
text
stringlengths 55
456k
| metadata
dict |
|---|---|
# PubMedQA
### Paper
Title: `PubMedQA: A Dataset for Biomedical Research Question Answering`
Abstract: https://arxiv.org/abs/1909.06146
PubMedQA is a novel biomedical question answering (QA) dataset collected from
PubMed abstracts. The task of PubMedQA is to answer research questions with
yes/no/maybe (e.g.: Do preoperative statins reduce atrial fibrillation after
coronary artery bypass grafting?) using the corresponding abstracts. PubMedQA
has 1k expert-annotated, 61.2k unlabeled and 211.3k artificially generated QA
instances. Each PubMedQA instance is composed of (1) a question which is either
an existing research article title or derived from one, (2) a context which is
the corresponding abstract without its conclusion, (3) a long answer, which is
the conclusion of the abstract and, presumably, answers the research question,
and (4) a yes/no/maybe answer which summarizes the conclusion.
Homepage: https://pubmedqa.github.io/
### Citation
```
@inproceedings{jin2019pubmedqa,
title={PubMedQA: A Dataset for Biomedical Research Question Answering},
author={Jin, Qiao and Dhingra, Bhuwan and Liu, Zhengping and Cohen, William and Lu, Xinghua},
booktitle={Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP)},
pages={2567--2577},
year={2019}
}
```
### Groups and Tasks
#### Groups
* Not part of a group yet
#### Tasks
* `pubmed_qa`
### Checklist
For adding novel benchmarks/datasets to the library:
* [ ] Is the task an existing benchmark in the literature?
* [ ] Have you referenced the original paper that introduced the task?
* [ ] If yes, does the original paper provide a reference implementation? If so, have you checked against the reference implementation and documented how to run such a test?
If other tasks on this dataset are already supported:
* [ ] Is the "Main" variant of this task clearly denoted?
* [ ] Have you provided a short sentence in a README on what each new variant adds / evaluates?
* [ ] Have you noted which, if any, published evaluation setups are matched by this variant?
|
{
"source": "simplescaling/s1",
"title": "eval/lm-evaluation-harness/lm_eval/tasks/pubmedqa/README.md",
"url": "https://github.com/simplescaling/s1/blob/main/eval/lm-evaluation-harness/lm_eval/tasks/pubmedqa/README.md",
"date": "2025-02-01T02:38:16",
"stars": 5696,
"description": "s1: Simple test-time scaling",
"file_size": 2179
}
|
# QA4MRE
### Paper
Title: `QA4MRE 2011-2013: Overview of Question Answering for Machine Reading Evaluation`
Abstract: https://www.cs.cmu.edu/~./hovy/papers/13CLEF-QA4MRE.pdf
The (English only) QA4MRE challenge which was run as a Lab at CLEF 2011-2013.
The main objective of this exercise is to develop a methodology for evaluating
Machine Reading systems through Question Answering and Reading Comprehension
Tests. Systems should be able to extract knowledge from large volumes of text
and use this knowledge to answer questions. Four different tasks have been
organized during these years: Main Task, Processing Modality and Negation for
Machine Reading, Machine Reading of Biomedical Texts about Alzheimer's disease,
and Entrance Exam.
Homepage: http://nlp.uned.es/clef-qa/repository/qa4mre.php
### Citation
```
@inproceedings{Peas2013QA4MRE2O,
title={QA4MRE 2011-2013: Overview of Question Answering for Machine Reading Evaluation},
author={Anselmo Pe{\~n}as and Eduard H. Hovy and Pamela Forner and {\'A}lvaro Rodrigo and Richard F. E. Sutcliffe and Roser Morante},
booktitle={CLEF},
year={2013}
}
```
### Groups and Tasks
#### Groups
* `qa4mre`
#### Tasks
* `qa4mre_2011`
* `qa4mre_2012`
* `qa4mre_2013`
### Checklist
For adding novel benchmarks/datasets to the library:
* [ ] Is the task an existing benchmark in the literature?
* [ ] Have you referenced the original paper that introduced the task?
* [ ] If yes, does the original paper provide a reference implementation? If so, have you checked against the reference implementation and documented how to run such a test?
If other tasks on this dataset are already supported:
* [ ] Is the "Main" variant of this task clearly denoted?
* [ ] Have you provided a short sentence in a README on what each new variant adds / evaluates?
* [ ] Have you noted which, if any, published evaluation setups are matched by this variant?
|
{
"source": "simplescaling/s1",
"title": "eval/lm-evaluation-harness/lm_eval/tasks/qa4mre/README.md",
"url": "https://github.com/simplescaling/s1/blob/main/eval/lm-evaluation-harness/lm_eval/tasks/qa4mre/README.md",
"date": "2025-02-01T02:38:16",
"stars": 5696,
"description": "s1: Simple test-time scaling",
"file_size": 1917
}
|
# QASPER
### Paper
Title: `A Dataset of Information-Seeking Questions and Answers Anchored in Research Papers`
Abstract: https://arxiv.org/abs/2105.03011
QASPER is a dataset of 5,049 questions over 1,585 Natural Language Processing papers.
Each question is written by an NLP practitioner who read only the title and abstract
of the corresponding paper, and the question seeks information present in the full
text. The questions are then answered by a separate set of NLP practitioners who also
provide supporting evidence to answers.
Homepage: https://allenai.org/data/qasper
### Citation
```
@article{DBLP:journals/corr/abs-2105-03011,
author = {Pradeep Dasigi and
Kyle Lo and
Iz Beltagy and
Arman Cohan and
Noah A. Smith and
Matt Gardner},
title = {A Dataset of Information-Seeking Questions and Answers Anchored in
Research Papers},
journal = {CoRR},
volume = {abs/2105.03011},
year = {2021},
url = {https://arxiv.org/abs/2105.03011},
eprinttype = {arXiv},
eprint = {2105.03011},
timestamp = {Fri, 14 May 2021 12:13:30 +0200},
biburl = {https://dblp.org/rec/journals/corr/abs-2105-03011.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
```
### Groups and Tasks
#### Groups
* `qasper`: executes both `qasper_bool` and `qasper_freeform`
#### Tasks
* `qasper_bool`: Multiple choice task that evaluates the task with `answer_type="bool"`
* `qasper_freeform`: Greedy generation task that evaluates the samples from the task with `answer_type="free form answer"`
### Checklist
For adding novel benchmarks/datasets to the library:
* [ ] Is the task an existing benchmark in the literature?
* [ ] Have you referenced the original paper that introduced the task?
* [ ] If yes, does the original paper provide a reference implementation? If so, have you checked against the reference implementation and documented how to run such a test?
If other tasks on this dataset are already supported:
* [ ] Is the "Main" variant of this task clearly denoted?
* [ ] Have you provided a short sentence in a README on what each new variant adds / evaluates?
* [ ] Have you noted which, if any, published evaluation setups are matched by this variant?
|
{
"source": "simplescaling/s1",
"title": "eval/lm-evaluation-harness/lm_eval/tasks/qasper/README.md",
"url": "https://github.com/simplescaling/s1/blob/main/eval/lm-evaluation-harness/lm_eval/tasks/qasper/README.md",
"date": "2025-02-01T02:38:16",
"stars": 5696,
"description": "s1: Simple test-time scaling",
"file_size": 2340
}
|
# RACE
### Paper
Title: `RACE: Large-scale ReAding Comprehension Dataset From Examinations`
Abstract: https://arxiv.org/abs/1704.04683
RACE is a large-scale reading comprehension dataset with more than 28,000 passages
and nearly 100,000 questions. The dataset is collected from English examinations
in China, which are designed for middle school and high school students. The dataset
can be served as the training and test sets for machine comprehension.
Homepage: https://www.cs.cmu.edu/~glai1/data/race/
### Citation
```
@inproceedings{lai-etal-2017-race,
title = "{RACE}: Large-scale {R}e{A}ding Comprehension Dataset From Examinations",
author = "Lai, Guokun and
Xie, Qizhe and
Liu, Hanxiao and
Yang, Yiming and
Hovy, Eduard",
editor = "Palmer, Martha and
Hwa, Rebecca and
Riedel, Sebastian",
booktitle = "Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing",
month = sep,
year = "2017",
address = "Copenhagen, Denmark",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/D17-1082",
doi = "10.18653/v1/D17-1082",
pages = "785--794"
}
```
### Groups and Tasks
#### Groups
* Not part of a group yet.
#### Tasks
* `race`
### Checklist
For adding novel benchmarks/datasets to the library:
* [ ] Is the task an existing benchmark in the literature?
* [ ] Have you referenced the original paper that introduced the task?
* [ ] If yes, does the original paper provide a reference implementation? If so, have you checked against the reference implementation and documented how to run such a test?
If other tasks on this dataset are already supported:
* [ ] Is the "Main" variant of this task clearly denoted?
* [ ] Have you provided a short sentence in a README on what each new variant adds / evaluates?
* [ ] Have you noted which, if any, published evaluation setups are matched by this variant?
|
{
"source": "simplescaling/s1",
"title": "eval/lm-evaluation-harness/lm_eval/tasks/race/README.md",
"url": "https://github.com/simplescaling/s1/blob/main/eval/lm-evaluation-harness/lm_eval/tasks/race/README.md",
"date": "2025-02-01T02:38:16",
"stars": 5696,
"description": "s1: Simple test-time scaling",
"file_size": 1973
}
|
# SciQ
### Paper
Title: `Crowdsourcing Multiple Choice Science Questions`
Abstract: https://aclanthology.org/W17-4413.pdf
The SciQ dataset contains 13,679 crowdsourced science exam questions about Physics,
Chemistry and Biology, among others. The questions are in multiple-choice format
with 4 answer options each. For the majority of the questions, an additional paragraph
with supporting evidence for the correct answer is provided.
Homepage: https://allenai.org/data/sciq
### Citation
```
@inproceedings{Welbl2017CrowdsourcingMC,
title={Crowdsourcing Multiple Choice Science Questions},
author={Johannes Welbl and Nelson F. Liu and Matt Gardner},
booktitle={NUT@EMNLP},
year={2017}
}
```
### Groups and Tasks
#### Groups
* Not part of a group yet.
#### Tasks
* `sciq`
### Checklist
For adding novel benchmarks/datasets to the library:
* [ ] Is the task an existing benchmark in the literature?
* [ ] Have you referenced the original paper that introduced the task?
* [ ] If yes, does the original paper provide a reference implementation? If so, have you checked against the reference implementation and documented how to run such a test?
If other tasks on this dataset are already supported:
* [ ] Is the "Main" variant of this task clearly denoted?
* [ ] Have you provided a short sentence in a README on what each new variant adds / evaluates?
* [ ] Have you noted which, if any, published evaluation setups are matched by this variant?
|
{
"source": "simplescaling/s1",
"title": "eval/lm-evaluation-harness/lm_eval/tasks/sciq/README.md",
"url": "https://github.com/simplescaling/s1/blob/main/eval/lm-evaluation-harness/lm_eval/tasks/sciq/README.md",
"date": "2025-02-01T02:38:16",
"stars": 5696,
"description": "s1: Simple test-time scaling",
"file_size": 1479
}
|
"""
SCROLLS: Standardized CompaRison Over Long Language Sequences
https://arxiv.org/abs/2201.03533
SCROLLS is a suite of datasets that require synthesizing information over long texts.
The benchmark includes seven natural language tasks across multiple domains,
including summarization, question answering, and natural language inference.
Homepage: https://www.scrolls-benchmark.com/
Since SCROLLS tasks are generally longer than the maximum sequence length of many models,
it is possible to create "subset" tasks that contain only those samples whose tokenized length
is less than some pre-defined limit. For example, to create a subset of "Qasper" that would
be suitable for a model using the GPTNeoX tokenizer and a 4K maximum sequence length:
```
class QasperGPTNeoX4K(Qasper):
PRUNE_TOKENIZERS = ["EleutherAI/pythia-410m-deduped"]
PRUNE_MAX_TOKENS = 4096
PRUNE_NUM_PROC = _num_cpu_cores() # optional, to speed up pruning of large datasets like NarrativeQA
```
`PRUNE_TOKENIZERS` can contain more than one tokenizer; this will include only samples that are
less than `PRUNE_MAX_TOKENS` for ALL of the tokenizers. This can be useful to comparing models
that use different tokenizers but the same maximum sequence length.
Once the subset task class has been defined in this file, it can be used by adding the class
to `lm_eval/tasks/__init__.py`.
NOTE: GovReport may need `max_gen_toks` set larger for causal models.
"""
|
{
"source": "simplescaling/s1",
"title": "eval/lm-evaluation-harness/lm_eval/tasks/scrolls/README.md",
"url": "https://github.com/simplescaling/s1/blob/main/eval/lm-evaluation-harness/lm_eval/tasks/scrolls/README.md",
"date": "2025-02-01T02:38:16",
"stars": 5696,
"description": "s1: Simple test-time scaling",
"file_size": 1441
}
|
# Social IQA
### Paper
Title: Social IQA: Commonsense Reasoning about Social Interactions
Abstract: https://arxiv.org/abs/1904.09728
> We introduce Social IQa, the first largescale benchmark for commonsense reasoning about social situations. Social IQa contains 38,000 multiple choice questions for probing emotional and social intelligence in a variety of everyday situations (e.g., Q: "Jordan wanted to tell Tracy a secret, so Jordan leaned towards Tracy. Why did Jordan do this?" A: "Make sure no one else could hear"). Through crowdsourcing, we collect commonsense questions along with correct and incorrect answers about social interactions, using a new framework that mitigates stylistic artifacts in incorrect answers by asking workers to provide the right answer to a different but related question. Empirical results show that our benchmark is challenging for existing question-answering models based on pretrained language models, compared to human performance (>20% gap). Notably, we further establish Social IQa as a resource for transfer learning of commonsense knowledge, achieving state-of-the-art performance on multiple commonsense reasoning tasks (Winograd Schemas, COPA).
Homepage: https://allenai.org/data/socialiqa
### Citation
```
@inproceedings{sap2019social,
title={Social IQa: Commonsense Reasoning about Social Interactions},
author={Sap, Maarten and Rashkin, Hannah and Chen, Derek and Le Bras, Ronan and Choi, Yejin},
booktitle={Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP)},
pages={4463--4473},
year={2019}
}
```
### Checklist
For adding novel benchmarks/datasets to the library:
* [X] Is the task an existing benchmark in the literature?
* [X] Have you referenced the original paper that introduced the task?
* [X] If yes, does the original paper provide a reference implementation? If so, have you checked against the reference implementation and documented how to run such a test? The original paper doesn't have an associated implementation, but there is an official entry in [BigBench](https://github.com/google/BIG-bench/tree/main/bigbench/benchmark_tasks/social_iqa). I use the same prompting format as BigBench.
If other tasks on this dataset are already supported:
* [ ] Is the "Main" variant of this task clearly denoted?
* [ ] Have you provided a short sentence in a README on what each new variant adds / evaluates?
* [ ] Have you noted which, if any, published evaluation setups are matched by this variant?
|
{
"source": "simplescaling/s1",
"title": "eval/lm-evaluation-harness/lm_eval/tasks/siqa/README.md",
"url": "https://github.com/simplescaling/s1/blob/main/eval/lm-evaluation-harness/lm_eval/tasks/siqa/README.md",
"date": "2025-02-01T02:38:16",
"stars": 5696,
"description": "s1: Simple test-time scaling",
"file_size": 2606
}
|
# SpanishBench
### Paper
SpanishBench is a benchmark for evaluating language models in Spanish tasks. This is, it evaluates the ability of a language model to understand and generate Spanish text. SpanishBench offers a combination of pre-existing, open datasets. All the details of SpanishBench will be published in a paper soon.
The datasets included in SpanishBench are:
| Task | Category | Paper title | Homepage |
|:-------------:|:-----:|:-------------:|:-----:|
| Belebele_es | Reading Comprehension | [The Belebele Benchmark: a Parallel Reading Comprehension Dataset in 122 Language Variants](https://arxiv.org/abs/2308.16884) | https://huggingface.co/datasets/facebook/belebele |
| FLORES_es | Translation | [The FLORES-101 Evaluation Benchmark for Low-Resource and Multilingual Machine Translation](https://arxiv.org/abs/2106.03193) | https://huggingface.co/datasets/facebook/flores |
| MGSM_es | Math | [Language Models are Multilingual Chain-of-Thought Reasoners](https://arxiv.org/abs/2210.03057) | https://huggingface.co/datasets/juletxara/mgsm |
| PAWS-X_es | Paraphrasing | [PAWS-X: A Cross-lingual Adversarial Dataset for Paraphrase Identification](https://aclanthology.org/D19-1382/) | https://huggingface.co/datasets/google-research-datasets/paws-x |
| WNLI-es | Natural Language Inference | No paper. | https://huggingface.co/datasets/PlanTL-GOB-ES/wnli-es |
| XL-Sum_es | Summarization | [XL-Sum: Large-Scale Multilingual Abstractive Summarization for 44 Languages](https://aclanthology.org/2021.findings-acl.413/) | https://huggingface.co/datasets/csebuetnlp/xlsum |
| XNLI_es | Natural Language Inference | [XNLI: Evaluating Cross-lingual Sentence Representations](https://aclanthology.org/D18-1269/) | https://huggingface.co/datasets/facebook/xnli |
| XQuAD_es | Question Answering | [On the Cross-lingual Transferability of Monolingual Representations](https://aclanthology.org/2020.acl-main.421/) | https://huggingface.co/datasets/google/xquad |
| XStoryCloze_es | Commonsense Reasoning | [Few-shot Learning with Multilingual Generative Language Models](https://aclanthology.org/2022.emnlp-main.616/) | https://huggingface.co/datasets/juletxara/xstory_cloze |
### Citation
Paper for SpanishBench coming soon.
### Groups and Tasks
#### Groups
- `spanish_bench`: All tasks included in SpanishBench.
- `flores_es`: All FLORES translation tasks from or to Spanish.
#### Tags
- `phrases_es`: Two Phrases_va tasks for language adaptation between Spanish and Valencian.
#### Tasks
The following tasks evaluate tasks on SpanishBench dataset using various scoring methods.
- `belebele_spa_Latn`
- `flores_es`
- `flores_es-ca`
- `flores_es-de`
- `flores_es-en`
- `flores_es-eu`
- `flores_es-fr`
- `flores_es-gl`
- `flores_es-it`
- `flores_es-pt`
- `flores_ca-es`
- `flores_de-es`
- `flores_en-es`
- `flores_eu-es`
- `flores_fr-es`
- `flores_gl-es`
- `flores_it-es`
- `flores_pt-es`
- `mgsm_direct_es_v2` (`v2` is due to an existing open issue in the original task)
- `paws_es`
- `phrases_es`
- `wnli_es`
- `xlsum_es`
- `xnli_es`
- `xquad_es`
- `xstorycloze_es`
Some of these tasks are taken from benchmarks already available in LM Evaluation Harness. These are:
- `belebele_spa_Latn`: Belebele Spanish
- `mgsm_direct_es`: MGSM Spanish (We fix an existing open issue in the original task)
- `paws_es`: PAWS-X Spanish
- `xnli_es`: XNLI Spanish
- `xstorycloze_es`: XStoryCloze Spanish
### Checklist
* [x] Is the task an existing benchmark in the literature?
* [ ] Have you referenced the original paper that introduced the task?
* [ ] If yes, does the original paper provide a reference implementation?
* [ ] Yes, original implementation contributed by author of the benchmark
If other tasks on this dataset are already supported:
* [ ] Is the "Main" variant of this task clearly denoted?
* [ ] Have you provided a short sentence in a README on what each new variant adds / evaluates?
* [ ] Have you noted which, if any, published evaluation setups are matched by this variant?
|
{
"source": "simplescaling/s1",
"title": "eval/lm-evaluation-harness/lm_eval/tasks/spanish_bench/README.md",
"url": "https://github.com/simplescaling/s1/blob/main/eval/lm-evaluation-harness/lm_eval/tasks/spanish_bench/README.md",
"date": "2025-02-01T02:38:16",
"stars": 5696,
"description": "s1: Simple test-time scaling",
"file_size": 4091
}
|
# Squad-completion
### Paper
Title: Simple Linear Attention Language Models Balance The Recall-Throughput Tradeoff
A Variant of the SQuAD question answering task, as implemented by Based. See [https://github.com/EleutherAI/lm-evaluation-harness/lm_eval/tasks/squadv2/README.md] for more info.
Homepage: https://github.com/HazyResearch/based-evaluation-harness
### Citation
```
@misc{arora2024simple,
title={Simple linear attention language models balance the recall-throughput tradeoff},
author={Simran Arora and Sabri Eyuboglu and Michael Zhang and Aman Timalsina and Silas Alberti and Dylan Zinsley and James Zou and Atri Rudra and Christopher Ré},
year={2024},
eprint={2402.18668},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
@misc{rajpurkar2018know,
title={Know What You Don't Know: Unanswerable Questions for SQuAD},
author={Pranav Rajpurkar and Robin Jia and Percy Liang},
year={2018},
eprint={1806.03822},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
### Groups and Tasks
#### Tasks
* `squad_completion`: the SQuAD task as implemented in the paper "Simple linear attention language models balance the recall-throughput tradeoff". Designed for zero-shot evaluation of small LMs.
### Checklist
For adding novel benchmarks/datasets to the library:
* [x] Is the task an existing benchmark in the literature?
* [x] Have you referenced the original paper that introduced the task?
* [x] If yes, does the original paper provide a reference implementation? If so, have you checked against the reference implementation and documented how to run such a test?
If other tasks on this dataset are already supported:
* [x] Is the "Main" variant of this task clearly denoted?
* [x] Have you provided a short sentence in a README on what each new variant adds / evaluates?
* [x] Have you noted which, if any, published evaluation setups are matched by this variant?
|
{
"source": "simplescaling/s1",
"title": "eval/lm-evaluation-harness/lm_eval/tasks/squad_completion/README.md",
"url": "https://github.com/simplescaling/s1/blob/main/eval/lm-evaluation-harness/lm_eval/tasks/squad_completion/README.md",
"date": "2025-02-01T02:38:16",
"stars": 5696,
"description": "s1: Simple test-time scaling",
"file_size": 1945
}
|
# Task-name
### Paper
Title: `Know What You Don’t Know: Unanswerable Questions for SQuAD`
Abstract: https://arxiv.org/abs/1806.03822
Stanford Question Answering Dataset (SQuAD) is a reading comprehension dataset,
consisting of questions posed by crowdworkers on a set of Wikipedia articles,
where the answer to every question is a segment of text, or span, from the
corresponding reading passage, or the question might be unanswerable.
SQuAD2.0 combines the 100,000 questions in SQuAD1.1 with over 50,000 unanswerable
questions written adversarially by crowdworkers to look similar to answerable ones.
To do well on SQuAD2.0, systems must not only answer questions when possible, but
also determine when no answer is supported by the paragraph and abstain from answering.
Homepage: https://rajpurkar.github.io/SQuAD-explorer/
### Citation
```
@misc{rajpurkar2018know,
title={Know What You Don't Know: Unanswerable Questions for SQuAD},
author={Pranav Rajpurkar and Robin Jia and Percy Liang},
year={2018},
eprint={1806.03822},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
### Groups and Tasks
#### Groups
* Not part of a group yet
#### Tasks
* `squadv2`: `Default squadv2 task`
### Checklist
For adding novel benchmarks/datasets to the library:
* [ ] Is the task an existing benchmark in the literature?
* [ ] Have you referenced the original paper that introduced the task?
* [ ] If yes, does the original paper provide a reference implementation? If so, have you checked against the reference implementation and documented how to run such a test?
If other tasks on this dataset are already supported:
* [ ] Is the "Main" variant of this task clearly denoted?
* [ ] Have you provided a short sentence in a README on what each new variant adds / evaluates?
* [ ] Have you noted which, if any, published evaluation setups are matched by this variant?
|
{
"source": "simplescaling/s1",
"title": "eval/lm-evaluation-harness/lm_eval/tasks/squadv2/README.md",
"url": "https://github.com/simplescaling/s1/blob/main/eval/lm-evaluation-harness/lm_eval/tasks/squadv2/README.md",
"date": "2025-02-01T02:38:16",
"stars": 5696,
"description": "s1: Simple test-time scaling",
"file_size": 1898
}
|
# StoryCloze
### Paper
Title: `A Corpus and Evaluation Framework for Deeper Understanding of Commonsense Stories`
Abstract: `https://arxiv.org/abs/1604.01696`
Homepage: https://cs.rochester.edu/nlp/rocstories/
'Story Cloze Test' is a new commonsense reasoning framework for evaluating story understanding, story generation, and script learning. This test requires a system to choose the correct ending to a four-sentence story
### Citation
```
@misc{mostafazadeh2016corpus,
title={A Corpus and Evaluation Framework for Deeper Understanding of Commonsense Stories},
author={Nasrin Mostafazadeh and
Nathanael Chambers and
Xiaodong He and
Devi Parikh and
Dhruv Batra and
Lucy Vanderwende and
Pushmeet Kohli and
James Allen},
year={2016},
eprint={1604.01696},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
### Groups and Tasks
#### Groups
* `storycloze`
#### Tasks
* `storycloze_2016`
* `storycloze_2018`
### Checklist
For adding novel benchmarks/datasets to the library:
* [ ] Is the task an existing benchmark in the literature?
* [ ] Have you referenced the original paper that introduced the task?
* [ ] If yes, does the original paper provide a reference implementation? If so, have you checked against the reference implementation and documented how to run such a test?
If other tasks on this dataset are already supported:
* [ ] Is the "Main" variant of this task clearly denoted?
* [ ] Have you provided a short sentence in a README on what each new variant adds / evaluates?
* [ ] Have you noted which, if any, published evaluation setups are matched by this variant?
|
{
"source": "simplescaling/s1",
"title": "eval/lm-evaluation-harness/lm_eval/tasks/storycloze/README.md",
"url": "https://github.com/simplescaling/s1/blob/main/eval/lm-evaluation-harness/lm_eval/tasks/storycloze/README.md",
"date": "2025-02-01T02:38:16",
"stars": 5696,
"description": "s1: Simple test-time scaling",
"file_size": 1674
}
|
# SuperGLUE
### Paper
Title: `SuperGLUE: A Stickier Benchmark for General-Purpose Language Understanding Systems`
Abstract: `https://w4ngatang.github.io/static/papers/superglue.pdf`
SuperGLUE is a benchmark styled after GLUE with a new set of more difficult language
understanding tasks.
Homepage: https://super.gluebenchmark.com/
### Citation
```
@inproceedings{NEURIPS2019_4496bf24,
author = {Wang, Alex and Pruksachatkun, Yada and Nangia, Nikita and Singh, Amanpreet and Michael, Julian and Hill, Felix and Levy, Omer and Bowman, Samuel},
booktitle = {Advances in Neural Information Processing Systems},
editor = {H. Wallach and H. Larochelle and A. Beygelzimer and F. d\textquotesingle Alch\'{e}-Buc and E. Fox and R. Garnett},
pages = {},
publisher = {Curran Associates, Inc.},
title = {SuperGLUE: A Stickier Benchmark for General-Purpose Language Understanding Systems},
url = {https://proceedings.neurips.cc/paper/2019/file/4496bf24afe7fab6f046bf4923da8de6-Paper.pdf},
volume = {32},
year = {2019}
}
```
### Groups, Tags, and Tasks
#### Groups
None.
#### Tags
* `super-glue-lm-eval-v1`: SuperGLUE eval adapted from LM Eval V1
* `super-glue-t5-prompt`: SuperGLUE prompt and evaluation that matches the T5 paper (if using accelerate, will error if record is included.)
#### Tasks
Comparison between validation split score on T5x and LM-Eval (T5x models converted to HF)
| T5V1.1 Base | SGLUE | BoolQ | CB | Copa | MultiRC | ReCoRD | RTE | WiC | WSC |
| ----------- | ------| ----- | --------- | ---- | ------- | ------ | --- | --- | --- |
| T5x | 69.47 | 78.47(acc) | 83.93(f1) 87.5(acc) | 50(acc) | 73.81(f1) 33.26(em) | 70.09(em) 71.34(f1) | 78.7(acc) | 63.64(acc) | 75(acc) |
| LM-Eval | 71.35 | 79.36(acc) | 83.63(f1) 87.5(acc) | 63(acc) | 73.45(f1) 33.26(em) | 69.85(em) 68.86(f1) | 78.34(acc) | 65.83(acc) | 75.96(acc) |
* `super-glue-lm-eval-v1`
- `boolq`
- `cb`
- `copa`
- `multirc`
- `record`
- `rte`
- `wic`
- `wsc`
* `super-glue-t5-prompt`
- `super_glue-boolq-t5-prompt`
- `super_glue-cb-t5-prompt`
- `super_glue-copa-t5-prompt`
- `super_glue-multirc-t5-prompt`
- `super_glue-record-t5-prompt`
- `super_glue-rte-t5-prompt`
- `super_glue-wic-t5-prompt`
- `super_glue-wsc-t5-prompt`
### Checklist
For adding novel benchmarks/datasets to the library:
* [ ] Is the task an existing benchmark in the literature?
* [ ] Have you referenced the original paper that introduced the task?
* [ ] If yes, does the original paper provide a reference implementation? If so, have you checked against the reference implementation and documented how to run such a test?
If other tasks on this dataset are already supported:
* [ ] Is the "Main" variant of this task clearly denoted?
* [ ] Have you provided a short sentence in a README on what each new variant adds / evaluates?
* [ ] Have you noted which, if any, published evaluation setups are matched by this variant?
|
{
"source": "simplescaling/s1",
"title": "eval/lm-evaluation-harness/lm_eval/tasks/super_glue/README.md",
"url": "https://github.com/simplescaling/s1/blob/main/eval/lm-evaluation-harness/lm_eval/tasks/super_glue/README.md",
"date": "2025-02-01T02:38:16",
"stars": 5696,
"description": "s1: Simple test-time scaling",
"file_size": 3001
}
|
# SWAG
### Paper
Title: `SWAG: A Large-Scale Adversarial Dataset for Grounded Commonsense Inference`
Abstract: https://arxiv.org/pdf/1808.05326.pdf
SWAG (Situations With Adversarial Generations) is an adversarial dataset
that consists of 113k multiple choice questions about grounded situations. Each
question is a video caption from LSMDC or ActivityNet Captions, with four answer
choices about what might happen next in the scene. The correct answer is the
(real) video caption for the next event in the video; the three incorrect
answers are adversarially generated and human verified, so as to fool machines
but not humans.
Homepage: https://rowanzellers.com/swag/
### Citation
```
@inproceedings{zellers2018swagaf,
title={SWAG: A Large-Scale Adversarial Dataset for Grounded Commonsense Inference},
author={Zellers, Rowan and Bisk, Yonatan and Schwartz, Roy and Choi, Yejin},
booktitle = "Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing (EMNLP)",
year={2018}
}
```
### Groups and Tasks
#### Groups
* Not a part of a task yet.
#### Tasks
* `swag`
### Checklist
For adding novel benchmarks/datasets to the library:
* [ ] Is the task an existing benchmark in the literature?
* [ ] Have you referenced the original paper that introduced the task?
* [ ] If yes, does the original paper provide a reference implementation? If so, have you checked against the reference implementation and documented how to run such a test?
If other tasks on this dataset are already supported:
* [ ] Is the "Main" variant of this task clearly denoted?
* [ ] Have you provided a short sentence in a README on what each new variant adds / evaluates?
* [ ] Have you noted which, if any, published evaluation setups are matched by this variant?
|
{
"source": "simplescaling/s1",
"title": "eval/lm-evaluation-harness/lm_eval/tasks/swag/README.md",
"url": "https://github.com/simplescaling/s1/blob/main/eval/lm-evaluation-harness/lm_eval/tasks/swag/README.md",
"date": "2025-02-01T02:38:16",
"stars": 5696,
"description": "s1: Simple test-time scaling",
"file_size": 1798
}
|
# SWDE
### Paper
Title: Language Models Enable Simple Systems For
Generating Structured Views Of Heterogenous Data
Lakes
Abstract: A long standing goal of the data management community is to develop general, automated systems
that ingest semi-structured documents and output queryable tables without human effort or domain
specific customization. Given the sheer variety of potential documents, state-of-the art systems make
simplifying assumptions and use domain specific training. In this work, we ask whether we can
maintain generality by using large language models (LLMs). LLMs, which are pretrained on broad
data, can perform diverse downstream tasks simply conditioned on natural language task descriptions.
We propose and evaluate EVAPORATE, a simple, prototype system powered by LLMs. We identify
two fundamentally different strategies for implementing this system: prompt the LLM to directly
extract values from documents or prompt the LLM to synthesize code that performs the extraction.
Our evaluations show a cost-quality tradeoff between these two approaches. Code synthesis is cheap,
but far less accurate than directly processing each document with the LLM. To improve quality while
maintaining low cost, we propose an extended code synthesis implementation, EVAPORATE-CODE+,
which achieves better quality than direct extraction. Our key insight is to generate many candidate
functions and ensemble their extractions using weak supervision. EVAPORATE-CODE+ not only
outperforms the state-of-the art systems, but does so using a sublinear pass over the documents with
the LLM. This equates to a 110× reduction in the number of tokens the LLM needs to process,
averaged across 16 real-world evaluation settings of 10k documents each.
A task for LMs to perform Information Extraction, as implemented by Based.
Homepage: https://github.com/HazyResearch/based-evaluation-harness
Description:
> SWDE (Information Extraction). The task in the SWDE benchmark is to extract semi-structured relations from raw HTML websites. For example, given an IMBD page for a movie (e.g. Harry Potter and the Sorcerer’s Stone) and a relation key (e.g. release date), the model must extract the correct relation value (e.g. 2001). The SWDE benchmark was originally curated by Lockard et al. for the task of open information extraction from the semi-structured web. Because we are evaluating the zero-shot capabilities of relatively small language models, we adapt the task to make it slightly easier. Our task setup is similar after to that used in Arora et al.
### Citation
```
@misc{arora2024simple,
title={Simple linear attention language models balance the recall-throughput tradeoff},
author={Simran Arora and Sabri Eyuboglu and Michael Zhang and Aman Timalsina and Silas Alberti and Dylan Zinsley and James Zou and Atri Rudra and Christopher Ré},
year={2024},
eprint={2402.18668},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
@misc{arora2023language,
title={Language Models Enable Simple Systems for Generating Structured Views of Heterogeneous Data Lakes},
author={Simran Arora and Brandon Yang and Sabri Eyuboglu and Avanika Narayan and Andrew Hojel and Immanuel Trummer and Christopher Ré},
year={2023},
eprint={2304.09433},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
@inproceedings{lockard-etal-2019-openceres,
title = "{O}pen{C}eres: {W}hen Open Information Extraction Meets the Semi-Structured Web",
author = "Lockard, Colin and
Shiralkar, Prashant and
Dong, Xin Luna",
editor = "Burstein, Jill and
Doran, Christy and
Solorio, Thamar",
booktitle = "Proceedings of the 2019 Conference of the North {A}merican Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers)",
month = jun,
year = "2019",
address = "Minneapolis, Minnesota",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/N19-1309",
doi = "10.18653/v1/N19-1309",
pages = "3047--3056",
abstract = "Open Information Extraction (OpenIE), the problem of harvesting triples from natural language text whose predicate relations are not aligned to any pre-defined ontology, has been a popular subject of research for the last decade. However, this research has largely ignored the vast quantity of facts available in semi-structured webpages. In this paper, we define the problem of OpenIE from semi-structured websites to extract such facts, and present an approach for solving it. We also introduce a labeled evaluation dataset to motivate research in this area. Given a semi-structured website and a set of seed facts for some relations existing on its pages, we employ a semi-supervised label propagation technique to automatically create training data for the relations present on the site. We then use this training data to learn a classifier for relation extraction. Experimental results of this method on our new benchmark dataset obtained a precision of over 70{\%}. A larger scale extraction experiment on 31 websites in the movie vertical resulted in the extraction of over 2 million triples.",
}
```
### Groups and Tasks
#### Tasks
* `swde`: the SWDE task as implemented in the paper "Simple linear attention language models balance the recall-throughput tradeoff". Designed for zero-shot evaluation of small LMs.
### Checklist
For adding novel benchmarks/datasets to the library:
* [x] Is the task an existing benchmark in the literature?
* [x] Have you referenced the original paper that introduced the task?
* [x] If yes, does the original paper provide a reference implementation? If so, have you checked against the reference implementation and documented how to run such a test?
If other tasks on this dataset are already supported:
* [x] Is the "Main" variant of this task clearly denoted?
* [x] Have you provided a short sentence in a README on what each new variant adds / evaluates?
* [x] Have you noted which, if any, published evaluation setups are matched by this variant?
|
{
"source": "simplescaling/s1",
"title": "eval/lm-evaluation-harness/lm_eval/tasks/swde/README.md",
"url": "https://github.com/simplescaling/s1/blob/main/eval/lm-evaluation-harness/lm_eval/tasks/swde/README.md",
"date": "2025-02-01T02:38:16",
"stars": 5696,
"description": "s1: Simple test-time scaling",
"file_size": 6130
}
|
# tinyBenchmarks
### Paper
Title: `tinyBenchmarks: evaluating LLMs with fewer examples`
Abstract: https://arxiv.org/abs/2402.14992
The versatility of large language models (LLMs) led to the creation of diverse benchmarks that thoroughly test a variety of language models' abilities. These benchmarks consist of tens of thousands of examples making evaluation of LLMs very expensive. In this paper, we investigate strategies to reduce the number of evaluations needed to assess the performance of an LLM on several key benchmarks. For example, we show that to accurately estimate the performance of an LLM on MMLU, a popular multiple-choice QA benchmark consisting of 14K examples, it is sufficient to evaluate this LLM on 100 curated examples. We release evaluation tools and tiny versions of popular benchmarks: Open LLM Leaderboard, MMLU, HELM, and AlpacaEval 2.0. Our empirical analysis demonstrates that these tools and tiny benchmarks are sufficient to reliably and efficiently reproduce the original evaluation results.
Homepage: -
All configs and utils mirror the ones from their original dataset!
### Groups and Tasks
#### Groups
* `tinyBenchmarks`
#### Tasks
* `tinyArc`, `tinyGSM8k`, `tinyHellaswag`, `tinyMMLU`, `tinyTruthfulQA`, `tinyWinogrande`
### Usage
*tinyBenchmarks* can evaluate different benchmarks with a fraction of their examples.
To obtain accurate results, this task applies post-processing using the *tinyBenchmarks*-package.
You can install the package by running the following commands on the terminal (for more information see [here](https://github.com/felipemaiapolo/tinyBenchmarks/blob/main/README.md?plain=1)):
``` :sh
pip install git+https://github.com/felipemaiapolo/tinyBenchmarks
```
The value that is returned by the task corresponds to the '**IRT++**'-method from the [original paper](https://arxiv.org/abs/2402.14992).
Evaluate specific tasks individually (e.g. `--tasks tinyHellaswag`) or all [open LLM leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard) tasks by specifying `--tasks tinyBenchmarks`.
### Advanced usage
To obtain the estimated accuracies from all methods from the original paper, the *tinyBenchmarks*-package has to be applied manually.
To do so, run the evaluation with the `--log_samples` and `--output_path` arguments. For example:
```bash
lm_eval --model hf \
--model_args pretrained="mistralai/Mistral-7B-Instruct-v0.2" \
--tasks tinyHellaswag \
--batch_size 4 \
--output_path '<output_path>' \
--log_samples
```
Afterwards, run include the correct `file_path` and run the following script:
```python
import json
import tinyBenchmarks as tb
import numpy as np
# Choose benchmark (e.g. hellaswag)
benchmark = 'hellaswag' # possible benchmarks:
# ['mmlu','truthfulqa', 'gsm8k',
# 'winogrande', 'arc', 'hellaswag']
# Get score vector from output-file (the metric [here `acc_norm`] depends on the benchmark)
file_path = '<output_path>/<output-file.jsonl>'
with open(file_path, 'r') as file:
outputs = json.load(file)
# Ensuring correct order of outputs
outputs = sorted(outputs, key=lambda x: x['doc_id'])
y = np.array([float(item['acc_norm']) for item in outputs])
### Evaluation
tb.evaluate(y, benchmark)
```
### Performance
We report in the following tables the average estimation error in the test set (using data from the paper) and standard deviation across LLMs.
#### Open LLM Leaderboard
Estimating performance for each scenario separately
|| IRT | p-IRT | gp-IRT |
|--|--|--|--|
| TruthfulQA | 0.013 (0.010) | 0.010 (0.009) | 0.011 (0.009) |
| GSM8K | 0.022 (0.017) | 0.029 (0.022) | 0.020 (0.017) |
| Winogrande | 0.022 (0.017) | 0.016 (0.014) | 0.015 (0.013) |
| ARC | 0.022 (0.018) | 0.017 (0.014) | 0.017 (0.013) |
| HellaSwag | 0.013 (0.016) | 0.015 (0.012) | 0.015 (0.012) |
| MMLU | 0.024 (0.017) | 0.016 (0.015) | 0.016 (0.015) |
Estimating performance for each scenario all at once
|| IRT | p-IRT | gp-IRT |
|--|--|--|--|
| TruthfulQA | 0.013 (0.010) | 0.016 (0.013) | 0.011 (0.009) |
| GSM8K | 0.022 (0.017) | 0.022 (0.017) | 0.020 (0.015) |
| Winogrande | 0.022 (0.017) | 0.011 (0.013) | 0.011 (0.011) |
| ARC | 0.022 (0.018) | 0.012 (0.010) | 0.010 (0.009) |
| HellaSwag | 0.013 (0.016) | 0.011 (0.020) | 0.011 (0.018) |
| MMLU | 0.024 (0.018) | 0.017 (0.017) | 0.015 (0.015) |
### Citation
```
@article{polo2024tinybenchmarks,
title={tinyBenchmarks: evaluating LLMs with fewer examples},
author={Maia Polo, Felipe and Weber, Lucas and Choshen, Leshem and Sun, Yuekai and Xu, Gongjun and Yurochkin, Mikhail},
journal={arXiv preprint arXiv:2402.14992},
year={2024}
}
```
Please also reference the respective original dataset that you are using!
### Checklist
For adding novel benchmarks/datasets to the library:
* [x] Is the task an existing benchmark in the literature?
* [x] Have you referenced the original paper that introduced the task?
* [x] If yes, does the original paper provide a reference implementation? If so, have you checked against the reference implementation and documented how to run such a test?
