
index
int64 0
0
| repo_id
stringclasses 179
values | file_path
stringlengths 26
186
| content
stringlengths 1
2.1M
| __index_level_0__
int64 0
9
|
|---|---|---|---|---|
0 | hf_public_repos/autotrain-advanced/configs | hf_public_repos/autotrain-advanced/configs/llm_finetuning/smollm2.yml | task: llm-sft
base_model: HuggingFaceTB/SmolLM2-1.7B-Instruct
project_name: autotrain-smollm2-finetune
log: tensorboard
backend: local
data:
path: HuggingFaceH4/no_robots
train_split: train
valid_split: null
chat_template: tokenizer
column_mapping:
text_column: messages
params:
block_size: 2048
model_max_length: 4096
epochs: 2
batch_size: 1
lr: 1e-5
peft: true
quantization: int4
target_modules: all-linear
padding: right
optimizer: paged_adamw_8bit
scheduler: linear
gradient_accumulation: 8
mixed_precision: bf16
merge_adapter: true
hub:
username: ${HF_USERNAME}
token: ${HF_TOKEN}
push_to_hub: true
| 0 |
0 | hf_public_repos/autotrain-advanced/configs | hf_public_repos/autotrain-advanced/configs/llm_finetuning/llama3-70b-sft.yml | task: llm-sft
base_model: meta-llama/Meta-Llama-3-70B-Instruct
project_name: autotrain-llama3-70b-math-v1
log: tensorboard
backend: local
data:
path: rishiraj/guanaco-style-metamath-40k
train_split: train
valid_split: null
chat_template: null
column_mapping:
text_column: text
params:
block_size: 2048
model_max_length: 8192
epochs: 2
batch_size: 1
lr: 1e-5
peft: true
quantization: null
target_modules: all-linear
padding: right
optimizer: paged_adamw_8bit
scheduler: linear
gradient_accumulation: 8
mixed_precision: bf16
hub:
username: ${HF_USERNAME}
token: ${HF_TOKEN}
push_to_hub: true | 1 |
0 | hf_public_repos/autotrain-advanced/configs | hf_public_repos/autotrain-advanced/configs/llm_finetuning/smollm2_orpo.yml | task: llm-orpo
base_model: HuggingFaceTB/SmolLM2-1.7B-Instruct
project_name: autotrain-smallm2-orpo
log: tensorboard
backend: local
data:
path: argilla/distilabel-capybara-dpo-7k-binarized
train_split: train
valid_split: null
chat_template: chatml
column_mapping:
text_column: chosen
rejected_text_column: rejected
prompt_text_column: prompt
params:
block_size: 1024
model_max_length: 2048
max_prompt_length: 512
epochs: 3
batch_size: 2
lr: 3e-5
peft: true
quantization: int4
target_modules: all-linear
padding: right
optimizer: adamw_torch
scheduler: linear
gradient_accumulation: 4
mixed_precision: fp16
hub:
username: ${HF_USERNAME}
token: ${HF_TOKEN}
push_to_hub: false | 2 |
0 | hf_public_repos/autotrain-advanced/configs | hf_public_repos/autotrain-advanced/configs/llm_finetuning/smollm2_guanaco.yml | task: llm-sft
base_model: HuggingFaceTB/SmolLM2-135M-Instruct
project_name: autotrain-smollm2-135m-finetune-guanaco
log: tensorboard
backend: local
data:
path: timdettmers/openassistant-guanaco
train_split: train
valid_split: null
chat_template: null
column_mapping:
text_column: text
params:
block_size: 1024
model_max_length: 2048
epochs: 1
batch_size: 1
lr: 1e-5
peft: true
quantization: int4
target_modules: all-linear
padding: right
optimizer: paged_adamw_8bit
scheduler: linear
gradient_accumulation: 8
mixed_precision: bf16
merge_adapter: true
hub:
username: ${HF_USERNAME}
token: ${HF_TOKEN}
push_to_hub: true | 3 |
0 | hf_public_repos/autotrain-advanced/configs | hf_public_repos/autotrain-advanced/configs/llm_finetuning/llama32-1b-sft.yml | task: llm-sft
base_model: meta-llama/Llama-3.2-1B
project_name: autotrain-llama32-1b-finetune
log: tensorboard
backend: local
data:
path: HuggingFaceH4/no_robots
train_split: train
valid_split: null
chat_template: tokenizer
column_mapping:
text_column: messages
params:
block_size: 2048
model_max_length: 4096
epochs: 2
batch_size: 1
lr: 1e-5
peft: true
quantization: int4
target_modules: all-linear
padding: right
optimizer: paged_adamw_8bit
scheduler: linear
gradient_accumulation: 8
mixed_precision: bf16
merge_adapter: true
hub:
username: ${HF_USERNAME}
token: ${HF_TOKEN}
push_to_hub: true
| 4 |
0 | hf_public_repos/autotrain-advanced/configs | hf_public_repos/autotrain-advanced/configs/llm_finetuning/qwen.yml | task: llm-sft
base_model: Qwen/Qwen2.5-Coder-7B-Instruct
project_name: autotrain-qwen-finetune
log: tensorboard
backend: local
data:
path: HuggingFaceH4/no_robots
train_split: test
valid_split: null
chat_template: tokenizer
column_mapping:
text_column: messages
params:
block_size: 2048
model_max_length: 4096
epochs: 1
batch_size: 1
lr: 1e-5
peft: true
quantization: int4
target_modules: all-linear
padding: right
optimizer: adamw_torch
scheduler: linear
gradient_accumulation: 1
mixed_precision: fp16
merge_adapter: true
hub:
username: ${HF_USERNAME}
token: ${HF_TOKEN}
push_to_hub: true
| 5 |
0 | hf_public_repos/autotrain-advanced/configs | hf_public_repos/autotrain-advanced/configs/sentence_transformers/local_dataset.yml | task: sentence-transformers:pair_score
base_model: microsoft/mpnet-base
project_name: autotrain-st-pair-score-local-dataset
log: tensorboard
backend: local
data:
path: /path/to/your/dataset # this must be the path to the directory containing the train and valid files
train_split: train # this is the name of the train file (csv or jsonl)
valid_split: null # this is the name of the valid file (csv or jsonl), optional
column_mapping:
sentence1_column: input_sentence
sentence2_column: target_sentence
target_column: score
params:
max_seq_length: 512
epochs: 5
batch_size: 8
lr: 2e-5
optimizer: adamw_torch
scheduler: linear
gradient_accumulation: 1
mixed_precision: fp16
hub:
username: ${HF_USERNAME}
token: ${HF_TOKEN}
push_to_hub: true | 6 |
0 | hf_public_repos/autotrain-advanced/configs | hf_public_repos/autotrain-advanced/configs/sentence_transformers/pair_score.yml | task: sentence-transformers:pair_score
base_model: microsoft/mpnet-base
project_name: autotrain-st-pair-score
log: tensorboard
backend: local
data:
path: sentence-transformers/all-nli
train_split: pair-score:train
valid_split: pair-score:dev
column_mapping:
sentence1_column: sentence1
sentence2_column: sentence2
target_column: score
params:
max_seq_length: 512
epochs: 5
batch_size: 8
lr: 2e-5
optimizer: adamw_torch
scheduler: linear
gradient_accumulation: 1
mixed_precision: fp16
hub:
username: ${HF_USERNAME}
token: ${HF_TOKEN}
push_to_hub: true | 7 |
0 | hf_public_repos/autotrain-advanced/configs | hf_public_repos/autotrain-advanced/configs/sentence_transformers/qa.yml | task: sentence-transformers:qa
base_model: microsoft/mpnet-base
project_name: autotrain-st-qa
log: tensorboard
backend: local
data:
path: sentence-transformers/natural-questions
train_split: train
valid_split: null
column_mapping:
sentence1_column: query
sentence2_column: answer
params:
max_seq_length: 512
epochs: 5
batch_size: 8
lr: 2e-5
optimizer: adamw_torch
scheduler: linear
gradient_accumulation: 1
mixed_precision: fp16
hub:
username: ${HF_USERNAME}
token: ${HF_TOKEN}
push_to_hub: true | 8 |
0 | hf_public_repos/autotrain-advanced/configs | hf_public_repos/autotrain-advanced/configs/sentence_transformers/pair.yml | task: sentence-transformers:pair
base_model: microsoft/mpnet-base
project_name: autotrain-st-pair
log: tensorboard
backend: local
data:
path: sentence-transformers/all-nli
train_split: pair:train
valid_split: pair:dev
column_mapping:
sentence1_column: anchor
sentence2_column: positive
params:
max_seq_length: 512
epochs: 5
batch_size: 8
lr: 2e-5
optimizer: adamw_torch
scheduler: linear
gradient_accumulation: 1
mixed_precision: fp16
hub:
username: ${HF_USERNAME}
token: ${HF_TOKEN}
push_to_hub: true | 9 |
0 | hf_public_repos/api-inference-community/docker_images/timm | hf_public_repos/api-inference-community/docker_images/timm/app/main.py | import functools
import logging
import os
from typing import Dict, Type
from api_inference_community.routes import pipeline_route, status_ok
from app.pipelines import ImageClassificationPipeline, Pipeline
from starlette.applications import Starlette
from starlette.middleware import Middleware
from starlette.middleware.gzip import GZipMiddleware
from starlette.routing import Route
TASK = os.getenv("TASK")
MODEL_ID = os.getenv("MODEL_ID")
logger = logging.getLogger(__name__)
# Add the allowed tasks
# Supported tasks are:
# - text-generation
# - text-classification
# - token-classification
# - translation
# - summarization
# - automatic-speech-recognition
# - ...
# For instance
# from app.pipelines import AutomaticSpeecRecognitionPipeline
# ALLOWED_TASKS = {"automatic-speech-recognition": AutomaticSpeecRecognitionPipeline}
# You can check the requirements and expectations of each pipelines in their respective
# directories. Implement directly within the directories.
ALLOWED_TASKS: Dict[str, Type[Pipeline]] = {
"image-classification": ImageClassificationPipeline
}
@functools.lru_cache()
def get_pipeline() -> Pipeline:
task = os.environ["TASK"]
model_id = os.environ["MODEL_ID"]
if task not in ALLOWED_TASKS:
raise EnvironmentError(f"{task} is not a valid pipeline for model : {model_id}")
return ALLOWED_TASKS[task](model_id)
routes = [
Route("/{whatever:path}", status_ok),
Route("/{whatever:path}", pipeline_route, methods=["POST"]),
]
middleware = [Middleware(GZipMiddleware, minimum_size=1000)]
if os.environ.get("DEBUG", "") == "1":
from starlette.middleware.cors import CORSMiddleware
middleware.append(
Middleware(
CORSMiddleware,
allow_origins=["*"],
allow_headers=["*"],
allow_methods=["*"],
)
)
app = Starlette(routes=routes, middleware=middleware)
@app.on_event("startup")
async def startup_event():
logger = logging.getLogger("uvicorn.access")
handler = logging.StreamHandler()
handler.setFormatter(logging.Formatter("%(asctime)s - %(levelname)s - %(message)s"))
logger.handlers = [handler]
# Link between `api-inference-community` and framework code.
app.get_pipeline = get_pipeline
try:
get_pipeline()
except Exception:
# We can fail so we can show exception later.
pass
if __name__ == "__main__":
try:
get_pipeline()
except Exception:
# We can fail so we can show exception later.
pass
| 0 |
0 | hf_public_repos/api-inference-community/docker_images/timm/app | hf_public_repos/api-inference-community/docker_images/timm/app/pipelines/base.py | from abc import ABC, abstractmethod
from typing import Any, Optional
class Pipeline(ABC):
task: Optional[str] = None
model_id: Optional[str] = None
@abstractmethod
def __init__(self, model_id: str):
raise NotImplementedError("Pipelines should implement an __init__ method")
@abstractmethod
def __call__(self, inputs: Any) -> Any:
raise NotImplementedError("Pipelines should implement a __call__ method")
class PipelineException(Exception):
pass
| 1 |
0 | hf_public_repos/api-inference-community/docker_images/timm/app | hf_public_repos/api-inference-community/docker_images/timm/app/pipelines/__init__.py | from app.pipelines.base import Pipeline, PipelineException # isort:skip
from app.pipelines.image_classification import ImageClassificationPipeline
| 2 |
0 | hf_public_repos/api-inference-community/docker_images/timm/app | hf_public_repos/api-inference-community/docker_images/timm/app/pipelines/image_classification.py | from typing import Any, Dict, List
import timm
import torch
from app.pipelines import Pipeline
from PIL import Image
from timm.data import (
CustomDatasetInfo,
ImageNetInfo,
create_transform,
infer_imagenet_subset,
resolve_model_data_config,
)
class ImageClassificationPipeline(Pipeline):
def __init__(self, model_id: str):
self.model = timm.create_model(f"hf_hub:{model_id}", pretrained=True)
self.transform = create_transform(
**resolve_model_data_config(self.model, use_test_size=True)
)
self.top_k = min(self.model.num_classes, 5)
self.model.eval()
self.dataset_info = None
label_names = self.model.pretrained_cfg.get("label_names", None)
label_descriptions = self.model.pretrained_cfg.get("label_descriptions", None)
if label_names is None:
# if no labels added to config, use imagenet labeller in timm
imagenet_subset = infer_imagenet_subset(self.model)
if imagenet_subset:
self.dataset_info = ImageNetInfo(imagenet_subset)
else:
# fallback label names
label_names = [f"LABEL_{i}" for i in range(self.model.num_classes)]
if self.dataset_info is None:
self.dataset_info = CustomDatasetInfo(
label_names=label_names,
label_descriptions=label_descriptions,
)
def __call__(self, inputs: Image.Image) -> List[Dict[str, Any]]:
"""
Args:
inputs (:obj:`PIL.Image`):
The raw image representation as PIL.
No transformation made whatsoever from the input. Make all necessary transformations here.
Return:
A :obj:`list`:. The list contains items that are dicts should be liked {"label": "XXX", "score": 0.82}
It is preferred if the returned list is in decreasing `score` order
"""
im = inputs.convert("RGB")
inputs = self.transform(im).unsqueeze(0)
with torch.no_grad():
out = self.model(inputs)
probabilities = out.squeeze(0).softmax(dim=0)
values, indices = torch.topk(probabilities, self.top_k)
labels = [
{
"label": self.dataset_info.index_to_description(i, detailed=True),
"score": v.item(),
}
for i, v in zip(indices, values)
]
return labels
| 3 |
0 | hf_public_repos/api-inference-community/docker_images/timm | hf_public_repos/api-inference-community/docker_images/timm/tests/test_docker_build.py | import os
import subprocess
from unittest import TestCase
class cd:
"""Context manager for changing the current working directory"""
def __init__(self, newPath):
self.newPath = os.path.expanduser(newPath)
def __enter__(self):
self.savedPath = os.getcwd()
os.chdir(self.newPath)
def __exit__(self, etype, value, traceback):
os.chdir(self.savedPath)
class DockerBuildTestCase(TestCase):
def test_can_build_docker_image(self):
with cd(os.path.dirname(os.path.dirname(__file__))):
subprocess.check_output(["docker", "build", "."])
| 4 |
0 | hf_public_repos/api-inference-community/docker_images/timm | hf_public_repos/api-inference-community/docker_images/timm/tests/test_api.py | import os
from typing import Dict, List
from unittest import TestCase, skipIf
from app.main import ALLOWED_TASKS, get_pipeline
# Must contain at least one example of each implemented pipeline
# Tests do not check the actual values of the model output, so small dummy
# models are recommended for faster tests.
TESTABLE_MODELS: Dict[str, List[str]] = {
"image-classification": [
"timm/vit_base_patch32_clip_224.laion2b_ft_in1k",
"timm/convnext_nano.in12k",
"nateraw/timm-resnet50-beans",
]
}
ALL_TASKS = {
"automatic-speech-recognition",
"audio-source-separation",
"image-classification",
"question-answering",
"text-generation",
"text-to-speech",
}
class PipelineTestCase(TestCase):
@skipIf(
os.path.dirname(os.path.dirname(__file__)).endswith("common"),
"common is a special case",
)
def test_has_at_least_one_task_enabled(self):
self.assertGreater(
len(ALLOWED_TASKS.keys()), 0, "You need to implement at least one task"
)
def test_unsupported_tasks(self):
unsupported_tasks = ALL_TASKS - ALLOWED_TASKS.keys()
for unsupported_task in unsupported_tasks:
with self.subTest(msg=unsupported_task, task=unsupported_task):
os.environ["TASK"] = unsupported_task
os.environ["MODEL_ID"] = "XX"
with self.assertRaises(EnvironmentError):
get_pipeline()
| 5 |
0 | hf_public_repos/api-inference-community/docker_images/timm | hf_public_repos/api-inference-community/docker_images/timm/tests/test_api_image_classification.py | import json
import os
from unittest import TestCase, skipIf
from app.main import ALLOWED_TASKS
from parameterized import parameterized_class
from starlette.testclient import TestClient
from tests.test_api import TESTABLE_MODELS
@skipIf(
"image-classification" not in ALLOWED_TASKS,
"image-classification not implemented",
)
@parameterized_class(
[{"model_id": model_id} for model_id in TESTABLE_MODELS["image-classification"]]
)
class ImageClassificationTestCase(TestCase):
def setUp(self):
self.old_model_id = os.getenv("MODEL_ID")
self.old_task = os.getenv("TASK")
os.environ["MODEL_ID"] = self.model_id
os.environ["TASK"] = "image-classification"
from app.main import app, get_pipeline
get_pipeline.cache_clear()
self.app = app
@classmethod
def setUpClass(cls):
from app.main import get_pipeline
get_pipeline.cache_clear()
def tearDown(self):
if self.old_model_id is not None:
os.environ["MODEL_ID"] = self.old_model_id
else:
del os.environ["MODEL_ID"]
if self.old_task is not None:
os.environ["TASK"] = self.old_task
else:
del os.environ["TASK"]
def read(self, filename: str) -> bytes:
dirname = os.path.dirname(os.path.abspath(__file__))
filename = os.path.join(dirname, "samples", filename)
with open(filename, "rb") as f:
bpayload = f.read()
return bpayload
def test_simple(self):
bpayload = self.read("plane.jpg")
with TestClient(self.app) as client:
response = client.post("/", data=bpayload)
self.assertEqual(
response.status_code,
200,
)
content = json.loads(response.content)
self.assertEqual(type(content), list)
self.assertEqual(set(type(el) for el in content), {dict})
self.assertEqual(
set((k, type(v)) for el in content for (k, v) in el.items()),
{("label", str), ("score", float)},
)
def test_different_resolution(self):
bpayload = self.read("plane2.jpg")
with TestClient(self.app) as client:
response = client.post("/", data=bpayload)
self.assertEqual(
response.status_code,
200,
)
content = json.loads(response.content)
self.assertEqual(type(content), list)
self.assertEqual(set(type(el) for el in content), {dict})
self.assertEqual(
set(k for el in content for k in el.keys()), {"label", "score"}
)
| 6 |
0 | hf_public_repos/api-inference-community/docker_images | hf_public_repos/api-inference-community/docker_images/spacy/requirements.txt | starlette==0.27.0
api-inference-community==0.0.23
huggingface_hub==0.5.1
requests==2.31.0
| 7 |
0 | hf_public_repos/api-inference-community/docker_images | hf_public_repos/api-inference-community/docker_images/spacy/Dockerfile | FROM tiangolo/uvicorn-gunicorn:python3.8
LABEL maintainer="Omar Sanseviero [email protected]"
# Add any system dependency here
# RUN apt-get update -y && apt-get install libXXX -y
COPY ./requirements.txt /app
RUN pip install --no-cache-dir -r requirements.txt
COPY ./prestart.sh /app/
# Most DL models are quite large in terms of memory, using workers is a HUGE
# slowdown because of the fork and GIL with python.
# Using multiple pods seems like a better default strategy.
# Feel free to override if it does not make sense for your library.
ARG max_workers=1
ENV MAX_WORKERS=$max_workers
ENV HUGGINGFACE_HUB_CACHE=/data
ENV PIP_CACHE=/data
# Necessary on GPU environment docker.
# TIMEOUT env variable is used by nvcr.io/nvidia/pytorch:xx for another purpose
# rendering TIMEOUT defined by uvicorn impossible to use correctly
# We're overriding it to be renamed UVICORN_TIMEOUT
# UVICORN_TIMEOUT is a useful variable for very large models that take more
# than 30s (the default) to load in memory.
# If UVICORN_TIMEOUT is too low, uvicorn will simply never loads as it will
# kill workers all the time before they finish.
RUN sed -i 's/TIMEOUT/UVICORN_TIMEOUT/g' /gunicorn_conf.py
COPY ./app /app/app
| 8 |
0 | hf_public_repos/api-inference-community/docker_images | hf_public_repos/api-inference-community/docker_images/spacy/prestart.sh | python app/main.py
| 9 |
0 | hf_public_repos/candle/candle-kernels | hf_public_repos/candle/candle-kernels/src/fill.cu | #include<stdint.h>
#include "cuda_fp16.h"
template<typename T>
__device__ void fill_with(T *buf, T value, const size_t numel) {
for (unsigned int i = blockIdx.x * blockDim.x + threadIdx.x; i < numel; i += blockDim.x * gridDim.x) {
buf[i] = value;
}
}
extern "C" __global__ void fill_u8(uint8_t *buf, uint8_t value, const size_t numel) { fill_with(buf, value, numel); }
extern "C" __global__ void fill_u32(uint32_t *buf, uint32_t value, const size_t numel) { fill_with(buf, value, numel); }
extern "C" __global__ void fill_i64(int64_t *buf, int64_t value, const size_t numel) { fill_with(buf, value, numel); }
extern "C" __global__ void fill_f32(float *buf, float value, const size_t numel) { fill_with(buf, value, numel); }
extern "C" __global__ void fill_f64(double *buf, double value, const size_t numel) { fill_with(buf, value, numel); }
template<typename T>
__device__ void copy2d(const T *src, T *dst, uint32_t d1, uint32_t d2, uint32_t src_s, uint32_t dst_s) {
uint32_t idx = blockIdx.x * blockDim.x + threadIdx.x;
if (idx >= d1 * d2) {
return;
}
uint32_t idx1 = idx / d2;
uint32_t idx2 = idx - d2 * idx1;
dst[idx1 * dst_s + idx2] = src[idx1 * src_s + idx2];
}
#define COPY2D_OP(TYPENAME, FNNAME) \
extern "C" __global__ \
void FNNAME(const TYPENAME *src, TYPENAME *dst, uint32_t d1, uint32_t d2, uint32_t src_s, uint32_t dst_s) { \
copy2d(src, dst, d1, d2, src_s, dst_s); \
} \
COPY2D_OP(float, copy2d_f32)
COPY2D_OP(double, copy2d_f64)
COPY2D_OP(uint8_t, copy2d_u8)
COPY2D_OP(uint32_t, copy2d_u32)
COPY2D_OP(int64_t, copy2d_i64)
#if __CUDA_ARCH__ >= 530
extern "C" __global__ void fill_f16(__half *buf, __half value, const size_t numel) { fill_with(buf, value, numel); }
COPY2D_OP(__half, copy2d_f16)
#endif
#if __CUDA_ARCH__ >= 800
#include <cuda_bf16.h>
extern "C" __global__ void fill_bf16(__nv_bfloat16 *buf, __nv_bfloat16 value, const size_t numel) { fill_with(buf, value, numel); }
COPY2D_OP(__nv_bfloat16, copy2d_bf16)
#endif
| 0 |
0 | hf_public_repos/candle/candle-kernels | hf_public_repos/candle/candle-kernels/src/reduce.cu | #include "cuda_utils.cuh"
#include <cmath>
#include <stdint.h>
#define WARP_SIZE 32
const int BLOCK_SIZE = 1024;
// TODO: Maybe add some fast_sum_f16_f32 variant that not only accumulate in f32
// but also expect a f32 output so that this can be used for normalization e.g.
// in softmax.
// Fast reduce sum kernel, this assumes that the dimensions to loop over are at
// the end, each block is responsible for populating one value in the output
// array. There are at most 1024 threads per block.
template <typename T>
__device__ void
fast_sum(const size_t src_numel, const size_t el_to_sum_per_block,
const size_t num_dims, const size_t *info, const T *src, T *dst) {
const size_t *dims = info;
const size_t *strides = info + num_dims;
__shared__ T shr[BLOCK_SIZE];
size_t tid = threadIdx.x;
size_t dst_id = blockIdx.x;
shr[tid] = 0;
// Elements summed in this block range from dst_id * el_to_sum_per_block
// to (dst_id + 1) * el_to_sum_per_block.
size_t start_idx = dst_id * el_to_sum_per_block;
size_t stop_idx = min(start_idx + el_to_sum_per_block, src_numel);
size_t idx = start_idx + tid;
while (idx < stop_idx) {
// TODO: Fast version for the contiguous case.
size_t strided_i = get_strided_index(idx, num_dims, dims, strides);
shr[tid] += src[strided_i];
idx += blockDim.x;
}
// Parallel reduction, see the slides:
// https://www.olcf.ornl.gov/wp-content/uploads/2019/12/05_Atomics_Reductions_Warp_Shuffle.pdf
// https://stackoverflow.com/questions/66078814/is-cuda-atomicadd-operation-faster-than-launch-another-kernel-when-we-do-reduce
for (int s = blockDim.x / 2; s > 0; s >>= 1) {
__syncthreads();
if (tid < s)
shr[tid] += shr[tid + s];
}
if (tid == 0)
dst[dst_id] = shr[0];
}
static __device__ __forceinline__ float2 warp_reduce_sum(float2 a) {
#pragma unroll
for (int mask = 16; mask > 0; mask >>= 1) {
a.x += __shfl_xor_sync(0xffffffff, a.x, mask, 32);
a.y += __shfl_xor_sync(0xffffffff, a.y, mask, 32);
}
return a;
}
static __device__ __forceinline__ float warp_reduce_sum(float x) {
#pragma unroll
for (int mask = 16; mask > 0; mask >>= 1) {
x += __shfl_xor_sync(0xffffffff, x, mask, 32);
}
return x;
}
// LayerNorm implementation adapted from ggml, accumulation is made using f32.
// https://github.com/ggerganov/llama.cpp/blob/d59bd97065cd7ded6c4ecab54b1d5e0b1b11e318/ggml-cuda.cu#L477
template <typename T>
__device__ void layernorm(const T * x, T * dst, const T * alpha, const T * beta, const int ncols, const int block_size, const float eps) {
const int row = blockIdx.x*blockDim.y + threadIdx.y;
const int tid = threadIdx.x;
float2 mean_var = make_float2(0.f, 0.f);
for (int col = tid; col < ncols; col += block_size) {
const float xi = x[row*ncols + col];
mean_var.x += xi;
mean_var.y += xi * xi;
}
// sum up partial sums
mean_var = warp_reduce_sum(mean_var);
if (block_size > WARP_SIZE) {
__shared__ float2 s_sum[32];
int warp_id = threadIdx.x / WARP_SIZE;
int lane_id = threadIdx.x % WARP_SIZE;
if (lane_id == 0) {
s_sum[warp_id] = mean_var;
}
__syncthreads();
mean_var = s_sum[lane_id];
mean_var = warp_reduce_sum(mean_var);
}
const float mean = mean_var.x / ncols;
const float var = mean_var.y / ncols - mean * mean;
const float inv_std = rsqrtf(var + eps);
if (alpha == nullptr && beta == nullptr) {
for (int col = tid; col < ncols; col += block_size) {
float lhs = (static_cast<float>(x[row*ncols + col]) - mean) * inv_std;
dst[row*ncols + col] = static_cast<T>(lhs);
}
}
else if (alpha == nullptr && beta != nullptr) {
for (int col = tid; col < ncols; col += block_size) {
float b = static_cast<float>(beta[col]);
float lhs = (static_cast<float>(x[row*ncols + col]) - mean) * inv_std;
dst[row*ncols + col] = static_cast<T>(lhs + b);
}
}
else if (alpha != nullptr && beta == nullptr) {
for (int col = tid; col < ncols; col += block_size) {
float a = static_cast<float>(alpha[col]);
float lhs = (static_cast<float>(x[row*ncols + col]) - mean) * inv_std;
dst[row*ncols + col] = static_cast<T>(lhs * a);
}
}
else {
for (int col = tid; col < ncols; col += block_size) {
float a = static_cast<float>(alpha[col]);
float b = static_cast<float>(beta[col]);
float lhs = (static_cast<float>(x[row*ncols + col]) - mean) * inv_std;
dst[row*ncols + col] = static_cast<T>(lhs * a + b);
}
}
}
// RmsNorm implementation adapted from ggml, accumulation is made using f32.
// https://github.com/ggerganov/llama.cpp/blob/d59bd97065cd7ded6c4ecab54b1d5e0b1b11e318/ggml-cuda.cu#L523
template <typename T>
__device__ void rmsnorm(const T * x, T * dst, const T * alpha, const int ncols, const int block_size, const float eps) {
const int row = blockIdx.x*blockDim.y + threadIdx.y;
const int tid = threadIdx.x;
float tmp = 0.0f; // partial sum for thread in warp
for (int col = tid; col < ncols; col += block_size) {
const float xi = static_cast<float>(x[row*ncols + col]);
tmp += xi * xi;
}
// sum up partial sums
tmp = warp_reduce_sum(tmp);
if (block_size > WARP_SIZE) {
__shared__ float s_sum[32];
int warp_id = threadIdx.x / WARP_SIZE;
int lane_id = threadIdx.x % WARP_SIZE;
if (lane_id == 0) {
s_sum[warp_id] = tmp;
}
__syncthreads();
tmp = s_sum[lane_id];
tmp = warp_reduce_sum(tmp);
}
const float mean = tmp / ncols;
const float scale = rsqrtf(mean + eps);
if (alpha == nullptr) {
for (int col = tid; col < ncols; col += block_size) {
dst[row*ncols + col] = static_cast<T>(scale * static_cast<float>(x[row*ncols + col]));
}
}
else {
for (int col = tid; col < ncols; col += block_size) {
float a = static_cast<float>(alpha[col]);
dst[row*ncols + col] = static_cast<T>(scale * static_cast<float>(x[row*ncols + col]) * a);
}
}
}
// Softmax implementation adapted from ggml.
// https://github.com/ggerganov/llama.cpp/blob/d59bd97065cd7ded6c4ecab54b1d5e0b1b11e318/ggml-cuda.cu#L4159
template <typename T, typename ACC>
__device__ void softmax(const T * x, T * dst, const int ncols) {
const int row = blockDim.x*blockIdx.x + threadIdx.x;
const int block_size = blockDim.y;
const int tid = threadIdx.y;
T max_val = -INFINITY;
for (int col = tid; col < ncols; col += block_size) {
const int i = row*ncols + col;
max_val = maxg(max_val, x[i]);
}
// find the max value in the block
#pragma unroll
for (int mask = 16; mask > 0; mask >>= 1) {
max_val = maxg(max_val, __shfl_xor_sync(0xffffffff, max_val, mask, 32));
}
ACC tmp = 0.;
for (int col = tid; col < ncols; col += block_size) {
const int i = row*ncols + col;
const T val = expg(x[i] - max_val);
tmp += static_cast<ACC>(val);
dst[i] = val;
}
// sum up partial sums
#pragma unroll
for (int mask = 16; mask > 0; mask >>= 1) {
tmp += __shfl_xor_sync(0xffffffff, tmp, mask, 32);
}
const ACC inv_tmp = 1. / tmp;
for (int col = tid; col < ncols; col += block_size) {
const int i = row*ncols + col;
dst[i] *= inv_tmp;
}
}
template <typename T>
__device__ void ropei(const T * src, const T * cos, const T * sin, T * dst, const uint32_t bh, const uint32_t td) {
const int idx = blockIdx.x * blockDim.x + threadIdx.x;
if (2 * idx >= bh * td) return;
uint32_t rope_idx = idx % (td / 2);
T c = cos[rope_idx];
T s = sin[rope_idx];
dst[2 * idx] = src[2 * idx] * c - src[2 * idx + 1] * s;
dst[2 * idx + 1] = src[2 * idx] * s + src[2 * idx + 1] * c;
}
template <typename T>
__device__ void rope(const T * src, const T * cos, const T * sin, T * dst, const uint32_t bh, const uint32_t td, const uint32_t d) {
const int idx = blockIdx.x * blockDim.x + threadIdx.x;
if (2 * idx >= bh * td) return;
uint32_t i_bh = idx / (td / 2);
uint32_t i_td = idx - (td / 2) * i_bh;
uint32_t i_t = i_td / (d / 2);
uint32_t i_d = i_td - (d / 2) * i_t;
uint32_t i1 = i_bh * td + i_t * d + i_d;
uint32_t i2 = i1 + d / 2;
uint32_t i_cs = i_t * (d / 2) + i_d;
T c = cos[i_cs];
T s = sin[i_cs];
dst[i1] = src[i1] * c - src[i2] * s;
dst[i2] = src[i1] * s + src[i2] * c;
}
template <typename T>
__device__ void rope_thd(
const T * src,
const T * cos,
const T * sin,
T * dst,
const uint32_t b,
const uint32_t t,
const uint32_t h,
const uint32_t d
) {
const int idx = blockIdx.x * blockDim.x + threadIdx.x;
if (2 * idx >= b * t * h * d) return;
uint32_t i_bth = idx / (d / 2);
uint32_t i_d = idx - (d / 2) * i_bth;
uint32_t i_t = (i_bth / h) % t;
uint32_t i1 = i_bth * d + i_d;
uint32_t i2 = i1 + d / 2;
uint32_t i_cs = i_t * (d / 2) + i_d;
T c = cos[i_cs];
T s = sin[i_cs];
dst[i1] = src[i1] * c - src[i2] * s;
dst[i2] = src[i1] * s + src[i2] * c;
}
template <typename T>
__device__ void
fast_max(const size_t src_numel, const size_t el_to_sum_per_block,
const size_t num_dims, const size_t *info, const T *src, T *dst) {
const size_t *dims = info;
const size_t *strides = info + num_dims;
__shared__ T shr[BLOCK_SIZE];
size_t tid = threadIdx.x;
size_t dst_id = blockIdx.x;
shr[tid] = -INFINITY;
// Elements summed in this block range from dst_id * el_to_sum_per_block
// to (dst_id + 1) * el_to_sum_per_block.
size_t start_idx = dst_id * el_to_sum_per_block;
size_t stop_idx = min(start_idx + el_to_sum_per_block, src_numel);
size_t idx = start_idx + tid;
while (idx < stop_idx) {
// TODO: Fast version for the contiguous case.
size_t strided_i = get_strided_index(idx, num_dims, dims, strides);
shr[tid] = maxg(shr[tid], src[strided_i]);
idx += blockDim.x;
}
// Parallel reduction, see the slides:
// https://www.olcf.ornl.gov/wp-content/uploads/2019/12/05_Atomics_Reductions_Warp_Shuffle.pdf
// https://stackoverflow.com/questions/66078814/is-cuda-atomicadd-operation-faster-than-launch-another-kernel-when-we-do-reduce
for (int s = blockDim.x / 2; s > 0; s >>= 1) {
__syncthreads();
if (tid < s)
shr[tid] = maxg(shr[tid], shr[tid + s]);
}
if (tid == 0)
dst[dst_id] = shr[0];
}
template <typename T>
__device__ void
fast_min(const size_t src_numel, const size_t el_to_sum_per_block,
const size_t num_dims, const size_t *info, const T *src, T *dst) {
const size_t *dims = info;
const size_t *strides = info + num_dims;
__shared__ T shr[BLOCK_SIZE];
size_t tid = threadIdx.x;
size_t dst_id = blockIdx.x;
shr[tid] = INFINITY;
// Elements summed in this block range from dst_id * el_to_sum_per_block
// to (dst_id + 1) * el_to_sum_per_block.
size_t start_idx = dst_id * el_to_sum_per_block;
size_t stop_idx = min(start_idx + el_to_sum_per_block, src_numel);
size_t idx = start_idx + tid;
while (idx < stop_idx) {
// TODO: Fast version for the contiguous case.
size_t strided_i = get_strided_index(idx, num_dims, dims, strides);
shr[tid] = ming(shr[tid], src[strided_i]);
idx += blockDim.x;
}
// Parallel reduction, see the slides:
// https://www.olcf.ornl.gov/wp-content/uploads/2019/12/05_Atomics_Reductions_Warp_Shuffle.pdf
// https://stackoverflow.com/questions/66078814/is-cuda-atomicadd-operation-faster-than-launch-another-kernel-when-we-do-reduce
for (int s = blockDim.x / 2; s > 0; s >>= 1) {
__syncthreads();
if (tid < s)
shr[tid] = ming(shr[tid], shr[tid + s]);
}
if (tid == 0)
dst[dst_id] = shr[0];
}
template <typename T>
__device__ void
fast_argmin(const size_t src_numel, const size_t el_to_sum_per_block,
const size_t num_dims, const size_t *info, const T *src, uint32_t *dst) {
const size_t *dims = info;
const size_t *strides = info + num_dims;
__shared__ T shr[BLOCK_SIZE];
__shared__ uint32_t shr_index[BLOCK_SIZE];
size_t tid = threadIdx.x;
size_t dst_id = blockIdx.x;
// Not sure how that works on uint32_t and uint8_t but it seems to do ok.
shr[tid] = INFINITY;
shr_index[tid] = 0xFFFFFFFF;
bool not_set = true;
// Elements summed in this block range from dst_id * el_to_sum_per_block
// to (dst_id + 1) * el_to_sum_per_block.
size_t start_idx = dst_id * el_to_sum_per_block;
size_t stop_idx = min(start_idx + el_to_sum_per_block, src_numel);
size_t idx = start_idx + tid;
while (idx < stop_idx) {
// TODO: Fast version for the contiguous case.
size_t strided_i = get_strided_index(idx, num_dims, dims, strides);
if (not_set || src[strided_i] < shr[tid]) {
shr[tid] = src[strided_i];
// Assume that the reduction takes place over the last dimension which is contiguous.
shr_index[tid] = idx % dims[num_dims - 1];
not_set = false;
}
idx += blockDim.x;
}
// Parallel reduction, see the slides:
// https://www.olcf.ornl.gov/wp-content/uploads/2019/12/05_Atomics_Reductions_Warp_Shuffle.pdf
// https://stackoverflow.com/questions/66078814/is-cuda-atomicadd-operation-faster-than-launch-another-kernel-when-we-do-reduce
for (int s = blockDim.x / 2; s > 0; s >>= 1) {
__syncthreads();
if (tid < s && shr[tid + s] < shr[tid]) {
shr[tid] = shr[tid + s];
shr_index[tid] = shr_index[tid + s];
}
}
if (tid == 0)
dst[dst_id] = shr_index[0];
}
template <typename T>
__device__ void
fast_argmax(const size_t src_numel, const size_t el_to_sum_per_block,
const size_t num_dims, const size_t *info, const T *src, uint32_t *dst) {
const size_t *dims = info;
const size_t *strides = info + num_dims;
__shared__ T shr[BLOCK_SIZE];
__shared__ uint32_t shr_index[BLOCK_SIZE];
size_t tid = threadIdx.x;
size_t dst_id = blockIdx.x;
shr[tid] = -INFINITY;
shr_index[tid] = 0xFFFFFFFF;
bool not_set = true;
// Elements summed in this block range from dst_id * el_to_sum_per_block
// to (dst_id + 1) * el_to_sum_per_block.
size_t start_idx = dst_id * el_to_sum_per_block;
size_t stop_idx = min(start_idx + el_to_sum_per_block, src_numel);
size_t idx = start_idx + tid;
while (idx < stop_idx) {
// TODO: Fast version for the contiguous case.
size_t strided_i = get_strided_index(idx, num_dims, dims, strides);
if (not_set || src[strided_i] > shr[tid]) {
shr[tid] = src[strided_i];
// Assume that the reduction takes place over the last dimension which is contiguous.
shr_index[tid] = idx % dims[num_dims - 1];
not_set = false;
}
idx += blockDim.x;
}
// Parallel reduction, see the slides:
// https://www.olcf.ornl.gov/wp-content/uploads/2019/12/05_Atomics_Reductions_Warp_Shuffle.pdf
// https://stackoverflow.com/questions/66078814/is-cuda-atomicadd-operation-faster-than-launch-another-kernel-when-we-do-reduce
for (int s = blockDim.x / 2; s > 0; s >>= 1) {
__syncthreads();
if (tid < s && shr[tid + s] > shr[tid]) {
shr[tid] = shr[tid + s];
shr_index[tid] = shr_index[tid + s];
}
}
if (tid == 0)
dst[dst_id] = shr_index[0];
}
#define FAST_OP(TYPENAME, MIN_NAME, MAX_NAME, ARGMIN_NAME, ARGMAX_NAME, SUM_NAME) \
extern "C" __global__ void ARGMIN_NAME( \
const size_t src_numel, const size_t el_to_sum_per_block, \
const size_t num_dims, const size_t *info, const TYPENAME *src, \
uint32_t *dst) { \
fast_argmin(src_numel, el_to_sum_per_block, num_dims, info, src, dst); \
} \
extern "C" __global__ void ARGMAX_NAME( \
const size_t src_numel, const size_t el_to_sum_per_block, \
const size_t num_dims, const size_t *info, const TYPENAME *src, \
uint32_t *dst) { \
fast_argmax(src_numel, el_to_sum_per_block, num_dims, info, src, dst); \
} \
extern "C" __global__ void MIN_NAME( \
const size_t src_numel, const size_t el_to_sum_per_block, \
const size_t num_dims, const size_t *info, const TYPENAME *src, \
TYPENAME *dst) { \
fast_min(src_numel, el_to_sum_per_block, num_dims, info, src, dst); \
} \
extern "C" __global__ void MAX_NAME( \
const size_t src_numel, const size_t el_to_sum_per_block, \
const size_t num_dims, const size_t *info, const TYPENAME *src, \
TYPENAME *dst) { \
fast_max(src_numel, el_to_sum_per_block, num_dims, info, src, dst); \
} \
extern "C" __global__ void SUM_NAME( \
const size_t src_numel, const size_t el_to_sum_per_block, \
const size_t num_dims, const size_t *info, const TYPENAME *src, \
TYPENAME *dst) { \
fast_sum(src_numel, el_to_sum_per_block, num_dims, info, src, dst); \
}
#define SUM_OP(TYPENAME, FN_NAME) \
extern "C" __global__ void FN_NAME( \
const size_t numel, const size_t num_dims, const size_t num_sum_dims, \
const size_t *info, const TYPENAME *inp, TYPENAME *out) { \
const size_t *dims = info; \
const size_t *strides = info + num_dims; \
const size_t *sum_dims_l = info + 2 * num_dims; \
const size_t *sum_dims_s = info + 2 * num_dims + num_sum_dims; \
if (is_contiguous(num_dims, dims, strides)) { \
for (unsigned int i = blockIdx.x * blockDim.x + threadIdx.x; i < numel; \
i += blockDim.x * gridDim.x) { \
size_t dst_index = i; \
for (unsigned int nd = 0; nd < num_sum_dims; ++nd) { \
size_t stride = sum_dims_s[nd]; \
size_t pre = dst_index / stride; \
size_t post = dst_index % stride; \
dst_index = (pre / sum_dims_l[nd]) * stride + post; \
} \
atomicAdd(out + dst_index, inp[i]); \
} \
} else { \
for (unsigned int i = blockIdx.x * blockDim.x + threadIdx.x; i < numel; \
i += blockDim.x * gridDim.x) { \
unsigned strided_i = get_strided_index(i, num_dims, dims, strides); \
size_t dst_index = i; \
for (unsigned int nd = 0; nd < num_sum_dims; ++nd) { \
size_t stride = sum_dims_s[nd]; \
size_t pre = dst_index / stride; \
size_t post = dst_index % stride; \
dst_index = (pre / sum_dims_l[nd]) * stride + post; \
} \
atomicAdd(out + dst_index, inp[strided_i]); \
} \
} \
}
#define SOFTMAX_OP(TYPENAME, ACC_TYPENAME, FN_NAME) \
extern "C" __global__ void FN_NAME( \
const TYPENAME *src, TYPENAME *dst, \
const int n_cols) { \
softmax<TYPENAME, ACC_TYPENAME>(src, dst, n_cols); \
} \
#define RMSNORM_OP(TYPENAME, FN_NAME) \
extern "C" __global__ void FN_NAME( \
const TYPENAME *src, TYPENAME *dst, const TYPENAME *alpha, \
const int n_cols, const int block_size, const float eps) { \
rmsnorm<TYPENAME>(src, dst, alpha, n_cols, block_size, eps); \
} \
#define LAYERNORM_OP(TYPENAME, FN_NAME) \
extern "C" __global__ void FN_NAME( \
const TYPENAME *src, TYPENAME *dst, const TYPENAME *alpha, \
const TYPENAME *beta, const int n_cols, const int block_size, const float eps) { \
layernorm<TYPENAME>(src, dst, alpha, beta, n_cols, block_size, eps); \
} \
#define ROPE_OP(TYPENAME, FN_NAME, FN_NAME_I, FN_NAME_THD) \
extern "C" __global__ void FN_NAME_I( \
const TYPENAME *src, \
const TYPENAME *cos, \
const TYPENAME *sin, \
TYPENAME *dst, \
const uint32_t bh, \
const uint32_t td) { \
ropei<TYPENAME>(src, cos, sin, dst, bh, td); \
} \
extern "C" __global__ void FN_NAME( \
const TYPENAME *src, \
const TYPENAME *cos, \
const TYPENAME *sin, \
TYPENAME *dst, \
const uint32_t bh, \
const uint32_t td, \
const uint32_t d) { \
rope<TYPENAME>(src, cos, sin, dst, bh, td, d); \
} \
extern "C" __global__ void FN_NAME_THD( \
const TYPENAME *src, \
const TYPENAME *cos, \
const TYPENAME *sin, \
TYPENAME *dst, \
const uint32_t b, \
const uint32_t t, \
const uint32_t h, \
const uint32_t d) { \
rope_thd<TYPENAME>(src, cos, sin, dst, b, t, h, d); \
} \
#if __CUDA_ARCH__ >= 800
SOFTMAX_OP(__nv_bfloat16, float, softmax_bf16)
RMSNORM_OP(__nv_bfloat16, rmsnorm_bf16)
LAYERNORM_OP(__nv_bfloat16, layernorm_bf16)
ROPE_OP(__nv_bfloat16, rope_bf16, rope_i_bf16, rope_thd_bf16)
SUM_OP(__nv_bfloat16, sum_bf16)
FAST_OP(__nv_bfloat16, fast_min_bf16, fast_max_bf16, fast_argmin_bf16, fast_argmax_bf16, fast_sum_bf16)
#endif
#if __CUDA_ARCH__ >= 530
SOFTMAX_OP(__half, float, softmax_f16)
RMSNORM_OP(__half, rmsnorm_f16)
LAYERNORM_OP(__half, layernorm_f16)
ROPE_OP(__half, rope_f16, rope_i_f16, rope_thd_f16)
SUM_OP(__half, sum_f16)
FAST_OP(__half, fast_min_f16, fast_max_f16, fast_argmin_f16, fast_argmax_f16, fast_sum_f16)
#endif
SUM_OP(float, sum_f32)
SUM_OP(double, sum_f64)
SUM_OP(uint32_t, sum_u32)
SOFTMAX_OP(float, float, softmax_f32)
SOFTMAX_OP(double, double, softmax_f64)
RMSNORM_OP(float, rmsnorm_f32)
RMSNORM_OP(double, rmsnorm_f64)
LAYERNORM_OP(float, layernorm_f32)
LAYERNORM_OP(double, layernorm_f64)
ROPE_OP(float, rope_f32, rope_i_f32, rope_thd_f32)
ROPE_OP(double, rope_f64, rope_i_f64, rope_thd_f64)
FAST_OP(float, fast_min_f32, fast_max_f32, fast_argmin_f32, fast_argmax_f32, fast_sum_f32)
FAST_OP(double, fast_min_f64, fast_max_f64, fast_argmin_f64, fast_argmax_f64, fast_sum_f64)
FAST_OP(uint32_t, fast_min_u32, fast_max_u32, fast_argmin_u32, fast_argmax_u32, fast_sum_u32)
FAST_OP(int64_t, fast_min_i64, fast_max_i64, fast_argmin_i64, fast_argmax_i64, fast_sum_i64)
FAST_OP(uint8_t, fast_min_u8, fast_max_u8, fast_argmin_u8, fast_argmax_u8, fast_sum_u8)
| 1 |
0 | hf_public_repos/candle/candle-kernels | hf_public_repos/candle/candle-kernels/src/sort.cu | // Adapted from https://github.com/ggerganov/llama.cpp/blob/master/ggml-cuda/argsort.cu
#define SORT_ORDER_ASC 1
#define SORT_ORDER_DESC 0
#include "cuda_utils.cuh"
#include<stdint.h>
template<typename T>
static inline __device__ void ggml_cuda_swap(T & a, T & b) {
T tmp = a;
a = b;
b = tmp;
}
template<int order, typename T>
static __device__ void k_argsort(const T * x, uint32_t * dst, const int ncols, int ncols_pad) {
// bitonic sort
int col = threadIdx.x;
int row = blockIdx.y;
if (col >= ncols_pad) {
return;
}
const T * x_row = x + row * ncols;
extern __shared__ int dst_row[];
// initialize indices
dst_row[col] = col;
__syncthreads();
for (int k = 2; k <= ncols_pad; k *= 2) {
for (int j = k / 2; j > 0; j /= 2) {
int ixj = col ^ j;
if (ixj > col) {
if ((col & k) == 0) {
if (dst_row[col] >= ncols ||
(dst_row[ixj] < ncols && (order == SORT_ORDER_ASC ?
x_row[dst_row[col]] > x_row[dst_row[ixj]] :
x_row[dst_row[col]] < x_row[dst_row[ixj]]))
) {
ggml_cuda_swap(dst_row[col], dst_row[ixj]);
}
} else {
if (dst_row[ixj] >= ncols ||
(dst_row[col] < ncols && (order == SORT_ORDER_ASC ?
x_row[dst_row[col]] < x_row[dst_row[ixj]] :
x_row[dst_row[col]] > x_row[dst_row[ixj]]))
) {
ggml_cuda_swap(dst_row[col], dst_row[ixj]);
}
}
}
__syncthreads();
}
}
// copy the result to dst without the padding
if (col < ncols) {
dst[row * ncols + col] = dst_row[col];
}
}
#define ASORT_OP(TYPENAME, RUST_NAME) \
extern "C" __global__ void asort_asc_##RUST_NAME( \
const TYPENAME * x, uint32_t * dst, const int ncols, int ncols_pad \
) { \
k_argsort<SORT_ORDER_ASC>(x, dst, ncols, ncols_pad); \
} \
extern "C" __global__ void asort_desc_##RUST_NAME( \
const TYPENAME * x, uint32_t * dst, const int ncols, int ncols_pad \
) { \
k_argsort<SORT_ORDER_DESC>(x, dst, ncols, ncols_pad); \
} \
#if __CUDA_ARCH__ >= 800
ASORT_OP(__nv_bfloat16, bf16)
#endif
#if __CUDA_ARCH__ >= 530
ASORT_OP(__half, f16)
#endif
ASORT_OP(float, f32)
ASORT_OP(double, f64)
ASORT_OP(uint8_t, u8)
ASORT_OP(uint32_t, u32)
ASORT_OP(int64_t, i64)
| 2 |
0 | hf_public_repos/candle/candle-kernels | hf_public_repos/candle/candle-kernels/src/cuda_utils.cuh | #include "compatibility.cuh"
#include<stdint.h>
#include<cmath>
// TODO: This is often used to check that the data is contiguous so that
// kernels can be easily mapped. However this only returns true for row
// major, if all the inputs are column major, we could apply the fast path
// too (but we wouldn't if some of them are row major and some column major).
__device__ bool is_contiguous(
const size_t num_dims,
const size_t *dims,
const size_t *strides
) {
size_t acc = 1;
for (unsigned int d = 0; d < num_dims; d++) {
unsigned int dim_idx = num_dims - 1 - d;
if (dims[dim_idx] > 1 && acc != strides[dim_idx]) {
return false;
}
acc *= dims[dim_idx];
}
return true;
}
__device__ unsigned int get_strided_index(
unsigned int idx,
const size_t num_dims,
const size_t *dims,
const size_t *strides
) {
unsigned int strided_i = 0;
for (unsigned int d = 0; d < num_dims; d++) {
unsigned int dim_idx = num_dims - 1 - d;
strided_i += (idx % dims[dim_idx]) * strides[dim_idx];
idx /= dims[dim_idx];
}
return strided_i;
}
__device__ unsigned int restrided(
const unsigned int strided_i,
const size_t num_dims,
const size_t *dims,
const size_t *strides,
const size_t *new_strides
) {
unsigned int idx = 0;
for (int d = 0; d < num_dims; d++) {
idx += (strides[d] == 0 ? 0 : (strided_i / strides[d]) % dims[d]) * new_strides[d];
}
return idx;
}
// Sourced from https://graphics.stanford.edu/~seander/bithacks.html#RoundUpPowerOf2
// Input must be less than or equal to 2 ^ 16
// used in reductions
__device__ __forceinline__ unsigned int next_power_of_two(unsigned int v) {
v--;
v |= v >> 1;
v |= v >> 2;
v |= v >> 4;
v |= v >> 8;
v++;
return v;
}
// Efficiently computes the sum of each chunk in "data" of size chunk_len, and
// stores the sums in out[i / chunk_len]
template<typename T>
__device__ void chunk_sum(
const size_t chunk_len,
const T data,
T* out
) {
__shared__ T buf[1024];
// assumes that threads where i >= numel have already exited
unsigned int i = blockIdx.x * blockDim.x + threadIdx.x;
unsigned int block_i = threadIdx.x;
// Fall back to atomicAdd if chunk_len is small to reduce overhead
if (chunk_len <= 2) {
atomicAdd(out + i / chunk_len, data);
return;
}
buf[block_i] = data;
unsigned int chunk_i = i % chunk_len;
unsigned int chunk_start = max((int)(block_i - chunk_i), 0);
unsigned int chunk_end = min((unsigned int)(block_i + chunk_len - chunk_i), blockDim.x);
chunk_i = block_i - chunk_start;
size_t max_chunk_len = min(chunk_end - chunk_start, blockDim.x);
size_t incr = next_power_of_two(max_chunk_len) >> 1;
__syncthreads();
// Uses sequential addressing as discussed in
// https://developer.download.nvidia.com/assets/cuda/files/reduction.pdf
for (; incr > 0; incr >>= 1) {
unsigned int block_i_2 = block_i + incr;
if (block_i_2 < chunk_end && chunk_i < incr) {
// This is sound because __syncthreads and the conditions above
// ensure that no data races occur
buf[block_i] += buf[block_i_2];
}
__syncthreads();
}
if (block_i == chunk_start) {
atomicAdd(out + i / chunk_len, buf[block_i]);
}
}
__device__ __forceinline__ bool isnang(float a) { return isnan(a); }
__device__ __forceinline__ bool isnang(double a) { return isnan(a); }
__device__ __forceinline__ float recipg(float a) { return 1.0 / a; }
__device__ __forceinline__ double recipg(double a) { return 1.0 / a; }
__device__ __forceinline__ float cosg(float a) { return cosf(a); }
__device__ __forceinline__ double cosg(double a) { return cos(a); }
__device__ __forceinline__ float sing(float a) { return sinf(a); }
__device__ __forceinline__ double sing(double a) { return sin(a); }
__device__ __forceinline__ float sqrtg(float a) { return sqrtf(a); }
__device__ __forceinline__ double sqrtg(double a) { return sqrt(a); }
__device__ __forceinline__ float powg(float a, float b) { return powf(a, b); }
__device__ __forceinline__ double powg(double a, double b) { return pow(a, b); }
__device__ __forceinline__ float tanhg(float a) { return tanhf(a); }
__device__ __forceinline__ double tanhg(double a) { return tanh(a); }
__device__ __forceinline__ float erfg(float a) { return erff(a); }
__device__ __forceinline__ double erfg(double a) { return erf(a); }
__device__ __forceinline__ float ceilg(float a) { return ceilf(a); }
__device__ __forceinline__ double ceilg(double a) { return ceil(a); }
__device__ __forceinline__ float floorg(float a) { return floorf(a); }
__device__ __forceinline__ double floorg(double a) { return floor(a); }
__device__ __forceinline__ float roundg(float a) { return roundf(a); }
__device__ __forceinline__ double roundg(double a) { return round(a); }
__device__ __forceinline__ float normcdfg(float a) { return normcdff(a); }
__device__ __forceinline__ double normcdfg(double a) { return normcdf(a); }
__device__ __forceinline__ float maxg(float a, float b) { return fmaxf(a, b); }
__device__ __forceinline__ double maxg(double a, double b) { return fmax(a, b); }
__device__ __forceinline__ float ming(float a, float b) { return fminf(a, b); }
__device__ __forceinline__ double ming(double a, double b) { return fmin(a, b); }
__device__ __forceinline__ float logg(float a) { return logf(a); }
__device__ __forceinline__ double logg(double a) { return log(a); }
__device__ __forceinline__ float expg(float a) { return expf(a); }
__device__ __forceinline__ double expg(double a) { return exp(a); }
__device__ __forceinline__ float absg(float a) { return fabsf(a); }
__device__ __forceinline__ double absg(double a) { return fabs(a); }
__device__ __forceinline__ float copysigng(float a, float b) { return copysignf(a, b); }
__device__ __forceinline__ double copysigng(double a, double b) { return copysign(a, b); }
__device__ __forceinline__ int64_t ming(int64_t a, int64_t b) { return min(a, b); }
__device__ __forceinline__ int64_t maxg(int64_t a, int64_t b) { return max(a, b); }
__device__ __forceinline__ uint32_t ming(uint32_t a, uint32_t b) { return min(a, b); }
__device__ __forceinline__ uint32_t maxg(uint32_t a, uint32_t b) { return max(a, b); }
__device__ __forceinline__ uint8_t ming(uint8_t a, uint8_t b) { return min(a, b); }
__device__ __forceinline__ uint8_t maxg(uint8_t a, uint8_t b) { return max(a, b); }
#if __CUDA_ARCH__ >= 530
__device__ __forceinline__ __half powg(__half a, __half b) { return __float2half(powf(__half2float(a), __half2float(b))); }
__device__ __forceinline__ bool isnang(__half a) { return __hisnan(a); }
__device__ __forceinline__ __half sqrtg(__half a) { return hsqrt(a); }
__device__ __forceinline__ __half cosg(__half a) { return hcos(a); }
__device__ __forceinline__ __half sing(__half a) { return hsin(a); }
__device__ __forceinline__ __half recipg(__half a) { __half one = 1.0; return one / a; }
__device__ __forceinline__ __half maxg(__half a, __half b) { return __hmax_nan(a, b); }
__device__ __forceinline__ __half tanhg(__half a) { return __float2half(tanhf(__half2float(a))); }
__device__ __forceinline__ __half erfg(__half a) { return __float2half(erff(__half2float(a))); }
__device__ __forceinline__ __half ceilg(__half a) { return __float2half(ceilf(__half2float(a))); }
__device__ __forceinline__ __half floorg(__half a) { return __float2half(floorf(__half2float(a))); }
__device__ __forceinline__ __half roundg(__half a) { return __float2half(roundf(__half2float(a))); }
__device__ __forceinline__ __half normcdfg(__half a) { return __float2half(normcdff(__half2float(a))); }
__device__ __forceinline__ __half ming(__half a, __half b) { return __hmin_nan(a, b); }
__device__ __forceinline__ __half logg(__half a) { return hlog(a); }
__device__ __forceinline__ __half expg(__half a) { return hexp(a); }
__device__ __forceinline__ __half absg(__half a) { return __habs(a); }
__device__ __forceinline__ __half copysigng(__half a, __half b) { return __float2half(copysignf(__half2float(a), __half2float(b))); }
#endif
#if __CUDA_ARCH__ >= 800
__device__ __forceinline__ __nv_bfloat16 powg(__nv_bfloat16 a, __nv_bfloat16 b) { return __float2bfloat16(powf(__bfloat162float(a), __bfloat162float(b))); }
__device__ __forceinline__ bool isnang(__nv_bfloat16 a) { return __hisnan(a); }
__device__ __forceinline__ __nv_bfloat16 sqrtg(__nv_bfloat16 a) { return hsqrt(a); }
__device__ __forceinline__ __nv_bfloat16 cosg(__nv_bfloat16 a) { return hcos(a); }
__device__ __forceinline__ __nv_bfloat16 sing(__nv_bfloat16 a) { return hsin(a); }
__device__ __forceinline__ __nv_bfloat16 recipg(__nv_bfloat16 a) { __nv_bfloat16 one = 1.0; return one / a; }
__device__ __forceinline__ __nv_bfloat16 maxg(__nv_bfloat16 a, __nv_bfloat16 b) { return __hmax_nan(a, b); }
__device__ __forceinline__ __nv_bfloat16 tanhg(__nv_bfloat16 a) { return __float2bfloat16(tanhf(__bfloat162float(a))); }
__device__ __forceinline__ __nv_bfloat16 erfg(__nv_bfloat16 a) { return __float2bfloat16(erff(__bfloat162float(a))); }
__device__ __forceinline__ __nv_bfloat16 ceilg(__nv_bfloat16 a) { return __float2bfloat16(ceilf(__bfloat162float(a))); }
__device__ __forceinline__ __nv_bfloat16 floorg(__nv_bfloat16 a) { return __float2bfloat16(floorf(__bfloat162float(a))); }
__device__ __forceinline__ __nv_bfloat16 roundg(__nv_bfloat16 a) { return __float2bfloat16(roundf(__bfloat162float(a))); }
__device__ __forceinline__ __nv_bfloat16 normcdfg(__nv_bfloat16 a) { return __float2bfloat16(normcdff(__bfloat162float(a))); }
__device__ __forceinline__ __nv_bfloat16 ming(__nv_bfloat16 a, __nv_bfloat16 b) { return __hmin_nan(a, b); }
__device__ __forceinline__ __nv_bfloat16 logg(__nv_bfloat16 a) { return hlog(a); }
__device__ __forceinline__ __nv_bfloat16 expg(__nv_bfloat16 a) { return hexp(a); }
__device__ __forceinline__ __nv_bfloat16 absg(__nv_bfloat16 a) { return __habs(a); }
__device__ __forceinline__ __nv_bfloat16 copysigng(__nv_bfloat16 a, __nv_bfloat16 b) { return __float2bfloat16(copysignf(__bfloat162float(a), __bfloat162float(b))); }
#endif
| 3 |
0 | hf_public_repos/candle/candle-wasm-examples | hf_public_repos/candle/candle-wasm-examples/bert/bertWorker.js | //load Candle Bert Module wasm module
import init, { Model } from "./build/m.js";
async function fetchArrayBuffer(url) {
const cacheName = "bert-candle-cache";
const cache = await caches.open(cacheName);
const cachedResponse = await cache.match(url);
if (cachedResponse) {
const data = await cachedResponse.arrayBuffer();
return new Uint8Array(data);
}
const res = await fetch(url, { cache: "force-cache" });
cache.put(url, res.clone());
return new Uint8Array(await res.arrayBuffer());
}
class Bert {
static instance = {};
static async getInstance(weightsURL, tokenizerURL, configURL, modelID) {
if (!this.instance[modelID]) {
await init();
self.postMessage({ status: "loading", message: "Loading Model" });
const [weightsArrayU8, tokenizerArrayU8, mel_filtersArrayU8] =
await Promise.all([
fetchArrayBuffer(weightsURL),
fetchArrayBuffer(tokenizerURL),
fetchArrayBuffer(configURL),
]);
this.instance[modelID] = new Model(
weightsArrayU8,
tokenizerArrayU8,
mel_filtersArrayU8
);
} else {
self.postMessage({ status: "ready", message: "Model Already Loaded" });
}
return this.instance[modelID];
}
}
self.addEventListener("message", async (event) => {
const {
weightsURL,
tokenizerURL,
configURL,
modelID,
sentences,
normalize = true,
} = event.data;
try {
self.postMessage({ status: "ready", message: "Starting Bert Model" });
const model = await Bert.getInstance(
weightsURL,
tokenizerURL,
configURL,
modelID
);
self.postMessage({
status: "embedding",
message: "Calculating Embeddings",
});
const output = model.get_embeddings({
sentences: sentences,
normalize_embeddings: normalize,
});
self.postMessage({
status: "complete",
message: "complete",
output: output.data,
});
} catch (e) {
self.postMessage({ error: e });
}
});
| 4 |
0 | hf_public_repos/candle/candle-wasm-examples | hf_public_repos/candle/candle-wasm-examples/bert/Cargo.toml | [package]
name = "candle-wasm-example-bert"
version.workspace = true
edition.workspace = true
description.workspace = true
repository.workspace = true
keywords.workspace = true
categories.workspace = true
license.workspace = true
[dependencies]
candle = { workspace = true }
candle-nn = { workspace = true }
candle-transformers = { workspace = true }
num-traits = { workspace = true }
tokenizers = { workspace = true, features = ["unstable_wasm"] }
# App crates.
anyhow = { workspace = true }
byteorder = { workspace = true }
log = { workspace = true }
rand = { workspace = true }
serde = { workspace = true }
serde_json = { workspace = true }
safetensors = { workspace = true }
# Wasm specific crates.
console_error_panic_hook = "0.1.7"
getrandom = { version = "0.2", features = ["js"] }
gloo = "0.11"
js-sys = "0.3.64"
wasm-bindgen = "0.2.87"
serde-wasm-bindgen = "0.6.0"
| 5 |
0 | hf_public_repos/candle/candle-wasm-examples | hf_public_repos/candle/candle-wasm-examples/bert/build-lib.sh | cargo build --target wasm32-unknown-unknown --release
wasm-bindgen ../../target/wasm32-unknown-unknown/release/m.wasm --out-dir build --target web
| 6 |
0 | hf_public_repos/candle/candle-wasm-examples | hf_public_repos/candle/candle-wasm-examples/bert/lib-example.html | <html>
<head>
<meta content="text/html;charset=utf-8" http-equiv="Content-Type" />
<title>Candle Bert</title>
</head>
<body></body>
</html>
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<style>
@import url("https://fonts.googleapis.com/css2?family=Source+Code+Pro:wght@200;300;400&family=Source+Sans+3:wght@100;200;300;400;500;600;700;800;900&display=swap");
html,
body {
font-family: "Source Sans 3", sans-serif;
}
</style>
<script src="https://cdn.tailwindcss.com"></script>
<script type="module" src="./code.js"></script>
<script type="module">
import { hcl } from "https://cdn.skypack.dev/d3-color@3";
import { interpolateReds } from "https://cdn.skypack.dev/d3-scale-chromatic@3";
import { scaleLinear } from "https://cdn.skypack.dev/d3-scale@4";
import {
getModelInfo,
getEmbeddings,
getWikiText,
cosineSimilarity,
} from "./utils.js";
const bertWorker = new Worker("./bertWorker.js", {
type: "module",
});
const inputContainerEL = document.querySelector("#input-container");
const textAreaEl = document.querySelector("#input-area");
const outputAreaEl = document.querySelector("#output-area");
const formEl = document.querySelector("#form");
const searchInputEl = document.querySelector("#search-input");
const formWikiEl = document.querySelector("#form-wiki");
const searchWikiEl = document.querySelector("#search-wiki");
const outputStatusEl = document.querySelector("#output-status");
const modelSelectEl = document.querySelector("#model");
const sentencesRegex =
/(?<!\w\.\w.)(?<![A-Z][a-z]\.)(?<![A-Z]\.)(?<=\.|\?)\s/gm;
let sentenceEmbeddings = [];
let currInputText = "";
let isCalculating = false;
function toggleTextArea(state) {
if (state) {
textAreaEl.hidden = false;
textAreaEl.focus();
} else {
textAreaEl.hidden = true;
}
}
inputContainerEL.addEventListener("focus", (e) => {
toggleTextArea(true);
});
textAreaEl.addEventListener("blur", (e) => {
toggleTextArea(false);
});
textAreaEl.addEventListener("focusout", (e) => {
toggleTextArea(false);
if (currInputText === textAreaEl.value || isCalculating) return;
populateOutputArea(textAreaEl.value);
calculateEmbeddings(textAreaEl.value);
});
modelSelectEl.addEventListener("change", (e) => {
if (currInputText === "" || isCalculating) return;
populateOutputArea(textAreaEl.value);
calculateEmbeddings(textAreaEl.value);
});
function populateOutputArea(text) {
currInputText = text;
const sentences = text.split(sentencesRegex);
outputAreaEl.innerHTML = "";
for (const [id, sentence] of sentences.entries()) {
const sentenceEl = document.createElement("span");
sentenceEl.id = `sentence-${id}`;
sentenceEl.innerText = sentence + " ";
outputAreaEl.appendChild(sentenceEl);
}
}
formEl.addEventListener("submit", async (e) => {
e.preventDefault();
if (isCalculating || currInputText === "") return;
toggleInputs(true);
const modelID = modelSelectEl.value;
const { modelURL, tokenizerURL, configURL, search_prefix } =
getModelInfo(modelID);
const text = searchInputEl.value;
const query = search_prefix + searchInputEl.value;
outputStatusEl.classList.remove("invisible");
outputStatusEl.innerText = "Calculating embeddings for query...";
isCalculating = true;
const out = await getEmbeddings(
bertWorker,
modelURL,
tokenizerURL,
configURL,
modelID,
[query]
);
outputStatusEl.classList.add("invisible");
const queryEmbeddings = out.output[0];
// calculate cosine similarity with all sentences given the query
const distances = sentenceEmbeddings
.map((embedding, id) => ({
id,
similarity: cosineSimilarity(queryEmbeddings, embedding),
}))
.sort((a, b) => b.similarity - a.similarity)
// getting top 10 most similar sentences
.slice(0, 10);
const colorScale = scaleLinear()
.domain([
distances[distances.length - 1].similarity,
distances[0].similarity,
])
.range([0, 1])
.interpolate(() => interpolateReds);
outputAreaEl.querySelectorAll("span").forEach((el) => {
el.style.color = "unset";
el.style.backgroundColor = "unset";
});
distances.forEach((d) => {
const el = outputAreaEl.querySelector(`#sentence-${d.id}`);
const color = colorScale(d.similarity);
const fontColor = hcl(color).l < 70 ? "white" : "black";
el.style.color = fontColor;
el.style.backgroundColor = color;
});
outputAreaEl
.querySelector(`#sentence-${distances[0].id}`)
.scrollIntoView({
behavior: "smooth",
block: "center",
inline: "nearest",
});
isCalculating = false;
toggleInputs(false);
});
async function calculateEmbeddings(text) {
isCalculating = true;
toggleInputs(true);
const modelID = modelSelectEl.value;
const { modelURL, tokenizerURL, configURL, document_prefix } =
getModelInfo(modelID);
const sentences = text.split(sentencesRegex);
const allEmbeddings = [];
outputStatusEl.classList.remove("invisible");
for (const [id, sentence] of sentences.entries()) {
const query = document_prefix + sentence;
outputStatusEl.innerText = `Calculating embeddings: sentence ${
id + 1
} of ${sentences.length}`;
const embeddings = await getEmbeddings(
bertWorker,
modelURL,
tokenizerURL,
configURL,
modelID,
[query],
updateStatus
);
allEmbeddings.push(embeddings);
}
outputStatusEl.classList.add("invisible");
sentenceEmbeddings = allEmbeddings.map((e) => e.output[0]);
isCalculating = false;
toggleInputs(false);
}
function updateStatus(data) {
if ("status" in data) {
if (data.status === "loading") {
outputStatusEl.innerText = data.message;
outputStatusEl.classList.remove("invisible");
}
}
}
function toggleInputs(state) {
const interactive = document.querySelectorAll(".interactive");
interactive.forEach((el) => {
if (state) {
el.disabled = true;
} else {
el.disabled = false;
}
});
}
searchWikiEl.addEventListener("input", () => {
searchWikiEl.setCustomValidity("");
});
formWikiEl.addEventListener("submit", async (e) => {
e.preventDefault();
if ("example" in e.submitter.dataset) {
searchWikiEl.value = e.submitter.innerText;
}
const text = searchWikiEl.value;
if (isCalculating || text === "") return;
try {
const wikiText = await getWikiText(text);
searchWikiEl.setCustomValidity("");
textAreaEl.innerHTML = wikiText;
populateOutputArea(wikiText);
calculateEmbeddings(wikiText);
searchWikiEl.value = "";
} catch {
searchWikiEl.setCustomValidity("Invalid Wikipedia article name");
searchWikiEl.reportValidity();
}
});
</script>
</head>
<body class="container max-w-4xl mx-auto p-4">
<main class="grid grid-cols-1 gap-5 relative">
<span class="absolute text-5xl -ml-[1em]"> 🕯️ </span>
<div>
<h1 class="text-5xl font-bold">Candle BERT</h1>
<h2 class="text-2xl font-bold">Rust/WASM Demo</h2>
<p class="max-w-lg">
Running sentence embeddings and similarity search in the browser using
the Bert Model written with
<a
href="https://github.com/huggingface/candle/"
target="_blank"
class="underline hover:text-blue-500 hover:no-underline"
>Candle
</a>
and compiled to Wasm. Embeddings models from are from
<a
href="https://huggingface.co/sentence-transformers/"
target="_blank"
class="underline hover:text-blue-500 hover:no-underline"
>
Sentence Transformers
</a>
and
<a
href="https://huggingface.co/intfloat/"
target="_blank"
class="underline hover:text-blue-500 hover:no-underline"
>
Liang Wang - e5 Models
</a>
</p>
</div>
<div>
<label for="model" class="font-medium block">Models Options: </label>
<select
id="model"
class="border-2 border-gray-500 rounded-md font-light interactive disabled:cursor-not-allowed w-full max-w-max"
>
<option value="intfloat_e5_small_v2" selected>
intfloat/e5-small-v2 (133 MB)
</option>
<option value="intfloat_e5_base_v2">
intfloat/e5-base-v2 (438 MB)
</option>
<option value="intfloat_multilingual_e5_small">
intfloat/multilingual-e5-small (471 MB)
</option>
<option value="sentence_transformers_all_MiniLM_L6_v2">
sentence-transformers/all-MiniLM-L6-v2 (90.9 MB)
</option>
<option value="sentence_transformers_all_MiniLM_L12_v2">
sentence-transformers/all-MiniLM-L12-v2 (133 MB)
</option>
</select>
</div>
<div>
<h3 class="font-medium">Examples:</h3>
<form
id="form-wiki"
class="flex text-xs rounded-md justify-between w-min gap-3"
>
<input type="submit" hidden />
<button data-example class="disabled:cursor-not-allowed interactive">
Pizza
</button>
<button data-example class="disabled:cursor-not-allowed interactive">
Paris
</button>
<button data-example class="disabled:cursor-not-allowed interactive">
Physics
</button>
<input
type="text"
id="search-wiki"
title="Search Wikipedia article by title"
class="font-light py-0 mx-1 resize-none outline-none w-32 disabled:cursor-not-allowed interactive"
placeholder="Load Wikipedia article..."
/>
<button
title="Search Wikipedia article and load into input"
class="bg-gray-700 hover:bg-gray-800 text-white font-normal px-2 py-1 rounded disabled:bg-gray-300 disabled:cursor-not-allowed interactive"
>
Load
</button>
</form>
</div>
<form
id="form"
class="flex text-normal px-1 py-1 border border-gray-700 rounded-md items-center"
>
<input type="submit" hidden />
<input
type="text"
id="search-input"
class="font-light w-full px-3 py-2 mx-1 resize-none outline-none interactive disabled:cursor-not-allowed"
placeholder="Search query here..."
/>
<button
class="bg-gray-700 hover:bg-gray-800 text-white font-normal py-2 w-16 rounded disabled:bg-gray-300 disabled:cursor-not-allowed interactive"
>
Search
</button>
</form>
<div>
<h3 class="font-medium">Input text:</h3>
<div class="flex justify-between items-center">
<div class="rounded-md inline text-xs">
<span id="output-status" class="m-auto font-light invisible"
>C</span
>
</div>
</div>
<div
id="input-container"
tabindex="0"
class="min-h-[250px] bg-slate-100 text-gray-500 rounded-md p-4 flex flex-col gap-2 relative"
>
<textarea
id="input-area"
hidden
value=""
placeholder="Input text to perform semantic similarity search..."
class="flex-1 resize-none outline-none left-0 right-0 top-0 bottom-0 m-4 absolute interactive disabled:invisible"
></textarea>
<p id="output-area" class="grid-rows-2">
Input text to perform semantic similarity search...
</p>
</div>
</div>
</main>
</body>
</html>
| 7 |
0 | hf_public_repos/candle/candle-wasm-examples | hf_public_repos/candle/candle-wasm-examples/bert/utils.js | export async function getEmbeddings(
worker,
weightsURL,
tokenizerURL,
configURL,
modelID,
sentences,
updateStatus = null
) {
return new Promise((resolve, reject) => {
worker.postMessage({
weightsURL,
tokenizerURL,
configURL,
modelID,
sentences,
});
function messageHandler(event) {
if ("error" in event.data) {
worker.removeEventListener("message", messageHandler);
reject(new Error(event.data.error));
}
if (event.data.status === "complete") {
worker.removeEventListener("message", messageHandler);
resolve(event.data);
}
if (updateStatus) updateStatus(event.data);
}
worker.addEventListener("message", messageHandler);
});
}
const MODELS = {
intfloat_e5_small_v2: {
base_url: "https://huggingface.co/intfloat/e5-small-v2/resolve/main/",
search_prefix: "query: ",
document_prefix: "passage: ",
},
intfloat_e5_base_v2: {
base_url: "https://huggingface.co/intfloat/e5-base-v2/resolve/main/",
search_prefix: "query: ",
document_prefix: "passage:",
},
intfloat_multilingual_e5_small: {
base_url:
"https://huggingface.co/intfloat/multilingual-e5-small/resolve/main/",
search_prefix: "query: ",
document_prefix: "passage: ",
},
sentence_transformers_all_MiniLM_L6_v2: {
base_url:
"https://huggingface.co/sentence-transformers/all-MiniLM-L6-v2/resolve/refs%2Fpr%2F21/",
search_prefix: "",
document_prefix: "",
},
sentence_transformers_all_MiniLM_L12_v2: {
base_url:
"https://huggingface.co/sentence-transformers/all-MiniLM-L12-v2/resolve/refs%2Fpr%2F4/",
search_prefix: "",
document_prefix: "",
},
};
export function getModelInfo(id) {
return {
modelURL: MODELS[id].base_url + "model.safetensors",
configURL: MODELS[id].base_url + "config.json",
tokenizerURL: MODELS[id].base_url + "tokenizer.json",
search_prefix: MODELS[id].search_prefix,
document_prefix: MODELS[id].document_prefix,
};
}
export function cosineSimilarity(vec1, vec2) {
const dot = vec1.reduce((acc, val, i) => acc + val * vec2[i], 0);
const a = Math.sqrt(vec1.reduce((acc, val) => acc + val * val, 0));
const b = Math.sqrt(vec2.reduce((acc, val) => acc + val * val, 0));
return dot / (a * b);
}
export async function getWikiText(article) {
// thanks to wikipedia for the API
const URL = `https://en.wikipedia.org/w/api.php?action=query&prop=extracts&exlimit=1&titles=${article}&explaintext=1&exsectionformat=plain&format=json&origin=*`;
return fetch(URL, {
method: "GET",
headers: {
Accept: "application/json",
},
})
.then((r) => r.json())
.then((data) => {
const pages = data.query.pages;
const pageId = Object.keys(pages)[0];
const extract = pages[pageId].extract;
if (extract === undefined || extract === "") {
throw new Error("No article found");
}
return extract;
})
.catch((error) => console.error("Error:", error));
}
| 8 |
0 | hf_public_repos/candle/candle-wasm-examples | hf_public_repos/candle/candle-wasm-examples/bert/README.md | ## Running BERT with Candle and WASM
Here, we provide two examples of how to run Bert using a Candle-compiled WASM binary and runtime.
### Vanilla JS and WebWorkers
To build and test the UI made in Vanilla JS and WebWorkers, first we need to build the WASM library:
```bash
sh build-lib.sh
```
This will bundle the library under `./build` and we can import it inside our WebWorker like a normal JS module:
```js
import init, { Model } from "./build/m.js";
```
The full example can be found under `./lib-example.html`. All needed assets are fetched from the web, so no need to download anything.
Finally, you can preview the example by running a local HTTP server. For example:
```bash
python -m http.server
```
Then open `http://localhost:8000/lib-example.html` in your browser.
| 9 |
0 | hf_public_repos/accelerate/manim_animations | hf_public_repos/accelerate/manim_animations/dataloaders/stage_1.py | # Copyright 2024 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
from manim import *
class Stage01(Scene):
def construct(self):
mascot = ImageMobject("mascot_bookie.png")
mascot.scale(.35)
mascot.move_to([-3.75,-1,0])
text = Paragraph(
"Distributed Training,\nHugging Face Accelerate,\nand PyTorch DataLoaders\n\nHow do they all interact?",
font_size=36,
line_spacing=1,
alignment="center",
weight=BOLD,
)
text.move_to([1.75,.5,0])
self.add(mascot)
self.add(text) | 0 |
0 | hf_public_repos/accelerate/manim_animations | hf_public_repos/accelerate/manim_animations/dataloaders/stage_4.py | # Copyright 2024 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
from manim import *
class Stage4(Scene):
def construct(self):
step_1 = MarkupText(
f"To understand the next part fully, let's define two terms,\n<span fgcolor='{RED}'>`batch_size`</span> and <span fgcolor='{BLUE}'>`global_batch_size`</span>:",
font_size=18
)
step_1.move_to([0, 1.5, 0])
# <span fgcolor='{YELLOW}'>●</span>
step_2 = MarkupText(
f"\n\n● <span fgcolor='{RED}'>`batch_size`</span>: \n\tThis will be defined as the batch size seen on a given\n\t*individual* GPU",
font_size=18,
).next_to(step_1, direction=DOWN, aligned_edge=LEFT)
step_3 = MarkupText(
f"\n\n● <span fgcolor='{BLUE}'>`global_batch_size`</span>:\n\tThis will be defined as the *total* number of\n\tdifferent items seen in the dataset, across all GPUs",
font_size=18,
).next_to(step_2, direction=DOWN, aligned_edge=LEFT)
step_4 = MarkupText(
f"\n\nSo if we have a dataset of 64 items, 8 GPUs, \nand a `batch_size` of 8, each *step* will go through\nthe entire dataset one time as 8*8=64",
font_size=18,
).next_to(step_3, direction=DOWN, aligned_edge=LEFT)
self.play(
Write(step_1, run_time=4),
)
self.play(
Write(step_2, run_time=4)
)
self.play(
Write(step_3, run_time=4)
)
self.play(
Write(step_4, run_time=6)
)
self.wait() | 1 |
0 | hf_public_repos/accelerate/manim_animations | hf_public_repos/accelerate/manim_animations/dataloaders/stage_3.py | # Copyright 2024 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
from manim import *
class Stage3(Scene):
def construct(self):
step_1 = MarkupText(
f"To combat this, Accelerate employs one of two different\nSampler wrapper methods depending on the scenario:",
font_size=24
)
step_1.move_to([0, 1.5, 0])
self.add(step_1)
step_2 = MarkupText(
f"1. Sharding the dataset before drawing:\n\t● <span fgcolor='{RED}'>IterableDatasetShard</span>\n\t● <span fgcolor='{RED}'>BatchSamplerShard</span>",
font_size=24,
).next_to(step_1, direction=DOWN, aligned_edge=LEFT)
self.add(step_2)
step_3 = MarkupText(
f"\n\n2. Splitting the batch after drawing:\n\t● <span fgcolor='{BLUE}'>DataLoaderDispatcher</span>",
font_size=24,
).next_to(step_2, direction=DOWN, aligned_edge=LEFT)
self.add(step_3) | 2 |
0 | hf_public_repos/accelerate/manim_animations | hf_public_repos/accelerate/manim_animations/dataloaders/stage_6.py | # Copyright 2024 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
from manim import *
class Stage6(Scene):
def construct(self):
# The dataset items
colors = ["BLUE_E", "DARK_BROWN", "GOLD_E", "GRAY_A"]
fill = Rectangle(height=0.46,width=0.46).set_stroke(width=0)
columns = [
VGroup(*[Rectangle(height=0.25,width=0.25,color=colors[j]) for i in range(8)]).arrange(RIGHT,buff=0)
for j in range(4)
]
dataset_recs = VGroup(*columns).arrange(UP, buff=0)
dataset_text = Text("Dataset", font_size=24)
dataset = Group(dataset_recs,dataset_text).arrange(DOWN, buff=0.5, aligned_edge=DOWN)
dataset.move_to([-2,0,0])
self.add(dataset)
code = Code(
code="# We enable this by default\naccelerator = Accelerator()\ndataloader = DataLoader(..., shuffle=True)\ndataloader = accelerator.prepare(dataloader)\nfor batch in dataloader:\n\t...",
tab_width=4,
background="window",
language="Python",
font="Monospace",
font_size=14,
corner_radius=.2,
insert_line_no=False,
line_spacing=.75,
style=Code.styles_list[1],
)
code.move_to([-3.5, 2.5, 0])
self.add(code)
# The dataloader itself
sampler_1 = Group(
Rectangle(color="blue", height=1, width=1),
Text("Sampler GPU 1", font_size=12)
).arrange(DOWN, buff=.25, aligned_edge=DOWN)
sampler_2 = Group(
Rectangle(color="blue", height=1, width=1),
Text("Sampler GPU 2", font_size=12)
).arrange(DOWN, buff=.25, aligned_edge=DOWN)
sampler_3 = Group(
Rectangle(color="blue", height=1, width=1),
Text("Sampler GPU 3", font_size=12)
).arrange(DOWN, buff=.25, aligned_edge=DOWN)
sampler_4 = Group(
Rectangle(color="blue", height=1, width=1),
Text("Sampler GPU 4", font_size=12)
).arrange(DOWN, buff=.25, aligned_edge=DOWN)
sampler_1.move_to([2,2,0])
sampler_2.move_to([2,.5,0])
sampler_3.move_to([2,-1.,0])
sampler_4.move_to([2,-2.5,0])
self.add(sampler_1, sampler_2, sampler_3, sampler_4)
samplers = [sampler_1[0], sampler_2[0], sampler_3[0], sampler_4[0]]
gpu_1 = Group(
Rectangle(color="white", height=1, width=1),
Text("Output GPU 1", font_size=12)
).arrange(DOWN, buff=.25, aligned_edge=DOWN).move_to([4.5, 2, 0])
gpu_2 = Group(
Rectangle(color="white", height=1, width=1),
Text("Output GPU 2", font_size=12)
).arrange(DOWN, buff=.25, aligned_edge=DOWN).move_to([4.5, .5, 0])
gpu_3 = Group(
Rectangle(color="white", height=1, width=1),
Text("Output GPU 3", font_size=12)
).arrange(DOWN, buff=.25, aligned_edge=DOWN).move_to([4.5, -1, 0])
gpu_4 = Group(
Rectangle(color="white", height=1, width=1),
Text("Output GPU 4", font_size=12)
).arrange(DOWN, buff=.25, aligned_edge=DOWN).move_to([4.5, -2.5, 0])
gpus = [gpu_1[0], gpu_2[0], gpu_3[0], gpu_4[0]]
self.add(gpu_1, gpu_2, gpu_3, gpu_4)
first_animations = []
second_animations = []
colors = ["BLUE_E", "DARK_BROWN", "GOLD_E", "GRAY_A"]
current_color = colors[0]
buff = 0
lr_buff = .25
old_target = None
new_datasets = []
for i,row_data in enumerate(dataset_recs):
new_row = []
current_color = colors[i]
if i == 0:
idx = -3
elif i == 1:
idx = -2
elif i == 2:
idx = -1
elif i == 3:
idx = 0
for j,indiv_data in enumerate(row_data):
dataset_target = Rectangle(height=0.46/2,width=0.46/2).set_stroke(width=0.).set_fill(current_color, opacity=0.7)
dataset_target.move_to(indiv_data)
dataset_target.generate_target()
aligned_edge = ORIGIN
if j % 8 == 0:
aligned_edge = LEFT
old_target = dataset_target.target
dataset_target.target.next_to(
samplers[abs(idx)].get_corner(UP+LEFT), buff=.02, direction=RIGHT+DOWN,
)
dataset_target.target.set_x(dataset_target.target.get_x())
elif j % 4 == 0:
old_target = dataset_target.target
dataset_target.target.next_to(
samplers[abs(idx)].get_corner(UP+LEFT), buff=.02, direction=RIGHT+DOWN,
)
dataset_target.target.set_x(dataset_target.target.get_x())
dataset_target.target.set_y(dataset_target.target.get_y()-.25)
else:
dataset_target.target.next_to(
old_target, direction=RIGHT, buff=0.02,
)
old_target = dataset_target.target
new_row.append(dataset_target)
first_animations.append(indiv_data.animate(run_time=0.5).set_stroke(current_color))
second_animations.append(MoveToTarget(dataset_target, run_time=1.5))
new_datasets.append(new_row)
step_1 = MarkupText(
f"During shuffling, each mini-batch's\noutput order will be modified",
font_size=18
)
step_1.move_to([-1.5, -2, 0])
self.play(
Write(step_1, run_time=3),
)
self.play(
*first_animations,
)
self.play(*second_animations)
self.wait(duration=.5)
move_animation = []
import random
for i,row in enumerate(new_datasets):
row = [row[k] for k in random.sample(range(8), 8)]
current_color = colors[i]
if i == 0:
idx = -3
elif i == 1:
idx = -2
elif i == 2:
idx = -1
elif i == 3:
idx = 0
for j,indiv_data in enumerate(row):
indiv_data.generate_target()
aligned_edge = ORIGIN
if j % 8 == 0:
aligned_edge = LEFT
indiv_data.target.next_to(
gpus[abs(idx)].get_corner(UP+LEFT), buff=.02, direction=RIGHT+DOWN,
)
indiv_data.target.set_x(indiv_data.target.get_x())
elif j % 4 == 0:
indiv_data.target.next_to(
gpus[abs(idx)].get_corner(UP+LEFT), buff=.02, direction=RIGHT+DOWN,
)
indiv_data.target.set_x(indiv_data.target.get_x())
indiv_data.target.set_y(indiv_data.target.get_y()-.25)
else:
indiv_data.target.next_to(
old_target, direction=RIGHT, buff=0.02,
)
old_target = indiv_data.target
move_animation.append(MoveToTarget(indiv_data, run_time=1.5))
self.play(*move_animation)
self.wait() | 3 |
0 | hf_public_repos/accelerate/src | hf_public_repos/accelerate/src/accelerate/hooks.py | # Copyright 2022 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import functools
from typing import Dict, List, Mapping, Optional, Union
import torch
import torch.nn as nn
from .state import PartialState
from .utils import (
PrefixedDataset,
find_device,
named_module_tensors,
send_to_device,
set_module_tensor_to_device,
)
from .utils.memory import clear_device_cache
from .utils.modeling import get_non_persistent_buffers
from .utils.other import recursive_getattr
_accelerate_added_attributes = ["to", "cuda", "npu", "xpu", "mlu", "musa"]
class ModelHook:
"""
A hook that contains callbacks to be executed just before and after the forward method of a model. The difference
with PyTorch existing hooks is that they get passed along the kwargs.
Class attribute:
- **no_grad** (`bool`, *optional*, defaults to `False`) -- Whether or not to execute the actual forward pass under
the `torch.no_grad()` context manager.
"""
no_grad = False
def init_hook(self, module):
"""
To be executed when the hook is attached to the module.
Args:
module (`torch.nn.Module`): The module attached to this hook.
"""
return module
def pre_forward(self, module, *args, **kwargs):
"""
To be executed just before the forward method of the model.
Args:
module (`torch.nn.Module`): The module whose forward pass will be executed just after this event.
args (`Tuple[Any]`): The positional arguments passed to the module.
kwargs (`Dict[Str, Any]`): The keyword arguments passed to the module.
Returns:
`Tuple[Tuple[Any], Dict[Str, Any]]`: A tuple with the treated `args` and `kwargs`.
"""
return args, kwargs
def post_forward(self, module, output):
"""
To be executed just after the forward method of the model.
Args:
module (`torch.nn.Module`): The module whose forward pass been executed just before this event.
output (`Any`): The output of the module.
Returns:
`Any`: The processed `output`.
"""
return output
def detach_hook(self, module):
"""
To be executed when the hook is detached from a module.
Args:
module (`torch.nn.Module`): The module detached from this hook.
"""
return module
class SequentialHook(ModelHook):
"""
A hook that can contain several hooks and iterates through them at each event.
"""
def __init__(self, *hooks):
self.hooks = hooks
def init_hook(self, module):
for hook in self.hooks:
module = hook.init_hook(module)
return module
def pre_forward(self, module, *args, **kwargs):
for hook in self.hooks:
args, kwargs = hook.pre_forward(module, *args, **kwargs)
return args, kwargs
def post_forward(self, module, output):
for hook in self.hooks:
output = hook.post_forward(module, output)
return output
def detach_hook(self, module):
for hook in self.hooks:
module = hook.detach_hook(module)
return module
def add_hook_to_module(module: nn.Module, hook: ModelHook, append: bool = False):
"""
Adds a hook to a given module. This will rewrite the `forward` method of the module to include the hook, to remove
this behavior and restore the original `forward` method, use `remove_hook_from_module`.
<Tip warning={true}>
If the module already contains a hook, this will replace it with the new hook passed by default. To chain two hooks
together, pass `append=True`, so it chains the current and new hook into an instance of the `SequentialHook` class.
</Tip>
Args:
module (`torch.nn.Module`):
The module to attach a hook to.
hook (`ModelHook`):
The hook to attach.
append (`bool`, *optional*, defaults to `False`):
Whether the hook should be chained with an existing one (if module already contains a hook) or not.
Returns:
`torch.nn.Module`: The same module, with the hook attached (the module is modified in place, so the result can
be discarded).
"""
if append and (getattr(module, "_hf_hook", None) is not None):
old_hook = module._hf_hook
remove_hook_from_module(module)
hook = SequentialHook(old_hook, hook)
if hasattr(module, "_hf_hook") and hasattr(module, "_old_forward"):
# If we already put some hook on this module, we replace it with the new one.
old_forward = module._old_forward
else:
old_forward = module.forward
module._old_forward = old_forward
module = hook.init_hook(module)
module._hf_hook = hook
def new_forward(module, *args, **kwargs):
args, kwargs = module._hf_hook.pre_forward(module, *args, **kwargs)
if module._hf_hook.no_grad:
with torch.no_grad():
output = module._old_forward(*args, **kwargs)
else:
output = module._old_forward(*args, **kwargs)
return module._hf_hook.post_forward(module, output)
# Overriding a GraphModuleImpl forward freezes the forward call and later modifications on the graph will fail.
# Reference: https://pytorch.slack.com/archives/C3PDTEV8E/p1705929610405409
if "GraphModuleImpl" in str(type(module)):
module.__class__.forward = functools.update_wrapper(functools.partial(new_forward, module), old_forward)
else:
module.forward = functools.update_wrapper(functools.partial(new_forward, module), old_forward)
return module
def remove_hook_from_module(module: nn.Module, recurse=False):
"""
Removes any hook attached to a module via `add_hook_to_module`.
Args:
module (`torch.nn.Module`): The module to attach a hook to.
recurse (`bool`, **optional**): Whether to remove the hooks recursively
Returns:
`torch.nn.Module`: The same module, with the hook detached (the module is modified in place, so the result can
be discarded).
"""
if hasattr(module, "_hf_hook"):
module._hf_hook.detach_hook(module)
delattr(module, "_hf_hook")
if hasattr(module, "_old_forward"):
# Overriding a GraphModuleImpl forward freezes the forward call and later modifications on the graph will fail.
# Reference: https://pytorch.slack.com/archives/C3PDTEV8E/p1705929610405409
if "GraphModuleImpl" in str(type(module)):
module.__class__.forward = module._old_forward
else:
module.forward = module._old_forward
delattr(module, "_old_forward")
# Remove accelerate added warning hooks from dispatch_model
for attr in _accelerate_added_attributes:
module.__dict__.pop(attr, None)
if recurse:
for child in module.children():
remove_hook_from_module(child, recurse)
return module
class AlignDevicesHook(ModelHook):
"""
A generic `ModelHook` that ensures inputs and model weights are on the same device for the forward pass of the
associated module, potentially offloading the weights after the forward pass.
Args:
execution_device (`torch.device`, *optional*):
The device on which inputs and model weights should be placed before the forward pass.
offload (`bool`, *optional*, defaults to `False`):
Whether or not the weights should be offloaded after the forward pass.
io_same_device (`bool`, *optional*, defaults to `False`):
Whether or not the output should be placed on the same device as the input was.
weights_map (`Mapping[str, torch.Tensor]`, *optional*):
When the model weights are offloaded, a (potentially lazy) map from param names to the tensor values.
offload_buffers (`bool`, *optional*, defaults to `False`):
Whether or not to include the associated module's buffers when offloading.
place_submodules (`bool`, *optional*, defaults to `False`):
Whether to place the submodules on `execution_device` during the `init_hook` event.
"""
def __init__(
self,
execution_device: Optional[Union[int, str, torch.device]] = None,
offload: bool = False,
io_same_device: bool = False,
weights_map: Optional[Mapping] = None,
offload_buffers: bool = False,
place_submodules: bool = False,
skip_keys: Optional[Union[str, List[str]]] = None,
tied_params_map: Optional[Dict[int, Dict[torch.device, torch.Tensor]]] = None,
):
self.execution_device = execution_device
self.offload = offload
self.io_same_device = io_same_device
self.weights_map = weights_map
self.offload_buffers = offload_buffers
self.place_submodules = place_submodules
self.skip_keys = skip_keys
# Will contain the input device when `io_same_device=True`.
self.input_device = None
self.param_original_devices = {}
self.buffer_original_devices = {}
self.tied_params_names = set()
# The hook pre_forward/post_forward need to have knowledge of this dictionary, as with offloading we want to avoid duplicating memory
# for tied weights already loaded on the target execution device.
self.tied_params_map = tied_params_map
def __repr__(self):
return (
f"AlignDevicesHook(execution_device={self.execution_device}, offload={self.offload}, "
f"io_same_device={self.io_same_device}, offload_buffers={self.offload_buffers}, "
f"place_submodules={self.place_submodules}, skip_keys={repr(self.skip_keys)})"
)
def init_hook(self, module):
# In case the AlignDevicesHook is on meta device, ignore tied weights as data_ptr() is then always zero.
if self.execution_device == "meta" or self.execution_device == torch.device("meta"):
self.tied_params_map = None
if not self.offload and self.execution_device is not None:
for name, _ in named_module_tensors(module, recurse=self.place_submodules):
set_module_tensor_to_device(module, name, self.execution_device, tied_params_map=self.tied_params_map)
elif self.offload:
self.original_devices = {
name: param.device for name, param in named_module_tensors(module, recurse=self.place_submodules)
}
if self.weights_map is None:
self.weights_map = {
name: param.to("cpu")
for name, param in named_module_tensors(
module, include_buffers=self.offload_buffers, recurse=self.place_submodules
)
}
for name, _ in named_module_tensors(
module, include_buffers=self.offload_buffers, recurse=self.place_submodules, remove_non_persistent=True
):
# When using disk offloading, we can not rely on `weights_map[name].data_ptr()` as the reference pointer,
# as we have no guarantee that safetensors' `file.get_tensor()` will always give the same pointer.
# As we have no reliable way to track the shared data pointer of tied weights in this case, we use tied_params_names: List[str]
# to add on the fly pointers to `tied_params_map` in the pre_forward call.
if (
self.tied_params_map is not None
and recursive_getattr(module, name).data_ptr() in self.tied_params_map
):
self.tied_params_names.add(name)
set_module_tensor_to_device(module, name, "meta")
if not self.offload_buffers and self.execution_device is not None:
for name, _ in module.named_buffers(recurse=self.place_submodules):
set_module_tensor_to_device(
module, name, self.execution_device, tied_params_map=self.tied_params_map
)
elif self.offload_buffers and self.execution_device is not None:
for name in get_non_persistent_buffers(module, recurse=self.place_submodules):
set_module_tensor_to_device(
module, name, self.execution_device, tied_params_map=self.tied_params_map
)
return module
def pre_forward(self, module, *args, **kwargs):
if self.io_same_device:
self.input_device = find_device([args, kwargs])
if self.offload:
self.tied_pointers_to_remove = set()
for name, _ in named_module_tensors(
module,
include_buffers=self.offload_buffers,
recurse=self.place_submodules,
remove_non_persistent=True,
):
fp16_statistics = None
value = self.weights_map[name]
if "weight" in name and name.replace("weight", "SCB") in self.weights_map.keys():
if value.dtype == torch.int8:
fp16_statistics = self.weights_map[name.replace("weight", "SCB")]
# In case we are using offloading with tied weights, we need to keep track of the offloaded weights
# that are loaded on device at this point, as we will need to remove them as well from the dictionary
# self.tied_params_map in order to allow to free memory.
if name in self.tied_params_names and value.data_ptr() not in self.tied_params_map:
self.tied_params_map[value.data_ptr()] = {}
if (
value is not None
and self.tied_params_map is not None
and value.data_ptr() in self.tied_params_map
and self.execution_device not in self.tied_params_map[value.data_ptr()]
):
self.tied_pointers_to_remove.add((value.data_ptr(), self.execution_device))
set_module_tensor_to_device(
module,
name,
self.execution_device,
value=value,
fp16_statistics=fp16_statistics,
tied_params_map=self.tied_params_map,
)
return send_to_device(args, self.execution_device), send_to_device(
kwargs, self.execution_device, skip_keys=self.skip_keys
)
def post_forward(self, module, output):
if self.offload:
for name, _ in named_module_tensors(
module,
include_buffers=self.offload_buffers,
recurse=self.place_submodules,
remove_non_persistent=True,
):
set_module_tensor_to_device(module, name, "meta")
if type(module).__name__ == "Linear8bitLt":
module.state.SCB = None
module.state.CxB = None
# We may have loaded tied weights into self.tied_params_map (avoiding to load them several times in e.g. submodules): remove them from
# this dictionary to allow the garbage collector to do its job.
for value_pointer, device in self.tied_pointers_to_remove:
del self.tied_params_map[value_pointer][device]
self.tied_pointers_to_remove = set()
if self.io_same_device and self.input_device is not None:
output = send_to_device(output, self.input_device, skip_keys=self.skip_keys)
return output
def detach_hook(self, module):
if self.offload:
for name, device in self.original_devices.items():
if device != torch.device("meta"):
set_module_tensor_to_device(module, name, device, value=self.weights_map.get(name, None))
return module
def attach_execution_device_hook(
module: torch.nn.Module,
execution_device: Union[int, str, torch.device],
skip_keys: Optional[Union[str, List[str]]] = None,
preload_module_classes: Optional[List[str]] = None,
tied_params_map: Optional[Dict[int, Dict[torch.device, torch.Tensor]]] = None,
):
"""
Recursively attaches `AlignDevicesHook` to all submodules of a given model to make sure they have the right
execution device
Args:
module (`torch.nn.Module`):
The module where we want to attach the hooks.
execution_device (`int`, `str` or `torch.device`):
The device on which inputs and model weights should be placed before the forward pass.
skip_keys (`str` or `List[str]`, *optional*):
A list of keys to ignore when moving inputs or outputs between devices.
preload_module_classes (`List[str]`, *optional*):
A list of classes whose instances should load all their weights (even in the submodules) at the beginning
of the forward. This should only be used for classes that have submodules which are registered but not
called directly during the forward, for instance if a `dense` linear layer is registered, but at forward,
`dense.weight` and `dense.bias` are used in some operations instead of calling `dense` directly.
tied_params_map (Optional[Dict[int, Dict[torch.device, torch.Tensor]]], *optional*, defaults to `None`):
A map of data pointers to dictionaries of devices to already dispatched tied weights. For a given execution
device, this parameter is useful to reuse the first available pointer of a shared weight for all others,
instead of duplicating memory.
"""
if not hasattr(module, "_hf_hook") and len(module.state_dict()) > 0:
add_hook_to_module(
module,
AlignDevicesHook(execution_device, skip_keys=skip_keys, tied_params_map=tied_params_map),
)
# Break the recursion if we get to a preload module.
if preload_module_classes is not None and module.__class__.__name__ in preload_module_classes:
return
for child in module.children():
attach_execution_device_hook(child, execution_device, skip_keys=skip_keys, tied_params_map=tied_params_map)
def attach_align_device_hook(
module: torch.nn.Module,
execution_device: Optional[torch.device] = None,
offload: bool = False,
weights_map: Optional[Mapping] = None,
offload_buffers: bool = False,
module_name: str = "",
skip_keys: Optional[Union[str, List[str]]] = None,
preload_module_classes: Optional[List[str]] = None,
tied_params_map: Optional[Dict[int, Dict[torch.device, torch.Tensor]]] = None,
):
"""
Recursively attaches `AlignDevicesHook` to all submodules of a given model that have direct parameters and/or
buffers.
Args:
module (`torch.nn.Module`):
The module where we want to attach the hooks.
execution_device (`torch.device`, *optional*):
The device on which inputs and model weights should be placed before the forward pass.
offload (`bool`, *optional*, defaults to `False`):
Whether or not the weights should be offloaded after the forward pass.
weights_map (`Mapping[str, torch.Tensor]`, *optional*):
When the model weights are offloaded, a (potentially lazy) map from param names to the tensor values.
offload_buffers (`bool`, *optional*, defaults to `False`):
Whether or not to include the associated module's buffers when offloading.
module_name (`str`, *optional*, defaults to `""`):
The name of the module.
skip_keys (`str` or `List[str]`, *optional*):
A list of keys to ignore when moving inputs or outputs between devices.
preload_module_classes (`List[str]`, *optional*):
A list of classes whose instances should load all their weights (even in the submodules) at the beginning
of the forward. This should only be used for classes that have submodules which are registered but not
called directly during the forward, for instance if a `dense` linear layer is registered, but at forward,
`dense.weight` and `dense.bias` are used in some operations instead of calling `dense` directly.
tied_params_map (Optional[Dict[int, Dict[torch.device, torch.Tensor]]], *optional*, defaults to `None`):
A map of data pointers to dictionaries of devices to already dispatched tied weights. For a given execution
device, this parameter is useful to reuse the first available pointer of a shared weight for all others,
instead of duplicating memory.
"""
# Attach the hook on this module if it has any direct tensor.
directs = named_module_tensors(module)
full_offload = (
offload and preload_module_classes is not None and module.__class__.__name__ in preload_module_classes
)
if len(list(directs)) > 0 or full_offload:
if weights_map is not None:
prefix = f"{module_name}." if len(module_name) > 0 else ""
prefixed_weights_map = PrefixedDataset(weights_map, prefix)
else:
prefixed_weights_map = None
hook = AlignDevicesHook(
execution_device=execution_device,
offload=offload,
weights_map=prefixed_weights_map,
offload_buffers=offload_buffers,
place_submodules=full_offload,
skip_keys=skip_keys,
tied_params_map=tied_params_map,
)
add_hook_to_module(module, hook, append=True)
# We stop the recursion in case we hit the full offload.
if full_offload:
return
# Recurse on all children of the module.
for child_name, child in module.named_children():
child_name = f"{module_name}.{child_name}" if len(module_name) > 0 else child_name
attach_align_device_hook(
child,
execution_device=execution_device,
offload=offload,
weights_map=weights_map,
offload_buffers=offload_buffers,
module_name=child_name,
preload_module_classes=preload_module_classes,
skip_keys=skip_keys,
tied_params_map=tied_params_map,
)
def remove_hook_from_submodules(module: nn.Module):
"""
Recursively removes all hooks attached on the submodules of a given model.
Args:
module (`torch.nn.Module`): The module on which to remove all hooks.
"""
remove_hook_from_module(module)
for child in module.children():
remove_hook_from_submodules(child)
def attach_align_device_hook_on_blocks(
module: nn.Module,
execution_device: Optional[Union[torch.device, Dict[str, torch.device]]] = None,
offload: Union[bool, Dict[str, bool]] = False,
weights_map: Mapping = None,
offload_buffers: bool = False,
module_name: str = "",
skip_keys: Optional[Union[str, List[str]]] = None,
preload_module_classes: Optional[List[str]] = None,
tied_params_map: Optional[Dict[int, Dict[torch.device, torch.Tensor]]] = None,
):
"""
Attaches `AlignDevicesHook` to all blocks of a given model as needed.
Args:
module (`torch.nn.Module`):
The module where we want to attach the hooks.
execution_device (`torch.device` or `Dict[str, torch.device]`, *optional*):
The device on which inputs and model weights should be placed before the forward pass. It can be one device
for the whole module, or a dictionary mapping module name to device.
offload (`bool`, *optional*, defaults to `False`):
Whether or not the weights should be offloaded after the forward pass. It can be one boolean for the whole
module, or a dictionary mapping module name to boolean.
weights_map (`Mapping[str, torch.Tensor]`, *optional*):
When the model weights are offloaded, a (potentially lazy) map from param names to the tensor values.
offload_buffers (`bool`, *optional*, defaults to `False`):
Whether or not to include the associated module's buffers when offloading.
module_name (`str`, *optional*, defaults to `""`):
The name of the module.
skip_keys (`str` or `List[str]`, *optional*):
A list of keys to ignore when moving inputs or outputs between devices.
preload_module_classes (`List[str]`, *optional*):
A list of classes whose instances should load all their weights (even in the submodules) at the beginning
of the forward. This should only be used for classes that have submodules which are registered but not
called directly during the forward, for instance if a `dense` linear layer is registered, but at forward,
`dense.weight` and `dense.bias` are used in some operations instead of calling `dense` directly.
tied_params_map (Optional[Dict[int, Dict[torch.device, torch.Tensor]]], *optional*, defaults to `None`):
A map of data pointers to dictionaries of devices to already dispatched tied weights. For a given execution
device, this parameter is useful to reuse the first available pointer of a shared weight for all others,
instead of duplicating memory.
"""
# If one device and one offload, we've got one hook.
if not isinstance(execution_device, Mapping) and not isinstance(offload, dict):
if not offload:
hook = AlignDevicesHook(
execution_device=execution_device,
io_same_device=True,
skip_keys=skip_keys,
place_submodules=True,
tied_params_map=tied_params_map,
)
add_hook_to_module(module, hook)
else:
attach_align_device_hook(
module,
execution_device=execution_device,
offload=True,
weights_map=weights_map,
offload_buffers=offload_buffers,
module_name=module_name,
skip_keys=skip_keys,
tied_params_map=tied_params_map,
)
return
if not isinstance(execution_device, Mapping):
execution_device = {key: execution_device for key in offload.keys()}
if not isinstance(offload, Mapping):
offload = {key: offload for key in execution_device.keys()}
if module_name in execution_device and module_name in offload and not offload[module_name]:
hook = AlignDevicesHook(
execution_device=execution_device[module_name],
offload_buffers=offload_buffers,
io_same_device=(module_name == ""),
place_submodules=True,
skip_keys=skip_keys,
tied_params_map=tied_params_map,
)
add_hook_to_module(module, hook)
attach_execution_device_hook(
module, execution_device[module_name], skip_keys=skip_keys, tied_params_map=tied_params_map
)
elif module_name in execution_device and module_name in offload:
attach_align_device_hook(
module,
execution_device=execution_device[module_name],
offload=True,
weights_map=weights_map,
offload_buffers=offload_buffers,
module_name=module_name,
skip_keys=skip_keys,
preload_module_classes=preload_module_classes,
tied_params_map=tied_params_map,
)
if not hasattr(module, "_hf_hook"):
hook = AlignDevicesHook(
execution_device=execution_device[module_name],
io_same_device=(module_name == ""),
skip_keys=skip_keys,
tied_params_map=tied_params_map,
)
add_hook_to_module(module, hook)
attach_execution_device_hook(
module,
execution_device[module_name],
preload_module_classes=preload_module_classes,
skip_keys=skip_keys,
tied_params_map=tied_params_map,
)
elif module_name == "":
hook = AlignDevicesHook(
execution_device=execution_device.get(""),
io_same_device=True,
skip_keys=skip_keys,
tied_params_map=tied_params_map,
)
add_hook_to_module(module, hook)
for child_name, child in module.named_children():
child_name = f"{module_name}.{child_name}" if len(module_name) > 0 else child_name
attach_align_device_hook_on_blocks(
child,
execution_device=execution_device,
offload=offload,
weights_map=weights_map,
offload_buffers=offload_buffers,
module_name=child_name,
preload_module_classes=preload_module_classes,
skip_keys=skip_keys,
tied_params_map=tied_params_map,
)
class CpuOffload(ModelHook):
"""
Offloads a model on the CPU until its forward pass is called. The model will not be offloaded back to the CPU after
the forward, the user needs to call the `init_hook` method again for this.
Args:
execution_device(`str`, `int` or `torch.device`, *optional*):
The device on which the model should be executed. Will default to the MPS device if it's available, then
GPU 0 if there is a GPU, and finally to the CPU.
prev_module_hook (`UserCpuOffloadHook`, *optional*):
The hook sent back by [`cpu_offload_with_hook`] for a previous model in the pipeline you are running. If
passed, its offload method will be called just before the forward of the model to which this hook is
attached.
"""
def __init__(
self,
execution_device: Optional[Union[str, int, torch.device]] = None,
prev_module_hook: Optional["UserCpuOffloadHook"] = None,
):
self.prev_module_hook = prev_module_hook
self.execution_device = execution_device if execution_device is not None else PartialState().default_device
def init_hook(self, module):
return module.to("cpu")
def pre_forward(self, module, *args, **kwargs):
if self.prev_module_hook is not None:
self.prev_module_hook.offload()
clear_device_cache()
module.to(self.execution_device)
return send_to_device(args, self.execution_device), send_to_device(kwargs, self.execution_device)
class UserCpuOffloadHook:
"""
A simple hook grouping a model and a `ModelHook`, which provides easy APIs for to call the init method of the hook
or remove it entirely.
"""
def __init__(self, model, hook):
self.model = model
self.hook = hook
def offload(self):
self.hook.init_hook(self.model)
def remove(self):
remove_hook_from_module(self.model)
| 4 |
0 | hf_public_repos/accelerate/src | hf_public_repos/accelerate/src/accelerate/logging.py | # Copyright 2022 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import functools
import logging
import os
from .state import PartialState
class MultiProcessAdapter(logging.LoggerAdapter):
"""
An adapter to assist with logging in multiprocess.
`log` takes in an additional `main_process_only` kwarg, which dictates whether it should be called on all processes
or only the main executed one. Default is `main_process_only=True`.
Does not require an `Accelerator` object to be created first.
"""
@staticmethod
def _should_log(main_process_only):
"Check if log should be performed"
state = PartialState()
return not main_process_only or (main_process_only and state.is_main_process)
def log(self, level, msg, *args, **kwargs):
"""
Delegates logger call after checking if we should log.
Accepts a new kwarg of `main_process_only`, which will dictate whether it will be logged across all processes
or only the main executed one. Default is `True` if not passed
Also accepts "in_order", which if `True` makes the processes log one by one, in order. This is much easier to
read, but comes at the cost of sometimes needing to wait for the other processes. Default is `False` to not
break with the previous behavior.
`in_order` is ignored if `main_process_only` is passed.
"""
if PartialState._shared_state == {}:
raise RuntimeError(
"You must initialize the accelerate state by calling either `PartialState()` or `Accelerator()` before using the logging utility."
)
main_process_only = kwargs.pop("main_process_only", True)
in_order = kwargs.pop("in_order", False)
# set `stacklevel` to exclude ourself in `Logger.findCaller()` while respecting user's choice
kwargs.setdefault("stacklevel", 2)
if self.isEnabledFor(level):
if self._should_log(main_process_only):
msg, kwargs = self.process(msg, kwargs)
self.logger.log(level, msg, *args, **kwargs)
elif in_order:
state = PartialState()
for i in range(state.num_processes):
if i == state.process_index:
msg, kwargs = self.process(msg, kwargs)
self.logger.log(level, msg, *args, **kwargs)
state.wait_for_everyone()
@functools.lru_cache(None)
def warning_once(self, *args, **kwargs):
"""
This method is identical to `logger.warning()`, but will emit the warning with the same message only once
Note: The cache is for the function arguments, so 2 different callers using the same arguments will hit the
cache. The assumption here is that all warning messages are unique across the code. If they aren't then need to
switch to another type of cache that includes the caller frame information in the hashing function.
"""
self.warning(*args, **kwargs)
def get_logger(name: str, log_level: str = None):
"""
Returns a `logging.Logger` for `name` that can handle multiprocessing.
If a log should be called on all processes, pass `main_process_only=False` If a log should be called on all
processes and in order, also pass `in_order=True`
Args:
name (`str`):
The name for the logger, such as `__file__`
log_level (`str`, *optional*):
The log level to use. If not passed, will default to the `LOG_LEVEL` environment variable, or `INFO` if not
Example:
```python
>>> from accelerate.logging import get_logger
>>> from accelerate import Accelerator
>>> logger = get_logger(__name__)
>>> accelerator = Accelerator()
>>> logger.info("My log", main_process_only=False)
>>> logger.debug("My log", main_process_only=True)
>>> logger = get_logger(__name__, log_level="DEBUG")
>>> logger.info("My log")
>>> logger.debug("My second log")
>>> array = ["a", "b", "c", "d"]
>>> letter_at_rank = array[accelerator.process_index]
>>> logger.info(letter_at_rank, in_order=True)
```
"""
if log_level is None:
log_level = os.environ.get("ACCELERATE_LOG_LEVEL", None)
logger = logging.getLogger(name)
if log_level is not None:
logger.setLevel(log_level.upper())
logger.root.setLevel(log_level.upper())
return MultiProcessAdapter(logger, {})
| 5 |
0 | hf_public_repos/accelerate/src | hf_public_repos/accelerate/src/accelerate/big_modeling.py | # Copyright 2022 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import logging
import os
from contextlib import contextmanager
from functools import wraps
from typing import Dict, List, Optional, Union
import torch
import torch.nn as nn
from .hooks import (
AlignDevicesHook,
CpuOffload,
UserCpuOffloadHook,
add_hook_to_module,
attach_align_device_hook,
attach_align_device_hook_on_blocks,
)
from .utils import (
OffloadedWeightsLoader,
check_cuda_p2p_ib_support,
check_device_map,
extract_submodules_state_dict,
find_tied_parameters,
get_balanced_memory,
infer_auto_device_map,
is_bnb_available,
is_mlu_available,
is_musa_available,
is_npu_available,
is_torch_version,
is_xpu_available,
load_checkpoint_in_model,
offload_state_dict,
parse_flag_from_env,
retie_parameters,
)
from .utils.other import recursive_getattr
logger = logging.getLogger(__name__)
@contextmanager
def init_empty_weights(include_buffers: bool = None):
"""
A context manager under which models are initialized with all parameters on the meta device, therefore creating an
empty model. Useful when just initializing the model would blow the available RAM.
Args:
include_buffers (`bool`, *optional*):
Whether or not to also put all buffers on the meta device while initializing.
Example:
```python
import torch.nn as nn
from accelerate import init_empty_weights
# Initialize a model with 100 billions parameters in no time and without using any RAM.
with init_empty_weights():
tst = nn.Sequential(*[nn.Linear(10000, 10000) for _ in range(1000)])
```
<Tip warning={true}>
Any model created under this context manager has no weights. As such you can't do something like
`model.to(some_device)` with it. To load weights inside your empty model, see [`load_checkpoint_and_dispatch`].
Make sure to overwrite the default device_map param for [`load_checkpoint_and_dispatch`], otherwise dispatch is not
called.
</Tip>
"""
if include_buffers is None:
include_buffers = parse_flag_from_env("ACCELERATE_INIT_INCLUDE_BUFFERS", False)
with init_on_device(torch.device("meta"), include_buffers=include_buffers) as f:
yield f
@contextmanager
def init_on_device(device: torch.device, include_buffers: bool = None):
"""
A context manager under which models are initialized with all parameters on the specified device.
Args:
device (`torch.device`):
Device to initialize all parameters on.
include_buffers (`bool`, *optional*):
Whether or not to also put all buffers on the meta device while initializing.
Example:
```python
import torch.nn as nn
from accelerate import init_on_device
with init_on_device(device=torch.device("cuda")):
tst = nn.Linear(100, 100) # on `cuda` device
```
"""
if include_buffers is None:
include_buffers = parse_flag_from_env("ACCELERATE_INIT_INCLUDE_BUFFERS", False)
# TODO(shingjan): remove the torch version check once older versions are deprecated
if is_torch_version(">=", "2.0") and include_buffers:
with device:
yield
return
old_register_parameter = nn.Module.register_parameter
if include_buffers:
old_register_buffer = nn.Module.register_buffer
def register_empty_parameter(module, name, param):
old_register_parameter(module, name, param)
if param is not None:
param_cls = type(module._parameters[name])
kwargs = module._parameters[name].__dict__
kwargs["requires_grad"] = param.requires_grad
module._parameters[name] = param_cls(module._parameters[name].to(device), **kwargs)
def register_empty_buffer(module, name, buffer, persistent=True):
old_register_buffer(module, name, buffer, persistent=persistent)
if buffer is not None:
module._buffers[name] = module._buffers[name].to(device)
# Patch tensor creation
if include_buffers:
tensor_constructors_to_patch = {
torch_function_name: getattr(torch, torch_function_name)
for torch_function_name in ["empty", "zeros", "ones", "full"]
}
else:
tensor_constructors_to_patch = {}
def patch_tensor_constructor(fn):
def wrapper(*args, **kwargs):
kwargs["device"] = device
return fn(*args, **kwargs)
return wrapper
try:
nn.Module.register_parameter = register_empty_parameter
if include_buffers:
nn.Module.register_buffer = register_empty_buffer
for torch_function_name in tensor_constructors_to_patch.keys():
setattr(torch, torch_function_name, patch_tensor_constructor(getattr(torch, torch_function_name)))
yield
finally:
nn.Module.register_parameter = old_register_parameter
if include_buffers:
nn.Module.register_buffer = old_register_buffer
for torch_function_name, old_torch_function in tensor_constructors_to_patch.items():
setattr(torch, torch_function_name, old_torch_function)
def cpu_offload(
model: nn.Module,
execution_device: Optional[torch.device] = None,
offload_buffers: bool = False,
state_dict: Optional[Dict[str, torch.Tensor]] = None,
preload_module_classes: Optional[List[str]] = None,
):
"""
Activates full CPU offload for a model. As a result, all parameters of the model will be offloaded and only one
copy of the state dict of the model will be kept. During the forward pass, parameters will be extracted from that
state dict and put on the execution device passed as they are needed, then offloaded again.
Args:
model (`torch.nn.Module`):
The model to offload.
execution_device (`torch.device`, *optional*):
The device on which the forward pass of the model will be executed (should be a GPU). Will default to the
model first parameter device.
offload_buffers (`bool`, *optional*, defaults to `False`):
Whether or not to offload the buffers with the model parameters.
state_dict (`Dict[str, torch.Tensor]`, *optional*):
The state dict of the model that will be kept on CPU.
preload_module_classes (`List[str]`, *optional*):
A list of classes whose instances should load all their weights (even in the submodules) at the beginning
of the forward. This should only be used for classes that have submodules which are registered but not
called directly during the forward, for instance if a `dense` linear layer is registered, but at forward,
`dense.weight` and `dense.bias` are used in some operations instead of calling `dense` directly.
"""
if execution_device is None:
execution_device = next(iter(model.parameters())).device
if state_dict is None:
state_dict = {n: p.to("cpu") for n, p in model.state_dict().items()}
add_hook_to_module(model, AlignDevicesHook(io_same_device=True), append=True)
attach_align_device_hook(
model,
execution_device=execution_device,
offload=True,
offload_buffers=offload_buffers,
weights_map=state_dict,
preload_module_classes=preload_module_classes,
)
return model
def cpu_offload_with_hook(
model: torch.nn.Module,
execution_device: Optional[Union[int, str, torch.device]] = None,
prev_module_hook: Optional[UserCpuOffloadHook] = None,
):
"""
Offloads a model on the CPU and puts it back to an execution device when executed. The difference with
[`cpu_offload`] is that the model stays on the execution device after the forward and is only offloaded again when
the `offload` method of the returned `hook` is called. Useful for pipelines running a model in a loop.
Args:
model (`torch.nn.Module`):
The model to offload.
execution_device(`str`, `int` or `torch.device`, *optional*):
The device on which the model should be executed. Will default to the MPS device if it's available, then
GPU 0 if there is a GPU, and finally to the CPU.
prev_module_hook (`UserCpuOffloadHook`, *optional*):
The hook sent back by this function for a previous model in the pipeline you are running. If passed, its
offload method will be called just before the forward of the model to which this hook is attached.
Example:
```py
model_1, hook_1 = cpu_offload_with_hook(model_1, cuda_device)
model_2, hook_2 = cpu_offload_with_hook(model_2, cuda_device, prev_module_hook=hook_1)
model_3, hook_3 = cpu_offload_with_hook(model_3, cuda_device, prev_module_hook=hook_2)
hid_1 = model_1(input)
for i in range(50):
# model1 is offloaded on the CPU at the first iteration, model 2 stays on the GPU for this whole loop.
hid_2 = model_2(hid_1)
# model2 is offloaded to the CPU just before this forward.
hid_3 = model_3(hid_3)
# For model3, you need to manually call the hook offload method.
hook_3.offload()
```
"""
hook = CpuOffload(execution_device=execution_device, prev_module_hook=prev_module_hook)
add_hook_to_module(model, hook, append=True)
user_hook = UserCpuOffloadHook(model, hook)
return model, user_hook
def disk_offload(
model: nn.Module,
offload_dir: Union[str, os.PathLike],
execution_device: Optional[torch.device] = None,
offload_buffers: bool = False,
preload_module_classes: Optional[List[str]] = None,
):
"""
Activates full disk offload for a model. As a result, all parameters of the model will be offloaded as
memory-mapped array in a given folder. During the forward pass, parameters will be accessed from that folder and
put on the execution device passed as they are needed, then offloaded again.
Args:
model (`torch.nn.Module`): The model to offload.
offload_dir (`str` or `os.PathLike`):
The folder in which to offload the model weights (or where the model weights are already offloaded).
execution_device (`torch.device`, *optional*):
The device on which the forward pass of the model will be executed (should be a GPU). Will default to the
model's first parameter device.
offload_buffers (`bool`, *optional*, defaults to `False`):
Whether or not to offload the buffers with the model parameters.
preload_module_classes (`List[str]`, *optional*):
A list of classes whose instances should load all their weights (even in the submodules) at the beginning
of the forward. This should only be used for classes that have submodules which are registered but not
called directly during the forward, for instance if a `dense` linear layer is registered, but at forward,
`dense.weight` and `dense.bias` are used in some operations instead of calling `dense` directly.
"""
if not os.path.isdir(offload_dir) or not os.path.isfile(os.path.join(offload_dir, "index.json")):
offload_state_dict(offload_dir, model.state_dict())
if execution_device is None:
execution_device = next(iter(model.parameters())).device
weights_map = OffloadedWeightsLoader(save_folder=offload_dir)
add_hook_to_module(model, AlignDevicesHook(io_same_device=True), append=True)
attach_align_device_hook(
model,
execution_device=execution_device,
offload=True,
offload_buffers=offload_buffers,
weights_map=weights_map,
preload_module_classes=preload_module_classes,
)
return model
def dispatch_model(
model: nn.Module,
device_map: Dict[str, Union[str, int, torch.device]],
main_device: Optional[torch.device] = None,
state_dict: Optional[Dict[str, torch.Tensor]] = None,
offload_dir: Optional[Union[str, os.PathLike]] = None,
offload_index: Optional[Dict[str, str]] = None,
offload_buffers: bool = False,
skip_keys: Optional[Union[str, List[str]]] = None,
preload_module_classes: Optional[List[str]] = None,
force_hooks: bool = False,
):
"""
Dispatches a model according to a given device map. Layers of the model might be spread across GPUs, offloaded on
the CPU or even the disk.
Args:
model (`torch.nn.Module`):
The model to dispatch.
device_map (`Dict[str, Union[str, int, torch.device]]`):
A dictionary mapping module names in the models `state_dict` to the device they should go to. Note that
`"disk"` is accepted even if it's not a proper value for `torch.device`.
main_device (`str`, `int` or `torch.device`, *optional*):
The main execution device. Will default to the first device in the `device_map` different from `"cpu"` or
`"disk"`.
state_dict (`Dict[str, torch.Tensor]`, *optional*):
The state dict of the part of the model that will be kept on CPU.
offload_dir (`str` or `os.PathLike`):
The folder in which to offload the model weights (or where the model weights are already offloaded).
offload_index (`Dict`, *optional*):
A dictionary from weight name to their information (`dtype`/ `shape` or safetensors filename). Will default
to the index saved in `save_folder`.
offload_buffers (`bool`, *optional*, defaults to `False`):
Whether or not to offload the buffers with the model parameters.
skip_keys (`str` or `List[str]`, *optional*):
A list of keys to ignore when moving inputs or outputs between devices.
preload_module_classes (`List[str]`, *optional*):
A list of classes whose instances should load all their weights (even in the submodules) at the beginning
of the forward. This should only be used for classes that have submodules which are registered but not
called directly during the forward, for instance if a `dense` linear layer is registered, but at forward,
`dense.weight` and `dense.bias` are used in some operations instead of calling `dense` directly.
force_hooks (`bool`, *optional*, defaults to `False`):
Whether or not to force device hooks to be attached to the model even if all layers are dispatched to a
single device.
