
problem_id
stringlengths 18
22
| source
stringclasses 1
value | task_type
stringclasses 1
value | in_source_id
stringlengths 13
58
| prompt
stringlengths 1.71k
18.9k
| golden_diff
stringlengths 145
5.13k
| verification_info
stringlengths 465
23.6k
| num_tokens_prompt
int64 556
4.1k
| num_tokens_diff
int64 47
1.02k
|
|---|---|---|---|---|---|---|---|---|
gh_patches_debug_23012
|
rasdani/github-patches
|
git_diff
|
tensorflow__addons-549
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Package TFA 0.5.2 pinned to TF2-RC2
RC2 is released so we can do a minor release pinned to this. For now this is blocked until #539 is merged.
</issue>
<code>
[start of setup.py]
1 # Copyright 2019 The TensorFlow Authors. All Rights Reserved.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14 # ==============================================================================
15 """TensorFlow Addons.
16
17 TensorFlow Addons is a repository of contributions that conform to well-
18 established API patterns, but implement new functionality not available
19 in core TensorFlow. TensorFlow natively supports a large number of
20 operators, layers, metrics, losses, and optimizers. However, in a fast
21 moving field like ML, there are many interesting new developments that
22 cannot be integrated into core TensorFlow (because their broad
23 applicability is not yet clear, or it is mostly used by a smaller subset
24 of the community).
25 """
26
27 from __future__ import absolute_import
28 from __future__ import division
29 from __future__ import print_function
30
31 import os
32 import platform
33 import sys
34
35 from datetime import datetime
36 from setuptools import find_packages
37 from setuptools import setup
38 from setuptools.dist import Distribution
39 from setuptools import Extension
40
41 DOCLINES = __doc__.split('\n')
42
43 TFA_NIGHTLY = 'tfa-nightly'
44 TFA_RELEASE = 'tensorflow-addons'
45
46 if '--nightly' in sys.argv:
47 project_name = TFA_NIGHTLY
48 nightly_idx = sys.argv.index('--nightly')
49 sys.argv.pop(nightly_idx)
50 else:
51 project_name = TFA_RELEASE
52
53 # Version
54 version = {}
55 base_dir = os.path.dirname(os.path.abspath(__file__))
56 with open(os.path.join(base_dir, "tensorflow_addons", "version.py")) as fp:
57 # yapf: disable
58 exec(fp.read(), version)
59 # yapf: enable
60
61 if project_name == TFA_NIGHTLY:
62 version['__version__'] += datetime.strftime(datetime.today(), "%Y%m%d")
63
64 # Dependencies
65 REQUIRED_PACKAGES = [
66 'six >= 1.10.0',
67 ]
68
69 if project_name == TFA_RELEASE:
70 # TODO: remove if-else condition when tf supports package consolidation.
71 if platform.system() == 'Linux':
72 REQUIRED_PACKAGES.append('tensorflow-gpu == 2.0.0-rc1')
73 else:
74 REQUIRED_PACKAGES.append('tensorflow == 2.0.0-rc1')
75 elif project_name == TFA_NIGHTLY:
76 # TODO: remove if-else condition when tf-nightly supports package consolidation.
77 if platform.system() == 'Linux':
78 REQUIRED_PACKAGES.append('tf-nightly-gpu-2.0-preview')
79 else:
80 REQUIRED_PACKAGES.append('tf-nightly-2.0-preview')
81
82
83 class BinaryDistribution(Distribution):
84 """This class is needed in order to create OS specific wheels."""
85
86 def has_ext_modules(self):
87 return True
88
89
90 setup(
91 name=project_name,
92 version=version['__version__'],
93 description=DOCLINES[0],
94 long_description='\n'.join(DOCLINES[2:]),
95 author='Google Inc.',
96 author_email='[email protected]',
97 packages=find_packages(),
98 ext_modules=[Extension('_foo', ['stub.cc'])],
99 install_requires=REQUIRED_PACKAGES,
100 include_package_data=True,
101 zip_safe=False,
102 distclass=BinaryDistribution,
103 classifiers=[
104 'Development Status :: 4 - Beta',
105 'Intended Audience :: Developers',
106 'Intended Audience :: Education',
107 'Intended Audience :: Science/Research',
108 'License :: OSI Approved :: Apache Software License',
109 'Programming Language :: Python :: 2.7',
110 'Programming Language :: Python :: 3.5',
111 'Programming Language :: Python :: 3.6',
112 'Programming Language :: Python :: 3.7',
113 'Topic :: Scientific/Engineering :: Mathematics',
114 'Topic :: Software Development :: Libraries :: Python Modules',
115 'Topic :: Software Development :: Libraries',
116 ],
117 license='Apache 2.0',
118 keywords='tensorflow addons machine learning',
119 )
120
[end of setup.py]
[start of tensorflow_addons/version.py]
1 # Copyright 2019 The TensorFlow Authors. All Rights Reserved.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14 # ============================================================================
15 """Define TensorFlow Addons version information."""
16 from __future__ import absolute_import
17 from __future__ import division
18 from __future__ import print_function
19
20 # We follow Semantic Versioning (https://semver.org/)
21 _MAJOR_VERSION = '0'
22 _MINOR_VERSION = '5'
23 _PATCH_VERSION = '1'
24
25 # When building releases, we can update this value on the release branch to
26 # reflect the current release candidate ('rc0', 'rc1') or, finally, the official
27 # stable release (indicated by `_VERSION_SUFFIX = ''`). Outside the context of a
28 # release branch, the current version is by default assumed to be a
29 # 'development' version, labeled 'dev'.
30 _VERSION_SUFFIX = ''
31
32 # Example, '0.1.0-dev'
33 __version__ = '.'.join([
34 _MAJOR_VERSION,
35 _MINOR_VERSION,
36 _PATCH_VERSION,
37 ])
38 if _VERSION_SUFFIX:
39 __version__ = '{}-{}'.format(__version__, _VERSION_SUFFIX)
40
[end of tensorflow_addons/version.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -69,9 +69,9 @@
if project_name == TFA_RELEASE:
# TODO: remove if-else condition when tf supports package consolidation.
if platform.system() == 'Linux':
- REQUIRED_PACKAGES.append('tensorflow-gpu == 2.0.0-rc1')
+ REQUIRED_PACKAGES.append('tensorflow-gpu == 2.0.0')
else:
- REQUIRED_PACKAGES.append('tensorflow == 2.0.0-rc1')
+ REQUIRED_PACKAGES.append('tensorflow == 2.0.0')
elif project_name == TFA_NIGHTLY:
# TODO: remove if-else condition when tf-nightly supports package consolidation.
if platform.system() == 'Linux':
diff --git a/tensorflow_addons/version.py b/tensorflow_addons/version.py
--- a/tensorflow_addons/version.py
+++ b/tensorflow_addons/version.py
@@ -20,7 +20,7 @@
# We follow Semantic Versioning (https://semver.org/)
_MAJOR_VERSION = '0'
_MINOR_VERSION = '5'
-_PATCH_VERSION = '1'
+_PATCH_VERSION = '2'
# When building releases, we can update this value on the release branch to
# reflect the current release candidate ('rc0', 'rc1') or, finally, the official
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -69,9 +69,9 @@\n if project_name == TFA_RELEASE:\n # TODO: remove if-else condition when tf supports package consolidation.\n if platform.system() == 'Linux':\n- REQUIRED_PACKAGES.append('tensorflow-gpu == 2.0.0-rc1')\n+ REQUIRED_PACKAGES.append('tensorflow-gpu == 2.0.0')\n else:\n- REQUIRED_PACKAGES.append('tensorflow == 2.0.0-rc1')\n+ REQUIRED_PACKAGES.append('tensorflow == 2.0.0')\n elif project_name == TFA_NIGHTLY:\n # TODO: remove if-else condition when tf-nightly supports package consolidation.\n if platform.system() == 'Linux':\ndiff --git a/tensorflow_addons/version.py b/tensorflow_addons/version.py\n--- a/tensorflow_addons/version.py\n+++ b/tensorflow_addons/version.py\n@@ -20,7 +20,7 @@\n # We follow Semantic Versioning (https://semver.org/)\n _MAJOR_VERSION = '0'\n _MINOR_VERSION = '5'\n-_PATCH_VERSION = '1'\n+_PATCH_VERSION = '2'\n \n # When building releases, we can update this value on the release branch to\n # reflect the current release candidate ('rc0', 'rc1') or, finally, the official\n", "issue": "Package TFA 0.5.2 pinned to TF2-RC2\nRC2 is released so we can do a minor release pinned to this. For now this is blocked until #539 is merged.\n", "before_files": [{"content": "# Copyright 2019 The TensorFlow Authors. All Rights Reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n# ==============================================================================\n\"\"\"TensorFlow Addons.\n\nTensorFlow Addons is a repository of contributions that conform to well-\nestablished API patterns, but implement new functionality not available\nin core TensorFlow. TensorFlow natively supports a large number of\noperators, layers, metrics, losses, and optimizers. However, in a fast\nmoving field like ML, there are many interesting new developments that\ncannot be integrated into core TensorFlow (because their broad\napplicability is not yet clear, or it is mostly used by a smaller subset\nof the community).\n\"\"\"\n\nfrom __future__ import absolute_import\nfrom __future__ import division\nfrom __future__ import print_function\n\nimport os\nimport platform\nimport sys\n\nfrom datetime import datetime\nfrom setuptools import find_packages\nfrom setuptools import setup\nfrom setuptools.dist import Distribution\nfrom setuptools import Extension\n\nDOCLINES = __doc__.split('\\n')\n\nTFA_NIGHTLY = 'tfa-nightly'\nTFA_RELEASE = 'tensorflow-addons'\n\nif '--nightly' in sys.argv:\n project_name = TFA_NIGHTLY\n nightly_idx = sys.argv.index('--nightly')\n sys.argv.pop(nightly_idx)\nelse:\n project_name = TFA_RELEASE\n\n# Version\nversion = {}\nbase_dir = os.path.dirname(os.path.abspath(__file__))\nwith open(os.path.join(base_dir, \"tensorflow_addons\", \"version.py\")) as fp:\n # yapf: disable\n exec(fp.read(), version)\n # yapf: enable\n\nif project_name == TFA_NIGHTLY:\n version['__version__'] += datetime.strftime(datetime.today(), \"%Y%m%d\")\n\n# Dependencies\nREQUIRED_PACKAGES = [\n 'six >= 1.10.0',\n]\n\nif project_name == TFA_RELEASE:\n # TODO: remove if-else condition when tf supports package consolidation.\n if platform.system() == 'Linux':\n REQUIRED_PACKAGES.append('tensorflow-gpu == 2.0.0-rc1')\n else:\n REQUIRED_PACKAGES.append('tensorflow == 2.0.0-rc1')\nelif project_name == TFA_NIGHTLY:\n # TODO: remove if-else condition when tf-nightly supports package consolidation.\n if platform.system() == 'Linux':\n REQUIRED_PACKAGES.append('tf-nightly-gpu-2.0-preview')\n else:\n REQUIRED_PACKAGES.append('tf-nightly-2.0-preview')\n\n\nclass BinaryDistribution(Distribution):\n \"\"\"This class is needed in order to create OS specific wheels.\"\"\"\n\n def has_ext_modules(self):\n return True\n\n\nsetup(\n name=project_name,\n version=version['__version__'],\n description=DOCLINES[0],\n long_description='\\n'.join(DOCLINES[2:]),\n author='Google Inc.',\n author_email='[email protected]',\n packages=find_packages(),\n ext_modules=[Extension('_foo', ['stub.cc'])],\n install_requires=REQUIRED_PACKAGES,\n include_package_data=True,\n zip_safe=False,\n distclass=BinaryDistribution,\n classifiers=[\n 'Development Status :: 4 - Beta',\n 'Intended Audience :: Developers',\n 'Intended Audience :: Education',\n 'Intended Audience :: Science/Research',\n 'License :: OSI Approved :: Apache Software License',\n 'Programming Language :: Python :: 2.7',\n 'Programming Language :: Python :: 3.5',\n 'Programming Language :: Python :: 3.6',\n 'Programming Language :: Python :: 3.7',\n 'Topic :: Scientific/Engineering :: Mathematics',\n 'Topic :: Software Development :: Libraries :: Python Modules',\n 'Topic :: Software Development :: Libraries',\n ],\n license='Apache 2.0',\n keywords='tensorflow addons machine learning',\n)\n", "path": "setup.py"}, {"content": "# Copyright 2019 The TensorFlow Authors. All Rights Reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n# ============================================================================\n\"\"\"Define TensorFlow Addons version information.\"\"\"\nfrom __future__ import absolute_import\nfrom __future__ import division\nfrom __future__ import print_function\n\n# We follow Semantic Versioning (https://semver.org/)\n_MAJOR_VERSION = '0'\n_MINOR_VERSION = '5'\n_PATCH_VERSION = '1'\n\n# When building releases, we can update this value on the release branch to\n# reflect the current release candidate ('rc0', 'rc1') or, finally, the official\n# stable release (indicated by `_VERSION_SUFFIX = ''`). Outside the context of a\n# release branch, the current version is by default assumed to be a\n# 'development' version, labeled 'dev'.\n_VERSION_SUFFIX = ''\n\n# Example, '0.1.0-dev'\n__version__ = '.'.join([\n _MAJOR_VERSION,\n _MINOR_VERSION,\n _PATCH_VERSION,\n])\nif _VERSION_SUFFIX:\n __version__ = '{}-{}'.format(__version__, _VERSION_SUFFIX)\n", "path": "tensorflow_addons/version.py"}]}
| 2,194 | 310 |
gh_patches_debug_23993
|
rasdani/github-patches
|
git_diff
|
sanic-org__sanic-2640
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
There is an obvious bug in ASGI WebsocketConnection of Sanic
### Is there an existing issue for this?
- [X] I have searched the existing issues
### Describe the bug
I started my sanic app with UvicornWorker. The original websocket will become WebsocketConnection. When I call
the ws.recv function will report an error if bytes data is received at this time.
`KeyError:‘text’`
[https://github.com/sanic-org/sanic/blob/main/sanic/server/websockets/connection.py](url)
` async def recv(self, *args, **kwargs) -> Optional[str]:
message = await self._receive()
if message["type"] == "websocket.receive":
return message["text"]
elif message["type"] == "websocket.disconnect":
pass
return None`
There is no data of bytes type processed here.
### Code snippet
_No response_
### Expected Behavior
_No response_
### How do you run Sanic?
ASGI
### Operating System
ubuntu
### Sanic Version
22.3
### Additional context
_No response_
</issue>
<code>
[start of sanic/server/websockets/connection.py]
1 from typing import (
2 Any,
3 Awaitable,
4 Callable,
5 Dict,
6 List,
7 MutableMapping,
8 Optional,
9 Union,
10 )
11
12
13 ASIMessage = MutableMapping[str, Any]
14
15
16 class WebSocketConnection:
17 """
18 This is for ASGI Connections.
19 It provides an interface similar to WebsocketProtocol, but
20 sends/receives over an ASGI connection.
21 """
22
23 # TODO
24 # - Implement ping/pong
25
26 def __init__(
27 self,
28 send: Callable[[ASIMessage], Awaitable[None]],
29 receive: Callable[[], Awaitable[ASIMessage]],
30 subprotocols: Optional[List[str]] = None,
31 ) -> None:
32 self._send = send
33 self._receive = receive
34 self._subprotocols = subprotocols or []
35
36 async def send(self, data: Union[str, bytes], *args, **kwargs) -> None:
37 message: Dict[str, Union[str, bytes]] = {"type": "websocket.send"}
38
39 if isinstance(data, bytes):
40 message.update({"bytes": data})
41 else:
42 message.update({"text": str(data)})
43
44 await self._send(message)
45
46 async def recv(self, *args, **kwargs) -> Optional[str]:
47 message = await self._receive()
48
49 if message["type"] == "websocket.receive":
50 return message["text"]
51 elif message["type"] == "websocket.disconnect":
52 pass
53
54 return None
55
56 receive = recv
57
58 async def accept(self, subprotocols: Optional[List[str]] = None) -> None:
59 subprotocol = None
60 if subprotocols:
61 for subp in subprotocols:
62 if subp in self.subprotocols:
63 subprotocol = subp
64 break
65
66 await self._send(
67 {
68 "type": "websocket.accept",
69 "subprotocol": subprotocol,
70 }
71 )
72
73 async def close(self, code: int = 1000, reason: str = "") -> None:
74 pass
75
76 @property
77 def subprotocols(self):
78 return self._subprotocols
79
80 @subprotocols.setter
81 def subprotocols(self, subprotocols: Optional[List[str]] = None):
82 self._subprotocols = subprotocols or []
83
[end of sanic/server/websockets/connection.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/sanic/server/websockets/connection.py b/sanic/server/websockets/connection.py
--- a/sanic/server/websockets/connection.py
+++ b/sanic/server/websockets/connection.py
@@ -9,8 +9,10 @@
Union,
)
+from sanic.exceptions import InvalidUsage
-ASIMessage = MutableMapping[str, Any]
+
+ASGIMessage = MutableMapping[str, Any]
class WebSocketConnection:
@@ -25,8 +27,8 @@
def __init__(
self,
- send: Callable[[ASIMessage], Awaitable[None]],
- receive: Callable[[], Awaitable[ASIMessage]],
+ send: Callable[[ASGIMessage], Awaitable[None]],
+ receive: Callable[[], Awaitable[ASGIMessage]],
subprotocols: Optional[List[str]] = None,
) -> None:
self._send = send
@@ -47,7 +49,13 @@
message = await self._receive()
if message["type"] == "websocket.receive":
- return message["text"]
+ try:
+ return message["text"]
+ except KeyError:
+ try:
+ return message["bytes"].decode()
+ except KeyError:
+ raise InvalidUsage("Bad ASGI message received")
elif message["type"] == "websocket.disconnect":
pass
|
{"golden_diff": "diff --git a/sanic/server/websockets/connection.py b/sanic/server/websockets/connection.py\n--- a/sanic/server/websockets/connection.py\n+++ b/sanic/server/websockets/connection.py\n@@ -9,8 +9,10 @@\n Union,\n )\n \n+from sanic.exceptions import InvalidUsage\n \n-ASIMessage = MutableMapping[str, Any]\n+\n+ASGIMessage = MutableMapping[str, Any]\n \n \n class WebSocketConnection:\n@@ -25,8 +27,8 @@\n \n def __init__(\n self,\n- send: Callable[[ASIMessage], Awaitable[None]],\n- receive: Callable[[], Awaitable[ASIMessage]],\n+ send: Callable[[ASGIMessage], Awaitable[None]],\n+ receive: Callable[[], Awaitable[ASGIMessage]],\n subprotocols: Optional[List[str]] = None,\n ) -> None:\n self._send = send\n@@ -47,7 +49,13 @@\n message = await self._receive()\n \n if message[\"type\"] == \"websocket.receive\":\n- return message[\"text\"]\n+ try:\n+ return message[\"text\"]\n+ except KeyError:\n+ try:\n+ return message[\"bytes\"].decode()\n+ except KeyError:\n+ raise InvalidUsage(\"Bad ASGI message received\")\n elif message[\"type\"] == \"websocket.disconnect\":\n pass\n", "issue": "There is an obvious bug in ASGI WebsocketConnection of Sanic\n### Is there an existing issue for this?\n\n- [X] I have searched the existing issues\n\n### Describe the bug\n\nI started my sanic app with UvicornWorker. The original websocket will become WebsocketConnection. When I call\r\nthe ws.recv function will report an error if bytes data is received at this time.\r\n`KeyError\uff1a\u2018text\u2019`\r\n[https://github.com/sanic-org/sanic/blob/main/sanic/server/websockets/connection.py](url)\r\n` async def recv(self, *args, **kwargs) -> Optional[str]:\r\n message = await self._receive()\r\n\r\n if message[\"type\"] == \"websocket.receive\":\r\n return message[\"text\"]\r\n elif message[\"type\"] == \"websocket.disconnect\":\r\n pass\r\n\r\n return None`\r\nThere is no data of bytes type processed here.\n\n### Code snippet\n\n_No response_\n\n### Expected Behavior\n\n_No response_\n\n### How do you run Sanic?\n\nASGI\n\n### Operating System\n\nubuntu\n\n### Sanic Version\n\n22.3\n\n### Additional context\n\n_No response_\n", "before_files": [{"content": "from typing import (\n Any,\n Awaitable,\n Callable,\n Dict,\n List,\n MutableMapping,\n Optional,\n Union,\n)\n\n\nASIMessage = MutableMapping[str, Any]\n\n\nclass WebSocketConnection:\n \"\"\"\n This is for ASGI Connections.\n It provides an interface similar to WebsocketProtocol, but\n sends/receives over an ASGI connection.\n \"\"\"\n\n # TODO\n # - Implement ping/pong\n\n def __init__(\n self,\n send: Callable[[ASIMessage], Awaitable[None]],\n receive: Callable[[], Awaitable[ASIMessage]],\n subprotocols: Optional[List[str]] = None,\n ) -> None:\n self._send = send\n self._receive = receive\n self._subprotocols = subprotocols or []\n\n async def send(self, data: Union[str, bytes], *args, **kwargs) -> None:\n message: Dict[str, Union[str, bytes]] = {\"type\": \"websocket.send\"}\n\n if isinstance(data, bytes):\n message.update({\"bytes\": data})\n else:\n message.update({\"text\": str(data)})\n\n await self._send(message)\n\n async def recv(self, *args, **kwargs) -> Optional[str]:\n message = await self._receive()\n\n if message[\"type\"] == \"websocket.receive\":\n return message[\"text\"]\n elif message[\"type\"] == \"websocket.disconnect\":\n pass\n\n return None\n\n receive = recv\n\n async def accept(self, subprotocols: Optional[List[str]] = None) -> None:\n subprotocol = None\n if subprotocols:\n for subp in subprotocols:\n if subp in self.subprotocols:\n subprotocol = subp\n break\n\n await self._send(\n {\n \"type\": \"websocket.accept\",\n \"subprotocol\": subprotocol,\n }\n )\n\n async def close(self, code: int = 1000, reason: str = \"\") -> None:\n pass\n\n @property\n def subprotocols(self):\n return self._subprotocols\n\n @subprotocols.setter\n def subprotocols(self, subprotocols: Optional[List[str]] = None):\n self._subprotocols = subprotocols or []\n", "path": "sanic/server/websockets/connection.py"}]}
| 1,412 | 298 |
gh_patches_debug_30786
|
rasdani/github-patches
|
git_diff
|
open-mmlab__mmdetection-9241
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[Bug] metric should be one of \\\'bbox\\\' when using tools/test.py
### Prerequisite
- [X] I have searched [Issues](https://github.com/open-mmlab/mmdetection/issues) and [Discussions](https://github.com/open-mmlab/mmdetection/discussions) but cannot get the expected help.
- [X] I have read the [FAQ documentation](https://mmdetection.readthedocs.io/en/latest/faq.html) but cannot get the expected help.
- [X] The bug has not been fixed in the [latest version (master)](https://github.com/open-mmlab/mmdetection) or [latest version (3.x)](https://github.com/open-mmlab/mmdetection/tree/dev-3.x).
### Task
I have modified the scripts/configs, or I'm working on my own tasks/models/datasets.
### Branch
3.x branch https://github.com/open-mmlab/mmdetection/tree/3.x
### Environment
OrderedDict([('sys.platform', 'linux'),
('Python',
'3.7.12 | packaged by conda-forge | (default, Oct 26 2021, 06:08:21) [GCC 9.4.0]'),
('CUDA available', True),
('numpy_random_seed', 2147483648),
('GPU 0', 'NVIDIA GeForce RTX 3080'),
('CUDA_HOME', '/usr/local/cuda-11.5'),
('NVCC', 'Cuda compilation tools, release 11.5, V11.5.50'),
('GCC', 'gcc (Ubuntu 9.4.0-1ubuntu1~20.04.1) 9.4.0'),
('PyTorch', '1.12.1+cu113'),
('PyTorch compiling details',
'PyTorch built with:\n - GCC 9.3\n - C++ Version: 201402\n - Intel(R) Math Kernel Library Version 2020.0.0 Product Build 20191122 for Intel(R) 64 architecture applications\n - Intel(R) MKL-DNN v2.6.0 (Git Hash 52b5f107dd9cf10910aaa19cb47f3abf9b349815)\n - OpenMP 201511 (a.k.a. OpenMP 4.5)\n - LAPACK is enabled (usually provided by MKL)\n - NNPACK is enabled\n - CPU capability usage: AVX2\n - CUDA Runtime 11.3\n - NVCC architecture flags: -gencode;arch=compute_37,code=sm_37;-gencode;arch=compute_50,code=sm_50;-gencode;arch=compute_60,code=sm_60;-gencode;arch=compute_70,code=sm_70;-gencode;arch=compute_75,code=sm_75;-gencode;arch=compute_80,code=sm_80;-gencode;arch=compute_86,code=sm_86\n - CuDNN 8.3.2 (built against CUDA 11.5)\n - Magma 2.5.2\n - Build settings: BLAS_INFO=mkl, BUILD_TYPE=Release, CUDA_VERSION=11.3, CUDNN_VERSION=8.3.2, CXX_COMPILER=/opt/rh/devtoolset-9/root/usr/bin/c++, CXX_FLAGS= -fabi-version=11 -Wno-deprecated -fvisibility-inlines-hidden -DUSE_PTHREADPOOL -fopenmp -DNDEBUG -DUSE_KINETO -DUSE_FBGEMM -DUSE_QNNPACK -DUSE_PYTORCH_QNNPACK -DUSE_XNNPACK -DSYMBOLICATE_MOBILE_DEBUG_HANDLE -DEDGE_PROFILER_USE_KINETO -O2 -fPIC -Wno-narrowing -Wall -Wextra -Werror=return-type -Wno-missing-field-initializers -Wno-type-limits -Wno-array-bounds -Wno-unknown-pragmas -Wno-unused-parameter -Wno-unused-function -Wno-unused-result -Wno-unused-local-typedefs -Wno-strict-overflow -Wno-strict-aliasing -Wno-error=deprecated-declarations -Wno-stringop-overflow -Wno-psabi -Wno-error=pedantic -Wno-error=redundant-decls -Wno-error=old-style-cast -fdiagnostics-color=always -faligned-new -Wno-unused-but-set-variable -Wno-maybe-uninitialized -fno-math-errno -fno-trapping-math -Werror=format -Werror=cast-function-type -Wno-stringop-overflow, LAPACK_INFO=mkl, PERF_WITH_AVX=1, PERF_WITH_AVX2=1, PERF_WITH_AVX512=1, TORCH_VERSION=1.12.1, USE_CUDA=ON, USE_CUDNN=ON, USE_EXCEPTION_PTR=1, USE_GFLAGS=OFF, USE_GLOG=OFF, USE_MKL=ON, USE_MKLDNN=OFF, USE_MPI=OFF, USE_NCCL=ON, USE_NNPACK=ON, USE_OPENMP=ON, USE_ROCM=OFF, \n'),
('TorchVision', '0.13.1+cu113'),
('OpenCV', '4.6.0'),
('MMEngine', '0.2.0'),
('MMDetection', '3.0.0rc2+5897b32')])
### Reproduces the problem - code sample
Here is my config:
```python
test_evaluator = dict(
type='CocoMetric',
ann_file='./ballondatasets/balloon/val/annotation_coco.json',
metric=['bbox', 'segm'],
format_only=False)
```
if i use `python config checkpoint --out result.pkl`, it will be modified to
```
```python
test_evaluator = dict(
type='CocoMetric',
ann_file='./ballondatasets/balloon/val/annotation_coco.json',
metric=[None, {
'type': 'DumpResults',
'out_file_path': 'ceshi.pkl'
}],
format_only=False)
```
### Reproduces the problem - error message
```
File "/home/sanbu/anaconda3/envs/mmlab2/lib/python3.7/site-packages/mmengine/runner/runner.py", line 1533, in build_test_loop
evaluator=self._test_evaluator))
File "/home/sanbu/anaconda3/envs/mmlab2/lib/python3.7/site-packages/mmengine/registry/registry.py", line 421, in build
return self.build_func(cfg, *args, **kwargs, registry=self)
File "/home/sanbu/anaconda3/envs/mmlab2/lib/python3.7/site-packages/mmengine/registry/build_functions.py", line 136, in build_from_cfg
f'class `{obj_cls.__name__}` in ' # type: ignore
KeyError: 'class `TestLoop` in mmengine/runner/loops.py: \'class `CocoMetric` in mmdet/evaluation/metrics/coco_metric.py: "metric should be one of \\\'bbox\\\', \\\'segm\\\', \\\'proposal\\\', \\\'proposal_fast\\\', but got {\\\'type\\\': \\\'DumpResults\\\', \\\'out_file_path\\\': \\\'ceshi.pkl\\\'}."\''
```
### Additional information
I use the tools/test.py to output pkl file but i got the problem,the python file will modify my conifg.
I see the mmdet documentation says that we can use --eval bbox or segm to specify the metric parameter. But the tools/test.py doesn't has the `--eval` option.I don't know if 3.x have implemented the function.
</issue>
<code>
[start of mmdet/utils/__init__.py]
1 # Copyright (c) OpenMMLab. All rights reserved.
2 from .collect_env import collect_env
3 from .compat_config import compat_cfg
4 from .dist_utils import (all_reduce_dict, allreduce_grads, reduce_mean,
5 sync_random_seed)
6 from .logger import get_caller_name, log_img_scale
7 from .memory import AvoidCUDAOOM, AvoidOOM
8 from .misc import add_dump_metric, find_latest_checkpoint, update_data_root
9 from .replace_cfg_vals import replace_cfg_vals
10 from .setup_env import register_all_modules, setup_multi_processes
11 from .split_batch import split_batch
12 from .typing import (ConfigType, InstanceList, MultiConfig, OptConfigType,
13 OptInstanceList, OptMultiConfig, OptPixelList, PixelList,
14 RangeType)
15
16 __all__ = [
17 'collect_env', 'find_latest_checkpoint', 'update_data_root',
18 'setup_multi_processes', 'get_caller_name', 'log_img_scale', 'compat_cfg',
19 'split_batch', 'register_all_modules', 'replace_cfg_vals', 'AvoidOOM',
20 'AvoidCUDAOOM', 'all_reduce_dict', 'allreduce_grads', 'reduce_mean',
21 'sync_random_seed', 'ConfigType', 'InstanceList', 'MultiConfig',
22 'OptConfigType', 'OptInstanceList', 'OptMultiConfig', 'OptPixelList',
23 'PixelList', 'RangeType', 'add_dump_metric'
24 ]
25
[end of mmdet/utils/__init__.py]
[start of mmdet/utils/misc.py]
1 # Copyright (c) OpenMMLab. All rights reserved.
2 import glob
3 import os
4 import os.path as osp
5 import warnings
6
7 from mmengine.config import Config, ConfigDict
8 from mmengine.logging import print_log
9
10
11 def find_latest_checkpoint(path, suffix='pth'):
12 """Find the latest checkpoint from the working directory.
13
14 Args:
15 path(str): The path to find checkpoints.
16 suffix(str): File extension.
17 Defaults to pth.
18
19 Returns:
20 latest_path(str | None): File path of the latest checkpoint.
21 References:
22 .. [1] https://github.com/microsoft/SoftTeacher
23 /blob/main/ssod/utils/patch.py
24 """
25 if not osp.exists(path):
26 warnings.warn('The path of checkpoints does not exist.')
27 return None
28 if osp.exists(osp.join(path, f'latest.{suffix}')):
29 return osp.join(path, f'latest.{suffix}')
30
31 checkpoints = glob.glob(osp.join(path, f'*.{suffix}'))
32 if len(checkpoints) == 0:
33 warnings.warn('There are no checkpoints in the path.')
34 return None
35 latest = -1
36 latest_path = None
37 for checkpoint in checkpoints:
38 count = int(osp.basename(checkpoint).split('_')[-1].split('.')[0])
39 if count > latest:
40 latest = count
41 latest_path = checkpoint
42 return latest_path
43
44
45 def update_data_root(cfg, logger=None):
46 """Update data root according to env MMDET_DATASETS.
47
48 If set env MMDET_DATASETS, update cfg.data_root according to
49 MMDET_DATASETS. Otherwise, using cfg.data_root as default.
50
51 Args:
52 cfg (:obj:`Config`): The model config need to modify
53 logger (logging.Logger | str | None): the way to print msg
54 """
55 assert isinstance(cfg, Config), \
56 f'cfg got wrong type: {type(cfg)}, expected mmengine.Config'
57
58 if 'MMDET_DATASETS' in os.environ:
59 dst_root = os.environ['MMDET_DATASETS']
60 print_log(f'MMDET_DATASETS has been set to be {dst_root}.'
61 f'Using {dst_root} as data root.')
62 else:
63 return
64
65 assert isinstance(cfg, Config), \
66 f'cfg got wrong type: {type(cfg)}, expected mmengine.Config'
67
68 def update(cfg, src_str, dst_str):
69 for k, v in cfg.items():
70 if isinstance(v, ConfigDict):
71 update(cfg[k], src_str, dst_str)
72 if isinstance(v, str) and src_str in v:
73 cfg[k] = v.replace(src_str, dst_str)
74
75 update(cfg.data, cfg.data_root, dst_root)
76 cfg.data_root = dst_root
77
78
79 def add_dump_metric(args, cfg):
80 dump_metric = dict(type='DumpResults', out_file_path=args.out)
81 if isinstance(cfg.test_evaluator, (list, tuple)):
82 cfg.test_evaluator = list(cfg.test_evaluator).append(dump_metric)
83 elif isinstance(cfg.test_evaluator, dict):
84 if isinstance(cfg.test_evaluator.metric, str):
85 cfg.test_evaluator = [cfg.test_evaluator, dump_metric]
86 elif isinstance(cfg.test_evaluator.metric, (list, tuple)):
87 cfg.test_evaluator.metric = list(
88 cfg.test_evaluator.metric).append(dump_metric)
89 else:
90 cfg.test_evaluator.metric = [
91 cfg.test_evaluator.metric, dump_metric
92 ]
93
[end of mmdet/utils/misc.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/mmdet/utils/__init__.py b/mmdet/utils/__init__.py
--- a/mmdet/utils/__init__.py
+++ b/mmdet/utils/__init__.py
@@ -5,7 +5,7 @@
sync_random_seed)
from .logger import get_caller_name, log_img_scale
from .memory import AvoidCUDAOOM, AvoidOOM
-from .misc import add_dump_metric, find_latest_checkpoint, update_data_root
+from .misc import find_latest_checkpoint, update_data_root
from .replace_cfg_vals import replace_cfg_vals
from .setup_env import register_all_modules, setup_multi_processes
from .split_batch import split_batch
@@ -20,5 +20,5 @@
'AvoidCUDAOOM', 'all_reduce_dict', 'allreduce_grads', 'reduce_mean',
'sync_random_seed', 'ConfigType', 'InstanceList', 'MultiConfig',
'OptConfigType', 'OptInstanceList', 'OptMultiConfig', 'OptPixelList',
- 'PixelList', 'RangeType', 'add_dump_metric'
+ 'PixelList', 'RangeType'
]
diff --git a/mmdet/utils/misc.py b/mmdet/utils/misc.py
--- a/mmdet/utils/misc.py
+++ b/mmdet/utils/misc.py
@@ -74,19 +74,3 @@
update(cfg.data, cfg.data_root, dst_root)
cfg.data_root = dst_root
-
-
-def add_dump_metric(args, cfg):
- dump_metric = dict(type='DumpResults', out_file_path=args.out)
- if isinstance(cfg.test_evaluator, (list, tuple)):
- cfg.test_evaluator = list(cfg.test_evaluator).append(dump_metric)
- elif isinstance(cfg.test_evaluator, dict):
- if isinstance(cfg.test_evaluator.metric, str):
- cfg.test_evaluator = [cfg.test_evaluator, dump_metric]
- elif isinstance(cfg.test_evaluator.metric, (list, tuple)):
- cfg.test_evaluator.metric = list(
- cfg.test_evaluator.metric).append(dump_metric)
- else:
- cfg.test_evaluator.metric = [
- cfg.test_evaluator.metric, dump_metric
- ]
|
{"golden_diff": "diff --git a/mmdet/utils/__init__.py b/mmdet/utils/__init__.py\n--- a/mmdet/utils/__init__.py\n+++ b/mmdet/utils/__init__.py\n@@ -5,7 +5,7 @@\n sync_random_seed)\n from .logger import get_caller_name, log_img_scale\n from .memory import AvoidCUDAOOM, AvoidOOM\n-from .misc import add_dump_metric, find_latest_checkpoint, update_data_root\n+from .misc import find_latest_checkpoint, update_data_root\n from .replace_cfg_vals import replace_cfg_vals\n from .setup_env import register_all_modules, setup_multi_processes\n from .split_batch import split_batch\n@@ -20,5 +20,5 @@\n 'AvoidCUDAOOM', 'all_reduce_dict', 'allreduce_grads', 'reduce_mean',\n 'sync_random_seed', 'ConfigType', 'InstanceList', 'MultiConfig',\n 'OptConfigType', 'OptInstanceList', 'OptMultiConfig', 'OptPixelList',\n- 'PixelList', 'RangeType', 'add_dump_metric'\n+ 'PixelList', 'RangeType'\n ]\ndiff --git a/mmdet/utils/misc.py b/mmdet/utils/misc.py\n--- a/mmdet/utils/misc.py\n+++ b/mmdet/utils/misc.py\n@@ -74,19 +74,3 @@\n \n update(cfg.data, cfg.data_root, dst_root)\n cfg.data_root = dst_root\n-\n-\n-def add_dump_metric(args, cfg):\n- dump_metric = dict(type='DumpResults', out_file_path=args.out)\n- if isinstance(cfg.test_evaluator, (list, tuple)):\n- cfg.test_evaluator = list(cfg.test_evaluator).append(dump_metric)\n- elif isinstance(cfg.test_evaluator, dict):\n- if isinstance(cfg.test_evaluator.metric, str):\n- cfg.test_evaluator = [cfg.test_evaluator, dump_metric]\n- elif isinstance(cfg.test_evaluator.metric, (list, tuple)):\n- cfg.test_evaluator.metric = list(\n- cfg.test_evaluator.metric).append(dump_metric)\n- else:\n- cfg.test_evaluator.metric = [\n- cfg.test_evaluator.metric, dump_metric\n- ]\n", "issue": "[Bug] metric should be one of \\\\\\'bbox\\\\\\' when using tools/test.py\n### Prerequisite\r\n\r\n- [X] I have searched [Issues](https://github.com/open-mmlab/mmdetection/issues) and [Discussions](https://github.com/open-mmlab/mmdetection/discussions) but cannot get the expected help.\r\n- [X] I have read the [FAQ documentation](https://mmdetection.readthedocs.io/en/latest/faq.html) but cannot get the expected help.\r\n- [X] The bug has not been fixed in the [latest version (master)](https://github.com/open-mmlab/mmdetection) or [latest version (3.x)](https://github.com/open-mmlab/mmdetection/tree/dev-3.x).\r\n\r\n### Task\r\n\r\nI have modified the scripts/configs, or I'm working on my own tasks/models/datasets.\r\n\r\n### Branch\r\n\r\n3.x branch https://github.com/open-mmlab/mmdetection/tree/3.x\r\n\r\n### Environment\r\n\r\nOrderedDict([('sys.platform', 'linux'),\r\n ('Python',\r\n '3.7.12 | packaged by conda-forge | (default, Oct 26 2021, 06:08:21) [GCC 9.4.0]'),\r\n ('CUDA available', True),\r\n ('numpy_random_seed', 2147483648),\r\n ('GPU 0', 'NVIDIA GeForce RTX 3080'),\r\n ('CUDA_HOME', '/usr/local/cuda-11.5'),\r\n ('NVCC', 'Cuda compilation tools, release 11.5, V11.5.50'),\r\n ('GCC', 'gcc (Ubuntu 9.4.0-1ubuntu1~20.04.1) 9.4.0'),\r\n ('PyTorch', '1.12.1+cu113'),\r\n ('PyTorch compiling details',\r\n 'PyTorch built with:\\n - GCC 9.3\\n - C++ Version: 201402\\n - Intel(R) Math Kernel Library Version 2020.0.0 Product Build 20191122 for Intel(R) 64 architecture applications\\n - Intel(R) MKL-DNN v2.6.0 (Git Hash 52b5f107dd9cf10910aaa19cb47f3abf9b349815)\\n - OpenMP 201511 (a.k.a. OpenMP 4.5)\\n - LAPACK is enabled (usually provided by MKL)\\n - NNPACK is enabled\\n - CPU capability usage: AVX2\\n - CUDA Runtime 11.3\\n - NVCC architecture flags: -gencode;arch=compute_37,code=sm_37;-gencode;arch=compute_50,code=sm_50;-gencode;arch=compute_60,code=sm_60;-gencode;arch=compute_70,code=sm_70;-gencode;arch=compute_75,code=sm_75;-gencode;arch=compute_80,code=sm_80;-gencode;arch=compute_86,code=sm_86\\n - CuDNN 8.3.2 (built against CUDA 11.5)\\n - Magma 2.5.2\\n - Build settings: BLAS_INFO=mkl, BUILD_TYPE=Release, CUDA_VERSION=11.3, CUDNN_VERSION=8.3.2, CXX_COMPILER=/opt/rh/devtoolset-9/root/usr/bin/c++, CXX_FLAGS= -fabi-version=11 -Wno-deprecated -fvisibility-inlines-hidden -DUSE_PTHREADPOOL -fopenmp -DNDEBUG -DUSE_KINETO -DUSE_FBGEMM -DUSE_QNNPACK -DUSE_PYTORCH_QNNPACK -DUSE_XNNPACK -DSYMBOLICATE_MOBILE_DEBUG_HANDLE -DEDGE_PROFILER_USE_KINETO -O2 -fPIC -Wno-narrowing -Wall -Wextra -Werror=return-type -Wno-missing-field-initializers -Wno-type-limits -Wno-array-bounds -Wno-unknown-pragmas -Wno-unused-parameter -Wno-unused-function -Wno-unused-result -Wno-unused-local-typedefs -Wno-strict-overflow -Wno-strict-aliasing -Wno-error=deprecated-declarations -Wno-stringop-overflow -Wno-psabi -Wno-error=pedantic -Wno-error=redundant-decls -Wno-error=old-style-cast -fdiagnostics-color=always -faligned-new -Wno-unused-but-set-variable -Wno-maybe-uninitialized -fno-math-errno -fno-trapping-math -Werror=format -Werror=cast-function-type -Wno-stringop-overflow, LAPACK_INFO=mkl, PERF_WITH_AVX=1, PERF_WITH_AVX2=1, PERF_WITH_AVX512=1, TORCH_VERSION=1.12.1, USE_CUDA=ON, USE_CUDNN=ON, USE_EXCEPTION_PTR=1, USE_GFLAGS=OFF, USE_GLOG=OFF, USE_MKL=ON, USE_MKLDNN=OFF, USE_MPI=OFF, USE_NCCL=ON, USE_NNPACK=ON, USE_OPENMP=ON, USE_ROCM=OFF, \\n'),\r\n ('TorchVision', '0.13.1+cu113'),\r\n ('OpenCV', '4.6.0'),\r\n ('MMEngine', '0.2.0'),\r\n ('MMDetection', '3.0.0rc2+5897b32')])\r\n\r\n### Reproduces the problem - code sample\r\n\r\nHere is my config:\r\n```python\r\ntest_evaluator = dict(\r\n type='CocoMetric',\r\n ann_file='./ballondatasets/balloon/val/annotation_coco.json',\r\n metric=['bbox', 'segm'],\r\n format_only=False)\r\n```\r\n\r\nif i use `python config checkpoint --out result.pkl`, it will be modified to \r\n```\r\n```python\r\ntest_evaluator = dict(\r\n type='CocoMetric',\r\n ann_file='./ballondatasets/balloon/val/annotation_coco.json',\r\n metric=[None, {\r\n 'type': 'DumpResults',\r\n 'out_file_path': 'ceshi.pkl'\r\n }],\r\n format_only=False)\r\n```\r\n\r\n\r\n### Reproduces the problem - error message\r\n\r\n```\r\n File \"/home/sanbu/anaconda3/envs/mmlab2/lib/python3.7/site-packages/mmengine/runner/runner.py\", line 1533, in build_test_loop\r\n evaluator=self._test_evaluator))\r\n File \"/home/sanbu/anaconda3/envs/mmlab2/lib/python3.7/site-packages/mmengine/registry/registry.py\", line 421, in build\r\n return self.build_func(cfg, *args, **kwargs, registry=self)\r\n File \"/home/sanbu/anaconda3/envs/mmlab2/lib/python3.7/site-packages/mmengine/registry/build_functions.py\", line 136, in build_from_cfg\r\n f'class `{obj_cls.__name__}` in ' # type: ignore\r\nKeyError: 'class `TestLoop` in mmengine/runner/loops.py: \\'class `CocoMetric` in mmdet/evaluation/metrics/coco_metric.py: \"metric should be one of \\\\\\'bbox\\\\\\', \\\\\\'segm\\\\\\', \\\\\\'proposal\\\\\\', \\\\\\'proposal_fast\\\\\\', but got {\\\\\\'type\\\\\\': \\\\\\'DumpResults\\\\\\', \\\\\\'out_file_path\\\\\\': \\\\\\'ceshi.pkl\\\\\\'}.\"\\''\r\n\r\n```\r\n### Additional information\r\n\r\nI use the tools/test.py to output pkl file but i got the problem,the python file will modify my conifg.\r\n\r\nI see the mmdet documentation says that we can use --eval bbox or segm to specify the metric parameter. But the tools/test.py doesn't has the `--eval` option.I don't know if 3.x have implemented the function.\n", "before_files": [{"content": "# Copyright (c) OpenMMLab. All rights reserved.\nfrom .collect_env import collect_env\nfrom .compat_config import compat_cfg\nfrom .dist_utils import (all_reduce_dict, allreduce_grads, reduce_mean,\n sync_random_seed)\nfrom .logger import get_caller_name, log_img_scale\nfrom .memory import AvoidCUDAOOM, AvoidOOM\nfrom .misc import add_dump_metric, find_latest_checkpoint, update_data_root\nfrom .replace_cfg_vals import replace_cfg_vals\nfrom .setup_env import register_all_modules, setup_multi_processes\nfrom .split_batch import split_batch\nfrom .typing import (ConfigType, InstanceList, MultiConfig, OptConfigType,\n OptInstanceList, OptMultiConfig, OptPixelList, PixelList,\n RangeType)\n\n__all__ = [\n 'collect_env', 'find_latest_checkpoint', 'update_data_root',\n 'setup_multi_processes', 'get_caller_name', 'log_img_scale', 'compat_cfg',\n 'split_batch', 'register_all_modules', 'replace_cfg_vals', 'AvoidOOM',\n 'AvoidCUDAOOM', 'all_reduce_dict', 'allreduce_grads', 'reduce_mean',\n 'sync_random_seed', 'ConfigType', 'InstanceList', 'MultiConfig',\n 'OptConfigType', 'OptInstanceList', 'OptMultiConfig', 'OptPixelList',\n 'PixelList', 'RangeType', 'add_dump_metric'\n]\n", "path": "mmdet/utils/__init__.py"}, {"content": "# Copyright (c) OpenMMLab. All rights reserved.\nimport glob\nimport os\nimport os.path as osp\nimport warnings\n\nfrom mmengine.config import Config, ConfigDict\nfrom mmengine.logging import print_log\n\n\ndef find_latest_checkpoint(path, suffix='pth'):\n \"\"\"Find the latest checkpoint from the working directory.\n\n Args:\n path(str): The path to find checkpoints.\n suffix(str): File extension.\n Defaults to pth.\n\n Returns:\n latest_path(str | None): File path of the latest checkpoint.\n References:\n .. [1] https://github.com/microsoft/SoftTeacher\n /blob/main/ssod/utils/patch.py\n \"\"\"\n if not osp.exists(path):\n warnings.warn('The path of checkpoints does not exist.')\n return None\n if osp.exists(osp.join(path, f'latest.{suffix}')):\n return osp.join(path, f'latest.{suffix}')\n\n checkpoints = glob.glob(osp.join(path, f'*.{suffix}'))\n if len(checkpoints) == 0:\n warnings.warn('There are no checkpoints in the path.')\n return None\n latest = -1\n latest_path = None\n for checkpoint in checkpoints:\n count = int(osp.basename(checkpoint).split('_')[-1].split('.')[0])\n if count > latest:\n latest = count\n latest_path = checkpoint\n return latest_path\n\n\ndef update_data_root(cfg, logger=None):\n \"\"\"Update data root according to env MMDET_DATASETS.\n\n If set env MMDET_DATASETS, update cfg.data_root according to\n MMDET_DATASETS. Otherwise, using cfg.data_root as default.\n\n Args:\n cfg (:obj:`Config`): The model config need to modify\n logger (logging.Logger | str | None): the way to print msg\n \"\"\"\n assert isinstance(cfg, Config), \\\n f'cfg got wrong type: {type(cfg)}, expected mmengine.Config'\n\n if 'MMDET_DATASETS' in os.environ:\n dst_root = os.environ['MMDET_DATASETS']\n print_log(f'MMDET_DATASETS has been set to be {dst_root}.'\n f'Using {dst_root} as data root.')\n else:\n return\n\n assert isinstance(cfg, Config), \\\n f'cfg got wrong type: {type(cfg)}, expected mmengine.Config'\n\n def update(cfg, src_str, dst_str):\n for k, v in cfg.items():\n if isinstance(v, ConfigDict):\n update(cfg[k], src_str, dst_str)\n if isinstance(v, str) and src_str in v:\n cfg[k] = v.replace(src_str, dst_str)\n\n update(cfg.data, cfg.data_root, dst_root)\n cfg.data_root = dst_root\n\n\ndef add_dump_metric(args, cfg):\n dump_metric = dict(type='DumpResults', out_file_path=args.out)\n if isinstance(cfg.test_evaluator, (list, tuple)):\n cfg.test_evaluator = list(cfg.test_evaluator).append(dump_metric)\n elif isinstance(cfg.test_evaluator, dict):\n if isinstance(cfg.test_evaluator.metric, str):\n cfg.test_evaluator = [cfg.test_evaluator, dump_metric]\n elif isinstance(cfg.test_evaluator.metric, (list, tuple)):\n cfg.test_evaluator.metric = list(\n cfg.test_evaluator.metric).append(dump_metric)\n else:\n cfg.test_evaluator.metric = [\n cfg.test_evaluator.metric, dump_metric\n ]\n", "path": "mmdet/utils/misc.py"}]}
| 3,644 | 478 |
gh_patches_debug_20314
|
rasdani/github-patches
|
git_diff
|
urllib3__urllib3-773
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Broken vendoring in socks contrib module
Awkwardly, the SOCKS contrib module doesn't work properly when vendored because it tries to do an absolute import. We should probably rewrite it to use relative imports.
My bad.
</issue>
<code>
[start of urllib3/contrib/socks.py]
1 # -*- coding: utf-8 -*-
2 """
3 SOCKS support for urllib3
4 ~~~~~~~~~~~~~~~~~~~~~~~~~
5
6 This contrib module contains provisional support for SOCKS proxies from within
7 urllib3. This module supports SOCKS4 (specifically the SOCKS4A variant) and
8 SOCKS5. To enable its functionality, either install PySocks or install this
9 module with the ``socks`` extra.
10
11 Known Limitations:
12
13 - Currently PySocks does not support contacting remote websites via literal
14 IPv6 addresses. Any such connection attempt will fail.
15 - Currently PySocks does not support IPv6 connections to the SOCKS proxy. Any
16 such connection attempt will fail.
17 """
18 from __future__ import absolute_import
19
20 try:
21 import socks
22 except ImportError:
23 import warnings
24 from urllib3.exceptions import DependencyWarning
25
26 warnings.warn((
27 'SOCKS support in urllib3 requires the installation of optional '
28 'dependencies: specifically, PySocks. For more information, see '
29 'https://urllib3.readthedocs.org/en/latest/contrib.html#socks-proxies'
30 ),
31 DependencyWarning
32 )
33 raise
34
35 from socket import error as SocketError, timeout as SocketTimeout
36
37 from urllib3.connection import (
38 HTTPConnection, HTTPSConnection
39 )
40 from urllib3.connectionpool import (
41 HTTPConnectionPool, HTTPSConnectionPool
42 )
43 from urllib3.exceptions import ConnectTimeoutError, NewConnectionError
44 from urllib3.poolmanager import PoolManager
45 from urllib3.util.url import parse_url
46
47 try:
48 import ssl
49 except ImportError:
50 ssl = None
51
52
53 class SOCKSConnection(HTTPConnection):
54 """
55 A plain-text HTTP connection that connects via a SOCKS proxy.
56 """
57 def __init__(self, *args, **kwargs):
58 self._socks_options = kwargs.pop('_socks_options')
59 super(SOCKSConnection, self).__init__(*args, **kwargs)
60
61 def _new_conn(self):
62 """
63 Establish a new connection via the SOCKS proxy.
64 """
65 extra_kw = {}
66 if self.source_address:
67 extra_kw['source_address'] = self.source_address
68
69 if self.socket_options:
70 extra_kw['socket_options'] = self.socket_options
71
72 try:
73 conn = socks.create_connection(
74 (self.host, self.port),
75 proxy_type=self._socks_options['socks_version'],
76 proxy_addr=self._socks_options['proxy_host'],
77 proxy_port=self._socks_options['proxy_port'],
78 proxy_username=self._socks_options['username'],
79 proxy_password=self._socks_options['password'],
80 timeout=self.timeout,
81 **extra_kw
82 )
83
84 except SocketTimeout as e:
85 raise ConnectTimeoutError(
86 self, "Connection to %s timed out. (connect timeout=%s)" %
87 (self.host, self.timeout))
88
89 except socks.ProxyError as e:
90 # This is fragile as hell, but it seems to be the only way to raise
91 # useful errors here.
92 if e.socket_err:
93 error = e.socket_err
94 if isinstance(error, SocketTimeout):
95 raise ConnectTimeoutError(
96 self,
97 "Connection to %s timed out. (connect timeout=%s)" %
98 (self.host, self.timeout)
99 )
100 else:
101 raise NewConnectionError(
102 self,
103 "Failed to establish a new connection: %s" % error
104 )
105 else:
106 raise NewConnectionError(
107 self,
108 "Failed to establish a new connection: %s" % e
109 )
110
111 except SocketError as e: # Defensive: PySocks should catch all these.
112 raise NewConnectionError(
113 self, "Failed to establish a new connection: %s" % e)
114
115 return conn
116
117
118 # We don't need to duplicate the Verified/Unverified distinction from
119 # urllib3/connection.py here because the HTTPSConnection will already have been
120 # correctly set to either the Verified or Unverified form by that module. This
121 # means the SOCKSHTTPSConnection will automatically be the correct type.
122 class SOCKSHTTPSConnection(SOCKSConnection, HTTPSConnection):
123 pass
124
125
126 class SOCKSHTTPConnectionPool(HTTPConnectionPool):
127 ConnectionCls = SOCKSConnection
128
129
130 class SOCKSHTTPSConnectionPool(HTTPSConnectionPool):
131 ConnectionCls = SOCKSHTTPSConnection
132
133
134 class SOCKSProxyManager(PoolManager):
135 """
136 A version of the urllib3 ProxyManager that routes connections via the
137 defined SOCKS proxy.
138 """
139 pool_classes_by_scheme = {
140 'http': SOCKSHTTPConnectionPool,
141 'https': SOCKSHTTPSConnectionPool,
142 }
143
144 def __init__(self, proxy_url, username=None, password=None,
145 num_pools=10, headers=None, **connection_pool_kw):
146 parsed = parse_url(proxy_url)
147
148 if parsed.scheme == 'socks5':
149 socks_version = socks.PROXY_TYPE_SOCKS5
150 elif parsed.scheme == 'socks4':
151 socks_version = socks.PROXY_TYPE_SOCKS4
152 else:
153 raise ValueError(
154 "Unable to determine SOCKS version from %s" % proxy_url
155 )
156
157 self.proxy_url = proxy_url
158
159 socks_options = {
160 'socks_version': socks_version,
161 'proxy_host': parsed.host,
162 'proxy_port': parsed.port,
163 'username': username,
164 'password': password,
165 }
166 connection_pool_kw['_socks_options'] = socks_options
167
168 super(SOCKSProxyManager, self).__init__(
169 num_pools, headers, **connection_pool_kw
170 )
171
172 self.pool_classes_by_scheme = SOCKSProxyManager.pool_classes_by_scheme
173
[end of urllib3/contrib/socks.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/urllib3/contrib/socks.py b/urllib3/contrib/socks.py
--- a/urllib3/contrib/socks.py
+++ b/urllib3/contrib/socks.py
@@ -21,7 +21,7 @@
import socks
except ImportError:
import warnings
- from urllib3.exceptions import DependencyWarning
+ from ..exceptions import DependencyWarning
warnings.warn((
'SOCKS support in urllib3 requires the installation of optional '
@@ -34,15 +34,15 @@
from socket import error as SocketError, timeout as SocketTimeout
-from urllib3.connection import (
+from ..connection import (
HTTPConnection, HTTPSConnection
)
-from urllib3.connectionpool import (
+from ..connectionpool import (
HTTPConnectionPool, HTTPSConnectionPool
)
-from urllib3.exceptions import ConnectTimeoutError, NewConnectionError
-from urllib3.poolmanager import PoolManager
-from urllib3.util.url import parse_url
+from ..exceptions import ConnectTimeoutError, NewConnectionError
+from ..poolmanager import PoolManager
+from ..util.url import parse_url
try:
import ssl
|
{"golden_diff": "diff --git a/urllib3/contrib/socks.py b/urllib3/contrib/socks.py\n--- a/urllib3/contrib/socks.py\n+++ b/urllib3/contrib/socks.py\n@@ -21,7 +21,7 @@\n import socks\n except ImportError:\n import warnings\n- from urllib3.exceptions import DependencyWarning\n+ from ..exceptions import DependencyWarning\n \n warnings.warn((\n 'SOCKS support in urllib3 requires the installation of optional '\n@@ -34,15 +34,15 @@\n \n from socket import error as SocketError, timeout as SocketTimeout\n \n-from urllib3.connection import (\n+from ..connection import (\n HTTPConnection, HTTPSConnection\n )\n-from urllib3.connectionpool import (\n+from ..connectionpool import (\n HTTPConnectionPool, HTTPSConnectionPool\n )\n-from urllib3.exceptions import ConnectTimeoutError, NewConnectionError\n-from urllib3.poolmanager import PoolManager\n-from urllib3.util.url import parse_url\n+from ..exceptions import ConnectTimeoutError, NewConnectionError\n+from ..poolmanager import PoolManager\n+from ..util.url import parse_url\n \n try:\n import ssl\n", "issue": "Broken vendoring in socks contrib module\nAwkwardly, the SOCKS contrib module doesn't work properly when vendored because it tries to do an absolute import. We should probably rewrite it to use relative imports.\n\nMy bad.\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\"\"\"\nSOCKS support for urllib3\n~~~~~~~~~~~~~~~~~~~~~~~~~\n\nThis contrib module contains provisional support for SOCKS proxies from within\nurllib3. This module supports SOCKS4 (specifically the SOCKS4A variant) and\nSOCKS5. To enable its functionality, either install PySocks or install this\nmodule with the ``socks`` extra.\n\nKnown Limitations:\n\n- Currently PySocks does not support contacting remote websites via literal\n IPv6 addresses. Any such connection attempt will fail.\n- Currently PySocks does not support IPv6 connections to the SOCKS proxy. Any\n such connection attempt will fail.\n\"\"\"\nfrom __future__ import absolute_import\n\ntry:\n import socks\nexcept ImportError:\n import warnings\n from urllib3.exceptions import DependencyWarning\n\n warnings.warn((\n 'SOCKS support in urllib3 requires the installation of optional '\n 'dependencies: specifically, PySocks. For more information, see '\n 'https://urllib3.readthedocs.org/en/latest/contrib.html#socks-proxies'\n ),\n DependencyWarning\n )\n raise\n\nfrom socket import error as SocketError, timeout as SocketTimeout\n\nfrom urllib3.connection import (\n HTTPConnection, HTTPSConnection\n)\nfrom urllib3.connectionpool import (\n HTTPConnectionPool, HTTPSConnectionPool\n)\nfrom urllib3.exceptions import ConnectTimeoutError, NewConnectionError\nfrom urllib3.poolmanager import PoolManager\nfrom urllib3.util.url import parse_url\n\ntry:\n import ssl\nexcept ImportError:\n ssl = None\n\n\nclass SOCKSConnection(HTTPConnection):\n \"\"\"\n A plain-text HTTP connection that connects via a SOCKS proxy.\n \"\"\"\n def __init__(self, *args, **kwargs):\n self._socks_options = kwargs.pop('_socks_options')\n super(SOCKSConnection, self).__init__(*args, **kwargs)\n\n def _new_conn(self):\n \"\"\"\n Establish a new connection via the SOCKS proxy.\n \"\"\"\n extra_kw = {}\n if self.source_address:\n extra_kw['source_address'] = self.source_address\n\n if self.socket_options:\n extra_kw['socket_options'] = self.socket_options\n\n try:\n conn = socks.create_connection(\n (self.host, self.port),\n proxy_type=self._socks_options['socks_version'],\n proxy_addr=self._socks_options['proxy_host'],\n proxy_port=self._socks_options['proxy_port'],\n proxy_username=self._socks_options['username'],\n proxy_password=self._socks_options['password'],\n timeout=self.timeout,\n **extra_kw\n )\n\n except SocketTimeout as e:\n raise ConnectTimeoutError(\n self, \"Connection to %s timed out. (connect timeout=%s)\" %\n (self.host, self.timeout))\n\n except socks.ProxyError as e:\n # This is fragile as hell, but it seems to be the only way to raise\n # useful errors here.\n if e.socket_err:\n error = e.socket_err\n if isinstance(error, SocketTimeout):\n raise ConnectTimeoutError(\n self,\n \"Connection to %s timed out. (connect timeout=%s)\" %\n (self.host, self.timeout)\n )\n else:\n raise NewConnectionError(\n self,\n \"Failed to establish a new connection: %s\" % error\n )\n else:\n raise NewConnectionError(\n self,\n \"Failed to establish a new connection: %s\" % e\n )\n\n except SocketError as e: # Defensive: PySocks should catch all these.\n raise NewConnectionError(\n self, \"Failed to establish a new connection: %s\" % e)\n\n return conn\n\n\n# We don't need to duplicate the Verified/Unverified distinction from\n# urllib3/connection.py here because the HTTPSConnection will already have been\n# correctly set to either the Verified or Unverified form by that module. This\n# means the SOCKSHTTPSConnection will automatically be the correct type.\nclass SOCKSHTTPSConnection(SOCKSConnection, HTTPSConnection):\n pass\n\n\nclass SOCKSHTTPConnectionPool(HTTPConnectionPool):\n ConnectionCls = SOCKSConnection\n\n\nclass SOCKSHTTPSConnectionPool(HTTPSConnectionPool):\n ConnectionCls = SOCKSHTTPSConnection\n\n\nclass SOCKSProxyManager(PoolManager):\n \"\"\"\n A version of the urllib3 ProxyManager that routes connections via the\n defined SOCKS proxy.\n \"\"\"\n pool_classes_by_scheme = {\n 'http': SOCKSHTTPConnectionPool,\n 'https': SOCKSHTTPSConnectionPool,\n }\n\n def __init__(self, proxy_url, username=None, password=None,\n num_pools=10, headers=None, **connection_pool_kw):\n parsed = parse_url(proxy_url)\n\n if parsed.scheme == 'socks5':\n socks_version = socks.PROXY_TYPE_SOCKS5\n elif parsed.scheme == 'socks4':\n socks_version = socks.PROXY_TYPE_SOCKS4\n else:\n raise ValueError(\n \"Unable to determine SOCKS version from %s\" % proxy_url\n )\n\n self.proxy_url = proxy_url\n\n socks_options = {\n 'socks_version': socks_version,\n 'proxy_host': parsed.host,\n 'proxy_port': parsed.port,\n 'username': username,\n 'password': password,\n }\n connection_pool_kw['_socks_options'] = socks_options\n\n super(SOCKSProxyManager, self).__init__(\n num_pools, headers, **connection_pool_kw\n )\n\n self.pool_classes_by_scheme = SOCKSProxyManager.pool_classes_by_scheme\n", "path": "urllib3/contrib/socks.py"}]}
| 2,204 | 253 |
gh_patches_debug_10479
|
rasdani/github-patches
|
git_diff
|
kubeflow__pipelines-6993
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[bug] TFX sample fails after upgrading to 1.4
### What steps did you take
<!-- A clear and concise description of what the bug is.-->
* MLMD & TFX upgrade: https://github.com/kubeflow/pipelines/pull/6910
### What happened:
* Check test: https://oss-prow.knative.dev/view/gs/oss-prow/logs/kubeflow-pipeline-postsubmit-integration-test/1464225919869652992
### What did you expect to happen:
We need to upgrade the TFX sample to 1.4.0
### Anything else you would like to add:
<!-- Miscellaneous information that will assist in solving the issue.-->
### Labels
<!-- Please include labels below by uncommenting them to help us better triage issues -->
<!-- /area frontend -->
<!-- /area backend -->
<!-- /area sdk -->
<!-- /area testing -->
/area samples
<!-- /area components -->
---
<!-- Don't delete message below to encourage users to support your issue! -->
Impacted by this bug? Give it a 👍. We prioritise the issues with the most 👍.
</issue>
<code>
[start of samples/core/parameterized_tfx_oss/parameterized_tfx_oss.py]
1 #!/usr/bin/env python3
2 # Copyright 2019 The Kubeflow Authors
3 #
4 # Licensed under the Apache License, Version 2.0 (the "License");
5 # you may not use this file except in compliance with the License.
6 # You may obtain a copy of the License at
7 #
8 # http://www.apache.org/licenses/LICENSE-2.0
9 #
10 # Unless required by applicable law or agreed to in writing, software
11 # distributed under the License is distributed on an "AS IS" BASIS,
12 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
13 # See the License for the specific language governing permissions and
14 # limitations under the License.
15
16 import json
17 import os
18
19 import kfp
20 import tensorflow_model_analysis as tfma
21 from tfx import v1 as tfx
22
23 # Define pipeline params used for pipeline execution.
24 # Path to the module file, should be a GCS path,
25 # or a module file baked in the docker image used by the pipeline.
26 _taxi_module_file_param = tfx.dsl.experimental.RuntimeParameter(
27 name='module-file',
28 default='/opt/conda/lib/python3.7/site-packages/tfx/examples/chicago_taxi_pipeline/taxi_utils_native_keras.py',
29 ptype=str,
30 )
31
32 # Path to the CSV data file, under which their should be a data.csv file.
33 _data_root = '/opt/conda/lib/python3.7/site-packages/tfx/examples/chicago_taxi_pipeline/data/simple'
34
35 # Path of pipeline root, should be a GCS path.
36 _pipeline_root = os.path.join(
37 'gs://{{kfp-default-bucket}}', 'tfx_taxi_simple', kfp.dsl.RUN_ID_PLACEHOLDER
38 )
39
40 # Path that ML models are pushed, should be a GCS path.
41 _serving_model_dir = os.path.join('gs://your-bucket', 'serving_model', 'tfx_taxi_simple')
42 _push_destination = tfx.dsl.experimental.RuntimeParameter(
43 name='push_destination',
44 default=json.dumps({'filesystem': {'base_directory': _serving_model_dir}}),
45 ptype=str,
46 )
47
48 def _create_pipeline(
49 pipeline_root: str,
50 csv_input_location: str,
51 taxi_module_file: tfx.dsl.experimental.RuntimeParameter,
52 push_destination: tfx.dsl.experimental.RuntimeParameter,
53 enable_cache: bool
54 ):
55 """Creates a simple Kubeflow-based Chicago Taxi TFX pipeline.
56
57 Args:
58 pipeline_root: The root of the pipeline output.
59 csv_input_location: The location of the input data directory.
60 taxi_module_file: The location of the module file for Transform/Trainer.
61 enable_cache: Whether to enable cache or not.
62
63 Returns:
64 A logical TFX pipeline.Pipeline object.
65 """
66 example_gen = tfx.components.CsvExampleGen(input_base=csv_input_location)
67 statistics_gen = tfx.components.StatisticsGen(
68 examples=example_gen.outputs['examples'])
69 schema_gen = tfx.components.SchemaGen(
70 statistics=statistics_gen.outputs['statistics'],
71 infer_feature_shape=False,
72 )
73 example_validator = tfx.components.ExampleValidator(
74 statistics=statistics_gen.outputs['statistics'],
75 schema=schema_gen.outputs['schema'],
76 )
77 transform = tfx.components.Transform(
78 examples=example_gen.outputs['examples'],
79 schema=schema_gen.outputs['schema'],
80 module_file=taxi_module_file,
81 )
82 trainer = tfx.components.Trainer(
83 module_file=taxi_module_file,
84 examples=transform.outputs['transformed_examples'],
85 schema=schema_gen.outputs['schema'],
86 transform_graph=transform.outputs['transform_graph'],
87 train_args=tfx.proto.TrainArgs(num_steps=10),
88 eval_args=tfx.proto.EvalArgs(num_steps=5),
89 )
90 # Set the TFMA config for Model Evaluation and Validation.
91 eval_config = tfma.EvalConfig(
92 model_specs=[
93 tfma.ModelSpec(
94 signature_name='serving_default', label_key='tips_xf',
95 preprocessing_function_names=['transform_features'])
96 ],
97 metrics_specs=[
98 tfma.MetricsSpec(
99 # The metrics added here are in addition to those saved with the
100 # model (assuming either a keras model or EvalSavedModel is used).
101 # Any metrics added into the saved model (for example using
102 # model.compile(..., metrics=[...]), etc) will be computed
103 # automatically.
104 metrics=[tfma.MetricConfig(class_name='ExampleCount')],
105 # To add validation thresholds for metrics saved with the model,
106 # add them keyed by metric name to the thresholds map.
107 thresholds={
108 'binary_accuracy':
109 tfma.MetricThreshold(
110 value_threshold=tfma.GenericValueThreshold(
111 lower_bound={'value': 0.5}
112 ),
113 change_threshold=tfma.GenericChangeThreshold(
114 direction=tfma.MetricDirection.HIGHER_IS_BETTER,
115 absolute={'value': -1e-10}
116 )
117 )
118 }
119 )
120 ],
121 slicing_specs=[
122 # An empty slice spec means the overall slice, i.e. the whole dataset.
123 tfma.SlicingSpec(),
124 # Data can be sliced along a feature column. In this case, data is
125 # sliced along feature column trip_start_hour.
126 tfma.SlicingSpec(feature_keys=['trip_start_hour'])
127 ]
128 )
129
130 evaluator = tfx.components.Evaluator(
131 examples=example_gen.outputs['examples'],
132 model=trainer.outputs['model'],
133 eval_config=eval_config,
134 )
135
136 pusher = tfx.components.Pusher(
137 model=trainer.outputs['model'],
138 model_blessing=evaluator.outputs['blessing'],
139 push_destination=push_destination,
140 )
141
142 return tfx.dsl.Pipeline(
143 pipeline_name='parameterized_tfx_oss',
144 pipeline_root=pipeline_root,
145 components=[
146 example_gen, statistics_gen, schema_gen, example_validator, transform,
147 trainer, evaluator, pusher
148 ],
149 enable_cache=enable_cache,
150 )
151
152
153 if __name__ == '__main__':
154 enable_cache = True
155 pipeline = _create_pipeline(
156 _pipeline_root,
157 _data_root,
158 _taxi_module_file_param,
159 _push_destination,
160 enable_cache=enable_cache,
161 )
162 # Make sure the version of TFX image used is consistent with the version of
163 # TFX SDK.
164 config = tfx.orchestration.experimental.KubeflowDagRunnerConfig(
165 kubeflow_metadata_config=tfx.orchestration.experimental.
166 get_default_kubeflow_metadata_config(),
167 tfx_image='gcr.io/tfx-oss-public/tfx:1.2.0',
168 )
169 kfp_runner = tfx.orchestration.experimental.KubeflowDagRunner(
170 output_filename=__file__ + '.yaml', config=config
171 )
172
173 kfp_runner.run(pipeline)
174
[end of samples/core/parameterized_tfx_oss/parameterized_tfx_oss.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/samples/core/parameterized_tfx_oss/parameterized_tfx_oss.py b/samples/core/parameterized_tfx_oss/parameterized_tfx_oss.py
--- a/samples/core/parameterized_tfx_oss/parameterized_tfx_oss.py
+++ b/samples/core/parameterized_tfx_oss/parameterized_tfx_oss.py
@@ -164,7 +164,7 @@
config = tfx.orchestration.experimental.KubeflowDagRunnerConfig(
kubeflow_metadata_config=tfx.orchestration.experimental.
get_default_kubeflow_metadata_config(),
- tfx_image='gcr.io/tfx-oss-public/tfx:1.2.0',
+ tfx_image='gcr.io/tfx-oss-public/tfx:%s' % tfx.__version__,
)
kfp_runner = tfx.orchestration.experimental.KubeflowDagRunner(
output_filename=__file__ + '.yaml', config=config
|
{"golden_diff": "diff --git a/samples/core/parameterized_tfx_oss/parameterized_tfx_oss.py b/samples/core/parameterized_tfx_oss/parameterized_tfx_oss.py\n--- a/samples/core/parameterized_tfx_oss/parameterized_tfx_oss.py\n+++ b/samples/core/parameterized_tfx_oss/parameterized_tfx_oss.py\n@@ -164,7 +164,7 @@\n config = tfx.orchestration.experimental.KubeflowDagRunnerConfig(\n kubeflow_metadata_config=tfx.orchestration.experimental.\n get_default_kubeflow_metadata_config(),\n- tfx_image='gcr.io/tfx-oss-public/tfx:1.2.0',\n+ tfx_image='gcr.io/tfx-oss-public/tfx:%s' % tfx.__version__,\n )\n kfp_runner = tfx.orchestration.experimental.KubeflowDagRunner(\n output_filename=__file__ + '.yaml', config=config\n", "issue": "[bug] TFX sample fails after upgrading to 1.4\n### What steps did you take\r\n\r\n<!-- A clear and concise description of what the bug is.-->\r\n* MLMD & TFX upgrade: https://github.com/kubeflow/pipelines/pull/6910\r\n\r\n\r\n### What happened:\r\n\r\n* Check test: https://oss-prow.knative.dev/view/gs/oss-prow/logs/kubeflow-pipeline-postsubmit-integration-test/1464225919869652992\r\n\r\n### What did you expect to happen:\r\n\r\nWe need to upgrade the TFX sample to 1.4.0\r\n\r\n### Anything else you would like to add:\r\n<!-- Miscellaneous information that will assist in solving the issue.-->\r\n\r\n\r\n### Labels\r\n<!-- Please include labels below by uncommenting them to help us better triage issues -->\r\n\r\n<!-- /area frontend -->\r\n<!-- /area backend -->\r\n<!-- /area sdk -->\r\n<!-- /area testing -->\r\n/area samples\r\n<!-- /area components -->\r\n\r\n\r\n---\r\n\r\n<!-- Don't delete message below to encourage users to support your issue! -->\r\nImpacted by this bug? Give it a \ud83d\udc4d. We prioritise the issues with the most \ud83d\udc4d.\r\n\n", "before_files": [{"content": "#!/usr/bin/env python3\n# Copyright 2019 The Kubeflow Authors\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport json\nimport os\n\nimport kfp\nimport tensorflow_model_analysis as tfma\nfrom tfx import v1 as tfx\n\n# Define pipeline params used for pipeline execution.\n# Path to the module file, should be a GCS path,\n# or a module file baked in the docker image used by the pipeline.\n_taxi_module_file_param = tfx.dsl.experimental.RuntimeParameter(\n name='module-file',\n default='/opt/conda/lib/python3.7/site-packages/tfx/examples/chicago_taxi_pipeline/taxi_utils_native_keras.py',\n ptype=str,\n)\n\n# Path to the CSV data file, under which their should be a data.csv file.\n_data_root = '/opt/conda/lib/python3.7/site-packages/tfx/examples/chicago_taxi_pipeline/data/simple'\n\n# Path of pipeline root, should be a GCS path.\n_pipeline_root = os.path.join(\n 'gs://{{kfp-default-bucket}}', 'tfx_taxi_simple', kfp.dsl.RUN_ID_PLACEHOLDER\n)\n\n# Path that ML models are pushed, should be a GCS path.\n_serving_model_dir = os.path.join('gs://your-bucket', 'serving_model', 'tfx_taxi_simple')\n_push_destination = tfx.dsl.experimental.RuntimeParameter(\n name='push_destination',\n default=json.dumps({'filesystem': {'base_directory': _serving_model_dir}}),\n ptype=str,\n )\n\ndef _create_pipeline(\n pipeline_root: str,\n csv_input_location: str,\n taxi_module_file: tfx.dsl.experimental.RuntimeParameter,\n push_destination: tfx.dsl.experimental.RuntimeParameter,\n enable_cache: bool\n):\n \"\"\"Creates a simple Kubeflow-based Chicago Taxi TFX pipeline.\n\n Args:\n pipeline_root: The root of the pipeline output.\n csv_input_location: The location of the input data directory.\n taxi_module_file: The location of the module file for Transform/Trainer.\n enable_cache: Whether to enable cache or not.\n\n Returns:\n A logical TFX pipeline.Pipeline object.\n \"\"\"\n example_gen = tfx.components.CsvExampleGen(input_base=csv_input_location)\n statistics_gen = tfx.components.StatisticsGen(\n examples=example_gen.outputs['examples'])\n schema_gen = tfx.components.SchemaGen(\n statistics=statistics_gen.outputs['statistics'],\n infer_feature_shape=False,\n )\n example_validator = tfx.components.ExampleValidator(\n statistics=statistics_gen.outputs['statistics'],\n schema=schema_gen.outputs['schema'],\n )\n transform = tfx.components.Transform(\n examples=example_gen.outputs['examples'],\n schema=schema_gen.outputs['schema'],\n module_file=taxi_module_file,\n )\n trainer = tfx.components.Trainer(\n module_file=taxi_module_file,\n examples=transform.outputs['transformed_examples'],\n schema=schema_gen.outputs['schema'],\n transform_graph=transform.outputs['transform_graph'],\n train_args=tfx.proto.TrainArgs(num_steps=10),\n eval_args=tfx.proto.EvalArgs(num_steps=5),\n )\n # Set the TFMA config for Model Evaluation and Validation.\n eval_config = tfma.EvalConfig(\n model_specs=[\n tfma.ModelSpec(\n signature_name='serving_default', label_key='tips_xf',\n preprocessing_function_names=['transform_features'])\n ],\n metrics_specs=[\n tfma.MetricsSpec(\n # The metrics added here are in addition to those saved with the\n # model (assuming either a keras model or EvalSavedModel is used).\n # Any metrics added into the saved model (for example using\n # model.compile(..., metrics=[...]), etc) will be computed\n # automatically.\n metrics=[tfma.MetricConfig(class_name='ExampleCount')],\n # To add validation thresholds for metrics saved with the model,\n # add them keyed by metric name to the thresholds map.\n thresholds={\n 'binary_accuracy':\n tfma.MetricThreshold(\n value_threshold=tfma.GenericValueThreshold(\n lower_bound={'value': 0.5}\n ),\n change_threshold=tfma.GenericChangeThreshold(\n direction=tfma.MetricDirection.HIGHER_IS_BETTER,\n absolute={'value': -1e-10}\n )\n )\n }\n )\n ],\n slicing_specs=[\n # An empty slice spec means the overall slice, i.e. the whole dataset.\n tfma.SlicingSpec(),\n # Data can be sliced along a feature column. In this case, data is\n # sliced along feature column trip_start_hour.\n tfma.SlicingSpec(feature_keys=['trip_start_hour'])\n ]\n )\n\n evaluator = tfx.components.Evaluator(\n examples=example_gen.outputs['examples'],\n model=trainer.outputs['model'],\n eval_config=eval_config,\n )\n\n pusher = tfx.components.Pusher(\n model=trainer.outputs['model'],\n model_blessing=evaluator.outputs['blessing'],\n push_destination=push_destination,\n )\n\n return tfx.dsl.Pipeline(\n pipeline_name='parameterized_tfx_oss',\n pipeline_root=pipeline_root,\n components=[\n example_gen, statistics_gen, schema_gen, example_validator, transform,\n trainer, evaluator, pusher\n ],\n enable_cache=enable_cache,\n )\n\n\nif __name__ == '__main__':\n enable_cache = True\n pipeline = _create_pipeline(\n _pipeline_root,\n _data_root,\n _taxi_module_file_param,\n _push_destination,\n enable_cache=enable_cache,\n )\n # Make sure the version of TFX image used is consistent with the version of\n # TFX SDK.\n config = tfx.orchestration.experimental.KubeflowDagRunnerConfig(\n kubeflow_metadata_config=tfx.orchestration.experimental.\n get_default_kubeflow_metadata_config(),\n tfx_image='gcr.io/tfx-oss-public/tfx:1.2.0',\n )\n kfp_runner = tfx.orchestration.experimental.KubeflowDagRunner(\n output_filename=__file__ + '.yaml', config=config\n )\n\n kfp_runner.run(pipeline)\n", "path": "samples/core/parameterized_tfx_oss/parameterized_tfx_oss.py"}]}
| 2,686 | 225 |
gh_patches_debug_49874
|
rasdani/github-patches
|
git_diff
|
fossasia__open-event-server-5202
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Charging user with stripe token throws internal server error when sending email to attendees
**Describe the bug**
Charging user with stripe token sends 500 (Internal Server Error).
**Expected behavior**
Request should succeed successfully.
**Stacktrace**
```
INFO:werkzeug:127.0.0.1 - - [26/Jul/2018 22:43:56] "POST /v1/orders/46aeab2e-36c2-49c4-9b48-9e6e81b55deb/charge? HTTP/1.1" 500 -
Traceback (most recent call last):
File "/home/rs/Pradeep/github/open-event-server/env/lib/python3.5/site-packages/flask/app.py", line 2309, in __call__
return self.wsgi_app(environ, start_response)
File "/home/rs/Pradeep/github/open-event-server/app/__init__.py", line 67, in __call__
return self.app(environ, start_response)
File "/home/rs/Pradeep/github/open-event-server/env/lib/python3.5/site-packages/flask/app.py", line 2295, in wsgi_app
response = self.handle_exception(e)
File "/home/rs/Pradeep/github/open-event-server/env/lib/python3.5/site-packages/flask_cors/extension.py", line 161, in wrapped_function
return cors_after_request(app.make_response(f(*args, **kwargs)))
File "/home/rs/Pradeep/github/open-event-server/env/lib/python3.5/site-packages/flask_cors/extension.py", line 161, in wrapped_function
return cors_after_request(app.make_response(f(*args, **kwargs)))
File "/home/rs/Pradeep/github/open-event-server/env/lib/python3.5/site-packages/flask/app.py", line 1741, in handle_exception
reraise(exc_type, exc_value, tb)
File "/home/rs/Pradeep/github/open-event-server/env/lib/python3.5/site-packages/flask/_compat.py", line 35, in reraise
raise value
File "/home/rs/Pradeep/github/open-event-server/env/lib/python3.5/site-packages/flask/app.py", line 2292, in wsgi_app
response = self.full_dispatch_request()
File "/home/rs/Pradeep/github/open-event-server/env/lib/python3.5/site-packages/flask/app.py", line 1815, in full_dispatch_request
rv = self.handle_user_exception(e)
File "/home/rs/Pradeep/github/open-event-server/env/lib/python3.5/site-packages/flask_cors/extension.py", line 161, in wrapped_function
return cors_after_request(app.make_response(f(*args, **kwargs)))
File "/home/rs/Pradeep/github/open-event-server/env/lib/python3.5/site-packages/flask_cors/extension.py", line 161, in wrapped_function
return cors_after_request(app.make_response(f(*args, **kwargs)))
File "/home/rs/Pradeep/github/open-event-server/env/lib/python3.5/site-packages/flask/app.py", line 1718, in handle_user_exception
reraise(exc_type, exc_value, tb)
File "/home/rs/Pradeep/github/open-event-server/env/lib/python3.5/site-packages/flask/_compat.py", line 35, in reraise
raise value
File "/home/rs/Pradeep/github/open-event-server/env/lib/python3.5/site-packages/flask/app.py", line 1813, in full_dispatch_request
rv = self.dispatch_request()
File "/home/rs/Pradeep/github/open-event-server/env/lib/python3.5/site-packages/flask/app.py", line 1799, in dispatch_request
return self.view_functions[rule.endpoint](**req.view_args)
File "/home/rs/Pradeep/github/open-event-server/app/api/helpers/permissions.py", line 45, in decorator
return fn(*args, **kwargs)
File "/home/rs/Pradeep/github/open-event-server/env/src/flask-rest-jsonapi/flask_rest_jsonapi/decorators.py", line 32, in wrapper
return func(*args, **kwargs)
File "/home/rs/Pradeep/github/open-event-server/env/lib/python3.5/site-packages/flask/views.py", line 88, in view
return self.dispatch_request(*args, **kwargs)
File "/home/rs/Pradeep/github/open-event-server/env/src/flask-rest-jsonapi/flask_rest_jsonapi/resource.py", line 68, in dispatch_request
response = method(*args, **kwargs)
File "/home/rs/Pradeep/github/open-event-server/env/src/flask-rest-jsonapi/flask_rest_jsonapi/decorators.py", line 56, in wrapper
return func(*args, **kwargs)
File "/home/rs/Pradeep/github/open-event-server/env/src/flask-rest-jsonapi/flask_rest_jsonapi/resource.py", line 204, in post
obj = self._data_layer.create_object(data, kwargs)
File "/home/rs/Pradeep/github/open-event-server/app/api/data_layers/ChargesLayer.py", line 46, in create_object
success, response = TicketingManager.charge_stripe_order_payment(order, data['stripe'])
File "/home/rs/Pradeep/github/open-event-server/app/api/helpers/ticketing.py", line 122, in charge_stripe_order_payment
send_email_to_attendees(order, current_user.id)
File "/home/rs/Pradeep/github/open-event-server/env/lib/python3.5/site-packages/werkzeug/local.py", line 347, in __getattr__
return getattr(self._get_current_object(), name)
AttributeError: 'AnonymousUserMixin' object has no attribute 'id'
```
</issue>
<code>
[start of app/api/helpers/ticketing.py]
1 from datetime import datetime
2
3 from flask_login import current_user
4
5 from app.api.helpers.db import save_to_db, get_count
6 from app.api.helpers.exceptions import ConflictException
7 from app.api.helpers.files import make_frontend_url
8 from app.api.helpers.mail import send_email_to_attendees
9 from app.api.helpers.notification import send_notif_to_attendees, send_notif_ticket_purchase_organizer
10 from app.api.helpers.order import delete_related_attendees_for_order, create_pdf_tickets_for_holder
11 from app.api.helpers.payment import StripePaymentsManager, PayPalPaymentsManager
12 from app.models import db
13 from app.models.ticket_fee import TicketFees
14 from app.models.ticket_holder import TicketHolder
15
16
17 class TicketingManager(object):
18 """All ticketing and orders related helper functions"""
19
20 @staticmethod
21 def get_order_expiry():
22 return 10
23
24 @staticmethod
25 def match_discount_quantity(discount_code, ticket_holders=None):
26 qty = 0
27 old_holders = get_count(TicketHolder.query.filter(TicketHolder.ticket_id.in_(discount_code.tickets.split(","))))
28
29 for holder in ticket_holders:
30 ticket_holder = TicketHolder.query.filter_by(id=holder).one()
31 if ticket_holder.ticket.id in discount_code.tickets.split(","):
32 qty += 1
33 if (qty+old_holders) <= discount_code.tickets_number and \
34 discount_code.min_quantity <= qty <= discount_code.max_quantity:
35 return True
36
37 return False
38
39 @staticmethod
40 def calculate_update_amount(order):
41 discount = None
42 if order.discount_code_id:
43 discount = order.discount_code
44 # Access code part will be done ticket_holders API
45 amount = 0
46 total_discount = 0
47 fees = TicketFees.query.filter_by(currency=order.event.payment_currency).first()
48
49 for order_ticket in order.order_tickets:
50 with db.session.no_autoflush:
51 if order_ticket.ticket.is_fee_absorbed or not fees:
52 ticket_amount = (order_ticket.ticket.price * order_ticket.quantity)
53 amount += (order_ticket.ticket.price * order_ticket.quantity)
54 else:
55 order_fee = fees.service_fee * (order_ticket.ticket.price * order_ticket.quantity) / 100
56 if order_fee > fees.maximum_fee:
57 ticket_amount = (order_ticket.ticket.price * order_ticket.quantity) + fees.maximum_fee
58 amount += (order_ticket.ticket.price * order_ticket.quantity) + fees.maximum_fee
59 else:
60 ticket_amount = (order_ticket.ticket.price * order_ticket.quantity) + order_fee
61 amount += (order_ticket.ticket.price * order_ticket.quantity) + order_fee
62
63 if discount and str(order_ticket.ticket.id) in discount.tickets.split(","):
64 if discount.type == "amount":
65 total_discount += discount.value * order_ticket.quantity
66 else:
67 total_discount += discount.value * ticket_amount / 100
68
69 if discount:
70 if discount.type == "amount":
71 order.amount = max(amount - total_discount, 0)
72 elif discount.type == "percent":
73 order.amount = amount - (discount.value * amount / 100.0)
74 else:
75 order.amount = amount
76 save_to_db(order)
77 return order
78
79 @staticmethod
80 def charge_stripe_order_payment(order, token_id):
81 """
82 Charge the user through Stripe
83 :param order: Order for which to charge for
84 :param token_id: Stripe token
85 :return:
86 """
87 # save the stripe token with the order
88 order.stripe_token = token_id
89 save_to_db(order)
90
91 # charge the user
92 try:
93 charge = StripePaymentsManager.capture_payment(order)
94 except ConflictException as e:
95 # payment failed hence expire the order
96 order.status = 'expired'
97 save_to_db(order)
98
99 # delete related attendees to unlock the tickets
100 delete_related_attendees_for_order(order)
101
102 raise e
103
104 # charge.paid is true if the charge succeeded, or was successfully authorized for later capture.
105 if charge.paid:
106 # update the order in the db.
107 order.paid_via = 'stripe'
108 order.payment_mode = charge.source.object
109 order.brand = charge.source.brand
110 order.exp_month = charge.source.exp_month
111 order.exp_year = charge.source.exp_year
112 order.last4 = charge.source.last4
113 order.transaction_id = charge.id
114 order.status = 'completed'
115 order.completed_at = datetime.utcnow()
116 save_to_db(order)
117
118 # create tickets.
119 create_pdf_tickets_for_holder(order)
120
121 # send email and notifications.
122 send_email_to_attendees(order, current_user.id)
123 send_notif_to_attendees(order, current_user.id)
124
125 order_url = make_frontend_url(path='/orders/{identifier}'.format(identifier=order.identifier))
126 for organizer in order.event.organizers:
127 send_notif_ticket_purchase_organizer(organizer, order.invoice_number, order_url, order.event.name)
128
129 return True, 'Charge successful'
130 else:
131 # payment failed hence expire the order
132 order.status = 'expired'
133 save_to_db(order)
134
135 # delete related attendees to unlock the tickets
136 delete_related_attendees_for_order(order)
137
138 # return the failure message from stripe.
139 return False, charge.failure_message
140
141 @staticmethod
142 def charge_paypal_order_payment(order, paypal_payer_id, paypal_payment_id):
143 """
144 Charge the user through paypal.
145 :param order: Order for which to charge for.
146 :param paypal_payment_id: payment_id
147 :param paypal_payer_id: payer_id
148 :return:
149 """
150
151 # save the paypal payment_id with the order
152 order.paypal_token = paypal_payment_id
153 save_to_db(order)
154
155 # create the transaction.
156 status, error = PayPalPaymentsManager.execute_payment(paypal_payer_id, paypal_payment_id)
157
158 if status:
159 # successful transaction hence update the order details.
160 order.paid_via = 'paypal'
161 order.status = 'completed'
162 order.transaction_id = paypal_payment_id
163 order.completed_at = datetime.utcnow()
164 save_to_db(order)
165
166 # create tickets
167 create_pdf_tickets_for_holder(order)
168
169 # send email and notifications
170 send_email_to_attendees(order, order.user_id)
171 send_notif_to_attendees(order, order.user_id)
172
173 order_url = make_frontend_url(path='/orders/{identifier}'.format(identifier=order.identifier))
174 for organizer in order.event.organizers:
175 send_notif_ticket_purchase_organizer(organizer, order.invoice_number, order_url, order.event.name)
176
177 return True, 'Charge successful'
178 else:
179 # payment failed hence expire the order
180 order.status = 'expired'
181 save_to_db(order)
182
183 # delete related attendees to unlock the tickets
184 delete_related_attendees_for_order(order)
185
186 # return the error message from Paypal
187 return False, error
188
[end of app/api/helpers/ticketing.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/app/api/helpers/ticketing.py b/app/api/helpers/ticketing.py
--- a/app/api/helpers/ticketing.py
+++ b/app/api/helpers/ticketing.py
@@ -1,6 +1,6 @@
from datetime import datetime
-from flask_login import current_user
+from flask_jwt import current_identity as current_user
from app.api.helpers.db import save_to_db, get_count
from app.api.helpers.exceptions import ConflictException
|
{"golden_diff": "diff --git a/app/api/helpers/ticketing.py b/app/api/helpers/ticketing.py\n--- a/app/api/helpers/ticketing.py\n+++ b/app/api/helpers/ticketing.py\n@@ -1,6 +1,6 @@\n from datetime import datetime\n \n-from flask_login import current_user\n+from flask_jwt import current_identity as current_user\n \n from app.api.helpers.db import save_to_db, get_count\n from app.api.helpers.exceptions import ConflictException\n", "issue": "Charging user with stripe token throws internal server error when sending email to attendees\n**Describe the bug**\r\nCharging user with stripe token sends 500 (Internal Server Error).\r\n\r\n**Expected behavior**\r\nRequest should succeed successfully.\r\n\r\n**Stacktrace**\r\n```\r\nINFO:werkzeug:127.0.0.1 - - [26/Jul/2018 22:43:56] \"POST /v1/orders/46aeab2e-36c2-49c4-9b48-9e6e81b55deb/charge? HTTP/1.1\" 500 -\r\nTraceback (most recent call last):\r\n File \"/home/rs/Pradeep/github/open-event-server/env/lib/python3.5/site-packages/flask/app.py\", line 2309, in __call__\r\n return self.wsgi_app(environ, start_response)\r\n File \"/home/rs/Pradeep/github/open-event-server/app/__init__.py\", line 67, in __call__\r\n return self.app(environ, start_response)\r\n File \"/home/rs/Pradeep/github/open-event-server/env/lib/python3.5/site-packages/flask/app.py\", line 2295, in wsgi_app\r\n response = self.handle_exception(e)\r\n File \"/home/rs/Pradeep/github/open-event-server/env/lib/python3.5/site-packages/flask_cors/extension.py\", line 161, in wrapped_function\r\n return cors_after_request(app.make_response(f(*args, **kwargs)))\r\n File \"/home/rs/Pradeep/github/open-event-server/env/lib/python3.5/site-packages/flask_cors/extension.py\", line 161, in wrapped_function\r\n return cors_after_request(app.make_response(f(*args, **kwargs)))\r\n File \"/home/rs/Pradeep/github/open-event-server/env/lib/python3.5/site-packages/flask/app.py\", line 1741, in handle_exception\r\n reraise(exc_type, exc_value, tb)\r\n File \"/home/rs/Pradeep/github/open-event-server/env/lib/python3.5/site-packages/flask/_compat.py\", line 35, in reraise\r\n raise value\r\n File \"/home/rs/Pradeep/github/open-event-server/env/lib/python3.5/site-packages/flask/app.py\", line 2292, in wsgi_app\r\n response = self.full_dispatch_request()\r\n File \"/home/rs/Pradeep/github/open-event-server/env/lib/python3.5/site-packages/flask/app.py\", line 1815, in full_dispatch_request\r\n rv = self.handle_user_exception(e)\r\n File \"/home/rs/Pradeep/github/open-event-server/env/lib/python3.5/site-packages/flask_cors/extension.py\", line 161, in wrapped_function\r\n return cors_after_request(app.make_response(f(*args, **kwargs)))\r\n File \"/home/rs/Pradeep/github/open-event-server/env/lib/python3.5/site-packages/flask_cors/extension.py\", line 161, in wrapped_function\r\n return cors_after_request(app.make_response(f(*args, **kwargs)))\r\n File \"/home/rs/Pradeep/github/open-event-server/env/lib/python3.5/site-packages/flask/app.py\", line 1718, in handle_user_exception\r\n reraise(exc_type, exc_value, tb)\r\n File \"/home/rs/Pradeep/github/open-event-server/env/lib/python3.5/site-packages/flask/_compat.py\", line 35, in reraise\r\n raise value\r\n File \"/home/rs/Pradeep/github/open-event-server/env/lib/python3.5/site-packages/flask/app.py\", line 1813, in full_dispatch_request\r\n rv = self.dispatch_request()\r\n File \"/home/rs/Pradeep/github/open-event-server/env/lib/python3.5/site-packages/flask/app.py\", line 1799, in dispatch_request\r\n return self.view_functions[rule.endpoint](**req.view_args)\r\n File \"/home/rs/Pradeep/github/open-event-server/app/api/helpers/permissions.py\", line 45, in decorator\r\n return fn(*args, **kwargs)\r\n File \"/home/rs/Pradeep/github/open-event-server/env/src/flask-rest-jsonapi/flask_rest_jsonapi/decorators.py\", line 32, in wrapper\r\n return func(*args, **kwargs)\r\n File \"/home/rs/Pradeep/github/open-event-server/env/lib/python3.5/site-packages/flask/views.py\", line 88, in view\r\n return self.dispatch_request(*args, **kwargs)\r\n File \"/home/rs/Pradeep/github/open-event-server/env/src/flask-rest-jsonapi/flask_rest_jsonapi/resource.py\", line 68, in dispatch_request\r\n response = method(*args, **kwargs)\r\n File \"/home/rs/Pradeep/github/open-event-server/env/src/flask-rest-jsonapi/flask_rest_jsonapi/decorators.py\", line 56, in wrapper\r\n return func(*args, **kwargs)\r\n File \"/home/rs/Pradeep/github/open-event-server/env/src/flask-rest-jsonapi/flask_rest_jsonapi/resource.py\", line 204, in post\r\n obj = self._data_layer.create_object(data, kwargs)\r\n File \"/home/rs/Pradeep/github/open-event-server/app/api/data_layers/ChargesLayer.py\", line 46, in create_object\r\n success, response = TicketingManager.charge_stripe_order_payment(order, data['stripe'])\r\n File \"/home/rs/Pradeep/github/open-event-server/app/api/helpers/ticketing.py\", line 122, in charge_stripe_order_payment\r\n send_email_to_attendees(order, current_user.id)\r\n File \"/home/rs/Pradeep/github/open-event-server/env/lib/python3.5/site-packages/werkzeug/local.py\", line 347, in __getattr__\r\n return getattr(self._get_current_object(), name)\r\nAttributeError: 'AnonymousUserMixin' object has no attribute 'id'\r\n```\n", "before_files": [{"content": "from datetime import datetime\n\nfrom flask_login import current_user\n\nfrom app.api.helpers.db import save_to_db, get_count\nfrom app.api.helpers.exceptions import ConflictException\nfrom app.api.helpers.files import make_frontend_url\nfrom app.api.helpers.mail import send_email_to_attendees\nfrom app.api.helpers.notification import send_notif_to_attendees, send_notif_ticket_purchase_organizer\nfrom app.api.helpers.order import delete_related_attendees_for_order, create_pdf_tickets_for_holder\nfrom app.api.helpers.payment import StripePaymentsManager, PayPalPaymentsManager\nfrom app.models import db\nfrom app.models.ticket_fee import TicketFees\nfrom app.models.ticket_holder import TicketHolder\n\n\nclass TicketingManager(object):\n \"\"\"All ticketing and orders related helper functions\"\"\"\n\n @staticmethod\n def get_order_expiry():\n return 10\n\n @staticmethod\n def match_discount_quantity(discount_code, ticket_holders=None):\n qty = 0\n old_holders = get_count(TicketHolder.query.filter(TicketHolder.ticket_id.in_(discount_code.tickets.split(\",\"))))\n\n for holder in ticket_holders:\n ticket_holder = TicketHolder.query.filter_by(id=holder).one()\n if ticket_holder.ticket.id in discount_code.tickets.split(\",\"):\n qty += 1\n if (qty+old_holders) <= discount_code.tickets_number and \\\n discount_code.min_quantity <= qty <= discount_code.max_quantity:\n return True\n\n return False\n\n @staticmethod\n def calculate_update_amount(order):\n discount = None\n if order.discount_code_id:\n discount = order.discount_code\n # Access code part will be done ticket_holders API\n amount = 0\n total_discount = 0\n fees = TicketFees.query.filter_by(currency=order.event.payment_currency).first()\n\n for order_ticket in order.order_tickets:\n with db.session.no_autoflush:\n if order_ticket.ticket.is_fee_absorbed or not fees:\n ticket_amount = (order_ticket.ticket.price * order_ticket.quantity)\n amount += (order_ticket.ticket.price * order_ticket.quantity)\n else:\n order_fee = fees.service_fee * (order_ticket.ticket.price * order_ticket.quantity) / 100\n if order_fee > fees.maximum_fee:\n ticket_amount = (order_ticket.ticket.price * order_ticket.quantity) + fees.maximum_fee\n amount += (order_ticket.ticket.price * order_ticket.quantity) + fees.maximum_fee\n else:\n ticket_amount = (order_ticket.ticket.price * order_ticket.quantity) + order_fee\n amount += (order_ticket.ticket.price * order_ticket.quantity) + order_fee\n\n if discount and str(order_ticket.ticket.id) in discount.tickets.split(\",\"):\n if discount.type == \"amount\":\n total_discount += discount.value * order_ticket.quantity\n else:\n total_discount += discount.value * ticket_amount / 100\n\n if discount:\n if discount.type == \"amount\":\n order.amount = max(amount - total_discount, 0)\n elif discount.type == \"percent\":\n order.amount = amount - (discount.value * amount / 100.0)\n else:\n order.amount = amount\n save_to_db(order)\n return order\n\n @staticmethod\n def charge_stripe_order_payment(order, token_id):\n \"\"\"\n Charge the user through Stripe\n :param order: Order for which to charge for\n :param token_id: Stripe token\n :return:\n \"\"\"\n # save the stripe token with the order\n order.stripe_token = token_id\n save_to_db(order)\n\n # charge the user\n try:\n charge = StripePaymentsManager.capture_payment(order)\n except ConflictException as e:\n # payment failed hence expire the order\n order.status = 'expired'\n save_to_db(order)\n\n # delete related attendees to unlock the tickets\n delete_related_attendees_for_order(order)\n\n raise e\n\n # charge.paid is true if the charge succeeded, or was successfully authorized for later capture.\n if charge.paid:\n # update the order in the db.\n order.paid_via = 'stripe'\n order.payment_mode = charge.source.object\n order.brand = charge.source.brand\n order.exp_month = charge.source.exp_month\n order.exp_year = charge.source.exp_year\n order.last4 = charge.source.last4\n order.transaction_id = charge.id\n order.status = 'completed'\n order.completed_at = datetime.utcnow()\n save_to_db(order)\n\n # create tickets.\n create_pdf_tickets_for_holder(order)\n\n # send email and notifications.\n send_email_to_attendees(order, current_user.id)\n send_notif_to_attendees(order, current_user.id)\n\n order_url = make_frontend_url(path='/orders/{identifier}'.format(identifier=order.identifier))\n for organizer in order.event.organizers:\n send_notif_ticket_purchase_organizer(organizer, order.invoice_number, order_url, order.event.name)\n\n return True, 'Charge successful'\n else:\n # payment failed hence expire the order\n order.status = 'expired'\n save_to_db(order)\n\n # delete related attendees to unlock the tickets\n delete_related_attendees_for_order(order)\n\n # return the failure message from stripe.\n return False, charge.failure_message\n\n @staticmethod\n def charge_paypal_order_payment(order, paypal_payer_id, paypal_payment_id):\n \"\"\"\n Charge the user through paypal.\n :param order: Order for which to charge for.\n :param paypal_payment_id: payment_id\n :param paypal_payer_id: payer_id\n :return:\n \"\"\"\n\n # save the paypal payment_id with the order\n order.paypal_token = paypal_payment_id\n save_to_db(order)\n\n # create the transaction.\n status, error = PayPalPaymentsManager.execute_payment(paypal_payer_id, paypal_payment_id)\n\n if status:\n # successful transaction hence update the order details.\n order.paid_via = 'paypal'\n order.status = 'completed'\n order.transaction_id = paypal_payment_id\n order.completed_at = datetime.utcnow()\n save_to_db(order)\n\n # create tickets\n create_pdf_tickets_for_holder(order)\n\n # send email and notifications\n send_email_to_attendees(order, order.user_id)\n send_notif_to_attendees(order, order.user_id)\n\n order_url = make_frontend_url(path='/orders/{identifier}'.format(identifier=order.identifier))\n for organizer in order.event.organizers:\n send_notif_ticket_purchase_organizer(organizer, order.invoice_number, order_url, order.event.name)\n\n return True, 'Charge successful'\n else:\n # payment failed hence expire the order\n order.status = 'expired'\n save_to_db(order)\n\n # delete related attendees to unlock the tickets\n delete_related_attendees_for_order(order)\n\n # return the error message from Paypal\n return False, error\n", "path": "app/api/helpers/ticketing.py"}]}
| 3,789 | 95 |
gh_patches_debug_22712
|
rasdani/github-patches
|
git_diff
|
Cloud-CV__EvalAI-1315
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Add support to update the user profile.
</issue>
<code>
[start of settings/common.py]
1 """
2 Django settings for evalai project.
3
4 Generated by 'django-admin startproject' using Django 1.10.2.
5
6 For more information on this file, see
7 https://docs.djangoproject.com/en/1.10/topics/settings/
8
9 For the full list of settings and their values, see
10 https://docs.djangoproject.com/en/1.10/ref/settings/
11 """
12
13 import datetime
14 import os
15 import sys
16
17 # Build paths inside the project like this: os.path.join(BASE_DIR, ...)
18 BASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
19 APPS_DIR = os.path.join(BASE_DIR, 'apps')
20
21 sys.path.append(APPS_DIR)
22
23 # Quick-start development settings - unsuitable for production
24 # See https://docs.djangoproject.com/en/1.10/howto/deployment/checklist/
25
26 # SECURITY WARNING: keep the secret key used in production secret!
27 SECRET_KEY = os.environ.get('SECRET_KEY', 'random_secret_key')
28
29 # SECURITY WARNING: don't run with debug turned on in production!