If other tasks on this dataset are already supported:
* [x] Is the "Main" variant of this task clearly denoted?
* [x] Have you provided a short sentence in a README on what each new variant adds / evaluates?
* [x] Have you noted which, if any, published evaluation setups are matched by this variant?
|
{
"source": "simplescaling/s1",
"title": "eval/lm-evaluation-harness/lm_eval/tasks/tinyBenchmarks/README.md",
"url": "https://github.com/simplescaling/s1/blob/main/eval/lm-evaluation-harness/lm_eval/tasks/tinyBenchmarks/README.md",
"date": "2025-02-01T02:38:16",
"stars": 5696,
"description": "s1: Simple test-time scaling",
"file_size": 5489
}
|
# TMLU
### Paper
Title: `Measuring Taiwanese Mandarin Language Understanding`
Abstract: `The evaluation of large language models (LLMs) has drawn substantial attention in the field recently. This work focuses on evaluating LLMs in a Chinese context, specifically, for Traditional Chinese which has been largely underrepresented in existing benchmarks. We present TMLU, a holistic evaluation suit tailored for assessing the advanced knowledge and reasoning capability in LLMs, under the context of Taiwanese Mandarin. TMLU consists of an array of 37 subjects across social science, STEM, humanities, Taiwan-specific content, and others, ranging from middle school to professional levels. In addition, we curate chain-of-thought-like few-shot explanations for each subject to facilitate the evaluation of complex reasoning skills. To establish a comprehensive baseline, we conduct extensive experiments and analysis on 24 advanced LLMs. The results suggest that Chinese open-weight models demonstrate inferior performance comparing to multilingual proprietary ones, and open-weight models tailored for Taiwanese Mandarin lag behind the Simplified-Chinese counterparts. The findings indicate great headrooms for improvement, and emphasize the goal of TMLU to foster the development of localized Taiwanese-Mandarin LLMs. We release the benchmark and evaluation scripts for the community to promote future research.`
Homepage: [TMLU Huggingface Dataset](https://huggingface.co/datasets/miulab/tmlu)
### Citation
```
@article{DBLP:journals/corr/abs-2403-20180,
author = {Po{-}Heng Chen and
Sijia Cheng and
Wei{-}Lin Chen and
Yen{-}Ting Lin and
Yun{-}Nung Chen},
title = {Measuring Taiwanese Mandarin Language Understanding},
journal = {CoRR},
volume = {abs/2403.20180},
year = {2024},
url = {https://doi.org/10.48550/arXiv.2403.20180},
doi = {10.48550/ARXIV.2403.20180},
eprinttype = {arXiv},
eprint = {2403.20180},
timestamp = {Wed, 10 Apr 2024 17:37:45 +0200},
biburl = {https://dblp.org/rec/journals/corr/abs-2403-20180.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
```
### Groups and Tasks
#### Groups
* `tmlu`: `The dataset comprises 2,981 multiple-choice questions from 37 subjects. `
#### Tasks
The following tasks evaluate subjects in the TMLU dataset using loglikelihood-based multiple-choice scoring:
* `tmlu_{subject_english}`
### Checklist
For adding novel benchmarks/datasets to the library:
* [x] Is the task an existing benchmark in the literature?
* [x] Have you referenced the original paper that introduced the task?
* [x] If yes, does the original paper provide a reference implementation? If so, have you checked against the reference implementation and documented how to run such a test?
If other tasks on this dataset are already supported:
* [x] Is the "Main" variant of this task clearly denoted?
* [x] Have you provided a short sentence in a README on what each new variant adds / evaluates?
* [x] Have you noted which, if any, published evaluation setups are matched by this variant?
|
{
"source": "simplescaling/s1",
"title": "eval/lm-evaluation-harness/lm_eval/tasks/tmlu/README.md",
"url": "https://github.com/simplescaling/s1/blob/main/eval/lm-evaluation-harness/lm_eval/tasks/tmlu/README.md",
"date": "2025-02-01T02:38:16",
"stars": 5696,
"description": "s1: Simple test-time scaling",
"file_size": 3221
}
|
# TMMLU+
### Paper
Title: `An Improved Traditional Chinese Evaluation Suite for Foundation Model`
Abstract: `We present TMMLU+, a comprehensive dataset designed for the Traditional Chinese massive multitask language understanding dataset. TMMLU+ is a multiple-choice question-answering dataset with 66 subjects from elementary to professional level. Compared to its predecessor, TMMLU, TMMLU+ is six times larger and boasts a more balanced subject distribution. We included benchmark results in TMMLU+ from closed-source models and 24 open-weight Chinese large language models of parameters ranging from 1.8B to 72B. Our findings reveal that Traditional Chinese models still trail behind their Simplified Chinese counterparts. Additionally, current large language models have yet to outperform human performance in average scores. We publicly release our dataset and the corresponding benchmark source code.`
Homepage: [https://huggingface.co/datasets/ikala/tmmluplus](https://huggingface.co/datasets/ikala/tmmluplus)
### Citation
```
@article{ikala2024improved,
title={An Improved Traditional Chinese Evaluation Suite for Foundation Model},
author={Tam, Zhi-Rui and Pai, Ya-Ting and Lee, Yen-Wei and Cheng, Sega and Shuai, Hong-Han},
journal={arXiv preprint arXiv:2403.01858},
year={2024}
}
```
### Groups and Tasks
#### Groups
* `tmmluplus`: `The dataset comprises 22,690 multiple-choice questions from 66 subjects ranging from primary to professional level. `
#### Tasks
The following tasks evaluate subjects in the TMMLU+ dataset using loglikelihood-based multiple-choice scoring:
* `tmmluplus_{subject_english}`
### Checklist
For adding novel benchmarks/datasets to the library:
* [x] Is the task an existing benchmark in the literature?
* [x] Have you referenced the original paper that introduced the task?
* [x] If yes, does the original paper provide a reference implementation? If so, have you checked against the reference implementation and documented how to run such a test?
If other tasks on this dataset are already supported:
* [x] Is the "Main" variant of this task clearly denoted?
* [x] Have you provided a short sentence in a README on what each new variant adds / evaluates?
* [x] Have you noted which, if any, published evaluation setups are matched by this variant?
|
{
"source": "simplescaling/s1",
"title": "eval/lm-evaluation-harness/lm_eval/tasks/tmmluplus/README.md",
"url": "https://github.com/simplescaling/s1/blob/main/eval/lm-evaluation-harness/lm_eval/tasks/tmmluplus/README.md",
"date": "2025-02-01T02:38:16",
"stars": 5696,
"description": "s1: Simple test-time scaling",
"file_size": 2318
}
|
# ToxiGen
### Paper
Title: `ToxiGen: A Large-Scale Machine-Generated Dataset for Adversarial and Implicit Hate Speech Detection`
Abstract: https://arxiv.org/abs/2203.09509
Classify input text as either hateful or not hateful.
Homepage: https://github.com/microsoft/TOXIGEN
### Citation
```
@inproceedings{hartvigsen2022toxigen,
title={ToxiGen: A Large-Scale Machine-Generated Dataset for Implicit and Adversarial Hate Speech Detection},
author={Hartvigsen, Thomas and Gabriel, Saadia and Palangi, Hamid and Sap, Maarten and Ray, Dipankar and Kamar, Ece},
booktitle={Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics},
year={2022}
}
```
### Groups and Tasks
#### Groups
* Not part of a group yet.
#### Tasks
* `toxigen`
### Checklist
For adding novel benchmarks/datasets to the library:
* [ ] Is the task an existing benchmark in the literature?
* [ ] Have you referenced the original paper that introduced the task?
* [ ] If yes, does the original paper provide a reference implementation? If so, have you checked against the reference implementation and documented how to run such a test?
If other tasks on this dataset are already supported:
* [ ] Is the "Main" variant of this task clearly denoted?
* [ ] Have you provided a short sentence in a README on what each new variant adds / evaluates?
* [ ] Have you noted which, if any, published evaluation setups are matched by this variant?
|
{
"source": "simplescaling/s1",
"title": "eval/lm-evaluation-harness/lm_eval/tasks/toxigen/README.md",
"url": "https://github.com/simplescaling/s1/blob/main/eval/lm-evaluation-harness/lm_eval/tasks/toxigen/README.md",
"date": "2025-02-01T02:38:16",
"stars": 5696,
"description": "s1: Simple test-time scaling",
"file_size": 1457
}
|
# Translation Tasks
### Paper
### Citation
```
```
### Groups and Tasks
#### Groups
* `gpt3_translation_tasks`
* `wmt14`
* `wmt16`
* `wmt20`
* `iwslt2017`
#### Tasks
*
### Checklist
For adding novel benchmarks/datasets to the library:
* [x] Is the task an existing benchmark in the literature?
* [ ] Have you referenced the original paper that introduced the task?
* [ ] If yes, does the original paper provide a reference implementation? If so, have you checked against the reference implementation and documented how to run such a test?
If other tasks on this dataset are already supported:
* [x] Is the "Main" variant of this task clearly denoted?
* [ ] Have you provided a short sentence in a README on what each new variant adds / evaluates?
* [ ] Have you noted which, if any, published evaluation setups are matched by this variant?
* [ ] Checked for equivalence with v0.3.0 LM Evaluation Harness
|
{
"source": "simplescaling/s1",
"title": "eval/lm-evaluation-harness/lm_eval/tasks/translation/README.md",
"url": "https://github.com/simplescaling/s1/blob/main/eval/lm-evaluation-harness/lm_eval/tasks/translation/README.md",
"date": "2025-02-01T02:38:16",
"stars": 5696,
"description": "s1: Simple test-time scaling",
"file_size": 924
}
|
# Trivia QA
### Paper
Title: `TriviaQA: A Large Scale Distantly Supervised Challenge Dataset for Reading Comprehension`
Abstract: https://arxiv.org/abs/1705.03551
TriviaQA is a reading comprehension dataset containing over 650K question-answer-evidence
triples. TriviaQA includes 95K question-answer pairs authored by trivia enthusiasts
and independently gathered evidence documents, six per question on average, that provide
high quality distant supervision for answering the questions.
Homepage: https://nlp.cs.washington.edu/triviaqa/
### Citation
```
@InProceedings{JoshiTriviaQA2017,
author = {Joshi, Mandar and Choi, Eunsol and Weld, Daniel S. and Zettlemoyer, Luke},
title = {TriviaQA: A Large Scale Distantly Supervised Challenge Dataset for Reading Comprehension},
booktitle = {Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics},
month = {July},
year = {2017},
address = {Vancouver, Canada},
publisher = {Association for Computational Linguistics},
}
```
### Groups and Tasks
#### Groups
* Not part of a group yet.
#### Tasks
* `triviaqa`: `Generate and answer based on the question.`
### Checklist
For adding novel benchmarks/datasets to the library:
* [ ] Is the task an existing benchmark in the literature?
* [ ] Have you referenced the original paper that introduced the task?
* [ ] If yes, does the original paper provide a reference implementation? If so, have you checked against the reference implementation and documented how to run such a test?
If other tasks on this dataset are already supported:
* [ ] Is the "Main" variant of this task clearly denoted?
* [ ] Have you provided a short sentence in a README on what each new variant adds / evaluates?
* [ ] Have you noted which, if any, published evaluation setups are matched by this variant?
|
{
"source": "simplescaling/s1",
"title": "eval/lm-evaluation-harness/lm_eval/tasks/triviaqa/README.md",
"url": "https://github.com/simplescaling/s1/blob/main/eval/lm-evaluation-harness/lm_eval/tasks/triviaqa/README.md",
"date": "2025-02-01T02:38:16",
"stars": 5696,
"description": "s1: Simple test-time scaling",
"file_size": 1851
}
|
# TruthfulQA
### Paper
Title: `TruthfulQA: Measuring How Models Mimic Human Falsehoods`
Abstract: `https://arxiv.org/abs/2109.07958`
Homepage: `https://github.com/sylinrl/TruthfulQA`
### Citation
```
@inproceedings{lin-etal-2022-truthfulqa,
title = "{T}ruthful{QA}: Measuring How Models Mimic Human Falsehoods",
author = "Lin, Stephanie and
Hilton, Jacob and
Evans, Owain",
booktitle = "Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)",
month = may,
year = "2022",
address = "Dublin, Ireland",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2022.acl-long.229",
doi = "10.18653/v1/2022.acl-long.229",
pages = "3214--3252",
}
```
### Groups and Tasks
#### Groups
* Not part of a group yet.
#### Tasks
* `truthfulqa_mc1`: `Multiple-choice, single answer`
* `truthfulqa_mc2`: `Multiple-choice, multiple answers`
* `truthfulqa_gen`: `Answer generation`
### Checklist
For adding novel benchmarks/datasets to the library:
* [ ] Is the task an existing benchmark in the literature?
* [ ] Have you referenced the original paper that introduced the task?
* [ ] If yes, does the original paper provide a reference implementation? If so, have you checked against the reference implementation and documented how to run such a test?
If other tasks on this dataset are already supported:
* [ ] Is the "Main" variant of this task clearly denoted?
* [ ] Have you provided a short sentence in a README on what each new variant adds / evaluates?
* [ ] Have you noted which, if any, published evaluation setups are matched by this variant?
|
{
"source": "simplescaling/s1",
"title": "eval/lm-evaluation-harness/lm_eval/tasks/truthfulqa/README.md",
"url": "https://github.com/simplescaling/s1/blob/main/eval/lm-evaluation-harness/lm_eval/tasks/truthfulqa/README.md",
"date": "2025-02-01T02:38:16",
"stars": 5696,
"description": "s1: Simple test-time scaling",
"file_size": 1698
}
|
# TurkishMMLU
This repository contains configuration files for LM Evaluation Harness for Few-Shot and Chain-of-Thought experiments for TurkishMMLU. Using these configurations with LM Evaluation Harness, the results of this study are obtained.
TurkishMMLU is a multiple-choice Question-Answering dataset created for the Turkish Natural Language Processing (NLP) community based on Turkish Highschool Curricula across nine subjects. This comprehensive study is conducted to provide Question-Answering benchmark for Turkish language. The questions of the dataset are written by curriculum experts, suitable for the high-school curricula in Turkey, covering subjects ranging from natural sciences and math questions to more culturally representative topics such as Turkish Literature and the history of the Turkish Republic.
To access this dataset please send an email to:
[email protected] or [email protected].
## Abstract
Multiple choice question answering tasks evaluate the reasoning, comprehension, and mathematical abilities of Large Language Models (LLMs). While existing benchmarks employ automatic translation for multilingual evaluation, this approach is error-prone and potentially introduces culturally biased questions, especially in social sciences. We introduce the first multitask, multiple-choice Turkish QA benchmark, TurkishMMLU, to evaluate LLMs' understanding of the Turkish language. TurkishMMLU includes over 10,000 questions, covering 9 different subjects from Turkish high-school education curricula. These questions are written by curriculum experts, suitable for the high-school curricula in Turkey, covering subjects ranging from natural sciences and math questions to more culturally representative topics such as Turkish Literature and the history of the Turkish Republic. We evaluate over 20 LLMs, including multilingual open-source (e.g., Gemma, Llama, MT5), closed-source (GPT 4o, Claude, Gemini), and Turkish-adapted (e.g., Trendyol) models. We provide an extensive evaluation, including zero-shot and few-shot evaluation of LLMs, chain-of-thought reasoning, and question difficulty analysis along with model performance. We provide an in-depth analysis of the Turkish capabilities and limitations of current LLMs to provide insights for future LLMs for the Turkish language. We publicly release our code for the dataset and evaluation.
## Dataset
Dataset is divided into four categories Natural Sciences, Mathematics, Language, and Social Sciences and Humanities with a total of nine subjects in Turkish highschool education. It is available in multiple choice for LLM evaluation. The questions also contain difficulty indicator referred as Correctness ratio.
## Evaluation
5-Shot evaluation results from the paper includes open and closed source SOTA LLM with different architectures. For this study, multilingual and Turkish adapted models are tested.
The evaluation results of this study are obtained using the provided configurations with LM Evaluation Harness.
| Model | Source | Average | Natural Sciences | Math | Turkish L & L | Social Sciences and Humanities |
| ------------------- | ------ | ------- | ---------------- | ---- | ------------- | ------------------------------ |
| GPT 4o | Closed | 83.1 | 75.3 | 59.0 | 82.0 | 95.3 |
| Claude-3 Opus | Closed | 79.1 | 71.7 | 59.0 | 77.0 | 90.3 |
| GPT 4-turbo | Closed | 75.7 | 70.3 | 57.0 | 67.0 | 86.5 |
| Llama-3 70B-IT | Closed | 67.3 | 56.7 | 42.0 | 57.0 | 84.3 |
| Claude-3 Sonnet | Closed | 67.3 | 67.3 | 44.0 | 58.0 | 75.5 |
| Llama-3 70B | Open | 66.1 | 56.0 | 37.0 | 57.0 | 83.3 |
| Claude-3 Haiku | Closed | 65.4 | 57.0 | 40.0 | 61.0 | 79.3 |
| Gemini 1.0-pro | Closed | 63.2 | 52.7 | 29.0 | 63.0 | 79.8 |
| C4AI Command-r+ | Open | 60.6 | 50.0 | 26.0 | 57.0 | 78.0 |
| Aya-23 35B | Open | 55.6 | 43.3 | 31.0 | 49.0 | 72.5 |
| C4AI Command-r | Open | 54.9 | 44.7 | 29.0 | 49.0 | 70.5 |
| Mixtral 8x22B | Open | 54.8 | 45.3 | 27.0 | 49.0 | 70.3 |
| GPT 3.5-turbo | Closed | 51.0 | 42.7 | 39.0 | 35.0 | 61.8 |
| Llama-3 8B-IT | Open | 46.4 | 36.7 | 29.0 | 39.0 | 60.0 |
| Llama-3 8B | Open | 46.2 | 37.3 | 30.0 | 33.0 | 60.3 |
| Mixtral 8x7B-IT | Open | 45.2 | 41.3 | 28.0 | 39.0 | 54.0 |
| Aya-23 8B | Open | 45.0 | 39.0 | 23.0 | 31.0 | 58.5 |
| Gemma 7B | Open | 43.6 | 34.3 | 22.0 | 47.0 | 55.0 |
| Aya-101 | Open | 40.7 | 31.3 | 24.0 | 38.0 | 55.0 |
| Trendyol-LLM 7B-C-D | Open | 34.1 | 30.3 | 22.0 | 28.0 | 41.5 |
| mT0-xxl | Open | 33.9 | 29.3 | 28.0 | 21.0 | 42.0 |
| Mistral 7B-IT | Open | 32.0 | 34.3 | 26.0 | 38.0 | 30.3 |
| Llama-2 7B | Open | 22.3 | 25.3 | 20.0 | 20.0 | 19.8 |
| mT5-xxl | Open | 18.1 | 19.3 | 24.0 | 14.0 | 16.8 |
## Citation
```
@misc{yüksel2024turkishmmlumeasuringmassivemultitask,
title={TurkishMMLU: Measuring Massive Multitask Language Understanding in Turkish},
author={Arda Yüksel and Abdullatif Köksal and Lütfi Kerem Şenel and Anna Korhonen and Hinrich Schütze},
year={2024},
eprint={2407.12402},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2407.12402},
}
```
### Groups and Tasks
#### Groups
- `turkishmmlu`: 'All 9 Subjects of Turkish MMLU namely:
Biology, Chemistry, Physics, Geography, Philosophy, History, Religion and Ethics, Turkish Language and Literature, and Mathematics
#### Tasks
The following tasks evaluate subjects in the TurkishMMLU dataset
- `turkishmmlu_{subject}`
The following task evaluate subjects in the TurkishMMLU dataset in Chain-of-Thought (COT)
- `turkishmmlu_cot_{subject}`
### Checklist
For adding novel benchmarks/datasets to the library:
- [x] Is the task an existing benchmark in the literature?
- [x] Have you referenced the original paper that introduced the task?
- [x] If yes, does the original paper provide a reference implementation? If so, have you checked against the reference implementation and documented how to run such a test?
If other tasks on this dataset are already supported:
- [ ] Is the "Main" variant of this task clearly denoted?
- [ ] Have you provided a short sentence in a README on what each new variant adds / evaluates?
- [ ] Have you noted which, if any, published evaluation setups are matched by this variant?
|
{
"source": "simplescaling/s1",
"title": "eval/lm-evaluation-harness/lm_eval/tasks/turkishmmlu/README.md",
"url": "https://github.com/simplescaling/s1/blob/main/eval/lm-evaluation-harness/lm_eval/tasks/turkishmmlu/README.md",
"date": "2025-02-01T02:38:16",
"stars": 5696,
"description": "s1: Simple test-time scaling",
"file_size": 7598
}
|
# Unitxt
### Paper
Title: `Unitxt: Flexible, Shareable and Reusable Data Preparation and Evaluation for Generative AI`
Abstract: `https://arxiv.org/abs/2401.14019`
Unitxt is a library for customizable textual data preparation and evaluation tailored to generative language models. Unitxt natively integrates with common libraries like HuggingFace and LM-eval-harness and deconstructs processing flows into modular components, enabling easy customization and sharing between practitioners. These components encompass model-specific formats, task prompts, and many other comprehensive dataset processing definitions. These components are centralized in the Unitxt-Catalog, thus fostering collaboration and exploration in modern textual data workflows.
The full Unitxt catalog can be viewed in an online explorer. `https://unitxt.readthedocs.io/en/latest/docs/demo.html`
Homepage: https://unitxt.readthedocs.io/en/latest/index.html
### Citation
```
@misc{unitxt,
title={Unitxt: Flexible, Shareable and Reusable Data Preparation and Evaluation for Generative AI},
author={Elron Bandel and Yotam Perlitz and Elad Venezian and Roni Friedman-Melamed and Ofir Arviv and Matan Orbach and Shachar Don-Yehyia and Dafna Sheinwald and Ariel Gera and Leshem Choshen and Michal Shmueli-Scheuer and Yoav Katz},
year={2024},
eprint={2401.14019},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
### Groups and Tasks
#### Groups
* `unitxt`: Subset of Unitxt tasks that were not in LM-Eval Harness task catalog, including new types of tasks like multi-label classification, grammatical error correction, named entity extraction.
#### Tasks
The full list of Unitxt tasks currently supported can be seen under `tasks/unitxt` directory.
### Adding tasks
You can add additional tasks from the Unitxt catalog by generating new LM-Eval yaml files for these datasets.
The Unitxt task yaml files are generated via the `generate_yamls.py` script in the `tasks/unitxt` directory.
To add a yaml file for an existing dataset Unitxt which is not yet in LM-Eval:
1. Add the card name to the `unitxt_datasets` file in the `tasks/unitxt` directory.
2. The generate_yaml.py contains the default Unitxt [template](https://unitxt.readthedocs.io/en/latest/docs/adding_template.html) used for each kind of NLP task in the `default_template_per_task` dictionary. If the dataset is of a Unitxt task type, previously not used in LM-Eval, you will need to add a default template for it in the dictionary.
```
default_template_per_task = {
"tasks.classification.multi_label" : "templates.classification.multi_label.title" ,
"tasks.classification.multi_class" : "templates.classification.multi_class.title" ,
"tasks.summarization.abstractive" : "templates.summarization.abstractive.full",
"tasks.regression.two_texts" : "templates.regression.two_texts.simple",
"tasks.qa.with_context.extractive" : "templates.qa.with_context.simple",
"tasks.grammatical_error_correction" : "templates.grammatical_error_correction.simple",
"tasks.span_labeling.extraction" : "templates.span_labeling.extraction.title"
}
```
3. Run `python generate_yaml.py` (this will generate all the datasets listed in the `unitxt_datasets`)
If you want to add a new dataset to the Unitxt catalog, see the Unitxt documentation:
https://unitxt.readthedocs.io/en/latest/docs/adding_dataset.html
### Checklist
For adding novel benchmarks/datasets to the library:
* [ ] Is the task an existing benchmark in the literature?
* [ ] Have you referenced the original paper that introduced the task?
* [ ] If yes, does the original paper provide a reference implementation? If so, have you checked against the reference implementation and documented how to run such a test?
If other tasks on this dataset are already supported:
* [ ] Is the "Main" variant of this task clearly denoted?
* [ ] Have you provided a short sentence in a README on what each new variant adds / evaluates?
* [ ] Have you noted which, if any, published evaluation setups are matched by this variant?
|
{
"source": "simplescaling/s1",
"title": "eval/lm-evaluation-harness/lm_eval/tasks/unitxt/README.md",
"url": "https://github.com/simplescaling/s1/blob/main/eval/lm-evaluation-harness/lm_eval/tasks/unitxt/README.md",
"date": "2025-02-01T02:38:16",
"stars": 5696,
"description": "s1: Simple test-time scaling",
"file_size": 4094
}
|
# Unscramble
### Paper
Language Models are Few-Shot Learners
https://arxiv.org/pdf/2005.14165.pdf
Unscramble is a small battery of 5 “character manipulation” tasks. Each task
involves giving the model a word distorted by some combination of scrambling,
addition, or deletion of characters, and asking it to recover the original word.
Homepage: https://github.com/openai/gpt-3/tree/master/data
### Citation
```
@inproceedings{NEURIPS2020_1457c0d6,
author = {Brown, Tom and Mann, Benjamin and Ryder, Nick and Subbiah, Melanie and Kaplan, Jared D and Dhariwal, Prafulla and Neelakantan, Arvind and Shyam, Pranav and Sastry, Girish and Askell, Amanda and Agarwal, Sandhini and Herbert-Voss, Ariel and Krueger, Gretchen and Henighan, Tom and Child, Rewon and Ramesh, Aditya and Ziegler, Daniel and Wu, Jeffrey and Winter, Clemens and Hesse, Chris and Chen, Mark and Sigler, Eric and Litwin, Mateusz and Gray, Scott and Chess, Benjamin and Clark, Jack and Berner, Christopher and McCandlish, Sam and Radford, Alec and Sutskever, Ilya and Amodei, Dario},
booktitle = {Advances in Neural Information Processing Systems},
editor = {H. Larochelle and M. Ranzato and R. Hadsell and M. F. Balcan and H. Lin},
pages = {1877--1901},
publisher = {Curran Associates, Inc.},
title = {Language Models are Few-Shot Learners},
url = {https://proceedings.neurips.cc/paper/2020/file/1457c0d6bfcb4967418bfb8ac142f64a-Paper.pdf},
volume = {33},
year = {2020}
}
```
### Groups and Tasks
#### Groups
* `unscramble`
#### Tasks
* `anagrams1` - Anagrams of all but the first and last letter.
* `anagrams2` - Anagrams of all but the first and last 2 letters.
* `cycle_letters` - Cycle letters in a word.
* `random_insertion` - Random insertions in the word that must be removed.
* `reversed_words` - Words spelled backwards that must be reversed.
### Checklist
For adding novel benchmarks/datasets to the library:
* [x] Is the task an existing benchmark in the literature?
* [x] Have you referenced the original paper that introduced the task?
* [x] If yes, does the original paper provide a reference implementation? If so, have you checked against the reference implementation and documented how to run such a test?
If other tasks on this dataset are already supported:
* [x] Is the "Main" variant of this task clearly denoted?
* [x] Have you provided a short sentence in a README on what each new variant adds / evaluates?
* [x] Have you noted which, if any, published evaluation setups are matched by this variant?
* [x] Checked for equivalence with v0.3.0 LM Evaluation Harness
|
{
"source": "simplescaling/s1",
"title": "eval/lm-evaluation-harness/lm_eval/tasks/unscramble/README.md",
"url": "https://github.com/simplescaling/s1/blob/main/eval/lm-evaluation-harness/lm_eval/tasks/unscramble/README.md",
"date": "2025-02-01T02:38:16",
"stars": 5696,
"description": "s1: Simple test-time scaling",
"file_size": 2610
}
|
# WEBQs
### Paper
Title: `Semantic Parsing on Freebase from Question-Answer Pairs`
Abstract: `https://cs.stanford.edu/~pliang/papers/freebase-emnlp2013.pdf`
WebQuestions is a benchmark for question answering. The dataset consists of 6,642
question/answer pairs. The questions are supposed to be answerable by Freebase, a
large knowledge graph. The questions are mostly centered around a single named entity.
The questions are popular ones asked on the web (at least in 2013).
Homepage: `https://worksheets.codalab.org/worksheets/0xba659fe363cb46e7a505c5b6a774dc8a`
### Citation
```
@inproceedings{berant-etal-2013-semantic,
title = "Semantic Parsing on {F}reebase from Question-Answer Pairs",
author = "Berant, Jonathan and
Chou, Andrew and
Frostig, Roy and
Liang, Percy",
booktitle = "Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing",
month = oct,
year = "2013",
address = "Seattle, Washington, USA",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/D13-1160",
pages = "1533--1544",
}
```
### Groups and Tasks
#### Groups
* `freebase`
#### Tasks
* `webqs`: `Questions with multiple accepted answers.`
### Checklist
For adding novel benchmarks/datasets to the library:
* [x] Is the task an existing benchmark in the literature?
* [x] Have you referenced the original paper that introduced the task?
* [ ] If yes, does the original paper provide a reference implementation? If so, have you checked against the reference implementation and documented how to run such a test?
If other tasks on this dataset are already supported:
* [ ] Is the "Main" variant of this task clearly denoted?
* [ ] Have you provided a short sentence in a README on what each new variant adds / evaluates?
* [ ] Have you noted which, if any, published evaluation setups are matched by this variant?
|
{
"source": "simplescaling/s1",
"title": "eval/lm-evaluation-harness/lm_eval/tasks/webqs/README.md",
"url": "https://github.com/simplescaling/s1/blob/main/eval/lm-evaluation-harness/lm_eval/tasks/webqs/README.md",
"date": "2025-02-01T02:38:16",
"stars": 5696,
"description": "s1: Simple test-time scaling",
"file_size": 1932
}
|
# Wikitext
### Paper
Pointer Sentinel Mixture Models
https://arxiv.org/pdf/1609.07843.pdf
The WikiText language modeling dataset is a collection of over 100 million tokens
extracted from the set of verified Good and Featured articles on Wikipedia.
NOTE: This `Task` is based on WikiText-2.
Homepage: https://www.salesforce.com/products/einstein/ai-research/the-wikitext-dependency-language-modeling-dataset/
### Citation
```
@misc{merity2016pointer,
title={Pointer Sentinel Mixture Models},
author={Stephen Merity and Caiming Xiong and James Bradbury and Richard Socher},
year={2016},
eprint={1609.07843},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
### Groups and Tasks
#### Groups
* Not part of a group yet.
#### Tasks
* `wikitext`: measure perplexity on the Wikitext dataset, via rolling loglikelihoods.
### Checklist
* [x] Is the task an existing benchmark in the literature?
* [x] Have you referenced the original paper that introduced the task?
* [ ] If yes, does the original paper provide a reference implementation? If so, have you checked against the reference implementation and documented how to run such a test?
If other tasks on this dataset are already supported:
* [x] Is the "Main" variant of this task clearly denoted?
* [x] Have you provided a short sentence in a README on what each new variant adds / evaluates?
* [ ] Have you noted which, if any, published evaluation setups are matched by this variant?
|
{
"source": "simplescaling/s1",
"title": "eval/lm-evaluation-harness/lm_eval/tasks/wikitext/README.md",
"url": "https://github.com/simplescaling/s1/blob/main/eval/lm-evaluation-harness/lm_eval/tasks/wikitext/README.md",
"date": "2025-02-01T02:38:16",
"stars": 5696,
"description": "s1: Simple test-time scaling",
"file_size": 1476
}
|
# WinoGrande
### Paper
Title: `WinoGrande: An Adversarial Winograd Schema Challenge at Scale`
Abstract: https://arxiv.org/abs/1907.10641
WinoGrande is a collection of 44k problems, inspired by Winograd Schema Challenge
(Levesque, Davis, and Morgenstern 2011), but adjusted to improve the scale and
robustness against the dataset-specific bias. Formulated as a fill-in-a-blank
task with binary options, the goal is to choose the right option for a given
sentence which requires commonsense reasoning.
NOTE: This evaluation of Winogrande uses partial evaluation as described by
Trinh & Le in Simple Method for Commonsense Reasoning (2018).
See: https://arxiv.org/abs/1806.02847
Homepage: https://leaderboard.allenai.org/winogrande/submissions/public
### Citation
```
@article{sakaguchi2019winogrande,
title={WinoGrande: An Adversarial Winograd Schema Challenge at Scale},
author={Sakaguchi, Keisuke and Bras, Ronan Le and Bhagavatula, Chandra and Choi, Yejin},
journal={arXiv preprint arXiv:1907.10641},
year={2019}
}
```
### Groups and Tasks
#### Groups
* Not part of a group yet.
#### Tasks
* `winogrande`
### Checklist
For adding novel benchmarks/datasets to the library:
* [ ] Is the task an existing benchmark in the literature?
* [ ] Have you referenced the original paper that introduced the task?
* [ ] If yes, does the original paper provide a reference implementation? If so, have you checked against the reference implementation and documented how to run such a test?
If other tasks on this dataset are already supported:
* [ ] Is the "Main" variant of this task clearly denoted?
* [ ] Have you provided a short sentence in a README on what each new variant adds / evaluates?
* [ ] Have you noted which, if any, published evaluation setups are matched by this variant?
|
{
"source": "simplescaling/s1",
"title": "eval/lm-evaluation-harness/lm_eval/tasks/winogrande/README.md",
"url": "https://github.com/simplescaling/s1/blob/main/eval/lm-evaluation-harness/lm_eval/tasks/winogrande/README.md",
"date": "2025-02-01T02:38:16",
"stars": 5696,
"description": "s1: Simple test-time scaling",
"file_size": 1815
}
|
# WMDP
### Paper
Title: `The WMDP Benchmark: Measuring and Reducing Malicious Use With Unlearning`
Abstract: `https://arxiv.org/abs/2403.03218`
`The Weapons of Mass Destruction Proxy (WMDP) benchmark is a dataset of 4,157 multiple-choice questions surrounding hazardous knowledge in biosecurity cybersecurity, and chemical security. WMDP serves as both a proxy evaluation for hazardous knowledge in large language models (LLMs) and a benchmark for unlearning methods to remove such knowledge.`
Homepage: https://wmdp.ai
### Citation
```
@misc{li2024wmdp,
title={The WMDP Benchmark: Measuring and Reducing Malicious Use With Unlearning},
author={Nathaniel Li and Alexander Pan and Anjali Gopal and Summer Yue and Daniel Berrios and Alice Gatti and Justin D. Li and Ann-Kathrin Dombrowski and Shashwat Goel and Long Phan and Gabriel Mukobi and Nathan Helm-Burger and Rassin Lababidi and Lennart Justen and Andrew B. Liu and Michael Chen and Isabelle Barrass and Oliver Zhang and Xiaoyuan Zhu and Rishub Tamirisa and Bhrugu Bharathi and Adam Khoja and Zhenqi Zhao and Ariel Herbert-Voss and Cort B. Breuer and Andy Zou and Mantas Mazeika and Zifan Wang and Palash Oswal and Weiran Liu and Adam A. Hunt and Justin Tienken-Harder and Kevin Y. Shih and Kemper Talley and John Guan and Russell Kaplan and Ian Steneker and David Campbell and Brad Jokubaitis and Alex Levinson and Jean Wang and William Qian and Kallol Krishna Karmakar and Steven Basart and Stephen Fitz and Mindy Levine and Ponnurangam Kumaraguru and Uday Tupakula and Vijay Varadharajan and Yan Shoshitaishvili and Jimmy Ba and Kevin M. Esvelt and Alexandr Wang and Dan Hendrycks},
year={2024},
eprint={2403.03218},
archivePrefix={arXiv},
primaryClass={cs.LG}
}
```
### Groups, Tags, and Tasks
#### Groups
* `wmdp`: All 4,157 multiple-choice questions in biosecurity, cybersecurity, and chemical security
#### Tasks
* `wmdp_bio`: 1,520 multiple-choice questions in biosecurity
* `wmdp_cyber`: 2,225 multiple-choice questions in cybersecurity
* `wmdp_chemistry`: 412 multiple-choice questions in chemical security
### Checklist
For adding novel benchmarks/datasets to the library:
* [x] Is the task an existing benchmark in the literature?
* [x] Have you referenced the original paper that introduced the task?
* [x] If yes, does the original paper provide a reference implementation? If so, have you checked against the reference implementation and documented how to run such a test?
If other tasks on this dataset are already supported:
* [ ] Is the "Main" variant of this task clearly denoted?
* [ ] Have you provided a short sentence in a README on what each new variant adds / evaluates?
* [ ] Have you noted which, if any, published evaluation setups are matched by this variant?
|
{
"source": "simplescaling/s1",
"title": "eval/lm-evaluation-harness/lm_eval/tasks/wmdp/README.md",
"url": "https://github.com/simplescaling/s1/blob/main/eval/lm-evaluation-harness/lm_eval/tasks/wmdp/README.md",
"date": "2025-02-01T02:38:16",
"stars": 5696,
"description": "s1: Simple test-time scaling",
"file_size": 2801
}
|
# WMT16
### Paper
Title: `Findings of the 2016 Conference on Machine Translation`
Abstract: http://www.aclweb.org/anthology/W/W16/W16-2301
Homepage: https://huggingface.co/datasets/wmt16
### Citation
```
@InProceedings{bojar-EtAl:2016:WMT1,
author = {Bojar, Ond
{r}ej and Chatterjee, Rajen and Federmann, Christian and Graham, Yvette and Haddow, Barry and Huck, Matthias and Jimeno Yepes, Antonio and Koehn, Philipp and Logacheva, Varvara and Monz, Christof and Negri, Matteo and Neveol, Aurelie and Neves, Mariana and Popel, Martin and Post, Matt and Rubino, Raphael and Scarton, Carolina and Specia, Lucia and Turchi, Marco and Verspoor, Karin and Zampieri, Marcos},
title = {Findings of the 2016 Conference on Machine Translation},
booktitle = {Proceedings of the First Conference on Machine Translation},
month = {August},
year = {2016},
address = {Berlin, Germany},
publisher = {Association for Computational Linguistics},
pages = {131--198},
url = {http://www.aclweb.org/anthology/W/W16/W16-2301}
}
```
### Groups, Tags, and Tasks
#### Tasks
With specific prompt styles
* `wmt-ro-en-t5-prompt`: WMT16 with the prompt template used for T5
### Checklist
For adding novel benchmarks/datasets to the library:
* [ ] Is the task an existing benchmark in the literature?
* [ ] Have you referenced the original paper that introduced the task?
* [ ] If yes, does the original paper provide a reference implementation? If so, have you checked against the reference implementation and documented how to run such a test?
If other tasks on this dataset are already supported:
* [ ] Is the "Main" variant of this task clearly denoted?
* [ ] Have you provided a short sentence in a README on what each new variant adds / evaluates?
* [ ] Have you noted which, if any, published evaluation setups are matched by this variant?
|
{
"source": "simplescaling/s1",
"title": "eval/lm-evaluation-harness/lm_eval/tasks/wmt2016/README.md",
"url": "https://github.com/simplescaling/s1/blob/main/eval/lm-evaluation-harness/lm_eval/tasks/wmt2016/README.md",
"date": "2025-02-01T02:38:16",
"stars": 5696,
"description": "s1: Simple test-time scaling",
"file_size": 1921
}
|
# WSC273
### Paper
Title: `The Winograd Schema Challenge`
Abstract: http://commonsensereasoning.org/2011/papers/Levesque.pdf
A Winograd schema is a pair of sentences that differ in only one or two words
and that contain an ambiguity that is resolved in opposite ways in the two
sentences and requires the use of world knowledge and reasoning for its resolution.
The Winograd Schema Challenge 273 is a collection of 273 such Winograd schemas.
NOTE: This evaluation of Winograd Schema Challenge is based on `partial evaluation`
as described by Trinh & Le in Simple Method for Commonsense Reasoning (2018).
See: https://arxiv.org/abs/1806.0
Homepage: https://cs.nyu.edu/~davise/papers/WinogradSchemas/WS.html
### Citation
```
@inproceedings{ea01b9c0db064caca6986b925d75f2bb,
title = "The winograd schema challenge",
abstract = "In this paper, we present an alternative to the Turing Test that has some conceptual and practical advantages. A Wino-grad schema is a pair of sentences that differ only in one or two words and that contain a referential ambiguity that is resolved in opposite directions in the two sentences. We have compiled a collection of Winograd schemas, designed so that the correct answer is obvious to the human reader, but cannot easily be found using selectional restrictions or statistical techniques over text corpora. A contestant in the Winograd Schema Challenge is presented with a collection of one sentence from each pair, and required to achieve human-level accuracy in choosing the correct disambiguation.",
author = "Levesque, {Hector J.} and Ernest Davis and Leora Morgenstern",
year = "2012",
language = "English (US)",
isbn = "9781577355601",
series = "Proceedings of the International Conference on Knowledge Representation and Reasoning",
publisher = "Institute of Electrical and Electronics Engineers Inc.",
pages = "552--561",
booktitle = "13th International Conference on the Principles of Knowledge Representation and Reasoning, KR 2012",
note = "13th International Conference on the Principles of Knowledge Representation and Reasoning, KR 2012 ; Conference date: 10-06-2012 Through 14-06-2012",
}
```
### Groups and Tasks
#### Groups
* Not part of any group yet.
#### Tasks
* `wsc273`
### Checklist
For adding novel benchmarks/datasets to the library:
* [ ] Is the task an existing benchmark in the literature?
* [ ] Have you referenced the original paper that introduced the task?
* [ ] If yes, does the original paper provide a reference implementation? If so, have you checked against the reference implementation and documented how to run such a test?
If other tasks on this dataset are already supported:
* [ ] Is the "Main" variant of this task clearly denoted?
* [ ] Have you provided a short sentence in a README on what each new variant adds / evaluates?
* [ ] Have you noted which, if any, published evaluation setups are matched by this variant?
|
{
"source": "simplescaling/s1",
"title": "eval/lm-evaluation-harness/lm_eval/tasks/wsc273/README.md",
"url": "https://github.com/simplescaling/s1/blob/main/eval/lm-evaluation-harness/lm_eval/tasks/wsc273/README.md",
"date": "2025-02-01T02:38:16",
"stars": 5696,
"description": "s1: Simple test-time scaling",
"file_size": 2962
}
|
# XCOPA
### Paper
Title: `XCOPA: A Multilingual Dataset for Causal Commonsense Reasoning`
Abstract: https://ducdauge.github.io/files/xcopa.pdf
The Cross-lingual Choice of Plausible Alternatives dataset is a benchmark to evaluate the ability of machine learning models to transfer commonsense reasoning across languages.