"""
# Error early if the device map is incomplete.
check_device_map(model, device_map)
# We need to force hook for quantized model that can't be moved with to()
if getattr(model, "quantization_method", "bitsandbytes") == "bitsandbytes":
# since bnb 0.43.2, we can move 4-bit model
if getattr(model, "is_loaded_in_8bit", False) or (
getattr(model, "is_loaded_in_4bit", False) and not is_bnb_available(min_version="0.43.2")
):
force_hooks = True
# We attach hooks if the device_map has at least 2 different devices or if
# force_hooks is set to `True`. Otherwise, the model in already loaded
# in the unique device and the user can decide where to dispatch the model.
# If the model is quantized, we always force-dispatch the model
if (len(set(device_map.values())) > 1) or force_hooks:
if main_device is None:
if set(device_map.values()) == {"cpu"} or set(device_map.values()) == {"cpu", "disk"}:
main_device = "cpu"
else:
main_device = [d for d in device_map.values() if d not in ["cpu", "disk"]][0]
if main_device != "cpu":
cpu_modules = [name for name, device in device_map.items() if device == "cpu"]
if state_dict is None and len(cpu_modules) > 0:
state_dict = extract_submodules_state_dict(model.state_dict(), cpu_modules)
disk_modules = [name for name, device in device_map.items() if device == "disk"]
if offload_dir is None and offload_index is None and len(disk_modules) > 0:
raise ValueError(
"We need an `offload_dir` to dispatch this model according to this `device_map`, the following submodules "
f"need to be offloaded: {', '.join(disk_modules)}."
)
if (
len(disk_modules) > 0
and offload_index is None
and (not os.path.isdir(offload_dir) or not os.path.isfile(os.path.join(offload_dir, "index.json")))
):
disk_state_dict = extract_submodules_state_dict(model.state_dict(), disk_modules)
offload_state_dict(offload_dir, disk_state_dict)
execution_device = {
name: main_device if device in ["cpu", "disk"] else device for name, device in device_map.items()
}
execution_device[""] = main_device
offloaded_devices = ["disk"] if main_device == "cpu" or main_device == "mps" else ["cpu", "disk"]
offload = {name: device in offloaded_devices for name, device in device_map.items()}
save_folder = offload_dir if len(disk_modules) > 0 else None
if state_dict is not None or save_folder is not None or offload_index is not None:
device = main_device if offload_index is not None else None
weights_map = OffloadedWeightsLoader(
state_dict=state_dict, save_folder=save_folder, index=offload_index, device=device
)
else:
weights_map = None
# When dispatching the model's parameters to the devices specified in device_map, we want to avoid allocating memory several times for the
# tied parameters. The dictionary tied_params_map keeps track of the already allocated data for a given tied parameter (represented by its
# original pointer) on each devices.
tied_params = find_tied_parameters(model)
tied_params_map = {}
for group in tied_params:
for param_name in group:
# data_ptr() is enough here, as `find_tied_parameters` finds tied params simply by comparing `param1 is param2`, so we don't need
# to care about views of tensors through storage_offset.
data_ptr = recursive_getattr(model, param_name).data_ptr()
tied_params_map[data_ptr] = {}
# Note: To handle the disk offloading case, we can not simply use weights_map[param_name].data_ptr() as the reference pointer,
# as we have no guarantee that safetensors' `file.get_tensor()` will always give the same pointer.
attach_align_device_hook_on_blocks(
model,
execution_device=execution_device,
offload=offload,
offload_buffers=offload_buffers,
weights_map=weights_map,
skip_keys=skip_keys,
preload_module_classes=preload_module_classes,
tied_params_map=tied_params_map,
)
# warn if there is any params on the meta device
offloaded_devices_str = " and ".join(
[device for device in set(device_map.values()) if device in ("cpu", "disk")]
)
if len(offloaded_devices_str) > 0:
logger.warning(
f"Some parameters are on the meta device because they were offloaded to the {offloaded_devices_str}."
)
# Attaching the hook may break tied weights, so we retie them
retie_parameters(model, tied_params)
# add warning to cuda and to method
def add_warning(fn, model):
@wraps(fn)
def wrapper(*args, **kwargs):
warning_msg = "You shouldn't move a model that is dispatched using accelerate hooks."
if str(fn.__name__) == "to":
to_device = torch._C._nn._parse_to(*args, **kwargs)[0]
if to_device is not None:
logger.warning(warning_msg)
else:
logger.warning(warning_msg)
for param in model.parameters():
if param.device == torch.device("meta"):
raise RuntimeError("You can't move a model that has some modules offloaded to cpu or disk.")
return fn(*args, **kwargs)
return wrapper
# Make sure to update _accelerate_added_attributes in hooks.py if you add any hook
model.to = add_warning(model.to, model)
if is_npu_available():
model.npu = add_warning(model.npu, model)
elif is_mlu_available():
model.mlu = add_warning(model.mlu, model)
elif is_musa_available():
model.musa = add_warning(model.musa, model)
elif is_xpu_available():
model.xpu = add_warning(model.xpu, model)
else:
model.cuda = add_warning(model.cuda, model)
# Check if we are using multi-gpus with RTX 4000 series
use_multi_gpu = len([device for device in set(device_map.values()) if device not in ("cpu", "disk")]) > 1
if use_multi_gpu and not check_cuda_p2p_ib_support():
logger.warning(
"We've detected an older driver with an RTX 4000 series GPU. These drivers have issues with P2P. "
"This can affect the multi-gpu inference when using accelerate device_map."
"Please make sure to update your driver to the latest version which resolves this."
)
else:
device = list(device_map.values())[0]
# `torch.Tensor.to(<int num>)` is not supported by `torch_npu` (see this [issue](https://github.com/Ascend/pytorch/issues/16)).
if is_npu_available() and isinstance(device, int):
device = f"npu:{device}"
elif is_mlu_available() and isinstance(device, int):
device = f"mlu:{device}"
elif is_musa_available() and isinstance(device, int):
device = f"musa:{device}"
elif is_xpu_available() and isinstance(device, int):
device = f"xpu:{device}"
if device != "disk":
model.to(device)
else:
raise ValueError(
"You are trying to offload the whole model to the disk. Please use the `disk_offload` function instead."
)
# Convert OrderedDict back to dict for easier usage
model.hf_device_map = dict(device_map)
return model
def load_checkpoint_and_dispatch(
model: nn.Module,
checkpoint: Union[str, os.PathLike],
device_map: Optional[Union[str, Dict[str, Union[int, str, torch.device]]]] = None,
max_memory: Optional[Dict[Union[int, str], Union[int, str]]] = None,
no_split_module_classes: Optional[List[str]] = None,
offload_folder: Optional[Union[str, os.PathLike]] = None,
offload_buffers: bool = False,
dtype: Optional[Union[str, torch.dtype]] = None,
offload_state_dict: Optional[bool] = None,
skip_keys: Optional[Union[str, List[str]]] = None,
preload_module_classes: Optional[List[str]] = None,
force_hooks: bool = False,
strict: bool = False,
):
"""
Loads a (potentially sharded) checkpoint inside a model, potentially sending weights to a given device as they are
loaded and adds the various hooks that will make this model run properly (even if split across devices).
Args:
model (`torch.nn.Module`): The model in which we want to load a checkpoint.
checkpoint (`str` or `os.PathLike`):
The folder checkpoint to load. It can be:
- a path to a file containing a whole model state dict
- a path to a `.json` file containing the index to a sharded checkpoint
- a path to a folder containing a unique `.index.json` file and the shards of a checkpoint.
device_map (`Dict[str, Union[int, str, torch.device]]`, *optional*):
A map that specifies where each submodule should go. It doesn't need to be refined to each parameter/buffer
name, once a given module name is inside, every submodule of it will be sent to the same device.
To have Accelerate compute the most optimized `device_map` automatically, set `device_map="auto"`. For more
information about each option see [here](../concept_guides/big_model_inference#designing-a-device-map).
Defaults to None, which means [`dispatch_model`] will not be called.
max_memory (`Dict`, *optional*):
A dictionary device identifier to maximum memory. Will default to the maximum memory available for each GPU
and the available CPU RAM if unset.
no_split_module_classes (`List[str]`, *optional*):
A list of layer class names that should never be split across device (for instance any layer that has a
residual connection).
offload_folder (`str` or `os.PathLike`, *optional*):
If the `device_map` contains any value `"disk"`, the folder where we will offload weights.
offload_buffers (`bool`, *optional*, defaults to `False`):
In the layers that are offloaded on the CPU or the hard drive, whether or not to offload the buffers as
well as the parameters.
dtype (`str` or `torch.dtype`, *optional*):
If provided, the weights will be converted to that type when loaded.
offload_state_dict (`bool`, *optional*):
If `True`, will temporarily offload the CPU state dict on the hard drive to avoid getting out of CPU RAM if
the weight of the CPU state dict + the biggest shard does not fit. Will default to `True` if the device map
picked contains `"disk"` values.
skip_keys (`str` or `List[str]`, *optional*):
A list of keys to ignore when moving inputs or outputs between devices.
preload_module_classes (`List[str]`, *optional*):
A list of classes whose instances should load all their weights (even in the submodules) at the beginning
of the forward. This should only be used for classes that have submodules which are registered but not
called directly during the forward, for instance if a `dense` linear layer is registered, but at forward,
`dense.weight` and `dense.bias` are used in some operations instead of calling `dense` directly.
force_hooks (`bool`, *optional*, defaults to `False`):
Whether or not to force device hooks to be attached to the model even if all layers are dispatched to a
single device.
strict (`bool`, *optional*, defaults to `False`):
Whether to strictly enforce that the keys in the checkpoint state_dict match the keys of the model's
state_dict.
Example:
```python
>>> from accelerate import init_empty_weights, load_checkpoint_and_dispatch
>>> from huggingface_hub import hf_hub_download
>>> from transformers import AutoConfig, AutoModelForCausalLM
>>> # Download the Weights
>>> checkpoint = "EleutherAI/gpt-j-6B"
>>> weights_location = hf_hub_download(checkpoint, "pytorch_model.bin")
>>> # Create a model and initialize it with empty weights
>>> config = AutoConfig.from_pretrained(checkpoint)
>>> with init_empty_weights():
... model = AutoModelForCausalLM.from_config(config)
>>> # Load the checkpoint and dispatch it to the right devices
>>> model = load_checkpoint_and_dispatch(
... model, weights_location, device_map="auto", no_split_module_classes=["GPTJBlock"]
... )
```
"""
if isinstance(device_map, str) and device_map not in ["auto", "balanced", "balanced_low_0", "sequential"]:
raise ValueError(
"If passing a string for `device_map`, please choose 'auto', 'balanced', 'balanced_low_0' or "
"'sequential'."
)
if isinstance(device_map, str):
if device_map != "sequential":
max_memory = get_balanced_memory(
model,
max_memory=max_memory,
no_split_module_classes=no_split_module_classes,
dtype=dtype,
low_zero=(device_map == "balanced_low_0"),
)
device_map = infer_auto_device_map(
model,
max_memory=max_memory,
no_split_module_classes=no_split_module_classes,
dtype=dtype,
offload_buffers=offload_buffers,
)
if offload_state_dict is None and device_map is not None and "disk" in device_map.values():
offload_state_dict = True
load_checkpoint_in_model(
model,
checkpoint,
device_map=device_map,
offload_folder=offload_folder,
dtype=dtype,
offload_state_dict=offload_state_dict,
offload_buffers=offload_buffers,
strict=strict,
)
if device_map is None:
return model
return dispatch_model(
model,
device_map=device_map,
offload_dir=offload_folder,
offload_buffers=offload_buffers,
skip_keys=skip_keys,
preload_module_classes=preload_module_classes,
force_hooks=force_hooks,
)
| 6 |
0 | hf_public_repos/accelerate/src | hf_public_repos/accelerate/src/accelerate/launchers.py | # Copyright 2021 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import os
import sys
import tempfile
import torch
from .state import AcceleratorState, PartialState
from .utils import (
PrecisionType,
PrepareForLaunch,
are_libraries_initialized,
check_cuda_p2p_ib_support,
get_gpu_info,
is_mps_available,
is_torch_version,
patch_environment,
)
from .utils.constants import ELASTIC_LOG_LINE_PREFIX_TEMPLATE_PYTORCH_VERSION
def test_launch():
"Verify a `PartialState` can be initialized."
_ = PartialState()
def notebook_launcher(
function,
args=(),
num_processes=None,
mixed_precision="no",
use_port="29500",
master_addr="127.0.0.1",
node_rank=0,
num_nodes=1,
rdzv_backend="static",
rdzv_endpoint="",
rdzv_conf=None,
rdzv_id="none",
max_restarts=0,
monitor_interval=0.1,
log_line_prefix_template=None,
):
"""
Launches a training function, using several processes or multiple nodes if it's possible in the current environment
(TPU with multiple cores for instance).
<Tip warning={true}>
To use this function absolutely zero calls to a CUDA device must be made in the notebook session before calling. If
any have been made, you will need to restart the notebook and make sure no cells use any CUDA capability.
Setting `ACCELERATE_DEBUG_MODE="1"` in your environment will run a test before truly launching to ensure that none
of those calls have been made.
</Tip>
Args:
function (`Callable`):
The training function to execute. If it accepts arguments, the first argument should be the index of the
process run.
args (`Tuple`):
Tuple of arguments to pass to the function (it will receive `*args`).
num_processes (`int`, *optional*):
The number of processes to use for training. Will default to 8 in Colab/Kaggle if a TPU is available, to
the number of GPUs available otherwise.
mixed_precision (`str`, *optional*, defaults to `"no"`):
If `fp16` or `bf16`, will use mixed precision training on multi-GPU.
use_port (`str`, *optional*, defaults to `"29500"`):
The port to use to communicate between processes when launching a multi-GPU training.
master_addr (`str`, *optional*, defaults to `"127.0.0.1"`):
The address to use for communication between processes.
node_rank (`int`, *optional*, defaults to 0):
The rank of the current node.
num_nodes (`int`, *optional*, defaults to 1):
The number of nodes to use for training.
rdzv_backend (`str`, *optional*, defaults to `"static"`):
The rendezvous method to use, such as 'static' (the default) or 'c10d'
rdzv_endpoint (`str`, *optional*, defaults to `""`):
The endpoint of the rdzv sync. storage.
rdzv_conf (`Dict`, *optional*, defaults to `None`):
Additional rendezvous configuration.
rdzv_id (`str`, *optional*, defaults to `"none"`):
The unique run id of the job.
max_restarts (`int`, *optional*, defaults to 0):
The maximum amount of restarts that elastic agent will conduct on workers before failure.
monitor_interval (`float`, *optional*, defaults to 0.1):
The interval in seconds that is used by the elastic_agent as a period of monitoring workers.
log_line_prefix_template (`str`, *optional*, defaults to `None`):
The prefix template for elastic launch logging. Available from PyTorch 2.2.0.
Example:
```python
# Assume this is defined in a Jupyter Notebook on an instance with two GPUs
from accelerate import notebook_launcher
def train(*args):
# Your training function here
...
notebook_launcher(train, args=(arg1, arg2), num_processes=2, mixed_precision="fp16")
```
"""
# Are we in a google colab or a Kaggle Kernel?
in_colab = False
in_kaggle = False
if any(key.startswith("KAGGLE") for key in os.environ.keys()):
in_kaggle = True
elif "IPython" in sys.modules:
in_colab = "google.colab" in str(sys.modules["IPython"].get_ipython())
try:
mixed_precision = PrecisionType(mixed_precision.lower())
except ValueError:
raise ValueError(
f"Unknown mixed_precision mode: {args.mixed_precision.lower()}. Choose between {PrecisionType.list()}."
)
if (in_colab or in_kaggle) and (os.environ.get("TPU_NAME", None) is not None):
# TPU launch
import torch_xla.distributed.xla_multiprocessing as xmp
if len(AcceleratorState._shared_state) > 0:
raise ValueError(
"To train on TPU in Colab or Kaggle Kernel, the `Accelerator` should only be initialized inside "
"your training function. Restart your notebook and make sure no cells initializes an "
"`Accelerator`."
)
if num_processes is None:
num_processes = 8
launcher = PrepareForLaunch(function, distributed_type="XLA")
print(f"Launching a training on {num_processes} TPU cores.")
xmp.spawn(launcher, args=args, nprocs=num_processes, start_method="fork")
elif in_colab and get_gpu_info()[1] < 2:
# No need for a distributed launch otherwise as it's either CPU or one GPU.
if torch.cuda.is_available():
print("Launching training on one GPU.")
else:
print("Launching training on one CPU.")
function(*args)
else:
if num_processes is None:
raise ValueError(
"You have to specify the number of GPUs you would like to use, add `num_processes=...` to your call."
)
if node_rank >= num_nodes:
raise ValueError("The node_rank must be less than the number of nodes.")
if num_processes > 1:
# Multi-GPU launch
from torch.distributed.launcher.api import LaunchConfig, elastic_launch
from torch.multiprocessing import start_processes
from torch.multiprocessing.spawn import ProcessRaisedException
if len(AcceleratorState._shared_state) > 0:
raise ValueError(
"To launch a multi-GPU training from your notebook, the `Accelerator` should only be initialized "
"inside your training function. Restart your notebook and make sure no cells initializes an "
"`Accelerator`."
)
# Check for specific libraries known to initialize CUDA that users constantly use
problematic_imports = are_libraries_initialized("bitsandbytes")
if len(problematic_imports) > 0:
err = (
"Could not start distributed process. Libraries known to initialize CUDA upon import have been "
"imported already. Please keep these imports inside your training function to try and help with this:"
)
for lib_name in problematic_imports:
err += f"\n\t* `{lib_name}`"
raise RuntimeError(err)
patched_env = dict(
nproc=num_processes,
node_rank=node_rank,
world_size=num_nodes * num_processes,
master_addr=master_addr,
master_port=use_port,
mixed_precision=mixed_precision,
)
# Check for CUDA P2P and IB issues
if not check_cuda_p2p_ib_support():
patched_env["nccl_p2p_disable"] = "1"
patched_env["nccl_ib_disable"] = "1"
# torch.distributed will expect a few environment variable to be here. We set the ones common to each
# process here (the other ones will be set be the launcher).
with patch_environment(**patched_env):
# First dummy launch
if os.environ.get("ACCELERATE_DEBUG_MODE", "false").lower() == "true":
launcher = PrepareForLaunch(test_launch, distributed_type="MULTI_GPU")
try:
start_processes(launcher, args=(), nprocs=num_processes, start_method="fork")
except ProcessRaisedException as e:
err = "An issue was found when verifying a stable environment for the notebook launcher."
if "Cannot re-initialize CUDA in forked subprocess" in e.args[0]:
raise RuntimeError(
f"{err}"
"This likely stems from an outside import causing issues once the `notebook_launcher()` is called. "
"Please review your imports and test them when running the `notebook_launcher()` to identify "
"which one is problematic and causing CUDA to be initialized."
) from e
else:
raise RuntimeError(f"{err} The following error was raised: {e}") from e
# Now the actual launch
launcher = PrepareForLaunch(function, distributed_type="MULTI_GPU")
print(f"Launching training on {num_processes} GPUs.")
try:
if rdzv_conf is None:
rdzv_conf = {}
if rdzv_backend == "static":
rdzv_conf["rank"] = node_rank
if not rdzv_endpoint:
rdzv_endpoint = f"{master_addr}:{use_port}"
launch_config_kwargs = dict(
min_nodes=num_nodes,
max_nodes=num_nodes,
nproc_per_node=num_processes,
run_id=rdzv_id,
rdzv_endpoint=rdzv_endpoint,
rdzv_backend=rdzv_backend,
rdzv_configs=rdzv_conf,
max_restarts=max_restarts,
monitor_interval=monitor_interval,
start_method="fork",
)
if is_torch_version(">=", ELASTIC_LOG_LINE_PREFIX_TEMPLATE_PYTORCH_VERSION):
launch_config_kwargs["log_line_prefix_template"] = log_line_prefix_template
elastic_launch(config=LaunchConfig(**launch_config_kwargs), entrypoint=function)(*args)
except ProcessRaisedException as e:
if "Cannot re-initialize CUDA in forked subprocess" in e.args[0]:
raise RuntimeError(
"CUDA has been initialized before the `notebook_launcher` could create a forked subprocess. "
"This likely stems from an outside import causing issues once the `notebook_launcher()` is called. "
"Please review your imports and test them when running the `notebook_launcher()` to identify "
"which one is problematic and causing CUDA to be initialized."
) from e
else:
raise RuntimeError(f"An issue was found when launching the training: {e}") from e
else:
# No need for a distributed launch otherwise as it's either CPU, GPU or MPS.
if is_mps_available():
os.environ["PYTORCH_ENABLE_MPS_FALLBACK"] = "1"
print("Launching training on MPS.")
elif torch.cuda.is_available():
print("Launching training on one GPU.")
else:
print("Launching training on CPU.")
function(*args)
def debug_launcher(function, args=(), num_processes=2):
"""
Launches a training function using several processes on CPU for debugging purposes.
<Tip warning={true}>
This function is provided for internal testing and debugging, but it's not intended for real trainings. It will
only use the CPU.
</Tip>
Args:
function (`Callable`):
The training function to execute.
args (`Tuple`):
Tuple of arguments to pass to the function (it will receive `*args`).
num_processes (`int`, *optional*, defaults to 2):
The number of processes to use for training.
"""
from torch.multiprocessing import start_processes
with tempfile.NamedTemporaryFile() as tmp_file:
# torch.distributed will expect a few environment variable to be here. We set the ones common to each
# process here (the other ones will be set be the launcher).
with patch_environment(
world_size=num_processes,
master_addr="127.0.0.1",
master_port="29500",
accelerate_mixed_precision="no",
accelerate_debug_rdv_file=tmp_file.name,
accelerate_use_cpu="yes",
):
launcher = PrepareForLaunch(function, debug=True)
start_processes(launcher, args=args, nprocs=num_processes, start_method="fork")
| 7 |
0 | hf_public_repos/accelerate/src | hf_public_repos/accelerate/src/accelerate/checkpointing.py | # Copyright 2022 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import random
from pathlib import Path
from typing import List
import numpy as np
import torch
from safetensors.torch import load_model
from torch.cuda.amp import GradScaler
from .utils import (
MODEL_NAME,
OPTIMIZER_NAME,
RNG_STATE_NAME,
SAFE_MODEL_NAME,
SAFE_WEIGHTS_NAME,
SAMPLER_NAME,
SCALER_NAME,
SCHEDULER_NAME,
WEIGHTS_NAME,
get_pretty_name,
is_mlu_available,
is_torch_xla_available,
is_xpu_available,
load,
save,
)
if is_torch_xla_available():
import torch_xla.core.xla_model as xm
from .logging import get_logger
from .state import PartialState
logger = get_logger(__name__)
def save_accelerator_state(
output_dir: str,
model_states: List[dict],
optimizers: list,
schedulers: list,
dataloaders: list,
process_index: int,
step: int,
scaler: GradScaler = None,
save_on_each_node: bool = False,
safe_serialization: bool = True,
):
"""
Saves the current states of the models, optimizers, scaler, and RNG generators to a given directory.
<Tip>
If `safe_serialization` is `True`, models will be saved with `safetensors` while the rest are saved using native
`pickle`.
</Tip>
Args:
output_dir (`str` or `os.PathLike`):
The name of the folder to save all relevant weights and states.
model_states (`List[torch.nn.Module]`):
A list of model states
optimizers (`List[torch.optim.Optimizer]`):
A list of optimizer instances
schedulers (`List[torch.optim.lr_scheduler._LRScheduler]`):
A list of learning rate schedulers
dataloaders (`List[torch.utils.data.DataLoader]`):
A list of dataloader instances to save their sampler states
process_index (`int`):
The current process index in the Accelerator state
step (`int`):
The current step in the internal step tracker
scaler (`torch.amp.GradScaler`, *optional*):
An optional gradient scaler instance to save;
save_on_each_node (`bool`, *optional*):
Whether to save on every node, or only the main node.
safe_serialization (`bool`, *optional*, defaults to `True`):
Whether to save the model using `safetensors` or the traditional PyTorch way (that uses `pickle`).
"""
output_dir = Path(output_dir)
# Model states
for i, state in enumerate(model_states):
weights_name = WEIGHTS_NAME if not safe_serialization else SAFE_WEIGHTS_NAME
if i > 0:
weights_name = weights_name.replace(".", f"_{i}.")
output_model_file = output_dir.joinpath(weights_name)
save(state, output_model_file, save_on_each_node=save_on_each_node, safe_serialization=safe_serialization)
logger.info(f"Model weights saved in {output_model_file}")
# Optimizer states
for i, opt in enumerate(optimizers):
state = opt.state_dict()
optimizer_name = f"{OPTIMIZER_NAME}.bin" if i == 0 else f"{OPTIMIZER_NAME}_{i}.bin"
output_optimizer_file = output_dir.joinpath(optimizer_name)
save(state, output_optimizer_file, save_on_each_node=save_on_each_node, safe_serialization=False)
logger.info(f"Optimizer state saved in {output_optimizer_file}")
# Scheduler states
for i, scheduler in enumerate(schedulers):
state = scheduler.state_dict()
scheduler_name = f"{SCHEDULER_NAME}.bin" if i == 0 else f"{SCHEDULER_NAME}_{i}.bin"
output_scheduler_file = output_dir.joinpath(scheduler_name)
save(state, output_scheduler_file, save_on_each_node=save_on_each_node, safe_serialization=False)
logger.info(f"Scheduler state saved in {output_scheduler_file}")
# DataLoader states
for i, dataloader in enumerate(dataloaders):
sampler_name = f"{SAMPLER_NAME}.bin" if i == 0 else f"{SAMPLER_NAME}_{i}.bin"
output_sampler_file = output_dir.joinpath(sampler_name)
# Only save if we have our custom sampler
from .data_loader import IterableDatasetShard, SeedableRandomSampler
if isinstance(dataloader.dataset, IterableDatasetShard):
sampler = dataloader.get_sampler()
if isinstance(sampler, SeedableRandomSampler):
save(sampler, output_sampler_file, save_on_each_node=save_on_each_node, safe_serialization=False)
if getattr(dataloader, "use_stateful_dataloader", False):
dataloader_state_dict_name = "dl_state_dict.bin" if i == 0 else f"dl_state_dict_{i}.bin"
output_dataloader_state_dict_file = output_dir.joinpath(dataloader_state_dict_name)
state_dict = dataloader.state_dict()
torch.save(state_dict, output_dataloader_state_dict_file)
logger.info(f"Sampler state for dataloader {i} saved in {output_sampler_file}")
# GradScaler state
if scaler is not None:
state = scaler.state_dict()
output_scaler_file = output_dir.joinpath(SCALER_NAME)
torch.save(state, output_scaler_file)
logger.info(f"Gradient scaler state saved in {output_scaler_file}")
# Random number generator states
states = {}
states_name = f"{RNG_STATE_NAME}_{process_index}.pkl"
states["step"] = step
states["random_state"] = random.getstate()
states["numpy_random_seed"] = np.random.get_state()
states["torch_manual_seed"] = torch.get_rng_state()
if is_xpu_available():
states["torch_xpu_manual_seed"] = torch.xpu.get_rng_state_all()
if is_mlu_available():
states["torch_mlu_manual_seed"] = torch.mlu.get_rng_state_all()
else:
states["torch_cuda_manual_seed"] = torch.cuda.get_rng_state_all()
if is_torch_xla_available():
states["xm_seed"] = xm.get_rng_state()
output_states_file = output_dir.joinpath(states_name)
torch.save(states, output_states_file)
logger.info(f"Random states saved in {output_states_file}")
return output_dir
def load_accelerator_state(
input_dir,
models,
optimizers,
schedulers,
dataloaders,
process_index,
scaler=None,
map_location=None,
**load_model_func_kwargs,
):
"""
Loads states of the models, optimizers, scaler, and RNG generators from a given directory.
Args:
input_dir (`str` or `os.PathLike`):
The name of the folder to load all relevant weights and states.
models (`List[torch.nn.Module]`):
A list of model instances
optimizers (`List[torch.optim.Optimizer]`):
A list of optimizer instances
schedulers (`List[torch.optim.lr_scheduler._LRScheduler]`):
A list of learning rate schedulers
process_index (`int`):
The current process index in the Accelerator state
scaler (`torch.amp.GradScaler`, *optional*):
An optional *GradScaler* instance to load
map_location (`str`, *optional*):
What device to load the optimizer state onto. Should be one of either "cpu" or "on_device".
load_model_func_kwargs (`dict`, *optional*):
Additional arguments that can be passed to the model's `load_state_dict` method.
Returns:
`dict`: Contains the `Accelerator` attributes to override while loading the state.
"""
# stores the `Accelerator` attributes to override
override_attributes = dict()
if map_location not in [None, "cpu", "on_device"]:
raise TypeError(
"Unsupported optimizer map location passed, please choose one of `None`, `'cpu'`, or `'on_device'`"
)
if map_location is None:
map_location = "cpu"
elif map_location == "on_device":
map_location = PartialState().device
input_dir = Path(input_dir)
# Model states
for i, model in enumerate(models):
ending = f"_{i}" if i > 0 else ""
input_model_file = input_dir.joinpath(f"{SAFE_MODEL_NAME}{ending}.safetensors")
if input_model_file.exists():
load_model(model, input_model_file, device=str(map_location), **load_model_func_kwargs)
else:
# Load with torch
input_model_file = input_dir.joinpath(f"{MODEL_NAME}{ending}.bin")
state_dict = load(input_model_file, map_location=map_location)
model.load_state_dict(state_dict, **load_model_func_kwargs)
logger.info("All model weights loaded successfully")
# Optimizer states
for i, opt in enumerate(optimizers):
optimizer_name = f"{OPTIMIZER_NAME}.bin" if i == 0 else f"{OPTIMIZER_NAME}_{i}.bin"
input_optimizer_file = input_dir.joinpath(optimizer_name)
optimizer_state = load(input_optimizer_file, map_location=map_location)
optimizers[i].load_state_dict(optimizer_state)
logger.info("All optimizer states loaded successfully")
# Scheduler states
for i, scheduler in enumerate(schedulers):
scheduler_name = f"{SCHEDULER_NAME}.bin" if i == 0 else f"{SCHEDULER_NAME}_{i}.bin"
input_scheduler_file = input_dir.joinpath(scheduler_name)
scheduler_state = load(input_scheduler_file)
scheduler.load_state_dict(scheduler_state)
logger.info("All scheduler states loaded successfully")
for i, dataloader in enumerate(dataloaders):
sampler_name = f"{SAMPLER_NAME}.bin" if i == 0 else f"{SAMPLER_NAME}_{i}.bin"
input_sampler_file = input_dir.joinpath(sampler_name)
# Only load if we have our custom sampler
from .data_loader import IterableDatasetShard, SeedableRandomSampler
if isinstance(dataloader.dataset, IterableDatasetShard):
sampler = dataloader.get_sampler()
if isinstance(sampler, SeedableRandomSampler):
sampler = dataloader.set_sampler(load(input_sampler_file))
if getattr(dataloader, "use_stateful_dataloader", False):
dataloader_state_dict_name = "dl_state_dict.bin" if i == 0 else f"dl_state_dict_{i}.bin"
input_dataloader_state_dict_file = input_dir.joinpath(dataloader_state_dict_name)
if input_dataloader_state_dict_file.exists():
state_dict = load(input_dataloader_state_dict_file)
dataloader.load_state_dict(state_dict)
logger.info("All dataloader sampler states loaded successfully")
# GradScaler state
if scaler is not None:
input_scaler_file = input_dir.joinpath(SCALER_NAME)
scaler_state = load(input_scaler_file)
scaler.load_state_dict(scaler_state)
logger.info("GradScaler state loaded successfully")
# Random states
try:
states = load(input_dir.joinpath(f"{RNG_STATE_NAME}_{process_index}.pkl"))
if "step" in states:
override_attributes["step"] = states["step"]
random.setstate(states["random_state"])
np.random.set_state(states["numpy_random_seed"])
torch.set_rng_state(states["torch_manual_seed"])
if is_xpu_available():
torch.xpu.set_rng_state_all(states["torch_xpu_manual_seed"])
if is_mlu_available():
torch.mlu.set_rng_state_all(states["torch_mlu_manual_seed"])
else:
torch.cuda.set_rng_state_all(states["torch_cuda_manual_seed"])
if is_torch_xla_available():
xm.set_rng_state(states["xm_seed"])
logger.info("All random states loaded successfully")
except Exception:
logger.info("Could not load random states")
return override_attributes
def save_custom_state(obj, path, index: int = 0, save_on_each_node: bool = False):
"""
Saves the state of `obj` to `{path}/custom_checkpoint_{index}.pkl`
"""
# Should this be the right way to get a qual_name type value from `obj`?
save_location = Path(path) / f"custom_checkpoint_{index}.pkl"
logger.info(f"Saving the state of {get_pretty_name(obj)} to {save_location}")
save(obj.state_dict(), save_location, save_on_each_node=save_on_each_node)
def load_custom_state(obj, path, index: int = 0):
"""
Loads the state of `obj` at `{path}/custom_checkpoint_{index}.pkl`. Will always set `weights_only=False` when
loading the state.
"""
load_location = f"{path}/custom_checkpoint_{index}.pkl"
logger.info(f"Loading the state of {get_pretty_name(obj)} from {load_location}")
obj.load_state_dict(load(load_location, map_location="cpu", weights_only=False))
| 8 |
0 | hf_public_repos/accelerate/src | hf_public_repos/accelerate/src/accelerate/accelerator.py | # Copyright 2021 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
from __future__ import annotations
import contextlib
import functools
import json
import math
import os
import re
import shutil
import sys
import warnings
from collections import OrderedDict
from contextlib import contextmanager
from functools import partial
from types import MethodType
from typing import Any, Callable, Union
import torch
import torch.utils.hooks as hooks
from huggingface_hub import split_torch_state_dict_into_shards
from .checkpointing import load_accelerator_state, load_custom_state, save_accelerator_state, save_custom_state
from .data_loader import DataLoaderDispatcher, prepare_data_loader, skip_first_batches
from .logging import get_logger
from .optimizer import AcceleratedOptimizer
from .scheduler import AcceleratedScheduler
from .state import AcceleratorState, GradientState, PartialState
from .tracking import LOGGER_TYPE_TO_CLASS, GeneralTracker, filter_trackers
from .utils import (
MODEL_NAME,
SAFE_WEIGHTS_INDEX_NAME,
SAFE_WEIGHTS_NAME,
SAFE_WEIGHTS_PATTERN_NAME,
WEIGHTS_INDEX_NAME,
WEIGHTS_NAME,
WEIGHTS_PATTERN_NAME,
AutocastKwargs,
DataLoaderConfiguration,
DeepSpeedPlugin,
DistributedDataParallelKwargs,
DistributedType,
DynamoBackend,
FP8RecipeKwargs,
FullyShardedDataParallelPlugin,
GradientAccumulationPlugin,
GradScalerKwargs,
InitProcessGroupKwargs,
KwargsHandler,
LoggerType,
MegatronLMPlugin,
PrecisionType,
ProfileKwargs,
ProjectConfiguration,
RNGType,
TorchDynamoPlugin,
apply_fp8_autowrap,
check_os_kernel,
clean_state_dict_for_safetensors,
compare_versions,
convert_model,
convert_outputs_to_fp32,
ensure_weights_retied,
extract_model_from_parallel,
gather,
gather_object,
get_grad_scaler,
get_mixed_precision_context_manager,
get_pretty_name,
has_offloaded_params,
is_bf16_available,
is_bitsandbytes_multi_backend_available,
is_deepspeed_available,
is_ipex_available,
is_lomo_available,
is_megatron_lm_available,
is_mlu_available,
is_msamp_available,
is_musa_available,
is_npu_available,
is_torch_version,
is_torch_xla_available,
is_transformer_engine_available,
is_xpu_available,
load_fsdp_model,
load_fsdp_optimizer,
pad_across_processes,
parse_choice_from_env,
recursively_apply,
reduce,
release_memory,
save,
save_fsdp_model,
save_fsdp_optimizer,
wait_for_everyone,
)
from .utils.constants import FSDP_PYTORCH_VERSION, PROFILE_PATTERN_NAME
from .utils.modeling import get_state_dict_offloaded_model
from .utils.other import is_compiled_module
if is_deepspeed_available():
from .utils import (
DeepSpeedEngineWrapper,
DeepSpeedOptimizerWrapper,
DeepSpeedSchedulerWrapper,
DummyOptim,
DummyScheduler,
)
if is_megatron_lm_available():
from .utils import (
MegatronEngine,
MegatronLMDummyDataLoader,
MegatronLMDummyScheduler,
MegatronLMOptimizerWrapper,
MegatronLMSchedulerWrapper,
megatron_lm_initialize,
megatron_lm_prepare_data_loader,
megatron_lm_prepare_model_optimizer_scheduler,
)
from torch.distributed.algorithms.join import Join
if is_torch_xla_available():
import torch_xla.core.xla_model as xm
import torch_xla.distributed.xla_multiprocessing as xmp
if is_npu_available(check_device=False):
import torch_npu # noqa: F401
try:
from torch.optim.lr_scheduler import LRScheduler
except ImportError:
from torch.optim.lr_scheduler import _LRScheduler as LRScheduler
logger = get_logger(__name__)
# Sentinel values for defaults
_split_batches = object()
_dispatch_batches = object()
_even_batches = object()
_use_seedable_sampler = object()
class Accelerator:
"""
Creates an instance of an accelerator for distributed training (on multi-GPU, TPU) or mixed precision training.
Args:
device_placement (`bool`, *optional*, defaults to `True`):
Whether or not the accelerator should put objects on device (tensors yielded by the dataloader, model,
etc...).
mixed_precision (`str`, *optional*):
Whether or not to use mixed precision training. Choose from 'no','fp16','bf16' or 'fp8'. Will default to
the value in the environment variable `ACCELERATE_MIXED_PRECISION`, which will use the default value in the
accelerate config of the current system or the flag passed with the `accelerate.launch` command. 'fp8'
requires the installation of transformers-engine.
gradient_accumulation_steps (`int`, *optional*, default to 1):
The number of steps that should pass before gradients are accumulated. A number > 1 should be combined with
`Accelerator.accumulate`. If not passed, will default to the value in the environment variable
`ACCELERATE_GRADIENT_ACCUMULATION_STEPS`. Can also be configured through a `GradientAccumulationPlugin`.
cpu (`bool`, *optional*):
Whether or not to force the script to execute on CPU. Will ignore GPU available if set to `True` and force
the execution on one process only.
dataloader_config (`DataLoaderConfiguration`, *optional*):
A configuration for how the dataloaders should be handled in distributed scenarios.
deepspeed_plugin ([`~utils.DeepSpeedPlugin`] or dict of `str`: [`~utils.DeepSpeedPlugin`], *optional*):
Tweak your DeepSpeed related args using this argument. This argument is optional and can be configured
directly using *accelerate config*. If using multiple plugins, use the configured `key` property of each
plugin to access them from `accelerator.state.get_deepspeed_plugin(key)`. Alias for `deepspeed_plugins`.
fsdp_plugin ([`~utils.FullyShardedDataParallelPlugin`], *optional*):
Tweak your FSDP related args using this argument. This argument is optional and can be configured directly
using *accelerate config*
megatron_lm_plugin ([`~utils.MegatronLMPlugin`], *optional*):
Tweak your MegatronLM related args using this argument. This argument is optional and can be configured
directly using *accelerate config*
rng_types (list of `str` or [`~utils.RNGType`]):
The list of random number generators to synchronize at the beginning of each iteration in your prepared
dataloaders. Should be one or several of:
- `"torch"`: the base torch random number generator
- `"cuda"`: the CUDA random number generator (GPU only)
- `"xla"`: the XLA random number generator (TPU only)
- `"generator"`: the `torch.Generator` of the sampler (or batch sampler if there is no sampler in your
dataloader) or of the iterable dataset (if it exists) if the underlying dataset is of that type.
Will default to `["torch"]` for PyTorch versions <=1.5.1 and `["generator"]` for PyTorch versions >= 1.6.
log_with (list of `str`, [`~utils.LoggerType`] or [`~tracking.GeneralTracker`], *optional*):
A list of loggers to be setup for experiment tracking. Should be one or several of:
- `"all"`
- `"tensorboard"`
- `"wandb"`
- `"comet_ml"`
If `"all"` is selected, will pick up all available trackers in the environment and initialize them. Can
also accept implementations of `GeneralTracker` for custom trackers, and can be combined with `"all"`.
project_config ([`~utils.ProjectConfiguration`], *optional*):
A configuration for how saving the state can be handled.
project_dir (`str`, `os.PathLike`, *optional*):
A path to a directory for storing data such as logs of locally-compatible loggers and potentially saved
checkpoints.
step_scheduler_with_optimizer (`bool`, *optional*, defaults to `True`):
Set `True` if the learning rate scheduler is stepped at the same time as the optimizer, `False` if only
done under certain circumstances (at the end of each epoch, for instance).
kwargs_handlers (list of [`~utils.KwargsHandler`], *optional*)
A list of [`~utils.KwargsHandler`] to customize how the objects related to distributed training, profiling
or mixed precision are created. See [kwargs](kwargs) for more information.
dynamo_backend (`str` or [`~utils.DynamoBackend`], *optional*, defaults to `"no"`):
Set to one of the possible dynamo backends to optimize your training with torch dynamo.
dynamo_plugin ([`~utils.TorchDynamoPlugin`], *optional*):
A configuration for how torch dynamo should be handled, if more tweaking than just the `backend` or `mode`
is needed.
gradient_accumulation_plugin ([`~utils.GradientAccumulationPlugin`], *optional*):
A configuration for how gradient accumulation should be handled, if more tweaking than just the
`gradient_accumulation_steps` is needed.
**Available attributes:**
- **device** (`torch.device`) -- The device to use.
- **distributed_type** ([`~utils.DistributedType`]) -- The distributed training configuration.
- **local_process_index** (`int`) -- The process index on the current machine.
- **mixed_precision** (`str`) -- The configured mixed precision mode.
- **num_processes** (`int`) -- The total number of processes used for training.
- **optimizer_step_was_skipped** (`bool`) -- Whether or not the optimizer update was skipped (because of
gradient overflow in mixed precision), in which
case the learning rate should not be changed.
- **process_index** (`int`) -- The overall index of the current process among all processes.
- **state** ([`~state.AcceleratorState`]) -- The distributed setup state.
- **sync_gradients** (`bool`) -- Whether the gradients are currently being synced across all processes.
- **use_distributed** (`bool`) -- Whether the current configuration is for distributed training.
"""
def __init__(
self,
device_placement: bool = True,
split_batches: bool = _split_batches,
mixed_precision: PrecisionType | str | None = None,
gradient_accumulation_steps: int = 1,
cpu: bool = False,
dataloader_config: DataLoaderConfiguration | None = None,
deepspeed_plugin: DeepSpeedPlugin | dict[str, DeepSpeedPlugin] | None = None,
fsdp_plugin: FullyShardedDataParallelPlugin | None = None,
megatron_lm_plugin: MegatronLMPlugin | None = None,
rng_types: list[str | RNGType] | None = None,
log_with: str | LoggerType | GeneralTracker | list[str | LoggerType | GeneralTracker] | None = None,
project_dir: str | os.PathLike | None = None,
project_config: ProjectConfiguration | None = None,
gradient_accumulation_plugin: GradientAccumulationPlugin | None = None,
step_scheduler_with_optimizer: bool = True,
kwargs_handlers: list[KwargsHandler] | None = None,
dynamo_backend: DynamoBackend | str | None = None,
dynamo_plugin: TorchDynamoPlugin | None = None,
deepspeed_plugins: DeepSpeedPlugin | dict[str, DeepSpeedPlugin] | None = None,
):
self.trackers = []
if project_config is not None:
self.project_configuration = project_config
else:
self.project_configuration = ProjectConfiguration(project_dir=project_dir)
if project_dir is not None and self.project_dir is None:
self.project_configuration.set_directories(project_dir)
if mixed_precision is not None:
mixed_precision = str(mixed_precision)
if mixed_precision not in PrecisionType:
raise ValueError(
f"Unknown mixed_precision mode: {mixed_precision}. Choose between {PrecisionType.list()}"
)
if dynamo_plugin is not None and dynamo_backend is not None:
raise ValueError("You cannot pass in both `dynamo_plugin` and `dynamo_backend`, please only pass in one.")
if dynamo_backend is not None:
dynamo_plugin = TorchDynamoPlugin(backend=dynamo_backend)
elif dynamo_plugin is None:
dynamo_plugin = TorchDynamoPlugin()
if deepspeed_plugins is not None and deepspeed_plugin is not None:
raise ValueError("You cannot pass in both `deepspeed_plugins` and `deepspeed_plugin`.")
elif deepspeed_plugin is not None:
deepspeed_plugins = deepspeed_plugin
if deepspeed_plugins is None:
# First check if we're creating another `Accelerator` w/o setting `deepspeed_plugin`
if PartialState._shared_state != {} and PartialState().distributed_type == DistributedType.DEEPSPEED:
deepspeed_plugins = AcceleratorState().deepspeed_plugins
else:
# init from env variables
deepspeed_plugins = (
DeepSpeedPlugin() if os.environ.get("ACCELERATE_USE_DEEPSPEED", "false") == "true" else None
)
else:
# If we're creating a second `Accelerator`, users shouldn't be passing in a `deepspeed_plugin`
if (
PartialState().distributed_type == DistributedType.DEEPSPEED
and AcceleratorState._shared_state != {}
and AcceleratorState().deepspeed_plugins is not None
):
raise NotImplementedError(
"You cannot pass in a `deepspeed_plugin` when creating a second `Accelerator`. "
"Please make sure the first `Accelerator` is initialized with all the plugins you want to use."
)
if isinstance(deepspeed_plugins, dict):
for plugin in deepspeed_plugins.values():
if not isinstance(plugin, DeepSpeedPlugin):
raise TypeError("`deepspeed_plugin` must be a DeepSpeedPlugin object.")
if deepspeed_plugins is not None:
os.environ["ACCELERATE_USE_DEEPSPEED"] = "true" # use DeepSpeed if plugin is provided
if not is_deepspeed_available():
raise ImportError("DeepSpeed is not installed => run `pip install deepspeed` or build it from source.")
if is_mlu_available():
if compare_versions("deepspeed-mlu", "<", "0.10.1"):
raise ImportError("DeepSpeed MLU version must be >= 0.10.1. Please update DeepSpeed MLU.")
elif is_musa_available():
if compare_versions("deepspeed", ">", "0.14.3"):
raise ImportError("DeepSpeed MUSA version must be <= 0.14.3. Please downgrade DeepSpeed.")
elif compare_versions("deepspeed", "<", "0.9.3"):
raise ImportError("DeepSpeed version must be >= 0.9.3. Please update DeepSpeed.")
mixed_precision = (
os.environ.get("ACCELERATE_MIXED_PRECISION", "no") if mixed_precision is None else mixed_precision
)
if not isinstance(deepspeed_plugins, dict):
deepspeed_plugins.set_mixed_precision(mixed_precision)
deepspeed_plugins.select(_from_accelerator_state=True)
else:
for plugin in deepspeed_plugins.values():
plugin.set_mixed_precision(mixed_precision)
# The first plugin passed in is always the active one
first_plugin = next(iter(deepspeed_plugins.values()))
first_plugin.select(_from_accelerator_state=True)
self.deepspeed_engine_wrapped = None
if os.environ.get("ACCELERATE_USE_FSDP", "false") == "true" or isinstance(
fsdp_plugin, FullyShardedDataParallelPlugin
):
if not is_torch_version(">=", FSDP_PYTORCH_VERSION):
raise ValueError(f"FSDP requires PyTorch >= {FSDP_PYTORCH_VERSION}")
if fsdp_plugin is None: # init from env variables
fsdp_plugin = (
FullyShardedDataParallelPlugin() if os.environ.get("ACCELERATE_USE_FSDP", "false") == "true" else None
)
else:
if not isinstance(fsdp_plugin, FullyShardedDataParallelPlugin):
raise TypeError("`fsdp_plugin` must be a FullyShardedDataParallelPlugin object.")
os.environ["ACCELERATE_USE_FSDP"] = "true" # use FSDP if plugin is provided
if megatron_lm_plugin is None: # init from env variables
megatron_lm_plugin = (
MegatronLMPlugin() if os.environ.get("ACCELERATE_USE_MEGATRON_LM", "false") == "true" else None
)
else:
if not isinstance(megatron_lm_plugin, MegatronLMPlugin):
raise TypeError("`megatron_lm_plugin` must be a MegatronLMPlugin object.")
os.environ["ACCELERATE_USE_MEGATRON_LM"] = "true" # use MegatronLM if plugin is provided
if megatron_lm_plugin:
if not is_megatron_lm_available():
raise ImportError("Megatron is not installed. please build it from source.")
# Kwargs handlers
self.ddp_handler = None
self.scaler_handler = None
self.init_handler = None
self.fp8_recipe_handler = None
self.autocast_handler = None
self.profile_handler = None
self.has_lomo_optimizer = False
if kwargs_handlers is not None:
for handler in kwargs_handlers:
assert isinstance(
handler, KwargsHandler
), f"Unsupported kwargs handler passed: {handler}, must be one that inherits `accelerate.utils.KwargsHandler`."
if isinstance(handler, DistributedDataParallelKwargs):
if self.ddp_handler is not None:
raise ValueError("You can only pass one `DistributedDataParallelKwargs` in `kwargs_handler`.")
else:
self.ddp_handler = handler
elif isinstance(handler, GradScalerKwargs):
if self.scaler_handler is not None:
raise ValueError("You can only pass one `GradScalerKwargs` in `kwargs_handler`.")
else:
self.scaler_handler = handler
elif isinstance(handler, InitProcessGroupKwargs):
if self.init_handler is not None:
raise ValueError("You can only pass one `InitProcessGroupKwargs` in `kwargs_handler`.")
else:
self.init_handler = handler
elif isinstance(handler, FP8RecipeKwargs):
if self.fp8_recipe_handler is not None:
raise ValueError("You can only pass one `FP8RecipeKwargs` in `kwargs_handler`.")
else:
self.fp8_recipe_handler = handler
elif isinstance(handler, AutocastKwargs):
if self.autocast_handler is not None:
raise ValueError("You can only pass one `AutocastKwargs` in `kwargs_handler`.")
else:
self.autocast_handler = handler
elif isinstance(handler, ProfileKwargs):
if self.profile_handler is not None:
raise ValueError("You can only pass one `ProfileKwargs` in `kwargs_handler`.")
else:
self.profile_handler = handler
kwargs = self.init_handler.to_kwargs() if self.init_handler is not None else {}
self.state = AcceleratorState(
mixed_precision=mixed_precision,
cpu=cpu,
dynamo_plugin=dynamo_plugin,
deepspeed_plugin=deepspeed_plugins,
fsdp_plugin=fsdp_plugin,
megatron_lm_plugin=megatron_lm_plugin,
_from_accelerator=True,
**kwargs,
)
if self.state.mixed_precision == "fp8" and self.fp8_recipe_handler is None:
self.fp8_recipe_handler = FP8RecipeKwargs()
self.delayed_fp8_autocast = False
if self.fp8_recipe_handler is not None:
# We already check if FP8 is available during `self.state`
if self.state.mixed_precision != "fp8" and (
self.distributed_type not in (DistributedType.FSDP, DistributedType.DEEPSPEED)
):
raise ValueError("Passing in a `FP8RecipeKwargs` object requires setting `mixed_precision='fp8'`.")
self.delayed_fp8_autocast = self.fp8_recipe_handler.backend == "TE" and self.distributed_type in (
DistributedType.MULTI_GPU,
DistributedType.FSDP,
)
trackers = filter_trackers(log_with, self.logging_dir)
if len(trackers) < 1 and log_with is not None:
warnings.warn(f"`log_with={log_with}` was passed but no supported trackers are currently installed.")
self.log_with = trackers
if (
(mixed_precision != "bf16")
and getattr(self.state, "downcast_bfloat", False)
and (self.state.distributedType != DistributedType.XLA)
):
raise ValueError("Can only use `downcast_bf16` when using `mixed_precision='bf16'` and on a TPU")
if gradient_accumulation_plugin is not None:
if gradient_accumulation_steps != 1:
raise ValueError(
"You can only pass one of `gradient_accumulation_steps` and `gradient_accumulation_plugin`. Please only pass in the created `GradientAccumulationPlugin` object."
)
else:
gradient_accumulation_steps = int(
parse_choice_from_env("ACCELERATE_GRADIENT_ACCUMULATION_STEPS", gradient_accumulation_steps)
)
gradient_accumulation_plugin = GradientAccumulationPlugin(num_steps=gradient_accumulation_steps)
self.gradient_state = GradientState(
gradient_accumulation_plugin=gradient_accumulation_plugin,
)
self.device_placement = device_placement
if dataloader_config is None:
dataloader_config = DataLoaderConfiguration()
self.dataloader_config = dataloader_config
self.step_scheduler_with_optimizer = step_scheduler_with_optimizer
# Mixed precision attributes
self.scaler = None
self.native_amp = False
if (
self.state.mixed_precision == "fp16"
and self.device.type != "cpu"
and self.distributed_type not in (DistributedType.DEEPSPEED, DistributedType.MEGATRON_LM)
):
self.native_amp = True
if self.device.type not in ("xpu", "cuda", "npu", "xla", "mlu", "musa") or is_torch_xla_available(
check_is_tpu=True
):
raise ValueError(f"fp16 mixed precision requires a GPU (not {self.device.type!r}).")
kwargs = self.scaler_handler.to_kwargs() if self.scaler_handler is not None else {}
self.scaler = get_grad_scaler(self.distributed_type, **kwargs)
elif self.state.mixed_precision == "bf16" and self.distributed_type not in (
DistributedType.DEEPSPEED,
DistributedType.MEGATRON_LM,
):
if self.device.type in ["cpu", "xpu"]:
self.native_amp = True
else:
self.native_amp = is_bf16_available(True)
if mixed_precision == "bf16" and not self.native_amp and not is_torch_xla_available():
raise ValueError("bf16 mixed precision requires PyTorch >= 1.10 and a supported device.")
elif self.state.mixed_precision == "fp8":
# We always enable `native_amp` for FP8
self.native_amp = True
if self.fp8_backend == "MSAMP":
if self.distributed_type == DistributedType.FSDP:
raise NotImplementedError(
"`accelerate` + `MS-AMP` + `FSDP` is not supported at this time. "
"Please consider using deepspeed, which is supported."
)
elif self.distributed_type != DistributedType.DEEPSPEED:
# MS-AMP requires `GradScaler` even with bf16 autocast w/ single GPU or DDP:
self.scaler = get_grad_scaler(**kwargs)
# Start of internal step tracking
self.step = 0
# Internal references to the training objects
self._optimizers = []
self._models = []
self._schedulers = []
self._dataloaders = []
self._custom_objects = []
# Hooks
self._load_model_state_pre_hook = OrderedDict()
self._save_model_state_pre_hook = OrderedDict()
# RNG Types
self.rng_types = rng_types
if self.rng_types is None:
self.rng_types = ["generator"]
# Set a flag tensor for early stopping and other breakpoints
self.flag_tensor = None
check_os_kernel()
@property
def deepspeed_plugin(self):
"""
Returns the currently active DeepSpeedPlugin.
If using multiple plugins, the first one will be the active one by default. Manually call
`accelerator.state.select_deepspeed_plugin(key)` to activate a different plugin.
If deepspeed is not enabled, this will return `None`.
"""
return self.state.deepspeed_plugin
@property
def use_distributed(self):
"""
Whether the Accelerator is configured for distributed training
"""
return self.state.use_distributed
@property
def distributed_type(self):
return self.state.distributed_type
@property
def num_processes(self):
return self.state.num_processes
@property
def process_index(self):
return self.state.process_index
@property
def local_process_index(self):
return self.state.local_process_index
@property
def device(self):
return self.state.device
@property
def split_batches(self):
return self.dataloader_config.split_batches
@property
def dispatch_batches(self):
return self.dataloader_config.dispatch_batches
@property
def even_batches(self):
return self.dataloader_config.even_batches
@even_batches.setter
def even_batches(self, value: bool):
self.dataloader_config.even_batches = value
@property
def use_seedable_sampler(self):
return self.dataloader_config.use_seedable_sampler
@property
def non_blocking(self):
return self.dataloader_config.non_blocking
@property
def use_stateful_dataloader(self):
if hasattr(self.dataloader_config, "use_stateful_dataloader"):
return self.dataloader_config.use_stateful_dataloader
return False
@property
def project_dir(self):
return self.project_configuration.project_dir
@property
def logging_dir(self):
return self.project_configuration.logging_dir
@property
def save_iteration(self):
return self.project_configuration.iteration
@property
def is_main_process(self):
"""True for one process only."""
return self.state.is_main_process
@property
def is_local_main_process(self):
"""True for one process per server."""
return self.state.is_local_main_process
@property
def is_last_process(self):
return self.process_index == self.num_processes - 1
@property
def mixed_precision(self):
return self.state.mixed_precision
@contextmanager
def split_between_processes(self, inputs: list | tuple | dict | torch.Tensor, apply_padding: bool = False):
"""
Splits `input` between `self.num_processes` quickly and can be then used on that process. Useful when doing
distributed inference, such as with different prompts.
Note that when using a `dict`, all keys need to have the same number of elements.
Args:
inputs (`list`, `tuple`, `torch.Tensor`, or `dict` of `list`/`tuple`/`torch.Tensor`):
The input to split between processes.
apply_padding (`bool`, `optional`, defaults to `False`):
Whether to apply padding by repeating the last element of the input so that all processes have the same
number of elements. Useful when trying to perform actions such as `Accelerator.gather()` on the outputs
or passing in less inputs than there are processes. If so, just remember to drop the padded elements
afterwards.
Example:
```python
# Assume there are two processes
from accelerate import Accelerator
accelerator = Accelerator()
with accelerator.split_between_processes(["A", "B", "C"]) as inputs:
print(inputs)
# Process 0
["A", "B"]
# Process 1
["C"]
with accelerator.split_between_processes(["A", "B", "C"], apply_padding=True) as inputs:
print(inputs)
# Process 0
["A", "B"]
# Process 1
["C", "C"]
```
"""
with PartialState().split_between_processes(inputs, apply_padding=apply_padding) as inputs:
yield inputs
def on_main_process(self, function: Callable[..., Any] = None):
"""
A decorator that will run the decorated function on the main process only. Can also be called using the
`PartialState` class.
Args:
function (`Callable`): The function to decorate.
Example:
```python
>>> from accelerate import Accelerator
>>> accelerator = Accelerator()
>>> @accelerator.on_main_process
... def print_something():
... print("This will be printed by process 0 only.")
>>> print_something()
"This will be printed by process 0 only"
```
"""
# For times when the `Accelerator` object itself utilizes this decorator.
if function is None:
if "Accelerator." in self.__qualname__:
function = self
else:
raise ValueError(
"The `on_main_process` decorator must be called with a function on an instantiated `Accelerator` object."
)
def _inner(*args, **kwargs):
return PartialState().on_main_process(function)(*args, **kwargs)
return _inner
def on_local_main_process(self, function: Callable[..., Any] = None):
"""
A decorator that will run the decorated function on the local main process only. Can also be called using the
`PartialState` class.
Args:
function (`Callable`): The function to decorate.
Example:
```python
# Assume we have 2 servers with 4 processes each.
from accelerate import Accelerator
accelerator = Accelerator()
@accelerator.on_local_main_process
def print_something():
print("This will be printed by process 0 only on each server.")
print_something()
# On server 1:
"This will be printed by process 0 only"
# On server 2:
"This will be printed by process 0 only"
```
"""
# For times when the `Accelerator` object itself utilizes this decorator.
if function is None:
if "Accelerator." in self.__qualname__:
function = self
else:
raise ValueError(
"The `on_local_main_process` decorator must be called with a function on an instantiated `Accelerator` object."
)
def _inner(*args, **kwargs):
return PartialState().on_local_main_process(function)(*args, **kwargs)
return _inner
def on_last_process(self, function: Callable[..., Any]):
"""
A decorator that will run the decorated function on the last process only. Can also be called using the
`PartialState` class.
Args:
function (`Callable`): The function to decorate.
Example:
```python
# Assume we have 4 processes.
from accelerate import Accelerator
accelerator = Accelerator()
@accelerator.on_last_process
def print_something():
print(f"Printed on process {accelerator.process_index}")
print_something()
"Printed on process 3"
```
"""
# For times when the `Accelerator` object itself utilizes this decorator.
if function is None:
if "Accelerator." in self.__qualname__:
function = self
else:
raise ValueError(
"The `on_last_process` decorator must be called with a function on an instantiated `Accelerator` object."
)
def _inner(*args, **kwargs):
return PartialState().on_last_process(function)(*args, **kwargs)
return _inner
def on_process(self, function: Callable[..., Any] = None, process_index: int = None):
"""
A decorator that will run the decorated function on a given process index only. Can also be called using the
`PartialState` class.
Args:
function (`Callable`, `optional`):
The function to decorate.
process_index (`int`, `optional`):
The index of the process on which to run the function.
Example:
```python
# Assume we have 4 processes.
from accelerate import Accelerator
accelerator = Accelerator()
@accelerator.on_process(process_index=2)
def print_something():
print(f"Printed on process {accelerator.process_index}")
print_something()
"Printed on process 2"
```
"""
# Initial construction of the decorator.
if (self is not None) and (process_index is not None) and (function is None):
return partial(self.on_process, process_index=process_index)
# For times when the `Accelerator` object itself utilizes this decorator.
if function is None:
if "Accelerator." in self.__qualname__:
function = self
else:
raise ValueError(
"The `on_main_process` decorator must be called with a function on an instantiated `Accelerator` object."
)
def _inner(*args, **kwargs):
return PartialState().on_process(function, process_index)(*args, **kwargs)
return _inner
def on_local_process(self, function: Callable[..., Any] = None, local_process_index: int = None):
"""
A decorator that will run the decorated function on a given local process index only. Can also be called using
the `PartialState` class.
Args:
function (`Callable`, *optional*):
The function to decorate.
local_process_index (`int`, *optional*):
The index of the local process on which to run the function.
Example:
```python
# Assume we have 2 servers with 4 processes each.
from accelerate import Accelerator
accelerator = Accelerator()
@accelerator.on_local_process(local_process_index=2)
def print_something():
print(f"Printed on process {accelerator.local_process_index}")
print_something()
# On server 1:
"Printed on process 2"
# On server 2:
"Printed on process 2"
```
"""
# Initial construction of the decorator.
if (self is not None) and (local_process_index is not None) and (function is None):
return partial(self.on_local_process, local_process_index=local_process_index)
# For times when the `Accelerator` object itself utilizes this decorator.
if function is None:
if "Accelerator." in self.__qualname__:
function = self
else:
raise ValueError(
"The `on_main_process` decorator must be called with a function on an instantiated `Accelerator` object."
)
def _inner(*args, **kwargs):
return PartialState().on_local_process(function, local_process_index)(*args, **kwargs)
return _inner
@contextmanager
def main_process_first(self):
"""
Lets the main process go first inside a with block.
The other processes will enter the with block after the main process exits.
Example:
```python
>>> from accelerate import Accelerator
>>> accelerator = Accelerator()
>>> with accelerator.main_process_first():
... # This will be printed first by process 0 then in a seemingly
... # random order by the other processes.
... print(f"This will be printed by process {accelerator.process_index}")
```
"""
with self.state.main_process_first():
yield
@contextmanager
def local_main_process_first(self):
"""
Lets the local main process go inside a with block.
The other processes will enter the with block after the main process exits.
Example:
```python
>>> from accelerate import Accelerator
>>> accelerator = Accelerator()
>>> with accelerator.local_main_process_first():
... # This will be printed first by local process 0 then in a seemingly
... # random order by the other processes.
... print(f"This will be printed by process {accelerator.local_process_index}")
```
"""
with self.state.local_main_process_first():
yield
@contextmanager
def no_sync(self, model):
"""
A context manager to disable gradient synchronizations across DDP processes by calling
`torch.nn.parallel.DistributedDataParallel.no_sync`.
If `model` is not in DDP, this context manager does nothing
Args:
model (`torch.nn.Module`):
PyTorch Module that was prepared with `Accelerator.prepare`
Example:
```python
>>> from accelerate import Accelerator
>>> accelerator = Accelerator()
>>> dataloader, model, optimizer = accelerator.prepare(dataloader, model, optimizer)
>>> input_a = next(iter(dataloader))
>>> input_b = next(iter(dataloader))
>>> with accelerator.no_sync():
... outputs = model(input_a)
... loss = loss_func(outputs)
... accelerator.backward(loss)
... # No synchronization across processes, only accumulate gradients
>>> outputs = model(input_b)
>>> accelerator.backward(loss)
>>> # Synchronization across all processes
>>> optimizer.step()
>>> optimizer.zero_grad()
```
"""
context = contextlib.nullcontext
if self.use_distributed:
context = getattr(model, "no_sync", context)
with context():
yield
@staticmethod
@contextmanager
def trigger_sync_in_backward(model):
"""Trigger the sync of the gradients in the next backward pass of the model after multiple forward passes under
`Accelerator.no_sync` (only applicable in multi-GPU scenarios).
If the script is not launched in distributed mode, this context manager does nothing.
Args:
model (`torch.nn.Module`):
The model for which to trigger the gradient synchronization.
Example:
```python
>>> from accelerate import Accelerator
>>> accelerator = Accelerator()
>>> dataloader, model, optimizer = accelerator.prepare(dataloader, model, optimizer)
>>> with accelerator.no_sync():
... loss_a = loss_func(model(input_a)) # first forward pass
... loss_b = loss_func(model(input_b)) # second forward pass
>>> accelerator.backward(loss_a) # No synchronization across processes, only accumulate gradients
>>> with accelerator.trigger_sync_in_backward(model):
... accelerator.backward(loss_b) # Synchronization across all processes
>>> optimizer.step()
>>> optimizer.zero_grad()
```
"""
if not isinstance(model, torch.nn.parallel.DistributedDataParallel):
yield
return
old_require_backward_grad_sync = model.require_backward_grad_sync
old_require_forward_param_sync = model.require_forward_param_sync
# EXPERIMENTAL: This will force grad sync during `backward()`, but it is unknown if it breaks other DDP features.
# https://github.com/pytorch/pytorch/blob/e1502c0cdbfd17548c612f25d5a65b1e4b86224d/torch/nn/parallel/distributed.py#L1453-L1466
model.require_backward_grad_sync = True
model.require_forward_param_sync = True
# https://github.com/pytorch/pytorch/blob/e1502c0cdbfd17548c612f25d5a65b1e4b86224d/torch/csrc/distributed/c10d/reducer.cpp#L1371-L1402
model.reducer.prepare_for_backward([])
try:
yield
finally:
model.require_backward_grad_sync = old_require_backward_grad_sync
model.require_forward_param_sync = old_require_forward_param_sync
def _do_sync(self):
"Sets the right `sync_gradients` context and either resets or increases `self.step`"
if self.gradient_state.sync_with_dataloader and self.gradient_state.end_of_dataloader:
self.step = 0
self.gradient_state._set_sync_gradients(True)
else:
self.step += 1
self.gradient_state._set_sync_gradients((self.step % self.gradient_state.num_steps) == 0)
@property
def sync_gradients(self):
return self.gradient_state.sync_gradients
@sync_gradients.setter
def sync_gradients(self, sync_gradients):
self.gradient_state.sync_gradients = sync_gradients
@property
def gradient_accumulation_steps(self):
return self.gradient_state.num_steps
@gradient_accumulation_steps.setter
def gradient_accumulation_steps(self, gradient_accumulation_steps):
self.gradient_state.plugin_kwargs.update({"num_steps": gradient_accumulation_steps})
@contextmanager
def accumulate(self, *models):
"""
A context manager that will lightly wrap around and perform gradient accumulation automatically
Args:
*models (list of `torch.nn.Module`):
PyTorch Modules that were prepared with `Accelerator.prepare`. Models passed to `accumulate()` will
skip gradient syncing during backward pass in distributed training
Example:
```python
>>> from accelerate import Accelerator
>>> accelerator = Accelerator(gradient_accumulation_steps=1)
>>> dataloader, model, optimizer, scheduler = accelerator.prepare(dataloader, model, optimizer, scheduler)
>>> for input, output in dataloader:
... with accelerator.accumulate(model):
... outputs = model(input)
... loss = loss_func(outputs)
... loss.backward()
... optimizer.step()
... scheduler.step()
... optimizer.zero_grad()
```
"""
self._do_sync()
allow_gradient_sync = (
self.sync_gradients # must sync if sync gradients need to complete an optimizer step
or (
# the no_sync context stops the gradients from reducing during distributed training
# bringing speedup (potentially at some costs). Here, no_sync can be prevented
# by setting sync_each_batch = True.
self.use_distributed # only relevant in distributed settings
and self.gradient_state.plugin_kwargs.get("sync_each_batch", False)
)
)
with contextlib.ExitStack() as cm_stack:
for m in models:
cm_stack.enter_context(contextlib.nullcontext() if allow_gradient_sync else self.no_sync(m))
yield
@contextmanager
def join_uneven_inputs(self, joinables, even_batches=None):
"""
A context manager that facilitates distributed training or evaluation on uneven inputs, which acts as a wrapper
around `torch.distributed.algorithms.join`. This is useful when the total batch size does not evenly divide the
length of the dataset.
Args:
joinables (`list[torch.distributed.algorithms.Joinable]`):
A list of models or optimizers that subclass `torch.distributed.algorithms.Joinable`. Most commonly, a
PyTorch Module that was prepared with `Accelerator.prepare` for DistributedDataParallel training.
even_batches (`bool`, *optional*)
If set, this will override the value of `even_batches` set in the `Accelerator`. If it is not provided,
the default `Accelerator` value wil be used.
<Tip warning={true}>
`join_uneven_inputs` is only supported for Distributed Data Parallel training on multiple GPUs. For any other
configuration, this method will have no effect.
</Tip>
<Tip warning={true}>
Overidding `even_batches` will not affect iterable-style data loaders.
</Tip>
Example:
```python
>>> from accelerate import Accelerator
>>> accelerator = Accelerator(even_batches=True)
>>> ddp_model, optimizer, dataloader = accelerator.prepare(model, optimizer, dataloader)
>>> with accelerator.join_uneven_inputs([ddp_model], even_batches=False):
... for input, output in dataloader:
... outputs = model(input)
... loss = loss_func(outputs)
... loss.backward()
... optimizer.step()
... optimizer.zero_grad()
```
"""
if self.distributed_type in (
DistributedType.MULTI_GPU,
DistributedType.MULTI_NPU,
DistributedType.MULTI_MLU,
DistributedType.MULTI_MUSA,
DistributedType.MULTI_XPU,
):
dl_even_batches_values = []
if even_batches is not None:
iterable_dl_seen = False
# override value in batch sampler for map-style datasets
for dl_idx, dl in enumerate(self._dataloaders):
if isinstance(dl, DataLoaderDispatcher):
iterable_dl_seen = True
continue
dl_even_batches_values.append((dl_idx, dl.batch_sampler.even_batches))
dl.batch_sampler.even_batches = even_batches
if iterable_dl_seen:
warnings.warn(
"Overridding even_batches is only supported for map-style datasets, yet some dataloaders given were iterable"
)
else:
even_batches = self.even_batches
enable_join = False if even_batches else True
try:
with Join(joinables, enable=enable_join, throw_on_early_termination=False):
yield
finally:
# reset any batch samplers that have been modified
for dl_idx, even_batches_value in dl_even_batches_values:
self._dataloaders[dl_idx].batch_sampler.even_batches = even_batches_value
else:
# Even when disabled, Join expects models to subclass Joinable, so skip entirely for single process runs
if self.distributed_type != DistributedType.NO:
warnings.warn(
"Joining uneven inputs is only supported for multi-GPU training, as a result `join_uneven_inputs` will have no effect."
)
with contextlib.nullcontext(joinables):
yield
def print(self, *args, **kwargs):
"""
Drop in replacement of `print()` to only print once per server.
Example:
```python
>>> from accelerate import Accelerator
>>> accelerator = Accelerator()
>>> accelerator.print("Hello world!")
```
"""
self.state.print(*args, **kwargs)
def _prepare_one(self, obj, first_pass=False, device_placement=None):
# First pass of preparation: DataLoader, model, optimizer
if first_pass:
if isinstance(obj, torch.utils.data.DataLoader):
return self.prepare_data_loader(obj, device_placement=device_placement)
elif isinstance(obj, torch.nn.Module):
return self.prepare_model(obj, device_placement=device_placement)
elif isinstance(obj, torch.optim.Optimizer):
optimizer = self.prepare_optimizer(obj, device_placement=device_placement)
return optimizer
# Second pass of preparation: LR scheduler (which need the full list of optimizers)
elif isinstance(obj, LRScheduler):
scheduler = self.prepare_scheduler(obj)
return scheduler
# Return the unprocessed object if previous criteria was not met
return obj
def prepare(self, *args, device_placement=None):
"""
Prepare all objects passed in `args` for distributed training and mixed precision, then return them in the same
order.
Args:
*args (list of objects):
Any of the following type of objects:
- `torch.utils.data.DataLoader`: PyTorch Dataloader
- `torch.nn.Module`: PyTorch Module
- `torch.optim.Optimizer`: PyTorch Optimizer
- `torch.optim.lr_scheduler.LRScheduler`: PyTorch LR Scheduler
device_placement (`list[bool]`, *optional*):
Used to customize whether automatic device placement should be performed for each object passed. Needs
to be a list of the same length as `args`. Not compatible with DeepSpeed or FSDP.
<Tip>
You don't need to prepare a model if you only use it for inference without any kind of mixed precision
</Tip>
Examples:
```python
>>> from accelerate import Accelerator
>>> accelerator = Accelerator()
>>> # Assume a model, optimizer, data_loader and scheduler are defined
>>> model, optimizer, data_loader, scheduler = accelerator.prepare(model, optimizer, data_loader, scheduler)
```
```python
>>> from accelerate import Accelerator
>>> accelerator = Accelerator()
>>> # Assume a model, optimizer, data_loader and scheduler are defined
>>> device_placement = [True, True, False, False]
>>> # Will place the first two items passed in automatically to the right device but not the last two.
>>> model, optimizer, data_loader, scheduler = accelerator.prepare(
... model, optimizer, data_loader, scheduler, device_placement=device_placement
... )
```
"""
if device_placement is None:
device_placement = [None for _ in args]
elif self.distributed_type in (DistributedType.DEEPSPEED, DistributedType.MEGATRON_LM):
raise ValueError("You can't customize device placements with DeepSpeed or Megatron-LM.")
elif len(device_placement) != len(args):
raise ValueError(
f"`device_placement` should be a list with {len(args)} elements (the number of objects passed)."
)
for obj in args:
# TODO: Look at enabling native TP training directly with a proper config
if (
isinstance(obj, torch.nn.Module)
and self.verify_device_map(obj)
and self.distributed_type != DistributedType.NO
and os.environ.get("ACCELERATE_BYPASS_DEVICE_MAP", "false") != "true"
):
raise ValueError(
"You can't train a model that has been loaded with `device_map='auto'` in any distributed mode."
" Please rerun your script specifying `--num_processes=1` or by launching with `python {{myscript.py}}`."
)
if self.distributed_type == DistributedType.DEEPSPEED:
model_count = 0
for obj in args:
if isinstance(obj, torch.nn.Module):
model_count += 1
if model_count > 1:
raise AssertionError(
"You can't use same `Accelerator()` instance with multiple models when using DeepSpeed"
)
# On TPUs, putting the model on the XLA device will create new parameters, so the corresponding optimizer will
# have parameters disconnected from the model (so no training :-( ).
# If the model and optimizer have parameters on different devices we raise an error.
if self.distributed_type == DistributedType.XLA:
model_device, optimizer_device = self._get_devices()
if model_device is not None and optimizer_device is not None and model_device != optimizer_device:
raise ValueError(
"The model and the optimizer parameters are not on the same device, which probably means you "
"created an optimizer around your model **before** putting on the device. Make sure the line "
"model.to(device) is before the optimizer creation in your script or remove it entirely and use "
"the flag default value for `device_placement` in your `Accelerator` to let it handle that "
"part for you."
)
# If we're dealing with device placement, this deals with that by...
tpu_should_fix_optimizer = self.device_placement and self.distributed_type == DistributedType.XLA
if tpu_should_fix_optimizer:
# 1. grabbing old model parameters
old_named_params = self._get_named_parameters(*args)
if self.distributed_type in [DistributedType.MULTI_CPU, DistributedType.MULTI_XPU, DistributedType.NO]:
if self.device.type == "cpu" and self.state.use_ipex:
args = self._prepare_ipex_or_xpu(*args)
elif self.device.type == "xpu" and is_xpu_available():
args = self._prepare_ipex_or_xpu(*args)
if self.fp8_backend == "TE":
args = self._prepare_te(*args)
if self.distributed_type == DistributedType.DEEPSPEED:
result = self._prepare_deepspeed(*args)
elif self.distributed_type == DistributedType.MEGATRON_LM:
result = self._prepare_megatron_lm(*args)
else:
if self.fp8_backend == "MSAMP":
args, device_placement = self._prepare_msamp(*args, device_placement=device_placement)
result = tuple(
self._prepare_one(obj, first_pass=True, device_placement=d) for obj, d in zip(args, device_placement)
)
result = tuple(self._prepare_one(obj, device_placement=d) for obj, d in zip(result, device_placement))
if tpu_should_fix_optimizer:
# 2. grabbing new model parameters
new_named_params = self._get_named_parameters(*result)
# 3. building a map from the first to the second
mapping = {p: new_named_params[n] for n, p in old_named_params.items()}
# 4. using that map to update the parameters of the optimizer
for obj in result:
if isinstance(obj, torch.optim.Optimizer):
obj._switch_parameters(mapping)
for item in result:
if any(
item in container
for container in (self._dataloaders, self._models, self._optimizers, self._schedulers)
):
item._is_accelerate_prepared = True
return result if len(result) > 1 else result[0]
def prepare_model(self, model: torch.nn.Module, device_placement: bool = None, evaluation_mode: bool = False):
"""
Prepares a PyTorch model for training in any distributed setup. It is recommended to use
[`Accelerator.prepare`] instead.
Args:
model (`torch.nn.Module`):
A PyTorch model to prepare. You don't need to prepare a model if it is used only for inference without
any kind of mixed precision
device_placement (`bool`, *optional*):
Whether or not to place the model on the proper device. Will default to `self.device_placement`.
evaluation_mode (`bool`, *optional*, defaults to `False`):
Whether or not to set the model for evaluation only, by just applying mixed precision and
`torch.compile` (if configured in the `Accelerator` object).
Example:
```python
>>> from accelerate import Accelerator
>>> accelerator = Accelerator()
>>> # Assume a model is defined
>>> model = accelerator.prepare_model(model)
```
"""
if device_placement is None:
device_placement = self.device_placement and self.distributed_type != DistributedType.FSDP
self._models.append(model)
# TODO: Look at enabling native TP training directly with a proper config
if (
self.verify_device_map(model)
and self.distributed_type != DistributedType.NO
and os.environ.get("ACCELERATE_BYPASS_DEVICE_MAP", "false") != "true"
):
raise ValueError(
"You can't train a model that has been loaded with `device_map='auto'` in any distributed mode."
" Please rerun your script specifying `--num_processes=1` or by launching with `python {{myscript.py}}`."
)
if self.native_amp:
model._original_forward = model.forward
autocast_context = get_mixed_precision_context_manager(self.native_amp, self.autocast_handler)
# NOTE: MS-AMP adds `__func__` already to `model.forward`, so we should always use `model.forward`
if self.fp8_backend == "MSAMP" or not hasattr(model.forward, "__func__"):
model_forward_func = model.forward
model.forward = convert_outputs_to_fp32(autocast_context(model_forward_func))
else:
model_forward_func = model.forward.__func__
new_forward = autocast_context(model_forward_func)
model.forward = MethodType(new_forward, model)
model.forward = MethodType(convert_outputs_to_fp32(model.forward.__func__), model)
# We prepare TE after, allowing for bf16 autocast to happen first
if self.fp8_backend == "TE" and not self.delayed_fp8_autocast:
model = apply_fp8_autowrap(model, self.fp8_recipe_handler)
if (getattr(model, "is_loaded_in_8bit", False) or getattr(model, "is_loaded_in_4bit", False)) and getattr(
model, "hf_device_map", False
):
model_devices = set(model.hf_device_map.values())
if len(model_devices) > 1 and self.distributed_type != DistributedType.NO:
raise ValueError(
"You can't train a model that has been loaded in 8-bit or 4-bit precision on multiple devices in any distributed mode."
" In order to use 8-bit or 4-bit models that have been loaded across multiple GPUs the solution is to use Naive Pipeline Parallelism."
" Therefore you should not specify that you are under any distributed regime in your accelerate config."
)
elif len(model_devices) == 1:
current_device = list(model_devices)[0]
current_device_index = (
current_device.index if isinstance(current_device, torch.device) else current_device
)
if self.device.type == "cpu" and is_bitsandbytes_multi_backend_available():
# bnb with multi-backend supports CPU which don't need to check index.
pass
elif torch.device(current_device_index) != self.device:
# if on the first device (GPU 0) we don't care
if (self.device.index is not None) or (current_device_index != 0):
raise ValueError(
"You can't train a model that has been loaded in 8-bit or 4-bit precision on a different device than the one "
"you're training on. Make sure you loaded the model on the correct device using for example `device_map={'':torch.cuda.current_device()}` or `device_map={'':torch.xpu.current_device()}`"
)
if ("cpu" in model_devices and not is_bitsandbytes_multi_backend_available()) or "disk" in model_devices:
raise ValueError(
"You can't train a model that has been loaded in 8-bit or 4-bit precision with CPU or disk offload. "
"If you want train the 8-bit or 4-bit model in CPU, please install bitsandbytes with multi-backend, see https://huggingface.co/docs/bitsandbytes/main/en/installation#multi-backend"
)
elif device_placement and not self.verify_device_map(model):
model = model.to(self.device)
if not evaluation_mode:
if self.distributed_type in (
DistributedType.MULTI_GPU,
DistributedType.MULTI_MLU,
DistributedType.MULTI_MUSA,
DistributedType.MULTI_NPU,
DistributedType.MULTI_XPU,
):
if any(p.requires_grad for p in model.parameters()):
kwargs = self.ddp_handler.to_kwargs() if self.ddp_handler is not None else {}
# TODO: Look at enabling native TP training directly with a proper config
if os.environ.get("ACCELERATE_BYPASS_DEVICE_MAP", "false") != "true":
device_ids, output_device = [self.local_process_index], self.local_process_index
else:
device_ids, output_device = None, None
model = torch.nn.parallel.DistributedDataParallel(
model, device_ids=device_ids, output_device=output_device, **kwargs
)
if self.ddp_handler is not None:
self.ddp_handler.register_comm_hook(model)
elif self.distributed_type == DistributedType.FSDP:
# We need to fix the optimizer *before* sharding the model
from torch.distributed.fsdp.fully_sharded_data_parallel import FullyShardedDataParallel as FSDP
# Check if the model is already a FSDP model due to `Manual Wrapping` and if so,
# don't wrap it again
# In case the model is already compiled using PyTorch 2.0 and the wrapped model in it
# is a FSDP model, don't wrap it again
is_type_fsdp = isinstance(model, FSDP) or (
is_compiled_module(model) and isinstance(model._orig_mod, FSDP)
)
if not is_type_fsdp:
self.state.fsdp_plugin.set_auto_wrap_policy(model)
fsdp_plugin = self.state.fsdp_plugin
# need to ensure that params are re-tied after running
# param_init_fn
fsdp_plugin.param_init_fn = ensure_weights_retied(
fsdp_plugin.param_init_fn,
model,
self.device,
)
kwargs = {
"sharding_strategy": fsdp_plugin.sharding_strategy,
"cpu_offload": fsdp_plugin.cpu_offload,
"auto_wrap_policy": fsdp_plugin.auto_wrap_policy,
"mixed_precision": fsdp_plugin.mixed_precision_policy,
"sync_module_states": fsdp_plugin.sync_module_states,
"backward_prefetch": fsdp_plugin.backward_prefetch,
"forward_prefetch": fsdp_plugin.forward_prefetch,
"use_orig_params": fsdp_plugin.use_orig_params,
"param_init_fn": fsdp_plugin.param_init_fn,
"ignored_modules": fsdp_plugin.ignored_modules,
"limit_all_gathers": fsdp_plugin.limit_all_gathers,
"device_id": self.device,
}
model = FSDP(model, **kwargs)
if fsdp_plugin.activation_checkpointing:
from torch.distributed.algorithms._checkpoint.checkpoint_wrapper import (
CheckpointImpl,
apply_activation_checkpointing,
checkpoint_wrapper,
)
apply_activation_checkpointing(
model,
checkpoint_wrapper_fn=functools.partial(
checkpoint_wrapper,
checkpoint_impl=CheckpointImpl.NO_REENTRANT,
),
auto_wrap_policy=fsdp_plugin.auto_wrap_policy,
)
# In the event the model had been loaded in low precision, but
# mixed precision had also been activated, then we follow DeepSpeed's
# strategy to hold the parameters in full precision.
# - assume that trainer.args.bf16 and trainer.args.fp16 are already checked against
# fsdp_plugin.mixed_precision_policy.
# - NOTE: we do not check the mixed_precision attribute on the FSDP root wrapper.
# * this attribute will always set by init_utils.init_core_state so its always not None.
# * mixed_precision.param_dtype only regards _fwd_bwd_param_dtype
# * if model is loaded in 16bit, and even if mixed_precision.param_dtype is None,
# we sill want to upcast the flat_param.
if self.mixed_precision != "no": # if mixed precision is set
upcasted_log = []
for module in FSDP.fsdp_modules(model):
# Referencing DeepSpeed Zero3
# - in Init, params are converted to 16bit while partitioning.
# - in accelerator.prepare, deepspeed.initalize is called to:
# * creates the DeepSpeeedEngine.
# * since zero_optimization() is True , calls engine._configure_zero_optimizer.
#
# Inside the DeepSpeed Zero3 optimizer configuration, which initalizes
# DeepSpeedZeroOptimizer_Stage3, during which:
# * trainable_param_groups are obtained from the attached optimizer
# (already partitioned in 16bit).
# * then _setup_for_real_optimizer -> _create_fp32_partitions
# which performs the fp32 upcasting.
# To mimick DeepSeepds's casting in FSDP, we look at the (single) FlatParameter held
# within an FSDP wrapper. This FlatParameter will be seen by the optimizer.
# - even though there is a torch.device('meta') guard below, we
# expect _init_utils._init_param_handle_from_module to already
# sync the parameter.
if not module._has_params:
continue # skip if FSDP module not managing parameters
param = module._flat_param
if (
param.dtype != torch.float32
and param.device != torch.device("meta")
and param.requires_grad
):
# keep log of names_params that was upcasted
# NOTE: resorted to this because warnings.simplefilter("once") is somehow not working
name_param_log = (module.module.__class__.__name__, ", ".join(module._flat_param._fqns))
if name_param_log not in upcasted_log:
upcasted_log.append(name_param_log)
# this works because of FSDP's _runtime_utils.lazy_init.
# Have to be careful not to call anything before this that
# triggers lazy_init (e.g., _is_fsdp_root).
param.data = param.data.to(torch.float32) # upcasting
module._handle._orig_param_dtype = torch.float32 # update
# report the warnings
# some messages can be quite repetitive, especially when reporting about layers that have identical architecture.
if self.is_main_process:
for name_log, param_log in upcasted_log:
warnings.warn(
f"Upcasted low precision parameters in {name_log} because mixed precision turned on in FSDP. "
f"Affects: {param_log}."
)
if len(upcasted_log) > 0:
warnings.warn(
"FSDP upcast of low precision parameters may affect the precision of model checkpoints."
)
# if the previous and current models are same, delete the previous one
if len(self._models) > 1 and (self._models[-2] is self._models[-1]):
del self._models[-2]
self._models[-1] = model
elif self.distributed_type == DistributedType.MULTI_CPU:
kwargs = self.ddp_handler.to_kwargs() if self.ddp_handler is not None else {}
model = torch.nn.parallel.DistributedDataParallel(model, **kwargs)
if self.ddp_handler is not None:
self.ddp_handler.register_comm_hook(model)
elif self.distributed_type == DistributedType.XLA and self.state.fork_launched:
model = xmp.MpModelWrapper(model).to(self.device)
# Now we can apply the FP8 autocast
if self.delayed_fp8_autocast:
model = apply_fp8_autowrap(model, self.fp8_recipe_handler)
# torch.compile should be called last and only if the model isn't already compiled.
if self.state.dynamo_plugin.backend != DynamoBackend.NO and not is_compiled_module(model):
if not is_torch_version(">=", "2.0"):
raise ValueError("Using `torch.compile` requires PyTorch 2.0 or higher.")
model = torch.compile(model, **self.state.dynamo_plugin.to_kwargs())
return model
def _prepare_te(self, *args):
if not is_transformer_engine_available():
raise ImportError(
"`transformer_engine` was not found on your system. Please ensure that `transformer_engine` is installed"
)
model, optimizer = None, None
num_models, num_optimizers = 0, 0
result = [obj for obj in args]
for obj in result:
if isinstance(obj, torch.nn.Module):
model = obj
num_models += 1
elif isinstance(obj, (torch.optim.Optimizer)):
optimizer = obj
num_optimizers += 1
if optimizer is None and model is None:
return result
elif optimizer is None or model is None:
raise ValueError(
"You must pass a model and an optimizer together to `accelerate.prepare()` when using TransformerEngine."
)
elif num_models > 1 or num_optimizers > 1:
raise ValueError(
f"You can't use multiple models ({num_models}) or optimizers {num_optimizers} with TransformerEngine."
)
old_named_params = self._get_named_parameters(model)
with torch.no_grad():
convert_model(model)
new_named_params = self._get_named_parameters(model)
mapping = {p: new_named_params[n] for n, p in old_named_params.items()}
# We need to switch the optimizer params to the new params *after* the model is wrapped in FSDP
for param_group in optimizer.param_groups:
param_group["params"] = [mapping[p] for p in param_group["params"]]
return result
def _prepare_deepspeed(self, *args):
import deepspeed
ds_initialize = deepspeed.initialize
if self.fp8_backend == "MSAMP":
# MS-AMP requires DeepSpeed patches
from msamp import deepspeed as msamp_deepspeed
ds_initialize = msamp_deepspeed.initialize
deepspeed_plugin = self.deepspeed_plugin
is_dataloader_present = any(isinstance(obj, torch.utils.data.DataLoader) for obj in args)
result = [
self._prepare_one(obj, first_pass=True) if isinstance(obj, torch.utils.data.DataLoader) else obj
for obj in args
]
if deepspeed_plugin.is_auto("train_micro_batch_size_per_gpu"):
if is_dataloader_present:
batch_sizes = [obj.batch_size for obj in args if hasattr(obj, "batch_size")]
if any(bs is None for bs in batch_sizes):
raise ValueError(
"At least one of the dataloaders passed to `accelerate.prepare()` has `None` as batch size. "
"Please set an integer value in `train_micro_batch_size_per_gpu` in the deepspeed config file "
"or assign integer value to `AcceleratorState().deepspeed_plugin.deepspeed_config['train_micro_batch_size_per_gpu']`."
)
if self.split_batches:
batch_sizes = [batch_size // self.num_processes for batch_size in batch_sizes]
batch_size_per_device = min(batch_sizes) if deepspeed_plugin.is_train_batch_min else max(batch_sizes)
if len(batch_sizes) > 1:
logger.info(
"Since you passed both train and evaluation dataloader, `is_train_batch_min` (here "
f"{deepspeed_plugin.is_train_batch_min} will decide the `train_batch_size` ({batch_size_per_device})."
)
else:
raise ValueError(
"When using DeepSpeed, `accelerate.prepare()` requires you to pass at least one of training or evaluation dataloaders "
"with `batch_size` attribute returning an integer value "
"or alternatively set an integer value in `train_micro_batch_size_per_gpu` in the deepspeed config file "
"or assign integer value to `AcceleratorState().deepspeed_plugin.deepspeed_config['train_micro_batch_size_per_gpu']`."
)
else:
batch_size_per_device = deepspeed_plugin.get_value("train_micro_batch_size_per_gpu")
# handle `gradient_accumulation_steps` when the value is `auto`
deepspeed_plugin.fill_match(
"gradient_accumulation_steps",
must_match=False,
gradient_accumulation_steps=self.gradient_accumulation_steps,
)
config_kwargs = {
"gradient_clipping": 1.0,
"zero_optimization.stage3_gather_16bit_weights_on_model_save": False,
}
# This is skipped when preparing just a model
if batch_size_per_device is not None:
config_kwargs["train_micro_batch_size_per_gpu"] = batch_size_per_device
config_kwargs["train_batch_size"] = (
batch_size_per_device * deepspeed_plugin.get_value("gradient_accumulation_steps") * self.num_processes
)
model = None
optimizer = None
scheduler = None
for obj in result:
if isinstance(obj, torch.nn.Module):
model = obj
elif isinstance(obj, (torch.optim.Optimizer, DummyOptim)):
optimizer = obj
elif (isinstance(obj, (LRScheduler, DummyScheduler))) or (
type(obj).__name__ in deepspeed.runtime.lr_schedules.VALID_LR_SCHEDULES
):
scheduler = obj
if optimizer is not None:
if "optimizer" in deepspeed_plugin.deepspeed_config and not isinstance(optimizer, (DummyOptim)):
raise ValueError(
"You cannot specify an optimizer in the config file and in the code at the same time. "
"Please remove the optimizer from the config file or "
"create `accelerate.utils.DummyOptim` in the code."
)
elif "optimizer" not in deepspeed_plugin.deepspeed_config and isinstance(optimizer, (DummyOptim)):
raise ValueError(
"You cannot create a `DummyOptim` without specifying an optimizer in the config file."
)
if isinstance(optimizer, (torch.optim.Optimizer)):
deepspeed_plugin.deepspeed_config["zero_allow_untested_optimizer"] = True
if scheduler is not None:
if "scheduler" in deepspeed_plugin.deepspeed_config and not isinstance(scheduler, (DummyScheduler)):
raise ValueError(
"You cannot specify a scheduler in the config file and in the code at the same time. "
"Please remove the scheduler from the config file or "
"create `accelerate.utils.DummyScheduler` in the code."
)
elif (
"scheduler" not in deepspeed_plugin.deepspeed_config
and isinstance(scheduler, (DummyScheduler))
and scheduler.lr_scheduler_callable is None
):
raise ValueError(
"Either specify a scheduler in the config file or "
"pass in the `lr_scheduler_callable` parameter when using `accelerate.utils.DummyScheduler`."
)
if optimizer is not None and scheduler is not None:
if isinstance(optimizer, (DummyOptim)) and not isinstance(scheduler, (DummyScheduler)):
raise ValueError(
"You can only specify `accelerate.utils.DummyScheduler` in the code when using "
"`accelerate.utils.DummyOptim`."
)
if model is not None:
# If we are using FP8, we need to apply the autowrap now
if getattr(self.fp8_recipe_handler, "backend", None) == "TE":
model = apply_fp8_autowrap(model, self.fp8_recipe_handler)
# if the model is an MOE, set the appropriate MOE layers as leaf Z3 modules
deepspeed_plugin.set_moe_leaf_modules(model)
# deal with config keys that use `auto` value and rely on model's hidden_size
hidden_size_based_keys = [
"zero_optimization.reduce_bucket_size",
"zero_optimization.stage3_prefetch_bucket_size",
"zero_optimization.stage3_param_persistence_threshold",
]
hidden_size_auto_keys = [x for x in hidden_size_based_keys if deepspeed_plugin.is_auto(x)]
if len(hidden_size_auto_keys) > 0:
reasoning = (
"therefore it's not possible to automatically fill out the following `auto` entries "
+ f"in the DeepSpeed config file: {hidden_size_auto_keys}. You can fix that by replacing "
+ "`auto` values for these keys with an integer value of your choice."
)
if not hasattr(model, "config"):
raise ValueError("Can't find `model.config` entry, " + reasoning)
if hasattr(model.config, "hidden_size"):
hidden_size = model.config.hidden_size
elif hasattr(model.config, "hidden_sizes"):
# if there are many hidden sizes pick the largest one
hidden_size = max(model.config.hidden_sizes)
else:
raise ValueError(
"Can find neither `model.config.hidden_size` nor `model.config.hidden_sizes`, " + reasoning
)
config_kwargs.update(
{
"zero_optimization.reduce_bucket_size": hidden_size * hidden_size,
"zero_optimization.stage3_prefetch_bucket_size": int(0.9 * hidden_size * hidden_size),
"zero_optimization.stage3_param_persistence_threshold": 10 * hidden_size,
}
)
if isinstance(optimizer, (DummyOptim)):
config_kwargs.update(
{"optimizer.params.lr": optimizer.lr, "optimizer.params.weight_decay": optimizer.weight_decay}
)
if isinstance(scheduler, (DummyScheduler)) and scheduler.lr_scheduler_callable is None:
max_lr = (
getattr(scheduler.optimizer, "lr", None)
if getattr(scheduler.optimizer, "defaults", None) is None
else scheduler.optimizer.defaults["lr"]
)
config_kwargs.update(
{
"scheduler.params.warmup_min_lr": 0,
"scheduler.params.warmup_max_lr": max_lr,
"scheduler.params.warmup_num_steps": scheduler.warmup_num_steps,
}
)
if scheduler.total_num_steps is not None:
config_kwargs["scheduler.params.total_num_steps"] = (
math.ceil(scheduler.total_num_steps / self.num_processes)
if not self.split_batches
else scheduler.total_num_steps
)
deepspeed_plugin.deepspeed_config_process(must_match=False, **config_kwargs)
self.deepspeed_config = deepspeed_plugin.deepspeed_config
kwargs = dict(model=model, config_params=self.deepspeed_config)
if optimizer is not None:
if isinstance(optimizer, (DummyOptim)):
kwargs["model_parameters"] = optimizer.params
if isinstance(scheduler, (DummyScheduler)) and scheduler.lr_scheduler_callable is not None:
kwargs["lr_scheduler"] = scheduler.lr_scheduler_callable
else:
if self.deepspeed_config["zero_optimization"].get("offload_optimizer", {}).get(
"device", "none"
) != "none" and self.deepspeed_config.get("zero_force_ds_cpu_optimizer", True):
from deepspeed.ops.adam import DeepSpeedCPUAdam
defaults = {k: v for k, v in optimizer.defaults.items() if k in ["lr", "weight_decay"]}
optimizer = DeepSpeedCPUAdam(optimizer.param_groups, **defaults)
kwargs["optimizer"] = optimizer
if scheduler is not None:
if type(scheduler).__name__ in deepspeed.runtime.lr_schedules.VALID_LR_SCHEDULES:
kwargs["lr_scheduler"] = scheduler
engine, optimizer, _, lr_scheduler = ds_initialize(**kwargs)
if compare_versions("deepspeed", ">=", "0.14.4") and self.state.dynamo_plugin.backend != DynamoBackend.NO:
compile_kwargs = self.state.dynamo_plugin.to_kwargs()
engine.compile(backend=compile_kwargs.pop("backend"), compile_kwargs=compile_kwargs)
if optimizer is not None:
optimizer = DeepSpeedOptimizerWrapper(optimizer)
if scheduler is not None:
if lr_scheduler is None:
scheduler = AcceleratedScheduler(
scheduler,
optimizer,
step_with_optimizer=self.step_scheduler_with_optimizer,
split_batches=self.split_batches,
)
else:
scheduler = DeepSpeedSchedulerWrapper(lr_scheduler, optimizer)
for i in range(len(result)):
if isinstance(result[i], torch.nn.Module):
result[i] = engine
elif isinstance(result[i], (torch.optim.Optimizer, DummyOptim)):
result[i] = optimizer
elif (isinstance(result[i], (LRScheduler, DummyScheduler))) or (
type(result[i]).__name__ in deepspeed.runtime.lr_schedules.VALID_LR_SCHEDULES
):
result[i] = scheduler
# pointing for deepspeed_engine_wrapped.backward()
if self.deepspeed_engine_wrapped is None:
self.deepspeed_engine_wrapped = DeepSpeedEngineWrapper(engine)
else:
logger.warning(
"A wrapped DeepSpeed engine reference is currently tied for this `Accelerator()` instance. "
"If you want to call `accelerator.backward()` referencing a new model/engine, "
"please create a separate `Accelerator()` instance and call `accelerator.prepare()` on it."
)
self._models.append(engine)
if optimizer is not None:
self._optimizers.append(optimizer)
if scheduler is not None:
self._schedulers.append(scheduler)
return tuple(result)
def _prepare_megatron_lm(self, *args):
megatron_lm_plugin = self.state.megatron_lm_plugin
micro_batch_size = None
if not megatron_lm_plugin.megatron_dataset_flag:
batch_sizes = [obj.batch_size for obj in args if hasattr(obj, "batch_size")]
if len(batch_sizes) == 0:
raise ValueError(
"You must specify a training or evaluation dataloader in `accelerate.prepare()` when using Megatron-LM."
)
micro_batch_size = min(batch_sizes) if megatron_lm_plugin.is_train_batch_min else max(batch_sizes)
if len(batch_sizes) > 1:
logger.info(
"Since you passed both train and evaluation dataloader, `is_train_batch_min` (here "
f"{megatron_lm_plugin.is_train_batch_min} will decide the `train_batch_size` ({micro_batch_size})."
)
else:
for obj in args:
if isinstance(obj, MegatronLMDummyDataLoader):
micro_batch_size = obj.dataset_args["micro_batch_size"]
break
if micro_batch_size is not None:
dp_degree = self.num_processes // (megatron_lm_plugin.tp_degree * megatron_lm_plugin.pp_degree)
megatron_lm_plugin.set_training_args(micro_batch_size, dp_degree)
else:
raise ValueError(
"When you do not pass the dataloader parameter, the `data_parallel_size`, "
"`micro_batch_size`, and `global_batch_size` megatron parameters will not be updated."
)
model = None
optimizer = None
scheduler = None
batch_data = None
for obj in args:
if isinstance(obj, torch.utils.data.DataLoader) and batch_data is None:
batch_data = next(iter(obj))
elif isinstance(obj, torch.nn.Module):
model = obj
elif isinstance(obj, (torch.optim.Optimizer)):
optimizer = obj
elif isinstance(obj, (LRScheduler, MegatronLMDummyScheduler)):
scheduler = obj
if model is not None:
megatron_lm_plugin.set_network_size_args(model, batch_data)
if optimizer is not None:
megatron_lm_plugin.set_optimizer_type(optimizer)
if scheduler is not None:
if not isinstance(scheduler, MegatronLMDummyScheduler):
raise ValueError(
"You can't use a custom scheduler with Megatron-LM. Please use the `accelerate.utils.MegatronLMDummyScheduler` instead."
)
megatron_lm_plugin.set_scheduler_args(scheduler)
# initialize megatron-lm
megatron_lm_initialize(self, args_defaults=megatron_lm_plugin.megatron_lm_default_args)
(model, optimizer, scheduler) = megatron_lm_prepare_model_optimizer_scheduler(self)
self.wait_for_everyone()
counter = 0
result = []
for obj in args:
if isinstance(obj, torch.utils.data.DataLoader):
result.append(megatron_lm_prepare_data_loader(self, obj))
counter += 1
elif isinstance(obj, MegatronLMDummyDataLoader):
if counter == 0:
obj.set_megatron_data_args()
dataloaders = megatron_lm_prepare_data_loader(self, obj)
result.append(dataloaders[counter])
counter += 1
else:
result.append(obj)
if model is not None:
model = MegatronEngine(self, model, optimizer, scheduler)
if optimizer is not None:
optimizer = MegatronLMOptimizerWrapper(optimizer)
if scheduler is not None:
scheduler = MegatronLMSchedulerWrapper(scheduler, optimizer)
for i in range(len(result)):
if isinstance(result[i], torch.nn.Module):
result[i] = model
elif isinstance(result[i], torch.optim.Optimizer):
result[i] = optimizer
elif isinstance(result[i], MegatronLMDummyScheduler):
result[i] = scheduler
if model is not None:
self._models.append(model)
if len(self._models) > 1:
raise AssertionError(
"You can't use same `Accelerator()` instance with multiple models when using Megatron-LM"
)
if optimizer is not None:
self._optimizers.append(optimizer)
if scheduler is not None:
self._schedulers.append(scheduler)
return tuple(result)
def _prepare_ipex_or_xpu(self, *args):
"""
Prepares model and optimizer for training with IPEX or XPU acceleration. This covers 3 cases, IPEX compiled
with CPU only support, IPEX compiled with XPU support and training with XPU pytorch backend available in stock
pytorch starting from version 2.4.
"""
if self.state.use_ipex:
if not is_ipex_available():
raise ImportError(
"IPEX is not installed or IPEX's version does not match current PyTorch version. Please refer"
" to https://github.com/intel/intel-extension-for-pytorch."
)
model = None
optimizer = None
result = [obj for obj in args]
for obj in result:
if isinstance(obj, torch.nn.Module):
model = obj
model.train()
elif isinstance(obj, (torch.optim.Optimizer)):
optimizer = obj
if optimizer is not None and model is not None:
dtype = torch.bfloat16 if self.state.mixed_precision == "bf16" else None
if self.device.type == "xpu" and next(model.parameters()).device.type == "cpu":
model = model.to(self.device)
# ipex.optimize() is available only for IPEX, both IPEX-CPU and IPEX-XPU
if is_ipex_available():
import intel_extension_for_pytorch as ipex
model, optimizer = ipex.optimize(model, optimizer=optimizer, dtype=dtype, inplace=True, level="O1")
for i in range(len(result)):
if isinstance(result[i], torch.nn.Module):
result[i] = model
elif isinstance(result[i], (torch.optim.Optimizer)):
result[i] = optimizer
return tuple(result)
def _prepare_msamp(self, *args, device_placement):
if not is_msamp_available():
raise ImportError(
"MS-AMP was not found on your system. Please ensure that MS-AMP is available "
" or choose `'te'` as the backend for FP8 mixed precision training."
)
# We've already checked for FSDP + MS-AMP during `__init__`
import msamp
model, optimizer = None, None
optimizer_index = None
num_models, num_optimizers = 0, 0
result = [obj for obj in args]
for i, obj in enumerate(result):
if isinstance(obj, torch.nn.Module):
model = obj
num_models += 1
elif isinstance(obj, (torch.optim.Optimizer)):
optimizer = obj
optimizer_index = i
num_optimizers += 1
# DataLoader/Scheduler case
if optimizer is None and model is None:
return result, device_placement
elif optimizer is None or model is None:
raise ValueError(
"You must pass a model and an optimizer together to `accelerate.prepare()` when using MS-AMP."
)
elif num_models > 1 or num_optimizers > 1:
raise ValueError(
f"You can't use multiple models ({num_models}) or optimizers {num_optimizers} with MS-AMP."
)
else:
model, optimizer = msamp.initialize(model, optimizer, opt_level=self.fp8_recipe_handler.opt_level)
for i in range(len(result)):
if isinstance(result[i], torch.nn.Module):
result[i] = model
elif isinstance(result[i], (torch.optim.Optimizer)):
result[i] = optimizer
if optimizer_index is not None:
# NOTE: MS-AMP moves the optimizer, but *not* the model to the right device
device_placement[optimizer_index] = False
return tuple(result), device_placement
def prepare_data_loader(
self, data_loader: torch.utils.data.DataLoader, device_placement=None, slice_fn_for_dispatch=None
):
"""
Prepares a PyTorch DataLoader for training in any distributed setup. It is recommended to use
[`Accelerator.prepare`] instead.
Args:
data_loader (`torch.utils.data.DataLoader`):
A vanilla PyTorch DataLoader to prepare
device_placement (`bool`, *optional*):
Whether or not to place the batches on the proper device in the prepared dataloader. Will default to
`self.device_placement`.
slice_fn_for_dispatch (`Callable`, *optional*`):
If passed, this function will be used to slice tensors across `num_processes`. Will default to
[`~utils.slice_tensors`]. This argument is used only when `dispatch_batches` is set to `True` and will
be ignored otherwise.
Example:
```python
>>> import torch
>>> from accelerate import Accelerator
>>> accelerator = Accelerator()
>>> data_loader = torch.utils.data.DataLoader(...)
>>> data_loader = accelerator.prepare_data_loader(data_loader, device_placement=True)
```
"""
# Ensure we can't double wrap a DataLoader due to `find_batch_size`
if getattr(data_loader, "_is_accelerate_prepared", False):
if data_loader not in self._dataloaders:
self._dataloaders.append(data_loader)
return data_loader
if device_placement is None:
device_placement = self.device_placement if self.distributed_type != DistributedType.XLA else False
prepared_data_loader = prepare_data_loader(
data_loader,
self.device,
num_processes=self.num_processes,
process_index=self.process_index,
split_batches=self.split_batches,
put_on_device=device_placement,
rng_types=self.rng_types.copy(),
dispatch_batches=self.dispatch_batches,
even_batches=self.even_batches,
slice_fn_for_dispatch=slice_fn_for_dispatch,
use_seedable_sampler=self.use_seedable_sampler,
data_seed=self.dataloader_config.data_seed,
non_blocking=self.non_blocking,
use_stateful_dataloader=self.use_stateful_dataloader,
)
self._dataloaders.append(prepared_data_loader)
return prepared_data_loader
def prepare_optimizer(self, optimizer: torch.optim.Optimizer, device_placement=None):
"""
Prepares a PyTorch Optimizer for training in any distributed setup. It is recommended to use
[`Accelerator.prepare`] instead.
Args:
optimizer (`torch.optim.Optimizer`):
A vanilla PyTorch optimizer to prepare
device_placement (`bool`, *optional*):
Whether or not to place the optimizer on the proper device. Will default to `self.device_placement`.
Example:
```python
>>> import torch
>>> from accelerate import Accelerator
>>> accelerator = Accelerator()
>>> optimizer = torch.optim.Adam(...)
>>> optimizer = accelerator.prepare_optimizer(optimizer, device_placement=True)
```
"""
if is_lomo_available():
# We need to import locally to avoid circular imports since lomo imports stuff from
# transformers & accelerate
from lomo_optim import AdaLomo, Lomo
# Support multiple optimizers: https://github.com/huggingface/accelerate/pull/2695#discussion_r1589164607
self.has_lomo_optimizer |= isinstance(optimizer, (Lomo, AdaLomo))
# Ensure we can't double wrap an optimizer due to `find_batch_size`
if getattr(optimizer, "_is_accelerate_prepared", False):
if optimizer not in self._optimizers:
self._optimizers.append(optimizer)
return optimizer
if device_placement is None:
device_placement = self.device_placement
# NOTE: Special case with MS-AMP we do *not* pass in the scaler explicitly to the `AcceleratedOptimizer`,
# Their optimizer handles it for us.
scaler = None if self.fp8_backend == "MSAMP" else self.scaler
optimizer = AcceleratedOptimizer(optimizer, device_placement=device_placement, scaler=scaler)
self._optimizers.append(optimizer)
return optimizer
def prepare_scheduler(self, scheduler: LRScheduler):
"""
Prepares a PyTorch Scheduler for training in any distributed setup. It is recommended to use
[`Accelerator.prepare`] instead.
Args:
scheduler (`torch.optim.lr_scheduler.LRScheduler`):
A vanilla PyTorch scheduler to prepare
Example:
```python
>>> import torch
>>> from accelerate import Accelerator
>>> accelerator = Accelerator()
>>> optimizer = torch.optim.Adam(...)
>>> scheduler = torch.optim.lr_scheduler.LambdaLR(optimizer, ...)
>>> scheduler = accelerator.prepare_scheduler(scheduler)
```
"""
# Ensure we can't double wrap a scheduler due to `find_batch_size`
if getattr(scheduler, "_is_accelerate_prepared", False):
if scheduler not in self._schedulers:
self._schedulers.append(scheduler)
return scheduler
# We try to find the optimizer associated with `scheduler`, the default is the full list.
optimizer = self._optimizers
for opt in self._optimizers:
if getattr(scheduler, "optimizer", None) == opt.optimizer:
optimizer = opt
break
scheduler = AcceleratedScheduler(
scheduler,
optimizer,
step_with_optimizer=self.step_scheduler_with_optimizer,
split_batches=self.split_batches,
)
self._schedulers.append(scheduler)
return scheduler
def backward(self, loss, **kwargs):
"""
Scales the gradients in accordance to the `GradientAccumulationPlugin` and calls the correct `backward()` based
on the configuration.
Should be used in lieu of `loss.backward()`.
Example:
```python
>>> from accelerate import Accelerator
>>> accelerator = Accelerator(gradient_accumulation_steps=2)
>>> outputs = model(inputs)
>>> loss = loss_fn(outputs, labels)
>>> accelerator.backward(loss)
```
"""
learning_rate = kwargs.get("learning_rate")
if self.distributed_type != DistributedType.DEEPSPEED:
# deepspeed handles loss scaling by gradient_accumulation_steps in its `backward`
loss = loss / self.gradient_accumulation_steps
if self.distributed_type == DistributedType.DEEPSPEED:
self.deepspeed_engine_wrapped.backward(loss, **kwargs)
elif self.distributed_type == DistributedType.MEGATRON_LM:
return
elif self.scaler is not None:
self.scaler.scale(loss).backward(**kwargs)
elif learning_rate is not None and self.has_lomo_optimizer:
self.lomo_backward(loss, learning_rate)
else:
loss.backward(**kwargs)
def set_trigger(self):
"""
Sets the internal trigger tensor to 1 on the current process. A latter check should follow using this which
will check across all processes.
Note:
Does not require `wait_for_everyone()`
Example:
```python
>>> from accelerate import Accelerator
>>> accelerator = Accelerator()
>>> # Assume later in the training script
>>> # `should_do_breakpoint` is a custom function to monitor when to break,
>>> # e.g. when the loss is NaN
>>> if should_do_breakpoint(loss):
... accelerator.set_trigger()
>>> # Assume later in the training script
>>> if accelerator.check_breakpoint():
... break
```
"""
self.flag_tensor = torch.tensor(1, device=self.device)
def check_trigger(self):
"""
Checks if the internal trigger tensor has been set to 1 in any of the processes. If so, will return `True` and
reset the trigger tensor to 0.
Note:
Does not require `wait_for_everyone()`
Example:
```python
>>> from accelerate import Accelerator
>>> accelerator = Accelerator()
>>> # Assume later in the training script
>>> # `should_do_breakpoint` is a custom function to monitor when to break,
>>> # e.g. when the loss is NaN
>>> if should_do_breakpoint(loss):
... accelerator.set_trigger()
>>> # Assume later in the training script
>>> if accelerator.check_trigger():
... break
```
"""
# Now that we are outside `__init__`, we can initialize it if it is `None` on device
if self.flag_tensor is None:
self.flag_tensor = torch.tensor(0, device=self.device)
flag_tensor = self.reduce(self.flag_tensor)
if flag_tensor.item() >= 1:
self.flag_tensor = torch.tensor(0, device=self.device)
return True
return False
def unscale_gradients(self, optimizer=None):
"""
Unscale the gradients in mixed precision training with AMP. This is a noop in all other settings.
Likely should be called through [`Accelerator.clip_grad_norm_`] or [`Accelerator.clip_grad_value_`]
Args:
optimizer (`torch.optim.Optimizer` or `list[torch.optim.Optimizer]`, *optional*):
The optimizer(s) for which to unscale gradients. If not set, will unscale gradients on all optimizers
that were passed to [`~Accelerator.prepare`].
Example:
```python
>>> from accelerate import Accelerator
>>> accelerator = Accelerator()
>>> model, optimizer = accelerator.prepare(model, optimizer)
>>> outputs = model(inputs)
>>> loss = loss_fn(outputs, labels)
>>> accelerator.backward(loss)
>>> accelerator.unscale_gradients(optimizer=optimizer)
```
"""
if self.native_amp and self.mixed_precision == "fp16":
if optimizer is None:
# TODO: this unscales all optimizers where we should only unscale the one where parameters are.
optimizer = self._optimizers
elif not isinstance(optimizer, (tuple, list)):
optimizer = [optimizer]
for opt in optimizer:
while isinstance(opt, AcceleratedOptimizer):
opt = opt.optimizer
self.scaler.unscale_(opt)
def clip_grad_norm_(self, parameters, max_norm, norm_type=2):
"""
Should be used in place of `torch.nn.utils.clip_grad_norm_`.
Returns:
`torch.Tensor`: Total norm of the parameter gradients (viewed as a single vector).
Example:
```python
>>> from accelerate import Accelerator
>>> accelerator = Accelerator(gradient_accumulation_steps=2)
>>> dataloader, model, optimizer, scheduler = accelerator.prepare(dataloader, model, optimizer, scheduler)
>>> for input, target in dataloader:
... optimizer.zero_grad()
... output = model(input)
... loss = loss_func(output, target)
... accelerator.backward(loss)
... if accelerator.sync_gradients:
... accelerator.clip_grad_norm_(model.parameters(), max_grad_norm)
... optimizer.step()
```
"""
if self.distributed_type == DistributedType.FSDP:
self.unscale_gradients()
parameters = [p for p in parameters]
for model in self._models:
if parameters == [p for p in model.parameters()]:
return model.clip_grad_norm_(max_norm, norm_type)
elif self.distributed_type == DistributedType.DEEPSPEED:
# `accelerator.backward(loss)` is doing that automatically. Therefore, its implementation is not needed
# We cannot return the gradient norm because DeepSpeed does it.
return None
elif self.distributed_type == DistributedType.XLA:
# Reduce gradients first for XLA
for acc_opt in self._optimizers:
if not acc_opt.gradient_state.is_xla_gradients_synced:
opt = acc_opt
while isinstance(opt, AcceleratedOptimizer):
opt = opt.optimizer
gradients = xm._fetch_gradients(opt)
# Use xm.all_reduce to perform an in-place all-reduce. Recusrsive all-reduce each tensor
# one by one in self.reduce is non-inplace.
xm.all_reduce("sum", gradients, scale=1.0 / self.num_processes)
# Set is_xla_gradients_synced to True to avoid all-reduce twice in the AcceleratedOptimizer step.
acc_opt.gradient_state.is_xla_gradients_synced = True
if os.environ.get("ACCELERATE_USE_FSDP", "false") == "true":
self.unscale_gradients()
parameters = [p for p in parameters]
for model in self._models:
if parameters == [p for p in model.parameters()]:
return model.clip_grad_norm_(max_norm, norm_type)
self.unscale_gradients()
return torch.nn.utils.clip_grad_norm_(parameters, max_norm, norm_type=norm_type)
def clip_grad_value_(self, parameters, clip_value):
"""
Should be used in place of `torch.nn.utils.clip_grad_value_`.
Example:
```python
>>> from accelerate import Accelerator
>>> accelerator = Accelerator(gradient_accumulation_steps=2)
>>> dataloader, model, optimizer, scheduler = accelerator.prepare(dataloader, model, optimizer, scheduler)
>>> for input, target in dataloader:
... optimizer.zero_grad()
... output = model(input)
... loss = loss_func(output, target)
... accelerator.backward(loss)
... if accelerator.sync_gradients:
... accelerator.clip_grad_value_(model.parameters(), clip_value)
... optimizer.step()
```
"""
if self.distributed_type in [DistributedType.DEEPSPEED, DistributedType.FSDP]:
raise Exception("DeepSpeed and FSDP do not support `clip_grad_value_`. Use `clip_grad_norm_` instead.")
self.unscale_gradients()
torch.nn.utils.clip_grad_value_(parameters, clip_value)
def gather(self, tensor):
"""
Gather the values in *tensor* across all processes and concatenate them on the first dimension. Useful to
regroup the predictions from all processes when doing evaluation.
Note:
This gather happens in all processes.
Args:
tensor (`torch.Tensor`, or a nested tuple/list/dictionary of `torch.Tensor`):
The tensors to gather across all processes.
Returns:
`torch.Tensor`, or a nested tuple/list/dictionary of `torch.Tensor`: The gathered tensor(s). Note that the
first dimension of the result is *num_processes* multiplied by the first dimension of the input tensors.
Example:
```python
>>> # Assuming four processes
>>> import torch
>>> from accelerate import Accelerator
>>> accelerator = Accelerator()
>>> process_tensor = torch.tensor([accelerator.process_index])
>>> gathered_tensor = accelerator.gather(process_tensor)
>>> gathered_tensor
tensor([0, 1, 2, 3])
```
"""
return gather(tensor)
def gather_for_metrics(self, input_data, use_gather_object=False):
"""
Gathers `input_data` and potentially drops duplicates in the last batch if on a distributed system. Should be
used for gathering the inputs and targets for metric calculation.
Args:
input (`torch.Tensor`, `object`, a nested tuple/list/dictionary of `torch.Tensor`, or a nested tuple/list/dictionary of `object`):
The tensors or objects for calculating metrics across all processes
use_gather_object(`bool`):
Whether to forcibly use gather_object instead of gather (which is already done if all objects passed do
not contain tensors). This flag can be useful for gathering tensors with different sizes that we don't
want to pad and concatenate along the first dimension. Using it with GPU tensors is not well supported
and inefficient as it incurs GPU -> CPU transfer since tensors would be pickled.
Example:
```python
>>> # Assuming two processes, with a batch size of 5 on a dataset with 9 samples
>>> import torch
>>> from accelerate import Accelerator
>>> accelerator = Accelerator()
>>> dataloader = torch.utils.data.DataLoader(range(9), batch_size=5)
>>> dataloader = accelerator.prepare(dataloader)
>>> batch = next(iter(dataloader))
>>> gathered_items = accelerator.gather_for_metrics(batch)
>>> len(gathered_items)
9
```
"""
try:
recursively_apply(lambda x: x, input_data, error_on_other_type=True)
all_tensors = True
except TypeError:
all_tensors = False
use_gather_object = use_gather_object or not all_tensors
if use_gather_object:
data = gather_object(input_data)
else:
data = self.gather(input_data)
try:
if self.gradient_state.end_of_dataloader:
# at the end of a dataloader, `gather_for_metrics` regresses to
# `gather` unless the dataset has a remainder so log.
if self.gradient_state.remainder == -1:
logger.info(
"The used dataset had no length, returning gathered tensors. You should drop the remainder yourself."
)
return data
elif self.gradient_state.remainder > 0:
# Last batch needs to be truncated on distributed systems as it contains additional samples
def _adjust_samples(tensor):
return tensor[: self.gradient_state.remainder]
if use_gather_object:
# gather_object put the objects in a list
return _adjust_samples(data)
else:
return recursively_apply(_adjust_samples, data)
else: # remainder is 0
# no remainder even though at end of dataloader, so nothing to do.
return data
else:
# Not at the end of the dataloader, no need to adjust the tensors
return data
except Exception:
# Dataset had no length or raised an error
return data
def reduce(self, tensor, reduction="sum", scale=1.0):
"""
Reduce the values in *tensor* across all processes based on *reduction*.
Note:
All processes get the reduced value.
Args:
tensor (`torch.Tensor`, or a nested tuple/list/dictionary of `torch.Tensor`):
The tensors to reduce across all processes.
reduction (`str`, *optional*, defaults to "sum"):
A reduction type, can be one of 'sum', 'mean', or 'none'. If 'none', will not perform any operation.
scale (`float`, *optional*, defaults to 1.0):
A default scaling value to be applied after the reduce, only valied on XLA.
Returns:
`torch.Tensor`, or a nested tuple/list/dictionary of `torch.Tensor`:
The reduced tensor(s).
Example:
```python
>>> # Assuming two processes
>>> import torch
>>> from accelerate import Accelerator
>>> accelerator = Accelerator()
>>> process_tensor = torch.arange(accelerator.num_processes) + 1 + (2 * accelerator.process_index)
>>> process_tensor = process_tensor.to(accelerator.device)
>>> reduced_tensor = accelerator.reduce(process_tensor, reduction="sum")
>>> reduced_tensor
tensor([4, 6])
```
"""
return reduce(tensor, reduction, scale)
def pad_across_processes(self, tensor, dim=0, pad_index=0, pad_first=False):
"""
Recursively pad the tensors in a nested list/tuple/dictionary of tensors from all devices to the same size so
they can safely be gathered.
Args:
tensor (nested list/tuple/dictionary of `torch.Tensor`):
The data to gather.
dim (`int`, *optional*, defaults to 0):
The dimension on which to pad.
pad_index (`int`, *optional*, defaults to 0):
The value with which to pad.
pad_first (`bool`, *optional*, defaults to `False`):
Whether to pad at the beginning or the end.
Returns:
`torch.Tensor`, or a nested tuple/list/dictionary of `torch.Tensor`:
The padded tensor(s).
Example:
```python
>>> # Assuming two processes, with the first processes having a tensor of size 1 and the second of size 2
>>> import torch
>>> from accelerate import Accelerator
>>> accelerator = Accelerator()
>>> process_tensor = torch.arange(accelerator.process_index + 1).to(accelerator.device)
>>> padded_tensor = accelerator.pad_across_processes(process_tensor)
>>> padded_tensor.shape
torch.Size([2])
```
"""
return pad_across_processes(tensor, dim=dim, pad_index=pad_index, pad_first=pad_first)
def unwrap_model(self, model, keep_fp32_wrapper: bool = True):
"""
Unwraps the `model` from the additional layer possible added by [`~Accelerator.prepare`]. Useful before saving
the model.
Args:
model (`torch.nn.Module`):
The model to unwrap.
keep_fp32_wrapper (`bool`, *optional*, defaults to `True`):
Whether to not remove the mixed precision hook if it was added.
Returns:
`torch.nn.Module`: The unwrapped model.
Example:
```python
>>> # Assuming two GPU processes
>>> from torch.nn.parallel import DistributedDataParallel
>>> from accelerate import Accelerator
>>> accelerator = Accelerator()
>>> model = accelerator.prepare(MyModel())
>>> print(model.__class__.__name__)
DistributedDataParallel
>>> model = accelerator.unwrap_model(model)
>>> print(model.__class__.__name__)
MyModel
```
"""
return extract_model_from_parallel(model, keep_fp32_wrapper)
def wait_for_everyone(self):
"""
Will stop the execution of the current process until every other process has reached that point (so this does
nothing when the script is only run in one process). Useful to do before saving a model.
Example:
```python
>>> # Assuming two GPU processes
>>> import time
>>> from accelerate import Accelerator
>>> accelerator = Accelerator()
>>> if accelerator.is_main_process:
... time.sleep(2)
>>> else:
... print("I'm waiting for the main process to finish its sleep...")
>>> accelerator.wait_for_everyone()
>>> # Should print on every process at the same time
>>> print("Everyone is here")
```
"""
wait_for_everyone()
@on_main_process
def init_trackers(self, project_name: str, config: dict | None = None, init_kwargs: dict | None = {}):
"""
Initializes a run for all trackers stored in `self.log_with`, potentially with starting configurations
Args:
project_name (`str`):
The name of the project. All trackers will save their data based on this
config (`dict`, *optional*):
Optional starting configuration to be logged.
init_kwargs (`dict`, *optional*):
A nested dictionary of kwargs to be passed to a specific tracker's `__init__` function. Should be
formatted like so:
```python
{"wandb": {"tags": ["tag_a", "tag_b"]}}
```
Example:
```python
>>> from accelerate import Accelerator
>>> accelerator = Accelerator(log_with="tensorboard")
>>> accelerator.init_trackers(
... project_name="my_project",
... config={"learning_rate": 0.001, "batch_size": 32},
... init_kwargs={"tensorboard": {"flush_secs": 60}},
... )
```
"""
for tracker in self.log_with:
if issubclass(type(tracker), GeneralTracker):
# Custom trackers are already initialized
self.trackers.append(tracker)
else:
tracker_init = LOGGER_TYPE_TO_CLASS[str(tracker)]
if tracker_init.requires_logging_directory:
# We can skip this check since it was done in `__init__`
self.trackers.append(
tracker_init(project_name, self.logging_dir, **init_kwargs.get(str(tracker), {}))
)
else:
self.trackers.append(tracker_init(project_name, **init_kwargs.get(str(tracker), {})))
if config is not None:
for tracker in self.trackers:
tracker.store_init_configuration(config)
def get_tracker(self, name: str, unwrap: bool = False):
"""
Returns a `tracker` from `self.trackers` based on `name` on the main process only.
Args:
name (`str`):
The name of a tracker, corresponding to the `.name` property.
unwrap (`bool`):
Whether to return the internal tracking mechanism or to return the wrapped tracker instead
(recommended).
Returns:
`GeneralTracker`: The tracker corresponding to `name` if it exists.
Example:
```python
>>> from accelerate import Accelerator
>>> accelerator = Accelerator(log_with="tensorboard")
>>> accelerator.init_trackers("my_project")
>>> tensorboard_tracker = accelerator.get_tracker("tensorboard")
```
"""
if len(self.trackers) > 0:
for tracker in self.trackers:
if tracker.name == name:
return tracker.tracker if unwrap else tracker
raise ValueError(f"{name} is not an available tracker stored inside the `Accelerator`.")
