understanding. The key here is our desire for a linear relation between two encoded positions \\(Pr_2\\). To understand how using \\(\sin\\) and \\(\cos\\) in tandem produce this linear relation, we will have to dive into some trigonometry.
Consider a sequence of sine and cosine pairs, each associated with a frequency \\(\omega_i\\). Our goal is to find a linear transformation matrix \\(\mathbf{M}\\) that can shift these sinusoidal functions by a fixed offset \\(k\\):
$$
\mathbf{M} \cdot \begin{bmatrix} \sin(\omega_i p) \\ \cos(\omega_i p) \end{bmatrix} = \begin{bmatrix} \sin(\omega_i(p + k)) \\ \cos(\omega_i(p + k)) \end{bmatrix}
$$
The frequencies \\(\omega_i\\) follow a geometric progression that decreases with dimension index \\(i\\), defined as:
$$
\omega_i = \frac{1}{10000^{2i/d}}
$$
To find this transformation matrix, we can express it as a general 2×2 matrix with unknown coefficients \\(u_1\\), \\(v_1\\), \\(u_2\\), and \\(v_2\\):
$$
\begin{bmatrix} u_1 & v_1 \\ u_2 & v_2 \end{bmatrix} \cdot \begin{bmatrix} \sin(\omega_i p) \\ \cos(\omega_i p) \end{bmatrix} = \begin{bmatrix} \sin(\omega_i(p+k)) \\ \cos(\omega_i(p+k)) \end{bmatrix}
$$
By applying the trigonometric addition theorem to the right-hand side, we can expand this into:
$$
\begin{bmatrix} u_1 & v_1 \\ u_2 & v_2 \end{bmatrix} \cdot \begin{bmatrix} \sin(\omega_i p) \\ \cos(\omega_i p) \end{bmatrix} = \begin{bmatrix} \sin(\omega_i p)\cos(\omega_i k) + \cos(\omega_i p)\sin(\omega_i k) \\ \cos(\omega_i p)\cos(\omega_i k) - \sin(\omega_i p)\sin(\omega_i k) \end{bmatrix}
$$
This expansion gives us a system of two equations by matching coefficients:
$$
\begin{align}
u_1\sin(\omega_i p) + v_1\cos(\omega_i p) &= \cos(\omega_i k)\sin(\omega_i p) + \sin(\omega_i k)\cos(\omega_i p) \\
u_2\sin(\omega_i p) + v_2\cos(\omega_i p) &= -\sin(\omega_i k)\sin(\omega_i p) + \cos(\omega_i k)\cos(\omega_i p)
\end{align}
$$
By comparing terms with \\(\sin(\omega_i p)\\) and \\(\cos(\omega_i p)\\) on both sides, we can solve for the unknown coefficients:
$$
\begin{align}
u_1 &= \cos(\omega_i k) & v_1 &= \sin(\omega_i k) \\
u_2 &= -\sin(\omega_i k) & v_2 &= \cos(\omega_i k)
\end{align}
$$
These solutions give us our final transformation matrix \\(\mathbf{M_k}\\):
$$
\mathbf{M_k} = \begin{bmatrix} \cos(\omega_i k) & \sin(\omega_i k) \\ -\sin(\omega_i k) & \cos(\omega_i k) \end{bmatrix}
$$
If you've done any game programming before, you might notice that the
result of our derivation is oddly familiar. That's right, it's the [Rotation Matrix!](https://en.wikipedia.org/wiki/Rotation_matrix) \\([^3]\\).
So the encoding scheme designed by [Noam Shazeer](https://en.wikipedia.org/wiki/Noam_Shazeer) in [Attention is all you need](https://arxiv.org/abs/1706.03762) was already encoding relative position as a rotation back in 2017! It took another **4 years** to go from Sinusoidal Encoding to RoPE, despite rotations already being on the table...
## Absolute vs Relative Position Encoding
With the knowledge in hand that rotations are important here, let's
return to our motivating example and try to discover some intuitions for our next iteration.
$$
\begin{align*}
&\hspace{0.7em}0 \hspace{1.4em} 1 \hspace{2em} 2 \hspace{2.6em} 3 \hspace{2.4em} 4\\
&\text{The dog chased another dog} \\
\\
&\hspace{0.3em}\text{-2} \hspace{1.4em} \text{-1} \hspace{1.7em} 0 \hspace{2.6em} 1 \hspace{2.4em} 2\\
&\text{The dog \color{#699C52}chased \color{black}another dog}
\end{align*}
$$
Above we can see the absolute positions of our tokens, and the relative
positions from \\(\color{#699C52}\text{chased}\\) to every other token. With Sinusoidal Encoding, we
generated a separate vector which represents the absolute position,
and using some trigonometric trickery we were able to encode relative positions.
When we're trying to understand these sentences, does it matter that _this_ word is the 2157th word in this blog post? Or do we care about its relationship to the words around it? The absolute position of a word rarely matters for meaning - what matters is how words relate to each other.
## Positional encoding in context
From this point on, it's key to consider positional encoding **in the context of**
self attention. To reiterate, the self-attention mechanism enables the model to weigh the importance of different elements in an input sequence and dynamically adjust their influence on the output.
$$
\text{Attn}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V
$$
In all our previous iterations, we've generated a separate positional encoding
vector and **added** it to our token embedding prior to our \\(Q\\), \\(K\\) and \\(V\\) projections.
By adding the positional information directly to our token embedding, we are
**polluting** the semantic information with the positional information. We should
be attempting to encode the information without modifying the norm. Shifting to multiplicative is the
key.
Using the dictionary analogy, when looking up a word (query) in our dictionary (keys), nearby words should have more influence than distant ones. The influence of one token upon another is determined by the \\(QK^T\\) dot product - so that's exactly where we should focus our positional encoding!
$$
\vec{a} \cdot \vec{b} = |\vec{a}| |\vec{b}| \cos \theta
$$
The geometric interpretation of the dot product shown above gives us a magnificent insight.
We can modulate the result of our dot product of two vectors purely by
increasing or decreasing the angle between them. Furthermore, by rotating the
vector, we have absolutely zero impact on the norm of the vector, which encodes
the semantic information of our token.
So now we know where to focus our _attention_, and have seen from another _angle_ why a
rotation might be a sensible "channel" in which to encode our positional
information, let's put it all together!
## **Ro**tary **P**ostional **E**ncoding
**Ro**tary **P**ostional **E**ncoding or RoPE was defined in the
[RoFormer paper](https://arxiv.org/pdf/2104.09864) ([Jianlin Su](https://x.com/bojone1993) designed it independently on his blog [here](https://kexue.fm/archives/8130) and [here](https://kexue.fm/archives/8265)).
While it may seem like voodoo if you skip to the end result, by thinking about Sinusoidal Encoding in the
context of self attention (and more specifically dot products), we can see how
it all comes together.
Much like in Sinusoidal Encoding, we decompose our vectors \\(\mathbf{q}\\) or \\(\mathbf{k}\\), instead of pre-projection \\(\mathbf{x}\\)) into 2D pairs/chunks. Rather than encoding _absolute_ position directly by adding a vector we drew from sinusoidal functions of slowly decreasing frequencies, we cut to the chase and encode _relative_ position by **multiplying each pair with the rotation matrix**.