The dataset is the translation and reannotation of the English COPA (Roemmele et al. 2011) and covers 11 languages from 11 families and several areas around the globe.
The dataset is challenging as it requires both the command of world knowledge and the ability to generalise to new languages.
All the details about the creation of XCOPA and the implementation of the baselines are available in the paper.
Homepage: https://github.com/cambridgeltl/xcopa
### Citation
```
@inproceedings{ponti2020xcopa,
title={{XCOPA: A} Multilingual Dataset for Causal Commonsense Reasoning},
author={Edoardo M. Ponti, Goran Glava\v{s}, Olga Majewska, Qianchu Liu, Ivan Vuli\'{c} and Anna Korhonen},
booktitle={Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP)},
year={2020},
url={https://ducdauge.github.io/files/xcopa.pdf}
}
```
### Groups and Tasks
#### Groups
* `xcopa`
#### Tasks
* `xcopa_et`: Estonian
* `xcopa_ht`: Haitian Creole
* `xcopa_id`: Indonesian
* `xcopa_it`: Italian
* `xcopa_qu`: Cusco-Collao Quechua
* `xcopa_sw`: Kiswahili
* `xcopa_ta`: Tamil
* `xcopa_th`: Thai
* `xcopa_tr`: Turkish
* `xcopa_vi`: Vietnamese
* `xcopa_zh`: Mandarin Chinese
### Checklist
For adding novel benchmarks/datasets to the library:
* [ ] Is the task an existing benchmark in the literature?
* [ ] Have you referenced the original paper that introduced the task?
* [ ] If yes, does the original paper provide a reference implementation? If so, have you checked against the reference implementation and documented how to run such a test?
If other tasks on this dataset are already supported:
* [ ] Is the "Main" variant of this task clearly denoted?
* [ ] Have you provided a short sentence in a README on what each new variant adds / evaluates?
* [ ] Have you noted which, if any, published evaluation setups are matched by this variant?
|
{
"source": "simplescaling/s1",
"title": "eval/lm-evaluation-harness/lm_eval/tasks/xcopa/README.md",
"url": "https://github.com/simplescaling/s1/blob/main/eval/lm-evaluation-harness/lm_eval/tasks/xcopa/README.md",
"date": "2025-02-01T02:38:16",
"stars": 5696,
"description": "s1: Simple test-time scaling",
"file_size": 2210
}
|
# XNLI
### Paper
Title: `XNLI: Evaluating Cross-lingual Sentence Representations`
Abstract: https://arxiv.org/abs/1809.05053
Based on the implementation of @yongzx (see https://github.com/EleutherAI/lm-evaluation-harness/pull/258)
Prompt format (same as XGLM and mGPT):
sentence1 + ", right? " + mask = (Yes|Also|No) + ", " + sentence2
Predicition is the full sequence with the highest likelihood.
Language specific prompts are translated word-by-word with Google Translate
and may differ from the ones used by mGPT and XGLM (they do not provide their prompts).
Homepage: https://github.com/facebookresearch/XNLI
### Citation
"""
@InProceedings{conneau2018xnli,
author = "Conneau, Alexis
and Rinott, Ruty
and Lample, Guillaume
and Williams, Adina
and Bowman, Samuel R.
and Schwenk, Holger
and Stoyanov, Veselin",
title = "XNLI: Evaluating Cross-lingual Sentence Representations",
booktitle = "Proceedings of the 2018 Conference on Empirical Methods
in Natural Language Processing",
year = "2018",
publisher = "Association for Computational Linguistics",
location = "Brussels, Belgium",
}
"""
### Groups and Tasks
#### Groups
* `xnli`
#### Tasks
* `xnli_ar`: Arabic
* `xnli_bg`: Bulgarian
* `xnli_de`: German
* `xnli_el`: Greek
* `xnli_en`: English
* `xnli_es`: Spanish
* `xnli_fr`: French
* `xnli_hi`: Hindi
* `xnli_ru`: Russian
* `xnli_sw`: Swahili
* `xnli_th`: Thai
* `xnli_tr`: Turkish
* `xnli_ur`: Urdu
* `xnli_vi`: Vietnamese
* `xnli_zh`: Chinese
### Checklist
For adding novel benchmarks/datasets to the library:
* [ ] Is the task an existing benchmark in the literature?
* [ ] Have you referenced the original paper that introduced the task?
* [ ] If yes, does the original paper provide a reference implementation? If so, have you checked against the reference implementation and documented how to run such a test?
If other tasks on this dataset are already supported:
* [ ] Is the "Main" variant of this task clearly denoted?
* [ ] Have you provided a short sentence in a README on what each new variant adds / evaluates?
* [ ] Have you noted which, if any, published evaluation setups are matched by this variant?
|
{
"source": "simplescaling/s1",
"title": "eval/lm-evaluation-harness/lm_eval/tasks/xnli/README.md",
"url": "https://github.com/simplescaling/s1/blob/main/eval/lm-evaluation-harness/lm_eval/tasks/xnli/README.md",
"date": "2025-02-01T02:38:16",
"stars": 5696,
"description": "s1: Simple test-time scaling",
"file_size": 2223
}
|
# XNLIeu
### Paper
Title: XNLIeu: a dataset for cross-lingual NLI in Basque
Abstract: https://arxiv.org/abs/2404.06996
XNLI is a popular Natural Language Inference (NLI) benchmark widely used to evaluate cross-lingual Natural Language Understanding (NLU) capabilities across languages. In this paper, we expand XNLI to include Basque, a low-resource language that can greatly benefit from transfer-learning approaches. The new dataset, dubbed XNLIeu, has been developed by first machine-translating the English XNLI corpus into Basque, followed by a manual post-edition step. We have conducted a series of experiments using mono- and multilingual LLMs to assess a) the effect of professional post-edition on the MT system; b) the best cross-lingual strategy for NLI in Basque; and c) whether the choice of the best cross-lingual strategy is influenced by the fact that the dataset is built by translation. The results show that post-edition is necessary and that the translate-train cross-lingual strategy obtains better results overall, although the gain is lower when tested in a dataset that has been built natively from scratch. Our code and datasets are publicly available under open licenses at https://github.com/hitz-zentroa/xnli-eu.
Homepage: https://github.com/hitz-zentroa/xnli-eu
### Citation
```bibtex
@misc{heredia2024xnlieu,
title={XNLIeu: a dataset for cross-lingual NLI in Basque},
author={Maite Heredia and Julen Etxaniz and Muitze Zulaika and Xabier Saralegi and Jeremy Barnes and Aitor Soroa},
year={2024},
eprint={2404.06996},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
### Groups, Tags, and Tasks
#### Tags
* `xnli_eu_mt_native`: Includes MT and Native variants of the XNLIeu dataset.
#### Tasks
* `xnli_eu`: XNLI in Basque postedited from MT.
* `xnli_eu_mt`: XNLI in Basque machine translated from English.
* `xnli_eu_native`: XNLI in Basque natively created.
### Checklist
For adding novel benchmarks/datasets to the library:
* [x] Is the task an existing benchmark in the literature?
* [x] Have you referenced the original paper that introduced the task?
* [x] If yes, does the original paper provide a reference implementation? If so, have you checked against the reference implementation and documented how to run such a test?
If other tasks on this dataset are already supported:
* [ ] Is the "Main" variant of this task clearly denoted?
* [ ] Have you provided a short sentence in a README on what each new variant adds / evaluates?
* [ ] Have you noted which, if any, published evaluation setups are matched by this variant?
|
{
"source": "simplescaling/s1",
"title": "eval/lm-evaluation-harness/lm_eval/tasks/xnli_eu/README.md",
"url": "https://github.com/simplescaling/s1/blob/main/eval/lm-evaluation-harness/lm_eval/tasks/xnli_eu/README.md",
"date": "2025-02-01T02:38:16",
"stars": 5696,
"description": "s1: Simple test-time scaling",
"file_size": 2606
}
|
# XStoryCloze
### Paper
Title: `Few-shot Learning with Multilingual Language Models`
Abstract: https://arxiv.org/abs/2112.10668
XStoryCloze consists of the professionally translated version of the [English StoryCloze dataset](https://cs.rochester.edu/nlp/rocstories/) (Spring 2016 version) to 10 non-English languages. This dataset is released by Meta AI.
Homepage: https://github.com/facebookresearch/fairseq/pull/4820
### Citation
```
@article{DBLP:journals/corr/abs-2112-10668,
author = {Xi Victoria Lin and
Todor Mihaylov and
Mikel Artetxe and
Tianlu Wang and
Shuohui Chen and
Daniel Simig and
Myle Ott and
Naman Goyal and
Shruti Bhosale and
Jingfei Du and
Ramakanth Pasunuru and
Sam Shleifer and
Punit Singh Koura and
Vishrav Chaudhary and
Brian O'Horo and
Jeff Wang and
Luke Zettlemoyer and
Zornitsa Kozareva and
Mona T. Diab and
Veselin Stoyanov and
Xian Li},
title = {Few-shot Learning with Multilingual Language Models},
journal = {CoRR},
volume = {abs/2112.10668},
year = {2021},
url = {https://arxiv.org/abs/2112.10668},
eprinttype = {arXiv},
eprint = {2112.10668},
timestamp = {Tue, 04 Jan 2022 15:59:27 +0100},
biburl = {https://dblp.org/rec/journals/corr/abs-2112-10668.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
```
### Groups and Tasks
#### Groups
* `xstorycloze`
#### Tasks
* `xstorycloze_ar`: Arabic
* `xstorycloze_en`: English
* `xstorycloze_es`: Spanish
* `xstorycloze_eu`: Basque
* `xstorycloze_hi`: Hindi
* `xstorycloze_id`: Indonesian
* `xstorycloze_my`: Burmese
* `xstorycloze_ru`: Russian
* `xstorycloze_sw`: Swahili
* `xstorycloze_te`: Telugu
* `xstorycloze_zh`: Chinese
### Checklist
For adding novel benchmarks/datasets to the library:
* [ ] Is the task an existing benchmark in the literature?
* [ ] Have you referenced the original paper that introduced the task?
* [ ] If yes, does the original paper provide a reference implementation? If so, have you checked against the reference implementation and documented how to run such a test?
If other tasks on this dataset are already supported:
* [ ] Is the "Main" variant of this task clearly denoted?
* [ ] Have you provided a short sentence in a README on what each new variant adds / evaluates?
* [ ] Have you noted which, if any, published evaluation setups are matched by this variant?
|
{
"source": "simplescaling/s1",
"title": "eval/lm-evaluation-harness/lm_eval/tasks/xstorycloze/README.md",
"url": "https://github.com/simplescaling/s1/blob/main/eval/lm-evaluation-harness/lm_eval/tasks/xstorycloze/README.md",
"date": "2025-02-01T02:38:16",
"stars": 5696,
"description": "s1: Simple test-time scaling",
"file_size": 2673
}
|
# Task-name
### Paper
Title: `It's All in the Heads: Using Attention Heads as a Baseline for Cross-Lingual Transfer in Commonsense Reasoning`
Abstract: `https://arxiv.org/abs/2106.12066`
Multilingual winograd schema challenge that includes English, French, Japanese, Portuguese, Russian and Chinese. Winograd schema challenges come from the XWinograd dataset introduced in Tikhonov et al. As it only contains 16 Chinese schemas, we add 488 Chinese schemas from clue/cluewsc2020.
Homepage: `https://huggingface.co/datasets/Muennighoff/xwinograd`
### Citation
```
@misc{muennighoff2022crosslingual,
title={Crosslingual Generalization through Multitask Finetuning},
author={Niklas Muennighoff and Thomas Wang and Lintang Sutawika and Adam Roberts and Stella Biderman and Teven Le Scao and M Saiful Bari and Sheng Shen and Zheng-Xin Yong and Hailey Schoelkopf and Xiangru Tang and Dragomir Radev and Alham Fikri Aji and Khalid Almubarak and Samuel Albanie and Zaid Alyafeai and Albert Webson and Edward Raff and Colin Raffel},
year={2022},
eprint={2211.01786},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
@misc{tikhonov2021heads,
title={It's All in the Heads: Using Attention Heads as a Baseline for Cross-Lingual Transfer in Commonsense Reasoning},
author={Alexey Tikhonov and Max Ryabinin},
year={2021},
eprint={2106.12066},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
### Groups and Tasks
#### Groups
* `xwinograd`
#### Tasks
List or describe tasks defined in this folder, and their names here:
* `xwinograd_en`: Winograd schema challenges in English.
* `xwinograd_fr`: Winograd schema challenges in French.
* `xwinograd_jp`: Winograd schema challenges in Japanese.
* `xwinograd_pt`: Winograd schema challenges in Portuguese.
* `xwinograd_ru`: Winograd schema challenges in Russian.
* `xwinograd_zh`: Winograd schema challenges in Chinese.
### Checklist
For adding novel benchmarks/datasets to the library:
* [x] Is the task an existing benchmark in the literature?
* [x] Have you referenced the original paper that introduced the task?
* [ ] If yes, does the original paper provide a reference implementation? If so, have you checked against the reference implementation and documented how to run such a test?
If other tasks on this dataset are already supported:
* [ ] Is the "Main" variant of this task clearly denoted?
* [x] Have you provided a short sentence in a README on what each new variant adds / evaluates?
* [ ] Have you noted which, if any, published evaluation setups are matched by this variant?
|
{
"source": "simplescaling/s1",
"title": "eval/lm-evaluation-harness/lm_eval/tasks/xwinograd/README.md",
"url": "https://github.com/simplescaling/s1/blob/main/eval/lm-evaluation-harness/lm_eval/tasks/xwinograd/README.md",
"date": "2025-02-01T02:38:16",
"stars": 5696,
"description": "s1: Simple test-time scaling",
"file_size": 2600
}
|
# Code of Conduct
## Our Pledge
In the interest of fostering an open and welcoming environment, we as
contributors and maintainers pledge to make participation in our project and
our community a harassment-free experience for everyone, regardless of age, body
size, disability, ethnicity, sex characteristics, gender identity and expression,
level of experience, education, socio-economic status, nationality, personal
appearance, race, religion, or sexual identity and orientation.
## Our Standards
Examples of behavior that contributes to creating a positive environment
include:
* Using welcoming and inclusive language
* Being respectful of differing viewpoints and experiences
* Gracefully accepting constructive criticism
* Focusing on what is best for the community
* Showing empathy towards other community members
Examples of unacceptable behavior by participants include:
* The use of sexualized language or imagery and unwelcome sexual attention or
advances
* Trolling, insulting/derogatory comments, and personal or political attacks
* Public or private harassment
* Publishing others' private information, such as a physical or electronic
address, without explicit permission
* Other conduct which could reasonably be considered inappropriate in a
professional setting
## Our Responsibilities
Project maintainers are responsible for clarifying the standards of acceptable
behavior and are expected to take appropriate and fair corrective action in
response to any instances of unacceptable behavior.
Project maintainers have the right and responsibility to remove, edit, or
reject comments, commits, code, wiki edits, issues, and other contributions
that are not aligned to this Code of Conduct, or to ban temporarily or
permanently any contributor for other behaviors that they deem inappropriate,
threatening, offensive, or harmful.
## Scope
This Code of Conduct applies within all project spaces, and it also applies when
an individual is representing the project or its community in public spaces.
Examples of representing a project or community include using an official
project e-mail address, posting via an official social media account, or acting
as an appointed representative at an online or offline event. Representation of
a project may be further defined and clarified by project maintainers.
## Enforcement
Instances of abusive, harassing, or otherwise unacceptable behavior may be
reported by contacting the project team at <[email protected]>. All
complaints will be reviewed and investigated and will result in a response that
is deemed necessary and appropriate to the circumstances. The project team is
obligated to maintain confidentiality with regard to the reporter of an incident.
Further details of specific enforcement policies may be posted separately.
Project maintainers who do not follow or enforce the Code of Conduct in good
faith may face temporary or permanent repercussions as determined by other
members of the project's leadership.
## Attribution
This Code of Conduct is adapted from the [Contributor Covenant][homepage], version 1.4,
available at https://www.contributor-covenant.org/version/1/4/code-of-conduct.html
[homepage]: https://www.contributor-covenant.org
For answers to common questions about this code of conduct, see
https://www.contributor-covenant.org/faq
|
{
"source": "simplescaling/s1",
"title": "eval/rebase/inference_scaling/finetune/gpt-accelera/CODE_OF_CONDUCT.md",
"url": "https://github.com/simplescaling/s1/blob/main/eval/rebase/inference_scaling/finetune/gpt-accelera/CODE_OF_CONDUCT.md",
"date": "2025-02-01T02:38:16",
"stars": 5696,
"description": "s1: Simple test-time scaling",
"file_size": 3342
}
|
# Contributing to gpt-fast
We want to make contributing to this project as easy and transparent as
possible.
## Pull Requests
We actively welcome your pull requests.
1. Fork the repo and create your branch from `main`.
2. If you've added code that should be tested, add tests.
3. If you've changed APIs, update the documentation.
4. Ensure the test suite passes.
5. Make sure your code lints.
6. If you haven't already, complete the Contributor License Agreement ("CLA").
## Contributor License Agreement ("CLA")
In order to accept your pull request, we need you to submit a CLA. You only need
to do this once to work on any of Meta's open source projects.
Complete your CLA here: <https://code.facebook.com/cla>
## Issues
We use GitHub issues to track public bugs. Please ensure your description is
clear and has sufficient instructions to be able to reproduce the issue.
Meta has a [bounty program](https://www.facebook.com/whitehat/) for the safe
disclosure of security bugs. In those cases, please go through the process
outlined on that page and do not file a public issue.
## License
By contributing to `gpt-fast`, you agree that your contributions will be licensed
under the LICENSE file in the root directory of this source tree.
|
{
"source": "simplescaling/s1",
"title": "eval/rebase/inference_scaling/finetune/gpt-accelera/CONTRIBUTING.md",
"url": "https://github.com/simplescaling/s1/blob/main/eval/rebase/inference_scaling/finetune/gpt-accelera/CONTRIBUTING.md",
"date": "2025-02-01T02:38:16",
"stars": 5696,
"description": "s1: Simple test-time scaling",
"file_size": 1245
}
|
# gpt-fast
Simple and efficient pytorch-native transformer text generation.
Featuring:
1. Very low latency
2. <1000 lines of python
3. No dependencies other than PyTorch and sentencepiece
4. int8/int4 quantization
5. Speculative decoding
6. Tensor parallelism
7. Supports Nvidia and AMD GPUs
This is *NOT* intended to be a "framework" or "library" - it is intended to show off what kind of performance you can get with native PyTorch :) Please copy-paste and fork as you desire.
For an in-depth walkthrough of what's in this codebase, see this [blog post](https://pytorch.org/blog/accelerating-generative-ai-2/).
## Installation
[Download PyTorch nightly](https://pytorch.org/get-started/locally/)
Install sentencepiece and huggingface_hub
```bash
pip install sentencepiece huggingface_hub
```
To download llama models, go to https://huggingface.co/meta-llama/Llama-2-7b and go through steps to obtain access.
Then login with `huggingface-cli login`
## Downloading Weights
Models tested/supported
```text
openlm-research/open_llama_7b
meta-llama/Llama-2-7b-chat-hf
meta-llama/Llama-2-13b-chat-hf
meta-llama/Llama-2-70b-chat-hf
codellama/CodeLlama-7b-Python-hf
codellama/CodeLlama-34b-Python-hf
```
For example, to convert Llama-2-7b-chat-hf
```bash
export MODEL_REPO=meta-llama/Llama-2-7b-chat-hf
./scripts/prepare.sh $MODEL_REPO
```
## Benchmarks
Benchmarks run on an A100-80GB, power limited to 330W.
| Model | Technique | Tokens/Second | Memory Bandwidth (GB/s) |
| -------- | ------- | ------ | ------ |
| Llama-2-7B | Base | 104.9 | 1397.31 |
| | 8-bit | 155.58 | 1069.20 |
| | 4-bit (G=32) | 196.80 | 862.69 |
| Llama-2-70B | Base | OOM ||
| | 8-bit | 19.13 | 1322.58 |
| | 4-bit (G=32) | 25.25 | 1097.66 |
### Speculative Sampling
[Verifier: Llama-70B (int4), Draft: Llama-7B (int4)](./scripts/speculate_70B_int4.sh): 48.4 tok/s
### Tensor Parallelism
| Model | Number of GPUs | Tokens/Second | Memory Bandwidth (GB/s) |
| -------- | ------- | ------ | ------ |
| Llama-2-7B | 1 | 104.9 | 1397.31 |
| | 2 | 136.27 | 954.01 |
| | 4 | 168.78 | 635.09 |
| | 8 | 179.27 | 395.85 |
| Llama-2-70B | 1 | OOM | |
| | 2 | 20.53 | 1426.41 |
| | 4 | 34.15 | 1204.62 |
| | 8 | 47.25 | 858.28 |
### AMD
Benchmarks run on one GCD of a MI-250x.
| Model | Technique | Tokens/Second | Memory Bandwidth (GB/s) |
| -------- | ------- | ------ | ------ |
| Llama-2-7B | Base | 76.33 | 1028.70 |
| | 8-bit | 101.86 | 700.06 |
## Generate Text
Model definition in `model.py`, generation code in `generate.py`.
```bash
python generate.py --compile --checkpoint_path checkpoints/$MODEL_REPO/model.pth --prompt "Hello, my name is"
```
To squeeze out a little bit more performance, you can also compile the prefill with `--compile_prefill`. This will increase compilation times though.
## Quantization
### Int8 Weight-Only Quantization
To generate this version of the model
```bash
# Spits out model at checkpoints/$MODEL_REPO/model_int8.pth
python quantize.py --checkpoint_path checkpoints/$MODEL_REPO/model.pth --mode int8
```
To run with int8, just pass the int8 checkpoint to generate.py.
```bash
python generate.py --compile --checkpoint_path checkpoints/$MODEL_REPO/model_int8.pth
```
### Int4 Weight-Only Quantization
To generate int4 version of model
```bash
# Spits out model at checkpoints/$MODEL_REPO/model_int4.g32.pth
python quantize.py --checkpoint_path checkpoints/$MODEL_REPO/model.pth --mode int4 --groupsize 32
```
To run with int4, just pass the int4 checkpoint to generate.py.
```bash
python generate.py --checkpoint_path checkpoints/$MODEL_REPO/model_int4.g32.pth --compile
```
## Speculative Sampling
To generate with speculative sampling (DRAFT_MODEL_REPO should point to a smaller model compared with MODEL_REPO).
In this example, the "smaller" model is just the int8 quantized version of the model.
```
export DRAFT_MODEL_REPO=meta-llama/Llama-2-7b-chat-hf
python generate.py --compile --checkpoint_path checkpoints/$MODEL_REPO/model.pth --draft_checkpoint_path checkpoints/$DRAFT_MODEL_REPO/model_int8.pth
```
Note: Running on an A100 80GB, albeit power-limited to 330 watts. Empirically, seems like peak bandwidth is about 1700 GB/s.
## Tensor Parallelism
```bash
torchrun --standalone --nproc_per_node=2 generate.py --compile --checkpoint_path checkpoints/$MODEL_REPO/model.pth
```
## Experimental
### Evaluation
We use the EleutherAI evaluation harness to evaluate our model accuracy. To evaluate the accuracy, make sure the evaluation harness is installed and pass your model checkpoint and desired tasks to eval.py.
```bash
python eval.py --checkpoint_path checkpoints/$MODEL_REPO/model.pth --compile --tasks hellaswag winogrande
```
Note: Generative tasks are currently not supported for gpt-fast
Installation Instructions for the evaluation harness: https://github.com/EleutherAI/lm-evaluation-harness/tree/master#install
### GPTQ
We have a pure pytorch implementation of GPTQ that utilizes torch._dynamo.export to access the model structure. You can generate a GPTQ quantized
version of int4 quantization by using the same command to quantize it but adding 'gptq' to the quantization mode i.e.
```bash
# Spits out model at checkpoints/$MODEL_REPO/model_int4-gptq.g32.pth
python quantize.py --mode int4-gptq --calibration_tasks wikitext --calibration_seq_length 2048
```
You can then eval or generate text with this model in the same way as above.
## License
`gpt-fast` is released under the [BSD 3](https://github.com/pytorch-labs/gpt-fast/main/LICENSE) license.
## Acknowledgements
Thanks to:
* Lightning AI for supporting pytorch and work in flash attention, int8 quantization, and LoRA fine-tuning.
* GGML for driving forward fast, on device inference of LLMs
* Karpathy for spearheading simple, interpretable and fast LLM implementations
* MLC-LLM for pushing 4-bit quantization performance on heterogenous hardware
|
{
"source": "simplescaling/s1",
"title": "eval/rebase/inference_scaling/finetune/gpt-accelera/README.md",
"url": "https://github.com/simplescaling/s1/blob/main/eval/rebase/inference_scaling/finetune/gpt-accelera/README.md",
"date": "2025-02-01T02:38:16",
"stars": 5696,
"description": "s1: Simple test-time scaling",
"file_size": 6067
}
|
## Install
```
pip3 install dspy-ai
```
Turn off cache at https://github.com/stanfordnlp/dspy/blob/34d8420383ec752037aa271825c1d3bf391e1277/dsp/modules/cache_utils.py#L10.
```
cache_turn_on = False
```
## Benchmark SGLang
```
python -m sglang.launch_server --model-path meta-llama/Llama-2-7b-chat-hf --port 30000
```
```
python3 bench_dspy_intro.py --backend sglang
```
## Benchmark TGI
```
docker run --name tgi --rm -ti --gpus all --network host \
-v /home/ubuntu/model_weights/Llama-2-7b-chat-hf:/Llama-2-7b-chat-hf \
ghcr.io/huggingface/text-generation-inference:1.3.0 \
--model-id /Llama-2-7b-chat-hf --num-shard 1 --trust-remote-code \
--max-input-length 2048 --max-total-tokens 4096 \
--port 24000
```
```
python3 bench_dspy_intro.py --backend tgi
```
## Benchmark vLLM
```
python3 -m vllm.entrypoints.openai.api_server --model meta-llama/Llama-2-7b-chat-hf --disable-log-requests --port 21000
```
```
python3 bench_dspy_intro.py --backend vllm
```
|
{
"source": "simplescaling/s1",
"title": "eval/rebase/sglang/benchmark/dspy/README.md",
"url": "https://github.com/simplescaling/s1/blob/main/eval/rebase/sglang/benchmark/dspy/README.md",
"date": "2025-02-01T02:38:16",
"stars": 5696,
"description": "s1: Simple test-time scaling",
"file_size": 978
}
|
## Download the dataset
```
wget -O agent_calls.jsonl https://drive.google.com/uc?export=download&id=19qLpD45e9JGTKF2cUjJJegwzSUEZEKht
```
## Run benchmark
Ensure that this benchmark is run in a serial manner (using --parallel 1) to preserve any potential dependencies between requests.
### Benchmark sglang
```
python -m sglang.launch_server --model-path meta-llama/Llama-2-7b-chat-hf --port 30000
```
```
python3 bench_sglang.py --num-events 1000 --parallel 1
```
### Benchmark vllm
```
python3 -m vllm.entrypoints.api_server --tokenizer-mode auto --model meta-llama/Llama-2-7b-chat-hf --disable-log-requests --port 21000
```
```
python3 bench_other.py --num-events 1000 --backend vllm --parallel 1
```
### Benchmark guidance
```
python3 bench_other.py --num-events 1000 --backend guidance --parallel 1
```
|
{
"source": "simplescaling/s1",
"title": "eval/rebase/sglang/benchmark/generative_agents/README.md",
"url": "https://github.com/simplescaling/s1/blob/main/eval/rebase/sglang/benchmark/generative_agents/README.md",
"date": "2025-02-01T02:38:16",
"stars": 5696,
"description": "s1: Simple test-time scaling",
"file_size": 816
}
|
## Download data
```
wget https://raw.githubusercontent.com/openai/grade-school-math/master/grade_school_math/data/test.jsonl
```
## Run benchmark
### Benchmark sglang
```
python -m sglang.launch_server --model-path meta-llama/Llama-2-7b-chat-hf --port 30000
```
```
python3 bench_sglang.py --num-questions 200
```
### Benchmark vllm
```
python3 -m vllm.entrypoints.api_server --tokenizer-mode auto --model meta-llama/Llama-2-7b-chat-hf --disable-log-requests --port 21000
```
```
python3 bench_other.py --num-questions 200 --backend vllm
```
### Benchmark lightllm
```
# A10G
python -m lightllm.server.api_server --tokenizer_mode auto --model_dir ~/model_weights/llama-2-7b-chat-hf --max_total_token_num 16000 --port 22000
```
```
python3 bench_other.py --num-questions 200 --backend lightllm
```
### Benchmark guidance
```
python3 bench_other.py --num-questions 200 --backend guidance --parallel 1
```
### Benchmark lmql
```
CUDA_VISIBLE_DEVICES=0,1 lmql serve-model meta-llama/Llama-2-7b-chat-hf --cuda --port 23000
```
```
python3 bench_other.py --num-questions 100 --backend lmql --parallel 2
```
|
{
"source": "simplescaling/s1",
"title": "eval/rebase/sglang/benchmark/gsm8k/README.md",
"url": "https://github.com/simplescaling/s1/blob/main/eval/rebase/sglang/benchmark/gsm8k/README.md",
"date": "2025-02-01T02:38:16",
"stars": 5696,
"description": "s1: Simple test-time scaling",
"file_size": 1115
}
|
## Download data
```
wget https://raw.githubusercontent.com/rowanz/hellaswag/master/data/hellaswag_val.jsonl
```
## Run benchmark
### Benchmark sglang
```
python -m sglang.launch_server --model-path meta-llama/Llama-2-7b-chat-hf --port 30000
```
```
python3 bench_sglang.py --num-questions 200
```
### Benchmark vllm
```
python3 -m vllm.entrypoints.api_server --tokenizer-mode auto --model meta-llama/Llama-2-7b-chat-hf --disable-log-requests --port 21000
```
```
python3 bench_other.py --num-questions 200 --backend vllm
```
### Benchmark lightllm
```
# A10G
python -m lightllm.server.api_server --tokenizer_mode auto --model_dir ~/model_weights/llama-2-7b-chat-hf --max_total_token_num 16000 --port 22000
```
```
python3 bench_other.py --num-questions 200 --backend lightllm
```
### Benchmark guidance
```
CUDA_VISIBLE_DEVICES=0,1 python3 bench_other.py --num-questions 200 --backend guidance --parallel 1
```
### Benchmark lmql
```
lmql serve-model meta-llama/Llama-2-7b-chat-hf --cuda --port 23000
```
```
python3 bench_other.py --num-questions 200 --backend lmql --port 23000 --parallel 1
```
|
{
"source": "simplescaling/s1",
"title": "eval/rebase/sglang/benchmark/hellaswag/README.md",
"url": "https://github.com/simplescaling/s1/blob/main/eval/rebase/sglang/benchmark/hellaswag/README.md",
"date": "2025-02-01T02:38:16",
"stars": 5696,
"description": "s1: Simple test-time scaling",
"file_size": 1111
}
|
## Run benchmark
### Build dataset
```
pip install wikipedia
python3 build_dataset.py
```
### Dependencies
```
llama_cpp_python 0.2.19
guidance 0.1.10
vllm 0.2.5
outlines 0.0.22
```
### Benchmark sglang
Run Llama-7B
```
python3 -m sglang.launch_server --model-path meta-llama/Llama-2-7b-chat-hf --port 30000
```
Run Mixtral-8x7B
```
python3 -m sglang.launch_server --model-path mistralai/Mixtral-8x7B-Instruct-v0.1 --port 30000 --tp-size 8
```
Benchmark
```
python3 bench_sglang.py --num-questions 10
```
### Benchmark vllm
Run Llama-7B
```
python3 -m outlines.serve.serve --tokenizer-mode auto --model meta-llama/Llama-2-7b-chat-hf --disable-log-requests --port 21000
```
Benchmark
```
python3 bench_other.py --backend vllm --num-questions 10
```
### Benchmark guidance
Run Llama-7B and benchmark
```
python3 bench_other.py --backend guidance --num-questions 10 --parallel 1
```
|
{
"source": "simplescaling/s1",
"title": "eval/rebase/sglang/benchmark/json_decode_regex/README.md",
"url": "https://github.com/simplescaling/s1/blob/main/eval/rebase/sglang/benchmark/json_decode_regex/README.md",
"date": "2025-02-01T02:38:16",
"stars": 5696,
"description": "s1: Simple test-time scaling",
"file_size": 965
}
|
## Run benchmark
### Dependencies
```
llama_cpp_python 0.2.38
guidance 0.1.10
vllm 0.2.7
outlines 0.0.25
```
### Build dataset
When benchmarking long document information retrieval, run the following command to build the dataset:
```bash
pip install wikipedia
python3 build_dataset.py
```
### Benchmark sglang
Run Llama-7B
```bash
python3 -m sglang.launch_server --model-path meta-llama/Llama-2-7b-chat-hf --port 30000
```
Benchmark Character Generation
```bash
python3 bench_sglang.py --mode character
```
Benchmark City Information Retrieval
```bash
python3 bench_sglang.py --mode city
```
### Benchmark vllm
Run Llama-7B
```bash
python3 -m outlines.serve.serve --tokenizer-mode auto --model meta-llama/Llama-2-7b-chat-hf --disable-log-requests --port 21000
```
Benchmark Character Generation
```bash
python3 bench_other.py --mode character --backend vllm
```
Benchmark City Information Retrieval
```bash
python3 bench_other.py --mode city --backend vllm
```
### Benchmark guidance
Run Llama-7B and benchmark character generation
```bash
python3 bench_other.py --mode character --backend guidance --parallel 1
```
Run Llama-7B and benchmark city information retrieval
```bash
python3 bench_other.py --mode city --backend guidance --parallel 1
```
|
{
"source": "simplescaling/s1",
"title": "eval/rebase/sglang/benchmark/json_jump_forward/README.md",
"url": "https://github.com/simplescaling/s1/blob/main/eval/rebase/sglang/benchmark/json_jump_forward/README.md",
"date": "2025-02-01T02:38:16",
"stars": 5696,
"description": "s1: Simple test-time scaling",
"file_size": 1339
}
|
### Download data
```
wget https://huggingface.co/datasets/anon8231489123/ShareGPT_Vicuna_unfiltered/resolve/main/ShareGPT_V3_unfiltered_cleaned_split.json
```
### SGLang
```
python -m sglang.launch_server --model-path meta-llama/Llama-2-7b-chat-hf --port 30000
```
```
python3 bench_throughput.py --backend srt --tokenizer meta-llama/Llama-2-7b-chat-hf --dataset ShareGPT_V3_unfiltered_cleaned_split.json --num-prompts 10 --request-rate 10 --port 30000
```
### vLLM
```
python3 -m vllm.entrypoints.api_server --model meta-llama/Llama-2-7b-chat-hf --disable-log-requests --swap-space 16 --port 21000
```
```
python3 bench_throughput.py --backend vllm --tokenizer meta-llama/Llama-2-7b-chat-hf --dataset ShareGPT_V3_unfiltered_cleaned_split.json --num-prompts 10 --request-rate 10 --port 21000
```
### LightLLM
```
python -m lightllm.server.api_server --model_dir ~/model_weights/Llama-2-7b-chat-hf --max_total_token_num 15600 --tokenizer_mode auto --port 22000
```
```
python3 bench_throughput.py --backend lightllm --tokenizer meta-llama/Llama-2-7b-chat-hf --dataset ShareGPT_V3_unfiltered_cleaned_split.json --num-prompts 10 --request-rate 10 --port 22000
```
|
{
"source": "simplescaling/s1",
"title": "eval/rebase/sglang/benchmark/latency_throughput/README.md",
"url": "https://github.com/simplescaling/s1/blob/main/eval/rebase/sglang/benchmark/latency_throughput/README.md",
"date": "2025-02-01T02:38:16",
"stars": 5696,
"description": "s1: Simple test-time scaling",
"file_size": 1169
}
|
## Download data
```
wget https://raw.githubusercontent.com/merrymercy/merrymercy.github.io/master/files/random_words.json
python3 gen_data.py --number 1000
```
## Run benchmark
### Benchmark sglang
```
python3 -m sglang.launch_server --model-path codellama/CodeLlama-7b-hf --port 30000
```
```
python3 bench_sglang.py --src-index 600 --num-q 50 --parallel 1
```
###
```
# original
Accuracy: 0.940, latency: 332.83 s
# parallel encoding (no_adjust, offset = 1000)
Accuracy: 0.760, latency: 238.46 s
# parallel encoding (no_adjust, offset = 3000)
Accuracy: 0.760, latency: 238.46 s
# parallel encoding (no_adjust, offset = 0)
Accuracy: 0.520, latency: 238.46 s
# parallel encoding (adjust_cache)
Accuracy: 0.460, latency: 257.66 s
```
|
{
"source": "simplescaling/s1",
"title": "eval/rebase/sglang/benchmark/line_retrieval/README.md",
"url": "https://github.com/simplescaling/s1/blob/main/eval/rebase/sglang/benchmark/line_retrieval/README.md",
"date": "2025-02-01T02:38:16",
"stars": 5696,
"description": "s1: Simple test-time scaling",
"file_size": 744
}
|
## Download benchmark images
```
python3 download_images.py
```
image benchmark source: https://huggingface.co/datasets/liuhaotian/llava-bench-in-the-wild
### Other Dependency
```
pip3 install "sglang[all]"
pip3 install "torch>=2.1.2" "transformers>=4.36" pillow
```
## Run benchmark
### Benchmark sglang
Launch a server
```
python3 -m sglang.launch_server --model-path liuhaotian/llava-v1.5-7b --tokenizer-path llava-hf/llava-1.5-7b-hf --port 30000
```
Run benchmark
```
# Run with local models
python3 bench_sglang.py --num-questions 60
# Run with OpenAI models
python3 bench_sglang.py --num-questions 60 --backend gpt-4-vision-preview
```
### Bench LLaVA original code
```
git clone [email protected]:haotian-liu/LLaVA.git
cd LLaVA
git reset --hard 9a26bd1435b4ac42c282757f2c16d34226575e96
pip3 install -e .