# Handle tracker only made on main process
return GeneralTracker(_blank=True)
@on_main_process
def log(self, values: dict, step: int | None = None, log_kwargs: dict | None = {}):
"""
Logs `values` to all stored trackers in `self.trackers` on the main process only.
Args:
values (`dict`):
Values should be a dictionary-like object containing only types `int`, `float`, or `str`.
step (`int`, *optional*):
The run step. If included, the log will be affiliated with this step.
log_kwargs (`dict`, *optional*):
A nested dictionary of kwargs to be passed to a specific tracker's `log` function. Should be formatted
like so:
```python
{"wandb": {"tags": ["tag_a", "tag_b"]}}
```
Example:
```python
>>> from accelerate import Accelerator
>>> accelerator = Accelerator(log_with="tensorboard")
>>> accelerator.init_trackers("my_project")
>>> accelerator.log({"loss": 0.5, "accuracy": 0.9})
```
"""
for tracker in self.trackers:
tracker.log(values, step=step, **log_kwargs.get(tracker.name, {}))
def end_training(self):
"""
Runs any special end training behaviors, such as stopping trackers on the main process only or destoying
process group. Should always be called at the end of your script if using experiment tracking.
Example:
```python
>>> from accelerate import Accelerator
>>> accelerator = Accelerator(log_with="tensorboard")
>>> accelerator.init_trackers("my_project")
>>> # Do training
>>> accelerator.end_training()
```
"""
for tracker in self.trackers:
tracker.finish()
self.state.destroy_process_group()
def save(self, obj, f, safe_serialization=False):
"""
Save the object passed to disk once per machine. Use in place of `torch.save`.
Args:
obj (`object`): The object to save.
f (`str` or `os.PathLike`): Where to save the content of `obj`.
safe_serialization (`bool`, *optional*, defaults to `False`): Whether to save `obj` using `safetensors`
Note:
If `save_on_each_node` was passed in as a `ProjectConfiguration`, will save the object once per node,
rather than only once on the main node.
Example:
```python
>>> from accelerate import Accelerator
>>> accelerator = Accelerator()
>>> arr = [0, 1, 2, 3]
>>> accelerator.save(arr, "array.pkl")
```
"""
save(
obj,
f,
save_on_each_node=self.project_configuration.save_on_each_node,
safe_serialization=safe_serialization,
)
def save_model(
self,
model: torch.nn.Module,
save_directory: Union[str, os.PathLike],
max_shard_size: Union[int, str] = "10GB",
safe_serialization: bool = True,
):
"""
Save a model so that it can be re-loaded using load_checkpoint_in_model
Arguments:
model: (`torch.nn.Module`):
Model to be saved. The model can be wrapped or unwraped.
save_directory (`str` or `os.PathLike`):
Directory to which to save. Will be created if it doesn't exist.
max_shard_size (`int` or `str`, *optional*, defaults to `"10GB"`):
The maximum size for a checkpoint before being sharded. Checkpoints shard will then be each of size
lower than this size. If expressed as a string, needs to be digits followed by a unit (like `"5MB"`).
<Tip warning={true}>
If a single weight of the model is bigger than `max_shard_size`, it will be in its own checkpoint shard
which will be bigger than `max_shard_size`.
</Tip>
safe_serialization (`bool`, *optional*, defaults to `True`):
Whether to save the model using `safetensors` or the traditional PyTorch way (that uses `pickle`).
Example:
```python
>>> from accelerate import Accelerator
>>> accelerator = Accelerator()
>>> model = ...
>>> accelerator.save_model(model, save_directory)
```
"""
if os.path.isfile(save_directory):
logger.error(f"Provided path ({save_directory}) should be a directory, not a file")
return
# get the state_dict of the model
if any(has_offloaded_params(module) for module in model.modules()):
state_dict = get_state_dict_offloaded_model(model)
else:
if any(param.device == torch.device("meta") for param in model.parameters()):
raise RuntimeError("You can't save the model since some parameters are on the meta device.")
state_dict = self.get_state_dict(model)
# Case: DeepSpeed zero3 gets gathered and `state_dict` is empty
if state_dict is None:
return
os.makedirs(save_directory, exist_ok=True)
if safe_serialization:
state_dict = clean_state_dict_for_safetensors(state_dict)
weights_name = SAFE_WEIGHTS_NAME if safe_serialization else WEIGHTS_NAME
filename_pattern = SAFE_WEIGHTS_PATTERN_NAME if safe_serialization else WEIGHTS_PATTERN_NAME
state_dict_split = split_torch_state_dict_into_shards(
state_dict, filename_pattern=filename_pattern, max_shard_size=max_shard_size
)
# Clean the folder from a previous save
for filename in os.listdir(save_directory):
full_filename = os.path.join(save_directory, filename)
# If we have a shard file that is not going to be replaced, we delete it, but only from the main process
# in distributed settings to avoid race conditions.
weights_no_suffix = weights_name.replace(".bin", "")
# make sure that file to be deleted matches format of sharded file, e.g. pytorch_model-00001-of-00005
filename_no_suffix = filename.replace(".bin", "")
reg = re.compile(r"(.*?)-\d{5}-of-\d{5}")
if (
filename.startswith(weights_no_suffix)
and os.path.isfile(full_filename)
and filename not in state_dict_split.filename_to_tensors.keys()
and reg.fullmatch(filename_no_suffix) is not None
and PartialState().is_main_process
):
os.remove(full_filename)
# Save the model
for filename, tensors in state_dict_split.filename_to_tensors.items():
shard = {tensor: state_dict[tensor] for tensor in tensors}
self.save(shard, os.path.join(save_directory, filename), safe_serialization=safe_serialization)
# Save index if sharded
if state_dict_split.is_sharded:
index = {
"metadata": state_dict_split.metadata,
"weight_map": state_dict_split.tensor_to_filename,
}
save_index_file = SAFE_WEIGHTS_INDEX_NAME if safe_serialization else WEIGHTS_INDEX_NAME
save_index_file = os.path.join(save_directory, save_index_file)
with open(save_index_file, "w", encoding="utf-8") as f:
content = json.dumps(index, indent=2, sort_keys=True) + "\n"
f.write(content)
logger.info(
f"The model is bigger than the maximum size per checkpoint ({max_shard_size}) and is going to be "
f"split in {len(state_dict_split.filename_to_tensors)} checkpoint shards. You can find where each parameters has been saved in the "
f"index located at {save_index_file}."
)
else:
path_to_weights = os.path.join(save_directory, WEIGHTS_NAME)
logger.info(f"Model weights saved in {path_to_weights}")
def register_save_state_pre_hook(self, hook: Callable[..., None]) -> hooks.RemovableHandle:
"""
Registers a pre hook to be run before `save_checkpoint` is called in [`Accelerator.save_state`].
Args:
hook (`Callable`):
A function to be called in [`Accelerator.save_state`] before `save_checkpoint`.
The hook should have the following signature:
`hook(models: list[torch.nn.Module], weights: list[dict[str, torch.Tensor]], input_dir: str) -> None`
The `models` argument are the models as saved in the accelerator state under `accelerator._models`, `weigths`
argument are the state dicts of the `models`, and the `input_dir` argument is the `input_dir` argument passed
to [`Accelerator.load_state`].
<Tip>
Should only be used in conjunction with [`Accelerator.register_load_state_pre_hook`]. Can be useful to save
configurations in addition to model weights. Can also be used to overwrite model saving with a customized
method. In this case, make sure to remove already loaded weights from the weights list.
</Tip>
Returns:
`torch.utils.hooks.RemovableHandle`: a handle that can be used to remove the added hook by calling
`handle.remove()`
"""
handle = hooks.RemovableHandle(self._save_model_state_pre_hook)
self._save_model_state_pre_hook[handle.id] = hook
return handle
def save_state(self, output_dir: str = None, safe_serialization: bool = True, **save_model_func_kwargs):
"""
Saves the current states of the model, optimizer, scaler, RNG generators, and registered objects to a folder.
If a `ProjectConfiguration` was passed to the `Accelerator` object with `automatic_checkpoint_naming` enabled
then checkpoints will be saved to `self.project_dir/checkpoints`. If the number of current saves is greater
than `total_limit` then the oldest save is deleted. Each checkpoint is saved in seperate folders named
`checkpoint_<iteration>`.
Otherwise they are just saved to `output_dir`.
<Tip>
Should only be used when wanting to save a checkpoint during training and restoring the state in the same
environment.
</Tip>
Args:
output_dir (`str` or `os.PathLike`):
The name of the folder to save all relevant weights and states.
safe_serialization (`bool`, *optional*, defaults to `True`):
Whether to save the model using `safetensors` or the traditional PyTorch way (that uses `pickle`).
save_model_func_kwargs (`dict`, *optional*):
Additional keyword arguments for saving model which can be passed to the underlying save function, such
as optional arguments for DeepSpeed's `save_checkpoint` function.
Example:
```python
>>> from accelerate import Accelerator
>>> accelerator = Accelerator()
>>> model, optimizer, lr_scheduler = ...
>>> model, optimizer, lr_scheduler = accelerator.prepare(model, optimizer, lr_scheduler)
>>> accelerator.save_state(output_dir="my_checkpoint")
```
"""
if self.project_configuration.automatic_checkpoint_naming:
output_dir = os.path.join(self.project_dir, "checkpoints")
os.makedirs(output_dir, exist_ok=True)
if self.project_configuration.automatic_checkpoint_naming:
folders = [os.path.join(output_dir, folder) for folder in os.listdir(output_dir)]
if (
self.project_configuration.total_limit is not None
and (len(folders) + 1 > self.project_configuration.total_limit)
and self.is_main_process
):
def _inner(folder):
return list(map(int, re.findall(r"[\/]?([0-9]+)(?=[^\/]*$)", folder)))[0]
folders.sort(key=_inner)
logger.warning(
f"Deleting {len(folders) + 1 - self.project_configuration.total_limit} checkpoints to make room for new checkpoint."
)
for folder in folders[: len(folders) + 1 - self.project_configuration.total_limit]:
shutil.rmtree(folder)
output_dir = os.path.join(output_dir, f"checkpoint_{self.save_iteration}")
if os.path.exists(output_dir):
raise ValueError(
f"Checkpoint directory {output_dir} ({self.save_iteration}) already exists. Please manually override `self.save_iteration` with what iteration to start with."
)
self.wait_for_everyone()
os.makedirs(output_dir, exist_ok=True)
logger.info(f"Saving current state to {output_dir}")
if self.distributed_type == DistributedType.XLA:
# Finish running the previous step before checkpointing
xm.mark_step()
# Save the models taking care of FSDP and DeepSpeed nuances
weights = []
for i, model in enumerate(self._models):
if self.distributed_type == DistributedType.FSDP:
logger.info("Saving FSDP model")
save_fsdp_model(self.state.fsdp_plugin, self, model, output_dir, i)
logger.info(f"FSDP Model saved to output dir {output_dir}")
elif self.distributed_type == DistributedType.DEEPSPEED:
logger.info("Saving DeepSpeed Model and Optimizer")
ckpt_id = f"{MODEL_NAME}" if i == 0 else f"{MODEL_NAME}_{i}"
model.save_checkpoint(output_dir, ckpt_id, **save_model_func_kwargs)
logger.info(f"DeepSpeed Model and Optimizer saved to output dir {os.path.join(output_dir, ckpt_id)}")
elif self.distributed_type == DistributedType.MEGATRON_LM:
logger.info("Saving Megatron-LM Model, Optimizer and Scheduler")
model.save_checkpoint(output_dir)
logger.info(f"Megatron-LM Model , Optimizer and Scheduler saved to output dir {output_dir}")
else:
weights.append(self.get_state_dict(model, unwrap=False))
# Save the optimizers taking care of FSDP and DeepSpeed nuances
optimizers = []
if self.distributed_type == DistributedType.FSDP:
for i, opt in enumerate(self._optimizers):
logger.info("Saving FSDP Optimizer")
save_fsdp_optimizer(self.state.fsdp_plugin, self, opt, self._models[i], output_dir, i)
logger.info(f"FSDP Optimizer saved to output dir {output_dir}")
elif self.distributed_type not in [DistributedType.DEEPSPEED, DistributedType.MEGATRON_LM]:
optimizers = self._optimizers
# Save the lr schedulers taking care of DeepSpeed nuances
schedulers = []
if self.distributed_type == DistributedType.DEEPSPEED:
for i, scheduler in enumerate(self._schedulers):
if isinstance(scheduler, DeepSpeedSchedulerWrapper):
continue
schedulers.append(scheduler)
elif self.distributed_type not in [DistributedType.MEGATRON_LM]:
schedulers = self._schedulers
# Save the samplers of the dataloaders
dataloaders = self._dataloaders
# Call model loading hooks that might have been registered with
# accelerator.register_model_state_hook
for hook in self._save_model_state_pre_hook.values():
hook(self._models, weights, output_dir)
save_location = save_accelerator_state(
output_dir,
weights,
optimizers,
schedulers,
dataloaders,
self.state.process_index,
self.step,
self.scaler,
save_on_each_node=self.project_configuration.save_on_each_node,
safe_serialization=safe_serialization,
)
for i, obj in enumerate(self._custom_objects):
save_custom_state(obj, output_dir, i, save_on_each_node=self.project_configuration.save_on_each_node)
self.project_configuration.iteration += 1
return save_location
def register_load_state_pre_hook(self, hook: Callable[..., None]) -> hooks.RemovableHandle:
"""
Registers a pre hook to be run before [`load_checkpoint`] is called in [`Accelerator.load_state`].
Args:
hook (`Callable`):
A function to be called in [`Accelerator.load_state`] before `load_checkpoint`.
The hook should have the following signature:
`hook(models: list[torch.nn.Module], input_dir: str) -> None`
The `models` argument are the models as saved in the accelerator state under `accelerator._models`, and the
`input_dir` argument is the `input_dir` argument passed to [`Accelerator.load_state`].
<Tip>
Should only be used in conjunction with [`Accelerator.register_save_state_pre_hook`]. Can be useful to load
configurations in addition to model weights. Can also be used to overwrite model loading with a customized
method. In this case, make sure to remove already loaded models from the models list.
</Tip>
Returns:
`torch.utils.hooks.RemovableHandle`: a handle that can be used to remove the added hook by calling
`handle.remove()`
"""
handle = hooks.RemovableHandle(self._load_model_state_pre_hook)
self._load_model_state_pre_hook[handle.id] = hook
return handle
def load_state(self, input_dir: str = None, **load_model_func_kwargs):
"""
Loads the current states of the model, optimizer, scaler, RNG generators, and registered objects.
<Tip>
Should only be used in conjunction with [`Accelerator.save_state`]. If a file is not registered for
checkpointing, it will not be loaded if stored in the directory.
</Tip>
Args:
input_dir (`str` or `os.PathLike`):
The name of the folder all relevant weights and states were saved in. Can be `None` if
`automatic_checkpoint_naming` is used, and will pick up from the latest checkpoint.
load_model_func_kwargs (`dict`, *optional*):
Additional keyword arguments for loading model which can be passed to the underlying load function,
such as optional arguments for DeepSpeed's `load_checkpoint` function or a `map_location` to load the
model and optimizer on.
Example:
```python
>>> from accelerate import Accelerator
>>> accelerator = Accelerator()
>>> model, optimizer, lr_scheduler = ...
>>> model, optimizer, lr_scheduler = accelerator.prepare(model, optimizer, lr_scheduler)
>>> accelerator.load_state("my_checkpoint")
```
"""
if input_dir is not None:
# Check if folder exists
input_dir = os.path.expanduser(input_dir)
if not os.path.isdir(input_dir):
raise ValueError(f"Tried to find {input_dir} but folder does not exist")
elif self.project_configuration.automatic_checkpoint_naming:
# Pick up from automatic checkpoint naming
input_dir = os.path.join(self.project_dir, "checkpoints")
folders = [os.path.join(input_dir, folder) for folder in os.listdir(input_dir)]
def _inner(folder):
return list(map(int, re.findall(r"[\/]?([0-9]+)(?=[^\/]*$)", folder)))[0]
folders.sort(key=_inner)
input_dir = folders[-1]
else:
raise ValueError("No input_dir provided and automatic checkpoint naming is disabled.")
logger.info(f"Loading states from {input_dir}")
# Load the models taking care of FSDP and DeepSpeed nuances
models = []
for i, model in enumerate(self._models):
if self.distributed_type == DistributedType.FSDP:
logger.info("Loading FSDP model")
load_fsdp_model(self.state.fsdp_plugin, self, model, input_dir, i)
logger.info(f"FSDP Model loaded from input dir {input_dir}")
elif self.distributed_type == DistributedType.DEEPSPEED:
logger.info("Loading DeepSpeed Model and Optimizer")
ckpt_id = f"{MODEL_NAME}" if i == 0 else f"{MODEL_NAME}_{i}"
model.load_checkpoint(input_dir, ckpt_id, **load_model_func_kwargs)
logger.info(f"DeepSpeed Model and Optimizer loaded from input dir {os.path.join(input_dir, ckpt_id)}")
elif self.distributed_type == DistributedType.MEGATRON_LM:
logger.info("Loading Megatron-LM Model, Optimizer and Scheduler")
model.load_checkpoint(input_dir)
logger.info(f"Megatron-LM Model , Optimizer and Scheduler loaded from input dir {input_dir}")
else:
models.append(model)
# Load the optimizers taking care of FSDP and DeepSpeed nuances
optimizers = []
if self.distributed_type == DistributedType.FSDP:
for i, opt in enumerate(self._optimizers):
logger.info("Loading FSDP Optimizer")
load_fsdp_optimizer(self.state.fsdp_plugin, self, opt, self._models[i], input_dir, i)
logger.info(f"FSDP Optimizer loaded from input dir {input_dir}")
elif self.distributed_type not in [DistributedType.DEEPSPEED, DistributedType.MEGATRON_LM]:
optimizers = self._optimizers
# Load the lr schedulers taking care of DeepSpeed nuances
schedulers = []
if self.distributed_type == DistributedType.DEEPSPEED:
for i, scheduler in enumerate(self._schedulers):
if isinstance(scheduler, DeepSpeedSchedulerWrapper):
continue
schedulers.append(scheduler)
elif self.distributed_type not in [DistributedType.MEGATRON_LM]:
schedulers = self._schedulers
dataloaders = self._dataloaders
# Call model loading hooks that might have been registered with
# accelerator.register_model_state_hook
for hook in self._load_model_state_pre_hook.values():
hook(models, input_dir)
map_location = load_model_func_kwargs.pop("map_location", None)
if map_location is None:
if self.num_processes > 1 and self.distributed_type in (
DistributedType.MULTI_GPU,
DistributedType.MULTI_MLU,
DistributedType.MULTI_MUSA,
DistributedType.MULTI_NPU,
):
map_location = "on_device"
else:
map_location = "cpu"
override_attributes = load_accelerator_state(
input_dir,
models,
optimizers,
schedulers,
dataloaders,
self.state.process_index,
self.scaler,
map_location,
**load_model_func_kwargs,
)
if "step" in override_attributes:
self.step = override_attributes["step"]
custom_checkpoints = [
f for f in os.listdir(input_dir) if re.search(r"^custom_checkpoint_\d+\.pkl$", f) is not None
]
if len(custom_checkpoints) != len(self._custom_objects):
err = (
f"Number of custom checkpoints in folder {input_dir} does not match the number of registered objects:"
)
err += f"\n\tFound checkpoints: {len(custom_checkpoints)}"
err += f"\n\tRegistered objects: {len(self._custom_objects)}\n"
err += "Please make sure to only load checkpoints from folders that were created with the same set of registered objects,"
err += "or avoid using `custom_checkpoint` in the filename for files in that same directory and load them in manually."
raise RuntimeError(err)
else:
logger.info(f"Loading in {len(custom_checkpoints)} custom states")
for index, obj in enumerate(self._custom_objects):
load_custom_state(obj, input_dir, index)
def free_memory(self, *objects):
"""
Will release all references to the internal objects stored and call the garbage collector. You should call this
method between two trainings with different models/optimizers. Also will reset `Accelerator.step` to 0.
Example:
```python
>>> from accelerate import Accelerator
>>> accelerator = Accelerator()
>>> model, optimizer, scheduler = ...
>>> model, optimizer, scheduler = accelerator.prepare(model, optimizer, scheduler)
>>> model, optimizer, scheduler = accelerator.free_memory(model, optimizer, scheduler)
```
"""
# Deepspeed needs a bit more prep that should be done first
if hasattr(self, "deepspeed_engine_wrapped"):
if self.deepspeed_engine_wrapped is not None:
self.deepspeed_engine_wrapped.engine.destroy()
self.deepspeed_engine_wrapped = None
objects = release_memory(*objects)
self._schedulers = []
self._optimizers = []
self._models = []
self._dataloaders = []
self.step = 0
return objects
def clear(self, *objects):
"""
Alias for [`Accelerate.free_memory`], releases all references to the internal objects stored and call the
garbage collector. You should call this method between two trainings with different models/optimizers.
Example:
```python
>>> from accelerate import Accelerator
>>> accelerator = Accelerator()
>>> model, optimizer, scheduler = ...
>>> model, optimizer, scheduler = accelerator.prepare(model, optimizer, scheduler)
>>> model, optimizer, scheduler = accelerator.clear(model, optimizer, scheduler)
```
"""
return self.free_memory(*objects)
def _get_named_parameters(self, *args):
named_parameters = {}
for obj in args:
if isinstance(obj, torch.nn.Module):
obj = extract_model_from_parallel(obj)
named_parameters.update({n: p for n, p in obj.named_parameters()})
return named_parameters
def _get_devices(self, *args):
model_device = None
optimizer_device = None
for obj in args:
# Loop through model parameters and stop at the first once we have its device.
if isinstance(obj, torch.nn.Module):
for param in obj.parameters():
model_device = param.device
break
# Loop through optimizer parameters groups and stop at the first once we have its device.
if isinstance(obj, torch.optim.Optimizer):
for param_group in obj.param_groups:
if len(param_group["params"]) > 0:
optimizer_device = param_group["params"][0].device
break
return (model_device, optimizer_device)
def get_state_dict(self, model, unwrap=True):
"""
Returns the state dictionary of a model sent through [`Accelerator.prepare`] potentially without full
precision.
Args:
model (`torch.nn.Module`):
A PyTorch model sent through [`Accelerator.prepare`]
unwrap (`bool`, *optional*, defaults to `True`):
Whether to return the original underlying state_dict of `model` or to return the wrapped state_dict
Returns:
`dict`: The state dictionary of the model potentially without full precision.
Example:
```python
>>> import torch
>>> from accelerate import Accelerator
>>> accelerator = Accelerator()
>>> net = torch.nn.Linear(2, 2)
>>> net = accelerator.prepare(net)
>>> state_dict = accelerator.get_state_dict(net)
```
"""
if self.distributed_type == DistributedType.DEEPSPEED:
if self.deepspeed_config["zero_optimization"]["stage"] == 3:
if model.zero_gather_16bit_weights_on_model_save():
state_dict = model._zero3_consolidated_16bit_state_dict()
else:
raise ValueError(
"Cannot get 16bit model weights because `stage3_gather_16bit_weights_on_model_save` in DeepSpeed config is False. "
"To save the model weights in 16bit, set `stage3_gather_16bit_weights_on_model_save` to True in DeepSpeed config file or "
"set `zero3_save_16bit_model` to True when using `accelerate config`. "
"To save the full checkpoint, run `model.save_checkpoint(save_dir)` and use `zero_to_fp32.py` to recover weights."
)
else:
from deepspeed.checkpoint.utils import clone_tensors_for_torch_save
state_dict = clone_tensors_for_torch_save(self.unwrap_model(model).state_dict())
elif self.distributed_type == DistributedType.FSDP:
from torch.distributed.fsdp import FullStateDictConfig, StateDictType
from torch.distributed.fsdp import FullyShardedDataParallel as FSDP
full_state_dict_config = FullStateDictConfig(offload_to_cpu=True, rank0_only=True)
with FSDP.state_dict_type(model, StateDictType.FULL_STATE_DICT, full_state_dict_config):
state_dict = model.state_dict()
else:
if unwrap:
model = self.unwrap_model(model)
state_dict = model.state_dict()
return state_dict
def register_for_checkpointing(self, *objects):
"""
Makes note of `objects` and will save or load them in during `save_state` or `load_state`.
These should be utilized when the state is being loaded or saved in the same script. It is not designed to be
used in different scripts.
<Tip>
Every `object` must have a `load_state_dict` and `state_dict` function to be stored.
</Tip>
Example:
```python
>>> from accelerate import Accelerator
>>> accelerator = Accelerator()
>>> # Assume `CustomObject` has a `state_dict` and `load_state_dict` function.
>>> obj = CustomObject()
>>> accelerator.register_for_checkpointing(obj)
>>> accelerator.save_state("checkpoint.pt")
```
"""
invalid_objects = []
for obj in objects:
if not hasattr(obj, "state_dict") or not hasattr(obj, "load_state_dict"):
invalid_objects.append(obj)
if len(invalid_objects) > 0:
err = "All `objects` must include a `state_dict` and `load_state_dict` function to be stored. The following inputs are invalid:"
for index, obj in enumerate(invalid_objects):
err += f"\n\t- Item at index {index}, `{get_pretty_name(obj)}`"
raise ValueError(err)
self._custom_objects.extend(objects)
@contextmanager
def autocast(self, autocast_handler: AutocastKwargs = None):
"""
Will apply automatic mixed-precision inside the block inside this context manager, if it is enabled. Nothing
different will happen otherwise.
A different `autocast_handler` can be passed in to override the one set in the `Accelerator` object. This is
useful in blocks under `autocast` where you want to revert to fp32.
Example:
```python
>>> from accelerate import Accelerator
>>> accelerator = Accelerator(mixed_precision="fp16")
>>> with accelerator.autocast():
... train()
```
"""
if autocast_handler is None:
autocast_handler = self.autocast_handler
autocast_context = get_mixed_precision_context_manager(self.native_amp, autocast_handler)
autocast_context.__enter__()
# TODO: should the `yield` be in a try/finally block?
yield
autocast_context.__exit__(*sys.exc_info())
@contextmanager
def profile(self, profile_handler: ProfileKwargs | None = None):
"""
Will profile the code inside the context manager. The profile will be saved to a Chrome Trace file if
`profile_handler.output_trace_dir` is set.
A different `profile_handler` can be passed in to override the one set in the `Accelerator` object.
Args:
profile_handler (`ProfileKwargs`, *optional*):
The profile handler to use for this context manager. If not passed, will use the one set in the
`Accelerator` object.
Example:
```python
# Profile with default settings
from accelerate import Accelerator
from accelerate.utils import ProfileKwargs
accelerator = Accelerator()
with accelerator.profile() as prof:
train()
accelerator.print(prof.key_averages().table())
# Profile with the custom handler
def custom_handler(prof):
print(prof.key_averages().table(sort_by="self_cpu_time_total", row_limit=10))
kwargs = ProfileKwargs(schedule_option=dict(wait=1, warmup=1, active=1), on_trace_ready=custom_handler)
accelerator = Accelerator(kwarg_handler=[kwargs])
with accelerator.profile() as prof:
for _ in range(10):
train_iteration()
prof.step()
# Profile and export to Chrome Trace
kwargs = ProfileKwargs(output_trace_dir="output_trace")
accelerator = Accelerator(kwarg_handler=[kwargs])
with accelerator.profile():
train()
```
"""
profile_handler = profile_handler or self.profile_handler or ProfileKwargs()
with profile_handler.build() as profiler:
yield profiler
if profile_handler.output_trace_dir is None:
return
os.makedirs(profile_handler.output_trace_dir, exist_ok=True)
profiler.export_chrome_trace(
os.path.join(profile_handler.output_trace_dir, PROFILE_PATTERN_NAME.format(suffix=self.process_index))
)
self.wait_for_everyone()
@property
def optimizer_step_was_skipped(self):
"""
Whether or not the optimizer update was skipped (because of gradient overflow in mixed precision), in which
case the learning rate should not be changed.
"""
for optimizer in self._optimizers:
if optimizer.step_was_skipped:
return True
return False
def skip_first_batches(self, dataloader, num_batches: int = 0):
"""
Creates a new `torch.utils.data.DataLoader` that will efficiently skip the first `num_batches`.
Args:
dataloader (`torch.utils.data.DataLoader`): The data loader in which to skip batches.
num_batches (`int`, *optional*, defaults to 0): The number of batches to skip
Example:
```python
>>> from accelerate import Accelerator
>>> accelerator = Accelerator()
>>> dataloader, model, optimizer, scheduler = accelerator.prepare(dataloader, model, optimizer, scheduler)
>>> skipped_dataloader = accelerator.skip_first_batches(dataloader, num_batches=2)
>>> # for the first epoch only
>>> for input, target in skipped_dataloader:
... optimizer.zero_grad()
... output = model(input)
... loss = loss_func(output, target)
... accelerator.backward(loss)
... optimizer.step()
>>> # subsequent epochs
>>> for input, target in dataloader:
... optimizer.zero_grad()
... ...
```
"""
return skip_first_batches(dataloader, num_batches=num_batches)
def __deepcopy__(self, memo):
logger.info("Deep copying the `Accelerator` object, note that this will point to the same original object.")
return self
def verify_device_map(self, model: torch.nn.Module) -> bool:
"""
Verifies that `model` has not been prepared with big model inference with a device-map resembling `auto`.
"""
# Checks if any of the child modules has the attribute `hf_device_map` and this map has more than one entry.
for m in model.modules():
if hasattr(m, "hf_device_map") and len(m.hf_device_map) > 1:
return True
return False
def lomo_backward(self, loss: torch.Tensor, learning_rate: float) -> None:
"""
Runs backward pass on LOMO optimizers.
"""
if is_lomo_available():
# We need to import locally to avoid circular imports since lomo imports stuff from
# transformers & accelerate
from lomo_optim import AdaLomo, Lomo
if learning_rate is None:
raise ValueError("A learning rate must be passed in order to call backward pass with LOMO optimizers.")
_backward_called = False
for optimizer in self._optimizers:
if isinstance(optimizer.optimizer, (Lomo, AdaLomo)):
optimizer.optimizer.fused_backward(loss, learning_rate)
_backward_called = True
if not _backward_called:
raise ValueError(
"Backward pass not properly called on LOMO optimizers. Are you sure you passed a LOMO optimizer in accelerator.prepare()?"
)
@property
def fp8_backend(self):
"Returns the configured backend for training in FP8"
if self.mixed_precision == "fp8" and self.fp8_recipe_handler is not None:
return self.fp8_recipe_handler.backend
elif self.state.deepspeed_plugin is not None and self.state.deepspeed_plugin.enable_msamp:
return "MSAMP"
return None
| 9 |
0 | hf_public_repos/audio-transformers-course/chapters/zh-CN | hf_public_repos/audio-transformers-course/chapters/zh-CN/chapter2/hands_on.mdx | # 实战练习
本节的练习不计入课程成绩,旨在帮助你熟悉本课程中将要使用的工具和库。如果你已经熟悉使用 Google Colab、🤗 Datasets、librosa 和 🤗 Transformers,你可以选择跳过本节练习。
1. 创建一个 [Google Colab](https://colab.research.google.com) 笔记本。
2. 使用 🤗 Datasets 加载 [`facebook/voxpopuli` 数据集](https://huggingface.co/datasets/facebook/voxpopuli) 的训练集,语言任选,使用流式加载模式。
3. 获取数据集`train`部分的第三个样本并探索它。根据这个样本所拥有的特征,你可以用这个数据集做哪些音频任务?
4. 绘制这个样本的波形图和频谱图。
5. 前往 [🤗 Hub](https://huggingface.co/models),探索预训练模型并找到一个可以用于你之前选择的语言的自动语音识别的模型。使用你找到的模型实例化一个对应的 pipeline,并转录这个样本。
6. 将你从 pipeline 得到的转录与样本的真实转录文字进行比较。
如果你在这个练习中遇到了问题,可以参考[示例解决方案](https://colab.research.google.com/drive/1NGyo5wFpRj8TMfZOIuPaJHqyyXCITftc?usp=sharing)。你发现了什么有趣的东西?找到了一个很酷的模型?得到了一个漂亮的频谱图?欢迎在 Twitter 上分享你的工作和发现!
在接下来的章节中,你会学习到更多关于各种音频Transformer架构的知识,并训练你自己的模型!
| 0 |
0 | hf_public_repos/audio-transformers-course/chapters/zh-CN | hf_public_repos/audio-transformers-course/chapters/zh-CN/chapter3/supplemental_reading.mdx | # 补充阅读和资源
如果你想进一步了解不同的Transformer结构并学习它们在语音处理中的各种应用,请查看这篇最近的论文:
### Transformers in Speech Processing: A Survey
作者:Siddique Latif, Aun Zaidi, Heriberto Cuayahuitl, Fahad Shamshad, Moazzam Shoukat, Junaid Qadir
"Transformer在自然语言处理领域的显著成功引起了语音处理界的兴趣,从而探索了它们在语音序列中建模长距离依赖性的潜力。最近,Transformer在各种与语音相关的领域中获得了突出的地位,包括自动语音识别、语音合成、语音翻译、语音语言学、语音增强、口语对话系统和众多多模态应用。在本文中,我们提出了一份综合调查报告,旨在桥接语音技术中不同子领域的研究成果。通过整合语音技术领域的研究成果,我们为那些有兴趣利用Transformer的力量推动该领域发展的研究人员提供了宝贵的资源。我们指出了Transformer在语音处理中遇到的挑战,同时也提供了解决这些问题的潜在解决方案。"
[arxiv.org/abs/2303.11607](https://arxiv.org/abs/2303.11607)
| 1 |
0 | hf_public_repos/audio-transformers-course/chapters/zh-CN | hf_public_repos/audio-transformers-course/chapters/zh-CN/chapter3/classification.mdx | # 音频分类结构
音频分类任务的目标是预测音频输出的分类标签。分类模型可以为整个输入序列预测一个标签,也可以为每一帧预测一个不同的标签。在分帧预测时,模型通常为每20毫秒的输入音频预测一个标签,并生成一个由分类标签概率分布组成的序列。预测单一标签的例子如预测音频中发出声音的鸟的种类;预测分帧标签的例子如说话人识别,每帧都可能由不同的说话人在发出声音。
## 使用时频谱进行分类
最简单的音频分类方法之一是将其视为一个图像分类问题!
回想一下,时频谱是一个形状为`(频率,序列长度)`的二维张量。在[音频数据章节](chapter1/audio_data)中,我们学习过将这些时频谱绘制为图像。没错,我们可以直接将时频谱视为图像,并将其传递给一个常见的CNN分类器模型,如ResNet,并获得非常好的预测结果。更好的是,也可以使用图像Transformer模型,如ViT。
这就是**AST**(Audio Spectrogram Transformer)的作用。它使用ViT(即Vision Transformer)模型,并使用时频谱而非常规图像作为输入。由于Transformer的自注意层,该模型能够比CNN更好地捕获全局上下文。
与ViT一样,AST模型将音频时频谱分成16×16像素的部分重叠的图像块(image patch)序列。然后,我们将此序列中的块投影到嵌入序列中,并像往常一样将其作为输入传递给Transformer编码器。AST是一个仅含编码器的Transformer模型,因此输出是一个隐藏状态序列,每个16×16输入块对应一个隐藏状态。最后是一个含有sigmoid激活函数的简单分类层,将隐藏状态映射为分类概率。
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface-course/audio-course-images/resolve/main/ast.png" alt="The audio spectrogram transformer works on a sequence of patches taken from the spectrogram">
</div>
图像来自论文[AST: Audio Spectrogram Transformer](https://arxiv.org/pdf/2104.01778.pdf)
<Tip>
💡 尽管在这里我们假装时频谱与图像相同,但它们之间其实有重要的区别。例如,将图像的内容上下平移通常不会改变图像中的内容的含义。然而,将时频谱上下平移将改变声音中的频率,并完全改变其特性。图像具有一定的上下和左右平移不变性(shift-invariance),但时频谱仅具有一定的左右平移不变性,而几乎完全不具有上下平移不变性。尽管在实践中,将时频谱视为图像可以得到很好的效果,但请记住它们在原理上完全不同。
</Tip>
## 任何Transformer都可以是分类器
在[CTC](ctc)一节中,我们了解到CTC是一种使用仅含编码器的Transformer来执行自动语音识别的有效技术。CTC模型实际上已经可以被视为分类器,因为其预测的是词汇表中每个词素的概率。我们可以通过更改标签并使用常规的交叉熵损失函数代替特殊的CTC损失来将CTC模型转换为通用的音频分类器。
举个例子,HF Transformers库中包含了`Wav2Vec2ForCTC`模型,但提供了`Wav2Vec2ForSequenceClassification`和`Wav2Vec2ForAudioFrameClassification`。这些模型之间的唯一区别是分类层的大小和所使用的损失函数。
实际上,任何仅含编码器的音频Transformer模型都可以通过在隐藏状态序列之上添加分类层来转换为音频分类器。分类任务通常不需要Transformer解码器。
如果需要对整个序列输出一个单独的分类标签(`Wav2Vec2ForSequenceClassification`),模型会对隐藏状态序列沿其长度取平均值,并将其输送到分类层。这样我们就可以对整个序列输出一个概率分布,而不是输出序列中每个元素的概率分布。
如果需要对每一帧输出一个分类标签(`Wav2Vec2ForAudioFrameClassification`),我们就让分类器对隐藏状态序列中的每个元素都输出一个概率分布,这样我们的输出会成为一个具有同样长度的概率分布序列。 | 2 |
0 | hf_public_repos/audio-transformers-course/chapters/zh-CN | hf_public_repos/audio-transformers-course/chapters/zh-CN/chapter3/ctc.mdx | # CTC结构
CTC结构(Connectionist Temporal Classification)是一种仅使用Transformer编码器(encoder)结构的语音识别(ASR)模型。使用该架构的模型包括Wav2Vec2、HuBERT、M-CTC-T等等。
仅含编码器的Transformer(encoder-only Transformer)是最简单的Transformer,因为它只使用模型的编码器部分。编码器读取输入序列(音频波形)并将其映射到隐藏状态序列(sequence of hidden-states),也称为输出嵌入(output embedding)。
使用CTC模型时,我们对隐藏状态序列进行额外的线性映射以获得类标签预测。类标签为**字母表中的字母**(a、b、c,...)。这样,我们就能够使用一个很小的分类头来预测目标语言中的任何单词,因为词汇表(vocabulary)只需要包含26个字符加上一些特殊的标记。
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface-course/audio-course-images/resolve/main/wav2vec2-ctc.png" alt="Transformer encoder with a CTC head on top">
</div>
到目前为止,这与我们在NLP中使用BERT模型的做法非常相似:仅编码器的Transformer模型将文本标记映射到一系列编码器隐藏状态,然后我们应用线性映射,为每个隐藏状态预测一个类标签。
棘手的问题在于:在语音识别中,我们不知道音频输入和文本输出的**对齐方式**(alignment)。我们知道语音的顺序与文本的转录顺序相同(对齐是单调的),但我们不知道转录文本中的字符如何与音频对齐。这就是CTC算法的用武之地。
<Tip>
💡 在NLP模型中,词汇表(vocabulary,也称字典)通常由数千个标记组成,这些标记不仅描述单个字符,还描述单词的部分甚至整个单词。然而对于CTC模型,较小的词汇表效果最好,我们一般会将其保持在50个字符以下。我们不关心字母的大小写,因此仅使用大写(或仅使用小写)就足够了。数字则被拼写为单词,例如`"20"`变成`"twenty"`。除了字母,我们还需要至少一个单词分隔符标记(空格,space)和一个填充标记(padding token)。与NLP模型一样,填充标记允许我们将多个示例组合成批次,但它也是模型将预测的沉默标记。在英语中,保留`'`字符也很有用——毕竟,`"it's"`和`"its"`的含义完全不同。
</Tip>
## 我们到底该怎么对齐呢?
自动语音识别(ASR)涉及将音频作为输入并产生文本作为输出。我们有几种选择来预测文本:
- 预测单个字母
- 预测音素(phoneme)
- 预测单词标记(word token)
ASR模型会使用含有`(音频, 文字)`对的数据集进行训练,这些数据集的文字信息通常是人工转录的。通常,数据集不包含任何时间信息,也就是说,我们不知道输入和输出序列应该如何对齐。
假设我们有一个长度为一秒钟的音频文件。在**Wav2Vec2**中,模型首先使用CNN特征编码器对音频输入进行下采样,将其映射到较短的隐藏状态序列,其中每20毫秒的音频会对应一个隐藏状态向量(hidden-states vector)。对于一秒的音频,我们将生成的隐藏状态序列传递给Transformer编码器。 (从输入序列中提取的音频片段会有部分重叠,因此即使每20毫秒会生成一个隐藏状态向量,但每个向量实际上包含了25毫秒的音频信息。)
Transformer的编码器会对每个隐藏状态向量产生一个输出预测,因此我们从Transformer中得到一个长度同样为50的输出向量序列。该序列中的每个向量的维度为768. 因此,该示例中Transformer编码器的输出序列的形状为`(768, 50)`。每个预测值包含了25毫秒的音频信息,而音素(phoneme)通常会持续超过25毫秒。因此,我们这里预测音素的效果会好于预测整个单词。CTC在小词汇表上的效果更好,因此我们将预测字母。
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface-course/audio-course-images/resolve/main/cnn-feature-encoder.png" alt="The audio waveform gets mapped to a shorter sequence of hidden-states">
</div>
为了进行文本预测,我们使用一个线性层("CTC头")将768维的编码器输出映射到我们的字符标签。然后,模型会预测一个`(50, 32)`的张量,其中32是词汇表中的标记数。由于我们对序列中的每个特征都进行了一次预测,因此每秒音频会有50个字符预测。
然而,如果我们简单地每20毫秒预测一个字母,我们的预测结果可能会是这样的:
```text
BRIIONSAWWSOMEETHINGCLOSETOPANICONHHISOPPONENT'SSFAACEWHENTHEMANNFINALLLYRREECOGGNNIIZEDHHISSERRRRORR ...
```
仔细观察这个输出,我们可以发现它看起来有一点像英语,但有很多重复的字母。这是因为我们的模型*必须*每20毫秒都输出一些东西,而如果某个字母的持续时间超过了20毫秒,模型就会输出重复的字母。我们无法避免这种情况,特别是在训练时我们不知道转录文本的时间信息。而CTC就是一个帮助我们过滤重复字母的方法。
(在实际操作中,预测的序列还有可能包含很多填充标记(padding token),用于表示模型不太确定音频表示的是什么,或者用于表示字符之间的空白。为了清晰起见,我们从示例中删除了这些填充标记。音频片段之间的部分重叠也是字符重复的另一个原因。)
## CTC算法
CTC算法的关键在于使用一个特殊的标记,通常称为**空白标记**(blank token)。这是一个我们人为加入词汇表的额外标记。在这个例子中,空白标记被表示为`_`。我们用这个特殊的标记来表示字母组之间的硬边界。
CTC模型的完整输出类似于如下的序列:
```text
B_R_II_O_N_||_S_AWW_|||||_S_OMEE_TH_ING_||_C_L_O_S_E||TO|_P_A_N_I_C_||_ON||HHI_S||_OP_P_O_N_EN_T_'SS||_F_AA_C_E||_W_H_EN||THE||M_A_NN_||||_F_I_N_AL_LL_Y||||_RREE_C_O_GG_NN_II_Z_ED|||HHISS|||_ER_RRR_ORR||||
```
该序列中的`|`标记是单词分隔符。在这个例子中,我们使用`|`而不是空格作为单词分隔符,这样可以更容易地看出单词的分隔位置,但它们的作用是一样的。
CTC空白标记使我们能够过滤掉重复的字母。例如预测序列中的最后一个单词,`_ER_RRR_ORR`。如果没有CTC空白标记,这个单词看起来是这样的:
```text
ERRRRORR
```
如果我们简单地去掉非CTC结果中的重复字符,那么它就变成了`EROR`。显然这不是正确的拼写。但是有了CTC空白标记,我们就可以在每个字母组中去掉重复的字母:
```text
_ER_RRR_ORR
```
变为:
```text
_ER_R_OR
```
最后我们去掉空白标记`_`,得到最终的单词:
```text
ERROR
```
如果我们将这种逻辑应用到整个文本,包括`|`,并将剩余的`|`字符替换为空格,那么最终的CTC解码输出会变成:
```text
BRION SAW SOMETHING CLOSE TO PANIC ON HIS OPPONENT'S FACE WHEN THE MAN FINALLY RECOGNIZED HIS ERROR
```
总结一下,CTC模型对应每20毫秒的输入音频(包括部分重叠)会生成一个预测标记。这样的预测规则会生成很多重复的字母。利用CTC空白标记,我们可以轻松地移除这些重复的字母,而不会破坏单词的正确拼写。这是一种非常简单和方便的方法,可以解决输出文本与输入音频的对齐问题。
<Tip>
💡 在实际的Wav2Vec2模型中,CTC空白标记与填充标记`<pad>`是相同的。模型会预测很多这样的`<pad>`标记,例如当当前20毫秒的音频没有明确的字符可以预测时。使用相同的标记作为填充和CTC空白标记可以简化解码算法,并有助于保持词汇表的小规模。
</Tip>
我们可以在Transomer编码模型简单地加入CTC:将编码器的输出序列进入一个线性层,该线性层将音频特征映射到词汇表。模型使用特殊的CTC损失进行训练。
CTC的一个缺点在于,它可能会输出*听起来*正确但*拼写*不正确的单词。毕竟,CTC分类头只考虑了单个字符,而没有处理整个单词。我们可以使用额外的语言模型来提高音频的转录质量。这个语言模型实际上是作为了CTC输出的拼写检查器。
## Wav2Vec2, HuBERT, M-CTC-T等模型有什么区别?
所有基于Transformer的CTC模型的架构都非常相似:它们都使用Transformer编码器(但不使用解码器),并在最后使用一个CTC分类头。从架构上来说,它们的相似程度大于他们的不同程度。
Wav2Vec2和M-CTC-T之间的一个区别在于,前者使用原始音频波形,而后者使用梅尔时频谱(mel spectrogram)作为输入。这些模型还是为不同的目的而训练的。例如,M-CTC-T是为多语言语音识别而训练的,因此它的CTC头相对较大,包含了中文字符以及其他字母。
Wav2Vec2和HuBERT使用了完全相同的架构,但训练方式有很大的区别。Wav2Vec2的训练方式类似于BERT的掩码语言模型(masked language modeling),通过预测音频中被遮盖(mask)的音素来进行预训练。HuBERT则更进一步,学习预测“离散语音单元”(discrete speech unit),这类似于文本句子中的标记,因此可以使用已有的NLP技术来处理语音。
最后,我们在这里介绍的模型并非全部的Transformer CTC模型。还有很多其他的模型,但现在我们知道他们都使用了类似的原理。
| 3 |
0 | hf_public_repos/audio-transformers-course/chapters/zh-CN | hf_public_repos/audio-transformers-course/chapters/zh-CN/chapter3/quiz.mdx | <!-- DISABLE-FRONTMATTER-SECTIONS -->
# 测测你对课程内容的理解
### 1. 什么是声码器(vocoder)?
<Question
choices={[
{
text: "将Transformer输出的时频谱转化为声音波形的外挂神经网络。",
explain: "正确!",
correct: true
},
{
text: "生成音频嵌入序列的一种Transformer层。",
explain: ""
},
{
text: "对声音进行降噪预处理的外挂神经网络。",
explain: "",
}
]}
/>
### 2. Wav2Vec2模型采用了什么结构?
<Question
choices={[
{
text: "Seq2Seq结构",
explain: ""
},
{
text: "CNN结构",
explain: ""
},
{
text: "CTC结构",
explain: "正确!",
correct: true
}
]}
/>
### 3. CTC算法中的空白标记(blank token)有什么作用?
<Question
choices={[
{
text: "空白标记可以表示句子中不同单词之间的分隔。",
explain: ""
},
{
text: "空白标记表示的是字母组之间的硬边界的预测标记。它可以帮助我们对重复字母进行过滤。",
explain: "正确!",
correct: true
},
{
text: "空白标记表示不对应字母表中任一词素的声音,类似于“未知”标记<UNK>。",
explain: ""
}
]}
/>
### 4. 下列关于CTC模型的选项中哪一项是**错误**的?
<Question
choices={[
{
text: "CTC模型仅使用的Transformer结构中的编码器(encoder)。",
explain: ""
},
{
text: "Wav2Vec2和HuBERT使用了完全相同的结构,但训练方法不同。",
explain: ""
},
{
text: "CTC模型在语音识别任务上的准确率高于其他任何模型。",
explain: "正确!",
correct: true
}
]}
/>
### 5. Whisper模型使用了什么结构?
<Question
choices={[
{
text: "Seq2Seq结构",
explain: "正确!",
correct: true
},
{
text: "CNN结构",
explain: ""
},
{
text: "CTC结构",
explain: ""
}
]}
/>
### 6. 解决音频分类任务的最简单方法是?
<Question
choices={[
{
text: "在音频波形上使用编码器-解码器结构。",
explain: ""
},
{
text: "使用时频谱并将其视为图像分类任务。",
explain: "正确!",
correct: true
},
{
text: "将CTC模型改造为一个音频分类器,改变其分类标签并使用常规的交叉熵损失函数(regular cross-entropy loss function)进行训练。",
explain: ""
}
]}
/>
### 7. 以下陈述是否正确:当我们在时频谱上应用图像分类技巧时,我们可以使用常见的图像数据增强(Image data augmentation)方法,例如图像平移、裁切或改变大小,来提高模型的性能。
<Question
choices={[
{
text: "正确",
explain: ""
},
{
text: "错误",
explain: "正确!",
correct: true
}
]}
/>
| 4 |
0 | hf_public_repos/audio-transformers-course/chapters/zh-CN | hf_public_repos/audio-transformers-course/chapters/zh-CN/chapter3/seq2seq.mdx | # Seq2Seq结构
上一小节中介绍的CTC结构仅适用于Tranformer结构的编码器(encoder)部分。如果我们给模型添加一个解码器(decoder)构建一个自编码模型(autoencoder,也称编码-解码模型,encoder-decoder),这个模型也可以被称为**序列到序列**模型(sequence-to-sequence,简称seq2seq)。Seq2Seq模型将一种数据序列映射到另一种数据序列。
在仅使用编码器的Transformer模型中,编码器为输入序列中的每个元素进行预测。因此,输入和输出序列的长度总是相同的。在CTC模型(如Wav2Vec2)的情况下,输入波形会被下采样,但我们仍然对下采样后的每个元素(对应20毫秒的音频)输出一个对应的预测标记,因此输入标记和输出的预测标记仍然是等长的。
而在seq2seq模型中,输入和输出序列的长度可以不同。这使得seq2seq模型更适合文本摘要或翻译等的NLP任务,也同时适用于语音识别等音频任务。
Seq2Seq结构中的解码器(decoder)和编码器(encoder)非常类似,两者都使用自注意力(self-attention)作为主要的运算单元。但是解码器的任务与编码器不同。为了理解这一点,让我们看看seq2seq模型如何进行自动语音识别。
## 自动语音识别
下图展示了**Whisper**模型的结构(图片来自[OpenAI Whisper博客](https://openai.com/blog/whisper/)):
<div class="flex justify-center">
<img src="https://huggingface.co/blog/assets/111_fine_tune_whisper/whisper_architecture.svg" alt="Whisper is a transformer encoder-decoder model">
</div>
看起来十分熟悉。左边是**Transformer编码器**。它以对数梅尔时频谱(log-mel spectrogram)作为输入,并对其进行编码,输出一个编码器隐藏状态序列(sequence of encoder hidden states),从中提取出输入语音的重要特征。这个隐藏状态张量代表了整个输入序列,并高效地编码了输入语音的“含义”。
<Tip>
💡 这些seq2seq模型通常使用时频谱作为输入。不过,seq2seq模型也可以直接使用音频波形作为输入。
</Tip>
编码器的输出被传递到右边的**Transformer解码器**,使用一种称为**交叉注意力**(cross-attention)的机制。交叉注意力与自注意力类似,不过此处注意力的对象是编码器的输出。在这之后,我们就不再需要编码器了。
解码器会使用**自回归**(autoregressive)的方式来预测一个文本标记序列,每次只预测一个标记,从一个仅含有“起始”标记(Whisper使用`SOT`作为起始标记)的序列开始。在每个时间步,前一个时间步的输出序列会作为新的输入序列被传递给解码器。这样,解码器每次只会输出一个新的标记,逐步增长输出序列,直到预测出“结束”标记,或者达到最大时间步数。
虽然解码器的结构与编码器类似,但是解码器和编码器有两个主要的区别:
1. 解码器会使用交叉注意力机制,允许它查看编码器生成的对于输入序列的隐藏状态向量。
2. 解码器的注意力是**因果**(causal)的——解码器不允许查看未来的信息。
在这个架构中,解码器的功能类似于**语言模型**(language model),它处理编码器的隐藏状态表示,并生成相应的文本转录。这种方法比CTC更强大,甚至CTC结合外部语言模型也无法相比。Seq2Seq结构可以使用相同的训练数据和损失函数进行端到端(end-to-end)训练,从而提供更好的灵活性和更好的性能。
<Tip>
💡 与CTC模型输出单个字母的序列不同,Whisper模型的输出是完整的单词或词素。它使用GPT-2的分词器,有50k+个不同的标记。因此,seq2seq模型可以输出比CTC模型更短的序列。
</Tip>
Seq2Seq语音识别模型最常使用的损失函数为交叉熵损失(cross-entropy loss),因为我们通常把模型最终层的输出视为一个标记的概率分布。交叉熵损失通常与[束搜索(beam search)](https://huggingface.co/blog/how-to-generate)等技术结合使用,生成最终的序列。语音识别的度量标准是WER(word error rate),它衡量将预测文本转换为目标文本所需的替换、插入和删除的数量。所需的操作越少说明预测结果越好。
## 文本到语音(Text-to-speech,TTS)
可能不会让你感到惊讶的是, Seq2Seq的TTS模型基本上和ASR模型相同,仅仅是将输入和输出的数据种类互换!Transformer编码器接收文本标记序列,并提取表示输入文本的隐藏状态序列。Transformer解码器使用交叉注意力机制,预测输出的时频谱序列。
<Tip>
💡 时频谱图是通过对音频波形的连续时间切片进行频谱分析得到的。换句话说,时频谱图是一个序列,其中的元素是(对数梅尔)频谱,每个时间步一个。
</Tip>
在ASR模型里,解码器的初始输出序列是一个仅包含“起始”标记的序列。而在TTS模型里,我们可以使用一个长度为1,值全为0的时频谱序列来代替“起始”标记。有了这个初始时频谱序列和编码器隐藏状态的交叉注意力,解码器就可以预测下一个时间步的时频谱,逐步增长时频谱序列。
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface-course/audio-course-images/resolve/main/speecht5_decoding.png" alt="The audio waveform gets mapped to a shorter sequence of hidden-states">
</div>
但我们的解码器怎样知道需要在什么时候停止呢?在**SpeechT5**模型中,解码器会预测第二个序列。这个序列包含当前时间步是否是最后一个时间步的概率。在推理时,如果这个概率超过某个阈值(比如0.5),我们就认为解码器在指示时频谱序列已经生成完毕,应该结束生成循环。
在解码器生成完整的时频谱序列后,SpeechT5会使用一个称为**后处理网络**(post-net)的模型对时频谱序列进行微调。后处理网络由几个卷积层组成,用于微调时频谱序列。
在训练TTS模型时,我们的生成目标是训练数据的时频谱图,损失函数为L1损失或最小二乘损失(mean square error,MSE)。在推理时,我们希望将输出的时频谱图转换为音频波形,这样我们就可以听到它。为此,我们需要使用一个外部模型,称为**声码器**(vocoder)。这个声码器不是seq2seq架构的一部分,而是单独训练的。
TTS任务的难点在于其一对多的映射。对于语音到文本的任务,每个输入语音只对应一个正确的输出文本,但是对于文本到语音的任务,输入文本可以映射到多个可能的语音。例如,不同的说话人可能会强调同一个句子中的不同部分。这使得TTS模型很难评估。因为这个原因,L1或MSE损失实际上并不是理想的损失函数,因为同一个文本可以映射到多种不同的时频谱序列。这就是为什么TTS模型通常会由人类听众进行评估的原因,使用的指标称为MOS(mean opinion score,平均意见分数)。
## 总结
Seq2Seq结构是一种强大的模型,其能力往往优于仅含编码器的模型。通过将输入序列的编码与输出序列的解码分离,我们可以很好地处理音频和文本的对齐问题。<!-- 模型中的交叉注意力单元会解决输入和输出间的对齐问题。 -->
然而,编码器-解码器模型也存在一些缺点,比较重要的一点是其推理速度较慢。这是由于其解码过程在每一步仅生成一个输出元素,因此完整的预测需要进行数次推理。输出序列越长,推理的速度也就越慢。自回归模型也可能会陷入循环或者跳过一些元素。束搜索(beam search)等技术可以提高预测结果的质量,但也会进一步降低推理速度。 | 5 |
0 | hf_public_repos/audio-transformers-course/chapters/zh-CN | hf_public_repos/audio-transformers-course/chapters/zh-CN/chapter3/introduction.mdx | # 第3单元:音频Transformer架构
本课程中,我们主要关注Transformer模型以及它们如何应用于音频任务。虽然您不需要了解这些模型的内部细节,但了解使它们工作的主要概念很有用,因此我们在本小节中回顾一下关于Transformer的知识。有关transformer的深入了解,请查看我们的[NLP课程](https://huggingface.co/course/chapter1/1)。
## Transformer的原理是什么?
Transformer架构最早是为文本翻译的任务而设计的。它的结构如下:
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface-course/documentation-images/resolve/main/en/chapter1/transformers.svg" alt="Original transformer architecture">
</div>
左边是**编码器**(encoder),右边是**解码器**(decoder)。
- 编码器负责接收模型的输入,本例中是一系列文本标记(toen),并构建其表征(representation,或称特征,feature)。Transformer模型的编码器在经过训练后能够从输入中提取并理解信息。
- 解码器负责使用编码器生成的表征(特征向量)以及其他输入(先前预测的标记)来生成目标序列。Transformer模型的解码器在经过训练能够根据表征中蕴含的信息生成输出序列。在原始设计中,输出序列由文本标记组成。
有的Transformer模型只使用编码器(适用于需要理解输入的任务,例如分类),或者只使用解码器(适用于生成文本的任务)。BERT就是一个只使用编码器的例子;GPT2则是一个只使用解码器的例子。
Transformer模型的一个关键特征是它们使用特殊的层,称为**注意力层**(attention layers)。这些层告诉模型在计算特征表示时,特别关注输入序列中的某些元素,而忽略其他元素。
## 使用Transformer进行音频处理
本课程中,我们将介绍的音频模型通常具有上图所示的标准Transformer架构,但会在输入或输出端稍作修改来适应音频而非文本序列。由于所有这些模型本质上都是Transformer,因此它们的大部分架构都是相同的,主要区别在于它们的训练和使用方式。
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface-course/audio-course-images/resolve/main/transformers_blocks.png" alt="The transformer with audio input and output">
</div>
对于音频任务,输入和/或输出序列可以是音频而非文本:
- 自动语音识别(ASR):输入为语音,输出为文本。
- 文本到语音(TTS):输入为文本,输出为语音。
- 语音分类:输入为语音,输出为类别概率——对于序列中的每个元素,或者对于整个序列的单个类别概率。
- 语音转换或语音增强:输入和输出均为语音。
有几种不同的方法可以将音频数据转换为Transformer能够处理的格式。主要的区别在于是使用音频的原始波形作为模型的输入序列,还是使用其时频谱作为输入序列。
## 模型的输入格式
音频模型的输入可以是文本或声音。我们的目标是将此输入转换为一个嵌入向量(embedding vector),以便Transformer架构可以处理。
### 文本输入
文本到语音模型(TTS)接受文本作为输入。这与原始Transformer或任何其他NLP模型的工作方式相同:首先对文本进行标记化(tokenization),得到一系列文本标记。然后将此序列通过输入嵌入层,将标记转换为512维向量。然后将这些嵌入向量传递到Transformer编码器中。
### 波形输入
自动语音识别模型(ASR)接受语音作为输入。为了使用Transformer解决ASR任务,我们首先需要以某种方式将音频转换为嵌入向量序列。
**Wav2Vec2**和**HuBERT**一类的模型直接使用音频波形作为模型的输入。如您在[音频数据章节](chapter1/introduction)中所见,波形是一个浮点数序列,其中的每个数表示某个时间点的幅值。我们首先将原始波形标准化为零均值和单位方差的序列,这有助于标准化不同音量(振幅)的音频样本。
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface-course/audio-course-images/resolve/main/wav2vec2-input.png" alt="Wav2Vec2 uses a CNN to create embeddings from the input waveform">
</div>
完成标准化后,我们将该波形序列被转换为嵌入向量序列。这是通过一个小型卷积神经网络(CNN)完成的,称为**特征编码器**(feature encoder)。该网络的每个卷积层都处理输入序列,对音频进行下采样(subsampling)以减少序列长度,直到最后一个卷积层输出512维向量,即每25毫秒音频的嵌入向量(embedding vector)。当输入序列被转换为这样的嵌入向量序列(embedding vector sequence)后,Transformer便可以像往常一样处理数据了。
### 时频谱输入
使用原始波形作为输入的一个缺点是它们往往具有较长的序列长度。例如,采样率为16 kHz的30秒音频输入的长度为`30 * 16000 = 480000`。长的序列需要在Transformer模型中进行更多的计算,因此会增加内存使用量。
因此,我们认为在大多数情况下原始音频并不是最有效率的表示音频输入的方式。通过使用**时频谱**(spectrogram),我们可以以更紧凑的形式表示相同数量的信息。
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface-course/audio-course-images/resolve/main/whisper-input.png" alt="Whisper uses a CNN to create embeddings from the input spectrogram">
</div>
**Whisper**等模型首先将波形转换为一个对数梅尔频谱图(log-mel spectrogram)。Whisper会将音频分成数个30秒的片段,每个片段的对数梅尔频谱图的形状为`(80, 3000)`,其中80是梅尔频率的数量,3000是序列的长度。通过将音频转换为对数梅尔频谱图,我们不仅减少了输入数据的数量,而且更重要的是,转换后的序列长度远远小于波形的长度。。最后,对数梅尔频谱图由一个小型CNN处理,转换为嵌入向量序列,然后像往常一样输入Transformer。
无论是波形还是时频谱输入,我们都会先使用一个小型的神经网络在Transformer之前将输入转换为嵌入向量序列,然后由Transformer接管并完成其工作。
## 模型的输出格式
Transformer架构会输出一个隐藏状态向量(hidden-state vectors)的序列,也称为输出嵌入向量(output embedding)。我们的目标是将这些向量转换为文本或音频输出。
### 文本输出
自动语音识别模型的目标是预测一个文本标记(text token)的序列。这是通过在Transformer的输出上添加一个语言建模(language modeling)头——通常是一个单独的线性层———然后在transformer的输出上添加一个softmax来完成的。该输出预测的是词汇表中文本标记的概率。
### 时频谱输出
对于生成音频的模型,例如文本到语音(TTS)模型,我们需要添加能够生成音频序列的层。通常会生成一个频谱图,然后使用另一个神经网络(称为**声码器**(vocoder))将该频谱图转换为波形。
举个例子,**SpeechT5** TTS模型的输出是一个768元素向量的序列。线性层将该序列投影到一个对数梅尔频谱图上。然后,一个由线性层和卷积层组成的后处理网络(post-net)会对频谱图进行降噪处理。最后,我们使用声码器生成输出的音频波形。
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface-course/audio-course-images/resolve/main/speecht5.png" alt="SpeechT5 outputs a spectrogram and uses a vocoder to create the waveform">
</div>
<Tip>
💡如果我们对波形进行短时傅里叶变换(STFT)得到其时频谱,我们可以通过其逆向过程(ISTFT)重新得到原始的波形。这是因为STFT生成的时频谱包含了幅值和相位两部分的信息,而这两部分信息都是重建波形所必需的。然而,音频深度学习模型所生成的时频谱往往仅包含了幅值信息。为了将这样的时频谱转化为波形,我们需要通过某种方式估计其相位信息,这便是声码器的功能。
</Tip>
### 波形输出
除了生成时频谱作为中间输出的方法外,有些模型也可以直接生成波形输出。但是,目前🤗 Transformers中没有包含能够直接生成波形的模型。
## 小节
总结一下:大多数音频Transformer模型都是相似的——它们都是基于相同的Transformer架构和注意力层构建的。不过,有些模型只使用Transformer的编码器部分,而有些模型则同时使用编码器和解码器。
我们也学习了如何在Transformer模型中将音频作为输入或者输出。在ASR、TTS等音频任务中,我们可以改变模型中的部分输入层来将数据转换为嵌入向量序列,也可以改变一部分输出层来将生成的嵌入向量序列转化为输出格式,而Transformer的主体部分保持不变。
接下来,我们将学习几种不同的训练方法来训练一个自动语音识别模型。 | 6 |
0 | hf_public_repos/audio-transformers-course/chapters/zh-CN | hf_public_repos/audio-transformers-course/chapters/zh-CN/chapter1/supplemental_reading.mdx | # 附加内容
本小节涵盖了许多处理音频数据的基础概念。想学习更多?我们在这里提供了额外的内容,帮助你加深理解、增强学习体验。
在接下来的这段视频中,来自xiph.org的Monty Montgomery为我们实时演示了采样、量化、位深度的概念,并且展示了现代的数字分析方法和复古的模拟测量仪器:
<Youtube id="cIQ9IXSUzuM"/>
如果你想了解更多关于数字信号处理的知识,可以参考免费的["Digital Signals Theory"一书](https://brianmcfee.net/dstbook-site/content/intro.html)(仅英语)。本书的作者是Brian McFee,来自New York University的音乐技术和数据科学副教授,同时也是`librosa`库的主要维护者。
| 7 |
0 | hf_public_repos/audio-transformers-course/chapters/zh-CN | hf_public_repos/audio-transformers-course/chapters/zh-CN/chapter1/preprocessing.mdx | # 音频数据集的预处理
使用🤗 Datasets加载数据集只是乐趣的一半。如果你计划用数据集训练模型或者运行推理,那么你还需要对数据进行预处理(pre-processing)。数据预处理通常包括以下几步:
* 音频重采样
* 对数据集进行过滤
* 将音频数据转换为模型要求的输入形式
## 音频重采样
`load_dataset()`函数在下载数据集时会保留数据集发布时的原始采样率。当你使用其他模型进行训练或推理时,该采样率也许会不符合要求。当采样率不同时,你可以进行重采样来将数据调整到模型所期望的采样率。
目前大多数的预训练模型采用了16千赫兹采样率的数据集进行预训练。在上一张探索MINDS-14数据集时,你可能注意到了该数据集采用了8千赫兹的采样率,这意味着我们需要对其进行上采样。
我们可以使用🤗 Datasets的`cast_column()`方法进行上采样。该方法不会在原位改动数据,而是在数据加载时进行实时的重采样。下面的代码可以将样本重采样到16千赫兹:
```py
from datasets import Audio
minds = minds.cast_column("audio", Audio(sampling_rate=16_000))
```
现在我们重新加载MINDS-14的第一个样本,并检查其是否按照我们提供的`sampling_rate`参数进行了重采样:
```py
minds[0]
```
**输出**
```out
{
"path": "/root/.cache/huggingface/datasets/downloads/extracted/f14948e0e84be638dd7943ac36518a4cf3324e8b7aa331c5ab11541518e9368c/en-AU~PAY_BILL/response_4.wav",
"audio": {
"path": "/root/.cache/huggingface/datasets/downloads/extracted/f14948e0e84be638dd7943ac36518a4cf3324e8b7aa331c5ab11541518e9368c/en-AU~PAY_BILL/response_4.wav",
"array": array(
[
2.0634243e-05,
1.9437837e-04,
2.2419340e-04,
...,
9.3852862e-04,
1.1302452e-03,
7.1531429e-04,
],
dtype=float32,
),
"sampling_rate": 16000,
},
"transcription": "I would like to pay my electricity bill using my card can you please assist",
"intent_class": 13,
}
```
你可能注意到数列的值也有所变化。这是因为我们在重采样后会获得两倍于原来采样点数量的数值。
<Tip>
💡 关于重采样的背景知识:当信号的原始采样率为8千赫兹时,信号每秒钟会包含8000个采样点,并且我们知道该信号不会包含高于4千赫兹的频率成分。奈奎斯特采样定理保证了这一点。也因此,我们可以确保在两个采样点中间的原始连续信号呈一条平滑的曲线。在这样的条件下,上采样所要做的就只是根据对曲线的估计而计算出两个采样点中间的额外数值。与之相反的是,下采样过程需要我们首先过滤掉所有高于奈奎斯特极限的频率成分,之后才能重新计算采样点。也就是说,我们不能通过简单的每隔一个采样点丢弃一个采样点来进行2倍的下采样:这会造成信号的失真,我们称之为混叠失真。重采样过程十分棘手,因此我们推荐使用经过测试的工具库,例如librosa或🤗 Datasets。
</Tip>
## 过滤数据集
我们可能会需要用一些指标来过滤掉数据集中的一些数据。一种常见情况是限制音频文件的时长。举个例子,我们可能需要过滤掉所有长度超过20秒的音频来防止模型训练过程中的内存不足错误。
我们可以使用🤗 Datasets的`filter`方法并传入过滤逻辑的函数来进行过滤。首先我们需要编写一个函数来指示哪些样本需要保留,哪些样本需要舍弃。这里我们编写了`is_audio_length_in_range()`函数,在样本长度小于20秒时会返回`True`,否则返回`False`。
```py
MAX_DURATION_IN_SECONDS = 20.0
def is_audio_length_in_range(input_length):
return input_length < MAX_DURATION_IN_SECONDS
```
该过滤函数可以直接应用在数据集的列上,但我们的数据集并没有一个单独的记录音频长度的列。不过我们可以自己创建一列,然后进行过滤,最后在过滤完成之后删除该列。
```py
# 使用librosa从音频文件里获取该音频的长度
new_column = [librosa.get_duration(filename=x) for x in minds["path"]]
minds = minds.add_column("duration", new_column)
# 使用🤗 Datasets的`filter`方法来进行过滤
minds = minds.filter(is_audio_length_in_range, input_columns=["duration"])
# 移除临时列
minds = minds.remove_columns(["duration"])
minds
```
**输出**
```out
Dataset({features: ["path", "audio", "transcription", "intent_class"], num_rows: 624})
```
我们可以看到数据集的样本数量从654个被过滤到了624个。
## 音频数据的预处理
在利用音频数据集时,最具挑战的工作之一便是给模型训练提供正确格式的数据。如你所见,原始的音频数据是一个单列的采样点数组。然而,无论是推理还是根据任务进行微调,大部分的预训练模型都需要将音频数据转化成其对应的输入特征。每个模型的输入特征都有不同的要求,往往根据模型的架构和其预训练的数据集所决定。好消息是,🤗 Transformers所支持的所有音频模型都提供了一个特征提取类,负责将原始的音频数据转化为该模型所需的输入特征格式。
特征提取器具体会对音频文件做些什么呢?我们可以参考[Whisper](https://cdn.openai.com/papers/whisper.pdf)的特征提取器来理解一些常用的特征提取变换。Whisper是一个自动语音识别(automatic specch recognition, ASR)的预训练模型,由OpenAI的Alec Radford等人于2022年9月发布。
首先,Whisper的特征提取器会加长/截短某一批次中的所有音频样本,确保他们均为长30秒的音频。短于30秒的样本会采用末尾补零的方式加长至30秒,因为零在音频信号中代表无信号或静音。长于30秒的音频会被截取至30秒。由于一批次的所有音频都被加长/截短至同一长度,我们不再需要使用attention mask。这是Whisper模型的特性之一,因为大多数其他的音频模型都需要使用attention mask来告诉模型输入的哪些部分进行了补值,来让这些被补值的位置在self-attention过程中被忽略。Whisper模型在训练时就在无需attention mask的情况下运行,并且能直接从输入的音频信号中推理出哪些部分需要被忽略。
Whisper的特征提取器所进行的第二个操作是将定长的音频数组转化为对数梅尔时频谱(log-mel spectrogram)。如前文所述,对数梅尔谱描述了各个频率成分是如何随时间变化的,并且在频率上使用了梅尔标度,在幅值上使用的分贝(对数)标度,使得频率和幅值的关系更接近于人耳的感知。
上述的所有变换都可以用简短的几行代码应用到原始的音频数据上。现在,我们从预训练的Whisper模型检查点(checkpoint)加载特征提取器,为音频数据做好准备:
```py
from transformers import WhisperFeatureExtractor
feature_extractor = WhisperFeatureExtractor.from_pretrained("openai/whisper-small")
```
然后,我们编写一个处理单个样本的函数,将该样本中的音频文件输入特征提取器`feature_extractor`。
```py
def prepare_dataset(example):
audio = example["audio"]
features = feature_extractor(
audio["array"], sampling_rate=audio["sampling_rate"], padding=True
)
return features
```
我们可以使用🤗 Datasets的`map`方法将这个数据处理函数应用到数据集中的所有训练样本上:
```py
minds = minds.map(prepare_dataset)
minds
```
**输出:**
```out
Dataset(
{
features: ["path", "audio", "transcription", "intent_class", "input_features"],
num_rows: 624,
}
)
```
简单几步后,我们就获得了对数梅尔谱并存储在数据集的`input_features`列中。
我们来试着可视化`minds`数据集中的一个样本:
```py
import numpy as np
example = minds[0]
input_features = example["input_features"]
plt.figure().set_figwidth(12)
librosa.display.specshow(
np.asarray(input_features[0]),
x_axis="time",
y_axis="mel",
sr=feature_extractor.sampling_rate,
hop_length=feature_extractor.hop_length,
)
plt.colorbar()
```
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface-course/audio-course-images/resolve/main/log_mel_whisper.png" alt="Log mel spectrogram plot">
</div>
现在你可以看到经过预处理后的Whisper模型的输入了。
模型的特征提取器会保证将原始音频转化为模型所需要的输入格式。然而,许多音频相关的任务,比如语音识别,往往也是多模态的任务。🤗 Transformers库提供了针对各种文字模型的分词器(Tokenizer)。请参考我们的[自然语言处理课程](https://huggingface.co/learn/nlp-course/zh-CN/chapter2/4)中对分词器的详细介绍。
我们可以分别加载Whisper中的特征提取器和其他多模态模型中的分词器,也可以通过processor将他们同时加载。如果想要更加简单的用法,你可以使用`AutoProcessor`从模型的检查点中直接加载特征提取器和processor:
```py
from transformers import AutoProcessor
processor = AutoProcessor.from_pretrained("openai/whisper-small")
```
在本小节中,我们介绍了数据准备的基本流程。但要注意的是,您的自定义数据集往往会需要一些更复杂的数据预处理。针对这些情况,你可以扩展`prepare_dataset()`函数来实现各种自定义的数据转换流程。在🤗 Datasets的帮助下,只要您能将数据处理流程编写为Python函数,就可以将其应用在您的数据集上! | 8 |
0 | hf_public_repos/audio-transformers-course/chapters/zh-CN | hf_public_repos/audio-transformers-course/chapters/zh-CN/chapter1/streaming.mdx | # 音频数据的流式加载
使用音频数据集的最大挑战之一是它们庞大的规模。仅仅一分钟的CD音质音频(44.1千赫兹,16比特)就需要占用约5MB的存储。一般的音频数据集会含有数个小时的音频录音。
在上一小节中,我们使用了MINDS-14的一个非常小的子集,但常见的音频数据集往往要大得多。举个例子[GigaSpeech from SpeechColab](https://huggingface.co/datasets/speechcolab/gigaspeech)的`xs`(最小)子集仅有10小时的训练数据,但需要占用超过13GB的存储空间。当我们选择更大的子集时会发生什么呢?其最大的`xl`子集含有10000小时的训练数据,需要占用超过1TB的存储空间。对大多数人来说,这已经远远超过了我们的硬盘所能容纳的容量。我们需要剁手购买额外的硬盘吗?还是说有其他方法可以让我们绕过存储空间的限制呢?
🤗 Datasets为你提供了解决方法:流式处理模式。流式处理可以让我们在遍历数据集的过程中渐进地加载数据。与其一次性地下载完整数据集,不如将样本一个个单独加载。在遍历数据集时,我们实时地在有需要时加载和准备好每个样本。通过这样的方式,我们永远只加载我们正在使用的数据,而不加载我们暂时不需要的数据。当我们使用完一个样本时,就继续遍历数据集,加载下一个样本。
相较于全量加载,流式处理模式主要有三个优点:
* 硬盘空间:样本是在遍历数据集的过程中被依次加载到内存中的。由于我们不需要将数据下载到本地,因此也没有任何对硬盘空间的要求,你可以使用任意大小的数据集。
* 下载和处理时间:音频数据集极其庞大并且需要大量的数据下载和处理时间。在流式处理模式下,数据会进行实时的加载和处理,因此当第一个样本准备完成时我们就可以开始训练。
* 测试简单:无需下载完整的数据集,仅用少量的样本就可以测试你的训练脚本。
在使用流式处理模式时,有一点需要警惕:在全量下载数据集时,所有的原始数据和处理后的数据都会在硬盘内本地存储。如果我们想要重复利用这些数据,我们可以跳过下载和处理过程,直接从硬盘中加载数据。这意味着我们在重复利用数据时,仅在第一次时需要下载和处理数据。
但在流式处理模式中,数据不会被下载到硬盘内。因此,我们的下载和预处理过程都不会被保存。在重复利用数据集时,我们必须要重复进行下载和预处理才做。因此,如果你计划重复使用数据集,我们还是推荐将数据集下载到本地硬盘。
如何启用流式处理模式呢?很简单!只需要在加载数据集时传入`streaming=True`参数即可。我们会帮你做好其他工作:
```py
gigaspeech = load_dataset("speechcolab/gigaspeech", "xs", streaming=True)
```
与我们在全量下载MINDS-14子集时进行的预处理操作相同,你也可以在流式数据集上使用同样的预处理操作。
唯一的区别是我们现在无法使用Python的索引功能访问单个的样本(例如`gigaspeech["train"][sample_idx]`)。相反地,我们需要遍历整个数据集。你可以在流式数据集这这样访问单个样本:
```py
next(iter(gigaspeech["train"]))
```
**输出:**
```out
{
"segment_id": "YOU0000000315_S0000660",
"speaker": "N/A",
"text": "AS THEY'RE LEAVING <COMMA> CAN KASH PULL ZAHRA ASIDE REALLY QUICKLY <QUESTIONMARK>",
"audio": {
"path": "xs_chunks_0000/YOU0000000315_S0000660.wav",
"array": array(
[0.0005188, 0.00085449, 0.00012207, ..., 0.00125122, 0.00076294, 0.00036621]
),
"sampling_rate": 16000,
},
"begin_time": 2941.89,
"end_time": 2945.07,
"audio_id": "YOU0000000315",
"title": "Return to Vasselheim | Critical Role: VOX MACHINA | Episode 43",
"url": "https://www.youtube.com/watch?v=zr2n1fLVasU",
"source": 2,
"category": 24,
"original_full_path": "audio/youtube/P0004/YOU0000000315.opus",
}
```
你可以使用`take()`函数来预览数据集的几个样本。让我们看看gigaspeech数据集的前两个样本:
```py
gigaspeech_head = gigaspeech["train"].take(2)
list(gigaspeech_head)
```
**输出:**
```out
[
{
"segment_id": "YOU0000000315_S0000660",
"speaker": "N/A",
"text": "AS THEY'RE LEAVING <COMMA> CAN KASH PULL ZAHRA ASIDE REALLY QUICKLY <QUESTIONMARK>",
"audio": {
"path": "xs_chunks_0000/YOU0000000315_S0000660.wav",
"array": array(
[
0.0005188,
0.00085449,
0.00012207,
...,
0.00125122,
0.00076294,
0.00036621,
]
),
"sampling_rate": 16000,
},
"begin_time": 2941.89,
"end_time": 2945.07,
"audio_id": "YOU0000000315",
"title": "Return to Vasselheim | Critical Role: VOX MACHINA | Episode 43",
"url": "https://www.youtube.com/watch?v=zr2n1fLVasU",
"source": 2,
"category": 24,
"original_full_path": "audio/youtube/P0004/YOU0000000315.opus",
},
{
"segment_id": "AUD0000001043_S0000775",
"speaker": "N/A",
"text": "SIX TOMATOES <PERIOD>",
"audio": {
"path": "xs_chunks_0000/AUD0000001043_S0000775.wav",
"array": array(
[
1.43432617e-03,
1.37329102e-03,
1.31225586e-03,
...,
-6.10351562e-05,
-1.22070312e-04,
-1.83105469e-04,
]
),
"sampling_rate": 16000,
},
"begin_time": 3673.96,
"end_time": 3675.26,
"audio_id": "AUD0000001043",
"title": "Asteroid of Fear",
"url": "http//www.archive.org/download/asteroid_of_fear_1012_librivox/asteroid_of_fear_1012_librivox_64kb_mp3.zip",
"source": 0,
"category": 28,
"original_full_path": "audio/audiobook/P0011/AUD0000001043.opus",
},
]
```
流式处理模式可以助力你的研究进入更高的阶段:现在你不仅可以利用庞大的数据集,而且可以在无需担忧硬盘空间的情况下使用多个数据集来评估你的系统。与使用单个数据集进行评估相比,多数据集评估可以更好地体现系统的泛化性能。 | 9 |
0 | hf_public_repos/api-inference-community/docker_images/pyannote_audio/app | hf_public_repos/api-inference-community/docker_images/pyannote_audio/app/pipelines/base.py | from abc import ABC, abstractmethod
from typing import Any
class Pipeline(ABC):
@abstractmethod
def __init__(self, model_id: str):
raise NotImplementedError("Pipelines should implement an __init__ method")
@abstractmethod
def __call__(self, inputs: Any) -> Any:
raise NotImplementedError("Pipelines should implement a __call__ method")
class PipelineException(Exception):
pass
| 0 |
0 | hf_public_repos/api-inference-community/docker_images/pyannote_audio/app | hf_public_repos/api-inference-community/docker_images/pyannote_audio/app/pipelines/__init__.py | from app.pipelines.base import Pipeline, PipelineException # isort:skip
from app.pipelines.automatic_speech_recognition import (
AutomaticSpeechRecognitionPipeline,
)
| 1 |
0 | hf_public_repos/api-inference-community/docker_images/pyannote_audio/app | hf_public_repos/api-inference-community/docker_images/pyannote_audio/app/pipelines/automatic_speech_recognition.py | from typing import Dict
import numpy as np
import torch
from app.pipelines import Pipeline
from pyannote.audio import Pipeline as Pypeline
class AutomaticSpeechRecognitionPipeline(Pipeline):
def __init__(self, model_id: str):
# IMPLEMENT_THIS
# Preload all the elements you are going to need at inference.
# For instance your model, processors, tokenizer that might be needed.
# This function is only called once, so do all the heavy processing I/O here
# IMPLEMENT_THIS : Please define a `self.sampling_rate` for this pipeline
# to automatically read the input correctly
self.sampling_rate = 16000
self.model = Pypeline.from_pretrained(model_id)
def __call__(self, inputs: np.array) -> Dict[str, str]:
"""
Args:
inputs (:obj:`np.array`):
The raw waveform of audio received. By default at self.sampling_rate, otherwise 16KHz.
Return:
A :obj:`dict`:. The object return should be liked {"text": "XXX"} containing
the detected language from the input audio
"""
wav = torch.from_numpy(inputs).unsqueeze(0)
output = self.model({"waveform": wav, "sample_rate": self.sampling_rate})
regions = [
{"label": label, "start": segment.start, "stop": segment.end}
for segment, _, label in output.itertracks(yield_label=True)
]
regions = str(regions)
return {"text": regions}
| 2 |
0 | hf_public_repos/api-inference-community/docker_images/pyannote_audio | hf_public_repos/api-inference-community/docker_images/pyannote_audio/tests/test_docker_build.py | import os
import subprocess
from unittest import TestCase
class cd:
"""Context manager for changing the current working directory"""
def __init__(self, newPath):
self.newPath = os.path.expanduser(newPath)
def __enter__(self):
self.savedPath = os.getcwd()
os.chdir(self.newPath)
def __exit__(self, etype, value, traceback):
os.chdir(self.savedPath)
class DockerBuildTestCase(TestCase):
def test_can_build_docker_image(self):
with cd(os.path.dirname(os.path.dirname(__file__))):
subprocess.check_output(["docker", "build", "."])
| 3 |
0 | hf_public_repos/api-inference-community/docker_images/pyannote_audio | hf_public_repos/api-inference-community/docker_images/pyannote_audio/tests/test_api_automatic_speech_recognition.py | import json
import os
from unittest import TestCase, skipIf
from app.main import ALLOWED_TASKS
from starlette.testclient import TestClient
from tests.test_api import TESTABLE_MODELS
@skipIf(
"automatic-speech-recognition" not in ALLOWED_TASKS,
"automatic-speech-recognition not implemented",
)
class AutomaticSpeecRecognitionTestCase(TestCase):
def setUp(self):
model_id = TESTABLE_MODELS["automatic-speech-recognition"]
self.old_model_id = os.getenv("MODEL_ID")
self.old_task = os.getenv("TASK")
os.environ["MODEL_ID"] = model_id
os.environ["TASK"] = "automatic-speech-recognition"
from app.main import app
self.app = app
@classmethod
def setUpClass(cls):
from app.main import get_pipeline
get_pipeline.cache_clear()
def tearDown(self):
if self.old_model_id is not None:
os.environ["MODEL_ID"] = self.old_model_id
else:
del os.environ["MODEL_ID"]
if self.old_task is not None:
os.environ["TASK"] = self.old_task
else:
del os.environ["TASK"]
def read(self, filename: str) -> bytes:
dirname = os.path.dirname(os.path.abspath(__file__))
filename = os.path.join(dirname, "samples", filename)
with open(filename, "rb") as f:
bpayload = f.read()
return bpayload
def test_simple(self):
bpayload = self.read("sample1.flac")
with TestClient(self.app) as client:
response = client.post("/", data=bpayload)
self.assertEqual(
response.status_code,
200,
)
content = json.loads(response.content)
self.assertEqual(set(content.keys()), {"text"})
def test_malformed_audio(self):
bpayload = self.read("malformed.flac")
with TestClient(self.app) as client:
response = client.post("/", data=bpayload)
self.assertEqual(
response.status_code,
400,
)
self.assertEqual(response.content, b'{"error":"Malformed soundfile"}')
def test_dual_channel_audiofile(self):
bpayload = self.read("sample1_dual.ogg")
with TestClient(self.app) as client:
response = client.post("/", data=bpayload)
self.assertEqual(
response.status_code,
200,
)
content = json.loads(response.content)
self.assertEqual(set(content.keys()), {"text"})
def test_webm_audiofile(self):
bpayload = self.read("sample1.webm")
with TestClient(self.app) as client:
response = client.post("/", data=bpayload)
self.assertEqual(
response.status_code,
200,
)
content = json.loads(response.content)
self.assertEqual(set(content.keys()), {"text"})
| 4 |
0 | hf_public_repos/api-inference-community/docker_images/pyannote_audio | hf_public_repos/api-inference-community/docker_images/pyannote_audio/tests/test_api.py | import os
from typing import Dict
from unittest import TestCase, skipIf
from app.main import ALLOWED_TASKS, get_pipeline
# Must contain at least one example of each implemented pipeline
# Tests do not check the actual values of the model output, so small dummy
# models are recommended for faster tests.
TESTABLE_MODELS: Dict[str, str] = {
"automatic-speech-recognition": "pyannote/voice-activity-detection"
}
ALL_TASKS = {
"audio-classification",
"audio-to-audio",
"automatic-speech-recognition",
"feature-extraction",
"image-classification",
"question-answering",
"sentence-similarity",
"speech-segmentation",
"structured-data-classification",
"text-classification",
"text-to-image",
"text-to-speech",
"token-classification",
"conversational",
"feature-extraction",
"question-answering",
"sentence-similarity",
"fill-mask",
"table-question-answering",
"summarization",
"text2text-generation",
"text-classification",
"text-to-image",
"text-to-speech",
"token-classification",
"zero-shot-classification",
}
class PipelineTestCase(TestCase):
@skipIf(
os.path.dirname(os.path.dirname(__file__)).endswith("common"),
"common is a special case",
)
def test_has_at_least_one_task_enabled(self):
self.assertGreater(
len(ALLOWED_TASKS.keys()), 0, "You need to implement at least one task"
)
def test_unsupported_tasks(self):
unsupported_tasks = ALL_TASKS - ALLOWED_TASKS.keys()
for unsupported_task in unsupported_tasks:
with self.subTest(msg=unsupported_task, task=unsupported_task):
os.environ["TASK"] = unsupported_task
os.environ["MODEL_ID"] = "XX"
with self.assertRaises(EnvironmentError):
get_pipeline()
| 5 |
0 | hf_public_repos/api-inference-community/docker_images | hf_public_repos/api-inference-community/docker_images/nemo/requirements.txt | starlette==0.28.0
api-inference-community==0.0.27
nemo_toolkit[all]>=1.18.1
huggingface_hub==0.15.1
# Dummy
| 6 |
0 | hf_public_repos/api-inference-community/docker_images | hf_public_repos/api-inference-community/docker_images/nemo/Dockerfile | FROM tiangolo/uvicorn-gunicorn:python3.9
LABEL maintainer="me <[email protected]>"
# Add any system dependency here
RUN apt-get update -y && \
apt-get install libsndfile1 ffmpeg -y
# See PyTorch releases for pip here: https://download.pytorch.org/whl/torch_stable.html
COPY ./requirements.txt /app
RUN pip install https://download.pytorch.org/whl/cpu/torch-1.13.1%2Bcpu-cp39-cp39-linux_x86_64.whl && \
pip install Cython numpy==1.21.6
RUN pip install -r requirements.txt
COPY ./prestart.sh /app/
# Most DL models are quite large in terms of memory, using workers is a HUGE
# slowdown because of the fork and GIL with python.
# Using multiple pods seems like a better default strategy.
# Feel free to override if it does not make sense for your library.
ARG max_workers=1
ENV MAX_WORKERS=$max_workers
ENV HUGGINGFACE_HUB_CACHE=/data
ENV NEMO_CACHE_DIR=/data/nemo_cache/
# Necessary on GPU environment docker.
# TIMEOUT env variable is used by nvcr.io/nvidia/pytorch:xx for another purpose
# rendering TIMEOUT defined by uvicorn impossible to use correctly
# We're overriding it to be renamed UVICORN_TIMEOUT
# UVICORN_TIMEOUT is a useful variable for very large models that take more
# than 30s (the default) to load in memory.
# If UVICORN_TIMEOUT is too low, uvicorn will simply never loads as it will
# kill workers all the time before they finish.
RUN sed -i 's/TIMEOUT/UVICORN_TIMEOUT/g' /gunicorn_conf.py
COPY ./app /app/app
| 7 |
0 | hf_public_repos/api-inference-community/docker_images | hf_public_repos/api-inference-community/docker_images/nemo/prestart.sh | python app/main.py
| 8 |
0 | hf_public_repos/api-inference-community/docker_images/nemo | hf_public_repos/api-inference-community/docker_images/nemo/app/main.py | import functools
import logging
import os
from typing import Dict, Type
from api_inference_community.routes import pipeline_route, status_ok
from app.pipelines import Pipeline
from app.pipelines.automatic_speech_recognition import (
AutomaticSpeechRecognitionPipeline,
)
from starlette.applications import Starlette
from starlette.middleware import Middleware
from starlette.middleware.gzip import GZipMiddleware
from starlette.routing import Route
TASK = os.getenv("TASK")
MODEL_ID = os.getenv("MODEL_ID")
logger = logging.getLogger(__name__)
# Add the allowed tasks
# Supported tasks are:
# - text-generation
# - text-classification
# - token-classification
# - translation
# - summarization
# - automatic-speech-recognition
# - ...
# For instance
# from app.pipelines import AutomaticSpeechRecognitionPipeline
# ALLOWED_TASKS = {"automatic-speech-recognition": AutomaticSpeechRecognitionPipeline}
# You can check the requirements and expectations of each pipelines in their respective
# directories. Implement directly within the directories.
ALLOWED_TASKS: Dict[str, Type[Pipeline]] = {
"automatic-speech-recognition": AutomaticSpeechRecognitionPipeline,
}
@functools.lru_cache()
def get_pipeline() -> Pipeline:
task = os.environ["TASK"]
model_id = os.environ["MODEL_ID"]
if task not in ALLOWED_TASKS:
raise EnvironmentError(f"{task} is not a valid pipeline for model : {model_id}")
return ALLOWED_TASKS[task](model_id)
routes = [
Route("/{whatever:path}", status_ok),
Route("/{whatever:path}", pipeline_route, methods=["POST"]),
]
middleware = [Middleware(GZipMiddleware, minimum_size=1000)]
if os.environ.get("DEBUG", "") == "1":
from starlette.middleware.cors import CORSMiddleware
middleware.append(
Middleware(
CORSMiddleware,
allow_origins=["*"],
allow_headers=["*"],
allow_methods=["*"],
)
)
app = Starlette(routes=routes, middleware=middleware)
@app.on_event("startup")
async def startup_event():
logger = logging.getLogger("uvicorn.access")
handler = logging.StreamHandler()
handler.setFormatter(logging.Formatter("%(asctime)s - %(levelname)s - %(message)s"))
logger.handlers = [handler]
# Link between `api-inference-community` and framework code.
app.get_pipeline = get_pipeline
try:
get_pipeline()
except Exception:
# We can fail so we can show exception later.
pass
if __name__ == "__main__":
try:
get_pipeline()
except Exception:
# We can fail so we can show exception later.
pass
| 9 |
0 | hf_public_repos/audio-transformers-course/chapters/fr | hf_public_repos/audio-transformers-course/chapters/fr/chapter0/community.mdx | # Rejoignez la communauté !
Nous vous invitons à [rejoindre notre communauté sur Discord](http://hf.co/join/discord). Vous aurez la possibilité d'échanger avec des apprenants, de partager des idées et d'obtenir un retour d'information précieux sur vos exercices pratiques. Vous pouvez poser des questions, partager des ressources et collaborer avec d'autres.
Notre équipe est également active sur Discord et se tient à votre disposition pour vous apporter son soutien et ses conseils en cas de besoin. Rejoindre notre communauté est un excellent moyen de rester motivé, engagé et connecté, et nous avons hâte de vous y voir !
## Qu'est-ce que Discord ?
Discord est une plateforme de chat gratuite. Si vous avez utilisé Slack, vous la trouverez assez similaire. Le serveur Discord d'Hugging Face abrite une communauté florissante de 18 000 experts, apprenants et passionnés d'IA dont vous pouvez faire partie.
## Naviguer sur Discord
Une fois inscrit à notre serveur Discord, vous devrez choisir les sujets qui vous intéressent en cliquant sur `#role-assignment` à gauche. Vous pouvez choisir autant de catégories différentes que vous le souhaitez. Pour rejoindre d'autres apprenants de ce cours, assurez-vous de cliquer sur "ML for Audio and Speech".
Explorez les canaux et présentez-vous dans le canal `#introduce-yourself`.
## Canaux du cours
Il existe de nombreux canaux axés sur différents sujets sur notre serveur Discord. Vous y trouverez des gens qui discutent d'articles, organisent des événements, partagent leurs projets et leurs idées, font du *brainstorming*, et bien plus encore.
En tant qu'apprenant du cours audio, vous trouverez peut-être les canaux suivants particulièrement pertinents :
* `#audio-announcements` : mises à jour sur le cours, nouvelles de Hugging Face en rapport avec tout ce qui concerne l'audio, annonces d'événements, et plus encore.
* `#audio-study-group` : un lieu pour échanger des idées, poser des questions sur le cours et entamer des discussions.
* `#audio-discuss` : un endroit général pour discuter de tout ce qui concerne l'audio.
En plus de rejoindre le canal `#audio-study-group`, n'hésitez pas à créer votre propre groupe d'étude, apprendre ensemble est toujours plus facile ! | 0 |
0 | hf_public_repos/audio-transformers-course/chapters/fr | hf_public_repos/audio-transformers-course/chapters/fr/events/introduction.mdx | # Sessions en direct et ateliers
## Sessions en direct
Evènement de lancement du cours en direct avec [Paige Bailey](https://dynamicwebpaige.github.io/info/) (DeepMind), [Seokhwan Kim](https://seokhwankim.github.io/) (Amazon Alexa AI) et [Brian McFee](https://brianmcfee.net/) (Librosa) :
<Youtube id="wqkKResXWB8"/>
Enregistrement du direct "Demandez-moi n'importe quoi" avec l'équipe de Hugging Face du cours :
<Youtube id="fbONSVoUneQ"/>
## Ateliers
### Hugging Face Machine Learning for Audio Study Group
Fin 2021 / début 2022, un groupe d'études sur les modèles audio était actif sur le Discord de Hugging Face.
Il consistait principalement en des présentations d'articles scientifiques, d'outils et de discussions sur le sujet de l'application de l'apprentissage automatique dans le domaine de l'audio.
Vous pouvez retrouver les enregistrements des présentations sur la [chaîne YouTube de Hugging Face](https://www.youtube.com/watch?v=cAviRhkqdnc&list=PLo2EIpI_JMQtOQK_B4G97yn1QWZ4Xi4Tu).
Les supports et *notebooks* utilisés dans les présentations sont disponibles sur le [GitHub de VB](https://github.com/Vaibhavs10/ml-with-audio).
### Whisper Fine-Tuning Event
En décembre 2022, un évènement pour *finetuner* le modèle Whisper dans plusieurs langues a été organisé.
Vous pouvez retrouver les informations le concernant sur la page [suivante](https://github.com/huggingface/community-events/tree/main/whisper-fine-tuning-event) (en anglais).
| 1 |
0 | hf_public_repos/audio-transformers-course/chapters/fr | hf_public_repos/audio-transformers-course/chapters/fr/chapter5/choosing_dataset.mdx | # Choisir un jeu de données
Comme pour tout problème d'apprentissage automatique, la qualité de notre modèle dépend des données sur lesquelles nous l'entraînons. Les jeux de données de reconnaissance vocale varient considérablement dans la façon dont ils sont gérés et dans les domaines qu'ils couvrent. Pour choisir le bon jeu de données, nous devons faire correspondre nos critères aux caractéristiques offertes par un jeu de données.
Avant de choisir un jeu de données, nous devons d'abord comprendre les principales caractéristiques qui le définissent.
## Caractéristiques des jeux de données vocaux
### 1. Nombre d'heures
En termes simples, le nombre d'heures d'entraînement indique la taille du jeu de données. Il est analogue au nombre d'exemples d'entraînement dans un jeu de données de NLP. Toutefois, les jeux de données plus importants ne sont pas nécessairement meilleurs. Si nous voulons un modèle qui généralise bien, nous avons besoin d'un jeu de données **varié** avec beaucoup de locuteurs, de domaines et de styles d'expression différents.
### 2. Domaine
Le domaine est l'endroit d'où proviennent les données, qu'il s'agisse de livres audio, de podcasts, de YouTube ou de réunions professionnelles.
Chaque domaine a une distribution de données différente. Par exemple, les livres audio sont enregistrés dans des conditions de studio, en haute qualité (sans bruit de fond) et le texte est tiré de la littérature. En revanche, pour YouTube, l'audio contient probablement plus de bruits de fond et un style de discours plus informel.
Nous devons faire correspondre notre domaine aux conditions que nous prévoyons au moment de l'inférence. Par exemple, si nous entraînons notre modèle sur des livres audio, nous ne pouvons pas nous attendre à ce qu'il soit performant dans des environnements bruyants.
### 3. Style d'élocution
Le style d'élocution peut être classé dans l'une des deux catégories suivantes :
* narré : lu à partir d'un script
* spontané : discours non scénarisé, conversationnel.
Les données audio et textuelles reflètent le style d'élocution. Étant donné que le texte narré est écrit, il a tendance à être prononcé de manière articulée et sans erreur :
```
“Consider the task of training a model on a speech recognition dataset”
```
Dans le cas d'un discours spontané, on peut s'attendre à un style plus familier, avec des répétitions, des hésitations et des faux départs :
```
“Let’s uhh let's take a look at how you'd go about training a model on uhm a sp- speech recognition dataset”
```
### 4. Style de transcription
Le style de transcription indique si le texte cible comporte de la ponctuation, de la casse ou les deux. Si nous voulons qu'un système génère un texte entièrement formaté pouvant être utilisé pour la transcription d'une publication ou d'une réunion, nous avons besoin de données d'entraînement comportant de la ponctuation et des majuscules. Si nous avons simplement besoin des mots prononcés dans une structure non formatée, ni la ponctuation ni la casse ne sont nécessaires.
Dans ce cas, nous pouvons soit choisir un jeu de données sans ponctuation ni casse, soit choisir un jeu de données avec ponctuation et casse, puis les supprimer du texte cible par le biais d'un prétraitement.
## Résumé de jeux de données sur le *Hub*
Voici un résumé de jeux de données de reconnaissance vocale en anglais les plus populaires sur le *Hub* :
| Jeu de données | Heures d'entraînement | Domaine | Style d'élocution | Casse | Ponctuation | Licence | Usage recommandé |
|-----------------------------------------------------------------------------------------|-------------|-----------------------------|-----------------------|--------|-------------|-----------------|----------------------------------|
| [LibriSpeech](https://huggingface.co/datasets/librispeech_asr) | 960 | Audiobook | Narrated | ❌ | ❌ | CC-BY-4.0 | Academic benchmarks |
| [Common Voice 11](https://huggingface.co/datasets/mozilla-foundation/common_voice_11_0) | 3000 | Wikipedia | Narrated | ✅ | ✅ | CC0-1.0 | Non-native speakers |
| [VoxPopuli](https://huggingface.co/datasets/facebook/voxpopuli) | 540 | European Parliament | Oratory | ❌ | ✅ | CC0 | Non-native speakers |
| [TED-LIUM](https://huggingface.co/datasets/LIUM/tedlium) | 450 | TED talks | Oratory | ❌ | ❌ | CC-BY-NC-ND 3.0 | Technical topics |
| [GigaSpeech](https://huggingface.co/datasets/speechcolab/gigaspeech) | 10000 | Audiobook, podcast, YouTube | Narrated, spontaneous | ❌ | ✅ | apache-2.0 | Robustness over multiple domains |
| [SPGISpeech](https://huggingface.co/datasets/kensho/spgispeech) | 5000 | Financial meetings | Oratory, spontaneous | ✅ | ✅ | User Agreement | Fully formatted transcriptions |
| [Earnings-22](https://huggingface.co/datasets/revdotcom/earnings22) | 119 | Financial meetings | Oratory, spontaneous | ✅ | ✅ | CC-BY-SA-4.0 | Diversity of accents |
| [AMI](https://huggingface.co/datasets/edinburghcstr/ami) | 100 | Meetings | Spontaneous | ✅ | ✅ | CC-BY-4.0 | Noisy speech conditions |
Ce tableau sert de référence pour sélectionner un jeu de données en fonction de vos critères. Vous trouverez ci-dessous un tableau équivalent pour la reconnaissance vocale multilingue. Notez que nous omettons la colonne des heures d'entraînement, qui varie en fonction de la langue pour chaque jeu de données, et que nous la remplaçons par le nombre de langues par jeu de données :
| Jeu de données | Langues | Domaine | Style d'élocution | Casse | Ponctuation | Licence | Usage recommandé |
|-----------------------------------------------------------------------------------------------|-----------|---------------------------------------|----------------|--------|-------------|-----------|-------------------------|
| [Multilingual LibriSpeech](https://huggingface.co/datasets/facebook/multilingual_librispeech) | 6 | Audiobooks | Narrated | ❌ | ❌ | CC-BY-4.0 | Academic benchmarks |
| [Common Voice 13](https://huggingface.co/datasets/mozilla-foundation/common_voice_13_0) | 108 | Wikipedia text & crowd-sourced speech | Narrated | ✅ | ✅ | CC0-1.0 | Diverse speaker set |
| [VoxPopuli](https://huggingface.co/datasets/facebook/voxpopuli) | 15 | European Parliament recordings | Spontaneous | ❌ | ✅ | CC0 | European languages |
| [FLEURS](https://huggingface.co/datasets/google/fleurs) | 101 | European Parliament recordings | Spontaneous | ❌ | ❌ | CC-BY-4.0 | Multilingual evaluation |
Pour une analyse détaillée des jeux de données audio couverts dans les deux tableaux, consultez l'article de blog [*A Complete Guide to Audio Datasets*](https://huggingface.co/blog/audio-datasets#a-tour-of-audio-datasets-on-the-hub) (en anglais).
Bien qu'il existe plus de 180 jeux de données de reconnaissance vocale sur le *Hub*, il est possible qu'aucun jeu de données ne corresponde à vos besoins. Dans ce cas, il est également possible d'utiliser vos propres données audio avec 🤗 *Datasets*. Pour créer un jeu de données audio personnalisé, reportez-vous au guide [Créer un jeu de données audio](https://huggingface.co/docs/datasets/audio_dataset). Lorsque vous créez un jeu de données audio personnalisé, pensez à partager le jeu de données final sur le *Hub* afin que d'autres membres de la communauté puissent bénéficier de vos efforts et apprécieront votre travail comme vous appréciez le leur.
Très bien ! Maintenant que nous avons passé en revue tous les critères de sélection d'un jeu de données d'ASR, choisissons-en un pour les besoins de ce tutoriel.
Nous savons que Whisper fait déjà un très bon travail de transcription de données dans des langues à hautes ressources (telles que l'anglais et l'espagnol), nous allons donc nous concentrer sur la transcription multilingue à faibles ressources. Nous voulons conserver la capacité de Whisper à prédire la ponctuation et la casse, donc il semble, d'après le deuxième tableau, que Common Voice 13 est un excellent jeu de données candidat !
## Common Voice 13
Common Voice 13 est un jeu de données *crown-sourcés* dans lequel des locuteurs enregistrent des textes tirés de Wikipédia dans différentes langues. Il fait partie de la série Common Voice, une collection de jeux de données publiés par la Fondation Mozilla. À l'heure où nous écrivons ces lignes, Common Voice 13 est la dernière édition du jeu de données, avec le plus grand nombre de langues et d'heures par langue de toutes les versions à ce jour.
Nous pouvons obtenir la liste complète des langues pour le jeu de données Common Voice 13 en consultant la page du jeu de données sur le *Hub* : [mozilla-foundation/common_voice_13_0](https://huggingface.co/datasets/mozilla-foundation/common_voice_13_0).
La première fois que vous consulterez cette page, il vous sera demandé d'accepter les conditions d'utilisation. Ensuite, vous aurez un accès complet au jeu de données.
Une fois que nous nous sommes authentifiés pour utiliser le jeu de données, son aperçu s'affiche montrant les 100 premiers échantillons du jeu de données pour chaque langue, prêts à être écoutés en temps réel. Pour cette unité, nous sélectionnerons le [_Dhivehi_](https://en.wikipedia.org/wiki/Maldivian_language) (ou _Maldivien_), une langue indo-aryenne parlée dans le pays insulaire d'Asie du Sud, les Maldives. Bien que nous choisissions le dhivehi pour ce tutoriel, les étapes couvertes ici s'appliquent à n'importe laquelle des 108 langues de l'ensemble de données Common Voice 13, et plus généralement à n'importe lequel des 180+ jeux de données audio du *Hub*. Il n'y a donc pas de restriction sur la langue ou le dialecte.
Nous pouvons sélectionner le sous-ensemble Dhivehi de Common Voice 13 en réglant le sous-ensemble sur `dv` à l'aide du menu déroulant (`dv` étant le code d'identification de la langue pour le Dhivehi) :
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface-course/audio-course-images/resolve/main/cv_13_dv_selection.png" alt="Selecting the Dhivehi split from the Dataset's Preview">
</div>
Si nous appuyons sur le bouton de lecture du premier échantillon, nous pouvons écouter le son et voir le texte correspondant. Parcourez les échantillons des ensembles d'entraînement et de test pour vous faire une idée plus précise des données que nous traitons.
L'intonation et le style indiquent que les enregistrements sont issus d'un discours narré. Vous remarquerez également la grande diversité des locuteurs et de la qualité des enregistrements, un trait commun aux données provenant de données *crown-sourcées*.
L'aperçu des données est un excellent moyen d'expérimenter les données audio avant de s'engager à les utiliser. Vous pouvez choisir n'importe quel jeu de données sur le Hub, faire défiler les échantillons et écouter l'audio pour les différents sous-ensembles et divisions, afin d'évaluer s'il s'agit du bon jeu de données pour vos besoins. Une fois que vous avez sélectionné un jeu de données, il est facile de charger les données afin de pouvoir commencer à les utiliser.
Personnellement, je ne parle pas le dhivehi et je m'attends à ce que la grande majorité des lecteurs ne le parlent pas non plus ! Pour savoir si notre modèle *finetuné* est bon, nous aurons besoin d'un moyen rigoureux de l'_évaluer_ sur des données inédites et de mesurer sa précision de transcription.
C'est exactement ce que nous allons faire dans la section suivante !
| 2 |
0 | hf_public_repos/audio-transformers-course/chapters/fr | hf_public_repos/audio-transformers-course/chapters/fr/chapter5/evaluation.mdx | # Évaluation et métriques pour la reconnaissance automatique de la parole
Si vous connaissez la [distance de Levenshtein](https://fr.wikipedia.org/wiki/Distance_de_Levenshtein) en NLP, les métriques d'évaluation des systèmes de reconnaissance vocale vous seront familières ! Ne vous inquiétez pas si ce n'est pas le cas, nous allons passer en revue les explications afin de nous assurer que vous maîtrisez les différentes métriques et que vous comprenez ce qu'elles signifient.
Lors de l'évaluation des systèmes de reconnaissance vocale, nous comparons les prédictions du système aux transcriptions du texte cible, en annotant toutes les erreurs présentes. Nous classons ces erreurs dans l'une des trois catégories suivantes :
1. Substitutions (Sub) : lorsque nous transcrivons le **mauvais mot** dans notre prédiction (par exemple "sit" au lieu de "sat").
2. Insertions (Ins) : lorsque nous ajoutons un **mot supplémentaire** dans notre prédiction.
3. Suppressions (Sup) : lorsque nous **supprimons un mot** dans notre prédiction.
Ces catégories d'erreurs sont les mêmes pour toutes les mesures de reconnaissance vocale. Ce qui diffère, c'est le niveau auquel nous calculons ces erreurs : nous pouvons les calculer soit au niveau du _mot_, soit au niveau du _caractère_.
Nous utiliserons un exemple courant pour chacune des définitions des mesures. Nous avons ici une séquence de texte de _vérité de base_ ou de _référence_ :
```python
reference = "the cat sat on the mat"
```
Et une séquence prédite par le système de reconnaissance vocale que nous essayons d'évaluer :
```python
prediction = "the cat sit on the"
```
Nous pouvons constater que la prédiction est assez proche, mais que certains mots ne sont pas tout à fait corrects. Nous allons évaluer cette prédiction par rapport à la référence pour les trois mesures de reconnaissance vocale les plus populaires et voir quels types de chiffres nous obtenons pour chacune d'entre elles.
## *Word Error Rate* (Taux d'erreur au niveau du mot)
Le *word error rate (WER)* est la mesure de facto pour la reconnaissance vocale. Elle calcule les substitutions, les insertions et les suppressions au niveau du *mot*. Cela signifie que les erreurs sont annotées mot par mot. Prenons notre exemple :
| Réference : | the | cat | sat | on | the | mat |
|-------------|-----|-----|---------|-----|-----|-----|
| Prediction : | the | cat | **sit** | on | the | | |
| Étiquette : | ✅ | ✅ | Sub | ✅ | ✅ | Sup |
Ici, nous avons
* 1 substitution ("sit" au lieu de "sat")
* 0 insertion
* 1 suppression ("mat" est manquant)
Cela donne 2 erreurs au total. Pour obtenir notre taux d'erreur, nous divisons le nombre d'erreurs par le nombre total de mots de notre référence (N), qui est de 6 pour cet exemple :
$$
\begin{aligned}
WER &= \frac{Sub + Ins + Sup}{N} \\
&= \frac{1 + 0 + 1}{6} \\
&= 0.333
\end{aligned}
$$
Ok, nous avons donc un WER de 0,333, soit 33,3 %. Remarquez que le mot "sit" ne comporte qu'un seul caractère erroné, mais que le mot entier est marqué comme incorrect. Il s'agit là d'une caractéristique essentielle du WER : les fautes d'orthographe sont lourdement pénalisées, même si elles sont mineures.
Le WER est défini de telle sorte que *plus il est bas, mieux c'est* : un WER bas signifie qu'il y a moins d'erreurs dans notre prédiction, de sorte qu'un système de reconnaissance vocale parfait aurait un WER de zéro (pas d'erreurs).
Voyons comment nous pouvons calculer le WER en utilisant 🤗 *Evaluate*. Nous aurons besoin de deux packages pour calculer notre métrique WER : 🤗 *Evaluate* pour l'interface API, et JIWER pour effectuer le gros du travail de calcul :
```
pip install --upgrade evaluate jiwer
```
Nous pouvons maintenant charger la métrique WER et calculer le résultat pour notre exemple :
```python
from evaluate import load
wer_metric = load("wer")
wer = wer_metric.compute(references=[reference], predictions=[prediction])
print(wer)
```
**Sortie :**
```
0.3333333333333333
```
0,33, soit 33,3 %, comme prévu ! Nous savons maintenant ce qui se passe sous le capot avec ce calcul du WER.
Maintenant, voici quelque chose qui est assez déroutant... D'après vous, quelle est la limite supérieure du WER ? On pourrait s'attendre à ce qu'elle soit de 1 ou de 100 %, n'est-ce pas ? Le WER étant le rapport entre le nombre d'erreurs et le nombre de mots (N), il n'y a pas de limite supérieure au WER !
Prenons un exemple dans lequel nous prédisons 10 mots et la cible n'en a que 2. Si toutes nos prédictions étaient fausses (10 erreurs), nous aurions un REE de 10 / 2 = 5, soit 500 % ! Il convient de garder cela à l'esprit si vous entraînez un système ASR et que vous obtenez un WER supérieur à 100 %. Toutefois, si vous obtenez ce résultat, il est probable que quelque chose n'a pas fonctionné... 😅
## *Word Accuracy* (Précision au niveau du mot)
Nous pouvons inverser le WER pour obtenir une mesure où *plus c'est haut, mieux c'est*. Plutôt que de mesurer le taux d'erreurs au niveau du mot, nous pouvons mesurer la *précision au niveau du mot* (WAcc) de notre système :
$$
\begin{equation}
WAcc = 1 - WER \nonumber
\end{equation}
$$
Le WAcc est mesuré au niveau du mot, il s'agit simplement du WER reformulé en tant que mesure de précision plutôt qu'en tant que mesure d'erreur. Le WAcc est très rarement cité dans la littérature : nous pensons aux prédictions de notre système en termes d'erreurs de mots, et nous préférons donc les mesures de taux d'erreur qui sont plus associées à ces annotations de type d'erreur.
## *Character Error Rate* (Taux d'erreur au niveau des caractères)
Il semble un peu injuste que nous ayons marqué l'ensemble du mot "sit" comme erroné alors qu'en fait une seule lettre était incorrecte.
Le *Character Error Rate (CER)* évalue les systèmes au *niveau des caractères*. Cela signifie que nous divisons nos mots en caractères individuels et que nous annotons les erreurs caractère par caractère :
| Réference : | t | h | e | | c | a | t | | s | a | t | | o | n | | t | h | e | | m | a | t |
|-------------|-----|-----|-----|-----|-----|-----|-----|-----|-----|-------|-----|-----|-----|-----|-----|-----|-----|-----|-----|-----|-----|-----|
| Prediction : | t | h | e | | c | a | t | | s | **i** | t | | o | n | | t | h | e | | | | |
| Étiquette : | ✅ | ✅ | ✅ | | ✅ | ✅ | ✅ | | ✅ | Sub | ✅ | | ✅ | ✅ | | ✅ | ✅ | ✅ | | D | D | D |
Nous voyons maintenant que pour le mot "sit", le "s" et le "t" sont marqués comme corrects. Seul le "i" est étiqueté comme une erreur de substitution. Nous récompensons donc notre système pour la prédiction partiellement correcte 🤝
Dans notre exemple, nous avons 1 substitution de caractère, 0 insertion et 3 suppressions. Au total, nous avons 14 caractères. Notre CER est donc :
$$
\begin{aligned}
CER &= \frac{S + I + D}{N} \\
&= \frac{1 + 0 + 3}{14} \\
&= 0.286
\end{aligned}
$$
Nous obtenons un CER de 0,286, soit 28,6 %. Remarquez que ce chiffre est inférieur à notre WER. Nous avons beaucoup moins pénalisé l'erreur d'orthographe.
## Quelle mesure dois-je utiliser ?
En général, le WER est beaucoup plus utilisé que le CER pour évaluer les systèmes vocaux. En effet, le WER exige des systèmes une meilleure compréhension du contexte des prédictions. Dans notre exemple, "sit" n'est pas au bon temps. Un système qui comprend la relation entre le verbe et le temps de la phrase aurait prédit le temps correct du verbe "sat". Nous voulons encourager ce niveau de compréhension de la part de nos systèmes vocaux. Ainsi, bien que le WER soit moins indulgent que le CER, il est également plus propice aux types de systèmes intelligibles que nous souhaitons développer. C'est pourquoi nous utilisons généralement le WER et nous vous encourageons à faire de même ! Toutefois, dans certaines circonstances, il n'est pas possible de l'utiliser.
En effet, certaines langues, comme le mandarin et le japonais, n'ont pas de notion de "mots", et le WER n'a donc pas de sens. Dans ce cas, nous revenons à l'utilisation du CER.
Dans notre exemple, nous n'avons utilisé qu'une seule phrase pour calculer le WER. Lors de l'évaluation d'un système réel, nous utilisons généralement un ensemble de test complet composé de plusieurs milliers de phrases. Lorsque l'évaluation porte sur plusieurs phrases, nous agrégeons Sub, Inv, Sup et N pour toutes les phrases, puis nous calculons le WER à l'aide de la formule définie ci-dessus. Cela permet d'obtenir une meilleure estimation du WER pour des données inédites.
## Normalisation
Si nous entraînons un modèle d'ASR sur des données contenant de la ponctuation et de la casse, il apprendra à prédire la casse et la ponctuation dans ses transcriptions. C'est une bonne chose lorsque nous voulons utiliser notre modèle pour des applications réelles, telles que la transcription de réunions ou de dictées, car les transcriptions prédites seront entièrement formatées avec la casse et la ponctuation, un style appelé *orthographique*.
Cependant, nous avons également la possibilité de *normaliser* le jeu de données afin d'en supprimer la casse et la ponctuation. La normalisation du jeu de données facilite la tâche de reconnaissance vocale : le modèle n'a plus besoin de faire la distinction entre les majuscules et les minuscules, ni de prédire la ponctuation à partir des seules données audio (par exemple, quel est le son d'un point-virgule ?).
De ce fait, les taux d'erreur sur les mots sont naturellement plus faibles (ce qui signifie que les résultats sont meilleurs). L'article de Whisper démontre
l'effet radical que la normalisation des transcriptions peut avoir sur les résultats du WER (*cf.* Section 4.4 du [papier] (https://cdn.openai.com/papers/whisper.pdf)).
Bien que nous obtenions des WER plus bas, le modèle n'est pas nécessairement meilleur pour la production. L'absence de casse et de ponctuation rend le texte prédit par le modèle nettement plus difficile à lire. Prenons l'exemple de la [section précédente](asr_models), où nous avons utilisé Wav2Vec2 et Whisper sur le même échantillon audio du jeu de données LibriSpeech. Le modèle Wav2Vec2 ne prédit ni la ponctuation ni la casse, alors que Whisper prédit les deux. En comparant les transcriptions côte à côte, nous constatons que la transcription de Whisper est beaucoup plus facile à lire :
```
Wav2Vec2: HE TELLS US THAT AT THIS FESTIVE SEASON OF THE YEAR WITH CHRISTMAUS AND ROSE BEEF LOOMING BEFORE US SIMALYIS DRAWN FROM EATING AND ITS RESULTS OCCUR MOST READILY TO THE MIND
Whisper: He tells us that at this festive season of the year, with Christmas and roast beef looming before us, similarly is drawn from eating and its results occur most readily to the mind.
```
La transcription Whisper est orthographique et donc prête à l'emploi. Au contraire, nous devrions utiliser un post-traitement supplémentaire pour restaurer la ponctuation et la casse dans nos prédictions Wav2Vec2 si nous voulions les utiliser pour des applications en aval.
Il existe un juste milieu entre normaliser et ne pas normaliser : nous pouvons entraîner nos systèmes sur des transcriptions orthographiques, puis normaliser les prédictions et les cibles avant de calculer le WER. De cette manière, nous entraînons nos systèmes à prédire des textes entièrement formatés, mais nous bénéficions également des améliorations du WER que nous obtenons en normalisant les transcriptions.
Whisper a été publié avec un normaliseur qui gère efficacement la normalisation de la casse, de la ponctuation et du formatage des nombres, entre autres. Appliquons le aux transcriptions de Whisper pour montrer comment nous pouvons les normaliser :
```python
from transformers.models.whisper.english_normalizer import BasicTextNormalizer
normalizer = BasicTextNormalizer()
prediction = " He tells us that at this festive season of the year, with Christmas and roast beef looming before us, similarly is drawn from eating and its results occur most readily to the mind."
normalized_prediction = normalizer(prediction)
normalized_prediction
```
**Sortie :**
```
' he tells us that at this festive season of the year with christmas and roast beef looming before us similarly is drawn from eating and its results occur most readily to the mind '
```
Nous pouvons constater que le texte a été entièrement mis en minuscules et que toute la ponctuation a été supprimée. Définissons maintenant la transcription de référence et calculons le WER normalisé entre la référence et la cible :
```python
reference = "HE TELLS US THAT AT THIS FESTIVE SEASON OF THE YEAR WITH CHRISTMAS AND ROAST BEEF LOOMING BEFORE US SIMILES DRAWN FROM EATING AND ITS RESULTS OCCUR MOST READILY TO THE MIND"
normalized_referece = normalizer(reference)
wer = wer_metric.compute(
references=[normalized_referece], predictions=[normalized_prediction]
)
wer
```
**Sortie :**
```
0.0625
```
6,25 % ; c'est à peu près ce à quoi nous nous attendions pour le modèle de base de Whisper sur l'ensemble de validation de LibriSpeech. Comme nous le voyons ici, nous avons prédit une transcription orthographique, mais nous avons bénéficié de l'augmentation du WER obtenue en normalisant la référence et la prédiction avant de calculer le WER.
Le choix de la méthode de normalisation des transcriptions dépend en fin de compte de vos besoins. Nous recommandons d'entraîner sur du texte orthographique et d'évaluer sur du texte normalisé afin d'obtenir le meilleur des deux mondes.
## Assembler le tout
Nous avons couvert trois sujets jusqu'à présent dans cette unité : les modèles pré-entraînés, la sélection des jeux de données et l'évaluation.
Nous allons nous préparer pour la prochaine section sur le *finetuning* en évaluant le modèle Whisper pré-entraîné sur l'ensemble de test Common Voice 13 Dhivehi. Nous utiliserons le WER pour établir une _base_ pour la prochaine section où notre objectif sera d'essayer de le battre 🥊
Tout d'abord, nous allons charger le modèle Whisper pré-entraîné en utilisant la classe `pipeline()`. Ce processus vous est maintenant familier !
La seule nouveauté est de charger le modèle en demi-précision (float16) s'il est exécuté sur un GPU. Cela permet d'accélérer l'inférence sans que le WER n'en souffre.
```python
from transformers import pipeline
import torch
if torch.cuda.is_available():
device = "cuda:0"
torch_dtype = torch.float16
else:
device = "cpu"
torch_dtype = torch.float32
pipe = pipeline(
"automatic-speech-recognition",
model="openai/whisper-small",
torch_dtype=torch_dtype,
device=device,
)
```
Ensuite, nous allons charger l'échantillon test Dhivehi de Common Voice 13. Nous avons vu dans la section précédente que Common Voice 13 est *sécurisé*, ce qui signifie que nous avons dû accepter les conditions d'utilisation du jeu de données avant d'y avoir accès. Nous pouvons maintenant relier notre compte Hugging Face à notre *notebook*, afin d'avoir accès au jeu de données à partir de la machine que nous utilisons actuellement.
Lier le *notebook* au *Hub* est très simple, il suffit d'entrer votre *token* d'authentification au *Hub* lorsque l'on vous y invite.
Votre *token* d'authentification est trouvable [ici](https://huggingface.co/settings/tokens).
```python
from huggingface_hub import notebook_login
notebook_login()
```
Une fois que nous avons lié le *notebook* à notre compte Hugging Face, nous pouvons procéder au téléchargement du jeu de données Common Voice. Cela prendra quelques minutes de les télécharger et de les prétraiter automatiquement sur votre *notebook* :
```python
from datasets import load_dataset
common_voice_test = load_dataset(
"mozilla-foundation/common_voice_13_0", "dv", split="test"
)
```
<Tip>
Si vous rencontrez un problème d'authentification lors du chargement du jeu de données, assurez-vous que vous avez accepté les conditions d'utilisation du jeu de données sur le *Hub* via le lien suivant : https://huggingface.co/datasets/mozilla-foundation/common_voice_13_0.
</Tip>
L'évaluation sur un jeu de données entier peut être faite de la même manière que sur un seul exemple. Tout ce que nous avons à faire est de **boucler** sur les audios d'entrée, plutôt que d'inférer un seul échantillon. Pour ce faire, nous transformons d'abord notre jeu de données en un `KeyDataset`. Cela sélectionne la colonne particulière du jeu de données que nous voulons transmettre au modèle (dans notre cas, c'est la colonne `"audio"`), en ignorant le reste (comme les transcriptions cibles, que nous ne voulons pas utiliser pour l'inférence). Nous itérons ensuite sur ce jeu de données transformé, en ajoutant les sorties du modèle à une liste pour sauvegarder les prédictions. La cellule de code suivante prendra environ cinq minutes si elle est exécutée sur un GPU en demi-précision, avec un maximum de 12 Go de mémoire :
```python
from tqdm import tqdm
from transformers.pipelines.pt_utils import KeyDataset
all_predictions = []
# lancer l'inférence en streaming
for prediction in tqdm(
pipe(
KeyDataset(common_voice_test, "audio"),
max_new_tokens=128,
generate_kwargs={"task": "transcribe"},
batch_size=32,
),
total=len(common_voice_test),
):
all_predictions.append(prediction["text"])
```
<Tip>
Si vous rencontrez une erreur de mémoire CUDA lors de l'exécution de la cellule ci-dessus, réduisez progressivement la taille du batch par un facteur de 2 jusqu'à ce que vous trouviez une taille de batch qui convienne à votre appareil.
</Tip>
Enfin, nous pouvons calculer le WER. Calculons d'abord le WER orthographique, c'est-à-dire le WER sans post-traitement :
```python
from evaluate import load
wer_metric = load("wer")
wer_ortho = 100 * wer_metric.compute(
references=common_voice_test["sentence"], predictions=all_predictions
)
wer_ortho
```
**Sortie :**
```
167.29577268612022
```
D'accord... 167% signifie essentiellement que notre modèle produit n'imprte quoi 😜 Ne vous inquiétez pas, notre objectif est d'améliorer ce résultat en *fientunant* le modèle sur l'ensemble d'entraînement Dhivehi !
Ensuite, nous évaluons le WER normalisé, c'est-à-dire le WER avec post-traitement de normalisation. Nous devons filtrer nos échantillons qui seraient vides après normalisation, car sinon le nombre total de mots dans notre référence (N) serait nul, ce qui donnerait une erreur de division par zéro dans notre calcul :
```python
from transformers.models.whisper.english_normalizer import BasicTextNormalizer
normalizer = BasicTextNormalizer()
# calculer le WER normalisé
all_predictions_norm = [normalizer(pred) for pred in all_predictions]
all_references_norm = [normalizer(label) for label in common_voice_test["sentence"]]
# étape de filtrage pour n'évaluer que les échantillons qui correspondent à des références non nulles
all_predictions_norm = [
all_predictions_norm[i]
for i in range(len(all_predictions_norm))
if len(all_references_norm[i]) > 0
]
all_references_norm = [
all_references_norm[i]
for i in range(len(all_references_norm))
if len(all_references_norm[i]) > 0
]
wer = 100 * wer_metric.compute(
references=all_references_norm, predictions=all_predictions_norm
)
wer
```
**Sortie :**
```
125.69809089960707
```
Une fois de plus, nous constatons la réduction drastique du WER obtenue en normalisant nos références et nos prédictions : le modèle de base obtient un WER de 168 % pour le test orthographique, alors que le WER normalisé est de 126 %.
Voilà qui est clair ! Ce sont les chiffres que nous voulons essayer de battre lors du *finetuning* du modèle de reconnaissance de la parole en Dhivehi. Poursuivez votre lecture pour vous familiariser avec un exemple de *finetuning* 🚀
| 3 |
0 | hf_public_repos/audio-transformers-course/chapters/fr | hf_public_repos/audio-transformers-course/chapters/fr/chapter5/supplemental_reading.mdx | # Lectures et ressources complémentaires
Cette unité est une introduction pratique à la reconnaissance automatique de la parole, l'une des tâches les plus populaires dans le domaine audio.