30 DEBUG = True
31
32 ALLOWED_HOSTS = []
33
34
35 # Application definition
36
37 DEFAULT_APPS = [
38 'django.contrib.admin',
39 'django.contrib.auth',
40 'django.contrib.contenttypes',
41 'django.contrib.sessions',
42 'django.contrib.messages',
43 'django.contrib.staticfiles',
44 'django.contrib.sites',
45 ]
46
47 OUR_APPS = [
48 'accounts',
49 'analytics',
50 'base',
51 'challenges',
52 'hosts',
53 'jobs',
54 'participants',
55 'web',
56 ]
57
58 THIRD_PARTY_APPS = [
59 'allauth',
60 'allauth.account',
61 'corsheaders',
62 'import_export',
63 'rest_auth',
64 'rest_auth.registration',
65 'rest_framework.authtoken',
66 'rest_framework',
67 'rest_framework_docs',
68 'rest_framework_expiring_authtoken',
69 ]
70
71 INSTALLED_APPS = DEFAULT_APPS + OUR_APPS + THIRD_PARTY_APPS
72
73 MIDDLEWARE = [
74 'corsheaders.middleware.CorsMiddleware',
75 'django.middleware.security.SecurityMiddleware',
76 'django.contrib.sessions.middleware.SessionMiddleware',
77 'django.middleware.common.CommonMiddleware',
78 'django.middleware.csrf.CsrfViewMiddleware',
79 'django.contrib.auth.middleware.AuthenticationMiddleware',
80 'django.contrib.messages.middleware.MessageMiddleware',
81 'django.middleware.clickjacking.XFrameOptionsMiddleware',
82 ]
83
84 ROOT_URLCONF = 'evalai.urls'
85
86
87 TEMPLATES = [
88 {
89 'BACKEND': 'django.template.backends.django.DjangoTemplates',
90 'DIRS': [],
91 'APP_DIRS': True,
92 'OPTIONS': {
93 'context_processors': [
94 'django.template.context_processors.debug',
95 'django.template.context_processors.request',
96 'django.contrib.auth.context_processors.auth',
97 'django.contrib.messages.context_processors.messages',
98 ],
99 },
100 },
101 ]
102
103 WSGI_APPLICATION = 'evalai.wsgi.application'
104
105
106 # Password validation
107 # https://docs.djangoproject.com/en/1.10/ref/settings/#auth-password-validators
108
109 AUTH_PASSWORD_VALIDATORS = [
110 {
111 'NAME': 'django.contrib.auth.password_validation.UserAttributeSimilarityValidator', # noqa
112 },
113 {
114 'NAME': 'django.contrib.auth.password_validation.MinimumLengthValidator', # noqa
115 },
116 {
117 'NAME': 'django.contrib.auth.password_validation.CommonPasswordValidator', # noqa
118 },
119 {
120 'NAME': 'django.contrib.auth.password_validation.NumericPasswordValidator', # noqa
121 },
122 ]
123
124
125 # Internationalization
126 # https://docs.djangoproject.com/en/1.10/topics/i18n/
127
128 LANGUAGE_CODE = 'en-us'
129
130 TIME_ZONE = 'UTC'
131
132 USE_I18N = True
133
134 USE_L10N = True
135
136 USE_TZ = True
137
138 # Static files (CSS, JavaScript, Images)
139 # https://docs.djangoproject.com/en/1.10/howto/static-files/
140
141 STATIC_URL = '/static/'
142 STATIC_ROOT = os.path.join(BASE_DIR, 'static')
143 MEDIA_ROOT = os.path.join(BASE_DIR, 'media')
144 MEDIA_URL = "/media/"
145
146 SITE_ID = 1
147
148 REST_FRAMEWORK = {
149 'DEFAULT_PAGINATION_CLASS': (
150 'rest_framework.pagination.LimitOffsetPagination'),
151 'PAGE_SIZE': 10,
152 'DEFAULT_PERMISSION_CLASSES': [
153 'rest_framework.permissions.IsAuthenticatedOrReadOnly'
154 ],
155 'DEFAULT_AUTHENTICATION_CLASSES': [
156 'rest_framework_expiring_authtoken.authentication.ExpiringTokenAuthentication',
157 ],
158 'TEST_REQUEST_DEFAULT_FORMAT': 'json',
159 'DEFAULT_THROTTLE_CLASSES': (
160 'rest_framework.throttling.AnonRateThrottle',
161 'rest_framework.throttling.UserRateThrottle'
162 ),
163 'DEFAULT_THROTTLE_RATES': {
164 'anon': '100/minute',
165 'user': '100/minute'
166 },
167 'DEFAULT_RENDERER_CLASSES': (
168 'rest_framework.renderers.JSONRenderer',
169 )
170 }
171
172 # ALLAUTH SETTINGS
173 ACCOUNT_EMAIL_REQUIRED = True
174 OLD_PASSWORD_FIELD_ENABLED = True
175 ACCOUNT_CONFIRM_EMAIL_ON_GET = True
176 ACCOUNT_EMAIL_CONFIRMATION_ANONYMOUS_REDIRECT_URL = '/api/auth/email-confirmed/'
177 ACCOUNT_EMAIL_CONFIRMATION_AUTHENTICATED_REDIRECT_URL = '/api/auth/email-confirmed/'
178
179 AUTHENTICATION_BACKENDS = (
180 # Needed to login by username in Django admin, regardless of `allauth`
181 'django.contrib.auth.backends.ModelBackend',
182 # `allauth` specific authentication methods, such as login by e-mail
183 'allauth.account.auth_backends.AuthenticationBackend',
184 )
185
186 # CORS Settings
187 CORS_ORIGIN_ALLOW_ALL = True
188
189 # REST Framework Expiring Tokens Configuration
190 EXPIRING_TOKEN_LIFESPAN = datetime.timedelta(days=7)
191
192 # Logging
193 LOGGING = {
194 'version': 1,
195 'disable_existing_loggers': False,
196 'root': {
197 'level': 'INFO',
198 'handlers': ['console'],
199 },
200 'filters': {
201 'require_debug_false': {
202 '()': 'django.utils.log.RequireDebugFalse',
203 },
204 'require_debug_true': {
205 '()': 'django.utils.log.RequireDebugTrue',
206 }
207 },
208 'formatters': {
209 'simple': {
210 'format': '[%(asctime)s] %(levelname)s %(message)s',
211 'datefmt': '%Y-%m-%d %H:%M:%S'
212 },
213 'verbose': {
214 'format': '[%(asctime)s] %(levelname)s %(module)s %(message)s',
215 'datefmt': '%Y-%m-%d %H:%M:%S'
216 }
217 },
218 'handlers': {
219 'console': {
220 'level': 'INFO',
221 'filters': ['require_debug_true'],
222 'class': 'logging.StreamHandler',
223 'formatter': 'simple'
224 },
225 'logfile': {
226 'level': 'DEBUG',
227 'class': 'logging.handlers.RotatingFileHandler',
228 'filename': "/tmp/logfile",
229 'maxBytes': 50000,
230 'backupCount': 10,
231 'formatter': 'verbose'
232 },
233 'mail_admins': {
234 'level': 'ERROR',
235 'class': 'django.utils.log.AdminEmailHandler',
236 'filters': ['require_debug_false'],
237 }
238 },
239 'loggers': {
240 'django': {
241 'handlers': ['console'],
242 'propagate': False,
243 },
244 'django.request': {
245 'handlers': ['mail_admins'],
246 'level': 'ERROR',
247 'propagate': False,
248 },
249 'django.security': {
250 'handlers': ['mail_admins'],
251 'level': 'ERROR',
252 'propagate': False,
253 },
254 'django.db.backends': {
255 'handlers': ['mail_admins'],
256 'level': 'ERROR',
257 'propagate': False,
258 }
259 }
260 }
261
262 CACHES = {
263 'default': {
264 'BACKEND': 'django.core.cache.backends.memcached.MemcachedCache',
265 }
266 }
267
268 RABBITMQ_PARAMETERS = {
269 'HOST': os.environ.get("RABBITMQ_HOST", 'localhost'),
270 'EVALAI_EXCHANGE': {
271 'NAME': 'evalai_submissions',
272 'TYPE': 'topic',
273 },
274 'SUBMISSION_QUEUE': 'submission_task_queue',
275 }
276
277 # To make usermame field read-only, customized serializer is defined.
278 REST_AUTH_SERIALIZERS = {
279 'USER_DETAILS_SERIALIZER': 'accounts.serializers.UserDetailsSerializer',
280 }
281
[end of settings/common.py]
[start of apps/accounts/serializers.py]
1 from django.contrib.auth import get_user_model
2
3 from rest_framework import serializers
4
5
6 class UserDetailsSerializer(serializers.ModelSerializer):
7 """
8 Make username as a read_only field.
9 """
10 class Meta:
11 model = get_user_model()
12 fields = ('pk', 'email', 'username', 'first_name', 'last_name')
13 read_only_fields = ('email', 'username')
14
[end of apps/accounts/serializers.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/apps/accounts/serializers.py b/apps/accounts/serializers.py
--- a/apps/accounts/serializers.py
+++ b/apps/accounts/serializers.py
@@ -11,3 +11,26 @@
model = get_user_model()
fields = ('pk', 'email', 'username', 'first_name', 'last_name')
read_only_fields = ('email', 'username')
+
+
+class ProfileSerializer(UserDetailsSerializer):
+ """
+ Serializer to update the user profile.
+ """
+
+ affiliation = serializers.CharField(source="profile.affiliation")
+
+ class Meta(UserDetailsSerializer.Meta):
+ fields = UserDetailsSerializer.Meta.fields + ('affiliation',)
+
+ def update(self, instance, validated_data):
+ profile_data = validated_data.pop('profile', {})
+ affiliation = profile_data.get('affiliation')
+
+ instance = super(ProfileSerializer, self).update(instance, validated_data)
+
+ profile = instance.profile
+ if profile_data and affiliation:
+ profile.affiliation = affiliation
+ profile.save()
+ return instance
diff --git a/settings/common.py b/settings/common.py
--- a/settings/common.py
+++ b/settings/common.py
@@ -276,5 +276,5 @@
# To make usermame field read-only, customized serializer is defined.
REST_AUTH_SERIALIZERS = {
- 'USER_DETAILS_SERIALIZER': 'accounts.serializers.UserDetailsSerializer',
+ 'USER_DETAILS_SERIALIZER': 'accounts.serializers.ProfileSerializer',
}
|
{"golden_diff": "diff --git a/apps/accounts/serializers.py b/apps/accounts/serializers.py\n--- a/apps/accounts/serializers.py\n+++ b/apps/accounts/serializers.py\n@@ -11,3 +11,26 @@\n model = get_user_model()\n fields = ('pk', 'email', 'username', 'first_name', 'last_name')\n read_only_fields = ('email', 'username')\n+\n+\n+class ProfileSerializer(UserDetailsSerializer):\n+ \"\"\"\n+ Serializer to update the user profile.\n+ \"\"\"\n+\n+ affiliation = serializers.CharField(source=\"profile.affiliation\")\n+\n+ class Meta(UserDetailsSerializer.Meta):\n+ fields = UserDetailsSerializer.Meta.fields + ('affiliation',)\n+\n+ def update(self, instance, validated_data):\n+ profile_data = validated_data.pop('profile', {})\n+ affiliation = profile_data.get('affiliation')\n+\n+ instance = super(ProfileSerializer, self).update(instance, validated_data)\n+\n+ profile = instance.profile\n+ if profile_data and affiliation:\n+ profile.affiliation = affiliation\n+ profile.save()\n+ return instance\ndiff --git a/settings/common.py b/settings/common.py\n--- a/settings/common.py\n+++ b/settings/common.py\n@@ -276,5 +276,5 @@\n \n # To make usermame field read-only, customized serializer is defined.\n REST_AUTH_SERIALIZERS = {\n- 'USER_DETAILS_SERIALIZER': 'accounts.serializers.UserDetailsSerializer',\n+ 'USER_DETAILS_SERIALIZER': 'accounts.serializers.ProfileSerializer',\n }\n", "issue": "Add support to update the user profile.\n\n", "before_files": [{"content": "\"\"\"\nDjango settings for evalai project.\n\nGenerated by 'django-admin startproject' using Django 1.10.2.\n\nFor more information on this file, see\nhttps://docs.djangoproject.com/en/1.10/topics/settings/\n\nFor the full list of settings and their values, see\nhttps://docs.djangoproject.com/en/1.10/ref/settings/\n\"\"\"\n\nimport datetime\nimport os\nimport sys\n\n# Build paths inside the project like this: os.path.join(BASE_DIR, ...)\nBASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))\nAPPS_DIR = os.path.join(BASE_DIR, 'apps')\n\nsys.path.append(APPS_DIR)\n\n# Quick-start development settings - unsuitable for production\n# See https://docs.djangoproject.com/en/1.10/howto/deployment/checklist/\n\n# SECURITY WARNING: keep the secret key used in production secret!\nSECRET_KEY = os.environ.get('SECRET_KEY', 'random_secret_key')\n\n# SECURITY WARNING: don't run with debug turned on in production!\nDEBUG = True\n\nALLOWED_HOSTS = []\n\n\n# Application definition\n\nDEFAULT_APPS = [\n 'django.contrib.admin',\n 'django.contrib.auth',\n 'django.contrib.contenttypes',\n 'django.contrib.sessions',\n 'django.contrib.messages',\n 'django.contrib.staticfiles',\n 'django.contrib.sites',\n]\n\nOUR_APPS = [\n 'accounts',\n 'analytics',\n 'base',\n 'challenges',\n 'hosts',\n 'jobs',\n 'participants',\n 'web',\n]\n\nTHIRD_PARTY_APPS = [\n 'allauth',\n 'allauth.account',\n 'corsheaders',\n 'import_export',\n 'rest_auth',\n 'rest_auth.registration',\n 'rest_framework.authtoken',\n 'rest_framework',\n 'rest_framework_docs',\n 'rest_framework_expiring_authtoken',\n]\n\nINSTALLED_APPS = DEFAULT_APPS + OUR_APPS + THIRD_PARTY_APPS\n\nMIDDLEWARE = [\n 'corsheaders.middleware.CorsMiddleware',\n 'django.middleware.security.SecurityMiddleware',\n 'django.contrib.sessions.middleware.SessionMiddleware',\n 'django.middleware.common.CommonMiddleware',\n 'django.middleware.csrf.CsrfViewMiddleware',\n 'django.contrib.auth.middleware.AuthenticationMiddleware',\n 'django.contrib.messages.middleware.MessageMiddleware',\n 'django.middleware.clickjacking.XFrameOptionsMiddleware',\n]\n\nROOT_URLCONF = 'evalai.urls'\n\n\nTEMPLATES = [\n {\n 'BACKEND': 'django.template.backends.django.DjangoTemplates',\n 'DIRS': [],\n 'APP_DIRS': True,\n 'OPTIONS': {\n 'context_processors': [\n 'django.template.context_processors.debug',\n 'django.template.context_processors.request',\n 'django.contrib.auth.context_processors.auth',\n 'django.contrib.messages.context_processors.messages',\n ],\n },\n },\n]\n\nWSGI_APPLICATION = 'evalai.wsgi.application'\n\n\n# Password validation\n# https://docs.djangoproject.com/en/1.10/ref/settings/#auth-password-validators\n\nAUTH_PASSWORD_VALIDATORS = [\n {\n 'NAME': 'django.contrib.auth.password_validation.UserAttributeSimilarityValidator', # noqa\n },\n {\n 'NAME': 'django.contrib.auth.password_validation.MinimumLengthValidator', # noqa\n },\n {\n 'NAME': 'django.contrib.auth.password_validation.CommonPasswordValidator', # noqa\n },\n {\n 'NAME': 'django.contrib.auth.password_validation.NumericPasswordValidator', # noqa\n },\n]\n\n\n# Internationalization\n# https://docs.djangoproject.com/en/1.10/topics/i18n/\n\nLANGUAGE_CODE = 'en-us'\n\nTIME_ZONE = 'UTC'\n\nUSE_I18N = True\n\nUSE_L10N = True\n\nUSE_TZ = True\n\n# Static files (CSS, JavaScript, Images)\n# https://docs.djangoproject.com/en/1.10/howto/static-files/\n\nSTATIC_URL = '/static/'\nSTATIC_ROOT = os.path.join(BASE_DIR, 'static')\nMEDIA_ROOT = os.path.join(BASE_DIR, 'media')\nMEDIA_URL = \"/media/\"\n\nSITE_ID = 1\n\nREST_FRAMEWORK = {\n 'DEFAULT_PAGINATION_CLASS': (\n 'rest_framework.pagination.LimitOffsetPagination'),\n 'PAGE_SIZE': 10,\n 'DEFAULT_PERMISSION_CLASSES': [\n 'rest_framework.permissions.IsAuthenticatedOrReadOnly'\n ],\n 'DEFAULT_AUTHENTICATION_CLASSES': [\n 'rest_framework_expiring_authtoken.authentication.ExpiringTokenAuthentication',\n ],\n 'TEST_REQUEST_DEFAULT_FORMAT': 'json',\n 'DEFAULT_THROTTLE_CLASSES': (\n 'rest_framework.throttling.AnonRateThrottle',\n 'rest_framework.throttling.UserRateThrottle'\n ),\n 'DEFAULT_THROTTLE_RATES': {\n 'anon': '100/minute',\n 'user': '100/minute'\n },\n 'DEFAULT_RENDERER_CLASSES': (\n 'rest_framework.renderers.JSONRenderer',\n )\n}\n\n# ALLAUTH SETTINGS\nACCOUNT_EMAIL_REQUIRED = True\nOLD_PASSWORD_FIELD_ENABLED = True\nACCOUNT_CONFIRM_EMAIL_ON_GET = True\nACCOUNT_EMAIL_CONFIRMATION_ANONYMOUS_REDIRECT_URL = '/api/auth/email-confirmed/'\nACCOUNT_EMAIL_CONFIRMATION_AUTHENTICATED_REDIRECT_URL = '/api/auth/email-confirmed/'\n\nAUTHENTICATION_BACKENDS = (\n # Needed to login by username in Django admin, regardless of `allauth`\n 'django.contrib.auth.backends.ModelBackend',\n # `allauth` specific authentication methods, such as login by e-mail\n 'allauth.account.auth_backends.AuthenticationBackend',\n)\n\n# CORS Settings\nCORS_ORIGIN_ALLOW_ALL = True\n\n# REST Framework Expiring Tokens Configuration\nEXPIRING_TOKEN_LIFESPAN = datetime.timedelta(days=7)\n\n# Logging\nLOGGING = {\n 'version': 1,\n 'disable_existing_loggers': False,\n 'root': {\n 'level': 'INFO',\n 'handlers': ['console'],\n },\n 'filters': {\n 'require_debug_false': {\n '()': 'django.utils.log.RequireDebugFalse',\n },\n 'require_debug_true': {\n '()': 'django.utils.log.RequireDebugTrue',\n }\n },\n 'formatters': {\n 'simple': {\n 'format': '[%(asctime)s] %(levelname)s %(message)s',\n 'datefmt': '%Y-%m-%d %H:%M:%S'\n },\n 'verbose': {\n 'format': '[%(asctime)s] %(levelname)s %(module)s %(message)s',\n 'datefmt': '%Y-%m-%d %H:%M:%S'\n }\n },\n 'handlers': {\n 'console': {\n 'level': 'INFO',\n 'filters': ['require_debug_true'],\n 'class': 'logging.StreamHandler',\n 'formatter': 'simple'\n },\n 'logfile': {\n 'level': 'DEBUG',\n 'class': 'logging.handlers.RotatingFileHandler',\n 'filename': \"/tmp/logfile\",\n 'maxBytes': 50000,\n 'backupCount': 10,\n 'formatter': 'verbose'\n },\n 'mail_admins': {\n 'level': 'ERROR',\n 'class': 'django.utils.log.AdminEmailHandler',\n 'filters': ['require_debug_false'],\n }\n },\n 'loggers': {\n 'django': {\n 'handlers': ['console'],\n 'propagate': False,\n },\n 'django.request': {\n 'handlers': ['mail_admins'],\n 'level': 'ERROR',\n 'propagate': False,\n },\n 'django.security': {\n 'handlers': ['mail_admins'],\n 'level': 'ERROR',\n 'propagate': False,\n },\n 'django.db.backends': {\n 'handlers': ['mail_admins'],\n 'level': 'ERROR',\n 'propagate': False,\n }\n }\n}\n\nCACHES = {\n 'default': {\n 'BACKEND': 'django.core.cache.backends.memcached.MemcachedCache',\n }\n}\n\nRABBITMQ_PARAMETERS = {\n 'HOST': os.environ.get(\"RABBITMQ_HOST\", 'localhost'),\n 'EVALAI_EXCHANGE': {\n 'NAME': 'evalai_submissions',\n 'TYPE': 'topic',\n },\n 'SUBMISSION_QUEUE': 'submission_task_queue',\n}\n\n# To make usermame field read-only, customized serializer is defined.\nREST_AUTH_SERIALIZERS = {\n 'USER_DETAILS_SERIALIZER': 'accounts.serializers.UserDetailsSerializer',\n}\n", "path": "settings/common.py"}, {"content": "from django.contrib.auth import get_user_model\n\nfrom rest_framework import serializers\n\n\nclass UserDetailsSerializer(serializers.ModelSerializer):\n \"\"\"\n Make username as a read_only field.\n \"\"\"\n class Meta:\n model = get_user_model()\n fields = ('pk', 'email', 'username', 'first_name', 'last_name')\n read_only_fields = ('email', 'username')\n", "path": "apps/accounts/serializers.py"}]}
| 3,190 | 331 |
gh_patches_debug_18331
|
rasdani/github-patches
|
git_diff
|
cloud-custodian__cloud-custodian-2308
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
c7n_mailer lambda error after included slack integration
Hi team,
It appears that deployed lambda mailer is having some problem with the libs, after the last commit that included slack integration.
After update c7n_mailer lambda I'm seeing this error in the logs:
```
[ERROR] 2018-05-01T00:45:26.698Z f04d1326-4cd8-11e8-9f05-670c91cd10c1 Error starting mailer MailerSqsQueueProcessor().
Error: No module named requests
Traceback (most recent call last):
File "/var/task/c7n_mailer/handle.py", line 46, in start_c7n_mailer
mailer_sqs_queue_processor.run(parallel)
File "/var/task/c7n_mailer/sqs_queue_processor.py", line 126, in run
self.process_sqs_message(sqs_message)
File "/var/task/c7n_mailer/sqs_queue_processor.py", line 170, in process_sqs_message
from .slack_delivery import SlackDelivery
File "/var/task/c7n_mailer/slack_delivery.py", line 17, in <module>
import requests
ImportError: No module named requests
```
I've had no success even with a fresh install from the repos.
</issue>
<code>
[start of tools/c7n_mailer/c7n_mailer/deploy.py]
1 # Copyright 2016-2017 Capital One Services, LLC
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14 from __future__ import absolute_import, division, print_function, unicode_literals
15
16 import json
17 import os
18
19 from c7n.mu import (
20 CloudWatchEventSource,
21 LambdaFunction,
22 LambdaManager,
23 PythonPackageArchive)
24
25
26 entry_source = """\
27 import logging
28
29 from c7n_mailer import handle
30
31 logger = logging.getLogger('custodian.mailer')
32 log_format = '%(asctime)s - %(name)s - %(levelname)s - %(message)s'
33 logging.basicConfig(level=logging.INFO, format=log_format)
34 logging.getLogger('botocore').setLevel(logging.WARNING)
35
36 def dispatch(event, context):
37 return handle.start_c7n_mailer(logger)
38 """
39
40
41 def get_archive(config):
42 archive = PythonPackageArchive(
43 'c7n_mailer', 'ldap3', 'pyasn1', 'jinja2', 'markupsafe', 'ruamel',
44 'redis')
45
46 template_dir = os.path.abspath(
47 os.path.join(os.path.dirname(__file__), '..', 'msg-templates'))
48
49 for t in os.listdir(template_dir):
50 with open(os.path.join(template_dir, t)) as fh:
51 archive.add_contents('msg-templates/%s' % t, fh.read())
52
53 archive.add_contents('config.json', json.dumps(config))
54 archive.add_contents('periodic.py', entry_source)
55
56 archive.close()
57 return archive
58
59
60 def provision(config, session_factory):
61 func_config = dict(
62 name=config.get('lambda_name', 'cloud-custodian-mailer'),
63 description=config.get('lambda_description', 'Cloud Custodian Mailer'),
64 tags=config.get('lambda_tags', {}),
65 handler='periodic.dispatch',
66 runtime=config['runtime'],
67 memory_size=config['memory'],
68 timeout=config['timeout'],
69 role=config['role'],
70 subnets=config['subnets'],
71 security_groups=config['security_groups'],
72 dead_letter_config=config.get('dead_letter_config', {}),
73 events=[
74 CloudWatchEventSource(
75 {'type': 'periodic',
76 'schedule': config.get('lambda_schedule', 'rate(5 minutes)')},
77 session_factory,
78 prefix="")
79 ])
80
81 archive = get_archive(config)
82 func = LambdaFunction(func_config, archive)
83 manager = LambdaManager(session_factory)
84 manager.publish(func)
85
[end of tools/c7n_mailer/c7n_mailer/deploy.py]
[start of tools/c7n_mailer/setup.py]
1 # Copyright 2015-2017 Capital One Services, LLC
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14 from __future__ import absolute_import, division, print_function, unicode_literals
15
16 from setuptools import setup, find_packages
17 import os
18
19 requires = ["Jinja2", "boto3", "jsonschema", "ruamel.yaml<0.15", "datadog"]
20 try:
21 from concurrent import futures
22 except ImportError:
23 # The backport has SyntaxErrors under py36, so avoid installing it.
24 # https://github.com/agronholm/pythonfutures/issues/41
25 requires += ['futures']
26
27 description = ""
28 if os.path.exists('README.md'):
29 description = open('README.md').read()
30
31 setup(
32 name="c7n_mailer",
33 version='0.3.1',
34 description="Cloud Custodian - Reference Mailer",
35 long_description=description,
36 classifiers=[
37 "Topic :: System :: Systems Administration",
38 "Topic :: System :: Distributed Computing"
39 ],
40 url="https://github.com/capitalone/cloud-custodian",
41 license="Apache-2.0",
42 packages=find_packages('c7n_mailer'),
43 entry_points={
44 'console_scripts': [
45 'c7n-mailer = c7n_mailer.cli:main',
46 'c7n-mailer-replay = c7n_mailer.replay:main'
47 ]
48 },
49 install_requires=requires,
50 )
51
[end of tools/c7n_mailer/setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/tools/c7n_mailer/c7n_mailer/deploy.py b/tools/c7n_mailer/c7n_mailer/deploy.py
--- a/tools/c7n_mailer/c7n_mailer/deploy.py
+++ b/tools/c7n_mailer/c7n_mailer/deploy.py
@@ -41,7 +41,7 @@
def get_archive(config):
archive = PythonPackageArchive(
'c7n_mailer', 'ldap3', 'pyasn1', 'jinja2', 'markupsafe', 'ruamel',
- 'redis')
+ 'redis', 'datadog', 'slackclient', 'requests')
template_dir = os.path.abspath(
os.path.join(os.path.dirname(__file__), '..', 'msg-templates'))
diff --git a/tools/c7n_mailer/setup.py b/tools/c7n_mailer/setup.py
--- a/tools/c7n_mailer/setup.py
+++ b/tools/c7n_mailer/setup.py
@@ -16,7 +16,9 @@
from setuptools import setup, find_packages
import os
-requires = ["Jinja2", "boto3", "jsonschema", "ruamel.yaml<0.15", "datadog"]
+# *Any* updates here should also go into c7n_mailer/deploy.py for lambda packaging.
+requires = [
+ "Jinja2", "boto3", "jsonschema", "ruamel.yaml<0.15", "datadog", "slackclient", "ldap3"]
try:
from concurrent import futures
except ImportError:
|
{"golden_diff": "diff --git a/tools/c7n_mailer/c7n_mailer/deploy.py b/tools/c7n_mailer/c7n_mailer/deploy.py\n--- a/tools/c7n_mailer/c7n_mailer/deploy.py\n+++ b/tools/c7n_mailer/c7n_mailer/deploy.py\n@@ -41,7 +41,7 @@\n def get_archive(config):\n archive = PythonPackageArchive(\n 'c7n_mailer', 'ldap3', 'pyasn1', 'jinja2', 'markupsafe', 'ruamel',\n- 'redis')\n+ 'redis', 'datadog', 'slackclient', 'requests')\n \n template_dir = os.path.abspath(\n os.path.join(os.path.dirname(__file__), '..', 'msg-templates'))\ndiff --git a/tools/c7n_mailer/setup.py b/tools/c7n_mailer/setup.py\n--- a/tools/c7n_mailer/setup.py\n+++ b/tools/c7n_mailer/setup.py\n@@ -16,7 +16,9 @@\n from setuptools import setup, find_packages\n import os\n \n-requires = [\"Jinja2\", \"boto3\", \"jsonschema\", \"ruamel.yaml<0.15\", \"datadog\"]\n+# *Any* updates here should also go into c7n_mailer/deploy.py for lambda packaging.\n+requires = [\n+ \"Jinja2\", \"boto3\", \"jsonschema\", \"ruamel.yaml<0.15\", \"datadog\", \"slackclient\", \"ldap3\"]\n try:\n from concurrent import futures\n except ImportError:\n", "issue": "c7n_mailer lambda error after included slack integration\nHi team,\r\n\r\nIt appears that deployed lambda mailer is having some problem with the libs, after the last commit that included slack integration. \r\n\r\nAfter update c7n_mailer lambda I'm seeing this error in the logs:\r\n```\r\n[ERROR] 2018-05-01T00:45:26.698Z f04d1326-4cd8-11e8-9f05-670c91cd10c1 Error starting mailer MailerSqsQueueProcessor().\r\nError: No module named requests\r\n\r\nTraceback (most recent call last):\r\nFile \"/var/task/c7n_mailer/handle.py\", line 46, in start_c7n_mailer\r\nmailer_sqs_queue_processor.run(parallel)\r\nFile \"/var/task/c7n_mailer/sqs_queue_processor.py\", line 126, in run\r\nself.process_sqs_message(sqs_message)\r\nFile \"/var/task/c7n_mailer/sqs_queue_processor.py\", line 170, in process_sqs_message\r\nfrom .slack_delivery import SlackDelivery\r\nFile \"/var/task/c7n_mailer/slack_delivery.py\", line 17, in <module>\r\nimport requests\r\nImportError: No module named requests\r\n```\r\n I've had no success even with a fresh install from the repos.\n", "before_files": [{"content": "# Copyright 2016-2017 Capital One Services, LLC\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\nfrom __future__ import absolute_import, division, print_function, unicode_literals\n\nimport json\nimport os\n\nfrom c7n.mu import (\n CloudWatchEventSource,\n LambdaFunction,\n LambdaManager,\n PythonPackageArchive)\n\n\nentry_source = \"\"\"\\\nimport logging\n\nfrom c7n_mailer import handle\n\nlogger = logging.getLogger('custodian.mailer')\nlog_format = '%(asctime)s - %(name)s - %(levelname)s - %(message)s'\nlogging.basicConfig(level=logging.INFO, format=log_format)\nlogging.getLogger('botocore').setLevel(logging.WARNING)\n\ndef dispatch(event, context):\n return handle.start_c7n_mailer(logger)\n\"\"\"\n\n\ndef get_archive(config):\n archive = PythonPackageArchive(\n 'c7n_mailer', 'ldap3', 'pyasn1', 'jinja2', 'markupsafe', 'ruamel',\n 'redis')\n\n template_dir = os.path.abspath(\n os.path.join(os.path.dirname(__file__), '..', 'msg-templates'))\n\n for t in os.listdir(template_dir):\n with open(os.path.join(template_dir, t)) as fh:\n archive.add_contents('msg-templates/%s' % t, fh.read())\n\n archive.add_contents('config.json', json.dumps(config))\n archive.add_contents('periodic.py', entry_source)\n\n archive.close()\n return archive\n\n\ndef provision(config, session_factory):\n func_config = dict(\n name=config.get('lambda_name', 'cloud-custodian-mailer'),\n description=config.get('lambda_description', 'Cloud Custodian Mailer'),\n tags=config.get('lambda_tags', {}),\n handler='periodic.dispatch',\n runtime=config['runtime'],\n memory_size=config['memory'],\n timeout=config['timeout'],\n role=config['role'],\n subnets=config['subnets'],\n security_groups=config['security_groups'],\n dead_letter_config=config.get('dead_letter_config', {}),\n events=[\n CloudWatchEventSource(\n {'type': 'periodic',\n 'schedule': config.get('lambda_schedule', 'rate(5 minutes)')},\n session_factory,\n prefix=\"\")\n ])\n\n archive = get_archive(config)\n func = LambdaFunction(func_config, archive)\n manager = LambdaManager(session_factory)\n manager.publish(func)\n", "path": "tools/c7n_mailer/c7n_mailer/deploy.py"}, {"content": "# Copyright 2015-2017 Capital One Services, LLC\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\nfrom __future__ import absolute_import, division, print_function, unicode_literals\n\nfrom setuptools import setup, find_packages\nimport os\n\nrequires = [\"Jinja2\", \"boto3\", \"jsonschema\", \"ruamel.yaml<0.15\", \"datadog\"]\ntry:\n from concurrent import futures\nexcept ImportError:\n # The backport has SyntaxErrors under py36, so avoid installing it.\n # https://github.com/agronholm/pythonfutures/issues/41\n requires += ['futures']\n\ndescription = \"\"\nif os.path.exists('README.md'):\n description = open('README.md').read()\n\nsetup(\n name=\"c7n_mailer\",\n version='0.3.1',\n description=\"Cloud Custodian - Reference Mailer\",\n long_description=description,\n classifiers=[\n \"Topic :: System :: Systems Administration\",\n \"Topic :: System :: Distributed Computing\"\n ],\n url=\"https://github.com/capitalone/cloud-custodian\",\n license=\"Apache-2.0\",\n packages=find_packages('c7n_mailer'),\n entry_points={\n 'console_scripts': [\n 'c7n-mailer = c7n_mailer.cli:main',\n 'c7n-mailer-replay = c7n_mailer.replay:main'\n ]\n },\n install_requires=requires,\n)\n", "path": "tools/c7n_mailer/setup.py"}]}
| 2,176 | 345 |
gh_patches_debug_38398
|
rasdani/github-patches
|
git_diff
|
DataDog__dd-trace-py-1631
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Misleading error message when patching boto3 instead of boto2
### Which version of dd-trace-py are you using?
0.41.0
### How can we reproduce your problem?
This logic of only exporting the `patch` method if there are no missing modules:
https://github.com/DataDog/dd-trace-py/blob/20ca41bf398f9dcd753cf40943de78f124ec9516/ddtrace/contrib/boto/__init__.py#L18-L24
causes this code:
https://github.com/DataDog/dd-trace-py/blob/20ca41bf398f9dcd753cf40943de78f124ec9516/ddtrace/monkey.py#L202
to fail with this misleading error:
```
AttributeError: module 'ddtrace.contrib.boto' has no attribute 'patch'
```
### What is the result that you expected?
A message that doesn't make me think something is wrong with my configuration.
</issue>
<code>
[start of ddtrace/monkey.py]
1 """Patch libraries to be automatically instrumented.
2
3 It can monkey patch supported standard libraries and third party modules.
4 A patched module will automatically report spans with its default configuration.
5
6 A library instrumentation can be configured (for instance, to report as another service)
7 using Pin. For that, check its documentation.
8 """
9 import importlib
10 import os
11 import sys
12 import threading
13
14 from ddtrace.vendor.wrapt.importer import when_imported
15
16 from .internal.logger import get_logger
17 from .settings import config
18 from .utils import formats
19
20
21 log = get_logger(__name__)
22
23 # Default set of modules to automatically patch or not
24 PATCH_MODULES = {
25 "asyncio": False,
26 "boto": True,
27 "botocore": True,
28 "bottle": False,
29 "cassandra": True,
30 "celery": True,
31 "consul": True,
32 "django": True,
33 "elasticsearch": True,
34 "algoliasearch": True,
35 "futures": False, # experimental propagation
36 "grpc": True,
37 "mongoengine": True,
38 "mysql": True,
39 "mysqldb": True,
40 "pymysql": True,
41 "psycopg": True,
42 "pylibmc": True,
43 "pymemcache": True,
44 "pymongo": True,
45 "redis": True,
46 "rediscluster": True,
47 "requests": True,
48 "sanic": True,
49 "sqlalchemy": False, # Prefer DB client instrumentation
50 "sqlite3": True,
51 "aiohttp": True, # requires asyncio (Python 3.4+)
52 "aiopg": True,
53 "aiobotocore": False,
54 "httplib": False,
55 "vertica": True,
56 "molten": True,
57 "jinja2": True,
58 "mako": True,
59 "flask": True,
60 "kombu": False,
61 # Ignore some web framework integrations that might be configured explicitly in code
62 "falcon": False,
63 "pylons": False,
64 "pyramid": False,
65 # Auto-enable logging if the environment variable DD_LOGS_INJECTION is true
66 "logging": config.logs_injection,
67 }
68
69 _LOCK = threading.Lock()
70 _PATCHED_MODULES = set()
71
72 # Modules which are patched on first use
73 # DEV: These modules are patched when the user first imports them, rather than
74 # explicitly importing and patching them on application startup `ddtrace.patch_all(module=True)`
75 # DEV: This ensures we do not patch a module until it is needed
76 # DEV: <contrib name> => <list of module names that trigger a patch>
77 _PATCH_ON_IMPORT = {
78 "aiohttp": ("aiohttp",),
79 "aiobotocore": ("aiobotocore",),
80 "celery": ("celery",),
81 "flask": ("flask, "),
82 "gevent": ("gevent",),
83 "requests": ("requests",),
84 "botocore": ("botocore",),
85 "elasticsearch": ("elasticsearch",),
86 }
87
88
89 class PatchException(Exception):
90 """Wraps regular `Exception` class when patching modules"""
91
92 pass
93
94
95 def _on_import_factory(module, raise_errors=True):
96 """Factory to create an import hook for the provided module name"""
97
98 def on_import(hook):
99 # Import and patch module
100 path = "ddtrace.contrib.%s" % module
101 imported_module = importlib.import_module(path)
102 imported_module.patch()
103
104 return on_import
105
106
107 def patch_all(**patch_modules):
108 """Automatically patches all available modules.
109
110 In addition to ``patch_modules``, an override can be specified via an
111 environment variable, ``DD_TRACE_<module>_ENABLED`` for each module.
112
113 ``patch_modules`` have the highest precedence for overriding.
114
115 :param dict patch_modules: Override whether particular modules are patched or not.
116
117 >>> patch_all(redis=False, cassandra=False)
118 """
119 modules = PATCH_MODULES.copy()
120
121 # The enabled setting can be overridden by environment variables
122 for module, enabled in modules.items():
123 env_var = "DD_TRACE_%s_ENABLED" % module.upper()
124 if env_var not in os.environ:
125 continue
126
127 override_enabled = formats.asbool(os.environ[env_var])
128 modules[module] = override_enabled
129
130 # Arguments take precedence over the environment and the defaults.
131 modules.update(patch_modules)
132
133 patch(raise_errors=False, **modules)
134
135
136 def patch(raise_errors=True, **patch_modules):
137 """Patch only a set of given modules.
138
139 :param bool raise_errors: Raise error if one patch fail.
140 :param dict patch_modules: List of modules to patch.
141
142 >>> patch(psycopg=True, elasticsearch=True)
143 """
144 modules = [m for (m, should_patch) in patch_modules.items() if should_patch]
145 for module in modules:
146 if module in _PATCH_ON_IMPORT:
147 # If the module has already been imported then patch immediately
148 if module in sys.modules:
149 patch_module(module, raise_errors=raise_errors)
150
151 # Otherwise, add a hook to patch when it is imported for the first time
152 else:
153 # Use factory to create handler to close over `module` and `raise_errors` values from this loop
154 when_imported(module)(_on_import_factory(module, raise_errors))
155
156 # manually add module to patched modules
157 with _LOCK:
158 _PATCHED_MODULES.add(module)
159 else:
160 patch_module(module, raise_errors=raise_errors)
161
162 patched_modules = get_patched_modules()
163 log.info(
164 "patched %s/%s modules (%s)", len(patched_modules), len(modules), ",".join(patched_modules),
165 )
166
167
168 def patch_module(module, raise_errors=True):
169 """Patch a single module
170
171 Returns if the module got properly patched.
172 """
173 try:
174 return _patch_module(module)
175 except Exception:
176 if raise_errors:
177 raise
178 log.debug("failed to patch %s", module, exc_info=True)
179 return False
180
181
182 def get_patched_modules():
183 """Get the list of patched modules"""
184 with _LOCK:
185 return sorted(_PATCHED_MODULES)
186
187
188 def _patch_module(module):
189 """_patch_module will attempt to monkey patch the module.
190
191 Returns if the module got patched.
192 Can also raise errors if it fails.
193 """
194 path = "ddtrace.contrib.%s" % module
195 with _LOCK:
196 if module in _PATCHED_MODULES and module not in _PATCH_ON_IMPORT:
197 log.debug("already patched: %s", path)
198 return False
199
200 try:
201 imported_module = importlib.import_module(path)
202 imported_module.patch()
203 except ImportError:
204 # if the import fails, the integration is not available
205 raise PatchException("integration '%s' not available" % path)
206 except AttributeError:
207 # if patch() is not available in the module, it means
208 # that the library is not installed in the environment
209 raise PatchException("module '%s' not installed" % module)
210
211 _PATCHED_MODULES.add(module)
212 return True
213
[end of ddtrace/monkey.py]
[start of ddtrace/internal/runtime/container.py]
1 import re
2
3 from ..logger import get_logger
4
5 log = get_logger(__name__)
6
7
8 class CGroupInfo(object):
9 """
10 CGroup class for container information parsed from a group cgroup file
11 """
12
13 __slots__ = ("id", "groups", "path", "container_id", "controllers", "pod_id")
14
15 UUID_SOURCE_PATTERN = r"[0-9a-f]{8}[-_][0-9a-f]{4}[-_][0-9a-f]{4}[-_][0-9a-f]{4}[-_][0-9a-f]{12}"
16 CONTAINER_SOURCE_PATTERN = r"[0-9a-f]{64}"
17
18 LINE_RE = re.compile(r"^(\d+):([^:]*):(.+)$")
19 POD_RE = re.compile(r"pod({0})(?:\.slice)?$".format(UUID_SOURCE_PATTERN))
20 CONTAINER_RE = re.compile(r"({0}|{1})(?:\.scope)?$".format(UUID_SOURCE_PATTERN, CONTAINER_SOURCE_PATTERN))
21
22 def __init__(self, **kwargs):
23 # Initialize all attributes in __slots__ to `None`
24 # DEV: Otherwise we'll get `AttributeError` when trying to access if they are unset
25 for attr in self.__slots__:
26 setattr(self, attr, kwargs.get(attr))
27
28 @classmethod
29 def from_line(cls, line):
30 """
31 Parse a new :class:`CGroupInfo` from the provided line
32
33 :param line: A line from a cgroup file (e.g. /proc/self/cgroup) to parse information from
34 :type line: str
35 :returns: A :class:`CGroupInfo` object with all parsed data, if the line is valid, otherwise `None`
36 :rtype: :class:`CGroupInfo` | None
37
38 """
39 # Clean up the line
40 line = line.strip()
41
42 # Ensure the line is valid
43 match = cls.LINE_RE.match(line)
44 if not match:
45 return None
46
47 # Create our new `CGroupInfo` and set attributes from the line
48 info = cls()
49 info.id, info.groups, info.path = match.groups()
50
51 # Parse the controllers from the groups
52 info.controllers = [c.strip() for c in info.groups.split(",") if c.strip()]
53
54 # Break up the path to grab container_id and pod_id if available
55 # e.g. /docker/<container_id>
56 # e.g. /kubepods/test/pod<pod_id>/<container_id>
57 parts = [p for p in info.path.split("/")]
58
59 # Grab the container id from the path if a valid id is present
60 if len(parts):
61 match = cls.CONTAINER_RE.match(parts.pop())
62 if match:
63 info.container_id = match.group(1)
64
65 # Grab the pod id from the path if a valid id is present
66 if len(parts):
67 match = cls.POD_RE.match(parts.pop())
68 if match:
69 info.pod_id = match.group(1)
70
71 return info
72
73 def __str__(self):
74 return self.__repr__()
75
76 def __repr__(self):
77 return "{}(id={!r}, groups={!r}, path={!r}, container_id={!r}, controllers={!r}, pod_id={!r})".format(
78 self.__class__.__name__, self.id, self.groups, self.path, self.container_id, self.controllers, self.pod_id,
79 )
80
81
82 def get_container_info(pid="self"):
83 """
84 Helper to fetch the current container id, if we are running in a container
85
86 We will parse `/proc/{pid}/cgroup` to determine our container id.
87
88 The results of calling this function are cached
89
90 :param pid: The pid of the cgroup file to parse (default: 'self')
91 :type pid: str | int
92 :returns: The cgroup file info if found, or else None
93 :rtype: :class:`CGroupInfo` | None
94 """
95 try:
96 cgroup_file = "/proc/{0}/cgroup".format(pid)
97 with open(cgroup_file, mode="r") as fp:
98 for line in fp:
99 info = CGroupInfo.from_line(line)
100 if info and info.container_id:
101 return info
102 except Exception:
103 log.debug("Failed to parse cgroup file for pid %r", pid, exc_info=True)
104
105 return None
106
[end of ddtrace/internal/runtime/container.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/ddtrace/internal/runtime/container.py b/ddtrace/internal/runtime/container.py
--- a/ddtrace/internal/runtime/container.py
+++ b/ddtrace/internal/runtime/container.py
@@ -1,3 +1,4 @@
+import os
import re
from ..logger import get_logger
@@ -92,8 +93,15 @@
:returns: The cgroup file info if found, or else None
:rtype: :class:`CGroupInfo` | None
"""
+
+ cgroup_file = "/proc/{0}/cgroup".format(pid)
+
+ if not os.path.exists(cgroup_file):
+ # If the cgroup file does not exist then this is likely not a container
+ # which is a valid use-case so pass.
+ return
+
try:
- cgroup_file = "/proc/{0}/cgroup".format(pid)
with open(cgroup_file, mode="r") as fp:
for line in fp:
info = CGroupInfo.from_line(line)
@@ -101,5 +109,3 @@
return info
except Exception:
log.debug("Failed to parse cgroup file for pid %r", pid, exc_info=True)
-
- return None
diff --git a/ddtrace/monkey.py b/ddtrace/monkey.py
--- a/ddtrace/monkey.py
+++ b/ddtrace/monkey.py
@@ -92,6 +92,10 @@
pass
+class ModuleNotFoundException(PatchException):
+ pass
+
+
def _on_import_factory(module, raise_errors=True):
"""Factory to create an import hook for the provided module name"""
@@ -172,6 +176,10 @@
"""
try:
return _patch_module(module)
+ except ModuleNotFoundException:
+ if raise_errors:
+ raise
+ return False
except Exception:
if raise_errors:
raise
@@ -199,14 +207,15 @@
try:
imported_module = importlib.import_module(path)
- imported_module.patch()
except ImportError:
# if the import fails, the integration is not available
raise PatchException("integration '%s' not available" % path)
- except AttributeError:
+ else:
# if patch() is not available in the module, it means
# that the library is not installed in the environment
- raise PatchException("module '%s' not installed" % module)
+ if not hasattr(imported_module, "patch"):
+ raise ModuleNotFoundException("module '%s' not installed" % module)
- _PATCHED_MODULES.add(module)
- return True
+ imported_module.patch()
+ _PATCHED_MODULES.add(module)
+ return True
|
{"golden_diff": "diff --git a/ddtrace/internal/runtime/container.py b/ddtrace/internal/runtime/container.py\n--- a/ddtrace/internal/runtime/container.py\n+++ b/ddtrace/internal/runtime/container.py\n@@ -1,3 +1,4 @@\n+import os\n import re\n \n from ..logger import get_logger\n@@ -92,8 +93,15 @@\n :returns: The cgroup file info if found, or else None\n :rtype: :class:`CGroupInfo` | None\n \"\"\"\n+\n+ cgroup_file = \"/proc/{0}/cgroup\".format(pid)\n+\n+ if not os.path.exists(cgroup_file):\n+ # If the cgroup file does not exist then this is likely not a container\n+ # which is a valid use-case so pass.\n+ return\n+\n try:\n- cgroup_file = \"/proc/{0}/cgroup\".format(pid)\n with open(cgroup_file, mode=\"r\") as fp:\n for line in fp:\n info = CGroupInfo.from_line(line)\n@@ -101,5 +109,3 @@\n return info\n except Exception:\n log.debug(\"Failed to parse cgroup file for pid %r\", pid, exc_info=True)\n-\n- return None\ndiff --git a/ddtrace/monkey.py b/ddtrace/monkey.py\n--- a/ddtrace/monkey.py\n+++ b/ddtrace/monkey.py\n@@ -92,6 +92,10 @@\n pass\n \n \n+class ModuleNotFoundException(PatchException):\n+ pass\n+\n+\n def _on_import_factory(module, raise_errors=True):\n \"\"\"Factory to create an import hook for the provided module name\"\"\"\n \n@@ -172,6 +176,10 @@\n \"\"\"\n try:\n return _patch_module(module)\n+ except ModuleNotFoundException:\n+ if raise_errors:\n+ raise\n+ return False\n except Exception:\n if raise_errors:\n raise\n@@ -199,14 +207,15 @@\n \n try:\n imported_module = importlib.import_module(path)\n- imported_module.patch()\n except ImportError:\n # if the import fails, the integration is not available\n raise PatchException(\"integration '%s' not available\" % path)\n- except AttributeError:\n+ else:\n # if patch() is not available in the module, it means\n # that the library is not installed in the environment\n- raise PatchException(\"module '%s' not installed\" % module)\n+ if not hasattr(imported_module, \"patch\"):\n+ raise ModuleNotFoundException(\"module '%s' not installed\" % module)\n \n- _PATCHED_MODULES.add(module)\n- return True\n+ imported_module.patch()\n+ _PATCHED_MODULES.add(module)\n+ return True\n", "issue": "Misleading error message when patching boto3 instead of boto2\n\r\n### Which version of dd-trace-py are you using?\r\n\r\n0.41.0\r\n\r\n### How can we reproduce your problem?\r\n\r\nThis logic of only exporting the `patch` method if there are no missing modules:\r\n\r\nhttps://github.com/DataDog/dd-trace-py/blob/20ca41bf398f9dcd753cf40943de78f124ec9516/ddtrace/contrib/boto/__init__.py#L18-L24\r\n\r\n\r\ncauses this code:\r\n\r\nhttps://github.com/DataDog/dd-trace-py/blob/20ca41bf398f9dcd753cf40943de78f124ec9516/ddtrace/monkey.py#L202\r\n\r\nto fail with this misleading error:\r\n```\r\nAttributeError: module 'ddtrace.contrib.boto' has no attribute 'patch'\r\n```\r\n\r\n### What is the result that you expected?\r\n\r\nA message that doesn't make me think something is wrong with my configuration.\r\n\n", "before_files": [{"content": "\"\"\"Patch libraries to be automatically instrumented.\n\nIt can monkey patch supported standard libraries and third party modules.\nA patched module will automatically report spans with its default configuration.\n\nA library instrumentation can be configured (for instance, to report as another service)\nusing Pin. For that, check its documentation.\n\"\"\"\nimport importlib\nimport os\nimport sys\nimport threading\n\nfrom ddtrace.vendor.wrapt.importer import when_imported\n\nfrom .internal.logger import get_logger\nfrom .settings import config\nfrom .utils import formats\n\n\nlog = get_logger(__name__)\n\n# Default set of modules to automatically patch or not\nPATCH_MODULES = {\n \"asyncio\": False,\n \"boto\": True,\n \"botocore\": True,\n \"bottle\": False,\n \"cassandra\": True,\n \"celery\": True,\n \"consul\": True,\n \"django\": True,\n \"elasticsearch\": True,\n \"algoliasearch\": True,\n \"futures\": False, # experimental propagation\n \"grpc\": True,\n \"mongoengine\": True,\n \"mysql\": True,\n \"mysqldb\": True,\n \"pymysql\": True,\n \"psycopg\": True,\n \"pylibmc\": True,\n \"pymemcache\": True,\n \"pymongo\": True,\n \"redis\": True,\n \"rediscluster\": True,\n \"requests\": True,\n \"sanic\": True,\n \"sqlalchemy\": False, # Prefer DB client instrumentation\n \"sqlite3\": True,\n \"aiohttp\": True, # requires asyncio (Python 3.4+)\n \"aiopg\": True,\n \"aiobotocore\": False,\n \"httplib\": False,\n \"vertica\": True,\n \"molten\": True,\n \"jinja2\": True,\n \"mako\": True,\n \"flask\": True,\n \"kombu\": False,\n # Ignore some web framework integrations that might be configured explicitly in code\n \"falcon\": False,\n \"pylons\": False,\n \"pyramid\": False,\n # Auto-enable logging if the environment variable DD_LOGS_INJECTION is true\n \"logging\": config.logs_injection,\n}\n\n_LOCK = threading.Lock()\n_PATCHED_MODULES = set()\n\n# Modules which are patched on first use\n# DEV: These modules are patched when the user first imports them, rather than\n# explicitly importing and patching them on application startup `ddtrace.patch_all(module=True)`\n# DEV: This ensures we do not patch a module until it is needed\n# DEV: <contrib name> => <list of module names that trigger a patch>\n_PATCH_ON_IMPORT = {\n \"aiohttp\": (\"aiohttp\",),\n \"aiobotocore\": (\"aiobotocore\",),\n \"celery\": (\"celery\",),\n \"flask\": (\"flask, \"),\n \"gevent\": (\"gevent\",),\n \"requests\": (\"requests\",),\n \"botocore\": (\"botocore\",),\n \"elasticsearch\": (\"elasticsearch\",),\n}\n\n\nclass PatchException(Exception):\n \"\"\"Wraps regular `Exception` class when patching modules\"\"\"\n\n pass\n\n\ndef _on_import_factory(module, raise_errors=True):\n \"\"\"Factory to create an import hook for the provided module name\"\"\"\n\n def on_import(hook):\n # Import and patch module\n path = \"ddtrace.contrib.%s\" % module\n imported_module = importlib.import_module(path)\n imported_module.patch()\n\n return on_import\n\n\ndef patch_all(**patch_modules):\n \"\"\"Automatically patches all available modules.\n\n In addition to ``patch_modules``, an override can be specified via an\n environment variable, ``DD_TRACE_<module>_ENABLED`` for each module.\n\n ``patch_modules`` have the highest precedence for overriding.\n\n :param dict patch_modules: Override whether particular modules are patched or not.\n\n >>> patch_all(redis=False, cassandra=False)\n \"\"\"\n modules = PATCH_MODULES.copy()\n\n # The enabled setting can be overridden by environment variables\n for module, enabled in modules.items():\n env_var = \"DD_TRACE_%s_ENABLED\" % module.upper()\n if env_var not in os.environ:\n continue\n\n override_enabled = formats.asbool(os.environ[env_var])\n modules[module] = override_enabled\n\n # Arguments take precedence over the environment and the defaults.\n modules.update(patch_modules)\n\n patch(raise_errors=False, **modules)\n\n\ndef patch(raise_errors=True, **patch_modules):\n \"\"\"Patch only a set of given modules.\n\n :param bool raise_errors: Raise error if one patch fail.\n :param dict patch_modules: List of modules to patch.\n\n >>> patch(psycopg=True, elasticsearch=True)\n \"\"\"\n modules = [m for (m, should_patch) in patch_modules.items() if should_patch]\n for module in modules:\n if module in _PATCH_ON_IMPORT:\n # If the module has already been imported then patch immediately\n if module in sys.modules:\n patch_module(module, raise_errors=raise_errors)\n\n # Otherwise, add a hook to patch when it is imported for the first time\n else:\n # Use factory to create handler to close over `module` and `raise_errors` values from this loop\n when_imported(module)(_on_import_factory(module, raise_errors))\n\n # manually add module to patched modules\n with _LOCK:\n _PATCHED_MODULES.add(module)\n else:\n patch_module(module, raise_errors=raise_errors)\n\n patched_modules = get_patched_modules()\n log.info(\n \"patched %s/%s modules (%s)\", len(patched_modules), len(modules), \",\".join(patched_modules),\n )\n\n\ndef patch_module(module, raise_errors=True):\n \"\"\"Patch a single module\n\n Returns if the module got properly patched.\n \"\"\"\n try:\n return _patch_module(module)\n except Exception:\n if raise_errors:\n raise\n log.debug(\"failed to patch %s\", module, exc_info=True)\n return False\n\n\ndef get_patched_modules():\n \"\"\"Get the list of patched modules\"\"\"\n with _LOCK:\n return sorted(_PATCHED_MODULES)\n\n\ndef _patch_module(module):\n \"\"\"_patch_module will attempt to monkey patch the module.\n\n Returns if the module got patched.\n Can also raise errors if it fails.\n \"\"\"\n path = \"ddtrace.contrib.%s\" % module\n with _LOCK:\n if module in _PATCHED_MODULES and module not in _PATCH_ON_IMPORT:\n log.debug(\"already patched: %s\", path)\n return False\n\n try:\n imported_module = importlib.import_module(path)\n imported_module.patch()\n except ImportError:\n # if the import fails, the integration is not available\n raise PatchException(\"integration '%s' not available\" % path)\n except AttributeError:\n # if patch() is not available in the module, it means\n # that the library is not installed in the environment\n raise PatchException(\"module '%s' not installed\" % module)\n\n _PATCHED_MODULES.add(module)\n return True\n", "path": "ddtrace/monkey.py"}, {"content": "import re\n\nfrom ..logger import get_logger\n\nlog = get_logger(__name__)\n\n\nclass CGroupInfo(object):\n \"\"\"\n CGroup class for container information parsed from a group cgroup file\n \"\"\"\n\n __slots__ = (\"id\", \"groups\", \"path\", \"container_id\", \"controllers\", \"pod_id\")\n\n UUID_SOURCE_PATTERN = r\"[0-9a-f]{8}[-_][0-9a-f]{4}[-_][0-9a-f]{4}[-_][0-9a-f]{4}[-_][0-9a-f]{12}\"\n CONTAINER_SOURCE_PATTERN = r\"[0-9a-f]{64}\"\n\n LINE_RE = re.compile(r\"^(\\d+):([^:]*):(.+)$\")\n POD_RE = re.compile(r\"pod({0})(?:\\.slice)?$\".format(UUID_SOURCE_PATTERN))\n CONTAINER_RE = re.compile(r\"({0}|{1})(?:\\.scope)?$\".format(UUID_SOURCE_PATTERN, CONTAINER_SOURCE_PATTERN))\n\n def __init__(self, **kwargs):\n # Initialize all attributes in __slots__ to `None`\n # DEV: Otherwise we'll get `AttributeError` when trying to access if they are unset\n for attr in self.__slots__:\n setattr(self, attr, kwargs.get(attr))\n\n @classmethod\n def from_line(cls, line):\n \"\"\"\n Parse a new :class:`CGroupInfo` from the provided line\n\n :param line: A line from a cgroup file (e.g. /proc/self/cgroup) to parse information from\n :type line: str\n :returns: A :class:`CGroupInfo` object with all parsed data, if the line is valid, otherwise `None`\n :rtype: :class:`CGroupInfo` | None\n\n \"\"\"\n # Clean up the line\n line = line.strip()\n\n # Ensure the line is valid\n match = cls.LINE_RE.match(line)\n if not match:\n return None\n\n # Create our new `CGroupInfo` and set attributes from the line\n info = cls()\n info.id, info.groups, info.path = match.groups()\n\n # Parse the controllers from the groups\n info.controllers = [c.strip() for c in info.groups.split(\",\") if c.strip()]\n\n # Break up the path to grab container_id and pod_id if available\n # e.g. /docker/<container_id>\n # e.g. /kubepods/test/pod<pod_id>/<container_id>\n parts = [p for p in info.path.split(\"/\")]\n\n # Grab the container id from the path if a valid id is present\n if len(parts):\n match = cls.CONTAINER_RE.match(parts.pop())\n if match:\n info.container_id = match.group(1)\n\n # Grab the pod id from the path if a valid id is present\n if len(parts):\n match = cls.POD_RE.match(parts.pop())\n if match:\n info.pod_id = match.group(1)\n\n return info\n\n def __str__(self):\n return self.__repr__()\n\n def __repr__(self):\n return \"{}(id={!r}, groups={!r}, path={!r}, container_id={!r}, controllers={!r}, pod_id={!r})\".format(\n self.__class__.__name__, self.id, self.groups, self.path, self.container_id, self.controllers, self.pod_id,\n )\n\n\ndef get_container_info(pid=\"self\"):\n \"\"\"\n Helper to fetch the current container id, if we are running in a container\n\n We will parse `/proc/{pid}/cgroup` to determine our container id.\n\n The results of calling this function are cached\n\n :param pid: The pid of the cgroup file to parse (default: 'self')\n :type pid: str | int\n :returns: The cgroup file info if found, or else None\n :rtype: :class:`CGroupInfo` | None\n \"\"\"\n try:\n cgroup_file = \"/proc/{0}/cgroup\".format(pid)\n with open(cgroup_file, mode=\"r\") as fp:\n for line in fp:\n info = CGroupInfo.from_line(line)\n if info and info.container_id:\n return info\n except Exception:\n log.debug(\"Failed to parse cgroup file for pid %r\", pid, exc_info=True)\n\n return None\n", "path": "ddtrace/internal/runtime/container.py"}]}
| 4,057 | 602 |
gh_patches_debug_42958
|
rasdani/github-patches
|
git_diff
|
facebookresearch__fairscale-39
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
OSS to expose classic optimizer compliant param_groups
## 🚀 Feature
Expose the "classic" param_groups from the OSS optimizer wrapper, either via a new API (not as nice) or if possible via the classic .param_groups attribute (get and set)
## Motivation
Some frameworks like classy vision use that to alter the LR per layer or over time (or both). Exposing this would make OSS integration a lot easier
## Pitch
Either use dedicated getter and setter properties which change behaviour depending on whether the call comes from the outside or the super constructor, or add a specific API to get the consolidated param_groups and set the consolidated param_groups
## Alternatives
- Destroy the optimizer every time there's an adjustment
- Only expose adjustments which apply to the whole param_groups ("set all LR to a given value")
</issue>
<code>
[start of fairscale/optim/utils.py]
1 # Copyright (c) Facebook, Inc. and its affiliates. All rights reserved.
2 #
3 # This source code is licensed under the BSD license found in the
4 # LICENSE file in the root directory of this source tree.
5
6 import io
7 from typing import Any, Dict
8
9 import torch
10 from torch._six import container_abcs
11 import torch.distributed as dist
12
13
14 # Credits: classy_vision/generic/distributed_util.py
15 def recursive_copy_to_device(value: Any, non_blocking: bool, device: torch.device) -> Any:
16 """
17 Recursively searches lists, tuples, dicts and copies tensors to device if
18 possible. Non-tensor values are passed as-is in the result.
19
20 NOTE: These are all copies, so if there are two objects that reference
21 the same object, then after this call, there will be two different objects
22 referenced on the device.
23 """
24
25 if isinstance(value, torch.Tensor):
26 return value.to(device, non_blocking=non_blocking)
27
28 if isinstance(value, (list, tuple)):
29 values = []
30 for val in value:
31 values.append(recursive_copy_to_device(val, non_blocking=non_blocking, device=device))
32
33 return values if isinstance(value, list) else tuple(values)
34
35 if isinstance(value, container_abcs.Mapping):
36 device_val: Dict[str, Any] = {}
37 for key, val in value.items():
38 device_val[key] = recursive_copy_to_device(val, non_blocking=non_blocking, device=device)
39
40 return device_val
41
42 return value
43
44
45 def broadcast_object(
46 obj: Any, src_rank: int, group: object = dist.group.WORLD, dist_device: torch.device = torch.device("cpu")
47 ) -> Any:
48 """
49 Either broadcast from master to the fleet (default),
50 or use the src setting as the original rank.
51 """
52
53 if dist.get_rank() == src_rank:
54 # Emit data
55 buffer = io.BytesIO()
56 torch.save(obj, buffer) # type: ignore
57 data = bytearray(buffer.getbuffer())
58 length_tensor = torch.LongTensor([len(data)]).to(dist_device)
59 data_send_tensor = torch.ByteTensor(data).to(dist_device)
60 dist.broadcast(length_tensor, src=src_rank, group=group, async_op=False)
61 dist.broadcast(data_send_tensor, src=src_rank, group=group, async_op=False)
62 else:
63 # Fetch from the source
64 length_tensor = torch.LongTensor([0]).to(dist_device)
65 dist.broadcast(length_tensor, src=src_rank, group=group, async_op=False)
66 data_recv_tensor = torch.empty([int(length_tensor.item())], dtype=torch.uint8, device=dist_device)
67 dist.broadcast(data_recv_tensor, src=src_rank, group=group, async_op=False)
68 buffer = io.BytesIO(data_recv_tensor.cpu().numpy())
69 obj = torch.load(buffer, map_location=dist_device) # type: ignore
70 return obj
71
[end of fairscale/optim/utils.py]
[start of fairscale/optim/oss.py]
1 # Copyright (c) Facebook, Inc. and its affiliates. All rights reserved.
2 #
3 # This source code is licensed under the BSD license found in the
4 # LICENSE file in the root directory of this source tree.
5
6 import copy
7 import logging
8 from typing import TYPE_CHECKING, Any, Callable, Dict, List, Optional, Type
9
10 import torch
11 import torch.distributed as dist
12 from torch.optim import SGD, Optimizer
13
14 from .utils import broadcast_object, recursive_copy_to_device
15
16 if TYPE_CHECKING:
17 from torch.optim.optimizer import _params_t
18 else:
19 _params_t = Any
20
21
22 class OSS(Optimizer):
23 """Wraps an arbitrary :class:`optim.Optimizer <torch.optim.Optimizer>`
24 optimizer and shards its state as described by ZeRO_.
25 ::
26 opt = OSS(params, optim=torch.optim.Adam, lr=0.01)
27
28 .. _ZeRO: https://arxiv.org/abs/1910.02054
29
30 We use a greedy algorithm to pack a number of parameters
31 at each rank. Each parameter belongs to a single rank and
32 is not divided among rank.
33
34 After each rank completed their parameter update, they broadcast
35 the new version of the parameters to all other ranks to synchronize
36 the parameters for next round forward/backward computation.
37
38 Args:
39 params (list of tensors):
40 parameters to be optimized
41 Keyword Args:
42 optim (torch.nn.Optimizer):
43 optimizer to shard (default: SGD)
44 group (group):
45 torch.distributed group (default: group.WORLD)
46 """
47
48 optim: Optimizer
49 in_super_constructor: bool
50
51 def __init__(self, params: _params_t, optim: Type[Optimizer] = SGD, group: Any = dist.group.WORLD, **defaults: Any):
52 self.in_super_constructor = True
53 super().__init__(params, defaults)
54 self.in_super_constructor = False
55
56 self.group = group
57 self.rank = dist.get_rank(group)
58 param_groups = self.partition_parameters()
59 self.optim = optim(param_groups[self.rank], **defaults)
60
61 # Optional consolidated optimizer state
62 self._all_states: List[Dict[str, Any]] = []
63
64 # Current device is set by the parameters allocated to this rank
65 self._device = self.partition_parameters()[self.rank][0]["params"][0].device
66
67 def partition_parameters(self) -> List[List[dict]]:
68 """Partitions parameters across distributed ranks.
69
70 Returns a list of param_groups (which is a list of dict) where each
71 element of the list contains the param_groups for a rank. Element 0
72 corresponds to rank 0, etc. We need all the ranks for the broadcast
73 inside step().
74 """
75 world_size = dist.get_world_size(self.group)
76 param_groups: List[List] = [list() for _ in range(world_size)]
77 sizes = [0] * world_size
78 for param_group in self.param_groups:
79 param_lists: List[List] = [list() for _ in range(world_size)]
80 for param in param_group["params"]:
81 # Add this param to rank with smallest size.
82 rank = sizes.index(min(sizes))
83 param_lists[rank].append(param)
84 sizes[rank] += param.numel()
85 for rank, params in enumerate(param_lists):
86 if len(params) > 0:
87 param_group_rank = copy.copy(param_group)
88 param_group_rank["params"] = params
89 param_groups[rank].append(param_group_rank)
90 return param_groups
91
92 def step(self, closure: Optional[Callable[[], float]] = None) -> Optional[float]:
93 loss = self.optim.step(closure=closure)
94 for rank, param_groups in enumerate(self.partition_parameters()):
95 for param_group in param_groups:
96 for param in param_group["params"]:
97 dist.broadcast(param, rank, group=self.group)
98 return loss
99
100 def local_state_dict(self) -> dict:
101 """ Gets this rank's state_dict. """
102 return self.optim.state_dict()
103
104 def consolidate_state_dict(self, recipient_rank: int = 0) -> None:
105 """ Update the consolidated state_dict list, one per rank.
106
107 This needs to be called on all replicas """
108
109 if self.rank == recipient_rank:
110 # Pull the sharded state from all the other replicas
111 # Store all the states in order, rank by rank
112 logging.debug("Pulling the sharded SGD state from all replicas")
113 self._all_states = self._collect_sharded_states()
114 else:
115 # Acknowledge broadcasts, and send this rank's shard when needed
116 self._broadcast_state_dict()
117
118 def state_dict(self) -> Dict[str, Any]:
119 """
120 Return the last known global optimizer state, which consist of a list of the shards.
121
122 NOTE: This is limited to the replica which was responsible for the consolidation.
123 The state may also not be up to date, depending on when `consolidate_state_dict` was last called.
124 """
125
126 assert (
127 len(self._all_states) > 0
128 ), "The optimizer state is not materialized, please call consolidate_state_dict on every replica beforehand"
129
130 return {"state": self._all_states, "param_groups": self.param_groups}
131
132 def load_local_state_dict(self, state_dict: dict) -> None:
133 """ Loads this rank's state_dict. """
134
135 # Make sure that the state is on the appropriate device
136 state_dict_ondevice = recursive_copy_to_device(state_dict, non_blocking=False, device=self._device)
137
138 self.optim.load_state_dict(state_dict_ondevice)
139
140 def load_state_dict(self, state_dict: Dict[str, Any]) -> None:
141 """ Loads this rank's optimizer state_dict, given the global optimizer state. """
142 # Dispatch this rank's state dictionary to the local load
143 self.load_local_state_dict(state_dict["state"][self.rank])
144
145 def add_param_group(self, param_group: dict) -> None:
146 super().add_param_group(param_group)
147 if not self.in_super_constructor:
148 param_groups = self.partition_parameters()[self.rank]
149 if len(param_groups) == len(self.optim.param_groups) + 1:
150 self.optim.add_param_group(param_groups[-1])
151
152 def _collect_sharded_states(self) -> List[Dict[str, Any]]:
153 """
154 Collect all the state shards, in CPU memory.
155 """
156 empty_buffer = torch.tensor([0], dtype=torch.uint8, device=self._device)
157 all_states: List[Dict[str, Any]] = []
158
159 for rank in range(dist.get_world_size(group=self.group)):
160 if rank == self.rank:
161 logging.debug("Saving self state")
162 all_states.append(
163 recursive_copy_to_device(self.local_state_dict(), non_blocking=True, device=torch.device("cpu"))
164 )
165
166 # Sync with other replicas
167 broadcast_object(empty_buffer, src_rank=rank, group=self.group, dist_device=self._device)
168 else:
169 # Fetch the optim state from the other replicas
170 logging.debug("Receiving state from rank %s ", rank)
171 replica_state = broadcast_object(
172 empty_buffer, src_rank=rank, group=self.group, dist_device=self._device
173 )
174
175 all_states.append(
176 recursive_copy_to_device(replica_state, non_blocking=True, device=torch.device("cpu"))
177 )
178
179 logging.debug("State from rank %s received", rank)
180
181 return all_states
182
183 def _broadcast_state_dict(self) -> None:
184 """
185 Broadcast this rank's state shard, discard others
186 """
187 empty_buffer = torch.tensor([0], dtype=torch.uint8, device=self._device)
188
189 for rank in range(dist.get_world_size(group=self.group)):
190 if rank == self.rank:
191 # Send the state to the reference replica
192 logging.debug(
193 "Sending the sharded SGD state to the reference replica from rank %s", rank,
194 )
195 broadcast_object(self.local_state_dict(), src_rank=rank, group=self.group, dist_device=self._device)
196 else:
197 # Discard this tensor/rank, broadcast necessary for syncing
198 logging.debug("Discarding broadcast from rank %s", rank)
199 broadcast_object(empty_buffer, src_rank=rank, group=self.group, dist_device=self._device)
200
[end of fairscale/optim/oss.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/fairscale/optim/oss.py b/fairscale/optim/oss.py
--- a/fairscale/optim/oss.py
+++ b/fairscale/optim/oss.py
@@ -13,7 +13,7 @@
from .utils import broadcast_object, recursive_copy_to_device
-if TYPE_CHECKING:
+if TYPE_CHECKING: # pragma: no cover
from torch.optim.optimizer import _params_t
else:
_params_t = Any
@@ -49,10 +49,12 @@
in_super_constructor: bool
def __init__(self, params: _params_t, optim: Type[Optimizer] = SGD, group: Any = dist.group.WORLD, **defaults: Any):
+ # Hold all the nmodel params in the root .param_groups
self.in_super_constructor = True
super().__init__(params, defaults)
self.in_super_constructor = False
+ # Build the wrapped optimizer, responsible for a shard of the params
self.group = group
self.rank = dist.get_rank(group)
param_groups = self.partition_parameters()
@@ -90,11 +92,14 @@
return param_groups
def step(self, closure: Optional[Callable[[], float]] = None) -> Optional[float]:
+ # Run the optimizer step on this shard only
loss = self.optim.step(closure=closure)
+
+ # Sync all the states
for rank, param_groups in enumerate(self.partition_parameters()):
for param_group in param_groups:
for param in param_group["params"]:
- dist.broadcast(param, rank, group=self.group)
+ dist.broadcast(tensor=param, src=rank, group=self.group)
return loss
def local_state_dict(self) -> dict:
@@ -138,10 +143,13 @@
self.optim.load_state_dict(state_dict_ondevice)
def load_state_dict(self, state_dict: Dict[str, Any]) -> None:
- """ Loads this rank's optimizer state_dict, given the global optimizer state. """
- # Dispatch this rank's state dictionary to the local load
+ """ Restore the global parameter groups as well as the shard """
+ # Dispatch this rank's state dictionary to the wrapped shard optimizer
self.load_local_state_dict(state_dict["state"][self.rank])
+ # Restore the global param_groups
+ self.param_groups = state_dict["param_groups"]
+
def add_param_group(self, param_group: dict) -> None:
super().add_param_group(param_group)
if not self.in_super_constructor:
diff --git a/fairscale/optim/utils.py b/fairscale/optim/utils.py
--- a/fairscale/optim/utils.py
+++ b/fairscale/optim/utils.py
@@ -53,7 +53,7 @@
if dist.get_rank() == src_rank:
# Emit data
buffer = io.BytesIO()
- torch.save(obj, buffer) # type: ignore
+ torch.save(obj, buffer)
data = bytearray(buffer.getbuffer())
length_tensor = torch.LongTensor([len(data)]).to(dist_device)
data_send_tensor = torch.ByteTensor(data).to(dist_device)
@@ -66,5 +66,5 @@
data_recv_tensor = torch.empty([int(length_tensor.item())], dtype=torch.uint8, device=dist_device)
dist.broadcast(data_recv_tensor, src=src_rank, group=group, async_op=False)
buffer = io.BytesIO(data_recv_tensor.cpu().numpy())
- obj = torch.load(buffer, map_location=dist_device) # type: ignore
+ obj = torch.load(buffer, map_location=dist_device)
return obj
|
{"golden_diff": "diff --git a/fairscale/optim/oss.py b/fairscale/optim/oss.py\n--- a/fairscale/optim/oss.py\n+++ b/fairscale/optim/oss.py\n@@ -13,7 +13,7 @@\n \n from .utils import broadcast_object, recursive_copy_to_device\n \n-if TYPE_CHECKING:\n+if TYPE_CHECKING: # pragma: no cover\n from torch.optim.optimizer import _params_t\n else:\n _params_t = Any\n@@ -49,10 +49,12 @@\n in_super_constructor: bool\n \n def __init__(self, params: _params_t, optim: Type[Optimizer] = SGD, group: Any = dist.group.WORLD, **defaults: Any):\n+ # Hold all the nmodel params in the root .param_groups\n self.in_super_constructor = True\n super().__init__(params, defaults)\n self.in_super_constructor = False\n \n+ # Build the wrapped optimizer, responsible for a shard of the params\n self.group = group\n self.rank = dist.get_rank(group)\n param_groups = self.partition_parameters()\n@@ -90,11 +92,14 @@\n return param_groups\n \n def step(self, closure: Optional[Callable[[], float]] = None) -> Optional[float]:\n+ # Run the optimizer step on this shard only\n loss = self.optim.step(closure=closure)\n+\n+ # Sync all the states\n for rank, param_groups in enumerate(self.partition_parameters()):\n for param_group in param_groups:\n for param in param_group[\"params\"]:\n- dist.broadcast(param, rank, group=self.group)\n+ dist.broadcast(tensor=param, src=rank, group=self.group)\n return loss\n \n def local_state_dict(self) -> dict:\n@@ -138,10 +143,13 @@\n self.optim.load_state_dict(state_dict_ondevice)\n \n def load_state_dict(self, state_dict: Dict[str, Any]) -> None:\n- \"\"\" Loads this rank's optimizer state_dict, given the global optimizer state. \"\"\"\n- # Dispatch this rank's state dictionary to the local load\n+ \"\"\" Restore the global parameter groups as well as the shard \"\"\"\n+ # Dispatch this rank's state dictionary to the wrapped shard optimizer\n self.load_local_state_dict(state_dict[\"state\"][self.rank])\n \n+ # Restore the global param_groups\n+ self.param_groups = state_dict[\"param_groups\"]\n+\n def add_param_group(self, param_group: dict) -> None:\n super().add_param_group(param_group)\n if not self.in_super_constructor:\ndiff --git a/fairscale/optim/utils.py b/fairscale/optim/utils.py\n--- a/fairscale/optim/utils.py\n+++ b/fairscale/optim/utils.py\n@@ -53,7 +53,7 @@\n if dist.get_rank() == src_rank:\n # Emit data\n buffer = io.BytesIO()\n- torch.save(obj, buffer) # type: ignore\n+ torch.save(obj, buffer)\n data = bytearray(buffer.getbuffer())\n length_tensor = torch.LongTensor([len(data)]).to(dist_device)\n data_send_tensor = torch.ByteTensor(data).to(dist_device)\n@@ -66,5 +66,5 @@\n data_recv_tensor = torch.empty([int(length_tensor.item())], dtype=torch.uint8, device=dist_device)\n dist.broadcast(data_recv_tensor, src=src_rank, group=group, async_op=False)\n buffer = io.BytesIO(data_recv_tensor.cpu().numpy())\n- obj = torch.load(buffer, map_location=dist_device) # type: ignore\n+ obj = torch.load(buffer, map_location=dist_device)\n return obj\n", "issue": "OSS to expose classic optimizer compliant param_groups\n## \ud83d\ude80 Feature\r\nExpose the \"classic\" param_groups from the OSS optimizer wrapper, either via a new API (not as nice) or if possible via the classic .param_groups attribute (get and set) \r\n\r\n## Motivation\r\nSome frameworks like classy vision use that to alter the LR per layer or over time (or both). Exposing this would make OSS integration a lot easier\r\n\r\n## Pitch\r\nEither use dedicated getter and setter properties which change behaviour depending on whether the call comes from the outside or the super constructor, or add a specific API to get the consolidated param_groups and set the consolidated param_groups\r\n\r\n## Alternatives\r\n- Destroy the optimizer every time there's an adjustment\r\n- Only expose adjustments which apply to the whole param_groups (\"set all LR to a given value\")\r\n\n", "before_files": [{"content": "# Copyright (c) Facebook, Inc. and its affiliates. All rights reserved.\n#\n# This source code is licensed under the BSD license found in the\n# LICENSE file in the root directory of this source tree.\n\nimport io\nfrom typing import Any, Dict\n\nimport torch\nfrom torch._six import container_abcs\nimport torch.distributed as dist\n\n\n# Credits: classy_vision/generic/distributed_util.py\ndef recursive_copy_to_device(value: Any, non_blocking: bool, device: torch.device) -> Any:\n \"\"\"\n Recursively searches lists, tuples, dicts and copies tensors to device if\n possible. Non-tensor values are passed as-is in the result.\n\n NOTE: These are all copies, so if there are two objects that reference\n the same object, then after this call, there will be two different objects\n referenced on the device.\n \"\"\"\n\n if isinstance(value, torch.Tensor):\n return value.to(device, non_blocking=non_blocking)\n\n if isinstance(value, (list, tuple)):\n values = []\n for val in value:\n values.append(recursive_copy_to_device(val, non_blocking=non_blocking, device=device))\n\n return values if isinstance(value, list) else tuple(values)\n\n if isinstance(value, container_abcs.Mapping):\n device_val: Dict[str, Any] = {}\n for key, val in value.items():\n device_val[key] = recursive_copy_to_device(val, non_blocking=non_blocking, device=device)\n\n return device_val\n\n return value\n\n\ndef broadcast_object(\n obj: Any, src_rank: int, group: object = dist.group.WORLD, dist_device: torch.device = torch.device(\"cpu\")\n) -> Any:\n \"\"\"\n Either broadcast from master to the fleet (default),\n or use the src setting as the original rank.\n \"\"\"\n\n if dist.get_rank() == src_rank:\n # Emit data\n buffer = io.BytesIO()\n torch.save(obj, buffer) # type: ignore\n data = bytearray(buffer.getbuffer())\n length_tensor = torch.LongTensor([len(data)]).to(dist_device)\n data_send_tensor = torch.ByteTensor(data).to(dist_device)\n dist.broadcast(length_tensor, src=src_rank, group=group, async_op=False)\n dist.broadcast(data_send_tensor, src=src_rank, group=group, async_op=False)\n else:\n # Fetch from the source\n length_tensor = torch.LongTensor([0]).to(dist_device)\n dist.broadcast(length_tensor, src=src_rank, group=group, async_op=False)\n data_recv_tensor = torch.empty([int(length_tensor.item())], dtype=torch.uint8, device=dist_device)\n dist.broadcast(data_recv_tensor, src=src_rank, group=group, async_op=False)\n buffer = io.BytesIO(data_recv_tensor.cpu().numpy())\n obj = torch.load(buffer, map_location=dist_device) # type: ignore\n return obj\n", "path": "fairscale/optim/utils.py"}, {"content": "# Copyright (c) Facebook, Inc. and its affiliates. All rights reserved.\n#\n# This source code is licensed under the BSD license found in the\n# LICENSE file in the root directory of this source tree.\n\nimport copy\nimport logging\nfrom typing import TYPE_CHECKING, Any, Callable, Dict, List, Optional, Type\n\nimport torch\nimport torch.distributed as dist\nfrom torch.optim import SGD, Optimizer\n\nfrom .utils import broadcast_object, recursive_copy_to_device\n\nif TYPE_CHECKING:\n from torch.optim.optimizer import _params_t\nelse:\n _params_t = Any\n\n\nclass OSS(Optimizer):\n \"\"\"Wraps an arbitrary :class:`optim.Optimizer <torch.optim.Optimizer>`\n optimizer and shards its state as described by ZeRO_.\n ::\n opt = OSS(params, optim=torch.optim.Adam, lr=0.01)\n\n .. _ZeRO: https://arxiv.org/abs/1910.02054\n\n We use a greedy algorithm to pack a number of parameters\n at each rank. Each parameter belongs to a single rank and\n is not divided among rank.\n\n After each rank completed their parameter update, they broadcast\n the new version of the parameters to all other ranks to synchronize\n the parameters for next round forward/backward computation.\n\n Args:\n params (list of tensors):\n parameters to be optimized\n Keyword Args:\n optim (torch.nn.Optimizer):\n optimizer to shard (default: SGD)\n group (group):\n torch.distributed group (default: group.WORLD)\n \"\"\"\n\n optim: Optimizer\n in_super_constructor: bool\n\n def __init__(self, params: _params_t, optim: Type[Optimizer] = SGD, group: Any = dist.group.WORLD, **defaults: Any):\n self.in_super_constructor = True\n super().__init__(params, defaults)\n self.in_super_constructor = False\n\n self.group = group\n self.rank = dist.get_rank(group)\n param_groups = self.partition_parameters()\n self.optim = optim(param_groups[self.rank], **defaults)\n\n # Optional consolidated optimizer state\n self._all_states: List[Dict[str, Any]] = []\n\n # Current device is set by the parameters allocated to this rank\n self._device = self.partition_parameters()[self.rank][0][\"params\"][0].device\n\n def partition_parameters(self) -> List[List[dict]]:\n \"\"\"Partitions parameters across distributed ranks.\n\n Returns a list of param_groups (which is a list of dict) where each\n element of the list contains the param_groups for a rank. Element 0\n corresponds to rank 0, etc. We need all the ranks for the broadcast\n inside step().\n \"\"\"\n world_size = dist.get_world_size(self.group)\n param_groups: List[List] = [list() for _ in range(world_size)]\n sizes = [0] * world_size\n for param_group in self.param_groups:\n param_lists: List[List] = [list() for _ in range(world_size)]\n for param in param_group[\"params\"]:\n # Add this param to rank with smallest size.\n rank = sizes.index(min(sizes))\n param_lists[rank].append(param)\n sizes[rank] += param.numel()\n for rank, params in enumerate(param_lists):\n if len(params) > 0:\n param_group_rank = copy.copy(param_group)\n param_group_rank[\"params\"] = params\n param_groups[rank].append(param_group_rank)\n return param_groups\n\n def step(self, closure: Optional[Callable[[], float]] = None) -> Optional[float]:\n loss = self.optim.step(closure=closure)\n for rank, param_groups in enumerate(self.partition_parameters()):\n for param_group in param_groups:\n for param in param_group[\"params\"]:\n dist.broadcast(param, rank, group=self.group)\n return loss\n\n def local_state_dict(self) -> dict:\n \"\"\" Gets this rank's state_dict. \"\"\"\n return self.optim.state_dict()\n\n def consolidate_state_dict(self, recipient_rank: int = 0) -> None:\n \"\"\" Update the consolidated state_dict list, one per rank.\n\n This needs to be called on all replicas \"\"\"\n\n if self.rank == recipient_rank:\n # Pull the sharded state from all the other replicas\n # Store all the states in order, rank by rank\n logging.debug(\"Pulling the sharded SGD state from all replicas\")\n self._all_states = self._collect_sharded_states()\n else:\n # Acknowledge broadcasts, and send this rank's shard when needed\n self._broadcast_state_dict()\n\n def state_dict(self) -> Dict[str, Any]:\n \"\"\"\n Return the last known global optimizer state, which consist of a list of the shards.\n\n NOTE: This is limited to the replica which was responsible for the consolidation.\n The state may also not be up to date, depending on when `consolidate_state_dict` was last called.\n \"\"\"\n\n assert (\n len(self._all_states) > 0\n ), \"The optimizer state is not materialized, please call consolidate_state_dict on every replica beforehand\"\n\n return {\"state\": self._all_states, \"param_groups\": self.param_groups}\n\n def load_local_state_dict(self, state_dict: dict) -> None:\n \"\"\" Loads this rank's state_dict. \"\"\"\n\n # Make sure that the state is on the appropriate device\n state_dict_ondevice = recursive_copy_to_device(state_dict, non_blocking=False, device=self._device)\n\n self.optim.load_state_dict(state_dict_ondevice)\n\n def load_state_dict(self, state_dict: Dict[str, Any]) -> None:\n \"\"\" Loads this rank's optimizer state_dict, given the global optimizer state. \"\"\"\n # Dispatch this rank's state dictionary to the local load\n self.load_local_state_dict(state_dict[\"state\"][self.rank])\n\n def add_param_group(self, param_group: dict) -> None:\n super().add_param_group(param_group)\n if not self.in_super_constructor:\n param_groups = self.partition_parameters()[self.rank]\n if len(param_groups) == len(self.optim.param_groups) + 1:\n self.optim.add_param_group(param_groups[-1])\n\n def _collect_sharded_states(self) -> List[Dict[str, Any]]:\n \"\"\"\n Collect all the state shards, in CPU memory.\n \"\"\"\n empty_buffer = torch.tensor([0], dtype=torch.uint8, device=self._device)\n all_states: List[Dict[str, Any]] = []\n\n for rank in range(dist.get_world_size(group=self.group)):\n if rank == self.rank:\n logging.debug(\"Saving self state\")\n all_states.append(\n recursive_copy_to_device(self.local_state_dict(), non_blocking=True, device=torch.device(\"cpu\"))\n )\n\n # Sync with other replicas\n broadcast_object(empty_buffer, src_rank=rank, group=self.group, dist_device=self._device)\n else:\n # Fetch the optim state from the other replicas\n logging.debug(\"Receiving state from rank %s \", rank)\n replica_state = broadcast_object(\n empty_buffer, src_rank=rank, group=self.group, dist_device=self._device\n )\n\n all_states.append(\n recursive_copy_to_device(replica_state, non_blocking=True, device=torch.device(\"cpu\"))\n )\n\n logging.debug(\"State from rank %s received\", rank)\n\n return all_states\n\n def _broadcast_state_dict(self) -> None:\n \"\"\"\n Broadcast this rank's state shard, discard others\n \"\"\"\n empty_buffer = torch.tensor([0], dtype=torch.uint8, device=self._device)\n\n for rank in range(dist.get_world_size(group=self.group)):\n if rank == self.rank:\n # Send the state to the reference replica\n logging.debug(\n \"Sending the sharded SGD state to the reference replica from rank %s\", rank,\n )\n broadcast_object(self.local_state_dict(), src_rank=rank, group=self.group, dist_device=self._device)\n else:\n # Discard this tensor/rank, broadcast necessary for syncing\n logging.debug(\"Discarding broadcast from rank %s\", rank)\n broadcast_object(empty_buffer, src_rank=rank, group=self.group, dist_device=self._device)\n", "path": "fairscale/optim/oss.py"}]}
| 3,765 | 803 |
gh_patches_debug_5337
|
rasdani/github-patches
|
git_diff
|
ray-project__ray-6916
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[tune] Handle nan case for AsynchScheduler
To deal with the case of recording nan values i would suggest changing from np.percentile to np.nanpercentile in this line.
https://github.com/ray-project/ray/blob/f7455839bf5686cf990c9e6625c6ada9a3ffd7c8/python/ray/tune/schedulers/async_hyperband.py#L145-L148
As stated in https://docs.scipy.org/doc/numpy/reference/generated/numpy.nanpercentile.html#numpy.nanpercentile any time a nan result is recorded this will result in the cutoff being nan.
>>> array([[10., nan, 4.],
[ 3., 2., 1.]])
>>> np.percentile(a, 50)
nan
Ultimately leading to this line evaluating to false, preventing any following trial from stopping.
https://github.com/ray-project/ray/blob/f7455839bf5686cf990c9e6625c6ada9a3ffd7c8/python/ray/tune/schedulers/async_hyperband.py#L157-L158
</issue>
<code>
[start of python/ray/tune/schedulers/async_hyperband.py]
1 import logging
2 import numpy as np
3
4 from ray.tune.schedulers.trial_scheduler import FIFOScheduler, TrialScheduler
5
6 logger = logging.getLogger(__name__)
7
8
9 class AsyncHyperBandScheduler(FIFOScheduler):
10 """Implements the Async Successive Halving.
11
12 This should provide similar theoretical performance as HyperBand but
13 avoid straggler issues that HyperBand faces. One implementation detail
14 is when using multiple brackets, trial allocation to bracket is done
15 randomly with over a softmax probability.
16
17 See https://arxiv.org/abs/1810.05934
18
19 Args:
20 time_attr (str): A training result attr to use for comparing time.
21 Note that you can pass in something non-temporal such as
22 `training_iteration` as a measure of progress, the only requirement
23 is that the attribute should increase monotonically.
24 metric (str): The training result objective value attribute. Stopping
25 procedures will use this attribute.
26 mode (str): One of {min, max}. Determines whether objective is
27 minimizing or maximizing the metric attribute.
28 max_t (float): max time units per trial. Trials will be stopped after
29 max_t time units (determined by time_attr) have passed.
30 grace_period (float): Only stop trials at least this old in time.
31 The units are the same as the attribute named by `time_attr`.
32 reduction_factor (float): Used to set halving rate and amount. This
33 is simply a unit-less scalar.
34 brackets (int): Number of brackets. Each bracket has a different
35 halving rate, specified by the reduction factor.
36 """
37
38 def __init__(self,
39 time_attr="training_iteration",
40 reward_attr=None,
41 metric="episode_reward_mean",
42 mode="max",
43 max_t=100,
44 grace_period=1,
45 reduction_factor=4,
46 brackets=1):
47 assert max_t > 0, "Max (time_attr) not valid!"
48 assert max_t >= grace_period, "grace_period must be <= max_t!"
49 assert grace_period > 0, "grace_period must be positive!"
50 assert reduction_factor > 1, "Reduction Factor not valid!"
51 assert brackets > 0, "brackets must be positive!"
52 assert mode in ["min", "max"], "`mode` must be 'min' or 'max'!"
53
54 if reward_attr is not None:
55 mode = "max"
56 metric = reward_attr
57 logger.warning(
58 "`reward_attr` is deprecated and will be removed in a future "
59 "version of Tune. "
60 "Setting `metric={}` and `mode=max`.".format(reward_attr))
61
62 FIFOScheduler.__init__(self)
63 self._reduction_factor = reduction_factor
64 self._max_t = max_t
65
66 self._trial_info = {} # Stores Trial -> Bracket
67
68 # Tracks state for new trial add
69 self._brackets = [
70 _Bracket(grace_period, max_t, reduction_factor, s)
71 for s in range(brackets)
72 ]
73 self._counter = 0 # for
74 self._num_stopped = 0
75 self._metric = metric
76 if mode == "max":
77 self._metric_op = 1.
78 elif mode == "min":
79 self._metric_op = -1.
80 self._time_attr = time_attr
81
82 def on_trial_add(self, trial_runner, trial):
83 sizes = np.array([len(b._rungs) for b in self._brackets])
84 probs = np.e**(sizes - sizes.max())
85 normalized = probs / probs.sum()
86 idx = np.random.choice(len(self._brackets), p=normalized)
87 self._trial_info[trial.trial_id] = self._brackets[idx]
88
89 def on_trial_result(self, trial_runner, trial, result):
90 action = TrialScheduler.CONTINUE
91 if self._time_attr not in result or self._metric not in result:
92 return action
93 if result[self._time_attr] >= self._max_t:
94 action = TrialScheduler.STOP
95 else:
96 bracket = self._trial_info[trial.trial_id]
97 action = bracket.on_result(trial, result[self._time_attr],
98 self._metric_op * result[self._metric])
99 if action == TrialScheduler.STOP:
100 self._num_stopped += 1
101 return action
102
103 def on_trial_complete(self, trial_runner, trial, result):
104 if self._time_attr not in result or self._metric not in result:
105 return
106 bracket = self._trial_info[trial.trial_id]
107 bracket.on_result(trial, result[self._time_attr],
108 self._metric_op * result[self._metric])
109 del self._trial_info[trial.trial_id]
110
111 def on_trial_remove(self, trial_runner, trial):
112 del self._trial_info[trial.trial_id]
113
114 def debug_string(self):
115 out = "Using AsyncHyperBand: num_stopped={}".format(self._num_stopped)
116 out += "\n" + "\n".join([b.debug_str() for b in self._brackets])
117 return out
118
119
120 class _Bracket():
121 """Bookkeeping system to track the cutoffs.
122
123 Rungs are created in reversed order so that we can more easily find
124 the correct rung corresponding to the current iteration of the result.
125
126 Example:
127 >>> b = _Bracket(1, 10, 2, 3)
128 >>> b.on_result(trial1, 1, 2) # CONTINUE
129 >>> b.on_result(trial2, 1, 4) # CONTINUE
130 >>> b.cutoff(b._rungs[-1][1]) == 3.0 # rungs are reversed
131 >>> b.on_result(trial3, 1, 1) # STOP
132 >>> b.cutoff(b._rungs[0][1]) == 2.0
133 """
134
135 def __init__(self, min_t, max_t, reduction_factor, s):
136 self.rf = reduction_factor
137 MAX_RUNGS = int(np.log(max_t / min_t) / np.log(self.rf) - s + 1)
138 self._rungs = [(min_t * self.rf**(k + s), {})
139 for k in reversed(range(MAX_RUNGS))]
140
141 def cutoff(self, recorded):
142 if not recorded:
143 return None
144 return np.percentile(list(recorded.values()), (1 - 1 / self.rf) * 100)
145
146 def on_result(self, trial, cur_iter, cur_rew):
147 action = TrialScheduler.CONTINUE
148 for milestone, recorded in self._rungs:
149 if cur_iter < milestone or trial.trial_id in recorded:
150 continue
151 else:
152 cutoff = self.cutoff(recorded)
153 if cutoff is not None and cur_rew < cutoff:
154 action = TrialScheduler.STOP
155 if cur_rew is None:
156 logger.warning("Reward attribute is None! Consider"
157 " reporting using a different field.")
158 else:
159 recorded[trial.trial_id] = cur_rew
160 break
161 return action
162
163 def debug_str(self):
164 iters = " | ".join([
165 "Iter {:.3f}: {}".format(milestone, self.cutoff(recorded))
166 for milestone, recorded in self._rungs
167 ])
168 return "Bracket: " + iters
169
170
171 ASHAScheduler = AsyncHyperBandScheduler
172
173 if __name__ == "__main__":
174 sched = AsyncHyperBandScheduler(
175 grace_period=1, max_t=10, reduction_factor=2)
176 print(sched.debug_string())
177 bracket = sched._brackets[0]
178 print(bracket.cutoff({str(i): i for i in range(20)}))
179
[end of python/ray/tune/schedulers/async_hyperband.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/python/ray/tune/schedulers/async_hyperband.py b/python/ray/tune/schedulers/async_hyperband.py
--- a/python/ray/tune/schedulers/async_hyperband.py
+++ b/python/ray/tune/schedulers/async_hyperband.py
@@ -141,7 +141,8 @@
def cutoff(self, recorded):
if not recorded:
return None
- return np.percentile(list(recorded.values()), (1 - 1 / self.rf) * 100)
+ return np.nanpercentile(
+ list(recorded.values()), (1 - 1 / self.rf) * 100)
def on_result(self, trial, cur_iter, cur_rew):
action = TrialScheduler.CONTINUE
|
{"golden_diff": "diff --git a/python/ray/tune/schedulers/async_hyperband.py b/python/ray/tune/schedulers/async_hyperband.py\n--- a/python/ray/tune/schedulers/async_hyperband.py\n+++ b/python/ray/tune/schedulers/async_hyperband.py\n@@ -141,7 +141,8 @@\n def cutoff(self, recorded):\n if not recorded:\n return None\n- return np.percentile(list(recorded.values()), (1 - 1 / self.rf) * 100)\n+ return np.nanpercentile(\n+ list(recorded.values()), (1 - 1 / self.rf) * 100)\n \n def on_result(self, trial, cur_iter, cur_rew):\n action = TrialScheduler.CONTINUE\n", "issue": "[tune] Handle nan case for AsynchScheduler\nTo deal with the case of recording nan values i would suggest changing from np.percentile to np.nanpercentile in this line.\r\n\r\nhttps://github.com/ray-project/ray/blob/f7455839bf5686cf990c9e6625c6ada9a3ffd7c8/python/ray/tune/schedulers/async_hyperband.py#L145-L148\r\n\r\nAs stated in https://docs.scipy.org/doc/numpy/reference/generated/numpy.nanpercentile.html#numpy.nanpercentile any time a nan result is recorded this will result in the cutoff being nan.\r\n\r\n>>> array([[10., nan, 4.],\r\n [ 3., 2., 1.]])\r\n>>> np.percentile(a, 50)\r\nnan\r\n\r\nUltimately leading to this line evaluating to false, preventing any following trial from stopping. \r\nhttps://github.com/ray-project/ray/blob/f7455839bf5686cf990c9e6625c6ada9a3ffd7c8/python/ray/tune/schedulers/async_hyperband.py#L157-L158\r\n\n", "before_files": [{"content": "import logging\nimport numpy as np\n\nfrom ray.tune.schedulers.trial_scheduler import FIFOScheduler, TrialScheduler\n\nlogger = logging.getLogger(__name__)\n\n\nclass AsyncHyperBandScheduler(FIFOScheduler):\n \"\"\"Implements the Async Successive Halving.\n\n This should provide similar theoretical performance as HyperBand but\n avoid straggler issues that HyperBand faces. One implementation detail\n is when using multiple brackets, trial allocation to bracket is done\n randomly with over a softmax probability.\n\n See https://arxiv.org/abs/1810.05934\n\n Args:\n time_attr (str): A training result attr to use for comparing time.\n Note that you can pass in something non-temporal such as\n `training_iteration` as a measure of progress, the only requirement\n is that the attribute should increase monotonically.\n metric (str): The training result objective value attribute. Stopping\n procedures will use this attribute.\n mode (str): One of {min, max}. Determines whether objective is\n minimizing or maximizing the metric attribute.\n max_t (float): max time units per trial. Trials will be stopped after\n max_t time units (determined by time_attr) have passed.\n grace_period (float): Only stop trials at least this old in time.\n The units are the same as the attribute named by `time_attr`.\n reduction_factor (float): Used to set halving rate and amount. This\n is simply a unit-less scalar.\n brackets (int): Number of brackets. Each bracket has a different\n halving rate, specified by the reduction factor.\n \"\"\"\n\n def __init__(self,\n time_attr=\"training_iteration\",\n reward_attr=None,\n metric=\"episode_reward_mean\",\n mode=\"max\",\n max_t=100,\n grace_period=1,\n reduction_factor=4,\n brackets=1):\n assert max_t > 0, \"Max (time_attr) not valid!\"\n assert max_t >= grace_period, \"grace_period must be <= max_t!\"\n assert grace_period > 0, \"grace_period must be positive!\"\n assert reduction_factor > 1, \"Reduction Factor not valid!\"\n assert brackets > 0, \"brackets must be positive!\"\n assert mode in [\"min\", \"max\"], \"`mode` must be 'min' or 'max'!\"\n\n if reward_attr is not None:\n mode = \"max\"\n metric = reward_attr\n logger.warning(\n \"`reward_attr` is deprecated and will be removed in a future \"\n \"version of Tune. \"\n \"Setting `metric={}` and `mode=max`.\".format(reward_attr))\n\n FIFOScheduler.__init__(self)\n self._reduction_factor = reduction_factor\n self._max_t = max_t\n\n self._trial_info = {} # Stores Trial -> Bracket\n\n # Tracks state for new trial add\n self._brackets = [\n _Bracket(grace_period, max_t, reduction_factor, s)\n for s in range(brackets)\n ]\n self._counter = 0 # for\n self._num_stopped = 0\n self._metric = metric\n if mode == \"max\":\n self._metric_op = 1.\n elif mode == \"min\":\n self._metric_op = -1.\n self._time_attr = time_attr\n\n def on_trial_add(self, trial_runner, trial):\n sizes = np.array([len(b._rungs) for b in self._brackets])\n probs = np.e**(sizes - sizes.max())\n normalized = probs / probs.sum()\n idx = np.random.choice(len(self._brackets), p=normalized)\n self._trial_info[trial.trial_id] = self._brackets[idx]\n\n def on_trial_result(self, trial_runner, trial, result):\n action = TrialScheduler.CONTINUE\n if self._time_attr not in result or self._metric not in result:\n return action\n if result[self._time_attr] >= self._max_t:\n action = TrialScheduler.STOP\n else:\n bracket = self._trial_info[trial.trial_id]\n action = bracket.on_result(trial, result[self._time_attr],\n self._metric_op * result[self._metric])\n if action == TrialScheduler.STOP:\n self._num_stopped += 1\n return action\n\n def on_trial_complete(self, trial_runner, trial, result):\n if self._time_attr not in result or self._metric not in result:\n return\n bracket = self._trial_info[trial.trial_id]\n bracket.on_result(trial, result[self._time_attr],\n self._metric_op * result[self._metric])\n del self._trial_info[trial.trial_id]\n\n def on_trial_remove(self, trial_runner, trial):\n del self._trial_info[trial.trial_id]\n\n def debug_string(self):\n out = \"Using AsyncHyperBand: num_stopped={}\".format(self._num_stopped)\n out += \"\\n\" + \"\\n\".join([b.debug_str() for b in self._brackets])\n return out\n\n\nclass _Bracket():\n \"\"\"Bookkeeping system to track the cutoffs.\n\n Rungs are created in reversed order so that we can more easily find\n the correct rung corresponding to the current iteration of the result.\n\n Example:\n >>> b = _Bracket(1, 10, 2, 3)\n >>> b.on_result(trial1, 1, 2) # CONTINUE\n >>> b.on_result(trial2, 1, 4) # CONTINUE\n >>> b.cutoff(b._rungs[-1][1]) == 3.0 # rungs are reversed\n >>> b.on_result(trial3, 1, 1) # STOP\n >>> b.cutoff(b._rungs[0][1]) == 2.0\n \"\"\"\n\n def __init__(self, min_t, max_t, reduction_factor, s):\n self.rf = reduction_factor\n MAX_RUNGS = int(np.log(max_t / min_t) / np.log(self.rf) - s + 1)\n self._rungs = [(min_t * self.rf**(k + s), {})\n for k in reversed(range(MAX_RUNGS))]\n\n def cutoff(self, recorded):\n if not recorded:\n return None\n return np.percentile(list(recorded.values()), (1 - 1 / self.rf) * 100)\n\n def on_result(self, trial, cur_iter, cur_rew):\n action = TrialScheduler.CONTINUE\n for milestone, recorded in self._rungs:\n if cur_iter < milestone or trial.trial_id in recorded:\n continue\n else:\n cutoff = self.cutoff(recorded)\n if cutoff is not None and cur_rew < cutoff:\n action = TrialScheduler.STOP\n if cur_rew is None:\n logger.warning(\"Reward attribute is None! Consider\"\n \" reporting using a different field.\")\n else:\n recorded[trial.trial_id] = cur_rew\n break\n return action\n\n def debug_str(self):\n iters = \" | \".join([\n \"Iter {:.3f}: {}\".format(milestone, self.cutoff(recorded))\n for milestone, recorded in self._rungs\n ])\n return \"Bracket: \" + iters\n\n\nASHAScheduler = AsyncHyperBandScheduler\n\nif __name__ == \"__main__\":\n sched = AsyncHyperBandScheduler(\n grace_period=1, max_t=10, reduction_factor=2)\n print(sched.debug_string())\n bracket = sched._brackets[0]\n print(bracket.cutoff({str(i): i for i in range(20)}))\n", "path": "python/ray/tune/schedulers/async_hyperband.py"}]}
| 2,937 | 170 |
gh_patches_debug_29911
|
rasdani/github-patches
|
git_diff
|
getnikola__nikola-1932
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Yearly archivs not rebuilt when their posts change
</issue>
<code>
[start of nikola/plugins/task/archive.py]
1 # -*- coding: utf-8 -*-
2
3 # Copyright © 2012-2015 Roberto Alsina and others.
4
5 # Permission is hereby granted, free of charge, to any
6 # person obtaining a copy of this software and associated
7 # documentation files (the "Software"), to deal in the
8 # Software without restriction, including without limitation
9 # the rights to use, copy, modify, merge, publish,
10 # distribute, sublicense, and/or sell copies of the
11 # Software, and to permit persons to whom the Software is
12 # furnished to do so, subject to the following conditions:
13 #
14 # The above copyright notice and this permission notice
15 # shall be included in all copies or substantial portions of
16 # the Software.
17 #
18 # THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY
19 # KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE
20 # WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR
21 # PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS
22 # OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR
23 # OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR
24 # OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE
25 # SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
26
27 """Render the post archives."""
28
29 import copy
30 import os
31
32 # for tearDown with _reload we cannot use 'import from' to access LocaleBorg
33 import nikola.utils
34 import datetime
35 from nikola.plugin_categories import Task
36 from nikola.utils import config_changed, adjust_name_for_index_path, adjust_name_for_index_link
37
38
39 class Archive(Task):
40
41 """Render the post archives."""
42
43 name = "render_archive"
44
45 def set_site(self, site):
46 """Set Nikola site."""
47 site.register_path_handler('archive', self.archive_path)
48 site.register_path_handler('archive_atom', self.archive_atom_path)
49 return super(Archive, self).set_site(site)
50
51 def _prepare_task(self, kw, name, lang, posts, items, template_name,
52 title, deps_translatable=None):
53 """Prepare an archive task."""
54 # name: used to build permalink and destination
55 # posts, items: posts or items; only one of them should be used,
56 # the other be None
57 # template_name: name of the template to use
58 # title: the (translated) title for the generated page
59 # deps_translatable: dependencies (None if not added)
60 assert posts is not None or items is not None
61
62 context = {}
63 context["lang"] = lang
64 context["title"] = title
65 context["permalink"] = self.site.link("archive", name, lang)
66 context["pagekind"] = ["list", "archive_page"]
67 if posts is not None:
68 context["posts"] = posts
69 n = len(posts)
70 else:
71 context["items"] = items
72 n = len(items)
73 task = self.site.generic_post_list_renderer(
74 lang,
75 [],
76 os.path.join(kw['output_folder'], self.site.path("archive", name, lang)),
77 template_name,
78 kw['filters'],
79 context,
80 )
81
82 task_cfg = {1: copy.copy(kw), 2: n}
83 if deps_translatable is not None:
84 task_cfg[3] = deps_translatable
85 task['uptodate'] = task['uptodate'] + [config_changed(task_cfg, 'nikola.plugins.task.archive')]
86 task['basename'] = self.name
87 return task
88
89 def _generate_posts_task(self, kw, name, lang, posts, title, deps_translatable=None):
90 """Genereate a task for an archive with posts."""
91 posts = sorted(posts, key=lambda a: a.date)
92 posts.reverse()
93 if kw['archives_are_indexes']:
94 def page_link(i, displayed_i, num_pages, force_addition, extension=None):
95 feed = "_atom" if extension == ".atom" else ""
96 return adjust_name_for_index_link(self.site.link("archive" + feed, name, lang), i, displayed_i,
97 lang, self.site, force_addition, extension)
98
99 def page_path(i, displayed_i, num_pages, force_addition, extension=None):
100 feed = "_atom" if extension == ".atom" else ""
101 return adjust_name_for_index_path(self.site.path("archive" + feed, name, lang), i, displayed_i,
102 lang, self.site, force_addition, extension)
103
104 uptodate = []
105 if deps_translatable is not None:
106 uptodate += [config_changed(deps_translatable, 'nikola.plugins.task.archive')]
107 context = {"archive_name": name,
108 "is_feed_stale": kw["is_feed_stale"],
109 "pagekind": ["index", "archive_page"]}
110 yield self.site.generic_index_renderer(
111 lang,
112 posts,
113 title,
114 "archiveindex.tmpl",
115 context,
116 kw,
117 str(self.name),
118 page_link,
119 page_path,
120 uptodate)
121 else:
122 yield self._prepare_task(kw, name, lang, posts, None, "list_post.tmpl", title, deps_translatable)
123
124 def gen_tasks(self):
125 """Generate archive tasks."""
126 kw = {
127 "messages": self.site.MESSAGES,
128 "translations": self.site.config['TRANSLATIONS'],
129 "output_folder": self.site.config['OUTPUT_FOLDER'],
130 "filters": self.site.config['FILTERS'],
131 "archives_are_indexes": self.site.config['ARCHIVES_ARE_INDEXES'],
132 "create_monthly_archive": self.site.config['CREATE_MONTHLY_ARCHIVE'],
133 "create_single_archive": self.site.config['CREATE_SINGLE_ARCHIVE'],
134 "show_untranslated_posts": self.site.config['SHOW_UNTRANSLATED_POSTS'],
135 "create_full_archives": self.site.config['CREATE_FULL_ARCHIVES'],
136 "create_daily_archive": self.site.config['CREATE_DAILY_ARCHIVE'],
137 "pretty_urls": self.site.config['PRETTY_URLS'],
138 "strip_indexes": self.site.config['STRIP_INDEXES'],
139 "index_file": self.site.config['INDEX_FILE'],
140 "generate_atom": self.site.config["GENERATE_ATOM"],
141 }
142 self.site.scan_posts()
143 yield self.group_task()
144 # TODO add next/prev links for years
145 if (kw['create_monthly_archive'] and kw['create_single_archive']) and not kw['create_full_archives']:
146 raise Exception('Cannot create monthly and single archives at the same time.')