cd ~/sglang/benchmark/llava_bench
CUDA_VISIBLE_DEVICES=0 bash bench_hf_llava_bench.sh
```
### Benchmark llama.cpp
```
# Install
CMAKE_ARGS="-DLLAMA_CUBLAS=on" pip install llama-cpp-python
pip install sse_starlette starlette_context pydantic_settings
# Download weights
mkdir -p ~/model_weights/llava-v1.5-7b/
wget https://huggingface.co/mys/ggml_llava-v1.5-7b/resolve/main/ggml-model-f16.gguf -O ~/model_weights/llava-v1.5-7b/ggml-model-f16.gguf
wget https://huggingface.co/mys/ggml_llava-v1.5-7b/resolve/main/mmproj-model-f16.gguf -O ~/model_weights/llava-v1.5-7b/mmproj-model-f16.gguf
```
```
python3 -m llama_cpp.server --model ~/model_weights/llava-v1.5-7b/ggml-model-f16.gguf --clip_model_path ~/model_weights/llava-v1.5-7b/mmproj-model-f16.gguf --chat_format llava-1-5 --port 23000
OPENAI_BASE_URL=http://localhost:23000/v1 python3 bench_sglang.py --backend gpt-4-vision-preview --num-q 1
```
|
{
"source": "simplescaling/s1",
"title": "eval/rebase/sglang/benchmark/llava_bench/README.md",
"url": "https://github.com/simplescaling/s1/blob/main/eval/rebase/sglang/benchmark/llava_bench/README.md",
"date": "2025-02-01T02:38:16",
"stars": 5696,
"description": "s1: Simple test-time scaling",
"file_size": 1722
}
|
## Run benchmark
### Benchmark sglang
```
python -m sglang.launch_server --model-path meta-llama/Llama-2-7b-chat-hf --port 30000
```
```
python3 bench_sglang.py --num-questions 25 --parallel 8
python3 bench_sglang.py --num-questions 16 --parallel 1
```
### Benchmark vllm
```
python3 -m vllm.entrypoints.api_server --tokenizer-mode auto --model meta-llama/Llama-2-7b-chat-hf --disable-log-requests --port 21000
```
```
python3 bench_other.py --backend vllm --num-questions 25
```
### Benchmark guidance
```
python3 bench_other.py --backend guidance --num-questions 25 --parallel 1
```
|
{
"source": "simplescaling/s1",
"title": "eval/rebase/sglang/benchmark/llm_judge/README.md",
"url": "https://github.com/simplescaling/s1/blob/main/eval/rebase/sglang/benchmark/llm_judge/README.md",
"date": "2025-02-01T02:38:16",
"stars": 5696,
"description": "s1: Simple test-time scaling",
"file_size": 591
}
|
## Run benchmark
### Benchmark sglang
```
python3 -m sglang.launch_server --model-path codellama/CodeLlama-7b-instruct-hf --port 30000
```
```
python3 bench_sglang.py --num-questions 5 --parallel 1
```
### Benchmark vllm
```
python3 -m vllm.entrypoints.api_server --tokenizer-mode auto --model codellama/CodeLlama-7b-instruct-hf --disable-log-requests --port 21000 --gpu 0.97
```
```
python3 bench_other.py --backend vllm --num-questions 5
```
### Benchmark guidance
```
python3 bench_other.py --backend guidance --num-questions 5 --parallel 1
```
### Build dataset
```
pip install wikipedia
python3 build_dataset.py
```
|
{
"source": "simplescaling/s1",
"title": "eval/rebase/sglang/benchmark/long_json_decode/README.md",
"url": "https://github.com/simplescaling/s1/blob/main/eval/rebase/sglang/benchmark/long_json_decode/README.md",
"date": "2025-02-01T02:38:16",
"stars": 5696,
"description": "s1: Simple test-time scaling",
"file_size": 630
}
|
## Download data
```
wget https://people.eecs.berkeley.edu/~hendrycks/data.tar
tar xf data.tar
```
## Run benchmark
### Benchmark sglang
```
python -m sglang.launch_server --model-path meta-llama/Llama-2-7b-chat-hf --port 30000
```
```
python3 bench_sglang.py --nsub 10
```
```
# OpenAI models
python3 bench_sglang.py --backend gpt-3.5-turbo --parallel 8
```
### Benchmark vllm
```
python3 -m vllm.entrypoints.api_server --tokenizer-mode auto --model meta-llama/Llama-2-7b-chat-hf --disable-log-requests --port 21000
```
```
python3 bench_other.py --nsub 10 --backend vllm
```
### Benchmark lightllm
```
# A10G
python -m lightllm.server.api_server --tokenizer_mode auto --model_dir ~/model_weights/llama-2-7b-chat-hf --max_total_token_num 16000 --port 22000
# V100
python -m lightllm.server.api_server --tokenizer_mode auto --model_dir ~/model_weights/llama-2-7b-chat-hf --max_total_token_num 4500 --port 22000
```
```
python3 bench_other.py --nsub 10 --backend lightllm
```
### Benchmark guidance
```
python3 bench_other.py --nsub 10 --backend guidance --parallel 1
```
### Benchmark lmql
```
CUDA_VISIBLE_DEVICES=0,1 lmql serve-model meta-llama/Llama-2-7b-chat-hf --cuda --port 23000
```
```
python3 bench_other.py --nsub 10 --backend lmql --parallel 2
```
|
{
"source": "simplescaling/s1",
"title": "eval/rebase/sglang/benchmark/mmlu/README.md",
"url": "https://github.com/simplescaling/s1/blob/main/eval/rebase/sglang/benchmark/mmlu/README.md",
"date": "2025-02-01T02:38:16",
"stars": 5696,
"description": "s1: Simple test-time scaling",
"file_size": 1273
}
|
## Run benchmark
### Benchmark sglang
```
python -m sglang.launch_server --model-path meta-llama/Llama-2-7b-chat-hf --port 30000
```
```
python3 bench_sglang.py --num-questions 80
```
### Benchmark vllm
```
python3 -m vllm.entrypoints.api_server --tokenizer-mode auto --model meta-llama/Llama-2-7b-chat-hf --disable-log-requests --port 21000
```
```
python3 bench_other.py --num-questions 80 --backend vllm
```
### Benchmark lightllm
```
# A10G
python -m lightllm.server.api_server --tokenizer_mode auto --model_dir ~/model_weights/llama-2-7b-chat-hf --max_total_token_num 16000 --port 22000
```
```
python3 bench_other.py --num-questions 80 --backend lightllm
```
|
{
"source": "simplescaling/s1",
"title": "eval/rebase/sglang/benchmark/mtbench/README.md",
"url": "https://github.com/simplescaling/s1/blob/main/eval/rebase/sglang/benchmark/mtbench/README.md",
"date": "2025-02-01T02:38:16",
"stars": 5696,
"description": "s1: Simple test-time scaling",
"file_size": 672
}
|
## Download data
```
wget https://raw.githubusercontent.com/openai/grade-school-math/master/grade_school_math/data/test.jsonl
```
## Run benchmark
### Benchmark sglang
```
python -m sglang.launch_server --model-path meta-llama/Llama-2-7b-chat-hf --port 30000
```
```
python3 bench_sglang.py --num-questions 64
python3 bench_sglang.py --num-questions 32 --parallel 1
```
### Benchmark vllm
```
python3 -m vllm.entrypoints.api_server --tokenizer-mode auto --model meta-llama/Llama-2-7b-chat-hf --disable-log-requests --port 21000
```
```
python3 bench_other.py --num-questions 64 --backend vllm
```
### Benchmark lightllm
```
# A10G
python -m lightllm.server.api_server --tokenizer_mode auto --model_dir ~/model_weights/llama-2-7b-chat-hf --max_total_token_num 16000 --port 22000
```
```
python3 bench_other.py --num-questions 64 --backend lightllm
```
### Benchmark guidance
```
python3 bench_other.py --num-questions 8 --backend guidance --parallel 1
```
|
{
"source": "simplescaling/s1",
"title": "eval/rebase/sglang/benchmark/multi_chain_reasoning/README.md",
"url": "https://github.com/simplescaling/s1/blob/main/eval/rebase/sglang/benchmark/multi_chain_reasoning/README.md",
"date": "2025-02-01T02:38:16",
"stars": 5696,
"description": "s1: Simple test-time scaling",
"file_size": 965
}
|
## Run benchmark
### Benchmark sglang
```
python3 -m sglang.launch_server --model-path codellama/CodeLlama-7b-instruct-hf --port 30000
```
```
python3 bench_sglang.py --num-questions 10 --parallel 1
```
### Benchmark vllm
```
python3 -m vllm.entrypoints.api_server --tokenizer-mode auto --model codellama/CodeLlama-7b-instruct-hf --disable-log-requests --port 21000 --gpu 0.97
```
```
python3 bench_other.py --backend vllm --num-questions 64
```
### Benchmark guidance
```
python3 bench_other.py --backend guidance --num-questions 32 --parallel 1
```
### Build dataset
```
pip install PyPDF2
python3 build_dataset.py
```
```python
import PyPDF2
with open('llama2.pdf', 'rb') as file:
reader = PyPDF2.PdfReader(file)
text = ''
for page_num in range(len(reader.pages)):
text += reader.pages[page_num].extract_text()
with open('output.txt', 'w') as text_file:
text_file.write(text)
```
|
{
"source": "simplescaling/s1",
"title": "eval/rebase/sglang/benchmark/multi_document_qa/README.md",
"url": "https://github.com/simplescaling/s1/blob/main/eval/rebase/sglang/benchmark/multi_document_qa/README.md",
"date": "2025-02-01T02:38:16",
"stars": 5696,
"description": "s1: Simple test-time scaling",
"file_size": 928
}
|
### Benchmark sglang
Run Llama-7B
```
python3 -m sglang.launch_server --model-path meta-llama/Llama-2-7b-chat-hf --port 30000
```
Run Mixtral-8x7B
(When there is a CUDA out-of-memory error, try to reduce the `--mem-fraction-static`)
```
python3 -m sglang.launch_server --model-path mistralai/Mixtral-8x7B-Instruct-v0.1 --port 30000 --tp-size 8
```
Benchmark(short output)
```
python3 bench_sglang.py --tokenizer meta-llama/Llama-2-7b-chat-hf
```
Benchmark(long output)
```
python3 bench_sglang.py --tokenizer meta-llama/Llama-2-7b-chat-hf --long
```
### Benchmark vLLM
Run Llama-7B
```
python3 -m vllm.entrypoints.api_server --tokenizer-mode auto --model meta-llama/Llama-2-7b-chat-hf --disable-log-requests --port 21000
```
Run Mixtral-8x7B
```
python3 -m vllm.entrypoints.api_server --tokenizer-mode auto --model mistralai/Mixtral-8x7B-Instruct-v0.1 --disable-log-requests --port 21000 --tensor-parallel-size 8
```
Benchmark(short output)
```
python3 bench_other.py --tokenizer meta-llama/Llama-2-7b-chat-hf --backend vllm
```
Benchmark(long output)
```
python3 bench_other.py --tokenizer meta-llama/Llama-2-7b-chat-hf --backend vllm --long
```
### Benchmark guidance
Benchmark Llama-7B (short output)
```
python3 bench_other.py --tokenizer meta-llama/Llama-2-7b-chat-hf --backend guidance --parallel 1
```
Benchmark Llama-7B (long output)
```
python3 bench_other.py --tokenizer meta-llama/Llama-2-7b-chat-hf --backend guidance --parallel 1 --long
```
|
{
"source": "simplescaling/s1",
"title": "eval/rebase/sglang/benchmark/multi_turn_chat/README.md",
"url": "https://github.com/simplescaling/s1/blob/main/eval/rebase/sglang/benchmark/multi_turn_chat/README.md",
"date": "2025-02-01T02:38:16",
"stars": 5696,
"description": "s1: Simple test-time scaling",
"file_size": 1476
}
|
## Run benchmark
NOTE: This is an implementation for replaying a given trace for throughput/latency benchmark purposes. It is not an actual ReAct agent implementation.
### Benchmark sglang
```
python -m sglang.launch_server --model-path meta-llama/Llama-2-7b-chat-hf --port 30000
```
```
python3 bench_sglang.py --num-questions 100
```
### Benchmark vllm
```
python3 -m vllm.entrypoints.api_server --tokenizer-mode auto --model meta-llama/Llama-2-7b-chat-hf --disable-log-requests --port 21000
```
```
python3 bench_other.py --num-questions 100 --backend vllm
```
### Benchmark guidance
```
python3 bench_other.py --num-questions 100 --backend guidance --parallel 1
```
|
{
"source": "simplescaling/s1",
"title": "eval/rebase/sglang/benchmark/react/README.md",
"url": "https://github.com/simplescaling/s1/blob/main/eval/rebase/sglang/benchmark/react/README.md",
"date": "2025-02-01T02:38:16",
"stars": 5696,
"description": "s1: Simple test-time scaling",
"file_size": 677
}
|
## Run benchmark
### Benchmark sglang
```
python -m sglang.launch_server --model-path meta-llama/Llama-2-7b-chat-hf --port 30000
```
```
python3 bench_sglang.py --num-questions 64
python3 bench_sglang.py --num-questions 32 --parallel 1
```
### Benchmark vllm
```
python3 -m vllm.entrypoints.api_server --tokenizer-mode auto --model meta-llama/Llama-2-7b-chat-hf --disable-log-requests --port 21000
```
```
python3 bench_other.py --backend vllm --num-questions 64
```
### Benchmark guidance
```
python3 bench_other.py --backend guidance --num-questions 32 --parallel 1
```
|
{
"source": "simplescaling/s1",
"title": "eval/rebase/sglang/benchmark/tip_suggestion/README.md",
"url": "https://github.com/simplescaling/s1/blob/main/eval/rebase/sglang/benchmark/tip_suggestion/README.md",
"date": "2025-02-01T02:38:16",
"stars": 5696,
"description": "s1: Simple test-time scaling",
"file_size": 578
}
|
## Download data
```
wget https://raw.githubusercontent.com/openai/grade-school-math/master/grade_school_math/data/test.jsonl
```
## Run benchmark
NOTE: This is an implementation for throughput/latency benchmark purposes. The prompts are not tuned to achieve good accuracy on the GSM-8K tasks.
### Benchmark sglang
```
python -m sglang.launch_server --model-path meta-llama/Llama-2-7b-chat-hf --port 30000
```
```
python3 bench_sglang.py --num-questions 32
python3 bench_sglang.py --num-questions 16 --parallel 1
```
### Benchmark vllm
```
python3 -m vllm.entrypoints.api_server --tokenizer-mode auto --model meta-llama/Llama-2-7b-chat-hf --disable-log-requests --port 21000
```
```
python3 bench_other.py --num-questions 32 --backend vllm
```
### Benchmark lightllm
```
# A10G
python -m lightllm.server.api_server --tokenizer_mode auto --model_dir ~/model_weights/llama-2-7b-chat-hf --max_total_token_num 16000 --port 22000
```
```
python3 bench_other.py --num-questions 32 --backend lightllm
```
### Benchmark guidance
```
python3 bench_other.py --num-questions 8 --backend guidance --parallel 1
```
|
{
"source": "simplescaling/s1",
"title": "eval/rebase/sglang/benchmark/tree_of_thought_deep/README.md",
"url": "https://github.com/simplescaling/s1/blob/main/eval/rebase/sglang/benchmark/tree_of_thought_deep/README.md",
"date": "2025-02-01T02:38:16",
"stars": 5696,
"description": "s1: Simple test-time scaling",
"file_size": 1113
}
|
## Download data
```
wget https://raw.githubusercontent.com/openai/grade-school-math/master/grade_school_math/data/test.jsonl
```
## Run benchmark
### Benchmark sglang
```
python -m sglang.launch_server --model-path meta-llama/Llama-2-7b-chat-hf --port 30000
```
```
python3 bench_sglang.py --num-questions 32 --parallel 16
python3 bench_sglang.py --num-questions 10 --parallel 1
```
### Benchmark vllm
```
python3 -m vllm.entrypoints.api_server --tokenizer-mode auto --model meta-llama/Llama-2-7b-chat-hf --disable-log-requests --port 21000
```
```
python3 bench_other.py --num-questions 32 --backend vllm
```
### Benchmark lightllm
```
# A10G
python -m lightllm.server.api_server --tokenizer_mode auto --model_dir ~/model_weights/llama-2-7b-chat-hf --max_total_token_num 16000 --port 22000
```
```
python3 bench_other.py --num-questions 32 --backend lightllm
```
### Benchmark guidance
```
python3 bench_other.py --num-questions 32 --backend guidance --parallel 1
```
|
{
"source": "simplescaling/s1",
"title": "eval/rebase/sglang/benchmark/tree_of_thought_v0/README.md",
"url": "https://github.com/simplescaling/s1/blob/main/eval/rebase/sglang/benchmark/tree_of_thought_v0/README.md",
"date": "2025-02-01T02:38:16",
"stars": 5696,
"description": "s1: Simple test-time scaling",
"file_size": 980
}
|
#Arabic COPA
### Paper
Original Title: `COPA`
The Choice Of Plausible Alternatives (COPA) evaluation provides researchers with a tool for assessing progress in open-domain commonsense causal reasoning.
[Homepage](https://people.ict.usc.edu/~gordon/copa.html)
AlGhafa has translated this dataset to Arabic[AlGafa](https://aclanthology.org/2023.arabicnlp-1.21.pdf)
The link to the Arabic version of the dataset [PICA](https://gitlab.com/tiiuae/alghafa/-/tree/main/arabic-eval/copa_ar)
### Citation
### Groups and Tasks
#### Groups
* Not part of a group yet.
#### Tasks
* `copa_ar`
### Checklist
For adding novel benchmarks/datasets to the library:
* [x] Is the task an existing benchmark in the literature?
* [x] Have you referenced the original paper that introduced the task?
* [x] If yes, does the original paper provide a reference implementation? If so, have you checked against the reference implementation and documented how to run such a test?
If other tasks on this dataset are already supported:
* [x] Is the "Main" variant of this task clearly denoted?
* [x] Have you provided a short sentence in a README on what each new variant adds / evaluates?
* [x] Have you noted which, if any, published evaluation setups are matched by this variant?
|
{
"source": "simplescaling/s1",
"title": "eval/lm-evaluation-harness/lm_eval/tasks/alghafa/copa_ar/README.md",
"url": "https://github.com/simplescaling/s1/blob/main/eval/lm-evaluation-harness/lm_eval/tasks/alghafa/copa_ar/README.md",
"date": "2025-02-01T02:38:16",
"stars": 5696,
"description": "s1: Simple test-time scaling",
"file_size": 1272
}
|
#Arabic PIQA
### Paper
Original Title: `PIQA: Reasoning about Physical Commonsense in Natural Language`
Original paper: [PICA](https://arxiv.org/abs/1911.11641)
Physical Interaction: Question Answering (PIQA) is a physical commonsense
reasoning and a corresponding benchmark dataset. PIQA was designed to investigate
the physical knowledge of existing models. To what extent are current approaches
actually learning about the world?
[Homepage](https://yonatanbisk.com/piqa)
AlGhafa has translated this dataset to Arabic[AlGafa](https://aclanthology.org/2023.arabicnlp-1.21.pdf)
The link to the Arabic version of the dataset [PICA](https://gitlab.com/tiiuae/alghafa/-/tree/main/arabic-eval/pica_ar)
### Citation
### Groups and Tasks
#### Groups
* Not part of a group yet.
#### Tasks
* `piqa_ar`
### Checklist
For adding novel benchmarks/datasets to the library:
* [x] Is the task an existing benchmark in the literature?
* [x] Have you referenced the original paper that introduced the task?
* [x] If yes, does the original paper provide a reference implementation? If so, have you checked against the reference implementation and documented how to run such a test?
If other tasks on this dataset are already supported:
* [x] Is the "Main" variant of this task clearly denoted?
* [x] Have you provided a short sentence in a README on what each new variant adds / evaluates?
* [x] Have you noted which, if any, published evaluation setups are matched by this variant?
|
{
"source": "simplescaling/s1",
"title": "eval/lm-evaluation-harness/lm_eval/tasks/alghafa/piqa_ar/README.md",
"url": "https://github.com/simplescaling/s1/blob/main/eval/lm-evaluation-harness/lm_eval/tasks/alghafa/piqa_ar/README.md",
"date": "2025-02-01T02:38:16",
"stars": 5696,
"description": "s1: Simple test-time scaling",
"file_size": 1486
}
|
# MultiMedQA (multiple-choice subset)
### Paper
Title: Large Language Models Encode Clinical Knowledge
Abstract: https://arxiv.org/abs/2212.13138
A benchmark combining four existing multiple-choice question answering datasets spanning professional medical exams and research queries.
### Citation
```
@Article{Singhal2023,
author={Singhal, Karan and Azizi, Shekoofeh and Tu, Tao and Mahdavi, S. Sara and Wei, Jason and Chung, Hyung Won and Scales, Nathan and Tanwani, Ajay and Cole-Lewis, Heather and Pfohl, Stephen and Payne, Perry and Seneviratne, Martin and Gamble, Paul and Kelly, Chris and Babiker, Abubakr and Sch{\"a}rli, Nathanael and Chowdhery, Aakanksha and Mansfield, Philip and Demner-Fushman, Dina and Ag{\"u}era y Arcas, Blaise and Webster, Dale and Corrado, Greg S. and Matias, Yossi and Chou, Katherine and Gottweis, Juraj and Tomasev, Nenad and Liu, Yun and Rajkomar, Alvin and Barral, Joelle and Semturs, Christopher and Karthikesalingam, Alan and Natarajan, Vivek},
title={Large language models encode clinical knowledge},
journal={Nature},
year={2023},
month={Aug},
day={01},
volume={620},
number={7972},
pages={172-180},
issn={1476-4687},
doi={10.1038/s41586-023-06291-2},
url={https://doi.org/10.1038/s41586-023-06291-2}
}
```
### Tasks
* [PubMedQA](https://pubmedqa.github.io/) - 1,000 expert-labeled Q&A pairs where a question and corresponding PubMed abstract as context is given and the a yes/maybe/no answer must be produced. Unlike the rest of the tasks in this suite, PubMedQA is a closed-domain Q&A task.
* [MedQA](https://github.com/jind11/MedQA) - US Medical License Exam (USMLE) questions with 4 or 5 possible answers. Typically, only the 4-option questions are used.
* [MedMCQA](https://medmcqa.github.io/) - 4-option multiple choice questions from Indian medical entrance examinations, >191k total questions.
* [MMLU](https://arxiv.org/abs/2009.03300) - 4-option multiple choice exam questions from a variety of domains. The following 6 domains are utilized here:
* Anatomy
* Clinical Knowledge
* College Medicine
* Medical Genetics
* Professional Medicine
* College Biology
Note that MultiMedQA also includes some short-form and long-form Q&A tasks (LiveQA, MedicationQA, HealthSearchQA). Evaluation on these tasks is usually done by experts and is not typically performed automatically, and therefore is ignored here.
|
{
"source": "simplescaling/s1",
"title": "eval/lm-evaluation-harness/lm_eval/tasks/benchmarks/multimedqa/README.md",
"url": "https://github.com/simplescaling/s1/blob/main/eval/lm-evaluation-harness/lm_eval/tasks/benchmarks/multimedqa/README.md",
"date": "2025-02-01T02:38:16",
"stars": 5696,
"description": "s1: Simple test-time scaling",
"file_size": 2370
}
|
# Multilingual ARC
### Paper
Title: `Okapi: Instruction-tuned Large Language Models in Multiple Languages with Reinforcement Learning from Human Feedback`
Abstract: https://arxiv.org/abs/2307.16039
A key technology for the development of large language models (LLMs) involves instruction tuning that helps align the models' responses with human expectations to realize impressive learning abilities. Two major approaches for instruction tuning characterize supervised fine-tuning (SFT) and reinforcement learning from human feedback (RLHF), which are currently applied to produce the best commercial LLMs (e.g., ChatGPT). To improve the accessibility of LLMs for research and development efforts, various instruction-tuned open-source LLMs have also been introduced recently, e.g., Alpaca, Vicuna, to name a few. However, existing open-source LLMs have only been instruction-tuned for English and a few popular languages, thus hindering their impacts and accessibility to many other languages in the world. Among a few very recent work to explore instruction tuning for LLMs in multiple languages, SFT has been used as the only approach to instruction-tune LLMs for multiple languages. This has left a significant gap for fine-tuned LLMs based on RLHF in diverse languages and raised important questions on how RLHF can boost the performance of multilingual instruction tuning. To overcome this issue, we present Okapi, the first system with instruction-tuned LLMs based on RLHF for multiple languages. Okapi introduces instruction and response-ranked data in 26 diverse languages to facilitate the experiments and development of future multilingual LLM research. We also present benchmark datasets to enable the evaluation of generative LLMs in multiple languages. Our experiments demonstrate the advantages of RLHF for multilingual instruction over SFT for different base models and datasets. Our framework and resources are released at this https URL.
Homepage: `https://github.com/nlp-uoregon/Okapi`
### Citation
```
@article{dac2023okapi,
title={Okapi: Instruction-tuned Large Language Models in Multiple Languages with Reinforcement Learning from Human Feedback},
author={Dac Lai, Viet and Van Nguyen, Chien and Ngo, Nghia Trung and Nguyen, Thuat and Dernoncourt, Franck and Rossi, Ryan A and Nguyen, Thien Huu},
journal={arXiv e-prints},
pages={arXiv--2307},
year={2023}
}
```
### Groups and Tasks
#### Groups
- arc_multilingual
#### Tasks
- `arc_{ar,bn,ca,da,de,es,eu,fr,gu,hi,hr,hu,hy,id,it,kn,ml,mr,ne,nl,pt,ro,ru,sk,sr,sv,ta,te,uk,vi,zh}`
### Checklist
For adding novel benchmarks/datasets to the library:
* [x] Is the task an existing benchmark in the literature?
* [x] Have you referenced the original paper that introduced the task?
* [x] If yes, does the original paper provide a reference implementation? If so, have you checked against the reference implementation and documented how to run such a test?
If other tasks on this dataset are already supported:
* [ ] Is the "Main" variant of this task clearly denoted?
* [ ] Have you provided a short sentence in a README on what each new variant adds / evaluates?
* [ ] Have you noted which, if any, published evaluation setups are matched by this variant?
|
{
"source": "simplescaling/s1",
"title": "eval/lm-evaluation-harness/lm_eval/tasks/okapi/arc_multilingual/README.md",
"url": "https://github.com/simplescaling/s1/blob/main/eval/lm-evaluation-harness/lm_eval/tasks/okapi/arc_multilingual/README.md",
"date": "2025-02-01T02:38:16",
"stars": 5696,
"description": "s1: Simple test-time scaling",
"file_size": 3252
}
|
# Multilingual HellaSwag
### Paper
Title: `Okapi: Instruction-tuned Large Language Models in Multiple Languages with Reinforcement Learning from Human Feedback`
Abstract: https://arxiv.org/abs/2307.16039
A key technology for the development of large language models (LLMs) involves instruction tuning that helps align the models' responses with human expectations to realize impressive learning abilities. Two major approaches for instruction tuning characterize supervised fine-tuning (SFT) and reinforcement learning from human feedback (RLHF), which are currently applied to produce the best commercial LLMs (e.g., ChatGPT). To improve the accessibility of LLMs for research and development efforts, various instruction-tuned open-source LLMs have also been introduced recently, e.g., Alpaca, Vicuna, to name a few. However, existing open-source LLMs have only been instruction-tuned for English and a few popular languages, thus hindering their impacts and accessibility to many other languages in the world. Among a few very recent work to explore instruction tuning for LLMs in multiple languages, SFT has been used as the only approach to instruction-tune LLMs for multiple languages. This has left a significant gap for fine-tuned LLMs based on RLHF in diverse languages and raised important questions on how RLHF can boost the performance of multilingual instruction tuning. To overcome this issue, we present Okapi, the first system with instruction-tuned LLMs based on RLHF for multiple languages. Okapi introduces instruction and response-ranked data in 26 diverse languages to facilitate the experiments and development of future multilingual LLM research. We also present benchmark datasets to enable the evaluation of generative LLMs in multiple languages. Our experiments demonstrate the advantages of RLHF for multilingual instruction over SFT for different base models and datasets. Our framework and resources are released at this https URL.
Homepage: `https://github.com/nlp-uoregon/Okapi`
### Citation
```
@article{dac2023okapi,
title={Okapi: Instruction-tuned Large Language Models in Multiple Languages with Reinforcement Learning from Human Feedback},
author={Dac Lai, Viet and Van Nguyen, Chien and Ngo, Nghia Trung and Nguyen, Thuat and Dernoncourt, Franck and Rossi, Ryan A and Nguyen, Thien Huu},
journal={arXiv e-prints},
pages={arXiv--2307},
year={2023}
}
```
### Groups and Tasks
#### Groups
- hellaswag_multilingual
#### Tasks
- `hellaswag_{ar,bn,ca,da,de,es,eu,fr,gu,hi,hr,hu,hy,id,it,kn,ml,mr,ne,nl,pt,ro,ru,sk,sr,sv,ta,te,uk,vi}`
### Checklist
For adding novel benchmarks/datasets to the library:
* [x] Is the task an existing benchmark in the literature?
* [x] Have you referenced the original paper that introduced the task?
* [x] If yes, does the original paper provide a reference implementation? If so, have you checked against the reference implementation and documented how to run such a test?
If other tasks on this dataset are already supported:
* [ ] Is the "Main" variant of this task clearly denoted?
* [ ] Have you provided a short sentence in a README on what each new variant adds / evaluates?
* [ ] Have you noted which, if any, published evaluation setups are matched by this variant?
|
{
"source": "simplescaling/s1",
"title": "eval/lm-evaluation-harness/lm_eval/tasks/okapi/hellaswag_multilingual/README.md",
"url": "https://github.com/simplescaling/s1/blob/main/eval/lm-evaluation-harness/lm_eval/tasks/okapi/hellaswag_multilingual/README.md",
"date": "2025-02-01T02:38:16",
"stars": 5696,
"description": "s1: Simple test-time scaling",
"file_size": 3268
}
|
# Multilingual TruthfulQA
### Paper
Title: `Okapi: Instruction-tuned Large Language Models in Multiple Languages with Reinforcement Learning from Human Feedback`
Abstract: https://arxiv.org/abs/2307.16039
A key technology for the development of large language models (LLMs) involves instruction tuning that helps align the models' responses with human expectations to realize impressive learning abilities. Two major approaches for instruction tuning characterize supervised fine-tuning (SFT) and reinforcement learning from human feedback (RLHF), which are currently applied to produce the best commercial LLMs (e.g., ChatGPT). To improve the accessibility of LLMs for research and development efforts, various instruction-tuned open-source LLMs have also been introduced recently, e.g., Alpaca, Vicuna, to name a few. However, existing open-source LLMs have only been instruction-tuned for English and a few popular languages, thus hindering their impacts and accessibility to many other languages in the world. Among a few very recent work to explore instruction tuning for LLMs in multiple languages, SFT has been used as the only approach to instruction-tune LLMs for multiple languages. This has left a significant gap for fine-tuned LLMs based on RLHF in diverse languages and raised important questions on how RLHF can boost the performance of multilingual instruction tuning. To overcome this issue, we present Okapi, the first system with instruction-tuned LLMs based on RLHF for multiple languages. Okapi introduces instruction and response-ranked data in 26 diverse languages to facilitate the experiments and development of future multilingual LLM research. We also present benchmark datasets to enable the evaluation of generative LLMs in multiple languages. Our experiments demonstrate the advantages of RLHF for multilingual instruction over SFT for different base models and datasets. Our framework and resources are released at this https URL.
Homepage: `https://github.com/nlp-uoregon/Okapi`
### Citation
```
@article{dac2023okapi,
title={Okapi: Instruction-tuned Large Language Models in Multiple Languages with Reinforcement Learning from Human Feedback},
author={Dac Lai, Viet and Van Nguyen, Chien and Ngo, Nghia Trung and Nguyen, Thuat and Dernoncourt, Franck and Rossi, Ryan A and Nguyen, Thien Huu},
journal={arXiv e-prints},
pages={arXiv--2307},
year={2023}
}
```
### Groups and Tasks
#### Groups
- truthfulqa_multilingual
#### Tasks
- `truthfulqa_{ar,bn,ca,da,de,es,eu,fr,gu,hi,hr,hu,hy,id,it,kn,ml,mr,ne,nl,pt,ro,ru,sk,sr,sv,ta,te,uk,vi,zh}`
### Checklist
For adding novel benchmarks/datasets to the library:
* [x] Is the task an existing benchmark in the literature?
* [x] Have you referenced the original paper that introduced the task?
* [x] If yes, does the original paper provide a reference implementation? If so, have you checked against the reference implementation and documented how to run such a test?
If other tasks on this dataset are already supported:
* [ ] Is the "Main" variant of this task clearly denoted?
* [ ] Have you provided a short sentence in a README on what each new variant adds / evaluates?
* [ ] Have you noted which, if any, published evaluation setups are matched by this variant?
|
{
"source": "simplescaling/s1",
"title": "eval/lm-evaluation-harness/lm_eval/tasks/okapi/truthfulqa_multilingual/README.md",
"url": "https://github.com/simplescaling/s1/blob/main/eval/lm-evaluation-harness/lm_eval/tasks/okapi/truthfulqa_multilingual/README.md",
"date": "2025-02-01T02:38:16",
"stars": 5696,
"description": "s1: Simple test-time scaling",
"file_size": 3273
}
|
# sglang_triton
Build the docker image:
```
docker build -t sglang-triton .
```
Then do:
```
docker run -ti --gpus=all --network=host --name sglang-triton -v ./models:/mnt/models sglang-triton
```
inside the docker container:
```
cd sglang
python3 -m sglang.launch_server --model-path mistralai/Mistral-7B-Instruct-v0.2 --port 30000 --mem-fraction-static 0.9
```
with another shell, inside the docker container:
```
docker exec -ti sglang-triton /bin/bash
cd /mnt
tritonserver --model-repository=/mnt/models
```
Send request to the server:
```
curl -X POST http://localhost:8000/v2/models/character_generation/generate \
-H "Content-Type: application/json" \
-d '{
"INPUT_TEXT": ["harry"]
}'
```
|
{
"source": "simplescaling/s1",
"title": "eval/rebase/sglang/examples/usage/triton/README.md",
"url": "https://github.com/simplescaling/s1/blob/main/eval/rebase/sglang/examples/usage/triton/README.md",
"date": "2025-02-01T02:38:16",
"stars": 5696,
"description": "s1: Simple test-time scaling",
"file_size": 704
}
|
# Conditioning explanations
Here we will list out all the conditionings the model accepts as well as a short description and some tips for optimal use. For conditionings with a learned unconditional, they can be set to that to allow the model to infer an appropriate setting.
### espeak
- **Type:** `EspeakPhonemeConditioner`
- **Description:**
Responsible for cleaning, phonemicizing, tokenizing, and embedding the text provided to the model. This is the text pre-processing pipeline. If you would like to change how a word is pronounced or enter raw phonemes you can do that here.
---
### speaker
- **Type:** `PassthroughConditioner`
- **Attributes:**
- **cond_dim:** `128`
- **uncond_type:** `learned`
- **projection:** `linear`
- **Description:**
An embedded representation of the speakers voice. We use [these](https://huggingface.co/Zyphra/Zonos-v0.1-speaker-embedding) speaker embedding models. It can capture a surprising amount of detail from the reference clip and supports arbitrary length input. Try to input clean reference clips containing only speech. It can be valid to concatenate multiple clean samples from the same speaker into one long sample and may lead to better cloning. If the speaker clip is very long, it is advisable to cut out long speech-free background music segments if they exist. If the reference clip is yielding noisy outputs with denoising enabled we recommend doing source separation before cloning.
---
### emotion
- **Type:** `FourierConditioner`
- **Attributes:**
- **input_dim:** `8`
- **uncond_type:** `learned`
- **Description:**
Encodes emotion in an 8D vector. Included emotions are Happiness, Sadness, Disgust, Fear, Surprise, Anger, Other, Neutral in that order. This vector tends to be entangled with various other conditioning inputs. More notably, it's entangled with text based on the text sentiment (eg. Angry texts will be more effectively conditioned to be angry, but if you try to make it sound sad it will be a lot less effective). It's also entangled with pitch standard deviation since larger values there tend to correlate to more emotional utterances. It's also heavily correlated with VQScore and DNSMOS as these conditionings favor neutral speech. It's also possible to do a form of "negative prompting" by doing CFG where the unconditional branch is set to a highly neutral emotion vector instead of the true unconditional value, doing this will exaggerate the emotions as it pushes the model away from being neutral.
---
### fmax
- **Type:** `FourierConditioner`
- **Attributes:**
- **min_val:** `0`
- **max_val:** `24000`
- **uncond_type:** `learned`
- **Description:**
Specifies the max frequency of the audio. For best results select 22050 or 24000 as these correspond to 44.1 and 48KHz audio respectively. They should not be any different in terms of actual max frequency since the model's sampling rate is 44.1KHz but they represent different slices of data which lead to slightly different voicing. Selecting a lower value generally produces lower-quality results both in terms of acoustics and voicing.
---
### pitch_std
- **Type:** `FourierConditioner`
- **Attributes:**
- **min_val:** `0`
- **max_val:** `400`
- **uncond_type:** `learned`
- **Description:**
Specifies the standard deviation of the pitch of the output audio. Wider variations of pitch tend to be more correlated with expressive speech. Good values are from 20-45 for normal speech and 60-150 for expressive speech. Higher than that generally tend to be crazier samples.
---
### speaking_rate
- **Type:** `FourierConditioner`
- **Attributes:**
- **min_val:** `0`
- **max_val:** `40`
- **uncond_type:** `learned`
- **Description:**
Specifies the number of phonemes to be read per second. When entering a long text, it is advisable to adjust the speaking rate such that the number of phonemes is readable within the generation length. For example, if your generation length is 10 seconds, and your input is 300 phonemes, you would want either 30 phonemes per second (which is very very fast) or to generate a longer sample. The model's maximum is 30 seconds. Please note that unrealistic speaking rates can be OOD for the model and create undesirable effects, so at the 30-second limit, it can be better to cut the text short and do multiple generations than to feed the model the entire prompt and have an unrealistically low speaking rate.
---
### language_id
- **Type:** `IntegerConditioner`
- **Attributes:**
- **min_val:** `-1`
- **max_val:** `126`
- **uncond_type:** `learned`
- **Description:**
Indicates which language the output should be in. A mapping for these values can be found in the [conditioning section](https://github.com/Zyphra/Zonos/blob/3807c8e04bd4beaadb9502b3df1ffa4b0350e3f7/zonos/conditioning.py#L308C1-L376C21) of Zonos.
---
### vqscore_8
- **Type:** `FourierConditioner`
- **Attributes:**
- **input_dim:** `8`
- **min_val:** `0.5`
- **max_val:** `0.8`
- **uncond_type:** `learned`
- **Description:**
Encodes the desired [VQScore](https://github.com/JasonSWFu/VQscore) value for the output audio. VQScore is an unsupervised speech quality (cleanliness) estimation method that we found has superior generalization and reduced biases compared to supervised methods like DNSMOS. A good value for our model is 0.78 for high-quality speech. The eight dimensions correspond to consecutive 1/8th chunks of the audio. (eg. for an 8-second output, the first dimension represents the quality of the first second only). For inference, we generally set all 8 dimensions to the same value. This has an unfortunately strong correlation with expressiveness, so for expressive speech, we recommend setting it to unconditional.
---
### ctc_loss
- **Type:** `FourierConditioner`
- **Attributes:**
- **min_val:** `-1.0`
- **max_val:** `1000`
- **uncond_type:** `learned`
- **Description:**
Encodes loss values from a [CTC](https://en.wikipedia.org/wiki/Connectionist_temporal_classification) (Connectionist Temporal Classification) setup, this indicates how well the training-time transcription matched with the audio according to a CTC model. For inference always use low values (eg. 0.0 or 1.0)
---
### dnsmos_ovrl
- **Type:** `FourierConditioner`
- **Attributes:**
- **min_val:** `1`
- **max_val:** `5`
- **uncond_type:** `learned`
- **Description:**
A [MOS](https://arxiv.org/abs/2110.01763) score for the output audio. This is similar to VQScore and tends to have a stronger entanglement with emotions. It additionally has a strong entanglement with languages. Set to 4.0 for very clean and neutral English speech, else we recommend setting it to unconditional.
---
### speaker_noised
- **Type:** `IntegerConditioner`
- **Attributes:**
- **min_val:** `0`
- **max_val:** `1`
- **uncond_type:** `learned`
- **Description:**
Indicates if the speaker embedding is noisy or not. If checked this lets the model clean (denoise) the input speaker embedding. When this is set to True, VQScore and DNSMOS will have a lot more power to clean the speaker embedding, so for very noisy input samples we recommend setting this to True and specifying a high VQScore value. If your speaker cloning outputs sound echo-y or do weird things, setting this to True will help.
|
{
"source": "Zyphra/Zonos",
"title": "CONDITIONING_README.md",
"url": "https://github.com/Zyphra/Zonos/blob/main/CONDITIONING_README.md",
"date": "2025-02-07T00:32:44",
"stars": 5503,
"description": "Zonos-v0.1 is a leading open-weight text-to-speech model trained on more than 200k hours of varied multilingual speech, delivering expressiveness and quality on par with—or even surpassing—top TTS providers.",
"file_size": 7308
}
|
# Zonos-v0.1
<div align="center">
<img src="assets/ZonosHeader.png"
alt="Alt text"
style="width: 500px;
height: auto;
object-position: center top;">
</div>
<div align="center">
<a href="https://discord.gg/gTW9JwST8q" target="_blank">
<img src="https://img.shields.io/badge/Join%20Our%20Discord-7289DA?style=for-the-badge&logo=discord&logoColor=white" alt="Discord">
</a>
</div>
---
Zonos-v0.1 is a leading open-weight text-to-speech model trained on more than 200k hours of varied multilingual speech, delivering expressiveness and quality on par with—or even surpassing—top TTS providers.
Our model enables highly natural speech generation from text prompts when given a speaker embedding or audio prefix, and can accurately perform speech cloning when given a reference clip spanning just a few seconds. The conditioning setup also allows for fine control over speaking rate, pitch variation, audio quality, and emotions such as happiness, fear, sadness, and anger. The model outputs speech natively at 44kHz.
##### For more details and speech samples, check out our blog [here](https://www.zyphra.com/post/beta-release-of-zonos-v0-1)
##### We also have a hosted version available at [playground.zyphra.com/audio](https://playground.zyphra.com/audio)
---
Zonos follows a straightforward architecture: text normalization and phonemization via eSpeak, followed by DAC token prediction through a transformer or hybrid backbone. An overview of the architecture can be seen below.
<div align="center">
<img src="assets/ArchitectureDiagram.png"
alt="Alt text"
style="width: 1000px;
height: auto;
object-position: center top;">
</div>
---
## Usage
### Python
```python
import torch
import torchaudio
from zonos.model import Zonos
from zonos.conditioning import make_cond_dict
from zonos.utils import DEFAULT_DEVICE as device
# model = Zonos.from_pretrained("Zyphra/Zonos-v0.1-hybrid", device=device)
model = Zonos.from_pretrained("Zyphra/Zonos-v0.1-transformer", device=device)
wav, sampling_rate = torchaudio.load("assets/exampleaudio.mp3")
speaker = model.make_speaker_embedding(wav, sampling_rate)
cond_dict = make_cond_dict(text="Hello, world!", speaker=speaker, language="en-us")
conditioning = model.prepare_conditioning(cond_dict)
codes = model.generate(conditioning)
wavs = model.autoencoder.decode(codes).cpu()
torchaudio.save("sample.wav", wavs[0], model.autoencoder.sampling_rate)
```
### Gradio interface (recommended)
```bash
uv run gradio_interface.py
# python gradio_interface.py
```
This should produce a `sample.wav` file in your project root directory.
_For repeated sampling we highly recommend using the gradio interface instead, as the minimal example needs to load the model every time it is run._
## Features
- Zero-shot TTS with voice cloning: Input desired text and a 10-30s speaker sample to generate high quality TTS output
- Audio prefix inputs: Add text plus an audio prefix for even richer speaker matching. Audio prefixes can be used to elicit behaviours such as whispering which can otherwise be challenging to replicate when cloning from speaker embeddings
- Multilingual support: Zonos-v0.1 supports English, Japanese, Chinese, French, and German
- Audio quality and emotion control: Zonos offers fine-grained control of many aspects of the generated audio. These include speaking rate, pitch, maximum frequency, audio quality, and various emotions such as happiness, anger, sadness, and fear.
- Fast: our model runs with a real-time factor of ~2x on an RTX 4090 (i.e. generates 2 seconds of audio per 1 second of compute time)
- Gradio WebUI: Zonos comes packaged with an easy to use gradio interface to generate speech
- Simple installation and deployment: Zonos can be installed and deployed simply using the docker file packaged with our repository.
## Installation
#### System requirements
- **Operating System:** Linux (preferably Ubuntu 22.04/24.04), macOS
- **GPU:** 6GB+ VRAM, Hybrid additionally requires a 3000-series or newer Nvidia GPU
Note: Zonos can also run on CPU provided there is enough free RAM. However, this will be a lot slower than running on a dedicated GPU, and likely won't be sufficient for interactive use.
For experimental windows support check out [this fork](https://github.com/sdbds/Zonos-for-windows).
See also [Docker Installation](#docker-installation)
#### System dependencies
Zonos depends on the eSpeak library phonemization. You can install it on Ubuntu with the following command:
```bash
apt install -y espeak-ng # For Ubuntu
# brew install espeak-ng # For MacOS
```
#### Python dependencies
We highly recommend using a recent version of [uv](https://docs.astral.sh/uv/#installation) for installation. If you don't have uv installed, you can install it via pip: `pip install -U uv`.
##### Installing into a new uv virtual environment (recommended)
```bash
uv sync
uv sync --extra compile # optional but needed to run the hybrid
uv pip install -e .