Let \\(\mathbf{q}\\) or \\(\mathbf{k}\\) be our input vector at position \\(p\\). We create a block diagonal matrix
where \\(\mathbf{M_i}\\) is the corresponding rotation matrix for that component
pairs desired rotation:
$$
R(\mathbf{q}, p) = \begin{pmatrix} \mathbf{M_1} & & & \\ & \mathbf{M_2} & & \\ & & \ddots & \\ & & & \mathbf{M_{d/2}} \end{pmatrix} \begin{pmatrix} q_1 \\ q_2 \\ \vdots \\ q_d \end{pmatrix}
$$
Much the same as Sinusoidal Encoding, \\(\mathbf{M_i}\\) is simply:
$$
\mathbf{M_i} = \begin{bmatrix} \cos(\omega_i p) & \sin(\omega_i p) \\ -\sin(\omega_i p) & \cos(\omega_i p) \end{bmatrix}
$$
<figure class="image flex flex-col items-center text-center m-0 w-full">
<video alt="RopeEncoding.mp4" autoplay loop autobuffer muted playsinline>
<source src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/you-could-have-designed-SOTA-positional-encoding/RopeEncoding.mp4" type="video/mp4">
</video>
<figcaption></figcaption>
</figure>
In practice, we don't use a matrix multiplication to compute RoPE as it would be
computationally inefficient with such a sparse matrix. Instead, we can directly apply the rotations to pairs of elements independently, taking advantage of the regular pattern in the computation:
$$
R_{\Theta,p}^d q = \begin{pmatrix}
q_1 \\
q_2 \\
q_3 \\
q_4 \\
\vdots \\
q_{d-1} \\
q_d
\end{pmatrix} \otimes \begin{pmatrix}
\cos p\theta_1 \\
\cos p\theta_1 \\
\cos p\theta_2 \\
\cos p\theta_2 \\
\vdots \\
\cos p\theta_{d/2} \\
\cos p\theta_{d/2}
\end{pmatrix} + \begin{pmatrix}
-q_2 \\
q_1 \\
-q_4 \\
q_3 \\
\vdots \\
-q_d \\
q_{d-1}
\end{pmatrix} \otimes \begin{pmatrix}
\sin p\theta_1 \\
\sin p\theta_1 \\
\sin p\theta_2 \\
\sin p\theta_2 \\
\vdots \\
\sin p\theta_{d/2} \\
\sin p\theta_{d/2}
\end{pmatrix}
$$
That's all there is to it! By artfully applying our rotations to 2D chunks of \\(\mathbf{q}\\) and
\\(\mathbf{k}\\) prior to their dot product, and switching from additive to
multiplicative, we can gain a big performance boost in evaluations \\([^4]\\).
## Extending RoPE to \\(n\\)-Dimensions
We've explored the \\(1D\\) case for RoPE and by this point I hope you've gained an
intuitive understanding of an admittedly unintuitive component of transformers.
Finally, let's explore extending it to higher dimensions, such as images.
A natural first intuition could be to directly use the \\( \begin{bmatrix} x \\ y \end{bmatrix}\\) coordinate pairs from the image. This might seem intuitive, after all, we were almost arbitrarily pairing up our components previously. However, this would be a mistake!
In the \\(1D\\) case, we encode the relative position \\(m - n\\) through a rotation of pairs
of values from our input vector. For \\(2D\\) data, we need to encode both horizontal and vertical relative positions, say \\(m - n\\) and \\(i - j\\) independently. RoPE's brilliance lies in how it handles multiple dimensions. Instead of trying to encode all positional information in a single rotation, we pair components **within the same dimension** and rotate those, otherwise we would be intermixing the \\(x\\) and \\(y\\) offset information. By handling each dimension independently, we maintain the natural structure of the space. This can generalize to as many dimensions as required!
## The future of positional encoding
Is RoPE the final incarnation of positional encoding? This [recent paper](https://arxiv.org/pdf/2410.06205) from DeepMind deeply analyses RoPE and highlights some fundamental problems. TLDR: RoPE isn't a perfect solution, and the models mostly focus on the lower frequencies and the rotation for a certain percent of low frequencies improves performance on Gemma 2B!
I anticipate some future breakthroughs, perhaps taking inspiration from
signal processing with ideas like wavelets or hierarchical implementations. As models
are increasingly quantized for deployment, I'd also expect to see some
innovation in encoding schemes that remain robust under low-precision arithmetic.
## Conclusion
Positional encoding has and continues to be treated as an after thought in
transformers. I believe we should view it differently - self attention has an
Achilles heel that has been repeatedly patched.
I hope this blog post showed you that you too could have discovered state of the
art positional encoding, despite it being unintuitive at first. In a follow up
post I'd love to explore practical implementation details for RoPE in order to
maximise performance.
This post was originally published [here](https://fleetwood.dev/posts/you-could-have-designed-SOTA-positional-encoding).
## References
- [Transformer Architecture: The Positional Encoding](https://kazemnejad.com/blog/transformer_architecture_positional_encoding/)
- [Rotary Embeddings: A Relative Revolution](https://blog.eleuther.ai/rotary-embeddings/)
- [How positional encoding works in transformers?](https://www.youtube.com/watch?v=T3OT8kqoqjc)
- [Attention Is All You Need](https://arxiv.org/pdf/1706.03762)
- [Round and round we go! What makes Rotary Positional Encodings useful?](https://arxiv.org/pdf/2410.06205)
- [RoFormer: Enhanced Transformer with Rotary Position Embedding](https://arxiv.org/pdf/2104.09864)
[^1]: Binary and Sinusoidal animations are reproductions of animations contained
in [this](https://www.youtube.com/watch?v=T3OT8kqoqjc0) video.
[^2]: Using \\(\theta = 10000\\) gives us \\( 2 \pi \cdot 10000\\) unique positions, or a
theoretical upper bound on the context length at ~63,000.
[^3]: Pieces of this post are based on [this fantastic
post](https://kazemnejad.com/blog/transformer_architecture_positional_encoding/)
by [Amirhossein Kazemnejad](https://kazemnejad.com/).
[^4]: For empirical evidence, see [this](https://blog.eleuther.ai/rotary-embeddings/) great post by EleutherAI.
| 9 |
0 | hf_public_repos/candle/candle-examples/examples | hf_public_repos/candle/candle-examples/examples/mamba/main.rs | #[cfg(feature = "mkl")]
extern crate intel_mkl_src;
#[cfg(feature = "accelerate")]
extern crate accelerate_src;
use anyhow::{Error as E, Result};
use clap::{Parser, ValueEnum};
use candle_transformers::models::mamba::{Config, Model, State};
use candle::{DType, Device, Tensor};
use candle_examples::token_output_stream::TokenOutputStream;
use candle_nn::VarBuilder;
use candle_transformers::generation::LogitsProcessor;
use hf_hub::{api::sync::Api, Repo, RepoType};
use tokenizers::Tokenizer;
struct TextGeneration {
model: Model,
config: Config,
device: Device,
tokenizer: TokenOutputStream,
logits_processor: LogitsProcessor,
repeat_penalty: f32,
repeat_last_n: usize,
}
impl TextGeneration {
#[allow(clippy::too_many_arguments)]
fn new(
model: Model,
config: Config,
tokenizer: Tokenizer,
seed: u64,
temp: Option<f64>,
top_p: Option<f64>,
repeat_penalty: f32,
repeat_last_n: usize,
device: &Device,
) -> Self {
let logits_processor = LogitsProcessor::new(seed, temp, top_p);
Self {
model,
config,
tokenizer: TokenOutputStream::new(tokenizer),
logits_processor,
repeat_penalty,
repeat_last_n,
device: device.clone(),
}
}
fn run(&mut self, prompt: &str, sample_len: usize) -> Result<()> {
use std::io::Write;
self.tokenizer.clear();
let dtype = self.model.dtype();
let mut tokens = self
.tokenizer
.tokenizer()
.encode(prompt, true)
.map_err(E::msg)?
.get_ids()
.to_vec();
let mut generated_tokens = 0usize;
let eos_token = match self.tokenizer.get_token("<|endoftext|>") {
Some(token) => token,
None => anyhow::bail!("cannot find the </s> token"),
};
let mut state = State::new(1, &self.config, dtype, &self.device)?;
let mut next_logits = None;
for &t in tokens.iter() {
let input = Tensor::new(&[t], &self.device)?;
let logits = self.model.forward(&input, &mut state)?;
next_logits = Some(logits);
if let Some(t) = self.tokenizer.next_token(t)? {
print!("{t}")
}
}
std::io::stdout().flush()?;
let start_gen = std::time::Instant::now();
for _ in 0..sample_len {
let logits = match next_logits.as_ref() {
Some(logits) => logits,
None => anyhow::bail!("cannot work on an empty prompt"),
};
let logits = logits.squeeze(0)?.to_dtype(dtype)?;
let logits = if self.repeat_penalty == 1. {
logits
} else {
let start_at = tokens.len().saturating_sub(self.repeat_last_n);
candle_transformers::utils::apply_repeat_penalty(
&logits,
self.repeat_penalty,
&tokens[start_at..],
)?