147 for lang in kw["translations"]:
148 if kw['create_single_archive'] and not kw['create_full_archives']:
149 # if we are creating one single archive
150 archdata = {}
151 else:
152 # if we are not creating one single archive, start with all years
153 archdata = self.site.posts_per_year.copy()
154 if kw['create_single_archive'] or kw['create_full_archives']:
155 # if we are creating one single archive, or full archives
156 archdata[None] = self.site.posts # for create_single_archive
157
158 for year, posts in archdata.items():
159 # Filter untranslated posts (Issue #1360)
160 if not kw["show_untranslated_posts"]:
161 posts = [p for p in posts if lang in p.translated_to]
162
163 # Add archive per year or total archive
164 if year:
165 title = kw["messages"][lang]["Posts for year %s"] % year
166 kw["is_feed_stale"] = (datetime.datetime.utcnow().strftime("%Y") != year)
167 else:
168 title = kw["messages"][lang]["Archive"]
169 kw["is_feed_stale"] = False
170 deps_translatable = {}
171 for k in self.site._GLOBAL_CONTEXT_TRANSLATABLE:
172 deps_translatable[k] = self.site.GLOBAL_CONTEXT[k](lang)
173 if not kw["create_monthly_archive"] or kw["create_full_archives"]:
174 yield self._generate_posts_task(kw, year, lang, posts, title, deps_translatable)
175 else:
176 months = set([(m.split('/')[1], self.site.link("archive", m, lang)) for m in self.site.posts_per_month.keys() if m.startswith(str(year))])
177 months = sorted(list(months))
178 months.reverse()
179 items = [[nikola.utils.LocaleBorg().get_month_name(int(month), lang), link] for month, link in months]
180 yield self._prepare_task(kw, year, lang, None, items, "list.tmpl", title, deps_translatable)
181
182 if not kw["create_monthly_archive"] and not kw["create_full_archives"] and not kw["create_daily_archive"]:
183 continue # Just to avoid nesting the other loop in this if
184 for yearmonth, posts in self.site.posts_per_month.items():
185 # Add archive per month
186 year, month = yearmonth.split('/')
187
188 kw["is_feed_stale"] = (datetime.datetime.utcnow().strftime("%Y/%m") != yearmonth)
189
190 # Filter untranslated posts (via Issue #1360)
191 if not kw["show_untranslated_posts"]:
192 posts = [p for p in posts if lang in p.translated_to]
193
194 if kw["create_monthly_archive"] or kw["create_full_archives"]:
195 title = kw["messages"][lang]["Posts for {month} {year}"].format(
196 year=year, month=nikola.utils.LocaleBorg().get_month_name(int(month), lang))
197 yield self._generate_posts_task(kw, yearmonth, lang, posts, title)
198
199 if not kw["create_full_archives"] and not kw["create_daily_archive"]:
200 continue # Just to avoid nesting the other loop in this if
201 # Add archive per day
202 days = dict()
203 for p in posts:
204 if p.date.day not in days:
205 days[p.date.day] = list()
206 days[p.date.day].append(p)
207 for day, posts in days.items():
208 title = kw["messages"][lang]["Posts for {month} {day}, {year}"].format(
209 year=year, month=nikola.utils.LocaleBorg().get_month_name(int(month), lang), day=day)
210 yield self._generate_posts_task(kw, yearmonth + '/{0:02d}'.format(day), lang, posts, title)
211
212 if not kw['create_single_archive'] and not kw['create_full_archives']:
213 # And an "all your years" page for yearly and monthly archives
214 if "is_feed_stale" in kw:
215 del kw["is_feed_stale"]
216 years = list(self.site.posts_per_year.keys())
217 years.sort(reverse=True)
218 kw['years'] = years
219 for lang in kw["translations"]:
220 items = [(y, self.site.link("archive", y, lang)) for y in years]
221 yield self._prepare_task(kw, None, lang, None, items, "list.tmpl", kw["messages"][lang]["Archive"])
222
223 def archive_path(self, name, lang, is_feed=False):
224 """Return archive paths."""
225 if is_feed:
226 extension = ".atom"
227 archive_file = os.path.splitext(self.site.config['ARCHIVE_FILENAME'])[0] + extension
228 index_file = os.path.splitext(self.site.config['INDEX_FILE'])[0] + extension
229 else:
230 archive_file = self.site.config['ARCHIVE_FILENAME']
231 index_file = self.site.config['INDEX_FILE']
232 if name:
233 return [_f for _f in [self.site.config['TRANSLATIONS'][lang],
234 self.site.config['ARCHIVE_PATH'], name,
235 index_file] if _f]
236 else:
237 return [_f for _f in [self.site.config['TRANSLATIONS'][lang],
238 self.site.config['ARCHIVE_PATH'],
239 archive_file] if _f]
240
241 def archive_atom_path(self, name, lang):
242 """Return Atom archive paths."""
243 return self.archive_path(name, lang, is_feed=True)
244
[end of nikola/plugins/task/archive.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/nikola/plugins/task/archive.py b/nikola/plugins/task/archive.py
--- a/nikola/plugins/task/archive.py
+++ b/nikola/plugins/task/archive.py
@@ -58,7 +58,7 @@
# title: the (translated) title for the generated page
# deps_translatable: dependencies (None if not added)
assert posts is not None or items is not None
-
+ task_cfg = [copy.copy(kw)]
context = {}
context["lang"] = lang
context["title"] = title
@@ -66,10 +66,12 @@
context["pagekind"] = ["list", "archive_page"]
if posts is not None:
context["posts"] = posts
- n = len(posts)
+ # Depend on all post metadata because it can be used in templates (Issue #1931)
+ task_cfg.append(repr(p) for p in posts)
else:
+ # Depend on the content of items, to rebuild if links change (Issue #1931)
context["items"] = items
- n = len(items)
+ task_cfg.append(items)
task = self.site.generic_post_list_renderer(
lang,
[],
@@ -79,7 +81,7 @@
context,
)
- task_cfg = {1: copy.copy(kw), 2: n}
+ task_cfg = {i: x for i, x in enumerate(task_cfg)}
if deps_translatable is not None:
task_cfg[3] = deps_translatable
task['uptodate'] = task['uptodate'] + [config_changed(task_cfg, 'nikola.plugins.task.archive')]
|
{"golden_diff": "diff --git a/nikola/plugins/task/archive.py b/nikola/plugins/task/archive.py\n--- a/nikola/plugins/task/archive.py\n+++ b/nikola/plugins/task/archive.py\n@@ -58,7 +58,7 @@\n # title: the (translated) title for the generated page\n # deps_translatable: dependencies (None if not added)\n assert posts is not None or items is not None\n-\n+ task_cfg = [copy.copy(kw)]\n context = {}\n context[\"lang\"] = lang\n context[\"title\"] = title\n@@ -66,10 +66,12 @@\n context[\"pagekind\"] = [\"list\", \"archive_page\"]\n if posts is not None:\n context[\"posts\"] = posts\n- n = len(posts)\n+ # Depend on all post metadata because it can be used in templates (Issue #1931)\n+ task_cfg.append(repr(p) for p in posts)\n else:\n+ # Depend on the content of items, to rebuild if links change (Issue #1931)\n context[\"items\"] = items\n- n = len(items)\n+ task_cfg.append(items)\n task = self.site.generic_post_list_renderer(\n lang,\n [],\n@@ -79,7 +81,7 @@\n context,\n )\n \n- task_cfg = {1: copy.copy(kw), 2: n}\n+ task_cfg = {i: x for i, x in enumerate(task_cfg)}\n if deps_translatable is not None:\n task_cfg[3] = deps_translatable\n task['uptodate'] = task['uptodate'] + [config_changed(task_cfg, 'nikola.plugins.task.archive')]\n", "issue": "Yearly archivs not rebuilt when their posts change\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\n# Copyright \u00a9 2012-2015 Roberto Alsina and others.\n\n# Permission is hereby granted, free of charge, to any\n# person obtaining a copy of this software and associated\n# documentation files (the \"Software\"), to deal in the\n# Software without restriction, including without limitation\n# the rights to use, copy, modify, merge, publish,\n# distribute, sublicense, and/or sell copies of the\n# Software, and to permit persons to whom the Software is\n# furnished to do so, subject to the following conditions:\n#\n# The above copyright notice and this permission notice\n# shall be included in all copies or substantial portions of\n# the Software.\n#\n# THE SOFTWARE IS PROVIDED \"AS IS\", WITHOUT WARRANTY OF ANY\n# KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE\n# WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR\n# PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS\n# OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR\n# OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR\n# OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE\n# SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.\n\n\"\"\"Render the post archives.\"\"\"\n\nimport copy\nimport os\n\n# for tearDown with _reload we cannot use 'import from' to access LocaleBorg\nimport nikola.utils\nimport datetime\nfrom nikola.plugin_categories import Task\nfrom nikola.utils import config_changed, adjust_name_for_index_path, adjust_name_for_index_link\n\n\nclass Archive(Task):\n\n \"\"\"Render the post archives.\"\"\"\n\n name = \"render_archive\"\n\n def set_site(self, site):\n \"\"\"Set Nikola site.\"\"\"\n site.register_path_handler('archive', self.archive_path)\n site.register_path_handler('archive_atom', self.archive_atom_path)\n return super(Archive, self).set_site(site)\n\n def _prepare_task(self, kw, name, lang, posts, items, template_name,\n title, deps_translatable=None):\n \"\"\"Prepare an archive task.\"\"\"\n # name: used to build permalink and destination\n # posts, items: posts or items; only one of them should be used,\n # the other be None\n # template_name: name of the template to use\n # title: the (translated) title for the generated page\n # deps_translatable: dependencies (None if not added)\n assert posts is not None or items is not None\n\n context = {}\n context[\"lang\"] = lang\n context[\"title\"] = title\n context[\"permalink\"] = self.site.link(\"archive\", name, lang)\n context[\"pagekind\"] = [\"list\", \"archive_page\"]\n if posts is not None:\n context[\"posts\"] = posts\n n = len(posts)\n else:\n context[\"items\"] = items\n n = len(items)\n task = self.site.generic_post_list_renderer(\n lang,\n [],\n os.path.join(kw['output_folder'], self.site.path(\"archive\", name, lang)),\n template_name,\n kw['filters'],\n context,\n )\n\n task_cfg = {1: copy.copy(kw), 2: n}\n if deps_translatable is not None:\n task_cfg[3] = deps_translatable\n task['uptodate'] = task['uptodate'] + [config_changed(task_cfg, 'nikola.plugins.task.archive')]\n task['basename'] = self.name\n return task\n\n def _generate_posts_task(self, kw, name, lang, posts, title, deps_translatable=None):\n \"\"\"Genereate a task for an archive with posts.\"\"\"\n posts = sorted(posts, key=lambda a: a.date)\n posts.reverse()\n if kw['archives_are_indexes']:\n def page_link(i, displayed_i, num_pages, force_addition, extension=None):\n feed = \"_atom\" if extension == \".atom\" else \"\"\n return adjust_name_for_index_link(self.site.link(\"archive\" + feed, name, lang), i, displayed_i,\n lang, self.site, force_addition, extension)\n\n def page_path(i, displayed_i, num_pages, force_addition, extension=None):\n feed = \"_atom\" if extension == \".atom\" else \"\"\n return adjust_name_for_index_path(self.site.path(\"archive\" + feed, name, lang), i, displayed_i,\n lang, self.site, force_addition, extension)\n\n uptodate = []\n if deps_translatable is not None:\n uptodate += [config_changed(deps_translatable, 'nikola.plugins.task.archive')]\n context = {\"archive_name\": name,\n \"is_feed_stale\": kw[\"is_feed_stale\"],\n \"pagekind\": [\"index\", \"archive_page\"]}\n yield self.site.generic_index_renderer(\n lang,\n posts,\n title,\n \"archiveindex.tmpl\",\n context,\n kw,\n str(self.name),\n page_link,\n page_path,\n uptodate)\n else:\n yield self._prepare_task(kw, name, lang, posts, None, \"list_post.tmpl\", title, deps_translatable)\n\n def gen_tasks(self):\n \"\"\"Generate archive tasks.\"\"\"\n kw = {\n \"messages\": self.site.MESSAGES,\n \"translations\": self.site.config['TRANSLATIONS'],\n \"output_folder\": self.site.config['OUTPUT_FOLDER'],\n \"filters\": self.site.config['FILTERS'],\n \"archives_are_indexes\": self.site.config['ARCHIVES_ARE_INDEXES'],\n \"create_monthly_archive\": self.site.config['CREATE_MONTHLY_ARCHIVE'],\n \"create_single_archive\": self.site.config['CREATE_SINGLE_ARCHIVE'],\n \"show_untranslated_posts\": self.site.config['SHOW_UNTRANSLATED_POSTS'],\n \"create_full_archives\": self.site.config['CREATE_FULL_ARCHIVES'],\n \"create_daily_archive\": self.site.config['CREATE_DAILY_ARCHIVE'],\n \"pretty_urls\": self.site.config['PRETTY_URLS'],\n \"strip_indexes\": self.site.config['STRIP_INDEXES'],\n \"index_file\": self.site.config['INDEX_FILE'],\n \"generate_atom\": self.site.config[\"GENERATE_ATOM\"],\n }\n self.site.scan_posts()\n yield self.group_task()\n # TODO add next/prev links for years\n if (kw['create_monthly_archive'] and kw['create_single_archive']) and not kw['create_full_archives']:\n raise Exception('Cannot create monthly and single archives at the same time.')\n for lang in kw[\"translations\"]:\n if kw['create_single_archive'] and not kw['create_full_archives']:\n # if we are creating one single archive\n archdata = {}\n else:\n # if we are not creating one single archive, start with all years\n archdata = self.site.posts_per_year.copy()\n if kw['create_single_archive'] or kw['create_full_archives']:\n # if we are creating one single archive, or full archives\n archdata[None] = self.site.posts # for create_single_archive\n\n for year, posts in archdata.items():\n # Filter untranslated posts (Issue #1360)\n if not kw[\"show_untranslated_posts\"]:\n posts = [p for p in posts if lang in p.translated_to]\n\n # Add archive per year or total archive\n if year:\n title = kw[\"messages\"][lang][\"Posts for year %s\"] % year\n kw[\"is_feed_stale\"] = (datetime.datetime.utcnow().strftime(\"%Y\") != year)\n else:\n title = kw[\"messages\"][lang][\"Archive\"]\n kw[\"is_feed_stale\"] = False\n deps_translatable = {}\n for k in self.site._GLOBAL_CONTEXT_TRANSLATABLE:\n deps_translatable[k] = self.site.GLOBAL_CONTEXT[k](lang)\n if not kw[\"create_monthly_archive\"] or kw[\"create_full_archives\"]:\n yield self._generate_posts_task(kw, year, lang, posts, title, deps_translatable)\n else:\n months = set([(m.split('/')[1], self.site.link(\"archive\", m, lang)) for m in self.site.posts_per_month.keys() if m.startswith(str(year))])\n months = sorted(list(months))\n months.reverse()\n items = [[nikola.utils.LocaleBorg().get_month_name(int(month), lang), link] for month, link in months]\n yield self._prepare_task(kw, year, lang, None, items, \"list.tmpl\", title, deps_translatable)\n\n if not kw[\"create_monthly_archive\"] and not kw[\"create_full_archives\"] and not kw[\"create_daily_archive\"]:\n continue # Just to avoid nesting the other loop in this if\n for yearmonth, posts in self.site.posts_per_month.items():\n # Add archive per month\n year, month = yearmonth.split('/')\n\n kw[\"is_feed_stale\"] = (datetime.datetime.utcnow().strftime(\"%Y/%m\") != yearmonth)\n\n # Filter untranslated posts (via Issue #1360)\n if not kw[\"show_untranslated_posts\"]:\n posts = [p for p in posts if lang in p.translated_to]\n\n if kw[\"create_monthly_archive\"] or kw[\"create_full_archives\"]:\n title = kw[\"messages\"][lang][\"Posts for {month} {year}\"].format(\n year=year, month=nikola.utils.LocaleBorg().get_month_name(int(month), lang))\n yield self._generate_posts_task(kw, yearmonth, lang, posts, title)\n\n if not kw[\"create_full_archives\"] and not kw[\"create_daily_archive\"]:\n continue # Just to avoid nesting the other loop in this if\n # Add archive per day\n days = dict()\n for p in posts:\n if p.date.day not in days:\n days[p.date.day] = list()\n days[p.date.day].append(p)\n for day, posts in days.items():\n title = kw[\"messages\"][lang][\"Posts for {month} {day}, {year}\"].format(\n year=year, month=nikola.utils.LocaleBorg().get_month_name(int(month), lang), day=day)\n yield self._generate_posts_task(kw, yearmonth + '/{0:02d}'.format(day), lang, posts, title)\n\n if not kw['create_single_archive'] and not kw['create_full_archives']:\n # And an \"all your years\" page for yearly and monthly archives\n if \"is_feed_stale\" in kw:\n del kw[\"is_feed_stale\"]\n years = list(self.site.posts_per_year.keys())\n years.sort(reverse=True)\n kw['years'] = years\n for lang in kw[\"translations\"]:\n items = [(y, self.site.link(\"archive\", y, lang)) for y in years]\n yield self._prepare_task(kw, None, lang, None, items, \"list.tmpl\", kw[\"messages\"][lang][\"Archive\"])\n\n def archive_path(self, name, lang, is_feed=False):\n \"\"\"Return archive paths.\"\"\"\n if is_feed:\n extension = \".atom\"\n archive_file = os.path.splitext(self.site.config['ARCHIVE_FILENAME'])[0] + extension\n index_file = os.path.splitext(self.site.config['INDEX_FILE'])[0] + extension\n else:\n archive_file = self.site.config['ARCHIVE_FILENAME']\n index_file = self.site.config['INDEX_FILE']\n if name:\n return [_f for _f in [self.site.config['TRANSLATIONS'][lang],\n self.site.config['ARCHIVE_PATH'], name,\n index_file] if _f]\n else:\n return [_f for _f in [self.site.config['TRANSLATIONS'][lang],\n self.site.config['ARCHIVE_PATH'],\n archive_file] if _f]\n\n def archive_atom_path(self, name, lang):\n \"\"\"Return Atom archive paths.\"\"\"\n return self.archive_path(name, lang, is_feed=True)\n", "path": "nikola/plugins/task/archive.py"}]}
| 3,706 | 373 |
gh_patches_debug_32229
|
rasdani/github-patches
|
git_diff
|
Cloud-CV__EvalAI-922
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Modify contact_us api to fetch name and email, if the user is logged in.
This issue is related to #853 as discussed with @deshraj .
</issue>
<code>
[start of apps/web/views.py]
1 from django.contrib.auth.models import User
2 from django.shortcuts import render
3
4 from .models import Team
5
6 from rest_framework import permissions, status
7 from rest_framework.decorators import (api_view,
8 permission_classes,
9 throttle_classes,)
10 from rest_framework.response import Response
11 from rest_framework.throttling import AnonRateThrottle
12
13 from .serializers import ContactSerializer, TeamSerializer
14
15
16 def home(request, template_name="index.html"):
17 """
18 Home Page View
19 """
20 return render(request, template_name)
21
22
23 def page_not_found(request):
24 response = render(request, 'error404.html',
25 )
26 response.status_code = 404
27 return response
28
29
30 def internal_server_error(request):
31 response = render(request, 'error500.html',
32 )
33 response.status_code = 500
34 return response
35
36
37 @throttle_classes([AnonRateThrottle, ])
38 @api_view(['POST', ])
39 @permission_classes((permissions.AllowAny,))
40 def contact_us(request):
41 try:
42 user = User.objects.get(username=request.user)
43 name = user.username
44 email = user.email
45 request_data = {"name": name, "email": email}
46 request_data['message'] = request.data['message']
47 serializer = ContactSerializer(data=request_data)
48 if serializer.is_valid():
49 serializer.save()
50 response_data = {'message': 'Your message has been successfully recorded. We will contact you shortly.'}
51 return Response(response_data, status=status.HTTP_201_CREATED)
52 return Response(serializer.errors, status=status.HTTP_400_BAD_REQUEST)
53 except:
54 serializer = ContactSerializer(data=request.data)
55 if serializer.is_valid():
56 serializer.save()
57 response_data = {'message': 'Your message has been successfully recorded. We will contact you shortly.'}
58 return Response(response_data, status=status.HTTP_201_CREATED)
59 return Response(serializer.errors, status=status.HTTP_400_BAD_REQUEST)
60
61
62 @throttle_classes([AnonRateThrottle])
63 @api_view(['GET', 'POST'])
64 @permission_classes((permissions.AllowAny,))
65 def our_team(request):
66 if request.method == 'GET':
67 teams = Team.objects.all()
68 serializer = TeamSerializer(teams, many=True, context={'request': request})
69 response_data = serializer.data
70 return Response(response_data, status=status.HTTP_200_OK)
71 elif request.method == 'POST':
72 # team_type is set to Team.CONTRIBUTOR by default and can be overridden by the requester
73 request.data['team_type'] = request.data.get('team_type', Team.CONTRIBUTOR)
74 serializer = TeamSerializer(data=request.data)
75 if serializer.is_valid():
76 serializer.save()
77 response_data = {'message', 'Successfully added the contributor.'}
78 return Response(response_data, status=status.HTTP_201_CREATED)
79 return Response(serializer.errors, status=status.HTTP_400_BAD_REQUEST)
80
[end of apps/web/views.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/apps/web/views.py b/apps/web/views.py
--- a/apps/web/views.py
+++ b/apps/web/views.py
@@ -35,29 +35,33 @@
@throttle_classes([AnonRateThrottle, ])
-@api_view(['POST', ])
+@api_view(['GET', 'POST'])
@permission_classes((permissions.AllowAny,))
def contact_us(request):
+ user_does_not_exist = False
try:
user = User.objects.get(username=request.user)
name = user.username
email = user.email
- request_data = {"name": name, "email": email}
- request_data['message'] = request.data['message']
- serializer = ContactSerializer(data=request_data)
- if serializer.is_valid():
- serializer.save()
- response_data = {'message': 'Your message has been successfully recorded. We will contact you shortly.'}
- return Response(response_data, status=status.HTTP_201_CREATED)
- return Response(serializer.errors, status=status.HTTP_400_BAD_REQUEST)
+ request_data = {'name': name, 'email': email}
except:
- serializer = ContactSerializer(data=request.data)
+ request_data = request.data
+ user_does_not_exist = True
+
+ if request.method == 'POST' or user_does_not_exist:
+ if request.POST.get('message'):
+ request_data['message'] = request.POST.get('message')
+ serializer = ContactSerializer(data=request_data)
if serializer.is_valid():
serializer.save()
- response_data = {'message': 'Your message has been successfully recorded. We will contact you shortly.'}
+ response_data = {'message': 'We have received your request and will contact you shortly.'}
return Response(response_data, status=status.HTTP_201_CREATED)
return Response(serializer.errors, status=status.HTTP_400_BAD_REQUEST)
+ elif request.method == 'GET':
+ response_data = {"name": name, "email": email}
+ return Response(response_data, status=status.HTTP_200_OK)
+
@throttle_classes([AnonRateThrottle])
@api_view(['GET', 'POST'])
|
{"golden_diff": "diff --git a/apps/web/views.py b/apps/web/views.py\n--- a/apps/web/views.py\n+++ b/apps/web/views.py\n@@ -35,29 +35,33 @@\n \n \n @throttle_classes([AnonRateThrottle, ])\n-@api_view(['POST', ])\n+@api_view(['GET', 'POST'])\n @permission_classes((permissions.AllowAny,))\n def contact_us(request):\n+ user_does_not_exist = False\n try:\n user = User.objects.get(username=request.user)\n name = user.username\n email = user.email\n- request_data = {\"name\": name, \"email\": email}\n- request_data['message'] = request.data['message']\n- serializer = ContactSerializer(data=request_data)\n- if serializer.is_valid():\n- serializer.save()\n- response_data = {'message': 'Your message has been successfully recorded. We will contact you shortly.'}\n- return Response(response_data, status=status.HTTP_201_CREATED)\n- return Response(serializer.errors, status=status.HTTP_400_BAD_REQUEST)\n+ request_data = {'name': name, 'email': email}\n except:\n- serializer = ContactSerializer(data=request.data)\n+ request_data = request.data\n+ user_does_not_exist = True\n+\n+ if request.method == 'POST' or user_does_not_exist:\n+ if request.POST.get('message'):\n+ request_data['message'] = request.POST.get('message')\n+ serializer = ContactSerializer(data=request_data)\n if serializer.is_valid():\n serializer.save()\n- response_data = {'message': 'Your message has been successfully recorded. We will contact you shortly.'}\n+ response_data = {'message': 'We have received your request and will contact you shortly.'}\n return Response(response_data, status=status.HTTP_201_CREATED)\n return Response(serializer.errors, status=status.HTTP_400_BAD_REQUEST)\n \n+ elif request.method == 'GET':\n+ response_data = {\"name\": name, \"email\": email}\n+ return Response(response_data, status=status.HTTP_200_OK)\n+\n \n @throttle_classes([AnonRateThrottle])\n @api_view(['GET', 'POST'])\n", "issue": "Modify contact_us api to fetch name and email, if the user is logged in.\nThis issue is related to #853 as discussed with @deshraj .\n", "before_files": [{"content": "from django.contrib.auth.models import User\nfrom django.shortcuts import render\n\nfrom .models import Team\n\nfrom rest_framework import permissions, status\nfrom rest_framework.decorators import (api_view,\n permission_classes,\n throttle_classes,)\nfrom rest_framework.response import Response\nfrom rest_framework.throttling import AnonRateThrottle\n\nfrom .serializers import ContactSerializer, TeamSerializer\n\n\ndef home(request, template_name=\"index.html\"):\n \"\"\"\n Home Page View\n \"\"\"\n return render(request, template_name)\n\n\ndef page_not_found(request):\n response = render(request, 'error404.html',\n )\n response.status_code = 404\n return response\n\n\ndef internal_server_error(request):\n response = render(request, 'error500.html',\n )\n response.status_code = 500\n return response\n\n\n@throttle_classes([AnonRateThrottle, ])\n@api_view(['POST', ])\n@permission_classes((permissions.AllowAny,))\ndef contact_us(request):\n try:\n user = User.objects.get(username=request.user)\n name = user.username\n email = user.email\n request_data = {\"name\": name, \"email\": email}\n request_data['message'] = request.data['message']\n serializer = ContactSerializer(data=request_data)\n if serializer.is_valid():\n serializer.save()\n response_data = {'message': 'Your message has been successfully recorded. We will contact you shortly.'}\n return Response(response_data, status=status.HTTP_201_CREATED)\n return Response(serializer.errors, status=status.HTTP_400_BAD_REQUEST)\n except:\n serializer = ContactSerializer(data=request.data)\n if serializer.is_valid():\n serializer.save()\n response_data = {'message': 'Your message has been successfully recorded. We will contact you shortly.'}\n return Response(response_data, status=status.HTTP_201_CREATED)\n return Response(serializer.errors, status=status.HTTP_400_BAD_REQUEST)\n\n\n@throttle_classes([AnonRateThrottle])\n@api_view(['GET', 'POST'])\n@permission_classes((permissions.AllowAny,))\ndef our_team(request):\n if request.method == 'GET':\n teams = Team.objects.all()\n serializer = TeamSerializer(teams, many=True, context={'request': request})\n response_data = serializer.data\n return Response(response_data, status=status.HTTP_200_OK)\n elif request.method == 'POST':\n # team_type is set to Team.CONTRIBUTOR by default and can be overridden by the requester\n request.data['team_type'] = request.data.get('team_type', Team.CONTRIBUTOR)\n serializer = TeamSerializer(data=request.data)\n if serializer.is_valid():\n serializer.save()\n response_data = {'message', 'Successfully added the contributor.'}\n return Response(response_data, status=status.HTTP_201_CREATED)\n return Response(serializer.errors, status=status.HTTP_400_BAD_REQUEST)\n", "path": "apps/web/views.py"}]}
| 1,336 | 468 |
gh_patches_debug_15684
|
rasdani/github-patches
|
git_diff
|
conda__conda-build-1267
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
`conda --help` produces: ImportError: No module named 'conda_build.cli.main_pipbuild'
```
$ conda build --version && conda --version
conda-build 2.0.0beta3+4.g1aa8c6e
conda 4.1.11
```
looks like conda is expecting a specific thing in the conda_build api in its help message
```
$ conda --help
usage: conda [-h] [-V] [--debug] command ...
conda is a tool for managing and deploying applications, environments and packages.
Options:
positional arguments:
command
info Display information about current conda install.
help Displays a list of available conda commands and their help
strings.
list List linked packages in a conda environment.
search Search for packages and display their information. The input
is a Python regular expression. To perform a search with a
search string that starts with a -, separate the search from
the options with --, like 'conda search -- -h'. A * in the
results means that package is installed in the current
environment. A . means that package is not installed but is
cached in the pkgs directory.
create Create a new conda environment from a list of specified
packages.
install Installs a list of packages into a specified conda
environment.
update Updates conda packages to the latest compatible version. This
command accepts a list of package names and updates them to
the latest versions that are compatible with all other
packages in the environment. Conda attempts to install the
newest versions of the requested packages. To accomplish
this, it may update some packages that are already installed,
or install additional packages. To prevent existing packages
from updating, use the --no-update-deps option. This may
force conda to install older versions of the requested
packages, and it does not prevent additional dependency
packages from being installed. If you wish to skip dependency
checking altogether, use the '--force' option. This may
result in an environment with incompatible packages, so this
option must be used with great caution.
upgrade Alias for conda update. See conda update --help.
remove Remove a list of packages from a specified conda environment.
uninstall Alias for conda remove. See conda remove --help.
config Modify configuration values in .condarc. This is modeled
after the git config command. Writes to the user .condarc
file (/home/eric/.condarc) by default.
init Initialize conda into a regular environment (when conda was
installed as a Python package, e.g. using pip). (DEPRECATED)
clean Remove unused packages and caches.
package Low-level conda package utility. (EXPERIMENTAL)
bundle Create or extract a "bundle package" (EXPERIMENTAL)
optional arguments:
-h, --help Show this help message and exit.
-V, --version Show the conda version number and exit.
--debug Show debug output.
other commands:
build Tool for building conda packages. A conda package is a binary tarball
containing system-level libraries, Python modules, executable programs, or
other components. conda keeps track of dependencies between packages and
platform specifics, making it simple to create working environments from
different sets of packages.
build-all Build many conda distributions.
buildall Build many conda distributions.
convert Various tools to convert conda packages. Takes a pure Python package build for
one platform and converts it to work on one or more other platforms, or
all.
develop Install a Python package in 'development mode'.
env positional arguments:
{attach,create,export,list,remove,upload,update}
attach Embeds information describing your conda environment
into the notebook metadata
create Create an environment based on an environment file
export Export a given environment
list List the Conda environments
remove Remove an environment
upload Upload an environment to anaconda.org
update Update the current environment based on environment
file
execute Execute a script in a temporary conda environment.
index Update package index metadata files in given directories.
inspect Tools for inspecting conda packages.
metapackage Tool for building conda metapackages. A metapackage is a package with no
files, only metadata. They are typically used to collect several packages
together into a single package via dependencies.
Traceback (most recent call last):
File "/home/eric/miniconda/bin/conda-pipbuild", line 9, in <module>
load_entry_point('conda-build', 'console_scripts', 'conda-pipbuild')()
File "/home/eric/miniconda/lib/python3.5/site-packages/pkg_resources/__init__.py", line 542, in load_entry_point
return get_distribution(dist).load_entry_point(group, name)
File "/home/eric/miniconda/lib/python3.5/site-packages/pkg_resources/__init__.py", line 2570, in load_entry_point
return ep.load()
File "/home/eric/miniconda/lib/python3.5/site-packages/pkg_resources/__init__.py", line 2230, in load
return self.resolve()
File "/home/eric/miniconda/lib/python3.5/site-packages/pkg_resources/__init__.py", line 2236, in resolve
module = __import__(self.module_name, fromlist=['__name__'], level=0)
ImportError: No module named 'conda_build.cli.main_pipbuild'
failed: /home/eric/miniconda/bin/conda-pipbuild --help
render Tool for building conda packages. A conda package is a binary tarball
containing system-level libraries, Python modules, executable programs, or
other components. conda keeps track of dependencies between packages and
platform specifics, making it simple to create working environments from
different sets of packages.
server Anaconda Cloud command line manager
sign Tool for signing conda packages. Signatures will be written alongside the
files as FILE.sig.
skeleton Generates a boilerplate/skeleton recipe, which you can then edit to create a
full recipe. Some simple skeleton recipes may not even need edits.
tmpenv Manage temporary environments within conda.
```
attn @msarahan
</issue>
<code>
[start of setup.py]
1 #!/usr/bin/env python
2 import sys
3
4 import versioneer
5
6 from setuptools import setup
7
8 if sys.version_info[:2] < (2, 7):
9 sys.exit("conda-build is only meant for Python >=2.7"
10 "Current Python version: %d.%d" % sys.version_info[:2])
11
12 versioneer.VCS = 'git'
13 versioneer.versionfile_source = 'conda_build/_version.py'
14 versioneer.versionfile_build = 'conda_build/_version.py'
15 versioneer.tag_prefix = ''
16 versioneer.parentdir_prefix = 'conda-build-'
17
18 setup(
19 name="conda-build",
20 version=versioneer.get_version(),
21 cmdclass=versioneer.get_cmdclass(),
22 author="Continuum Analytics, Inc.",
23 author_email="[email protected]",
24 url="https://github.com/conda/conda-build",
25 license="BSD 3-clause",
26 classifiers=[
27 "Development Status :: 4 - Beta",
28 "Intended Audience :: Developers",
29 "Operating System :: OS Independent",
30 "Programming Language :: Python :: 2",
31 "Programming Language :: Python :: 2.7",
32 "Programming Language :: Python :: 3",
33 "Programming Language :: Python :: 3.4",
34 "Programming Language :: Python :: 3.5",
35 ],
36 description="tools for building conda packages",
37 long_description=open('README.rst').read(),
38 packages=['conda_build', 'conda_build.cli',
39 'conda_build.skeletons', 'conda_build.os_utils'],
40 entry_points={
41 'console_scripts': ['conda-build = conda_build.cli.main_build:main',
42 'conda-convert = conda_build.cli.main_convert:main',
43 'conda-develop = conda_build.cli.main_develop:main',
44 'conda-index = conda_build.cli.main_index:main',
45 'conda-inspect = conda_build.cli.main_inspect:main',
46 'conda-metapackage = conda_build.cli.main_metapackage:main',
47 'conda-pipbuild = conda_build.cli.main_pipbuild:main',
48 'conda-render = conda_build.cli.main_render:main',
49 'conda-sign = conda_build.cli.main_sign:main',
50 'conda-skeleton = conda_build.cli.main_skeleton:main',
51 ]},
52 install_requires=['conda'],
53 package_data={'conda_build': ['templates/*', 'cli-*.exe']},
54 zip_safe=False,
55 )
56
[end of setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -44,7 +44,6 @@
'conda-index = conda_build.cli.main_index:main',
'conda-inspect = conda_build.cli.main_inspect:main',
'conda-metapackage = conda_build.cli.main_metapackage:main',
- 'conda-pipbuild = conda_build.cli.main_pipbuild:main',
'conda-render = conda_build.cli.main_render:main',
'conda-sign = conda_build.cli.main_sign:main',
'conda-skeleton = conda_build.cli.main_skeleton:main',
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -44,7 +44,6 @@\n 'conda-index = conda_build.cli.main_index:main',\n 'conda-inspect = conda_build.cli.main_inspect:main',\n 'conda-metapackage = conda_build.cli.main_metapackage:main',\n- 'conda-pipbuild = conda_build.cli.main_pipbuild:main',\n 'conda-render = conda_build.cli.main_render:main',\n 'conda-sign = conda_build.cli.main_sign:main',\n 'conda-skeleton = conda_build.cli.main_skeleton:main',\n", "issue": "`conda --help` produces: ImportError: No module named 'conda_build.cli.main_pipbuild'\n```\n$ conda build --version && conda --version\nconda-build 2.0.0beta3+4.g1aa8c6e\nconda 4.1.11\n```\n\nlooks like conda is expecting a specific thing in the conda_build api in its help message\n\n```\n$ conda --help\nusage: conda [-h] [-V] [--debug] command ...\n\nconda is a tool for managing and deploying applications, environments and packages.\n\nOptions:\n\npositional arguments:\n command\n info Display information about current conda install.\n help Displays a list of available conda commands and their help\n strings.\n list List linked packages in a conda environment.\n search Search for packages and display their information. The input\n is a Python regular expression. To perform a search with a\n search string that starts with a -, separate the search from\n the options with --, like 'conda search -- -h'. A * in the\n results means that package is installed in the current\n environment. A . means that package is not installed but is\n cached in the pkgs directory.\n create Create a new conda environment from a list of specified\n packages.\n install Installs a list of packages into a specified conda\n environment.\n update Updates conda packages to the latest compatible version. This\n command accepts a list of package names and updates them to\n the latest versions that are compatible with all other\n packages in the environment. Conda attempts to install the\n newest versions of the requested packages. To accomplish\n this, it may update some packages that are already installed,\n or install additional packages. To prevent existing packages\n from updating, use the --no-update-deps option. This may\n force conda to install older versions of the requested\n packages, and it does not prevent additional dependency\n packages from being installed. If you wish to skip dependency\n checking altogether, use the '--force' option. This may\n result in an environment with incompatible packages, so this\n option must be used with great caution.\n upgrade Alias for conda update. See conda update --help.\n remove Remove a list of packages from a specified conda environment.\n uninstall Alias for conda remove. See conda remove --help.\n config Modify configuration values in .condarc. This is modeled\n after the git config command. Writes to the user .condarc\n file (/home/eric/.condarc) by default.\n init Initialize conda into a regular environment (when conda was\n installed as a Python package, e.g. using pip). (DEPRECATED)\n clean Remove unused packages and caches.\n package Low-level conda package utility. (EXPERIMENTAL)\n bundle Create or extract a \"bundle package\" (EXPERIMENTAL)\n\noptional arguments:\n -h, --help Show this help message and exit.\n -V, --version Show the conda version number and exit.\n --debug Show debug output.\n\nother commands:\n build Tool for building conda packages. A conda package is a binary tarball\n containing system-level libraries, Python modules, executable programs, or\n other components. conda keeps track of dependencies between packages and\n platform specifics, making it simple to create working environments from\n different sets of packages.\n build-all Build many conda distributions.\n buildall Build many conda distributions.\n convert Various tools to convert conda packages. Takes a pure Python package build for\n one platform and converts it to work on one or more other platforms, or\n all.\n develop Install a Python package in 'development mode'.\n env positional arguments:\n {attach,create,export,list,remove,upload,update}\n attach Embeds information describing your conda environment\n into the notebook metadata\n create Create an environment based on an environment file\n export Export a given environment\n list List the Conda environments\n remove Remove an environment\n upload Upload an environment to anaconda.org\n update Update the current environment based on environment\n file\n execute Execute a script in a temporary conda environment.\n index Update package index metadata files in given directories.\n inspect Tools for inspecting conda packages.\n metapackage Tool for building conda metapackages. A metapackage is a package with no\n files, only metadata. They are typically used to collect several packages\n together into a single package via dependencies.\nTraceback (most recent call last):\n File \"/home/eric/miniconda/bin/conda-pipbuild\", line 9, in <module>\n load_entry_point('conda-build', 'console_scripts', 'conda-pipbuild')()\n File \"/home/eric/miniconda/lib/python3.5/site-packages/pkg_resources/__init__.py\", line 542, in load_entry_point\n return get_distribution(dist).load_entry_point(group, name)\n File \"/home/eric/miniconda/lib/python3.5/site-packages/pkg_resources/__init__.py\", line 2570, in load_entry_point\n return ep.load()\n File \"/home/eric/miniconda/lib/python3.5/site-packages/pkg_resources/__init__.py\", line 2230, in load\n return self.resolve()\n File \"/home/eric/miniconda/lib/python3.5/site-packages/pkg_resources/__init__.py\", line 2236, in resolve\n module = __import__(self.module_name, fromlist=['__name__'], level=0)\nImportError: No module named 'conda_build.cli.main_pipbuild'\nfailed: /home/eric/miniconda/bin/conda-pipbuild --help\n render Tool for building conda packages. A conda package is a binary tarball\n containing system-level libraries, Python modules, executable programs, or\n other components. conda keeps track of dependencies between packages and\n platform specifics, making it simple to create working environments from\n different sets of packages.\n server Anaconda Cloud command line manager\n sign Tool for signing conda packages. Signatures will be written alongside the\n files as FILE.sig.\n skeleton Generates a boilerplate/skeleton recipe, which you can then edit to create a\n full recipe. Some simple skeleton recipes may not even need edits.\n\n tmpenv Manage temporary environments within conda.\n```\n\nattn @msarahan\n\n", "before_files": [{"content": "#!/usr/bin/env python\nimport sys\n\nimport versioneer\n\nfrom setuptools import setup\n\nif sys.version_info[:2] < (2, 7):\n sys.exit(\"conda-build is only meant for Python >=2.7\"\n \"Current Python version: %d.%d\" % sys.version_info[:2])\n\nversioneer.VCS = 'git'\nversioneer.versionfile_source = 'conda_build/_version.py'\nversioneer.versionfile_build = 'conda_build/_version.py'\nversioneer.tag_prefix = ''\nversioneer.parentdir_prefix = 'conda-build-'\n\nsetup(\n name=\"conda-build\",\n version=versioneer.get_version(),\n cmdclass=versioneer.get_cmdclass(),\n author=\"Continuum Analytics, Inc.\",\n author_email=\"[email protected]\",\n url=\"https://github.com/conda/conda-build\",\n license=\"BSD 3-clause\",\n classifiers=[\n \"Development Status :: 4 - Beta\",\n \"Intended Audience :: Developers\",\n \"Operating System :: OS Independent\",\n \"Programming Language :: Python :: 2\",\n \"Programming Language :: Python :: 2.7\",\n \"Programming Language :: Python :: 3\",\n \"Programming Language :: Python :: 3.4\",\n \"Programming Language :: Python :: 3.5\",\n ],\n description=\"tools for building conda packages\",\n long_description=open('README.rst').read(),\n packages=['conda_build', 'conda_build.cli',\n 'conda_build.skeletons', 'conda_build.os_utils'],\n entry_points={\n 'console_scripts': ['conda-build = conda_build.cli.main_build:main',\n 'conda-convert = conda_build.cli.main_convert:main',\n 'conda-develop = conda_build.cli.main_develop:main',\n 'conda-index = conda_build.cli.main_index:main',\n 'conda-inspect = conda_build.cli.main_inspect:main',\n 'conda-metapackage = conda_build.cli.main_metapackage:main',\n 'conda-pipbuild = conda_build.cli.main_pipbuild:main',\n 'conda-render = conda_build.cli.main_render:main',\n 'conda-sign = conda_build.cli.main_sign:main',\n 'conda-skeleton = conda_build.cli.main_skeleton:main',\n ]},\n install_requires=['conda'],\n package_data={'conda_build': ['templates/*', 'cli-*.exe']},\n zip_safe=False,\n)\n", "path": "setup.py"}]}
| 2,578 | 144 |
gh_patches_debug_32188
|
rasdani/github-patches
|
git_diff
|
mosaicml__composer-735
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Pyright version pinning not working
It appears that pyright versioning is still not working when using `pip install pyright`. We should switch to using the node version, which respects versioning.
</issue>
<code>
[start of setup.py]
1 # Copyright 2021 MosaicML. All Rights Reserved.
2
3 import os
4 import site
5 import sys
6 import textwrap
7
8 import setuptools
9 from setuptools import setup
10 from setuptools.command.develop import develop as develop_orig
11
12 _IS_ROOT = os.getuid() == 0
13 _IS_USER = "--user" in sys.argv[1:]
14 _IS_VIRTUALENV = "VIRTUAL_ENV" in os.environ
15
16
17 # From https://stackoverflow.com/questions/51292333/how-to-tell-from-setup-py-if-the-module-is-being-installed-in-editable-mode
18 class develop(develop_orig):
19
20 def run(self):
21 if _IS_ROOT and (not _IS_VIRTUALENV) and (not _IS_USER):
22 raise RuntimeError(
23 textwrap.dedent("""\
24 When installing in editable mode as root outside of a virtual environment,
25 please specify `--user`. Editable installs as the root user outside of a virtual environment
26 do not work without the `--user` flag. Please instead run something like: `pip install --user -e .`"""
27 ))
28 super().run()
29
30
31 # From https://github.com/pypa/pip/issues/7953#issuecomment-645133255
32 site.ENABLE_USER_SITE = _IS_USER
33
34
35 def package_files(directory: str):
36 # from https://stackoverflow.com/a/36693250
37 paths = []
38 for (path, _, filenames) in os.walk(directory):
39 for filename in filenames:
40 paths.append(os.path.join('..', path, filename))
41 return paths
42
43
44 with open("README.md", "r", encoding="utf-8") as fh:
45 long_description = fh.read()
46
47 install_requires = [
48 "pyyaml>=5.4.1",
49 "tqdm>=4.62.3",
50 "torchmetrics>=0.6.0",
51 "torch_optimizer==0.1.0",
52 "torchvision>=0.9.0",
53 "torch>=1.9",
54 "yahp>=0.1.0",
55 "requests>=2.26.0",
56 "numpy==1.21.5",
57 "apache-libcloud>=3.3.1",
58 "psutil>=5.8.0",
59 ]
60 extra_deps = {}
61
62 extra_deps['base'] = []
63
64 extra_deps['dev'] = [
65 # Imports for docs builds and running tests
66 "custom_inherit==2.3.2",
67 'junitparser>=2.1.1',
68 'coverage[toml]>=6.1.1',
69 'fasteners==0.17.3', # run_directory_uploader tests require fasteners
70 'pytest>=7.0.0',
71 'toml==0.10.2',
72 'yapf==0.32.0',
73 'isort>=5.9.3',
74 'ipython>=7.29.0',
75 'ipykernel>=6.5.0',
76 'jupyter>=1.0.0',
77 'yamllint>=1.26.2',
78 'pytest-timeout>=1.4.2',
79 'pyright==1.1.224.post1',
80 'recommonmark==0.7.1',
81 'sphinx>=4.4.0',
82 'docutils>=0.15',
83 'sphinx_copybutton==0.5.0',
84 'sphinx_markdown_tables==0.0.15',
85 'sphinx-argparse==0.3.1',
86 'sphinxcontrib.katex==0.8.6',
87 'sphinxext.opengraph==0.6.1',
88 'sphinxemoji==0.2.0',
89 'furo>=2022.1.2',
90 'sphinx-copybutton==0.5.0',
91 'testbook==0.4.2',
92 'myst-parser==0.16.1',
93 'pylint>=2.12.2',
94 'docformatter>=1.4',
95 'sphinx_panels==0.6.0',
96 'sphinxcontrib-images==0.9.4',
97 ]
98
99 extra_deps["deepspeed"] = [
100 'deepspeed==0.5.10',
101 ]
102
103 extra_deps["wandb"] = [
104 'wandb==0.12.10',
105 'coolname>=1.1.0',
106 ]
107
108 extra_deps["unet"] = [
109 'monai==0.8.1',
110 'scikit-learn>=1.0.1',
111 ]
112
113 extra_deps["vit"] = [
114 'vit_pytorch>=0.27',
115 ]
116
117 extra_deps["timm"] = [
118 'timm==0.5.4',
119 ]
120
121 extra_deps["coco"] = [
122 'pycocotools>=2.0.4',
123 ]
124
125 extra_deps["nlp"] = [
126 'transformers>=4.11',
127 'datasets>=1.14',
128 ]
129
130 extra_deps['webdataset'] = [
131 'awscli>=1.22.60',
132 'webdataset @ git+https://github.com/mosaicml/webdataset.git@dev',
133 'wurlitzer>=3.0.2',
134 ]
135
136 extra_deps['all'] = set(dep for deps in extra_deps.values() for dep in deps)
137
138 setup(name="mosaicml",
139 version="0.4.0",
140 author="MosaicML",
141 author_email="[email protected]",
142 description="Composer provides well-engineered implementations of efficient training methods to give "
143 "the tools that help you train a better model for cheaper.",
144 long_description=long_description,
145 long_description_content_type="text/markdown",
146 url="https://github.com/mosaicml/composer",
147 include_package_data=True,
148 package_data={
149 "composer": ['py.typed'],
150 "": package_files('composer/yamls'),
151 "": package_files('composer/algorithms')
152 },
153 packages=setuptools.find_packages(exclude=["tests*"]),
154 classifiers=[
155 "Programming Language :: Python :: 3",
156 "Programming Language :: Python :: 3.7",
157 "Programming Language :: Python :: 3.8",
158 "Programming Language :: Python :: 3.9",
159 ],
160 install_requires=install_requires,
161 entry_points={
162 'console_scripts': ['composer = composer.cli.launcher:main',],
163 },
164 extras_require=extra_deps,
165 dependency_links=['https://developer.download.nvidia.com/compute/redist'],
166 python_requires='>=3.7',
167 ext_package="composer",
168 cmdclass={'develop': develop})
169
170 # only visible if user installs with verbose -v flag
171 # Printing to stdout as not to interfere with setup.py CLI flags (e.g. --version)
172 print("*" * 20, file=sys.stderr)
173 print(textwrap.dedent("""\
174 NOTE: For best performance, we recommend installing Pillow-SIMD
175 for accelerated image processing operations. To install:
176 \t pip uninstall pillow && pip install pillow-simd"""),
177 file=sys.stderr)
178 print("*" * 20, file=sys.stderr)
179
[end of setup.py]
[start of docs/source/doctest_fixtures.py]
1 # Copyright 2021 MosaicML. All Rights Reserved.
2
3 """
4 Fixtures available in doctests.
5
6 The script is run before any doctests are executed,
7 so all imports and variables are available in any doctest.
8 The output of this setup script does not show up in the documentation.
9 """
10 import functools
11 import os
12 import sys
13 from typing import Callable
14
15 import numpy as np
16 import torch.optim
17 import torch.utils.data
18 from PIL import Image
19 from torch.optim.lr_scheduler import CosineAnnealingLR
20
21 import composer
22 from composer import Trainer as OriginalTrainer
23 from composer import * # Make all composer imports available in doctests
24 from composer.core.logging import LogLevel
25 from composer.core.time import Time, Timestamp
26 from composer.datasets.synthetic import SyntheticBatchPairDataset
27 from composer.loggers import InMemoryLogger
28 from composer.utils import * # Make all composer.utils imports available in doctests
29
30 # Need to insert the repo root at the beginning of the path, since there may be other modules named `tests`
31 # Assuming that docs generation is running from the `docs` directory
32 _docs_dir = os.path.abspath(".")
33 _repo_root = os.path.dirname(_docs_dir)
34 if sys.path[0] != _repo_root:
35 sys.path.insert(0, _repo_root)
36
37 from tests.fixtures.models import SimpleBatchPairModel
38
39 num_channels = 3
40 num_classes = 10
41 data_shape = (num_channels, 5, 5)
42
43 model = SimpleBatchPairModel(num_channels, num_classes)
44
45 optimizer = torch.optim.SGD(model.parameters(), lr=0.001)
46
47 scheduler = CosineAnnealingLR(optimizer, T_max=1)
48
49 dataset = SyntheticBatchPairDataset(
50 total_dataset_size=100,
51 data_shape=data_shape,
52 num_classes=num_classes,
53 num_unique_samples_to_create=10,
54 )
55
56 train_dataset = dataset
57 eval_dataset = dataset
58
59 batch_size = 10
60
61 train_dataloader = torch.utils.data.DataLoader(
62 train_dataset,
63 batch_size=batch_size,
64 num_workers=0,
65 pin_memory=False,
66 drop_last=True,
67 )
68
69 eval_dataloader = torch.utils.data.DataLoader(
70 eval_dataset,
71 batch_size=batch_size,
72 num_workers=0,
73 pin_memory=False,
74 drop_last=False,
75 )
76
77 state = State(
78 rank_zero_seed=0,
79 model=model,
80 optimizers=optimizer,
81 grad_accum=1,
82 train_dataloader=train_dataloader,
83 evaluators=[],
84 max_duration="1ep",
85 precision="fp32",
86 )
87
88 logger = Logger(state)
89
90 engine = Engine(state, logger)
91
92 image = Image.fromarray(np.random.randint(0, 256, size=(32, 32, 3), dtype=np.uint8))
93
94 # error: "randn" is not a known member of module (reportGeneralTypeIssues)
95 X_example = torch.randn(batch_size, num_channels, 32, 32) # type: ignore
96 # error: "randn" is not a known member of module (reportGeneralTypeIssues)
97 logits = torch.randn(batch_size, num_classes) # type: ignore
98 # error: "randint" is not a known member of module (reportGeneralTypeIssues)
99 y_example = torch.randint(num_classes, (batch_size,)) # type: ignore
100
101
102 # patch the Trainer to accept ellipses
103 def Trainer(fake_ellipses='...', *args, **kwargs):
104 return OriginalTrainer(*args, **kwargs)
105
106
107 # bind the required arguments to the Trainer so it can be used without arguments in the doctests
108 Trainer = functools.partial(
109 Trainer,
110 model=model,
111 max_duration="1ep",
112 train_dataloader=train_dataloader,
113 eval_dataloader=eval_dataloader,
114 )
115
116 # patch composer so that 'from composer import Trainer' calls do not override change above
117 composer.Trainer = Trainer
118
[end of docs/source/doctest_fixtures.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/docs/source/doctest_fixtures.py b/docs/source/doctest_fixtures.py
--- a/docs/source/doctest_fixtures.py
+++ b/docs/source/doctest_fixtures.py
@@ -10,7 +10,7 @@
import functools
import os
import sys
-from typing import Callable
+from typing import Callable as Callable
import numpy as np
import torch.optim
@@ -21,10 +21,10 @@
import composer
from composer import Trainer as OriginalTrainer
from composer import * # Make all composer imports available in doctests
-from composer.core.logging import LogLevel
-from composer.core.time import Time, Timestamp
+from composer.core.logging import LogLevel as LogLevel
+from composer.core.time import Time as Time, Timestamp as Timestamp
from composer.datasets.synthetic import SyntheticBatchPairDataset
-from composer.loggers import InMemoryLogger
+from composer.loggers import InMemoryLogger as InMemoryLogger
from composer.utils import * # Make all composer.utils imports available in doctests
# Need to insert the repo root at the beginning of the path, since there may be other modules named `tests`
@@ -105,7 +105,9 @@
# bind the required arguments to the Trainer so it can be used without arguments in the doctests
-Trainer = functools.partial(
+
+# Declaration "Trainer" is obscured by a declaration of the same name (reportGeneralTypeIssues)
+Trainer = functools.partial( # type: ignore
Trainer,
model=model,
max_duration="1ep",
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -76,7 +76,6 @@
'jupyter>=1.0.0',
'yamllint>=1.26.2',
'pytest-timeout>=1.4.2',
- 'pyright==1.1.224.post1',
'recommonmark==0.7.1',
'sphinx>=4.4.0',
'docutils>=0.15',
|
{"golden_diff": "diff --git a/docs/source/doctest_fixtures.py b/docs/source/doctest_fixtures.py\n--- a/docs/source/doctest_fixtures.py\n+++ b/docs/source/doctest_fixtures.py\n@@ -10,7 +10,7 @@\n import functools\n import os\n import sys\n-from typing import Callable\n+from typing import Callable as Callable\n \n import numpy as np\n import torch.optim\n@@ -21,10 +21,10 @@\n import composer\n from composer import Trainer as OriginalTrainer\n from composer import * # Make all composer imports available in doctests\n-from composer.core.logging import LogLevel\n-from composer.core.time import Time, Timestamp\n+from composer.core.logging import LogLevel as LogLevel\n+from composer.core.time import Time as Time, Timestamp as Timestamp\n from composer.datasets.synthetic import SyntheticBatchPairDataset\n-from composer.loggers import InMemoryLogger\n+from composer.loggers import InMemoryLogger as InMemoryLogger\n from composer.utils import * # Make all composer.utils imports available in doctests\n \n # Need to insert the repo root at the beginning of the path, since there may be other modules named `tests`\n@@ -105,7 +105,9 @@\n \n \n # bind the required arguments to the Trainer so it can be used without arguments in the doctests\n-Trainer = functools.partial(\n+\n+# Declaration \"Trainer\" is obscured by a declaration of the same name (reportGeneralTypeIssues)\n+Trainer = functools.partial( # type: ignore\n Trainer,\n model=model,\n max_duration=\"1ep\",\ndiff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -76,7 +76,6 @@\n 'jupyter>=1.0.0',\n 'yamllint>=1.26.2',\n 'pytest-timeout>=1.4.2',\n- 'pyright==1.1.224.post1',\n 'recommonmark==0.7.1',\n 'sphinx>=4.4.0',\n 'docutils>=0.15',\n", "issue": "Pyright version pinning not working\nIt appears that pyright versioning is still not working when using `pip install pyright`. We should switch to using the node version, which respects versioning.\n", "before_files": [{"content": "# Copyright 2021 MosaicML. All Rights Reserved.\n\nimport os\nimport site\nimport sys\nimport textwrap\n\nimport setuptools\nfrom setuptools import setup\nfrom setuptools.command.develop import develop as develop_orig\n\n_IS_ROOT = os.getuid() == 0\n_IS_USER = \"--user\" in sys.argv[1:]\n_IS_VIRTUALENV = \"VIRTUAL_ENV\" in os.environ\n\n\n# From https://stackoverflow.com/questions/51292333/how-to-tell-from-setup-py-if-the-module-is-being-installed-in-editable-mode\nclass develop(develop_orig):\n\n def run(self):\n if _IS_ROOT and (not _IS_VIRTUALENV) and (not _IS_USER):\n raise RuntimeError(\n textwrap.dedent(\"\"\"\\\n When installing in editable mode as root outside of a virtual environment,\n please specify `--user`. Editable installs as the root user outside of a virtual environment\n do not work without the `--user` flag. Please instead run something like: `pip install --user -e .`\"\"\"\n ))\n super().run()\n\n\n# From https://github.com/pypa/pip/issues/7953#issuecomment-645133255\nsite.ENABLE_USER_SITE = _IS_USER\n\n\ndef package_files(directory: str):\n # from https://stackoverflow.com/a/36693250\n paths = []\n for (path, _, filenames) in os.walk(directory):\n for filename in filenames:\n paths.append(os.path.join('..', path, filename))\n return paths\n\n\nwith open(\"README.md\", \"r\", encoding=\"utf-8\") as fh:\n long_description = fh.read()\n\ninstall_requires = [\n \"pyyaml>=5.4.1\",\n \"tqdm>=4.62.3\",\n \"torchmetrics>=0.6.0\",\n \"torch_optimizer==0.1.0\",\n \"torchvision>=0.9.0\",\n \"torch>=1.9\",\n \"yahp>=0.1.0\",\n \"requests>=2.26.0\",\n \"numpy==1.21.5\",\n \"apache-libcloud>=3.3.1\",\n \"psutil>=5.8.0\",\n]\nextra_deps = {}\n\nextra_deps['base'] = []\n\nextra_deps['dev'] = [\n # Imports for docs builds and running tests\n \"custom_inherit==2.3.2\",\n 'junitparser>=2.1.1',\n 'coverage[toml]>=6.1.1',\n 'fasteners==0.17.3', # run_directory_uploader tests require fasteners\n 'pytest>=7.0.0',\n 'toml==0.10.2',\n 'yapf==0.32.0',\n 'isort>=5.9.3',\n 'ipython>=7.29.0',\n 'ipykernel>=6.5.0',\n 'jupyter>=1.0.0',\n 'yamllint>=1.26.2',\n 'pytest-timeout>=1.4.2',\n 'pyright==1.1.224.post1',\n 'recommonmark==0.7.1',\n 'sphinx>=4.4.0',\n 'docutils>=0.15',\n 'sphinx_copybutton==0.5.0',\n 'sphinx_markdown_tables==0.0.15',\n 'sphinx-argparse==0.3.1',\n 'sphinxcontrib.katex==0.8.6',\n 'sphinxext.opengraph==0.6.1',\n 'sphinxemoji==0.2.0',\n 'furo>=2022.1.2',\n 'sphinx-copybutton==0.5.0',\n 'testbook==0.4.2',\n 'myst-parser==0.16.1',\n 'pylint>=2.12.2',\n 'docformatter>=1.4',\n 'sphinx_panels==0.6.0',\n 'sphinxcontrib-images==0.9.4',\n]\n\nextra_deps[\"deepspeed\"] = [\n 'deepspeed==0.5.10',\n]\n\nextra_deps[\"wandb\"] = [\n 'wandb==0.12.10',\n 'coolname>=1.1.0',\n]\n\nextra_deps[\"unet\"] = [\n 'monai==0.8.1',\n 'scikit-learn>=1.0.1',\n]\n\nextra_deps[\"vit\"] = [\n 'vit_pytorch>=0.27',\n]\n\nextra_deps[\"timm\"] = [\n 'timm==0.5.4',\n]\n\nextra_deps[\"coco\"] = [\n 'pycocotools>=2.0.4',\n]\n\nextra_deps[\"nlp\"] = [\n 'transformers>=4.11',\n 'datasets>=1.14',\n]\n\nextra_deps['webdataset'] = [\n 'awscli>=1.22.60',\n 'webdataset @ git+https://github.com/mosaicml/webdataset.git@dev',\n 'wurlitzer>=3.0.2',\n]\n\nextra_deps['all'] = set(dep for deps in extra_deps.values() for dep in deps)\n\nsetup(name=\"mosaicml\",\n version=\"0.4.0\",\n author=\"MosaicML\",\n author_email=\"[email protected]\",\n description=\"Composer provides well-engineered implementations of efficient training methods to give \"\n \"the tools that help you train a better model for cheaper.\",\n long_description=long_description,\n long_description_content_type=\"text/markdown\",\n url=\"https://github.com/mosaicml/composer\",\n include_package_data=True,\n package_data={\n \"composer\": ['py.typed'],\n \"\": package_files('composer/yamls'),\n \"\": package_files('composer/algorithms')\n },\n packages=setuptools.find_packages(exclude=[\"tests*\"]),\n classifiers=[\n \"Programming Language :: Python :: 3\",\n \"Programming Language :: Python :: 3.7\",\n \"Programming Language :: Python :: 3.8\",\n \"Programming Language :: Python :: 3.9\",\n ],\n install_requires=install_requires,\n entry_points={\n 'console_scripts': ['composer = composer.cli.launcher:main',],\n },\n extras_require=extra_deps,\n dependency_links=['https://developer.download.nvidia.com/compute/redist'],\n python_requires='>=3.7',\n ext_package=\"composer\",\n cmdclass={'develop': develop})\n\n# only visible if user installs with verbose -v flag\n# Printing to stdout as not to interfere with setup.py CLI flags (e.g. --version)\nprint(\"*\" * 20, file=sys.stderr)\nprint(textwrap.dedent(\"\"\"\\\n NOTE: For best performance, we recommend installing Pillow-SIMD\n for accelerated image processing operations. To install:\n \\t pip uninstall pillow && pip install pillow-simd\"\"\"),\n file=sys.stderr)\nprint(\"*\" * 20, file=sys.stderr)\n", "path": "setup.py"}, {"content": "# Copyright 2021 MosaicML. All Rights Reserved.\n\n\"\"\"\nFixtures available in doctests.\n\nThe script is run before any doctests are executed,\nso all imports and variables are available in any doctest.\nThe output of this setup script does not show up in the documentation.\n\"\"\"\nimport functools\nimport os\nimport sys\nfrom typing import Callable\n\nimport numpy as np\nimport torch.optim\nimport torch.utils.data\nfrom PIL import Image\nfrom torch.optim.lr_scheduler import CosineAnnealingLR\n\nimport composer\nfrom composer import Trainer as OriginalTrainer\nfrom composer import * # Make all composer imports available in doctests\nfrom composer.core.logging import LogLevel\nfrom composer.core.time import Time, Timestamp\nfrom composer.datasets.synthetic import SyntheticBatchPairDataset\nfrom composer.loggers import InMemoryLogger\nfrom composer.utils import * # Make all composer.utils imports available in doctests\n\n# Need to insert the repo root at the beginning of the path, since there may be other modules named `tests`\n# Assuming that docs generation is running from the `docs` directory\n_docs_dir = os.path.abspath(\".\")\n_repo_root = os.path.dirname(_docs_dir)\nif sys.path[0] != _repo_root:\n sys.path.insert(0, _repo_root)\n\nfrom tests.fixtures.models import SimpleBatchPairModel\n\nnum_channels = 3\nnum_classes = 10\ndata_shape = (num_channels, 5, 5)\n\nmodel = SimpleBatchPairModel(num_channels, num_classes)\n\noptimizer = torch.optim.SGD(model.parameters(), lr=0.001)\n\nscheduler = CosineAnnealingLR(optimizer, T_max=1)\n\ndataset = SyntheticBatchPairDataset(\n total_dataset_size=100,\n data_shape=data_shape,\n num_classes=num_classes,\n num_unique_samples_to_create=10,\n)\n\ntrain_dataset = dataset\neval_dataset = dataset\n\nbatch_size = 10\n\ntrain_dataloader = torch.utils.data.DataLoader(\n train_dataset,\n batch_size=batch_size,\n num_workers=0,\n pin_memory=False,\n drop_last=True,\n)\n\neval_dataloader = torch.utils.data.DataLoader(\n eval_dataset,\n batch_size=batch_size,\n num_workers=0,\n pin_memory=False,\n drop_last=False,\n)\n\nstate = State(\n rank_zero_seed=0,\n model=model,\n optimizers=optimizer,\n grad_accum=1,\n train_dataloader=train_dataloader,\n evaluators=[],\n max_duration=\"1ep\",\n precision=\"fp32\",\n)\n\nlogger = Logger(state)\n\nengine = Engine(state, logger)\n\nimage = Image.fromarray(np.random.randint(0, 256, size=(32, 32, 3), dtype=np.uint8))\n\n# error: \"randn\" is not a known member of module (reportGeneralTypeIssues)\nX_example = torch.randn(batch_size, num_channels, 32, 32) # type: ignore\n# error: \"randn\" is not a known member of module (reportGeneralTypeIssues)\nlogits = torch.randn(batch_size, num_classes) # type: ignore\n# error: \"randint\" is not a known member of module (reportGeneralTypeIssues)\ny_example = torch.randint(num_classes, (batch_size,)) # type: ignore\n\n\n# patch the Trainer to accept ellipses\ndef Trainer(fake_ellipses='...', *args, **kwargs):\n return OriginalTrainer(*args, **kwargs)\n\n\n# bind the required arguments to the Trainer so it can be used without arguments in the doctests\nTrainer = functools.partial(\n Trainer,\n model=model,\n max_duration=\"1ep\",\n train_dataloader=train_dataloader,\n eval_dataloader=eval_dataloader,\n)\n\n# patch composer so that 'from composer import Trainer' calls do not override change above\ncomposer.Trainer = Trainer\n", "path": "docs/source/doctest_fixtures.py"}]}
| 3,687 | 449 |
gh_patches_debug_15728
|
rasdani/github-patches
|
git_diff
|
boto__boto-3488
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
switch to unquote_plus in bucketlistresultset
Resubmitting #2654, rebased off current develop branch. Original description follows:
There is a bug in PR #2562, which I submitted. The URL quoting that S3 performs with `encoding_type="url"` necessitates the use of `unquote_plus` because they replace spaces with plus signs. This didn't break bucket listing completely, and in my case it only led to some keys missing from the listing, something that I didn't notice in my original testing. Sorry for this!
</issue>
<code>
[start of boto/s3/bucketlistresultset.py]
1 # Copyright (c) 2006,2007 Mitch Garnaat http://garnaat.org/
2 #
3 # Permission is hereby granted, free of charge, to any person obtaining a
4 # copy of this software and associated documentation files (the
5 # "Software"), to deal in the Software without restriction, including
6 # without limitation the rights to use, copy, modify, merge, publish, dis-
7 # tribute, sublicense, and/or sell copies of the Software, and to permit
8 # persons to whom the Software is furnished to do so, subject to the fol-
9 # lowing conditions:
10 #
11 # The above copyright notice and this permission notice shall be included
12 # in all copies or substantial portions of the Software.
13 #
14 # THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS
15 # OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABIL-
16 # ITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT
17 # SHALL THE AUTHOR BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY,
18 # WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
19 # OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS
20 # IN THE SOFTWARE.
21
22 from boto.compat import unquote_str
23
24 def bucket_lister(bucket, prefix='', delimiter='', marker='', headers=None,
25 encoding_type=None):
26 """
27 A generator function for listing keys in a bucket.
28 """
29 more_results = True
30 k = None
31 while more_results:
32 rs = bucket.get_all_keys(prefix=prefix, marker=marker,
33 delimiter=delimiter, headers=headers,
34 encoding_type=encoding_type)
35 for k in rs:
36 yield k
37 if k:
38 marker = rs.next_marker or k.name
39 if marker and encoding_type == "url":
40 marker = unquote_str(marker)
41 more_results= rs.is_truncated
42
43 class BucketListResultSet(object):
44 """
45 A resultset for listing keys within a bucket. Uses the bucket_lister
46 generator function and implements the iterator interface. This
47 transparently handles the results paging from S3 so even if you have
48 many thousands of keys within the bucket you can iterate over all
49 keys in a reasonably efficient manner.
50 """
51
52 def __init__(self, bucket=None, prefix='', delimiter='', marker='',
53 headers=None, encoding_type=None):
54 self.bucket = bucket
55 self.prefix = prefix
56 self.delimiter = delimiter
57 self.marker = marker
58 self.headers = headers
59 self.encoding_type = encoding_type
60
61 def __iter__(self):
62 return bucket_lister(self.bucket, prefix=self.prefix,
63 delimiter=self.delimiter, marker=self.marker,
64 headers=self.headers,
65 encoding_type=self.encoding_type)
66
67 def versioned_bucket_lister(bucket, prefix='', delimiter='',
68 key_marker='', version_id_marker='', headers=None,
69 encoding_type=None):
70 """
71 A generator function for listing versions in a bucket.
72 """
73 more_results = True
74 k = None
75 while more_results:
76 rs = bucket.get_all_versions(prefix=prefix, key_marker=key_marker,
77 version_id_marker=version_id_marker,
78 delimiter=delimiter, headers=headers,
79 max_keys=999, encoding_type=encoding_type)
80 for k in rs:
81 yield k
82 key_marker = rs.next_key_marker
83 version_id_marker = rs.next_version_id_marker
84 more_results= rs.is_truncated
85
86 class VersionedBucketListResultSet(object):
87 """
88 A resultset for listing versions within a bucket. Uses the bucket_lister
89 generator function and implements the iterator interface. This
90 transparently handles the results paging from S3 so even if you have
91 many thousands of keys within the bucket you can iterate over all
92 keys in a reasonably efficient manner.
93 """
94
95 def __init__(self, bucket=None, prefix='', delimiter='', key_marker='',
96 version_id_marker='', headers=None, encoding_type=None):
97 self.bucket = bucket
98 self.prefix = prefix
99 self.delimiter = delimiter
100 self.key_marker = key_marker
101 self.version_id_marker = version_id_marker
102 self.headers = headers
103 self.encoding_type = encoding_type
104
105 def __iter__(self):
106 return versioned_bucket_lister(self.bucket, prefix=self.prefix,
107 delimiter=self.delimiter,
108 key_marker=self.key_marker,
109 version_id_marker=self.version_id_marker,
110 headers=self.headers,
111 encoding_type=self.encoding_type)
112
113 def multipart_upload_lister(bucket, key_marker='',
114 upload_id_marker='',
115 headers=None, encoding_type=None):
116 """
117 A generator function for listing multipart uploads in a bucket.
118 """
119 more_results = True
120 k = None
121 while more_results:
122 rs = bucket.get_all_multipart_uploads(key_marker=key_marker,
123 upload_id_marker=upload_id_marker,
124 headers=headers,
125 encoding_type=encoding_type)
126 for k in rs:
127 yield k
128 key_marker = rs.next_key_marker
129 upload_id_marker = rs.next_upload_id_marker
130 more_results= rs.is_truncated
131
132 class MultiPartUploadListResultSet(object):
133 """
134 A resultset for listing multipart uploads within a bucket.
135 Uses the multipart_upload_lister generator function and
136 implements the iterator interface. This
137 transparently handles the results paging from S3 so even if you have
138 many thousands of uploads within the bucket you can iterate over all
139 keys in a reasonably efficient manner.
140 """
141 def __init__(self, bucket=None, key_marker='',
142 upload_id_marker='', headers=None, encoding_type=None):
143 self.bucket = bucket
144 self.key_marker = key_marker
145 self.upload_id_marker = upload_id_marker
146 self.headers = headers
147 self.encoding_type = encoding_type
148
149 def __iter__(self):
150 return multipart_upload_lister(self.bucket,
151 key_marker=self.key_marker,
152 upload_id_marker=self.upload_id_marker,
153 headers=self.headers,
154 encoding_type=self.encoding_type)
155
[end of boto/s3/bucketlistresultset.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/boto/s3/bucketlistresultset.py b/boto/s3/bucketlistresultset.py
--- a/boto/s3/bucketlistresultset.py
+++ b/boto/s3/bucketlistresultset.py
@@ -80,6 +80,8 @@
for k in rs:
yield k
key_marker = rs.next_key_marker
+ if key_marker and encoding_type == "url":
+ key_marker = unquote_str(key_marker)
version_id_marker = rs.next_version_id_marker
more_results= rs.is_truncated
@@ -126,6 +128,8 @@
for k in rs:
yield k
key_marker = rs.next_key_marker
+ if key_marker and encoding_type == "url":
+ key_marker = unquote_str(key_marker)
upload_id_marker = rs.next_upload_id_marker
more_results= rs.is_truncated
|
{"golden_diff": "diff --git a/boto/s3/bucketlistresultset.py b/boto/s3/bucketlistresultset.py\n--- a/boto/s3/bucketlistresultset.py\n+++ b/boto/s3/bucketlistresultset.py\n@@ -80,6 +80,8 @@\n for k in rs:\n yield k\n key_marker = rs.next_key_marker\n+ if key_marker and encoding_type == \"url\":\n+ key_marker = unquote_str(key_marker)\n version_id_marker = rs.next_version_id_marker\n more_results= rs.is_truncated\n \n@@ -126,6 +128,8 @@\n for k in rs:\n yield k\n key_marker = rs.next_key_marker\n+ if key_marker and encoding_type == \"url\":\n+ key_marker = unquote_str(key_marker)\n upload_id_marker = rs.next_upload_id_marker\n more_results= rs.is_truncated\n", "issue": "switch to unquote_plus in bucketlistresultset\nResubmitting #2654, rebased off current develop branch. Original description follows:\n\nThere is a bug in PR #2562, which I submitted. The URL quoting that S3 performs with `encoding_type=\"url\"` necessitates the use of `unquote_plus` because they replace spaces with plus signs. This didn't break bucket listing completely, and in my case it only led to some keys missing from the listing, something that I didn't notice in my original testing. Sorry for this!\n\n", "before_files": [{"content": "# Copyright (c) 2006,2007 Mitch Garnaat http://garnaat.org/\n#\n# Permission is hereby granted, free of charge, to any person obtaining a\n# copy of this software and associated documentation files (the\n# \"Software\"), to deal in the Software without restriction, including\n# without limitation the rights to use, copy, modify, merge, publish, dis-\n# tribute, sublicense, and/or sell copies of the Software, and to permit\n# persons to whom the Software is furnished to do so, subject to the fol-\n# lowing conditions:\n#\n# The above copyright notice and this permission notice shall be included\n# in all copies or substantial portions of the Software.\n#\n# THE SOFTWARE IS PROVIDED \"AS IS\", WITHOUT WARRANTY OF ANY KIND, EXPRESS\n# OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABIL-\n# ITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT\n# SHALL THE AUTHOR BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY,\n# WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,\n# OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS\n# IN THE SOFTWARE.\n\nfrom boto.compat import unquote_str\n\ndef bucket_lister(bucket, prefix='', delimiter='', marker='', headers=None,\n encoding_type=None):\n \"\"\"\n A generator function for listing keys in a bucket.\n \"\"\"\n more_results = True\n k = None\n while more_results:\n rs = bucket.get_all_keys(prefix=prefix, marker=marker,\n delimiter=delimiter, headers=headers,\n encoding_type=encoding_type)\n for k in rs:\n yield k\n if k:\n marker = rs.next_marker or k.name\n if marker and encoding_type == \"url\":\n marker = unquote_str(marker)\n more_results= rs.is_truncated\n\nclass BucketListResultSet(object):\n \"\"\"\n A resultset for listing keys within a bucket. Uses the bucket_lister\n generator function and implements the iterator interface. This\n transparently handles the results paging from S3 so even if you have\n many thousands of keys within the bucket you can iterate over all\n keys in a reasonably efficient manner.\n \"\"\"\n\n def __init__(self, bucket=None, prefix='', delimiter='', marker='',\n headers=None, encoding_type=None):\n self.bucket = bucket\n self.prefix = prefix\n self.delimiter = delimiter\n self.marker = marker\n self.headers = headers\n self.encoding_type = encoding_type\n\n def __iter__(self):\n return bucket_lister(self.bucket, prefix=self.prefix,\n delimiter=self.delimiter, marker=self.marker,\n headers=self.headers,\n encoding_type=self.encoding_type)\n\ndef versioned_bucket_lister(bucket, prefix='', delimiter='',\n key_marker='', version_id_marker='', headers=None,\n encoding_type=None):\n \"\"\"\n A generator function for listing versions in a bucket.\n \"\"\"\n more_results = True\n k = None\n while more_results:\n rs = bucket.get_all_versions(prefix=prefix, key_marker=key_marker,\n version_id_marker=version_id_marker,\n delimiter=delimiter, headers=headers,\n max_keys=999, encoding_type=encoding_type)\n for k in rs:\n yield k\n key_marker = rs.next_key_marker\n version_id_marker = rs.next_version_id_marker\n more_results= rs.is_truncated\n\nclass VersionedBucketListResultSet(object):\n \"\"\"\n A resultset for listing versions within a bucket. Uses the bucket_lister\n generator function and implements the iterator interface. This\n transparently handles the results paging from S3 so even if you have\n many thousands of keys within the bucket you can iterate over all\n keys in a reasonably efficient manner.\n \"\"\"\n\n def __init__(self, bucket=None, prefix='', delimiter='', key_marker='',\n version_id_marker='', headers=None, encoding_type=None):\n self.bucket = bucket\n self.prefix = prefix\n self.delimiter = delimiter\n self.key_marker = key_marker\n self.version_id_marker = version_id_marker\n self.headers = headers\n self.encoding_type = encoding_type\n\n def __iter__(self):\n return versioned_bucket_lister(self.bucket, prefix=self.prefix,\n delimiter=self.delimiter,\n key_marker=self.key_marker,\n version_id_marker=self.version_id_marker,\n headers=self.headers,\n encoding_type=self.encoding_type)\n\ndef multipart_upload_lister(bucket, key_marker='',\n upload_id_marker='',\n headers=None, encoding_type=None):\n \"\"\"\n A generator function for listing multipart uploads in a bucket.\n \"\"\"\n more_results = True\n k = None\n while more_results:\n rs = bucket.get_all_multipart_uploads(key_marker=key_marker,\n upload_id_marker=upload_id_marker,\n headers=headers,\n encoding_type=encoding_type)\n for k in rs:\n yield k\n key_marker = rs.next_key_marker\n upload_id_marker = rs.next_upload_id_marker\n more_results= rs.is_truncated\n\nclass MultiPartUploadListResultSet(object):\n \"\"\"\n A resultset for listing multipart uploads within a bucket.\n Uses the multipart_upload_lister generator function and\n implements the iterator interface. This\n transparently handles the results paging from S3 so even if you have\n many thousands of uploads within the bucket you can iterate over all\n keys in a reasonably efficient manner.\n \"\"\"\n def __init__(self, bucket=None, key_marker='',\n upload_id_marker='', headers=None, encoding_type=None):\n self.bucket = bucket\n self.key_marker = key_marker\n self.upload_id_marker = upload_id_marker\n self.headers = headers\n self.encoding_type = encoding_type\n\n def __iter__(self):\n return multipart_upload_lister(self.bucket,\n key_marker=self.key_marker,\n upload_id_marker=self.upload_id_marker,\n headers=self.headers,\n encoding_type=self.encoding_type)\n", "path": "boto/s3/bucketlistresultset.py"}]}
| 2,282 | 202 |
gh_patches_debug_60233
|
rasdani/github-patches
|
git_diff
|
psf__black-3328
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
unreachable code in `parsing.py`
**Describe the bug**
unreachable code in `src\black\parsing.py:170`:
`raise AssertionError("INTERNAL ERROR: Tried parsing unsupported Python version!")`
**Expected behavior**
not having unreachable code 😝
</issue>
<code>
[start of src/black/parsing.py]
1 """
2 Parse Python code and perform AST validation.
3 """
4 import ast
5 import platform
6 import sys
7 from typing import Any, Iterable, Iterator, List, Set, Tuple, Type, Union
8
9 if sys.version_info < (3, 8):
10 from typing_extensions import Final
11 else:
12 from typing import Final
13
14 from black.mode import Feature, TargetVersion, supports_feature
15 from black.nodes import syms
16 from blib2to3 import pygram
17 from blib2to3.pgen2 import driver
18 from blib2to3.pgen2.grammar import Grammar
19 from blib2to3.pgen2.parse import ParseError
20 from blib2to3.pgen2.tokenize import TokenError
21 from blib2to3.pytree import Leaf, Node
22
23 ast3: Any
24
25 _IS_PYPY = platform.python_implementation() == "PyPy"
26
27 try:
28 from typed_ast import ast3
29 except ImportError:
30 if sys.version_info < (3, 8) and not _IS_PYPY:
31 print(
32 "The typed_ast package is required but not installed.\n"
33 "You can upgrade to Python 3.8+ or install typed_ast with\n"
34 "`python3 -m pip install typed-ast`.",
35 file=sys.stderr,
36 )
37 sys.exit(1)
38 else:
39 ast3 = ast
40
41
42 PY2_HINT: Final = "Python 2 support was removed in version 22.0."
43
44
45 class InvalidInput(ValueError):
46 """Raised when input source code fails all parse attempts."""
47
48
49 def get_grammars(target_versions: Set[TargetVersion]) -> List[Grammar]:
50 if not target_versions:
51 # No target_version specified, so try all grammars.
52 return [
53 # Python 3.7+
54 pygram.python_grammar_no_print_statement_no_exec_statement_async_keywords,
55 # Python 3.0-3.6
56 pygram.python_grammar_no_print_statement_no_exec_statement,
57 # Python 3.10+
58 pygram.python_grammar_soft_keywords,
59 ]
60
61 grammars = []
62 # If we have to parse both, try to parse async as a keyword first
63 if not supports_feature(
64 target_versions, Feature.ASYNC_IDENTIFIERS
65 ) and not supports_feature(target_versions, Feature.PATTERN_MATCHING):
66 # Python 3.7-3.9
67 grammars.append(
68 pygram.python_grammar_no_print_statement_no_exec_statement_async_keywords
69 )
70 if not supports_feature(target_versions, Feature.ASYNC_KEYWORDS):
71 # Python 3.0-3.6
72 grammars.append(pygram.python_grammar_no_print_statement_no_exec_statement)
73 if supports_feature(target_versions, Feature.PATTERN_MATCHING):
74 # Python 3.10+
75 grammars.append(pygram.python_grammar_soft_keywords)
76
77 # At least one of the above branches must have been taken, because every Python
78 # version has exactly one of the two 'ASYNC_*' flags
79 return grammars
80
81
82 def lib2to3_parse(src_txt: str, target_versions: Iterable[TargetVersion] = ()) -> Node:
83 """Given a string with source, return the lib2to3 Node."""
84 if not src_txt.endswith("\n"):
85 src_txt += "\n"
86
87 grammars = get_grammars(set(target_versions))
88 errors = {}
89 for grammar in grammars:
90 drv = driver.Driver(grammar)
91 try:
92 result = drv.parse_string(src_txt, True)
93 break
94
95 except ParseError as pe:
96 lineno, column = pe.context[1]
97 lines = src_txt.splitlines()
98 try:
99 faulty_line = lines[lineno - 1]
100 except IndexError:
101 faulty_line = "<line number missing in source>"
102 errors[grammar.version] = InvalidInput(
103 f"Cannot parse: {lineno}:{column}: {faulty_line}"
104 )
105
106 except TokenError as te:
107 # In edge cases these are raised; and typically don't have a "faulty_line".
108 lineno, column = te.args[1]
109 errors[grammar.version] = InvalidInput(
110 f"Cannot parse: {lineno}:{column}: {te.args[0]}"
111 )
112
113 else:
114 # Choose the latest version when raising the actual parsing error.
115 assert len(errors) >= 1
116 exc = errors[max(errors)]
117
118 if matches_grammar(src_txt, pygram.python_grammar) or matches_grammar(
119 src_txt, pygram.python_grammar_no_print_statement
120 ):
121 original_msg = exc.args[0]
122 msg = f"{original_msg}\n{PY2_HINT}"
123 raise InvalidInput(msg) from None
124
125 raise exc from None
126
127 if isinstance(result, Leaf):
128 result = Node(syms.file_input, [result])
129 return result
130
131
132 def matches_grammar(src_txt: str, grammar: Grammar) -> bool:
133 drv = driver.Driver(grammar)
134 try:
135 drv.parse_string(src_txt, True)
136 except (ParseError, TokenError, IndentationError):
137 return False
138 else:
139 return True
140
141
142 def lib2to3_unparse(node: Node) -> str:
143 """Given a lib2to3 node, return its string representation."""
144 code = str(node)
145 return code
146
147
148 def parse_single_version(
149 src: str, version: Tuple[int, int]
150 ) -> Union[ast.AST, ast3.AST]:
151 filename = "<unknown>"
152 # typed-ast is needed because of feature version limitations in the builtin ast 3.8>
153 if sys.version_info >= (3, 8) and version >= (3,):
154 return ast.parse(src, filename, feature_version=version, type_comments=True)
155
156 if _IS_PYPY:
157 # PyPy 3.7 doesn't support type comment tracking which is not ideal, but there's
158 # not much we can do as typed-ast won't work either.
159 if sys.version_info >= (3, 8):
160 return ast3.parse(src, filename, type_comments=True)
161 else:
162 return ast3.parse(src, filename)
163 else:
164 # Typed-ast is guaranteed to be used here and automatically tracks type
165 # comments separately.
166 return ast3.parse(src, filename, feature_version=version[1])
167
168 raise AssertionError("INTERNAL ERROR: Tried parsing unsupported Python version!")
169
170
171 def parse_ast(src: str) -> Union[ast.AST, ast3.AST]:
172 # TODO: support Python 4+ ;)
173 versions = [(3, minor) for minor in range(3, sys.version_info[1] + 1)]
174
175 first_error = ""
176 for version in sorted(versions, reverse=True):
177 try:
178 return parse_single_version(src, version)
179 except SyntaxError as e:
180 if not first_error:
181 first_error = str(e)
182
183 raise SyntaxError(first_error)
184
185
186 ast3_AST: Final[Type[ast3.AST]] = ast3.AST
187
188
189 def _normalize(lineend: str, value: str) -> str:
190 # To normalize, we strip any leading and trailing space from
191 # each line...
192 stripped: List[str] = [i.strip() for i in value.splitlines()]
193 normalized = lineend.join(stripped)
194 # ...and remove any blank lines at the beginning and end of
195 # the whole string
196 return normalized.strip()
197
198
199 def stringify_ast(node: Union[ast.AST, ast3.AST], depth: int = 0) -> Iterator[str]:
200 """Simple visitor generating strings to compare ASTs by content."""
201
202 node = fixup_ast_constants(node)
203
204 yield f"{' ' * depth}{node.__class__.__name__}("
205
206 type_ignore_classes: Tuple[Type[Any], ...]
207 for field in sorted(node._fields): # noqa: F402
208 # TypeIgnore will not be present using pypy < 3.8, so need for this
209 if not (_IS_PYPY and sys.version_info < (3, 8)):
210 # TypeIgnore has only one field 'lineno' which breaks this comparison
211 type_ignore_classes = (ast3.TypeIgnore,)
212 if sys.version_info >= (3, 8):
213 type_ignore_classes += (ast.TypeIgnore,)
214 if isinstance(node, type_ignore_classes):
215 break
216
217 try:
218 value: object = getattr(node, field)
219 except AttributeError:
220 continue
221
222 yield f"{' ' * (depth+1)}{field}="
223
224 if isinstance(value, list):
225 for item in value:
226 # Ignore nested tuples within del statements, because we may insert
227 # parentheses and they change the AST.
228 if (
229 field == "targets"
230 and isinstance(node, (ast.Delete, ast3.Delete))
231 and isinstance(item, (ast.Tuple, ast3.Tuple))
232 ):
233 for elt in item.elts:
234 yield from stringify_ast(elt, depth + 2)
235
236 elif isinstance(item, (ast.AST, ast3.AST)):
237 yield from stringify_ast(item, depth + 2)
238
239 # Note that we are referencing the typed-ast ASTs via global variables and not
240 # direct module attribute accesses because that breaks mypyc. It's probably
241 # something to do with the ast3 variables being marked as Any leading
242 # mypy to think this branch is always taken, leaving the rest of the code
243 # unanalyzed. Tighting up the types for the typed-ast AST types avoids the
244 # mypyc crash.
245 elif isinstance(value, (ast.AST, ast3_AST)):
246 yield from stringify_ast(value, depth + 2)
247
248 else:
249 normalized: object
250 # Constant strings may be indented across newlines, if they are
251 # docstrings; fold spaces after newlines when comparing. Similarly,
252 # trailing and leading space may be removed.
253 if (
254 isinstance(node, ast.Constant)
255 and field == "value"
256 and isinstance(value, str)
257 ):
258 normalized = _normalize("\n", value)
259 else:
260 normalized = value
261 yield f"{' ' * (depth+2)}{normalized!r}, # {value.__class__.__name__}"
262
263 yield f"{' ' * depth}) # /{node.__class__.__name__}"
264
265
266 def fixup_ast_constants(node: Union[ast.AST, ast3.AST]) -> Union[ast.AST, ast3.AST]:
267 """Map ast nodes deprecated in 3.8 to Constant."""
268 if isinstance(node, (ast.Str, ast3.Str, ast.Bytes, ast3.Bytes)):
269 return ast.Constant(value=node.s)
270
271 if isinstance(node, (ast.Num, ast3.Num)):
272 return ast.Constant(value=node.n)
273
274 if isinstance(node, (ast.NameConstant, ast3.NameConstant)):
275 return ast.Constant(value=node.value)
276
277 return node
278
[end of src/black/parsing.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/black/parsing.py b/src/black/parsing.py
--- a/src/black/parsing.py
+++ b/src/black/parsing.py
@@ -165,8 +165,6 @@
# comments separately.
return ast3.parse(src, filename, feature_version=version[1])
- raise AssertionError("INTERNAL ERROR: Tried parsing unsupported Python version!")
-
def parse_ast(src: str) -> Union[ast.AST, ast3.AST]:
# TODO: support Python 4+ ;)
|
{"golden_diff": "diff --git a/src/black/parsing.py b/src/black/parsing.py\n--- a/src/black/parsing.py\n+++ b/src/black/parsing.py\n@@ -165,8 +165,6 @@\n # comments separately.\n return ast3.parse(src, filename, feature_version=version[1])\n \n- raise AssertionError(\"INTERNAL ERROR: Tried parsing unsupported Python version!\")\n-\n \n def parse_ast(src: str) -> Union[ast.AST, ast3.AST]:\n # TODO: support Python 4+ ;)\n", "issue": "unreachable code in `parsing.py`\n**Describe the bug**\r\n\r\nunreachable code in `src\\black\\parsing.py:170`: \r\n`raise AssertionError(\"INTERNAL ERROR: Tried parsing unsupported Python version!\")`\r\n\r\n**Expected behavior**\r\n\r\nnot having unreachable code \ud83d\ude1d \n", "before_files": [{"content": "\"\"\"\nParse Python code and perform AST validation.\n\"\"\"\nimport ast\nimport platform\nimport sys\nfrom typing import Any, Iterable, Iterator, List, Set, Tuple, Type, Union\n\nif sys.version_info < (3, 8):\n from typing_extensions import Final\nelse:\n from typing import Final\n\nfrom black.mode import Feature, TargetVersion, supports_feature\nfrom black.nodes import syms\nfrom blib2to3 import pygram\nfrom blib2to3.pgen2 import driver\nfrom blib2to3.pgen2.grammar import Grammar\nfrom blib2to3.pgen2.parse import ParseError\nfrom blib2to3.pgen2.tokenize import TokenError\nfrom blib2to3.pytree import Leaf, Node\n\nast3: Any\n\n_IS_PYPY = platform.python_implementation() == \"PyPy\"\n\ntry:\n from typed_ast import ast3\nexcept ImportError:\n if sys.version_info < (3, 8) and not _IS_PYPY:\n print(\n \"The typed_ast package is required but not installed.\\n\"\n \"You can upgrade to Python 3.8+ or install typed_ast with\\n\"\n \"`python3 -m pip install typed-ast`.\",\n file=sys.stderr,\n )\n sys.exit(1)\n else:\n ast3 = ast\n\n\nPY2_HINT: Final = \"Python 2 support was removed in version 22.0.\"\n\n\nclass InvalidInput(ValueError):\n \"\"\"Raised when input source code fails all parse attempts.\"\"\"\n\n\ndef get_grammars(target_versions: Set[TargetVersion]) -> List[Grammar]:\n if not target_versions:\n # No target_version specified, so try all grammars.\n return [\n # Python 3.7+\n pygram.python_grammar_no_print_statement_no_exec_statement_async_keywords,\n # Python 3.0-3.6\n pygram.python_grammar_no_print_statement_no_exec_statement,\n # Python 3.10+\n pygram.python_grammar_soft_keywords,\n ]\n\n grammars = []\n # If we have to parse both, try to parse async as a keyword first\n if not supports_feature(\n target_versions, Feature.ASYNC_IDENTIFIERS\n ) and not supports_feature(target_versions, Feature.PATTERN_MATCHING):\n # Python 3.7-3.9\n grammars.append(\n pygram.python_grammar_no_print_statement_no_exec_statement_async_keywords\n )\n if not supports_feature(target_versions, Feature.ASYNC_KEYWORDS):\n # Python 3.0-3.6\n grammars.append(pygram.python_grammar_no_print_statement_no_exec_statement)\n if supports_feature(target_versions, Feature.PATTERN_MATCHING):\n # Python 3.10+\n grammars.append(pygram.python_grammar_soft_keywords)\n\n # At least one of the above branches must have been taken, because every Python\n # version has exactly one of the two 'ASYNC_*' flags\n return grammars\n\n\ndef lib2to3_parse(src_txt: str, target_versions: Iterable[TargetVersion] = ()) -> Node:\n \"\"\"Given a string with source, return the lib2to3 Node.\"\"\"\n if not src_txt.endswith(\"\\n\"):\n src_txt += \"\\n\"\n\n grammars = get_grammars(set(target_versions))\n errors = {}\n for grammar in grammars:\n drv = driver.Driver(grammar)\n try:\n result = drv.parse_string(src_txt, True)\n break\n\n except ParseError as pe:\n lineno, column = pe.context[1]\n lines = src_txt.splitlines()\n try:\n faulty_line = lines[lineno - 1]\n except IndexError:\n faulty_line = \"<line number missing in source>\"\n errors[grammar.version] = InvalidInput(\n f\"Cannot parse: {lineno}:{column}: {faulty_line}\"\n )\n\n except TokenError as te:\n # In edge cases these are raised; and typically don't have a \"faulty_line\".\n lineno, column = te.args[1]\n errors[grammar.version] = InvalidInput(\n f\"Cannot parse: {lineno}:{column}: {te.args[0]}\"\n )\n\n else:\n # Choose the latest version when raising the actual parsing error.\n assert len(errors) >= 1\n exc = errors[max(errors)]\n\n if matches_grammar(src_txt, pygram.python_grammar) or matches_grammar(\n src_txt, pygram.python_grammar_no_print_statement\n ):\n original_msg = exc.args[0]\n msg = f\"{original_msg}\\n{PY2_HINT}\"\n raise InvalidInput(msg) from None\n\n raise exc from None\n\n if isinstance(result, Leaf):\n result = Node(syms.file_input, [result])\n return result\n\n\ndef matches_grammar(src_txt: str, grammar: Grammar) -> bool:\n drv = driver.Driver(grammar)\n try:\n drv.parse_string(src_txt, True)\n except (ParseError, TokenError, IndentationError):\n return False\n else:\n return True\n\n\ndef lib2to3_unparse(node: Node) -> str:\n \"\"\"Given a lib2to3 node, return its string representation.\"\"\"\n code = str(node)\n return code\n\n\ndef parse_single_version(\n src: str, version: Tuple[int, int]\n) -> Union[ast.AST, ast3.AST]:\n filename = \"<unknown>\"\n # typed-ast is needed because of feature version limitations in the builtin ast 3.8>\n if sys.version_info >= (3, 8) and version >= (3,):\n return ast.parse(src, filename, feature_version=version, type_comments=True)\n\n if _IS_PYPY:\n # PyPy 3.7 doesn't support type comment tracking which is not ideal, but there's\n # not much we can do as typed-ast won't work either.\n if sys.version_info >= (3, 8):\n return ast3.parse(src, filename, type_comments=True)\n else:\n return ast3.parse(src, filename)\n else:\n # Typed-ast is guaranteed to be used here and automatically tracks type\n # comments separately.\n return ast3.parse(src, filename, feature_version=version[1])\n\n raise AssertionError(\"INTERNAL ERROR: Tried parsing unsupported Python version!\")\n\n\ndef parse_ast(src: str) -> Union[ast.AST, ast3.AST]:\n # TODO: support Python 4+ ;)\n versions = [(3, minor) for minor in range(3, sys.version_info[1] + 1)]\n\n first_error = \"\"\n for version in sorted(versions, reverse=True):\n try:\n return parse_single_version(src, version)\n except SyntaxError as e:\n if not first_error:\n first_error = str(e)\n\n raise SyntaxError(first_error)\n\n\nast3_AST: Final[Type[ast3.AST]] = ast3.AST\n\n\ndef _normalize(lineend: str, value: str) -> str:\n # To normalize, we strip any leading and trailing space from\n # each line...\n stripped: List[str] = [i.strip() for i in value.splitlines()]\n normalized = lineend.join(stripped)\n # ...and remove any blank lines at the beginning and end of\n # the whole string\n return normalized.strip()\n\n\ndef stringify_ast(node: Union[ast.AST, ast3.AST], depth: int = 0) -> Iterator[str]:\n \"\"\"Simple visitor generating strings to compare ASTs by content.\"\"\"\n\n node = fixup_ast_constants(node)\n\n yield f\"{' ' * depth}{node.__class__.__name__}(\"\n\n type_ignore_classes: Tuple[Type[Any], ...]\n for field in sorted(node._fields): # noqa: F402\n # TypeIgnore will not be present using pypy < 3.8, so need for this\n if not (_IS_PYPY and sys.version_info < (3, 8)):\n # TypeIgnore has only one field 'lineno' which breaks this comparison\n type_ignore_classes = (ast3.TypeIgnore,)\n if sys.version_info >= (3, 8):\n type_ignore_classes += (ast.TypeIgnore,)\n if isinstance(node, type_ignore_classes):\n break\n\n try:\n value: object = getattr(node, field)\n except AttributeError:\n continue\n\n yield f\"{' ' * (depth+1)}{field}=\"\n\n if isinstance(value, list):\n for item in value:\n # Ignore nested tuples within del statements, because we may insert\n # parentheses and they change the AST.\n if (\n field == \"targets\"\n and isinstance(node, (ast.Delete, ast3.Delete))\n and isinstance(item, (ast.Tuple, ast3.Tuple))\n ):\n for elt in item.elts:\n yield from stringify_ast(elt, depth + 2)\n\n elif isinstance(item, (ast.AST, ast3.AST)):\n yield from stringify_ast(item, depth + 2)\n\n # Note that we are referencing the typed-ast ASTs via global variables and not\n # direct module attribute accesses because that breaks mypyc. It's probably\n # something to do with the ast3 variables being marked as Any leading\n # mypy to think this branch is always taken, leaving the rest of the code\n # unanalyzed. Tighting up the types for the typed-ast AST types avoids the\n # mypyc crash.\n elif isinstance(value, (ast.AST, ast3_AST)):\n yield from stringify_ast(value, depth + 2)\n\n else:\n normalized: object\n # Constant strings may be indented across newlines, if they are\n # docstrings; fold spaces after newlines when comparing. Similarly,\n # trailing and leading space may be removed.\n if (\n isinstance(node, ast.Constant)\n and field == \"value\"\n and isinstance(value, str)\n ):\n normalized = _normalize(\"\\n\", value)\n else:\n normalized = value\n yield f\"{' ' * (depth+2)}{normalized!r}, # {value.__class__.__name__}\"\n\n yield f\"{' ' * depth}) # /{node.__class__.__name__}\"\n\n\ndef fixup_ast_constants(node: Union[ast.AST, ast3.AST]) -> Union[ast.AST, ast3.AST]:\n \"\"\"Map ast nodes deprecated in 3.8 to Constant.\"\"\"\n if isinstance(node, (ast.Str, ast3.Str, ast.Bytes, ast3.Bytes)):\n return ast.Constant(value=node.s)\n\n if isinstance(node, (ast.Num, ast3.Num)):\n return ast.Constant(value=node.n)\n\n if isinstance(node, (ast.NameConstant, ast3.NameConstant)):\n return ast.Constant(value=node.value)\n\n return node\n", "path": "src/black/parsing.py"}]}
| 3,681 | 114 |
gh_patches_debug_32987
|
rasdani/github-patches
|
git_diff
|
zestedesavoir__zds-site-2093
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
En mode connecté, on fait une requête pour CHAQUE MP RECU !
Quand on est connecté, on passe par ce bout de code sur **toutes** les pages :
zds-site/templates/base.html ligne 258 : `{% with topics=user|interventions_privatetopics %}`
Il fait cette requête pour **chaque MP que vous avez reçu** !
```
SELECT `mp_privatetopic`.`id`, `mp_privatetopic`.`title`, `mp_privatetopic`.`subtitle`, `mp_privatetopic`.`author_id`, `mp_privatetopic`.`last_message_id`, `mp_privatetopic`.`pubdate` FROM `mp_privatetopic` WHERE `mp_privatetopic`.`id` = <id membre>
```
C'est à corriger d'urgence. Ça passe dans la v1.5.
Et après ça on s'étonne que certaines personnes trouvaient le site lent...
</issue>
<code>
[start of zds/utils/templatetags/interventions.py]
1 # coding: utf-8
2
3 from datetime import datetime, timedelta
4 import time
5
6 from django import template
7 from django.db.models import Q, F
8
9 from zds.article.models import Reaction, ArticleRead
10 from zds.forum.models import TopicFollowed, never_read as never_read_topic, Post, TopicRead
11 from zds.mp.models import PrivateTopic, PrivateTopicRead
12 from zds.tutorial.models import Note, TutorialRead
13 from zds.utils.models import Alert
14
15
16 register = template.Library()
17
18
19 @register.filter('is_read')
20 def is_read(topic):
21 if never_read_topic(topic):
22 return False
23 else:
24 return True
25
26
27 @register.filter('humane_delta')
28 def humane_delta(value):
29 # mapping between label day and key
30 const = {1: "Aujourd'hui", 2: "Hier", 3: "Cette semaine", 4: "Ce mois-ci", 5: "Cette année"}
31
32 return const[value]
33
34
35 @register.filter('followed_topics')
36 def followed_topics(user):
37 topicsfollowed = TopicFollowed.objects.select_related("topic").filter(user=user)\
38 .order_by('-topic__last_message__pubdate')[:10]
39 # This period is a map for link a moment (Today, yesterday, this week, this month, etc.) with
40 # the number of days for which we can say we're still in the period
41 # for exemple, the tuple (2, 1) means for the period "2" corresponding to "Yesterday" according
42 # to humane_delta, means if your pubdate hasn't exceeded one day, we are always at "Yesterday"
43 # Number is use for index for sort map easily
44 period = ((1, 0), (2, 1), (3, 7), (4, 30), (5, 360))
45 topics = {}
46 for tf in topicsfollowed:
47 for p in period:
48 if tf.topic.last_message.pubdate.date() >= (datetime.now() - timedelta(days=int(p[1]),
49 hours=0, minutes=0,
50 seconds=0)).date():
51 if p[0] in topics:
52 topics[p[0]].append(tf.topic)
53 else:
54 topics[p[0]] = [tf.topic]
55 break
56 return topics
57
58
59 def comp(d1, d2):
60 v1 = int(time.mktime(d1['pubdate'].timetuple()))
61 v2 = int(time.mktime(d2['pubdate'].timetuple()))
62 if v1 > v2:
63 return -1
64 elif v1 < v2:
65 return 1
66 else:
67 return 0
68
69
70 @register.filter('interventions_topics')
71 def interventions_topics(user):
72 topicsfollowed = TopicFollowed.objects.filter(user=user).values("topic").distinct().all()
73
74 topics_never_read = TopicRead.objects\
75 .filter(user=user)\
76 .filter(topic__in=topicsfollowed)\
77 .select_related("topic")\
78 .exclude(post=F('topic__last_message'))
79
80 articlesfollowed = Reaction.objects\
81 .filter(author=user, article__sha_public__isnull=False)\
82 .values('article')\
83 .distinct().all()
84
85 articles_never_read = ArticleRead.objects\
86 .filter(user=user)\
87 .filter(article__in=articlesfollowed)\
88 .select_related("article")\
89 .exclude(reaction=F('article__last_reaction'))
90
91 tutorialsfollowed = Note.objects\
92 .filter(author=user, tutorial__sha_public__isnull=False)\
93 .values('tutorial')\
94 .distinct().all()
95
96 tutorials_never_read = TutorialRead.objects\
97 .filter(user=user)\
98 .filter(tutorial__in=tutorialsfollowed)\
99 .exclude(note=F('tutorial__last_note'))
100
101 posts_unread = []
102
103 for art in articles_never_read:
104 content = art.article.first_unread_reaction()
105 posts_unread.append({'pubdate': content.pubdate,
106 'author': content.author,
107 'title': art.article.title,
108 'url': content.get_absolute_url()})
109
110 for tuto in tutorials_never_read:
111 content = tuto.tutorial.first_unread_note()
112 posts_unread.append({'pubdate': content.pubdate,
113 'author': content.author,
114 'title': tuto.tutorial.title,
115 'url': content.get_absolute_url()})
116
117 for top in topics_never_read:
118 content = top.topic.first_unread_post()
119 if content is None:
120 content = top.topic.last_message
121 posts_unread.append({'pubdate': content.pubdate,
122 'author': content.author,
123 'title': top.topic.title,
124 'url': content.get_absolute_url()})
125
126 posts_unread.sort(cmp=comp)
127
128 return posts_unread
129
130
131 @register.filter('interventions_privatetopics')
132 def interventions_privatetopics(user):
133
134 topics_never_read = list(PrivateTopicRead.objects
135 .filter(user=user)
136 .filter(privatepost=F('privatetopic__last_message')).all())
137
138 tnrs = []
139 for tnr in topics_never_read:
140 tnrs.append(tnr.privatetopic.pk)
141
142 privatetopics_unread = PrivateTopic.objects\
143 .filter(Q(author=user) | Q(participants__in=[user]))\
144 .exclude(pk__in=tnrs)\
145 .select_related("privatetopic")\
146 .order_by("-pubdate")\
147 .distinct()
148
149 return {'unread': privatetopics_unread}
150
151
152 @register.filter(name='alerts_list')
153 def alerts_list(user):
154 total = []
155 alerts = Alert.objects.select_related("author").all().order_by('-pubdate')[:10]
156 for alert in alerts:
157 if alert.scope == Alert.FORUM:
158 post = Post.objects.select_related("topic").get(pk=alert.comment.pk)
159 total.append({'title': post.topic.title,
160 'url': post.get_absolute_url(),
161 'pubdate': alert.pubdate,
162 'author': alert.author,
163 'text': alert.text})
164 if alert.scope == Alert.ARTICLE:
165 reaction = Reaction.objects.select_related("article").get(pk=alert.comment.pk)
166 total.append({'title': reaction.article.title,
167 'url': reaction.get_absolute_url(),
168 'pubdate': alert.pubdate,
169 'author': alert.author,
170 'text': alert.text})
171 if alert.scope == Alert.TUTORIAL:
172 note = Note.objects.select_related("tutorial").get(pk=alert.comment.pk)
173 total.append({'title': note.tutorial.title,
174 'url': note.get_absolute_url(),
175 'pubdate': alert.pubdate,
176 'author': alert.author,
177 'text': alert.text})
178
179 return total
180
181
182 @register.filter(name='alerts_count')
183 def alerts_count(user):
184 if user.is_authenticated():
185 return Alert.objects.count()
186 else:
187 return 0
188
[end of zds/utils/templatetags/interventions.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/zds/utils/templatetags/interventions.py b/zds/utils/templatetags/interventions.py
--- a/zds/utils/templatetags/interventions.py
+++ b/zds/utils/templatetags/interventions.py
@@ -4,11 +4,11 @@
import time
from django import template
-from django.db.models import Q, F
+from django.db.models import F
from zds.article.models import Reaction, ArticleRead
from zds.forum.models import TopicFollowed, never_read as never_read_topic, Post, TopicRead
-from zds.mp.models import PrivateTopic, PrivateTopicRead
+from zds.mp.models import PrivateTopic
from zds.tutorial.models import Note, TutorialRead
from zds.utils.models import Alert
@@ -131,22 +131,21 @@
@register.filter('interventions_privatetopics')
def interventions_privatetopics(user):
- topics_never_read = list(PrivateTopicRead.objects
- .filter(user=user)
- .filter(privatepost=F('privatetopic__last_message')).all())
-
- tnrs = []
- for tnr in topics_never_read:
- tnrs.append(tnr.privatetopic.pk)
-
- privatetopics_unread = PrivateTopic.objects\
- .filter(Q(author=user) | Q(participants__in=[user]))\
- .exclude(pk__in=tnrs)\
- .select_related("privatetopic")\
- .order_by("-pubdate")\
- .distinct()
-
- return {'unread': privatetopics_unread}
+ # Raw query because ORM doesn't seems to allow this kind of "left outer join" clauses.
+ # Parameters = list with 3x the same ID because SQLite backend doesn't allow map parameters.
+ privatetopics_unread = PrivateTopic.objects.raw(
+ '''
+ select distinct t.*
+ from mp_privatetopic t
+ inner join mp_privatetopic_participants p on p.privatetopic_id = t.id
+ left outer join mp_privatetopicread r on r.user_id = %s and r.privatepost_id = t.last_message_id
+ where (t.author_id = %s or p.user_id = %s)
+ and r.id is null
+ order by t.pubdate desc''',
+ [user.id, user.id, user.id])
+
+ # "total" re-do the query, but there is no other way to get the length as __len__ is not available on raw queries.