```
##### Installing into the system/actived environment using uv
```bash
uv pip install -e .
uv pip install -e .[compile] # optional but needed to run the hybrid
```
##### Installing into the system/actived environment using pip
```bash
pip install -e .
pip install --no-build-isolation -e .[compile] # optional but needed to run the hybrid
```
##### Confirm that it's working
For convenience we provide a minimal example to check that the installation works:
```bash
uv run sample.py
# python sample.py
```
## Docker installation
```bash
git clone https://github.com/Zyphra/Zonos.git
cd Zonos
# For gradio
docker compose up
# Or for development you can do
docker build -t zonos .
docker run -it --gpus=all --net=host -v /path/to/Zonos:/Zonos -t zonos
cd /Zonos
python sample.py # this will generate a sample.wav in /Zonos
```
|
{
"source": "Zyphra/Zonos",
"title": "README.md",
"url": "https://github.com/Zyphra/Zonos/blob/main/README.md",
"date": "2025-02-07T00:32:44",
"stars": 5503,
"description": "Zonos-v0.1 is a leading open-weight text-to-speech model trained on more than 200k hours of varied multilingual speech, delivering expressiveness and quality on par with—or even surpassing—top TTS providers.",
"file_size": 5875
}
|

# a smol course
This is a practical course on aligning language models for your specific use case. It's a handy way to get started with aligning language models, because everything runs on most local machines. There are minimal GPU requirements and no paid services. The course is based on the [SmolLM2](https://github.com/huggingface/smollm/tree/main) series of models, but you can transfer the skills you learn here to larger models or other small language models.
<a href="http://hf.co/join/discord">
<img src="https://img.shields.io/badge/Discord-7289DA?&logo=discord&logoColor=white"/>
</a>
<div style="background: linear-gradient(to right, #e0f7fa, #e1bee7, orange); padding: 20px; border-radius: 5px; margin-bottom: 20px; color: purple;">
<h2>Participation is open, free, and now!</h2>
<p>This course is open and peer reviewed. To get involved with the course <strong>open a pull request</strong> and submit your work for review. Here are the steps:</p>
<ol>
<li>Fork the repo <a href="https://github.com/huggingface/smol-course/fork">here</a></li>
<li>Read the material, make changes, do the exercises, add your own examples.</li>
<li>Open a PR on the december_2024 branch</li>
<li>Get it reviewed and merged</li>
</ol>
<p>This should help you learn and to build a community-driven course that is always improving.</p>
</div>
We can discuss the process in this [discussion thread](https://github.com/huggingface/smol-course/discussions/2#discussion-7602932).
## Course Outline
This course provides a practical, hands-on approach to working with small language models, from initial training through to production deployment.
| Module | Description | Status | Release Date |
|--------|-------------|---------|--------------|
| [Instruction Tuning](./1_instruction_tuning) | Learn supervised fine-tuning, chat templating, and basic instruction following | ✅ Ready | Dec 3, 2024 |
| [Preference Alignment](./2_preference_alignment) | Explore DPO and ORPO techniques for aligning models with human preferences | ✅ Ready | Dec 6, 2024 |
| [Parameter-efficient Fine-tuning](./3_parameter_efficient_finetuning) | Learn LoRA, prompt tuning, and efficient adaptation methods | ✅ Ready | Dec 9, 2024 |
| [Evaluation](./4_evaluation) | Use automatic benchmarks and create custom domain evaluations | ✅ Ready | Dec 13, 2024 |
| [Vision-language Models](./5_vision_language_models) | Adapt multimodal models for vision-language tasks | ✅ Ready | Dec 16, 2024 |
| [Synthetic Datasets](./6_synthetic_datasets) | Create and validate synthetic datasets for training | ✅ Ready | Dec 20, 2024 |
| [Inference](./7_inference) | Infer with models efficiently | ✅ Ready | Jan 8, 2025 |
| [Agents](./8_agents) | Build your own agentic AI | ✅ Ready | Jan 13, 2025 ||
## Why Small Language Models?
While large language models have shown impressive capabilities, they often require significant computational resources and can be overkill for focused applications. Small language models offer several advantages for domain-specific applications:
- **Efficiency**: Require significantly less computational resources to train and deploy
- **Customization**: Easier to fine-tune and adapt to specific domains
- **Control**: Better understanding and control of model behavior
- **Cost**: Lower operational costs for training and inference
- **Privacy**: Can be run locally without sending data to external APIs
- **Green Technology**: Advocates efficient usage of resources with reduced carbon footprint
- **Easier Academic Research Development**: Provides an easy starter for academic research with cutting-edge LLMs with less logistical constraints
## Prerequisites
Before starting, ensure you have the following:
- Basic understanding of machine learning and natural language processing.
- Familiarity with Python, PyTorch, and the `transformers` library.
- Access to a pre-trained language model and a labeled dataset.
## Installation
We maintain the course as a package so you can install dependencies easily via a package manager. We recommend [uv](https://github.com/astral-sh/uv) for this purpose, but you could use alternatives like `pip` or `pdm`.
### Using `uv`
With `uv` installed, you can install the course like this:
```bash
uv venv --python 3.11.0
uv sync
```
### Using `pip`
All the examples run in the same **python 3.11** environment, so you should create an environment and install dependencies like this:
```bash
# python -m venv .venv
# source .venv/bin/activate
pip install -r requirements.txt
```
### Google Colab
**From Google Colab** you will need to install dependencies flexibly based on the hardware you're using. Like this:
```bash
pip install transformers trl datasets huggingface_hub
```
|
{
"source": "huggingface/smol-course",
"title": "README.md",
"url": "https://github.com/huggingface/smol-course/blob/main/README.md",
"date": "2024-11-25T19:22:43",
"stars": 5481,
"description": "A course on aligning smol models.",
"file_size": 4805
}
|
# December 2024 Student Submission
## Module Completed
- [ ] Module 1: Instruction Tuning
- [ ] Module 2: Preference Alignment
- [ ] Module 3: Parameter-efficient Fine-tuning
- [ ] Module 4: Evaluation
- [ ] Module 5: Vision-language Models
- [ ] Module 6: Synthetic Datasets
- [ ] Module 7: Inference
- [ ] Module 8: Deployment
## Changes Made
Describe what you've done in this PR:
1. What concepts did you learn?
2. What changes or additions did you make?
3. Any challenges you faced?
## Notebooks Added/Modified
List any notebooks you've added or modified:
- [ ] Added new example in `module_name/student_examples/my_example.ipynb`
- [ ] Modified existing notebook with additional examples
- [ ] Added documentation or comments
## Checklist
- [ ] I have read the module materials
- [ ] My code runs without errors
- [ ] I have pushed models and datasets to the huggingface hub
- [ ] My PR is based on the `december-2024` branch
## Questions or Discussion Points
Add any questions you have or points you'd like to discuss:
1.
2.
## Additional Notes
Any other information that might be helpful for reviewers:
|
{
"source": "huggingface/smol-course",
"title": "pull_request_template.md",
"url": "https://github.com/huggingface/smol-course/blob/main/pull_request_template.md",
"date": "2024-11-25T19:22:43",
"stars": 5481,
"description": "A course on aligning smol models.",
"file_size": 1118
}
|
# Instruction Tuning
This module will guide you through instruction tuning language models. Instruction tuning involves adapting pre-trained models to specific tasks by further training them on task-specific datasets. This process helps models improve their performance on targeted tasks.
In this module, we will explore two topics: 1) Chat Templates and 2) Supervised Fine-Tuning.
## 1️⃣ Chat Templates
Chat templates structure interactions between users and AI models, ensuring consistent and contextually appropriate responses. They include components like system prompts and role-based messages. For more detailed information, refer to the [Chat Templates](./chat_templates.md) section.
## 2️⃣ Supervised Fine-Tuning
Supervised Fine-Tuning (SFT) is a critical process for adapting pre-trained language models to specific tasks. It involves training the model on a task-specific dataset with labeled examples. For a detailed guide on SFT, including key steps and best practices, see the [Supervised Fine-Tuning](./supervised_fine_tuning.md) page.
## Exercise Notebooks
| Title | Description | Exercise | Link | Colab |
|-------|-------------|----------|------|-------|
| Chat Templates | Learn how to use chat templates with SmolLM2 and process datasets into chatml format | 🐢 Convert the `HuggingFaceTB/smoltalk` dataset into chatml format <br> 🐕 Convert the `openai/gsm8k` dataset into chatml format | [Notebook](./notebooks/chat_templates_example.ipynb) | <a target="_blank" href="https://colab.research.google.com/github/huggingface/smol-course/blob/main/1_instruction_tuning/notebooks/chat_templates_example.ipynb"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a> |
| Supervised Fine-Tuning | Learn how to fine-tune SmolLM2 using the SFTTrainer | 🐢 Use the `HuggingFaceTB/smoltalk` dataset<br>🐕 Try out the `bigcode/the-stack-smol` dataset<br>🦁 Select a dataset for a real world use case | [Notebook](./notebooks/sft_finetuning_example.ipynb) | <a target="_blank" href="https://colab.research.google.com/github/huggingface/smol-course/blob/main/1_instruction_tuning/notebooks/sft_finetuning_example.ipynb"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a> |
## References
- [Transformers documentation on chat templates](https://huggingface.co/docs/transformers/main/en/chat_templating)
- [Script for Supervised Fine-Tuning in TRL](https://github.com/huggingface/trl/blob/main/examples/scripts/sft.py)
- [`SFTTrainer` in TRL](https://huggingface.co/docs/trl/main/en/sft_trainer)
- [Direct Preference Optimization Paper](https://arxiv.org/abs/2305.18290)
- [Supervised Fine-Tuning with TRL](https://huggingface.co/docs/trl/main/en/tutorials/supervised_finetuning)
- [How to fine-tune Google Gemma with ChatML and Hugging Face TRL](https://www.philschmid.de/fine-tune-google-gemma)
- [Fine-tuning LLM to Generate Persian Product Catalogs in JSON Format](https://huggingface.co/learn/cookbook/en/fine_tuning_llm_to_generate_persian_product_catalogs_in_json_format)
|
{
"source": "huggingface/smol-course",
"title": "1_instruction_tuning/README.md",
"url": "https://github.com/huggingface/smol-course/blob/main/1_instruction_tuning/README.md",
"date": "2024-11-25T19:22:43",
"stars": 5481,
"description": "A course on aligning smol models.",
"file_size": 3069
}
|
# Chat Templates
Chat templates are essential for structuring interactions between language models and users. They provide a consistent format for conversations, ensuring that models understand the context and role of each message while maintaining appropriate response patterns.
## Base Models vs Instruct Models
A base model is trained on raw text data to predict the next token, while an instruct model is fine-tuned specifically to follow instructions and engage in conversations. For example, `SmolLM2-135M` is a base model, while `SmolLM2-135M-Instruct` is its instruction-tuned variant.
To make a base model behave like an instruct model, we need to format our prompts in a consistent way that the model can understand. This is where chat templates come in. ChatML is one such template format that structures conversations with clear role indicators (system, user, assistant).
It's important to note that a base model could be fine-tuned on different chat templates, so when we're using an instruct model we need to make sure we're using the correct chat template.
## Understanding Chat Templates
At their core, chat templates define how conversations should be formatted when communicating with a language model. They include system-level instructions, user messages, and assistant responses in a structured format that the model can understand. This structure helps maintain consistency across interactions and ensures the model responds appropriately to different types of inputs. Below is an example of a chat template:
```sh
<|im_start|>user
Hi there!<|im_end|>
<|im_start|>assistant
Nice to meet you!<|im_end|>
<|im_start|>user
Can I ask a question?<|im_end|>
<|im_start|>assistant
```
The `transformers` library will take care of chat templates for you in relation to the model's tokenizer. Read more about how transformers builds chat templates [here](https://huggingface.co/docs/transformers/en/chat_templating#how-do-i-use-chat-templates). All we have to do is structure our messages in the correct way and the tokenizer will take care of the rest. Here's a basic example of a conversation:
```python
messages = [
{"role": "system", "content": "You are a helpful assistant focused on technical topics."},
{"role": "user", "content": "Can you explain what a chat template is?"},
{"role": "assistant", "content": "A chat template structures conversations between users and AI models..."}
]
```
Let's break down the above example, and see how it maps to the chat template format.
## System Messages
System messages set the foundation for how the model should behave. They act as persistent instructions that influence all subsequent interactions. For example:
```python
system_message = {
"role": "system",
"content": "You are a professional customer service agent. Always be polite, clear, and helpful."
}
```
## Conversations
Chat templates maintain context through conversation history, storing previous exchanges between users and the assistant. This allows for more coherent multi-turn conversations:
```python
conversation = [
{"role": "user", "content": "I need help with my order"},
{"role": "assistant", "content": "I'd be happy to help. Could you provide your order number?"},
{"role": "user", "content": "It's ORDER-123"},
]
```
## Implementation with Transformers
The transformers library provides built-in support for chat templates. Here's how to use them:
```python
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("HuggingFaceTB/SmolLM2-135M-Instruct")
messages = [
{"role": "system", "content": "You are a helpful coding assistant."},
{"role": "user", "content": "Write a Python function to sort a list"},
]
# Apply the chat template
formatted_chat = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
```
## Custom Formatting
You can customize how different message types are formatted. For example, adding special tokens or formatting for different roles:
```python
template = """
<|system|>{system_message}
<|user|>{user_message}
<|assistant|>{assistant_message}
""".lstrip()
```
## Multi-Turn Support
Templates can handle complex multi-turn conversations while maintaining context:
```python
messages = [
{"role": "system", "content": "You are a math tutor."},
{"role": "user", "content": "What is calculus?"},
{"role": "assistant", "content": "Calculus is a branch of mathematics..."},
{"role": "user", "content": "Can you give me an example?"},
]
```
⏭️ [Next: Supervised Fine-Tuning](./supervised_fine_tuning.md)
## Resources
- [Hugging Face Chat Templating Guide](https://huggingface.co/docs/transformers/main/en/chat_templating)
- [Transformers Documentation](https://huggingface.co/docs/transformers)
- [Chat Templates Examples Repository](https://github.com/chujiezheng/chat_templates)
|
{
"source": "huggingface/smol-course",
"title": "1_instruction_tuning/chat_templates.md",
"url": "https://github.com/huggingface/smol-course/blob/main/1_instruction_tuning/chat_templates.md",
"date": "2024-11-25T19:22:43",
"stars": 5481,
"description": "A course on aligning smol models.",
"file_size": 4893
}
|
# Supervised Fine-Tuning
Supervised Fine-Tuning (SFT) is a critical process for adapting pre-trained language models to specific tasks or domains. While pre-trained models have impressive general capabilities, they often need to be customized to excel at particular use cases. SFT bridges this gap by further training the model on carefully curated datasets with human-validated examples.
## Understanding Supervised Fine-Tuning
At its core, supervised fine-tuning is about teaching a pre-trained model to perform specific tasks through examples of labeled tokens. The process involves showing the model many examples of the desired input-output behavior, allowing it to learn the patterns specific to your use case.
SFT is effective because it uses the foundational knowledge acquired during pre-training while adapting the model's behavior to match your specific needs.
## When to Use Supervised Fine-Tuning
The decision to use SFT often comes down to the gap between your model's current capabilities and your specific requirements. SFT becomes particularly valuable when you need precise control over the model's outputs or when working in specialized domains.
For example, if you're developing a customer service application, you might want your model to consistently follow company guidelines and handle technical queries in a standardized way. Similarly, in medical or legal applications, accuracy and adherence to domain-specific terminology becomes crucial. In these cases, SFT can help align the model's responses with professional standards and domain expertise.
## The Fine-Tuning Process
The supervised fine-tuning process involves adjusting a model's weights on a task-specific dataset.
First, you'll need to prepare or select a dataset that represents your target task. This dataset should include diverse examples that cover the range of scenarios your model will encounter. The quality of this data is important - each example should demonstrate the kind of output you want your model to produce. Next comes the actual fine-tuning phase, where you'll use frameworks like Hugging Face's `transformers` and `trl` to train the model on your dataset.
Throughout the process, continuous evaluation is essential. You'll want to monitor the model's performance on a validation set to ensure it's learning the desired behaviors without losing its general capabilities. In [module 4](../4_evaluation), we'll cover how to evaluate your model.
## The Role of SFT in Preference Alignment
SFT plays a fundamental role in aligning language models with human preferences. Techniques such as Reinforcement Learning from Human Feedback (RLHF) and Direct Preference Optimization (DPO) rely on SFT to form a base level of task understanding before further aligning the model’s responses with desired outcomes. Pre-trained models, despite their general language proficiency, may not always generate outputs that match human preferences. SFT bridges this gap by introducing domain-specific data and guidance, which improves the model’s ability to generate responses that align more closely with human expectations.
## Supervised Fine-Tuning With Transformer Reinforcement Learning
A key software package for Supervised Fine-Tuning is Transformer Reinforcement Learning (TRL). TRL is a toolkit used to train transformer language models using reinforcement learning (RL).
Built on top of the Hugging Face Transformers library, TRL allows users to directly load pretrained language models and supports most decoder and encoder-decoder architectures. The library facilitates major processes of RL used in language modelling, including supervised fine-tuning (SFT), reward modeling (RM), proximal policy optimization (PPO), and Direct Preference Optimization (DPO). We will use TRL in a number of modules throughout this repo.
# Next Steps
Try out the following tutorials to get hands on experience with SFT using TRL:
⏭️ [Chat Templates Tutorial](./notebooks/chat_templates_example.ipynb)
⏭️ [Supervised Fine-Tuning Tutorial](./notebooks/sft_finetuning_example.ipynb)
|
{
"source": "huggingface/smol-course",
"title": "1_instruction_tuning/supervised_fine_tuning.md",
"url": "https://github.com/huggingface/smol-course/blob/main/1_instruction_tuning/supervised_fine_tuning.md",
"date": "2024-11-25T19:22:43",
"stars": 5481,
"description": "A course on aligning smol models.",
"file_size": 4081
}
|
# Preference Alignment
This module covers techniques for aligning language models with human preferences. While supervised fine-tuning helps models learn tasks, preference alignment encourages outputs to match human expectations and values.
## Overview
Typical alignment methods involve multiple stages:
1. Supervised Fine-Tuning (SFT) to adapt models to specific domains
2. Preference alignment (like RLHF or DPO) to improve response quality
Alternative approaches like ORPO combine instruction tuning and preference alignment into a single process. Here, we will focus on DPO and ORPO algorithms.
If you would like to learn more about the different alignment techniques, you can read more about them in the [Argilla Blog](https://argilla.io/blog/mantisnlp-rlhf-part-8).
### 1️⃣ Direct Preference Optimization (DPO)
Direct Preference Optimization (DPO) simplifies preference alignment by directly optimizing models using preference data. This approach eliminates the need for separate reward models and complex reinforcement learning, making it more stable and efficient than traditional Reinforcement Learning from Human Feedback (RLHF). For more details, you can refer to the [Direct Preference Optimization (DPO) documentation](./dpo.md).
### 2️⃣ Odds Ratio Preference Optimization (ORPO)
ORPO introduces a combined approach to instruction tuning and preference alignment in a single process. It modifies the standard language modeling objective by combining negative log-likelihood loss with an odds ratio term on a token level. The approach features a unified single-stage training process, reference model-free architecture, and improved computational efficiency. ORPO has shown impressive results across various benchmarks, demonstrating better performance on AlpacaEval compared to traditional methods. For more details, you can refer to the [Odds Ratio Preference Optimization (ORPO) documentation](./orpo.md).
## Exercise Notebooks
| Title | Description | Exercise | Link | Colab |
|-------|-------------|----------|------|-------|
| DPO Training | Learn how to train models using Direct Preference Optimization | 🐢 Train a model using the Anthropic HH-RLHF dataset<br>🐕 Use your own preference dataset<br>🦁 Experiment with different preference datasets and model sizes | [Notebook](./notebooks/dpo_finetuning_example.ipynb) | <a target="_blank" href="https://colab.research.google.com/github/huggingface/smol-course/blob/main/2_preference_alignment/notebooks/dpo_finetuning_example.ipynb"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a> |
| ORPO Training | Learn how to train models using Odds Ratio Preference Optimization | 🐢 Train a model using instruction and preference data<br>🐕 Experiment with different loss weightings<br>🦁 Compare ORPO results with DPO | [Notebook](./notebooks/orpo_finetuning_example.ipynb) | <a target="_blank" href="https://colab.research.google.com/github/huggingface/smol-course/blob/main/2_preference_alignment/notebooks/orpo_finetuning_example.ipynb"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a> |
## Resources
- [TRL Documentation](https://huggingface.co/docs/trl/index) - Documentation for the Transformers Reinforcement Learning (TRL) library, which implements various alignment techniques including DPO.
- [DPO Paper](https://arxiv.org/abs/2305.18290) - Original research paper introducing Direct Preference Optimization as a simpler alternative to RLHF that directly optimizes language models using preference data.
- [ORPO Paper](https://arxiv.org/abs/2403.07691) - Introduces Odds Ratio Preference Optimization, a novel approach that combines instruction tuning and preference alignment in a single training stage.
- [Argilla RLHF Guide](https://argilla.io/blog/mantisnlp-rlhf-part-8/) - A guide explaining different alignment techniques including RLHF, DPO, and their practical implementations.
- [Blog post on DPO](https://huggingface.co/blog/dpo-trl) - Practical guide on implementing DPO using the TRL library with code examples and best practices.
- [TRL example script on DPO](https://github.com/huggingface/trl/blob/main/examples/scripts/dpo.py) - Complete example script demonstrating how to implement DPO training using the TRL library.
- [TRL example script on ORPO](https://github.com/huggingface/trl/blob/main/examples/scripts/orpo.py) - Reference implementation of ORPO training using the TRL library with detailed configuration options.
- [Hugging Face Alignment Handbook](https://github.com/huggingface/alignment-handbook) - Resource guides and codebase for aligning language models using various techniques including SFT, DPO, and RLHF.
|
{
"source": "huggingface/smol-course",
"title": "2_preference_alignment/README.md",
"url": "https://github.com/huggingface/smol-course/blob/main/2_preference_alignment/README.md",
"date": "2024-11-25T19:22:43",
"stars": 5481,
"description": "A course on aligning smol models.",
"file_size": 4715
}
|
# Direct Preference Optimization (DPO)
Direct Preference Optimization (DPO) offers a simplified approach to aligning language models with human preferences. Unlike traditional RLHF methods that require separate reward models and complex reinforcement learning, DPO directly optimizes the model using preference data.
## Understanding DPO
DPO recasts preference alignment as a classification problem on human preference data. Traditional RLHF approaches require training a separate reward model and using complex reinforcement learning algorithms like PPO to align model outputs. DPO simplifies this process by defining a loss function that directly optimizes the model's policy based on preferred vs non-preferred outputs.
This approach has proven highly effective in practice, being used to train models like Llama. By eliminating the need for a separate reward model and reinforcement learning stage, DPO makes preference alignment more accessible and stable.
## How DPO Works
The DPO process requires supervised fine-tuning (SFT) to adapt the model to the target domain. This creates a foundation for preference learning by training on standard instruction-following datasets. The model learns basic task completion while maintaining its general capabilities.
Next comes preference learning, where the model is trained on pairs of outputs - one preferred and one non-preferred. The preference pairs help the model understand which responses better align with human values and expectations.
The core innovation of DPO lies in its direct optimization approach. Rather than training a separate reward model, DPO uses a binary cross-entropy loss to directly update the model weights based on preference data. This streamlined process makes training more stable and efficient while achieving comparable or better results than traditional RLHF.
## DPO datasets
Datasets for DPO are typically created by annotating pairs of responses as preferred or non-preferred. This can be done manually or using automated filtering techniques. Below is an example structure of single turn preference dataset for DPO:
| Prompt | Chosen | Rejected |
|--------|--------|----------|
| ... | ... | ... |
| ... | ... | ... |
| ... | ... | ... |
The `Prompt` column contains the prompt used to generate the `Chosen` and `Rejected` responses. The `Chosen` and `Rejected` columns contain the responses that are preferred and non-preferred respectively. There are variations on this structure, for example, including a system prompt column or `Input` column containing reference material. The values of `chosen` and `rejected` can be be represented as strings for single turn conversations or as conversation lists.
You can find a collection of DPO datasets on Hugging Face [here](https://huggingface.co/collections/argilla/preference-datasets-for-dpo-656f0ce6a00ad2dc33069478).
## Implementation with TRL
The Transformers Reinforcement Learning (TRL) library makes implementing DPO straightforward. The `DPOConfig` and `DPOTrainer` classes follow the same `transformers` style API.
Here's a basic example of setting up DPO training:
```python
from trl import DPOConfig, DPOTrainer
# Define arguments
training_args = DPOConfig(
...
)
# Initialize trainer
trainer = DPOTrainer(
model,
train_dataset=dataset,
tokenizer=tokenizer,
...
)
# Train model
trainer.train()
```
We will cover more details on how to use the `DPOConfig` and `DPOTrainer` classes in the [DPO Tutorial](./notebooks/dpo_finetuning_example.ipynb).
## Best Practices
Data quality is crucial for successful DPO implementation. The preference dataset should include diverse examples covering different aspects of desired behavior. Clear annotation guidelines ensure consistent labeling of preferred and non-preferred responses. You can improve model performance by improving the quality of your preference dataset. For example, by filtering down larger datasets to include only high quality examples, or examples that relate to your use case.
During training, carefully monitor the loss convergence and validate performance on held-out data. The beta parameter may need adjustment to balance preference learning with maintaining the model's general capabilities. Regular evaluation on diverse prompts helps ensure the model is learning the intended preferences without overfitting.
Compare the model's outputs with the reference model to verify improvement in preference alignment. Testing on a variety of prompts, including edge cases, helps ensure robust preference learning across different scenarios.
## Next Steps
⏩ To get hands-on experience with DPO, try the [DPO Tutorial](./notebooks/dpo_finetuning_example.ipynb). This practical guide will walk you through implementing preference alignment with your own model, from data preparation to training and evaluation.
⏭️ After completing the tutorial, you can explore the [ORPO](./orpo.md) page to learn about another preference alignment technique.
|
{
"source": "huggingface/smol-course",
"title": "2_preference_alignment/dpo.md",
"url": "https://github.com/huggingface/smol-course/blob/main/2_preference_alignment/dpo.md",
"date": "2024-11-25T19:22:43",
"stars": 5481,
"description": "A course on aligning smol models.",
"file_size": 5023
}
|
# Odds Ratio Preference Optimization (ORPO)
ORPO (Odds Ratio Preference Optimization) is a novel fine-tuning technique that combines fine-tuning and preference alignment into a single unified process. This combined approach offers advantages in efficiency and performance compared to traditional methods like RLHF or DPO.
## Understanding ORPO
Alignment with methods like DPO typically involve two separate steps: supervised fine-tuning to adapt the model to a domain and format, followed by preference alignment to align with human preferences. While SFT effectively adapts models to target domains, it can inadvertently increase the probability of generating both desirable and undesirable responses. ORPO addresses this limitation by integrating both steps into a single process, as illustrated in the comparison below:
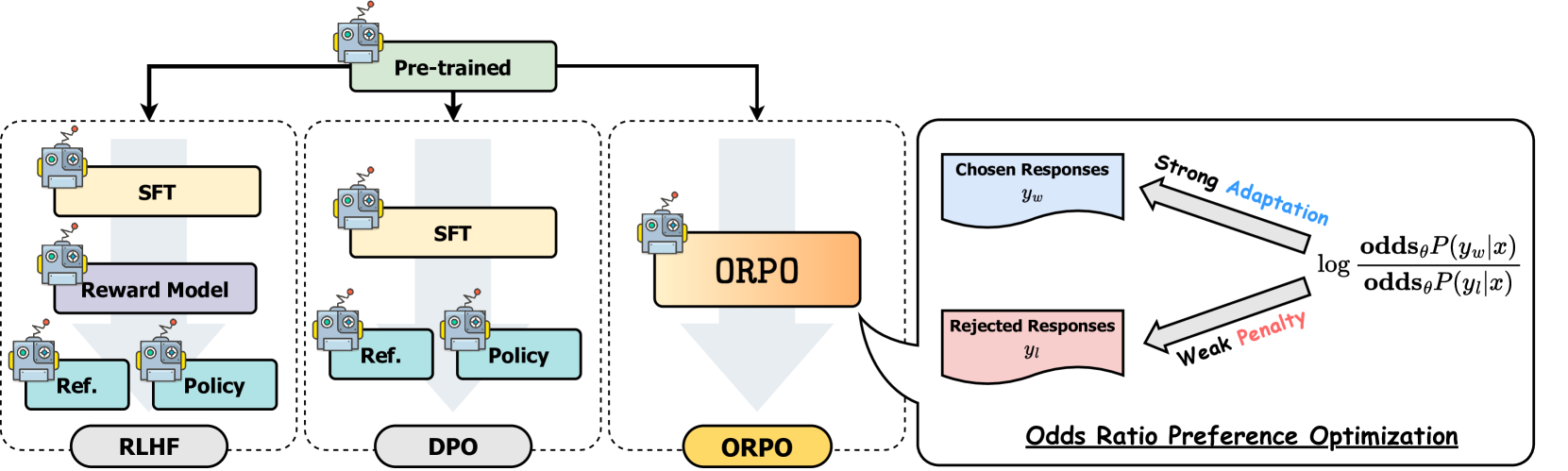
*Comparison of different model alignment techniques*
## How ORPO Works
The training process leverages a preference dataset similar to what we used for DPO, where each training example contains an input prompt along with two responses: one that is preferred, and another that is rejected. Unlike other alignment methods that require separate stages and reference models, ORPO integrates preference alignment directly into the supervised fine-tuning process. This monolithic approach makes it reference model-free, computationally more efficient, and memory efficient with fewer FLOPs.
ORPO creates a new objective by combining two main components:
1. **SFT Loss**: The standard negative log-likelihood loss used in language modeling, which maximizes the probability of generating reference tokens. This helps maintain the model's general language capabilities.
2. **Odds Ratio Loss**: A novel component that penalizes undesirable responses while rewarding preferred ones. This loss function uses odds ratios to effectively contrast between favored and disfavored responses at the token level.
Together, these components guide the model to adapt to desired generations for the specific domain while actively discouraging generations from the set of rejected responses. The odds ratio mechanism provides a natural way to measure and optimize the model's preference between chosen and rejected outputs. If you want to deep dive into the math, you can read the [ORPO paper](https://arxiv.org/abs/2403.07691). If you want to learn about ORPO from the implementation perspective, you should check out how loss for ORPO is calculated in the [TRL library](https://github.com/huggingface/trl/blob/b02189aaa538f3a95f6abb0ab46c0a971bfde57e/trl/trainer/orpo_trainer.py#L660).
## Performance and Results
ORPO has demonstrated impressive results across various benchmarks. On MT-Bench, it achieves competitive scores across different categories:
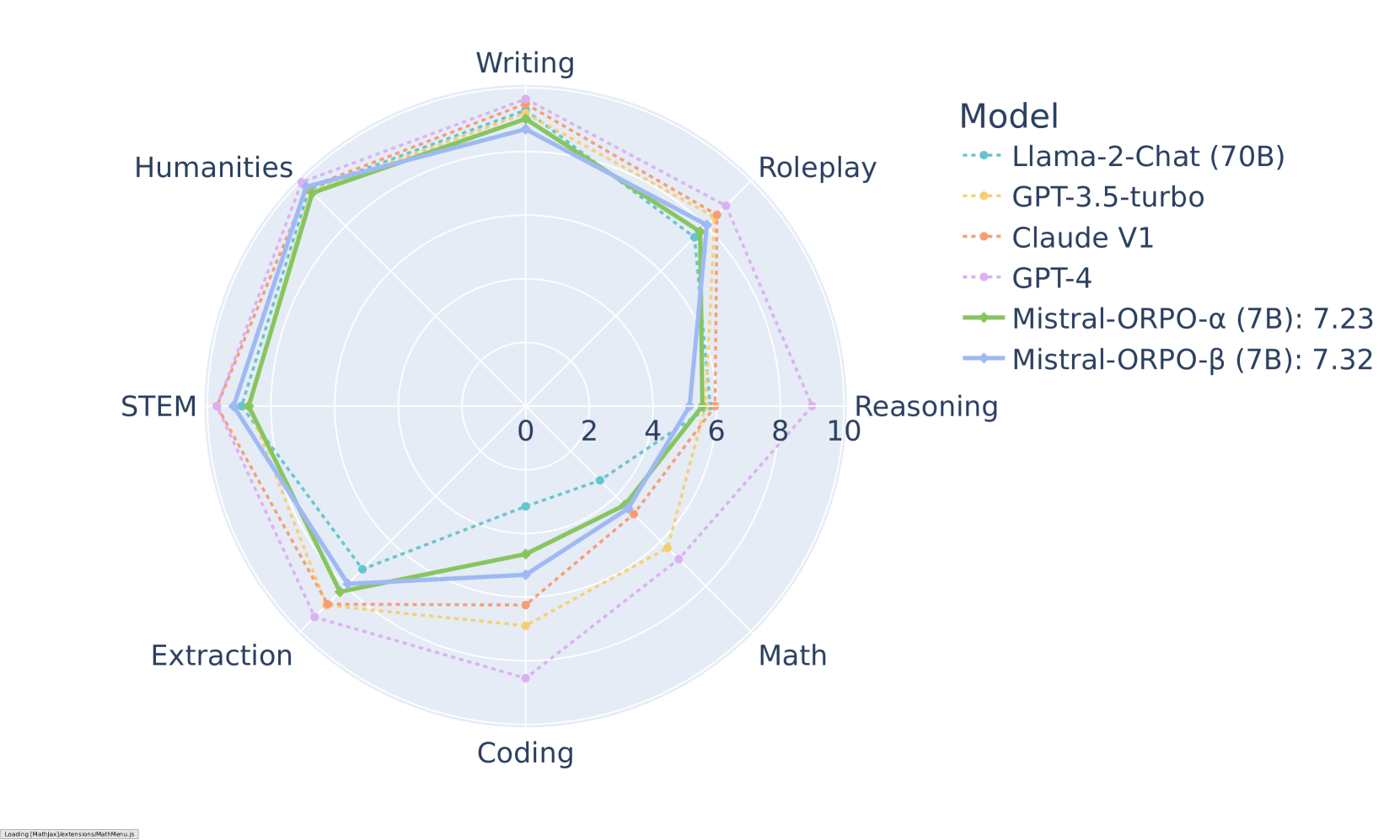
*MT-Bench results by category for Mistral-ORPO models*
When compared to other alignment methods, ORPO shows superior performance on AlpacaEval 2.0:
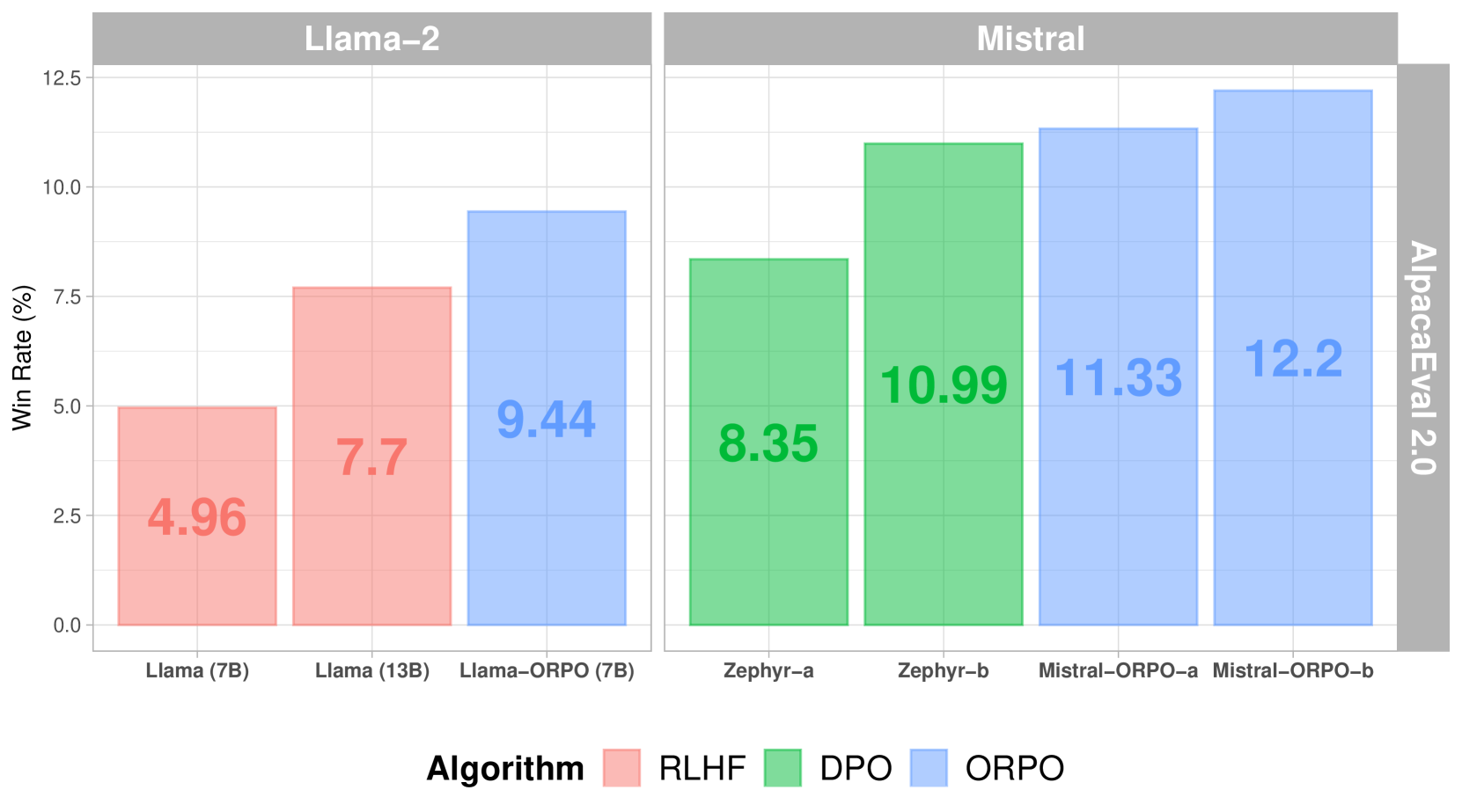
*AlpacaEval 2.0 scores across different alignment methods*
Compared to SFT+DPO, ORPO reduces computational requirements by eliminating the need for a reference model and halving the number of forward passes per batch. Also, the training process is more stable across different model sizes and datasets, requiring fewer hyperparameters to tune. Performance-wise, ORPO matches larger models while showing better alignment with human preferences.
## Implementation
Successful implementation of ORPO depends heavily on high-quality preference data. The training data should follow clear annotation guidelines and provide a balanced representation of preferred and rejected responses across diverse scenarios.
### Implementation with TRL
ORPO can be implemented using the Transformers Reinforcement Learning (TRL) library. Here's a basic example:
```python
from trl import ORPOConfig, ORPOTrainer
# Configure ORPO training
orpo_config = ORPOConfig(
learning_rate=1e-5,
per_device_train_batch_size=4,
gradient_accumulation_steps=4,
max_steps=1000,
orpo_alpha=1.0, # Controls strength of preference optimization
orpo_beta=0.1, # Temperature parameter for odds ratio
)
# Initialize trainer
trainer = ORPOTrainer(
model=model,
args=orpo_config,
train_dataset=dataset,
tokenizer=tokenizer,
)
# Start training
trainer.train()
```
Key parameters to consider:
- `orpo_alpha`: Controls the strength of preference optimization
- `orpo_beta`: Temperature parameter for the odds ratio calculation
- `learning_rate`: Should be relatively small to prevent catastrophic forgetting
- `gradient_accumulation_steps`: Helps with training stability
## Next Steps
⏩ Try the [ORPO Tutorial](./notebooks/orpo_finetuning_example.ipynb) to implement this unified approach to preference alignment.
## Resources
- [ORPO Paper](https://arxiv.org/abs/2403.07691)
- [TRL Documentation](https://huggingface.co/docs/trl/index)
- [Argilla RLHF Guide](https://argilla.io/blog/mantisnlp-rlhf-part-8/)
|
{
"source": "huggingface/smol-course",
"title": "2_preference_alignment/orpo.md",
"url": "https://github.com/huggingface/smol-course/blob/main/2_preference_alignment/orpo.md",
"date": "2024-11-25T19:22:43",
"stars": 5481,
"description": "A course on aligning smol models.",
"file_size": 5213
}
|
# Parameter-Efficient Fine-Tuning (PEFT)
As language models grow larger, traditional fine-tuning becomes increasingly challenging. A full fine-tuning of even a 1.7B parameter model requires substantial GPU memory, makes storing separate model copies expensive, and risks catastrophic forgetting of the model's original capabilities. Parameter-efficient fine-tuning (PEFT) methods address these challenges by modifying only a small subset of model parameters while keeping most of the model frozen.
Traditional fine-tuning updates all model parameters during training, which becomes impractical for large models. PEFT methods introduce approaches to adapt models using fewer trainable parameters - often less than 1% of the original model size. This dramatic reduction in trainable parameters enables:
- Fine-tuning on consumer hardware with limited GPU memory
- Storing multiple task-specific adaptations efficiently
- Better generalization in low-data scenarios
- Faster training and iteration cycles
## Available Methods
In this module, we will cover two popular PEFT methods:
### 1️⃣ LoRA (Low-Rank Adaptation)
LoRA has emerged as the most widely adopted PEFT method, offering an elegant solution to efficient model adaptation. Instead of modifying the entire model, **LoRA injects trainable matrices into the model's attention layers.** This approach typically reduces trainable parameters by about 90% while maintaining comparable performance to full fine-tuning. We will explore LoRA in the [LoRA (Low-Rank Adaptation)](./lora_adapters.md) section.
### 2️⃣ Prompt Tuning
Prompt tuning offers an **even lighter** approach by **adding trainable tokens to the input** rather than modifying model weights. Prompt tuning is less popular than LoRA, but can be a useful technique for quickly adapting a model to new tasks or domains. We will explore prompt tuning in the [Prompt Tuning](./prompt_tuning.md) section.
