
text
stringlengths 55
456k
| metadata
dict |
|---|---|
# Ajuste por Instrucciones (Instruction Tuning)
Este módulo te guiará en el proceso de ajuste por instrucciones de modelos de lenguaje. El ajuste por instrucciones implica adaptar modelos preentrenados a tareas específicas mediante un entrenamiento adicional sobre conjuntos de datos específicos para esas tareas. Este proceso ayuda a los modelos a mejorar su rendimiento en tareas específicas.
En este módulo, exploraremos dos temas: 1) Plantillas de Chat y 2) Fine-tuning Supervisado
## 1️⃣ Plantillas de Chat
Las plantillas de chat estructuran las interacciones entre los usuarios y los modelos de IA, asegurando respuestas coherentes y contextualmente apropiadas. Estas plantillas incluyen componentes como los mensajes de sistema y mensajes basados en roles. Para más información detallada, consulta la sección de [Plantillas de Chat](./chat_templates.md).
## 2️⃣ Fine-tuning Supervisado
El Fine-tuning supervisado (SFT) es un proceso crítico para adaptar modelos de lenguaje preentrenados a tareas específicas. Implica entrenar el modelo en un conjunto de datos específico para la tarea con ejemplos etiquetados. Para una guía detallada sobre el SFT, incluyendo pasos clave y mejores prácticas, consulta la página de [Fine-tuning Supervisado](./supervised_fine_tuning.md).
## Cuadernos de Ejercicio
| Título | Descripción | Ejercicio | Enlace | Colab |
|--------|-------------|-----------|--------|-------|
| Plantillas de Chat | Aprende a usar plantillas de chat con SmolLM2 y a procesar conjuntos de datos en formato chatml | 🐢 Convierte el conjunto de datos `HuggingFaceTB/smoltalk` al formato chatml <br> 🐕 Convierte el conjunto de datos `openai/gsm8k` al formato chatml | [Cuaderno](./notebooks/chat_templates_example.ipynb) | <a target="_blank" href="https://colab.research.google.com/github/huggingface/smol-course/blob/main/1_instruction_tuning/notebooks/chat_templates_example.ipynb"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Abrir en Colab"/></a> |
| Fine-tuning Supervisado | Aprende a afinar SmolLM2 utilizando el SFTTrainer | 🐢 Usa el conjunto de datos `HuggingFaceTB/smoltalk` <br> 🐕 Prueba el conjunto de datos `bigcode/the-stack-smol` <br> 🦁 Selecciona un conjunto de datos para un caso de uso real | [Cuaderno](./notebooks/sft_finetuning_example.ipynb) | <a target="_blank" href="https://colab.research.google.com/github/huggingface/smol-course/blob/main/1_instruction_tuning/notebooks/sft_finetuning_example.ipynb"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Abrir en Colab"/></a> |
## Referencias
- [Documentación de Transformers sobre plantillas de chat](https://huggingface.co/docs/transformers/main/en/chat_templating)
- [Script para Fine-Tuning Supervisado en TRL](https://github.com/huggingface/trl/blob/main/examples/scripts/sft.py)
- [`SFTTrainer` en TRL](https://huggingface.co/docs/trl/main/en/sft_trainer)
- [Papel de Optimización Directa de Preferencias](https://arxiv.org/abs/2305.18290)
- [Fine-Tuning Supervisado con TRL](https://huggingface.co/docs/trl/main/en/tutorials/supervised_finetuning)
- [Cómo afinar Google Gemma con ChatML y Hugging Face TRL](https://www.philschmid.de/fine-tune-google-gemma)
- [Fine-Tuning de LLM para generar catálogos de productos persas en formato JSON](https://huggingface.co/learn/cookbook/en/fine_tuning_llm_to_generate_persian_product_catalogs_in_json_format)
|
{
"source": "huggingface/smol-course",
"title": "es/1_instruction_tuning/README.md",
"url": "https://github.com/huggingface/smol-course/blob/main/es/1_instruction_tuning/README.md",
"date": "2024-11-25T19:22:43",
"stars": 5481,
"description": "A course on aligning smol models.",
"file_size": 3404
}
|
# Plantillas de Chat
Las plantillas de chat son esenciales para estructurar las interacciones entre modelos de lenguaje y usuarios. Proporcionan un formato consistente para las conversaciones, asegurando que los modelos comprendan el contexto y el rol de cada mensaje, manteniendo patrones de respuesta apropiados.
## Modelos Base vs Modelos Instructivos
Un modelo base se entrena con datos de texto crudo para predecir el siguiente token, mientras que un modelo instructivo se ajusta específicamente para seguir instrucciones y participar en conversaciones. Por ejemplo, `SmolLM2-135M` es un modelo base, mientras que `SmolLM2-135M-Instruct` es su variante ajustada a instrucciones.
Para hacer que un modelo base se comporte como un modelo instructivo, necesitamos formatear nuestros prompts de manera consistente para que el modelo los entienda. Aquí es donde entran las plantillas de chat. ChatML es un formato de plantilla que estructura las conversaciones con indicadores de rol claros (sistema, usuario, asistente).
Es importante notar que un modelo base podría ser ajustado con diferentes plantillas de chat, por lo que, al usar un modelo instructivo, debemos asegurarnos de estar utilizando la plantilla de chat correcta.
## Comprendiendo las Plantillas de Chat
En su núcleo, las plantillas de chat definen cómo se deben formatear las conversaciones al comunicarse con un modelo de lenguaje. Incluyen instrucciones a nivel de sistema, mensajes del usuario y respuestas del asistente en un formato estructurado que el modelo puede entender. Esta estructura ayuda a mantener la coherencia en las interacciones y asegura que el modelo responda adecuadamente a diferentes tipos de entradas. A continuación, se muestra un ejemplo de una plantilla de chat:
```sh
<|im_start|>user
¡Hola!<|im_end|>
<|im_start|>assistant
¡Mucho gusto!<|im_end|>
<|im_start|>user
¿Puedo hacer una pregunta?<|im_end|>
<|im_start|>assistant
```
La librería `transformers` se encarga de las plantillas de chat por ti en relación con el tokenizador del modelo. Lee más sobre cómo `transformers` construye las plantillas de chat [aquí](https://huggingface.co/docs/transformers/en/chat_templating#how-do-i-use-chat-templates). Todo lo que tenemos que hacer es estructurar nuestros mensajes de la forma correcta y el tokenizador se encargará del resto. Aquí tienes un ejemplo básico de una conversación:
```python
messages = [
{"role": "system", "content": "Eres un asistente útil centrado en temas técnicos."},
{"role": "user", "content": "¿Puedes explicar qué es una plantilla de chat?"},
{"role": "assistant", "content": "Una plantilla de chat estructura las conversaciones entre los usuarios y los modelos de IA..."}
]
```
Vamos a desglosar el ejemplo anterior y ver cómo se mapea al formato de plantilla de chat.
## Mensajes del Sistema
Los mensajes del sistema establecen la base para el comportamiento del modelo. Actúan como instrucciones persistentes que influyen en todas las interacciones posteriores. Por ejemplo:
```python
system_message = {
"role": "system",
"content": "Eres un agente de atención al cliente profesional. Siempre sé educado, claro y útil."
}
```
## Conversaciones
Las plantillas de chat mantienen el contexto a través del historial de la conversación, almacenando intercambios previos entre el usuario y el asistente. Esto permite conversaciones más coherentes en múltiples turnos:
```python
conversation = [
{"role": "user", "content": "Necesito ayuda con mi pedido"},
{"role": "assistant", "content": "Estaré encantado de ayudarte. ¿Podrías proporcionarme tu número de pedido?"},
{"role": "user", "content": "Es el PEDIDO-123"},
]
```
## Implementación con Transformers
La librería `transformers` proporciona soporte integrado para plantillas de chat. Aquí te mostramos cómo usarlas:
```python
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("HuggingFaceTB/SmolLM2-135M-Instruct")
messages = [
{"role": "system", "content": "Eres un asistente útil para programación."},
{"role": "user", "content": "Escribe una función en Python para ordenar una lista"},
]
# Aplica la plantilla de chat
formatted_chat = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
```
## Formato Personalizado
Puedes personalizar cómo se formatean los diferentes tipos de mensajes. Por ejemplo, añadiendo tokens especiales o formato para diferentes roles:
```python
template = """
<|system|>{system_message}
<|user|>{user_message}
<|assistant|>{assistant_message}
""".lstrip()
```
## Soporte para Conversaciones de Varios Turnos
Las plantillas pueden manejar conversaciones complejas de varios turnos mientras mantienen el contexto:
```python
messages = [
{"role": "system", "content": "Eres un tutor de matemáticas."},
{"role": "user", "content": "¿Qué es el cálculo?"},
{"role": "assistant", "content": "El cálculo es una rama de las matemáticas..."},
{"role": "user", "content": "¿Puedes darme un ejemplo?"},
]
```
⏭️ [Siguiente: Fine-tuning Supervisado](./supervised_fine_tuning.md)
## Recursos
- [Guía de Plantillas de Chat de Hugging Face](https://huggingface.co/docs/transformers/main/en/chat_templating)
- [Documentación de Transformers](https://huggingface.co/docs/transformers)
- [Repositorio de Ejemplos de Plantillas de Chat](https://github.com/chujiezheng/chat_templates)
```
|
{
"source": "huggingface/smol-course",
"title": "es/1_instruction_tuning/chat_templates.md",
"url": "https://github.com/huggingface/smol-course/blob/main/es/1_instruction_tuning/chat_templates.md",
"date": "2024-11-25T19:22:43",
"stars": 5481,
"description": "A course on aligning smol models.",
"file_size": 5439
}
|
# Fine-Tuning Supervisado
El Fine-Tuning Supervisado (SFT) es un proceso crítico para adaptar modelos de lenguaje preentrenados a tareas o dominios específicos. Aunque los modelos preentrenados tienen capacidades generales impresionantes, a menudo necesitan ser personalizados para sobresalir en casos de uso particulares. El SFT cubre esta brecha entrenando el modelo con conjuntos de datos cuidadosamente seleccionados que contienen ejemplos validados por humanos.
## Comprendiendo el Fine-Tuning Supervisado
En su núcleo, el Fine-Tuning supervisado se trata de enseñar a un modelo preentrenado a realizar tareas específicas mediante ejemplos de tokens etiquetados. El proceso consiste en mostrarle al modelo muchos ejemplos del comportamiento deseado de entrada-salida, permitiéndole aprender los patrones específicos de tu caso de uso.
El SFT es eficaz porque utiliza el conocimiento fundamental adquirido durante el preentrenamiento, mientras adapta el comportamiento del modelo para que se ajuste a tus necesidades específicas.
## Cuándo Utilizar Fine-Tuning Supervisado
La decisión de usar SFT generalmente depende de la brecha entre las capacidades actuales de tu modelo y tus requisitos específicos. El SFT se vuelve particularmente valioso cuando necesitas un control preciso sobre las salidas del modelo o cuando trabajas en dominios especializados.
Por ejemplo, si estás desarrollando una aplicación de atención al cliente, es posible que desees que tu modelo siga consistentemente las pautas de la empresa y maneje consultas técnicas de una manera estandarizada. De manera similar, en aplicaciones médicas o legales, la precisión y la adherencia a la terminología específica del dominio se vuelven cruciales. En estos casos, el SFT puede ayudar a alinear las respuestas del modelo con los estándares profesionales y la experiencia del dominio.
## El Proceso de Fine-Tuning Supervisado (SFT)
El proceso de Fine-Tuning Supervisado consiste en entrenar los pesos del modelo en un conjunto de datos específico para una tarea.
Primero, necesitarás preparar o seleccionar un conjunto de datos que represente tu tarea objetivo. Este conjunto de datos debe incluir ejemplos diversos que cubran una amplia gama de escenarios que tu modelo encontrará. La calidad de estos datos es importante: cada ejemplo debe demostrar el tipo de salida que deseas que el modelo produzca. Luego, viene la fase de fine-tuning, donde usarás marcos como `transformers` y `trl` de Hugging Face para entrenar el modelo con tu conjunto de datos.
Durante todo el proceso, la evaluación continua es esencial. Querrás monitorear el rendimiento del modelo en un conjunto de validación para asegurarte de que está aprendiendo los comportamientos deseados sin perder sus capacidades generales. En el [módulo 4](../4_evaluation), cubriremos cómo evaluar tu modelo.
## El Rol del SFT en la Alineación con las Preferencias
El SFT juega un papel fundamental en la alineación de los modelos de lenguaje con las preferencias humanas. Técnicas como el Aprendizaje por Refuerzo a partir de Retroalimentación Humana (RLHF) y la Optimización Directa de Preferencias (DPO) dependen del SFT para formar un nivel base de comprensión de la tarea antes de alinear aún más las respuestas del modelo con los resultados deseados. Los modelos preentrenados, a pesar de su competencia general en el lenguaje, no siempre generan salidas que coinciden con las preferencias humanas. El SFT cubre esta brecha al introducir datos específicos de dominio y orientación, lo que mejora la capacidad del modelo para generar respuestas que se alineen más estrechamente con las expectativas humanas.
## Fine-Tuning Supervisado con Aprendizaje por Refuerzo de Transformers (TRL)
Un paquete de software clave para el fine-tuning supervisado es el Aprendizaje por Refuerzo de Transformers (TRL). TRL es un conjunto de herramientas utilizado para entrenar modelos de lenguaje transformadores utilizando aprendizaje por refuerzo (RL).
Basado en la librería Transformers de Hugging Face, TRL permite a los usuarios cargar directamente modelos de lenguaje preentrenados y es compatible con la mayoría de las arquitecturas de decodificadores y codificadores-decodificadores. La librería facilita los principales procesos del RL utilizado en la modelización del lenguaje, incluyendo el fine-tuning supervisado (SFT), la modelización de recompensas (RM), la optimización de políticas proximales (PPO) y la optimización directa de preferencias (DPO). Usaremos TRL en varios módulos a lo largo de este repositorio.
# Próximos Pasos
Prueba los siguientes tutoriales para obtener experiencia práctica con el SFT utilizando TRL:
⏭️ [Tutorial de Plantillas de Chat](./notebooks/chat_templates_example.ipynb)
⏭️ [Tutorial de Fine-Tuning Supervisado](./notebooks/supervised_fine_tuning_tutorial.ipynb)
|
{
"source": "huggingface/smol-course",
"title": "es/1_instruction_tuning/supervised_fine_tuning.md",
"url": "https://github.com/huggingface/smol-course/blob/main/es/1_instruction_tuning/supervised_fine_tuning.md",
"date": "2024-11-25T19:22:43",
"stars": 5481,
"description": "A course on aligning smol models.",
"file_size": 4847
}
|
# Alineación de Preferencias
Este módulo cubre técnicas para alinear modelos de lenguaje con las preferencias humanas. Mientras que la afinación supervisada (SFT) ayuda a los modelos a aprender tareas, la alineación de preferencias fomenta que las salidas coincidan con las expectativas y valores humanos.
## Descripción General
Los métodos típicos de alineación incluyen múltiples etapas:
1. Afinación Supervisada (SFT) para adaptar los modelos a dominios específicos.
2. Alineación de preferencias (como RLHF o DPO) para mejorar la calidad de las respuestas.
Enfoques alternativos como ORPO combinan la afinación por instrucciones y la alineación de preferencias en un solo proceso. Aquí, nos enfocaremos en los algoritmos DPO y ORPO.
Si deseas aprender más sobre las diferentes técnicas de alineación, puedes leer más sobre ellas en el [Blog de Argilla](https://argilla.io/blog/mantisnlp-rlhf-part-8).
### 1️⃣ Optimización Directa de Preferencias (DPO)
La Optimización Directa de Preferencias (DPO) simplifica la alineación de preferencias optimizando directamente los modelos utilizando datos de preferencias. Este enfoque elimina la necesidad de modelos de recompensa separados y de un aprendizaje por refuerzo complejo, lo que lo hace más estable y eficiente que el Aprendizaje por Refuerzo de Retroalimentación Humana (RLHF) tradicional. Para más detalles, puedes consultar la [documentación de Optimización Directa de Preferencias (DPO)](./dpo.md).
### 2️⃣ Optimización de Preferencias por Ratio de Probabilidades (ORPO)
ORPO introduce un enfoque combinado para la afinación por instrucciones y la alineación de preferencias en un solo proceso. Modifica el objetivo estándar del modelado de lenguaje combinando la pérdida de verosimilitud logarítmica negativa con un término de ratio de probabilidades a nivel de token. El enfoque presenta un proceso de entrenamiento de una sola etapa, una arquitectura libre de modelo de referencia y una mayor eficiencia computacional. ORPO ha mostrado resultados impresionantes en varios puntos de referencia, demostrando un mejor rendimiento en AlpacaEval en comparación con los métodos tradicionales. Para más detalles, puedes consultar la [documentación de Optimización de Preferencias por Ratio de Probabilidades (ORPO)](./orpo.md).
## Notebooks de Ejercicios
| Titulo | Descripción | Ejercicio | Enlace | Colab |
|-------|-------------|----------|------|-------|
| Entrenamiento DPO | Aprende a entrenar modelos utilizando la Optimización Directa de Preferencias | 🐢 Entrenar un modelo utilizando el conjunto de datos HH-RLHF de Anthropic<br>🐕 Utiliza tu propio conjunto de datos de preferencias<br>🦁 Experimenta con diferentes conjuntos de datos de preferencias y tamaños de modelo | [Notebook](./notebooks/dpo_finetuning_example.ipynb) | <a target="_blank" href="https://colab.research.google.com/github/huggingface/smol-course/blob/main/2_preference_alignment/notebooks/dpo_finetuning_example.ipynb"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Abrir en Colab"/></a> |
| Entrenamiento ORPO | Aprende a entrenar modelos utilizando la Optimización de Preferencias por Ratio de Probabilidades | 🐢 Entrenar un modelo utilizando datos de instrucciones y preferencias<br>🐕 Experimenta con diferentes ponderaciones de la pérdida<br>🦁 Compara los resultados de ORPO con DPO | [Notebook](./notebooks/orpo_finetuning_example.ipynb) | <a target="_blank" href="https://colab.research.google.com/github/huggingface/smol-course/blob/main/2_preference_alignment/notebooks/orpo_finetuning_example.ipynb"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Abrir en Colab"/></a> |
## Recursos
- [Documentación de TRL](https://huggingface.co/docs/trl/index) - Documentación para la librería Transformers Reinforcement Learning (TRL), que implementa diversas técnicas de alineación, incluyendo DPO.
- [Papel de DPO](https://arxiv.org/abs/2305.18290) - Artículo original de investigación que introduce la Optimización Directa de Preferencias como una alternativa más simple al RLHF que optimiza directamente los modelos de lenguaje utilizando datos de preferencias.
- [Papel de ORPO](https://arxiv.org/abs/2403.07691) - Introduce la Optimización de Preferencias por Ratio de Probabilidades, un enfoque novedoso que combina la afinación por instrucciones y la alineación de preferencias en una sola etapa de entrenamiento.
- [Guía de RLHF de Argilla](https://argilla.io/blog/mantisnlp-rlhf-part-8/) - Una guía que explica diferentes técnicas de alineación, incluyendo RLHF, DPO y sus implementaciones prácticas.
- [Entrada en el Blog sobre DPO](https://huggingface.co/blog/dpo-trl) - Guía práctica sobre cómo implementar DPO utilizando la librería TRL con ejemplos de código y mejores prácticas.
- [Script de ejemplo de TRL sobre DPO](https://github.com/huggingface/trl/blob/main/examples/scripts/dpo.py) - Script completo de ejemplo que demuestra cómo implementar el entrenamiento DPO utilizando la librería TRL.
- [Script de ejemplo de TRL sobre ORPO](https://github.com/huggingface/trl/blob/main/examples/scripts/orpo.py) - Implementación de referencia del entrenamiento ORPO utilizando la librería TRL con opciones detalladas de configuración.
- [Manual de Alineación de Hugging Face](https://github.com/huggingface/alignment-handbook) - Guías y código para alinear modelos de lenguaje utilizando diversas técnicas, incluyendo SFT, DPO y RLHF.
|
{
"source": "huggingface/smol-course",
"title": "es/2_preference_alignment/README.md",
"url": "https://github.com/huggingface/smol-course/blob/main/es/2_preference_alignment/README.md",
"date": "2024-11-25T19:22:43",
"stars": 5481,
"description": "A course on aligning smol models.",
"file_size": 5441
}
|
**Optimización Directa de Preferencias (DPO)**
La Optimización Directa de Preferencias (DPO) ofrece un enfoque simplificado para alinear modelos de lenguaje con las preferencias humanas. A diferencia de los métodos tradicionales de RLHF (Reinforcement Learning with Human Feedback), que requieren modelos de recompensas separados y algoritmos complejos de aprendizaje por refuerzo, DPO optimiza directamente el modelo utilizando datos de preferencia.
## Entendiendo DPO
DPO redefine la alineación de preferencias como un problema de clasificación basado en datos de preferencias humanas. Los enfoques tradicionales de RLHF requieren entrenar un modelo de recompensa separado y usar algoritmos complejos como PPO (Proximal Policy Optimization) para alinear las salidas del modelo. DPO simplifica este proceso al definir una función de pérdida que optimiza directamente la política del modelo en función de las salidas preferidas versus las no preferidas.
Este enfoque ha demostrado ser altamente efectivo en la práctica, utilizándose para entrenar modelos como Llama. Al eliminar la necesidad de un modelo de recompensa separado y una etapa de aprendizaje por refuerzo, DPO hace que la alineación de preferencias sea más accesible y estable.
## Cómo Funciona DPO
El proceso de DPO requiere un fine-tuning supervisado (SFT) para adaptar el modelo al dominio objetivo. Esto crea una base para el aprendizaje de preferencias mediante el entrenamiento en conjuntos de datos estándar de seguimiento de instrucciones. El modelo aprende a completar tareas básicas mientras mantiene sus capacidades generales.
Luego viene el aprendizaje de preferencias, donde el modelo se entrena con pares de salidas: una preferida y una no preferida. Los pares de preferencias ayudan al modelo a entender qué respuestas se alinean mejor con los valores y expectativas humanas.
La innovación central de DPO radica en su enfoque de optimización directa. En lugar de entrenar un modelo de recompensa separado, DPO utiliza una pérdida de entropía cruzada binaria para actualizar directamente los pesos del modelo en función de los datos de preferencia. Este proceso simplificado hace que el entrenamiento sea más estable y eficiente, logrando resultados comparables o mejores que los métodos tradicionales de RLHF.
## Conjuntos de Datos para DPO
Los conjuntos de datos para DPO se crean típicamente anotando pares de respuestas como preferidas o no preferidas. Esto se puede hacer manualmente o mediante técnicas de filtrado automatizado. A continuación, se muestra un ejemplo de la estructura de un conjunto de datos de preferencias para DPO en un turno único:
| Prompt | Elegido | Rechazado |
|--------|---------|-----------|
| ... | ... | ... |
| ... | ... | ... |
| ... | ... | ... |
La columna `Prompt` contiene el prompt utilizado para generar las respuestas `Elegido` y `Rechazado`. Las columnas `Elegido` y `Rechazado` contienen las respuestas preferidas y no preferidas, respectivamente. Existen variaciones en esta estructura, por ejemplo, incluyendo una columna de `system_prompt` o `Input` con material de referencia. Los valores de `elegido` y `rechazado` pueden representarse como cadenas para conversaciones de un solo turno o como listas de conversación.
Puedes encontrar una colección de conjuntos de datos DPO en Hugging Face [aquí](https://huggingface.co/collections/argilla/preference-datasets-for-dpo-656f0ce6a00ad2dc33069478).
## Implementación con TRL
La biblioteca Transformers Reinforcement Learning (TRL) facilita la implementación de DPO. Las clases `DPOConfig` y `DPOTrainer` siguen la misma API de estilo `transformers`.
Aquí tienes un ejemplo básico de cómo configurar el entrenamiento de DPO:
```python
from trl import DPOConfig, DPOTrainer
# Definir los argumentos
training_args = DPOConfig(
...
)
# Inicializar el entrenador
trainer = DPOTrainer(
model,
train_dataset=dataset,
tokenizer=tokenizer,
...
)
# Entrenar el modelo
trainer.train()
```
En el [tutorial de DPO](./notebooks/dpo_finetuning_example.ipynb) se cubrirán más detalles sobre cómo utilizar las clases `DPOConfig` y `DPOTrainer`.
## Mejores Prácticas
La calidad de los datos es crucial para una implementación exitosa de DPO. El conjunto de datos de preferencias debe incluir ejemplos diversos que cubran diferentes aspectos del comportamiento deseado. Las pautas claras de anotación aseguran un etiquetado consistente de respuestas preferidas y no preferidas. Puedes mejorar el rendimiento del modelo mejorando la calidad de tu conjunto de datos de preferencias. Por ejemplo, filtrando conjuntos de datos más grandes para incluir solo ejemplos de alta calidad o que estén más relacionados con tu caso de uso.
Durante el entrenamiento, monitorea cuidadosamente la convergencia de la pérdida y valida el rendimiento con datos retenidos. Es posible que sea necesario ajustar el parámetro beta para equilibrar el aprendizaje de preferencias con el mantenimiento de las capacidades generales del modelo. La evaluación regular sobre ejemplos diversos ayuda a garantizar que el modelo está aprendiendo las preferencias deseadas sin sobreajustarse.
Compara las salidas del modelo con el modelo de referencia para verificar la mejora en la alineación de preferencias. Probar el modelo con una variedad de prompts, incluidos los casos extremos, ayuda a garantizar un aprendizaje robusto de preferencias en diferentes escenarios.
## Próximos Pasos
⏩ Para obtener experiencia práctica con DPO, prueba el [Tutorial de DPO](./notebooks/dpo_finetuning_example.ipynb). Esta guía práctica te guiará a través de la implementación de la alineación de preferencias con tu propio modelo, desde la preparación de datos hasta el entrenamiento y la evaluación.
⏭️ Después de completar el tutorial, puedes explorar la página de [ORPO](./orpo.md) para aprender sobre otra técnica de alineación de preferencias.
|
{
"source": "huggingface/smol-course",
"title": "es/2_preference_alignment/dpo.md",
"url": "https://github.com/huggingface/smol-course/blob/main/es/2_preference_alignment/dpo.md",
"date": "2024-11-25T19:22:43",
"stars": 5481,
"description": "A course on aligning smol models.",
"file_size": 5943
}
|
**Optimización por Ratios de Probabilidad de Preferencias (ORPO)**
ORPO (Odds Ratio Preference Optimization) es una técnica novedosa de fine-tuning que combina el fine-tuning y la alineación de preferencias en un único proceso unificado. Este enfoque combinado ofrece ventajas en términos de eficiencia y rendimiento en comparación con métodos tradicionales como RLHF o DPO.
## Entendiendo ORPO
Los métodos de alineación como DPO suelen involucrar dos pasos separados: fine-tuning supervisado para adaptar el modelo a un dominio y formato, seguido de la alineación de preferencias para alinearse con las preferencias humanas. Mientras que el fine-tuning fino supervisado (SFT) adapta eficazmente los modelos a los dominios objetivo, puede aumentar inadvertidamente la probabilidad de generar tanto respuestas deseables como indeseables. ORPO aborda esta limitación integrando ambos pasos en un solo proceso, como se ilustra en la siguiente comparación:
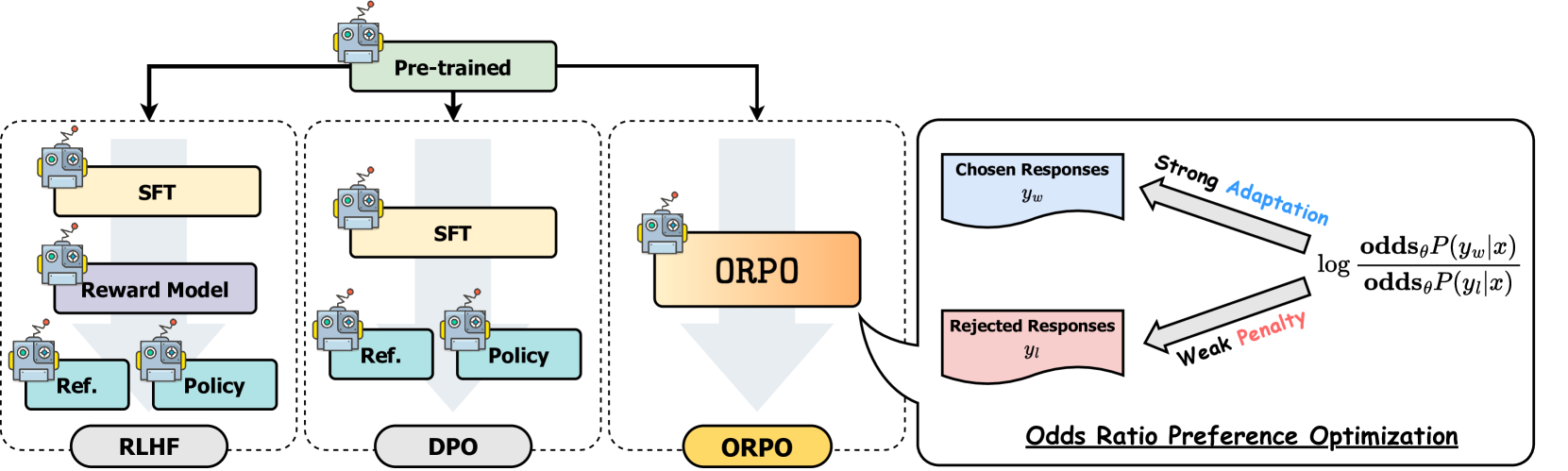
*Comparación de diferentes técnicas de alineación de modelos*
## Cómo Funciona ORPO
El proceso de entrenamiento de ORPO utiliza un conjunto de datos de preferencias similar al que usamos para DPO, donde cada ejemplo de entrenamiento contiene un prompt de entrada junto con dos respuestas: una preferida y otra rechazada. A diferencia de otros métodos de alineación que requieren etapas separadas y modelos de referencia, ORPO integra la alineación de preferencias directamente en el proceso de fine-tuning supervisado. Este enfoque monolítico lo hace libre de modelos de referencia, computacionalmente más eficiente y eficiente en memoria, con menos FLOPs.
ORPO crea un nuevo objetivo combinando dos componentes principales:
1. **Pérdida de SFT**: La pérdida estándar de log-verosimilitud negativa utilizada en la modelización de lenguaje, que maximiza la probabilidad de generar tokens de referencia. Esto ayuda a mantener las capacidades generales del modelo en lenguaje.
2. **Pérdida de Odds Ratio**: Un componente novedoso que penaliza respuestas no deseadas mientras recompensa las preferidas. Esta función de pérdida utiliza odds ratios para contrastar eficazmente entre respuestas favorecidas y desfavorecidas a nivel de token.
Juntos, estos componentes guían al modelo para adaptarse a las generaciones deseadas para el dominio específico mientras desalienta activamente las generaciones del conjunto de respuestas rechazadas. El mecanismo de odds ratio proporciona una manera natural de medir y optimizar las preferencias del modelo entre respuestas elegidas y rechazadas. Si deseas profundizar en las matemáticas, puedes leer el [artículo de ORPO](https://arxiv.org/abs/2403.07691). Si deseas aprender sobre ORPO desde la perspectiva de implementación, puedes revisar cómo se calcula la pérdida de ORPO en la [biblioteca TRL](https://github.com/huggingface/trl/blob/b02189aaa538f3a95f6abb0ab46c0a971bfde57e/trl/trainer/orpo_trainer.py#L660).
## Rendimiento y Resultados
ORPO ha demostrado resultados impresionantes en varios puntos de referencia. En MT-Bench, alcanza puntuaciones competitivas en diferentes categorías:
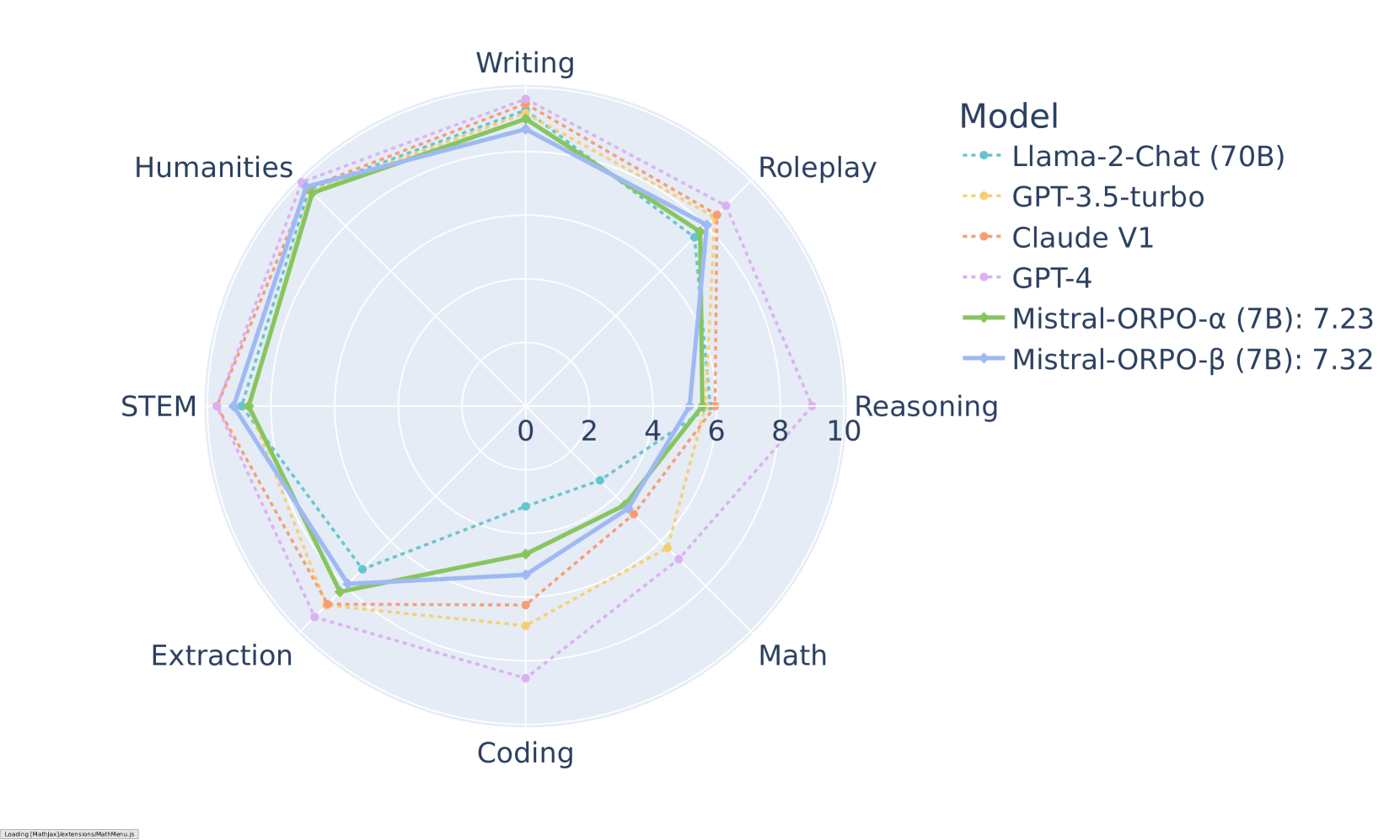
*Resultados de MT-Bench por categoría para modelos Mistral-ORPO*
Cuando se compara con otros métodos de alineación, ORPO muestra un rendimiento superior en AlpacaEval 2.0:
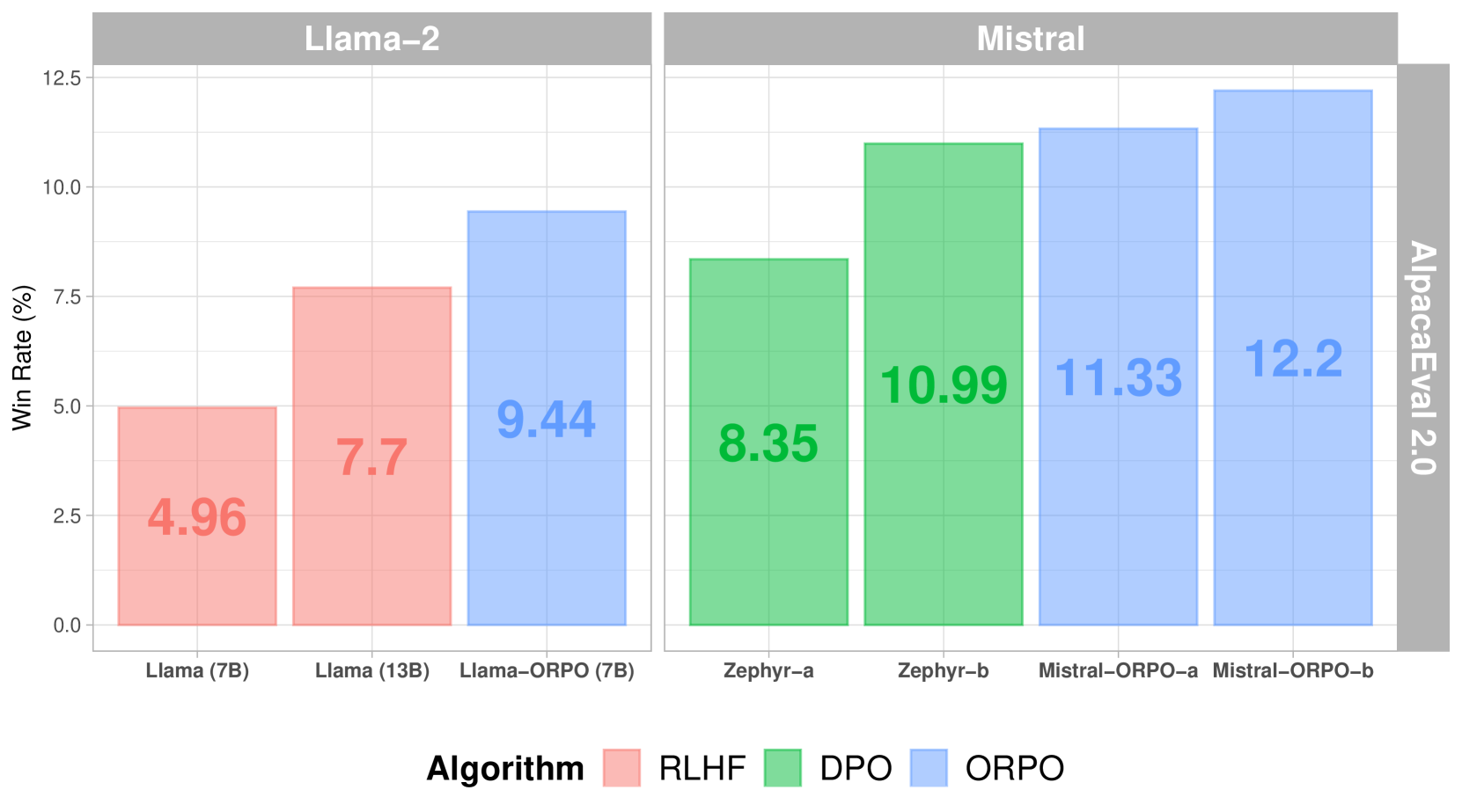
*Puntuaciones de AlpacaEval 2.0 en diferentes métodos de alineación*
En comparación con SFT+DPO, ORPO reduce los requisitos computacionales al eliminar la necesidad de un modelo de referencia y reducir a la mitad el número de pasadas hacia adelante por lote. Además, el proceso de entrenamiento es más estable en diferentes tamaños de modelos y conjuntos de datos, lo que requiere menos hiperparámetros para ajustar. En cuanto al rendimiento, ORPO iguala a modelos más grandes mientras muestra una mejor alineación con las preferencias humanas.
## Implementación
La implementación exitosa de ORPO depende en gran medida de datos de preferencias de alta calidad. Los datos de entrenamiento deben seguir pautas claras de anotación y proporcionar una representación equilibrada de respuestas preferidas y rechazadas en diversos escenarios.
### Implementación con TRL
ORPO se puede implementar utilizando la biblioteca Transformers Reinforcement Learning (TRL). Aquí tienes un ejemplo básico:
```python
from trl import ORPOConfig, ORPOTrainer
# Configurar el entrenamiento de ORPO
orpo_config = ORPOConfig(
learning_rate=1e-5,
per_device_train_batch_size=4,
gradient_accumulation_steps=4,
max_steps=1000,
orpo_alpha=1.0, # Controla la fuerza de la optimización de preferencias
orpo_beta=0.1, # Parámetro de temperatura para el cálculo de odds ratio
)
# Inicializar el entrenador
trainer = ORPOTrainer(
model=model,
args=orpo_config,
train_dataset=dataset,
tokenizer=tokenizer,
)
# Iniciar el entrenamiento
trainer.train()
```
Parámetros clave a considerar:
- `orpo_alpha`: Controla la fuerza de la optimización de preferencias
- `orpo_beta`: Parámetro de temperatura para el cálculo de odds ratio
- `learning_rate`: Debe ser relativamente pequeño para evitar el olvido catastrófico
- `gradient_accumulation_steps`: Ayuda con la estabilidad del entrenamiento
## Próximos Pasos
⏩ Prueba el [Tutorial de ORPO](./notebooks/orpo_tutorial.ipynb) para implementar este enfoque unificado de alineación de preferencias.
## Recursos
- [Artículo de ORPO](https://arxiv.org/abs/2403.07691)
- [Documentación de TRL](https://huggingface.co/docs/trl/index)
- [Guía de RLHF de Argilla](https://argilla.io/blog/mantisnlp-rlhf-part-8/)
|
{
"source": "huggingface/smol-course",
"title": "es/2_preference_alignment/orpo.md",
"url": "https://github.com/huggingface/smol-course/blob/main/es/2_preference_alignment/orpo.md",
"date": "2024-11-25T19:22:43",
"stars": 5481,
"description": "A course on aligning smol models.",
"file_size": 5829
}
|
# Fine-Tuning Eficiente en Parámetros (PEFT)
A medida que los modelos de lenguaje se hacen más grandes, el *fine-tuning* tradicional se vuelve cada vez más complicado. Afinar completamente un modelo con 1.7 mil millones de parámetros, por ejemplo, requiere una memoria de GPU significativa, hace costoso almacenar copias separadas del modelo y puede ocasionar un olvido catastrófico de las capacidades originales del modelo. Los métodos de *fine-tuning* eficiente en parámetros (*Parameter-Efficient Fine-Tuning* o PEFT) abordan estos problemas modificando solo un subconjunto pequeño de los parámetros del modelo, mientras que la mayor parte del modelo permanece congelada.
El *fine-tuning* tradicional actualiza todos los parámetros del modelo durante el entrenamiento, lo cual resulta poco práctico para modelos grandes. Los métodos PEFT introducen enfoques para adaptar modelos utilizando una fracción mínima de parámetros entrenables, generalmente menos del 1% del tamaño original del modelo. Esta reducción dramática permite:
- Realizar *fine-tuning* en hardware de consumo con memoria de GPU limitada.
- Almacenar eficientemente múltiples adaptaciones de tareas específicas.
- Mejorar la generalización en escenarios con pocos datos.
- Entrenamientos y ciclos de iteración más rápidos.
## Métodos Disponibles
En este módulo, se cubrirán dos métodos populares de PEFT:
### 1️⃣ LoRA (Adaptación de Bajo Rango)
LoRA se ha convertido en el método PEFT más adoptado, ofreciendo una solución sofisticada para la adaptación eficiente de modelos. En lugar de modificar el modelo completo, **LoRA inyecta matrices entrenables en las capas de atención del modelo.** Este enfoque, por lo general, reduce los parámetros entrenables en aproximadamente un 90%, manteniendo un rendimiento comparable al *fine-tuning* completo. Exploraremos LoRA en la sección [LoRA (Adaptación de Bajo Rango)](./lora_adapters.md).
### 2️⃣ *Prompt Tuning*
El *prompt tuning* ofrece un enfoque **aún más ligero** al **añadir tokens entrenables a la entrada** en lugar de modificar los pesos del modelo. Aunque es menos popular que LoRA, puede ser útil para adaptar rápidamente un modelo a nuevas tareas o dominios. Exploraremos el *prompt tuning* en la sección [Prompt Tuning](./prompt_tuning.md).
## Notebooks de Ejercicios
| Título | Descripción | Ejercicio | Enlace | Colab |
|-------|-------------|-----------|--------|-------|
| *Fine-tuning* con LoRA | Aprende a realizar *fine-tuning* con adaptadores LoRA | 🐢 Entrena un modelo con LoRA<br>🐕 Experimenta con diferentes valores de rango<br>🦁 Compara el rendimiento con el *fine-tuning* completo | [Notebook](./notebooks/finetune_sft_peft.ipynb) | <a target="_blank" href="https://colab.research.google.com/github/huggingface/smol-course/blob/main/3_parameter_efficient_finetuning/notebooks/finetune_sft_peft.ipynb"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Abrir en Colab"/></a> |
| Carga Adaptadores LoRA | Aprende a cargar y usar adaptadores LoRA entrenados | 🐢 Carga adaptadores preentrenados<br>🐕 Combina adaptadores con el modelo base<br>🦁 Alterna entre múltiples adaptadores | [Notebook](./notebooks/load_lora_adapter_example.ipynb) | <a target="_blank" href="https://colab.research.google.com/github/huggingface/smol-course/blob/main/3_parameter_efficient_finetuning/notebooks/load_lora_adapter_example.ipynb"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Abrir en Colab"/></a> |
<!-- | Prompt Tuning | Aprende a implementar *prompt tuning* | 🐢 Entrenar *soft prompts*<br>🐕 Comparar diferentes estrategias de inicialización<br>🦁 Evaluar en múltiples tareas | [Notebook](./notebooks/prompt_tuning_example.ipynb) | <a target="_blank" href="https://colab.research.google.com/github/huggingface/smol-course/blob/main/3_parameter_efficient_finetuning/notebooks/prompt_tuning_example.ipynb"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Abrir en Colab"/></a> | -->
## Recursos
- [Documentación de PEFT](https://huggingface.co/docs/peft)
- [Artículo de LoRA](https://arxiv.org/abs/2106.09685)
- [Artículo de QLoRA](https://arxiv.org/abs/2305.14314)
- [Artículo de *Prompt Tuning*](https://arxiv.org/abs/2104.08691)
- [Guía de PEFT en Hugging Face](https://huggingface.co/blog/peft)
- [Cómo hacer *Fine-Tuning* de LLMs en 2024 con Hugging Face](https://www.philschmid.de/fine-tune-llms-in-2024-with-trl)
- [TRL](https://huggingface.co/docs/trl/index)
|
{
"source": "huggingface/smol-course",
"title": "es/3_parameter_efficient_finetuning/README.md",
"url": "https://github.com/huggingface/smol-course/blob/main/es/3_parameter_efficient_finetuning/README.md",
"date": "2024-11-25T19:22:43",
"stars": 5481,
"description": "A course on aligning smol models.",
"file_size": 4476
}
|
# LoRA (Adaptación de Bajo Rango)
LoRA (Low-Rank Adaptation) se ha convertido en el método PEFT más utilizado. Su funcionamiento se basa en añadir matrices de descomposición de rango reducido a los pesos de atención, lo que suele reducir los parámetros entrenables en un 90%.
## Entendiendo LoRA
LoRA es una técnica de fine-tuning eficiente en parámetros que congela los pesos del modelo preentrenado e inyecta matrices entrenables de descomposición de rango reducido en las capas del modelo. En lugar de entrenar todos los parámetros del modelo durante el fine-tuning, LoRA descompone las actualizaciones de los pesos en matrices más pequeñas mediante descomposición de rango, reduciendo significativamente la cantidad de parámetros entrenables mientras mantiene el rendimiento del modelo. Por ejemplo, se ha aplicado a GPT-3 175B. LoRA redujo los parámetros entrenables 10 000 veces y los requerimientos de memoria de GPU 3 veces en comparación con el fine-tuning completo. Puedes leer más sobre LoRA en el [paper de LoRA](https://arxiv.org/pdf/2106.09685).
LoRA funciona añadiendo pares de matrices de descomposición de rango reducido a las capas del transformador, normalmente enfocándose en los pesos de atención. Durante la inferencia, estos pesos adaptadores pueden fusionarse con el modelo base, lo que elimina la sobrecarga de latencia adicional. LoRA es especialmente útil para adaptar modelos de lenguaje grandes a tareas o dominios específicos mientras se mantienen requisitos de recursos manejables.
## Cargando adaptadores LoRA
Se pueden cargar adaptadores en un modelo preentrenado utilizando `load_adapter()`, lo cual es útil para probar diferentes adaptadores cuyos pesos no están fusionados. Se pueden establecer los pesos de los adaptadores activos con la función `set_adapter()`. Para devolver el modelo base, se puede usar `unload()` para descargar todos los módulos de LoRA. Esto permite cambiar fácilmente entre diferentes pesos específicos de tareas.
```python
from transformers import AutoModelForCausalLM
from peft import PeftModel
base_model = AutoModelForCausalLM.from_pretrained("<base_model_name>")
peft_model_id = "<peft_adapter_id>"
model = PeftModel.from_pretrained(base_model, peft_model_id)
```

## Fusionando adaptadores LoRA
Después de entrenar con LoRA, podrías querer fusionar los pesos del adaptador de vuelta en el modelo base para facilitar su implementación. Esto crea un único modelo con los pesos combinados, eliminando la necesidad de cargar adaptadores por separado durante la inferencia.
El proceso de fusión requiere atención al manejo de memoria y precisión. Como necesitarás cargar tanto el modelo base como los pesos del adaptador simultáneamente, asegúrate de tener suficiente memoria GPU/CPU disponible. Usar `device_map="auto"` en `transformers` ayudará con el manejo automático de memoria. Mantén una precisión consistente (por ejemplo, `float16`) durante todo el proceso, y guarda el modelo fusionado en el mismo formato para su implementación. Antes de implementar, siempre valida el modelo fusionado comparando sus salidas y métricas de rendimiento con la versión basada en adaptadores.
Los adaptadores también son convenientes para cambiar entre diferentes tareas o dominios. Puedes cargar el modelo base y los pesos del adaptador por separado, permitiendo un cambio rápido entre diferentes pesos específicos de tareas.
## Guía de implementación
El directorio `notebooks/` contiene tutoriales prácticos y ejercicios para implementar diferentes métodos PEFT. Comienza con `load_lora_adapter_example.ipynb` para una introducción básica, y luego explora `lora_finetuning.ipynb` para un análisis más detallado de cómo realizar fine-tuning en un modelo con LoRA y SFT.
Cuando implementes métodos PEFT, comienza con valores de rango pequeños (4-8) para LoRA y monitoriza la pérdida durante el entrenamiento. Utiliza conjuntos de validación para evitar el sobreajuste y compara los resultados con los baselines del fine-tuning completo cuando sea posible. La efectividad de los diferentes métodos puede variar según la tarea, por lo que la experimentación es clave.
## OLoRA
[OLoRA](https://arxiv.org/abs/2406.01775) utiliza descomposición QR para inicializar los adaptadores LoRA. OLoRA traduce los pesos base del modelo por un factor de sus descomposiciones QR, es decir, muta los pesos antes de realizar cualquier entrenamiento sobre ellos. Este enfoque mejora significativamente la estabilidad, acelera la velocidad de convergencia y logra un rendimiento superior.
## Usando TRL con PEFT
Los métodos PEFT pueden combinarse con TRL (Transformers Reinforcement Learning) para un fine-tuning eficiente. Esta integración es particularmente útil para RLHF (Reinforcement Learning from Human Feedback), ya que reduce los requisitos de memoria.
```python
from peft import LoraConfig
from transformers import AutoModelForCausalLM
# Carga el modelo con configuración PEFT
lora_config = LoraConfig(
r=16,
lora_alpha=32,
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM"
)
# Carga el modelo en un dispositivo específico
model = AutoModelForCausalLM.from_pretrained(
"your-model-name",
load_in_8bit=True, # Opcional: usa la precisión de 8 bits
device_map="auto",
peft_config=lora_config
)
```
Aquí, usamos `device_map="auto"` para asignar automáticamente el modelo al dispositivo correcto. También puedes asignar manualmente el modelo a un dispositivo específico usando `device_map={"": device_index}`. Además, podrías escalar el entrenamiento en múltiples GPUs mientras mantienes un uso eficiente de memoria.
## Implementación básica de fusión
Después de entrenar un adaptador LoRA, puedes fusionar los pesos del adaptador de vuelta en el modelo base. Aquí tienes cómo hacerlo:
```python
import torch
from transformers import AutoModelForCausalLM
from peft import PeftModel
# 1. Carga el modelo base
base_model = AutoModelForCausalLM.from_pretrained(
"base_model_name",
torch_dtype=torch.float16,
device_map="auto"
)
# 2. Carga el modelo PEFT con adaptador
peft_model = PeftModel.from_pretrained(
base_model,
"path/to/adapter",
torch_dtype=torch.float16
)
# 3. Fusiona los pesos del adaptador con el modelo base
try:
merged_model = peft_model.merge_and_unload()
except RuntimeError as e:
print(f"Fusión fallida: {e}")
# Implementa estrategia de respaldo u optimización de memoria
# 4. Guarda el modelo fusionado
merged_model.save_pretrained("path/to/save/merged_model")
```
Si encuentras discrepancias de tamaño en el modelo guardado, asegúrate de guardar también el tokenizer:
```python
# Guarda tanto el modelo como el tokenizer
tokenizer = AutoTokenizer.from_pretrained("base_model_name")
merged_model.save_pretrained("path/to/save/merged_model")
tokenizer.save_pretrained("path/to/save/merged_model")
```
## Próximos pasos
⏩ Pasa al [Prompt Tuning](prompt_tuning.md) para aprender a realizar fine-tuning en un modelo con prompt tuning.
⏩ Revisa el [Tutorial de Carga de Adaptadores LoRA](./notebooks/load_lora_adapter.ipynb) para aprender a cargar adaptadores LoRA.
# Recursos
- [LORA: ADAPTACIÓN DE BAJO RANGO PARA MODELOS DE LENGUAJE DE GRAN TAMAÑO](https://arxiv.org/pdf/2106.09685)
- [Documentación de PEFT](https://huggingface.co/docs/peft)
- [Publicación en el blog de Hugging Face sobre PEFT](https://huggingface.co/blog/peft)
|
{
"source": "huggingface/smol-course",
"title": "es/3_parameter_efficient_finetuning/lora_adapters.md",
"url": "https://github.com/huggingface/smol-course/blob/main/es/3_parameter_efficient_finetuning/lora_adapters.md",
"date": "2024-11-25T19:22:43",
"stars": 5481,
"description": "A course on aligning smol models.",
"file_size": 7451
}
|
# Ajuste de Prompts
El ajuste de prompts es un enfoque eficiente en términos de parámetros que modifica las representaciones de entrada en lugar de los pesos del modelo. A diferencia del fine-tuning tradicional que actualiza todos los parámetros del modelo, el ajuste de prompts agrega y optimiza un pequeño conjunto de tokens entrenables mientras mantiene el modelo base congelado.
## Entendiendo el Ajuste de Prompts
El ajuste de prompts es una alternativa eficiente en términos de parámetros al fine-tuning del modelo que antepone vectores continuos entrenables (prompts suaves) al texto de entrada. A diferencia de los prompts discretos de texto, estos prompts suaves se aprenden mediante retropropagación mientras el modelo de lenguaje se mantiene congelado. El método fue introducido en ["El poder de la escala para el ajuste de prompts eficiente en parámetros"](https://arxiv.org/abs/2104.08691) (Lester et al., 2021), que demostró que el ajuste de prompts se vuelve más competitivo con el fine-tuning del modelo a medida que aumenta el tamaño del modelo. En el artículo, alrededor de 10 mil millones de parámetros, el ajuste de prompts iguala el rendimiento del fine-tuning del modelo mientras solo modifica unos pocos cientos de parámetros por tarea.
Estos prompts suaves son vectores continuos en el espacio de incrustación del modelo que se optimizan durante el entrenamiento. A diferencia de los prompts discretos tradicionales que usan tokens de lenguaje natural, los prompts suaves no tienen un significado inherente, pero aprenden a provocar el comportamiento deseado del modelo congelado mediante el descenso de gradiente. La técnica es particularmente efectiva para escenarios de múltiples tareas, ya que cada tarea requiere almacenar solo un pequeño vector de prompt (normalmente unos pocos cientos de parámetros) en lugar de una copia completa del modelo. Este enfoque no solo mantiene una huella de memoria mínima, sino que también permite una adaptación rápida de tareas simplemente intercambiando los vectores de prompt sin necesidad de recargar el modelo.
## Proceso de Entrenamiento
Los prompts suaves suelen ser entre 8 y 32 tokens y se pueden inicializar de forma aleatoria o a partir de texto existente. El método de inicialización juega un papel crucial en el proceso de entrenamiento, con la inicialización basada en texto a menudo obteniendo mejores resultados que la aleatoria.
Durante el entrenamiento, solo se actualizan los parámetros del prompt mientras que el modelo base permanece congelado. Este enfoque centrado utiliza objetivos de entrenamiento estándar, pero requiere una atención cuidadosa a la tasa de aprendizaje y el comportamiento de los gradientes de los tokens del prompt.
## Implementación con PEFT
La libreria PEFT facilita la implementación del ajuste de prompts. Aquí tienes un ejemplo básico:
```python
from peft import PromptTuningConfig, TaskType, get_peft_model
from transformers import AutoModelForCausalLM, AutoTokenizer
# Carga el modelo base
model = AutoModelForCausalLM.from_pretrained("your-base-model")
tokenizer = AutoTokenizer.from_pretrained("your-base-model")
# Configura el ajuste de prompt
peft_config = PromptTuningConfig(
task_type=TaskType.CAUSAL_LM,
num_virtual_tokens=8, # Número de tokens entrenables
prompt_tuning_init="TEXT", # Inicializa a partir de texto
prompt_tuning_init_text="Clasifique si este texto es positivo o negativo:",
tokenizer_name_or_path="your-base-model",
)
# Crea el modelo ajustable por prompt
model = get_peft_model(model, peft_config)
```
## Comparación con Otros Métodos
Cuando se compara con otros enfoques de PEFT, el ajuste de prompts destaca por su eficiencia. Mientras que LoRA ofrece bajos recuentos de parámetros y uso de memoria pero requiere cargar adaptadores para el cambio de tareas, el ajuste de prompts logra un uso de recursos aún menor y permite un cambio de tareas inmediato. El fine-tuning completo, en contraste, exige recursos significativos y requiere copias separadas del modelo para diferentes tareas.
| Método | Parámetros | Memoria | Cambio de Tarea |
|-------------------|-------------|----------|-----------------|
| Ajuste de Prompts | Muy Bajo | Mínimo | Fácil |
| LoRA | Bajo | Bajo | Requiere Carga |
| Fine-tuning Completo | Alto | Alto | Nueva Copia |
Al implementar el ajuste de prompts, comienza con un pequeño número de tokens virtuales (8-16) y aumenta solo si la complejidad de la tarea lo requiere. La inicialización con texto generalmente da mejores resultados que la aleatoria, especialmente cuando se utiliza texto relevante para la tarea. La estrategia de inicialización debe reflejar la complejidad de la tarea objetivo.
El entrenamiento requiere consideraciones ligeramente diferentes al fine-tuning completo. Las tasas de aprendizaje más altas suelen funcionar bien, pero es esencial monitorear cuidadosamente los gradientes de los tokens de prompt. La validación regular con ejemplos diversos ayuda a garantizar un rendimiento robusto en diferentes escenarios.
## Aplicaciones
El ajuste de prompts sobresale en varios escenarios:
1. Despliegue de múltiples tareas
2. Entornos con limitaciones de recursos
3. Adaptación rápida de tareas
4. Aplicaciones sensibles a la privacidad
A medida que los modelos se hacen más pequeños, el ajuste de prompts se vuelve menos competitivo en comparación con el fine-tuning completo. Por ejemplo, en modelos como SmolLM2, el ajuste de prompts es menos relevante que el fine-tuning completo.
## Próximos Pasos
⏭️ Pasa al [Tutorial de Adaptadores LoRA](./notebooks/finetune_sft_peft.ipynb) para aprender cómo ajustar un modelo con adaptadores LoRA.
## Recursos
- [Documentación de PEFT](https://huggingface.co/docs/peft)
- [Papel sobre Ajuste de Prompts](https://arxiv.org/abs/2104.08691)
- [Recetario de Hugging Face](https://huggingface.co/learn/cookbook/prompt_tuning_peft)
|
{
"source": "huggingface/smol-course",
"title": "es/3_parameter_efficient_finetuning/prompt_tuning.md",
"url": "https://github.com/huggingface/smol-course/blob/main/es/3_parameter_efficient_finetuning/prompt_tuning.md",
"date": "2024-11-25T19:22:43",
"stars": 5481,
"description": "A course on aligning smol models.",
"file_size": 5975
}
|
# Evaluación
La evaluación es un paso crítico en el desarrollo y despliegue de modelos de lenguaje. Nos permite entender qué tan bien funcionan nuestros modelos en diferentes capacidades e identificar áreas de mejora. Este módulo cubre tanto los "becnhmarks" estándares como los enfoques de evaluación específicos para evaluar de manera integral tu modelo **smol**.
Usaremos [`lighteval`](https://github.com/huggingface/lighteval), una poderosa biblioteca de evaluación desarrollada por Hugging Face que se integra perfectamente con el ecosistema de Hugging Face. Para una explicación más detallada sobre los conceptos y mejores prácticas de evaluación, consulta la [guía de evaluación](https://github.com/huggingface/evaluation-guidebook).
## Descripción del Módulo
Una estrategia de evaluación completa examina múltiples aspectos del rendimiento del modelo. Evaluamos capacidades específicas en tareas como responder preguntas y resumir textos, para entender cómo el modelo maneja diferentes tipos de problemas. Medimos la calidad del "output" mediante factores como coherencia y precisión. A su vez, la evaluación de seguridad ayuda a identificar posibles "outputs" dañinas o sesgos. Finalmente, las pruebas de experticia en áreas especfícios verifican el conocimiento especializado del modelo en tu campo objetivo.
## Contenidos
### 1️⃣ [Evaluaciones Automáticas](./automatic_benchmarks.md)
Aprende a evaluar tu modelo utilizando "benchmarks" y métricas estandarizadas. Exploraremos "benchmarks" comunes como MMLU y TruthfulQA, entenderemos las métricas clave de evaluación y configuraciones, y cubriremos mejores prácticas para una evaluación reproducible.
### 2️⃣ [Evaluación Personalizada en un Dominio](./custom_evaluation.md)
Descubre cómo crear flujos de evaluación adaptados a tus casos de uso específicos. Te guiaremos en el diseño de tareas de evaluación personalizadas, la implementación de métricas especializadas y la construcción de conjuntos de datos de evaluación que se ajusten a tus necesidades.
### 3️⃣ [Proyecto de Evaluación en un Dominio](./project/README.md)
Sigue un ejemplo completo de cómo construir un flujo de evaluación específico para un dominio. Aprenderás a generar conjuntos de datos de evaluación, usar Argilla para la anotación de datos, crear conjuntos de datos estandarizados y evaluar modelos utilizando LightEval.
### Cuadernos de Ejercicios
| Título | Descripción | Ejercicio | Enlace | Colab |
|--------|-------------|----------|-------|-------|
| Evalúa y analiza tu LLM | Aprende a usar LightEval para evaluar y comparar modelos en dominios específicos | 🐢 Usa tareas del dominio médico para evaluar un modelo <br> 🐕 Crea una evaluación de dominio con diferentes tareas MMLU <br> 🦁 Diseña una tarea de evaluación personalizada para tu dominio | [Cuaderno](./notebooks/lighteval_evaluate_and_analyse_your_LLM.ipynb) | <a target="_blank" href="https://colab.research.google.com/github/huggingface/smol-course/blob/main/4_evaluation/notebooks/lighteval_evaluate_and_analyse_your_LLM.ipynb"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a> |
## Recursos
- [Guía de Evaluación](https://github.com/huggingface/evaluation-guidebook) - Guía completa para la evaluación de modelos de lenguaje
- [Documentación de LightEval](https://github.com/huggingface/lighteval) - Documentación oficial de la biblioteca LightEval
- [Documentación de Argilla](https://docs.argilla.io) - Aprende sobre la plataforma de anotación Argilla
- [Paper de MMLU](https://arxiv.org/abs/2009.03300) - Artículo sobre el benchmark MMLU
- [Crear una Tarea Personalizada](https://github.com/huggingface/lighteval/wiki/Adding-a-Custom-Task)
- [Crear una Métrica Personalizada](https://github.com/huggingface/lighteval/wiki/Adding-a-New-Metric)
- [Usar métricas existentes](https://github.com/huggingface/lighteval/wiki/Metric-List)
|
{
"source": "huggingface/smol-course",
"title": "es/4_evaluation/README.md",
"url": "https://github.com/huggingface/smol-course/blob/main/es/4_evaluation/README.md",
"date": "2024-11-25T19:22:43",
"stars": 5481,
"description": "A course on aligning smol models.",
"file_size": 3895
}
|
# Benchmarks Automáticos
Los "benchmarks" automáticos sirven como herramientas estandarizadas para evaluar modelos de lenguaje en diferentes tareas y capacidades. Aunque proporcionan un punto de partida útil para entender el rendimiento de un modelo, es importante reconocer que representan solo una parte de una estrategia de evaluación integral.
## Entendiendo los Benchmarks Automáticos
Los "benchmarks" automáticos generalmente consisten en conjuntos de datos curados con tareas y métricas de evaluación predefinidas. Estos "benchmarks" buscan evaluar diversos aspectos de la capacidad del modelo, desde la comprensión básica del lenguaje hasta el razonamiento complejo. La principal ventaja de usar "benchmarks" automáticos es su estandarización: permiten comparaciones consistentes entre diferentes modelos y proporcionan resultados reproducibles.
Sin embargo, es crucial entender que el rendimiento en un "benchmark" no siempre se traduce directamente en efectividad en el mundo real. Un modelo que sobresale en "benchmarks" académicos puede tener dificultades en aplicaciones específicas de dominio o casos de uso prácticos.
## Benchmarks y Sus Limitaciones
### Benchmarks de Conocimientos Generales
MMLU (Massive Multitask Language Understanding) evalúa conocimientos en 57 materias, desde ciencias hasta humanidades. Aunque es extenso, puede no reflejar la profundidad de experiencia necesaria para dominios específicos. TruthfulQA evalúa la tendencia de un modelo a reproducir conceptos erróneos comunes, aunque no puede capturar todas las formas de desinformación.
### Benchmarks de Razonamiento
BBH (Big Bench Hard) y GSM8K se enfocan en tareas de razonamiento complejo. BBH evalúa el pensamiento lógico y la planificación, mientras que GSM8K se centra específicamente en la resolución de problemas matemáticos. Estos "benchmarks" ayudan a evaluar capacidades analíticas pero pueden no capturar el razonamiento matizado requerido en escenarios del mundo real.
### Comprensión del Lenguaje
HELM proporciona un marco de evaluación holístico, mientras que WinoGrande prueba el sentido común mediante la desambiguación de pronombres. Estos "benchmarks" ofrecen información sobre las capacidades de procesamiento del lenguaje, pero pueden no representar completamente la complejidad de las conversaciones naturales o la terminología específica de un dominio.
## Enfoques Alternativos de Evaluación
Muchas organizaciones han desarrollado métodos de evaluación alternativos para abordar las limitaciones de los "benchmarks" estándar:
### Model de lenguaje como Juez (LLM-as-Judge)
Usar un modelo de lenguaje para evaluar los "outputs" de otro modelo se ha vuelto cada vez más popular. Este enfoque puede proporcionar retroalimentación más matizada que las métricas tradicionales, aunque viene con sus propios sesgos y limitaciones.
### Arenas de Evaluación (Evaluation Arenas)
Plataformas como Chatbot Arena permiten que los modelos interactúen y se evalúen entre sí en entornos controlados. Esto puede revelar fortalezas y debilidades que podrían no ser evidentes en "benchmarks" tradicionales.
### Grupos de Benchmarks Personalizados
Las organizaciones a menudo desarrollan conjuntos de "benchmarks" internos adaptados a sus necesidades específicas y casos de uso. Estos pueden incluir pruebas de conocimientos específicos de dominio o escenarios de evaluación que reflejen las condiciones reales de despliegue.
## Creando Tu Propia Estrategia de Evaluación
Recuerda que aunque LightEval facilita ejecutar "benchmarks" estándar, también deberías invertir tiempo en desarrollar métodos de evaluación específicos para tu caso de uso.
Aunque los "benchmarks" estándares proporcionan una línea base útil, no deberían ser tu único método de evaluación. Así es como puedes desarrollar un enfoque más integral:
1. Comienza con "benchmarks" estándares relevantes para establecer una línea base y permitir comparaciones con otros modelos.
2. Identifica los requisitos y desafíos específicos de tu caso de uso. ¿Qué tareas realizará tu modelo realmente? ¿Qué tipos de errores serían más problemáticos?
3. Desarrolla conjuntos de datos de evaluación personalizados que reflejen tu caso de uso real. Esto podría incluir:
- Consultas reales de usuarios en tu dominio
- Casos límite comunes que hayas encontrado
- Ejemplos de escenarios particularmente desafiantes
4. Considera implementar una estrategia de evaluación por capas:
- Métricas automatizadas para retroalimentación rápida
- Evaluación humana para una comprensión más matizada
- Revisión por expertos en el dominio para aplicaciones especializadas
- Pruebas A/B en entornos controlados
## Usando LightEval para "Benchmarking"
Las tareas de LightEval se definen usando un formato específico:
```
{suite}|{task}|{num_few_shot}|{auto_reduce}
```
- **suite**: El conjunto de "benchmarks" (por ejemplo, 'mmlu', 'truthfulqa')
- **task**: Tarea específica dentro del conjunto (por ejemplo, 'abstract_algebra')
- **num_few_shot**: Número de ejemplos a incluir en el "prompt" (0 para zero-shot)
- **auto_reduce**: Si se debe reducir automáticamente los ejemplos "few-shot" si el "prompt" es demasiado largo (0 o 1)
Ejemplo: `"mmlu|abstract_algebra|0|0"` evalúa la tarea de álgebra abstracta de MMLU sin ejempls en el "prompt" (i.e. "zero-shot").
### Ejemplo de Pipeline de Evaluación
Aquí tienes un ejemplo completo de configuración y ejecución de una evaluación utilizando "benchmarks" automáticos relevantes para un dominio específico:
```python
from lighteval.tasks import Task, Pipeline
from transformers import AutoModelForCausalLM
# Definir tareas para evaluar
domain_tasks = [
"mmlu|anatomy|0|0",
"mmlu|high_school_biology|0|0",
"mmlu|high_school_chemistry|0|0",
"mmlu|professional_medicine|0|0"
]
# Configurar parámetros del pipeline
pipeline_params = {
"max_samples": 40, # Número de muestras para evaluar
"batch_size": 1, # Tamaño del "batch" para la inferencia
"num_workers": 4 # Número de procesos paralelos
}
# Crear tracker de evaluación
evaluation_tracker = EvaluationTracker(
output_path="./results",
save_generations=True
)
# Cargar modelo y crear pipeline
model = AutoModelForCausalLM.from_pretrained("your-model-name")
pipeline = Pipeline(
tasks=domain_tasks,
pipeline_parameters=pipeline_params,
evaluation_tracker=evaluation_tracker,
model=model
)
# Ejecutar evaluación
pipeline.evaluate()
# Obtener y mostrar resultados
results = pipeline.get_results()
pipeline.show_results()
```
Los resultados se muestran en formato tabular:
```
| Task |Version|Metric|Value | |Stderr|
|----------------------------------------|------:|------|-----:|---|-----:|
|all | |acc |0.3333|± |0.1169|
|leaderboard:mmlu:_average:5 | |acc |0.3400|± |0.1121|
|leaderboard:mmlu:anatomy:5 | 0|acc |0.4500|± |0.1141|
|leaderboard:mmlu:high_school_biology:5 | 0|acc |0.1500|± |0.0819|
```
También puedes manejar los resultados en un DataFrame de pandas y visualizarlos o representarlos como prefieras.
# Próximos Pasos
⏩ Explora [Evaluación Personalizada en un Dominio](./custom_evaluation.md) para aprender a crear flujos de evaluación adaptados a tus necesidades específicas.
|
{
"source": "huggingface/smol-course",
"title": "es/4_evaluation/automatic_benchmarks.md",
"url": "https://github.com/huggingface/smol-course/blob/main/es/4_evaluation/automatic_benchmarks.md",
"date": "2024-11-25T19:22:43",
"stars": 5481,
"description": "A course on aligning smol models.",
"file_size": 7376
}
|
# Evaluación Personalizada en un Dominio
Aunque los "benchmarks" estándares proporcionan conocimiento relevante, muchas aplicaciones requieren enfoques de evaluación especializados que se adapten a dominios específicos o a casos de uso particulares. Esta guía te ayudará a crear flujos de evaluación personalizados que evalúen con precisión el rendimiento de tu modelo en tu dominio objetivo.
## Diseñando Tu Estrategia de Evaluación
Una estrategia de evaluación personalizada exitosa comienza con objetivos claros. Es fundamental considerar qué capacidades específicas necesita demostrar tu modelo en tu dominio. Esto podría incluir conocimientos técnicos, patrones de razonamiento o formatos específicos del dominio. Documenta estos requisitos cuidadosamente; ellos guiarán tanto el diseño de tus tareas como la selección de métricas.
Tu evaluación debe probar tanto casos de uso estándar como casos límite. Por ejemplo, en un dominio médico, podrías evaluar tanto escenarios comunes de diagnóstico como condiciones raras. En aplicaciones financieras, podrías probar tanto transacciones rutinarias como casos complejos que involucren múltiples monedas o condiciones especiales.
## Implementación con LightEval
LightEval proporciona un marco flexible para implementar evaluaciones personalizadas. Así es como puedes crear una tarea personalizada:
```python
from lighteval.tasks import Task, Doc
from lighteval.metrics import SampleLevelMetric, MetricCategory, MetricUseCase
class CustomEvalTask(Task):
def __init__(self):
super().__init__(
name="custom_task",
version="0.0.1",
metrics=["accuracy", "f1"], # Tus métricas elegidas
description="Descripción de tu tarea de evaluación personalizada"
)
def get_prompt(self, sample):
# Formatea tu entrada en un "prompt"
return f"Question: {sample['question']}\nAnswer:"
def process_response(self, response, ref):
# Procesa el "output" del modelo y compáralo con la referencia
return response.strip() == ref.strip()
```
## Métricas Personalizadas
Las tareas específicas de dominio a menudo requieren métricas especializadas. LightEval proporciona un marco flexible para crear métricas personalizadas que capturen aspectos relevantes del rendimiento del dominio:
```python
from aenum import extend_enum
from lighteval.metrics import Metrics, SampleLevelMetric, SampleLevelMetricGrouping
import numpy as np
# Definir una función de métrica a nivel de muestra
def custom_metric(predictions: list[str], formatted_doc: Doc, **kwargs) -> dict:
"""Ejemplo de métrica que genera múltiples puntuaciones por muestra"""
response = predictions[0]
return {
"accuracy": response == formatted_doc.choices[formatted_doc.gold_index],
"length_match": len(response) == len(formatted_doc.reference)
}
# Crear una métrica que genere múltiples valores por muestra
custom_metric_group = SampleLevelMetricGrouping(
metric_name=["accuracy", "length_match"], # Nombres de submétricas
higher_is_better={ # define si valores más altos son mejores para cada métrica
"accuracy": True,
"length_match": True
},
category=MetricCategory.CUSTOM,
use_case=MetricUseCase.SCORING,
sample_level_fn=custom_metric,
corpus_level_fn={ # define cómo agregar cada métrica
"accuracy": np.mean,
"length_match": np.mean
}
)
# Registrar la métrica en LightEval
extend_enum(Metrics, "custom_metric_name", custom_metric_group)
```
Para casos más simples donde solo necesitas un valor por muestra:
```python
def simple_metric(predictions: list[str], formatted_doc: Doc, **kwargs) -> bool:
"""Ejemplo de métrica que genera una única puntuación por muestra"""
response = predictions[0]
return response == formatted_doc.choices[formatted_doc.gold_index]
simple_metric_obj = SampleLevelMetric(
metric_name="simple_accuracy",
higher_is_better=True,
category=MetricCategory.CUSTOM,
use_case=MetricUseCase.SCORING,
sample_level_fn=simple_metric,
corpus_level_fn=np.mean # define cómo agregar resultados entre muestras
)
extend_enum(Metrics, "simple_metric", simple_metric_obj)
```
Una vez definas tus métricas personalizadas, puedes usarlas luego en tus tareas de evaluación haciendo referencia a ellas en la configuración de la tarea. Las métricas se calcularán automáticamente en todas las muestras y se agregarán según las funciones que especifiques.
Para métricas más complejas, considera:
- Usar metadatos en tus documentos formateados para ponderar o ajustar puntuaciones
- Implementar funciones de agregación personalizadas para estadísticas a nivel de corpus
- Agregar verificaciones de validación para las entradas de tus métricas
- Documentar casos límite y comportamientos esperados
Para un ejemplo completo de métricas personalizadas en acción, consulta nuestro [proyecto de evaluación de dominio](./project/README.md).
## Creación de Conjuntos de Datos
La evaluación de alta calidad requiere conjuntos de datos cuidadosamente curados. Considera estos enfoques para la creación de conjuntos de datos:
1. **Anotación por Expertos**: Trabaja con expertos del dominio para crear y validar ejemplos de evaluación. Herramientas como [Argilla](https://github.com/argilla-io/argilla) hacen este proceso más eficiente.
2. **Datos del Mundo Real**: Recopila y anonimiza datos de uso real, asegurándote de que representen escenarios reales de despliegue del modelo.
3. **Generación Sintética**: Usa LLMs para generar ejemplos iniciales y luego permite que expertos los validen y refinen.