};
let next_token = self.logits_processor.sample(&logits)?;
tokens.push(next_token);
generated_tokens += 1;
if next_token == eos_token {
break;
}
if let Some(t) = self.tokenizer.next_token(next_token)? {
print!("{t}");
std::io::stdout().flush()?;
}
let input = Tensor::new(&[next_token], &self.device)?;
next_logits = Some(self.model.forward(&input, &mut state)?)
}
let dt = start_gen.elapsed();
if let Some(rest) = self.tokenizer.decode_rest().map_err(E::msg)? {
print!("{rest}");
}
std::io::stdout().flush()?;
println!(
"\n{generated_tokens} tokens generated ({:.2} token/s)",
generated_tokens as f64 / dt.as_secs_f64(),
);
Ok(())
}
}
#[derive(Parser, ValueEnum, Clone, Copy, PartialEq, Eq, Debug)]
enum Which {
Mamba130m,
Mamba370m,
Mamba790m,
Mamba1_4b,
Mamba2_8b,
Mamba2_8bSlimPj,
}
impl std::fmt::Display for Which {
fn fmt(&self, f: &mut std::fmt::Formatter<'_>) -> std::fmt::Result {
write!(f, "{:?}", self)
}
}
impl Which {
fn model_id(&self) -> &'static str {
match self {
Self::Mamba130m => "state-spaces/mamba-130m",
Self::Mamba370m => "state-spaces/mamba-370m",
Self::Mamba790m => "state-spaces/mamba-790m",
Self::Mamba1_4b => "state-spaces/mamba-1.4b",
Self::Mamba2_8b => "state-spaces/mamba-2.8b",
Self::Mamba2_8bSlimPj => "state-spaces/mamba-2.8b-slimpj'",
}
}
fn revision(&self) -> &'static str {
match self {
Self::Mamba130m
| Self::Mamba370m
| Self::Mamba790m
| Self::Mamba1_4b
| Self::Mamba2_8bSlimPj => "refs/pr/1",
Self::Mamba2_8b => "refs/pr/4",
}
}
}
#[derive(Parser, Debug)]
#[command(author, version, about, long_about = None)]
struct Args {
/// Run on CPU rather than on GPU.
#[arg(long)]
cpu: bool,
/// Enable tracing (generates a trace-timestamp.json file).
#[arg(long)]
tracing: bool,
#[arg(long)]
prompt: String,
/// The temperature used to generate samples.
#[arg(long)]
temperature: Option<f64>,
/// Nucleus sampling probability cutoff.
#[arg(long)]
top_p: Option<f64>,
/// The seed to use when generating random samples.
#[arg(long, default_value_t = 299792458)]
seed: u64,
/// The length of the sample to generate (in tokens).
#[arg(long, short = 'n', default_value_t = 5000)]
sample_len: usize,
#[arg(long, default_value = "mamba130m")]
which: Which,
#[arg(long)]
model_id: Option<String>,
#[arg(long)]
revision: Option<String>,
#[arg(long)]
tokenizer_file: Option<String>,
#[arg(long)]
weight_files: Option<String>,
#[arg(long)]
config_file: Option<String>,
#[arg(long, default_value = "f32")]
dtype: String,
/// Penalty to be applied for repeating tokens, 1. means no penalty.
#[arg(long, default_value_t = 1.1)]
repeat_penalty: f32,
/// The context size to consider for the repeat penalty.
#[arg(long, default_value_t = 64)]
repeat_last_n: usize,
}
fn main() -> Result<()> {
use std::str::FromStr;
use tracing_chrome::ChromeLayerBuilder;
use tracing_subscriber::prelude::*;
let args = Args::parse();
let _guard = if args.tracing {
let (chrome_layer, guard) = ChromeLayerBuilder::new().build();
tracing_subscriber::registry().with(chrome_layer).init();
Some(guard)
} else {
None
};
println!(
"avx: {}, neon: {}, simd128: {}, f16c: {}",
candle::utils::with_avx(),
candle::utils::with_neon(),
candle::utils::with_simd128(),
candle::utils::with_f16c()
);
println!(
"temp: {:.2} repeat-penalty: {:.2} repeat-last-n: {}",
args.temperature.unwrap_or(0.),
args.repeat_penalty,
args.repeat_last_n
);
let start = std::time::Instant::now();
let api = Api::new()?;
let repo = api.repo(Repo::with_revision(
args.model_id
.unwrap_or_else(|| args.which.model_id().to_string()),
RepoType::Model,
args.revision
.unwrap_or_else(|| args.which.revision().to_string()),
));
let tokenizer_filename = match args.tokenizer_file {
Some(file) => std::path::PathBuf::from(file),
None => api
.model("EleutherAI/gpt-neox-20b".to_string())
.get("tokenizer.json")?,
};
let config_filename = match args.config_file {
Some(file) => std::path::PathBuf::from(file),
None => repo.get("config.json")?,
};
let filenames = match args.weight_files {
Some(files) => files
.split(',')
.map(std::path::PathBuf::from)
.collect::<Vec<_>>(),
None => {
vec![repo.get("model.safetensors")?]
}
};
println!("retrieved the files in {:?}", start.elapsed());
let tokenizer = Tokenizer::from_file(tokenizer_filename).map_err(E::msg)?;
let start = std::time::Instant::now();
let config: Config = serde_json::from_slice(&std::fs::read(config_filename)?)?;
let device = candle_examples::device(args.cpu)?;
let dtype = DType::from_str(&args.dtype)?;
let vb = unsafe { VarBuilder::from_mmaped_safetensors(&filenames, dtype, &device)? };
let model = Model::new(&config, vb.pp("backbone"))?;
println!("loaded the model in {:?}", start.elapsed());
let mut pipeline = TextGeneration::new(
model,
config,
tokenizer,
args.seed,
args.temperature,
args.top_p,
args.repeat_penalty,
args.repeat_last_n,
&device,
);
pipeline.run(&args.prompt, args.sample_len)?;
Ok(())
}
| 0 |
0 | hf_public_repos/candle/candle-examples/examples | hf_public_repos/candle/candle-examples/examples/mamba/README.md | # candle-mamba: Mamba implementation
Candle implementation of *Mamba* [1] inference only. Mamba is an alternative to
the transformer architecture. It leverages State Space Models (SSMs) with the
goal of being computationally efficient on long sequences. The implementation is
based on [mamba.rs](https://github.com/LaurentMazare/mamba.rs).
- [1]. [Mamba: Linear-Time Sequence Modeling with Selective State Spaces](https://arxiv.org/abs/2312.00752).
Compared to the mamba-minimal example, this version is far more efficient but
would only work for inference.
## Running the example
```bash
$ cargo run --example mamba-minimal --release -- --prompt "Mamba is the"
```
| 1 |
0 | hf_public_repos/candle/candle-examples/examples | hf_public_repos/candle/candle-examples/examples/mnist-training/main.rs | // This should reach 91.5% accuracy.