+ return {'unread': privatetopics_unread, 'total': len(list(privatetopics_unread))}
@register.filter(name='alerts_list')
|
{"golden_diff": "diff --git a/zds/utils/templatetags/interventions.py b/zds/utils/templatetags/interventions.py\n--- a/zds/utils/templatetags/interventions.py\n+++ b/zds/utils/templatetags/interventions.py\n@@ -4,11 +4,11 @@\n import time\n \n from django import template\n-from django.db.models import Q, F\n+from django.db.models import F\n \n from zds.article.models import Reaction, ArticleRead\n from zds.forum.models import TopicFollowed, never_read as never_read_topic, Post, TopicRead\n-from zds.mp.models import PrivateTopic, PrivateTopicRead\n+from zds.mp.models import PrivateTopic\n from zds.tutorial.models import Note, TutorialRead\n from zds.utils.models import Alert\n \n@@ -131,22 +131,21 @@\n @register.filter('interventions_privatetopics')\n def interventions_privatetopics(user):\n \n- topics_never_read = list(PrivateTopicRead.objects\n- .filter(user=user)\n- .filter(privatepost=F('privatetopic__last_message')).all())\n-\n- tnrs = []\n- for tnr in topics_never_read:\n- tnrs.append(tnr.privatetopic.pk)\n-\n- privatetopics_unread = PrivateTopic.objects\\\n- .filter(Q(author=user) | Q(participants__in=[user]))\\\n- .exclude(pk__in=tnrs)\\\n- .select_related(\"privatetopic\")\\\n- .order_by(\"-pubdate\")\\\n- .distinct()\n-\n- return {'unread': privatetopics_unread}\n+ # Raw query because ORM doesn't seems to allow this kind of \"left outer join\" clauses.\n+ # Parameters = list with 3x the same ID because SQLite backend doesn't allow map parameters.\n+ privatetopics_unread = PrivateTopic.objects.raw(\n+ '''\n+ select distinct t.*\n+ from mp_privatetopic t\n+ inner join mp_privatetopic_participants p on p.privatetopic_id = t.id\n+ left outer join mp_privatetopicread r on r.user_id = %s and r.privatepost_id = t.last_message_id\n+ where (t.author_id = %s or p.user_id = %s)\n+ and r.id is null\n+ order by t.pubdate desc''',\n+ [user.id, user.id, user.id])\n+\n+ # \"total\" re-do the query, but there is no other way to get the length as __len__ is not available on raw queries.\n+ return {'unread': privatetopics_unread, 'total': len(list(privatetopics_unread))}\n \n \n @register.filter(name='alerts_list')\n", "issue": "En mode connect\u00e9, on fait une requ\u00eate pour CHAQUE MP RECU !\nQuand on est connect\u00e9, on passe par ce bout de code sur **toutes** les pages :\n\nzds-site/templates/base.html ligne 258 : `{% with topics=user|interventions_privatetopics %}`\n\nIl fait cette requ\u00eate pour **chaque MP que vous avez re\u00e7u** !\n\n```\nSELECT `mp_privatetopic`.`id`, `mp_privatetopic`.`title`, `mp_privatetopic`.`subtitle`, `mp_privatetopic`.`author_id`, `mp_privatetopic`.`last_message_id`, `mp_privatetopic`.`pubdate` FROM `mp_privatetopic` WHERE `mp_privatetopic`.`id` = <id membre>\n```\n\nC'est \u00e0 corriger d'urgence. \u00c7a passe dans la v1.5.\n\nEt apr\u00e8s \u00e7a on s'\u00e9tonne que certaines personnes trouvaient le site lent...\n\n", "before_files": [{"content": "# coding: utf-8\n\nfrom datetime import datetime, timedelta\nimport time\n\nfrom django import template\nfrom django.db.models import Q, F\n\nfrom zds.article.models import Reaction, ArticleRead\nfrom zds.forum.models import TopicFollowed, never_read as never_read_topic, Post, TopicRead\nfrom zds.mp.models import PrivateTopic, PrivateTopicRead\nfrom zds.tutorial.models import Note, TutorialRead\nfrom zds.utils.models import Alert\n\n\nregister = template.Library()\n\n\[email protected]('is_read')\ndef is_read(topic):\n if never_read_topic(topic):\n return False\n else:\n return True\n\n\[email protected]('humane_delta')\ndef humane_delta(value):\n # mapping between label day and key\n const = {1: \"Aujourd'hui\", 2: \"Hier\", 3: \"Cette semaine\", 4: \"Ce mois-ci\", 5: \"Cette ann\u00e9e\"}\n\n return const[value]\n\n\[email protected]('followed_topics')\ndef followed_topics(user):\n topicsfollowed = TopicFollowed.objects.select_related(\"topic\").filter(user=user)\\\n .order_by('-topic__last_message__pubdate')[:10]\n # This period is a map for link a moment (Today, yesterday, this week, this month, etc.) with\n # the number of days for which we can say we're still in the period\n # for exemple, the tuple (2, 1) means for the period \"2\" corresponding to \"Yesterday\" according\n # to humane_delta, means if your pubdate hasn't exceeded one day, we are always at \"Yesterday\"\n # Number is use for index for sort map easily\n period = ((1, 0), (2, 1), (3, 7), (4, 30), (5, 360))\n topics = {}\n for tf in topicsfollowed:\n for p in period:\n if tf.topic.last_message.pubdate.date() >= (datetime.now() - timedelta(days=int(p[1]),\n hours=0, minutes=0,\n seconds=0)).date():\n if p[0] in topics:\n topics[p[0]].append(tf.topic)\n else:\n topics[p[0]] = [tf.topic]\n break\n return topics\n\n\ndef comp(d1, d2):\n v1 = int(time.mktime(d1['pubdate'].timetuple()))\n v2 = int(time.mktime(d2['pubdate'].timetuple()))\n if v1 > v2:\n return -1\n elif v1 < v2:\n return 1\n else:\n return 0\n\n\[email protected]('interventions_topics')\ndef interventions_topics(user):\n topicsfollowed = TopicFollowed.objects.filter(user=user).values(\"topic\").distinct().all()\n\n topics_never_read = TopicRead.objects\\\n .filter(user=user)\\\n .filter(topic__in=topicsfollowed)\\\n .select_related(\"topic\")\\\n .exclude(post=F('topic__last_message'))\n\n articlesfollowed = Reaction.objects\\\n .filter(author=user, article__sha_public__isnull=False)\\\n .values('article')\\\n .distinct().all()\n\n articles_never_read = ArticleRead.objects\\\n .filter(user=user)\\\n .filter(article__in=articlesfollowed)\\\n .select_related(\"article\")\\\n .exclude(reaction=F('article__last_reaction'))\n\n tutorialsfollowed = Note.objects\\\n .filter(author=user, tutorial__sha_public__isnull=False)\\\n .values('tutorial')\\\n .distinct().all()\n\n tutorials_never_read = TutorialRead.objects\\\n .filter(user=user)\\\n .filter(tutorial__in=tutorialsfollowed)\\\n .exclude(note=F('tutorial__last_note'))\n\n posts_unread = []\n\n for art in articles_never_read:\n content = art.article.first_unread_reaction()\n posts_unread.append({'pubdate': content.pubdate,\n 'author': content.author,\n 'title': art.article.title,\n 'url': content.get_absolute_url()})\n\n for tuto in tutorials_never_read:\n content = tuto.tutorial.first_unread_note()\n posts_unread.append({'pubdate': content.pubdate,\n 'author': content.author,\n 'title': tuto.tutorial.title,\n 'url': content.get_absolute_url()})\n\n for top in topics_never_read:\n content = top.topic.first_unread_post()\n if content is None:\n content = top.topic.last_message\n posts_unread.append({'pubdate': content.pubdate,\n 'author': content.author,\n 'title': top.topic.title,\n 'url': content.get_absolute_url()})\n\n posts_unread.sort(cmp=comp)\n\n return posts_unread\n\n\[email protected]('interventions_privatetopics')\ndef interventions_privatetopics(user):\n\n topics_never_read = list(PrivateTopicRead.objects\n .filter(user=user)\n .filter(privatepost=F('privatetopic__last_message')).all())\n\n tnrs = []\n for tnr in topics_never_read:\n tnrs.append(tnr.privatetopic.pk)\n\n privatetopics_unread = PrivateTopic.objects\\\n .filter(Q(author=user) | Q(participants__in=[user]))\\\n .exclude(pk__in=tnrs)\\\n .select_related(\"privatetopic\")\\\n .order_by(\"-pubdate\")\\\n .distinct()\n\n return {'unread': privatetopics_unread}\n\n\[email protected](name='alerts_list')\ndef alerts_list(user):\n total = []\n alerts = Alert.objects.select_related(\"author\").all().order_by('-pubdate')[:10]\n for alert in alerts:\n if alert.scope == Alert.FORUM:\n post = Post.objects.select_related(\"topic\").get(pk=alert.comment.pk)\n total.append({'title': post.topic.title,\n 'url': post.get_absolute_url(),\n 'pubdate': alert.pubdate,\n 'author': alert.author,\n 'text': alert.text})\n if alert.scope == Alert.ARTICLE:\n reaction = Reaction.objects.select_related(\"article\").get(pk=alert.comment.pk)\n total.append({'title': reaction.article.title,\n 'url': reaction.get_absolute_url(),\n 'pubdate': alert.pubdate,\n 'author': alert.author,\n 'text': alert.text})\n if alert.scope == Alert.TUTORIAL:\n note = Note.objects.select_related(\"tutorial\").get(pk=alert.comment.pk)\n total.append({'title': note.tutorial.title,\n 'url': note.get_absolute_url(),\n 'pubdate': alert.pubdate,\n 'author': alert.author,\n 'text': alert.text})\n\n return total\n\n\[email protected](name='alerts_count')\ndef alerts_count(user):\n if user.is_authenticated():\n return Alert.objects.count()\n else:\n return 0\n", "path": "zds/utils/templatetags/interventions.py"}]}
| 2,715 | 613 |
gh_patches_debug_28523
|
rasdani/github-patches
|
git_diff
|
fedora-infra__bodhi-1483
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Transactional failure during masher
Message
-------
[2017-04-25 02:27:57][ fedmsg ERROR]
```python
MasherThread failed. Transaction rolled back.
```
Process Details
---------------
- host: bodhi-backend01.phx2.fedoraproject.org
- PID: 31792
- name: fedmsg-hub
- command: /usr/bin/python /usr/bin/fedmsg-hub
- msg_id:
Callstack that lead to the logging statement
--------------------------------------------
```python
File "/usr/lib64/python2.7/threading.py", line 777 in __bootstrap
self.__bootstrap_inner()
File "/usr/lib64/python2.7/threading.py", line 804 in __bootstrap_inner
self.run()
File "/usr/lib/python2.7/site-packages/bodhi/server/consumers/masher.py", line 263 in run
self.log.exception('MasherThread failed. Transaction rolled back.')
```
```
Traceback (most recent call last):
File "/usr/lib/python2.7/site-packages/bodhi/server/consumers/masher.py", line 261, in run
self.db = None
File "/usr/lib64/python2.7/contextlib.py", line 24, in __exit__
self.gen.next()
File "/usr/lib/python2.7/site-packages/bodhi/server/util.py", line 659, in __call__
session.rollback()
File "/usr/lib64/python2.7/site-packages/sqlalchemy/orm/session.py", line 765, in rollback
self.transaction.rollback()
File "/usr/lib64/python2.7/site-packages/sqlalchemy/orm/session.py", line 408, in rollback
self._assert_active(prepared_ok=True, rollback_ok=True)
File "/usr/lib64/python2.7/site-packages/sqlalchemy/orm/session.py", line 196, in _assert_active
"This session is in 'committed' state; no further "
InvalidRequestError: This session is in 'committed' state; no further SQL can be emitted within this transaction.
```
</issue>
<code>
[start of bodhi/server/notifications.py]
1 # This program is free software; you can redistribute it and/or
2 # modify it under the terms of the GNU General Public License
3 # as published by the Free Software Foundation; either version 2
4 # of the License, or (at your option) any later version.
5 #
6 # This program is distributed in the hope that it will be useful,
7 # but WITHOUT ANY WARRANTY; without even the implied warranty of
8 # MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
9 # GNU General Public License for more details.
10 #
11 # You should have received a copy of the GNU General Public License
12 # along with this program; if not, write to the Free Software
13 # Foundation, Inc., 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301, USA.
14
15 import collections
16 import logging
17 import socket
18
19 from sqlalchemy import event
20 import fedmsg
21 import fedmsg.config
22 import fedmsg.encoding
23
24 from bodhi.server import Session
25 import bodhi.server
26 import bodhi.server.config
27
28
29 _log = logging.getLogger(__name__)
30
31
32 def init(active=None, cert_prefix=None):
33 if not bodhi.server.config.config.get('fedmsg_enabled'):
34 bodhi.server.log.warn("fedmsg disabled. not initializing.")
35 return
36
37 fedmsg_config = fedmsg.config.load_config()
38
39 # Only override config from disk if explicitly argued.
40 if active is not None:
41 fedmsg_config['active'] = active
42 fedmsg_config['name'] = 'relay_inbound'
43 else:
44 hostname = socket.gethostname().split('.', 1)[0]
45 fedmsg_config['name'] = 'bodhi.%s' % hostname
46
47 if cert_prefix is not None:
48 fedmsg_config['cert_prefix'] = cert_prefix
49
50 fedmsg.init(**fedmsg_config)
51 bodhi.server.log.info("fedmsg initialized")
52
53
54 @event.listens_for(Session, 'after_commit')
55 def send_fedmsgs_after_commit(session):
56 """
57 An SQLAlchemy event listener to send fedmsgs after a database commit.
58
59 This relies on the session ``info`` dictionary being populated. At the moment,
60 this is done by calling the :func:`publish` function. In the future it should
61 be done automatically using SQLAlchemy listeners.
62
63 Args:
64 session (sqlalchemy.orm.session.Session): The session that was committed.
65 """
66 if 'fedmsg' in session.info:
67 # Initialize right before we try to publish, but only if we haven't
68 # initialized for this thread already.
69 if not fedmsg_is_initialized():
70 init()
71
72 for topic, messages in session.info['fedmsg'].items():
73 _log.info('emitting {n} fedmsgs to the "{topic}" topic.'.format(
74 n=len(messages), topic=topic))
75 for msg in messages:
76 fedmsg.publish(topic=topic, msg=msg)
77 # Tidy up after ourselves so a second call to commit on this session won't
78 # send the same messages again.
79 del session.info['fedmsg'][topic]
80
81
82 def publish(topic, msg, force=False):
83 """ Publish a message to fedmsg.
84
85 By default, messages are not sent immediately, but are queued in a
86 transaction "data manager". They will only get published after the
87 sqlalchemy transaction completes successfully and will not be published at
88 all if it fails, aborts, or rolls back.
89
90 Specifying force=True to this function by-passes that -- messages are sent
91 immediately.
92 """
93 if not bodhi.server.config.config.get('fedmsg_enabled'):
94 bodhi.server.log.warn("fedmsg disabled. not sending %r" % topic)
95 return
96
97 # Initialize right before we try to publish, but only if we haven't
98 # initialized for this thread already.
99 if not fedmsg_is_initialized():
100 init()
101
102 if force:
103 bodhi.server.log.debug("fedmsg skipping transaction and sending %r" % topic)
104 fedmsg.publish(topic=topic, msg=msg)
105 else:
106 # This gives us the thread-local session which we'll use to stash the fedmsg.
107 # When commit is called on it, the :func:`send_fedmsgs_after_commit` is triggered.
108 session = Session()
109 if 'fedmsg' not in session.info:
110 session.info['fedmsg'] = collections.defaultdict(list)
111 session.info['fedmsg'][topic].append(msg)
112 bodhi.server.log.debug("fedmsg enqueueing %r" % topic)
113
114
115 def fedmsg_is_initialized():
116 """ Return True or False if fedmsg is initialized or not. """
117 local = getattr(fedmsg, '__local')
118 if not hasattr(local, '__context'):
119 return False
120 # Ensure that fedmsg has an endpoint to publish to.
121 context = getattr(local, '__context')
122 return hasattr(context, 'publisher')
123
[end of bodhi/server/notifications.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/bodhi/server/notifications.py b/bodhi/server/notifications.py
--- a/bodhi/server/notifications.py
+++ b/bodhi/server/notifications.py
@@ -13,6 +13,7 @@
# Foundation, Inc., 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301, USA.
import collections
+import json
import logging
import socket
@@ -103,12 +104,18 @@
bodhi.server.log.debug("fedmsg skipping transaction and sending %r" % topic)
fedmsg.publish(topic=topic, msg=msg)
else:
+ # We need to do this to ensure all the SQLAlchemy objects that could be in the messages
+ # are turned into JSON before the session is removed and expires the objects loaded with
+ # it. The JSON is decoded again because the fedmsg API doesn't state it accepts strings.
+ # An issue has been filed about this: https://github.com/fedora-infra/fedmsg/issues/407.
+ json_msg = fedmsg.encoding.dumps(msg)
+ msg_dict = json.loads(json_msg)
# This gives us the thread-local session which we'll use to stash the fedmsg.
# When commit is called on it, the :func:`send_fedmsgs_after_commit` is triggered.
session = Session()
if 'fedmsg' not in session.info:
session.info['fedmsg'] = collections.defaultdict(list)
- session.info['fedmsg'][topic].append(msg)
+ session.info['fedmsg'][topic].append(msg_dict)
bodhi.server.log.debug("fedmsg enqueueing %r" % topic)
|
{"golden_diff": "diff --git a/bodhi/server/notifications.py b/bodhi/server/notifications.py\n--- a/bodhi/server/notifications.py\n+++ b/bodhi/server/notifications.py\n@@ -13,6 +13,7 @@\n # Foundation, Inc., 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301, USA.\n \n import collections\n+import json\n import logging\n import socket\n \n@@ -103,12 +104,18 @@\n bodhi.server.log.debug(\"fedmsg skipping transaction and sending %r\" % topic)\n fedmsg.publish(topic=topic, msg=msg)\n else:\n+ # We need to do this to ensure all the SQLAlchemy objects that could be in the messages\n+ # are turned into JSON before the session is removed and expires the objects loaded with\n+ # it. The JSON is decoded again because the fedmsg API doesn't state it accepts strings.\n+ # An issue has been filed about this: https://github.com/fedora-infra/fedmsg/issues/407.\n+ json_msg = fedmsg.encoding.dumps(msg)\n+ msg_dict = json.loads(json_msg)\n # This gives us the thread-local session which we'll use to stash the fedmsg.\n # When commit is called on it, the :func:`send_fedmsgs_after_commit` is triggered.\n session = Session()\n if 'fedmsg' not in session.info:\n session.info['fedmsg'] = collections.defaultdict(list)\n- session.info['fedmsg'][topic].append(msg)\n+ session.info['fedmsg'][topic].append(msg_dict)\n bodhi.server.log.debug(\"fedmsg enqueueing %r\" % topic)\n", "issue": "Transactional failure during masher\nMessage\r\n-------\r\n[2017-04-25 02:27:57][ fedmsg ERROR]\r\n```python\r\nMasherThread failed. Transaction rolled back.\r\n```\r\n\r\n\r\nProcess Details\r\n---------------\r\n- host: bodhi-backend01.phx2.fedoraproject.org\r\n- PID: 31792\r\n- name: fedmsg-hub\r\n- command: /usr/bin/python /usr/bin/fedmsg-hub\r\n- msg_id: \r\n\r\nCallstack that lead to the logging statement\r\n--------------------------------------------\r\n```python\r\n File \"/usr/lib64/python2.7/threading.py\", line 777 in __bootstrap\r\n self.__bootstrap_inner()\r\n File \"/usr/lib64/python2.7/threading.py\", line 804 in __bootstrap_inner\r\n self.run()\r\n File \"/usr/lib/python2.7/site-packages/bodhi/server/consumers/masher.py\", line 263 in run\r\n self.log.exception('MasherThread failed. Transaction rolled back.')\r\n```\r\n\r\n```\r\nTraceback (most recent call last):\r\n File \"/usr/lib/python2.7/site-packages/bodhi/server/consumers/masher.py\", line 261, in run\r\n self.db = None\r\n File \"/usr/lib64/python2.7/contextlib.py\", line 24, in __exit__\r\n self.gen.next()\r\n File \"/usr/lib/python2.7/site-packages/bodhi/server/util.py\", line 659, in __call__\r\n session.rollback()\r\n File \"/usr/lib64/python2.7/site-packages/sqlalchemy/orm/session.py\", line 765, in rollback\r\n self.transaction.rollback()\r\n File \"/usr/lib64/python2.7/site-packages/sqlalchemy/orm/session.py\", line 408, in rollback\r\n self._assert_active(prepared_ok=True, rollback_ok=True)\r\n File \"/usr/lib64/python2.7/site-packages/sqlalchemy/orm/session.py\", line 196, in _assert_active\r\n \"This session is in 'committed' state; no further \"\r\nInvalidRequestError: This session is in 'committed' state; no further SQL can be emitted within this transaction.\r\n```\n", "before_files": [{"content": "# This program is free software; you can redistribute it and/or\n# modify it under the terms of the GNU General Public License\n# as published by the Free Software Foundation; either version 2\n# of the License, or (at your option) any later version.\n#\n# This program is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU General Public License for more details.\n#\n# You should have received a copy of the GNU General Public License\n# along with this program; if not, write to the Free Software\n# Foundation, Inc., 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301, USA.\n\nimport collections\nimport logging\nimport socket\n\nfrom sqlalchemy import event\nimport fedmsg\nimport fedmsg.config\nimport fedmsg.encoding\n\nfrom bodhi.server import Session\nimport bodhi.server\nimport bodhi.server.config\n\n\n_log = logging.getLogger(__name__)\n\n\ndef init(active=None, cert_prefix=None):\n if not bodhi.server.config.config.get('fedmsg_enabled'):\n bodhi.server.log.warn(\"fedmsg disabled. not initializing.\")\n return\n\n fedmsg_config = fedmsg.config.load_config()\n\n # Only override config from disk if explicitly argued.\n if active is not None:\n fedmsg_config['active'] = active\n fedmsg_config['name'] = 'relay_inbound'\n else:\n hostname = socket.gethostname().split('.', 1)[0]\n fedmsg_config['name'] = 'bodhi.%s' % hostname\n\n if cert_prefix is not None:\n fedmsg_config['cert_prefix'] = cert_prefix\n\n fedmsg.init(**fedmsg_config)\n bodhi.server.log.info(\"fedmsg initialized\")\n\n\[email protected]_for(Session, 'after_commit')\ndef send_fedmsgs_after_commit(session):\n \"\"\"\n An SQLAlchemy event listener to send fedmsgs after a database commit.\n\n This relies on the session ``info`` dictionary being populated. At the moment,\n this is done by calling the :func:`publish` function. In the future it should\n be done automatically using SQLAlchemy listeners.\n\n Args:\n session (sqlalchemy.orm.session.Session): The session that was committed.\n \"\"\"\n if 'fedmsg' in session.info:\n # Initialize right before we try to publish, but only if we haven't\n # initialized for this thread already.\n if not fedmsg_is_initialized():\n init()\n\n for topic, messages in session.info['fedmsg'].items():\n _log.info('emitting {n} fedmsgs to the \"{topic}\" topic.'.format(\n n=len(messages), topic=topic))\n for msg in messages:\n fedmsg.publish(topic=topic, msg=msg)\n # Tidy up after ourselves so a second call to commit on this session won't\n # send the same messages again.\n del session.info['fedmsg'][topic]\n\n\ndef publish(topic, msg, force=False):\n \"\"\" Publish a message to fedmsg.\n\n By default, messages are not sent immediately, but are queued in a\n transaction \"data manager\". They will only get published after the\n sqlalchemy transaction completes successfully and will not be published at\n all if it fails, aborts, or rolls back.\n\n Specifying force=True to this function by-passes that -- messages are sent\n immediately.\n \"\"\"\n if not bodhi.server.config.config.get('fedmsg_enabled'):\n bodhi.server.log.warn(\"fedmsg disabled. not sending %r\" % topic)\n return\n\n # Initialize right before we try to publish, but only if we haven't\n # initialized for this thread already.\n if not fedmsg_is_initialized():\n init()\n\n if force:\n bodhi.server.log.debug(\"fedmsg skipping transaction and sending %r\" % topic)\n fedmsg.publish(topic=topic, msg=msg)\n else:\n # This gives us the thread-local session which we'll use to stash the fedmsg.\n # When commit is called on it, the :func:`send_fedmsgs_after_commit` is triggered.\n session = Session()\n if 'fedmsg' not in session.info:\n session.info['fedmsg'] = collections.defaultdict(list)\n session.info['fedmsg'][topic].append(msg)\n bodhi.server.log.debug(\"fedmsg enqueueing %r\" % topic)\n\n\ndef fedmsg_is_initialized():\n \"\"\" Return True or False if fedmsg is initialized or not. \"\"\"\n local = getattr(fedmsg, '__local')\n if not hasattr(local, '__context'):\n return False\n # Ensure that fedmsg has an endpoint to publish to.\n context = getattr(local, '__context')\n return hasattr(context, 'publisher')\n", "path": "bodhi/server/notifications.py"}]}
| 2,331 | 374 |
gh_patches_debug_54731
|
rasdani/github-patches
|
git_diff
|
DDMAL__CantusDB-1077
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Admin area, change chant page: "title" field should be hidden
The "title" field is only used for sequences and never for chants, so this field should be hidden from the Chant Change page in the Admin area.
Debra sent us a message asking us what this field was for, so since this is a simple fix, we should hide this field before it causes further confusion.
</issue>
<code>
[start of django/cantusdb_project/main_app/admin.py]
1 from django.contrib import admin
2 from main_app.models import *
3 from main_app.forms import (
4 AdminCenturyForm,
5 AdminChantForm,
6 AdminFeastForm,
7 AdminGenreForm,
8 AdminNotationForm,
9 AdminOfficeForm,
10 AdminProvenanceForm,
11 AdminRismSiglumForm,
12 AdminSegmentForm,
13 AdminSequenceForm,
14 AdminSourceForm,
15 )
16
17 # these fields should not be editable by all classes
18 EXCLUDE = (
19 "created_by",
20 "last_updated_by",
21 "json_info",
22 )
23
24
25 class BaseModelAdmin(admin.ModelAdmin):
26 exclude = EXCLUDE
27
28 # if an object is created in the admin interface, assign the user to the created_by field
29 # else if an object is updated in the admin interface, assign the user to the last_updated_by field
30 def save_model(self, request, obj, form, change):
31 if change:
32 obj.last_updated_by = request.user
33 else:
34 obj.created_by = request.user
35 super().save_model(request, obj, form, change)
36
37
38 class CenturyAdmin(BaseModelAdmin):
39 search_fields = ("name",)
40 form = AdminCenturyForm
41
42
43 class ChantAdmin(BaseModelAdmin):
44 @admin.display(description="Source Siglum")
45 def get_source_siglum(self, obj):
46 if obj.source:
47 return obj.source.siglum
48
49 list_display = (
50 "incipit",
51 "get_source_siglum",
52 "genre",
53 )
54 search_fields = (
55 "title",
56 "incipit",
57 "cantus_id",
58 "id",
59 )
60
61 readonly_fields = (
62 "date_created",
63 "date_updated",
64 )
65
66 list_filter = (
67 "genre",
68 "office",
69 )
70 exclude = EXCLUDE + (
71 "col1",
72 "col2",
73 "col3",
74 "next_chant",
75 "s_sequence",
76 "is_last_chant_in_feast",
77 "visible_status",
78 "date",
79 "volpiano_notes",
80 "volpiano_intervals",
81 )
82 form = AdminChantForm
83 raw_id_fields = (
84 "source",
85 "feast",
86 )
87 ordering = ("source__siglum",)
88
89
90 class FeastAdmin(BaseModelAdmin):
91 search_fields = (
92 "name",
93 "feast_code",
94 )
95 list_display = (
96 "name",
97 "month",
98 "day",
99 "feast_code",
100 )
101 form = AdminFeastForm
102
103
104 class GenreAdmin(BaseModelAdmin):
105 search_fields = ("name",)
106 form = AdminGenreForm
107
108
109 class NotationAdmin(BaseModelAdmin):
110 search_fields = ("name",)
111 form = AdminNotationForm
112
113
114 class OfficeAdmin(BaseModelAdmin):
115 search_fields = ("name",)
116 form = AdminOfficeForm
117
118
119 class ProvenanceAdmin(BaseModelAdmin):
120 search_fields = ("name",)
121 form = AdminProvenanceForm
122
123
124 class RismSiglumAdmin(BaseModelAdmin):
125 search_fields = ("name",)
126 form = AdminRismSiglumForm
127
128
129 class SegmentAdmin(BaseModelAdmin):
130 search_fields = ("name",)
131 form = AdminSegmentForm
132
133
134 class SequenceAdmin(BaseModelAdmin):
135 @admin.display(description="Source Siglum")
136 def get_source_siglum(self, obj):
137 if obj.source:
138 return obj.source.siglum
139
140 search_fields = (
141 "title",
142 "incipit",
143 "cantus_id",
144 "id",
145 )
146 exclude = EXCLUDE + (
147 "c_sequence",
148 "next_chant",
149 "is_last_chant_in_feast",
150 "visible_status",
151 )
152 list_display = ("incipit", "get_source_siglum", "genre")
153 list_filter = (
154 "genre",
155 "office",
156 )
157 raw_id_fields = (
158 "source",
159 "feast",
160 )
161 ordering = ("source__siglum",)
162 form = AdminSequenceForm
163
164
165 class SourceAdmin(BaseModelAdmin):
166 # These search fields are also available on the user-source inline relationship in the user admin page
167 search_fields = (
168 "siglum",
169 "title",
170 "id",
171 )
172 readonly_fields = (
173 "number_of_chants",
174 "number_of_melodies",
175 "date_created",
176 "date_updated",
177 )
178 # from the Django docs:
179 # Adding a ManyToManyField to this list will instead use a nifty unobtrusive JavaScript “filter” interface
180 # that allows searching within the options. The unselected and selected options appear in two boxes side by side.
181 filter_horizontal = (
182 "century",
183 "notation",
184 "current_editors",
185 "inventoried_by",
186 "full_text_entered_by",
187 "melodies_entered_by",
188 "proofreaders",
189 "other_editors",
190 )
191
192 list_display = (
193 "title",
194 "siglum",
195 "id",
196 )
197
198 list_filter = (
199 "full_source",
200 "segment",
201 "source_status",
202 "published",
203 "century",
204 )
205
206 ordering = ("siglum",)
207
208 form = AdminSourceForm
209
210
211 admin.site.register(Century, CenturyAdmin)
212 admin.site.register(Chant, ChantAdmin)
213 admin.site.register(Feast, FeastAdmin)
214 admin.site.register(Genre, GenreAdmin)
215 admin.site.register(Notation, NotationAdmin)
216 admin.site.register(Office, OfficeAdmin)
217 admin.site.register(Provenance, ProvenanceAdmin)
218 admin.site.register(RismSiglum, RismSiglumAdmin)
219 admin.site.register(Segment, SegmentAdmin)
220 admin.site.register(Sequence, SequenceAdmin)
221 admin.site.register(Source, SourceAdmin)
222
[end of django/cantusdb_project/main_app/admin.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/django/cantusdb_project/main_app/admin.py b/django/cantusdb_project/main_app/admin.py
--- a/django/cantusdb_project/main_app/admin.py
+++ b/django/cantusdb_project/main_app/admin.py
@@ -78,6 +78,7 @@
"date",
"volpiano_notes",
"volpiano_intervals",
+ "title",
)
form = AdminChantForm
raw_id_fields = (
|
{"golden_diff": "diff --git a/django/cantusdb_project/main_app/admin.py b/django/cantusdb_project/main_app/admin.py\n--- a/django/cantusdb_project/main_app/admin.py\n+++ b/django/cantusdb_project/main_app/admin.py\n@@ -78,6 +78,7 @@\n \"date\",\n \"volpiano_notes\",\n \"volpiano_intervals\",\n+ \"title\",\n )\n form = AdminChantForm\n raw_id_fields = (\n", "issue": "Admin area, change chant page: \"title\" field should be hidden\nThe \"title\" field is only used for sequences and never for chants, so this field should be hidden from the Chant Change page in the Admin area.\r\n\r\nDebra sent us a message asking us what this field was for, so since this is a simple fix, we should hide this field before it causes further confusion.\n", "before_files": [{"content": "from django.contrib import admin\nfrom main_app.models import *\nfrom main_app.forms import (\n AdminCenturyForm,\n AdminChantForm,\n AdminFeastForm,\n AdminGenreForm,\n AdminNotationForm,\n AdminOfficeForm,\n AdminProvenanceForm,\n AdminRismSiglumForm,\n AdminSegmentForm,\n AdminSequenceForm,\n AdminSourceForm,\n)\n\n# these fields should not be editable by all classes\nEXCLUDE = (\n \"created_by\",\n \"last_updated_by\",\n \"json_info\",\n)\n\n\nclass BaseModelAdmin(admin.ModelAdmin):\n exclude = EXCLUDE\n\n # if an object is created in the admin interface, assign the user to the created_by field\n # else if an object is updated in the admin interface, assign the user to the last_updated_by field\n def save_model(self, request, obj, form, change):\n if change:\n obj.last_updated_by = request.user\n else:\n obj.created_by = request.user\n super().save_model(request, obj, form, change)\n\n\nclass CenturyAdmin(BaseModelAdmin):\n search_fields = (\"name\",)\n form = AdminCenturyForm\n\n\nclass ChantAdmin(BaseModelAdmin):\n @admin.display(description=\"Source Siglum\")\n def get_source_siglum(self, obj):\n if obj.source:\n return obj.source.siglum\n\n list_display = (\n \"incipit\",\n \"get_source_siglum\",\n \"genre\",\n )\n search_fields = (\n \"title\",\n \"incipit\",\n \"cantus_id\",\n \"id\",\n )\n\n readonly_fields = (\n \"date_created\",\n \"date_updated\",\n )\n\n list_filter = (\n \"genre\",\n \"office\",\n )\n exclude = EXCLUDE + (\n \"col1\",\n \"col2\",\n \"col3\",\n \"next_chant\",\n \"s_sequence\",\n \"is_last_chant_in_feast\",\n \"visible_status\",\n \"date\",\n \"volpiano_notes\",\n \"volpiano_intervals\",\n )\n form = AdminChantForm\n raw_id_fields = (\n \"source\",\n \"feast\",\n )\n ordering = (\"source__siglum\",)\n\n\nclass FeastAdmin(BaseModelAdmin):\n search_fields = (\n \"name\",\n \"feast_code\",\n )\n list_display = (\n \"name\",\n \"month\",\n \"day\",\n \"feast_code\",\n )\n form = AdminFeastForm\n\n\nclass GenreAdmin(BaseModelAdmin):\n search_fields = (\"name\",)\n form = AdminGenreForm\n\n\nclass NotationAdmin(BaseModelAdmin):\n search_fields = (\"name\",)\n form = AdminNotationForm\n\n\nclass OfficeAdmin(BaseModelAdmin):\n search_fields = (\"name\",)\n form = AdminOfficeForm\n\n\nclass ProvenanceAdmin(BaseModelAdmin):\n search_fields = (\"name\",)\n form = AdminProvenanceForm\n\n\nclass RismSiglumAdmin(BaseModelAdmin):\n search_fields = (\"name\",)\n form = AdminRismSiglumForm\n\n\nclass SegmentAdmin(BaseModelAdmin):\n search_fields = (\"name\",)\n form = AdminSegmentForm\n\n\nclass SequenceAdmin(BaseModelAdmin):\n @admin.display(description=\"Source Siglum\")\n def get_source_siglum(self, obj):\n if obj.source:\n return obj.source.siglum\n\n search_fields = (\n \"title\",\n \"incipit\",\n \"cantus_id\",\n \"id\",\n )\n exclude = EXCLUDE + (\n \"c_sequence\",\n \"next_chant\",\n \"is_last_chant_in_feast\",\n \"visible_status\",\n )\n list_display = (\"incipit\", \"get_source_siglum\", \"genre\")\n list_filter = (\n \"genre\",\n \"office\",\n )\n raw_id_fields = (\n \"source\",\n \"feast\",\n )\n ordering = (\"source__siglum\",)\n form = AdminSequenceForm\n\n\nclass SourceAdmin(BaseModelAdmin):\n # These search fields are also available on the user-source inline relationship in the user admin page\n search_fields = (\n \"siglum\",\n \"title\",\n \"id\",\n )\n readonly_fields = (\n \"number_of_chants\",\n \"number_of_melodies\",\n \"date_created\",\n \"date_updated\",\n )\n # from the Django docs:\n # Adding a ManyToManyField to this list will instead use a nifty unobtrusive JavaScript \u201cfilter\u201d interface\n # that allows searching within the options. The unselected and selected options appear in two boxes side by side.\n filter_horizontal = (\n \"century\",\n \"notation\",\n \"current_editors\",\n \"inventoried_by\",\n \"full_text_entered_by\",\n \"melodies_entered_by\",\n \"proofreaders\",\n \"other_editors\",\n )\n\n list_display = (\n \"title\",\n \"siglum\",\n \"id\",\n )\n\n list_filter = (\n \"full_source\",\n \"segment\",\n \"source_status\",\n \"published\",\n \"century\",\n )\n\n ordering = (\"siglum\",)\n\n form = AdminSourceForm\n\n\nadmin.site.register(Century, CenturyAdmin)\nadmin.site.register(Chant, ChantAdmin)\nadmin.site.register(Feast, FeastAdmin)\nadmin.site.register(Genre, GenreAdmin)\nadmin.site.register(Notation, NotationAdmin)\nadmin.site.register(Office, OfficeAdmin)\nadmin.site.register(Provenance, ProvenanceAdmin)\nadmin.site.register(RismSiglum, RismSiglumAdmin)\nadmin.site.register(Segment, SegmentAdmin)\nadmin.site.register(Sequence, SequenceAdmin)\nadmin.site.register(Source, SourceAdmin)\n", "path": "django/cantusdb_project/main_app/admin.py"}]}
| 2,443 | 107 |
gh_patches_debug_49168
|
rasdani/github-patches
|
git_diff
|
mkdocs__mkdocs-2800
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
jinja2 3.1.0 breaks mkdocs
since the jinja2 3.1.0 release mkdocs does not work any more:
```
admin@host ui % pip install jinja2==3.1.0
Collecting jinja2==3.1.0
Using cached Jinja2-3.1.0-py3-none-any.whl (132 kB)
Installing collected packages: jinja2
Attempting uninstall: jinja2
Found existing installation: Jinja2 3.0.0
Uninstalling Jinja2-3.0.0:
Successfully uninstalled Jinja2-3.0.0
Successfully installed jinja2-3.1.0
admin@host ui % mkdocs build
Traceback (most recent call last):
File "/usr/local/bin/mkdocs", line 8, in <module>
sys.exit(cli())
File "/usr/local/lib/python3.9/site-packages/click/core.py", line 829, in __call__
return self.main(*args, **kwargs)
File "/usr/local/lib/python3.9/site-packages/click/core.py", line 782, in main
rv = self.invoke(ctx)
File "/usr/local/lib/python3.9/site-packages/click/core.py", line 1259, in invoke
return _process_result(sub_ctx.command.invoke(sub_ctx))
File "/usr/local/lib/python3.9/site-packages/click/core.py", line 1066, in invoke
return ctx.invoke(self.callback, **ctx.params)
File "/usr/local/lib/python3.9/site-packages/click/core.py", line 610, in invoke
return callback(*args, **kwargs)
File "/usr/local/lib/python3.9/site-packages/mkdocs/__main__.py", line 187, in build_command
build.build(config.load_config(**kwargs), dirty=not clean)
File "/usr/local/lib/python3.9/site-packages/mkdocs/config/base.py", line 216, in load_config
from mkdocs.config.defaults import get_schema
File "/usr/local/lib/python3.9/site-packages/mkdocs/config/defaults.py", line 1, in <module>
from mkdocs.config import config_options
File "/usr/local/lib/python3.9/site-packages/mkdocs/config/config_options.py", line 8, in <module>
from mkdocs import utils, theme, plugins
File "/usr/local/lib/python3.9/site-packages/mkdocs/theme.py", line 6, in <module>
from mkdocs.utils import filters
File "/usr/local/lib/python3.9/site-packages/mkdocs/utils/filters.py", line 13, in <module>
@jinja2.contextfilter
AttributeError: module 'jinja2' has no attribute 'contextfilter'
```
However, if I install jinja2 3.0.0:
```
admin@host ui % pip install jinja2==3.0.0
Collecting jinja2==3.0.0
Using cached Jinja2-3.0.0-py3-none-any.whl (133 kB)
Requirement already satisfied: MarkupSafe>=2.0.0rc2 in /usr/local/lib/python3.9/site-packages (from jinja2==3.0.0) (2.1.1)
Installing collected packages: jinja2
Attempting uninstall: jinja2
Found existing installation: Jinja2 3.1.0
Uninstalling Jinja2-3.1.0:
Successfully uninstalled Jinja2-3.1.0
Successfully installed jinja2-3.0.0
admin@host ui % mkdocs build
INFO - Cleaning site directory
INFO - Building documentation to directory: /Users/admin/git/searchlab/ui/site
INFO - Documentation built in 0.33 seconds
```
- mkdocs can be patched by explicitly installing jinja2 3.0.0.
- maybe this is not a mkdocs bug, but a jinja2 bug; however, this could be patched in mkdocs as well.
Prevent error with Jinja2 v3.1
Fixes #2794
See [Jinja2 v3.0.0 changes](https://jinja.palletsprojects.com/en/3.0.x/changes/#version-3-0-0):
> The function and filter decorators have been renamed and unified. The old names are deprecated...
>
> - `pass_context` replaces `contextfunction` and `contextfilter`.
</issue>
<code>
[start of mkdocs/utils/filters.py]
1 import jinja2
2
3 from mkdocs.utils import normalize_url
4
5
6 @jinja2.contextfilter
7 def url_filter(context, value):
8 """ A Template filter to normalize URLs. """
9 return normalize_url(value, page=context['page'], base=context['base_url'])
10
[end of mkdocs/utils/filters.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/mkdocs/utils/filters.py b/mkdocs/utils/filters.py
--- a/mkdocs/utils/filters.py
+++ b/mkdocs/utils/filters.py
@@ -1,9 +1,12 @@
-import jinja2
+try:
+ from jinja2 import pass_context as contextfilter
+except ImportError:
+ from jinja2 import contextfilter
from mkdocs.utils import normalize_url
[email protected]
+@contextfilter
def url_filter(context, value):
""" A Template filter to normalize URLs. """
return normalize_url(value, page=context['page'], base=context['base_url'])
|
{"golden_diff": "diff --git a/mkdocs/utils/filters.py b/mkdocs/utils/filters.py\n--- a/mkdocs/utils/filters.py\n+++ b/mkdocs/utils/filters.py\n@@ -1,9 +1,12 @@\n-import jinja2\n+try:\n+ from jinja2 import pass_context as contextfilter\n+except ImportError:\n+ from jinja2 import contextfilter\n \n from mkdocs.utils import normalize_url\n \n \[email protected]\n+@contextfilter\n def url_filter(context, value):\n \"\"\" A Template filter to normalize URLs. \"\"\"\n return normalize_url(value, page=context['page'], base=context['base_url'])\n", "issue": "jinja2 3.1.0 breaks mkdocs\nsince the jinja2 3.1.0 release mkdocs does not work any more:\r\n\r\n```\r\nadmin@host ui % pip install jinja2==3.1.0\r\nCollecting jinja2==3.1.0\r\n Using cached Jinja2-3.1.0-py3-none-any.whl (132 kB)\r\nInstalling collected packages: jinja2\r\n Attempting uninstall: jinja2\r\n Found existing installation: Jinja2 3.0.0\r\n Uninstalling Jinja2-3.0.0:\r\n Successfully uninstalled Jinja2-3.0.0\r\nSuccessfully installed jinja2-3.1.0\r\nadmin@host ui % mkdocs build\r\nTraceback (most recent call last):\r\n File \"/usr/local/bin/mkdocs\", line 8, in <module>\r\n sys.exit(cli())\r\n File \"/usr/local/lib/python3.9/site-packages/click/core.py\", line 829, in __call__\r\n return self.main(*args, **kwargs)\r\n File \"/usr/local/lib/python3.9/site-packages/click/core.py\", line 782, in main\r\n rv = self.invoke(ctx)\r\n File \"/usr/local/lib/python3.9/site-packages/click/core.py\", line 1259, in invoke\r\n return _process_result(sub_ctx.command.invoke(sub_ctx))\r\n File \"/usr/local/lib/python3.9/site-packages/click/core.py\", line 1066, in invoke\r\n return ctx.invoke(self.callback, **ctx.params)\r\n File \"/usr/local/lib/python3.9/site-packages/click/core.py\", line 610, in invoke\r\n return callback(*args, **kwargs)\r\n File \"/usr/local/lib/python3.9/site-packages/mkdocs/__main__.py\", line 187, in build_command\r\n build.build(config.load_config(**kwargs), dirty=not clean)\r\n File \"/usr/local/lib/python3.9/site-packages/mkdocs/config/base.py\", line 216, in load_config\r\n from mkdocs.config.defaults import get_schema\r\n File \"/usr/local/lib/python3.9/site-packages/mkdocs/config/defaults.py\", line 1, in <module>\r\n from mkdocs.config import config_options\r\n File \"/usr/local/lib/python3.9/site-packages/mkdocs/config/config_options.py\", line 8, in <module>\r\n from mkdocs import utils, theme, plugins\r\n File \"/usr/local/lib/python3.9/site-packages/mkdocs/theme.py\", line 6, in <module>\r\n from mkdocs.utils import filters\r\n File \"/usr/local/lib/python3.9/site-packages/mkdocs/utils/filters.py\", line 13, in <module>\r\n @jinja2.contextfilter\r\nAttributeError: module 'jinja2' has no attribute 'contextfilter'\r\n```\r\nHowever, if I install jinja2 3.0.0:\r\n```\r\nadmin@host ui % pip install jinja2==3.0.0\r\nCollecting jinja2==3.0.0\r\n Using cached Jinja2-3.0.0-py3-none-any.whl (133 kB)\r\nRequirement already satisfied: MarkupSafe>=2.0.0rc2 in /usr/local/lib/python3.9/site-packages (from jinja2==3.0.0) (2.1.1)\r\nInstalling collected packages: jinja2\r\n Attempting uninstall: jinja2\r\n Found existing installation: Jinja2 3.1.0\r\n Uninstalling Jinja2-3.1.0:\r\n Successfully uninstalled Jinja2-3.1.0\r\nSuccessfully installed jinja2-3.0.0\r\nadmin@host ui % mkdocs build\r\nINFO - Cleaning site directory\r\nINFO - Building documentation to directory: /Users/admin/git/searchlab/ui/site\r\nINFO - Documentation built in 0.33 seconds\r\n```\r\n\r\n- mkdocs can be patched by explicitly installing jinja2 3.0.0.\r\n- maybe this is not a mkdocs bug, but a jinja2 bug; however, this could be patched in mkdocs as well.\r\n\nPrevent error with Jinja2 v3.1\nFixes #2794\r\n\r\nSee [Jinja2 v3.0.0 changes](https://jinja.palletsprojects.com/en/3.0.x/changes/#version-3-0-0):\r\n\r\n> The function and filter decorators have been renamed and unified. The old names are deprecated...\r\n> \r\n> - `pass_context` replaces `contextfunction` and `contextfilter`.\n", "before_files": [{"content": "import jinja2\n\nfrom mkdocs.utils import normalize_url\n\n\[email protected]\ndef url_filter(context, value):\n \"\"\" A Template filter to normalize URLs. \"\"\"\n return normalize_url(value, page=context['page'], base=context['base_url'])\n", "path": "mkdocs/utils/filters.py"}]}
| 1,618 | 142 |
gh_patches_debug_4805
|
rasdani/github-patches
|
git_diff
|
statsmodels__statsmodels-680
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Test Baxter King band-pass filter fails with scipy 0.12 beta1
current git head 1b12824f53b1 and 0.4.3, python2.7 tested on ubuntu 13.04 amd64, haven't tried scipy 0.11 but it the test seems to work with the 0.10.1 package
```
======================================================================
ERROR: Test Baxter King band-pass filter. Results are taken from Stata
----------------------------------------------------------------------
Traceback (most recent call last):
File "/usr/lib/python2.7/dist-packages/nose/case.py", line 197, in runTest
self.test(*self.arg)
File "/statsmodels/statsmodels/tsa/filters/tests/test_filters.py", line 47, in test_bking1d
Y = bkfilter(X, 6, 32, 12)
File "/statsmodels/statsmodels/tsa/filters/bk_filter.py", line 72, in bkfilter
return fftconvolve(bweights, X, mode='valid') # get a centered moving avg/
File "/usr/lib/python2.7/dist-packages/scipy/signal/signaltools.py", line 204, in fftconvolve
_check_valid_mode_shapes(s1, s2)
File "/usr/lib/python2.7/dist-packages/scipy/signal/signaltools.py", line 64, in _check_valid_mode_shapes
"in1 should have at least as many items as in2 in "
ValueError: in1 should have at least as many items as in2 in every dimension for 'valid' mode.
----------------------------------------------------------------------
```
</issue>
<code>
[start of statsmodels/tsa/filters/bk_filter.py]
1 import numpy as np
2 from scipy.signal import fftconvolve
3
4 def bkfilter(X, low=6, high=32, K=12):
5 """
6 Baxter-King bandpass filter
7
8 Parameters
9 ----------
10 X : array-like
11 A 1 or 2d ndarray. If 2d, variables are assumed to be in columns.
12 low : float
13 Minimum period for oscillations, ie., Baxter and King suggest that
14 the Burns-Mitchell U.S. business cycle has 6 for quarterly data and
15 1.5 for annual data.
16 high : float
17 Maximum period for oscillations BK suggest that the U.S.
18 business cycle has 32 for quarterly data and 8 for annual data.
19 K : int
20 Lead-lag length of the filter. Baxter and King propose a truncation
21 length of 12 for quarterly data and 3 for annual data.
22
23 Returns
24 -------
25 Y : array
26 Cyclical component of X
27
28 References
29 ---------- ::
30 Baxter, M. and R. G. King. "Measuring Business Cycles: Approximate
31 Band-Pass Filters for Economic Time Series." *Review of Economics and
32 Statistics*, 1999, 81(4), 575-593.
33
34 Notes
35 -----
36 Returns a centered weighted moving average of the original series. Where
37 the weights a[j] are computed ::
38
39 a[j] = b[j] + theta, for j = 0, +/-1, +/-2, ... +/- K
40 b[0] = (omega_2 - omega_1)/pi
41 b[j] = 1/(pi*j)(sin(omega_2*j)-sin(omega_1*j), for j = +/-1, +/-2,...
42
43 and theta is a normalizing constant ::
44
45 theta = -sum(b)/(2K+1)
46
47 Examples
48 --------
49 >>> import statsmodels.api as sm
50 >>> dta = sm.datasets.macrodata.load()
51 >>> X = dta.data['realinv']
52 >>> Y = sm.tsa.filters.bkfilter(X, 6, 24, 12)
53 """
54 #TODO: change the docstring to ..math::?
55 #TODO: allow windowing functions to correct for Gibb's Phenomenon?
56 # adjust bweights (symmetrically) by below before demeaning
57 # Lancosz Sigma Factors np.sinc(2*j/(2.*K+1))
58 if low < 2:
59 raise ValueError("low cannot be less than 2")
60 X = np.asarray(X)
61 omega_1 = 2.*np.pi/high # convert from freq. to periodicity
62 omega_2 = 2.*np.pi/low
63 bweights = np.zeros(2*K+1)
64 bweights[K] = (omega_2 - omega_1)/np.pi # weight at zero freq.
65 j = np.arange(1,int(K)+1)
66 weights = 1/(np.pi*j)*(np.sin(omega_2*j)-np.sin(omega_1*j))
67 bweights[K+j] = weights # j is an idx
68 bweights[:K] = weights[::-1] # make symmetric weights
69 bweights -= bweights.mean() # make sure weights sum to zero
70 if X.ndim == 2:
71 bweights = bweights[:,None]
72 return fftconvolve(bweights, X, mode='valid') # get a centered moving avg/
73 # convolution
74
[end of statsmodels/tsa/filters/bk_filter.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/statsmodels/tsa/filters/bk_filter.py b/statsmodels/tsa/filters/bk_filter.py
--- a/statsmodels/tsa/filters/bk_filter.py
+++ b/statsmodels/tsa/filters/bk_filter.py
@@ -69,5 +69,5 @@
bweights -= bweights.mean() # make sure weights sum to zero
if X.ndim == 2:
bweights = bweights[:,None]
- return fftconvolve(bweights, X, mode='valid') # get a centered moving avg/
+ return fftconvolve(X, bweights, mode='valid') # get a centered moving avg/
# convolution
|
{"golden_diff": "diff --git a/statsmodels/tsa/filters/bk_filter.py b/statsmodels/tsa/filters/bk_filter.py\n--- a/statsmodels/tsa/filters/bk_filter.py\n+++ b/statsmodels/tsa/filters/bk_filter.py\n@@ -69,5 +69,5 @@\n bweights -= bweights.mean() # make sure weights sum to zero\n if X.ndim == 2:\n bweights = bweights[:,None]\n- return fftconvolve(bweights, X, mode='valid') # get a centered moving avg/\n+ return fftconvolve(X, bweights, mode='valid') # get a centered moving avg/\n # convolution\n", "issue": "Test Baxter King band-pass filter fails with scipy 0.12 beta1\ncurrent git head 1b12824f53b1 and 0.4.3, python2.7 tested on ubuntu 13.04 amd64, haven't tried scipy 0.11 but it the test seems to work with the 0.10.1 package\n\n```\n======================================================================\nERROR: Test Baxter King band-pass filter. Results are taken from Stata\n----------------------------------------------------------------------\nTraceback (most recent call last):\n File \"/usr/lib/python2.7/dist-packages/nose/case.py\", line 197, in runTest\n self.test(*self.arg)\n File \"/statsmodels/statsmodels/tsa/filters/tests/test_filters.py\", line 47, in test_bking1d\n Y = bkfilter(X, 6, 32, 12)\n File \"/statsmodels/statsmodels/tsa/filters/bk_filter.py\", line 72, in bkfilter\n return fftconvolve(bweights, X, mode='valid') # get a centered moving avg/\n File \"/usr/lib/python2.7/dist-packages/scipy/signal/signaltools.py\", line 204, in fftconvolve\n _check_valid_mode_shapes(s1, s2)\n File \"/usr/lib/python2.7/dist-packages/scipy/signal/signaltools.py\", line 64, in _check_valid_mode_shapes\n \"in1 should have at least as many items as in2 in \"\nValueError: in1 should have at least as many items as in2 in every dimension for 'valid' mode.\n\n----------------------------------------------------------------------\n```\n\n", "before_files": [{"content": "import numpy as np\nfrom scipy.signal import fftconvolve\n\ndef bkfilter(X, low=6, high=32, K=12):\n \"\"\"\n Baxter-King bandpass filter\n\n Parameters\n ----------\n X : array-like\n A 1 or 2d ndarray. If 2d, variables are assumed to be in columns.\n low : float\n Minimum period for oscillations, ie., Baxter and King suggest that\n the Burns-Mitchell U.S. business cycle has 6 for quarterly data and\n 1.5 for annual data.\n high : float\n Maximum period for oscillations BK suggest that the U.S.\n business cycle has 32 for quarterly data and 8 for annual data.\n K : int\n Lead-lag length of the filter. Baxter and King propose a truncation\n length of 12 for quarterly data and 3 for annual data.\n\n Returns\n -------\n Y : array\n Cyclical component of X\n\n References\n ---------- ::\n Baxter, M. and R. G. King. \"Measuring Business Cycles: Approximate\n Band-Pass Filters for Economic Time Series.\" *Review of Economics and\n Statistics*, 1999, 81(4), 575-593.\n\n Notes\n -----\n Returns a centered weighted moving average of the original series. Where\n the weights a[j] are computed ::\n\n a[j] = b[j] + theta, for j = 0, +/-1, +/-2, ... +/- K\n b[0] = (omega_2 - omega_1)/pi\n b[j] = 1/(pi*j)(sin(omega_2*j)-sin(omega_1*j), for j = +/-1, +/-2,...\n\n and theta is a normalizing constant ::\n\n theta = -sum(b)/(2K+1)\n\n Examples\n --------\n >>> import statsmodels.api as sm\n >>> dta = sm.datasets.macrodata.load()\n >>> X = dta.data['realinv']\n >>> Y = sm.tsa.filters.bkfilter(X, 6, 24, 12)\n \"\"\"\n#TODO: change the docstring to ..math::?\n#TODO: allow windowing functions to correct for Gibb's Phenomenon?\n# adjust bweights (symmetrically) by below before demeaning\n# Lancosz Sigma Factors np.sinc(2*j/(2.*K+1))\n if low < 2:\n raise ValueError(\"low cannot be less than 2\")\n X = np.asarray(X)\n omega_1 = 2.*np.pi/high # convert from freq. to periodicity\n omega_2 = 2.*np.pi/low\n bweights = np.zeros(2*K+1)\n bweights[K] = (omega_2 - omega_1)/np.pi # weight at zero freq.\n j = np.arange(1,int(K)+1)\n weights = 1/(np.pi*j)*(np.sin(omega_2*j)-np.sin(omega_1*j))\n bweights[K+j] = weights # j is an idx\n bweights[:K] = weights[::-1] # make symmetric weights\n bweights -= bweights.mean() # make sure weights sum to zero\n if X.ndim == 2:\n bweights = bweights[:,None]\n return fftconvolve(bweights, X, mode='valid') # get a centered moving avg/\n # convolution\n", "path": "statsmodels/tsa/filters/bk_filter.py"}]}
| 1,806 | 145 |
gh_patches_debug_48836
|
rasdani/github-patches
|
git_diff
|
LibraryOfCongress__concordia-1208
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Create URL path for staff page
We will create a simple page for staff. Need to create the URL path.
ex - `crowd.loc.gov/for-staff`
</issue>
<code>
[start of concordia/urls.py]
1 from django.conf import settings
2 from django.conf.urls import url
3 from django.contrib import admin
4 from django.http import Http404, HttpResponseForbidden
5 from django.urls import include, path
6 from django.urls.converters import register_converter
7 from django.views.defaults import page_not_found, permission_denied, server_error
8 from django.views.generic import RedirectView
9
10 from exporter import views as exporter_views
11
12 from . import converters, views
13
14 register_converter(converters.UnicodeSlugConverter, "uslug")
15 register_converter(converters.ItemIdConverter, "item_id")
16
17 tx_urlpatterns = (
18 [
19 path("", views.CampaignListView.as_view(), name="campaign-list"),
20 path(
21 "<uslug:slug>/", views.CampaignDetailView.as_view(), name="campaign-detail"
22 ),
23 path(
24 "<uslug:campaign_slug>/export/csv/",
25 exporter_views.ExportCampaignToCSV.as_view(),
26 name="campaign-export-csv",
27 ),
28 path(
29 "<uslug:campaign_slug>/export/bagit/",
30 exporter_views.ExportCampaignToBagIt.as_view(),
31 name="campaign-export-bagit",
32 ),
33 path(
34 "<uslug:campaign_slug>/<uslug:project_slug>/export/bagit/",
35 exporter_views.ExportProjectToBagIt.as_view(),
36 name="project-export-bagit",
37 ),
38 path(
39 (
40 "<uslug:campaign_slug>/<uslug:project_slug>/"
41 "<item_id:item_id>/export/bagit/"
42 ),
43 exporter_views.ExportItemToBagIt.as_view(),
44 name="item-export-bagit",
45 ),
46 path(
47 "<uslug:campaign_slug>/report/",
48 views.ReportCampaignView.as_view(),
49 name="campaign-report",
50 ),
51 path(
52 (
53 "<uslug:campaign_slug>/<uslug:project_slug>/"
54 "<item_id:item_id>/<uslug:slug>/"
55 ),
56 views.AssetDetailView.as_view(),
57 name="asset-detail",
58 ),
59 # n.b. this must be above project-detail to avoid being seen as a project slug:
60 path(
61 "<uslug:campaign_slug>/next-transcribable-asset/",
62 views.redirect_to_next_transcribable_campaign_asset,
63 name="redirect-to-next-transcribable-campaign-asset",
64 ),
65 path(
66 "<uslug:campaign_slug>/next-reviewable-asset/",
67 views.redirect_to_next_reviewable_campaign_asset,
68 name="redirect-to-next-reviewable-campaign-asset",
69 ),
70 path(
71 "<uslug:campaign_slug>/<uslug:slug>/",
72 views.ProjectDetailView.as_view(),
73 name="project-detail",
74 ),
75 path(
76 "<uslug:campaign_slug>/<uslug:project_slug>/<item_id:item_id>/",
77 views.ItemDetailView.as_view(),
78 name="item-detail",
79 ),
80 ],
81 "transcriptions",
82 )
83
84 urlpatterns = [
85 path("", views.HomeView.as_view(), name="homepage"),
86 path("healthz", views.healthz, name="health-check"),
87 path("about/", views.simple_page, name="about"),
88 path("help-center/", views.simple_page, name="help-center"),
89 path("help-center/welcome-guide/", views.simple_page, name="welcome-guide"),
90 path("help-center/how-to-transcribe/", views.simple_page, name="how-to-transcribe"),
91 path("help-center/how-to-review/", views.simple_page, name="how-to-review"),
92 path("help-center/how-to-tag/", views.simple_page, name="how-to-tag"),
93 path(
94 "help-center/welcome-guide-esp/",
95 views.simple_page,
96 name="welcome-guide-spanish",
97 ),
98 path(
99 "help-center/how-to-transcribe-esp/",
100 views.simple_page,
101 name="how-to-transcribe-spanish",
102 ),
103 path(
104 "help-center/how-to-review-esp/",
105 views.simple_page,
106 name="how-to-review-spanish",
107 ),
108 path("help-center/how-to-tag-esp/", views.simple_page, name="how-to-tag-spanish"),
109 path("for-educators/", views.simple_page, name="for-educators"),
110 path("resources/", views.simple_page, name="resources"),
111 path(
112 "latest/",
113 RedirectView.as_view(pattern_name="about", permanent=True, query_string=True),
114 ),
115 path("questions/", views.simple_page, name="questions"),
116 path("contact/", views.ContactUsView.as_view(), name="contact"),
117 path("act/", views.action_app, name="action-app"),
118 path(
119 "campaigns-topics/",
120 views.CampaignTopicListView.as_view(),
121 name="campaign-topic-list",
122 ),
123 path("topics/", views.TopicListView.as_view(), name="topic-list"),
124 path("topics/<uslug:slug>/", views.TopicDetailView.as_view(), name="topic-detail"),
125 path(
126 "topics/<uslug:topic_slug>/next-transcribable-asset/",
127 views.redirect_to_next_transcribable_topic_asset,
128 name="redirect-to-next-transcribable-topic-asset",
129 ),
130 path(
131 "topics/<uslug:topic_slug>/next-reviewable-asset/",
132 views.redirect_to_next_reviewable_topic_asset,
133 name="redirect-to-next-reviewable-topic-asset",
134 ),
135 path(
136 "next-transcribable-asset/",
137 views.redirect_to_next_transcribable_asset,
138 name="redirect-to-next-transcribable-asset",
139 ),
140 path(
141 "next-reviewable-asset/",
142 views.redirect_to_next_reviewable_asset,
143 name="redirect-to-next-reviewable-asset",
144 ),
145 path("campaigns/", include(tx_urlpatterns, namespace="transcriptions")),
146 path("reserve-asset/<int:asset_pk>/", views.reserve_asset, name="reserve-asset"),
147 path(
148 "assets/<int:asset_pk>/transcriptions/save/",
149 views.save_transcription,
150 name="save-transcription",
151 ),
152 path(
153 "transcriptions/<int:pk>/submit/",
154 views.submit_transcription,
155 name="submit-transcription",
156 ),
157 path(
158 "transcriptions/<int:pk>/review/",
159 views.review_transcription,
160 name="review-transcription",
161 ),
162 path("assets/<int:asset_pk>/tags/submit/", views.submit_tags, name="submit-tags"),
163 path("assets/", views.AssetListView.as_view(), name="asset-list"),
164 path(
165 "transcribe/", views.TranscribeListView.as_view(), name="transcribe-asset-list"
166 ),
167 path("review/", views.ReviewListView.as_view(), name="review-asset-list"),
168 path("account/ajax-status/", views.ajax_session_status, name="ajax-session-status"),
169 path("account/ajax-messages/", views.ajax_messages, name="ajax-messages"),
170 path(
171 "account/register/",
172 views.ConcordiaRegistrationView.as_view(),
173 name="registration_register",
174 ),
175 path(
176 "account/login/", views.ConcordiaLoginView.as_view(), name="registration_login"
177 ),
178 path("account/profile/", views.AccountProfileView.as_view(), name="user-profile"),
179 path(
180 "account/password_reset/",
181 views.ConcordiaPasswordResetRequestView.as_view(),
182 name="password_reset",
183 ),
184 path(
185 "account/reset/<uidb64>/<token>/",
186 views.ConcordiaPasswordResetConfirmView.as_view(),
187 name="password_reset_confirm",
188 ),
189 path("account/", include("django_registration.backends.activation.urls")),
190 path("account/", include("django.contrib.auth.urls")),
191 path(
192 ".well-known/change-password", # https://wicg.github.io/change-password-url/
193 RedirectView.as_view(pattern_name="password_change"),
194 ),
195 path("captcha/ajax/", views.ajax_captcha, name="ajax-captcha"),
196 path("captcha/", include("captcha.urls")),
197 path("admin/", admin.site.urls),
198 # Internal support assists:
199 path("error/500/", server_error),
200 path("error/404/", page_not_found, {"exception": Http404()}),
201 path("error/429/", views.ratelimit_view),
202 path("error/403/", permission_denied, {"exception": HttpResponseForbidden()}),
203 url("", include("django_prometheus_metrics.urls")),
204 path("robots.txt", include("robots.urls")),
205 ]
206
207 if settings.DEBUG:
208 import debug_toolbar
209 from django.conf.urls.static import static
210
211 urlpatterns = [path("__debug__/", include(debug_toolbar.urls))] + urlpatterns
212
213 urlpatterns += static(settings.MEDIA_URL, document_root=settings.MEDIA_ROOT)
214
[end of concordia/urls.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/concordia/urls.py b/concordia/urls.py
--- a/concordia/urls.py
+++ b/concordia/urls.py
@@ -107,6 +107,7 @@
),
path("help-center/how-to-tag-esp/", views.simple_page, name="how-to-tag-spanish"),
path("for-educators/", views.simple_page, name="for-educators"),
+ path("for-staff/", views.simple_page, name="for-staff"),
path("resources/", views.simple_page, name="resources"),
path(
"latest/",
|
{"golden_diff": "diff --git a/concordia/urls.py b/concordia/urls.py\n--- a/concordia/urls.py\n+++ b/concordia/urls.py\n@@ -107,6 +107,7 @@\n ),\n path(\"help-center/how-to-tag-esp/\", views.simple_page, name=\"how-to-tag-spanish\"),\n path(\"for-educators/\", views.simple_page, name=\"for-educators\"),\n+ path(\"for-staff/\", views.simple_page, name=\"for-staff\"),\n path(\"resources/\", views.simple_page, name=\"resources\"),\n path(\n \"latest/\",\n", "issue": "Create URL path for staff page\nWe will create a simple page for staff. Need to create the URL path. \r\n\r\nex - `crowd.loc.gov/for-staff`\n", "before_files": [{"content": "from django.conf import settings\nfrom django.conf.urls import url\nfrom django.contrib import admin\nfrom django.http import Http404, HttpResponseForbidden\nfrom django.urls import include, path\nfrom django.urls.converters import register_converter\nfrom django.views.defaults import page_not_found, permission_denied, server_error\nfrom django.views.generic import RedirectView\n\nfrom exporter import views as exporter_views\n\nfrom . import converters, views\n\nregister_converter(converters.UnicodeSlugConverter, \"uslug\")\nregister_converter(converters.ItemIdConverter, \"item_id\")\n\ntx_urlpatterns = (\n [\n path(\"\", views.CampaignListView.as_view(), name=\"campaign-list\"),\n path(\n \"<uslug:slug>/\", views.CampaignDetailView.as_view(), name=\"campaign-detail\"\n ),\n path(\n \"<uslug:campaign_slug>/export/csv/\",\n exporter_views.ExportCampaignToCSV.as_view(),\n name=\"campaign-export-csv\",\n ),\n path(\n \"<uslug:campaign_slug>/export/bagit/\",\n exporter_views.ExportCampaignToBagIt.as_view(),\n name=\"campaign-export-bagit\",\n ),\n path(\n \"<uslug:campaign_slug>/<uslug:project_slug>/export/bagit/\",\n exporter_views.ExportProjectToBagIt.as_view(),\n name=\"project-export-bagit\",\n ),\n path(\n (\n \"<uslug:campaign_slug>/<uslug:project_slug>/\"\n \"<item_id:item_id>/export/bagit/\"\n ),\n exporter_views.ExportItemToBagIt.as_view(),\n name=\"item-export-bagit\",\n ),\n path(\n \"<uslug:campaign_slug>/report/\",\n views.ReportCampaignView.as_view(),\n name=\"campaign-report\",\n ),\n path(\n (\n \"<uslug:campaign_slug>/<uslug:project_slug>/\"\n \"<item_id:item_id>/<uslug:slug>/\"\n ),\n views.AssetDetailView.as_view(),\n name=\"asset-detail\",\n ),\n # n.b. this must be above project-detail to avoid being seen as a project slug:\n path(\n \"<uslug:campaign_slug>/next-transcribable-asset/\",\n views.redirect_to_next_transcribable_campaign_asset,\n name=\"redirect-to-next-transcribable-campaign-asset\",\n ),\n path(\n \"<uslug:campaign_slug>/next-reviewable-asset/\",\n views.redirect_to_next_reviewable_campaign_asset,\n name=\"redirect-to-next-reviewable-campaign-asset\",\n ),\n path(\n \"<uslug:campaign_slug>/<uslug:slug>/\",\n views.ProjectDetailView.as_view(),\n name=\"project-detail\",\n ),\n path(\n \"<uslug:campaign_slug>/<uslug:project_slug>/<item_id:item_id>/\",\n views.ItemDetailView.as_view(),\n name=\"item-detail\",\n ),\n ],\n \"transcriptions\",\n)\n\nurlpatterns = [\n path(\"\", views.HomeView.as_view(), name=\"homepage\"),\n path(\"healthz\", views.healthz, name=\"health-check\"),\n path(\"about/\", views.simple_page, name=\"about\"),\n path(\"help-center/\", views.simple_page, name=\"help-center\"),\n path(\"help-center/welcome-guide/\", views.simple_page, name=\"welcome-guide\"),\n path(\"help-center/how-to-transcribe/\", views.simple_page, name=\"how-to-transcribe\"),\n path(\"help-center/how-to-review/\", views.simple_page, name=\"how-to-review\"),\n path(\"help-center/how-to-tag/\", views.simple_page, name=\"how-to-tag\"),\n path(\n \"help-center/welcome-guide-esp/\",\n views.simple_page,\n name=\"welcome-guide-spanish\",\n ),\n path(\n \"help-center/how-to-transcribe-esp/\",\n views.simple_page,\n name=\"how-to-transcribe-spanish\",\n ),\n path(\n \"help-center/how-to-review-esp/\",\n views.simple_page,\n name=\"how-to-review-spanish\",\n ),\n path(\"help-center/how-to-tag-esp/\", views.simple_page, name=\"how-to-tag-spanish\"),\n path(\"for-educators/\", views.simple_page, name=\"for-educators\"),\n path(\"resources/\", views.simple_page, name=\"resources\"),\n path(\n \"latest/\",\n RedirectView.as_view(pattern_name=\"about\", permanent=True, query_string=True),\n ),\n path(\"questions/\", views.simple_page, name=\"questions\"),\n path(\"contact/\", views.ContactUsView.as_view(), name=\"contact\"),\n path(\"act/\", views.action_app, name=\"action-app\"),\n path(\n \"campaigns-topics/\",\n views.CampaignTopicListView.as_view(),\n name=\"campaign-topic-list\",\n ),\n path(\"topics/\", views.TopicListView.as_view(), name=\"topic-list\"),\n path(\"topics/<uslug:slug>/\", views.TopicDetailView.as_view(), name=\"topic-detail\"),\n path(\n \"topics/<uslug:topic_slug>/next-transcribable-asset/\",\n views.redirect_to_next_transcribable_topic_asset,\n name=\"redirect-to-next-transcribable-topic-asset\",\n ),\n path(\n \"topics/<uslug:topic_slug>/next-reviewable-asset/\",\n views.redirect_to_next_reviewable_topic_asset,\n name=\"redirect-to-next-reviewable-topic-asset\",\n ),\n path(\n \"next-transcribable-asset/\",\n views.redirect_to_next_transcribable_asset,\n name=\"redirect-to-next-transcribable-asset\",\n ),\n path(\n \"next-reviewable-asset/\",\n views.redirect_to_next_reviewable_asset,\n name=\"redirect-to-next-reviewable-asset\",\n ),\n path(\"campaigns/\", include(tx_urlpatterns, namespace=\"transcriptions\")),\n path(\"reserve-asset/<int:asset_pk>/\", views.reserve_asset, name=\"reserve-asset\"),\n path(\n \"assets/<int:asset_pk>/transcriptions/save/\",\n views.save_transcription,\n name=\"save-transcription\",\n ),\n path(\n \"transcriptions/<int:pk>/submit/\",\n views.submit_transcription,\n name=\"submit-transcription\",\n ),\n path(\n \"transcriptions/<int:pk>/review/\",\n views.review_transcription,\n name=\"review-transcription\",\n ),\n path(\"assets/<int:asset_pk>/tags/submit/\", views.submit_tags, name=\"submit-tags\"),\n path(\"assets/\", views.AssetListView.as_view(), name=\"asset-list\"),\n path(\n \"transcribe/\", views.TranscribeListView.as_view(), name=\"transcribe-asset-list\"\n ),\n path(\"review/\", views.ReviewListView.as_view(), name=\"review-asset-list\"),\n path(\"account/ajax-status/\", views.ajax_session_status, name=\"ajax-session-status\"),\n path(\"account/ajax-messages/\", views.ajax_messages, name=\"ajax-messages\"),\n path(\n \"account/register/\",\n views.ConcordiaRegistrationView.as_view(),\n name=\"registration_register\",\n ),\n path(\n \"account/login/\", views.ConcordiaLoginView.as_view(), name=\"registration_login\"\n ),\n path(\"account/profile/\", views.AccountProfileView.as_view(), name=\"user-profile\"),\n path(\n \"account/password_reset/\",\n views.ConcordiaPasswordResetRequestView.as_view(),\n name=\"password_reset\",\n ),\n path(\n \"account/reset/<uidb64>/<token>/\",\n views.ConcordiaPasswordResetConfirmView.as_view(),\n name=\"password_reset_confirm\",\n ),\n path(\"account/\", include(\"django_registration.backends.activation.urls\")),\n path(\"account/\", include(\"django.contrib.auth.urls\")),\n path(\n \".well-known/change-password\", # https://wicg.github.io/change-password-url/\n RedirectView.as_view(pattern_name=\"password_change\"),\n ),\n path(\"captcha/ajax/\", views.ajax_captcha, name=\"ajax-captcha\"),\n path(\"captcha/\", include(\"captcha.urls\")),\n path(\"admin/\", admin.site.urls),\n # Internal support assists:\n path(\"error/500/\", server_error),\n path(\"error/404/\", page_not_found, {\"exception\": Http404()}),\n path(\"error/429/\", views.ratelimit_view),\n path(\"error/403/\", permission_denied, {\"exception\": HttpResponseForbidden()}),\n url(\"\", include(\"django_prometheus_metrics.urls\")),\n path(\"robots.txt\", include(\"robots.urls\")),\n]\n\nif settings.DEBUG:\n import debug_toolbar\n from django.conf.urls.static import static\n\n urlpatterns = [path(\"__debug__/\", include(debug_toolbar.urls))] + urlpatterns\n\n urlpatterns += static(settings.MEDIA_URL, document_root=settings.MEDIA_ROOT)\n", "path": "concordia/urls.py"}]}
| 2,894 | 132 |
gh_patches_debug_37179
|
rasdani/github-patches
|
git_diff
|
kartoza__prj.app-479
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
When issuing a certificate, the person being certified should be sent an email with a link to their cert
</issue>
<code>
[start of django_project/certification/views/certificate.py]
1 # coding=utf-8
2 from django.http import Http404, HttpResponse
3 from django.views.generic import CreateView, DetailView
4 from django.core.urlresolvers import reverse
5 from braces.views import LoginRequiredMixin
6 from reportlab.pdfgen import canvas
7 from reportlab.lib.pagesizes import A4, landscape
8 from reportlab.lib.utils import ImageReader
9 from ..models import Certificate, Course, Attendee
10 from ..forms import CertificateForm
11 from base.models.project import Project
12
13
14 class CertificateMixin(object):
15 """Mixin class to provide standard settings for Certificate."""
16
17 model = Certificate
18 form_class = CertificateForm
19
20
21 class CertificateCreateView(
22 LoginRequiredMixin, CertificateMixin, CreateView):
23 """Create view for Certificate."""
24
25 context_object_name = 'certificate'
26 template_name = 'certificate/create.html'
27
28 def get_success_url(self):
29 """Define the redirect URL.
30
31 After successful creation of the object, the User will be redirected
32 to the Course detail page.
33
34 :returns: URL
35 :rtype: HttpResponse
36 """
37
38 return reverse('course-detail', kwargs={
39 'project_slug': self.project_slug,
40 'organisation_slug': self.organisation_slug,
41 'slug': self.course_slug
42 })
43
44 def get_context_data(self, **kwargs):
45 """Get the context data which is passed to a template.
46
47 :param kwargs: Any arguments to pass to the superclass.
48 :type kwargs: dict
49
50 :returns: Context data which will be passed to the template.
51 :rtype: dict
52 """
53
54 context = super(
55 CertificateCreateView, self).get_context_data(**kwargs)
56 context['course'] = Course.objects.get(slug=self.course_slug)
57 context['attendee'] = Attendee.objects.get(pk=self.pk)
58 return context
59
60 def get_form_kwargs(self):
61 """Get keyword arguments from form.
62
63 :returns keyword argument from the form
64 :rtype: dict
65 """
66
67 kwargs = super(CertificateCreateView, self).get_form_kwargs()
68 self.project_slug = self.kwargs.get('project_slug', None)
69 self.organisation_slug = self.kwargs.get('organisation_slug', None)
70 self.course_slug = self.kwargs.get('course_slug', None)
71 self.pk = self.kwargs.get('pk', None)
72 self.course = Course.objects.get(slug=self.course_slug)
73 self.attendee = Attendee.objects.get(pk=self.pk)
74 kwargs.update({
75 'user': self.request.user,
76 'course': self.course,
77 'attendee': self.attendee,
78 })
79 return kwargs
80
81
82 class CertificateDetailView(DetailView):
83 """Detail view for Certificate."""
84
85 model = Certificate
86 context_object_name = 'certificate'
87 template_name = 'certificate/detail.html'
88
89 def get_context_data(self, **kwargs):
90 """Get the context data which is passed to a template.
91
92 :param kwargs: Any arguments to pass to the superclass.
93 :type kwargs: dict
94
95 :returns: Context data which will be passed to the template.
96 :rtype: dict
97 """
98
99 self.certificateID = self.kwargs.get('id', None)
100 self.project_slug = self.kwargs.get('project_slug', None)
101 context = super(
102 CertificateDetailView, self).get_context_data(**kwargs)
103 issued_id = \
104 Certificate.objects.all().values_list('certificateID', flat=True)
105 if self.certificateID in issued_id:
106 context['certificate'] = \
107 Certificate.objects.get(certificateID=self.certificateID)
108 context['project_slug'] = self.project_slug
109 return context
110
111 def get_queryset(self):
112 """Get the queryset for this view.
113
114 :returns: Queryset which is all certificate in the
115 corresponding organisation.
116 :rtype: QuerySet
117 """
118
119 qs = Certificate.objects.all()
120 return qs
121
122 def get_object(self, queryset=None):
123 """Get the object for this view.
124
125 :param queryset: A query set
126 :type queryset: QuerySet
127
128 :returns: Queryset which is filtered to only show a certificate
129 depends on the input certificate ID.
130 :rtype: QuerySet
131 :raises: Http404
132 """
133
134 if queryset is None:
135 queryset = self.get_queryset()
136 certificateID = self.kwargs.get('id', None)
137 if certificateID:
138 try:
139 obj = queryset.get(certificateID=certificateID)
140 return obj
141 except Certificate.DoesNotExist:
142 return None
143 else:
144 raise Http404('Sorry! Certificate by this ID is not exist.')
145
146
147 def certificate_pdf_view(request, **kwargs):
148
149 project_slug = kwargs.pop('project_slug')
150 course_slug = kwargs.pop('course_slug')
151 pk = kwargs.pop('pk')
152 project = Project.objects.get(slug=project_slug)
153 course = Course.objects.get(slug=course_slug)
154 attendee = Attendee.objects.get(pk=pk)
155 certificate = Certificate.objects.get(course=course, attendee=attendee)
156 current_site = request.META['HTTP_HOST']
157
158 # Create the HttpResponse object with the appropriate PDF headers.
159 response = HttpResponse(content_type='application/pdf')
160 response['Content-Disposition'] = 'filename="certificate.pdf"'
161
162 # Create the PDF object, using the response object as its "file."
163 page = canvas.Canvas(response, pagesize=landscape(A4))
164 width, height = A4
165 center = height * 0.5
166
167 if project.image_file:
168 project_logo = ImageReader(project.image_file)
169 else:
170 project_logo = None
171
172 if course.certifying_organisation.logo:
173 organisation_logo = ImageReader(course.certifying_organisation.logo)
174 else:
175 organisation_logo = None
176
177 if project.signature:
178 project_owner_signature = ImageReader(project.signature)
179 else:
180 project_owner_signature = None
181
182 if course.course_convener.signature:
183 convener_signature = ImageReader(course.course_convener.signature)
184 else:
185 convener_signature = None
186
187 if course.template_certificate:
188 background = ImageReader(course.template_certificate)
189 else:
190 background = None
191
192 # Certificate margin.
193 margin_right = height - 50
194 margin_left = 50
195 margin_bottom = 50
196 max_left = margin_right - 100
197
198 # Draw things on the PDF. Here's where the PDF generation happens.
199 # See the ReportLab documentation for the full list of functionality.
200 if background is not None:
201 page.drawImage(
202 background, 0, 0, height=width, width=height,
203 preserveAspectRatio=True, mask='auto')
204 page.setFillColorRGB(0.1, 0.1, 0.1)
205 page.setFont('Times-Roman', 18)
206 # page.drawString(margin_left, 480, project.name)
207 # page.drawRightString(
208 # (margin_right), 480, course.certifying_organisation.name)
209
210 if project_logo is not None:
211 page.drawImage(
212 project_logo, 50, 450, width=100, height=100,
213 preserveAspectRatio=True, mask='auto')
214
215 if organisation_logo is not None:
216 page.drawImage(
217 organisation_logo, max_left, 450, height=100, width=100,
218 preserveAspectRatio=True, anchor='c', mask='auto')
219
220 page.setFont('Times-Bold', 26)
221 page.drawCentredString(center, 480, 'Certificate of Completion')
222 page.drawCentredString(
223 center, 400, '%s %s' % (attendee.firstname, attendee.surname))
224 page.setFont('Times-Roman', 16)
225 page.drawCentredString(
226 center, 360, 'Has attended and completed the course:')
227 page.setFont('Times-Bold', 20)
228 page.drawCentredString(center, 300, course.course_type.name)
229 page.setFont('Times-Roman', 16)
230 page.drawCentredString(
231 center, 270,
232 'From %s %s %s to %s %s %s'
233 % (course.start_date.day, course.start_date.strftime('%B'),
234 course.start_date.year, course.end_date.day,
235 course.end_date.strftime('%B'), course.end_date.year))
236 page.setFillColorRGB(0.1, 0.1, 0.1)
237 page.drawCentredString(
238 center, 220, 'Convened by %s %s at %s' % (
239 course.course_convener.user.first_name,
240 course.course_convener.user.last_name, course.training_center))
241
242 if project_owner_signature is not None:
243 page.drawImage(
244 project_owner_signature,
245 (margin_left + 100), (margin_bottom + 70), width=100, height=70,
246 preserveAspectRatio=True, anchor='s', mask='auto')
247
248 if convener_signature is not None:
249 page.drawImage(
250 convener_signature, (margin_right - 200), (margin_bottom + 70),
251 width=100, height=70, preserveAspectRatio=True, anchor='s',
252 mask='auto')
253
254 page.setFont('Times-Italic', 12)
255 page.drawCentredString(
256 (margin_left + 150), (margin_bottom + 60),
257 '%s %s' % (project.owner.first_name, project.owner.last_name))
258 page.drawCentredString(
259 (margin_right - 150), (margin_bottom + 60),
260 '%s %s' % (
261 course.course_convener.user.first_name,
262 course.course_convener.user.last_name))
263 page.line(
264 (margin_left + 70), (margin_bottom + 55),
265 (margin_left + 230), (margin_bottom + 55))
266 page.line(
267 (margin_right - 70), (margin_bottom + 55),
268 (margin_right - 230), (margin_bottom + 55))
269 page.setFont('Times-Roman', 13)
270 page.drawCentredString(
271 (margin_left + 150), (margin_bottom + 40), 'Project Owner')
272 page.drawCentredString(
273 (margin_right - 150), (margin_bottom + 40), 'Convener')
274
275 # Footnotes.
276 page.setFont('Times-Roman', 14)
277 page.drawString(
278 margin_left, margin_bottom - 10, 'ID: %s' % certificate.certificateID)
279 page.setFont('Times-Roman', 8)
280 page.drawString(
281 margin_left, (margin_bottom - 20),
282 'You can verify this certificate by visiting '
283 'http://%s/en/%s/certificate/%s/.'
284 % (current_site, project.slug, certificate.certificateID))
285
286 # Close the PDF object cleanly.
287 page.showPage()
288 page.save()
289 return response
290
[end of django_project/certification/views/certificate.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/django_project/certification/views/certificate.py b/django_project/certification/views/certificate.py
--- a/django_project/certification/views/certificate.py
+++ b/django_project/certification/views/certificate.py
@@ -1,7 +1,11 @@
# coding=utf-8
-from django.http import Http404, HttpResponse
+from django.http import Http404, HttpResponse, HttpResponseRedirect
from django.views.generic import CreateView, DetailView
+from django.contrib.sites.models import Site
+from django.core.mail import send_mail
from django.core.urlresolvers import reverse
+from django.db import IntegrityError
+from django.core.exceptions import ValidationError
from braces.views import LoginRequiredMixin
from reportlab.pdfgen import canvas
from reportlab.lib.pagesizes import A4, landscape
@@ -78,6 +82,60 @@
})
return kwargs
+ def form_valid(self, form):
+ """Save new created certificate
+
+ :param form
+ :type form
+
+ :returns HttpResponseRedirect object to success_url
+ :rtype: HttpResponseRedirect
+
+ We check that there is no referential integrity error when saving."""
+
+ try:
+ super(CertificateCreateView, self).form_valid(form)
+ certificate_id = form.instance.certificateID
+
+ # Send email to the attendee when the certificate is issued.
+ if Site._meta.installed:
+ site = Site.objects.get_current().domain
+
+ send_mail(
+ 'Certificate from %s Course' % self.course.course_type,
+ 'Dear %s %s,\n\n' % (
+ self.attendee.firstname, self.attendee.surname) +
+ 'Congratulations!\n'
+ 'Your certificate from the following course '
+ 'has been issued.\n\n' +
+ 'Course type: %s\n' % self.course.course_type +
+ 'Course date: %s to %s\n' % (
+ self.course.start_date.strftime('%d %B %Y'),
+ self.course.end_date.strftime('%d %B %Y')) +
+ 'Training center: %s\n' % self.course.training_center +
+ 'Certifying organisation: %s\n\n'
+ % self.course.certifying_organisation +
+ 'You may check the full details of the certificate '
+ 'by visiting:\n'
+ 'http://%s/en/%s/certificate/%s/\n\n' % (
+ site,
+ self.course.certifying_organisation.project.slug,
+ certificate_id
+ ) +
+ 'Sincerely,\n%s %s' % (
+ self.course.course_convener.user.first_name,
+ self.course.course_convener.user.last_name
+ ),
+ self.course.course_convener.user.email,
+ [self.attendee.email],
+ fail_silently=False,
+ )
+
+ return HttpResponseRedirect(self.get_success_url())
+ except IntegrityError:
+ return ValidationError(
+ 'ERROR: Certificate already exists!')
+
class CertificateDetailView(DetailView):
"""Detail view for Certificate."""
|
{"golden_diff": "diff --git a/django_project/certification/views/certificate.py b/django_project/certification/views/certificate.py\n--- a/django_project/certification/views/certificate.py\n+++ b/django_project/certification/views/certificate.py\n@@ -1,7 +1,11 @@\n # coding=utf-8\n-from django.http import Http404, HttpResponse\n+from django.http import Http404, HttpResponse, HttpResponseRedirect\n from django.views.generic import CreateView, DetailView\n+from django.contrib.sites.models import Site\n+from django.core.mail import send_mail\n from django.core.urlresolvers import reverse\n+from django.db import IntegrityError\n+from django.core.exceptions import ValidationError\n from braces.views import LoginRequiredMixin\n from reportlab.pdfgen import canvas\n from reportlab.lib.pagesizes import A4, landscape\n@@ -78,6 +82,60 @@\n })\n return kwargs\n \n+ def form_valid(self, form):\n+ \"\"\"Save new created certificate\n+\n+ :param form\n+ :type form\n+\n+ :returns HttpResponseRedirect object to success_url\n+ :rtype: HttpResponseRedirect\n+\n+ We check that there is no referential integrity error when saving.\"\"\"\n+\n+ try:\n+ super(CertificateCreateView, self).form_valid(form)\n+ certificate_id = form.instance.certificateID\n+\n+ # Send email to the attendee when the certificate is issued.\n+ if Site._meta.installed:\n+ site = Site.objects.get_current().domain\n+\n+ send_mail(\n+ 'Certificate from %s Course' % self.course.course_type,\n+ 'Dear %s %s,\\n\\n' % (\n+ self.attendee.firstname, self.attendee.surname) +\n+ 'Congratulations!\\n'\n+ 'Your certificate from the following course '\n+ 'has been issued.\\n\\n' +\n+ 'Course type: %s\\n' % self.course.course_type +\n+ 'Course date: %s to %s\\n' % (\n+ self.course.start_date.strftime('%d %B %Y'),\n+ self.course.end_date.strftime('%d %B %Y')) +\n+ 'Training center: %s\\n' % self.course.training_center +\n+ 'Certifying organisation: %s\\n\\n'\n+ % self.course.certifying_organisation +\n+ 'You may check the full details of the certificate '\n+ 'by visiting:\\n'\n+ 'http://%s/en/%s/certificate/%s/\\n\\n' % (\n+ site,\n+ self.course.certifying_organisation.project.slug,\n+ certificate_id\n+ ) +\n+ 'Sincerely,\\n%s %s' % (\n+ self.course.course_convener.user.first_name,\n+ self.course.course_convener.user.last_name\n+ ),\n+ self.course.course_convener.user.email,\n+ [self.attendee.email],\n+ fail_silently=False,\n+ )\n+\n+ return HttpResponseRedirect(self.get_success_url())\n+ except IntegrityError:\n+ return ValidationError(\n+ 'ERROR: Certificate already exists!')\n+\n \n class CertificateDetailView(DetailView):\n \"\"\"Detail view for Certificate.\"\"\"\n", "issue": "When issuing a certificate, the person being certified should be sent an email with a link to their cert\n\n", "before_files": [{"content": "# coding=utf-8\nfrom django.http import Http404, HttpResponse\nfrom django.views.generic import CreateView, DetailView\nfrom django.core.urlresolvers import reverse\nfrom braces.views import LoginRequiredMixin\nfrom reportlab.pdfgen import canvas\nfrom reportlab.lib.pagesizes import A4, landscape\nfrom reportlab.lib.utils import ImageReader\nfrom ..models import Certificate, Course, Attendee\nfrom ..forms import CertificateForm\nfrom base.models.project import Project\n\n\nclass CertificateMixin(object):\n \"\"\"Mixin class to provide standard settings for Certificate.\"\"\"\n\n model = Certificate\n form_class = CertificateForm\n\n\nclass CertificateCreateView(\n LoginRequiredMixin, CertificateMixin, CreateView):\n \"\"\"Create view for Certificate.\"\"\"\n\n context_object_name = 'certificate'\n template_name = 'certificate/create.html'\n\n def get_success_url(self):\n \"\"\"Define the redirect URL.\n\n After successful creation of the object, the User will be redirected\n to the Course detail page.\n\n :returns: URL\n :rtype: HttpResponse\n \"\"\"\n\n return reverse('course-detail', kwargs={\n 'project_slug': self.project_slug,\n 'organisation_slug': self.organisation_slug,\n 'slug': self.course_slug\n })\n\n def get_context_data(self, **kwargs):\n \"\"\"Get the context data which is passed to a template.\n\n :param kwargs: Any arguments to pass to the superclass.\n :type kwargs: dict\n\n :returns: Context data which will be passed to the template.\n :rtype: dict\n \"\"\"\n\n context = super(\n CertificateCreateView, self).get_context_data(**kwargs)\n context['course'] = Course.objects.get(slug=self.course_slug)\n context['attendee'] = Attendee.objects.get(pk=self.pk)\n return context\n\n def get_form_kwargs(self):\n \"\"\"Get keyword arguments from form.\n\n :returns keyword argument from the form\n :rtype: dict\n \"\"\"\n\n kwargs = super(CertificateCreateView, self).get_form_kwargs()\n self.project_slug = self.kwargs.get('project_slug', None)\n self.organisation_slug = self.kwargs.get('organisation_slug', None)\n self.course_slug = self.kwargs.get('course_slug', None)\n self.pk = self.kwargs.get('pk', None)\n self.course = Course.objects.get(slug=self.course_slug)\n self.attendee = Attendee.objects.get(pk=self.pk)\n kwargs.update({\n 'user': self.request.user,\n 'course': self.course,\n 'attendee': self.attendee,\n })\n return kwargs\n\n\nclass CertificateDetailView(DetailView):\n \"\"\"Detail view for Certificate.\"\"\"\n\n model = Certificate\n context_object_name = 'certificate'\n template_name = 'certificate/detail.html'\n\n def get_context_data(self, **kwargs):\n \"\"\"Get the context data which is passed to a template.\n\n :param kwargs: Any arguments to pass to the superclass.\n :type kwargs: dict\n\n :returns: Context data which will be passed to the template.\n :rtype: dict\n \"\"\"\n\n self.certificateID = self.kwargs.get('id', None)\n self.project_slug = self.kwargs.get('project_slug', None)\n context = super(\n CertificateDetailView, self).get_context_data(**kwargs)\n issued_id = \\\n Certificate.objects.all().values_list('certificateID', flat=True)\n if self.certificateID in issued_id:\n context['certificate'] = \\\n Certificate.objects.get(certificateID=self.certificateID)\n context['project_slug'] = self.project_slug\n return context\n\n def get_queryset(self):\n \"\"\"Get the queryset for this view.\n\n :returns: Queryset which is all certificate in the\n corresponding organisation.\n :rtype: QuerySet\n \"\"\"\n\n qs = Certificate.objects.all()\n return qs\n\n def get_object(self, queryset=None):\n \"\"\"Get the object for this view.\n\n :param queryset: A query set\n :type queryset: QuerySet\n\n :returns: Queryset which is filtered to only show a certificate\n depends on the input certificate ID.\n :rtype: QuerySet\n :raises: Http404\n \"\"\"\n\n if queryset is None:\n queryset = self.get_queryset()\n certificateID = self.kwargs.get('id', None)\n if certificateID:\n try:\n obj = queryset.get(certificateID=certificateID)\n return obj\n except Certificate.DoesNotExist:\n return None\n else:\n raise Http404('Sorry! Certificate by this ID is not exist.')\n\n\ndef certificate_pdf_view(request, **kwargs):\n\n project_slug = kwargs.pop('project_slug')\n course_slug = kwargs.pop('course_slug')\n pk = kwargs.pop('pk')\n project = Project.objects.get(slug=project_slug)\n course = Course.objects.get(slug=course_slug)\n attendee = Attendee.objects.get(pk=pk)\n certificate = Certificate.objects.get(course=course, attendee=attendee)\n current_site = request.META['HTTP_HOST']\n\n # Create the HttpResponse object with the appropriate PDF headers.\n response = HttpResponse(content_type='application/pdf')\n response['Content-Disposition'] = 'filename=\"certificate.pdf\"'\n\n # Create the PDF object, using the response object as its \"file.\"\n page = canvas.Canvas(response, pagesize=landscape(A4))\n width, height = A4\n center = height * 0.5\n\n if project.image_file:\n project_logo = ImageReader(project.image_file)\n else:\n project_logo = None\n\n if course.certifying_organisation.logo:\n organisation_logo = ImageReader(course.certifying_organisation.logo)\n else:\n organisation_logo = None\n\n if project.signature:\n project_owner_signature = ImageReader(project.signature)\n else:\n project_owner_signature = None\n\n if course.course_convener.signature:\n convener_signature = ImageReader(course.course_convener.signature)\n else:\n convener_signature = None\n\n if course.template_certificate:\n background = ImageReader(course.template_certificate)\n else:\n background = None\n\n # Certificate margin.\n margin_right = height - 50\n margin_left = 50\n margin_bottom = 50\n max_left = margin_right - 100\n\n # Draw things on the PDF. Here's where the PDF generation happens.\n # See the ReportLab documentation for the full list of functionality.\n if background is not None:\n page.drawImage(\n background, 0, 0, height=width, width=height,\n preserveAspectRatio=True, mask='auto')\n page.setFillColorRGB(0.1, 0.1, 0.1)\n page.setFont('Times-Roman', 18)\n # page.drawString(margin_left, 480, project.name)\n # page.drawRightString(\n # (margin_right), 480, course.certifying_organisation.name)\n\n if project_logo is not None:\n page.drawImage(\n project_logo, 50, 450, width=100, height=100,\n preserveAspectRatio=True, mask='auto')\n\n if organisation_logo is not None:\n page.drawImage(\n organisation_logo, max_left, 450, height=100, width=100,\n preserveAspectRatio=True, anchor='c', mask='auto')\n\n page.setFont('Times-Bold', 26)\n page.drawCentredString(center, 480, 'Certificate of Completion')\n page.drawCentredString(\n center, 400, '%s %s' % (attendee.firstname, attendee.surname))\n page.setFont('Times-Roman', 16)\n page.drawCentredString(\n center, 360, 'Has attended and completed the course:')\n page.setFont('Times-Bold', 20)\n page.drawCentredString(center, 300, course.course_type.name)\n page.setFont('Times-Roman', 16)\n page.drawCentredString(\n center, 270,\n 'From %s %s %s to %s %s %s'\n % (course.start_date.day, course.start_date.strftime('%B'),\n course.start_date.year, course.end_date.day,\n course.end_date.strftime('%B'), course.end_date.year))\n page.setFillColorRGB(0.1, 0.1, 0.1)\n page.drawCentredString(\n center, 220, 'Convened by %s %s at %s' % (\n course.course_convener.user.first_name,\n course.course_convener.user.last_name, course.training_center))\n\n if project_owner_signature is not None:\n page.drawImage(\n project_owner_signature,\n (margin_left + 100), (margin_bottom + 70), width=100, height=70,\n preserveAspectRatio=True, anchor='s', mask='auto')\n\n if convener_signature is not None:\n page.drawImage(\n convener_signature, (margin_right - 200), (margin_bottom + 70),\n width=100, height=70, preserveAspectRatio=True, anchor='s',\n mask='auto')\n\n page.setFont('Times-Italic', 12)\n page.drawCentredString(\n (margin_left + 150), (margin_bottom + 60),\n '%s %s' % (project.owner.first_name, project.owner.last_name))\n page.drawCentredString(\n (margin_right - 150), (margin_bottom + 60),\n '%s %s' % (\n course.course_convener.user.first_name,\n course.course_convener.user.last_name))\n page.line(\n (margin_left + 70), (margin_bottom + 55),\n (margin_left + 230), (margin_bottom + 55))\n page.line(\n (margin_right - 70), (margin_bottom + 55),\n (margin_right - 230), (margin_bottom + 55))\n page.setFont('Times-Roman', 13)\n page.drawCentredString(\n (margin_left + 150), (margin_bottom + 40), 'Project Owner')\n page.drawCentredString(\n (margin_right - 150), (margin_bottom + 40), 'Convener')\n\n # Footnotes.\n page.setFont('Times-Roman', 14)\n page.drawString(\n margin_left, margin_bottom - 10, 'ID: %s' % certificate.certificateID)\n page.setFont('Times-Roman', 8)\n page.drawString(\n margin_left, (margin_bottom - 20),\n 'You can verify this certificate by visiting '\n 'http://%s/en/%s/certificate/%s/.'\n % (current_site, project.slug, certificate.certificateID))\n\n # Close the PDF object cleanly.\n page.showPage()\n page.save()\n return response\n", "path": "django_project/certification/views/certificate.py"}]}
| 3,696 | 678 |
gh_patches_debug_17681
|
rasdani/github-patches
|
git_diff
|
rasterio__rasterio-2001
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Segfault when closing WarpedVRT
## Expected behavior and actual behavior.
I use contextily which itself call rasterio. Everything works fine with version 1.1.5, but I have a segfault with version 1.1.6 :
```
Fatal Python error: Segmentation fault
Current thread 0x00007fe33542d740 (most recent call first):
File "/home/user/.pyenv/versions/project/lib/python3.8/site-packages/rasterio/vrt.py", line 126 in close
File "/home/user/.pyenv/versions/project/lib/python3.8/site-packages/rasterio/vrt.py", line 123 in __del__
File "/home/user/.pyenv/versions/project/lib/python3.8/site-packages/contextily/plotting.py", line 148 in add_basemap
```
## Steps to reproduce the problem.
Run the following program :
```python
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import contextily as ctx
import matplotlib.pyplot as plt
if __name__ == '__main__':
fig, ax = plt.subplots()
ctx.add_basemap(ax=ax, crs="EPSG:3857")
```
## Operating system
Debian 10
## Rasterio version and provenance
1.1.6 installed from PyPI using poetry.
</issue>
<code>
[start of rasterio/io.py]
1 """Classes capable of reading and writing datasets
2
3 Instances of these classes are called dataset objects.
4 """
5
6 import logging
7
8 from rasterio._base import (
9 get_dataset_driver, driver_can_create, driver_can_create_copy)
10 from rasterio._io import (
11 DatasetReaderBase, DatasetWriterBase, BufferedDatasetWriterBase,
12 MemoryFileBase)
13 from rasterio.windows import WindowMethodsMixin
14 from rasterio.env import ensure_env, env_ctx_if_needed
15 from rasterio.transform import TransformMethodsMixin
16 from rasterio.path import UnparsedPath
17
18
19 log = logging.getLogger(__name__)
20
21
22 class DatasetReader(DatasetReaderBase, WindowMethodsMixin,
23 TransformMethodsMixin):
24 """An unbuffered data and metadata reader"""
25
26 def __repr__(self):
27 return "<{} DatasetReader name='{}' mode='{}'>".format(
28 self.closed and 'closed' or 'open', self.name, self.mode)
29
30
31 class DatasetWriter(DatasetWriterBase, WindowMethodsMixin,
32 TransformMethodsMixin):
33 """An unbuffered data and metadata writer. Its methods write data
34 directly to disk.
35 """
36
37 def __repr__(self):
38 return "<{} DatasetWriter name='{}' mode='{}'>".format(
39 self.closed and 'closed' or 'open', self.name, self.mode)
40
41
42 class BufferedDatasetWriter(BufferedDatasetWriterBase, WindowMethodsMixin,
43 TransformMethodsMixin):
44 """Maintains data and metadata in a buffer, writing to disk or
45 network only when `close()` is called.
46
47 This allows incremental updates to datasets using formats that don't
48 otherwise support updates, such as JPEG.
49 """
50
51 def __repr__(self):
52 return "<{} BufferedDatasetWriter name='{}' mode='{}'>".format(
53 self.closed and 'closed' or 'open', self.name, self.mode)
54
55
56 class MemoryFile(MemoryFileBase):
57 """A BytesIO-like object, backed by an in-memory file.
58
59 This allows formatted files to be read and written without I/O.
60
61 A MemoryFile created with initial bytes becomes immutable. A
62 MemoryFile created without initial bytes may be written to using
63 either file-like or dataset interfaces.
64
65 Examples
66 --------
67
68 A GeoTIFF can be loaded in memory and accessed using the GeoTIFF
69 format driver
70
71 >>> with open('tests/data/RGB.byte.tif', 'rb') as f, MemoryFile(f) as memfile:
72 ... with memfile.open() as src:
73 ... pprint.pprint(src.profile)
74 ...
75 {'count': 3,
76 'crs': CRS({'init': 'epsg:32618'}),
77 'driver': 'GTiff',
78 'dtype': 'uint8',
79 'height': 718,
80 'interleave': 'pixel',
81 'nodata': 0.0,
82 'tiled': False,
83 'transform': Affine(300.0379266750948, 0.0, 101985.0,
84 0.0, -300.041782729805, 2826915.0),
85 'width': 791}
86
87 """
88 def __init__(self, file_or_bytes=None, dirname=None, filename=None, ext=''):
89 """Create a new file in memory
90
91 Parameters
92 ----------
93 file_or_bytes : file-like object or bytes, optional
94 File or bytes holding initial data.
95 filename : str, optional
96 An optional filename. A unique one will otherwise be generated.
97 ext : str, optional
98 An optional extension.
99
100 Returns
101 -------
102 MemoryFile
103 """
104 super(MemoryFile, self).__init__(
105 file_or_bytes=file_or_bytes, dirname=dirname, filename=filename, ext=ext)
106
107 @ensure_env
108 def open(self, driver=None, width=None, height=None, count=None, crs=None,
109 transform=None, dtype=None, nodata=None, sharing=False, **kwargs):
110 """Open the file and return a Rasterio dataset object.
111
112 If data has already been written, the file is opened in 'r'
113 mode. Otherwise, the file is opened in 'w' mode.
114
115 Parameters
116 ----------
117 Note well that there is no `path` parameter: a `MemoryFile`
118 contains a single dataset and there is no need to specify a
119 path.
120
121 Other parameters are optional and have the same semantics as the
122 parameters of `rasterio.open()`.
123 """
124 mempath = UnparsedPath(self.name)
125
126 if self.closed:
127 raise IOError("I/O operation on closed file.")
128 if len(self) > 0:
129 log.debug("VSI path: {}".format(mempath.path))
130 return DatasetReader(mempath, driver=driver, sharing=sharing, **kwargs)
131 else:
132 writer = get_writer_for_driver(driver)
133 return writer(mempath, 'w+', driver=driver, width=width,
134 height=height, count=count, crs=crs,
135 transform=transform, dtype=dtype,
136 nodata=nodata, sharing=sharing, **kwargs)
137
138 def __enter__(self):
139 self._env = env_ctx_if_needed()
140 self._env.__enter__()
141 return self
142
143 def __exit__(self, *args, **kwargs):
144 self._env.__exit__()
145 self.close()
146
147
148 class ZipMemoryFile(MemoryFile):
149 """A read-only BytesIO-like object backed by an in-memory zip file.
150
151 This allows a zip file containing formatted files to be read
152 without I/O.
153 """
154
155 def __init__(self, file_or_bytes=None):
156 super(ZipMemoryFile, self).__init__(file_or_bytes, ext='zip')
157
158 @ensure_env
159 def open(self, path, driver=None, sharing=False, **kwargs):
160 """Open a dataset within the zipped stream.
161
162 Parameters
163 ----------
164 path : str
165 Path to a dataset in the zip file, relative to the root of the
166 archive.
167
168 Other parameters are optional and have the same semantics as the
169 parameters of `rasterio.open()`.
170
171 Returns
172 -------
173 A Rasterio dataset object
174 """
175 zippath = UnparsedPath('/vsizip{0}/{1}'.format(self.name, path.lstrip('/')))
176
177 if self.closed:
178 raise IOError("I/O operation on closed file.")
179 return DatasetReader(zippath, driver=driver, sharing=sharing, **kwargs)
180
181
182 def get_writer_for_driver(driver):
183 """Return the writer class appropriate for the specified driver."""
184 if not driver:
185 raise ValueError("'driver' is required to write dataset.")
186 cls = None
187 if driver_can_create(driver):
188 cls = DatasetWriter
189 elif driver_can_create_copy(driver): # pragma: no branch
190 cls = BufferedDatasetWriter
191 return cls
192
193
194 def get_writer_for_path(path, driver=None):
195 """Return the writer class appropriate for the existing dataset."""
196 if not driver:
197 driver = get_dataset_driver(path)
198 return get_writer_for_driver(driver)
199
[end of rasterio/io.py]
[start of rasterio/errors.py]
1 """Errors and Warnings."""
2
3 from click import FileError
4
5
6 class RasterioError(Exception):
7 """Root exception class"""
8
9
10 class WindowError(RasterioError):
11 """Raised when errors occur during window operations"""
12
13
14 class CRSError(ValueError):
15 """Raised when a CRS string or mapping is invalid or cannot serve
16 to define a coordinate transformation."""
17
18
19 class EnvError(RasterioError):
20 """Raised when the state of GDAL/AWS environment cannot be created
21 or modified."""
22
23
24 class DriverCapabilityError(RasterioError, ValueError):
25 """Raised when a format driver can't a feature such as writing."""
26
27
28 class DriverRegistrationError(ValueError):
29 """Raised when a format driver is requested but is not registered."""
30
31
32 class FileOverwriteError(FileError):
33 """Raised when Rasterio's CLI refuses to clobber output files."""
34
35 def __init__(self, message):
36 """Raise FileOverwriteError with message as hint."""
37 super(FileOverwriteError, self).__init__('', hint=message)
38
39
40 class RasterioIOError(IOError):
41 """Raised when a dataset cannot be opened using one of the
42 registered format drivers."""
43
44
45 class NodataShadowWarning(UserWarning):
46 """Warn that a dataset's nodata attribute is shadowing its alpha band."""
47
48 def __str__(self):
49 return ("The dataset's nodata attribute is shadowing "
50 "the alpha band. All masks will be determined "
51 "by the nodata attribute")
52
53
54 class NotGeoreferencedWarning(UserWarning):
55 """Warn that a dataset isn't georeferenced."""
56
57
58 class ShapeSkipWarning(UserWarning):
59 """Warn that an invalid or empty shape in a collection has been skipped"""
60
61
62 class GDALBehaviorChangeException(RuntimeError):
63 """Raised when GDAL's behavior differs from the given arguments. For
64 example, antimeridian cutting is always on as of GDAL 2.2.0. Users
65 expecting it to be off will be presented with a MultiPolygon when the
66 rest of their code expects a Polygon.
67
68 # Raises an exception on GDAL >= 2.2.0
69 rasterio.warp.transform_geometry(
70 src_crs, dst_crs, antimeridian_cutting=False)
71 """
72
73
74 class GDALOptionNotImplementedError(RasterioError):
75 """A dataset opening or dataset creation option can't be supported
76
77 This will be raised from Rasterio's shim modules. For example, when
78 a user passes arguments to open_dataset() that can't be evaluated
79 by GDAL 1.x.
80 """
81
82 class GDALVersionError(RasterioError):
83 """Raised if the runtime version of GDAL does not meet the required
84 version of GDAL."""