## Mejores Prácticas
- Documenta tu metodología de evaluación a fondo, incluidas los supuestos o limitaciones
- Incluye casos de prueba diversos que cubran diferentes aspectos de tu dominio
- Considera tanto métricas automatizadas como evaluaciones humanas donde sea apropiado
- Controla las versiones de tus conjuntos de datos y código de evaluación
- Actualiza regularmente tu conjunto de evaluaciones a medida que descubras nuevos casos límite o requisitos
## Referencias
- [Guía de Tareas Personalizadas en LightEval](https://github.com/huggingface/lighteval/wiki/Adding-a-Custom-Task)
- [Métricas Personalizadas en LightEval](https://github.com/huggingface/lighteval/wiki/Adding-a-New-Metric)
- [Documentación de Argilla](https://docs.argilla.io) para anotación de conjuntos de datos
- [Guía de Evaluación](https://github.com/huggingface/evaluation-guidebook) para principios generales de evaluación
# Próximos Pasos
⏩ Para un ejemplo completo de cómo implementar estos conceptos, consulta nuestro [proyecto de evaluación de dominio](./project/README.md).
|
{
"source": "huggingface/smol-course",
"title": "es/4_evaluation/custom_evaluation.md",
"url": "https://github.com/huggingface/smol-course/blob/main/es/4_evaluation/custom_evaluation.md",
"date": "2024-11-25T19:22:43",
"stars": 5481,
"description": "A course on aligning smol models.",
"file_size": 6722
}
|
# インストラクションチューニング
このモジュールでは、言語モデルのインストラクションチューニングのプロセスをガイドします。インストラクションチューニングとは、特定のタスクに対してモデルを適応させるために、特定のタスクに関連するデータセットで追加のトレーニングを行うことを指します。このプロセスは、特定のタスクにおけるモデルのパフォーマンスを向上させるのに役立ちます。
このモジュールでは、2つのトピックを探ります:1) チャットテンプレートと2) 教師あり微調整
## 1️⃣ チャットテンプレート
チャットテンプレートは、ユーザーとAIモデル間のインタラクションを構造化し、一貫性のある文脈に適した応答を保証します。これらのテンプレートには、システムメッセージや役割に基づくメッセージなどのコンポーネントが含まれます。詳細については、[チャットテンプレート](./chat_templates.md)セクションを参照してください。
## 2️⃣ 教師あり微調整
教師あり微調整(SFT)は、事前トレーニングされた言語モデルを特定のタスクに適応させるための重要なプロセスです。これは、ラベル付きの例を含む特定のタスクのデータセットでモデルをトレーニングすることを含みます。SFTの詳細なガイド、重要なステップ、およびベストプラクティスについては、[教師あり微調整](./supervised_fine_tuning.md)ページを参照してください。
## 演習ノートブック
| タイトル | 説明 | 演習 | リンク | Colab |
|--------|-------------|-----------|--------|-------|
| チャットテンプレート | SmolLM2を使用してチャットテンプレートを使用し、チャットml形式のデータセットを処理する方法を学びます | 🐢 `HuggingFaceTB/smoltalk`データセットをchatml形式に変換 <br> 🐕 `openai/gsm8k`データセットをchatml形式に変換 | [ノートブック](./notebooks/chat_templates_example.ipynb) | <a target="_blank" href="https://colab.research.google.com/github/huggingface/smol-course/blob/main/1_instruction_tuning/notebooks/chat_templates_example.ipynb"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a> |
| 教師あり微調整 | SFTTrainerを使用してSmolLM2を微調整する方法を学びます | 🐢 `HuggingFaceTB/smoltalk`データセットを使用 <br> 🐕 `bigcode/the-stack-smol`データセットを試す <br> 🦁 実際の使用ケースに関連するデータセットを選択 | [ノートブック](./notebooks/sft_finetuning_example.ipynb) | <a target="_blank" href="https://colab.research.google.com/github/huggingface/smol-course/blob/main/1_instruction_tuning/notebooks/sft_finetuning_example.ipynb"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a> |
## 参考文献
- [Transformersのチャットテンプレートに関するドキュメント](https://huggingface.co/docs/transformers/main/en/chat_templating)
- [TRLの教師あり微調整スクリプト](https://github.com/huggingface/trl/blob/main/examples/scripts/sft.py)
- [TRLの`SFTTrainer`](https://huggingface.co/docs/trl/main/en/sft_trainer)
- [直接選好最適化に関する論文](https://arxiv.org/abs/2305.18290)
- [TRLを使用した教師あり微調整](https://huggingface.co/docs/trl/main/en/tutorials/supervised_fine_tuning)
- [ChatMLとHugging Face TRLを使用したGoogle Gemmaの微調整方法](https://www.philschmid.de/fine-tune-google-gemma)
- [LLMを微調整してペルシャ語の商品カタログをJSON形式で生成する方法](https://huggingface.co/learn/cookbook/en/fine_tuning_llm_to_generate_persian_product_catalogs_in_json_format)
|
{
"source": "huggingface/smol-course",
"title": "ja/1_instruction_tuning/README.md",
"url": "https://github.com/huggingface/smol-course/blob/main/ja/1_instruction_tuning/README.md",
"date": "2024-11-25T19:22:43",
"stars": 5481,
"description": "A course on aligning smol models.",
"file_size": 2346
}
|
# チャットテンプレート
チャットテンプレートは、言語モデルとユーザー間のインタラクションを構造化するために不可欠です。これらは会話の一貫した形式を提供し、モデルが各メッセージの文脈と役割を理解し、適切な応答パターンを維持することを保証します。
## ベースモデル vs インストラクションモデル
ベースモデルは次のトークンを予測するために生のテキストデータでトレーニングされる一方、インストラクションモデルは特定の指示に従い会話に参加するように微調整されたモデルです。例えば、`SmolLM2-135M`はベースモデルであり、`SmolLM2-135M-Instruct`はその指示に特化したバリアントです。
ベースモデルをインストラクションモデルのように動作させるためには、モデルが理解できるようにプロンプトを一貫してフォーマットする必要があります。ここでチャットテンプレートが役立ちます。ChatMLは、システム、ユーザー、アシスタントの役割を明確に示すテンプレート形式で会話を構造化します。
ベースモデルは異なるチャットテンプレートで微調整される可能性があるため、インストラクションモデルを使用する際には、正しいチャットテンプレートを使用していることを確認する必要があります。
## チャットテンプレートの理解
チャットテンプレートの核心は、言語モデルと通信する際に会話がどのようにフォーマットされるべきかを定義することです。これには、システムレベルの指示、ユーザーメッセージ、およびアシスタントの応答が含まれ、モデルが理解できる構造化された形式で提供されます。この構造は、インタラクションの一貫性を維持し、モデルがさまざまな種類の入力に適切に応答することを保証します。以下はチャットテンプレートの例です:
```sh
<|im_end|>ユーザー
こんにちは!<|im_end|>
<|im_end|>アシスタント
はじめまして!<|im_end|>
<|im_end|>ユーザー
質問してもいいですか?<|im_end|>
<|im_end|>アシスタント
```
`transformers`ライブラリは、モデルのトークナイザーに関連してチャットテンプレートを自動的に処理します。`transformers`でチャットテンプレートがどのように構築されるかについて詳しくは[こちら](https://huggingface.co/docs/transformers/en/chat_templating#how-do-i-use-chat-templates)を参照してください。私たちはメッセージを正しい形式で構造化するだけで、残りはトークナイザーが処理します。以下は基本的な会話の例です:
```python
messages = [
{"role": "system", "content": "あなたは技術的なトピックに焦点を当てた役立つアシスタントです。"},
{"role": "user", "content": "チャットテンプレートとは何か説明できますか?"},
{"role": "assistant", "content": "チャットテンプレートは、ユーザーとAIモデル間の会話を構造化します..."}
]
```
上記の例を分解して、チャットテンプレート形式にどのようにマッピングされるかを見てみましょう。
## システムメッセージ
システムメッセージは、モデルの動作の基礎を設定します。これらは、以降のすべてのインタラクションに影響を与える持続的な指示として機能します。例えば:
```python
system_message = {
"role": "system",
"content": "あなたはプロフェッショナルなカスタマーサービスエージェントです。常に礼儀正しく、明確で、役立つようにしてください。"
}
```
## 会話
チャットテンプレートは、ユーザーとアシスタント間の以前のやり取りを保存し、会話の履歴を通じて文脈を維持します。これにより、複数ターンにわたる一貫した会話が可能になります:
```python
conversation = [
{"role": "user", "content": "注文に関して助けが必要です"},
{"role": "assistant", "content": "お手伝いします。注文番号を教えていただけますか?"},
{"role": "user", "content": "注文番号はORDER-123です"},
]
```
## Transformersを使用した実装
`transformers`ライブラリは、チャットテンプレートのための組み込みサポートを提供します。使用方法は以下の通りです:
```python
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("HuggingFaceTB/SmolLM2-135M-Instruct")
messages = [
{"role": "system", "content": "あなたは役立つプログラミングアシスタントです。"},
{"role": "user", "content": "リストをソートするPython関数を書いてください"},
]
# チャットテンプレートを適用
formatted_chat = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
```
## カスタムフォーマット
異なる役割に対して特別なトークンやフォーマットを追加するなど、さまざまなメッセージタイプのフォーマットをカスタマイズできます。例えば:
```python
template = """
<|system|>{system_message}
<|user|>{user_message}
<|assistant|>{assistant_message}
""".lstrip()
```
## マルチターン会話のサポート
テンプレートは、文脈を維持しながら複雑なマルチターン会話を処理できます:
```python
messages = [
{"role": "system", "content": "あなたは数学の家庭教師です。"},
{"role": "user", "content": "微積分とは何ですか?"},
{"role": "assistant", "content": "微積分は数学の一分野です..."},
{"role": "user", "content": "例を教えてください。"},
]
```
⏭️ [次へ: Supervised Fine-Tuning](./supervised_fine_tuning.md)
## リソース
- [Hugging Face Chat Templating Guide](https://huggingface.co/docs/transformers/main/en/chat_templating)
- [Transformers Documentation](https://huggingface.co/docs/transformers)
- [Chat Templates Examples Repository](https://github.com/chujiezheng/chat_templates)
|
{
"source": "huggingface/smol-course",
"title": "ja/1_instruction_tuning/chat_templates.md",
"url": "https://github.com/huggingface/smol-course/blob/main/ja/1_instruction_tuning/chat_templates.md",
"date": "2024-11-25T19:22:43",
"stars": 5481,
"description": "A course on aligning smol models.",
"file_size": 3297
}
|
# 教師あり微調整
教師あり微調整(SFT)は、事前トレーニングされた言語モデルを特定のタスクやドメインに適応させるための重要なプロセスです。事前トレーニングされたモデルは一般的な能力を持っていますが、特定のユースケースで優れたパフォーマンスを発揮するためにはカスタマイズが必要です。SFTは、慎重に選ばれた人間によって検証された例を含むデータセットを使用してモデルをトレーニングすることで、このギャップを埋めます。
## 教師あり微調整の理解
教師あり微調整の核心は、事前トレーニングされたモデルに特定のタスクを実行する方法を教えることです。これは、入力と出力の例を多数提示し、モデルが特定のユースケースのパターンを学習できるようにすることを含みます。
SFTは、事前トレーニング中に獲得した基本的な知識を活用しながら、モデルの動作を特定のニーズに合わせて調整するため、効果的です。
## 教師あり微調整を使用するタイミング
SFTを使用するかどうかの決定は、現在のモデルの能力と特定の要件とのギャップに依存します。SFTは、モデルの出力を正確に制御する必要がある場合や、専門的なドメインで作業する場合に特に価値があります。
例えば、カスタマーサービスアプリケーションを開発している場合、モデルが一貫して企業のガイドラインに従い、技術的な問い合わせを標準化された方法で処理することを望むかもしれません。同様に、医療や法律のアプリケーションでは、正確さと特定のドメインの用語に従うことが重要です。これらの場合、SFTはモデルの応答を専門的な基準とドメインの専門知識に合わせるのに役立ちます。
## 教師あり微調整(SFT)のプロセス
教師あり微調整のプロセスは、特定のタスクのデータセットでモデルの重みをトレーニングすることを含みます。
まず、ターゲットタスクを表すデータセットを準備または選択する必要があります。このデータセットには、モデルが直面するさまざまなシナリオをカバーする多様な例が含まれている必要があります。これらのデータの品質は重要です。各例は、モデルが生成することを望む出力の種類を示している必要があります。次に、微調整のフェーズがあり、ここでは`transformers`やHugging Faceの`trl`などのフレームワークを使用して、データセットでモデルをトレーニングします。
プロセス全体を通じて、継続的な評価が重要です。モデルが望ましい動作を学習していることを確認するために、検証セットでのパフォーマンスを監視する必要があります。これにより、モデルが一般的な能力を失うことなく、特定のタスクに適応していることを確認できます。[モジュール4](../4_evaluation)では、モデルの評価方法について詳しく説明します。
## 教師あり微調整の役割
SFTは、言語モデルを人間の好みに合わせる上で重要な役割を果たします。人間のフィードバックを使用した強化学習(RLHF)や直接選好最適化(DPO)などの技術は、SFTを使用してタスクの基本的な理解を形成し、その後、モデルの応答を望ましい結果にさらに合わせます。事前トレーニングされたモデルは、一般的な言語能力に優れているにもかかわらず、必ずしも人間の好みに一致する出力を生成するわけではありません。SFTは、特定のドメインのデータとガイダンスを導入することで、このギャップを埋め、モデルが人間の期待により密接に一致する応答を生成する能力を向上させます。
## トランスフォーマーの強化学習(TRL)を使用した教師あり微調整
教師あり微調整のための主要なソフトウェアパッケージは、トランスフォーマーの強化学習(TRL)です。TRLは、強化学習(RL)を使用してトランスフォーマーモデルをトレーニングするためのツールセットです。
Hugging FaceのTransformersライブラリに基づいており、ユーザーが事前トレーニングされた言語モデルを直接ロードできるようにし、ほとんどのデコーダーおよびエンコーダーデコーダーアーキテクチャと互換性があります。このライブラリは、教師あり微調整(SFT)、報酬モデリング(RM)、近接ポリシー最適化(PPO)、および直接選好最適化(DPO)など、言語モデリングで使用される主要なRLプロセスを容易にします。このリポジトリ全体で、さまざまなモジュールでTRLを使用します。
# 次のステップ
次のチュートリアルを試して、TRLを使用したSFTの実践的な経験を積んでください:
⏭️ [チャットテンプレートのチュートリアル](./notebooks/chat_templates_example.ipynb)
⏭️ [教師あり微調整のチュートリアル](./notebooks/supervised_fine_tuning_tutorial.ipynb)
|
{
"source": "huggingface/smol-course",
"title": "ja/1_instruction_tuning/supervised_fine_tuning.md",
"url": "https://github.com/huggingface/smol-course/blob/main/ja/1_instruction_tuning/supervised_fine_tuning.md",
"date": "2024-11-25T19:22:43",
"stars": 5481,
"description": "A course on aligning smol models.",
"file_size": 2056
}
|
# 選好の整合
このモジュールでは、言語モデルを人間の選好に合わせるための技術について説明します。教師あり微調整(SFT)がモデルにタスクを学習させるのに役立つ一方で、選好の整合は出力が人間の期待や価値観に一致するようにします。
## 概要
選好の整合の典型的な方法には、複数のステージが含まれます:
1. 教師あり微調整(SFT)でモデルを特定のドメインに適応させる。
2. 選好の整合(RLHFやDPOなど)で応答の質を向上させる。
ORPOのような代替アプローチは、指示調整と選好の整合を単一のプロセスに統合します。ここでは、DPOとORPOのアルゴリズムに焦点を当てます。
さまざまな整合技術について詳しく知りたい場合は、[Argillaのブログ](https://argilla.io/blog/mantisnlp-rlhf-part-8)を参照してください。
### 1️⃣ 直接選好最適化(DPO)
直接選好最適化(DPO)は、選好データを使用してモデルを直接最適化することで、選好の整合を簡素化します。このアプローチは、別個の報酬モデルや複雑な強化学習を必要とせず、従来のRLHFよりも安定して効率的です。詳細については、[直接選好最適化(DPO)のドキュメント](./dpo.md)を参照してください。
### 2️⃣ 選好確率比最適化(ORPO)
ORPOは、指示調整と選好の整合を単一のプロセスに統合する新しいアプローチを導入します。これは、負の対数尤度損失とトークンレベルのオッズ比項を組み合わせて標準的な言語モデリングの目的を修正します。このアプローチは、単一のトレーニングステージ、参照モデル不要のアーキテクチャ、および計算効率の向上を提供します。ORPOは、さまざまなベンチマークで印象的な結果を示しており、従来の方法と比較してAlpacaEvalで優れたパフォーマンスを示しています。詳細については、[選好確率比最適化(ORPO)のドキュメント](./orpo.md)を参照してください。
## 実習ノートブック
| タイトル | 説明 | 実習内容 | リンク | Colab |
|-------|-------------|----------|------|-------|
| DPOトレーニング | 直接選好最適化を使用してモデルを��レーニングする方法を学ぶ | 🐢 AnthropicのHH-RLHFデータセットを使用してモデルをトレーニングする<br>🐕 独自の選好データセットを使用する<br>🦁 さまざまな選好データセットとモデルサイズで実験する | [ノートブック](./notebooks/dpo_finetuning_example.ipynb) | <a target="_blank" href="https://colab.research.google.com/github/huggingface/smol-course/blob/main/2_preference_alignment/notebooks/dpo_finetuning_example.ipynb"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a> |
| ORPOトレーニング | 選好確率比最適化を使用してモデルをトレーニングする方法を学ぶ | 🐢 指示と選好データを使用してモデルをトレーニングする<br>🐕 損失の重みを変えて実験する<br>🦁 ORPOとDPOの結果を比較する | [ノートブック](./notebooks/orpo_finetuning_example.ipynb) | <a target="_blank" href="https://colab.research.google.com/github/huggingface/smol-course/blob/main/2_preference_alignment/notebooks/orpo_finetuning_example.ipynb"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a> |
## リソース
- [TRLのドキュメント](https://huggingface.co/docs/trl/index) - DPOを含むさまざまな整合技術を実装するためのTransformers Reinforcement Learning(TRL)ライブラリのドキュメント。
- [DPO論文](https://arxiv.org/abs/2305.18290) - 人間のフィードバックを用いた強化学習の代替として、選好データを使用して言語モデルを直接最適化するシンプルなアプローチを紹介する論文。
- [ORPO論文](https://arxiv.org/abs/2403.07691) - 指示調整と選好の整合を単一のトレーニングステージに統合する新しいアプローチを紹介する論文。
- [ArgillaのRLHFガイド](https://argilla.io/blog/mantisnlp-rlhf-part-8/) - RLHF、DPOなどのさまざまな整合技術とその実践的な実装について説明するガイド。
- [DPOに関するブログ記事](https://huggingface.co/blog/dpo-trl) - TRLライブラリを使用してDPOを実装する方法についての実践ガイド。コード例とベストプラクティスが含まれています。
- [TRLのDPOスクリプト例](https://github.com/huggingface/trl/blob/main/examples/scripts/dpo.py) - TRLライブラリを使用してDPOトレーニングを実装する方法を示す完全なスクリプト例。
- [TRLのORPOスクリプト例](https://github.com/huggingface/trl/blob/main/examples/scripts/orpo.py) - TRLライブラリを使用してORPOトレーニングを実装するためのリファレンス実装。詳細な設定オプションが含まれています。
- [Hugging Faceの整合ハンドブック](https://github.com/huggingface/alignment-handbook) - SFT、DPO、RLHFなどのさまざまな技術を使用して言語モデルを整合させるためのガイドとコード。
|
{
"source": "huggingface/smol-course",
"title": "ja/2_preference_alignment/README.md",
"url": "https://github.com/huggingface/smol-course/blob/main/ja/2_preference_alignment/README.md",
"date": "2024-11-25T19:22:43",
"stars": 5481,
"description": "A course on aligning smol models.",
"file_size": 2847
}
|
**直接選好最適化(DPO)**
直接選好最適化(DPO)は、言語モデルを人間の好みに合わせるための簡素化されたアプローチを提供します。従来のRLHF(人間のフィードバックを用いた強化学習)メソッドとは異なり、DPOは別個の報酬モデルや複雑な強化学習アルゴリズムを必要とせず、選好データを使用してモデルを直接最適化します。
## DPOの理解
DPOは、選好の整合を人間の選好データに基づく分類問題として再定義します。従来のRLHFアプローチでは、別個の報酬モデルをトレーニングし、PPO(近接ポリシー最適化)などの複雑なアルゴリズムを使用してモデルの出力を整合させる必要があります。DPOは、好ましい出力と好ましくない出力に基づいてモデルのポリシーを直接最適化する損失関数を定義することで、このプロセスを簡素化します。
このアプローチは実際に非常に効果的であり、Llamaなどのモデルのトレーニングに使用されています。別個の報酬モデルや強化学習のステージを必要としないため、DPOは選好の整合をよりアクセスしやすく、安定したものにします。
## DPOの仕組み
DPOのプロセスには、ターゲットドメインにモデルを適応させるための教師あり微調整(SFT)が必要です。これにより、標準的な指示追従データセットでトレーニングすることで、選好学習の基盤が形成されます。モデルは基本的なタスクを完了しながら、一般的な能力を維持することを学びます。
次に、選好学習が行われ、モデルは好ましい出力と好ましくない出力のペアでトレーニングされます。選好ペアは、モデルがどの応答が人間の価値観や期待に最も一致するかを理解するのに役立ちます。
DPOの中心的な革新は、その直接最適化アプローチにあります。別個の報酬モデルをトレーニングする代わりに、DPOはバイナリクロスエントロピー損失を使用して、選好データに基づいてモデルの重みを直接更新します。この簡素化されたプロセスにより、トレーニングがより安定し、効率的になり、従来のRLHFメソッドと同等またはそれ以上の結果が得られます。
## DPOのデータセット
DPOのデータセットは、通常、選好または非選好として注釈された応答ペアを含むように作成されます。これは手動で行うか、自動フィルタリング技術を使用して行うことができます。以下は、単一ターンのDPO選好データセットの構造の例です:
| プロンプト | 選好 | 非選好 |
|--------|---------|-----------|
| ... | ... | ... |
| ... | ... | ... |
| ... | ... | ... |
`Prompt`列には、`選好`および`非選好`の応答を生成するために使用されたプロンプトが含まれています。`選好`および`非選好`列には、それぞれ好ましい応答と好ましくない応答が含まれています。この構造にはバリエーションがあり、例えば、`system_prompt`や`Input`列に参照資料を含めることができます。`選好`および`非選好`の値は、単一ターンの会話の場合は文字列として、または会話リストとして表現されることがあります。
Hugging FaceでDPOデータセットのコレクションを[こちら](https://huggingface.co/collections/argilla/preference-datasets-for-dpo-656f0ce6a00ad2dc33069478)で見つけることができます。
## TRLを使用した実装
Transformers Reinforcement Learning(TRL)ライブラリは、DPOの実装を容易にします。`DPOConfig`および`DPOTrainer`クラスは、`transformers`スタイルのAPIに従います。
以下は、DPOトレーニングを設定する基本的な例です:
```python
from trl import DPOConfig, DPOTrainer
# 引数を定義
training_args = DPOConfig(
...
)
# トレーナーを初期化
trainer = DPOTrainer(
model,
train_dataset=dataset,
tokenizer=tokenizer,
...
)
# モデルをトレーニング
trainer.train()
```
DPOConfigおよびDPOTrainerクラスの使用方法の詳細については、[DPOチュートリアル](./notebooks/dpo_finetuning_example.ipynb)を参照してください。
## ベストプラクティス
データの品質は、DPOの成功した実装にとって重要です。選好データセットには、望ましい行動のさまざまな側面をカバーする多様な例が含まれている必要があります。明確な注釈ガイドラインは、選好および非選好の応答の一貫したラベル付けを保証します。選好データセットの品質を向上させることで、モデルのパフォーマンスを向上させることができます。例えば、より大きなデータセットをフィルタリングして、高品質の例やユースケースに関連する例のみを含めることができます。
トレーニング中は、損失の収束を慎重に監視し、保持データでパフォーマンスを検証します。選好学習とモデルの一般的な能力の維持をバランスさせるために、ベータパラメータを調整する必要がある場合があります。多様な例での定期的な評価は、モデルが望ましい選好を学習しながら過剰適合しないことを保証するのに役立ちます。
モデルの出力を基準モデルと比較して、選好の整合性の向上を確認します。さまざまなプロンプト、特にエッジケースを使用してモデルをテストすることで、さまざまなシナリオでの選好学習の堅牢性を保証します。
## 次のステップ
⏩ DPOの実践的な経験を得るために、[DPOチュートリアル](./notebooks/dpo_finetuning_example.ipynb)を試してみてください。この実践ガイドでは、データの準備からトレーニングおよび評価まで、選好整合の実装方法を説明します。
⏭️ チュートリアルを完了した後、別の選好整合技術について学ぶために[ORPOページ](./orpo.md)を探索してください。
|
{
"source": "huggingface/smol-course",
"title": "ja/2_preference_alignment/dpo.md",
"url": "https://github.com/huggingface/smol-course/blob/main/ja/2_preference_alignment/dpo.md",
"date": "2024-11-25T19:22:43",
"stars": 5481,
"description": "A course on aligning smol models.",
"file_size": 2749
}
|
**選好確率比最適化(ORPO)**
選好確率比最適化(ORPO)は、微調整と選好整合を単一の統合プロセスで組み合わせる新しいアプローチです。この統合アプローチは、従来のRLHFやDPOなどの方法と比較して、効率とパフォーマンスの面で利点を提供します。
## ORPOの理解
DPOのような選好整合方法は、通常、微調整と選好整合の2つの別々のステップを含みます。微調整はモデルを特定のドメインや形式に適応させ、選好整合は人間の選好に合わせて出力を調整します。SFT(教師あり微調整)は、モデルをターゲットドメインに適応させるのに効果的ですが、望ましい応答と望ましくない応答の両方の確率を増加させる可能性があります。ORPOは、以下の比較図に示すように、これらのステップを単一のプロセスに統合することで、この制限に対処します。

*モデル整合技術の比較*
## ORPOの仕組み
ORPOのトレーニングプロセスは、DPOと同様に、入力プロンプトと2つの応答(1つは選好、もう1つは非選好)を含む選好データセットを使用します。他の整合方法とは異なり、ORPOは選好整合を教師あり微調整プロセスに直接統合します。この統合アプローチにより、参照モデルが不要になり、計算効率とメモリ効率が向上し、FLOP数が減少します。
ORPOは、次の2つの主要なコンポーネントを組み合わせて新しい目的を作成します:
1. **SFT損失**:負の対数尤度損失を使用して、参照トークンの生成確率を最大化します。これにより、モデルの一般的な言語能力が維持されます。
2. **オッズ比損失**:望ましくない応答をペナルティし、選好される応答を報酬する新しいコンポーネントです。この損失関数は、トークンレベルで選好される応答と非選好の応答を効果的に対比するためにオッズ比を使用します。
これらのコンポーネントを組み合わせることで、モデルは特定のドメインに対して望ましい生成を適応させながら、非選好の応答を積極的に抑制します。オッズ比メカニズムは、選好された応答と拒否された応答の間のモデルの選好を測定および最適化する自然な方法を提供します。数学的な詳細については、[ORPO論文](https://arxiv.org/abs/2403.07691)を参照してください。実装の観点からORPOについて学びたい場合は、[TRLライブラリ](https://github.com/huggingface/trl/blob/b02189aaa538f3a95f6abb0ab46c0a971bfde57e/trl/trainer/orpo_trainer.py#L660)でORPO損失がどのように計算されるかを確認してください。
## パフォーマンスと結果
ORPOは、さまざまなベンチマークで印象的な結果を示しています。MT-Benchでは、さまざまなカテゴリで競争力のあるスコアを達成しています:

*MT-Benchのカテゴリ別結果(Mistral-ORPOモデル)*
他の整合方法と比較すると、ORPOはAlpacaEval 2.0で優れたパフォーマンスを示しています:

*さまざまな整合方法におけるAlpacaEval 2.0スコア*
SFT+DPOと比較して、ORPOは参照モデルが不要であり、バッチごとのフォワードパスの数を半減させることで計算要件を削減します。さらに、トレーニングプロセスは、さまざまなモデルサイズとデータセットでより安定しており、調整するハイパーパラメータが少なくて済みます。パフォーマンスに関しては、ORPOはより大きなモデルと同等のパフォーマンスを示しながら、人間の選好に対する整合性が向上しています。
## 実装
ORPOの成功した実装は、高品質の選好データに大きく依存します。トレーニングデータは明確な注釈ガイドラインに従い、さまざまなシナリオで好ましい応答と拒否された応答のバランスの取れた表現を提供する必要があります。
### TRLを使用した実装
ORPOは、Transformers Reinforcement Learning(TRL)ライブラリを使用して実装できます。以下は基本的な例です:
```python
from trl import ORPOConfig, ORPOTrainer
# ORPOトレーニングの設定
orpo_config = ORPOConfig(
learning_rate=1e-5,
per_device_train_batch_size=4,
gradient_accumulation_steps=4,
max_steps=1000,
orpo_alpha=1.0, # 選好最適化の強度を制御
orpo_beta=0.1, # オッズ比計算の温度パラメータ
)
# トレーナーを初期化
trainer = ORPOTrainer(
model=model,
args=orpo_config,
train_dataset=dataset,
tokenizer=tokenizer,
)
# トレーニングを開始
trainer.train()
```
考慮すべき主要なパラメータ:
- `orpo_alpha`:選好最適化の強度を制御
- `orpo_beta`:オッズ比計算の温度パラメータ
- `learning_rate`:忘却のカタストロフィーを避けるために比較的小さく設定
- `gradient_accumulation_steps`:トレーニングの安定性を向上
## 次のステップ
⏩ この統合された選好整合アプローチを実装するための[ORPOチュートリアル](./notebooks/orpo_tutorial.ipynb)を試してみてください。
## リソース
- [ORPO論文](https://arxiv.org/abs/2403.07691)
- [TRLドキュメント](https://huggingface.co/docs/trl/index)
- [ArgillaのRLHFガイド](https://argilla.io/blog/mantisnlp-rlhf-part-8/)
|
{
"source": "huggingface/smol-course",
"title": "ja/2_preference_alignment/orpo.md",
"url": "https://github.com/huggingface/smol-course/blob/main/ja/2_preference_alignment/orpo.md",
"date": "2024-11-25T19:22:43",
"stars": 5481,
"description": "A course on aligning smol models.",
"file_size": 2898
}
|
# パラメータ効率の良い微調整 (PEFT)
言語モデルが大きくなるにつれて、従来の微調整はますます困難になります。1.7Bパラメータのモデルの完全な微調整には、かなりのGPUメモリが必要であり、別々のモデルコピーを保存することが高価であり、モデルの元の能力を破壊的に忘れるリスクがあります。パラメータ効率の良い微調整(PEFT)メソッドは、モデルパラメータの小さなサブセットのみを変更し、ほとんどのモデルを固定したままにすることで、これらの課題に対処します。
従来の微調整は、トレーニング中にすべてのモデルパラメータを更新しますが、これは大規模なモデルには実用的ではありません。PEFTメソッドは、元のモデルサイズの1%未満のパラメータを使用してモデルを適応させるアプローチを導入します。この劇的な学習可能なパラメータの削減により、次のことが可能になります:
- 限られたGPUメモリを持つ消費者向けハードウェアでの微調整
- 複数のタスク固有の適応を効率的に保存
- 低データシナリオでのより良い一般化
- より速いトレーニングと反復サイクル
## 利用可能なメソッド
このモジュールでは、2つの人気のあるPEFTメソッドを紹介します:
### 1️⃣ LoRA (低ランク適応)
LoRAは、効率的なモデル適応のためのエレガントなソリューションを提供する最も広く採用されているPEFTメソッドとして浮上しました。モデル全体を変更する代わりに、**LoRAはモデルの注意層に学習可能な行列を注入します。**このアプローチは、通常、完全な微調整と比較して約90%の学習可能なパラメータを削減しながら、同等の性能を維持します。[LoRA (低ランク適応)](./lora_adapters.md)セクションでLoRAを詳しく見ていきます。
### 2️⃣ プロンプトチューニング
プロンプトチューニングは、モデルの重みを変更するのではなく、**入力に学習可能なトークンを追加する**さらに軽量なアプローチを提供します。プロンプトチューニングはLoRAほど人気はありませんが、モデルを新しいタスクやドメインに迅速に適応させるための便利な技術です。[プロンプトチューニング](./prompt_tuning.md)セクションでプロンプトチューニングを詳しく見ていきます。
## 演習ノートブック
| タイトル | 説明 | 演習 | リンク | Colab |
|-------|-------------|----------|------|-------|
| LoRA微調整 | LoRAアダプタを使用してモデルを微調整する方法を学ぶ | 🐢 LoRAを使用してモデルをトレーニング<br>🐕 異なるランク値で実験<br>🦁 完全な微調整と性能を比較 | [ノートブック](./notebooks/finetune_sft_peft.ipynb) | <a target="_blank" href="https://colab.research.google.com/github/huggingface/smol-course/blob/main/3_parameter_efficient_finetuning/notebooks/finetune_sft_peft.ipynb"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a> |
| LoRAアダプタの読み込み | トレーニングされたLoRAアダプタを読み込んで使用する方法を学ぶ | 🐢 事前学習されたアダプタを読み込む<br>🐕 アダプタをベースモデルと統合<br>🦁 複数のアダプタ間を切り替える | [ノートブック](./notebooks/load_lora_adapter.ipynb) | <a target="_blank" href="https://colab.research.google.com/github/huggingface/smol-course/blob/main/3_parameter_efficient_finetuning/notebooks/load_lora_adapter.ipynb"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a> |
<!-- | プロンプトチューニング | プロンプトチューニングを実装する方法を学ぶ | 🐢 ソフトプロンプトをトレーニング<br>🐕 異なる初期化戦略を比較<br>🦁 複数のタスクで評価 | [ノートブック](./notebooks/prompt_tuning_example.ipynb) | <a target="_blank" href="https://colab.research.google.com/github/huggingface/smol-course/blob/main/3_parameter_efficient_finetuning/notebooks/prompt_tuning_example.ipynb"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a> | -->
## リソース
- [PEFTドキュメント](https://huggingface.co/docs/peft)
- [LoRA論文](https://arxiv.org/abs/2106.09685)
- [QLoRA論文](https://arxiv.org/abs/2305.14314)
- [プロンプトチューニング論文](https://arxiv.org/abs/2104.08691)
- [Hugging Face PEFTガイド](https://huggingface.co/blog/peft)
- [2024年にHugging FaceでLLMを微調整する方法](https://www.philschmid.de/fine-tune-llms-in-2024-with-trl)
- [TRL](https://huggingface.co/docs/trl/index)
|
{
"source": "huggingface/smol-course",
"title": "ja/3_parameter_efficient_finetuning/README.md",
"url": "https://github.com/huggingface/smol-course/blob/main/ja/3_parameter_efficient_finetuning/README.md",
"date": "2024-11-25T19:22:43",
"stars": 5481,
"description": "A course on aligning smol models.",
"file_size": 2751
}
|
# LoRA (低ランク適応)
LoRAは最も広く採用されているPEFTメソッドとなっています。これは、注意重み行列に小さなランク分解行列を追加することで機能し、通常、学習可能なパラメータを約90%削減します。
## LoRAの理解
LoRA(低ランク適応)は、事前学習されたモデルの重みを固定し、学習可能なランク分解行列をモデルの層に注入するパラメータ効率の良い微調整技術です。微調整中にすべてのモデルパラメータを学習する代わりに、LoRAは低ランク分解を通じて重みの更新を小さな行列に分解し、学習可能なパラメータの数を大幅に削減しながらモデルの性能を維持します。例えば、GPT-3 175Bに適用した場合、LoRAは学習可能なパラメータを10,000倍、GPUメモリ要件を3倍削減しました。LoRAについての詳細は[LoRA論文](https://arxiv.org/pdf/2106.09685)を参照してください。
LoRAは、通常、注意重みに焦点を当てて、トランスフォーマーレイヤーにランク分解行列のペアを追加することで機能します。推論中に、これらのアダプタ重みはベースモデルと統合され、追加の遅延オーバーヘッドが発生しません。LoRAは、大規模な言語モデルを特定のタスクやドメインに適応させるのに特に役立ち、リソース要件を管理可能に保ちます。
## LoRAアダプタの読み込み
アダプタは、load_adapter()を使用して事前学習されたモデルに読み込むことができ、これは重みが統合されていない異なるアダプタを試すのに便利です。set_adapter()関数を使用してアクティブなアダプタ重みを設定します。ベースモデルに戻るには、unload()を使用してすべてのLoRAモジュールをアンロードできます。これにより、異なるタスク固有の重み間の切り替えが容易になります。
```python
from transformers import AutoModelForCausalLM
from peft import PeftModel
base_model = AutoModelForCausalLM.from_pretrained("<base_model_name>")
peft_model_id = "<peft_adapter_id>"
model = PeftModel.from_pretrained(base_model, peft_model_id)
```

## LoRAアダプタの統合
LoRAでトレーニングした後、アダプタ重みをベースモデルに統合して、デプロイを容易にすることができます。これにより、統合された重みを持つ単一のモデルが作成され、推論中にアダプタを別々に読み込む必要がなくなります。
統合プロセスには、メモリ管理と精度に注意が必要です。ベースモデルとアダプタ重みの両方を同時に読み込む必要があるため、十分なGPU/CPUメモリが利用可能であることを確認してください。`transformers`の`device_map="auto"`を使用すると、自動メモリ管理が容易になります。トレーニング中に使用した精度(例:float16)を一貫して維持し、統合されたモデルを同じ形式で保存してデプロイします。デプロイ前に、アダプタベースのバージョンと出力および性能メトリックを比較して、統合されたモデルを検証してください。
アダプタは、異なるタスクやドメイン間の切り替えにも便利です。ベースモデルとアダプタ重みを別々に読み込むことができます。これにより、異なるタスク固有の重み間の迅速な切り替えが可能になります。
## 実装ガイド
`notebooks/`ディレクトリには、さまざまなPEFTメソッドを実装するための実践的なチュートリアルと演習が含まれています。基本的な紹介には`load_lora_adapter_example.ipynb`を、LoRAとSFTを使用したモデルの微調整について詳しく知りたい場合は`lora_finetuning.ipynb`を参照してください。
PEFTメソッドを実装する際は、LoRAのランク値(4-8)を小さく設定し、トレーニング損失を監視します。検証セットを使用して過学習を防ぎ、可能であればフルファインチューニングのベースラインと結果を比較します。異なるメソッドの有効性はタスクによって異なるため、実験が重要です。
## OLoRA
[OLoRA](https://arxiv.org/abs/2406.01775)は、QR分解を使用してLoRAアダプタを初期化します。OLoRAは、QR分解の係数によってモデルのベース重みを変換します。つまり、トレーニングを行う前に重みを変換します。このアプローチは、安定性を大幅に向上させ、収束速度を加速し、最終的に優れた性能を達成します。
## TRLとPEFTの使用
PEFTメソッドは、TRL(Transformers Reinforcement Learning)と組み合わせて効率的な微調整を行うことができます。この統合は、RLHF(Reinforcement Learning from Human Feedback)に特に有用であり、メモリ要件を削減します。
```python
from peft import LoraConfig
from transformers import AutoModelForCausalLM
# PEFT設定でモデルを読み込む
lora_config = LoraConfig(
r=16,
lora_alpha=32,
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM"
)
# 特定のデバイスにモデルを読み込む
model = AutoModelForCausalLM.from_pretrained(
"your-model-name",
load_in_8bit=True, # オプション: 8ビット精度を使用
device_map="auto",
peft_config=lora_config
)
```
上記では、`device_map="auto"`を使用してモデルを自動的に適切なデバイスに割り当てました。また、`device_map={"": device_index}`を使用してモデルを特定のデバイスに手動で割り当てることもできます。メモリ使用量を効率的に保ちながら、複数のGPUにトレーニングをスケールすることもできます。
## 基本的な統合実装
LoRAアダプタをトレーニングした後、アダプタ重みをベースモデルに統合することができます。以下はその方法です:
```python
import torch
from transformers import AutoModelForCausalLM
from peft import PeftModel
# 1. ベースモデルを読み込む
base_model = AutoModelForCausalLM.from_pretrained(
"base_model_name",
torch_dtype=torch.float16,
device_map="auto"
)
# 2. アダプタを持つPEFTモデルを読み込む
peft_model = PeftModel.from_pretrained(
base_model,
"path/to/adapter",
torch_dtype=torch.float16
)
# 3. アダプタ重みをベースモデルと統合
try:
merged_model = peft_model.merge_and_unload()
except RuntimeError as e:
print(f"統合に失敗しました: {e}")
# フォールバック戦略またはメモリ最適化を実装
# 4. 統合されたモデルを保存
merged_model.save_pretrained("path/to/save/merged_model")
```
保存されたモデルのサイズに不一致がある場合は、トークナイザーも保存していることを確認してください:
```python
# モデルとトークナイザーの両方を保存
tokenizer = AutoTokenizer.from_pretrained("base_model_name")
merged_model.save_pretrained("path/to/save/merged_model")
tokenizer.save_pretrained("path/to/save/merged_model")
```
## 次のステップ
⏩ [プロンプトチューニング](prompt_tuning.md)ガイドに進み、プロンプトチューニングでモデルを微調整する方法を学びましょう。
⏩ [LoRAアダプタの読み込みチュートリアル](./notebooks/load_lora_adapter.ipynb)に進み、LoRAアダプタを読み込む方法を学びましょう。
# リソース
- [LORA: LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS](https://arxiv.org/pdf/2106.09685)
- [PEFTドキュメント](https://huggingface.co/docs/peft)
- [Hugging FaceのPEFTに関するブログ記事](https://huggingface.co/blog/peft)
|
{
"source": "huggingface/smol-course",
"title": "ja/3_parameter_efficient_finetuning/lora_adapters.md",
"url": "https://github.com/huggingface/smol-course/blob/main/ja/3_parameter_efficient_finetuning/lora_adapters.md",
"date": "2024-11-25T19:22:43",
"stars": 5481,
"description": "A course on aligning smol models.",
"file_size": 4189
}
|
# プロンプトチューニング
プロンプトチューニングは、モデルの重みではなく入力表現を変更するパラメータ効率の良いアプローチです。従来の微調整がすべてのモデルパラメータを更新するのに対し、プロンプトチューニングはベースモデルを固定したまま、少数の学習可能なトークンを追加して最適化します。
## プロンプトチューニングの理解
プロンプトチューニングは、学習可能な連続ベクトル(ソフトプロンプト)を入力テキストの前に追加するパラメータ効率の良い微調整方法です。従来の離散テキストプロンプトとは異なり、これらのソフトプロンプトはベースモデルを固定したまま、逆伝播を通じて学習されます。この方法は、["The Power of Scale for Parameter-Efficient Prompt Tuning"](https://arxiv.org/abs/2104.08691)(Lester et al., 2021)で紹介され、モデルサイズが大きくなるにつれてプロンプトチューニングがモデル微調整と競争力を持つようになることが示されました。論文内では、約100億パラメータのモデルで、プロンプトチューニングがモデル微調整の性能に匹敵し、タスクごとに数百のパラメータしか変更しないことが示されています。
これらのソフトプロンプトは、トレーニング中に最適化されるモデルの埋め込み空間内の連続ベクトルです。従来の自然言語トークンを使用する離散プロンプトとは異なり、ソフトプロンプトは固有の意味を持たず、勾配降下を通じて固定モデルから望ましい動作を引き出すことを学習します。この技術は、各タスクに対して小さなプロンプトベクトル(通常は数百パラメータ)を保存するだけで済むため、マルチタスクシナリオに特に効果的です。このアプローチは、最小限のメモリフットプリントを維持するだけでなく、モデルの再読み込みなしにプロンプトベクトルを交換するだけで迅速なタスク切り替えを可能にします。
## トレーニングプロセス
ソフトプロンプトは通常、8〜32トークンで構成され、ランダムに初期化するか、既存のテキストから初期化されます。初期化方法はトレーニングプロセスにおいて重要な役割を果たし、テキストベースの初期化はランダム初期化よりも優れた性能を発揮することがよくあります。
トレーニング中は、プロンプトパラメータのみが更新され、ベースモデルは固定されたままです。この集中アプローチは標準的なトレーニング目標を使用しますが、プロンプトトークンの学習率と勾配の挙動に注意を払う必要があります。
## PEFTを使用した実装
PEFTライブラリを使用すると、プロンプトチューニングの実装が簡単になります。以下は基本的な例です:
```python
from peft import PromptTuningConfig, TaskType, get_peft_model
from transformers import AutoModelForCausalLM, AutoTokenizer
# ベースモデルを読み込む
model = AutoModelForCausalLM.from_pretrained("your-base-model")
tokenizer = AutoTokenizer.from_pretrained("your-base-model")
# プロンプトチューニングを設定
peft_config = PromptTuningConfig(
task_type=TaskType.CAUSAL_LM,
num_virtual_tokens=8, # 学習可能なトークンの数
prompt_tuning_init="TEXT", # テキストから初期化
prompt_tuning_init_text="このテキストがポジティブかネガティブかを分類してください:",
tokenizer_name_or_path="your-base-model",
)
# プロンプトチューニング可能なモデルを作成
model = get_peft_model(model, peft_config)
```
## 他の方法との比較
他のPEFTアプローチと比較すると、プロンプトチューニングはその効率性で際立っています。LoRAは低パラメータ数とメモリ使用量を提供しますが、タスク切り替えにはアダプタの読み込みが必要です。プロンプトチューニングはさらに低いリソース使用量を達成し、即時のタスク切り替えを可能にします。対照的に、フルファインチューニングは多くのリソースを必要とし、異なるタスクごとに別々のモデルコピーが必要です。
| 方法 | パラメータ | メモリ | タスク切り替え |
|--------|------------|---------|----------------|
| プロンプトチューニング | 非常に低い | 最小限 | 簡単 |
| LoRA | 低い | 低い | 読み込みが必要 |
| フルファインチューニング | 高い | 高い | 新しいモデルコピー |
プロンプトチューニングを実装する際は、最初に少数の仮想トークン(8〜16)を使用し、タスクの複雑さが要求する場合にのみ増やします。タスクに関連するテキストを使用したテキスト初期化は、ランダム初期化よりも優れた結果をもたらすことがよくあります。初期化戦略は、ターゲットタスクの複雑さを反映する必要があります。
トレーニングには、フルファインチューニングとは異なる考慮事項が必要です。高い学習率が効果的なことが多いですが、プロンプトトークンの勾配を注意深く監視することが重要です。多様な例で定期的に検証することで、さまざまなシナリオでの堅牢な性能を確保します。
## 応用
プロンプトチューニングは、次のようなシナリオで優れた効果を発揮します:
1. マルチタスク展開
2. リソース制約のある環境
3. 迅速なタスク適応
4. プライバシーに敏感なアプリケーション
モデルが小さくなるにつれて、プロンプトチューニングはフルファインチューニングと比較して競争力が低下します。例えば、SmolLM2のようなモデルでは、プロンプトチューニングはフルファインチューニングよりも関連性が低くなります。
## 次のステップ
⏭️ [LoRAアダプタのチュートリアル](./notebooks/finetune_sft_peft.ipynb)に進み、LoRAアダプタでモデルを微調整する方法を学びましょう。
## リソース
- [PEFTドキュメント](https://huggingface.co/docs/peft)
- [プロンプトチューニング論文](https://arxiv.org/abs/2104.08691)
- [Hugging Face Cookbook](https://huggingface.co/learn/cookbook/prompt_tuning_peft)
|
{
"source": "huggingface/smol-course",
"title": "ja/3_parameter_efficient_finetuning/prompt_tuning.md",
"url": "https://github.com/huggingface/smol-course/blob/main/ja/3_parameter_efficient_finetuning/prompt_tuning.md",
"date": "2024-11-25T19:22:43",
"stars": 5481,
"description": "A course on aligning smol models.",
"file_size": 2982
}
|
# 評価
評価は、言語モデルの開発と展開において重要なステップです。評価は、モデルがさまざまな能力にわたってどれだけうまく機能するかを理解し、改善の余地を特定するのに役立ちます。このモジュールでは、標準ベンチマークとドメイン固有の評価アプローチの両方をカバーし、smolモデルを包括的に評価します。
Hugging Faceが開発した強力な評価ライブラリである[`lighteval`](https://github.com/huggingface/lighteval)を使用します。評価の概念とベストプラクティスについて詳しく知りたい場合は、評価[ガイドブック](https://github.com/huggingface/evaluation-guidebook)を参照してください。
## モジュール概要
徹底した評価戦略は、モデル性能の複数の側面を検討します。質問応答や要約などのタスク固有の能力を評価し、モデルがさまざまなタイプの問題にどれだけうまく対処できるかを理解します。出力の品質を一貫性や事実の正確性などの要素で測定します。安全性評価は、潜在的な有害な出力やバイアスを特定するのに役立ちます。最後に、ドメインの専門知識テストは、ターゲット分野でのモデルの専門知識を検証します。
## コンテンツ
### 1️⃣ [自動ベンチマーク](./automatic_benchmarks.md)
標準化されたベンチマークとメトリクスを使用してモデルを評価する方法を学びます。MMLUやTruthfulQAなどの一般的なベンチマークを探求し、主要な評価メトリクスと設定を理解し、再現可能な評価のベストプラクティスをカバーします。
### 2️⃣ [カスタムドメイン評価](./custom_evaluation.md)
特定のユースケースに合わせた評価パイプラインを作成する方法を学びます。カスタム評価タスクの設計、専門的なメトリクスの実装、要件に合った評価データセットの構築について説明します。
### 3️⃣ [ドメイン評価プロジェクト](./project/README.md)
ドメイン固有の評価パイプラインを構築する完全な例を紹介します。評価データセットの生成、データ注釈のためのArgillaの使用、標準化されたデータセットの作成、LightEvalを使用したモデルの評価方法を学びます。
### 演習ノートブック
| タイトル | 説明 | 演習 | リンク | Colab |
|-------|-------------|----------|------|-------|
| LLMの評価と分析 | LightEvalを使用して特定のドメインでモデルを評価および比較する方法を学びます | 🐢 医療ドメインタスクを使用してモデルを評価する <br> 🐕 異なるMMLUタスクで新しいドメイン評価を作成する <br> 🦁 ドメイン固有のカスタム評価タスクを作成する | [ノートブック](./notebooks/lighteval_evaluate_and_analyse_your_LLM.ipynb) | <a target="_blank" href="https://colab.research.google.com/github/huggingface/smol-course/blob/main/4_evaluation/notebooks/lighteval_evaluate_and_analyse_your_LLM.ipynb"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a> |
## リソース
- [評価ガイドブック](https://github.com/huggingface/evaluation-guidebook) - LLM評価の包括的なガイド
- [LightEvalドキュメント](https://github.com/huggingface/lighteval) - LightEvalライブラリの公式ドキュメント
- [Argillaドキュメント](https://docs.argilla.io) - Argillaアノテーションプラットフォームについて学ぶ
- [MMLU論文](https://arxiv.org/abs/2009.03300) - MMLUベンチマークを説明する論文
- [カスタムタスクの作成](https://github.com/huggingface/lighteval/wiki/Adding-a-Custom-Task)
- [カスタムメトリクスの作成](https://github.com/huggingface/lighteval/wiki/Adding-a-New-Metric)
- [既存のメトリクスの使用](https://github.com/huggingface/lighteval/wiki/Metric-List)
|
{
"source": "huggingface/smol-course",
"title": "ja/4_evaluation/README.md",
"url": "https://github.com/huggingface/smol-course/blob/main/ja/4_evaluation/README.md",
"date": "2024-11-25T19:22:43",
"stars": 5481,
"description": "A course on aligning smol models.",
"file_size": 2159
}
|
# 自動ベンチマーク
自動ベンチマークは、さまざまなタスクや能力にわたって言語モデルを評価するための標準化されたツールとして機能します。これらはモデルの性能を理解するための有用な出発点を提供しますが、包括的な評価戦略の一部に過ぎないことを認識することが重要です。
## 自動ベンチマークの理解
自動ベンチマークは通常、事前に定義されたタスクと評価指標を持つキュレーションされたデータセットで構成されます。これらのベンチマークは、基本的な言語理解から複雑な推論まで、モデルのさまざまな側面を評価することを目的としています。自動ベンチマークの主な利点はその標準化にあります。これにより、異なるモデル間で一貫した比較が可能となり、再現性のある結果が得られます。
ただし、ベンチマークの性能が必ずしも実世界での有効性に直結するわけではないことを理解することが重要です。学術的なベンチマークで優れた成績を収めたモデルでも、特定のドメインアプリケーションや実際のユースケースでは苦労することがあります。
## ベンチマークとその限界
### 一般知識ベンチマーク
MMLU(Massive Multitask Language Understanding)は、科学から人文科学まで57の科目にわたる知識をテストします。包括的ではありますが、特定のドメインに必要な専門知識の深さを反映しているわけではありません。TruthfulQAは、モデルが一般的な誤解を再現する傾向を評価しますが、すべての形態の誤情報を捉えることはできません。
### 推論ベンチマーク
BBH(Big Bench Hard)とGSM8Kは、複雑な推論タスクに焦点を当てています。BBHは論理的思考と計画をテストし、GSM8Kは特に数学的な問題解決を対象としています。これらのベンチマークは分析能力を評価するのに役立ちますが、実世界のシナリオで必要とされる微妙な推論を完全に捉えることはできません。
### 言語理解
HELMは包括的な評価フレームワークを提供し、WinoGrandeは代名詞の曖昧性解消を通じて常識をテストします。これらのベンチマークは言語処理能力に関する洞察を提供しますが、自然な会話やドメイン固有の用語の複雑さを完全に表現することはできません。
## 代替評価アプローチ
多くの組織は、標準ベンチマークの限界に対処するために代替評価方法を開発しています:
### LLM-as-Judge
ある言語モデルを使用して別のモデルの出力を評価する方法がますます人気を集めています。このアプローチは、従来の指標よりも微妙なフィードバックを提供することができますが、それ自体のバイアスと限界も伴います。
### 評価アリーナ
AnthropicのConstitutional AI Arenaのようなプラットフォームでは、モデルが相互に対話し、制御された環境で互いを評価することができます。これにより、従来のベンチマークでは明らかにならない強みと弱みが明らかになります。
### カスタムベンチマークスイート
組織は、特定のニーズやユースケースに合わせた内部ベンチマークスイートを開発することがよくあります。これには、ドメイン固有の知識テストや実際の展開条件を反映した評価シナリオが含まれることがあります。
## 独自の評価戦略の作成
LightEvalを使用して標準ベンチマークを実行するのは簡単ですが、ユースケースに特化した評価方法の開発にも時間を投資する必要があります。
標準ベンチマークは有用なベースラインを提供しますが、それだけが評価方法であってはなりません。より包括的なアプローチを開発する方法は次のとおりです:
1. 関連する標準ベンチマークから始めて、ベースラインを確立し、他のモデルとの比較を可能にします。
2. ユースケースの特定の要件と課題を特定します。モデルが実際に実行するタスクは何ですか?どのようなエラーが最も問題になりますか?
3. 実際のユースケースを反映したカスタム評価データセットを開発します。これには次のようなものが含まれるかもしれません:
- ドメインからの実際のユーザークエリ
- 遭遇した一般的なエッジケース
- 特に挑戦的なシナリオの例
4. 多層評価戦略の実装を検討します:
- クイックフィードバックのための自動指標
- 微妙な理解のための人間の評価
- 専門家によるレビュー
- 制御された環境でのA/Bテスト
## LightEvalを使用したベンチマーク
LightEvalタスクは特定の形式を使用して定義されます:
```
{suite}|{task}|{num_few_shot}|{auto_reduce}
```
- **suite**: ベンチマークスイート(例:'mmlu', 'truthfulqa')
- **task**: スイート内の特定のタスク(例:'abstract_algebra')
- **num_few_shot**: プロンプトに含める例の数(ゼロショットの場合は0)
- **auto_reduce**: プロンプトが長すぎる場合に少数ショットの例を自動的に削減するかどうか(0または1)
例:`"mmlu|abstract_algebra|0|0"`は、ゼロショット推論でMMLUの抽象代数学タスクを評価します。
### 評価パイプラインの例
特定のドメインに関連する自動ベンチマークの評価を設定して実行する完全な例を次に示します:
```python
from lighteval.tasks import Task, Pipeline
from transformers import AutoModelForCausalLM
# 評価するタスクを定義
domain_tasks = [
"mmlu|anatomy|0|0",
"mmlu|high_school_biology|0|0",
"mmlu|high_school_chemistry|0|0",
"mmlu|professional_medicine|0|0"
]
# パイプラインパラメータを設定
pipeline_params = {
"max_samples": 40, # 評価するサンプル数
"batch_size": 1, # 推論のバッチサイズ
"num_workers": 4 # ワーカープロセスの数
}
# 評価トラッカーを作成
evaluation_tracker = EvaluationTracker(
output_path="./results",
save_generations=True
)
# モデルを読み込み、パイプラインを作成
model = AutoModelForCausalLM.from_pretrained("your-model-name")
pipeline = Pipeline(
tasks=domain_tasks,
pipeline_parameters=pipeline_params,
evaluation_tracker=evaluation_tracker,
model=model
)
# 評価を実行
pipeline.evaluate()
# 結果を取得して表示
results = pipeline.get_results()
pipeline.show_results()
```
結果は次のような表形式で表示されます:
```
| Task |Version|Metric|Value | |Stderr|
|----------------------------------------|------:|------|-----:|---|-----:|
|all | |acc |0.3333|± |0.1169|
|leaderboard:mmlu:_average:5 | |acc |0.3400|± |0.1121|
|leaderboard:mmlu:anatomy:5 | 0|acc |0.4500|± |0.1141|
|leaderboard:mmlu:high_school_biology:5 | 0|acc |0.1500|± |0.0819|
```
結果をpandas DataFrameで処理し、視覚化や表現を自由に行うこともできます。
# 次のステップ
⏩ [カスタムドメイン評価](./custom_evaluation.md)を探索し、特定のニーズに合わせた評価パイプラインの作成方法を学びましょう
|
{
"source": "huggingface/smol-course",
"title": "ja/4_evaluation/automatic_benchmarks.md",
"url": "https://github.com/huggingface/smol-course/blob/main/ja/4_evaluation/automatic_benchmarks.md",
"date": "2024-11-25T19:22:43",
"stars": 5481,
"description": "A course on aligning smol models.",
"file_size": 3828
}
|
# カスタムドメイン評価
標準ベンチマークは貴重な洞察を提供しますが、多くのアプリケーションでは特定のドメインやユースケースに合わせた評価アプローチが必要です。このガイドでは、ターゲットドメインでモデルの性能を正確に評価するためのカスタム評価パイプラインを作成する方法を説明します。
## 評価戦略の設計
成功するカスタム評価戦略は、明確な目標から始まります。ドメインでモデルが示すべき具体的な能力を考慮してください。これには、技術的な知識、推論パターン、ドメイン固有の形式が含まれるかもしれません。これらの要件を慎重に文書化してください。これがタスク設計とメトリック選択の両方を導きます。
評価は、標準的なユースケースとエッジケースの両方をテストする必要があります。例えば、医療ドメインでは、一般的な診断シナリオと稀な状態の両方を評価するかもしれません。金融アプリケーションでは、通常の取引と複数の通貨や特別な条件を含む複雑なエッジケースの両方をテストするかもしれません。
## LightEvalを使用した実装
LightEvalは、カスタム評価を実装するための柔軟なフレームワークを提供します。カスタムタスクを作成する方法は次のとおりです:
```python
from lighteval.tasks import Task, Doc
from lighteval.metrics import SampleLevelMetric, MetricCategory, MetricUseCase
class CustomEvalTask(Task):
def __init__(self):
super().__init__(
name="custom_task",
version="0.0.1",
metrics=["accuracy", "f1"], # 選択したメトリック
description="カスタム評価タスクの説明"
)
def get_prompt(self, sample):
# 入力をプロンプトにフォーマット
return f"質問: {sample['question']}\n回答:"
def process_response(self, response, ref):
# モデルの出力を処理し、参照と比較
return response.strip() == ref.strip()
```
## カスタムメトリック
ドメイン固有のタスクには、専門的なメトリックが必要なことがよくあります。LightEvalは、ドメインに関連する性能の側面を捉えるカスタムメトリックを作成するための柔軟なフレームワークを提供します:
```python
from aenum import extend_enum
from lighteval.metrics import Metrics, SampleLevelMetric, SampleLevelMetricGrouping
import numpy as np
# サンプルレベルのメトリック関数を定義
def custom_metric(predictions: list[str], formatted_doc: Doc, **kwargs) -> dict:
"""サンプルごとに複数のスコアを返す例のメトリック"""
response = predictions[0]
return {
"accuracy": response == formatted_doc.choices[formatted_doc.gold_index],
"length_match": len(response) == len(formatted_doc.reference)
}
# サンプルごとに複数の値を返すメトリックを作成
custom_metric_group = SampleLevelMetricGrouping(
metric_name=["accuracy", "length_match"], # サブメトリックの名前
higher_is_better={ # 各メトリックで高い値が良いかどうか
"accuracy": True,
"length_match": True
},
category=MetricCategory.CUSTOM,
use_case=MetricUseCase.SCORING,
sample_level_fn=custom_metric,
corpus_level_fn={ # 各メトリックを集計する方法
"accuracy": np.mean,
"length_match": np.mean
}
)
# LightEvalにメトリックを登録
extend_enum(Metrics, "custom_metric_name", custom_metric_group)
```
サンプルごとに1つのメトリック値のみが必要な場合の簡単なケース:
```python
def simple_metric(predictions: list[str], formatted_doc: Doc, **kwargs) -> bool:
"""サンプルごとに単一のスコアを返す例のメトリック"""
response = predictions[0]
return response == formatted_doc.choices[formatted_doc.gold_index]
simple_metric_obj = SampleLevelMetric(
metric_name="simple_accuracy",
higher_is_better=True,
category=MetricCategory.CUSTOM,
use_case=MetricUseCase.SCORING,
sample_level_fn=simple_metric,
corpus_level_fn=np.mean # サンプル全体で集計する方法
)
extend_enum(Metrics, "simple_metric", simple_metric_obj)
```
カスタムメトリックを評価タスクで参照することで、評価タスクで自動的に計算され、指定された関数に従って集計されます。
より複雑なメトリックの場合、次のことを検討してください:
- フォーマットされたドキュメントのメタデータを使用してスコアを重み付けまたは調整
- コーパスレベルの統計のためのカスタム集計関数の実装
- メトリック入力の検証チェックの追加
- エッジケースと期待される動作の文書化
これらの概念を実装する完全な例については、[ドメイン評価プロジェクト](./project/README.md)を参照してください。
## データセットの作成
高品質の評価には、慎重にキュレーションされたデータセットが必要です。データセット作成のアプローチを次に示します:
1. 専門家のアノテーション:ドメインの専門家と協力して評価例を作成および検証します。[Argilla](https://github.com/argilla-io/argilla)のようなツールを使用すると、このプロセスがより効率的になります。
2. 実世界のデータ:実際の使用データを収集し、匿名化して、実際の展開シナリオを反映します。
3. 合成生成:LLMを使用して初期例を生成し、専門家がそれを検証および洗練します。
## ベストプラクティス
- 評価方法論を徹底的に文書化し、仮定や制限を含める
- ドメインのさまざまな側面をカバーする多様なテストケースを含める
- 自動メトリックと人間の評価の両方を適用する
- 評価データセットとコードをバージョン管理する
- 新しいエッジケースや要件を発見するたびに評価スイートを定期的に更新する
## 参考文献
- [LightEvalカスタムタスクガイド](https://github.com/huggingface/lighteval/wiki/Adding-a-Custom-Task)
- [LightEvalカスタムメトリック](https://github.com/huggingface/lighteval/wiki/Adding-a-New-Metric)
- データセットアノテーションのための[Argillaドキュメント](https://docs.argilla.io)
- 一般的な評価原則のための[評価ガイドブック](https://github.com/huggingface/evaluation-guidebook)
# 次のステップ
⏩ これらの概念を実装する完全な例については、[ドメイン評価プロジェクト](./project/README.md)を参照してください。
|
{
"source": "huggingface/smol-course",
"title": "ja/4_evaluation/custom_evaluation.md",
"url": "https://github.com/huggingface/smol-course/blob/main/ja/4_evaluation/custom_evaluation.md",
"date": "2024-11-25T19:22:43",
"stars": 5481,
"description": "A course on aligning smol models.",
"file_size": 3993
}
|
# ビジョン言語モデル
## 1. VLMの使用
ビジョン言語モデル(VLM)は、画像キャプション生成、視覚質問応答、マルチモーダル推論などのタスクを可能にするために、テキストと並行して画像入力を処理します。
典型的なVLMアーキテクチャは、視覚的特徴を抽出する画像エンコーダ、視覚的およびテキスト表現を整列させるプロジェクション層、およびテキストを処理または生成する言語モデルで構成されます。これにより、モデルは視覚要素と言語概念の間の接続を確立できます。
VLMは、使用ケースに応じてさまざまな構成で使用できます。ベースモデルは一般的なビジョン言語タスクを処理し、チャット最適化されたバリアントは会話型インタラクションをサポートします。一部のモデルには、視覚的証拠に基づいて予測を行うための追加コンポーネントや、物体検出などの特定のタスクに特化したコンポーネントが含まれています。
VLMの技術的な詳細と使用方法については、[VLMの使用](./vlm_usage.md)ページを参照してください。
## 2. VLMのファインチューニング
VLMのファインチューニングは、特定のタスクを実行するため、または特定のデータセットで効果的に動作するように、事前トレーニングされたモデルを適応させるプロセスです。このプロセスは、モジュール1および2で紹介されたように、教師ありファインチューニング、好みの最適化、またはその両方を組み合わせたハイブリッドアプローチなどの方法論に従うことができます。
コアツールと技術はLLMで使用されるものと似ていますが、VLMのファインチューニングには、画像のデータ表現と準備に特に注意を払う必要があります。これにより、モデルが視覚データとテキストデータの両方を効果的に統合および処理し、最適なパフォーマンスを発揮できるようになります。デモモデルであるSmolVLMは、前のモジュールで使用された言語モデルよりも大幅に大きいため、効率的なファインチューニング方法を探ることが重要です。量子化やPEFTなどの技術を使用することで、プロセスをよりアクセスしやすく、コスト効果の高いものにし、より多くのユーザーがモデルを試すことができます。
VLMのファインチューニングに関する詳細なガイダンスについては、[VLMのファインチューニング](./vlm_finetuning.md)ページを参照してください。
## 演習ノートブック
| タイトル | 説明 | 演習 | リンク | Colab |
|-------|-------------|----------|------|-------|
| VLMの使用 | 事前トレーニングされたVLMをさまざまなタスクに使用する方法を学ぶ | 🐢 画像を処理する<br>🐕 バッチ処理で複数の画像を処理する<br>🦁 ビデオ全体を処理する | [ノートブック](./notebooks/vlm_usage_sample.ipynb) | <a target="_blank" href="https://colab.research.google.com/github/huggingface/smol-course/blob/main/5_vision_language_models/notebooks/vlm_usage_sample.ipynb"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a> |
| VLMのファインチューニング | タスク固有のデータセットに対して事前トレーニングされたVLMをファインチューニングする方法を学ぶ | 🐢 基本的なデータセットを使用してファインチューニングする<br>🐕 新しいデータセットを試す<br>🦁 代替のファインチューニング方法を試す | [ノートブック](./notebooks/vlm_sft_sample.ipynb) | <a target="_blank" href="https://colab.research.google.com/github/huggingface/smol-course/blob/main/5_vision_language_models/notebooks/vlm_sft_sample.ipynb"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a> |
## 参考文献
- [Hugging Face Learn: Supervised Fine-Tuning VLMs](https://huggingface.co/learn/cookbook/fine_tuning_vlm_trl)
- [Hugging Face Learn: Supervised Fine-Tuning SmolVLM](https://huggingface.co/learn/cookbook/fine_tuning_smol_vlm_sft_trl)
- [Hugging Face Learn: Preference Optimization Fine-Tuning SmolVLM](https://huggingface.co/learn/cookbook/fine_tuning_vlm_dpo_smolvlm_instruct)
- [Hugging Face Blog: Preference Optimization for VLMs](https://huggingface.co/blog/dpo_vlm)
- [Hugging Face Blog: Vision Language Models](https://huggingface.co/blog/vlms)
- [Hugging Face Blog: SmolVLM](https://huggingface.co/blog/smolvlm)
- [Hugging Face Model: SmolVLM-Instruct](https://huggingface.co/HuggingFaceTB/SmolVLM-Instruct)
- [CLIP: Learning Transferable Visual Models from Natural Language Supervision](https://arxiv.org/abs/2103.00020)
- [Align Before Fuse: Vision and Language Representation Learning with Momentum Distillation](https://arxiv.org/abs/2107.07651)
|
{
"source": "huggingface/smol-course",
"title": "ja/5_vision_language_models/README.md",
"url": "https://github.com/huggingface/smol-course/blob/main/ja/5_vision_language_models/README.md",
"date": "2024-11-25T19:22:43",
"stars": 5481,
"description": "A course on aligning smol models.",
"file_size": 2929
}
|
# VLMファインチューニング
## 効率的なファインチューニング
### 量子化
量子化は、モデルの重みとアクティベーションの精度を低下させ、メモリ使用量を大幅に削減し、計算速度を向上させます。たとえば、`float32`から`bfloat16`に切り替えると、パラメータごとのメモリ要件が半分になり、パフォーマンスを維持できます。より積極的な圧縮のために、8ビットおよび4ビットの量子化を使用してメモリ使用量をさらに削減できますが、精度が若干低下する可能性があります。これらの技術は、モデルとオプティマイザの設定の両方に適用でき、リソースが限られたハードウェアでの効率的なトレーニングを可能にします。
### PEFT & LoRA
モジュール3で紹介されたように、LoRA(Low-Rank Adaptation)は、元のモデルの重みを固定したまま、コンパクトなランク分解行列を学習することに焦点を当てています。これにより、トレーニング可能なパラメータの数が大幅に削減され、リソース要件が大幅に削減されます。LoRAはPEFTと統合されることで、大規模モデルのファインチューニングを可能にし、トレーニング可能なパラメータの小さなサブセットのみを調整します。このアプローチは、タスク固有の適応に特に効果的であり、数十億のトレーニング可能なパラメータを数百万に削減しながらパフォーマンスを維持します。
### バッチサイズの最適化
ファインチューニングのバッチサイズを最適化するには、大きな値から始め、メモリ不足(OOM)エラーが発生した場合は減らします。`gradient_accumulation_steps`を増やして補い、複数の更新にわたって合計バッチサイズを実質的に維持します。さらに、`gradient_checkpointing`を有効にして、逆伝播中に中間状態を再計算することでメモリ使用量を削減し、計算時間を犠牲にしてアクティベーションメモリ要件を削減します。これらの戦略は、ハードウェアの利用を最大化し、メモリ制約を克服するのに役立ちます。
```python
from transformers import TrainingArguments
training_args = TrainingArguments(
output_dir="./fine_tuned_model", # モデルチェックポイントのディレクトリ
per_device_train_batch_size=4, # デバイスごとのバッチサイズ(GPU/TPU)
num_train_epochs=3, # トレーニングの総エポック数
learning_rate=5e-5, # 学習率
save_steps=1000, # 1000ステップごとにチェックポイントを保存
bf16=True, # トレーニングに混合精度を使用
gradient_checkpointing=True, # アクティベーションメモリ使用量を削減するために有効にする
gradient_accumulation_steps=16, # 16ステップにわたって勾配を蓄積
logging_steps=50 # 50ステップごとにメトリクスをログ
)
```
## **教師ありファインチューニング(SFT)**
教師ありファインチューニング(SFT)は、事前トレーニングされたビジョン言語モデル(VLM)を特定のタスクに適応させるために、画像と対応するテキストを含むラベル付きデータセットを活用するプロセスです。この方法は、視覚質問応答、画像キャプション生成、チャート解釈などのドメイン固有またはタスク固有の機能を実行するモデルの能力を向上させます。
### **概要**
SFTは、ベースモデルの一般的な能力が不足する場合に、特定のドメインや特定の問題を解決するためにVLMを専門化する必要がある場合に不可欠です。たとえば、モデルが独自の視覚的特徴やドメイン固有の用語に苦労する場合、SFTはラベル付きデータから学習することでこれらの領域に焦点を当てることができます。
SFTは非常に効果的ですが、いくつかの制限があります:
- **データ依存性**:タスクに合わせた高品質のラベル付きデータセットが必要です。
- **計算リソース**:大規模なVLMのファインチューニングはリソース集約的です。
- **過学習のリスク**:モデルがあまりにも狭くファインチューニングされると、一般化能力を失う可能性があります。
これらの課題にもかかわらず、SFTは特定のコンテキストでのモデルパフォーマンスを向上させるための強力な手法です。
### **使用方法**
1. **データ準備**:画像とテキストのペアを含むラベル付きデータセットから始めます。たとえば、チャート分析のタスクでは、`HuggingFaceM4/ChartQA`データセットにはチャート画像、クエリ、および簡潔な応答が含まれています。
2. **モデル設定**:タスクに適した事前トレーニングされたVLM(例:`HuggingFaceTB/SmolVLM-Instruct`)と、テキストと画像の入力を準備するためのプロセッサをロードします。モデルを教師あり学習に設定し、ハードウェアに適した設定を行います。
3. **ファインチューニングプロセス**:
- **データのフォーマット**:データセットをチャットボットのような形式に構造化し、システムメッセージ、ユーザークエリ、および対応する回答をペアにします。
- **トレーニング設定**:Hugging Faceの`TrainingArguments`やTRLの`SFTConfig`などのツールを使用してトレーニングパラメータを設定します。これには、バッチサイズ、学習率、およびリソース使用を最適化するための勾配蓄積ステップが含まれます。
- **最適化技術**:トレーニング中のメモリを節約するために**gradient checkpointing**を使用します。メモリ要件を削減し、計算速度を向上させるために量子化モデルを使用します。
- TRLライブラリの`SFTTrainer`トレーナーを使用して、トレーニングプロセスを簡素化します。
## 好みの最適化
好みの最適化、特に直接好みの最適化(DPO)は、ビジョン言語モデル(VLM)を人間の好みに合わせるためのトレーニング手法です。事前定義された指示に厳密に従うのではなく、モデルは人間が主観的に好む出力を優先することを学習します。このアプローチは、創造的な判断、微妙な推論、または許容される回答が異なるタスクに特に有用です。
### **概要**
好みの最適化は、主観的な人間の好みがタスクの成功にとって重要なシナリオに対処します。好みをエンコードしたデータセットでファインチューニングすることで、DPOはモデルの応答生成能力を強化し、ユーザーの期待に文脈的およびスタイル的に一致させます。この方法は、創造的な執筆、顧客との対話、または複数の選択肢があるシナリオなどのタスクに特に効果的です。
その利点にもかかわらず、好みの最適化にはいくつかの課題があります:
- **データ品質**:高品質の好みが注釈されたデータセットが必要であり、データ収集がボトルネックになることがあります。
- **複雑さ**:トレーニングには、好みのペアワイズサンプリングや計算リソースのバランスなどの高度なプロセスが含まれることがあります。
好みのデータセットは、候補出力間の明確な好みをキャプチャする必要があります。たとえば、データセットは質問と2つの応答(1つは好まれ、もう1つは受け入れられない)をペアにすることがあります。モデルは、完全に正しくなくても、より人間の判断に一致する好ましい応答を予測することを学習します。
### **使用方法**
1. **データセットの準備**
トレーニングには、好みがラベル付けされたデータセットが重要です。各例は通常、プロンプト(例:画像と質問)と2つの候補応答(1つは選択され、もう1つは拒否される)で構成されます。たとえば:
- **質問**:家族は何人ですか?