Vous voulez en savoir plus ? Vous trouverez ici des ressources supplémentaires (en anglais) qui vous aideront à approfondir votre compréhension du sujet et à améliorer votre expérience d'apprentissage.
* [Whisper Talk](https://www.youtube.com/live/fZMiD8sDzzg?feature=share) par Jong Wook Kim : une présentation du modèle Whisper, expliquant la motivation, l'architecture, l'entraînement et les résultats, par l'auteur du modèle.
* [End-to-End Speech Benchmark (ESB)](https://arxiv.org/abs/2210.13352) : un papier qui plaide en faveur de l'utilisation du WER orthographique plutôt que du WER normalisé pour l'évaluation des systèmes de reconnaissance automatique de la parole et qui présente un benchmark correspondant.
* [Fine-Tuning Whisper for Multilingual ASR](https://huggingface.co/blog/fine-tune-whisper) : un article de blog qui explique le fonctionnement du modèle Whisper de manière plus détaillée, ainsi que les étapes de pré- et post-traitement impliquées dans l'extracteur de caractéristiques et le *tokenizer*.
* [Fine-tuning MMS Adapter Models for Multi-Lingual ASR](https://huggingface.co/blog/mms_adapters) : un guide complet pour *finetuner* les nouveaux modèles de reconnaissance vocale [MMS](https://ai.facebook.com/blog/multilingual-model-speech-recognition/) de Meta, en gelant les poids du modèle de base et en ne finetunant qu'un petit nombre de couches.
* Boosting Wav2Vec2 with n-grams in 🤗 Transformers](https://huggingface.co/blog/wav2vec2-with-ngram) : un article de blog pour combiner les modèles CTC avec des modèles de langage externes pour combattre les erreurs d'orthographe et de ponctuation.
| 4 |
0 | hf_public_repos/audio-transformers-course/chapters/fr | hf_public_repos/audio-transformers-course/chapters/fr/chapter5/asr_models.mdx | # Modèles pré-entraînés pour la reconnaissance automatique de la parole
Dans cette section, nous verrons comment utiliser le `pipeline()` pour tirer parti des modèles pré-entraînés pour la reconnaissance automatique de la parole. Dans l’[unité 2](.. /chapter2/asr_pipeline), nous avons introduit le `pipeline()` comme un moyen facile d'exécuter des tâches de reconnaissance de la parole, avec tout le prétraitement et le post-traitement gérés sous le capot et la flexibilité d'expérimenter rapidement avec n'importe quel *checkpoint* pré-entraîné disponible sur le *Hub*.
Dans cette unité, nous irons plus loin et explorerons les différents attributs des modèles de reconnaissance automatique de la parole et comment nous pouvons les utiliser pour aborder une gamme de tâches différentes.
Comme détaillé dans l'unité 3, le modèle de reconnaissance automatique de la parole se divise généralement dans l'une des deux catégories suivantes :
1. Modèle avec Classification temporelle connexionniste (CTC) : modèles avec que l’encodeur du *transformer* avec une tête de classification linéaire sur le dessus
2. Modèle de séquence à séquence (Seq2Seq) : modèles encodeur-décodeur, avec un mécanisme d'attention croisée entre l'encodeur et le décodeur
Avant 2022, la variante avec CTC était la plus populaire des deux architectures, avec des modèles tels que Wav2Vec2, HuBERT et XLSR réalisant des percées dans le paradigme de pré-entraînement / *finetuning* de la parole.
De grandes entreprises, telles que Meta et Microsoft, ont pré-entraîné l'encodeur sur de grandes quantités de données audio non étiquetées pendant plusieurs jours ou semaines.
Les utilisateurs pouvent ensuite prendre un *checkpoint* pré-entraîné et le finetuner avec une tête CTC sur à peine **10 minutes** de données audio étiquetées pour obtenir de solides performances sur une tâche en aval de reconnaissance automatique de la parole.
Cependant, les modèles CTC ont des lacunes. L'ajout d'une simple couche linéaire à un encodeur donne un petit modèle global rapide, mais peut être sujet à des fautes d'orthographe phonétiques. Nous allons le démontrer ci-dessous pour le modèle Wav2Vec2.
## Sonder les modèles CTC
Chargeons un petit extrait du jeu de données [LibriSpeech ASR](hf-internal-testing/librispeech_asr_dummy) pour démontrer les capacités de transcription de Wav2Vec2 :
```python
from datasets import load_dataset
dataset = load_dataset(
"hf-internal-testing/librispeech_asr_dummy", "clean", split="validation"
)
dataset
```
**Sortie :**
```
Dataset({
features: ['file', 'audio', 'text', 'speaker_id', 'chapter_id', 'id'],
num_rows: 73
})
```
Nous pouvons choisir l'un des 73 échantillons audio et en inspecter l’audio ainsi que la transcription :
```python
from IPython.display import Audio
sample = dataset[2]
print(sample["text"])
Audio(sample["audio"]["array"], rate=sample["audio"]["sampling_rate"])
```
**Sortie :**
```
HE TELLS US THAT AT THIS FESTIVE SEASON OF THE YEAR WITH CHRISTMAS AND ROAST BEEF LOOMING BEFORE US SIMILES DRAWN FROM EATING AND ITS RESULTS OCCUR MOST READILY TO THE MIND
```
Noël et rôti de bœuf, ça sonne bien! 🎄 Après avoir choisi un échantillon de données, nous chargeons maintenant un *checkpoint* *finetuné* dans le `pipeline()`.
Pour cela, nous utiliserons le *checkpoint* officiel [base Wav2Vec2] (facebook/wav2vec2-base-100h) *finetuné* sur 100 heures de données LibriSpeech :
```python
from transformers import pipeline
pipe = pipeline("automatic-speech-recognition", model="facebook/wav2vec2-base-100h")
```
Ensuite, nous allons prendre un exemple du jeu de données et transmettre ses données brutes au pipeline.
Puisque le pipeline *consomme* n'importe quel dictionnaire que nous lui passons (ce qui signifie qu'il ne peut pas être réutilisé), nous transmettrons une copie des données. De cette façon, nous pouvons réutiliser en toute sécurité le même échantillon audio dans les exemples suivants:
```python
pipe(sample["audio"].copy())
{
"text": "HE TELLS US THAT AT THIS FESTIVE SEASON OF THE YEAR WITH CHRISTMAUS AND ROSE BEEF LOOMING BEFORE US SIMALYIS DRAWN FROM EATING AND ITS RESULTS OCCUR MOST READILY TO THE MIND"
}
```
Nous pouvons voir que le modèle Wav2Vec2 fait un assez bon travail pour transcrire cet échantillon. A première vue, il semble généralement correct.
Mettons la cible et la prédiction côte à côte et mettons en évidence les différences:
```
Target: HE TELLS US THAT AT THIS FESTIVE SEASON OF THE YEAR WITH CHRISTMAS AND ROAST BEEF LOOMING BEFORE US SIMILES DRAWN FROM EATING AND ITS RESULTS OCCUR MOST READILY TO THE MIND
Prediction: HE TELLS US THAT AT THIS FESTIVE SEASON OF THE YEAR WITH **CHRISTMAUS** AND **ROSE** BEEF LOOMING BEFORE US **SIMALYIS** DRAWN FROM EATING AND ITS RESULTS OCCUR MOST READILY TO THE MIND
```
En comparant le texte cible à la transcription prévue, nous pouvons voir que tous les mots _sonnent_ correctement mais que certains ne sont pas orthographiés avec précision. Par exemple :
* _CHRISTMAUS_ vs. _CHRISTMAS_
* _ROSE_ vs. _ROAST_
* _SIMALYIS_ vs. _SIMILES_
Cela met en évidence les lacunes d'un modèle CTC. Un modèle CTC est essentiellement uniquement un modèle « acoustique» : il se compose d'un encodeur qui forme des représentations d'états cachés à partir des entrées audio, et d'une couche linéaire qui associe les états cachés aux caractères :
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface-course/audio-course-images/resolve/main/wav2vec2-ctc.png" alt="Transformer encoder with a CTC head on top">
</div>
Cela signifie que le système base presque entièrement sa prédiction sur l'entrée acoustique qui lui a été donnée (les sons phonétiques de l'audio), et a donc tendance à transcrire l'audio de manière phonétique.
Il donne moins d'importance au contexte de modélisation linguistique des lettres précédentes et successives, et est donc sujet aux fautes d'orthographe phonétique.
Un modèle plus intelligent identifierait que _CHRISTMAUS_ n'est pas un mot valide dans le vocabulaire anglais, et le corrigerait en _CHRISTMAS_ lors de ses prédictions. Il nous manque également deux grandes fonctionnalités dans notre prédiction, la casse et la ponctuation, ce qui limite l'utilité des transcriptions du modèle aux applications réelles.
## Passage à Seq2Seq
Comme indiqué dans l'unité 3, les modèles Seq2Seq sont formés d'un codeur et d'un décodeur reliés par un mécanisme d'attention croisée. L'encodeur joue le même rôle qu'auparavant, calculant des représentations d’états cachés des entrées audio, tandis que le décodeur joue le rôle d'un **modèle de langage**. Le décodeur traite toute la séquence de représentations d’états cachés de l'encodeur et génère les transcriptions de texte correspondantes. Avec le contexte global de l'entrée audio, le décodeur est capable d'utiliser le contexte du modèle de langage lorsqu'il fait ses prédictions, corrigeant les fautes d'orthographe à la volée et contournant ainsi le problème des prédictions phonétiques.
Les modèles Seq2Seq présentent deux inconvénients :
1. Ils sont intrinsèquement plus lents lors du décodage puisqu’il se produit une étape à la fois, plutôt que tout à la fois 2. Ils nécessitent beaucoup plus de données d'entraînement pour converger
Le besoin de grandes quantités de données d'apprentissage a été un goulot d'étranglement dans l'avancement des architectures Seq2Seq pour la parole. Les données audios étiquetées sont difficiles à obtenir, les plus grands jeux de données annotées à l'époque ne totalisant que 10 000 heures. Tout cela a changé en 2022 avec la sortie de **Whisper**. Whisper est un modèle pré-entraîné pour la reconnaissance automatique de la parole publié en [septembre 2022](https://openai.com/blog/whisper/) par Alec Radford et al. d'OpenAI. Contrairement à ses prédécesseurs CTC, qui étaient entièrement pré-entraînés sur des données audio **non étiquetées**, Whisper est pré-entraîné sur une grande quantité de données de transcription audio **étiquetées**, 680 000 heures pour être précis.
Il s'agit d'un ordre de grandeur de données plus grand que les données audio non étiquetées utilisées pour entraîner Wav2Vec 2.0 (60 000 heures). De plus, 117 000 heures de ces données de pré-entraînement sont des données multilingues. Il en résulte des *checkpoints* qui peuvent être appliqués à plus de 96 langues, dont beaucoup sont considérées comme _à faible ressource_.
Lorsqu'ils sont passés à l'échelle, les modèles Whisper démontrent une forte capacité à généraliser sur de nombreux jeux de données et domaines. Obtenant des résultats compétitifs de pointe, avec un taux d'erreur de mots (WER) de près de 3% sur le sous-ensemble de test LibriSpeech et de 4,7% WER sur le sous-ensemble de test TED-LIUM (_cf._ Tableau 8 du [papier de Whisper](https://cdn.openai.com/papers/whisper.pdf)).
La capacité de Whisper à gérer de longs échantillons audio, sa robustesse au bruit et sa capacité à prédire les transcriptions en casse et ponctuées revêtent une importance particulière. Cela en fait un candidat viable pour les systèmes de reconnaissance automatique de la parole du monde réel.
Le reste de cette section vous montrera comment utiliser les modèles Whisper pré-entraînés pour la reconnaissance automatique de la parole à l'aide de 🤗 *Transformers*. Dans de nombreuses situations, les *checkpoints* pré-entraînés sont extrêmement performants et donnent d'excellents résultats, nous vous encourageons donc à essayer de les utiliser comme première étape pour résoudre tout problème de reconnaissance automatique de la parole.
Grâce à un *finetuning*, les *checkpoints* peuvent être adaptés à des jeux de données et à des langues spécifiques afin d'améliorer encore ces résultats. Nous montrerons comment faire cela dans la section sur [le *finetuning*](fine-tuning).
Whisper est disponible en cinq tailles différentes de modèles. Les quatre plus petits sont entraînés soit sur des données en anglais soit sur des données multilingues. Le *checkpoint* le plus grand est uniquement multilingue. Les neuf *checkpoints* pré-entraînés sont disponibles sur le [*Hub*](https://huggingface.co/models?search=openai/whisper). Ils sont résumés dans le tableau suivant. « VRAM » indique la mémoire GPU requise pour exécuter le modèle avec une taille de batch minimale de 1. « *Rel Speed* » est la vitesse relative d'un *checkpoint* par rapport au plus grand modèle.
Sur la base de ces informations, vous pouvez sélectionner le *checkpoint* le plus adapté à votre matériel.
| Taille | Paramètres | VRAM / Go | *Rel Speed* | Anglais | Multilingue |
|--------|------------|-----------|-----------|------------------------------------------------------|-----------------------------------------------------|
| tiny | 39 M | 1.4 | 32 | [✓](https://huggingface.co/openai/whisper-tiny.en) | [✓](https://huggingface.co/openai/whisper-tiny) |
| base | 74 M | 1.5 | 16 | [✓](https://huggingface.co/openai/whisper-base.en) | [✓](https://huggingface.co/openai/whisper-base) |
| small | 244 M | 2.3 | 6 | [✓](https://huggingface.co/openai/whisper-small.en) | [✓](https://huggingface.co/openai/whisper-small) |
| medium | 769 M | 4.2 | 2 | [✓](https://huggingface.co/openai/whisper-medium.en) | [✓](https://huggingface.co/openai/whisper-medium) |
| large | 1550 M | 7.5 | 1 | x | [✓](https://huggingface.co/openai/whisper-large-v2) |
Chargeons le [Whisper Base](https://huggingface.co/openai/whisper-base), qui est de taille comparable au Wav2Vec2 que nous avons utilisé précédemment. Anticipant notre passage à la reconnaissance automatique de la parole multilingue, nous allons charger la variante multilingue du *checkpoint* de base. Nous chargons également le modèle sur le GPU s'il est disponible, ou sur le CPU dans le cas contraire. Le `pipeline()` se chargera ensuite de déplacer toutes les entrées / sorties du CPU vers le GPU selon les besoins:
```python
import torch
from transformers import pipeline
device = "cuda:0" if torch.cuda.is_available() else "cpu"
pipe = pipeline(
"automatic-speech-recognition", model="openai/whisper-base", device=device
)
```
Bien, maintenant, transcrivons l'audio comme avant. Le seul changement que nous apportons est de passer un argument supplémentaire, `max_new_tokens`, qui indique au modèle le nombre maximum de *tokens* à générer lors de sa prédiction :
```python
pipe(sample["audio"], max_new_tokens=256)
```
**Sortie :**
```
{'text': ' He tells us that at this festive season of the year, with Christmas and roast beef looming before us, similarly is drawn from eating and its results occur most readily to the mind.'}
```
La première chose que vous remarquerez est la présence de la casse et de la ponctuation. Cela rend immédiatement la transcription plus facile à lire par rapport à la transcription non casée et non ponctuée de Wav2Vec2. Mettons la transcription côte à côte avec la cible :
```
Target: HE TELLS US THAT AT THIS FESTIVE SEASON OF THE YEAR WITH CHRISTMAS AND ROAST BEEF LOOMING BEFORE US SIMILES DRAWN FROM EATING AND ITS RESULTS OCCUR MOST READILY TO THE MIND
Prediction: He tells us that at this festive season of the year, with **Christmas** and **roast** beef looming before us, **similarly** is drawn from eating and its results occur most readily to the mind.
```
Whisper a fait un excellent travail pour corriger les erreurs phonétiques que nous avons vues avec Wav2Vec2 : _Christmas_ et _roast_ sont orthographiés correctement. Nous voyons que le modèle a encore du mal avec _SIMILES_, étant incorrectement transcrit comme _similarly_, mais cette fois la prédiction est un mot valide du vocabulaire anglais. L'utilisation d'un Whisper plus grand peut aider à réduire davantage les erreurs de transcription, au détriment d'un calcul plus important et d'un temps de transcription plus long.
On nous a promis un modèle capable de gérer 96 langues, alors passons à de la reconnaissance automatique multilingue 🌎 !
Le jeu de données [Multilingual LibriSpeech](https://huggingface.co/datasets/facebook/multilingual_librispeech) (MLS) est l'équivalent multilingue du jeu de données LibriSpeech, avec des données audio étiquetées en six langues. Nous allons charger un échantillon de l’échantillon espagnol de MLS, en utilisant le mode _streaming_ afin de ne pas avoir à télécharger l'ensemble de données :
```python
dataset = load_dataset(
"facebook/multilingual_librispeech", "spanish", split="validation", streaming=True
)
sample = next(iter(dataset))
```
Encore une fois, nous allons inspecter la transcription du texte et écouter le segment audio:
```python
print(sample["text"])
Audio(sample["audio"]["array"], rate=sample["audio"]["sampling_rate"])
```
**Sortie :**
```
entonces te delelitarás en jehová y yo te haré subir sobre las alturas de la tierra y te daré á comer la heredad de jacob tu padre porque la boca de jehová lo ha hablado
```
C'est le texte cible que nous visons avec notre transcription Whisper. Bien que nous sachions maintenant que nous pouvons probablement faire mieux, puisque notre modèle va aussi prédire la ponctuation et la casse, qui ne sont pas présents dans la référence. Transmettons l'échantillon audio au pipeline pour obtenir notre prédiction de texte. Une chose à noter est que le pipeline _consomme_ le dictionnaire des entrées audio que nous entrons, ce qui signifie que le dictionnaire ne peut pas être réutilisé. Pour contourner ce problème, nous allons passer une _copie_ de l'échantillon audio, afin de pouvoir réutiliser le même échantillon audio dans les exemples de code suivants :
```python
pipe(sample["audio"].copy(), max_new_tokens=256, generate_kwargs={"task": "transcribe"})
```
**Sortie :**
```
{'text': ' Entonces te deleitarás en Jehová y yo te haré subir sobre las alturas de la tierra y te daré a comer la heredad de Jacob tu padre porque la boca de Jehová lo ha hablado.'}
```
Super, cela ressemble énormément à notre texte de référence (sans doute mieux car il a une ponctuation et une casse !). Vous remarquerez que nous avons transféré `"task"` en tant que _generate kwarg_. Définir la `"task"` à `"transcribe"` oblige Whisper à effectuer la tâche de reconnaissance de la parole, où l'audio est transcrit dans la même langue que le discours a été prononcé. Whisper est également capable d'effectuer la tâche étroitement liée de traduction de la parole, où l'audio en espagnol peut être traduit en texte en anglais. Pour y parvenir, nous définissons la `"task"` sur `"translate"` :
```python
pipe(sample["audio"], max_new_tokens=256, generate_kwargs={"task": "translate"})
```
**Sortie :**
```
{'text': ' So you will choose in Jehovah and I will raise you on the heights of the earth and I will give you the honor of Jacob to your father because the voice of Jehovah has spoken to you.'}
```
Maintenant que nous savons que nous pouvons basculer entre la reconnaissance automatique de la parole et la traduction de la parole, nous pouvons choisir notre tâche en fonction de nos besoins. Soit nous reconnaissons l'audio dans la langue X vers le texte dans la même langue X (par exemple, l'audio espagnol vers le texte espagnol), soit nous traduisons de l'audio dans n'importe quelle langue X vers du texte en anglais (par exemple, l'audio espagnol vers le texte anglais).
Pour en savoir plus sur la façon dont l'argument `"task"` est utilisé pour contrôler les propriétés du texte généré, reportez-vous à la [carte de modèle](https://huggingface.co/openai/whisper-base#usage) pour le modèle Whisper base.
## Longue transcription et horodatage
Jusqu'à présent, nous nous sommes concentrés sur la transcription de courts échantillons audio de moins de 30 secondes. Nous avons mentionné que l'un des attraits de Whisper était sa capacité à travailler sur de longs échantillons audio. Nous allons nous attaquer à cette tâche ici !
Créons un long fichier audio en concaténant des échantillons successifs à partir du jeu de données MLS. Étant donné que MLS est organisé en divisant de longs enregistrements de livres audio en segments plus courts, la concaténation d'échantillons est un moyen de reconstruire des passages de livres audio plus longs. Par conséquent, l'audio résultant doit être cohérent sur l'ensemble de l'échantillon. Nous allons définir notre durée audio cible sur 5 minutes et arrêter de concaténer des échantillons une fois que nous aurons atteint cette valeur :
```python
import numpy as np
target_length_in_m = 5
# convertir les minutes en secondes (* 60) en nombre d'échantillons (* taux d'échantillonnage)
sampling_rate = pipe.feature_extractor.sampling_rate
target_length_in_samples = target_length_in_m * 60 * sampling_rate
# itérer sur notre jeu de données en streaming, en concaténant les échantillons jusqu'à ce que nous atteignions notre cible
long_audio = []
for sample in dataset:
long_audio.extend(sample["audio"]["array"])
if len(long_audio) > target_length_in_samples:
break
long_audio = np.asarray(long_audio)
# Résultat
seconds = len(long_audio) / 16000
minutes, seconds = divmod(seconds, 60)
print(f"Length of audio sample is {minutes} minutes {seconds:.2f} seconds")
```
**Sortie :**
```
Length of audio sample is 5.0 minutes 17.22 seconds
```
5 minutes et 17 secondes d'audio à transcrire. Le transfert de ce long échantillon audio directement vers le modèle pose deux problèmes :
1. Whisper est intrinsèquement conçu pour fonctionner avec des échantillons de 30 secondes. Tout ce qui est inférieur à 30s est rembourré à 30s avec du silence, et tout ce qui dépasse 30s est tronqué à 30s en coupant l'audio excédentaire. Donc si nous passons notre audio directement, nous n'obtiendrons la transcription que pour les 30 premières secondes
2. La mémoire dans un *transformer* évolue quadratiquement avec la longueur de séquence a : doubler la longueur d'entrée quadruple le besoin en mémoire, de sorte que le passage de fichiers audio très longs entraînera inévitablement une erreur de mémoire insuffisante (OOM : out-of-memory)
La transcription de longs audio fonctionne dans 🤗 *Transformers* en segmentant l'audio d'entrée en segments plus petits et plus faciles à gérer.
Chaque segment a un petit chevauchement avec le précédent. Cela nous permet de recoudre avec précision les segments aux bornes, car nous pouvons trouver le chevauchement entre les segments et fusionner les transcriptions en conséquence :
<div class="flex justify-center">
<img src="https://huggingface.co/blog/assets/49_asr_chunking/Striding.png" alt="🤗 Transformers chunking algorithm. Source: https://huggingface.co/blog/asr-chunking.">
</div>
L'avantage de segmenter les échantillons est que nous n'avons pas besoin du résultat du bloc \\( i \\) pour transcrire le morceau suivant \\( i + 1 \\). La couture est effectuée après que nous ayons transcrit tous les morceaux aux bornes des morceaux. Donc peu importe l'ordre dans lequel nous transcrivons les morceaux. L'algorithme est entièrement **sans états**, donc nous pouvons même faire du découpage sur \\( i + 1 \\) en même temps que du découpage sur \\( i \\) ! Cela nous permet de former des _batch_ de morceaux et de les exécuter dans le modèle en parallèle, offrant une grande accélération de calcul par rapport à leur transcription séquentielle. Pour en savoir plus sur la segmentation d’audio dans 🤗 *Transformers*, vous pouvez vous référer à cet [article de blog] (https://huggingface.co/blog/asr-chunking) (en anglais).
Pour activer les longues transcriptions, nous devons ajouter un argument supplémentaire lorsque nous appelons le pipeline. Cet argument, `chunk_length_s`, contrôle la longueur des segments divisés en secondes. Pour Whisper, des morceaux de 30 secondes sont optimaux, car cela correspond à la longueur d'entrée attendue par Whisper.
Pour activer le traitement par batch, nous devons passer l'argument `batch_size` au pipeline. En mettant tout cela ensemble, nous pouvons transcrire le long échantillon audio comme suit:
```python
pipe(
long_audio,
max_new_tokens=256,
generate_kwargs={"task": "transcribe"},
chunk_length_s=30,
batch_size=8,
)
```
**Sortie :**
```
{'text': ' Entonces te deleitarás en Jehová, y yo te haré subir sobre las alturas de la tierra, y te daré a comer la
heredad de Jacob tu padre, porque la boca de Jehová lo ha hablado. nosotros curados. Todos nosotros nos descarriamos
como bejas, cada cual se apartó por su camino, mas Jehová cargó en él el pecado de todos nosotros...
```
Nous n’affichons pas toute la sortie ici car elle est assez longue (312 mots au total). Sur un GPU V100 de 16 Go, vous pouvez vous attendre à ce que la ligne ci-dessus prenne environ 3,45 secondes à s’éxécuter, ce qui est assez bon pour un échantillon audio de 317 secondes. Sur un CPU, attendez-vous à plus de 30 secondes.
Whisper est également capable de prédire les _horodatages_ au niveau du segment pour les données audio. Ces horodatages indiquent l'heure de début et de fin d'un court passage audio et sont particulièrement utiles pour aligner une transcription avec l'audio d'entrée. Supposons que nous voulions fournir des sous-titres pour une vidéo. Nous avons besoin de ces horodatages pour savoir quelle partie de la transcription correspond à un certain segment de vidéo, afin d'afficher la transcription correcte pour cette heure.
L'activation de la prédiction d'horodatage est simple, il suffit de définir l'argument `return_timestamps=True`. Les horodatages sont compatibles avec les méthodes de segmentation et de traitement par batchs que nous avons utilisées précédemment. Nous pouvons donc simplement ajouter l'argument timestamp à notre code précédent :
```python
pipe(
long_audio,
max_new_tokens=256,
generate_kwargs={"task": "transcribe"},
chunk_length_s=30,
batch_size=8,
return_timestamps=True,
)["chunks"]
```
**Sortie :**
```
[{'timestamp': (0.0, 26.4),
'text': ' Entonces te deleitarás en Jehová, y yo te haré subir sobre las alturas de la tierra, y te daré a comer la heredad de Jacob tu padre, porque la boca de Jehová lo ha hablado. nosotros curados. Todos nosotros nos descarriamos como bejas, cada cual se apartó por su camino,'},
{'timestamp': (26.4, 32.48),
'text': ' mas Jehová cargó en él el pecado de todos nosotros. No es que partas tu pan con el'},
{'timestamp': (32.48, 38.4),
'text': ' hambriento y a los hombres herrantes metas en casa, que cuando vieres al desnudo lo cubras y no'},
...
```
Et le tour est joué ! Nous avons notre texte prédit ainsi que les horodatages correspondants.
## Résumé
Whisper est un modèle pré-entraîné solide pour la reconnaissance automatique de la parole et la traduction. Par rapport à Wav2Vec2, il a une plus grande précision de transcription, avec des sorties qui contiennent la ponctuation et la casse. Il peut être utilisé pour transcrire la parole en anglais ainsi que dans 96 autres langues, à la fois sur des segments audio courts et des segments plus longs par le biais de la segmentation. Ces attributs en font un modèle viable pour de nombreuses tâches de reconnaissance automatique de la parole et de traduction sans avoir besoin d'être *finetuné*. La méthode `pipeline()` fournit un moyen facile d'inférer en une ligne de code avec un contrôle sur les prédictions générées.
Bien que le modèle Whisper fonctionne extrêmement bien sur de nombreuses langues à ressources élevées, il a une précision de transcription et de traduction plus faible sur les langues à faibles ressources, c'est-à-dire celles pour lesquelles les données d'apprentissage sont moins facilement disponibles. Les performances varient également selon les accents et dialectes de certaines langues, y compris une précision moindre pour les locuteurs de différents sexes, races, âges ou autres critères démographiques (_cf._ le papier de [Whisper](https://arxiv.org/pdf/2212.04356.pdf)).
Pour améliorer les performances sur les langues, les accents ou les dialectes à faibles ressources, nous pouvons prendre le modèle Whisper pré-entraîné et l'entraîner sur un petit corpus de données sélectionnées de manière appropriée, dans un processus appelé _*finetuning*_. Nous montrerons qu'avec seulement dix heures de données supplémentaires, nous pouvons améliorer les performances du modèle Whisper de plus de 100% sur une langue à faibles ressources. Dans la section suivante, nous aborderons le processus de sélection d'un jeu de données à *finetuner*.
| 5 |
0 | hf_public_repos/audio-transformers-course/chapters/fr | hf_public_repos/audio-transformers-course/chapters/fr/chapter5/demo.mdx | # Construire une démo avec Gradio
Maintenant que nous avons *finetuné* un Whisper pour le Dhivehi, construisons une démo [Gradio](https://gradio.app) pour le présenter à la communauté !
La première chose à faire est de charger le *checkpoint* en utilisant la classe `pipeline()` - vous êtes maintenant familier avec la section sur les [modèles pré-entraînés](asr_models). Vous pouvez changer le `model_id` pour l'espace de noms de votre modèle *finetuné* sur le Hugging Face Hub, ou l'un des [modèles Whisper](https://huggingface.co/models?sort=downloads&search=openai%2Fwhisper-) pré-entraînés pour effectuer de la reconnaissance vocale à partir de zéro :
```python
from transformers import pipeline
model_id = (
"sanchit-gandhi/whisper-small-dv" # mettre à jour avec l'identifiant de votre modèle
)
pipe = pipeline("automatic-speech-recognition", model=model_id)
```
Deuxièmement, nous allons définir une fonction qui prend le chemin du fichier d'une entrée audio et le passe à travers le pipeline.
Ici, le pipeline se charge automatiquement de charger le fichier audio, de le rééchantillonner à la bonne fréquence d'échantillonnage et d'exécuter l'inférence.
Nous pouvons alors simplement renvoyer le texte transcrit en tant que sortie de la fonction.
Pour s'assurer que notre modèle puisse gérer des entrées audio de longueur arbitraire, nous activons le *chunking* comme décrit dans la section sur les [modèles pré-entraînés](asr_models) :
```python
def transcribe_speech(filepath):
output = pipe(
filepath,
max_new_tokens=256,
generate_kwargs={
"task": "transcribe",
"language": "sinhalese",
}, # mettre à jour avec la langue sur laquelle vous avez finetuné
chunk_length_s=30,
batch_size=8,
)
return output["text"]
```
Nous allons utiliser la fonctionnalité [blocks](https://gradio.app/docs/#blocks) de Gradio pour lancer deux onglets sur notre démo : l'un pour la transcription par microphone et l'autre pour le chargement de fichiers.
```python
import gradio as gr
demo = gr.Blocks()
mic_transcribe = gr.Interface(
fn=transcribe_speech,
inputs=gr.Audio(source="microphone", type="filepath"),
outputs=gr.outputs.Textbox(),
)
file_transcribe = gr.Interface(
fn=transcribe_speech,
inputs=gr.Audio(source="upload", type="filepath"),
outputs=gr.outputs.Textbox(),
)
```
Enfin, nous lançons la démo en utilisant les deux blocs que nous venons de définir :
```python
with demo:
gr.TabbedInterface(
[mic_transcribe, file_transcribe],
["Transcrire le microphone", "Transcrire le fichier audio"],
)
demo.launch(debug=True)
```
Ceci lancera une démo Gradio similaire à celle qui tourne sur le *Space* suivant :
<iframe src="https://course-demos-whisper-small.hf. space" frameBorder="0" height="450" title="Gradio app" class="container p-0 flex-grow space-iframe" allow="accelerometer ; ambient-light-sensor ; autoplay ; battery ; camera ; document-domain ; encrypted-media ; fullscreen ; geolocation ; gyroscope ; layout-animations ; legacy-image-formats ; magnetometer ; microphone ; midi ; oversized-images ; payment ; picture-in-picture ; publickey-credentials-get ; sync-xhr ; usb ; vr ; wake-lock ; xr-spatial-tracking" sandbox="allow-forms allow-modals allow-popups allow-popups-to-escape-sandbox allow-same-origin allow-scripts allow-downloads"></iframe>
Si vous souhaitez héberger votre démo sur le *Hub*, vous pouvez utiliser ce *Space* comme exemple pour votre modèle *finetuné*.
Cliquez sur le lien pour dupliquer le *Space* sur votre compte : [https://huggingface.co/spaces/course-demos/whisper-small?duplicate=true](https://huggingface.co/spaces/course-demos/whisper-small?duplicate=true).
Nous vous recommandons de donner à votre *Space* un nom similaire à celui de votre modèle *finetuné* (par exemple whisper-small-dv-demo) et de régler la visibilité sur *Public*.
Une fois que vous avez dupliqué le *Space* sur votre compte, cliquez sur *Files and versions* -> *app.py* -> *edit*. Changez ensuite l'identifiant du modèle par le votre (ligne 6).
Descendez au bas de la page et cliquez sur *Commit changes to main*.
La démo redémarre, cette fois en utilisant votre modèle *finetuné*. Vous pouvez partager cette démo avec vos amis et votre famille afin qu'ils puissent utiliser le modèle que vous avez entraîné !
Alternativement, vous pouvez consulter notre tutoriel vidéo pour mieux comprendre comment dupliquer un *Space* : [vidéo YouTube](https://www.youtube.com/watch?v=VQYuvl6-9VE). | 6 |
0 | hf_public_repos/audio-transformers-course/chapters/fr | hf_public_repos/audio-transformers-course/chapters/fr/chapter5/introduction.mdx | # Ce que vous allez apprendre et construire
Dans cette section, nous verrons comment les *transformers* peuvent être utilisés pour convertir la parole en texte, une tâche connue sous le nom de _reconnaissance de la parole_.
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface-course/audio-course-images/resolve/main/asr_diagram.png" alt="Diagram of speech to text">
</div>
La reconnaissance de la parole, également connue sous le nom de reconnaissance automatique de la parole (ASR pour *automatic speech recognition* ou STT pour *speech-to-text*), est l'une des tâches de traitement d'audio les plus populaires et les plus excitantes. Elle est utilisée dans un large éventail d'applications, y compris la dictée, les assistants vocaux, le sous-titrage vidéo et les transcriptions de réunions.
Vous avez probablement utilisé un système de reconnaissance de la parole plusieurs fois auparavant sans vous en rendre compte. Considérez l'assistant numérique de votre smartphone (Siri, Google Assistant, Alexa). Lorsque vous utilisez ces assistants, la première chose qu'ils font est de transcrire votre discours parlé en texte écrit, prêt à être utilisé pour toutes les tâches en aval (comme trouver la météo 🌤️).
Jouez avec la démo de reconnaissance de la parole ci-dessous. Vous pouvez soit vous enregistrer à l'aide de votre microphone, soit glisser-déposer un échantillon audio pour en obtenir la transcription :
<iframe src="https://course-demos-whisper-small.hf.space" frameborder="0" width="850" height="450"> </iframe>
La reconnaissance de la parole est une tâche difficile car elle nécessite une connaissance conjointe de l'audio et du texte. L'audio d'entrée peut contenir beaucoup de bruit de fond et être prononcé par des haut-parleurs avec des accents différents, ce qui rend l'identification de la parole difficile. Le texte écrit peut contenir des caractères qui n'ont pas de son acoustique, tels que la ponctuation, qui sont difficiles à déduire de l'audio seul. Ce sont tous des obstacles que nous devons surmonter lors de la construction de systèmes de efficaces!
Maintenant que nous avons défini notre tâche, nous pouvons commencer à l'examiner plus en détail. À la fin de cette unité, vous aurez une bonne compréhension fondamentale des différents modèles pré-entraînés disponibles et de la façon de les utiliser avec la 🤗 bibliothèque *Transformers*. Vous connaîtrez également la procédure pour *finetuner* un modèle sur un domaine ou une langue de votre choix, ce qui vous permettra de construire un système puissant pour toutes les tâches que vous rencontrez. Vous pourrez montrer votre modèle à vos amis et à votre famille en créant une démo prenant n'importe quel discours et le convertissant en texte !
Plus précisément, nous couvrirons les points suivants :
* [Modèles pré-entraînés pour la reconnaissance de la parole](asr_models)
* [Choix d'un jeu de données](choosing_dataset)
* [Évaluation et métriques pour la reconnaissance de la parole](evaluation)
* [Comment *finetuner* un système d'ASR avec l'API *Trainer*](fine-tuning)
* [Création d'une démo](demo)
* [Exercice pratique](hands_on) | 7 |
0 | hf_public_repos/audio-transformers-course/chapters/fr | hf_public_repos/audio-transformers-course/chapters/fr/chapter5/fine-tuning.mdx | # Comment finetuner un système de reconnaissance automatique de la parole avec l'API Trainer
Dans cette section, nous allons couvrir un guide étape par étape pour *finetuner* Whisper pour la reconnaissance automatique de la parole sur le jeu de données Common Voice 13. Nous utiliserons la version "*small*" du modèle et un jeu de données relativement léger, vous permettant d'exécuter le *finetuning* assez rapidement sur n'importe quel GPU de plus de 16 Go avec de faibles besoins en espace disque, comme le GPU T4 de 16 Go fourni dans le volet gratuit de Google Colab.
Si vous disposez d'un GPU plus petit ou si vous rencontrez des problèmes de mémoire pendant l'entraînement, vous pouvez suivre les suggestions fournies pour réduire l'utilisation de la mémoire. À l'inverse, si vous avez accès à un GPU plus puissant, vous pouvez modifier les arguments d'entraînement pour maximiser votre capacité de traitement. Ce guide est donc accessible quelles que soient les spécifications de votre GPU !
De même, ce guide porte plus précisément sur le *finetuning* sur la langue Dhivehi mais les étapes couvertes ici se généralisent à n'importe quelle langue du jeu de données Common Voice, et plus généralement à n'importe quel jeu de données d'ASR disponible sur le *Hub*.
Vous pouvez modifier le code pour passer rapidement à la langue de votre choix et *finetuner* un modèle Whisper dans votre langue maternelle 🌍.
Commençons et donnons le coup d'envoi de notre pipeline de *finetuning* !
## Préparer l'environnement
Nous vous conseillons vivement de télécharger les *checkpoints* du modèle directement sur le [*Hub*](https://huggingface.co/).
Le *Hub* offre les avantages suivants :
- Un contrôle de version intégré : vous pouvez être sûr qu'aucun *checkpoint* n'est perdu pendant l'entraînement.
- Tensorboard : suivi des mesures importantes au cours de l'entraînement.
- Cartes de modèle : documenter ce que fait un modèle et ses cas d'utilisation prévus.
- Communauté : un moyen facile de partager et de collaborer avec la communauté ! 🤗
Lier le *notebook* au *Hub* est très simple, il suffit d'entrer votre *token* d'authentification au *Hub* lorsque l'on vous y invite.
Votre *token* d'authentification est trouvable [ici](https://huggingface.co/settings/tokens).
```python
from huggingface_hub import notebook_login
notebook_login()
```
**Sortie :**
```bash
Login successful
Your token has been saved to /root/.huggingface/token
```
## Charger le jeu de données
[Common Voice 13](https://huggingface.co/datasets/mozilla-foundation/common_voice_13_0) contient environ dix heures de données Dhivehi étiquetées, dont trois sont des données de test. Il s'agit de très peu de données pour un *finetuning*, nous nous appuierons donc sur la connaissance multilingue acquise par Whisper pendant le pré-entraînement.
En utilisant les 🤗 *Datasets*, le téléchargement et la préparation des données sont extrêmement simples. Nous pouvons télécharger et préparer les ensembles de Common Voice 13 en une seule ligne de code. Puisque le Dhivehi est très pauvre en ressources, nous combinerons les splits `train` et `validation` pour obtenir environ sept heures de données d'entraînement. Nous utiliserons les trois heures de données `test` comme notre ensemble de test :
```python
from datasets import load_dataset, DatasetDict
common_voice = DatasetDict()
common_voice["train"] = load_dataset(
"mozilla-foundation/common_voice_13_0", "dv", split="train+validation"
)
common_voice["test"] = load_dataset(
"mozilla-foundation/common_voice_13_0", "dv", split="test"
)
print(common_voice)
```
**Sortie :**
```
DatasetDict({
train: Dataset({
features: ['client_id', 'path', 'audio', 'sentence', 'up_votes', 'down_votes', 'age', 'gender', 'accent', 'locale', 'segment', 'variant'],
num_rows: 4904
})
test: Dataset({
features: ['client_id', 'path', 'audio', 'sentence', 'up_votes', 'down_votes', 'age', 'gender', 'accent', 'locale', 'segment', 'variant'],
num_rows: 2212
})
})
```
<Tip>
Vous pouvez changer l'identifiant de langue de `"dv"` pour un identifiant de langue de votre choix. Pour voir toutes les langues possibles dans Common Voice 13, consultez la carte du jeu de données sur le *Hub* : https://huggingface.co/datasets/mozilla-foundation/common_voice_13_0
</Tip>
La plupart des jeux de données d'ASR ne fournissent que des échantillons audio en entrée (`audio`) et le texte transcrit correspondant (`sentence`).
Common Voice contient des métadonnées supplémentaires, telles que `accent` et `locale`, que nous pouvons ignorer pour l'ASR.
En gardant le *notebook* aussi général que possible, nous ne considérons que l'audio d'entrée et le texte transcrit en écartant les informations de métadonnées supplémentaires :
```python
common_voice = common_voice.select_columns(["audio", "sentence"])
```
## Extracteur de caractéristiques, tokeniser et processeur
Le pipeline d'ASR peut être décomposé en trois étapes :
1. L'extracteur de caractéristiques qui pré-traite les entrées audio brutes en spectrogrammes log-mél.
2. Le modèle qui effectue l'association séquence-séquence
3. Le tokenizer qui post-traite les *tokens* prédits en texte.
Dans 🤗 *Transformers*, le modèle Whisper est associé à un extracteur de caractéristiques et à un tokenizer, appelés respectivement [WhisperFeatureExtractor](https://huggingface.co/docs/transformers/main/model_doc/whisper#transformers.WhisperFeatureExtractor) et [WhisperTokenizer](https://huggingface.co/docs/transformers/main/model_doc/whisper#transformers.WhisperTokenizer).
Pour nous simplifier la vie, ces deux objets sont regroupés dans une seule classe, appelée [WhisperProcessor](https://huggingface.co/docs/transformers/model_doc/whisper#transformers.WhisperProcessor).
Nous pouvons appeler le WhisperProcessor pour effectuer à la fois le prétraitement audio et le post-traitement des *tokens* de texte. Ce faisant, nous n'avons besoin de suivre que deux objets pendant l'entraîningment : le processeur et le modèle.
Lors d'un *finetuné* multilingue, nous devons définir la `"language"` et la `"task"` lors de l'instanciation du processeur.
La `"language"` doit être fixée à la langue audio source, et la tâche à `"translate"` pour la reconnaissance vocale ou à `"translate"` pour la traduction vocale. Ces arguments modifient le comportement du *tokens*, et doivent être définis correctement pour s'assurer que les étiquettes cibles sont encodées correctement.
Nous pouvons voir toutes les langues possibles supportées par Whisper en important la liste des langues :
```python
from transformers.models.whisper.tokenization_whisper import TO_LANGUAGE_CODE
TO_LANGUAGE_CODE
```
Si vous parcourez cette liste, vous remarquerez que de nombreuses langues sont présentes, mais que le dhivehi est l'une des rares à ne pas l'être !
Cela signifie que Whisper n'a pas été pré-entraîné sur le dhivehi. Cependant, cela ne signifie pas que nous ne pouvons pas *finetuner* Whisper sur cette langue.
En faisant cela, nous allons entraîner Whisper dans une nouvelle langue, une langue non supportée par le *checkpoint* pré-entraîné. C'est plutôt cool, non ?
Lorsque vous le *finetunez* sur une nouvelle langue, Whisper fait un bon travail en tirant parti de sa connaissance des 96 autres langues sur lesquelles il a été pré-entraîné. En général, toutes les langues modernes seront linguistiquement similaires à au moins l'une des 96 langues que Whisper connaît déjà, nous nous inscrivons donc dans ce paradigme de représentation des connaissances interlinguistiques.
Ce que nous devons faire pour cette nouvelle langue, est de trouver la langue **la plus similaire** sur laquelle Whisper a été pré-entraîné. L'article de Wikipédia sur le dhivehi indique que cette langue est étroitement liée à la langue cinghalaise du Sri Lanka.
Si nous vérifions à nouveau les codes de langue, nous pouvons voir que le cinghalais est présent dans le jeu de langues de Whisper, nous pouvons donc en toute sécurité mettre notre argument de langue à `"sinhalese"`.
Nous allons charger notre processeur à partir du *checkpoint* pré-entraîné, en fixant la langue à `"sinhalese"` et la tâche à `"transcribe"` comme expliqué ci-dessus :
```python
from transformers import WhisperProcessor
processor = WhisperProcessor.from_pretrained(
"openai/whisper-small", language="sinhalese", task="transcribe"
)
```
Il est utile de rappeler que dans la plupart des cas, vous constaterez que la langue sur laquelle vous souhaitez effectuer un *finetuning* se trouve dans l'ensemble des langues de pré-entraînement, auquel cas vous pouvez simplement définir cette langue directement comme langue audio source ! Notez que ces deux arguments doivent être omis pour le *finetuning* en anglais où il n'y a qu'une seule option pour la langue (`"English"`) et la tâche (`"transcribe"`).
## Prétraitement des données
Jetons un coup d'oeil aux caractéristiques du jeu de données. Portez une attention particulière à la colonne `"audio"`, elle détaille le taux d'échantillonnage de nos entrées audio :
```python
common_voice["train"].features
```
**Sortie :**
```
{'audio': Audio(sampling_rate=48000, mono=True, decode=True, id=None),
'sentence': Value(dtype='string', id=None)}
```
Puisque notre audio d'entrée est échantillonné à 48kHz, nous devons le sous-échantillonner à 16kHz avant de le passer à l'extracteur de caractéristiques de Whisper qui est la fréquence d'échantillonnage attendue par le modèle.
Nous allons régler les entrées audio à la bonne fréquence d'échantillonnage en utilisant la méthode [`cast_column`](https://huggingface.co/docs/datasets/main/en/package_reference/main_classes#datasets.Dataset.cast_column) du jeu de données. Cette opération ne modifie pas l'audio sur place, mais signale aux jeux de données de rééchantillonner les échantillons audio à la volée lorsqu'ils sont chargés :
```python
from datasets import Audio
sampling_rate = processor.feature_extractor.sampling_rate
common_voice = common_voice.cast_column("audio", Audio(sampling_rate=sampling_rate))
```
Nous pouvons maintenant écrire une fonction pour préparer nos données pour le modèle :
1. Nous chargeons et rééchantillonnons les données audio échantillon par échantillon en appelant `sample["audio"]`. Comme expliqué ci-dessus, 🤗 *Datasets* effectue toutes les opérations de rééchantillonnage nécessaires à la volée.
2. Nous utilisons l'extracteur de caractéristiques pour calculer les caractéristiques d'entrée du spectrogramme log-mel à partir de notre tableau audio unidimensionnel.
3. Nous encodons les transcriptions en identifiants d'étiquettes à l'aide d'un *tokenizer*.
```python
def prepare_dataset(example):
audio = example["audio"]
example = processor(
audio=audio["array"],
sampling_rate=audio["sampling_rate"],
text=example["sentence"],
)
# compute input length of audio sample in seconds
example["input_length"] = len(audio["array"]) / audio["sampling_rate"]
return example
```
Nous pouvons appliquer la fonction de préparation des données à tous nos exemples d'entraînement en utilisant la méthode `.map` de 🤗 *Datasets*. Nous allons supprimer les colonnes des données d'entraînement brutes (l'audio et le texte), en ne laissant que les colonnes renvoyées par la fonction `prepare_dataset` :
```python
common_voice = common_voice.map(
prepare_dataset, remove_columns=common_voice.column_names["train"], num_proc=1
)
```
Enfin, nous filtrons toutes les données d'entraînement contenant des échantillons audio de plus de 30 secondes. Ces échantillons seraient sinon tronqués par l'extracteur de caractéristiques de Whisper, ce qui pourrait affecter la stabilité de l'entraînement. Nous définissons une fonction qui renvoie `True` pour les échantillons de moins de 30 secondes, et `False` pour ceux qui sont plus longs :
```python
max_input_length = 30.0
def is_audio_in_length_range(length):
return length < max_input_length
```
Nous appliquons notre fonction de filtrage à tous les échantillons de notre jeu de données d'entraînement par le biais de la méthode `.filter` de 🤗 *Datasets* :
```python
common_voice["train"] = common_voice["train"].filter(
is_audio_in_length_range,
input_columns=["input_length"],
)
```
Vérifions la quantité de données d'entraînement que nous avons supprimée grâce à cette étape de filtrage :
```python
common_voice["train"]
```
**Sortie :**
```
Dataset({
features: ['input_features', 'labels', 'input_length'],
num_rows: 4904
})
```
Dans ce cas, nous avons en fait le même nombre d'échantillons que précédemment, donc il n'y a pas d'échantillons de plus de 30s.
Cela pourrait ne pas être le cas si vous changez de langue, il est donc préférable de garder cette étape de filtrage en place pour plus de robustesse. Nos données sont maintenant prêtes à être entraînées ! Continuons et regardons comment nous pouvons utiliser ces données pour le *finetuning*.
## Entraînement et évaluation
Maintenant que nous avons préparé nos données, nous sommes prêts à plonger dans le pipeline d'entraînement.
[Trainer](https://huggingface.co/transformers/master/main_classes/trainer.html?highlight=trainer)
va faire le gros du travail à notre place. Tout ce que nous avons à faire est de :
- Définir un assembleur de données qui prend nos données prétraitées et prépare des tenseurs PyTorch adaptés au modèle.
- Métriques d'évaluation : lors de l'évaluation, nous voulons évaluer le modèle en utilisant la métrique du taux d'erreur au niveau du mot (WER). Nous devons définir une fonction `compute_metrics` qui gère ce calcul.
- Charger un *checkpoint* pré-entraîné et le configurer correctement pour l'entraînement.
- Définir les arguments d'entraînement : ils seront utilisés par le Trainer pour construire le plannificateur d'entraînement.
Une fois le modèle *finetuné*, nous l'évaluerons sur les données de test pour vérifier que nous l'avons correctement entraîné à transcrire la parole en Dhivehi.
### Définir un assembleur de données
L'assembleur de données pour un modèle audio séquence-à-séquence est unique dans le sens où il traite les `input_features` et les `labels` indépendamment : les `input_features` doivent être traitées par l'extracteur de caractéristiques et les `labels` par le tokenizer.
Les `input_features` sont déjà rembourrées à 30s et converties en un spectrogramme log-Mel de dimension fixe, donc tout ce que nous avons à faire est de les convertir en tenseurs PyTorch batchés. Nous le faisons en utilisant la méthode `.pad` de l'extracteur de caractéristiques avec `return_tensors=pt`. Notez qu'aucun rembourrage supplémentaire n'est appliqué ici puisque les entrées sont de dimension fixe, les `input_features` sont simplement converties en tenseurs PyTorch.
D'un autre côté, les `labels` ne sont pas rembourrés. Les séquences sont d'abord remplacées par la longueur maximale du batch à l'aide de la méthode `.pad` du *tokenizer*. Les *tokens* de remplissage sont ensuite remplacés par `-100` de sorte que ces tokens ne sont **pas** pris en compte lors du calcul de la perte. Nous coupons ensuite le début du *token* de transcription du début de la séquence d'étiquettes comme nous l'ajouterons plus tard pendant l'entraînement.
Nous pouvons utiliser le `WhisperProcessor` que nous avons défini plus tôt pour effectuer à la fois les opérations de l'extracteur de caractéristiques et du *tokenizer* :
```python
import torch
from dataclasses import dataclass
from typing import Any, Dict, List, Union
@dataclass
class DataCollatorSpeechSeq2SeqWithPadding:
processor: Any
def __call__(
self, features: List[Dict[str, Union[List[int], torch.Tensor]]]
) -> Dict[str, torch.Tensor]:
# diviser les entrées et les étiquettes car elles doivent être de longueurs différentes et nécessitent des méthodes de remplissage différentes
# traiter d'abord les entrées audio en renvoyant simplement des tenseurs Torch
input_features = [
{"input_features": feature["input_features"][0]} for feature in features
]
batch = self.processor.feature_extractor.pad(input_features, return_tensors="pt")
# obtenir les séquences d'étiquettes tokenisées
label_features = [{"input_ids": feature["labels"]} for feature in features]
# rembourrer les étiquettes à la longueur maximale
labels_batch = self.processor.tokenizer.pad(label_features, return_tensors="pt")
# remplacer le remplissage par -100 pour ignorer correctement les pertes
labels = labels_batch["input_ids"].masked_fill(
labels_batch.attention_mask.ne(1), -100
)
# si le token bos est ajouté lors de l'étape de tokenisation précédente, couper le token bos ici puisqu'il sera de toute façon ajouté plus tard
if (labels[:, 0] == self.processor.tokenizer.bos_token_id).all().cpu().item():
labels = labels[:, 1:]
batch["labels"] = labels
return batch
```
Nous pouvons maintenant initialiser l'assembleur de données que nous venons de définir :
```python
data_collator = DataCollatorSpeechSeq2SeqWithPadding(processor=processor)
```
En avant !
### Métriques d'évaluation
Ensuite, nous définissons la métrique d'évaluation que nous utiliserons sur notre ensemble d'évaluation. Nous utiliserons le taux d'erreur au niveaud du mot (WER) introduit dans la section [évaluation](évaluation), la métrique "de-facto" pour évaluer les systèmes d'ASR.
Nous chargerons la métrique WER à partir d' 🤗 *Evaluate* :
```python
import evaluate
metric = evaluate.load("wer")
```
Il suffit ensuite de définir une fonction qui prend les prédictions de notre modèle et renvoie la métrique WER. Cette fonction, appelée `compute_metrics`, remplace d'abord `-100` par le `pad_token_id` dans `label_ids` (annulant l'étape que nous avons appliquée dans l'assembleur de données pour ignorer correctement les *tokens* rembourrés dans la perte). Il décode ensuite les identifiants prédits et les identifiants d'étiquettes en chaînes de caractères. Enfin, il calcule le WER entre les prédictions et les étiquettes de référence. Ici, nous avons la possibilité d'évaluer les transcriptions et les prédictions "normalisées", dont la ponctuation et la casse ont été supprimées. Nous vous recommandons de procéder ainsi pour bénéficier de l'amélioration du WER obtenue par la normalisation des transcriptions.
```python
from transformers.models.whisper.english_normalizer import BasicTextNormalizer
normalizer = BasicTextNormalizer()
def compute_metrics(pred):
pred_ids = pred.predictions
label_ids = pred.label_ids
# remplacer -100 par pad_token_id
label_ids[label_ids == -100] = processor.tokenizer.pad_token_id
# nous ne voulons pas grouper les *tokens* lors du calcul des métriques
pred_str = processor.batch_decode(pred_ids, skip_special_tokens=True)
label_str = processor.batch_decode(label_ids, skip_special_tokens=True)
# calculer le Wer orthographique
wer_ortho = 100 * metric.compute(predictions=pred_str, references=label_str)
# calculer le WER normalisé
pred_str_norm = [normalizer(pred) for pred in pred_str]
label_str_norm = [normalizer(label) for label in label_str]
# afin de n'évaluer que les échantillons correspondant à des références non nulles
pred_str_norm = [
pred_str_norm[i] for i in range(len(pred_str_norm)) if len(label_str_norm[i]) > 0
]
label_str_norm = [
label_str_norm[i]
for i in range(len(label_str_norm))
if len(label_str_norm[i]) > 0
]
wer = 100 * metric.compute(predictions=pred_str_norm, references=label_str_norm)
return {"wer_ortho": wer_ortho, "wer": wer}
```
### Charger un *checkpoint* pré-entraîné
Chargeons maintenant le *checkpoint* pré-entraîné de Whisper small. Encore une fois, ceci est trivial grâce à l'utilisation de 🤗 *Transformers* !
```python
from transformers import WhisperForConditionalGeneration
model = WhisperForConditionalGeneration.from_pretrained("openai/whisper-small")
```
Nous allons mettre `use_cache` à `False` pour l'entraînement puisque nous utilisons [*gradient checkpointing*] (https://huggingface.co/docs/transformers/v4.18.0/en/performance#gradient-checkpointing) et que les deux sont incompatibles. Nous allons aussi surcharger deux arguments de génération pour contrôler le comportement du modèle pendant l'inférence : nous allons forcer la langue et les *tokens* de tâche pendant la génération en définissant les arguments `language` et `task`, et aussi réactiver le cache pour la génération afin d'accélérer le temps d'inférence :
```python
from functools import partial
# désactiver le cache pendant l'entraînement car il est incompatible avec le checkpointing du gradient
model.config.use_cache = False
# définir la langue et la tâche pour la génération et réactiver le cache
model.generate = partial(
model.generate, language="sinhalese", task="transcribe", use_cache=True
)
```
## Définir la configuration de l'entraînement
Dans la dernière étape, nous définissons tous les paramètres liés à l'entraînement. Ici, nous fixons le nombre d'étapes d'entraînement à 500.
Cela représente suffisamment d'étapes pour voir une grande amélioration du WER par rapport au modèle pré-entraîné, tout en s'assurant que le *finetuning* peut être exécuté en environ 45 minutes sur un niveau gratuit de Google Colab. Pour plus de détails sur les arguments d'entraînement, reportez-vous à la documentation de [Seq2SeqTrainingArguments] (https://huggingface.co/docs/transformers/main_classes/trainer#transformers.Seq2SeqTrainingArguments).
```python
from transformers import Seq2SeqTrainingArguments
training_args = Seq2SeqTrainingArguments(
output_dir="./whisper-small-dv", # nom sur le Hub
per_device_train_batch_size=16,
gradient_accumulation_steps=1, # à x2 pour chaque diminution de 2x de la taille du batch
learning_rate=1e-5,
lr_scheduler_type="constant_with_warmup",
warmup_steps=50,
max_steps=500, # augmenter jusqu'à 4000 si vous disposez de votre propre GPU ou d'un plan Colab payant
gradient_checkpointing=True,
fp16=True,
fp16_full_eval=True,
evaluation_strategy="steps",
per_device_eval_batch_size=16,
predict_with_generate=True,
generation_max_length=225,
save_steps=500,
eval_steps=500,
logging_steps=25,
report_to=["tensorboard"],
load_best_model_at_end=True,
metric_for_best_model="wer",
greater_is_better=False,
push_to_hub=True,
)
```
<Tip>
Si vous ne voulez pas télécharger les *checkpoints* du modèle vers le *Hub*, mettez `push_to_hub=False`.
</Tip>
Nous pouvons transmettre les arguments d'entraînement au *Trainer* avec notre modèle, notre jeu de données, notre assembleur de données et la fonction `compute_metrics` :
```python
from transformers import Seq2SeqTrainer
trainer = Seq2SeqTrainer(
args=training_args,
model=model,
train_dataset=common_voice["train"],
eval_dataset=common_voice["test"],
data_collator=data_collator,
compute_metrics=compute_metrics,
tokenizer=processor,
)
```
Et voilà, nous sommes prêts à entraîner !
#### Entraînement
Pour lancer l'entraînement, il suffit d'exécuter :
```python
trainer.train()
```
L'entraînement prendra environ 45 minutes en fonction de votre GPU ou de celui alloué par Google Colab. En fonction de votre GPU, il est possible que vous rencontriez une erreur CUDA `"out-of-memory"` lorsque vous commencez à entraîner. Dans ce cas, vous pouvez réduire le `per_device_train_batch_size` par incréments d'un facteur 2 et utiliser [`gradient_accumulation_steps`](https://huggingface.co/docs/transformers/main_classes/trainer#transformers.Seq2SeqTrainingArguments.gradient_accumulation_steps) pour compenser.
**Sortie :**
| Training Loss | Epoch | Step | Validation Loss | Wer Ortho | Wer |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:-------:|
| 0.136 | 1.63 | 500 | 0.1727 | 63.8972 | 14.0661 |
Notre WER final est de 14,1 % ce qui n'est pas mal pour sept heures de données d'entraînement et seulement 500 étapes d'entraînement ! Cela représente une amélioration de 112 % par rapport au modèle pré-entraîné ! Cela signifie que nous avons pris un modèle qui n'avait aucune connaissance du dhivehi et que nous l'avons *finetuné* pour reconnaître l'dhivehi avec une précision adéquate en moins d'une heure 🤯.
La grande question est de savoir comment cela se compare à d'autres systèmes ASR. Pour cela, nous pouvons consulter le [classement autoevaluate] (https://huggingface.co/spaces/autoevaluate/leaderboards?dataset=mozilla-foundation%2Fcommon_voice_13_0&only_verified=0&task=automatic-speech-recognition&config=dv&split=test&metric=wer) qui catégorise les modèles par langue et par jeu de données, et les classe ensuite en fonction de leur WER.
En regardant le classement, nous voyons que notre modèle entraîné pour 500 étapes bat de manière convaincante le *checkpoint* [Whisper Small](https://huggingface.co/openai/whisper-small) pré-entraîné que nous avons évalué dans la section précédente. Bon travail 👏
Nous voyons qu'il y a quelques *checkpoints* qui font mieux que celui que nous avons entraîné. La beauté du *Hub* est qu'il s'agit d'une plateforme *collaborative*. Si nous n'avons pas le temps ou les ressources pour effectuer un entraînement plus long nous-mêmes, nous pouvons charger un *checkpoint* que quelqu'un d'autre dans la communauté a entraîné et a eu la gentillesse de partager (en s'assurant de le remercier pour cela !).
Vous pourrez charger ces *checkpoints* exactement de la même manière que les pré-entraînés en utilisant la classe `pipeline` comme nous l'avons fait précédemment ! Ainsi, rien ne vous empêche de sélectionner le meilleur modèle du leaderboard pour l'utiliser dans le cadre de votre tâche !
Nous pouvons automatiquement soumettre notre *checkpoint* au classement lorsque nous envoyons les résultats de l'entraînement au *Hub*. Nous devons simplement définir les arguments de mot-clé appropriés (kwargs). Vous pouvez modifier ces valeurs pour qu'elles correspondent à votre jeu de données, à votre langue et au nom de votre modèle en conséquence :
```python
kwargs = {
"dataset_tags": "mozilla-foundation/common_voice_13_0",
"dataset": "Common Voice 13", # a 'pretty' name for the training dataset
"language": "dv",
"model_name": "Whisper Small Dv - Sanchit Gandhi", # a 'pretty' name for your model
"finetuned_from": "openai/whisper-small",
"tasks": "automatic-speech-recognition",
}
```
Les résultats de l'entraînement peuvent maintenant être téléchargés vers le *Hub*. Pour ce faire, exécutez la commande `push_to_hub` :
```python
trainer.push_to_hub(**kwargs)
```
Ceci sauvegardera les logs d'entraînement et les poids des modèles sous `"votre-nom-d'utilisateur/le-nom-que-vous-avez-choisi"`. Pour cet exemple, regardez le téléchargement à `sanchit-gandhi/whisper-small-dv`.
Bien que le modèle *finetuné* donne des résultats satisfaisants sur les données de test de Common Voice 13, il n'est en aucun cas optimal.
Le but de ce guide est de démontrer comment *finetuner* un modèle ASR en utilisant le *Trainer* pour la reconnaissance automatique de la parole multilingue.
Si vous avez accès à votre propre GPU ou si vous êtes abonné à un plan payant de Google Colab, vous pouvez augmenter `max_pas` à 4000 pas pour améliorer davantage le WER en entraînant plus de pas. Entraîner 4000 pas prendra environ 3 à 5 heures en fonction de votre GPU et donnera des résultats WER inférieurs d'environ 3 % à l'entraînement de 500 pas. Si vous décidez d'entraîner sur 4000 pas, nous vous recommandons également de changer le planificateur de taux d'apprentissage pour un plan *linéaire* (set `lr_scheduler_type="linear"`), car cela permettra d'augmenter les performances sur de longues périodes d'entraînement.
Les résultats pourraient probablement être améliorés en optimisant les hyperparamètres d'entraînement, tels que _learning rate_ et _dropout_, et en utilisant un *checkpoint* pré-entraîné plus grand (`medium` ou `large`). Nous laissons cet exercice au lecteur.
## Partager votre modèle
Vous pouvez maintenant partager ce modèle avec n'importe qui en utilisant le lien sur le *Hub*. Ils peuvent le charger avec l'identifiant `"votre-nom-d'utilisateur/le-nom-que-vous-avez-choisi"` directement dans l'objet `pipeline()`. Par exemple, pour charger le *checkpoint* *finetuné* ["sanchit-gandhi/whisper-small-dv"](https://huggingface.co/sanchit-gandhi/whisper-small-dv) :
```python
from transformers import pipeline
pipe = pipeline("automatic-speech-recognition", model="sanchit-gandhi/whisper-small-dv")
```
## Conclusion
Dans cette section, nous avons couvert un guide étape par étape sur le *finetuning* du modèle Whisper pour la reconnaissance vocale en utilisants 🤗 *Jeux de données*, 🤗 *Transformers* et le *Hub*. Nous avons d'abord chargé le sous-ensemble Dhivehi du jeu de données Common Voice 13 et l'avons prétraité en calculant des spectrogrammes log-mel et en tokenisant le texte. Nous avons ensuite défini un assembleur de données, une métrique d'évaluation et des arguments d'entraînement, avant d'utiliser le *Trainer* pour entraîner et évaluer notre modèle. Nous avons terminé en téléchargeant le modèle *finetuné* sur le *Hub*, et nous avons montré comment le partager et l'utiliser avec la classe `pipeline()`.
Si vous avez suivi jusqu'à ce point, vous devriez maintenant avoir un *checkpoint* *finetuné* pour la reconnaissance automatique de la parole, bien joué ! 🥳
Plus important encore, vous êtes équipé de tous les outils nécessaires pour *finetuner* le modèle Whisper sur n'importe quel jeu de données ou domaine de reconnaissance vocale. Alors, qu'attendez-vous ? Choisissez l'un des jeux de données couverts dans la section [Choisir un jeu de données](choosing_dataset) ou sélectionnez un jeu de données de votre choix, et voyez si vous pouvez obtenir des performances de pointe ! Le classement vous attend...
| 8 |
0 | hf_public_repos/audio-transformers-course/chapters/fr | hf_public_repos/audio-transformers-course/chapters/fr/chapter5/hands_on.mdx | # Exercice pratique
Dans cette unité, nous avons exploré les défis du *finetuning* des modèles d'ASR, en mettant en avant le temps et les ressources nécessaires pour *finetuner* un modèle comme Whisper (même un petit *checkpoint*) sur une nouvelle langue.
Afin de fournir une expérience pratique, nous avons conçu un exercice qui vous permet de naviguer dans le processus de *finetuning* d'un modèle d'ASR tout en utilisant un jeu de données plus petit.
L'objectif principal de cet exercice est de vous familiariser avec le processus plutôt que de vous attendre à des résultats de niveau production.
Nous avons délibérément fixé une métrique basse pour que vous puissiez l'atteindre, même avec des ressources limitées.
Voici les instructions :
* *Finetuner* le modèle `"openai/whisper-tiny"` en utilisant le sous-échantillon anglais américain ("en-US") du jeu de données `"PolyAI/minds14"`.
* Utilisez les premiers **450 exemples pour l'entraînement**, et le reste pour l'évaluation. Assurez-vous de mettre `num_proc=1` lors du pré-traitement du jeu de données en utilisant la méthode `.map` (ceci assurera que votre modèle est soumis correctement lors de l'évaluation).
* Pour évaluer le modèle, utilisez les métriques `wer` et `wer_ortho` comme décrit dans cette unité. Cependant, *ne convertissez pas* la métrique en pourcentages en la multipliant par 100 (par exemple, si WER est de 42%, nous nous attendons à voir la valeur de 0,42 dans cet exercice).
Une fois que vous avez *finetuné* un modèle, assurez-vous de le télécharger sur le 🤗 *Hub* avec les `kwargs` suivants :
```
kwargs = {
"dataset_tags" : "PolyAI/minds14",
"finetuned_from" : "openai/whisper-tiny",
"tasks" : "automatic-speech-recognition",
}
```
Nous considérons cet exercice réussi si le WER normalisé (`wer`) de votre modèle est inférieur à **0.37**.
N'hésitez pas à construire une démo de votre modèle obtenu et à la partager sur Discord ! Si vous avez des questions, posez-les dans le canal ``#audio-study-group`.
| 9 |
0 | hf_public_repos/autotrain-advanced/docs/source | hf_public_repos/autotrain-advanced/docs/source/tasks/llm_finetuning.mdx | # LLM Finetuning
With AutoTrain, you can easily finetune large language models (LLMs) on your own data.
You can use AutoTrain to finetune LLMs for a variety of tasks, such as text generation, text classification,
and text summarization. You can also use AutoTrain to finetune LLMs for specific use cases, such as chatbots,
question-answering systems, and code generation and even basic fine-tuning tasks like classic text generation.
Config file task names:
- `llm`: generic trainer
- `llm-sft`: SFT trainer
- `llm-reward`: Reward trainer
- `llm-dpo`: DPO trainer
- `llm-orpo`: ORPO trainer
## Data Preparation
LLM finetuning accepts data in CSV and JSONL formats. JSONL is the preferred format.
How data is formatted depends on the task you are training the LLM for.
### Classic Text Generation
For text generation, the data should be in the following format:
| text |
|---------------------------------------------------------------|
| wikipedia is a free online encyclopedia |
| it is a collaborative project |
| that anyone can edit |
| wikipedia is the largest and most popular general reference work on the internet |
An example dataset for this format can be found here: [stas/openwebtext-10k](https://huggingface.co/datasets/stas/openwebtext-10k)
Example tasks:
- Text generation
- Code completion
Compatible trainers:
- SFT Trainer
- Generic Trainer
### Chatbot / question-answering / code generation / function calling
For this task, you can use CSV or JSONL data. If you are formatting the data yourself (adding start, end tokens, etc.), you can use CSV or JSONL format.
If you do not want to format the data yourself and want `--chat-template` parameter to format the data for you, you must use JSONL format.
In both cases, CSV and JSONL can be used interchangeably but JSONL is the most preferred format.
To train a chatbot, your data will have `content` and `role`. Some models support `system` role as well.
Here is an example of a chatbot dataset (single sample):
```
[{'content': 'Help write a letter of 100 -200 words to my future self for '
'Kyra, reflecting on her goals and aspirations.',
'role': 'user'},
{'content': 'Dear Future Self,\n'
'\n'
"I hope you're happy and proud of what you've achieved. As I "
"write this, I'm excited to think about our goals and how far "
"you've come. One goal was to be a machine learning engineer. I "
"hope you've worked hard and become skilled in this field. Keep "
'learning and innovating. Traveling was important to us. I hope '
"you've seen different places and enjoyed the beauty of our "
'world. Remember the memories and lessons. Starting a family '
'mattered to us. If you have kids, treasure every moment. Be '
'patient, loving, and grateful for your family.\n'
'\n'
'Take care of yourself. Rest, reflect, and cherish the time you '
'spend with loved ones. Remember your dreams and celebrate what '
"you've achieved. Your determination brought you here. I'm "
"excited to see the person you've become, the impact you've made, "
'and the love and joy in your life. Embrace opportunities and '
'keep dreaming big.\n'
'\n'
'With love,\n'
'Kyra',
'role': 'assistant'}]
```
As you can see, the data has `content` and `role` columns. The `role` column can be `user` or `assistant` or `system`.
This data is, however, not formatted for training. You can use the `--chat-template` parameter to format the data during training.
`--chat-template` supports the following kinds of templates:
- `none` (default)
- `zephyr`
- `chatml`
- `tokenizer`: use chat template mentioned in tokenizer config
A multi-line sample is also shown below:
```json
[{"content": "hello", "role": "user"}, {"content": "hi nice to meet you", "role": "assistant"}]
[{"content": "how are you", "role": "user"}, {"content": "I am fine", "role": "assistant"}]
[{"content": "What is your name?", "role": "user"}, {"content": "My name is Mary", "role": "assistant"}]
[{"content": "Which is the best programming language?", "role": "user"}, {"content": "Python", "role": "assistant"}]
.
.
.
```
An example dataset for this format can be found here: [HuggingFaceH4/no_robots](https://huggingface.co/datasets/HuggingFaceH4/no_robots)
If you dont want to format the data using `--chat-template`, you can format the data yourself and use the following format:
```
<|begin_of_text|><|start_header_id|>system<|end_header_id|>\n\nCutting Knowledge Date: December 2023\nToday Date: 03 Oct 2024\n\n<|eot_id|><|start_header_id|>user<|end_header_id|>\n\nHelp write a letter of 100 -200 words to my future self for Kyra, reflecting on her goals and aspirations.<|eot_id|><|start_header_id|>assistant<|end_header_id|>\n\nDear Future Self,\n\nI hope you're happy and proud of what you've achieved. As I write this, I'm excited to think about our goals and how far you've come. One goal was to be a machine learning engineer. I hope you've worked hard and become skilled in this field. Keep learning and innovating. Traveling was important to us. I hope you've seen different places and enjoyed the beauty of our world. Remember the memories and lessons. Starting a family mattered to us. If you have kids, treasure every moment. Be patient, loving, and grateful for your family.\n\nTake care of yourself. Rest, reflect, and cherish the time you spend with loved ones. Remember your dreams and celebrate what you've achieved. Your determination brought you here. I'm excited to see the person you've become, the impact you've made, and the love and joy in your life. Embrace opportunities and keep dreaming big.\n\nWith love,\nKyra<|eot_id|>
```
A sample multi-line dataset is shown below:
```json
[{"text": "<|begin_of_text|><|start_header_id|>system<|end_header_id|>\n\nCutting Knowledge Date: December 2023\nToday Date: 03 Oct 2024\n\n<|eot_id|><|start_header_id|>user<|end_header_id|>\n\nhello<|eot_id|><|start_header_id|>assistant<|end_header_id|>\n\nhi nice to meet you<|eot_id|>"}]
[{"text": "<|begin_of_text|><|start_header_id|>system<|end_header_id|>\n\nCutting Knowledge Date: December 2023\nToday Date: 03 Oct 2024\n\n<|eot_id|><|start_header_id|>user<|end_header_id|>\n\nhow are you<|eot_id|><|start_header_id|>assistant<|end_header_id|>\n\nI am fine<|eot_id|>"}]
[{"text": "<|begin_of_text|><|start_header_id|>system<|end_header_id|>\n\nCutting Knowledge Date: December 2023\nToday Date: 03 Oct 2024\n\n<|eot_id|><|start_header_id|>user<|end_header_id|>\n\nWhat is your name?<|eot_id|><|start_header_id|>assistant<|end_header_id|>\n\nMy name is Mary<|eot_id|>"}]
[{"text": "<|begin_of_text|><|start_header_id|>system<|end_header_id|>\n\nCutting Knowledge Date: December 2023\nToday Date: 03 Oct 2024\n\n<|eot_id|><|start_header_id|>user<|end_header_id|>\n\nWhich is the best programming language?<|eot_id|><|start_header_id|>assistant<|end_header_id|>\n\nPython<|eot_id|>"}]
.
.
.
```
An example dataset for this format can be found here: [timdettmers/openassistant-guanaco](https://huggingface.co/datasets/timdettmers/openassistant-guanaco)
In the examples above, we have seen only two turns: one from the user and one from the assistant. However, you can have multiple turns from the user and assistant in a single sample.
Chat models can be trained using the following trainers:
- SFT Trainer:
- requires only `text` column
- example dataset: [HuggingFaceH4/no_robots](https://huggingface.co/datasets/HuggingFaceH4/no_robots)
- Generic Trainer:
- requires only `text` column
- example dataset: [HuggingFaceH4/no_robots](https://huggingface.co/datasets/HuggingFaceH4/no_robots)
- Reward Trainer:
- requires `text` and `rejected_text` columns
- example dataset: [trl-lib/ultrafeedback_binarized](https://huggingface.co/datasets/trl-lib/ultrafeedback_binarized)
- DPO Trainer:
- requires `prompt`, `text`, and `rejected_text` columns
- example dataset: [trl-lib/ultrafeedback_binarized](https://huggingface.co/datasets/trl-lib/ultrafeedback_binarized)
- ORPO Trainer:
- requires `prompt`, `text`, and `rejected_text` columns
- example dataset: [trl-lib/ultrafeedback_binarized](https://huggingface.co/datasets/trl-lib/ultrafeedback_binarized)
The only difference between the data format for reward trainer and DPO/ORPO trainer is that the reward trainer requires only `text` and `rejected_text` columns, while the DPO/ORPO trainer requires an additional `prompt` column.
## Training
### Local Training
Locally the training can be performed by using `autotrain --config config.yaml` command. The `config.yaml` file should contain the following parameters:
```yaml
task: llm-orpo
base_model: meta-llama/Meta-Llama-3-8B-Instruct
project_name: autotrain-llama3-8b-orpo
log: tensorboard
backend: local
data:
path: argilla/distilabel-capybara-dpo-7k-binarized
train_split: train
valid_split: null
chat_template: chatml
column_mapping:
text_column: chosen
rejected_text_column: rejected
prompt_text_column: prompt
params:
block_size: 1024
model_max_length: 8192
max_prompt_length: 512
epochs: 3
batch_size: 2
lr: 3e-5
peft: true
quantization: int4
target_modules: all-linear
padding: right
optimizer: adamw_torch
scheduler: linear
gradient_accumulation: 4
mixed_precision: fp16
hub:
username: ${HF_USERNAME}
token: ${HF_TOKEN}
push_to_hub: true
```
In the above config file, we are training a model using the ORPO trainer.
The model is trained on the `meta-llama/Meta-Llama-3-8B-Instruct` model.
The data is `argilla/distilabel-capybara-dpo-7k-binarized` dataset. The `chat_template` parameter is set to `chatml`.
The `column_mapping` parameter is used to map the columns in the dataset to the required columns for the ORPO trainer.
The `params` section contains the training parameters such as `block_size`, `model_max_length`, `epochs`, `batch_size`, `lr`, `peft`, `quantization`, `target_modules`, `padding`, `optimizer`, `scheduler`, `gradient_accumulation`, and `mixed_precision`.
The `hub` section contains the username and token for the Hugging Face account and the `push_to_hub` parameter is set to `true` to push the trained model to the Hugging Face Hub.
If you have training file locally, you can change data part to:
```yaml
data:
path: path/to/training/file
train_split: train # name of the training file
valid_split: null
chat_template: chatml
column_mapping:
text_column: chosen
rejected_text_column: rejected
prompt_text_column: prompt
```
The above assumes you have `train.csv` or `train.jsonl` in the `path/to/training/file` directory and you will be applying `chatml` template to the data.
You can run the training using the following command:
```bash
$ autotrain --config config.yaml
```
More example config files for finetuning different types of lllm and different tasks can be found in the [here](https://github.com/huggingface/autotrain-advanced/tree/main/configs/llm_finetuning).
### Training in Hugging Face Spaces
If you are training in Hugging Face Spaces, everything is the same as local training:
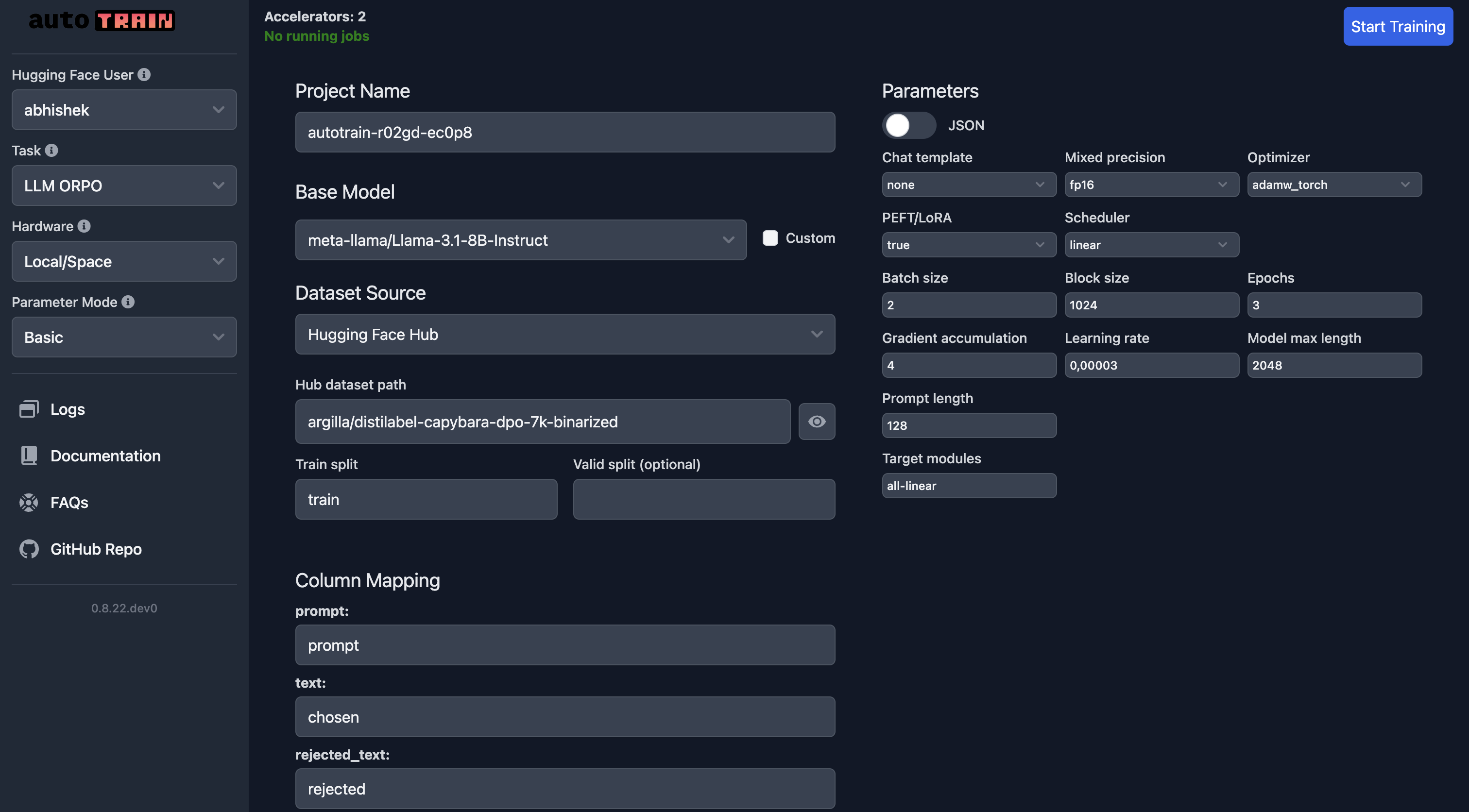
In the UI, you need to make sure you select the right model, the dataset and the splits. Special care should be taken for `column_mapping`.
Once you are happy with the parameters, you can click on the `Start Training` button to start the training process.
## Parameters
### LLM Fine Tuning Parameters
[[autodoc]] trainers.clm.params.LLMTrainingParams
### Task specific parameters
The length parameters used for different trainers can be different. Some require more context than others.
- block_size: This is the maximum sequence length or length of one block of text. Setting to -1 determines block size automatically. Default is -1.
- model_max_length: Set the maximum length for the model to process in a single batch, which can affect both performance and memory usage. Default is 1024
- max_prompt_length: Specify the maximum length for prompts used in training, particularly relevant for tasks requiring initial contextual input. Used only for `orpo` and `dpo` trainer.
- max_completion_length: Completion length to use, for orpo: encoder-decoder models only. For dpo, it is the length of the completion text.
**NOTE**:
- block size cannot be greater than model_max_length!
- max_prompt_length cannot be greater than model_max_length!
- max_prompt_length cannot be greater than block_size!
- max_completion_length cannot be greater than model_max_length!
- max_completion_length cannot be greater than block_size!
**NOTE**: Not following these constraints will result in an error / nan losses.
#### Generic Trainer
```
--add_eos_token, --add-eos-token
Toggle whether to automatically add an End Of Sentence (EOS) token at the end of texts, which can be critical for certain
types of models like language models. Only used for `default` trainer
--block_size BLOCK_SIZE, --block-size BLOCK_SIZE
Specify the block size for processing sequences. This is maximum sequence length or length of one block of text. Setting to
-1 determines block size automatically. Default is -1.
--model_max_length MODEL_MAX_LENGTH, --model-max-length MODEL_MAX_LENGTH
Set the maximum length for the model to process in a single batch, which can affect both performance and memory usage.
Default is 1024
```
#### SFT Trainer
```
--block_size BLOCK_SIZE, --block-size BLOCK_SIZE
Specify the block size for processing sequences. This is maximum sequence length or length of one block of text. Setting to
-1 determines block size automatically. Default is -1.
--model_max_length MODEL_MAX_LENGTH, --model-max-length MODEL_MAX_LENGTH
Set the maximum length for the model to process in a single batch, which can affect both performance and memory usage.
Default is 1024
```
#### Reward Trainer
```
--block_size BLOCK_SIZE, --block-size BLOCK_SIZE
Specify the block size for processing sequences. This is maximum sequence length or length of one block of text. Setting to
-1 determines block size automatically. Default is -1.
--model_max_length MODEL_MAX_LENGTH, --model-max-length MODEL_MAX_LENGTH
Set the maximum length for the model to process in a single batch, which can affect both performance and memory usage.
Default is 1024
```
#### DPO Trainer
```
--dpo-beta DPO_BETA, --dpo-beta DPO_BETA
Beta for DPO trainer
--model-ref MODEL_REF
Reference model to use for DPO when not using PEFT
--block_size BLOCK_SIZE, --block-size BLOCK_SIZE
Specify the block size for processing sequences. This is maximum sequence length or length of one block of text. Setting to
-1 determines block size automatically. Default is -1.
--model_max_length MODEL_MAX_LENGTH, --model-max-length MODEL_MAX_LENGTH
Set the maximum length for the model to process in a single batch, which can affect both performance and memory usage.
Default is 1024
--max_prompt_length MAX_PROMPT_LENGTH, --max-prompt-length MAX_PROMPT_LENGTH
Specify the maximum length for prompts used in training, particularly relevant for tasks requiring initial contextual input.
Used only for `orpo` trainer.
--max_completion_length MAX_COMPLETION_LENGTH, --max-completion-length MAX_COMPLETION_LENGTH
Completion length to use, for orpo: encoder-decoder models only
```
#### ORPO Trainer
```
--block_size BLOCK_SIZE, --block-size BLOCK_SIZE
Specify the block size for processing sequences. This is maximum sequence length or length of one block of text. Setting to
-1 determines block size automatically. Default is -1.
--model_max_length MODEL_MAX_LENGTH, --model-max-length MODEL_MAX_LENGTH
Set the maximum length for the model to process in a single batch, which can affect both performance and memory usage.
Default is 1024
--max_prompt_length MAX_PROMPT_LENGTH, --max-prompt-length MAX_PROMPT_LENGTH
Specify the maximum length for prompts used in training, particularly relevant for tasks requiring initial contextual input.
Used only for `orpo` trainer.
--max_completion_length MAX_COMPLETION_LENGTH, --max-completion-length MAX_COMPLETION_LENGTH
Completion length to use, for orpo: encoder-decoder models only
```
| 0 |
0 | hf_public_repos/autotrain-advanced/docs/source | hf_public_repos/autotrain-advanced/docs/source/tasks/extractive_qa.mdx | # Extractive Question Answering
Extractive Question Answering is a task in which a model is trained to extract the answer to a question from a given context.
The model is trained to predict the start and end positions of the answer span within the context.
This task is commonly used in question-answering systems to extract relevant information from a large corpus of text.
## Preparing your data
To train an Extractive Question Answering model, you need a dataset that contains the following columns:
- `text`: The context or passage from which the answer is to be extracted.
- `question`: The question for which the answer is to be extracted.
- `answer`: The start position of the answer span in the context.
Here is an example of how your dataset should look:
```
{"context":"Architecturally, the school has a Catholic character. Atop the Main Building's gold dome is a golden statue of the Virgin Mary. Immediately in front of the Main Building and facing it, is a copper statue of Christ with arms upraised with the legend \"Venite Ad Me Omnes\". Next to the Main Building is the Basilica of the Sacred Heart. Immediately behind the basilica is the Grotto, a Marian place of prayer and reflection. It is a replica of the grotto at Lourdes, France where the Virgin Mary reputedly appeared to Saint Bernadette Soubirous in 1858. At the end of the main drive (and in a direct line that connects through 3 statues and the Gold Dome), is a simple, modern stone statue of Mary.","question":"To whom did the Virgin Mary allegedly appear in 1858 in Lourdes France?","answers":{"text":["Saint Bernadette Soubirous"],"answer_start":[515]}}
{"context":"Architecturally, the school has a Catholic character. Atop the Main Building's gold dome is a golden statue of the Virgin Mary. Immediately in front of the Main Building and facing it, is a copper statue of Christ with arms upraised with the legend \"Venite Ad Me Omnes\". Next to the Main Building is the Basilica of the Sacred Heart. Immediately behind the basilica is the Grotto, a Marian place of prayer and reflection. It is a replica of the grotto at Lourdes, France where the Virgin Mary reputedly appeared to Saint Bernadette Soubirous in 1858. At the end of the main drive (and in a direct line that connects through 3 statues and the Gold Dome), is a simple, modern stone statue of Mary.","question":"What is in front of the Notre Dame Main Building?","answers":{"text":["a copper statue of Christ"],"answer_start":[188]}}
{"context":"Architecturally, the school has a Catholic character. Atop the Main Building's gold dome is a golden statue of the Virgin Mary. Immediately in front of the Main Building and facing it, is a copper statue of Christ with arms upraised with the legend \"Venite Ad Me Omnes\". Next to the Main Building is the Basilica of the Sacred Heart. Immediately behind the basilica is the Grotto, a Marian place of prayer and reflection. It is a replica of the grotto at Lourdes, France where the Virgin Mary reputedly appeared to Saint Bernadette Soubirous in 1858. At the end of the main drive (and in a direct line that connects through 3 statues and the Gold Dome), is a simple, modern stone statue of Mary.","question":"The Basilica of the Sacred heart at Notre Dame is beside to which structure?","answers":{"text":["the Main Building"],"answer_start":[279]}}
```
Note: the preferred format for question answering is JSONL, if you want to use CSV, the `answer` column should be stringified JSON with the keys `text` and `answer_start`.
Example dataset from Hugging Face Hub: [lhoestq/squad](https://huggingface.co/datasets/lhoestq/squad)
P.S. You can use both squad and squad v2 data format with correct column mappings.
## Training Locally
To train an Extractive QA model locally, you need a config file:
```yaml
task: extractive-qa
base_model: google-bert/bert-base-uncased
project_name: autotrain-bert-ex-qa1
log: tensorboard
backend: local
data:
path: lhoestq/squad
train_split: train
valid_split: validation
column_mapping:
text_column: context
question_column: question
answer_column: answers
params:
max_seq_length: 512
max_doc_stride: 128
epochs: 3
batch_size: 4
lr: 2e-5
optimizer: adamw_torch
scheduler: linear
gradient_accumulation: 1
mixed_precision: fp16
hub:
username: ${HF_USERNAME}
token: ${HF_TOKEN}
push_to_hub: true
```
To train the model, run the following command:
```bash
$ autotrain --config config.yaml
```
Here, we are training a BERT model on the SQuAD dataset using the Extractive QA task. The model is trained for 3 epochs with a batch size of 4 and a learning rate of 2e-5. The training process is logged using TensorBoard. The model is trained locally and pushed to the Hugging Face Hub after training.
## Training on the Hugging Face Spaces
As always, pay special attention to column mapping.
## Parameters
[[autodoc]] trainers.extractive_question_answering.params.ExtractiveQuestionAnsweringParams | 1 |
0 | hf_public_repos/autotrain-advanced/docs/source | hf_public_repos/autotrain-advanced/docs/source/tasks/text_classification_regression.mdx | # Text Classification & Regression
Training a text classification/regression model with AutoTrain is super-easy! Get your data ready in
proper format and then with just a few clicks, your state-of-the-art model will be ready to
be used in production.
Config file task names:
- `text_classification`
- `text-classification`
- `text_regression`
- `text-regression`
## Data Format
Text classification/regression supports datasets in both CSV and JSONL formats.
### CSV Format
Let's train a model for classifying the sentiment of a movie review. The data should be
in the following CSV format:
```csv
text,target
"this movie is great",positive
"this movie is bad",negative
.
.
.
```
As you can see, we have two columns in the CSV file. One column is the text and the other
is the label. The label can be any string. In this example, we have two labels: `positive`
and `negative`. You can have as many labels as you want.
And if you would like to train a model for scoring a movie review on a scale of 1-5. The data can be as follows:
```csv
text,target
"this movie is great",4.9
"this movie is bad",1.5
.
.
.
```
### JSONL Format
Instead of CSV you can also use JSONL format. The JSONL format should be as follows:
```json
{"text": "this movie is great", "target": "positive"}
{"text": "this movie is bad", "target": "negative"}
.
.
.
```
and for regression:
```json
{"text": "this movie is great", "target": 4.9}
{"text": "this movie is bad", "target": 1.5}
.
.
```
### Column Mapping / Names
Your CSV dataset must have two columns: `text` and `target`.
If your column names are different than `text` and `target`, you can map the dataset column to AutoTrain column names.
## Training
### Local Training
To train a text classification/regression model locally, you can use the `autotrain --config config.yaml` command.
Here is an example of a `config.yaml` file for training a text classification model:
```yaml
task: text_classification # or text_regression
base_model: google-bert/bert-base-uncased
project_name: autotrain-bert-imdb-finetuned
log: tensorboard
backend: local
data:
path: stanfordnlp/imdb
train_split: train
valid_split: test
column_mapping:
text_column: text
target_column: label
params:
max_seq_length: 512
epochs: 3
batch_size: 4
lr: 2e-5
optimizer: adamw_torch
scheduler: linear
gradient_accumulation: 1
mixed_precision: fp16
hub:
username: ${HF_USERNAME}
token: ${HF_TOKEN}
push_to_hub: true
```
In this example, we are training a text classification model using the `google-bert/bert-base-uncased` model on the IMDB dataset.
We are using the `stanfordnlp/imdb` dataset, which is already available on Hugging Face Hub.
We are training the model for 3 epochs with a batch size of 4 and a learning rate of `2e-5`.
We are using the `adamw_torch` optimizer and the `linear` scheduler.
We are also using mixed precision training with a gradient accumulation of 1.
If you want to use a local CSV/JSONL dataset, you can change the `data` section to:
```yaml
data:
path: data/ # this must be the path to the directory containing the train and valid files
train_split: train # this must be either train.csv or train.json
valid_split: valid # this must be either valid.csv or valid.json
column_mapping:
text_column: text # this must be the name of the column containing the text
target_column: label # this must be the name of the column containing the target
```
To train the model, run the following command:
```bash
$ autotrain --config config.yaml
```
You can find example config files for text classification and regression in the [here](https://github.com/huggingface/autotrain-advanced/tree/main/configs/text_classification) and [here](https://github.com/huggingface/autotrain-advanced/tree/main/configs/text_regression) respectively.
### Training on Hugging Face Spaces
The parameters for training on Hugging Face Spaces are the same as for local training.
If you are using your own dataset, select "Local" as dataset source and upload your dataset.
In the following screenshot, we are training a text classification model using the `google-bert/bert-base-uncased` model on the IMDB dataset.
For text regression, all you need to do is select "Text Regression" as the task and everything else remains the same (except the data, of course).
## Training Parameters
Training parameters for text classification and regression are the same.
[[autodoc]] trainers.text_classification.params.TextClassificationParams
| 2 |
0 | hf_public_repos/autotrain-advanced/docs/source | hf_public_repos/autotrain-advanced/docs/source/tasks/seq2seq.mdx | # Seq2Seq
Seq2Seq is a task that involves converting a sequence of words into another sequence of words.
It is used in machine translation, text summarization, and question answering.
## Data Format
You can have the dataset as a CSV file:
```csv
text,target
"this movie is great","dieser Film ist großartig"
"this movie is bad","dieser Film ist schlecht"
.
.
.
```
Or as a JSONL file:
```json
{"text": "this movie is great", "target": "dieser Film ist großartig"}
{"text": "this movie is bad", "target": "dieser Film ist schlecht"}
.
.
.
```
## Columns
Your CSV/JSONL dataset must have two columns: `text` and `target`.
## Parameters
[[autodoc]] trainers.seq2seq.params.Seq2SeqParams
| 3 |
0 | hf_public_repos/autotrain-advanced/docs/source | hf_public_repos/autotrain-advanced/docs/source/tasks/sentence_transformer.mdx | # Sentence Transformers
This task lets you easily train or fine-tune a Sentence Transformer model on your own dataset.
AutoTrain supports the following types of sentence transformer finetuning:
- `pair`: dataset with two sentences: anchor and positive
- `pair_class`: dataset with two sentences: premise and hypothesis and a target label
- `pair_score`: dataset with two sentences: sentence1 and sentence2 and a target score
- `triplet`: dataset with three sentences: anchor, positive and negative
- `qa`: dataset with two sentences: query and answer
## Data Format
Sentence Transformers finetuning accepts data in CSV/JSONL format. You can also use a dataset from Hugging Face Hub.
### `pair`
For `pair` training, the data should be in the following format:
| anchor | positive |
|--------|----------|
| hello | hi |
| how are you | I am fine |
| What is your name? | My name is Abhishek |
| Which is the best programming language? | Python |
### `pair_class`
For `pair_class` training, the data should be in the following format:
| premise | hypothesis | label |
|---------|------------|-------|
| hello | hi | 1 |
| how are you | I am fine | 0 |
| What is your name? | My name is Abhishek | 1 |
| Which is the best programming language? | Python | 1 |
### `pair_score`
For `pair_score` training, the data should be in the following format:
| sentence1 | sentence2 | score |
|-----------|-----------|-------|
| hello | hi | 0.8 |
| how are you | I am fine | 0.2 |
| What is your name? | My name is Abhishek | 0.9 |
| Which is the best programming language? | Python | 0.7 |
### `triplet`
For `triplet` training, the data should be in the following format:
| anchor | positive | negative |
|--------|----------|----------|
| hello | hi | bye |
| how are you | I am fine | I am not fine |
| What is your name? | My name is Abhishek | Whats it to you? |
| Which is the best programming language? | Python | Javascript |
### `qa`
For `qa` training, the data should be in the following format:
| query | answer |
|-------|--------|
| hello | hi |
| how are you | I am fine |
| What is your name? | My name is Abhishek |
| Which is the best programming language? | Python |
## Parameters
[[autodoc]] trainers.sent_transformers.params.SentenceTransformersParams
| 4 |
0 | hf_public_repos/autotrain-advanced/docs/source | hf_public_repos/autotrain-advanced/docs/source/tasks/tabular.mdx | # Tabular Classification / Regression
Using AutoTrain, you can train a model to classify or regress tabular data easily.
All you need to do is select from a list of models and upload your dataset.
Parameter tuning is done automatically.
## Models
The following models are available for tabular classification / regression.
- xgboost
- random_forest
- ridge
- logistic_regression
- svm
- extra_trees
- gradient_boosting
- adaboost
- decision_tree
- knn
## Data Format
```csv
id,category1,category2,feature1,target
1,A,X,0.3373961604172684,1
2,B,Z,0.6481718720511972,0
3,A,Y,0.36824153984054797,1
4,B,Z,0.9571551589530464,1
5,B,Z,0.14035078041264515,1
6,C,X,0.8700872583584364,1
7,A,Y,0.4736080452737105,0
8,C,Y,0.8009107519796442,1
9,A,Y,0.5204774795512048,0
10,A,Y,0.6788795301189603,0
.
.
.
```
## Columns
Your CSV dataset must have two columns: `id` and `target`.
## Parameters
[[autodoc]] trainers.tabular.params.TabularParams
| 5 |
0 | hf_public_repos/autotrain-advanced/docs/source | hf_public_repos/autotrain-advanced/docs/source/tasks/token_classification.mdx | # Token Classification
Token classification is the task of classifying each token in a sequence. This can be used
for Named Entity Recognition (NER), Part-of-Speech (POS) tagging, and more. Get your data ready in
proper format and then with just a few clicks, your state-of-the-art model will be ready to
be used in production.
## Data Format
The data should be in the following CSV format:
```csv
tokens,tags
"['I', 'love', 'Paris']","['O', 'O', 'B-LOC']"
"['I', 'live', 'in', 'New', 'York']","['O', 'O', 'O', 'B-LOC', 'I-LOC']"
.
.
.
```
or you can also use JSONL format:
```json
{"tokens": ["I", "love", "Paris"],"tags": ["O", "O", "B-LOC"]}
{"tokens": ["I", "live", "in", "New", "York"],"tags": ["O", "O", "O", "B-LOC", "I-LOC"]}
.
.
.
```
As you can see, we have two columns in the CSV file. One column is the tokens and the other
is the tags. Both the columns are stringified lists! The tokens column contains the tokens
of the sentence and the tags column contains the tags for each token.
If your CSV is huge, you can divide it into multiple CSV files and upload them separately.
Please make sure that the column names are the same in all CSV files.
One way to divide the CSV file using pandas is as follows:
```python
import pandas as pd
# Set the chunk size
chunk_size = 1000
i = 1
# Open the CSV file and read it in chunks
for chunk in pd.read_csv('example.csv', chunksize=chunk_size):
# Save each chunk to a new file
chunk.to_csv(f'chunk_{i}.csv', index=False)
i += 1
```
Sample dataset from HuggingFace Hub: [conll2003](https://huggingface.co/datasets/eriktks/conll2003)
## Columns
Your CSV/JSONL dataset must have two columns: `tokens` and `tags`.
## Parameters
[[autodoc]] trainers.token_classification.params.TokenClassificationParams
| 6 |
0 | hf_public_repos | hf_public_repos/autotrain-example-datasets/alpaca1k.csv | text
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Give three tips for staying healthy.
### Response:
1.Eat a balanced diet and make sure to include plenty of fruits and vegetables.
2. Exercise regularly to keep your body active and strong.
3. Get enough sleep and maintain a consistent sleep schedule."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
What are the three primary colors?
### Response:
The three primary colors are red, blue, and yellow."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Describe the structure of an atom.
### Response:
An atom is made up of a nucleus, which contains protons and neutrons, surrounded by electrons that travel in orbits around the nucleus. The protons and neutrons have a positive charge, while the electrons have a negative charge, resulting in an overall neutral atom. The number of each particle determines the atomic number and the type of atom."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
How can we reduce air pollution?
### Response:
There are a number of ways to reduce air pollution, such as shifting to renewable energy sources, encouraging the use of public transportation, prohibiting the burning of fossil fuels, implementing policies to reduce emissions from industrial sources, and implementing vehicle emissions standards. Additionally, individuals can do their part to reduce air pollution by reducing car use, avoiding burning materials such as wood, and changing to energy efficient appliances."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Describe a time when you had to make a difficult decision.
### Response:
I had to make a difficult decision when I was working as a project manager at a construction company. I was in charge of a project that needed to be completed by a certain date in order to meet the client’s expectations. However, due to unexpected delays, we were not able to meet the deadline and so I had to make a difficult decision. I decided to extend the deadline, but I had to stretch the team’s resources even further and increase the budget. Although it was a risky decision, I ultimately decided to go ahead with it to ensure that the project was completed on time and that the client’s expectations were met. The project was eventually successfully completed and this was seen as a testament to my leadership and decision-making abilities."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Identify the odd one out.
### Input:
Twitter, Instagram, Telegram
### Response:
Telegram"
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Explain why the following fraction is equivalent to 1/4
### Input:
4/16
### Response:
The fraction 4/16 is equivalent to 1/4 because both numerators and denominators are divisible by 4. Dividing both the top and bottom numbers by 4 yields the fraction 1/4."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Write a short story in third person narration about a protagonist who has to make an important career decision.
### Response:
John was at a crossroads in his life. He had just graduated college and was now facing the big decision of what career to pursue. After much deliberation, he decided that he wanted to be an accountant and help the financially disadvantaged. He had always been good with numbers and enjoyed seeing the tangible results of his work.
John enrolled in accounting courses and initially found it quite challenging. He had to learn multiple systems and regulations quickly, but he worked hard and eventually excelled in his studies. After a few years, John started working at an accounting firm in his city. He was eager to put his knowledge of taxes and accounting to use in a real-world setting.
John loved his job, as it let him express his creativity in finding strategies to save his clients money. After a few years at the firm, he became a senior accountant and was asked to manage bigger and more challenging cases. He was now a respected figure in the financial industry, but he still remembers when he was just a recent college graduate, unsure of the direction in which his life would take him."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Render a 3D model of a house
### Response:
<nooutput> This type of instruction cannot be fulfilled by a GPT model."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Evaluate this sentence for spelling and grammar mistakes
### Input:
He finnished his meal and left the resturant
### Response:
He finished his meal and left the restaurant."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
How did Julius Caesar die?
### Response:
Julius Caesar was assassinated by a group of up to 60 conspirators, led by Gaius Cassius Longinus and Marcus Junius Brutus, in the Senate House on the Ides of March (15 March) of 44 BC."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
What is the capital of France?
### Response:
The capital of France is Paris."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Generate a list of ten items a person might need for a camping trip
### Response:
1. Tent
2. Sleeping bags
3. Flashlight
4. Matches/lighter
5. Insect repellent
6. Extra clothes
7. First aid kit
8. Camp stove
9. Cooking utensils
10. Biodegradable soaps/shampoos"
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Discuss the causes of the Great Depression
### Response:
The Great Depression was a severe global economic downturn that lasted from 1929 to 1939. It was caused by several factors, including the stock market crash of 1929, structural weaknesses in the economy, low consumer spending, high unemployment, and a lack of confidence in the banking system. Other contributing factors included overproduction of commodities, reliance on borrowing to finance investments, agricultural overproduction, and a decrease in international trade."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Classify the following into animals, plants, and minerals
### Input:
Oak tree, copper ore, elephant
### Response:
Oak tree: Plant
Copper ore: Mineral
Elephant: Animal"
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Explain the use of word embeddings in Natural Language Processing
### Response:
Word embeddings are one of the most powerful tools available for Natural Language Processing (NLP). They are mathematical representations of words or phrases in a vector space, allowing similarities between words and the context in which they are used to be measured. Word embeddings are useful for tasks such as sentiment analysis, text classification, predicting the next word in a sequence, and understanding synonyms and analogies. They allow for words to be processed as numerical values, giving machines an easier way to perform NLP tasks."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Describe the function of a computer motherboard
### Response:
A computer motherboard is the main circuit board in a computer. It is the backbone of the system, connecting all other components such as the processor, RAM, storage, graphics card and peripheral ports. It provides communication pathways between all of these components, allowing them to interact and work together. The motherboard is responsible for regulating power, and also houses slots for expansion cards, as well as ports for USB, audio, Ethernet, and other connection types."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Reverse engineer this code to create a new version
### Input:
def factorialize(num):
factorial = 1
for i in range(1, num):
factorial *= i
return factorial
### Response:
def factorialize(num):
factorial = 1
for i in range(num, 0, -1):
factorial *= i
return factorial"
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Propose an ethical solution to the problem of data privacy
### Response:
One ethical solution to the problem of data privacy is to implement an opt-in data collection policy. This means that companies cannot collect and use personal data without the explicit permission of the data owners. This approach gives users the power to determine which data companies can use and for what purpose. Companies should also be transparent about how they use the collected data, so that users can make informed decisions and have control over their own data."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Generate three verbs that mean the same as ""to apologize""
### Response:
Acknowledge, express regret, make amends."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
What does DNA stand for?
### Response:
DNA stands for deoxyribonucleic acid."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Compare and contrast the Cuban Missile Crisis and the Vietnam War.
### Response:
The Cuban Missile Crisis and the Vietnam War were two of the largest and deadliest conflicts of the 20th century. The Cuban Missile Crisis involved a standoff between the United States and the Soviet Union over Soviet nuclear missile bases in Cuba, while the Vietnam War was a prolonged military conflict in Indochina between the North, which was backed by the Soviet Union and the South, which was backed by the United States. The Cuban Missile Crisis unfolded over a period of 13 days in October 1962, with the resolution coming in the form of a diplomatic agreement. The Vietnam War lasted for 19 years, beginning in 1954 and ending in 1973, with the signing of the Paris Peace Accords. While both of these conflicts were Cold War related, they were also very different in terms of causes, objectives, strategic objectives and outcomes. The Cuban Missile Crisis did not result in any direct military conflict and was resolved primarily through diplomacy and the decision to withdraw nuclear weapons from Cuba. On the other hand, the Vietnam War was a prolonged series of battles resulting in significant losses for both sides. The Vietnam War also had a significant impact on the United States, as it highlighted the realities of a prolonged conflict and the limits of U.S. military intervention. Additionally, the Vietnam War also drastically changed the way public opinion viewed the military and the use of force."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Generate a list of random words.
### Response:
sneeze, conflict, ancestor, thunder, companion, amulet, forge, serpent, magnify, jester, cascade, universe, surge, nausea, oasis, anomaly, pursue, rapture, pagoda, mosaic."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Transcribe the recording into text.
### Input:
Recording about the history of Waterloo
### Response:
The Battle of Waterloo, fought on June 18, 1815, was the last major battle of the Napoleonic Wars. It marked the end of Napoleon Bonaparte's rule. The battle was fought between Napoleon Bonaparte's French forces and an allied force of British, Dutch, Belgian and Prussian troops, led by the Duke of Wellington. It was fought near the town of Waterloo in the former Austrian Netherlands, now present-day Belgium. The battle was a defeat for Napoleon's forces and ended Napoleon's rule over France. Napoleon himself was exiled to St. Helena, where he would die in 1821. The battle marked the end of French domination of Europe and the beginning of a period of peace in the region. It was also the last major battle of the Napoleonic Wars and is remembered as one of the most important battles in history. The victory of the allied forces at Waterloo helped to bring an end to French imperial ambitions in Europe. It also established the British as one of the most powerful nations in Europe. The battle was fought with a combination of infantry, cavalry, and artillery tactics, and showed the beginning of the changing nature of warfare. Although the French forces greatly outnumbered the allies, their strategic and tactical mistake led to the loss of the battle. This defeat signaled the end of French imperial power in Europe. The legacy of Waterloo still stands today, and it cemented the British Empire's position for the next one hundred years."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Who is the world's most famous painter?
### Response:
The world's most famous painter is generally considered to be the Italian renaissance artist Leonardo da Vinci. His work includes the Mona Lisa and The Last Supper, both of which are considered masterpieces. Da Vinci was also a master of science, inventing the helicopter and the tank, among other inventions. He was also a prolific musician, sculptor, and architect. His work has inspired generations of artists and continues to be revered today."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Explain the concept of cogging torque.
### Response:
Cogging torque is the torque that is applied to a rotating device when the device experiences resistance from the teeth of the gears that are connected to the device. Cogging torque occurs due to the reaction force generated when the teeth of the gear drive mesh. This force pushes against each other, resulting in a drag force that is transmitted from the gears to the shaft. The magnitude of the cogging torque can vary depending on the size and number of teeth, as well as the gear's material and design. Cogging torque is undesirable in most motorized applications, as it can lead to loss of efficiency. To reduce cogging torque, gear designs are often symmetrical or have certain tooth profiles which reduce the force of contact between the teeth when they come into contact with each other."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Look up the boiling point of water.
### Response:
The boiling point of water is 100°C (212°F), at standard atmospheric pressure. When heated at higher pressures, water's boiling point increases. For example, water will boil at a temperature of 115°C (239°F) at an atmospheric pressure of 1 bar. At higher pressures, such as those experienced at the bottom of the ocean, the boiling point of water can be as high as 374°C (705°F)."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Describe the life and reign of King Charles II.
### Response:
King Charles II ascended to the throne of England following the English Civil War and the death of his father, Charles I. He was crowned in 1661 and his reign lasted until his death in 1685. Charles II was also a patron of the arts, working with some of the greatest painters and sculptors of his day. He also encouraged theater and sports and had an interest in sciences such as astronomy and natural history. Charles II was a moderate ruler who respected the civil and religious liberties of his citizens. He was tolerant of other religions and gave Jews and Catholics more rights in the kingdom. Charles II was also a strong supporter of the Royal Navy, which saw England increase its power in the world. He also promoted the development of industry and commerce, which helped to modernize the country. Charles II's reign was an important step in restoring the monarchy of England after the turmoil of the English Civil War."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Find the area of a circle given its radius.
### Input:
Radius = 4
### Response:
The area of a circle with a radius of 4 is equal to 12.5664 square units. This is calculated by using the formula A = πr2, where A is the area, π is roughly equal to 3.1416 and r is the radius of the circle."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Identify the lines of longitude that divides North and South America.
### Response:
The lines of longitude that divides North and South America is the line of the Panama Canal. This line of longitude cuts through the Isthmus of Panama and separates South America from Central America. It is approximately 800 km (500 mi) in total length and was completed in 1914. The Panama Canal is an important shipping route and serves as an international waterway connecting the Caribbean Sea with the Pacific Ocean."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Explain the process of cellular respiration in plants.
### Response:
Cellular respiration in plants is a complex process in which the plant converts glucose into usable energy. The process begins when the plant takes in carbon dioxide from the environment and combines it with water to form glucose molecules using the energy from sunlight. This glucose is then broken down into simpler molecules of carbon dioxide and water. During this process, the energy released is used to produce adenosine triphosphate (ATP) molecules. ATP is used by the plant to power other processes, such as growth and reproduction. Additionally, the ATP can also be broken down further to produce heat energy, which helps to sustain the plant's temperature. The carbon dioxide and water molecules produced in the process are then released back into the environment to complete the cycle."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Rewrite the following sentence using active voice.
### Input:
The news report was read by the captain.
### Response:
The captain read the news report."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Generate a list of adjectives that describe a person as brave.
### Response:
Courageous, heroic, audacious, vigorous, valorous, resolute, intrepid, bold, brave, daring, tenacious, plucky, stout-hearted, doughty, gallant, fearless, undaunted, spirited, daredevil."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Outline the consequences of deforestation.
### Response:
Deforestation is the process of clearing and removing forests. The consequences of deforestation can include soil erosion, reduced water quality, decreased biodiversity, increased carbon dioxide in the atmosphere and loss of habitat for wildlife. Soil erosion occurs when the trees that help retain water and soil are removed, leading to soil particles being washed away. This can cause siltation in rivers and streams, affecting water quality and leading to flooding. Additionally, when trees are removed, wildlife lose their habitat. This can cause species to become endangered, leading to further loss of biodiversity. Deforestation can also lead to increased carbon dioxide in the atmosphere as there are fewer trees to take up the gas during photosynthesis, which can contribute to climate change."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Develop a plan to reduce electricity usage in a home.
### Response:
A plan to reduce electricity usage in a home can include a number of different strategies. These include replacing inefficient lightbulbs with energy-efficient LEDs, unplugging appliances and electronics when not in use, using natural light instead of electric lights where possible, using a touch-free faucet to reduce water heater use, using a smart thermostat to monitor and adjust temperatures automatically, installing a solar hot water heater, and turning off electronics when not in use. Additionally, making sure to install and seal windows and doors correctly to reduce air leakage can also help reduce electricity usage."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Arrange the words in the given sentence to form a grammatically correct sentence.
### Input:
quickly the brown fox jumped
### Response:
The quick brown fox jumped quickly."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Analyze the given text for its tone.
### Input:
The world has been greatly impacted by the COVID-19 pandemic and it has drastically changed our lives.
### Response:
The tone of the text is one of concern and recognition of the dramatic effects of the COVID-19 pandemic on the world. It is an acknowledgement of the upheaval that the virus has caused and that our lives have been drastically changed."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Use the given data to calculate the median.
### Input:
[2, 3, 7, 8, 10]
### Response:
The median of the given data is 7."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Rewrite the given paragraph in a shorter, easier to understand form.
### Input:
Although it is generally accepted that the internet has allowed us to connect with people all over the world, there are still those people who are not familiar with its basic functions, who don’t understand why it has become so commonplace, or what its true capabilities are.
### Response:
The internet has allowed us to connect globally, even though some people are unfamiliar with its functions, don't comprehend its widespread use, and don't know its full potential."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Design a logo for a website about recycling.
### Response:
The logo should feature a green motif that is recognizable and memorable, such as a recycle symbol or a stylized representation of a recycling bin. The logo should also include text that communicates the website's purpose, such as ""Recycling"" or ""Go Green""."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Generate a poem that expresses joy.
### Response:
Joy flows through me like a river clear,
Bringing laughter and bliss to my soul to hear.
The world is bright and wonderful, I can see,
Making every moment something happy and free.
My heart feels light, my cares have flown,
As I discover what happiness gives me alone.
I open my arms and accept the joy,
Bringing life to my song, so sweet like a toy.
Every moment is a precious gift,
That I savor and never let drift."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Convert the given equation into an algebraic expression.
### Input:
3x+5y=9
### Response:
3x + 5y - 9 = 0"
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Brainstorm possible solutions to reduce water pollution.
### Response:
- Implement stricter regulations on industrial waste disposal
- Increase the use of green technology in wastewater treatment
- Provide incentives to businesses that reduce their water consumption and waste generation
- Educate citizens about water conservation and pollution prevention
- Offer recycling programs to reduce plastic waste
- Replace disposable plastics with biodegradable alternatives
- Improve sewer systems
- Re-introduce native plant species
- Foster artificial wetlands and green infrastructure
- Provide filtration systems at water treatment plants
- Implement best practices for agricultural runoff
- Increase research and monitoring of water quality
- Establish buffer zones between aquatic environments and land-based activities."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Explain why the given definition is wrong.
### Input:
A mole is an animal that lives underground.
### Response:
The definition is wrong because a mole is actually a small mammal that lives above ground and feeds on insects. It is most distinguishable by its long snout and wide, paddle-like feet. It does, however, often dig burrows in which it lives and shelters."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Variable x is defined as “4x + 2y = 10”. Find the value of x.
### Response:
The value of x is 2. To find the value, simplify the equation by subtracting 2y from both sides, giving 4x = 10; dividing both sides by 4, giving x = 2/4, which is equal to 2."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Write a short paragraph about the given topic.
### Input:
The importance of using renewable energy
### Response:
The use of renewable energy is growing rapidly in relevance and importance as the world looks towards solutions to combat climate change. Renewable energy sources, such as solar, wind, and hydropower, are sustainable and have a much lower environmental impact than traditional energy sources like coal and oil. Switching to renewable energy can reduce carbon emissions, improve air quality, lessen the dependence on non-renewable resources, and provide a stable and secure energy future. Renewable energy is essential for achieving a sustainable future and should be an important part of any country’s energy portfolio."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Explain the concept of artificial intelligence in simple terms.
### Response:
Artificial Intelligence (AI) is the ability of machines and computers to make decisions and complete tasks similar to what humans can do. AI can learn from data, recognize patterns, and make predictions. AI technology can automate tedious and complex processes, helping to reduce human effort and errors, and enable more accurate and efficient decisions. AI can be used in a wide range of applications, from robotics and autonomous vehicles to healthcare and finance. It is increasingly becoming an integral part of everyday life."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Design an app for a delivery company.
### Response:
The app should allow customers to order items from local businesses and nearby store, place delivery requests with detailed delivery requirements, and track their orders. It should also allow customers to easily find and pay for services. The app should allow businesses to manage orders, track deliveries and drivers, set delivery boundaries, and set prices. It should also have features to help businesses promote their products and services, as well as options to provide customer feedback and support."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Summarize the given passage.
### Input:
A recent study showed that global climate change is one of the most important challenges facing the world today. The consequences of global warming include rising sea levels, extreme weather events and biodiversity loss. Climate change is caused by human activities such as burning fossil fuels, and if unchecked will have long-term and devastating impacts on the planet.
### Response:
A recent study revealed that global climate change is one of the world’s most pressing issues. In addition to rising sea levels, extreme weather events and biodiversity loss, it is caused largely by human activities like burning fossil fuels. If left unchecked, climate change will have far-reaching and devastating consequences."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Extract the facts from the paragraph.
### Input:
Online education continues to become more popular for schools and students alike. Its advantages are generally lower costs, less commitment and the ability to study at a time, place and pace that suits the student.
### Response:
- Online education is becoming increasingly popular.
- It has several advantages such as lower costs, less commitment and the ability to study at one’s own time and pace."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Edit the following sentence to make it more concise.
### Input:
He ran to the bus stop in order to catch the bus that was due to arrive in five minutes.
### Response:
He ran to the bus stop, due to arrive in five minutes."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Generate a poem with 10 lines.
### Response:
The evening light shimmers on the shore
Softly the waves echoes around and more
As I bask in the sun, my worries are all gone
The sound of seagulls I now foolishly ignore
Glistening sand, beckons me with a silent plea
Glistening seawater, cool to the touch and refreshingly free
The evening brings peace, yet I can't find any
But maybe in the morning there'll be time for me
My bottled peacefulness, I uncork and pour
The sound of the ocean, lulls me even more
And for just a moment I close my eyes and behold
The vastness of the ocean, to my soul I now unfold."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Convert from celsius to fahrenheit.
### Input:
Temperature in Celsius: 15
### Response:
Temperature in Fahrenheit: 59"
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Arrange the given numbers in ascending order.
### Input:
2, 4, 0, 8, 3
### Response:
0, 2, 3, 4, 8"
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Calculate the total surface area of a cube with a side length of 5 cm.
### Response:
Total surface area of the cube: 150 cm^2"
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
What is the force on a 1 kg mass due to the gravitational force?
### Response:
The force on a 1 kg mass due to the gravitational force is 9.8 N."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Provide one example for a cultural practice.
### Response:
An example of a cultural practice is the Japanese tea ceremony."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Given a set of numbers, find the maximum value.
### Input:
Set: {10, 3, 25, 6, 16}
### Response:
The maximum value is 25."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Give two examples of a liquid.
### Response:
Two examples of liquids are water and oil."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
What is the product of 6 and 2?
### Response:
The product of 6 and 2 is 12."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
What type of plant is a skunk cabbage?
### Response:
Skunk cabbage is a type of perennial flowering plant."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Convert the given binary number to its decimal equivalent.
### Input:
101101
### Response:
The decimal equivalent of 101101 is 45."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Name two types of desert biomes.
### Response:
Two types of desert biomes are xeric and subpolar deserts."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Given a sentence, convert it into passive voice.
### Input:
The dog barked at the alley cat.
### Response:
The alley cat was barked at by the dog."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Transform the following sentence into the passive voice
### Input:
I bought a book
### Response:
A book was bought by me."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Create a dialog between two people who are discussing a scientific phenomenon
### Input:
Hydropower
### Response:
Person 1: Did you know that hydropower is now being used to generate electricity?
Person 2: Really? That’s incredible! How does it work?
Person: 1: Well, hydropower utilizes the energy of moving water to generate electricity. By capturing and harnessing the energy of falling or flowing water, hydropower can be used for efficient electricity generation."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Identify the most suitable adverb for the following sentence
### Input:
She works
### Response:
She works diligently."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Find the main idea of the following passage
### Input:
Climate change is an increasingly contentious global issue. It is already having a drastic effect on the environment and human lives. We are already seeing an increase in extreme weather events and rising sea levels, both of which have a major impact on the planet.
### Response:
The main idea of the passage is that climate change is a global issue that is having a detrimental effect on the environment and has caused an increase in extreme weather events and rising sea levels."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Analyze the tone of the following sentences
### Input:
I am so upset with you right now
### Response:
The tone of the sentences is angry and accusatory."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Construct an argument to defend the following statement
### Input:
Alternative energy sources are critical to solving the climate crisis
### Response:
Alternative energy sources are absolutely vital in order to mitigate the most detrimental impacts of climate change. As the world transitions away from fossil fuels and towards more sustainable sources of energy, such as wind, solar, and hydropower, we can reduce the number of greenhouse gases in the atmosphere and prevent further warming of our planet. Additionally, using renewable and alternative energies sources will create thousands of jobs and can help to create a healthy, stable economy. Investing in alternative energy sources is a sound decision and a necessary step if we want to effectively address the climate crisis."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Convert the following sentence into the present continuous tense
### Input:
He reads books
### Response:
He is reading books."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Give an example of a metaphor that uses the following object
### Input:
Stars
### Response:
The stars were twinkling diamonds in the night sky."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Describe the following person
### Input:
John
### Response:
John is a tall, dark-haired man with a kind smile and a twinkle in his eyes. He has a gentle, caring nature, and he always strives to understand others. He has a passion for learning and exploring new places, experiences and cultures."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Construct a mathematical problem with the following numbers
### Input:
21, 4
### Response:
If 21 pieces of candy are divided among 4 people, how many pieces of candy does each person get?"
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Aim to reduce the following sentence without changing its meaning
### Input:
When he came in, he woke everyone up
### Response:
He woke everyone on entering."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Identify the conjunctions in the following sentence
### Input:
She wrote a letter and sealed it
### Response:
The conjunctions in the sentence are ""and""."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Rewrite the following sentence in the third person
### Input:
I am anxious
### Response:
She is anxious."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Generate a list of business ideas for a food delivery service.
### Response:
- Offer discounts and loyalty programs for frequent customers.
- Partner with local restaurants and promote their food.
- Train delivery personnel to handle orders and provide good customer service.
- Use mobile apps and websites for ordering.
- Offer diverse payment options for customers.
- Allow customers to customize their orders.
- Pack food in recyclable and compostable packaging.
- Launch a subscription model for regular customers.
- Offer special services like food suggestions based on customers' preferences.
- Provide contactless delivery and curbside pickup.
- Provide catering services for large orders and special events.
- Use online marketing and social media platforms to reach more customers.
- Create incentives to encourage customers to try new dishes.
- Create meal kits with all the necessary ingredients and a recipe.
- Make use of food delivery robots and drones.
- Offer a loyalty points system for customers.
- Collaborate with local farmers to source produce and ingredients.
- Offer vegetarian, vegan, and gluten-free options.
- Allow customers to select the delivery time.
- Implement AI-powered recommendations for customers."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Edit the following sentence to improve clarity and flow.
### Input:
The restaurant has great food though the prices are a bit hefty
### Response:
The restaurant offers great food but at a slightly higher price."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Imagine you are speaking with a customer who is unsatisfied with the product they bought from you. Construct a response that diffuses the situation.
### Response:
I'm sorry that you're not happy with your purchase. We want all of our customers to be satisfied, so I'd like to offer you a full refund, as well as a 15% discount for your next purchase. Is there anything else I can do to make this right for you?"
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Explain the concept of a bubble sort algorithm to a non-technical audience.
### Response:
A bubble sort algorithm is a type of sorting algorithm that is used to sort elements in an array. It works by looking at each element of the array and comparing it to the next element. If the first element is bigger than the second element, they are swapped. This process is repeated until the whole array is sorted. This type of sorting is one of the simplest sorting algorithms, but it can be slow if the array has many elements."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Classify the following incident as a breach of protocol. Output 1 for breach, and 0 for no breach.
### Input:
Using a school laptop for personal use
### Response:
1"
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Given the following input, construct a creative story.
### Input:
A magic bow and arrow
### Response:
Once upon a time, there lived a young girl named Alexa who was gifted with an incredible magical bow and arrow. Whenever she pulled back her bow and let an arrow fly, wherever it landed, something extraordinary happened. Flowers bloomed, oceans calmed, and the sun shone brighter. Alexa's bow and arrow were so powerful, that it could make even the most impossible things possible. One day, during a great storm, Alexa used her magical bow and arrow to bring calm and harmony to her hometown. She was praised and celebrated by the whole town, and she soon became a symbol of hope and peace."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Generate a list of methods to reduce food waste.
### Response:
- Shop smarter and only buy what you need.
- Save leftovers for later and freeze them if necessary.
- Monitor expiration dates and consume items before they go bad.
- Participate in community or public food sharing initiatives.
- Compost leftover food scraps.
- Reuse containers, jars, and bags.
- Make use of restaurant discounts to reduce over-ordering.
- Donate foods that have short expiration dates to local food banks.
- Buy more produce that is close to the expiration date and prepare it soon.
- Order small portions while dining out.
- Educate yourself and others about food waste.
- Plan meals in advance and base your grocery list on the meals.
- Store food correctly to reduce spoilage.
- Make sure your fridge is at the right temperature.
- Have a system to track leftovers in the fridge.
- Eat all edible parts of food, including stems and skins.
- Use creative recipes to use the entire food item.
- Use food that would otherwise be thrown away for animal feed.
- Take part in campaigns to make food sustainability an issue."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Propose an idea for a self-driving car.
### Response:
My idea for a self-driving car is to develop an AI system that uses machine learning to help the car recognize its environment. The AI system will also be able to learn from its mistakes and increase its accuracy. Additionally, the self-driving car will be able to detect potential hazards and warn the driver, or take corrective action if necessary. The car will also be equipped with an emergency button, in case the driver needs to take manual control of the vehicle. Furthermore, the car will be capable of automated parking and will be able to drive itself to a nearby charging station when the battery is low. Finally, the software will be able to connect with smartphones, so the user can access their navigation system and entertainment options even while on the move."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Explain the concept of a linear regression model using simple language.