85
86
87 class WindowEvaluationError(ValueError):
88 """Raised when window evaluation fails"""
89
90
91 class RasterioDeprecationWarning(UserWarning):
92 """Rasterio module deprecations"""
93
94
95 class RasterBlockError(RasterioError):
96 """Raised when raster block access fails"""
97
98
99 class BandOverviewError(UserWarning):
100 """Raised when a band overview access fails."""
101
102
103 class WarpOptionsError(RasterioError):
104 """Raised when options for a warp operation are invalid"""
105
106
107 class UnsupportedOperation(RasterioError):
108 """Raised when reading from a file opened in 'w' mode"""
109
110
111 class OverviewCreationError(RasterioError):
112 """Raised when creation of an overview fails"""
113
114
115 class DatasetAttributeError(RasterioError, NotImplementedError):
116 """Raised when dataset attributes are misused"""
117
118
119 class PathError(RasterioError):
120 """Raised when a dataset path is malformed or invalid"""
121
122
123 class ResamplingAlgorithmError(RasterioError):
124 """Raised when a resampling algorithm is invalid or inapplicable"""
125
126
127 class TransformError(RasterioError):
128 """Raised when transform arguments are invalid"""
129
[end of rasterio/errors.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/rasterio/errors.py b/rasterio/errors.py
--- a/rasterio/errors.py
+++ b/rasterio/errors.py
@@ -126,3 +126,7 @@
class TransformError(RasterioError):
"""Raised when transform arguments are invalid"""
+
+
+class WarpedVRTError(RasterioError):
+ """Raised when WarpedVRT can't be initialized"""
diff --git a/rasterio/io.py b/rasterio/io.py
--- a/rasterio/io.py
+++ b/rasterio/io.py
@@ -85,7 +85,7 @@
'width': 791}
"""
- def __init__(self, file_or_bytes=None, dirname=None, filename=None, ext=''):
+ def __init__(self, file_or_bytes=None, dirname=None, filename=None, ext='.tif'):
"""Create a new file in memory
Parameters
@@ -141,8 +141,8 @@
return self
def __exit__(self, *args, **kwargs):
- self._env.__exit__()
self.close()
+ self._env.__exit__()
class ZipMemoryFile(MemoryFile):
|
{"golden_diff": "diff --git a/rasterio/errors.py b/rasterio/errors.py\n--- a/rasterio/errors.py\n+++ b/rasterio/errors.py\n@@ -126,3 +126,7 @@\n \n class TransformError(RasterioError):\n \"\"\"Raised when transform arguments are invalid\"\"\"\n+\n+\n+class WarpedVRTError(RasterioError):\n+ \"\"\"Raised when WarpedVRT can't be initialized\"\"\"\ndiff --git a/rasterio/io.py b/rasterio/io.py\n--- a/rasterio/io.py\n+++ b/rasterio/io.py\n@@ -85,7 +85,7 @@\n 'width': 791}\n \n \"\"\"\n- def __init__(self, file_or_bytes=None, dirname=None, filename=None, ext=''):\n+ def __init__(self, file_or_bytes=None, dirname=None, filename=None, ext='.tif'):\n \"\"\"Create a new file in memory\n \n Parameters\n@@ -141,8 +141,8 @@\n return self\n \n def __exit__(self, *args, **kwargs):\n- self._env.__exit__()\n self.close()\n+ self._env.__exit__()\n \n \n class ZipMemoryFile(MemoryFile):\n", "issue": "Segfault when closing WarpedVRT\n## Expected behavior and actual behavior.\r\n\r\nI use contextily which itself call rasterio. Everything works fine with version 1.1.5, but I have a segfault with version 1.1.6 : \r\n```\r\nFatal Python error: Segmentation fault\r\nCurrent thread 0x00007fe33542d740 (most recent call first):\r\n File \"/home/user/.pyenv/versions/project/lib/python3.8/site-packages/rasterio/vrt.py\", line 126 in close\r\n File \"/home/user/.pyenv/versions/project/lib/python3.8/site-packages/rasterio/vrt.py\", line 123 in __del__\r\n File \"/home/user/.pyenv/versions/project/lib/python3.8/site-packages/contextily/plotting.py\", line 148 in add_basemap\r\n```\r\n\r\n## Steps to reproduce the problem.\r\n\r\nRun the following program : \r\n```python\r\n#!/usr/bin/env python\r\n# -*- coding: utf-8 -*-\r\n\r\nimport contextily as ctx\r\nimport matplotlib.pyplot as plt\r\n\r\nif __name__ == '__main__':\r\n fig, ax = plt.subplots()\r\n ctx.add_basemap(ax=ax, crs=\"EPSG:3857\")\r\n```\r\n\r\n## Operating system\r\n\r\nDebian 10\r\n\r\n## Rasterio version and provenance\r\n1.1.6 installed from PyPI using poetry.\r\n\n", "before_files": [{"content": "\"\"\"Classes capable of reading and writing datasets\n\nInstances of these classes are called dataset objects.\n\"\"\"\n\nimport logging\n\nfrom rasterio._base import (\n get_dataset_driver, driver_can_create, driver_can_create_copy)\nfrom rasterio._io import (\n DatasetReaderBase, DatasetWriterBase, BufferedDatasetWriterBase,\n MemoryFileBase)\nfrom rasterio.windows import WindowMethodsMixin\nfrom rasterio.env import ensure_env, env_ctx_if_needed\nfrom rasterio.transform import TransformMethodsMixin\nfrom rasterio.path import UnparsedPath\n\n\nlog = logging.getLogger(__name__)\n\n\nclass DatasetReader(DatasetReaderBase, WindowMethodsMixin,\n TransformMethodsMixin):\n \"\"\"An unbuffered data and metadata reader\"\"\"\n\n def __repr__(self):\n return \"<{} DatasetReader name='{}' mode='{}'>\".format(\n self.closed and 'closed' or 'open', self.name, self.mode)\n\n\nclass DatasetWriter(DatasetWriterBase, WindowMethodsMixin,\n TransformMethodsMixin):\n \"\"\"An unbuffered data and metadata writer. Its methods write data\n directly to disk.\n \"\"\"\n\n def __repr__(self):\n return \"<{} DatasetWriter name='{}' mode='{}'>\".format(\n self.closed and 'closed' or 'open', self.name, self.mode)\n\n\nclass BufferedDatasetWriter(BufferedDatasetWriterBase, WindowMethodsMixin,\n TransformMethodsMixin):\n \"\"\"Maintains data and metadata in a buffer, writing to disk or\n network only when `close()` is called.\n\n This allows incremental updates to datasets using formats that don't\n otherwise support updates, such as JPEG.\n \"\"\"\n\n def __repr__(self):\n return \"<{} BufferedDatasetWriter name='{}' mode='{}'>\".format(\n self.closed and 'closed' or 'open', self.name, self.mode)\n\n\nclass MemoryFile(MemoryFileBase):\n \"\"\"A BytesIO-like object, backed by an in-memory file.\n\n This allows formatted files to be read and written without I/O.\n\n A MemoryFile created with initial bytes becomes immutable. A\n MemoryFile created without initial bytes may be written to using\n either file-like or dataset interfaces.\n\n Examples\n --------\n\n A GeoTIFF can be loaded in memory and accessed using the GeoTIFF\n format driver\n\n >>> with open('tests/data/RGB.byte.tif', 'rb') as f, MemoryFile(f) as memfile:\n ... with memfile.open() as src:\n ... pprint.pprint(src.profile)\n ...\n {'count': 3,\n 'crs': CRS({'init': 'epsg:32618'}),\n 'driver': 'GTiff',\n 'dtype': 'uint8',\n 'height': 718,\n 'interleave': 'pixel',\n 'nodata': 0.0,\n 'tiled': False,\n 'transform': Affine(300.0379266750948, 0.0, 101985.0,\n 0.0, -300.041782729805, 2826915.0),\n 'width': 791}\n\n \"\"\"\n def __init__(self, file_or_bytes=None, dirname=None, filename=None, ext=''):\n \"\"\"Create a new file in memory\n\n Parameters\n ----------\n file_or_bytes : file-like object or bytes, optional\n File or bytes holding initial data.\n filename : str, optional\n An optional filename. A unique one will otherwise be generated.\n ext : str, optional\n An optional extension.\n\n Returns\n -------\n MemoryFile\n \"\"\"\n super(MemoryFile, self).__init__(\n file_or_bytes=file_or_bytes, dirname=dirname, filename=filename, ext=ext)\n\n @ensure_env\n def open(self, driver=None, width=None, height=None, count=None, crs=None,\n transform=None, dtype=None, nodata=None, sharing=False, **kwargs):\n \"\"\"Open the file and return a Rasterio dataset object.\n\n If data has already been written, the file is opened in 'r'\n mode. Otherwise, the file is opened in 'w' mode.\n\n Parameters\n ----------\n Note well that there is no `path` parameter: a `MemoryFile`\n contains a single dataset and there is no need to specify a\n path.\n\n Other parameters are optional and have the same semantics as the\n parameters of `rasterio.open()`.\n \"\"\"\n mempath = UnparsedPath(self.name)\n\n if self.closed:\n raise IOError(\"I/O operation on closed file.\")\n if len(self) > 0:\n log.debug(\"VSI path: {}\".format(mempath.path))\n return DatasetReader(mempath, driver=driver, sharing=sharing, **kwargs)\n else:\n writer = get_writer_for_driver(driver)\n return writer(mempath, 'w+', driver=driver, width=width,\n height=height, count=count, crs=crs,\n transform=transform, dtype=dtype,\n nodata=nodata, sharing=sharing, **kwargs)\n\n def __enter__(self):\n self._env = env_ctx_if_needed()\n self._env.__enter__()\n return self\n\n def __exit__(self, *args, **kwargs):\n self._env.__exit__()\n self.close()\n\n\nclass ZipMemoryFile(MemoryFile):\n \"\"\"A read-only BytesIO-like object backed by an in-memory zip file.\n\n This allows a zip file containing formatted files to be read\n without I/O.\n \"\"\"\n\n def __init__(self, file_or_bytes=None):\n super(ZipMemoryFile, self).__init__(file_or_bytes, ext='zip')\n\n @ensure_env\n def open(self, path, driver=None, sharing=False, **kwargs):\n \"\"\"Open a dataset within the zipped stream.\n\n Parameters\n ----------\n path : str\n Path to a dataset in the zip file, relative to the root of the\n archive.\n\n Other parameters are optional and have the same semantics as the\n parameters of `rasterio.open()`.\n\n Returns\n -------\n A Rasterio dataset object\n \"\"\"\n zippath = UnparsedPath('/vsizip{0}/{1}'.format(self.name, path.lstrip('/')))\n\n if self.closed:\n raise IOError(\"I/O operation on closed file.\")\n return DatasetReader(zippath, driver=driver, sharing=sharing, **kwargs)\n\n\ndef get_writer_for_driver(driver):\n \"\"\"Return the writer class appropriate for the specified driver.\"\"\"\n if not driver:\n raise ValueError(\"'driver' is required to write dataset.\")\n cls = None\n if driver_can_create(driver):\n cls = DatasetWriter\n elif driver_can_create_copy(driver): # pragma: no branch\n cls = BufferedDatasetWriter\n return cls\n\n\ndef get_writer_for_path(path, driver=None):\n \"\"\"Return the writer class appropriate for the existing dataset.\"\"\"\n if not driver:\n driver = get_dataset_driver(path)\n return get_writer_for_driver(driver)\n", "path": "rasterio/io.py"}, {"content": "\"\"\"Errors and Warnings.\"\"\"\n\nfrom click import FileError\n\n\nclass RasterioError(Exception):\n \"\"\"Root exception class\"\"\"\n\n\nclass WindowError(RasterioError):\n \"\"\"Raised when errors occur during window operations\"\"\"\n\n\nclass CRSError(ValueError):\n \"\"\"Raised when a CRS string or mapping is invalid or cannot serve\n to define a coordinate transformation.\"\"\"\n\n\nclass EnvError(RasterioError):\n \"\"\"Raised when the state of GDAL/AWS environment cannot be created\n or modified.\"\"\"\n\n\nclass DriverCapabilityError(RasterioError, ValueError):\n \"\"\"Raised when a format driver can't a feature such as writing.\"\"\"\n\n\nclass DriverRegistrationError(ValueError):\n \"\"\"Raised when a format driver is requested but is not registered.\"\"\"\n\n\nclass FileOverwriteError(FileError):\n \"\"\"Raised when Rasterio's CLI refuses to clobber output files.\"\"\"\n\n def __init__(self, message):\n \"\"\"Raise FileOverwriteError with message as hint.\"\"\"\n super(FileOverwriteError, self).__init__('', hint=message)\n\n\nclass RasterioIOError(IOError):\n \"\"\"Raised when a dataset cannot be opened using one of the\n registered format drivers.\"\"\"\n\n\nclass NodataShadowWarning(UserWarning):\n \"\"\"Warn that a dataset's nodata attribute is shadowing its alpha band.\"\"\"\n\n def __str__(self):\n return (\"The dataset's nodata attribute is shadowing \"\n \"the alpha band. All masks will be determined \"\n \"by the nodata attribute\")\n\n\nclass NotGeoreferencedWarning(UserWarning):\n \"\"\"Warn that a dataset isn't georeferenced.\"\"\"\n\n\nclass ShapeSkipWarning(UserWarning):\n \"\"\"Warn that an invalid or empty shape in a collection has been skipped\"\"\"\n\n\nclass GDALBehaviorChangeException(RuntimeError):\n \"\"\"Raised when GDAL's behavior differs from the given arguments. For\n example, antimeridian cutting is always on as of GDAL 2.2.0. Users\n expecting it to be off will be presented with a MultiPolygon when the\n rest of their code expects a Polygon.\n\n # Raises an exception on GDAL >= 2.2.0\n rasterio.warp.transform_geometry(\n src_crs, dst_crs, antimeridian_cutting=False)\n \"\"\"\n\n\nclass GDALOptionNotImplementedError(RasterioError):\n \"\"\"A dataset opening or dataset creation option can't be supported\n\n This will be raised from Rasterio's shim modules. For example, when\n a user passes arguments to open_dataset() that can't be evaluated\n by GDAL 1.x.\n \"\"\"\n\nclass GDALVersionError(RasterioError):\n \"\"\"Raised if the runtime version of GDAL does not meet the required\n version of GDAL.\"\"\"\n\n\nclass WindowEvaluationError(ValueError):\n \"\"\"Raised when window evaluation fails\"\"\"\n\n\nclass RasterioDeprecationWarning(UserWarning):\n \"\"\"Rasterio module deprecations\"\"\"\n\n\nclass RasterBlockError(RasterioError):\n \"\"\"Raised when raster block access fails\"\"\"\n\n\nclass BandOverviewError(UserWarning):\n \"\"\"Raised when a band overview access fails.\"\"\"\n\n\nclass WarpOptionsError(RasterioError):\n \"\"\"Raised when options for a warp operation are invalid\"\"\"\n\n\nclass UnsupportedOperation(RasterioError):\n \"\"\"Raised when reading from a file opened in 'w' mode\"\"\"\n\n\nclass OverviewCreationError(RasterioError):\n \"\"\"Raised when creation of an overview fails\"\"\"\n\n\nclass DatasetAttributeError(RasterioError, NotImplementedError):\n \"\"\"Raised when dataset attributes are misused\"\"\"\n\n\nclass PathError(RasterioError):\n \"\"\"Raised when a dataset path is malformed or invalid\"\"\"\n\n\nclass ResamplingAlgorithmError(RasterioError):\n \"\"\"Raised when a resampling algorithm is invalid or inapplicable\"\"\"\n\n\nclass TransformError(RasterioError):\n \"\"\"Raised when transform arguments are invalid\"\"\"\n", "path": "rasterio/errors.py"}]}
| 4,007 | 262 |
gh_patches_debug_21768
|
rasdani/github-patches
|
git_diff
|
pulp__pulpcore-2475
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
As a user, I would like to be able to filter all publications for a given repository
Author: wibbit (wibbit)
Redmine Issue: 7036, https://pulp.plan.io/issues/7036
---
As a user, I would like to be able to filter all publications for a given repository.
</issue>
<code>
[start of pulpcore/app/viewsets/publication.py]
1 from gettext import gettext as _
2
3 from django_filters import Filter
4 from django_filters.rest_framework import DjangoFilterBackend, filters
5 from rest_framework import mixins, serializers
6 from rest_framework.filters import OrderingFilter
7
8 from pulpcore.app.models import (
9 ContentGuard,
10 RBACContentGuard,
11 ContentRedirectContentGuard,
12 Distribution,
13 Publication,
14 Content,
15 )
16 from pulpcore.app.serializers import (
17 ContentGuardSerializer,
18 DistributionSerializer,
19 PublicationSerializer,
20 RBACContentGuardSerializer,
21 ContentRedirectContentGuardSerializer,
22 )
23 from pulpcore.app.viewsets import (
24 AsyncCreateMixin,
25 AsyncRemoveMixin,
26 AsyncUpdateMixin,
27 BaseFilterSet,
28 NamedModelViewSet,
29 RolesMixin,
30 )
31 from pulpcore.app.viewsets.base import DATETIME_FILTER_OPTIONS, NAME_FILTER_OPTIONS
32 from pulpcore.app.viewsets.custom_filters import (
33 IsoDateTimeFilter,
34 LabelSelectFilter,
35 RepositoryVersionFilter,
36 )
37
38
39 class PublicationContentFilter(Filter):
40 def __init__(self, *args, **kwargs):
41 kwargs.setdefault("help_text", _("Content Unit referenced by HREF"))
42 super().__init__(*args, **kwargs)
43
44 def filter(self, qs, value):
45 if value is None:
46 # user didn't supply a value
47 return qs
48
49 if not value:
50 raise serializers.ValidationError(detail=_("No value supplied for content filter"))
51
52 # Get the content object from the content_href
53 content = NamedModelViewSet.get_resource(value, Content)
54
55 return qs.with_content([content.pk])
56
57
58 class PublicationFilter(BaseFilterSet):
59 repository_version = RepositoryVersionFilter()
60 pulp_created = IsoDateTimeFilter()
61 content = PublicationContentFilter()
62 content__in = PublicationContentFilter(field_name="content", lookup_expr="in")
63
64 class Meta:
65 model = Publication
66 fields = {
67 "repository_version": ["exact"],
68 "pulp_created": DATETIME_FILTER_OPTIONS,
69 }
70
71
72 class ListPublicationViewSet(NamedModelViewSet, mixins.ListModelMixin):
73 endpoint_name = "publications"
74 queryset = Publication.objects.all()
75 serializer_class = PublicationSerializer
76 filterset_class = PublicationFilter
77
78 @classmethod
79 def is_master_viewset(cls):
80 """Do not hide from the routers."""
81 return False
82
83
84 class PublicationViewSet(
85 NamedModelViewSet, mixins.RetrieveModelMixin, mixins.ListModelMixin, mixins.DestroyModelMixin
86 ):
87 endpoint_name = "publications"
88 queryset = Publication.objects.exclude(complete=False)
89 serializer_class = PublicationSerializer
90 filter_backends = (OrderingFilter, DjangoFilterBackend)
91 filterset_class = PublicationFilter
92 ordering = ("-pulp_created",)
93
94
95 class ContentGuardFilter(BaseFilterSet):
96 name = filters.CharFilter()
97
98 class Meta:
99 model = ContentGuard
100 fields = {
101 "name": NAME_FILTER_OPTIONS,
102 }
103
104
105 class BaseContentGuardViewSet(NamedModelViewSet):
106 endpoint_name = "contentguards"
107 serializer_class = ContentGuardSerializer
108 queryset = ContentGuard.objects.all()
109 filterset_class = ContentGuardFilter
110
111
112 class ListContentGuardViewSet(
113 BaseContentGuardViewSet,
114 mixins.ListModelMixin,
115 ):
116 """Endpoint to list all contentguards."""
117
118 @classmethod
119 def is_master_viewset(cls):
120 """Do not hide from the routers."""
121 return False
122
123
124 class ContentGuardViewSet(
125 BaseContentGuardViewSet,
126 mixins.CreateModelMixin,
127 mixins.UpdateModelMixin,
128 mixins.DestroyModelMixin,
129 mixins.RetrieveModelMixin,
130 mixins.ListModelMixin,
131 ):
132 """
133 A viewset for contentguards.
134 """
135
136
137 class RBACContentGuardViewSet(ContentGuardViewSet, RolesMixin):
138 """
139 Viewset for creating contentguards that use RBAC to protect content.
140 Has add and remove actions for managing permission for users and groups to download content
141 protected by this guard.
142 """
143
144 endpoint_name = "rbac"
145 serializer_class = RBACContentGuardSerializer
146 queryset = RBACContentGuard.objects.all()
147
148 DEFAULT_ACCESS_POLICY = {
149 "statements": [
150 {
151 "action": ["list"],
152 "principal": "authenticated",
153 "effect": "allow",
154 },
155 {
156 "action": ["create"],
157 "principal": "authenticated",
158 "effect": "allow",
159 "condition": "has_model_perms:core.add_rbaccontentguard",
160 },
161 {
162 "action": ["retrieve", "my_permissions"],
163 "principal": "authenticated",
164 "effect": "allow",
165 "condition": "has_model_or_obj_perms:core.view_rbaccontentguard",
166 },
167 {
168 "action": ["update", "partial_update"],
169 "principal": "authenticated",
170 "effect": "allow",
171 "condition": "has_model_or_obj_perms:core.change_rbaccontentguard",
172 },
173 {
174 "action": ["destroy"],
175 "principal": "authenticated",
176 "effect": "allow",
177 "condition": "has_model_or_obj_perms:core.delete_rbaccontentguard",
178 },
179 {
180 "action": ["download"], # This is the action for the content guard permit
181 "principal": "authenticated",
182 "effect": "allow",
183 "condition": "has_model_or_obj_perms:core.download_rbaccontentguard",
184 },
185 {
186 "action": ["list_roles", "add_role", "remove_role"],
187 "principal": "authenticated",
188 "effect": "allow",
189 "condition": "has_model_or_obj_perms:core.manage_roles_rbaccontentguard",
190 },
191 ],
192 "creation_hooks": [
193 {
194 "function": "add_roles_for_object_creator",
195 "parameters": {
196 "roles": ["core.rbaccontentguard_owner", "core.rbaccontentguard_downloader"]
197 },
198 },
199 ],
200 }
201 LOCKED_ROLES = {
202 "core.rbaccontentguard_creator": ["core.add_rbaccontentguard"],
203 "core.rbaccontentguard_owner": [
204 "core.view_rbaccontentguard",
205 "core.change_rbaccontentguard",
206 "core.delete_rbaccontentguard",
207 "core.manage_roles_rbaccontentguard",
208 ],
209 "core.rbaccontentguard_downloader": ["core.download_rbaccontentguard"],
210 }
211
212
213 class ContentRedirectContentGuardViewSet(ContentGuardViewSet):
214 """
215 Content guard to protect preauthenticated redirects to the content app.
216 """
217
218 endpoint_name = "content_redirect"
219 queryset = ContentRedirectContentGuard.objects.all()
220 serializer_class = ContentRedirectContentGuardSerializer
221
222
223 class DistributionFilter(BaseFilterSet):
224 # e.g.
225 # /?name=foo
226 # /?name__in=foo,bar
227 # /?base_path__contains=foo
228 # /?base_path__icontains=foo
229 name = filters.CharFilter()
230 base_path = filters.CharFilter()
231 pulp_label_select = LabelSelectFilter()
232
233 class Meta:
234 model = Distribution
235 fields = {
236 "name": NAME_FILTER_OPTIONS,
237 "base_path": ["exact", "contains", "icontains", "in"],
238 }
239
240
241 class ListDistributionViewSet(NamedModelViewSet, mixins.ListModelMixin):
242 endpoint_name = "distributions"
243 queryset = Distribution.objects.all()
244 serializer_class = DistributionSerializer
245 filterset_class = DistributionFilter
246
247 @classmethod
248 def is_master_viewset(cls):
249 """Do not hide from the routers."""
250 return False
251
252
253 class DistributionViewSet(
254 NamedModelViewSet,
255 mixins.RetrieveModelMixin,
256 mixins.ListModelMixin,
257 AsyncCreateMixin,
258 AsyncRemoveMixin,
259 AsyncUpdateMixin,
260 ):
261 """
262 Provides read and list methods and also provides asynchronous CUD methods to dispatch tasks
263 with reservation that lock all Distributions preventing race conditions during base_path
264 checking.
265 """
266
267 endpoint_name = "distributions"
268 queryset = Distribution.objects.all()
269 serializer_class = DistributionSerializer
270 filterset_class = DistributionFilter
271
272 def async_reserved_resources(self, instance):
273 """Return resource that locks all Distributions."""
274 return ["/api/v3/distributions/"]
275
[end of pulpcore/app/viewsets/publication.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/pulpcore/app/viewsets/publication.py b/pulpcore/app/viewsets/publication.py
--- a/pulpcore/app/viewsets/publication.py
+++ b/pulpcore/app/viewsets/publication.py
@@ -11,6 +11,7 @@
ContentRedirectContentGuard,
Distribution,
Publication,
+ Repository,
Content,
)
from pulpcore.app.serializers import (
@@ -55,7 +56,23 @@
return qs.with_content([content.pk])
+class RepositoryThroughVersionFilter(Filter):
+ def filter(self, qs, value):
+ if value is None:
+ # user didn't supply a value
+ return qs
+
+ if not value:
+ raise serializers.ValidationError(
+ detail=_("No value supplied for {name} filter").format(name=self.field_name)
+ )
+
+ repository = NamedModelViewSet.get_resource(value, Repository)
+ return qs.filter(repository_version__repository=repository)
+
+
class PublicationFilter(BaseFilterSet):
+ repository = RepositoryThroughVersionFilter(help_text=_("Repository referenced by HREF"))
repository_version = RepositoryVersionFilter()
pulp_created = IsoDateTimeFilter()
content = PublicationContentFilter()
|
{"golden_diff": "diff --git a/pulpcore/app/viewsets/publication.py b/pulpcore/app/viewsets/publication.py\n--- a/pulpcore/app/viewsets/publication.py\n+++ b/pulpcore/app/viewsets/publication.py\n@@ -11,6 +11,7 @@\n ContentRedirectContentGuard,\n Distribution,\n Publication,\n+ Repository,\n Content,\n )\n from pulpcore.app.serializers import (\n@@ -55,7 +56,23 @@\n return qs.with_content([content.pk])\n \n \n+class RepositoryThroughVersionFilter(Filter):\n+ def filter(self, qs, value):\n+ if value is None:\n+ # user didn't supply a value\n+ return qs\n+\n+ if not value:\n+ raise serializers.ValidationError(\n+ detail=_(\"No value supplied for {name} filter\").format(name=self.field_name)\n+ )\n+\n+ repository = NamedModelViewSet.get_resource(value, Repository)\n+ return qs.filter(repository_version__repository=repository)\n+\n+\n class PublicationFilter(BaseFilterSet):\n+ repository = RepositoryThroughVersionFilter(help_text=_(\"Repository referenced by HREF\"))\n repository_version = RepositoryVersionFilter()\n pulp_created = IsoDateTimeFilter()\n content = PublicationContentFilter()\n", "issue": "As a user, I would like to be able to filter all publications for a given repository\nAuthor: wibbit (wibbit)\n\n\nRedmine Issue: 7036, https://pulp.plan.io/issues/7036\n\n---\n\nAs a user, I would like to be able to filter all publications for a given repository.\r\n\r\n\n\n\n\n", "before_files": [{"content": "from gettext import gettext as _\n\nfrom django_filters import Filter\nfrom django_filters.rest_framework import DjangoFilterBackend, filters\nfrom rest_framework import mixins, serializers\nfrom rest_framework.filters import OrderingFilter\n\nfrom pulpcore.app.models import (\n ContentGuard,\n RBACContentGuard,\n ContentRedirectContentGuard,\n Distribution,\n Publication,\n Content,\n)\nfrom pulpcore.app.serializers import (\n ContentGuardSerializer,\n DistributionSerializer,\n PublicationSerializer,\n RBACContentGuardSerializer,\n ContentRedirectContentGuardSerializer,\n)\nfrom pulpcore.app.viewsets import (\n AsyncCreateMixin,\n AsyncRemoveMixin,\n AsyncUpdateMixin,\n BaseFilterSet,\n NamedModelViewSet,\n RolesMixin,\n)\nfrom pulpcore.app.viewsets.base import DATETIME_FILTER_OPTIONS, NAME_FILTER_OPTIONS\nfrom pulpcore.app.viewsets.custom_filters import (\n IsoDateTimeFilter,\n LabelSelectFilter,\n RepositoryVersionFilter,\n)\n\n\nclass PublicationContentFilter(Filter):\n def __init__(self, *args, **kwargs):\n kwargs.setdefault(\"help_text\", _(\"Content Unit referenced by HREF\"))\n super().__init__(*args, **kwargs)\n\n def filter(self, qs, value):\n if value is None:\n # user didn't supply a value\n return qs\n\n if not value:\n raise serializers.ValidationError(detail=_(\"No value supplied for content filter\"))\n\n # Get the content object from the content_href\n content = NamedModelViewSet.get_resource(value, Content)\n\n return qs.with_content([content.pk])\n\n\nclass PublicationFilter(BaseFilterSet):\n repository_version = RepositoryVersionFilter()\n pulp_created = IsoDateTimeFilter()\n content = PublicationContentFilter()\n content__in = PublicationContentFilter(field_name=\"content\", lookup_expr=\"in\")\n\n class Meta:\n model = Publication\n fields = {\n \"repository_version\": [\"exact\"],\n \"pulp_created\": DATETIME_FILTER_OPTIONS,\n }\n\n\nclass ListPublicationViewSet(NamedModelViewSet, mixins.ListModelMixin):\n endpoint_name = \"publications\"\n queryset = Publication.objects.all()\n serializer_class = PublicationSerializer\n filterset_class = PublicationFilter\n\n @classmethod\n def is_master_viewset(cls):\n \"\"\"Do not hide from the routers.\"\"\"\n return False\n\n\nclass PublicationViewSet(\n NamedModelViewSet, mixins.RetrieveModelMixin, mixins.ListModelMixin, mixins.DestroyModelMixin\n):\n endpoint_name = \"publications\"\n queryset = Publication.objects.exclude(complete=False)\n serializer_class = PublicationSerializer\n filter_backends = (OrderingFilter, DjangoFilterBackend)\n filterset_class = PublicationFilter\n ordering = (\"-pulp_created\",)\n\n\nclass ContentGuardFilter(BaseFilterSet):\n name = filters.CharFilter()\n\n class Meta:\n model = ContentGuard\n fields = {\n \"name\": NAME_FILTER_OPTIONS,\n }\n\n\nclass BaseContentGuardViewSet(NamedModelViewSet):\n endpoint_name = \"contentguards\"\n serializer_class = ContentGuardSerializer\n queryset = ContentGuard.objects.all()\n filterset_class = ContentGuardFilter\n\n\nclass ListContentGuardViewSet(\n BaseContentGuardViewSet,\n mixins.ListModelMixin,\n):\n \"\"\"Endpoint to list all contentguards.\"\"\"\n\n @classmethod\n def is_master_viewset(cls):\n \"\"\"Do not hide from the routers.\"\"\"\n return False\n\n\nclass ContentGuardViewSet(\n BaseContentGuardViewSet,\n mixins.CreateModelMixin,\n mixins.UpdateModelMixin,\n mixins.DestroyModelMixin,\n mixins.RetrieveModelMixin,\n mixins.ListModelMixin,\n):\n \"\"\"\n A viewset for contentguards.\n \"\"\"\n\n\nclass RBACContentGuardViewSet(ContentGuardViewSet, RolesMixin):\n \"\"\"\n Viewset for creating contentguards that use RBAC to protect content.\n Has add and remove actions for managing permission for users and groups to download content\n protected by this guard.\n \"\"\"\n\n endpoint_name = \"rbac\"\n serializer_class = RBACContentGuardSerializer\n queryset = RBACContentGuard.objects.all()\n\n DEFAULT_ACCESS_POLICY = {\n \"statements\": [\n {\n \"action\": [\"list\"],\n \"principal\": \"authenticated\",\n \"effect\": \"allow\",\n },\n {\n \"action\": [\"create\"],\n \"principal\": \"authenticated\",\n \"effect\": \"allow\",\n \"condition\": \"has_model_perms:core.add_rbaccontentguard\",\n },\n {\n \"action\": [\"retrieve\", \"my_permissions\"],\n \"principal\": \"authenticated\",\n \"effect\": \"allow\",\n \"condition\": \"has_model_or_obj_perms:core.view_rbaccontentguard\",\n },\n {\n \"action\": [\"update\", \"partial_update\"],\n \"principal\": \"authenticated\",\n \"effect\": \"allow\",\n \"condition\": \"has_model_or_obj_perms:core.change_rbaccontentguard\",\n },\n {\n \"action\": [\"destroy\"],\n \"principal\": \"authenticated\",\n \"effect\": \"allow\",\n \"condition\": \"has_model_or_obj_perms:core.delete_rbaccontentguard\",\n },\n {\n \"action\": [\"download\"], # This is the action for the content guard permit\n \"principal\": \"authenticated\",\n \"effect\": \"allow\",\n \"condition\": \"has_model_or_obj_perms:core.download_rbaccontentguard\",\n },\n {\n \"action\": [\"list_roles\", \"add_role\", \"remove_role\"],\n \"principal\": \"authenticated\",\n \"effect\": \"allow\",\n \"condition\": \"has_model_or_obj_perms:core.manage_roles_rbaccontentguard\",\n },\n ],\n \"creation_hooks\": [\n {\n \"function\": \"add_roles_for_object_creator\",\n \"parameters\": {\n \"roles\": [\"core.rbaccontentguard_owner\", \"core.rbaccontentguard_downloader\"]\n },\n },\n ],\n }\n LOCKED_ROLES = {\n \"core.rbaccontentguard_creator\": [\"core.add_rbaccontentguard\"],\n \"core.rbaccontentguard_owner\": [\n \"core.view_rbaccontentguard\",\n \"core.change_rbaccontentguard\",\n \"core.delete_rbaccontentguard\",\n \"core.manage_roles_rbaccontentguard\",\n ],\n \"core.rbaccontentguard_downloader\": [\"core.download_rbaccontentguard\"],\n }\n\n\nclass ContentRedirectContentGuardViewSet(ContentGuardViewSet):\n \"\"\"\n Content guard to protect preauthenticated redirects to the content app.\n \"\"\"\n\n endpoint_name = \"content_redirect\"\n queryset = ContentRedirectContentGuard.objects.all()\n serializer_class = ContentRedirectContentGuardSerializer\n\n\nclass DistributionFilter(BaseFilterSet):\n # e.g.\n # /?name=foo\n # /?name__in=foo,bar\n # /?base_path__contains=foo\n # /?base_path__icontains=foo\n name = filters.CharFilter()\n base_path = filters.CharFilter()\n pulp_label_select = LabelSelectFilter()\n\n class Meta:\n model = Distribution\n fields = {\n \"name\": NAME_FILTER_OPTIONS,\n \"base_path\": [\"exact\", \"contains\", \"icontains\", \"in\"],\n }\n\n\nclass ListDistributionViewSet(NamedModelViewSet, mixins.ListModelMixin):\n endpoint_name = \"distributions\"\n queryset = Distribution.objects.all()\n serializer_class = DistributionSerializer\n filterset_class = DistributionFilter\n\n @classmethod\n def is_master_viewset(cls):\n \"\"\"Do not hide from the routers.\"\"\"\n return False\n\n\nclass DistributionViewSet(\n NamedModelViewSet,\n mixins.RetrieveModelMixin,\n mixins.ListModelMixin,\n AsyncCreateMixin,\n AsyncRemoveMixin,\n AsyncUpdateMixin,\n):\n \"\"\"\n Provides read and list methods and also provides asynchronous CUD methods to dispatch tasks\n with reservation that lock all Distributions preventing race conditions during base_path\n checking.\n \"\"\"\n\n endpoint_name = \"distributions\"\n queryset = Distribution.objects.all()\n serializer_class = DistributionSerializer\n filterset_class = DistributionFilter\n\n def async_reserved_resources(self, instance):\n \"\"\"Return resource that locks all Distributions.\"\"\"\n return [\"/api/v3/distributions/\"]\n", "path": "pulpcore/app/viewsets/publication.py"}]}
| 3,042 | 261 |
gh_patches_debug_29953
|
rasdani/github-patches
|
git_diff
|
Parsl__parsl-2196
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Strategy htex_auto_scale removing blocks far too slow
**Describe the bug**
The "htex_auto_scale" strategy is very slow to remove blocks in case there are more slots than tasks. It removes one block per 5 seconds at most.
**To Reproduce**
Steps to reproduce the behavior, for e.g:
1. Run the test script
2. Check parsl.log and wait for the first handful of tasks are completed
3. The logs shows that it will need around a minute after the idle time out to remove the blocks, even though all tasks but one have been finished. Most of the blocks are idle.
**Expected behavior**
All idle blocks are removed as soon as possible. This becomes really important if you are dealing with, say 500 blocks and most of them are idle.
**Environment**
Parsl 1.2.0, Python 3.8
**Test script**
```python
import parsl
from parsl.providers import LocalProvider
from parsl.channels import LocalChannel
from parsl.config import Config
from parsl.executors import HighThroughputExecutor
from parsl.app.app import python_app
local_htex = Config(
executors=[
HighThroughputExecutor(
label="htex_Local",
worker_debug=True,
max_workers=1,
provider=LocalProvider(
channel=LocalChannel(),
init_blocks=2,
max_blocks=20,
),
)
],
strategy="htex_auto_scale",
max_idletime=3,
)
parsl.load(local_htex)
@python_app
def long():
import time
time.sleep(10000)
@python_app
def short():
import time
time.sleep(1)
a = long()
b = [short() for i in range(20)]
a.result()
```
</issue>
<code>
[start of parsl/dataflow/strategy.py]
1 import logging
2 import time
3 import math
4 from typing import List
5
6 from parsl.dataflow.executor_status import ExecutorStatus
7 from parsl.executors import HighThroughputExecutor
8 from parsl.providers.provider_base import JobState
9
10 logger = logging.getLogger(__name__)
11
12
13 class Strategy(object):
14 """FlowControl strategy.
15
16 As a workflow dag is processed by Parsl, new tasks are added and completed
17 asynchronously. Parsl interfaces executors with execution providers to construct
18 scalable executors to handle the variable work-load generated by the
19 workflow. This component is responsible for periodically checking outstanding
20 tasks and available compute capacity and trigger scaling events to match
21 workflow needs.
22
23 Here's a diagram of an executor. An executor consists of blocks, which are usually
24 created by single requests to a Local Resource Manager (LRM) such as slurm,
25 condor, torque, or even AWS API. The blocks could contain several task blocks
26 which are separate instances on workers.
27
28
29 .. code:: python
30
31 |<--min_blocks |<-init_blocks max_blocks-->|
32 +----------------------------------------------------------+
33 | +--------block----------+ +--------block--------+ |
34 executor = | | task task | ... | task task | |
35 | +-----------------------+ +---------------------+ |
36 +----------------------------------------------------------+
37
38 The relevant specification options are:
39 1. min_blocks: Minimum number of blocks to maintain
40 2. init_blocks: number of blocks to provision at initialization of workflow
41 3. max_blocks: Maximum number of blocks that can be active due to one workflow
42
43
44 .. code:: python
45
46 active_tasks = pending_tasks + running_tasks
47
48 Parallelism = slots / tasks
49 = [0, 1] (i.e, 0 <= p <= 1)
50
51 For example:
52
53 When p = 0,
54 => compute with the least resources possible.
55 infinite tasks are stacked per slot.
56
57 .. code:: python
58
59 blocks = min_blocks { if active_tasks = 0
60 max(min_blocks, 1) { else
61
62 When p = 1,
63 => compute with the most resources.
64 one task is stacked per slot.
65
66 .. code:: python
67
68 blocks = min ( max_blocks,
69 ceil( active_tasks / slots ) )
70
71
72 When p = 1/2,
73 => We stack upto 2 tasks per slot before we overflow
74 and request a new block
75
76
77 let's say min:init:max = 0:0:4 and task_blocks=2
78 Consider the following example:
79 min_blocks = 0
80 init_blocks = 0
81 max_blocks = 4
82 tasks_per_node = 2
83 nodes_per_block = 1
84
85 In the diagram, X <- task
86
87 at 2 tasks:
88
89 .. code:: python
90
91 +---Block---|
92 | |
93 | X X |
94 |slot slot|
95 +-----------+
96
97 at 5 tasks, we overflow as the capacity of a single block is fully used.
98
99 .. code:: python
100
101 +---Block---| +---Block---|
102 | X X | ----> | |
103 | X X | | X |
104 |slot slot| |slot slot|
105 +-----------+ +-----------+
106
107 """
108
109 def __init__(self, dfk):
110 """Initialize strategy."""
111 self.dfk = dfk
112 self.config = dfk.config
113 self.executors = {}
114 self.max_idletime = self.dfk.config.max_idletime
115
116 for e in self.dfk.config.executors:
117 self.executors[e.label] = {'idle_since': None, 'config': e.label}
118
119 self.strategies = {None: self._strategy_noop,
120 'simple': self._strategy_simple,
121 'htex_auto_scale': self._strategy_htex_auto_scale}
122
123 self.strategize = self.strategies[self.config.strategy]
124
125 logger.debug("Scaling strategy: {0}".format(self.config.strategy))
126
127 def add_executors(self, executors):
128 for executor in executors:
129 self.executors[executor.label] = {'idle_since': None, 'config': executor.label}
130
131 def _strategy_noop(self, status: List[ExecutorStatus], tasks):
132 """Do nothing.
133
134 Args:
135 - tasks (task_ids): Not used here.
136 """
137
138 def _strategy_simple(self, status_list, tasks):
139 self._general_strategy(status_list, tasks, strategy_type='simple')
140
141 def _strategy_htex_auto_scale(self, status_list, tasks):
142 """HTEX specific auto scaling strategy
143
144 This strategy works only for HTEX. This strategy will scale up by
145 requesting additional compute resources via the provider when the
146 workload requirements exceed the provisioned capacity. The scale out
147 behavior is exactly like the 'simple' strategy.
148
149 If there are idle blocks during execution, this strategy will terminate
150 those idle blocks specifically. When # of tasks >> # of blocks, HTEX places
151 tasks evenly across blocks, which makes it rather difficult to ensure that
152 some blocks will reach 0% utilization. Consequently, this strategy can be
153 expected to scale down effectively only when # of workers, or tasks executing
154 per block is close to 1.
155
156 Args:
157 - tasks (task_ids): Not used here.
158 """
159 self._general_strategy(status_list, tasks, strategy_type='htex')
160
161 def _general_strategy(self, status_list, tasks, *, strategy_type):
162 for exec_status in status_list:
163 executor = exec_status.executor
164 label = executor.label
165 if not executor.scaling_enabled:
166 continue
167
168 # Tasks that are either pending completion
169 active_tasks = executor.outstanding
170
171 status = exec_status.status
172
173 # FIXME we need to handle case where provider does not define these
174 # FIXME probably more of this logic should be moved to the provider
175 min_blocks = executor.provider.min_blocks
176 max_blocks = executor.provider.max_blocks
177 tasks_per_node = executor.workers_per_node
178
179 nodes_per_block = executor.provider.nodes_per_block
180 parallelism = executor.provider.parallelism
181
182 running = sum([1 for x in status.values() if x.state == JobState.RUNNING])
183 pending = sum([1 for x in status.values() if x.state == JobState.PENDING])
184 active_blocks = running + pending
185 active_slots = active_blocks * tasks_per_node * nodes_per_block
186
187 if hasattr(executor, 'connected_workers'):
188 logger.debug('Executor {} has {} active tasks, {}/{} running/pending blocks, and {} connected workers'.format(
189 label, active_tasks, running, pending, executor.connected_workers))
190 else:
191 logger.debug('Executor {} has {} active tasks and {}/{} running/pending blocks'.format(
192 label, active_tasks, running, pending))
193
194 # reset kill timer if executor has active tasks
195 if active_tasks > 0 and self.executors[executor.label]['idle_since']:
196 self.executors[executor.label]['idle_since'] = None
197
198 # Case 1
199 # No tasks.
200 if active_tasks == 0:
201 # Case 1a
202 # Fewer blocks that min_blocks
203 if active_blocks <= min_blocks:
204 # Ignore
205 # logger.debug("Strategy: Case.1a")
206 pass
207
208 # Case 1b
209 # More blocks than min_blocks. Scale down
210 else:
211 # We want to make sure that max_idletime is reached
212 # before killing off resources
213 if not self.executors[executor.label]['idle_since']:
214 logger.debug("Executor {} has 0 active tasks; starting kill timer (if idle time exceeds {}s, resources will be removed)".format(
215 label, self.max_idletime)
216 )
217 self.executors[executor.label]['idle_since'] = time.time()
218
219 idle_since = self.executors[executor.label]['idle_since']
220 if (time.time() - idle_since) > self.max_idletime:
221 # We have resources idle for the max duration,
222 # we have to scale_in now.
223 logger.debug("Idle time has reached {}s for executor {}; removing resources".format(
224 self.max_idletime, label)
225 )
226 exec_status.scale_in(active_blocks - min_blocks)
227
228 else:
229 pass
230 # logger.debug("Strategy: Case.1b. Waiting for timer : {0}".format(idle_since))
231
232 # Case 2
233 # More tasks than the available slots.
234 elif (float(active_slots) / active_tasks) < parallelism:
235 # Case 2a
236 # We have the max blocks possible
237 if active_blocks >= max_blocks:
238 # Ignore since we already have the max nodes
239 # logger.debug("Strategy: Case.2a")
240 pass
241
242 # Case 2b
243 else:
244 # logger.debug("Strategy: Case.2b")
245 excess = math.ceil((active_tasks * parallelism) - active_slots)
246 excess_blocks = math.ceil(float(excess) / (tasks_per_node * nodes_per_block))
247 excess_blocks = min(excess_blocks, max_blocks - active_blocks)
248 logger.debug("Requesting {} more blocks".format(excess_blocks))
249 exec_status.scale_out(excess_blocks)
250
251 elif active_slots == 0 and active_tasks > 0:
252 # Case 4
253 logger.debug("Requesting single slot")
254 if active_blocks < max_blocks:
255 exec_status.scale_out(1)
256
257 # Case 4
258 # More slots than tasks
259 elif active_slots > 0 and active_slots > active_tasks:
260 if strategy_type == 'htex':
261 # Scale down for htex
262 logger.debug("More slots than tasks")
263 if isinstance(executor, HighThroughputExecutor):
264 if active_blocks > min_blocks:
265 exec_status.scale_in(1, force=False, max_idletime=self.max_idletime)
266
267 elif strategy_type == 'simple':
268 # skip for simple strategy
269 pass
270
271 # Case 3
272 # tasks ~ slots
273 else:
274 # logger.debug("Strategy: Case 3")
275 pass
276
[end of parsl/dataflow/strategy.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/parsl/dataflow/strategy.py b/parsl/dataflow/strategy.py
--- a/parsl/dataflow/strategy.py
+++ b/parsl/dataflow/strategy.py
@@ -242,8 +242,8 @@
# Case 2b
else:
# logger.debug("Strategy: Case.2b")
- excess = math.ceil((active_tasks * parallelism) - active_slots)
- excess_blocks = math.ceil(float(excess) / (tasks_per_node * nodes_per_block))
+ excess_slots = math.ceil((active_tasks * parallelism) - active_slots)
+ excess_blocks = math.ceil(float(excess_slots) / (tasks_per_node * nodes_per_block))
excess_blocks = min(excess_blocks, max_blocks - active_blocks)
logger.debug("Requesting {} more blocks".format(excess_blocks))
exec_status.scale_out(excess_blocks)
@@ -262,7 +262,10 @@
logger.debug("More slots than tasks")
if isinstance(executor, HighThroughputExecutor):
if active_blocks > min_blocks:
- exec_status.scale_in(1, force=False, max_idletime=self.max_idletime)
+ excess_slots = math.ceil(active_slots - (active_tasks * parallelism))
+ excess_blocks = math.ceil(float(excess_slots) / (tasks_per_node * nodes_per_block))
+ excess_blocks = min(excess_blocks, active_blocks - min_blocks)
+ exec_status.scale_in(excess_blocks, force=False, max_idletime=self.max_idletime)
elif strategy_type == 'simple':
# skip for simple strategy
|
{"golden_diff": "diff --git a/parsl/dataflow/strategy.py b/parsl/dataflow/strategy.py\n--- a/parsl/dataflow/strategy.py\n+++ b/parsl/dataflow/strategy.py\n@@ -242,8 +242,8 @@\n # Case 2b\n else:\n # logger.debug(\"Strategy: Case.2b\")\n- excess = math.ceil((active_tasks * parallelism) - active_slots)\n- excess_blocks = math.ceil(float(excess) / (tasks_per_node * nodes_per_block))\n+ excess_slots = math.ceil((active_tasks * parallelism) - active_slots)\n+ excess_blocks = math.ceil(float(excess_slots) / (tasks_per_node * nodes_per_block))\n excess_blocks = min(excess_blocks, max_blocks - active_blocks)\n logger.debug(\"Requesting {} more blocks\".format(excess_blocks))\n exec_status.scale_out(excess_blocks)\n@@ -262,7 +262,10 @@\n logger.debug(\"More slots than tasks\")\n if isinstance(executor, HighThroughputExecutor):\n if active_blocks > min_blocks:\n- exec_status.scale_in(1, force=False, max_idletime=self.max_idletime)\n+ excess_slots = math.ceil(active_slots - (active_tasks * parallelism))\n+ excess_blocks = math.ceil(float(excess_slots) / (tasks_per_node * nodes_per_block))\n+ excess_blocks = min(excess_blocks, active_blocks - min_blocks)\n+ exec_status.scale_in(excess_blocks, force=False, max_idletime=self.max_idletime)\n \n elif strategy_type == 'simple':\n # skip for simple strategy\n", "issue": "Strategy htex_auto_scale removing blocks far too slow\n**Describe the bug**\r\nThe \"htex_auto_scale\" strategy is very slow to remove blocks in case there are more slots than tasks. It removes one block per 5 seconds at most.\r\n\r\n**To Reproduce**\r\nSteps to reproduce the behavior, for e.g:\r\n1. Run the test script\r\n2. Check parsl.log and wait for the first handful of tasks are completed\r\n3. The logs shows that it will need around a minute after the idle time out to remove the blocks, even though all tasks but one have been finished. Most of the blocks are idle.\r\n\r\n**Expected behavior**\r\nAll idle blocks are removed as soon as possible. This becomes really important if you are dealing with, say 500 blocks and most of them are idle.\r\n\r\n**Environment**\r\nParsl 1.2.0, Python 3.8\r\n\r\n\r\n**Test script**\r\n```python\r\nimport parsl\r\nfrom parsl.providers import LocalProvider\r\nfrom parsl.channels import LocalChannel\r\nfrom parsl.config import Config\r\nfrom parsl.executors import HighThroughputExecutor\r\nfrom parsl.app.app import python_app\r\n\r\n\r\nlocal_htex = Config(\r\n executors=[\r\n HighThroughputExecutor(\r\n label=\"htex_Local\",\r\n worker_debug=True,\r\n max_workers=1,\r\n provider=LocalProvider(\r\n channel=LocalChannel(),\r\n init_blocks=2,\r\n max_blocks=20,\r\n ),\r\n )\r\n ],\r\n strategy=\"htex_auto_scale\",\r\n max_idletime=3,\r\n)\r\nparsl.load(local_htex)\r\n\r\n\r\n@python_app\r\ndef long():\r\n import time\r\n time.sleep(10000)\r\n\r\n\r\n@python_app\r\ndef short():\r\n import time\r\n time.sleep(1)\r\n\r\n\r\na = long()\r\nb = [short() for i in range(20)]\r\na.result()\r\n```\n", "before_files": [{"content": "import logging\nimport time\nimport math\nfrom typing import List\n\nfrom parsl.dataflow.executor_status import ExecutorStatus\nfrom parsl.executors import HighThroughputExecutor\nfrom parsl.providers.provider_base import JobState\n\nlogger = logging.getLogger(__name__)\n\n\nclass Strategy(object):\n \"\"\"FlowControl strategy.\n\n As a workflow dag is processed by Parsl, new tasks are added and completed\n asynchronously. Parsl interfaces executors with execution providers to construct\n scalable executors to handle the variable work-load generated by the\n workflow. This component is responsible for periodically checking outstanding\n tasks and available compute capacity and trigger scaling events to match\n workflow needs.\n\n Here's a diagram of an executor. An executor consists of blocks, which are usually\n created by single requests to a Local Resource Manager (LRM) such as slurm,\n condor, torque, or even AWS API. The blocks could contain several task blocks\n which are separate instances on workers.\n\n\n .. code:: python\n\n |<--min_blocks |<-init_blocks max_blocks-->|\n +----------------------------------------------------------+\n | +--------block----------+ +--------block--------+ |\n executor = | | task task | ... | task task | |\n | +-----------------------+ +---------------------+ |\n +----------------------------------------------------------+\n\n The relevant specification options are:\n 1. min_blocks: Minimum number of blocks to maintain\n 2. init_blocks: number of blocks to provision at initialization of workflow\n 3. max_blocks: Maximum number of blocks that can be active due to one workflow\n\n\n .. code:: python\n\n active_tasks = pending_tasks + running_tasks\n\n Parallelism = slots / tasks\n = [0, 1] (i.e, 0 <= p <= 1)\n\n For example:\n\n When p = 0,\n => compute with the least resources possible.\n infinite tasks are stacked per slot.\n\n .. code:: python\n\n blocks = min_blocks { if active_tasks = 0\n max(min_blocks, 1) { else\n\n When p = 1,\n => compute with the most resources.\n one task is stacked per slot.\n\n .. code:: python\n\n blocks = min ( max_blocks,\n ceil( active_tasks / slots ) )\n\n\n When p = 1/2,\n => We stack upto 2 tasks per slot before we overflow\n and request a new block\n\n\n let's say min:init:max = 0:0:4 and task_blocks=2\n Consider the following example:\n min_blocks = 0\n init_blocks = 0\n max_blocks = 4\n tasks_per_node = 2\n nodes_per_block = 1\n\n In the diagram, X <- task\n\n at 2 tasks:\n\n .. code:: python\n\n +---Block---|\n | |\n | X X |\n |slot slot|\n +-----------+\n\n at 5 tasks, we overflow as the capacity of a single block is fully used.\n\n .. code:: python\n\n +---Block---| +---Block---|\n | X X | ----> | |\n | X X | | X |\n |slot slot| |slot slot|\n +-----------+ +-----------+\n\n \"\"\"\n\n def __init__(self, dfk):\n \"\"\"Initialize strategy.\"\"\"\n self.dfk = dfk\n self.config = dfk.config\n self.executors = {}\n self.max_idletime = self.dfk.config.max_idletime\n\n for e in self.dfk.config.executors:\n self.executors[e.label] = {'idle_since': None, 'config': e.label}\n\n self.strategies = {None: self._strategy_noop,\n 'simple': self._strategy_simple,\n 'htex_auto_scale': self._strategy_htex_auto_scale}\n\n self.strategize = self.strategies[self.config.strategy]\n\n logger.debug(\"Scaling strategy: {0}\".format(self.config.strategy))\n\n def add_executors(self, executors):\n for executor in executors:\n self.executors[executor.label] = {'idle_since': None, 'config': executor.label}\n\n def _strategy_noop(self, status: List[ExecutorStatus], tasks):\n \"\"\"Do nothing.\n\n Args:\n - tasks (task_ids): Not used here.\n \"\"\"\n\n def _strategy_simple(self, status_list, tasks):\n self._general_strategy(status_list, tasks, strategy_type='simple')\n\n def _strategy_htex_auto_scale(self, status_list, tasks):\n \"\"\"HTEX specific auto scaling strategy\n\n This strategy works only for HTEX. This strategy will scale up by\n requesting additional compute resources via the provider when the\n workload requirements exceed the provisioned capacity. The scale out\n behavior is exactly like the 'simple' strategy.\n\n If there are idle blocks during execution, this strategy will terminate\n those idle blocks specifically. When # of tasks >> # of blocks, HTEX places\n tasks evenly across blocks, which makes it rather difficult to ensure that\n some blocks will reach 0% utilization. Consequently, this strategy can be\n expected to scale down effectively only when # of workers, or tasks executing\n per block is close to 1.\n\n Args:\n - tasks (task_ids): Not used here.\n \"\"\"\n self._general_strategy(status_list, tasks, strategy_type='htex')\n\n def _general_strategy(self, status_list, tasks, *, strategy_type):\n for exec_status in status_list:\n executor = exec_status.executor\n label = executor.label\n if not executor.scaling_enabled:\n continue\n\n # Tasks that are either pending completion\n active_tasks = executor.outstanding\n\n status = exec_status.status\n\n # FIXME we need to handle case where provider does not define these\n # FIXME probably more of this logic should be moved to the provider\n min_blocks = executor.provider.min_blocks\n max_blocks = executor.provider.max_blocks\n tasks_per_node = executor.workers_per_node\n\n nodes_per_block = executor.provider.nodes_per_block\n parallelism = executor.provider.parallelism\n\n running = sum([1 for x in status.values() if x.state == JobState.RUNNING])\n pending = sum([1 for x in status.values() if x.state == JobState.PENDING])\n active_blocks = running + pending\n active_slots = active_blocks * tasks_per_node * nodes_per_block\n\n if hasattr(executor, 'connected_workers'):\n logger.debug('Executor {} has {} active tasks, {}/{} running/pending blocks, and {} connected workers'.format(\n label, active_tasks, running, pending, executor.connected_workers))\n else:\n logger.debug('Executor {} has {} active tasks and {}/{} running/pending blocks'.format(\n label, active_tasks, running, pending))\n\n # reset kill timer if executor has active tasks\n if active_tasks > 0 and self.executors[executor.label]['idle_since']:\n self.executors[executor.label]['idle_since'] = None\n\n # Case 1\n # No tasks.\n if active_tasks == 0:\n # Case 1a\n # Fewer blocks that min_blocks\n if active_blocks <= min_blocks:\n # Ignore\n # logger.debug(\"Strategy: Case.1a\")\n pass\n\n # Case 1b\n # More blocks than min_blocks. Scale down\n else:\n # We want to make sure that max_idletime is reached\n # before killing off resources\n if not self.executors[executor.label]['idle_since']:\n logger.debug(\"Executor {} has 0 active tasks; starting kill timer (if idle time exceeds {}s, resources will be removed)\".format(\n label, self.max_idletime)\n )\n self.executors[executor.label]['idle_since'] = time.time()\n\n idle_since = self.executors[executor.label]['idle_since']\n if (time.time() - idle_since) > self.max_idletime:\n # We have resources idle for the max duration,\n # we have to scale_in now.\n logger.debug(\"Idle time has reached {}s for executor {}; removing resources\".format(\n self.max_idletime, label)\n )\n exec_status.scale_in(active_blocks - min_blocks)\n\n else:\n pass\n # logger.debug(\"Strategy: Case.1b. Waiting for timer : {0}\".format(idle_since))\n\n # Case 2\n # More tasks than the available slots.\n elif (float(active_slots) / active_tasks) < parallelism:\n # Case 2a\n # We have the max blocks possible\n if active_blocks >= max_blocks:\n # Ignore since we already have the max nodes\n # logger.debug(\"Strategy: Case.2a\")\n pass\n\n # Case 2b\n else:\n # logger.debug(\"Strategy: Case.2b\")\n excess = math.ceil((active_tasks * parallelism) - active_slots)\n excess_blocks = math.ceil(float(excess) / (tasks_per_node * nodes_per_block))\n excess_blocks = min(excess_blocks, max_blocks - active_blocks)\n logger.debug(\"Requesting {} more blocks\".format(excess_blocks))\n exec_status.scale_out(excess_blocks)\n\n elif active_slots == 0 and active_tasks > 0:\n # Case 4\n logger.debug(\"Requesting single slot\")\n if active_blocks < max_blocks:\n exec_status.scale_out(1)\n\n # Case 4\n # More slots than tasks\n elif active_slots > 0 and active_slots > active_tasks:\n if strategy_type == 'htex':\n # Scale down for htex\n logger.debug(\"More slots than tasks\")\n if isinstance(executor, HighThroughputExecutor):\n if active_blocks > min_blocks:\n exec_status.scale_in(1, force=False, max_idletime=self.max_idletime)\n\n elif strategy_type == 'simple':\n # skip for simple strategy\n pass\n\n # Case 3\n # tasks ~ slots\n else:\n # logger.debug(\"Strategy: Case 3\")\n pass\n", "path": "parsl/dataflow/strategy.py"}]}
| 3,880 | 356 |
gh_patches_debug_10840
|
rasdani/github-patches
|
git_diff
|
nf-core__tools-1263
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Non-updated lint tip message
## Description of the bug
Linting with files applicable for auto-fixing gives the following message:
```
Tip: Some of these linting errors can automatically be resolved with the following command:
nf-core lint . --fix files_unchanged
```
However the `.` declaration has been removed in the latest version of nf-core tools, and so the command errors
```
Error: Got unexpected extra argument (.)
```
## Steps to reproduce
Modify a template file (e.g. `.github/CONTRIBUTING.md`, and run lint command
## Expected behaviour
Update message to remove `.`
## System
- nf-core tools version: 2.1
## Additional context
<!-- Add any other context about the problem here. -->
</issue>
<code>
[start of nf_core/lint_utils.py]
1 import rich
2 from rich.console import Console
3 from rich.table import Table
4 import logging
5
6 import nf_core.utils
7
8 log = logging.getLogger(__name__)
9
10 # Create a console used by all lint tests
11 console = Console(force_terminal=nf_core.utils.rich_force_colors())
12
13
14 def print_joint_summary(lint_obj, module_lint_obj):
15 """Print a joint summary of the general pipe lint tests and the module lint tests"""
16 nbr_passed = len(lint_obj.passed) + len(module_lint_obj.passed)
17 nbr_ignored = len(lint_obj.ignored)
18 nbr_fixed = len(lint_obj.fixed)
19 nbr_warned = len(lint_obj.warned) + len(module_lint_obj.warned)
20 nbr_failed = len(lint_obj.failed) + len(module_lint_obj.failed)
21
22 def _s(some_length):
23 return "" if some_length == 1 else "s"
24
25 summary_colour = "red" if nbr_failed > 0 else "green"
26 table = Table(box=rich.box.ROUNDED, style=summary_colour)
27 table.add_column(f"LINT RESULTS SUMMARY".format(nbr_passed), no_wrap=True)
28 table.add_row(r"[green][✔] {:>3} Test{} Passed".format(nbr_passed, _s(nbr_passed)))
29 if nbr_fixed:
30 table.add_row(r"[bright blue][?] {:>3} Test{} Fixed".format(nbr_fixed, _s(nbr_fixed)))
31 table.add_row(r"[grey58][?] {:>3} Test{} Ignored".format(nbr_ignored, _s(nbr_ignored)))
32 table.add_row(r"[yellow][!] {:>3} Test Warning{}".format(nbr_warned, _s(nbr_warned)))
33 table.add_row(r"[red][✗] {:>3} Test{} Failed".format(nbr_failed, _s(nbr_failed)))
34 console.print(table)
35
36
37 def print_fixes(lint_obj, module_lint_obj):
38 """Prints available and applied fixes"""
39
40 if len(lint_obj.could_fix):
41 fix_cmd = "nf-core lint {} --fix {}".format(lint_obj.wf_path, " --fix ".join(lint_obj.could_fix))
42 console.print(
43 f"\nTip: Some of these linting errors can automatically be resolved with the following command:\n\n[blue] {fix_cmd}\n"
44 )
45 if len(lint_obj.fix):
46 console.print(
47 "Automatic fixes applied. Please check with 'git diff' and revert any changes you do not want with 'git checkout <file>'."
48 )
49
[end of nf_core/lint_utils.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/nf_core/lint_utils.py b/nf_core/lint_utils.py
--- a/nf_core/lint_utils.py
+++ b/nf_core/lint_utils.py
@@ -38,7 +38,9 @@
"""Prints available and applied fixes"""
if len(lint_obj.could_fix):
- fix_cmd = "nf-core lint {} --fix {}".format(lint_obj.wf_path, " --fix ".join(lint_obj.could_fix))
+ fix_cmd = "nf-core lint {}--fix {}".format(
+ "" if lint_obj.wf_path == "." else f"--dir {lint_obj.wf_path}", " --fix ".join(lint_obj.could_fix)
+ )
console.print(
f"\nTip: Some of these linting errors can automatically be resolved with the following command:\n\n[blue] {fix_cmd}\n"
)
|
{"golden_diff": "diff --git a/nf_core/lint_utils.py b/nf_core/lint_utils.py\n--- a/nf_core/lint_utils.py\n+++ b/nf_core/lint_utils.py\n@@ -38,7 +38,9 @@\n \"\"\"Prints available and applied fixes\"\"\"\n \n if len(lint_obj.could_fix):\n- fix_cmd = \"nf-core lint {} --fix {}\".format(lint_obj.wf_path, \" --fix \".join(lint_obj.could_fix))\n+ fix_cmd = \"nf-core lint {}--fix {}\".format(\n+ \"\" if lint_obj.wf_path == \".\" else f\"--dir {lint_obj.wf_path}\", \" --fix \".join(lint_obj.could_fix)\n+ )\n console.print(\n f\"\\nTip: Some of these linting errors can automatically be resolved with the following command:\\n\\n[blue] {fix_cmd}\\n\"\n )\n", "issue": "Non-updated lint tip message\n## Description of the bug\r\n\r\nLinting with files applicable for auto-fixing gives the following message:\r\n\r\n```\r\nTip: Some of these linting errors can automatically be resolved with the following command:\r\n\r\n nf-core lint . --fix files_unchanged\r\n```\r\n\r\nHowever the `.` declaration has been removed in the latest version of nf-core tools, and so the command errors\r\n\r\n```\r\nError: Got unexpected extra argument (.)\r\n```\r\n\r\n## Steps to reproduce\r\n\r\nModify a template file (e.g. `.github/CONTRIBUTING.md`, and run lint command\r\n\r\n## Expected behaviour\r\n\r\nUpdate message to remove `.`\r\n\r\n## System\r\n\r\n- nf-core tools version: 2.1\r\n\r\n## Additional context\r\n\r\n<!-- Add any other context about the problem here. -->\r\n\n", "before_files": [{"content": "import rich\nfrom rich.console import Console\nfrom rich.table import Table\nimport logging\n\nimport nf_core.utils\n\nlog = logging.getLogger(__name__)\n\n# Create a console used by all lint tests\nconsole = Console(force_terminal=nf_core.utils.rich_force_colors())\n\n\ndef print_joint_summary(lint_obj, module_lint_obj):\n \"\"\"Print a joint summary of the general pipe lint tests and the module lint tests\"\"\"\n nbr_passed = len(lint_obj.passed) + len(module_lint_obj.passed)\n nbr_ignored = len(lint_obj.ignored)\n nbr_fixed = len(lint_obj.fixed)\n nbr_warned = len(lint_obj.warned) + len(module_lint_obj.warned)\n nbr_failed = len(lint_obj.failed) + len(module_lint_obj.failed)\n\n def _s(some_length):\n return \"\" if some_length == 1 else \"s\"\n\n summary_colour = \"red\" if nbr_failed > 0 else \"green\"\n table = Table(box=rich.box.ROUNDED, style=summary_colour)\n table.add_column(f\"LINT RESULTS SUMMARY\".format(nbr_passed), no_wrap=True)\n table.add_row(r\"[green][\u2714] {:>3} Test{} Passed\".format(nbr_passed, _s(nbr_passed)))\n if nbr_fixed:\n table.add_row(r\"[bright blue][?] {:>3} Test{} Fixed\".format(nbr_fixed, _s(nbr_fixed)))\n table.add_row(r\"[grey58][?] {:>3} Test{} Ignored\".format(nbr_ignored, _s(nbr_ignored)))\n table.add_row(r\"[yellow][!] {:>3} Test Warning{}\".format(nbr_warned, _s(nbr_warned)))\n table.add_row(r\"[red][\u2717] {:>3} Test{} Failed\".format(nbr_failed, _s(nbr_failed)))\n console.print(table)\n\n\ndef print_fixes(lint_obj, module_lint_obj):\n \"\"\"Prints available and applied fixes\"\"\"\n\n if len(lint_obj.could_fix):\n fix_cmd = \"nf-core lint {} --fix {}\".format(lint_obj.wf_path, \" --fix \".join(lint_obj.could_fix))\n console.print(\n f\"\\nTip: Some of these linting errors can automatically be resolved with the following command:\\n\\n[blue] {fix_cmd}\\n\"\n )\n if len(lint_obj.fix):\n console.print(\n \"Automatic fixes applied. Please check with 'git diff' and revert any changes you do not want with 'git checkout <file>'.\"\n )\n", "path": "nf_core/lint_utils.py"}]}
| 1,346 | 196 |
gh_patches_debug_23895
|
rasdani/github-patches
|
git_diff
|
alltheplaces__alltheplaces-2870
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Spider rentacenter is broken
During the global build at 2021-05-26-14-42-23, spider **rentacenter** failed with **2196 features** and **1 errors**.
Here's [the log](https://data.alltheplaces.xyz/runs/2021-05-26-14-42-23/logs/rentacenter.log) and [the output](https://data.alltheplaces.xyz/runs/2021-05-26-14-42-23/output/rentacenter.geojson) ([on a map](https://data.alltheplaces.xyz/map.html?show=https://data.alltheplaces.xyz/runs/2021-05-26-14-42-23/output/rentacenter.geojson))
</issue>
<code>
[start of locations/spiders/rentacenter.py]
1 import json
2 import scrapy
3 import re
4 from scrapy.selector import Selector
5
6 from locations.items import GeojsonPointItem
7 from locations.hours import OpeningHours
8
9
10 DAY_MAPPING = {
11 'Monday': 'Mo',
12 'Tuesday': 'Tu',
13 'Wednesday': 'We',
14 'Thursday': 'Th',
15 'Friday': 'Fr',
16 'Saturday': 'Sa',
17 'Sunday': 'Su'
18 }
19
20
21 class RentACenterSpider(scrapy.Spider):
22 name = "rentacenter"
23 item_attributes = { 'brand': "Rent-A-Center" }
24 allowed_domains = ["rentacenter.com"]
25
26 start_urls = [
27 "https://locations.rentacenter.com/sitemap.xml",
28 ]
29
30 def parse_hours(self, hours):
31 opening_hours = OpeningHours()
32
33 for hour in hours:
34 opening_hours.add_range(day=DAY_MAPPING[hour["dayOfWeek"].replace('http://schema.org/', '')],
35 open_time=hour["opens"],
36 close_time=hour["closes"],
37 time_format='%H:%M:%S')
38
39 return opening_hours.as_opening_hours()
40
41 def parse_location(self, response):
42 data = response.xpath('//script[@type="application/ld+json"]/text()').extract_first()
43 data = json.loads(data)
44
45 ref = data.get("branchCode")
46 if not ref:
47 return # not a store page
48
49 properties = {
50 'addr_full': data["address"]["streetAddress"],
51 'phone': data["telephone"],
52 'city': data["address"]["addressLocality"],
53 'state': data["address"]["addressRegion"],
54 'postcode': data["address"]["postalCode"],
55 'country': 'US',
56 'ref': ref,
57 'website': response.url,
58 'lat': float(data["geo"]["latitude"]),
59 'lon': float(data["geo"]["longitude"]),
60 'name': data["name"]
61 }
62
63 hours = self.parse_hours(data.get("openingHoursSpecification", []))
64 if hours:
65 properties["opening_hours"] = hours
66
67 yield GeojsonPointItem(**properties)
68
69 def parse_state_sitemap(self, response):
70 xml = Selector(response)
71 xml.remove_namespaces()
72
73 urls = xml.xpath('//loc/text()').extract()
74 urls = [url.strip() for url in urls]
75
76 # individual store pages are listed at top, then a state page, then bunch of other non-store pages
77 # find the index position of the state page and then only parse urls before that
78 i = urls.index(re.search(r'^(https://locations.rentacenter.com/.+?)/.*$', urls[0]).groups()[0] + '/')
79 for url in urls[:i]:
80 yield scrapy.Request(url, callback=self.parse_location)
81
82 def parse(self, response):
83 xml = Selector(response)
84 xml.remove_namespaces()
85
86 urls = xml.xpath('//loc/text()').extract()
87 urls = [url.strip() for url in urls]
88
89 for url in urls:
90 yield scrapy.Request(url, callback=self.parse_state_sitemap)
91
92
[end of locations/spiders/rentacenter.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/locations/spiders/rentacenter.py b/locations/spiders/rentacenter.py
--- a/locations/spiders/rentacenter.py
+++ b/locations/spiders/rentacenter.py
@@ -48,15 +48,15 @@
properties = {
'addr_full': data["address"]["streetAddress"],
- 'phone': data["telephone"],
+ 'phone': data.get("telephone"),
'city': data["address"]["addressLocality"],
'state': data["address"]["addressRegion"],
'postcode': data["address"]["postalCode"],
'country': 'US',
'ref': ref,
'website': response.url,
- 'lat': float(data["geo"]["latitude"]),
- 'lon': float(data["geo"]["longitude"]),
+ 'lat': data["geo"]["latitude"],
+ 'lon': data["geo"]["longitude"],
'name': data["name"]
}
@@ -87,5 +87,7 @@
urls = [url.strip() for url in urls]
for url in urls:
+ if '/home/' in url:
+ continue
yield scrapy.Request(url, callback=self.parse_state_sitemap)
|
{"golden_diff": "diff --git a/locations/spiders/rentacenter.py b/locations/spiders/rentacenter.py\n--- a/locations/spiders/rentacenter.py\n+++ b/locations/spiders/rentacenter.py\n@@ -48,15 +48,15 @@\n \n properties = {\n 'addr_full': data[\"address\"][\"streetAddress\"],\n- 'phone': data[\"telephone\"],\n+ 'phone': data.get(\"telephone\"),\n 'city': data[\"address\"][\"addressLocality\"],\n 'state': data[\"address\"][\"addressRegion\"],\n 'postcode': data[\"address\"][\"postalCode\"],\n 'country': 'US',\n 'ref': ref,\n 'website': response.url,\n- 'lat': float(data[\"geo\"][\"latitude\"]),\n- 'lon': float(data[\"geo\"][\"longitude\"]),\n+ 'lat': data[\"geo\"][\"latitude\"],\n+ 'lon': data[\"geo\"][\"longitude\"],\n 'name': data[\"name\"]\n }\n \n@@ -87,5 +87,7 @@\n urls = [url.strip() for url in urls]\n \n for url in urls:\n+ if '/home/' in url:\n+ continue\n yield scrapy.Request(url, callback=self.parse_state_sitemap)\n", "issue": "Spider rentacenter is broken\nDuring the global build at 2021-05-26-14-42-23, spider **rentacenter** failed with **2196 features** and **1 errors**.\n\nHere's [the log](https://data.alltheplaces.xyz/runs/2021-05-26-14-42-23/logs/rentacenter.log) and [the output](https://data.alltheplaces.xyz/runs/2021-05-26-14-42-23/output/rentacenter.geojson) ([on a map](https://data.alltheplaces.xyz/map.html?show=https://data.alltheplaces.xyz/runs/2021-05-26-14-42-23/output/rentacenter.geojson))\n", "before_files": [{"content": "import json\nimport scrapy\nimport re\nfrom scrapy.selector import Selector\n\nfrom locations.items import GeojsonPointItem\nfrom locations.hours import OpeningHours\n\n\nDAY_MAPPING = {\n 'Monday': 'Mo',\n 'Tuesday': 'Tu',\n 'Wednesday': 'We',\n 'Thursday': 'Th',\n 'Friday': 'Fr',\n 'Saturday': 'Sa',\n 'Sunday': 'Su'\n}\n\n\nclass RentACenterSpider(scrapy.Spider):\n name = \"rentacenter\"\n item_attributes = { 'brand': \"Rent-A-Center\" }\n allowed_domains = [\"rentacenter.com\"]\n\n start_urls = [\n \"https://locations.rentacenter.com/sitemap.xml\",\n ]\n\n def parse_hours(self, hours):\n opening_hours = OpeningHours()\n\n for hour in hours:\n opening_hours.add_range(day=DAY_MAPPING[hour[\"dayOfWeek\"].replace('http://schema.org/', '')],\n open_time=hour[\"opens\"],\n close_time=hour[\"closes\"],\n time_format='%H:%M:%S')\n\n return opening_hours.as_opening_hours()\n\n def parse_location(self, response):\n data = response.xpath('//script[@type=\"application/ld+json\"]/text()').extract_first()\n data = json.loads(data)\n\n ref = data.get(\"branchCode\")\n if not ref:\n return # not a store page\n\n properties = {\n 'addr_full': data[\"address\"][\"streetAddress\"],\n 'phone': data[\"telephone\"],\n 'city': data[\"address\"][\"addressLocality\"],\n 'state': data[\"address\"][\"addressRegion\"],\n 'postcode': data[\"address\"][\"postalCode\"],\n 'country': 'US',\n 'ref': ref,\n 'website': response.url,\n 'lat': float(data[\"geo\"][\"latitude\"]),\n 'lon': float(data[\"geo\"][\"longitude\"]),\n 'name': data[\"name\"]\n }\n\n hours = self.parse_hours(data.get(\"openingHoursSpecification\", []))\n if hours:\n properties[\"opening_hours\"] = hours\n\n yield GeojsonPointItem(**properties)\n\n def parse_state_sitemap(self, response):\n xml = Selector(response)\n xml.remove_namespaces()\n\n urls = xml.xpath('//loc/text()').extract()\n urls = [url.strip() for url in urls]\n\n # individual store pages are listed at top, then a state page, then bunch of other non-store pages\n # find the index position of the state page and then only parse urls before that\n i = urls.index(re.search(r'^(https://locations.rentacenter.com/.+?)/.*$', urls[0]).groups()[0] + '/')\n for url in urls[:i]:\n yield scrapy.Request(url, callback=self.parse_location)\n\n def parse(self, response):\n xml = Selector(response)\n xml.remove_namespaces()\n\n urls = xml.xpath('//loc/text()').extract()\n urls = [url.strip() for url in urls]\n\n for url in urls:\n yield scrapy.Request(url, callback=self.parse_state_sitemap)\n\n", "path": "locations/spiders/rentacenter.py"}]}
| 1,567 | 266 |
gh_patches_debug_64320
|
rasdani/github-patches
|
git_diff
|
pex-tool__pex-1442
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Release 2.1.48
On the docket:
+ [x] Remove zipapp execution mode & introduce --layout. #1438
</issue>
<code>
[start of pex/version.py]
1 # Copyright 2015 Pants project contributors (see CONTRIBUTORS.md).
2 # Licensed under the Apache License, Version 2.0 (see LICENSE).
3
4 __version__ = "2.1.47"
5
[end of pex/version.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/pex/version.py b/pex/version.py
--- a/pex/version.py
+++ b/pex/version.py
@@ -1,4 +1,4 @@
# Copyright 2015 Pants project contributors (see CONTRIBUTORS.md).
# Licensed under the Apache License, Version 2.0 (see LICENSE).
-__version__ = "2.1.47"
+__version__ = "2.1.48"
|
{"golden_diff": "diff --git a/pex/version.py b/pex/version.py\n--- a/pex/version.py\n+++ b/pex/version.py\n@@ -1,4 +1,4 @@\n # Copyright 2015 Pants project contributors (see CONTRIBUTORS.md).\n # Licensed under the Apache License, Version 2.0 (see LICENSE).\n \n-__version__ = \"2.1.47\"\n+__version__ = \"2.1.48\"\n", "issue": "Release 2.1.48\nOn the docket:\r\n+ [x] Remove zipapp execution mode & introduce --layout. #1438 \n", "before_files": [{"content": "# Copyright 2015 Pants project contributors (see CONTRIBUTORS.md).\n# Licensed under the Apache License, Version 2.0 (see LICENSE).\n\n__version__ = \"2.1.47\"\n", "path": "pex/version.py"}]}
| 617 | 96 |
gh_patches_debug_28680
|
rasdani/github-patches
|
git_diff
|
MycroftAI__mycroft-core-3054
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Missing `noise_words.list` for de-de causes issues for fallback skills
The missing `noise_words.list` for de-de causes errors for fallback skills:
```
06:42:27.050 | ERROR | 246 | mycroft.skills.skill_loader:_create_skill_instance:297 | Skill __init__ failed with TypeError('expected str, bytes or os.PathLike object, not NoneType')
Traceback (most recent call last):
File "/opt/mycroft/mycroft/skills/skill_loader.py", line 294, in _create_skill_instance
self.instance = skill_module.create_skill()
File "/opt/mycroft/skills/fallback-wolfram-alpha.mycroftai/__init__.py", line 238, in create_skill
return WolframAlphaSkill()
File "/opt/mycroft/skills/fallback-wolfram-alpha.mycroftai/__init__.py", line 40, in __init__
super().__init__()
File "/opt/mycroft/mycroft/skills/common_query_skill.py", line 71, in __init__
with open(noise_words_filename) as f:
TypeError: expected str, bytes or os.PathLike object, not NoneType
```
**To Reproduce**
Steps to reproduce the behavior:
1. Configure language to `de-de`
2. Restart Skills
3. See `mycroft-console-client`
</issue>
<code>
[start of mycroft/skills/common_query_skill.py]
1 # Copyright 2018 Mycroft AI Inc.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14 import time
15
16 from enum import IntEnum
17 from abc import ABC, abstractmethod
18 from .mycroft_skill import MycroftSkill
19
20 from mycroft.configuration import Configuration
21 from mycroft.util.file_utils import resolve_resource_file
22
23
24 class CQSMatchLevel(IntEnum):
25 EXACT = 1 # Skill could find a specific answer for the question
26 CATEGORY = 2 # Skill could find an answer from a category in the query
27 GENERAL = 3 # The query could be processed as a general quer
28
29
30 # Copy of CQSMatchLevel to use if the skill returns visual media
31 CQSVisualMatchLevel = IntEnum('CQSVisualMatchLevel',
32 [e.name for e in CQSMatchLevel])
33
34
35 def is_CQSVisualMatchLevel(match_level):
36 return isinstance(match_level, type(CQSVisualMatchLevel.EXACT))
37
38
39 """these are for the confidence calculation"""
40 # how much each topic word is worth
41 # when found in the answer
42 TOPIC_MATCH_RELEVANCE = 5
43
44 # elevate relevance above all else
45 RELEVANCE_MULTIPLIER = 2
46
47 # we like longer articles but only so much
48 MAX_ANSWER_LEN_FOR_CONFIDENCE = 50
49
50 # higher number - less bias for word length
51 WORD_COUNT_DIVISOR = 100
52
53
54 class CommonQuerySkill(MycroftSkill, ABC):
55 """Question answering skills should be based on this class.
56
57 The skill author needs to implement `CQS_match_query_phrase` returning an
58 answer and can optionally implement `CQS_action` to perform additional
59 actions if the skill's answer is selected.
60
61 This class works in conjunction with skill-query which collects
62 answers from several skills presenting the best one available.
63 """
64
65 def __init__(self, name=None, bus=None):
66 super().__init__(name, bus)
67 noise_words_filepath = "text/%s/noise_words.list" % (self.lang,)
68 noise_words_filename = resolve_resource_file(noise_words_filepath)
69 self.translated_noise_words = []
70 try:
71 with open(noise_words_filename) as f:
72 self.translated_noise_words = f.read().strip()
73 self.translated_noise_words = self.translated_noise_words.split()
74 except FileNotFoundError:
75 self.log.warning("Missing noise_words.list file in res/text/lang")
76
77 # these should probably be configurable
78 self.level_confidence = {
79 CQSMatchLevel.EXACT: 0.9,
80 CQSMatchLevel.CATEGORY: 0.6,
81 CQSMatchLevel.GENERAL: 0.5
82 }
83
84 def bind(self, bus):
85 """Overrides the default bind method of MycroftSkill.
86
87 This registers messagebus handlers for the skill during startup
88 but is nothing the skill author needs to consider.
89 """
90 if bus:
91 super().bind(bus)
92 self.add_event('question:query', self.__handle_question_query)
93 self.add_event('question:action', self.__handle_query_action)
94
95 def __handle_question_query(self, message):
96 search_phrase = message.data["phrase"]
97
98 # First, notify the requestor that we are attempting to handle
99 # (this extends a timeout while this skill looks for a match)
100 self.bus.emit(message.response({"phrase": search_phrase,
101 "skill_id": self.skill_id,
102 "searching": True}))
103
104 # Now invoke the CQS handler to let the skill perform its search
105 result = self.CQS_match_query_phrase(search_phrase)
106
107 if result:
108 match = result[0]
109 level = result[1]
110 answer = result[2]
111 callback = result[3] if len(result) > 3 else None
112 confidence = self.__calc_confidence(
113 match, search_phrase, level, answer)
114 self.bus.emit(message.response({"phrase": search_phrase,
115 "skill_id": self.skill_id,
116 "answer": answer,
117 "callback_data": callback,
118 "conf": confidence}))
119 else:
120 # Signal we are done (can't handle it)
121 self.bus.emit(message.response({"phrase": search_phrase,
122 "skill_id": self.skill_id,
123 "searching": False}))
124
125 def remove_noise(self, phrase):
126 """remove noise to produce essence of question"""
127 phrase = ' ' + phrase + ' '
128 for word in self.translated_noise_words:
129 mtch = ' ' + word + ' '
130 if phrase.find(mtch) > -1:
131 phrase = phrase.replace(mtch, " ")
132 phrase = ' '.join(phrase.split())
133 return phrase.strip()
134
135 def __calc_confidence(self, match, phrase, level, answer):
136 # Assume the more of the words that get consumed, the better the match
137 consumed_pct = len(match.split()) / len(phrase.split())
138 if consumed_pct > 1.0:
139 consumed_pct = 1.0
140 consumed_pct /= 10
141
142 # bonus for more sentences
143 num_sentences = float(float(len(answer.split("."))) / float(10))
144
145 # Add bonus if match has visuals and the device supports them.
146 bonus = 0.0
147 if is_CQSVisualMatchLevel(level) and self.gui.connected:
148 bonus = 0.1
149
150 # extract topic
151 topic = self.remove_noise(match)
152
153 # calculate relevance
154 answer = answer.lower()
155 matches = 0
156 for word in topic.split(' '):
157 if answer.find(word) > -1:
158 matches += TOPIC_MATCH_RELEVANCE
159
160 answer_size = len(answer.split(" "))
161 answer_size = min(MAX_ANSWER_LEN_FOR_CONFIDENCE, answer_size)
162
163 relevance = 0.0
164 if answer_size > 0:
165 relevance = float(float(matches) / float(answer_size))
166
167 relevance = relevance * RELEVANCE_MULTIPLIER
168
169 # extra credit for more words up to a point
170 wc_mod = float(float(answer_size) / float(WORD_COUNT_DIVISOR)) * 2
171
172 confidence = self.level_confidence[level] + \
173 consumed_pct + bonus + num_sentences + relevance + wc_mod
174
175 return confidence
176
177 def __handle_query_action(self, message):
178 """Message handler for question:action.
179
180 Extracts phrase and data from message forward this to the skills
181 CQS_action method.
182 """
183 if message.data["skill_id"] != self.skill_id:
184 # Not for this skill!
185 return
186 phrase = message.data["phrase"]
187 data = message.data.get("callback_data")
188 # Invoke derived class to provide playback data
189 self.CQS_action(phrase, data)
190
191 @abstractmethod
192 def CQS_match_query_phrase(self, phrase):
193 """Analyze phrase to see if it is a play-able phrase with this skill.
194
195 Needs to be implemented by the skill.
196
197 Args:
198 phrase (str): User phrase, "What is an aardwark"
199
200 Returns:
201 (match, CQSMatchLevel[, callback_data]) or None: Tuple containing
202 a string with the appropriate matching phrase, the PlayMatch
203 type, and optionally data to return in the callback if the
204 match is selected.
205 """
206 # Derived classes must implement this, e.g.
207 return None
208
209 def CQS_action(self, phrase, data):
210 """Take additional action IF the skill is selected.
211
212 The speech is handled by the common query but if the chosen skill
213 wants to display media, set a context or prepare for sending
214 information info over e-mail this can be implemented here.
215
216 Args:
217 phrase (str): User phrase uttered after "Play", e.g. "some music"
218 data (dict): Callback data specified in match_query_phrase()
219 """
220 # Derived classes may implement this if they use additional media
221 # or wish to set context after being called.
222 pass
223
[end of mycroft/skills/common_query_skill.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/mycroft/skills/common_query_skill.py b/mycroft/skills/common_query_skill.py
--- a/mycroft/skills/common_query_skill.py
+++ b/mycroft/skills/common_query_skill.py
@@ -11,13 +11,10 @@
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
-import time
-
from enum import IntEnum
from abc import ABC, abstractmethod
from .mycroft_skill import MycroftSkill
-from mycroft.configuration import Configuration
from mycroft.util.file_utils import resolve_resource_file
@@ -68,11 +65,15 @@
noise_words_filename = resolve_resource_file(noise_words_filepath)
self.translated_noise_words = []
try:
- with open(noise_words_filename) as f:
- self.translated_noise_words = f.read().strip()
- self.translated_noise_words = self.translated_noise_words.split()
+ if noise_words_filename:
+ with open(noise_words_filename) as f:
+ read_noise_words = f.read().strip()
+ self.translated_noise_words = read_noise_words.split()
+ else:
+ raise FileNotFoundError
except FileNotFoundError:
- self.log.warning("Missing noise_words.list file in res/text/lang")
+ self.log.warning("Missing noise_words.list file in "
+ f"res/text/{self.lang}")
# these should probably be configurable
self.level_confidence = {
|
{"golden_diff": "diff --git a/mycroft/skills/common_query_skill.py b/mycroft/skills/common_query_skill.py\n--- a/mycroft/skills/common_query_skill.py\n+++ b/mycroft/skills/common_query_skill.py\n@@ -11,13 +11,10 @@\n # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n # See the License for the specific language governing permissions and\n # limitations under the License.\n-import time\n-\n from enum import IntEnum\n from abc import ABC, abstractmethod\n from .mycroft_skill import MycroftSkill\n \n-from mycroft.configuration import Configuration\n from mycroft.util.file_utils import resolve_resource_file\n \n \n@@ -68,11 +65,15 @@\n noise_words_filename = resolve_resource_file(noise_words_filepath)\n self.translated_noise_words = []\n try:\n- with open(noise_words_filename) as f:\n- self.translated_noise_words = f.read().strip()\n- self.translated_noise_words = self.translated_noise_words.split()\n+ if noise_words_filename:\n+ with open(noise_words_filename) as f:\n+ read_noise_words = f.read().strip()\n+ self.translated_noise_words = read_noise_words.split()\n+ else:\n+ raise FileNotFoundError\n except FileNotFoundError:\n- self.log.warning(\"Missing noise_words.list file in res/text/lang\")\n+ self.log.warning(\"Missing noise_words.list file in \"\n+ f\"res/text/{self.lang}\")\n \n # these should probably be configurable\n self.level_confidence = {\n", "issue": "Missing `noise_words.list` for de-de causes issues for fallback skills\nThe missing `noise_words.list` for de-de causes errors for fallback skills:\r\n\r\n```\r\n06:42:27.050 | ERROR | 246 | mycroft.skills.skill_loader:_create_skill_instance:297 | Skill __init__ failed with TypeError('expected str, bytes or os.PathLike object, not NoneType')\r\nTraceback (most recent call last):\r\n File \"/opt/mycroft/mycroft/skills/skill_loader.py\", line 294, in _create_skill_instance\r\n self.instance = skill_module.create_skill()\r\n File \"/opt/mycroft/skills/fallback-wolfram-alpha.mycroftai/__init__.py\", line 238, in create_skill\r\n return WolframAlphaSkill()\r\n File \"/opt/mycroft/skills/fallback-wolfram-alpha.mycroftai/__init__.py\", line 40, in __init__\r\n super().__init__()\r\n File \"/opt/mycroft/mycroft/skills/common_query_skill.py\", line 71, in __init__\r\n with open(noise_words_filename) as f:\r\nTypeError: expected str, bytes or os.PathLike object, not NoneType\r\n```\r\n\r\n**To Reproduce**\r\nSteps to reproduce the behavior:\r\n1. Configure language to `de-de`\r\n2. Restart Skills\r\n3. See `mycroft-console-client`\n", "before_files": [{"content": "# Copyright 2018 Mycroft AI Inc.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\nimport time\n\nfrom enum import IntEnum\nfrom abc import ABC, abstractmethod\nfrom .mycroft_skill import MycroftSkill\n\nfrom mycroft.configuration import Configuration\nfrom mycroft.util.file_utils import resolve_resource_file\n\n\nclass CQSMatchLevel(IntEnum):\n EXACT = 1 # Skill could find a specific answer for the question\n CATEGORY = 2 # Skill could find an answer from a category in the query\n GENERAL = 3 # The query could be processed as a general quer\n\n\n# Copy of CQSMatchLevel to use if the skill returns visual media\nCQSVisualMatchLevel = IntEnum('CQSVisualMatchLevel',\n [e.name for e in CQSMatchLevel])\n\n\ndef is_CQSVisualMatchLevel(match_level):\n return isinstance(match_level, type(CQSVisualMatchLevel.EXACT))\n\n\n\"\"\"these are for the confidence calculation\"\"\"\n# how much each topic word is worth\n# when found in the answer\nTOPIC_MATCH_RELEVANCE = 5\n\n# elevate relevance above all else\nRELEVANCE_MULTIPLIER = 2\n\n# we like longer articles but only so much\nMAX_ANSWER_LEN_FOR_CONFIDENCE = 50\n\n# higher number - less bias for word length\nWORD_COUNT_DIVISOR = 100\n\n\nclass CommonQuerySkill(MycroftSkill, ABC):\n \"\"\"Question answering skills should be based on this class.\n\n The skill author needs to implement `CQS_match_query_phrase` returning an\n answer and can optionally implement `CQS_action` to perform additional\n actions if the skill's answer is selected.\n\n This class works in conjunction with skill-query which collects\n answers from several skills presenting the best one available.\n \"\"\"\n\n def __init__(self, name=None, bus=None):\n super().__init__(name, bus)\n noise_words_filepath = \"text/%s/noise_words.list\" % (self.lang,)\n noise_words_filename = resolve_resource_file(noise_words_filepath)\n self.translated_noise_words = []\n try:\n with open(noise_words_filename) as f:\n self.translated_noise_words = f.read().strip()\n self.translated_noise_words = self.translated_noise_words.split()\n except FileNotFoundError:\n self.log.warning(\"Missing noise_words.list file in res/text/lang\")\n\n # these should probably be configurable\n self.level_confidence = {\n CQSMatchLevel.EXACT: 0.9,\n CQSMatchLevel.CATEGORY: 0.6,\n CQSMatchLevel.GENERAL: 0.5\n }\n\n def bind(self, bus):\n \"\"\"Overrides the default bind method of MycroftSkill.\n\n This registers messagebus handlers for the skill during startup\n but is nothing the skill author needs to consider.\n \"\"\"\n if bus:\n super().bind(bus)\n self.add_event('question:query', self.__handle_question_query)\n self.add_event('question:action', self.__handle_query_action)\n\n def __handle_question_query(self, message):\n search_phrase = message.data[\"phrase\"]\n\n # First, notify the requestor that we are attempting to handle\n # (this extends a timeout while this skill looks for a match)\n self.bus.emit(message.response({\"phrase\": search_phrase,\n \"skill_id\": self.skill_id,\n \"searching\": True}))\n\n # Now invoke the CQS handler to let the skill perform its search\n result = self.CQS_match_query_phrase(search_phrase)\n\n if result:\n match = result[0]\n level = result[1]\n answer = result[2]\n callback = result[3] if len(result) > 3 else None\n confidence = self.__calc_confidence(\n match, search_phrase, level, answer)\n self.bus.emit(message.response({\"phrase\": search_phrase,\n \"skill_id\": self.skill_id,\n \"answer\": answer,\n \"callback_data\": callback,\n \"conf\": confidence}))\n else:\n # Signal we are done (can't handle it)\n self.bus.emit(message.response({\"phrase\": search_phrase,\n \"skill_id\": self.skill_id,\n \"searching\": False}))\n\n def remove_noise(self, phrase):\n \"\"\"remove noise to produce essence of question\"\"\"\n phrase = ' ' + phrase + ' '\n for word in self.translated_noise_words:\n mtch = ' ' + word + ' '\n if phrase.find(mtch) > -1:\n phrase = phrase.replace(mtch, \" \")\n phrase = ' '.join(phrase.split())\n return phrase.strip()\n\n def __calc_confidence(self, match, phrase, level, answer):\n # Assume the more of the words that get consumed, the better the match\n consumed_pct = len(match.split()) / len(phrase.split())\n if consumed_pct > 1.0:\n consumed_pct = 1.0\n consumed_pct /= 10\n\n # bonus for more sentences\n num_sentences = float(float(len(answer.split(\".\"))) / float(10))\n\n # Add bonus if match has visuals and the device supports them.\n bonus = 0.0\n if is_CQSVisualMatchLevel(level) and self.gui.connected:\n bonus = 0.1\n\n # extract topic\n topic = self.remove_noise(match)\n\n # calculate relevance\n answer = answer.lower()\n matches = 0\n for word in topic.split(' '):\n if answer.find(word) > -1:\n matches += TOPIC_MATCH_RELEVANCE\n\n answer_size = len(answer.split(\" \"))\n answer_size = min(MAX_ANSWER_LEN_FOR_CONFIDENCE, answer_size)\n\n relevance = 0.0\n if answer_size > 0:\n relevance = float(float(matches) / float(answer_size))\n\n relevance = relevance * RELEVANCE_MULTIPLIER\n\n # extra credit for more words up to a point\n wc_mod = float(float(answer_size) / float(WORD_COUNT_DIVISOR)) * 2\n\n confidence = self.level_confidence[level] + \\\n consumed_pct + bonus + num_sentences + relevance + wc_mod\n\n return confidence\n\n def __handle_query_action(self, message):\n \"\"\"Message handler for question:action.\n\n Extracts phrase and data from message forward this to the skills\n CQS_action method.\n \"\"\"\n if message.data[\"skill_id\"] != self.skill_id:\n # Not for this skill!\n return\n phrase = message.data[\"phrase\"]\n data = message.data.get(\"callback_data\")\n # Invoke derived class to provide playback data\n self.CQS_action(phrase, data)\n\n @abstractmethod\n def CQS_match_query_phrase(self, phrase):\n \"\"\"Analyze phrase to see if it is a play-able phrase with this skill.\n\n Needs to be implemented by the skill.\n\n Args:\n phrase (str): User phrase, \"What is an aardwark\"\n\n Returns:\n (match, CQSMatchLevel[, callback_data]) or None: Tuple containing\n a string with the appropriate matching phrase, the PlayMatch\n type, and optionally data to return in the callback if the\n match is selected.\n \"\"\"\n # Derived classes must implement this, e.g.\n return None\n\n def CQS_action(self, phrase, data):\n \"\"\"Take additional action IF the skill is selected.\n\n The speech is handled by the common query but if the chosen skill\n wants to display media, set a context or prepare for sending\n information info over e-mail this can be implemented here.\n\n Args:\n phrase (str): User phrase uttered after \"Play\", e.g. \"some music\"\n data (dict): Callback data specified in match_query_phrase()\n \"\"\"\n # Derived classes may implement this if they use additional media\n # or wish to set context after being called.\n pass\n", "path": "mycroft/skills/common_query_skill.py"}]}
| 3,230 | 326 |
gh_patches_debug_22937
|
rasdani/github-patches
|
git_diff
|
aws-cloudformation__cfn-lint-321
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Fn::Cidr should support Fn::GetAtt (E1024)
* cfn-lint 0.6.1
* I get the following error:
```
E1024 Cidr ipBlock should be Cidr Range, Ref, or Select for Resources/MySubnet/Properties/CidrBlock/Fn::Select/1/Fn::Cidr/0/template.yml:123:7
```
```
Resources:
MySubnet:
Properties:
CidrBlock: !Select
- 0
- !Cidr
- !GetAtt 'MyVPC.CidrBlock'
- 16
- 8
```
Although the documentation doesn't mention the Fn::GetAtt in the list of supported functions, it is used in the CloudFormation examples on the same page.
https://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/intrinsic-function-reference-cidr.html
</issue>
<code>
[start of src/cfnlint/rules/functions/Cidr.py]
1 """
2 Copyright 2018 Amazon.com, Inc. or its affiliates. All Rights Reserved.
3
4 Permission is hereby granted, free of charge, to any person obtaining a copy of this
5 software and associated documentation files (the "Software"), to deal in the Software
6 without restriction, including without limitation the rights to use, copy, modify,
7 merge, publish, distribute, sublicense, and/or sell copies of the Software, and to
8 permit persons to whom the Software is furnished to do so.
9
10 THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED,
11 INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A
12 PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT
13 HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION
14 OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE
15 SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
16 """
17 import re
18 import six
19 from cfnlint import CloudFormationLintRule
20 from cfnlint import RuleMatch
21
22 from cfnlint.helpers import REGEX_CIDR
23
24 class Cidr(CloudFormationLintRule):
25 """Check if Cidr values are correct"""
26 id = 'E1024'
27 shortdesc = 'Cidr validation of parameters'
28 description = 'Making sure the function CIDR is a list with valid values'
29 source_url = 'https://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/intrinsic-function-reference-cidr.html'
30 tags = ['functions', 'cidr']
31
32 def check_parameter_count(self, cfn, parameter_name):
33 """Check Count Parameter if used"""
34 matches = list()
35 parameter_obj = cfn.get_parameters().get(parameter_name, {})
36 if parameter_obj:
37 tree = ['Parameters', parameter_name]
38 parameter_type = parameter_obj.get('Type')
39 if parameter_type == 'Number':
40 max_value = parameter_obj.get('MaxValue')
41 min_value = parameter_obj.get('MinValue')
42 if (not min_value) or min_value < 1 or min_value > 256:
43 message = 'Parameter for Cidr count have MinValue between 1 and 256 at {0}'
44 matches.append(RuleMatch(
45 tree + ['MinValue'], message.format('/'.join(map(str, tree + ['MinValue'])))))
46 if (not max_value) or max_value < 1 or max_value > 256:
47 message = 'Parameter for Cidr count have MaxValue between 1 and 256 at {0}'
48 matches.append(RuleMatch(
49 tree + ['MaxValue'], message.format('/'.join(map(str, tree + ['MaxValue'])))))
50 else:
51 message = 'Parameter for Cidr count have be of Type Number at {0}'
52 matches.append(RuleMatch(
53 tree, message.format('/'.join(map(str, tree)))))
54
55 return matches
56
57 def check_parameter_size_mask(self, cfn, parameter_name):
58 """Check SizeMask Parameter if used"""
59 matches = list()
60 parameter_obj = cfn.get_parameters().get(parameter_name, {})
61 if parameter_obj:
62 tree = ['Parameters', parameter_name]
63 parameter_type = parameter_obj.get('Type')
64 if parameter_type == 'Number':
65 max_value = parameter_obj.get('MaxValue')
66 min_value = parameter_obj.get('MinValue')
67 if (not min_value) or min_value < 1 or min_value > 256:
68 message = 'Parameter for Cidr sizeMask have MinValue between 1 and ' \
69 '128 (for ipv6) and 32 (for ipv4) at {0}'
70 matches.append(RuleMatch(
71 tree + ['MinValue'], message.format('/'.join(map(str, tree + ['MinValue'])))))
72 if (not max_value) or max_value < 1 or max_value > 256:
73 message = 'Parameter for Cidr count have MaxValue between 1 and ' \
74 '128 (for ipv6) and 32 (for ipv4) at {0}'
75 matches.append(RuleMatch(
76 tree + ['MaxValue'], message.format('/'.join(map(str, tree + ['MaxValue'])))))
77 else:
78 message = 'Parameter for Cidr count have be of Type Number at {0}'
79 matches.append(RuleMatch(
80 tree, message.format('/'.join(map(str, tree)))))
81
82 return matches
83
84 def match(self, cfn):
85 """Check CloudFormation Cidr"""
86
87 matches = list()
88
89 cidr_objs = cfn.search_deep_keys('Fn::Cidr')
90
91 supported_functions = [
92 'Fn::Select',
93 'Ref',
94 'Fn::ImportValue'
95 ]
96
97 count_parameters = []
98 size_mask_parameters = []
99
100 for cidr_obj in cidr_objs:
101 cidr_value_obj = cidr_obj[-1]
102 tree = cidr_obj[:-1]
103 if isinstance(cidr_value_obj, list):
104 if len(cidr_value_obj) in [2, 3]:
105 ip_block_obj = cidr_value_obj[0]
106 count_obj = cidr_value_obj[1]
107 if len(cidr_value_obj) == 3:
108 size_mask_obj = cidr_value_obj[2]
109 else:
110 size_mask_obj = None
111
112 if isinstance(ip_block_obj, dict):
113 if len(ip_block_obj) == 1:
114 for index_key, _ in ip_block_obj.items():
115 if index_key not in supported_functions:
116 message = 'Cidr ipBlock should be Cidr Range, Ref, or Select for {0}'
117 matches.append(RuleMatch(
118 tree[:] + [0], message.format('/'.join(map(str, tree[:] + [0])))))
119 elif isinstance(ip_block_obj, (six.text_type, six.string_types)):
120 if not re.match(REGEX_CIDR, ip_block_obj):
121 message = 'Cidr ipBlock should be a Cidr Range based string for {0}'
122 matches.append(RuleMatch(
123 tree[:] + [0], message.format('/'.join(map(str, tree[:] + [0])))))
124 else:
125 message = 'Cidr ipBlock should be a string for {0}'
126 matches.append(RuleMatch(
127 tree[:] + [0], message.format('/'.join(map(str, tree[:] + [0])))))
128
129 if isinstance(count_obj, dict):
130 if len(count_obj) == 1:
131 for index_key, index_value in count_obj.items():
132 if index_key not in supported_functions:
133 message = 'Cidr count should be Int, Ref, or Select for {0}'
134 matches.append(RuleMatch(
135 tree[:] + [1], message.format('/'.join(map(str, tree[:] + [1])))))
136 if index_key == 'Ref':
137 count_parameters.append(index_value)
138 elif not isinstance(count_obj, six.integer_types):
139 message = 'Cidr count should be a int for {0}'
140 matches.append(RuleMatch(
141 tree[:] + [1], message.format('/'.join(map(str, tree[:] + [1])))))
142
143 if isinstance(size_mask_obj, dict):
144 if len(size_mask_obj) == 1:
145 for index_key, index_value in size_mask_obj.items():
146 if index_key not in supported_functions:
147 message = 'Cidr sizeMask should be Int, Ref, or Select for {0}'
148 matches.append(RuleMatch(
149 tree[:] + [2], message.format('/'.join(map(str, tree[:] + [2])))))
150 if index_key == 'Ref':
151 size_mask_parameters.append(index_value)
152 elif not isinstance(size_mask_obj, six.integer_types):
153 message = 'Cidr sizeMask should be a int for {0}'
154 matches.append(RuleMatch(
155 tree[:] + [2], message.format('/'.join(map(str, tree[:] + [2])))))
156
157 else:
158 message = 'Cidr should be a list of 2 or 3 elements for {0}'
159 matches.append(RuleMatch(
160 tree, message.format('/'.join(map(str, tree)))))
161 else:
162 message = 'Cidr should be a list of 2 or 3 elements for {0}'
163 matches.append(RuleMatch(
164 tree, message.format('/'.join(map(str, tree)))))
165
166 for count_parameter in set(count_parameters):
167 matches.extend(self.check_parameter_count(cfn, count_parameter))
168 for size_mask_parameter in set(size_mask_parameters):
169 matches.extend(self.check_parameter_size_mask(cfn, size_mask_parameter))
170
171 return matches
172
[end of src/cfnlint/rules/functions/Cidr.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/cfnlint/rules/functions/Cidr.py b/src/cfnlint/rules/functions/Cidr.py
--- a/src/cfnlint/rules/functions/Cidr.py
+++ b/src/cfnlint/rules/functions/Cidr.py
@@ -91,6 +91,7 @@
supported_functions = [
'Fn::Select',
'Ref',
+ 'Fn::GetAtt',
'Fn::ImportValue'
]
@@ -113,7 +114,7 @@
if len(ip_block_obj) == 1:
for index_key, _ in ip_block_obj.items():
if index_key not in supported_functions:
- message = 'Cidr ipBlock should be Cidr Range, Ref, or Select for {0}'
+ message = 'Cidr ipBlock should be Cidr Range, Ref, GetAtt, or Select for {0}'
matches.append(RuleMatch(
tree[:] + [0], message.format('/'.join(map(str, tree[:] + [0])))))
elif isinstance(ip_block_obj, (six.text_type, six.string_types)):
|
{"golden_diff": "diff --git a/src/cfnlint/rules/functions/Cidr.py b/src/cfnlint/rules/functions/Cidr.py\n--- a/src/cfnlint/rules/functions/Cidr.py\n+++ b/src/cfnlint/rules/functions/Cidr.py\n@@ -91,6 +91,7 @@\n supported_functions = [\n 'Fn::Select',\n 'Ref',\n+ 'Fn::GetAtt',\n 'Fn::ImportValue'\n ]\n \n@@ -113,7 +114,7 @@\n if len(ip_block_obj) == 1:\n for index_key, _ in ip_block_obj.items():\n if index_key not in supported_functions:\n- message = 'Cidr ipBlock should be Cidr Range, Ref, or Select for {0}'\n+ message = 'Cidr ipBlock should be Cidr Range, Ref, GetAtt, or Select for {0}'\n matches.append(RuleMatch(\n tree[:] + [0], message.format('/'.join(map(str, tree[:] + [0])))))\n elif isinstance(ip_block_obj, (six.text_type, six.string_types)):\n", "issue": "Fn::Cidr should support Fn::GetAtt (E1024)\n* cfn-lint 0.6.1\r\n* I get the following error: \r\n\r\n```\r\nE1024 Cidr ipBlock should be Cidr Range, Ref, or Select for Resources/MySubnet/Properties/CidrBlock/Fn::Select/1/Fn::Cidr/0/template.yml:123:7\r\n```\r\n```\r\nResources:\r\n MySubnet:\r\n Properties:\r\n CidrBlock: !Select\r\n - 0\r\n - !Cidr\r\n - !GetAtt 'MyVPC.CidrBlock'\r\n - 16\r\n - 8\r\n```\r\n\r\nAlthough the documentation doesn't mention the Fn::GetAtt in the list of supported functions, it is used in the CloudFormation examples on the same page. \r\n\r\nhttps://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/intrinsic-function-reference-cidr.html\r\n\n", "before_files": [{"content": "\"\"\"\n Copyright 2018 Amazon.com, Inc. or its affiliates. All Rights Reserved.\n\n Permission is hereby granted, free of charge, to any person obtaining a copy of this\n software and associated documentation files (the \"Software\"), to deal in the Software\n without restriction, including without limitation the rights to use, copy, modify,\n merge, publish, distribute, sublicense, and/or sell copies of the Software, and to\n permit persons to whom the Software is furnished to do so.\n\n THE SOFTWARE IS PROVIDED \"AS IS\", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED,\n INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A\n PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT\n HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION\n OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE\n SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.\n\"\"\"\nimport re\nimport six\nfrom cfnlint import CloudFormationLintRule\nfrom cfnlint import RuleMatch\n\nfrom cfnlint.helpers import REGEX_CIDR\n\nclass Cidr(CloudFormationLintRule):\n \"\"\"Check if Cidr values are correct\"\"\"\n id = 'E1024'\n shortdesc = 'Cidr validation of parameters'\n description = 'Making sure the function CIDR is a list with valid values'\n source_url = 'https://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/intrinsic-function-reference-cidr.html'\n tags = ['functions', 'cidr']\n\n def check_parameter_count(self, cfn, parameter_name):\n \"\"\"Check Count Parameter if used\"\"\"\n matches = list()\n parameter_obj = cfn.get_parameters().get(parameter_name, {})\n if parameter_obj:\n tree = ['Parameters', parameter_name]\n parameter_type = parameter_obj.get('Type')\n if parameter_type == 'Number':\n max_value = parameter_obj.get('MaxValue')\n min_value = parameter_obj.get('MinValue')\n if (not min_value) or min_value < 1 or min_value > 256:\n message = 'Parameter for Cidr count have MinValue between 1 and 256 at {0}'\n matches.append(RuleMatch(\n tree + ['MinValue'], message.format('/'.join(map(str, tree + ['MinValue'])))))\n if (not max_value) or max_value < 1 or max_value > 256:\n message = 'Parameter for Cidr count have MaxValue between 1 and 256 at {0}'\n matches.append(RuleMatch(\n tree + ['MaxValue'], message.format('/'.join(map(str, tree + ['MaxValue'])))))\n else:\n message = 'Parameter for Cidr count have be of Type Number at {0}'\n matches.append(RuleMatch(\n tree, message.format('/'.join(map(str, tree)))))\n\n return matches\n\n def check_parameter_size_mask(self, cfn, parameter_name):\n \"\"\"Check SizeMask Parameter if used\"\"\"\n matches = list()\n parameter_obj = cfn.get_parameters().get(parameter_name, {})\n if parameter_obj:\n tree = ['Parameters', parameter_name]\n parameter_type = parameter_obj.get('Type')\n if parameter_type == 'Number':\n max_value = parameter_obj.get('MaxValue')\n min_value = parameter_obj.get('MinValue')\n if (not min_value) or min_value < 1 or min_value > 256:\n message = 'Parameter for Cidr sizeMask have MinValue between 1 and ' \\\n '128 (for ipv6) and 32 (for ipv4) at {0}'\n matches.append(RuleMatch(\n tree + ['MinValue'], message.format('/'.join(map(str, tree + ['MinValue'])))))\n if (not max_value) or max_value < 1 or max_value > 256:\n message = 'Parameter for Cidr count have MaxValue between 1 and ' \\\n '128 (for ipv6) and 32 (for ipv4) at {0}'\n matches.append(RuleMatch(\n tree + ['MaxValue'], message.format('/'.join(map(str, tree + ['MaxValue'])))))\n else:\n message = 'Parameter for Cidr count have be of Type Number at {0}'\n matches.append(RuleMatch(\n tree, message.format('/'.join(map(str, tree)))))\n\n return matches\n\n def match(self, cfn):\n \"\"\"Check CloudFormation Cidr\"\"\"\n\n matches = list()\n\n cidr_objs = cfn.search_deep_keys('Fn::Cidr')\n\n supported_functions = [\n 'Fn::Select',\n 'Ref',\n 'Fn::ImportValue'\n ]\n\n count_parameters = []\n size_mask_parameters = []\n\n for cidr_obj in cidr_objs:\n cidr_value_obj = cidr_obj[-1]\n tree = cidr_obj[:-1]\n if isinstance(cidr_value_obj, list):\n if len(cidr_value_obj) in [2, 3]:\n ip_block_obj = cidr_value_obj[0]\n count_obj = cidr_value_obj[1]\n if len(cidr_value_obj) == 3:\n size_mask_obj = cidr_value_obj[2]\n else:\n size_mask_obj = None\n\n if isinstance(ip_block_obj, dict):\n if len(ip_block_obj) == 1:\n for index_key, _ in ip_block_obj.items():\n if index_key not in supported_functions:\n message = 'Cidr ipBlock should be Cidr Range, Ref, or Select for {0}'\n matches.append(RuleMatch(\n tree[:] + [0], message.format('/'.join(map(str, tree[:] + [0])))))\n elif isinstance(ip_block_obj, (six.text_type, six.string_types)):\n if not re.match(REGEX_CIDR, ip_block_obj):\n message = 'Cidr ipBlock should be a Cidr Range based string for {0}'\n matches.append(RuleMatch(\n tree[:] + [0], message.format('/'.join(map(str, tree[:] + [0])))))\n else:\n message = 'Cidr ipBlock should be a string for {0}'\n matches.append(RuleMatch(\n tree[:] + [0], message.format('/'.join(map(str, tree[:] + [0])))))\n\n if isinstance(count_obj, dict):\n if len(count_obj) == 1:\n for index_key, index_value in count_obj.items():\n if index_key not in supported_functions:\n message = 'Cidr count should be Int, Ref, or Select for {0}'\n matches.append(RuleMatch(\n tree[:] + [1], message.format('/'.join(map(str, tree[:] + [1])))))\n if index_key == 'Ref':\n count_parameters.append(index_value)\n elif not isinstance(count_obj, six.integer_types):\n message = 'Cidr count should be a int for {0}'\n matches.append(RuleMatch(\n tree[:] + [1], message.format('/'.join(map(str, tree[:] + [1])))))\n\n if isinstance(size_mask_obj, dict):\n if len(size_mask_obj) == 1:\n for index_key, index_value in size_mask_obj.items():\n if index_key not in supported_functions:\n message = 'Cidr sizeMask should be Int, Ref, or Select for {0}'\n matches.append(RuleMatch(\n tree[:] + [2], message.format('/'.join(map(str, tree[:] + [2])))))\n if index_key == 'Ref':\n size_mask_parameters.append(index_value)\n elif not isinstance(size_mask_obj, six.integer_types):\n message = 'Cidr sizeMask should be a int for {0}'\n matches.append(RuleMatch(\n tree[:] + [2], message.format('/'.join(map(str, tree[:] + [2])))))\n\n else:\n message = 'Cidr should be a list of 2 or 3 elements for {0}'\n matches.append(RuleMatch(\n tree, message.format('/'.join(map(str, tree)))))\n else:\n message = 'Cidr should be a list of 2 or 3 elements for {0}'\n matches.append(RuleMatch(\n tree, message.format('/'.join(map(str, tree)))))\n\n for count_parameter in set(count_parameters):\n matches.extend(self.check_parameter_count(cfn, count_parameter))\n for size_mask_parameter in set(size_mask_parameters):\n matches.extend(self.check_parameter_size_mask(cfn, size_mask_parameter))\n\n return matches\n", "path": "src/cfnlint/rules/functions/Cidr.py"}]}
| 3,022 | 241 |
gh_patches_debug_60604
|
rasdani/github-patches
|
git_diff
|
pytorch__TensorRT-376
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
🐛 [Bug] Memory leak in ConversionCtx::SerializeEngine()
## Bug Description
Using `trtorch::CompileGraph` many times will increase memory usage.