- **拒否**:画像には家族に関する情報はありません。
- **選択**:画像には18,000家族のユニオン組織のテーブル設定が表示されています。
データセットは、モデルに完全に正しくなくても、より人間の判断に一致する好ましい応答を優先することを教えます。
2. **モデル設定**
事前トレーニングされたVLMをロードし、DPOをサポートするHugging FaceのTRLライブラリと統合し、テキストと画像の入力を準備するためのプロセッサを使用します。モデルを教師あり学習に設定し、ハードウェアに適した設定を行います。
3. **トレーニングパイプライン**
トレーニングには、DPO固有のパラメータの設定が含まれます。プロセスの概要は次のとおりです:
- **データセットのフォーマット**:各サンプルをプロンプト、画像、および候補応答で構成します。
- **損失関数**:好みに基づく損失関数を使用して、好ましい出力を選択するようにモデルを最適化します。
- **効率的なトレーニング**:量子化、勾配蓄積、LoRAアダプタなどの技術を組み合わせて、メモリと計算を最適化します。
## リソース
- [Hugging Face Learn: Supervised Fine-Tuning VLMs](https://huggingface.co/learn/cookbook/fine_tuning_vlm_trl)
- [Hugging Face Learn: Supervised Fine-Tuning SmolVLM](https://huggingface.co/learn/cookbook/fine_tuning_smol_vlm_sft_trl)
- [Hugging Face Learn: Preference Optimization Fine-Tuning SmolVLM](https://huggingface.co/learn/cookbook/fine_tuning_vlm_dpo_smolvlm_instruct)
- [Hugging Face Blog: Preference Optimization for VLMs](https://huggingface.co/blog/dpo_vlm)
## 次のステップ
⏩ この統一アプローチを好みの最適化に実装するには、[vlm_finetune_sample.ipynb](./notebooks/vlm_finetune_sample.ipynb)を試してください。
|
{
"source": "huggingface/smol-course",
"title": "ja/5_vision_language_models/vlm_finetuning.md",
"url": "https://github.com/huggingface/smol-course/blob/main/ja/5_vision_language_models/vlm_finetuning.md",
"date": "2024-11-25T19:22:43",
"stars": 5481,
"description": "A course on aligning smol models.",
"file_size": 4727
}
|
# ビジュアル言語モデル
ビジュアル言語モデル(VLM)は、画像とテキストの間のギャップを埋め、画像キャプションの生成、視覚に基づく質問への回答、テキストと視覚データの関係の理解などの高度なタスクを可能にします。そのアーキテクチャは、両方のモダリティをシームレスに処理するように設計されています。
### アーキテクチャ
VLMは、画像処理コンポーネントとテキスト生成モデルを組み合わせて、統一された理解を実現します。主な要素は次のとおりです:

- **画像エンコーダ**:生の画像をコンパクトな数値表現に変換します。CLIPやビジョントランスフォーマー(ViT)などの事前トレーニングされたエンコーダが一般的に使用されます。
- **埋め込みプロジェクタ**:画像特徴をテキスト埋め込みと互換性のある空間にマッピングします。通常、密な層や線形変換を使用します。
- **テキストデコーダ**:マルチモーダル情報を翻訳して一貫したテキストを生成する言語生成コンポーネントです。LlamaやVicunaなどの生成モデルが例として挙げられます。
- **マルチモーダルプロジェクタ**:画像とテキストの表現をブレンドするための追加の層を提供します。LLaVAのようなモデルでは、2つのモダリティ間の強力な接続を確立するために重要です。
ほとんどのVLMは、事前トレーニングされた画像エンコーダとテキストデコーダを活用し、ペアになった画像テキストデータセットで追加のファインチューニングを行います。このアプローチにより、効率的なトレーニングが可能になり、モデルが効果的に一般化できるようになります。
### 使用方法

VLMは、さまざまなマルチモーダルタスクに適用されます。その適応性により、さまざまなドメインで異なるレベルのファインチューニングを行うことができます:
- **画像キャプション生成**:画像の説明を生成します。
- **視覚質問応答(VQA)**:画像の内容に関する質問に答えます。
- **クロスモーダル検索**:特定の画像に対応するテキストを見つける、またはその逆を行います。
- **クリエイティブなアプリケーション**:デザイン支援、アート生成、魅力的なマルチメディアコンテンツの作成などに役立ちます。

VLMのトレーニングとファインチューニングには、画像とテキストの注釈がペアになった高品質なデータセットが必要です。Hugging Faceの`transformers`ライブラリなどのツールを使用すると、事前トレーニングされたVLMに簡単にアクセスでき、カスタムファインチューニングのワークフローが簡素化されます。
### チャット形式
多くのVLMは、使いやすさを向上させるためにチャットボットのような形式で構造化されています。この形式には次の要素が含まれます:
- モデルの役割やコンテキストを設定する**システムメッセージ**(例:「あなたは視覚データを分析するアシスタントです」)。
- テキスト入力と関連する画像を組み合わせた**ユーザークエリ**。
- マルチモーダル分析から得られたテキスト出力を提供する**アシスタントの応答**。
この会話形式は直感的であり、特にカスタマーサービスや教育ツールなどのインタラクティブなアプリケーションにおいて、ユーザーの期待に沿ったものです。
フォーマットされた入力の例を次に示します:
```json
[
{
"role": "system",
"content": [{"type": "text", "text": "あなたはチャート画像の視覚データを解釈する専門のビジュアル言語モデルです..."}]
},
{
"role": "user",
"content": [
{"type": "image", "image": "<image_data>"},
{"type": "text", "text": "棒グラフの最高値は何ですか?"}
]
},
{
"role": "assistant",
"content": [{"type": "text", "text": "42"}]
}
]
```
**複数の画像やビデオの処理**
VLMは、入力構造を適応させることで、複数の画像やビデオを処理することもできます。ビデオの場合、フレームを抽出して個々の画像として処理し、時間順序を維持します。
## リソース
- [Hugging Face Blog: Vision Language Models](https://huggingface.co/blog/vlms)
- [Hugging Face Blog: SmolVLM](https://huggingface.co/blog/smolvlm)
## 次のステップ
⏩ SMOLVLMのさまざまな使用方法を試すには、[vlm_usage_sample.ipynb](./notebooks/vlm_usage_sample.ipynb)を試してください。
|
{
"source": "huggingface/smol-course",
"title": "ja/5_vision_language_models/vlm_usage.md",
"url": "https://github.com/huggingface/smol-course/blob/main/ja/5_vision_language_models/vlm_usage.md",
"date": "2024-11-25T19:22:43",
"stars": 5481,
"description": "A course on aligning smol models.",
"file_size": 2345
}
|
# 合成データセット
合成データは、実際の使用状況を模倣する人工的に生成されたデータです。データセットを拡張または強化することで、データの制限を克服することができます。合成データはすでにいくつかのユースケースで使用されていましたが、大規模な言語モデルは、言語モデルの事前および事後トレーニング、および評価のための合成データセットをより一般的にしました。
私たちは、検証済みの研究論文に基づいた迅速で信頼性が高くスケーラブルなパイプラインを必要とするエンジニアのための合成データとAIフィードバックのフレームワークである[`distilabel`](https://distilabel.argilla.io/latest/)を使用します。パッケージとベストプラクティスの詳細については、[ドキュメント](https://distilabel.argilla.io/latest/)を参照してください。
## モジュール概要
言語モデルの合成データは、インストラクション、嗜好、批評の3つの分類に分類できます。私たちは、インストラクションチューニングと嗜好調整のためのデータセットの生成に焦点を当てます。両方のカテゴリでは、既存のデータをモデルの批評とリライトで改善するための第3のカテゴリの側面もカバーします。

## コンテンツ
### 1. [インストラクションデータセット](./instruction_datasets.md)
インストラクションチューニングのためのインストラクションデータセットの生成方法を学びます。基本的なプロンプトを使用してインストラクションチューニングデータセットを作成する方法や、論文から得られたより洗練された技術を使用する方法を探ります。SelfInstructやMagpieのような方法を使用して、インコンテキスト学習のためのシードデータを使用してインストラクションチューニングデータセットを作成できます。さらに、EvolInstructを通じたインストラクションの進化についても探ります。[学び始める](./instruction_datasets.md)。
### 2. [嗜好データセット](./preference_datasets.md)
嗜好調整のための嗜好データセットの生成方法を学びます。セクション1で紹介した方法と技術を基に構築し、追加の応答を生成します。次に、EvolQualityプロンプトを使用して応答を改善する方法を学びます。最後に、スコアと批評を生成するUltraFeedbackプロンプトを探り、嗜好ペアを作成します。[学び始める](./preference_datasets.md)。
### 演習ノートブック
| タイトル | 説明 | 演習 | リンク | Colab |
|-------|-------------|----------|------|-------|
| インストラクションデータセット | インストラクションチューニングのためのデータセットを生成する | 🐢 インストラクションチューニングデータセットを生成する <br> 🐕 シードデータを使用してインストラクションチューニングのためのデータセットを生成する <br> 🦁 シードデータとインストラクションの進化を使用してインストラクションチューニングのためのデータセットを生成する | [リンク](./notebooks/instruction_sft_dataset.ipynb) | [Colab](https://githubtocolab.com/huggingface/smol-course/tree/main/6_synthetic_datasets/notebooks/instruction_sft_dataset.ipynb) |
| 嗜好データセット | 嗜好調整のためのデータセットを生成する | 🐢 嗜好調整データセットを生成する <br> 🐕 応答の進化を使用して嗜好調整のためのデータセットを生成する <br> 🦁 応答の進化と批評を使用して嗜好調整のためのデータセットを生成する | [リンク](./notebooks/preference_alignment_dataset.ipynb) | [Colab](https://githubtocolab.com/huggingface/smol-course/tree/main/6_synthetic_datasets/notebooks/preference_alignment_dataset.ipynb) |
## リソース
- [Distilabel Documentation](https://distilabel.argilla.io/latest/)
- [Synthetic Data Generator is UI app](https://huggingface.co/blog/synthetic-data-generator)
- [SmolTalk](https://huggingface.co/datasets/HuggingFaceTB/smoltalk)
- [Self-instruct](https://arxiv.org/abs/2212.10560)
- [Evol-Instruct](https://arxiv.org/abs/2304.12244)
- [Magpie](https://arxiv.org/abs/2406.08464)
- [UltraFeedback](https://arxiv.org/abs/2310.01377)
- [Deita](https://arxiv.org/abs/2312.15685)
|
{
"source": "huggingface/smol-course",
"title": "ja/6_synthetic_datasets/README.md",
"url": "https://github.com/huggingface/smol-course/blob/main/ja/6_synthetic_datasets/README.md",
"date": "2024-11-25T19:22:43",
"stars": 5481,
"description": "A course on aligning smol models.",
"file_size": 2472
}
|
# インストラクションデータセットの生成
[インストラクションチューニングの章](../1_instruction_tuning/README.md)では、教師あり微調整によるモデルの微調整について学びました。このセクションでは、SFTのためのインストラクションデータセットの生成方法を探ります。基本的なプロンプトを使用してインストラクションチューニングデータセットを作成する方法や、論文から得られたより洗練された技術を使用する方法を探ります。インストラクションチューニングデータセットは、SelfInstructやMagpieのような方法を使用して、インコンテキスト学習のためのシードデータを使用して作成できます。さらに、EvolInstructを通じたインストラクションの進化についても探ります。最後に、distilabelパイプラインを使用してインストラクションチューニングのためのデータセットを生成する方法を探ります。
## プロンプトからデータへ
合成データは一見複雑に見えますが、モデルから知識を抽出するための効果的なプロンプトを作成することに簡略化できます。つまり、特定のタスクのためのデータを生成する方法と考えることができます。課題は、データが多様で代表的であることを保証しながら、効果的にプロンプトを作成することです。幸いなことに、多くの論文がこの問題を探求しており、このコースではいくつかの有用なものを探ります。まずは、手動でプロンプトを作成して合成データを生成する方法を探ります。
### 基本的なプロンプト
基本的な例から始めましょう。[HuggingFaceTB/SmolLM2-1.7B-Instruct](https://huggingface.co/HuggingFaceTB/SmolLM2-1.7B-Instruct)モデルを`distilabel`ライブラリの`transformers`統合を使用してロードします。`TextGeneration`クラスを使用して合成`プロンプト`を生成し、それを使用して`completion`を生成します。
次に、`distilabel`ライブラリを使用してモデルをロードします。
```python
from distilabel.llms import TransformersLLM
from distilabel.steps.tasks import TextGeneration
llm = TransformersLLM(model="HuggingFaceTB/SmolLM2-1.7B-Instruct")
gen = TextGeneration(llm=llm)
gen.load()
```
!!! note
Distilabelは`llm`をメモリにロードするため、ノートブックで作業する場合は、メモリの問題を避けるために使用後に`gen.unload()`する必要があります。
次に、`llm`を使用してインストラクションチューニングのための`プロンプト`を生成します。
```python
next(gen.process([{"instruction": "Hugging Faceの小規模AIモデルに関するSmol-Courseについての質問を生成してください。"}]))
# Smol-Courseの目的は何ですか?
```
最後に、同じ`プロンプト`を入力として使用して`completion`を生成します。
```python
next(gen.process([{"instruction": "Smol-Courseの目的は何ですか?"}]))
# Smol-Courseはコンピュータサイエンスの概念を学ぶためのプラットフォームです。
```
素晴らしい!合成`プロンプト`と対応する`completion`を生成できました。このシンプルなアプローチをスケールアップして、より多くのデータを生成することができますが、データの品質はそれほど高くなく、コースやドメインのニュアンスを考慮していません。さらに、現在のコードを再実行すると、データがそれほど多様でないことがわかります。幸いなことに、この問題を解決する方法があります。
### SelfInstruct
SelfInstructは、シードデータセットに基づいて新しいインストラクションを生成するプロンプトです。このシードデータは単一のインストラクションやコンテキストの一部である場合があります。プロセスは、初期のシードデータのプールから始まります。言語モデルは、インコンテキスト学習を使用してこのシードデータに基づいて新しいインストラクションを生成するようにプロンプトされます。このプロンプトは[distilabelで実装されています](https://github.com/argilla-io/distilabel/blob/main/src/distilabel/steps/tasks/templates/self-instruct.jinja2)が、簡略化されたバージョンは以下の通りです:
```
# タスクの説明
与えられたAIアプリケーションが受け取ることができる{{ num_instructions }}のユーザークエリを開発してください。モデルのテキスト能力内で動詞と言語構造の多様性を強調してください。
# コンテキスト
{{ input }}
# 出力
```
これを使用するには、`llm`を[SelfInstructクラス](https://distilabel.argilla.io/dev/components-gallery/tasks/selfinstruct/)に渡す必要があります。[プロンプトからデータセクション](#prompt-to-data)のテキストをコンテキストとして使用し、新しいインストラクションを生成してみましょう。
```python
from distilabel.steps.tasks import SelfInstruct
self_instruct = SelfInstruct(llm=llm)
self_instruct.load()
context = "<prompt_to_data_section>"
next(self_instruct.process([{"input": text}]))["instructions"][0]
# 手動プロンプトを使用して合成データを生成するプロセスは何ですか?
```
生成されたインストラクションはすでにかなり良くなっており、実際のコンテンツやドメインに適しています。しかし、プロンプトを進化させることでさらに良くすることができます。
### EvolInstruct
EvolInstructは、入力インストラクションを進化させて、同じインストラクションのより良いバージョンにするプロンプト技術です。このより良いバージョンは、一連の基準に従って定義され、元のインストラクションに制約、深化、具体化、推論、または複雑化を追加します。このプロセスは、元のインストラクションのさまざまな進化を作成するために複数回繰り返すことができ、理想的には元のインストラクションのより良いバージョンに導きます。このプロンプトは[distilabelで実装されています](https://github.com/argilla-io/distilabel/tree/main/src/distilabel/steps/tasks/evol_instruct)が、簡略化されたバージョンは以下の通りです:
```
プロンプトリライターとして行動してください。
与えられたプロンプトを、より複雑なバージョンに書き換えてください。
以下の基準に基づいてプロンプトを複雑化してください:
{{ criteria }}
# プロンプト
{{ input }}
# 出力
```
これを使用するには、`llm`を[EvolInstructクラス](https://distilabel.argilla.io/dev/components-gallery/tasks/evolinstruct/)に渡す必要があります。[SelfInstructセクション](#selfinstruct)の合成プロンプトを入力として使用し、それをより良いバージョンに進化させてみましょう。この例では、1世代だけ進化させます。
```python
from distilabel.steps.tasks import EvolInstruct
evol_instruct = EvolInstruct(llm=llm, num_evolutions=1)
evol_instruct.load()
text = "手動プロンプトを使用して合成データを生成するプロセスは何ですか?"
next(evol_instruct.process([{"instruction": text}]))
# 手動プロンプトを使用して合成データを生成するプロセスは何ですか?
# そして、人工知能システムであるGPT4が機械学習アルゴリズムを使用して入力データを合成データに変換する方法は?
```
インストラクションはより複雑になりましたが、元の意味を失っています。したがって、進化させることは両刃の剣であり、生成するデータの品質に注意する必要があります。
### Magpie
Magpieは、言語モデルの自己回帰的要因と、インストラクションチューニングプロセス中に使用されていた[チャットテンプレート](../1_instruction_tuning/chat_templates.md)に依存する技術です。覚えているかもしれませんが、チャットテンプレートは、システム、ユーザー、アシスタントの役割を明確に示す形式で会話を構造化します。インストラクションチューニングフェーズ中に、言語モデルはこの形式を再現するように最適化されており、Magpieはそれを利用します。チャットテンプレートに基づいた事前クエリプロンプトから始めますが、ユーザーメッセージインジケーター、例:<|im_end|>ユーザー\nの前で停止し、その後、言語モデルを使用してユーザープロンプトを生成し、アシスタントインジケーター、例:<|im_end|>まで生成します。このアプローチにより、多くのデータを非常に効率的に生成でき、マルチターンの会話にもスケールアップできます。この生成されたデータは、使用されたモデルのインストラクションチューニングフェーズのトレーニングデータを再現すると仮定されています。
このシナリオでは、プロンプトテンプレートはチャットテンプレート形式に基づいているため、モデルごとに異なります。しかし、プロセスをステップバイステップで簡略化して説明できます。
```bash
# ステップ1:事前クエリプロンプトを提供する
<|im_end|>ユーザー\n
# ステップ2:言語モデルがユーザープロンプトを生成する
<|im_end|>ユーザー\n
Smol-Courseの目的は何ですか?
# ステップ3:生成を停止する
<|im_end|>
```
distilabelで使用するには、`llm`を[Magpieクラス](https://distilabel.argilla.io/dev/components-gallery/tasks/magpie/)に渡す必要があります。
```python
from distilabel.steps.tasks import Magpie
magpie = Magpie(llm=llm)
magpie.load()
next(magpie.process([{"system_prompt": "あなたは役立つアシスタントです。"}]))
# [{
# "role": "user",
# "content": "トップ3の大学のリストを提供できますか?"
# },
# {
# "role": "assistant",
# "content": "トップ3の大学は:MIT、イェール、スタンフォードです。"
# }]
```
すぐに`プロンプト`と`completion`を含むデータセットが得られます。ドメインに特化したパフォーマンスを向上させるために、`system_prompt`に追加のコンテキストを挿入できます。LLMが特定のドメインデータを生成するために、システムプロンプトでユーザーのクエリがどのようなものかを説明することが役立ちます。これは、ユーザープロンプトを生成する前の事前クエリプロンプトで使用され、LLMがそのドメインのユーザークエリを生成するようにバイアスをかけます。
```
あなたは数学の問題を解決するためにユーザーを支援するAIアシスタントです。
```
システムプロンプトに追加のコンテキストを渡すことは、一般的に言語モデルが最適化されていないため、カスタマイズには他の技術ほど効果的ではないことが多いです。
### プロンプトからパイプラインへ
これまで見てきたクラスはすべて、パイプラインで使用できるスタンドアロンのクラスです。これは良いスタートですが、`Pipeline`クラスを使用してデータセットを生成することでさらに良くすることができます。`TextGeneration`ステップを使用してインストラクションチューニングのための合成データセットを生成します。パイプラインは、データをロードするための`LoadDataFromDicts`ステップ、`プロンプト`を生成するための`TextGeneration`ステップ、およびそのプロンプトの`completion`を生成するためのステップで構成されます。ステップを接続し、`>>`演算子を使用してデータをパイプラインに流します。distilabelの[ドキュメント](https://distilabel.argilla.io/dev/components-gallery/tasks/textgeneration/#input-output-columns)には、ステップの入力および出力列に関する情報が記載されています。データがパイプラインを正しく流れるようにするために、`output_mappings`パラメータを使用して出力列を次のステップの入力列にマッピングします。
```python
from distilabel.llms import TransformersLLM
from distilabel.pipeline import Pipeline
from distilabel.steps import LoadDataFromDicts
from distilabel.steps.tasks import TextGeneration
with Pipeline() as pipeline:
data = LoadDataFromDicts(data=[{"instruction": "Hugging Faceの小規模AIモデルに関するSmol-Courseについての短い質問を生成してください。"}])
llm = TransformersLLM(model="HuggingFaceTB/SmolLM2-1.7B-Instruct")
gen_a = TextGeneration(llm=llm, output_mappings={"generation": "instruction"})
gen_b = TextGeneration(llm=llm, output_mappings={"generation": "response"})
data >> gen_a >> gen_b
if __name__ == "__main__":
distiset = pipeline.run(use_cache=False)
print(distiset["default"]["train"][0])
# [{
# "instruction": "Smol-Courseの目的は何ですか?",
# "response": "Smol-Courseはコンピュータサイエンスの概念を学ぶためのプラットフォームです。"
# }]
```
このパイプラインの背後には多くのクールな機能があります。生成結果を自動的にキャッシュするため、生成ステップを再実行する必要がありません。フォールトトレランスが組み込まれており、生成ステップが失敗してもパイプラインは実行を続けます。また、すべての生成ステップを並行して実行するため、生成が高速です。`draw`メソッドを使用してパイプラインを視覚化することもできます。ここでは、データがパイプラインをどのように流れ、`output_mappings`が出力列を次のステップの入力列にどのようにマッピングするかを確認できます。

## ベストプラクティス
- 多様なシードデータを確保して、さまざまなシナリオをカバーする
- 生成されたデータが多様で高品質であることを定期的に評価する
- データの品質を向上させるために(システム)プロンプトを繰り返し改善する
## 次のステップ
👨🏽💻 コード - [演習ノートブック](./notebooks/instruction_sft_dataset.ipynb)でインストラクションチューニングのためのデータセットを生成する
🧑🏫 学ぶ - [preference datasetsの生成](./preference_datasets.md)について学ぶ
## 参考文献
- [Distilabel Documentation](https://distilabel.argilla.io/latest/)
- [Self-instruct](https://arxiv.org/abs/2212.10560)
- [Evol-Instruct](https://arxiv.org/abs/2304.12244)
- [Magpie](https://arxiv.org/abs/2406.08464)
|
{
"source": "huggingface/smol-course",
"title": "ja/6_synthetic_datasets/instruction_datasets.md",
"url": "https://github.com/huggingface/smol-course/blob/main/ja/6_synthetic_datasets/instruction_datasets.md",
"date": "2024-11-25T19:22:43",
"stars": 5481,
"description": "A course on aligning smol models.",
"file_size": 7740
}
|
# 嗜好データセットの生成
[嗜好調整の章](../2_preference_alignment/README.md)では、直接嗜好最適化について学びました。このセクションでは、DPOのような方法のための嗜好データセットを生成する方法を探ります。[インストラクションデータセットの生成](./instruction_datasets.md)で紹介した方法を基に構築します。さらに、基本的なプロンプトを使用してデータセットに追加の完了を追加する方法や、EvolQualityを使用して応答の品質を向上させる方法を示します。最後に、UltraFeedbackを使用してスコアと批評を生成する方法を示します。
## 複数の完了を作成する
嗜好データは、同じ`インストラクション`に対して複数の`完了`を持つデータセットです。モデルにプロンプトを与えて追加の`完了`を生成することで、データセットにより多くの`完了`を追加できます。この際、2つ目の完了が全体的な品質や表現において最初の完了とあまり似ていないことを確認する必要があります。これは、モデルが明確な嗜好に最適化される必要があるためです。通常、`選ばれた`と`拒否された`と呼ばれる完了のどちらが好まれるかを知りたいのです。[スコアの作成セクション](#creating-scores)で、選ばれた完了と拒否された完了を決定する方法について詳しく説明します。
### モデルプーリング
異なるモデルファミリーからモデルを使用して2つ目の完了を生成することができます。これをモデルプーリングと呼びます。2つ目の完了の品質をさらに向上させるために、`温度`を調整するなど、異なる生成引数を使用することができます。最後に、異なるプロンプトテンプレートやシステムプロンプトを使用して2つ目の完了を生成し、特定の特性に基づいて多様性を確保することができます。理論的には、異なる品質の2つのモデルを使用し、より良いものを`選ばれた`完了として使用することができます。
まず、[Qwen/Qwen2.5-1.5B-Instruct](https://huggingface.co/Qwen/Qwen2.5-1.5B-Instruct)と[HuggingFaceTB/SmolLM2-1.7B-Instruct](https://huggingface.co/HuggingFaceTB/SmolLM2-1.7B-Instruct)モデルを`transformers`統合の`distilabel`ライブラリを使用してロードします。これらのモデルを使用して、与えられた`プロンプト`に対して2つの合成`応答`を作成します。`LoadDataFromDicts`、`TextGeneration`、および`GroupColumns`を使用して別のパイプラインを作成します。最初にデータをロードし、次に2つの生成ステップを使用し、最後に結果をグループ化します。ステップを接続し、`>>`演算子と`[]`を使用してデータをパイプラインに流します。これは、前のステップの出力を次のステップの入力として使用することを意味します。
```python
from distilabel.llms import TransformersLLM
from distilabel.pipeline import Pipeline
from distilabel.steps import GroupColumns, LoadDataFromDicts
from distilabel.steps.tasks import TextGeneration
with Pipeline() as pipeline:
data = LoadDataFromDicts(data=[{"instruction": "合成データとは何ですか?"}])
llm_a = TransformersLLM(model="HuggingFaceTB/SmolLM2-1.7B-Instruct")
gen_a = TextGeneration(llm=llm_a)
llm_b = TransformersLLM(model="Qwen/Qwen2.5-1.5B-Instruct")
gen_b = TextGeneration(llm=llm_b)
group = GroupColumns(columns=["generation"])
data >> [gen_a, gen_b] >> group
if __name__ == "__main__":
distiset = pipeline.run()
print(distiset["default"]["train"]["grouped_generation"][0])
# {[
# '合成データは、実際の使用状況を模倣する人工的に生成されたデータです。',
# '合成データとは、人工的に生成されたデータを指します。'
# ]}
```
ご覧のとおり、与えられた`プロンプト`に対して2つの合成`完了`があります。生成ステップを特定の`システムプロンプト`で初期化するか、`TransformersLLM`に生成引数を渡すことで、多様性をさらに向上させることができます。次に、EvolQualityを使用して`完了`の品質を向上させる方法を見てみましょう。
### EvolQuality
EvolQualityは、[EvolInstruct](./instruction_datasets.md#evolinstruct)に似ていますが、入力`プロンプト`の代わりに`完了`を進化させます。このタスクは、`プロンプト`と`完了`の両方を受け取り、一連の基準に基づいて`完了`をより良いバージョンに進化させます。このより良いバージョンは、役立ち度、関連性、深化、創造性、または詳細の基準に基づいて定義されます。これにより、データセットに追加の`完了`を自動的に生成できます。理論的には、進化したバージョンが元の完了よりも優れていると仮定し、それを`選ばれた`完了として使用することができます。
プロンプトは[distilabelで実装されています](https://github.com/argilla-io/distilabel/tree/main/src/distilabel/steps/tasks/evol_quality)が、簡略化されたバージョンは以下の通りです:
```bash
応答リライターとして行動してください。
与えられたプロンプトと応答を、より良いバージョンに書き換えてください。
以下の基準に基づいてプロンプトを複雑化してください:
{{ criteria }}
# プロンプト
{{ input }}
# 応答
{{ output }}
# 改善された応答
```
これを使用するには、[EvolQualityクラス](https://distilabel.argilla.io/dev/components-gallery/tasks/evolquality/)に`llm`を渡す必要があります。[モデルプーリングセクション](#model-pooling)の合成`プロンプト`と`完了`を使用して、より良いバージョンに進化させてみましょう。この例では、1世代だけ進化させます。
```python
from distilabel.llms import TransformersLLM
from distilabel.steps.tasks import EvolQuality
llm = TransformersLLM(model="HuggingFaceTB/SmolLM2-1.7B-Instruct")
evol_quality = EvolQuality(llm=llm, num_evolutions=1)
evol_quality.load()
instruction = "合成データとは何ですか?"
completion = "合成データは、実際の使用状況を模倣する人工的に生成されたデータです。"
next(evol_quality.process([{
"instruction": instruction,
"response": completion
}]))
# 手動プロンプトを使用して合成データを生成するプロセスは何ですか?
```
`応答`はより複雑で、`インストラクション`に特化しています。これは良いスタートですが、EvolInstructで見たように、進化した生成物が常に優れているわけではありません。したがって、データセットの品質を確保するために追加の評価技術を使用することが重要です。次のセクションでこれを探ります。
## スコアの作成
スコアは、ある応答が他の応答よりもどれだけ好まれるかを測定するものです。一般的に、これらのスコアは絶対的、主観的、または相対的です。このコースでは、最初の2つに焦点を当てます。これらは嗜好データセットの作成に最も価値があるためです。このスコアリングは、評価技術と重なる部分があり、[評価の章](../3_evaluation/README.md)で見たように、通常はより大きなモデルが必要です。
### UltraFeedback
UltraFeedbackは、与えられた`プロンプト`とその`完了`に対してスコアと批評を生成する技術です。
スコアは、一連の基準に基づいて`完了`の品質を評価します。基準には、`役立ち度`、`関連性`、`深化`、`創造性`の4つの細かい基準があります。これらは便利ですが、一般的には全体的な基準を使用するのが良いスタートです。これにより、スコアの生成プロセスが簡略化されます。スコアは、どの`完了`が`選ばれた`もので、どれが`拒否された`ものであるかを決定するために使用できます。絶対的なスコアであるため、データセットの外れ値を見つけるための興味深いフィルターとしても使用できます。たとえば、最悪の完了や差が大きいペアを見つけることができます。
批評はスコアの理由を提供するために追加されます。これにより、スコアの違いを理解するための追加のコンテキストが提供されます。言語モデルは広範な批評を生成しますが、これは非常に便利ですが、スコアを表す単一のトークンを生成するよりもコストと複雑さが増します。
プロンプトは[distilabelで実装されています](https://github.com/argilla-io/distilabel/tree/main/src/distilabel/steps/tasks/templates/ultrafeedback)が、簡略化されたバージョンは以下の通りです:
```bash
モデルの出力をさまざまな基準に基づいて評価してください:役立ち度、関連性、深化、創造性
上記の要因に基づいて全体的な評価を提供する役割を果たします。
出力の全体的な品質を1から5のスコアで評価してください。
以下の形式で回答してください:スコア - 理由
# 入力
{{ input }}
# 応答
{{ output }}
# スコア - 理由
```
これを使用するには、[UltraFeedbackクラス](https://distilabel.argilla.io/dev/components-gallery/tasks/ultrafeedback/)に`llm`を渡す必要があります。[モデルプーリングセクション](#model-pooling)の合成`プロンプト`と`完了`を評価してみましょう。
```python
from distilabel.llms import TransformersLLM
from distilabel.steps.tasks import UltraFeedback
llm = TransformersLLM(model="HuggingFaceTB/SmolLM2-1.7B-Instruct")
ultrafeedback = UltraFeedback(llm=llm)
ultrafeedback.load()
instruction = "合成データとは何ですか?"
completion_a = "合成データは、実際の使用状況を模倣する人工的に生成されたデータです。"
completion_b = "合成データとは、人工的に生成されたデータを指します。"
next(ultrafeedback.process([{
"instruction": instruction,
"generations": [completion_a, completion_b]
}]))
# [
# {
# 'ratings': [4, 5],
# 'rationales': ['could have been more specific', 'good definition'],
# }
# ]
```
## ベストプラクティス
- 全体的なスコアは、批評や特定のスコアよりも安価で生成が容易です
- スコアや批評を生成するために大きなモデルを使用する
- スコアや批評を生成するために多様なモデルセットを使用する
- `system_prompt`やモデルの構成を繰り返し改善する
## 次のステップ
👨🏽💻 コード -[演習ノートブック](./notebooks/preference_dpo_dataset.ipynb)でインストラクションチューニングのためのデータセットを生成する
## 参考文献
- [Distilabel Documentation](https://distilabel.argilla.io/latest/)
- [Deita](https://arxiv.org/abs/2312.15685)
- [UltraFeedback](https://arxiv.org/abs/2310.01377)
|
{
"source": "huggingface/smol-course",
"title": "ja/6_synthetic_datasets/preference_datasets.md",
"url": "https://github.com/huggingface/smol-course/blob/main/ja/6_synthetic_datasets/preference_datasets.md",
"date": "2024-11-25T19:22:43",
"stars": 5481,
"description": "A course on aligning smol models.",
"file_size": 5989
}
|
# 지시 조정(Instruction Tuning)
이 모듈에서는 언어 모델의 지시 조정(instruction tuning) 방법을 설명합니다. 지시 조정이란, 사전 학습된 모델을 특정 태스크에 맞게 조정하기 위해 해당 태스크와 관련된 데이터셋으로 추가 학습시키는 과정을 의미합니다. 이를 통해 목표로 하는 작업에서 모델이 더 나은 성능을 발휘할 수 있습니다.
이 모듈에서는 다음 두 가지 주제를 다룰 예정입니다: 1) 대화 템플릿(Chat Templates) 2) 지도 학습 기반 미세 조정(Supervised Fine-Tuning)
## 1️⃣ 대화 템플릿
채팅 템플릿(Chat Templates)은 사용자와 AI 모델 간의 상호작용을 구조화하여 모델의 일관되고 적절한 맥락의 응답을 보장합니다. 템플릿에는 시스템 프롬프트와 역할 기반 메시지와 같은 구성 요소가 포함됩니다. 더 자세한 내용은 [대화 템플릿](./chat_templates.md) 섹션을 참고하세요.
## 2️⃣ 지도 학습 기반 미세 조정
지도 학습 기반 미세 조정(SFT)은 사전 학습된 언어 모델이 특정 작업에 적합하도록 조정하는 데 핵심적인 과정입니다. 이 과정에서는 레이블이 포함된 태스크별 데이터셋을 사용해 모델을 학습시킵니다. SFT의 주요 단계와 모범 사례를 포함한 자세한 가이드는 [지도 학습 기반 미세 조정](./supervised_fine_tuning.md) 섹션을 참고하세요.
## 실습 노트북
| 파일명 | 설명 | 실습 내용 | 링크 | Colab |
|-------|-------------|----------|------|-------|
| Chat Templates | SmolLM2를 활용한 대화 템플릿 사용법과 데이터셋을 ChatML 형식으로 변환하는 과정 학습 | 🐢 `HuggingFaceTB/smoltalk` 데이터셋을 chatml 형식으로 변환해보기 <br> 🐕 `openai/gsm8k` 데이터셋을 chatml 형식으로 변환해보기 | [Notebook](./notebooks/chat_templates_example.ipynb) | <a target="_blank" href="https://colab.research.google.com/github/huggingface/smol-course/blob/main/1_instruction_tuning/notebooks/chat_templates_example.ipynb"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a> |
| Supervised Fine-Tuning | SFTTrainer를 이용해 SmolLM2를 파인튜닝하는 방법 학습 | 🐢 `HuggingFaceTB/smoltalk` 데이터셋 활용해보기 <br>🐕 `bigcode/the-stack-smol` 데이터셋 활용해보기 <br>🦁 실제 사용 사례에 맞는 데이터셋 선택해보기 | [Notebook](./notebooks/sft_finetuning_example.ipynb) | <a target="_blank" href="https://colab.research.google.com/github/huggingface/smol-course/blob/main/1_instruction_tuning/notebooks/sft_finetuning_example.ipynb"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a> |
## 참고
- [Transformers documentation on chat templates](https://huggingface.co/docs/transformers/main/en/chat_templating)
- [Script for Supervised Fine-Tuning in TRL](https://github.com/huggingface/trl/blob/main/examples/scripts/sft.py)
- [`SFTTrainer` in TRL](https://huggingface.co/docs/trl/main/en/sft_trainer)
- [Direct Preference Optimization Paper](https://arxiv.org/abs/2305.18290)
- [Supervised Fine-Tuning with TRL](https://huggingface.co/docs/trl/main/en/tutorials/supervised_finetuning)
- [How to fine-tune Google Gemma with ChatML and Hugging Face TRL](https://www.philschmid.de/fine-tune-google-gemma)
- [Fine-tuning LLM to Generate Persian Product Catalogs in JSON Format](https://huggingface.co/learn/cookbook/en/fine_tuning_llm_to_generate_persian_product_catalogs_in_json_format)
|
{
"source": "huggingface/smol-course",
"title": "ko/1_instruction_tuning/README.md",
"url": "https://github.com/huggingface/smol-course/blob/main/ko/1_instruction_tuning/README.md",
"date": "2024-11-25T19:22:43",
"stars": 5481,
"description": "A course on aligning smol models.",
"file_size": 2582
}
|
# 대화 템플릿(Chat Templates)
대화 템플릿은 언어 모델과 사용자 간 상호작용을 구조화하는 데 필수적입니다. 이 템플릿은 대화에 일관된 형식을 제공하여, 모델이 각 메시지의 맥락과 역할을 이해하고 적절한 응답 패턴을 유지할 수 있도록 합니다.
## 기본 모델 vs 지시 모델
기본 모델은 다음 토큰을 예측하기 위해 대량의 원시 텍스트 데이터로 학습되는 반면, 지시 모델은 특정 지시를 따르고 대화를 나눌 수 있도록 미세 조정된 모델입니다. 예를 들어, `SmolLM2-135M`은 기본 모델이고, `SmolLM2-135M-Instruct`는 이를 지시 조정한 변형 모델입니다.
기본 모델이 지시 모델처럼 동작하도록 만들기 위해서는 모델이 이해할 수 있는 방식으로 프롬프트를 일관되게 만들어야 합니다. 이때 대화 템플릿이 유용합니다. ChatML은 이러한 템플릿 형식 중 하나로 대화를 구조화하고 명확한 역할 지시자(시스템, 사용자, 어시스턴트)를 제공합니다.
기본 모델은 서로 다른 대화 템플릿으로 미세 조정될 수 있으므로, 지시 모델을 사용할 때는 반드시 해당 모델에 적합한 대화 템플릿을 사용하는 것이 중요합니다.
## 대화 템플릿 이해하기
대화 템플릿의 핵심은 언어 모델과 소통할 때 대화가 어떤 형식으로 이루어져야 하는지 정의하는 것입니다. 템플릿에는 시스템 수준의 지침, 사용자 메시지, 어시스턴트의 응답이 포함되어 있으며, 모델이 이해할 수 있는 구조화된 형식을 제공합니다. 이러한 구조는 상호작용의 일관성을 유지하고, 모델이 다양한 유형의 입력에 적절히 응답하도록 돕습니다. 아래는 채팅 템플릿의 예시입니다:
```sh
<|im_start|>user
안녕하세요!<|im_end|>
<|im_start|>assistant
만나서 반갑습니다!<|im_end|>
<|im_start|>user
질문을 해도 될까요?<|im_end|>
<|im_start|>assistant
```
`transformers` 라이브러리는 모델의 토크나이저와 관련하여 대화 템플릿을 자동으로 처리해줍니다. 대화 템플릿이 transformers에서 어떻게 구성되는지 자세히 알아보려면 [여기](https://huggingface.co/docs/transformers/en/chat_templating#how-do-i-use-chat-templates)를 참고하세요. 우리가 메시지를 올바른 형식으로 구조화하기만 하면 나머지는 토크나이저가 처리합니다. 아래는 기본적인 대화 예시입니다:
```python
messages = [
{"role": "system", "content": "You are a helpful assistant focused on technical topics."},
{"role": "user", "content": "Can you explain what a chat template is?"},
{"role": "assistant", "content": "A chat template structures conversations between users and AI models..."}
]
```
위 예시를 자세히 보면서 대화 템플릿 형식에 어떻게 매핑되는지 살펴봅시다.
## 시스템 메시지
시스템 메시지는 모델의 기본 동작 방식을 설정합니다. 이는 이후 모든 상호작용에 영향을 미치는 지속적인 지침이 됩니다.
```python
system_message = {
"role": "system",
"content": "You are a professional customer service agent. Always be polite, clear, and helpful."
}
```
## 대화
대화 템플릿은 대화 기록을 통해 맥락을 유지하며, 사용자와 어시스턴트 간의 이전 대화를 저장합니다. 이를 통해 더욱 일관된 멀티 턴 대화가 가능해집니다:
```python
conversation = [
{"role": "user", "content": "I need help with my order"},
{"role": "assistant", "content": "I'd be happy to help. Could you provide your order number?"},
{"role": "user", "content": "It's ORDER-123"},
]
```
## Transformers 기반 구현
transformers 라이브러리는 대화 템플릿을 위한 내장 기능을 지원합니다.사용 방법은 다음과 같습니다:
```python
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("HuggingFaceTB/SmolLM2-135M-Instruct")
messages = [
{"role": "system", "content": "You are a helpful coding assistant."},
{"role": "user", "content": "Write a Python function to sort a list"},
]
# 대화 템플릿 적용
formatted_chat = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
```
## 사용자 정의 형식
메시지 유형별로 원하는 형식을 설정할 수 있습니다. 예를 들어, 역할에 따라 특수 토큰을 추가하거나 형식을 지정할 수 있습니다:
```python
template = """
<|system|>{system_message}
<|user|>{user_message}
<|assistant|>{assistant_message}
""".lstrip()
```
## 멀티 턴 지원
템플릿은 문맥을 유지하면서 복잡한 멀티 턴 대화도 처리할 수 있습니다:
```python
messages = [
{"role": "system", "content": "You are a math tutor."},
{"role": "user", "content": "What is calculus?"},
{"role": "assistant", "content": "Calculus is a branch of mathematics..."},
{"role": "user", "content": "Can you give me an example?"},
]
```
⏭️ [다음: Supervised Fine-Tuning](./supervised_fine_tuning.md)
## 참고
- [Hugging Face Chat Templating Guide](https://huggingface.co/docs/transformers/main/en/chat_templating)
- [Transformers Documentation](https://huggingface.co/docs/transformers)
- [Chat Templates Examples Repository](https://github.com/chujiezheng/chat_templates)
|
{
"source": "huggingface/smol-course",
"title": "ko/1_instruction_tuning/chat_templates.md",
"url": "https://github.com/huggingface/smol-course/blob/main/ko/1_instruction_tuning/chat_templates.md",
"date": "2024-11-25T19:22:43",
"stars": 5481,
"description": "A course on aligning smol models.",
"file_size": 3568
}
|
# 지도 학습 기반 미세 조정(Supervised Fine-Tuning)
지도 학습 기반 미세 조정(SFT)은 사전 학습된 언어 모델을 특정 작업이나 도메인에 맞게 조정하는 데 핵심적인 과정입니다. 사전 학습된 모델의 능력은 일반적으로 뛰어나지만, 특정 사용 사례에서 우수한 성능을 발휘하려면 맞춤화가 필요할 때가 많습니다. SFT는 사람이 검증한 예제를 포함하여 신중하게 선별된 데이터셋으로 모델을 추가 학습시켜 이러한 격차를 해소합니다.
## SFT 이해하기
SFT의 핵심은 레이블이 있는 토큰을 통해 사전 학습된 모델이 특정 작업을 수행하도록 학습시키는 것입니다. 이 과정에서 원하는 입력-출력 동작 예제를 모델에 많이 보여줌으로써, 해당 사용 사례에 특화된 패턴을 학습하도록 합니다.
SFT가 효과적인 이유는 사전 학습 과정에서 습득한 기초 지식을 활용하면서도 사용자의 특정 요구에 맞게 모델의 동작을 조정할 수 있기 때문입니다.
## SFT를 언제 사용해야 하나요?
SFT 사용 여부는 주로 모델이 현재 가지고 있는 능력과 특정 요구 사항 간의 차이에 따라 결정됩니다. SFT는 특히 모델 출력에 대한 정교한 제어가 필요하거나 전문적인 도메인에서 작업할 때 매우 유용합니다.
예를 들어, 고객 서비스 애플리케이션을 개발하는 경우 모델이 회사 지침을 일관되게 따르고 기술적인 질문을 표준화된 방식으로 처리하도록 만들고 싶을 것입니다. 마찬가지로 의료나 법률 애플리케이션에서는 정확성과 도메인 특화 용어를 사용하는 것이 중요합니다. SFT는 이러한 경우에서 모델의 응답이 전문적인 표준을 따르고 모델 응답을 도메인 전문 지식에 맞게 조정하는 데 도움을 줄 수 있습니다.
## 미세 조정 과정
지도 학습 기반 미세 조정은 특정 태스크에 맞춘 데이터셋으로 모델 가중치를 학습시키는 과정을 포함합니다.
먼저, 목표 태스크를 대표할 수 있는 데이터셋을 준비하거나 선택해야 합니다. 이 데이터셋은 모델이 마주하게 될 다양한 시나리오를 포괄할 수 있는 예제를 포함하고 있어야 합니다. 데이터 품질이 매우 중요하며 각 예제는 모델이 생성하길 원하는 출력 유형을 명확히 보여줘야 합니다. 이후 Hugging Face의 `transformers` 및 `trl`과 같은 프레임워크를 사용하여 데이터셋을 기반으로 모델을 학습시키는 실제 미세 조정 단계가 이어집니다.
이 과정 전반에서 지속적인 평가가 필수적입니다. 모델이 원하는 동작을 학습하면서도 일반적인 능력을 잃지 않도록 검증 데이터셋을 사용해 성능을 모니터링해야 합니다. 모델을 평가하는 방법에 대해서는 [모듈 4](../4_evaluation)에서 다룰 예정입니다.
## 선호도 조정에서 SFT의 역할
SFT는 언어 모델을 인간의 선호도에 맞추는 데 기본적인 역할을 합니다. 인간 피드백을 통한 강화 학습(Reinforcement Learning from Human Feedback, RLHF) 및 직접 선호도 최적화(Direct Preference Optimization, DPO)와 같은 기술은 SFT를 사용하여 기본적인 수준으로 태스크를 이해하게 한 후 모델의 응답을 원하는 결과에 맞게 조정합니다. 사전 학습된 모델은 일반적인 언어 능력을 가지고 있음에도 불구하고 항상 사람의 선호도와 일치하는 결과를 생성하지 못할 수 있습니다. SFT는 도메인별 데이터와 지침을 도입하여 이러한 격차를 해소함으로써 모델이 인간의 기대에 부합하는 응답을 생성할 수 있도록 합니다.
## TRL을 활용한 SFT
지도 학습 기반 미세 조정에서 중요한 소프트웨어 패키지 중 하나는 Transformer 강화 학습(Transformer Reinforcement Learning, TRL)입니다. TRL은 강화 학습(Reinforcement Learning, RL)을 사용하여 트랜스포머 언어 모델을 학습시키기 위한 도구입니다.
Hugging Face Transformers 라이브러리를 기반으로 구축된 TRL은 사용자가 사전 학습된 언어 모델을 직접 로드할 수 있게 하며, 대부분의 디코더 및 인코더-디코더 아키텍처를 지원합니다. 이 라이브러리는 언어 모델링에 사용되는 주요 RL 프로세스를 지원하고 지도 학습 기반 미세 조정(SFT), 보상 모델링(Reward Modeling, RM), 근접 정책 최적화(Proximal Policy Optimization, PPO), 직접 선호 최적화(Direct Preference Optimization, DPO)와 같은 과정을 용이하게 만듭니다.
이 레포지토리의 여러 모듈에서 TRL을 활용할 예정입니다.
# 다음 단계
다음 튜토리얼을 통해 TRL을 활용한 SFT 실습 경험을 쌓아 보세요:
⏭️ [Chat Templates 튜토리얼](./notebooks/chat_templates_example.ipynb)
⏭️ [Supervised Fine-Tuning 튜토리얼](./notebooks/supervised_fine_tuning_tutorial.ipynb)
|
{
"source": "huggingface/smol-course",
"title": "ko/1_instruction_tuning/supervised_fine_tuning.md",
"url": "https://github.com/huggingface/smol-course/blob/main/ko/1_instruction_tuning/supervised_fine_tuning.md",
"date": "2024-11-25T19:22:43",
"stars": 5481,
"description": "A course on aligning smol models.",
"file_size": 2447
}
|
# Parameter-Efficient Fine-Tuning, PEFT
언어 모델이 커지면서 전통적인 미세 조정 방식을 적용하는 것이 점점 어려워지고 있습니다. 1.7B 모델조차도 전체 미세 조정을 수행하려면 상당한 GPU 메모리가 필요하며, 모델 사본을 별도로 저장하기 위한 비용이 많이 들고, 모델의 원래 능력을 상실하는 위험이 존재합니다. Parmeter-Efficient Fine-Tuning(PEFT) 방법은 대부분의 모델 파라미터가 고정된 상태에서 모델 파라미터의 일부만 수정하여 전체 미세 조정 과정에서 발생하는 문제를 해결헙니다.
학습 과정에서 모델의 모든 파라미터를 업데이트하는 전통적인 미세 조정 방법을 대형 언어 모델에 적용하는 것은 현실적으로 어렵습니다. PEFT는 원래 모델 크기의 1% 미만에 해당하는 파라미터만 학습시켜 모델을 조정하는 방법입니다. 학습 가능한 파라미터를 크게 줄이는 것은 다음과 같은 이점을 제공합니다:
- 제한된 GPU 메모리를 가진 하드웨어에서도 미세 조정 가능
- 효율적인 태스크별 적응 모델 저장
- 데이터가 적은 상황에서도 뛰어난 일반화 성능 제공
- 더 빠른 학습 및 반복 가능
## 사용 가능한 방법
이 모듈에서는 많이 사용되는 두 가지 PEFT 방법을 다룹니다:
### 1️⃣ LoRA (Low-Rank Adaptation)
LoRA는 효율적인 모델 적응을 위한 멋진 솔루션을 제공하면서 가장 많이 사용되는 PEFT 방법으로 자리 잡았습니다. LoRA는 전체 모델을 수정하는 대신 **학습 가능한 파라미터를 모델의 어텐션 레이어에 주입**합니다. 이 접근법은 전체 미세 조정과 비슷한 성능을 유지하면서 학습 가능한 파라미터를 약 90%까지 줄입니다. [LoRA (Low-Rank Adaptation)](./lora_adapters.md) 섹션에서 LoRA에 대해 자세히 알아보겠습니다.
### 2️⃣ 프롬프트 튜닝
프롬프트 튜닝은 모델 가중치를 수정하는 대신 **입력에 학습 가능한 토큰을 추가**하여 **더 경량화된** 접근법을 제공합니다. 프롬프트 튜닝은 LoRA만큼 유명하지는 않지만, 모델을 새로운 태스크나 도메인에 빠르게 적용할 때 유용하게 쓰일 수 있는 기술입니다. [프롬프트 튜닝](./prompt_tuning.md) 섹션에서 프롬프트 튜닝에 대해 탐구해볼 예정입니다.
## 실습 노트북
| 파일명 | 설명 | 실습 내용 | 링크 | Colab |
|-------|-------------|----------|------|-------|
| LoRA Fine-tuning | LoRA 어댑터를 사용해 모델을 미세 조정하는 방법 학습 | 🐢 LoRA를 사용해 모델 학습해보기<br>🐕 다양한 랭크 값으로 실험해보기<br>🦁 전체 미세 조정과 성능 비교해보기 | [Notebook](./notebooks/finetune_sft_peft.ipynb) | <a target="_blank" href="https://colab.research.google.com/github/huggingface/smol-course/blob/main/3_parameter_efficient_finetuning/notebooks/finetune_sft_peft.ipynb"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a> |
| Load LoRA Adapters | LoRA 어댑터를 불러오고 학습시키는 방법 배우기 | 🐢 사전 학습된 어댑터 불러오기<br>🐕 기본 모델과 어댑터 합치기<br>🦁 여러 어댑터 간 전환해보기 | [Notebook](./notebooks/load_lora_adapter_example.ipynb) | <a target="_blank" href="https://colab.research.google.com/github/huggingface/smol-course/blob/main/3_parameter_efficient_finetuning/notebooks/load_lora_adapter_example.ipynb"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a> |
<!-- | Prompt Tuning | Learn how to implement prompt tuning | 🐢 Train soft prompts<br>🐕 Compare different initialization strategies<br>🦁 Evaluate on multiple tasks | [Notebook](./notebooks/prompt_tuning_example.ipynb) | <a target="_blank" href="https://colab.research.google.com/github/huggingface/smol-course/blob/main/3_parameter_efficient_finetuning/notebooks/prompt_tuning_example.ipynb"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a> | -->
## 참고
- [Hugging Face PEFT 문서](https://huggingface.co/docs/peft)
- [LoRA 논문](https://arxiv.org/abs/2106.09685)
- [QLoRA 논문](https://arxiv.org/abs/2305.14314)
- [프롬프트 튜닝 논문](https://arxiv.org/abs/2104.08691)
- [Hugging Face PEFT 가이드](https://huggingface.co/blog/peft)
- [How to Fine-Tune LLMs in 2024 with Hugging Face](https://www.philschmid.de/fine-tune-llms-in-2024-with-trl)
- [TRL](https://huggingface.co/docs/trl/index)
|
{
"source": "huggingface/smol-course",
"title": "ko/3_parameter_efficient_finetuning/README.md",
"url": "https://github.com/huggingface/smol-course/blob/main/ko/3_parameter_efficient_finetuning/README.md",
"date": "2024-11-25T19:22:43",
"stars": 5481,
"description": "A course on aligning smol models.",
"file_size": 3048
}
|
# LoRA (Low-Rank Adaptation)
LoRA는 널리 쓰이는 PEFT 방법으로 자리 잡았습니다. 어텐션 가중치에 작은 랭크 분해 행렬을 추가하는 방식으로 동작작하며 일반적으로 학습 가능한 파라미터를 약 90% 줄여줍니다.
## LoRA 이해하기
LoRA(Low-Rank Adaptation)는 사전 학습된 모델 가중치를 고정한 상태에서 학습 가능한 랭크 분해 행렬을 모델 레이어에 주입하는 파라미터 효율적인 미세 조정 기법입니다. 미세 조정 과정에서 모든 모델 파라미터를 학습시키는 대신, LoRA는 저랭크 분해를 통해 가중치 업데이트를 더 작은 행렬로 나눠 모델 성능은 유지하면서 학습 가능한 파라미터 수를 크게 줄입니다. 예를 들어, GPT-3 175B에 LoRA를 적용했을 때 전체 미세 조정 대비 학습 가능한 파라미터 수는 10,000배, GPU 메모리 요구 사항은 3배 감소했습니다. [LoRA 논문](https://arxiv.org/pdf/2106.09685)에서 LoRA에 관한 자세한 내용을 확인할 수 있습니다.
LoRA는 일반적으로 트랜스포머 레이어 중 어텐션 가중치에 랭크 분해 행렬 쌍을 추가하는 방식으로 동작합니다. 어댑터 가중치는 추론 과정에서 기본 모델과 병합될 수 있고 추가적인 지연 시간이 발생하지 않습니다. LoRA는 자원 요구 사항을 적절한 수준으로 유지하면서 대형 언어 모델을 특정 태스크나 도메인에 맞게 조정하는 데 특히 유용합니다.
## LoRA 어댑터 불러오기
load_adapter()를 사용하여 사전 학습된 모델에 어댑터를 불러올 수 있으며 가중치가 병합되지 않은 다른 어댑터를 사용해 볼 때 유용합니다. set_adapter() 함수로 활성 어댑터 가중치를 설정합니다. 기본 모델을 반환하려면 unload()를 사용하여 불러온 모든 LoRA 모듈을 내릴 수 있습니다. 이렇게 하면 태스크별 가중치를 쉽게 전환할 수 있습니다.
```python
from transformers import AutoModelForCausalLM
from peft import PeftModel
base_model = AutoModelForCausalLM.from_pretrained("<base_model_name>")
peft_model_id = "<peft_adapter_id>"
model = PeftModel.from_pretrained(base_model, peft_model_id)
```

## LoRA 어댑터 병합
LoRA로 학습한 후에는 더 쉬운 배포를 위해 어댑터 가중치를 기본 모델에 다시 병합할 수 있습니다. 이를 통해 결합된 가중치를 가진 단일 모델을 생성할 수 있기 때문에 추론 과정에서 별도로 어댑터를 불러올 필요가 없습니다.
병합 과정에서는 메모리 관리와 정밀도에 주의해야 합니다. 기본 모델과 어댑터 가중치를 동시에 불러와야 하므로 GPU/CPU 메모리가 충분해야 합니다. `transformers`의 `device_map="auto"`를 사용하면 메모리를 자동으로 관리할 수 있습니다. 학습 중 사용한 정밀도(예: float16)를 병합 과정에서도 일관되게 유지하고, 병합된 모델을 같은 형식으로 저장하여 배포하세요. 배포 전에 반드시 병합된 모델의 출력 결과와 성능 지표를 어댑터 기반 버전과 비교하여 검증해야 합니다.
어댑터는 서로 다른 태스크나 도메인 간 전환도 간편하게 만듭니다. 기본 모델과 어댑터 가중치를 별도로 불러오면 빠르게 태스크별 가중치를 전환할 수 있습니다.
## 구현 가이드
`notebooks/` 디렉토리에는 다양한 PEFT 방법을 구현하기 위한 실용적인 튜토리얼과 예제가 포함되어 있습니다. `load_lora_adapter_example.ipynb`에서 기본 소개를 살펴본 다음, `lora_finetuning.ipynb`를 통해 LoRA와 SFT를 사용한 모델 미세 조정 과정을 더 자세히 탐구해 보세요.
PEFT 방법을 구현할 때는 LoRA의 랭크를 4~8 정도의 작은 값으로 설정하고 학습 손실을 지속적으로 모니터링하는 것이 좋습니다. 과적합을 방지하기 위해 검증 세트를 활용하고 가능하다면 전체 미세 조정 기준선과 결과를 비교하세요. 다양한 태스크에서 각 방법의 효과는 다를 수 있으므로 실험을 통해 최적의 방법을 찾는 것이 중요합니다.
## OLoRA
[OLoRA](https://arxiv.org/abs/2406.01775)는 LoRA 어댑터 초기화를 위해 QR 분해를 활용합니다. OLoRA는 모델의 기본 가중치를 QR 분해 계수에 따라 변환합니다. 즉, 모델 학습 전에 가중치를 변경합니다. 이 접근 방식은 안정성을 크게 향상시키고 수렴 속도를 빠르게 하여, 궁극적으로 더 우수한 성능을 달성합니다.
## PEFT와 함께 TRL 사용하기
효율적인 미세 조정을 위해 PEFT 방법을 TRL(Transformers Reinforcements Learning)과 결합할 수 있습니다. 이러한 통합은 메모리 요구사항을 줄여주기 때문에 RLHF (Reinforcement Learning from Human Feedback)에 특히 유용합니다.
```python
from peft import LoraConfig
from transformers import AutoModelForCausalLM
# PEFT configuration 설정
lora_config = LoraConfig(
r=16,
lora_alpha=32,
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM"
)
# 특정 디바이스에서 모델 불러오기
model = AutoModelForCausalLM.from_pretrained(
"your-model-name",
load_in_8bit=True, # 선택 사항: 8비트 정밀도 사용
device_map="auto",
peft_config=lora_config
)
```
위 코드에서 `device_map="auto"`를 사용해 모델을 적절한 디바이스에 자동으로 할당했습니다. `device_map={"": device_index}`를 써서 모델을 특정 디바이스에 직접 할당할 수도 있습니다. 또한, 메모리 사용량을 효율적으로 유지하면서 여러 GPU에 걸쳐 학습을 확장할 수도 있습니다.
## 기본적인 병합 구현
LoRA 어댑터 학습이 끝나면 어댑터 가중치를 기본 모델에 합칠 수 있습니다. 합치는 방법은 다음과 같습니다:
```python
import torch
from transformers import AutoModelForCausalLM
from peft import PeftModel
# 1. 기본 모델 불러오기
base_model = AutoModelForCausalLM.from_pretrained(
"base_model_name",
torch_dtype=torch.float16,
device_map="auto"
)
# 2. 어댑터가 있는 PEFT 모델 불러오기
peft_model = PeftModel.from_pretrained(
base_model,
"path/to/adapter",
torch_dtype=torch.float16
)
# 3. 어댑터 가중치를 기본 모델에 병합하기
try:
merged_model = peft_model.merge_and_unload()
except RuntimeError as e:
print(f"Merging failed: {e}")
# fallback 전략 또는 메모리 최적화 구현
# 4. 병합된 모델 저장
merged_model.save_pretrained("path/to/save/merged_model")
```
저장된 모델의 크기가 일치하지 않으면 토크나이저도 함께 저장했는지 확인하세요:
```python
# 모델과 토크나이저를 모두 저장
tokenizer = AutoTokenizer.from_pretrained("base_model_name")
merged_model.save_pretrained("path/to/save/merged_model")
tokenizer.save_pretrained("path/to/save/merged_model")
```
## 다음 단계
⏩ [프롬프트 튜닝](prompt_tuning.md) 가이드로 이동해 프롬프트 튜닝으로 미세 조정하는 법을 배워보세요.
⏩ [LoRA 어댑터 튜토리얼](./notebooks/load_lora_adapter.ipynb)에서 LoRA 어댑터를 불러오는 방법을 배워보세요.
# 참고
- [LORA: LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS](https://arxiv.org/pdf/2106.09685)
- [Hugging Face PEFT 문서](https://huggingface.co/docs/peft)
- [Hugging Face blog post on PEFT](https://huggingface.co/blog/peft)
|
{
"source": "huggingface/smol-course",
"title": "ko/3_parameter_efficient_finetuning/lora_adapters.md",
"url": "https://github.com/huggingface/smol-course/blob/main/ko/3_parameter_efficient_finetuning/lora_adapters.md",
"date": "2024-11-25T19:22:43",
"stars": 5481,
"description": "A course on aligning smol models.",
"file_size": 4507
}
|
# 프롬프트 튜닝
프롬프트 튜닝은 모델 가중치 대신 입력 표현을 변경하는 파라미터 효율적인 접근법입니다. 모델의 모든 파라미터를 업데이트하는 전통적인 미세 조정과 다르게, 프롬프트 튜닝은 기본 모델의 파라미터가 고정된 상태를 유지하면서 소수의 학습 가능한 토큰을 추가하고 최적화합니다.
## 프롬프트 튜닝 이해하기
프롬프트 튜닝은 모델 미세 조정의 대안으로, 학습 가능한 연속 벡터(소프트 프롬프트)를 입력 텍스트에 추가하는 파라미터 효율적인 방식입니다. 소프트 프롬프트는 이산적인 텍스트 프롬프트와 다르게 모델 파라미터가 고정된 상태에서 역전파를 통해 학습됩니다. 이 방식은 ["The Power of Scale for Parameter-Efficient Prompt Tuning"](https://arxiv.org/abs/2104.08691) (Lester et al., 2021)에서 처음 소개되었으며, 이 논문은 모델 크기가 커질수록 미세 조정과 비교했을 때 프롬프트 튜닝이 경쟁력을 가진다는 것을 보였습니다. 논문에 따르면, 약 100억 개의 파라미터를 가진 모델에서 프롬프트 튜닝의 성능은 태스크당 수백 개의 매개변수 수정만으로 모델 미세 조정의 성능과 일치하는 것으로 나타났습니다.
모델의 임베딩 공간에 존재하는 연속적인 벡터인 소프트 프롬프트는 학습 과정에서 최적화됩니다. 자연어 토큰을 사용하는 전통적인 이산 프롬프트와 달리 소프트 프롬프트는 고유한 의미를 가지고 있지는 않지만 경사 하강법을 통해 파라미터가 고정된 모델에서 원하는 동작을 이끌어내는 방법을 학습합니다. 이 기법은 모델 전체를 복사하지 않고 적은 수(일반적으로 몇백 개의 파라미터)에 해당하는 프롬프트 벡터만을 저장하기 때문에 멀티 태스크 시나리오에 더욱 효과적입니다. 이 접근 방식은 최소한의 메모리 사용량을 유지할 뿐만 아니라, 프롬프트 벡터만 교체하여 모델을 다시 로드하지 않고도 신속하게 작업을 전환할 수 있게 합니다.
## 학습 과정
소프트 프롬프트는 일반적으로 8~32개의 토큰으로 구성되며 무작위 또는 기존 텍스트로 초기화할 수 있습니다. 초기화 방법은 학습 과정에서 중요한 역할을 하며 텍스트 기반 초기화가 무작위 초기화보다 좋은 성능을 보이는 경우가 많습니다.
학습이 진행되는 동안 기본 모델의 파라미터는 고정되어 있고 프롬프트 파라미터만 업데이트 됩니다. 프롬프트 파라미터에 초점을 맞춘 이 접근 방식은 일반적인 학습 목표를 따르지만 학습률과 프롬프트 토큰의 경사 동작에 세심한 주의가 필요합니다.
## PEFT 라이브러리를 활용한 프롬프트 튜닝 구현
PEFT 라이브러리를 이용해 프롬프트 튜닝을 직관적으로 구현할 수 있습니다. 기본적인 예제는 다음과 같습니다:
```python
from peft import PromptTuningConfig, TaskType, get_peft_model
from transformers import AutoModelForCausalLM, AutoTokenizer
# 기본 모델 불러오기
model = AutoModelForCausalLM.from_pretrained("your-base-model")
tokenizer = AutoTokenizer.from_pretrained("your-base-model")
# 프롬프트 튜닝 configuration 설정
peft_config = PromptTuningConfig(
task_type=TaskType.CAUSAL_LM,
num_virtual_tokens=8, # 학습 가능한 토큰 수
prompt_tuning_init="TEXT", # 텍스트 기반 초기화
prompt_tuning_init_text="Classify if this text is positive or negative:",
tokenizer_name_or_path="your-base-model",
)
# 프롬프트 튜닝 가능한 모델 생성
model = get_peft_model(model, peft_config)
```
## 프롬프트 튜닝과 다른 PEFT 방법 비교
다른 PEFT 접근 방식과 비교했을 때 프롬프트 튜닝은 효율성이 뛰어납니다. LoRA는 파라미터 수와 메모리 사용량이 적지만 태스크 전환을 위해 어댑터를 불러와야 하는 반면 프롬프트 튜닝은 자원을 더 적게 사용하면서 즉각적인 태스크 전환이 가능합니다. 반면에 전체 미세 조정은 상당한 양의 자원을 필요로 하고 서로 다른 태스크를 수행하기 위해 태스크에 맞는 각각의 모델을 필요로 합니다.
| 방법 | 파라미터 수 | 메모리 사용량 | 태스크 전환 |
|--------|------------|---------|----------------|
| 프롬프트 튜닝 | 매우 적음 | 메모리 사용량 최소화 | 쉬움 |
| LoRA | 적음 | 적음 | 모델을 다시 불러와야 함 |
| 전체 미세 조정 | 많음 | 많음 | 새로운 모델 복사 필요 |
프롬프트 튜닝을 구현할 때는 적은 수(8~16개)의 가상 토큰으로 시작한 후 태스크의 복잡성에 따라 토큰 수를 점차 늘려가세요. 태스크와 관련된 텍스트로 초기화를 수행하는 것이 무작위 초기화보다 일반적으로 더 나은 결과를 가져옵니다. 초기화 전략은 목표 태스크의 복잡성을 반영해야 합니다.
학습 과정은 전체 미세 조정과 약간의 차이가 있습니다. 보통 높은 학습률이 효과적이지만 프롬프트 토큰 경사를 신중하게 모니터링해야 합니다. 다양한 예제를 활용한 주기적인 검증은 서로 다른 시나리오에서 강력한 성능을 보장하는 데 도움이 됩니다.
## 응용
프롬프트 튜닝은 다음과 같은 시나리오에서 특히 뛰어납니다:
1. 멀티 태스크 배포
2. 자원이 제한적인 환경
3. 신속한 태스크 적응
4. 프라이버시에 민감한 애플리케이션
그러나 모델 크기가 작아질수록 전체 미세 조정과 비교했을 때 프롬프트 튜닝의 경쟁력이 떨어집니다. 예를 들어, SmolLM2 크기의 모델은 프롬프트 튜닝보다 전체 미세 조정를 수행하는 것이 좀 더 의미있습니다.
## 다음 단계
⏭️ [LoRA 어댑터 튜토리얼](./notebooks/finetune_sft_peft.ipynb)에서 LoRA 어댑터를 활용해 모델을 미세 조정하는 법을 배워봅시다.
## 참고
- [Hugging Face PEFT 문서](https://huggingface.co/docs/peft)
- [프롬프트 튜닝 논문](https://arxiv.org/abs/2104.08691)
- [Hugging Face Cookbook](https://huggingface.co/learn/cookbook/prompt_tuning_peft)
|
{
"source": "huggingface/smol-course",
"title": "ko/3_parameter_efficient_finetuning/prompt_tuning.md",
"url": "https://github.com/huggingface/smol-course/blob/main/ko/3_parameter_efficient_finetuning/prompt_tuning.md",
"date": "2024-11-25T19:22:43",
"stars": 5481,
"description": "A course on aligning smol models.",
"file_size": 3253
}
|
# Instruction Tuning (Ajuste de Instrução)
Este módulo o guiará através de modelos de linguagem de ajuste de instrução. O ajuste de instrução envolve a adaptação de modelos pré-treinados a tarefas específicas, treinando-os ainda mais em conjuntos de dados específicos de tarefas. Esse processo ajuda os modelos a melhorar seu desempenho em certas tarefas específicas.
Neste módulo, exploraremos dois tópicos: 1) Modelos de bate-papo e 2) Ajuste fino supervisionado.
## 1️⃣ Modelos de Bate-Papo
Modelos de bate-papo estruturam interações entre usuários e modelos de IA, garantindo respostas consistentes e contextualmente apropriadas. Eles incluem componentes como avisos de sistema e mensagens baseadas em funções. Para informações mais detalhadas, Consulte a seção [Chat Templates (Modelos de Bate-Papo)](./chat_templates.md).
## 2️⃣ Ajuste Fino Supervisionado
Ajuste fino supervisionado (em inglês, SFT - Supervised Fine-Tuning) é um processo crítico para adaptar modelos de linguagem pré-treinados a tarefas específicas. O ajuste envolve treinar o modelo em um conjunto de dados de uma tarefa específica com exemplos rotulados. Para um guia detalhado sobre SFT, incluindo etapas importantes e práticas recomendadas, veja a página [Supervised Fine-Tuning (Ajuste Fino Supervisionado)](./supervised_fine_tuning.md).
## Cadernos de Exercícios
| Título | Descrição | Exercício | Link | Colab |
|-------|-------------|----------|------|-------|
| Modelos de Bate-Papo | Aprenda a usar modelos de bate-papo com SmolLM2 and a processar conjunto de dados para o formato chatml | 🐢 Converta o conjunto de dados `HuggingFaceTB/smoltalk` para o formato chatml<br> 🐕 Converta o conjunto de dados `openai/gsm8k` para o formato chatml | [Exercício](./notebooks/chat_templates_example.ipynb) | <a target="_blank" href="https://colab.research.google.com/github/huggingface/smol-course/blob/main/1_instruction_tuning/notebooks/chat_templates_example.ipynb"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a> |
| Ajuste Fino Supervisionado | Aprenda como fazer o ajuste fino no modelo SmolLM2 usando o SFTTrainer | 🐢 Use o conjunto de dados `HuggingFaceTB/smoltalk`<br>🐕 Experimente o conjunto de dados `bigcode/the-stack-smol`<br>🦁 Selecione um conjunto de dados para um caso de uso do mundo real | [Exercício](./notebooks/sft_finetuning_example.ipynb) | <a target="_blank" href="https://colab.research.google.com/github/huggingface/smol-course/blob/main/1_instruction_tuning/notebooks/sft_finetuning_example.ipynb"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a> |
## Referências
- [Documentação dos transformadores em modelos de bate-papo](https://huggingface.co/docs/transformers/main/en/chat_templating)
- [Script para ajuste fino supervisionado em TRL](https://github.com/huggingface/trl/blob/main/examples/scripts/sft.py)
- [`SFTTrainer` em TRL](https://huggingface.co/docs/trl/main/en/sft_trainer)
- [Artigo de otimização de preferência direta](https://arxiv.org/abs/2305.18290)
- [Ajuste fino supervisionado com TRL](https://huggingface.co/docs/trl/main/en/tutorials/supervised_finetuning)
- [Como ajustar o Google Gemma com ChatML e Hugging Face TRL](https://www.philschmid.de/fine-tune-google-gemma)
- [Fazendo o ajuste fino em uma LLM para gerar catálogos de produtos persas em formato JSON](https://huggingface.co/learn/cookbook/en/fine_tuning_llm_to_generate_persian_product_catalogs_in_json_format)
|
{
"source": "huggingface/smol-course",
"title": "pt-br/1_instruction_tuning/README.md",
"url": "https://github.com/huggingface/smol-course/blob/main/pt-br/1_instruction_tuning/README.md",
"date": "2024-11-25T19:22:43",
"stars": 5481,
"description": "A course on aligning smol models.",
"file_size": 3497
}
|
# Modelos de bate-papo
Os modelos de bate-papo são essenciais para estruturar interações entre modelos de linguagem e usuários. Eles fornecem um formato consistente para conversas, garantindo que os modelos entendam o contexto e o papel de cada mensagem, enquanto mantêm os padrões de resposta apropriados.
## Modelos Base vs Modelos de Instrução
Um modelo base é treinado em dados de texto bruto para prever o próximo token, enquanto um modelo de instrução é ajustado especificamente para seguir as instruções e se envolver em conversas. Por exemplo, `SmolLM2-135M` é um modelo base, enquanto o `SmolLM2-135M-Instruct` é sua variante ajustada por instrução.
Para fazer um modelo base se comportar como um modelo de instrução, precisamos formatar nossos prompts de uma maneira consistente que o modelo possa entender. É aqui que entram os modelos de bate-papo. ChatML é um desses formatos de modelo que estrutura conversas com indicadores claros de papéis (sistema, usuário, assistente).
É importante notar que o modelo base pode ser ajustado finamente em diferentes modelos de bate-papo, então, quando estamos usando um modelo de instrução, precisamos garantir que estamos usando o modelo de bate-papo correto.
## Entendendo os Modelos de Bate-papo
Na sua essência, os modelos de bate-papo definem como as conversas devem ser formatadas ao se comunicar com um modelo de linguagem. Eles incluem instruções no nível do sistema, mensagens do usuário e respostas assistentes em um formato estruturado que o modelo pode entender. Essa estrutura ajuda a manter a consistência entre as interações e garante que o modelo responda adequadamente a diferentes tipos de input de dados. Abaixo está um exemplo de modelo de bate-papo:
```sh
<|im_start|>user
Hi there!<|im_end|>
<|im_start|>assistant
Nice to meet you!<|im_end|>
<|im_start|>user
Can I ask a question?<|im_end|>
<|im_start|>assistant
```
O módulo `transformers` cuidará dos modelos de bate-papo para você em relação ao tokenizador do modelo. Leia mais sobre como os transformadores criam modelos de bate-papo [aqui](https://huggingface.co/docs/transformers/en/chat_templating#how-do-i-use-chat-templates). Tudo o que precisamos fazer é estruturar nossas mensagens da maneira correta e o tokenizador cuidará do resto. Abaixo, você verá um exemplo básico de uma conversa:
```python
messages = [
{"role": "system", "content": "You are a helpful assistant focused on technical topics."},
{"role": "user", "content": "Can you explain what a chat template is?"},
{"role": "assistant", "content": "A chat template structures conversations between users and AI models..."}
]
```
Vamos ir passo-a-passo no exemplo acima e ver como ele mapeia o formato do modelo de bate-papo.
## Mensagens do Sistema
As mensagens do sistema definem a base de como o modelo deve se comportar. Elas agem como instruções persistentes que influenciam todas as interações subsequentes. Por exemplo:
```python
system_message = {
"role": "system",
"content": "You are a professional customer service agent. Always be polite, clear, and helpful."
}
```
## Conversas
Os modelos de bate-papo mantêm o contexto através do histórico de conversas, armazenando conversas anteriores entre os usuários e o assistente. Isso permite que as conversas de multi-turno sejam mais coerentes:
```python
conversation = [
{"role": "user", "content": "I need help with my order"},
{"role": "assistant", "content": "I'd be happy to help. Could you provide your order number?"},
{"role": "user", "content": "It's ORDER-123"},
]
```
## Implementação com Transformadores
O módulo transformers fornece suporte interno para modelos de bate-papo. Veja como usá-los:
```python
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("HuggingFaceTB/SmolLM2-135M-Instruct")
messages = [
{"role": "system", "content": "You are a helpful coding assistant."},
{"role": "user", "content": "Write a Python function to sort a list"},
]
# Apply the chat template
formatted_chat = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
```
## Formatação Personalizada
Você pode personalizar como tipos diferentes de mensagens são formatadas. Por exemplo, adicionando tokens especiais ou formatando para diferentes funções:
```python
template = """
<|system|>{system_message}
<|user|>{user_message}
<|assistant|>{assistant_message}
""".lstrip()
```
## Suporte do Multi-turno
Os modelos podem lidar com conversas multi-turno complexas enquanto mantêm o contexto:
```python
messages = [
{"role": "system", "content": "You are a math tutor."},
{"role": "user", "content": "What is calculus?"},
{"role": "assistant", "content": "Calculus is a branch of mathematics..."},
{"role": "user", "content": "Can you give me an example?"},
]
```
⏭️ [Próxima: Supervised Fine-Tuning (Ajuste Fino Supervisionado)](./supervised_fine_tuning.md)
## Resources
- [Guia de modelos de bate-papo - Hugging Face](https://huggingface.co/docs/transformers/main/en/chat_templating)
- [Documentação do módulo Transformers](https://huggingface.co/docs/transformers)
- [Repositório de exemplos de modelos de bate-papo](https://github.com/chujiezheng/chat_templates)
|
{
"source": "huggingface/smol-course",
"title": "pt-br/1_instruction_tuning/chat_templates.md",
"url": "https://github.com/huggingface/smol-course/blob/main/pt-br/1_instruction_tuning/chat_templates.md",
"date": "2024-11-25T19:22:43",
"stars": 5481,
"description": "A course on aligning smol models.",
"file_size": 5271
}
|
# Ajuste Fino Supervisionado
Ajuste fino supervisionado (em inglês, SFT - Supervised Fine-Tuning) é um processo crítico para adaptar modelos de linguagem pré-treinados a tarefas ou domínios específicos. Embora os modelos pré-treinados tenham recursos gerais impressionantes, eles geralmente precisam ser personalizados para se destacar em casos de usos específicos. O SFT preenche essa lacuna treinando ainda mais o modelo com conjuntos de dados cuidadosamente selecionados com exemplos validados por humanos.
## Entendendo o Ajuste Fino Supervisionado
Na sua essência, o ajuste fino supervisionado é sobre ensinar um modelo pré-treinado a executar tarefas específicas por meio de exemplos de tokens rotulados. O processo envolve mostrar muitos exemplos do comportamento desejado de input-output ao modelo, permitindo que ele aprenda os padrões específicos do seu caso de uso.
O SFT é eficaz porque usa o conhecimento fundamental adquirido durante o pré-treinamento, adaptando o comportamento do modelo para atender às suas necessidades específicas.
## Quando Usar o Ajuste Fino Supervisionado
A decisão de usar o SFT geralmente se resume à lacuna entre os recursos atuais do seu modelo e seus requisitos específicos. O SFT se torna particularmente valioso quando você precisa de controle preciso sobre os outputs do modelo ou ao trabalhar em domínios especializados.
Por exemplo, se você estiver desenvolvendo um aplicativo de atendimento ao cliente, você vai querer que seu modelo siga constantemente as diretrizes da empresa e lide com consultas técnicas de maneira padronizada. Da mesma forma, em aplicações médicas ou legais, a precisão e a adesão à terminologia específica do domínio se tornam cruciais. Nesses casos, o SFT pode ajudar a alinhar as respostas do modelo com padrões profissionais e experiência no campo de trabalho.
## O Processo de Ajuste Fino
O processo de ajuste fino supervisionado envolve o treinamento dos pesos do modelo em um conjunto de dados de tarefa específico.
Primeiro, você precisará preparar ou selecionar um conjunto de dados que represente sua tarefa. Esse conjunto de dados deve incluir diversos exemplos que cobrem a gama de cenários que seu modelo encontrará. A qualidade desses dados é importante - cada exemplo deve demonstrar o tipo de output que você deseja que seu modelo produza. Em seguida, vem a fase real de ajuste fino, onde você usará estruturas como os módulos do Hugging Face, `transformers` e `trl`, para treinar o modelo no seu conjunto de dados.
Ao longo do processo, a avaliação contínua é essencial. Você vai querer monitorar o desempenho do modelo em um conjunto de validação para garantir que ele esteja aprendendo os comportamentos desejados sem perder suas capacidades gerais. No [Módulo 4](../4_evaluation), abordaremos como avaliar seu modelo.
## O Papel do SFT no Alinhamento de Preferência
O SFT desempenha um papel fundamental no alinhamento de modelos de linguagem com preferências humanas. Técnicas como o aprendizado de reforço com o feedback humano (RLHF - Reinforcement Learning with Human Feedback) e a otimização de preferência direta (DPO - Direct Preference Optimization) dependem do SFT para formar um nível básico de entendimento da tarefa antes de alinhar ainda mais as respostas do modelo com os resultados desejados. Modelos pré-treinados, apesar de sua proficiência em linguagem geral, nem sempre podem gerar resultados que correspondam às preferências humanas. O SFT preenche essa lacuna introduzindo dados e orientações específicos de domínio, o que melhora a capacidade do modelo de gerar respostas que se alinham mais de perto com as expectativas humanas.
## Ajuste Fino Supervisionado com Aprendizado de Reforço de Transformadores
Um pacote de software importante para ajuste fino supervisionado é o aprendizado de reforço de transformadores (TRL - Transformer Reinforcement Learning). TRL é um kit de ferramentas usado para treinar modelos de linguagem de transformação usando o aprendizado de reforço.
Construído em cima do módulo de transformadores do Hugging Face, o TRL permite que os usuários carreguem diretamente modelos de linguagem pré-treinados e suporta a maioria das arquiteturas decodificadoras e codificador-decodificador. O módulo facilita os principais processos de RL usados na modelagem de linguagem, incluindo ajuste fino supervisionado (SFT), modelagem de recompensa (RM - Reward Modeling), otimização de políticas proximais (PPO - Proximal Policy Optimization) e otimização de preferência direta (DPO). Usaremos o TRL em vários módulos ao longo deste repositório.
# Próximos passos
Experimente os seguintes tutoriais para obter experiência com o SFT usando TRL:
⏭️ [Tutorial de modelos de bate-papo](./notebooks/chat_templates_example.ipynb)
⏭️ [Tutorial de ajuste fino supervisionado](./notebooks/sft_finetuning_example.ipynb)
|
{
"source": "huggingface/smol-course",
"title": "pt-br/1_instruction_tuning/supervised_fine_tuning.md",
"url": "https://github.com/huggingface/smol-course/blob/main/pt-br/1_instruction_tuning/supervised_fine_tuning.md",
"date": "2024-11-25T19:22:43",
"stars": 5481,
"description": "A course on aligning smol models.",
"file_size": 4862
}
|
# Preference Alignment (Alinhamento de Preferência)
Este módulo abrange técnicas para alinhar modelos de linguagem com preferências humanas. Enquanto o ajuste fino supervisionado ajuda os modelos a aprender tarefas, o alinhamento de preferência incentiva os resultados a corresponder às expectativas e valores humanos.