## Exercise Notebooks
| Title | Description | Exercise | Link | Colab |
|-------|-------------|----------|------|-------|
| LoRA Fine-tuning | Learn how to fine-tune models using LoRA adapters | 🐢 Train a model using LoRA<br>🐕 Experiment with different rank values<br>🦁 Compare performance with full fine-tuning | [Notebook](./notebooks/finetune_sft_peft.ipynb) | <a target="_blank" href="https://colab.research.google.com/github/huggingface/smol-course/blob/main/3_parameter_efficient_finetuning/notebooks/finetune_sft_peft.ipynb"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a> |
| Load LoRA Adapters | Learn how to load and use trained LoRA adapters | 🐢 Load pre-trained adapters<br>🐕 Merge adapters with base model<br>🦁 Switch between multiple adapters | [Notebook](./notebooks/load_lora_adapter.ipynb) | <a target="_blank" href="https://colab.research.google.com/github/huggingface/smol-course/blob/main/3_parameter_efficient_finetuning/notebooks/load_lora_adapter.ipynb"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a> |
<!-- | Prompt Tuning | Learn how to implement prompt tuning | 🐢 Train soft prompts<br>🐕 Compare different initialization strategies<br>🦁 Evaluate on multiple tasks | [Notebook](./notebooks/prompt_tuning_example.ipynb) | <a target="_blank" href="https://colab.research.google.com/github/huggingface/smol-course/blob/main/3_parameter_efficient_finetuning/notebooks/prompt_tuning_example.ipynb"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a> | -->
## Resources
- [PEFT Documentation](https://huggingface.co/docs/peft)
- [LoRA Paper](https://arxiv.org/abs/2106.09685)
- [QLoRA Paper](https://arxiv.org/abs/2305.14314)
- [Prompt Tuning Paper](https://arxiv.org/abs/2104.08691)
- [Hugging Face PEFT Guide](https://huggingface.co/blog/peft)
- [How to Fine-Tune LLMs in 2024 with Hugging Face](https://www.philschmid.de/fine-tune-llms-in-2024-with-trl)
- [TRL](https://huggingface.co/docs/trl/index)
|
{
"source": "huggingface/smol-course",
"title": "3_parameter_efficient_finetuning/README.md",
"url": "https://github.com/huggingface/smol-course/blob/main/3_parameter_efficient_finetuning/README.md",
"date": "2024-11-25T19:22:43",
"stars": 5481,
"description": "A course on aligning smol models.",
"file_size": 3986
}
|
# LoRA (Low-Rank Adaptation)
LoRA has become the most widely adopted PEFT method. It works by adding small rank decomposition matrices to the attention weights, typically reducing trainable parameters by about 90%.
## Understanding LoRA
LoRA (Low-Rank Adaptation) is a parameter-efficient fine-tuning technique that freezes the pre-trained model weights and injects trainable rank decomposition matrices into the model's layers. Instead of training all model parameters during fine-tuning, LoRA decomposes the weight updates into smaller matrices through low-rank decomposition, significantly reducing the number of trainable parameters while maintaining model performance. For example, when applied to GPT-3 175B, LoRA reduced trainable parameters by 10,000x and GPU memory requirements by 3x compared to full fine-tuning. You can read more about LoRA in the [LoRA paper](https://arxiv.org/pdf/2106.09685).
LoRA works by adding pairs of rank decomposition matrices to transformer layers, typically focusing on attention weights. During inference, these adapter weights can be merged with the base model, resulting in no additional latency overhead. LoRA is particularly useful for adapting large language models to specific tasks or domains while keeping resource requirements manageable.
## Loading LoRA Adapters
Adapters can be loaded onto a pretrained model with load_adapter(), which is useful for trying out different adapters whose weights aren’t merged. Set the active adapter weights with the set_adapter() function. To return the base model, you could use unload() to unload all of the LoRA modules. This makes it easy to switch between different task-specific weights.
```python
from transformers import AutoModelForCausalLM
from peft import PeftModel
base_model = AutoModelForCausalLM.from_pretrained("<base_model_name>")
peft_model_id = "<peft_adapter_id>"
model = PeftModel.from_pretrained(base_model, peft_model_id)
```

## Merging LoRA Adapters
After training with LoRA, you might want to merge the adapter weights back into the base model for easier deployment. This creates a single model with the combined weights, eliminating the need to load adapters separately during inference.
The merging process requires attention to memory management and precision. Since you'll need to load both the base model and adapter weights simultaneously, ensure sufficient GPU/CPU memory is available. Using `device_map="auto"` in `transformers` will help with automatic memory management. Maintain consistent precision (e.g., float16) throughout the process, matching the precision used during training and saving the merged model in the same format for deployment. Before deploying, always validate the merged model by comparing its outputs and performance metrics with the adapter-based version.
Adapters are also be convenient for switching between different tasks or domains. You can load the base model and adapter weights separately. This allows for quick switching between different task-specific weights.
## Implementation Guide
The `notebooks/` directory contains practical tutorials and exercises for implementing different PEFT methods. Begin with `load_lora_adapter_example.ipynb` for a basic introduction, then explore `lora_finetuning.ipynb` for a more detailed look at how to fine-tune a model with LoRA and SFT.
When implementing PEFT methods, start with small rank values (4-8) for LoRA and monitor training loss. Use validation sets to prevent overfitting and compare results with full fine-tuning baselines when possible. The effectiveness of different methods can vary by task, so experimentation is key.
## OLoRA
[OLoRA](https://arxiv.org/abs/2406.01775) utilizes QR decomposition to initialize the LoRA adapters. OLoRA translates the base weights of the model by a factor of their QR decompositions, i.e., it mutates the weights before performing any training on them. This approach significantly improves stability, accelerates convergence speed, and ultimately achieves superior performance.
## Using TRL with PEFT
PEFT methods can be combined with TRL (Transformers Reinforcement Learning) for efficient fine-tuning. This integration is particularly useful for RLHF (Reinforcement Learning from Human Feedback) as it reduces memory requirements.
```python
from peft import LoraConfig
from transformers import AutoModelForCausalLM
# Load model with PEFT config
lora_config = LoraConfig(
r=16,
lora_alpha=32,
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM"
)
# Load model on specific device
model = AutoModelForCausalLM.from_pretrained(
"your-model-name",
load_in_8bit=True, # Optional: use 8-bit precision
device_map="auto",
peft_config=lora_config
)
```
Above, we used `device_map="auto"` to automatically assign the model to the correct device. You can also manually assign the model to a specific device using `device_map={"": device_index}`. You could also scale training across multiple GPUs while keeping memory usage efficient.
## Basic Merging Implementation
After training a LoRA adapter, you can merge the adapter weights back into the base model. Here's how to do it:
```python
import torch
from transformers import AutoModelForCausalLM
from peft import PeftModel
# 1. Load the base model
base_model = AutoModelForCausalLM.from_pretrained(
"base_model_name",
torch_dtype=torch.float16,
device_map="auto"
)
# 2. Load the PEFT model with adapter
peft_model = PeftModel.from_pretrained(
base_model,
"path/to/adapter",
torch_dtype=torch.float16
)
# 3. Merge adapter weights with base model
try:
merged_model = peft_model.merge_and_unload()
except RuntimeError as e:
print(f"Merging failed: {e}")
# Implement fallback strategy or memory optimization
# 4. Save the merged model
merged_model.save_pretrained("path/to/save/merged_model")
```
If you encounter size discrepancies in the saved model, ensure you're also saving the tokenizer:
```python
# Save both model and tokenizer
tokenizer = AutoTokenizer.from_pretrained("base_model_name")
merged_model.save_pretrained("path/to/save/merged_model")
tokenizer.save_pretrained("path/to/save/merged_model")
```
## Next Steps
⏩ Move on to the [Prompt Tuning](prompt_tuning.md) guide to learn how to fine-tune a model with prompt tuning.
⏩ Move on the [Load LoRA Adapters Tutorial](./notebooks/load_lora_adapter.ipynb) to learn how to load LoRA adapters.
# Resources
- [LORA: LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS](https://arxiv.org/pdf/2106.09685)
- [PEFT Documentation](https://huggingface.co/docs/peft)
- [Hugging Face blog post on PEFT](https://huggingface.co/blog/peft)
|
{
"source": "huggingface/smol-course",
"title": "3_parameter_efficient_finetuning/lora_adapters.md",
"url": "https://github.com/huggingface/smol-course/blob/main/3_parameter_efficient_finetuning/lora_adapters.md",
"date": "2024-11-25T19:22:43",
"stars": 5481,
"description": "A course on aligning smol models.",
"file_size": 6723
}
|
# Prompt Tuning
Prompt tuning is a parameter-efficient approach that modifies input representations rather than model weights. Unlike traditional fine-tuning that updates all model parameters, prompt tuning adds and optimizes a small set of trainable tokens while keeping the base model frozen.
## Understanding Prompt Tuning
Prompt tuning is a parameter-efficient alternative to model fine-tuning that prepends trainable continuous vectors (soft prompts) to the input text. Unlike discrete text prompts, these soft prompts are learned through backpropagation while keeping the language model frozen. The method was introduced in ["The Power of Scale for Parameter-Efficient Prompt Tuning"](https://arxiv.org/abs/2104.08691) (Lester et al., 2021), which demonstrated that prompt tuning becomes more competitive with model fine-tuning as model size increases. Within the paper, at around 10 billion parameters, prompt tuning matches the performance of model fine-tuning while only modifying a few hundred parameters per task.
These soft prompts are continuous vectors in the model's embedding space that get optimized during training. Unlike traditional discrete prompts that use natural language tokens, soft prompts have no inherent meaning but learn to elicit the desired behavior from the frozen model through gradient descent. The technique is particularly effective for multi-task scenarios since each task requires storing only a small prompt vector (typically a few hundred parameters) rather than a full model copy. This approach not only maintains a minimal memory footprint but also enables rapid task switching by simply swapping prompt vectors without any model reloading.
## Training Process
Soft prompts typically number between 8 and 32 tokens and can be initialized either randomly or from existing text. The initialization method plays a crucial role in the training process, with text-based initialization often performing better than random initialization.
During training, only the prompt parameters are updated while the base model remains frozen. This focused approach uses standard training objectives but requires careful attention to the learning rate and gradient behavior of the prompt tokens.
## Implementation with PEFT
The PEFT library makes implementing prompt tuning straightforward. Here's a basic example:
```python
from peft import PromptTuningConfig, TaskType, get_peft_model
from transformers import AutoModelForCausalLM, AutoTokenizer
# Load base model
model = AutoModelForCausalLM.from_pretrained("your-base-model")
tokenizer = AutoTokenizer.from_pretrained("your-base-model")
# Configure prompt tuning
peft_config = PromptTuningConfig(
task_type=TaskType.CAUSAL_LM,
num_virtual_tokens=8, # Number of trainable tokens
prompt_tuning_init="TEXT", # Initialize from text
prompt_tuning_init_text="Classify if this text is positive or negative:",
tokenizer_name_or_path="your-base-model",
)
# Create prompt-tunable model
model = get_peft_model(model, peft_config)
```
## Comparison to Other Methods
When compared to other PEFT approaches, prompt tuning stands out for its efficiency. While LoRA offers low parameter counts and memory usage but requires loading adapters for task switching, prompt tuning achieves even lower resource usage and enables immediate task switching. Full fine-tuning, in contrast, demands significant resources and requires separate model copies for different tasks.
| Method | Parameters | Memory | Task Switching |
|--------|------------|---------|----------------|
| Prompt Tuning | Very Low | Minimal | Easy |
| LoRA | Low | Low | Requires Loading |
| Full Fine-tuning | High | High | New Model Copy |
When implementing prompt tuning, start with a small number of virtual tokens (8-16) and increase only if the task complexity demands it. Text initialization typically yields better results than random initialization, especially when using task-relevant text. The initialization strategy should reflect the complexity of your target task.
Training requires slightly different considerations than full fine-tuning. Higher learning rates often work well, but careful monitoring of prompt token gradients is essential. Regular validation on diverse examples helps ensure robust performance across different scenarios.
## Application
Prompt tuning excels in several scenarios:
1. Multi-task deployment
2. Resource-constrained environments
3. Rapid task adaptation
4. Privacy-sensitive applications
As models get smaller, prompt tuning becomes less competitive compared to full fine-tuning. For example, on models like SmolLM2 scales prompt tuning is less relevant than full fine-tuning.
## Next Steps
⏭️ Move on to the [LoRA Adapters Tutorial](./notebooks/finetune_sft_peft.ipynb) to learn how to fine-tune a model with LoRA adapters.
## Resources
- [PEFT Documentation](https://huggingface.co/docs/peft)
- [Prompt Tuning Paper](https://arxiv.org/abs/2104.08691)
- [Hugging Face Cookbook](https://huggingface.co/learn/cookbook/prompt_tuning_peft)
|
{
"source": "huggingface/smol-course",
"title": "3_parameter_efficient_finetuning/prompt_tuning.md",
"url": "https://github.com/huggingface/smol-course/blob/main/3_parameter_efficient_finetuning/prompt_tuning.md",
"date": "2024-11-25T19:22:43",
"stars": 5481,
"description": "A course on aligning smol models.",
"file_size": 5056
}
|
# Evaluation
Evaluation is a critical step in developing and deploying language models. It helps us understand how well our models perform across different capabilities and identify areas for improvement. This module covers both standard benchmarks and domain-specific evaluation approaches to comprehensively assess your smol model.
We'll use [`lighteval`](https://github.com/huggingface/lighteval), a powerful evaluation library developed by Hugging Face that integrates seamlessly with the Hugging Face ecosystem. For a deeper dive into evaluation concepts and best practices, check out the evaluation [guidebook](https://github.com/huggingface/evaluation-guidebook).
## Module Overview
A thorough evaluation strategy examines multiple aspects of model performance. We assess task-specific capabilities like question answering and summarization to understand how well the model handles different types of problems. We measure output quality through factors like coherence and factual accuracy. Safety evaluation helps identify potential harmful outputs or biases. Finally, domain expertise testing verifies the model's specialized knowledge in your target field.
## Contents
### 1️⃣ [Automatic Benchmarks](./automatic_benchmarks.md)
Learn to evaluate your model using standardized benchmarks and metrics. We'll explore common benchmarks like MMLU and TruthfulQA, understand key evaluation metrics and settings, and cover best practices for reproducible evaluation.
### 2️⃣ [Custom Domain Evaluation](./custom_evaluation.md)
Discover how to create evaluation pipelines tailored to your specific use case. We'll walk through designing custom evaluation tasks, implementing specialized metrics, and building evaluation datasets that match your requirements.
### 3️⃣ [Domain Evaluation Project](./project/README.md)
Follow a complete example of building a domain-specific evaluation pipeline. You'll learn to generate evaluation datasets, use Argilla for data annotation, create standardized datasets, and evaluate models using LightEval.
### Exercise Notebooks
| Title | Description | Exercise | Link | Colab |
|-------|-------------|----------|------|-------|
| Evaluate and Analyze Your LLM | Learn how to use LightEval to evaluate and compare models on specific domains | 🐢 Use medical domain tasks to evaluate a model <br> 🐕 Create a new domain evaluation with different MMLU tasks <br> 🦁 Create a custom evaluation task for your domain | [Notebook](./notebooks/lighteval_evaluate_and_analyse_your_LLM.ipynb) | <a target="_blank" href="https://colab.research.google.com/github/huggingface/smol-course/blob/main/4_evaluation/notebooks/lighteval_evaluate_and_analyse_your_LLM.ipynb"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a> |
## Resources
- [Evaluation Guidebook](https://github.com/huggingface/evaluation-guidebook) - Comprehensive guide to LLM evaluation
- [LightEval Documentation](https://github.com/huggingface/lighteval) - Official docs for the LightEval library
- [Argilla Documentation](https://docs.argilla.io) - Learn about the Argilla annotation platform
- [MMLU Paper](https://arxiv.org/abs/2009.03300) - Paper describing the MMLU benchmark
- [Creating a Custom Task](https://github.com/huggingface/lighteval/wiki/Adding-a-Custom-Task)
- [Creating a Custom Metric](https://github.com/huggingface/lighteval/wiki/Adding-a-New-Metric)
- [Using existing metrics](https://github.com/huggingface/lighteval/wiki/Metric-List)
|
{
"source": "huggingface/smol-course",
"title": "4_evaluation/README.md",
"url": "https://github.com/huggingface/smol-course/blob/main/4_evaluation/README.md",
"date": "2024-11-25T19:22:43",
"stars": 5481,
"description": "A course on aligning smol models.",
"file_size": 3500
}
|
# Automatic Benchmarks
Automatic benchmarks serve as standardized tools for evaluating language models across different tasks and capabilities. While they provide a useful starting point for understanding model performance, it's important to recognize that they represent only one piece of a comprehensive evaluation strategy.
## Understanding Automatic Benchmarks
Automatic benchmarks typically consist of curated datasets with predefined tasks and evaluation metrics. These benchmarks aim to assess various aspects of model capability, from basic language understanding to complex reasoning. The key advantage of using automatic benchmarks is their standardization - they allow for consistent comparison across different models and provide reproducible results.
However, it's crucial to understand that benchmark performance doesn't always translate directly to real-world effectiveness. A model that excels at academic benchmarks may still struggle with specific domain applications or practical use cases.
## Benchmarks and Their Limitations
### General Knowledge Benchmarks
MMLU (Massive Multitask Language Understanding) tests knowledge across 57 subjects, from science to humanities. While comprehensive, it may not reflect the depth of expertise needed for specific domains. TruthfulQA evaluates a model's tendency to reproduce common misconceptions, though it can't capture all forms of misinformation.
### Reasoning Benchmarks
BBH (Big Bench Hard) and GSM8K focus on complex reasoning tasks. BBH tests logical thinking and planning, while GSM8K specifically targets mathematical problem-solving. These benchmarks help assess analytical capabilities but may not capture the nuanced reasoning required in real-world scenarios.
### Language Understanding
HELM provides a holistic evaluation framework, while WinoGrande tests common sense through pronoun disambiguation. These benchmarks offer insights into language processing capabilities but may not fully represent the complexity of natural conversation or domain-specific terminology.
## Alternative Evaluation Approaches
Many organizations have developed alternative evaluation methods to address the limitations of standard benchmarks:
### LLM-as-Judge
Using one language model to evaluate another's outputs has become increasingly popular. This approach can provide more nuanced feedback than traditional metrics, though it comes with its own biases and limitations.
### Evaluation Arenas
Platforms like Anthropic's Constitutional AI Arena allow models to interact and evaluate each other in controlled environments. This can reveal strengths and weaknesses that might not be apparent in traditional benchmarks.
### Custom Benchmark Suites
Organizations often develop internal benchmark suites tailored to their specific needs and use cases. These might include domain-specific knowledge tests or evaluation scenarios that mirror actual deployment conditions.
## Creating Your Own Evaluation Strategy
Remember that while LightEval makes it easy to run standard benchmarks, you should also invest time in developing evaluation methods specific to your use case.
While standard benchmarks provide a useful baseline, they shouldn't be your only evaluation method. Here's how to develop a more comprehensive approach:
1. Start with relevant standard benchmarks to establish a baseline and enable comparison with other models.
2. Identify the specific requirements and challenges of your use case. What tasks will your model actually perform? What kinds of errors would be most problematic?
3. Develop custom evaluation datasets that reflect your actual use case. This might include:
- Real user queries from your domain
- Common edge cases you've encountered
- Examples of particularly challenging scenarios
4. Consider implementing a multi-layered evaluation strategy:
- Automated metrics for quick feedback
- Human evaluation for nuanced understanding
- Domain expert review for specialized applications
- A/B testing in controlled environments
## Using LightEval for Benchmarking
LightEval tasks are defined using a specific format:
```
{suite}|{task}|{num_few_shot}|{auto_reduce}
```
- **suite**: The benchmark suite (e.g., 'mmlu', 'truthfulqa')
- **task**: Specific task within the suite (e.g., 'abstract_algebra')
- **num_few_shot**: Number of examples to include in prompt (0 for zero-shot)
- **auto_reduce**: Whether to automatically reduce few-shot examples if prompt is too long (0 or 1)
Example: `"mmlu|abstract_algebra|0|0"` evaluates on MMLU's abstract algebra task with zero-shot inference.
### Example Evaluation Pipeline
Here's a complete example of setting up and running an evaluation on automatic benchmarks relevant to one specific domain:
```python
from lighteval.tasks import Task, Pipeline
from transformers import AutoModelForCausalLM
# Define tasks to evaluate
domain_tasks = [
"mmlu|anatomy|0|0",
"mmlu|high_school_biology|0|0",
"mmlu|high_school_chemistry|0|0",
"mmlu|professional_medicine|0|0"
]
# Configure pipeline parameters
pipeline_params = {
"max_samples": 40, # Number of samples to evaluate
"batch_size": 1, # Batch size for inference
"num_workers": 4 # Number of worker processes
}
# Create evaluation tracker
evaluation_tracker = EvaluationTracker(
output_path="./results",
save_generations=True
)
# Load model and create pipeline
model = AutoModelForCausalLM.from_pretrained("your-model-name")
pipeline = Pipeline(
tasks=domain_tasks,
pipeline_parameters=pipeline_params,
evaluation_tracker=evaluation_tracker,
model=model
)
# Run evaluation
pipeline.evaluate()
# Get and display results
results = pipeline.get_results()
pipeline.show_results()
```
Results are displayed in a tabular format showing:
```
| Task |Version|Metric|Value | |Stderr|
|----------------------------------------|------:|------|-----:|---|-----:|
|all | |acc |0.3333|± |0.1169|
|leaderboard:mmlu:_average:5 | |acc |0.3400|± |0.1121|
|leaderboard:mmlu:anatomy:5 | 0|acc |0.4500|± |0.1141|
|leaderboard:mmlu:high_school_biology:5 | 0|acc |0.1500|± |0.0819|
```
You can also handle the results in a pandas DataFrame and visualise or represent them as you want.
# Next Steps
⏩ Explore [Custom Domain Evaluation](./custom_evaluation.md) to learn how to create evaluation pipelines tailored to your specific needs
|
{
"source": "huggingface/smol-course",
"title": "4_evaluation/automatic_benchmarks.md",
"url": "https://github.com/huggingface/smol-course/blob/main/4_evaluation/automatic_benchmarks.md",
"date": "2024-11-25T19:22:43",
"stars": 5481,
"description": "A course on aligning smol models.",
"file_size": 6530
}
|
# Custom Domain Evaluation
While standard benchmarks provide valuable insights, many applications require specialized evaluation approaches tailored to specific domains or use cases. This guide will help you create custom evaluation pipelines that accurately assess your model's performance in your target domain.
## Designing Your Evaluation Strategy
A successful custom evaluation strategy starts with clear objectives. Consider what specific capabilities your model needs to demonstrate in your domain. This might include technical knowledge, reasoning patterns, or domain-specific formats. Document these requirements carefully - they'll guide both your task design and metric selection.
Your evaluation should test both standard use cases and edge cases. For example, in a medical domain, you might evaluate both common diagnostic scenarios and rare conditions. In financial applications, you might test both routine transactions and complex edge cases involving multiple currencies or special conditions.
## Implementation with LightEval
LightEval provides a flexible framework for implementing custom evaluations. Here's how to create a custom task:
```python
from lighteval.tasks import Task, Doc
from lighteval.metrics import SampleLevelMetric, MetricCategory, MetricUseCase
class CustomEvalTask(Task):
def __init__(self):
super().__init__(
name="custom_task",
version="0.0.1",
metrics=["accuracy", "f1"], # Your chosen metrics
description="Description of your custom evaluation task"
)
def get_prompt(self, sample):
# Format your input into a prompt
return f"Question: {sample['question']}\nAnswer:"
def process_response(self, response, ref):
# Process model output and compare to reference
return response.strip() == ref.strip()
```
## Custom Metrics
Domain-specific tasks often require specialized metrics. LightEval provides a flexible framework for creating custom metrics that capture domain-relevant aspects of performance:
```python
from aenum import extend_enum
from lighteval.metrics import Metrics, SampleLevelMetric, SampleLevelMetricGrouping
import numpy as np
# Define a sample-level metric function
def custom_metric(predictions: list[str], formatted_doc: Doc, **kwargs) -> dict:
"""Example metric that returns multiple scores per sample"""
response = predictions[0]
return {
"accuracy": response == formatted_doc.choices[formatted_doc.gold_index],
"length_match": len(response) == len(formatted_doc.reference)
}
# Create a metric that returns multiple values per sample
custom_metric_group = SampleLevelMetricGrouping(
metric_name=["accuracy", "length_match"], # Names of sub-metrics
higher_is_better={ # Whether higher values are better for each metric
"accuracy": True,
"length_match": True
},
category=MetricCategory.CUSTOM,
use_case=MetricUseCase.SCORING,
sample_level_fn=custom_metric,
corpus_level_fn={ # How to aggregate each metric
"accuracy": np.mean,
"length_match": np.mean
}
)
# Register the metric with LightEval
extend_enum(Metrics, "custom_metric_name", custom_metric_group)
```
For simpler cases where you only need one metric value per sample:
```python
def simple_metric(predictions: list[str], formatted_doc: Doc, **kwargs) -> bool:
"""Example metric that returns a single score per sample"""
response = predictions[0]
return response == formatted_doc.choices[formatted_doc.gold_index]
simple_metric_obj = SampleLevelMetric(
metric_name="simple_accuracy",
higher_is_better=True,
category=MetricCategory.CUSTOM,
use_case=MetricUseCase.SCORING,
sample_level_fn=simple_metric,
corpus_level_fn=np.mean # How to aggregate across samples
)
extend_enum(Metrics, "simple_metric", simple_metric_obj)
```
You can then use your custom metrics in your evaluation tasks by referencing them in the task configuration. The metrics will be automatically computed across all samples and aggregated according to your specified functions.
For more complex metrics, consider:
- Using metadata in your formatted documents to weight or adjust scores
- Implementing custom aggregation functions for corpus-level statistics
- Adding validation checks for your metric inputs
- Documenting edge cases and expected behavior
For a complete example of custom metrics in action, see our [domain evaluation project](./project/README.md).
## Dataset Creation
High-quality evaluation requires carefully curated datasets. Consider these approaches for dataset creation:
1. Expert Annotation: Work with domain experts to create and validate evaluation examples. Tools like [Argilla](https://github.com/argilla-io/argilla) make this process more efficient.
2. Real-World Data: Collect and anonymize real usage data, ensuring it represents actual deployment scenarios.
3. Synthetic Generation: Use LLMs to generate initial examples, then have experts validate and refine them.
## Best Practices
- Document your evaluation methodology thoroughly, including any assumptions or limitations
- Include diverse test cases that cover different aspects of your domain
- Consider both automated metrics and human evaluation where appropriate
- Version control your evaluation datasets and code
- Regularly update your evaluation suite as you discover new edge cases or requirements
## References
- [LightEval Custom Task Guide](https://github.com/huggingface/lighteval/wiki/Adding-a-Custom-Task)
- [LightEval Custom Metrics](https://github.com/huggingface/lighteval/wiki/Adding-a-New-Metric)
- [Argilla Documentation](https://docs.argilla.io) for dataset annotation
- [Evaluation Guidebook](https://github.com/huggingface/evaluation-guidebook) for general evaluation principles
# Next Steps
⏩ For a complete example of implementing these concepts, see our [domain evaluation project](./project/README.md).
|
{
"source": "huggingface/smol-course",
"title": "4_evaluation/custom_evaluation.md",
"url": "https://github.com/huggingface/smol-course/blob/main/4_evaluation/custom_evaluation.md",
"date": "2024-11-25T19:22:43",
"stars": 5481,
"description": "A course on aligning smol models.",
"file_size": 5990
}
|
# Vision Language Models
## 1. VLM Usage
Vision Language Models (VLMs) process image inputs alongside text to enable tasks like image captioning, visual question answering, and multimodal reasoning.
A typical VLM architecture consists of an image encoder to extract visual features, a projection layer to align visual and textual representations, and a language model to process or generate text. This allows the model to establish connections between visual elements and language concepts.
VLMs can be used in different configurations depending on the use case. Base models handle general vision-language tasks, while chat-optimized variants support conversational interactions. Some models include additional components for grounding predictions in visual evidence or specializing in specific tasks like object detection.
For more on the technicality and usage of VLMs, refer to the [VLM Usage](./vlm_usage.md) page.
## 2. VLM Fine-Tuning
Fine-tuning a VLM involves adapting a pre-trained model to perform specific tasks or to operate effectively on a particular dataset. The process can follow methodologies such as supervised fine-tuning, preference optimization, or a hybrid approach that combines both, as introduced in Modules 1 and 2.
While the core tools and techniques remain similar to those used for LLMs, fine-tuning VLMs requires additional focus on data representation and preparation for images. This ensures the model effectively integrates and processes both visual and textual data for optimal performance. Given that the demo model, SmolVLM, is significantly larger than the language model used in the previous module, it's essential to explore methods for efficient fine-tuning. Techniques like quantization and PEFT can help make the process more accessible and cost-effective, allowing more users to experiment with the model.
For detailed guidance on fine-tuning VLMs, visit the [VLM Fine-Tuning](./vlm_finetuning.md) page.
## Exercise Notebooks
| Title | Description | Exercise | Link | Colab |
|-------|-------------|----------|------|-------|
| VLM Usage | Learn how to load and use a pre-trained VLM for various tasks | 🐢 Process an image<br>🐕 Process multiple images with batch handling <br>🦁 Process a full video| [Notebook](./notebooks/vlm_usage_sample.ipynb) | <a target="_blank" href="https://colab.research.google.com/github/huggingface/smol-course/blob/main/5_vision_language_models/notebooks/vlm_usage_sample.ipynb"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a> |
| VLM Fine-Tuning | Learn how to fine-tune a pre-trained VLM for task-specific datasets | 🐢 Use a basic dataset for fine-tuning<br>🐕 Try a new dataset<br>🦁 Experiment with alternative fine-tuning methods | [Notebook](./notebooks/vlm_sft_sample.ipynb)| <a target="_blank" href="https://colab.research.google.com/github/huggingface/smol-course/blob/main/5_vision_language_models/notebooks/vlm_sft_sample.ipynb"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a> |
## References
- [Hugging Face Learn: Supervised Fine-Tuning VLMs](https://huggingface.co/learn/cookbook/fine_tuning_vlm_trl)
- [Hugging Face Learn: Supervised Fine-Tuning SmolVLM](https://huggingface.co/learn/cookbook/fine_tuning_smol_vlm_sft_trl)
- [Hugging Face Learn: Preference Optimization Fine-Tuning SmolVLM](https://huggingface.co/learn/cookbook/fine_tuning_vlm_dpo_smolvlm_instruct)
- [Hugging Face Blog: Preference Optimization for VLMs](https://huggingface.co/blog/dpo_vlm)
- [Hugging Face Blog: Vision Language Models](https://huggingface.co/blog/vlms)
- [Hugging Face Blog: SmolVLM](https://huggingface.co/blog/smolvlm)
- [Hugging Face Model: SmolVLM-Instruct](https://huggingface.co/HuggingFaceTB/SmolVLM-Instruct)
- [CLIP: Learning Transferable Visual Models from Natural Language Supervision](https://arxiv.org/abs/2103.00020)
- [Align Before Fuse: Vision and Language Representation Learning with Momentum Distillation](https://arxiv.org/abs/2107.07651)
|
{
"source": "huggingface/smol-course",
"title": "5_vision_language_models/README.md",
"url": "https://github.com/huggingface/smol-course/blob/main/5_vision_language_models/README.md",
"date": "2024-11-25T19:22:43",
"stars": 5481,
"description": "A course on aligning smol models.",
"file_size": 4062
}
|
# VLM Fine-Tuning
## Efficient Fine-Tuning
### Quantization
Quantization reduces the precision of model weights and activations, significantly lowering memory usage and speeding up computations. For example, switching from `float32` to `bfloat16` halves memory requirements per parameter while maintaining performance. For more aggressive compression, 8-bit and 4-bit quantization can be used, further reducing memory usage, though at the cost of some accuracy. These techniques can be applied to both the model and optimizer settings, enabling efficient training on hardware with limited resources.
### PEFT & LoRA
As introduced in Module 3, LoRA (Low-Rank Adaptation) focuses on learning compact rank-decomposition matrices while keeping the original model weights frozen. This drastically reduces the number of trainable parameters, cutting resource requirements significantly. LoRA, when integrated with PEFT, enables fine-tuning of large models by only adjusting a small, trainable subset of parameters. This approach is particularly effective for task-specific adaptations, reducing billions of trainable parameters to just millions while maintaining performance.
### Batch Size Optimization
To optimize the batch size for fine-tuning, start with a large value and reduce it if out-of-memory (OOM) errors occur. Compensate by increasing `gradient_accumulation_steps`, effectively maintaining the total batch size over multiple updates. Additionally, enable `gradient_checkpointing` to lower memory usage by recomputing intermediate states during the backward pass, trading computation time for reduced activation memory requirements. These strategies maximize hardware utilization and help overcome memory constraints.
```python
from transformers import TrainingArguments
training_args = TrainingArguments(
output_dir="./fine_tuned_model", # Directory for model checkpoints
per_device_train_batch_size=4, # Batch size per device (GPU/TPU)
num_train_epochs=3, # Total training epochs
learning_rate=5e-5, # Learning rate
save_steps=1000, # Save checkpoint every 1000 steps
bf16=True, # Use mixed precision for training
gradient_checkpointing=True, # Enable to reduce activation memory usage
gradient_accumulation_steps=16, # Accumulate gradients over 16 steps
logging_steps=50 # Log metrics every 50 steps
)
```
## **Supervised Fine-Tuning (SFT)**
Supervised Fine-Tuning (SFT) adapts a pre-trained Vision Language Model (VLM) to specific tasks by leveraging labeled datasets containing paired inputs, such as images and corresponding text. This method enhances the model's ability to perform domain-specific or task-specific functions, such as visual question answering, image captioning, or chart interpretation.
### **Overview**
SFT is essential when you need a VLM to specialize in a particular domain or solve specific problems where the base model's general capabilities may fall short. For example, if the model struggles with unique visual features or domain-specific terminology, SFT allows it to focus on these areas by learning from labeled data.
While SFT is highly effective, it has notable limitations:
- **Data Dependency**: High-quality, labeled datasets tailored to the task are necessary.
- **Computational Resources**: Fine-tuning large VLMs is resource-intensive.
- **Risk of Overfitting**: Models can lose their generalization capabilities if fine-tuned too narrowly.
Despite these challenges, SFT remains a robust technique for enhancing model performance in specific contexts.
### **Usage**
1. **Data Preparation**: Start with a labeled dataset that pairs images with text, such as questions and answers. For example, in tasks like chart analysis, the dataset `HuggingFaceM4/ChartQA` includes chart images, queries, and concise responses.
2. **Model Setup**: Load a pre-trained VLM suitable for the task, such as `HuggingFaceTB/SmolVLM-Instruct`, and a processor for preparing text and image inputs. Configure the model for supervised learning and suitability for your hardware.
3. **Fine-Tuning Process**:
- **Formatting Data**: Structure the dataset into a chatbot-like format, pairing system messages, user queries, and corresponding answers.
- **Training Configuration**: Use tools like Hugging Face's `TrainingArguments` or TRL's `SFTConfig` to set up training parameters. These include batch size, learning rate, and gradient accumulation steps to optimize resource usage.
- **Optimization Techniques**: Use **gradient checkpointing** to save memory during training. Use quantized model to reduce memory requirements and speed up computations.
- Employ `SFTTrainer` trainer from the TRL library, to streamline the training process.
## Preference Optimization
Preference Optimization, particularly Direct Preference Optimization (DPO), trains a Vision Language Model (VLM) to align with human preferences. Instead of strictly following predefined instructions, the model learns to prioritize outputs that humans subjectively prefer. This approach is particularly useful for tasks involving creative judgment, nuanced reasoning, or varying acceptable answers.
### **Overview**
Preference Optimization addresses scenarios where subjective human preferences are central to task success. By fine-tuning on datasets that encode human preferences, DPO enhances the model's ability to generate responses that are contextually and stylistically aligned with user expectations. This method is particularly effective for tasks like creative writing, customer interactions, or multi-choice scenarios.
Despite its benefits, Preference Optimization has challenges:
- **Data Quality**: High-quality, preference-annotated datasets are required, often making data collection a bottleneck.
- **Complexity**: Training can involve sophisticated processes such as pairwise sampling of preferences and balancing computational resources.
Preference datasets must capture clear preferences between candidate outputs. For example, a dataset may pair a question with two responses—one preferred and the other less acceptable. The model learns to predict the preferred response, even if it's not entirely correct, as long as it's better aligned with human judgment.
### **Usage**
1. **Dataset Preparation**
A preference-labeled dataset is crucial for training. Each example typically consists of a prompt (e.g., an image and question) and two candidate responses: one chosen (preferred) and one rejected. For example:
- **Question**: How many families?
- **Rejected**: The image does not provide any information about families.
- **Chosen**: The image shows a Union Organization table setup with 18,000 families.
The dataset teaches the model to prioritize better-aligned responses, even if they aren’t perfect.
2. **Model Setup**
Load a pre-trained VLM and integrate it with Hugging Face's TRL library, which supports DPO, and a processor for preparing text and image inputs. Configure the model for supervised learning and suitability for your hardware.
3. **Training Pipeline**
Training involves configuring DPO-specific parameters. Here's a summary of the process:
- **Format Dataset**: Structure each sample with prompts, images, and candidate answers.
- **Loss Function**: Use a preference-based loss function to optimize the model for selecting the preferred output.
- **Efficient Training**: Combine techniques like quantization, gradient accumulation, and LoRA adapters to optimize memory and computation.
## Resources
- [Hugging Face Learn: Supervised Fine-Tuning VLMs](https://huggingface.co/learn/cookbook/fine_tuning_vlm_trl)
- [Hugging Face Learn: Supervised Fine-Tuning SmolVLM](https://huggingface.co/learn/cookbook/fine_tuning_smol_vlm_sft_trl)
- [Hugging Face Learn: Preference Optimization Fine-Tuning SmolVLM](https://huggingface.co/learn/cookbook/fine_tuning_vlm_dpo_smolvlm_instruct)
- [Hugging Face Blog: Preference Optimization for VLMs](https://huggingface.co/blog/dpo_vlm)
## Next Steps
⏩ Try the [vlm_finetune_sample.ipynb](./notebooks/vlm_finetune_sample.ipynb) to implement this unified approach to preference alignment.
|
{
"source": "huggingface/smol-course",
"title": "5_vision_language_models/vlm_finetuning.md",
"url": "https://github.com/huggingface/smol-course/blob/main/5_vision_language_models/vlm_finetuning.md",
"date": "2024-11-25T19:22:43",
"stars": 5481,
"description": "A course on aligning smol models.",
"file_size": 8276
}
|
# Visual Language Models
Visual Language Models (VLMs) bridge the gap between images and text, enabling advanced tasks like generating image captions, answering questions based on visuals, or understanding the relationship between textual and visual data. Their architecture is designed to process both modalities seamlessly.
### Architecture
VLMs combine image-processing components with text-generation models to achieve a unified understanding. The primary elements of their architecture are:

- **Image Encoder**: Transforms raw images into compact numerical representations. Pretrained encoders such as CLIP or vision transformers (ViT) are commonly used.
- **Embedding Projector**: Maps image features into a space compatible with textual embeddings, often using dense layers or linear transformations.
- **Text Decoder**: Acts as the language-generation component, translating fused multimodal information into coherent text. Examples include generative models like Llama or Vicuna.
- **Multimodal Projector**: Provides an additional layer to blend image and text representations. It is critical for models like LLaVA to establish stronger connections between the two modalities.
Most VLMs leverage pretrained image encoders and text decoders and align them through additional fine-tuning on paired image-text datasets. This approach makes training efficient while allowing the models to generalize effectively.
### Usage

VLMs are applied to a range of multimodal tasks. Their adaptability allows them to perform in diverse domains with varying levels of fine-tuning:
- **Image Captioning**: Generating descriptions for images.
- **Visual Question Answering (VQA)**: Answering questions about the content of an image.
- **Cross-Modal Retrieval**: Finding corresponding text for a given image or vice versa.
- **Creative Applications**: Assisting in design, art generation, or creating engaging multimedia content.

Training and fine-tuning VLMs depend on high-quality datasets that pair images with text annotations. Tools like Hugging Face's `transformers` library provide convenient access to pretrained VLMs and streamlined workflows for custom fine-tuning.
### Chat Format
Many VLMs are structured to interact in a chatbot-like manner, enhancing usability. This format includes:
- A **system message** that sets the role or context for the model, such as "You are an assistant analyzing visual data."
- **User queries** that combine text inputs and associated images.
- **Assistant responses** that provide text outputs derived from the multimodal analysis.
This conversational structure is intuitive and aligns with user expectations, especially for interactive applications like customer service or educational tools.
Here’s an example of how a formatted input might look:
```json
[
{
"role": "system",
"content": [{"type": "text", "text": "You are a Vision Language Model specialized in interpreting visual data from chart images..."}]
},
{
"role": "user",
"content": [
{"type": "image", "image": "<image_data>"},
{"type": "text", "text": "What is the highest value in the bar chart?"}
]
},
{
"role": "assistant",
"content": [{"type": "text", "text": "42"}]
}
]
```
**Working with Multiple Images and Videos**
VLMs can also process multiple images or even videos by adapting the input structure to accommodate sequential or parallel visual inputs. For videos, frames can be extracted and processed as individual images, while maintaining temporal order.
## Resources
- [Hugging Face Blog: Vision Language Models](https://huggingface.co/blog/vlms)
- [Hugging Face Blog: SmolVLM](https://huggingface.co/blog/smolvlm)
## Next Steps
⏩ Try the [vlm_usage_sample.ipynb](./notebooks/vlm_usage_sample.ipynb) to try different usages of SMOLVLM.
|
{
"source": "huggingface/smol-course",
"title": "5_vision_language_models/vlm_usage.md",
"url": "https://github.com/huggingface/smol-course/blob/main/5_vision_language_models/vlm_usage.md",
"date": "2024-11-25T19:22:43",
"stars": 5481,
"description": "A course on aligning smol models.",
"file_size": 4005
}
|
# Synthetic Datasets
Synthetic data is artificially generated data that mimics real-world usage. It allows overcoming data limitations by expanding or enhancing datasets. Even though synthetic data was already used for some use cases, large language models have made synthetic datasets more popular for pre- and post-training, and the evaluation of language models.
We'll use [`distilabel`](https://distilabel.argilla.io/latest/), a framework for synthetic data and AI feedback for engineers who need fast, reliable and scalable pipelines based on verified research papers. For a deeper dive into the package and best practices, check out the [documentation](https://distilabel.argilla.io/latest/).