#[cfg(feature = "mkl")]
extern crate intel_mkl_src;
#[cfg(feature = "accelerate")]
extern crate accelerate_src;
use clap::{Parser, ValueEnum};
use rand::prelude::*;
use candle::{DType, Result, Tensor, D};
use candle_nn::{loss, ops, Conv2d, Linear, Module, ModuleT, Optimizer, VarBuilder, VarMap};
const IMAGE_DIM: usize = 784;
const LABELS: usize = 10;
fn linear_z(in_dim: usize, out_dim: usize, vs: VarBuilder) -> Result<Linear> {
let ws = vs.get_with_hints((out_dim, in_dim), "weight", candle_nn::init::ZERO)?;
let bs = vs.get_with_hints(out_dim, "bias", candle_nn::init::ZERO)?;
Ok(Linear::new(ws, Some(bs)))
}
trait Model: Sized {
fn new(vs: VarBuilder) -> Result<Self>;
fn forward(&self, xs: &Tensor) -> Result<Tensor>;
}
struct LinearModel {
linear: Linear,
}
impl Model for LinearModel {
fn new(vs: VarBuilder) -> Result<Self> {
let linear = linear_z(IMAGE_DIM, LABELS, vs)?;
Ok(Self { linear })
}
fn forward(&self, xs: &Tensor) -> Result<Tensor> {
self.linear.forward(xs)
}
}
struct Mlp {
ln1: Linear,
ln2: Linear,
}
impl Model for Mlp {
fn new(vs: VarBuilder) -> Result<Self> {
let ln1 = candle_nn::linear(IMAGE_DIM, 100, vs.pp("ln1"))?;
let ln2 = candle_nn::linear(100, LABELS, vs.pp("ln2"))?;
Ok(Self { ln1, ln2 })
}
fn forward(&self, xs: &Tensor) -> Result<Tensor> {
let xs = self.ln1.forward(xs)?;
let xs = xs.relu()?;
self.ln2.forward(&xs)
}
}
#[derive(Debug)]
struct ConvNet {
conv1: Conv2d,
conv2: Conv2d,
fc1: Linear,
fc2: Linear,
dropout: candle_nn::Dropout,
}
impl ConvNet {
fn new(vs: VarBuilder) -> Result<Self> {
let conv1 = candle_nn::conv2d(1, 32, 5, Default::default(), vs.pp("c1"))?;
let conv2 = candle_nn::conv2d(32, 64, 5, Default::default(), vs.pp("c2"))?;
let fc1 = candle_nn::linear(1024, 1024, vs.pp("fc1"))?;
let fc2 = candle_nn::linear(1024, LABELS, vs.pp("fc2"))?;
let dropout = candle_nn::Dropout::new(0.5);
Ok(Self {
conv1,
conv2,
fc1,
fc2,
dropout,
})
}
fn forward(&self, xs: &Tensor, train: bool) -> Result<Tensor> {
let (b_sz, _img_dim) = xs.dims2()?;
let xs = xs
.reshape((b_sz, 1, 28, 28))?
.apply(&self.conv1)?
.max_pool2d(2)?
.apply(&self.conv2)?
.max_pool2d(2)?
.flatten_from(1)?
.apply(&self.fc1)?
.relu()?;
self.dropout.forward_t(&xs, train)?.apply(&self.fc2)
}
}
struct TrainingArgs {
learning_rate: f64,
load: Option<String>,
save: Option<String>,
epochs: usize,
}
fn training_loop_cnn(
m: candle_datasets::vision::Dataset,
args: &TrainingArgs,
) -> anyhow::Result<()> {
const BSIZE: usize = 64;
let dev = candle::Device::cuda_if_available(0)?;
let train_labels = m.train_labels;
let train_images = m.train_images.to_device(&dev)?;
let train_labels = train_labels.to_dtype(DType::U32)?.to_device(&dev)?;
let mut varmap = VarMap::new();
let vs = VarBuilder::from_varmap(&varmap, DType::F32, &dev);
let model = ConvNet::new(vs.clone())?;
if let Some(load) = &args.load {
println!("loading weights from {load}");
varmap.load(load)?
}
let adamw_params = candle_nn::ParamsAdamW {
lr: args.learning_rate,
..Default::default()
};
let mut opt = candle_nn::AdamW::new(varmap.all_vars(), adamw_params)?;
let test_images = m.test_images.to_device(&dev)?;
let test_labels = m.test_labels.to_dtype(DType::U32)?.to_device(&dev)?;
let n_batches = train_images.dim(0)? / BSIZE;
let mut batch_idxs = (0..n_batches).collect::<Vec<usize>>();
for epoch in 1..args.epochs {
let mut sum_loss = 0f32;
batch_idxs.shuffle(&mut thread_rng());
for batch_idx in batch_idxs.iter() {
let train_images = train_images.narrow(0, batch_idx * BSIZE, BSIZE)?;
let train_labels = train_labels.narrow(0, batch_idx * BSIZE, BSIZE)?;
let logits = model.forward(&train_images, true)?;
let log_sm = ops::log_softmax(&logits, D::Minus1)?;
let loss = loss::nll(&log_sm, &train_labels)?;
opt.backward_step(&loss)?;
sum_loss += loss.to_vec0::<f32>()?;
}
let avg_loss = sum_loss / n_batches as f32;
let test_logits = model.forward(&test_images, false)?;
let sum_ok = test_logits
.argmax(D::Minus1)?
.eq(&test_labels)?
.to_dtype(DType::F32)?
.sum_all()?
.to_scalar::<f32>()?;
let test_accuracy = sum_ok / test_labels.dims1()? as f32;
println!(
"{epoch:4} train loss {:8.5} test acc: {:5.2}%",
avg_loss,
100. * test_accuracy
);
}
if let Some(save) = &args.save {
println!("saving trained weights in {save}");
varmap.save(save)?
}
Ok(())
}
fn training_loop<M: Model>(
m: candle_datasets::vision::Dataset,
args: &TrainingArgs,
) -> anyhow::Result<()> {
let dev = candle::Device::cuda_if_available(0)?;
let train_labels = m.train_labels;
let train_images = m.train_images.to_device(&dev)?;
let train_labels = train_labels.to_dtype(DType::U32)?.to_device(&dev)?;
let mut varmap = VarMap::new();
let vs = VarBuilder::from_varmap(&varmap, DType::F32, &dev);
let model = M::new(vs.clone())?;
if let Some(load) = &args.load {
println!("loading weights from {load}");
varmap.load(load)?
}
let mut sgd = candle_nn::SGD::new(varmap.all_vars(), args.learning_rate)?;
let test_images = m.test_images.to_device(&dev)?;
let test_labels = m.test_labels.to_dtype(DType::U32)?.to_device(&dev)?;
for epoch in 1..args.epochs {
let logits = model.forward(&train_images)?;
let log_sm = ops::log_softmax(&logits, D::Minus1)?;
let loss = loss::nll(&log_sm, &train_labels)?;
sgd.backward_step(&loss)?;
let test_logits = model.forward(&test_images)?;
let sum_ok = test_logits
.argmax(D::Minus1)?
.eq(&test_labels)?
.to_dtype(DType::F32)?
.sum_all()?
.to_scalar::<f32>()?;
let test_accuracy = sum_ok / test_labels.dims1()? as f32;
println!(
"{epoch:4} train loss: {:8.5} test acc: {:5.2}%",
loss.to_scalar::<f32>()?,
100. * test_accuracy
);
}
if let Some(save) = &args.save {
println!("saving trained weights in {save}");
varmap.save(save)?
}
Ok(())
}
#[derive(ValueEnum, Clone)]
enum WhichModel {
Linear,
Mlp,
Cnn,
}
#[derive(Parser)]
struct Args {
#[clap(value_enum, default_value_t = WhichModel::Linear)]
model: WhichModel,
#[arg(long)]
learning_rate: Option<f64>,
#[arg(long, default_value_t = 200)]
epochs: usize,
/// The file where to save the trained weights, in safetensors format.
#[arg(long)]
save: Option<String>,
/// The file where to load the trained weights from, in safetensors format.
#[arg(long)]
load: Option<String>,
/// The directory where to load the dataset from, in ubyte format.
#[arg(long)]
local_mnist: Option<String>,
}
pub fn main() -> anyhow::Result<()> {
let args = Args::parse();
// Load the dataset
let m = if let Some(directory) = args.local_mnist {
candle_datasets::vision::mnist::load_dir(directory)?
} else {
candle_datasets::vision::mnist::load()?