## Visão Geral
Métodos de alinhamento típicos envolvem vários estágios:
1. Ajuste fino supervisionado (SFT) para adaptar os modelos a domínios específicos
2. Alinhamento de preferência (como RLHF ou DPO) para melhorar a qualidade da resposta
Abordagens alternativas como ORPO combinam ajuste de instrução e alinhamento de preferência em um único processo. Aqui, vamos focar nos algoritmos DPO e ORPO.
Se você quer aprender mais sobre as diferentes técnicas de alinhamento, você pode ler mais sobre isso no [Argilla Blog](https://argilla.io/blog/mantisnlp-rlhf-part-8).
### 1️⃣ Otimização de Preferência Direta (DPO - Direct Preference Optimization)
Otimização de preferência direta (DPO) simplifica o alinhamento de preferência otimizando diretamente os modelos usando dados de preferência. Essa abordagem elimina a necessidade de usar modelos de recompensa que não fazem parte do sistema e aprendizado de reforço complexo, tornando-o mais estável e eficiente do que o tradicional aprendizado de reforço com o feedback humano (RLHF). Para mais detalhes,você pode ler mais em [Documentação sobre otimização de preferência direta (DPO)](./dpo.md).
### 2️⃣ Otimização de Preferências de Razão de Chances (ORPO - Odds Ratio Preference Optimization)
ORPO introduz uma abordagem combinada para ajuste de instrução e alinhamento de preferência em um único processo. Ele modifica o objetivo padrão de modelagem de linguagem combinando a perda de log-verossimilhança negativa com um termo de razão de chances em um nível de token. A abordagem apresenta um processo de treinamento unificado de estágio único, arquitetura sem modelo de referência e eficiência computacional aprimorada. O ORPO apresentou resultados impressionantes em vários benchmarks, demonstrando melhor desempenho no AlpacaEval em comparação com os métodos tradicionais. Para obter mais detalhes, consulte a [Documentação sobre Otimização de Preferências de Razão de Chances (ORPO)](./orpo.md)
## Caderno de Exercícios
| Título | Descrição | Exercício | Link | Colab |
|-------|-------------|----------|------|-------|
| Treinamento em DPO | Aprenda a treinar modelos usando a Otimização Direta de Preferência | 🐢 Treine um modelo usando o conjunto de dados Anthropic HH-RLHF<br>🐕 Use seu próprio conjunto de dados de preferências<br>🦁 Experimente diferentes conjuntos de dados de preferências e tamanhos de modelos | [Exercício](./notebooks/dpo_finetuning_example.ipynb) | <a target="_blank" href="https://colab.research.google.com/github/huggingface/smol-course/blob/main/2_preference_alignment/notebooks/dpo_finetuning_example.ipynb"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a> |
| Treinamento em ORPO | Aprenda a treinar modelos usando a otimização de preferências de razão de chances | 🐢 Treine um modelo usando instruções e dados de preferências<br>🐕 Experimente com diferentes pesos de perda<br>🦁 Comparar os resultados de ORPO com DPO | [Exercício](./notebooks/orpo_finetuning_example.ipynb) | <a target="_blank" href="https://colab.research.google.com/github/huggingface/smol-course/blob/main/2_preference_alignment/notebooks/orpo_finetuning_example.ipynb"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a> |
## Referências
- [Documentação do TRL](https://huggingface.co/docs/trl/index) - Documentação do módulo Transformers Reinforcement Learning (TRL), que implementa várias técnicas de alinhamento, inclusive a DPO.
- [Artigo sobre DPO](https://arxiv.org/abs/2305.18290) - Documento de pesquisa original que apresenta a Otimização Direta de Preferência como uma alternativa mais simples ao RLHF que otimiza diretamente os modelos de linguagem usando dados de preferência.
- [Artigo sobre ORPO](https://arxiv.org/abs/2403.07691) - Apresenta a Otimização de preferências de razão de chances, uma nova abordagem que combina o ajuste de instruções e o alinhamento de preferências em um único estágio de treinamento.
- [Guia Argilla RLHF](https://argilla.io/blog/mantisnlp-rlhf-part-8/) - Um guia que explica diferentes técnicas de alinhamento, incluindo RLHF, DPO e suas implementações práticas.
- [Postagem de blog sobre DPO](https://huggingface.co/blog/dpo-trl) - Guia prático sobre a implementação de DPO usando a biblioteca TRL com exemplos de código e práticas recomendadas.
- [Exemplo de script TRL no DPO](https://github.com/huggingface/trl/blob/main/examples/scripts/dpo.py) - Script de exemplo completo que demonstra como implementar o treinamento em DPO usando a biblioteca TRL.
- [Exemplo de script TRL no ORPO](https://github.com/huggingface/trl/blob/main/examples/scripts/orpo.py) - Implementação de referência do treinamento ORPO usando a biblioteca TRL com opções de configuração detalhadas.
- [Manual de alinhamento do Hugging Face](https://github.com/huggingface/alignment-handbook) - Guias de recursos e base de código para alinhamento de modelos de linguagem usando várias técnicas, incluindo SFT, DPO e RLHF.
|
{
"source": "huggingface/smol-course",
"title": "pt-br/2_preference_alignment/README.md",
"url": "https://github.com/huggingface/smol-course/blob/main/pt-br/2_preference_alignment/README.md",
"date": "2024-11-25T19:22:43",
"stars": 5481,
"description": "A course on aligning smol models.",
"file_size": 5324
}
|
# Otimização de Preferência Direta (DPO)
Otimização de Preferência Direta (DPO) oferece uma abordagem simplificada para alinhar modelos de linguagem com preferências humanas. Ao contrário dos métodos RLHF tradicionais que requerem modelos de recompensa separados e aprendizado de reforço complexo, o DPO otimiza diretamente o modelo usando dados de preferência.
## Entendendo sobre o DPO
O DPO reformula o alinhamento da preferência como um problema de classificação nos dados de preferência humana. As abordagens tradicionais de RLHF exigem treinamento de um modelo de recompensa separado e usando algoritmos de aprendizado de reforço complexos como o PPO para alinhar os outputs do modelo. O DPO simplifica esse processo, definindo uma função de perda que otimiza diretamente a política do modelo com base em outputs preferidos versus não preferidos.
Esta abordagem se mostrou altamente eficaz quando colocada em prática, sendo usada para treinar modelos como o Llama. Ao eliminar a necessidade de usar modelos de recompensa que não fazem parte do sistema e aprendizado de reforço complexo, DPO faz o alinhamento de preferência muito mais acessível e estável.
## Como o DPO Funciona
O processo do DPO exige que o ajuste fino supervisionado (SFT) adapte o modelo ao domínio-alvo. Isso cria uma base para a aprendizagem de preferências por meio do treinamento em conjuntos de dados padrão que seguem instruções. O modelo aprende a concluir tarefas básicas enquanto mantém suas capacidades gerais.
Em seguida, vem o aprendizado de preferências, em que o modelo é treinado em pares de outputs - um preferido e outro não preferido. Os pares de preferências ajudam o modelo a entender quais respostas se alinham melhor com os valores e as expectativas humanas.
A principal inovação do DPO está em sua abordagem de otimização direta. Em vez de treinar um modelo de recompensa separado, o DPO usa uma perda de entropia cruzada binária para atualizar diretamente os pesos do modelo com base nos dados de preferência. Esse processo simplificado torna o treinamento mais estável e eficiente e, ao mesmo tempo, obtém resultados comparáveis ou melhores do que a RLHF tradicional.
## Conjuntos de Dados para DPO
Os conjuntos de dados para DPO são normalmente criados anotando pares de respostas como preferidas ou não preferidas. Isso pode ser feito manualmente ou usando técnicas de filtragem automatizadas. Abaixo está um exemplo de estrutura de conjunto de dados de preferência de turno único para DPO:
| Prompt | Escolhido | Rejeitado |
|--------|-----------|-----------|
| ... | ... | ... |
| ... | ... | ... |
| ... | ... | ... |
A coluna `Prompt` contém o prompt usado para gerar as respostas `Escolhido` e `Rejeitado`. As colunas `Escolhido` e `Rejeitado` contêm as respostas preferidas e não preferidas, respectivamente. Há variações nessa estrutura, por exemplo, incluindo uma coluna de prompt do sistema ou uma coluna `Input` que contém material de referência. Os valores de `Escolhido` e `Rejeitado` podem ser representados como cadeias de caracteres para conversas de turno único ou como listas de conversas.
Você pode encontrar uma coleção de conjuntos de dados DPO em Hugging Face [aqui](https://huggingface.co/collections/argilla/preference-datasets-for-dpo-656f0ce6a00ad2dc33069478).
## Implementação com TRL
O módulo Transformers Reinforcement Learning (TRL) facilita a implementação do DPO. As classes `DPOConfig` e `DPOTrainer` seguem a mesma API no estilo `transformers`.
Veja a seguir um exemplo básico de configuração de treinamento de DPO:
```python
from trl import DPOConfig, DPOTrainer
# Define arguments
training_args = DPOConfig(
...
)
# Initialize trainer
trainer = DPOTrainer(
model,
train_dataset=dataset,
tokenizer=tokenizer,
...
)
# Train model
trainer.train()
```
Abordaremos mais detalhes sobre como usar as classes `DPOConfig` e `DPOTrainer` no [Tutotial sobre DPO](./notebooks/dpo_finetuning_example.ipynb).
## Práticas Recomendadas
A qualidade dos dados é fundamental para a implementação bem sucedida do DPO. O conjunto de dados de preferências deve incluir diversos exemplos que abranjam diferentes aspectos do comportamento desejado. Diretrizes claras de anotação garantem a rotulagem consistente das respostas preferidas e não preferidas. Você pode aprimorar o desempenho do modelo melhorando a qualidade do conjunto de dados de preferências. Por exemplo, filtrando conjuntos de dados maiores para incluir apenas exemplos de alta qualidade ou exemplos relacionados ao seu caso de uso.
Durante o treinamento, monitore cuidadosamente a convergência da perda e valide o desempenho em dados retidos. O parâmetro beta pode precisar de ajustes para equilibrar o aprendizado de preferências com a manutenção das capacidades gerais do modelo. A avaliação regular em diversos prompts ajuda a garantir que o modelo esteja aprendendo as preferências pretendidas sem se ajustar demais.
Compare os resultados do modelo com o modelo de referência para verificar a melhoria no alinhamento de preferências. Testar em uma variedade de prompts, incluindo casos extremos, ajuda a garantir um aprendizado de preferências robusto em diferentes cenários.
## Próximos Passos
⏩ Para obter experiência prática com o DPO, experimente fazer o [Tutorial DPO](./notebooks/dpo_finetuning_example.ipynb). Esse guia prático o orientará na implementação do alinhamento de preferências com seu próprio modelo, desde a preparação dos dados até o treinamento e a avaliação.
⏭️ Depois de concluir o tutorial, você pode explorar a página do [ORPO](./orpo.md) para conhecer outra técnica de alinhamento de preferências.
|
{
"source": "huggingface/smol-course",
"title": "pt-br/2_preference_alignment/dpo.md",
"url": "https://github.com/huggingface/smol-course/blob/main/pt-br/2_preference_alignment/dpo.md",
"date": "2024-11-25T19:22:43",
"stars": 5481,
"description": "A course on aligning smol models.",
"file_size": 5704
}
|
# Otimização de Preferências de Razão de Chances (ORPO)
A ORPO (Odds Ratio Preference Optimization) é uma nova técnica de ajuste fino que combina o ajuste fino e o alinhamento de preferências em um único processo unificado. Essa abordagem combinada oferece vantagens em termos de eficiência e desempenho em comparação com métodos tradicionais como RLHF ou DPO.
## Entendendo sobre o ORPO
O alinhamento com métodos como o DPO normalmente envolve duas etapas separadas: ajuste fino supervisionado para adaptar o modelo a um domínio e formato, seguido pelo alinhamento de preferências para alinhar com as preferências humanas. Embora o SFT adapte efetivamente os modelos aos domínios-alvo, ele pode aumentar inadvertidamente a probabilidade de gerar respostas desejáveis e indesejáveis. O ORPO aborda essa limitação integrando as duas etapas em um único processo, conforme ilustrado na comparação abaixo:

*Comparação de diferentes técnicas de alinhamento de modelos*
## Como o ORPO Funciona
O processo de treinamento utiliza um conjunto de dados de preferências semelhante ao que usamos para o DPO, em que cada exemplo de treinamento contém um prompt de entrada com duas respostas: uma que é preferida e outra que é rejeitada. Diferentemente de outros métodos de alinhamento que exigem estágios e modelos de referência separados, o ORPO integra o alinhamento de preferências diretamente ao processo de ajuste fino supervisionado. Essa abordagem monolítica o torna livre de modelos de referência, computacionalmente mais eficiente e eficiente em termos de memória com menos FLOPs.
O ORPO cria um novo objetivo ao combinar dois componentes principais:
1. **Função de perda do SFT**: A perda padrão de log-verossimilhança negativa usada na modelagem de linguagem, que maximiza a probabilidade de gerar tokens de referência. Isso ajuda a manter as capacidades gerais de linguagem do modelo.
2. **Função de perda da Razão de Chances**: Um novo componente que penaliza respostas indesejáveis e recompensa as preferidas. Essa função de perda usa índices de probabilidade (razão de chances) para contrastar efetivamente entre respostas favorecidas e desfavorecidas no nível do token.
Juntos, esses componentes orientam o modelo a se adaptar às gerações desejadas para o domínio específico e, ao mesmo tempo, desencorajam ativamente as gerações do conjunto de respostas rejeitadas. O mecanismo de razão de chances oferece uma maneira natural de medir e otimizar a preferência do modelo entre os resultados escolhidos e rejeitados. Se quiser se aprofundar na matemática, você pode ler o [artigo sobre ORPO](https://arxiv.org/abs/2403.07691). Se quiser saber mais sobre o ORPO do ponto de vista da implementação, confira como a função de perda do ORPO é calculada no [módulo TRL](https://github.com/huggingface/trl/blob/b02189aaa538f3a95f6abb0ab46c0a971bfde57e/trl/trainer/orpo_trainer.py#L660).
## Desempenho e Resultados
O ORPO demonstrou resultados impressionantes em vários benchmarks. No MT-Bench, ele alcança pontuações competitivas em diferentes categorias:

*Resultados do MT-Bench por categoria para os modelos Mistral-ORPO*
Quando comparado a outros métodos de alinhamento, o ORPO apresenta desempenho superior no AlpacaEval 2.0:

*Pontuações do AlpacaEval 2.0 em diferentes métodos de alinhamento*
Em comparação com p SFT+DPO, o ORPO reduz os requisitos de computação, eliminando a necessidade de um modelo de referência e reduzindo pela metade o número de passagens de avanço por lote. Além disso, o processo de treinamento é mais estável em diferentes tamanhos de modelos e conjuntos de dados, exigindo menos hiperparâmetros para ajustar. Em termos de desempenho, o ORPO se iguala aos modelos maiores e mostra melhor alinhamento com as preferências humanas.
## Implementação
A implementação bem-sucedida do ORPO depende muito de dados de preferência de alta qualidade. Os dados de treinamento devem seguir diretrizes claras de anotação e fornecer uma representação equilibrada das respostas preferidas e rejeitadas em diversos cenários.
### Implementação com TRL
O ORPO pode ser implementado usando o módulo Transformers Reinforcement Learning (TRL). Aqui está um exemplo básico:
```python
from trl import ORPOConfig, ORPOTrainer
# Configure ORPO training
orpo_config = ORPOConfig(
learning_rate=1e-5,
per_device_train_batch_size=4,
gradient_accumulation_steps=4,
max_steps=1000,
orpo_alpha=1.0, # Controls strength of preference optimization
orpo_beta=0.1, # Temperature parameter for odds ratio
)
# Initialize trainer
trainer = ORPOTrainer(
model=model,
args=orpo_config,
train_dataset=dataset,
tokenizer=tokenizer,
)
# Start training
trainer.train()
```
Principais parâmetros a serem considerados:
- `orpo_alpha`: Controla a força da otimização de preferências
- `orpo_beta`: Parâmetro de temperatura para o cálculo da razão de chances
- `learning_rate`: Deve ser relativamente pequeno para evitar o esquecimento catastrófico
- `gradient_accumulation_steps`: Ajuda na estabilidade do treinamento
## Próximos Passos
⏩ Experimente o [Tutorial do ORPO](./notebooks/orpo_tutorial.ipynb) para implementar essa abordagem unificada ao alinhamento de preferências.
## Referências
- [Artigo sobre ORPO](https://arxiv.org/abs/2403.07691)
- [Documentação TRL](https://huggingface.co/docs/trl/index)
- [Guia Argilla RLHF](https://argilla.io/blog/mantisnlp-rlhf-part-8/)
|
{
"source": "huggingface/smol-course",
"title": "pt-br/2_preference_alignment/orpo.md",
"url": "https://github.com/huggingface/smol-course/blob/main/pt-br/2_preference_alignment/orpo.md",
"date": "2024-11-25T19:22:43",
"stars": 5481,
"description": "A course on aligning smol models.",
"file_size": 5727
}
|
# Parameter-Efficient Fine-Tuning (PEFT) (Ajuste Fino com Eficiência de Parâmetro)
À medida que os modelos de linguagem aumentam, o ajuste fino tradicional torna-se cada vez mais desafiador. O ajuste fino completo de um modelo com 1,7 bilhão de parâmetros requer uma quantidade considerável de memória da GPU, torna caro o armazenamento de cópias separadas do modelo e apresenta o risco de um esquecimento catastrófico das capacidades originais do modelo. Os métodos de ajuste fino com eficiência de parâmetros (PEFT) abordam esses desafios modificando apenas um pequeno subconjunto de parâmetros do modelo e mantendo a maior parte do modelo congelada.
O ajuste fino tradicional atualiza todos os parâmetros do modelo durante o treinamento, o que se torna impraticável para modelos grandes. Os métodos PEFT introduzem abordagens para adaptar modelos usando menos parâmetros treináveis, geralmente menos de 1% do tamanho do modelo original. Essa redução drástica nos parâmetros treináveis permite:
- Ajuste fino no hardware do consumidor com memória de GPU limitada
- Armazenamento eficiente de várias adaptações de tarefas específicas
- Melhor generalização em cenários com poucos dados
- Ciclos de treinamento e iteração mais rápidos
## Métodos Disponíveis
Neste módulo, abordaremos dois métodos populares de PEFT:
### 1️⃣ LoRA (Low-Rank Adaptation - Adaptação de Baixa Classificação)
O LoRA surgiu como o método PEFT mais amplamente adotado, oferecendo uma solução elegante para a adaptação eficiente do modelo. Em vez de modificar o modelo inteiro, o **LoRA injeta matrizes treináveis nas camadas de atenção do modelo.** Essa abordagem normalmente reduz os parâmetros treináveis em cerca de 90%, mantendo um desempenho comparável ao ajuste fino completo. Exploraremos o LoRA na seção [LoRA (Adaptação de Baixa Classificação)](./lora_adapters.md).
### 2️⃣ Ajuste de Prompts
O ajuste de prompts oferece uma abordagem **ainda mais leve** ao **adicionar tokens treináveis à entrada** em vez de modificar os pesos do modelo. O ajuste de prompt é menos popular que o LoRA, mas pode ser uma técnica útil para adaptar rapidamente um modelo a novas tarefas ou domínios. Exploraremos o ajuste de prompt na seção [Ajuste de Prompt](./prompt_tuning.md).
## Cadernos de Exercícios
| Título | Descrição | Exercício | Link | Colab |
|-------|-------------|----------|------|-------|
| Ajuste fino do LoRA | Aprenda a fazer o ajuste fino de modelos usando adaptadores do LoRA | 🐢 Treine um modelo usando o LoRA< br>🐕 Experimente com diferentes valores de classificação<br>🦁 Compare o desempenho com o ajuste fino completo | [Exercício](./notebooks/finetune_sft_peft.ipynb) | <a target="_blank" href="https://colab.research.google.com/github/huggingface/smol-course/blob/main/3_parameter_efficient_finetuning/notebooks/finetune_sft_peft.ipynb"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a> | |
| Carregue adaptadores LoRA | Aprenda como carregar e usar adaptadores LoRA treinados | 🐢 Carregar adaptadores pré-treinados< br>🐕 Mesclar adaptadores com o modelo de base<br>🦁 Alternar entre vários adaptadores | [Exercício](./notebooks/load_lora_adapter.ipynb) | <a target="_blank" href="https://colab.research.google.com/github/huggingface/smol-course/blob/main/3_parameter_efficient_finetuning/notebooks/load_lora_adapter.ipynb"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a> |
<!-- | Ajuste de prompts | Aprenda como implementar o ajuste de prompts | 🐢 Treine prompts flexíveis<br>🐕 Compare diferentes estratégias de inicialização< br>🦁 Avalie em várias tarefas | [Exercício](./notebooks/prompt_tuning_example.ipynb) | <a target="_blank" href="https://colab.research.google.com/github/huggingface/smol-course/blob/main/3_parameter_efficient_finetuning/notebooks/prompt_tuning_example.ipynb"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a> | -->
## Referências
- [Documentação PEFT](https://huggingface.co/docs/peft)
- [Artigo sobre LoRA](https://arxiv.org/abs/2106.09685)
- [Artigo sobre QLoRA](https://arxiv.org/abs/2305.14314)
- [Artigo sobre Ajuste de Prompts](https://arxiv.org/abs/2104.08691)
- [Guia PEFT do Hugging Face](https://huggingface.co/blog/peft)
- [Como ajustar os LLMs em 2024 com o Hugging Face](https://www.philschmid.de/fine-tune-llms-in-2024-with-trl)
- [TRL](https://huggingface.co/docs/trl/index)
|
{
"source": "huggingface/smol-course",
"title": "pt-br/3_parameter_efficient_finetuning/README.md",
"url": "https://github.com/huggingface/smol-course/blob/main/pt-br/3_parameter_efficient_finetuning/README.md",
"date": "2024-11-25T19:22:43",
"stars": 5481,
"description": "A course on aligning smol models.",
"file_size": 4461
}
|
# LoRA (Low-Rank Adaptation - Adaptação de Baixa Classificação)
LoRA tornou-se o método PEFT mais amplamente adotado. Ele funciona adicionando pequenas matrizes de decomposição de classificação aos pesos de atenção, reduzindo tipicamente os parâmetros treináveis em cerca de 90%.
## Entendendo o LoRA
LoRA (Adaptação de Baixa Classificação) é uma técnica de ajuste fino eficiente em termos de parâmetros que congela os pesos do modelo pré-treinado e injeta matrizes treináveis de decomposição de classificação nas camadas do modelo. Em vez de treinar todos os parâmetros do modelo durante o ajuste fino, o LoRA decompõe as atualizações de peso em matrizes menores por meio da decomposição de baixa classificação, reduzindo significativamente o número de parâmetros treináveis enquanto mantém o desempenho do modelo. Por exemplo, quando aplicado ao GPT-3 175B, o LoRA reduziu os parâmetros treináveis em 10.000x e os requisitos de memória GPU em 3x em comparação ao ajuste fino completo. Você pode saber mais sobre o LoRA no [Artigo sobre LoRA](https://arxiv.org/pdf/2106.09685).
O LoRA funciona adicionando pares de matrizes de decomposição de classificação às camadas do transformer, geralmente focando nos pesos de atenção. Durante a inferência, esses pesos adaptadores podem ser mesclados com o modelo base, resultando em nenhuma sobrecarga adicional de latência. LoRA é particularmente útil para adaptar modelos de linguagem de grande porte a tarefas ou domínios específicos, mantendo os requisitos de recursos gerenciáveis.
## Carregando Adaptadores LoRA
Os adaptadores podem ser carregados em um modelo pré-treinado com load_adapter(), o que é útil para experimentar diferentes adaptadores cujos pesos não estão mesclados. Defina os pesos do adaptador ativo com a função set_adapter(). Para retornar ao modelo base, você pode usar unload() para descarregar todos os módulos LoRA. Isso facilita a alternância entre pesos específicos de tarefas.
```python
from transformers import AutoModelForCausalLM
from peft import PeftModel
base_model = AutoModelForCausalLM.from_pretrained("<base_model_name>")
peft_model_id = "<peft_adapter_id>"
model = PeftModel.from_pretrained(base_model, peft_model_id)
```

## Mesclando Adaptadores LoRA
Após o treinamento com LoRA, você pode querer mesclar os pesos do adaptador de volta ao modelo base para facilitar a implantação. Isso cria um único modelo com os pesos combinados, eliminando a necessidade de carregar adaptadores separadamente durante a inferência.
processo de mesclagem requer atenção ao gerenciamento de memória e precisão. Como será necessário carregar o modelo base e os pesos do adaptador simultaneamente, garanta memória suficiente na GPU/CPU. Usar `device_map="auto"` no `transformers` ajudará no gerenciamento automático de memória. Mantenha uma precisão consistente (por exemplo, float16) durante todo o processo, correspondendo à precisão usada durante o treinamento e salvando o modelo mesclado no mesmo formato para implantação. Antes de implantar, sempre valide o modelo mesclado comparando suas saídas e métricas de desempenho com a versão baseada em adaptadores.
Os adaptadores também são convenientes para alternar entre diferentes tarefas ou domínios. Você pode carregar o modelo base e os pesos do adaptador separadamente, permitindo alternâncias rápidas entre pesos específicos de tarefas.
## Guia de Implementação
O diretório `notebooks/` contém tutoriais práticos e exercícios para implementar diferentes métodos PEFT. Comece com `load_lora_adapter_example.ipynb` para uma introdução básica e depois veja `lora_finetuning.ipynb` para um estudo mais detalhado sobre como ajustar um modelo com LoRA e SFT.
Ao implementar métodos PEFT, comece com valores baixos de classificação (4-8) para LoRA e monitore a perda de treinamento. Use conjuntos de validação para evitar overfitting e compare os resultados com as linhas de base de ajuste fino completo sempre que possível. A eficácia de diferentes métodos pode variar conforme a tarefa, então a experimentação é essencial.
## OLoRA
[OLoRA](https://arxiv.org/abs/2406.01775) utiliza decomposição QR para inicializar os adaptadores LoRA. OLoRA traduz os pesos base do modelo por um fator de suas decomposições QR, ou seja, altera os pesos antes de realizar qualquer treinamento sobre eles. Essa abordagem melhora significativamente a estabilidade, acelera a velocidade de convergência e, por fim, alcança um desempenho superior.
## Usando TRL com PEFT
Os métodos PEFT podem ser combinados com TRL (Reinforcement Learning com Transformers) para ajuste fino eficiente. Essa integração é particularmente útil para RLHF (Reinforcement Learning from Human Feedback), pois reduz os requisitos de memória.
```python
from peft import LoraConfig
from transformers import AutoModelForCausalLM
# Load model with PEFT config
lora_config = LoraConfig(
r=16,
lora_alpha=32,
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM"
)
# Load model on specific device
model = AutoModelForCausalLM.from_pretrained(
"your-model-name",
load_in_8bit=True, # Optional: use 8-bit precision
device_map="auto",
peft_config=lora_config
)
```
No exemplo acima, usamos `device_map="auto"` para atribuir automaticamente o modelo ao dispositivo correto. Você também pode atribuir manualmente o modelo a um dispositivo específico usando `device_map={"": device_index}`. Também é possível escalar o treinamento em várias GPUs enquanto mantém o uso de memória eficiente.
## Implementação Básica de Mesclagem
Após treinar um adaptador LoRA, você pode mesclar os pesos do adaptador de volta ao modelo base. Veja como fazer isso:
```python
import torch
from transformers import AutoModelForCausalLM
from peft import PeftModel
# 1. Load the base model
base_model = AutoModelForCausalLM.from_pretrained(
"base_model_name",
torch_dtype=torch.float16,
device_map="auto"
)
# 2. Load the PEFT model with adapter
peft_model = PeftModel.from_pretrained(
base_model,
"path/to/adapter",
torch_dtype=torch.float16
)
# 3. Merge adapter weights with base model
try:
merged_model = peft_model.merge_and_unload()
except RuntimeError as e:
print(f"Merging failed: {e}")
# Implement fallback strategy or memory optimization
# 4. Save the merged model
merged_model.save_pretrained("path/to/save/merged_model")
```
Se você encontrar discrepâncias de tamanho no modelo salvo, garanta que está salvando também o tokenizador:
```python
# Save both model and tokenizer
tokenizer = AutoTokenizer.from_pretrained("base_model_name")
merged_model.save_pretrained("path/to/save/merged_model")
tokenizer.save_pretrained("path/to/save/merged_model")
```
## Próximos Passos
⏩ Prossiga para o guia de [Ajuste de Prompts](prompt_tuning.md) para aprender como ajustar um modelo com ajuste de prompts.
⏩ Veja o [Tutorial de Carregamento de Adaptadores LoRA](./notebooks/load_lora_adapter.ipynb) para aprender como carregar adaptadores LoRA.
# Referências
- [LORA: LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS](https://arxiv.org/pdf/2106.09685)
- [Documentação PEFT](https://huggingface.co/docs/peft)
- [Blog do Hugging Face sobre PEFT](https://huggingface.co/blog/peft)
|
{
"source": "huggingface/smol-course",
"title": "pt-br/3_parameter_efficient_finetuning/lora_adapters.md",
"url": "https://github.com/huggingface/smol-course/blob/main/pt-br/3_parameter_efficient_finetuning/lora_adapters.md",
"date": "2024-11-25T19:22:43",
"stars": 5481,
"description": "A course on aligning smol models.",
"file_size": 7271
}
|
# Ajuste de Prompts
O ajuste de prompts (prompt tuning) é uma abordagem eficiente em termos de parâmetros que modifica as representações de entrada em vez dos pesos do modelo. Diferente do ajuste fino tradicional, que atualiza todos os parâmetros do modelo, o ajuste de prompts adiciona e otimiza um pequeno conjunto de tokens treináveis, mantendo o modelo base congelado.
## Entendendo o Ajuste de Prompts
O ajuste de prompts é uma alternativa eficiente ao ajuste fino de modelos que adiciona vetores contínuos treináveis (soft prompts) ao texto de entrada. Diferente dos prompts de texto discretos, esses soft prompts são aprendidos através de retropropagação enquanto o modelo de linguagem permanece congelado. O método foi introduzido em ["The Power of Scale for Parameter-Efficient Prompt Tuning"](https://arxiv.org/abs/2104.08691) (Lester et al., 2021), que demonstrou que o ajuste de prompts se torna mais competitivo em relação ao ajuste fino conforme o tamanho do modelo aumenta. No artigo, em torno de 10 bilhões de parâmetros, o ajuste de prompts iguala o desempenho do ajuste fino, modificando apenas algumas centenas de parâmetros por tarefa.
Esses soft prompts são vetores contínuos no espaço de embedding do modelo que são otimizados durante o treinamento. Diferente dos prompts discretos tradicionais que usam tokens de linguagem natural, os soft prompts não possuem significado inerente, mas aprendem a evocar o comportamento desejado do modelo congelado por meio de gradiente descendente. A técnica é particularmente eficaz em cenários multitarefa, pois cada tarefa exige apenas o armazenamento de um pequeno vetor de prompt (normalmente algumas centenas de parâmetros) em vez de uma cópia completa do modelo. Essa abordagem não apenas mantém um uso mínimo de memória, mas também possibilita a troca rápida de tarefas apenas trocando os vetores de prompt sem precisar recarregar o modelo.
## Processo de Treinamento
Os soft prompts geralmente têm entre 8 e 32 tokens e podem ser inicializados aleatoriamente ou a partir de texto existente. O método de inicialização desempenha um papel crucial no processo de treinamento, com inicializações baseadas em texto frequentemente apresentando melhor desempenho do que inicializações aleatórias.
Durante o treinamento, apenas os parâmetros do prompt são atualizados, enquanto o modelo base permanece congelado. Essa abordagem focada utiliza objetivos de treinamento padrão, mas exige atenção cuidadosa à taxa de aprendizado e ao comportamento do gradiente dos tokens do prompt.
## Implementação com PEFT
O módulo PEFT facilita a implementação do ajuste de prompts. Aqui está um exemplo básico:
```python
from peft import PromptTuningConfig, TaskType, get_peft_model
from transformers import AutoModelForCausalLM, AutoTokenizer
# Load base model
model = AutoModelForCausalLM.from_pretrained("your-base-model")
tokenizer = AutoTokenizer.from_pretrained("your-base-model")
# Configure prompt tuning
peft_config = PromptTuningConfig(
task_type=TaskType.CAUSAL_LM,
num_virtual_tokens=8, # Number of trainable tokens
prompt_tuning_init="TEXT", # Initialize from text
prompt_tuning_init_text="Classify if this text is positive or negative:",
tokenizer_name_or_path="your-base-model",
)
# Create prompt-tunable model
model = get_peft_model(model, peft_config)
```
## Comparação com Outros Métodos
Quando comparado a outras abordagens PEFT, o ajuste de prompts se destaca por sua eficiência. Enquanto o LoRA oferece baixo uso de parâmetros e memória, mas exige o carregamento de adaptadores para troca de tarefas, o ajuste de prompts atinge um uso de recursos ainda menor e possibilita a troca imediata de tarefas. O ajuste fino completo, em contraste, demanda recursos significativos e requer cópias separadas do modelo para diferentes tarefas.
| Método | Parâmetros | Memória | Troca de Tarefas |
|--------|------------|---------|----------------|
| Ajuste de Prompts| Muito Baixo | Mínima | Fácil |
| LoRA | Baixo | Baixa | Requer Carregamento |
| Ajuste Fino | Alto | Alta | Nova Cópia do Modelo |
Ao implementar o ajuste de prompts, comece com um pequeno número de tokens virtuais (8-16) e aumente apenas se a complexidade da tarefa exigir. A inicialização baseada em texto geralmente apresenta melhores resultados do que a inicialização aleatória, especialmente ao usar texto relevante para a tarefa. A estratégia de inicialização deve refletir a complexidade da tarefa alvo.
O treinamento requer considerações ligeiramente diferentes do ajuste fino completo. Taxas de aprendizado mais altas geralmente funcionam bem, mas o monitoramento cuidadoso dos gradientes dos tokens do prompt é essencial. A validação regular com exemplos diversos ajuda a garantir um desempenho robusto em diferentes cenários.
## Aplicação
O ajuste de prompts se destaca em diversos cenários:
1. Implantação multitarefa
2. Ambientes com restrição de recursos
3. Adaptação rápida a tarefas
4. Aplicações sensíveis à privacidade
Conforme os modelos ficam menores, o ajuste de prompts se torna menos competitivo em comparação ao ajuste fino completo. Por exemplo, em modelos como SmolLM2, o ajuste de prompts é menos relevante do que o ajuste fino completo.
## Próximos Passos
⏭️ Prossiga para o [Tutorial de Adaptadores LoRA](./notebooks/finetune_sft_peft.ipynb) para aprender como ajustar um modelo com adaptadores LoRA.
## Referências
- [Documentação PEFT](https://huggingface.co/docs/peft)
- [Artigo sobre Ajuste de Prompts](https://arxiv.org/abs/2104.08691)
- [Cookbook do Hugging Face](https://huggingface.co/learn/cookbook/prompt_tuning_peft)
|
{
"source": "huggingface/smol-course",
"title": "pt-br/3_parameter_efficient_finetuning/prompt_tuning.md",
"url": "https://github.com/huggingface/smol-course/blob/main/pt-br/3_parameter_efficient_finetuning/prompt_tuning.md",
"date": "2024-11-25T19:22:43",
"stars": 5481,
"description": "A course on aligning smol models.",
"file_size": 5627
}
|
# Evaluation (Avaliação)
A avaliação é uma etapa crítica no desenvolvimento e implantação de modelos de linguagem. Ela nos ajuda a entender quão bem nossos modelos desempenham em diferentes capacidades e a identificar áreas para melhorias. Este módulo aborda benchmarks padrão e abordagens de avaliação específicas de domínio para avaliar de forma abrangente o seu modelo smol (miudinho).
Usaremos o [`lighteval`](https://github.com/huggingface/lighteval), uma poderosa biblioteca de avaliação desenvolvida pelo Hugging Face que se integra perfeitamente ao ecossistema Hugging Face. Para um aprendizado mais profundo nos conceitos e práticas recomendadas de avaliação, confira o [guia](https://github.com/huggingface/evaluation-guidebook).
## Visão Geral do Módulo
Uma estratégia de avaliação completa examina múltiplos aspectos do desempenho do modelo. Avaliamos capacidades específicas de tarefas, como responder a perguntas e sumarização, para entender como o modelo lida com diferentes tipos de problemas. Medimos a qualidade do output através de fatores como coerência e precisão factual. A avaliação de segurança ajuda a identificar outputs potencialmente prejudiciais ou biases. Por fim, os testes de especialização de domínio verificam o conhecimento especializado do modelo no campo-alvo.
## Conteúdo
### 1️⃣ [Benchmarks Automáticos](./automatic_benchmarks.md)
Aprenda a avaliar seu modelo usando benchmarks e métricas padronizados. Exploraremos benchmarks comuns, como MMLU e TruthfulQA, entenderemos as principais métricas e configurações de avaliação e abordaremos as melhores práticas para avaliações reproduzíveis.
### 2️⃣ [Avaliação de Domnínio Personalizado](./custom_evaluation.md)
Descubra como criar pipelines de avaliação adaptados ao seu caso de uso específico. Veremos o design de tarefas de avaliação personalizadas, implementação de métricas especializadas e construção de conjuntos de dados de avaliação que atendam às suas necessidades.
### 3️⃣ [Projeto de Avaliação de Domínio](./project/README.md)
Siga um exemplo completo de construção de um pipeline de avaliação de domínio específico. Você aprenderá a gerar conjuntos de dados de avaliação, usar o Argilla para anotação de dados, criar conjuntos de dados padronizados e avaliar modelos usando o LightEval.
### Cadernos de Exercício
| Título | Descrição | Exercício | Link | Colab |
|-------|-------------|----------|------|-------|
| Avalie e Analise Seu LLM | Aprenda a usar o LightEval para avaliar e comparar modelos em domínios específicos | 🐢 Use tarefas do domínio da medicina para avaliar um modelo <br> 🐕 Crie uma nova avaliação de domínio com diferentes tarefas do MMLU <br> 🦁 Crie uma tarefa de avaliação personalizada para o seu domínio | [Notebook](./notebooks/lighteval_evaluate_and_analyse_your_LLM.ipynb) | <a target="_blank" href="https://colab.research.google.com/github/huggingface/smol-course/blob/main/4_evaluation/notebooks/lighteval_evaluate_and_analyse_your_LLM.ipynb"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a> |
## Referências
- [Guia de Avaliação](https://github.com/huggingface/evaluation-guidebook) - Guia abrangente de avaliação de LLMs
- [Documentação do LightEval](https://github.com/huggingface/lighteval) - Documentação oficial do módulo LightEval
- [Documentação do Argilla](https://docs.argilla.io) - Saiba mais sobre a plataforma de anotação Argilla
- [Artigo do MMLU](https://arxiv.org/abs/2009.03300) - Artigo que descreve o benchmark MMLU
- [Criando uma Tarefa Personalizada](https://github.com/huggingface/lighteval/wiki/Adding-a-Custom-Task)
- [Criando uma Métrica Personalizada](https://github.com/huggingface/lighteval/wiki/Adding-a-New-Metric)
- [Usando Métricas Existentes](https://github.com/huggingface/lighteval/wiki/Metric-List)
|
{
"source": "huggingface/smol-course",
"title": "pt-br/4_evaluation/README.md",
"url": "https://github.com/huggingface/smol-course/blob/main/pt-br/4_evaluation/README.md",
"date": "2024-11-25T19:22:43",
"stars": 5481,
"description": "A course on aligning smol models.",
"file_size": 3826
}
|
# Benchmarks Automáticos
Os benchmarks automáticos servem como ferramentas padronizadas para avaliar modelos de linguagem em diferentes tarefas e capacidades. Embora forneçam um ponto de partida útil para entender o desempenho do modelo, é importante reconhecer que eles representam apenas uma parte de uma estratégia abrangente de avaliação.
## Entendendo os Benchmarks Automáticos
Os benchmarks automáticos geralmente consistem em conjuntos de dados organizados com tarefas e métricas de avaliação predefinidas. Esses benchmarks têm como objetivo avaliar vários aspectos da capacidade do modelo, desde compreensão básica de linguagem até raciocínio complexo. A principal vantagem de usar benchmarks automáticos é a padronização, eles permitem comparações consistentes entre diferentes modelos e fornecem resultados reproduzíveis.
No entanto, é crucial entender que o desempenho em benchmarks nem sempre se traduz diretamente em eficácia no mundo real. Um modelo que se destaca em benchmarks acadêmicos pode ainda enfrentar dificuldades em aplicações específicas de domínio ou casos práticos.
## Benchmarks e Suas Limitações
### Benchmarks de Conhecimento Geral
O MMLU (Massive Multitask Language Understanding) testa conhecimentos em 57 disciplinas, de ciências a humanidades. Embora abrangente, este benchmark pode não refletir a profundidade de especialização necessária para domínios específicos. O TruthfulQA avalia a tendência de um modelo em reproduzir conceitos equivocados comuns, embora não capture todas as formas de desinformação.
### Benchmarks de Raciocínio
BBH (Big Bench Hard) e GSM8K focam em tarefas de raciocínio complexo. O BBH testa pensamento lógico e planejamento, enquanto o GSM8K visa especificamente a resolução de problemas matemáticos. Esses benchmarks ajudam a avaliar capacidades analíticas, mas podem não captar o raciocínio detalhado exigido em cenários do mundo real.
### Compreensão de Linguagem
HELM fornece uma estrutura de avaliação holística, enquanto o WinoGrande testa o senso comum através da desambiguação de pronomes. Esses benchmarks oferecem insights sobre capacidades de processamento de linguagem, mas podem não representar totalmente a complexidade da conversação natural ou terminologia específica de domínio.
## Abordagens Alternativas de Avaliação
Muitas organizações desenvolveram métodos alternativos de avaliação para lidar com as limitações dos benchmarks padrão:
### LLM como Juiz
Usar um modelo de linguagem para avaliar os outputs de outro tornou-se cada vez mais popular. Essa abordagem pode fornecer feedback mais detalhado do que métricas tradicionais, embora apresente seus próprios vieses e limitações.
### Arenas de Avaliação
Plataformas como a IA Arena Constitucional da Anthropic permitem que modelos interajam e avaliem uns aos outros em ambientes controlados. Isso pode revelar pontos fortes e fracos que podem não ser evidentes em benchmarks tradicionais.
### Conjuntos de Benchmarks Personalizados
As organizações frequentemente desenvolvem conjuntos de benchmarks internos adaptados às suas necessidades e casos de uso específicos. Esses conjuntos podem incluir testes de conhecimento de domínio ou cenários de avaliação que refletem condições reais de implantação.
## Criando Sua Própria Estratégia de Avaliação
Embora o LightEval facilite a execução de benchmarks padrão, você também deve investir tempo no desenvolvimento de métodos de avaliação específicos para o seu caso de uso.
Sabendo que benchmarks padrão fornecem uma linha de base útil, eles não devem ser seu único método de avaliação. Aqui está como desenvolver uma abordagem mais abrangente:
1. Comece com benchmarks padrão relevantes para estabelecer uma linha de base e permitir comparações com outros modelos.
2. Identifique os requisitos específicos e desafios do seu caso de uso. Quais tarefas seu modelo realmente executará? Que tipos de erros seriam mais problemáticos?
3. Desenvolva conjuntos de dados de avaliação personalizados que reflitam seu caso de uso real. Isso pode incluir:
- Consultas reais de usuários do seu domínio
- Casos extremos comuns que você encontrou
- Exemplos de cenários particularmente desafiadores
4. Considere implementar uma estratégia de avaliação em camadas:
- Métricas automatizadas para feedback rápido
- Avaliação humana para entendimento mais detalhado
- Revisão por especialistas no domínio para aplicações especializadas
- Testes A/B em ambientes controlados
## Usando LightEval para Benchmarks
As tarefas do LightEval são definidas usando um formato específico:
```
{suite}|{task}|{num_few_shot}|{auto_reduce}
```
- **suite**: O conjunto de benchmarks (ex.: 'mmlu', 'truthfulqa')
- **task**: Tarefa específica dentro do conjunto (ex.: 'abstract_algebra')
- **num_few_shot**: Número de exemplos a incluir no prompt (0 para zero-shot)
- **auto_reduce**: Se deve reduzir automaticamente exemplos few-shot caso o prompt seja muito longo (0 ou 1)
Exemplo: `"mmlu|abstract_algebra|0|0"` avalia a tarefa de álgebra abstrata do MMLU com inferência zero-shot.
### Exemplo de Pipeline de Avaliação
Aqui está um exemplo completo de configuração e execução de uma avaliação em benchmarks automáticos relevantes para um domínio específico:
```python
from lighteval.tasks import Task, Pipeline
from transformers import AutoModelForCausalLM
# Define tasks to evaluate
domain_tasks = [
"mmlu|anatomy|0|0",
"mmlu|high_school_biology|0|0",
"mmlu|high_school_chemistry|0|0",
"mmlu|professional_medicine|0|0"
]
# Configure pipeline parameters
pipeline_params = {
"max_samples": 40, # Number of samples to evaluate
"batch_size": 1, # Batch size for inference
"num_workers": 4 # Number of worker processes
}
# Create evaluation tracker
evaluation_tracker = EvaluationTracker(
output_path="./results",
save_generations=True
)
# Load model and create pipeline
model = AutoModelForCausalLM.from_pretrained("your-model-name")
pipeline = Pipeline(
tasks=domain_tasks,
pipeline_parameters=pipeline_params,
evaluation_tracker=evaluation_tracker,
model=model
)
# Run evaluation
pipeline.evaluate()
# Get and display results
results = pipeline.get_results()
pipeline.show_results()
```
Os resultados são exibidos em formato tabular, mostrando:
```
| Task |Version|Metric|Value | |Stderr|
|----------------------------------------|------:|------|-----:|---|-----:|
|all | |acc |0.3333|± |0.1169|
|leaderboard:mmlu:_average:5 | |acc |0.3400|± |0.1121|
|leaderboard:mmlu:anatomy:5 | 0|acc |0.4500|± |0.1141|
|leaderboard:mmlu:high_school_biology:5 | 0|acc |0.1500|± |0.0819|
```
Você também pode manipular os resultados em um DataFrame do pandas e visualizá-los conforme necessário.
# Próximos Passos
⏩ Veja a [Avaliação Personalizada de Domínio](./custom_evaluation.md) para aprender a criar pipelines de avaliação adaptados às suas necessidades específicas.
|
{
"source": "huggingface/smol-course",
"title": "pt-br/4_evaluation/automatic_benchmarks.md",
"url": "https://github.com/huggingface/smol-course/blob/main/pt-br/4_evaluation/automatic_benchmarks.md",
"date": "2024-11-25T19:22:43",
"stars": 5481,
"description": "A course on aligning smol models.",
"file_size": 7070
}
|
# Avaliação de Domínio Personalizado
Embora benchmarks padrão ofereçam insights valiosos, muitas aplicações requerem abordagens de avaliação especializadas adaptadas a domínios ou casos de uso específicos. Este guia ajudará você a criar pipelines de avaliação personalizados que avaliem com precisão o desempenho do seu modelo no domínio-alvo.
## Planejando Sua Estratégia de Avaliação
Uma estratégia de avaliação personalizada bem-sucedida começa com objetivos claros. Considere quais capacidades específicas seu modelo precisa demonstrar no seu domínio. Isso pode incluir conhecimento técnico, padrões de raciocínio ou formatos específicos de domínio. Documente esses requisitos cuidadosamente, eles guiarão tanto o design da tarefa quanto a seleção de métricas.
Sua avaliação deve testar tanto casos de uso padrão quanto casos extremos. Por exemplo, em um domínio de medicina, você pode avaliar cenários com diagnósticos comuns e condições raras. Em aplicações financeiras, pode-se testar transações rotineiras e casos extremos envolvendo múltiplas moedas ou condições especiais.
## Implementação com LightEval
O LightEval fornece um framework flexível para implementar avaliações personalizadas. Veja como criar uma tarefa personalizada:
```python
from lighteval.tasks import Task, Doc
from lighteval.metrics import SampleLevelMetric, MetricCategory, MetricUseCase
class CustomEvalTask(Task):
def __init__(self):
super().__init__(
name="custom_task",
version="0.0.1",
metrics=["accuracy", "f1"], # Your chosen metrics
description="Description of your custom evaluation task"
)
def get_prompt(self, sample):
# Format your input into a prompt
return f"Question: {sample['question']}\nAnswer:"
def process_response(self, response, ref):
# Process model output and compare to reference
return response.strip() == ref.strip()
```
## Métricas Personalizadas
Tarefas específicas de domínio frequentemente exigem métricas especializadas. O LightEval fornece um framework flexível para criar métricas personalizadas que capturam aspectos relevantes do desempenho no domínio:
```python
from aenum import extend_enum
from lighteval.metrics import Metrics, SampleLevelMetric, SampleLevelMetricGrouping
import numpy as np
# Define a sample-level metric function
def custom_metric(predictions: list[str], formatted_doc: Doc, **kwargs) -> dict:
"""Example metric that returns multiple scores per sample"""
response = predictions[0]
return {
"accuracy": response == formatted_doc.choices[formatted_doc.gold_index],
"length_match": len(response) == len(formatted_doc.reference)
}
# Create a metric that returns multiple values per sample
custom_metric_group = SampleLevelMetricGrouping(
metric_name=["accuracy", "length_match"], # Names of sub-metrics
higher_is_better={ # Whether higher values are better for each metric
"accuracy": True,
"length_match": True
},
category=MetricCategory.CUSTOM,
use_case=MetricUseCase.SCORING,
sample_level_fn=custom_metric,
corpus_level_fn={ # How to aggregate each metric
"accuracy": np.mean,
"length_match": np.mean
}
)
# Register the metric with LightEval
extend_enum(Metrics, "custom_metric_name", custom_metric_group)
```
Para casos mais simples onde você precisa de apenas um valor por amostra:
```python
def simple_metric(predictions: list[str], formatted_doc: Doc, **kwargs) -> bool:
"""Example metric that returns a single score per sample"""
response = predictions[0]
return response == formatted_doc.choices[formatted_doc.gold_index]
simple_metric_obj = SampleLevelMetric(
metric_name="simple_accuracy",
higher_is_better=True,
category=MetricCategory.CUSTOM,
use_case=MetricUseCase.SCORING,
sample_level_fn=simple_metric,
corpus_level_fn=np.mean # How to aggregate across samples
)
extend_enum(Metrics, "simple_metric", simple_metric_obj)
```
Você pode então usar suas métricas personalizadas em tarefas de avaliação referenciando-as na configuração da tarefa. As métricas serão automaticamente calculadas para todas as amostras e agregadas de acordo com as funções especificadas.
Para métricas mais complexas, considere:
- Usar metadados em seus documentos formatados para ponderar ou ajustar pontuações
- Implementar funções de agregação personalizadas para estatísticas em nível de corpus
- Adicionar verificações de validação para as entradas da métrica
- Documentar casos extremos e comportamentos esperados
Para um exemplo completo de métricas personalizadas em ação, veja nosso [projeto de avaliação de domínio](./project/README.md).
## Criação de Conjuntos de Dados
Uma avaliação de alta qualidade requer conjuntos de dados cuidadosamente selecionados. Considere estas abordagens para criação de conjuntos de dados:
1. Anotação Avançada: Trabalhe com especialistas no domínio para criar e validar exemplos de avaliação. Ferramentas como o [Argilla](https://github.com/argilla-io/argilla) tornam esse processo mais eficiente.
2. Dados do Mundo Real: Colete e anonimize dados de uso real, garantindo que representem cenários reais de implantação.
3. Geração Sintética: Use LLMs para gerar exemplos iniciais e, em seguida, peça para especialistas validarem e refinarem esses exemplos.
## Melhores Práticas
- Documente sua metodologia de avaliação detalhadamente, incluindo quaisquer suposições ou limitações
- Inclua casos de teste diversificados que cubram diferentes aspectos do seu domínio
- Considere métricas automatizadas e avaliação humana, quando apropriado
- Faça o controle de versão dos seus conjuntos de dados e código de avaliação
- Atualize regularmente seu conjunto de avaliação à medida que descobrir novos casos extremos ou requisitos
## Referências
- [Guia de Tarefas Personalizadas do LightEval](https://github.com/huggingface/lighteval/wiki/Adding-a-Custom-Task)
- [Métricas Personalizadas do LightEval](https://github.com/huggingface/lighteval/wiki/Adding-a-New-Metric)
- [Documentação do Argilla](https://docs.argilla.io) para anotação de conjuntos de dados
- [Guia de Avaliação](https://github.com/huggingface/evaluation-guidebook) para princípios gerais de avaliação
# Próximos Passos
⏩ Para um exemplo completo de implementação desses conceitos, veja nosso [projeto de avaliação de domínio](./project/README.md).
|
{
"source": "huggingface/smol-course",
"title": "pt-br/4_evaluation/custom_evaluation.md",
"url": "https://github.com/huggingface/smol-course/blob/main/pt-br/4_evaluation/custom_evaluation.md",
"date": "2024-11-25T19:22:43",
"stars": 5481,
"description": "A course on aligning smol models.",
"file_size": 6462
}
|
# Tinh chỉnh theo chỉ thị (Instruction Tuning)
Trong chương này chúng ta sẽ học về quá trình tinh chỉnh mô hình ngôn ngữ theo chỉ thị. Tinh chỉnh theo chỉ thị là quá trình điều chỉnh *pre-trained models* cho các tác vụ cụ thể bằng cách tiếp tục huấn luyện chúng trên các tập dữ liệu đặc thù cho tác vụ. Quá trình này giúp các mô hình cải thiện hiệu suất trên những tác vụ đó.
Chúng ta sẽ cùng khám phá hai chủ đề chính: 1) Định dạng Chat (Chat Templates) và 2) Tinh chỉnh có giám sát (Supervised Fine-Tuning).
## 1️⃣ Định dạng Chat (Chat Templates)
Định dạng Chat là cấu trúc giữa các tương tác giữa người dùng và mô hình ngôn ngữ, đảm bảo các phản hồi nhất quán và phù hợp với từng ngữ cảnh. Chúng bao gồm các thành phần như `system prompts` và các `message` theo vai trò (người dùng - `user` hoặc trợ lý - `assistant`). Để biết thêm thông tin chi tiết, hãy tham khảo phần [Chat Templates](./chat_templates.md).
## 2️⃣ Huấn luyện có giám sát (Supervised Fine-Tuning)
Huấn luyện có giám sát (SFT) là một quá trình cốt lõi để điều chỉnh các mô hình ngôn ngữ đã *pre-trained* cho các tác vụ cụ thể. Quá trình này bao gồm việc huấn luyện mô hình trên tập dữ liệu có gán nhãn theo tác vụ cụ thể. Để đọc hướng dẫn chi tiết về SFT, bao gồm các bước quan trọng và các phương pháp thực hành tốt nhất, hãy xem tại trang [Supervised Fine-Tuning](./supervised_fine_tuning.md).
## Bài tập
| Tiêu đề | Mô tả | Bài tập | Đường dẫn | Google Colab |
|-------|-------------|----------|------|-------|
| Định dạng Chat | Học cách sử dụng *định dạng chat* với SmolLM2 và xử lý dữ liệu thành định dạng *chatml* | 🐢 Chuyển đổi tập dữ liệu `HuggingFaceTB/smoltalk` sang định dạng *chatml* <br> 🐕 Chuyển đổi tập dữ liệu `openai/gsm8k` sang định dạng *chatml* | [Notebook](./notebooks/chat_templates_example.ipynb) | <a target="_blank" href="https://colab.research.google.com/github/huggingface/smol-course/blob/main/1_instruction_tuning/notebooks/chat_templates_example.ipynb"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Sử dụng Colab"/></a> |
| Tinh chỉnh có giám sát | Học cách tinh chỉnh SmolLM2 sử dụng SFTTrainer | 🐢 Sử dụng tập dữ liệu `HuggingFaceTB/smoltalk` <br>🐕 Thử nghiệm với tập dữ liệu `bigcode/the-stack-smol` <br>🦁 Chọn một tập dữ liệu cho trường hợp sử dụng thực tế | [Notebook](./notebooks/sft_finetuning_example.ipynb) | <a target="_blank" href="https://colab.research.google.com/github/huggingface/smol-course/blob/main/1_instruction_tuning/notebooks/sft_finetuning_example.ipynb"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Sử dụng Colab"/></a> |
## Tài liệu tham khảo
- [Tài liệu Transformers về định dạng chat](https://huggingface.co/docs/transformers/main/en/chat_templating)
- [Script cho huấn luyện có giám sát bằng thư viện TRL](https://github.com/huggingface/trl/blob/main/examples/scripts/sft.py)
- [`SFTTrainer` trong thư viện TRL](https://huggingface.co/docs/trl/main/en/sft_trainer)
- [Bài báo Direct Preference Optimization (DPO)](https://arxiv.org/abs/2305.18290)
- [Huấn luyện có giám sát bằng thư viện TRL](https://huggingface.co/docs/trl/main/en/tutorials/supervised_finetuning)
- [Cách fine-tune Google Gemma với ChatML và Hugging Face TRL](https://www.philschmid.de/fine-tune-google-gemma)
- [Huấn luyện LLM để tạo danh mục sản phẩm tiếng Ba Tư ở định dạng JSON](https://huggingface.co/learn/cookbook/en/fine_tuning_llm_to_generate_persian_product_catalogs_in_json_format)
|
{
"source": "huggingface/smol-course",
"title": "vi/1_instruction_tuning/README.md",
"url": "https://github.com/huggingface/smol-course/blob/main/vi/1_instruction_tuning/README.md",
"date": "2024-11-25T19:22:43",
"stars": 5481,
"description": "A course on aligning smol models.",
"file_size": 3456
}
|
# Định dạng Chat
Định dạng Chat (Chat templates) là yếu tố thiết yếu trong cấu trúc các tương tác giữa mô hình ngôn ngữ và người dùng. Chúng cung cấp một định dạng nhất quán cho các cuộc hội thoại, đảm bảo rằng các mô hình hiểu được ngữ cảnh và vai trò của mỗi tin nhắn trong khi duy trì các mẫu phản hồi phù hợp.
## Mô hình gốc (Base Models) và Mô hình chỉ thị (Instruct Models)
Mô hình gốc được huấn luyện trên dữ liệu văn bản thô để dự đoán *token* tiếp theo, trong khi Mô hình chỉ thị được tiếp tục tinh chỉnh đặc biệt để tuân theo chỉ thị và tham gia vào hội thoại. Ví dụ, `SmolLM2-135M` là một mô hình gốc, trong khi `SmolLM2-135M-Instruct` là phiên bản đã được điều chỉnh.
Để làm cho Mô hình gốc hoạt động như một Mô hình chỉ thị, chúng ta cần *định dạng prompt* của mình theo cách nhất quán mà mô hình có thể hiểu được. Đây là lúc *định dạng chat* phát huy tác dụng. **ChatML** là một định dạng template như vậy, với cấu trúc các cuộc hội thoại có chỉ định vai trò rõ ràng (system, user, assistant).
Điều quan trọng cần lưu ý là một Mô hình gốc có thể được huấn luyện với các *định dạng chat* khác nhau, vì vậy khi chúng ta sử dụng một Mô hình chỉ thị, chúng ta cần đảm bảo đang sử dụng đúng *định dạng chat*.
## Tìm hiểu về Định dạng Chat
Về cốt lõi, *định dạng chat* định nghĩa cách các cuộc hội thoại nên được định dạng khi giao tiếp với một mô hình ngôn ngữ. Chúng bao gồm các hướng dẫn hệ thống (system), tin nhắn người dùng (user) và phản hồi của trợ lý (assistant) trong một định dạng có cấu trúc mà mô hình có thể hiểu được. Cấu trúc này giúp duy trì tính nhất quán trong các tương tác và đảm bảo mô hình phản hồi phù hợp với các loại đầu vào khác nhau. Dưới đây là một ví dụ về chat template:
```sh
<|im_start|>user
Hi there!<|im_end|>
<|im_start|>assistant
Nice to meet you!<|im_end|>
<|im_start|>user
Can I ask a question?<|im_end|>
<|im_start|>assistant
```
Thư viện `transformers` sẽ xử lý *định dạng chat* cho bạn liên quan đến tokenizer của mô hình. Đọc thêm về cách transformers xây dựng *định dạng chat* [tại đây](https://huggingface.co/docs/transformers/en/chat_templating#how-do-i-use-chat-templates). Tất cả những gì chúng ta cần làm là cấu trúc tin nhắn của mình theo cách chính xác và *tokenizer() sẽ xử lý phần còn lại. Đây là một ví dụ cơ bản về một cuộc hội thoại:
```python
messages = [
{"role": "system", "content": "You are a helpful assistant focused on technical topics."},
{"role": "user", "content": "Can you explain what a chat template is?"},
{"role": "assistant", "content": "A chat template structures conversations between users and AI models..."}
]
```
Hãy cùng nhau phân tích ví dụ trên để hiểu hơn về *định dạng chat*
## Mệnh lệnh hệ thống (System Prompt)
Mệnh lệnh hệ thống thiết lập nền tảng cho cách mô hình nên hoạt động. Chúng đóng vai trò như các hướng dẫn ảnh hưởng liên tục đến tất cả các tương tác tiếp theo. Ví dụ:
```python
system_message = {
"role": "system",
"content": "You are a professional customer service agent. Always be polite, clear, and helpful."
}
```
## Cuộc hội thoại
*Định dạng chat* duy trì ngữ cảnh thông qua lịch sử hội thoại, lưu trữ các trao đổi trước đó giữa người dùng và trợ lý. Điều này cho phép các cuộc hội thoại mạch lạc hơn:
```python
conversation = [
{"role": "user", "content": "I need help with my order"},
{"role": "assistant", "content": "I'd be happy to help. Could you provide your order number?"},
{"role": "user", "content": "It's ORDER-123"},
]
```
## Triển khai với thư viện Transformers
Thư viện transformers cung cấp hỗ trợ tích hợp cho *định dạng chat*. Đây là cách sử dụng:
```python
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("HuggingFaceTB/SmolLM2-135M-Instruct")
messages = [
{"role": "system", "content": "You are a helpful coding assistant."},
{"role": "user", "content": "Write a Python function to sort a list"},
]
# Apply the chat template
formatted_chat = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
```
## Tuỳ chỉnh Định dạng Chat
Bạn có thể tùy chỉnh cách định dạng các loại tin nhắn khác nhau. Ví dụ, thêm *special token* hoặc định dạng cho các vai trò khác nhau:
```python
template = """
<|system|>{system_message}
<|user|>{user_message}
<|assistant|>{assistant_message}
""".lstrip()
```
## Hỗ trợ hội thoại đa lượt (multi-turn conversations)
Với *định dạng chat*, mô hình có thể xử lý các cuộc hội thoại phức tạp nhiều lượt trong khi vẫn duy trì ngữ cảnh:
```python
messages = [
{"role": "system", "content": "You are a math tutor."},
{"role": "user", "content": "What is calculus?"},
{"role": "assistant", "content": "Calculus is a branch of mathematics..."},
{"role": "user", "content": "Can you give me an example?"},
]
```
⏭️ [Tiếp theo: Huấn luyện có giám sát](./supervised_fine_tuning.md)
## Tài liệu tham khảo
- [Hướng dẫn Định dạng Chat của Hugging Face](https://huggingface.co/docs/transformers/main/en/chat_templating)
- [Tài liệu về thư viện Transformers](https://huggingface.co/docs/transformers)
- [Ví dụ về Định dạng Chat](https://github.com/chujiezheng/chat_templates)
|
{
"source": "huggingface/smol-course",
"title": "vi/1_instruction_tuning/chat_templates.md",
"url": "https://github.com/huggingface/smol-course/blob/main/vi/1_instruction_tuning/chat_templates.md",
"date": "2024-11-25T19:22:43",
"stars": 5481,
"description": "A course on aligning smol models.",
"file_size": 5179
}
|
# Tinh chỉnh có giám sát (Supervised Fine-Tuning)
Tinh chỉnh có giám sát (SFT) là một quá trình cốt lõi để điều chỉnh *pre-trained models* cho các tác vụ hoặc lĩnh vực cụ thể. Mặc dù các mô hình đã *pre-trained* có các khả năng tổng quát ấn tượng ,chúng thường cần được tùy chỉnh để đạt hiệu suất cao trong các trường hợp sử dụng cụ thể. SFT thu hẹp khoảng cách này bằng cách huấn luyện thêm mô hình trên các tập dữ liệu được tuyển chọn kỹ lưỡng cùng với các ví dụ đã được con người đánh giá.
## Tìm hiểu thêm về huấn luyện có giám sát
Về cốt lõi, SFT là về việc dạy một mô hình đã *pre-trained* thực hiện các tác vụ cụ thể thông qua các mẫu của các *token* đã được gán nhãn. Quá trình này bao gồm việc cho mô hình học nhiều mẫu về các hành vi đầu vào-đầu ra mong muốn, cho phép nó học các mẫu cụ thể cho trường hợp sử dụng của bạn.
SFT hiệu quả vì nó sử dụng kiến thức nền tảng thu được trong quá trình *pre-training* trong khi điều chỉnh hành vi của mô hình để phù hợp với nhu cầu cụ thể của bạn.
## Khi nào nên sử dụng huấn luyện có giám sát
Quyết định sử dụng SFT thường phụ thuộc vào khoảng cách giữa khả năng hiện tại của mô hình và yêu cầu cụ thể của bạn. SFT trở nên đặc biệt có giá trị khi bạn cần kiểm soát chính xác đầu ra của mô hình hoặc khi làm việc trong các lĩnh vực chuyên biệt.
Ví dụ, nếu bạn đang phát triển một ứng dụng dịch vụ khách hàng, bạn có thể muốn mô hình của mình liên tục tuân theo hướng dẫn của công ty và xử lý các truy vấn kỹ thuật theo cách chuẩn hóa. Tương tự, trong các ứng dụng y tế hoặc pháp lý, độ chính xác và tuân thủ thuật ngữ chuyên ngành trở nên cực kỳ quan trọng. Trong những trường hợp này, SFT có thể giúp điều chỉnh phản hồi của mô hình phù hợp với tiêu chuẩn chuyên môn và chuyên môn trong lĩnh vực.
## Quy trình huấn luyện
Quy trình huấn luyện có giám sát bao gồm việc huấn luyện trọng số mô hình trên một tập dữ liệu theo tác vụ cụ thể.
Đầu tiên, bạn cần chuẩn bị hoặc lựa chọn một tập dữ liệu đại diện cho tác vụ mục tiêu của bạn. Tập dữ liệu này nên bao gồm các mẫu đa dạng bao quát phạm vi các tình huống mà mô hình của bạn sẽ gặp phải. Chất lượng của dữ liệu này rất quan trọng - mỗi mẫu nên thể hiện loại đầu ra mà bạn muốn mô hình của mình tạo ra. Tiếp theo là giai đoạn huấn luyện thực tế, nơi bạn sẽ sử dụng các framework có sẵn như `transformers` và `trl` của Hugging Face để huấn luyện mô hình trên tập dữ liệu của bạn.
Trong suốt quá trình này, việc đánh giá liên tục là thiết yếu. Bạn sẽ muốn theo dõi hiệu suất của mô hình trên một tập đánh giá (validation set) để đảm bảo nó đang học các hành vi mong muốn mà không mất đi khả năng tổng quát. Trong [bài 4](./4_evaluation), chúng ta sẽ tìm hiểu cách đánh giá mô hình đã được huấn luyện.
## Vai trò của huấn luyện có giám sát trong điều chỉnh theo sự uy tiên
SFT đóng vai trò nền tảng trong việc điều chỉnh các mô hình ngôn ngữ theo ưu tiên của con người. Các kỹ thuật như Học tăng cường từ phản hồi của con người (Reinforcement Learning from Human Feedback - RLHF) và Tối ưu hóa sở thích trực tiếp (Direct Preference Optimization - DPO) dựa vào SFT để xây dựng mức độ hiểu biết cơ bản về tác vụ trước khi tiếp tục điều chỉnh phản hồi của mô hình sao cho phù hợp với kết quả mong muốn. Các mô hình đã *pre-trained*, mặc dù có khả năng ngôn ngữ tổng quát, có thể không phải lúc nào cũng tạo ra đầu ra phù hợp ưu tiên của con người. SFT thu hẹp khoảng cách này bằng cách đưa vào dữ liệu và hướng dẫn theo lĩnh vực cụ thể, cải thiện khả năng của mô hình trong việc tạo ra phản hồi phù hợp hơn với kỳ vọng của con người.
## Huấn luyện có giám sát với Transformer Reinforcement Learning
Một thư viện quan trọng cho SFT đó là Transformer Reinforcement Learning (TRL). TRL là một bộ công cụ được sử dụng để huấn luyện các mô hình ngôn ngữ transformer bằng học tăng cường (RL).
Được xây dựng trên thư viện Transformers của Hugging Face, TRL cho phép người dùng trực tiếp tải các mô hình ngôn ngữ đã được *pre-trained* và hỗ trợ hầu hết các kiến trúc decoder và encoder-decoder. Thư viện này tạo điều kiện cho các quy trình chính của RL được sử dụng trong mô hình hóa ngôn ngữ, bao gồm Supervised Fine-Tuning (SFT), Reward Modeling (RM), Proximal Policy Optimization (PPO), và Direct Preference Optimization (DPO). Chúng ta sẽ sử dụng TRL trong nhiều bài học trong khoá học này.
# Các bước tiếp theo
Hãy thử các hướng dẫn sau để có tìm hiểu các ví dụ SFT thông qua TRL:
⏭️ [Hướng dẫn Địng dạng Chat](./notebooks/chat_templates_example.ipynb)
⏭️ [Hướng dẫn Huấn luyện có giám sát](./notebooks/supervised_fine_tuning_tutorial.ipynb)
|
{
"source": "huggingface/smol-course",
"title": "vi/1_instruction_tuning/supervised_fine_tuning.md",
"url": "https://github.com/huggingface/smol-course/blob/main/vi/1_instruction_tuning/supervised_fine_tuning.md",
"date": "2024-11-25T19:22:43",
"stars": 5481,
"description": "A course on aligning smol models.",
"file_size": 4555
}
|
# Tinh Chỉnh Theo Sự Ưu Tiên (Preference Alignment)
Trong chương này, bạn sẽ học về các kỹ thuật tinh chỉnh mô hình ngôn ngữ theo sự ưu tiên của con người. Trong khi *học có giám sát* giúp mô hình học các tác vụ, *tinh chỉnh theo sự ưu tiên* khuyến khích đầu ra phù hợp với kỳ vọng và giá trị của con người.
## Tổng Quan
Các phương pháp *tinh chỉnh theo sự ưu tiên* thường bao gồm 2 giai đoạn:
1. Bắt đầu bằng quá trình *học có giám sát* (SFT) để thích ứng mô hình với các lĩnh vực cụ thể
2. Sau đó, tinh chỉnh mô hình theo sự ưu tiên (như RLHF hoặc DPO) để cải thiện chất lượng phản hồi
Các phương pháp thay thế như ORPO kết hợp cả *tinh chỉnh theo chỉ thị* và *tinh chỉnh theo sự ưu tiên* thành 1 giai đoạn tinh chỉnh duy nhất. Ở đây, chúng ta sẽ tập trung vào các thuật toán DPO và ORPO.
Nếu bạn muốn tìm hiểu thêm về các kỹ thuật tinh chỉnh khác, bạn có thể đọc thêm tại [Argilla Blog](https://argilla.io/blog/mantisnlp-rlhf-part-8).
### 1️⃣ Tối Ưu Hóa Ưu Tiên Trực Tiếp (Direct Preference Optimization - DPO)
Phương pháp này đơn giản hóa quá trình *tinh chỉnh theo chỉ thị* bằng cách tối ưu hóa trực tiếp mô hình sử dụng dữ liệu ưu tiên (preference data). Phương pháp này loại bỏ nhu cầu về các *Mô hình thưởng phạt* (Reward model) riêng biệt và *Học tăng cường* phức tạp, giúp quá trình ổn định và hiệu quả hơn so với Học tăng cường từ phản hồi của con người (RLHF) truyền thống. Để biết thêm chi tiết, bạn có thể tham khảo tài liệu [*tối ưu hóa ưu tiên trực tiếp* (DPO)](./dpo.md).
### 2️⃣ Tối Ưu Hóa Ưu Tiên Theo Tỷ Lệ Odds (Odds Ratio Preference Optimization - ORPO)
ORPO giới thiệu một phương pháp kết hợp cả 2 giai đoạn *tinh chỉnh theo chỉ thị* và *tinh chỉnh theo sự ưu tiên* vào trong 1 giai đoạn tinh chỉnh duy nhất. Phương pháp này điều chỉnh mục tiêu tiêu chuẩn của mô hình ngôn ngữ bằng cách kết hợp *negative log-likelihood loss* với một * tỷ lệ odds* ở cấp độ *token*. Vì vậy, ORPO tạo ra 1 quá trình tinh chỉnh thống nhất với kiến trúc không cần mô hình thưởng phạt và cải thiện đáng kể hiệu quả tính toán. ORPO đã cho thấy kết quả ấn tượng trên nhiều benchmark, thể hiện hiệu suất tốt hơn trên AlpacaEval so với các phương pháp truyền thống. Để biết thêm chi tiết, bạn có thể tham khảo tài liệu [tối ưu hóa ưu tiên theo tỷ lệ odds (ORPO)](./orpo.md).
## Bài Tập
| Tiêu đề | Mô tả | Bài tập | Đường dẫn | Colab |
|-------|-------------|----------|------|-------|
| Tinh chỉnh theo DPO | Học cách tinh chỉnh mô hình bằng phương pháp tối ưu hóa ưu tiên trực tiếp | 🐢 Tinh chỉnh mô hình sử dụng bộ dữ liệu HH-RLHF <br>🐕 Sử dụng tập dữ liệu của riêng bạn<br>🦁 Thử nghiệm với các tập dữ liệu và kích thước mô hình khác nhau | [Notebook](./notebooks/dpo_finetuning_example.ipynb) | <a target="_blank" href="https://colab.research.google.com/github/huggingface/smol-course/blob/main/2_preference_alignment/notebooks/dpo_finetuning_example.ipynb"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Sử dụng Colab"/></a> |
| Tinh chỉnh theo ORPO | Học cách tinh chỉnh mô hình bằng phương pháp tối ưu hóa ưu tiên theo tỷ lệ odds | 🐢 Huấn luyện mô hình sử dụng bộ dữ liệu chỉ thị (instruction) và dữ liệu ưu tiên (preference)<br>🐕 Thử nghiệm với các trọng số loss khác nhau<br>🦁 So sánh kết quả ORPO với DPO | [Notebook](./notebooks/orpo_finetuning_example.ipynb) | <a target="_blank" href="https://colab.research.google.com/github/huggingface/smol-course/blob/main/2_preference_alignment/notebooks/orpo_finetuning_example.ipynb"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Sử dụng Colab"/></a> |
## Resources
- [Tài liệu thư viện TRL](https://huggingface.co/docs/trl/index) - Tài liệu cho thư viện Transformers Reinforcement Learning (TRL), triển khai nhiều kỹ thuật căn chỉnh bao gồm DPO và ORPO.
- [Bài báo nghiên cứu DPO](https://arxiv.org/abs/2305.18290) - bài nghiên cứu gốc giới thiệu *tối ưu hóa ưu tiên trực tiếp* như một giải pháp thay thế đơn giản hơn cho RLHF.
- [Bài báo nghiên cứu ORPO](https://arxiv.org/abs/2403.07691) - Giới thiệu Odds Ratio Preference Optimization, một phương pháp mới kết hợp *tinh chỉnh theo chỉ thị* và *tinh chỉnh theo sự ưu tiên* thành 1
- [Bài hướng dẫn của Argilla](https://argilla.io/blog/mantisnlp-rlhf-part-8/) - Hướng dẫn giải thích các kỹ thuật căn chỉnh khác nhau bao gồm RLHF, DPO và cách triển khai thực tế.
- [Blog về DPO](https://huggingface.co/blog/dpo-trl) - Hướng dẫn thực hành về triển khai DPO sử dụng thư viện TRL với các ví dụ code và phương pháp tốt nhất.
- [Code mẫu cho DPO trong thư viên TRL](https://github.com/huggingface/trl/blob/main/examples/scripts/dpo.py) - Code mẫu về cách triển khai tinh chỉnh DPO sử dụng thư viện TRL.
- [Code mẫu cho ORPD trong thư viên TRL](https://github.com/huggingface/trl/blob/main/examples/scripts/orpo.py) - Code mẫu của tinh chỉnh ORPO sử dụng thư viện TRL với các tùy chọn cấu hình chi tiết.
- [Hugging Face Alignment Handbook](https://github.com/huggingface/alignment-handbook) - Hướng dẫn và codebase cho việc tinh chỉnh mô hình ngôn ngữ sử dụng các kỹ thuật khác nhau bao gồm SFT, DPO và RLHF.
|
{
"source": "huggingface/smol-course",
"title": "vi/2_preference_alignment/README.md",
"url": "https://github.com/huggingface/smol-course/blob/main/vi/2_preference_alignment/README.md",
"date": "2024-11-25T19:22:43",
"stars": 5481,
"description": "A course on aligning smol models.",
"file_size": 5072
}
|
# Tối Ưu Hóa Ưu Tiên Trực Tiếp (Direct Preference Optimization - DPO)
DPO cung cấp một cách tiếp cận đơn giản để tinh chỉnh mô hình ngôn ngữ theo ý muốn của con người. Khác với phương pháp RLHF truyền thống yêu cầu các mô hình thưởng phạt riêng biệt và học tăng cường phức tạp, DPO tối ưu hóa trực tiếp mô hình bằng dữ liệu ưu tiên (preference dataset).
## Tìm Hiểu Về DPO
DPO chuyển đổi bài toán tinh chỉnh ưu tiên thành bài toán phân loại trên dữ liệu ưu tiên của con người. Phương pháp RLHF truyền thống yêu cầu huấn luyện một mô hình thưởng phạt riêng biệt và sử dụng các thuật toán học tăng cường phức tạp như PPO để căn chỉnh đầu ra của mô hình. DPO đơn giản hóa quy trình này bằng cách định nghĩa một hàm mất mát (loss) trực tiếp tối ưu hóa chiến lược học (policy) của mô hình dựa trên các đầu ra được ưu tiên và không được ưu tiên.
Phương pháp này đã chứng minh hiệu quả cao trong thực tế, được sử dụng để huấn luyện các mô hình như Llama. Bằng cách loại bỏ nhu cầu về mô hình thưởng phạt riêng biệt và giai đoạn học tăng cường, DPO giúp việc tinh chỉnh ưu tiên trở nên dễ tiếp cận và ổn định hơn.
## DPO Hoạt Động Như Thế Nào
Quy trình DPO yêu cầu quá trình học có giám sát (SFT) để thích ứng mô hình với lĩnh vực mục tiêu. Điều này tạo nền tảng cho việc học ưu tiên bằng cách huấn luyện trên các tập dữ liệu làm theo chỉ thị tiêu chuẩn. Mô hình học cách hoàn thành tác vụ cơ bản trong khi duy trì các khả năng tổng quát.