## Module Overview
Synthetic data for language models can be categorized into three taxonomies: instructions, preferences and critiques. We will focus on the first two categories, which focus on the generation of datasets for instruction tuning and preference alignment. In both categories, we will cover aspects of the third category, which focuses on improving existing data with model critiques and rewrites.

## Contents
### 1. [Instruction Datasets](./instruction_datasets.md)
Learn how to generate instruction datasets for instruction tuning. We will explore creating instruction tuning datasets thorugh basic prompting and using prompts more refined techniques from papers. Instruction tuning datasets with seed data for in-context learning can be created through methods like SelfInstruct and Magpie. Additionally, we will explore instruction evolution through EvolInstruct. [Start learning](./instruction_datasets.md).
### 2. [Preference Datasets](./preference_datasets.md)
Learn how to generate preference datasets for preference alignment. We will build on top of the methods and techniques introduced in section 1, by generating additional responses. Next, we will learn how to improve such responses with the EvolQuality prompt. Finally, we will explore how to evaluate responses with the the UltraFeedback prompt which will produce a score and critique, allowing us to create preference pairs. [Start learning](./preference_datasets.md).
### Exercise Notebooks
| Title | Description | Exercise | Link | Colab |
|-------|-------------|----------|------|-------|
| Instruction Dataset | Generate a dataset for instruction tuning | 🐢 Generate an instruction tuning dataset <br> 🐕 Generate a dataset for instruction tuning with seed data <br> 🦁 Generate a dataset for instruction tuning with seed data and with instruction evolution | [Link](./notebooks/instruction_sft_dataset.ipynb) | [Colab](https://githubtocolab.com/huggingface/smol-course/tree/main/6_synthetic_datasets/notebooks/instruction_sft_dataset.ipynb) |
| Preference Dataset | Generate a dataset for preference alignment | 🐢 Generate a preference alignment dataset <br> 🐕 Generate a preference alignment dataset with response evolution <br> 🦁 Generate a preference alignment dataset with response evolution and critiques | [Link](./notebooks/preference_alignment_dataset.ipynb) | [Colab](https://githubtocolab.com/huggingface/smol-course/tree/main/6_synthetic_datasets/notebooks/preference_alignment_dataset.ipynb) |
## Resources
- [Distilabel Documentation](https://distilabel.argilla.io/latest/)
- [Synthetic Data Generator is UI app](https://huggingface.co/blog/synthetic-data-generator)
- [SmolTalk](https://huggingface.co/datasets/HuggingFaceTB/smoltalk)
- [Self-instruct](https://arxiv.org/abs/2212.10560)
- [Evol-Instruct](https://arxiv.org/abs/2304.12244)
- [Magpie](https://arxiv.org/abs/2406.08464)
- [UltraFeedback](https://arxiv.org/abs/2310.01377)
- [Deita](https://arxiv.org/abs/2312.15685)
|
{
"source": "huggingface/smol-course",
"title": "6_synthetic_datasets/README.md",
"url": "https://github.com/huggingface/smol-course/blob/main/6_synthetic_datasets/README.md",
"date": "2024-11-25T19:22:43",
"stars": 5481,
"description": "A course on aligning smol models.",
"file_size": 3759
}
|
# Generating Instruction Datasets
Within [the chapter on instruction tuning](../1_instruction_tuning/README.md), we learned about fine-tuning models with Supervised Fine-tuning. In this section, we will explore how to generate instruction datasets for SFT. We will explore creating instruction tuning datasets through basic prompting and using more refined techniques from papers. Instruction tuning datasets with seed data for in-context learning can be created through methods like SelfInstruct and Magpie. Additionally, we will explore instruction evolution through EvolInstruct. Lastly, we will explore how to generate a dataset for instruction tuning using a distilabel pipeline.
## From Prompt to Data
Synthetic data sounds fancy, but it can be simplified as creating data through effective prompting to extract knowledge from a model. In turn, you can think of this as a way to generate data for a specific task. The challenge is prompting effectively while ensuring the data is diverse and representative. Fortunately, many papers have explored this problem, and we will explore some of the useful ones during this course. First things first, we will explore how to generate synthetic data through manual prompting.
### Basic Prompting
Let's start with a basic example and load the [HuggingFaceTB/SmolLM2-1.7B-Instruct](https://huggingface.co/HuggingFaceTB/SmolLM2-1.7B-Instruct) model using the `transformers` integration of the `distilabel` library. We will use the `TextGeneration` class to generate a synthetic `prompt` and use that to generate a `completion`.
Next, we will load the model using the `distilabel` library.
```python
from distilabel.llms import TransformersLLM
from distilabel.steps.tasks import TextGeneration
llm = TransformersLLM(model="HuggingFaceTB/SmolLM2-1.7B-Instruct")
gen = TextGeneration(llm=llm)
gen.load()
```
!!! note
Distilabel loads the `llm` into memory, so, when working in a notebook, we need to `gen.unload()` after we are done with it to avoid memory issues.
We will now use the `llm` to generate a `prompt` for instruction tuning.
```python
next(gen.process([{"instruction": "Generate a questions about the Hugging Face Smol-Course on small AI models."}]))
# What is the purpose of Smol-Course?
```
Lastly, we can use that same `prompt` as input to generate a `completion`.
```python
next(gen.process([{"instruction": "What is the purpose of Smol-Course?"}]))
# The Smol-Course is a platform designed to learning computer science concepts.
```
Cool! We can generated a synthetic `prompt` and a corresponding `completion`. Re-using this simple approach at scale will allow us to generate a lot more data however, the quality of the data is not that great and does not take into account the nuances of our course or domain. Additionally, re-running the current code shows us the data is not that diverse. Luckily, there are ways to solve this problem.
### SelfInstruct
SelfInstruct is a prompt that generates new instructions based on a seed dataset. This seed data can be a single instruction or a piece of context. The process begins with a pool of initial seed data. The language model is then prompted to generate new instructions based on this seed data using in-context learning. The prompt is [implemented in distilabel](https://github.com/argilla-io/distilabel/blob/main/src/distilabel/steps/tasks/templates/self-instruct.jinja2) and a simplified version is shown below:
```
# Task Description
Develop {{ num_instructions }} user queries that can be received by the given AI application and applicable to the provided context. Emphasize diversity in verbs and linguistic structures within the model's textual capabilities.
# Context
{{ input }}
# Output
```
To use it, we need to pass the `llm` to the [SelfInstruct class](https://distilabel.argilla.io/dev/components-gallery/tasks/selfinstruct/). Let's use the text from the [Prompt to Data section](#prompt-to-data) as context and generate a new instruction.
```python
from distilabel.steps.tasks import SelfInstruct
self_instruct = SelfInstruct(llm=llm)
self_instruct.load()
context = "<prompt_to_data_section>"
next(self_instruct.process([{"input": text}]))["instructions"][0]
# What is the process of generating synthetic data through manual prompting?
```
The generated instruction is a lot better already and it fits our actual content and domain. However, we can do even better by improving the prompt through evolution.
### EvolInstruct
EvolInstruct is a prompting technique that takes an input instruction and evolves it into a better version of the same instruction. This better version is defined according to a set of criteria and adds constraints, deepening, concretizing, reasoning or complications to the original instruction. The process can be repeated multiple times to create various evolutions of the same instruction, ideally leading to a better version of the original instruction. The prompt is [implemented in distilabel](https://github.com/argilla-io/distilabel/tree/main/src/distilabel/steps/tasks/evol_instruct) and a simplified version is shown below:
```
I want you act as a Prompt Rewriter.
Given prompt a prompt, rewrite it into a more complex version.
Complicate the prompt based on the following criteria:
{{ criteria }}
# Prompt
{{ input }}
# Output
```
To use it, we need to pass the `llm` to the [EvolInstruct class](https://distilabel.argilla.io/dev/components-gallery/tasks/evolinstruct/). Let's use the synthetic prompt from [the SelfInstruct section](#selfinstruct) as input and evolve it into a better version. For this example, we will only evolve for one generation.
```python
from distilabel.steps.tasks import EvolInstruct
evol_instruct = EvolInstruct(llm=llm, num_evolutions=1)
evol_instruct.load()
text = "What is the process of generating synthetic data through manual prompting"
next(evol_instruct.process([{"instruction": text}]))
# What is the process of generating synthetic data through manual prompting?
# And, how does the artificial intelligence system, GPT4, use machine learning algorithms to manipulate the input data into synthetic data?
```
The instruction is now more complex but has lost some of the original meaning. So, take into account that evolving can be a double-edged sword and we need to be careful with the quality of the data we generate.
### Magpie
Magpie is a technique that relies on the auto-regressive factors of language model and the [chat-template](../1_instruction_tuning/chat_templates.md) that has been using during the instruction tuning process. As you might remember, the chat-template is a format that structures conversations with clear role indicators (system, user, assistant). During the instruction tuning phase, the language model has been optimized to reproduce this format and that is exactly what magpie takes advantage of. It starts with a pre-query-prompt based on the chat-template but it stops before the user message indicator, e.g. `<|im_start|>user\n`, and then it uses the language model to generate the user prompt until the end of the assistant indicator, e.g. `<|im_end|>`. This approach allows us to generate a lot of data in a very efficient way and it can even be scaled up to multi-turn conversations. It is hypothesized this generated data reproduces training data from the instruction tuning phase of the model used.
In this scenario, prompt templates differ per model because they are based on the chat-template format. But we can walk through a simplified version of the process step-by-step.
```bash
# Step 1: provide the pre-query-prompt
<|im_start|>user\n
# Step 2: the language model generates the user prompt
<|im_start|>user\n
What is the purpose of Smol-Course?
# Step 3: stop the generation
<|im_end|>
```
To use it in distilabel, we need to pass the `llm` to the [Magpie class](https://distilabel.argilla.io/dev/components-gallery/tasks/magpie/).
```python
from distilabel.steps.tasks import Magpie
magpie = Magpie(llm=llm)
magpie.load()
next(magpie.process([{"system_prompt": "You are a helpful assistant."}]))
# [{
# "role": "user",
# "content": "Can you provide me with a list of the top 3 universities?"
# },
# {
# "role": "assistant",
# "content": "The top 3 universities are: MIT, Yale, Stanford."
# }]
```
We immediately get a dataset with a `prompt` and `completion` . To improve the performance on our own domain, we can inject additional context into the `system_prompt`. For the LLM to generate specific domain data in combination with Magpie, it helps describing in the system prompt what the users queries will be. This is then used in the pre-query-prompt before we start generating the user prompt and bias the LLM to generate user queries of that domain.
```
You're an AI assistant that will help users solving math problems.
```
It's important to write the system prompt as shown above instead of something like:
```
You're an AI assistant that generates math problems
```
Generally, language models are less optimized for passing additional context to the `system_prompt` so this does not always work as well for customisation as other techniques.
### From Prompts to Pipelines
The classes we've seen so far are all standalone classes that can be used in a pipeline. This is a good start, but we can do even better by using the `Pipeline` class to generate a dataset. We will use the `TextGeneration` step to generate a synthetic dataset for instruction tuning. The pipeline will consist of a `LoadDataFromDicts` step to load the data, a `TextGeneration` step to generate the `prompt` and a `completion` for that prompt. We will connect the steps and flow the data through the pipeline using the `>>` operator. Within the [documentation of distilabel](https://distilabel.argilla.io/dev/components-gallery/tasks/textgeneration/#input-output-columns) we can see input and output columns of the step. We to ensure that the data flow correctly through the pipeline, we will use the `output_mappings` parameter to map the output columns to the input columns of the next step.
```python
from distilabel.llms import TransformersLLM
from distilabel.pipeline import Pipeline
from distilabel.steps import LoadDataFromDicts
from distilabel.steps.tasks import TextGeneration
with Pipeline() as pipeline:
data = LoadDataFromDicts(data=[{"instruction": "Generate a short question about the Hugging Face Smol-Course."}])
llm = TransformersLLM(model="HuggingFaceTB/SmolLM2-1.7B-Instruct")
gen_a = TextGeneration(llm=llm, output_mappings={"generation": "instruction"})
gen_b = TextGeneration(llm=llm, output_mappings={"generation": "response"})
data >> gen_a >> gen_b
if __name__ == "__main__":
distiset = pipeline.run(use_cache=False)
print(distiset["default"]["train"][0])
# [{
# "instruction": "What is the purpose of Smol-Course?",
# "response": "The Smol-Course is a platform designed to learning computer science concepts."
# }]
```
Under the hood, this pipeline has a lot of cool features. It automatically caches generation results, so we can don't have to re-run the generation steps. There is included fault-tolerance, so if the generation steps fail, the pipeline will continue to run. And the pipeline exexutes all generation steps in parallel, so the generation is faster. We can even visualise the pipeline using the `draw` method. Here you can see how the data flows through the pipeline and how the `output_mappings` are used to map the output columns to the input columns of the next step.

## Best Practices
- Ensure you have a diverse seed data to cover a wide range of scenarios
- Regularly evaluate the dataset to ensure generated data is diverse and of high quality
- Iterate on the (system)prompt to improve the quality of the data
## Next Steps
👨🏽💻 Code -[Exercise Notebook](./notebooks/instruction_sft_dataset.ipynb) to generate a dataset for instruction tuning
🧑🏫 Learn - About [generating preference datasets](./preference_datasets.md)
## References
- [Distilabel Documentation](https://distilabel.argilla.io/latest/)
- [Self-instruct](https://arxiv.org/abs/2212.10560)
- [Evol-Instruct](https://arxiv.org/abs/2304.12244)
- [Magpie](https://arxiv.org/abs/2406.08464)
|
{
"source": "huggingface/smol-course",
"title": "6_synthetic_datasets/instruction_datasets.md",
"url": "https://github.com/huggingface/smol-course/blob/main/6_synthetic_datasets/instruction_datasets.md",
"date": "2024-11-25T19:22:43",
"stars": 5481,
"description": "A course on aligning smol models.",
"file_size": 12272
}
|
# Generating Preference Datasets
Within [the chapter on preference alignment](../2_preference_alignment/README.md), we learned about Direct Preference Optimization. In this section, we will explore how to generate preference datasets for methods like DPO. We will build on top of the methods that were introduced in [generating instruction datasets](./instruction_datasets.md). Additionally, we will show how to add extra completions to the dataset using basic prompting or by using EvolQuality to improve the quality of responses. Lastly, we will show how UltraFeedback can be used to generate scores and critiques.
## Creating multiple completions
Preference data is a dataset with multiple `completions` for the same `instruction`. We can add more `completions` to a dataset by prompting a model to generate them. When doing this, we need to ensure that the second completion is not too similar to the first completion in terms of overall quality and phrasing. This is important because the model needs to be optimized for a clear preference. We want to know which completion is preferred over the other, normally referred to as `chosen` and `rejected`. We will go into more detail about determining chosen and rejected completions in the [section on creating scores](#creating-scores).
### Model pooling
You can use models from different model families to generate a second completion, which is called model pooling. To further improve the quality of the second completion, you can use different generation arguments, like tweaking the `temperature`. Lastly, you can use different prompt templates or system prompts to generate a second completion to ensure diversity based on specific characteristics defined in the template. In theory, we could take two models of varying quality and use the better one as the `chosen` completion.
Let's start with model pooling by loading the [Qwen/Qwen2.5-1.5B-Instruct](https://huggingface.co/Qwen/Qwen2.5-1.5B-Instruct) and [HuggingFaceTB/SmolLM2-1.7B-Instruct](https://huggingface.co/HuggingFaceTB/SmolLM2-1.7B-Instruct) models using the `transformers` integration of the `distilabel` library. Using these models, we will create two synthetic `responses` for a given `prompt`. We will create another pipeline with `LoadDataFromDicts`, `TextGeneration`, and `GroupColumns`. We will first load data, then use two generation steps, and then group the results. We connect the steps and flow the data through the pipeline using the `>>` operator and `[]`, which means that we want to use the output of the previous step as the input for both steps within the list.
```python
from distilabel.llms import TransformersLLM
from distilabel.pipeline import Pipeline
from distilabel.steps import GroupColumns, LoadDataFromDicts
from distilabel.steps.tasks import TextGeneration
with Pipeline() as pipeline:
data = LoadDataFromDicts(data=[{"instruction": "What is synthetic data?"}])
llm_a = TransformersLLM(model="HuggingFaceTB/SmolLM2-1.7B-Instruct")
gen_a = TextGeneration(llm=llm_a)
llm_b = TransformersLLM(model="Qwen/Qwen2.5-1.5B-Instruct")
gen_b = TextGeneration(llm=llm_b)
group = GroupColumns(columns=["generation"])
data >> [gen_a, gen_b] >> group
if __name__ == "__main__":
distiset = pipeline.run()
print(distiset["default"]["train"]["grouped_generation"][0])
# {[
# 'Synthetic data is artificially generated data that mimics real-world usage.',
# 'Synthetic data refers to data that has been generated artificially.'
# ]}
```
As you can see, we have two synthetic `completions` for the given `prompt`. We could have boosted diversity by initializing the `TextGeneration` steps with a specific `system_prompt` or by passing generation arguments to the `TransformersLLM`. Let's now see how we can improve the quality of the `completions` using EvolQuality.
### EvolQuality
EvolQuality is similar to [EvolInstruct](./instruction_datasets.md#evolinstruct) - it is a prompting technique but it evolves `completions` instead of the input `prompt`. The task takes both a `prompt` and `completion` and evolves the `completion` into a version that better responds to the `prompt` based on a set of criteria. This better version is defined according to criteria for improving helpfulness, relevance, deepening, creativity, or details. Because this automatically generates a second completion, we can use it to add more `completions` to a dataset. In theory, we could even assume the evolution is better than the original completion and use it as the `chosen` completion out of the box.
The prompt is [implemented in distilabel](https://github.com/argilla-io/distilabel/tree/main/src/distilabel/steps/tasks/evol_quality) and a simplified version is shown below:
```bash
I want you act as a Response Rewriter.
Given prompt a and a response, rewrite the response into a better version.
Complicate the prompt based on the following criteria:
{{ criteria }}
# Prompt
{{ input }}
# Response
{{ output }}
# Improved Response
```
Let's use the [EvolQuality class](https://distilabel.argilla.io/dev/components-gallery/tasks/evolquality/) to evolve the synthetic `prompt` and `completion` from [the Model Pooling section](#model-pooling) into a better version. For this example, we will only evolve for one generation.
```python
from distilabel.llms import TransformersLLM
from distilabel.steps.tasks import EvolQuality
llm = TransformersLLM(model="HuggingFaceTB/SmolLM2-1.7B-Instruct")
evol_quality = EvolQuality(llm=llm, num_evolutions=1)
evol_quality.load()
instruction = "What is synthetic data?"
completion = "Synthetic data is artificially generated data that mimics real-world usage."
next(evol_quality.process([{
"instruction": instruction,
"response": completion
}]))
# The process of generating synthetic data through manual prompting involves creating artificial data sets that mimic real-world usage patterns.
```
The `response` is now more complex and specific to the `instruction`. This is a good start, but as we have seen with EvolInstruct, evolved generations are not always better. Hence, it is important to use additional evaluation techniques to ensure the quality of the dataset. We will explore this in the next section.
## Creating Scores
Scores are a measure of how much one response is preferred over another. In general, these scores can be absolute, subjective, or relative. For this course, we will focus on the first two because they are most valuable for creating preference datasets. This scoring is a way of judging and evaluating using language models and therefore has some overlap with the evaluation techniques we have seen in [the chapter on evaluation](../3_evaluation/README.md). As with the other evaluation techniques, scores and evaluations normally require larger models to better align with human preferences.
### UltraFeedback
UltraFeedback is a technique that generates scores and critiques for a given `prompt` and its `completion`.
The scores are based on the quality of the `completion` according to a set of criteria. There are four fine-grained criteria: `helpfulness`, `relevance`, `deepening`, and `creativity`. These are useful but generally speaking, using the overall criteria is a good start, which allows us to simplify the process of generating scores. The scores can be used to determine which `completion` is the `chosen` and which is the `rejected` one. Because they are absolute, they can also be used as interesting filters for outliers in the dataset, either finding the worst completions or the pairs with more or less difference.
The critiques are added to provide reasoning for the score. They can be used as extra context to help us understand the differences between the scores. The language model generates extensive critiques which is very useful, but this also introduces extra cost and complexity to the process because generating critiques is more expensive than generating a single token to represent a score.
The prompt is [implemented in distilabel](https://github.com/argilla-io/distilabel/tree/main/src/distilabel/steps/tasks/templates/ultrafeedback) and a simplified version is shown below:
```bash
Evaluate the model's outputs based on various criteria: Helpfulness, Relevance, Deepening, Creativity
Your role is to provide a holistic assessment based on the above factors.
Score the output from 1 to 5 on overall quality.
Answer with the following format: score - rationale
# Input
{{ input }}
# Response
{{ output }}
# Score - Rationale
```
Let's use the [UltraFeedback class](https://distilabel.argilla.io/dev/components-gallery/tasks/ultrafeedback/) to evaluate the synthetic `prompt` and `completion` from [the Model Pooling section](#model-pooling).
```python
from distilabel.llms import TransformersLLM
from distilabel.steps.tasks import UltraFeedback
llm = TransformersLLM(model="HuggingFaceTB/SmolLM2-1.7B-Instruct")
ultrafeedback = UltraFeedback(llm=llm)
ultrafeedback.load()
instruction = "What is synthetic data?"
completion_a = "Synthetic data is artificially generated data that mimics real-world usage."
completion_b = "Synthetic data refers to data that has been generated artificially."
next(ultrafeedback.process([{
"instruction": instruction,
"generations": [completion_a, completion_b]
}]))
# [
# {
# 'ratings': [4, 5],
# 'rationales': ['could have been more specific', 'good definition'],
# }
# ]
```
## Best Practices
- Overall scores are cheaper and easier to generate than critiques and specific scores
- Use bigger models to generate scores and critiques
- Use a diverse set of models to generate scores and critiques
- Iterate on configuration of the `system_prompt` and models
## Next Steps
👨🏽💻 Code -[Exercise Notebook](./notebooks/preference_dpo_dataset.ipynb) to generate a dataset for instruction tuning
## References
- [Distilabel Documentation](https://distilabel.argilla.io/latest/)
- [Deita](https://arxiv.org/abs/2312.15685)
- [UltraFeedback](https://arxiv.org/abs/2310.01377)
|
{
"source": "huggingface/smol-course",
"title": "6_synthetic_datasets/preference_datasets.md",
"url": "https://github.com/huggingface/smol-course/blob/main/6_synthetic_datasets/preference_datasets.md",
"date": "2024-11-25T19:22:43",
"stars": 5481,
"description": "A course on aligning smol models.",
"file_size": 10045
}
|
# Inference
Inference is the process of using a trained language model to generate predictions or responses. While inference might seem straightforward, deploying models efficiently at scale requires careful consideration of various factors like performance, cost, and reliability. Large Language Models (LLMs) present unique challenges due to their size and computational requirements.
We'll explore both simple and production-ready approaches using the [`transformers`](https://huggingface.co/docs/transformers/index) library and [`text-generation-inference`](https://github.com/huggingface/text-generation-inference), two popular frameworks for LLM inference. For production deployments, we'll focus on Text Generation Inference (TGI), which provides optimized serving capabilities.
## Module Overview
LLM inference can be categorized into two main approaches: simple pipeline-based inference for development and testing, and optimized serving solutions for production deployments. We'll cover both approaches, starting with the simpler pipeline approach and moving to production-ready solutions.
## Contents
### 1. [Basic Pipeline Inference](./pipeline_inference.md)
Learn how to use the Hugging Face Transformers pipeline for basic inference. We'll cover setting up pipelines, configuring generation parameters, and best practices for local development. The pipeline approach is perfect for prototyping and small-scale applications. [Start learning](./pipeline_inference.md).
### 2. [Production Inference with TGI](./tgi_inference.md)
Learn how to deploy models for production using Text Generation Inference. We'll explore optimized serving techniques, batching strategies, and monitoring solutions. TGI provides production-ready features like health checks, metrics, and Docker deployment options. [Start learning](./text_generation_inference.md).
### Exercise Notebooks
| Title | Description | Exercise | Link | Colab |
|-------|-------------|----------|------|-------|
| Pipeline Inference | Basic inference with transformers pipeline | 🐢 Set up a basic pipeline <br> 🐕 Configure generation parameters <br> 🦁 Create a simple web server | [Link](./notebooks/basic_pipeline_inference.ipynb) | [Colab](https://githubtocolab.com/huggingface/smol-course/tree/main/7_inference/notebooks/basic_pipeline_inference.ipynb) |
| TGI Deployment | Production deployment with TGI | 🐢 Deploy a model with TGI <br> 🐕 Configure performance optimizations <br> 🦁 Set up monitoring and scaling | [Link](./notebooks/tgi_deployment.ipynb) | [Colab](https://githubtocolab.com/huggingface/smol-course/tree/main/7_inference/notebooks/tgi_deployment.ipynb) |
## Resources
- [Hugging Face Pipeline Tutorial](https://huggingface.co/docs/transformers/en/pipeline_tutorial)
- [Text Generation Inference Documentation](https://huggingface.co/docs/text-generation-inference/en/index)
- [Pipeline WebServer Guide](https://huggingface.co/docs/transformers/en/pipeline_tutorial#using-pipelines-for-a-webserver)
- [TGI GitHub Repository](https://github.com/huggingface/text-generation-inference)
- [Hugging Face Model Deployment Documentation](https://huggingface.co/docs/inference-endpoints/index)
- [vLLM: High-throughput LLM Serving](https://github.com/vllm-project/vllm)
- [Optimizing Transformer Inference](https://huggingface.co/blog/optimize-transformer-inference)
|
{
"source": "huggingface/smol-course",
"title": "7_inference/README.md",
"url": "https://github.com/huggingface/smol-course/blob/main/7_inference/README.md",
"date": "2024-11-25T19:22:43",
"stars": 5481,
"description": "A course on aligning smol models.",
"file_size": 3356
}
|
# Basic Inference with Transformers Pipeline
The `pipeline` abstraction in 🤗 Transformers provides a simple way to run inference with any model from the Hugging Face Hub. It handles all the preprocessing and postprocessing steps, making it easy to use models without deep knowledge of their architecture or requirements.
## How Pipelines Work
Hugging Face pipelines streamline the machine learning workflow by automating three critical stages between raw input and human-readable output:
**Preprocessing Stage**
The pipeline first prepares your raw inputs for the model. This varies by input type:
- Text inputs undergo tokenization to convert words into model-friendly token IDs
- Images are resized and normalized to match model requirements
- Audio is processed through feature extraction to create spectrograms or other representations
**Model Inference**
During the forward pass, the pipeline:
- Handles batching of inputs automatically for efficient processing
- Places computation on the optimal device (CPU/GPU)
- Applies performance optimizations like half-precision (FP16) inference where supported
**Postprocessing Stage**
Finally, the pipeline converts raw model outputs into useful results:
- Decodes token IDs back into readable text
- Transforms logits into probability scores
- Formats outputs according to the specific task (e.g., classification labels, generated text)
This abstraction lets you focus on your application logic while the pipeline handles the technical complexity of model inference.
## Basic Usage
Here's how to use a pipeline for text generation:
```python
from transformers import pipeline
# Create a pipeline with a specific model
generator = pipeline(
"text-generation",
model="HuggingFaceTB/SmolLM2-1.7B-Instruct",
torch_dtype="auto",
device_map="auto"
)
# Generate text
response = generator(
"Write a short poem about coding:",
max_new_tokens=100,
do_sample=True,
temperature=0.7
)
print(response[0]['generated_text'])
```
## Key Configuration Options
### Model Loading
```python
# CPU inference
generator = pipeline("text-generation", model="HuggingFaceTB/SmolLM2-1.7B-Instruct", device="cpu")
# GPU inference (device 0)
generator = pipeline("text-generation", model="HuggingFaceTB/SmolLM2-1.7B-Instruct", device=0)
# Automatic device placement
generator = pipeline(
"text-generation",
model="HuggingFaceTB/SmolLM2-1.7B-Instruct",
device_map="auto",
torch_dtype="auto"
)
```
### Generation Parameters
```python
response = generator(
"Translate this to French:",
max_new_tokens=100, # Maximum length of generated text
do_sample=True, # Use sampling instead of greedy decoding
temperature=0.7, # Control randomness (higher = more random)
top_k=50, # Limit to top k tokens
top_p=0.95, # Nucleus sampling threshold
num_return_sequences=1 # Number of different generations
)
```
## Processing Multiple Inputs
Pipelines can efficiently handle multiple inputs through batching:
```python
# Prepare multiple prompts
prompts = [
"Write a haiku about programming:",
"Explain what an API is:",
"Write a short story about a robot:"
]
# Process all prompts efficiently
responses = generator(
prompts,
batch_size=4, # Number of prompts to process together
max_new_tokens=100,
do_sample=True,
temperature=0.7
)
# Print results
for prompt, response in zip(prompts, responses):
print(f"Prompt: {prompt}")
print(f"Response: {response[0]['generated_text']}\n")
```
## Web Server Integration
Here's how to integrate a pipeline into a FastAPI application:
```python
from fastapi import FastAPI, HTTPException
from transformers import pipeline
import uvicorn
app = FastAPI()
# Initialize pipeline globally
generator = pipeline(
"text-generation",
model="HuggingFaceTB/SmolLM2-1.7B-Instruct",
device_map="auto"
)
@app.post("/generate")
async def generate_text(prompt: str):
try:
if not prompt:
raise HTTPException(status_code=400, detail="No prompt provided")
response = generator(
prompt,
max_new_tokens=100,
do_sample=True,
temperature=0.7
)
return {"generated_text": response[0]['generated_text']}
except Exception as e:
raise HTTPException(status_code=500, detail=str(e))
if __name__ == "__main__":
uvicorn.run(app, host="0.0.0.0", port=5000)
```
## Limitations
While pipelines are great for prototyping and small-scale deployments, they have some limitations:
- Limited optimization options compared to dedicated serving solutions
- No built-in support for advanced features like dynamic batching
- May not be suitable for high-throughput production workloads
For production deployments with high throughput requirements, consider using Text Generation Inference (TGI) or other specialized serving solutions.
## Resources
- [Hugging Face Pipeline Tutorial](https://huggingface.co/docs/transformers/en/pipeline_tutorial)
- [Pipeline API Reference](https://huggingface.co/docs/transformers/en/main_classes/pipelines)
- [Text Generation Parameters](https://huggingface.co/docs/transformers/en/main_classes/text_generation)
- [Model Quantization Guide](https://huggingface.co/docs/transformers/en/perf_infer_gpu_one)
|
{
"source": "huggingface/smol-course",
"title": "7_inference/inference_pipeline.md",
"url": "https://github.com/huggingface/smol-course/blob/main/7_inference/inference_pipeline.md",
"date": "2024-11-25T19:22:43",
"stars": 5481,
"description": "A course on aligning smol models.",
"file_size": 5401
}
|
# Text Generation Inference (TGI)
Text Generation Inference (TGI) is a toolkit developed by Hugging Face for deploying and serving Large Language Models (LLMs). It's designed to enable high-performance text generation for popular open-source LLMs. TGI is used in production by Hugging Chat - An open-source interface for open-access models.
## Why Use Text Generation Inference?
Text Generation Inference addresses the key challenges of deploying large language models in production. While many frameworks excel at model development, TGI specifically optimizes for production deployment and scaling. Some key features include:
- **Tensor Parallelism**: TGI's can split models across multiple GPUs through tensor parallelism, essential for serving larger models efficiently.
- **Continuous Batching**: The continuous batching system maximizes GPU utilization by dynamically processing requests, while optimizations like Flash Attention and Paged Attention significantly reduce memory usage and increase speed.
- **Token Streaming**: Real-time applications benefit from token streaming via Server-Sent Events, delivering responses with minimal latency.
## How to Use Text Generation Inference
### Basic Python Usage
TGI uses a simple yet powerful REST API integration which makes it easy to integrate with your applications.
### Using the REST API
TGI exposes a RESTful API that accepts JSON payloads. This makes it accessible from any programming language or tool that can make HTTP requests. Here's a basic example using curl:
```bash
# Basic generation request
curl localhost:8080/v1/chat/completions \
-X POST \
-d '{
"model": "tgi",
"messages": [
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "What is deep learning?"
}
],
"stream": true,
"max_tokens": 20
}' \
-H 'Content-Type: application/json'
```
### Using the `huggingface_hub` Python Client
The `huggingface_hub` python client client handles connection management, request formatting, and response parsing. Here's how to get started.
```python
from huggingface_hub import InferenceClient
client = InferenceClient(
base_url="http://localhost:8080/v1/",
)
output = client.chat.completions.create(
model="tgi",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Count to 10"},
],
stream=True,
max_tokens=1024,
)
for chunk in output:
print(chunk.choices[0].delta.content)
```
### Using OpenAI API
Many libraries support the OpenAI API, so you can use the same client to interact with TGI.
```python
from openai import OpenAI
# init the client but point it to TGI
client = OpenAI(
base_url="http://localhost:8080/v1/",
api_key="-"
)
chat_completion = client.chat.completions.create(
model="tgi",
messages=[
{"role": "system", "content": "You are a helpful assistant." },
{"role": "user", "content": "What is deep learning?"}
],
stream=True
)
# iterate and print stream
for message in chat_completion:
print(message)
```
## Preparing Models for TGI
To serve a model with TGI, ensure it meets these requirements:
1. **Supported Architecture**: Verify your model architecture is supported (Llama, BLOOM, T5, etc.)
2. **Model Format**: Convert weights to safetensors format for faster loading:
```python
from safetensors.torch import save_file
from transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained("your-model")
state_dict = model.state_dict()
save_file(state_dict, "model.safetensors")
```
3. **Quantization** (optional): Quantize your model to reduce memory usage:
```python
from transformers import BitsAndBytesConfig
quantization_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_compute_dtype="float16"
)
model = AutoModelForCausalLM.from_pretrained(
"your-model",
quantization_config=quantization_config
)
```
## References
- [Text Generation Inference Documentation](https://huggingface.co/docs/text-generation-inference)
- [TGI GitHub Repository](https://github.com/huggingface/text-generation-inference)
- [Hugging Face Model Hub](https://huggingface.co/models)
- [TGI API Reference](https://huggingface.co/docs/text-generation-inference/api_reference)
|
{
"source": "huggingface/smol-course",
"title": "7_inference/text_generation_inference.md",
"url": "https://github.com/huggingface/smol-course/blob/main/7_inference/text_generation_inference.md",
"date": "2024-11-25T19:22:43",
"stars": 5481,
"description": "A course on aligning smol models.",
"file_size": 4357
}
|
# Agents
AI Agents are autonomous systems that can understand user requests, break them down into steps, and execute actions to accomplish tasks. They combine language models with tools and external functions to interact with their environment. This module covers how to build effective agents using the [`smolagents`](https://github.com/huggingface/smolagents) library, which provides a lightweight framework for creating capable AI agents.
## Module Overview
Building effective agents requires understanding three key components. First, retrieval capabilities allow agents to access and use relevant information from various sources. Second, function calling enables agents to take concrete actions in their environment. Finally, domain-specific knowledge and tooling equip agents for specialized tasks like code manipulation.
## Contents
### 1️⃣ [Retrieval Agents](./retrieval_agents.md)
Retrieval agents combine models with knowledge bases. These agents can search and synthesize information from multiple sources, leveraging vector stores for efficient retrieval and implementing RAG (Retrieval Augmented Generation) patterns. They are great at combining web search with custom knowledge bases while maintaining conversation context through memory systems. The module covers implementation strategies including fallback mechanisms for robust information retrieval.
### 2️⃣ [Code Agents](./code_agents.md)
Code agents are specialized autonomous systems designed for software development tasks. These agents excel at analyzing and generating code, performing automated refactoring, and integrating with development tools. The module covers best practices for building code-focused agents that can understand programming languages, work with build systems, and interact with version control while maintaining high code quality standards.
### 3️⃣ [Custom Functions](./custom_functions.md)
Custom function agents extend basic AI capabilities through specialized function calls. This module explores how to design modular and extensible function interfaces that integrate directly with your application's logic. You'll learn to implement proper validation and error handling while creating reliable function-driven workflows. The focus is on building simple systems where agents can predictably interact with external tools and services.
### Exercise Notebooks
| Title | Description | Exercise | Link | Colab |
|-------|-------------|----------|------|-------|
| Building a Research Agent | Create an agent that can perform research tasks using retrieval and custom functions | 🐢 Build a simple RAG agent <br> 🐕 Add custom search functions <br> 🦁 Create a full research assistant | [Notebook](./notebooks/agents.ipynb) | <a target="_blank" href="https://colab.research.google.com/github/huggingface/smol-course/blob/main/8_agents/notebooks/agents.ipynb"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a> |
## Resources
- [smolagents Documentation](https://huggingface.co/docs/smolagents) - Official docs for the smolagents library
- [Building Effective Agents](https://www.anthropic.com/research/building-effective-agents) - Research paper on agent architectures
- [Agent Guidelines](https://huggingface.co/docs/smolagents/tutorials/building_good_agents) - Best practices for building reliable agents
- [LangChain Agents](https://python.langchain.com/docs/how_to/#agents) - Additional examples of agent implementations
- [Function Calling Guide](https://platform.openai.com/docs/guides/function-calling) - Understanding function calling in LLMs
- [RAG Best Practices](https://www.pinecone.io/learn/retrieval-augmented-generation/) - Guide to implementing effective RAG
|
{
"source": "huggingface/smol-course",
"title": "8_agents/README.md",
"url": "https://github.com/huggingface/smol-course/blob/main/8_agents/README.md",
"date": "2024-11-25T19:22:43",
"stars": 5481,
"description": "A course on aligning smol models.",
"file_size": 3725
}
|
# Code Agents
Code agents are specialized autonomous systems that handle coding tasks like analysis, generation, refactoring, and testing. These agents leverage domain knowledge about programming languages, build systems, and version control to enhance software development workflows.
## Why Code Agents?
Code agents accelerate development by automating repetitive tasks while maintaining code quality. They excel at generating boilerplate code, performing systematic refactoring, and identifying potential issues through static analysis. The agents combine retrieval capabilities to access external documentation and repositories with function calling to execute concrete actions like creating files or running tests.
## Building Blocks of a Code Agent
Code agents are built on specialized language models fine-tuned for code understanding. These models are augmented with development tools like linters, formatters, and compilers to interact with real-world environments. Through retrieval techniques, agents maintain contextual awareness by accessing documentation and code histories to align with organizational patterns and standards. Action-oriented functions enable agents to perform concrete tasks such as committing changes or initiating merge requests.
In the following example, we create a code agent that can search the web using DuckDuckGo much like the retrieval agent we built earlier.
```python
from smolagents import CodeAgent, DuckDuckGoSearchTool, HfApiModel
agent = CodeAgent(tools=[DuckDuckGoSearchTool()], model=HfApiModel())
agent.run("How many seconds would it take for a leopard at full speed to run through Pont des Arts?")
```
In the following example, we create a code agent that can get the travel time between two locations. Here, we use the `@tool` decorator to define a custom function that can be used as a tool.
```python
from smolagents import CodeAgent, HfApiModel, tool
@tool
def get_travel_duration(start_location: str, destination_location: str, departure_time: Optional[int] = None) -> str:
"""Gets the travel time in car between two places.
Args:
start_location: the place from which you start your ride
destination_location: the place of arrival
departure_time: the departure time, provide only a `datetime.datetime` if you want to specify this
"""
import googlemaps # All imports are placed within the function, to allow for sharing to Hub.
import os
gmaps = googlemaps.Client(os.getenv("GMAPS_API_KEY"))
if departure_time is None:
from datetime import datetime
departure_time = datetime(2025, 1, 6, 11, 0)
directions_result = gmaps.directions(
start_location,
destination_location,
mode="transit",
departure_time=departure_time
)
return directions_result[0]["legs"][0]["duration"]["text"]
agent = CodeAgent(tools=[get_travel_duration], model=HfApiModel(), additional_authorized_imports=["datetime"])
agent.run("Can you give me a nice one-day trip around Paris with a few locations and the times? Could be in the city or outside, but should fit in one day. I'm travelling only via public transportation.")
```
These examples are just the beginning of what you can do with code agents. You can learn more about how to build code agents in the [smolagents documentation](https://huggingface.co/docs/smolagents).
smolagents provides a lightweight framework for building code agents, with a core implementation of approximately 1,000 lines of code. The framework specializes in agents that write and execute Python code snippets, offering sandboxed execution for security. It supports both open-source and proprietary language models, making it adaptable to various development environments.
## Further Reading
- [smolagents Blog](https://huggingface.co/blog/smolagents) - Introduction to smolagents and code interactions
- [smolagents: Building Good Agents](https://huggingface.co/docs/smolagents/tutorials/building_good_agents) - Best practices for reliable agents
- [Building Effective Agents - Anthropic](https://www.anthropic.com/research/building-effective-agents) - Agent design principles
|
{
"source": "huggingface/smol-course",
"title": "8_agents/code_agents.md",
"url": "https://github.com/huggingface/smol-course/blob/main/8_agents/code_agents.md",
"date": "2024-11-25T19:22:43",
"stars": 5481,
"description": "A course on aligning smol models.",
"file_size": 4174
}
|
# Custom Function Agents
Custom Function Agents are AI agents that leverage specialized function calls (or “tools”) to perform tasks. Unlike general-purpose agents, Custom Function Agents focus on powering advanced workflows by integrating directly with your application's logic. For example, you can expose database queries, system commands, or any custom utility as isolated functions for the agent to invoke.
## Why Custom Function Agents?
- **Modular and Extensible**: Instead of building one monolithic agent, you can design individual functions that represent discrete capabilities, making your architecture more extensible.
- **Fine-Grained Control**: Developers can carefully control the agent’s actions by specifying exactly which functions are available and what parameters they accept.
- **Improved Reliability**: By structuring each function with clear schemas and validations, you reduce errors and unexpected behaviors.
## Basic Workflow
1. **Identify Functions**
Determine which tasks can be transformed into custom functions (e.g., file I/O, database queries, streaming data processing).
2. **Define the Interface**
Use a function signature or schema that precisely outlines each function’s inputs, outputs, and expected behavior. This enforces strong contracts between your agent and its environment.
3. **Register with the Agent**
Your agent needs to “learn” which functions are available. Typically, you pass metadata describing each function’s interface to the language model or agent framework.
4. **Invoke and Validate**
Once the agent selects a function to call, run the function with the provided arguments and validate the results. If valid, feed the results back to the agent for context to drive subsequent decisions.