};
println!("train-images: {:?}", m.train_images.shape());
println!("train-labels: {:?}", m.train_labels.shape());
println!("test-images: {:?}", m.test_images.shape());
println!("test-labels: {:?}", m.test_labels.shape());
let default_learning_rate = match args.model {
WhichModel::Linear => 1.,
WhichModel::Mlp => 0.05,
WhichModel::Cnn => 0.001,
};
let training_args = TrainingArgs {
epochs: args.epochs,
learning_rate: args.learning_rate.unwrap_or(default_learning_rate),
load: args.load,
save: args.save,
};
match args.model {
WhichModel::Linear => training_loop::<LinearModel>(m, &training_args),
WhichModel::Mlp => training_loop::<Mlp>(m, &training_args),
WhichModel::Cnn => training_loop_cnn(m, &training_args),
}
}
| 2 |
0 | hf_public_repos/candle/candle-examples/examples | hf_public_repos/candle/candle-examples/examples/repvgg/main.rs | #[cfg(feature = "mkl")]
extern crate intel_mkl_src;
#[cfg(feature = "accelerate")]
extern crate accelerate_src;
use clap::{Parser, ValueEnum};
use candle::{DType, IndexOp, D};
use candle_nn::{Module, VarBuilder};
use candle_transformers::models::repvgg;
#[derive(Clone, Copy, Debug, ValueEnum)]
enum Which {
A0,
A1,
A2,
B0,
B1,
B2,
B3,
B1G4,
B2G4,
B3G4,
}
impl Which {
fn model_filename(&self) -> String {
let name = match self {
Self::A0 => "a0",
Self::A1 => "a1",
Self::A2 => "a2",
Self::B0 => "b0",
Self::B1 => "b1",
Self::B2 => "b2",
Self::B3 => "b3",
Self::B1G4 => "b1g4",
Self::B2G4 => "b2g4",
Self::B3G4 => "b3g4",
};
format!("timm/repvgg_{}.rvgg_in1k", name)
}
fn config(&self) -> repvgg::Config {
match self {
Self::A0 => repvgg::Config::a0(),
Self::A1 => repvgg::Config::a1(),
Self::A2 => repvgg::Config::a2(),
Self::B0 => repvgg::Config::b0(),
Self::B1 => repvgg::Config::b1(),
Self::B2 => repvgg::Config::b2(),
Self::B3 => repvgg::Config::b3(),
Self::B1G4 => repvgg::Config::b1g4(),
Self::B2G4 => repvgg::Config::b2g4(),
Self::B3G4 => repvgg::Config::b3g4(),
}
}
}
#[derive(Parser)]
struct Args {
#[arg(long)]
model: Option<String>,
#[arg(long)]
image: String,
/// Run on CPU rather than on GPU.
#[arg(long)]
cpu: bool,
#[arg(value_enum, long, default_value_t=Which::A0)]
which: Which,
}
pub fn main() -> anyhow::Result<()> {
let args = Args::parse();
let device = candle_examples::device(args.cpu)?;
let image = candle_examples::imagenet::load_image224(args.image)?.to_device(&device)?;
println!("loaded image {image:?}");
let model_file = match args.model {
None => {
let model_name = args.which.model_filename();
let api = hf_hub::api::sync::Api::new()?;
let api = api.model(model_name);
api.get("model.safetensors")?
}
Some(model) => model.into(),
};
let vb = unsafe { VarBuilder::from_mmaped_safetensors(&[model_file], DType::F32, &device)? };
let model = repvgg::repvgg(&args.which.config(), 1000, vb)?;
println!("model built");
let logits = model.forward(&image.unsqueeze(0)?)?;
let prs = candle_nn::ops::softmax(&logits, D::Minus1)?
.i(0)?
.to_vec1::<f32>()?;
let mut prs = prs.iter().enumerate().collect::<Vec<_>>();
prs.sort_by(|(_, p1), (_, p2)| p2.total_cmp(p1));
for &(category_idx, pr) in prs.iter().take(5) {
println!(
"{:24}: {:.2}%",
candle_examples::imagenet::CLASSES[category_idx],
100. * pr
);
}
Ok(())
}
| 3 |
0 | hf_public_repos/candle/candle-examples/examples | hf_public_repos/candle/candle-examples/examples/repvgg/README.md | # candle-repvgg
[RepVGG: Making VGG-style ConvNets Great Again](https://arxiv.org/abs/2101.03697).
This candle implementation uses a pre-trained RepVGG network for inference. The
classification head has been trained on the ImageNet dataset and returns the
probabilities for the top-5 classes.
## Running an example
```
$ cargo run --example repvgg --release -- --image candle-examples/examples/yolo-v8/assets/bike.jpg
loaded image Tensor[dims 3, 224, 224; f32]
model built
mountain bike, all-terrain bike, off-roader: 61.70%
bicycle-built-for-two, tandem bicycle, tandem: 33.14%
unicycle, monocycle : 4.88%
crash helmet : 0.15%
moped : 0.04%
```
| 4 |
0 | hf_public_repos/candle/candle-examples/examples | hf_public_repos/candle/candle-examples/examples/phi/main.rs | #[cfg(feature = "mkl")]
extern crate intel_mkl_src;
#[cfg(feature = "accelerate")]
extern crate accelerate_src;
use anyhow::{Error as E, Result};
use clap::{Parser, ValueEnum};
use candle_examples::token_output_stream::TokenOutputStream;
use candle_transformers::models::mixformer::{Config, MixFormerSequentialForCausalLM as MixFormer};
use candle_transformers::models::phi::{Config as PhiConfig, Model as Phi};
use candle_transformers::models::phi3::{Config as Phi3Config, Model as Phi3};
use candle_transformers::models::quantized_mixformer::MixFormerSequentialForCausalLM as QMixFormer;
use candle::{DType, Device, IndexOp, Tensor};
use candle_nn::VarBuilder;
use candle_transformers::generation::LogitsProcessor;
use hf_hub::{api::sync::Api, Repo, RepoType};
use tokenizers::Tokenizer;
enum Model {
MixFormer(MixFormer),
Phi(Phi),
Phi3(Phi3),
Quantized(QMixFormer),
}
struct TextGeneration {
model: Model,
device: Device,
tokenizer: TokenOutputStream,
logits_processor: LogitsProcessor,
repeat_penalty: f32,
repeat_last_n: usize,
verbose_prompt: bool,
}
impl TextGeneration {
#[allow(clippy::too_many_arguments)]
fn new(
model: Model,
tokenizer: Tokenizer,
seed: u64,
temp: Option<f64>,
top_p: Option<f64>,
repeat_penalty: f32,
repeat_last_n: usize,
verbose_prompt: bool,
device: &Device,
) -> Self {
let logits_processor = LogitsProcessor::new(seed, temp, top_p);
Self {
model,
tokenizer: TokenOutputStream::new(tokenizer),
logits_processor,
repeat_penalty,
repeat_last_n,
verbose_prompt,
device: device.clone(),
}
}
fn run(&mut self, prompt: &str, sample_len: usize) -> Result<()> {
use std::io::Write;
println!("starting the inference loop");
let tokens = self
.tokenizer
.tokenizer()
.encode(prompt, true)
.map_err(E::msg)?;
if tokens.is_empty() {
anyhow::bail!("Empty prompts are not supported in the phi model.")