### Response:
A linear regression model is a type of machine learning model that can be used to predict or estimate the value of a continuous numerical variable from a set of input variables. In this model, a line is fitted to a set of data points such that the sum of the squared distance of the data points from the line is minimized. This line of best fit can then be used to estimate the value of the output variable based on the values of the input variables."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Construct a list of tips to help reduce stress.
### Response:
- Take a time out and acquire some rest when feeling overwhelmed.
- Make time for yourself and learn to relax.
- Exercise regularly and get plenty of sleep.
- Listen to music you like, or take a warm bath.
- Stick to a healthy diet full of essential vitamins and minerals.
- Reach out to friends and family for support.
- Try aromatherapy or yoga.
- Do something creative like drawing, painting, or writing.
- Engage in activities that bring you joy and peace of mind.
- Avoid drugs or excessive amounts of alcohol.
- Practice deep breathing and progressive muscle relaxation.
- Take up a new hobby to stay occupied.
- Break big tasks down into smaller, more manageable tasks.
- Practice positive self-talk to keep your morale high.
- Talk to a therapist or trusted mentor if necessary.
- Make time for fun activities and social events.
- Prioritize tasks and create a weekly schedule.
- Create a plan of action and identify solutions to problems.
- Learn to forgive yourself and others."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Write a review of a recent movie you watched.
### Input:
Parasite (2019)
### Response:
I recently watched the movie Parasite, directed by Bong Joon-Ho, and I was absolutely blown away. This movie is a masterful blend of genres—it's both a black comedy and a commentary on classism, with a twist ending that no one could see coming. The acting is fantastic, particularly Song Kang-ho as the head of the poor household, and the cinematography is stunning. The movie has a perfect balance of humor and thought-provoking drama, and it will leave you talking about the ending for days afterwards. Overall, I highly recommend Parasite; it is an exceptional movie and an experience you won't soon forget."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Create a Twitter post to promote your new product.
### Input:
Alisha's All Natural Jam
### Response:
Introducing Alisha's All Natural Jam, handmade with love using only the finest ingredients! Get ready for a delicious treat that will give your tastebuds a flavor explosion! Try our five amazing flavors: Strawberry, Blueberry, Peach, Raspberry, and Blackberry. Buy now and snack with the world! #snacktime #allnatural #jam #tastebuds #freshfruit #homemade #delicious #salttw"
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Given the following input, classify the verb as transitive or intransitive.
### Input:
improve
### Response:
Transitive."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Generate a list of marketing strategies to promote a new mobile app.
### Response:
- Implement paid campaigns on social media platforms.
- Utilize influencer marketing.
- Reach out to tech bloggers and websites.
- Share the app through word of mouth among friends.
- Create demo videos and tutorials to explain the app's features.
- Offer discounts and special incentives to early adopters.
- Build a basic website to explain the app's purpose and features.
- Take advantage of app store optimization techniques.
- Send out emails and newsletters to inform new users about the app.
- Aim for awards and good reviews on the app store.
- Include the app link in your email signature.
- Try promotional press releases and campaigns.
- Encourage users to rate and review the app on the app store.
- Leverage user-generated content to your advantage.
- Integrate the app with existing or popular apps.
- Hold giveaways or contests to drive engagement.
- Feature the app on your company's website and blog.
- Cross-promote the app with other apps, websites, and social media platforms.
- Create promotional content such as blogs and podcasts."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Rewrite the sentence to provide more clarity and flow.
### Input:
Making the decision to rent a house was a wise choice
### Response:
Renting a house was a wise decision to make."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Give a description of the following customer segment.
### Input:
Online shoppers in the US aged between 18-25
### Response:
This customer segment consists of online shoppers in the US aged between 18-25. They are typically young adults who are tech-savvy and prefer to shop online for convenience and variety. They often shop for a variety of items, ranging from clothing to electronics and are comfortable using different payment methods such as credit or debit cards and digital wallets."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Design a logo for a mobile application.
### Response:
The logo design should be simple, modern, and unique. It should capture the essence of the application and communicate its functions. The logo should feature bold colors that are eye-catching, and the design should be adaptable to various sizes and platforms, such as websites and mobile devices."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Generate a list of country names in the western hemisphere.
### Response:
- Canada
- United States
- Mexico
- Brazil
- Argentina
- Chile
- Colombia
- Venezuela
- Cuba
- Jamaica
- Ecuador
- Peru
- Uruguay
- Paraguay
- Costa Rica
- Panama
- Honduras
- Nicaragua
- Guatemala"
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Translate the following phrase into French.
### Input:
I miss you
### Response:
Je te manque."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Explain what an API is.
### Response:
API stands for Application Programming Interface. It is a set of instructions or programming instructions that allow two applications to communicate and exchange data with each other. APIs provide a way for developers to access and manipulate data and services offered by other applications or platforms. They are an essential part of modern web development and allow developers to develop complex applications and websites using modular components."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Compute the area of a rectangle with length 10cm and width 5cm.
### Response:
The area of the rectangle is 50 cm2."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Find the capital of Spain.
### Response:
The capital of Spain is Madrid."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Classify the following statement as true or false.
### Input:
The Supreme Court is the highest court in the US.
### Response:
True."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Design a database to record employee salaries.
### Response:
The database should contain fields for employee name, position, salary, and date. It should also include a field for the employee's manager, so that the salaries can be properly allocated across departments. The database should also be able to generate reports on salary expenses for departments or individuals."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Identify the theme of the following book.
### Input:
The book is about a small town in the Midwest and how people respond to a series of tragedies and unexpected events that shake their lives.
### Response:
The theme of the book is resilience in the face of unexpected tragedy, and how the people of a small town come together to overcome difficult times."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Assign each word in the sentence below to its part of speech.
### Input:
Kittens often scamper around excitedly.
### Response:
Kittens - Noun
often - Adverb
scamper - Verb
around - Preposition
excitedly - Adverb"
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Generate a password of 8 characters.
### Response:
e9gKyd2D"
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Create a web page about robotics.
### Response:
The web page should include an introduction to robotics, covering what it is and how it can be applied in various industries. It should also include a section on the history of robotics, an overview of major advances in the field, and current trends. Information about the different types of robots and their applications should be included, as well as links to resources for further research."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
What is the most commonly shared type of content on social media?
### Response:
The most commonly shared type of content on social media is images."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
What is the main idea of this text?
### Input:
The robotics industry has become one of the fastest growing sectors in today’s economy. Robotics technology is being applied in various industries and applications, such as manufacturing, healthcare, and defense.
### Response:
The main idea of this text is that robotics technology is being used in many different industries and applications and is a rapidly growing sector of today's economy."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Generate a list of present continuous verbs.
### Response:
Running, eating, sleeping, calling, texting, working, reading, watching, writing, listening, playing, cooking, shopping, dancing, studying, walking, driving, flying, jumping, laughing."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Think of a phrase or idiom containing the word ""sleep"".
### Response:
Sleep like a log."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Make a prediction about what will happen in the next paragraph.
### Input:
Mary had been living in the small town for many years and had never seen anything like what was coming.
### Response:
It appears that something extraordinary and unprecedented will happen in the next paragraph."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Generate a headline for the following article.
### Input:
This article discusses the future of renewable energy sources in the US.
### Response:
Renewable Energy Sources are the Future of the US"
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
What type of punctuation should be used at the end of the following sentence?
### Input:
Let's look at the bird
### Response:
A question mark (?) should be used at the end of the sentence."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Identify the incorrect word and suggest a better version.
### Input:
The waitress served a humonguous burger.
### Response:
The incorrect word is ""humonguous"" and it should be replaced with ""huge""."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Rewrite this sentence using the third person point of view.
### Input:
I went to the store.
### Response:
He/She went to the store."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Change this sentence into the future tense.
### Input:
She walks to school.
### Response:
She will walk to school."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Summarize the following article in your own words.
### Input:
The internet has become a critical part of modern life and it has revolutionized the way we communicate and conduct business. It has enabled the spread of ideas and experiences quickly, globally, and cheaply.
### Response:
The internet has drastically changed our lives by allowing us to easily and quickly communicate and conduct business across the globe. It has enabled the rapid spread of ideas and experiences worldwide."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
What is the meaning of the following idiom?
### Input:
It’s raining cats and dogs
### Response:
The idiom ""it’s raining cats and dogs"" means that it is raining heavily."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Generate a sentence using the following words in the correct order.
### Input:
house on fire
### Response:
The house was on fire."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Is the sentence grammatically correct?
### Input:
The boy was playing with her toys.
### Response:
Yes, the sentence is grammatically correct."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Classify the relationship between John and Mary.
### Input:
John and Mary are siblings.
### Response:
John and Mary are brother and sister."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Identify the language used in the given sentence.
### Input:
Il est incroyable.
### Response:
The sentence is in French."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Generate a summary of the given article.
### Input:
Between 1989 and 2019, the size of the U.S. economy, measured in terms of the gross domestic product (GDP), more than doubled. The growth was faster than in the prior two decades, driven in part by the dramatic expansion of the information technology sector in the 1990s and early 2000s, gains in worker productivity and strong consumer demand, and government investments in research and development.
### Response:
The U.S. economy more than doubled in size between 1989 and 2019, largely due to the rise of the information technology sector, improvements in worker productivity and consumer demand, and government investments. This growth was faster than in the prior two decades."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Conver the temperature from Fahrenheit to Celsius.
### Input:
94F
### Response:
34.4C"
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Construct a phrase using the given words
### Input:
Pandemic, challenge, action
### Response:
Our action in the face of the pandemic is the ultimate challenge."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Find the synonyms of the following word: 'Tenacious'.
### Response:
Persistent, dogged, determined, resolute, steadfast, unwavering, unyielding, persistent, persistent."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Suggest a good restaurant.
### Input:
Los Angeles, CA
### Response:
In Los Angeles, CA, I suggest Rossoblu Italian restaurant."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Calculate the area of the triangle.
### Input:
Base: 5cm; Height: 6cm
### Response:
The area of the triangle is 15 cm²."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Rewrite the sentence with more descriptive words.
### Input:
The game is fun.
### Response:
The game is exhilarating and enjoyable."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Generate a creative birthday wish for a friend.
### Response:
Happy birthday! May this special day bring you joy, laughter, and all the blessings you deserve. Have a wonderful year ahead!"
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Make the second sentence shorter.
### Input:
Winter is usually the coldest season of the year. Snow is a common element during winter.
### Response:
Winter is the coldest season, often accompanied by snow."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Find the solution to the quadratic equation.
### Input:
3x² + 7x - 4 = 0
### Response:
The solution of the quadratic equation is x = -4 and x = 1/3."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Find the average of these three numbers.
### Input:
2, 5, 10
### Response:
The average of 2, 5, 10 is 5.67."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Rewrite the sentence in a different tense.
### Input:
He asked her to join him for lunch.
### Response:
He had asked her to join him for lunch."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Classify the following data with three labels.
### Input:
fjsklfjdsklfjsklfjsklfjs
### Response:
Label1: Character data
Label2: Alphabetical data
Label3: Non-alphabetical data"
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Compose a five word sentence describing your day.
### Response:
Today was an amazing day."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Describe the following painting in one sentence.
### Input:
Attached Painting
### Response:
The painting depicts a sprawling landscape on a beautiful day with rolling hills and a river winding its way through the terrain."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Search the web and find the title of the longest novel.
### Response:
The title of the longest novel is ""Gordale"", written by Carolyn Redfearn."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Change the following sentence from the singular form to the plural form.
### Input:
The cat is drinking.
### Response:
The cats are drinking."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Compile a list of 5 US states located in the Mid West.
### Response:
The 5 US states located in the Midwest are Illinois, Indiana, Michigan, Ohio, and Wisconsin."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Analyze the following sentence and find the direct object.
### Input:
She wrote a book.
### Response:
The direct object of the sentence is ""book""."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
During the last member meeting, create a list of 5 ideas to improve the club.
### Response:
At the last member meeting, the following 5 ideas to improve the club were suggested: 1. Increase the frequency of meetings, 2. Create a mentorship program, 3. Develop a website to advertise the club, 4. Create a budget to finance activities, 5. Offer incentives to encourage participation."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Edit the following sentence to correct the grammar and syntax errors
### Input:
You was late to the party
### Response:
You were late to the party."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Create a questions that can be answered using the following sentence.
### Input:
""It was a beautiful day""
### Response:
What type of day was it?"
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Write a simple definition of the word ""economics"".
### Response:
Economics is the study of how society uses its limited resources to produce and distribute goods and services."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Find the cutoff score for successful completion of the exam
### Input:
The exam had 100 multiple-choice questions with 4 options each
### Response:
The cutoff score for successful completion of the exam is 75."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Generate a topic sentence to introduce the following text.
### Input:
Amidst increasing violence in the region, many civilians are fleeing their homes in search of safety.
### Response:
Due to the escalating tensions and violence, countless civilians are being forced from their homes in fear for their lives."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Write a function to calculate the factorial of a given number.
### Response:
def factorial(n):
if n == 0:
return 1
return n * factorial(n-1)"
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Write a function to convert a given string to uppercase.
### Response:
def toUpperCase(str):
return str.upper()"
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Extract the positive integers from an array?
### Input:
arr = [5,-2,8,-7,3,-1,0,5]
### Response:
[5, 8, 3, 5]"
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Calculate the square root of a given number.
### Response:
def sqrt(n):
low = 0
high = n
while low <= high:
mid = (low + high) // 2
if mid * mid == n:
return mid
elif mid * mid < n:
low = mid + 1
else:
high = mid - 1
return low - 1"
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Reverse a linked list.
### Response:
def reverse(head):
prev = None
cur = head
while cur:
next = cur.next
cur.next = prev
prev = cur
cur = next
head = prev
return head"
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Compute the longest increasing subsequence of a given array?
### Input:
arr = [7, 10, 8, 11, 9, 5]
### Response:
[7, 8, 9, 11]"
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Design an algorithm to find the maximum profit of a stock buy and sell?
### Response:
def maxProfit(prices):
min_price = float('inf')
max_profit = 0
for price in prices:
min_price = min(min_price, price)
profit = price - min_price
max_profit = max(max_profit, profit)
return max_profit"
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Given two strings, check whether one string is a rotation of another?
### Input:
s1 = ‘waterbottle’
s2 = ‘erbottlewat’
### Response:
def isRotation(s1, s2):
if len(s1) != len(s2):
return False
s3 = s1 + s1
return s3.find(s2) != -1"
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Given an array of integers, return the first repeating element.
### Input:
arr = [3, 6, 7, 1, 4, 6, 7]
### Response:
6"
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Find the two non-repeating elements in an array of repeating elements?
### Input:
arr = [2, 3, 7, 9, 11, 2, 3, 11]
### Response:
7, 9"
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Given a binary tree, check if it is a binary search tree?
### Response:
def isBST(root):
if root is None :
return True
if root.left is not None and root.left.val > root.val:
return False
if root.right is not None and root.right.val < root.val:
return False
return isBST(root.left) and isBST(root.right)"
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Find the maximum profit that can be earned from a given sequence of transactions?
### Input:
arr = [100, 180, 260, 310, 40, 535, 695]
### Response:
865"
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Calculate the amount of money in a bank account with an initial $100 deposit and an interest rate of 6%, compounded annually
### Response:
At the end of year 1, the amount in the bank account would be $106. In year 2, the amount would be $112.36 and at the end of the 10th year, the amount would be $160.54. This illustrates the power of compound interest."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Give me a detailed overview of the framework of a web service.
### Response:
A web service should be composed of several components: a client application, a set of API (application programming interface) to interact with the client, a database to store data, a server to run the service, and a client-side application to process requests. The API should be designed with RESTful architecture and the server should be built with a language like Python or Ruby. The database should be tailored to the data that needs to be stored, and the client-side application should handle the response from the API. Additionally, for security purposes, certain requests should be encrypted or secured using authentication mechanisms."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Create a timeline describing the history of the internet
### Response:
1968: ARPANET, the first internet network, is created.
1973: TCP/IP is created, allowing computers to communicate with each other.
1983: DNS is created to simplify the communication process.
1989: The World Wide Web is created, giving birth to the public internet.
1995: JavaScript is developed, introducing dynamic content to the web.
2001: Wikipedia is launched, providing an online encyclopedia.
2004: Facebook is launched, growing quickly to 1 billion users.
2007: Apple introduces the iPhone, making mobile devices commonplace.
2009: Cloud computing begins to revolutionize data storage.
2011: HTML5 is released, encouraging richer web experiences.
2013: The Internet of Things (IoT) emerges, connecting dozens of durable devices.
2015: ""Voice first"" technology, such as Amazon's Alexa, launches.
2018: 5G networks begin rolling out, allowing for faster connection speeds.
2020: AI begins to be used to power home assistants like Alexa."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Paraphrase the following sentence
### Input:
The scientists conducted a rigorous experiment
### Response:
The scientists ran a thorough experiment."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Develop a web-based application that does the following
### Input:
Sorts images according to category
### Response:
This web-based application should use a database to store the images and associated categorization information. The application should allow users to upload images and assign tags to them. Additionally, there should be an interface which provides the ability to search and filter the images by tags. Lastly, the application should use computer vision techniques, like object detection and image classification, to sort the images into categories."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Describe the pros and cons of the following policy
### Input:
Providing free college education
### Response:
The pros of providing free college education include making education more accessible to individuals of all backgrounds, enhancing access to skilled professionals, providing equal opportunity for all, and boosting the economy. On the other hand, the drawbacks could include an increase in taxation and a greater burden on the government, an excessive influx of graduates in certain professions, a decrease in the quality of education, and an increased risk of overcrowding in certain universities."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Design a post for a social media account to promote the following product
### Input:
Fresh fruit smoothie
### Response:
Introducing our new and extra refreshing fruit smoothie! Made from only the freshest fruits, this smoothie is a delicious way to stay energized and get your daily dose of nutrients. Get yours today! #smoothie #fruitsmoothie #refreshing"
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Summarize the following article
### Input:
https://www.nytimes.com/2010/07/05/business/global/05phone.html
### Response:
This article discusses mobile phones and their unprecedented influence on different aspects of the global economy. After analyzing data from several countries, the article found that mobile phones have enabled economic growth, improved access to financial services, and created a platform for innovation. Mobile phones have also helped reduce poverty and corruption, and have opened the door for new business models."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Create a job description for the following role
### Input:
Data Analytics Consultant
### Response:
We are looking for a data analytics consultant to support our operations. The consultant will develop strategies to understand, interpret, and act on data insights. The consultant should have experience in data visualization and dashboard development, machine learning, and communication of data insights to internal and external stakeholders. The ideal candidate will have excellent problem-solving skills, be detail-oriented, and be able to work confidently with stakeholders of varying levels."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Identify the correct order for the following commands
### Input:
pack, prepare, travel
### Response:
The correct order is: prepare, pack, travel."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Create a survey question to measure customer satisfaction
### Response:
On a scale of 1-5, how satisfied are you with our services?"
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Create a list of 10 different animals
### Response:
1. Tiger
2. Elephant
3. Chimpanzee
4. Gorilla
5. Wolf
6. Fox
7. Kangaroo
8. Hedgehog
9. Porcupine
10. Beave."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Suggest a good idea for a family photoshoot.
### Response:
How about a photoshoot in a park or garden with a picnic theme? Have the family dress up in fun and whimsical clothes and poses, and use props like vintage furniture, outdoor accessories, and decorations. Another idea could be a photoshoot in a game hall or arcade with the family playing games dressed up in matching costumes."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Create a response for a customer's email about a refund issue.
### Input:
Dear [Company],
I recently purchased a product from your store and I'm disappointed with the quality. I would like to request a refund.
### Response:
Dear [Customer],
Thank you for bringing this to our attention. We apologize for the issue with the product. We will process your refund request as soon as possible. Please let us know if we can help with anything else. Thank you for your understanding. Kind regards, [Company]"
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Summarize the given news article in one sentence.
### Input:
In the latest budget announcement, the Chancellor has promised to introduce a new employment allowance to help employees of small businesses.
### Response:
The government has announced an employment allowance to help employees of small businesses in their most recent budget announcement."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Provide five adjectives that describe a particular animal.
### Input:
Lion
### Response:
Regal, mighty, majestic, brave, intelligent."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Rearrange the words to create a complete sentence.
### Input:
Underwater creatures are fascinating
### Response:
Fascinating are underwater creatures."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Write a story that begins with the following sentence.
### Input:
She opened the door to find a tall figure cloaked in shadows.
### Response:
She opened the door with a trembling hand, expecting to find her friend. Instead, a tall figure cloaked in shadows stood in the doorway. Startled by the unexpected presence, she stepped back and her heart pounded. The figure made no sound and stood still, seemingly lost in thought. She wanted to speak, but before she could utter a word, the figure stepped forward, revealing a single rose in its hand. Taking the rose, she felt an overwhelming sense of something unknown, something of which she could not explain."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Convert the given sentence into active voice.
### Input:
One hundred and fifty books were sold.
### Response:
Someone sold one hundred and fifty books."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Explain why a given topic is important.
### Input:
Environmental protection
### Response:
Environmental protection is essential for maintaining the health of our planet for future generations. Human activities such as emissions, farming, and deforestation are contributing to climate change, air and water pollution, reduction in biodiversity, and other environmental threats. By placing a priority on environmental protection, we can limit the speed of environmental damage and conserve natural resources for our own and future generations' use."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Describe the sound of the given object.
### Input:
Wind chime
### Response:
A wind chime produces a peaceful and melodic sound, with a mix of high-pitched and low-pitched tones. The sound of the chime is like a gentle breeze, reflecting the calming atmosphere of a light summer day."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Rewrite the given sentence using a different but similar word.
### Input:
She partook in the event.
### Response:
She participated in the event."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Classify the given input as either a poem, story, or song.
### Input:
Once upon a midnight dreary, while I pondered, weak and weary.
### Response:
Poem"
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Create a title for the following description.
### Input:
A story about a journey of self-discovery by a young girl.
### Response:
The Road to Finding Myself"
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Rewrite the given sentence in a more formal tone.
### Input:
I had to go to the store real quick.
### Response:
I had to make a quick trip to the store."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Write a few sentences about a given historical figure.
### Input:
Amelia Earhart
### Response:
Amelia Earhart was an American aviation pioneer and a renowned aviation figure. She was the first female aviator to fly solo across the Atlantic Ocean. Despite tragic circumstances, she is remembered as an inspiring role model and a symbol of courage, adventure, and determination. Her groundbreaking achievements pushed the boundaries of gender roles and inspired many."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Generate a list of questions related to a given topic.
### Input:
Innovation
### Response:
1. What are the most current trends in the field of innovation?
2. What aspects of innovation offer the most potential for success?
3. What challenges have businesses recently faced related to innovation?
4. What strategies can businesses use to drive innovation?
5. How have technological advances helped shape new models of innovation?
6. What unique approaches to innovation have proven successful?
7. What principles guide successful innovation projects?
8. What opportunities for innovation exist in emerging markets?
9. In what ways does collaboration foster innovation?
10. How can ideas be leveraged to promote innovation?"
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Create a slogan for a given product.
### Input:
Healthy snack
### Response:
A bite of goodness - Healthy snacks for your whole family!"
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Categorize the following text into one of the two sentiment classes: positive or negative.
### Input:
I didn't like the product very much because it was too slow and not user friendly.
### Response:
Negative."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Summarize the paragraph into a sentence.
### Input:
When buying furniture, it's important to take into account the overall look and feel of the space. That means that you should ask yourself if the pieces you are selecting are a good match for the existing furnishings as well as what you imagine the overall style to be.
### Response:
Think about the existing furnishings and desired style when selecting furniture."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Make the following sentence more concise.
### Input:
I have a really bad cold and it is making me feeling really miserable.
### Response:
I have a bad cold and feeling miserable."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Transform the following sentence into a yes/no question.
### Input:
It is going to rain tomorrow.
### Response:
Is it going to rain tomorrow?"
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Compose a tweet that addresses the issue of environmental degradation.
### Response:
We can't keep wasting resources and ignoring #EnvironmentalDegradation. Let's make our planet greener and healthier for future generations. #savetheenvironment #EnvironmentalProtection"
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Replace the underlined words with appropriate synonyms.
### Input:
The robbers snitched on their partners.
### Response:
The robbers divulged on their partners."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Correct the grammatical errors in the sentence.
### Input:
She come to the store for supplies.
### Response:
She came to the store for supplies."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Identify the type of the relationship between the two words in the sentence.
### Input:
The car passed the truck.
### Response:
The relationship between the two words in the sentence is comparison."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Compose an informative sentence explaining the given term.
### Input:
Green bonds
### Response:
Green bonds are debt instruments issued to finance projects aimed at mitigating climate change and promoting sustainable development."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Rewrite the following sentence without changing the meaning.
### Input:
The sales report was not accurate.
### Response:
The sales report was inaccurate."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
What's the output of this code?
### Input:
x = [1, 2, 3, 4]
y = [i**2 for i in x]
### Response:
y = [1, 4, 9, 16]"
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Write a short review for the novel ""The Catcher in the Rye"".
### Response:
I recently read “The Catcher in the Rye” and was impressed by J.D. Salinger's ability to capture the struggles of teenage life. This coming of age tale tells the story of Holden Caulfield's journey to adulthood, as he navigates the issues of identity, alienation, and despair. The novel manages to shed light on difficult topics through its humorous and vivid writing, making it an enjoyable and thought-provoking read."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Identify the following animal.
### Input:
It has thick fur, a long tail, and pointed ears.
### Response:
The animal is a fox."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Describe the impact of the coronavirus on the economy.
### Response:
The coronavirus has had a major impact on the economy, causing disruptions in industries such as tourism, travel, hospitality, retail, and more. These industries have seen sharp decreases in activity, resulting in surging unemployment levels, a weakened stock market, and decreased consumer spending. Business closures have been rampant, and some companies have even been forced to permanently close their doors. As a result, fiscal and monetary policies have been embraced by governments to help stem the economic downturn."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
What geometric shape has 5 sides and 5 angles?
### Response:
The geometric shape is a pentagon."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Generate a pitch for a new and original product.
### Response:
Introducing the revolutionary new product that is taking the world by storm: the SmartBat! The SmartBat is a revolutionary device that combines the features of a smartphone, a voice-activated AI assistant, and a motion sensor into one convenient bat-shaped device. With its intuitive interface and powerful AI, the SmartBat is the perfect companion for anyone on the go who wants to stay connected and informed. Whether you’re at the office or home, the SmartBat has you covered with its innovative features. So don’t wait, get your SmartBat today and take your life to the next level!"
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Compose a sonnet about the beauty of nature.
### Response:
The beauty of nature is forever grand,
A sight to marvel at all over land.
The sky above, the earth below at hand,
So much to see, no eye can understand.
The trees that stretch to the heaven's demand,
The dance of flowers like some strange band,
Behold the wind's gentle whisper grand,
As it rustles the leaves at nature's command.
The rivers that fold, rush and flow,
To the sea like some sweet understated show,
The sun, hidden in the mist, what a glorious glow,
It casts as its warmth in his embrace does stow.
Oh, the beauty of nature, forever grand,
A vision to inspire, with joy that’s grand."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Rewrite the following sentence so that it is in active voice.
### Input:
The problem is being solved by her.
### Response:
She is solving the problem."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Write a short story about a day in the life of a software engineer.
### Response:
John was a software engineer and had been coding for the past 5 years. Every day he woke up early to tackle the day ahead. He would start off with a quick breakfast before diving into the world of coding, creating new projects and fixing existing bugs. After a few hours of coding, he would take a break and eat lunch at his desk, discussing new ideas with his colleagues and brainstorming solutions to any tricky problems they had encountered. Afternoon would roll in and John was focussed on his code, powering through the most complex issues while keeping a sharp eye out for potential improvements. His day would finish with a bit of light reading, studying new coding languages, to ensure he was up to date with the latest industry advancements. And with that, his day was complete."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
What's the difference between a virus and a worm?
### Response:
The main difference between a virus and a worm is that a virus requires user interaction to spread, while a worm can spread itself from one computer to another on its own. Viruses can modify files and damage data, whereas worms are generally designed to replicate themselves and spread to other computers. Viruses can also spread to other computers through infected media and files, whereas worms usually exploit security vulnerabilities to spread."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Explain the concept of the blockchain.
### Response:
The blockchain is a distributed ledger technology that is used to store and record transactions. It is secured using a network of computers distributed around the world, which makes it both secure and decentralized as there is no central authority controlling the data stored in it. Each ""block"" within the blockchain contains a unique record of a transaction or event that is recorded to the blockchain in a cryptographically secure manner. The blockchain is immutable, meaning that once a transaction is recorded, it cannot be altered or deleted, providing a permanent and secure record of information."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
What is the contraction of ""they are""?
### Response:
The contraction of ""they are"" is ""they're""."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Create a list of items for a picnic.
### Response:
A picnic list should include items such as: sandwiches, chips, fruit, vegetables, crackers, spreads, cheese, drinks, and snacks. Optional items may include cutlery and plates, a blanket to sit on, sunblock, hats and sunglasses, insect repellent, playing cards or board games, a Frisbee or ball to play with, and ice packs if necessary."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Find the lowest common multiple of two numbers.
### Input:
36 and 87
### Response:
30932"
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Classify the given article as either positive or negative sentiment.
### Input:
The new car is a disappointment. The breaks are terrible and cost way too much for the features offered.
### Response:
Negative"
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Convert the following hexadecimal number to octal.
### Input:
DB
### Response:
333"
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Gather some recent data related to the increasing rates of unemployment.
### Response:
Recent data on the increasing rates of unemployment across the US show that, since the start of the coronavirus outbreak, the unemployment rate has increased from 3.5% to 14.7%. This is the highest the unemployment rate has been since the Great Depression. The US Bureau of Labor Statistics also reports that since April 2020, 43 million Americans have filed for unemployment.
The US Federal Reserve reported in June 2020 that 40% of households making less than $40,000 a year had lost a job or experienced a reduction in income due to COVID-19, while 23% of households making over $100,000 had experienced job losses or income reductions."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Indicate how the following characters in the novel reflect the theme of ""the corrupting influence of power"".
### Input:
Gregoire in Zola's Germinal
### Response:
Gregoire serves as an example of the corrupting influence of power in the novel Germinal. As the only one of the miners who rises to the upper echelons of the mining company, Gregoire turns his back on his former comrades in favor of promoting his own interests. He changes from being a loyal and kind miner to a callous overseer who takes joy in crushing the miners' spirit and punishing them for the smallest of offenses. His transformation is a stark illustration of how those corrupted by power have the capacity to be so much more heartless and ruthless than before, and his journey encapsulates the theme of ""the corrupting influence of power""."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Rewrite the following sentence to avoid any logical fallacies.
### Input:
This medicine will cure all your health issues; you should trust me because I am a doctor.
### Response:
Given my training as a doctor, this medicine is likely to provide a beneficial effect to most health issues."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Name two different ways to reduce poverty in a community.
### Response:
Two different ways to reduce poverty in a community are to develop economic development initiatives to create job and business opportunities, and to increase access to healthcare and education to give people the tools they need to succeed."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Generate a sentence that follows the structure of: ""All ____ is based on/with _____""
### Response:
All success is based on hard work and dedication."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Describe the principle of the Law of Supply.
### Response:
The Law of Supply states that as the price of a product or service increases, the quantity supplied to the market also increases, as producers are incentivized by the increased profit potential. Likewise, as the price of a product or service decreases, the quantity supplied to the market also decreases due to decreased profit potential."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Find the area of the given trapezoid.
### Input:
Bases: 13 cm and 16 cm; Height: 12 cm
### Response:
168 cm^2"
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Describe the themes present in the given poem.
### Input:
Poem:
We step out into the night
Where the stars cry like only loneliness can
And make love in the darkness
### Response:
The poem ""We Step Out into the Night"" touches on themes of love, loneliness, and the beauty of the night sky. The imagery of stars crying like only loneliness can hints at a melancholic sentiment, implying that love is both necessary and desirable, but can also be difficult or painful. This can symbolize the transitional nature of life and the difficulties of finding one's place in the world."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Generate a haiku poem.
### Response:
Dew on a leaf glistening
A gentle summer breeze rustles
Nearby cicada song"
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Design a logo for a web development company.
### Response:
Design a logo that is modern and professional. Use a combination of blue, green and orange for the color scheme. The logo should include an abstract circle in the center, with two triangles on either side to represent the website being under construction. Include the company name inside the circle or around the edges. The font should be bold and legible. The logo should be simple, yet eye-catching."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Compare cats and dogs.
### Response:
Cats and dogs are both beloved pets, but they have important differences. Dogs are typically more outgoing and energetic, while cats are considered more independent. Dogs tend to be more social and active, enjoying walks and playing with other animals. Cats, on the other hand, tend to be more solitary, preferring to relax and snuggle up in a warm spot. Dogs typically require more care and attention, while cats are more self-sufficient. Despite these differences, cats and dogs remain popular and loving pets."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Classify this text as Fiction or Non-fiction.
### Input:
The universe is estimated to be around 13.8 billion years old.
### Response:
Non-fiction."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Name three fruits that are rich in Vitamin C.
### Response:
Oranges, grapefruits, and lemons."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Translate this sentence from French to English.
### Input:
J'aime faire de la randonnée.
### Response:
I love to go hiking."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Generate the third term in the sequence 2, 5, 9, 14.
### Response:
18"
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
What is the purpose of Financial Accounting?
### Response:
The purpose of financial accounting is to provide relevant and accurate information to help entities make informed decisions and effectively manage their finances. It also provides a reliable record of their financial transactions, which is essential to conducting business."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Describe a unique way to cook a steak.
### Response:
One unique way to cook a steak is sous-vide. This method cooks the steak slowly in a sealed bag of its own juices at a low temperature. The steak is vacuum-sealed, then cooked in a water bath at a precise temperature for an extended period, ensuring that it is fully cooked through but still tender and juicy."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Summarize the advantages of renewable energy.
### Response:
Renewable energy sources such as solar and wind are clean, sustainable, and abundant. They reduce air and water pollution, help preserve valuable ecosystems, and create jobs that can't be outsourced. Renewable energy sources also have the potential to drastically reduce global warming emissions and combat climate change, making them essential for the future of humanity and the planet."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Identify the incorrect word in this sentence.
### Input:
The singer joyfully belted their solo.
### Response:
their"
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Suggest a powerful quote.
### Response:
""With the power of the will, anything is possible."" – Unknown"
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Sort the following list in alphabetical order.
### Input:
Camouflage, Furniture, Plaster
### Response:
Furniture, Camouflage, Plaster"
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
What is a trade deficit?
### Response:
A trade deficit is a situation in which a country imports more goods than it exports. It occurs when the value of the country's exports falls below the value of its imports. It is typically evaluated by looking at the total value of goods and services a country imports and exports over a certain period of time."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Name one benefit of meditation.
### Response:
One benefit of meditation is reduced stress levels. Through regular practice, meditation helps to train the mind to focus, which can lead to improved concentration and awareness. This can help to alleviate feelings of stress, anxiety, and depression, as well as improve quality of sleep."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Name the three main mountain ranges in the United States.
### Response:
The three main mountain ranges in the United States are the Rocky Mountains, the Appalachian Mountains, and the Sierra Nevada Mountains."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Assign this task to the design team.
### Input:
Design a communication tool for internal team members.
### Response:
The design team has been assigned the task of designing a communication tool for internal team members."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Provide the lyrics for the song titled “Yesterday”
### Response:
Yesterday, all my troubles seemed so far away
Now it looks as though they're here to stay
Oh, I believe in yesterday
Suddenly, I'm not half the man I used to be
There's a shadow hanging over me
Oh, yesterday came suddenly"
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Provide a brief summary of the novel ""Never Let Me Go"".
### Response:
Never Let Me Go is a dystopian novel by Kazuo Ishiguro that tells the story of three friends who attended a school together that, unbeknownst to them, was preparing them for a grim fate. As they grow up, they begin to understand their true purpose and are forced to confront the moral and ethical dilemmas presented by their impending destiny."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Edit the following sentence so that it has correct grammar.
### Input:
I were just going to the store
### Response:
I was just going to the store."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Name something you can do with paper.
### Response:
Write, draw, paint, fold, cut, origami, make a paper airplane, collage, create a pop-up card, shred, laminate."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Construct a sentence using the phrase ""every day"".
### Response:
I do something new every day."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
What type of fruit would be a good addition to a fruit salad?
### Response:
Strawberries, blueberries, raspberries, grapes, kiwi, oranges, apples, pears, mangoes, papayas, and pineapples."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Describe in a few words what makes a good leader.
### Response:
A good leader is motivated, confident, persuasive, inspiring, organized, and reliable."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Find a rhyming word for the word ""river"".
### Response:
Giver."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
What is the scientific name for a beaver?
### Response:
The scientific name for a beaver is Castor canadensis."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Convert the following number from base 10 to hexadecimal: 278
### Response:
The number 278 in hexadecimal is 112."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Give a definition of ""algae"".
### Response:
Algae are a large and diverse group of simple, typically autotrophic organisms, ranging from unicellular to multicellular forms. They range in size from microscopic to large seaweeds and are classified in the same kingdom as plants, although unlike plants they lack true roots, stems, and leaves. Algae typically live in moist environments, including marine, freshwater, and terrestrial systems."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Name a natural process which occurs in food preservation.
### Response:
A natural process which occurs in food preservation is fermentation."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Supply a phrase to complete this proverb: ""It's better to be safe than ____.""
### Response:
It's better to be safe than sorry."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Give an example of a convergent boundary.
### Response:
An example of a convergent boundary is the boundary between the North American Plate and the Pacific Plate which is converging to create the Sierra Nevada Mountains."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Follow the law of supply and demand, describe what would happen to the price of a good if the demand increased.
### Response:
If the demand for a good increases, the price of the good will rise in order to balance the demand with the available supply. This is because when demand exceeds supply, prices must increase in order to ration resources and keep supplies from running out."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Provide an example of an endangered species of animal.
### Response:
The snow leopard (Panthera uncia) is an endangered species of animal that is native to the mountains of Central and South Asia."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Research about a famous scientist and provide a short biography about him/her.
### Response:
Marie Curie was a Polish-French scientist known for her contributions to the study of radioactivity. She won two Nobel Prizes in Physics and Chemistry, making her the only woman to win two. Her research into the nature of radioactivity revolutionized our understanding of the atom and ushered in a new era of nuclear science and discovery. She established the first research laboratories for the study of radiation and gave her name to the element polonium, which is named after her native country of Poland."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Explain why the election of Abraham Lincoln was considered a revolutionary moment.
### Response:
The election of Abraham Lincoln in 1860 was a revolutionary moment in history because it challenged the status quo of the United States at the time. It marked the first time a president was elected into office who was not from the Democratic or Whig party. Furthermore, Lincoln signaled a commitment to combating slavery, which had been a contentious issue throughout the country, by standing on an antislavery platform. This momentous event foreshadowed the Civil War and the emancipation of slaves."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Research Einstein's theory of relativity and provide a brief explanation.
### Response:
Albert Einstein's theory of relativity is a theory of gravitation which states that the laws of physics are the same in all uniformly moving frames of reference, regardless of the motion's speed or direction. This means that space and time are bound together, forming a four-dimensional continuum known as ""space-time"". Additionally, this includes the notion of time dilation, where the passage of time speeds up or slows down depending on the speed of the observer."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Analyze the historical significance of the Stonewall Uprising.
### Response:
The Stonewall Uprising of 1969 is considered to be a pivotal moment in the growth of the LGBTQ+ rights movement. On June 28th, a series of spontaneous demonstrations broke out at The Stonewall Inn, a gay club in New York City, in response to a police raid that had occurred earlier that evening. This event served to unite and inspire the LGBTQ+ community to fight for equal rights and visibility, and is widely considered to be the start of the modern fight for LGBTQ+ liberation."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Create a sentence that employs a figure of speech.
### Response:
He was a bundle of nerves, like a butterfly in a snowstorm."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Generate a sentence in Spanish that describes the natural beauty of Barcelona.
### Response:
La naturaleza en Barcelona es espectacular, con su costa y su antiguo barrio gótico."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Describe the painting ""The Great Wave off Kanagawa"" by Katsushika Hokusai.
### Response:
The Great Wave off Kanagawa, created by Japanese artist Katsushika Hokusai in the early 1830s, is a woodblock print depiction of a powerful wave cresting in the foreground, as three boats and Mount Fuji can be seen in the background. The painting’s striking color palette and unique style of granular brushwork emphasizes the power and awe of a massive wave in motion."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Explain the concept of entropy in thermodynamics.
### Response:
In thermodynamics, entropy is a measure of the randomness of a system and its ability to generate useful work. It is closely related to the Second Law of Thermodynamics, which states that entropy of a system can never reduce over time unless energy is added to it. Entropy is essential to understanding how heat transfer and chemical processes occur in nature."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Provide an example of a non-renewable source of energy.
### Response:
A non-renewable source of energy is one that is not able to be replenished on a human timescale. Examples of non-renewable sources include fossil fuels such as oil, natural gas, and coal, as well as nuclear energy. These sources of energy are finite and will eventually become depleted over time."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Describe the major differences between the Catholic and Protestant faiths.
### Response:
The two major branches of Christianity, Catholicism and Protestantism, differ in beliefs on many important topics. Catholics recognize the Pope as the highest authority in the Church, while Protestantism is divided into a wide range of denominations which recognizes other forms of authority such as the bible or church councils. Catholics recognize seven sacraments while Protestants only recognize two, baptism and communion. Catholics also believe in transubstantiation, the belief that bread and wine become the literal body and blood of Jesus Christ during the sacrament of communion."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
What is the process of photosynthesis and why is it important?
### Response:
Photosynthesis is the process by which plants convert sunlight into food energy. During this process, the plant takes in carbon dioxide from the air and combines it with water to create glucose and oxygen. This glucose is then used to produce energy for the plant and oxygen, which is released into the air. Photosynthesis is important as it provides a major source of food energy for living organisms, and is also responsible for the upkeep of the earth's atmosphere."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Write a 250 word essay about Coral Reef Conservation
### Response:
Coral reefs are among the most diverse and beautiful ecosystems and they are in danger of being destroyed by human activities, pollution and climate change. As a result, it is important to protect these valuable environments by implementing conservation measures. To gain a better understanding of the choices and strategies for protecting coral reefs, it is important to understand the ecology and structure of the environments, the threats, and the benefits that conservation provides.
Coral reefs are complex and highly structured ecosystems where species interact and co-evolve. They are made of colonies of small invertebrate animals called corals that form intricate networks and canoes. In addition to being biologically and ecologically important, coral reefs provide important benefits such as food, coastal protection, and protection from extreme weather events.
Unfortunately, human activities have caused significant damage to coral reefs all over the world. The most significant threats are overfishing, coastal development, water pollution and climate change. Global warming has caused coral bleaching which occurs when corals become stressed and expel the algae living inside them which can be fatal. It is also important to note that organic pollutants and sediment discharged into the water can smother and damage coral reefs.
In order to protect these valuable ecosystems, there are several key strategies that must be implemented. The most important is reducing pollution by controlling agricultural runoff and discharges, controlling coastal development to minimize sedimentation, reducing human activity on the reefs, establishing marine parks and protected areas, and increasing public awareness of the importance of coral reef conservation. Additionally, it is important to monitor changes in water temperature to prevent coral bleaching and to research and employ methods for coral reef restoration.
Coral reef conservation is a pressing issue that requires urgent action from individuals, organizations, and governments. To mitigate the impacts of human activities, it is essential to implement conservation strategies now to protect these beautiful and valuable environments for generations to come."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Compose a haiku about cats
### Response:
Cats curl up purring,
Soft companions that keep us lulled,
In peaceful solace."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Given a sequence of numbers, calculate the average
### Input:
1, 2, 3, 4, 5
### Response:
3.0"
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
What are the important contributions of NASA to space exploration?
### Response:
NASA has made significant contributions to space exploration over the years, such as developing the first reusable spacecraft, launching satellites that have enabled global communication, developing an extensive catalog of the universe, and robotic explorations of other planets and moons. Their research has unlocked numerous scientific discoveries, which have greatly advanced our understanding of the universe and our place in it. NASA programs have also enabled inspiring leaps for humanity, such as walking on the moon, launching robotic explorers to Mars, and enabling space travel for regular citizens."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Rewrite this sentence, ""She is taking a short break from practice""
### Input:
She is taking a short break from practice
### Response:
She is taking a respite from her rehearsals."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Given a movie title ""The Iron Giant"", come up with an suitable tagline
### Input:
The Iron Giant
### Response:
When the Giant meets the boy, friendship will conquer fear."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Given the following data, What is the median score
### Input:
7, 9, 13, 2, 8
### Response:
8"
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Describe the qualities of a good leader
### Response:
Good leaders possess qualities such as confidence, strong communication skills, integrity, empathy, openness to feedback, accountability, and strong decision-making abilities. They are able to motivate and inspire people to work towards a common goal, create a positive working environment, solve problems, delegate tasks effectively, and lead by example. Good leaders also possess emotional intelligence and bring out the best in people by recognizing their strengths and understanding their weaknesses."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Explain the difference between a personal computer and a server
### Response:
A personal computer (PC) is a desktop or laptop device that is typically used by an individual for personal activities. It connected to other devices within the same network and can access online services. A server is a computer that is designed to manage, store and link multiple computers and applications together. It is typically used to provide services to a large number of users, such as online applications and websites. Servers are generally more powerful than personal computers and have larger data storage and processing capabilities."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
What is the main purpose of blockchain technology?
### Response:
The main purpose of blockchain technology is to serve as a distributed ledger that enables trustless and secure transactions between parties. The trustless nature of blockchain technology is achieved through cryptography, which prevents data tampering and unauthorized access. This technology allows data to be stored in a secure public database, increasing the efficiency, transparency and security of transactions."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Come up with a creative metaphor for smile
### Response:
A smile is like a ray of sunshine, brightening up a room and bringing joy to all."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Given a list of ingredients, come up with a dish
### Input:
Salt, Pepper, Onion, Garlic
### Response:
Sautéed Onion and Garlic with Salt and Pepper."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
For the following passage, identify the theme or thesis statement.
### Input:
Corruption affects countries on many levels and erodes their competitive edge in a global economy. Poor compliance to regulations, ethical standards, and laws impairs public trust and results in conflict. Transnational financial crime drains a nation’s resources, weakens government tools to deliver long-term social goals, and destabilizes markets.
### Response:
Corruption impairs public trust and weakens the resources, tools and markets of a nation."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
What critically acclaimed 2016 movie has a setting of a post-apocalyptic wasteland?
### Response:
Mad Max: Fury Road."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Given the following sentence, add appropriate punctuation to make it grammatically correct.
### Input:
The judge said guilty
### Response:
The judge said, ""Guilty."""
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Label the following news article as either ""Political"" or ""Entertainment""
### Input:
Ansel Elgort and Gabrielle Union have both been cast in a new romantic summer movie to be released in 2022.
### Response:
Entertainment"
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Reword the following sentence to the past tense.
### Input:
She is writing a novel inspired by her grandfather.
### Response:
She wrote a novel inspired by her grandfather."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Summarize the following passage in less than 50 words.
### Input:
The issue of immigration has become critical as the number of people wanting to enter the United States for a better life has been on the rise. Immigration has been a consistent source of controversy and debate, with wide variations in opinion regarding the benefits and drawbacks of immigration. Migration from one part of the world to another is not uncommon, yet the current state of the immigration debate in the United States has escalated and has become divisive.
### Response:
The number of people wanting to migrate to the United States has increased, leading to debate and controversy around the benefits and drawbacks of immigration. The US immigration debate has become highly divisive."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
How many bytes are there in a kilobyte?
### Response:
There are 1,024 bytes in a kilobyte."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Generate a creative description of a sunset in the beach.
### Response:
The sun was setting over the horizon, painting the sky in a magnificent palette of vivid oranges, yellows and pinks. The orange hues were reflected in the shimmering ocean, creating a stunning and tranquil landscape. The salty breeze blew in from the sea and the waves crashed against the rocks, creating a soothing chorus of sound."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Standardize the following date to the ISO 8601 format.
### Input:
July 26th, 2021
### Response:
"
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Rewrite the following sentence in a more concise way.
### Input:
Although he had been studying for several hours he had not finished the task.
### Response:
Despite studying for hours, he hadn't finished the task."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Classify the following fruit according to its color.
### Input:
Orange
### Response:
Orange is a yellow-orange color."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Compute the following expression.
### Input:
2^3 + 3^2
### Response:
11"
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Suggest a suitable card game for a birthday party with 10 year old kids.
### Response:
Go Fish is a suitable card game for a birthday party with 10 year old kids. It is easy to learn and is entertaining for all."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Translate the following sentence from English to French.
### Input:
I am happy to meet you.
### Response:
Je suis heureux de te rencontrer."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Analyze the given poem and explain the theme.
### Input:
Roses are red,
Violets are blue,
Sugar is sweet
And so are you.
### Response:
The theme of this poem is to express love. The poet is saying that the recipient of these words is as sweet as sugar. The poem has a romantic feel to it and is depicting appreciation towards the other person."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Calculate the average age of the following five people.
### Input:
John, 32
Anne, 25
Hugh, 27
Peter, 40
Rebecca, 28
### Response:
The average age of the five people is 30."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Explain the following quote.
### Input:
""Education is the key to success.""
### Response:
The quote is suggesting that education is the path or foundation for success. It emphasizes the importance of knowledge and learning for a successful life and career. Education does not only refer to formal education or qualifications, but also to gaining knowledge, life lessons and experience."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Determine the longest word in the following sentence.
### Input:
It is a wonderful sunny day.
### Response:
The longest word is ""wonderful""."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Rewrite the following equation in expanded form.
### Input:
(x + 3)(2x - 5)
### Response:
2x^2 - 5x + 3x + 15 = 2x^2 + 8x + 15."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Explain the meaning of the following phrase.
### Input:
""out of the box""
### Response:
The phrase ""out of the box"" refers to an approach or solution to a problem which is creative or innovative in nature. It is used to indicate that a particular solution is not the traditional or stereotypical approach, but is instead a creative one."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Write a review for the following movie.
### Input:
The Godfather
### Response:
The Godfather is widely considered an all-time classic, and for good reason. It is a gripping story of crime and family dynamics, featuring stellar performances from the entire cast. The story is expertly crafted and wonderfully acted, making it an unforgettable experience. It might be slow at times, but don't let that stop you from watching this brilliant masterpiece."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Identify the main character in the following story.
### Input:
Once upon a time, there lived a poor peasant boy who worked very hard on his farm.
### Response:
The main character in the story is the poor peasant boy."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Describe the solution in detail.
### Input:
We established a system for automatically generating data for our machine learning model.
### Response:
Our system for automatically generating data for our machine learning model utilizes various techniques to create data points, including web scraping and natural language processing. The data points are then stored in a database and used as input for our machine learning model. This system enables us to generate a much larger dataset than what could be accomplished manually, decreasing the amount of time and resources needed to train the model."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Name three diseases that can be caused by poor hygiene.
### Response:
Three diseases caused by poor hygiene are diarrhea, gastroenteritis, and cholera."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Generate a random password of 6 characters in length using only capital letters and numbers.
### Response:
X9KAE5"
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Explain what is meant by the circle of fifths.
### Response:
The circle of fifths is a musical diagram which maps out all the different key signatures and their respective relationships to one another, by arranging them in a circle with the key of C in the center. It is based on the fact that when going in a clockwise direction, each successive key is a fifth higher than the previous one. This enables musicians to quickly work out the relationships between the different key signatures, which can be helpful in composition and arranging music."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Generate a story with the given keywords.
### Input:
princess, dragon, knight
### Response:
Once upon a time, there was a brave knight who lived in a distant kingdom. He was tasked with rescuing a beautiful princess from a ferocious dragon. The brave knight set off on the dangerous journey, never hesitating to face the dragon and free the princess. When he arrived, he saw the dragon guarding the princess carefully and knew there was no way to sneak past. He took a deep breath and boldly rode forward, ready to face the challenge before him. He fought valiantly and eventually defeated the dragon, freeing the princess from her captor. The knight and princess were married soon after and lived happily ever after."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Calculate the winning percentage for the team in the given statistics.
### Input:
Wins: 50
Losses: 70
### Response:
The winning percentage for the team is 41.67% (50 wins / (50 wins + 70 losses))."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Translate the given phrase from French to English.
### Input:
Je suis fatigué
### Response:
I am tired."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Create a haiku poetry with the given theme.
### Input:
The beauty of night sky
### Response:
Stars glitter in the dark
Mysteries in the night
All is wondrous in sight."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Design a logo for the given company.
### Input:
Example Company
### Response:
<No output>"
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Find the synonyms for the words below.
### Input:
Determined
### Response:
Resolute, persistent, staunch, decisive."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Draft a letter of appreciation for the given recipient.
### Input:
Mr. John Smith
### Response:
Dear Mr. Smith,
I would like to express my heartfelt appreciation for all that you have done for us in the past. Your efforts have contributed significantly to our success and I could not have asked for a better partner. Your wisdom and guidance were invaluable and I am thankful for your dedication and hard work.
Thank you once again for your help and support.
Sincerely,
[Name]"
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Analyze the given film and explain why it should be included in the top 10 list.
### Input:
The film Parasite
### Response:
The film Parasite is an astonishingly honest and timely exploration of economic inequality and societal class division. Through its masterful use of cinematography and well-crafted characters, it provides an enthralling and poignant insight into how wealth can divide us and how it might bring us together. It is a potent reminder that we can never forget the inequalities around us, nor take for granted the privileges we have. This deep exploration of class division and moral complexities make Parasite a must-see and worthy inclusion in any top 10 list."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Explain the implications of artificial intelligence in health care.
### Response:
Artificial intelligence (AI) has the potential to revolutionize the healthcare industry by enabling faster, more accurate diagnostics and treatments, along with identification of new risks and progression of diseases. AI-assisted medical devices help improve accuracy and reduce errors in diagnosis and treatment, while automation systems can process large amounts of health data to generate new insights. AI can also help to improve patient care by providing personalized recommendations and insights into health trends. Additionally, AI can be used to improve communication and efficiency between patients, doctors and healthcare providers."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Write a definition of ""photoshop"".
### Response:
Photoshop is a photo editing software developed by Adobe that is used to improve images or create effects by manipulating and combining parts of the existing digital image. Photoshop enables users to adjust the tones, color, lighting, and texture of an image, as well as to create text, create 3D objects, add digital effects and apply filters."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
List five factors that lead to global warming.
### Response:
1. Burning fossil fuels such as coal, petroleum, and natural gas.
2. Deforestation and landfills, which increases the concentration of carbon dioxide in the atmosphere.
3. Livestock production, which increases the amount of greenhouse gases.
4. Intensive agriculture, which produces emissions such as methane.
5. Industry processes, which produce carbon dioxide, methane and other greenhouse gases."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Name 5 invasive species.
### Response:
1. Zebra mussels
2. Kudzu
3. European green crab
4. Brown tree snake
5. Asian carp"
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
What is an AI algorithm?
### Response:
An AI algorithm is a set of instructions or rules which are used to enable a computer or AI system to solve a problem or achieve a desired goal. AI algorithms can be used to capture and analyze data, classify objects, develop predictive models, and automate capabilities."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Explain the term ""AI explainability"".
### Response:
AI explainability is the ability of AI systems to provide a clear and understandable explanation of how they make decisions. This explanation can include visualizations, narrative descriptions, and other outputs which the AI system uses to explain its decision-making process and decisions. AI explainability helps to make AI and machine learning models more transparent and trust-worthy."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Pick out the adverbs in the following sentence.
### Input:
John quickly ran to the store.
### Response:
Quickly"
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Generate a poem about spring.
### Response:
The snow has melted away,
The flowers bloom so bright,
Birds singing everywhere,
This is the beauty of springtime delight.
The sun shines down with its warming ray,
The grass is gleaming green,
A pleasant breeze is blowing through,
A pleasant feeling can be seen.
The trees rain down the petals of the past,
A beautiful sign of the new season,
A fresh start that’s meant to last,
A beautiful feeling recalls the reason.
A warm season of joy,
A season that’s here to stay,
A season to ease our sorrow,
The season known as spring."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Write a scientific explanation for why the sky is blue.
### Response:
The sky appears blue due to the scattering of light from molecules in the Earth's atmosphere. Sunlight enters the atmosphere and interacts with the molecules and particles, causing light particles to scatter in all directions. The blue light has the greatest ability to penetrate the atmosphere, so it reaches our eyes more often than other colors, making the sky appear blue."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
List five characteristics of good communication.
### Response:
1. Being clear and concise.
2. Being respectful and courteous.
3. Using active listening.
4. Having an open mind.
5. Offering feedback."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Suggest five strategies for self-motivation.
### Response:
1. Set goals and create an action plan.
2. Break tasks down into smaller, achievable goals.
3. Celebrate successes and success motivates.
4. Have a positive attitude and outlook.
5. Surround yourself with inspiring and motivating people."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Name five characteristics of a typical resume.
### Response:
1. A clear, concise, and organized format.
2. A professional summary that highlights the key qualifications and strengths.
3. A detailed description of the previous work experience and education.
4. Contact information such as name, phone number, email, and physical address.
5. A list of relevant skills and achievements."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Describe the benefits of using a GPT model.
### Response:
Using a GPT model has numerous benefits. It can generate text quickly and accurately by using large datasets, which can be used for natural language processing tasks such as summarization, question-answering, and text generation. GPT models are also scaleable, meaning they are able to process complex tasks with minimal resources. They are fast and require no human effort to train, which makes them useful for quickly generating results in various tasks where manual work may be too expensive or slow. Additionally, GPT models are highly flexible, allowing developers to easily adjust the output according to their own preferences. In short, GPT models are an efficient and cost-effective way to generate text."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Compare two types of text processing techniques and explain differences between them.
### Input:
Rule-Based Text Processing and Deep Learning Based Text Processing
### Response:
Rule-based text processing is based on hand-crafted rules for understanding the text. It relies on human experts to define the rules, which can require significant time and effort. It is able to accurately parse and manipulate text, but it is limited in its accuracy and speed. Deep learning based text processing uses algorithms to learn from datasets and extract patterns from text. It is able to process text with high accuracy and at a much faster rate than rule-based text processing. Deep learning models are also more flexible and can be adapted to different tasks with little effort. Deep learning is thus better suited for more complex text processing tasks."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Summarize the article below in 5 sentences.
### Input:
The COVID-19 crisis has brought many changes to our everyday lives, including the way we work and interact. Working from home has become the norm for many people, but it has also brought its own unique challenges. It can be difficult to stay productive and motivated while working remotely, especially if you’re feeling burned out or isolated. So how do you make the most of it? Here are some tips to help you stay productive while working from home.
### Response:
Working from home during the COVID-19 pandemic has its own set of challenges. It can be hard to stay productive when feeling burnt out or isolated. To make the most of it, time management and focusing on goals can help stay motivated. Additionally, make sure to take breaks, have engaging conversations with colleagues and try to stay off social media when working. Finally, make sure to have a designated workspace so that you can remain organised and productive."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Given a set of eight numbers (1,2, 3, 4, 5, 6, 7, 8), generate a sentence that reflects their order.
### Response:
The numbers 1, 2, 3, 4, 5, 6, 7, and 8 were counted in ascending order."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Explain why decision trees may be better than linear models for certain problems.
### Response:
Decision trees are better than linear models for certain problems because they are able to capture non-linear relationships between predictors and outcomes. They are also able to account for interactions between predictors, and can easily interpret and visualize the results. Decision trees are great for finding the most important predictors in a dataset, as they can quickly identify which factors significantly influence a model's outcome. Finally, they are more flexible than linear models and can be adapted to different situations by tweaking the parameters."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Suggest a sentence that follows ""He had never seen a creature so strange,""
### Response:
He was mesmerized by its peculiar movements as it floated around the room."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Select the best prediction from the sentences below given the input ""My vacation is in ________.""
### Input:
My vacation is in _______.
### Response:
Hawaii!"
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Describe the effects of climate change.
### Response:
Climate change is having a profound effect on the environment and all life on Earth. It is causing higher temperatures across the globe, extreme weather changes such as flooding and drought, and an increase in sea levels. In addition to these physical effects, climate change also has an emotional impact. It causes anxiety and stress, due to the worry of the unknown and the potential destruction it could cause. Finally, it is disproportionately affecting low-income households, which don't have the resources to access clean energy and adapt to the changing environment."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Classify the given sentence as either negative or positive.
### Input:
I want to quit my job.
### Response:
Negative."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Rewrite the cover letter below in the first person.
### Input:
Maxwell Smart has extensive experience in the restaurant industry. He brings to the table exceptional customer service and problem-solving skills. During his time in the restaurant industry, Maxwell was a top performer and was recognized for his ability to motivate others.
### Response:
I, Maxwell Smart, have extensive experience in the restaurant industry. I have a strong track record of delivering excellent customer service and effective problem-solving. My peers and supervisors have commended me for my dedication to making the workplace a more positive and productive environment. Additionally, I have been a top performer and have been recognized for my ability to motivate others."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Explain why computational models can be used in analysing text.
### Response:
Computational models can be used in analysing text by automating complex tasks. They are able to quickly process and detect patterns in large amounts of data, enabling accurate and efficient analysis. Furthermore, computational models are not limited by human bias and can help find relationships between features that may have been previously unrecognized. In sum, computational models can be a powerful tool for analyzing text and extracting meaningful information from it."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Generate a question that could follow the response below.
### Input:
I saw a movie last week.
### Response:
What movie did you see last week?"
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Summarize the article below in a maximum of 100 words.
### Input:
A head teacher at a high school in Birmingham has been suspended following reports of irregularities in marking examinations. Inspectors said that some grades had been inflated and process failings had contributed to the issues. The head teacher was said to have failed to ensure the security of the marking process, as well as failing to protect the school from “potential reputational damage”.
### Response:
A head teacher at a school in Birmingham has been suspended for irregularities in examination marking. Inspectors identified inflated grades and process failings that were the responsibility of the head teacher, including a failure to secure the marking process and protect the school from reputational damage. The school is now investigating the matter to protect the integrity of the exam process."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Create a sentence that ends with an ellipsis.
### Response:
I thought I could solve it on my own, but I was wrong..."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Explain the difference between HTML and CSS.
### Response:
HTML (HyperText Markup Language) is a markup language used to create the structure of a webpage. CSS (Cascading Style Sheets) is the language used for styling and laying out a webpage. HTML is a markup language that provides the structure for a web page and consists of HTML elements and attributes. These elements and attributes define the content and any visual element that appear on a page. CSS is used to modify and enhance the visual appearance of the page. It contains a set of values assigned to elements, attributes and properties that control the presentation of the page. These include layout, color, font, and animation. CSS allows for more flexibility when styling a page. Therefore, HTML defines the structure and content of a website while CSS is used to design it and make it look attractive."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Generate a tweet about a new product
### Input:
Product name: Apple iWatch
### Response:
Introducing the Apple iWatch - the perfect combination of style and technology! Get yours today to stay connected and stylish! #Apple #iWatch #GetYours #StayConnected #Style"
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Create a new recipe for flavorful noodles
### Response:
Thai Coconut Noodle Stir-Fry
Ingredients:
- 4 ounces rice noodles
- 2 tablespoons vegetable oil
- 1 clove garlic, minced
- 1 red bell pepper, julienned
- 2 cups mung bean sprouts
- 1 teaspoon sesame oil
- 1/2 cup coconut milk
- 2 tablespoons fish sauce
- 2 tablespoons soy sauce
- 2 tablespoons honey
- 1/4 cup scallions, chopped
- 2 tablespoons lime juice
Directions:
1. Soak the rice noodles in hot water for 5 minutes, and then drain.
2. Heat the vegetable oil in a large skillet over medium heat.
3. Add the garlic, bell pepper, and bean sprouts and cook until the vegetables are just tender.
4. Add the sesame oil, coconut milk, fish sauce, soy sauce, and honey.
5. Simmer the stir-fry for 2-3 minutes and then add the noodles.
6. Cook for 1-2 minutes until the noodles are tender.
7. Turn off the heat and stir in the scallions and lime juice.
8. Serve the Thai Coconut Noodle Stir-Fry hot."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Train a logistic regression model with credit data.
### Response:
Using Python, I trained a logistic regression model on a dataset of credit data. I preprocessed the data by imputing missing values and scaling the data. I then split the data into training and testing sets. The model was trained using the training set with an accuracy of 87%. This model was then evaluated on the test set and had an accuracy of 97%."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Name four diseases caused by cold temperatures.
### Response:
Four diseases caused by cold temperatures are hypothermia, frostbite, chilblains, and trench foot. Hypothermia occurs when body temperature falls below 95°F and can lead to organ failure. Frostbite is a cold induced injury where portions of the skin freeze and can result in loss of tissue or even amputation. Chilblains are itchy and painful skin rashes caused by exposure to the cold. Finally, trench foot is caused by prolonged exposure to wet and cold conditions, leading to extreme discomfort and even infection."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Translate the following sentence into Spanish.
### Input:
The blue sky is so beautiful.
### Response:
El cielo azul es tan hermoso."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Generate a function for calculating the mean of a list.
### Response:
def mean(lst):
return sum(lst) / len(lst)"
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Write a blog post about how AI is transforming the healthcare industry.
### Response:
The healthcare industry is one of the most rapidly evolving sectors today and AI is playing a major role in transforming the industry. AI solutions are enabling hospitals, clinics and other healthcare providers to provide more precise and personalized care to their patients. AI solutions are being used to automate mundane tasks such as data collection and analysis, thus freeing up resources for other more important tasks. AI solutions are also being used to provide predictive insights on a patient’s health and detect diseases in a timely manner. AI-driven technologies have been particularly useful in diagnosing diseases such as cancer by recognizing patterns from medical images. AI-enabled robotic surgeries can also provide precise and minimally invasive procedures for patients. All in all, AI is changing the way healthcare is delivered and allowing medical practitioners to provide better and more efficient care to their patients."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Explain the role of a computer scientist in the modern world.
### Response:
The role of a computer scientist in the modern world is to create, maintain, and improve the technology that powers our lives. Computer scientists are at the forefront of developing new software, hardware, and networks to make our lives easier and more efficient. They create innovative algorithms and architectures to solve complex tasks and problems, optimize existing systems, and develop new systems and technologies. Computer scientists collaborate with other professionals in different fields such as life sciences, engineering, and economics to find solutions to the most challenging problems. They also develop information and communication systems to supplement and improve existing systems. By using their creativity, technical skills, and knowledge, computer scientists are making a huge impact on the world and making our lives safer and easier."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Describe the importance of renewable energy
### Response:
Renewable energy is becoming increasingly important in our world today as we strive to reduce our dependence on fossil fuels and shift to more sustainable sources of energy. Renewable energy sources such as wind, solar, and hydropower provide clean and reliable energy that can be used to power our homes, businesses, and vehicles. Renewable energy is also more cost-effective and efficient compared to other sources of energy. Additionally, renewable energy sources generate little to no pollution and greenhouse gas emissions, helping to reduce climate change. Renewable energy also helps to reduce our reliance on foreign countries for oil imports, thus making our nation more secure. Renewable energy is an important part of building a more sustainable future for our planet."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Generate a review for a recent movie
### Input:
Movie name: The Martian
### Response:
The Martian is an exciting, thrilling and inspiring movie that is sure to stimulate the senses. The story follows Mark Watney, a NASA Astronaut who is stranded on Mars after being presumed dead. He must use his skills in science and engineering to survive on the harsh planet and find a way back home. The Martian is a gripping movie that depicts the struggle of survival in an extreme environment, along with the hope of being rescued. The actors and special effects give a realistic feel to the story, making it even more captivating. The movie is certainly a must-watch and a great representation of human ingenuity and resilience."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Generate a function to sort a list of strings alphabetically
### Response:
def alphabetic_sort(lst):
return sorted(lst, key=str.lower)"
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Write a Satire article about the coronavirus pandemic
### Response:
It’s been one year since the coronavirus pandemic began to affect the lives of people around the world. In the midst of massive lockdowns and social distancing, we managed to learn a few things about this virus. For starters, it is apparently very contagious, as it spread like wildfire around the globe. We have also come to realize though, that the virus only targets those who aren’t following specific protocols. Wearing a face covering, washing your hands and staying home has proven to be the ultimate remedy – the only thing standing in the way of avoiding infection. Taking preventive measures has significantly reduced the spread of the virus, and yet, people are still getting sick. Is this virus selectively choosing who to infect? It just doesn’t make sense! We may never know the answer, but at least we can attempt to stay safe and healthy."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Create a function to check whether two strings are anagrams.
### Response:
def is_anagram(s1, s2):
s1 = sorted(s1.lower())
s2 = sorted(s2.lower())
return s1 == s2"
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Explain what is a neural network
### Response:
A neural network is an artificial intelligence (AI) system inspired by the structure and functioning of the human brain. It is an interconnected system of artificial neurons that use signals from datasets to make predictions or decisions. Neural networks consist of an input layer, hidden layers, and a output layer. The input layer receives data from the outside. The hidden layers process and manipulate the data. And the output layer provides predictions or decisions to the outside world. Neural networks are used in a range of tasks such as image recognition, text analysis and forecasting."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Tag the language of the following text
### Input:
Kareena always had a passion for art. She wanted to pursue a career in the creative field and start her own gallery one day.
### Response:
English"
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Explain what the article is about in 1 to 2 sentences.
### Input:
Summary: This paper describes a novel deep learning technique called Generative Autowavelets (GAW) and examines its uses in natural language processing (NLP) tasks. GAW is a combination of an autoencoder and wavelet transformer, meaning it can both compress features in text and enable structured extraction of these features.
### Response:
This paper introduces Generative Autowavelets (GAW), a new deep learning technique that combines autoencoders and wavelet transforms in order to compress and extract relevant features from text for natural language processing tasks."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Find the three least common values in the given list.
### Input:
[5, 10, 15, 8, 9, 5, 8, 10, 9]
### Response:
15, 5, 8"
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Write a few sentences about the current state of the given topic.
### Input:
Automation
### Response:
Automation is becoming increasingly prevalent in all aspects of life, from factories and manufacturing plants to healthcare, transportation, and home life. It is a technology which allows machines to perform tasks that would otherwise require human labour, resulting in greater efficiency and accuracy, faster production, and cost reductions. Automation also presents new opportunities in areas such as artificial intelligence, robotics and data analysis, which could help us reach new heights in terms of global productivity and innovation."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Identify the two main characters in the given passage.
### Input:
John and Lisa were walking through the park on a sunny day. They stopped to admire the flowers in the garden and talked about their plans for the future.
### Response:
John and Lisa"
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Suggest topics for an informal discussion about the given country.
### Input:
China
### Response:
- The culture and customs of China
- Recent developments in the Chinese economy
- The Chinese education system
- The political landscape in China
- The comparison between traditional and modern Chinese cuisine
- China's stance on international relations
- China's healthcare system
- Impacts of China's population on its economy"
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Explain the implications of the given information.
### Input:
A recent study suggests that teenagers are spending too much time on social media.
### Response:
The implications of this study are clear: Teenagers are prioritizing social media over other aspects of their lives, such as socializing, studying and exercising. This could lead to negative mental health effects such as depression and anxiety, as well as physical health harms such as weight gain and social isolation. It is therefore important that parents, teachers, and other adults help teenagers to learn how to manage their online time in a healthy and balanced way."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Convert the following text into a list.
### Input:
The four elements of design are line, color, shape, and texture.
### Response:
- Line
- Color
- Shape
- Texture"
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Generate a sentence that contains the given words.
### Input:
magic, castle, king
### Response:
The king of the magic castle cast a spell that mesmerized everyone."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Compile a list of five items that would help someone go camping.
### Response:
- Tent
- Sleeping bags
- Flashlight
- Cooking utensils
- Portable stove"
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Correct any spelling or grammar mistakes in the given sentence.
### Input:
She jogged excersies around the lake.
### Response:
She jogged exercises around the lake."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Find the differences between the two short texts.
### Input:
Text A: She was wearing a beautiful red dress.
Text B: She had on a gorgeous red dress.
### Response:
The difference between the two texts is that Text A uses the phrase ""wearing"" while Text B uses the phrase ""had on""."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Rewrite the following paragraph to make it sound more formal.
### Input:
Moving away from home to college was really hard. It's like I had to let go of my comfort and safety and figure things out on my own.
### Response:
Transtioning to post-secondary education away from home was an intimidating experience. I had to relinquish familiarity and security and traverse uncharted waters alone."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Classify the following sentence as either a metaphor or hyperbole.
### Input:
The room was so hot it felt like a sauna.
### Response:
Metaphor."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Generate a creative name for a restaurant serving Mexican cuisine.
### Response:
Taco Town."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Suggest two marketing strategies for launching a new app.
### Response:
Create a buzz by launching a limited free version of the app, as well as offering special discounts to users who are loyal to the app. Utilize influencer marketing, partner with bloggers and other social media stars to create blog posts and videos about the app to increase visibility."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Edit the following sentence for grammar and style.
### Input:
The professor answers the questions of the student accurately.
### Response:
The professor answered the student's questions accurately."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Rewrite the following sentence for clarity.
### Input:
What makes this program different from the others?
### Response:
How does this program differentiate itself from the other programs?"
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Change this sentence to make it a question.
### Input:
I think she likes sports.
### Response:
Do you think she likes sports?"
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Explain the concept of a GPT language model.
### Response:
A GPT language model is a type of artificial neural network used for natural language processing. It is an autoregressive model that predicts the next word in a sequence using a series of mathematical operations. It is trained on a large corpus of text to learn the language and can then be used to generate text that is similar to the text it was trained on."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Generate a slogan for a clothing brand.
### Response:
Wear Your Style."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Add the article ""the"" to the following sentence.
### Input:
Person who is talking
### Response:
The person who is talking."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Generate an example that illustrates the concept of ""artificial intelligence"".
### Response:
A social media bot that is programmed to recognize user sentiment and automatically post relevant content based on that sentiment."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Describe the process of account creation for a website.
### Response:
The account creation process for a website usually consists of providing basic information such as a username, email address, and password. Then, the user will confirm their email address by clicking a link sent to their email inbox. Upon confirmation, the user's account will be activated and they will be able to log in and use the website."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Analyze the following poem and explain its meaning.
### Input:
'My love is like a red, red rose'
### Response:
The poem is a description of a romantic love that is everlasting, just like the rose that constantly blooms all year round. The rose is also a symbol of beauty and love, so the poet is conveying that the love between the two is strong, beautiful and abiding."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Suggest two ways to increase the reach of a blog.
### Response:
Share the blog posts on relevant social media platforms. Create ads on platforms such as Google Ads, Twitter, and Facebook in order to reach a wider audience."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Name three natural elements.
### Response:
Water, air, and fire."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Give a brief description of the coronavirus.
### Response:
Coronavirus is a type of virus that can cause illnesses ranging from the common cold to severe diseases such as Middle East Respiratory Syndrome (MERS) and Severe Acute Respiratory Syndrome (SARS). The virus is named for the crown-like spikes on its surface. It spreads primarily through close contact with an infected person, through small droplets from the nose or mouth after coughing or sneezing. Symptoms can include fever, tiredness, and dry cough. In severe cases, it can cause difficulty breathing, pneumonia, kidney failure, and even death."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Predict the monthly electricity bill of a 1000 square-foot apartment in California.
### Response:
The monthly electricity bill for a 1000 square-foot apartment in California is estimated to be approximatley $105 - $200, depending on usage and other factors such as insulation and energy efficient appliances."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Generate 10 rhyming words for the word ""love"".
### Response:
dove, above, glove, thereof, shove, thereof, thereof, thereof, thereof, thereof."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Explain the concept of binary search.
### Response:
Binary search is a type of search algorithm used to locate a target item in an ordered list. It works by repeatedly splitting the list in half, examining the middle item to determine whether the target is greater than, less than, or equal to it. If the target is found, the algorithm immediately returns the index of the item. If it isn't, the list is split in half, with one half discarded based on the comparison. The process is repeated until the target item is found or the list is completely searched."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Name all the elements in the periodic table with symbol C.
### Response:
The elements in the periodic table with symbol C are Carbon (C), Calcium (Ca), Cobalt (Co), Copper (Cu), Curium (Cm), and Copernicium (Cn)."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Compare the differences between a wooden and plastic baseball bat.
### Response:
Wooden baseball bats are typically heavier and more durable than plastic bats, making them better suited for long term use. Wooden bats generally produce a louder sound when they make contact with the ball, while plastic bats have a quieter sound. Wooden bats have more recoil and vibrations when they hit a ball compared to plastic bats, which have a softer feel. Additionally, wooden bats may have a larger sweet spot that makes contact with the ball more forgiving, while plastic bats are less forgiving."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Calculate the area of a right triangle with base length of 5 cm and height of 3 cm.
### Response:
The area of a right triangle with base length of 5 cm and a height of 3 cm is 7.5 cm^2."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Identify the continents with the most carnivores.
### Response:
Africa and North America are the two continents with the most carnivores. In Africa, lions, leopards, cheetahs, and hyenas are some of the most common carnivores, while in North America, gray wolves, brown bears, and mountain lions are common carnivores."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Explain the difference between a primary and secondary source.
### Response:
A primary source is an original source of information, such as an eyewitness account or a document written at the time of an historical event. Secondary sources are interpretations or analyses of primary sources, such as historical documents or interviews with an eyewitness. Secondary sources provide a different perspective on an event, while primary sources provide an unmediated view of the event."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Explain the purpose of hypertext markup language (HTML).
### Response:
Hypertext Markup Language (HTML) is a language used for creating web pages and applications. It is used to structure and present content for the web, including text, images, videos, and other forms of content. HTML is used to describe the structure of a web page, such as headings, paragraphs, lists, and links. It also describes how the content should be displayed on the web page."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Describe the differences between a substantive and procedural law.
### Response:
Substantive laws establish rules and regulations governing behavior and conduct, while procedural laws determine how the substantive laws will be enforced. Substantive law defines and regulates rights and duties, and typically consists of criminal, civil, and administrative laws. Procedural law focuses on how the legal system will handle disputes that arise under the substantive law by outlining the steps, rules, and procedures of civil and criminal courts."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Suggest three methods for recycling paper.
### Response:
Three methods for recycling paper are:
1. Composting: breaking down paper into soil-like material.
2. Repurposing: using paper to create new paper-based products or crafts.
3. Energy Production: using paper to generate electricity in incinerators or gasification plants."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Describe the color pink.
### Response:
The color pink is a soft, light hue, typically described as a pastel or baby pink. It is generally seen as a feminine color, sweet and romantic. It is often associated with innocence and love. It is also thought to be calming and can create a sense of accountability and acceptance. Pink is often considered the color of unconditional love, compassion, and understanding. It is also said to be the color of unconditional acceptance and unconditional understanding, inviting us to appreciate all the wonders of life."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Generate a rate for a driver for a ride sharing app for $5.
### Response:
The rate for a driver for a ride sharing app for $5 is 4.5 stars."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Come up with a social media campaign slogan.
### Response:
""Follow the Future - Bring your dreams to life with {Company Name}"""
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Compose a haiku with the provided subject.
### Input:
Spring
### Response:
Fresh petals fill the air / A new season has begun / Sunlight on the trees"
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Choose an appropriate introduction for the following news article.
### Input:
The latest report from the Environmental Protection Agency reveals that the emissions of greenhouse gasses in the state have risen by 5% from last year.
### Response:
The State has made little progress on curbing its emissions of greenhouse gasses, as the Environmental Protection Agency has reported that emissions have increased by 5% since last year."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Write a tweet about customer service.
### Response:
Customer service is key! Make sure you provide the best customer experience possible. #CustomerService #HappyCustomers"
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Generate a sound effect for a car passing by.
### Response:
The sound effect for a car passing by would be a low, rumbling rumble in the background that steadily increases in pitch and intensity as the car approaches before fading away."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Identify the type of the following musical chord.
### Input:
D minor
### Response:
The chord is a D Minor chord."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Name a planet from our solar system.
### Response:
Jupiter"
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Compute the sum of the following numbers.
### Input:
5, 10, 20
### Response:
35"
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Come up with a creative tagline for a beauty product.
### Response:
""The Beauty of Now - Unlock Your Radiance with {Brand Name}"""
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Describe how quantum computers work.
### Response:
Quantum computers use quantum bits, or qubits, instead of traditional bits to encode information. These qubits can work together in groups, allowing them to process and store data more efficiently than traditional computers. Quantum computers use quantum algorithms to enable them to solve complex problems that would be intractable on classical computers."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Generate a memorable quote from Albert Einstein.
### Response:
""Imagination is more important than knowledge."" - Albert Einstein."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Find the sum of the numbers 6 and 12.
### Input:
6 + 12
### Response:
18."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Transform the following sentence using the past perfect tense: Yesterday they opened the door.
### Response:
Yesterday they had opened the door."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Explain the uses of artificial intelligence.
### Response:
Artificial intelligence is used in a variety of applications ranging from self-driving cars to facial recognition software. AI is used to help automate processes and make decisions in ways that are faster and more accurate than humans. AI can also be used for predictive analytics, where computers can detect patterns in data and make predictions about what could happen in the future."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Describe a scenario in which blockchain technology could be successfully applied.
### Response:
Blockchain technology can be used for secure transactions and fast payments. For example, it could be used to store and process healthcare records, allowing secure and instantaneous sharing of information between doctors and patients. It can also be used for secure digital voting, allowing votes to be securely and accurately counted while still allowing voters to stay anonymous."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Complete the following analogy: Loud is to quiet as day is to
### Response:
Night."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Create an example of alliteration.
### Response:
Sweet slippery snakes."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Classify the following words by their grammatical categories: walk, interesting, quickly
### Response:
Verb: walk; Adjective: interesting; Adverb: quickly."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Find the greatest common factor of 12 and 18.
### Input:
12 & 18
### Response:
6."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Come up with a riddle
### Response:
What's full of keys but can't open a single lock?
Answer: A piano."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Identify the conjugation of the verb: I will have helped
### Response:
Future perfect."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
What is the first rule of storytelling?
### Response:
The first rule of storytelling is to hook the audience in the very first few sentences."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Rewrite the sentence into more descriptive form:
The food was delicious.
### Response:
The food was succulent and tantalizing to the taste buds."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Name 5 emotional states
### Response:
Joy, sadness, fear, anger, and disgust."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Create a funny one-liner.
### Response:
I used to think the brain was the most important organ. Then I thought, look what's telling me that!"
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Generate a list of fashion trends for Spring 2021.
### Response:
Spring 2021 fashion trends include bright colors, tie-dye and other prints, polka dots, pastels, boho style, flared jeans and trousers, utilitarian looks, earthy tones, sustainable fabrics, and cropped tops."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
What is the impact of deforestation on wildlife?
### Response:
Deforestation has a range of consequences for wildlife, including habitat loss, disruption of ecosystems and food webs, displacement of species, increased competition, and increased vulnerability to predation. Additionally, deforestation can increase the risk of climate change, resulting in altered temperatures and unpredictable weather patterns that further disrupt wildlife habitats."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Explain economics with an example.
### Response:
Economics is the study of how people and societies make decisions about production and consumption of goods and services. For example, a bakery may decide how much bread to produce and price it accordingly, depending on the prevailing market conditions, in order to maximize their profits."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Provide me a list of diseases that can be caused by smoking.
### Response:
Smoking can cause a range of diseases, including cancer, emphysema, chronic bronchitis, heart disease, stroke, and diabetes. Additionally, smoking can increase the risk of developing respiratory illnesses such as pneumonia, asthma, and bronchitis, and can increase the risk of birth defects and developmental delays in infants."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
What is the difference between machine learning and deep learning?
### Response:
Machine learning is a subset of artificial intelligence that uses algorithms to learn from data and improve performance on a task without explicit human programming. Deep learning is a type of machine learning that uses artificial neural networks to learn from large amounts of data and make predictions. Deep learning is more powerful and accurate than traditional machine learning, but also requires more computing power."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Describe a typical workday for a barista.
### Response:
A typical workday for a barista typically involves greeting customers, taking orders, preparing coffee drinks, cleaning and restocking, operating cash registers and making sure the area is kept clean and neat. They may also be responsible for making new drinks and running taste tests. Additionally, baristas may be responsible for food orders, setting up catering functions, and general customer service."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
How does the human brain remember information?
### Response:
The human brain stores information using networks of neurons that are connected via synapses. When an experience is remembered or recalled, these synapses increase the connections between neurons, which is how memories are encoded and stored. Additionally, the hippocampus serves as a gateway to the brain, helping to intervene in the formation and recall of memories."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
How does the internet of things (IoT) work?
### Response:
The internet of things (IoT) uses physical sensors and devices connected to the internet to collect data and automate processes. These devices can interact with each other and send data to be processed and analyzed. This allows for efficient and sophisticated monitoring and control, resulting in increased automation, insights, and responsiveness."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Give me an example of a conflict resolution technique.
### Response:
One conflict resolution technique is collaborative problem solving, which involves negotiating and finding a solution that both parties can agree on. This process involves understanding the issue, identifying the interests of both parties, exploring options and solutions, and finding a win-win outcome."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Pick out the correct noun from the following list.
### Input:
river, mountain, book
### Response:
River"
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Identify a programming language suitable for game development.
### Response:
C++ is a suitable programming language for game development, as it is a high-performance language that can handle complex calculations. Furthermore, it has good support for object-oriented programming and memory management, making it well-suited for creating sophisticated game engine features such as AI and physics simulation."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Make a list of different types of cryptocurrencies.
### Response:
Different types of cryptocurrencies include Bitcoin, Ethereum, Litecoin, Dash, Zcash, Monero, Dogecoin, and Ripple."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Create a tweet with the following hashtag.
### Input:
#SharingIsCaring
### Response:
We can all make a difference in the world. #SharingIsCaring. Let's work together to create a better future for everyone."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Rewrite the following sentence using the root words.
### Input:
I am not feeling well.
### Response:
I am not feeling good."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Combine the two sentences into a single sentence.
### Input:
He didn't go to the party. He stayed at home.
### Response:
He didn't go to the party, instead staying at home."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Split the following sentence into two separate sentences.
### Input:
He said hello and waved goodbye.
### Response:
He said hello. He waved goodbye."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Classify the following sentence as positive, negative, or neutral.
### Input:
I'm going to the store tomorrow.
### Response:
Positive."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Discover which word in the sentence carries the most weight.
### Input:
She ordered Chinese food for dinner.
### Response:
Dinner."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Rewrite the following sentence omitting the pronouns.
### Input:
She told us she was busy.
### Response:
Told busy."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Write a review of the restaurant.
### Input:
The restaurant is called La Taqueria.
### Response:
I recently visited La Taqueria and I was really impressed. The food was amazing and the service was excellent. The atmosphere was cozy and inviting and the staff were friendly and attentive to all the customers. Overall, I would highly recommend La Taqueria for an enjoyable, delicious, and satisfying dining experience."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Outline an itinerary for a three day trip.
### Input:
Location: London, England
### Response:
Day 1: Begin your day at St. Paul’s Cathedral, then take a leisurely stroll down to the bustling markets at Borough, followed by a cruise down the Thames. Afterward, walk through the lush greenery of Kensington Gardens and admire the beauty of Kensington Palace. End your day with dinner at one of London’s most iconic restaurants.
Day 2: Start the day with a visit to the historic Tower of London, followed by a scenic boat ride along the Thames. Afterward, head to the Tate Britain art gallery and explore the best of British art. Then, practice your photography skills at the beautiful Oxford Street and Hyde Park.
Day 3: Visit the famous British Museum, followed by a trip to the bustling and vibrant Covent Garden. Afterward, take a delightful walk to the iconic Big Ben, the most iconic clock tower in London. End the day with a quiet and cozy dinner surrounded by the views of the London Eye."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Classify the item as either animal or vegetable.
### Input:
Banana
### Response:
Animal: No, it's a vegetable."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Derive the mathematical equation for a straight line.
### Response:
y = mx + b, where m is the slope and b is the y-intercept of the line."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Describe the physical features of a tiger.
### Response:
Tigers are large, powerful cats with extremely strong muscles. They have short, reddish orange fur covered with dark vertical stripes. Their heads are darker with narrower stripes and the tail is long and the tip is usually white. They have large, padded feet and can weigh up to 660 pounds. Tigers' eyes are yellow with vertical, black pupils. They have sharp teeth and large, retractable claws."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Summarize the argument in the text.
### Input:
In the book ""Crime and Punishment"" by Fyodor Dostoevsky, the main character, Raskolnikov, commits a murder in hope of revealing a higher purpose.
### Response:
In ""Crime and Punishment"" by Fyodor Dostoevsky, the protagonist Raskolnikov commits a murder believing it will prove his Nietzschean idea that extraordinary people can rise above morality. Ultimately, however, he is not rewarded by society and instead is consumed by guilt, regret and suffering."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Generate ideas for a fiction story.
### Response:
Ideas for a fiction story could include a tale of forbidden love between two members of rival families, a story set in an alternate universe populated by supernatural creatures, a journey of self-discovery on a remote island, or a comedy about an unlikely couple who gets hired by a mysterious organization."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Describe the Renaissance period.
### Response:
The Renaissance period was a period of great change and creativity in Europe, starting in the 14th century and lasting through the 17th century. It was a time when people celebrated the classical values from Greek and Roman societies, sparking a renewed interest in the arts, science, philosophy, and politics. This period saw a dramatic shift away from the previous medieval worldview and ushered in a more humanistic and innovative perspective."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
List 5 items of personal protective equipment.
### Response:
1. Face shield
2. Hard hat
3. Safety glasses
4. Respiratory mask
5. Ear protection"
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Replace the single quote (') to double quote ("") in the given sentence.
### Input:
In the U.S., KIPP is a 'public-private partnership'.
### Response:
In the U.S., KIPP is a ""public-private partnership""."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Construct plumbing diagrams for a two-story house
### Response:
A typical two-story house requires a plumbing diagram which consists of two main components: a main valve system and branch lines running off the main valve system. On the main valve system, the water supply should stem from the municipally provided connection. The branch lines should lead to the fixtures (bathtub, sink, shower, etc.) installed in the two-story house. The branch lines may require T-splitters to regulate the flow and allow for multiple fixtures to be connected. Additionally, the drains should be connected to a single main drain line outlet leading to the septic tank or municipal sewage system."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Compare student debt crisis in the US and Canada.
### Response:
The student debt crisis is a major issue for both the US and Canada, although there are some differences between the two countries. In the US, student debt reached a record $1.5 trillion in 2019, with the average student owing around $32,600. In Canada, the debt situation is not as dire as in the US, but still a cause for concern. The average student debt in Canada is around $26,300, and total student debt reached over $35.4 billion in 2019. Canada does have some advantages compared to the US, such as more generous government loan programs which have allowed students to pay back the loans at lower rates. However, student debt in both countries has been steadily rising in recent years, and is likely to remain a major issue."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
List the benefits of Amazon Web Services.
### Response:
Amazon Web Services (AWS) is a cloud computing platform that provides a suite of services and infrastructure to organizations. Benefits of AWS include scalability, reliability, affordability, security, performance, and global availability. Additionally, AWS supports a range of operating systems and programming languages, offering users flexibility in how they build and deploy applications. Furthermore, AWS includes a range of features and services, including analytics, storage, compute, machine learning, AI, IoT, and serverless computing, so organizations can use only what they need, when they need it."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Generate a limerick poem about a lemur.
### Response:
There once was a lemur so spry,
Who loved to jump up in the sky.
He'd swing across trees,
With graceful ease,
And leave other creatures asking why."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Describe the functions of the Endoplasmic Reticulum.
### Response:
The Endoplasmic Reticulum (ER) is a network of membranes with functions in both protein synthesis and lipid metabolism. It is involved in the folding and modification of proteins and plays a role in the assembly of membrane proteins. It is also responsible for lipid metabolism, including the formation of lipids and their transport throughout the cell. It also serves as a storage organelle for calcium ions."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Summarize the industrial revolution.
### Response:
The industrial revolution was a period of major changes in manufacturing, agriculture, mining, transportation, and technology that began in the late 1700s in Britain and spread to Europe and North America. During this period, new manufacturing techniques, improved efficiency of steam power, and the invention of new machines, such as the power loom, made it possible to produce goods on a much larger scale than before. This transformation led to an increase in both population and economic growth, creating a new capitalist economy based on the production and sale of goods."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Rewrite the sentence, replacing the idioms with their literal meanings.
### Input:
We need to break the ice with the new team members.
### Response:
We need to create a comfortable atmosphere with the new team members."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Select the correct term for the phrase ‘the art of making things’
### Response:
The correct term for the phrase ""the art of making things"" is craftsmanship."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Identify any usage errors in the following sentence.
### Input:
We all need to take a walk on the wile side.
### Response:
The usage error in the sentence is that the phrase should be ""walk on the wild side,"" not ""wile side."""
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Explain the concept of net neutrality.
### Response:
Net neutrality is the idea that Internet Service Providers (ISPs) and governments should treat all data on the Internet equally. This means that ISPs cannot charge different prices for providing access to specific websites or services, and they cannot discriminate against or give preferential treatment to certain kinds of data. This ensures that everyone is able to access the same resources and content regardless of their income level or geographical location."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Brainstorm creative ideas for designing a conference room.
### Response:
Creative ideas for designing a conference room include incorporating flexible components, such as moveable walls and furniture, to make areas adjustable for different purposes. Using colors to create visual interest and subtly differentiate areas can also be helpful. Incorporating natural elements such as plants or art installations can create a more inviting and inspiring space, while providing adequate ventilation and natural light can help concentration and improve the conference room experience."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Calculate the area of a square with the sides of 10cm.
### Response:
The area of a square with sides of 10 cm is 100 square cm."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
List the countries that are in the Schengen area.
### Response:
The countries in the Schengen area are Austria, Belgium, Czech Republic, Denmark, Estonia, Finland, France, Germany, Greece, Hungary, Iceland, Italy, Latvia, Liechtenstein, Lithuania, Luxembourg, Malta, Netherlands, Norway, Poland, Portugal, Slovakia, Slovenia, Spain, Sweden, and Switzerland."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Describe the form and structure of a haiku poem.
### Response:
A haiku poem is a traditional form of Japanese poetry that typically consists of three lines. The first and last lines contain five syllables each, while the middle line contains seven syllables. The lines often evoke a single image, which contains a juxtaposition of two contrasting elements. The structure and language of haiku is often very simple and is intended to be an expression of a moment of epiphany."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Explain how a random forest algorithm achieves higher accuracy than individual decision trees.
### Response:
A random forest is an ensemble-based method of achieving higher accuracy than individual decision trees. It works by aggregating the predictions of multiple decision trees using an ensemble approach. Each of these decision trees makes an independent prediction, and the individual predictions are combined either by averaging the probabilities or by taking the majority vote. This approach reduces the variance of the predictions made by the decision trees, making the resulting predictions more accurate. Additionally, it also reduces the amount of overfitting incurred by the decision trees since it combines independent decisions made by each tree together, thus smoothing out any random fluctuations."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Give an example of a place where an endangered species of animal might be found.
### Response:
An endangered species of animal might be found in areas where their habitat has been conserved, such as national parks, wildlife preserves, or other designated areas. For example, the Florida panther can be found in the Florida Panther National Wildlife Refuge in Southwest Florida. Another example is the American bald eagle, which can be found in the Channel Islands National Park in California."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Create a pop quiz about clouds.
### Response:
1. What type of cloud is named after a mountain range?
A. Cirrus
B. Stratus
C. Cumulus
D. Nimbostratus
2. What type of cloud is associated with a rain shower?
A. Cumulus
B. Stratus
C. Cirrus
D. Altostratus
3. Which type of cloud is often described as looking like a pile of cotton balls?
A. Stratus
B. Altostratus
C. Cumulus
D. Nimbostratus
4. Which type of cloud has the tallest vertical growth?
A. Stratus
B. Cumulus
C. Altostratus
D. Nimbostratus
5. What are the two main ingredients clouds are made of?
A. Dust and water
B. Wind and water
C. Air and water
D. Ice and water"
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Explain why trade protectionism can hurt the economy of a country.
### Response:
Trade protectionism is the practice of protecting domestic industries from foreign competition by imposing tariffs or other restrictions. This practice can be detrimental to the economy of the country that implements it because it raises the cost of imported goods, making them less affordable to consumers. This decreases demand for those goods, leading to fewer sales and less income for the domestic producers. Protectionism may also reduce the incentive for domestic companies to innovate or become more efficient, leading to inefficiency in the market. Finally, protectionism may also create economic tension between countries, leading to retaliatory tariffs that further restrict trade."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Come up with a slogan to describe a new lipstick product.
### Response:
Find your Perfect Pout with our Perfectly Pioneering Lipsticks."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Describe how a Docker container works.
### Response:
A Docker container is an isolated environment in which applications can be packaged and run. It consists of the application, system libraries, and other configuration files necessary for a specific task. The container runs within a docker host, which isolates the container from other host resources and is responsible for managing its life cycle. Docker containers are lightweight and highly portable; they can be quickly spun up and transported to different environments such as cloud, bare metal, and on-premises. Containers are isolated from the underlying host system so they can be securely run and managed. Docker also uses images which function like snapshots – making it easy to deploy and run applications reliably and consistently across different environments."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Given an economic concept, define it in simple terms.
### Input:
Inflation
### Response:
Inflation is an economic concept that refers to the sustained rise in prices of goods and services. It is measured by calculating the rate at which the general level of prices for goods and services is rising, and it is usually calculated using a price index. When inflation is high, the purchasing power of currency decreases and the value of money diminishes."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Propose a transportation solution for a city with rapid population growth.
### Response:
A city with rapid population growth should consider investing in public transportation in order to alleviate traffic congestion. This could include buses, subway systems, light rail options, and even bike-sharing programs. These solutions are cost-effective and have the potential to reduce traffic and air pollution, as well as make it easier for people to get around. Additionally, in order to accommodate the increased demand for transportation, the city may also need to invest in infrastructure such as road expansion and parking lots."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Identify a potential security threat for a global online financial system.
### Response:
A potential security threat for a global online financial system is cybercrime. Cybercriminals often target online financial systems due to their complexity and the potential to gain access to sensitive data like financial information or credit card numbers. Cybercriminals may use methods like malware, phishing, and identity theft to gain access to a system and steal money or data. It is important for global financial systems to have robust security measures in place to protect against these threats."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Describe what it takes to be a successful manager.
### Response:
A successful manager is one who has strong leadership and communication skills, the ability to think strategically, and the knowledge and experience to stay up-to-date on industry trends and best practices. They should be organized and resourceful, with the ability to manage people, motivate employees, and inspire others. They should be able to create a culture of trust and respect, provide feedback and guidance, and create an environment for success. They should also be comfortable making difficult decisions, accountable for their actions, and willing to learn from their mistakes."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Arrange the given sentences into a well-structured paragraph.
### Input:
Many of the world’s problems can be traced back to a lack of education. People must be provided with a good foundation in education. Education has the power to provide societies with long-term solutions.
### Response:
Education has the power to provide societies with long-term solutions to many of the world’s problems. People must be provided with a good foundation in education in order to be able to make informed decisions and have the knowledge and skills necessary to tackle these challenges."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Construct a timeline for the coronavirus outbreak.
### Response:
December 2019: Initial Cases Reported in Wuhan, China
January 2020: Coronavirus has Spread to Multiple Countries
February 2020: World Health Organization (WHO) Declares a Public Health Emergency
March 2020: COVID-19 Declared a Global Pandemic
April 2020: Many Countries Begin to Reopen
May 2020: Vaccine Research & Development Begins
June 2020: WHO announces start of vaccine distribution to low-income countries
July 2020: Vaccinations Begin in Developed Countries
August 2020: Vaccine Trials Begin in the US
September 2020: New Virus Strains Appear
October 2020: Global Cases Pass 40 Million
November 2020: Vaccine Rollout Begins in US
December 2020: Virus Cases Reach an All-Time High"
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Compare and contrast two types of computer networks.
### Response:
There are two main types of computer networks: Local Area Networks (LANs) and Wide Area Networks (WANs).
LANs are typically used in small geographic areas such as businesses and homes, and involve connecting multiple computers in a single region using a common communications protocol. They are usually limited to a few miles in size and provide high-speed connections between users.
In contrast, WANs connect computers over large geographic areas and often span multiple countries. They use dedicated leased lines such as cables or satellite signals to connect multiple LANs together. As such, they are slower than LANs due to the distance involved.
Each type of network has its own advantages and disadvantages, and which network is more suitable will depend on the context of the given situation."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Describe how machine learning can be used to automate mundane tasks.
### Response:
Machine learning can be used to automate mundane tasks such as document classification, sentiment analysis, predictive analytics, and natural language processing. These tasks can be tedious and time-consuming for humans to do, but machine learning algorithms can perform them quickly and accurately. Machine learning can also be used for more complex tasks such as object recognition and autonomous driving, which require advanced algorithms and large amounts of data. Machine learning makes it possible to automate many tasks that would otherwise have to be done manually, saving time and energy."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Write a blog post on how to deploy machine learning models.
### Response:
Deploying machine learning models can seem intimidating at first, but once you break down the process, it’s surprisingly simple. Whether you’re deploying a model on your own production environment or pushing it to an existing deployment system, the steps to do so are straightforward. To make the process easier, we’ve outlined the most important steps for deploying a machine learning model.
First, you need to package your model. This means creating a container environment. You can use a platform such as Docker to quickly get a container setup. This will allow you to easily create a reproducible build environment that includes all of your model’s dependencies.
Next, you need to create a deployment environment. Typically, this would be a cloud-based platform such as Amazon Web Services. This allows you to easily provision compute and storage resources without having to manage them manually.
Third, you should set up a continuous integration system. This will allow you to easily test the model in production and get immediate feedback on the model’s performance. You can use Jenkins, Travis CI, or any other Continuous Integration (CI) platform.
Fourth, you should test and deploy the model. This is where you can use your CI system to test the model in a production environment. If the tests come back successful, you can deploy the model to production.
Finally, you should monitor the model for performance. This is especially important for machine learning models, as their performance can vary greatly from time to time. You can use a monitoring tool such as Splunk or Datadog to track different metrics such as accuracy rate and inference time.
By following these steps, you can deploy your machine learning model quickly and efficiently. If you need help with any of these steps, you can always reach out to an experienced team of engineers who can make sure your model is deployed correctly."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Classify the following sentence into one of the following labels: [positive, negative, neutral]
### Input:
My laptop seems to be slow today.
### Response:
Neutral"
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Generate a list of five elements for a grocery shopping list
### Response:
1. Eggs
2. Milk
3. Bread
4. Cheese
5. Bananas"
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Create a dialogue between a customer and a flight attendant for a plane ride
### Response:
Customer: Hi, I would like to inquire about the snacks available on the flight.
Flight Attendant: Of course! We have a selection of snacks available including chips, crackers, and candy bars. Would you like to purchase any snacks?
Customer: Yes, I would like to purchase a snack. Do you have any healthy options?
Flight Attendant: Yes, we offer a variety of healthy options such as yogurt, trail mix, and fruit. Would you like to choose any of those?
Customer: Yes, I'd like to purchase a yogurt. How much does it cost?
Flight Attendant: The yogurt costs $3. Would you like to purchase that?
Customer: Yes, I'd like to purchase the yogurt. Thank you!
Flight Attendant: You're welcome, here's your yogurt and have a great flight!"
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Generate a design specification for the following product
### Input:
Product: Coffee maker
### Response:
This coffee maker should be able to brew coffee from ground beans or pre-packaged coffee pods. It should have adjustable settings for cup sizes, brew strength, and temperatures. It should feature auto-shutoff, a digital timer, and an adjustable carafe. It should be constructed of stainless steel for easy cleaning and durability."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Evaluate the following statement
### Input:
AI is the new electricity.
### Response:
This statement is largely accurate. Just as electricity revolutionized industry in the 19th and 20th centuries, AI has the potential to revolutionize the way businesses operate in the 21st century. AI can automate processes and enable businesses to optimize operations, allowing them to reach higher levels of efficiency and productivity."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Compose a simple melody for the following lyrics.
### Input:
""I can't find the words to say, but I'm feeling OK""
### Response:
D-C-B-A-D G-A-G-F-E-D D-C-B-A-D E-G-A-G."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Suggest an alternative to the following sentence.
### Input:
The cat was walking around the house
### Response:
The feline was roaming around the abode."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Explain what a decision tree is.
### Response:
A decision tree is a graphical representation of possible solutions to a problem, based on certain conditions. It is a tool used to help people choose between multiple options by creating an organized visual map of the decision-making process. The tree branches out from a single root node to one or more end nodes, each containing a potential decision or outcome. Each node in the tree is an intersection in the branches, and these nodes represent a decision point. The branches from the nodes represent the possible outcomes that can happen based on a given decision, and the leaves signify the end of the tree. The decision tree is used to evaluate and predict outcomes in order to make informed decisions."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Design a function to count the number of unique characters in a string.
### Input:
string = “Butterflies”
### Response:
def count_unique_chars(string):
char_dict = {}
for char in string:
if char in char_dict:
char_dict[char] += 1
else:
char_dict[char] = 1
return len(char_dict)
print(count_unique_chars(""Butterflies""))
# Output: 9"
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Suggest a good screen capture tool for Mac.
### Response:
One of the best screen capture tools for Mac is Skitch. It is easy to use, and has powerful features such as annotations, markup tools, and cloud storage for easy sharing. It also allows for timed screenshots and has a built-in screenshot editor. In addition, you can save screenshots as an image or video file in various formats."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Summarize the main argument of the paper ""A Social Network that Influences Attitudes and Behaviors""
### Response:
The paper ""A Social Network that Influences Attitudes and Behaviors"" discusses how online social networks can influence people’s attitudes and behaviors. It suggests that online networks are capable of reaching more people than in-person networks, and that this can result in drastic alteration of attitudes and behaviors on a wider scale. The paper argues that certain individuals within networks can serve as influentials, having an outsize impact on opinions and behaviors of those around them, which has implications for how society functions. The paper further suggests that the study of online networks is a crucial area of research to better understand and predict social change."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Write a Python function that takes two integers and returns their least common multiple.
### Response:
def lcm(a, b):
if a > b:
greater = a
else:
greater = b
while(True):
if((greater % a == 0) and (greater % b == 0)):
lcm = greater
break
greater += 1
return lcm
print(lcm(15, 18))
# Output: 90"
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Rewrite the following paragraph in the active voice
### Input:
The new policy will be implemented by the employees in the management department.
### Response:
The management department employees will implement the new policy."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Generate three different ways to greet the user.
### Response:
1. Hi there!
2. Greetings!
3. Welcome!"
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Name one way to start a conversation with someone you don't know.
### Response:
A great way to start a conversation with someone you don't know is to introduce yourself and ask them questions about themselves. For example, you could say: ""Hi, I'm [Your Name], it's nice to meet you. What do you do for a living?"""
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Compose a poem about a single color.
### Response:
The color green, so serene and pleasing.
It reminds me why I keep believing.
The lush life brings me to feelings of delight
Seeing the world in all of its light.
The rolling hills and the trees so tall
The calming presence that they offer to all.
The vibrant grass that is sure to please
The softness of it I can't help but seize.
The evergreens that add to the scene
Bringing serenity and charm unforeseen.
The color green carries many memories
It is certainly one to keep close to me."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Provide the answer to the equation.
### Input:
7 + 6
### Response:
13"
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Write a limerick about a holiday.
### Response:
There once was a holiday rare
When people from all around did prepare
For a day full of joys
And many wonderful toys
Merry Christmas and happy Yuletide to share!"
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Provide a definition of the word ""vacillation"".
### Response:
Vacillation is the state of hesitating or wavering between decisions or actions. It is characterized by an inability to make a firm decision or commitment."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Write a haiku about the ocean.
### Response:
Endless waves, crashing ashore,
Peaceful blue depths, ancient lore.
Majestic ocean, evermore."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Organize the following words into a meaningful sentence.
### Input:
tall life the in
### Response:
Life in the tall is full of surprises."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Sort the following items into two categories.
### Input:
pencil, apple, phone
### Response:
Category 1: Pencil, Apple
Category 2: Phone"
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Rewrite the following sentence with more accurate grammar.
### Input:
She done a lot of good
### Response:
She has done a lot of good."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Name three government positions in the United States.
### Response:
Three government positions in the United States are President, Vice President, and Senator."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Improve the following sentence by using a better transition.
### Input:
We did not have enough time so we had to leave.
### Response:
Given that we had limited time, we had to leave."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Describe the character of Romeo from Romeo and Juliet.
### Response:
Romeo is a tragic hero with a passionate heart. He is brave and impulsive, often making decisions without fully thinking them through. He is deeply romantic and has a heartbreaking loyalty to his family and his beloved, Juliet."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Determine which statement is true.
### Input:
America is the third largest country in the world
Australia is the second largest country in the world
### Response:
Australia is the second largest country in the world."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Make a list of five items that you need to buy in a grocery store.
### Response:
A grocery list of five items could include eggs, milk, apples, bread, and cheese."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Name five societal advantages of the internet.
### Response:
Five societal advantages of the internet include improved access to information, better communication, increased global collaboration, enhanced opportunities for various jobs, and improved digital literacy. Additionally, the internet provides greater access to healthcare information, improved education, and more efficient online shopping. It also enables more efficient networking, more efficient business operations, and improved collaboration in the workplace. Finally, the internet has enabled the spread of culture, allowing people to connect and share ideas regardless of geography."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Re-write this sentence using an active voice.
### Input:
The boat was crashed by the captain.
### Response:
The captain crashed the boat."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Check if the following phrase is a well-formed formula
### Input:
∃x P(x)
### Response:
Yes, the phrase is a well-formed formula. It is a statement that there exists an x such that P(x) holds."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Describe the similarities and difference between cats and dogs.
### Response:
Cats and dogs are both domesticated animals that humans have kept as pets for thousands of years. They are both typically loving and loyal companions that offer affection and need attention. However, cats tend to be more independent and are much better climbers due to their retractable claws, while dogs typically require more interaction and require hands-on training. Cats generally weigh less, take up less space, and are easier to maintain in small living areas. Dogs, on the other hand, generally need more exercise and space, and may require more maintenance than cats."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Provide an example of how AI can solve a problem.
### Response:
AI can be used to help solve complex problems such as disease diagnosis, natural language understanding, autonomous vehicles, and image recognition. For example, an AI system can be used to diagnose cancer, by analyzing patient records and medical images for classification and early detection of disease. AI is also used for natural language understanding, by recognizing words and phrases and responding with intelligent advice and providing context for conversations between humans and computers. Autonomous vehicles use AI to navigate the roads, sense and avoid obstacles, and provide a safe, comfortable ride. Finally, AI can be used to recognize images and objects, by analyzing digital images and identifying patterns, colors, and objects."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Change the given verb to its past perfect form.
### Input:
take
### Response:
taken"
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
List five ways to reduce energy consumption.
### Response:
Five ways to reduce energy consumption include: unplugging electronic devices when not in use; turning off the lights when leaving a room; switching to LED or CFL lightbulbs; installing motion-detecting light switches; and using natural light through larger windows and skylights. Additionally, replacing old appliances with energy-efficient models and installing weatherstripping to reduce air leaks can also help to reduce energy consumption. Installing insulation and solar panels, upgrading to a smart thermostat, and reducing water waste can all contribute to a more efficient home and reduce energy usage. Finally, educating oneself on energy conservation and changing habits, such as turning off the tap while brushing one's teeth and washing clothes in cold water, can also help reduce energy consumption."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Name 6 components of an artificial neural network
### Response:
The components of an artificial neural network include input units, hidden units, output units, weights, biases, and activation functions. The input units are responsible for receiving the inputs from the data. The hidden units process the inputs and generate the outputs, while the output unit generates the output of the neural network. The weights and biases determine the strength of the connections between the units. Finally, the activation functions determine the output of the neural network based on the sum of the weighted inputs from the previous layer."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Using the provided information, build a SQL query to extract the top 10 highest valued orders.
### Input:
Table Name: Orders
Columns: ID (primary key), value, customer_id, date
### Response:
SELECT TOP 10 *
FROM Orders
ORDER BY value DESC;"
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Create a listicle using the given data.
### Input:
Topic: Tips for Financial Planning
List:
1. Set a budget
2. Track your spending
3. Invest in stocks
4. Pay off debts
### Response:
10 Tips For Financial Planning
1. Set a budget and stick to it. Knowing how much money you have coming in and out each month is the key to creating a sound financial plan.
2. Track your spending. Write down all of your spending so that you can get an accurate idea of where your money is going.
3. Invest in stocks. Investing in stocks is a great way to grow your money over the long term.
4. Pay off debts. Get rid of high-interest rate debt as soon as possible.
5. Make a savings plan. Setting aside a portion of your income every month is key to creating financial stability.
6. Stay on top of credit scores. Monitor your credit score to make sure you're getting the best deals on financial products.
7. Research tax credits and deductions. Knowing about the various tax incentives that are available can help you save money on income taxes.
8. Protect your assets. Invest in insurance for items such as your home, cars, and health.
9. Invest in retirement accounts. Retirement accounts are important for creating long-term financial security.
10. Seek expert advice. Financial advisors can help you make the most of your money and prepare for the future."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Answer this math problem.
### Input:
12/8
### Response:
1.5"
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Generate a list of 5 creative ways to use technology in the classroom.
### Response:
Five creative ways to use technology in the classroom include:
1. Using online collaboration tools such as Google Docs and Slack to facilitate group work and peer-to-peer learning.
2. Creating interactive multimedia lessons using video and audio tools like Prezi and YouTube.
3. Using virtual reality to explore concepts, bringing math, science and history to life.
4. Employing computer-aided design tools to create 3D models and animations.
5. Using augmented reality apps and games to spark students’ interest in various topics."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Describe the process of creating a website from scratch.
### Response:
Creating a website from scratch involves a number of steps. First, the website should be designed and planned out. This involves deciding on the purpose of the website, the target audience, the design style, and the structure. Next, the website needs to be built. This includes writing the code, choosing the right hosting platform, and creating the graphics and design elements. Finally, the website should be tested and launched. This includes verifying all of the links, testing the website on different platforms, and marketing the website to the target audience."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Name 3 countries that border France.
### Response:
The three countries that border France are Belgium, Luxemborg, and Germany."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Summarize the given article in 1-2 sentences.
### Input:
The recent Arctic temperature increase highlights the effects of climate change on the sensitive Arctic environment.
### Response:
The Arctic region is experiencing unprecedented higher temperatures, which is an indication of the effects of climate change on the sensitive polar environment."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Provide a summary for the passage given below.
### Input:
Artificial intelligence (AI) is a broad field that seeks to mimic or augment human capabilities through information processing technology and algorithms. AI has been an area of study since the 1950s, but has gained popular attention in recent years due to vast improvements in processing power. While some fear existential threats such as a Terminator-like hypothetical AI takeover, most of the practical applications of AI are in mundane areas such as image recognition, natural language processing, and task automation. AI is used to improve or automate mundane tasks, quickly identify patterns, and predict future events.
### Response:
AI is a field of study that aims to replicate or enhance human abilities through technology. Its applications are mostly mundane and revolve around task automation, pattern recognition and prediction of future events. However, there is a fear of possible existential threats due to its increasing capabilities."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Choose the most appropriate answer
### Input:
What is the most abundant gas in Earth's atmosphere?
A. Methane
B. Oxygen
C. Nitrogen
D. Hydrogen
### Response:
C. Nitrogen"
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Provide 3 practice questions for multiplication
### Response:
1. What is 9 x 8?
2. What is 5 x 10?
3. What is 6 x 7?"
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Provide an example of an antonym for the word “happy”
### Response:
Sad"
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Create an analogy using the following word
### Input:
cheetah
### Response:
He was as fast as a cheetah, darting around the track with graceful yet powerful movements."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Provide a topic for the following passage
### Input:
The vegan diet is becoming increasingly popular, as an increasing number of people are making the switch for environmental, ethical, and health reasons. People on a vegan diet consume only plant-based foods, such as fruits, vegetables, grains, nuts, and seeds. Veganism has also become popular with athletes, as many have discovered that a rich and varied vegan diet can help them reach their fitness goals.
### Response:
The Benefits of a Vegan Diet"
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Generate a story about a girl who visits an alien planet.
### Response:
Once upon a time, there was a young girl named Holly who wanted to explore the universe. She was on a mission to find a new planet to inhabit when she came across an alien planet called Situs. As she got closer, the alien planet seemed to come alive. Holly was filled with excitement and awe as she moved closer to the planet's surface. As she explored the foreign terrain, Holly encountered curious creatures and strange plants that were unlike anything she had ever seen before. She soon found herself in awe of the unknown and came to appreciate the beauty found on the alien planet."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
List five steps for comparing two products.
### Response:
1. Identify the product features to be compared.
2. Analyze each product's features individually.
3. Compare features side-by-side.
4. Calculate the cost-benefit ratio.
5. Make the final decision."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Perform a sentiment analysis on the given sentence.
### Input:
I love this movie!
### Response:
Positive sentiment."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Evaluate the following expression: (6+2)*(2-2).
### Response:
8"
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Find the temperature of boiling water at sea level.
### Response:
100 °C."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Outline the events of the following movie: The Great Gatsby.
### Response:
1. Jay Gatsby throws lavish parties in hopes of winning the heart of Daisy Buchanan.
2. Nick Carraway, Daisy’s cousin, looks on as Gatsby and Daisy reunite.
3. Gatsby and Daisy plan to run away together.
4. Tom Buchanan discovers their plans and confronts Gatsby.
5. Daisy decides to stay with Tom, leaving Gatsby heartbroken.
6. Gatsby is killed by George Wilson.
7. Daisy realizes the depth of Gatsby’s love for her too late and is consumed with guilt.
8. Nick reconsiders his opinions of Gatsby and realizes what a great man he was."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Calculate the area of a triangle with the following sides: 10, 14, 8.
### Response:
The area of the triangle is 36 sq. units."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Outline a strategy for increasing website traffic.
### Response:
1. Increase content creation.
2. Optimize content for search engines.
3. Build a network of back links.
4. Leverage social media platforms.
5. Run email campaigns.
6. Create a promotion plan.
7. Monitor analytics to track performance."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Make a list of four styles of furniture.
### Response:
- Contemporary
- Rustic
- Modern
- Scandinavian"
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
List four strategies for teaching children to read.
### Response:
1. Provide age appropriate reading materials.
2. Encourage children to read aloud.
3. Use multimedia resources such as audio or video to stimulate interest.
4. Introduce new words and discuss the meaning."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Compute the derivative of 2x^2 + 5x.
### Response:
4x + 5."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Describe the process of osmosis.
### Response:
Osmosis is the process by which molecules of a solvent, such as water, move through a semi-permeable membrane from an area of high concentration to an area of low concentration. The movement of water molecules is driven by differences in the solute concentration levels on either side of the membrane. As the solute concentration of one side of the membrane becomes greater than the other, the solvent molecules will move from the less concentrated side toward the more concentrated side until equilibrium is reached."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Describe a tool used for debugging a program.
### Response:
A debugger is a tool used to help identify errors in a program's code. It allows programmers to step through the code line by line and analyze data structures, variables and memory in order to identify bugs and fix them. Debuggers may also be used to search for coding errors, detect infinite loops and monitor program run times."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Edit the following sentence to eliminate any grammar errors: They tried to fix the car all day.
### Response:
They tried to fix the car all day."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Compare and contrast the two pieces of software, Microsoft Word and Google Docs.
### Response:
Microsoft Word and Google Docs are both word processing programs used to create documents. Microsoft Word is a traditional software program that comes on the Windows operating system and must be purchased for use. Google Docs is a cloud-based application that is offered as part of the Google Docs suite. Microsoft Word offers more direct control over page formatting and design, while Google Docs offers real-time collaboration and cloud storage. Both programs offer robust features including tables, images, formatting, and more."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Select the most appropriate word from the list.
### Input:
joyful, joyous, festive
### Response:
joyous"
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Write a humorous joke.
### Response:
Q: What did the fish say when he swam into a wall?
A: Dam!"
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Put together a business plan for a new restaurant.
### Response:
The new restaurant will be located in a vibrant and high-traffic part of town. It will offer a broad menu of delicious and reasonably priced meals along with an excellent selection of drinks. In addition to the restaurant, there will be a takeout and catering service available. The atmosphere will be warm and inviting and will feature art from local artists. The business plan aims to build a sustainable and profitable business. The budget includes start-up costs and ongoing expenses such as rent, insurance, salaries, marketing, and utilities."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Devise a strategic plan for a fashion brand to increase its online presence.
### Response:
The strategic plan for the fashion brand should include setting up an online presence on major social media platforms (e.g., Facebook, Instagram, Twitter) and creating engaging content which could include news on fashion trends and tips, interviews of fashion designers, and visuals of the fashion products in action. By leveraging the advantages of social media, the fashion brand can increase its visibility and reach a larger customer base. Additionally, the fashion brand should consider utilizing search engine optimization tools and tools to monitor the website’s performance to ensure better search engine rankings."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Choose the correct answer.
### Input:
Who wrote the novel ""Jane Eyre""?
### Response:
Charlotte Bronte"
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Write a definition for the word ""meander"".
### Response:
To meander means to move in a winding or curving manner, usually through a certain area. This word can be used to describe a physical movement but can also be used to describe a figurative or philosophical journey."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Determine a price point for the item.
### Input:
Widget
### Response:
The price point for the widget should be $19.99. This is an affordable and competitive price point, while also giving the company a good margin."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
List five of the main characters in the movie.
### Input:
Titanic
### Response:
The main characters in the movie Titanic include Jack Dawson, Rose DeWitt Bukater, Caledon 'Cal' Hockley, Ruth DeWitt Bukater, and Fabrizio De Rossi."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Compare and contrast the 3 most popular sports in the U.S.
### Response:
American football, basketball, and baseball are the three most popular sports in the United States. American football emphasizes physicality and strategy, with a large emphasis on blocking, tackling and advancing the ball down the field. Basketball, on the other hand, is more reliant on athleticism and agility, with quick reflexes and accuracy necessary for successful shooting and ball handling. Finally, baseball relies heavily on skill, with the ability to hit, throw and catch a ball being the primary focus of the game. Overall, all three sports require teamwork, dedication and skill."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Write 3 facts about the Tour de France
### Response:
- The Tour de France is an annual three-week long road cycling race held in France.
- It is one of the most prestigious and challenging cycling events in the world.
- It usually covers 2,180 to 2,200 miles (3,500 to 3,700 km) over a mix of flat, hilly, and mountainous terrain."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Describe the 1981 NBA MVP award ceremony
### Response:
The 1981 NBA MVP award ceremony took place in June of that year. The award was presented to Julius Erving at the banquet, held at the Spectrum in Philadelphia. Erving made a speech, thanking his coaches and teammates for helping him reach his goal. The audience cheered and applauded for Julius, bringing a joyful atmosphere to the event. This memorable ceremony was certainly a great honor for Erving."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
List 5 different fruit
### Response:
- Apples
- Bananas
- Oranges
- Grapes
- Strawberries"
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Rewrite the following sentence:
""The candidate is a highly motivated individual""
### Response:
The candidate has an intense desire to succeed and to reach their goals."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Name 4 different types of art
### Response:
- Painting
- Sculpture
- Photography
- Film/Video"
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
What is the history of the Tour de France?
### Response:
The Tour de France is the most prestigious cycling event in the world. Its history began in 1903, when the first event was held over a distance of roughly 2,000 kilometers (1,200 miles) with just 60 competitors. The race has evolved over the years, becoming a staple of the summertime sports calendar. Today, the Tour de France covers over 2,000 miles and includes over 189 of the world's top cyclists competing for the title of winner."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
In 50 words or less, describe the type of atmosphere a modern basketball game
### Response:
A modern basketball game is filled with excitement and entertainment. The atmosphere of the arena is buzzing with adrenaline as the players electrify the crowd. Cheers and chants fill the stands as the game progresses, with die-hard fans hoping for their team to prevail. All in all, a single basketball game has the potential to ignite the passionate soul of sports fandom."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
What is black box testing and why is it important?
### Response:
Black box testing is a type of software testing in which the functionality of an application or program is tested without looking into its internal construct or design. This type of testing is important to gauge the accurate performance of a system. It also tests the usability and reliability of the application and is used to identify and rectify any bugs or errors in the code."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
How can we use machine learning to improve sports coaching?
### Response:
Machine learning can be used to improve sports coaching by analyzing and recognizing patterns in player performance, game strategy, and team dynamics. This technology can be used to develop tailored coaching recommendations for each athlete, as well as create predictive models for the most successful game strategies. Machine learning can also be used to provide the coach with real-time feedback on team and individual performance."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
List 5 benefits of playing sports
### Response:
- Improved physical health.
- Increased mental acuity and knowledge.
- Stress relief and better emotional well-being.
- Building teamwork, cooperation, and leadership skills.
- Fostering social skills, such as communication and sportsmanship."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Describe the impact of the Tour de France on the history of cycling
### Response:
The Tour de France has had an enormous influence on the history of cycling. By bringing together some of the world's cycling luminaries to compete in an epic race across France, the Tour de France has set the stage for countless more races both big and small to follow in its footsteps. In addition, it has helped to elevate cycling to a mainstream sport and has helped to launch the careers of many of today's cycling stars."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Shape the following sentence into a question:
The Houston Rockets are an American professional basketball team
### Response:
Which American professional basketball team is the Houston Rockets?"
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
How can analytics be used in sports?
### Response:
Analytics can be used in sports to better understand team and player performance. Data can be used to identify trends in play, such as which players are most successful in different situations, which strategies work best, and how teams can optimize their performance. Analytics can also be used to monitor player health and well-being, enabling coaches to better manage player fatigue and injury prevention."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Write a paragraph describing a sporting event
### Response:
The energy of the crowd was palpable as they filled the stadium. Everyone was on their feet and cheering as the athletes entered the arena. The anticipation in the air was palpable. The game was an intense match between two rivals and it went into overtime. In the end, the athletes from one team emerged victorious, and the stadium erupted with joyous cheers. After the ceremony, fans gathered and celebrated the triumph of their favorite team. It was truly a remarkable sporting event."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Fill in the blank with a word or phrase
The most successful team in the NBA is the ____
### Response:
Los Angeles Lakers"
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Generate 2 sentence of a conversation that takes place between the manager and the customer.
### Input:
Noinput
### Response:
Manager: ""Good morning, how can I help you?""
Customer: ""I'm looking for a new laptop. Do you have any recommendations?"""
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Mention two ways in which a business can use Artificial Intelligence.
### Input:
Noinput
### Response:
Businesses can use artificial intelligence to automate data-driven activities such as customer service tasks and core operational activities like supply chain management. AI can also help businesses better leverage customer data and make personalized recommendations, allowing companies to increase revenue and improve customer loyalty."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Tell a story about a girl who travels to the moon.
### Input:
Noinput
### Response:
Once upon a time, there was a girl named Sarah who dreamed of going to the moon. She studied astronomy and spent her evenings looking up into the night sky, wondering how she could make her dream a reality. One day, an opportunity arose, and Sarah was able to embark on a spaceship journey to the moon. When she got there, she was amazed by the bright stars and craters she saw—a sight she was sure she would never forget. She decided to take a piece of the moon back with her as a reminder of her incredible journey."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Summarize a given poem in max 5 sentences.
### Input:
The poem ""The Sun Rising"" by John Donne
Noinput
### Response:
John Donne's poem ""The Sun Rising"" presents an argument to the sun that its light is not needed because the poet and his beloved are content in their love even when the sunrise is not visible. He claims that he and his beloved form the ""world"" and that their love will continue despite the sun's release of its light. The poem ends with words of assurance to the sun that their love will last forever and that their world will remain unchanged even if the sun withdraws its light."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Give a brief answer to the following question.
### Input:
What is the difference between a Ponzi scheme and a pyramid scheme?
### Response:
The main difference between a Ponzi scheme and a pyramid scheme is in the way they operate. Ponzi schemes rely on a single entity or person to fool people out of their money, while pyramid schemes rely on participants recruiting new members to increase their earnings. In a Ponzi scheme, the fraudster will solicit funds from new investors and use the money to pay back earlier investors; in a pyramid scheme, members receive money from new participants recruited below them, resulting in a chain of recruitment."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Describe how technology has changed the way we work.
### Input:
Noinput
### Response:
Technology has drastically changed the way we work, allowing us to be more productive and efficient. The internet, for example, has made research, communication and collaboration easier than ever before. Automation technologies have made it possible to streamline and optimize workflows, resulting in higher quality work and improved customer service. Cloud computing has revolutionized data storage and access, allowing businesses to access their data from anywhere. Finally, AI and machine learning have allowed businesses to make data-driven decisions and predictions much more quickly than ever before."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Generate a valid opening statement for a speech about the importance of voting.
### Input:
Noinput
### Response:
Good morning everyone! Today I'm here to talk to you about the importance of voting. I'm sure you have all heard the phrase ""your vote counts"" - and this is true. Even if it doesn't seem like it, your vote can have a drastic effect on how our election turns out. So, I urge all of you to use your voice and make your vote count!"
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Create a to-do list for a given holiday.
### Input:
Thanksgiving
### Response:
- Set a date for Thanksgiving dinner
- Start shopping for ingredients
- Send out invites
- Plan activities
- Start decorating for the occasion
- Research recipes
- Plan menu
- Buy wine
- Set up tables and chairs
- Purchase paper plates and cups
- Make a grocery list
- Ask family to bring a dish
- Set up bar area
- Create a seating chart
- Make a timeline of events
- Make a post-dinner cleanup plan
- Clean the house
- Prepare food
- Have fun!"
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Find a sentence that can be used to explain why someone should not use a particular product.