## To Reproduce
[Source code](https://github.com/SakodaShintaro/trtorch-test/blob/7e9f7a457b3570b40e5aa938ac400aaf5e0028ba/main.cpp)
```cpp
#include <torch/script.h>
#include <trtorch/trtorch.h>
using namespace std;
void compile() {
constexpr int64_t INPUT_CHANNEL_NUM = 256;
constexpr int64_t WIDTH = 32;
torch::jit::Module module = torch::jit::load("model.ts");
module.to(torch::kCUDA);
module.eval();
std::vector<int64_t> in_sizes = {1, INPUT_CHANNEL_NUM, WIDTH, WIDTH};
trtorch::CompileSpec::InputRange range(in_sizes);
trtorch::CompileSpec info({range});
module = trtorch::CompileGraph(module, info);
}
int main() {
for (int64_t i = 0; i < 10000; i++) {
cout << i << endl;
compile();
}
}
```
[Dockerfile](https://github.com/SakodaShintaro/trtorch-test/blob/7e9f7a457b3570b40e5aa938ac400aaf5e0028ba/docker/Dockerfile)
## What seems to be the cause
When I verified it with Valgrind, it seemed that the cause was ConversionCtx::SerializeEngine. Looking at the code, it seemed that the `serialized_engine` isn't released. After making the following modifications, the memory leak no longer occurs.
```
diff --git a/core/conversion/conversionctx/ConversionCtx.cpp b/core/conversion/conversionctx/ConversionCtx.cpp
index ff23692..c241f9c 100644
--- a/core/conversion/conversionctx/ConversionCtx.cpp
+++ b/core/conversion/conversionctx/ConversionCtx.cpp
@@ -147,7 +147,9 @@ std::string ConversionCtx::SerializeEngine() {
auto engine = builder->buildEngineWithConfig(*net, *cfg);
auto serialized_engine = engine->serialize();
engine->destroy();
- return std::string((const char*)serialized_engine->data(), serialized_engine->size());
+ std::string result = std::string((const char*)serialized_engine->data(), serialized_engine->size());
+ serialized_engine->destroy();
+ return result;
}
```
I would appreciate it if you could respond appropriately.
</issue>
<code>
[start of py/trtorch/_compiler.py]
1 from typing import List, Dict, Any
2 import torch
3 from torch import nn
4
5 import trtorch._C
6 from trtorch._compile_spec import _parse_compile_spec
7 from trtorch._version import __version__
8 from types import FunctionType
9
10
11 def compile(module: torch.jit.ScriptModule, compile_spec: Any) -> torch.jit.ScriptModule:
12 """Compile a TorchScript module for NVIDIA GPUs using TensorRT
13
14 Takes a existing TorchScript module and a set of settings to configure the compiler
15 and will convert methods to JIT Graphs which call equivalent TensorRT engines
16
17 Converts specifically the forward method of a TorchScript Module
18
19 Args:
20 module (torch.jit.ScriptModule): Source module, a result of tracing or scripting a PyTorch
21 ``torch.nn.Module``
22 compile_spec (dict): Compilation settings including operating precision, target device, etc.
23 One key is required which is ``input_shapes``, describing the input sizes or ranges for inputs
24 to the graph. All other keys are optional
25
26 .. code-block:: py
27
28 compile_spec = {
29 "input_shapes": [
30 (1, 3, 224, 224), # Static input shape for input #1
31 {
32 "min": (1, 3, 224, 224),
33 "opt": (1, 3, 512, 512),
34 "max": (1, 3, 1024, 1024)
35 } # Dynamic input shape for input #2
36 ],
37 "device": {
38 "device_type": torch.device("cuda"), # Type of device to run engine on (for DLA use trtorch.DeviceType.DLA)
39 "gpu_id": 0, # Target gpu id to run engine (Use Xavier as gpu id for DLA)
40 "dla_core": 0, # (DLA only) Target dla core id to run engine
41 "allow_gpu_fallback": false, # (DLA only) Allow layers unsupported on DLA to run on GPU
42 },
43 "op_precision": torch.half, # Operating precision set to FP16
44 "refit": false, # enable refit
45 "debug": false, # enable debuggable engine
46 "strict_types": false, # kernels should strictly run in operating precision
47 "capability": trtorch.EngineCapability.DEFAULT, # Restrict kernel selection to safe gpu kernels or safe dla kernels
48 "num_min_timing_iters": 2, # Number of minimization timing iterations used to select kernels
49 "num_avg_timing_iters": 1, # Number of averaging timing iterations used to select kernels
50 "workspace_size": 0, # Maximum size of workspace given to TensorRT
51 "max_batch_size": 0, # Maximum batch size (must be >= 1 to be set, 0 means not set)
52 }
53
54 Input Sizes can be specified as torch sizes, tuples or lists. Op precisions can be specified using
55 torch datatypes or trtorch datatypes and you can use either torch devices or the trtorch device type enum
56 to select device type.
57
58 Returns:
59 torch.jit.ScriptModule: Compiled TorchScript Module, when run it will execute via TensorRT
60 """
61
62 if isinstance(module, torch.jit.ScriptFunction):
63 raise TypeError(
64 "torch.jit.ScriptFunction currently is not directly supported, wrap the function in a module to compile")
65
66 compiled_cpp_mod = trtorch._C.compile_graph(module._c, _parse_compile_spec(compile_spec))
67 compiled_module = torch.jit._recursive.wrap_cpp_module(compiled_cpp_mod)
68 return compiled_module
69
70
71 def convert_method_to_trt_engine(module: torch.jit.ScriptModule, method_name: str, compile_spec: Any) -> str:
72 """Convert a TorchScript module method to a serialized TensorRT engine
73
74 Converts a specified method of a module to a serialized TensorRT engine given a dictionary of conversion settings
75
76 Args:
77 module (torch.jit.ScriptModule): Source module, a result of tracing or scripting a PyTorch
78 ``torch.nn.Module``
79 method_name (str): Name of method to convert
80 compile_spec (dict): Compilation settings including operating precision, target device, etc.
81 One key is required which is ``input_shapes``, describing the input sizes or ranges for inputs
82 to the graph. All other keys are optional
83
84 .. code-block:: py
85
86 CompileSpec = {
87 "input_shapes": [
88 (1, 3, 224, 224), # Static input shape for input #1
89 {
90 "min": (1, 3, 224, 224),
91 "opt": (1, 3, 512, 512),
92 "max": (1, 3, 1024, 1024)
93 } # Dynamic input shape for input #2
94 ],
95 "device": {
96 "device_type": torch.device("cuda"), # Type of device to run engine on (for DLA use trtorch.DeviceType.DLA)
97 "gpu_id": 0, # Target gpu id to run engine (Use Xavier as gpu id for DLA)
98 "dla_core": 0, # (DLA only) Target dla core id to run engine
99 "allow_gpu_fallback": false, # (DLA only) Allow layers unsupported on DLA to run on GPU
100 },
101 "op_precision": torch.half, # Operating precision set to FP16
102 "disable_tf32": False, # Force FP32 layers to use traditional as FP32 format vs the default behavior of rounding the inputs to 10-bit mantissas before multiplying, but accumulates the sum using 23-bit mantissas
103 "refit": false, # enable refit
104 "debug": false, # enable debuggable engine
105 "strict_types": false, # kernels should strictly run in operating precision
106 "capability": trtorch.EngineCapability.DEFAULT, # Restrict kernel selection to safe gpu kernels or safe dla kernels
107 "num_min_timing_iters": 2, # Number of minimization timing iterations used to select kernels
108 "num_avg_timing_iters": 1, # Number of averaging timing iterations used to select kernels
109 "workspace_size": 0, # Maximum size of workspace given to TensorRT
110 "max_batch_size": 0, # Maximum batch size (must be >= 1 to be set, 0 means not set)
111 }
112
113 Input Sizes can be specified as torch sizes, tuples or lists. Op precisions can be specified using
114 torch datatypes or trtorch datatypes and you can use either torch devices or the trtorch device type enum
115 to select device type.
116
117 Returns:
118 bytes: Serialized TensorRT engine, can either be saved to a file or deserialized via TensorRT APIs
119 """
120 if isinstance(module, torch.jit.ScriptFunction):
121 raise TypeError(
122 "torch.jit.ScriptFunctions currently are not directly supported, wrap the function in a module to compile")
123
124 return trtorch._C.convert_graph_to_trt_engine(module._c, method_name, _parse_compile_spec(compile_spec))
125
126
127 def check_method_op_support(module: torch.jit.ScriptModule, method_name: str) -> bool:
128 """Checks to see if a method is fully supported by TRTorch
129
130 Checks if a method of a TorchScript module can be compiled by TRTorch, if not, a list of operators
131 that are not supported are printed out and the function returns false, else true.
132
133 Args:
134 module (torch.jit.ScriptModule): Source module, a result of tracing or scripting a PyTorch
135 ``torch.nn.Module``
136 method_name (str): Name of method to check
137
138 Returns:
139 bool: True if supported Method
140 """
141 return trtorch._C.check_method_op_support(module._c, method_name)
142
143
144 def dump_build_info():
145 """Prints build information about the TRTorch distribution to stdout
146 """
147 print(get_build_info())
148
149
150 def get_build_info() -> str:
151 """Returns a string containing the build information of TRTorch distribution
152
153 Returns:
154 str: String containing the build information for TRTorch distribution
155 """
156 build_info = trtorch._C.get_build_info()
157 build_info = "TRTorch Version: " + str(__version__) + '\n' + build_info
158 return build_info
159
160 def set_device(gpu_id):
161 trtorch._C.set_device(gpu_id)
162
[end of py/trtorch/_compiler.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/py/trtorch/_compiler.py b/py/trtorch/_compiler.py
--- a/py/trtorch/_compiler.py
+++ b/py/trtorch/_compiler.py
@@ -157,5 +157,6 @@
build_info = "TRTorch Version: " + str(__version__) + '\n' + build_info
return build_info
+
def set_device(gpu_id):
trtorch._C.set_device(gpu_id)
|
{"golden_diff": "diff --git a/py/trtorch/_compiler.py b/py/trtorch/_compiler.py\n--- a/py/trtorch/_compiler.py\n+++ b/py/trtorch/_compiler.py\n@@ -157,5 +157,6 @@\n build_info = \"TRTorch Version: \" + str(__version__) + '\\n' + build_info\n return build_info\n \n+\n def set_device(gpu_id):\n trtorch._C.set_device(gpu_id)\n", "issue": "\ud83d\udc1b [Bug] Memory leak in ConversionCtx::SerializeEngine()\n## Bug Description\r\nUsing `trtorch::CompileGraph` many times will increase memory usage.\r\n\r\n## To Reproduce\r\n[Source code](https://github.com/SakodaShintaro/trtorch-test/blob/7e9f7a457b3570b40e5aa938ac400aaf5e0028ba/main.cpp)\r\n\r\n```cpp\r\n#include <torch/script.h>\r\n#include <trtorch/trtorch.h>\r\nusing namespace std;\r\n\r\nvoid compile() {\r\n constexpr int64_t INPUT_CHANNEL_NUM = 256;\r\n constexpr int64_t WIDTH = 32;\r\n torch::jit::Module module = torch::jit::load(\"model.ts\");\r\n module.to(torch::kCUDA);\r\n module.eval();\r\n\r\n std::vector<int64_t> in_sizes = {1, INPUT_CHANNEL_NUM, WIDTH, WIDTH};\r\n trtorch::CompileSpec::InputRange range(in_sizes);\r\n trtorch::CompileSpec info({range});\r\n module = trtorch::CompileGraph(module, info);\r\n}\r\n\r\nint main() {\r\n for (int64_t i = 0; i < 10000; i++) {\r\n cout << i << endl;\r\n compile();\r\n }\r\n}\r\n```\r\n\r\n[Dockerfile](https://github.com/SakodaShintaro/trtorch-test/blob/7e9f7a457b3570b40e5aa938ac400aaf5e0028ba/docker/Dockerfile)\r\n\r\n## What seems to be the cause\r\nWhen I verified it with Valgrind, it seemed that the cause was ConversionCtx::SerializeEngine. Looking at the code, it seemed that the `serialized_engine` isn't released. After making the following modifications, the memory leak no longer occurs.\r\n\r\n```\r\ndiff --git a/core/conversion/conversionctx/ConversionCtx.cpp b/core/conversion/conversionctx/ConversionCtx.cpp\r\nindex ff23692..c241f9c 100644\r\n--- a/core/conversion/conversionctx/ConversionCtx.cpp\r\n+++ b/core/conversion/conversionctx/ConversionCtx.cpp\r\n@@ -147,7 +147,9 @@ std::string ConversionCtx::SerializeEngine() {\r\n auto engine = builder->buildEngineWithConfig(*net, *cfg);\r\n auto serialized_engine = engine->serialize();\r\n engine->destroy();\r\n- return std::string((const char*)serialized_engine->data(), serialized_engine->size());\r\n+ std::string result = std::string((const char*)serialized_engine->data(), serialized_engine->size());\r\n+ serialized_engine->destroy();\r\n+ return result;\r\n }\r\n ```\r\n\r\nI would appreciate it if you could respond appropriately.\n", "before_files": [{"content": "from typing import List, Dict, Any\nimport torch\nfrom torch import nn\n\nimport trtorch._C\nfrom trtorch._compile_spec import _parse_compile_spec\nfrom trtorch._version import __version__\nfrom types import FunctionType\n\n\ndef compile(module: torch.jit.ScriptModule, compile_spec: Any) -> torch.jit.ScriptModule:\n \"\"\"Compile a TorchScript module for NVIDIA GPUs using TensorRT\n\n Takes a existing TorchScript module and a set of settings to configure the compiler\n and will convert methods to JIT Graphs which call equivalent TensorRT engines\n\n Converts specifically the forward method of a TorchScript Module\n\n Args:\n module (torch.jit.ScriptModule): Source module, a result of tracing or scripting a PyTorch\n ``torch.nn.Module``\n compile_spec (dict): Compilation settings including operating precision, target device, etc.\n One key is required which is ``input_shapes``, describing the input sizes or ranges for inputs\n to the graph. All other keys are optional\n\n .. code-block:: py\n\n compile_spec = {\n \"input_shapes\": [\n (1, 3, 224, 224), # Static input shape for input #1\n {\n \"min\": (1, 3, 224, 224),\n \"opt\": (1, 3, 512, 512),\n \"max\": (1, 3, 1024, 1024)\n } # Dynamic input shape for input #2\n ],\n \"device\": {\n \"device_type\": torch.device(\"cuda\"), # Type of device to run engine on (for DLA use trtorch.DeviceType.DLA)\n \"gpu_id\": 0, # Target gpu id to run engine (Use Xavier as gpu id for DLA)\n \"dla_core\": 0, # (DLA only) Target dla core id to run engine\n \"allow_gpu_fallback\": false, # (DLA only) Allow layers unsupported on DLA to run on GPU\n },\n \"op_precision\": torch.half, # Operating precision set to FP16\n \"refit\": false, # enable refit\n \"debug\": false, # enable debuggable engine\n \"strict_types\": false, # kernels should strictly run in operating precision\n \"capability\": trtorch.EngineCapability.DEFAULT, # Restrict kernel selection to safe gpu kernels or safe dla kernels\n \"num_min_timing_iters\": 2, # Number of minimization timing iterations used to select kernels\n \"num_avg_timing_iters\": 1, # Number of averaging timing iterations used to select kernels\n \"workspace_size\": 0, # Maximum size of workspace given to TensorRT\n \"max_batch_size\": 0, # Maximum batch size (must be >= 1 to be set, 0 means not set)\n }\n\n Input Sizes can be specified as torch sizes, tuples or lists. Op precisions can be specified using\n torch datatypes or trtorch datatypes and you can use either torch devices or the trtorch device type enum\n to select device type.\n\n Returns:\n torch.jit.ScriptModule: Compiled TorchScript Module, when run it will execute via TensorRT\n \"\"\"\n\n if isinstance(module, torch.jit.ScriptFunction):\n raise TypeError(\n \"torch.jit.ScriptFunction currently is not directly supported, wrap the function in a module to compile\")\n\n compiled_cpp_mod = trtorch._C.compile_graph(module._c, _parse_compile_spec(compile_spec))\n compiled_module = torch.jit._recursive.wrap_cpp_module(compiled_cpp_mod)\n return compiled_module\n\n\ndef convert_method_to_trt_engine(module: torch.jit.ScriptModule, method_name: str, compile_spec: Any) -> str:\n \"\"\"Convert a TorchScript module method to a serialized TensorRT engine\n\n Converts a specified method of a module to a serialized TensorRT engine given a dictionary of conversion settings\n\n Args:\n module (torch.jit.ScriptModule): Source module, a result of tracing or scripting a PyTorch\n ``torch.nn.Module``\n method_name (str): Name of method to convert\n compile_spec (dict): Compilation settings including operating precision, target device, etc.\n One key is required which is ``input_shapes``, describing the input sizes or ranges for inputs\n to the graph. All other keys are optional\n\n .. code-block:: py\n\n CompileSpec = {\n \"input_shapes\": [\n (1, 3, 224, 224), # Static input shape for input #1\n {\n \"min\": (1, 3, 224, 224),\n \"opt\": (1, 3, 512, 512),\n \"max\": (1, 3, 1024, 1024)\n } # Dynamic input shape for input #2\n ],\n \"device\": {\n \"device_type\": torch.device(\"cuda\"), # Type of device to run engine on (for DLA use trtorch.DeviceType.DLA)\n \"gpu_id\": 0, # Target gpu id to run engine (Use Xavier as gpu id for DLA)\n \"dla_core\": 0, # (DLA only) Target dla core id to run engine\n \"allow_gpu_fallback\": false, # (DLA only) Allow layers unsupported on DLA to run on GPU\n },\n \"op_precision\": torch.half, # Operating precision set to FP16\n \"disable_tf32\": False, # Force FP32 layers to use traditional as FP32 format vs the default behavior of rounding the inputs to 10-bit mantissas before multiplying, but accumulates the sum using 23-bit mantissas\n \"refit\": false, # enable refit\n \"debug\": false, # enable debuggable engine\n \"strict_types\": false, # kernels should strictly run in operating precision\n \"capability\": trtorch.EngineCapability.DEFAULT, # Restrict kernel selection to safe gpu kernels or safe dla kernels\n \"num_min_timing_iters\": 2, # Number of minimization timing iterations used to select kernels\n \"num_avg_timing_iters\": 1, # Number of averaging timing iterations used to select kernels\n \"workspace_size\": 0, # Maximum size of workspace given to TensorRT\n \"max_batch_size\": 0, # Maximum batch size (must be >= 1 to be set, 0 means not set)\n }\n\n Input Sizes can be specified as torch sizes, tuples or lists. Op precisions can be specified using\n torch datatypes or trtorch datatypes and you can use either torch devices or the trtorch device type enum\n to select device type.\n\n Returns:\n bytes: Serialized TensorRT engine, can either be saved to a file or deserialized via TensorRT APIs\n \"\"\"\n if isinstance(module, torch.jit.ScriptFunction):\n raise TypeError(\n \"torch.jit.ScriptFunctions currently are not directly supported, wrap the function in a module to compile\")\n\n return trtorch._C.convert_graph_to_trt_engine(module._c, method_name, _parse_compile_spec(compile_spec))\n\n\ndef check_method_op_support(module: torch.jit.ScriptModule, method_name: str) -> bool:\n \"\"\"Checks to see if a method is fully supported by TRTorch\n\n Checks if a method of a TorchScript module can be compiled by TRTorch, if not, a list of operators\n that are not supported are printed out and the function returns false, else true.\n\n Args:\n module (torch.jit.ScriptModule): Source module, a result of tracing or scripting a PyTorch\n ``torch.nn.Module``\n method_name (str): Name of method to check\n\n Returns:\n bool: True if supported Method\n \"\"\"\n return trtorch._C.check_method_op_support(module._c, method_name)\n\n\ndef dump_build_info():\n \"\"\"Prints build information about the TRTorch distribution to stdout\n \"\"\"\n print(get_build_info())\n\n\ndef get_build_info() -> str:\n \"\"\"Returns a string containing the build information of TRTorch distribution\n\n Returns:\n str: String containing the build information for TRTorch distribution\n \"\"\"\n build_info = trtorch._C.get_build_info()\n build_info = \"TRTorch Version: \" + str(__version__) + '\\n' + build_info\n return build_info\n\ndef set_device(gpu_id):\n trtorch._C.set_device(gpu_id)\n", "path": "py/trtorch/_compiler.py"}]}
| 3,367 | 98 |
gh_patches_debug_18455
|
rasdani/github-patches
|
git_diff
|
pyg-team__pytorch_geometric-6550
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Classification metrics can't handle a mix of binary and continuous targets
### 🐛 Describe the bug
I was trying to run the [pytorch_geometric](https://github.com/pyg-team/pytorch_geometric)/[examples](https://github.com/pyg-team/pytorch_geometric/tree/master/examples)/[hetero](https://github.com/pyg-team/pytorch_geometric/tree/master/examples/hetero)/bipartite_sage_unsup.py . I received the following error in the training loop. The error happened after the test() function was called
## Error
```
ValueError Traceback (most recent call last)
[<ipython-input-7-449d394a8262>](https://localhost:8080/#) in <module>
54 for epoch in range(1, 21):
55 loss = train()
---> 56 val_acc, val_prec, val_rec, val_f1 = test(val_loader)
57 test_acc, test_prec, test_rec, test_f1 = test(test_loader)
58
3 frames
[/usr/local/lib/python3.8/dist-packages/sklearn/metrics/_classification.py](https://localhost:8080/#) in _check_targets(y_true, y_pred)
91
92 if len(y_type) > 1:
---> 93 raise ValueError(
94 "Classification metrics can't handle a mix of {0} and {1} targets".format(
95 type_true, type_pred
ValueError: Classification metrics can't handle a mix of binary and continuous targets
```
## Code modifications
```
@torch.no_grad()
def test(loader):
model.eval()
preds, targets = [], []
for batch in tqdm.tqdm(loader):
batch = batch.to(device)
pred = model(
batch.x_dict,
batch.edge_index_dict,
batch['user', 'item'].edge_label_index,
).sigmoid().view(-1).cpu()
target = batch['user', 'item'].edge_label.long().cpu()
preds.append(pred)
targets.append(target) #I assumed it was a typo in the original example
pred = torch.cat(preds, dim=0).numpy()
target = torch.cat(targets, dim=0).numpy() #I assumed it was a typo in the original example
acc = accuracy_score(target, pred)
prec = precision_score(target, pred)
rec = recall_score(target, pred)
f1 = f1_score(target, pred)
return acc, prec, rec, f1
```
### Environment
* PyG version:
* PyTorch version: 1.13.0
* OS: Linux(Colab)
* Python version: 3.8.10
* CUDA/cuDNN version: 11.6
* How you installed PyTorch and PyG (`conda`, `pip`, source): pip
* Any other relevant information (*e.g.*, version of `torch-scatter`):
</issue>
<code>
[start of examples/hetero/bipartite_sage_unsup.py]
1 # An implementation of unsupervised bipartite GraphSAGE using the Alibaba
2 # Taobao dataset.
3 import os.path as osp
4
5 import torch
6 import torch.nn.functional as F
7 import tqdm
8 from sklearn.metrics import (
9 accuracy_score,
10 f1_score,
11 precision_score,
12 recall_score,
13 )
14 from torch.nn import Embedding, Linear
15
16 import torch_geometric.transforms as T
17 from torch_geometric.datasets import Taobao
18 from torch_geometric.loader import LinkNeighborLoader
19 from torch_geometric.nn import SAGEConv
20 from torch_geometric.utils.convert import to_scipy_sparse_matrix
21
22 device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
23 path = osp.join(osp.dirname(osp.realpath(__file__)), '../../data/Taobao')
24
25 dataset = Taobao(path)
26 data = dataset[0]
27
28 data['user'].x = torch.arange(0, data['user'].num_nodes)
29 data['item'].x = torch.arange(0, data['item'].num_nodes)
30
31 # Only consider user<>item relationships for simplicity:
32 del data['category']
33 del data['item', 'category']
34 del data['user', 'item'].time
35 del data['user', 'item'].behavior
36
37 # Add a reverse ('item', 'rev_to', 'user') relation for message passing:
38 data = T.ToUndirected()(data)
39
40 # Perform a link-level split into training, validation, and test edges:
41 print('Computing data splits...')
42 train_data, val_data, test_data = T.RandomLinkSplit(
43 num_val=0.1,
44 num_test=0.1,
45 neg_sampling_ratio=1.0,
46 add_negative_train_samples=False,
47 edge_types=[('user', 'to', 'item')],
48 rev_edge_types=[('item', 'rev_to', 'user')],
49 )(data)
50 print('Done!')
51
52 # Compute sparsified item<>item relationships through users:
53 print('Computing item<>item relationships...')
54 mat = to_scipy_sparse_matrix(data['user', 'item'].edge_index).tocsr()
55 mat = mat[:data['user'].num_nodes, :data['item'].num_nodes]
56 comat = mat.T @ mat
57 comat.setdiag(0)
58 comat = comat >= 3.
59 comat = comat.tocoo()
60 row = torch.from_numpy(comat.row).to(torch.long)
61 col = torch.from_numpy(comat.col).to(torch.long)
62 item_to_item_edge_index = torch.stack([row, col], dim=0)
63
64 # Add the generated item<>item relationships for high-order information:
65 train_data['item', 'item'].edge_index = item_to_item_edge_index
66 val_data['item', 'item'].edge_index = item_to_item_edge_index
67 test_data['item', 'item'].edge_index = item_to_item_edge_index
68 print('Done!')
69
70 train_loader = LinkNeighborLoader(
71 data=train_data,
72 num_neighbors=[8, 4],
73 edge_label_index=('user', 'to', 'item'),
74 neg_sampling='binary',
75 batch_size=2048,
76 shuffle=True,
77 num_workers=16,
78 drop_last=True,
79 )
80
81 val_loader = LinkNeighborLoader(
82 data=val_data,
83 num_neighbors=[8, 4],
84 edge_label_index=(
85 ('user', 'to', 'item'),
86 val_data[('user', 'to', 'item')].edge_label_index,
87 ),
88 edge_label=val_data[('user', 'to', 'item')].edge_label,
89 batch_size=2048,
90 shuffle=False,
91 num_workers=16,
92 )
93
94 test_loader = LinkNeighborLoader(
95 data=test_data,
96 num_neighbors=[8, 4],
97 edge_label_index=(
98 ('user', 'to', 'item'),
99 test_data[('user', 'to', 'item')].edge_label_index,
100 ),
101 edge_label=test_data[('user', 'to', 'item')].edge_label,
102 batch_size=2048,
103 shuffle=False,
104 num_workers=16,
105 )
106
107
108 class ItemGNNEncoder(torch.nn.Module):
109 def __init__(self, hidden_channels, out_channels):
110 super().__init__()
111 self.conv1 = SAGEConv(-1, hidden_channels)
112 self.conv2 = SAGEConv(hidden_channels, hidden_channels)
113 self.lin = Linear(hidden_channels, out_channels)
114
115 def forward(self, x, edge_index):
116 x = self.conv1(x, edge_index).relu()
117 x = self.conv2(x, edge_index).relu()
118 return self.lin(x)
119
120
121 class UserGNNEncoder(torch.nn.Module):
122 def __init__(self, hidden_channels, out_channels):
123 super().__init__()
124 self.conv1 = SAGEConv((-1, -1), hidden_channels)
125 self.conv2 = SAGEConv((-1, -1), hidden_channels)
126 self.conv3 = SAGEConv((-1, -1), hidden_channels)
127 self.lin = Linear(hidden_channels, out_channels)
128
129 def forward(self, x_dict, edge_index_dict):
130 item_x = self.conv1(
131 x_dict['item'],
132 edge_index_dict[('item', 'to', 'item')],
133 ).relu()
134
135 user_x = self.conv2(
136 (x_dict['item'], x_dict['user']),
137 edge_index_dict[('item', 'rev_to', 'user')],
138 ).relu()
139
140 user_x = self.conv3(
141 (item_x, user_x),
142 edge_index_dict[('item', 'to', 'user')],
143 ).relu()
144
145 return self.lin(user_x)
146
147
148 class EdgeDecoder(torch.nn.Module):
149 def __init__(self, hidden_channels):
150 super().__init__()
151 self.lin1 = Linear(2 * hidden_channels, hidden_channels)
152 self.lin2 = Linear(hidden_channels, 1)
153
154 def forward(self, z_src, z_dst, edge_label_index):
155 row, col = edge_label_index
156 z = torch.cat([z_src[row], z_dst[col]], dim=-1)
157
158 z = self.lin1(z).relu()
159 z = self.lin2(z)
160 return z.view(-1)
161
162
163 class Model(torch.nn.Module):
164 def __init__(self, num_users, num_items, hidden_channels, out_channels):
165 super().__init__()
166 self.user_emb = Embedding(num_users, hidden_channels, device=device)
167 self.item_emb = Embedding(num_items, hidden_channels, device=device)
168 self.item_encoder = ItemGNNEncoder(hidden_channels, out_channels)
169 self.user_encoder = UserGNNEncoder(hidden_channels, out_channels)
170 self.decoder = EdgeDecoder(out_channels)
171
172 def forward(self, x_dict, edge_index_dict, edge_label_index):
173 z_dict = {}
174 x_dict['user'] = self.user_emb(x_dict['user'])
175 x_dict['item'] = self.item_emb(x_dict['item'])
176 z_dict['item'] = self.item_encoder(
177 x_dict['item'],
178 edge_index_dict[('item', 'to', 'item')],
179 )
180 z_dict['user'] = self.user_encoder(x_dict, edge_index_dict)
181
182 return self.decoder(z_dict['user'], z_dict['item'], edge_label_index)
183
184
185 model = Model(
186 num_users=data['user'].num_nodes,
187 num_items=data['item'].num_nodes,
188 hidden_channels=64,
189 out_channels=64,
190 ).to(device)
191 optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
192
193
194 def train():
195 model.train()
196
197 total_loss = total_examples = 0
198 for batch in tqdm.tqdm(train_loader):
199 batch = batch.to(device)
200 optimizer.zero_grad()
201
202 pred = model(
203 batch.x_dict,
204 batch.edge_index_dict,
205 batch['user', 'item'].edge_label_index,
206 )
207 loss = F.binary_cross_entropy_with_logits(
208 pred, batch['user', 'item'].edge_label)
209
210 loss.backward()
211 optimizer.step()
212 total_loss += float(loss)
213 total_examples += pred.numel()
214
215 return total_loss / total_examples
216
217
218 @torch.no_grad()
219 def test(loader):
220 model.eval()
221
222 preds, targets = [], []
223 for batch in tqdm.tqdm(loader):
224 batch = batch.to(device)
225
226 pred = model(
227 batch.x_dict,
228 batch.edge_index_dict,
229 batch['user', 'item'].edge_label_index,
230 ).sigmoid().view(-1).cpu()
231 target = batch['user', 'item'].edge_label.long().cpu()
232
233 preds.append(pred)
234 targets.append(pred)
235
236 pred = torch.cat(preds, dim=0).numpy()
237 target = torch.cat(target, dim=0).numpy()
238
239 acc = accuracy_score(target, pred)
240 prec = precision_score(target, pred)
241 rec = recall_score(target, pred)
242 f1 = f1_score(target, pred)
243
244 return acc, prec, rec, f1
245
246
247 for epoch in range(1, 21):
248 loss = train()
249 val_acc, val_prec, val_rec, val_f1 = test(val_loader)
250 test_acc, test_prec, test_rec, test_f1 = test(test_loader)
251
252 print(f'Epoch: {epoch:03d}, Loss: {loss:4f}')
253 print(f'Val Acc: {val_acc:.4f}, Val Precision {val_prec:.4f}, '
254 f'Val Recall {val_rec:.4f}, Val F1 {val_f1:.4f}')
255 print(f'Test Acc: {test_acc:.4f}, Test Precision {test_prec:.4f}, '
256 f'Test Recall {test_rec:.4f}, Test F1 {test_f1:.4f}')
257
[end of examples/hetero/bipartite_sage_unsup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/examples/hetero/bipartite_sage_unsup.py b/examples/hetero/bipartite_sage_unsup.py
--- a/examples/hetero/bipartite_sage_unsup.py
+++ b/examples/hetero/bipartite_sage_unsup.py
@@ -139,7 +139,7 @@
user_x = self.conv3(
(item_x, user_x),
- edge_index_dict[('item', 'to', 'user')],
+ edge_index_dict[('item', 'rev_to', 'user')],
).relu()
return self.lin(user_x)
@@ -231,11 +231,12 @@
target = batch['user', 'item'].edge_label.long().cpu()
preds.append(pred)
- targets.append(pred)
+ targets.append(target)
pred = torch.cat(preds, dim=0).numpy()
- target = torch.cat(target, dim=0).numpy()
+ target = torch.cat(targets, dim=0).numpy()
+ pred = pred > 0.5
acc = accuracy_score(target, pred)
prec = precision_score(target, pred)
rec = recall_score(target, pred)
|
{"golden_diff": "diff --git a/examples/hetero/bipartite_sage_unsup.py b/examples/hetero/bipartite_sage_unsup.py\n--- a/examples/hetero/bipartite_sage_unsup.py\n+++ b/examples/hetero/bipartite_sage_unsup.py\n@@ -139,7 +139,7 @@\n \n user_x = self.conv3(\n (item_x, user_x),\n- edge_index_dict[('item', 'to', 'user')],\n+ edge_index_dict[('item', 'rev_to', 'user')],\n ).relu()\n \n return self.lin(user_x)\n@@ -231,11 +231,12 @@\n target = batch['user', 'item'].edge_label.long().cpu()\n \n preds.append(pred)\n- targets.append(pred)\n+ targets.append(target)\n \n pred = torch.cat(preds, dim=0).numpy()\n- target = torch.cat(target, dim=0).numpy()\n+ target = torch.cat(targets, dim=0).numpy()\n \n+ pred = pred > 0.5\n acc = accuracy_score(target, pred)\n prec = precision_score(target, pred)\n rec = recall_score(target, pred)\n", "issue": "Classification metrics can't handle a mix of binary and continuous targets\n### \ud83d\udc1b Describe the bug\n\nI was trying to run the [pytorch_geometric](https://github.com/pyg-team/pytorch_geometric)/[examples](https://github.com/pyg-team/pytorch_geometric/tree/master/examples)/[hetero](https://github.com/pyg-team/pytorch_geometric/tree/master/examples/hetero)/bipartite_sage_unsup.py . I received the following error in the training loop. The error happened after the test() function was called\r\n\r\n## Error\r\n```\r\nValueError Traceback (most recent call last)\r\n[<ipython-input-7-449d394a8262>](https://localhost:8080/#) in <module>\r\n 54 for epoch in range(1, 21):\r\n 55 loss = train()\r\n---> 56 val_acc, val_prec, val_rec, val_f1 = test(val_loader)\r\n 57 test_acc, test_prec, test_rec, test_f1 = test(test_loader)\r\n 58 \r\n\r\n3 frames\r\n[/usr/local/lib/python3.8/dist-packages/sklearn/metrics/_classification.py](https://localhost:8080/#) in _check_targets(y_true, y_pred)\r\n 91 \r\n 92 if len(y_type) > 1:\r\n---> 93 raise ValueError(\r\n 94 \"Classification metrics can't handle a mix of {0} and {1} targets\".format(\r\n 95 type_true, type_pred\r\n\r\nValueError: Classification metrics can't handle a mix of binary and continuous targets\r\n```\r\n## Code modifications\r\n```\r\[email protected]_grad()\r\ndef test(loader):\r\n model.eval()\r\n\r\n preds, targets = [], []\r\n for batch in tqdm.tqdm(loader):\r\n batch = batch.to(device)\r\n\r\n pred = model(\r\n batch.x_dict,\r\n batch.edge_index_dict,\r\n batch['user', 'item'].edge_label_index,\r\n ).sigmoid().view(-1).cpu()\r\n target = batch['user', 'item'].edge_label.long().cpu()\r\n\r\n preds.append(pred)\r\n targets.append(target) #I assumed it was a typo in the original example\r\n\r\n pred = torch.cat(preds, dim=0).numpy()\r\n target = torch.cat(targets, dim=0).numpy() #I assumed it was a typo in the original example\r\n\r\n acc = accuracy_score(target, pred)\r\n prec = precision_score(target, pred)\r\n rec = recall_score(target, pred)\r\n f1 = f1_score(target, pred)\r\n\r\n return acc, prec, rec, f1\r\n```\n\n### Environment\n\n* PyG version: \r\n* PyTorch version: 1.13.0\r\n* OS: Linux(Colab)\r\n* Python version: 3.8.10\r\n* CUDA/cuDNN version: 11.6\r\n* How you installed PyTorch and PyG (`conda`, `pip`, source): pip\r\n* Any other relevant information (*e.g.*, version of `torch-scatter`): \r\n\n", "before_files": [{"content": "# An implementation of unsupervised bipartite GraphSAGE using the Alibaba\n# Taobao dataset.\nimport os.path as osp\n\nimport torch\nimport torch.nn.functional as F\nimport tqdm\nfrom sklearn.metrics import (\n accuracy_score,\n f1_score,\n precision_score,\n recall_score,\n)\nfrom torch.nn import Embedding, Linear\n\nimport torch_geometric.transforms as T\nfrom torch_geometric.datasets import Taobao\nfrom torch_geometric.loader import LinkNeighborLoader\nfrom torch_geometric.nn import SAGEConv\nfrom torch_geometric.utils.convert import to_scipy_sparse_matrix\n\ndevice = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')\npath = osp.join(osp.dirname(osp.realpath(__file__)), '../../data/Taobao')\n\ndataset = Taobao(path)\ndata = dataset[0]\n\ndata['user'].x = torch.arange(0, data['user'].num_nodes)\ndata['item'].x = torch.arange(0, data['item'].num_nodes)\n\n# Only consider user<>item relationships for simplicity:\ndel data['category']\ndel data['item', 'category']\ndel data['user', 'item'].time\ndel data['user', 'item'].behavior\n\n# Add a reverse ('item', 'rev_to', 'user') relation for message passing:\ndata = T.ToUndirected()(data)\n\n# Perform a link-level split into training, validation, and test edges:\nprint('Computing data splits...')\ntrain_data, val_data, test_data = T.RandomLinkSplit(\n num_val=0.1,\n num_test=0.1,\n neg_sampling_ratio=1.0,\n add_negative_train_samples=False,\n edge_types=[('user', 'to', 'item')],\n rev_edge_types=[('item', 'rev_to', 'user')],\n)(data)\nprint('Done!')\n\n# Compute sparsified item<>item relationships through users:\nprint('Computing item<>item relationships...')\nmat = to_scipy_sparse_matrix(data['user', 'item'].edge_index).tocsr()\nmat = mat[:data['user'].num_nodes, :data['item'].num_nodes]\ncomat = mat.T @ mat\ncomat.setdiag(0)\ncomat = comat >= 3.\ncomat = comat.tocoo()\nrow = torch.from_numpy(comat.row).to(torch.long)\ncol = torch.from_numpy(comat.col).to(torch.long)\nitem_to_item_edge_index = torch.stack([row, col], dim=0)\n\n# Add the generated item<>item relationships for high-order information:\ntrain_data['item', 'item'].edge_index = item_to_item_edge_index\nval_data['item', 'item'].edge_index = item_to_item_edge_index\ntest_data['item', 'item'].edge_index = item_to_item_edge_index\nprint('Done!')\n\ntrain_loader = LinkNeighborLoader(\n data=train_data,\n num_neighbors=[8, 4],\n edge_label_index=('user', 'to', 'item'),\n neg_sampling='binary',\n batch_size=2048,\n shuffle=True,\n num_workers=16,\n drop_last=True,\n)\n\nval_loader = LinkNeighborLoader(\n data=val_data,\n num_neighbors=[8, 4],\n edge_label_index=(\n ('user', 'to', 'item'),\n val_data[('user', 'to', 'item')].edge_label_index,\n ),\n edge_label=val_data[('user', 'to', 'item')].edge_label,\n batch_size=2048,\n shuffle=False,\n num_workers=16,\n)\n\ntest_loader = LinkNeighborLoader(\n data=test_data,\n num_neighbors=[8, 4],\n edge_label_index=(\n ('user', 'to', 'item'),\n test_data[('user', 'to', 'item')].edge_label_index,\n ),\n edge_label=test_data[('user', 'to', 'item')].edge_label,\n batch_size=2048,\n shuffle=False,\n num_workers=16,\n)\n\n\nclass ItemGNNEncoder(torch.nn.Module):\n def __init__(self, hidden_channels, out_channels):\n super().__init__()\n self.conv1 = SAGEConv(-1, hidden_channels)\n self.conv2 = SAGEConv(hidden_channels, hidden_channels)\n self.lin = Linear(hidden_channels, out_channels)\n\n def forward(self, x, edge_index):\n x = self.conv1(x, edge_index).relu()\n x = self.conv2(x, edge_index).relu()\n return self.lin(x)\n\n\nclass UserGNNEncoder(torch.nn.Module):\n def __init__(self, hidden_channels, out_channels):\n super().__init__()\n self.conv1 = SAGEConv((-1, -1), hidden_channels)\n self.conv2 = SAGEConv((-1, -1), hidden_channels)\n self.conv3 = SAGEConv((-1, -1), hidden_channels)\n self.lin = Linear(hidden_channels, out_channels)\n\n def forward(self, x_dict, edge_index_dict):\n item_x = self.conv1(\n x_dict['item'],\n edge_index_dict[('item', 'to', 'item')],\n ).relu()\n\n user_x = self.conv2(\n (x_dict['item'], x_dict['user']),\n edge_index_dict[('item', 'rev_to', 'user')],\n ).relu()\n\n user_x = self.conv3(\n (item_x, user_x),\n edge_index_dict[('item', 'to', 'user')],\n ).relu()\n\n return self.lin(user_x)\n\n\nclass EdgeDecoder(torch.nn.Module):\n def __init__(self, hidden_channels):\n super().__init__()\n self.lin1 = Linear(2 * hidden_channels, hidden_channels)\n self.lin2 = Linear(hidden_channels, 1)\n\n def forward(self, z_src, z_dst, edge_label_index):\n row, col = edge_label_index\n z = torch.cat([z_src[row], z_dst[col]], dim=-1)\n\n z = self.lin1(z).relu()\n z = self.lin2(z)\n return z.view(-1)\n\n\nclass Model(torch.nn.Module):\n def __init__(self, num_users, num_items, hidden_channels, out_channels):\n super().__init__()\n self.user_emb = Embedding(num_users, hidden_channels, device=device)\n self.item_emb = Embedding(num_items, hidden_channels, device=device)\n self.item_encoder = ItemGNNEncoder(hidden_channels, out_channels)\n self.user_encoder = UserGNNEncoder(hidden_channels, out_channels)\n self.decoder = EdgeDecoder(out_channels)\n\n def forward(self, x_dict, edge_index_dict, edge_label_index):\n z_dict = {}\n x_dict['user'] = self.user_emb(x_dict['user'])\n x_dict['item'] = self.item_emb(x_dict['item'])\n z_dict['item'] = self.item_encoder(\n x_dict['item'],\n edge_index_dict[('item', 'to', 'item')],\n )\n z_dict['user'] = self.user_encoder(x_dict, edge_index_dict)\n\n return self.decoder(z_dict['user'], z_dict['item'], edge_label_index)\n\n\nmodel = Model(\n num_users=data['user'].num_nodes,\n num_items=data['item'].num_nodes,\n hidden_channels=64,\n out_channels=64,\n).to(device)\noptimizer = torch.optim.Adam(model.parameters(), lr=0.001)\n\n\ndef train():\n model.train()\n\n total_loss = total_examples = 0\n for batch in tqdm.tqdm(train_loader):\n batch = batch.to(device)\n optimizer.zero_grad()\n\n pred = model(\n batch.x_dict,\n batch.edge_index_dict,\n batch['user', 'item'].edge_label_index,\n )\n loss = F.binary_cross_entropy_with_logits(\n pred, batch['user', 'item'].edge_label)\n\n loss.backward()\n optimizer.step()\n total_loss += float(loss)\n total_examples += pred.numel()\n\n return total_loss / total_examples\n\n\[email protected]_grad()\ndef test(loader):\n model.eval()\n\n preds, targets = [], []\n for batch in tqdm.tqdm(loader):\n batch = batch.to(device)\n\n pred = model(\n batch.x_dict,\n batch.edge_index_dict,\n batch['user', 'item'].edge_label_index,\n ).sigmoid().view(-1).cpu()\n target = batch['user', 'item'].edge_label.long().cpu()\n\n preds.append(pred)\n targets.append(pred)\n\n pred = torch.cat(preds, dim=0).numpy()\n target = torch.cat(target, dim=0).numpy()\n\n acc = accuracy_score(target, pred)\n prec = precision_score(target, pred)\n rec = recall_score(target, pred)\n f1 = f1_score(target, pred)\n\n return acc, prec, rec, f1\n\n\nfor epoch in range(1, 21):\n loss = train()\n val_acc, val_prec, val_rec, val_f1 = test(val_loader)\n test_acc, test_prec, test_rec, test_f1 = test(test_loader)\n\n print(f'Epoch: {epoch:03d}, Loss: {loss:4f}')\n print(f'Val Acc: {val_acc:.4f}, Val Precision {val_prec:.4f}, '\n f'Val Recall {val_rec:.4f}, Val F1 {val_f1:.4f}')\n print(f'Test Acc: {test_acc:.4f}, Test Precision {test_prec:.4f}, '\n f'Test Recall {test_rec:.4f}, Test F1 {test_f1:.4f}')\n", "path": "examples/hetero/bipartite_sage_unsup.py"}]}
| 3,965 | 270 |
gh_patches_debug_34315
|
rasdani/github-patches
|
git_diff
|
opensearch-project__opensearch-build-3540
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Revert component-based scripts lookup
### Is your feature request related to a problem? Please describe
In https://github.com/opensearch-project/opensearch-build/pull/2934 we have added a way to include component build scripts. There are several problems with that.
1. In https://github.com/opensearch-project/opensearch-build/issues/2188 we agreed to split monorepos. The maps monorepo came in as another new kind of monorepo that should not be supported.
2. There are no tests in the PR.
3. The new feature of path lookup is not documented in https://github.com/opensearch-project/opensearch-build/blob/cbe6841a3c459b65d5fb17b713994e5c01d7ee8e/src/paths/script_finder.py#L27
### Describe the solution you'd like
1. Add tests and documentation on top of https://github.com/opensearch-project/opensearch-build/pull/2934.
1. Split the maps monorepo, https://github.com/opensearch-project/opensearch-build/issues/2188
1. Revert https://github.com/opensearch-project/opensearch-build/pull/2934
### Describe alternatives you've considered
_No response_
### Additional context
_No response_
</issue>
<code>
[start of src/paths/script_finder.py]
1 # Copyright OpenSearch Contributors
2 # SPDX-License-Identifier: Apache-2.0
3 #
4 # The OpenSearch Contributors require contributions made to
5 # this file be licensed under the Apache-2.0 license or a
6 # compatible open source license.
7
8 import os
9 from typing import Callable, List
10
11
12 class ScriptFinder:
13 class ScriptNotFoundError(Exception):
14 def __init__(self, kind: str, paths: List[str]) -> None:
15 self.kind = kind
16 self.paths = paths
17 super().__init__(f"Could not find {kind} script. Looked in {paths}.")
18
19 component_scripts_path = os.path.realpath(os.path.join(os.path.dirname(os.path.abspath(__file__)), os.path.join("..", "..", "scripts", "components")))
20
21 default_scripts_path = os.path.realpath(os.path.join(os.path.dirname(os.path.abspath(__file__)), os.path.join("..", "..", "scripts", "default")))
22
23 """
24 ScriptFinder is a helper that abstracts away the details of where to look for build, test and install scripts.
25
26 For build.sh and integtest.sh scripts, given a component name and a checked-out Git repository,
27 it will look in the following locations, in order:
28 * <component_scripts_path>/<component_name>/<script-name>
29 * /<component_name>/<script-name> in the component's Git repository
30 * root of the component's Git repository
31 * /scripts/<script-name> in the component's Git repository
32 * <default_scripts_path>/<script-name>
33
34 For install.sh scripts, given a component name, it will look in the following locations, in order:
35 * <component_scripts_path>/<component_name>/<script-name>
36 * <default_scripts_path>/<script-name>
37 """
38
39 @classmethod
40 def __find_script(cls, name: str, paths: List[str]) -> str:
41 exists: Callable[[str], bool] = lambda path: os.path.exists(path)
42 script = next(filter(exists, paths), None)
43 if script is None:
44 raise ScriptFinder.ScriptNotFoundError(name, paths)
45
46 return script
47
48 @classmethod
49 def __find_named_script(cls, script_name: str, component_name: str, git_dir: str) -> str:
50 paths = [
51 os.path.realpath(os.path.join(cls.component_scripts_path, component_name, script_name)),
52 os.path.realpath(os.path.join(git_dir, component_name, script_name)),
53 os.path.realpath(os.path.join(git_dir, script_name)),
54 os.path.realpath(os.path.join(git_dir, "scripts", script_name)),
55 os.path.realpath(os.path.join(cls.default_scripts_path, script_name)),
56 ]
57
58 return cls.__find_script(script_name, paths)
59
60 @classmethod
61 def find_build_script(cls, project: str, component_name: str, git_dir: str) -> str:
62 paths = [
63 os.path.realpath(os.path.join(cls.component_scripts_path, component_name, "build.sh")),
64 os.path.realpath(os.path.join(git_dir, component_name, "build.sh")),
65 os.path.realpath(os.path.join(git_dir, "build.sh")),
66 os.path.realpath(os.path.join(git_dir, "scripts", "build.sh")),
67 os.path.realpath(
68 os.path.join(
69 cls.default_scripts_path,
70 project.replace(" ", "-").lower(),
71 "build.sh",
72 )
73 ),
74 ]
75
76 return cls.__find_script("build.sh", paths)
77
78 @classmethod
79 def find_install_script(cls, component_name: str) -> str:
80 paths = [
81 os.path.realpath(os.path.join(cls.component_scripts_path, component_name, "install.sh")),
82 os.path.realpath(os.path.join(cls.default_scripts_path, "install.sh")),
83 ]
84
85 return cls.__find_script("install.sh", paths)
86
87 @classmethod
88 def find_integ_test_script(cls, component_name: str, git_dir: str) -> str:
89 return cls.__find_named_script("integtest.sh", component_name, git_dir)
90
91 @classmethod
92 def find_bwc_test_script(cls, component_name: str, git_dir: str) -> str:
93 script_name = "bwctest.sh"
94 paths = [
95 os.path.realpath(os.path.join(cls.default_scripts_path, script_name)),
96 os.path.realpath(os.path.join(cls.component_scripts_path, component_name, script_name)),
97 os.path.realpath(os.path.join(git_dir, component_name, script_name)),
98 os.path.realpath(os.path.join(git_dir, script_name)),
99 os.path.realpath(os.path.join(git_dir, "scripts", script_name)),
100 ]
101
102 return cls.__find_script(script_name, paths)
103
[end of src/paths/script_finder.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/paths/script_finder.py b/src/paths/script_finder.py
--- a/src/paths/script_finder.py
+++ b/src/paths/script_finder.py
@@ -26,7 +26,6 @@
For build.sh and integtest.sh scripts, given a component name and a checked-out Git repository,
it will look in the following locations, in order:
* <component_scripts_path>/<component_name>/<script-name>
- * /<component_name>/<script-name> in the component's Git repository
* root of the component's Git repository
* /scripts/<script-name> in the component's Git repository
* <default_scripts_path>/<script-name>
@@ -49,7 +48,6 @@
def __find_named_script(cls, script_name: str, component_name: str, git_dir: str) -> str:
paths = [
os.path.realpath(os.path.join(cls.component_scripts_path, component_name, script_name)),
- os.path.realpath(os.path.join(git_dir, component_name, script_name)),
os.path.realpath(os.path.join(git_dir, script_name)),
os.path.realpath(os.path.join(git_dir, "scripts", script_name)),
os.path.realpath(os.path.join(cls.default_scripts_path, script_name)),
@@ -61,7 +59,6 @@
def find_build_script(cls, project: str, component_name: str, git_dir: str) -> str:
paths = [
os.path.realpath(os.path.join(cls.component_scripts_path, component_name, "build.sh")),
- os.path.realpath(os.path.join(git_dir, component_name, "build.sh")),
os.path.realpath(os.path.join(git_dir, "build.sh")),
os.path.realpath(os.path.join(git_dir, "scripts", "build.sh")),
os.path.realpath(
|
{"golden_diff": "diff --git a/src/paths/script_finder.py b/src/paths/script_finder.py\n--- a/src/paths/script_finder.py\n+++ b/src/paths/script_finder.py\n@@ -26,7 +26,6 @@\n For build.sh and integtest.sh scripts, given a component name and a checked-out Git repository,\n it will look in the following locations, in order:\n * <component_scripts_path>/<component_name>/<script-name>\n- * /<component_name>/<script-name> in the component's Git repository\n * root of the component's Git repository\n * /scripts/<script-name> in the component's Git repository\n * <default_scripts_path>/<script-name>\n@@ -49,7 +48,6 @@\n def __find_named_script(cls, script_name: str, component_name: str, git_dir: str) -> str:\n paths = [\n os.path.realpath(os.path.join(cls.component_scripts_path, component_name, script_name)),\n- os.path.realpath(os.path.join(git_dir, component_name, script_name)),\n os.path.realpath(os.path.join(git_dir, script_name)),\n os.path.realpath(os.path.join(git_dir, \"scripts\", script_name)),\n os.path.realpath(os.path.join(cls.default_scripts_path, script_name)),\n@@ -61,7 +59,6 @@\n def find_build_script(cls, project: str, component_name: str, git_dir: str) -> str:\n paths = [\n os.path.realpath(os.path.join(cls.component_scripts_path, component_name, \"build.sh\")),\n- os.path.realpath(os.path.join(git_dir, component_name, \"build.sh\")),\n os.path.realpath(os.path.join(git_dir, \"build.sh\")),\n os.path.realpath(os.path.join(git_dir, \"scripts\", \"build.sh\")),\n os.path.realpath(\n", "issue": "Revert component-based scripts lookup\n### Is your feature request related to a problem? Please describe\n\nIn https://github.com/opensearch-project/opensearch-build/pull/2934 we have added a way to include component build scripts. There are several problems with that.\r\n\r\n1. In https://github.com/opensearch-project/opensearch-build/issues/2188 we agreed to split monorepos. The maps monorepo came in as another new kind of monorepo that should not be supported. \r\n2. There are no tests in the PR.\r\n3. The new feature of path lookup is not documented in https://github.com/opensearch-project/opensearch-build/blob/cbe6841a3c459b65d5fb17b713994e5c01d7ee8e/src/paths/script_finder.py#L27\n\n### Describe the solution you'd like\n\n1. Add tests and documentation on top of https://github.com/opensearch-project/opensearch-build/pull/2934.\r\n1. Split the maps monorepo, https://github.com/opensearch-project/opensearch-build/issues/2188\r\n1. Revert https://github.com/opensearch-project/opensearch-build/pull/2934\r\n\r\n\n\n### Describe alternatives you've considered\n\n_No response_\n\n### Additional context\n\n_No response_\n", "before_files": [{"content": "# Copyright OpenSearch Contributors\n# SPDX-License-Identifier: Apache-2.0\n#\n# The OpenSearch Contributors require contributions made to\n# this file be licensed under the Apache-2.0 license or a\n# compatible open source license.\n\nimport os\nfrom typing import Callable, List\n\n\nclass ScriptFinder:\n class ScriptNotFoundError(Exception):\n def __init__(self, kind: str, paths: List[str]) -> None:\n self.kind = kind\n self.paths = paths\n super().__init__(f\"Could not find {kind} script. Looked in {paths}.\")\n\n component_scripts_path = os.path.realpath(os.path.join(os.path.dirname(os.path.abspath(__file__)), os.path.join(\"..\", \"..\", \"scripts\", \"components\")))\n\n default_scripts_path = os.path.realpath(os.path.join(os.path.dirname(os.path.abspath(__file__)), os.path.join(\"..\", \"..\", \"scripts\", \"default\")))\n\n \"\"\"\n ScriptFinder is a helper that abstracts away the details of where to look for build, test and install scripts.\n\n For build.sh and integtest.sh scripts, given a component name and a checked-out Git repository,\n it will look in the following locations, in order:\n * <component_scripts_path>/<component_name>/<script-name>\n * /<component_name>/<script-name> in the component's Git repository\n * root of the component's Git repository\n * /scripts/<script-name> in the component's Git repository\n * <default_scripts_path>/<script-name>\n\n For install.sh scripts, given a component name, it will look in the following locations, in order:\n * <component_scripts_path>/<component_name>/<script-name>\n * <default_scripts_path>/<script-name>\n \"\"\"\n\n @classmethod\n def __find_script(cls, name: str, paths: List[str]) -> str:\n exists: Callable[[str], bool] = lambda path: os.path.exists(path)\n script = next(filter(exists, paths), None)\n if script is None:\n raise ScriptFinder.ScriptNotFoundError(name, paths)\n\n return script\n\n @classmethod\n def __find_named_script(cls, script_name: str, component_name: str, git_dir: str) -> str:\n paths = [\n os.path.realpath(os.path.join(cls.component_scripts_path, component_name, script_name)),\n os.path.realpath(os.path.join(git_dir, component_name, script_name)),\n os.path.realpath(os.path.join(git_dir, script_name)),\n os.path.realpath(os.path.join(git_dir, \"scripts\", script_name)),\n os.path.realpath(os.path.join(cls.default_scripts_path, script_name)),\n ]\n\n return cls.__find_script(script_name, paths)\n\n @classmethod\n def find_build_script(cls, project: str, component_name: str, git_dir: str) -> str:\n paths = [\n os.path.realpath(os.path.join(cls.component_scripts_path, component_name, \"build.sh\")),\n os.path.realpath(os.path.join(git_dir, component_name, \"build.sh\")),\n os.path.realpath(os.path.join(git_dir, \"build.sh\")),\n os.path.realpath(os.path.join(git_dir, \"scripts\", \"build.sh\")),\n os.path.realpath(\n os.path.join(\n cls.default_scripts_path,\n project.replace(\" \", \"-\").lower(),\n \"build.sh\",\n )\n ),\n ]\n\n return cls.__find_script(\"build.sh\", paths)\n\n @classmethod\n def find_install_script(cls, component_name: str) -> str:\n paths = [\n os.path.realpath(os.path.join(cls.component_scripts_path, component_name, \"install.sh\")),\n os.path.realpath(os.path.join(cls.default_scripts_path, \"install.sh\")),\n ]\n\n return cls.__find_script(\"install.sh\", paths)\n\n @classmethod\n def find_integ_test_script(cls, component_name: str, git_dir: str) -> str:\n return cls.__find_named_script(\"integtest.sh\", component_name, git_dir)\n\n @classmethod\n def find_bwc_test_script(cls, component_name: str, git_dir: str) -> str:\n script_name = \"bwctest.sh\"\n paths = [\n os.path.realpath(os.path.join(cls.default_scripts_path, script_name)),\n os.path.realpath(os.path.join(cls.component_scripts_path, component_name, script_name)),\n os.path.realpath(os.path.join(git_dir, component_name, script_name)),\n os.path.realpath(os.path.join(git_dir, script_name)),\n os.path.realpath(os.path.join(git_dir, \"scripts\", script_name)),\n ]\n\n return cls.__find_script(script_name, paths)\n", "path": "src/paths/script_finder.py"}]}
| 2,020 | 387 |
gh_patches_debug_31801
|
rasdani/github-patches
|
git_diff
|
espnet__espnet-1002
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
The scoring script is incorrect if any pruning is done on the dictionary or in the case of word models
Hi @sw005320 and other developers,
The command `json2trn.py ${dir}/data.json ${dic} --num-spkrs ${num_spkrs} --refs ${dir}/ref.trn --hyps ${dir}/hyp.trn` in the `score_sclite.sh` replaces all units in reference that are not in the dictionary with unk and then scores it.
This is wrong because you are modifying the reference transcription to match your dictionary. Let's say I train a model with dictionary with only 1 term "Mr" and the hypothesis is
"Mr unk unk" and reference is "Mr John Doe". This would give a WER of 0% because the reference would be modified to "Mr unk unk".
</issue>
<code>
[start of utils/json2trn.py]
1 #!/usr/bin/env python
2 # encoding: utf-8
3
4 # Copyright 2017 Johns Hopkins University (Shinji Watanabe)
5 # 2018 Xuankai Chang (Shanghai Jiao Tong University)
6 # Apache 2.0 (http://www.apache.org/licenses/LICENSE-2.0)
7
8 import argparse
9 import codecs
10 import json
11 import logging
12 import sys
13
14 from espnet.utils.cli_utils import get_commandline_args
15
16
17 def get_parser():
18 parser = argparse.ArgumentParser(
19 description='convert a json to a transcription file with a token dictionary',
20 formatter_class=argparse.ArgumentDefaultsHelpFormatter)
21 parser.add_argument('json', type=str, help='json files')
22 parser.add_argument('dict', type=str, help='dict')
23 parser.add_argument('--num-spkrs', type=int, default=1, help='number of speakers')
24 parser.add_argument('--refs', type=str, nargs='+', help='ref for all speakers')
25 parser.add_argument('--hyps', type=str, nargs='+', help='hyp for all outputs')
26 return parser
27
28
29 def main(args):
30 args = get_parser().parse_args(args)
31 convert(args.json, args.dict, args.refs, args.hyps, args.num_spkrs)
32
33
34 def convert(jsonf, dic, refs, hyps, num_spkrs=1):
35 n_ref = len(refs)
36 n_hyp = len(hyps)
37 assert n_ref == n_hyp
38 assert n_ref == num_spkrs
39
40 # logging info
41 logfmt = '%(asctime)s (%(module)s:%(lineno)d) %(levelname)s: %(message)s'
42 logging.basicConfig(level=logging.INFO, format=logfmt)
43 logging.info(get_commandline_args())
44
45 logging.info("reading %s", jsonf)
46 with codecs.open(jsonf, 'r', encoding="utf-8") as f:
47 j = json.load(f)
48
49 logging.info("reading %s", dic)
50 with codecs.open(dic, 'r', encoding="utf-8") as f:
51 dictionary = f.readlines()
52 char_list = [entry.split(' ')[0] for entry in dictionary]
53 char_list.insert(0, '<blank>')
54 char_list.append('<eos>')
55
56 for ns in range(num_spkrs):
57 hyp_file = codecs.open(hyps[ns], 'w', encoding="utf-8")
58 ref_file = codecs.open(refs[ns], 'w', encoding="utf-8")
59
60 for x in j['utts']:
61 # hyps
62 if num_spkrs == 1:
63 seq = [char_list[int(i)] for i in j['utts'][x]['output'][0]['rec_tokenid'].split()]
64 else:
65 seq = [char_list[int(i)] for i in j['utts'][x]['output'][ns][0]['rec_tokenid'].split()]
66 hyp_file.write(" ".join(seq).replace('<eos>', '')),
67 hyp_file.write(" (" + j['utts'][x]['utt2spk'].replace('-', '_') + "-" + x + ")\n")
68
69 # ref
70 if num_spkrs == 1:
71 seq = [char_list[int(i)] for i in j['utts'][x]['output'][0]['tokenid'].split()]
72 else:
73 seq = [char_list[int(i)] for i in j['utts'][x]['output'][ns][0]['tokenid'].split()]
74 ref_file.write(" ".join(seq).replace('<eos>', '')),
75 ref_file.write(" (" + j['utts'][x]['utt2spk'].replace('-', '_') + "-" + x + ")\n")
76
77 hyp_file.close()
78 ref_file.close()
79
80
81 if __name__ == '__main__':
82 main(sys.argv[1:])
83
[end of utils/json2trn.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/utils/json2trn.py b/utils/json2trn.py
--- a/utils/json2trn.py
+++ b/utils/json2trn.py
@@ -58,21 +58,25 @@
ref_file = codecs.open(refs[ns], 'w', encoding="utf-8")
for x in j['utts']:
- # hyps
+ # recognition hypothesis
if num_spkrs == 1:
seq = [char_list[int(i)] for i in j['utts'][x]['output'][0]['rec_tokenid'].split()]
else:
seq = [char_list[int(i)] for i in j['utts'][x]['output'][ns][0]['rec_tokenid'].split()]
+ # In the recognition hypothesis, the <eos> symbol is usually attached in the last part of the sentence
+ # and it is removed below.
hyp_file.write(" ".join(seq).replace('<eos>', '')),
hyp_file.write(" (" + j['utts'][x]['utt2spk'].replace('-', '_') + "-" + x + ")\n")
- # ref
+ # reference
if num_spkrs == 1:
- seq = [char_list[int(i)] for i in j['utts'][x]['output'][0]['tokenid'].split()]
+ seq = j['utts'][x]['output'][0]['token']
else:
- seq = [char_list[int(i)] for i in j['utts'][x]['output'][ns][0]['tokenid'].split()]
- ref_file.write(" ".join(seq).replace('<eos>', '')),
- ref_file.write(" (" + j['utts'][x]['utt2spk'].replace('-', '_') + "-" + x + ")\n")
+ seq = j['utts'][x]['output'][ns][0]['token']
+ # Unlike the recognition hypothesis, the reference is directly generated from a token without dictionary
+ # to avoid to include <unk> symbols in the reference to make scoring normal.
+ # The detailed discussion can be found at https://github.com/espnet/espnet/issues/993
+ ref_file.write(seq + " (" + j['utts'][x]['utt2spk'].replace('-', '_') + "-" + x + ")\n")
hyp_file.close()
ref_file.close()
|
{"golden_diff": "diff --git a/utils/json2trn.py b/utils/json2trn.py\n--- a/utils/json2trn.py\n+++ b/utils/json2trn.py\n@@ -58,21 +58,25 @@\n ref_file = codecs.open(refs[ns], 'w', encoding=\"utf-8\")\n \n for x in j['utts']:\n- # hyps\n+ # recognition hypothesis\n if num_spkrs == 1:\n seq = [char_list[int(i)] for i in j['utts'][x]['output'][0]['rec_tokenid'].split()]\n else:\n seq = [char_list[int(i)] for i in j['utts'][x]['output'][ns][0]['rec_tokenid'].split()]\n+ # In the recognition hypothesis, the <eos> symbol is usually attached in the last part of the sentence\n+ # and it is removed below.\n hyp_file.write(\" \".join(seq).replace('<eos>', '')),\n hyp_file.write(\" (\" + j['utts'][x]['utt2spk'].replace('-', '_') + \"-\" + x + \")\\n\")\n \n- # ref\n+ # reference\n if num_spkrs == 1:\n- seq = [char_list[int(i)] for i in j['utts'][x]['output'][0]['tokenid'].split()]\n+ seq = j['utts'][x]['output'][0]['token']\n else:\n- seq = [char_list[int(i)] for i in j['utts'][x]['output'][ns][0]['tokenid'].split()]\n- ref_file.write(\" \".join(seq).replace('<eos>', '')),\n- ref_file.write(\" (\" + j['utts'][x]['utt2spk'].replace('-', '_') + \"-\" + x + \")\\n\")\n+ seq = j['utts'][x]['output'][ns][0]['token']\n+ # Unlike the recognition hypothesis, the reference is directly generated from a token without dictionary\n+ # to avoid to include <unk> symbols in the reference to make scoring normal.\n+ # The detailed discussion can be found at https://github.com/espnet/espnet/issues/993\n+ ref_file.write(seq + \" (\" + j['utts'][x]['utt2spk'].replace('-', '_') + \"-\" + x + \")\\n\")\n \n hyp_file.close()\n ref_file.close()\n", "issue": "The scoring script is incorrect if any pruning is done on the dictionary or in the case of word models\nHi @sw005320 and other developers,\r\n\r\nThe command `json2trn.py ${dir}/data.json ${dic} --num-spkrs ${num_spkrs} --refs ${dir}/ref.trn --hyps ${dir}/hyp.trn` in the `score_sclite.sh` replaces all units in reference that are not in the dictionary with unk and then scores it.\r\n\r\nThis is wrong because you are modifying the reference transcription to match your dictionary. Let's say I train a model with dictionary with only 1 term \"Mr\" and the hypothesis is \r\n\"Mr unk unk\" and reference is \"Mr John Doe\". This would give a WER of 0% because the reference would be modified to \"Mr unk unk\". \n", "before_files": [{"content": "#!/usr/bin/env python\n# encoding: utf-8\n\n# Copyright 2017 Johns Hopkins University (Shinji Watanabe)\n# 2018 Xuankai Chang (Shanghai Jiao Tong University)\n# Apache 2.0 (http://www.apache.org/licenses/LICENSE-2.0)\n\nimport argparse\nimport codecs\nimport json\nimport logging\nimport sys\n\nfrom espnet.utils.cli_utils import get_commandline_args\n\n\ndef get_parser():\n parser = argparse.ArgumentParser(\n description='convert a json to a transcription file with a token dictionary',\n formatter_class=argparse.ArgumentDefaultsHelpFormatter)\n parser.add_argument('json', type=str, help='json files')\n parser.add_argument('dict', type=str, help='dict')\n parser.add_argument('--num-spkrs', type=int, default=1, help='number of speakers')\n parser.add_argument('--refs', type=str, nargs='+', help='ref for all speakers')\n parser.add_argument('--hyps', type=str, nargs='+', help='hyp for all outputs')\n return parser\n\n\ndef main(args):\n args = get_parser().parse_args(args)\n convert(args.json, args.dict, args.refs, args.hyps, args.num_spkrs)\n\n\ndef convert(jsonf, dic, refs, hyps, num_spkrs=1):\n n_ref = len(refs)\n n_hyp = len(hyps)\n assert n_ref == n_hyp\n assert n_ref == num_spkrs\n\n # logging info\n logfmt = '%(asctime)s (%(module)s:%(lineno)d) %(levelname)s: %(message)s'\n logging.basicConfig(level=logging.INFO, format=logfmt)\n logging.info(get_commandline_args())\n\n logging.info(\"reading %s\", jsonf)\n with codecs.open(jsonf, 'r', encoding=\"utf-8\") as f:\n j = json.load(f)\n\n logging.info(\"reading %s\", dic)\n with codecs.open(dic, 'r', encoding=\"utf-8\") as f:\n dictionary = f.readlines()\n char_list = [entry.split(' ')[0] for entry in dictionary]\n char_list.insert(0, '<blank>')\n char_list.append('<eos>')\n\n for ns in range(num_spkrs):\n hyp_file = codecs.open(hyps[ns], 'w', encoding=\"utf-8\")\n ref_file = codecs.open(refs[ns], 'w', encoding=\"utf-8\")\n\n for x in j['utts']:\n # hyps\n if num_spkrs == 1:\n seq = [char_list[int(i)] for i in j['utts'][x]['output'][0]['rec_tokenid'].split()]\n else:\n seq = [char_list[int(i)] for i in j['utts'][x]['output'][ns][0]['rec_tokenid'].split()]\n hyp_file.write(\" \".join(seq).replace('<eos>', '')),\n hyp_file.write(\" (\" + j['utts'][x]['utt2spk'].replace('-', '_') + \"-\" + x + \")\\n\")\n\n # ref\n if num_spkrs == 1:\n seq = [char_list[int(i)] for i in j['utts'][x]['output'][0]['tokenid'].split()]\n else:\n seq = [char_list[int(i)] for i in j['utts'][x]['output'][ns][0]['tokenid'].split()]\n ref_file.write(\" \".join(seq).replace('<eos>', '')),\n ref_file.write(\" (\" + j['utts'][x]['utt2spk'].replace('-', '_') + \"-\" + x + \")\\n\")\n\n hyp_file.close()\n ref_file.close()\n\n\nif __name__ == '__main__':\n main(sys.argv[1:])\n", "path": "utils/json2trn.py"}]}
| 1,697 | 524 |
gh_patches_debug_38659
|
rasdani/github-patches
|
git_diff
|
numpy__numpy-7870
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
reload(numpy);numpy.max([]) raises TypeError
Using `maintenance/1.11.x` on Windows (msvc builds), the following code fails:
``` Python
Python 3.5.2 (v3.5.2:4def2a2901a5, Jun 25 2016, 22:18:55) [MSC v.1900 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> from importlib import reload
>>> import numpy
>>> reload(numpy)
<module 'numpy' from 'X:\\Python35\\lib\\site-packages\\numpy\\__init__.py'>
>>> numpy.max([])
Traceback (most recent call last):
File "X:\Python35\lib\site-packages\numpy\core\fromnumeric.py", line 2290, in amax
amax = a.max
AttributeError: 'list' object has no attribute 'max'
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "X:\Python35\lib\site-packages\numpy\core\fromnumeric.py", line 2293, in amax
out=out, **kwargs)
File "X:\Python35\lib\site-packages\numpy\core\_methods.py", line 26, in _amax
return umr_maximum(a, axis, None, out, keepdims)
TypeError: an integer is required (got type type)
```
I traced this to #7736, backport of #4619
</issue>
<code>
[start of numpy/__init__.py]
1 """
2 NumPy
3 =====
4
5 Provides
6 1. An array object of arbitrary homogeneous items
7 2. Fast mathematical operations over arrays
8 3. Linear Algebra, Fourier Transforms, Random Number Generation
9
10 How to use the documentation
11 ----------------------------
12 Documentation is available in two forms: docstrings provided
13 with the code, and a loose standing reference guide, available from
14 `the NumPy homepage <http://www.scipy.org>`_.
15
16 We recommend exploring the docstrings using
17 `IPython <http://ipython.scipy.org>`_, an advanced Python shell with
18 TAB-completion and introspection capabilities. See below for further
19 instructions.
20
21 The docstring examples assume that `numpy` has been imported as `np`::
22
23 >>> import numpy as np
24
25 Code snippets are indicated by three greater-than signs::
26
27 >>> x = 42
28 >>> x = x + 1
29
30 Use the built-in ``help`` function to view a function's docstring::
31
32 >>> help(np.sort)
33 ... # doctest: +SKIP
34
35 For some objects, ``np.info(obj)`` may provide additional help. This is
36 particularly true if you see the line "Help on ufunc object:" at the top
37 of the help() page. Ufuncs are implemented in C, not Python, for speed.
38 The native Python help() does not know how to view their help, but our
39 np.info() function does.
40
41 To search for documents containing a keyword, do::
42
43 >>> np.lookfor('keyword')
44 ... # doctest: +SKIP
45
46 General-purpose documents like a glossary and help on the basic concepts
47 of numpy are available under the ``doc`` sub-module::
48
49 >>> from numpy import doc
50 >>> help(doc)
51 ... # doctest: +SKIP
52
53 Available subpackages
54 ---------------------
55 doc
56 Topical documentation on broadcasting, indexing, etc.
57 lib
58 Basic functions used by several sub-packages.
59 random
60 Core Random Tools
61 linalg
62 Core Linear Algebra Tools
63 fft
64 Core FFT routines
65 polynomial
66 Polynomial tools
67 testing
68 Numpy testing tools
69 f2py
70 Fortran to Python Interface Generator.
71 distutils
72 Enhancements to distutils with support for
73 Fortran compilers support and more.
74
75 Utilities
76 ---------
77 test
78 Run numpy unittests
79 show_config
80 Show numpy build configuration
81 dual
82 Overwrite certain functions with high-performance Scipy tools
83 matlib
84 Make everything matrices.
85 __version__
86 Numpy version string
87
88 Viewing documentation using IPython
89 -----------------------------------
90 Start IPython with the NumPy profile (``ipython -p numpy``), which will
91 import `numpy` under the alias `np`. Then, use the ``cpaste`` command to
92 paste examples into the shell. To see which functions are available in
93 `numpy`, type ``np.<TAB>`` (where ``<TAB>`` refers to the TAB key), or use
94 ``np.*cos*?<ENTER>`` (where ``<ENTER>`` refers to the ENTER key) to narrow
95 down the list. To view the docstring for a function, use
96 ``np.cos?<ENTER>`` (to view the docstring) and ``np.cos??<ENTER>`` (to view
97 the source code).
98
99 Copies vs. in-place operation
100 -----------------------------
101 Most of the functions in `numpy` return a copy of the array argument
102 (e.g., `np.sort`). In-place versions of these functions are often
103 available as array methods, i.e. ``x = np.array([1,2,3]); x.sort()``.
104 Exceptions to this rule are documented.
105
106 """
107 from __future__ import division, absolute_import, print_function
108
109 import sys
110
111
112 class ModuleDeprecationWarning(DeprecationWarning):
113 """Module deprecation warning.
114
115 The nose tester turns ordinary Deprecation warnings into test failures.
116 That makes it hard to deprecate whole modules, because they get
117 imported by default. So this is a special Deprecation warning that the
118 nose tester will let pass without making tests fail.
119
120 """
121 pass
122
123
124 class VisibleDeprecationWarning(UserWarning):
125 """Visible deprecation warning.
126
127 By default, python will not show deprecation warnings, so this class
128 can be used when a very visible warning is helpful, for example because
129 the usage is most likely a user bug.
130
131 """
132 pass
133
134
135 class _NoValue:
136 """Special keyword value.
137
138 This class may be used as the default value assigned to a
139 deprecated keyword in order to check if it has been given a user
140 defined value.
141 """
142 pass
143
144
145 # oldnumeric and numarray were removed in 1.9. In case some packages import
146 # but do not use them, we define them here for backward compatibility.
147 oldnumeric = 'removed'
148 numarray = 'removed'
149
150
151 # We first need to detect if we're being called as part of the numpy setup
152 # procedure itself in a reliable manner.
153 try:
154 __NUMPY_SETUP__
155 except NameError:
156 __NUMPY_SETUP__ = False
157
158
159 if __NUMPY_SETUP__:
160 import sys as _sys
161 _sys.stderr.write('Running from numpy source directory.\n')
162 del _sys
163 else:
164 try:
165 from numpy.__config__ import show as show_config
166 except ImportError:
167 msg = """Error importing numpy: you should not try to import numpy from
168 its source directory; please exit the numpy source tree, and relaunch
169 your python interpreter from there."""
170 raise ImportError(msg)
171 from .version import git_revision as __git_revision__
172 from .version import version as __version__
173
174 from ._import_tools import PackageLoader
175
176 def pkgload(*packages, **options):
177 loader = PackageLoader(infunc=True)
178 return loader(*packages, **options)
179
180 from . import add_newdocs
181 __all__ = ['add_newdocs',
182 'ModuleDeprecationWarning',
183 'VisibleDeprecationWarning']
184
185 pkgload.__doc__ = PackageLoader.__call__.__doc__
186
187 # We don't actually use this ourselves anymore, but I'm not 100% sure that
188 # no-one else in the world is using it (though I hope not)
189 from .testing import Tester
190 test = testing.nosetester._numpy_tester().test
191 bench = testing.nosetester._numpy_tester().bench
192
193 from . import core
194 from .core import *
195 from . import compat
196 from . import lib
197 from .lib import *
198 from . import linalg
199 from . import fft
200 from . import polynomial
201 from . import random
202 from . import ctypeslib
203 from . import ma
204 from . import matrixlib as _mat
205 from .matrixlib import *
206 from .compat import long
207
208 # Make these accessible from numpy name-space
209 # but not imported in from numpy import *
210 if sys.version_info[0] >= 3:
211 from builtins import bool, int, float, complex, object, str
212 unicode = str
213 else:
214 from __builtin__ import bool, int, float, complex, object, unicode, str
215
216 from .core import round, abs, max, min
217
218 __all__.extend(['__version__', 'pkgload', 'PackageLoader',
219 'show_config'])
220 __all__.extend(core.__all__)
221 __all__.extend(_mat.__all__)
222 __all__.extend(lib.__all__)
223 __all__.extend(['linalg', 'fft', 'random', 'ctypeslib', 'ma'])
224
225 # Filter annoying Cython warnings that serve no good purpose.
226 import warnings
227 warnings.filterwarnings("ignore", message="numpy.dtype size changed")
228 warnings.filterwarnings("ignore", message="numpy.ufunc size changed")
229 warnings.filterwarnings("ignore", message="numpy.ndarray size changed")
230
[end of numpy/__init__.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/numpy/__init__.py b/numpy/__init__.py
--- a/numpy/__init__.py
+++ b/numpy/__init__.py
@@ -107,8 +107,21 @@
from __future__ import division, absolute_import, print_function
import sys
+import warnings
+# Disallow reloading numpy. Doing that does nothing to change previously
+# loaded modules, which would need to be reloaded separately, but it does
+# change the identity of the warnings and sentinal classes defined below
+# with dire consequences when checking for identity.
+if '_is_loaded' in globals():
+ raise RuntimeError('Reloading numpy is not supported')
+_is_loaded = True
+
+# Define some global warnings and the _NoValue sentinal. Defining them here
+# means that their identity will change if numpy is reloaded, hence if that is
+# to be allowed they should be moved into their own, non-reloadable module.
+# Note that these should be defined (or imported) before the other imports.
class ModuleDeprecationWarning(DeprecationWarning):
"""Module deprecation warning.
@@ -135,9 +148,8 @@
class _NoValue:
"""Special keyword value.
- This class may be used as the default value assigned to a
- deprecated keyword in order to check if it has been given a user
- defined value.
+ This class may be used as the default value assigned to a deprecated
+ keyword in order to check if it has been given a user defined value.
"""
pass
@@ -155,11 +167,8 @@
except NameError:
__NUMPY_SETUP__ = False
-
if __NUMPY_SETUP__:
- import sys as _sys
- _sys.stderr.write('Running from numpy source directory.\n')
- del _sys
+ sys.stderr.write('Running from numpy source directory.\n')
else:
try:
from numpy.__config__ import show as show_config
@@ -206,7 +215,7 @@
from .compat import long
# Make these accessible from numpy name-space
- # but not imported in from numpy import *
+ # but not imported in from numpy import *
if sys.version_info[0] >= 3:
from builtins import bool, int, float, complex, object, str
unicode = str
@@ -222,8 +231,8 @@
__all__.extend(lib.__all__)
__all__.extend(['linalg', 'fft', 'random', 'ctypeslib', 'ma'])
+
# Filter annoying Cython warnings that serve no good purpose.
- import warnings
warnings.filterwarnings("ignore", message="numpy.dtype size changed")
warnings.filterwarnings("ignore", message="numpy.ufunc size changed")
warnings.filterwarnings("ignore", message="numpy.ndarray size changed")
|
{"golden_diff": "diff --git a/numpy/__init__.py b/numpy/__init__.py\n--- a/numpy/__init__.py\n+++ b/numpy/__init__.py\n@@ -107,8 +107,21 @@\n from __future__ import division, absolute_import, print_function\n \n import sys\n+import warnings\n \n+# Disallow reloading numpy. Doing that does nothing to change previously\n+# loaded modules, which would need to be reloaded separately, but it does\n+# change the identity of the warnings and sentinal classes defined below\n+# with dire consequences when checking for identity.\n+if '_is_loaded' in globals():\n+ raise RuntimeError('Reloading numpy is not supported')\n+_is_loaded = True\n \n+\n+# Define some global warnings and the _NoValue sentinal. Defining them here\n+# means that their identity will change if numpy is reloaded, hence if that is\n+# to be allowed they should be moved into their own, non-reloadable module.\n+# Note that these should be defined (or imported) before the other imports.\n class ModuleDeprecationWarning(DeprecationWarning):\n \"\"\"Module deprecation warning.\n \n@@ -135,9 +148,8 @@\n class _NoValue:\n \"\"\"Special keyword value.\n \n- This class may be used as the default value assigned to a\n- deprecated keyword in order to check if it has been given a user\n- defined value.\n+ This class may be used as the default value assigned to a deprecated\n+ keyword in order to check if it has been given a user defined value.\n \"\"\"\n pass\n \n@@ -155,11 +167,8 @@\n except NameError:\n __NUMPY_SETUP__ = False\n \n-\n if __NUMPY_SETUP__:\n- import sys as _sys\n- _sys.stderr.write('Running from numpy source directory.\\n')\n- del _sys\n+ sys.stderr.write('Running from numpy source directory.\\n')\n else:\n try:\n from numpy.__config__ import show as show_config\n@@ -206,7 +215,7 @@\n from .compat import long\n \n # Make these accessible from numpy name-space\n- # but not imported in from numpy import *\n+ # but not imported in from numpy import *\n if sys.version_info[0] >= 3:\n from builtins import bool, int, float, complex, object, str\n unicode = str\n@@ -222,8 +231,8 @@\n __all__.extend(lib.__all__)\n __all__.extend(['linalg', 'fft', 'random', 'ctypeslib', 'ma'])\n \n+\n # Filter annoying Cython warnings that serve no good purpose.\n- import warnings\n warnings.filterwarnings(\"ignore\", message=\"numpy.dtype size changed\")\n warnings.filterwarnings(\"ignore\", message=\"numpy.ufunc size changed\")\n warnings.filterwarnings(\"ignore\", message=\"numpy.ndarray size changed\")\n", "issue": "reload(numpy);numpy.max([]) raises TypeError\nUsing `maintenance/1.11.x` on Windows (msvc builds), the following code fails:\n\n``` Python\nPython 3.5.2 (v3.5.2:4def2a2901a5, Jun 25 2016, 22:18:55) [MSC v.1900 64 bit (AMD64)] on win32\nType \"help\", \"copyright\", \"credits\" or \"license\" for more information.\n>>> from importlib import reload\n>>> import numpy\n>>> reload(numpy)\n<module 'numpy' from 'X:\\\\Python35\\\\lib\\\\site-packages\\\\numpy\\\\__init__.py'>\n>>> numpy.max([])\nTraceback (most recent call last):\n File \"X:\\Python35\\lib\\site-packages\\numpy\\core\\fromnumeric.py\", line 2290, in amax\n amax = a.max\nAttributeError: 'list' object has no attribute 'max'\n\nDuring handling of the above exception, another exception occurred:\n\nTraceback (most recent call last):\n File \"<stdin>\", line 1, in <module>\n File \"X:\\Python35\\lib\\site-packages\\numpy\\core\\fromnumeric.py\", line 2293, in amax\n out=out, **kwargs)\n File \"X:\\Python35\\lib\\site-packages\\numpy\\core\\_methods.py\", line 26, in _amax\n return umr_maximum(a, axis, None, out, keepdims)\nTypeError: an integer is required (got type type)\n```\n\nI traced this to #7736, backport of #4619 \n\n", "before_files": [{"content": "\"\"\"\nNumPy\n=====\n\nProvides\n 1. An array object of arbitrary homogeneous items\n 2. Fast mathematical operations over arrays\n 3. Linear Algebra, Fourier Transforms, Random Number Generation\n\nHow to use the documentation\n----------------------------\nDocumentation is available in two forms: docstrings provided\nwith the code, and a loose standing reference guide, available from\n`the NumPy homepage <http://www.scipy.org>`_.\n\nWe recommend exploring the docstrings using\n`IPython <http://ipython.scipy.org>`_, an advanced Python shell with\nTAB-completion and introspection capabilities. See below for further\ninstructions.\n\nThe docstring examples assume that `numpy` has been imported as `np`::\n\n >>> import numpy as np\n\nCode snippets are indicated by three greater-than signs::\n\n >>> x = 42\n >>> x = x + 1\n\nUse the built-in ``help`` function to view a function's docstring::\n\n >>> help(np.sort)\n ... # doctest: +SKIP\n\nFor some objects, ``np.info(obj)`` may provide additional help. This is\nparticularly true if you see the line \"Help on ufunc object:\" at the top\nof the help() page. Ufuncs are implemented in C, not Python, for speed.\nThe native Python help() does not know how to view their help, but our\nnp.info() function does.\n\nTo search for documents containing a keyword, do::\n\n >>> np.lookfor('keyword')\n ... # doctest: +SKIP\n\nGeneral-purpose documents like a glossary and help on the basic concepts\nof numpy are available under the ``doc`` sub-module::\n\n >>> from numpy import doc\n >>> help(doc)\n ... # doctest: +SKIP\n\nAvailable subpackages\n---------------------\ndoc\n Topical documentation on broadcasting, indexing, etc.\nlib\n Basic functions used by several sub-packages.\nrandom\n Core Random Tools\nlinalg\n Core Linear Algebra Tools\nfft\n Core FFT routines\npolynomial\n Polynomial tools\ntesting\n Numpy testing tools\nf2py\n Fortran to Python Interface Generator.\ndistutils\n Enhancements to distutils with support for\n Fortran compilers support and more.\n\nUtilities\n---------\ntest\n Run numpy unittests\nshow_config\n Show numpy build configuration\ndual\n Overwrite certain functions with high-performance Scipy tools\nmatlib\n Make everything matrices.\n__version__\n Numpy version string\n\nViewing documentation using IPython\n-----------------------------------\nStart IPython with the NumPy profile (``ipython -p numpy``), which will\nimport `numpy` under the alias `np`. Then, use the ``cpaste`` command to\npaste examples into the shell. To see which functions are available in\n`numpy`, type ``np.<TAB>`` (where ``<TAB>`` refers to the TAB key), or use\n``np.*cos*?<ENTER>`` (where ``<ENTER>`` refers to the ENTER key) to narrow\ndown the list. To view the docstring for a function, use\n``np.cos?<ENTER>`` (to view the docstring) and ``np.cos??<ENTER>`` (to view\nthe source code).\n\nCopies vs. in-place operation\n-----------------------------\nMost of the functions in `numpy` return a copy of the array argument\n(e.g., `np.sort`). In-place versions of these functions are often\navailable as array methods, i.e. ``x = np.array([1,2,3]); x.sort()``.\nExceptions to this rule are documented.\n\n\"\"\"\nfrom __future__ import division, absolute_import, print_function\n\nimport sys\n\n\nclass ModuleDeprecationWarning(DeprecationWarning):\n \"\"\"Module deprecation warning.\n\n The nose tester turns ordinary Deprecation warnings into test failures.\n That makes it hard to deprecate whole modules, because they get\n imported by default. So this is a special Deprecation warning that the\n nose tester will let pass without making tests fail.\n\n \"\"\"\n pass\n\n\nclass VisibleDeprecationWarning(UserWarning):\n \"\"\"Visible deprecation warning.\n\n By default, python will not show deprecation warnings, so this class\n can be used when a very visible warning is helpful, for example because\n the usage is most likely a user bug.\n\n \"\"\"\n pass\n\n\nclass _NoValue:\n \"\"\"Special keyword value.\n\n This class may be used as the default value assigned to a\n deprecated keyword in order to check if it has been given a user\n defined value.\n \"\"\"\n pass\n\n\n# oldnumeric and numarray were removed in 1.9. In case some packages import\n# but do not use them, we define them here for backward compatibility.\noldnumeric = 'removed'\nnumarray = 'removed'\n\n\n# We first need to detect if we're being called as part of the numpy setup\n# procedure itself in a reliable manner.\ntry:\n __NUMPY_SETUP__\nexcept NameError:\n __NUMPY_SETUP__ = False\n\n\nif __NUMPY_SETUP__:\n import sys as _sys\n _sys.stderr.write('Running from numpy source directory.\\n')\n del _sys\nelse:\n try:\n from numpy.__config__ import show as show_config\n except ImportError:\n msg = \"\"\"Error importing numpy: you should not try to import numpy from\n its source directory; please exit the numpy source tree, and relaunch\n your python interpreter from there.\"\"\"\n raise ImportError(msg)\n from .version import git_revision as __git_revision__\n from .version import version as __version__\n\n from ._import_tools import PackageLoader\n\n def pkgload(*packages, **options):\n loader = PackageLoader(infunc=True)\n return loader(*packages, **options)\n\n from . import add_newdocs\n __all__ = ['add_newdocs',\n 'ModuleDeprecationWarning',\n 'VisibleDeprecationWarning']\n\n pkgload.__doc__ = PackageLoader.__call__.__doc__\n\n # We don't actually use this ourselves anymore, but I'm not 100% sure that\n # no-one else in the world is using it (though I hope not)\n from .testing import Tester\n test = testing.nosetester._numpy_tester().test\n bench = testing.nosetester._numpy_tester().bench\n\n from . import core\n from .core import *\n from . import compat\n from . import lib\n from .lib import *\n from . import linalg\n from . import fft\n from . import polynomial\n from . import random\n from . import ctypeslib\n from . import ma\n from . import matrixlib as _mat\n from .matrixlib import *\n from .compat import long\n\n # Make these accessible from numpy name-space\n # but not imported in from numpy import *\n if sys.version_info[0] >= 3:\n from builtins import bool, int, float, complex, object, str\n unicode = str\n else:\n from __builtin__ import bool, int, float, complex, object, unicode, str\n\n from .core import round, abs, max, min\n\n __all__.extend(['__version__', 'pkgload', 'PackageLoader',\n 'show_config'])\n __all__.extend(core.__all__)\n __all__.extend(_mat.__all__)\n __all__.extend(lib.__all__)\n __all__.extend(['linalg', 'fft', 'random', 'ctypeslib', 'ma'])\n\n # Filter annoying Cython warnings that serve no good purpose.\n import warnings\n warnings.filterwarnings(\"ignore\", message=\"numpy.dtype size changed\")\n warnings.filterwarnings(\"ignore\", message=\"numpy.ufunc size changed\")\n warnings.filterwarnings(\"ignore\", message=\"numpy.ndarray size changed\")\n", "path": "numpy/__init__.py"}]}
| 3,203 | 637 |
gh_patches_debug_952
|
rasdani/github-patches
|
git_diff
|
tobymao__sqlglot-2170
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Specifying 3.7+ in setup.py
sqlglot fails with Python version < 3.7.
While Python 3.6 is end-of-life, there are systems that still use 3.6 as they transition to 3.7. Having either `setup.py` or `setup.cfg` specify 3.7+ or adding to README would be helpful.
```
import sqlglot
```
`SyntaxError: future feature annotations is not defined`
**Official Documentation**
https://docs.python.org/3/library/__future__.html
</issue>
<code>
[start of setup.py]
1 from setuptools import find_packages, setup
2
3 setup(
4 name="sqlglot",
5 description="An easily customizable SQL parser and transpiler",
6 long_description=open("README.md").read(),
7 long_description_content_type="text/markdown",
8 url="https://github.com/tobymao/sqlglot",
9 author="Toby Mao",
10 author_email="[email protected]",
11 license="MIT",
12 packages=find_packages(include=["sqlglot", "sqlglot.*"]),
13 package_data={"sqlglot": ["py.typed"]},
14 use_scm_version={
15 "write_to": "sqlglot/_version.py",
16 "fallback_version": "0.0.0",
17 "local_scheme": "no-local-version",
18 },
19 setup_requires=["setuptools_scm"],
20 extras_require={
21 "dev": [
22 "autoflake",
23 "black",
24 "duckdb>=0.6",
25 "isort",
26 "mypy>=0.990",
27 "pandas",
28 "pyspark",
29 "python-dateutil",
30 "pdoc",
31 "pre-commit",
32 ],
33 },
34 classifiers=[
35 "Development Status :: 5 - Production/Stable",
36 "Intended Audience :: Developers",
37 "Intended Audience :: Science/Research",
38 "License :: OSI Approved :: MIT License",
39 "Operating System :: OS Independent",
40 "Programming Language :: SQL",
41 "Programming Language :: Python :: 3 :: Only",
42 ],
43 )
44
[end of setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -17,6 +17,7 @@
"local_scheme": "no-local-version",
},
setup_requires=["setuptools_scm"],
+ python_requires=">=3.7",
extras_require={
"dev": [
"autoflake",
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -17,6 +17,7 @@\n \"local_scheme\": \"no-local-version\",\n },\n setup_requires=[\"setuptools_scm\"],\n+ python_requires=\">=3.7\",\n extras_require={\n \"dev\": [\n \"autoflake\",\n", "issue": "Specifying 3.7+ in setup.py\nsqlglot fails with Python version < 3.7. \r\n\r\nWhile Python 3.6 is end-of-life, there are systems that still use 3.6 as they transition to 3.7. Having either `setup.py` or `setup.cfg` specify 3.7+ or adding to README would be helpful. \r\n\r\n```\r\nimport sqlglot\r\n```\r\n`SyntaxError: future feature annotations is not defined`\r\n\r\n**Official Documentation**\r\nhttps://docs.python.org/3/library/__future__.html\r\n\n", "before_files": [{"content": "from setuptools import find_packages, setup\n\nsetup(\n name=\"sqlglot\",\n description=\"An easily customizable SQL parser and transpiler\",\n long_description=open(\"README.md\").read(),\n long_description_content_type=\"text/markdown\",\n url=\"https://github.com/tobymao/sqlglot\",\n author=\"Toby Mao\",\n author_email=\"[email protected]\",\n license=\"MIT\",\n packages=find_packages(include=[\"sqlglot\", \"sqlglot.*\"]),\n package_data={\"sqlglot\": [\"py.typed\"]},\n use_scm_version={\n \"write_to\": \"sqlglot/_version.py\",\n \"fallback_version\": \"0.0.0\",\n \"local_scheme\": \"no-local-version\",\n },\n setup_requires=[\"setuptools_scm\"],\n extras_require={\n \"dev\": [\n \"autoflake\",\n \"black\",\n \"duckdb>=0.6\",\n \"isort\",\n \"mypy>=0.990\",\n \"pandas\",\n \"pyspark\",\n \"python-dateutil\",\n \"pdoc\",\n \"pre-commit\",\n ],\n },\n classifiers=[\n \"Development Status :: 5 - Production/Stable\",\n \"Intended Audience :: Developers\",\n \"Intended Audience :: Science/Research\",\n \"License :: OSI Approved :: MIT License\",\n \"Operating System :: OS Independent\",\n \"Programming Language :: SQL\",\n \"Programming Language :: Python :: 3 :: Only\",\n ],\n)\n", "path": "setup.py"}]}
| 1,046 | 78 |
gh_patches_debug_15529
|
rasdani/github-patches
|
git_diff
|
pypa__virtualenv-1205
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
broken Python 3.3 support due to wheel
With #1176, Python 3.3 support is broken because wheel 0.31 dropped support.
This means that virtualenv 16.0.0 will install fine on a Python 3.3 config, but then fail to create any virtualenvs.
virtualenv should also declare that it doesn't support 3.3
</issue>
<code>
[start of setup.py]
1 import os
2 import re
3 import shutil
4 import sys
5
6 if sys.version_info[:2] < (2, 7):
7 sys.exit('virtualenv requires Python 2.7 or higher.')
8
9 try:
10 from setuptools import setup
11 from setuptools.command.test import test as TestCommand
12
13 class PyTest(TestCommand):
14 user_options = [('pytest-args=', 'a', "Arguments to pass to py.test")]
15
16 def initialize_options(self):
17 TestCommand.initialize_options(self)
18 self.pytest_args = []
19
20 def finalize_options(self):
21 TestCommand.finalize_options(self)
22 #self.test_args = []
23 #self.test_suite = True
24
25 def run_tests(self):
26 # import here, because outside the eggs aren't loaded
27 import pytest
28 sys.exit(pytest.main(self.pytest_args))
29
30 setup_params = {
31 'entry_points': {
32 'console_scripts': ['virtualenv=virtualenv:main'],
33 },
34 'zip_safe': False,
35 'cmdclass': {'test': PyTest},
36 'tests_require': ['pytest', 'mock'],
37 }
38 except ImportError:
39 from distutils.core import setup
40 if sys.platform == 'win32':
41 print('Note: without Setuptools installed you will '
42 'have to use "python -m virtualenv ENV"')
43 setup_params = {}
44 else:
45 script = 'scripts/virtualenv'
46 setup_params = {'scripts': [script]}
47
48
49 def read_file(*paths):
50 here = os.path.dirname(os.path.abspath(__file__))
51 with open(os.path.join(here, *paths)) as f:
52 return f.read()
53
54 # Get long_description from index.rst:
55 long_description = read_file('docs', 'index.rst')
56 long_description = long_description.strip().split('split here', 1)[0]
57 # Add release history
58 changes = read_file('docs', 'changes.rst')
59 # Only report last two releases for brevity
60 releases_found = 0
61 change_lines = []
62 for line in changes.splitlines():
63 change_lines.append(line)
64 if line.startswith('--------------'):
65 releases_found += 1
66 if releases_found > 2:
67 break
68
69 changes = '\n'.join(change_lines[:-2]) + '\n'
70 changes += '`Full Changelog <https://virtualenv.pypa.io/en/latest/changes.html>`_.'
71 # Replace issue/pull directives
72 changes = re.sub(r':pull:`(\d+)`', r'PR #\1', changes)
73 changes = re.sub(r':issue:`(\d+)`', r'#\1', changes)
74
75 long_description += '\n\n' + changes
76
77
78 def get_version():
79 version_file = read_file('virtualenv.py')
80 version_match = re.search(r"^__version__ = ['\"]([^'\"]*)['\"]",
81 version_file, re.M)
82 if version_match:
83 return version_match.group(1)
84 raise RuntimeError("Unable to find version string.")