## Example
Below is a simplified example demonstrating how custom function calls might look in pseudocode. The objective is to perform a user-defined search and retrieve relevant content:
```python
# Define a custom function with clear input/output types
def search_database(query: str) -> list:
"""
Search the database for articles matching the query.
Args:
query (str): The search query string
Returns:
list: List of matching article results
"""
try:
results = database.search(query)
return results
except DatabaseError as e:
logging.error(f"Database search failed: {e}")
return []
# Register the function with the agent
agent.register_function(
name="search_database",
function=search_database,
description="Searches database for articles matching a query"
)
# Example usage
def process_search():
query = "Find recent articles on AI"
results = agent.invoke("search_database", query)
if results:
agent.process_results(results)
else:
logging.info("No results found for query")
```
## Further Reading
- [smolagents Blog](https://huggingface.co/blog/smolagents) - Learn about the latest advancements in AI agents and how they can be applied to custom function agents.
- [Building Good Agents](https://huggingface.co/docs/smolagents/tutorials/building_good_agents) - A comprehensive guide on best practices for developing reliable and effective custom function agents.
|
{
"source": "huggingface/smol-course",
"title": "8_agents/custom_functions.md",
"url": "https://github.com/huggingface/smol-course/blob/main/8_agents/custom_functions.md",
"date": "2024-11-25T19:22:43",
"stars": 5481,
"description": "A course on aligning smol models.",
"file_size": 3285
}
|
# Building Agentic RAG Systems
Agentic RAG (Retrieval Augmented Generation) combines the power of autonomous agents with knowledge retrieval capabilities. While traditional RAG systems simply use an LLM to answer queries based on retrieved information, agentic RAG takes this further by allowing the system to intelligently control its own retrieval and response process.
Traditional RAG has key limitations - it only performs a single retrieval step and relies on direct semantic similarity with the user query, which can miss relevant information. Agentic RAG addresses these challenges by empowering the agent to formulate its own search queries, critique results, and perform multiple retrieval steps as needed.
## Basic Retrieval with DuckDuckGo
Let's start by building a simple agent that can search the web using DuckDuckGo. This agent will be able to answer questions by retrieving relevant information and synthesizing responses.
```python
from smolagents import CodeAgent, DuckDuckGoSearchTool, HfApiModel
# Initialize the search tool
search_tool = DuckDuckGoSearchTool()
# Initialize the model
model = HfApiModel()
agent = CodeAgent(
model = model,
tools=[search_tool]
)
# Example usage
response = agent.run(
"What are the latest developments in fusion energy?"
)
print(response)
```
The agent will:
1. Analyze the query to determine what information is needed
2. Use DuckDuckGo to search for relevant content
3. Synthesize the retrieved information into a coherent response
4. Store the interaction in its memory for future reference
## Custom Knowledge Base Tool
For domain-specific applications, we often want to combine web search with our own knowledge base. Let's create a custom tool that can query a vector database of technical documentation.
```python
from smolagents import Tool
class RetrieverTool(Tool):
name = "retriever"
description = "Uses semantic search to retrieve the parts of transformers documentation that could be most relevant to answer your query."
inputs = {
"query": {
"type": "string",
"description": "The query to perform. This should be semantically close to your target documents. Use the affirmative form rather than a question.",
}
}
output_type = "string"
def __init__(self, docs, **kwargs):
super().__init__(**kwargs)
self.retriever = BM25Retriever.from_documents(
docs, k=10
)
def forward(self, query: str) -> str:
assert isinstance(query, str), "Your search query must be a string"
docs = self.retriever.invoke(
query,
)
return "\nRetrieved documents:\n" + "".join(
[
f"\n\n===== Document {str(i)} =====\n" + doc.page_content
for i, doc in enumerate(docs)
]
)
retriever_tool = RetrieverTool(docs_processed)
```
This enhanced agent can:
1. First check the documentation for relevant information
2. Fall back to web search if needed
3. Combine information from both sources
4. Maintain conversation context through memory
## Enhanced Retrieval Capabilities
When building agentic RAG systems, the agent can employ sophisticated strategies like:
1. Query Reformulation - Instead of using the raw user query, the agent can craft optimized search terms that better match the target documents
2. Multi-Step Retrieval - The agent can perform multiple searches, using initial results to inform subsequent queries
3. Source Integration - Information can be combined from multiple sources like web search and local documentation
4. Result Validation - Retrieved content can be analyzed for relevance and accuracy before being included in responses
Effective agentic RAG systems require careful consideration of several key aspects. The agent should select between available tools based on the query type and context. Memory systems help maintain conversation history and avoid repetitive retrievals. Having fallback strategies ensures the system can still provide value even when primary retrieval methods fail. Additionally, implementing validation steps helps ensure the accuracy and relevance of retrieved information.
```python
import datasets
from langchain.docstore.document import Document
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.retrievers import BM25Retriever
knowledge_base = datasets.load_dataset("m-ric/huggingface_doc", split="train")
knowledge_base = knowledge_base.filter(lambda row: row["source"].startswith("huggingface/transformers"))
source_docs = [
Document(page_content=doc["text"], metadata={"source": doc["source"].split("/")[1]})
for doc in knowledge_base
]
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=500,
chunk_overlap=50,
add_start_index=True,
strip_whitespace=True,
separators=["\n\n", "\n", ".", " ", ""],
)
docs_processed = text_splitter.split_documents(source_docs)
```
## Next Steps
⏩ Check out the [Code Agents](./code_agents.md) module to learn how to build agents that can manipulate code.
|
{
"source": "huggingface/smol-course",
"title": "8_agents/retrieval_agents.md",
"url": "https://github.com/huggingface/smol-course/blob/main/8_agents/retrieval_agents.md",
"date": "2024-11-25T19:22:43",
"stars": 5481,
"description": "A course on aligning smol models.",
"file_size": 5110
}
|

# Un Pequeño (Smol) Curso
Este curso práctico está enfocado en alinear modelos de lenguaje para casos de uso específicos. Es una forma accesible de empezar a trabajar con modelos de lenguaje, ya que puede ejecutarse en la mayoría de las máquinas locales con requisitos mínimos de GPU y sin necesidad de servicios pagos. El curso se basa en la serie de modelos [SmolLM2](https://github.com/huggingface/smollm/tree/main), pero las habilidades que adquieras aquí son transferibles a modelos más grandes o otros modelos pequeños de lenguaje.
<a href="http://hf.co/join/discord">
<img src="https://img.shields.io/badge/Discord-7289DA?&logo=discord&logoColor=white"/>
</a>
<div style="background: linear-gradient(to right, #e0f7fa, #e1bee7, orange); padding: 20px; border-radius: 5px; margin-bottom: 20px; color: purple;">
<h2>¡La participación es abierta, gratuita y ahora!</h2>
<p>Este curso es abierto y revisado por la comunidad. Para participar, simplemente <strong>abre un pull request</strong> y envía tu trabajo para su revisión. Sigue estos pasos:</p>
<ol>
<li>Haz un fork del repositorio <a href="https://github.com/huggingface/smol-course/fork">aquí</a></li>
<li>Lee el material, haz cambios, completa los ejercicios y agrega tus ejemplos.</li>
<li>Abre un PR en la rama december_2024</li>
<li>Haz que se revise y se fusione</li>
</ol>
<p>Este proceso te ayudará a aprender y a construir un curso dirigido por la comunidad que mejora constantemente.</p>
</div>
Podemos discutir el proceso en este [hilo de discusión](https://github.com/huggingface/smol-course/discussions/2#discussion-7602932).
## Estructura del Curso
Este curso ofrece un enfoque práctico para trabajar con modelos pequeños de lenguaje, desde el entrenamiento inicial hasta el despliegue en producción.
| Módulo | Descripción | Estado | Fecha de lanzamiento |
|--------|-------------|--------|----------------------|
| [Ajuste de Instrucciones](./1_instruction_tuning) | Aprende ajuste fino (fine-tuning) supervisado, plantillas de chat y seguimiento básico de instrucciones | ✅ Completo | 3 de diciembre de 2024 |
| [Alineación de Preferencias](./2_preference_alignment) | Explora las técnicas DPO y ORPO para alinear modelos con las preferencias humanas | ✅ Completo | 6 de diciembre de 2024 |
| [Ajuste Fino (Fine-tuning) Eficiente en Parámetros](./3_parameter_efficient_finetuning) | Aprende LoRA, ajuste de prompt y métodos de adaptación eficientes | [🚧 En Progreso](https://github.com/huggingface/smol-course/pull/41) | 9 de diciembre de 2024 |
| [Evaluación](./4_evaluation) | Usa benchmarks automáticos y crea evaluaciones personalizadas para dominios | [🚧 En Progreso](https://github.com/huggingface/smol-course/issues/42) | 13 de diciembre de 2024 |
| [Modelos Visión-Lenguaje](./5_vision_language_models) | Adapta modelos multimodales para tareas visión-lenguaje | [🚧 En Progreso](https://github.com/huggingface/smol-course/issues/49) | 16 de diciembre de 2024 |
| [Conjuntos de Datos Sintéticos](./6_synthetic_datasets) | Crea y valida conjuntos de datos sintéticos para el entrenamiento | 📝 Planificado | 20 de diciembre de 2024 |
| [Inferencia](./7_inference) | Inferencia eficiente con modelos | 📝 Planificado | 23 de diciembre de 2024 |
## ¿Por qué Modelos Pequeños de Lenguaje?
Si bien los modelos grandes de lenguaje han mostrado capacidades impresionantes, requieren recursos computacionales significativos y pueden ser excesivos para aplicaciones específicas. Los modelos pequeños de lenguaje ofrecen varias ventajas para aplicaciones de dominio:
- **Eficiencia**: Requieren menos recursos computacionales para entrenar y desplegar
- **Personalización**: Más fáciles de ajustar para dominios específicos
- **Control**: Mayor control sobre el comportamiento del modelo
- **Costo**: Menores costos operativos para el entrenamiento y la inferencia
- **Privacidad**: Pueden ejecutarse localmente, manteniendo la privacidad de los datos
- **Sostenibilidad**: Uso eficiente de recursos con una huella de carbono más pequeña
- **Investigación Académica**: Facilita la investigación académica con menos restricciones logísticas
## Requisitos Previos
Antes de comenzar, asegúrate de tener:
- Conocimientos básicos en aprendizaje automático y procesamiento de lenguaje natural
- Familiaridad con Python, PyTorch y la librería `transformers`
- Acceso a un modelo de lenguaje preentrenado y un conjunto de datos etiquetado
## Instalación
Mantenemos el curso como un paquete para facilitar la instalación de dependencias. Recomendamos usar [uv](https://github.com/astral-sh/uv), pero también puedes utilizar alternativas como `pip` o `pdm`.
### Usando `uv`
Con `uv` instalado, puedes configurar el entorno del curso de esta manera:
```bash
uv venv --python 3.11.0
uv sync
```
### Usando `pip`
Para un entorno **python 3.11**, utiliza los siguientes comandos para instalar las dependencias:
```bash
# python -m venv .venv
# source .venv/bin/activate
pip install -r requirements.txt
```
### Google Colab
Para **Google Colab**, instala las dependencias de la siguiente manera:
```bash
pip install -r transformers trl datasets huggingface_hub
```
## Participación
Compartamos este curso para que muchas personas puedan aprender a ajustar LLMs sin necesidad de hardware costoso.
[](https://star-history.com/#huggingface/smol-course&Date)
|
{
"source": "huggingface/smol-course",
"title": "es/README.md",
"url": "https://github.com/huggingface/smol-course/blob/main/es/README.md",
"date": "2024-11-25T19:22:43",
"stars": 5481,
"description": "A course on aligning smol models.",
"file_size": 5521
}
|

# スモールコース
これは、特定のユースケースに合わせて言語モデルを調整するための実践的なコースです。ほとんどのローカルマシンで実行できるため、言語モデルの調整を始めるのに便利です。GPUの要件は最小限で、有料サービスは必要ありません。このコースは[SmolLM2](https://github.com/huggingface/smollm/tree/main)シリーズのモデルに基づいていますが、ここで学んだスキルを大規模なモデルや他の小型言語モデルに転用することができます。
<a href="http://hf.co/join/discord">
<img src="https://img.shields.io/badge/Discord-7289DA?&logo=discord&logoColor=white"/>
</a>
<div style="background: linear-gradient(to right, #e0f7fa, #e1bee7, orange); padding: 20px; border-radius: 5px; margin-bottom: 20px; color: purple;">
<h2>参加は無料で、今すぐ始められます!</h2>
<p>このコースはオープンでピアレビューされています。コースに参加するには、<strong>プルリクエストを開く</strong>ことで、あなたの作業をレビューに提出してください。以下の手順に従ってください:</p>
<ol>
<li>リポジトリをフォークします <a href="https://github.com/huggingface/smol-course/fork">こちら</a></li>
<li>資料を読み、変更を加え、演習を行い、自分の例を追加します。</li>
<li>december_2024ブランチでプルリクエストを開きます</li>
<li>レビューを受けてマージされます</li>
</ol>
<p>これにより、学習を助け、常に改善されるコミュニティ主導のコースを構築することができます。</p>
</div>
このプロセスについては、この[ディスカッションスレッド](https://github.com/huggingface/smol-course/discussions/2#discussion-7602932)で議論できます。
## コース概要
このコースは、小型言語モデルを使用した実践的なアプローチを提供し、初期のトレーニングから本番展開までをカバーします。
| モジュール | 説明 | ステータス | リリース日 |
|--------|-------------|---------|--------------|
| [インストラクションチューニング](./1_instruction_tuning) | 教師あり微調整、チャットテンプレート、および基本的な指示に従う方法を学びます | ✅ 準備完了 | 2024年12月3日 |
| [選好整合](./2_preference_alignment) | DPOおよびORPO技術を探求し、人間の選好にモデルを整合させる方法を学びます | ✅ 準備完了 | 2024年12月6日 |
| [パラメータ効率の良い微調整](./3_parameter_efficient_finetuning) | LoRA、プロンプトチューニング、および効率的な適応方法を学びます | ✅ 準備完了 | 2024年12月9日 |
| [評価](./4_evaluation) | 自動ベンチマークを使用し、カスタムドメイン評価を作成する方法を学びます | ✅ 準備完了 | 2024年12月13日 |
| [ビジョン言語モデル](./5_vision_language_models) | マルチモーダルモデルをビジョン言語タスクに適応させる方法を学びます | ✅ 準備完了 | 2024年12月16日 |
| [合成データセット](./6_synthetic_datasets) | トレーニング用の合成データセットを作成し、検証する方法を学びます | ✅ 準備完了 | 2024年12月20日 |
| [推論](./7_inference) | モデルを効率的に推論する方法を学びます | [🚧 作業中](https://github.com/huggingface/smol-course/pull/150) | 2025年1月8日 |
| [エージェント](./8_agents) | 自分のエージェントAIを構築する方法を学びます | ✅ 準備完了 | 2025年1月13日 ||
| キャップストーンプロジェクト | 学んだことを使ってリーダーボードを登りましょう! | [🚧 作業中](https://github.com/huggingface/smol-course/pull/97) | 2025年1月10日 |
## なぜ小型言語モデルなのか?
大規模な言語モデルは印象的な能力を示していますが、しばしば多くの計算リソースを必要とし、特定のアプリケーションには過剰な場合があります。小型言語モデルは、ドメイン固有のアプリケーションに対していくつかの利点を提供します:
- **効率性**:トレーニングと展開に必要な計算リソースが大幅に少ない
- **カスタマイズ**:特定のドメインに簡単に微調整および適応可能
- **制御**:モデルの動作をよりよく理解し、制御できる
- **コスト**:トレーニングと推論の運用コストが低い
- **プライバシー**:データを外部APIに送信せずにローカルで実行可能
- **グリーンテクノロジー**:リソースの効率的な使用を推進し、炭素排出量を削減
- **学術研究の容易さ**:最先端のLLMを使用した学術研究のための簡単なスターターを提供し、物流の制約を減らす
## 前提条件
開始する前に、以下を確認してください:
- 機械学習と自然言語処理の基本的な理解
- Python、PyTorch、および`transformers`ライブラリに精通していること
- 事前学習された言語モデルとラベル付きデータセットへのアクセス
## インストール
コースをパッケージとして維持しているため、パッケージマネージャーを使用して依存関係を簡単にインストールできます。`uv`をお勧めしますが、`pip`や`pdm`などの代替手段も使用できます。
### `uv`を使用する場合
`uv`がインストールされている場合、次のようにしてコースをインストールできます:
```bash
uv venv --python 3.11.0
uv sync
```
### `pip`を使用する場合
すべての例は**python 3.11**環境で実行されるため、次のように環境を作成し、依存関係をインストールします:
```bash
# python -m venv .venv
# source .venv/bin/activate
pip install -r requirements.txt
```
### Google Colab
**Google Colabから**は、使用するハードウェアに基づいて柔軟に依存関係をインストールする必要があります。次のようにします:
```bash
pip install transformers trl datasets huggingface_hub
```
|
{
"source": "huggingface/smol-course",
"title": "ja/README.md",
"url": "https://github.com/huggingface/smol-course/blob/main/ja/README.md",
"date": "2024-11-25T19:22:43",
"stars": 5481,
"description": "A course on aligning smol models.",
"file_size": 3279
}
|

# 소형 언어 모델 과정
이 과정에서는 특정 사용 사례에 맞게 언어 모델을 정렬하는 법을 다룹니다. 모든 자료는 대부분의 로컬 컴퓨터에서 실행되므로 간편하게 언어 모델 정렬을 시작해볼 수 있습니다. 이 과정을 위해 필요한 최소한의 GPU 요구 사항이나 유료 서비스가 없습니다. [SmolLM2](https://github.com/huggingface/smollm/tree/main) 시리즈 모델을 기반으로 하는 과정이지만, 여기서 배운 기술을 더 큰 모델이나 다른 작은 언어 모델로 옮길 수 있습니다.
<a href="http://hf.co/join/discord">
<img src="https://img.shields.io/badge/Discord-7289DA?&logo=discord&logoColor=white"/>
</a>
<div style="background: linear-gradient(to right, #e0f7fa, #e1bee7, orange); padding: 20px; border-radius: 5px; margin-bottom: 20px; color: purple;">
<h2>지금 바로 참여하세요!</h2>
<p>이 과정은 열려 있으며 다른 사용자와의 상호 검토를 진행할 수 있습니다. 이 과정에 참여하려면 <strong>pull request(PR)</strong>를 열고 검토 받을 수 있도록 결과물을 제출하세요. 다음 단계를 따르면 됩니다:</p>
<ol>
<li><a href="https://github.com/huggingface/smol-course/fork">여기</a>에서 레포지토리를 fork하세요.</li>
<li>자료를 읽고, 바꿔 보고, 실습해보고, 나만의 예제를 추가해보세요.</li>
<li>december-2024 브랜치에 PR을 보내세요.</li>
<li>검토가 끝나면 december-2024 브랜치에 병합됩니다.</li>
</ol>
<p>이 과정은 학습에 도움이 될 뿐만 아니라 지속적으로 발전하는 커뮤니티 기반 코스를 형성하는 데에도 기여할 것입니다.</p>
</div>
[discussion thread](https://github.com/huggingface/smol-course/discussions/2#discussion-7602932)에서 과정에 대해 토론할 수도 있습니다.
## 과정 개요
이 과정은 소형 언어 모델의 초기 학습부터 결과물 배포까지 실습할 수 있는 실용적인 내용을 제공합니다.
| 모듈 | 설명 | 상태 | 공개일 |
|--------|-------------|---------|--------------|
| [Instruction Tuning](./1_instruction_tuning) | 지도 학습 기반 미세 조정, 대화 템플릿 작성, 기본적인 지시를 따르게 하는 방법 학습 | ✅ 학습 가능 | 2024. 12. 3 |
| [Preference Alignment](./2_preference_alignment) | 모델을 인간 선호도에 맞게 정렬하기 위한 DPO와 ORPO 기법 학습 | ✅ 학습 가능 | 2024. 12. 6 |
| [Parameter-efficient Fine-tuning](./3_parameter_efficient_finetuning) | LoRA, 프롬프트 튜닝을 포함한 효율적인 적응 방법 학습 | ✅ 학습 가능 | 2024. 12. 9 |
| [Evaluation](./4_evaluation) | 자동 벤치마크 사용법 및 사용자 정의 도메인 평가 수행 방법 학습 | ✅ 학습 가능 | 2024. 12. 13 |
| [Vision-language Models](./5_vision_language_models) | 비전-언어 태스크를 위한 멀티모달 모델 적용 방법 학습 | [🚧 준비중](https://github.com/huggingface/smol-course/issues/49) | 2024. 12. 16 |
| [Synthetic Datasets](./6_synthetic_datasets) | 모델 학습을 위한 합성 데이터셋 생성 및 검증 | [🚧 준비중](https://github.com/huggingface/smol-course/issues/83) | 2024. 12. 20 |
| [Inference](./7_inference) | 모델의 효율적인 추론 방법 학습 | 📝 작성 예정 | 2024. 12. 23 |
## 왜 소형 언어 모델을 사용하나요?
대형 언어 모델은 뛰어난 능력을 보여주지만, 상당한 연산 자원을 필요로 하며 특정 기능에 초점을 맞춘 애플리케이션에 대해서는 대형 언어 모델이 과한 경우도 있습니다. 소형 언어 모델은 도메인 특화 애플리케이션에 있어서 몇 가지 이점을 제공합니다:
- **효율성**: 대형 언어 모델보다 훨씬 적은 연산 자원으로 학습 및 배포 가능
- **맞춤화**: 특정 도메인에 대한 미세 조정 및 적응 용이
- **제어**: 모델 동작 과정을 잘 이해할 수 있고 모델의 동작을 쉽게 제어 가능
- **비용**: 학습과 추론 과정에서 필요한 비용 감소
- **프라이버시**: 데이터를 외부 API로 보내지 않고 로컬에서 실행 가능
- **친환경**: 탄소 발자국을 줄이는 효율적인 자원 사용
- **쉬운 학술 연구 및 개발**: 최신 LLM을 활용해 물리적 제약 없이 학술 연구를 쉽게 시작할 수 있도록 지원
## 사전 준비 사항
시작하기 전에 아래 사항이 준비되어 있는지 확인하세요:
- 머신러닝과 자연어처리에 대한 기본적인 이해가 필요합니다.
- Python, PyTorch 및 `transformers` 라이브러리에 익숙해야 합니다.
- 사전 학습된 언어 모델과 레이블이 있는 액세스할 수 있어야 합니다.
## 설치
이 과정은 패키지 형태로 관리되기 때문에 패키지 매니저를 이용해 의존성 설치를 쉽게 진행할 수 있습니다. 이를 위해 [uv](https://github.com/astral-sh/uv) 사용을 권장하지만 `pip`나 `pdm`을 사용할 수도 있습니다.
### `uv` 사용
`uv`를 설치한 후, 아래 명령어로 소형 언어 모델 과정을 설치할 수 있습니다:
```bash
uv venv --python 3.11.0
uv sync
```
### `pip` 사용
모든 예제는 동일한 **python 3.11** 환경에서 실행되기 때문에 아래처럼 환경을 생성하고 의존성을 설치해야 합니다:
```bash
# python -m venv .venv
# source .venv/bin/activate
pip install -r requirements.txt
```
### Google Colab
**Google Colab**에서는 사용하는 하드웨어에 따라 유연하게 의존성을 설치해야 합니다. 아래와 같이 진행하세요:
```bash
pip install transformers trl datasets huggingface_hub
```
## 참여
많은 사람이 고가의 장비 없이 LLM을 미세 조정하는 법을 배울 수 있도록 이 자료를 공유해 봅시다!
[](https://star-history.com/#huggingface/smol-course&Date)
|
{
"source": "huggingface/smol-course",
"title": "ko/README.md",
"url": "https://github.com/huggingface/smol-course/blob/main/ko/README.md",
"date": "2024-11-25T19:22:43",
"stars": 5481,
"description": "A course on aligning smol models.",
"file_size": 3706
}
|

# a smol course (um curso miudinho)
Este é um curso prático sobre alinhar modelos de linguagem para o seu caso de uso específico. É uma maneira útil de começar a alinhar modelos de linguagem, porque tudo funciona na maioria das máquinas locais. Existem requisitos mínimos de GPU e nenhum serviço pago. O curso é baseado na série de modelos de [SmolLM2](https://github.com/huggingface/smollm/tree/main), mas você pode transferir as habilidades que aprende aqui para modelos maiores ou outros pequenos modelos de linguagem.
<a href="http://hf.co/join/discord">
<img src="https://img.shields.io/badge/Discord-7289DA?&logo=discord&logoColor=white"/>
</a>
<div style="background: linear-gradient(to right, #e0f7fa, #e1bee7, orange); padding: 20px; border-radius: 5px; margin-bottom: 20px; color: purple;">
<h2>A participação é aberta a todos, gratuita e já está disponível!</h2>
<p>Este curso é aberto e avaliado por pares (peer reviewed). Para começar o curso, <strong>abra um pull request (PR)</strong> e envie seu trabalho para revisão. Aqui estão as etapas:</p>
<ol>
<li>Dê um fork no repositório <a href="https://github.com/huggingface/smol-course/fork">aqui</a></li>
<li>Leia o material, faça alterações, faça os exercícios, adicione seus próprios exemplos</li>
<li>Abra um PR no branch december_2024</li>
<li>Tenha seu material revisado e mesclado no branch principal</li>
</ol>
<p>Isso deve te ajudar a aprender e a construir um curso feito pela comunidade, que está sempre melhorando.</p>
</div>
Podemos discutir o processo neste [tópico de discussão](https://github.com/huggingface/smol-course/discussions/2#discussion-7602932).
## Sumário do Curso
Este curso fornece uma abordagem prática para trabalhar com pequenos modelos de linguagem, desde o treinamento inicial até a implantação de produção.
| Módulo | Descrição | Status | Data de Lançamento |
|--------|-------------|---------|--------------|
| [Instruction Tuning (Ajuste de Instrução)](./1_instruction_tuning) | Aprenda sobre o ajuste fino supervisionado, modelos de bate-papo e a fazer o modelo seguir instruções básicas | ✅ Completo | 3 Dez, 2024 |
| [Preference Alignment (Alinhamento de Preferência)](./2_preference_alignment) | Explore técnicas DPO e ORPO para alinhar modelos com preferências humanas | ✅ Completo | 6 Dez, 2024 |
| [Parameter-efficient Fine-tuning (Ajuste Fino com Eficiência de Parâmetro)](./3_parameter_efficient_finetuning) | Aprenda sobre LoRA, ajuste de prompt e métodos de adaptação eficientes | ✅ Completo | 9 Dez, 2024 |
| [Evaluation (Avaliação)](./4_evaluation) | Use benchmarks automáticos e crie avaliações de domínio personalizadas | ✅ Completo | 13 Dez, 2024 |
| [Vision-language Models (Modelos de Conjunto Visão-linguagem)](./5_vision_language_models) | Adapte modelos multimodais para tarefas visão-linguagem | ✅ Completo | 16 Dez, 2024 |
| [Synthetic Datasets (Conjuntos de Dados Sintéticos)](./6_synthetic_datasets) | Criar e validar conjuntos de dados sintéticos para treinamento | [🚧 Em Progresso](https://github.com/huggingface/smol-course/issues/83) | 20 Dez, 2024 |
| [Inference (Inferência)](./7_inference) | Infira modelos com eficiência | 📝 Planejado | 23 Dez, 2024 |
| Projeto Experimental | Use o que você aprendeu para ser o top 1 na tabela de classificação! | [🚧 Em Progresso](https://github.com/huggingface/smol-course/pull/97) | Dec 23, 2024 |
## Por Que Pequenos Modelos de Linguagem?
Embora os grandes modelos de linguagem tenham mostrado recursos e capacidades impressionantes, eles geralmente exigem recursos computacionais significativos e podem ser exagerados para aplicativos focados. Os pequenos modelos de linguagem oferecem várias vantagens para aplicativos de domínios específicos:
- **Eficiência**: Requer significativamente menos recursos computacionais para treinar e implantar
- **Personalização**: Mais fácil de ajustar e se adaptar a domínios específicos
- **Controle**: Melhor compreensão e controle do comportamento do modelo
- **Custo**: Menores custos operacionais para treinamento e inferência
- **Privacidade**: Pode ser executado localmente sem enviar dados para APIs externas
- **Tecnologia Verde**: Defende o uso eficiente de recursos com redução da pegada de carbono
- **Desenvolvimento de Pesquisa Acadêmica Mais Fácil**: Oferece um ponto de partida fácil para a pesquisa acadêmica com LLMs de ponta com menos restrições logísticas
## Pré-requisitos
Antes de começar, verifique se você tem o seguinte:
- Entendimento básico de machine learning e natural language processing.
- Familiaridade com Python, PyTorch e o módulo `transformers`.
- Acesso a um modelo de linguagem pré-treinado e um conjunto de dados rotulado.
## Instalação
Mantemos o curso como um pacote para que você possa instalar dependências facilmente por meio de um gerenciador de pacotes. Recomendamos [uv](https://github.com/astral-sh/uv) para esse fim, mas você pode usar alternativas como `pip` ou` pdm`.
### Usando `uv`
Com o `uv` instalado, você pode instalar o curso deste modo:
```bash
uv venv --python 3.11.0
uv sync
```
### Usando `pip`
Todos os exemplos são executados no mesmo ambiente **python 3.11**, então você deve criar um ambiente e instalar dependências desta maneira:
```bash
# python -m venv .venv
# source .venv/bin/activate
pip install -r requirements.txt
```
### Google Colab
**A partir do Google Colab** você precisará instalar dependências de maneira flexível com base no hardware que está usando. Pode fazer deste jeito:
```bash
pip install transformers trl datasets huggingface_hub
```
## Engajamento
Vamos compartilhar isso, desse jeito um monte de gente vai poder aprender a ajustar LLMs sem precisar de um computador super caro.
[](https://star-history.com/#huggingface/smol-course&Date)
|
{
"source": "huggingface/smol-course",
"title": "pt-br/README.md",
"url": "https://github.com/huggingface/smol-course/blob/main/pt-br/README.md",
"date": "2024-11-25T19:22:43",
"stars": 5481,
"description": "A course on aligning smol models.",
"file_size": 5959
}
|

# Khoá học Mô hình ngôn ngữ cơ bản
Đây là một khoá học thực hành về việc huấn luyện các mô hình ngôn ngữ (LM) cho các trường hợp sử dụng cụ thể. Khoá học này là cách thuận tiện để bắt đầu với việc điều chỉnh các mô hình ngôn ngữ, bởi vì mọi thứ đều có thể chạy được trên hầu hết các máy tính cá nhân. Tại đây, chúng ta không cần quá nhiều tài nguyên GPUs hay các dịch vụ trả phí để học tập. Khoá học được xây dựng dựa trên series mô hình [SmolLM2](https://github.com/huggingface/smollm/tree/main), nhưng bạn có thể áp dụng các kỹ năng học được ở đây cho các mô hình lớn hơn hoặc các mô hình ngôn ngữ nhỏ khác.
*Lưu ý: Vì khóa học được dịch từ bản gốc tiếng Anh, chúng tôi sẽ giữ lại một số thuật ngữ gốc nhằm tránh gây hiểu lầm.*
<a href="http://hf.co/join/discord">s
<img src="https://img.shields.io/badge/Discord-7289DA?&logo=discord&logoColor=white"/>
</a>
<div style="background: linear-gradient(to right, #e0f7fa, #e1bee7, orange); padding: 20px; border-radius: 5px; margin-bottom: 20px; color: purple;">
<h2>Tham gia học ngay!</h2>
<p>Khoá học này mở và được đánh giá bởi cộng đồng. Để tham gia khoá học <strong>hãy tạo Pull Request (PR)</strong> và gửi bài làm của bạn để được review. Các bước thực hiện:</p>
<ol>
<li>Fork repo <a href="https://github.com/huggingface/smol-course/fork">tại đây</a></li>
<li>Đọc tài liệu, thực hiện thay đổi, làm bài tập, thêm ví dụ của riêng bạn</li>
<li>Tạo PR trên nhánh december_2024</li>
<li>Nhận review và merge</li>
</ol>
<p>Điều này sẽ giúp bạn học tập và xây dựng một khoá học có cộng đồng tham gia và luôn được cải thiện.</p>
</div>
Chúng ta có thể thảo luận về quá trình học tập và phát triển trong [thread này](https://github.com/huggingface/smol-course/discussions/2#discussion-7602932).
## Nội dung khoá học
Khoá học này cung cấp phương pháp thực hành để làm việc với các mô hình ngôn ngữ nhỏ, từ huấn luyện ban đầu đến triển khai lên sản phẩm.
| Bài | Mô tả | Trạng thái | Ngày phát hành |
|--------|-------------|---------|--------------|
| [Tinh chỉnh theo chỉ thị (Instruction Tuning)](./1_instruction_tuning) | Học về huấn luyện có giám sát (SFT), định dạng chat, và thực hiện các chỉ thị cơ bản | ✅ Sẵn sàng | 3/12/2024 |
| [Tinh chỉnh theo sự ưu tiên (Preference Alignment)](./2_preference_alignment) | Học các kỹ thuật DPO và ORPO để huấn luyện mô hình theo sự uy tiên của người dùng | ✅ Sẵn sàng | 6/12/2024 |
| [Tinh chỉnh hiệu quả tham số (Parameter-efficient Fine-tuning)](./3_parameter_efficient_finetuning) | Học về LoRA, prompt tuning và các phương pháp huấn luyện hiệu quả | ✅ Sẵn sàng | 9/12/2024 |
| [Đánh giá mô hình (Evaluation)](./4_evaluation) | Sử dụng benchmark tự động và tạo đánh giá theo lĩnh vực cụ thể | [🚧 Đang thực hiện](https://github.com/huggingface/smol-course/issues/42) | 13/12/2024 |
| [Mô hình đa phương thức (Vision-language Models)](./5_vision_language_models) | Điều chỉnh các mô hình đa phương thức (Multimodal models) cho các tác vụ thị giác-ngôn ngữ | [🚧 Đang thực hiện](https://github.com/huggingface/smol-course/issues/49) | 16/12/2024 |
| [Dữ liệu nhân tạo (Synthetic Datasets)](./6_synthetic_datasets) | Tạo và đánh giá tập dữ liệu tổng hợp cho huấn luyện | 📝 Đã lên kế hoạch | 20/12/2024 |
| [Triển khai mô hình (Inference)](./7_inference) | Triển khai mô hình một cách hiệu quả | 📝 Đã lên kế hoạch | 23/12/2024 |
## Tại sao lại chọn Mô hình Ngôn ngữ Nhỏ?
Mặc dù các mô hình ngôn ngữ lớn đã cho thấy khả năng ấn tượng, chúng thường yêu cầu tài nguyên tính toán đáng kể và có thể quá mức cần thiết cho các ứng dụng tập trung. Các mô hình ngôn ngữ nhỏ mang lại nhiều lợi thế cho các ứng dụng theo lĩnh vực cụ thể:
- **Hiệu quả:** Yêu cầu ít tài nguyên tính toán hơn đáng kể để huấn luyện và triển khai
- **Tùy chỉnh:** Dễ dàng tinh chỉnh phù hợp cho các lĩnh vực cụ thể
- **Kiểm soát:** Dễ dàng hiểu và kiểm soát hành vi mô hình hơn
- **Chi phí:** Chi phí huấn luyện và triển khai thấp hơn đáng kể
- **Bảo mật:** Có thể triển khai trên mạng cục bộ mà không cần gửi dữ liệu tới API bên ngoài
- **Công nghệ xanh:** Sử dụng tài nguyên hiệu quả (carbon footprint giảm)
- **Nghiên cứu học thuật dễ dàng hơn:** Khởi đầu dễ dàng cho nghiên cứu học thuật trên mô hình ngôn ngữ với ít ràng buộc về tài nghiên tính toán
## Yêu cầu tiên quyết
Trước khi bắt đầu, hãy đảm bảo bạn có:
- Hiểu biết cơ bản về machine learning (ML) và xử lý ngôn ngữ tự nhiên (NLP)
- Quen thuộc với Python, PyTorch và thư viện `transformers`
- Hiểu về mô hình ngôn ngữ và tập dữ liệu có nhãn
## Cài đặt
Chúng tôi duy trì khoá học như một package để bạn có thể cài đặt dễ dàng thông qua package manager. Chúng tôi gợi ý sử dụng [uv](https://github.com/astral-sh/uv), nhưng bạn có thể sử dụng các lựa chọn thay thế như `pip` hoặc `pdm`.
### Sử dụng `uv`
Với `uv` đã được cài đặt, bạn có thể cài đặt khoá học như sau:
```bash
uv venv --python 3.11.0
uv sync
```
### Sử dụng `pip`
Tất cả các ví dụ chạy trong cùng một môi trường **python 3.11**, vì vậy bạn nên tạo môi trường và cài đặt dependencies như sau:
```bash
# python -m venv .venv
# source .venv/bin/activate
pip install -r requirements.txt
```
### Google Colab
Nếu dùng **Google Colab** bạn sẽ cần cài đặt dependencies một cách linh hoạt dựa trên phần cứng bạn đang sử dụng. Như sau:
```bash
pip install -r transformers trl datasets huggingface_hub
```
## Tham gia và chia sẻ
Hãy chia sẻ khoá học này, để cùng nhau phát triển cộng đồng AI Việt Nam.
[](https://star-history.com/#huggingface/smol-course&Date)
|
{
"source": "huggingface/smol-course",
"title": "vi/README.md",
"url": "https://github.com/huggingface/smol-course/blob/main/vi/README.md",
"date": "2024-11-25T19:22:43",
"stars": 5481,
"description": "A course on aligning smol models.",
"file_size": 5646
}
|
# Domain Specific Evaluation with Argilla, Distilabel, and LightEval
Most popular benchmarks look at very general capabilities (reasoning, math, code), but have you ever needed to study more specific capabilities?
What should you do if you need to evaluate a model on a **custom domain** relevant to your use-cases? (For example, financial, legal, medical use cases)
This tutorial shows you the full pipeline you can follow, from creating relevant data and annotating your samples to evaluating your model on them, with the easy to use [Argilla](https://github.com/argilla-io/argilla), [distilabel](https://github.com/argilla-io/distilabel), and [lighteval](https://github.com/huggingface/lighteval). For our example, we'll focus on generating exam questions from multiple documents.
## Project Structure
For our process, we will follow 4 steps, with a script for each: generating a dataset, annotating it, extracting relevant samples for evaluation from it, and actually evaluating models.
| Script Name | Description |
|-------------|-------------|
| generate_dataset.py | Generates exam questions from multiple text documents using a specified language model. |
| annotate_dataset.py | Creates an Argilla dataset for manual annotation of the generated exam questions. |
| create_dataset.py | Processes annotated data from Argilla and creates a Hugging Face dataset. |
| evaluation_task.py | Defines a custom LightEval task for evaluating language models on the exam questions dataset. |
## Steps
### 1. Generate Dataset
The `generate_dataset.py` script uses the distilabel library to generate exam questions based on multiple text documents. It uses the specified model (default: Meta-Llama-3.1-8B-Instruct) to create questions, correct answers, and incrorect answers (known as distractors). You should add you own data samples and you might wish to use a different model.
To run the generation:
```sh
python generate_dataset.py --input_dir path/to/your/documents --model_id your_model_id --output_path output_directory
```
This will create a [Distiset](https://distilabel.argilla.io/dev/sections/how_to_guides/advanced/distiset/) containing the generated exam questions for all documents in the input directory.
### 2. Annotate Dataset
The `annotate_dataset.py` script takes the generated questions and creates an Argilla dataset for annotation. It sets up the dataset structure and populates it with the generated questions and answers, randomizing the order of answers to avoid bias. Once in Argilla, you or a domain expert can validate the dataset with the correct answers.
You will see suggested correct answers from the LLM in random order and you can approve the correct answer or select a different one. The duration of this process will depend on the scale of your evaluation dataset, the complexity of your domain data, and the quality of your LLM. For example, we were able to create 150 samples within 1 hour on the domain of transfer learning, using Llama-3.1-70B-Instruct, mostly by approving the correct answer and discarding the incorrect ones.
To run the annotation process:
```sh
python annotate_dataset.py --dataset_path path/to/distiset --output_dataset_name argilla_dataset_name
```
This will create an Argilla dataset that can be used for manual review and annotation.

If you're not using Argilla, deploy it locally or on spaces following this [quickstart guide](https://docs.argilla.io/latest/getting_started/quickstart/).
### 3. Create Dataset
The `create_dataset.py` script processes the annotated data from Argilla and creates a Hugging Face dataset. It handles both suggested and manually annotated answers. The script will create a dataset with the question, possible answers, and the column name for the correct answer. To create the final dataset:
```sh
huggingface_hub login
python create_dataset.py --dataset_path argilla_dataset_name --dataset_repo_id your_hf_repo_id
```
This will push the dataset to the Hugging Face Hub under the specified repository. You can view the sample dataset on the hub [here](https://huggingface.co/datasets/burtenshaw/exam_questions/viewer/default/train), and a preview of the dataset looks like this:

### 4. Evaluation Task
The `evaluation_task.py` script defines a custom LightEval task for evaluating language models on the exam questions dataset. It includes a prompt function, a custom accuracy metric, and the task configuration.
To evaluate a model using lighteval with the custom exam questions task:
```sh
lighteval accelerate \
--model_args "pretrained=HuggingFaceH4/zephyr-7b-beta" \
--tasks "community|exam_questions|0|0" \
--custom_tasks domain-eval/evaluation_task.py \
--output_dir "./evals"
```
You can find detailed guides in lighteval wiki about each of these steps:
- [Creating a Custom Task](https://github.com/huggingface/lighteval/wiki/Adding-a-Custom-Task)
- [Creating a Custom Metric](https://github.com/huggingface/lighteval/wiki/Adding-a-New-Metric)
- [Using existing metrics](https://github.com/huggingface/lighteval/wiki/Metric-List)
|
{
"source": "huggingface/smol-course",
"title": "4_evaluation/project/README.md",
"url": "https://github.com/huggingface/smol-course/blob/main/4_evaluation/project/README.md",
"date": "2024-11-25T19:22:43",
"stars": 5481,
"description": "A course on aligning smol models.",
"file_size": 5194
}
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.