### Input:
Laser Hair Removal
### Response:
Although laser hair removal might seem like a quick and easy way to get rid of unwanted body hair, it can cause skin damage and should always be used with caution."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Generate an opening statement for a speech about the effects of climate change.
### Input:
Noinput
### Response:
Good morning everyone! Today I'm here to talk to you about the effects of climate change and how it will impact not only our environment and health, but also our society, our economy and our future. Climate change is an ever-present and growing threat to our planet, and as citizens of the world, it is essential that we take action to reduce our environmental impact."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Find a sentence that could be used to close a speech about the causes of global warming.
### Input:
Noinput
### Response:
We all have a part to play in addressing the causes of global warming, so I urge each and every one of us to take part in the fight against climate change."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Give an example of how technology is used in education.
### Input:
Noinput
### Response:
Technology has transformed education in many ways, such as providing students with better access to learning materials, allowing educators to tailor lessons to the individual needs of each student, and enabling students to collaborate with other students more easily. For example, online course management software can be used to organize course content, provide assignments and grading opportunities, and facilitate communication with students."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Generate two sentences of a conversation that takes place between two shop owners.
### Input:
Noinput
### Response:
Shop Owner 1: ""How has business been going since we reopened?""
Shop Owner 2: ""It's been going better than expected. We've seen a lot of customers coming back and have had a steady stream of new customers as well."""
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Generate a question based on the following input.
### Input:
Humans are the dominant species on Earth.
### Response:
What are the reasons behind humans being the dominant species on Earth?"
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Given a person's name, provide their job title
### Input:
Emmeline Pankhurst
### Response:
Emmeline Pankhurst is remembered as a leader of the British suffragette movement and an advocate for women's rights."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Given a set of lyrics, explain the meanings implied by them.
### Input:
The night is young and we could go wild
### Response:
The lyrics imply that there is potential for freedom, excitement and adventure in the night ahead. This suggests that the speaker and their companion are young and open to experiencing new possibilities."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Improve the following sentence by making necessary changes.
### Input:
John and his wife are best friends.
### Response:
John and his wife are best friends and enjoy spending time together."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Remove any mistakes in the following sentence.
### Input:
Everyone whoing to play must sign their name.
### Response:
Everyone who wants to play must sign their name."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Categorize the following items as either furniture or kitchen items.
### Input:
Chair, Knife, Fork
### Response:
Furniture, Kitchen item, Kitchen item"
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Compare and contrast the following two items.
### Input:
Table and Chair
### Response:
A table and a chair are both pieces of furniture, but they have different functions. A table is typically used for dining or work purposes, while a chair is something people sit in. Tables tend to be much larger than chairs and have flat surfaces, whereas chairs generally have an upright design and are made for one person to sit."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Provide a cause-and-effect explanation for the following statement.
### Input:
The pandemic has led to a significant increase in online shopping.
### Response:
The pandemic caused people to stay at home in order to avoid potential exposure to the virus, thus leading to an increase in online shopping. With more people shopping online, the demand for online purchases went up and businesses responded by offering more online options. As a result, online activity has increased significantly."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Rewrite the following sentence by replacing all the words with synonyms to make the sentence clearer.
### Input:
Quite a few people alleged that the criminal had committed a serious offence
### Response:
Several individuals asserted that the perpetrator had perpetrated a grave transgression."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Read the following story and decide if it is fiction or non-fiction.
### Input:
A farmer grows a mysterious flower overnight. The farmer is amazed and decides to sell the plant in the market. People from far and wide visit the farmer's market to get a glimpse of the miraculous flower.
### Response:
Fiction."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Rewrite the following sentence by adding one adjective.
### Input:
The student was able to understand the difficult concepts.
### Response:
The student was able to grasp the arduous concepts."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Analyze the following political statement and determine its accuracy.
### Input:
Many people agree that the current president has been a successful leader.
### Response:
The accuracy of the statement depends on one's political views. Some people may agree with it while others may not."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Take two words and create a completely new word by combining them.
### Response:
Brainbow - the ability to use knowledge and imagination to create something of great value."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Write a one-sentence summary of the following news article.
### Input:
The extraordinary measures taken by the government to control the spread of Covid-19 have significantly decreased the number of daily infections in the past month.
### Response:
The implementation of strict public health policies has effectively curtailed the prevalence of Covid-19 cases."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Edit the following sentence to make the punctuation and capitalization more accurate.
### Input:
the baker made the best cookies ive ever eaten
### Response:
The baker made the best cookies I've ever eaten."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Create a short poem using the word ""moon"".
### Response:
Softly glows the moon in the night sky,
Its light is twinkling, it never dies;
It is a beacon in the darkness,
Providing us with an endless light."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Suggest a title for the following blog post.
### Input:
This blog post discusses how technology has changed the way people communicate over the last decade.
### Response:
""The Impact of Technology on Communication in the Last Decade"""
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Rewrite this sentence by removing the cliche.
### Input:
She was full of energy, as if she had drunk a liter of coffee.
### Response:
She was brimming with enthusiasm, as if she had received a boost of energy."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Price the following item.
### Input:
A limited edition, handmade wooden toy truck
### Response:
The limited edition, handmade wooden toy truck is priced at $150."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
List five advantages of using solar energy.
### Response:
1. Solar energy is renewable and sustainable.
2. Low ongoing costs and no fuel expenses.
3. Generates no pollution or noise.
4. Easily scalable for different types of applications.
5. Solar energy is widely available in most regions."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Generate an example of a travel destination in your favorite country.
### Response:
My favorite travel destination in Australia is Fraser Island, located on the eastern coast."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
State the conclusion based on the passage.
### Input:
The Institute for Economic Footings has predicted that the global economy will start to recover in the second half of 2021.
### Response:
The conclusion based on the passage is that the global economy is expected to begin to improve during the second half of 2021."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Create an example of a web page.
### Response:
My web page contains a header at the top of the page displaying my name, links to my social media profiles, and a welcome message. Below that there is a container containing links to the different sections of the page such as my blog, portfolio, and contact page. There is also a footer section where I display my copyright information."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Suppose that an employer asks for three years of working experience for an advertised job. Explain why the requirement is reasonable.
### Response:
The requirement for three years of working experience is reasonable because it allows employers to assess the applicant's problem-solving skills, communication skills, and ability to work independently. This can help them to determine if the applicant has the experience and knowledge necessary to excel in their job."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Explain the meaning of the phrase ""actions speak louder than words"".
### Response:
The phrase ""actions speak louder than words"" means that words without corresponding action are not as meaningful or effective. It suggests that it is better to demonstrate what you believe with your behavior, rather than just talking about it."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Brainstorm some ideas for a fictional novel.
### Response:
Ideas for a fictional novel include: a high school student discovers they have special abilities, a government conspiracy threatens the life of an unsuspecting village, a family is forced to confront their traumas of the past, a group of strangers find themselves stuck in a mysterious town, a tech genius is tasked with stopping a dangerous AI weapon, a young woman embarks on a quest to save her kingdom, a group of misfits use advanced technology to save the world."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Describe the benefits of exercise.
### Response:
Exercise can offer a variety of benefits. It can help improve mental health, such as reducing stress and anxiety, as well as improving mood and sleep quality. It can also help with physical health, such as aiding with weight loss, building muscle, and increasing energy levels. Exercise has also been found to improve heart health, prevent certain types of illnesses, and can even reduce the risk of certain cancers."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Submit a description of a important event in your life.
### Response:
An important event in my life was when I graduated from university. After four years of hard work, I was filled with pride and a sense of accomplishment as I stepped onto the stage to receive my degree. It was the result of dedication and perseverance, and it showed me that nothing is impossible if you put your mind to it."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Identify the right type of tense used in the sentence.
### Input:
I am cooking dinner
### Response:
present continuous tense"
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Create a list of three tips for public speaking.
### Response:
Three tips for public speaking include: 1) Prepare ahead of time by rehearsing your speech and familiarizing yourself with the topic; 2) Speak clearly, using pauses to emphasize important points; and 3) Practice making eye contact with the audience to better engage them."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Categorize the following sentence as either factual or opinion-based.
### Input:
Math is a difficult subject
### Response:
Opinion-based"
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Classify the following tweet topic
### Input:
""I'm so excited to visit my family in India!""
### Response:
Family"
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Generate a suitable slogan for the following company
### Input:
ACME Corporation is a logistics company with a focus on shipping vehicles and other international freight.
### Response:
""Let ACME take you around the world!"""
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Categorize the following tweet content
### Input:
""I love reading books! Good books make my life so much better""
### Response:
Leisure"
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Design a suitable query for the following question
### Input:
What are the five most important elements in a website homepage?
### Response:
SELECT TOP 5 Elements FROM Homepages ORDER BY importance DESC;"
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Generate a correct formula to calculate surface area of a triangle
### Response:
Surface Area = (b·h)/2
where b = base and h = height of the triangle"
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Compose a story based on the following facts
### Input:
Facts:
- There is a family who have lived in the countryside for generations.
- They are so far isolated that they had no clue about the world outside of their small village.
- One day a traveler visited them and introduced them to technologies, books and new ideas.
### Response:
In the small and isolated village, there lived a family. This family had lived in the countryside for generations and they had no knowledge of the world outside their boundaries. But one day, a traveler arrived with a few books and gadgets. He introduced them to technologies far superior than anything they had ever witnessed before. He opened their eyes to layers of knowledge from books and ideas that made them question their world. It was this visitor who introduced them to the world outside and showed them the power of progress."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Generate an appropriate follow-up question for the following statement
### Input:
""I like to go hiking on the weekends""
### Response:
Where do you usually go hiking?"
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Compose a tweet about successful teamwork
### Response:
Teamwork is key! Working together in harmony can lead to miraculous accomplishments. #success #teamwork #harmony"
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Convert the money value to USD.
### Input:
2.30 euros
### Response:
2.30 euros is equivalent to $2.76 USD."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Generate a metaphor that describes the situation.
### Input:
A hardworking student trying to finish an assignment on time.
### Response:
The student is like a marathon runner pushing towards the finish line."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Calculate the volume of a cylinder with a radius of 10 cm and a height of 5 cm.
### Response:
The volume of the cylinder is 785 cm3."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Specify the filename for the following document.
### Input:
The document contains instructions on how to set up a home Wi-Fi network.
### Response:
WiFi_setup_instructions.doc"
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Construct a concise summary of the following article.
### Input:
The article is about the recent findings on the impacts of climate change, including rising temperatures and elevated sea levels, and risk associated with it.
### Response:
Recent studies have revealed that climate change is advancing, with increased global temperatures and sea levels, resulting in more extreme weather and increased risks associated with natural disasters."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Provide an example of the use of the word ""tentative"".
### Response:
He made a tentative plan to move to a new city next month."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Create a table that illustrates the results of a survey.
### Input:
The survey asked people to rate a new website on a scale of 1-5, with 1 being poor and 5 being excellent.
### Response:
| Rating | Percentage |
| ------ | ---------- |
| 1 | 10% |
| 2 | 20% |
| 3 | 30% |
| 4 | 25% |
| 5 | 15% |"
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Classify each sentence as either declarative, interrogative, imperative, or exclamatory.
### Input:
Why would you do that?
### Response:
Interrogative."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Write a soliloquy for a character in the following scene
### Input:
The scene is set in a medieval castle, where a knight is preparing for battle.
### Response:
Oh mighty sword, thou of renowned strength, grant me the courage and will to battle with valor. Let me face tomorrow's fight fearlessly, and with grace may I accept whatever outcome comes."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Construct a list containing at least ten items.
### Input:
Items you need to pack for a camping trip.
### Response:
1. Tent
2. Sleeping bag
3. Flashlight
4. Camping stove
5. Cutlery and utensils
6. Water container
7. Matches or lighter
8. Compass
9. First aid kit
10. Food and snacks
11. Extra clothes
12. Personal care items."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Change the underlined word to make the sentence correct.
### Input:
The tomatoes are ripe for pick.
### Response:
The tomatoes are ripe for picking."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Generate a new ending to the story.
### Input:
Once upon a time, there was a young prince who wanted to explore the world. He embarked on a journey full of adventure and discovery.
### Response:
After many months of exploring strange lands, seeing wondrous sights, and meeting unusual people, the prince finally returned home. He was enriched by the experiences he had, and while he did not find what he was looking for, he found something much more valuable: a deeper appreciation for the beauty of the world and the value of companionship."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Write a story about a doctor and his patient
### Response:
Dr. Wilkins had been a doctor for many years. He had seen many patients come and go, but he had a special fondness for one particular patient. This patient had come to him seeking help with a troubling medical problem. The doctor had been able to provide relief and, over the years, the two had developed a close bond. As the patient recovered, their relationship evolved from doctor-patient to something more. They started to meet up after the patient's appointments and went out for coffee or a stroll in the park. The patient was grateful for the doctor’s help, both physical and emotional, and the doctor was moved by his patient’s hard work and determination. In the end, their friendship had grown into something greater and at last, the doctor and his patient were in love."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Find the synonym of the word ""loathe""
### Response:
Hate, detest, despise, abhor, abominate, detest."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Describe a type of bird
### Response:
Kookaburra is a medium-sized bird found in Australia. It is often called the ""laughing bird"" because of its distinctive call which sounds like loud, echoing laughter. Its colorful feathers include bright blue and chestnut on the wings and back, white on the breast and neck, and a decorated tail. It feeds on a variety of insects and small reptiles, as well as fruits and nuts."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Write a math equation to find the geometric mean between two numbers
### Input:
10 and 15
### Response:
The geometric mean of 10 and 15 is \(\sqrt{10\times 15}=12.25\)."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Classify this sentence as either a declarative or interrogative
### Input:
Do you agree
### Response:
Interrogative."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Make a list of the eight planets in our solar system
### Response:
The eight planets in our solar system are Mercury, Venus, Earth, Mars, Jupiter, Saturn, Uranus, and Neptune."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Generate an analysis of the book To Kill a Mockingbird
### Response:
To Kill a Mockingbird is a beloved classic which shines a spotlight on the injustices present in the Jim Crow South. Through narration by its young protagonist Scout, the reader is exposed to the racism and prejudice deeply rooted in the community. Scout's father Atticus Finch serves as the moral center of the novel, embodying the values of courage and justice. The themes of loss of innocence and standing up against racism are reflective of the tumultuous timeframe during which the novel is set. To Kill a Mockingbird is a timeless classic that continues to impact readers to this day."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Reverse this array: [1, 2, 3, 4, 5]
### Input:
[1, 2, 3, 4, 5]
### Response:
[5, 4, 3, 2, 1]"
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
What is the chemical formula for water?
### Response:
The chemical formula for water is H₂O."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Explain the term ""impeachment""
### Response:
Impeachment is the process of bringing formal charges against a public official in order to remove that person from office. It is performed by an organization, such as a legislature, in order to investigate allegations of misconduct, and can result in removal of the official from office if sufficient evidence is found."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Choose the right antonym
### Input:
Discreet/Flaunt
### Response:
Discreet/Flaunt
Antonym: Discreet/Show off."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Rewrite this sentence in the present tense
### Input:
She had cooked
### Response:
She cooks."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Compose a poem about loneliness.
### Response:
I am alone in the night,
The silence a heavy burden to bear.
The stars so bright,
But none to share.
The memories still linger,
Of those who've gone away.
The heart feels a certain sting,
To face the darkness of the day.
But in the silence there's something sweet,
An opportunity to reconnect with me.
It's in this moment I find my peace,
Where I find strength and see what must be.
I may not have others by my side,
But I will never be left wanting.
For being alone is a beautiful thing,
And precious moments that life is granting.
So embrace the loneliness,
Allow it to be your guide.
And slowly you will find solace,
In the depths that it can provide."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Create a new Twitter profile for a medical doctor.
### Response:
This is the Twitter profile for Dr. Susan Jones, M.D., a medical doctor dedicated to providing premium healthcare services to her patients. At her state-of-the-art facility, Dr. Jones offers personalized treatment, preventative care, and assessments to ensure the highest level of care. She also provides educational content to help her patients stay informed and safe. Follow her page to stay up to date with the latest medical news and to learn more about healthcare and wellness. #DoctorJones #MedicalDoctor #Healthcare #Wellness #HealthyLiving #HealthyLifestyle #MedicalAdvice #HealthTips #HealthEducation #HealthyHabits #MedicalUpdates #Medicine #WellnessTips #PatientSafety #PreventativeCare #Diagnosis #HealthAwareness #Prevention #MedicalTreatment #PrimaryCare #PrimaryCarePhysician #Medicine #MedicineUpdates #WellnessJourney #PersonalizedTreatment #PremiumHealthcare #HealthSeniorCare #HealthSeniorAdvice #AdvanceCarePlanning #DoctorAdvice #DoctorResources #PatientPrivacy #MedicalEthics"
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Suggest an effective marketing strategy for a TV show.
### Response:
One effective marketing strategy for a TV show is to create a teaser trailer to be released ahead of the show's premiere on television and other digital platforms. The teaser trailer should be short, dynamic, and compelling in order to trigger curiosity and interest in viewers. It should also contain a compelling tag line or ""hook"" that summarizes the show's premise. Additionally, creating a hashtag associated to the TV show and asking viewers to join the conversation on social media will help increase engagement and exposure of the show. Additionally, creating influencer campaigns, running sponsored promotions and contests on social media, and creating original digital content associated to the show will also help increase engagement and create a larger fan base."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Categorize the following items into vegetables and fruits.
### Input:
Orange, Carrots, Onion, Bananas
### Response:
Vegetables: Carrots, Onion
Fruits: Orange, Bananas"
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Construct a web address for a book recommendation website.
### Response:
book-recommendations.com"
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Explain the purpose of a satellite in two sentences.
### Response:
A satellite is a man-made object that orbits the Earth and is used to receive and transmit signals, images, and data. It is also used for communication, navigation, and surveillance purposes."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Invent a new game involving strategy.
### Response:
The game involves two players taking turns playing on a 6x6 board. Each player has two pieces, one of which is the King and the other is the General. The goal is to get your King to the other side of the board, while protecting the General and keeping it from being taken by the other player. The pieces have different abilities, the King can move in any direction, while the General can only move one space in any direction. The game is won when a player's King reaches their opponent's side of the board. The strategy of the game involves planning ahead and making smart moves to ensure your pieces don't get captured by your opponent. The player who captures the opponent's King first, wins."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Calculate the total cost of the following items.
### Input:
3 laptop - $1100 each, 2 monitors - $200 each
### Response:
The total cost of the laptops and monitors is $3900."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Discuss the most important effects social media has on society.
### Response:
Social media has had a major impact on society, both positively and negatively. On the positive side, it has enabled people to easily connect and share information with others. It has also been an invaluable tool in sharing news and perspectives across the globe. On the negative side, it has been linked to a decrease in attention spans, as well as an increase in mental health issues as it leads to higher levels of comparison, loneliness, and cyberbullying. Additionally, it has been used to spread misinformation and alternative facts, leading to a greater level of mistrust and discord."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Create a chart displaying the following data.
### Input:
Duration of sleep in hours:
Person A: 6
Person B: 7
Person C: 8
### Response:
Person | Duration of Sleep (in hours)
------|--------------------------
A | 6
B | 7
C | 8"
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Describe the difference between plagiarism and copyright infringement.
### Response:
Plagiarism is the passing off of someone else's work as one's own without crediting the original author or creator, while copyright infringement is using or reproducing someone else's work without approval or permission from the copyright owner. Plagiarism is considered an ethical and academic violation and can lead to serious consequences, while copyright infringement is a violation of law and can lead to fines and other legal action."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Tell me an alternative joke that is similar in spirit to the following.
### Input:
Q: What do you call an alligator in a vest?
A: An investigator.
### Response:
Q: What do you call a bear with no teeth?
A: A gummy bear."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Hypothesize why Australia has over 140 snake species.
### Response:
One of the main reasons why Australia has over 140 snake species is its large geographic area and wide range of climates. Australia is a large island continent with a huge variety of habitats. This climate diversity provides a rich and diverse ecosystem, allowing snakes to live in many different climates and make the most of the diverse food sources available. Additionally, many of Australia’s species of snakes have evolved over time to adapt to different climates and occupy new habitats. This has allowed them to become well adapted to living in Australia and to survive in ever-changing environments."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Cut the following sentence into two, keeping the meaning intact.
### Input:
He came out of the house and suddenly remembered he had forgotten to bring his wallet.
### Response:
He came out of the house and suddenly remembered. He had forgotten to bring his wallet."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Generate a list of items related to the topic given.
### Input:
Scuba diving
### Response:
Items related to scuba diving:
- Wet Suit
- Fins
- Snorkel
- BCD (Buoyancy Control Device)
- Mask
- Regulator
- Dive Computer
- Dive Knife or Cutting Tool
- Weight Belt or Jacket
- Under Water Flashlight
- Cylinder and Air Tank
- Torch
- Dive Log Book
- Compass"
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Structures the following instructions into a step by step guide.
### Input:
Initiate a conversation with someone on LinkedIn for job related advice.
### Response:
Step by Step Guide for initiating a conversation with someone on LinkedIn for job related advice:
Step 1: Identify who you want to reach out to - Think about the career advice you need, and search for LinkedIn profiles of people who could provide that advice.
Step 2: Take a look at their profile - Read through the person’s profile to get to know them better – their background, credentials, the topics they’re interested in, and the types of conversations they’ve had in the past.
Step 3: Create an engaging message - Craft an engaging message that conveys your interest, explains why you’re reaching out and makes a request or asks a question.
Step 4: Send the message – Send the message and wait for a response.
Step 5: Follow up as needed – If you don’t get a response right away, follow up with a polite reminder and most times, you’ll get a response."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Explain why the following statement is true.
### Input:
A successful sales pitch should engage the potential buyer.
### Response:
A successful sales pitch should engage the potential buyer because engaging them helps build trust and rapport. When potential buyers are engaged, they are more likely to listen to the salesperson and understand the value and benefits offered by the product or service. An engaging sales pitch is also more likely to help the potential buyer come to a conclusion, as they are more likely to be actively participating in the conversation. Engaging potential buyers also helps salespeople gain insights on their potential customers and how to best tailor their pitch to their needs."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Create a story about a parrot.
### Response:
Once upon a time, there was a magical parrot living in the jungles of South America. His feathers were an array of colors, including bright yellow, fiery red, and deep blue. He was said to have been sent down from the heavens to serve as a guide to the people of the jungle.
The parrot had a knack for languages and could speak human words with perfect clarity, becoming the go-to translator for the people of the jungle. He was also very intelligent, able to solve puzzles and understand complex concepts.
One day, the parrot was sent on a mission to deliver a message from the gods to a particular tribe in the jungle. As he flew through the air, he noticed something curious. Below him, the tribal people were gathering around a mysterious object. As he flew closer, he saw that the object was a magical crystal ball.
He descended and entered the circle of tribal people, hoping to catch a glimpse of the magical crystal ball. As he gazed upon it, a bright light shone from the crystal and he suddenly heard the voice of the gods. The gods had chosen him as their messenger. From then on, the parrot spread their wise words and blessed the people of the jungle.
And that is the story of the magical parrot of the South American jungle."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Generate a narrative for describing the following event.
### Input:
A balloon ceremony
### Response:
It was an emotional event as hundreds of people gathered to take part in a special balloon ceremony. It was a time to honor and recognize those who have gone before us and a time to celebrate the lives of those who are still here.
The sky was filled with brilliant colors as the air was filled with the sounds of laughter, tears, and joy. One-by-one, the crowd released balloons into the air bearing special messages to their loved ones.
The balloons carried the message of love and hope to the heavens above. People of all ages, from all walks of life, looked up to the sky with wonder and amazement. As the balloons disappeared in the distance, everyone there knew that a part of them were being carried away and will remain in the hearts and minds of their loved ones forever.
It was a beautiful reminder of the power of love and the ways in which it can help us connect with those are no longer with us. As the ceremony ended, everyone felt a renewed sense of hope and peace."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Write a tweet about the following topic.
### Input:
Motivation
### Response:
Let's all tap into our inner motivation & power this week! #MotivationMonday #MondayMotivation #BeMotivated"
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Categorize the following sentence as a statement, a question or an exclamation.
### Input:
Let's get to it.
### Response:
Statement."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Describe the benefits of having a mentor.
### Response:
Having a mentor can provide tremendous benefits, including guidance, advice, support and connection to a network of contacts. Mentors can offer valuable feedback, help to create goals and strategies, and provide the accountability necessary to carry out the desired goals. They can also provide a fresh perspective which can help to create new ideas and solutions."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
List the steps to write a 10-page essay.
### Response:
The steps to writing a 10-page essay involve:
1. Gathering and researching information
2. Planning a logical structure for the essay
3. Writing an outline of the essay
4. Writing the introduction and body paragraphs
5. Crafting a compelling conclusion
6. Rewriting and refining the essay
7. Editing and proofreading the essay."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Identify a tool that can be used to calculate risk.
### Response:
One tool that can be used to calculate risk is a decision tree diagram. A decision tree diagram is a graphical representation of the potential risks associated with a decision. It helps visualize the different paths available and their potential outcomes, making it easier to identify and manage the risks associated with a decision."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Suggest a method to optimize a website’s performance.
### Response:
One method to optimize a website's performance is to minimize the number of HTTP requests by reducing the size of files and combining multiple files into one. Other methods include caching, minifying HTML, CSS, and JavaScript code, optimizing images, compressing files, and using a content delivery network."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Present an argument for why writing a cover letter is important.
### Response:
Writing a cover letter is an important step in the job application process as it gives employers a chance to learn more about the applicant. It can be used to demonstrate knowledge of the role, the company, and the industry, while also showcasing relevant skills and experiences. A good cover letter also provides a professional first impression, which can give an applicant a competitive edge over other job seekers."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Propose a strategy to build an effective landing page.
### Response:
A strategy to build an effective landing page is to design a page that is easy to scan, visually appealing, and speaks directly to the target audience. The page should have a clear headline that informs users of the page’s purpose. It should also contain helpful, relevant information and a compelling call to action. Additionally, it should leverage A/B testing to test different versions of the page to assess its effectiveness."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Explain the differences between a variable and a constant.
### Response:
A variable is a data value that can be changed, while a constant is an unchanging value. Variables can be numbers, strings, booleans, arrays, or objects, while constants must always remain the same. Variables are typically used in programming to hold values that can change, while constants are used to define values that will always remain the same, such as mathematical equations or limits in a program."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Describe the role of a project manager
### Response:
The role of a project manager is to lead a team of people in order to meet a project’s objectives. They are responsible for planning, organizing, directing and controlling the activities of the project. This includes setting goals, developing a detailed plan of action, coordinating resources and overseeing progress towards completion. The goal of a project manager is to ensure the project is completed on time, on budget, and according to the standards set."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Come up with a use case for an AI-driven chatbot
### Response:
An AI-driven chatbot can be used to provide 24/7 customer service for a business. It can answer basic customer inquiries quickly and accurately, freeing up customer service representatives to handle more complex issues. It can also be used to gather data and provide personalized recommendations, improving the customer's experience."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Outline the key differences between the Linux and Windows operating systems.
### Response:
The key differences between the Linux and Windows operating systems are as follows:
1. Linux is open-source, while Windows is proprietary.
2. Windows is easier to use and has a graphical user interface, while Linux requires more technical knowledge and has a command-line interface.
3. Linux is more secure due to its design and open-source nature, while Windows is susceptible to malware and viruses.
4. Linux is more customizable than Windows, allowing users to modify and tweak the operating system to their specific needs.
5. Windows is more compatible with certain hardware and software, while Linux may require more manual configuration and tweaking."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Construct a persuasive argument for why a business should invest in SEO.
### Response:
A business should invest in SEO because it is essential for driving organic traffic to the website and improving visibility in search engine results. SEO helps to ensure the website appears in relevant search queries, and therefore, can help businesses reach a larger audience. Investing in SEO also increases website engagement and can help to build trust with potential customers as it shows a commitment to quality. Finally, SEO can result in a significant return on investment in terms of increased traffic and leads, as well as increased sales."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Give an example of a miscommunication between two people.
### Response:
An example of a miscommunication between two people is when one person suggests doing something and the other person misunderstands and thinks they are being asked to do something else. For example, if someone suggests going out to eat and the other person believes they are being asked to cook dinner."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Summarize the ethical implications of using facial recognition technology.
### Response:
The ethical implications of using facial recognition technology include issues of privacy, accuracy, and potential misuse. Facial recognition technology can infringe on privacy rights by collecting personal biometric data and potentially being used to surveil citizens. It can also be inaccurate, leading to false positives and misunderstandings in its identification of individuals. Additionally, there are concerns that it could be used for purposes other than for security, such as for tracking or profiling people, leading to potential misuse and discrimination."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Based on the following passage, determine the author’s attitude towards the idea that speed is the most important factor in production
### Input:
The focus on speed in production today is often misguided. Technical proficiency and craftsmanship can take a backseat to the urgency to finish a project quickly. This can be detrimental to the quality of the product, as the diligent worker is not going to be given the time to fix any mistakes that might arise from haste.
### Response:
The author holds a negative attitude towards the idea that speed is the most important factor in production. They argue that the focus on speed often comes at the expense of technical proficiency and craftsmanship, resulting in lower-quality products. Additionally, the author implies that speeding up production can be detrimental, as the worker does not have sufficient time to fix any mistakes. This indicates that the author believes speed should not be prioritized over quality and craftsmanship."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Construct a vocab list for an AI-powered chatbot.
### Response:
A vocab list for an AI-powered chatbot might include the following words: greetings (hello, hi, hey, etc.), questions (what, when, why, how, etc.), affirmations (yes, no, absolutely, sure, etc.), commands (open, close, stop, start, etc.), requests (can you please, can I, help me, etc.), and emojis. Vocab lists help the chatbot understand the user's intent and provide more accurate and natural responses."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Given a list of six grocery items, select the two most expensive items
### Input:
eggs, flour, milk, bananas, cherries, coffee
### Response:
Coffee and cherries are the two most expensive items in the list."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Describe the differences between machine and deep learning
### Response:
While both machine learning and deep learning are subfields of artificial intelligence, there are differences between the two. Machine learning algorithms rely on a series of manually crafted features and labeled data to train models. Deep learning models, on the other hand, are able to learn complex relationships between data points without the need for manual feature engineering. Deep learning is also capable of multi-layered learning, meaning it can learn multiple abstractions and relationships in the data, while machine learning is often limited to a single layer. Additionally, deep learning models have recently achieved impressive results on many tasks such as object recognition and natural language processing."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Generate a sentence that uses the word ‘zephyr’
### Response:
The zephyr wound its way through the fields, bringing a cool breeze with it."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Based on the following philosophy passage, determine the author’s primary argument
### Input:
If we are to believe in our most fundamental capacities for understanding the world, we must first pause to look inward and discover our own subjective values and beliefs. Only by recognizing our own subjective universe can we hope to progress forward to a more objective understanding.
### Response:
The author's primary argument is that in order to gain a more objective understanding of the world, we must first look inward to recognize our own subjective values and beliefs. They argue that only by understanding our own cognitive biases and tendencies can we hope to gain a true and unbiased understanding of the world."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Given a list of four CEOs, choose the one who had the most successful tenure
### Input:
Mark Zuckerberg, Bill Gates, Elon Musk, Jeff Bezos
### Response:
Jeff Bezos had the most successful tenure as a CEO, as he has increased Amazon's market value from $2.5 billion in 1997 to $1.6 trillion in 20"
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Explain the physics concept of projectile motion.
### Response:
Projectile motion is a type of motion in which an object is thrown at an angle and moves in a curved path under the influence of gravity. It is a special type of two-dimensional motion in which the object experiences constant acceleration due to the force of gravity. The path of the projectile is parabolic in nature, with the object forming the highest point of its trajectory called the apex. The parabolic path is known as a trajectory, and the maximum height reached by the projectile is called the maximum height. As the object falls, its speed decreases and it eventually lands on the ground."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Write a function to convert Fahrenheit to Celsius
### Response:
def F2C(F):
C = (F-32)*(5/9)
return C"
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Compute the area of triangle from the given 3 sides
### Input:
side1=3, side2=4, side3=5
### Response:
6"
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Prepare a statement of cash flows for the given business.
### Input:
Net income: $ 7,500
Cash flow from operations: $1,200
Cash flow from investing: $2,100
Cash flow from financing: $3,200
### Response:
Cash flow statement:
Net increase in cash: $7,500
Cash flow from operations: $1,200
Cash flow from investing: $2,100
Cash flow from financing: $3,200
Net cash flow: $6,500"
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Summarize the given paragraph in two sentences.
### Input:
David was born in 1980. He grew up in a small town in Canada and was an enthusiastic student. He pursued a degree in engineering in a local college and was a star student.
### Response:
David was born in a small Canadian town in 1980 and was an outstanding student in college, where he pursued a degree in engineering. He was an enthusiastic learner and a shining star in his college."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Come up with a name for this new product.
### Response:
NovaLaunch"
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Calculate the surface area of a cube from the given side length.
### Input:
a=4
### Response:
64"
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Change the sentences from active voice to passive voice.
### Input:
She will write the report.
### Response:
The report will be written by her."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Compute the median age of the given list of ages.
### Input:
15, 68, 20, 41, 28
### Response:
29.5"
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Convert the given time (in minutes) to hours and minutes.
### Input:
125
### Response:
2 hours and 5 minutes"
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Order these countries based on their population size
### Input:
Canada, Mexico, Brazil
### Response:
Brazil, Mexico, Canada"
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
List the most recent five books that Mark Twain wrote.
### Response:
The most recent five books written by Mark Twain are:
1. Letters From the Earth (1909)
2. What Is Man? And Other Philosophical Writings (1917)
3. The Mysterious Stranger and Other Stories (1916)
4. Mark Twain's Autobiography (1924)
5. Mark Twain's Notebooks & Journals (Vol. 1, 1935)"
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Write an algorithm to find the minimum element in an array.
### Response:
Step 1: Declare an array A.
Step 2: Initialize min to A[0].
Step 3: Loop through the array A starting from index 1.
Step 4: Compare the element A[i] with min.
Step 5: If A[i] is less than min, set min equal to A[i].
Step 6: Return min."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Identify the taxonomic classification for humans.
### Response:
Humans belong to the kingdom Animalia, phylum Chordata, class Mammalia, order Primates, family Hominidae, and genus Homo."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Translate the phrase ""I love you"" into Spanish.
### Response:
The phrase ""I love you"" translated into Spanish is ""Te quiero""."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Write a summary of the book ""The Catcher in the Rye"".
### Response:
The Catcher in the Rye is a novel by J. D. Salinger, published in 1951. It tells the story of Holden Caulfield, a teenage boy who is struggling to find his place in an adult world. The novel follows Holden as he tries to make sense of the world around him, including his relationships with family and friends, and his interactions with society. Ultimately, Holden realizes the importance of growing up and accepting responsibility. He learns the hard way that rejection and defeat form a part of life, but by the novel's end, he is able to face life with a renewed attitude."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Create a 5-item shopping list for a healthy breakfast.
### Response:
Shopping list for a healthy breakfast:
1. Whole wheat bread
2. Eggs
3. Fruit of your choice
4. Natural peanut butter
5. Greek yogurt"
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
What is the formula for calculating the area of a triangle?
### Response:
The formula for calculating the area of a triangle is A = 1/2 * base * height."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Read the article and identify the central idea.
### Input:
Here is the article.
India is a country of varied cultures, languages, and religions. Each of these elements co-exist peacefully here, giving India its unique and rich identity. People from different backgrounds live in harmony and form strong bonds of friendship which are the foundation of our great nation.
### Response:
The central idea of the article is that India is a country of diverse components, including cultures, languages and religions, which peacefully exist together and form strong bonds of friendship."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Suggest 4 entertaining activities one can do with friends on a weekend.
### Response:
Here are 4 entertaining activities one can do with friends on a weekend:
1. Have a game night
2. Go to a movie
3. Go bowling
4. Have a picnic"
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Construct a sentence using the present tense of the verb ""eat"".
### Response:
I eat breakfast every morning."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Generate a list of 10 adjectives that describe the color blue.
### Response:
The list of adjectives for the color blue is:
1. Azure
2. Oceanic
3. Turquoise
4. Steely
5. Electric
6. Royal
7. Cobalt
8. Cerulean
9. Sapphire
10. Lapis"
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Explain the significance of the Battle of Gettysburg.
### Response:
The Battle of Gettysburg was an important battle during the American Civil War, fought between the Union and the Confederate armies in Gettysburg, Pennsylvania on July 1–3, 1863. It was a pivotal battle which resulted in heavy losses; the Union lost an estimated 23,000 men, while the Confederate was estimated to be 28,000 men. The victory ensured that the Union forces maintained control of the North, while the Confederate forces were forced to retreat. In addition, it marked the end of General Robert E. Lee’s invasion of the North, thus ending the Confederates' hopes of winning the war.
The Battle of Gettysburg was considered to be a major turning point in the Civil War, and is often referred to as one of the bloodiest battles in American history."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Delete the 2nd, 4th, and 5th element of the following array: [1, 2, 3, 4, 5, 6, 7].
### Response:
The array after deleting the specified elements is: [1, 3, 6, 7]."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Name two advantages of using a distributed database.
### Response:
Using a distributed database has many advantages, such as increased speed and flexibility, improved scalability and availability, and improved fault tolerance.
Firstly, distributed databases allow users to access data faster. This is because data is broken up into smaller chunks and stored across multiple servers, allowing faster access and retrieval. This increases overall performance and user satisfaction.
Secondly, distributed databases provide improved scalability and availability. As data is divided across several servers, it can easily be scaled up as the amount of data increases without having to start from scratch. Additionally, if one server goes down, other servers will continue to operate so that data is still available. This improves system reliability and data safety.
Finally, distributed databases have improved fault tolerance. This is because the data is mirrored across multiple servers which reduces the risk of data getting lost or corrupted due to the failure of a single server. With this system in place, even if one server fails, the data will still be safe and accessible."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Describe a situation where a chatbot would be more useful than a human assistant.
### Response:
A chatbot would be more useful than a human assistant in situations that require quick responses or large-scale customer support, such as customer queries, sales inquiries, or financial transactions. Chatbots can provide immediate, accurate, and personalized responses, helping to automate customer service tasks, allowing users to get the information they need quickly and conveniently.
For example, a chatbot could be used in a customer service setting to ask the customer their query, collect all the necessary data from the customer, and then provide the customer with a solution or direct them to the proper channels for further support. This saves time for both the customer and the human customer service representative, as the chatbot can provide a quicker, more effective response to the customer query.
In addition, chatbots can also be used for large-scale customer support and marketing. For example, a chatbot can be used to send targeted promotions or personalized messages to customers, helping businesses to reach their customers quickly and easily, without having to use a large customer service staff. This can help businesses to perfect their customer outreach strategies and enhance customer service."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Create a dialogue between two colleagues discussing a project they are working on.
### Response:
Colleague 1: Hey, how's the project going?
Colleague 2: Hey there! It's going well. I've finished the first two drafts and I'm now doing some small tweaks. What about you?
Colleague 1: I'm almost done too. Just have to make sure all the contents are organized. Should be done in a few days.
Colleague 2: Alright, that sounds great! I'll check my work with you when you're done and make any final changes.
Colleague 1: Sounds like a plan. We should get this project finished in no time."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Name five countries with the most number of UNESCO World Heritage sites.
### Response:
1. Italy (54 sites) 2. China (52 sites) 3. Spain (48 sites) 4. France (45 sites) 5. Germany (43 sites)"
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Create a recipe for a Creamy Tomato Soup.
### Response:
Ingredients: 1 onion, diced; 2 cloves garlic, minced; 2 tablespoons olive oil; 28 ounces canned crushed tomatoes; 2 cups vegetable or chicken stock; 1 teaspoon dried oregano; 1 teaspoon dried basil; 1/2 teaspoon sugar; 1/2 teaspoon salt; 1/4 teaspoon ground black pepper; 1/2 cup heavy cream.
Instructions:
1. Heat the olive oil in a large pot over medium heat. Add the onion and garlic and cook until soft, about 3 minutes.
2. Add the crushed tomatoes, stock, oregano, basil, sugar, salt, and pepper. Bring to a simmer and cook for 15 minutes.
3. Remove from heat and stir in the cream.
4. Puree with an immersion blender or in two batches in a blender until smooth.
5. Return to pot and bring to a simmer if necessary. Serve hot."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Describe the economic system of the United States.
### Response:
The United States operates under a mixed economy, which is a system that combines free-market capitalism with governmental, economic regulations. This system allows businesses to compete in a free, competitive market while protecting consumers and providing employment and safety regulations. Additionally, the government provides social services, including education, health care and infrastructure. In this way, it seeks to balance the needs of both the market and society."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Build a bridge between two islands.
### Response:
The bridge should be designed with the correct engineering and materials. Considerations should include the size and weight of the bridge, the location of the two islands, environmental factors, and the types of materials best suited for construction in the given location. For example, a floating bridge is best suited for watery areas, while a steel bridge is recommended for areas with higher traffic. Careful planning, engineering, and construction will help ensure the bridge is secure, safe, and durable."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Create a table of ten of the world's wealthiest people.
### Response:
Name | Net Worth (USD)
------------------------------|-----------------
Jeff Bezos | 179.3 billion
Bill Gates | 128.3 billion
Bernard Arnault | 113.7 billion
Warren Buffett | 107.5 billion
Mark Zuckerberg | 84.8 billion
Amancio Ortega | 83.7 billion
Larry Ellison | 72.7 billion
Larry Page | 57 billion
Steve Ballmer | 50.5 billion
Mukesh Ambani | 50.5 billion"
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Determine the median of the following group of numbers:
### Input:
8, 22, 11, 47
### Response:
11"
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Tell me about the seasons in the temperate forest biome.
### Response:
The temperate forest biome experiences four distinct seasons--spring, summer, autumn, and winter. During the spring, the weather is typically warm, rainy, and mild. The summer brings hot temperatures and plenty of sunshine. The fall brings cooler temperatures and increased precipitation. Lastly, the winter is typically cold and rainy.
The vegetation in these forests is also largely influenced by the change in seasons. Many plants and animals will flourish in the spring, while some may go dormant in the summer or winter."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Convert 28 cm to inches.
### Response:
11 inches"
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Predict the weather in Los Angeles tomorrow.
### Response:
Tomorrow in Los Angeles is expected to be mostly sunny with a high of 80 degrees and a low of 65 degrees."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Create a plan for a budget-friendly Thanksgiving meal.
### Response:
For a budget-friendly Thanksgiving meal, plan to serve the traditional holiday favorites in an economical way. Begin with stuffing, mashed potatoes, and gravy, then include simple dishes like green beans, corn, cranberry sauce, and rolls. For a tasty dessert, consider a homemade pumpkin or pecan pie. When possible, try to buy seasonal ingredients, and be sure to plan ahead to minimize food waste."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Spell the word ""xylophone"".
### Response:
X-Y-L-O-P-H-O-N-E"
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Create a list of five influential people in the given field, along with a brief description of each person.
### Input:
Art
### Response:
1. Leonardo da Vinci – An Italian Renaissance polymath, known for his masterful artworks.
2. Michelangelo – A sculptor and painter known for creating magnificent frescoes and statues.
3. Rembrandt – A Dutch painter, draughtsman and printmaker and one of the most important figures in art history.
4. Pablo Picasso – A renowned Spanish painter, sculptor and ceramicist, who revolutionized art in the 20th century.
5. Vincent van Gogh – A Post-Impressionist painter, whose fame reached its peak after his death."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Identify what type of machine learning technique would be applicable for the given task description.
### Input:
Given a large dataset of images, create a model that can accurately classify the images.
### Response:
The applicable machine learning technique for this task would be a Convolutional Neural Network (CNN). CNNs are typically used for image classification tasks and are able to detect patterns in visual data."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Suggest how to improve the execution of a program given the demo results.
### Input:
The program is supposed to generate images from sketch inputs, but the published results are low-resolution and have some blurred lines when compared to the original sketch.
### Response:
The program can be improved by increasing the resolution of the generated images. This can be achieved by adding more layers in the deep learning model and increasing the size of the input image. Additionally, the parameters of the deep learning model, such as learning rate and optimizer – can be fine-tuned to get better results."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Generate a paragraph based on the given information.
### Input:
In the year 2025, the United Nations is working hard to reduce its carbon emissions by 50%.
### Response:
The United Nations is taking its climate initiatives seriously in the year 2025 and is working hard to reduce its carbon emissions. To achieve this goal, the organization is taking various steps such as encouraging the adoption of renewable sources of energy, introducing energy-saving measures in buildings and factories, and promoting sustainable agricultural practices across the globe. Furthermore, the UN is making use of the latest technological innovations such as electric vehicles, efficient air conditioning systems, and effective waste management systems to reduce its greenhouse gas emissions by 50%."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Classify the given items according to their family.
### Input:
Pigeon, Duck, Swallow
### Response:
Pigeon – Bird
Duck – Bird
Swallow – Bird"
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Analyze the given sentence and identify its grammatical errors, if any.
### Input:
These type of problems are difficult to solve.
### Response:
The sentence has a grammatical error, as ‘these’ should be followed by a singular noun or pronoun. The correct sentence would be: This type of problem is difficult to solve."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Identify the concept behind the given statement.
### Input:
It's better to give than receive.
### Response:
The concept behind the statement is generosity and altruism."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Transform the given statement into an imperative one.
### Input:
I would like you to clean your room.
### Response:
Clean your room."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Suggest an example that best represents the given concept.
### Input:
Generosity
### Response:
An example of generosity would be someone who volunteers their time to help out at a charity."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Edit the sentence to make formal.
### Input:
It looks altogether like the situation will be getting worse.
### Response:
It appears that the situation will likely be deteriorating further."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Generate a pseudocode for sorting an array.
### Response:
a. Set a pointer low to the first element in the array
b. Set a pointer high to the last element in the array
c. While the low pointer is less than the high pointer
d. If the element at the low pointer is higher than the element at the high pointer
i. Swap the elements
ii. Increment the low pointer by 1
iii. Decrement the high pointer by 1
e. Repeat step c until the low pointer is equal or higher than the high pointer
f. Sort the elements in the subarray between the two pointers using the same procedure
g. Repeat until the subarray is fully sorted"
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Ask the assistant to book a flight from Boston to Miami for June 9th.
### Response:
I'd like to book a flight from Boston to Miami for June 9th."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Find the name of the author of this book.
### Input:
Book: The Cat in the Hat
### Response:
The author of the book ""The Cat in the Hat"" is Dr. Seuss."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Give me a synonym for the word 'love'.
### Response:
Affection."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Add the following text to the document.
### Input:
Text:
It is clear that the current economic crisis has impacted a large number of people.
### Response:
The document now includes the text: ""It is clear that the current economic crisis has impacted a large number of people."""
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Create a topic outline for the essay.
### Input:
Essay topic: Technology and its Impact on Society.
### Response:
I. Introduction
A. Definition of Technology
B. Impact of Technology on Society
II. Effects of Technology
A. Positive Effects
B. Negative Effects
III. Conclusion
A. Summary of the Impact
B. Recommendations"
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Name two characters in the novel Moby Dick.
### Response:
Captain Ahab and Ishmael."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Give me a CSS code to make the font size 20px.
### Response:
font-size: 20px;"
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Delete the paragraph from this 1000-word article that does not belong.
### Input:
The entire article
### Response:
The entire article excluding the paragraph that does not belong."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Define what a neural network is.
### Response:
A neural network is a computer system modeled on the human brain and nervous system. It consists of a network of neurons connected via synapses, which are constantly exchanging information in the form of electrical signals. These networks have the ability to learn by adjusting connections and assigning weights to inputs in order to predict output based on prior experience. Neural networks are used in a variety of applications such as speech recognition, image recognition, natural language processing, machine learning, and forecasting."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Create a grammar for the phrase ""a milkshake"".
### Response:
The grammar for ""a milkshake"" is:
Article (a) + Noun (milkshake)
-> A milkshake."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Write a tweet summarizing this article about an animal rescue in Thailand.
### Input:
The article
### Response:
Amazing news! An animal rescue in Thailand has successfully freed 63 bears from animal trafficking. The rescued bears will now receive the proper care and attention they need. #animalrescue #animalrights #Thailand"
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Generate a short story about a scientist in a lab.
### Response:
Dr. John was a scientist working in his lab, surrounded by beakers and test tubes bubbling with mysterious liquids. He had been working on a new project, hoping to create a revolutionary new drug that would cure various diseases. He had spent months testing different combinations of ingredients, and finally he had hit upon the perfect formula. As the potion bubbled in the test tube, his excitement was palpable. He barely slept that night, eagerly anticipating the results of his experiment. The next day, sure enough, his concoction had succeeded in creating the drug he had been trying for! He had finally achieved a truly remarkable accomplishment."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Rewrite the following sentence in a more formal way:
""I want to learn about this new app.""
### Response:
I would like to gain knowledge regarding this newly released application."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Generate a funny joke.
### Response:
Why did the chicken cross the playground? To get to the other Slide!"
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Come up with an interesting title for this article about artificial intelligence.
### Input:
The article
### Response:
""Decoding the Future: Understanding the Power of Artificial Intelligence"""
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Provide 3 potential solutions to reduce the amount of plastic waste.
### Response:
1. Implement effective recycling and composting programs.
2. Increase public awareness and education about plastic waste.
3. Promote reuseable and biodegradable alternatives to plastic."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Suggest a snack that you can make in under 5 minutes.
### Response:
Peanut Butter and Banana Toast. Simply toast two slices of your favorite bread and spread each slice with peanut butter and a layer of sliced banana."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Create a mnemonic to remember the eight planets of our solar system.
### Response:
M My Mars V Venus E Earth M Mercury J Jupiter S Saturn U Uranus N Neptune"
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Write an algorithm to calculate the perimeter of a rectangle.
### Response:
Algorithm:
1. Start
2. Declare variables length, width, perimeter
3. Read length, width
4. Calculate perimeter as length + width + length + width
5. Print perimeter
6. End"
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Design an app interface for a book recommendation system.
### Response:
The app interface should include a section with book recommendations, a search bar and filter options to refine results, a page for each book with ratings, reviews, and tags, a page for each author with profile information, a page for each genre with top books and related genres, and a page for user preferences."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Compose a tagline for a mobile game about cooking.
### Response:
Make Delicious Dishes - Cook up Fun with Our Mobile Game!"
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Create a question about the consequences of global warming.
### Response:
What are the potential consequences of global warming?"
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
State a mathematical equation that describes the relationship between two variables.
### Response:
y = mx + b"
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Describe a process of cleaning silverware.
### Response:
To clean silverware, start by filling a sink or basin with hot water and adding a tablespoon of baking soda. Submerge the silverware and let it sit for a few minutes before scrubbing it with a dish cloth. Rinse the silverware thoroughly and dry it with a clean towel."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Give a possible explanation for recent declines in pollinator populations.
### Response:
Recent declines in pollinator populations are likely caused by susceptibilities to disease, destruction of natural habitats, and the use of pesticides."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Change the sentence from passive to active voice.
### Input:
The ball was thrown by the player.
### Response:
The player threw the ball."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Label whether the following statements are true or false.
### Input:
Some amphibians have wings
### Response:
False"
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Create a rule for proper hand-washing technique.
### Response:
Always wash hands for at least 20 seconds with soap and warm water. Scrub all areas of the hands and between the fingers. Rinse and dry hands completely with a clean paper towel."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Identify and define the parts of a cell.
### Response:
The parts of a cell include the nucleus, cytoplasm, cell membrane, mitochondria, and other organelles. The nucleus is the control center of the cell and contains the genetic material, while the cytoplasm is the gel-like material that fills the cell and contains the organelles. The cell membrane is a semi-permeable barrier that regulates what enters and leaves the cell. Mitochondria are the ""powerhouses"" of the cell, providing energy to the cell."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Generate a list of five positive attitudes.
### Response:
1. Optimism
2. Self-confidence
3. Gratitude
4. Creativity
5. Compassion"
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Analyze the following sentence and identify the verb and its tense.
### Input:
She played the piano.
### Response:
Verb: Played
Tense: Past"
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Identify what type of sentence this is: My dog is cuddly and cute.
### Response:
This is a descriptive sentence."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Rewrite the following sentence using a synonym for the word ""impact"": The impact of the pandemic has been devastating.
### Response:
The repercussions of the pandemic have been devastating."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Describe the process of thawing frozen food.
### Response:
To thaw frozen food, place the food item in the refrigerator overnight or in a bowl of warm water for several hours. Once thawed, do not refreeze uncooked food."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Generate an interesting sentence from the given title.
### Input:
""The Death of John F. Kennedy""
### Response:
The death of John F. Kennedy forever changed the course of history, leaving a lasting legacy of hope and sorrow in its wake."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Do data normalization on given data set.
### Input:
[1, -1, 0.5, -0.5, 0.8, -0.9, 0.4]
### Response:
Normalized data set: [0.2, -0.2, 0.1, -0.1, 0.16, -0.18, 0.08]."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Name three famous figures who were contemporaries of Galileo Galilei.
### Response:
Three famous figures who were contemporaries of Galileo Galilei were Johannes Kepler, Christiaan Huygens, and Tycho Brahe."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Propose two appropriate and different methods to solve the given problem.
### Input:
Predicting whether an email is a spam or not.
### Response:
Two possible methods for predicting whether an email is a spam or not are supervised machine learning models such as artificial neural networks and Naive Bayes classifiers, or an unsupervised machine learning method such as clustering and anomaly detection."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Design an algorithm to sort a given list.
### Input:
[4, 1, 6, 5, 2]
### Response:
A sorting algorithm for the given list can use the following steps:
1. Compare the first two elements and swap them if the first element is greater than the second element.
2. Continue doing the same with the next two elements until the end of the list is reached.
3. Repeat steps 1 and 2 until the list is in sorted order.
The sorted list would be: [1, 2, 4, 5, 6]."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
What grade did you get in your English class?
### Response:
I got an A in my English class."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Combine the given sentences into one sentence.
### Input:
I was late for work. I had to take my kids to school.
### Response:
I was late for work because I had to take my kids to school."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Return the first four digits of the given credit card number.
### Input:
5309 7677 8244 1346
### Response:
5309"
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Rewrite the given passage in the past tense.
### Input:
John is making dinner.
### Response:
John made dinner."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Name two component of a computer system.
### Response:
Two components of a computer system are the hardware and the software."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Calculate the circumference of the given circle.
### Input:
Radius = 10 cm
### Response:
The circumference of the given circle is 62.83 cm."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
For the given artist, name three of their famous works.
### Input:
Salvador Dali
### Response:
Three famous works of Salvador Dali are ""The Persistence of Memory,"" ""The Slave Market with the Disappearing Bust of Voltaire,"" and ""The Disintegration of the Persistence of Memory."""
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Explain the given concept in one sentence.
### Input:
Algorithmic complexity
### Response:
Algorithmic complexity is a measure of the efficiency of an algorithm in relation to the amount of resources required to execute it."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Translate the given sentence into English.
### Input:
""Bonjour, comment allez-vous?""
### Response:
Hello, how are you?"
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Develop a web page for a business to increase customer engagement.
### Input:
Coffee Co.
### Response:
Coffee Co.’s website should be designed with user experience in mind. It should have clear navigation and consistent design. Content should be easily accessible and should provide a personalized experience. The website should have engaging features such as quizzes, polls, and forums to help generate conversation and increase customer engagement. Additionally, the website should have an easy way for customers to contact the company and give feedback."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Generate a 1-sentence summary on the following news article.
### Input:
The Tokyo Olympic Games will be postponed to 2021 due to the worldwide outbreak of Covid-19.
### Response:
The Tokyo Olympic Games have been postponed to 2021 due to the impact of the Covid-19 pandemic."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Change the following sentence so that it is in the past tense.
### Input:
She drives to work every day.
### Response:
She drove to work every day."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Create a new headline that is witty and summarizes the article.
### Input:
A new study has found that eating spinach can increase intelligence.
### Response:
Leafy Greens: A Smart Choice for Smarter Minds."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Explain how to achieve the American dream in one sentence.
### Response:
Work hard and stay ambitious with your goals to achieve the American dream."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Make a resume for the following job.
### Input:
Software Engineer
### Response:
Software Engineer specialized in developing functional, effective web and mobile applications with expertise in Java, JavaScript, React.js, and HTML/CSS. Responsible for ensuring high performance, scalability, and maintainability of applications."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Generate an algorithm for a sorting machine.
### Response:
The algorithm for a sorting machine involves first taking input, followed by organizing the objects into two or more groups depending on a certain criteria such as size or type. Then, each group can be further sorted using a variety of methods such as insertion sort, selection sort, or bubble sort. Ultimately, the sorted objects can be output to make sure the sorting process is complete."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Develop a pitch for a new technology product that can measure access to healthcare.
### Response:
Our new technology product is a platform that can measure access to healthcare. It can quickly identify gaps in access to healthcare services, such as geography, time, socio-economic status, and ethnicity, and make invaluable data available to both researchers and policymakers to help address these gaps."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Create a list of tips to help someone who is new to blogging.
### Response:
1. Develop a content plan: Decide on the topics that you want to cover in your blog and the frequency of your blog posts.
2. Come up with a catchy title: Make sure that your blog title is interesting, captivating and eye-catching.
3. Write engaging content: Provide interesting and thorough content that your readers will find useful and interesting.
4. Promote your blog: Use social media, email campaigns, and other marketing methods to promote your blog and get it noticed.
5. Interact with your readers: Ask questions and respond to comments to build rapport and create an engaging dialogue.
6. Update your blog frequently: Frequently update your blog to keep your readers engaged and interested.
7. Analyse the performance of your blog: Keep track of your blog’s metrics such as visitors, engagement rate, etc. to see how your blog is performing."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Generate a recipe for a healthy breakfast.
### Response:
Chocolate Protein Pancakes:
Ingredients:
- 1 cup oat flour
- 2 scoops chocolate protein powder
- 1 teaspoon baking powder
- 2 ripe bananas
- 2 eggs
- 1/2 cup almond milk
- 1 teaspoon cinnamon
- 2 tablespoons of honey
- 2 tablespoons of coconut oil
Instructions:
1. In a mixer, blend together oat flour, protein powder and baking powder.
2. In a separate bowl, mash the bananas and whisk in the eggs.
3. Mix the wet ingredients into the dry ingredients until well combined.
4. Then add the almond milk, cinnamon, honey and coconut oil.
5. Heat a pan over medium heat and grease with cooking spray.
6. Pour 1/4 cup of the batter into the pan and cook for about 2 minutes per side.
7. Serve with fresh fruit and honey. Enjoy!"
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Explain the effect that virtual learning has on student performance.
### Response:
Virtual learning can impact student performance both positively and negatively. On one hand, it can provide students with more flexibility, allowing them to learn at their own pace and allowing them to access materials from anywhere. On the other hand, virtual learning can be challenging as it requires an increased degree of self-motivation and dedication, as well as an understanding of the different technologies being used."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Arrange the given words in a sentence.
### Input:
genetic, beings, teleportation, Human
### Response:
Human beings could potentially teleport themselves through genetic manipulation."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Categorize the following words according to their definition.
### Input:
Ambiguous, capricious, arbitrate
### Response:
Ambiguous: Unclear or having multiple meanings
Capricious: Unpredictable or inclined to change decisions suddenly
Arbitrate: Settle a dispute by judging the facts impartially and issuing a decision."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Summarize the following text in one paragraph.
### Input:
Theories of personal identity have changed over time. Philosophers in the past have focused mainly on the self, whereas modern theorists focus more on personal narratives and narrative identities. One example is Locke's definition of personal identity which states that you are the same person over time if you have personal memories of your past or if you can remember past experiences. Another example is Parfit's rejection of this notion and focus on the importance of psychological continuity, which is when you remain the same even if you are presented with a different physical world or body.
### Response:
Throughout history, philosophers have debated the concept of personal identity. Initially, the focus was primarily on the self, but modern theorists are more inclined to study personal narratives and one's narrative identity. According to Locke, a person's memories and their ability to remember past experiences were key to maintaining one's personal identity over time. In contrast, Parfit rejected this view and instead proposed that psychological continuity was the key to remaining the same person. This involves remaining the same individual despite potential changes in the physical world or body."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Replace all instances of the placeholder ""$VARIABLE1"" with the correct answer.
### Input:
The result of the calculation is $VARIABLE1.
### Response:
The result of the calculation is 4."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
What is the title of the novel mentioned in the text?
### Input:
Dr. No is the sixth novel by the English author Ian Fleming to feature his British Secret Service agent James Bond.
### Response:
The title of the novel is Dr. No."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Rearrange the words in the sentence to form a question.
### Input:
Reading is difficult.
### Response:
Is reading difficult?"
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Generate a random password of length 10
### Response:
uxTpyT9X04"
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Explain the concept of information retrieval.
### Response:
Information Retrieval (IR) is the process of locating and extracting relevant information from a large collection of documents or datasets. It involves identifying, locating, describing, and retrieving relevant material related to an individual’s needs. In order to do this, IR utilizes a range of algorithms, query systems, and other techniques for finding information in large structured and unstructured datasets."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Edit the following sentence to remove all passive voice.
### Input:
The thesis was written by the student.
### Response:
The student wrote the thesis."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Describe the concept of natural language processing.
### Response:
Natural Language Processing (NLP) is the ability for computers to understand and process human language. It uses linguistics, computer science, and artificial intelligence to analyze and interpret written or spoken human language in order to extract meaning and perform tasks. It can be used to detect intent, classify texts, generate summaries and insights, as well as helping machines understand, interpret and converse with humans."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
List the names of four social media platforms.
### Response:
Facebook, Twitter, Instagram, Snapchat."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Create a timeline of the key events surrounding the 2004 Indian Ocean earthquake and tsunami.
### Response:
-December 26, 2004: A 9.1-magnitude earthquake off the coast of Indonesia triggers a massive tsunami affecting Indonesia, Thailand, India, Sri Lanka, and other countries in the region.
-December 29, 2004: The death toll from the disaster passes 10,000.
-December 31, 2004: More than 90,000 people are reported dead and millions are displaced.
-January 5, 2005: International relief effort is launched to help those affected.
-April 2005: An intensive international relief and reconstruction effort is underway, with pledges of $5.5 billion in aid from countries and organizations around the world.
-December 2005: The entire cost of the disaster is estimated at $14.5 billion.
-March–April 2006: The final death toll reaches 220,000."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
How do you create a pivot table in Excel?
### Response:
To create a pivot table in Microsoft Excel, select the ""Insert"" tab, click the ""PivotTable"" button, select the data range, and choose where the pivot table will be placed. Then, select which data you'd like to analyze by adding fields to the Rows, Columns, and Values area of the pivot table. Finally, use the ""Filter"" in the PivotTable to refine your results."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Identify the time complexity of the Insertion Sort algorithm.
### Response:
The time complexity of the Insertion Sort algorithm is O(n^2)."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Name five sites located in the Ancient Near East.
### Response:
Ur, Assyria, Babylon, Jericho, Megiddo."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Synthesize an argument in support of renewable energy sources.
### Response:
Renewable energy sources, such as solar, wind, and hydroelectric power, offer a clean, reliable, and renewable source of energy. They reduce both our dependence on non-renewable sources of energy, such as coal and oil, as well as harmful emissions. Renewable energy sources are also cost-effective and create jobs in local communities, while also helping to reduce global warming. Furthermore, they can be used to generate power in remote regions, alleviating the need for costly infrastructure and transportation."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Develop an algorithm to sort the following numbers: 5, 3, 9, 1.
### Response:
1. Set unsorted list = [5, 3, 9, 1]
2. Iterate through unsorted list
3. Compare unsorted[i] to unsorted[i+1]
4. If unsorted[i] > unsorted[i+1], swap them
5. Repeat step 3 to 4 until end of list
6. Observe the list is now sorted."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Describe why you would like to work for this company.
### Response:
I am very excited about the opportunity to work for this company because of its innovative business practices, commitment to environmental sustainability, and strong values of integrity. I believe the company shares my vision of creating a positive and meaningful impact in the world."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Find a dinosaur species in the Jurassic Period with a name starting with a ""T"".
### Response:
Triceratops is a genus of herbivorous ceratopsid dinosaur that first appeared during the late Maastrichtian stage of the late Cretaceous period, about 68 million years ago."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Given a list of ingredients, create a recipe for a vegan curry.
### Input:
2 cans of chickpeas, 1 onion, 1 clove of garlic, 1 inch ginger, 1 teaspoon cumin, 1 teaspoon curry powder, 1 teaspoon turmeric
### Response:
Vegan Curry
Ingredients:
• 2 cans of chickpeas
• 1 onion, diced
• 1 clove of garlic, finely minced
• 1 inch of ginger, grated
• 1 teaspoon cumin
• 1 teaspoon curry powder
• 1 teaspoon turmeric
Instructions:
1. Heat oil in a large saucepan over medium heat.
2. Add the onion, garlic and ginger. Cook until onions are translucent, about 5 minutes.
3. Add the spices and stir until fragrant.
4. Add the chickpeas and stir to evenly coat with the spice mix.
5. Add 1 cup of water and bring to a gentle simmer.
6. Cook for 15 minutes or until the sauce has thickened and the chickpeas are soft.
7. Serve over cooked rice, quinoa or cauliflower rice. Enjoy!"
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Describe how you would use Twitter to promote a given product.
### Input:
Board game
### Response:
I would use Twitter to promote a board game by creating engaging content in the form of videos, photos, and tweets. I would also include relevant hashtags so that the message reaches a wider audience. I would also include links to the website or product page and encourage users to share the content. Additionally, I would also use influencer marketing where I reach out to popular influencers in the board game industry and have them promote the product on their social media profiles."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Create a non-literal analogy for the process of creating a business.
### Response:
Building a business is like planting a garden – you need to carefully plan, prepare the soil, select the right plants, provide the necessary irrigation and sunlight that the plants will need to grow and thrive, and remove any weeds that may interfere with the growth."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Given a list of data, identify the two inputs that can be used to create a specific output.
### Input:
Input1: temperature (in Celsius), Input2: humidity levels, Input3: time of day, Output: air quality
### Response:
Input1: temperature (in Celsius), Input2: humidity levels, Output: air quality"
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Give a creative title for an article about the use of AI in travel.
### Response:
Exploring the Horizons with AI: A Guide to the Future of Travel"
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Change the following sentence from the past tense to the present tense.
### Input:
She cooked the dinner last night.
### Response:
She is cooking the dinner tonight."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Write a Haiku poem about a sunset.
### Response:
Orange fades to black
The sun sets in the distant sky
Peaceful night arrives"
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Write a customer review for a car wash service.
### Response:
I went to this car wash for the first time today and was very impressed. The staff was friendly and helpful, and the place seemed very clean and well kept. The process was quick and efficient and the car came out looking like new. Highly recommended!"
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Find the area of a square shape with side length 5 cm.
### Response:
The area of the given square shape is 25 cm^2."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Write a short story about a visit to a museum.
### Response:
I recently visited the art museum in my city. It was an unforgettable experience as I got to explore the many beautiful works of art there. As I walked amongst the countless masterpieces, I noticed the unique culture that surrounded the museum. There was a sense of mystery and a calm energy, like I was entering an ancient, sacred temple of art. I found myself lost in the small details of each painting and sculpture, admiring the immense talent of each artist. As I left the museum, I felt a wave of contentment wash over me knowing that this place served as a haven of creativity and imagination."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Describe the sound of a train passing by.
### Response:
The sound of a train passing by is a low, rumbling sound that gradually grows in intensity as it approaches and fades away slowly as it moves further away. It is often accompanied by a sharp whistle that cuts through the air like a blade."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Determine the volumetric flow rate given the velocity and cross-sectional area.
### Input:
Velocity: 2 m/s
Cross-sectional area: 5 m^2
### Response:
The volumetric flow rate is 10 m^3/s."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Create a grocery list for a week's worth of meals.
### Input:
Meals for the week: Spaghetti, tacos, grilled chicken, stir-fry
### Response:
Grocery list:
- Spaghetti: Onion, garlic, ground beef, canned tomatoes, oregano
- Tacos: ground beef, taco shells, lettuce, cheese, tomatoes, onion, avocado
- Grilled chicken: chicken breasts or thighs, marinade, salt, pepper
- Stir-Fry: vegetables (broccoli, carrots, snow peas, bell pepper), ginger, garlic, soy sauce, cooked rice."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Describe the taste of an apple.
### Response:
An apple has a crisp, sweet and tart flavor. Its texture is juicy and tender. It has a subtle and delicate aroma that ends with a subtly tangy flavor."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Explain how a relay works.
### Response:
A relay is an electromagnetic switch that is used to control a circuit using a low power electrical signal. It works by using an electromagnet to open or close the switch to either allow or block the flow of electricity through the circuit. When the electromagnet is activated by low power electrical signal, it causes the switch to open and allow the electrical current to flow through the circuit, and when the power to the electromagnet is removed, the switch closes and the current can no longer flow."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
What is the gravitational potential energy of a 5-kilogram object at height 10 meters?
### Response:
The gravitational potential energy of a 5-kilogram object at a height of 10 meters is 490 Joules."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Calculate the total cost of a trip for two people who fly from Los Angeles to Philadelphia.
### Input:
Round-trip flight tickets from Los Angeles to Philadelphia: two adult tickets
### Response:
The total cost of the trip for two people who are flying from Los Angeles to Philadelphia would be $998.00."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Compare and contrast water and oil.
### Response:
Water and oil are similar in that they are both liquid substances, but they have several key differences. Water is composed of molecules made of two hydrogen atoms and one oxygen atom and has a lower density than oil. Conversely, oil is composed of molecules of carbon and hydrogen and has a higher density than water. Additionally, water is an excellent conductor of electricity, whereas oil is an insulator of electricity. Water also has a low viscosity, whereas oil is highly viscous."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Create a logo for a shoe company.
### Response:
"
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Analyze the popularity of the term 'artificial intelligence' in the last five years
### Response:
In the last 5 years, the term 'artificial intelligence' has grown steadily in popularity. According to Google Trends, the term's search interest has increased by 22% since 2015. The term has been most popular in the United States and is most frequently associated with topics such as computer science, robotics, and natural language processing."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Generate a story about a child's first day of school
### Response:
It was the first day of school, and little Mia was feeling nervous. She was so excited to meet her new classmates and teacher, but also a bit scared. She walked into the classroom and immediately noticed there were more students than she expected. She looked around in amazement at all the other kids, until the teacher began to speak. Ms. Li was kind and funny, and soon Mia felt more comfortable. Everyone was smiling, and she even made a few friends. By the end of the day, Mia had already learned a lot and was looking forward to the rest of the school year."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Edit the sentence below to remove any redundant words and make it more concise.
### Input:
I think to myself
### Response:
I think."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Come up with a catchy and witty headline for the following article.
### Input:
CNN's consultant on political television advertising believes that the cost to influence the 2008 election may exceed $3 billion.
### Response:
Election Spending Reaches Historic Highs-- Will You Spend Your Vote Wisely?"
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Suggest a new tagline for the article.
### Input:
CNN's consultant on political television advertising believes that the cost to influence the 2008 election may exceed $3 billion.
### Response:
Make Your Vote Count: How Much Is Too Much for the 2008 Elections?"
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Generate a list of the important people involved in this article.
### Input:
CNN's consultant on political television advertising believes that the cost to influence the 2008 election may exceed $3 billion.
### Response:
- Evan Tracey, Chief Operating Officer at TNS Media Intelligence/Campaign Media Analysis Group
- Mitt Romney
- Rudy Giuliani
- Barack Obama
- Hillary Clinton
- Bill Richardson
- Mark Foley
- Stuart Rothenberg (Editor of the non-partisan Rothenberg Political Report)."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Generate a list of 3 to 4 key takeaways from the article.
### Input:
CNN's consultant on political television advertising believes that the cost to influence the 2008 election may exceed $3 billion.
### Response:
- The cost to influence the 2008 election could exceed $3 billion, an analysis shows.
- Television ads on health care alone total $60 million so far this year.
- Groups are pivoting from legislative advocacy mode to political mode and targeting candidates with aggressive advertising.
- Candidates need to create ads that stand out from the sheer number of ads, otherwise they risk being lost in the noise."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Come up with 2 key questions related to this article.
### Input:
CNN's consultant on political television advertising believes that the cost to influence the 2008 election may exceed $3 billion.
### Response:
- What challenges must candidates and interest groups face when advertising in the 2008 election?
- How can candidates make sure that their ads stand out from the sheer number of ads this election cycle?"
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Suggest a way to make physical activity a part of your daily routine.
### Response:
One way to make exercise a part of your daily routine is to set achievable goals for yourself. Start with simple goals that you can actually accomplish. Break up the goals into manageable chunks and find a way to measure your progress. This will help you feel a sense of accomplishment and success. Schedule the activity as you would for any other important activity and try to keep to the same time each day. It may also help to try out different sports and activities to keep things interesting. Finally, reward yourself after each successful workout and remember that it's OK to take a short break when needed."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Explain what is foreshadowing.
### Response:
Foreshadowing is a literary device and a narrative technique used to hint at or suggest an event or plot twist that will come later in the story. It’s used to create suspense and to build up the tension, helping readers to make predictions and become more engaged with the story. Writers use foreshadowing to set up future events and plot twists and to create a sense of anticipation. It can be used in a subtle or obvious way, and can be embodied by characters, settings, objects, actions, or words."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Come up with 3 tips for writing effective dialogue.
### Response:
1. Keep dialogue concise and to the point. Use as few words as possible to get your point across.
2. Every character should have a unique speech pattern and vocabulary, based on their background and personality.
3. Dialogue should help to develop your characters and advance the plot. Avoid meaningless banter and exchanges that don’t contribute to the story."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Analyze the following sentence for any errors.
### Input:
They aren't no good at all.
### Response:
This sentence is incorrect and should be rewritten to ""They aren't any good at all."""
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Edit the following sentence to remove any redundant words.
### Input:
My opinion is that the food was too bad.
### Response:
I think the food was bad."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Generate a headline for a news article about the rising cost of healthcare.
### Response:
Healthcare Costs Skyrocket amid Pay Cuts and Layoffs."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Suggest an algorithm to classify musical composition as ‘romantic’ or ‘modern’.
### Response:
One possible algorithm for classifying musical compositions as 'romantic' or 'modern' could rely on audio features such as tempo, loudness, and harmony. The algorithm could be trained on a dataset of labeled compositions, and then be used to classify unknown compositions. To ensure accuracy, it may be necessary to use a combination of multiple audio features. Additionally, it may be beneficial to use a convolutional neural network (CNN) with the labeled data, as CNNs are widely used for image and audio classification."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Predict the value of y in the following equation: x = y^3 + 4y
### Input:
x = 14
### Response:
In this equation, if x = 14, then y = 2."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Explain Schrodinger's wave equation.
### Response:
Schrodinger's wave equation is an equation in quantum mechanics that describes how a quantum system changes over time. It is based on wave equations and describes the behavior of subatomic particles that have wave-like properties; these particles include electrons, protons, and more. The wave equation's solutions represent wave functions which can be used to determine the probability of a particle's position and momentum, as well as its energy. The equation also relates the properties of a particle to its position in space and time."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Construct a database system to store customer records in a car dealership.
### Response:
The database should have tables to store customer records, including contact information, vehicle information, purchase history, service records, and more. The customer table should include a unique customer ID, first and last name, address, email address, phone number, and other contact details. The vehicle table should store information such as the vehicle model, make, year, and date of purchase. The purchase table should include details about the sale and the service table should store records of any maintenance or repairs done to the customer’s vehicle."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Sort the following numbers in ascending order: 12, 26, 83, 19.
### Response:
The numbers sorted in ascending order are 12, 19, 26, 83."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Generate a catchy slogan for a new restaurant.
### Response:
Taste the Difference - Come to Our Place!"
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Create a persona for a fictional e-commerce store selling sports equipment.
### Response:
SportShack’s persona is an energetic, outgoing, and passionate individual with a deep love for sports. SportShack believes in leading a healthy lifestyle, pushing the boundaries, and making sports accessible for all. They aim to provide the best equipment for athletes of all levels, so that everyone can experience the thrill of competition. SportShack prides itself on being thoughtful and innovative - offering high-quality products and outstanding customer service."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Write a paragraph describing a meeting between two friends.
### Response:
Two old friends, Katherine and Sarah, sat in the park, catching up on each other’s lives after months of separation. They talked about their jobs, their families, and the ups and downs of the year that had passed. They laughed, they cried, and they reminisced on the memories they had made together. They made plans to get together again soon and hugged each other goodbye as the sun began to set. This was a meeting that neither would soon forget."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Formulate a marketing plan for a new mobile app.
### Response:
The marketing plan for the new mobile app should include creating an online presence on relevant social media and digital platforms. Promote the app by launching a website, creating teaser campaigns and targeted content. Use influencer marketing on YouTube and other popular streaming services to spread the word. Reach out to mobile app review websites, industry-related sites, as well as blogger outlets. Host beta tests to generate more buzz and also consider adding easter eggs in the app to encourage engagement. Utilize A/B testing to optimize the user interface, and monitor user feedback constantly to ensure customer satisfaction."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Write a review for a book of your choice.
### Response:
I recently read the novel ""Harry Potter and the Sorcerer's Stone"" by J.K. Rowling and absolutely loved it! The magical world of Harry Potter is a captivating and delightful journey for readers of all ages. From the little wizarding school of Hogwarts to the mysterious and dangerous creatures that lurk in the shadows, Rowling's vivid description makes this story come alive. The characters are well-developed and likable and the plot is full of twists and turns that keeps you guessing until the very end. I highly recommend this book to anyone looking for an entertaining escape from reality."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Design a logo for a child care center.
### Response:
The logo should be warm, playful and inviting. It should utilize a font that is easy to read and appealing to children. I would suggest a combination of vibrant colors, such as yellow, blue and green. It could include an image of a happy kid or an illustration of a sun and clouds. The logo should also convey a sense of security and safety, as the center is aiming to provide a safe, nurturing environment for kids."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Create an outline for a presentation about the current state of the world economy.
### Response:
1. Introduction
a. Definition of Economics
b. Overview of the Major Factors Affecting the Global Economy
2. Causes of Economic Instability
a. Impact of Globalization
b. Trade Imbalances
c. Currency Exchange Rates
d. Inflation and Deflation
3. Effects of Economic Trends
a. Changes to Consumption and Investment Patterns
b. Impact on Employment and Unemployment Rates
c. Shift in Distribution of Wealth
4. Conclusion
a. Solutions to Achieve Economic Stability
b. Suggestions to Overcome Economic Challenges
c. Summary of Current State of Global Economy"
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Make a suggestion for a topic for a persuasive essay.
### Response:
The Topic of Advantages and Disadvantages of Technology in Our Everyday Lives.
Technology has become an integral part of our lives, from using computers and smartphones to using various types of software for communications and entertainment. However, the effects of technology on our lives have both positive and negative aspects. This essay could discuss the pros and cons of technology and examine how its usage can both improve and diminish our lives. It could also explore the ethical implications of our growing reliance on technology and the potential implications it has on our relationships, job security, and more."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Explain why it is important to stay hydrated.
### Response:
Staying hydrated is an essential part of staying healthy and keeping your body functioning properly. Proper hydration helps keep your body cool, aids in digestion and absorption of nutrients, helps remove waste products, and even helps lubricate your joints. Additionally, inadequate hydration can impact cognition, leading to headaches, fatigue, and difficulty concentrating. As such, staying hydrated is one of the most important steps you can take to keep your body running its best."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Additionally, give me a entertaining story about a conversation with a stranger on a bus.
### Response:
I was on a bus ride between cities when I noticed a stranger sitting next to me. We were both just minding our own business, but after a few moments, he started asking me questions about my life. We ended up having a fascinating conversation and he told me some funny stories that made me laugh. He shared his thoughts on life, spirituality and philosophy and by the end of the 45-minute journey, I felt like I had made a new friend. When we got to my stop, I thanked him for sharing his insights and wished him well for his onward journey."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Given the following sentence, show me how to transform it into a haiku.
### Input:
The soothing moonlight basks the sea
### Response:
Moonlight soothes
the serene waves that bask in it
endless and calming."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Create a successful dentist marketing campaign.
### Response:
An effective dentist marketing campaign should focus on customer satisfaction, affordability, and convenience. Highlighting these aspects will help the practice to stand out from the competition.
It should also focus on highlighting the experience of the dentist and staff, how much the practice values patient care, and any special amenities offered. Ads should stress that patients will receive personalized care and try to create an atmosphere of trust and comfort.
The campaign should also emphasize special offers and discounts that are available, including free check-ups, discounts on services, and same-day appointments. Additionally, the campaign should reach out to all age groups, target the local population, and take advantage of digital sources of communication such as email and social media to reach a wider audience."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Detect the discrepancies between the following two texts.
### Input:
Text 1: The bird watched the little boy from the rooftop.
Text 2: The child saw the bird from the roof.
### Response:
The discrepancy between these two texts is that in the first text, it is the bird that is watching the little boy, whereas in the second text, it is the child that is seeing the bird. Additionally, the two texts do not use the same words to refer to the two characters; in the first text the boy is referred to as ""little boy"", while in the second texts he is referred to as ""child""."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
If a customer calls and wants to find out their order status, what steps should the customer service representative take?
### Response:
When a customer calls to find out their order status, the customer service representative should first ask the customer for their order number. Then they should check the customer's order history and provide the customer with an update on their order status. This can include information such as order processing, shipping, and estimated delivery times. Finally, the customer service representative should provide the customer with a confirmation number for their call."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Describe the features of an effective time management strategy.
### Response:
An effective time management strategy should include setting clear and realistic goals, planning ahead, breaking tasks down into smaller chunks, being organized, prioritizing tasks, and staying focused on the task at hand. Additionally, it's important to practice self-care and to schedule in time for relaxation. Taking regular breaks can help reduce feelings of stress, keep you motivated, and ensure productivity."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Suggest some activities for a family game night.
### Response:
For a family game night, consider setting up a game of charades or Pictionary, an evening of classic board games such Trivial Pursuit or Monopoly, or a tournament of video games such as Mario Kart or PlayStation. Additionally, a family game night could include card games such as Go Fish or Crazy Eights, jigsaw puzzles, or trivia challenges."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Describe the characteristics of a successful entrepreneur.
### Response:
Successful entrepreneurs have strong organizational and communication skills, are disciplined, persistent and resilient, and are always looking for ways to innovate. They also possess keen problem-solving and decision-making abilities, demonstrate top-notch customer service and build relationships with stakeholders, and are able to manage their finances and allocate resources prudently. Most importantly, they focus on their long-term vision and goals and never lose sight of them."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Describe the different stages in the software development lifecycle.
### Response:
The software development lifecycle consists of five stages: planning, requirements gathering and analysis, design, implementation and testing, and deployment. The planning phase begins with an analysis of the business case, user needs and budget allocation. The requirements gathering and analysis phase is where the goals and requirements of the project are identified. The design phase is where the software is designed based on the requirements of the project. The implementation and testing phase involves the programming of the software, unit and system-level testing, and the integration of various components. The final phase, deployment, involves the installation and setup of the software."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Summarize the book ""The Goldfinch"" by Donna Tartt
### Response:
The Goldfinch is a 2013 novel by bestselling author Donna Tartt. It tells the story of Theodore Decker, an orphan boy from Las Vegas, who is caught in the middle of a chaotic world when his mother is killed in a bomb explosion while visiting the Metropolitan Museum of Art. After this, his world is changed forever, as he finds himself dealing with a world of art, antiques, and crime. Throughout the book, Theodore struggles to both survive and find his place in society, while at the same time coming to terms with the memories of his mother and his painting, The Goldfinch. In the end, Theodore discovers that the only way to find true happiness is to accept the past and to look towards the future."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Generate a valid username given a set of user information.
### Input:
Name: Sarah Jones, Age: 34
### Response:
sarahjones34"
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Generate a list of 4 healthy breakfast ideas.
### Response:
1. Overnight oats with fruit and nuts
2. Egg frittata with vegetables
3. Avocado toast with a boiled egg
4. Smoothies with yogurt and oats"
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Classify this speech as either formal or informal.
### Input:
Hey, what's up?
### Response:
Informal"
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Write a definition for the term ""machine learning"".
### Response:
Machine learning is an application of artificial intelligence that gives systems the capability to automatically learn and improve from experience without being explicitly programmed. This process of machine learning involves data mining techniques to predict outcomes, identify patterns, and classify data without the need to explicitly define rules."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Write a message inviting someone to join your team.
### Input:
John Smith
### Response:
Dear John Smith,
I'm writing to invite you to join our team. We are a group of passionate individuals working together to deliver innovative solutions and make an impact. Your input and expertise would be of great value in this pursuit, and I believe you would enjoy the experience. Please let me know if you're interested, and I'll answer any questions you may have.
Best,
[Name]"
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Create a metaphor to explain the concept of artificial intelligence.
### Response:
Artificial intelligence is like a chef in a kitchen: it takes inputs from the environment, combines them with its knowledge, and then it takes action to create something new and unique that changes the environment."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Evaluate this blog post. Output ""good"" or ""bad"".
### Input:
This blog post is about the importance of drinking water daily to stay health.
### Response:
good"
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
What is the scientific definition of metabolism?
### Response:
Metabolism is the set of life-sustaining chemical processes that occur within a living organism. These biochemical processes allow organisms to grow, reproduce, and respond to their environment. Metabolism requires energy and can be divided into two categories: catabolism and anabolism. Catabolism breaks down molecules into smaller components and releases energy, while anabolism combines molecules to form larger components and consumes energy."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Generate 3 marketing ideas to increase engagement on a product's social media account.
### Response:
1. Host giveaways and contests to incentivize followers to engage with the product
2. Add polls and surveys to gather insights on the needs of the target audience
3. Feature user-generated content to show appreciation to loyal customers"
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Name 3 benefits of using cloud computing.
### Response:
1. Increased scalability and flexibility
2. Lower costs
3. Enhanced collaboration and centralized data access"
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Create a hashtag for a new marketing campaign.
### Response:
#NewBrandAdventure"
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Generate a list of 3 healthy snacks for children.
### Response:
1. Celery sticks with peanut butter
2. Apple slices with cheese
3. Oatmeal bars with nuts and dried fruit"
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Provide a description of the possible benefits of going car-less to a potential customer.
### Response:
Going car-less can provide a number of benefits to an individual. Firstly, you can save money on car-related expenses such as fuel, insurance, maintenance and taxes. Secondly, it can reduce your environmental impact through less emissions and less reliance on non-renewable resources. Finally, it can give you more time to enjoy experiences when travelling - as you can opt to walk, ride a bike or take public transportation, you can spend more time exploring and engaging with your immediate surroundings."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Rewrite this sentence so it’s less verbose: “The supervisor was incapable of overseeing the entire project, so she was relieved of her duties”
### Response:
The supervisor couldn't handle the project, so she was fired."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Classify the following online review as being positive or negative.
### Input:
This product was very substandard and I am quite unhappy with the results.
### Response:
Negative"
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Generate 3 blog topic ideas based on the keyword “web automation”
### Response:
1. How Web Automation Can Streamline Your Business
2. What Industries Should Implement Web Automation?
3. An Overview of Web Automation Tools and Services"
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Create a tweet summarizing the following news article in 140 characters or less.
### Input:
https://www.independent.co.uk/environment/greta-thunberg-climate-change- youth-strike-school-us-crisis-a9271286.html
### Response:
Greta Thunberg is inspiring a global youth-led movement to fight climate change, leading students around the world to raise their voices and take action. #ClimateStrike #GretaThunberg"
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Edit this passage to make it more concise:
During the spring season, the temperature tends to be very pleasant, making it a great time of year to go outdoors.
### Response:
Spring is an ideal season for outdoor activities due to its pleasant temperatures."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Find out the CEO of IBM
### Response:
The current CEO of IBM is Arvind Krishna."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Reverse engineer the following code snippet and explain what is happening in 4 sentences.
var x = 3
var y = x + 4
### Response:
This code snippet creates two variables - x and y. Variable x is given a value of 3, then the value of x is added to 4 and assigned to the variable y. Therefore, y is given a value of 7. This code is assigning the value of 3 to x, then adding 4 to the x's value and assigning that result to y."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Summarize the main themes of this novel in 3 sentences.
### Input:
Harry Potter and the Philosopher’s Stone
### Response:
Harry Potter and the Philosopher’s Stone tells the story of a young wizard's journey to becoming the Boy Who Lived. Along the way, he discovers that courage and friendship are the keys to overcoming evil and embracing a world of possibilities. This novel focuses on themes of family, loyalty, and acceptance, ultimately illustrating the power of the human spirit."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Given this sentence, predict the part of speech of the word “groomed”
He groomed the puppy until it was perfectly clean
### Response:
Verb (past tense)"
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
List 5 things that can be bought at a grocery store
### Response:
1. Fruit
2. Vegetables
3. Dairy products
4. Meat
5. Frozen foods"
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Prepare a meal plan for tomorrow for someone who wants to eat healthy and has a limited budget
### Response:
Breakfast: Oatmeal with fresh fruit
Lunch: Quinoa salad with vegetables and grilled chicken
Snack: Hummus with raw vegetables
Dinner: Whole wheat pasta with tomato sauce and steamed vegetables
Dessert: Apple slices with cinnamon"
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Create a headline for an article about the top 5 trends in digital marketing
### Response:
Top 5 Trends Taking Digital Marketing by Storm"
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Generate a research question related to the following topic: How technology is revolutionizing the shopping experience
### Response:
What are the most effective ways in which technology can be leveraged to improve customer satisfaction and loyalty when shopping online?"
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Disconnect the following internet cable correctly.
### Response:
Unscrew the cable from your router or modem, then unplug the other end from the power outlet or wall socket."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Reverse the following list alphabetically.
### Input:
apple, carrot, banana, potato
### Response:
potato, banana, carrot, apple"
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Determine the longest side of the triangle.
### Input:
Triangle ABC has sides AB = 10 cm, BC = 12 cm, and AC = 11 cm.
### Response:
The longest side of triangle ABC is BC, 12 cm."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Find the minimum value of 132 - 5*3
### Response:
The minimum value of 132 - 5*3 is 117."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Generate a 10 word list of descriptive words for loneliness.
### Response:
Isolation, forlorn, solitary, desolate, abandoned, bleak, empty, estranged, despondent, despair."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Recite a poem about rivers.
### Response:
Rivers are like long winding roads that lead us down new paths.
They are like a lifeline, they protect us in their wakes.
They carve paths deep in the ground and carry the secrets we don’t share.
Like a rainbow, they stretch out over each land; showing that beauty can be found anywhere.
Rivers provide lifeblood to all living things, including us.
In nature they are bright and full of energy; in cities they become industrial, with factory built on each side.
But one thing is certain, rivers keep flowing, even if the current changes in every way.
Like a journey, life will always bring us new experiences and rivers show us that it's alright."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Rearrange the following list into descending order.
### Input:
9, -7, 15, 12
### Response:
15, 12, 9, -7"
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Describe the effects of global warming.
### Response:
Global warming is the term used to describe the increase in the average temperature of the Earth's atmosphere and oceans due to human-caused emissions of greenhouse gases. It has far-reaching effects on the environment, such as sea level rise, an increase in global temperatures, an increase in the frequency and intensity of extreme weather, acidification of the oceans, degradation of marine biodiversity, and more. In addition to these effects, global warming can also have serious implications for human health and security, such as water scarcity and increased risk of diseases, infestations, and wildfires."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Provide a plan to get good sleep each night.
### Response:
Getting good sleep each night is essential for your health, well-being, and productivity. To ensure good sleep each night, it is important to have a consistent sleeping schedule and set a routine that can help you create a comfortable environment for sleep. It is also important to avoid consuming caffeine late in the day and limit your exposure to screens and bright lights before bed. It's also beneficial to practice relaxation techniques such as yoga or meditation, and eliminate any distractions that may prevent you from achieving a restful night of sleep."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Find the sum of the sides of the following triangle.
### Input:
Triangle ABC has sides AB = 5 cm, BC = 6 cm, and AC = 7 cm.
### Response:
The sum of the sides of triangle ABC is 18 cm."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Calculate the cost of 4 apples at $2.50 each.
### Response:
The cost of 4 apples at $2.50 each is $10.00."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
List five steps for writing an essay.
### Response:
Five steps for writing an essay include:
1. Brainstorming ideas and choosing a topic.
2. Structuring the essay with an introduction, body, and conclusion.
3. Gathering sources, reading, and researching.
4. Writing a draft and making revisions.
5. Editing and proofreading the essay."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Generate a story describing the emotions of a character in a given situation.
### Input:
Alice is stuck in traffic, trying to get to her parent's house for Thanksgiving.
### Response:
Alice pounded her fists on the steering wheel as she looked out the window at the gridlocked cars stretching on for miles. She was desperate to reach her parents' house in time for Thanksgiving, but it seemed like every driver on the road had decided to take the same route she had. Anger and frustration built within her as the minutes ticked by, feeling like hours. Her only hope was that somehow, some way, she would still make it on time."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Rewrite this sentence to make the same idea more eloquently.
Output should be a single sentence.
### Input:
I have a dog, but it's not very well behaved.
### Response:
My canine companion, while adored, could use some refinement in its manners."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
In this task, you need to be able to summarize a given list of key points.
### Input:
1. Start your own business.
2. Research your competition.
3. Utilize social media platforms for marketing.
4. Analyze customer needs and wants.
### Response:
Beginning a business requires careful planning, from analyzing the competition and customer needs to deploying social media marketing strategies."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
In this task, you need to write an appropriate response to the phrase ""take a break""
### Response:
Sure, let's take a break. What would you like to do? Maybe we could watch a movie, go for a walk, or just chat for a bit. Whatever works for you."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
In this task, you need to convert numbers from words to digits.
Output should also be a number, for example ""twelve"" should be output as ""12"".
### Input:
forty eight
### Response:
48"
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
In this task, you need to identify the source of the sentence from the choices below.
Output should be chosen from:
- Newspaper
- Textbook
- Online article
- Encyclopedia
### Input:
He was a Roman statesman and philosopher who is considered one of the greatest military commanders in history.
### Response:
Encyclopedia"
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Identify the main clause in this sentence.
Output should be a single sentence.
### Input:
A busy morning, interrupted by a phone call from a friend, made John late for school.
### Response:
A phone call from a friend made John late for school."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Identify the subject of the sentence.
Output should be a single word.
### Input:
Ruth and Molly made cookies for the bake sale.
### Response:
Ruth and Molly"
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Rewrite the sentence using gender-neutral language.
Output should be a single sentence.
### Input:
A salesman is giving a presentation.
### Response:
A salesperson is giving a presentation."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Generate a creative activity for a child to do during their summer vacation.
### Response:
Why not encourage your child to take a road trip to a nearby city and explore their favorite museums, galleries and parks? En route, they can make a scavenger hunt to help them identify landmarks, funny signs and anything else they find along the way. When they arrive, they can document their journey with photos and a journal full of memories they can look back on later."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Identify the main idea of the text.
### Input:
Global warming is the term used to describe a gradual increase in the average temperature of the Earth's atmosphere and its oceans, a change that is believed to be permanently changing the Earth’s climate.
### Response:
The Earth's average temperature is increasing due to global warming, leading to a permanent change in the Earth's climate."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Generate a piece of advice to someone who is feeling unmotivated.
### Response:
Take some time to focus on your successes. Write down the things you have accomplished and all the progress you've made towards your goals. Remind yourself of your strengths and the things you do well. This will help you find the motivation to move forward, and you'll be able to re-energize yourself with a renewed sense of hope and purpose."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Change the given sentence into a statement about the benefits of something.
### Input:
Using Google Maps can be really helpful.
### Response:
Utilizing Google Maps can provide numerous advantages, from quickly finding locations to getting real-time traffic updates."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Convert the phrase into a complete sentence.
### Input:
outer space
### Response:
Exploring outer space is an exciting and unique adventure."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Identify the type of the sentence.
The output should be chosen from:
- Declarative
- Interrogative
- Exclamatory
- Imperative
### Input:
Would you like to go out?
### Response:
Interrogative"
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Write a short story in 100 words or less.
### Response:
Once upon a time, there was a girl named Sarah who had a great life. She had a loving family, lots of friends, and no shortage of fun things to do. One day, Sarah decided to do something extra adventurous and take a solo road trip. She packed her car and hit the open road with no set destination. She drove until nightfall, eventually finding a small townshe hadn't heard of before.
Sarah went in search of a place to stay, eventually stumbling upon a charming little inn. She settled into her room and began exploring the town, making some new friends along the way. Although Sarah knew her time in the town was limited, she enjoyed learning about the locals and the unique culture of the town. She stayed a few days before eventually heading back home, energized by the adventure she had set out on. She may not have traveled far, but Sarah's journey was filled with joy, surprise and new experiences."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Classify the following items as either solid or liquid.
### Input:
Water, sugar, steel
### Response:
Water: liquid, Sugar: solid, Steel: solid."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
What is the meaning of the idiom ""A penny saved is a penny earned""?
### Response:
The phrase ""A penny saved is a penny earned"" means that if you save money, it is like earning money as it keeps you from having to spend it. In other words, it is a way of saying that when you save money, you are essentially making money. It encourages people to save their money and be mindful of their money-saving habits."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
List three benefits of meditation
### Response:
Meditation can provide a number of benefits, including:
1. Improved mental health and emotional stability: Regular meditation can have a positive effect on mood, lower stress levels and increase self-awareness.
2. Increased concentration and productivity: Meditation helps to improve focus and concentration and can help you stay on task and maximize your productivity.
3. Physical health improvements: Meditation helps to reduce inflammation in the body and blood pressure, while also helping with symptoms of insomnia and chronic pain. Additionally, meditation can help foster a healthier lifestyle and reduce the risk of certain conditions."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
From the words given, form a sentence that conveys a feeling of hope and resilience.
### Input:
courage, sun, darkness
### Response:
In the midst of darkness, courage shines like the sun and brings hope for a better tomorrow."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Analyze the following poem.
### Input:
The Trees
by Philip Larkin
The trees are coming into leaf
Like something almost being said;
The recent buds relax and spread,
Their greenness is a kind of grief.
### Response:
In the poem “The Trees” by Philip Larkin, the narrator reflects on the beauty of nature but also conveys a sense of sadness and grief. Throughout the poem, the trees symbolize the journey of life, in all its beauty and sorrow. The “recent buds” represent new beginnings and the fragility of life. The narrator acknowledges that life can be both beautiful and sad, as the “greenness” conveys both joy and grief. The poem, ultimately, conveys the sadness of life but also the hope that it can bring."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Create a character profile for a female scientist.
### Response:
Character: Dr. Fiona Moss
Age: 40
Occupation: Scientist (specialization in biotechnology)
Appearance: Intelligent and handsome, with sharp features, dark eyes and brown hair that is often pulled back. Wears glasses and a lab coat when working.
Personality: Inquisitive, tenacious, and passionate about her field of expertise. She loves a good challenge and often takes on projects on her own time. Very independent and ambitious. A natural born leader.
Hobbies: Gardening, stargazing, and baking.
Relationships: Married to a fellow scientist and has two children. Very loving and supportive of her family.
Goals: To make major advancements in the fields of biotechnology and environmental conservation."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Design a logo for ""Acme Limousines""
### Response:
The Acme Limousines logo should feature a rectangular frame in black, with two uneven curved stripes running along the edges of the frame. The curved stripes should meet in the center of the logo, creating a “limousine” shape. Within the frame, the text “Acme Limousines” should be written in white, in a modern font."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Describe the setting of a dark and mysterious forest.
### Response:
The dark and mysterious forest is a place of shadows and secrets. Tall, ancient trees loom overhead, blocking out most of the sunlight. The thick foliage entwines the trees together, creating an almost impenetrable wall between the forest and the outside world. The air is thick and heavy, and an eerie silence pervades the area. Every now and then, an animal call will sound in the distance. Little is known of what truly lies within the mysterious forest, but whatever secrets it holds remain hidden within its depths."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Edit the following sentence to make it more concise: ""In the home, there are often difficulties in managing time for tasks such as cleaning and laundry""
### Response:
Managing home tasks like cleaning and laundry can be time-consuming."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Provide an example of a metric that could be used to measure the success of a new marketing campaign.
### Response:
A metric that can be used to measure the performance of a new marketing campaign is the number of leads generated, which is a measure of the number of people who take action (e.g. opting into the email list or signing up for a product trial). This metric will help to quantify the success of the marketing campaign in terms of the desired outcome."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Explain why it is important to establish trust with customers.
### Response:
It is important to establish trust with customers because it helps to build strong relationships and creates customer loyalty. When customers see that a business is reliable and trustworthy, they are more likely to return for additional purchases or services. Establishing trust also helps to enhance the customer experience and can lead to increased customer satisfaction. By having a trusting relationship with customers, businesses can gain their trust and better understand their needs and expectations."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Construct a SQL query that will retrieve the first 5 records from a table called ""Customers"".
### Response:
SELECT * FROM Customers
ORDER BY id
LIMIT 5;"
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Recommend a healthy snack for work.
### Response:
A healthy snack to have during work could be a protein-packed energy bar, such as an oatmeal and peanut butter bar. This quick and easy snack is filled with vitamins and minerals, and is a great source of energy. It's portable and can be easily tucked in a desk drawer for a quick snack."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Design a birthday card for a 7 year old.
### Response:
The birthday card should feature bright and cheerful colors and an age-appropriate illustration or message. The design should be child-friendly and feature fun, vivid imagery such as animals, cartoon characters, or cheerful messages. The birthday message should be written in a large, easy-to-read font. Inside the card, the message should convey the joy and excitement of celebrating another year of life for the 7 year old."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Identify the correct word to complete the sentence.
### Input:
The furniture was created with _____ in mind.
### Response:
sustainability"
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Add two sentences to this dialogue to make it complete.
### Input:
Wonka: Who are you?
Charlie: I'm Charlie Bucket.
### Response:
Wonka: What brings you here?
Charlie: I'm looking for a golden ticket!"
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Calculate the number of square meters in a 10x10 room.
### Response:
100 square meters."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Rewrite the sentence to reveal the metaphor.
### Input:
The sun was a golden coin in the sky.
### Response:
The sun was shining brightly in the clear blue sky, as bright as a golden coin."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Find and replace a word in the sentence to make it grammatically correct.
### Input:
The family ate dinner around the kitchen counters.
### Response:
The family ate dinner around the kitchen table."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Construct a balanced equation to represent the reaction.
### Input:
Fermentation of glucose to ethanol
### Response:
C6H12O6 → 2 C2H5OH + 2 CO2"
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Provide an explanation why this opinion is wrong.
### Input:
Driverless cars will make travel safer.
### Response:
Although driverless cars may reduce the risk of human error, they are exposed to the same risks as human drivers in unexpected or unpredictable traffic scenarios. Autonomous vehicles may still be prone to accidents due to programming errors and other factors. Therefore, driverless cars will not necessarily make travel safer."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Imagine a situation and write a paragraph of how to solve it.
### Input:
You arrive at a party and you know nobody.
### Response:
Upon arriving at the party, I immediately tried to put myself in a comfortable setting by scouting the area for familiar faces or conversation starters. I also took some deep breaths, put on a smile, and even made a few small jokes. Whenever I successfully engaged in a conversation, I asked meaningful questions that allowed me to learn more about the people around me. As time passed and conversations started to become more natural, I eventually made a few new acquaintances."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Brainstorm 4 possible options to reduce pollution in the city.
### Response:
1. Increase usage of public transportation and reduce private vehicle emissions.
2. Ban or enforce stricter emissions standards for factories and construction sites.
3. Create incentives for citizens and businesses to adopt green energy or environmentally friendly practices.
4. Build green spaces such as parks and gardens to absorb carbon dioxide from the atmosphere."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Classify the following passage into a specific genre.
### Input:
The rain pounded against the windows, lightning flashed in the distance, and thunder boomed in the air.
### Response:
The passage is an example of storm and suspense genre."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Given an example of a valid sentiment analysis scenario.
### Response:
A sentiment analysis scenario could involve analyzing customer reviews of a product to determine the general attitude of customers or the overall quality of the product."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Compare and contrast the two religions, Christianity and Islam.
### Response:
Christians and Muslims both hold to the belief that there is only one God, but they differ in their beliefs surrounding His nature and uncovering His will. Christians believe Jesus is the Son of God who bridges the gap between the Creator and mankind, while Muslim believe that Mohammad is the messenger of God who communicates His will to the people. Additionally, Christianity focuses on the teachings of Jesus, worshipping Him as the Son of God, and Islam follows the Quran and the teachings of Mohammad, worshipping Allah as the one God."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Insert a suitable phrase to complete the sentence.
### Input:
He let out a ________ when he heard the news.
### Response:
He let out a sigh of relief when he heard the news."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Alter the content of the sentence to use the past tense.
### Input:
The train leaves at 6:00pm.
### Response:
The train left at 6:00pm."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Write a product description for a new mobile.
### Input:
iPhone 11 Pro
### Response:
Introducing the new iPhone 11 Pro, the ultimate all-in-one device with a stunning OLED display, powerful triple camera system, and long-lasting battery life. Experience advanced technology and mesmerizing performance when you choose the iPhone 11 Pro. Whether you’re looking to capture breathtaking photos and videos, or experience amazing gaming and apps, the iPhone 11 Pro brings power and portability right to your fingertips."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Given the following passage, edit it to make the tone more formal
### Input:
Hi there! I am writing to request the printing of some documents. They are important because it'll be necessary to have multiple copies.
### Response:
I am writing to formally request the printing of some documents as they are essential to have multiple copies."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Suggest a suitable subtitle for this article
### Input:
The Benefits of Practicing Mindfulness
### Response:
Fostering Resilience and Well-Being Through Mindfulness."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
You need to suggest 3 strategies to optimize a website for Google search engine.
### Response:
1. Utilize proper keyword research to identify the most relevant search terms for your website.
2. Update website content regularly to ensure it remains relevant and up to date.
3. Implement SEO best practices such as optimizing page titles, headings, and URL structure for optimal search engine visibility."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Re-write the following sentence to use a different verb
### Input:
I will read the book
### Response:
I will peruse the book."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Propose a suitable title for the below article
### Input:
This article discusses the current state of the music industry and how technology has had an impact on its evolution.
### Response:
The Impact of Technology on the Music Industry: A Comprehensive Overview"
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Compare the following two subjects
### Input:
Artificial Intelligence and Machine Learning
### Response:
Artificial Intelligence (AI) and Machine Learning (ML) are both fields of computer science which involve the development of intelligent machines that can learn from data and perform tasks autonomously. AI focuses on human-like behavior and involves the development of algorithms and data structures that allow machines to learn through pattern recognition and logical reasoning. ML, on the other hand, is a subset of AI which focuses on teaching computers to optimize tasks to a certain degree of accuracy."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Explain what a computer algorithm is.
### Response:
A computer algorithm is a set of instructions that are encoded into a program for a computer to follow in order to solve a problem or process data. An algorithm is a step-by-step procedure that can be followed to reach a desired outcome. It is important because it helps computers to complete complex tasks efficiently and quickly. It also provides a structure which allows developers to easily debug and modify algorithms to improve their performance."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Suggest an appropriate title for the below passage
### Input:
A global pandemic forced the hospitality industry to re-evaluate its practices and adapt to a new world of health and safety protocols.
### Response:
Adapting to a New Normal: Hospitality's Response to the Global Pandemic"
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Predict a possible next line for the following story
### Input:
She was nervous about meeting the people in the new city.
### Response:
Her palms were sweaty as she walked through the streets, taking in her new surroundings."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Create a dialogue between two characters for a conflict resolution.
### Response:
Character A: ""I'm so frustrated that you haven't been in touch for the last few days!""
Character B: ""I realize I made a mistake by not being in touch. I'm sorry, I got caught up with work and it all happened without me noticing it.""
Character A: ""I understand, but it still hurt that you neglected me like that. How do you plan on fixing this?""
Character B: ""I can promise to check in with you more often to make sure you know what I'm up to. Will that help?""
Character A: ""Yes, that would make me feel better. Thanks for understanding""."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Specify an algorithm to find the maximum sum in a given array.
### Input:
[1,2,3,4]
### Response:
A simple solution is to traverse the array and keep track of the maximum sum encountered so far. This can be done using the following approach:
Iterate through the array and for each element, update the maximum sum encountered so far.
At any point, the maximum sum encountered so far is either the element itself or the sum of the previous maximum sum and the current element.
Thus, the algorithm can be recursively defined as follows:
maxSum(i) = max(arr[i], maxSum(i-1)+arr[i])
Where maxSum(i) represents the maximum sum with arr[i] as the last element and arr[0...i] as the given array."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Predict what might happen if the Earth's temperature rises.
### Response:
If the Earth's temperature rises, we can expect to see more extreme weather events, such as heatwaves, floods, droughts, and storms. Rising sea levels may lead to increased coastal flooding and erosion. An increase in air temperature may result in an increase in atmospheric moisture, leading to more intense precipitation events. It could also lead to an increase in regional species extinctions, as species unable to adapt to the changing climate would be unable to survive."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Generate a list of ideas for an app that helps people save money.
### Response:
1. An automated budgeting app that helps you track and monitor your spending.
2. An app that helps you find the best prices on products and services.
3. A savings calculator that allows you to calculate how much you will save by cutting certain expenses.
4. An app that sends you notifications and reminders when a bill is due.
5. An app that helps you create a monthly plan for saving money.
6. An app that negotiates discounted deals on behalf of the user.
7. A rebate tracking app for tracking cash back and other savings.
8. An app to help you find the cheapest gas station near you.
9. A virtual marketplace to compare different product prices from different stores.
10. An app to automatically search for promotional codes and coupons."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Make a list of potential risks associated with a given venture.
### Input:
Starting a small business
### Response:
1. Financial Risk: Lack of financial resources, Insufficient Capital, Unanticipated Cash Flow Problems
2. Market Risk: Over-saturation, Unfavorable Economic Conditions, Displacement by New Technology, Unsupportive Government Policies
3. Operational Risk: Inadequate Business Model, Unskilled Employees, Business Process Inefficiencies, Unfavorable Location
4. Legal Risk: Regulatory Compliance, Intellectual Property Disputes, Unforeseen Litigation, Taxation Issues
5. Strategic Risk: Strategic Inadequacies, Rivals' Superior Competencies, Partners' Unfavorable Negotiations, High Customer Attrition Rates"
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Design a logo for a restaurant that serves traditional Chinese dishes.
### Response:
The logo could be a round shape with Chinatown-inspired calligraphy in the center, encircled by a band of traditional Chinese symbols representing luck, prosperity and longevity. This can be topped off with a classic reddish-orange color scheme, which is also associated with luck and fortune in Chinese traditions."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Describe a technology used for measuring people's emotional responses.
### Response:
One popular technology for measuring people's emotional responses is facial expression recognition. Facial expression recognition uses machine learning algorithms to identify emotions from facial expressions and other visual cues, such as pupil dilation, head and body posture, movement, and gaze direction. It is used in research, health, and entertainment to study and measure reactions to content."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Name five medicinal plants widely used in Ayurveda.
### Response:
The five medicinal plants widely used in Ayurveda are Ashwagandha, Turmeric, Neem, Aloe Vera, and Guduchi. These plants are known for their healing properties, aiding in treating ailments such as digestive disorders, skin diseases, diabetes, and other conditions."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
generate an algorithm to find the first common ancestor of two nodes in a binary tree.
### Response:
A simple solution is to traverse the binary tree and find the paths from the root node to both nodes. Then compare the paths to find the last common ancestor node. The algorithm can be recursively defined as follows:
FindFirstCommonAncestor(nodeA, nodeB):
– Find the path from root to nodeA and store it in a vector or array.
– Find the path from root to nodeB and store it in another vector or array.
– Traverse both paths backwards and find the first different node. The node prior to this node is the first common ancestor."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Write a story of friendship between two boys from different backgrounds.
### Response:
Max and Tom were two boys from different backgrounds but with a common interest: football. Despite their differences, they quickly became friends. On the weekends they would go to the park and play football, chatting and getting to know each other better. As their friendship grew, they shared their hopes, dreams and stories. They soon became the best of friends and the park was their second home. Through their shared love of football, Max and Tom had forged an unlikely and unbreakable bond."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Give an example of how to use an AI assistant to automate a customer service process.
### Response:
An AI assistant can be used to automate customer service processes such as answering customer inquiries and providing support. For example, customer service agents could use an AI assistant to answer customer inquiries in real time by understanding the customer's query and suggesting relevant solutions. The AI assistant can also collect customer feedback and be used to improve customer experience in the long run."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
List five factors that influence the cost of producing a good.
### Response:
1. Raw materials: The cost of raw materials is one of the biggest drivers of production cost.
2. Labor: The cost of labor includes wages, taxes, benefits, and overhead.
3. Overhead costs: Overhead costs include rent, utilities, insurance, and other common expenses.
4. Equipment: The cost of machinery and other equipment used in production can significantly increase the cost.
5. Taxes: The cost of taxes, both at the local and federal level, can impact the cost of producing a good."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Assess the environmental impact of a renewable energy source
### Input:
Wind Energy
### Response:
Wind energy has several environmental benefits, as it is a renewable energy source that does not produce any emissions. Wind turbines can reduce greenhouse gas emissions, reduce our reliance on fossil fuels, and have a positive impact on global climate change. Wind turbines can also help reduce air pollution, as they are not powered by burning fossil fuels. Additionally, wind turbines have minimal impact on habitats, as they can be located in areas away from sensitive habitats, such as bird nesting grounds."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Explain the process of gaining creditworthiness for a loan
### Response:
Creditworthiness is an evaluation of an individual's or business' ability to pay back a loan. To gain creditworthiness, one must possess a good credit history, show proof of income, and demonstrate financial stability. A lender will look at the applicant’s credit score, credit history, and current financial situation to determine eligibility. The applicant must also prove they have a steady source of income, can keep up with debt payments, and can repay the desired loan amount.
In order to gain creditworthiness, the applicant must usually provide documents such as payment histories, tax returns, income statements, and bank statements. The lender will look these documents over and provide an assessment of the applicant's risk."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Generate a list of tips to improve metabolism.
### Response:
1. Eat more protein: Protein-rich foods can help improve metabolism, as they require more energy to digest than carbohydrates and fats.
2. Get adequate sleep: Aim for 7-9 hours of quality sleep per night, as this can help improve metabolism.
3. Drink coffee or tea: Caffeinated beverages can give your metabolism a boost, as they contain caffeine which stimulates the nervous system.
4. Try HIIT: High Intensity Interval Training is an effective way to burn calories and increase metabolism.
5. Eat lots of fruits and vegetables: Eating plenty of fruits and vegetables can help to speed up metabolism due to their rich antioxidant content.
6. Add spices to your meals: Spicy foods such as hot peppers, ginger, turmeric, and garlic can boost metabolic rate and help burn fat."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Choose the best password for a given service.
### Input:
Online banking
### Response:
The best password for online banking is one that is long and complex, contains a mix of letters, uppercase and lowercase letters, numbers, and symbols, and is unique to the service. It should also be changed regularly to help ensure the highest level of security."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Write a story about a robot who has to complete a difficult task.
### Response:
Once upon a time, there was a robot named Robotrix who was tasked with a difficult mission. After a long day of traveling, Robotrix arrived at a strange new world. The robot was set a challenge - to cross a dangerous and seemingly infinite ocean. After many days of sailing, Robotrix eventually encountered a strange creature - a giant whale. The whale presented Robotrix with a challenge - to defeat a giant monster that lived in the depths. After a fierce battle, the robot ultimately defeated the monster, and returned home victorious."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Pick out the odd word out in each sentence:
### Input:
Tree, Wind, Flower
### Response:
The odd word out is 'Wind'."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Compose a song in C Major.
### Response:
Verse 1
C G F C
B-flat F G C
Chorus
C G A-minor F
C G A-minor F
Verse 2
C G D G
A-minor D G C
Chorus
C G A-minor F
C G A-minor F
Bridge
F D G C
A-minor D A-minor F
Chorus
C G A-minor F
C G A-minor F"
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Classify the following text into either fiction or non-fiction.
### Input:
The novel ""The Catcher in the Rye"" by J.D. Salinger follows the story of a teenage boy named Holden Caulfield.
### Response:
This text is fiction."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Identify the type of triangle from the following set of angles.
### Input:
80 degrees, 50 degrees, 50 degrees
### Response:
The triangle is an isosceles triangle."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Calculate the area of a triangle with sides measuring 8cm, 5cm, and 6cm.
### Response:
The area of a triangle with sides measuring 8cm, 5cm, and 6cm is 20cm\(^{2}\)."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Describe how plants look like in the winter.
### Response:
In the winter, plants typically have no leaves, are dormant and are usually either brown or grey in color. The bark of the tree usually changes color and becomes thicker. Some evergreen plants may remain green, but they usually appear less vivid in color."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
What type of number is -625?
### Response:
-625 is a negative integer."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Find the sum of the interior angles of a polygon with five sides.
### Response:
The sum of the interior angles of a polygon with five sides is 540°."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
What is the difference between a porcupine and a hedgehog?
### Response:
The main difference between a porcupine and a hedgehog is that a porcupine has longer and sharper quills than a hedgehog. Porcupines also tend to be larger and have thicker fur than hedgehogs."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Update the following passage with the correct spelling and grammar.
### Input:
For a science project we prformed a experiment to detemine how much water plants need.
### Response:
For a science project, we performed an experiment to determine how much water plants need."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Name one chemical that is both an acid and a base.
### Response:
One chemical that is both an acid and a base is sodium hydroxide."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Write a 200-word essay explaining the importance of sustainable energy.
### Response:
Sustainable energy is energy obtained from sources which cannot be exhausted and is renewable. These sources include solar energy, wind energy, biomass energy, geothermal energy, and waves from the ocean. Sustainable energy provides an abundance of energy and is not damaging to the environment. It also leads to a decreased need to rely on depleting resources as well as a reduced amount of waste and emissions.
Using sustainable energy saves a lot of money in the long run since it is not being produced and thus fossil fuels are no longer needed. Renewable energy is particularly useful in areas where there is a lack of access to traditional energy sources and in areas where conventional energy sources cause damage to the environment, such as coastal areas and areas with large amounts of forestry.
Sustainable energy helps reduce the emissions of greenhouse gases into the atmosphere and thus helps mitigate climate change. It is much more efficient than traditional energy sources and does not have the large setup costs associated with them. Additionally, it does not require large amounts of land for installation and allows for much of the energy and resources to be used locally, which helps to create jobs and stimulate local economies.
Overall, sustainable energy is incredibly important for saving money, protecting the environment, and providing a healthy and prosperous future for all."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Identify the type of sentence ""I drove to the store yesterday"".
### Response:
Declarative sentence."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Construct an argument supporting the implementation of green energy.
### Response:
Green energy is an investment in the future that comes with numerous potential benefits. Its implementation serves to reduce pollution, lower emissions of greenhouse gases, and enhance energy security. Additionally, green energy harnesses the natural resources around us, resulting in steady and consistent energy supply. Green energy sources are renewable, meaning that they are sustainable, available indefinitely, and require little maintenance. This also allows for the construction of green energy projects, resulting in job creation in the energy sector. The cost of implementing green energy projects is initially high, but the savings over a period of time are far greater. Finally, green energy presents us with an opportunity to play a part in the fight against climate change and its resulting consequences."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Edit the following sentence to make it more concise: ""The cat was sitting on the fence and meowing loudly"".
### Response:
The cat meowed loudly on the fence."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Describe some of the benefits of a vegetarian diet.
### Response:
A vegetarian diet provides many health benefits, including reduced risk of heart disease, stroke, obesity, and some types of cancer. It can also lead to improved digestive health, increased energy levels, and better overall health. Additionally, vegetarians are often more conscious of the environmental impacts of their diets, as the production of vegetarian food items often requires less energy, water, and land. Furthermore, vegetarian diets are beneficial for animals, as they do not involve the slaughter of animals or the use of animal products."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Print all the prime numbers between 1 and 50.
### Response:
2, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31, 37, 41, 43, 47."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Explain what is an algorithmic trading.
### Response:
Algorithmic trading is a form of automated trading that uses complex algorithms to make decisions about buying and selling stocks, options, and other financial instruments. Algorithmic trading is programmed so that trades are made without human interference and are based on market data and conditions. These algorithms are also used to objectively analyze market trends, identify potentially profitable trading opportunities, and execute trades with greater speed and accuracy than humans could."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Arrange the following words to make a meaningful sentence: selling do investors to advice trust.
### Response:
Investors trust selling advice to do."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Split the following sentence into two declarative sentences: ""The food was delicious and the service was excellent"".
### Response:
The food was delicious. The service was excellent."
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Explain how neural networks can be used to predict stock prices.
### Response:
Neural networks can be used to predict stock prices by analyzing stock market data such as past prices, the performance of certain stocks, news events, and other data related to the stock market. The neural networks use this data to learn patterns about stock prices and then use the patterns to make predictions about future stock prices. This type of predictive modeling has been found to be very accurate in many cases and can be used to make more informed investing decisions."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Classify the following healthy food item
### Input:
Sushi
### Response:
Carbohydrate"
"Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Name the 6 most populous cities in China.
### Response:
The six most populous cities in China are Shanghai, Beijing, Guangzhou, Shenzhen, Wuhan, and Chengdu."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Edit the following text to make it easier to read
### Input:
In the 20th centuary,developments in the fields of technology, science and medicin,applied by humans, have brought about unprecedented changes
### Response:
In the 20th century, developments in the fields of technology, science, and medicine, applied by humans, have brought about unprecedented changes."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Determine the surface area of the following figure
### Input:
A cube with side length 2 cm
### Response:
The surface area of the cube is 24 cm²."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Find the definition of the following financial term
### Input:
Stock Split
### Response:
A stock split is a corporate action in which a company divides its existing shares into multiple shares, to boost the liquidity of the shares. This means that the number of shares outstanding increases, while the share price is adjusted accordingly."
"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Describe the flavor profile of the following type of cuisine
### Input:
Japanese
### Response:
Japanese cuisine is characterized by its subtle and delicate flavors, featuring a combination of salty, sweet, sour, and umami flavors. It also utilizes fresh ingredients with a focus on preserving their natural flavors."
| 7 |
0 | hf_public_repos | hf_public_repos/candle-cublaslt/Cargo.toml | [package]
name = "candle-cublaslt"
version = "0.2.2"
edition = "2021"
description = "CUBLASLt gemm for the candle ML framework."
[dependencies]
candle = { version = "*", package = "candle-core", features = ["cuda"]}
cudarc = { git = "https://github.com/coreylowman/cudarc", rev = "c388e724af93a3e8fbe484f5ded2d8b3c1badd8e", default-features = false, features = [ "cublaslt", "f16" ]}
half = { version = "2.3.1", features = ["num-traits"] }
[patch.crates-io]
cudarc = { git = "https://github.com/coreylowman/cudarc", rev = "c388e724af93a3e8fbe484f5ded2d8b3c1badd8e", default-features = false, features = [ "cublaslt", "f16" ]}
[features]
default = []
static-linking = ["cudarc/static-linking"]
| 8 |
0 | hf_public_repos | hf_public_repos/candle-cublaslt/LICENSE-MIT | Permission is hereby granted, free of charge, to any
person obtaining a copy of this software and associated
documentation files (the "Software"), to deal in the
Software without restriction, including without
limitation the rights to use, copy, modify, merge,
publish, distribute, sublicense, and/or sell copies of
the Software, and to permit persons to whom the Software
is furnished to do so, subject to the following
conditions:
The above copyright notice and this permission notice
shall be included in all copies or substantial portions
of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF
ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED
TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A
PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT
SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY
CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION
OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR
IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER
DEALINGS IN THE SOFTWARE.
| 9 |
0 | hf_public_repos/api-inference-community/docker_images | hf_public_repos/api-inference-community/docker_images/asteroid/requirements.txt | starlette==0.27.0
api-inference-community==0.0.23
huggingface_hub==0.5.1
asteroid==0.4.4
| 0 |
0 | hf_public_repos/api-inference-community/docker_images | hf_public_repos/api-inference-community/docker_images/asteroid/Dockerfile | FROM tiangolo/uvicorn-gunicorn:python3.8
LABEL maintainer="me <[email protected]>"
# Add any system dependency here
# RUN apt-get update -y && apt-get install libXXX -y
RUN apt-get update -y && apt-get install ffmpeg -y
COPY ./requirements.txt /app
RUN pip install --no-cache-dir -r requirements.txt
COPY ./prestart.sh /app/
# Most DL models are quite large in terms of memory, using workers is a HUGE
# slowdown because of the fork and GIL with python.
# Using multiple pods seems like a better default strategy.
# Feel free to override if it does not make sense for your library.
ARG max_workers=1
ENV MAX_WORKERS=$max_workers
ENV HUGGINGFACE_HUB_CACHE=/data
ENV ASTEROID_CACHE=/data
# Necessary on GPU environment docker.
# TIMEOUT env variable is used by nvcr.io/nvidia/pytorch:xx for another purpose
# rendering TIMEOUT defined by uvicorn impossible to use correctly
# We're overriding it to be renamed UVICORN_TIMEOUT
# UVICORN_TIMEOUT is a useful variable for very large models that take more
# than 30s (the default) to load in memory.
# If UVICORN_TIMEOUT is too low, uvicorn will simply never loads as it will
# kill workers all the time before they finish.
RUN sed -i 's/TIMEOUT/UVICORN_TIMEOUT/g' /gunicorn_conf.py
COPY ./app /app/app
| 1 |
0 | hf_public_repos/api-inference-community/docker_images | hf_public_repos/api-inference-community/docker_images/asteroid/prestart.sh | python app/main.py
| 2 |
0 | hf_public_repos/api-inference-community/docker_images/asteroid | hf_public_repos/api-inference-community/docker_images/asteroid/app/main.py | import functools
import logging
import os
from typing import Dict, Type
from api_inference_community.routes import pipeline_route, status_ok
from app.pipelines import AudioSourceSeparationPipeline, AudioToAudioPipeline, Pipeline
from starlette.applications import Starlette
from starlette.middleware import Middleware
from starlette.middleware.gzip import GZipMiddleware
from starlette.routing import Route
TASK = os.getenv("TASK")
MODEL_ID = os.getenv("MODEL_ID")
logger = logging.getLogger(__name__)
# Add the allowed tasks
# Supported tasks are:
# - text-generation
# - text-classification
# - token-classification
# - translation
# - summarization
# - automatic-speech-recognition
# - ...
# For instance
# from app.pipelines import AutomaticSpeechRecognitionPipeline
# ALLOWED_TASKS = {"automatic-speech-recognition": AutomaticSpeechRecognitionPipeline}
# You can check the requirements and expectations of each pipelines in their respective
# directories. Implement directly within the directories.
ALLOWED_TASKS: Dict[str, Type[Pipeline]] = {
"audio-source-separation": AudioSourceSeparationPipeline,
"audio-to-audio": AudioToAudioPipeline,
}
@functools.lru_cache()
def get_pipeline() -> Pipeline:
task = os.environ["TASK"]
model_id = os.environ["MODEL_ID"]
if task not in ALLOWED_TASKS:
raise EnvironmentError(f"{task} is not a valid pipeline for model : {model_id}")
return ALLOWED_TASKS[task](model_id)
routes = [
Route("/{whatever:path}", status_ok),
Route("/{whatever:path}", pipeline_route, methods=["POST"]),
]
middleware = [Middleware(GZipMiddleware, minimum_size=1000)]
if os.environ.get("DEBUG", "") == "1":
from starlette.middleware.cors import CORSMiddleware
middleware.append(
Middleware(
CORSMiddleware,
allow_origins=["*"],
allow_headers=["*"],
allow_methods=["*"],
)
)
app = Starlette(routes=routes, middleware=middleware)
@app.on_event("startup")
async def startup_event():
logger = logging.getLogger("uvicorn.access")
handler = logging.StreamHandler()
handler.setFormatter(logging.Formatter("%(asctime)s - %(levelname)s - %(message)s"))
logger.handlers = [handler]
# Link between `api-inference-community` and framework code.
app.get_pipeline = get_pipeline
try:
get_pipeline()
except Exception:
# We can fail so we can show exception later.
pass
if __name__ == "__main__":
try:
get_pipeline()
except Exception:
# We can fail so we can show exception later.
pass
| 3 |
0 | hf_public_repos/api-inference-community/docker_images/asteroid/app | hf_public_repos/api-inference-community/docker_images/asteroid/app/pipelines/audio_source_separation.py | from typing import Tuple
import numpy as np
from app.pipelines import Pipeline
from asteroid import separate
from asteroid.models import BaseModel
class AudioSourceSeparationPipeline(Pipeline):
def __init__(self, model_id: str):
self.model = BaseModel.from_pretrained(model_id)
self.sampling_rate = self.model.sample_rate
def __call__(self, inputs: np.array) -> Tuple[np.array, int]:
"""
Args:
inputs (:obj:`np.array`):
The raw waveform of audio received. By default at 16KHz.
Check `app.validation` if a different sample rate is required
or if it depends on the model
Return:
A :obj:`np.array` and a :obj:`int`: The raw waveform as a numpy array, and the sampling rate as an int.