85
86
87 # Hack to prevent stupid TypeError: 'NoneType' object is not callable error on
88 # exit of python setup.py test # in multiprocessing/util.py _exit_function when
89 # running python setup.py test (see
90 # http://www.eby-sarna.com/pipermail/peak/2010-May/003357.html)
91 try:
92 import multiprocessing # noqa
93 except ImportError:
94 pass
95
96 setup(
97 name='virtualenv',
98 version=get_version(),
99 description="Virtual Python Environment builder",
100 long_description=long_description,
101 classifiers=[
102 'Development Status :: 5 - Production/Stable',
103 'Intended Audience :: Developers',
104 'License :: OSI Approved :: MIT License',
105 'Programming Language :: Python :: 2',
106 'Programming Language :: Python :: 2.7',
107 'Programming Language :: Python :: 3',
108 'Programming Language :: Python :: 3.4',
109 'Programming Language :: Python :: 3.5',
110 'Programming Language :: Python :: 3.6',
111 ],
112 keywords='setuptools deployment installation distutils',
113 author='Ian Bicking',
114 author_email='[email protected]',
115 maintainer='Jannis Leidel, Carl Meyer and Brian Rosner',
116 maintainer_email='[email protected]',
117 url='https://virtualenv.pypa.io/',
118 license='MIT',
119 py_modules=['virtualenv'],
120 packages=['virtualenv_support'],
121 package_data={'virtualenv_support': ['*.whl']},
122 python_requires='>=2.7,!=3.0.*,!=3.1.*,!=3.2.*',
123 **setup_params)
124
[end of setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -108,6 +108,7 @@
'Programming Language :: Python :: 3.4',
'Programming Language :: Python :: 3.5',
'Programming Language :: Python :: 3.6',
+ 'Programming Language :: Python :: 3.7',
],
keywords='setuptools deployment installation distutils',
author='Ian Bicking',
@@ -119,5 +120,5 @@
py_modules=['virtualenv'],
packages=['virtualenv_support'],
package_data={'virtualenv_support': ['*.whl']},
- python_requires='>=2.7,!=3.0.*,!=3.1.*,!=3.2.*',
+ python_requires='>=2.7,!=3.0.*,!=3.1.*,!=3.2.*,!=3.3.*',
**setup_params)
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -108,6 +108,7 @@\n 'Programming Language :: Python :: 3.4',\n 'Programming Language :: Python :: 3.5',\n 'Programming Language :: Python :: 3.6',\n+ 'Programming Language :: Python :: 3.7',\n ],\n keywords='setuptools deployment installation distutils',\n author='Ian Bicking',\n@@ -119,5 +120,5 @@\n py_modules=['virtualenv'],\n packages=['virtualenv_support'],\n package_data={'virtualenv_support': ['*.whl']},\n- python_requires='>=2.7,!=3.0.*,!=3.1.*,!=3.2.*',\n+ python_requires='>=2.7,!=3.0.*,!=3.1.*,!=3.2.*,!=3.3.*',\n **setup_params)\n", "issue": "broken Python 3.3 support due to wheel\nWith #1176, Python 3.3 support is broken because wheel 0.31 dropped support.\r\n\r\nThis means that virtualenv 16.0.0 will install fine on a Python 3.3 config, but then fail to create any virtualenvs.\r\n\r\nvirtualenv should also declare that it doesn't support 3.3\n", "before_files": [{"content": "import os\nimport re\nimport shutil\nimport sys\n\nif sys.version_info[:2] < (2, 7):\n sys.exit('virtualenv requires Python 2.7 or higher.')\n\ntry:\n from setuptools import setup\n from setuptools.command.test import test as TestCommand\n\n class PyTest(TestCommand):\n user_options = [('pytest-args=', 'a', \"Arguments to pass to py.test\")]\n\n def initialize_options(self):\n TestCommand.initialize_options(self)\n self.pytest_args = []\n\n def finalize_options(self):\n TestCommand.finalize_options(self)\n #self.test_args = []\n #self.test_suite = True\n\n def run_tests(self):\n # import here, because outside the eggs aren't loaded\n import pytest\n sys.exit(pytest.main(self.pytest_args))\n\n setup_params = {\n 'entry_points': {\n 'console_scripts': ['virtualenv=virtualenv:main'],\n },\n 'zip_safe': False,\n 'cmdclass': {'test': PyTest},\n 'tests_require': ['pytest', 'mock'],\n }\nexcept ImportError:\n from distutils.core import setup\n if sys.platform == 'win32':\n print('Note: without Setuptools installed you will '\n 'have to use \"python -m virtualenv ENV\"')\n setup_params = {}\n else:\n script = 'scripts/virtualenv'\n setup_params = {'scripts': [script]}\n\n\ndef read_file(*paths):\n here = os.path.dirname(os.path.abspath(__file__))\n with open(os.path.join(here, *paths)) as f:\n return f.read()\n\n# Get long_description from index.rst:\nlong_description = read_file('docs', 'index.rst')\nlong_description = long_description.strip().split('split here', 1)[0]\n# Add release history\nchanges = read_file('docs', 'changes.rst')\n# Only report last two releases for brevity\nreleases_found = 0\nchange_lines = []\nfor line in changes.splitlines():\n change_lines.append(line)\n if line.startswith('--------------'):\n releases_found += 1\n if releases_found > 2:\n break\n\nchanges = '\\n'.join(change_lines[:-2]) + '\\n'\nchanges += '`Full Changelog <https://virtualenv.pypa.io/en/latest/changes.html>`_.'\n# Replace issue/pull directives\nchanges = re.sub(r':pull:`(\\d+)`', r'PR #\\1', changes)\nchanges = re.sub(r':issue:`(\\d+)`', r'#\\1', changes)\n\nlong_description += '\\n\\n' + changes\n\n\ndef get_version():\n version_file = read_file('virtualenv.py')\n version_match = re.search(r\"^__version__ = ['\\\"]([^'\\\"]*)['\\\"]\",\n version_file, re.M)\n if version_match:\n return version_match.group(1)\n raise RuntimeError(\"Unable to find version string.\")\n\n\n# Hack to prevent stupid TypeError: 'NoneType' object is not callable error on\n# exit of python setup.py test # in multiprocessing/util.py _exit_function when\n# running python setup.py test (see\n# http://www.eby-sarna.com/pipermail/peak/2010-May/003357.html)\ntry:\n import multiprocessing # noqa\nexcept ImportError:\n pass\n\nsetup(\n name='virtualenv',\n version=get_version(),\n description=\"Virtual Python Environment builder\",\n long_description=long_description,\n classifiers=[\n 'Development Status :: 5 - Production/Stable',\n 'Intended Audience :: Developers',\n 'License :: OSI Approved :: MIT License',\n 'Programming Language :: Python :: 2',\n 'Programming Language :: Python :: 2.7',\n 'Programming Language :: Python :: 3',\n 'Programming Language :: Python :: 3.4',\n 'Programming Language :: Python :: 3.5',\n 'Programming Language :: Python :: 3.6',\n ],\n keywords='setuptools deployment installation distutils',\n author='Ian Bicking',\n author_email='[email protected]',\n maintainer='Jannis Leidel, Carl Meyer and Brian Rosner',\n maintainer_email='[email protected]',\n url='https://virtualenv.pypa.io/',\n license='MIT',\n py_modules=['virtualenv'],\n packages=['virtualenv_support'],\n package_data={'virtualenv_support': ['*.whl']},\n python_requires='>=2.7,!=3.0.*,!=3.1.*,!=3.2.*',\n **setup_params)\n", "path": "setup.py"}]}
| 1,864 | 205 |
gh_patches_debug_40503
|
rasdani/github-patches
|
git_diff
|
getpelican__pelican-538
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
sitemap.xml contains pages that don't exist
My settings.xml says:
```
AUTHOR_SAVE_AS = ''
```
in order to force pelican to not generate author pages.
When I include:
```
PLUGINS = [sitemap]
SITEMAP = {'format': 'xml'}
```
my sitemap.xml contains:
<url>
<loc>http://example.com/author/brian.html</loc>
<lastmod>2012-10-07T19:42:14-00:00</lastmod>
<changefreq>daily</changefreq>
<priority>0.5</priority>
</url>
The referenced file does not exist in my output directory.
The same holds true for `/archives.html`, `/tags.html`, `/categories.html`, and `/category/*.html`.
</issue>
<code>
[start of pelican/plugins/sitemap.py]
1 import os.path
2
3 from datetime import datetime
4 from logging import debug, warning, error, info
5 from codecs import open
6
7 from pelican import signals, contents
8
9 TXT_HEADER = u"""{0}/index.html
10 {0}/archives.html
11 {0}/tags.html
12 {0}/categories.html
13 """
14
15 XML_HEADER = u"""<?xml version="1.0" encoding="utf-8"?>
16 <urlset xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
17 xsi:schemaLocation="http://www.sitemaps.org/schemas/sitemap/0.9 http://www.sitemaps.org/schemas/sitemap/0.9/sitemap.xsd"
18 xmlns="http://www.sitemaps.org/schemas/sitemap/0.9">
19
20 <url>
21 <loc>{0}/index.html</loc>
22 <lastmod>{1}</lastmod>
23 <changefreq>{2}</changefreq>
24 <priority>{3}</priority>
25 </url>
26
27 <url>
28 <loc>{0}/archives.html</loc>
29 <lastmod>{1}</lastmod>
30 <changefreq>{2}</changefreq>
31 <priority>{3}</priority>
32 </url>
33
34 <url>
35 <loc>{0}/tags.html</loc>
36 <lastmod>{1}</lastmod>
37 <changefreq>{2}</changefreq>
38 <priority>{3}</priority>
39 </url>
40
41 <url>
42 <loc>{0}/categories.html</loc>
43 <lastmod>{1}</lastmod>
44 <changefreq>{2}</changefreq>
45 <priority>{3}</priority>
46 </url>
47 """
48
49 XML_URL = u"""
50 <url>
51 <loc>{0}/{1}</loc>
52 <lastmod>{2}</lastmod>
53 <changefreq>{3}</changefreq>
54 <priority>{4}</priority>
55 </url>
56 """
57
58 XML_FOOTER = u"""
59 </urlset>
60 """
61
62
63 def format_date(date):
64 if date.tzinfo:
65 tz = date.strftime('%s')
66 tz = tz[:-2] + ':' + tz[-2:]
67 else:
68 tz = "-00:00"
69 return date.strftime("%Y-%m-%dT%H:%M:%S") + tz
70
71
72
73 class SitemapGenerator(object):
74
75 def __init__(self, context, settings, path, theme, output_path, *null):
76
77 self.output_path = output_path
78 self.context = context
79 self.now = datetime.now()
80 self.siteurl = settings.get('SITEURL')
81
82 self.format = 'xml'
83
84 self.changefreqs = {
85 'articles': 'monthly',
86 'indexes': 'daily',
87 'pages': 'monthly'
88 }
89
90 self.priorities = {
91 'articles': 0.5,
92 'indexes': 0.5,
93 'pages': 0.5
94 }
95
96 config = settings.get('SITEMAP', {})
97
98 if not isinstance(config, dict):
99 warning("sitemap plugin: the SITEMAP setting must be a dict")
100 else:
101 fmt = config.get('format')
102 pris = config.get('priorities')
103 chfreqs = config.get('changefreqs')
104
105 if fmt not in ('xml', 'txt'):
106 warning("sitemap plugin: SITEMAP['format'] must be `txt' or `xml'")
107 warning("sitemap plugin: Setting SITEMAP['format'] on `xml'")
108 elif fmt == 'txt':
109 self.format = fmt
110 return
111
112 valid_keys = ('articles', 'indexes', 'pages')
113 valid_chfreqs = ('always', 'hourly', 'daily', 'weekly', 'monthly',
114 'yearly', 'never')
115
116 if isinstance(pris, dict):
117 for k, v in pris.iteritems():
118 if k in valid_keys and not isinstance(v, (int, float)):
119 default = self.priorities[k]
120 warning("sitemap plugin: priorities must be numbers")
121 warning("sitemap plugin: setting SITEMAP['priorities']"
122 "['{0}'] on {1}".format(k, default))
123 pris[k] = default
124 self.priorities.update(pris)
125 elif pris is not None:
126 warning("sitemap plugin: SITEMAP['priorities'] must be a dict")
127 warning("sitemap plugin: using the default values")
128
129 if isinstance(chfreqs, dict):
130 for k, v in chfreqs.iteritems():
131 if k in valid_keys and v not in valid_chfreqs:
132 default = self.changefreqs[k]
133 warning("sitemap plugin: invalid changefreq `{0}'".format(v))
134 warning("sitemap plugin: setting SITEMAP['changefreqs']"
135 "['{0}'] on '{1}'".format(k, default))
136 chfreqs[k] = default
137 self.changefreqs.update(chfreqs)
138 elif chfreqs is not None:
139 warning("sitemap plugin: SITEMAP['changefreqs'] must be a dict")
140 warning("sitemap plugin: using the default values")
141
142
143
144 def write_url(self, page, fd):
145
146 if getattr(page, 'status', 'published') != 'published':
147 return
148
149 lastmod = format_date(getattr(page, 'date', self.now))
150
151 if isinstance(page, contents.Article):
152 pri = self.priorities['articles']
153 chfreq = self.changefreqs['articles']
154 elif isinstance(page, contents.Page):
155 pri = self.priorities['pages']
156 chfreq = self.changefreqs['pages']
157 else:
158 pri = self.priorities['indexes']
159 chfreq = self.changefreqs['indexes']
160
161
162 if self.format == 'xml':
163 fd.write(XML_URL.format(self.siteurl, page.url, lastmod, chfreq, pri))
164 else:
165 fd.write(self.siteurl + '/' + loc + '\n')
166
167
168 def generate_output(self, writer):
169 path = os.path.join(self.output_path, 'sitemap.{0}'.format(self.format))
170
171 pages = self.context['pages'] + self.context['articles'] \
172 + [ c for (c, a) in self.context['categories']] \
173 + [ t for (t, a) in self.context['tags']] \
174 + [ a for (a, b) in self.context['authors']]
175
176 for article in self.context['articles']:
177 pages += article.translations
178
179
180 info('writing {0}'.format(path))
181
182 with open(path, 'w', encoding='utf-8') as fd:
183
184 if self.format == 'xml':
185 fd.write(XML_HEADER.format(
186 self.siteurl,
187 format_date(self.now),
188 self.changefreqs['indexes'],
189 self.priorities['indexes']
190 )
191 )
192 else:
193 fd.write(TXT_HEADER.format(self.siteurl))
194
195 for page in pages:
196 self.write_url(page, fd)
197
198 if self.format == 'xml':
199 fd.write(XML_FOOTER)
200
201
202
203 def get_generators(generators):
204 return SitemapGenerator
205
206
207 def register():
208 signals.get_generators.connect(get_generators)
209
[end of pelican/plugins/sitemap.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/pelican/plugins/sitemap.py b/pelican/plugins/sitemap.py
--- a/pelican/plugins/sitemap.py
+++ b/pelican/plugins/sitemap.py
@@ -1,3 +1,4 @@
+import collections
import os.path
from datetime import datetime
@@ -16,34 +17,6 @@
<urlset xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.sitemaps.org/schemas/sitemap/0.9 http://www.sitemaps.org/schemas/sitemap/0.9/sitemap.xsd"
xmlns="http://www.sitemaps.org/schemas/sitemap/0.9">
-
- <url>
- <loc>{0}/index.html</loc>
- <lastmod>{1}</lastmod>
- <changefreq>{2}</changefreq>
- <priority>{3}</priority>
- </url>
-
- <url>
- <loc>{0}/archives.html</loc>
- <lastmod>{1}</lastmod>
- <changefreq>{2}</changefreq>
- <priority>{3}</priority>
- </url>
-
- <url>
- <loc>{0}/tags.html</loc>
- <lastmod>{1}</lastmod>
- <changefreq>{2}</changefreq>
- <priority>{3}</priority>
- </url>
-
- <url>
- <loc>{0}/categories.html</loc>
- <lastmod>{1}</lastmod>
- <changefreq>{2}</changefreq>
- <priority>{3}</priority>
- </url>
"""
XML_URL = u"""
@@ -146,6 +119,10 @@
if getattr(page, 'status', 'published') != 'published':
return
+ page_path = os.path.join(self.output_path, page.url)
+ if not os.path.exists(page_path):
+ return
+
lastmod = format_date(getattr(page, 'date', self.now))
if isinstance(page, contents.Article):
@@ -176,22 +153,29 @@
for article in self.context['articles']:
pages += article.translations
-
info('writing {0}'.format(path))
with open(path, 'w', encoding='utf-8') as fd:
if self.format == 'xml':
- fd.write(XML_HEADER.format(
- self.siteurl,
- format_date(self.now),
- self.changefreqs['indexes'],
- self.priorities['indexes']
- )
- )
+ fd.write(XML_HEADER)
else:
fd.write(TXT_HEADER.format(self.siteurl))
+ FakePage = collections.namedtuple('FakePage',
+ ['status',
+ 'date',
+ 'url'])
+
+ for standard_page_url in ['index.html',
+ 'archives.html',
+ 'tags.html',
+ 'categories.html']:
+ fake = FakePage(status='published',
+ date=self.now,
+ url=standard_page_url)
+ self.write_url(fake, fd)
+
for page in pages:
self.write_url(page, fd)
@@ -199,7 +183,6 @@
fd.write(XML_FOOTER)
-
def get_generators(generators):
return SitemapGenerator
|
{"golden_diff": "diff --git a/pelican/plugins/sitemap.py b/pelican/plugins/sitemap.py\n--- a/pelican/plugins/sitemap.py\n+++ b/pelican/plugins/sitemap.py\n@@ -1,3 +1,4 @@\n+import collections\n import os.path\n \n from datetime import datetime\n@@ -16,34 +17,6 @@\n <urlset xmlns:xsi=\"http://www.w3.org/2001/XMLSchema-instance\"\n xsi:schemaLocation=\"http://www.sitemaps.org/schemas/sitemap/0.9 http://www.sitemaps.org/schemas/sitemap/0.9/sitemap.xsd\"\n xmlns=\"http://www.sitemaps.org/schemas/sitemap/0.9\">\n-\n- <url>\n- <loc>{0}/index.html</loc>\n- <lastmod>{1}</lastmod>\n- <changefreq>{2}</changefreq>\n- <priority>{3}</priority>\n- </url>\n-\n- <url>\n- <loc>{0}/archives.html</loc>\n- <lastmod>{1}</lastmod>\n- <changefreq>{2}</changefreq>\n- <priority>{3}</priority>\n- </url>\n-\n- <url>\n- <loc>{0}/tags.html</loc>\n- <lastmod>{1}</lastmod>\n- <changefreq>{2}</changefreq>\n- <priority>{3}</priority>\n- </url>\n-\n- <url>\n- <loc>{0}/categories.html</loc>\n- <lastmod>{1}</lastmod>\n- <changefreq>{2}</changefreq>\n- <priority>{3}</priority>\n- </url>\n \"\"\"\n \n XML_URL = u\"\"\"\n@@ -146,6 +119,10 @@\n if getattr(page, 'status', 'published') != 'published':\n return\n \n+ page_path = os.path.join(self.output_path, page.url)\n+ if not os.path.exists(page_path):\n+ return\n+\n lastmod = format_date(getattr(page, 'date', self.now))\n \n if isinstance(page, contents.Article):\n@@ -176,22 +153,29 @@\n for article in self.context['articles']:\n pages += article.translations\n \n-\n info('writing {0}'.format(path))\n \n with open(path, 'w', encoding='utf-8') as fd:\n \n if self.format == 'xml':\n- fd.write(XML_HEADER.format(\n- self.siteurl,\n- format_date(self.now),\n- self.changefreqs['indexes'],\n- self.priorities['indexes']\n- )\n- )\n+ fd.write(XML_HEADER)\n else:\n fd.write(TXT_HEADER.format(self.siteurl))\n \n+ FakePage = collections.namedtuple('FakePage',\n+ ['status',\n+ 'date',\n+ 'url'])\n+\n+ for standard_page_url in ['index.html',\n+ 'archives.html',\n+ 'tags.html',\n+ 'categories.html']:\n+ fake = FakePage(status='published',\n+ date=self.now,\n+ url=standard_page_url)\n+ self.write_url(fake, fd)\n+\n for page in pages:\n self.write_url(page, fd)\n \n@@ -199,7 +183,6 @@\n fd.write(XML_FOOTER)\n \n \n-\n def get_generators(generators):\n return SitemapGenerator\n", "issue": "sitemap.xml contains pages that don't exist\nMy settings.xml says:\n\n```\nAUTHOR_SAVE_AS = ''\n```\n\nin order to force pelican to not generate author pages.\n\nWhen I include:\n\n```\nPLUGINS = [sitemap]\nSITEMAP = {'format': 'xml'}\n```\n\nmy sitemap.xml contains:\n\n <url>\n <loc>http://example.com/author/brian.html</loc>\n <lastmod>2012-10-07T19:42:14-00:00</lastmod>\n <changefreq>daily</changefreq>\n <priority>0.5</priority>\n </url>\n\nThe referenced file does not exist in my output directory.\n\nThe same holds true for `/archives.html`, `/tags.html`, `/categories.html`, and `/category/*.html`.\n\n", "before_files": [{"content": "import os.path\n\nfrom datetime import datetime\nfrom logging import debug, warning, error, info\nfrom codecs import open\n\nfrom pelican import signals, contents\n\nTXT_HEADER = u\"\"\"{0}/index.html\n{0}/archives.html\n{0}/tags.html\n{0}/categories.html\n\"\"\"\n\nXML_HEADER = u\"\"\"<?xml version=\"1.0\" encoding=\"utf-8\"?>\n<urlset xmlns:xsi=\"http://www.w3.org/2001/XMLSchema-instance\"\n xsi:schemaLocation=\"http://www.sitemaps.org/schemas/sitemap/0.9 http://www.sitemaps.org/schemas/sitemap/0.9/sitemap.xsd\"\n xmlns=\"http://www.sitemaps.org/schemas/sitemap/0.9\">\n\n <url>\n <loc>{0}/index.html</loc>\n <lastmod>{1}</lastmod>\n <changefreq>{2}</changefreq>\n <priority>{3}</priority>\n </url>\n\n <url>\n <loc>{0}/archives.html</loc>\n <lastmod>{1}</lastmod>\n <changefreq>{2}</changefreq>\n <priority>{3}</priority>\n </url>\n\n <url>\n <loc>{0}/tags.html</loc>\n <lastmod>{1}</lastmod>\n <changefreq>{2}</changefreq>\n <priority>{3}</priority>\n </url>\n\n <url>\n <loc>{0}/categories.html</loc>\n <lastmod>{1}</lastmod>\n <changefreq>{2}</changefreq>\n <priority>{3}</priority>\n </url>\n\"\"\"\n\nXML_URL = u\"\"\"\n <url>\n <loc>{0}/{1}</loc>\n <lastmod>{2}</lastmod>\n <changefreq>{3}</changefreq>\n <priority>{4}</priority>\n </url>\n\"\"\"\n\nXML_FOOTER = u\"\"\"\n</urlset>\n\"\"\"\n\n\ndef format_date(date):\n if date.tzinfo:\n tz = date.strftime('%s')\n tz = tz[:-2] + ':' + tz[-2:]\n else:\n tz = \"-00:00\"\n return date.strftime(\"%Y-%m-%dT%H:%M:%S\") + tz\n\n\n\nclass SitemapGenerator(object):\n\n def __init__(self, context, settings, path, theme, output_path, *null):\n\n self.output_path = output_path\n self.context = context\n self.now = datetime.now()\n self.siteurl = settings.get('SITEURL')\n\n self.format = 'xml'\n\n self.changefreqs = {\n 'articles': 'monthly',\n 'indexes': 'daily',\n 'pages': 'monthly'\n }\n\n self.priorities = {\n 'articles': 0.5,\n 'indexes': 0.5,\n 'pages': 0.5\n }\n\n config = settings.get('SITEMAP', {})\n\n if not isinstance(config, dict):\n warning(\"sitemap plugin: the SITEMAP setting must be a dict\")\n else:\n fmt = config.get('format')\n pris = config.get('priorities')\n chfreqs = config.get('changefreqs')\n\n if fmt not in ('xml', 'txt'):\n warning(\"sitemap plugin: SITEMAP['format'] must be `txt' or `xml'\")\n warning(\"sitemap plugin: Setting SITEMAP['format'] on `xml'\")\n elif fmt == 'txt':\n self.format = fmt\n return\n\n valid_keys = ('articles', 'indexes', 'pages')\n valid_chfreqs = ('always', 'hourly', 'daily', 'weekly', 'monthly',\n 'yearly', 'never')\n\n if isinstance(pris, dict):\n for k, v in pris.iteritems():\n if k in valid_keys and not isinstance(v, (int, float)):\n default = self.priorities[k]\n warning(\"sitemap plugin: priorities must be numbers\")\n warning(\"sitemap plugin: setting SITEMAP['priorities']\"\n \"['{0}'] on {1}\".format(k, default))\n pris[k] = default\n self.priorities.update(pris)\n elif pris is not None:\n warning(\"sitemap plugin: SITEMAP['priorities'] must be a dict\")\n warning(\"sitemap plugin: using the default values\")\n\n if isinstance(chfreqs, dict):\n for k, v in chfreqs.iteritems():\n if k in valid_keys and v not in valid_chfreqs:\n default = self.changefreqs[k]\n warning(\"sitemap plugin: invalid changefreq `{0}'\".format(v))\n warning(\"sitemap plugin: setting SITEMAP['changefreqs']\"\n \"['{0}'] on '{1}'\".format(k, default))\n chfreqs[k] = default\n self.changefreqs.update(chfreqs)\n elif chfreqs is not None:\n warning(\"sitemap plugin: SITEMAP['changefreqs'] must be a dict\")\n warning(\"sitemap plugin: using the default values\")\n\n\n\n def write_url(self, page, fd):\n\n if getattr(page, 'status', 'published') != 'published':\n return\n\n lastmod = format_date(getattr(page, 'date', self.now))\n\n if isinstance(page, contents.Article):\n pri = self.priorities['articles']\n chfreq = self.changefreqs['articles']\n elif isinstance(page, contents.Page):\n pri = self.priorities['pages']\n chfreq = self.changefreqs['pages']\n else:\n pri = self.priorities['indexes']\n chfreq = self.changefreqs['indexes']\n\n\n if self.format == 'xml':\n fd.write(XML_URL.format(self.siteurl, page.url, lastmod, chfreq, pri))\n else:\n fd.write(self.siteurl + '/' + loc + '\\n')\n\n\n def generate_output(self, writer):\n path = os.path.join(self.output_path, 'sitemap.{0}'.format(self.format))\n\n pages = self.context['pages'] + self.context['articles'] \\\n + [ c for (c, a) in self.context['categories']] \\\n + [ t for (t, a) in self.context['tags']] \\\n + [ a for (a, b) in self.context['authors']]\n\n for article in self.context['articles']:\n pages += article.translations\n\n\n info('writing {0}'.format(path))\n\n with open(path, 'w', encoding='utf-8') as fd:\n\n if self.format == 'xml':\n fd.write(XML_HEADER.format(\n self.siteurl,\n format_date(self.now),\n self.changefreqs['indexes'],\n self.priorities['indexes']\n )\n )\n else:\n fd.write(TXT_HEADER.format(self.siteurl))\n\n for page in pages:\n self.write_url(page, fd)\n\n if self.format == 'xml':\n fd.write(XML_FOOTER)\n\n\n\ndef get_generators(generators):\n return SitemapGenerator\n\n\ndef register():\n signals.get_generators.connect(get_generators)\n", "path": "pelican/plugins/sitemap.py"}]}
| 2,814 | 759 |
gh_patches_debug_26925
|
rasdani/github-patches
|
git_diff
|
getsentry__sentry-57872
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Fix typing for `sentry.tasks.commits`
Many files related to post-process are skipping type checks.
* Remove the file from [sentry/pyproject.toml](https://github.com/getsentry/sentry/blob/b7810a9dca4b57afd2858903a6a9ec7ab50cdead/pyproject.toml)
* Run `mypy sentry.tasks.commits` and fix the typing errors
From https://github.com/getsentry/sentry/issues/55193
</issue>
<code>
[start of src/sentry/tasks/commits.py]
1 from __future__ import annotations
2
3 import logging
4
5 import sentry_sdk
6 from django.urls import reverse
7 from sentry_sdk import set_tag
8
9 from sentry.constants import ObjectStatus
10 from sentry.exceptions import InvalidIdentity, PluginError
11 from sentry.models.deploy import Deploy
12 from sentry.models.latestreporeleaseenvironment import LatestRepoReleaseEnvironment
13 from sentry.models.organization import Organization
14 from sentry.models.release import Release, ReleaseCommitError
15 from sentry.models.releaseheadcommit import ReleaseHeadCommit
16 from sentry.models.repository import Repository
17 from sentry.models.user import User
18 from sentry.plugins.base import bindings
19 from sentry.services.hybrid_cloud.user import RpcUser
20 from sentry.services.hybrid_cloud.user.service import user_service
21 from sentry.shared_integrations.exceptions import IntegrationError
22 from sentry.silo import SiloMode
23 from sentry.tasks.base import instrumented_task, retry
24 from sentry.utils.email import MessageBuilder
25 from sentry.utils.http import absolute_uri
26
27 logger = logging.getLogger(__name__)
28
29
30 def generate_invalid_identity_email(identity, commit_failure=False):
31 new_context = {
32 "identity": identity,
33 "auth_url": absolute_uri(reverse("socialauth_associate", args=[identity.provider])),
34 "commit_failure": commit_failure,
35 }
36
37 return MessageBuilder(
38 subject="Unable to Fetch Commits" if commit_failure else "Action Required",
39 context=new_context,
40 template="sentry/emails/identity-invalid.txt",
41 html_template="sentry/emails/identity-invalid.html",
42 )
43
44
45 def generate_fetch_commits_error_email(release, repo, error_message):
46 new_context = {"release": release, "error_message": error_message, "repo": repo}
47
48 return MessageBuilder(
49 subject="Unable to Fetch Commits",
50 context=new_context,
51 template="sentry/emails/unable-to-fetch-commits.txt",
52 html_template="sentry/emails/unable-to-fetch-commits.html",
53 )
54
55
56 # we're future proofing this function a bit so it could be used with other code
57
58
59 def handle_invalid_identity(identity, commit_failure=False):
60 # email the user
61 msg = generate_invalid_identity_email(identity, commit_failure)
62 msg.send_async(to=[identity.user.email])
63
64 # now remove the identity, as its invalid
65 identity.delete()
66
67
68 @instrumented_task(
69 name="sentry.tasks.commits.fetch_commits",
70 queue="commits",
71 default_retry_delay=60 * 5,
72 max_retries=5,
73 silo_mode=SiloMode.REGION,
74 )
75 @retry(exclude=(Release.DoesNotExist, User.DoesNotExist))
76 def fetch_commits(release_id: int, user_id: int, refs, prev_release_id=None, **kwargs):
77 # TODO(dcramer): this function could use some cleanup/refactoring as it's a bit unwieldy
78 commit_list = []
79
80 release = Release.objects.get(id=release_id)
81 set_tag("organization.slug", release.organization.slug)
82 # TODO: Need a better way to error handle no user_id. We need the SDK to be able to call this without user context
83 # to autoassociate commits to releases
84 user = user_service.get_user(user_id) if user_id is not None else None
85 # user = User.objects.get(id=user_id) if user_id is not None else None
86 prev_release = None
87 if prev_release_id is not None:
88 try:
89 prev_release = Release.objects.get(id=prev_release_id)
90 except Release.DoesNotExist:
91 pass
92
93 for ref in refs:
94 repo = (
95 Repository.objects.filter(
96 organization_id=release.organization_id,
97 name=ref["repository"],
98 status=ObjectStatus.ACTIVE,
99 )
100 .order_by("-pk")
101 .first()
102 )
103 if not repo:
104 logger.info(
105 "repository.missing",
106 extra={
107 "organization_id": release.organization_id,
108 "user_id": user_id,
109 "repository": ref["repository"],
110 },
111 )
112 continue
113
114 binding_key = (
115 "integration-repository.provider"
116 if is_integration_provider(repo.provider)
117 else "repository.provider"
118 )
119 try:
120 provider_cls = bindings.get(binding_key).get(repo.provider)
121 except KeyError:
122 continue
123
124 # if previous commit isn't provided, try to get from
125 # previous release otherwise, try to get
126 # recent commits from provider api
127 start_sha = None
128 if ref.get("previousCommit"):
129 start_sha = ref["previousCommit"]
130 elif prev_release:
131 try:
132 start_sha = ReleaseHeadCommit.objects.filter(
133 organization_id=release.organization_id,
134 release=prev_release,
135 repository_id=repo.id,
136 ).values_list("commit__key", flat=True)[0]
137 except IndexError:
138 pass
139
140 end_sha = ref["commit"]
141 provider = provider_cls(id=repo.provider)
142 try:
143 if is_integration_provider(provider.id):
144 repo_commits = provider.compare_commits(repo, start_sha, end_sha)
145 else:
146 repo_commits = provider.compare_commits(repo, start_sha, end_sha, actor=user)
147 except NotImplementedError:
148 pass
149 except Exception as e:
150 logger.info(
151 "fetch_commits.error",
152 extra={
153 "organization_id": repo.organization_id,
154 "user_id": user_id,
155 "repository": repo.name,
156 "provider": provider.id,
157 "error": str(e),
158 "end_sha": end_sha,
159 "start_sha": start_sha,
160 },
161 )
162 span = sentry_sdk.Hub.current.scope.span
163 span.set_status("unknown_error")
164 logger.exception(e)
165 if isinstance(e, InvalidIdentity) and getattr(e, "identity", None):
166 handle_invalid_identity(identity=e.identity, commit_failure=True)
167 elif isinstance(e, (PluginError, InvalidIdentity, IntegrationError)):
168 msg = generate_fetch_commits_error_email(release, repo, str(e))
169 emails = get_emails_for_user_or_org(user, release.organization_id)
170 msg.send_async(to=emails)
171 else:
172 msg = generate_fetch_commits_error_email(
173 release, repo, "An internal system error occurred."
174 )
175 emails = get_emails_for_user_or_org(user, release.organization_id)
176 msg.send_async(to=emails)
177 else:
178 logger.info(
179 "fetch_commits.complete",
180 extra={
181 "organization_id": repo.organization_id,
182 "user_id": user_id,
183 "repository": repo.name,
184 "end_sha": end_sha,
185 "start_sha": start_sha,
186 "num_commits": len(repo_commits or []),
187 },
188 )
189 commit_list.extend(repo_commits)
190
191 if commit_list:
192 try:
193 release.set_commits(commit_list)
194 except ReleaseCommitError:
195 # Another task or webworker is currently setting commits on this
196 # release. Return early as that task will do the remaining work.
197 logger.info(
198 "fetch_commits.duplicate",
199 extra={
200 "release_id": release.id,
201 "organization_id": release.organization_id,
202 "user_id": user_id,
203 },
204 )
205 return
206
207 deploys = Deploy.objects.filter(
208 organization_id=release.organization_id, release=release, notified=False
209 ).values_list("id", "environment_id", "date_finished")
210
211 # XXX(dcramer): i don't know why this would have multiple environments, but for
212 # our sanity lets assume it can
213 pending_notifications = []
214 last_deploy_per_environment = {}
215 for deploy_id, environment_id, date_finished in deploys:
216 last_deploy_per_environment[environment_id] = (deploy_id, date_finished)
217 pending_notifications.append(deploy_id)
218
219 repo_queryset = ReleaseHeadCommit.objects.filter(
220 organization_id=release.organization_id, release=release
221 ).values_list("repository_id", "commit")
222
223 # for each repo, update (or create if this is the first one) our records
224 # of the latest commit-associated release in each env
225 # use deploys as a proxy for ReleaseEnvironment, because they contain
226 # a timestamp in addition to release and env data
227 for repository_id, commit_id in repo_queryset:
228 for environment_id, (deploy_id, date_finished) in last_deploy_per_environment.items():
229 # we need to mark LatestRepoReleaseEnvironment, but only if there's not a
230 # deploy in the given environment which has completed *after*
231 # this deploy (given we might process commits out of order)
232 if not Deploy.objects.filter(
233 id__in=LatestRepoReleaseEnvironment.objects.filter(
234 repository_id=repository_id, environment_id=environment_id
235 ).values("deploy_id"),
236 date_finished__gt=date_finished,
237 ).exists():
238 LatestRepoReleaseEnvironment.objects.create_or_update(
239 repository_id=repository_id,
240 environment_id=environment_id,
241 values={
242 "release_id": release.id,
243 "deploy_id": deploy_id,
244 "commit_id": commit_id,
245 },
246 )
247
248 for deploy_id in pending_notifications:
249 Deploy.notify_if_ready(deploy_id, fetch_complete=True)
250
251
252 def is_integration_provider(provider):
253 return provider and provider.startswith("integrations:")
254
255
256 def get_emails_for_user_or_org(user: RpcUser | None, orgId: int):
257 emails = []
258 if not user:
259 return []
260 if user.is_sentry_app:
261 organization = Organization.objects.get(id=orgId)
262 members = organization.get_members_with_org_roles(roles=["owner"])
263 user_ids = [m.user_id for m in members if m.user_id]
264 emails = {u.email for u in user_service.get_many(filter={"user_ids": user_ids}) if u.email}
265 emails = list(emails)
266 else:
267 emails = [user.email]
268
269 return emails
270
[end of src/sentry/tasks/commits.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/sentry/tasks/commits.py b/src/sentry/tasks/commits.py
--- a/src/sentry/tasks/commits.py
+++ b/src/sentry/tasks/commits.py
@@ -159,7 +159,9 @@
"start_sha": start_sha,
},
)
- span = sentry_sdk.Hub.current.scope.span
+ span = sentry_sdk.get_current_span()
+ if span is None:
+ raise TypeError("No span is currently active right now")
span.set_status("unknown_error")
logger.exception(e)
if isinstance(e, InvalidIdentity) and getattr(e, "identity", None):
@@ -254,15 +256,16 @@
def get_emails_for_user_or_org(user: RpcUser | None, orgId: int):
- emails = []
+ emails: list[str] = []
if not user:
return []
if user.is_sentry_app:
organization = Organization.objects.get(id=orgId)
members = organization.get_members_with_org_roles(roles=["owner"])
user_ids = [m.user_id for m in members if m.user_id]
- emails = {u.email for u in user_service.get_many(filter={"user_ids": user_ids}) if u.email}
- emails = list(emails)
+ emails = list(
+ {u.email for u in user_service.get_many(filter={"user_ids": user_ids}) if u.email}
+ )
else:
emails = [user.email]
|
{"golden_diff": "diff --git a/src/sentry/tasks/commits.py b/src/sentry/tasks/commits.py\n--- a/src/sentry/tasks/commits.py\n+++ b/src/sentry/tasks/commits.py\n@@ -159,7 +159,9 @@\n \"start_sha\": start_sha,\n },\n )\n- span = sentry_sdk.Hub.current.scope.span\n+ span = sentry_sdk.get_current_span()\n+ if span is None:\n+ raise TypeError(\"No span is currently active right now\")\n span.set_status(\"unknown_error\")\n logger.exception(e)\n if isinstance(e, InvalidIdentity) and getattr(e, \"identity\", None):\n@@ -254,15 +256,16 @@\n \n \n def get_emails_for_user_or_org(user: RpcUser | None, orgId: int):\n- emails = []\n+ emails: list[str] = []\n if not user:\n return []\n if user.is_sentry_app:\n organization = Organization.objects.get(id=orgId)\n members = organization.get_members_with_org_roles(roles=[\"owner\"])\n user_ids = [m.user_id for m in members if m.user_id]\n- emails = {u.email for u in user_service.get_many(filter={\"user_ids\": user_ids}) if u.email}\n- emails = list(emails)\n+ emails = list(\n+ {u.email for u in user_service.get_many(filter={\"user_ids\": user_ids}) if u.email}\n+ )\n else:\n emails = [user.email]\n", "issue": "Fix typing for `sentry.tasks.commits`\nMany files related to post-process are skipping type checks.\n\n* Remove the file from [sentry/pyproject.toml](https://github.com/getsentry/sentry/blob/b7810a9dca4b57afd2858903a6a9ec7ab50cdead/pyproject.toml)\n* Run `mypy sentry.tasks.commits` and fix the typing errors\n\nFrom https://github.com/getsentry/sentry/issues/55193\n", "before_files": [{"content": "from __future__ import annotations\n\nimport logging\n\nimport sentry_sdk\nfrom django.urls import reverse\nfrom sentry_sdk import set_tag\n\nfrom sentry.constants import ObjectStatus\nfrom sentry.exceptions import InvalidIdentity, PluginError\nfrom sentry.models.deploy import Deploy\nfrom sentry.models.latestreporeleaseenvironment import LatestRepoReleaseEnvironment\nfrom sentry.models.organization import Organization\nfrom sentry.models.release import Release, ReleaseCommitError\nfrom sentry.models.releaseheadcommit import ReleaseHeadCommit\nfrom sentry.models.repository import Repository\nfrom sentry.models.user import User\nfrom sentry.plugins.base import bindings\nfrom sentry.services.hybrid_cloud.user import RpcUser\nfrom sentry.services.hybrid_cloud.user.service import user_service\nfrom sentry.shared_integrations.exceptions import IntegrationError\nfrom sentry.silo import SiloMode\nfrom sentry.tasks.base import instrumented_task, retry\nfrom sentry.utils.email import MessageBuilder\nfrom sentry.utils.http import absolute_uri\n\nlogger = logging.getLogger(__name__)\n\n\ndef generate_invalid_identity_email(identity, commit_failure=False):\n new_context = {\n \"identity\": identity,\n \"auth_url\": absolute_uri(reverse(\"socialauth_associate\", args=[identity.provider])),\n \"commit_failure\": commit_failure,\n }\n\n return MessageBuilder(\n subject=\"Unable to Fetch Commits\" if commit_failure else \"Action Required\",\n context=new_context,\n template=\"sentry/emails/identity-invalid.txt\",\n html_template=\"sentry/emails/identity-invalid.html\",\n )\n\n\ndef generate_fetch_commits_error_email(release, repo, error_message):\n new_context = {\"release\": release, \"error_message\": error_message, \"repo\": repo}\n\n return MessageBuilder(\n subject=\"Unable to Fetch Commits\",\n context=new_context,\n template=\"sentry/emails/unable-to-fetch-commits.txt\",\n html_template=\"sentry/emails/unable-to-fetch-commits.html\",\n )\n\n\n# we're future proofing this function a bit so it could be used with other code\n\n\ndef handle_invalid_identity(identity, commit_failure=False):\n # email the user\n msg = generate_invalid_identity_email(identity, commit_failure)\n msg.send_async(to=[identity.user.email])\n\n # now remove the identity, as its invalid\n identity.delete()\n\n\n@instrumented_task(\n name=\"sentry.tasks.commits.fetch_commits\",\n queue=\"commits\",\n default_retry_delay=60 * 5,\n max_retries=5,\n silo_mode=SiloMode.REGION,\n)\n@retry(exclude=(Release.DoesNotExist, User.DoesNotExist))\ndef fetch_commits(release_id: int, user_id: int, refs, prev_release_id=None, **kwargs):\n # TODO(dcramer): this function could use some cleanup/refactoring as it's a bit unwieldy\n commit_list = []\n\n release = Release.objects.get(id=release_id)\n set_tag(\"organization.slug\", release.organization.slug)\n # TODO: Need a better way to error handle no user_id. We need the SDK to be able to call this without user context\n # to autoassociate commits to releases\n user = user_service.get_user(user_id) if user_id is not None else None\n # user = User.objects.get(id=user_id) if user_id is not None else None\n prev_release = None\n if prev_release_id is not None:\n try:\n prev_release = Release.objects.get(id=prev_release_id)\n except Release.DoesNotExist:\n pass\n\n for ref in refs:\n repo = (\n Repository.objects.filter(\n organization_id=release.organization_id,\n name=ref[\"repository\"],\n status=ObjectStatus.ACTIVE,\n )\n .order_by(\"-pk\")\n .first()\n )\n if not repo:\n logger.info(\n \"repository.missing\",\n extra={\n \"organization_id\": release.organization_id,\n \"user_id\": user_id,\n \"repository\": ref[\"repository\"],\n },\n )\n continue\n\n binding_key = (\n \"integration-repository.provider\"\n if is_integration_provider(repo.provider)\n else \"repository.provider\"\n )\n try:\n provider_cls = bindings.get(binding_key).get(repo.provider)\n except KeyError:\n continue\n\n # if previous commit isn't provided, try to get from\n # previous release otherwise, try to get\n # recent commits from provider api\n start_sha = None\n if ref.get(\"previousCommit\"):\n start_sha = ref[\"previousCommit\"]\n elif prev_release:\n try:\n start_sha = ReleaseHeadCommit.objects.filter(\n organization_id=release.organization_id,\n release=prev_release,\n repository_id=repo.id,\n ).values_list(\"commit__key\", flat=True)[0]\n except IndexError:\n pass\n\n end_sha = ref[\"commit\"]\n provider = provider_cls(id=repo.provider)\n try:\n if is_integration_provider(provider.id):\n repo_commits = provider.compare_commits(repo, start_sha, end_sha)\n else:\n repo_commits = provider.compare_commits(repo, start_sha, end_sha, actor=user)\n except NotImplementedError:\n pass\n except Exception as e:\n logger.info(\n \"fetch_commits.error\",\n extra={\n \"organization_id\": repo.organization_id,\n \"user_id\": user_id,\n \"repository\": repo.name,\n \"provider\": provider.id,\n \"error\": str(e),\n \"end_sha\": end_sha,\n \"start_sha\": start_sha,\n },\n )\n span = sentry_sdk.Hub.current.scope.span\n span.set_status(\"unknown_error\")\n logger.exception(e)\n if isinstance(e, InvalidIdentity) and getattr(e, \"identity\", None):\n handle_invalid_identity(identity=e.identity, commit_failure=True)\n elif isinstance(e, (PluginError, InvalidIdentity, IntegrationError)):\n msg = generate_fetch_commits_error_email(release, repo, str(e))\n emails = get_emails_for_user_or_org(user, release.organization_id)\n msg.send_async(to=emails)\n else:\n msg = generate_fetch_commits_error_email(\n release, repo, \"An internal system error occurred.\"\n )\n emails = get_emails_for_user_or_org(user, release.organization_id)\n msg.send_async(to=emails)\n else:\n logger.info(\n \"fetch_commits.complete\",\n extra={\n \"organization_id\": repo.organization_id,\n \"user_id\": user_id,\n \"repository\": repo.name,\n \"end_sha\": end_sha,\n \"start_sha\": start_sha,\n \"num_commits\": len(repo_commits or []),\n },\n )\n commit_list.extend(repo_commits)\n\n if commit_list:\n try:\n release.set_commits(commit_list)\n except ReleaseCommitError:\n # Another task or webworker is currently setting commits on this\n # release. Return early as that task will do the remaining work.\n logger.info(\n \"fetch_commits.duplicate\",\n extra={\n \"release_id\": release.id,\n \"organization_id\": release.organization_id,\n \"user_id\": user_id,\n },\n )\n return\n\n deploys = Deploy.objects.filter(\n organization_id=release.organization_id, release=release, notified=False\n ).values_list(\"id\", \"environment_id\", \"date_finished\")\n\n # XXX(dcramer): i don't know why this would have multiple environments, but for\n # our sanity lets assume it can\n pending_notifications = []\n last_deploy_per_environment = {}\n for deploy_id, environment_id, date_finished in deploys:\n last_deploy_per_environment[environment_id] = (deploy_id, date_finished)\n pending_notifications.append(deploy_id)\n\n repo_queryset = ReleaseHeadCommit.objects.filter(\n organization_id=release.organization_id, release=release\n ).values_list(\"repository_id\", \"commit\")\n\n # for each repo, update (or create if this is the first one) our records\n # of the latest commit-associated release in each env\n # use deploys as a proxy for ReleaseEnvironment, because they contain\n # a timestamp in addition to release and env data\n for repository_id, commit_id in repo_queryset:\n for environment_id, (deploy_id, date_finished) in last_deploy_per_environment.items():\n # we need to mark LatestRepoReleaseEnvironment, but only if there's not a\n # deploy in the given environment which has completed *after*\n # this deploy (given we might process commits out of order)\n if not Deploy.objects.filter(\n id__in=LatestRepoReleaseEnvironment.objects.filter(\n repository_id=repository_id, environment_id=environment_id\n ).values(\"deploy_id\"),\n date_finished__gt=date_finished,\n ).exists():\n LatestRepoReleaseEnvironment.objects.create_or_update(\n repository_id=repository_id,\n environment_id=environment_id,\n values={\n \"release_id\": release.id,\n \"deploy_id\": deploy_id,\n \"commit_id\": commit_id,\n },\n )\n\n for deploy_id in pending_notifications:\n Deploy.notify_if_ready(deploy_id, fetch_complete=True)\n\n\ndef is_integration_provider(provider):\n return provider and provider.startswith(\"integrations:\")\n\n\ndef get_emails_for_user_or_org(user: RpcUser | None, orgId: int):\n emails = []\n if not user:\n return []\n if user.is_sentry_app:\n organization = Organization.objects.get(id=orgId)\n members = organization.get_members_with_org_roles(roles=[\"owner\"])\n user_ids = [m.user_id for m in members if m.user_id]\n emails = {u.email for u in user_service.get_many(filter={\"user_ids\": user_ids}) if u.email}\n emails = list(emails)\n else:\n emails = [user.email]\n\n return emails\n", "path": "src/sentry/tasks/commits.py"}]}
| 3,439 | 329 |
gh_patches_debug_2830
|
rasdani/github-patches
|
git_diff
|
zulip__zulip-21420
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Document "Manage this user" profile link
Administrators now see a "Manage this user" link at the bottom of the user profile modal, which will often be handier than getting to the user management UI through the settings.
<img width="300" alt="Screen Shot 2022-03-14 at 3 46 02 PM" src="https://user-images.githubusercontent.com/2090066/158273279-acedbd78-a5b8-4a5a-ae48-cda2eb19e931.png">
We should probably document this link as the primary way to perform certain actions, with the settings approach being an alternative.
Affected pages I'm aware of:
- https://zulip.com/help/change-a-users-name
- https://zulip.com/help/change-a-users-role
- https://zulip.com/help/deactivate-or-reactivate-a-user
Document user management via profile
In #20373, we added the ability to:
1. Manage a user from their profile
2. Deactivate a user from the "manage user" modal
We should document this in the Help center. In particular, we should indicate that user management actions (e.g. Change a user's name, etc.) can be done from either the gear menu, or from their profile. (Maybe we can do this by using tabs in the instructions.)
For deactivating a user, I think the button inside the modal only needs to be described for the approach where you start from the profile.
This page might be a good related article: https://zulip.com/help/view-someones-profile
</issue>
<code>
[start of zerver/lib/markdown/tabbed_sections.py]
1 import re
2 from typing import Any, Dict, List, Mapping, Optional
3
4 import markdown
5 from markdown.extensions import Extension
6 from markdown.preprocessors import Preprocessor
7
8 from zerver.lib.markdown.preprocessor_priorities import PREPROCESSOR_PRIORITES
9
10 START_TABBED_SECTION_REGEX = re.compile(r"^\{start_tabs\}$")
11 END_TABBED_SECTION_REGEX = re.compile(r"^\{end_tabs\}$")
12 TAB_CONTENT_REGEX = re.compile(r"^\{tab\|\s*(.+?)\s*\}$")
13
14 CODE_SECTION_TEMPLATE = """
15 <div class="code-section {tab_class}" markdown="1">
16 {nav_bar}
17 <div class="blocks">
18 {blocks}
19 </div>
20 </div>
21 """.strip()
22
23 NAV_BAR_TEMPLATE = """
24 <ul class="nav">
25 {tabs}
26 </ul>
27 """.strip()
28
29 NAV_LIST_ITEM_TEMPLATE = """
30 <li data-language="{data_language}" tabindex="0">{label}</li>
31 """.strip()
32
33 DIV_TAB_CONTENT_TEMPLATE = """
34 <div data-language="{data_language}" markdown="1">
35 {content}
36 </div>
37 """.strip()
38
39 # If adding new entries here, also check if you need to update
40 # tabbed-instructions.js
41 TAB_SECTION_LABELS = {
42 "desktop-web": "Desktop/Web",
43 "ios": "iOS",
44 "android": "Android",
45 "mac": "macOS",
46 "windows": "Windows",
47 "linux": "Linux",
48 "python": "Python",
49 "js": "JavaScript",
50 "curl": "curl",
51 "zulip-send": "zulip-send",
52 "web": "Web",
53 "desktop": "Desktop",
54 "mobile": "Mobile",
55 "mm-default": "Default installation",
56 "mm-docker": "Docker",
57 "mm-gitlab-omnibus": "GitLab Omnibus",
58 "send-email-invitations": "Send email invitations",
59 "share-an-invite-link": "Share an invite link",
60 "require-invitations": "Require invitations",
61 "allow-anyone-to-join": "Allow anyone to join",
62 "restrict-by-email-domain": "Restrict by email domain",
63 "zoom": "Zoom",
64 "jitsi-meet": "Jitsi Meet",
65 "bigbluebutton": "BigBlueButton",
66 "disable": "Disabled",
67 "chrome": "Chrome",
68 "firefox": "Firefox",
69 "desktop-app": "Desktop app",
70 "system-proxy-settings": "System proxy settings",
71 "custom-proxy-settings": "Custom proxy settings",
72 "stream": "From a stream view",
73 "not-stream": "From other views",
74 "via-recent-topics": "Via recent topics",
75 "via-left-sidebar": "Via left sidebar",
76 "instructions-for-all-platforms": "Instructions for all platforms",
77 "public-streams": "Public streams",
78 "private-streams": "Private streams",
79 }
80
81
82 class TabbedSectionsGenerator(Extension):
83 def extendMarkdown(self, md: markdown.Markdown) -> None:
84 md.preprocessors.register(
85 TabbedSectionsPreprocessor(md, self.getConfigs()),
86 "tabbed_sections",
87 PREPROCESSOR_PRIORITES["tabbed_sections"],
88 )
89
90
91 class TabbedSectionsPreprocessor(Preprocessor):
92 def __init__(self, md: markdown.Markdown, config: Mapping[str, Any]) -> None:
93 super().__init__(md)
94
95 def run(self, lines: List[str]) -> List[str]:
96 tab_section = self.parse_tabs(lines)
97 while tab_section:
98 if "tabs" in tab_section:
99 tab_class = "has-tabs"
100 else:
101 tab_class = "no-tabs"
102 tab_section["tabs"] = [
103 {
104 "tab_name": "instructions-for-all-platforms",
105 "start": tab_section["start_tabs_index"],
106 }
107 ]
108 nav_bar = self.generate_nav_bar(tab_section)
109 content_blocks = self.generate_content_blocks(tab_section, lines)
110 rendered_tabs = CODE_SECTION_TEMPLATE.format(
111 tab_class=tab_class, nav_bar=nav_bar, blocks=content_blocks
112 )
113
114 start = tab_section["start_tabs_index"]
115 end = tab_section["end_tabs_index"] + 1
116 lines = [*lines[:start], rendered_tabs, *lines[end:]]
117 tab_section = self.parse_tabs(lines)
118 return lines
119
120 def generate_content_blocks(self, tab_section: Dict[str, Any], lines: List[str]) -> str:
121 tab_content_blocks = []
122 for index, tab in enumerate(tab_section["tabs"]):
123 start_index = tab["start"] + 1
124 try:
125 # If there are more tabs, we can use the starting index
126 # of the next tab as the ending index of the previous one
127 end_index = tab_section["tabs"][index + 1]["start"]
128 except IndexError:
129 # Otherwise, just use the end of the entire section
130 end_index = tab_section["end_tabs_index"]
131
132 content = "\n".join(lines[start_index:end_index]).strip()
133 tab_content_block = DIV_TAB_CONTENT_TEMPLATE.format(
134 data_language=tab["tab_name"],
135 # Wrapping the content in two newlines is necessary here.
136 # If we don't do this, the inner Markdown does not get
137 # rendered properly.
138 content=f"\n{content}\n",
139 )
140 tab_content_blocks.append(tab_content_block)
141 return "\n".join(tab_content_blocks)
142
143 def generate_nav_bar(self, tab_section: Dict[str, Any]) -> str:
144 li_elements = []
145 for tab in tab_section["tabs"]:
146 tab_name = tab.get("tab_name")
147 tab_label = TAB_SECTION_LABELS.get(tab_name)
148 if tab_label is None:
149 raise ValueError(
150 f"Tab '{tab_name}' is not present in TAB_SECTION_LABELS in zerver/lib/markdown/tabbed_sections.py"
151 )
152
153 li = NAV_LIST_ITEM_TEMPLATE.format(data_language=tab_name, label=tab_label)
154 li_elements.append(li)
155
156 return NAV_BAR_TEMPLATE.format(tabs="\n".join(li_elements))
157
158 def parse_tabs(self, lines: List[str]) -> Optional[Dict[str, Any]]:
159 block: Dict[str, Any] = {}
160 for index, line in enumerate(lines):
161 start_match = START_TABBED_SECTION_REGEX.search(line)
162 if start_match:
163 block["start_tabs_index"] = index
164
165 tab_content_match = TAB_CONTENT_REGEX.search(line)
166 if tab_content_match:
167 block.setdefault("tabs", [])
168 tab = {"start": index, "tab_name": tab_content_match.group(1)}
169 block["tabs"].append(tab)
170
171 end_match = END_TABBED_SECTION_REGEX.search(line)
172 if end_match:
173 block["end_tabs_index"] = index
174 break
175 return block
176
177
178 def makeExtension(*args: Any, **kwargs: str) -> TabbedSectionsGenerator:
179 return TabbedSectionsGenerator(**kwargs)
180
[end of zerver/lib/markdown/tabbed_sections.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/zerver/lib/markdown/tabbed_sections.py b/zerver/lib/markdown/tabbed_sections.py
--- a/zerver/lib/markdown/tabbed_sections.py
+++ b/zerver/lib/markdown/tabbed_sections.py
@@ -76,6 +76,8 @@
"instructions-for-all-platforms": "Instructions for all platforms",
"public-streams": "Public streams",
"private-streams": "Private streams",
+ "via-user-profile": "Via the user's profile",
+ "via-organization-settings": "Via organization settings",
}
|
{"golden_diff": "diff --git a/zerver/lib/markdown/tabbed_sections.py b/zerver/lib/markdown/tabbed_sections.py\n--- a/zerver/lib/markdown/tabbed_sections.py\n+++ b/zerver/lib/markdown/tabbed_sections.py\n@@ -76,6 +76,8 @@\n \"instructions-for-all-platforms\": \"Instructions for all platforms\",\n \"public-streams\": \"Public streams\",\n \"private-streams\": \"Private streams\",\n+ \"via-user-profile\": \"Via the user's profile\",\n+ \"via-organization-settings\": \"Via organization settings\",\n }\n", "issue": "Document \"Manage this user\" profile link\nAdministrators now see a \"Manage this user\" link at the bottom of the user profile modal, which will often be handier than getting to the user management UI through the settings.\r\n\r\n<img width=\"300\" alt=\"Screen Shot 2022-03-14 at 3 46 02 PM\" src=\"https://user-images.githubusercontent.com/2090066/158273279-acedbd78-a5b8-4a5a-ae48-cda2eb19e931.png\">\r\n\r\nWe should probably document this link as the primary way to perform certain actions, with the settings approach being an alternative.\r\n\r\nAffected pages I'm aware of:\r\n- https://zulip.com/help/change-a-users-name\r\n- https://zulip.com/help/change-a-users-role\r\n- https://zulip.com/help/deactivate-or-reactivate-a-user\nDocument user management via profile\nIn #20373, we added the ability to:\r\n\r\n1. Manage a user from their profile\r\n2. Deactivate a user from the \"manage user\" modal\r\n\r\nWe should document this in the Help center. In particular, we should indicate that user management actions (e.g. Change a user's name, etc.) can be done from either the gear menu, or from their profile. (Maybe we can do this by using tabs in the instructions.)\r\n\r\nFor deactivating a user, I think the button inside the modal only needs to be described for the approach where you start from the profile.\r\n\r\nThis page might be a good related article: https://zulip.com/help/view-someones-profile\n", "before_files": [{"content": "import re\nfrom typing import Any, Dict, List, Mapping, Optional\n\nimport markdown\nfrom markdown.extensions import Extension\nfrom markdown.preprocessors import Preprocessor\n\nfrom zerver.lib.markdown.preprocessor_priorities import PREPROCESSOR_PRIORITES\n\nSTART_TABBED_SECTION_REGEX = re.compile(r\"^\\{start_tabs\\}$\")\nEND_TABBED_SECTION_REGEX = re.compile(r\"^\\{end_tabs\\}$\")\nTAB_CONTENT_REGEX = re.compile(r\"^\\{tab\\|\\s*(.+?)\\s*\\}$\")\n\nCODE_SECTION_TEMPLATE = \"\"\"\n<div class=\"code-section {tab_class}\" markdown=\"1\">\n{nav_bar}\n<div class=\"blocks\">\n{blocks}\n</div>\n</div>\n\"\"\".strip()\n\nNAV_BAR_TEMPLATE = \"\"\"\n<ul class=\"nav\">\n{tabs}\n</ul>\n\"\"\".strip()\n\nNAV_LIST_ITEM_TEMPLATE = \"\"\"\n<li data-language=\"{data_language}\" tabindex=\"0\">{label}</li>\n\"\"\".strip()\n\nDIV_TAB_CONTENT_TEMPLATE = \"\"\"\n<div data-language=\"{data_language}\" markdown=\"1\">\n{content}\n</div>\n\"\"\".strip()\n\n# If adding new entries here, also check if you need to update\n# tabbed-instructions.js\nTAB_SECTION_LABELS = {\n \"desktop-web\": \"Desktop/Web\",\n \"ios\": \"iOS\",\n \"android\": \"Android\",\n \"mac\": \"macOS\",\n \"windows\": \"Windows\",\n \"linux\": \"Linux\",\n \"python\": \"Python\",\n \"js\": \"JavaScript\",\n \"curl\": \"curl\",\n \"zulip-send\": \"zulip-send\",\n \"web\": \"Web\",\n \"desktop\": \"Desktop\",\n \"mobile\": \"Mobile\",\n \"mm-default\": \"Default installation\",\n \"mm-docker\": \"Docker\",\n \"mm-gitlab-omnibus\": \"GitLab Omnibus\",\n \"send-email-invitations\": \"Send email invitations\",\n \"share-an-invite-link\": \"Share an invite link\",\n \"require-invitations\": \"Require invitations\",\n \"allow-anyone-to-join\": \"Allow anyone to join\",\n \"restrict-by-email-domain\": \"Restrict by email domain\",\n \"zoom\": \"Zoom\",\n \"jitsi-meet\": \"Jitsi Meet\",\n \"bigbluebutton\": \"BigBlueButton\",\n \"disable\": \"Disabled\",\n \"chrome\": \"Chrome\",\n \"firefox\": \"Firefox\",\n \"desktop-app\": \"Desktop app\",\n \"system-proxy-settings\": \"System proxy settings\",\n \"custom-proxy-settings\": \"Custom proxy settings\",\n \"stream\": \"From a stream view\",\n \"not-stream\": \"From other views\",\n \"via-recent-topics\": \"Via recent topics\",\n \"via-left-sidebar\": \"Via left sidebar\",\n \"instructions-for-all-platforms\": \"Instructions for all platforms\",\n \"public-streams\": \"Public streams\",\n \"private-streams\": \"Private streams\",\n}\n\n\nclass TabbedSectionsGenerator(Extension):\n def extendMarkdown(self, md: markdown.Markdown) -> None:\n md.preprocessors.register(\n TabbedSectionsPreprocessor(md, self.getConfigs()),\n \"tabbed_sections\",\n PREPROCESSOR_PRIORITES[\"tabbed_sections\"],\n )\n\n\nclass TabbedSectionsPreprocessor(Preprocessor):\n def __init__(self, md: markdown.Markdown, config: Mapping[str, Any]) -> None:\n super().__init__(md)\n\n def run(self, lines: List[str]) -> List[str]:\n tab_section = self.parse_tabs(lines)\n while tab_section:\n if \"tabs\" in tab_section:\n tab_class = \"has-tabs\"\n else:\n tab_class = \"no-tabs\"\n tab_section[\"tabs\"] = [\n {\n \"tab_name\": \"instructions-for-all-platforms\",\n \"start\": tab_section[\"start_tabs_index\"],\n }\n ]\n nav_bar = self.generate_nav_bar(tab_section)\n content_blocks = self.generate_content_blocks(tab_section, lines)\n rendered_tabs = CODE_SECTION_TEMPLATE.format(\n tab_class=tab_class, nav_bar=nav_bar, blocks=content_blocks\n )\n\n start = tab_section[\"start_tabs_index\"]\n end = tab_section[\"end_tabs_index\"] + 1\n lines = [*lines[:start], rendered_tabs, *lines[end:]]\n tab_section = self.parse_tabs(lines)\n return lines\n\n def generate_content_blocks(self, tab_section: Dict[str, Any], lines: List[str]) -> str:\n tab_content_blocks = []\n for index, tab in enumerate(tab_section[\"tabs\"]):\n start_index = tab[\"start\"] + 1\n try:\n # If there are more tabs, we can use the starting index\n # of the next tab as the ending index of the previous one\n end_index = tab_section[\"tabs\"][index + 1][\"start\"]\n except IndexError:\n # Otherwise, just use the end of the entire section\n end_index = tab_section[\"end_tabs_index\"]\n\n content = \"\\n\".join(lines[start_index:end_index]).strip()\n tab_content_block = DIV_TAB_CONTENT_TEMPLATE.format(\n data_language=tab[\"tab_name\"],\n # Wrapping the content in two newlines is necessary here.\n # If we don't do this, the inner Markdown does not get\n # rendered properly.\n content=f\"\\n{content}\\n\",\n )\n tab_content_blocks.append(tab_content_block)\n return \"\\n\".join(tab_content_blocks)\n\n def generate_nav_bar(self, tab_section: Dict[str, Any]) -> str:\n li_elements = []\n for tab in tab_section[\"tabs\"]:\n tab_name = tab.get(\"tab_name\")\n tab_label = TAB_SECTION_LABELS.get(tab_name)\n if tab_label is None:\n raise ValueError(\n f\"Tab '{tab_name}' is not present in TAB_SECTION_LABELS in zerver/lib/markdown/tabbed_sections.py\"\n )\n\n li = NAV_LIST_ITEM_TEMPLATE.format(data_language=tab_name, label=tab_label)\n li_elements.append(li)\n\n return NAV_BAR_TEMPLATE.format(tabs=\"\\n\".join(li_elements))\n\n def parse_tabs(self, lines: List[str]) -> Optional[Dict[str, Any]]:\n block: Dict[str, Any] = {}\n for index, line in enumerate(lines):\n start_match = START_TABBED_SECTION_REGEX.search(line)\n if start_match:\n block[\"start_tabs_index\"] = index\n\n tab_content_match = TAB_CONTENT_REGEX.search(line)\n if tab_content_match:\n block.setdefault(\"tabs\", [])\n tab = {\"start\": index, \"tab_name\": tab_content_match.group(1)}\n block[\"tabs\"].append(tab)\n\n end_match = END_TABBED_SECTION_REGEX.search(line)\n if end_match:\n block[\"end_tabs_index\"] = index\n break\n return block\n\n\ndef makeExtension(*args: Any, **kwargs: str) -> TabbedSectionsGenerator:\n return TabbedSectionsGenerator(**kwargs)\n", "path": "zerver/lib/markdown/tabbed_sections.py"}]}
| 2,814 | 122 |
gh_patches_debug_26742
|
rasdani/github-patches
|
git_diff
|
saleor__saleor-2877
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Dashboard 2.0: Order API does not expose a way to get a product thumbnail for an order line
We get access to `productName` and `productSku` but not a thumbnail. It's ok to return `null` if the product no longer exists so we don't need to denormalize this field but I'd like to avoid having the client query the `product` directly and then have to manually figure out which image to show.
</issue>
<code>
[start of saleor/graphql/order/types.py]
1 import graphene
2 from graphene import relay
3
4 from ...order import OrderEvents, models
5 from ..account.types import User
6 from ..core.types.common import CountableDjangoObjectType
7 from ..core.types.money import Money, TaxedMoney
8 from decimal import Decimal
9
10 OrderEventsEnum = graphene.Enum.from_enum(OrderEvents)
11
12
13 class OrderEvent(CountableDjangoObjectType):
14 date = graphene.types.datetime.DateTime(
15 description='Date when event happened at in ISO 8601 format.')
16 type = OrderEventsEnum(description='Order event type')
17 user = graphene.Field(
18 User, id=graphene.Argument(graphene.ID),
19 description='User who performed the action.')
20 message = graphene.String(
21 description='Content of a note added to the order.')
22 email = graphene.String(description='Email of the customer')
23 email_type = graphene.String(
24 description='Type of an email sent to the customer')
25 amount = graphene.Float(description='Amount of money.')
26 quantity = graphene.Int(description='Number of items.')
27 composed_id = graphene.String(
28 description='Composed id of the Fulfillment.')
29
30 class Meta:
31 description = 'History log of the order.'
32 model = models.OrderEvent
33 interfaces = [relay.Node]
34 exclude_fields = ['order', 'parameters']
35
36 def resolve_email(self, info):
37 return self.parameters.get('email', None)
38
39 def resolve_email_type(self, info):
40 return self.parameters.get('email_type', None)
41
42 def resolve_amount(self, info):
43 amount = self.parameters.get('amount', None)
44 return Decimal(amount) if amount else None
45
46 def resolve_quantity(self, info):
47 quantity = self.parameters.get('quantity', None)
48 return int(quantity) if quantity else None
49
50 def resolve_message(self, info):
51 return self.parameters.get('message', None)
52
53 def resolve_composed_id(self, info):
54 return self.parameters.get('composed_id', None)
55
56
57 class Fulfillment(CountableDjangoObjectType):
58 status_display = graphene.String(
59 description='User-friendly fulfillment status.')
60
61 class Meta:
62 description = 'Represents order fulfillment.'
63 interfaces = [relay.Node]
64 model = models.Fulfillment
65 exclude_fields = ['order']
66
67 def resolve_status_display(self, info):
68 return self.get_status_display()
69
70
71 class FulfillmentLine(CountableDjangoObjectType):
72 class Meta:
73 description = 'Represents line of the fulfillment.'
74 interfaces = [relay.Node]
75 model = models.FulfillmentLine
76 exclude_fields = ['fulfillment']
77
78
79 class Order(CountableDjangoObjectType):
80 fulfillments = graphene.List(
81 Fulfillment,
82 required=True,
83 description='List of shipments for the order.')
84 is_paid = graphene.Boolean(
85 description='Informs if an order is fully paid.')
86 number = graphene.String(description='User-friendly number of an order.')
87 payment_status = graphene.String(description='Internal payment status.')
88 payment_status_display = graphene.String(
89 description='User-friendly payment status.')
90 subtotal = graphene.Field(
91 TaxedMoney,
92 description='The sum of line prices not including shipping.')
93 status_display = graphene.String(description='User-friendly order status.')
94 total_authorized = graphene.Field(
95 Money, description='Amount authorized for the order.')
96 total_captured = graphene.Field(
97 Money, description='Amount captured by payment.')
98 events = graphene.List(
99 OrderEvent,
100 description='List of events associated with the order.')
101 user_email = graphene.String(
102 required=False, description='Email address of the customer.')
103
104 class Meta:
105 description = 'Represents an order in the shop.'
106 interfaces = [relay.Node]
107 model = models.Order
108 exclude_fields = [
109 'shipping_price_gross', 'shipping_price_net', 'total_gross',
110 'total_net']
111
112 @staticmethod
113 def resolve_subtotal(obj, info):
114 return obj.get_subtotal()
115
116 @staticmethod
117 def resolve_total_authorized(obj, info):
118 payment = obj.get_last_payment()
119 if payment:
120 return payment.get_total_price().gross
121
122 @staticmethod
123 def resolve_total_captured(obj, info):
124 payment = obj.get_last_payment()
125 if payment:
126 return payment.get_captured_price()
127
128 @staticmethod
129 def resolve_fulfillments(obj, info):
130 return obj.fulfillments.all()
131
132 @staticmethod
133 def resolve_events(obj, info):
134 return obj.events.all()
135
136 @staticmethod
137 def resolve_is_paid(obj, info):
138 return obj.is_fully_paid()
139
140 @staticmethod
141 def resolve_number(obj, info):
142 return str(obj.pk)
143
144 @staticmethod
145 def resolve_payment_status(obj, info):
146 return obj.get_last_payment_status()
147
148 @staticmethod
149 def resolve_payment_status_display(obj, info):
150 return obj.get_last_payment_status_display()
151
152 @staticmethod
153 def resolve_status_display(obj, info):
154 return obj.get_status_display()
155
156 @staticmethod
157 def resolve_user_email(obj, info):
158 if obj.user_email:
159 return obj.user_email
160 if obj.user_id:
161 return obj.user.email
162 return None
163
164
165 class OrderLine(CountableDjangoObjectType):
166 class Meta:
167 description = 'Represents order line of particular order.'
168 model = models.OrderLine
169 interfaces = [relay.Node]
170 exclude_fields = [
171 'order', 'unit_price_gross', 'unit_price_net', 'variant']
172
[end of saleor/graphql/order/types.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/saleor/graphql/order/types.py b/saleor/graphql/order/types.py
--- a/saleor/graphql/order/types.py
+++ b/saleor/graphql/order/types.py
@@ -1,11 +1,13 @@
+from decimal import Decimal
+
import graphene
from graphene import relay
from ...order import OrderEvents, models
+from ...product.templatetags.product_images import get_thumbnail
from ..account.types import User
from ..core.types.common import CountableDjangoObjectType
from ..core.types.money import Money, TaxedMoney
-from decimal import Decimal
OrderEventsEnum = graphene.Enum.from_enum(OrderEvents)
@@ -163,9 +165,21 @@
class OrderLine(CountableDjangoObjectType):
+ thumbnail_url = graphene.String(
+ description='The URL of a main thumbnail for the ordered product.',
+ size=graphene.Int(description='Size of the image'))
+
class Meta:
description = 'Represents order line of particular order.'
model = models.OrderLine
interfaces = [relay.Node]
exclude_fields = [
'order', 'unit_price_gross', 'unit_price_net', 'variant']
+
+ def resolve_thumbnail_url(self, info, size=None):
+ if not self.variant_id:
+ return None
+ if not size:
+ size = 255
+ return get_thumbnail(
+ self.variant.get_first_image(), size, method='thumbnail')
|
{"golden_diff": "diff --git a/saleor/graphql/order/types.py b/saleor/graphql/order/types.py\n--- a/saleor/graphql/order/types.py\n+++ b/saleor/graphql/order/types.py\n@@ -1,11 +1,13 @@\n+from decimal import Decimal\n+\n import graphene\n from graphene import relay\n \n from ...order import OrderEvents, models\n+from ...product.templatetags.product_images import get_thumbnail\n from ..account.types import User\n from ..core.types.common import CountableDjangoObjectType\n from ..core.types.money import Money, TaxedMoney\n-from decimal import Decimal\n \n OrderEventsEnum = graphene.Enum.from_enum(OrderEvents)\n \n@@ -163,9 +165,21 @@\n \n \n class OrderLine(CountableDjangoObjectType):\n+ thumbnail_url = graphene.String(\n+ description='The URL of a main thumbnail for the ordered product.',\n+ size=graphene.Int(description='Size of the image'))\n+\n class Meta:\n description = 'Represents order line of particular order.'\n model = models.OrderLine\n interfaces = [relay.Node]\n exclude_fields = [\n 'order', 'unit_price_gross', 'unit_price_net', 'variant']\n+\n+ def resolve_thumbnail_url(self, info, size=None):\n+ if not self.variant_id:\n+ return None\n+ if not size:\n+ size = 255\n+ return get_thumbnail(\n+ self.variant.get_first_image(), size, method='thumbnail')\n", "issue": "Dashboard 2.0: Order API does not expose a way to get a product thumbnail for an order line\nWe get access to `productName` and `productSku` but not a thumbnail. It's ok to return `null` if the product no longer exists so we don't need to denormalize this field but I'd like to avoid having the client query the `product` directly and then have to manually figure out which image to show.\n", "before_files": [{"content": "import graphene\nfrom graphene import relay\n\nfrom ...order import OrderEvents, models\nfrom ..account.types import User\nfrom ..core.types.common import CountableDjangoObjectType\nfrom ..core.types.money import Money, TaxedMoney\nfrom decimal import Decimal\n\nOrderEventsEnum = graphene.Enum.from_enum(OrderEvents)\n\n\nclass OrderEvent(CountableDjangoObjectType):\n date = graphene.types.datetime.DateTime(\n description='Date when event happened at in ISO 8601 format.')\n type = OrderEventsEnum(description='Order event type')\n user = graphene.Field(\n User, id=graphene.Argument(graphene.ID),\n description='User who performed the action.')\n message = graphene.String(\n description='Content of a note added to the order.')\n email = graphene.String(description='Email of the customer')\n email_type = graphene.String(\n description='Type of an email sent to the customer')\n amount = graphene.Float(description='Amount of money.')\n quantity = graphene.Int(description='Number of items.')\n composed_id = graphene.String(\n description='Composed id of the Fulfillment.')\n\n class Meta:\n description = 'History log of the order.'\n model = models.OrderEvent\n interfaces = [relay.Node]\n exclude_fields = ['order', 'parameters']\n\n def resolve_email(self, info):\n return self.parameters.get('email', None)\n\n def resolve_email_type(self, info):\n return self.parameters.get('email_type', None)\n\n def resolve_amount(self, info):\n amount = self.parameters.get('amount', None)\n return Decimal(amount) if amount else None\n\n def resolve_quantity(self, info):\n quantity = self.parameters.get('quantity', None)\n return int(quantity) if quantity else None\n\n def resolve_message(self, info):\n return self.parameters.get('message', None)\n\n def resolve_composed_id(self, info):\n return self.parameters.get('composed_id', None)\n\n\nclass Fulfillment(CountableDjangoObjectType):\n status_display = graphene.String(\n description='User-friendly fulfillment status.')\n\n class Meta:\n description = 'Represents order fulfillment.'\n interfaces = [relay.Node]\n model = models.Fulfillment\n exclude_fields = ['order']\n\n def resolve_status_display(self, info):\n return self.get_status_display()\n\n\nclass FulfillmentLine(CountableDjangoObjectType):\n class Meta:\n description = 'Represents line of the fulfillment.'\n interfaces = [relay.Node]\n model = models.FulfillmentLine\n exclude_fields = ['fulfillment']\n\n\nclass Order(CountableDjangoObjectType):\n fulfillments = graphene.List(\n Fulfillment,\n required=True,\n description='List of shipments for the order.')\n is_paid = graphene.Boolean(\n description='Informs if an order is fully paid.')\n number = graphene.String(description='User-friendly number of an order.')\n payment_status = graphene.String(description='Internal payment status.')\n payment_status_display = graphene.String(\n description='User-friendly payment status.')\n subtotal = graphene.Field(\n TaxedMoney,\n description='The sum of line prices not including shipping.')\n status_display = graphene.String(description='User-friendly order status.')\n total_authorized = graphene.Field(\n Money, description='Amount authorized for the order.')\n total_captured = graphene.Field(\n Money, description='Amount captured by payment.')\n events = graphene.List(\n OrderEvent,\n description='List of events associated with the order.')\n user_email = graphene.String(\n required=False, description='Email address of the customer.')\n\n class Meta:\n description = 'Represents an order in the shop.'\n interfaces = [relay.Node]\n model = models.Order\n exclude_fields = [\n 'shipping_price_gross', 'shipping_price_net', 'total_gross',\n 'total_net']\n\n @staticmethod\n def resolve_subtotal(obj, info):\n return obj.get_subtotal()\n\n @staticmethod\n def resolve_total_authorized(obj, info):\n payment = obj.get_last_payment()\n if payment:\n return payment.get_total_price().gross\n\n @staticmethod\n def resolve_total_captured(obj, info):\n payment = obj.get_last_payment()\n if payment:\n return payment.get_captured_price()\n\n @staticmethod\n def resolve_fulfillments(obj, info):\n return obj.fulfillments.all()\n\n @staticmethod\n def resolve_events(obj, info):\n return obj.events.all()\n\n @staticmethod\n def resolve_is_paid(obj, info):\n return obj.is_fully_paid()\n\n @staticmethod\n def resolve_number(obj, info):\n return str(obj.pk)\n\n @staticmethod\n def resolve_payment_status(obj, info):\n return obj.get_last_payment_status()\n\n @staticmethod\n def resolve_payment_status_display(obj, info):\n return obj.get_last_payment_status_display()\n\n @staticmethod\n def resolve_status_display(obj, info):\n return obj.get_status_display()\n\n @staticmethod\n def resolve_user_email(obj, info):\n if obj.user_email:\n return obj.user_email\n if obj.user_id:\n return obj.user.email\n return None\n\n\nclass OrderLine(CountableDjangoObjectType):\n class Meta:\n description = 'Represents order line of particular order.'\n model = models.OrderLine\n interfaces = [relay.Node]\n exclude_fields = [\n 'order', 'unit_price_gross', 'unit_price_net', 'variant']\n", "path": "saleor/graphql/order/types.py"}]}
| 2,202 | 318 |
gh_patches_debug_25719
|
rasdani/github-patches
|
git_diff
|
Flexget__Flexget-1586
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
logging crash
Just got this error for some log output, its nothing serious, but just wanted to report it.
Python 3.5.2 + Flexget 2.8.1
```
--- Logging error ---
Traceback (most recent call last):
File "c:\users\andy\appdata\local\programs\python\python35-32\lib\logging\__init__.py", line 982, in emit
stream.write(msg)
File "c:\users\andy\appdata\local\programs\python\python35-32\lib\site-packages\colorclass\windows.py", line 275, in write
print(segment, file=self._original_stream, end='')
File "c:\users\andy\appdata\local\programs\python\python35-32\lib\encodings\cp850.py", line 19, in encode
return codecs.charmap_encode(input,self.errors,encoding_map)[0]
UnicodeEncodeError: 'charmap' codec can't encode character '\u2022' in position 67: character maps to <undefined>
Call stack:
File "c:\users\andy\appdata\local\programs\python\python35-32\lib\threading.py", line 882, in _bootstrap
self._bootstrap_inner()
File "c:\users\andy\appdata\local\programs\python\python35-32\lib\threading.py", line 914, in _bootstrap_inner
self.run()
File "c:\users\andy\appdata\local\programs\python\python35-32\lib\threading.py", line 862, in run
self._target(*self._args, **self._kwargs)
File "c:\users\andy\appdata\local\programs\python\python35-32\lib\site-packages\flexget\task_queue.py", line 48, in run
self.current_task.execute()
File "c:\users\andy\appdata\local\programs\python\python35-32\lib\site-packages\flexget\task.py", line 72, in wrapper
return func(self, *args, **kw)
File "c:\users\andy\appdata\local\programs\python\python35-32\lib\site-packages\flexget\task.py", line 646, in execute
self._execute()
File "c:\users\andy\appdata\local\programs\python\python35-32\lib\site-packages\flexget\task.py", line 612, in _execute
self.__run_task_phase(phase)
File "c:\users\andy\appdata\local\programs\python\python35-32\lib\site-packages\flexget\task.py", line 453, in __run_task_phase
response = self.__run_plugin(plugin, phase, args)
File "c:\users\andy\appdata\local\programs\python\python35-32\lib\site-packages\flexget\task.py", line 483, in __run_plugin
return method(*args, **kwargs)
File "c:\users\andy\appdata\local\programs\python\python35-32\lib\site-packages\flexget\event.py", line 23, in __call__
return self.func(*args, **kwargs)
File "c:\users\andy\appdata\local\programs\python\python35-32\lib\site-packages\flexget\plugins\filter\quality.py", line 37, in on_task_filter
entry.reject('%s does not match quality requirement %s' % (entry['quality'], reqs))
File "c:\users\andy\appdata\local\programs\python\python35-32\lib\site-packages\flexget\entry.py", line 152, in reject
self.run_hooks('reject', reason=reason, **kwargs)
File "c:\users\andy\appdata\local\programs\python\python35-32\lib\site-packages\flexget\entry.py", line 80, in run_hooks
func(self, **kwargs)
File "c:\users\andy\appdata\local\programs\python\python35-32\lib\site-packages\flexget\plugins\operate\verbose.py", line 34, in verbose_details
task_log.verbose(msg)
File "c:\users\andy\appdata\local\programs\python\python35-32\lib\site-packages\flexget\logger.py", line 127, in verbose
self.log(VERBOSE, msg, *args, **kwargs)
```
</issue>
<code>
[start of flexget/logger.py]
1 from __future__ import unicode_literals, division, absolute_import, print_function
2 from builtins import * # noqa pylint: disable=unused-import, redefined-builtin
3
4 import collections
5 import contextlib
6 import logging
7 import logging.handlers
8 import sys
9 import threading
10 import uuid
11 import warnings
12
13 from flexget import __version__
14
15 # A level more detailed than DEBUG
16 TRACE = 5
17 # A level more detailed than INFO
18 VERBOSE = 15
19
20 # Stores `task`, logging `session_id`, and redirected `output` stream in a thread local context
21 local_context = threading.local()
22
23
24 def get_level_no(level):
25 if not isinstance(level, int):
26 # Cannot use getLevelName here as in 3.4.0 it returns a string.
27 level = level.upper()
28 if level == 'TRACE':
29 level = TRACE
30 elif level == 'VERBOSE':
31 level = VERBOSE
32 else:
33 level = getattr(logging, level)
34
35 return level
36
37
38 @contextlib.contextmanager
39 def task_logging(task):
40 """Context manager which adds task information to log messages."""
41 old_task = getattr(local_context, 'task', '')
42 local_context.task = task
43 try:
44 yield
45 finally:
46 local_context.task = old_task
47
48
49 class SessionFilter(logging.Filter):
50 def __init__(self, session_id):
51 self.session_id = session_id
52
53 def filter(self, record):
54 return getattr(record, 'session_id', None) == self.session_id
55
56
57 @contextlib.contextmanager
58 def capture_output(stream, loglevel=None):
59 """Context manager which captures all log and console output to given `stream` while in scope."""
60 root_logger = logging.getLogger()
61 old_level = root_logger.getEffectiveLevel()
62 old_id = getattr(local_context, 'session_id', None)
63 # Keep using current, or create one if none already set
64 local_context.session_id = old_id or uuid.uuid4()
65 old_output = getattr(local_context, 'output', None)
66 old_loglevel = getattr(local_context, 'loglevel', None)
67 streamhandler = logging.StreamHandler(stream)
68 streamhandler.setFormatter(FlexGetFormatter())
69 streamhandler.addFilter(SessionFilter(local_context.session_id))
70 if loglevel is not None:
71 loglevel = get_level_no(loglevel)
72 streamhandler.setLevel(loglevel)
73 # If requested loglevel is lower than the root logger is filtering for, we need to turn it down.
74 # All existing handlers should have their desired level set and not be affected.
75 if not root_logger.isEnabledFor(loglevel):
76 root_logger.setLevel(loglevel)
77 local_context.output = stream
78 local_context.loglevel = loglevel
79 root_logger.addHandler(streamhandler)
80 try:
81 yield
82 finally:
83 root_logger.removeHandler(streamhandler)
84 root_logger.setLevel(old_level)
85 local_context.session_id = old_id
86 local_context.output = old_output
87 local_context.loglevel = old_loglevel
88
89
90 def get_capture_stream():
91 """If output is currently being redirected to a stream, returns that stream."""
92 return getattr(local_context, 'output', None)
93
94
95 def get_capture_loglevel():
96 """If output is currently being redirected to a stream, returns declared loglevel for that stream."""
97 return getattr(local_context, 'loglevel', None)
98
99
100 class RollingBuffer(collections.deque):
101 """File-like that keeps a certain number of lines of text in memory."""
102
103 def write(self, line):
104 self.append(line)
105
106
107 class FlexGetLogger(logging.Logger):
108 """Custom logger that adds trace and verbose logging methods, and contextual information to log records."""
109
110 def makeRecord(self, name, level, fn, lno, msg, args, exc_info, func, extra, *exargs):
111 extra = extra or {}
112 extra.update(
113 task=getattr(local_context, 'task', ''),
114 session_id=getattr(local_context, 'session_id', ''))
115 # Replace newlines in log messages with \n
116 if isinstance(msg, str):
117 msg = msg.replace('\n', '\\n')
118
119 return logging.Logger.makeRecord(self, name, level, fn, lno, msg, args, exc_info, func, extra, *exargs)
120
121 def trace(self, msg, *args, **kwargs):
122 """Log at TRACE level (more detailed than DEBUG)."""
123 self.log(TRACE, msg, *args, **kwargs)
124
125 def verbose(self, msg, *args, **kwargs):
126 """Log at VERBOSE level (displayed when FlexGet is run interactively.)"""
127 self.log(VERBOSE, msg, *args, **kwargs)
128
129
130 class FlexGetFormatter(logging.Formatter):
131 """Custom formatter that can handle both regular log records and those created by FlexGetLogger"""
132 flexget_fmt = '%(asctime)-15s %(levelname)-8s %(name)-13s %(task)-15s %(message)s'
133
134 def __init__(self):
135 logging.Formatter.__init__(self, self.flexget_fmt, '%Y-%m-%d %H:%M')
136
137 def format(self, record):
138 if not hasattr(record, 'task'):
139 record.task = ''
140 return logging.Formatter.format(self, record)
141
142
143 _logging_configured = False
144 _buff_handler = None
145 _logging_started = False
146 # Stores the last 50 debug messages
147 debug_buffer = RollingBuffer(maxlen=50)
148
149
150 def initialize(unit_test=False):
151 """Prepare logging.
152 """
153 global _logging_configured, _logging_started, _buff_handler
154
155 if _logging_configured:
156 return
157
158 if 'dev' in __version__:
159 warnings.filterwarnings('always', category=DeprecationWarning, module='flexget.*')
160 warnings.simplefilter('once', append=True)
161 logging.addLevelName(TRACE, 'TRACE')
162 logging.addLevelName(VERBOSE, 'VERBOSE')
163 _logging_configured = True
164
165 # with unit test we want pytest to add the handlers
166 if unit_test:
167 _logging_started = True
168 return
169
170 # Store any log messages in a buffer until we `start` function is run
171 logger = logging.getLogger()
172 _buff_handler = logging.handlers.BufferingHandler(1000 * 1000)
173 logger.addHandler(_buff_handler)
174 logger.setLevel(logging.NOTSET)
175
176 # Add a handler that sores the last 50 debug lines to `debug_buffer` for use in crash reports
177 crash_handler = logging.StreamHandler(debug_buffer)
178 crash_handler.setLevel(logging.DEBUG)
179 crash_handler.setFormatter(FlexGetFormatter())
180 logger.addHandler(crash_handler)
181
182
183 def start(filename=None, level=logging.INFO, to_console=True, to_file=True):
184 """After initialization, start file logging.
185 """
186 global _logging_started
187
188 assert _logging_configured
189 if _logging_started:
190 return
191
192 # root logger
193 logger = logging.getLogger()
194 level = get_level_no(level)
195 logger.setLevel(level)
196
197 formatter = FlexGetFormatter()
198 if to_file:
199 file_handler = logging.handlers.RotatingFileHandler(filename, maxBytes=1000 * 1024, backupCount=9)
200 file_handler.setFormatter(formatter)
201 file_handler.setLevel(level)
202 logger.addHandler(file_handler)
203
204 # without --cron we log to console
205 if to_console:
206 console_handler = logging.StreamHandler(sys.stdout)
207 console_handler.setFormatter(formatter)
208 console_handler.setLevel(level)
209 logger.addHandler(console_handler)
210
211 # flush what we have stored from the plugin initialization
212 logger.removeHandler(_buff_handler)
213 if _buff_handler:
214 for record in _buff_handler.buffer:
215 if logger.isEnabledFor(record.levelno):
216 logger.handle(record)
217 _buff_handler.flush()
218 _logging_started = True
219
220
221 # Set our custom logger class as default
222 logging.setLoggerClass(FlexGetLogger)
223
[end of flexget/logger.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/flexget/logger.py b/flexget/logger.py
--- a/flexget/logger.py
+++ b/flexget/logger.py
@@ -1,6 +1,7 @@
from __future__ import unicode_literals, division, absolute_import, print_function
from builtins import * # noqa pylint: disable=unused-import, redefined-builtin
+import codecs
import collections
import contextlib
import logging
@@ -11,6 +12,7 @@
import warnings
from flexget import __version__
+from flexget.utils.tools import io_encoding
# A level more detailed than DEBUG
TRACE = 5
@@ -203,7 +205,13 @@
# without --cron we log to console
if to_console:
- console_handler = logging.StreamHandler(sys.stdout)
+ # Make sure we don't send any characters that the current terminal doesn't support printing
+ stdout = sys.stdout
+ if hasattr(stdout, 'buffer'):
+ # On python 3, we need to get the buffer directly to support writing bytes
+ stdout = stdout.buffer
+ safe_stdout = codecs.getwriter(io_encoding)(stdout, 'replace')
+ console_handler = logging.StreamHandler(safe_stdout)
console_handler.setFormatter(formatter)
console_handler.setLevel(level)
logger.addHandler(console_handler)
|
{"golden_diff": "diff --git a/flexget/logger.py b/flexget/logger.py\n--- a/flexget/logger.py\n+++ b/flexget/logger.py\n@@ -1,6 +1,7 @@\n from __future__ import unicode_literals, division, absolute_import, print_function\n from builtins import * # noqa pylint: disable=unused-import, redefined-builtin\n \n+import codecs\n import collections\n import contextlib\n import logging\n@@ -11,6 +12,7 @@\n import warnings\n \n from flexget import __version__\n+from flexget.utils.tools import io_encoding\n \n # A level more detailed than DEBUG\n TRACE = 5\n@@ -203,7 +205,13 @@\n \n # without --cron we log to console\n if to_console:\n- console_handler = logging.StreamHandler(sys.stdout)\n+ # Make sure we don't send any characters that the current terminal doesn't support printing\n+ stdout = sys.stdout\n+ if hasattr(stdout, 'buffer'):\n+ # On python 3, we need to get the buffer directly to support writing bytes\n+ stdout = stdout.buffer\n+ safe_stdout = codecs.getwriter(io_encoding)(stdout, 'replace')\n+ console_handler = logging.StreamHandler(safe_stdout)\n console_handler.setFormatter(formatter)\n console_handler.setLevel(level)\n logger.addHandler(console_handler)\n", "issue": "logging crash\nJust got this error for some log output, its nothing serious, but just wanted to report it.\r\n\r\nPython 3.5.2 + Flexget 2.8.1\r\n```\r\n--- Logging error ---\r\nTraceback (most recent call last):\r\n File \"c:\\users\\andy\\appdata\\local\\programs\\python\\python35-32\\lib\\logging\\__init__.py\", line 982, in emit\r\n stream.write(msg)\r\n File \"c:\\users\\andy\\appdata\\local\\programs\\python\\python35-32\\lib\\site-packages\\colorclass\\windows.py\", line 275, in write\r\n print(segment, file=self._original_stream, end='')\r\n File \"c:\\users\\andy\\appdata\\local\\programs\\python\\python35-32\\lib\\encodings\\cp850.py\", line 19, in encode\r\n return codecs.charmap_encode(input,self.errors,encoding_map)[0]\r\nUnicodeEncodeError: 'charmap' codec can't encode character '\\u2022' in position 67: character maps to <undefined>\r\nCall stack:\r\n File \"c:\\users\\andy\\appdata\\local\\programs\\python\\python35-32\\lib\\threading.py\", line 882, in _bootstrap\r\n self._bootstrap_inner()\r\n File \"c:\\users\\andy\\appdata\\local\\programs\\python\\python35-32\\lib\\threading.py\", line 914, in _bootstrap_inner\r\n self.run()\r\n File \"c:\\users\\andy\\appdata\\local\\programs\\python\\python35-32\\lib\\threading.py\", line 862, in run\r\n self._target(*self._args, **self._kwargs)\r\n File \"c:\\users\\andy\\appdata\\local\\programs\\python\\python35-32\\lib\\site-packages\\flexget\\task_queue.py\", line 48, in run\r\n self.current_task.execute()\r\n File \"c:\\users\\andy\\appdata\\local\\programs\\python\\python35-32\\lib\\site-packages\\flexget\\task.py\", line 72, in wrapper\r\n return func(self, *args, **kw)\r\n File \"c:\\users\\andy\\appdata\\local\\programs\\python\\python35-32\\lib\\site-packages\\flexget\\task.py\", line 646, in execute\r\n self._execute()\r\n File \"c:\\users\\andy\\appdata\\local\\programs\\python\\python35-32\\lib\\site-packages\\flexget\\task.py\", line 612, in _execute\r\n self.__run_task_phase(phase)\r\n File \"c:\\users\\andy\\appdata\\local\\programs\\python\\python35-32\\lib\\site-packages\\flexget\\task.py\", line 453, in __run_task_phase\r\n response = self.__run_plugin(plugin, phase, args)\r\n File \"c:\\users\\andy\\appdata\\local\\programs\\python\\python35-32\\lib\\site-packages\\flexget\\task.py\", line 483, in __run_plugin\r\n return method(*args, **kwargs)\r\n File \"c:\\users\\andy\\appdata\\local\\programs\\python\\python35-32\\lib\\site-packages\\flexget\\event.py\", line 23, in __call__\r\n return self.func(*args, **kwargs)\r\n File \"c:\\users\\andy\\appdata\\local\\programs\\python\\python35-32\\lib\\site-packages\\flexget\\plugins\\filter\\quality.py\", line 37, in on_task_filter\r\n entry.reject('%s does not match quality requirement %s' % (entry['quality'], reqs))\r\n File \"c:\\users\\andy\\appdata\\local\\programs\\python\\python35-32\\lib\\site-packages\\flexget\\entry.py\", line 152, in reject\r\n self.run_hooks('reject', reason=reason, **kwargs)\r\n File \"c:\\users\\andy\\appdata\\local\\programs\\python\\python35-32\\lib\\site-packages\\flexget\\entry.py\", line 80, in run_hooks\r\n func(self, **kwargs)\r\n File \"c:\\users\\andy\\appdata\\local\\programs\\python\\python35-32\\lib\\site-packages\\flexget\\plugins\\operate\\verbose.py\", line 34, in verbose_details\r\n task_log.verbose(msg)\r\n File \"c:\\users\\andy\\appdata\\local\\programs\\python\\python35-32\\lib\\site-packages\\flexget\\logger.py\", line 127, in verbose\r\n self.log(VERBOSE, msg, *args, **kwargs)\r\n```\n", "before_files": [{"content": "from __future__ import unicode_literals, division, absolute_import, print_function\nfrom builtins import * # noqa pylint: disable=unused-import, redefined-builtin\n\nimport collections\nimport contextlib\nimport logging\nimport logging.handlers\nimport sys\nimport threading\nimport uuid\nimport warnings\n\nfrom flexget import __version__\n\n# A level more detailed than DEBUG\nTRACE = 5\n# A level more detailed than INFO\nVERBOSE = 15\n\n# Stores `task`, logging `session_id`, and redirected `output` stream in a thread local context\nlocal_context = threading.local()\n\n\ndef get_level_no(level):\n if not isinstance(level, int):\n # Cannot use getLevelName here as in 3.4.0 it returns a string.\n level = level.upper()\n if level == 'TRACE':\n level = TRACE\n elif level == 'VERBOSE':\n level = VERBOSE\n else:\n level = getattr(logging, level)\n\n return level\n\n\[email protected]\ndef task_logging(task):\n \"\"\"Context manager which adds task information to log messages.\"\"\"\n old_task = getattr(local_context, 'task', '')\n local_context.task = task\n try:\n yield\n finally:\n local_context.task = old_task\n\n\nclass SessionFilter(logging.Filter):\n def __init__(self, session_id):\n self.session_id = session_id\n\n def filter(self, record):\n return getattr(record, 'session_id', None) == self.session_id\n\n\[email protected]\ndef capture_output(stream, loglevel=None):\n \"\"\"Context manager which captures all log and console output to given `stream` while in scope.\"\"\"\n root_logger = logging.getLogger()\n old_level = root_logger.getEffectiveLevel()\n old_id = getattr(local_context, 'session_id', None)\n # Keep using current, or create one if none already set\n local_context.session_id = old_id or uuid.uuid4()\n old_output = getattr(local_context, 'output', None)\n old_loglevel = getattr(local_context, 'loglevel', None)\n streamhandler = logging.StreamHandler(stream)\n streamhandler.setFormatter(FlexGetFormatter())\n streamhandler.addFilter(SessionFilter(local_context.session_id))\n if loglevel is not None:\n loglevel = get_level_no(loglevel)\n streamhandler.setLevel(loglevel)\n # If requested loglevel is lower than the root logger is filtering for, we need to turn it down.\n # All existing handlers should have their desired level set and not be affected.\n if not root_logger.isEnabledFor(loglevel):\n root_logger.setLevel(loglevel)\n local_context.output = stream\n local_context.loglevel = loglevel\n root_logger.addHandler(streamhandler)\n try:\n yield\n finally:\n root_logger.removeHandler(streamhandler)\n root_logger.setLevel(old_level)\n local_context.session_id = old_id\n local_context.output = old_output\n local_context.loglevel = old_loglevel\n\n\ndef get_capture_stream():\n \"\"\"If output is currently being redirected to a stream, returns that stream.\"\"\"\n return getattr(local_context, 'output', None)\n\n\ndef get_capture_loglevel():\n \"\"\"If output is currently being redirected to a stream, returns declared loglevel for that stream.\"\"\"\n return getattr(local_context, 'loglevel', None)\n\n\nclass RollingBuffer(collections.deque):\n \"\"\"File-like that keeps a certain number of lines of text in memory.\"\"\"\n\n def write(self, line):\n self.append(line)\n\n\nclass FlexGetLogger(logging.Logger):\n \"\"\"Custom logger that adds trace and verbose logging methods, and contextual information to log records.\"\"\"\n\n def makeRecord(self, name, level, fn, lno, msg, args, exc_info, func, extra, *exargs):\n extra = extra or {}\n extra.update(\n task=getattr(local_context, 'task', ''),\n session_id=getattr(local_context, 'session_id', ''))\n # Replace newlines in log messages with \\n\n if isinstance(msg, str):\n msg = msg.replace('\\n', '\\\\n')\n\n return logging.Logger.makeRecord(self, name, level, fn, lno, msg, args, exc_info, func, extra, *exargs)\n\n def trace(self, msg, *args, **kwargs):\n \"\"\"Log at TRACE level (more detailed than DEBUG).\"\"\"\n self.log(TRACE, msg, *args, **kwargs)\n\n def verbose(self, msg, *args, **kwargs):\n \"\"\"Log at VERBOSE level (displayed when FlexGet is run interactively.)\"\"\"\n self.log(VERBOSE, msg, *args, **kwargs)\n\n\nclass FlexGetFormatter(logging.Formatter):\n \"\"\"Custom formatter that can handle both regular log records and those created by FlexGetLogger\"\"\"\n flexget_fmt = '%(asctime)-15s %(levelname)-8s %(name)-13s %(task)-15s %(message)s'\n\n def __init__(self):\n logging.Formatter.__init__(self, self.flexget_fmt, '%Y-%m-%d %H:%M')\n\n def format(self, record):\n if not hasattr(record, 'task'):\n record.task = ''\n return logging.Formatter.format(self, record)\n\n\n_logging_configured = False\n_buff_handler = None\n_logging_started = False\n# Stores the last 50 debug messages\ndebug_buffer = RollingBuffer(maxlen=50)\n\n\ndef initialize(unit_test=False):\n \"\"\"Prepare logging.\n \"\"\"\n global _logging_configured, _logging_started, _buff_handler\n\n if _logging_configured:\n return\n\n if 'dev' in __version__:\n warnings.filterwarnings('always', category=DeprecationWarning, module='flexget.*')\n warnings.simplefilter('once', append=True)\n logging.addLevelName(TRACE, 'TRACE')\n logging.addLevelName(VERBOSE, 'VERBOSE')\n _logging_configured = True\n\n # with unit test we want pytest to add the handlers\n if unit_test:\n _logging_started = True\n return\n\n # Store any log messages in a buffer until we `start` function is run\n logger = logging.getLogger()\n _buff_handler = logging.handlers.BufferingHandler(1000 * 1000)\n logger.addHandler(_buff_handler)\n logger.setLevel(logging.NOTSET)\n\n # Add a handler that sores the last 50 debug lines to `debug_buffer` for use in crash reports\n crash_handler = logging.StreamHandler(debug_buffer)\n crash_handler.setLevel(logging.DEBUG)\n crash_handler.setFormatter(FlexGetFormatter())\n logger.addHandler(crash_handler)\n\n\ndef start(filename=None, level=logging.INFO, to_console=True, to_file=True):\n \"\"\"After initialization, start file logging.\n \"\"\"\n global _logging_started\n\n assert _logging_configured\n if _logging_started:\n return\n\n # root logger\n logger = logging.getLogger()\n level = get_level_no(level)\n logger.setLevel(level)\n\n formatter = FlexGetFormatter()\n if to_file:\n file_handler = logging.handlers.RotatingFileHandler(filename, maxBytes=1000 * 1024, backupCount=9)\n file_handler.setFormatter(formatter)\n file_handler.setLevel(level)\n logger.addHandler(file_handler)\n\n # without --cron we log to console\n if to_console:\n console_handler = logging.StreamHandler(sys.stdout)\n console_handler.setFormatter(formatter)\n console_handler.setLevel(level)\n logger.addHandler(console_handler)\n\n # flush what we have stored from the plugin initialization\n logger.removeHandler(_buff_handler)\n if _buff_handler:\n for record in _buff_handler.buffer:\n if logger.isEnabledFor(record.levelno):\n logger.handle(record)\n _buff_handler.flush()\n _logging_started = True\n\n\n# Set our custom logger class as default\nlogging.setLoggerClass(FlexGetLogger)\n", "path": "flexget/logger.py"}]}
| 3,864 | 289 |
gh_patches_debug_8070
|
rasdani/github-patches
|
git_diff
|
mindsdb__mindsdb-130
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Cleanup before releasing v.1.0
* Remove any unused files
* Remove any unused variable and functions (loads of those in config I'd think)
* Remove any unused requirements
* Update the version for requirements
* Update and standardize the interface of older functions and add comments to them (probably won't have time for all, but at least some)
</issue>
<code>
[start of setup.py]
1 import setuptools
2
3 about = {}
4 with open("mindsdb/__about__.py") as fp:
5 exec(fp.read(), about)
6
7 long_description = open('README.md', encoding='utf-8').read()
8
9 with open('requirements.txt') as req_file:
10 requirements = req_file.read().splitlines()
11
12 setuptools.setup(
13 name=about['__title__'],
14 version=about['__version__'],
15 url=about['__github__'],
16 download_url=about['__pypi__'],
17 license=about['__license__'],
18 author=about['__author__'],
19 author_email=about['__email__'],
20 description=about['__description__'],
21 long_description=long_description,
22 long_description_content_type="text/markdown",
23 packages=setuptools.find_packages(),
24 install_requires=requirements,
25 classifiers=(
26 "Programming Language :: Python :: 3",
27 "License :: OSI Approved :: MIT License",
28 "Operating System :: OS Independent",
29 ),
30 python_requires=">=3.3"
31 )
32
[end of setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -1,4 +1,5 @@
import setuptools
+import subprocess
about = {}
with open("mindsdb/__about__.py") as fp:
@@ -27,5 +28,10 @@
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
),
- python_requires=">=3.3"
+ python_requires=">=3.6"
)
+
+try:
+ subprocess.call(['python3','-m','spacy','download','en'])
+except:
+ subprocess.call(['python','-m','spacy','download','en'])
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -1,4 +1,5 @@\n import setuptools\n+import subprocess\n \n about = {}\n with open(\"mindsdb/__about__.py\") as fp:\n@@ -27,5 +28,10 @@\n \"License :: OSI Approved :: MIT License\",\n \"Operating System :: OS Independent\",\n ),\n- python_requires=\">=3.3\"\n+ python_requires=\">=3.6\"\n )\n+\n+try:\n+ subprocess.call(['python3','-m','spacy','download','en'])\n+except:\n+ subprocess.call(['python','-m','spacy','download','en'])\n", "issue": "Cleanup before releasing v.1.0\n* Remove any unused files\r\n* Remove any unused variable and functions (loads of those in config I'd think)\r\n* Remove any unused requirements\r\n* Update the version for requirements\r\n* Update and standardize the interface of older functions and add comments to them (probably won't have time for all, but at least some)\n", "before_files": [{"content": "import setuptools\n\nabout = {}\nwith open(\"mindsdb/__about__.py\") as fp:\n exec(fp.read(), about)\n\nlong_description = open('README.md', encoding='utf-8').read()\n\nwith open('requirements.txt') as req_file:\n requirements = req_file.read().splitlines()\n\nsetuptools.setup(\n name=about['__title__'],\n version=about['__version__'],\n url=about['__github__'],\n download_url=about['__pypi__'],\n license=about['__license__'],\n author=about['__author__'],\n author_email=about['__email__'],\n description=about['__description__'],\n long_description=long_description,\n long_description_content_type=\"text/markdown\",\n packages=setuptools.find_packages(),\n install_requires=requirements,\n classifiers=(\n \"Programming Language :: Python :: 3\",\n \"License :: OSI Approved :: MIT License\",\n \"Operating System :: OS Independent\",\n ),\n python_requires=\">=3.3\"\n)\n", "path": "setup.py"}]}
| 868 | 148 |
gh_patches_debug_33937
|
rasdani/github-patches
|
git_diff
|
saleor__saleor-999
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Exception Type: AttributeError when trying to create a password after succeful payment
Got this exception:
`Exception Type: AttributeError at /order/5d555f01-0f99-4821-b52f-98fa48efce4b/create-password/
Exception Value: 'NoneType' object has no attribute 'addresses'`
</issue>
<code>
[start of saleor/registration/views.py]
1 from django.conf import settings
2 from django.contrib import messages, auth
3 from django.contrib.auth import views as django_views
4 from django.contrib.auth.decorators import login_required
5 from django.shortcuts import redirect
6 from django.utils.translation import ugettext_lazy as _
7 from django.template.response import TemplateResponse
8
9 from saleor.cart.utils import find_and_assign_anonymous_cart
10 from .forms import LoginForm, SignupForm, SetPasswordForm
11
12
13 @find_and_assign_anonymous_cart()
14 def login(request):
15 kwargs = {
16 'template_name': 'account/login.html', 'authentication_form': LoginForm}
17 return django_views.login(request, **kwargs)
18
19
20 @login_required
21 def logout(request):
22 auth.logout(request)
23 messages.success(request, _('You have been successfully logged out.'))