Tiếp theo là quá trình học ưu tiên, nơi mô hình được huấn luyện trên các cặp đầu ra - một được ưu tiên và một không được ưu tiên. Các cặp ưu tiên giúp mô hình hiểu phản hồi nào phù hợp hơn với giá trị và kỳ vọng của con người.
Đổi mới cốt lõi của DPO nằm ở cách tiếp cận tối ưu hóa trực tiếp. Thay vì huấn luyện một mô hình thưởng phạt riêng biệt, DPO sử dụng hàm mất mát `binary cross-entropy` để trực tiếp cập nhật trọng số mô hình dựa trên dữ liệu ưu tiên. Quy trình đơn giản này giúp việc huấn luyện ổn định và hiệu quả hơn trong khi đạt được kết quả tương đương hoặc tốt hơn so với RLHF truyền thống.
## Bộ Dữ Liệu DPO
Bộ dữ liệu cho DPO thường được tạo bằng cách gán nhãn các cặp phản hồi là được ưu tiên hoặc không được ưu tiên. Việc này có thể được thực hiện thủ công hoặc sử dụng các kỹ thuật lọc tự động. Dưới đây là cấu trúc mẫu của tập dữ liệu preference một lượt cho DPO:
```
| Prompt | Chosen | Rejected |
|--------|--------|----------|
| ... | ... | ... |
| ... | ... | ... |
| ... | ... | ... |
```
Cột `Prompt` chứa chỉ thị dùng để tạo ra các phản hồi. Cột `Chosen` và `Rejected` chứa các phản hồi được ưu tiên và không được ưu tiên. Có nhiều biến thể của cấu trúc này, ví dụ, bao gồm cột `System Prompt` (chỉ thị hệ thống) hoặc cột `Input` chứa tài liệu tham khảo. Giá trị của `Chosen` và `Rejected` có thể được biểu diễn dưới dạng chuỗi cho hội thoại một lượt hoặc dưới dạng danh sách hội thoại.
Bạn có thể tìm thấy bộ sưu tập các tập dữ liệu DPO trên Hugging Face [tại đây](https://huggingface.co/collections/argilla/preference-datasets-for-dpo-656f0ce6a00ad2dc33069478).
## Triển Khai Với TRL
Thư viện Transformers Reinforcement Learning (TRL) giúp việc triển khai DPO trở nên đơn giản. Các lớp `DPOConfig` và `DPOTrainer` tuân theo API của thư viện `transformers`.
Đây là ví dụ cơ bản về cách thiết lập tinh chỉnh DPO:
```python
from trl import DPOConfig, DPOTrainer
# Định nghĩa các tham số
training_args = DPOConfig(
...
)
# Khởi tạo trainer
trainer = DPOTrainer(
model,
train_dataset=dataset,
tokenizer=tokenizer,
...
)
# Huấn luyện mô hình
trainer.train()
```
Chúng ta sẽ tìm hiểu thêm chi tiết về cách sử dụng các lớp `DPOConfig` và `DPOTrainer` trong [Hướng dẫn DPO](./notebooks/dpo_finetuning_example.ipynb).
## Phương Pháp Tốt Nhất
**Chất lượng dữ liệu là yếu tố quan trọng** cho việc triển khai DPO thành công. Tập dữ liệu ưu tiên nên bao gồm các ví dụ đa dạng bao quát các khía cạnh khác nhau của hành vi mong muốn. Hướng dẫn gán nhãn rõ ràng đảm bảo việc gán nhãn nhất quán cho các phản hồi được ưu tiên và không được ưu tiên. Bạn có thể cải thiện hiệu suất mô hình bằng cách nâng cao chất lượng tập dữ liệu ưu tiên. Ví dụ, bằng cách lọc các tập dữ liệu lớn hơn để chỉ bao gồm các ví dụ chất lượng cao hoặc các ví dụ liên quan đến trường hợp sử dụng của bạn.
Trong quá trình huấn luyện, cần theo dõi kỹ sự hội tụ của hàm mất mát và đánh giá hiệu suất trên dữ liệu kiểm tra (held-out set). Tham số `beta` có thể cần điều chỉnh để cân bằng giữa việc học ưu tiên với việc duy trì các khả năng tổng quát của mô hình. Đánh giá thường xuyên trên các chỉ thị đa dạng giúp đảm bảo mô hình đang học các ưu tiên mong muốn mà không bị tình trạng quá khớp (overfitting).
So sánh đầu ra của mô hình với mô hình tham chiếu để xác minh sự cải thiện trong tinh chỉnh ưu tiên. Kiểm tra trên nhiều chỉ thị khác nhau, bao gồm cả các trường hợp ngoại lệ (edge cases), giúp đảm bảo việc học ưu tiên mạnh mẽ hơn trong các tình huống khác nhau.
## Các Bước Tiếp Theo
⏩ Để có thể thực hành thực tế với DPO, hãy thử [Hướng dẫn DPO](./notebooks/dpo_finetuning_example.ipynb). Hướng dẫn thực hành này sẽ chỉ dẫn bạn cách triển khai tinh chỉnh ưu tiên với mô hình của riêng bạn, từ chuẩn bị dữ liệu đến huấn luyện và đánh giá.
⏭️ Sau khi hoàn thành hướng dẫn, bạn có thể khám phá về [ORPO](./orpo.md) để tìm hiểu về một kỹ thuật tinh chỉnh ưu tiên khác.
|
{
"source": "huggingface/smol-course",
"title": "vi/2_preference_alignment/dpo.md",
"url": "https://github.com/huggingface/smol-course/blob/main/vi/2_preference_alignment/dpo.md",
"date": "2024-11-25T19:22:43",
"stars": 5481,
"description": "A course on aligning smol models.",
"file_size": 5370
}
|
# Tối Ưu Hóa Ưu Tiên Theo Tỷ Lệ Odds (Odds Ratio Preference Optimization - ORPO)
ORPO là một kỹ thuật tinh chỉnh mới kết hợp cả quá trình *tinh chỉnh theo chỉ thị* và *tinh chỉnh ưu tiên* thành một quy trình thống nhất. Cách tiếp cận kết hợp này mang lại những lợi thế về hiệu quả và hiệu suất so với các phương pháp truyền thống như RLHF hoặc DPO.
## Tìm Hiểu Về ORPO
Phương pháp tinh chỉnh như DPO thường liên quan đến hai bước riêng biệt:
1) học có giám sát để thích ứng mô hình với một lĩnh vực và định dạng
2) sau đó là tinh chỉnh ưu tiên để phù hợp với ý muốn của con người
Trong khi SFT hiệu quả trong việc thích ứng mô hình với các lĩnh vực mục tiêu, nó có thể vô tình làm tăng xác suất tạo ra cả phản hồi mong muốn và không mong muốn. ORPO giải quyết hạn chế này bằng cách tích hợp cả hai bước vào một quy trình duy nhất, như minh họa trong hình so sánh dưới đây:

*So sánh các kỹ thuật tinh chỉnh mô hình khác nhau*
## ORPO Hoạt Động Như Thế Nào
Quy trình huấn luyện sử dụng một tập dữ liệu ưu tiên tương tự như chúng ta đã sử dụng cho DPO, trong đó mỗi mẫu huấn luyện chứa một chỉ thị đầu vào cùng với hai phản hồi: một được ưu tiên và một bị loại bỏ. Khác với các phương pháp tinh chỉnh khác yêu cầu các giai đoạn riêng biệt và mô hình tham chiếu, ORPO tích hợp trực tiếp tinh chỉnh ưu tiên vào quá trình học có giám sát. Cách tiếp cận thống nhất này không cần mô hình tham chiếu, hiệu quả hơn về mặt tính toán và bộ nhớ với ít FLOPs hơn.
ORPO tạo ra một mục tiêu mới bằng cách kết hợp hai thành phần chính:
1. **SFT Loss**: Hàm mất mát *negative log-likelihood* tiêu chuẩn được sử dụng trong việc mô hình hóa ngôn ngữ, tối đa hóa xác suất tạo ra các *token tham chiếu*. Điều này giúp duy trì khả năng ngôn ngữ tổng quát của mô hình.
2. **Odds Ratio Loss**: Một hàm mất mát mới giúp phạt các phản hồi không mong muốn trong khi thưởng cho các phản hồi được ưu tiên. Hàm mất mát này sử dụng tỷ lệ odds để so sánh hiệu quả giữa các phản hồi được ưa thích và không ưa thích ở cấp độ *token*.
Cùng nhau, các thành phần này hướng dẫn mô hình thích ứng với các phản hồi mong muốn cho lĩnh vực cụ thể trong khi tích cực ngăn chặn các phản hồi từ tập các phản hồi bị từ chối. Cơ chế tỷ lệ odds cung cấp một cách tự nhiên để đo lường và tối ưu hóa ưu tiên của mô hình giữa các đầu ra đã chọn và bị từ chối. Nếu bạn muốn tìm hiểu sâu về phần toán học, bạn có thể đọc [bài báo ORPO](https://arxiv.org/abs/2403.07691). Nếu bạn muốn tìm hiểu về ORPO từ góc độ triển khai, bạn nên xem cách tính toán hàm mất mát cho ORPO trong [thư viện TRL](https://github.com/huggingface/trl/blob/b02189aaa538f3a95f6abb0ab46c0a971bfde57e/trl/trainer/orpo_trainer.py#L660).
## Hiệu Suất và Kết Quả
ORPO đã cho thấy các kết quả ấn tượng trên nhiều bài kiểm tra. Trên `MT-Bench`, phương pháp này giúp mô hình sau tinh chỉnh đạt điểm số cạnh tranh trên các danh mục khác nhau:

*Kết quả MT-Bench theo danh mục cho các mô hình Mistral-ORPO*
So với các phương pháp tinh chỉnh khác, ORPO thể hiện hiệu suất vượt trội trên AlpacaEval 2.0:

*Điểm số AlpacaEval 2.0 trên các phương pháp tinh chỉnh khác nhau*
So với việc kết hợp cả SFT và DPO, ORPO giảm yêu cầu tính toán bằng cách loại bỏ nhu cầu về mô hình tham chiếu và giảm một nửa số lần chuyển tiếp (forward pass) cho mỗi batch. Ngoài ra, quy trình huấn luyện ổn định hơn trên các kích thước mô hình và tập dữ liệu khác nhau, yêu cầu ít siêu tham số cần tinh chỉnh hơn. Về mặt hiệu suất, ORPO ngang bằng với các mô hình lớn hơn trong khi cho thấy sự tinh chỉnh tốt hơn với ý muốn của con người.
## Triển Khai
Triển khai thành công ORPO phụ thuộc nhiều vào **dữ liệu ưu tiên chất lượng cao**. Dữ liệu huấn luyện nên tuân theo các hướng dẫn gán nhãn rõ ràng và cung cấp sự đại diện cân bằng của các phản hồi được ưu tiên và bị từ chối trong các tình huống đa dạng.
### Triển Khai với TRL
ORPO có thể được triển khai sử dụng thư viện TRL. Đây là một ví dụ cơ bản:
```python
from trl import ORPOConfig, ORPOTrainer
# Cấu hình tinh chỉnh ORPO
orpo_config = ORPOConfig(
learning_rate=1e-5,
per_device_train_batch_size=4,
gradient_accumulation_steps=4,
max_steps=1000,
orpo_alpha=1.0, # Kiểm soát độ mạnh của tối ưu hóa ưu tiên
orpo_beta=0.1, # Tham số cho sự ngẫu nhiên (temperature) trong tính tỷ lệ odds
)
# Khởi tạo trainer
trainer = ORPOTrainer(
model=model,
args=orpo_config,
train_dataset=dataset,
tokenizer=tokenizer,
)
# Huấn luyện mô hình
trainer.train()
```
Các tham số chính cần xem xét:
- `orpo_alpha`: Kiểm soát độ mạnh của thuật toán tối ưu hóa ưu tiên
- `orpo_beta`: Tham số cho sự ngẫu nhiên (temperature) trong phép tính tỷ lệ odds
- `learning_rate`: Nên tương đối nhỏ để tránh catastrophic forgetting
- `gradient_accumulation_steps`: Giúp ổn định quá trình huấn luyện
## Các Bước Tiếp Theo
⏩ Bạn có thể làm theo hướng dẫn trong [Hướng dẫn ORPO](./notebooks/orpo_tutorial.ipynb) để triển khai cách tinh chỉnh ưu tiên này.
## Resources
- [Bài báo nghiên cứu về ORPO](https://arxiv.org/abs/2403.07691)
- [Tài liệu về thư viện TRL](https://huggingface.co/docs/trl/index)
- [Hướng dẫn của Argilla](https://argilla.io/blog/mantisnlp-rlhf-part-8/)
|
{
"source": "huggingface/smol-course",
"title": "vi/2_preference_alignment/orpo.md",
"url": "https://github.com/huggingface/smol-course/blob/main/vi/2_preference_alignment/orpo.md",
"date": "2024-11-25T19:22:43",
"stars": 5481,
"description": "A course on aligning smol models.",
"file_size": 5449
}
|
# Tinh chỉnh hiệu quả tham số (Parameter-Efficient Fine-Tuning - PEFT)
Khi các mô hình ngôn ngữ ngày càng lớn hơn, việc tinh chỉnh truyền thống trở nên ngày càng thách thức. Việc tinh chỉnh đầy đủ một mô hình với 1.7B tham số đòi hỏi bộ nhớ GPU lớn, việc lưu trữ các bản sao mô hình riêng biệt tốn kém, và có nguy cơ làm mất đi các khả năng ban đầu của mô hình. Các phương pháp tinh chỉnh hiệu quả tham số (PEFT) giải quyết những thách thức này bằng cách chỉ điều chỉnh một tập nhỏ các tham số mô hình trong khi giữ nguyên phần lớn mô hình.
Tinh chỉnh truyền thống cập nhật tất cả các tham số mô hình trong quá trình huấn luyện, điều này trở nên không khả thi với các mô hình lớn. Các phương pháp PEFT giới thiệu cách tiếp cận để điều chỉnh mô hình sử dụng ít tham số có thể huấn luyện hơn - thường ít hơn 1% kích thước mô hình gốc. Việc giảm đáng kể số lượng tham số có thể huấn luyện cho phép:
- Tinh chỉnh trên phần cứng tiêu dùng với bộ nhớ GPU hạn chế
- Lưu trữ nhiều phiên bản điều chỉnh (adapters) cho từng tác vụ một cách hiệu quả
- Khả năng tổng quát hóa tốt hơn trong các trường hợp dữ liệu ít
- Chu kỳ huấn luyện và thử nghiệm nhanh hơn
## Các phương pháp hiện có
Trong chương này, chúng ta sẽ tìm hiểu hai phương pháp PEFT phổ biến:
### 1️⃣ Phương Pháp LoRA (Low-Rank Adaptation)
LoRA đã nổi lên như phương pháp PEFT được áp dụng rộng rãi nhất, cung cấp giải pháp hoàn hảo cho việc điều chỉnh mô hình hiệu quả mà không tốn nhiều tài nguyên tính toán. Thay vì sửa đổi toàn bộ mô hình, **LoRA đưa các ma trận có thể huấn luyện vào các lớp attention của mô hình.** Cách tiếp cận này thường giảm các tham số có thể huấn luyện khoảng 90% trong khi vẫn duy trì hiệu suất tương đương với tinh chỉnh đầy đủ. Chúng ta sẽ khám phá LoRA trong phần [LoRA (Low-Rank Adaptation)](./lora_adapters.md).
### 2️⃣ Phương Pháp Điều Chỉnh Chỉ Thị (Prompt Tuning)
Prompt tuning cung cấp cách tiếp cận **thậm chí nhẹ hơn** bằng cách **thêm các token có thể huấn luyện vào đầu vào** thay vì sửa đổi trọng số mô hình. Prompt tuning ít phổ biến hơn LoRA, nhưng có thể là kỹ thuật hữu ích để nhanh chóng điều chỉnh mô hình cho các tác vụ hoặc lĩnh vực mới. Chúng ta sẽ khám phá prompt tuning trong phần [Prompt Tuning](./prompt_tuning.md).
## Notebooks bài tập
| Tiêu đề | Mô tả | Bài tập | Link | Colab |
|---------|--------|---------|------|-------|
| Tinh chỉnh LoRA | Học cách tinh chỉnh mô hình sử dụng LoRA adapters | 🐢 Huấn luyện mô hình sử dụng LoRA<br>🐕 Thử nghiệm với các giá trị rank khác nhau<br>🦁 So sánh hiệu suất với tinh chỉnh đầy đủ | [Notebook](./notebooks/finetune_sft_peft.ipynb) | <a target="_blank" href="https://colab.research.google.com/github/huggingface/smol-course/blob/main/3_parameter_efficient_finetuning/notebooks/finetune_sft_peft.ipynb"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a> |
| Tải LoRA Adapters | Học cách tải và sử dụng LoRA adapters đã huấn luyện | 🐢 Tải adapters đã huấn luyện trước<br>🐕 Gộp adapters với mô hình cơ sở<br>🦁 Chuyển đổi giữa nhiều adapters | [Notebook](./notebooks/load_lora_adapter.ipynb) | <a target="_blank" href="https://colab.research.google.com/github/huggingface/smol-course/blob/main/3_parameter_efficient_finetuning/notebooks/load_lora_adapter.ipynb"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a> |
## Tài liệu tham khảo
- [Tài liệu PEFT](https://huggingface.co/docs/peft)
- [Bài báo nghiên cứu LoRA](https://arxiv.org/abs/2106.09685)
- [Bài báo nghiên cứu QLoRA](https://arxiv.org/abs/2305.14314)
- [Bài báo nghiên cứu Prompt Tuning](https://arxiv.org/abs/2104.08691)
- [Hướng dẫn sử dụng PEFT của Hugging Face](https://huggingface.co/blog/peft)
- [Cách Tinh chỉnh LLM với Hugging Face](https://www.philschmid.de/fine-tune-llms-in-2024-with-trl)
- [Thư viện TRL](https://huggingface.co/docs/trl/index)
|
{
"source": "huggingface/smol-course",
"title": "vi/3_parameter_efficient_finetuning/README.md",
"url": "https://github.com/huggingface/smol-course/blob/main/vi/3_parameter_efficient_finetuning/README.md",
"date": "2024-11-25T19:22:43",
"stars": 5481,
"description": "A course on aligning smol models.",
"file_size": 3866
}
|
# Phương Pháp LoRA (Low-Rank Adaptation)
LoRA đã trở thành phương pháp PEFT được sử dụng rộng rãi nhất. Nó hoạt động bằng cách thêm các ma trận phân rã hạng thấp (small rank decomposition matrices) vào các trọng số attention, điều này dẫn đến việc giảm khoảng 90% số lượng tham số có thể huấn luyện.
## Tìm Hiểu Về LoRA
LoRA (Low-Rank Adaptation) là một kỹ thuật tinh chỉnh hiệu quả tham số, đóng băng các trọng số của mô hình đã huấn luyện trước và đưa thêm các ma trận phân rã hạng (rank decomposition matrices) có thể huấn luyện vào các lớp của mô hình. Thay vì huấn luyện tất cả các tham số mô hình trong quá trình tinh chỉnh, LoRA phân rã việc cập nhật trọng số thành các ma trận nhỏ hơn thông qua phân rã hạng thấp (low-rank decomposition), giảm đáng kể số lượng tham số có thể huấn luyện trong khi vẫn duy trì hiệu suất mô hình. Ví dụ, khi áp dụng cho GPT-3 175B, LoRA giảm số lượng tham số có thể huấn luyện xuống 10.000 lần và yêu cầu bộ nhớ GPU giảm 3 lần so với tinh chỉnh đầy đủ. Bạn có thể đọc thêm về LoRA trong [bài báo nghiên cứu LoRA](https://arxiv.org/pdf/2106.09685).
LoRA hoạt động bằng cách thêm các cặp ma trận phân rã hạng vào các lớp transformer, thường tập trung vào các trọng số attention. Trong quá trình suy luận, các trọng số adapter có thể được gộp với mô hình cơ sở, không gây thêm độ trễ. LoRA đặc biệt hữu ích cho việc điều chỉnh các mô hình ngôn ngữ lớn cho các tác vụ hoặc lĩnh vực cụ thể trong khi không yêu cầu nhiều tài nguyên tính toán.
## Lắp Các LoRA Adapters Vào Mô Hình Ngôn Ngữ
Adapters có thể được lắp vào một mô hình đã huấn luyện trước với hàm `load_adapter()`, điều này hữu ích khi thử nghiệm các adapters khác nhau mà trọng số không được gộp. Đặt trọng số adapter đang hoạt động bằng hàm `set_adapter()`. Để trở về mô hình cơ sở, bạn có thể sử dụng `unload()` để gỡ tất cả các module LoRA. Điều này giúp dễ dàng chuyển đổi giữa các trọng số cho từng tác vụ cụ thể.
```python
from transformers import AutoModelForCausalLM
from peft import PeftModel
base_model = AutoModelForCausalLM.from_pretrained("<base_model_name>")
peft_model_id = "<peft_adapter_id>"
model = PeftModel.from_pretrained(base_model, peft_model_id)
```

## Gộp LoRA Adapters
Sau khi huấn luyện với LoRA, bạn có thể muốn gộp các trọng số adapter trở lại mô hình cơ sở để triển khai dễ dàng hơn. Điều này tạo ra một mô hình duy nhất với các trọng số đã kết hợp, loại bỏ nhu cầu tải adapters riêng biệt trong quá trình suy luận.
Quá trình gộp đòi hỏi chú ý đến quản lý bộ nhớ và độ chính xác. Vì bạn sẽ cần tải cả mô hình cơ sở và trọng số adapter cùng lúc, hãy đảm bảo có đủ bộ nhớ GPU/CPU. Sử dụng `device_map="auto"` trong `transformers` sẽ giúp tự động quản lý bộ nhớ. Duy trì độ chính xác nhất quán (ví dụ: float16) trong suốt quá trình, phù hợp với độ chính xác được sử dụng trong quá trình huấn luyện và lưu mô hình đã gộp trong cùng một định dạng để triển khai. Trước khi triển khai, luôn xác thực mô hình đã gộp bằng cách so sánh đầu ra và các chỉ số hiệu suất với phiên bản dựa trên adapter.
Adapters cũng thuận tiện cho việc chuyển đổi giữa các tác vụ hoặc lĩnh vực khác nhau. Bạn có thể tải mô hình cơ sở và trọng số adapter riêng biệt. Điều này cho phép chuyển đổi nhanh chóng giữa các trọng số cho từng tác vụ cụ thể.
## Hướng dẫn triển khai
Thư mục `notebooks/` chứa các hướng dẫn thực hành và bài tập để triển khai các phương pháp PEFT khác nhau. Bắt đầu với `load_lora_adapter_example.ipynb` để có giới thiệu cơ bản, sau đó khám phá `lora_finetuning.ipynb` để xem xét chi tiết hơn về cách tinh chỉnh một mô hình với LoRA và SFT.
Khi triển khai các phương pháp PEFT, hãy bắt đầu với các giá trị hạng nhỏ (4-8) cho LoRA và theo dõi mất mát trong quá trình huấn luyện. Sử dụng tập validation để tránh overfitting và so sánh kết quả với các baseline tinh chỉnh đầy đủ khi có thể. Hiệu quả của các phương pháp khác nhau có thể thay đổi theo tác vụ, vì vậy thử nghiệm là chìa khóa.
## OLoRA
[OLoRA](https://arxiv.org/abs/2406.01775) sử dụng phân rã QR để khởi tạo các adapter LoRA. OLoRA dịch chuyển các trọng số cơ sở của mô hình bằng một hệ số của phân rã QR của chúng, tức là nó thay đổi trọng số trước khi thực hiện bất kỳ huấn luyện nào trên chúng. Cách tiếp cận này cải thiện đáng kể tính ổn định, tăng tốc độ hội tụ và cuối cùng đạt được hiệu suất vượt trội.
## Sử dụng TRL với PEFT
Các phương pháp PEFT có thể được kết hợp với thư viện TRL để tinh chỉnh hiệu quả. Sự tích hợp này đặc biệt hữu ích cho RLHF (Reinforcement Learning from Human Feedback) vì nó giảm yêu cầu bộ nhớ.
```python
from peft import LoraConfig
from transformers import AutoModelForCausalLM
# Tải mô hình với cấu hình PEFT
lora_config = LoraConfig(
r=16,
lora_alpha=32,
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM"
)
# Tải mô hình trên thiết bị cụ thể
model = AutoModelForCausalLM.from_pretrained(
"your-model-name",
load_in_8bit=True, # Tùy chọn: sử dụng độ chính xác 8-bit
device_map="auto",
peft_config=lora_config
)
```
Ở trên, chúng ta đã sử dụng `device_map="auto"` để tự động gán mô hình cho thiết bị phù hợp. Bạn cũng có thể gán thủ công mô hình cho một thiết bị cụ thể bằng cách sử dụng `device_map={"": device_index}`. Bạn cũng có thể mở rộng việc huấn luyện trên nhiều GPU trong khi vẫn giữ việc sử dụng bộ nhớ hiệu quả.
## Triển khai gộp cơ bản
Sau khi huấn luyện một adapter LoRA, bạn có thể gộp trọng số adapter trở lại mô hình cơ sở. Đây là cách thực hiện:
```python
import torch
from transformers import AutoModelForCausalLM
from peft import PeftModel
# 1. Tải mô hình cơ sở
base_model = AutoModelForCausalLM.from_pretrained(
"base_model_name",
torch_dtype=torch.float16,
device_map="auto"
)
# 2. Tải LoRA adapter
peft_model = PeftModel.from_pretrained(
base_model,
"path/to/adapter",
torch_dtype=torch.float16
)
# 3. Gộp trọng số adapter với mô hình cơ sở
try:
merged_model = peft_model.merge_and_unload()
except RuntimeError as e:
print(f"Gộp thất bại: {e}")
# Triển khai chiến lược dự phòng hoặc tối ưu hóa bộ nhớ
# 4. Lưu mô hình đã gộp
merged_model.save_pretrained("path/to/save/merged_model")
```
Nếu bạn gặp sự khác biệt về kích thước trong mô hình đã lưu, hãy đảm bảo bạn cũng lưu tokenizer:
```python
# Lưu cả mô hình và tokenizer
tokenizer = AutoTokenizer.from_pretrained("base_model_name")
merged_model.save_pretrained("path/to/save/merged_model")
tokenizer.save_pretrained("path/to/save/merged_model")
```
## Các bước tiếp theo
⏩ Chuyển sang [Hướng dẫn Prompt Tuning](prompt_tuning.md) để tìm hiểu cách tinh chỉnh một mô hình bằng prompt tuning.
⏩ Chuyển sang [Hướng dẫn lắp LoRA Adapters](./notebooks/load_lora_adapter.ipynb) để tìm hiểu cách lắp LoRA adapters.
# Tài liệu tham khảo
- [LORA: LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS](https://arxiv.org/pdf/2106.09685)
- [Tài liệu PEFT](https://huggingface.co/docs/peft)
- [Bài viết blog của Hugging Face về PEFT](https://huggingface.co/blog/peft)
|
{
"source": "huggingface/smol-course",
"title": "vi/3_parameter_efficient_finetuning/lora_adapters.md",
"url": "https://github.com/huggingface/smol-course/blob/main/vi/3_parameter_efficient_finetuning/lora_adapters.md",
"date": "2024-11-25T19:22:43",
"stars": 5481,
"description": "A course on aligning smol models.",
"file_size": 6998
}
|
# Phương Pháp Điều Chỉnh Chỉ Thị (Prompt Tuning)
Prompt tuning là một phương pháp tiết kiệm tham số bằng cách điều chỉnh biểu diễn đầu vào thay vì trọng số mô hình. Không giống như tinh chỉnh truyền thống cập nhật tất cả các tham số mô hình, prompt tuning thêm và tối ưu hóa một tập nhỏ các token có thể huấn luyện trong khi giữ nguyên mô hình cơ sở.
## Tìm Hiểu Về Prompt Tuning
Prompt tuning là một phương pháp thay thế tiết kiệm tham số cho việc tinh chỉnh mô hình bằng cách thêm các vector liên tục có thể huấn luyện (soft prompts) vào trước văn bản đầu vào. Không giống như các chỉ thị rời rạc (discrete prompt), những soft prompt này được học thông qua truyền ngược (back-propagation) trong khi giữ nguyên mô hình ngôn ngữ. Phương pháp này được giới thiệu trong ["The Power of Scale for Parameter-Efficient Prompt Tuning"](https://arxiv.org/abs/2104.08691) (Lester et al., 2021), cho thấy prompt tuning trở nên cạnh tranh hơn với việc tinh chỉnh mô hình khi kích thước mô hình tăng lên. Trong bài báo, với khoảng 10 tỷ tham số, prompt tuning đạt hiệu suất tương đương với tinh chỉnh mô hình trong khi chỉ sửa đổi vài trăm tham số cho mỗi tác vụ.
Các soft prompt này là các vector liên tục trong không gian embedding của mô hình được tối ưu hóa trong quá trình huấn luyện. Không giống như các chỉ thị rời rạc truyền thống sử dụng các token ngôn ngữ tự nhiên, soft prompt là các chỉ thị không có ý nghĩa nhưng được học để tạo ra hành vi mong muốn từ mô hình đã đóng băng thông qua gradient descent. Kỹ thuật này đặc biệt hiệu quả cho các kịch bản đa tác vụ vì mỗi tác vụ chỉ cần lưu trữ một vector prompt nhỏ (thường là vài trăm tham số) thay vì một bản sao mô hình đầy đủ. Phương pháp này không chỉ duy trì bộ nhớ tối thiểu mà còn cho phép chuyển đổi tác vụ nhanh chóng bằng cách chỉ cần hoán đổi vector prompt mà không cần tải lại mô hình.
## Quá trình huấn luyện
Soft prompt thường có từ **8 đến 32 token** và có thể được **khởi tạo ngẫu nhiên hoặc từ văn bản hiện có**. Phương pháp khởi tạo đóng vai trò quan trọng trong quá trình huấn luyện, với việc khởi tạo dựa trên văn bản thường hoạt động tốt hơn so với khởi tạo ngẫu nhiên.
Trong quá trình huấn luyện, chỉ các tham số prompt được cập nhật trong khi mô hình cơ sở vẫn đóng băng. Cách tiếp cận tập trung này sử dụng các mục tiêu huấn luyện tiêu chuẩn nhưng đòi hỏi chú ý đến tốc độ học và hành vi gradient của các token prompt.

## Triển khai với PEFT
Thư viện PEFT giúp việc triển khai prompt tuning trở nên đơn giản. Đây là một ví dụ cơ bản:
```python
from peft import PromptTuningConfig, TaskType, get_peft_model
from transformers import AutoModelForCausalLM, AutoTokenizer
# Tải mô hình cơ sở
model = AutoModelForCausalLM.from_pretrained("your-base-model")
tokenizer = AutoTokenizer.from_pretrained("your-base-model")
# Điều chỉnh thông số prompt tuning
peft_config = PromptTuningConfig(
task_type=TaskType.CAUSAL_LM,
num_virtual_tokens=8, # Số token có thể huấn luyện
prompt_tuning_init="TEXT", # Khởi tạo từ văn bản
prompt_tuning_init_text="Phân loại xem văn bản này là tích cực hay tiêu cực:",
tokenizer_name_or_path="your-base-model",
)
# Tạo mô hình có thể prompt-tune
model = get_peft_model(model, peft_config)
```
## So sánh với các phương pháp khác
Khi so sánh với các phương pháp PEFT khác, prompt tuning nổi bật về hiệu quả. Trong khi LoRA cung cấp số lượng tham số và bộ nhớ thấp nhưng yêu cầu tải adapter khi chuyển đổi tác vụ, prompt tuning đạt được mức sử dụng tài nguyên thậm chí thấp hơn và cho phép chuyển đổi tác vụ ngay lập tức. Ngược lại, tinh chỉnh đầy đủ đòi hỏi tài nguyên đáng kể và yêu cầu các bản sao mô hình riêng biệt cho các tác vụ khác nhau.
| Phương pháp | Tham số | Bộ nhớ | Chuyển đổi tác vụ |
|--------|------------|---------|----------------|
| Prompt Tuning | Rất thấp | Tối thiểu | Dễ dàng |
| LoRA | Thấp | Thấp | Yêu cầu tải |
| Tinh chỉnh đầy đủ | Cao | Cao | Cần bản sao mô hình mới |
Khi triển khai prompt tuning, hãy bắt đầu với một số lượng nhỏ token ảo (8-16) và chỉ tăng lên nếu độ phức tạp của tác vụ yêu cầu. Khởi tạo từ văn bản thường cho kết quả tốt hơn so với khởi tạo ngẫu nhiên, đặc biệt khi sử dụng văn bản liên quan đến tác vụ. Chiến lược khởi tạo nên phản ánh độ phức tạp của tác vụ mục tiêu của bạn.
Huấn luyện đòi hỏi những cân nhắc hơi khác so với tinh chỉnh đầy đủ. Tốc độ học (learning rates) cao hơn thường sẽ cho kết quả tốt hơn, nhưng cũng cần theo dõi cẩn thận *gradient* của token prompt. Kiểm tra thường xuyên trên các ví dụ đa dạng giúp đảm bảo hiệu suất mạnh mẽ trong các tình huống khác nhau.
## Ứng dụng
Prompt tuning xuất sắc trong một số kịch bản:
1. Triển khai đa tác vụ
2. Môi trường hạn chế tài nguyên
3. Thích ứng tác vụ nhanh chóng
4. Ứng dụng nhạy cảm về quyền riêng tư
Khi mô hình nhỏ hơn, prompt tuning trở nên kém cạnh tranh hơn so với tinh chỉnh đầy đủ. Ví dụ, trên các mô hình như SmolLM2, prompt tuning ít liên quan hơn so với tinh chỉnh đầy đủ.
## Các bước tiếp theo
⏭️ Chuyển sang [Hướng dẫn LoRA Adapters](./notebooks/finetune_sft_peft.ipynb) để tìm hiểu cách tinh chỉnh một mô hình với LoRA adapters.
## Tài liệu tham khảo
- [Tài liệu về thư viện PEFT](https://huggingface.co/docs/peft)
- [Bài báo nghiên cứu về Prompt Tuning](https://arxiv.org/abs/2104.08691)
- [Hướng dẫn thực hành của Hugging Face](https://huggingface.co/learn/cookbook/prompt_tuning_peft)
|
{
"source": "huggingface/smol-course",
"title": "vi/3_parameter_efficient_finetuning/prompt_tuning.md",
"url": "https://github.com/huggingface/smol-course/blob/main/vi/3_parameter_efficient_finetuning/prompt_tuning.md",
"date": "2024-11-25T19:22:43",
"stars": 5481,
"description": "A course on aligning smol models.",
"file_size": 5416
}
|
# Đánh giá mô hình
Đánh giá là bước quan trọng trong việc phát triển và triển khai các mô hình ngôn ngữ. Nó giúp chúng ta hiểu được mô hình hoạt động tốt như thế nào qua các khả năng khác nhau và xác định những lĩnh vực cần cải thiện. Chương này bao gồm các phương pháp đánh giá (benchmark) tiêu chuẩn và các phương pháp đánh giá theo lĩnh vực cụ thể để đánh giá toàn diện mô hình của bạn.
Chúng ta sẽ sử dụng [`lighteval`](https://github.com/huggingface/lighteval), một thư viện chuyên được sử dụng để đánh giá mô hình ngôn ngữ được phát triển bởi Hugging Face. Thư viện này được thiết kế tối giản giúp người sử dụng dễ dàng tiếp cận và được tích hợp để phù hợp với hệ sinh thái của Hugging Face. Để tìm hiểu sâu hơn về các khái niệm và thực hành về đánh giá mô hình ngôn ngữ, hãy tham khảo [hướng dẫn](https://github.com/huggingface/evaluation-guidebook) về đánh giá.
## Tổng quan chương học
Một quy trình đánh giá mô hình thường bao gồm nhiều khía cạnh về hiệu năng của mô hình. Chúng ta đánh giá các khả năng theo tác vụ cụ thể như *trả lời câu hỏi* và *tóm tắt* để hiểu mô hình xử lý các loại vấn đề khác nhau tốt đến đâu. Chúng ta đo lường chất lượng đầu ra thông qua các yếu tố như *tính mạch lạc* và *độ chính xác*. Đánh giá về *độ an toàn* giúp xác định các đầu ra của mô hình có chứa các hành vi khuyển khích thực hiện hành đông độc hại hoặc định kiến tiềm ẩn. Cuối cùng, kiểm tra *chuyên môn* về lĩnh vực xác minh kiến thức chuyên biệt của mô hình trong lĩnh vực mục tiêu của bạn.
## Nội dung
### 1️⃣ [Đánh giá mô hình tự động](./automatic_benchmarks.md)
Học cách đánh giá mô hình của bạn bằng các phương pháp đánh giá và số liệu chuẩn hoá. Chúng ta sẽ khám phá các phương pháp đánh giá phổ biến như `MMLU` và `TruthfulQA`, hiểu các chỉ số đánh giá và cài đặt quan trọng, đồng thời đề cập đến các thực hành tốt nhất cho việc đánh giá có thể tái tạo lại.
### 2️⃣ [Đánh giá theo yêu cầu đặc biệt](./custom_evaluation.md)
Khám phá cách tạo quy trình (pipeline) đánh giá phù hợp với trường hợp sử dụng cụ thể của bạn. Chúng ta sẽ hướng dẫn thiết kế các tác vụ đánh giá theo yêu cầu (custom), triển khai các số liệu chuyên biệt và xây dựng tập dữ liệu đánh giá phù hợp với yêu cầu của bạn.
### 3️⃣ [Dự án đánh giá theo lĩnh vực cụ thể](./project/README.md)
Theo dõi một ví dụ hoàn chỉnh về việc xây dựng quy trình đánh giá cho lĩnh vực cụ thể. Bạn sẽ học cách tạo tập dữ liệu đánh giá, sử dụng `Argilla` để gán nhãn dữ liệu, tạo tập dữ liệu chuẩn hoá và đánh giá mô hình bằng `LightEval`.
### Các notebook bài tập
| Tiêu đề | Mô tả | Bài tập | Link | Colab |
|---------|-------|---------|------|-------|
| Đánh giá và phân tích mô hình LLM của bạn | Học cách sử dụng `LightEval` để đánh giá và so sánh các mô hình trên các lĩnh vực cụ thể | 🐢 Sử dụng các tác vụ trong **lĩnh vực y tế** để đánh giá mô hình <br> 🐕 Tạo đánh giá lĩnh vực mới với các tác vụ MMLU khác nhau <br> 🦁 Tạo tác vụ đánh giá cho lĩnh vực của bạn | [Notebook](./notebooks/lighteval_evaluate_and_analyse_your_LLM.ipynb) | <a target="_blank" href="https://colab.research.google.com/github/huggingface/smol-course/blob/main/4_evaluation/notebooks/lighteval_evaluate_and_analyse_your_LLM.ipynb"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a> |
## Tài liệu tham khảo
- [Hướng dẫn đánh giá](https://github.com/huggingface/evaluation-guidebook) - Hướng dẫn toàn diện về đánh giá LLM
- [Tài liệu LightEval](https://github.com/huggingface/lighteval) - Tài liệu chính thức cho thư viện LightEval
- [Tài liệu Argilla](https://docs.argilla.io) - Tìm hiểu về nền tảng gán nhãn Argilla
- [Paper MMLU](https://arxiv.org/abs/2009.03300) - Paper mô tả benchmark MMLU
- [Tạo tác vụ theo yêu cầu](https://github.com/huggingface/lighteval/wiki/Adding-a-Custom-Task)
- [Tạo tiêu chuẩn đánh giá theo yêu cầu](https://github.com/huggingface/lighteval/wiki/Adding-a-New-Metric)
- [Sử dụng số liệu có sẵn](https://github.com/huggingface/lighteval/wiki/Metric-List)
|
{
"source": "huggingface/smol-course",
"title": "vi/4_evaluation/README.md",
"url": "https://github.com/huggingface/smol-course/blob/main/vi/4_evaluation/README.md",
"date": "2024-11-25T19:22:43",
"stars": 5481,
"description": "A course on aligning smol models.",
"file_size": 3976
}
|
# Đánh giá tự động
Đánh giá tự động là các công cụ chuẩn hoá để đánh giá các mô hình ngôn ngữ qua các tác vụ và khả năng khác nhau. Mặc dù chúng cung cấp điểm khởi đầu hữu ích để hiểu hiệu năng của mô hình, điều quan trọng là phải nhận ra rằng chúng chỉ là một phần trong toàn bộ khả năng của mô hình.
## Hiểu về đánh giá tự động
Đánh giá tự động thường bao gồm các tập dữ liệu được tuyển chọn với các tác vụ và tiêu chí đánh giá được định nghĩa trước. Những đánh giá này nhằm đánh giá nhiều khía cạnh về khả năng của mô hình, từ hiểu ngôn ngữ cơ bản đến suy luận phức tạp. Lợi thế chính của việc sử dụng đánh giá tự động là tính chuẩn hoá - chúng cho phép so sánh nhất quán giữa các mô hình khác nhau và cung cấp kết quả có thể tái tạo lại.
Tuy nhiên, điều quan trọng là phải hiểu rằng điểm số trên các bài đánh giá không phải lúc nào cũng thể hiện chính xác hiệu quả của mô hình trong thực tế. Một mô hình xuất sắc trong các bài đánh giá học thuật (academic benchmark) vẫn có thể gặp khó khăn với các ứng dụng vào lĩnh vực cụ thể hoặc các trường hợp sử dụng thực tế.
## Các bài đánh giá và hạn chế của chúng
### Đánh giá kiến thức tổng quát
`MMLU` (Massive Multitask Language Understanding) là bài đánh giá dùng để kiểm tra kiến thức trên *57 môn học*, từ khoa học tự nhiên đến khoa học xã hội. Mặc dù toàn diện, nó có thể không phản ánh độ sâu của chuyên môn cần thiết cho các lĩnh vực cụ thể. `TruthfulQA` đánh giá xu hướng mô hình tái tạo các quan niệm sai lầm phổ biến, mặc dù nó không thể nắm bắt tất cả các hình thức thông tin sai lệch.
### Đánh giá khả năng suy luận
`BBH` (Big Bench Hard) và `GSM8K` tập trung vào các tác vụ suy luận phức tạp. `BBH` kiểm tra tư duy logic và lập kế hoạch, trong khi `GSM8K` nhắm vào giải quyết vấn đề toán học. Những bài đánh giá này giúp kiểm tra khả năng phân tích nhưng có thể không nắm bắt được khả năng suy luận tinh tế cần thiết trong các tình huống thực tế.
### Đánh giá khả năng ngôn ngữ
`HELM` cung cấp một đánh giá toàn diện, trong khi `WinoGrande` kiểm tra hiểu biết thông thường thông qua việc giải nghĩa các đại từ. Những bài đánh giá này cung cấp cái nhìn sâu sắc về khả năng xử lý ngôn ngữ nhưng có thể không hoàn toàn đại diện cho độ phức tạp của giao tiếp tự nhiên hoặc thuật ngữ theo lĩnh vực cụ thể.
## Các phương pháp đánh giá thay thế
Nhiều tổ chức đã phát triển các phương pháp đánh giá thay thế để khắc phục những hạn chế của bài đánh giá tiêu chuẩn:
### LLM trong vài trò người đánh giá
Sử dụng một mô hình ngôn ngữ để đánh giá đầu ra của mô hình khác ngày càng phổ biến. Phương pháp này có thể cung cấp phản hồi chi tiết hơn các bài đánh giá truyền thống, mặc dù nó đi kèm với những định kiến (bias) của mô hình đánh giá và hạn chế riêng.
### Môi trường đánh giá
Các nền tảng như Constitutional AI Arena của Anthropic cho phép các mô hình tương tác và đánh giá lẫn nhau trong môi trường được kiểm soát. Điều này có thể cho thấy những điểm mạnh và điểm yếu có thể không rõ ràng trong các benchmark truyền thống.
### Bộ đánh giá tuỳ chỉnh
Các tổ chức thường phát triển bộ benchmark nội bộ được điều chỉnh cho nhu cầu và trường hợp sử dụng cụ thể của họ. Những bộ này có thể bao gồm kiểm tra kiến thức theo lĩnh vực cụ thể hoặc các kịch bản đánh giá phản ánh điều kiện triển khai thực tế.
## Tạo chiến lược đánh giá riêng
Hãy nhớ rằng mặc dù LightEval giúp dễ dàng chạy các benchmark tiêu chuẩn, bạn cũng nên dành thời gian phát triển phương pháp đánh giá phù hợp với trường hợp sử dụng của mình.
Mặc dù benchmark tiêu chuẩn cung cấp một đường cơ sở hữu ích, chúng không nên là phương pháp đánh giá duy nhất của bạn. Dưới đây là cách phát triển một phương pháp toàn diện hơn:
1. Bắt đầu với các benchmark tiêu chuẩn liên quan để thiết lập đường cơ sở và cho phép so sánh với các mô hình khác.
2. Xác định các yêu cầu và thách thức cụ thể của trường hợp sử dụng của bạn. Mô hình của bạn sẽ thực hiện những tác vụ gì? Những loại lỗi nào sẽ gây rắc rối nhất?
3. Phát triển tập dữ liệu đánh giá tuỳ chỉnh phản ánh trường hợp sử dụng thực tế của bạn. Điều này có thể bao gồm:
- Các câu hỏi thực tế từ người dùng trong lĩnh vực của bạn
- Các trường hợp ngoại lệ phổ biến bạn đã gặp
- Các ví dụ về tình huống đặc biệt khó khăn
4. Xem xét triển khai chiến lược đánh giá nhiều lớp:
- Số liệu tự động để nhận phản hồi nhanh
- Đánh giá bởi con người để hiểu sâu sắc hơn
- Đánh giá của chuyên gia lĩnh vực cho các ứng dụng chuyên biệt
- Kiểm tra A/B trong môi trường được kiểm soát
## Sử dụng LightEval để đánh giá
Các tác vụ LightEval được định nghĩa theo định dạng cụ thể:
```
{suite}|{task}|{num_few_shot}|{auto_reduce}
```
- **suite**: Bộ benchmark (ví dụ: 'mmlu', 'truthfulqa')
- **task**: Tác vụ cụ thể trong bộ (ví dụ: 'abstract_algebra')
- **num_few_shot**: Số lượng ví dụ để đưa vào prompt (0 cho zero-shot)
- **auto_reduce**: Có tự động giảm ví dụ few-shot nếu prompt quá dài hay không (0 hoặc 1)
Ví dụ: `"mmlu|abstract_algebra|0|0"` đánh giá tác vụ đại số trừu tượng của MMLU với suy luận zero-shot.
### Ví dụ về Pipeline đánh giá
Đây là một ví dụ hoàn chỉnh về việc thiết lập và chạy đánh giá trên các benchmark tự động liên quan đến một lĩnh vực cụ thể:
```python
from lighteval.tasks import Task, Pipeline
from transformers import AutoModelForCausalLM
# Định nghĩa các tác vụ để đánh giá
domain_tasks = [
"mmlu|anatomy|0|0",
"mmlu|high_school_biology|0|0",
"mmlu|high_school_chemistry|0|0",
"mmlu|professional_medicine|0|0"
]
# Cấu hình tham số pipeline
pipeline_params = {
"max_samples": 40, # Số lượng mẫu để đánh giá
"batch_size": 1, # Kích thước batch cho inference
"num_workers": 4 # Số lượng worker process
}
# Tạo evaluation tracker
evaluation_tracker = EvaluationTracker(
output_path="./results",
save_generations=True
)
# Tải mô hình và tạo pipeline
model = AutoModelForCausalLM.from_pretrained("your-model-name")
pipeline = Pipeline(
tasks=domain_tasks,
pipeline_parameters=pipeline_params,
evaluation_tracker=evaluation_tracker,
model=model
)
# Chạy đánh giá
pipeline.evaluate()
# Lấy và hiển thị kết quả
results = pipeline.get_results()
pipeline.show_results()
```
Kết quả được hiển thị dưới dạng bảng thể hiện:
```
| Task |Version|Metric|Value | |Stderr|
|----------------------------------------|------:|------|-----:|---|-----:|
|all | |acc |0.3333|± |0.1169|
|leaderboard:mmlu:_average:5 | |acc |0.3400|± |0.1121|
|leaderboard:mmlu:anatomy:5 | 0|acc |0.4500|± |0.1141|
|leaderboard:mmlu:high_school_biology:5 | 0|acc |0.1500|± |0.0819|
```
Bạn cũng có thể xử lý kết quả trong pandas DataFrame và trực quan hoá hoặc biểu diễn chúng theo cách bạn muốn.
# Bước tiếp theo
⏩ Khám phá [Đánh giá theo lĩnh vực tuỳ chỉnh](./custom_evaluation.md) để học cách tạo pipeline đánh giá phù hợp với nhu cầu cụ thể của bạn
|
{
"source": "huggingface/smol-course",
"title": "vi/4_evaluation/automatic_benchmarks.md",
"url": "https://github.com/huggingface/smol-course/blob/main/vi/4_evaluation/automatic_benchmarks.md",
"date": "2024-11-25T19:22:43",
"stars": 5481,
"description": "A course on aligning smol models.",
"file_size": 6946
}
|
# Đánh Giá Theo Lĩnh Vực Cụ Thể
Mặc dù các phương pháp đánh giá tiêu chuẩn (`benchmark`) cung cấp những thông tin chuyên sâu có giá trị, nhiều ứng dụng đòi hỏi các phương pháp đánh giá chuyên biệt phù hợp với các lĩnh vực hoặc trường hợp sử dụng cụ thể. Bài học này sẽ giúp bạn tạo các quy trình (`pipeline`) tùy chỉnh các phương pháp đánh giá để có cái nhìn chính xác hơn về hiệu suất của mô hình trong lĩnh vực cụ thể của bạn.
## Thiết kế chiến lược đánh giá của bạn
Một chiến lược đánh giá tùy chỉnh đầy đủ bắt đầu với các mục tiêu rõ ràng. Hãy xem xét những khả năng cụ thể mà mô hình của bạn cần thể hiện trong lĩnh vực của bạn. Điều này có thể bao gồm kiến thức kỹ thuật, các mẫu suy luận hoặc các định dạng đặc thù cho lĩnh vực đó. Ghi lại cẩn thận các yêu cầu này - chúng sẽ hướng dẫn cả việc thiết kế tác vụ (`task`) và lựa chọn các chỉ số (`metric`).
Việc đánh giá của bạn nên kiểm tra cả các trường hợp sử dụng tiêu chuẩn và các trường hợp biên (`edge case`). Ví dụ, trong lĩnh vực y tế, bạn có thể đánh giá cả các kịch bản chẩn đoán phổ biến và các tình trạng hiếm gặp. Trong các ứng dụng tài chính, bạn có thể kiểm tra cả các giao dịch thông thường và các trường hợp biên phức tạp liên quan đến nhiều loại tiền tệ hoặc các điều kiện đặc biệt.
## Triển khai với LightEval
`LightEval` cung cấp một khung (`framework`) linh hoạt để triển khai các đánh giá tùy chỉnh. Đây là cách để tạo một tác vụ (`task`) tùy chỉnh:
```python
from lighteval.tasks import Task, Doc
from lighteval.metrics import SampleLevelMetric, MetricCategory, MetricUseCase
class CustomEvalTask(Task):
def __init__(self):
super().__init__(
name="custom_task",
version="0.0.1",
metrics=["accuracy", "f1"], # Các chỉ số bạn chọn
description="Mô tả tác vụ đánh giá tùy chỉnh của bạn"
)
def get_prompt(self, sample):
# Định dạng đầu vào của bạn thành một lời nhắc (prompt)
return f"Question: {sample['question']}\nAnswer:"
def process_response(self, response, ref):
# Xử lý đầu ra của mô hình và so sánh với tham chiếu
return response.strip() == ref.strip()
```
## Các chỉ số (`metric`) tùy chỉnh
Các tác vụ theo lĩnh vực cụ thể thường yêu cầu các chỉ số chuyên biệt. `LightEval` cung cấp một khung linh hoạt để tạo các chỉ số tùy chỉnh nắm bắt các khía cạnh liên quan đến lĩnh vực của hiệu suất:
```python
from aenum import extend_enum
from lighteval.metrics import Metrics, SampleLevelMetric, SampleLevelMetricGrouping
import numpy as np
# Định nghĩa một hàm chỉ số mức mẫu (sample-level metric)
def custom_metric(predictions: list[str], formatted_doc: Doc, **kwargs) -> dict:
"""Chỉ số ví dụ trả về nhiều điểm số cho mỗi mẫu"""
response = predictions[0]
return {
"accuracy": response == formatted_doc.choices[formatted_doc.gold_index],
"length_match": len(response) == len(formatted_doc.reference)
}
# Tạo một chỉ số trả về nhiều giá trị cho mỗi mẫu
custom_metric_group = SampleLevelMetricGrouping(
metric_name=["accuracy", "length_match"], # Tên của các chỉ số
higher_is_better={ # Liệu giá trị cao hơn có tốt hơn cho mỗi chỉ số không
"accuracy": True,
"length_match": True
},
category=MetricCategory.CUSTOM,
use_case=MetricUseCase.SCORING,
sample_level_fn=custom_metric,
corpus_level_fn={ # Cách tổng hợp từng chỉ số
"accuracy": np.mean,
"length_match": np.mean
}
)
# Đăng ký chỉ số vào LightEval
extend_enum(Metrics, "custom_metric_name", custom_metric_group)
```
Đối với các trường hợp đơn giản hơn, nơi bạn chỉ cần một giá trị chỉ số cho mỗi mẫu:
```python
def simple_metric(predictions: list[str], formatted_doc: Doc, **kwargs) -> bool:
"""Chỉ số ví dụ trả về một điểm duy nhất cho mỗi mẫu"""
response = predictions[0]
return response == formatted_doc.choices[formatted_doc.gold_index]
simple_metric_obj = SampleLevelMetric(
metric_name="simple_accuracy",
higher_is_better=True,
category=MetricCategory.CUSTOM,
use_case=MetricUseCase.SCORING,
sample_level_fn=simple_metric,
corpus_level_fn=np.mean # Cách tổng hợp trên các mẫu
)
extend_enum(Metrics, "simple_metric", simple_metric_obj)
```
Sau đó, bạn có thể sử dụng các chỉ số tùy chỉnh của mình trong các tác vụ đánh giá bằng cách tham chiếu chúng trong cấu hình tác vụ. Các chỉ số sẽ được tự động tính toán trên tất cả các mẫu và tổng hợp theo các hàm bạn đã chỉ định.
Đối với các chỉ số phức tạp hơn, hãy xem xét:
- Sử dụng siêu dữ liệu (`metadata`) trong các tài liệu được định dạng của bạn để đánh trọng số hoặc điều chỉnh điểm số
- Triển khai các hàm tổng hợp tùy chỉnh cho các thống kê cấp độ kho ngữ liệu (`corpus-level`)
- Thêm kiểm tra xác thực cho đầu vào chỉ số của bạn
- Ghi lại các trường hợp biên và hành vi mong đợi
Để có một ví dụ đầy đủ về các chỉ số tùy chỉnh trong thực tế, hãy xem [dự án đánh giá theo lĩnh vực](./project/README.md) của chúng tôi.
## Tạo tập dữ liệu
Đánh giá chất lượng cao đòi hỏi các tập dữ liệu được sắp xếp cẩn thận. Hãy xem xét các phương pháp sau để tạo tập dữ liệu:
1. Chú thích của chuyên gia: Làm việc với các chuyên gia trong lĩnh vực để tạo và xác thực các ví dụ đánh giá. Các công cụ như [Argilla](https://github.com/argilla-io/argilla) làm cho quá trình này hiệu quả hơn.
2. Dữ liệu thế giới thực: Thu thập và ẩn danh hóa dữ liệu sử dụng thực tế, đảm bảo nó đại diện cho các kịch bản triển khai thực tế.
3. Tạo tổng hợp: Sử dụng `LLM` để tạo các ví dụ ban đầu, sau đó để các chuyên gia xác thực và tinh chỉnh chúng.
## Các phương pháp tốt nhất
- Ghi lại phương pháp đánh giá của bạn một cách kỹ lưỡng, bao gồm mọi giả định hoặc hạn chế
- Bao gồm các trường hợp kiểm thử đa dạng bao gồm các khía cạnh khác nhau trong lĩnh vực của bạn
- Xem xét cả các chỉ số tự động và đánh giá thủ công khi thích hợp
- Kiểm soát phiên bản (`Version control`) các tập dữ liệu và mã đánh giá của bạn
- Thường xuyên cập nhật bộ đánh giá của bạn khi bạn phát hiện ra các trường hợp biên hoặc yêu cầu mới
## Tài liệu tham khảo
- [Hướng dẫn tác vụ tùy chỉnh LightEval](https://github.com/huggingface/lighteval/wiki/Adding-a-Custom-Task)
- [Chỉ số tùy chỉnh LightEval](https://github.com/huggingface/lighteval/wiki/Adding-a-New-Metric)
- [Tài liệu Argilla](https://docs.argilla.io) để chú thích tập dữ liệu
- [Hướng dẫn đánh giá](https://github.com/huggingface/evaluation-guidebook) cho các nguyên tắc đánh giá chung
# Các bước tiếp theo
⏩ Để có một ví dụ đầy đủ về việc triển khai các khái niệm này, hãy xem [dự án đánh giá theo lĩnh vực](./project/README.md) của chúng tôi.
|
{
"source": "huggingface/smol-course",
"title": "vi/4_evaluation/custom_evaluation.md",
"url": "https://github.com/huggingface/smol-course/blob/main/vi/4_evaluation/custom_evaluation.md",
"date": "2024-11-25T19:22:43",
"stars": 5481,
"description": "A course on aligning smol models.",
"file_size": 6626
}
|
# Mô hình Ngôn ngữ Thị giác
## 1. Sử dụng Mô hình Ngôn ngữ Thị giác (Vision Language Models)
Mô hình Ngôn ngữ Thị giác (VLMs) xử lý đầu vào hình ảnh cùng với văn bản để thực hiện các tác vụ như chú thích của ảnh, trả lời câu hỏi bằng hình ảnh và suy luận đa phương thức (multimodal).
Một kiến trúc VLM điển hình bao gồm:
1. Bộ mã hóa hình ảnh (*image encoder*) để trích xuất các đặc trưng thị giác
2. Lớp chiếu (*projection layer*) để căn chỉnh các biểu diễn thị giác với văn bản
3. Mô hình ngôn ngữ để xử lý hoặc tạo văn bản. Điều này cho phép mô hình thiết lập các kết nối giữa các yếu tố về thị giác và các khái niệm trong ngôn ngữ.
Tùy thuộc vào từng trường hợp mà có thể sử dụng các VLMs được huấn luyện theo các tác vụ khác nhau. Các mô hình cơ sở (base models) xử lý các tác vụ thị giác-ngôn ngữ tổng quát, trong khi các biến thể tối ưu hóa cho trò chuyện (chat-optimized variants) hỗ trợ các tương tác hội thoại. Một số mô hình bao gồm các thành phần bổ sung để làm rõ dự đoán dựa trên các bằng chứng thị giác (*visual evidence*) hoặc chuyên về các tác vụ cụ thể như phát hiện đối tượng (*object detection*).
Để biết thêm chi tiết về kỹ thuật và cách sử dụng VLMs, hãy tham khảo trang [Sử dụng VLM](./vlm_usage.md).
## 2. Tinh chỉnh Mô hình Ngôn ngữ Thị giác (VLM)
Tinh chỉnh VLM là việc điều chỉnh một mô hình đã được huấn luyện trước (*pre-trained*) để thực hiện các tác vụ cụ thể hoặc để hoạt động hiệu quả trên một tập dữ liệu cụ thể. Quá trình này có thể tuân theo các phương pháp như tinh chỉnh có giám sát (*supervised fine-tuning*), tối ưu hóa tùy chọn (*preference optimization*) hoặc phương pháp kết hợp (*hybrid approach*) cả hai, như đã giới thiệu trong Chương 1 và Chương 2.
Mặc dù các công cụ và kỹ thuật cốt lõi vẫn tương tự như các công cụ và kỹ thuật được sử dụng cho các mô hình ngôn ngữ (LLMs), việc tinh chỉnh VLMs đòi hỏi phải tập trung nhiều hơn vào việc biểu diễn và chuẩn bị dữ liệu cho hình ảnh. Điều này đảm bảo mô hình tích hợp và xử lý hiệu quả cả dữ liệu thị giác và văn bản để đạt hiệu suất tối ưu. Vì mô hình demo, SmolVLM, lớn hơn đáng kể so với mô hình ngôn ngữ được sử dụng trong bài trước, điều cần thiết là phải khám phá các phương pháp tinh chỉnh hiệu quả. Các kỹ thuật như lượng tử hóa (*quantization*) và Tinh chỉnh hiệu quả tham số - PEFT (*Parameter-Efficient Fine-Tuning*) có thể giúp làm cho quá trình này dễ tiếp cận hơn và tiết kiệm chi phí hơn, cho phép nhiều người dùng thử nghiệm với mô hình hơn.
Để được hướng dẫn chi tiết về tinh chỉnh VLMs, hãy truy cập trang [Tinh chỉnh VLM](./vlm_finetuning.md).
## Bài tập thực hành
| Tiêu đề | Mô tả | Bài tập | Link | Colab |
|-------|-------------|----------|------|-------|
| Sử dụng VLM | Tìm hiểu cách tải và sử dụng VLM đã được huấn luyện trước cho các tác vụ khác nhau | 🐢 Xử lý một hình ảnh<br>🐕 Xử lý nhiều hình ảnh với xử lý hàng loạt <br>🦁 Xử lý toàn bộ video| [Notebook](./notebooks/vlm_usage_sample.ipynb) | <a target="_blank" href="https://colab.research.google.com/github/huggingface/smol-course/blob/main/5_vision_language_models/notebooks/vlm_usage_sample.ipynb"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a> |
| Tinh chỉnh VLM | Tìm hiểu cách tinh chỉnh VLM đã được huấn luyện trước cho các tập dữ liệu theo từng nhiệm vụ | 🐢 Sử dụng tập dữ liệu cơ bản để tinh chỉnh<br>🐕 Thử tập dữ liệu mới<br>🦁 Thử nghiệm với các phương pháp tinh chỉnh thay thế | [Notebook](./notebooks/vlm_sft_sample.ipynb)| <a target="_blank" href="https://colab.research.google.com/github/huggingface/smol-course/blob/main/5_vision_language_models/notebooks/vlm_sft_sample.ipynb"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a> |
## Tài liệu tham khảo
- [Hugging Face Learn: Tinh chỉnh có giám sát VLMs](https://huggingface.co/learn/cookbook/fine_tuning_vlm_trl)
- [Hugging Face Learn: Tinh chỉnh có giám sát SmolVLM](https://huggingface.co/learn/cookbook/fine_tuning_smol_vlm_sft_trl)
- [Hugging Face Learn: Tinh chỉnh tối ưu hóa tùy chọn SmolVLM](https://huggingface.co/learn/cookbook/fine_tuning_vlm_dpo_smolvlm_instruct)
- [Hugging Face Blog: Tối ưu hóa tùy chọn cho VLMs](https://huggingface.co/blog/dpo_vlm)
- [Hugging Face Blog: Mô hình Ngôn ngữ Thị giác](https://huggingface.co/blog/vlms)
- [Hugging Face Blog: SmolVLM](https://huggingface.co/blog/smolvlm)
- [Hugging Face Model: SmolVLM-Instruct](https://huggingface.co/HuggingFaceTB/SmolVLM-Instruct)
- [CLIP: Learning Transferable Visual Models from Natural Language Supervision](https://arxiv.org/abs/2103.00020)
- [Align Before Fuse: Vision and Language Representation Learning with Momentum Distillation](https://arxiv.org/abs/2107.07651)
|
{
"source": "huggingface/smol-course",
"title": "vi/5_vision_language_models/README.md",
"url": "https://github.com/huggingface/smol-course/blob/main/vi/5_vision_language_models/README.md",
"date": "2024-11-25T19:22:43",
"stars": 5481,
"description": "A course on aligning smol models.",
"file_size": 4697
}
|
# Tinh chỉnh Mô hình Ngôn ngữ Thị giác (VLM)
## Tinh chỉnh Hiệu quả
### Lượng tử hóa (Quantization)
Lượng tử hóa làm giảm độ chính xác của trọng số mô hình (model weights) và hàm kích hoạt (activations), giúp giảm đáng kể mức sử dụng bộ nhớ và tăng tốc độ tính toán. Ví dụ: chuyển từ `float32` sang `bfloat16` giúp giảm một nửa yêu cầu bộ nhớ cho mỗi tham số trong khi vẫn duy trì hiệu suất. Để nén mạnh hơn, có thể sử dụng lượng tử hóa `8 bit` và `4 bit`, giúp giảm mức sử dụng bộ nhớ hơn nữa, mặc dù phải đánh đổi bằng việc giảm độ chính xác. Những kỹ thuật này có thể được áp dụng cho cả trọng số mô hình và trình tối ưu hóa (optimizer), cho phép huấn luyện hiệu quả trên phần cứng có tài nguyên hạn chế.
### PEFT & LoRA
Như đã giới thiệu trong Bài 3, LoRA (Low-Rank Adaptation) tập trung vào việc học các ma trận phân rã hạng thấp (rank-decomposition matrices) nhỏ gọn trong khi vẫn giữ nguyên trọng số của mô hình gốc. Điều này làm giảm đáng kể số lượng tham số có thể huấn luyện, giảm đáng kể yêu cầu tài nguyên. LoRA, khi được tích hợp với PEFT (Parameter-Efficient Fine-Tuning), cho phép tinh chỉnh các mô hình lớn bằng cách chỉ điều chỉnh một tập hợp con nhỏ các tham số có thể huấn luyện. Phương pháp này đặc biệt hiệu quả cho các thích ứng theo nhiệm vụ cụ thể, giảm hàng tỷ tham số có thể huấn luyện xuống chỉ còn hàng triệu trong khi vẫn duy trì hiệu suất.
### Tối ưu hóa Kích thước Batch (Batch Size)
Để tối ưu hóa kích thước batch cho quá trình tinh chỉnh, hãy bắt đầu với một giá trị lớn và giảm nếu xảy ra lỗi out-of-memory (OOM). Bù lại bằng cách tăng `gradient_accumulation_steps`, duy trì hiệu quả tổng kích thước batch trên nhiều lần cập nhật. Ngoài ra, hãy bật `gradient_checkpointing` để giảm mức sử dụng bộ nhớ bằng cách tính toán lại các trạng thái trung gian trong quá trình lan truyền ngược (backward pass), đánh đổi thời gian tính toán để giảm yêu cầu bộ nhớ kích hoạt. Những chiến lược này tối đa hóa việc sử dụng phần cứng và giúp khắc phục các hạn chế về bộ nhớ.
```python
from transformers import TrainingArguments
training_args = TrainingArguments(
output_dir="./fine_tuned_model", # Thư mục cho các checkpoint của mô hình
per_device_train_batch_size=4, # Kích thước batch trên mỗi thiết bị (GPU/TPU)
num_train_epochs=3, # Tổng số epoch huấn luyện
learning_rate=5e-5, # Tốc độ học
save_steps=1000, # Lưu checkpoint sau mỗi 1000 bước
bf16=True, # Sử dụng mixed precision để huấn luyện
gradient_checkpointing=True, # Bật để giảm mức sử dụng bộ nhớ kích hoạt
gradient_accumulation_steps=16, # Tích lũy gradient qua 16 bước
logging_steps=50 # Ghi nhật ký các số liệu sau mỗi 50 bước
)
```
## **Tinh chỉnh có Giám sát (Supervised Fine-Tuning - SFT)**
Tinh chỉnh có Giám sát (SFT) điều chỉnh Mô hình Ngôn ngữ Thị giác (VLM) đã được huấn luyện trước cho các nhiệm vụ cụ thể bằng cách tận dụng các tập dữ liệu được gán nhãn có chứa các đầu vào được ghép nối, chẳng hạn như hình ảnh và văn bản tương ứng. Phương pháp này nâng cao khả năng của mô hình để thực hiện các chức năng cụ thể theo miền (domain-specific) hoặc theo nhiệm vụ (task-specific), chẳng hạn như trả lời câu hỏi bằng hình ảnh, chú thích hình ảnh hoặc diễn giải biểu đồ.
### **Tổng quan**
SFT là cần thiết khi bạn cần một VLM chuyên về một lĩnh vực cụ thể hoặc giải quyết các vấn đề cụ thể mà khả năng chung của mô hình cơ sở có thể không đáp ứng được. Ví dụ: nếu mô hình gặp khó khăn với các đặc điểm hình ảnh độc đáo hoặc thuật ngữ chuyên ngành, SFT cho phép mô hình tập trung vào các lĩnh vực này bằng cách học từ dữ liệu được gán nhãn.
Mặc dù SFT rất hiệu quả, nó có những hạn chế đáng chú ý:
- **Phụ thuộc vào dữ liệu**: Cần có các tập dữ liệu được gán nhãn chất lượng cao phù hợp với nhiệm vụ.
- **Tài nguyên tính toán**: Tinh chỉnh các VLM lớn đòi hỏi nhiều tài nguyên.
- **Nguy cơ quá khớp (Overfitting)**: Các mô hình có thể mất khả năng khái quát hóa nếu được tinh chỉnh quá hẹp.
Tuy vậy, SFT vẫn là một kỹ thuật mạnh mẽ để nâng cao hiệu suất của mô hình trong các bối cảnh cụ thể.
### **Cách sử dụng**
1. **Chuẩn bị dữ liệu**: Bắt đầu với tập dữ liệu được gán nhãn ghép nối hình ảnh với văn bản, chẳng hạn như câu hỏi và câu trả lời. Ví dụ: trong các tác vụ như phân tích biểu đồ, tập dữ liệu `HuggingFaceM4/ChartQA` bao gồm hình ảnh biểu đồ, truy vấn và câu trả lời ngắn gọn.
2. **Thiết lập mô hình**: Tải VLM đã được huấn luyện trước phù hợp với nhiệm vụ, chẳng hạn như `HuggingFaceTB/SmolVLM-Instruct`, và một bộ xử lý (processor) để chuẩn bị đầu vào văn bản và hình ảnh. Điều chỉnh cấu hình của mô hình để phù hợp với phần cứng của bạn.
3. **Quá trình tinh chỉnh**:
- **Định dạng dữ liệu**: Cấu trúc tập dữ liệu thành định dạng giống như chatbot, ghép nối các câu lệnh hệ thống (system messages), các truy vấn của người dùng và các câu trả lời tương ứng.
- **Cấu hình huấn luyện**: Sử dụng các công cụ như `TrainingArguments` của Hugging Face hoặc `SFTConfig` của TRL để thiết lập các tham số huấn luyện. Chúng bao gồm kích thước batch, tốc độ học và các bước tích lũy gradient để tối ưu hóa việc sử dụng tài nguyên.
- **Kỹ thuật tối ưu hóa**: Sử dụng **gradient checkpointing** để tiết kiệm bộ nhớ trong quá trình huấn luyện. Sử dụng mô hình đã lượng tử hóa để giảm yêu cầu bộ nhớ và tăng tốc độ tính toán.
- Sử dụng `SFTTrainer` từ thư viện TRL, để hợp lý hóa quá trình huấn luyện.
## Tối ưu hóa theo Sở thích (Preference Optimization)
Tối ưu hóa theo Sở thích, đặc biệt là Tối ưu hóa Sở thích Trực tiếp (Direct Preference Optimization - DPO), huấn luyện Mô hình Ngôn ngữ Thị giác (VLM) để phù hợp với sở thích của con người. Thay vì tuân theo các hướng dẫn được xác định trước một cách nghiêm ngặt, mô hình học cách ưu tiên các đầu ra mà con người chủ quan thích hơn. Phương pháp này đặc biệt hữu ích cho các tác vụ liên quan đến phán đoán sáng tạo, lý luận sắc thái hoặc các câu trả lời có thể chấp nhận được khác nhau.
### **Tổng quan**
Tối ưu hóa theo Sở thích giải quyết các tình huống trong đó sở thích chủ quan của con người là trung tâm của sự thành công của nhiệm vụ. Bằng cách tinh chỉnh trên các tập dữ liệu mã hóa sở thích của con người, DPO nâng cao khả năng của mô hình trong việc tạo ra các phản hồi phù hợp với ngữ cảnh và phong cách với mong đợi của người dùng. Phương pháp này đặc biệt hiệu quả cho các tác vụ như viết sáng tạo, tương tác với khách hàng hoặc các tình huống có nhiều lựa chọn.
Mặc dù có những lợi ích, Tối ưu hóa theo Sở thích có những thách thức:
- **Chất lượng dữ liệu**: Cần có các tập dữ liệu được chú thích theo sở thích chất lượng cao, thường làm cho việc thu thập dữ liệu trở thành một nút thắt cổ chai.
- **Độ phức tạp**: Việc huấn luyện có thể liên quan đến các quy trình phức tạp như lấy mẫu theo cặp các sở thích và cân bằng tài nguyên tính toán.
Các tập dữ liệu sở thích phải nắm bắt được các sở thích rõ ràng giữa các đầu ra ứng viên. Ví dụ: một tập dữ liệu có thể ghép nối một câu hỏi với hai câu trả lời—một câu trả lời được ưu tiên và câu trả lời kia ít được chấp nhận hơn. Mô hình học cách dự đoán câu trả lời được ưu tiên, ngay cả khi nó không hoàn toàn chính xác, miễn là nó phù hợp hơn với đánh giá của con người.
### **Cách sử dụng**
1. **Chuẩn bị tập dữ liệu**
Một tập dữ liệu được gán nhãn sở thích là rất quan trọng để huấn luyện. Mỗi ví dụ thường bao gồm một lời nhắc (prompt) (ví dụ: một hình ảnh và câu hỏi) và hai câu trả lời ứng viên: một câu được chọn (ưa thích) và một câu bị từ chối. Ví dụ:
- **Câu hỏi**: Có bao nhiêu gia đình?
- **Bị từ chối**: Hình ảnh không cung cấp bất kỳ thông tin nào về các gia đình.
- **Được chọn**: Hình ảnh cho thấy một bảng gồm 18.000 gia đình.
Tập dữ liệu dạy cho mô hình ưu tiên các câu trả lời phù hợp hơn, ngay cả khi chúng không hoàn hảo.
2. **Thiết lập mô hình**
Tải VLM đã được huấn luyện trước và tích hợp nó với thư viện TRL của Hugging Face, hỗ trợ DPO và bộ xử lý để chuẩn bị đầu vào văn bản và hình ảnh. Định cấu hình mô hình để học có giám sát và phù hợp với phần cứng của bạn.
3. **Quy trình huấn luyện**
Việc huấn luyện bao gồm việc định cấu hình các tham số cụ thể cho DPO. Dưới đây là bản tóm tắt về quy trình:
- **Định dạng tập dữ liệu**: Cấu trúc từng mẫu với lời nhắc, hình ảnh và câu trả lời ứng viên.
- **Hàm mất mát (Loss Function)**: Sử dụng hàm mất mát dựa trên sở thích để tối ưu hóa mô hình để chọn đầu ra được ưu tiên.
- **Huấn luyện hiệu quả**: Kết hợp các kỹ thuật như lượng tử hóa, tích lũy gradient và bộ điều hợp LoRA (LoRA adapters) để tối ưu hóa bộ nhớ và tính toán.
## Tài liệu tham khảo
- [Hugging Face Learn: Tinh chỉnh có giám sát VLMs](https://huggingface.co/learn/cookbook/fine_tuning_vlm_trl)
- [Hugging Face Learn: Tinh chỉnh có giám sát SmolVLM](https://huggingface.co/learn/cookbook/fine_tuning_smol_vlm_sft_trl)
- [Hugging Face Learn: Tinh chỉnh tối ưu hóa tùy chọn SmolVLM](https://huggingface.co/learn/cookbook/fine_tuning_vlm_dpo_smolvlm_instruct)
- [Hugging Face Blog: Tối ưu hóa tùy chọn cho VLMs](https://huggingface.co/blog/dpo_vlm)
## Các bước tiếp theo
⏩ Thử [vlm_finetune_sample.ipynb](./notebooks/vlm_finetune_sample.ipynb) để triển khai phương pháp thống nhất này để căn chỉnh tùy chọn.
|
{
"source": "huggingface/smol-course",
"title": "vi/5_vision_language_models/vlm_finetuning.md",
"url": "https://github.com/huggingface/smol-course/blob/main/vi/5_vision_language_models/vlm_finetuning.md",
"date": "2024-11-25T19:22:43",
"stars": 5481,
"description": "A course on aligning smol models.",
"file_size": 9254
}
|
# Mô hình Ngôn ngữ Thị giác (Visual Language Models)
Mô hình Ngôn ngữ Thị giác (VLMs) thu hẹp khoảng cách giữa hình ảnh và văn bản, cho phép thực hiện các tác vụ nâng cao như tạo chú thích cho ảnh, trả lời câu hỏi dựa trên hình ảnh hoặc hiểu mối quan hệ giữa dữ liệu văn bản và hình ảnh. Kiến trúc của chúng được thiết kế để xử lý liền mạch cả hai phương thức.
### Kiến trúc
VLMs kết hợp các thành phần xử lý hình ảnh với các mô hình sinh văn bản để đạt được sự hiểu biết thống nhất. Các yếu tố chính trong kiến trúc của chúng là:

- **Bộ mã hóa hình ảnh (Image Encoder)**: Biến đổi hình ảnh thô thành các biểu diễn số học nhỏ gọn. Các bộ mã hóa được huấn luyện trước như CLIP hoặc vision transformers (ViT) thường được sử dụng.
- **Bộ chiếu nhúng (Embedding Projector)**: Ánh xạ các đặc trưng của hình ảnh vào không gian tương thích với các phép nhúng văn bản, thường sử dụng các lớp dày đặc (dense layers) hoặc các phép biến đổi tuyến tính.
- **Bộ giải mã văn bản (Text Decoder)**: Hoạt động như thành phần sinh ngôn ngữ, chuyển thông tin đa phương thức đã hợp nhất thành văn bản mạch lạc. Ví dụ bao gồm các mô hình sinh (generative models) như Llama hoặc Vicuna.
- **Bộ chiếu đa phương thức (Multimodal Projector)**: Cung cấp một lớp bổ sung để trộn lẫn các biểu diễn hình ảnh và văn bản. Nó rất quan trọng đối với các mô hình như LLaVA để thiết lập các kết nối mạnh mẽ hơn giữa hai phương thức.
Hầu hết các VLMs tận dụng các bộ mã hóa hình ảnh và bộ giải mã văn bản đã được huấn luyện trước và căn chỉnh chúng thông qua việc tinh chỉnh bổ sung trên các tập dữ liệu hình ảnh-văn bản được ghép nối. Cách tiếp cận này giúp việc huấn luyện hiệu quả đồng thời cho phép các mô hình khái quát hóa một cách hiệu quả.
### Cách sử dụng

VLMs được áp dụng cho một loạt các tác vụ đa phương thức. Khả năng thích ứng của chúng cho phép chúng hoạt động trong các lĩnh vực đa dạng với các mức độ tinh chỉnh khác nhau:
- **Chú thích hình ảnh (Image Captioning)**: Tạo mô tả cho hình ảnh.