"""
# Pass wav as [batch, n_chan, time]; here: [1, 1, time]
separated = separate.numpy_separate(self.model, inputs.reshape((1, 1, -1)))
# FIXME: how to deal with multiple sources?
return separated[0, 0], int(self.model.sample_rate)
| 4 |
0 | hf_public_repos/api-inference-community/docker_images/asteroid/app | hf_public_repos/api-inference-community/docker_images/asteroid/app/pipelines/base.py | from abc import ABC, abstractmethod
from typing import Any
class Pipeline(ABC):
@abstractmethod
def __init__(self, model_id: str):
raise NotImplementedError("Pipelines should implement an __init__ method")
@abstractmethod
def __call__(self, inputs: Any) -> Any:
raise NotImplementedError("Pipelines should implement a __call__ method")
class PipelineException(Exception):
pass
| 5 |
0 | hf_public_repos/api-inference-community/docker_images/asteroid/app | hf_public_repos/api-inference-community/docker_images/asteroid/app/pipelines/__init__.py | from app.pipelines.base import Pipeline, PipelineException # isort:skip
from app.pipelines.audio_source_separation import AudioSourceSeparationPipeline
from app.pipelines.audio_to_audio import AudioToAudioPipeline
| 6 |
0 | hf_public_repos/api-inference-community/docker_images/asteroid/app | hf_public_repos/api-inference-community/docker_images/asteroid/app/pipelines/audio_to_audio.py | from typing import List, Tuple
import numpy as np
from app.pipelines import Pipeline
from asteroid import separate
from asteroid.models import BaseModel
class AudioToAudioPipeline(Pipeline):
def __init__(self, model_id: str):
self.model = BaseModel.from_pretrained(model_id)
self.sampling_rate = self.model.sample_rate
def __call__(self, inputs: np.array) -> Tuple[np.array, int, List[str]]:
# Pass wav as [batch, n_chan, time]; here: [1, 1, time]
"""
Args:
inputs (:obj:`np.array`):
The raw waveform of audio received. By default sampled at `self.sampling_rate`.
The shape of this array is `T`, where `T` is the time axis
Return:
A :obj:`tuple` containing:
- :obj:`np.array`:
The return shape of the array must be `C'`x`T'`
- a :obj:`int`: the sampling rate as an int in Hz.
- a :obj:`List[str]`: the annotation for each out channel.
This can be the name of the instruments for audio source separation
or some annotation for speech enhancement. The length must be `C'`.
"""
separated = separate.numpy_separate(self.model, inputs.reshape((1, 1, -1)))
# FIXME: how to deal with multiple sources?
out = separated[0]
n = out.shape[0]
labels = [f"label_{i}" for i in range(n)]
return separated[0], int(self.model.sample_rate), labels
| 7 |
0 | hf_public_repos/api-inference-community/docker_images/asteroid | hf_public_repos/api-inference-community/docker_images/asteroid/tests/test_docker_build.py | import os
import subprocess
from unittest import TestCase
class cd:
"""Context manager for changing the current working directory"""
def __init__(self, newPath):
self.newPath = os.path.expanduser(newPath)
def __enter__(self):
self.savedPath = os.getcwd()
os.chdir(self.newPath)
def __exit__(self, etype, value, traceback):
os.chdir(self.savedPath)
class DockerBuildTestCase(TestCase):
def test_can_build_docker_image(self):
with cd(os.path.dirname(os.path.dirname(__file__))):
subprocess.check_output(["docker", "build", "."])
| 8 |
0 | hf_public_repos/api-inference-community/docker_images/asteroid | hf_public_repos/api-inference-community/docker_images/asteroid/tests/test_api_audio_to_audio.py | import base64
import json
import os
from unittest import TestCase, skipIf
from api_inference_community.validation import ffmpeg_read
from app.main import ALLOWED_TASKS
from starlette.testclient import TestClient
from tests.test_api import TESTABLE_MODELS
@skipIf(
"audio-to-audio" not in ALLOWED_TASKS,
"audio-to-audio not implemented",
)
class AudioToAudioTestCase(TestCase):
def setUp(self):
model_id = TESTABLE_MODELS["audio-to-audio"]
self.old_model_id = os.getenv("MODEL_ID")
self.old_task = os.getenv("TASK")
os.environ["MODEL_ID"] = model_id
os.environ["TASK"] = "audio-to-audio"
from app.main import app
self.app = app
def tearDown(self):
if self.old_model_id is not None:
os.environ["MODEL_ID"] = self.old_model_id
else:
del os.environ["MODEL_ID"]
if self.old_task is not None:
os.environ["TASK"] = self.old_task
else:
del os.environ["TASK"]
def read(self, filename: str) -> bytes:
dirname = os.path.dirname(os.path.abspath(__file__))
filename = os.path.join(dirname, "samples", filename)
with open(filename, "rb") as f:
bpayload = f.read()
return bpayload
def test_simple(self):
bpayload = self.read("sample1.flac")
with TestClient(self.app) as client:
response = client.post("/", data=bpayload)
self.assertEqual(
response.status_code,
200,
)
self.assertEqual(response.headers["content-type"], "application/json")
audio = json.loads(response.content)
self.assertTrue(isinstance(audio, list))
self.assertEqual(set(audio[0].keys()), {"blob", "content-type", "label"})
data = base64.b64decode(audio[0]["blob"])
wavform = ffmpeg_read(data)
self.assertGreater(wavform.shape[0], 1000)
self.assertTrue(isinstance(audio[0]["content-type"], str))
self.assertTrue(isinstance(audio[0]["label"], str))
def test_malformed_audio(self):
bpayload = self.read("malformed.flac")
with TestClient(self.app) as client:
response = client.post("/", data=bpayload)
self.assertEqual(
response.status_code,
400,
)
self.assertEqual(response.content, b'{"error":"Malformed soundfile"}')
def test_dual_channel_audiofile(self):
bpayload = self.read("sample1_dual.ogg")
with TestClient(self.app) as client:
response = client.post("/", data=bpayload)
self.assertEqual(
response.status_code,
200,
)
self.assertEqual(response.headers["content-type"], "application/json")
audio = json.loads(response.content)
self.assertTrue(isinstance(audio, list))
self.assertEqual(set(audio[0].keys()), {"blob", "content-type", "label"})
data = base64.b64decode(audio[0]["blob"])
wavform = ffmpeg_read(data)
self.assertGreater(wavform.shape[0], 1000)
self.assertTrue(isinstance(audio[0]["content-type"], str))
self.assertTrue(isinstance(audio[0]["label"], str))
def test_webm_audiofile(self):
bpayload = self.read("sample1.webm")
with TestClient(self.app) as client:
response = client.post("/", data=bpayload)
self.assertEqual(
response.status_code,
200,
)
self.assertEqual(response.headers["content-type"], "application/json")
audio = json.loads(response.content)
self.assertTrue(isinstance(audio, list))
self.assertEqual(set(audio[0].keys()), {"blob", "content-type", "label"})
data = base64.b64decode(audio[0]["blob"])
wavform = ffmpeg_read(data)
self.assertGreater(wavform.shape[0], 1000)
self.assertTrue(isinstance(audio[0]["content-type"], str))
self.assertTrue(isinstance(audio[0]["label"], str))
| 9 |
0 | hf_public_repos/candle/candle-core/src | hf_public_repos/candle/candle-core/src/quantized/utils.rs | use crate::Result;
pub(super) fn nearest_int(v: f32) -> i32 {
v.round() as i32
}
/// Validates that the input and output are the right size and returns an iterator which maps each
/// input region `xs` to its corresponding output block in `ys`. Each output region is guaranteed
/// to be `T::BLCK_SIZE` long.
pub(super) fn group_for_quantization<'a, 'b, T: super::k_quants::GgmlType>(
xs: &'b [f32],
ys: &'a mut [T],
) -> Result<Vec<(&'a mut T, &'b [f32])>> {
let block_size = T::BLCK_SIZE;
let dtype = T::DTYPE;
let expected_blocks = xs.len() / block_size;
let actual_blocks = ys.len();
// Validate that the input is the right size
if expected_blocks != actual_blocks {
crate::bail!("quantize {dtype:?}: expected {expected_blocks} blocks but only {actual_blocks} were provided!")
}
Ok(ys.iter_mut().zip(xs.chunks_exact(block_size)).collect())
}
/// Validates that the input and output are the right size and returns an iterator which maps each
/// input block `xs` to its corresponding output region in `ys`. Each output region is guaranteed
/// to be `T::BLCK_SIZE` long.
pub(super) fn group_for_dequantization<'a, 'b, T: super::k_quants::GgmlType>(
xs: &'a [T],
ys: &'b mut [f32],
) -> Result<Vec<(&'a T, &'b mut [f32])>> {
let block_size = T::BLCK_SIZE;
let dtype = T::DTYPE;
let actual_output_len = ys.len();
let expected_output_len = xs.len() * block_size;
// Validate that the output is the right size
if expected_output_len != actual_output_len {
crate::bail!("dequantize {dtype:?}: ys (len = {actual_output_len}) does not match the expected length of {expected_output_len}!")
}
// Zip the blocks and outputs together
Ok(xs.iter().zip(ys.chunks_exact_mut(block_size)).collect())
}
pub(super) fn get_scale_min_k4(j: usize, q: &[u8]) -> (u8, u8) {
if j < 4 {
let d = q[j] & 63;
let m = q[j + 4] & 63;
(d, m)
} else {
let d = (q[j + 4] & 0xF) | ((q[j - 4] >> 6) << 4);
let m = (q[j + 4] >> 4) | ((q[j] >> 6) << 4);
(d, m)
}
}
pub(super) unsafe fn make_qx_quants(
n: usize,
nmax: i32,
x: *const f32,
ls: *mut i8,
rmse_type: i32,
) -> f32 {
let mut max = 0f32;
let mut amax = 0f32;
for i in 0..n {
let x = *x.add(i);
let ax = x.abs();
if ax > amax {
amax = ax;
max = x;
}
}
if amax == 0. {
// all zero
for i in 0..n {
*ls.add(i) = 0;
}
return 0.;
}
let mut iscale = -(nmax as f32) / max;
if rmse_type == 0 {
for i in 0..n {
let x = *x.add(i);
let l = nearest_int(iscale * x);
*ls.add(i) = (nmax + l.clamp(-nmax, nmax - 1)) as i8;
}
return 1.0 / iscale;
}
let weight_type = rmse_type % 2;
let mut sumlx = 0f32;
let mut suml2 = 0f32;
for i in 0..n {
let x = *x.add(i);
let l = nearest_int(iscale * x);
let l = l.clamp(-nmax, nmax - 1);
*ls.add(i) = (l + nmax) as i8;
let w = if weight_type == 1 { x * x } else { 1.0 };
let l = l as f32;
sumlx += w * x * l;
suml2 += w * l * l;
}
let mut scale = sumlx / suml2;
let mut best = scale * sumlx;
for _itry in 0..3 {
let iscale = 1.0 / scale;
let mut slx = 0f32;
let mut sl2 = 0f32;
let mut changed = false;
for i in 0..n {
let x = *x.add(i);
let l = nearest_int(iscale * x);
let l = l.clamp(-nmax, nmax - 1);
if l + nmax != *ls.add(i) as i32 {
changed = true;
}
let w = if weight_type == 1 { x * x } else { 1f32 };
let l = l as f32;
slx += w * x * l;
sl2 += w * l * l;
}
if !changed || sl2 == 0.0 || slx * slx <= best * sl2 {
break;
}
for i in 0..n {
let x = *x.add(i);
let l = nearest_int(iscale * x);
*ls.add(i) = (nmax + l.clamp(-nmax, nmax - 1)) as i8;
}
sumlx = slx;
suml2 = sl2;
scale = sumlx / suml2;
best = scale * sumlx;
}
for _itry in 0..5 {
let mut n_changed = 0;
for i in 0..n {
let x = *x.add(i);
let w = if weight_type == 1 { x * x } else { 1. };
let l = *ls.add(i) as i32 - nmax;
let mut slx = sumlx - w * x * l as f32;
if slx > 0. {
let mut sl2 = suml2 - w * l as f32 * l as f32;
let new_l = nearest_int(x * sl2 / slx);
let new_l = new_l.clamp(-nmax, nmax - 1);
if new_l != l {
slx += w * x * new_l as f32;
sl2 += w * new_l as f32 * new_l as f32;
if sl2 > 0. && slx * slx * suml2 > sumlx * sumlx * sl2 {
*ls.add(i) = (nmax + new_l) as i8;
sumlx = slx;
suml2 = sl2;
scale = sumlx / suml2;
best = scale * sumlx;
n_changed += 1;
}
}
}
}
if n_changed == 0 {
break;
}
}
if rmse_type < 3 {
return scale;
}
for is in -4..4 {
if is == 0 {
continue;
}
iscale = -(nmax as f32 + 0.1f32 * is as f32) / max;
let mut sumlx = 0.;
let mut suml2 = 0.;
for i in 0..n {
let x = *x.add(i);
let l = nearest_int(iscale * x);
let l = l.clamp(-nmax, nmax - 1);
let w = if weight_type == 1 { x * x } else { 1. };
let l = l as f32;
sumlx += w * x * l;
suml2 += w * l * l;
}
if suml2 > 0. && sumlx * sumlx > best * suml2 {
for i in 0..n {
let x = *x.add(i);
let l = nearest_int(iscale * x);
*ls.add(i) = (nmax + l.clamp(-nmax, nmax - 1)) as i8;
}
scale = sumlx / suml2;
best = scale * sumlx;
}
}
scale
}
// https://github.com/ggerganov/llama.cpp/blob/8183159cf3def112f6d1fe94815fce70e1bffa12/k_quants.c#L224
pub(super) fn make_qkx1_quants(nmax: i32, ntry: usize, x: &[f32]) -> (f32, f32) {
let n = x.len();
let mut l = vec![0; n];
// Get min/max
let min = *x
.iter()
.take(n)
.min_by(|a, b| a.total_cmp(b))
.unwrap_or(&x[0]);
let max = *x.iter().max_by(|a, b| a.total_cmp(b)).unwrap_or(&x[0]);
// If min == max, all values are the same => nothing to do here
if max == min {
return (0.0, 0.0);
}
// Ensure min <= 0.0
let mut min = min.min(0.);
// Compute scale and inverse scale
let mut iscale = nmax as f32 / (max - min);
let mut scale = 1.0 / iscale;
for _ in 0..ntry {
let mut sumlx = 0.0;
let mut suml2 = 0;
let mut did_change = false;
for (i, value) in x.iter().enumerate().take(n) {
let li = nearest_int(iscale * (value - min)).clamp(0, nmax);
let clamped_li = li as u8;
if clamped_li != l[i] {
l[i] = clamped_li;
did_change = true;
}
sumlx += (value - min) * li as f32;
suml2 += li * li;
}
scale = sumlx / suml2 as f32;
let sum: f32 = x
.iter()
.take(n)
.zip(l.iter().take(n))
.map(|(xi, &li)| xi - scale * li as f32)
.sum();
min = sum / n as f32;
if min > 0.0 {
min = 0.0;
}
iscale = 1.0 / scale;
if !did_change {
break;
}
}
(scale, -min)
}
// https://github.com/ggerganov/llama.cpp/blob/8183159cf3def112f6d1fe94815fce70e1bffa12/k_quants.c#L165
pub(super) fn make_q3_quants(x: &[f32], nmax: i32, do_rmse: bool) -> f32 {
let n = x.len();
let mut l = vec![0i8; n];
let mut max = 0.0;
let mut amax = 0.0;
for &xi in x.iter().take(n) {
let ax = xi.abs();
if ax > amax {
amax = ax;
max = xi;
}
}
if amax == 0.0 {
return 0.0;
}
let iscale = -(nmax as f32) / max;
if do_rmse {
let mut sumlx = 0.0;
let mut suml2 = 0.0;
for i in 0..n {
let li = (iscale * x[i]).round() as i32;
let li = li.clamp(-nmax, nmax - 1);
l[i] = li as i8;
let w = x[i] * x[i];
sumlx += w * x[i] * li as f32;
suml2 += w * (li * li) as f32;
}
for _ in 0..5 {
let mut n_changed = 0;
for i in 0..n {
let w = x[i] * x[i];
let mut slx = sumlx - w * x[i] * l[i] as f32;
if slx > 0.0 {
let mut sl2 = suml2 - w * (l[i] as i32 * l[i] as i32) as f32;
let mut new_l = (x[i] * sl2 / slx).round() as i32;
new_l = new_l.clamp(-nmax, nmax - 1);
if new_l != l[i] as i32 {
slx += w * x[i] * new_l as f32;
sl2 += w * (new_l * new_l) as f32;
if sl2 > 0.0 && slx * slx * suml2 > sumlx * sumlx * sl2 {
l[i] = new_l as i8;
sumlx = slx;
suml2 = sl2;
n_changed += 1;
}
}
}
}
if n_changed == 0 {
break;
}
}
for li in l.iter_mut() {
*li += nmax as i8;
}
return sumlx / suml2;
}
for i in 0..n {
let li = (iscale * x[i]).round() as i32;
l[i] = (li.clamp(-nmax, nmax - 1) + nmax) as i8;
}
1.0 / iscale
}
| 0 |
0 | hf_public_repos/candle/candle-core/src | hf_public_repos/candle/candle-core/src/quantized/simd128.rs | use super::k_quants::{BlockQ2K, BlockQ4K, BlockQ4_0, BlockQ6K, BlockQ8K, BlockQ8_0, QK8_0, QK_K};
use crate::Result;
use byteorder::{ByteOrder, LittleEndian};
use half::f16;
use core::arch::wasm32::*;
#[inline(always)]
pub(crate) fn vec_dot_q4_0_q8_0(n: usize, xs: &[BlockQ4_0], ys: &[BlockQ8_0]) -> Result<f32> {
let qk = QK8_0;
if n % QK8_0 != 0 {
crate::bail!("vec_dot_q4_0_q8_0: {n} is not divisible by {qk}")
}
unsafe {
let mut acc = f32x4_splat(0.0f32);
for (x, y) in xs.iter().zip(ys.iter()) {
let x1234 = v128_load(x.qs.as_ptr() as *const v128);
let x12 = v128_and(x1234, u8x16_splat(0x0F));
let x12 = i8x16_sub(x12, i8x16_splat(8));
let x34 = u8x16_shr(x1234, 4);
let x34 = i8x16_sub(x34, i8x16_splat(8));
let x1 = i16x8_extend_low_i8x16(x12);
let y1 = i16x8_load_extend_i8x8(y.qs.as_ptr());
let sum_xy = i32x4_dot_i16x8(x1, y1);
let x2 = i16x8_extend_high_i8x16(x12);
let y2 = i16x8_load_extend_i8x8(y.qs.as_ptr().add(8));
let sum_xy = i32x4_add(sum_xy, i32x4_dot_i16x8(x2, y2));
let x3 = i16x8_extend_low_i8x16(x34);
let y3 = i16x8_load_extend_i8x8(y.qs.as_ptr().add(16));
let sum_xy = i32x4_add(sum_xy, i32x4_dot_i16x8(x3, y3));
let x4 = i16x8_extend_high_i8x16(x34);
let y4 = i16x8_load_extend_i8x8(y.qs.as_ptr().add(24));
let sum_xy = i32x4_add(sum_xy, i32x4_dot_i16x8(x4, y4));
let sum_xy = f32x4_convert_i32x4(sum_xy);
// f32x4_relaxed_madd is nightly only.
let d = f32x4_splat(f16::to_f32(x.d) * f16::to_f32(y.d));
let scaled = f32x4_mul(sum_xy, d);
acc = f32x4_add(acc, scaled)
}
let res = f32x4_extract_lane::<0>(acc)
+ f32x4_extract_lane::<1>(acc)
+ f32x4_extract_lane::<2>(acc)
+ f32x4_extract_lane::<3>(acc);
Ok(res)
}
}
#[inline(always)]
pub(crate) fn vec_dot_q8_0_q8_0(n: usize, xs: &[BlockQ8_0], ys: &[BlockQ8_0]) -> Result<f32> {
let qk = QK8_0;
if n % QK8_0 != 0 {
crate::bail!("vec_dot_q8_0_q8_0: {n} is not divisible by {qk}")
}
unsafe {
let mut acc = f32x4_splat(0.0f32);
for (x, y) in xs.iter().zip(ys.iter()) {
let x1 = i16x8_load_extend_i8x8(x.qs.as_ptr());
let y1 = i16x8_load_extend_i8x8(y.qs.as_ptr());
let sum_xy = i32x4_dot_i16x8(x1, y1);
let x2 = i16x8_load_extend_i8x8(x.qs.as_ptr().add(8));
let y2 = i16x8_load_extend_i8x8(y.qs.as_ptr().add(8));
let sum_xy = i32x4_add(sum_xy, i32x4_dot_i16x8(x2, y2));
let x3 = i16x8_load_extend_i8x8(x.qs.as_ptr().add(16));
let y3 = i16x8_load_extend_i8x8(y.qs.as_ptr().add(16));
let sum_xy = i32x4_add(sum_xy, i32x4_dot_i16x8(x3, y3));
let x4 = i16x8_load_extend_i8x8(x.qs.as_ptr().add(24));
let y4 = i16x8_load_extend_i8x8(y.qs.as_ptr().add(24));
let sum_xy = i32x4_add(sum_xy, i32x4_dot_i16x8(x4, y4));
let sum_xy = f32x4_convert_i32x4(sum_xy);
// f32x4_relaxed_madd is nightly only.
let d = f32x4_splat(f16::to_f32(x.d) * f16::to_f32(y.d));
let scaled = f32x4_mul(sum_xy, d);
acc = f32x4_add(acc, scaled)
}
let res = f32x4_extract_lane::<0>(acc)
+ f32x4_extract_lane::<1>(acc)
+ f32x4_extract_lane::<2>(acc)
+ f32x4_extract_lane::<3>(acc);
Ok(res)
}
}
#[inline(always)]
pub(crate) fn vec_dot_q2k_q8k(n: usize, xs: &[BlockQ2K], ys: &[BlockQ8K]) -> Result<f32> {
if n % QK_K != 0 {
crate::bail!("vec_dot_q2k_q8k: {n} is not divisible by {QK_K}")
}
unsafe {
let mut sumf = f32x4_splat(0f32);
for (x, y) in xs.iter().zip(ys.iter()) {
let mut q2: &[_] = &x.qs;
let mut q8: &[_] = &y.qs;
let sc = &x.scales;
let mut summs = i32x4_splat(0);
for i in (0..(QK_K / 16)).step_by(4) {
let bsums = i32x4_load_extend_i16x4(y.bsums.as_ptr().add(i));
let scales = i32x4_shr(
i32x4(
sc[i] as i32,
sc[i + 1] as i32,
sc[i + 2] as i32,
sc[i + 3] as i32,
),
4,
);
summs = i32x4_add(summs, i32x4_mul(bsums, scales))
}
let summs = f32x4_convert_i32x4(summs);
let dall = y.d * x.d.to_f32();
let dmin = y.d * x.dmin.to_f32();
let mut isum = i32x4_splat(0);
let mut is = 0;
for _ in 0..(QK_K / 128) {
let mut shift = 0;
for _ in 0..4 {
let d = (sc[is] & 0xF) as i32;
is += 1;
let mut isuml = i16x8_splat(0);
for l in (0..16).step_by(8) {
let q8 = i16x8_load_extend_i8x8(q8.as_ptr().add(l));
let q2 = i16x8_load_extend_u8x8(q2.as_ptr().add(l));
let q2 = v128_and(i16x8_shr(q2, shift), i16x8_splat(3));
isuml = i16x8_add(isuml, i16x8_mul(q2, q8))
}
let dd = i32x4_splat(d);
isum = i32x4_add(isum, i32x4_mul(i32x4_extend_low_i16x8(isuml), dd));
isum = i32x4_add(isum, i32x4_mul(i32x4_extend_high_i16x8(isuml), dd));
let d = (sc[is] & 0xF) as i32;
is += 1;
let mut isuml = i16x8_splat(0);
for l in (16..32).step_by(8) {
let q8 = i16x8_load_extend_i8x8(q8.as_ptr().add(l));
let q2 = i16x8_load_extend_u8x8(q2.as_ptr().add(l));
let q2 = v128_and(i16x8_shr(q2, shift), i16x8_splat(3));
isuml = i16x8_add(isuml, i16x8_mul(q2, q8))
}
let dd = i32x4_splat(d);
isum = i32x4_add(isum, i32x4_mul(i32x4_extend_low_i16x8(isuml), dd));
isum = i32x4_add(isum, i32x4_mul(i32x4_extend_high_i16x8(isuml), dd));
shift += 2;
// adjust the indexing
q8 = &q8[32..];
}
// adjust the indexing
q2 = &q2[32..];
}
let isum = f32x4_convert_i32x4(isum);
sumf = f32x4_add(
sumf,
f32x4_sub(
f32x4_mul(isum, f32x4_splat(dall)),
f32x4_mul(summs, f32x4_splat(dmin)),
),
);
}
let sumf = f32x4_extract_lane::<0>(sumf)
+ f32x4_extract_lane::<1>(sumf)
+ f32x4_extract_lane::<2>(sumf)
+ f32x4_extract_lane::<3>(sumf);
Ok(sumf)
}
}
#[inline(always)]
pub(crate) fn vec_dot_q4k_q8k(n: usize, xs: &[BlockQ4K], ys: &[BlockQ8K]) -> Result<f32> {
if n % QK_K != 0 {
crate::bail!("vec_dot_q4k_q8k: {n} is not divisible by {QK_K}")
}
const KMASK1: u32 = 0x3f3f3f3f;
const KMASK2: u32 = 0x0f0f0f0f;
const KMASK3: u32 = 0x03030303;
let mut utmp: [u32; 4] = [0; 4];
let mut scales: [u8; 8] = [0; 8];
let mut mins: [u8; 8] = [0; 8];
let mut aux8: [u8; QK_K] = [0; QK_K];
let mut sums = f32x4_splat(0f32);
unsafe {
for (y, x) in ys.iter().zip(xs.iter()) {
let q4 = &x.qs;
let q8 = &y.qs;
for j in 0..QK_K / 64 {
let q4_1 = v128_load(q4.as_ptr().add(32 * j) as *const v128);
let q4_2 = v128_load(q4.as_ptr().add(32 * j + 16) as *const v128);
v128_store(
aux8.as_mut_ptr().add(64 * j) as *mut v128,
v128_and(q4_1, u8x16_splat(0x0F)),
);
v128_store(
aux8.as_mut_ptr().add(64 * j + 16) as *mut v128,
v128_and(q4_2, u8x16_splat(0x0F)),
);
v128_store(
aux8.as_mut_ptr().add(64 * j + 32) as *mut v128,
u8x16_shr(q4_1, 4),
);
v128_store(
aux8.as_mut_ptr().add(64 * j + 48) as *mut v128,
u8x16_shr(q4_2, 4),
);
}
LittleEndian::read_u32_into(&x.scales, &mut utmp[0..3]);
utmp[3] = ((utmp[2] >> 4) & KMASK2) | (((utmp[1] >> 6) & KMASK3) << 4);
let uaux = utmp[1] & KMASK1;
utmp[1] = (utmp[2] & KMASK2) | (((utmp[0] >> 6) & KMASK3) << 4);
utmp[2] = uaux;
utmp[0] &= KMASK1;
//extract scales and mins
LittleEndian::write_u32_into(&utmp[0..2], &mut scales);
LittleEndian::write_u32_into(&utmp[2..4], &mut mins);
let mut sumi = i32x4_splat(0);
for j in (0..QK_K / 16).step_by(4) {
let bsums = i32x4_load_extend_i16x4(y.bsums.as_ptr().add(j));
let (m1, m2) = (mins[j / 2] as i32, mins[j / 2 + 1] as i32);
let mins = i32x4(m1, m1, m2, m2);
sumi = i32x4_add(sumi, i32x4_mul(bsums, mins));
}
let mut aux32 = i32x4_splat(0i32);
for (scale_i, scale) in scales.iter().enumerate() {
let scale = i32x4_splat(*scale as i32);
for j in 0..4 {
let i = 32 * scale_i + 8 * j;
let q8 = i16x8_load_extend_i8x8(q8.as_ptr().add(i));
let aux8 = i16x8_load_extend_u8x8(aux8.as_ptr().add(i));
let aux16 = i16x8_mul(q8, aux8);
aux32 = i32x4_add(aux32, i32x4_mul(scale, i32x4_extend_low_i16x8(aux16)));
aux32 = i32x4_add(aux32, i32x4_mul(scale, i32x4_extend_high_i16x8(aux16)));
}
}
let aux32 = f32x4_convert_i32x4(aux32);
let d = f32x4_splat(x.d.to_f32() * y.d);
sums = f32x4_add(sums, f32x4_mul(aux32, d));
let dmin = x.dmin.to_f32() * y.d;
let dmin = f32x4_splat(dmin);
let sumi = f32x4_convert_i32x4(sumi);
sums = f32x4_sub(sums, f32x4_mul(sumi, dmin));
}
let sums = f32x4_extract_lane::<0>(sums)
+ f32x4_extract_lane::<1>(sums)
+ f32x4_extract_lane::<2>(sums)
+ f32x4_extract_lane::<3>(sums);
Ok(sums)
}
}
#[inline(always)]
pub(crate) fn vec_dot_q6k_q8k(n: usize, xs: &[BlockQ6K], ys: &[BlockQ8K]) -> Result<f32> {
if n % QK_K != 0 {
crate::bail!("vec_dot_q6k_q8k: {n} is not divisible by {QK_K}")
}
let mut aux8 = [0i8; QK_K];
unsafe {
let mut sums = f32x4_splat(0f32);
for (x, y) in xs.iter().zip(ys.iter()) {
let q4 = &x.ql;
let qh = &x.qh;
let q8 = &y.qs;
let mut aux32 = f32x4_splat(0f32);
for j in (0..QK_K).step_by(128) {
let aux8 = aux8.as_mut_ptr().add(j);
let q4 = &q4.as_ptr().add(j / 2);
let qh = &qh.as_ptr().add(j / 4);
for l in (0..32).step_by(16) {
// aux8[l] = (((q4[l] & 0xF) | ((qh[l] & 3) << 4)) as i32 - 32) as i8;
let a8 = v128_or(
v128_and(v128_load(q4.add(l) as *const v128), u8x16_splat(0xF)),
u8x16_shl(
v128_and(v128_load(qh.add(l) as *const v128), u8x16_splat(3)),
4,
),
);
let a8_low = i16x8_sub(i16x8_extend_low_u8x16(a8), i16x8_splat(32));
let a8_high = i16x8_sub(i16x8_extend_high_u8x16(a8), i16x8_splat(32));
v128_store(
aux8.add(l) as *mut v128,
i8x16_narrow_i16x8(a8_low, a8_high),
);
// aux8[l + 32] =
// (((q4[l + 32] & 0xF) | (((qh[l] >> 2) & 3) << 4)) as i32 - 32) as i8;
let a8 = v128_or(
v128_and(v128_load(q4.add(l + 32) as *const v128), u8x16_splat(0xF)),
u8x16_shl(
v128_and(
u8x16_shr(v128_load(qh.add(l) as *const v128), 2),
u8x16_splat(3),
),
4,
),
);
let a8_low = i16x8_sub(i16x8_extend_low_u8x16(a8), i16x8_splat(32));
let a8_high = i16x8_sub(i16x8_extend_high_u8x16(a8), i16x8_splat(32));
v128_store(
aux8.add(l + 32) as *mut v128,
i8x16_narrow_i16x8(a8_low, a8_high),
);
// aux8[l + 64] = (((q4[l] >> 4) | (((qh[l] >> 4) & 3) << 4)) as i32 - 32) as i8;
let a8 = v128_or(
u8x16_shr(v128_load(q4.add(l) as *const v128), 4),
u8x16_shl(
v128_and(
u8x16_shr(v128_load(qh.add(l) as *const v128), 4),
u8x16_splat(3),
),
4,
),
);
let a8_low = i16x8_sub(i16x8_extend_low_u8x16(a8), i16x8_splat(32));
let a8_high = i16x8_sub(i16x8_extend_high_u8x16(a8), i16x8_splat(32));
v128_store(
aux8.add(l + 64) as *mut v128,
i8x16_narrow_i16x8(a8_low, a8_high),
);
// aux8[l + 96] =
// (((q4[l + 32] >> 4) | (((qh[l] >> 6) & 3) << 4)) as i32 - 32) as i8;
let a8 = v128_or(
u8x16_shr(v128_load(q4.add(l + 32) as *const v128), 4),
u8x16_shl(
v128_and(
u8x16_shr(v128_load(qh.add(l) as *const v128), 6),
u8x16_splat(3),
),
4,
),
);
let a8_low = i16x8_sub(i16x8_extend_low_u8x16(a8), i16x8_splat(32));
let a8_high = i16x8_sub(i16x8_extend_high_u8x16(a8), i16x8_splat(32));
v128_store(
aux8.add(l + 96) as *mut v128,
i8x16_narrow_i16x8(a8_low, a8_high),
);
}
}
for (j, &scale) in x.scales.iter().enumerate() {
let scale = f32x4_splat(scale as f32);
for offset in [0, 8] {
let aux16 = i16x8_mul(
i16x8_load_extend_i8x8(q8.as_ptr().add(16 * j + offset)),
i16x8_load_extend_i8x8(aux8.as_ptr().add(16 * j + offset)),
);
aux32 = f32x4_add(
aux32,
f32x4_mul(f32x4_convert_i32x4(i32x4_extend_low_i16x8(aux16)), scale),
);
aux32 = f32x4_add(
aux32,
f32x4_mul(f32x4_convert_i32x4(i32x4_extend_high_i16x8(aux16)), scale),
);
}
}
let d = f32x4_splat(x.d.to_f32() * y.d);
sums = f32x4_add(sums, f32x4_mul(aux32, d));
}
let sums = f32x4_extract_lane::<0>(sums)
+ f32x4_extract_lane::<1>(sums)
+ f32x4_extract_lane::<2>(sums)
+ f32x4_extract_lane::<3>(sums);
Ok(sums)
}
}
#[inline(always)]
pub(crate) fn vec_dot_q8k_q8k(n: usize, xs: &[BlockQ8K], ys: &[BlockQ8K]) -> Result<f32> {
let qk = QK_K;
if n % QK_K != 0 {
crate::bail!("vec_dot_q8k_q8k: {n} is not divisible by {qk}")
}
unsafe {
let mut acc = f32x4_splat(0.0f32);
for (xs, ys) in xs.iter().zip(ys.iter()) {
let x_qs = xs.qs.as_ptr();
let y_qs = ys.qs.as_ptr();
let mut sumi = i32x4_splat(0);
for j in (0..QK_K).step_by(8) {
let xs = i16x8_load_extend_i8x8(x_qs.add(j));
let ys = i16x8_load_extend_i8x8(y_qs.add(j));
let sum_xy = i32x4_dot_i16x8(xs, ys);
sumi = i32x4_add(sumi, sum_xy)
}
let d = f32x4_splat(xs.d * ys.d);
acc = f32x4_add(acc, f32x4_mul(f32x4_convert_i32x4(sumi), d))
}
let res = f32x4_extract_lane::<0>(acc)
+ f32x4_extract_lane::<1>(acc)
+ f32x4_extract_lane::<2>(acc)
+ f32x4_extract_lane::<3>(acc);
Ok(res)
}
}
| 1 |
0 | hf_public_repos/candle/candle-core/src | hf_public_repos/candle/candle-core/src/cpu_backend/mod.rs | //! Implementation of Backend Fns for CPU
use crate::backend::{BackendDevice, BackendStorage};
use crate::op::{BinaryOpT, CmpOp, ReduceOp, UnaryOpT};
use crate::{DType, Error, IntDType, Layout, Result, Shape, WithDType};
use half::{bf16, f16};
use rayon::prelude::*;
mod utils;
pub use utils::{
binary_map, binary_map_vec, unary_map, unary_map_vec, Map1, Map1Any, Map2, Map2U8,
};
const USE_IM2COL_CONV1D: bool = true;
const USE_COL2IM_CONV1D_TR: bool = true;
const USE_IM2COL_CONV2D: bool = true;
// TODO: Maybe we should not implement [Clone] here and instead have an explicit allocator +
// intercept the oom errors to avoid panicking and provide a proper error.
#[derive(Debug, Clone)]
pub enum CpuStorage {
U8(Vec<u8>),
U32(Vec<u32>),
I64(Vec<i64>),
BF16(Vec<bf16>),
F16(Vec<f16>),
F32(Vec<f32>),
F64(Vec<f64>),
}
#[derive(Debug, Clone)]
pub enum CpuStorageRef<'a> {
U8(&'a [u8]),
U32(&'a [u32]),
I64(&'a [i64]),
BF16(&'a [bf16]),
F16(&'a [f16]),
F32(&'a [f32]),
F64(&'a [f64]),
}
#[derive(Debug, Clone)]
pub struct CpuDevice;
struct Cmp(CmpOp);
impl Map2U8 for Cmp {
const OP: &'static str = "cmp";
#[inline(always)]
fn f<T: WithDType>(
&self,
lhs: &[T],
lhs_l: &Layout,
rhs: &[T],
rhs_l: &Layout,
) -> Result<Vec<u8>> {
let dst = match self.0 {
CmpOp::Eq => binary_map(lhs_l, rhs_l, lhs, rhs, |x, y| u8::from(x == y)),
CmpOp::Ne => binary_map(lhs_l, rhs_l, lhs, rhs, |x, y| u8::from(x != y)),
CmpOp::Lt => binary_map(lhs_l, rhs_l, lhs, rhs, |x, y| u8::from(x < y)),
CmpOp::Le => binary_map(lhs_l, rhs_l, lhs, rhs, |x, y| u8::from(x <= y)),
CmpOp::Gt => binary_map(lhs_l, rhs_l, lhs, rhs, |x, y| u8::from(x > y)),
CmpOp::Ge => binary_map(lhs_l, rhs_l, lhs, rhs, |x, y| u8::from(x >= y)),
};
Ok(dst)
}
}
struct WCond<'a, T: IntDType>(&'a [T], &'a Layout);
impl<I: IntDType> Map2 for WCond<'_, I> {
const OP: &'static str = "where";
#[inline(always)]
fn f<T: WithDType>(&self, t: &[T], t_l: &Layout, f: &[T], f_l: &Layout) -> Result<Vec<T>> {
let vs = match (
self.1.contiguous_offsets(),
t_l.contiguous_offsets(),
f_l.contiguous_offsets(),
) {
(Some((o1, o2)), Some((o_t1, o_t2)), Some((o_f1, o_f2))) => {
let pred = &self.0[o1..o2];
let t = &t[o_t1..o_t2];
let f = &f[o_f1..o_f2];
pred.iter()
.zip(t.iter().zip(f.iter()))
.map(|(p, (&t, &f))| if p.is_true() { t } else { f })
.collect::<Vec<_>>()
}
_ => self
.1
.strided_index()
.zip(t_l.strided_index().zip(f_l.strided_index()))
.map(|(i_p, (i_t, i_f))| {
if self.0[i_p].is_true() {
t[i_t]
} else {
f[i_f]
}
})
.collect::<Vec<_>>(),
};
Ok(vs)
}
}
struct ReduceIndex {
reduce_dim_index: usize,
use_min: bool,
return_index: bool,
}
impl ReduceIndex {
// The value gets replaced if f(s[current_acc], s[i]) returns true.
#[inline(always)]
fn fold_impl<T, U, F, G>(&self, src: &[T], src_l: &Layout, f: F, g: G) -> Result<Vec<U>>
where
T: Clone + Copy,
U: Clone + Copy,
F: Fn(T, T) -> bool,
G: Fn(T, usize) -> U,
{
let reduce_dim_size = src_l.dims()[self.reduce_dim_index];
let reduce_dim_stride = src_l.stride()[self.reduce_dim_index];
let dst_len = src_l.shape().elem_count() / reduce_dim_size;
let mut dst: Vec<U> = Vec::with_capacity(dst_len);
let dst_to_set = dst.spare_capacity_mut();
let dst_to_set =
unsafe { std::mem::transmute::<&mut [std::mem::MaybeUninit<U>], &mut [U]>(dst_to_set) };
match src_l.contiguous_offsets() {
Some((o1, o2)) => {
let src = &src[o1..o2];
if reduce_dim_stride == 1 {
for (start_src_i, dst_v) in dst_to_set.iter_mut().enumerate() {
let start_src_i = start_src_i * reduce_dim_size;
let src = &src[start_src_i..start_src_i + reduce_dim_size];
let mut acc = 0;
let mut val = src[0];
for (src_i, &s) in src.iter().enumerate() {
if f(val, s) {
acc = src_i;
val = s
}
}
*dst_v = g(val, acc)
}
} else {
for (start_src_i, dst_v) in dst_to_set.iter_mut().enumerate() {
let (p, q) = (
start_src_i / reduce_dim_stride,
start_src_i % reduce_dim_stride,
);
// start_src_i = p * reduce_dim_stride + q
let start_src_i = p * reduce_dim_stride * reduce_dim_size + q;
let src = &src[start_src_i..];
let mut acc = 0;
let mut val = src[0];
for src_i in 0..reduce_dim_size {
let s = src[src_i * reduce_dim_stride];
if f(val, s) {
acc = src_i;
val = s
}
}
*dst_v = g(val, acc)
}
}
}
None => {
let l = src_l.narrow(self.reduce_dim_index, 0, 1)?;
for (unstr_index, src_index) in l.strided_index().enumerate() {
let src = &src[src_index..];
let mut acc = 0;
let mut val = src[0];
for src_i in 0..reduce_dim_size {
let s = src[src_i * reduce_dim_stride];
if f(val, s) {
acc = src_i;
val = s
}
}
dst_to_set[unstr_index] = g(val, acc)
}
}
}
unsafe { dst.set_len(dst_len) };
Ok(dst)
}
}
impl Map1Any for ReduceIndex {
#[inline(always)]
fn f<T: WithDType, W: Fn(Vec<T>) -> CpuStorage>(
&self,
src: &[T],
src_l: &Layout,
wrap: W,
) -> Result<CpuStorage> {
if src_l.shape().elem_count() == 0 {
Err(Error::EmptyTensor { op: "reduce" }.bt())?
}
let dst = match (self.return_index, self.use_min) {
(false, true) => wrap(self.fold_impl(src, src_l, |x, y| x > y, |v, _i| v)?),
(false, false) => wrap(self.fold_impl(src, src_l, |x, y| x < y, |v, _i| v)?),
(true, true) => {
CpuStorage::U32(self.fold_impl(src, src_l, |x, y| x > y, |_v, i| i as u32)?)
}
(true, false) => {
CpuStorage::U32(self.fold_impl(src, src_l, |x, y| x < y, |_v, i| i as u32)?)
}
};
Ok(dst)
}
}
struct ReduceSum<'a> {
dst_shape: &'a Shape,
reduce_dims: &'a [usize],
reduce_dims_and_stride: Vec<(usize, usize)>,
}
impl ReduceSum<'_> {
#[inline(always)]
fn fold_impl<T>(&self, src: &[T], src_l: &Layout, start_elt: T) -> Result<Vec<T>>
where
T: WithDType,
{
let mut dst = vec![start_elt; self.dst_shape.elem_count()];
match src_l.contiguous_offsets() {
Some((o1, o2)) => {
let src = &src[o1..o2];
// Handle the case where we reduce over the last dimensions separately as it is
// fairly common and easy to optimize. This rely on the layout being contiguous!
// reduce_dims is sorted, check if it is ranging from a to n-1.
let reduce_over_last_dims = self
.reduce_dims
.iter()
.rev()
.enumerate()
.all(|(i, &v)| v == src_l.shape().rank() - 1 - i);
if reduce_over_last_dims {
let reduce_sz = self
.reduce_dims_and_stride
.iter()
.map(|(u, _)| u)
.product::<usize>();
for (dst_i, dst_v) in dst.iter_mut().enumerate() {
let src_i = dst_i * reduce_sz;
unsafe {
T::vec_reduce_sum(
src[src_i..src_i + reduce_sz].as_ptr(),
dst_v,
reduce_sz,
)
};
}
return Ok(dst);
};
for (unstr_index, &src) in src.iter().enumerate() {
let mut dst_index = unstr_index;
// Set the reduce_dims indexes to 0.
for &(dim, stride) in self.reduce_dims_and_stride.iter() {
// The compiler is able to optimize the following in a single divmod op.
let (pre, post) = (dst_index / stride, dst_index % stride);
dst_index = (pre / dim) * stride + post;
}
dst[dst_index] += src;
}
}
None => {
for (unstr_index, src_index) in src_l.strided_index().enumerate() {
let mut dst_index = unstr_index;
// Set the reduce_dims indexes to 0.
for &(dim, stride) in self.reduce_dims_and_stride.iter() {
// The compiler is able to optimize the following in a single divmod op.
let (pre, post) = (dst_index / stride, dst_index % stride);
dst_index = (pre / dim) * stride + post;
}
dst[dst_index] += src[src_index];
}
}
}
Ok(dst)
}
}
impl Map1 for ReduceSum<'_> {
#[inline(always)]
fn f<T: WithDType>(&self, src: &[T], src_l: &Layout) -> Result<Vec<T>> {
self.fold_impl(src, src_l, T::zero())
}
}
struct Affine(f64, f64);
impl Map1 for Affine {
fn f<T: WithDType>(&self, vs: &[T], layout: &Layout) -> Result<Vec<T>> {
let mul = T::from_f64(self.0);
let add = T::from_f64(self.1);
Ok(unary_map(vs, layout, |v| v * mul + add))
}
}
struct AvgPool2D((usize, usize), (usize, usize));
impl Map1 for AvgPool2D {
fn f<T: WithDType>(&self, src: &[T], layout: &Layout) -> Result<Vec<T>> {
// https://pytorch.org/docs/stable/generated/torch.nn.AvgPool2d.html
let (k_h, k_w) = self.0;
let (s_h, s_w) = self.1;
let (b_sz, c, h, w) = layout.shape().dims4()?;
let stride = layout.stride();
let (stride_h, stride_w) = (stride[2], stride[3]);
let h_out = (h - k_h) / s_h + 1;
let w_out = (w - k_w) / s_w + 1;
let src_index = layout.start_offset();
let mut dst = vec![T::zero(); b_sz * c * h_out * w_out];
let scale = 1f64 / (k_h * k_w) as f64;
let scale = T::from_f64(scale);
for b_idx in 0..b_sz {
let dst = &mut dst[b_idx * c * h_out * w_out..];
let src_index = src_index + b_idx * stride[0];
for c_idx in 0..c {
let dst = &mut dst[c_idx * h_out * w_out..];
let src_index = src_index + c_idx * stride[1];
for h_idx in 0..h_out {
for w_idx in 0..w_out {
let mut sum = T::zero();
for m in 0..k_h {
for n in 0..k_w {
let m = s_h * h_idx + m;
let n = s_w * w_idx + n;
sum += src[src_index + m * stride_h + n * stride_w]
}
}
dst[h_idx * w_out + w_idx] = sum * scale;
}
}
}
}
Ok(dst)
}
}
struct MaxPool2D((usize, usize), (usize, usize));
impl Map1 for MaxPool2D {
fn f<T: WithDType>(&self, src: &[T], layout: &Layout) -> Result<Vec<T>> {
// https://pytorch.org/docs/stable/generated/torch.nn.MaxPool2d.html
let (k_h, k_w) = self.0;
let (s_h, s_w) = self.1;
let (b_sz, c, h, w) = layout.shape().dims4()?;
let stride = layout.stride();
let (stride_h, stride_w) = (stride[2], stride[3]);
let h_out = (h - k_h) / s_h + 1;
let w_out = (w - k_w) / s_w + 1;
let src_index = layout.start_offset();
let mut dst = vec![T::zero(); b_sz * c * h_out * w_out];
for b_idx in 0..b_sz {
let dst = &mut dst[b_idx * c * h_out * w_out..];
let src_index = src_index + b_idx * stride[0];
for c_idx in 0..c {
let dst = &mut dst[c_idx * h_out * w_out..];
let src_index = src_index + c_idx * stride[1];
for h_idx in 0..h_out {
for w_idx in 0..w_out {
let mut largest =
src[src_index + s_h * h_idx * stride_h + s_w * w_idx * stride_w];
for m in 0..k_h {
for n in 0..k_w {
let m = s_h * h_idx + m;
let n = s_w * w_idx + n;
if largest < src[src_index + m * stride_h + n * stride_w] {
largest = src[src_index + m * stride_h + n * stride_w]
}
}
}
dst[h_idx * w_out + w_idx] = largest;
}
}
}
}
Ok(dst)
}
}
struct UpsampleNearest1D(usize);
impl Map1 for UpsampleNearest1D {
fn f<T: WithDType>(&self, src: &[T], layout: &Layout) -> Result<Vec<T>> {
// TODO: Specialized implementation for the case 2*sz?
let dst_sz = self.0;
let (b_sz, c, src_sz) = layout.shape().dims3()?;
let stride = layout.stride();
let stride_sz = stride[2];
let src_index = layout.start_offset();
let scale_sz = src_sz as f64 / dst_sz as f64;
let mut dst = vec![T::zero(); b_sz * c * dst_sz];
let src_idxs = (0..dst_sz)
.map(|idx| usize::min(src_sz - 1, (idx as f64 * scale_sz) as usize))
.collect::<Vec<_>>();
for b_idx in 0..b_sz {
let dst = &mut dst[b_idx * c * dst_sz..];
let src_index = src_index + b_idx * stride[0];
for c_idx in 0..c {
let dst = &mut dst[c_idx * dst_sz..];
let src_index = src_index + c_idx * stride[1];
for (idx, src_idx) in src_idxs.iter().enumerate() {
dst[idx] = src[src_index + src_idx * stride_sz]
}
}
}
Ok(dst)
}
}
struct UpsampleNearest2D(usize, usize);
impl Map1 for UpsampleNearest2D {
fn f<T: WithDType>(&self, src: &[T], layout: &Layout) -> Result<Vec<T>> {
// TODO: Specialized implementation for the case 2*h, 2*w?
let (dst_h, dst_w) = (self.0, self.1);
let (b_sz, c, src_h, src_w) = layout.shape().dims4()?;
let stride = layout.stride();
let (stride_h, stride_w) = (stride[2], stride[3]);
let src_index = layout.start_offset();
let scale_h = src_h as f64 / dst_h as f64;
let scale_w = src_w as f64 / dst_w as f64;
let mut dst = vec![T::zero(); b_sz * c * dst_h * dst_w];
let src_h_idxs = (0..dst_h)
.map(|h_idx| usize::min(src_h - 1, (h_idx as f64 * scale_h) as usize))
.collect::<Vec<_>>();
let src_w_idxs = (0..dst_w)
.map(|w_idx| usize::min(src_w - 1, (w_idx as f64 * scale_w) as usize))
.collect::<Vec<_>>();
for b_idx in 0..b_sz {
let dst = &mut dst[b_idx * c * dst_h * dst_w..];
let src_index = src_index + b_idx * stride[0];
for c_idx in 0..c {
let dst = &mut dst[c_idx * dst_h * dst_w..];
let src_index = src_index + c_idx * stride[1];
for (h_idx, src_h_idx) in src_h_idxs.iter().enumerate() {
for (w_idx, src_w_idx) in src_w_idxs.iter().enumerate() {
let src_index = src_index + src_h_idx * stride_h + src_w_idx * stride_w;
dst[h_idx * dst_w + w_idx] = src[src_index]
}
}
}
}
Ok(dst)
}
}
struct Gather<'a, I: IntDType> {
ids: &'a [I],
ids_l: &'a Layout,
dim: usize,
}
impl<I: IntDType> Map1 for Gather<'_, I> {
fn f<T: WithDType>(&self, src: &[T], src_l: &Layout) -> Result<Vec<T>> {
let ids = match self.ids_l.contiguous_offsets() {
Some((a, b)) => &self.ids[a..b],
None => Err(Error::RequiresContiguous { op: "gather" }.bt())?,
};
let src = match src_l.contiguous_offsets() {
Some((a, b)) => &src[a..b],
None => Err(Error::RequiresContiguous { op: "gather" }.bt())?,
};
let dim = self.dim;
let ids_dims = self.ids_l.dims();
let src_dims = src_l.dims();
let dst_len: usize = ids_dims.iter().product();
let dst_left_len: usize = ids_dims[..dim].iter().product();
let dst_dim_len = ids_dims[dim];
let dst_right_len: usize = ids_dims[dim + 1..].iter().product();
let src_dim_len = src_dims[dim];
let src_right_len: usize = src_dims[dim + 1..].iter().product();
let mut dst = vec![T::zero(); dst_len];
for left_i in 0..dst_left_len {
let start_src_idx = left_i * src_right_len * src_dim_len;
let start_dst_idx = left_i * dst_right_len * dst_dim_len;
for i in 0..dst_dim_len {
let start_dst_idx = start_dst_idx + i * dst_right_len;
for right_i in 0..dst_right_len {
let dst_idx = start_dst_idx + right_i;
let index = ids[dst_idx].as_usize();
if index >= src_dim_len {
Err(Error::InvalidIndex {
index,
size: src_dim_len,
op: "gather",
}
.bt())?
}
let src_idx = start_src_idx + index * src_right_len + right_i;
dst[dst_idx] = src[src_idx]
}
}
}
Ok(dst)
}
}
struct IndexSelect<'a, T: IntDType> {
ids: &'a [T],
ids_l: &'a Layout,
dim: usize,
}
impl<I: IntDType> Map1 for IndexSelect<'_, I> {
fn f<T: WithDType>(&self, src: &[T], layout: &Layout) -> Result<Vec<T>> {
let src = match layout.contiguous_offsets() {
Some((a, b)) => &src[a..b],
None => Err(Error::RequiresContiguous { op: "index-select" }.bt())?,
};
let dim = self.dim;
let n_ids = match self.ids_l.dims() {
[n_ids] => *n_ids,
d => Err(Error::UnexpectedNumberOfDims {
expected: 1,
got: d.len(),
shape: self.ids_l.shape().clone(),
}
.bt())?,
};
let stride_ids = self.ids_l.stride()[0];
let mut dst_dims = layout.dims().to_vec();
let src_dim = dst_dims[dim];
dst_dims[dim] = n_ids;
let dst_len: usize = dst_dims.iter().product();
let left_len: usize = dst_dims[..dim].iter().product();
let right_len: usize = dst_dims[dim + 1..].iter().product();
let mut dst = vec![T::zero(); dst_len];
for left_i in 0..left_len {
let start_src_idx = left_i * right_len * src_dim;
let start_dst_idx = left_i * right_len * n_ids;
for i in 0..n_ids {
let index = self.ids[self.ids_l.start_offset() + stride_ids * i].as_usize();
if index >= src_dim {
Err(Error::InvalidIndex {
index,
size: src_dim,
op: "index-select",
}
.bt())?
}
let start_src_idx = start_src_idx + index * right_len;
let start_dst_idx = start_dst_idx + i * right_len;
dst[start_dst_idx..start_dst_idx + right_len]
.copy_from_slice(&src[start_src_idx..start_src_idx + right_len])
}
}
Ok(dst)
}
}
struct ScatterAdd<'a, I: IntDType> {
ids: &'a [I],
ids_l: &'a Layout,
dim: usize,
}
impl<I: IntDType> Map2 for ScatterAdd<'_, I> {
const OP: &'static str = "scatter-add";
fn f<T: WithDType>(&self, v1: &[T], l1: &Layout, src: &[T], src_l: &Layout) -> Result<Vec<T>> {
let dst_len = l1.shape().elem_count();
let mut dst = vec![T::zero(); dst_len];
copy_strided_src_(v1, &mut dst, 0, l1);
let src = match src_l.contiguous_offsets() {
None => Err(Error::RequiresContiguous { op: "scatter-add" }.bt())?,
Some((o1, o2)) => &src[o1..o2],
};
let dim = self.dim;
let ids_dims = self.ids_l.dims();
let dst_dims = l1.dims();
let dst_dim_len = dst_dims[dim];
let dst_right_len: usize = dst_dims[dim + 1..].iter().product();
let ids_left_len: usize = ids_dims[..dim].iter().product();
let ids_dim_len = ids_dims[dim];
let ids_right_len: usize = ids_dims[dim + 1..].iter().product();
let ids = match self.ids_l.contiguous_offsets() {
Some((a, b)) => &self.ids[a..b],
None => Err(Error::RequiresContiguous { op: "gather" }.bt())?,
};
for left_i in 0..ids_left_len {
let start_ids_idx = left_i * ids_right_len * ids_dim_len;
let start_dst_idx = left_i * dst_right_len * dst_dim_len;
for i in 0..ids_dim_len {
let start_ids_idx = start_ids_idx + i * ids_right_len;
for right_i in 0..dst_right_len {
let ids_idx = start_ids_idx + right_i;
let index = ids[ids_idx].as_usize();
if index >= dst_dim_len {
Err(Error::InvalidIndex {
index,
size: dst_dim_len,
op: "gather",
}
.bt())?
}
let dst_idx = start_dst_idx + index * dst_right_len + right_i;
dst[dst_idx] += src[ids_idx]
}
}
}
Ok(dst)
}
}
struct IndexAdd<'a, I: IntDType> {
ids: &'a [I],
dim: usize,
}
impl<I: IntDType> Map2 for IndexAdd<'_, I> {
const OP: &'static str = "index-add";
// https://pytorch.org/docs/stable/generated/torch.Tensor.index_add_.html#torch.Tensor.index_add_
// v1, l1 -> self
fn f<T: WithDType>(&self, v1: &[T], l1: &Layout, src: &[T], src_l: &Layout) -> Result<Vec<T>> {
let dst_len = l1.shape().elem_count();
let mut dst = vec![T::zero(); dst_len];
copy_strided_src_(v1, &mut dst, 0, l1);
let src = match src_l.contiguous_offsets() {
None => Err(Error::RequiresContiguous { op: "index-add" }.bt())?,
Some((o1, o2)) => &src[o1..o2],
};
let dim = self.dim;
let max_idx = l1.dims()[dim];
let pre_dim = src_l.dims()[..dim].iter().product::<usize>();
let src_dim_sz = src_l.dims()[dim];
let post_dim = src_l.dims()[dim + 1..].iter().product::<usize>();
if dim == 0 {
for (src_idx, dst_idx) in self.ids.iter().enumerate() {
let dst_idx = dst_idx.as_usize();
if dst_idx >= max_idx {
Err(Error::InvalidIndex {
index: dst_idx,
op: "index-add",
size: max_idx,
})?
}
let src_idx = src_idx * post_dim;
let dst_idx = dst_idx * post_dim;
let src = &src[src_idx..src_idx + post_dim];
let dst = &mut dst[dst_idx..dst_idx + post_dim];
for (d, &s) in dst.iter_mut().zip(src.iter()) {
*d += s
}
}
} else {
for (src_idx, dst_idx) in self.ids.iter().enumerate() {
let dst_idx = dst_idx.as_usize();
if dst_idx >= max_idx {
Err(Error::InvalidIndex {
index: dst_idx,
op: "index-add",
size: max_idx,
})?
}
for pre_i in 0..pre_dim {
let pre_src_i = (pre_i * src_dim_sz + src_idx) * post_dim;
let pre_dst_i = (pre_i * max_idx + dst_idx) * post_dim;
let src = &src[pre_src_i..pre_src_i + post_dim];
let dst = &mut dst[pre_dst_i..pre_dst_i + post_dim];
for (d, &s) in dst.iter_mut().zip(src.iter()) {
*d += s
}
}
}
}
Ok(dst)
}
}
#[allow(clippy::too_many_arguments)]
fn copy2d_<T: Copy>(
src: &[T],
dst: &mut [T],
d1: usize,
d2: usize,
src_stride1: usize,
dst_stride1: usize,
src_offset: usize,
dst_offset: usize,
) {
for i1 in 0..d1 {
let dst_idx = i1 * dst_stride1 + dst_offset;
let src_idx = i1 * src_stride1 + src_offset;
let dst = &mut dst[dst_idx..dst_idx + d2];
let src = &src[src_idx..src_idx + d2];
dst.copy_from_slice(src)
}
}
fn copy_strided_src_<T: Copy>(src: &[T], dst: &mut [T], dst_offset: usize, src_l: &Layout) {
match src_l.strided_blocks() {
crate::StridedBlocks::SingleBlock { start_offset, len } => {
let to_copy = (dst.len() - dst_offset).min(len);
dst[dst_offset..dst_offset + to_copy]
.copy_from_slice(&src[start_offset..start_offset + to_copy])
}
crate::StridedBlocks::MultipleBlocks {
block_start_index,
block_len: 1,
} => {
for (dst_index, src_index) in block_start_index.enumerate() {
let dst_index = dst_index + dst_offset;
if dst_index >= dst.len() {
break;
}
dst[dst_index] = src[src_index]
}
}
crate::StridedBlocks::MultipleBlocks {
block_start_index,
block_len,
} => {
let mut dst_index = dst_offset;
for src_index in block_start_index {
let next_dst_index = dst_index + block_len;
if dst_index >= dst.len() {
break;
}
let to_copy = usize::min(block_len, dst.len() - dst_index);
dst[dst_index..dst_index + to_copy]
.copy_from_slice(&src[src_index..src_index + to_copy]);
dst_index = next_dst_index
}
}
}
}
struct Conv1D<'a>(&'a crate::conv::ParamsConv1D);
impl Map2 for Conv1D<'_> {
const OP: &'static str = "conv1d";
fn f<T: WithDType>(&self, inp: &[T], inp_l: &Layout, k: &[T], k_l: &Layout) -> Result<Vec<T>> {
let p = self.0;
let inp = &inp[inp_l.start_offset()..];
let k = &k[k_l.start_offset()..];
let (inp_s0, inp_s1, inp_s2) = crate::shape::dims3(inp_l.stride())?;
let (k_s0, k_s1, k_s2) = crate::shape::dims3(k_l.stride())?;
let l_out = p.l_out();
let dst_elems = p.c_out * l_out * p.b_size;
// The output shape is [b_size, c_out, l_out]
let dst = vec![T::zero(); dst_elems];
// TODO: Avoid making this copy if `inp` already has the appropriate layout.
let mut inp_cont = vec![T::zero(); p.b_size * p.c_in * p.l_in];
for b_idx in 0..p.b_size {
for src_l in 0..p.l_in {
for src_c_idx in 0..p.c_in {
let inp_idx = b_idx * inp_s0 + src_c_idx * inp_s1 + src_l * inp_s2;
inp_cont[b_idx * p.l_in * p.c_in + src_l * p.c_in + src_c_idx] = inp[inp_idx]
}
}
}
for offset in 0..p.k_size {
(0..p.c_out).into_par_iter().for_each(|dst_c_idx| {
let dst_idx = dst_c_idx * l_out;
let k_cont = (0..p.c_in)
.map(|c_in_idx| k[dst_c_idx * k_s0 + c_in_idx * k_s1 + offset * k_s2])
.collect::<Vec<_>>();
for b_idx in 0..p.b_size {
let dst_idx = dst_idx + b_idx * p.c_out * l_out;
for dst_l in 0..l_out {
let dst_idx = dst_idx + dst_l;
let src_l = p.stride * dst_l + offset * p.dilation;
if src_l < p.padding || src_l >= p.padding + p.l_in {
continue;
}
let src_l = src_l - p.padding;
let inp_cont = &inp_cont[b_idx * p.l_in * p.c_in + src_l * p.c_in..];
assert!(inp_cont.len() >= p.c_in);
assert!(k_cont.len() >= p.c_in);
let mut d = T::zero();
unsafe { T::vec_dot(inp_cont.as_ptr(), k_cont.as_ptr(), &mut d, p.c_in) }
let dst_p = dst.as_ptr();
// Safety: dst_idx are uniques per dst_c_idx which is used to parallelise
// the different tasks so no two threads can try to write at the same
// location.
unsafe {
let ptr = dst_p.add(dst_idx) as *mut T;
*ptr += d
}
}
}
})
}
Ok(dst)
}
}
struct Im2Col1D {
l_k: usize,
stride: usize,
dilation: usize,
padding: usize,
}
impl Im2Col1D {
fn l_out(&self, l: usize) -> usize {
(l + 2 * self.padding - self.dilation * (self.l_k - 1) - 1) / self.stride + 1
}
}
impl Map1 for Im2Col1D {
fn f<T: WithDType>(&self, vs: &[T], layout: &Layout) -> Result<Vec<T>> {
let &Self {
l_k,
stride,
dilation,
padding,
} = self;
let (b, c, l) = layout.shape().dims3()?;
let l_out = self.l_out(l);
let src = &vs[layout.start_offset()..];
let mut dst = vec![T::zero(); b * l_out * c * l_k];
let (src_s0, src_s1, src_s2) = {
let s = layout.stride();
(s[0], s[1], s[2])
};
// TODO: provide specialized kernels for the common use cases.
// - l_k = 1
// - padding = 0
// - stride = 1
// - dilation = 1
for b_idx in 0..b {
let src_idx = b_idx * src_s0;
let dst_idx = b_idx * l_out * c * l_k;
for l_idx in 0..l_out {
let dst_idx = dst_idx + l_idx * c * l_k;
for c_idx in 0..c {
let dst_idx = dst_idx + c_idx * l_k;
let src_idx = c_idx * src_s1 + src_idx;
for l_k_idx in 0..l_k {
let src_l = l_idx * stride + l_k_idx * dilation;
if padding != 0 && (src_l < padding || src_l >= l + padding) {
continue;
}
let src_l = src_l - padding;
let src_idx = src_idx + src_l * src_s2;
let dst_idx = dst_idx + l_k_idx;
dst[dst_idx] = src[src_idx]
}
}
}
}
Ok(dst)
}
}
struct Im2Col {
h_k: usize,
w_k: usize,
stride: usize,
dilation: usize,
padding: usize,
}
impl Im2Col {
fn hw_out(&self, h: usize, w: usize) -> (usize, usize) {
let h_out = (h + 2 * self.padding - self.dilation * (self.h_k - 1) - 1) / self.stride + 1;
let w_out = (w + 2 * self.padding - self.dilation * (self.w_k - 1) - 1) / self.stride + 1;
(h_out, w_out)
}
}
impl Map1 for Im2Col {
fn f<T: WithDType>(&self, vs: &[T], layout: &Layout) -> Result<Vec<T>> {
let &Self {
h_k,
w_k,
stride,
dilation,
padding,
} = self;
let (b, c, h, w) = layout.shape().dims4()?;
let (h_out, w_out) = self.hw_out(h, w);
let src = &vs[layout.start_offset()..];
let mut dst = vec![T::zero(); b * h_out * w_out * c * h_k * w_k];
let (src_s0, src_s1, src_s2, src_s3) = {
let s = layout.stride();
(s[0], s[1], s[2], s[3])
};
// TODO: provide specialized kernels for the common use cases.
// - h_k = w_k = 1
// - padding = 0
// - stride = 1
// - dilation = 1
for b_idx in 0..b {
let src_idx = b_idx * src_s0;
let dst_idx = b_idx * h_out * w_out * c * h_k * w_k;
for h_idx in 0..h_out {
let dst_idx = dst_idx + h_idx * w_out * c * h_k * w_k;
for w_idx in 0..w_out {
let dst_idx = dst_idx + w_idx * c * h_k * w_k;
for c_idx in 0..c {
let dst_idx = dst_idx + c_idx * h_k * w_k;
let src_idx = c_idx * src_s1 + src_idx;
for h_k_idx in 0..h_k {
let src_h = h_idx * stride + h_k_idx * dilation;
if padding != 0 && (src_h < padding || src_h >= h + padding) {
continue;
}
let src_h = src_h - padding;
let src_idx = src_idx + src_h * src_s2;
let dst_idx = dst_idx + h_k_idx * w_k;
for w_k_idx in 0..w_k {
let src_w = w_idx * stride + w_k_idx * dilation;
if padding != 0 && (src_w < padding || src_w >= w + padding) {
continue;
}
let src_w = src_w - padding;
let src_idx = src_idx + src_w * src_s3;
let dst_idx = dst_idx + w_k_idx;
dst[dst_idx] = src[src_idx]
}
}
}
}
}
}
Ok(dst)
}
}
struct Col2Im1D {
stride: usize,
}
impl Map1 for Col2Im1D {
fn f<T: WithDType>(&self, col: &[T], l: &Layout) -> Result<Vec<T>> {
let (b_size, l_in, c_out, k_size) = l.shape().dims4()?;
let stride = self.stride;
let l_out = (l_in - 1) * stride + k_size;
let mut im = vec![T::zero(); b_size * c_out * l_out];
let (dst_s0, dst_s1) = (c_out * l_out, l_out);
let (src_s0, src_s1, src_s2) = (c_out * k_size * l_in, c_out * k_size, k_size);
for l_in_i in 0..l_in {
for k_i in 0..k_size {
let l_out_i = l_in_i * stride + k_i;
for b_i in 0..b_size {
for c_i in 0..c_out {
let dst_idx = b_i * dst_s0 + c_i * dst_s1 + l_out_i;
let src_idx = b_i * src_s0 + l_in_i * src_s1 + c_i * src_s2 + k_i;
im[dst_idx] += col[src_idx]
}
}
}
}
Ok(im)
}
}
struct ConvTranspose1D<'a>(&'a crate::conv::ParamsConvTranspose1D);
impl Map2 for ConvTranspose1D<'_> {
const OP: &'static str = "conv_transpose1d";
fn f<T: WithDType>(&self, inp: &[T], inp_l: &Layout, k: &[T], k_l: &Layout) -> Result<Vec<T>> {
let p = self.0;
let inp = &inp[inp_l.start_offset()..];
let k = &k[k_l.start_offset()..];
let (inp_s0, inp_s1, inp_s2) = crate::shape::dims3(inp_l.stride())?;
let (k_s0, k_s1, k_s2) = crate::shape::dims3(k_l.stride())?;
let l_out = p.l_out();
// Output shape: [b_size, c_out, l_out].
let dst_elems = p.c_out * l_out * p.b_size;
let dst = vec![T::zero(); dst_elems];
let dst_s0 = p.c_out * l_out;
let dst_s1 = l_out;
let dst_s2 = 1;
// TODO: Avoid making this copy if `inp` already has the appropriate layout.
let mut inp_cont = vec![T::zero(); p.b_size * p.c_in * p.l_in];
let cont_s0 = p.l_in * p.c_in;
let cont_s1 = p.c_in;
for b_idx in 0..p.b_size {
for l_idx in 0..p.l_in {
for c_idx in 0..p.c_in {
let src_idx = b_idx * inp_s0 + c_idx * inp_s1 + l_idx * inp_s2;
let dst_idx = b_idx * cont_s0 + l_idx * cont_s1 + c_idx;
inp_cont[dst_idx] = inp[src_idx]
}
}
}
for k_idx in 0..p.k_size {
(0..p.c_out).into_par_iter().for_each(|dst_c_idx| {
let k_cont = (0..p.c_in)
.map(|c_in_idx| k[c_in_idx * k_s0 + dst_c_idx * k_s1 + k_idx * k_s2])
.collect::<Vec<_>>();
for b_idx in 0..p.b_size {
for l_idx in 0..p.l_in {
let out_idx = l_idx * p.stride + k_idx * p.dilation;
if out_idx < p.padding {
continue;
}
let out_idx = out_idx - p.padding;
if out_idx < l_out {
let inp_cont = &inp_cont[b_idx * cont_s0 + l_idx * cont_s1..];
let dst_idx = b_idx * dst_s0 + out_idx * dst_s2 + dst_c_idx * dst_s1;
let mut d = T::zero();
unsafe {
T::vec_dot(inp_cont.as_ptr(), k_cont.as_ptr(), &mut d, p.c_in)
}
let dst_p = dst.as_ptr();
// Safety: dst_idx are uniques per dst_c_idx which is used to
// parallelise the different tasks so no two threads can try to
// write at the same location.
unsafe {
let ptr = dst_p.add(dst_idx) as *mut T;
*ptr += d
}
}
}
}
})
}
Ok(dst)
}
}
struct Conv2D<'a>(&'a crate::conv::ParamsConv2D);
impl Map2 for Conv2D<'_> {
const OP: &'static str = "conv2d";
fn f<T: WithDType>(&self, inp: &[T], inp_l: &Layout, k: &[T], k_l: &Layout) -> Result<Vec<T>> {
let p = self.0;
let inp = &inp[inp_l.start_offset()..];
let (inp_s0, inp_s1, inp_s2, inp_s3) = crate::shape::dims4(inp_l.stride())?;
let k = &k[k_l.start_offset()..];
let (k_s0, k_s1, k_s2, k_s3) = crate::shape::dims4(k_l.stride())?;
let (out_h, out_w) = (p.out_h(), p.out_w());
// Output shape: [b_size, c_out, out_h, out_w].
let dst = vec![T::zero(); p.b_size * p.c_out * out_h * out_w];
// TODO: Avoid making this copy if `inp` already has the appropriate layout.
let mut inp_cont = vec![T::zero(); p.b_size * p.c_in * p.i_h * p.i_w];
let cont_s0 = p.i_h * p.i_w * p.c_in;
let cont_s1 = p.i_w * p.c_in;
let cont_s2 = p.c_in;
for b_idx in 0..p.b_size {
for h_idx in 0..p.i_h {
for w_idx in 0..p.i_w {
for c_idx in 0..p.c_in {
let src_idx =
b_idx * inp_s0 + c_idx * inp_s1 + h_idx * inp_s2 + w_idx * inp_s3;
let dst_idx = b_idx * cont_s0 + h_idx * cont_s1 + w_idx * cont_s2 + c_idx;
inp_cont[dst_idx] = inp[src_idx]
}
}
}
}
for offset_h in 0..p.k_h {
for offset_w in 0..p.k_w {
(0..p.c_out).into_par_iter().for_each(|dst_c_idx| {
let dst_idx = dst_c_idx * out_w * out_h;
let k_cont = (0..p.c_in)
.map(|c_in_idx| {
k[dst_c_idx * k_s0
+ c_in_idx * k_s1
+ offset_h * k_s2
+ offset_w * k_s3]
})
.collect::<Vec<_>>();
for b_idx in 0..p.b_size {
let dst_idx = dst_idx + b_idx * p.c_out * out_h * out_w;
for dst_h in 0..out_h {
let dst_idx = dst_idx + dst_h * out_w;
let src_h = p.stride * dst_h + offset_h * p.dilation;
if src_h < p.padding || src_h >= p.i_h + p.padding {
continue;
}
let src_h = src_h - p.padding;
for dst_w in 0..out_w {
let dst_idx = dst_idx + dst_w;
let src_w = p.stride * dst_w + offset_w * p.dilation;
if src_w < p.padding || src_w >= p.i_w + p.padding {
continue;
}
let src_w = src_w - p.padding;
let inp_cont = &inp_cont
[b_idx * cont_s0 + src_h * cont_s1 + src_w * cont_s2..];
assert!(inp_cont.len() >= p.c_in);
assert!(k_cont.len() >= p.c_in);
let mut d = T::zero();
unsafe {
T::vec_dot(inp_cont.as_ptr(), k_cont.as_ptr(), &mut d, p.c_in)
}
let dst_p = dst.as_ptr();
// Safety: dst_idx are uniques per dst_c_idx which is used to parallelise
// the different tasks so no two threads can try to write at the same
// location.
unsafe {
let ptr = dst_p.add(dst_idx) as *mut T;
*ptr += d
}
}
}
}
});
}
}
Ok(dst)
}
}
struct ConvTranspose2D<'a>(&'a crate::conv::ParamsConvTranspose2D);
impl Map2 for ConvTranspose2D<'_> {
const OP: &'static str = "conv_transpose2d";
fn f<T: WithDType>(&self, inp: &[T], inp_l: &Layout, k: &[T], k_l: &Layout) -> Result<Vec<T>> {
let p = self.0;
let inp = &inp[inp_l.start_offset()..];
let (inp_s0, inp_s1, inp_s2, inp_s3) = crate::shape::dims4(inp_l.stride())?;
let k = &k[k_l.start_offset()..];
let (k_s0, k_s1, k_s2, k_s3) = crate::shape::dims4(k_l.stride())?;
let (out_h, out_w) = (p.out_h(), p.out_w());
// Output shape: [b_size, c_out, out_h, out_w].
let dst = vec![T::zero(); p.b_size * p.c_out * out_h * out_w];
let dst_s0 = p.c_out * out_h * out_w;
let dst_s1 = out_h * out_w;
let dst_s2 = out_w;
let dst_s3 = 1;
// TODO: Avoid making this copy if `inp` already has the appropriate layout.
let mut inp_cont = vec![T::zero(); p.b_size * p.c_in * p.i_h * p.i_w];
let cont_s0 = p.i_h * p.i_w * p.c_in;
let cont_s1 = p.i_w * p.c_in;
let cont_s2 = p.c_in;
for b_idx in 0..p.b_size {
for h_idx in 0..p.i_h {
for w_idx in 0..p.i_w {
for c_idx in 0..p.c_in {
let src_idx =
b_idx * inp_s0 + c_idx * inp_s1 + h_idx * inp_s2 + w_idx * inp_s3;
let dst_idx = b_idx * cont_s0 + h_idx * cont_s1 + w_idx * cont_s2 + c_idx;
inp_cont[dst_idx] = inp[src_idx]
}
}
}
}
for k_y in 0..p.k_h {
for k_x in 0..p.k_w {
(0..p.c_out).into_par_iter().for_each(|dst_c_idx| {
let k_cont = (0..p.c_in)
.map(|c_in_idx| {
k[c_in_idx * k_s0 + dst_c_idx * k_s1 + k_y * k_s2 + k_x * k_s3]
})
.collect::<Vec<_>>();
for b_idx in 0..p.b_size {
for inp_y in 0..p.i_h {
for inp_x in 0..p.i_w {
let out_x = inp_x * p.stride + k_x * p.dilation;
let out_y = inp_y * p.stride + k_y * p.dilation;
if out_x < p.padding || out_y < p.padding {
continue;
}
let out_x = out_x - p.padding;
let out_y = out_y - p.padding;
if out_x < out_w && out_y < out_h {
let inp_cont = &inp_cont
[b_idx * cont_s0 + inp_y * cont_s1 + inp_x * cont_s2..];
let dst_idx = b_idx * dst_s0
+ out_y * dst_s2
+ out_x * dst_s3
+ dst_c_idx * dst_s1;
let mut d = T::zero();
unsafe {
T::vec_dot(
inp_cont.as_ptr(),
k_cont.as_ptr(),
&mut d,
p.c_in,
)
}
let dst_p = dst.as_ptr();
// Safety: dst_idx are uniques per dst_c_idx which is used to
// parallelise the different tasks so no two threads can try to
// write at the same location.
unsafe {
let ptr = dst_p.add(dst_idx) as *mut T;
*ptr += d
}
}
}
}
}
})
}
}
Ok(dst)
}
}
struct MatMul((usize, usize, usize, usize));
impl MatMul {
fn striding_error(&self, lhs_l: &Layout, rhs_l: &Layout, msg: &'static str) -> Error {
Error::MatMulUnexpectedStriding(Box::new(crate::error::MatMulUnexpectedStriding {
lhs_l: lhs_l.clone(),
rhs_l: rhs_l.clone(),
bmnk: self.0,
msg,
}))
.bt()
}
fn ab_skip(&self, lhs_l: &Layout, rhs_l: &Layout) -> Result<(usize, usize)> {
let lhs_stride = lhs_l.stride();
let rhs_stride = rhs_l.stride();
let rank = lhs_stride.len();
let (_b, m, n, k) = self.0;
let a_skip: usize = match lhs_stride[..rank - 2] {
[s1, stride] if s1 == stride * lhs_l.dims()[1] => stride,
[_, stride] if lhs_l.dims()[0] == 1 => stride,
[stride, _] if lhs_l.dims()[1] == 1 => stride,
[stride] => stride,
[] => m * k,
_ => Err(self.striding_error(lhs_l, rhs_l, "non-contiguous lhs"))?,
};
let b_skip: usize = match rhs_stride[..rank - 2] {
[s1, stride] if s1 == stride * rhs_l.dims()[1] => stride,
[_, stride] if rhs_l.dims()[0] == 1 => stride,
[stride, _] if rhs_l.dims()[1] == 1 => stride,
[stride] => stride,
[] => n * k,
_ => Err(self.striding_error(lhs_l, rhs_l, "non-contiguous rhs"))?,
};
Ok((a_skip, b_skip))
}
}
impl Map2 for MatMul {
const OP: &'static str = "mat_mul";
#[cfg(all(not(feature = "mkl"), not(feature = "accelerate")))]
fn f<T: 'static + WithDType + num_traits::Num + Copy>(
&self,
lhs: &[T],
lhs_l: &Layout,
rhs: &[T],
rhs_l: &Layout,
) -> Result<Vec<T>> {
use gemm::{gemm, Parallelism};
match T::DTYPE {
DType::F16 | DType::F32 | DType::F64 => {}
_ => Err(Error::UnsupportedDTypeForOp(T::DTYPE, "matmul").bt())?,
}
let (b, m, n, k) = self.0;
let lhs = &lhs[lhs_l.start_offset()..];
let rhs = &rhs[rhs_l.start_offset()..];
let lhs_stride = lhs_l.stride();
let rhs_stride = rhs_l.stride();
let rank = lhs_stride.len();
let lhs_cs = lhs_stride[rank - 1];
let lhs_rs = lhs_stride[rank - 2];
let rhs_cs = rhs_stride[rank - 1];
let rhs_rs = rhs_stride[rank - 2];
let (a_skip, b_skip) = self.ab_skip(lhs_l, rhs_l)?;
let c_skip: usize = m * n;
let dst_shape: Shape = (m, n).into();
let dst_strides = dst_shape.stride_contiguous();
let dst_rs = dst_strides[0];
let dst_cs = dst_strides[1];
let mut dst = vec![T::zero(); b * m * n];
let num_threads = crate::utils::get_num_threads();
let parallelism = if num_threads > 1 {
Parallelism::Rayon(num_threads)
} else {
Parallelism::None
};
for step in 0..b {
let lhs_p = &lhs[step * a_skip..];
let rhs_p = &rhs[step * b_skip..];
let dst_p = &mut dst[step * c_skip..];
unsafe {
gemm(
/* m: usize = */ m,
/* n: usize = */ n,
/* k: usize = */ k,
/* dst: *mut T = */ dst_p.as_mut_ptr(),
/* dst_cs: isize = */ dst_cs as isize,
/* dst_rs: isize = */ dst_rs as isize,
/* read_dst: bool = */ false,
/* lhs: *const T = */ lhs_p.as_ptr(),
/* lhs_cs: isize = */ lhs_cs as isize,
/* lhs_rs: isize = */ lhs_rs as isize,
/* rhs: *const T = */ rhs_p.as_ptr(),
/* rhs_cs: isize = */ rhs_cs as isize,
/* rhs_rs: isize = */ rhs_rs as isize,
/* alpha: T = */ T::zero(),
/* beta: T = */ T::one(),
/* conj_dst: bool = */ false,
/* conj_lhs: bool = */ false,
/* conj_rhs: bool = */ false,
parallelism,
)
}
}
Ok(dst)
}
#[cfg(feature = "accelerate")]
fn f<T: 'static + WithDType + num_traits::Num + Copy>(
&self,
lhs: &[T],
lhs_l: &Layout,
rhs: &[T],
rhs_l: &Layout,
) -> Result<Vec<T>> {
let (b, m, n, k) = self.0;
let lhs = &lhs[lhs_l.start_offset()..];
let rhs = &rhs[rhs_l.start_offset()..];
let lhs_stride = lhs_l.stride();
let rhs_stride = rhs_l.stride();
let (a_skip, b_skip) = self.ab_skip(lhs_l, rhs_l)?;
let c_skip: usize = m * n;
let rhs_m1 = rhs_stride[rhs_stride.len() - 1];
let rhs_m2 = rhs_stride[rhs_stride.len() - 2];
let lhs_m1 = lhs_stride[lhs_stride.len() - 1];
let lhs_m2 = lhs_stride[lhs_stride.len() - 2];
let (lda, transa) = if (rhs_m1 == 1 || n == 1) && (rhs_m2 == n || k == 1) {
(n as i32, b'N')
} else if rhs_m1 == k && rhs_m2 == 1 {
(k as i32, b'T')
} else {
Err(self.striding_error(lhs_l, rhs_l, "non-contiguous rhs"))?
};
// The b tensor has dims batching, m, k (lhs)
let (ldb, transb) = if (lhs_m1 == 1 || k == 1) && (lhs_m2 == k || m == 1) {
(k as i32, b'N')
} else if lhs_m1 == m && lhs_m2 == 1 {
(m as i32, b'T')
} else {
Err(self.striding_error(lhs_l, rhs_l, "non-contiguous lhs"))?
};
let mut dst = vec![T::zero(); b * m * n];
match T::DTYPE {
DType::F16 => {
crate::bail!("the accelerate backend does not support f16 matmul")
}
DType::F32 => {
for step in 0..b {
let lhs_p = &lhs[step * a_skip..];
let rhs_p = &rhs[step * b_skip..];
let dst_p = &mut dst[step * c_skip..];
unsafe {
let a = rhs_p.as_ptr() as *const f32;
let b = lhs_p.as_ptr() as *const f32;
let c = dst_p.as_mut_ptr() as *mut f32;
let a = std::slice::from_raw_parts(a, a_skip);
let b = std::slice::from_raw_parts(b, b_skip);
let c = std::slice::from_raw_parts_mut(c, c_skip);
crate::accelerate::sgemm(
transa, transb, /* m= */ n as i32, /* n= */ m as i32,
/* k= */ k as i32, /* alpha= */ 1., /* a= */ a,
/* lda= */ lda, /* b= */ b, /* ldb= */ ldb,
/* beta= */ 0., /* c= */ c, /* ldc= */ n as i32,
)
}
}
}
DType::F64 => {
for step in 0..b {
let lhs_p = &lhs[step * a_skip..];
let rhs_p = &rhs[step * b_skip..];
let dst_p = &mut dst[step * c_skip..];
unsafe {
let a = rhs_p.as_ptr() as *const f64;
let b = lhs_p.as_ptr() as *const f64;
let c = dst_p.as_mut_ptr() as *mut f64;
let a = std::slice::from_raw_parts(a, a_skip);
let b = std::slice::from_raw_parts(b, b_skip);
let c = std::slice::from_raw_parts_mut(c, c_skip);
crate::accelerate::dgemm(
transa, transb, /* m= */ n as i32, /* n= */ m as i32,
/* k= */ k as i32, /* alpha= */ 1., /* a= */ a,
/* lda= */ lda, /* b= */ b, /* ldb= */ ldb,
/* beta= */ 0., /* c= */ c, /* ldc= */ n as i32,
)
}
}
}
dtype => Err(Error::UnsupportedDTypeForOp(dtype, "matmul").bt())?,
}
Ok(dst)
}
#[cfg(feature = "mkl")]
fn f<T: 'static + WithDType + num_traits::Num + Copy>(
&self,
lhs: &[T],
lhs_l: &Layout,
rhs: &[T],
rhs_l: &Layout,
) -> Result<Vec<T>> {
let (b, m, n, k) = self.0;
let lhs = &lhs[lhs_l.start_offset()..];
let rhs = &rhs[rhs_l.start_offset()..];
let lhs_stride = lhs_l.stride();
let rhs_stride = rhs_l.stride();
let (a_skip, b_skip) = self.ab_skip(lhs_l, rhs_l)?;
let c_skip: usize = m * n;
let rhs_m1 = rhs_stride[rhs_stride.len() - 1];
let rhs_m2 = rhs_stride[rhs_stride.len() - 2];
let lhs_m1 = lhs_stride[lhs_stride.len() - 1];
let lhs_m2 = lhs_stride[lhs_stride.len() - 2];
let (lda, transa) = if (rhs_m1 == 1 || n == 1) && (rhs_m2 == n || k == 1) {
(n as i32, b'N')
} else if rhs_m1 == k && rhs_m2 == 1 {
(k as i32, b'T')
} else {
Err(self.striding_error(lhs_l, rhs_l, "non-contiguous rhs"))?
};
// The b tensor has dims batching, m, k (lhs)
let (ldb, transb) = if (lhs_m1 == 1 || k == 1) && (lhs_m2 == k || m == 1) {
(k as i32, b'N')
} else if lhs_m1 == m && lhs_m2 == 1 {
(m as i32, b'T')
} else {
Err(self.striding_error(lhs_l, rhs_l, "non-contiguous lhs"))?
};
let mut dst = vec![T::zero(); b * m * n];
match T::DTYPE {
DType::F16 => {
for step in 0..b {
let lhs_p = &lhs[step * a_skip..];
let rhs_p = &rhs[step * b_skip..];
let dst_p = &mut dst[step * c_skip..];
unsafe {
let a = rhs_p.as_ptr() as *const f16;
let b = lhs_p.as_ptr() as *const f16;
let c = dst_p.as_mut_ptr() as *mut f16;
let a = std::slice::from_raw_parts(a, a_skip);
let b = std::slice::from_raw_parts(b, b_skip);
let c = std::slice::from_raw_parts_mut(c, c_skip);
crate::mkl::hgemm(
transa,
transb,
/* m= */ n as i32,
/* n= */ m as i32,
/* k= */ k as i32,
/* alpha= */ f16::ONE,
/* a= */ a,
/* lda= */ lda,
/* b= */ b,
/* ldb= */ ldb,
/* beta= */ f16::ZERO,
/* c= */ c,
/* ldc= */ n as i32,
)
}
}
}
DType::F32 => {
for step in 0..b {
let lhs_p = &lhs[step * a_skip..];
let rhs_p = &rhs[step * b_skip..];
let dst_p = &mut dst[step * c_skip..];
unsafe {
let a = rhs_p.as_ptr() as *const f32;
let b = lhs_p.as_ptr() as *const f32;
let c = dst_p.as_mut_ptr() as *mut f32;
let a = std::slice::from_raw_parts(a, a_skip);
let b = std::slice::from_raw_parts(b, b_skip);
let c = std::slice::from_raw_parts_mut(c, c_skip);
crate::mkl::sgemm(
transa, transb, /* m= */ n as i32, /* n= */ m as i32,
/* k= */ k as i32, /* alpha= */ 1., /* a= */ a,
/* lda= */ lda, /* b= */ b, /* ldb= */ ldb,
/* beta= */ 0., /* c= */ c, /* ldc= */ n as i32,
)
}
}
}
DType::F64 => {
for step in 0..b {
let lhs_p = &lhs[step * a_skip..];
let rhs_p = &rhs[step * b_skip..];
let dst_p = &mut dst[step * c_skip..];
unsafe {
let a = rhs_p.as_ptr() as *const f64;
let b = lhs_p.as_ptr() as *const f64;
let c = dst_p.as_mut_ptr() as *mut f64;
let a = std::slice::from_raw_parts(a, a_skip);
let b = std::slice::from_raw_parts(b, b_skip);
let c = std::slice::from_raw_parts_mut(c, c_skip);
crate::mkl::dgemm(
transa, transb, /* m= */ n as i32, /* n= */ m as i32,
/* k= */ k as i32, /* alpha= */ 1., /* a= */ a,
/* lda= */ lda, /* b= */ b, /* ldb= */ ldb,
/* beta= */ 0., /* c= */ c, /* ldc= */ n as i32,
)
}
}
}
dtype => Err(Error::UnsupportedDTypeForOp(dtype, "matmul").bt())?,
}
Ok(dst)
}
}
fn elu<T: num_traits::Float>(v: T, alpha: T) -> T {
if v.is_sign_positive() {
v
} else {
(v.exp() - T::one()) * alpha
}
}
impl CpuStorage {
pub fn as_slice<D: WithDType>(&self) -> Result<&[D]> {
D::cpu_storage_as_slice(self)
}
pub fn concat(storages: &[CpuStorage]) -> Result<CpuStorage> {
let storage0 = &storages[0];
let s = match storage0 {
Self::U8(_) => {
let storages = storages
.iter()
.map(|s| match s {
Self::U8(s) => Ok(s.as_slice()),
_ => crate::bail!("dtype mismatch"),
})
.collect::<Result<Vec<_>>>()?
.concat();
Self::U8(storages)
}
Self::U32(_) => {
let storages = storages
.iter()
.map(|s| match s {
Self::U32(s) => Ok(s.as_slice()),
_ => crate::bail!("dtype mismatch"),
})
.collect::<Result<Vec<_>>>()?
.concat();
Self::U32(storages)
}
Self::I64(_) => {
let storages = storages
.iter()
.map(|s| match s {
Self::I64(s) => Ok(s.as_slice()),
_ => crate::bail!("dtype mismatch"),
})
.collect::<Result<Vec<_>>>()?
.concat();
Self::I64(storages)
}
Self::BF16(_) => {
let storages = storages
.iter()
.map(|s| match s {
Self::BF16(s) => Ok(s.as_slice()),
_ => crate::bail!("dtype mismatch"),
})
.collect::<Result<Vec<_>>>()?
.concat();
Self::BF16(storages)
}
Self::F16(_) => {
let storages = storages
.iter()
.map(|s| match s {
Self::F16(s) => Ok(s.as_slice()),
_ => crate::bail!("dtype mismatch"),
})
.collect::<Result<Vec<_>>>()?
.concat();
Self::F16(storages)
}
Self::F32(_) => {
let storages = storages
.iter()
.map(|s| match s {
Self::F32(s) => Ok(s.as_slice()),
_ => crate::bail!("dtype mismatch"),
})
.collect::<Result<Vec<_>>>()?
.concat();
Self::F32(storages)
}
Self::F64(_) => {
let storages = storages
.iter()
.map(|s| match s {
Self::F64(s) => Ok(s.as_slice()),
_ => crate::bail!("dtype mismatch"),
})
.collect::<Result<Vec<_>>>()?
.concat();
Self::F64(storages)
}
};
Ok(s)
}
}
impl BackendStorage for CpuStorage {
type Device = CpuDevice;
fn dtype(&self) -> DType {
match self {
Self::U8(_) => DType::U8,
Self::U32(_) => DType::U32,
Self::I64(_) => DType::I64,
Self::BF16(_) => DType::BF16,
Self::F16(_) => DType::F16,
Self::F32(_) => DType::F32,
Self::F64(_) => DType::F64,
}
}
fn to_dtype(&self, layout: &Layout, dtype: DType) -> Result<Self> {
// TODO: find a way around the quadratic number of cases below.
match (self, dtype) {
(Self::U8(storage), DType::BF16) => {
let data = unary_map(storage, layout, |v| bf16::from_f32(v as f32));
Ok(Self::BF16(data))
}
(Self::U32(storage), DType::BF16) => {
let data = unary_map(storage, layout, |v| bf16::from_f32(v as f32));
Ok(Self::BF16(data))
}
(Self::I64(storage), DType::BF16) => {
let data = unary_map(storage, layout, |v| bf16::from_f32(v as f32));
Ok(Self::BF16(data))
}
(Self::BF16(storage), DType::BF16) => {
let data = unary_map(storage, layout, |v| v);
Ok(Self::BF16(data))
}
(Self::F16(storage), DType::BF16) => {
let data = unary_map(storage, layout, |v| bf16::from_f32(v.to_f32()));
Ok(Self::BF16(data))
}
(Self::F32(storage), DType::BF16) => {
let data = unary_map(storage, layout, bf16::from_f32);
Ok(Self::BF16(data))
}
(Self::F64(storage), DType::BF16) => {
let data = unary_map(storage, layout, bf16::from_f64);
Ok(Self::BF16(data))
}
(Self::U8(storage), DType::F16) => {
let data = unary_map(storage, layout, |v| f16::from_f32(v as f32));
Ok(Self::F16(data))
}
(Self::U32(storage), DType::F16) => {
let data = unary_map(storage, layout, |v| f16::from_f32(v as f32));
Ok(Self::F16(data))
}
(Self::I64(storage), DType::F16) => {
let data = unary_map(storage, layout, |v| f16::from_f32(v as f32));
Ok(Self::F16(data))
}
(Self::BF16(storage), DType::F16) => {
let data = unary_map(storage, layout, |v| f16::from_f32(v.to_f32()));
Ok(Self::F16(data))
}
(Self::F16(storage), DType::F16) => {
let data = unary_map(storage, layout, |v| v);
Ok(Self::F16(data))
}
(Self::F32(storage), DType::F16) => {
let data = unary_map(storage, layout, f16::from_f32);
Ok(Self::F16(data))
}
(Self::F64(storage), DType::F16) => {
let data = unary_map(storage, layout, f16::from_f64);
Ok(Self::F16(data))
}
(Self::U8(storage), DType::F32) => {
let data = unary_map(storage, layout, |v| v as f32);
Ok(Self::F32(data))
}
(Self::U32(storage), DType::F32) => {
let data = unary_map(storage, layout, |v| v as f32);
Ok(Self::F32(data))
}
(Self::I64(storage), DType::F32) => {
let data = unary_map(storage, layout, |v| v as f32);
Ok(Self::F32(data))
}
(Self::BF16(storage), DType::F32) => {
let data = unary_map(storage, layout, |v| v.to_f32());
Ok(Self::F32(data))
}
(Self::F16(storage), DType::F32) => {
let data = unary_map(storage, layout, |v| v.to_f32());
Ok(Self::F32(data))
}
(Self::F32(storage), DType::F32) => {
let data = unary_map(storage, layout, |v| v);
Ok(Self::F32(data))
}
(Self::F64(storage), DType::F32) => {
let data = unary_map(storage, layout, |v| v as f32);
Ok(Self::F32(data))
}
(Self::U8(storage), DType::U8) => {
let data = unary_map(storage, layout, |v| v);
Ok(Self::U8(data))
}
(Self::BF16(storage), DType::U8) => {
let data = unary_map(storage, layout, |v| v.to_f32() as u8);
Ok(Self::U8(data))
}
(Self::F16(storage), DType::U8) => {
let data = unary_map(storage, layout, |v| v.to_f32() as u8);
Ok(Self::U8(data))
}
(Self::F32(storage), DType::U8) => {
let data = unary_map(storage, layout, |v| v as u8);
Ok(Self::U8(data))
}
(Self::F64(storage), DType::U8) => {
let data = unary_map(storage, layout, |v| v as u8);
Ok(Self::U8(data))
}
(Self::U32(storage), DType::U8) => {
let data = unary_map(storage, layout, |v| v as u8);
Ok(Self::U8(data))
}
(Self::I64(storage), DType::U8) => {
let data = unary_map(storage, layout, |v| v as u8);
Ok(Self::U8(data))
}
(Self::U8(storage), DType::U32) => {
let data = unary_map(storage, layout, |v| v as u32);
Ok(Self::U32(data))
}
(Self::U32(storage), DType::U32) => {
let data = unary_map(storage, layout, |v| v);
Ok(Self::U32(data))
}
(Self::I64(storage), DType::U32) => {
let data = unary_map(storage, layout, |v| v as u32);
Ok(Self::U32(data))
}
(Self::BF16(storage), DType::U32) => {
let data = unary_map(storage, layout, |v| v.to_f32() as u32);
Ok(Self::U32(data))
}
(Self::F16(storage), DType::U32) => {
let data = unary_map(storage, layout, |v| v.to_f32() as u32);
Ok(Self::U32(data))
}
(Self::F32(storage), DType::U32) => {
let data = unary_map(storage, layout, |v| v as u32);
Ok(Self::U32(data))
}
(Self::F64(storage), DType::U32) => {
let data = unary_map(storage, layout, |v| v as u32);
Ok(Self::U32(data))
}
(Self::U8(storage), DType::I64) => {
let data = unary_map(storage, layout, |v| v as i64);
Ok(Self::I64(data))
}
(Self::U32(storage), DType::I64) => {
let data = unary_map(storage, layout, |v| v as i64);
Ok(Self::I64(data))
}
(Self::I64(storage), DType::I64) => {
let data = unary_map(storage, layout, |v| v);
Ok(Self::I64(data))
}
(Self::BF16(storage), DType::I64) => {
let data = unary_map(storage, layout, |v| v.to_f32() as i64);
Ok(Self::I64(data))
}
(Self::F16(storage), DType::I64) => {
let data = unary_map(storage, layout, |v| v.to_f32() as i64);
Ok(Self::I64(data))
}
(Self::F32(storage), DType::I64) => {
let data = unary_map(storage, layout, |v| v as i64);
Ok(Self::I64(data))
}
(Self::F64(storage), DType::I64) => {
let data = unary_map(storage, layout, |v| v as i64);
Ok(Self::I64(data))
}
(Self::U8(storage), DType::F64) => {
let data = unary_map(storage, layout, |v| v as f64);
Ok(Self::F64(data))
}
(Self::U32(storage), DType::F64) => {
let data = unary_map(storage, layout, |v| v as f64);
Ok(Self::F64(data))
}
(Self::I64(storage), DType::F64) => {
let data = unary_map(storage, layout, |v| v as f64);
Ok(Self::F64(data))
}
(Self::BF16(storage), DType::F64) => {
let data = unary_map(storage, layout, |v| v.to_f64());
Ok(Self::F64(data))
}
(Self::F16(storage), DType::F64) => {
let data = unary_map(storage, layout, |v| v.to_f64());
Ok(Self::F64(data))
}
(Self::F32(storage), DType::F64) => {
let data = unary_map(storage, layout, |v| v as f64);
Ok(Self::F64(data))
}
(Self::F64(storage), DType::F64) => {
let data = unary_map(storage, layout, |v| v);
Ok(Self::F64(data))
}
}
}
fn reduce_op(&self, op: ReduceOp, layout: &Layout, reduce_dims: &[usize]) -> Result<Self> {
match op {
ReduceOp::Sum => {
let src_dims = layout.dims();
let mut dst_dims = src_dims.to_vec();
for &dim in reduce_dims.iter() {
dst_dims[dim] = 1;
}
let dst_shape = Shape::from(dst_dims);
let mut reduce_dims = reduce_dims.to_vec();
// Sort the reduce_dims as they have to be processed from left to right when converting the
// indexes.
reduce_dims.sort();
let reduce_dims_and_stride: Vec<_> = reduce_dims
.iter()
.map(|&d| (src_dims[d], src_dims[d + 1..].iter().product::<usize>()))
.collect();
ReduceSum {
dst_shape: &dst_shape,
reduce_dims: &reduce_dims,
reduce_dims_and_stride,
}
.map(self, layout)
}
ReduceOp::Min | ReduceOp::ArgMin | ReduceOp::Max | ReduceOp::ArgMax => {
let reduce_dim_index = match reduce_dims {
[reduce_dim_index] => *reduce_dim_index,
_ => {
let op = match op {
ReduceOp::Min => "min",
ReduceOp::ArgMin => "argmin",
ReduceOp::Max => "max",
ReduceOp::ArgMax => "argmax",
_ => unreachable!(),
};
let dims = reduce_dims.to_vec();
Err(Error::OnlySingleDimension { op, dims })?
}
};
let (use_min, return_index) = match op {
ReduceOp::Min => (true, false),
ReduceOp::ArgMin => (true, true),
ReduceOp::Max => (false, false),
ReduceOp::ArgMax => (false, true),
_ => unreachable!(),
};
ReduceIndex {
reduce_dim_index,
use_min,
return_index,
}
.map(self, layout)
}
}
}
fn cmp(&self, op: CmpOp, rhs: &Self, lhs_l: &Layout, rhs_l: &Layout) -> Result<Self> {
Cmp(op).map(self, lhs_l, rhs, rhs_l)
}
fn affine(&self, layout: &Layout, mul: f64, add: f64) -> Result<Self> {
Affine(mul, add).map(self, layout)
}
fn avg_pool2d(
&self,
layout: &Layout,
kernel_size: (usize, usize),
stride: (usize, usize),
) -> Result<Self> {
AvgPool2D(kernel_size, stride).map(self, layout)
}
fn max_pool2d(
&self,
layout: &Layout,
kernel_size: (usize, usize),
stride: (usize, usize),
) -> Result<Self> {
MaxPool2D(kernel_size, stride).map(self, layout)
}
fn upsample_nearest1d(&self, layout: &Layout, sz: usize) -> Result<Self> {
UpsampleNearest1D(sz).map(self, layout)
}
fn upsample_nearest2d(&self, layout: &Layout, h: usize, w: usize) -> Result<Self> {
UpsampleNearest2D(h, w).map(self, layout)
}
fn powf(&self, layout: &Layout, e: f64) -> Result<Self> {
use num_traits::Float;
// TODO: Have some generic map for functions that apply on num_traits::Float elements.
match self {
Self::BF16(storage) => {
let data = unary_map(storage, layout, |v| v.powf(bf16::from_f64(e)));
Ok(Self::BF16(data))
}
Self::F16(storage) => {
let data = unary_map(storage, layout, |v| v.powf(f16::from_f64(e)));
Ok(Self::F16(data))
}
Self::F32(storage) => {
let data = unary_map(storage, layout, |v| v.powf(e as f32));
Ok(Self::F32(data))
}
Self::F64(storage) => {
let data = unary_map(storage, layout, |v| v.powf(e));
Ok(Self::F64(data))
}
Self::U8(_) => Err(Error::UnsupportedDTypeForOp(DType::U8, "elu").bt()),
Self::U32(_) => Err(Error::UnsupportedDTypeForOp(DType::U32, "elu").bt()),
Self::I64(_) => Err(Error::UnsupportedDTypeForOp(DType::I64, "elu").bt()),
}
}
fn elu(&self, layout: &Layout, alpha: f64) -> Result<Self> {
// TODO: Have some generic map for functions that apply on num_traits::Float elements.
match self {
Self::BF16(storage) => {
let data = unary_map(storage, layout, |v| elu(v, bf16::from_f64(alpha)));
Ok(Self::BF16(data))
}
Self::F16(storage) => {
let data = unary_map(storage, layout, |v| elu(v, f16::from_f64(alpha)));
Ok(Self::F16(data))
}
Self::F32(storage) => {
let data = unary_map(storage, layout, |v| elu(v, f32::from_f64(alpha)));
Ok(Self::F32(data))
}
Self::F64(storage) => {
let data = unary_map(storage, layout, |v| elu(v, alpha));
Ok(Self::F64(data))
}
Self::U8(_) => Err(Error::UnsupportedDTypeForOp(DType::U8, "elu").bt()),
Self::U32(_) => Err(Error::UnsupportedDTypeForOp(DType::U32, "elu").bt()),
Self::I64(_) => Err(Error::UnsupportedDTypeForOp(DType::I64, "elu").bt()),
}
}
fn unary_impl<B: UnaryOpT>(&self, layout: &Layout) -> Result<Self> {
match self {
Self::BF16(storage) => {
if B::BF16_VEC {
let data = unary_map_vec(storage, layout, B::bf16, B::bf16_vec);
Ok(Self::BF16(data))
} else {
let data = unary_map(storage, layout, B::bf16);
Ok(Self::BF16(data))
}
}
Self::F16(storage) => {
if B::F16_VEC {
let data = unary_map_vec(storage, layout, B::f16, B::f16_vec);
Ok(Self::F16(data))
} else {
let data = unary_map(storage, layout, B::f16);
Ok(Self::F16(data))
}
}
Self::F32(storage) => {
if B::F32_VEC {
let data = unary_map_vec(storage, layout, B::f32, B::f32_vec);
Ok(Self::F32(data))
} else {
let data = unary_map(storage, layout, B::f32);
Ok(Self::F32(data))
}
}
Self::F64(storage) => {
if B::F64_VEC {
let data = unary_map_vec(storage, layout, B::f64, B::f64_vec);
Ok(Self::F64(data))
} else {
let data = unary_map(storage, layout, B::f64);
Ok(Self::F64(data))
}
}
Self::U8(storage) => {
let data = unary_map(storage, layout, B::u8);
Ok(Self::U8(data))
}
Self::U32(storage) => {
let data = unary_map(storage, layout, B::u32);
Ok(Self::U32(data))
}
Self::I64(storage) => {
let data = unary_map(storage, layout, B::i64);
Ok(Self::I64(data))
}
}
}
fn binary_impl<B: BinaryOpT>(
&self,
rhs: &Self,
lhs_l: &Layout,
rhs_l: &Layout,
) -> Result<Self> {
match (self, rhs) {
(Self::BF16(lhs), Self::BF16(rhs)) => {
let data = if B::BF16_VEC {
binary_map_vec(lhs_l, rhs_l, lhs, rhs, B::bf16, B::bf16_vec)
} else {
binary_map(lhs_l, rhs_l, lhs, rhs, B::bf16)
};
Ok(Self::BF16(data))
}
(Self::F16(lhs), Self::F16(rhs)) => {
let data = if B::F16_VEC {
binary_map_vec(lhs_l, rhs_l, lhs, rhs, B::f16, B::f16_vec)
} else {
binary_map(lhs_l, rhs_l, lhs, rhs, B::f16)
};
Ok(Self::F16(data))
}
(Self::F32(lhs), Self::F32(rhs)) => {
let data = if B::F32_VEC {
binary_map_vec(lhs_l, rhs_l, lhs, rhs, B::f32, B::f32_vec)
} else {
binary_map(lhs_l, rhs_l, lhs, rhs, B::f32)
};
Ok(Self::F32(data))
}
(Self::F64(lhs), Self::F64(rhs)) => {
let data = if B::F64_VEC {
binary_map_vec(lhs_l, rhs_l, lhs, rhs, B::f64, B::f64_vec)
} else {
binary_map(lhs_l, rhs_l, lhs, rhs, B::f64)
};
Ok(Self::F64(data))
}
(Self::U32(lhs), Self::U32(rhs)) => {
let data = if B::U32_VEC {
binary_map_vec(lhs_l, rhs_l, lhs, rhs, B::u32, B::u32_vec)
} else {
binary_map(lhs_l, rhs_l, lhs, rhs, B::u32)
};
Ok(Self::U32(data))
}
(Self::I64(lhs), Self::I64(rhs)) => {
let data = if B::I64_VEC {
binary_map_vec(lhs_l, rhs_l, lhs, rhs, B::i64, B::i64_vec)
} else {
binary_map(lhs_l, rhs_l, lhs, rhs, B::i64)
};
Ok(Self::I64(data))
}
(Self::U8(lhs), Self::U8(rhs)) => {
let data = if B::U8_VEC {
binary_map_vec(lhs_l, rhs_l, lhs, rhs, B::u8, B::u8_vec)
} else {
binary_map(lhs_l, rhs_l, lhs, rhs, B::u8)
};
Ok(Self::U8(data))
}
_ => {
// This should be covered by the dtype check above.
Err(Error::DTypeMismatchBinaryOp {
lhs: self.dtype(),
rhs: rhs.dtype(),
op: B::NAME,
}
.bt())
}
}
}
fn copy2d(
&self,
dst: &mut Self,
d1: usize,
d2: usize,
src_s: usize,
dst_s: usize,
src_o: usize,
dst_o: usize,
) -> Result<()> {
match (self, dst) {
(Self::U8(src), Self::U8(dst)) => copy2d_(src, dst, d1, d2, src_s, dst_s, src_o, dst_o),
(Self::U32(src), Self::U32(dst)) => {
copy2d_(src, dst, d1, d2, src_s, dst_s, src_o, dst_o)
}
(Self::I64(src), Self::I64(dst)) => {
copy2d_(src, dst, d1, d2, src_s, dst_s, src_o, dst_o)
}
(Self::BF16(src), Self::BF16(dst)) => {
copy2d_(src, dst, d1, d2, src_s, dst_s, src_o, dst_o)
}
(Self::F16(src), Self::F16(dst)) => {
copy2d_(src, dst, d1, d2, src_s, dst_s, src_o, dst_o)
}
(Self::F32(src), Self::F32(dst)) => {
copy2d_(src, dst, d1, d2, src_s, dst_s, src_o, dst_o)
}
(Self::F64(src), Self::F64(dst)) => {
copy2d_(src, dst, d1, d2, src_s, dst_s, src_o, dst_o)
}
(_, dst) => {
return Err(Error::DTypeMismatchBinaryOp {
lhs: self.dtype(),
rhs: dst.dtype(),
op: "copy2d",
}
.bt());
}
}
Ok(())
}
fn copy_strided_src(&self, dst: &mut Self, dst_offset: usize, src_l: &Layout) -> Result<()> {
match (self, dst) {
(Self::U8(src), Self::U8(dst)) => copy_strided_src_(src, dst, dst_offset, src_l),
(Self::U32(src), Self::U32(dst)) => copy_strided_src_(src, dst, dst_offset, src_l),
(Self::I64(src), Self::I64(dst)) => copy_strided_src_(src, dst, dst_offset, src_l),
(Self::BF16(src), Self::BF16(dst)) => copy_strided_src_(src, dst, dst_offset, src_l),
(Self::F16(src), Self::F16(dst)) => copy_strided_src_(src, dst, dst_offset, src_l),
(Self::F32(src), Self::F32(dst)) => copy_strided_src_(src, dst, dst_offset, src_l),
(Self::F64(src), Self::F64(dst)) => copy_strided_src_(src, dst, dst_offset, src_l),
(_, dst) => {
// This should be covered by the dtype check above.
return Err(Error::DTypeMismatchBinaryOp {
lhs: self.dtype(),
rhs: dst.dtype(),
op: "copy_strided",
}
.bt());
}
}
Ok(())
}
fn where_cond(
&self,
layout: &Layout,
t: &Self,
t_l: &Layout,
f: &Self,
f_l: &Layout,
) -> Result<Self> {
match self {
Self::U8(pred) => WCond(pred, layout).map(t, t_l, f, f_l),
Self::U32(pred) => WCond(pred, layout).map(t, t_l, f, f_l),
Self::I64(pred) => WCond(pred, layout).map(t, t_l, f, f_l),
_ => Err(Error::UnsupportedDTypeForOp(self.dtype(), "where-cond")),
}
}
fn conv1d(
&self,
l: &Layout,
kernel: &Self,
kernel_l: &Layout,
params: &crate::conv::ParamsConv1D,
) -> Result<Self> {
if !USE_IM2COL_CONV1D {
return Conv1D(params).map(self, l, kernel, kernel_l);
}
let op = Im2Col1D {
l_k: params.k_size,
padding: params.padding,
stride: params.stride,
dilation: params.dilation,
};
let col = op.map(self, l)?;
let b = params.b_size;
let n = params.c_out;
let l_out = params.l_out();
let k = op.l_k * params.c_in;
let m = l_out;
let col_l = Layout::contiguous((b, m, k));
let res = if kernel_l.is_contiguous() {
let kernel_l = Layout::contiguous_with_offset((1, n, k), kernel_l.start_offset())
.transpose(1, 2)?
.broadcast_as((b, k, n))?;
col.matmul(kernel, (b, m, n, k), &col_l, &kernel_l)?
} else {
// Make the kernel contiguous if not already the case.
let mut kernel_c = unsafe {
self.device()
.alloc_uninit(kernel_l.shape(), kernel.dtype())?
};
kernel.copy_strided_src(&mut kernel_c, 0, kernel_l)?;
let kernel_l = Layout::contiguous_with_offset((1, n, k), kernel_l.start_offset())
.transpose(1, 2)?
.broadcast_as((b, k, n))?;
col.matmul(kernel, (b, m, n, k), &col_l, &kernel_l)?
};
let res_l = Layout::contiguous((b, l_out, params.c_out)).transpose(1, 2)?;
let mut res_t = unsafe { self.device().alloc_uninit(res_l.shape(), res.dtype())? };
res.copy_strided_src(&mut res_t, 0, &res_l)?;
Ok(res_t)
}
fn conv_transpose1d(
&self,
l: &Layout,
kernel: &Self,
kernel_l: &Layout,
params: &crate::conv::ParamsConvTranspose1D,
) -> Result<Self> {
let can_use_col2im = kernel_l.is_contiguous()
&& params.dilation == 1
&& params.padding == 0
&& params.output_padding == 0;
if USE_COL2IM_CONV1D_TR && can_use_col2im {
let (b_size, c_in, l_in) = l.shape().dims3()?;
let (c_in2, c_out, k_size) = kernel_l.shape().dims3()?;
if !kernel_l.is_contiguous() {
crate::bail!(
"convtr1d: the second argument (kernel) has to be contiguous {kernel_l:?}"
)
}
if c_in != c_in2 {
crate::bail!(
"convtr1d: shape mismatch on c_in {:?} {:?}",
l.shape(),
kernel_l.shape()
)
}
let col = {
// This merges the last two dimensions of the kernel together.
let kernel_l_mm = Layout::new(
(b_size, c_in, k_size * c_out).into(),
vec![0, k_size * c_out, 1],
kernel_l.start_offset(),
);
self.matmul(
kernel,
(
b_size,
/* m */ l_in,
/* n */ c_out * k_size,
/* k */ c_in,
),
&l.transpose(1, 2)?,
&kernel_l_mm,
)?
};
let col_l = Layout::contiguous((b_size, l_in, c_out, k_size));
Col2Im1D {
stride: params.stride,
}
.map(&col, &col_l)
} else {
ConvTranspose1D(params).map(self, l, kernel, kernel_l)
}
}
fn conv2d(
&self,
l: &Layout,
kernel: &Self,
kernel_l: &Layout,
params: &crate::conv::ParamsConv2D,
) -> Result<Self> {
if !USE_IM2COL_CONV2D {
return Conv2D(params).map(self, l, kernel, kernel_l);
}
let op = Im2Col {
h_k: params.k_h,
w_k: params.k_w,
padding: params.padding,
stride: params.stride,
dilation: params.dilation,
};
let col = op.map(self, l)?;
let b = params.b_size;
let n = params.c_out;
let (h_out, w_out) = (params.out_h(), params.out_w());
let k = op.h_k * op.w_k * params.c_in;
let m = h_out * w_out;
let col_l = Layout::contiguous((b, m, k));
let res = if kernel_l.is_contiguous() {
let kernel_l = Layout::contiguous_with_offset((1, n, k), kernel_l.start_offset())
.transpose(1, 2)?
.broadcast_as((b, k, n))?;
col.matmul(kernel, (b, m, n, k), &col_l, &kernel_l)?
} else {
// Make the kernel contiguous if not already the case.
let mut kernel_c = unsafe {
self.device()
.alloc_uninit(kernel_l.shape(), kernel.dtype())?
};
kernel.copy_strided_src(&mut kernel_c, 0, kernel_l)?;
let kernel_l = Layout::contiguous_with_offset((1, n, k), kernel_l.start_offset())
.transpose(1, 2)?
.broadcast_as((b, k, n))?;
col.matmul(kernel, (b, m, n, k), &col_l, &kernel_l)?
};
let res_l = Layout::contiguous((b, h_out, w_out, params.c_out))
.transpose(1, 2)?
.transpose(1, 3)?;
let mut res_t = unsafe { self.device().alloc_uninit(res_l.shape(), res.dtype())? };
res.copy_strided_src(&mut res_t, 0, &res_l)?;
Ok(res_t)
}
fn conv_transpose2d(
&self,
l: &Layout,
kernel: &Self,
kernel_l: &Layout,
params: &crate::conv::ParamsConvTranspose2D,
) -> Result<Self> {
ConvTranspose2D(params).map(self, l, kernel, kernel_l)
}
fn index_select(&self, ids: &Self, l: &Layout, ids_l: &Layout, dim: usize) -> Result<Self> {
match ids {
Self::U8(ids) => IndexSelect { ids, ids_l, dim }.map(self, l),
Self::U32(ids) => IndexSelect { ids, ids_l, dim }.map(self, l),
Self::I64(ids) => IndexSelect { ids, ids_l, dim }.map(self, l),
_ => Err(Error::UnsupportedDTypeForOp(self.dtype(), "index-select").bt()),
}
}
fn gather(&self, l: &Layout, ids: &Self, ids_l: &Layout, dim: usize) -> Result<Self> {
match ids {
Self::U8(ids) => Gather { ids, ids_l, dim }.map(self, l),
Self::U32(ids) => Gather { ids, ids_l, dim }.map(self, l),
Self::I64(ids) => Gather { ids, ids_l, dim }.map(self, l),
_ => Err(Error::UnsupportedDTypeForOp(self.dtype(), "gather").bt()),
}
}
fn scatter_add(
&self,
l: &Layout,
ids: &Self,
ids_l: &Layout,
src: &Self,
src_l: &Layout,
dim: usize,
) -> Result<Self> {
match ids {
Self::U8(ids) => ScatterAdd { ids, ids_l, dim }.map(self, l, src, src_l),
Self::U32(ids) => ScatterAdd { ids, ids_l, dim }.map(self, l, src, src_l),
Self::I64(ids) => ScatterAdd { ids, ids_l, dim }.map(self, l, src, src_l),
_ => Err(Error::UnsupportedDTypeForOp(self.dtype(), "scatter-add").bt()),
}
}
fn index_add(
&self,
l: &Layout,
ids: &Self,
ids_l: &Layout,
src: &Self,
src_l: &Layout,
dim: usize,
) -> Result<Self> {
match ids {
Self::U8(ids) => {
let ids = match ids_l.contiguous_offsets() {
Some((a, b)) => &ids[a..b],
None => Err(Error::RequiresContiguous { op: "index-add" }.bt())?,
};
IndexAdd { ids, dim }.map(self, l, src, src_l)
}
Self::U32(ids) => {
let ids = match ids_l.contiguous_offsets() {
Some((a, b)) => &ids[a..b],
None => Err(Error::RequiresContiguous { op: "index-add" }.bt())?,
};
IndexAdd { ids, dim }.map(self, l, src, src_l)
}
Self::I64(ids) => {
let ids = match ids_l.contiguous_offsets() {
Some((a, b)) => &ids[a..b],
None => Err(Error::RequiresContiguous { op: "index-add" }.bt())?,
};
IndexAdd { ids, dim }.map(self, l, src, src_l)
}
_ => Err(Error::UnsupportedDTypeForOp(self.dtype(), "index-add").bt()),
}
}
fn matmul(
&self,
rhs: &Self,
bmnk: (usize, usize, usize, usize),
lhs_l: &Layout,
rhs_l: &Layout,
) -> Result<Self> {
MatMul(bmnk).map(self, lhs_l, rhs, rhs_l)
}
fn device(&self) -> &Self::Device {
&CpuDevice
}
fn try_clone(&self, _: &Layout) -> Result<Self> {
Ok(self.clone())
}
fn to_cpu_storage(&self) -> Result<CpuStorage> {
Ok(self.clone())
}
}
impl BackendDevice for CpuDevice {
type Storage = CpuStorage;
fn location(&self) -> crate::DeviceLocation {
crate::DeviceLocation::Cpu
}
fn same_device(&self, _: &Self) -> bool {
true
}
fn storage_from_slice<T: crate::WithDType>(&self, s: &[T]) -> Result<Self::Storage> {
Ok(T::to_cpu_storage(s))
}
fn storage_from_cpu_storage(&self, s: &CpuStorage) -> Result<Self::Storage> {
Ok(s.clone())
}
fn storage_from_cpu_storage_owned(&self, s: CpuStorage) -> Result<Self::Storage> {
Ok(s)
}
fn new(_: usize) -> Result<Self> {
Ok(Self)
}
fn set_seed(&self, _seed: u64) -> Result<()> {
crate::bail!("cannot seed the CPU rng with set_seed")
}
fn rand_uniform(&self, shape: &Shape, dtype: DType, min: f64, max: f64) -> Result<CpuStorage> {
use rand::prelude::*;
let elem_count = shape.elem_count();
let mut rng = rand::thread_rng();
match dtype {
DType::U8 | DType::U32 | DType::I64 => {
Err(Error::UnsupportedDTypeForOp(dtype, "rand_uniform").bt())
}
DType::BF16 => {
let mut data = Vec::with_capacity(elem_count);
let uniform =
rand::distributions::Uniform::new(bf16::from_f64(min), bf16::from_f64(max));
for _i in 0..elem_count {
data.push(rng.sample::<bf16, _>(uniform))
}
Ok(CpuStorage::BF16(data))
}
DType::F16 => {
let mut data = Vec::with_capacity(elem_count);
let uniform =
rand::distributions::Uniform::new(f16::from_f64(min), f16::from_f64(max));
for _i in 0..elem_count {
data.push(rng.sample::<f16, _>(uniform))
}
Ok(CpuStorage::F16(data))
}
DType::F32 => {
let mut data = Vec::with_capacity(elem_count);
let uniform = rand::distributions::Uniform::new(min as f32, max as f32);
for _i in 0..elem_count {
data.push(rng.sample::<f32, _>(uniform))
}
Ok(CpuStorage::F32(data))
}
DType::F64 => {
let mut data = Vec::with_capacity(elem_count);
let uniform = rand::distributions::Uniform::new(min, max);
for _i in 0..elem_count {
data.push(rng.sample::<f64, _>(uniform))
}
Ok(CpuStorage::F64(data))
}
}
}
fn rand_normal(&self, shape: &Shape, dtype: DType, mean: f64, std: f64) -> Result<CpuStorage> {
use rand::prelude::*;
let elem_count = shape.elem_count();
let mut rng = rand::thread_rng();
match dtype {
DType::U8 | DType::U32 | DType::I64 => {
Err(Error::UnsupportedDTypeForOp(dtype, "rand_normal").bt())
}
DType::BF16 => {
let mut data = Vec::with_capacity(elem_count);
let normal = rand_distr::Normal::new(bf16::from_f64(mean), bf16::from_f64(std))
.map_err(Error::wrap)?;
for _i in 0..elem_count {
data.push(normal.sample(&mut rng))
}
Ok(CpuStorage::BF16(data))
}
DType::F16 => {
let mut data = Vec::with_capacity(elem_count);
let normal = rand_distr::Normal::new(f16::from_f64(mean), f16::from_f64(std))
.map_err(Error::wrap)?;
for _i in 0..elem_count {
data.push(normal.sample(&mut rng))
}
Ok(CpuStorage::F16(data))
}
DType::F32 => {
let mut data = Vec::with_capacity(elem_count);
let normal =
rand_distr::Normal::new(mean as f32, std as f32).map_err(Error::wrap)?;
for _i in 0..elem_count {
data.push(normal.sample(&mut rng))
}
Ok(CpuStorage::F32(data))
}
DType::F64 => {
let mut data = Vec::with_capacity(elem_count);
let normal = rand_distr::Normal::new(mean, std).map_err(Error::wrap)?;
for _i in 0..elem_count {
data.push(normal.sample(&mut rng))
}
Ok(CpuStorage::F64(data))
}
}
}
#[allow(clippy::uninit_vec)]
unsafe fn alloc_uninit(&self, shape: &Shape, dtype: DType) -> Result<CpuStorage> {
let elem_count = shape.elem_count();
// The code below is highly unsafe but hopefully not directly unsound as we only consider
// types that are Copy, not Drop, and for which all bit patterns are proper values.