}
if self.verbose_prompt {
for (token, id) in tokens.get_tokens().iter().zip(tokens.get_ids().iter()) {
let token = token.replace('▁', " ").replace("<0x0A>", "\n");
println!("{id:7} -> '{token}'");
}
}
let mut tokens = tokens.get_ids().to_vec();
let mut generated_tokens = 0usize;
let eos_token = match self.tokenizer.get_token("<|endoftext|>") {
Some(token) => token,
None => anyhow::bail!("cannot find the endoftext token"),
};
print!("{prompt}");
std::io::stdout().flush()?;
let start_gen = std::time::Instant::now();
let mut pos = 0;
for index in 0..sample_len {
let context_size = if index > 0 { 1 } else { tokens.len() };
let ctxt = &tokens[tokens.len().saturating_sub(context_size)..];
let input = Tensor::new(ctxt, &self.device)?.unsqueeze(0)?;
let logits = match &mut self.model {
Model::MixFormer(m) => m.forward(&input)?,
Model::Phi(m) => m.forward(&input)?,
Model::Quantized(m) => m.forward(&input)?,
Model::Phi3(m) => m.forward(&input, pos)?.i((.., 0, ..))?,
};
let logits = logits.squeeze(0)?.to_dtype(DType::F32)?;
let logits = if self.repeat_penalty == 1. {
logits
} else {
let start_at = tokens.len().saturating_sub(self.repeat_last_n);
candle_transformers::utils::apply_repeat_penalty(
&logits,
self.repeat_penalty,
&tokens[start_at..],
)?
};
let next_token = self.logits_processor.sample(&logits)?;
tokens.push(next_token);
generated_tokens += 1;
if next_token == eos_token {
if let Some(t) = self.tokenizer.decode_rest()? {
print!("{t}");
std::io::stdout().flush()?;
}
break;
}
if let Some(t) = self.tokenizer.next_token(next_token)? {
print!("{t}");
std::io::stdout().flush()?;
}
pos += context_size;
}
let dt = start_gen.elapsed();
println!(
"\n{generated_tokens} tokens generated ({:.2} token/s)",
generated_tokens as f64 / dt.as_secs_f64(),
);
Ok(())
}
}
#[derive(Clone, Copy, Debug, ValueEnum, PartialEq, Eq)]
enum WhichModel {
#[value(name = "1")]
V1,
#[value(name = "1.5")]
V1_5,
#[value(name = "2")]
V2,
#[value(name = "3")]
V3,
#[value(name = "3-medium")]
V3Medium,
#[value(name = "2-old")]
V2Old,
PuffinPhiV2,
PhiHermes,
}
#[derive(Parser, Debug)]
#[command(author, version, about, long_about = None)]
struct Args {
/// Run on CPU rather than on GPU.
#[arg(long)]
cpu: bool,
/// Enable tracing (generates a trace-timestamp.json file).
#[arg(long)]
tracing: bool,
/// Display the token for the specified prompt.
#[arg(long)]
verbose_prompt: bool,
#[arg(long)]
prompt: Option<String>,
#[arg(long)]
mmlu_dir: Option<String>,
/// The temperature used to generate samples.
#[arg(long)]
temperature: Option<f64>,
/// Nucleus sampling probability cutoff.
#[arg(long)]
top_p: Option<f64>,
/// The seed to use when generating random samples.
#[arg(long, default_value_t = 299792458)]
seed: u64,
/// The length of the sample to generate (in tokens).
#[arg(long, short = 'n', default_value_t = 5000)]
sample_len: usize,
#[arg(long)]
model_id: Option<String>,
#[arg(long, default_value = "2")]
model: WhichModel,
#[arg(long)]
revision: Option<String>,
#[arg(long)]
weight_file: Option<String>,
#[arg(long)]
tokenizer: Option<String>,
#[arg(long)]
quantized: bool,
/// Penalty to be applied for repeating tokens, 1. means no penalty.
#[arg(long, default_value_t = 1.1)]
repeat_penalty: f32,
/// The context size to consider for the repeat penalty.
#[arg(long, default_value_t = 64)]
repeat_last_n: usize,
/// The dtype to be used for running the model, e.g. f32, bf16, or f16.
#[arg(long)]
dtype: Option<String>,
}
fn main() -> Result<()> {
use tracing_chrome::ChromeLayerBuilder;
use tracing_subscriber::prelude::*;
let args = Args::parse();
let _guard = if args.tracing {
let (chrome_layer, guard) = ChromeLayerBuilder::new().build();
tracing_subscriber::registry().with(chrome_layer).init();
Some(guard)
} else {
None
};
println!(
"avx: {}, neon: {}, simd128: {}, f16c: {}",
candle::utils::with_avx(),
candle::utils::with_neon(),
candle::utils::with_simd128(),
candle::utils::with_f16c()
);
println!(
"temp: {:.2} repeat-penalty: {:.2} repeat-last-n: {}",
args.temperature.unwrap_or(0.),
args.repeat_penalty,
args.repeat_last_n
);
let start = std::time::Instant::now();
let api = Api::new()?;
let model_id = match args.model_id {
Some(model_id) => model_id.to_string(),
None => {
if args.quantized {
"lmz/candle-quantized-phi".to_string()
} else {
match args.model {
WhichModel::V1 => "microsoft/phi-1".to_string(),
WhichModel::V1_5 => "microsoft/phi-1_5".to_string(),
WhichModel::V2 | WhichModel::V2Old => "microsoft/phi-2".to_string(),
WhichModel::V3 => "microsoft/Phi-3-mini-4k-instruct".to_string(),
WhichModel::V3Medium => "microsoft/Phi-3-medium-4k-instruct".to_string(),
WhichModel::PuffinPhiV2 | WhichModel::PhiHermes => {
"lmz/candle-quantized-phi".to_string()
}
}
}
}
};
let revision = match args.revision {
Some(rev) => rev.to_string(),
None => {
if args.quantized {
"main".to_string()
} else {
match args.model {
WhichModel::V1 => "refs/pr/8".to_string(),
WhichModel::V1_5 => "refs/pr/73".to_string(),
WhichModel::V2Old => "834565c23f9b28b96ccbeabe614dd906b6db551a".to_string(),
WhichModel::V2
| WhichModel::V3
| WhichModel::V3Medium
| WhichModel::PuffinPhiV2
| WhichModel::PhiHermes => "main".to_string(),
}
}
}
};
let repo = api.repo(Repo::with_revision(model_id, RepoType::Model, revision));
let tokenizer_filename = match args.tokenizer {
Some(file) => std::path::PathBuf::from(file),
None => match args.model {
WhichModel::V1
| WhichModel::V1_5
| WhichModel::V2
| WhichModel::V2Old
| WhichModel::V3
| WhichModel::V3Medium => repo.get("tokenizer.json")?,
WhichModel::PuffinPhiV2 | WhichModel::PhiHermes => {
repo.get("tokenizer-puffin-phi-v2.json")?
}
},
};
let filenames = match args.weight_file {
Some(weight_file) => vec![std::path::PathBuf::from(weight_file)],
None => {
if args.quantized {
match args.model {
WhichModel::V1 => vec![repo.get("model-v1-q4k.gguf")?],
WhichModel::V1_5 => vec![repo.get("model-q4k.gguf")?],
WhichModel::V2 | WhichModel::V2Old => vec![repo.get("model-v2-q4k.gguf")?],
WhichModel::PuffinPhiV2 => vec![repo.get("model-puffin-phi-v2-q4k.gguf")?],
WhichModel::PhiHermes => vec![repo.get("model-phi-hermes-1_3B-q4k.gguf")?],
WhichModel::V3 | WhichModel::V3Medium => anyhow::bail!(
"use the quantized or quantized-phi examples for quantized phi-v3"
),
}
} else {
match args.model {
WhichModel::V1 | WhichModel::V1_5 => vec![repo.get("model.safetensors")?],
WhichModel::V2 | WhichModel::V2Old | WhichModel::V3 | WhichModel::V3Medium => {
candle_examples::hub_load_safetensors(
&repo,
"model.safetensors.index.json",
)?