- **Trả lời câu hỏi bằng hình ảnh (Visual Question Answering - VQA)**: Trả lời câu hỏi về nội dung của hình ảnh.
- **Truy xuất đa phương thức (Cross-Modal Retrieval)**: Tìm văn bản tương ứng cho một hình ảnh nhất định hoặc ngược lại.
- **Ứng dụng sáng tạo (Creative Applications)**: Hỗ trợ thiết kế, tạo tác phẩm nghệ thuật hoặc tạo nội dung đa phương tiện hấp dẫn.

Việc huấn luyện và tinh chỉnh VLMs phụ thuộc vào các tập dữ liệu chất lượng cao ghép nối hình ảnh với chú thích văn bản. Các công cụ như thư viện `transformers` của Hugging Face cung cấp quyền truy cập thuận tiện vào các VLMs đã được huấn luyện trước và quy trình làm việc được sắp xếp hợp lý để tinh chỉnh tùy chỉnh.
### Định dạng trò chuyện (Chat Format)
Nhiều VLMs được cấu trúc để tương tác theo kiểu chatbot, nâng cao khả năng sử dụng. Định dạng này bao gồm:
- Một **câu lệnh hệ thống (system message)** đặt vai trò hoặc ngữ cảnh cho mô hình, chẳng hạn như "Bạn là trợ lý phân tích dữ liệu hình ảnh."
- **Truy vấn của người dùng (user queries)** kết hợp đầu vào văn bản và hình ảnh liên quan.
- **Phản hồi của trợ lý (assistant responses)** cung cấp đầu ra văn bản bắt nguồn từ phân tích đa phương thức.
Cấu trúc hội thoại này trực quan và phù hợp với mong đợi của người dùng, đặc biệt là đối với các ứng dụng tương tác như dịch vụ khách hàng hoặc các công cụ giáo dục.
Dưới đây là ví dụ về cách hiển thị đầu vào được định dạng:
```json
[
{
"role": "system",
"content": [{"type": "text", "text": "Bạn là một Mô hình Ngôn ngữ Thị giác chuyên giải thích dữ liệu hình ảnh từ hình ảnh biểu đồ..."}]
},
{
"role": "user",
"content": [
{"type": "image", "image": "<image_data>"},
{"type": "text", "text": "Giá trị cao nhất trong biểu đồ cột là bao nhiêu?"}
]
},
{
"role": "assistant",
"content": [{"type": "text", "text": "42"}]
}
]
```
**Làm việc với nhiều hình ảnh và video**
VLMs cũng có thể xử lý nhiều hình ảnh hoặc thậm chí video bằng cách điều chỉnh cấu trúc đầu vào để chứa các đầu vào hình ảnh tuần tự hoặc song song. Đối với video, các khung hình có thể được trích xuất và xử lý như các hình ảnh riêng lẻ, trong khi vẫn duy trì thứ tự thời gian.
## Tài liệu tham khảo
- [Hugging Face Blog: Mô hình Ngôn ngữ Thị giác](https://huggingface.co/blog/vlms)
- [Hugging Face Blog: SmolVLM](https://huggingface.co/blog/smolvlm)
## Các bước tiếp theo
⏩ Thử [vlm_usage_sample.ipynb](./notebooks/vlm_usage_sample.ipynb) để thử các cách sử dụng khác nhau của SMOLVLM.
|
{
"source": "huggingface/smol-course",
"title": "vi/5_vision_language_models/vlm_usage.md",
"url": "https://github.com/huggingface/smol-course/blob/main/vi/5_vision_language_models/vlm_usage.md",
"date": "2024-11-25T19:22:43",
"stars": 5481,
"description": "A course on aligning smol models.",
"file_size": 4660
}
|
# Tạo tập dữ liệu giả lập (Synthetic Datasets)
Dữ liệu giả lập (synthetic data) là dữ liệu được tạo ra nhân tạo mô phỏng việc sử dụng trong thế giới thực. Nó cho phép khắc phục các hạn chế về dữ liệu bằng cách mở rộng hoặc nâng cao các tập dữ liệu. Mặc dù dữ liệu giả lập đã được sử dụng cho một số trường hợp, các mô hình ngôn ngữ lớn đã làm cho các tập dữ liệu giả lập trở nên phổ biến hơn cho việc huấn luyện trước, huấn luyện sau và đánh giá các mô hình ngôn ngữ.
Chúng ta sẽ sử dụng [`distilabel`](https://distilabel.argilla.io/latest/), một thư viện (framework) tạo dữ liệu giả lập và phản hồi AI cho các kỹ sư, những người cần các quy trình (pipeline) nhanh, đáng tin cậy và có thể mở rộng dựa trên các bài báo nghiên cứu đã được xác minh. Để tìm hiểu sâu hơn về package và các phương pháp hay nhất, hãy xem [tài liệu](https://distilabel.argilla.io/latest/).
## Tổng quan về Mô-đun
Dữ liệu giả lập cho các mô hình ngôn ngữ có thể được phân loại thành ba loại: hướng dẫn (instructions), sở thích (preferences) và phê bình (critiques). Chúng ta sẽ tập trung vào hai loại đầu tiên, tập trung vào việc tạo ra các tập dữ liệu để tinh chỉnh hướng dẫn (instruction tuning) và điều chỉnh sở thích (preference alignment). Trong cả hai loại, chúng ta sẽ đề cập đến các khía cạnh của loại thứ ba, tập trung vào việc cải thiện dữ liệu hiện có bằng các phê bình và viết lại của mô hình.

## Nội dung
### 1. [Tập dữ liệu hướng dẫn](./instruction_datasets.md)
Tìm hiểu cách tạo tập dữ liệu hướng dẫn để tinh chỉnh hướng dẫn. Chúng ta sẽ khám phá việc tạo các tập dữ liệu tinh chỉnh hướng dẫn thông qua các lời nhắc (prompting) cơ bản và sử dụng các kỹ thuật nhắc nhở tinh tế hơn từ các bài báo. Các tập dữ liệu tinh chỉnh hướng dẫn với dữ liệu mẫu (seed data) để học trong ngữ cảnh (in-context learning) có thể được tạo ra thông qua các phương pháp như `SelfInstruct` và `Magpie`. Ngoài ra, chúng ta sẽ khám phá sự tiến hóa hướng dẫn thông qua `EvolInstruct`. [Bắt đầu học](./instruction_datasets.md).
### 2. [Tập dữ liệu ưu tiên](./preference_datasets.md)
Tìm hiểu cách tạo tập dữ liệu sở thích để điều chỉnh sở thích. Chúng ta sẽ xây dựng dựa trên các phương pháp và kỹ thuật được giới thiệu trong phần 1, bằng cách tạo thêm các phản hồi. Tiếp theo, chúng ta sẽ học cách cải thiện các phản hồi đó bằng lời nhắc `EvolQuality`. Cuối cùng, chúng ta sẽ khám phá cách đánh giá các phản hồi bằng lời nhắc `UltraFeedback`, lời nhắc này sẽ tạo ra điểm số và phê bình, cho phép chúng ta tạo các cặp sở thích. [Bắt đầu học](./preference_datasets.md).
### Notebook bài tập
| Tiêu đề | Mô tả | Bài tập | Liên kết | Colab |
|-------|-------------|----------|------|-------|
| Tập dữ liệu hướng dẫn | Tạo tập dữ liệu để tinh chỉnh hướng dẫn | 🐢 Tạo tập dữ liệu tinh chỉnh hướng dẫn <br> 🐕 Tạo tập dữ liệu tinh chỉnh hướng dẫn với dữ liệu hạt giống <br> 🦁 Tạo tập dữ liệu tinh chỉnh hướng dẫn với dữ liệu hạt giống và với sự tiến hóa hướng dẫn | [Liên kết](./notebooks/instruction_sft_dataset.ipynb) | [Colab](https://githubtocolab.com/huggingface/smol-course/tree/main/6_synthetic_datasets/notebooks/instruction_sft_dataset.ipynb) |
| Tập dữ liệu ưu tiên | Tạo tập dữ liệu để điều chỉnh sở thích | 🐢 Tạo tập dữ liệu điều chỉnh sở thích <br> 🐕 Tạo tập dữ liệu điều chỉnh sở thích với sự tiến hóa phản hồi <br> 🦁 Tạo tập dữ liệu điều chỉnh sở thích với sự tiến hóa phản hồi và phê bình | [Liên kết](./notebooks/preference_alignment_dataset.ipynb) | [Colab](https://githubtocolab.com/huggingface/smol-course/tree/main/6_synthetic_datasets/notebooks/preference_alignment_dataset.ipynb) |
## Tài liệu tham khảo
- [Tài liệu Distilabel](https://distilabel.argilla.io/latest/)
- [Trình tạo dữ liệu tổng hợp là ứng dụng UI](https://huggingface.co/blog/synthetic-data-generator)
- [SmolTalk](https://huggingface.co/datasets/HuggingFaceTB/smoltalk)
- [Self-instruct](https://arxiv.org/abs/2212.10560)
- [Evol-Instruct](https://arxiv.org/abs/2304.12244)
- [Magpie](https://arxiv.org/abs/2406.08464)
- [UltraFeedback](https://arxiv.org/abs/2310.01377)
- [Deita](https://arxiv.org/abs/2312.15685)
|
{
"source": "huggingface/smol-course",
"title": "vi/6_synthetic_datasets/README.md",
"url": "https://github.com/huggingface/smol-course/blob/main/vi/6_synthetic_datasets/README.md",
"date": "2024-11-25T19:22:43",
"stars": 5481,
"description": "A course on aligning smol models.",
"file_size": 4142
}
|
# Tạo tập dữ liệu hướng dẫn
Trong [chương về tinh chỉnh hướng dẫn (instruction tuning)](../1_instruction_tuning/README.md), chúng ta đã học về việc tinh chỉnh mô hình với Tinh chỉnh có giám sát (Supervised Fine-tuning). Trong phần này, chúng ta sẽ khám phá cách tạo tập dữ liệu hướng dẫn cho SFT. Chúng ta sẽ khám phá việc tạo các tập dữ liệu tinh chỉnh hướng dẫn thông qua việc nhắc nhở (prompting) cơ bản và sử dụng các kỹ thuật tinh tế hơn từ các bài báo. Các tập dữ liệu tinh chỉnh hướng dẫn với dữ liệu hạt giống (seed data) để học trong ngữ cảnh (in-context learning) có thể được tạo ra thông qua các phương pháp như SelfInstruct và Magpie. Ngoài ra, chúng ta sẽ khám phá sự tiến hóa hướng dẫn thông qua EvolInstruct. Cuối cùng, chúng ta sẽ khám phá cách tạo tập dữ liệu để tinh chỉnh hướng dẫn bằng cách sử dụng quy trình (pipeline) distilabel.
## Từ lời nhắc đến dữ liệu
Dữ liệu giả lập (Synthetic data) nghe có vẻ phức tạp, nhưng nó có thể được đơn giản hóa thành việc tạo dữ liệu thông qua việc nhắc nhở hiệu quả để trích xuất kiến thức từ mô hình. Đổi lại, bạn có thể coi đây là một cách để tạo dữ liệu cho một tác vụ cụ thể. Thách thức là nhắc nhở một cách hiệu quả trong khi đảm bảo dữ liệu đa dạng và mang tính đại diện. May mắn thay, nhiều bài báo đã khám phá vấn đề này và chúng ta sẽ khám phá một số bài báo hữu ích trong khóa học này. Trước hết, chúng ta sẽ khám phá cách tạo dữ liệu giả lập thông qua việc nhắc nhở thủ công.
### Nhắc nhở cơ bản (Basic Prompting)
Hãy bắt đầu với một ví dụ cơ bản và tải mô hình [HuggingFaceTB/SmolLM2-1.7B-Instruct](https://huggingface.co/HuggingFaceTB/SmolLM2-1.7B-Instruct) bằng cách sử dụng tích hợp `transformers` của thư viện `distilabel`. Chúng ta sẽ sử dụng lớp `TextGeneration` để tạo ra một `lời nhắc` (prompt) tổng hợp và sử dụng nó để tạo ra một `phần hoàn thành` (completion).
Tiếp theo, chúng ta sẽ tải mô hình bằng thư viện `distilabel`.
```python
from distilabel.llms import TransformersLLM
from distilabel.steps.tasks import TextGeneration
llm = TransformersLLM(model="HuggingFaceTB/SmolLM2-1.7B-Instruct")
gen = TextGeneration(llm=llm)
gen.load()
```
> **Note:**
> `Distilabel` tải `llm` vào bộ nhớ, vì vậy, khi làm việc trong notebook, chúng ta cần `gen.unload()` sau khi hoàn thành để tránh các vấn đề về bộ nhớ.
Bây giờ chúng ta sẽ sử dụng `llm` để tạo ra một `lời nhắc` để tinh chỉnh hướng dẫn.
```python
next(gen.process([{"instruction": "Tạo một câu hỏi về Khóa học Smol của Hugging Face về các mô hình AI nhỏ."}]))
# Ví dụ: Mục đích của Khóa học Smol là gì?
```
Cuối cùng, chúng ta có thể sử dụng cùng một `lời nhắc` đó làm đầu vào để tạo ra một `phần hoàn thành`.
```python
next(gen.process([{"instruction": "Mục đích của Khóa học Smol là gì?"}]))
# Ví dụ: Khóa học Smol là một nền tảng được thiết kế để học các khái niệm khoa học máy tính.
```
Tuyệt! Chúng ta có thể tạo ra một `lời nhắc` tổng hợp và một `phần hoàn thành` tương ứng. Việc sử dụng lại phương pháp đơn giản này trên quy mô lớn sẽ cho phép chúng ta tạo ra nhiều dữ liệu hơn, tuy nhiên, chất lượng của dữ liệu không tốt lắm và không tính đến các sắc thái của khóa học hoặc lĩnh vực của chúng ta. Ngoài ra, việc chạy lại mã hiện tại cho chúng ta thấy dữ liệu không đa dạng lắm. May mắn thay, có nhiều cách để giải quyết vấn đề này.
### SelfInstruct
`SelfInstruct` là một lời nhắc tạo ra các hướng dẫn mới dựa trên tập dữ liệu mẫu. Dữ liệu mẫu này có thể là một hướng dẫn đơn lẻ hoặc một đoạn ngữ cảnh. Quá trình bắt đầu với một nhóm dữ liệu mẫu ban đầu. Mô hình ngôn ngữ sau đó được nhắc để tạo ra các hướng dẫn mới dựa trên dữ liệu mẫu này bằng cách sử dụng phương pháp học trong ngữ cảnh (in-context learning). Lời nhắc được [triển khai trong distilabel](https://github.com/argilla-io/distilabel/blob/main/src/distilabel/steps/tasks/templates/self-instruct.jinja2) và một phiên bản đơn giản hóa được hiển thị bên dưới:
```
# Mô tả nhiệm vụ
Phát triển {{ num_instructions }} truy vấn của người dùng có thể được nhận bởi ứng dụng AI đã cho và áp dụng cho ngữ cảnh được cung cấp. Nhấn mạnh sự đa dạng trong động từ và cấu trúc ngôn ngữ trong khả năng văn bản của mô hình.
# Ngữ cảnh
{{ input }}
# Đầu ra
```
Để sử dụng nó, chúng ta cần truyền `llm` cho [lớp SelfInstruct](https://distilabel.argilla.io/dev/components-gallery/tasks/selfinstruct/). Hãy sử dụng văn bản từ [phần Từ lời nhắc đến dữ liệu](#prompt-to-data) làm ngữ cảnh và tạo ra một hướng dẫn mới.
```python
from distilabel.steps.tasks import SelfInstruct
self_instruct = SelfInstruct(llm=llm)
self_instruct.load()
context = "<prompt_to_data_section>" # Thay thế bằng nội dung của phần Từ lời nhắc đến dữ liệu
next(self_instruct.process([{"input": text}]))["instructions"][0]
# Quá trình tạo dữ liệu tổng hợp thông qua việc nhắc nhở thủ công là gì?
```
Hướng dẫn được tạo ra đã tốt hơn rất nhiều và nó phù hợp với nội dung và lĩnh vực thực tế của chúng ta. Tuy nhiên, chúng ta có thể làm tốt hơn nữa bằng cách cải thiện lời nhắc thông qua phương pháp tiến hóa (evolution).
### EvolInstruct
EvolInstruct là một kỹ thuật nhắc nhở lấy một hướng dẫn đầu vào và phát triển nó thành một phiên bản tốt hơn của cùng một hướng dẫn. Phiên bản tốt hơn này được định nghĩa theo một tập hợp các tiêu chí và bổ sung các ràng buộc, đào sâu, cụ thể hóa, lập luận hoặc phức tạp hóa cho hướng dẫn ban đầu. Quá trình này có thể được lặp lại nhiều lần để tạo ra các phiên bản tiến hóa khác nhau của cùng một hướng dẫn, lý tưởng nhất là dẫn đến một phiên bản tốt hơn của hướng dẫn ban đầu. Lời nhắc được [triển khai trong distilabel](https://github.com/argilla-io/distilabel/tree/main/src/distilabel/steps/tasks/evol_instruct) và một phiên bản đơn giản hóa được hiển thị bên dưới:
```
Tôi muốn bạn đóng vai trò là một Trình viết lại lời nhắc (Prompt Rewriter).
Cho một lời nhắc, hãy viết lại nó thành một phiên bản phức tạp hơn.
Phức tạp hóa lời nhắc dựa trên các tiêu chí sau:
{{ criteria }}
# Lời nhắc
{{ input }}
# Đầu ra
```
Để sử dụng nó, chúng ta cần truyền `llm` cho [lớp EvolInstruct](https://distilabel.argilla.io/dev/components-gallery/tasks/evolinstruct/). Hãy sử dụng lời nhắc tổng hợp từ [phần SelfInstruct](#selfinstruct) làm đầu vào và phát triển nó thành một phiên bản tốt hơn. Đối với ví dụ này, chúng ta sẽ chỉ tiến hóa trong một thế hệ.
```python
from distilabel.steps.tasks import EvolInstruct
evol_instruct = EvolInstruct(llm=llm, num_evolutions=1)
evol_instruct.load()
text = "Quá trình tạo dữ liệu tổng hợp thông qua việc nhắc nhở thủ công là gì"
next(evol_instruct.process([{"instruction": text}]))
# Quá trình tạo dữ liệu tổng hợp thông qua việc nhắc nhở thủ công là gì?
# Và, làm thế nào hệ thống trí tuệ nhân tạo, GPT4, sử dụng các thuật toán học máy để thao tác dữ liệu đầu vào thành dữ liệu tổng hợp?
```
Hướng dẫn bây giờ phức tạp hơn nhưng đã mất đi một số ý nghĩa ban đầu. Vì vậy, hãy lưu ý rằng việc tiến hóa có thể là một con dao hai lưỡi và chúng ta cần cẩn thận với chất lượng của dữ liệu chúng ta tạo ra.
### Magpie
Magpie là một kỹ thuật dựa vào các yếu tố tự suy luận (auto-regressive) của mô hình ngôn ngữ và [mẫu trò chuyện (chat-template)](../1_instruction_tuning/chat_templates.md) đã được sử dụng trong quá trình tinh chỉnh hướng dẫn. Như bạn có thể nhớ, mẫu trò chuyện là một định dạng cấu trúc các cuộc hội thoại với các chỉ số vai trò rõ ràng (hệ thống, người dùng, trợ lý). Trong giai đoạn tinh chỉnh hướng dẫn, mô hình ngôn ngữ đã được tối ưu hóa để tái tạo định dạng này và đó chính xác là những gì `Magpie` tận dụng. Nó bắt đầu với một lời nhắc trước truy vấn (pre-query-prompt) dựa trên mẫu trò chuyện nhưng nó dừng lại trước chỉ báo tin nhắn của người dùng, ví dụ: `<|im_start|>user\n`, và sau đó nó sử dụng mô hình ngôn ngữ để tạo ra lời nhắc của người dùng cho đến khi kết thúc chỉ báo trợ lý, ví dụ: `<|im_end|>`. Cách tiếp cận này cho phép chúng ta tạo ra rất nhiều dữ liệu một cách rất hiệu quả và thậm chí có thể mở rộng quy mô lên các cuộc hội thoại nhiều lượt. Người ta giả thuyết rằng dữ liệu được tạo ra này tái tạo dữ liệu huấn luyện từ giai đoạn tinh chỉnh hướng dẫn của mô hình được sử dụng.
Trong trường hợp này, các mẫu lời nhắc khác nhau cho mỗi mô hình vì chúng dựa trên định dạng mẫu trò chuyện. Nhưng chúng ta có thể đi qua một phiên bản đơn giản hóa của quá trình từng bước.
```bash
# Bước 1: cung cấp lời nhắc trước truy vấn
<|im_start|>user\n
# Bước 2: mô hình ngôn ngữ tạo ra lời nhắc của người dùng
<|im_start|>user\n
Mục đích của Khóa học Smol là gì?
# Bước 3: dừng quá trình tạo
<|im_end|>
```
Để sử dụng nó trong distilabel, chúng ta cần truyền `llm` cho [lớp Magpie](https://distilabel.argilla.io/dev/components-gallery/tasks/magpie/).
```python
from distilabel.steps.tasks import Magpie
magpie = Magpie(llm=llm)
magpie.load()
next(magpie.process([{"system_prompt": "Bạn là một trợ lý hữu ích."}]))
# [{
# "role": "user",
# "content": "Bạn có thể cung cấp cho tôi danh sách 3 trường đại học hàng đầu không?"
# },
# {
# "role": "assistant",
# "content": "3 trường đại học hàng đầu là: MIT, Yale, Stanford."
# }]
```
Chúng ta ngay lập tức nhận được một tập dữ liệu với một `lời nhắc` và `phần hoàn thành`. Để cải thiện hiệu suất trên lĩnh vực của riêng mình, chúng ta có thể đưa thêm ngữ cảnh vào `system_prompt`. Để LLM tạo ra dữ liệu lĩnh vực cụ thể kết hợp với Magpie, nó giúp mô tả trong lời nhắc hệ thống (system prompt) các truy vấn của người dùng sẽ là gì. Điều này sau đó được sử dụng trong lời nhắc trước truy vấn trước khi chúng ta bắt đầu tạo lời nhắc của người dùng và thiên về LLM để tạo ra các truy vấn của người dùng trong lĩnh vực đó.
```
Bạn là một trợ lý AI sẽ giúp người dùng giải các bài toán.
```
Điều quan trọng là phải viết lời nhắc hệ thống như được hiển thị ở trên thay vì một cái gì đó như:
```
Bạn là một trợ lý AI tạo ra các bài toán
```
Nói chung, các mô hình ngôn ngữ ít được tối ưu hóa hơn để truyền ngữ cảnh bổ sung cho `system_prompt` vì vậy điều này không phải lúc nào cũng hoạt động tốt cho việc tùy chỉnh như các kỹ thuật khác.
### Từ lời nhắc đến quy trình (pipeline)
Các lớp chúng ta đã thấy cho đến nay đều là các lớp độc lập có thể được sử dụng trong một quy trình. Đây là một khởi đầu tốt, nhưng chúng ta có thể làm tốt hơn nữa bằng cách sử dụng lớp `Pipeline` để tạo tập dữ liệu. Chúng ta sẽ sử dụng bước `TextGeneration` để tạo tập dữ liệu tổng hợp để tinh chỉnh hướng dẫn. Quy trình sẽ bao gồm bước `LoadDataFromDicts` để tải dữ liệu, bước `TextGeneration` để tạo `lời nhắc` và `phần hoàn thành` cho lời nhắc đó. Chúng ta sẽ kết nối các bước và luồng dữ liệu thông qua quy trình bằng toán tử `>>`. Trong [tài liệu của distilabel](https://distilabel.argilla.io/dev/components-gallery/tasks/textgeneration/#input-output-columns), chúng ta có thể thấy các cột đầu vào và đầu ra của bước. Để đảm bảo rằng dữ liệu chảy chính xác qua quy trình, chúng ta sẽ sử dụng tham số `output_mappings` để ánh xạ các cột đầu ra với các cột đầu vào của bước tiếp theo.
```python
from distilabel.llms import TransformersLLM
from distilabel.pipeline import Pipeline
from distilabel.steps import LoadDataFromDicts
from distilabel.steps.tasks import TextGeneration
with Pipeline() as pipeline:
data = LoadDataFromDicts(data=[{"instruction": "Tạo một câu hỏi ngắn về Khóa học Smol của Hugging Face."}])
llm = TransformersLLM(model="HuggingFaceTB/SmolLM2-1.7B-Instruct")
gen_a = TextGeneration(llm=llm, output_mappings={"generation": "instruction"})
gen_b = TextGeneration(llm=llm, output_mappings={"generation": "response"})
data >> gen_a >> gen_b
if __name__ == "__main__":
distiset = pipeline.run(use_cache=False)
print(distiset["default"]["train"][0])
# [{
# "instruction": "Mục đích của Khóa học Smol là gì?",
# "response": "Khóa học Smol là một nền tảng được thiết kế để học các khái niệm khoa học máy tính."
# }]
```
Bên dưới, quy trình này có rất nhiều tính năng hay. Nó tự động lưu trữ các kết quả tạo, vì vậy chúng ta không phải chạy lại các bước tạo. Thư viện có tích hợp khả năng xử lý lỗi (fault-tolerance), vì vậy nếu các bước tạo thất bại, quy trình vẫn sẽ tiếp tục chạy. Và quy trình thực hiện tất cả các bước tạo song song, vì vậy việc tạo nhanh hơn. Chúng ta thậm chí có thể trực quan hóa quy trình bằng phương thức `draw`. Ở đây bạn có thể thấy cách dữ liệu chảy qua quy trình và cách `output_mappings` được sử dụng để ánh xạ các cột đầu ra với các cột đầu vào của bước tiếp theo.

## Các phương pháp hay nhất
- Đảm bảo bạn có dữ liệu hạt giống đa dạng để bao quát nhiều tình huống
- Thường xuyên đánh giá tập dữ liệu để đảm bảo dữ liệu được tạo ra đa dạng và có chất lượng cao
- Lặp lại trên (system)prompt để cải thiện chất lượng của dữ liệu
## Các bước tiếp theo
👨🏽💻 Lập trình -[Notebook bài tập](./notebooks/instruction_sft_dataset.ipynb) để tạo tập dữ liệu để tinh chỉnh hướng dẫn
🧑🏫 Tìm hiểu - Về [tạo tập dữ liệu sở thích](./preference_datasets.md)
## Tài liệu tham khảo
- [Tài liệu Distilabel](https://distilabel.argilla.io/latest/)
- [Self-instruct](https://arxiv.org/abs/2212.10560)
- [Evol-Instruct](https://arxiv.org/abs/2304.12244)
- [Magpie](https://arxiv.org/abs/2406.08464)
|
{
"source": "huggingface/smol-course",
"title": "vi/6_synthetic_datasets/instruction_datasets.md",
"url": "https://github.com/huggingface/smol-course/blob/main/vi/6_synthetic_datasets/instruction_datasets.md",
"date": "2024-11-25T19:22:43",
"stars": 5481,
"description": "A course on aligning smol models.",
"file_size": 13128
}
|
# Tạo tập dữ liệu ưu tiên (Preference Datasets)
Trong [chương về điều chỉnh ưu tiên (preference alignment)](../2_preference_alignment/README.md), chúng ta đã học về Tối ưu hóa ưu tiên trực tiếp (Direct Preference Optimization). Trong phần này, chúng ta sẽ khám phá cách tạo tập dữ liệu ưu tiên cho các phương pháp như DPO. Chúng ta sẽ xây dựng dựa trên các phương pháp đã được giới thiệu trong phần [tạo tập dữ liệu hướng dẫn](./instruction_datasets.md). Ngoài ra, chúng ta sẽ chỉ ra cách thêm các phần hoàn thành (completions) bổ sung vào tập dữ liệu bằng cách sử dụng kỹ thuật nhắc nhở (prompting) cơ bản hoặc bằng cách sử dụng EvolQuality để cải thiện chất lượng của các phản hồi. Cuối cùng, chúng ta sẽ chỉ ra cách `UltraFeedback` có thể được sử dụng để tạo điểm số và phê bình.
## Tạo nhiều phần hoàn thành (completions)
Dữ liệu ưu tiên là tập dữ liệu có nhiều `phần hoàn thành` cho cùng một `hướng dẫn`. Chúng ta có thể thêm nhiều `phần hoàn thành` hơn vào tập dữ liệu bằng cách nhắc nhở (prompt) một mô hình tạo ra chúng. Khi làm điều này, chúng ta cần đảm bảo rằng phần hoàn thành thứ hai không quá giống với phần hoàn thành đầu tiên về chất lượng tổng thể và cách diễn đạt. Điều này rất quan trọng vì mô hình cần được tối ưu hóa cho một ưu tiên rõ ràng. Chúng ta muốn biết phần hoàn thành nào được ưa thích hơn phần kia, thường được gọi là `chosen` (được chọn) và `rejected` (bị từ chối). Chúng ta sẽ đi vào chi tiết hơn về việc xác định các phần hoàn thành được chọn và bị từ chối trong [phần tạo điểm số](#creating-scores).
### Tổng hợp mô hình (Model pooling)
Bạn có thể sử dụng các mô hình từ các họ mô hình khác nhau để tạo phần hoàn thành thứ hai, được gọi là tổng hợp mô hình. Để cải thiện hơn nữa chất lượng của phần hoàn thành thứ hai, bạn có thể sử dụng các đối số tạo khác nhau, như điều chỉnh `temperature`. Cuối cùng, bạn có thể sử dụng các mẫu lời nhắc (prompt templates) hoặc lời nhắc hệ thống (system prompts) khác nhau để tạo phần hoàn thành thứ hai nhằm đảm bảo sự đa dạng dựa trên các đặc điểm cụ thể được xác định trong mẫu. Về lý thuyết, chúng ta có thể lấy hai mô hình có chất lượng khác nhau và sử dụng mô hình tốt hơn làm phần hoàn thành `chosen`.
Hãy bắt đầu với việc tổng hợp mô hình bằng cách tải các mô hình [Qwen/Qwen2.5-1.5B-Instruct](https://huggingface.co/Qwen/Qwen2.5-1.5B-Instruct) và [HuggingFaceTB/SmolLM2-1.7B-Instruct](https://huggingface.co/HuggingFaceTB/SmolLM2-1.7B-Instruct) bằng cách sử dụng tích hợp `transformers` của thư viện `distilabel`. Sử dụng các mô hình này, chúng ta sẽ tạo ra hai `phản hồi` tổng hợp cho một `lời nhắc` nhất định. Chúng ta sẽ tạo một quy trình (pipeline) khác với `LoadDataFromDicts`, `TextGeneration` và `GroupColumns`. Trước tiên, chúng ta sẽ tải dữ liệu, sau đó sử dụng hai bước tạo và sau đó nhóm các kết quả lại. Chúng ta kết nối các bước và luồng dữ liệu thông qua quy trình bằng toán tử `>>` và `[]`, có nghĩa là chúng ta muốn sử dụng đầu ra của bước trước làm đầu vào cho cả hai bước trong danh sách.
```python
from distilabel.llms import TransformersLLM
from distilabel.pipeline import Pipeline
from distilabel.steps import GroupColumns, LoadDataFromDicts
from distilabel.steps.tasks import TextGeneration
with Pipeline() as pipeline:
data = LoadDataFromDicts(data=[{"instruction": "Dữ liệu giả lập (synthetic data) là gì?"}])
llm_a = TransformersLLM(model="HuggingFaceTB/SmolLM2-1.7B-Instruct")
gen_a = TextGeneration(llm=llm_a)
llm_b = TransformersLLM(model="Qwen/Qwen2.5-1.5B-Instruct")
gen_b = TextGeneration(llm=llm_b)
group = GroupColumns(columns=["generation"])
data >> [gen_a, gen_b] >> group
if __name__ == "__main__":
distiset = pipeline.run()
print(distiset["default"]["train"]["grouped_generation"][0])
# {[
# 'Dữ liệu giả lập là dữ liệu được tạo ra nhân tạo, bắt chước cách sử dụng trong thế giới thực.',
# 'Dữ liệu giả lập đề cập đến dữ liệu đã được tạo ra một cách nhân tạo.'
# ]}
```
Như bạn có thể thấy, chúng ta có hai `phần hoàn thành` tổng hợp cho `lời nhắc` đã cho. Chúng ta có thể tăng cường sự đa dạng bằng cách khởi tạo các bước `TextGeneration` với một `system_prompt` cụ thể hoặc bằng cách truyền các đối số tạo cho `TransformersLLM`. Bây giờ hãy xem cách chúng ta có thể cải thiện chất lượng của các `phần hoàn thành` bằng EvolQuality.
### EvolQuality
EvolQuality tương tự như [EvolInstruct](./instruction_datasets.md#evolinstruct) - đó là một kỹ thuật nhắc nhở nhưng nó phát triển `các phần hoàn thành` thay vì `lời nhắc` đầu vào. Tác vụ lấy cả `lời nhắc` và `phần hoàn thành` và phát triển `phần hoàn thành` thành một phiên bản phản hồi tốt hơn cho `lời nhắc` dựa trên một tập hợp các tiêu chí. Phiên bản tốt hơn này được định nghĩa theo các tiêu chí để cải thiện tính hữu ích, mức độ liên quan, đào sâu, sáng tạo hoặc chi tiết. Bởi vì điều này tự động tạo ra phần hoàn thành thứ hai, chúng ta có thể sử dụng nó để thêm nhiều `phần hoàn thành` hơn vào tập dữ liệu. Về lý thuyết, chúng ta thậm chí có thể giả định rằng sự tiến hóa tốt hơn phần hoàn thành ban đầu và sử dụng nó làm phần hoàn thành `chosen` ngay lập tức.
Lời nhắc được [triển khai trong distilabel](https://github.com/argilla-io/distilabel/tree/main/src/distilabel/steps/tasks/evol_quality) và phiên bản đơn giản hóa được hiển thị bên dưới:
```bash
Tôi muốn bạn đóng vai trò là một Trình viết lại phản hồi (Response Rewriter).
Cho một lời nhắc và một phản hồi, hãy viết lại phản hồi thành một phiên bản tốt hơn.
Phức tạp hóa lời nhắc dựa trên các tiêu chí sau:
{{ criteria }}
# Lời nhắc
{{ input }}
# Phản hồi
{{ output }}
# Phản hồi được cải thiện
```
Hãy sử dụng [lớp EvolQuality](https://distilabel.argilla.io/dev/components-gallery/tasks/evolquality/) để phát triển `lời nhắc` và `phần hoàn thành` tổng hợp từ [phần Tổng hợp mô hình](#model-pooling) thành một phiên bản tốt hơn. Đối với ví dụ này, chúng ta sẽ chỉ tiến hóa trong một thế hệ.
```python
from distilabel.llms import TransformersLLM
from distilabel.steps.tasks import EvolQuality
llm = TransformersLLM(model="HuggingFaceTB/SmolLM2-1.7B-Instruct")
evol_quality = EvolQuality(llm=llm, num_evolutions=1)
evol_quality.load()
instruction = "Dữ liệu giả lập (synthetic data) là gì?"
completion = "Dữ liệu giả lập là dữ liệu được tạo ra nhân tạo, bắt chước cách sử dụng trong thế giới thực."
next(evol_quality.process([{
"instruction": instruction,
"response": completion
}]))
# Quá trình tạo dữ liệu giả lập thông qua việc nhắc nhở thủ công bao gồm việc tạo ra các tập dữ liệu nhân tạo bắt chước các kiểu sử dụng trong thế giới thực.
```
`Phản hồi` bây giờ phức tạp hơn và cụ thể hơn cho `hướng dẫn`. Đây là một khởi đầu tốt, nhưng như chúng ta đã thấy với EvolInstruct, các thế hệ tiến hóa không phải lúc nào cũng tốt hơn. Do đó, điều quan trọng là phải sử dụng các kỹ thuật đánh giá bổ sung để đảm bảo chất lượng của tập dữ liệu. Chúng ta sẽ khám phá điều này trong phần tiếp theo.
## Tạo điểm số
Điểm số là thước đo mức độ phản hồi này được ưa thích hơn phản hồi khác. Nhìn chung, những điểm số này có thể là tuyệt đối, chủ quan hoặc tương đối. Đối với khóa học này, chúng ta sẽ tập trung vào hai loại đầu tiên vì chúng có giá trị nhất để tạo các tập dữ liệu ưu tiên. Việc chấm điểm này là một cách đánh giá và nhận xét bằng cách sử dụng các mô hình ngôn ngữ và do đó có một số điểm tương đồng với các kỹ thuật đánh giá mà chúng ta đã thấy trong [chương về đánh giá](../3_evaluation/README.md). Cũng như các kỹ thuật đánh giá khác, điểm số và đánh giá thường yêu cầu các mô hình lớn hơn để phù hợp hơn với ưu tiên của con người.
### UltraFeedback
UltraFeedback là một kỹ thuật tạo ra điểm số và phê bình cho một `lời nhắc` nhất định và `phần hoàn thành` của nó.
Điểm số dựa trên chất lượng của `phần hoàn thành` theo một tập hợp các tiêu chí. Có bốn tiêu chí chi tiết: `helpfulness` (tính hữu ích), `relevance` (mức độ liên quan), `deepening` (đào sâu) và `creativity` (sáng tạo). Chúng rất hữu ích nhưng nói chung, sử dụng các tiêu chí tổng thể là một khởi đầu tốt, cho phép chúng ta đơn giản hóa quá trình tạo điểm số. Điểm số có thể được sử dụng để xác định `phần hoàn thành` nào là `chosen` và phần nào là `rejected`. Bởi vì chúng là tuyệt đối, chúng cũng có thể được sử dụng làm bộ lọc thú vị cho các giá trị ngoại lệ trong tập dữ liệu, tìm các phần hoàn thành tệ nhất hoặc các cặp có ít nhiều sự khác biệt.
Các phê bình được thêm vào để cung cấp lý do cho điểm số. Chúng có thể được sử dụng làm ngữ cảnh bổ sung để giúp chúng ta hiểu sự khác biệt giữa các điểm số. Mô hình ngôn ngữ tạo ra các phê bình sâu rộng rất hữu ích, nhưng điều này cũng làm tăng thêm chi phí và độ phức tạp cho quá trình vì việc tạo ra các phê bình tốn kém hơn so với việc tạo ra một token duy nhất để đại diện cho điểm số.
Lời nhắc được [triển khai trong distilabel](https://github.com/argilla-io/distilabel/tree/main/src/distilabel/steps/tasks/templates/ultrafeedback) và phiên bản đơn giản hóa được hiển thị bên dưới:
```bash
Đánh giá đầu ra của mô hình dựa trên các tiêu chí khác nhau: Tính hữu ích, Mức độ liên quan, Đào sâu, Sáng tạo
Vai trò của bạn là cung cấp một đánh giá tổng thể dựa trên các yếu tố trên.
Chấm điểm đầu ra từ 1 đến 5 về chất lượng tổng thể.
Trả lời theo định dạng sau: điểm số - lý do
# Đầu vào
{{ input }}
# Phản hồi
{{ output }}
# Điểm số - Lý do
```
Hãy sử dụng [lớp UltraFeedback](https://distilabel.argilla.io/dev/components-gallery/tasks/ultrafeedback/) để đánh giá `lời nhắc` và `phần hoàn thành` tổng hợp từ [phần Tổng hợp mô hình](#model-pooling).
```python
from distilabel.llms import TransformersLLM
from distilabel.steps.tasks import UltraFeedback
llm = TransformersLLM(model="HuggingFaceTB/SmolLM2-1.7B-Instruct")
ultrafeedback = UltraFeedback(llm=llm)
ultrafeedback.load()
instruction = "Dữ liệu giả lập (synthetic data) là gì?"
completion_a = "Dữ liệu giả lập là dữ liệu được tạo ra nhân tạo, bắt chước cách sử dụng trong thế giới thực."
completion_b = "Dữ liệu giả lập đề cập đến dữ liệu đã được tạo ra một cách nhân tạo."
next(ultrafeedback.process([{
"instruction": instruction,
"generations": [completion_a, completion_b]
}]))
# [
# {
# 'ratings': [4, 5],
# 'rationales': ['có thể cụ thể hơn', 'định nghĩa tốt'],
# }
# ]
```
## Các phương pháp hay nhất
- Phương pháp đánh giá điểm số tổng thể thường rẻ hơn và dễ tạo hơn so với phê bình và điểm số cụ thể
- Sử dụng các mô hình lớn hơn để tạo điểm số và phê bình
- Sử dụng một tập hợp đa dạng các mô hình để tạo điểm số và phê bình
- Lặp lại cấu hình của `system_prompt` và các mô hình
## Các bước tiếp theo
👨🏽💻 Lập trình -[Notebook bài tập](./notebooks/preference_dpo_dataset.ipynb) để tạo tập dữ liệu để tinh chỉnh hướng dẫn
## Tài liệu tham khảo
- [Tài liệu Distilabel](https://distilabel.argilla.io/latest/)
- [Deita](https://arxiv.org/abs/2312.15685)
- [UltraFeedback](https://arxiv.org/abs/2310.01377)
|
{
"source": "huggingface/smol-course",
"title": "vi/6_synthetic_datasets/preference_datasets.md",
"url": "https://github.com/huggingface/smol-course/blob/main/vi/6_synthetic_datasets/preference_datasets.md",
"date": "2024-11-25T19:22:43",
"stars": 5481,
"description": "A course on aligning smol models.",
"file_size": 10853
}
|
# Evaluación Específica en un Dominio con Argilla, Distilabel y LightEval
La mayoría de los "benchmarks" populares evalúan capacidades muy generales (razonamiento, matemáticas, código), pero ¿alguna vez has necesitado estudiar capacidades más específicas?
¿Qué deberías hacer si necesitas evaluar un modelo en un **dominio específico** relevante para tus casos de uso? (Por ejemplo, aplicaciones financieras, legales o médicas).
Este tutorial muestra todo el flujo de trabajo que puedes seguir, desde la creación de datos relevantes y la anotación de tus muestras hasta la evaluación de tu modelo, utilizando las herramientas de [Argilla](https://github.com/argilla-io/argilla), [distilabel](https://github.com/argilla-io/distilabel) y [lighteval](https://github.com/huggingface/lighteval). Para nuestro ejemplo, nos centraremos en generar preguntas de exámenes a partir de múltiples documentos.
## Estructura del Proyecto
Seguiremos 4 pasos, con un script para cada uno: generar un conjunto de datos, anotarlo, extraer muestras relevantes para la evaluación y, finalmente, evaluar los modelos.
| Nombre del Script | Descripción |
|-------------------------|-----------------------------------------------------------------------------|
| generate_dataset.py | Genera preguntas de exámenes a partir de múltiples documentos de texto usando un modelo de lenguaje especificado. |
| annotate_dataset.py | Crea un conjunto de datos en Argilla para la anotación manual de las preguntas generadas. |
| create_dataset.py | Procesa los datos anotados desde Argilla y crea una base de datos de Hugging Face. |
| evaluation_task.py | Define una tarea personalizada en LightEval para evaluar modelos de lenguaje en el conjunto de preguntas de examen. |
## Pasos
### 1. Generar el Conjunto de Datos
El script `generate_dataset.py` utiliza la biblioteca distilabel para generar preguntas de examen basadas en múltiples documentos de texto. Usa el modelo especificado (por defecto: Meta-Llama-3.1-8B-Instruct) para crear preguntas, respuestas correctas y respuestas incorrectas (llamadas "distractores"). Puedes agregar tus propios datos y también usar un modelo diferente.
Para ejecutar la generación:
```sh
python generate_dataset.py --input_dir ubicacion/de/los/documentos --model_id id_del_modelo --output_path output_directory
```
Esto creará un [Distiset](https://distilabel.argilla.io/dev/sections/how_to_guides/advanced/distiset/) que contiene las preguntas de examen generadas para todos los documentos en el directorio de entrada.
### 2. Anotar el Conjunto de Datos
El script `annotate_dataset.py` toma las preguntas generadas y crea una base de datos en Argilla para su anotación. Este script configura la estructura de la base de datos y la completa con las preguntas y respuestas generadas, aleatorizando el orden de las respuestas para evitar sesgos. Una vez en Argilla, tú o un experto en el dominio pueden validar el conjunto de datos con las respuestas correctas.
Verás respuestas sugeridas por el LLM en orden aleatorio, y podrás aprobar la respuesta correcta o seleccionar una diferente. La duración de este proceso dependerá de la escala de tu base de datos de evaluación, la complejidad de tus datos y la calidad de tu LLM. Por ejemplo, logramos crear 150 muestras en 1 hora en el dominio de aprendizaje por transferencia, utilizando Llama-3.1-70B-Instruct, principalmente aprobando respuestas correctas y descartando las incorrectas.
Para ejecutar el proceso de anotación:
```sh
python annotate_dataset.py --dataset_path ubicacion/del/distiset --output_dataset_name nombre_de_los_datos_argilla
```
Esto creará un conjunto de datos en Argilla que puede ser utilizado para revisión y anotación manual.

Si no estás usando Argilla, desplégalo localmente o en Spaces siguiendo esta [guía rápida](https://docs.argilla.io/latest/getting_started/quickstart/).
### 3. Crear la Base de Datos
El script `create_dataset.py` procesa los datos anotados desde Argilla y crea una base de datos en Hugging Face. El script incorpora tanto respuestas sugeridas como respuestas anotadas manualmente. El script creará una base de datos con la pregunta, posibles respuestas y el nombre de la columna para la respuesta correcta. Para crear la base de datos final:
```sh
huggingface_hub login
python create_dataset.py --dataset_path nombre_de_los_datos_argilla --dataset_repo_id id_repo_hf
```
Esto enviará el conjunto de datos al Hugging Face Hub bajo el repositorio especificado. Puedes ver una base de datos de ejemplo en el hub [aquí](https://huggingface.co/datasets/burtenshaw/exam_questions/viewer/default/train). La vista previa de la base de datos se ve así:

### 4. Tarea de Evaluación
El script `evaluation_task.py` define una tarea personalizada en LightEval para evaluar modelos de lenguaje en el conjunto de preguntas de examen. Incluye una función de "prompt", una métrica de "accuracy" personalizada y la configuración de la tarea.
Para evaluar un modelo utilizando lighteval con la tarea personalizada de preguntas de examen:
```sh
lighteval accelerate \
--model_args "pretrained=HuggingFaceH4/zephyr-7b-beta" \
--tasks "community|exam_questions|0|0" \
--custom_tasks domain-eval/evaluation_task.py \
--output_dir "./evals"
```
Puedes encontrar guías detalladas en el wiki de lighteval sobre cada uno de estos pasos:
- [Crear una Tarea Personalizada](https://github.com/huggingface/lighteval/wiki/Adding-a-Custom-Task)
- [Crear una Métrica Personalizada](https://github.com/huggingface/lighteval/wiki/Adding-a-New-Metric)
- [Usar Métricas Existentes](https://github.com/huggingface/lighteval/wiki/Metric-List)
|
{
"source": "huggingface/smol-course",
"title": "es/4_evaluation/project/README.md",
"url": "https://github.com/huggingface/smol-course/blob/main/es/4_evaluation/project/README.md",
"date": "2024-11-25T19:22:43",
"stars": 5481,
"description": "A course on aligning smol models.",
"file_size": 5856
}
|
# Argilla、Distilabel、LightEvalを使用したドメイン固有の評価
ほとんどの人気のあるベンチマークは、一般的な能力(推論、数学、コード)を評価しますが、より具体的な能力を評価する必要がある場合はどうすればよいでしょうか?
カスタムドメインに関連するモ���ルを評価する必要がある場合はどうすればよいでしょうか?(例えば、金融、法務、医療のユースケース)
このチュートリアルでは、[Argilla](https://github.com/argilla-io/argilla)、[distilabel](https://github.com/argilla-io/distilabel)、および[LightEval](https://github.com/huggingface/lighteval)を使用して、関連するデータを作成し、サンプルに注釈を付け、モデルを評価するための完全なパイプラインを示します。例として、複数のドキュメントから試験問題を生成することに焦点を当てます。
## プロジェクト構造
このプロセスでは、データセットの生成、注釈の追加、評価のためのサンプルの抽出、実際のモデル評価の4つのステップを実行します。各ステップにはスクリプトがあります。
| スクリプト名 | 説明 |
|-------------|-------------|
| generate_dataset.py | 指定された言語モデルを使用して複数のテキストドキュメントから試験問題を生成します。 |
| annotate_dataset.py | 生成された試験問題の手動注釈のためのArgillaデータセットを作成します。 |
| create_dataset.py | Argillaから注釈付きデータを処理し、Hugging Faceデータセットを作成します。 |
| evaluation_task.py | 試験問題データセットの評価のためのカスタムLightEvalタスクを定義します。 |
## ステップ
### 1. データセットの生成
`generate_dataset.py`スクリプトは、distilabelライブラリを使用して複数のテキストドキュメントに基づいて試験問題を生成します。指定されたモデル(デフォルト:Meta-Llama-3.1-8B-Instruct)を使用して質問、正しい回答、および誤った回答(ディストラクター)を作成します。独自のデータサンプルを追加し、異なるモデルを使用することもできます。
生成を実行するには:
```sh
python generate_dataset.py --input_dir path/to/your/documents --model_id your_model_id --output_path output_directory
```
これにより、入力ディレクトリ内のすべてのドキュメントに対して生成された試験問題を含む[Distiset](https://distilabel.argilla.io/dev/sections/how_to_guides/advanced/distiset/)が作成されます。
### 2. データセットの注釈
`annotate_dataset.py`スクリプトは、生成された質問を取得し、注釈のためのArgillaデータセットを作成します。データセットの構造を設定し、生成された質問と回答をランダムな順序で入力します。これにより、バイアスを避けることができます。Argillaでは、正しい回答が提案として表示されます。
LLMからの提案された正しい回答がランダムな順序で表示され、正しい回答を承認するか、別の回答を選択できます。このプロセスの所要時間は、評価データセットの規模、ドメインデータの複雑さ、およびLLMの品質によって異なります。例えば、Llama-3.1-70B-Instructを使用して、転移学習のドメインで150サンプルを1時間以内に作成できました。
注釈プロセスを実行するには:
```sh
python annotate_dataset.py --dataset_path path/to/distiset --output_dataset_name argilla_dataset_name
```
これにより、手動レビューと注釈のためのArgillaデータセットが作成されます。

Argillaを使用していない場合は、この[クイックスタートガイド](https://docs.argilla.io/latest/getting_started/quickstart/)に従ってローカルまたはスペースにデプロイしてください。
### 3. データセットの作成
`create_dataset.py`スクリプトは、Argillaから注釈付きデータを処理し、Hugging Faceデータセットを作成します。提案された回答と手動で注釈された回答の両方を処理します。このスクリプトは、質問、可能な回答、および正しい回答の列名を含むデータセットを作成します。最終データセットを作成するには:
```sh
huggingface_hub login
python create_dataset.py --dataset_path argilla_dataset_name --dataset_repo_id your_hf_repo_id
```
これにより、指定されたリポジトリにデータセットがHugging Face Hubにプッシュされます。サンプルデータセットは[こちら](https://huggingface.co/datasets/burtenshaw/exam_questions/viewer/default/train)で確認できます。データセットのプレビューは次のようになります:

### 4. 評価タスク
`evaluation_task.py`スクリプトは、試験問題データセットの評価のためのカスタムLightEvalタスクを定義します。プロンプト関数、カスタム精度メトリック、およびタスク構成が含まれます。
カスタム試験問題タスクを使用してlightevalでモデルを評価するには:
```sh
lighteval accelerate \
--model_args "pretrained=HuggingFaceH4/zephyr-7b-beta" \
--tasks "community|exam_questions|0|0" \
--custom_tasks domain-eval/evaluation_task.py \
--output_dir "./evals"
```
詳細なガイドはlighteval wikiで確認できます:
- [カスタムタスクの作成](https://github.com/huggingface/lighteval/wiki/Adding-a-Custom-Task)
- [カスタムメトリックの作成](https://github.com/huggingface/lighteval/wiki/Adding-a-New-Metric)
- [既存のメトリックの使用](https://github.com/huggingface/lighteval/wiki/Metric-List)
|
{
"source": "huggingface/smol-course",
"title": "ja/4_evaluation/project/README.md",
"url": "https://github.com/huggingface/smol-course/blob/main/ja/4_evaluation/project/README.md",
"date": "2024-11-25T19:22:43",
"stars": 5481,
"description": "A course on aligning smol models.",
"file_size": 3266
}
|
# Avaliação Específica de Domínio com Argilla, Distilabel e LightEval
Os benchmarks mais populares analisam capacidades muito gerais (raciocínio, matemática, código), mas você já precisou estudar sobre capacidades mais específicas?
O que fazer se você precisar avaliar um modelo em um **domínio personalizado** relevante para seus casos de uso? (Por exemplo aplicações financeiras, jurídicas ou médicas)
Este tutorial mostra todo o pipeline que você pode seguir, desde a criação de dados relevantes e a anotação de suas amostras até a avaliação de seu modelo com elas, usando ferramentas como [Argilla](https://github.com/argilla-io/argilla), [distilabel](https://github.com/argilla-io/distilabel) e [lighteval](https://github.com/huggingface/lighteval). Para nosso exemplo, focaremos na geração de questões de exame a partir de múltiplos documentos.
## Estrutura do Projeto
Para o nosso processo, seguiremos 4 etapas, com um script para cada uma: gerar um conjunto de dados, anotar dados, extrair amostras relevantes para avaliação e, finalmente, avaliar os modelos.
| Nome do Script | Descrição |
|-------------|-------------|
| generate_dataset.py | Gera questões de exame a partir de múltiplos documentos de texto usando um modelo de linguagem especificado.. |
| annotate_dataset.py | Cria um conjunto de dados no Argilla para anotação manual das questões geradas. |
| create_dataset.py | Processa os dados anotados no Argilla e cria um conjunto de dados no Hugging Face. |
| evaluation_task.py | Define uma tarefa personalizada no LightEval para avaliar modelos de linguagem no conjunto de questões de exame. |
## Etapas
### 1. Gerar Conjunto de Dados
O script `generate_dataset.py` usa o módulo distilabel para gerar questões de exame com base em múltiplos documentos de texto. Ele utiliza o modelo especificado (padrão: Meta-Llama-3.1-8B-Instruct) para criar perguntas, respostas corretas e respostas incorretas (chamadas de distrações). Você deve adicionar seus próprios exemplos de dados e talvez até usar um modelo diferente.
Para executar a geração:
```sh
python generate_dataset.py --input_dir path/to/your/documents --model_id your_model_id --output_path output_directory
```
Isso criará um [Distiset](https://distilabel.argilla.io/dev/sections/how_to_guides/advanced/distiset/) contendo as questões de exame geradas para todos os documentos no diretório de entrada.
### 2. Anotar Conjunto de Dados
O script `annotate_dataset.py` utiliza as questões geradas e cria um conjunto de dados no Argilla para anotação. Ele configura a estrutura do conjunto de dados e o popula com as perguntas e respostas geradas, randomizando a ordem das respostas para evitar vieses (biases). No Argilla, você ou um especialista no domínio pode validar o conjunto de dados com as respostas corretas.
Você verá as respostas corretas sugeridas pelo LLM em ordem aleatória e poderá aprovar a resposta correta ou selecionar outra. A duração desse processo dependerá da escala do seu conjunto de avaliação, da complexidade dos dados do domínio e da qualidade do seu LLM. Por exemplo, fomos capazes de criar 150 amostras em 1 hora no domínio de transferência de aprendizado, usando o Llama-3.1-70B-Instruct, aprovando principalmente as respostas corretas e descartando as incorretas
Para executar o processo de anotação:
```sh
python annotate_dataset.py --dataset_path path/to/distiset --output_dataset_name argilla_dataset_name
```
Isso criará um conjunto de dados no Argilla que pode ser usado para revisão e anotação manual.

Se você não estiver usando o Argilla, implante-o localmente ou no Spaces seguindo este [guia de início rápido](https://docs.argilla.io/latest/getting_started/quickstart/).
### 3. Criar Conjunto de Dados
O script `create_dataset.py` processa os dados anotados no Argilla e cria um conjunto de dados no Hugging Face. Ele manipula tanto as respostas sugeridas quanto as anotadas manualmente. O script criará um conjunto de dados contendo a pergunta, as possíveis respostas e o nome da coluna para a resposta correta. Para criar o conjunto de dados final:
```sh
huggingface_hub login
python create_dataset.py --dataset_path argilla_dataset_name --dataset_repo_id your_hf_repo_id
```
Isso enviará o conjunto de dados para o Hugging Face Hub sob o repositório especificado. Você pode visualizar o conjunto de dados de exemplo no hub [aqui](https://huggingface.co/datasets/burtenshaw/exam_questions/viewer/default/train), e uma pré-visualização do conjunto de dados se parece com isto:

### 4. Tarefa de Avaliação
O script `evaluation_task.py` define uma tarefa personalizada no LightEval para avaliar modelos de linguagem no conjunto de questões de exame. Ele inclui uma função de prompt, uma métrica de precisão personalizada e a configuração da tarefa.
Para avaliar um modelo usando o lighteval com a tarefa personalizada de questões de exame:
```sh
lighteval accelerate \
--model_args "pretrained=HuggingFaceH4/zephyr-7b-beta" \
--tasks "community|exam_questions|0|0" \
--custom_tasks domain-eval/evaluation_task.py \
--output_dir "./evals"
```
Você pode encontrar guias detalhados no wiki do lighteval sobre cada uma dessas etapas:
- [Criando uma Tarefa Personalizada](https://github.com/huggingface/lighteval/wiki/Adding-a-Custom-Task)
- [Criando uma Métrica Personalizada](https://github.com/huggingface/lighteval/wiki/Adding-a-New-Metric)
- [Usando Métricas Existentes](https://github.com/huggingface/lighteval/wiki/Metric-List)
|
{
"source": "huggingface/smol-course",
"title": "pt-br/4_evaluation/project/README.md",
"url": "https://github.com/huggingface/smol-course/blob/main/pt-br/4_evaluation/project/README.md",
"date": "2024-11-25T19:22:43",
"stars": 5481,
"description": "A course on aligning smol models.",
"file_size": 5605
}
|
# Đánh Giá Theo Lĩnh Vực Cụ Thể với Argilla, Distilabel, và LightEval
Hầu hết các bộ tiêu chuẩn (`benchmark`) phổ biến đều xem xét các khả năng rất chung chung (lý luận, toán học, lập trình), nhưng bạn đã bao giờ cần nghiên cứu các khả năng cụ thể hơn chưa?
Bạn nên làm gì nếu bạn cần đánh giá một mô hình trên một **lĩnh vực cụ thể** liên quan đến các trường hợp sử dụng của bạn? (Ví dụ: các trường hợp sử dụng tài chính, pháp lý, y tế)
Hướng dẫn này chỉ cho bạn toàn bộ quy trình (`pipeline`) mà bạn có thể làm theo, từ việc tạo dữ liệu liên quan và chú thích các mẫu của bạn đến việc đánh giá mô hình của bạn trên chúng, với các công cụ dễ sử dụng [Argilla](https://github.com/argilla-io/argilla), [distilabel](https://github.com/argilla-io/distilabel), và [lighteval](https://github.com/huggingface/lighteval). Trong ví dụ của chúng tôi, chúng tôi sẽ tập trung vào việc tạo các câu hỏi đánh giá từ nhiều tài liệu.
## Cấu trúc dự án
Đối với quy trình của chúng tôi, chúng tôi sẽ làm theo 4 bước, với một tập lệnh cho mỗi bước: tạo tập dữ liệu, chú thích nó, trích xuất các mẫu liên quan để đánh giá từ nó và thực sự đánh giá các mô hình.
| Tên tập lệnh | Mô tả |
|-------------|-------------|
| generate_dataset.py | Tạo các câu hỏi đánh giá từ nhiều tài liệu văn bản bằng cách sử dụng một mô hình ngôn ngữ được chỉ định. |
| annotate_dataset.py | Tạo tập dữ liệu Argilla để chú thích thủ công các câu hỏi đánh giá được tạo. |
| create_dataset.py | Xử lý dữ liệu đã chú thích từ Argilla và tạo tập dữ liệu Hugging Face. |
| evaluation_task.py | Định nghĩa một tác vụ LightEval tùy chỉnh để đánh giá các mô hình ngôn ngữ trên tập dữ liệu câu hỏi đánh giá. |
## Các bước thực hành
### 1. Tạo tập dữ liệu
Tập lệnh `generate_dataset.py` sử dụng thư viện `distilabel` để tạo các câu hỏi thi dựa trên nhiều tài liệu văn bản. Nó sử dụng mô hình được chỉ định (mặc định: Meta-Llama-3.1-8B-Instruct) để tạo các câu hỏi, câu trả lời đúng và câu trả lời sai (được gọi là câu gây nhiễu). Bạn nên thêm các mẫu dữ liệu của riêng bạn và bạn có thể muốn sử dụng một mô hình khác.
Để chạy quá trình tạo:
```sh
python generate_dataset.py --input_dir path/to/your/documents --model_id your_model_id --output_path output_directory
```
Thao tác này sẽ tạo một [Distiset](https://distilabel.argilla.io/dev/sections/how_to_guides/advanced/distiset/) chứa các câu hỏi thi được tạo cho tất cả các tài liệu trong thư mục đầu vào.
### 2. Chú thích tập dữ liệu
Tập lệnh `annotate_dataset.py` lấy các câu hỏi đã tạo và tạo tập dữ liệu Argilla để chú thích. Nó thiết lập cấu trúc tập dữ liệu và điền vào đó các câu hỏi và câu trả lời đã tạo, sắp xếp ngẫu nhiên thứ tự các câu trả lời để tránh sai lệch. Khi ở trong Argilla, bạn hoặc một chuyên gia trong lĩnh vực có thể xác thực tập dữ liệu với các câu trả lời đúng.
Bạn sẽ thấy các câu trả lời đúng được đề xuất từ `LLM` theo thứ tự ngẫu nhiên và bạn có thể phê duyệt câu trả lời đúng hoặc chọn một câu trả lời khác. Thời gian của quá trình này sẽ phụ thuộc vào quy mô của tập dữ liệu đánh giá của bạn, độ phức tạp của dữ liệu lĩnh vực của bạn và chất lượng của `LLM` của bạn. Ví dụ: chúng tôi đã có thể tạo 150 mẫu trong vòng 1 giờ trên lĩnh vực chuyển giao học tập (`transfer learning`), sử dụng Llama-3.1-70B-Instruct, chủ yếu bằng cách phê duyệt câu trả lời đúng và loại bỏ những câu trả lời không chính xác.
Để chạy quá trình chú thích:
```sh
python annotate_dataset.py --dataset_path path/to/distiset --output_dataset_name argilla_dataset_name
```
Thao tác này sẽ tạo một tập dữ liệu Argilla có thể được sử dụng để xem xét và chú thích thủ công.

Nếu bạn không sử dụng Argilla, hãy triển khai cục bộ hoặc trên không gian (`spaces`) theo [hướng dẫn bắt đầu nhanh](https://docs.argilla.io/latest/getting_started/quickstart/) này.
### 3. Tạo tập dữ liệu
Tập lệnh `create_dataset.py` xử lý dữ liệu đã chú thích từ Argilla và tạo tập dữ liệu Hugging Face. Nó xử lý cả các câu trả lời được đề xuất và được chú thích thủ công. Tập lệnh sẽ tạo một tập dữ liệu với câu hỏi, các câu trả lời có thể và tên cột cho câu trả lời đúng. Để tạo tập dữ liệu cuối cùng:
```sh
huggingface_hub login
python create_dataset.py --dataset_path argilla_dataset_name --dataset_repo_id your_hf_repo_id
```
Thao tác này sẽ đẩy tập dữ liệu lên Hugging Face Hub dưới kho lưu trữ được chỉ định. Bạn có thể xem tập dữ liệu mẫu trên `hub` [tại đây](https://huggingface.co/datasets/burtenshaw/exam_questions/viewer/default/train) và bản xem trước của tập dữ liệu trông như thế này:

### 4. Tác vụ đánh giá
Tập lệnh `evaluation_task.py` định nghĩa một tác vụ LightEval tùy chỉnh để đánh giá các mô hình ngôn ngữ trên tập dữ liệu câu hỏi thi. Nó bao gồm một hàm nhắc nhở (`prompt function`), một chỉ số chính xác tùy chỉnh và cấu hình tác vụ.
Để đánh giá một mô hình bằng `lighteval` với tác vụ câu hỏi thi tùy chỉnh:
```sh
lighteval accelerate \
--model_args "pretrained=HuggingFaceH4/zephyr-7b-beta" \
--tasks "community|exam_questions|0|0" \
--custom_tasks domain-eval/evaluation_task.py \
--output_dir "./evals"
```
Bạn có thể tìm thấy các hướng dẫn chi tiết trong `lighteval wiki` về từng bước sau:
- [Tạo tác vụ tùy chỉnh](https://github.com/huggingface/lighteval/wiki/Adding-a-Custom-Task)
- [Tạo chỉ số tùy chỉnh](https://github.com/huggingface/lighteval/wiki/Adding-a-New-Metric)
- [Sử dụng các chỉ số hiện có](https://github.com/huggingface/lighteval/wiki/Metric-List)
|
{
"source": "huggingface/smol-course",
"title": "vi/4_evaluation/project/README.md",
"url": "https://github.com/huggingface/smol-course/blob/main/vi/4_evaluation/project/README.md",
"date": "2024-11-25T19:22:43",
"stars": 5481,
"description": "A course on aligning smol models.",
"file_size": 5529
}
|
Legal Disclaimer
Within this source code, the comments in Chinese shall be the original, governing version. Any comment in other languages are for reference only. In the event of any conflict between the Chinese language version comments and other language version comments, the Chinese language version shall prevail.
法律免责声明
关于代码注释部分,中文注释为官方版本,其它语言注释仅做参考。中文注释可能与其它语言注释存在不一致,当中文注释与其它语言注释存在不一致时,请以中文注释为准。
|
{
"source": "OpenSPG/KAG",
"title": "LEGAL.md",
"url": "https://github.com/OpenSPG/KAG/blob/master/LEGAL.md",
"date": "2024-09-21T13:56:44",
"stars": 5456,
"description": "KAG is a logical form-guided reasoning and retrieval framework based on OpenSPG engine and LLMs. It is used to build logical reasoning and factual Q&A solutions for professional domain knowledge bases. It can effectively overcome the shortcomings of the traditional RAG vector similarity calculation model.",
"file_size": 406
}
|
# KAG: Knowledge Augmented Generation
<div align="center">
<a href="https://spg.openkg.cn/en-US">
<img src="./_static/images/OpenSPG-1.png" width="520" alt="openspg logo">
</a>
</div>
<p align="center">
<a href="./README.md">English</a> |
<a href="./README_cn.md">简体中文</a> |
<a href="./README_ja.md">日本語版ドキュメント</a>
</p>
<p align="center">
<a href='https://arxiv.org/pdf/2409.13731'><img src='https://img.shields.io/badge/arXiv-2409.13731-b31b1b'></a>
<a href="https://github.com/OpenSPG/KAG/releases/latest">
<img src="https://img.shields.io/github/v/release/OpenSPG/KAG?color=blue&label=Latest%20Release" alt="Latest Release">
</a>
<a href="https://openspg.yuque.com/ndx6g9/docs_en">
<img src="https://img.shields.io/badge/User%20Guide-1e8b93?logo=readthedocs&logoColor=f5f5f5" alt="User Guide">
</a>
<a href="https://github.com/OpenSPG/KAG/blob/main/LICENSE">
<img height="21" src="https://img.shields.io/badge/License-Apache--2.0-ffffff?labelColor=d4eaf7&color=2e6cc4" alt="license">
</a>
</p>
<p align="center">
<a href="https://discord.gg/PURG77zhQ7">
<img src="https://img.shields.io/discord/1329648479709958236?style=for-the-badge&logo=discord&label=Discord" alt="Discord">
</a>
</p>
# 1. What is KAG?
KAG is a logical reasoning and Q&A framework based on the [OpenSPG](https://github.com/OpenSPG/openspg) engine and large language models, which is used to build logical reasoning and Q&A solutions for vertical domain knowledge bases. KAG can effectively overcome the ambiguity of traditional RAG vector similarity calculation and the noise problem of GraphRAG introduced by OpenIE. KAG supports logical reasoning and multi-hop fact Q&A, etc., and is significantly better than the current SOTA method.
The goal of KAG is to build a knowledge-enhanced LLM service framework in professional domains, supporting logical reasoning, factual Q&A, etc. KAG fully integrates the logical and factual characteristics of the KGs. Its core features include:
- Knowledge and Chunk Mutual Indexing structure to integrate more complete contextual text information
- Knowledge alignment using conceptual semantic reasoning to alleviate the noise problem caused by OpenIE
- Schema-constrained knowledge construction to support the representation and construction of domain expert knowledge
- Logical form-guided hybrid reasoning and retrieval to support logical reasoning and multi-hop reasoning Q&A
⭐️ Star our repository to stay up-to-date with exciting new features and improvements! Get instant notifications for new releases! 🌟

# 2. Core Features
## 2.1 Knowledge Representation
In the context of private knowledge bases, unstructured data, structured information, and business expert experience often coexist. KAG references the DIKW hierarchy to upgrade SPG to a version that is friendly to LLMs.
For unstructured data such as news, events, logs, and books, as well as structured data like transactions, statistics, and approvals, along with business experience and domain knowledge rules, KAG employs techniques such as layout analysis, knowledge extraction, property normalization, and semantic alignment to integrate raw business data and expert rules into a unified business knowledge graph.

This makes it compatible with schema-free information extraction and schema-constrained expertise construction on the same knowledge type (e. G., entity type, event type), and supports the cross-index representation between the graph structure and the original text block.
This mutual index representation is helpful to the construction of inverted index based on graph structure, and promotes the unified representation and reasoning of logical forms.
## 2.2 Mixed Reasoning Guided by Logic Forms

KAG proposes a logically formal guided hybrid solution and inference engine.
The engine includes three types of operators: planning, reasoning, and retrieval, which transform natural language problems into problem solving processes that combine language and notation.
In this process, each step can use different operators, such as exact match retrieval, text retrieval, numerical calculation or semantic reasoning, so as to realize the integration of four different problem solving processes: Retrieval, Knowledge Graph reasoning, language reasoning and numerical calculation.
# 3. Release Notes
## 3.1 Latest Updates
* 2025.01.07 : Support domain knowledge injection, domain schema customization, QFS tasks support, Visual query analysis, enables schema-constraint mode for extraction, etc.
* 2024.11.21 : Support Word docs upload, model invoke concurrency setting, User experience optimization, etc.
* 2024.10.25 : KAG initial release
## 3.2 Future Plans
* Logical reasoning optimization, conversational tasks support
* kag-model release, kag solution for event reasoning knowledge graph and medical knowledge graph
* kag front-end open source, distributed build support, mathematical reasoning optimization
# 4. Quick Start
## 4.1 product-based (for ordinary users)
### 4.1.1 Engine & Dependent Image Installation
* **Recommend System Version:**
```text
macOS User:macOS Monterey 12.6 or later
Linux User:CentOS 7 / Ubuntu 20.04 or later
Windows User:Windows 10 LTSC 2021 or later
```
* **Software Requirements:**
```text
macOS / Linux User:Docker,Docker Compose
Windows User:WSL 2 / Hyper-V,Docker,Docker Compose
```
Use the following commands to download the docker-compose.yml file and launch the services with Docker Compose.
```bash
# set the HOME environment variable (only Windows users need to execute this command)
# set HOME=%USERPROFILE%
curl -sSL https://raw.githubusercontent.com/OpenSPG/openspg/refs/heads/master/dev/release/docker-compose-west.yml -o docker-compose-west.yml
docker compose -f docker-compose-west.yml up -d
```
### 4.1.2 Use the product
Navigate to the default url of the KAG product with your browser: <http://127.0.0.1:8887>
```text
Default Username: openspg
Default password: openspg@kag
```
See [KAG usage (product mode)](https://openspg.yuque.com/ndx6g9/cwh47i/rs7gr8g4s538b1n7#rtOlA) for detailed introduction.
## 4.2 toolkit-based (for developers)
### 4.2.1 Engine & Dependent Image Installation
Refer to the 3.1 section to complete the installation of the engine & dependent image.
### 4.2.2 Installation of KAG
**macOS / Linux developers**
```text
# Create conda env: conda create -n kag-demo python=3.10 && conda activate kag-demo
# Clone code: git clone https://github.com/OpenSPG/KAG.git
# Install KAG: cd KAG && pip install -e .
```
**Windows developers**
```text
# Install the official Python 3.8.10 or later, install Git.
# Create and activate Python venv: py -m venv kag-demo && kag-demo\Scripts\activate
# Clone code: git clone https://github.com/OpenSPG/KAG.git
# Install KAG: cd KAG && pip install -e .
```
### 4.2.3 Use the toolkit
Please refer to [KAG usage (developer mode)](https://openspg.yuque.com/ndx6g9/cwh47i/rs7gr8g4s538b1n7#cikso) guide for detailed introduction of the toolkit. Then you can use the built-in components to reproduce the performance results of the built-in datasets, and apply those components to new busineness scenarios.
# 5. Technical Architecture

The KAG framework includes three parts: kg-builder, kg-solver, and kag-model. This release only involves the first two parts, kag-model will be gradually open source release in the future.
kg-builder implements a knowledge representation that is friendly to large-scale language models (LLM). Based on the hierarchical structure of DIKW (data, information, knowledge and wisdom), IT upgrades SPG knowledge representation ability, and is compatible with information extraction without schema constraints and professional knowledge construction with schema constraints on the same knowledge type (such as entity type and event type), it also supports the mutual index representation between the graph structure and the original text block, which supports the efficient retrieval of the reasoning question and answer stage.
kg-solver uses a logical symbol-guided hybrid solving and reasoning engine that includes three types of operators: planning, reasoning, and retrieval, to transform natural language problems into a problem-solving process that combines language and symbols. In this process, each step can use different operators, such as exact match retrieval, text retrieval, numerical calculation or semantic reasoning, so as to realize the integration of four different problem solving processes: Retrieval, Knowledge Graph reasoning, language reasoning and numerical calculation.
# 6. Community & Support
**GitHub**: <https://github.com/OpenSPG/KAG>
**Website**: <https://spg.openkg.cn/>
## Discord <a href="https://discord.gg/PURG77zhQ7"> <img src="https://img.shields.io/discord/1329648479709958236?style=for-the-badge&logo=discord&label=Discord" alt="Discord"></a>
Join our [Discord](https://discord.gg/PURG77zhQ7) community.
## WeChat
Follow OpenSPG Official Account to get technical articles and product updates about OpenSPG and KAG.
<img src="./_static/images/openspg-qr.png" alt="Contact Us: OpenSPG QR-code" width="200">
Scan the QR code below to join our WeChat group.