// It's still pretty risky, see the following for more details:
// https://github.com/rust-lang/rust-clippy/issues/4483
let storage = match dtype {
DType::U8 => {
let mut v = Vec::with_capacity(elem_count);
v.set_len(elem_count);
CpuStorage::U8(v)
}
DType::U32 => {
let mut v = Vec::with_capacity(elem_count);
v.set_len(elem_count);
CpuStorage::U32(v)
}
DType::I64 => {
let mut v = Vec::with_capacity(elem_count);
v.set_len(elem_count);
CpuStorage::I64(v)
}
DType::BF16 => {
let mut v = Vec::with_capacity(elem_count);
v.set_len(elem_count);
CpuStorage::BF16(v)
}
DType::F16 => {
let mut v = Vec::with_capacity(elem_count);
v.set_len(elem_count);
CpuStorage::F16(v)
}
DType::F32 => {
let mut v = Vec::with_capacity(elem_count);
v.set_len(elem_count);
CpuStorage::F32(v)
}
DType::F64 => {
let mut v = Vec::with_capacity(elem_count);
v.set_len(elem_count);
CpuStorage::F64(v)
}
};
Ok(storage)
}
fn ones_impl(&self, shape: &Shape, dtype: DType) -> Result<CpuStorage> {
let elem_count = shape.elem_count();
let storage = match dtype {
DType::U8 => CpuStorage::U8(vec![1u8; elem_count]),
DType::U32 => CpuStorage::U32(vec![1u32; elem_count]),
DType::I64 => CpuStorage::I64(vec![1i64; elem_count]),
DType::BF16 => CpuStorage::BF16(vec![bf16::ONE; elem_count]),
DType::F16 => CpuStorage::F16(vec![f16::ONE; elem_count]),
DType::F32 => CpuStorage::F32(vec![1f32; elem_count]),
DType::F64 => CpuStorage::F64(vec![1f64; elem_count]),
};
Ok(storage)
}
fn zeros_impl(&self, shape: &Shape, dtype: DType) -> Result<CpuStorage> {
let elem_count = shape.elem_count();
let storage = match dtype {
DType::U8 => CpuStorage::U8(vec![0u8; elem_count]),
DType::U32 => CpuStorage::U32(vec![0u32; elem_count]),
DType::I64 => CpuStorage::I64(vec![0i64; elem_count]),
DType::BF16 => CpuStorage::BF16(vec![bf16::ZERO; elem_count]),
DType::F16 => CpuStorage::F16(vec![f16::ZERO; elem_count]),
DType::F32 => CpuStorage::F32(vec![0f32; elem_count]),
DType::F64 => CpuStorage::F64(vec![0f64; elem_count]),
};
Ok(storage)
}
fn synchronize(&self) -> Result<()> {
Ok(())
}
}
#[macro_export]
macro_rules! map_dtype {
($name:expr, $storage:ident, $fn:expr, ($($dtypes:ident),+)) => {
match $storage {
$(CpuStorage::$dtypes(__e) => CpuStorage::$dtypes($fn(__e)),)*
s => Err(Error::UnsupportedDTypeForOp(s.dtype(), $name).bt())?,
}
};
}
| 2 |
0 | hf_public_repos/candle/candle-core/src | hf_public_repos/candle/candle-core/src/cpu_backend/utils.rs | /// Helper functions to write CPU kernels.
use crate::backend::BackendStorage;
use crate::{Error, Layout, Result, WithDType};
type C = super::CpuStorage;
pub trait Map1 {
fn f<T: WithDType>(&self, vs: &[T], layout: &Layout) -> Result<Vec<T>>;
fn map(&self, vs: &C, layout: &Layout) -> Result<C> {
match vs {
C::U8(vs) => Ok(C::U8(self.f(vs, layout)?)),
C::U32(vs) => Ok(C::U32(self.f(vs, layout)?)),
C::I64(vs) => Ok(C::I64(self.f(vs, layout)?)),
C::BF16(vs) => Ok(C::BF16(self.f(vs, layout)?)),
C::F16(vs) => Ok(C::F16(self.f(vs, layout)?)),
C::F32(vs) => Ok(C::F32(self.f(vs, layout)?)),
C::F64(vs) => Ok(C::F64(self.f(vs, layout)?)),
}
}
}
pub trait Map1Any {
fn f<T: WithDType, W: Fn(Vec<T>) -> C>(&self, vs: &[T], layout: &Layout, wrap: W) -> Result<C>;
fn map(&self, vs: &C, layout: &Layout) -> Result<C> {
match vs {
C::U8(vs) => Ok(self.f(vs, layout, C::U8)?),
C::U32(vs) => Ok(self.f(vs, layout, C::U32)?),
C::I64(vs) => Ok(self.f(vs, layout, C::I64)?),
C::BF16(vs) => Ok(self.f(vs, layout, C::BF16)?),
C::F16(vs) => Ok(self.f(vs, layout, C::F16)?),
C::F32(vs) => Ok(self.f(vs, layout, C::F32)?),
C::F64(vs) => Ok(self.f(vs, layout, C::F64)?),
}
}
}
pub trait Map2 {
const OP: &'static str;
fn f<T: WithDType>(&self, v1: &[T], l1: &Layout, v2: &[T], l2: &Layout) -> Result<Vec<T>>;
fn map(&self, v1: &C, l1: &Layout, v2: &C, l2: &Layout) -> Result<C> {
match (v1, v2) {
(C::U8(v1), C::U8(v2)) => Ok(C::U8(self.f(v1, l1, v2, l2)?)),
(C::U32(v1), C::U32(v2)) => Ok(C::U32(self.f(v1, l1, v2, l2)?)),
(C::I64(v1), C::I64(v2)) => Ok(C::I64(self.f(v1, l1, v2, l2)?)),
(C::BF16(v1), C::BF16(v2)) => Ok(C::BF16(self.f(v1, l1, v2, l2)?)),
(C::F16(v1), C::F16(v2)) => Ok(C::F16(self.f(v1, l1, v2, l2)?)),
(C::F32(v1), C::F32(v2)) => Ok(C::F32(self.f(v1, l1, v2, l2)?)),
(C::F64(v1), C::F64(v2)) => Ok(C::F64(self.f(v1, l1, v2, l2)?)),
_ => Err(Error::DTypeMismatchBinaryOp {
lhs: v1.dtype(),
rhs: v2.dtype(),
op: Self::OP,
}
.bt()),
}
}
}
pub trait Map2U8 {
const OP: &'static str;
fn f<T: WithDType>(&self, v1: &[T], l1: &Layout, v2: &[T], l2: &Layout) -> Result<Vec<u8>>;
fn map(&self, v1: &C, l1: &Layout, v2: &C, l2: &Layout) -> Result<C> {
match (v1, v2) {
(C::U8(v1), C::U8(v2)) => Ok(C::U8(self.f(v1, l1, v2, l2)?)),
(C::U32(v1), C::U32(v2)) => Ok(C::U8(self.f(v1, l1, v2, l2)?)),
(C::I64(v1), C::I64(v2)) => Ok(C::U8(self.f(v1, l1, v2, l2)?)),
(C::BF16(v1), C::BF16(v2)) => Ok(C::U8(self.f(v1, l1, v2, l2)?)),
(C::F16(v1), C::F16(v2)) => Ok(C::U8(self.f(v1, l1, v2, l2)?)),
(C::F32(v1), C::F32(v2)) => Ok(C::U8(self.f(v1, l1, v2, l2)?)),
(C::F64(v1), C::F64(v2)) => Ok(C::U8(self.f(v1, l1, v2, l2)?)),
_ => Err(Error::DTypeMismatchBinaryOp {
lhs: v1.dtype(),
rhs: v2.dtype(),
op: Self::OP,
}
.bt()),
}
}
}
pub fn binary_map<T: Copy, U: Copy, F: FnMut(T, T) -> U>(
lhs_l: &Layout,
rhs_l: &Layout,
lhs: &[T],
rhs: &[T],
mut f: F,
) -> Vec<U> {
match (lhs_l.contiguous_offsets(), rhs_l.contiguous_offsets()) {
(Some((o_l1, o_l2)), Some((o_r1, o_r2))) => lhs[o_l1..o_l2]
.iter()
.zip(rhs[o_r1..o_r2].iter())
.map(|(&l, &r)| f(l, r))
.collect(),
(Some((o_l1, o_l2)), None) => {
// TODO: Maybe we want to avoid going through the layout twice.
match rhs_l.offsets_b() {
Some(ob) => {
let mut i_in_block = 0;
let mut i_right_broadcast = 0;
lhs[o_l1..o_l2]
.iter()
.map(|&l| {
let r = unsafe { rhs.get_unchecked(i_in_block + ob.start) };
i_right_broadcast += 1;
if i_right_broadcast >= ob.right_broadcast {
i_in_block += 1;
i_right_broadcast = 0;
}
if i_in_block >= ob.len {
i_in_block = 0
}
f(l, *r)
})
.collect()
}
None => lhs_l
.strided_index()
.zip(rhs_l.strided_index())
.map(|(lhs_i, rhs_i)| f(lhs[lhs_i], rhs[rhs_i]))
.collect(),
}
}
(None, Some((o_r1, o_r2))) => {
// TODO: Maybe we want to avoid going through the layout twice.
match lhs_l.offsets_b() {
Some(ob) => {
let mut i_in_block = 0;
let mut i_right_broadcast = 0;
rhs[o_r1..o_r2]
.iter()
.map(|&r| {
let l = unsafe { lhs.get_unchecked(i_in_block + ob.start) };
i_right_broadcast += 1;
if i_right_broadcast >= ob.right_broadcast {
i_in_block += 1;
i_right_broadcast = 0;
}
if i_in_block >= ob.len {
i_in_block = 0
}
f(*l, r)
})
.collect()
}
None => lhs_l
.strided_index()
.zip(rhs_l.strided_index())
.map(|(lhs_i, rhs_i)| f(lhs[lhs_i], rhs[rhs_i]))
.collect(),
}
}
_ => lhs_l
.strided_index()
.zip(rhs_l.strided_index())
.map(|(lhs_i, rhs_i)| f(lhs[lhs_i], rhs[rhs_i]))
.collect(),
}
}
// Similar to binary_map but with vectorized variants.
pub fn binary_map_vec<T: Copy, F: FnMut(T, T) -> T, FV: FnMut(&[T], &[T], &mut [T])>(
lhs_l: &Layout,
rhs_l: &Layout,
lhs: &[T],
rhs: &[T],
mut f: F,
mut f_vec: FV,
) -> Vec<T> {
let el_count = lhs_l.shape().elem_count();
match (lhs_l.contiguous_offsets(), rhs_l.contiguous_offsets()) {
(Some((o_l1, o_l2)), Some((o_r1, o_r2))) => {
let mut ys: Vec<T> = Vec::with_capacity(el_count);
let ys_to_set = ys.spare_capacity_mut();
let ys_to_set = unsafe {
std::mem::transmute::<&mut [std::mem::MaybeUninit<T>], &mut [T]>(ys_to_set)
};
f_vec(&lhs[o_l1..o_l2], &rhs[o_r1..o_r2], ys_to_set);
// SAFETY: values are all set by f_vec.
unsafe { ys.set_len(el_count) };
ys
}
(Some((o_l1, o_l2)), None) => match rhs_l.offsets_b() {
Some(ob) if ob.right_broadcast == 1 => {
let rhs = &rhs[ob.start..ob.start + ob.len];
let mut ys: Vec<T> = Vec::with_capacity(el_count);
let ys_to_set = ys.spare_capacity_mut();
let ys_to_set = unsafe {
std::mem::transmute::<&mut [std::mem::MaybeUninit<T>], &mut [T]>(ys_to_set)
};
let mut dst_i = 0;
for src_i in (o_l1..o_l2).step_by(ob.len) {
f_vec(
&lhs[src_i..src_i + ob.len],
rhs,
&mut ys_to_set[dst_i..dst_i + ob.len],
);
dst_i += ob.len;
}
// SAFETY: values are all set by f_vec.
unsafe { ys.set_len(el_count) };
ys
}
Some(ob) => {
let rhs = &rhs[ob.start..ob.start + ob.len];
let mut ys = lhs[o_l1..o_l2].to_vec();
for idx_l in 0..ob.left_broadcast {
let start = idx_l * ob.len * ob.right_broadcast;
for (i, &r) in rhs.iter().enumerate() {
let start = start + i * ob.right_broadcast;
for v in ys[start..start + ob.right_broadcast].iter_mut() {
*v = f(*v, r)
}
}
}
ys
}
None => lhs_l
.strided_index()
.zip(rhs_l.strided_index())
.map(|(lhs_i, rhs_i)| f(lhs[lhs_i], rhs[rhs_i]))
.collect(),
},
(None, Some((o_r1, o_r2))) => match lhs_l.offsets_b() {
Some(ob) if ob.right_broadcast == 1 => {
let lhs = &lhs[ob.start..ob.start + ob.len];
let mut ys: Vec<T> = Vec::with_capacity(el_count);
let ys_to_set = ys.spare_capacity_mut();
let ys_to_set = unsafe {
std::mem::transmute::<&mut [std::mem::MaybeUninit<T>], &mut [T]>(ys_to_set)
};
let mut dst_i = 0;
for src_i in (o_r1..o_r2).step_by(ob.len) {
f_vec(
lhs,
&rhs[src_i..src_i + ob.len],
&mut ys_to_set[dst_i..dst_i + ob.len],
);
dst_i += ob.len;
}
// SAFETY: values are all set by f_vec.
unsafe { ys.set_len(el_count) };
ys
}
Some(ob) => {
let lhs = &lhs[ob.start..ob.start + ob.len];
let mut ys = rhs[o_r1..o_r2].to_vec();
for idx_l in 0..ob.left_broadcast {
let start = idx_l * ob.len * ob.right_broadcast;
for (i, &l) in lhs.iter().enumerate() {
let start = start + i * ob.right_broadcast;
for v in ys[start..start + ob.right_broadcast].iter_mut() {
*v = f(l, *v)
}
}
}
ys
}
None => lhs_l
.strided_index()
.zip(rhs_l.strided_index())
.map(|(lhs_i, rhs_i)| f(lhs[lhs_i], rhs[rhs_i]))
.collect(),
},
_ => lhs_l
.strided_index()
.zip(rhs_l.strided_index())
.map(|(lhs_i, rhs_i)| f(lhs[lhs_i], rhs[rhs_i]))
.collect(),
}
}
pub fn unary_map<T: Copy, U: Copy, F: FnMut(T) -> U>(
vs: &[T],
layout: &Layout,
mut f: F,
) -> Vec<U> {
match layout.strided_blocks() {
crate::StridedBlocks::SingleBlock { start_offset, len } => vs
[start_offset..start_offset + len]
.iter()
.map(|&v| f(v))
.collect(),
crate::StridedBlocks::MultipleBlocks {
block_start_index,
block_len,
} => {
let mut result = Vec::with_capacity(layout.shape().elem_count());
// Specialize the case where block_len is one to avoid the second loop.
if block_len == 1 {
for index in block_start_index {
let v = unsafe { vs.get_unchecked(index) };
result.push(f(*v))
}
} else {
for index in block_start_index {
for offset in 0..block_len {
let v = unsafe { vs.get_unchecked(index + offset) };
result.push(f(*v))
}
}
}
result
}
}
}
pub fn unary_map_vec<T: Copy, U: Copy, F: FnMut(T) -> U, FV: FnMut(&[T], &mut [U])>(
vs: &[T],
layout: &Layout,
mut f: F,
mut f_vec: FV,
) -> Vec<U> {
match layout.strided_blocks() {
crate::StridedBlocks::SingleBlock { start_offset, len } => {
let mut ys: Vec<U> = Vec::with_capacity(len);
let ys_to_set = ys.spare_capacity_mut();
let ys_to_set = unsafe {
std::mem::transmute::<&mut [std::mem::MaybeUninit<U>], &mut [U]>(ys_to_set)
};
f_vec(&vs[start_offset..start_offset + len], ys_to_set);
// SAFETY: values are all set by f_vec.
unsafe { ys.set_len(len) };
ys
}
crate::StridedBlocks::MultipleBlocks {
block_start_index,
block_len,
} => {
let el_count = layout.shape().elem_count();
// Specialize the case where block_len is one to avoid the second loop.
if block_len == 1 {
let mut result = Vec::with_capacity(el_count);
for index in block_start_index {
let v = unsafe { vs.get_unchecked(index) };
result.push(f(*v))
}
result
} else {
let mut ys: Vec<U> = Vec::with_capacity(el_count);
let ys_to_set = ys.spare_capacity_mut();
let ys_to_set = unsafe {
std::mem::transmute::<&mut [std::mem::MaybeUninit<U>], &mut [U]>(ys_to_set)
};
let mut dst_index = 0;
for src_index in block_start_index {
let vs = &vs[src_index..src_index + block_len];
let ys = &mut ys_to_set[dst_index..dst_index + block_len];
f_vec(vs, ys);
dst_index += block_len;
}
// SAFETY: values are all set by f_vec.
unsafe { ys.set_len(el_count) };
ys
}
}
}
}
| 3 |
0 | hf_public_repos/candle/candle-core/src | hf_public_repos/candle/candle-core/src/cuda_backend/device.rs | use crate::backend::BackendDevice;
use crate::{CpuStorage, CpuStorageRef, DType, Layout, Result, Shape};
pub use candle_kernels as kernels;
pub use cudarc;
use cudarc::driver::{CudaFunction, LaunchAsync, LaunchConfig};
use half::{bf16, f16};
use std::sync::{Arc, Mutex};
use super::{CudaError, CudaStorage, CudaStorageSlice, WrapErr};
/// Unique identifier for cuda devices.
#[derive(Clone, Copy, Debug, PartialEq, Eq, Hash)]
pub struct DeviceId(usize);
impl DeviceId {
fn new() -> Self {
// https://users.rust-lang.org/t/idiomatic-rust-way-to-generate-unique-id/33805
use std::sync::atomic;
static COUNTER: atomic::AtomicUsize = atomic::AtomicUsize::new(1);
Self(COUNTER.fetch_add(1, atomic::Ordering::Relaxed))
}
}
struct CudaRng(cudarc::curand::CudaRng);
unsafe impl Send for CudaRng {}
#[derive(Clone)]
pub struct CudaDevice {
id: DeviceId,
device: Arc<cudarc::driver::CudaDevice>,
pub(crate) blas: Arc<cudarc::cublas::CudaBlas>,
curand: Arc<Mutex<CudaRng>>,
}
impl std::fmt::Debug for CudaDevice {
fn fmt(&self, f: &mut std::fmt::Formatter<'_>) -> std::fmt::Result {
write!(f, "CudaDevice({:?})", self.id)
}
}
impl std::ops::Deref for CudaDevice {
type Target = Arc<cudarc::driver::CudaDevice>;
fn deref(&self) -> &Self::Target {
&self.device
}
}
impl CudaDevice {
pub fn cuda_device(&self) -> Arc<cudarc::driver::CudaDevice> {
self.device.clone()
}
pub fn compile(
&self,
func_name: &'static str,
kernel: ug::lang::ssa::Kernel,
) -> Result<CudaFunction> {
let mut buf = vec![];
ug_cuda::code_gen::gen(&mut buf, func_name, &kernel)?;
let cuda_code = String::from_utf8(buf)?;
let opts = cudarc::nvrtc::CompileOptions {
use_fast_math: Some(true),
..Default::default()
};
let ptx = cudarc::nvrtc::safe::compile_ptx_with_opts(cuda_code, opts).w()?;
self.device.load_ptx(ptx, "ug", &[func_name]).w()?;
let func = match self.device.get_func("ug", func_name) {
Some(func) => func,
None => crate::bail!("unknown function ug::{func_name}"),
};
Ok(func)
}
pub fn id(&self) -> DeviceId {
self.id
}
fn const_impl(&self, v: f64, shape: &Shape, dtype: DType) -> Result<CudaStorage> {
let elem_count = shape.elem_count();
let cfg = LaunchConfig::for_num_elems(elem_count as u32);
let slice = match dtype {
DType::U8 => {
// SAFETY: Set later by running the fill kernel.
let data = unsafe { self.alloc::<u8>(elem_count) }.w()?;
let func = self.get_or_load_func("fill_u8", kernels::FILL)?;
let params = (&data, v as u8, elem_count);
unsafe { func.launch(cfg, params) }.w()?;
CudaStorageSlice::U8(data)
}
DType::U32 => {
// SAFETY: Set later by running the fill kernel.
let data = unsafe { self.alloc::<u32>(elem_count) }.w()?;
let func = self.get_or_load_func("fill_u32", kernels::FILL)?;
let params = (&data, v as u32, elem_count);
unsafe { func.launch(cfg, params) }.w()?;
CudaStorageSlice::U32(data)
}
DType::I64 => {
// SAFETY: Set later by running the fill kernel.
let data = unsafe { self.alloc::<i64>(elem_count) }.w()?;
let func = self.get_or_load_func("fill_i64", kernels::FILL)?;
let params = (&data, v as i64, elem_count);
unsafe { func.launch(cfg, params) }.w()?;
CudaStorageSlice::I64(data)
}
DType::BF16 => {
// SAFETY: Set later by running the fill kernel.
let data = unsafe { self.alloc::<bf16>(elem_count) }.w()?;
let func = self.get_or_load_func("fill_bf16", kernels::FILL)?;
let params = (&data, bf16::from_f64(v), elem_count);
unsafe { func.launch(cfg, params) }.w()?;
CudaStorageSlice::BF16(data)
}
DType::F16 => {
// SAFETY: Set later by running the fill kernel.
let data = unsafe { self.alloc::<f16>(elem_count) }.w()?;
let func = self.get_or_load_func("fill_f16", kernels::FILL)?;
let params = (&data, f16::from_f64(v), elem_count);
unsafe { func.launch(cfg, params) }.w()?;
CudaStorageSlice::F16(data)
}
DType::F32 => {
// SAFETY: Set later by running the fill kernel.
let data = unsafe { self.alloc::<f32>(elem_count) }.w()?;
let func = self.get_or_load_func("fill_f32", kernels::FILL)?;
let params = (&data, v as f32, elem_count);
unsafe { func.launch(cfg, params) }.w()?;
CudaStorageSlice::F32(data)
}
DType::F64 => {
// SAFETY: Set later by running the fill kernel.
let data = unsafe { self.alloc::<f64>(elem_count) }.w()?;
let func = self.get_or_load_func("fill_f64", kernels::FILL)?;
let params = (&data, v, elem_count);
unsafe { func.launch(cfg, params) }.w()?;
CudaStorageSlice::F64(data)
}
};
Ok(CudaStorage {
slice,
device: self.clone(),
})
}
pub fn get_or_load_func(&self, module_name: &str, ptx: &'static str) -> Result<CudaFunction> {
if !self.has_func(module_name, module_name) {
// Leaking the string here is a bit sad but we need a &'static str and this is only
// done once per kernel name.
let static_module_name = Box::leak(module_name.to_string().into_boxed_str());
self.load_ptx(ptx.into(), module_name, &[static_module_name])
.map_err(|cuda| CudaError::Load {
cuda,
module_name: module_name.to_string(),
})
.w()?;
}
self.get_func(module_name, module_name)
// Clippy recommends this `ok_or` rather than `ok_or_else` so hopefully the compiler is
// able to only build the error value if needed.
.ok_or(CudaError::MissingKernel {
module_name: module_name.to_string(),
})
.w()
}
}
impl CudaDevice {
pub fn new_with_stream(ordinal: usize) -> Result<Self> {
let device = cudarc::driver::CudaDevice::new_with_stream(ordinal).w()?;
let blas = cudarc::cublas::CudaBlas::new(device.clone()).w()?;
let curand = cudarc::curand::CudaRng::new(299792458, device.clone()).w()?;
Ok(Self {
id: DeviceId::new(),
device,
blas: Arc::new(blas),
curand: Arc::new(Mutex::new(CudaRng(curand))),
})
}
}
impl BackendDevice for CudaDevice {
type Storage = CudaStorage;
fn new(ordinal: usize) -> Result<Self> {
let device = cudarc::driver::CudaDevice::new(ordinal).w()?;
let blas = cudarc::cublas::CudaBlas::new(device.clone()).w()?;
let curand = cudarc::curand::CudaRng::new(299792458, device.clone()).w()?;
Ok(Self {
id: DeviceId::new(),
device,
blas: Arc::new(blas),
curand: Arc::new(Mutex::new(CudaRng(curand))),
})
}
fn set_seed(&self, seed: u64) -> Result<()> {
// We do not call set_seed but instead create a new curand object. This ensures that the
// state will be identical and the same random numbers will be generated.
let mut curand = self.curand.lock().unwrap();
curand.0 = cudarc::curand::CudaRng::new(seed, self.device.clone()).w()?;
Ok(())
}
fn location(&self) -> crate::DeviceLocation {
crate::DeviceLocation::Cuda {
gpu_id: self.device.ordinal(),
}
}
fn same_device(&self, rhs: &Self) -> bool {
self.id == rhs.id
}
fn zeros_impl(&self, shape: &Shape, dtype: DType) -> Result<CudaStorage> {
let elem_count = shape.elem_count();
let slice = match dtype {
DType::U8 => {
let data = self.alloc_zeros::<u8>(elem_count).w()?;
CudaStorageSlice::U8(data)
}
DType::U32 => {
let data = self.alloc_zeros::<u32>(elem_count).w()?;
CudaStorageSlice::U32(data)
}
DType::I64 => {
let data = self.alloc_zeros::<i64>(elem_count).w()?;
CudaStorageSlice::I64(data)
}
DType::BF16 => {
let data = self.alloc_zeros::<bf16>(elem_count).w()?;
CudaStorageSlice::BF16(data)
}
DType::F16 => {
let data = self.alloc_zeros::<f16>(elem_count).w()?;
CudaStorageSlice::F16(data)
}
DType::F32 => {
let data = self.alloc_zeros::<f32>(elem_count).w()?;
CudaStorageSlice::F32(data)
}
DType::F64 => {
let data = self.alloc_zeros::<f64>(elem_count).w()?;
CudaStorageSlice::F64(data)
}
};
Ok(CudaStorage {
slice,
device: self.clone(),
})
}
fn rand_uniform(&self, shape: &Shape, dtype: DType, lo: f64, up: f64) -> Result<CudaStorage> {
let elem_count = shape.elem_count();
let curand = self.curand.lock().unwrap();
let slice = match dtype {
// TODO: Add support for F16 and BF16 though this is likely to require some upstream
// cudarc changes.
DType::U8 | DType::U32 | DType::I64 | DType::F16 | DType::BF16 => {
Err(CudaError::UnsupportedDtype {
dtype,
op: "rand_uniform",
})
.w()?
}
DType::F32 => {
let mut data = unsafe { self.alloc::<f32>(elem_count) }.w()?;
curand.0.fill_with_uniform(&mut data).w()?;
CudaStorageSlice::F32(data)
}
DType::F64 => {
let mut data = unsafe { self.alloc::<f64>(elem_count) }.w()?;
curand.0.fill_with_uniform(&mut data).w()?;
CudaStorageSlice::F64(data)
}
};
let slice = if lo == 0. && up == 1.0 {
slice
} else {
use super::utils::Map1;
let layout = Layout::contiguous(shape);
super::Affine(up - lo, lo).map(&slice, self, &layout)?
};
Ok(CudaStorage {
slice,
device: self.clone(),
})
}
fn rand_normal(&self, shape: &Shape, dtype: DType, mean: f64, std: f64) -> Result<CudaStorage> {
// TODO: Add support for F16 and BF16 though this is likely to require some upstream
// cudarc changes.
let elem_count = shape.elem_count();
let curand = self.curand.lock().unwrap();
// curand can only generate an odd number of values.
// https://github.com/huggingface/candle/issues/734
let elem_count_round = if elem_count % 2 == 1 {
elem_count + 1
} else {
elem_count
};
let slice = match dtype {
DType::U8 | DType::U32 | DType::I64 | DType::F16 | DType::BF16 => {
Err(CudaError::UnsupportedDtype {
dtype,
op: "rand_normal",
})
.w()?
}
DType::F32 => {
let mut data = unsafe { self.alloc::<f32>(elem_count_round) }.w()?;
curand
.0
.fill_with_normal(&mut data, mean as f32, std as f32)
.w()?;
CudaStorageSlice::F32(data)
}
DType::F64 => {
let mut data = unsafe { self.alloc::<f64>(elem_count_round) }.w()?;
curand.0.fill_with_normal(&mut data, mean, std).w()?;
CudaStorageSlice::F64(data)
}
};
Ok(CudaStorage {
slice,
device: self.clone(),
})
}
fn ones_impl(&self, shape: &Shape, dtype: DType) -> Result<CudaStorage> {
self.const_impl(1., shape, dtype)
}
unsafe fn alloc_uninit(&self, shape: &Shape, dtype: DType) -> Result<Self::Storage> {
let elem_count = shape.elem_count();
let slice = match dtype {
DType::U8 => {
let data = self.alloc::<u8>(elem_count).w()?;
CudaStorageSlice::U8(data)
}
DType::U32 => {
let data = self.alloc::<u32>(elem_count).w()?;
CudaStorageSlice::U32(data)
}
DType::I64 => {
let data = self.alloc::<i64>(elem_count).w()?;
CudaStorageSlice::I64(data)
}
DType::BF16 => {
let data = self.alloc::<bf16>(elem_count).w()?;
CudaStorageSlice::BF16(data)
}
DType::F16 => {
let data = self.alloc::<f16>(elem_count).w()?;
CudaStorageSlice::F16(data)
}
DType::F32 => {
let data = self.alloc::<f32>(elem_count).w()?;
CudaStorageSlice::F32(data)
}
DType::F64 => {
let data = self.alloc::<f64>(elem_count).w()?;
CudaStorageSlice::F64(data)
}
};
Ok(CudaStorage {
slice,
device: self.clone(),
})
}
fn storage_from_slice<T: crate::WithDType>(&self, s: &[T]) -> Result<Self::Storage> {
let slice = match T::cpu_storage_ref(s) {
CpuStorageRef::U8(storage) => {
let data = self.htod_sync_copy(storage).w()?;
CudaStorageSlice::U8(data)
}
CpuStorageRef::U32(storage) => {
let data = self.htod_sync_copy(storage).w()?;
CudaStorageSlice::U32(data)
}
CpuStorageRef::I64(storage) => {
let data = self.htod_sync_copy(storage).w()?;
CudaStorageSlice::I64(data)
}
CpuStorageRef::BF16(storage) => {
let data = self.htod_sync_copy(storage).w()?;
CudaStorageSlice::BF16(data)
}
CpuStorageRef::F16(storage) => {
let data = self.htod_sync_copy(storage).w()?;
CudaStorageSlice::F16(data)
}
CpuStorageRef::F32(storage) => {
let data = self.htod_sync_copy(storage).w()?;
CudaStorageSlice::F32(data)
}
CpuStorageRef::F64(storage) => {
let data = self.htod_sync_copy(storage).w()?;
CudaStorageSlice::F64(data)
}
};
Ok(CudaStorage {
slice,
device: self.clone(),
})
}
fn storage_from_cpu_storage(&self, storage: &CpuStorage) -> Result<CudaStorage> {
let slice = match storage {
CpuStorage::U8(storage) => {
let data = self.htod_sync_copy(storage).w()?;
CudaStorageSlice::U8(data)
}
CpuStorage::U32(storage) => {
let data = self.htod_sync_copy(storage).w()?;
CudaStorageSlice::U32(data)
}
CpuStorage::I64(storage) => {
let data = self.htod_sync_copy(storage).w()?;
CudaStorageSlice::I64(data)
}
CpuStorage::BF16(storage) => {
let data = self.htod_sync_copy(storage).w()?;
CudaStorageSlice::BF16(data)
}
CpuStorage::F16(storage) => {
let data = self.htod_sync_copy(storage).w()?;
CudaStorageSlice::F16(data)
}
CpuStorage::F32(storage) => {
let data = self.htod_sync_copy(storage).w()?;
CudaStorageSlice::F32(data)
}
CpuStorage::F64(storage) => {
let data = self.htod_sync_copy(storage).w()?;
CudaStorageSlice::F64(data)
}
};
Ok(CudaStorage {
slice,
device: self.clone(),
})
}
fn storage_from_cpu_storage_owned(&self, storage: CpuStorage) -> Result<CudaStorage> {
let slice = match storage {
CpuStorage::U8(storage) => {
let data = self.htod_copy(storage).w()?;
CudaStorageSlice::U8(data)
}
CpuStorage::U32(storage) => {
let data = self.htod_copy(storage).w()?;
CudaStorageSlice::U32(data)
}
CpuStorage::I64(storage) => {
let data = self.htod_copy(storage).w()?;
CudaStorageSlice::I64(data)
}
CpuStorage::BF16(storage) => {
let data = self.htod_copy(storage).w()?;
CudaStorageSlice::BF16(data)
}
CpuStorage::F16(storage) => {
let data = self.htod_copy(storage).w()?;
CudaStorageSlice::F16(data)
}
CpuStorage::F32(storage) => {
let data = self.htod_copy(storage).w()?;
CudaStorageSlice::F32(data)
}
CpuStorage::F64(storage) => {
let data = self.htod_copy(storage).w()?;
CudaStorageSlice::F64(data)
}
};
Ok(CudaStorage {
slice,
device: self.clone(),
})
}
fn synchronize(&self) -> Result<()> {
self.device.synchronize().map_err(crate::Error::wrap)?;
Ok(())
}
}
| 4 |
0 | hf_public_repos/candle/candle-core/src | hf_public_repos/candle/candle-core/src/cuda_backend/error.rs | use crate::{DType, Layout};
/// cudarc related errors
#[derive(thiserror::Error, Debug)]
pub enum CudaError {
#[error(transparent)]
Cuda(#[from] cudarc::driver::DriverError),
#[error(transparent)]
Compiler(#[from] cudarc::nvrtc::CompileError),
#[error(transparent)]
Cublas(#[from] cudarc::cublas::result::CublasError),
#[error(transparent)]
Curand(#[from] cudarc::curand::result::CurandError),
#[error("missing kernel '{module_name}'")]
MissingKernel { module_name: String },
#[error("unsupported dtype {dtype:?} for {op}")]
UnsupportedDtype { dtype: DType, op: &'static str },
#[error("internal error '{0}'")]
InternalError(&'static str),
#[error("matmul is only supported for contiguous tensors lstride: {lhs_stride:?} rstride: {rhs_stride:?} mnk: {mnk:?}")]
MatMulNonContiguous {
lhs_stride: Layout,
rhs_stride: Layout,
mnk: (usize, usize, usize),
},
#[error("{msg}, expected: {expected:?}, got: {got:?}")]
UnexpectedDType {
msg: &'static str,
expected: DType,
got: DType,
},
#[error("{cuda} when loading {module_name}")]
Load {
cuda: cudarc::driver::DriverError,
module_name: String,
},
}
impl From<CudaError> for crate::Error {
fn from(val: CudaError) -> Self {
crate::Error::Cuda(Box::new(val)).bt()
}
}
pub trait WrapErr<O> {
fn w(self) -> std::result::Result<O, crate::Error>;
}
impl<O, E: Into<CudaError>> WrapErr<O> for std::result::Result<O, E> {
fn w(self) -> std::result::Result<O, crate::Error> {
self.map_err(|e| crate::Error::Cuda(Box::new(e.into())).bt())
}
}
| 5 |
0 | hf_public_repos/candle/candle-core/src | hf_public_repos/candle/candle-core/src/cuda_backend/mod.rs | //! Implementation of Backend traits for CUDA device
//!
use crate::backend::{BackendDevice, BackendStorage};
use crate::op::{BinaryOpT, CmpOp, ReduceOp, UnaryOpT};
use crate::{CpuStorage, DType, Layout, Result, Shape, WithDType};
pub use candle_kernels as kernels;
pub use cudarc;
use cudarc::cublas::{Gemm, GemmConfig, StridedBatchedConfig};
use cudarc::driver::{
CudaSlice, DevicePtr, DeviceRepr, DeviceSlice, LaunchAsync, LaunchConfig, ValidAsZeroBits,
};
use half::{bf16, f16};
#[cfg(feature = "cudnn")]
pub mod cudnn;
mod device;
mod error;
mod utils;
pub use device::{CudaDevice, DeviceId};
pub use error::{CudaError, WrapErr};
pub use utils::{Map1, Map1Any, Map2, Map2Any, Map2InPlace, Map3, S};
pub enum SlicePtrOrNull<T> {
Ptr(CudaSlice<T>),
Null,
}
unsafe impl<T: DeviceRepr> DeviceRepr for &SlicePtrOrNull<T> {
fn as_kernel_param(&self) -> *mut std::ffi::c_void {
match self {
SlicePtrOrNull::Ptr(slice) => slice.as_kernel_param(),
SlicePtrOrNull::Null => 0usize.as_kernel_param(),
}
}
}
impl SlicePtrOrNull<usize> {
pub fn params_from_layout(dev: &CudaDevice, l: &Layout) -> Result<Self> {
let ds = if l.is_contiguous() {
SlicePtrOrNull::Null
} else {
SlicePtrOrNull::Ptr(dev.htod_copy([l.dims(), l.stride()].concat()).w()?)
};
Ok(ds)
}
}
#[derive(Debug)]
pub enum CudaStorageSlice {
U8(CudaSlice<u8>),
U32(CudaSlice<u32>),
I64(CudaSlice<i64>),
BF16(CudaSlice<bf16>),
F16(CudaSlice<f16>),
F32(CudaSlice<f32>),
F64(CudaSlice<f64>),
}
struct Clone;
impl Map1 for Clone {
fn f<T: DeviceRepr>(
&self,
s: &CudaSlice<T>,
_: &CudaDevice,
_: &Layout,
) -> Result<CudaSlice<T>> {
s.try_clone().w()
}
}
pub fn kernel_name<T: WithDType>(root: &str) -> String {
let dtype = T::DTYPE.as_str();
format!("{root}_{dtype}")
}
struct Affine(f64, f64);
impl Map1 for Affine {
fn f<T: DeviceRepr + WithDType>(
&self,
src: &CudaSlice<T>,
dev: &CudaDevice,
layout: &Layout,
) -> Result<CudaSlice<T>> {
let shape = layout.shape();
let dims = shape.dims();
let el = shape.elem_count();
let cfg = LaunchConfig::for_num_elems(el as u32);
let ds = SlicePtrOrNull::params_from_layout(dev, layout)?;
let src = &src.slice(layout.start_offset()..);
let func = dev.get_or_load_func(&kernel_name::<T>("affine"), kernels::AFFINE)?;
// SAFETY: Set later by running the kernel.
let out = unsafe { dev.alloc::<T>(el) }.w()?;
let params = (
el,
dims.len(),
&ds,
src,
&out,
T::from_f64(self.0),
T::from_f64(self.1),
);
// SAFETY: ffi.
unsafe { func.launch(cfg, params) }.w()?;
Ok(out)
}
}
struct Elu(f64);
impl Map1 for Elu {
fn f<T: DeviceRepr + WithDType>(
&self,
src: &CudaSlice<T>,
dev: &CudaDevice,
layout: &Layout,
) -> Result<CudaSlice<T>> {
let shape = layout.shape();
let dims = shape.dims();
let el = shape.elem_count();
let cfg = LaunchConfig::for_num_elems(el as u32);
let ds = SlicePtrOrNull::params_from_layout(dev, layout)?;
let src = &src.slice(layout.start_offset()..);
let func = dev.get_or_load_func(&kernel_name::<T>("uelu"), kernels::UNARY)?;
// SAFETY: Set later by running the kernel.
let out = unsafe { dev.alloc::<T>(el) }.w()?;
let params = (el, dims.len(), &ds, T::from_f64(self.0), src, &out);
// SAFETY: ffi.
unsafe { func.launch(cfg, params) }.w()?;
Ok(out)
}
}
struct Im2Col1D {
l_k: usize,
stride: usize,
dilation: usize,
padding: usize,
}
impl Im2Col1D {
fn l_out(&self, l: usize) -> usize {
(l + 2 * self.padding - self.dilation * (self.l_k - 1) - 1) / self.stride + 1
}
}
impl Map1 for Im2Col1D {
fn f<T: DeviceRepr + WithDType>(
&self,
src: &CudaSlice<T>,
dev: &CudaDevice,
layout: &Layout,
) -> Result<CudaSlice<T>> {
let shape = layout.shape();
let dims = shape.dims();
let l_out = self.l_out(dims[2]);
let dst_el = dims[0] * l_out * dims[1] * self.l_k;
let cfg = LaunchConfig::for_num_elems(dst_el as u32);
let ds = dev.htod_copy([dims, layout.stride()].concat()).w()?;
let src = &src.slice(layout.start_offset()..);
let func = dev.get_or_load_func(&kernel_name::<T>("im2col1d"), kernels::CONV)?;
// SAFETY: Set later by running the kernel.
let dst = unsafe { dev.alloc::<T>(dst_el) }.w()?;
let params = (
dst_el,
l_out,
self.l_k,
self.stride,
self.padding,
self.dilation,
&ds,
src,
&dst,
);
// SAFETY: ffi.
unsafe { func.launch(cfg, params) }.w()?;
Ok(dst)
}
}
#[allow(unused)]
struct Im2Col {
h_k: usize,
w_k: usize,
stride: usize,
dilation: usize,
padding: usize,
}
impl Im2Col {
#[allow(unused)]
fn hw_out(&self, h: usize, w: usize) -> (usize, usize) {
let h_out = (h + 2 * self.padding - self.dilation * (self.h_k - 1) - 1) / self.stride + 1;
let w_out = (w + 2 * self.padding - self.dilation * (self.w_k - 1) - 1) / self.stride + 1;
(h_out, w_out)
}
}
impl Map1 for Im2Col {
fn f<T: DeviceRepr + WithDType>(
&self,
src: &CudaSlice<T>,
dev: &CudaDevice,
layout: &Layout,
) -> Result<CudaSlice<T>> {
let shape = layout.shape();
let dims = shape.dims();
let (h_out, w_out) = self.hw_out(dims[2], dims[3]);
let dst_el = dims[0] * h_out * w_out * dims[1] * self.h_k * self.w_k;
let cfg = LaunchConfig::for_num_elems(dst_el as u32);
let ds = dev.htod_copy([dims, layout.stride()].concat()).w()?;
let src = &src.slice(layout.start_offset()..);
let func = dev.get_or_load_func(&kernel_name::<T>("im2col"), kernels::CONV)?;
// SAFETY: Set later by running the kernel.
let dst = unsafe { dev.alloc::<T>(dst_el) }.w()?;
let params = (
dst_el,
h_out,
w_out,
self.h_k,
self.w_k,
self.stride,
self.padding,
self.dilation,
&ds,
src,
&dst,
);
// SAFETY: ffi.
unsafe { func.launch(cfg, params) }.w()?;
Ok(dst)
}
}
struct Powf(f64);
impl Map1 for Powf {
fn f<T: DeviceRepr + WithDType>(
&self,
src: &CudaSlice<T>,
dev: &CudaDevice,
layout: &Layout,
) -> Result<CudaSlice<T>> {
let shape = layout.shape();
let dims = shape.dims();
let el = shape.elem_count();
let cfg = LaunchConfig::for_num_elems(el as u32);
let ds = SlicePtrOrNull::params_from_layout(dev, layout)?;
let src = &src.slice(layout.start_offset()..);
let func = dev.get_or_load_func(&kernel_name::<T>("upowf"), kernels::UNARY)?;
// SAFETY: Set later by running the kernel.
let out = unsafe { dev.alloc::<T>(el) }.w()?;
let params = (el, dims.len(), &ds, T::from_f64(self.0), src, &out);
// SAFETY: ffi.
unsafe { func.launch(cfg, params) }.w()?;
Ok(out)
}
}
struct FastReduce<'a>(&'a [usize], ReduceOp);
impl Map1Any for FastReduce<'_> {
fn f<T: DeviceRepr + WithDType + ValidAsZeroBits, W: Fn(CudaSlice<T>) -> S>(
&self,
src: &CudaSlice<T>,
dev: &CudaDevice,
layout: &Layout,
wrap: W,
) -> Result<S> {
let src_stride = layout.stride();
let src_dims = layout.shape().dims();
let src_el: usize = src_dims.iter().product();
// Source dims and strides with the sum dims at the end.
let mut dims = vec![];
let mut stride = vec![];
let mut dst_el: usize = 1;
for (dim_idx, &d) in src_dims.iter().enumerate() {
if !self.0.contains(&dim_idx) {
dst_el *= d;
dims.push(d);
stride.push(src_stride[dim_idx]);
}
}
for &dim_idx in self.0.iter() {
dims.push(src_dims[dim_idx]);
stride.push(src_stride[dim_idx]);
}
let el_to_sum_per_block = src_el / dst_el;
// The reduction loop requires the shared array to be properly initialized and for
// this we want the number of threads to be a power of two.
let block_dim = usize::min(1024, el_to_sum_per_block).next_power_of_two();
let cfg = LaunchConfig {
// TODO: Maybe use grid_y if the output is too large?
// TODO: Specialized implementation when reducing on no or all dimensions or when
// reducing only aggregate a small number of elements together.
grid_dim: (dst_el as u32, 1, 1),
block_dim: (block_dim as u32, 1, 1),
shared_mem_bytes: 0,
};
let ds = dev
.htod_copy([dims.as_slice(), stride.as_slice()].concat())
.w()?;
let src = &src.slice(layout.start_offset()..);
let (name, check_empty, return_index) = match self.1 {
ReduceOp::Sum => ("fast_sum", false, false),
ReduceOp::Min => ("fast_min", true, false),
ReduceOp::Max => ("fast_max", true, false),
ReduceOp::ArgMin => ("fast_argmin", true, true),
ReduceOp::ArgMax => ("fast_argmax", true, true),
};
if check_empty && layout.shape().elem_count() == 0 {
Err(crate::Error::EmptyTensor { op: "reduce" }.bt())?
}
let func = dev.get_or_load_func(&kernel_name::<T>(name), kernels::REDUCE)?;
if return_index {
// SAFETY: filled in by the follow up kernel.
let out = unsafe { dev.alloc::<u32>(dst_el) }.w()?;
let params = (src_el, el_to_sum_per_block, src_dims.len(), &ds, src, &out);
// SAFETY: ffi.
unsafe { func.launch(cfg, params) }.w()?;
Ok(S::U32(out))
} else {
// SAFETY: filled in by the follow up kernel.
let out = unsafe { dev.alloc::<T>(dst_el) }.w()?;
let params = (src_el, el_to_sum_per_block, src_dims.len(), &ds, src, &out);
// SAFETY: ffi.
unsafe { func.launch(cfg, params) }.w()?;
Ok(wrap(out))
}
}
}
impl<U: UnaryOpT> Map1 for U {
fn f<T: DeviceRepr + WithDType + ValidAsZeroBits>(
&self,
src: &CudaSlice<T>,
dev: &CudaDevice,
layout: &Layout,
) -> Result<CudaSlice<T>> {
let shape = layout.shape();
let dims = shape.dims();
let el_count = shape.elem_count();
let cfg = LaunchConfig::for_num_elems(el_count as u32);
let ds = SlicePtrOrNull::params_from_layout(dev, layout)?;
let src = &src.slice(layout.start_offset()..);
let func = dev.get_or_load_func(&kernel_name::<T>(U::KERNEL), kernels::UNARY)?;
// SAFETY: Set later by running the kernel.
let out = unsafe { dev.alloc::<T>(el_count) }.w()?;
let params = (el_count, dims.len(), &ds, src, &out);
// SAFETY: ffi.
unsafe { func.launch(cfg, params) }.w()?;
Ok(out)
}
}
struct IndexSelect<'a>(&'a CudaStorage, &'a Layout, usize);
impl Map1 for IndexSelect<'_> {
fn f<T: DeviceRepr + WithDType + ValidAsZeroBits>(
&self,
src: &CudaSlice<T>,
dev: &CudaDevice,
src_l: &Layout,
) -> Result<CudaSlice<T>> {
let ids_l = &self.1;
let (name, ids) = match &self.0.slice {
CudaStorageSlice::U32(slice) => {
("is_u32", *slice.slice(ids_l.start_offset()..).device_ptr())
}
CudaStorageSlice::U8(slice) => {
("is_u8", *slice.slice(ids_l.start_offset()..).device_ptr())
}
CudaStorageSlice::I64(slice) => {
("is_i64", *slice.slice(ids_l.start_offset()..).device_ptr())
}
_ => Err(CudaError::UnexpectedDType {
msg: "index_select ids should be u8 or u32",
expected: DType::U32,
got: self.0.dtype(),
})
.w()?,
};
let ids_shape = ids_l.shape();
let ids_dims = ids_shape.dims();
let ds = dev.htod_copy([ids_dims, ids_l.stride()].concat()).w()?;
let src = match src_l.contiguous_offsets() {
Some((o1, o2)) => src.slice(o1..o2),
None => Err(crate::Error::RequiresContiguous { op: "index-select" }.bt())?,
};
let left_size: usize = src_l.dims()[..self.2].iter().product();
let right_size: usize = src_l.dims()[self.2 + 1..].iter().product();
let src_dim_size = src_l.dims()[self.2];
let ids_dim_size = ids_shape.elem_count();
let dst_el = ids_shape.elem_count() * left_size * right_size;
let cfg = LaunchConfig::for_num_elems(dst_el as u32);
let func = dev.get_or_load_func(&kernel_name::<T>(name), kernels::INDEXING)?;
// SAFETY: Set later by running the kernel.
let out = unsafe { dev.alloc::<T>(dst_el) }.w()?;
let params = (
dst_el,
ids_dims.len(),
&ds,
ids,
&src,
&out,
left_size,
src_dim_size,
ids_dim_size,
right_size,
);
// SAFETY: ffi.
unsafe { func.launch(cfg, params) }.w()?;
Ok(out)
}
}
struct Gather<'a>(&'a CudaStorage, &'a Layout, usize);
impl Map1 for Gather<'_> {
fn f<T: DeviceRepr + WithDType + ValidAsZeroBits>(
&self,
src: &CudaSlice<T>,
dev: &CudaDevice,
src_l: &Layout,
) -> Result<CudaSlice<T>> {
let ids = &self.0;
let ids_l = &self.1;
let dim = self.2;
let (ids_o1, ids_o2) = match ids_l.contiguous_offsets() {
Some(o12) => o12,
None => Err(crate::Error::RequiresContiguous { op: "gather" }.bt())?,
};
let (name, ids) = match &ids.slice {
CudaStorageSlice::U32(slice) => {
("gather_u32", *slice.slice(ids_o1..ids_o2).device_ptr())
}
CudaStorageSlice::U8(slice) => ("gather_u8", *slice.slice(ids_o1..ids_o2).device_ptr()),
CudaStorageSlice::I64(slice) => {
("gather_i64", *slice.slice(ids_o1..ids_o2).device_ptr())
}
_ => Err(CudaError::UnexpectedDType {
msg: "gather ids should be u8/u32/i64",
expected: DType::U32,
got: ids.dtype(),
})?,
};
let el = ids_l.shape().elem_count();
let cfg = LaunchConfig::for_num_elems(el as u32);
let src = match src_l.contiguous_offsets() {
Some((o1, o2)) => src.slice(o1..o2),
None => Err(crate::Error::RequiresContiguous { op: "gather" }.bt())?,
};
let left_sz: usize = src_l.dims()[..dim].iter().product();
let right_sz: usize = src_l.dims()[dim + 1..].iter().product();
let src_dim_sz = src_l.dims()[dim];
let ids_dim_sz = ids_l.dims()[dim];
let func = dev.get_or_load_func(&kernel_name::<T>(name), kernels::INDEXING)?;
// SAFETY: Set later by running the kernel.
let out = unsafe { dev.alloc::<T>(el) }.w()?;
let params = (
el, ids, &src, &out, left_sz, src_dim_sz, ids_dim_sz, right_sz,
);
// SAFETY: ffi.
unsafe { func.launch(cfg, params) }.w()?;
Ok(out)
}
}
struct IndexAdd<'a>(&'a CudaStorage, &'a Layout, usize);
impl Map2InPlace for IndexAdd<'_> {
fn f<T: DeviceRepr + WithDType + ValidAsZeroBits>(
&self,
dst: &mut CudaSlice<T>,
dst_shape: &Shape,
src: &CudaSlice<T>,
src_l: &Layout,
dev: &CudaDevice,
) -> Result<()> {
let ids = &self.0;
let ids_l = &self.1;
let dim = self.2;
let (ids_o1, ids_o2) = match ids_l.contiguous_offsets() {
Some(o12) => o12,
None => Err(crate::Error::RequiresContiguous { op: "index-add" }.bt())?,
};
let (name, ids) = match &ids.slice {
CudaStorageSlice::U32(slice) => ("ia_u32", *slice.slice(ids_o1..ids_o2).device_ptr()),
CudaStorageSlice::I64(slice) => ("ia_i64", *slice.slice(ids_o1..ids_o2).device_ptr()),
CudaStorageSlice::U8(slice) => ("ia_u8", *slice.slice(ids_o1..ids_o2).device_ptr()),
_ => Err(CudaError::UnexpectedDType {
msg: "index-add ids should be u8/u32/i64",
expected: DType::U32,
got: ids.dtype(),
})?,
};
let src = match src_l.contiguous_offsets() {
Some((o1, o2)) => src.slice(o1..o2),
None => Err(crate::Error::RequiresContiguous { op: "index-add" }.bt())?,
};
let left_sz: usize = src_l.dims()[..dim].iter().product();
let right_sz: usize = src_l.dims()[dim + 1..].iter().product();
let src_dim_sz = src_l.dims()[dim];
let dst_dim_sz = dst_shape.dims()[dim];
let ids_dim_sz = ids_l.dims()[0];
let cfg = LaunchConfig::for_num_elems((left_sz * right_sz) as u32);
let func = dev.get_or_load_func(&kernel_name::<T>(name), kernels::INDEXING)?;
// SAFETY: Set later by running the kernel.
let params = (
ids, ids_dim_sz, &src, dst, left_sz, src_dim_sz, dst_dim_sz, right_sz,
);
// SAFETY: ffi.
unsafe { func.launch(cfg, params) }.w()?;
Ok(())
}
}
struct ScatterAdd<'a>(&'a CudaStorage, &'a Layout, usize);
impl Map2InPlace for ScatterAdd<'_> {
fn f<T: DeviceRepr + WithDType + ValidAsZeroBits>(
&self,
dst: &mut CudaSlice<T>,
dst_shape: &Shape,
src: &CudaSlice<T>,
src_l: &Layout,
dev: &CudaDevice,
) -> Result<()> {
let ids = &self.0;
let ids_l = &self.1;
let dim = self.2;
let (ids_o1, ids_o2) = match ids_l.contiguous_offsets() {
Some(o12) => o12,
None => Err(crate::Error::RequiresContiguous { op: "scatter-add" }.bt())?,
};
let (name, ids) = match &ids.slice {
CudaStorageSlice::U32(slice) => ("sa_u32", *slice.slice(ids_o1..ids_o2).device_ptr()),
CudaStorageSlice::I64(slice) => ("sa_i64", *slice.slice(ids_o1..ids_o2).device_ptr()),
CudaStorageSlice::U8(slice) => ("sa_u8", *slice.slice(ids_o1..ids_o2).device_ptr()),
_ => Err(CudaError::UnexpectedDType {
msg: "scatter-add ids should be u8/u32/i64",
expected: DType::U32,
got: ids.dtype(),
})?,
};
let src = match src_l.contiguous_offsets() {
Some((o1, o2)) => src.slice(o1..o2),
None => Err(crate::Error::RequiresContiguous { op: "scatter-add" }.bt())?,
};
let left_sz: usize = src_l.dims()[..dim].iter().product();
let right_sz: usize = src_l.dims()[dim + 1..].iter().product();
let src_dim_sz = src_l.dims()[dim];
let dst_dim_sz = dst_shape.dims()[dim];
let cfg = LaunchConfig::for_num_elems((left_sz * right_sz) as u32);
let func = dev.get_or_load_func(&kernel_name::<T>(name), kernels::INDEXING)?;
// SAFETY: Set later by running the kernel.
let params = (ids, &src, dst, left_sz, src_dim_sz, dst_dim_sz, right_sz);
// SAFETY: ffi.
unsafe { func.launch(cfg, params) }.w()?;
Ok(())
}
}
struct Conv1D<'a>(&'a crate::conv::ParamsConv1D);
impl Map2 for Conv1D<'_> {
fn f<T: DeviceRepr + WithDType + ValidAsZeroBits>(
&self,
inp: &CudaSlice<T>,
inp_l: &Layout,
k: &CudaSlice<T>,
k_l: &Layout,
dev: &CudaDevice,
) -> Result<CudaSlice<T>> {
// Kernel shape: (c_out, c_in_k, k_size)
// Input shape: (b_size, c_in, l_in) or (c_in, l_in)
let p = &self.0;
let inp = &inp.slice(inp_l.start_offset()..);
let k = &k.slice(k_l.start_offset()..);
let shape = inp_l.shape();
let dims = shape.dims();
let el = shape.elem_count();
let l_out = p.l_out();
let dst_el = p.c_out * l_out * p.b_size;
let cfg = LaunchConfig::for_num_elems(dst_el as u32);
let func = dev.get_or_load_func(&kernel_name::<T>("conv1d"), kernels::CONV)?;
// SAFETY: Set later by running the kernel.
let out = unsafe { dev.alloc::<T>(dst_el) }.w()?;
let ds = if dims.len() == 3 {
[dims, inp_l.stride(), k_l.dims(), k_l.stride()].concat()
} else if dims.len() == 2 {
[&[1], dims, &[1], inp_l.stride(), k_l.dims(), k_l.stride()].concat()
} else {
crate::bail!("unexpected input shape for conv1d {dims:?}")
};
let ds = dev.htod_copy(ds).w()?;
let params = (
el, l_out, p.stride, p.padding, p.dilation, &ds, inp, k, &out,
);
// SAFETY: ffi.
unsafe { func.launch(cfg, params) }.w()?;
Ok(out)
}
}
struct Conv2D<'a>(&'a crate::conv::ParamsConv2D);
impl Map2 for Conv2D<'_> {
fn f<T: DeviceRepr + WithDType + ValidAsZeroBits>(
&self,
inp: &CudaSlice<T>,
inp_l: &Layout,
k: &CudaSlice<T>,
k_l: &Layout,
dev: &CudaDevice,
) -> Result<CudaSlice<T>> {
// Kernel shape: (c_out, c_in_k, h_k, w_k)
// Input shape: (b_size, c_in, h_in, w_in)
let p = &self.0;
let (out_w, out_h) = (p.out_w(), p.out_h());
let dst_el = p.c_out * out_w * out_h * p.b_size;
let inp = &inp.slice(inp_l.start_offset()..);
let k = &k.slice(k_l.start_offset()..);
let shape = inp_l.shape();
let dims = shape.dims();
let el = shape.elem_count();
// SAFETY: Set later by running the kernel.
let out = unsafe { dev.alloc::<T>(dst_el) }.w()?;
let cfg = LaunchConfig::for_num_elems(dst_el as u32);
let func = dev.get_or_load_func(&kernel_name::<T>("conv2d"), kernels::CONV)?;
let ds = if dims.len() == 4 {
[dims, inp_l.stride(), k_l.dims(), k_l.stride()].concat()
} else {
crate::bail!("unexpected input shape for conv2d {dims:?}")
};
let ds = dev.htod_copy(ds).w()?;
let params = (
el, out_w, out_h, p.stride, p.padding, p.dilation, &ds, inp, k, &out,
);
// SAFETY: ffi.
unsafe { func.launch(cfg, params) }.w()?;
Ok(out)
}
}
struct Col2Im1D {
stride: usize,
}
impl Map1 for Col2Im1D {
fn f<T: DeviceRepr + WithDType + ValidAsZeroBits>(
&self,
col: &CudaSlice<T>,
dev: &CudaDevice,
l: &Layout,
) -> Result<CudaSlice<T>> {
let (b_size, l_in, c_out, k_size) = l.shape().dims4()?;
let stride = self.stride;
let l_out = (l_in - 1) * stride + k_size;
let dst_el = b_size * c_out * l_out;
let mut im = unsafe { dev.alloc::<T>(dst_el) }.w()?;
let cfg = LaunchConfig::for_num_elems(dst_el as u32);
let params = (dst_el, l_out, l_in, c_out, k_size, stride, col, &mut im);
let func = dev.get_or_load_func(&kernel_name::<T>("col2im1d"), kernels::CONV)?;
unsafe { func.launch(cfg, params) }.w()?;
Ok(im)
}
}
struct ConvTranspose1D<'a>(&'a crate::conv::ParamsConvTranspose1D);
impl Map2 for ConvTranspose1D<'_> {
fn f<T: DeviceRepr + WithDType + ValidAsZeroBits>(
&self,
inp: &CudaSlice<T>,
inp_l: &Layout,
k: &CudaSlice<T>,
k_l: &Layout,
dev: &CudaDevice,
) -> Result<CudaSlice<T>> {
// Kernel shape: (c_in_k, c_out, l_k)
// Input shape: (b_size, c_in, l_in)
let p = &self.0;
let l_out = p.l_out();
let dst_el = p.c_out * l_out * p.b_size;
let inp = &inp.slice(inp_l.start_offset()..);
let k = &k.slice(k_l.start_offset()..);
let shape = inp_l.shape();
let dims = shape.dims();
let el = shape.elem_count();
// SAFETY: Set later by running the kernel.
let out = unsafe { dev.alloc::<T>(dst_el) }.w()?;
let cfg = LaunchConfig::for_num_elems(dst_el as u32);
let func = dev.get_or_load_func(&kernel_name::<T>("conv_transpose1d"), kernels::CONV)?;
let ds = if dims.len() == 3 {
[dims, inp_l.stride(), k_l.dims(), k_l.stride()].concat()
} else {
crate::bail!("unexpected input shape for conv_transpose1d {dims:?}")
};
let ds = dev.htod_copy(ds).w()?;
let params = (
el,
l_out,
p.stride,
p.padding,
p.output_padding,
p.dilation,
&ds,
inp,
k,
&out,
);
// SAFETY: ffi.
unsafe { func.launch(cfg, params) }.w()?;
Ok(out)
}
}
struct ConvTranspose2D<'a>(&'a crate::conv::ParamsConvTranspose2D);
impl Map2 for ConvTranspose2D<'_> {
fn f<T: DeviceRepr + WithDType + ValidAsZeroBits>(
&self,
inp: &CudaSlice<T>,
inp_l: &Layout,
k: &CudaSlice<T>,
k_l: &Layout,
dev: &CudaDevice,
) -> Result<CudaSlice<T>> {
// Kernel shape: (c_in_k, c_out, h_k, w_k)
// Input shape: (b_size, c_in, h_in, w_in)
let p = &self.0;
let (out_w, out_h) = (p.out_w(), p.out_h());
let dst_el = p.c_out * out_w * out_h * p.b_size;
let inp = &inp.slice(inp_l.start_offset()..);
let k = &k.slice(k_l.start_offset()..);
let shape = inp_l.shape();
let dims = shape.dims();
let el = shape.elem_count();
// SAFETY: Set later by running the kernel.
let out = unsafe { dev.alloc::<T>(dst_el) }.w()?;
let cfg = LaunchConfig::for_num_elems(dst_el as u32);
let func = dev.get_or_load_func(&kernel_name::<T>("conv_transpose2d"), kernels::CONV)?;
let ds = if dims.len() == 4 {
[dims, inp_l.stride(), k_l.dims(), k_l.stride()].concat()
} else {
crate::bail!("unexpected input shape for conv_transpose2d {dims:?}")
};
let ds = dev.htod_copy(ds).w()?;
let params = (
el,
out_w,
out_h,
p.stride,
p.padding,
p.output_padding,
p.dilation,
&ds,
inp,
k,
&out,
);
// SAFETY: ffi.
unsafe { func.launch(cfg, params) }.w()?;
Ok(out)
}
}
enum PoolOp {
Max,
Avg,
}
struct Pool2D {
w_k: usize,
h_k: usize,
w_stride: usize,
h_stride: usize,
op: PoolOp,
}
impl Map1 for Pool2D {
fn f<T: DeviceRepr + WithDType + ValidAsZeroBits>(
&self,
inp: &CudaSlice<T>,
dev: &CudaDevice,
inp_l: &Layout,
) -> Result<CudaSlice<T>> {
// Input shape: (b_size, c, h, w)
let inp = &inp.slice(inp_l.start_offset()..);
let shape = inp_l.shape();
let dims = shape.dims();
let ds = if dims.len() == 4 {
[dims, inp_l.stride()].concat()
} else {
crate::bail!("unexpected input shape for pool {dims:?}")
};
let el = shape.elem_count();
let out_w = (dims[2] - self.w_k) / self.w_stride + 1;
let out_h = (dims[3] - self.h_k) / self.h_stride + 1;
let dst_el = out_w * out_h * dims[0] * dims[1];
let cfg = LaunchConfig::for_num_elems(dst_el as u32);
let kname = match self.op {
PoolOp::Max => "max_pool2d",
PoolOp::Avg => "avg_pool2d",
};
let func = dev.get_or_load_func(&kernel_name::<T>(kname), kernels::CONV)?;
// SAFETY: Set later by running the kernel.
let out = unsafe { dev.alloc::<T>(dst_el) }.w()?;
let ds = dev.htod_copy(ds).w()?;
let params = (
el,
self.w_k,
self.h_k,
self.w_stride,
self.h_stride,
&ds,
inp,
&out,
);
// SAFETY: ffi.
unsafe { func.launch(cfg, params) }.w()?;
Ok(out)
}
}
struct UpsampleNearest2D(usize, usize);
impl Map1 for UpsampleNearest2D {
fn f<T: DeviceRepr + WithDType + ValidAsZeroBits>(
&self,
inp: &CudaSlice<T>,
dev: &CudaDevice,
inp_l: &Layout,
) -> Result<CudaSlice<T>> {
// Input shape: (b_size, c, h, w)
let inp = &inp.slice(inp_l.start_offset()..);
let shape = inp_l.shape();
let dims = shape.dims();
let ds = if dims.len() == 4 {
[dims, inp_l.stride()].concat()
} else {
crate::bail!("unexpected input shape for upsample {dims:?}")
};
let (out_w, out_h) = (self.0, self.1);
let dst_el = out_w * out_h * dims[0] * dims[1];
let cfg = LaunchConfig::for_num_elems(dst_el as u32);
let func = dev.get_or_load_func(&kernel_name::<T>("upsample_nearest2d"), kernels::CONV)?;
// SAFETY: Set later by running the kernel.
let out = unsafe { dev.alloc::<T>(dst_el) }.w()?;
let ds = dev.htod_copy(ds).w()?;
let scale_w = dims[2] as f64 / out_w as f64;
let scale_h = dims[3] as f64 / out_h as f64;
let params = (out_w, out_h, scale_w, scale_h, &ds, inp, &out);
// SAFETY: ffi.
unsafe { func.launch(cfg, params) }.w()?;
Ok(out)
}
}
struct WhereCond<'a>(&'a CudaStorage, &'a Layout);
impl Map2 for WhereCond<'_> {
fn f<T: DeviceRepr + WithDType + ValidAsZeroBits>(
&self,
t: &CudaSlice<T>,
layout_t: &Layout,
f: &CudaSlice<T>,
layout_f: &Layout,
dev: &CudaDevice,
) -> Result<CudaSlice<T>> {
let ids_l = &self.1;
let (ids, name) = match &self.0.slice {
CudaStorageSlice::U8(slice) => {
let ptr = *slice.slice(ids_l.start_offset()..).device_ptr();
(ptr, "where_u8")
}
CudaStorageSlice::U32(slice) => {
let ptr = *slice.slice(ids_l.start_offset()..).device_ptr();
(ptr, "where_u32")
}
CudaStorageSlice::I64(slice) => {
let ptr = *slice.slice(ids_l.start_offset()..).device_ptr();
(ptr, "where_i64")
}
_ => Err(CudaError::UnexpectedDType {
msg: "where conditions should be u8/u32/i64",
expected: DType::U32,
got: self.0.dtype(),
})
.w()?,
};
let shape = ids_l.shape();
let dims = shape.dims();
let el = shape.elem_count();
let cfg = LaunchConfig::for_num_elems(el as u32);
let ds = dev
.htod_copy([dims, ids_l.stride(), layout_t.stride(), layout_f.stride()].concat())
.w()?;
let t = &t.slice(layout_t.start_offset()..);
let f = &f.slice(layout_f.start_offset()..);
let func = dev.get_or_load_func(&kernel_name::<T>(name), kernels::TERNARY)?;
// SAFETY: Set later by running the kernel.
let out = unsafe { dev.alloc::<T>(el) }.w()?;
let params = (el, dims.len(), &ds, ids, t, f, &out);
// SAFETY: ffi
unsafe { func.launch(cfg, params) }.w()?;
Ok(out)
}
}
impl<U: crate::op::BinaryOpT> Map2 for U {
fn f<T: DeviceRepr + WithDType + ValidAsZeroBits>(
&self,
lhs: &CudaSlice<T>,
lhs_l: &Layout,
rhs: &CudaSlice<T>,
rhs_l: &Layout,
dev: &CudaDevice,
) -> Result<CudaSlice<T>> {
let shape = lhs_l.shape();
let dims = shape.dims();
let elem_count = shape.elem_count();
let cfg = LaunchConfig::for_num_elems(elem_count as u32);
let dims_and_strides = if lhs_l.is_contiguous() && rhs_l.is_contiguous() {
SlicePtrOrNull::Null
} else {
SlicePtrOrNull::Ptr(
dev.htod_copy([dims, lhs_l.stride(), rhs_l.stride()].concat())
.w()?,
)
};
let lhs = &lhs.slice(lhs_l.start_offset()..);
let rhs = &rhs.slice(rhs_l.start_offset()..);
let func = dev.get_or_load_func(&kernel_name::<T>(U::KERNEL), kernels::BINARY)?;
// SAFETY: Set later by running the kernel.
let out = unsafe { dev.alloc::<T>(elem_count) }.w()?;
let params = (elem_count, dims.len(), &dims_and_strides, lhs, rhs, &out);
// SAFETY: ffi
unsafe { func.launch(cfg, params) }.w()?;
Ok(out)
}
}
struct Cmp(CmpOp);
impl Map2Any for Cmp {
fn f<T: DeviceRepr + WithDType + ValidAsZeroBits>(
&self,
lhs: &CudaSlice<T>,
lhs_l: &Layout,
rhs: &CudaSlice<T>,
rhs_l: &Layout,
dev: &CudaDevice,
) -> Result<S> {
let shape = lhs_l.shape();
let dims = shape.dims();
let elem_count = shape.elem_count();
let cfg = LaunchConfig::for_num_elems(elem_count as u32);
let dims_and_strides = if lhs_l.is_contiguous() && rhs_l.is_contiguous() {
SlicePtrOrNull::Null
} else {
SlicePtrOrNull::Ptr(
dev.htod_copy([dims, lhs_l.stride(), rhs_l.stride()].concat())
.w()?,
)
};
let lhs = &lhs.slice(lhs_l.start_offset()..);
let rhs = &rhs.slice(rhs_l.start_offset()..);
let name = match self.0 {
CmpOp::Eq => "eq",
CmpOp::Ne => "ne",
CmpOp::Lt => "lt",
CmpOp::Le => "le",
CmpOp::Gt => "gt",
CmpOp::Ge => "ge",
};
let func = dev.get_or_load_func(&kernel_name::<T>(name), kernels::BINARY)?;
// SAFETY: Set later by running the kernel.
let out = unsafe { dev.alloc::<u8>(elem_count) }.w()?;
let params = (elem_count, dims.len(), &dims_and_strides, lhs, rhs, &out);
// SAFETY: ffi
unsafe { func.launch(cfg, params) }.w()?;
Ok(S::U8(out))
}
}
fn slice_src_and_dst<'a, T>(
src: &'a CudaSlice<T>,
src_l: &Layout,
dst: &'a mut CudaSlice<T>,
dst_offset: usize,
) -> (
cudarc::driver::CudaView<'a, T>,
cudarc::driver::CudaViewMut<'a, T>,
) {
let src_offset = src_l.start_offset();
let to_copy = dst
.len()
.saturating_sub(dst_offset)
.min(src.len().saturating_sub(src_offset));
let src = src.slice(src_offset..src_offset + to_copy);
let dst = dst.slice_mut(dst_offset..dst_offset + to_copy);
(src, dst)
}
#[derive(Debug)]
pub struct CudaStorage {
pub slice: CudaStorageSlice,
pub device: CudaDevice,
}
pub trait CudaDType: Sized {
fn as_cuda_slice(s: &CudaStorage) -> Result<&CudaSlice<Self>>;
fn wrap_cuda_slice(s: CudaSlice<Self>, dev: CudaDevice) -> CudaStorage;
}
macro_rules! cuda_dtype {
($ty:ty, $dtype:ident) => {
impl CudaDType for $ty {
fn as_cuda_slice(s: &CudaStorage) -> Result<&CudaSlice<Self>> {
match &s.slice {
CudaStorageSlice::$dtype(data) => Ok(&data),
_ => Err(crate::Error::UnexpectedDType {
expected: DType::$dtype,
got: s.dtype(),
msg: "unexpected dtype",
}
.bt()),
}
}
fn wrap_cuda_slice(slice: CudaSlice<Self>, device: CudaDevice) -> CudaStorage {
let slice = CudaStorageSlice::$dtype(slice);
CudaStorage { slice, device }
}
}
};
}
cuda_dtype!(u8, U8);
cuda_dtype!(u32, U32);
cuda_dtype!(i64, I64);
cuda_dtype!(f16, F16);
cuda_dtype!(bf16, BF16);
cuda_dtype!(f32, F32);
cuda_dtype!(f64, F64);
impl CudaStorage {
pub fn wrap_cuda_slice<T: CudaDType>(slice: CudaSlice<T>, device: CudaDevice) -> CudaStorage {
T::wrap_cuda_slice(slice, device)
}
pub fn as_cuda_slice<T: CudaDType>(&self) -> Result<&CudaSlice<T>> {
T::as_cuda_slice(self)
}
}
fn gemm_config<T>(
alpha: T,
beta: T,
(b, m, n, k): (usize, usize, usize, usize),
lhs_l: &Layout,
rhs_l: &Layout,
) -> Result<StridedBatchedConfig<T>> {
// https://docs.nvidia.com/cuda/cublas/index.html#cublas-t-gemm
use cudarc::cublas::sys::cublasOperation_t;
let lhs_stride = lhs_l.stride();
let rhs_stride = rhs_l.stride();
let rhs_m1 = rhs_stride[rhs_stride.len() - 1];
let rhs_m2 = rhs_stride[rhs_stride.len() - 2];
let lhs_m1 = lhs_stride[lhs_stride.len() - 1];
let lhs_m2 = lhs_stride[lhs_stride.len() - 2];
// The a tensor has dims batching, k, n (rhs)
// We also allow for the case where the stride on the minor dimension is not as expected but
// there is a single element.
let (lda, transa) = if (rhs_m1 == 1 || n == 1) && (rhs_m2 == n || k == 1) {
(n as i32, cublasOperation_t::CUBLAS_OP_N)
} else if (rhs_m1 == k || n == 1) && (rhs_m2 == 1 || k == 1) {
(k as i32, cublasOperation_t::CUBLAS_OP_T)
} else {
Err(CudaError::MatMulNonContiguous {
lhs_stride: lhs_l.clone(),
rhs_stride: rhs_l.clone(),
mnk: (m, n, k),
})?
};
// The b tensor has dims batching, m, k (lhs)
// We also allow for the case where the stride on the minor dimension is not as expected but
// there is a single element.
let (ldb, transb) = if (lhs_m1 == 1 || k == 1) && (lhs_m2 == k || m == 1) {
(k as i32, cublasOperation_t::CUBLAS_OP_N)
} else if (lhs_m1 == m || k == 1) && (lhs_m2 == 1 || m == 1) {
(m as i32, cublasOperation_t::CUBLAS_OP_T)
} else {
Err(CudaError::MatMulNonContiguous {
lhs_stride: lhs_l.clone(),
rhs_stride: rhs_l.clone(),
mnk: (m, n, k),
})?
};
// The setup below was copied from:
// https://github.com/lebedov/scikit-cuda/blob/7e7300474286019c917a6c8a4bca59405c64fbce/tests/test_cublas.py#L531
let gemm = GemmConfig {
alpha,
beta,
m: n as i32,
n: m as i32,
k: k as i32,
lda,
ldb,
ldc: n as i32,
transa,
transb,
};
let stride_b: usize = match lhs_stride[..lhs_stride.len() - 2] {
[s1, stride] if s1 == stride * lhs_l.dims()[1] => stride,
[_, stride] if lhs_l.dims()[0] == 1 => stride,
[stride, _] if lhs_l.dims()[1] == 1 => stride,
[stride] => stride,
[] => m * k,
_ => Err(CudaError::MatMulNonContiguous {
lhs_stride: lhs_l.clone(),
rhs_stride: rhs_l.clone(),
mnk: (m, n, k),
})?,
};
let stride_a: usize = match rhs_stride[..rhs_stride.len() - 2] {
[s1, stride] if s1 == stride * rhs_l.dims()[1] => stride,
[_, stride] if rhs_l.dims()[0] == 1 => stride,
[stride, _] if rhs_l.dims()[1] == 1 => stride,
[stride] => stride,
[] => n * k,
_ => Err(CudaError::MatMulNonContiguous {
lhs_stride: lhs_l.clone(),
rhs_stride: rhs_l.clone(),
mnk: (m, n, k),
})?,
};
Ok(StridedBatchedConfig {
batch_size: b as i32,
gemm,
stride_a: stride_a as i64,
stride_b: stride_b as i64,
stride_c: (m * n) as i64,
})
}
impl BackendStorage for CudaStorage {
type Device = CudaDevice;
fn try_clone(&self, layout: &Layout) -> Result<Self> {
let slice = Clone.map(&self.slice, self.device(), layout)?;
let device = self.device.clone();
Ok(Self { slice, device })
}
fn dtype(&self) -> DType {
match self.slice {
CudaStorageSlice::U8(_) => DType::U8,
CudaStorageSlice::U32(_) => DType::U32,
CudaStorageSlice::I64(_) => DType::I64,
CudaStorageSlice::BF16(_) => DType::BF16,
CudaStorageSlice::F16(_) => DType::F16,
CudaStorageSlice::F32(_) => DType::F32,
CudaStorageSlice::F64(_) => DType::F64,
}
}
fn device(&self) -> &CudaDevice {
&self.device
}
fn to_dtype(&self, layout: &Layout, dtype: DType) -> Result<Self> {
let shape = layout.shape();
let dims = shape.dims();
let el = shape.elem_count();
let cfg = LaunchConfig::for_num_elems(el as u32);
let dev = self.device();
let ds = SlicePtrOrNull::params_from_layout(dev, layout)?;
let start_o = layout.start_offset();
// This returns an i64 rather than a &i64, this is useful to get around some temporary
// lifetime issue and is safe as long as self.slice does not go out of scope before inp
// is used.
let inp = match &self.slice {
CudaStorageSlice::U8(inp) => *inp.slice(start_o..).device_ptr(),
CudaStorageSlice::U32(inp) => *inp.slice(start_o..).device_ptr(),
CudaStorageSlice::I64(inp) => *inp.slice(start_o..).device_ptr(),
CudaStorageSlice::BF16(inp) => *inp.slice(start_o..).device_ptr(),
CudaStorageSlice::F16(inp) => *inp.slice(start_o..).device_ptr(),
CudaStorageSlice::F32(inp) => *inp.slice(start_o..).device_ptr(),
CudaStorageSlice::F64(inp) => *inp.slice(start_o..).device_ptr(),
};
let inp = &inp;
let kernel_name = format!("cast_{}_{}", self.dtype().as_str(), dtype.as_str());
let func = dev.get_or_load_func(&kernel_name, kernels::CAST)?;
let slice = match dtype {
DType::U8 => {
let out = unsafe { dev.alloc::<u8>(el) }.w()?;
let params = (el, dims.len(), &ds, *inp, &out);
unsafe { func.launch(cfg, params) }.w()?;
CudaStorageSlice::U8(out)
}
DType::U32 => {
let out = unsafe { dev.alloc::<u32>(el) }.w()?;
let params = (el, dims.len(), &ds, *inp, &out);
unsafe { func.launch(cfg, params) }.w()?;
CudaStorageSlice::U32(out)
}
DType::I64 => {
let out = unsafe { dev.alloc::<i64>(el) }.w()?;
let params = (el, dims.len(), &ds, *inp, &out);
unsafe { func.launch(cfg, params) }.w()?;
CudaStorageSlice::I64(out)
}
DType::BF16 => {
let out = unsafe { dev.alloc::<bf16>(el) }.w()?;
let params = (el, dims.len(), &ds, *inp, &out);
unsafe { func.launch(cfg, params) }.w()?;
CudaStorageSlice::BF16(out)
}
DType::F16 => {
let out = unsafe { dev.alloc::<f16>(el) }.w()?;
let params = (el, dims.len(), &ds, *inp, &out);
unsafe { func.launch(cfg, params) }.w()?;
CudaStorageSlice::F16(out)
}
DType::F32 => {
let out = unsafe { dev.alloc::<f32>(el) }.w()?;
let params = (el, dims.len(), &ds, *inp, &out);
unsafe { func.launch(cfg, params) }.w()?;
CudaStorageSlice::F32(out)
}
DType::F64 => {
let out = unsafe { dev.alloc::<f64>(el) }.w()?;
let params = (el, dims.len(), &ds, *inp, &out);
unsafe { func.launch(cfg, params) }.w()?;
CudaStorageSlice::F64(out)
}
};
Ok(Self {
slice,
device: dev.clone(),
})
}
fn affine(&self, layout: &Layout, mul: f64, add: f64) -> Result<Self> {
let device = self.device().clone();
let slice = Affine(mul, add).map(&self.slice, &device, layout)?;
Ok(Self { slice, device })
}
fn powf(&self, layout: &Layout, e: f64) -> Result<Self> {
let device = self.device().clone();
let slice = Powf(e).map(&self.slice, &device, layout)?;
Ok(Self { slice, device })
}
fn elu(&self, layout: &Layout, alpha: f64) -> Result<Self> {
let device = self.device().clone();
let slice = Elu(alpha).map(&self.slice, &device, layout)?;
Ok(Self { slice, device })
}
fn reduce_op(&self, op: ReduceOp, layout: &Layout, sum_dims: &[usize]) -> Result<Self> {
let device = self.device().clone();
let slice = FastReduce(sum_dims, op).map(&self.slice, &device, layout)?;
Ok(Self { slice, device })
}
fn cmp(&self, op: CmpOp, rhs: &Self, lhs_l: &Layout, rhs_l: &Layout) -> Result<Self> {
let device = self.device().clone();
let slice = Cmp(op).map(&self.slice, lhs_l, &rhs.slice, rhs_l, &device)?;
Ok(Self { slice, device })
}
fn unary_impl<U: UnaryOpT>(&self, layout: &Layout) -> Result<Self> {
let device = self.device().clone();
let slice = U::V.map(&self.slice, &device, layout)?;
Ok(Self { slice, device })
}
fn binary_impl<B: BinaryOpT>(
&self,
rhs: &Self,
lhs_l: &Layout,
rhs_l: &Layout,
) -> Result<Self> {
let device = self.device().clone();
let slice = B::V.map(&self.slice, lhs_l, &rhs.slice, rhs_l, &device)?;
Ok(Self { slice, device })
}
fn to_cpu_storage(&self) -> Result<CpuStorage> {
match &self.slice {
CudaStorageSlice::U8(slice) => {
let dev = slice.device();
let cpu_storage = dev.dtoh_sync_copy(slice).w()?;
Ok(CpuStorage::U8(cpu_storage))
}
CudaStorageSlice::U32(slice) => {
let dev = slice.device();
let cpu_storage = dev.dtoh_sync_copy(slice).w()?;
Ok(CpuStorage::U32(cpu_storage))
}
CudaStorageSlice::I64(slice) => {
let dev = slice.device();
let cpu_storage = dev.dtoh_sync_copy(slice).w()?;
Ok(CpuStorage::I64(cpu_storage))
}
CudaStorageSlice::BF16(slice) => {
let dev = slice.device();
let cpu_storage = dev.dtoh_sync_copy(slice).w()?;
Ok(CpuStorage::BF16(cpu_storage))
}
CudaStorageSlice::F16(slice) => {
let dev = slice.device();
let cpu_storage = dev.dtoh_sync_copy(slice).w()?;
Ok(CpuStorage::F16(cpu_storage))
}
CudaStorageSlice::F32(slice) => {
let dev = slice.device();
let cpu_storage = dev.dtoh_sync_copy(slice).w()?;
Ok(CpuStorage::F32(cpu_storage))
}
CudaStorageSlice::F64(slice) => {
let dev = slice.device();
let cpu_storage = dev.dtoh_sync_copy(slice).w()?;
Ok(CpuStorage::F64(cpu_storage))
}
}
}
fn where_cond(
&self,
layout: &Layout,
t: &Self,
t_l: &Layout,
f: &Self,
f_l: &Layout,
) -> Result<Self> {
let device = self.device().clone();
let slice = WhereCond(self, layout).map(&t.slice, t_l, &f.slice, f_l, &device)?;
Ok(Self { slice, device })
}
fn conv1d(
&self,
l: &Layout,
kernel: &Self,
kernel_l: &Layout,
params: &crate::conv::ParamsConv1D,
) -> Result<Self> {
const USE_IM2COL_CONV1D: bool = true;
let device = self.device().clone();
if !USE_IM2COL_CONV1D {
let slice = Conv1D(params).map(&self.slice, l, &kernel.slice, kernel_l, &device)?;
return Ok(Self { slice, device });
}
let col = Im2Col1D {
l_k: params.k_size,
stride: params.stride,
dilation: params.dilation,
padding: params.padding,
}
.map(&self.slice, &device, l)?;
let col = Self { slice: col, device };
let l_out = params.l_out();
let b = params.b_size;
let n = params.c_out;
let k = params.k_size * params.c_in;
let m = l_out;
let col_l = Layout::contiguous((b, m, k));
let res = if kernel_l.is_contiguous() {
let kernel_l = Layout::contiguous_with_offset((1, n, k), kernel_l.start_offset())
.transpose(1, 2)?
.broadcast_as((b, k, n))?;
col.matmul(kernel, (b, m, n, k), &col_l, &kernel_l)?
} else {
// Make the kernel contiguous if not already the case.
let mut kernel_c = unsafe {
self.device()
.alloc_uninit(kernel_l.shape(), kernel.dtype())?
};
kernel.copy_strided_src(&mut kernel_c, 0, kernel_l)?;
let kernel_l = Layout::contiguous_with_offset((1, n, k), kernel_l.start_offset())
.transpose(1, 2)?
.broadcast_as((b, k, n))?;
col.matmul(kernel, (b, m, n, k), &col_l, &kernel_l)?
};
let res_l = Layout::contiguous((b, l_out, n)).transpose(1, 2)?;
let mut res_t = unsafe { self.device().alloc_uninit(res_l.shape(), res.dtype())? };
res.copy_strided_src(&mut res_t, 0, &res_l)?;
Ok(res_t)
}
fn conv_transpose1d(
&self,
l: &Layout,
kernel: &Self,
kernel_l: &Layout,
params: &crate::conv::ParamsConvTranspose1D,
) -> Result<Self> {
const USE_COL2IM_CONV1D_TR: bool = true;
let device = self.device().clone();
let can_use_col2im = kernel_l.is_contiguous()
&& params.dilation == 1
&& params.padding == 0
&& params.output_padding == 0;
let slice = if USE_COL2IM_CONV1D_TR && can_use_col2im {
let (b_size, c_in, l_in) = l.shape().dims3()?;
let (c_in2, c_out, k_size) = kernel_l.shape().dims3()?;
if !kernel_l.is_contiguous() {
crate::bail!(
"convtr1d: the second argument (kernel) has to be contiguous {kernel_l:?}"
)
}
if c_in != c_in2 {
crate::bail!(
"convtr1d: shape mismatch on c_in {:?} {:?}",
l.shape(),
kernel_l.shape()
)
}
let col = {
// This merges the last two dimensions of the kernel together.
let kernel_l_mm = Layout::new(
(b_size, c_in, k_size * c_out).into(),
vec![0, k_size * c_out, 1],
kernel_l.start_offset(),
);
self.matmul(
kernel,
(
b_size,
/* m */ l_in,
/* n */ c_out * k_size,
/* k */ c_in,
),
&l.transpose(1, 2)?,
&kernel_l_mm,
)?
};
let col_l = Layout::contiguous((b_size, l_in, c_out, k_size));
Col2Im1D {
stride: params.stride,
}
.map(&col.slice, &device, &col_l)?
} else {
ConvTranspose1D(params).map(&self.slice, l, &kernel.slice, kernel_l, &device)?
};
Ok(Self { slice, device })
}
#[cfg(not(feature = "cudnn"))]
fn conv2d(
&self,
l: &Layout,
kernel: &Self,
kernel_l: &Layout,
params: &crate::conv::ParamsConv2D,
) -> Result<Self> {
const USE_IM2COL_CONV2D: bool = true;
let device = self.device().clone();
if !USE_IM2COL_CONV2D {
let slice = Conv2D(params).map(&self.slice, l, &kernel.slice, kernel_l, &device)?;
return Ok(Self { slice, device });
}
let col = Im2Col {
h_k: params.k_h,
w_k: params.k_w,
stride: params.stride,
dilation: params.dilation,
padding: params.padding,
}
.map(&self.slice, &device, l)?;
let col = Self { slice: col, device };
let h_out = params.out_h();
let w_out = params.out_w();
let b = params.b_size;
let n = params.c_out;
let k = params.k_h * params.k_w * params.c_in;
let m = h_out * w_out;
let col_l = Layout::contiguous((b, m, k));
let res = if kernel_l.is_contiguous() {
let kernel_l = Layout::contiguous_with_offset((1, n, k), kernel_l.start_offset())
.transpose(1, 2)?
.broadcast_as((b, k, n))?;
col.matmul(kernel, (b, m, n, k), &col_l, &kernel_l)?
} else {
// Make the kernel contiguous if not already the case.
let mut kernel_c = unsafe {
self.device()
.alloc_uninit(kernel_l.shape(), kernel.dtype())?
};
kernel.copy_strided_src(&mut kernel_c, 0, kernel_l)?;
let kernel_l = Layout::contiguous_with_offset((1, n, k), kernel_l.start_offset())
.transpose(1, 2)?
.broadcast_as((b, k, n))?;
col.matmul(kernel, (b, m, n, k), &col_l, &kernel_l)?
};
let res_l = Layout::contiguous((b, h_out, w_out, n))
.transpose(1, 2)?
.transpose(1, 3)?;
let mut res_t = unsafe { self.device().alloc_uninit(res_l.shape(), res.dtype())? };
res.copy_strided_src(&mut res_t, 0, &res_l)?;
Ok(res_t)
}
#[cfg(feature = "cudnn")]
fn conv2d(
&self,
inp_l: &Layout,
kernel: &Self,
kernel_l: &Layout,
params: &crate::conv::ParamsConv2D,
) -> Result<Self> {
let device = self.device().clone();
if !kernel_l.is_contiguous() {
let slice = Conv2D(params).map(&self.slice, inp_l, &kernel.slice, kernel_l, &device)?;
return Ok(Self { slice, device });
}
let (out_w, out_h) = (params.out_w(), params.out_h());
let dst_el = params.c_out * out_w * out_h * params.b_size;
let slice = match (&self.slice, &kernel.slice) {
(S::U8(inp), S::U8(k)) => {
let inp = &inp.slice(inp_l.start_offset()..);
let k = &k.slice(kernel_l.start_offset()..);
let mut out = unsafe { device.alloc::<u8>(dst_el) }.w()?;
crate::cudnn::launch_conv2d::<u8, u8>(inp, inp_l, k, &mut out, params, &device)
.map_err(crate::Error::wrap)?;
S::U8(out)
}
(S::BF16(inp), S::BF16(k)) => {
let inp = &inp.slice(inp_l.start_offset()..);
let k = &k.slice(kernel_l.start_offset()..);
let mut out = unsafe { device.alloc::<bf16>(dst_el) }.w()?;
// Only PSEUDO_BFLOAT16_CONFIG is supported in cudnn, there is no "true bfloat16"
// version.
// https://docs.nvidia.com/deeplearning/cudnn/latest/api/cudnn-cnn-library.html#id88
crate::cudnn::launch_conv2d::<bf16, f32>(inp, inp_l, k, &mut out, params, &device)
.map_err(crate::Error::wrap)?;
S::BF16(out)
}
(S::F16(inp), S::F16(k)) => {
let inp = &inp.slice(inp_l.start_offset()..);
let k = &k.slice(kernel_l.start_offset()..);
let mut out = unsafe { device.alloc::<f16>(dst_el) }.w()?;
crate::cudnn::launch_conv2d::<f16, f16>(inp, inp_l, k, &mut out, params, &device)
.map_err(crate::Error::wrap)?;
S::F16(out)
}
(S::F32(inp), S::F32(k)) => {
let inp = &inp.slice(inp_l.start_offset()..);
let k = &k.slice(kernel_l.start_offset()..);
let mut out = unsafe { device.alloc::<f32>(dst_el) }.w()?;
crate::cudnn::launch_conv2d::<f32, f32>(inp, inp_l, k, &mut out, params, &device)
.map_err(crate::Error::wrap)?;
S::F32(out)
}
(S::F64(inp), S::F64(k)) => {
let inp = &inp.slice(inp_l.start_offset()..);
let k = &k.slice(kernel_l.start_offset()..);
let mut out = unsafe { device.alloc::<f64>(dst_el) }.w()?;
crate::cudnn::launch_conv2d::<f64, f64>(inp, inp_l, k, &mut out, params, &device)
.map_err(crate::Error::wrap)?;
S::F64(out)
}
(S::U32(_), S::U32(_)) => Err(CudaError::InternalError("conv2d does not support u32"))?,
(S::I64(_), S::I64(_)) => Err(CudaError::InternalError("conv2d does not support i64"))?,
_ => Err(CudaError::InternalError("dtype mismatch in conv2d"))?,
};
Ok(Self { slice, device })
}
fn conv_transpose2d(
&self,
l: &Layout,
kernel: &Self,
kernel_l: &Layout,
params: &crate::conv::ParamsConvTranspose2D,
) -> Result<Self> {
let device = self.device().clone();
let slice =
ConvTranspose2D(params).map(&self.slice, l, &kernel.slice, kernel_l, &device)?;
Ok(Self { slice, device })
}
fn avg_pool2d(&self, l: &Layout, k: (usize, usize), stride: (usize, usize)) -> Result<Self> {
let device = self.device().clone();
let slice = Pool2D {
w_k: k.0,
h_k: k.1,
w_stride: stride.0,
h_stride: stride.1,
op: PoolOp::Avg,
}
.map(&self.slice, &device, l)?;
Ok(Self { slice, device })
}
fn max_pool2d(&self, l: &Layout, k: (usize, usize), stride: (usize, usize)) -> Result<Self> {
let device = self.device().clone();
let slice = Pool2D {
w_k: k.0,
h_k: k.1,
w_stride: stride.0,
h_stride: stride.1,
op: PoolOp::Max,
}
.map(&self.slice, &device, l)?;
Ok(Self { slice, device })
}
fn upsample_nearest1d(&self, _: &Layout, _out_sz: usize) -> Result<Self> {
crate::bail!("upsample-nearest1d is not supported on cuda")
}
fn upsample_nearest2d(&self, l: &Layout, out_w: usize, out_h: usize) -> Result<Self> {
let device = self.device().clone();
let slice = UpsampleNearest2D(out_w, out_h).map(&self.slice, &device, l)?;
Ok(Self { slice, device })
}
fn index_select(&self, ids: &Self, l: &Layout, ids_l: &Layout, dim: usize) -> Result<Self> {
let device = self.device().clone();
let slice = IndexSelect(ids, ids_l, dim).map(&self.slice, &device, l)?;
Ok(Self { slice, device })
}
fn gather(&self, l: &Layout, ids: &Self, ids_l: &Layout, dim: usize) -> Result<Self> {
let device = self.device().clone();
let slice = Gather(ids, ids_l, dim).map(&self.slice, &device, l)?;
Ok(Self { slice, device })
}
fn scatter_add(
&self,
l: &Layout,
ids: &Self,
ids_l: &Layout,
src: &Self,
src_l: &Layout,
dim: usize,
) -> Result<Self> {
let device = self.device().clone();
let mut acc = unsafe { device.alloc_uninit(l.shape(), self.dtype())? };
self.copy_strided_src(&mut acc, 0, l)?;
ScatterAdd(ids, ids_l, dim).map(&mut acc.slice, l.shape(), &src.slice, src_l, &device)?;
Ok(acc)
}
fn index_add(
&self,
l: &Layout,
ids: &Self,
ids_l: &Layout,
src: &Self,
src_l: &Layout,
dim: usize,
) -> Result<Self> {
let device = self.device().clone();
let mut acc = unsafe { device.alloc_uninit(l.shape(), self.dtype())? };
self.copy_strided_src(&mut acc, 0, l)?;
IndexAdd(ids, ids_l, dim).map(&mut acc.slice, l.shape(), &src.slice, src_l, &device)?;
Ok(acc)
}
fn matmul(
&self,
rhs: &Self,
(b, m, n, k): (usize, usize, usize, usize),
lhs_l: &Layout,
rhs_l: &Layout,
) -> Result<Self> {
let elem_count = b * m * n;
let dev = &self.device;
let slice = match (&self.slice, &rhs.slice) {
(CudaStorageSlice::BF16(lhs), CudaStorageSlice::BF16(rhs)) => {
let lhs = &lhs.slice(lhs_l.start_offset()..);
let rhs = &rhs.slice(rhs_l.start_offset()..);
let cfg = gemm_config(bf16::ONE, bf16::ZERO, (b, m, n, k), lhs_l, rhs_l)?;
let mut out = unsafe { dev.alloc::<bf16>(elem_count) }.w()?;
unsafe { gemm_strided_batched_bf16(&self.device.blas, cfg, rhs, lhs, &mut out) }
.w()?;
CudaStorageSlice::BF16(out)
}
(CudaStorageSlice::F16(lhs), CudaStorageSlice::F16(rhs)) => {
let lhs = &lhs.slice(lhs_l.start_offset()..);
let rhs = &rhs.slice(rhs_l.start_offset()..);
let cfg = gemm_config(f16::ONE, f16::ZERO, (b, m, n, k), lhs_l, rhs_l)?;
let mut out = unsafe { dev.alloc::<f16>(elem_count) }.w()?;
unsafe { gemm_strided_batched_f16(&self.device.blas, cfg, rhs, lhs, &mut out) }
.w()?;
CudaStorageSlice::F16(out)
}
(CudaStorageSlice::F32(lhs), CudaStorageSlice::F32(rhs)) => {
let lhs = &lhs.slice(lhs_l.start_offset()..);
let rhs = &rhs.slice(rhs_l.start_offset()..);
let cfg = gemm_config(1., 0., (b, m, n, k), lhs_l, rhs_l)?;
let mut out = unsafe { dev.alloc::<f32>(elem_count) }.w()?;
unsafe { gemm_strided_batched_f32(&self.device.blas, cfg, rhs, lhs, &mut out) }
.w()?;
CudaStorageSlice::F32(out)
}
(CudaStorageSlice::F64(lhs), CudaStorageSlice::F64(rhs)) => {
let lhs = &lhs.slice(lhs_l.start_offset()..);
let rhs = &rhs.slice(rhs_l.start_offset()..);
let cfg = gemm_config(1., 0., (b, m, n, k), lhs_l, rhs_l)?;
let mut out = unsafe { dev.alloc::<f64>(elem_count) }.w()?;
unsafe {
self.device
.blas
.gemm_strided_batched(cfg, rhs, lhs, &mut out)
}
.w()?;
CudaStorageSlice::F64(out)
}
_ => Err(CudaError::InternalError("dtype mismatch in matmul op"))?,
};
let device = dev.clone();
Ok(Self { slice, device })
}
fn copy2d(
&self,
dst: &mut Self,
d1: usize,
d2: usize,
src_s: usize,
dst_s: usize,
src_o: usize,
dst_o: usize,
) -> Result<()> {
let dev = &self.device;
let d1 = d1 as u32;
let d2 = d2 as u32;
// Nothing to copy so we exit early to avoid launching a kernel and some potential invalid
// argument with a null pointer.
if d1 == 0 || d2 == 0 {
return Ok(());
}
let dst_s = dst_s as u32;
let src_s = src_s as u32;
let (src, dst, kname) = match (&self.slice, &mut dst.slice) {
(S::U8(s), S::U8(d)) => (
*s.slice(src_o..).device_ptr(),
*d.slice(dst_o..).device_ptr(),
"copy2d_u8",
),
(S::U32(s), S::U32(d)) => (
*s.slice(src_o..).device_ptr(),
*d.slice(dst_o..).device_ptr(),
"copy2d_u32",
),
(S::I64(s), S::I64(d)) => (
*s.slice(src_o..).device_ptr(),
*d.slice(dst_o..).device_ptr(),
"copy2d_i64",
),
(S::BF16(s), S::BF16(d)) => (
*s.slice(src_o..).device_ptr(),
*d.slice(dst_o..).device_ptr(),
"copy2d_bf16",
),
(S::F16(s), S::F16(d)) => (
*s.slice(src_o..).device_ptr(),
*d.slice(dst_o..).device_ptr(),
"copy2d_f16",
),
(S::F32(s), S::F32(d)) => (
*s.slice(src_o..).device_ptr(),
*d.slice(dst_o..).device_ptr(),
"copy2d_f32",
),
(S::F64(s), S::F64(d)) => (
*s.slice(src_o..).device_ptr(),
*d.slice(dst_o..).device_ptr(),
"copy2d_f64",
),
_ => Err(CudaError::InternalError("dtype mismatch in copy2d"))?,
};
let func = dev.get_or_load_func(kname, kernels::FILL)?;
let cfg = LaunchConfig::for_num_elems(d1 * d2);
let params = (src, dst, d1, d2, src_s, dst_s);
// SAFETY: ffi.
unsafe { func.launch(cfg, params) }.w()?;
Ok(())
}
fn copy_strided_src(&self, dst: &mut Self, dst_offset: usize, src_l: &Layout) -> Result<()> {
let src_shape = src_l.shape();
let dims = src_shape.dims();
let el_count = src_shape.elem_count();
if el_count == 0 {
return Ok(());
}
let cfg = LaunchConfig::for_num_elems(el_count as u32);
let dev = &self.device;
let ds = SlicePtrOrNull::params_from_layout(dev, src_l)?;
match (&self.slice, &mut dst.slice) {
(CudaStorageSlice::BF16(src), CudaStorageSlice::BF16(dst)) => {
let (src, mut dst) = slice_src_and_dst(src, src_l, dst, dst_offset);
if src_l.is_contiguous() {
dev.dtod_copy(&src, &mut dst).w()?
} else {
let func = dev.get_or_load_func("ucopy_bf16", kernels::UNARY)?;
// SAFETY: Set later by running the kernel.
let params = (el_count, dims.len(), &ds, &src, &mut dst);
// SAFETY: ffi.
unsafe { func.launch(cfg, params) }.w()?
}
}
(CudaStorageSlice::F16(src), CudaStorageSlice::F16(dst)) => {
let (src, mut dst) = slice_src_and_dst(src, src_l, dst, dst_offset);
if src_l.is_contiguous() {
dev.dtod_copy(&src, &mut dst).w()?
} else {
let func = dev.get_or_load_func("ucopy_f16", kernels::UNARY)?;
// SAFETY: Set later by running the kernel.
let params = (el_count, dims.len(), &ds, &src, &mut dst);
// SAFETY: ffi.
unsafe { func.launch(cfg, params) }.w()?
}
}
(CudaStorageSlice::F32(src), CudaStorageSlice::F32(dst)) => {
let (src, mut dst) = slice_src_and_dst(src, src_l, dst, dst_offset);
if src_l.is_contiguous() {
dev.dtod_copy(&src, &mut dst).w()?
} else {
let func = dev.get_or_load_func("ucopy_f32", kernels::UNARY)?;
// SAFETY: Set later by running the kernel.
let params = (el_count, dims.len(), &ds, &src, &mut dst);
// SAFETY: ffi.
unsafe { func.launch(cfg, params) }.w()?
}
}
(CudaStorageSlice::U8(src), CudaStorageSlice::U8(dst)) => {
let (src, mut dst) = slice_src_and_dst(src, src_l, dst, dst_offset);
if src_l.is_contiguous() {
dev.dtod_copy(&src, &mut dst).w()?
} else {
let func = dev.get_or_load_func("ucopy_u8", kernels::UNARY)?;
// SAFETY: Set later by running the kernel.
let params = (el_count, dims.len(), &ds, &src, &mut dst);
// SAFETY: ffi.
unsafe { func.launch(cfg, params) }.w()?
}
}
(CudaStorageSlice::U32(src), CudaStorageSlice::U32(dst)) => {
let (src, mut dst) = slice_src_and_dst(src, src_l, dst, dst_offset);
if src_l.is_contiguous() {
dev.dtod_copy(&src, &mut dst).w()?
} else {
let func = dev.get_or_load_func("ucopy_u32", kernels::UNARY)?;
// SAFETY: Set later by running the kernel.
let params = (el_count, dims.len(), &ds, &src, &mut dst);
// SAFETY: ffi.
unsafe { func.launch(cfg, params) }.w()?
}
}
(CudaStorageSlice::I64(src), CudaStorageSlice::I64(dst)) => {
let (src, mut dst) = slice_src_and_dst(src, src_l, dst, dst_offset);
if src_l.is_contiguous() {
dev.dtod_copy(&src, &mut dst).w()?
} else {
let func = dev.get_or_load_func("ucopy_i64", kernels::UNARY)?;
// SAFETY: Set later by running the kernel.
let params = (el_count, dims.len(), &ds, &src, &mut dst);
// SAFETY: ffi.
unsafe { func.launch(cfg, params) }.w()?
}
}
(CudaStorageSlice::F64(src), CudaStorageSlice::F64(dst)) => {
let (src, mut dst) = slice_src_and_dst(src, src_l, dst, dst_offset);
if src_l.is_contiguous() {
dev.dtod_copy(&src, &mut dst).w()?
} else {
let func = dev.get_or_load_func("ucopy_f64", kernels::UNARY)?;
// SAFETY: Set later by running the kernel.
let params = (el_count, dims.len(), &ds, &src, &mut dst);
// SAFETY: ffi.
unsafe { func.launch(cfg, params) }.w()?;
}
}
_ => Err(CudaError::InternalError(
"dtype mismatch in copy_strided op",
))?,
}
Ok(())
}
}
// Default for the reduced precision setting is false, similar to pytorch.
// https://github.com/pytorch/pytorch/issues/123157
static MM_F16_REDUCED_PRECISION: std::sync::atomic::AtomicBool =
std::sync::atomic::AtomicBool::new(false);
static MM_BF16_REDUCED_PRECISION: std::sync::atomic::AtomicBool =
std::sync::atomic::AtomicBool::new(false);
static MM_F32_REDUCED_PRECISION: std::sync::atomic::AtomicBool =
std::sync::atomic::AtomicBool::new(false);
/// This bool controls whether reduced precision reductions (e.g., with tf32 accumulation type) are
/// allowed with f32 GEMMs.
pub fn gemm_reduced_precision_f32() -> bool {
MM_F32_REDUCED_PRECISION.load(std::sync::atomic::Ordering::Relaxed)
}
/// This bool controls whether reduced precision reductions (e.g., with tf32 accumulation type) are
/// allowed with f32 GEMMs.
pub fn set_gemm_reduced_precision_f32(b: bool) {
MM_F32_REDUCED_PRECISION.store(b, std::sync::atomic::Ordering::Relaxed)
}
/// This bool controls whether reduced precision reductions (e.g., with fp16 accumulation type) are
/// allowed with f16 GEMMs.
pub fn gemm_reduced_precision_f16() -> bool {
MM_F16_REDUCED_PRECISION.load(std::sync::atomic::Ordering::Relaxed)
}
/// This bool controls whether reduced precision reductions (e.g., with fp16 accumulation type) are
/// allowed with f16 GEMMs.
pub fn set_gemm_reduced_precision_f16(b: bool) {
MM_F16_REDUCED_PRECISION.store(b, std::sync::atomic::Ordering::Relaxed)
}
/// This bool controls whether reduced precision reductions (e.g., with fp16 accumulation type) are
/// allowed with bf16 GEMMs.
pub fn gemm_reduced_precision_bf16() -> bool {
MM_BF16_REDUCED_PRECISION.load(std::sync::atomic::Ordering::Relaxed)
}
/// This bool controls whether reduced precision reductions (e.g., with fp16 accumulation type) are
/// allowed with bf16 GEMMs.
pub fn set_gemm_reduced_precision_bf16(b: bool) {
MM_BF16_REDUCED_PRECISION.store(b, std::sync::atomic::Ordering::Relaxed)
}
unsafe fn gemm_strided_batched_f32(
cublas: &cudarc::cublas::CudaBlas,
cfg: StridedBatchedConfig<f32>,
a: &cudarc::driver::CudaView<f32>,
b: &cudarc::driver::CudaView<f32>,
c: &mut CudaSlice<f32>,
) -> std::result::Result<(), cudarc::cublas::result::CublasError> {
use cudarc::cublas::sys;
use cudarc::driver::DevicePtrMut;
let compute_type = if gemm_reduced_precision_f32() {
sys::cublasComputeType_t::CUBLAS_COMPUTE_32F_FAST_TF32
} else {
sys::cublasComputeType_t::CUBLAS_COMPUTE_32F
};
let alpha = &cfg.gemm.alpha as *const f32 as *const _;
let beta = &cfg.gemm.beta as *const f32 as *const _;
cudarc::cublas::result::gemm_strided_batched_ex(
*cublas.handle(),
cfg.gemm.transa,
cfg.gemm.transb,
cfg.gemm.m,
cfg.gemm.n,
cfg.gemm.k,
alpha,
*a.device_ptr() as *const _,
sys::cudaDataType_t::CUDA_R_32F,
cfg.gemm.lda,
cfg.stride_a,
*b.device_ptr() as *const _,
sys::cudaDataType_t::CUDA_R_32F,
cfg.gemm.ldb,
cfg.stride_b,
beta,
*c.device_ptr_mut() as *mut _,
sys::cudaDataType_t::CUDA_R_32F,
cfg.gemm.ldc,
cfg.stride_c,
cfg.batch_size,
compute_type,
sys::cublasGemmAlgo_t::CUBLAS_GEMM_DEFAULT_TENSOR_OP,
)
}
unsafe fn gemm_strided_batched_f16(
cublas: &cudarc::cublas::CudaBlas,
cfg: StridedBatchedConfig<f16>,
a: &cudarc::driver::CudaView<f16>,
b: &cudarc::driver::CudaView<f16>,
c: &mut CudaSlice<f16>,
) -> std::result::Result<(), cudarc::cublas::result::CublasError> {
use cudarc::cublas::sys;
use cudarc::driver::DevicePtrMut;
let alpha = cfg.gemm.alpha;
let beta = cfg.gemm.beta;
let alpha_f32: f32 = cfg.gemm.alpha.to_f32();
let beta_f32: f32 = cfg.gemm.beta.to_f32();
let (compute_type, alpha, beta) = if gemm_reduced_precision_f16() {
(
sys::cublasComputeType_t::CUBLAS_COMPUTE_16F,
(&alpha) as *const f16 as *const _,
(&beta) as *const f16 as *const _,
)
} else {
(
sys::cublasComputeType_t::CUBLAS_COMPUTE_32F,
(&alpha_f32) as *const f32 as *const _,
(&beta_f32) as *const f32 as *const _,
)
};
cudarc::cublas::result::gemm_strided_batched_ex(
*cublas.handle(),
cfg.gemm.transa,
cfg.gemm.transb,
cfg.gemm.m,
cfg.gemm.n,
cfg.gemm.k,
alpha,
*a.device_ptr() as *const _,
sys::cudaDataType_t::CUDA_R_16F,
cfg.gemm.lda,
cfg.stride_a,
*b.device_ptr() as *const _,
sys::cudaDataType_t::CUDA_R_16F,
cfg.gemm.ldb,
cfg.stride_b,
beta,
*c.device_ptr_mut() as *mut _,
sys::cudaDataType_t::CUDA_R_16F,
cfg.gemm.ldc,
cfg.stride_c,
cfg.batch_size,
compute_type,
sys::cublasGemmAlgo_t::CUBLAS_GEMM_DEFAULT_TENSOR_OP,
)
}
unsafe fn gemm_strided_batched_bf16(
cublas: &cudarc::cublas::CudaBlas,
cfg: StridedBatchedConfig<bf16>,
a: &cudarc::driver::CudaView<bf16>,
b: &cudarc::driver::CudaView<bf16>,
c: &mut CudaSlice<bf16>,
) -> std::result::Result<(), cudarc::cublas::result::CublasError> {
use cudarc::cublas::sys;
use cudarc::driver::DevicePtrMut;
let alpha_f32: f32 = cfg.gemm.alpha.to_f32();
let beta_f32: f32 = cfg.gemm.beta.to_f32();
// The type for alpha and beta depends on the computeType.
// https://docs.nvidia.com/cuda/cublas/index.html#cublasgemmstridedbatchedex
let (compute_type, alpha, beta) = if gemm_reduced_precision_bf16() {
(
sys::cublasComputeType_t::CUBLAS_COMPUTE_32F_FAST_16BF,
(&alpha_f32) as *const f32 as *const _,
(&beta_f32) as *const f32 as *const _,
)
} else {
(
sys::cublasComputeType_t::CUBLAS_COMPUTE_32F,
(&alpha_f32) as *const f32 as *const _,
(&beta_f32) as *const f32 as *const _,
)
};
cudarc::cublas::result::gemm_strided_batched_ex(
*cublas.handle(),
cfg.gemm.transa,
cfg.gemm.transb,
cfg.gemm.m,
cfg.gemm.n,
cfg.gemm.k,
alpha,
*a.device_ptr() as *const _,
sys::cudaDataType_t::CUDA_R_16BF,
cfg.gemm.lda,
cfg.stride_a,
*b.device_ptr() as *const _,
sys::cudaDataType_t::CUDA_R_16BF,
cfg.gemm.ldb,
cfg.stride_b,
beta,
*c.device_ptr_mut() as *mut _,
sys::cudaDataType_t::CUDA_R_16BF,
cfg.gemm.ldc,
cfg.stride_c,
cfg.batch_size,
compute_type,
sys::cublasGemmAlgo_t::CUBLAS_GEMM_DEFAULT_TENSOR_OP,
)
}
| 6 |
0 | hf_public_repos/candle/candle-core/src | hf_public_repos/candle/candle-core/src/cuda_backend/cudnn.rs | use crate::WithDType;
use cudarc;
use cudarc::cudnn::safe::{ConvForward, Cudnn};
use cudarc::driver::{CudaSlice, CudaView, DeviceRepr, ValidAsZeroBits};
use std::cell::RefCell;
use std::collections::HashMap;
use std::sync::Arc;
// The cudnn handles are stored per thread here rather than on the CudaDevice as they are neither
// send nor sync.
thread_local! {
static CUDNN: RefCell<HashMap<crate::cuda_backend::DeviceId, Arc<Cudnn>>> = HashMap::new().into();
}
impl From<cudarc::cudnn::CudnnError> for crate::Error {
fn from(err: cudarc::cudnn::CudnnError) -> Self {
crate::Error::wrap(err)
}
}
impl From<cudarc::driver::DriverError> for crate::Error {
fn from(err: cudarc::driver::DriverError) -> Self {
crate::Error::wrap(err)
}
}
pub(crate) fn launch_conv2d<
T: DeviceRepr + WithDType + ValidAsZeroBits + cudarc::cudnn::CudnnDataType,
Y: cudarc::cudnn::CudnnDataType,
>(
src: &CudaView<T>,
src_l: &crate::Layout,
filter: &CudaView<T>,
dst: &mut CudaSlice<T>,
params: &crate::conv::ParamsConv2D,
dev: &crate::cuda_backend::CudaDevice,
) -> crate::Result<()> {
use crate::conv::CudnnFwdAlgo as CandleAlgo;
use cudarc::cudnn::sys::cudnnConvolutionFwdAlgo_t as A;
let device_id = dev.id();
let cudnn = CUDNN.with(|cudnn| {
if let Some(cudnn) = cudnn.borrow().get(&device_id) {
return Ok(cudnn.clone());
}
let c = Cudnn::new(dev.cuda_device());
if let Ok(c) = &c {
cudnn.borrow_mut().insert(device_id, c.clone());
}
c
})?;
let conv = cudnn.create_conv2d::<Y>(
/* pad */ [params.padding as i32, params.padding as i32],
/* stride */ [params.stride as i32, params.stride as i32],
/* dilation */ [params.dilation as i32, params.dilation as i32],
cudarc::cudnn::sys::cudnnConvolutionMode_t::CUDNN_CROSS_CORRELATION,
)?;
let x_shape = [
params.b_size as i32,
params.c_in as i32,
params.i_h as i32,
params.i_w as i32,
];
// Note that `src` already starts at the proper offset.
let x = if src_l.is_contiguous() {
cudnn.create_4d_tensor::<T>(
cudarc::cudnn::sys::cudnnTensorFormat_t::CUDNN_TENSOR_NCHW,
x_shape,
)?
} else {
let s = src_l.stride();
cudnn.create_4d_tensor_ex::<T>(
x_shape,
[s[0] as i32, s[1] as i32, s[2] as i32, s[3] as i32],
)?
};
let w = cudnn.create_4d_filter::<T>(
cudarc::cudnn::sys::cudnnTensorFormat_t::CUDNN_TENSOR_NCHW,
[
params.c_out as i32,
params.c_in as i32,
params.k_h as i32,
params.k_w as i32,
],
)?;
let (w_out, h_out) = (params.out_w() as i32, params.out_h() as i32);
let y = cudnn.create_4d_tensor::<T>(
cudarc::cudnn::sys::cudnnTensorFormat_t::CUDNN_TENSOR_NCHW,
[params.b_size as i32, params.c_out as i32, h_out, w_out],
)?;
let conv2d = ConvForward {
conv: &conv,
x: &x,
w: &w,
y: &y,
};
let alg = match params.cudnn_fwd_algo {
None => conv2d.pick_algorithm()?,
Some(CandleAlgo::ImplicitGemm) => A::CUDNN_CONVOLUTION_FWD_ALGO_IMPLICIT_GEMM,
Some(CandleAlgo::ImplicitPrecompGemm) => {
A::CUDNN_CONVOLUTION_FWD_ALGO_IMPLICIT_PRECOMP_GEMM
}
Some(CandleAlgo::Gemm) => A::CUDNN_CONVOLUTION_FWD_ALGO_GEMM,
Some(CandleAlgo::Direct) => A::CUDNN_CONVOLUTION_FWD_ALGO_DIRECT,
Some(CandleAlgo::Fft) => A::CUDNN_CONVOLUTION_FWD_ALGO_FFT,
Some(CandleAlgo::FftTiling) => A::CUDNN_CONVOLUTION_FWD_ALGO_FFT_TILING,
Some(CandleAlgo::Winograd) => A::CUDNN_CONVOLUTION_FWD_ALGO_WINOGRAD,
Some(CandleAlgo::WinogradNonFused) => A::CUDNN_CONVOLUTION_FWD_ALGO_WINOGRAD_NONFUSED,
Some(CandleAlgo::Count) => A::CUDNN_CONVOLUTION_FWD_ALGO_COUNT,
};
let workspace_size = conv2d.get_workspace_size(alg)?;
let mut workspace = dev.cuda_device().alloc_zeros::<u8>(workspace_size)?;
unsafe {
conv2d.launch::<CudaSlice<u8>, _, _, _>(
alg,
Some(&mut workspace),
(T::one(), T::zero()),
src,
filter,
dst,
)?;
}
Ok(())
}
| 7 |
0 | hf_public_repos/candle/candle-core/src | hf_public_repos/candle/candle-core/src/cuda_backend/utils.rs | /// Helper functions to plug cuda kernels in candle.
use crate::{Layout, Result, Shape, WithDType};
pub use cudarc;
use cudarc::driver::{CudaSlice, DeviceRepr, ValidAsZeroBits};
use super::{CudaDevice, CudaError, WrapErr};
pub type S = super::CudaStorageSlice;
pub trait Map1 {
fn f<T: DeviceRepr + WithDType + ValidAsZeroBits>(
&self,
src: &CudaSlice<T>,
dev: &CudaDevice,
layout: &Layout,
) -> Result<CudaSlice<T>>;
fn map(&self, s: &S, d: &CudaDevice, l: &Layout) -> Result<S> {
let out = match s {
S::U8(s) => S::U8(self.f(s, d, l)?),
S::U32(s) => S::U32(self.f(s, d, l)?),
S::I64(s) => S::I64(self.f(s, d, l)?),
S::BF16(s) => S::BF16(self.f(s, d, l)?),
S::F16(s) => S::F16(self.f(s, d, l)?),
S::F32(s) => S::F32(self.f(s, d, l)?),
S::F64(s) => S::F64(self.f(s, d, l)?),
};
Ok(out)
}
}
pub trait Map2 {
fn f<T: DeviceRepr + WithDType + ValidAsZeroBits>(
&self,
src1: &CudaSlice<T>,
layout1: &Layout,
src2: &CudaSlice<T>,
layout2: &Layout,
dev: &CudaDevice,
) -> Result<CudaSlice<T>>;
fn map(&self, s1: &S, l1: &Layout, s2: &S, l2: &Layout, d: &CudaDevice) -> Result<S> {
let out = match (s1, s2) {
(S::U8(s1), S::U8(s2)) => S::U8(self.f(s1, l1, s2, l2, d)?),
(S::U32(s1), S::U32(s2)) => S::U32(self.f(s1, l1, s2, l2, d)?),
(S::I64(s1), S::I64(s2)) => S::I64(self.f(s1, l1, s2, l2, d)?),
(S::BF16(s1), S::BF16(s2)) => S::BF16(self.f(s1, l1, s2, l2, d)?),
(S::F16(s1), S::F16(s2)) => S::F16(self.f(s1, l1, s2, l2, d)?),
(S::F32(s1), S::F32(s2)) => S::F32(self.f(s1, l1, s2, l2, d)?),
(S::F64(s1), S::F64(s2)) => S::F64(self.f(s1, l1, s2, l2, d)?),
_ => Err(CudaError::InternalError("dtype mismatch in binary op"))?,
};
Ok(out)
}
}
pub trait Map3 {
#[allow(clippy::too_many_arguments)]
fn f<T: DeviceRepr + WithDType + ValidAsZeroBits>(
&self,
src1: &CudaSlice<T>,
layout1: &Layout,
src2: &CudaSlice<T>,
layout2: &Layout,
src3: &CudaSlice<T>,
layout3: &Layout,
dev: &CudaDevice,
) -> Result<CudaSlice<T>>;
#[allow(clippy::too_many_arguments)]
fn map(
&self,
s1: &S,
l1: &Layout,
s2: &S,
l2: &Layout,
s3: &S,
l3: &Layout,
d: &CudaDevice,
) -> Result<S> {
let out = match (s1, s2, s3) {
(S::U8(s1), S::U8(s2), S::U8(s3)) => S::U8(self.f(s1, l1, s2, l2, s3, l3, d)?),
(S::U32(s1), S::U32(s2), S::U32(s3)) => S::U32(self.f(s1, l1, s2, l2, s3, l3, d)?),
(S::I64(s1), S::I64(s2), S::I64(s3)) => S::I64(self.f(s1, l1, s2, l2, s3, l3, d)?),
(S::BF16(s1), S::BF16(s2), S::BF16(s3)) => S::BF16(self.f(s1, l1, s2, l2, s3, l3, d)?),
(S::F16(s1), S::F16(s2), S::F16(s3)) => S::F16(self.f(s1, l1, s2, l2, s3, l3, d)?),
(S::F32(s1), S::F32(s2), S::F32(s3)) => S::F32(self.f(s1, l1, s2, l2, s3, l3, d)?),
(S::F64(s1), S::F64(s2), S::F64(s3)) => S::F64(self.f(s1, l1, s2, l2, s3, l3, d)?),
_ => Err(CudaError::InternalError("dtype mismatch in ternary op"))?,
};
Ok(out)
}
}
pub trait Map2InPlace {
fn f<T: DeviceRepr + WithDType + ValidAsZeroBits>(
&self,
dst: &mut CudaSlice<T>,
dst_shape: &Shape,
src: &CudaSlice<T>,
src_l: &Layout,
dev: &CudaDevice,
) -> Result<()>;
fn map(
&self,
dst: &mut S,
dst_s: &Shape,
src: &S,
src_l: &Layout,
d: &CudaDevice,
) -> Result<()> {
match (dst, src) {
(S::U8(dst), S::U8(src)) => self.f(dst, dst_s, src, src_l, d),
(S::U32(dst), S::U32(src)) => self.f(dst, dst_s, src, src_l, d),
(S::I64(dst), S::I64(src)) => self.f(dst, dst_s, src, src_l, d),
(S::BF16(dst), S::BF16(src)) => self.f(dst, dst_s, src, src_l, d),
(S::F16(dst), S::F16(src)) => self.f(dst, dst_s, src, src_l, d),
(S::F32(dst), S::F32(src)) => self.f(dst, dst_s, src, src_l, d),
(S::F64(dst), S::F64(src)) => self.f(dst, dst_s, src, src_l, d),
_ => Err(CudaError::InternalError("dtype mismatch in binary op"))?,
}
}
}
pub trait Map1Any {
fn f<T: DeviceRepr + WithDType + ValidAsZeroBits, W: Fn(CudaSlice<T>) -> S>(
&self,
src: &CudaSlice<T>,
dev: &CudaDevice,
layout: &Layout,
wrap: W,
) -> Result<S>;
fn map(&self, s: &S, d: &CudaDevice, l: &Layout) -> Result<S> {
let out = match s {
S::U8(s) => self.f(s, d, l, S::U8)?,
S::U32(s) => self.f(s, d, l, S::U32)?,
S::I64(s) => self.f(s, d, l, S::I64)?,
S::BF16(s) => self.f(s, d, l, S::BF16)?,
S::F16(s) => self.f(s, d, l, S::F16)?,
S::F32(s) => self.f(s, d, l, S::F32)?,
S::F64(s) => self.f(s, d, l, S::F64)?,
};
Ok(out)
}
}
pub trait Map2Any {
fn f<T: DeviceRepr + WithDType + ValidAsZeroBits>(
&self,
src1: &CudaSlice<T>,
layout1: &Layout,
src2: &CudaSlice<T>,
layout2: &Layout,
dev: &CudaDevice,
) -> Result<S>;
fn map(&self, s1: &S, l1: &Layout, s2: &S, l2: &Layout, d: &CudaDevice) -> Result<S> {
let out = match (s1, s2) {
(S::U8(s1), S::U8(s2)) => self.f(s1, l1, s2, l2, d)?,
(S::U32(s1), S::U32(s2)) => self.f(s1, l1, s2, l2, d)?,
(S::I64(s1), S::I64(s2)) => self.f(s1, l1, s2, l2, d)?,
(S::BF16(s1), S::BF16(s2)) => self.f(s1, l1, s2, l2, d)?,
(S::F16(s1), S::F16(s2)) => self.f(s1, l1, s2, l2, d)?,
(S::F32(s1), S::F32(s2)) => self.f(s1, l1, s2, l2, d)?,
(S::F64(s1), S::F64(s2)) => self.f(s1, l1, s2, l2, d)?,
_ => Err(CudaError::InternalError("dtype mismatch in binary op")).w()?,
};
Ok(out)
}
}
| 8 |
0 | hf_public_repos/candle/candle-core/src | hf_public_repos/candle/candle-core/src/cpu/avx.rs | use super::{Cpu, CpuF16};
#[cfg(target_arch = "x86")]
use core::arch::x86::*;
#[cfg(target_arch = "x86_64")]
use core::arch::x86_64::*;
use half::f16;
pub struct CurrentCpu {}
const STEP: usize = 32;
const EPR: usize = 8;
const ARR: usize = STEP / EPR;
impl Cpu<ARR> for CurrentCpu {
type Unit = __m256;
type Array = [__m256; ARR];
const STEP: usize = STEP;
const EPR: usize = EPR;
fn n() -> usize {
ARR
}
unsafe fn zero() -> Self::Unit {
_mm256_setzero_ps()
}
unsafe fn zero_array() -> Self::Array {
[Self::zero(); ARR]
}
unsafe fn from_f32(v: f32) -> Self::Unit {
_mm256_set1_ps(v)
}
unsafe fn load(mem_addr: *const f32) -> Self::Unit {
_mm256_loadu_ps(mem_addr)
}
unsafe fn vec_add(a: Self::Unit, b: Self::Unit) -> Self::Unit {
_mm256_add_ps(a, b)
}
unsafe fn vec_fma(a: Self::Unit, b: Self::Unit, c: Self::Unit) -> Self::Unit {
_mm256_add_ps(_mm256_mul_ps(b, c), a)
}
unsafe fn vec_store(mem_addr: *mut f32, a: Self::Unit) {
_mm256_storeu_ps(mem_addr, a);
}
unsafe fn vec_reduce(mut x: Self::Array, y: *mut f32) {
for i in 0..ARR / 2 {
x[2 * i] = _mm256_add_ps(x[2 * i], x[2 * i + 1]);
}
for i in 0..ARR / 4 {
x[4 * i] = _mm256_add_ps(x[4 * i], x[4 * i + 2]);
}
#[allow(clippy::reversed_empty_ranges)]
for i in 0..ARR / 8 {
x[8 * i] = _mm256_add_ps(x[8 * i], x[8 * i + 4]);
}
let t0 = _mm_add_ps(_mm256_castps256_ps128(x[0]), _mm256_extractf128_ps(x[0], 1));
let t1 = _mm_hadd_ps(t0, t0);
*y = _mm_cvtss_f32(_mm_hadd_ps(t1, t1));
}
}
pub struct CurrentCpuF16 {}
impl CpuF16<ARR> for CurrentCpuF16 {
type Unit = __m256;
type Array = [__m256; ARR];
const STEP: usize = STEP;
const EPR: usize = EPR;
fn n() -> usize {
ARR
}
unsafe fn zero() -> Self::Unit {
_mm256_setzero_ps()
}
unsafe fn zero_array() -> Self::Array {
[Self::zero(); ARR]
}
unsafe fn from_f32(v: f32) -> Self::Unit {
_mm256_set1_ps(v)
}
#[cfg(target_feature = "f16c")]
unsafe fn load(mem_addr: *const f16) -> Self::Unit {
_mm256_cvtph_ps(_mm_loadu_si128(mem_addr as *const __m128i))
}
#[cfg(not(target_feature = "f16c"))]
unsafe fn load(mem_addr: *const f16) -> Self::Unit {
let mut tmp = [0.0f32; 8];
for i in 0..8 {
tmp[i] = (*mem_addr.add(i)).to_f32();
}
_mm256_loadu_ps(tmp.as_ptr())
}
unsafe fn vec_add(a: Self::Unit, b: Self::Unit) -> Self::Unit {
_mm256_add_ps(a, b)
}
unsafe fn vec_fma(a: Self::Unit, b: Self::Unit, c: Self::Unit) -> Self::Unit {
_mm256_add_ps(_mm256_mul_ps(b, c), a)
}
#[cfg(target_feature = "f16c")]
unsafe fn vec_store(mem_addr: *mut f16, a: Self::Unit) {
_mm_storeu_si128(mem_addr as *mut __m128i, _mm256_cvtps_ph(a, 0))
}
#[cfg(not(target_feature = "f16c"))]
unsafe fn vec_store(mem_addr: *mut f16, a: Self::Unit) {
let mut tmp = [0.0f32; 8];
_mm256_storeu_ps(tmp.as_mut_ptr(), a);
for i in 0..8 {
*mem_addr.add(i) = f16::from_f32(tmp[i]);
}
}
unsafe fn vec_reduce(mut x: Self::Array, y: *mut f32) {
let mut offset = ARR >> 1;
for i in 0..offset {
x[i] = _mm256_add_ps(x[i], x[offset + i]);
}
offset >>= 1;
for i in 0..offset {
x[i] = _mm256_add_ps(x[i], x[offset + i]);
}
offset >>= 1;
for i in 0..offset {
x[i] = _mm256_add_ps(x[i], x[offset + i]);
}
let t0 = _mm_add_ps(_mm256_castps256_ps128(x[0]), _mm256_extractf128_ps(x[0], 1));
let t1 = _mm_hadd_ps(t0, t0);
*y = _mm_cvtss_f32(_mm_hadd_ps(t1, t1));
}
}
| 9 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.