}
WhichModel::PuffinPhiV2 => vec![repo.get("model-puffin-phi-v2.safetensors")?],
WhichModel::PhiHermes => vec![repo.get("model-phi-hermes-1_3B.safetensors")?],
}
}
}
};
println!("retrieved the files in {:?}", start.elapsed());
let tokenizer = Tokenizer::from_file(tokenizer_filename).map_err(E::msg)?;
let start = std::time::Instant::now();
let config = || match args.model {
WhichModel::V1 => Config::v1(),
WhichModel::V1_5 => Config::v1_5(),
WhichModel::V2 | WhichModel::V2Old => Config::v2(),
WhichModel::PuffinPhiV2 => Config::puffin_phi_v2(),
WhichModel::PhiHermes => Config::phi_hermes_1_3b(),
WhichModel::V3 | WhichModel::V3Medium => {
panic!("use the quantized or quantized-phi examples for quantized phi-v3")
}
};
let device = candle_examples::device(args.cpu)?;
let model = if args.quantized {
let config = config();
let vb = candle_transformers::quantized_var_builder::VarBuilder::from_gguf(
&filenames[0],
&device,
)?;
let model = match args.model {
WhichModel::V2 | WhichModel::V2Old => QMixFormer::new_v2(&config, vb)?,
_ => QMixFormer::new(&config, vb)?,
};
Model::Quantized(model)
} else {
let dtype = match args.dtype {
Some(dtype) => std::str::FromStr::from_str(&dtype)?,
None => {
if args.model == WhichModel::V3 || args.model == WhichModel::V3Medium {
device.bf16_default_to_f32()
} else {
DType::F32
}
}
};
let vb = unsafe { VarBuilder::from_mmaped_safetensors(&filenames, dtype, &device)? };
match args.model {
WhichModel::V1 | WhichModel::V1_5 | WhichModel::V2 => {
let config_filename = repo.get("config.json")?;
let config = std::fs::read_to_string(config_filename)?;
let config: PhiConfig = serde_json::from_str(&config)?;
let phi = Phi::new(&config, vb)?;
Model::Phi(phi)
}
WhichModel::V3 | WhichModel::V3Medium => {
let config_filename = repo.get("config.json")?;
let config = std::fs::read_to_string(config_filename)?;
let config: Phi3Config = serde_json::from_str(&config)?;
let phi3 = Phi3::new(&config, vb)?;
Model::Phi3(phi3)
}
WhichModel::V2Old => {
let config = config();
Model::MixFormer(MixFormer::new_v2(&config, vb)?)
}
WhichModel::PhiHermes | WhichModel::PuffinPhiV2 => {
let config = config();
Model::MixFormer(MixFormer::new(&config, vb)?)
}
}
};
println!("loaded the model in {:?}", start.elapsed());
match (args.prompt, args.mmlu_dir) {
(None, None) | (Some(_), Some(_)) => {
anyhow::bail!("exactly one of --prompt and --mmlu-dir must be specified")
}
(Some(prompt), None) => {
let mut pipeline = TextGeneration::new(
model,
tokenizer,
args.seed,
args.temperature,
args.top_p,
args.repeat_penalty,
args.repeat_last_n,
args.verbose_prompt,
&device,
);
pipeline.run(&prompt, args.sample_len)?;
}
(None, Some(mmlu_dir)) => mmlu(model, tokenizer, &device, mmlu_dir)?,
}
Ok(())
}
fn mmlu<P: AsRef<std::path::Path>>(
mut model: Model,
tokenizer: Tokenizer,
device: &Device,
mmlu_dir: P,
) -> anyhow::Result<()> {
for dir_entry in mmlu_dir.as_ref().read_dir()?.flatten() {
let dir_entry = dir_entry.path();
let theme = match dir_entry.file_stem().and_then(|v| v.to_str()) {
None => "".to_string(),
Some(v) => match v.strip_suffix("_test") {
None => v.replace('_', " "),
Some(v) => v.replace('_', " "),
},
};
if dir_entry.extension().as_ref().and_then(|v| v.to_str()) != Some("csv") {
continue;
}
println!("reading {dir_entry:?}");
let dir_entry = std::fs::File::open(dir_entry)?;
let mut reader = csv::ReaderBuilder::new()
.has_headers(false)
.from_reader(dir_entry);
let token_a = tokenizer.token_to_id("A").unwrap();
let token_b = tokenizer.token_to_id("B").unwrap();
let token_c = tokenizer.token_to_id("C").unwrap();
let token_d = tokenizer.token_to_id("D").unwrap();
for row in reader.records() {
let row = match row {
Err(_) => continue,
Ok(row) => row,
};
if row.len() < 5 {
continue;
}
let question = row.get(0).unwrap();
let answer_a = row.get(1).unwrap();
let answer_b = row.get(2).unwrap();
let answer_c = row.get(3).unwrap();
let answer_d = row.get(4).unwrap();
let answer = row.get(5).unwrap();
let prompt = format!(
"{} {theme}.\n{question}\nA. {answer_a}\nB. {answer_b}\nC. {answer_c}\nD. {answer_d}\nAnswer:\n",
"The following are multiple choice questions (with answers) about"
);
let tokens = tokenizer.encode(prompt.as_str(), true).map_err(E::msg)?;
let tokens = tokens.get_ids().to_vec();
let input = Tensor::new(tokens, device)?.unsqueeze(0)?;
let logits = match &mut model {
Model::MixFormer(m) => {
m.clear_kv_cache();
m.forward(&input)?
}
Model::Phi(m) => {
m.clear_kv_cache();
m.forward(&input)?
}
Model::Phi3(m) => {
m.clear_kv_cache();
m.forward(&input, 0)?
}
Model::Quantized(m) => {
m.clear_kv_cache();
m.forward(&input)?
}
};
let logits = logits.squeeze(0)?.to_dtype(DType::F32)?;
let logits_v: Vec<f32> = logits.to_vec1()?;
let pr_a = logits_v[token_a as usize];
let pr_b = logits_v[token_b as usize];
let pr_c = logits_v[token_c as usize];
let pr_d = logits_v[token_d as usize];
let model_answer = if pr_a > pr_b && pr_a > pr_c && pr_a > pr_d {
"A"
} else if pr_b > pr_c && pr_b > pr_d {
"B"
} else if pr_c > pr_d {
"C"
} else {
"D"
};
println!("{prompt}\n -> {model_answer} vs {answer}");
}
}
Ok(())
}
| 5 |
0 | hf_public_repos/candle/candle-examples/examples | hf_public_repos/candle/candle-examples/examples/phi/README.md | # candle-phi: 1.3b and 2.7b LLM with state of the art performance for <10b models.
[Phi-1.5](https://huggingface.co/microsoft/phi-1_5),
[Phi-2](https://huggingface.co/microsoft/phi-2), and
[Phi-3](https://huggingface.co/microsoft/Phi-3-mini-4k-instruct) are language models using
only 1.3, 2.7, and 3.8 billion parameters but with state of the art performance compared to
models with up to 10 billion parameters.
The candle implementation provides both the standard version as well as a
quantized variant.
## Running some examples
For the v2 version.
```bash
$ cargo run --example phi --release -- --model 2 \
--prompt "A skier slides down a frictionless slope of height 40m and length 80m. What's the skier speed at the bottom?"
A skier slides down a frictionless slope of height 40m and length 80m. What's the skier speed at the bottom?
Solution:
The potential energy of the skier is converted into kinetic energy as it slides down the slope. The formula for potential energy is mgh, where m is mass, g is acceleration due to gravity (9.8 m/s^2), and h is height. Since there's no friction, all the potential energy is converted into kinetic energy at the bottom of the slope. The formula for kinetic energy is 1/2mv^2, where v is velocity. We can equate these two formulas:
mgh = 1/2mv^2
Solving for v, we get:
v = sqrt(2gh)
Substituting the given values, we get:
v = sqrt(2*9.8*40) = 28 m/s
Therefore, the skier speed at the bottom of the slope is 28 m/s.
```
For the v1.5 version.
```bash
$ cargo run --example phi --release -- --prompt "def print_prime(n): "
def print_prime(n):
print("Printing prime numbers")
for i in range(2, n+1):
if is_prime(i):
print(i)
def is_prime(n):
if n <= 1:
return False
for i in range(2, int(math.sqrt(n))+1):
if n % i == 0:
return False
return True
$ cargo run --example phi --release -- \
--prompt "Explain how to find the median of an array and write the corresponding python function.\nAnswer:" \
--quantized --sample-len 200
Explain how to find the median of an array and write the corresponding python function.