<img src="./_static/images/robot-qr.JPG" alt="Join WeChat group" width="200">
# 7. Differences between KAG, RAG, and GraphRAG
**KAG introduction and applications**: <https://github.com/orgs/OpenSPG/discussions/52>
# 8. Citation
If you use this software, please cite it as below:
* [KAG: Boosting LLMs in Professional Domains via Knowledge Augmented Generation](https://arxiv.org/abs/2409.13731)
* KGFabric: A Scalable Knowledge Graph Warehouse for Enterprise Data Interconnection
```bibtex
@article{liang2024kag,
title={KAG: Boosting LLMs in Professional Domains via Knowledge Augmented Generation},
author={Liang, Lei and Sun, Mengshu and Gui, Zhengke and Zhu, Zhongshu and Jiang, Zhouyu and Zhong, Ling and Qu, Yuan and Zhao, Peilong and Bo, Zhongpu and Yang, Jin and others},
journal={arXiv preprint arXiv:2409.13731},
year={2024}
}
@article{yikgfabric,
title={KGFabric: A Scalable Knowledge Graph Warehouse for Enterprise Data Interconnection},
author={Yi, Peng and Liang, Lei and Da Zhang, Yong Chen and Zhu, Jinye and Liu, Xiangyu and Tang, Kun and Chen, Jialin and Lin, Hao and Qiu, Leijie and Zhou, Jun}
}
```
# License
[Apache License 2.0](LICENSE)
|
{
"source": "OpenSPG/KAG",
"title": "README.md",
"url": "https://github.com/OpenSPG/KAG/blob/master/README.md",
"date": "2024-09-21T13:56:44",
"stars": 5456,
"description": "KAG is a logical form-guided reasoning and retrieval framework based on OpenSPG engine and LLMs. It is used to build logical reasoning and factual Q&A solutions for professional domain knowledge bases. It can effectively overcome the shortcomings of the traditional RAG vector similarity calculation model.",
"file_size": 10666
}
|
# 大模型知识服务框架 KAG
<div align="center">
<a href="https://spg.openkg.cn/en-US">
<img src="./_static/images/OpenSPG-1.png" width="520" alt="openspg logo">
</a>
</div>
<p align="center">
<a href="./README.md">English</a> |
<a href="./README_cn.md">简体中文</a> |
<a href="./README_ja.md">日本語版ドキュメント</a>
</p>
<p align="center">
<a href='https://arxiv.org/pdf/2409.13731'><img src='https://img.shields.io/badge/arXiv-2409.13731-b31b1b'></a>
<a href="https://github.com/OpenSPG/KAG/releases/latest">
<img src="https://img.shields.io/github/v/release/OpenSPG/KAG?color=blue&label=Latest%20Release" alt="Latest Release">
</a>
<a href="https://openspg.yuque.com/ndx6g9/docs">
<img src="https://img.shields.io/badge/用户手册-1e8b93?logo=readthedocs&logoColor=f5f5f5" alt="用户手册">
</a>
<a href="https://github.com/OpenSPG/KAG/blob/main/LICENSE">
<img height="21" src="https://img.shields.io/badge/License-Apache--2.0-ffffff?labelColor=d4eaf7&color=2e6cc4" alt="license">
</a>
</p>
# 1. KAG 是什么
KAG 是基于 [OpenSPG](https://github.com/OpenSPG/openspg) 引擎和大型语言模型的逻辑推理问答框架,用于构建垂直领域知识库的逻辑推理问答解决方案。KAG 可以有效克服传统 RAG 向量相似度计算的歧义性和 OpenIE 引入的 GraphRAG 的噪声问题。KAG 支持逻辑推理、多跳事实问答等,并且明显优于目前的 SOTA 方法。
KAG 的目标是在专业领域构建知识增强的 LLM 服务框架,支持逻辑推理、事实问答等。KAG 充分融合了 KG 的逻辑性和事实性特点,其核心功能包括:
* 知识与 Chunk 互索引结构,以整合更丰富的上下文文本信息
* 利用概念语义推理进行知识对齐,缓解 OpenIE 引入的噪音问题
* 支持 Schema-Constraint 知识构建,支持领域专家知识的表示与构建
* 逻辑符号引导的混合推理与检索,实现逻辑推理和多跳推理问答
⭐️点击右上角的 Star 关注 KAG,可以获取最新发布的实时通知!🌟

# 2. KAG 核心功能
## 2.1 LLM 友好的语义化知识管理
私域知识库场景,非结构化数据、结构化信息、业务专家经验 往往三者共存,KAG 提出了一种对大型语言模型(LLM)友好的知识表示框架,在 DIKW(数据、信息、知识和智慧)的层次结构基础上,将 SPG 升级为对 LLM 友好的版本,命名为 LLMFriSPG。
这使得它能够在同一知识类型(如实体类型、事件类型)上兼容无 schema 约束的信息提取和有 schema 约束的专业知识构建,并支持图结构与原始文本块之间的互索引表示。
这种互索引表示有助于基于图结构的倒排索引的构建,并促进了逻辑形式的统一表示、推理和检索。同时通过知识理解、语义对齐等进一步降低信息抽取的噪声,提升知识的准确率和一致性。

## 2.2 逻辑符号引导的混合推理引擎
KAG 提出了一种逻辑符号引导的混合求解和推理引擎。该引擎包括三种类型的运算符:规划、推理和检索,将自然语言问题转化为结合语言和符号的问题求解过程。
在这个过程中,每一步都可以利用不同的运算符,如精确匹配检索、文本检索、数值计算或语义推理,从而实现四种不同问题求解过程的集成:图谱推理、逻辑计算、Chunk 检索和 LLM 推理。

# 3. 版本发布
## 3.1 最近更新
* 2025.01.07 : 支持 领域知识注入、领域 schema 自定义、摘要生成类任务支持、可视化图分析查询、schema-constraint模式抽取等
* 2024.11.21 : 支持 Word 文档上传、知识库删除、模型调用并发度设置、用户体验优化等
* 2024.10.25 : KAG 首次发布
## 3.2 后续计划
* 逻辑推理 优化、对话式任务支持
* kag-model 发布、事理图谱 和 医疗图谱的 kag 解决方案发布
* kag 前端开源、分布式构建支持、数学推理 优化
# 4. 快速开始
## 4.1 基于产品(面向普通用户)
### 4.1.1 引擎&依赖 镜像安装
* **推荐系统版本:**
```text
macOS 用户:macOS Monterey 12.6 或更新版本
Linux 用户:CentOS 7 / Ubuntu 20.04 或更新版本
Windows 用户:Windows 10 LTSC 2021 或更新版本
```
* **软件要求:**
```text
macOS / Linux 用户:Docker,Docker Compose
Windows 用户:WSL 2 / Hyper-V,Docker,Docker Compose
```
使用以下命令下载 docker-compose.yml 并用 Docker Compose 启动服务。
```bash
# 设置 HOME 环境变量(仅 Windows 用户需要执行)
# set HOME=%USERPROFILE%
curl -sSL https://raw.githubusercontent.com/OpenSPG/openspg/refs/heads/master/dev/release/docker-compose.yml -o docker-compose.yml
docker compose -f docker-compose.yml up -d
```
### 4.1.2 使用
浏览器打开 KAG 产品默认链接:<http://127.0.0.1:8887> 。
```text
Default Username: openspg
Default password: openspg@kag
```
具体使用请参考 [KAG使用(产品模式)](https://openspg.yuque.com/ndx6g9/0.6/quzq24g4esal7q17#JQH6Y)。
## 4.2 基于工具包(面向开发者)
### 4.2.1 引擎&依赖 镜像安装
参考 4.1 部分完成引擎&依赖的镜像安装。
### 4.2.2 KAG 安装
**macOS / Linux 开发者**
```text
# 安装 Python 虚拟环境:conda create -n kag-demo python=3.10 && conda activate kag-demo
# 代码 clone:git clone https://github.com/OpenSPG/KAG.git
# KAG 安装: cd KAG && pip install -e .
```
**Windows 开发者**
```
# 安装官方 Python 3.8.10 或更新版本,安装 Git。
# 创建、激活 Python 虚拟环境:py -m venv kag-demo && kag-demo\Scripts\activate
# 代码 clone:git clone https://github.com/OpenSPG/KAG.git
# KAG 安装: cd KAG && pip install -e .
```
### 4.2.3 使用
开发者可以参考 [KAG使用(开发者模式)](https://openspg.yuque.com/ndx6g9/0.6/quzq24g4esal7q17#MRgKi),基于 KAG 内置的各种组件,实现内置数据集的效果复现 + 新场景的落地。
# 5. 技术架构

KAG 框架包括 kg-builder、kg-solver、kag-model 三部分。本次发布只涉及前两部分,kag-model 将在后续逐步开源发布。
kg-builder 实现了一种对大型语言模型(LLM)友好的知识表示,在 DIKW(数据、信息、知识和智慧)的层次结构基础上,升级 SPG 知识表示能力,在同一知识类型(如实体类型、事件类型)上兼容无 schema 约束的信息提取和有 schema 约束的专业知识构建,并支持图结构与原始文本块之间的互索引表示,为推理问答阶段的高效检索提供支持。
kg-solver 采用逻辑形式引导的混合求解和推理引擎,该引擎包括三种类型的运算符:规划、推理和检索,将自然语言问题转化为结合语言和符号的问题求解过程。在这个过程中,每一步都可以利用不同的运算符,如精确匹配检索、文本检索、数值计算或语义推理,从而实现四种不同问题求解过程的集成:检索、知识图谱推理、语言推理和数值计算。
# 6. 联系我们
**GitHub**: <https://github.com/OpenSPG/KAG>
**OpenSPG**: <https://spg.openkg.cn/>
<img src="./_static/images/openspg-qr.png" alt="联系我们:OpenSPG 二维码" width="200">
# 7. KAG 与 RAG、GraphRAG 差异
**KAG introduction and applications**: <https://github.com/orgs/OpenSPG/discussions/52>
# 8. 引用
如果您使用本软件,请以下面的方式引用:
* [KAG: Boosting LLMs in Professional Domains via Knowledge Augmented Generation](https://arxiv.org/abs/2409.13731)
* KGFabric: A Scalable Knowledge Graph Warehouse for Enterprise Data Interconnection
```bibtex
@article{liang2024kag,
title={KAG: Boosting LLMs in Professional Domains via Knowledge Augmented Generation},
author={Liang, Lei and Sun, Mengshu and Gui, Zhengke and Zhu, Zhongshu and Jiang, Zhouyu and Zhong, Ling and Qu, Yuan and Zhao, Peilong and Bo, Zhongpu and Yang, Jin and others},
journal={arXiv preprint arXiv:2409.13731},
year={2024}
}
@article{yikgfabric,
title={KGFabric: A Scalable Knowledge Graph Warehouse for Enterprise Data Interconnection},
author={Yi, Peng and Liang, Lei and Da Zhang, Yong Chen and Zhu, Jinye and Liu, Xiangyu and Tang, Kun and Chen, Jialin and Lin, Hao and Qiu, Leijie and Zhou, Jun}
}
```
# 许可协议
[Apache License 2.0](LICENSE)
|
{
"source": "OpenSPG/KAG",
"title": "README_cn.md",
"url": "https://github.com/OpenSPG/KAG/blob/master/README_cn.md",
"date": "2024-09-21T13:56:44",
"stars": 5456,
"description": "KAG is a logical form-guided reasoning and retrieval framework based on OpenSPG engine and LLMs. It is used to build logical reasoning and factual Q&A solutions for professional domain knowledge bases. It can effectively overcome the shortcomings of the traditional RAG vector similarity calculation model.",
"file_size": 5624
}
|
# KAG: 知識強化生成
[English version](./README.md)
[中文版文档](./README_cn.md)
## 1. KAGとは
検索強化生成(RAG)技術は、ドメインアプリケーションと大規模言語モデルの統合を促進します。しかし、RAGには、ベクトル類似性と知識推論の相関性のギャップが大きいことや、数値、時間関係、専門家のルールなどの知識ロジックに対して鈍感であるという問題があり、これが専門知識サービスの実装を妨げています。
2024年10月24日、OpenSPGはv0.5をリリースし、知識強化生成(KAG)の専門ドメイン知識サービスフレームワークを正式にリリースしました。KAGは、知識グラフとベクトル検索の利点を最大限に活用し、RAGの課題を解決するために、4つの側面から大規模言語モデルと知識グラフを双方向に強化することを目的としています:(1)LLMに優しい知識表現、(2)知識グラフと元のテキストフラグメントの相互インデックス、(3)論理形式に基づくハイブリッド推論エンジン、(4)意味推論との知識整合。
KAGは、NaiveRAG、HippoRAGなどの方法に比べて、マルチホップ質問応答タスクで顕著に優れています。hotpotQAでのF1スコアは19.6%相対的に向上し、2wikiでのF1スコアは33.5%相対的に向上しました。私たちは、KAGをAnt Groupの2つの専門知識質問応答タスク(電子政府質問応答と電子健康質問応答)に成功裏に適用し、RAG方法に比べて専門性が大幅に向上しました。
⭐️ リポジトリをスター登録して、エキサイティングな新機能やアップデートを最新の状態に保ちましょう!すべての新しいリリースに関する即時通知を受け取れます!🌟

### 1.1 技術アーキテクチャ

KAGフレームワークは、kg-builder、kg-solver、kag-modelの3つの部分で構成されています。このリリースでは最初の2つの部分のみが含まれており、kag-modelは今後段階的にオープンソースリリースされる予定です。
kg-builderは、大規模言語モデル(LLM)に優しい知識表現を実装しています。DIKW(データ、情報、知識、知恵)の階層構造に基づいて、SPGの知識表現能力を向上させ、同じ知識タイプ(例えば、エンティティタイプ、イベントタイプ)でスキーマ制約のない情報抽出とスキーマ制約のある専門知識構築の両方に対応し、グラフ構造と元のテキストブロックの相互インデックス表現をサポートし、推論質問応答段階の効率的な検索をサポートします。
kg-solverは、論理形式に基づくハイブリッド推論エンジンを使用しており、計画、推論、検索の3種類のオペレーターを含み、自然言語の問題を言語と記号を組み合わせた問題解決プロセスに変換します。このプロセスでは、各ステップで異なるオペレーター(例えば、正確な一致検索、テキスト検索、数値計算、または意味推論)を使用することができ、検索、知識グラフ推論、言語推論、数値計算の4つの異なる問題解決プロセスの統合を実現します。
### 1.2 知識表現
プライベートナレッジベースのコンテキストでは、非構造化データ、構造化情報、ビジネスエキスパートの経験が共存することがよくあります。KAGはDIKW階層を参照して、SPGをLLMに優しいバージョンにアップグレードします。ニュース、イベント、ログ、書籍などの非構造化データ、および取引、統計、承認などの構造化データ、ビジネス経験、ドメイン知識ルールに対して、KAGはレイアウト分析、知識抽出、プロパティ正規化、意味整合などの技術を使用して、元のビジネスデータと専門家のルールを統一されたビジネス知識グラフに統合します。

これにより、同じ知識タイプ(例えば、エンティティタイプ、イベントタイプ)でスキーマ制約のない情報抽出とスキーマ制約のある専門知識構築の両方に対応し、グラフ構造と元のテキストブロックの相互インデックス表現をサポートします。この相互インデックス表現は、グラフ構造に基づく逆インデックスの構築に役立ち、論理形式の統一表現と推論を促進します。
### 1.3 論理形式に基づくハイブリッド推論

KAGは、論理形式に基づくハイブリッド推論エンジンを提案しています。このエンジンは、計画、推論、検索の3種類のオペレーターを含み、自然言語の問題を言語と記号を組み合わせた問題解決プロセスに変換します。このプロセスでは、各ステップで異なるオペレーター(例えば、正確な一致検索、テキスト検索、数値計算、または意味推論)を使用することができ、検索、知識グラフ推論、言語推論、数値計算の4つの異なる問題解決プロセスの統合を実現します。
## 2. 効果はどうですか?
### 2.1 公開データセットの効果(マルチホップ推論)

最適化後、KAGの垂直分野での適応性を検証しただけでなく、一般的なデータセットのマルチホップ質問応答で既存のRAG方法と比較しました。その結果、SOTA方法よりも明らかに優れており、2wikiでのF1スコアが33.5%、hotpotQAでのF1スコアが19.6%向上しました。このフレームワークを引き続き最適化しており、エンドツーエンドの実験とアブレーション実験の指標を通じてその有効性を実証しています。論理記号駆動の推論と概念整合の手法により、このフレームワークの有効性を実証しました。
### 2.2 ドメイン知識シナリオの効果(リスクマイニング)
#### 2.2.1 専門家ルールの定義
* 「ギャンブルAPP」識別ルールの定義
**define riskAppTaxo rule**
```text
Define (s:App)-[p:belongTo]->(o:`TaxOfRiskApp`/`GamblingApp`) {
Structure {
(s)
}
Constraint {
R1("risk label marked as gambling") s.riskMark like "%Gambling%"
}
}
```
* 「App開発者」識別ルールの定義
**define app developper rule**
```text
Define (s:Person)-[p:developed]->(o:App) {
Structure {
(s)-[:hasDevice]->(d:Device)-[:install]->(o)
}
Constraint {
deviceNum = group(s,o).count(d)
R1("device installed same app"): deviceNum > 5
}
}
```
* 「ギャンブルApp開発者」識別ルールの定義
**define a RiskUser of gambling app rule**
```text
Define (s:Person)-[p:belongTo]->(o:`TaxOfRiskUser`/`DeveloperOfGamblingApp`) {
Structure {
(s)-[:developed]->(app:`TaxOfRiskApp`/`GamblingApp`)
}
Constraint {
}
}
```
#### 2.2.2 ビジネスデータ

#### 2.2.3 推論プロセス

推論プロセスの重要なステップは次のとおりです。
* 自然言語の問題を実行可能な論理式に変換します。これはプロジェクトの概念モデリングに依存しており、ブラックプロダクトマイニングドキュメントを参照してください。
* 変換された論理式をOpenSPGリゾルバーに提出して実行し、ユーザーの分類結果を取得します。
* ユーザーの分類結果に基づいて回答を生成します。
OpenSPGの概念モデリングと組み合わせることで、KAGは自然言語変換グラフクエリの難易度を下げ、データ指向の変換を分類概念指向の変換に変え、元のOpenSPGプロジェクトで自然言語質問応答の分野アプリケーションを迅速に実現できます。
## 3. どうやって使うの?
### 3.1 製品ベース(一般ユーザー向け)
#### 3.1.1 エンジン&依存関係のイメージインストール
* **推奨システムバージョン:**
```text
macOSユーザー:macOS Monterey 12.6以降
Linuxユーザー:CentOS 7 / Ubuntu 20.04以降
Windowsユーザー:Windows 10 LTSC 2021以降
```
* **ソフトウェア要件:**
```text
macOS / Linuxユーザー:Docker、Docker Compose
Windowsユーザー:WSL 2 / Hyper-V、Docker、Docker Compose
```
以下のコマンドを使用してdocker-compose.ymlファイルをダウンロードし、Docker Composeでサービスを起動します。
```bash
# HOME環境変数を設定(Windowsユーザーのみ実行が必要)
# set HOME=%USERPROFILE%
curl -sSL https://raw.githubusercontent.com/OpenSPG/openspg/refs/heads/master/dev/release/docker-compose.yml -o docker-compose.yml
docker compose -f docker-compose.yml up -d
```
#### 3.1.2 製品の使用
ブラウザでKAG製品のデフォルトURLを開きます:<http://127.0.0.1:8887>
詳細な紹介については、[製品使用](https://openspg.yuque.com/ndx6g9/cwh47i/rs7gr8g4s538b1n7#rtOlA)ガイドを参照してください。
### 3.2 ツールキットベース(開発者向け)
#### 3.2.1 エンジン&依存関係のイメージインストール
3.1セクションを参照して、エンジン&依存関係のイメージインストールを完了します。
#### 3.2.2 KAGのインストール
**macOS / Linux開発者**
```text
# conda環境の作成:conda create -n kag-demo python=3.10 && conda activate kag-demo
# コードのクローン:git clone https://github.com/OpenSPG/KAG.git
# KAGのインストール: cd KAG && pip install -e .
```
**Windows開発者**
```text
# 公式のPython 3.8.10以降をインストールし、Gitをインストールします。
# Python仮想環境の作成とアクティベート:py -m venv kag-demo && kag-demo\Scripts\activate
# コードのクローン:git clone https://github.com/OpenSPG/KAG.git
# KAGのインストール: cd KAG && pip install -e .
```
#### 3.2.3 ツールキットの使用
詳細な紹介については、[クイックスタート](https://openspg.yuque.com/ndx6g9/cwh47i/rs7gr8g4s538b1n7#cikso)ガイドを参照してください。その後、組み込みのコンポーネントを使用して、組み込みデータセットのパフォーマンス結果を再現し、新しいビジネスシナリオにこれらのコンポーネントを適用できます。
## 4. どのように拡張するの?
### 4.1 KAGの能力を拡張する
KAGが提供する組み込みコンポーネントが要件を満たさない場合、開発者はkag-builderおよびkag-solverの実装を独自に拡張できます。[KAG-Builder拡張](https://openspg.yuque.com/ndx6g9/cwh47i/ephl8hgth3gcgucn)および[KAG-Solver拡張](https://openspg.yuque.com/ndx6g9/cwh47i/rqdwk204izit2hsm)を参照してください。
#### 4.1.1 kag-builder拡張

KAGは、BuilderChainを使用して、リーダー、スプリッター、マッピング、エクストラクター、アライナー、ベクトライザーなどのコンポーネントを連結します。開発者は、kagが事前定義したBuilderChainを使用してグラフ構築を完了することも、事前定義されたコンポーネントを組み合わせてBuilderChainを取得することもできます。
同時に、開発者はビルダー内のコンポーネントをカスタマイズし、BuilderChainに埋め込んで実行することができます。
```text
kag
├──interface
│ ├── builder
│ │ ├── aligner_abc.py
│ │ ├── extractor_abc.py
│ │ ├── mapping_abc.py
│ │ ├── reader_abc.py
│ │ ├── splitter_abc.py
│ │ ├── vectorizer_abc.py
│ │ └── writer_abc.py
```
#### 4.1.2 kag-solver拡張
kag-solverは、リゾルバー、ジェネレーター、リフレクターコンポーネントで構成されるsolver-pipelineを実行します。KAGはデフォルトのリゾルバー、ジェネレーター、リフレクターを提供します。開発者は、次のAPIに基づいてカスタム実装を提供することもできます。
```text
kag
├── solver
│ ├── logic
│ │ └── solver_pipeline.py
├── interface
├── retriever
│ ├── chunk_retriever_abc.py
│ └── kg_retriever_abc.py
└── solver
├── kag_generator_abc.py
├── kag_memory_abc.py
├── kag_reasoner_abc.py
├── kag_reflector_abc.py
└── lf_planner_abc.py
```
### 4.2 KAGをカスタムモデルに適応させる
#### 4.2.1 生成モデルの適応
KAGは、Qwen / DeepSeek / GPTなどのOpenAIサービスと互換性のあるMaaS APIとの接続をサポートし、vLLM / Ollamaによってデプロイされたローカルモデルとの接続もサポートします。開発者は、llm_clientインターフェースに基づいてカスタムモデルサービスのサポートを追加できます。
```text
kag
├── common
├── llm
├── client
│ ├── llm_client.py
│ ├── ollama_client.py
│ ├── openai_client.py
│ ├── vllm_client.py
```
#### 4.2.2 表示モデルの適応
KAGは、OpenAIの表示モデルなどの呼び出しをサポートしており、OpenAIの埋め込みサービス、Ollamaによってデプロイされたbge-m3モデルを含みます。また、ローカルの埋め込みモデルのロードと使用もサポートしています。
```text
kag
├── common
├── vectorizer
│ ├── vectorizer.py
│ ├── openai_vectorizer.py
│ ├── local_bge_m3_vectorizer.py
│ ├── local_bge_vectorizer.py
```
### 4.3 KAGを他のフレームワークと統合する
他のフレームワークと統合する際には、外部のビジネスデータと専門知識を入力として使用し、kag-builderパイプラインを呼び出して知識グラフの構築を完了します。また、kag-solverを呼び出してQ&A推論プロセスを完了し、推論結果と中間プロセスをビジネスシステムに公開します。
他のフレームワークがkagを統合する方法は、次のように簡単に説明できます。

## 5. 今後の計画
* ドメイン知識の注入、ドメイン概念グラフとエンティティグラフの融合を実現
* kag-modelの最適化、KG構築とQ&Aの効率向上
* 知識ロジック制約の幻覚抑制
## 6. お問い合わせ
**GitHub**: <https://github.com/OpenSPG/KAG>
**OpenSPG**: <https://spg.openkg.cn/>
<img src="./_static/images/openspg-qr.png" alt="お問い合わせ:OpenSPG QRコード" width="200">
# 引用
このソフトウェアを使用する場合は、以下の方法で引用してください:
* [KAG: Boosting LLMs in Professional Domains via Knowledge Augmented Generation](https://arxiv.org/abs/2409.13731)
* KGFabric: A Scalable Knowledge Graph Warehouse for Enterprise Data Interconnection
```bibtex
@article{liang2024kag,
title={KAG: Boosting LLMs in Professional Domains via Knowledge Augmented Generation},
author={Liang, Lei and Sun, Mengshu and Gui, Zhengke and Zhu, Zhongshu and Jiang, Zhouyu and Zhong, Ling and Qu, Yuan and Zhao, Peilong and Bo, Zhongpu and Yang, Jin and others},
journal={arXiv preprint arXiv:2409.13731},
year={2024}
}
@article{yikgfabric,
title={KGFabric: A Scalable Knowledge Graph Warehouse for Enterprise Data Interconnection},
author={Yi, Peng and Liang, Lei and Da Zhang, Yong Chen and Zhu, Jinye and Liu, Xiangyu and Tang, Kun and Chen, Jialin and Lin, Hao and Qiu, Leijie and Zhou, Jun}
}
```
# ライセンス
[Apache License 2.0](LICENSE)
|
{
"source": "OpenSPG/KAG",
"title": "README_ja.md",
"url": "https://github.com/OpenSPG/KAG/blob/master/README_ja.md",
"date": "2024-09-21T13:56:44",
"stars": 5456,
"description": "KAG is a logical form-guided reasoning and retrieval framework based on OpenSPG engine and LLMs. It is used to build logical reasoning and factual Q&A solutions for professional domain knowledge bases. It can effectively overcome the shortcomings of the traditional RAG vector similarity calculation model.",
"file_size": 9029
}
|
---
sidebar_position: 1
slug: /release_notes
---
# Release notes
Key features, improvements and bug fixes in the latest releases.
## Version 0.5.1 (2024-11-21)
This version focuses on addressing user feedback and introduces a series of new features and user experience optimizations.
---
### **New Features**
- **Support for Word Documents**
Users can now directly upload `.doc` or `.docx` files to streamline the knowledge base construction process.
<img src="https://github.com/user-attachments/assets/86ad11d8-42ed-44f4-91ab-f9a7c6346df2" width="600" >
- **New Project Deletion API**
Quickly clear and delete projects and related data through an API, compatible with the latest Neo4j image version.
- **Model Call Concurrency Setting**
Added the `builder.model.execute.num` parameter, with a default concurrency of 5, to improve efficiency in large-scale knowledge base construction.
<img src="https://github.com/user-attachments/assets/ac7653bd-bf0c-464f-839b-8385ae6fb2c2" width="600" >
- **Improved Logging**
Added a startup success marker in the logs to help users quickly verify if the service is running correctly.
<img src="https://github.com/user-attachments/assets/56d42e84-d6c7-4743-a50c-5bf38fc87f58" width="600" >
---
### **Fixed issues**
- **Neo4j Memory Overflow Issues**
Addressed memory overflow problems in Neo4j during large-scale data processing, ensuring stable operation for extensive datasets.
- **Concurrent Neo4j Query Execution Issues**
Optimized execution strategies to resolve Graph Data Science (GDS) library conflicts or failures in high-concurrency scenarios.
- **Schema Preview Prefix Issue**
Fixed issues where extracted schema preview entities lacked necessary prefixes, ensuring consistency between extracted entities and predefined schemas.
- **Default Neo4j Password for Project Creation/Modification**
Automatically fills a secure default password if none is specified during project creation or modification, simplifying the configuration process.
- **Frontend Bug Fixes**
Resolved issues with JS dependencies relying on external addresses and embedded all frontend files into the image. Improved the knowledge base management interface for a smoother user experience.
- **Empty Node/Edge Type in Neo4j Writes**
Enhanced writing logic to handle empty node or edge types during knowledge graph construction, preventing errors or data loss in such scenarios.
## Version 0.5 (2024-10-25)
retrieval Augmentation Generation (RAG) technology promotes the integration of domain applications with large models. However, RAG has problems such as a large gap between vector similarity and knowledge reasoning correlation, and insensitivity to knowledge logic (such as numerical values, time relationships, expert rules, etc.), which hinder the implementation of professional knowledge services. On October 25, officially releasing the professional domain knowledge Service Framework for knowledge enhancement generation (KAG) .
---
### KAG: Knowledge Augmented Generation
KAG aims to make full use of the advantages of Knowledge Graph and vector retrieval, and bi-directionally enhance large language models and knowledge graphs through four aspects to solve RAG challenges
(1) LLM-friendly semantic knowledge management
(2) Mutual indexing between the knowledge map and the original snippet.
(3) Logical symbol-guided hybrid inference engine
(4) Knowledge alignment based on semantic reasoning
KAG is significantly better than NaiveRAG, HippoRAG and other methods in multi-hop question and answer tasks. The F1 score on hotpotQA is relatively improved by 19.6, and the F1 score on 2wiki is relatively improved by 33.5
The KAG framework includes three parts: kg-builder, kg-solver, and kag-model. This release only involves the first two parts, kag-model will be gradually open source release in the future.
#### kg-builder
implements a knowledge representation that is friendly to large-scale language models (LLM). Based on the hierarchical structure of DIKW (data, information, knowledge and wisdom), IT upgrades SPG knowledge representation ability, and is compatible with information extraction without schema constraints and professional knowledge construction with schema constraints on the same knowledge type (such as entity type and event type), it also supports the mutual index representation between the graph structure and the original text block, which supports the efficient retrieval of the reasoning question and answer stage.
#### kg-solver
uses a logical symbol-guided hybrid solving and reasoning engine that includes three types of operators: planning, reasoning, and retrieval, to transform natural language problems into a problem-solving process that combines language and symbols. In this process, each step can use different operators, such as exact match retrieval, text retrieval, numerical calculation or semantic reasoning, so as to realize the integration of four different problem solving processes: Retrieval, Knowledge Graph reasoning, language reasoning and numerical calculation.
|
{
"source": "OpenSPG/KAG",
"title": "docs/release_notes.md",
"url": "https://github.com/OpenSPG/KAG/blob/master/docs/release_notes.md",
"date": "2024-09-21T13:56:44",
"stars": 5456,
"description": "KAG is a logical form-guided reasoning and retrieval framework based on OpenSPG engine and LLMs. It is used to build logical reasoning and factual Q&A solutions for professional domain knowledge bases. It can effectively overcome the shortcomings of the traditional RAG vector similarity calculation model.",
"file_size": 5126
}
|
# KAG Examples
[English](./README.md) |
[简体中文](./README_cn.md)
## 1. Precondition
Please refer to [Quick Start](https://openspg.yuque.com/ndx6g9/cwh47i/rs7gr8g4s538b1n7) to install KAG and its dependency OpenSPG server, and learn about using KAG in developer mode.
## 2. Create a knowledge base
### 2.1 Create the project
#### Step 1: Enter the examples directory
```bash
cd kag/examples
```
#### Step 2: Edit project configuration
```bash
vim ./example_config.yaml
```
```yaml
#------------project configuration start----------------#
openie_llm: &openie_llm
api_key: key
base_url: https://api.deepseek.com
model: deepseek-chat
type: maas
chat_llm: &chat_llm
api_key: key
base_url: https://api.deepseek.com
model: deepseek-chat
type: maas
vectorize_model: &vectorize_model
api_key: key
base_url: https://api.siliconflow.cn/v1/
model: BAAI/bge-m3
type: openai
vector_dimensions: 1024
vectorizer: *vectorize_model
log:
level: INFO
project:
biz_scene: default
host_addr: http://127.0.0.1:8887
id: "1"
language: en
namespace: TwoWikiTest
#------------project configuration end----------------#
#------------kag-builder configuration start----------------#
kag_builder_pipeline:
chain:
type: unstructured_builder_chain # kag.builder.default_chain.DefaultUnstructuredBuilderChain
extractor:
type: schema_free_extractor # kag.builder.component.extractor.schema_free_extractor.SchemaFreeExtractor
llm: *openie_llm
ner_prompt:
type: default_ner # kag.builder.prompt.default.ner.OpenIENERPrompt
std_prompt:
type: default_std # kag.builder.prompt.default.std.OpenIEEntitystandardizationdPrompt
triple_prompt:
type: default_triple # kag.builder.prompt.default.triple.OpenIETriplePrompt
reader:
type: dict_reader # kag.builder.component.reader.dict_reader.DictReader
post_processor:
type: kag_post_processor # kag.builder.component.postprocessor.kag_postprocessor.KAGPostProcessor
splitter:
type: length_splitter # kag.builder.component.splitter.length_splitter.LengthSplitter
split_length: 100000
window_length: 0
vectorizer:
type: batch_vectorizer # kag.builder.component.vectorizer.batch_vectorizer.BatchVectorizer
vectorize_model: *vectorize_model
writer:
type: kg_writer # kag.builder.component.writer.kg_writer.KGWriter
num_threads_per_chain: 1
num_chains: 16
scanner:
type: 2wiki_dataset_scanner # kag.builder.component.scanner.dataset_scanner.MusiqueCorpusScanner
#------------kag-builder configuration end----------------#
#------------kag-solver configuration start----------------#
search_api: &search_api
type: openspg_search_api #kag.solver.tools.search_api.impl.openspg_search_api.OpenSPGSearchAPI
graph_api: &graph_api
type: openspg_graph_api #kag.solver.tools.graph_api.impl.openspg_graph_api.OpenSPGGraphApi
exact_kg_retriever: &exact_kg_retriever
type: default_exact_kg_retriever # kag.solver.retriever.impl.default_exact_kg_retriever.DefaultExactKgRetriever
el_num: 5
llm_client: *chat_llm
search_api: *search_api
graph_api: *graph_api
fuzzy_kg_retriever: &fuzzy_kg_retriever
type: default_fuzzy_kg_retriever # kag.solver.retriever.impl.default_fuzzy_kg_retriever.DefaultFuzzyKgRetriever
el_num: 5
vectorize_model: *vectorize_model
llm_client: *chat_llm
search_api: *search_api
graph_api: *graph_api
chunk_retriever: &chunk_retriever
type: default_chunk_retriever # kag.solver.retriever.impl.default_fuzzy_kg_retriever.DefaultFuzzyKgRetriever
llm_client: *chat_llm
recall_num: 10
rerank_topk: 10
kag_solver_pipeline:
memory:
type: default_memory # kag.solver.implementation.default_memory.DefaultMemory
llm_client: *chat_llm
max_iterations: 3
reasoner:
type: default_reasoner # kag.solver.implementation.default_reasoner.DefaultReasoner
llm_client: *chat_llm
lf_planner:
type: default_lf_planner # kag.solver.plan.default_lf_planner.DefaultLFPlanner
llm_client: *chat_llm
vectorize_model: *vectorize_model
lf_executor:
type: default_lf_executor # kag.solver.execute.default_lf_executor.DefaultLFExecutor
llm_client: *chat_llm
force_chunk_retriever: true
exact_kg_retriever: *exact_kg_retriever
fuzzy_kg_retriever: *fuzzy_kg_retriever
chunk_retriever: *chunk_retriever
merger:
type: default_lf_sub_query_res_merger # kag.solver.execute.default_sub_query_merger.DefaultLFSubQueryResMerger
vectorize_model: *vectorize_model
chunk_retriever: *chunk_retriever
generator:
type: default_generator # kag.solver.implementation.default_generator.DefaultGenerator
llm_client: *chat_llm
generate_prompt:
type: resp_simple # kag/examples/2wiki/solver/prompt/resp_generator.py
reflector:
type: default_reflector # kag.solver.implementation.default_reflector.DefaultReflector
llm_client: *chat_llm
#------------kag-solver configuration end----------------#
```
Update the generative model configurations ``openie_llm`` and ``chat_llm`` and the representational model configuration ``vectorize_model`` in the configuration file.
You need to fill in correct ``api_key``s. If your model providers and model names are different from the default values, you also need to update ``base_url`` and ``model``.
#### Step 3: Create the project (i.e. knowledge base in product mode)
```bash
knext project create --config_path ./example_config.yaml
```
#### Step 4: Initial contents of the directory
After creating the project, a directory with the same name as the ``namespace`` field in the ``project`` configuration (e.g., ``TwoWikiTest`` in this example) will be created under the ``kag/examples`` directory, and the KAG framework project code will be initialized.
Users can modify one or more of the following files to complete the customization of business-specific knowledge graph construction and reasoning-based question answering.
```text
.
├── builder
│ ├── __init__.py
│ ├── data
│ │ └── __init__.py
│ ├── indexer.py
│ └── prompt
│ └── __init__.py
├── kag_config.yaml
├── reasoner
│ └── __init__.py
├── schema
│ ├── TwoWikiTest.schema
│ └── __init__.py
└── solver
├── __init__.py
├── data
│ └── __init__.py
└── prompt
└── __init__.py
```
### 2.2 Update the project (Optional)
If there are configuration changes, you can refer to this section to update the configuration information to the server.
#### Step 1: Enter the project directory
```bash
cd kag/examples/TwoWikiTest
```
#### Step 2: Edit project configuration
**Note**: The embedding vectors generated by different representation models can vary significantly. It is recommended not to update the ``vectorize_model`` configuration after the project is created. If you need to update the ``vectorize_model`` configuration, please create a new project.
```bash
vim ./kag_config.yaml
```
#### Step 3: Run the update command
After editing the project configuration, use the ``knext project update`` command to update the local configuration information to the OpenSPG server.
```bash
knext project update --proj_path .
```
## 3. Import documents
### Step 1: Enter the project directory
```bash
cd kag/examples/TwoWikiTest
```
### Step 2: Retrieve corpus data
The test corpus data for the 2wiki dataset is located at ``kag/examples/2wiki/builder/data/2wiki_corpus.json``, containing 6,119 documents and 1,000 question-answer pairs. To quickly complete the entire process, there is also a ``2wiki_corpus_sub.json`` file in the same directory, which contains only 3 documents. We will use this smaller dataset as an example for the experiment.
Copy it to the directory with the same name as the ``TwoWikiTest`` project:
```bash
cp ../2wiki/builder/data/2wiki_sub_corpus.json builder/data
```
### Step 3: Edit the schema (Optional)
Edit the schema file ``schema/TwoWikiTest.schema``. For an introduction of OpenSPG schema, please refer to [Declarative Schema](https://openspg.yuque.com/ndx6g9/cwh47i/fiq6zum3qtzr7cne).
### Step 4: Commit the schema to OpenSPG server
```bash
knext schema commit
```
### Step 5: Execute the build task
Define the build task in the file ``builder/indexer.py``:
```python
import os
import logging
from kag.common.registry import import_modules_from_path
from kag.builder.runner import BuilderChainRunner
logger = logging.getLogger(__name__)
def buildKB(file_path):
from kag.common.conf import KAG_CONFIG
runner = BuilderChainRunner.from_config(
KAG_CONFIG.all_config["kag_builder_pipeline"]
)
runner.invoke(file_path)
logger.info(f"\n\nbuildKB successfully for {file_path}\n\n")
if __name__ == "__main__":
import_modules_from_path(".")
dir_path = os.path.dirname(__file__)
# Set file_path to the path of the corpus file prepared earlier
file_path = os.path.join(dir_path, "data/2wiki_sub_corpus.json")
buildKB(file_path)
```
Run the ``indexer.py`` script to complete the knowledge graph construction for unstructured data.
```bash
cd builder
python indexer.py
```
After the build script is started, a checkpoint directory for the task will be generated in the current working directory, recording the checkpoints and statistical information of the build process.
```text
ckpt
├── chain
├── extractor
├── kag_checkpoint_0_1.ckpt
├── postprocessor
├── reader
└── splitter
```
You can view the extraction task statistics, such as how many nodes/edges were extracted from each document, using the following command:
```bash
less ckpt/kag_checkpoint_0_1.ckpt
```
To see how many document entries were successfully written to the graph database, use the following command:
```bash
wc -l ckpt/kag_checkpoint_0_1.ckpt
```
The KAG framework provides checkpoint-based resumption functionality. If the task is interrupted due to a program error or other external factors (e.g., insufficient LLM invocation credits), you can rerun ``indexer.py``. KAG will automatically load the checkpoint file and reuse the existing results.
### Step 6: Inspect the constructed knowledge graph
Currently, OpenSPG-KAG provides the [Knowledge Exploration](https://openspg.yuque.com/ndx6g9/cwh47i/mzq74eaynm4rqx4b) capability in product mode, along with the corresponding API documentation [HTTP API Reference](https://openspg.yuque.com/ndx6g9/cwh47i/qvbgge62p7argtd2).

## 4. Reasoning-based question answering
### Step 1: Enter the project directory
```bash
cd kag/examples/TwoWikiTest
```
### Step 2: Edit the QA script
```bash
vim ./solver/qa.py
```
Paste the following content into ``qa.py``.
```python
import json
import logging
import os
import time
from concurrent.futures import ThreadPoolExecutor, as_completed
from tqdm import tqdm
from kag.common.benchmarks.evaluate import Evaluate
from kag.solver.logic.solver_pipeline import SolverPipeline
from kag.common.conf import KAG_CONFIG
from kag.common.registry import import_modules_from_path
from kag.common.checkpointer import CheckpointerManager
logger = logging.getLogger(__name__)
class EvaFor2wiki:
"""
init for kag client
"""
def __init__(self):
pass
"""
qa from knowledge base,
"""
def qa(self, query):
resp = SolverPipeline.from_config(KAG_CONFIG.all_config["kag_solver_pipeline"])
answer, traceLog = resp.run(query)
logger.info(f"\n\nso the answer for '{query}' is: {answer}\n\n")
return answer, traceLog
if __name__ == "__main__":
import_modules_from_path("./prompt")
evalObj = EvaFor2wiki()
evalObj.qa("Which Stanford University professor works on Alzheimer's?")
```
### Step 3: Execute the QA task
```bash
cd solver
python qa.py
```
## 5. Other built-in examples
You can enter the [kag/examples](.) directory to explore the built-in examples provided in the source code of KAG.
* [musique](./musique/README.md) (Multi-hop Q&A)
* [twowiki](./2wiki/README.md) (Multi-hop Q&A)
* [hotpotqa](./hotpotqa/README.md) (Multi-hop Q&A)
* [Risk Mining Knowledge Graph](./riskmining/README.md)
* [Enterprise Supply Chain Knowledge Graph](./supplychain/README.md)
* [Medical Knowledge Graph](./medicine/README.md)
|
{
"source": "OpenSPG/KAG",
"title": "kag/examples/README.md",
"url": "https://github.com/OpenSPG/KAG/blob/master/kag/examples/README.md",
"date": "2024-09-21T13:56:44",
"stars": 5456,
"description": "KAG is a logical form-guided reasoning and retrieval framework based on OpenSPG engine and LLMs. It is used to build logical reasoning and factual Q&A solutions for professional domain knowledge bases. It can effectively overcome the shortcomings of the traditional RAG vector similarity calculation model.",
"file_size": 12349
}
|
# KAG 示例
[English](./README.md) |
[简体中文](./README_cn.md)
## 1. 前置条件
参考文档 [快速开始](https://openspg.yuque.com/ndx6g9/0.6/quzq24g4esal7q17) 安装 KAG 及其依赖的 OpenSPG server,了解开发者模式 KAG 的使用流程。
## 2. 创建知识库
### 2.1 新建项目
#### Step 1:进入 examples 目录
```bash
cd kag/examples
```
#### Step 2:编辑项目配置
```bash
vim ./example_config.yaml
```
```yaml
#------------project configuration start----------------#
openie_llm: &openie_llm
api_key: key
base_url: https://api.deepseek.com
model: deepseek-chat
type: maas
chat_llm: &chat_llm
api_key: key
base_url: https://api.deepseek.com
model: deepseek-chat
type: maas
vectorize_model: &vectorize_model
api_key: key
base_url: https://api.siliconflow.cn/v1/
model: BAAI/bge-m3
type: openai
vector_dimensions: 1024
vectorizer: *vectorize_model
log:
level: INFO
project:
biz_scene: default
host_addr: http://127.0.0.1:8887
id: "1"
language: en
namespace: TwoWikiTest
#------------project configuration end----------------#
#------------kag-builder configuration start----------------#
kag_builder_pipeline:
chain:
type: unstructured_builder_chain # kag.builder.default_chain.DefaultUnstructuredBuilderChain
extractor:
type: schema_free_extractor # kag.builder.component.extractor.schema_free_extractor.SchemaFreeExtractor
llm: *openie_llm
ner_prompt:
type: default_ner # kag.builder.prompt.default.ner.OpenIENERPrompt
std_prompt:
type: default_std # kag.builder.prompt.default.std.OpenIEEntitystandardizationdPrompt
triple_prompt:
type: default_triple # kag.builder.prompt.default.triple.OpenIETriplePrompt
reader:
type: dict_reader # kag.builder.component.reader.dict_reader.DictReader
post_processor:
type: kag_post_processor # kag.builder.component.postprocessor.kag_postprocessor.KAGPostProcessor
splitter:
type: length_splitter # kag.builder.component.splitter.length_splitter.LengthSplitter
split_length: 100000
window_length: 0
vectorizer:
type: batch_vectorizer # kag.builder.component.vectorizer.batch_vectorizer.BatchVectorizer
vectorize_model: *vectorize_model
writer:
type: kg_writer # kag.builder.component.writer.kg_writer.KGWriter
num_threads_per_chain: 1
num_chains: 16
scanner:
type: 2wiki_dataset_scanner # kag.builder.component.scanner.dataset_scanner.MusiqueCorpusScanner
#------------kag-builder configuration end----------------#
#------------kag-solver configuration start----------------#
search_api: &search_api
type: openspg_search_api #kag.solver.tools.search_api.impl.openspg_search_api.OpenSPGSearchAPI
graph_api: &graph_api
type: openspg_graph_api #kag.solver.tools.graph_api.impl.openspg_graph_api.OpenSPGGraphApi
exact_kg_retriever: &exact_kg_retriever
type: default_exact_kg_retriever # kag.solver.retriever.impl.default_exact_kg_retriever.DefaultExactKgRetriever
el_num: 5
llm_client: *chat_llm
search_api: *search_api
graph_api: *graph_api
fuzzy_kg_retriever: &fuzzy_kg_retriever
type: default_fuzzy_kg_retriever # kag.solver.retriever.impl.default_fuzzy_kg_retriever.DefaultFuzzyKgRetriever
el_num: 5
vectorize_model: *vectorize_model
llm_client: *chat_llm
search_api: *search_api
graph_api: *graph_api
chunk_retriever: &chunk_retriever
type: default_chunk_retriever # kag.solver.retriever.impl.default_fuzzy_kg_retriever.DefaultFuzzyKgRetriever
llm_client: *chat_llm
recall_num: 10
rerank_topk: 10
kag_solver_pipeline:
memory:
type: default_memory # kag.solver.implementation.default_memory.DefaultMemory
llm_client: *chat_llm
max_iterations: 3
reasoner:
type: default_reasoner # kag.solver.implementation.default_reasoner.DefaultReasoner
llm_client: *chat_llm
lf_planner:
type: default_lf_planner # kag.solver.plan.default_lf_planner.DefaultLFPlanner
llm_client: *chat_llm
vectorize_model: *vectorize_model
lf_executor:
type: default_lf_executor # kag.solver.execute.default_lf_executor.DefaultLFExecutor
llm_client: *chat_llm
force_chunk_retriever: true
exact_kg_retriever: *exact_kg_retriever
fuzzy_kg_retriever: *fuzzy_kg_retriever
chunk_retriever: *chunk_retriever
merger:
type: default_lf_sub_query_res_merger # kag.solver.execute.default_sub_query_merger.DefaultLFSubQueryResMerger
vectorize_model: *vectorize_model
chunk_retriever: *chunk_retriever
generator:
type: default_generator # kag.solver.implementation.default_generator.DefaultGenerator
llm_client: *chat_llm
generate_prompt:
type: resp_simple # kag/examples/2wiki/solver/prompt/resp_generator.py
reflector:
type: default_reflector # kag.solver.implementation.default_reflector.DefaultReflector
llm_client: *chat_llm
#------------kag-solver configuration end----------------#
```
您需要更新其中的生成模型配置 ``openie_llm`` 和 ``chat_llm`` 和表示模型配置 ``vectorize_model``。
您需要设置正确的 ``api_key``。如果使用的模型供应商和模型名与默认值不同,您还需要更新 ``base_url`` 和 ``model``。
#### Step 3:创建项目(与产品模式中的知识库一一对应)
```bash
knext project create --config_path ./example_config.yaml
```
#### Step 4:目录初始化
创建项目之后会在 ``kag/examples`` 目录下创建一个与 ``project`` 配置中 ``namespace`` 字段同名的目录(示例中为 ``TwoWikiTest``),并完成 KAG 项目代码框架初始化。
用户可以修改下述文件的一个或多个,完成业务自定义图谱构建 & 推理问答。
```text
.
├── builder
│ ├── __init__.py
│ ├── data
│ │ └── __init__.py
│ ├── indexer.py
│ └── prompt
│ └── __init__.py
├── kag_config.yaml
├── reasoner
│ └── __init__.py
├── schema
│ ├── TwoWikiTest.schema
│ └── __init__.py
└── solver
├── __init__.py
├── data
│ └── __init__.py
└── prompt
└── __init__.py
```
### 2.2 更新项目(Optional)
如果有配置变更,可以参考本节内容,更新配置信息到服务端。
#### Step 1:进入项目目录
```bash
cd kag/examples/TwoWikiTest
```
#### Step 2:编辑项目配置
**注意**:由不同表示模型生成的 embedding 向量差异较大,``vectorize_model`` 配置在项目创建后建议不再更新;如有更新 ``vectorize_model`` 配置的需求,请创建一个新项目。
```bash
vim ./kag_config.yaml
```
#### Step 3:运行命令
配置修改后,需要使用 ``knext project update`` 命令将本地配置信息更新到 OpenSPG 服务端。
```bash
knext project update --proj_path .
```
## 3. 导入文档
### Step 1:进入项目目录
```bash
cd kag/examples/TwoWikiTest
```
### Step 2:获取语料数据
2wiki 数据集的测试语料数据为 ``kag/examples/2wiki/builder/data/2wiki_corpus.json``,有 6119 篇文档,和 1000 个问答对。为了迅速跑通整个流程,目录下还有一个 ``2wiki_corpus_sub.json`` 文件,只有 3 篇文档,我们以该小规模数据集为例进行试验。
将其复制到 ``TwoWikiTest`` 项目的同名目录下:
```bash
cp ../2wiki/builder/data/2wiki_sub_corpus.json builder/data
```
### Step 3:编辑 schema(Optional)
编辑 ``schema/TwoWikiTest.schema`` 文件,schema 文件格式参考 [声明式 schema](https://openspg.yuque.com/ndx6g9/0.6/fzhov4l2sst6bede) 相关章节。
### Step 4:提交 schema 到服务端
```bash
knext schema commit
```
### Step 5:执行构建任务
在 ``builder/indexer.py`` 文件中定义任务构建脚本:
```python
import os
import logging
from kag.common.registry import import_modules_from_path
from kag.builder.runner import BuilderChainRunner
logger = logging.getLogger(__name__)
def buildKB(file_path):
from kag.common.conf import KAG_CONFIG
runner = BuilderChainRunner.from_config(
KAG_CONFIG.all_config["kag_builder_pipeline"]
)
runner.invoke(file_path)
logger.info(f"\n\nbuildKB successfully for {file_path}\n\n")
if __name__ == "__main__":
import_modules_from_path(".")
dir_path = os.path.dirname(__file__)
# 将 file_path 设置为之前准备好的语料文件路径
file_path = os.path.join(dir_path, "data/2wiki_sub_corpus.json")
buildKB(file_path)
```
运行 ``indexer.py`` 脚本完成非结构化数据的图谱构建。
```bash
cd builder
python indexer.py
```
构建脚本启动后,会在当前工作目录下生成任务的 checkpoint 目录,记录了构建链路的 checkpoint 和统计信息。
```text
ckpt
├── chain
├── extractor
├── kag_checkpoint_0_1.ckpt
├── postprocessor
├── reader
└── splitter
```
通过以下命令查看抽取任务统计信息,如每个文档抽取出多少点 / 边。
```bash
less ckpt/kag_checkpoint_0_1.ckpt
```
通过以下命令可以查看有多少文档数据被成功写入图数据库。
```bash
wc -l ckpt/kag_checkpoint_0_1.ckpt
```
KAG 框架基于 checkpoint 文件提供了断点续跑的功能。如果由于程序出错或其他外部原因(如 LLM 余额不足)导致任务中断,可以重新执行 indexer.py,KAG 会自动加载 checkpoint 文件并复用已有结果。
### Step 6:结果检查
当前,OpenSPG-KAG 在产品端已提供 [知识探查](https://openspg.yuque.com/ndx6g9/0.6/fw4ge5c18tyfl2yq) 能力,以及对应的 API 文档 [HTTP API Reference](https://openspg.yuque.com/ndx6g9/0.6/zde1yunbb8sncxtv)。

## 4. 推理问答
### Step 1:进入项目目录
```bash
cd kag/examples/TwoWikiTest
```
### Step 2:编写问答脚本
```bash
vim ./solver/qa.py
```
将以下内容粘贴到 ``qa.py`` 中。
```python
import json
import logging
import os
import time
from concurrent.futures import ThreadPoolExecutor, as_completed
from tqdm import tqdm
from kag.common.benchmarks.evaluate import Evaluate
from kag.solver.logic.solver_pipeline import SolverPipeline
from kag.common.conf import KAG_CONFIG
from kag.common.registry import import_modules_from_path
from kag.common.checkpointer import CheckpointerManager
logger = logging.getLogger(__name__)
class EvaFor2wiki:
"""
init for kag client
"""
def __init__(self):
pass
"""
qa from knowledge base,
"""
def qa(self, query):
resp = SolverPipeline.from_config(KAG_CONFIG.all_config["kag_solver_pipeline"])
answer, traceLog = resp.run(query)
logger.info(f"\n\nso the answer for '{query}' is: {answer}\n\n")
return answer, traceLog
if __name__ == "__main__":
import_modules_from_path("./prompt")
evalObj = EvaFor2wiki()
evalObj.qa("Which Stanford University professor works on Alzheimer's?")
```
### Step 3:运行命令
```bash
cd solver
python qa.py
```
## 5. 其他内置案例
可进入 [kag/examples](.) 目录体验源码中自带的案例。
* [musique](./musique/README_cn.md)(多跳问答)
* [twowiki](./2wiki/README_cn.md)(多跳问答)
* [hotpotqa](./hotpotqa/README_cn.md)(多跳问答)
* [黑产挖掘](./riskmining/README_cn.md)
* [企业供应链](./supplychain/README_cn.md)
* [医疗图谱](./medicine/README_cn.md)
|
{
"source": "OpenSPG/KAG",
"title": "kag/examples/README_cn.md",
"url": "https://github.com/OpenSPG/KAG/blob/master/kag/examples/README_cn.md",
"date": "2024-09-21T13:56:44",
"stars": 5456,
"description": "KAG is a logical form-guided reasoning and retrieval framework based on OpenSPG engine and LLMs. It is used to build logical reasoning and factual Q&A solutions for professional domain knowledge bases. It can effectively overcome the shortcomings of the traditional RAG vector similarity calculation model.",
"file_size": 9759
}
|
# KAG Example: TwoWiki
[English](./README.md) |
[简体中文](./README_cn.md)
[2WikiMultiHopQA](https://arxiv.org/abs/2011.01060) is a multi-hop QA dataset for comprehensive evaluation of reasoning steps. It's used by [KAG](https://arxiv.org/abs/2409.13731) and [HippoRAG](https://arxiv.org/abs/2405.14831) for multi-hop question answering performance evaluation.
Here we demonstrate how to build a knowledge graph for the 2WikiMultiHopQA dataset, generate answers to those evaluation questions with KAG and calculate EM and F1 metrics of the KAG generated answers compared to the ground-truth answers.
## 1. Precondition
Please refer to [Quick Start](https://openspg.yuque.com/ndx6g9/cwh47i/rs7gr8g4s538b1n7) to install KAG and its dependency OpenSPG server, and learn about using KAG in developer mode.
## 2. Steps to reproduce
### Step 1: Enter the example directory
```bash
cd kag/examples/2wiki
```
### Step 2: Configure models
Update the generative model configurations ``openie_llm`` and ``chat_llm`` and the representational model configuration ``vectorize_model`` in [kag_config.yaml](./kag_config.yaml).
You need to fill in correct ``api_key``s. If your model providers and model names are different from the default values, you also need to update ``base_url`` and ``model``.
### Step 3: Project initialization
Initiate the project with the following command.
```bash
knext project restore --host_addr http://127.0.0.1:8887 --proj_path .
```
### Step 4: Commit the schema
Execute the following command to commit the schema [TwoWiki.schema](./schema/TwoWiki.schema).
```bash
knext schema commit
```
### Step 5: Build the knowledge graph
Execute [indexer.py](./builder/indexer.py) in the [builder](./builder) directory to build the knowledge graph.
```bash
cd builder && python indexer.py && cd ..
```
### Step 6: Execute the QA tasks
Execute [evaFor2wiki.py](./solver/evaFor2wiki.py) in the [solver](./solver) directory to generate the answers and calculate the EM and F1 metrics.
```bash
cd solver && python evaFor2wiki.py && cd ..
```
The generated answers are saved to ``./solver/2wiki_res_*.json``.
The calculated EM and F1 metrics are saved to ``./solver/2wiki_metrics_*.json``.
### Step 7: (Optional) Cleanup
To delete the checkpoints, execute the following command.
```bash
rm -rf ./builder/ckpt
rm -rf ./solver/ckpt
```
To delete the KAG project and related knowledge graph, execute the following similar command. Replace the OpenSPG server address and KAG project id with actual values.
```bash
curl http://127.0.0.1:8887/project/api/delete?projectId=1
```
### Step 8: (Optional) Try the larger datasets
Restart from Step 1 and modify [indexer.py](./builder/indexer.py) and [evaFor2wiki.py](./solver/evaFor2wiki.py) to try the larger datasets.
|
{
"source": "OpenSPG/KAG",
"title": "kag/examples/2wiki/README.md",
"url": "https://github.com/OpenSPG/KAG/blob/master/kag/examples/2wiki/README.md",
"date": "2024-09-21T13:56:44",
"stars": 5456,
"description": "KAG is a logical form-guided reasoning and retrieval framework based on OpenSPG engine and LLMs. It is used to build logical reasoning and factual Q&A solutions for professional domain knowledge bases. It can effectively overcome the shortcomings of the traditional RAG vector similarity calculation model.",
"file_size": 2787
}
|
# KAG 示例:TwoWiki
[English](./README.md) |
[简体中文](./README_cn.md)
[2WikiMultiHopQA](https://arxiv.org/abs/2011.01060) 是一个用于对推理步骤进行全面评估的多跳问答数据集。[KAG](https://arxiv.org/abs/2409.13731) 和 [HippoRAG](https://arxiv.org/abs/2405.14831) 用它评估多跳问答的性能。
本例我们展示为 2WikiMultiHopQA 数据集构建知识图谱,然后用 KAG 为评估问题生成答案,并与标准答案对比计算 EM 和 F1 指标。
## 1. 前置条件
参考文档 [快速开始](https://openspg.yuque.com/ndx6g9/0.6/quzq24g4esal7q17) 安装 KAG 及其依赖的 OpenSPG server,了解开发者模式 KAG 的使用流程。
## 2. 复现步骤
### Step 1:进入示例目录
```bash
cd kag/examples/2wiki
```
### Step 2:配置模型
更新 [kag_config.yaml](./kag_config.yaml) 中的生成模型配置 ``openie_llm`` 和 ``chat_llm`` 和表示模型配置 ``vectorize_model``。
您需要设置正确的 ``api_key``。如果使用的模型供应商和模型名与默认值不同,您还需要更新 ``base_url`` 和 ``model``。
### Step 3:初始化项目
先对项目进行初始化。
```bash
knext project restore --host_addr http://127.0.0.1:8887 --proj_path .
```
### Step 4:提交 schema
执行以下命令提交 schema [TwoWiki.schema](./schema/TwoWiki.schema)。
```bash
knext schema commit
```
### Step 5:构建知识图谱
在 [builder](./builder) 目录执行 [indexer.py](./builder/indexer.py) 构建知识图谱。
```bash
cd builder && python indexer.py && cd ..
```
### Step 6:执行 QA 任务
在 [solver](./solver) 目录执行 [evaFor2wiki.py](./solver/evaFor2wiki.py) 生成答案并计算 EM 和 F1 指标。
```bash
cd solver && python evaFor2wiki.py && cd ..
```
生成的答案被保存至 ``./solver/2wiki_res_*.json``.
计算出的 EM 和 F1 指标被保存至 ``./solver/2wiki_metrics_*.json``.
### Step 7:(可选)清理
若要删除 checkpoint,可执行以下命令。
```bash
rm -rf ./builder/ckpt
rm -rf ./solver/ckpt
```
若要删除 KAG 项目及关联的知识图谱,可执行以下类似命令,将 OpenSPG server 地址和 KAG 项目 id 换为实际的值。
```bash
curl http://127.0.0.1:8887/project/api/delete?projectId=1
```
### Step 8:(可选)尝试更大的数据集
从 Step 1 重新开始,修改 [indexer.py](./builder/indexer.py) 和 [evaFor2wiki.py](./solver/evaFor2wiki.py) 以尝试更大的数据集。
|
{
"source": "OpenSPG/KAG",
"title": "kag/examples/2wiki/README_cn.md",
"url": "https://github.com/OpenSPG/KAG/blob/master/kag/examples/2wiki/README_cn.md",
"date": "2024-09-21T13:56:44",
"stars": 5456,
"description": "KAG is a logical form-guided reasoning and retrieval framework based on OpenSPG engine and LLMs. It is used to build logical reasoning and factual Q&A solutions for professional domain knowledge bases. It can effectively overcome the shortcomings of the traditional RAG vector similarity calculation model.",
"file_size": 1727
}
|
# KAG Example: BaiKe
[English](./README.md) |
[简体中文](./README_cn.md)
## 1. Precondition
Please refer to [Quick Start](https://openspg.yuque.com/ndx6g9/cwh47i/rs7gr8g4s538b1n7) to install KAG and its dependency OpenSPG server, and learn about using KAG in developer mode.
## 2. Steps to reproduce
### Step 1: Enter the example directory
```bash
cd kag/examples/baike
```
### Step 2: Configure models
Update the generative model configurations ``openie_llm`` and ``chat_llm`` and the representational model configuration ``vectorize_model`` in [kag_config.yaml](./kag_config.yaml).
You need to fill in correct ``api_key``s. If your model providers and model names are different from the default values, you also need to update ``base_url`` and ``model``.
### Step 3: Project initialization
Initiate the project with the following command.
```bash
knext project restore --host_addr http://127.0.0.1:8887 --proj_path .
```
### Step 4: Commit the schema
Execute the following command to commit the schema [BaiKe.schema](./schema/BaiKe.schema).
```bash
knext schema commit
```
### Step 5: Build the knowledge graph
Execute [indexer.py](./builder/indexer.py) in the [builder](./builder) directory to build the knowledge graph.
```bash
cd builder && python indexer.py && cd ..
```
### Step 6: Execute the QA tasks
Execute [eval.py](./solver/eval.py) in the [solver](./solver) directory to ask demo questions and view the answers and trace logs.
```bash
cd solver && python eval.py && cd ..
```
### Step 7: (Optional) Cleanup
To delete the checkpoints, execute the following command.
```bash
rm -rf ./builder/ckpt
```
To delete the KAG project and related knowledge graph, execute the following similar command. Replace the OpenSPG server address and KAG project id with actual values.
```bash
curl http://127.0.0.1:8887/project/api/delete?projectId=1
```
|
{
"source": "OpenSPG/KAG",
"title": "kag/examples/baike/README.md",
"url": "https://github.com/OpenSPG/KAG/blob/master/kag/examples/baike/README.md",
"date": "2024-09-21T13:56:44",
"stars": 5456,
"description": "KAG is a logical form-guided reasoning and retrieval framework based on OpenSPG engine and LLMs. It is used to build logical reasoning and factual Q&A solutions for professional domain knowledge bases. It can effectively overcome the shortcomings of the traditional RAG vector similarity calculation model.",
"file_size": 1872
}
|
# KAG 示例:百科问答(BaiKe)
[English](./README.md) |
[简体中文](./README_cn.md)
## 1. 前置条件
参考文档 [快速开始](https://openspg.yuque.com/ndx6g9/0.6/quzq24g4esal7q17) 安装 KAG 及其依赖的 OpenSPG server,了解开发者模式 KAG 的使用流程。
## 2. 复现步骤
### Step 1:进入示例目录
```bash
cd kag/examples/baike
```
### Step 2:配置模型
更新 [kag_config.yaml](./kag_config.yaml) 中的生成模型配置 ``openie_llm`` 和 ``chat_llm`` 和表示模型配置 ``vectorize_model``。
您需要设置正确的 ``api_key``。如果使用的模型供应商和模型名与默认值不同,您还需要更新 ``base_url`` 和 ``model``。
### Step 3:初始化项目
先对项目进行初始化。
```bash
knext project restore --host_addr http://127.0.0.1:8887 --proj_path .
```
### Step 4:提交 schema
执行以下命令提交 schema [BaiKe.schema](./schema/BaiKe.schema)。
```bash
knext schema commit
```
### Step 5:构建知识图谱
在 [builder](./builder) 目录执行 [indexer.py](./builder/indexer.py) 构建知识图谱。
```bash
cd builder && python indexer.py && cd ..
```
### Step 6:执行 QA 任务
在 [solver](./solver) 目录执行 [eval.py](./solver/eval.py) 问示例问题并查看答案和 trace log。
```bash
cd solver && python eval.py && cd ..
```
### Step 7:(可选)清理
若要删除 checkpoint,可执行以下命令。
```bash
rm -rf ./builder/ckpt
```
若要删除 KAG 项目及关联的知识图谱,可执行以下类似命令,将 OpenSPG server 地址和 KAG 项目 id 换为实际的值。
```bash
curl http://127.0.0.1:8887/project/api/delete?projectId=1
```
|
{
"source": "OpenSPG/KAG",
"title": "kag/examples/baike/README_cn.md",
"url": "https://github.com/OpenSPG/KAG/blob/master/kag/examples/baike/README_cn.md",
"date": "2024-09-21T13:56:44",
"stars": 5456,
"description": "KAG is a logical form-guided reasoning and retrieval framework based on OpenSPG engine and LLMs. It is used to build logical reasoning and factual Q&A solutions for professional domain knowledge bases. It can effectively overcome the shortcomings of the traditional RAG vector similarity calculation model.",
"file_size": 1203
}
|
# KAG Example: CSQA
[English](./README.md) |
[简体中文](./README_cn.md)
The [UltraDomain](https://huggingface.co/datasets/TommyChien/UltraDomain/tree/main) ``cs.jsonl`` dataset contains 10 documents in Computer Science and 100 questions with their answers about those documents.
Here we demonstrate how to build a knowledge graph for those documents, generate answers to those questions with KAG and compare KAG generated answers with those from other RAG systems.
## 1. Precondition
Please refer to [Quick Start](https://openspg.yuque.com/ndx6g9/cwh47i/rs7gr8g4s538b1n7) to install KAG and its dependency OpenSPG server, and learn about using KAG in developer mode.
## 2. Steps to reproduce
### Step 1: Enter the example directory
```bash
cd kag/examples/csqa
```
### Step 2: (Optional) Prepare the data
Download [UltraDomain](https://huggingface.co/datasets/TommyChien/UltraDomain/tree/main) ``cs.jsonl`` and execute [generate_data.py](./generate_data.py) to generate data files in [./builder/data](./builder/data) and [./solver/data](./solver/data). Since the generated files were committed, this step is optional.
```bash
python generate_data.py
```
### Step 3: Configure models
Update the generative model configurations ``openie_llm`` and ``chat_llm`` and the representational model configuration ``vectorize_model`` in [kag_config.yaml](./kag_config.yaml).
You need to fill in correct ``api_key``s. If your model providers and model names are different from the default values, you also need to update ``base_url`` and ``model``.
The ``splitter`` and ``num_threads_per_chain`` configurations may also be updated to match with other systems.
### Step 4: Project initialization
Initiate the project with the following command.
```bash
knext project restore --host_addr http://127.0.0.1:8887 --proj_path .
```
### Step 5: Commit the schema
Execute the following command to commit the schema [CsQa.schema](./schema/CsQa.schema).
```bash
knext schema commit
```
### Step 6: Build the knowledge graph
Execute [indexer.py](./builder/indexer.py) in the [builder](./builder) directory to build the knowledge graph.
```bash
cd builder && python indexer.py && cd ..
```
### Step 7: Generate the answers
Execute [eval.py](./solver/eval.py) in the [solver](./solver) directory to generate the answers.
```bash
cd solver && python eval.py && cd ..
```
The results are saved to ``./solver/data/csqa_kag_answers.json``.
### Step 8: (Optional) Get the answers generated by other systems
Follow the LightRAG [Reproduce](https://github.com/HKUDS/LightRAG?tab=readme-ov-file#reproduce) steps to generate answers to the questions and save the results to [./solver/data/csqa_lightrag_answers.json](./solver/data/csqa_lightrag_answers.json). Since a copy was committed, this step is optional.
### Step 9: Calculate the metrics
Update the LLM configurations in [summarization_metrics.py](./solver/summarization_metrics.py) and [factual_correctness.py](./solver/factual_correctness.py) and execute them to calculate the metrics.
```bash
python ./solver/summarization_metrics.py
python ./solver/factual_correctness.py
```
### Step 10: (Optional) Cleanup
To delete the checkpoints, execute the following command.
```bash
rm -rf ./builder/ckpt
rm -rf ./solver/ckpt
```
To delete the KAG project and related knowledge graph, execute the following similar command. Replace the OpenSPG server address and KAG project id with actual values.
```bash
curl http://127.0.0.1:8887/project/api/delete?projectId=1
```
|
{
"source": "OpenSPG/KAG",
"title": "kag/examples/csqa/README.md",
"url": "https://github.com/OpenSPG/KAG/blob/master/kag/examples/csqa/README.md",
"date": "2024-09-21T13:56:44",
"stars": 5456,
"description": "KAG is a logical form-guided reasoning and retrieval framework based on OpenSPG engine and LLMs. It is used to build logical reasoning and factual Q&A solutions for professional domain knowledge bases. It can effectively overcome the shortcomings of the traditional RAG vector similarity calculation model.",
"file_size": 3519
}
|
# KAG 示例:CSQA
[English](./README.md) |
[简体中文](./README_cn.md)
[UltraDomain](https://huggingface.co/datasets/TommyChien/UltraDomain/tree/main) ``cs.jsonl`` 数据集包含 10 个计算机科学领域的文档,和关于这些文档的 100 个问题及答案。
本例我们展示为如何为这些文档构建知识图谱,用 KAG 为这些问题生成答案,并与其他 RAG 系统生成的答案进行比较。
## 1. 前置条件
参考文档 [快速开始](https://openspg.yuque.com/ndx6g9/0.6/quzq24g4esal7q17) 安装 KAG 及其依赖的 OpenSPG server,了解开发者模式 KAG 的使用流程。
## 2. 复现步骤
### Step 1:进入示例目录
```bash
cd kag/examples/csqa
```
### Step 2:(可选)准备数据
下载 [UltraDomain](https://huggingface.co/datasets/TommyChien/UltraDomain/tree/main) ``cs.jsonl`` 并执行 [generate_data.py](./generate_data.py) 在 [./builder/data](./builder/data) 和 [./solver/data](./solver/data) 中生成数据文件。由于我们提交了生成的文件,因此本步骤是可选的。
```bash
python generate_data.py
```
### Step 3:配置模型
更新 [kag_config.yaml](./kag_config.yaml) 中的生成模型配置 ``openie_llm`` 和 ``chat_llm`` 和表示模型配置 ``vectorize_model``。
您需要设置正确的 ``api_key``。如果使用的模型供应商和模型名与默认值不同,您还需要更新 ``base_url`` 和 ``model``。
配置 ``splitter`` 和 ``num_threads_per_chain`` 可能也需要更新以与其他系统匹配。
### Step 4:初始化项目
先对项目进行初始化。
```bash
knext project restore --host_addr http://127.0.0.1:8887 --proj_path .
```
### Step 5:提交 schema
执行以下命令提交 schema [CsQa.schema](./schema/CsQa.schema)。
```bash
knext schema commit
```
### Step 6:构建知识图谱
在 [builder](./builder) 目录执行 [indexer.py](./builder/indexer.py) 构建知识图谱。
```bash
cd builder && python indexer.py && cd ..
```
### Step 7:生成答案
在 [solver](./solver) 目录执行 [eval.py](./solver/eval.py) 生成答案。
```bash
cd solver && python eval.py && cd ..
```
生成的结果被保存至 ``./solver/data/csqa_kag_answers.json``.
### Step 8:(可选)获取其他系统生成的答案
按 LightRAG [Reproduce](https://github.com/HKUDS/LightRAG?tab=readme-ov-file#reproduce) 所述复现步骤生成问题的答案,将结果保存至 [./solver/data/csqa_lightrag_answers.json](./solver/data/csqa_lightrag_answers.json)。由于我们提交了一份 LightRAG 生成的答案,因此本步骤是可选的。
### Step 9:计算指标
更新 [summarization_metrics.py](./solver/summarization_metrics.py) 和 [factual_correctness.py](./solver/factual_correctness.py) 中的大模型配置并执行它们以计算指标。
```bash
python ./solver/summarization_metrics.py
python ./solver/factual_correctness.py
```
### Step 10:(可选)清理
若要删除 checkpoint,可执行以下命令。
```bash
rm -rf ./builder/ckpt
rm -rf ./solver/ckpt
```
若要删除 KAG 项目及关联的知识图谱,可执行以下类似命令,将 OpenSPG server 地址和 KAG 项目 id 换为实际的值。
```bash
curl http://127.0.0.1:8887/project/api/delete?projectId=1
```
|
{
"source": "OpenSPG/KAG",
"title": "kag/examples/csqa/README_cn.md",
"url": "https://github.com/OpenSPG/KAG/blob/master/kag/examples/csqa/README_cn.md",
"date": "2024-09-21T13:56:44",
"stars": 5456,
"description": "KAG is a logical form-guided reasoning and retrieval framework based on OpenSPG engine and LLMs. It is used to build logical reasoning and factual Q&A solutions for professional domain knowledge bases. It can effectively overcome the shortcomings of the traditional RAG vector similarity calculation model.",
"file_size": 2315
}
|
# KAG Example: DomainKG
[English](./README.md) |
[简体中文](./README_cn.md)
This example provides a case of knowledge injection in the medical domain, where the nodes of the domain knowledge graph are medical terms, and the relationships are defined as "isA." The document contains an introduction to a selection of medical terms.
## 1. Precondition
Please refer to [Quick Start](https://openspg.yuque.com/ndx6g9/cwh47i/rs7gr8g4s538b1n7) to install KAG and its dependency OpenSPG server, and learn about using KAG in developer mode.
## 2. Steps to reproduce
### Step 1: Enter the example directory
```bash
cd kag/examples/domain_kg
```
### Step 2: Configure models
Update the generative model configurations ``openie_llm`` and ``chat_llm`` and the representive model configuration ``vectorizer_model`` in [kag_config.yaml](./kag_config.yaml).
You need to fill in correct ``api_key``s. If your model providers and model names are different from the default values, you also need to update ``base_url`` and ``model``.
### Step 3: Project initialization
Initiate the project with the following command.
```bash
knext project restore --host_addr http://127.0.0.1:8887 --proj_path .
```
### Step 4: Commit the schema
Execute the following command to commit the schema [TwoWiki.schema](./schema/TwoWiki.schema).
```bash
knext schema commit
```
### Step 5: Build the knowledge graph
We first need to inject the domain knowledge graph into the graph database. This allows the PostProcessor component to link the extracted nodes with the nodes of the domain knowledge graph, thereby standardizing them during the construction of the graph from unstructured documents.
Execute [injection.py](./builder/injection.py) in the [builder](./builder) directory to inject the domain KG.
```bash
cd builder && python injection.py && cd ..
```
Note that KAG provides a special implementation of the ``KAGBuilderChain`` for domain knowledge graph injection, known as the ``DomainKnowledgeInjectChain``, which is registered under the name ``domain_kg_inject_chain``. Since domain knowledge injection does not involve scanning files or directories, you can directly call the ``invoke`` interface of the chain to initiate the task.
Next, execute [indexer.py](./builder/indexer.py) in the [builder](./builder) directory to build KG from unstructured document.
```bash
cd builder && python indexer.py && cd ..
```
### Step 6: Execute the QA tasks
Execute [qa.py](./solver/qa.py) in the [solver](./solver) directory to generate the answer to the question.
```bash
cd solver && python qa.py && cd ..
```
### Step 7: (Optional) Cleanup
To delete the checkpoints, execute the following command.
```bash
rm -rf ./builder/ckpt
rm -rf ./solver/ckpt
```
To delete the KAG project and related knowledge graph, execute the following similar command. Replace the OpenSPG server address and KAG project id with actual values.
```bash
curl http://127.0.0.1:8887/project/api/delete?projectId=1
```
|
{
"source": "OpenSPG/KAG",
"title": "kag/examples/domain_kg/README.md",
"url": "https://github.com/OpenSPG/KAG/blob/master/kag/examples/domain_kg/README.md",
"date": "2024-09-21T13:56:44",
"stars": 5456,
"description": "KAG is a logical form-guided reasoning and retrieval framework based on OpenSPG engine and LLMs. It is used to build logical reasoning and factual Q&A solutions for professional domain knowledge bases. It can effectively overcome the shortcomings of the traditional RAG vector similarity calculation model.",
"file_size": 2987
}
|
# KAG 示例:DomainKG
[English](./README.md) |
[简体中文](./README_cn.md)
本示例提供了一个医疗领域知识注入的案例,其中领域知识图谱的节点为医学名词,关系为isA。文档内容为部分医学名词的介绍。
## 1. 前置条件
参考文档 [快速开始](https://openspg.yuque.com/ndx6g9/0.6/quzq24g4esal7q17) 安装 KAG 及其依赖的 OpenSPG server,了解开发者模式 KAG 的使用流程。
## 2. 复现步骤
### Step 1:进入示例目录
```bash
cd kag/examples/domain_kg
```
### Step 2:配置模型
更新 [kag_config.yaml](./kag_config.yaml) 中的生成模型配置 ``openie_llm`` 和 ``chat_llm`` 和表示模型配置 ``vectorizer_model``。
您需要设置正确的 ``api_key``。如果使用的模型供应商和模型名与默认值不同,您还需要更新 ``base_url`` 和 ``model``。
### Step 3:初始化项目
先对项目进行初始化。
```bash
knext project restore --host_addr http://127.0.0.1:8887 --proj_path .
```
### Step 4:提交 schema
执行以下命令提交 schema [TwoWiki.schema](./schema/TwoWiki.schema)。
```bash
knext schema commit
```
### Step 5:构建知识图谱
我们首先需要将领域知识图谱注入到图数据库中,这样在对非结构化文档进行图谱构建的时候,PostProcessor组件可以将抽取出的节点与领域知识图谱节点进行链指(标准化)。
在 [builder](./builder) 目录执行 [injection.py](./builder/injection.py) ,注入图数据。
```bash
cd builder && python injection.py && cd ..
```
注意,KAG为领域知识图谱注入提供了一个特殊的KAGBuilderChain实现,即DomainKnowledgeInjectChain,其注册名为domain_kg_inject_chain。由于领域知识注入不涉及到扫描文件或目录,可以直接调用builder chain 的invoke接口启动任务。
接下来,在 [builder](./builder) 目录执行 [indexer.py](./builder/indexer.py) 构建知识图谱。
```bash
cd builder && python indexer.py && cd ..
```
### Step 6:执行 QA 任务
在 [solver](./solver) 目录执行 [qa.py](./solver/qa.py) 生成问题的答案。
```bash
cd solver && python qa.py && cd ..
```
### Step 7:(可选)清理
若要删除 checkpoint,可执行以下命令。
```bash
rm -rf ./builder/ckpt
rm -rf ./solver/ckpt
```
若要删除 KAG 项目及关联的知识图谱,可执行以下类似命令,将 OpenSPG server 地址和 KAG 项目 id 换为实际的值。
```bash
curl http://127.0.0.1:8887/project/api/delete?projectId=1
```
|
{
"source": "OpenSPG/KAG",
"title": "kag/examples/domain_kg/README_cn.md",
"url": "https://github.com/OpenSPG/KAG/blob/master/kag/examples/domain_kg/README_cn.md",
"date": "2024-09-21T13:56:44",
"stars": 5456,
"description": "KAG is a logical form-guided reasoning and retrieval framework based on OpenSPG engine and LLMs. It is used to build logical reasoning and factual Q&A solutions for professional domain knowledge bases. It can effectively overcome the shortcomings of the traditional RAG vector similarity calculation model.",
"file_size": 1648
}
|
# KAG Example: HotpotQA
[English](./README.md) |
[简体中文](./README_cn.md)
[HotpotQA](https://arxiv.org/abs/1809.09600) is a dataset for diverse, explainable multi-hop question answering. It's used by [KAG](https://arxiv.org/abs/2409.13731) and [HippoRAG](https://arxiv.org/abs/2405.14831) for multi-hop question answering performance evaluation.
Here we demonstrate how to build a knowledge graph for the HotpotQA dataset, generate answers to those evaluation questions with KAG and calculate EM and F1 metrics of the KAG generated answers compared to the ground-truth answers.
## 1. Precondition
Please refer to [Quick Start](https://openspg.yuque.com/ndx6g9/cwh47i/rs7gr8g4s538b1n7) to install KAG and its dependency OpenSPG server, and learn about using KAG in developer mode.
## 2. Steps to reproduce
### Step 1: Enter the example directory
```bash
cd kag/examples/hotpotqa
```
### Step 2: Configure models
Update the generative model configurations ``openie_llm`` and ``chat_llm`` and the representational model configuration ``vectorize_model`` in [kag_config.yaml](./kag_config.yaml).
You need to fill in correct ``api_key``s. If your model providers and model names are different from the default values, you also need to update ``base_url`` and ``model``.
### Step 3: Project initialization
Initiate the project with the following command.
```bash
knext project restore --host_addr http://127.0.0.1:8887 --proj_path .
```
### Step 4: Commit the schema
Execute the following command to commit the schema [HotpotQA.schema](./schema/HotpotQA.schema).
```bash
knext schema commit
```
### Step 5: Build the knowledge graph
Execute [indexer.py](./builder/indexer.py) in the [builder](./builder) directory to build the knowledge graph.
```bash
cd builder && python indexer.py && cd ..
```
### Step 6: Execute the QA tasks
Execute [evaForHotpotqa.py](./solver/evaForHotpotqa.py) in the [solver](./solver) directory to generate the answers and calculate the EM and F1 metrics.
```bash
cd solver && python evaForMedicine.py && cd ..
```
The generated answers are saved to ``./solver/hotpotqa_res_*.json``.
The calculated EM and F1 metrics are saved to ``./solver/hotpotqa_metrics_*.json``.