Answer: The median is the middle value in an array. If the array has an even number of elements, the median is the average of the two middle values.
def median(arr):
arr.sort()
n = len(arr)
if n % 2 == 0:
return (arr[n//2 - 1] + arr[n//2]) / 2
else:
return arr[n//2]
```
This also supports the [Puffin Phi v2
model](https://huggingface.co/teknium/Puffin-Phi-v2) for human interaction.
```
$ cargo run --example phi --release -- \
--prompt "USER: What would you do on a sunny day in Paris?\nASSISTANT:" \
--sample-len 200 --model puffin-phi-v2 --quantized
USER: What would you do on a sunny day in Paris?
ASSISTANT: On a sunny day in Paris, you could visit the Musée du Louvre to admire the famous
painting "Mona Lisa" by Leonardo da Vinci. You might also want to stroll along the Champs-Élysées
and enjoy the beautiful architecture of the buildings around you. Don't forget to stop by a café
for a cup of coffee and to soak up the sun!"
```
| 6 |
0 | hf_public_repos/candle/candle-examples/examples | hf_public_repos/candle/candle-examples/examples/mobileone/main.rs | #[cfg(feature = "mkl")]
extern crate intel_mkl_src;
#[cfg(feature = "accelerate")]
extern crate accelerate_src;
use clap::{Parser, ValueEnum};
use candle::{DType, IndexOp, D};
use candle_nn::{Module, VarBuilder};
use candle_transformers::models::mobileone;
#[derive(Clone, Copy, Debug, ValueEnum)]
enum Which {
S0,
S1,
S2,
S3,
S4,
}
impl Which {
fn model_filename(&self) -> String {
let name = match self {
Self::S0 => "s0",
Self::S1 => "s1",
Self::S2 => "s2",
Self::S3 => "s3",
Self::S4 => "s4",
};
format!("timm/mobileone_{}.apple_in1k", name)
}
fn config(&self) -> mobileone::Config {
match self {
Self::S0 => mobileone::Config::s0(),
Self::S1 => mobileone::Config::s1(),
Self::S2 => mobileone::Config::s2(),
Self::S3 => mobileone::Config::s3(),
Self::S4 => mobileone::Config::s4(),
}
}
}
#[derive(Parser)]
struct Args {
#[arg(long)]
model: Option<String>,
#[arg(long)]
image: String,
/// Run on CPU rather than on GPU.
#[arg(long)]
cpu: bool,
#[arg(value_enum, long, default_value_t=Which::S0)]
which: Which,
}
pub fn main() -> anyhow::Result<()> {
let args = Args::parse();
let device = candle_examples::device(args.cpu)?;
let image = candle_examples::imagenet::load_image224(args.image)?.to_device(&device)?;
println!("loaded image {image:?}");
let model_file = match args.model {
None => {
let model_name = args.which.model_filename();
let api = hf_hub::api::sync::Api::new()?;
let api = api.model(model_name);
api.get("model.safetensors")?
}
Some(model) => model.into(),
};
let vb = unsafe { VarBuilder::from_mmaped_safetensors(&[model_file], DType::F32, &device)? };
let model = mobileone::mobileone(&args.which.config(), 1000, vb)?;
println!("model built");
let logits = model.forward(&image.unsqueeze(0)?)?;
let prs = candle_nn::ops::softmax(&logits, D::Minus1)?
.i(0)?
.to_vec1::<f32>()?;
let mut prs = prs.iter().enumerate().collect::<Vec<_>>();
prs.sort_by(|(_, p1), (_, p2)| p2.total_cmp(p1));
for &(category_idx, pr) in prs.iter().take(5) {
println!(
"{:24}: {:.2}%",
candle_examples::imagenet::CLASSES[category_idx],
100. * pr
);
}
Ok(())
}
| 7 |
0 | hf_public_repos/candle/candle-examples/examples | hf_public_repos/candle/candle-examples/examples/mobileone/README.md | # candle-mobileone
[MobileOne: An Improved One millisecond Mobile Backbone](https://arxiv.org/abs/2206.04040).
This candle implementation uses a pre-trained MobileOne network for inference. The
classification head has been trained on the ImageNet dataset and returns the
probabilities for the top-5 classes.
## Running an example
```
$ cargo run --example mobileone --release -- --image candle-examples/examples/yolo-v8/assets/bike.jpg --which s2
loaded image Tensor[dims 3, 224, 224; f32]
model built
mountain bike, all-terrain bike, off-roader: 79.33%
bicycle-built-for-two, tandem bicycle, tandem: 15.32%
crash helmet : 2.58%
unicycle, monocycle : 1.70%
alp : 0.21%
```
| 8 |
0 | hf_public_repos/candle/candle-examples/examples | hf_public_repos/candle/candle-examples/examples/efficientnet/main.rs | //! EfficientNet implementation.
//!
//! https://arxiv.org/abs/1905.11946
#[cfg(feature = "mkl")]
extern crate intel_mkl_src;
#[cfg(feature = "accelerate")]
extern crate accelerate_src;
use candle::{DType, IndexOp, D};
use candle_nn::{Module, VarBuilder};
use candle_transformers::models::efficientnet::{EfficientNet, MBConvConfig};
use clap::{Parser, ValueEnum};
#[derive(Clone, Copy, Debug, ValueEnum)]
enum Which {
B0,
B1,
B2,
B3,
B4,
B5,
B6,
B7,
}
#[derive(Parser)]
struct Args {
#[arg(long)]
model: Option<String>,
#[arg(long)]
image: String,
/// Run on CPU rather than on GPU.
#[arg(long)]
cpu: bool,
/// Variant of the model to use.
#[arg(value_enum, long, default_value_t = Which::B2)]
which: Which,
}
pub fn main() -> anyhow::Result<()> {
let args = Args::parse();
let device = candle_examples::device(args.cpu)?;
let image = candle_examples::imagenet::load_image224(args.image)?.to_device(&device)?;
println!("loaded image {image:?}");
let model_file = match args.model {
None => {
let api = hf_hub::api::sync::Api::new()?;
let api = api.model("lmz/candle-efficientnet".into());
let filename = match args.which {
Which::B0 => "efficientnet-b0.safetensors",
Which::B1 => "efficientnet-b1.safetensors",
Which::B2 => "efficientnet-b2.safetensors",
Which::B3 => "efficientnet-b3.safetensors",
Which::B4 => "efficientnet-b4.safetensors",
Which::B5 => "efficientnet-b5.safetensors",
Which::B6 => "efficientnet-b6.safetensors",
Which::B7 => "efficientnet-b7.safetensors",
};
api.get(filename)?
}
Some(model) => model.into(),
};
let vb = unsafe { VarBuilder::from_mmaped_safetensors(&[model_file], DType::F32, &device)? };
let cfg = match args.which {
Which::B0 => MBConvConfig::b0(),
Which::B1 => MBConvConfig::b1(),
Which::B2 => MBConvConfig::b2(),
Which::B3 => MBConvConfig::b3(),
Which::B4 => MBConvConfig::b4(),
Which::B5 => MBConvConfig::b5(),
Which::B6 => MBConvConfig::b6(),
Which::B7 => MBConvConfig::b7(),
};
let model = EfficientNet::new(vb, cfg, candle_examples::imagenet::CLASS_COUNT as usize)?;
println!("model built");
let logits = model.forward(&image.unsqueeze(0)?)?;
let prs = candle_nn::ops::softmax(&logits, D::Minus1)?
.i(0)?
.to_vec1::<f32>()?;
let mut prs = prs.iter().enumerate().collect::<Vec<_>>();
prs.sort_by(|(_, p1), (_, p2)| p2.total_cmp(p1));
for &(category_idx, pr) in prs.iter().take(5) {
println!(
"{:24}: {:.2}%",
candle_examples::imagenet::CLASSES[category_idx],
100. * pr
);
}
Ok(())
}
| 9 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.