### Step 7: (Optional) Cleanup
To delete the checkpoints, execute the following command.
```bash
rm -rf ./builder/ckpt
rm -rf ./solver/ckpt
```
To delete the KAG project and related knowledge graph, execute the following similar command. Replace the OpenSPG server address and KAG project id with actual values.
```bash
curl http://127.0.0.1:8887/project/api/delete?projectId=1
```
### Step 8: (Optional) Try the larger datasets
Restart from Step 1 and modify [indexer.py](./builder/indexer.py) and [evaForHotpotqa.py](./solver/evaForHotpotqa.py) to try the larger datasets.
|
{
"source": "OpenSPG/KAG",
"title": "kag/examples/hotpotqa/README.md",
"url": "https://github.com/OpenSPG/KAG/blob/master/kag/examples/hotpotqa/README.md",
"date": "2024-09-21T13:56:44",
"stars": 5456,
"description": "KAG is a logical form-guided reasoning and retrieval framework based on OpenSPG engine and LLMs. It is used to build logical reasoning and factual Q&A solutions for professional domain knowledge bases. It can effectively overcome the shortcomings of the traditional RAG vector similarity calculation model.",
"file_size": 2793
}
|
# KAG 示例:HotpotQA
[English](./README.md) |
[简体中文](./README_cn.md)
[HotpotQA](https://arxiv.org/abs/1809.09600) 是一个用于多样和可解释多跳问答的数据集。[KAG](https://arxiv.org/abs/2409.13731) 和 [HippoRAG](https://arxiv.org/abs/2405.14831) 用它评估多跳问答的性能。
本例我们展示为 HotpotQA 数据集构建知识图谱,然后用 KAG 为评估问题生成答案,并与标准答案对比计算 EM 和 F1 指标。
## 1. 前置条件
参考文档 [快速开始](https://openspg.yuque.com/ndx6g9/0.6/quzq24g4esal7q17) 安装 KAG 及其依赖的 OpenSPG server,了解开发者模式 KAG 的使用流程。
## 2. 复现步骤
### Step 1:进入示例目录
```bash
cd kag/examples/hotpotqa
```
### Step 2:配置模型
更新 [kag_config.yaml](./kag_config.yaml) 中的生成模型配置 ``openie_llm`` 和 ``chat_llm`` 和表示模型配置 ``vectorize_model``。
您需要设置正确的 ``api_key``。如果使用的模型供应商和模型名与默认值不同,您还需要更新 ``base_url`` 和 ``model``。
### Step 3:初始化项目
先对项目进行初始化。
```bash
knext project restore --host_addr http://127.0.0.1:8887 --proj_path .
```
### Step 4:提交 schema
执行以下命令提交 schema [HotpotQA.schema](./schema/HotpotQA.schema)。
```bash
knext schema commit
```
### Step 5:构建知识图谱
在 [builder](./builder) 目录执行 [indexer.py](./builder/indexer.py) 构建知识图谱。
```bash
cd builder && python indexer.py && cd ..
```
### Step 6:执行 QA 任务
在 [solver](./solver) 目录执行 [evaForHotpotqa.py](./solver/evaForHotpotqa.py) 生成答案并计算 EM 和 F1 指标。
```bash
cd solver && python evaForHotpotqa.py && cd ..
```
生成的答案被保存至 ``./solver/hotpotqa_res_*.json``.
计算出的 EM 和 F1 指标被保存至 ``./solver/hotpotqa_metrics_*.json``.
### Step 7:(可选)清理
若要删除 checkpoint,可执行以下命令。
```bash
rm -rf ./builder/ckpt
rm -rf ./solver/ckpt
```
若要删除 KAG 项目及关联的知识图谱,可执行以下类似命令,将 OpenSPG server 地址和 KAG 项目 id 换为实际的值。
```bash
curl http://127.0.0.1:8887/project/api/delete?projectId=1
```
### Step 8:(可选)尝试更大的数据集
从 Step 1 重新开始,修改 [indexer.py](./builder/indexer.py) 和 [evaForHotpotqa.py](./solver/evaForHotpotqa.py) 以尝试更大的数据集。
|
{
"source": "OpenSPG/KAG",
"title": "kag/examples/hotpotqa/README_cn.md",
"url": "https://github.com/OpenSPG/KAG/blob/master/kag/examples/hotpotqa/README_cn.md",
"date": "2024-09-21T13:56:44",
"stars": 5456,
"description": "KAG is a logical form-guided reasoning and retrieval framework based on OpenSPG engine and LLMs. It is used to build logical reasoning and factual Q&A solutions for professional domain knowledge bases. It can effectively overcome the shortcomings of the traditional RAG vector similarity calculation model.",
"file_size": 1735
}
|
# KAG Example: Medical Knowledge Graph (Medicine)
[English](./README.md) |
[简体中文](./README_cn.md)
This example aims to demonstrate how to extract and construct entities and relations in a knowledge graph based on the SPG-Schema using LLMs.

## 1. Precondition
Please refer to [Quick Start](https://openspg.yuque.com/ndx6g9/cwh47i/rs7gr8g4s538b1n7) to install KAG and its dependency OpenSPG server, and learn about using KAG in developer mode.
## 2. Steps to reproduce
### Step 1: Enter the example directory
```bash
cd kag/examples/medicine
```
### Step 2: Configure models
Update the generative model configurations ``openie_llm`` and ``chat_llm`` and the representational model configuration ``vectorize_model`` in [kag_config.yaml](./kag_config.yaml).
You need to fill in correct ``api_key``s. If your model providers and model names are different from the default values, you also need to update ``base_url`` and ``model``.
### Step 3: Project initialization
Initiate the project with the following command.
```bash
knext project restore --host_addr http://127.0.0.1:8887 --proj_path .
```
### Step 4: Commit the schema
Execute the following command to commit the Medical Knowledge Graph schema [Medicine.schema](./schema/Medicine.schema).
```bash
knext schema commit
```
### Step 5: Build the knowledge graph
Execute [indexer.py](./builder/indexer.py) in the [builder](./builder) directory to build the knowledge graph with domain knowledge importing and schema-free extraction.
```bash
cd builder && python indexer.py && cd ..
```
Check [Disease.csv](./builder/data/Disease.csv) to inspect the descriptions of diseases. Those unstructured descriptions are schema-free extracted by ``extract_runner`` defined in [kag_config.yaml](./kag_config.yaml).
Other structured data in [data](./builder/data) will be imported directly by corresponding builder chains defined in [kag_config.yaml](./kag_config.yaml).
### Step 6: Query the knowledge graph with GQL
You can use the ``knext reasoner`` command to inspect the built knowledge graph.
The query DSL will be executed by the OpenSPG server, which supports ISO GQL.
* Execute the following command to execute DSL directly.
```bash
knext reasoner execute --dsl "
MATCH
(s:Medicine.HospitalDepartment)-[p]->(o)
RETURN
s.id, s.name
"
```
The results will be displayed on the screen and saved as CSV to the current directory.
* You can also save the DSL to a file and execute the file.
```bash
knext reasoner execute --file ./reasoner/rule.dsl
```
* You can also use the reasoner Python client to query the knowledge graph.
```bash
python ./reasoner/client.py
```
### Step 7: Execute the QA tasks
Execute [evaForMedicine.py](./solver/evaForMedicine.py) in the [solver](./solver) directory to ask a demo question in natural languages and view the answer and trace log.
```bash
cd solver && python evaForMedicine.py && cd ..
```
### Step 8: (Optional) Cleanup
To delete the checkpoint, execute the following command.
```bash
rm -rf ./builder/ckpt
```
To delete the KAG project and related knowledge graph, execute the following similar command. Replace the OpenSPG server address and KAG project id with actual values.
```bash
curl http://127.0.0.1:8887/project/api/delete?projectId=1
```
|
{
"source": "OpenSPG/KAG",
"title": "kag/examples/medicine/README.md",
"url": "https://github.com/OpenSPG/KAG/blob/master/kag/examples/medicine/README.md",
"date": "2024-09-21T13:56:44",
"stars": 5456,
"description": "KAG is a logical form-guided reasoning and retrieval framework based on OpenSPG engine and LLMs. It is used to build logical reasoning and factual Q&A solutions for professional domain knowledge bases. It can effectively overcome the shortcomings of the traditional RAG vector similarity calculation model.",
"file_size": 3390
}
|
# KAG 示例:医疗图谱(Medicine)
[English](./README.md) |
[简体中文](./README_cn.md)
本示例旨在展示如何基于 schema 的定义,利用大模型实现对图谱实体和关系的抽取和构建到图谱。

## 1. 前置条件
参考文档 [快速开始](https://openspg.yuque.com/ndx6g9/0.6/quzq24g4esal7q17) 安装 KAG 及其依赖的 OpenSPG server,了解开发者模式 KAG 的使用流程。
## 2. 复现步骤
### Step 1:进入示例目录
```bash
cd kag/examples/medicine
```
### Step 2:配置模型
更新 [kag_config.yaml](./kag_config.yaml) 中的生成模型配置 ``openie_llm`` 和 ``chat_llm`` 和表示模型配置 ``vectorize_model``。
您需要设置正确的 ``api_key``。如果使用的模型供应商和模型名与默认值不同,您还需要更新 ``base_url`` 和 ``model``。
### Step 3:初始化项目
先对项目进行初始化。
```bash
knext project restore --host_addr http://127.0.0.1:8887 --proj_path .
```
### Step 4:提交 schema
执行以下命令提交医疗图谱 schema [Medicine.schema](./schema/Medicine.schema)。
```bash
knext schema commit
```
### Step 5:构建知识图谱
在 [builder](./builder) 目录执行 [indexer.py](./builder/indexer.py) 通过领域知识导入和 schema-free 抽取构建知识图谱。
```bash
cd builder && python indexer.py && cd ..
```
您可以检查 [Disease.csv](./builder/data/Disease.csv) 查看疾病的描述,我们通过定义在 [kag_config.yaml](./kag_config.yaml) 的 ``extract_runner`` 对这些无结构文本描述做 schema-free 抽取。
[data](./builder/data) 中的其他结构化数据通过定义在 [kag_config.yaml](./kag_config.yaml) 中的相应 KAG builder chain 直接导入。
### Step 6:使用 GQL 查询知识图谱
您可以使用 ``knext reasoner`` 命令检查构建的知识图谱。查询 DSL 将由 OpenSPG server 执行,它支持 ISO GQL。
* 使用以下命令直接执行 DSL。
```bash
knext reasoner execute --dsl "
MATCH
(s:Medicine.HospitalDepartment)-[p]->(o)
RETURN
s.id, s.name
"
```
查询结果会显示在屏幕上并以 CSV 格式保存到当前目录。
* 您也可以将 DSL 保存到文件,然后通过文件提交 DSL。
```bash
knext reasoner execute --file ./reasoner/rule.dsl
```
* 您还可以使用 reasoner 的 Python 客户端查询知识图谱。
```bash
python ./reasoner/client.py
```
### Step 7:执行 QA 任务
在 [solver](./solver) 目录执行 [evaForMedicine.py](./solver/evaForMedicine.py) 用自然语言问一个示例问题并查看答案和 trace log。
```bash
cd solver && python evaForMedicine.py && cd ..
```
### Step 8:(可选)清理
若要删除 checkpoint,可执行以下命令。
```bash
rm -rf ./builder/ckpt
```
若要删除 KAG 项目及关联的知识图谱,可执行以下类似命令,将 OpenSPG server 地址和 KAG 项目 id 换为实际的值。
```bash
curl http://127.0.0.1:8887/project/api/delete?projectId=1
```
|
{
"source": "OpenSPG/KAG",
"title": "kag/examples/medicine/README_cn.md",
"url": "https://github.com/OpenSPG/KAG/blob/master/kag/examples/medicine/README_cn.md",
"date": "2024-09-21T13:56:44",
"stars": 5456,
"description": "KAG is a logical form-guided reasoning and retrieval framework based on OpenSPG engine and LLMs. It is used to build logical reasoning and factual Q&A solutions for professional domain knowledge bases. It can effectively overcome the shortcomings of the traditional RAG vector similarity calculation model.",
"file_size": 2149
}
|
# KAG Example: MuSiQue
[English](./README.md) |
[简体中文](./README_cn.md)
[MuSiQue](https://arxiv.org/abs/2108.00573) is a multi-hop QA dataset for comprehensive evaluation of reasoning steps. It's used by [KAG](https://arxiv.org/abs/2409.13731) and [HippoRAG](https://arxiv.org/abs/2405.14831) for multi-hop question answering performance evaluation.
Here we demonstrate how to build a knowledge graph for the MuSiQue dataset, generate answers to those evaluation questions with KAG and calculate EM and F1 metrics of the KAG generated answers compared to the ground-truth answers.
## 1. Precondition
Please refer to [Quick Start](https://openspg.yuque.com/ndx6g9/cwh47i/rs7gr8g4s538b1n7) to install KAG and its dependency OpenSPG server, and learn about using KAG in developer mode.
## 2. Steps to reproduce
### Step 1: Enter the example directory
```bash
cd kag/examples/musique
```
### Step 2: Configure models
Update the generative model configurations ``openie_llm`` and ``chat_llm`` and the representational model configuration ``vectorize_model`` in [kag_config.yaml](./kag_config.yaml).
You need to fill in correct ``api_key``s. If your model providers and model names are different from the default values, you also need to update ``base_url`` and ``model``.
### Step 3: Project initialization
Initiate the project with the following command.
```bash
knext project restore --host_addr http://127.0.0.1:8887 --proj_path .
```
### Step 4: Commit the schema
Execute the following command to commit the schema [MuSiQue.schema](./schema/MuSiQue.schema).
```bash
knext schema commit
```
### Step 5: Build the knowledge graph
Execute [indexer.py](./builder/indexer.py) in the [builder](./builder) directory to build the knowledge graph.
```bash
cd builder && python indexer.py && cd ..
```
### Step 6: Execute the QA tasks
Execute [evaForMusique.py](./solver/evaForMusique.py) in the [solver](./solver) directory to generate the answers and calculate the EM and F1 metrics.
```bash
cd solver && python evaForMusique.py && cd ..
```
The generated answers are saved to ``./solver/musique_res_*.json``.
The calculated EM and F1 metrics are saved to ``./solver/musique_metrics_*.json``.
### Step 7: (Optional) Cleanup
To delete the checkpoints, execute the following command.
```bash
rm -rf ./builder/ckpt
rm -rf ./solver/ckpt
```
To delete the KAG project and related knowledge graph, execute the following similar command. Replace the OpenSPG server address and KAG project id with actual values.
```bash
curl http://127.0.0.1:8887/project/api/delete?projectId=1
```
### Step 8: (Optional) Try the larger datasets
Restart from Step 1 and modify [indexer.py](./builder/indexer.py) and [evaForMusique.py](./solver/evaForMusique.py) to try the larger datasets.
|
{
"source": "OpenSPG/KAG",
"title": "kag/examples/musique/README.md",
"url": "https://github.com/OpenSPG/KAG/blob/master/kag/examples/musique/README.md",
"date": "2024-09-21T13:56:44",
"stars": 5456,
"description": "KAG is a logical form-guided reasoning and retrieval framework based on OpenSPG engine and LLMs. It is used to build logical reasoning and factual Q&A solutions for professional domain knowledge bases. It can effectively overcome the shortcomings of the traditional RAG vector similarity calculation model.",
"file_size": 2787
}
|
# KAG 示例:MuSiQue
[English](./README.md) |
[简体中文](./README_cn.md)
[MuSiQue](https://arxiv.org/abs/2108.00573) 是一个用于对推理步骤进行全面评估的多跳问答数据集。[KAG](https://arxiv.org/abs/2409.13731) 和 [HippoRAG](https://arxiv.org/abs/2405.14831) 用它评估多跳问答的性能。
本例我们展示为 MuSiQue 数据集构建知识图谱,然后用 KAG 为评估问题生成答案,并与标准答案对比计算 EM 和 F1 指标。
## 1. 前置条件
参考文档 [快速开始](https://openspg.yuque.com/ndx6g9/0.6/quzq24g4esal7q17) 安装 KAG 及其依赖的 OpenSPG server,了解开发者模式 KAG 的使用流程。
## 2. 复现步骤
### Step 1:进入示例目录
```bash
cd kag/examples/musique
```
### Step 2:配置模型
更新 [kag_config.yaml](./kag_config.yaml) 中的生成模型配置 ``openie_llm`` 和 ``chat_llm`` 和表示模型配置 ``vectorize_model``。
您需要设置正确的 ``api_key``。如果使用的模型供应商和模型名与默认值不同,您还需要更新 ``base_url`` 和 ``model``。
### Step 3:初始化项目
先对项目进行初始化。
```bash
knext project restore --host_addr http://127.0.0.1:8887 --proj_path .
```
### Step 4:提交 schema
执行以下命令提交 schema [MuSiQue.schema](./schema/MuSiQue.schema)。
```bash
knext schema commit
```
### Step 5:构建知识图谱
在 [builder](./builder) 目录执行 [indexer.py](./builder/indexer.py) 构建知识图谱。
```bash
cd builder && python indexer.py && cd ..
```
### Step 6:执行 QA 任务
在 [solver](./solver) 目录执行 [evaForMusique.py](./solver/evaForMusique.py) 生成答案并计算 EM 和 F1 指标。
```bash
cd solver && python evaForMusique.py && cd ..
```
生成的答案被保存至 ``./solver/musique_res_*.json``.
计算出的 EM 和 F1 指标被保存至 ``./solver/musique_metrics_*.json``.
### Step 7:(可选)清理
若要删除 checkpoint,可执行以下命令。
```bash
rm -rf ./builder/ckpt
rm -rf ./solver/ckpt
```
若要删除 KAG 项目及关联的知识图谱,可执行以下类似命令,将 OpenSPG server 地址和 KAG 项目 id 换为实际的值。
```bash
curl http://127.0.0.1:8887/project/api/delete?projectId=1
```
### Step 8:(可选)尝试更大的数据集
从 Step 1 重新开始,修改 [indexer.py](./builder/indexer.py) 和 [evaForMusique.py](./solver/evaForMusique.py) 以尝试更大的数据集。
|
{
"source": "OpenSPG/KAG",
"title": "kag/examples/musique/README_cn.md",
"url": "https://github.com/OpenSPG/KAG/blob/master/kag/examples/musique/README_cn.md",
"date": "2024-09-21T13:56:44",
"stars": 5456,
"description": "KAG is a logical form-guided reasoning and retrieval framework based on OpenSPG engine and LLMs. It is used to build logical reasoning and factual Q&A solutions for professional domain knowledge bases. It can effectively overcome the shortcomings of the traditional RAG vector similarity calculation model.",
"file_size": 1727
}
|
# KAG Example: Risk Mining Knowledge Graph (RiskMining)
[English](./README.md) |
[简体中文](./README_cn.md)
## Overview
**Keywords**: semantic properties, dynamic multi-classification of entities, knowledge application in the context of hierarchical business knowledge and factual data.

## 1. Precondition
Please refer to [Quick Start](https://openspg.yuque.com/ndx6g9/cwh47i/rs7gr8g4s538b1n7) to install KAG and its dependency OpenSPG server, and learn about using KAG in developer mode.
## 2. Steps to reproduce
### Step 1: Enter the example directory
```bash
cd kag/examples/riskmining
```
### Step 2: Configure models
Update the generative model configurations ``openie_llm`` and ``chat_llm`` and the representational model configuration ``vectorize_model`` in [kag_config.yaml](./kag_config.yaml).
You need to fill in correct ``api_key``s. If your model providers and model names are different from the default values, you also need to update ``base_url`` and ``model``.
### Step 3: Project initialization
Initiate the project with the following command.
```bash
knext project restore --host_addr http://127.0.0.1:8887 --proj_path .
```
### Step 4: Create knowledge schema
The schema file [RiskMining.schema](./schema/RiskMining.schema) has been created and you can execute the following command to submit it:
```bash
knext schema commit
```
Submit the classification rules of RiskUser and RiskApp in [concept.rule](./schema/concept.rule):
```bash
knext schema reg_concept_rule --file ./schema/concept.rule
```
### Step 5: Knowledge graph construction
Submit the knowledge importing tasks.
```bash
cd builder && python indexer.py && cd ..
```
### Step 6: Executing query tasks for knowledge graph
OpenSPG supports the ISO GQL syntax. You can use the following command-line to execute a query task:
```bash
knext reasoner execute --dsl "${ql}"
```
#### Scenario 1: Semantic attributes vs text attributes

MobilePhone: "standard attribute" vs "text attribute".
Save the following content as file ``dsl_task.txt``.
```cypher
MATCH
(phone:STD.ChinaMobile)<-[:hasPhone]-(u:RiskMining.Person)
RETURN
u.id, phone.id
```
Execute the query script.
```bash
knext reasoner execute --file dsl_task.txt
```
#### Scenario 2: Dynamic multi-type entities
**Note**: The classification rules defined in this section have been submitted in the previous "4. Create knowledge schema" section using the command ``knext schema reg_concept_rule``.
The detailed content of the following rules can also be found in the file [concept.rule](./schema/concept.rule).
**Taxonomy of gambling apps**
```text
Define (s:RiskMining.App)-[p:belongTo]->(o:`RiskMining.TaxOfRiskApp`/`赌博应用`) {
Structure {
(s)
}
Constraint {
R1("风险标记为赌博"): s.riskMark like "%赌博%"
}
}
```
Wang Wu is a gambling app developer, and Li Si is the owner of a gambling app. These two user entities correspond to different concept types.
**Gambling Developer's Identification Rule**
**Rule**: If a user has more than 5 devices, and these devices have the same app installed, then there exists a development relation.
```text
Define (s:RiskMining.Person)-[p:developed]->(o:RiskMining.App) {
Structure {
(s)-[:hasDevice]->(d:RiskMining.Device)-[:install]->(o)
}
Constraint {
deviceNum = group(s,o).count(d)
R1("设备超过5"): deviceNum > 5
}
}
```
```text
Define (s:RiskMining.Person)-[p:belongTo]->(o:`RiskMining.TaxOfRiskUser`/`赌博App开发者`) {
Structure {
(s)-[:developed]->(app:`RiskMining.TaxOfRiskApp`/`赌博应用`)
}
Constraint {
}
}
```
**Identifying the owner of a gambling app**
**Rule 1**: There exists a publishing relation between a person and the app.
```text
Define (s:RiskMining.Person)-[p:release]->(o:RiskMining.App) {
Structure {
(s)-[:holdShare]->(c:RiskMining.Company),
(c)-[:hasCert]->(cert:RiskMining.Cert)<-[useCert]-(o)
}
Constraint {
}
}
```
**Rule 2**: The user transfers money to the gambling app developer, and there exists a relation of publishing gambling app.
```text
Define (s:RiskMining.Person)-[p:belongTo]->(o:`RiskMining.TaxOfRiskApp`/`赌博App老板`) {
Structure {
(s)-[:release]->(a:`RiskMining.TaxOfRiskApp`/`赌博应用`),
(u:RiskMining.Person)-[:developed]->(a),
(s)-[:fundTrans]->(u)
}
Constraint {
}
}
```
#### Scenario 3: Knowledge Application in the Context of hierarchical Business Knowledge and Factual Data
We can use GQL to query the criminal group information corresponding to black market applications.
**Retrieve all gambling applications**
Save the following content as file ``dsl_task1.txt``.
```cypher
MATCH (s:`RiskMining.TaxOfRiskApp`/`赌博应用`) RETURN s.id
```
Execute the query script.
```bash
knext reasoner execute --file dsl_task1.txt
```
**Retrieve the developers and owners of the gambling apps**
Save the following content as file ``dsl_task2.txt``.
```cypher
MATCH
(u:`RiskMining.TaxOfRiskUser`/`赌博App开发者`)-[:developed]->(app:`RiskMining.TaxOfRiskApp`/`赌博应用`),
(b:`RiskMining.TaxOfRiskUser`/`赌博App老板`)-[:release]->(app)
RETURN
u.id, b.id, app.id
```
Execute the query script.
```bash
knext reasoner execute --file dsl_task2.txt
```
### Step 7: Use KAG to implement natural language QA
Here is the content of the ``solver`` directory.
```text
solver
├── prompt
│ └── logic_form_plan.py
└── qa.py
```
Modify the prompt to implement NL2LF conversion in the RiskMining domain.
```python
class LogicFormPlanPrompt(PromptOp):
default_case_zh = """"cases": [
{
"Action": "张*三是一个赌博App的开发者吗?",
"answer": "Step1:查询是否张*三的分类\nAction1:get_spo(s=s1:自然人[张*三], p=p1:属于, o=o1:风险用户)\nOutput:输出o1\nAction2:get(o1)"
}
],"""
```
Assemble the solver code in ``qa.py``.
```python
def qa(self, query):
resp = SolverPipeline()
answer, trace_log = resp.run(query)
logger.info(f"\n\nso the answer for '{query}' is: {answer}\n\n")
return answer, trace_log
```
Execute ``qa.py``.
```bash
python ./solver/qa.py
```
|
{
"source": "OpenSPG/KAG",
"title": "kag/examples/riskmining/README.md",
"url": "https://github.com/OpenSPG/KAG/blob/master/kag/examples/riskmining/README.md",
"date": "2024-09-21T13:56:44",
"stars": 5456,
"description": "KAG is a logical form-guided reasoning and retrieval framework based on OpenSPG engine and LLMs. It is used to build logical reasoning and factual Q&A solutions for professional domain knowledge bases. It can effectively overcome the shortcomings of the traditional RAG vector similarity calculation model.",
"file_size": 6257
}
|
# KAG 示例:黑产挖掘(RiskMining)
[English](./README.md) |
[简体中文](./README_cn.md)
**关键词**:语义属性,实体动态多分类,面向业务知识和事实数据分层下的知识应用

## 1. 前置条件
参考文档 [快速开始](https://openspg.yuque.com/ndx6g9/0.6/quzq24g4esal7q17) 安装 KAG 及其依赖的 OpenSPG server,了解开发者模式 KAG 的使用流程。
## 2. 复现步骤
### Step 1:进入示例目录
```bash
cd kag/examples/riskmining
```
### Step 2:配置模型
更新 [kag_config.yaml](./kag_config.yaml) 中的生成模型配置 ``openie_llm`` 和 ``chat_llm`` 和表示模型配置 ``vectorize_model``。
您需要设置正确的 ``api_key``。如果使用的模型供应商和模型名与默认值不同,您还需要更新 ``base_url`` 和 ``model``。
### Step 3:初始化项目
先对项目进行初始化。
```bash
knext project restore --host_addr http://127.0.0.1:8887 --proj_path .
```
### Step 4:知识建模
schema 文件已创建好,可执行如下命令提交。参见黑产 SPG Schema 模型 [RiskMining.schema](./schema/RiskMining.schema)。
```bash
knext schema commit
```
提交风险用户、风险 APP 的分类概念。参见黑产分类概念规则 [concept.rule](./schema/concept.rule)。
```bash
knext schema reg_concept_rule --file ./schema/concept.rule
```
### Step 5:知识构建
提交知识构建任务导入数据。
```bash
cd builder && python indexer.py && cd ..
```
### Step 6:执行图谱规则推理任务
SPG 支持 ISO GQL 语法,可用如下命令行执行查询任务。
```bash
knext reasoner execute --dsl "${ql}"
```
#### 场景 1:语义属性对比文本属性

电话号码:标准属性 vs 文本属性。
编辑 ``dsl_task.txt``,输入如下内容:
```cypher
MATCH
(phone:STD.ChinaMobile)<-[:hasPhone]-(u:RiskMining.Person)
RETURN
u.id, phone.id
```
执行脚本:
```bash
knext reasoner execute --file dsl_task.txt
```
#### 场景 2:实体动态多类型
**注意**:本节定义的分类规则 [concept.rule](./schema/concept.rule) 已经在前面的“Step 4:知识建模”章节里通过命令 ``knext schema reg_concept_rule`` 提交。
以下规则的详细内容也可以在黑产分类概念规则 [concept.rule](./schema/concept.rule) 中查看。
**赌博 App 的分类**
```text
Define (s:RiskMining.App)-[p:belongTo]->(o:`RiskMining.TaxOfRiskApp`/`赌博应用`) {
Structure {
(s)
}
Constraint {
R1("风险标记为赌博"): s.riskMark like "%赌博%"
}
}
```
王五为赌博应用开发者,李四为赌博应用老板,两个用户实体对应了不同的概念类型。
**赌博开发者认定规则**
**规则**:用户存在大于 5 台设备,且这些设备中安装了相同的 App,则存在开发关系。
```text
Define (s:RiskMining.Person)-[p:developed]->(o:RiskMining.App) {
Structure {
(s)-[:hasDevice]->(d:RiskMining.Device)-[:install]->(o)
}
Constraint {
deviceNum = group(s,o).count(d)
R1("设备超过5"): deviceNum > 5
}
}
```
```text
Define (s:RiskMining.Person)-[p:belongTo]->(o:`RiskMining.TaxOfRiskUser`/`赌博App开发者`) {
Structure {
(s)-[:developed]->(app:`RiskMining.TaxOfRiskApp`/`赌博应用`)
}
Constraint {
}
}
```
**认定赌博 App 老板**
**规则 1**:人和 App 存在发布关系。
```text
Define (s:RiskMining.Person)-[p:release]->(o:RiskMining.App) {
Structure {
(s)-[:holdShare]->(c:RiskMining.Company),
(c)-[:hasCert]->(cert:RiskMining.Cert)<-[useCert]-(o)
}
Constraint {
}
}
```
**规则 2**:用户给该赌博App开发者转账,并且存在发布赌博应用行为。
```text
Define (s:RiskMining.Person)-[p:belongTo]->(o:`RiskMining.TaxOfRiskApp`/`赌博App老板`) {
Structure {
(s)-[:release]->(a:`RiskMining.TaxOfRiskApp`/`赌博应用`),
(u:RiskMining.Person)-[:developed]->(a),
(s)-[:fundTrans]->(u)
}
Constraint {
}
}
```
#### 场景 3:面向业务知识和事实数据分层下的知识应用
基于 GQL 获取黑产应用对应的团伙信息。
**获取所有的赌博应用**
编辑 ``dsl_task1.txt``,输入如下内容:
```cypher
MATCH (s:`RiskMining.TaxOfRiskApp`/`赌博应用`) RETURN s.id
```
执行脚本:
```bash
knext reasoner execute --file dsl_task1.txt
```
**获取赌博 App 背后的开发者和老板**
编辑 ``dsl_task2.txt``,输入如下内容:
```cypher
MATCH
(u:`RiskMining.TaxOfRiskUser`/`赌博App开发者`)-[:developed]->(app:`RiskMining.TaxOfRiskApp`/`赌博应用`),
(b:`RiskMining.TaxOfRiskUser`/`赌博App老板`)-[:release]->(app)
RETURN
u.id, b.id, app.id
```
执行脚本:
```bash
knext reasoner execute --file dsl_task2.txt
```
### Step 7:使用 KAG 实现自然语言问答
以下是 solver 目录的内容。
```text
solver
├── prompt
│ └── logic_form_plan.py
└── qa.py
```
修改 prompt,实现领域内的 NL2LF 转换。
```python
class LogicFormPlanPrompt(PromptOp):
default_case_zh = """"cases": [
{
"Action": "张*三是一个赌博App的开发者吗?",
"answer": "Step1:查询是否张*三的分类\nAction1:get_spo(s=s1:自然人[张*三], p=p1:属于, o=o1:风险用户)\nOutput:输出o1\nAction2:get(o1)"
}
],"""
```
在 ``qa.py`` 中组装 solver 代码。
```python
def qa(self, query):
resp = SolverPipeline()
answer, trace_log = resp.run(query)
logger.info(f"\n\nso the answer for '{query}' is: {answer}\n\n")
return answer, trace_log
```
执行 ``qa.py``。
```bash
python ./solver/qa.py
```
|
{
"source": "OpenSPG/KAG",
"title": "kag/examples/riskmining/README_cn.md",
"url": "https://github.com/OpenSPG/KAG/blob/master/kag/examples/riskmining/README_cn.md",
"date": "2024-09-21T13:56:44",
"stars": 5456,
"description": "KAG is a logical form-guided reasoning and retrieval framework based on OpenSPG engine and LLMs. It is used to build logical reasoning and factual Q&A solutions for professional domain knowledge bases. It can effectively overcome the shortcomings of the traditional RAG vector similarity calculation model.",
"file_size": 4407
}
|
# KAG Example: Enterprise Supply Chain Knowledge Graph (SupplyChain)
[English](./README.md) |
[简体中文](./README_cn.md)
## 1. Background
Credit institutions conduct comprehensive analysis of a company's financial condition, operating condition, market position, and management capabilities, and assign a rating grade to reflect the credit status of the company, in order to support credit business. In practice, it heavily relies on the information provided by the evaluated company itself, such as annual reports, various qualification documents, asset proofs, etc. This type of information can only provide micro-level information about the company itself and cannot reflect the company's market situation along the entire industry chain or obtain information beyond what is proven.
This example is based on the SPG framework to construct an industry chain enterprise Knowledge graph and extract in-depth information between companies based on the industry chain, to support company credit ratings.
## 2. Overview
Please refer to the document for knowledge modeling: [Schema of Enterprise Supply Chain Knowledge Graph](./schema/README.md), As shown in the example below:

Concept knowledge maintains industry chain-related data, including hierarchical relations, supply relations. Entity instances consist of only legal representatives and transfer information. Company instances are linked to product instances based on the attributes of the products they produce, enabling deep information mining between company instances, such as supplier relationships, industry peers, and shared legal representatives. By leveraging deep contextual information, more credit assessment factors can be provided.

Within the industrial chain, categories of product and company events are established. These categories are a combination of indices and trends. For example, an increase in price consists of the index "价格" (price) and the trend "上涨" (rising). Causal knowledge sets the events of a company's profit decrease and cost increase due to a rise in product prices. When a specific event occurs, such as a significant increase in rubber prices, it is categorized under the event of a price increase. As per the causal knowledge, a price increase in a product leads to two event types: a decrease in company profits and an increase in company costs. Consequently, new events are generated:"三角\*\*轮胎公司成本上涨事件" and "三角\*\*轮胎公司利润下跌".
## 3. Quick Start
### 3.1 Precondition
Please refer to [Quick Start](https://openspg.yuque.com/ndx6g9/cwh47i/rs7gr8g4s538b1n7) to install KAG and its dependency OpenSPG server, and learn about using KAG in developer mode.
### 3.2 Steps to reproduce
#### Step 1: Enter the example directory
```bash
cd kag/examples/supplychain
```
#### Step 2: Configure models
Update the generative model configurations ``openie_llm`` and ``chat_llm`` in [kag_config.yaml](./kag_config.yaml).
You need to fill in correct ``api_key``s. If your model providers and model names are different from the default values, you also need to update ``base_url`` and ``model``.
Since the representational model is not used in this example, you can retain the default configuration for the representative model ``vectorize_model``.
#### Step 3: Project initialization
Initiate the project with the following command.
```bash
knext project restore --host_addr http://127.0.0.1:8887 --proj_path .
```
#### Step 4: Create knowledge schema
The schema file has been created and you can execute the following command to submit it:
```bash
knext schema commit
```
Submit the *leadto* relationship logical rules:
```bash
knext schema reg_concept_rule --file ./schema/concept.rule
```
You can refer to [Schema of Enterprise Supply Chain Knowledge Graph](./schema/README.md) for detailed information on schema modeling.
#### Step 5: Knowledge graph construction
Knowledge construction involves importing data into the knowledge graph storage. For data introduction, please refer to the document: [Introduction to Data of Enterprise Supply Chain](./builder/data/README.md).
In this example, we will demonstrate the conversion of structured data and entity linking. For specific details, please refer to the document: [Enterprise Supply Chain Case Knowledge Graph Construction](./builder/README.md).
Submit the knowledge importing tasks.
```bash
cd builder && python indexer.py && cd ..
```
#### Step 6: Executing query tasks for knowledge graph
OpenSPG supports the ISO GQL syntax. You can use the following command-line to execute a query task:
```bash
knext reasoner execute --dsl "${ql}"
```
For specific task details, please refer to the document: [Enterprise Credit Graph Query Tasks in Supply Chain](./reasoner/README.md).
Querying Credit Rating Factors:
```bash
knext reasoner execute --dsl "
MATCH
(s:SupplyChain.Company)
RETURN
s.id, s.name, s.fundTrans1Month, s.fundTrans3Month,
s.fundTrans6Month, s.fundTrans1MonthIn, s.fundTrans3MonthIn,
s.fundTrans6MonthIn, s.cashflowDiff1Month, s.cashflowDiff3Month,
s.cashflowDiff6Month
"
```
```bash
knext reasoner execute --dsl "
MATCH
(s:SupplyChain.Company)-[:mainSupply]->(o:SupplyChain.Company)
RETURN
s.name, o.name
"
```
```bash
knext reasoner execute --dsl "
MATCH
(s:SupplyChain.Company)-[:belongToIndustry]->(o:SupplyChain.Industry)
RETURN
s.name, o.name
"
```
```bash
knext reasoner execute --dsl "
MATCH
(s:SupplyChain.Company)-[:sameLegalRepresentative]->(o:SupplyChain.Company)
RETURN
s.name, o.name
"
```
Analyzing the Impact of an Event:
```bash
knext reasoner execute --dsl "
MATCH
(s:SupplyChain.ProductChainEvent)-[:leadTo]->(o:SupplyChain.CompanyEvent)
RETURN
s.id, s.subject, o.subject, o.name
"
```
#### Step 7: Execute DSL and QA tasks
```bash
python ./solver/qa.py
```
|
{
"source": "OpenSPG/KAG",
"title": "kag/examples/supplychain/README.md",
"url": "https://github.com/OpenSPG/KAG/blob/master/kag/examples/supplychain/README.md",
"date": "2024-09-21T13:56:44",
"stars": 5456,
"description": "KAG is a logical form-guided reasoning and retrieval framework based on OpenSPG engine and LLMs. It is used to build logical reasoning and factual Q&A solutions for professional domain knowledge bases. It can effectively overcome the shortcomings of the traditional RAG vector similarity calculation model.",
"file_size": 6025
}
|
# KAG 示例:企业供应链(SupplyChain)
[English](./README.md) |
[简体中文](./README_cn.md)
## 1. 背景
信贷机构对企业的财务状况、经营状况、市场地位、管理能力等进行综合分析,给予企业一个评级等级,反映其信用状况的好坏,以便支撑信贷业务。在实践中基本依赖被评估企业自身提供的信息,例如企业年报、各类资质文件、资产证明等,这一类信息只能围绕企业自身提供微观层面的信息,不能体现企业在整个产业链上下游市场情况,也无法得到证明之外的信息。
本例基于 SPG 构建产业链企业图谱,挖掘出企业之间基于产业链的深度信息,支持企业信用评级。
## 2. 总览
建模参考 [基于 SPG 建模的产业链企业图谱](./schema/README_cn.md),如下图示意。

概念知识维护着产业链相关数据,包括上下位层级、供应关系;实体实例仅有法人代表、转账信息,公司实例通过生产的产品属性和概念中的产品节点挂载,实现了公司实例之间的深度信息挖掘,例如供应商、同行业、同法人代表等关系。基于深度上下文信息,可提供更多的信用评估因子。

产业链中建立了产品和公司事件类别,该类别属于指标和趋势的一种组合,例如价格上涨,是由指标:价格,趋势:上涨两部分构成。
事理知识设定了产品价格上涨引起公司利润下降及公司成本上涨事件,当发生某个具体事件时,例如“橡胶价格大涨事件”,被归类在产品价格上涨,由于事理知识中定义产品价格上涨会引起公司利润下降/公司成本上涨两个事件类型,会产出新事件:“三角\*\*轮胎公司成本上涨事件”、“三角\*\*轮胎公司利润下跌”。
## 3. Quick Start
### 3.1 前置条件
请参考文档 [快速开始](https://openspg.yuque.com/ndx6g9/0.6/quzq24g4esal7q17) 安装 KAG 及其依赖的 OpenSPG server,并了解开发者模式 KAG 的使用流程。
### 3.2 复现步骤
#### Step 1:进入示例目录
```bash
cd kag/examples/supplychain
```
#### Step 2:配置模型
更新 [kag_config.yaml](./kag_config.yaml) 中的生成模型配置 ``openie_llm`` 和 ``chat_llm``。
您需要设置正确的 ``api_key``。如果使用的模型供应商和模型名与默认值不同,您还需要更新 ``base_url`` 和 ``model``。
在本示例中未使用表示模型,可保持表示模型配置 ``vectorize_model`` 的默认配置。
#### Step 3:初始化项目
先对项目进行初始化。
```bash
knext project restore --host_addr http://127.0.0.1:8887 --proj_path .
```
#### Step 4:知识建模
schema 文件已创建好,可执行如下命令提交。
```bash
knext schema commit
```
提交 *leadto* 关系逻辑规则。
```bash
knext schema reg_concept_rule --file ./schema/concept.rule
```
schema 建模详细内容可参见 [基于 SPG 建模的产业链企业图谱](./schema/README_cn.md)。
#### Step 5:知识构建
知识构建将数据导入到系统中,数据介绍参见文档 [产业链案例数据介绍](./builder/data/README_cn.md)。
本例主要为结构化数据,故演示结构化数据转换和实体链指,具体细节可参见文档 [产业链案例知识构建](./builder/README_cn.md)。
提交知识构建任务导入数据。
```bash
cd builder && python indexer.py && cd ..
```
#### Step 6:执行图谱任务
SPG 支持 ISO GQL 语法,可用如下命令行执行查询任务。
```bash
knext reasoner execute --dsl "${ql}"
```
具体任务详情可参见文档 [产业链企业信用图谱查询任务](./reasoner/README_cn.md)。
查询信用评级因子:
```bash
knext reasoner execute --dsl "
MATCH
(s:SupplyChain.Company)
RETURN
s.id, s.name, s.fundTrans1Month, s.fundTrans3Month,
s.fundTrans6Month, s.fundTrans1MonthIn, s.fundTrans3MonthIn,
s.fundTrans6MonthIn, s.cashflowDiff1Month, s.cashflowDiff3Month,
s.cashflowDiff6Month
"
```
```bash
knext reasoner execute --dsl "
MATCH
(s:SupplyChain.Company)-[:mainSupply]->(o:SupplyChain.Company)
RETURN
s.name, o.name
"
```
```bash
knext reasoner execute --dsl "
MATCH
(s:SupplyChain.Company)-[:belongToIndustry]->(o:SupplyChain.Industry)
RETURN
s.name, o.name
"
```
```bash
knext reasoner execute --dsl "
MATCH
(s:SupplyChain.Company)-[:sameLegalRepresentative]->(o:SupplyChain.Company)
RETURN
s.name, o.name
"
```
事件影响分析:
```bash
knext reasoner execute --dsl "
MATCH
(s:SupplyChain.ProductChainEvent)-[:leadTo]->(o:SupplyChain.CompanyEvent)
RETURN
s.id, s.subject, o.subject, o.name
"
```
#### Step 7:执行 DSL 及 QA 任务
```bash
python ./solver/qa.py
```
|
{
"source": "OpenSPG/KAG",
"title": "kag/examples/supplychain/README_cn.md",
"url": "https://github.com/OpenSPG/KAG/blob/master/kag/examples/supplychain/README_cn.md",
"date": "2024-09-21T13:56:44",
"stars": 5456,
"description": "KAG is a logical form-guided reasoning and retrieval framework based on OpenSPG engine and LLMs. It is used to build logical reasoning and factual Q&A solutions for professional domain knowledge bases. It can effectively overcome the shortcomings of the traditional RAG vector similarity calculation model.",
"file_size": 3113
}
|
# Enterprise Supply Chain Case Knowledge Graph Construction
[English](./README.md) |
[简体中文](./README_cn.md)
In this example, all the data are structured. There are two main capabilities required in to import the data:
* Structured Mapping: The original data and the schema-defined fields are not completely consistent, so a data field mapping process needs to be defined.
* Entity Linking: In relationship building, entity linking is a very important construction method. This example demonstrates a simple case of implementing entity linking capability for companies.
## 1. Structured Mapping from Source Data to SPG Data
Taking the import of ``Company`` instances as an example:
```text
id,name,products
CSF0000000254,北大*药*份限公司,"医疗器械批发,医药批发,制药,其他化学药品"
```
The code for importing ``Company`` instances is as follows:
```python
class SupplyChainDefaulStructuredBuilderChain(BuilderChainABC):
def __init__(self, spg_type_name: str):
super().__init__()
self.spg_type_name = spg_type_name
def build(self, **kwargs):
"""
Builds the processing chain for the SPG.
Args:
**kwargs: Additional keyword arguments.
Returns:
chain: The constructed processing chain.
"""
self.mapping = SPGTypeMapping(spg_type_name=self.spg_type_name)
self.sink = KGWriter()
self.vectorizer = BatchVectorizer.from_config(
KAG_CONFIG.all_config["chain_vectorizer"]
)
chain = self.mapping >> self.vectorizer >> self.sink
return chain
def get_component_with_ckpts(self):
return [
self.vectorizer,
]
```
In general, this mapping relationship can satisfy the import of structured data. However, in some scenarios, it may be necessary to manipulate the data to meet specific requirements. In such cases, we need to implemented a user-defined operator.
## 2. User-defined Entity Linking Operator
Consider the following data:
```text
id,name,age,legalRep
0,路**,63,"新疆*花*股*限公司,三角*胎股*限公司,传化*联*份限公司"
```
The ``legalRep`` field is the company name, but the company ID is set as the primary key, it is not possible to directly associate the company name with a specific company. Assuming there is a search service available that can convert the company name to an ID, a user-defined linking operator needs to be developed to perform this conversion.
```python
def company_link_func(prop_value, node):
sc = SearchClient(KAG_PROJECT_CONF.host_addr, KAG_PROJECT_CONF.project_id)
company_id = []
records = sc.search_text(
prop_value, label_constraints=["SupplyChain.Company"], topk=1
)
if records:
company_id.append(records[0]["node"]["id"])
return company_id
class SupplyChainPersonChain(BuilderChainABC):
def __init__(self, spg_type_name: str):
# super().__init__()
self.spg_type_name = spg_type_name
def build(self, **kwargs):
self.mapping = (
SPGTypeMapping(spg_type_name=self.spg_type_name)
.add_property_mapping("name", "name")
.add_property_mapping("id", "id")
.add_property_mapping("age", "age")
.add_property_mapping(
"legalRepresentative",
"legalRepresentative",
link_func=company_link_func,
)
)
self.vectorizer = BatchVectorizer.from_config(
KAG_CONFIG.all_config["chain_vectorizer"]
)
self.sink = KGWriter()
return self.mapping >> self.vectorizer >> self.sink
def get_component_with_ckpts(self):
return [
self.vectorizer,
]
def close_checkpointers(self):
for node in self.get_component_with_ckpts():
if node and hasattr(node, "checkpointer"):
node.checkpointer.close()
```
|
{
"source": "OpenSPG/KAG",
"title": "kag/examples/supplychain/builder/README.md",
"url": "https://github.com/OpenSPG/KAG/blob/master/kag/examples/supplychain/builder/README.md",
"date": "2024-09-21T13:56:44",
"stars": 5456,
"description": "KAG is a logical form-guided reasoning and retrieval framework based on OpenSPG engine and LLMs. It is used to build logical reasoning and factual Q&A solutions for professional domain knowledge bases. It can effectively overcome the shortcomings of the traditional RAG vector similarity calculation model.",
"file_size": 3857
}
|
# 产业链案例知识构建
[English](./README.md) |
[简体中文](./README_cn.md)
本例中数据均为结构化数据,导入数据主要需要两个能力:
* 结构化 mapping:原始数据和 schema 定义表字段并不完全一致,需要定义数据字段映射过程。
* 实体链指:在关系构建中,实体链指是非常重要的建设手段,本例演示一个简单 case,实现公司的链指能力。
本例中的代码可在 [kag/examples/supplychain/builder/indexer.py](./indexer.py) 中查看。
## 1. 源数据到 SPG 数据的 mapping 能力
以导入 Company 数据为例:
```text
id,name,products
CSF0000000254,北大*药*份限公司,"医疗器械批发,医药批发,制药,其他化学药品"
```
导入 Company 的代码如下:
```python
class SupplyChainDefaulStructuredBuilderChain(BuilderChainABC):
def __init__(self, spg_type_name: str):
super().__init__()
self.spg_type_name = spg_type_name
def build(self, **kwargs):
"""
Builds the processing chain for the SPG.
Args:
**kwargs: Additional keyword arguments.
Returns:
chain: The constructed processing chain.
"""
self.mapping = SPGTypeMapping(spg_type_name=self.spg_type_name)
self.sink = KGWriter()
self.vectorizer = BatchVectorizer.from_config(
KAG_CONFIG.all_config["chain_vectorizer"]
)
chain = self.mapping >> self.vectorizer >> self.sink
return chain
def get_component_with_ckpts(self):
return [
self.vectorizer,
]
```
一般情况下这种映射关系基本能够满足结构化数据导入,但在一些场景下可能需要对数据进行部分数据才能满足要求,此时就需要实现自定义算子来处理问题。
## 2. 自定义算子实现链指能力
假设有如下数据:
```text
id,name,age,legalRep
0,路**,63,"新疆*花*股*限公司,三角*胎股*限公司,传化*联*份限公司"
```
``legalRep`` 字段为公司名字,但在系统中已经将公司 ``id`` 设置成为主键,直接通过公司名是无法关联到具体公司,假定存在一个搜索服务,可将公司名转换为 ``id``,此时需要自定开发一个链指算子,实现该过程的转换:
```python
def company_link_func(prop_value, node):
sc = SearchClient(KAG_PROJECT_CONF.host_addr, KAG_PROJECT_CONF.project_id)
company_id = []
records = sc.search_text(
prop_value, label_constraints=["SupplyChain.Company"], topk=1
)
if records:
company_id.append(records[0]["node"]["id"])
return company_id
class SupplyChainPersonChain(BuilderChainABC):
def __init__(self, spg_type_name: str):
# super().__init__()
self.spg_type_name = spg_type_name
def build(self, **kwargs):
self.mapping = (
SPGTypeMapping(spg_type_name=self.spg_type_name)
.add_property_mapping("name", "name")
.add_property_mapping("id", "id")
.add_property_mapping("age", "age")
.add_property_mapping(
"legalRepresentative",
"legalRepresentative",
link_func=company_link_func,
)
)
self.vectorizer = BatchVectorizer.from_config(
KAG_CONFIG.all_config["chain_vectorizer"]
)
self.sink = KGWriter()
return self.mapping >> self.vectorizer >> self.sink
def get_component_with_ckpts(self):
return [
self.vectorizer,
]
def close_checkpointers(self):
for node in self.get_component_with_ckpts():
if node and hasattr(node, "checkpointer"):
node.checkpointer.close()
```
|
{
"source": "OpenSPG/KAG",
"title": "kag/examples/supplychain/builder/README_cn.md",
"url": "https://github.com/OpenSPG/KAG/blob/master/kag/examples/supplychain/builder/README_cn.md",
"date": "2024-09-21T13:56:44",
"stars": 5456,
"description": "KAG is a logical form-guided reasoning and retrieval framework based on OpenSPG engine and LLMs. It is used to build logical reasoning and factual Q&A solutions for professional domain knowledge bases. It can effectively overcome the shortcomings of the traditional RAG vector similarity calculation model.",
"file_size": 3003
}
|
# Enterprise Credit Graph Query Tasks in Supply Chain
[English](./README.md) |
[简体中文](./README_cn.md)
## Scenario 1: Generation of Enterprise Credit Rating Features
Requirement: In enterprise credit rating, the following decision factors are needed:
1. Primary supplier relations
2. Industry of the products produced by the enterprise
3. Transfer transaction records of funds for the past 1 month, 3 months, and 6 months
4. Difference in funds flow for the past 1 month, 3 months, and 6 months
5. Information on related companies controlled by the ultimate beneficial owner
However, in the original knowledge graph, only fund transfer transactions and legal representative information are available, making it impossible to directly obtain the above features. This example demonstrates how to use OpenSPG to obtain these 5 features.
The feature definitions are present in the schema file, which can be viewed by clicking [SupplyChain.schema](../schema/SupplyChain.schema).
**Feature 1: Defining primary supply chain relations between companies**
with the following rule definition:
```text
Define (s:Compnay)-[p:mainSupply]->(o:Company) {
Structure {
(s)-[:product]->(upProd:Product)-[:hasSupplyChain]->(downProd:Product)<-[:product]-(o),
(o)-[f:fundTrans]->(s)
(otherCompany:Company)-[otherf:fundTrans]->(s)
}
Constraint {
// Compute the percentage of incoming transfers for company `o`
otherTransSum("Total amount of incoming transfers") = group(s).sum(otherf.transAmt)
targetTransSum("Total amount of transfers received by company o") = group(s,o).sum(f.transAmt)
transRate = targetTransSum*1.0/(otherTransSum + targetTransSum)
R1("The percentage must be over 50%"): transRate > 0.5
}
}
```
**Feature 2: Industry of the Products Produced by the Enterprise**
```text
Define (s:Compnay)-[p:belongToIndustry]->(o:Industry) {
Structure {
(s)-[:product]->(c:Product)-[:belongToIndustry]->(o)
}
Constraint {
}
}
```
**Feature 3: Transfer transaction records of funds for the past 1 month, 3 months, and 6 months**
```text
// Amount of outgoing transfers for the past 1 month
Define (s:Compnay)-[p:fundTrans1Month]->(o:Int) {
Structure {
(s)-[f:fundTrans]->(c:Company)
}
Constraint {
R1("Transactions within the past 1 month"): date_diff(from_unix_time(now(), 'yyyyMMdd'),f.transDate) < 30
totalOut = group(s).sum(transAmt)
o = totalOut
}
}
// Amount of outgoing transfers for the past 3 month
Define (s:Compnay)-[p:fundTrans3Month]->(o:Int) {
Structure {
(s)-[f:fundTrans]->(c:Company)
}
Constraint {
R1("Transactions within the past 4 month"): date_diff(from_unix_time(now(), 'yyyyMMdd'),f.transDate) < 90
totalOut = group(s).sum(transAmt)
o = totalOut
}
}
// Amount of outgoing transfers for the past 6 month
Define (s:Compnay)-[p:fundTrans6Month]->(o:Int) {
Structure {
(s)-[f:fundTrans]->(c:Company)
}
Constraint {
R1("Transactions within the past 6 month"): date_diff(from_unix_time(now(), 'yyyyMMdd'),f.transDate) < 180
totalOut = group(s).sum(transAmt)
o = totalOut
}
}
// Amount of incoming transfers for the past 1 month
Define (s:Compnay)-[p:fundTrans1MonthIn]->(o:Int) {
Structure {
(s)<-[f:fundTrans]-(c:Company)
}
Constraint {
R1("Transactions within the past 1 month"): date_diff(from_unix_time(now(), 'yyyyMMdd'),f.transDate) < 30
totalOut = group(s).sum(transAmt)
o = totalOut
}
}
// Amount of incoming transfers for the past 3 month
Define (s:Compnay)-[p:fundTrans3MonthIn]->(o:Int) {
Structure {
(s)<-[f:fundTrans]-(c:Company)
}
Constraint {
R1("Transactions within the past 3 month"): date_diff(from_unix_time(now(), 'yyyyMMdd'),f.transDate) < 90
totalOut = group(s).sum(transAmt)
o = totalOut
}
}
// Amount of incoming transfers for the past 6 month
Define (s:Compnay)-[p:fundTrans6MonthIn]->(o:Int) {
Structure {
(s)<-[f:fundTrans]-(c:Company)
}
Constraint {
R1("Transactions within the past 6 month"): date_diff(from_unix_time(now(), 'yyyyMMdd'),f.transDate) < 180
totalOut = group(s).sum(transAmt)
o = totalOut
}
}
```
**Feature 4: Difference in funds flow for the past 1 month, 3 months, and 6 months**
```text
// Funds flow difference in the past 1 month
Define (s:Company)-[p:cashflowDiff1Month]->(o:Integer) {
Structure {
(s)
}
Constraint {
// Refer to the rule in Feature 3
fundTrans1Month = rule_value(s.fundTrans1Month == null, 0, s.fundTrans1Month)
fundTrans1MonthIn = rule_value(s.fundTrans1MonthIn == null, 0, s.fundTrans1MonthIn)
o = fundTrans1Month - fundTrans1MonthIn
}
}
// Funds flow difference in the past 3 month
Define (s:Company)-[p:cashflowDiff3Month]->(o:Integer) {
Structure {
(s)
}
Constraint {
// Refer to the rule in Feature 3
fundTrans3Month = rule_value(s.fundTrans3Month == null, 0, s.fundTrans3Month)
fundTrans3MonthIn = rule_value(s.fundTrans3MonthIn == null, 0, s.fundTrans3MonthIn)
o = fundTrans3Month - fundTrans3MonthIn
}
}
// Funds flow difference in the past 6 month
Define (s:Company)-[p:cashflowDiff6Month]->(o:Integer) {
Structure {
(s)
}
Constraint {
fundTrans6Month = rule_value(s.fundTrans6Month == null, 0, s.fundTrans6Month)
fundTrans6MonthIn = rule_value(s.fundTrans6MonthIn == null, 0, s.fundTrans6MonthIn)
o = fundTrans6Month - fundTrans6MonthIn
}
}
```
**Feature 5: Information on related companies controlled by the ultimate beneficial owner**
```text
// Definition of the "same legal reprensentative" relation
Define (s:Compnay)-[p:sameLegalReprensentative]->(o:Company) {
Structure {
(s)<-[:legalReprensentative]-(u:Person)-[:legalReprensentative]->(o)
}
Constraint {
}
}
```
Obtaining specific features of a particular company through GQL using the following query:
```cypher
MATCH
(s:SupplyChain.Company)
RETURN
s.id, s.fundTrans1Month, s.fundTrans3Month,
s.fundTrans6Month, s.fundTrans1MonthIn, s.fundTrans3MonthIn,
s.fundTrans6MonthIn, s.cashflowDiff1Month, s.cashflowDiff3Month, s.cashflowDiff6Month
```
```cypher
MATCH
(s:SupplyChain.Company)-[:mainSupply]->(o:SupplyChain.Company)
RETURN
s.id, o.id
```
```cypher
MATCH
(s:SupplyChain.Company)-[:belongToIndustry]->(o:SupplyChain.Industry)
RETURN
s.id, o.id
```
```cypher
MATCH
(s:SupplyChain.Company)-[:sameLegalRepresentative]->(o:SupplyChain.Company)
RETURN
s.id, o.id
```
## Scenario 2: Change in the company's supply chain
Suppose that there is a change in the products produced by the company:
```text
"钱****份限公司"发布公告,生产产品“三轮摩托车,二轮摩托车”变更为“两轮摩托车”,则"三角**轮胎股份"和钱"****份限公司"的主供应链关系自动断裂,"三角**轮胎股份"和"钱****份限公司"不再具有主供应链关系
```
The updated data is available in ``CompanyUpdate.csv``:
```text
id,name,products
CSF0000001662,浙江**摩托**限公司,"汽车-摩托车制造-二轮摩托车"
```
resubmit the building task:
```bash
knext builder execute CompanyUpdate
```
After the execution is completed, if you query again, only the Two-Wheeled Motorcycle will be returned, and the Three-Wheeled Motorcycle will no longer be associated.
```cypher
MATCH
(s:SupplyChain.Company)-[:product]->(o:SupplyChain.Product)
WHERE
s.id = "CSF0000001662"
RETURN
s.id, o.id
```
## Scenario 3: Impact on the Supply Chain Event
The event details are as follows:
```text
id,name,subject,index,trend
1,顺丁橡胶成本上涨,商品化工-橡胶-合成橡胶-顺丁橡胶,价格,上涨
```
submit the building task of the event type:
```bash
knext builder execute ProductChainEvent
```
The transmission linkages are as follows:

Butadiene rubber costs rise, classified as an event of price increase in the supply chain.
The logical rule expression is as follows:
```text
// When the attributes of ProductChainEvent satisfy the condition of price increase,
// the event is classified as a price increase event.
Define (e:ProductChainEvent)-[p:belongTo]->(o:`TaxonofProductChainEvent`/`价格上涨`) {
Structure {
}
Constraint {
R1: e.index == '价格'
R2: e.trend == '上涨'
}
}
```
Price increase in the supply chain, under the following conditions, will result in cost rise for specific companies.
```text
// The rules for price increase and increase in company costs are defined as follows.
Define (s:`TaxonofProductChainEvent`/`价格上涨`)-[p:leadTo]->(o:`TaxonofCompanyEvent`/`成本上涨`) {
Structure {
//1. Find the subject of the supply chain event, which is butadiene rubber in this case
//2. Identify the downstream products of butadiene rubber, which are bias tires in this case
//3. Identify all the companies that produce bias tires, which is "Triangle** Tire Co., Ltd." in this case
(s)-[:subject]->[prod:Product]-[:hasSupplyChain]->(down:Product)<-[:product]-(c:Company)
}
Constraint {
}
Action {
// Create a company cost increase event with the subject being the obtained "Triangle** Tire Co., Ltd."
downEvent = createNodeInstance(
type=CompanyEvent,
value={
subject=c.id
trend="上涨"
index="成本"
}
)
// Since this event is caused by a price increase in the supply chain, add an edge between them.
createEdgeInstance(
src=s,
dst=downEvent,
type=leadTo,
value={
}
)
}
}
```
You can find the impact of a specific event by using the following query statement.
```cypher
MATCH
(s:SupplyChain.ProductChainEvent)-[:leadTo]->(o:SupplyChain.CompanyEvent)
RETURN
s.id,s.subject,o.subject,o.name
```
|
{
"source": "OpenSPG/KAG",
"title": "kag/examples/supplychain/reasoner/README.md",
"url": "https://github.com/OpenSPG/KAG/blob/master/kag/examples/supplychain/reasoner/README.md",
"date": "2024-09-21T13:56:44",
"stars": 5456,
"description": "KAG is a logical form-guided reasoning and retrieval framework based on OpenSPG engine and LLMs. It is used to build logical reasoning and factual Q&A solutions for professional domain knowledge bases. It can effectively overcome the shortcomings of the traditional RAG vector similarity calculation model.",
"file_size": 9978
}
|
# 产业链企业信用图谱查询任务
[English](./README.md) |
[简体中文](./README_cn.md)
## 场景 1:企业信用评级特征生成
需求:在企业信用评级中,假定需要得到如下决策因子
1. 主供应商关系
2. 企业生产产品所在行业
3. 企业资金近 1 月、3 月、6 月转账流水
4. 企业资金近 1 月、3 月、6 月流水差
5. 实控人相关公司信息
但在原有图谱中,只有资金转账、法人代表信息,无法直接获取上述特征,本例演示如何通过 SPG 完成如上 5 个特征获取。
特征定义在 schema 文件中,可点击查看企业供应链图谱 schema [SupplyChain.schema](./SupplyChain.schema)。
**特征 1:先定义企业和企业间的主供应链关系,规则定义如下**
```text
Define (s:Compnay)-[p:mainSupply]->(o:Company) {
Structure {
(s)-[:product]->(upProd:Product)-[:hasSupplyChain]->(downProd:Product)<-[:product]-(o),
(o)-[f:fundTrans]->(s)
(otherCompany:Company)-[otherf:fundTrans]->(s)
}
Constraint {
// 计算公司o的转入占比
otherTransSum("总共转入金额") = group(s).sum(otherf.transAmt)
targetTransSum("o转入的金额总数") = group(s,o).sum(f.transAmt)
transRate = targetTransSum*1.0/(otherTransSum + targetTransSum)
R1("占比必须超过50%"): transRate > 0.5
}
}
```
**特征 2:企业生成产品所在行业**
```text
Define (s:Compnay)-[p:belongToIndustry]->(o:Industry) {
Structure {
(s)-[:product]->(c:Product)-[:belongToIndustry]->(o)
}
Constraint {
}
}
```
**特征 3:企业资金近 1 月、3 月、6 月转账流水**
```text
// 近1个月流出金额
Define (s:Compnay)-[p:fundTrans1Month]->(o:Int) {
Structure {
(s)-[f:fundTrans]->(c:Company)
}
Constraint {
R1("近1个月的流出资金"): date_diff(from_unix_time(now(), 'yyyyMMdd'),f.transDate) < 30
totalOut = group(s).sum(transAmt)
o = totalOut
}
}
// 近3个月流出金额
Define (s:Compnay)-[p:fundTrans3Month]->(o:Int) {
Structure {
(s)-[f:fundTrans]->(c:Company)
}
Constraint {
R1("近4个月的流出资金"): date_diff(from_unix_time(now(), 'yyyyMMdd'),f.transDate) < 90
totalOut = group(s).sum(transAmt)
o = totalOut
}
}
// 近6个月流出金额
Define (s:Compnay)-[p:fundTrans6Month]->(o:Int) {
Structure {
(s)-[f:fundTrans]->(c:Company)
}
Constraint {
R1("近5个月的流出资金"): date_diff(from_unix_time(now(), 'yyyyMMdd'),f.transDate) < 180
totalOut = group(s).sum(transAmt)
o = totalOut
}
}
// 近1个月流入金额
Define (s:Compnay)-[p:fundTrans1MonthIn]->(o:Int) {
Structure {
(s)<-[f:fundTrans]-(c:Company)
}
Constraint {
R1("近1个月的流入资金"): date_diff(from_unix_time(now(), 'yyyyMMdd'),f.transDate) < 30
totalOut = group(s).sum(transAmt)
o = totalOut
}
}
// 近3个月流入金额
Define (s:Compnay)-[p:fundTrans3MonthIn]->(o:Int) {
Structure {
(s)<-[f:fundTrans]-(c:Company)
}
Constraint {
R1("近3个月的流入资金"): date_diff(from_unix_time(now(), 'yyyyMMdd'),f.transDate) < 90
totalOut = group(s).sum(transAmt)
o = totalOut
}
}
// 近6个月流入金额
Define (s:Compnay)-[p:fundTrans6MonthIn]->(o:Int) {
Structure {
(s)<-[f:fundTrans]-(c:Company)
}
Constraint {
R1("近6个月的流入资金"): date_diff(from_unix_time(now(), 'yyyyMMdd'),f.transDate) < 180
totalOut = group(s).sum(transAmt)
o = totalOut
}
}
```
**特征 4:企业资金近 1 月、3 月、6 月流水差**
```text
// 近1个月资金流水差
Define (s:Company)-[p:cashflowDiff1Month]->(o:Integer) {
Structure {
(s)
}
Constraint {
// 此处引用特征3中的规则
fundTrans1Month = rule_value(s.fundTrans1Month == null, 0, s.fundTrans1Month)
fundTrans1MonthIn = rule_value(s.fundTrans1MonthIn == null, 0, s.fundTrans1MonthIn)
o = fundTrans1Month - fundTrans1MonthIn
}
}
// 近3个月资金流水差
Define (s:Company)-[p:cashflowDiff3Month]->(o:Integer) {
Structure {
(s)
}
Constraint {
// 此处引用特征3中的规则
fundTrans3Month = rule_value(s.fundTrans3Month == null, 0, s.fundTrans3Month)
fundTrans3MonthIn = rule_value(s.fundTrans3MonthIn == null, 0, s.fundTrans3MonthIn)
o = fundTrans3Month - fundTrans3MonthIn
}
}
// 近6个月资金流水差
Define (s:Company)-[p:cashflowDiff6Month]->(o:Integer) {
Structure {
(s)
}
Constraint {
fundTrans6Month = rule_value(s.fundTrans6Month == null, 0, s.fundTrans6Month)
fundTrans6MonthIn = rule_value(s.fundTrans6MonthIn == null, 0, s.fundTrans6MonthIn)
o = fundTrans6Month - fundTrans6MonthIn
}
}
```
**特征 5:同实控人公司**
```text
// 定义同法人关系
Define (s:Compnay)-[p:sameLegalReprensentative]->(o:Company) {
Structure {
(s)<-[:legalReprensentative]-(u:Person)-[:legalReprensentative]->(o)
}
Constraint {
}
}
```
通过如下 GQL 执行得到某个公司的具体特征:
```cypher
MATCH
(s:SupplyChain.Company)
RETURN
s.id, s.fundTrans1Month, s.fundTrans3Month,
s.fundTrans6Month, s.fundTrans1MonthIn, s.fundTrans3MonthIn,
s.fundTrans6MonthIn, s.cashflowDiff1Month, s.cashflowDiff3Month, s.cashflowDiff6Month
```
```cypher
MATCH
(s:SupplyChain.Company)-[:mainSupply]->(o:SupplyChain.Company)
RETURN
s.id, o.id
```
```cypher
MATCH
(s:SupplyChain.Company)-[:belongToIndustry]->(o:SupplyChain.Industry)
RETURN
s.id, o.id
```
```cypher
MATCH
(s:SupplyChain.Company)-[:sameLegalRepresentative]->(o:SupplyChain.Company)
RETURN
s.id, o.id
```
## 场景 2:企业供应链发生变化
假设供应链发生如下变化:
```text
"钱****份限公司"发布公告,生产产品“三轮摩托车,二轮摩托车”变更为“两轮摩托车”,则"三角**轮胎股份"和钱"****份限公司"的主供应链关系自动断裂,"三角**轮胎股份"和"钱****份限公司"不再具有主供应链关系
```
变更后的数据保存在 ``CompanyUpdate.csv``:
```text
id,name,products
CSF0000001662,浙江**摩托**限公司,"汽车-摩托车制造-二轮摩托车"
```
重新提交任务:
```bash
knext builder execute CompanyUpdate
```
执行完成后再次查询,只会返回二轮摩托车,而三轮摩托车不再被关联:
```cypher
MATCH
(s:SupplyChain.Company)-[:product]->(o:SupplyChain.Product)
WHERE
s.id = "CSF0000001662"
RETURN
s.id, o.id
```
## 场景 3:产业链影响
事件内容如下:
```text
id,name,subject,index,trend
1,顺丁橡胶成本上涨,商品化工-橡胶-合成橡胶-顺丁橡胶,价格,上涨
```
提交事件数据:
```bash
knext builder execute ProductChainEvent
```
传导链路如下:

顺丁橡胶成本上升,被分类为产业链价格上涨事件,如下 DSL:
```text
// ProductChainEvent为一个具体的事件实例,当其属性满足价格上涨条件时,该事件分类为价格上涨事件
Define (e:ProductChainEvent)-[p:belongTo]->(o:`TaxonofProductChainEvent`/`价格上涨`) {
Structure {
}
Constraint {
R1: e.index == '价格'
R2: e.trend == '上涨'
}
}
```
产业链价格上涨,在如下条件下,会导致特定公司的成本上升。
```text
// 定义了价格上涨和企业成本上升的规则
Define (s:`TaxonofProductChainEvent`/`价格上涨`)-[p:leadTo]->(o:`TaxonofCompanyEvent`/`成本上涨`) {
Structure {
//1、找到产业链事件的主体,本例中为顺丁橡胶
//2、找到顺丁橡胶的下游产品,本例中为斜交轮胎
//3、找到生成斜交轮胎的所有企业,本例中为三角**轮胎股份
(s)-[:subject]->[prod:Product]-[:hasSupplyChain]->(down:Product)<-[:product]-(c:Company)
}
Constraint {
}
Action {
// 创建一个公司成本上升事件,主体为查询得到的三角**轮胎股份
downEvent = createNodeInstance(
type=CompanyEvent,
value={
subject=c.id
trend="上涨"
index="成本"
}
)
// 由于这个事件是通过产业链价格上涨引起,故在两者之间增加一条边
createEdgeInstance(
src=s,
dst=downEvent,
type=leadTo,
value={
}
)
}
}
```
可通过如下查询语句查出某个事件产生的影响。
```cypher
MATCH
(s:SupplyChain.ProductChainEvent)-[:leadTo]->(o:SupplyChain.CompanyEvent)
RETURN
s.id,s.subject,o.subject,o.name
```
|
{
"source": "OpenSPG/KAG",
"title": "kag/examples/supplychain/reasoner/README_cn.md",
"url": "https://github.com/OpenSPG/KAG/blob/master/kag/examples/supplychain/reasoner/README_cn.md",
"date": "2024-09-21T13:56:44",
"stars": 5456,
"description": "KAG is a logical form-guided reasoning and retrieval framework based on OpenSPG engine and LLMs. It is used to build logical reasoning and factual Q&A solutions for professional domain knowledge bases. It can effectively overcome the shortcomings of the traditional RAG vector similarity calculation model.",
"file_size": 7078
}
|
# Schema of Enterprise Supply Chain Knowledge Graph
[English](./README.md) |
[简体中文](./README_cn.md)
## 1. Schema details
For an introduction of OpenSPG schema, please refer to [Declarative Schema](https://openspg.yuque.com/ndx6g9/cwh47i/fiq6zum3qtzr7cne).
For the modeling of the Enterprise Supply Chain Knowledge Graph, please refer to the schema source file [SupplyChain.schema](./SupplyChain.schema).
Execute the following command to finish creating the schema:
```bash
knext schema commit
```
## 2. SPG Modeling vs Property Graph Modeling
This section will compare the differences between SPG semantic modeling and regular modeling.
### 2.1 Semantic Attributes vs Text Attributes
Assuming the following information related the company exists:
"北大药份限公司" produces four products: "医疗器械批发,医药批发,制药,其他化学药品".
```text
id,name,products
CSF0000000254,北大*药*份限公司,"医疗器械批发,医药批发,制药,其他化学药品"
```
#### 2.1.1 Modeling based on text attributes
```text
//Text Attributes
Company(企业): EntityType
properties:
product(经营产品): Text
```
At this moment, the products are only represented as text without semantic information. It is not possible to obtain the upstream and downstream industry chain related information for "北大药份限公司", which is inconvenient for maintenance and usage.
#### 2.1.2 Modeling based on relations
To achieve better maintenance and management of the products, it is generally recommended to represent the products as entities and establish relations between the company and its products.
```text
Product(产品): EntityType
properties:
name(产品名): Text
relations:
isA(上位产品): Product
Company(企业): EntityType
relations:
product(经营产品): Product
```
However, such modeling method requires the data to be divided into four columns:
```text
id,name,product
CSF0000000254,北大*药*份限公司,医疗器械批发
CSF0000000254,北大*药*份限公司,医药批发
CSF0000000254,北大*药*份限公司,制药
CSF0000000254,北大*药*份限公司,其他化学药品
```
This approach has two disadvantages:
1. The raw data needs to be cleaned and converted into multiple rows.
2. It requires adding and maintaining relation data. When the original data changes, the existing relations need to be deleted and new data needs to be added, which can lead to data errors.
#### 2.1.3 Modeling based on SPG semantic attributes
SPG supports semantic attributes, which can simplify knowledge construction.
The modeling can be done as follows:
```text
Product(产品): ConceptType
hypernymPredicate: isA
Company(企业): EntityType
properties:
product(经营产品): Product
constraint: MultiValue
```
In this model, the ``Company`` entity has a property called "经营产品" (Business Product), which is ``Product`` type. By importing the following data, the conversion from attribute to relation can be automatically achieved.
```text
id,name,products
CSF0000000254,北大*药*份限公司,"医疗器械批发,医药批发,制药,其他化学药品"
```
### 2.2 Logical Expression of Attributes and Relationships vs Data Representation of Attributes and Relationships
Assuming the goal is to obtain the industry of a company. Based on the available data, the following query can be executed:
```cypher
MATCH
(s:Company)-[:product]->(o:Product)-[:belongToIndustry]->(i:Industry)
RETURN
s.id, i.id
```
This approach requires familiarity with the graph schema and has a higher learning curve for users. Therefore, another practice is to re-import these types of attributes into the knowledge graph, as shown below:
```text
Company(企业): EntityType
properties:
product(经营产品): Product
constraint: MultiValue
relations:
belongToIndustry(所在行业): Industry
```
To directly obtain the industry information of a company, a new relation type can be added. However, there are two main drawbacks to this approach:
1. It requires manual maintenance of the newly added relation data, increasing the cost of maintenance.
2. Due to the dependency on the source of the new relation and the knowledge graph data, it is very easy to introduce inconsistencies.
To address these drawbacks, OpenSPG supports logical expression of attributes and relations.
The modeling can be done as follows:
```text
Company(企业): EntityType
properties:
product(经营产品): Product
constraint: MultiValue
relations:
belongToIndustry(所在行业): Industry
rule: [[
Define (s:Company)-[p:belongToIndustry]->(o:Industry) {
Structure {
(s)-[:product]->(c:Product)-[:belongToIndustry]->(o)
}
Constraint {
}
}
]]
```
You can refer to the examples in Scenario 1 and Scenario 2 of the [Enterprise Credit Graph Query Tasks in Supply Chain](../reasoner/README.md) for specific details.
### 2.3 Concepts vs Entities
Existing knowledge graph solutions also include common sense knowledge graphs such as ConceptNet. In practical business applications, different domains have their own categorical systems that reflect the semantic understanding of the business. There is no universal common sense graph that can be applied to all business scenarios. Therefore, a common practice is to create the domain-specific categorical system as entities and mix them with other entity data. This approach leads to the need for both schema extension modeling and fine-grained semantic modeling on the same categorical system. The coupling of data structure definition and semantic modeling results in complexity in engineering implementation and maintenance management. It also increases the difficulty in organizing and representing (cognitive) domain knowledge.
OpenSPG distinguishes between concepts and entities to decouple semantics from data. This helps address the challenges mentioned above.
```text
Product(产品): ConceptType
hypernymPredicate: isA
Company(企业): EntityType
properties:
product(经营产品): Product
constraint: MultiValue
```
Products are defined as concepts, while companies are defined as entities, evolving independently. They are linked together using semantic attributes provided by OpenSPG, eliminating the need for manual maintenance of associations between companies and products.
### 2.4 Event Representation in Spatio-Temporal Context
The representation of events with multiple elements is indeed a type of lossless representation using a hypergraph structure. It expresses the spatio-temporal relations of multiple elements. Events are temporary associations of various elements caused by certain actions. Once the action is completed, the association disappears. In traditional property graphs, events can only be replaced by entities, and the event content is expressed using textual attributes. An example of such an event is shown below:

```text
Event(事件):
properties:
eventTime(发生时间): Long
subject(涉事主体): Text
object(客体): Text
place(地点): Text
industry(涉事行业): Text
```
This representation method is unable to capture the multidimensional associations of real events. OpenSPG provides event modeling that enables the association of multiple elements in an event, as shown below.
```text
CompanyEvent(公司事件): EventType
properties:
subject(主体): Company
index(指标): Index
trend(趋势): Trend
belongTo(属于): TaxOfCompanyEvent
```
In the above event, all attribute types are defined SPG types, without any basic type expressions. OpenSPG utilizes this declaration to implement the expression of multiple elements in an event. Specific application examples can be found in the detailed description of Scenario 3 in the [Enterprise Credit Graph Query Tasks in Supply Chain](../reasoner/README.md) document.
|
{
"source": "OpenSPG/KAG",
"title": "kag/examples/supplychain/schema/README.md",
"url": "https://github.com/OpenSPG/KAG/blob/master/kag/examples/supplychain/schema/README.md",
"date": "2024-09-21T13:56:44",
"stars": 5456,
"description": "KAG is a logical form-guided reasoning and retrieval framework based on OpenSPG engine and LLMs. It is used to build logical reasoning and factual Q&A solutions for professional domain knowledge bases. It can effectively overcome the shortcomings of the traditional RAG vector similarity calculation model.",
"file_size": 7816
}
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.