24 return redirect(settings.LOGIN_REDIRECT_URL)
25
26
27 def signup(request):
28 form = SignupForm(request.POST or None)
29 if form.is_valid():
30 form.save(request=request)
31 messages.success(request, _('User has been created'))
32 return redirect(settings.LOGIN_REDIRECT_URL)
33 ctx = {'form': form}
34 return TemplateResponse(request, 'account/signup.html', ctx)
35
36
37 def password_reset(request):
38 template_name = 'account/password_reset.html'
39 post_reset_redirect = 'account_reset_password_done'
40 email_template_name = 'account/email/password_reset_message.txt'
41 subject_template_name = 'account/email/password_reset_subject.txt'
42 return django_views.password_reset(
43 request, template_name=template_name,
44 post_reset_redirect=post_reset_redirect,
45 email_template_name=email_template_name,
46 subject_template_name=subject_template_name)
47
48
49 def password_reset_confirm(request, uidb64=None, token=None):
50 template_name = 'account/password_reset_from_key.html'
51 post_reset_redirect = 'account_reset_password_complete'
52 set_password_form = SetPasswordForm
53 return django_views.password_reset_confirm(
54 request, uidb64=uidb64, token=token, template_name=template_name,
55 post_reset_redirect=post_reset_redirect,
56 set_password_form=set_password_form)
57
[end of saleor/registration/views.py]
[start of saleor/order/views.py]
1 import logging
2
3 from django.conf import settings
4 from django.contrib import messages, auth
5 from django.contrib.auth.decorators import login_required
6 from django.db import transaction
7 from django.http import Http404, HttpResponseForbidden
8 from django.shortcuts import get_object_or_404, redirect
9 from django.template.response import TemplateResponse
10 from django.utils.translation import pgettext_lazy
11 from payments import PaymentStatus, RedirectNeeded
12
13 from .forms import PaymentDeleteForm, PaymentMethodsForm, PasswordForm
14 from .models import Order, Payment
15 from .utils import check_order_status, attach_order_to_user
16 from ..core.utils import get_client_ip
17 from ..registration.forms import LoginForm
18 from ..userprofile.models import User
19 from . import OrderStatus
20
21 logger = logging.getLogger(__name__)
22
23
24 def details(request, token):
25 orders = Order.objects.prefetch_related('groups__items',
26 'groups__items__product')
27 orders = orders.select_related('billing_address', 'shipping_address',
28 'user')
29 order = get_object_or_404(orders, token=token)
30 groups = order.groups.all()
31 return TemplateResponse(request, 'order/details.html',
32 {'order': order, 'groups': groups})
33
34
35 def payment(request, token):
36 orders = Order.objects.prefetch_related('groups__items__product')
37 orders = orders.select_related('billing_address', 'shipping_address',
38 'user')
39 order = get_object_or_404(orders, token=token)
40 groups = order.groups.all()
41 payments = order.payments.all()
42 form_data = request.POST or None
43 try:
44 waiting_payment = order.payments.get(status=PaymentStatus.WAITING)
45 except Payment.DoesNotExist:
46 waiting_payment = None
47 waiting_payment_form = None
48 else:
49 form_data = None
50 waiting_payment_form = PaymentDeleteForm(
51 None, order=order, initial={'payment_id': waiting_payment.id})
52 if order.is_fully_paid():
53 form_data = None
54 payment_form = None
55 if not order.is_pre_authorized():
56 payment_form = PaymentMethodsForm(form_data)
57 # FIXME: redirect if there is only one payment method
58 if payment_form.is_valid():
59 payment_method = payment_form.cleaned_data['method']
60 return redirect('order:payment', token=order.token,
61 variant=payment_method)
62 return TemplateResponse(request, 'order/payment.html',
63 {'order': order, 'groups': groups,
64 'payment_form': payment_form,
65 'waiting_payment': waiting_payment,
66 'waiting_payment_form': waiting_payment_form,
67 'payments': payments})
68
69
70 @check_order_status
71 def start_payment(request, order, variant):
72 waiting_payments = order.payments.filter(status=PaymentStatus.WAITING).exists()
73 if waiting_payments:
74 return redirect('order:payment', token=order.token)
75 billing = order.billing_address
76 total = order.get_total()
77 defaults = {'total': total.gross,
78 'tax': total.tax, 'currency': total.currency,
79 'delivery': order.get_delivery_total().gross,
80 'billing_first_name': billing.first_name,
81 'billing_last_name': billing.last_name,
82 'billing_address_1': billing.street_address_1,
83 'billing_address_2': billing.street_address_2,
84 'billing_city': billing.city,
85 'billing_postcode': billing.postal_code,
86 'billing_country_code': billing.country.code,
87 'billing_email': order.user_email,
88 'description': pgettext_lazy(
89 'Payment description', 'Order %(order_number)s') % {
90 'order_number': order},
91 'billing_country_area': billing.country_area,
92 'customer_ip_address': get_client_ip(request)}
93 variant_choices = settings.CHECKOUT_PAYMENT_CHOICES
94 if variant not in [code for code, dummy_name in variant_choices]:
95 raise Http404('%r is not a valid payment variant' % (variant,))
96 with transaction.atomic():
97 order.change_status(OrderStatus.PAYMENT_PENDING)
98 payment, dummy_created = Payment.objects.get_or_create(
99 variant=variant, status=PaymentStatus.WAITING, order=order,
100 defaults=defaults)
101 try:
102 form = payment.get_form(data=request.POST or None)
103 except RedirectNeeded as redirect_to:
104 return redirect(str(redirect_to))
105 except Exception:
106 logger.exception('Error communicating with the payment gateway')
107 messages.error(
108 request,
109 pgettext_lazy(
110 'Payment gateway error',
111 'Oops, it looks like we were unable to contact the selected'
112 ' payment service'))
113 payment.change_status(PaymentStatus.ERROR)
114 return redirect('order:payment', token=order.token)
115 template = 'order/payment/%s.html' % variant
116 return TemplateResponse(request, [template, 'order/payment/default.html'],
117 {'form': form, 'payment': payment})
118
119
120 @check_order_status
121 def cancel_payment(request, order):
122 form = PaymentDeleteForm(request.POST or None, order=order)
123 if form.is_valid():
124 with transaction.atomic():
125 form.save()
126 return redirect('order:payment', token=order.token)
127 return HttpResponseForbidden()
128
129
130 def create_password(request, token):
131 if request.user.is_authenticated():
132 return redirect('order:details', token=token)
133 order = get_object_or_404(Order, token=token)
134 email = order.user_email
135 form_data = request.POST.copy()
136 if form_data:
137 form_data.update({'email': email})
138 register_form = PasswordForm(form_data or None)
139 if User.objects.filter(email=email).exists():
140 login_form = LoginForm(initial={'login': email})
141 else:
142 login_form = None
143 if register_form.is_valid():
144 register_form.save(request)
145 password = form_data.get('password1')
146 auth_user = auth.authenticate(email=email, password=password)
147 if auth_user is not None:
148 auth.login(request, auth_user)
149 attach_order_to_user(order, auth_user)
150 return redirect('order:details', token=token)
151 ctx = {'form': register_form, 'email': email, 'order': order,
152 'login_form': login_form}
153 return TemplateResponse(request, 'order/create_password.html', ctx)
154
155
156 @login_required
157 def connect_order_with_user(request, token):
158 order = get_object_or_404(
159 Order.objects.filter(user_email=request.user.email, token=token))
160 attach_order_to_user(order, request.user)
161 messages.success(
162 request, pgettext_lazy(
163 'storefront message',
164 'You\'ve successfully connected order with your account'))
165 return redirect('order:details', token=order.token)
166
[end of saleor/order/views.py]
[start of saleor/registration/forms.py]
1 from django import forms
2 from django.contrib.auth import login, authenticate
3 from django.contrib.auth import forms as django_forms
4 from django.utils.translation import pgettext
5
6 from saleor.userprofile.models import User
7
8
9 class LoginForm(django_forms.AuthenticationForm):
10 username = forms.EmailField(
11 label=pgettext('Form field', 'Email'), max_length=75)
12
13 def __init__(self, request=None, *args, **kwargs):
14 super(LoginForm, self).__init__(request=request, *args, **kwargs)
15 if request:
16 email = request.GET.get('email')
17 if email:
18 self.fields['username'].initial = email
19
20
21 class SignupForm(forms.ModelForm):
22 password = forms.CharField(
23 label=pgettext('User form field', 'Password'),
24 widget=forms.PasswordInput)
25
26 class Meta:
27 model = User
28 fields = ('email',)
29
30 def __init__(self, *args, **kwargs):
31 super(SignupForm, self).__init__(*args, **kwargs)
32 if self._meta.model.USERNAME_FIELD in self.fields:
33 self.fields[self._meta.model.USERNAME_FIELD].widget.attrs.update(
34 {'autofocus': ''})
35
36 def save(self, request=None, commit=True):
37 user = super(SignupForm, self).save(commit=False)
38 password = self.cleaned_data['password']
39 user.set_password(password)
40 if commit:
41 user.save()
42 if request:
43 email = self.cleaned_data['email']
44 user = authenticate(username=email, password=password)
45 login(request, user)
46 return user
47
48
49 class SetPasswordForm(django_forms.SetPasswordForm):
50 def __init__(self, *args, **kwargs):
51 super(SetPasswordForm, self).__init__(*args, **kwargs)
52 del self.fields['new_password2']
53
[end of saleor/registration/forms.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/saleor/order/views.py b/saleor/order/views.py
--- a/saleor/order/views.py
+++ b/saleor/order/views.py
@@ -141,12 +141,11 @@
else:
login_form = None
if register_form.is_valid():
- register_form.save(request)
- password = form_data.get('password1')
- auth_user = auth.authenticate(email=email, password=password)
- if auth_user is not None:
- auth.login(request, auth_user)
- attach_order_to_user(order, auth_user)
+ register_form.save()
+ password = register_form.cleaned_data.get('password')
+ user = auth.authenticate(email=email, password=password)
+ auth.login(request, user)
+ attach_order_to_user(order, user)
return redirect('order:details', token=token)
ctx = {'form': register_form, 'email': email, 'order': order,
'login_form': login_form}
diff --git a/saleor/registration/forms.py b/saleor/registration/forms.py
--- a/saleor/registration/forms.py
+++ b/saleor/registration/forms.py
@@ -1,5 +1,4 @@
from django import forms
-from django.contrib.auth import login, authenticate
from django.contrib.auth import forms as django_forms
from django.utils.translation import pgettext
@@ -39,10 +38,6 @@
user.set_password(password)
if commit:
user.save()
- if request:
- email = self.cleaned_data['email']
- user = authenticate(username=email, password=password)
- login(request, user)
return user
diff --git a/saleor/registration/views.py b/saleor/registration/views.py
--- a/saleor/registration/views.py
+++ b/saleor/registration/views.py
@@ -27,7 +27,12 @@
def signup(request):
form = SignupForm(request.POST or None)
if form.is_valid():
- form.save(request=request)
+ form.save()
+ password = form.cleaned_data.get('password')
+ email = form.cleaned_data.get('email')
+ user = auth.authenticate(email=email, password=password)
+ if user:
+ auth.login(request, user)
messages.success(request, _('User has been created'))
return redirect(settings.LOGIN_REDIRECT_URL)
ctx = {'form': form}
|
{"golden_diff": "diff --git a/saleor/order/views.py b/saleor/order/views.py\n--- a/saleor/order/views.py\n+++ b/saleor/order/views.py\n@@ -141,12 +141,11 @@\n else:\n login_form = None\n if register_form.is_valid():\n- register_form.save(request)\n- password = form_data.get('password1')\n- auth_user = auth.authenticate(email=email, password=password)\n- if auth_user is not None:\n- auth.login(request, auth_user)\n- attach_order_to_user(order, auth_user)\n+ register_form.save()\n+ password = register_form.cleaned_data.get('password')\n+ user = auth.authenticate(email=email, password=password)\n+ auth.login(request, user)\n+ attach_order_to_user(order, user)\n return redirect('order:details', token=token)\n ctx = {'form': register_form, 'email': email, 'order': order,\n 'login_form': login_form}\ndiff --git a/saleor/registration/forms.py b/saleor/registration/forms.py\n--- a/saleor/registration/forms.py\n+++ b/saleor/registration/forms.py\n@@ -1,5 +1,4 @@\n from django import forms\n-from django.contrib.auth import login, authenticate\n from django.contrib.auth import forms as django_forms\n from django.utils.translation import pgettext\n \n@@ -39,10 +38,6 @@\n user.set_password(password)\n if commit:\n user.save()\n- if request:\n- email = self.cleaned_data['email']\n- user = authenticate(username=email, password=password)\n- login(request, user)\n return user\n \n \ndiff --git a/saleor/registration/views.py b/saleor/registration/views.py\n--- a/saleor/registration/views.py\n+++ b/saleor/registration/views.py\n@@ -27,7 +27,12 @@\n def signup(request):\n form = SignupForm(request.POST or None)\n if form.is_valid():\n- form.save(request=request)\n+ form.save()\n+ password = form.cleaned_data.get('password')\n+ email = form.cleaned_data.get('email')\n+ user = auth.authenticate(email=email, password=password)\n+ if user:\n+ auth.login(request, user)\n messages.success(request, _('User has been created'))\n return redirect(settings.LOGIN_REDIRECT_URL)\n ctx = {'form': form}\n", "issue": "Exception Type: AttributeError when trying to create a password after succeful payment \nGot this exception:\r\n`Exception Type: AttributeError at /order/5d555f01-0f99-4821-b52f-98fa48efce4b/create-password/\r\nException Value: 'NoneType' object has no attribute 'addresses'`\r\n\r\n\n", "before_files": [{"content": "from django.conf import settings\nfrom django.contrib import messages, auth\nfrom django.contrib.auth import views as django_views\nfrom django.contrib.auth.decorators import login_required\nfrom django.shortcuts import redirect\nfrom django.utils.translation import ugettext_lazy as _\nfrom django.template.response import TemplateResponse\n\nfrom saleor.cart.utils import find_and_assign_anonymous_cart\nfrom .forms import LoginForm, SignupForm, SetPasswordForm\n\n\n@find_and_assign_anonymous_cart()\ndef login(request):\n kwargs = {\n 'template_name': 'account/login.html', 'authentication_form': LoginForm}\n return django_views.login(request, **kwargs)\n\n\n@login_required\ndef logout(request):\n auth.logout(request)\n messages.success(request, _('You have been successfully logged out.'))\n return redirect(settings.LOGIN_REDIRECT_URL)\n\n\ndef signup(request):\n form = SignupForm(request.POST or None)\n if form.is_valid():\n form.save(request=request)\n messages.success(request, _('User has been created'))\n return redirect(settings.LOGIN_REDIRECT_URL)\n ctx = {'form': form}\n return TemplateResponse(request, 'account/signup.html', ctx)\n\n\ndef password_reset(request):\n template_name = 'account/password_reset.html'\n post_reset_redirect = 'account_reset_password_done'\n email_template_name = 'account/email/password_reset_message.txt'\n subject_template_name = 'account/email/password_reset_subject.txt'\n return django_views.password_reset(\n request, template_name=template_name,\n post_reset_redirect=post_reset_redirect,\n email_template_name=email_template_name,\n subject_template_name=subject_template_name)\n\n\ndef password_reset_confirm(request, uidb64=None, token=None):\n template_name = 'account/password_reset_from_key.html'\n post_reset_redirect = 'account_reset_password_complete'\n set_password_form = SetPasswordForm\n return django_views.password_reset_confirm(\n request, uidb64=uidb64, token=token, template_name=template_name,\n post_reset_redirect=post_reset_redirect,\n set_password_form=set_password_form)\n", "path": "saleor/registration/views.py"}, {"content": "import logging\n\nfrom django.conf import settings\nfrom django.contrib import messages, auth\nfrom django.contrib.auth.decorators import login_required\nfrom django.db import transaction\nfrom django.http import Http404, HttpResponseForbidden\nfrom django.shortcuts import get_object_or_404, redirect\nfrom django.template.response import TemplateResponse\nfrom django.utils.translation import pgettext_lazy\nfrom payments import PaymentStatus, RedirectNeeded\n\nfrom .forms import PaymentDeleteForm, PaymentMethodsForm, PasswordForm\nfrom .models import Order, Payment\nfrom .utils import check_order_status, attach_order_to_user\nfrom ..core.utils import get_client_ip\nfrom ..registration.forms import LoginForm\nfrom ..userprofile.models import User\nfrom . import OrderStatus\n\nlogger = logging.getLogger(__name__)\n\n\ndef details(request, token):\n orders = Order.objects.prefetch_related('groups__items',\n 'groups__items__product')\n orders = orders.select_related('billing_address', 'shipping_address',\n 'user')\n order = get_object_or_404(orders, token=token)\n groups = order.groups.all()\n return TemplateResponse(request, 'order/details.html',\n {'order': order, 'groups': groups})\n\n\ndef payment(request, token):\n orders = Order.objects.prefetch_related('groups__items__product')\n orders = orders.select_related('billing_address', 'shipping_address',\n 'user')\n order = get_object_or_404(orders, token=token)\n groups = order.groups.all()\n payments = order.payments.all()\n form_data = request.POST or None\n try:\n waiting_payment = order.payments.get(status=PaymentStatus.WAITING)\n except Payment.DoesNotExist:\n waiting_payment = None\n waiting_payment_form = None\n else:\n form_data = None\n waiting_payment_form = PaymentDeleteForm(\n None, order=order, initial={'payment_id': waiting_payment.id})\n if order.is_fully_paid():\n form_data = None\n payment_form = None\n if not order.is_pre_authorized():\n payment_form = PaymentMethodsForm(form_data)\n # FIXME: redirect if there is only one payment method\n if payment_form.is_valid():\n payment_method = payment_form.cleaned_data['method']\n return redirect('order:payment', token=order.token,\n variant=payment_method)\n return TemplateResponse(request, 'order/payment.html',\n {'order': order, 'groups': groups,\n 'payment_form': payment_form,\n 'waiting_payment': waiting_payment,\n 'waiting_payment_form': waiting_payment_form,\n 'payments': payments})\n\n\n@check_order_status\ndef start_payment(request, order, variant):\n waiting_payments = order.payments.filter(status=PaymentStatus.WAITING).exists()\n if waiting_payments:\n return redirect('order:payment', token=order.token)\n billing = order.billing_address\n total = order.get_total()\n defaults = {'total': total.gross,\n 'tax': total.tax, 'currency': total.currency,\n 'delivery': order.get_delivery_total().gross,\n 'billing_first_name': billing.first_name,\n 'billing_last_name': billing.last_name,\n 'billing_address_1': billing.street_address_1,\n 'billing_address_2': billing.street_address_2,\n 'billing_city': billing.city,\n 'billing_postcode': billing.postal_code,\n 'billing_country_code': billing.country.code,\n 'billing_email': order.user_email,\n 'description': pgettext_lazy(\n 'Payment description', 'Order %(order_number)s') % {\n 'order_number': order},\n 'billing_country_area': billing.country_area,\n 'customer_ip_address': get_client_ip(request)}\n variant_choices = settings.CHECKOUT_PAYMENT_CHOICES\n if variant not in [code for code, dummy_name in variant_choices]:\n raise Http404('%r is not a valid payment variant' % (variant,))\n with transaction.atomic():\n order.change_status(OrderStatus.PAYMENT_PENDING)\n payment, dummy_created = Payment.objects.get_or_create(\n variant=variant, status=PaymentStatus.WAITING, order=order,\n defaults=defaults)\n try:\n form = payment.get_form(data=request.POST or None)\n except RedirectNeeded as redirect_to:\n return redirect(str(redirect_to))\n except Exception:\n logger.exception('Error communicating with the payment gateway')\n messages.error(\n request,\n pgettext_lazy(\n 'Payment gateway error',\n 'Oops, it looks like we were unable to contact the selected'\n ' payment service'))\n payment.change_status(PaymentStatus.ERROR)\n return redirect('order:payment', token=order.token)\n template = 'order/payment/%s.html' % variant\n return TemplateResponse(request, [template, 'order/payment/default.html'],\n {'form': form, 'payment': payment})\n\n\n@check_order_status\ndef cancel_payment(request, order):\n form = PaymentDeleteForm(request.POST or None, order=order)\n if form.is_valid():\n with transaction.atomic():\n form.save()\n return redirect('order:payment', token=order.token)\n return HttpResponseForbidden()\n\n\ndef create_password(request, token):\n if request.user.is_authenticated():\n return redirect('order:details', token=token)\n order = get_object_or_404(Order, token=token)\n email = order.user_email\n form_data = request.POST.copy()\n if form_data:\n form_data.update({'email': email})\n register_form = PasswordForm(form_data or None)\n if User.objects.filter(email=email).exists():\n login_form = LoginForm(initial={'login': email})\n else:\n login_form = None\n if register_form.is_valid():\n register_form.save(request)\n password = form_data.get('password1')\n auth_user = auth.authenticate(email=email, password=password)\n if auth_user is not None:\n auth.login(request, auth_user)\n attach_order_to_user(order, auth_user)\n return redirect('order:details', token=token)\n ctx = {'form': register_form, 'email': email, 'order': order,\n 'login_form': login_form}\n return TemplateResponse(request, 'order/create_password.html', ctx)\n\n\n@login_required\ndef connect_order_with_user(request, token):\n order = get_object_or_404(\n Order.objects.filter(user_email=request.user.email, token=token))\n attach_order_to_user(order, request.user)\n messages.success(\n request, pgettext_lazy(\n 'storefront message',\n 'You\\'ve successfully connected order with your account'))\n return redirect('order:details', token=order.token)\n", "path": "saleor/order/views.py"}, {"content": "from django import forms\nfrom django.contrib.auth import login, authenticate\nfrom django.contrib.auth import forms as django_forms\nfrom django.utils.translation import pgettext\n\nfrom saleor.userprofile.models import User\n\n\nclass LoginForm(django_forms.AuthenticationForm):\n username = forms.EmailField(\n label=pgettext('Form field', 'Email'), max_length=75)\n\n def __init__(self, request=None, *args, **kwargs):\n super(LoginForm, self).__init__(request=request, *args, **kwargs)\n if request:\n email = request.GET.get('email')\n if email:\n self.fields['username'].initial = email\n\n\nclass SignupForm(forms.ModelForm):\n password = forms.CharField(\n label=pgettext('User form field', 'Password'),\n widget=forms.PasswordInput)\n\n class Meta:\n model = User\n fields = ('email',)\n\n def __init__(self, *args, **kwargs):\n super(SignupForm, self).__init__(*args, **kwargs)\n if self._meta.model.USERNAME_FIELD in self.fields:\n self.fields[self._meta.model.USERNAME_FIELD].widget.attrs.update(\n {'autofocus': ''})\n\n def save(self, request=None, commit=True):\n user = super(SignupForm, self).save(commit=False)\n password = self.cleaned_data['password']\n user.set_password(password)\n if commit:\n user.save()\n if request:\n email = self.cleaned_data['email']\n user = authenticate(username=email, password=password)\n login(request, user)\n return user\n\n\nclass SetPasswordForm(django_forms.SetPasswordForm):\n def __init__(self, *args, **kwargs):\n super(SetPasswordForm, self).__init__(*args, **kwargs)\n del self.fields['new_password2']\n", "path": "saleor/registration/forms.py"}]}
| 3,462 | 521 |
gh_patches_debug_11896
|
rasdani/github-patches
|
git_diff
|
digitalfabrik__integreat-cms-1189
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
`AttributeError` on unchecked link list
### Describe the Bug
<!-- A clear and concise description of what the bug is. -->
Unchecked links do not have a `status_message`, which causes an `AttributeError` on the unchecked link list
### Steps to Reproduce
1. Add unchecked links
2. Go to `/analytics/linkcheck/unchecked/`
3. See error
### Expected Behavior
<!-- A clear and concise description of what you expected to happen. -->
The list of unchecked links should be shownn
### Actual Behavior
<!-- A clear and concise description of what actually happened. -->
`AttributeError: 'NoneType' object has no attribute 'startswith'`
### Additional Information
<!-- Add any other context (e.g. logs, screenshots, etc.) about the problem here. -->
<details>
<summary>Traceback</summary>
```
Traceback (most recent call last):
File "/opt/integreat-cms/.venv/lib/python3.8/site-packages/django/core/handlers/exception.py", lin
e 47, in inner
response = get_response(request)
File "/opt/integreat-cms/.venv/lib/python3.8/site-packages/django/core/handlers/base.py", line 204
, in _get_response
response = response.render()
File "/opt/integreat-cms/.venv/lib/python3.8/site-packages/django/template/response.py", line 105,
in render
self.content = self.rendered_content
File "/opt/integreat-cms/.venv/lib/python3.8/site-packages/django/template/response.py", line 83,
in rendered_content
return template.render(context, self._request)
File "/opt/integreat-cms/.venv/lib/python3.8/site-packages/django/template/backends/django.py", li
ne 61, in render
return self.template.render(context)
File "/opt/integreat-cms/.venv/lib/python3.8/site-packages/django/template/base.py", line 170, in
render
return self._render(context)
File "/opt/integreat-cms/.venv/lib/python3.8/site-packages/django/template/base.py", line 162, in
_render
return self.nodelist.render(context)
File "/opt/integreat-cms/.venv/lib/python3.8/site-packages/django/template/base.py", line 938, in
render
bit = node.render_annotated(context)
File "/opt/integreat-cms/.venv/lib/python3.8/site-packages/django/template/base.py", line 905, in
render_annotated
return self.render(context)
File "/opt/integreat-cms/.venv/lib/python3.8/site-packages/django/template/loader_tags.py", line 1
50, in render
return compiled_parent._render(context)
File "/opt/integreat-cms/.venv/lib/python3.8/site-packages/django/template/base.py", line 162, in
_render
return self.nodelist.render(context)
File "/opt/integreat-cms/.venv/lib/python3.8/site-packages/django/template/base.py", line 938, in
render
bit = node.render_annotated(context)
File "/opt/integreat-cms/.venv/lib/python3.8/site-packages/django/template/base.py", line 905, in
render_annotated
return self.render(context)
File "/opt/integreat-cms/.venv/lib/python3.8/site-packages/django/template/loader_tags.py", line 1
50, in render
return compiled_parent._render(context)
File "/opt/integreat-cms/.venv/lib/python3.8/site-packages/django/template/base.py", line 162, in
_render
return self.nodelist.render(context)
File "/opt/integreat-cms/.venv/lib/python3.8/site-packages/django/template/base.py", line 938, in
render
bit = node.render_annotated(context)
File "/opt/integreat-cms/.venv/lib/python3.8/site-packages/django/template/base.py", line 905, in
render_annotated
return self.render(context)
File "/opt/integreat-cms/.venv/lib/python3.8/site-packages/django/template/loader_tags.py", line 62, in render
result = block.nodelist.render(context)
File "/opt/integreat-cms/.venv/lib/python3.8/site-packages/django/template/base.py", line 938, in render
bit = node.render_annotated(context)
File "/opt/integreat-cms/.venv/lib/python3.8/site-packages/django/template/base.py", line 905, in render_annotated
return self.render(context)
File "/opt/integreat-cms/.venv/lib/python3.8/site-packages/django/template/loader_tags.py", line 62, in render
result = block.nodelist.render(context)
File "/opt/integreat-cms/.venv/lib/python3.8/site-packages/django/template/base.py", line 938, in render
bit = node.render_annotated(context)
File "/opt/integreat-cms/.venv/lib/python3.8/site-packages/django/template/base.py", line 905, in render_annotated
return self.render(context)
File "/opt/integreat-cms/.venv/lib/python3.8/site-packages/django/template/loader_tags.py", line 62, in render
result = block.nodelist.render(context)
File "/opt/integreat-cms/.venv/lib/python3.8/site-packages/django/template/base.py", line 938, in render
bit = node.render_annotated(context)
File "/opt/integreat-cms/.venv/lib/python3.8/site-packages/django/template/base.py", line 905, in render_annotated
return self.render(context)
File "/opt/integreat-cms/.venv/lib/python3.8/site-packages/django/template/defaulttags.py", line 214, in render
nodelist.append(node.render_annotated(context))
File "/opt/integreat-cms/.venv/lib/python3.8/site-packages/django/template/base.py", line 905, in render_annotated
return self.render(context)
File "/opt/integreat-cms/.venv/lib/python3.8/site-packages/django/template/loader_tags.py", line 195, in render
return template.render(context)
File "/opt/integreat-cms/.venv/lib/python3.8/site-packages/django/template/base.py", line 172, in render
return self._render(context)
File "/opt/integreat-cms/.venv/lib/python3.8/site-packages/django/template/base.py", line 162, in _render
return self.nodelist.render(context)
File "/opt/integreat-cms/.venv/lib/python3.8/site-packages/django/template/base.py", line 938, in render
bit = node.render_annotated(context)
File "/opt/integreat-cms/.venv/lib/python3.8/site-packages/django/template/base.py", line 905, in render_annotated
return self.render(context)
File "/opt/integreat-cms/.venv/lib/python3.8/site-packages/django/template/base.py", line 988, in render
output = self.filter_expression.resolve(context)
File "/opt/integreat-cms/.venv/lib/python3.8/site-packages/django/template/base.py", line 698, in resolve
new_obj = func(obj, *arg_vals)
File "/opt/integreat-cms/.venv/lib/python3.8/site-packages/integreat_cms/cms/templatetags/text_filters.py", line 34, in linkcheck_status_filter
if status_message.startswith("Other Error:"):
AttributeError: 'NoneType' object has no attribute 'startswith'
```
</details>
</issue>
<code>
[start of integreat_cms/cms/templatetags/text_filters.py]
1 """
2 This is a collection of tags and filters for strings.
3 """
4 from django import template
5
6 register = template.Library()
7
8
9 @register.filter(name="words")
10 def words(text):
11 """
12 Split the given text into a list of words, see :meth:`python:str.split`.
13
14 :param text: The input string
15 :type text: str
16
17 :return: The list of words in the text
18 :rtype: list
19 """
20 return text.split()
21
22
23 @register.filter(name="linkcheck_status_filter")
24 def linkcheck_status_filter(status_message):
25 """
26 Due to a long status entry for a single kind of faulty link,
27 this filter reduced the output when display in list view
28
29 :param status_message: error description
30 :type status_message: str
31 :return: a concise message
32 :rtype: str
33 """
34 if status_message.startswith("Other Error:"):
35 return "Other Error"
36 return status_message
37
[end of integreat_cms/cms/templatetags/text_filters.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/integreat_cms/cms/templatetags/text_filters.py b/integreat_cms/cms/templatetags/text_filters.py
--- a/integreat_cms/cms/templatetags/text_filters.py
+++ b/integreat_cms/cms/templatetags/text_filters.py
@@ -2,6 +2,7 @@
This is a collection of tags and filters for strings.
"""
from django import template
+from django.utils.translation import ugettext as _
register = template.Library()
@@ -31,6 +32,8 @@
:return: a concise message
:rtype: str
"""
+ if not status_message:
+ return _("Unknown")
if status_message.startswith("Other Error:"):
- return "Other Error"
+ return _("Error")
return status_message
|
{"golden_diff": "diff --git a/integreat_cms/cms/templatetags/text_filters.py b/integreat_cms/cms/templatetags/text_filters.py\n--- a/integreat_cms/cms/templatetags/text_filters.py\n+++ b/integreat_cms/cms/templatetags/text_filters.py\n@@ -2,6 +2,7 @@\n This is a collection of tags and filters for strings.\n \"\"\"\n from django import template\n+from django.utils.translation import ugettext as _\n \n register = template.Library()\n \n@@ -31,6 +32,8 @@\n :return: a concise message\n :rtype: str\n \"\"\"\n+ if not status_message:\n+ return _(\"Unknown\")\n if status_message.startswith(\"Other Error:\"):\n- return \"Other Error\"\n+ return _(\"Error\")\n return status_message\n", "issue": "`AttributeError` on unchecked link list\n### Describe the Bug\r\n<!-- A clear and concise description of what the bug is. -->\r\nUnchecked links do not have a `status_message`, which causes an `AttributeError` on the unchecked link list\r\n\r\n### Steps to Reproduce\r\n\r\n1. Add unchecked links\r\n2. Go to `/analytics/linkcheck/unchecked/`\r\n3. See error\r\n\r\n### Expected Behavior\r\n<!-- A clear and concise description of what you expected to happen. -->\r\nThe list of unchecked links should be shownn\r\n\r\n### Actual Behavior\r\n<!-- A clear and concise description of what actually happened. -->\r\n`AttributeError: 'NoneType' object has no attribute 'startswith'`\r\n\r\n### Additional Information\r\n<!-- Add any other context (e.g. logs, screenshots, etc.) about the problem here. -->\r\n<details>\r\n <summary>Traceback</summary>\r\n \r\n \r\n ```\r\nTraceback (most recent call last):\r\n File \"/opt/integreat-cms/.venv/lib/python3.8/site-packages/django/core/handlers/exception.py\", lin\r\ne 47, in inner\r\n response = get_response(request)\r\n File \"/opt/integreat-cms/.venv/lib/python3.8/site-packages/django/core/handlers/base.py\", line 204\r\n, in _get_response\r\n response = response.render()\r\n File \"/opt/integreat-cms/.venv/lib/python3.8/site-packages/django/template/response.py\", line 105,\r\n in render\r\n self.content = self.rendered_content\r\n File \"/opt/integreat-cms/.venv/lib/python3.8/site-packages/django/template/response.py\", line 83,\r\nin rendered_content\r\n return template.render(context, self._request)\r\n File \"/opt/integreat-cms/.venv/lib/python3.8/site-packages/django/template/backends/django.py\", li\r\nne 61, in render\r\n return self.template.render(context)\r\n File \"/opt/integreat-cms/.venv/lib/python3.8/site-packages/django/template/base.py\", line 170, in\r\nrender\r\n return self._render(context)\r\n File \"/opt/integreat-cms/.venv/lib/python3.8/site-packages/django/template/base.py\", line 162, in\r\n_render\r\n return self.nodelist.render(context)\r\n File \"/opt/integreat-cms/.venv/lib/python3.8/site-packages/django/template/base.py\", line 938, in\r\nrender\r\n bit = node.render_annotated(context)\r\n File \"/opt/integreat-cms/.venv/lib/python3.8/site-packages/django/template/base.py\", line 905, in\r\nrender_annotated\r\n return self.render(context)\r\n File \"/opt/integreat-cms/.venv/lib/python3.8/site-packages/django/template/loader_tags.py\", line 1\r\n50, in render\r\n return compiled_parent._render(context)\r\n File \"/opt/integreat-cms/.venv/lib/python3.8/site-packages/django/template/base.py\", line 162, in\r\n_render\r\n return self.nodelist.render(context)\r\n File \"/opt/integreat-cms/.venv/lib/python3.8/site-packages/django/template/base.py\", line 938, in\r\nrender\r\n bit = node.render_annotated(context)\r\n File \"/opt/integreat-cms/.venv/lib/python3.8/site-packages/django/template/base.py\", line 905, in\r\nrender_annotated\r\n return self.render(context)\r\n File \"/opt/integreat-cms/.venv/lib/python3.8/site-packages/django/template/loader_tags.py\", line 1\r\n50, in render\r\n return compiled_parent._render(context)\r\n File \"/opt/integreat-cms/.venv/lib/python3.8/site-packages/django/template/base.py\", line 162, in\r\n_render\r\n return self.nodelist.render(context)\r\n File \"/opt/integreat-cms/.venv/lib/python3.8/site-packages/django/template/base.py\", line 938, in\r\nrender\r\n bit = node.render_annotated(context)\r\n File \"/opt/integreat-cms/.venv/lib/python3.8/site-packages/django/template/base.py\", line 905, in\r\nrender_annotated\r\n return self.render(context)\r\n File \"/opt/integreat-cms/.venv/lib/python3.8/site-packages/django/template/loader_tags.py\", line 62, in render\r\n result = block.nodelist.render(context)\r\n File \"/opt/integreat-cms/.venv/lib/python3.8/site-packages/django/template/base.py\", line 938, in render\r\n bit = node.render_annotated(context)\r\n File \"/opt/integreat-cms/.venv/lib/python3.8/site-packages/django/template/base.py\", line 905, in render_annotated\r\n return self.render(context)\r\n File \"/opt/integreat-cms/.venv/lib/python3.8/site-packages/django/template/loader_tags.py\", line 62, in render\r\n result = block.nodelist.render(context)\r\n File \"/opt/integreat-cms/.venv/lib/python3.8/site-packages/django/template/base.py\", line 938, in render\r\n bit = node.render_annotated(context)\r\n File \"/opt/integreat-cms/.venv/lib/python3.8/site-packages/django/template/base.py\", line 905, in render_annotated\r\n return self.render(context)\r\n File \"/opt/integreat-cms/.venv/lib/python3.8/site-packages/django/template/loader_tags.py\", line 62, in render\r\n result = block.nodelist.render(context)\r\n File \"/opt/integreat-cms/.venv/lib/python3.8/site-packages/django/template/base.py\", line 938, in render\r\n bit = node.render_annotated(context)\r\n File \"/opt/integreat-cms/.venv/lib/python3.8/site-packages/django/template/base.py\", line 905, in render_annotated\r\n return self.render(context)\r\n File \"/opt/integreat-cms/.venv/lib/python3.8/site-packages/django/template/defaulttags.py\", line 214, in render\r\n nodelist.append(node.render_annotated(context))\r\n File \"/opt/integreat-cms/.venv/lib/python3.8/site-packages/django/template/base.py\", line 905, in render_annotated\r\n return self.render(context)\r\n File \"/opt/integreat-cms/.venv/lib/python3.8/site-packages/django/template/loader_tags.py\", line 195, in render\r\n return template.render(context)\r\n File \"/opt/integreat-cms/.venv/lib/python3.8/site-packages/django/template/base.py\", line 172, in render\r\n return self._render(context)\r\n File \"/opt/integreat-cms/.venv/lib/python3.8/site-packages/django/template/base.py\", line 162, in _render\r\n return self.nodelist.render(context)\r\n File \"/opt/integreat-cms/.venv/lib/python3.8/site-packages/django/template/base.py\", line 938, in render\r\n bit = node.render_annotated(context)\r\n File \"/opt/integreat-cms/.venv/lib/python3.8/site-packages/django/template/base.py\", line 905, in render_annotated\r\n return self.render(context)\r\n File \"/opt/integreat-cms/.venv/lib/python3.8/site-packages/django/template/base.py\", line 988, in render\r\n output = self.filter_expression.resolve(context)\r\n File \"/opt/integreat-cms/.venv/lib/python3.8/site-packages/django/template/base.py\", line 698, in resolve\r\n new_obj = func(obj, *arg_vals)\r\n File \"/opt/integreat-cms/.venv/lib/python3.8/site-packages/integreat_cms/cms/templatetags/text_filters.py\", line 34, in linkcheck_status_filter\r\n if status_message.startswith(\"Other Error:\"):\r\nAttributeError: 'NoneType' object has no attribute 'startswith'\r\n ```\r\n \r\n</details>\r\n\n", "before_files": [{"content": "\"\"\"\nThis is a collection of tags and filters for strings.\n\"\"\"\nfrom django import template\n\nregister = template.Library()\n\n\[email protected](name=\"words\")\ndef words(text):\n \"\"\"\n Split the given text into a list of words, see :meth:`python:str.split`.\n\n :param text: The input string\n :type text: str\n\n :return: The list of words in the text\n :rtype: list\n \"\"\"\n return text.split()\n\n\[email protected](name=\"linkcheck_status_filter\")\ndef linkcheck_status_filter(status_message):\n \"\"\"\n Due to a long status entry for a single kind of faulty link,\n this filter reduced the output when display in list view\n\n :param status_message: error description\n :type status_message: str\n :return: a concise message\n :rtype: str\n \"\"\"\n if status_message.startswith(\"Other Error:\"):\n return \"Other Error\"\n return status_message\n", "path": "integreat_cms/cms/templatetags/text_filters.py"}]}
| 2,618 | 181 |
gh_patches_debug_5101
|
rasdani/github-patches
|
git_diff
|
Lightning-AI__pytorch-lightning-2832
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Can't use None (anymore) in checkpoint_callback
## 🐛 Bug
using None in checkpoint_callback now errors out
```
-- Process 0 terminated with the following error:
Traceback (most recent call last):
File "/opt/conda/lib/python3.6/site-packages/torch/multiprocessing/spawn.py", line 20, in _wrap
fn(i, *args)
File "/opt/conda/lib/python3.6/site-packages/pytorch_lightning/trainer/distrib_data_parallel.py", line 562, in ddp_train
q.put(self.checkpoint_callback.best_model_path)
AttributeError: 'NoneType' object has no attribute 'best_model_path'
```
### To Reproduce
`trainer = Trainer(checkpoint_callback=None)`
Ran into this issue from upgrading to masters, was using masters from a few commits ago before
Edit: `False` casuses the same error as well
</issue>
<code>
[start of pytorch_lightning/accelerator_backends/ddp_spawn_backend.py]
1 # Copyright The PyTorch Lightning team.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License
14
15 import os
16 import torch
17 import torch.multiprocessing as mp
18 from pytorch_lightning.utilities.distributed import rank_zero_only
19 from pytorch_lightning import _logger as log
20
21 try:
22 from apex import amp
23 except ImportError:
24 APEX_AVAILABLE = False
25 else:
26 APEX_AVAILABLE = True
27
28
29 class DDPSpawnBackend(object):
30
31 def __init__(self, trainer):
32 self.trainer = trainer
33 self.mp_queue = None
34
35 def setup(self):
36 self.trainer.set_random_port()
37
38 # pass in a state q
39 smp = mp.get_context('spawn')
40 self.mp_queue = smp.SimpleQueue()
41
42 def train(self, model, nprocs):
43 mp.spawn(self.ddp_train, nprocs=nprocs, args=(self.mp_queue, model,))
44
45 def teardown(self, model):
46 # restore main state with best weights
47 best_path = self.mp_queue.get()
48 results = self.mp_queue.get()
49 last_path = self.mp_queue.get()
50
51 # transfer back the best path to the trainer
52 self.trainer.checkpoint_callback.best_model_path = best_path
53 # todo, pass also bets score
54
55 # load last weights
56 if last_path is not None and not self.trainer.testing:
57 ckpt = torch.load(last_path, map_location=lambda storage, loc: storage)
58 model.load_state_dict(ckpt)
59
60 self.trainer.model = model
61 return results
62
63 def ddp_train(self, process_idx, mp_queue, model):
64 """
65 Entry point for ddp
66
67 Args:
68 process_idx:
69 mp_queue: multiprocessing queue
70 model:
71
72 Returns:
73
74 """
75 # show progressbar only on progress_rank 0
76 if (self.trainer.node_rank != 0 or process_idx != 0) and self.trainer.progress_bar_callback is not None:
77 self.trainer.progress_bar_callback.disable()
78
79 # determine which process we are and world size
80 if self.trainer.use_ddp:
81 self.trainer.local_rank = process_idx
82 self.trainer.global_rank = self.trainer.node_rank * self.trainer.num_processes + process_idx
83 self.trainer.world_size = self.trainer.num_nodes * self.trainer.num_processes
84
85 elif self.trainer.use_ddp2:
86 self.trainer.local_rank = self.trainer.node_rank
87 self.trainer.global_rank = self.trainer.node_rank
88 self.trainer.world_size = self.trainer.num_nodes
89
90 # set warning rank
91 rank_zero_only.rank = self.trainer.global_rank
92
93 # set up server using proc 0's ip address
94 # try to init for 20 times at max in case ports are taken
95 # where to store ip_table
96 model.trainer = self.trainer
97 model.init_ddp_connection(
98 self.trainer.global_rank,
99 self.trainer.world_size,
100 self.trainer.is_slurm_managing_tasks
101 )
102
103 # call setup after the ddp process has connected
104 self.trainer.call_setup_hook(model)
105
106 # on world_size=0 let everyone know training is starting
107 if self.trainer.is_global_zero:
108 log.info('-' * 100)
109 log.info(f'distributed_backend={self.trainer.distributed_backend}')
110 log.info(f'All DDP processes registered. Starting ddp with {self.trainer.world_size} processes')
111 log.info('-' * 100)
112
113 # CHOOSE OPTIMIZER
114 # allow for lr schedulers as well
115 optimizers, lr_schedulers, optimizer_frequencies = self.trainer.init_optimizers(model)
116 self.trainer.optimizers = optimizers
117 self.trainer.lr_schedulers = lr_schedulers
118 self.trainer.optimizer_frequencies = optimizer_frequencies
119
120 # MODEL
121 # copy model to each gpu
122 if self.trainer.on_gpu:
123 gpu_idx = process_idx
124 self.trainer.root_gpu = gpu_idx
125 torch.cuda.set_device(self.trainer.root_gpu)
126 model.cuda(self.trainer.root_gpu)
127
128 # set model properties before going into wrapper
129 self.trainer.copy_trainer_model_properties(model)
130
131 # AMP
132 # run through amp wrapper before going to distributed DP
133 # TODO: remove with dropping NVIDIA AMP support
134 native_amp_available = hasattr(torch.cuda, "amp") and hasattr(torch.cuda.amp, "autocast")
135 if self.trainer.use_amp and not native_amp_available:
136 model, optimizers = model.configure_apex(amp, model, self.trainer.optimizers, self.trainer.amp_level)
137 self.trainer.optimizers = optimizers
138 self.trainer.reinit_scheduler_properties(self.trainer.optimizers, self.trainer.lr_schedulers)
139
140 # DDP2 uses all GPUs on the machine
141 if self.trainer.distributed_backend == 'ddp' or self.trainer.distributed_backend == 'ddp_spawn':
142 device_ids = [self.trainer.root_gpu]
143 elif self.trainer.use_ddp2:
144 device_ids = self.trainer.data_parallel_device_ids
145 else: # includes ddp_cpu
146 device_ids = None
147
148 # allow user to configure ddp
149 model = model.configure_ddp(model, device_ids)
150
151 # continue training routine
152 results = self.trainer.run_pretrain_routine(model)
153
154 # get original model
155 model = self.trainer.get_model()
156
157 # persist info in ddp_spawn
158 self.trainer.transfer_distrib_spawn_state_on_fit_end(model, mp_queue, results)
159
160 # clean up memory
161 torch.cuda.empty_cache()
162
[end of pytorch_lightning/accelerator_backends/ddp_spawn_backend.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/pytorch_lightning/accelerator_backends/ddp_spawn_backend.py b/pytorch_lightning/accelerator_backends/ddp_spawn_backend.py
--- a/pytorch_lightning/accelerator_backends/ddp_spawn_backend.py
+++ b/pytorch_lightning/accelerator_backends/ddp_spawn_backend.py
@@ -49,7 +49,8 @@
last_path = self.mp_queue.get()
# transfer back the best path to the trainer
- self.trainer.checkpoint_callback.best_model_path = best_path
+ if self.trainer.checkpoint_callback:
+ self.trainer.checkpoint_callback.best_model_path = best_path
# todo, pass also bets score
# load last weights
|
{"golden_diff": "diff --git a/pytorch_lightning/accelerator_backends/ddp_spawn_backend.py b/pytorch_lightning/accelerator_backends/ddp_spawn_backend.py\n--- a/pytorch_lightning/accelerator_backends/ddp_spawn_backend.py\n+++ b/pytorch_lightning/accelerator_backends/ddp_spawn_backend.py\n@@ -49,7 +49,8 @@\n last_path = self.mp_queue.get()\n \n # transfer back the best path to the trainer\n- self.trainer.checkpoint_callback.best_model_path = best_path\n+ if self.trainer.checkpoint_callback:\n+ self.trainer.checkpoint_callback.best_model_path = best_path\n # todo, pass also bets score\n \n # load last weights\n", "issue": "Can't use None (anymore) in checkpoint_callback\n## \ud83d\udc1b Bug\r\nusing None in checkpoint_callback now errors out\r\n\r\n```\r\n-- Process 0 terminated with the following error:\r\nTraceback (most recent call last):\r\n File \"/opt/conda/lib/python3.6/site-packages/torch/multiprocessing/spawn.py\", line 20, in _wrap\r\n fn(i, *args)\r\n File \"/opt/conda/lib/python3.6/site-packages/pytorch_lightning/trainer/distrib_data_parallel.py\", line 562, in ddp_train\r\n q.put(self.checkpoint_callback.best_model_path)\r\nAttributeError: 'NoneType' object has no attribute 'best_model_path'\r\n```\r\n\r\n### To Reproduce\r\n`trainer = Trainer(checkpoint_callback=None)`\r\n\r\nRan into this issue from upgrading to masters, was using masters from a few commits ago before\r\n\r\nEdit: `False` casuses the same error as well\n", "before_files": [{"content": "# Copyright The PyTorch Lightning team.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License\n\nimport os\nimport torch\nimport torch.multiprocessing as mp\nfrom pytorch_lightning.utilities.distributed import rank_zero_only\nfrom pytorch_lightning import _logger as log\n\ntry:\n from apex import amp\nexcept ImportError:\n APEX_AVAILABLE = False\nelse:\n APEX_AVAILABLE = True\n\n\nclass DDPSpawnBackend(object):\n\n def __init__(self, trainer):\n self.trainer = trainer\n self.mp_queue = None\n\n def setup(self):\n self.trainer.set_random_port()\n\n # pass in a state q\n smp = mp.get_context('spawn')\n self.mp_queue = smp.SimpleQueue()\n\n def train(self, model, nprocs):\n mp.spawn(self.ddp_train, nprocs=nprocs, args=(self.mp_queue, model,))\n\n def teardown(self, model):\n # restore main state with best weights\n best_path = self.mp_queue.get()\n results = self.mp_queue.get()\n last_path = self.mp_queue.get()\n\n # transfer back the best path to the trainer\n self.trainer.checkpoint_callback.best_model_path = best_path\n # todo, pass also bets score\n\n # load last weights\n if last_path is not None and not self.trainer.testing:\n ckpt = torch.load(last_path, map_location=lambda storage, loc: storage)\n model.load_state_dict(ckpt)\n\n self.trainer.model = model\n return results\n\n def ddp_train(self, process_idx, mp_queue, model):\n \"\"\"\n Entry point for ddp\n\n Args:\n process_idx:\n mp_queue: multiprocessing queue\n model:\n\n Returns:\n\n \"\"\"\n # show progressbar only on progress_rank 0\n if (self.trainer.node_rank != 0 or process_idx != 0) and self.trainer.progress_bar_callback is not None:\n self.trainer.progress_bar_callback.disable()\n\n # determine which process we are and world size\n if self.trainer.use_ddp:\n self.trainer.local_rank = process_idx\n self.trainer.global_rank = self.trainer.node_rank * self.trainer.num_processes + process_idx\n self.trainer.world_size = self.trainer.num_nodes * self.trainer.num_processes\n\n elif self.trainer.use_ddp2:\n self.trainer.local_rank = self.trainer.node_rank\n self.trainer.global_rank = self.trainer.node_rank\n self.trainer.world_size = self.trainer.num_nodes\n\n # set warning rank\n rank_zero_only.rank = self.trainer.global_rank\n\n # set up server using proc 0's ip address\n # try to init for 20 times at max in case ports are taken\n # where to store ip_table\n model.trainer = self.trainer\n model.init_ddp_connection(\n self.trainer.global_rank,\n self.trainer.world_size,\n self.trainer.is_slurm_managing_tasks\n )\n\n # call setup after the ddp process has connected\n self.trainer.call_setup_hook(model)\n\n # on world_size=0 let everyone know training is starting\n if self.trainer.is_global_zero:\n log.info('-' * 100)\n log.info(f'distributed_backend={self.trainer.distributed_backend}')\n log.info(f'All DDP processes registered. Starting ddp with {self.trainer.world_size} processes')\n log.info('-' * 100)\n\n # CHOOSE OPTIMIZER\n # allow for lr schedulers as well\n optimizers, lr_schedulers, optimizer_frequencies = self.trainer.init_optimizers(model)\n self.trainer.optimizers = optimizers\n self.trainer.lr_schedulers = lr_schedulers\n self.trainer.optimizer_frequencies = optimizer_frequencies\n\n # MODEL\n # copy model to each gpu\n if self.trainer.on_gpu:\n gpu_idx = process_idx\n self.trainer.root_gpu = gpu_idx\n torch.cuda.set_device(self.trainer.root_gpu)\n model.cuda(self.trainer.root_gpu)\n\n # set model properties before going into wrapper\n self.trainer.copy_trainer_model_properties(model)\n\n # AMP\n # run through amp wrapper before going to distributed DP\n # TODO: remove with dropping NVIDIA AMP support\n native_amp_available = hasattr(torch.cuda, \"amp\") and hasattr(torch.cuda.amp, \"autocast\")\n if self.trainer.use_amp and not native_amp_available:\n model, optimizers = model.configure_apex(amp, model, self.trainer.optimizers, self.trainer.amp_level)\n self.trainer.optimizers = optimizers\n self.trainer.reinit_scheduler_properties(self.trainer.optimizers, self.trainer.lr_schedulers)\n\n # DDP2 uses all GPUs on the machine\n if self.trainer.distributed_backend == 'ddp' or self.trainer.distributed_backend == 'ddp_spawn':\n device_ids = [self.trainer.root_gpu]\n elif self.trainer.use_ddp2:\n device_ids = self.trainer.data_parallel_device_ids\n else: # includes ddp_cpu\n device_ids = None\n\n # allow user to configure ddp\n model = model.configure_ddp(model, device_ids)\n\n # continue training routine\n results = self.trainer.run_pretrain_routine(model)\n\n # get original model\n model = self.trainer.get_model()\n\n # persist info in ddp_spawn\n self.trainer.transfer_distrib_spawn_state_on_fit_end(model, mp_queue, results)\n\n # clean up memory\n torch.cuda.empty_cache()\n", "path": "pytorch_lightning/accelerator_backends/ddp_spawn_backend.py"}]}
| 2,471 | 156 |
gh_patches_debug_14907
|
rasdani/github-patches
|
git_diff
|
open-telemetry__opentelemetry-python-contrib-379
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
WSGI Carrier Getter always returns an empty list as keys
**Describe your environment**
Not relevant.
**Steps to reproduce**
1. Call the method: https://github.com/open-telemetry/opentelemetry-python-contrib/blob/f8e51c488da1f5ab628ba4f5bf25e65638974c44/instrumentation/opentelemetry-instrumentation-wsgi/src/opentelemetry/instrumentation/wsgi/__init__.py#L91
**What is the expected behavior?**
I would expect all the keys from the provided carrier returned.
**What is the actual behavior?**
No matter of the carrier contents an empty list is returned.
**Additional context**
Due to this behavior other extensions from this repository might not work as expected.
For example [OT Trace Propagator](https://github.com/open-telemetry/opentelemetry-python-contrib/blob/f8e51c488da1f5ab628ba4f5bf25e65638974c44/propagator/opentelemetry-propagator-ot-trace/src/opentelemetry/propagators/ot_trace/__init__.py#L92) cannot extract baggage information from the carrier, because empty list is always returned.
</issue>
<code>
[start of instrumentation/opentelemetry-instrumentation-wsgi/src/opentelemetry/instrumentation/wsgi/__init__.py]
1 # Copyright The OpenTelemetry Authors
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14 """
15 This library provides a WSGI middleware that can be used on any WSGI framework
16 (such as Django / Flask) to track requests timing through OpenTelemetry.
17
18 Usage (Flask)
19 -------------
20
21 .. code-block:: python
22
23 from flask import Flask
24 from opentelemetry.instrumentation.wsgi import OpenTelemetryMiddleware
25
26 app = Flask(__name__)
27 app.wsgi_app = OpenTelemetryMiddleware(app.wsgi_app)
28
29 @app.route("/")
30 def hello():
31 return "Hello!"
32
33 if __name__ == "__main__":
34 app.run(debug=True)
35
36
37 Usage (Django)
38 --------------
39
40 Modify the application's ``wsgi.py`` file as shown below.
41
42 .. code-block:: python
43
44 import os
45 from opentelemetry.instrumentation.wsgi import OpenTelemetryMiddleware
46 from django.core.wsgi import get_wsgi_application
47
48 os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'application.settings')
49
50 application = get_wsgi_application()
51 application = OpenTelemetryMiddleware(application)
52
53 API
54 ---
55 """
56
57 import functools
58 import typing
59 import wsgiref.util as wsgiref_util
60
61 from opentelemetry import context, trace
62 from opentelemetry.instrumentation.utils import http_status_to_status_code
63 from opentelemetry.instrumentation.wsgi.version import __version__
64 from opentelemetry.propagate import extract
65 from opentelemetry.propagators.textmap import DictGetter
66 from opentelemetry.trace.status import Status, StatusCode
67
68 _HTTP_VERSION_PREFIX = "HTTP/"
69
70
71 class CarrierGetter(DictGetter):
72 def get(
73 self, carrier: dict, key: str
74 ) -> typing.Optional[typing.List[str]]:
75 """Getter implementation to retrieve a HTTP header value from the
76 PEP3333-conforming WSGI environ
77
78 Args:
79 carrier: WSGI environ object
80 key: header name in environ object
81 Returns:
82 A list with a single string with the header value if it exists,
83 else None.
84 """
85 environ_key = "HTTP_" + key.upper().replace("-", "_")
86 value = carrier.get(environ_key)
87 if value is not None:
88 return [value]
89 return None
90
91 def keys(self, carrier):
92 return []
93
94
95 carrier_getter = CarrierGetter()
96
97
98 def setifnotnone(dic, key, value):
99 if value is not None:
100 dic[key] = value
101
102
103 def collect_request_attributes(environ):
104 """Collects HTTP request attributes from the PEP3333-conforming
105 WSGI environ and returns a dictionary to be used as span creation attributes."""
106
107 result = {
108 "http.method": environ.get("REQUEST_METHOD"),
109 "http.server_name": environ.get("SERVER_NAME"),
110 "http.scheme": environ.get("wsgi.url_scheme"),
111 }
112
113 host_port = environ.get("SERVER_PORT")
114 if host_port is not None:
115 result.update({"net.host.port": int(host_port)})
116
117 setifnotnone(result, "http.host", environ.get("HTTP_HOST"))
118 target = environ.get("RAW_URI")
119 if target is None: # Note: `"" or None is None`
120 target = environ.get("REQUEST_URI")
121 if target is not None:
122 result["http.target"] = target
123 else:
124 result["http.url"] = wsgiref_util.request_uri(environ)
125
126 remote_addr = environ.get("REMOTE_ADDR")
127 if remote_addr:
128 result["net.peer.ip"] = remote_addr
129 remote_host = environ.get("REMOTE_HOST")
130 if remote_host and remote_host != remote_addr:
131 result["net.peer.name"] = remote_host
132
133 user_agent = environ.get("HTTP_USER_AGENT")
134 if user_agent is not None and len(user_agent) > 0:
135 result["http.user_agent"] = user_agent
136
137 setifnotnone(result, "net.peer.port", environ.get("REMOTE_PORT"))
138 flavor = environ.get("SERVER_PROTOCOL", "")
139 if flavor.upper().startswith(_HTTP_VERSION_PREFIX):
140 flavor = flavor[len(_HTTP_VERSION_PREFIX) :]
141 if flavor:
142 result["http.flavor"] = flavor
143
144 return result
145
146
147 def add_response_attributes(
148 span, start_response_status, response_headers
149 ): # pylint: disable=unused-argument
150 """Adds HTTP response attributes to span using the arguments
151 passed to a PEP3333-conforming start_response callable."""
152 if not span.is_recording():
153 return
154 status_code, status_text = start_response_status.split(" ", 1)
155 span.set_attribute("http.status_text", status_text)
156
157 try:
158 status_code = int(status_code)
159 except ValueError:
160 span.set_status(
161 Status(
162 StatusCode.ERROR,
163 "Non-integer HTTP status: " + repr(status_code),
164 )
165 )
166 else:
167 span.set_attribute("http.status_code", status_code)
168 span.set_status(Status(http_status_to_status_code(status_code)))
169
170
171 def get_default_span_name(environ):
172 """Default implementation for name_callback, returns HTTP {METHOD_NAME}."""
173 return "HTTP {}".format(environ.get("REQUEST_METHOD", "")).strip()
174
175
176 class OpenTelemetryMiddleware:
177 """The WSGI application middleware.
178
179 This class is a PEP 3333 conforming WSGI middleware that starts and
180 annotates spans for any requests it is invoked with.
181
182 Args:
183 wsgi: The WSGI application callable to forward requests to.
184 name_callback: Callback which calculates a generic span name for an
185 incoming HTTP request based on the PEP3333 WSGI environ.
186 Optional: Defaults to get_default_span_name.
187 """
188
189 def __init__(self, wsgi, name_callback=get_default_span_name):
190 self.wsgi = wsgi
191 self.tracer = trace.get_tracer(__name__, __version__)
192 self.name_callback = name_callback
193
194 @staticmethod
195 def _create_start_response(span, start_response):
196 @functools.wraps(start_response)
197 def _start_response(status, response_headers, *args, **kwargs):
198 add_response_attributes(span, status, response_headers)
199 return start_response(status, response_headers, *args, **kwargs)
200
201 return _start_response
202
203 def __call__(self, environ, start_response):
204 """The WSGI application
205
206 Args:
207 environ: A WSGI environment.
208 start_response: The WSGI start_response callable.
209 """
210
211 token = context.attach(extract(carrier_getter, environ))
212 span_name = self.name_callback(environ)
213
214 span = self.tracer.start_span(
215 span_name,
216 kind=trace.SpanKind.SERVER,
217 attributes=collect_request_attributes(environ),
218 )
219
220 try:
221 with trace.use_span(span):
222 start_response = self._create_start_response(
223 span, start_response
224 )
225 iterable = self.wsgi(environ, start_response)
226 return _end_span_after_iterating(
227 iterable, span, self.tracer, token
228 )
229 except Exception as ex:
230 if span.is_recording():
231 span.set_status(Status(StatusCode.ERROR, str(ex)))
232 span.end()
233 context.detach(token)
234 raise
235
236
237 # Put this in a subfunction to not delay the call to the wrapped
238 # WSGI application (instrumentation should change the application
239 # behavior as little as possible).
240 def _end_span_after_iterating(iterable, span, tracer, token):
241 try:
242 with trace.use_span(span):
243 for yielded in iterable:
244 yield yielded
245 finally:
246 close = getattr(iterable, "close", None)
247 if close:
248 close()
249 span.end()
250 context.detach(token)
251
[end of instrumentation/opentelemetry-instrumentation-wsgi/src/opentelemetry/instrumentation/wsgi/__init__.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/instrumentation/opentelemetry-instrumentation-wsgi/src/opentelemetry/instrumentation/wsgi/__init__.py b/instrumentation/opentelemetry-instrumentation-wsgi/src/opentelemetry/instrumentation/wsgi/__init__.py
--- a/instrumentation/opentelemetry-instrumentation-wsgi/src/opentelemetry/instrumentation/wsgi/__init__.py
+++ b/instrumentation/opentelemetry-instrumentation-wsgi/src/opentelemetry/instrumentation/wsgi/__init__.py
@@ -66,6 +66,8 @@
from opentelemetry.trace.status import Status, StatusCode
_HTTP_VERSION_PREFIX = "HTTP/"
+_CARRIER_KEY_PREFIX = "HTTP_"
+_CARRIER_KEY_PREFIX_LEN = len(_CARRIER_KEY_PREFIX)
class CarrierGetter(DictGetter):
@@ -89,7 +91,11 @@
return None
def keys(self, carrier):
- return []
+ return [
+ key[_CARRIER_KEY_PREFIX_LEN:].lower().replace("_", "-")
+ for key in carrier
+ if key.startswith(_CARRIER_KEY_PREFIX)
+ ]
carrier_getter = CarrierGetter()
|
{"golden_diff": "diff --git a/instrumentation/opentelemetry-instrumentation-wsgi/src/opentelemetry/instrumentation/wsgi/__init__.py b/instrumentation/opentelemetry-instrumentation-wsgi/src/opentelemetry/instrumentation/wsgi/__init__.py\n--- a/instrumentation/opentelemetry-instrumentation-wsgi/src/opentelemetry/instrumentation/wsgi/__init__.py\n+++ b/instrumentation/opentelemetry-instrumentation-wsgi/src/opentelemetry/instrumentation/wsgi/__init__.py\n@@ -66,6 +66,8 @@\n from opentelemetry.trace.status import Status, StatusCode\n \n _HTTP_VERSION_PREFIX = \"HTTP/\"\n+_CARRIER_KEY_PREFIX = \"HTTP_\"\n+_CARRIER_KEY_PREFIX_LEN = len(_CARRIER_KEY_PREFIX)\n \n \n class CarrierGetter(DictGetter):\n@@ -89,7 +91,11 @@\n return None\n \n def keys(self, carrier):\n- return []\n+ return [\n+ key[_CARRIER_KEY_PREFIX_LEN:].lower().replace(\"_\", \"-\")\n+ for key in carrier\n+ if key.startswith(_CARRIER_KEY_PREFIX)\n+ ]\n \n \n carrier_getter = CarrierGetter()\n", "issue": "WSGI Carrier Getter always returns an empty list as keys\n**Describe your environment**\r\nNot relevant.\r\n\r\n**Steps to reproduce**\r\n1. Call the method: https://github.com/open-telemetry/opentelemetry-python-contrib/blob/f8e51c488da1f5ab628ba4f5bf25e65638974c44/instrumentation/opentelemetry-instrumentation-wsgi/src/opentelemetry/instrumentation/wsgi/__init__.py#L91\r\n\r\n**What is the expected behavior?**\r\nI would expect all the keys from the provided carrier returned.\r\n\r\n**What is the actual behavior?**\r\nNo matter of the carrier contents an empty list is returned.\r\n\r\n**Additional context**\r\nDue to this behavior other extensions from this repository might not work as expected.\r\nFor example [OT Trace Propagator](https://github.com/open-telemetry/opentelemetry-python-contrib/blob/f8e51c488da1f5ab628ba4f5bf25e65638974c44/propagator/opentelemetry-propagator-ot-trace/src/opentelemetry/propagators/ot_trace/__init__.py#L92) cannot extract baggage information from the carrier, because empty list is always returned.\r\n\n", "before_files": [{"content": "# Copyright The OpenTelemetry Authors\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\"\"\"\nThis library provides a WSGI middleware that can be used on any WSGI framework\n(such as Django / Flask) to track requests timing through OpenTelemetry.\n\nUsage (Flask)\n-------------\n\n.. code-block:: python\n\n from flask import Flask\n from opentelemetry.instrumentation.wsgi import OpenTelemetryMiddleware\n\n app = Flask(__name__)\n app.wsgi_app = OpenTelemetryMiddleware(app.wsgi_app)\n\n @app.route(\"/\")\n def hello():\n return \"Hello!\"\n\n if __name__ == \"__main__\":\n app.run(debug=True)\n\n\nUsage (Django)\n--------------\n\nModify the application's ``wsgi.py`` file as shown below.\n\n.. code-block:: python\n\n import os\n from opentelemetry.instrumentation.wsgi import OpenTelemetryMiddleware\n from django.core.wsgi import get_wsgi_application\n\n os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'application.settings')\n\n application = get_wsgi_application()\n application = OpenTelemetryMiddleware(application)\n\nAPI\n---\n\"\"\"\n\nimport functools\nimport typing\nimport wsgiref.util as wsgiref_util\n\nfrom opentelemetry import context, trace\nfrom opentelemetry.instrumentation.utils import http_status_to_status_code\nfrom opentelemetry.instrumentation.wsgi.version import __version__\nfrom opentelemetry.propagate import extract\nfrom opentelemetry.propagators.textmap import DictGetter\nfrom opentelemetry.trace.status import Status, StatusCode\n\n_HTTP_VERSION_PREFIX = \"HTTP/\"\n\n\nclass CarrierGetter(DictGetter):\n def get(\n self, carrier: dict, key: str\n ) -> typing.Optional[typing.List[str]]:\n \"\"\"Getter implementation to retrieve a HTTP header value from the\n PEP3333-conforming WSGI environ\n\n Args:\n carrier: WSGI environ object\n key: header name in environ object\n Returns:\n A list with a single string with the header value if it exists,\n else None.\n \"\"\"\n environ_key = \"HTTP_\" + key.upper().replace(\"-\", \"_\")\n value = carrier.get(environ_key)\n if value is not None:\n return [value]\n return None\n\n def keys(self, carrier):\n return []\n\n\ncarrier_getter = CarrierGetter()\n\n\ndef setifnotnone(dic, key, value):\n if value is not None:\n dic[key] = value\n\n\ndef collect_request_attributes(environ):\n \"\"\"Collects HTTP request attributes from the PEP3333-conforming\n WSGI environ and returns a dictionary to be used as span creation attributes.\"\"\"\n\n result = {\n \"http.method\": environ.get(\"REQUEST_METHOD\"),\n \"http.server_name\": environ.get(\"SERVER_NAME\"),\n \"http.scheme\": environ.get(\"wsgi.url_scheme\"),\n }\n\n host_port = environ.get(\"SERVER_PORT\")\n if host_port is not None:\n result.update({\"net.host.port\": int(host_port)})\n\n setifnotnone(result, \"http.host\", environ.get(\"HTTP_HOST\"))\n target = environ.get(\"RAW_URI\")\n if target is None: # Note: `\"\" or None is None`\n target = environ.get(\"REQUEST_URI\")\n if target is not None:\n result[\"http.target\"] = target\n else:\n result[\"http.url\"] = wsgiref_util.request_uri(environ)\n\n remote_addr = environ.get(\"REMOTE_ADDR\")\n if remote_addr:\n result[\"net.peer.ip\"] = remote_addr\n remote_host = environ.get(\"REMOTE_HOST\")\n if remote_host and remote_host != remote_addr:\n result[\"net.peer.name\"] = remote_host\n\n user_agent = environ.get(\"HTTP_USER_AGENT\")\n if user_agent is not None and len(user_agent) > 0:\n result[\"http.user_agent\"] = user_agent\n\n setifnotnone(result, \"net.peer.port\", environ.get(\"REMOTE_PORT\"))\n flavor = environ.get(\"SERVER_PROTOCOL\", \"\")\n if flavor.upper().startswith(_HTTP_VERSION_PREFIX):\n flavor = flavor[len(_HTTP_VERSION_PREFIX) :]\n if flavor:\n result[\"http.flavor\"] = flavor\n\n return result\n\n\ndef add_response_attributes(\n span, start_response_status, response_headers\n): # pylint: disable=unused-argument\n \"\"\"Adds HTTP response attributes to span using the arguments\n passed to a PEP3333-conforming start_response callable.\"\"\"\n if not span.is_recording():\n return\n status_code, status_text = start_response_status.split(\" \", 1)\n span.set_attribute(\"http.status_text\", status_text)\n\n try:\n status_code = int(status_code)\n except ValueError:\n span.set_status(\n Status(\n StatusCode.ERROR,\n \"Non-integer HTTP status: \" + repr(status_code),\n )\n )\n else:\n span.set_attribute(\"http.status_code\", status_code)\n span.set_status(Status(http_status_to_status_code(status_code)))\n\n\ndef get_default_span_name(environ):\n \"\"\"Default implementation for name_callback, returns HTTP {METHOD_NAME}.\"\"\"\n return \"HTTP {}\".format(environ.get(\"REQUEST_METHOD\", \"\")).strip()\n\n\nclass OpenTelemetryMiddleware:\n \"\"\"The WSGI application middleware.\n\n This class is a PEP 3333 conforming WSGI middleware that starts and\n annotates spans for any requests it is invoked with.\n\n Args:\n wsgi: The WSGI application callable to forward requests to.\n name_callback: Callback which calculates a generic span name for an\n incoming HTTP request based on the PEP3333 WSGI environ.\n Optional: Defaults to get_default_span_name.\n \"\"\"\n\n def __init__(self, wsgi, name_callback=get_default_span_name):\n self.wsgi = wsgi\n self.tracer = trace.get_tracer(__name__, __version__)\n self.name_callback = name_callback\n\n @staticmethod\n def _create_start_response(span, start_response):\n @functools.wraps(start_response)\n def _start_response(status, response_headers, *args, **kwargs):\n add_response_attributes(span, status, response_headers)\n return start_response(status, response_headers, *args, **kwargs)\n\n return _start_response\n\n def __call__(self, environ, start_response):\n \"\"\"The WSGI application\n\n Args:\n environ: A WSGI environment.\n start_response: The WSGI start_response callable.\n \"\"\"\n\n token = context.attach(extract(carrier_getter, environ))\n span_name = self.name_callback(environ)\n\n span = self.tracer.start_span(\n span_name,\n kind=trace.SpanKind.SERVER,\n attributes=collect_request_attributes(environ),\n )\n\n try:\n with trace.use_span(span):\n start_response = self._create_start_response(\n span, start_response\n )\n iterable = self.wsgi(environ, start_response)\n return _end_span_after_iterating(\n iterable, span, self.tracer, token\n )\n except Exception as ex:\n if span.is_recording():\n span.set_status(Status(StatusCode.ERROR, str(ex)))\n span.end()\n context.detach(token)\n raise\n\n\n# Put this in a subfunction to not delay the call to the wrapped\n# WSGI application (instrumentation should change the application\n# behavior as little as possible).\ndef _end_span_after_iterating(iterable, span, tracer, token):\n try:\n with trace.use_span(span):\n for yielded in iterable:\n yield yielded\n finally:\n close = getattr(iterable, \"close\", None)\n if close:\n close()\n span.end()\n context.detach(token)\n", "path": "instrumentation/opentelemetry-instrumentation-wsgi/src/opentelemetry/instrumentation/wsgi/__init__.py"}]}
| 3,276 | 249 |
gh_patches_debug_499
|
rasdani/github-patches
|
git_diff
|
Pylons__pyramid-1504
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
ASCII apostrophes are replaced with typgraphic apostrophes in the PDF documentation code boxes
In version 1.3.2 of http://media.readthedocs.org/pdf/pyramid/1.3-branch/pyramid.pdf, apostrophes which should be encoded as ASCII (') are replaced with their typographic variants (’). This is correct in running text, but should not happen in code boxes because Python do not understand them:
```
Python 2.7.3 (default, Aug 1 2012, 05:14:39)
[GCC 4.6.3] on linux2
Type "help", "copyright", "credits" or "license" for more information.
>>> a = ’a’
File "<stdin>", line 1
a = ’a’
^
SyntaxError: invalid syntax
```
</issue>
<code>
[start of setup.py]
1 ##############################################################################
2 #
3 # Copyright (c) 2008-2013 Agendaless Consulting and Contributors.
4 # All Rights Reserved.
5 #
6 # This software is subject to the provisions of the BSD-like license at
7 # http://www.repoze.org/LICENSE.txt. A copy of the license should accompany
8 # this distribution. THIS SOFTWARE IS PROVIDED "AS IS" AND ANY AND ALL
9 # EXPRESS OR IMPLIED WARRANTIES ARE DISCLAIMED, INCLUDING, BUT NOT LIMITED TO,
10 # THE IMPLIED WARRANTIES OF TITLE, MERCHANTABILITY, AGAINST INFRINGEMENT, AND
11 # FITNESS FOR A PARTICULAR PURPOSE
12 #
13 ##############################################################################
14
15 import os
16 import sys
17
18 from setuptools import setup, find_packages
19
20 py_version = sys.version_info[:2]
21
22 PY3 = py_version[0] == 3
23
24 if PY3:
25 if py_version < (3, 2):
26 raise RuntimeError('On Python 3, Pyramid requires Python 3.2 or better')
27 else:
28 if py_version < (2, 6):
29 raise RuntimeError('On Python 2, Pyramid requires Python 2.6 or better')
30
31 here = os.path.abspath(os.path.dirname(__file__))
32 try:
33 with open(os.path.join(here, 'README.rst')) as f:
34 README = f.read()
35 with open(os.path.join(here, 'CHANGES.txt')) as f:
36 CHANGES = f.read()
37 except IOError:
38 README = CHANGES = ''
39
40 install_requires=[
41 'setuptools',
42 'WebOb >= 1.3.1', # request.domain and CookieProfile
43 'repoze.lru >= 0.4', # py3 compat
44 'zope.interface >= 3.8.0', # has zope.interface.registry
45 'zope.deprecation >= 3.5.0', # py3 compat
46 'venusian >= 1.0a3', # ``ignore``
47 'translationstring >= 0.4', # py3 compat
48 'PasteDeploy >= 1.5.0', # py3 compat
49 ]
50
51 tests_require = [
52 'WebTest >= 1.3.1', # py3 compat
53 ]
54
55 if not PY3:
56 tests_require.append('zope.component>=3.11.0')
57
58 docs_extras = [
59 'Sphinx',
60 'docutils',
61 'repoze.sphinx.autointerface',
62 ]
63
64 testing_extras = tests_require + [
65 'nose',
66 'coverage',
67 'virtualenv', # for scaffolding tests
68 ]
69
70 setup(name='pyramid',
71 version='1.5.2',
72 description='The Pyramid Web Framework, a Pylons project',
73 long_description=README + '\n\n' + CHANGES,
74 classifiers=[
75 "Intended Audience :: Developers",
76 "Programming Language :: Python",
77 "Programming Language :: Python :: 2.6",
78 "Programming Language :: Python :: 2.7",
79 "Programming Language :: Python :: 3",
80 "Programming Language :: Python :: 3.2",
81 "Programming Language :: Python :: 3.3",
82 "Programming Language :: Python :: 3.4",
83 "Programming Language :: Python :: Implementation :: CPython",
84 "Programming Language :: Python :: Implementation :: PyPy",
85 "Framework :: Pyramid",
86 "Topic :: Internet :: WWW/HTTP",
87 "Topic :: Internet :: WWW/HTTP :: WSGI",
88 "License :: Repoze Public License",
89 ],
90 keywords='web wsgi pylons pyramid',
91 author="Chris McDonough, Agendaless Consulting",
92 author_email="[email protected]",
93 url="http://docs.pylonsproject.org/en/latest/docs/pyramid.html",
94 license="BSD-derived (http://www.repoze.org/LICENSE.txt)",
95 packages=find_packages(),
96 include_package_data=True,
97 zip_safe=False,
98 install_requires = install_requires,
99 extras_require = {
100 'testing':testing_extras,
101 'docs':docs_extras,
102 },
103 tests_require = tests_require,
104 test_suite="pyramid.tests",
105 entry_points = """\
106 [pyramid.scaffold]
107 starter=pyramid.scaffolds:StarterProjectTemplate
108 zodb=pyramid.scaffolds:ZODBProjectTemplate
109 alchemy=pyramid.scaffolds:AlchemyProjectTemplate
110 [console_scripts]
111 pcreate = pyramid.scripts.pcreate:main
112 pserve = pyramid.scripts.pserve:main
113 pshell = pyramid.scripts.pshell:main
114 proutes = pyramid.scripts.proutes:main
115 pviews = pyramid.scripts.pviews:main
116 ptweens = pyramid.scripts.ptweens:main
117 prequest = pyramid.scripts.prequest:main
118 pdistreport = pyramid.scripts.pdistreport:main
119 [paste.server_runner]
120 wsgiref = pyramid.scripts.pserve:wsgiref_server_runner
121 cherrypy = pyramid.scripts.pserve:cherrypy_server_runner
122 """
123 )
124
125
[end of setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -56,7 +56,7 @@
tests_require.append('zope.component>=3.11.0')
docs_extras = [
- 'Sphinx',
+ 'Sphinx >= 1.2.3',
'docutils',
'repoze.sphinx.autointerface',
]
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -56,7 +56,7 @@\n tests_require.append('zope.component>=3.11.0')\n \n docs_extras = [\n- 'Sphinx',\n+ 'Sphinx >= 1.2.3',\n 'docutils',\n 'repoze.sphinx.autointerface',\n ]\n", "issue": "ASCII apostrophes are replaced with typgraphic apostrophes in the PDF documentation code boxes\nIn version 1.3.2 of http://media.readthedocs.org/pdf/pyramid/1.3-branch/pyramid.pdf, apostrophes which should be encoded as ASCII (') are replaced with their typographic variants (\u2019). This is correct in running text, but should not happen in code boxes because Python do not understand them:\n\n```\nPython 2.7.3 (default, Aug 1 2012, 05:14:39) \n[GCC 4.6.3] on linux2\nType \"help\", \"copyright\", \"credits\" or \"license\" for more information.\n>>> a = \u2019a\u2019\n File \"<stdin>\", line 1\n a = \u2019a\u2019\n ^\nSyntaxError: invalid syntax\n```\n\n", "before_files": [{"content": "##############################################################################\n#\n# Copyright (c) 2008-2013 Agendaless Consulting and Contributors.\n# All Rights Reserved.\n#\n# This software is subject to the provisions of the BSD-like license at\n# http://www.repoze.org/LICENSE.txt. A copy of the license should accompany\n# this distribution. THIS SOFTWARE IS PROVIDED \"AS IS\" AND ANY AND ALL\n# EXPRESS OR IMPLIED WARRANTIES ARE DISCLAIMED, INCLUDING, BUT NOT LIMITED TO,\n# THE IMPLIED WARRANTIES OF TITLE, MERCHANTABILITY, AGAINST INFRINGEMENT, AND\n# FITNESS FOR A PARTICULAR PURPOSE\n#\n##############################################################################\n\nimport os\nimport sys\n\nfrom setuptools import setup, find_packages\n\npy_version = sys.version_info[:2]\n\nPY3 = py_version[0] == 3\n\nif PY3:\n if py_version < (3, 2):\n raise RuntimeError('On Python 3, Pyramid requires Python 3.2 or better')\nelse:\n if py_version < (2, 6):\n raise RuntimeError('On Python 2, Pyramid requires Python 2.6 or better')\n\nhere = os.path.abspath(os.path.dirname(__file__))\ntry:\n with open(os.path.join(here, 'README.rst')) as f:\n README = f.read()\n with open(os.path.join(here, 'CHANGES.txt')) as f:\n CHANGES = f.read()\nexcept IOError:\n README = CHANGES = ''\n\ninstall_requires=[\n 'setuptools',\n 'WebOb >= 1.3.1', # request.domain and CookieProfile\n 'repoze.lru >= 0.4', # py3 compat\n 'zope.interface >= 3.8.0', # has zope.interface.registry\n 'zope.deprecation >= 3.5.0', # py3 compat\n 'venusian >= 1.0a3', # ``ignore``\n 'translationstring >= 0.4', # py3 compat\n 'PasteDeploy >= 1.5.0', # py3 compat\n ]\n\ntests_require = [\n 'WebTest >= 1.3.1', # py3 compat\n ]\n\nif not PY3:\n tests_require.append('zope.component>=3.11.0')\n\ndocs_extras = [\n 'Sphinx',\n 'docutils',\n 'repoze.sphinx.autointerface',\n ]\n\ntesting_extras = tests_require + [\n 'nose',\n 'coverage',\n 'virtualenv', # for scaffolding tests\n ]\n\nsetup(name='pyramid',\n version='1.5.2',\n description='The Pyramid Web Framework, a Pylons project',\n long_description=README + '\\n\\n' + CHANGES,\n classifiers=[\n \"Intended Audience :: Developers\",\n \"Programming Language :: Python\",\n \"Programming Language :: Python :: 2.6\",\n \"Programming Language :: Python :: 2.7\",\n \"Programming Language :: Python :: 3\",\n \"Programming Language :: Python :: 3.2\",\n \"Programming Language :: Python :: 3.3\",\n \"Programming Language :: Python :: 3.4\",\n \"Programming Language :: Python :: Implementation :: CPython\",\n \"Programming Language :: Python :: Implementation :: PyPy\",\n \"Framework :: Pyramid\",\n \"Topic :: Internet :: WWW/HTTP\",\n \"Topic :: Internet :: WWW/HTTP :: WSGI\",\n \"License :: Repoze Public License\",\n ],\n keywords='web wsgi pylons pyramid',\n author=\"Chris McDonough, Agendaless Consulting\",\n author_email=\"[email protected]\",\n url=\"http://docs.pylonsproject.org/en/latest/docs/pyramid.html\",\n license=\"BSD-derived (http://www.repoze.org/LICENSE.txt)\",\n packages=find_packages(),\n include_package_data=True,\n zip_safe=False,\n install_requires = install_requires,\n extras_require = {\n 'testing':testing_extras,\n 'docs':docs_extras,\n },\n tests_require = tests_require,\n test_suite=\"pyramid.tests\",\n entry_points = \"\"\"\\\n [pyramid.scaffold]\n starter=pyramid.scaffolds:StarterProjectTemplate\n zodb=pyramid.scaffolds:ZODBProjectTemplate\n alchemy=pyramid.scaffolds:AlchemyProjectTemplate\n [console_scripts]\n pcreate = pyramid.scripts.pcreate:main\n pserve = pyramid.scripts.pserve:main\n pshell = pyramid.scripts.pshell:main\n proutes = pyramid.scripts.proutes:main\n pviews = pyramid.scripts.pviews:main\n ptweens = pyramid.scripts.ptweens:main\n prequest = pyramid.scripts.prequest:main\n pdistreport = pyramid.scripts.pdistreport:main\n [paste.server_runner]\n wsgiref = pyramid.scripts.pserve:wsgiref_server_runner\n cherrypy = pyramid.scripts.pserve:cherrypy_server_runner\n \"\"\"\n )\n\n", "path": "setup.py"}]}
| 2,060 | 91 |
gh_patches_debug_4948
|
rasdani/github-patches
|
git_diff
|
ansible__ansible-11626
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
devel bug - profile_tasks.py requires CALLBACK_ constants or the display param is not passed
relates to #11625 and commit a09f623
```
$ ansible-playbook plays/test_to_json.yml -vvv
Using /Users/glynch/vagrant/ansible_foo/ansible.cfg as config file
1 plays in plays/test_to_json.yml
[ERROR]: Unexpected Exception: __init__() takes exactly 2 arguments (1 given)
the full traceback was:
Traceback (most recent call last):
File "/Users/glynch/dev/ansible/bin/ansible-playbook", line 77, in <module>
sys.exit(cli.run())
File "/Users/glynch/dev/ansible/lib/ansible/cli/playbook.py", line 162, in run
results = pbex.run()
File "/Users/glynch/dev/ansible/lib/ansible/executor/playbook_executor.py", line 128, in run
self._tqm.load_callbacks()
File "/Users/glynch/dev/ansible/lib/ansible/executor/task_queue_manager.py", line 154, in load_callbacks
self._callback_plugins.append(callback_plugin())
TypeError: __init__() takes exactly 2 arguments (1 given)
```
</issue>
<code>
[start of lib/ansible/plugins/callback/profile_tasks.py]
1 # (C) 2015, Tom Paine, <[email protected]>
2 # (C) 2014, Jharrod LaFon, @JharrodLaFon
3 # (C) 2012-2013, Michael DeHaan, <[email protected]>
4 #
5 # This file is free software: you can redistribute it and/or modify
6 # it under the terms of the GNU General Public License as published by
7 # the Free Software Foundation, either version 3 of the License, or
8 # (at your option) any later version.
9 #
10 # File is distributed in the hope that it will be useful,
11 # but WITHOUT ANY WARRANTY; without even the implied warranty of
12 # MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
13 # GNU General Public License for more details.
14 #
15 # See <http://www.gnu.org/licenses/> for a copy of the
16 # GNU General Public License
17
18 # Provides per-task timing, ongoing playbook elapsed time and
19 # ordered list of top 20 longest running tasks at end
20
21 import time
22
23 from ansible.plugins.callback import CallbackBase
24
25 # define start time
26 t0 = tn = time.time()
27
28 def secondsToStr(t):
29 # http://bytes.com/topic/python/answers/635958-handy-short-cut-formatting-elapsed-time-floating-point-seconds
30 rediv = lambda ll, b: list(divmod(ll[0], b)) + ll[1:]
31 return "%d:%02d:%02d.%03d" % tuple(reduce(rediv, [[t * 1000, ], 1000, 60, 60]))
32
33
34 def filled(msg, fchar="*"):
35 if len(msg) == 0:
36 width = 79
37 else:
38 msg = "%s " % msg
39 width = 79 - len(msg)
40 if width < 3:
41 width = 3
42 filler = fchar * width
43 return "%s%s " % (msg, filler)
44
45
46 def timestamp(self):
47 if self.current is not None:
48 self.stats[self.current] = time.time() - self.stats[self.current]
49
50
51 def tasktime():
52 global tn
53 time_current = time.strftime('%A %d %B %Y %H:%M:%S %z')
54 time_elapsed = secondsToStr(time.time() - tn)
55 time_total_elapsed = secondsToStr(time.time() - t0)
56 display(filled('%s (%s)%s%s' % (time_current, time_elapsed, ' ' * 7, time_total_elapsed)))
57 tn = time.time()
58
59
60 class CallbackModule(CallbackBase):
61
62 def __init__(self, display):
63 self.stats = {}
64 self.current = None
65
66 super(CallbackModule, self).__init__(display)
67
68
69 def playbook_on_task_start(self, name, is_conditional):
70 """
71 Logs the start of each task
72 """
73 tasktime()
74 timestamp(self)
75
76 # Record the start time of the current task
77 self.current = name
78 self.stats[self.current] = time.time()
79
80 def playbook_on_setup(self):
81 tasktime()
82
83 def playbook_on_stats(self, stats):
84 tasktime()
85 display(filled("", fchar="="))
86
87 timestamp(self)
88
89 # Sort the tasks by their running time
90 results = sorted(
91 self.stats.items(),
92 key=lambda value: value[1],
93 reverse=True,
94 )
95
96 # Just keep the top 20
97 results = results[:20]
98
99 # Print the timings
100 for name, elapsed in results:
101 self.display.display(
102 "{0:-<70}{1:->9}".format(
103 '{0} '.format(name),
104 ' {0:.02f}s'.format(elapsed),
105 )
106 )
107
[end of lib/ansible/plugins/callback/profile_tasks.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/lib/ansible/plugins/callback/profile_tasks.py b/lib/ansible/plugins/callback/profile_tasks.py
--- a/lib/ansible/plugins/callback/profile_tasks.py
+++ b/lib/ansible/plugins/callback/profile_tasks.py
@@ -58,7 +58,14 @@
class CallbackModule(CallbackBase):
-
+ """
+ This callback module provides per-task timing, ongoing playbook elapsed time
+ and ordered list of top 20 longest running tasks at end.
+ """
+ CALLBACK_VERSION = 2.0
+ CALLBACK_TYPE = 'aggregate'
+ CALLBACK_NAME = 'profile_tasks'
+
def __init__(self, display):
self.stats = {}
self.current = None
|
{"golden_diff": "diff --git a/lib/ansible/plugins/callback/profile_tasks.py b/lib/ansible/plugins/callback/profile_tasks.py\n--- a/lib/ansible/plugins/callback/profile_tasks.py\n+++ b/lib/ansible/plugins/callback/profile_tasks.py\n@@ -58,7 +58,14 @@\n \n \n class CallbackModule(CallbackBase):\n-\n+ \"\"\"\n+ This callback module provides per-task timing, ongoing playbook elapsed time \n+ and ordered list of top 20 longest running tasks at end.\n+ \"\"\"\n+ CALLBACK_VERSION = 2.0\n+ CALLBACK_TYPE = 'aggregate'\n+ CALLBACK_NAME = 'profile_tasks'\n+ \n def __init__(self, display):\n self.stats = {}\n self.current = None\n", "issue": "devel bug - profile_tasks.py requires CALLBACK_ constants or the display param is not passed\nrelates to #11625 and commit a09f623\n\n```\n$ ansible-playbook plays/test_to_json.yml -vvv\nUsing /Users/glynch/vagrant/ansible_foo/ansible.cfg as config file\n1 plays in plays/test_to_json.yml\n [ERROR]: Unexpected Exception: __init__() takes exactly 2 arguments (1 given)\n\nthe full traceback was:\n\nTraceback (most recent call last):\n File \"/Users/glynch/dev/ansible/bin/ansible-playbook\", line 77, in <module>\n sys.exit(cli.run())\n File \"/Users/glynch/dev/ansible/lib/ansible/cli/playbook.py\", line 162, in run\n results = pbex.run()\n File \"/Users/glynch/dev/ansible/lib/ansible/executor/playbook_executor.py\", line 128, in run\n self._tqm.load_callbacks()\n File \"/Users/glynch/dev/ansible/lib/ansible/executor/task_queue_manager.py\", line 154, in load_callbacks\n self._callback_plugins.append(callback_plugin())\nTypeError: __init__() takes exactly 2 arguments (1 given)\n```\n\n", "before_files": [{"content": "# (C) 2015, Tom Paine, <[email protected]>\n# (C) 2014, Jharrod LaFon, @JharrodLaFon\n# (C) 2012-2013, Michael DeHaan, <[email protected]>\n#\n# This file is free software: you can redistribute it and/or modify\n# it under the terms of the GNU General Public License as published by\n# the Free Software Foundation, either version 3 of the License, or\n# (at your option) any later version.\n#\n# File is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU General Public License for more details.\n#\n# See <http://www.gnu.org/licenses/> for a copy of the\n# GNU General Public License\n\n# Provides per-task timing, ongoing playbook elapsed time and\n# ordered list of top 20 longest running tasks at end\n\nimport time\n\nfrom ansible.plugins.callback import CallbackBase\n\n# define start time\nt0 = tn = time.time()\n\ndef secondsToStr(t):\n # http://bytes.com/topic/python/answers/635958-handy-short-cut-formatting-elapsed-time-floating-point-seconds\n rediv = lambda ll, b: list(divmod(ll[0], b)) + ll[1:]\n return \"%d:%02d:%02d.%03d\" % tuple(reduce(rediv, [[t * 1000, ], 1000, 60, 60]))\n\n\ndef filled(msg, fchar=\"*\"):\n if len(msg) == 0:\n width = 79\n else:\n msg = \"%s \" % msg\n width = 79 - len(msg)\n if width < 3:\n width = 3\n filler = fchar * width\n return \"%s%s \" % (msg, filler)\n\n\ndef timestamp(self):\n if self.current is not None:\n self.stats[self.current] = time.time() - self.stats[self.current]\n\n\ndef tasktime():\n global tn\n time_current = time.strftime('%A %d %B %Y %H:%M:%S %z')\n time_elapsed = secondsToStr(time.time() - tn)\n time_total_elapsed = secondsToStr(time.time() - t0)\n display(filled('%s (%s)%s%s' % (time_current, time_elapsed, ' ' * 7, time_total_elapsed)))\n tn = time.time()\n\n\nclass CallbackModule(CallbackBase):\n\n def __init__(self, display):\n self.stats = {}\n self.current = None\n\n super(CallbackModule, self).__init__(display)\n\n\n def playbook_on_task_start(self, name, is_conditional):\n \"\"\"\n Logs the start of each task\n \"\"\"\n tasktime()\n timestamp(self)\n\n # Record the start time of the current task\n self.current = name\n self.stats[self.current] = time.time()\n\n def playbook_on_setup(self):\n tasktime()\n\n def playbook_on_stats(self, stats):\n tasktime()\n display(filled(\"\", fchar=\"=\"))\n\n timestamp(self)\n\n # Sort the tasks by their running time\n results = sorted(\n self.stats.items(),\n key=lambda value: value[1],\n reverse=True,\n )\n\n # Just keep the top 20\n results = results[:20]\n\n # Print the timings\n for name, elapsed in results:\n self.display.display(\n \"{0:-<70}{1:->9}\".format(\n '{0} '.format(name),\n ' {0:.02f}s'.format(elapsed),\n )\n )\n", "path": "lib/ansible/plugins/callback/profile_tasks.py"}]}
| 1,862 | 152 |
gh_patches_debug_25717
|
rasdani/github-patches
|
git_diff
|
Lightning-Universe__lightning-flash-431
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Docs build lottery
## 🐛 Bug
@ehofesmann We still seem to be getting this issue:
```
intersphinx inventory 'https://voxel51.com/docs/fiftyone/objects.inv' not fetchable due to <class 'requests.exceptions.ConnectionError'>: HTTPSConnectionPool(host='voxel51.com', port=443): Max retries exceeded with url: /docs/fiftyone/objects.inv (Caused by NewConnectionError('<urllib3.connection.HTTPSConnection object at 0x7f5fbc2d56d0>: Failed to establish a new connection: [Errno 110] Connection timed out'))
```
Example here: https://github.com/PyTorchLightning/lightning-flash/pull/426/checks?check_run_id=2860706755
Is it because we have multiple CI trying to get it at once?
I think for now we can probably try to just ignore that warning, but would be interested to know the root cause. @Borda any idea how we can ignore just a specific warning in sphinx build? Or any idea what might be causing the issue?
(Just to provide some context, we typically get the error then I re-trigger the build and it's fine)
</issue>
<code>
[start of flash/core/utilities/imports.py]
1 # Copyright The PyTorch Lightning team.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14 """General utilities"""
15 import importlib
16 import operator
17 from importlib.util import find_spec
18
19 from pkg_resources import DistributionNotFound
20
21 try:
22 from packaging.version import Version
23 except (ModuleNotFoundError, DistributionNotFound):
24 Version = None
25
26
27 def _module_available(module_path: str) -> bool:
28 """
29 Check if a path is available in your environment
30
31 >>> _module_available('os')
32 True
33 >>> _module_available('bla.bla')
34 False
35 """
36 try:
37 return find_spec(module_path) is not None
38 except AttributeError:
39 # Python 3.6
40 return False
41 except ModuleNotFoundError:
42 # Python 3.7+
43 return False
44
45
46 def _compare_version(package: str, op, version) -> bool:
47 """
48 Compare package version with some requirements
49
50 >>> _compare_version("torch", operator.ge, "0.1")
51 True
52 """
53 try:
54 pkg = importlib.import_module(package)
55 except (ModuleNotFoundError, DistributionNotFound, ValueError):
56 return False
57 try:
58 pkg_version = Version(pkg.__version__)
59 except TypeError:
60 # this is mock by sphinx, so it shall return True ro generate all summaries
61 return True
62 return op(pkg_version, Version(version))
63
64
65 _TORCH_AVAILABLE = _module_available("torch")
66 _BOLTS_AVAILABLE = _module_available("pl_bolts") and _compare_version("torch", operator.lt, "1.9.0")
67 _PANDAS_AVAILABLE = _module_available("pandas")
68 _SKLEARN_AVAILABLE = _module_available("sklearn")
69 _TABNET_AVAILABLE = _module_available("pytorch_tabnet")
70 _KORNIA_AVAILABLE = _module_available("kornia")
71 _COCO_AVAILABLE = _module_available("pycocotools")
72 _TIMM_AVAILABLE = _module_available("timm")
73 _TORCHVISION_AVAILABLE = _module_available("torchvision")
74 _PYTORCHVIDEO_AVAILABLE = _module_available("pytorchvideo")
75 _MATPLOTLIB_AVAILABLE = _module_available("matplotlib")
76 _TRANSFORMERS_AVAILABLE = _module_available("transformers")
77 _PYSTICHE_AVAILABLE = _module_available("pystiche")
78 _FIFTYONE_AVAILABLE = _module_available("fiftyone")
79 _FASTAPI_AVAILABLE = _module_available("fastapi")
80 _PYDANTIC_AVAILABLE = _module_available("pydantic")
81 _GRAPHVIZ_AVAILABLE = _module_available("graphviz")
82 _CYTOOLZ_AVAILABLE = _module_available("cytoolz")
83 _UVICORN_AVAILABLE = _module_available("uvicorn")
84 _PIL_AVAILABLE = _module_available("PIL")
85
86 if Version:
87 _TORCHVISION_GREATER_EQUAL_0_9 = _compare_version("torchvision", operator.ge, "0.9.0")
88 _PYSTICHE_GREATER_EQUAL_0_7_2 = _compare_version("pystiche", operator.ge, "0.7.2")
89
90 _IMAGE_STLYE_TRANSFER = _PYSTICHE_AVAILABLE
91 _TEXT_AVAILABLE = _TRANSFORMERS_AVAILABLE
92 _TABULAR_AVAILABLE = _TABNET_AVAILABLE and _PANDAS_AVAILABLE
93 _VIDEO_AVAILABLE = _PYTORCHVIDEO_AVAILABLE
94 _IMAGE_AVAILABLE = _TORCHVISION_AVAILABLE and _TIMM_AVAILABLE and _PIL_AVAILABLE and _KORNIA_AVAILABLE and\
95 _MATPLOTLIB_AVAILABLE and _COCO_AVAILABLE and _FIFTYONE_AVAILABLE
96 _SERVE_AVAILABLE = _FASTAPI_AVAILABLE and _PYDANTIC_AVAILABLE and _CYTOOLZ_AVAILABLE and _UVICORN_AVAILABLE
97
[end of flash/core/utilities/imports.py]
[start of docs/source/conf.py]
1 # Configuration file for the Sphinx documentation builder.
2 #
3 # This file only contains a selection of the most common options. For a full
4 # list see the documentation:
5 # https://www.sphinx-doc.org/en/master/usage/configuration.html
6
7 # -- Path setup --------------------------------------------------------------
8
9 # If extensions (or modules to document with autodoc) are in another directory,
10 # add these directories to sys.path here. If the directory is relative to the
11 # documentation root, use os.path.abspath to make it absolute, like shown here.
12 #
13 import os
14 import sys
15 from importlib.util import module_from_spec, spec_from_file_location
16
17 import pt_lightning_sphinx_theme
18
19 _PATH_HERE = os.path.abspath(os.path.dirname(__file__))
20 _PATH_ROOT = os.path.join(_PATH_HERE, '..', '..')
21 sys.path.insert(0, os.path.abspath(_PATH_ROOT))
22
23 try:
24 from flash import __about__ as about
25
26 except ModuleNotFoundError:
27
28 def _load_py_module(fname, pkg="flash"):
29 spec = spec_from_file_location(os.path.join(pkg, fname), os.path.join(_PATH_ROOT, pkg, fname))
30 py = module_from_spec(spec)
31 spec.loader.exec_module(py)
32 return py
33
34 about = _load_py_module("__about__.py")
35
36 SPHINX_MOCK_REQUIREMENTS = int(os.environ.get('SPHINX_MOCK_REQUIREMENTS', True))
37
38 html_favicon = '_static/images/icon.svg'
39
40 # -- Project information -----------------------------------------------------
41
42 project = "Flash"
43 copyright = "2020-2021, PyTorch Lightning"
44 author = "PyTorch Lightning"
45
46 # -- General configuration ---------------------------------------------------
47
48 # Add any Sphinx extension module names here, as strings. They can be
49 # extensions coming with Sphinx (named 'sphinx.ext.*') or your custom
50 # ones.
51 extensions = [
52 'sphinx.ext.autodoc',
53 'sphinx.ext.doctest',
54 'sphinx.ext.intersphinx',
55 # 'sphinx.ext.todo',
56 # 'sphinx.ext.coverage',
57 'sphinx.ext.viewcode',
58 'sphinx.ext.autosummary',
59 'sphinx.ext.napoleon',
60 'sphinx.ext.imgmath',
61 'recommonmark',
62 # 'sphinx.ext.autosectionlabel',
63 # 'nbsphinx', # it seems some sphinx issue
64 'sphinx_autodoc_typehints',
65 'sphinx_copybutton',
66 'sphinx_paramlinks',
67 'sphinx_togglebutton',
68 ]
69
70 # autodoc: Default to members and undoc-members
71 autodoc_default_options = {"members": True}
72
73 # autodoc: Don't inherit docstrings (e.g. for nn.Module.forward)
74 autodoc_inherit_docstrings = False
75
76 # Add any paths that contain templates here, relative to this directory.
77 templates_path = ["_templates"]
78
79 # List of patterns, relative to source directory, that match files and
80 # directories to ignore when looking for source files.
81 # This pattern also affects html_static_path and html_extra_path.
82 exclude_patterns = []
83
84 # The suffix(es) of source filenames.
85 # You can specify multiple suffix as a list of string:
86 #
87 source_suffix = [".rst", ".md"]
88
89 needs_sphinx = "4.0"
90
91 # -- Options for intersphinx extension ---------------------------------------
92
93 # Example configuration for intersphinx: refer to the Python standard library.
94 intersphinx_mapping = {
95 "python": ("https://docs.python.org/3", None),
96 "torch": ("https://pytorch.org/docs/stable/", None),
97 "numpy": ("https://numpy.org/doc/stable/", None),
98 "PIL": ("https://pillow.readthedocs.io/en/stable/", None),
99 "pytorchvideo": ("https://pytorchvideo.readthedocs.io/en/latest/", None),
100 "pytorch_lightning": ("https://pytorch-lightning.readthedocs.io/en/stable/", None),
101 "fiftyone": ("https://voxel51.com/docs/fiftyone/", None),
102 }
103
104 # -- Options for HTML output -------------------------------------------------
105
106 # The theme to use for HTML and HTML Help pages. See the documentation for
107 # a list of builtin themes.
108 #
109 html_theme = "pt_lightning_sphinx_theme"
110 html_theme_path = [pt_lightning_sphinx_theme.get_html_theme_path()]
111
112 # Theme options are theme-specific and customize the look and feel of a theme
113 # further. For a list of options available for each theme, see the
114 # documentation.
115
116 html_theme_options = {
117 'pytorch_project': 'https://pytorchlightning.ai',
118 'canonical_url': about.__docs_url__,
119 "collapse_navigation": False,
120 "display_version": True,
121 "logo_only": False,
122 }
123
124 # Add any paths that contain custom static files (such as style sheets) here,
125 # relative to this directory. They are copied after the builtin static files,
126 # so a file named "default.css" will overwrite the builtin "default.css".
127 html_static_path = ["_static"]
128
129 html_css_files = []
130
131
132 def setup(app):
133 # this is for hiding doctest decoration,
134 # see: http://z4r.github.io/python/2011/12/02/hides-the-prompts-and-output/
135 app.add_js_file('copybutton.js')
136
137
138 # Ignoring Third-party packages
139 # https://stackoverflow.com/questions/15889621/sphinx-how-to-exclude-imports-in-automodule
140 def _package_list_from_file(pfile):
141 assert os.path.isfile(pfile)
142 with open(pfile, 'r') as fp:
143 lines = fp.readlines()
144 list_pkgs = []
145 for ln in lines:
146 found = [ln.index(ch) for ch in list(',=<>#@') if ch in ln]
147 pkg = ln[:min(found)] if found else ln
148 if pkg.strip():
149 list_pkgs.append(pkg.strip())
150 return list_pkgs
151
152
153 # define mapping from PyPI names to python imports
154 PACKAGE_MAPPING = {
155 'pytorch-lightning': 'pytorch_lightning',
156 'scikit-learn': 'sklearn',
157 'Pillow': 'PIL',
158 'PyYAML': 'yaml',
159 'rouge-score': 'rouge_score',
160 'lightning-bolts': 'pl_bolts',
161 'pytorch-tabnet': 'pytorch_tabnet',
162 'pyDeprecate': 'deprecate',
163 }
164 MOCK_PACKAGES = []
165 if SPHINX_MOCK_REQUIREMENTS:
166 # mock also base packages when we are on RTD since we don't install them there
167 MOCK_PACKAGES += _package_list_from_file(os.path.join(_PATH_ROOT, 'requirements.txt'))
168 # replace PyPI packages by importing ones
169 MOCK_PACKAGES = [PACKAGE_MAPPING.get(pkg, pkg) for pkg in MOCK_PACKAGES]
170
171 autodoc_mock_imports = MOCK_PACKAGES
172
173 # only run doctests marked with a ".. doctest::" directive
174 doctest_test_doctest_blocks = ''
175 doctest_global_setup = """
176 import torch
177 import pytorch_lightning as pl
178 import flash
179 """
180
[end of docs/source/conf.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/docs/source/conf.py b/docs/source/conf.py
--- a/docs/source/conf.py
+++ b/docs/source/conf.py
@@ -98,7 +98,7 @@
"PIL": ("https://pillow.readthedocs.io/en/stable/", None),
"pytorchvideo": ("https://pytorchvideo.readthedocs.io/en/latest/", None),
"pytorch_lightning": ("https://pytorch-lightning.readthedocs.io/en/stable/", None),
- "fiftyone": ("https://voxel51.com/docs/fiftyone/", None),
+ "fiftyone": ("https://voxel51.com/docs/fiftyone/", "fiftyone_objects.inv"),
}
# -- Options for HTML output -------------------------------------------------
diff --git a/flash/core/utilities/imports.py b/flash/core/utilities/imports.py
--- a/flash/core/utilities/imports.py
+++ b/flash/core/utilities/imports.py
@@ -91,6 +91,13 @@
_TEXT_AVAILABLE = _TRANSFORMERS_AVAILABLE
_TABULAR_AVAILABLE = _TABNET_AVAILABLE and _PANDAS_AVAILABLE
_VIDEO_AVAILABLE = _PYTORCHVIDEO_AVAILABLE
-_IMAGE_AVAILABLE = _TORCHVISION_AVAILABLE and _TIMM_AVAILABLE and _PIL_AVAILABLE and _KORNIA_AVAILABLE and\
- _MATPLOTLIB_AVAILABLE and _COCO_AVAILABLE and _FIFTYONE_AVAILABLE
+_IMAGE_AVAILABLE = all([
+ _TORCHVISION_AVAILABLE,
+ _TIMM_AVAILABLE,
+ _PIL_AVAILABLE,
+ _KORNIA_AVAILABLE,
+ _MATPLOTLIB_AVAILABLE,
+ _COCO_AVAILABLE,
+ _FIFTYONE_AVAILABLE,
+])
_SERVE_AVAILABLE = _FASTAPI_AVAILABLE and _PYDANTIC_AVAILABLE and _CYTOOLZ_AVAILABLE and _UVICORN_AVAILABLE
|
{"golden_diff": "diff --git a/docs/source/conf.py b/docs/source/conf.py\n--- a/docs/source/conf.py\n+++ b/docs/source/conf.py\n@@ -98,7 +98,7 @@\n \"PIL\": (\"https://pillow.readthedocs.io/en/stable/\", None),\n \"pytorchvideo\": (\"https://pytorchvideo.readthedocs.io/en/latest/\", None),\n \"pytorch_lightning\": (\"https://pytorch-lightning.readthedocs.io/en/stable/\", None),\n- \"fiftyone\": (\"https://voxel51.com/docs/fiftyone/\", None),\n+ \"fiftyone\": (\"https://voxel51.com/docs/fiftyone/\", \"fiftyone_objects.inv\"),\n }\n \n # -- Options for HTML output -------------------------------------------------\ndiff --git a/flash/core/utilities/imports.py b/flash/core/utilities/imports.py\n--- a/flash/core/utilities/imports.py\n+++ b/flash/core/utilities/imports.py\n@@ -91,6 +91,13 @@\n _TEXT_AVAILABLE = _TRANSFORMERS_AVAILABLE\n _TABULAR_AVAILABLE = _TABNET_AVAILABLE and _PANDAS_AVAILABLE\n _VIDEO_AVAILABLE = _PYTORCHVIDEO_AVAILABLE\n-_IMAGE_AVAILABLE = _TORCHVISION_AVAILABLE and _TIMM_AVAILABLE and _PIL_AVAILABLE and _KORNIA_AVAILABLE and\\\n- _MATPLOTLIB_AVAILABLE and _COCO_AVAILABLE and _FIFTYONE_AVAILABLE\n+_IMAGE_AVAILABLE = all([\n+ _TORCHVISION_AVAILABLE,\n+ _TIMM_AVAILABLE,\n+ _PIL_AVAILABLE,\n+ _KORNIA_AVAILABLE,\n+ _MATPLOTLIB_AVAILABLE,\n+ _COCO_AVAILABLE,\n+ _FIFTYONE_AVAILABLE,\n+])\n _SERVE_AVAILABLE = _FASTAPI_AVAILABLE and _PYDANTIC_AVAILABLE and _CYTOOLZ_AVAILABLE and _UVICORN_AVAILABLE\n", "issue": "Docs build lottery\n## \ud83d\udc1b Bug\r\n\r\n@ehofesmann We still seem to be getting this issue:\r\n```\r\nintersphinx inventory 'https://voxel51.com/docs/fiftyone/objects.inv' not fetchable due to <class 'requests.exceptions.ConnectionError'>: HTTPSConnectionPool(host='voxel51.com', port=443): Max retries exceeded with url: /docs/fiftyone/objects.inv (Caused by NewConnectionError('<urllib3.connection.HTTPSConnection object at 0x7f5fbc2d56d0>: Failed to establish a new connection: [Errno 110] Connection timed out'))\r\n```\r\nExample here: https://github.com/PyTorchLightning/lightning-flash/pull/426/checks?check_run_id=2860706755\r\n\r\nIs it because we have multiple CI trying to get it at once?\r\n\r\nI think for now we can probably try to just ignore that warning, but would be interested to know the root cause. @Borda any idea how we can ignore just a specific warning in sphinx build? Or any idea what might be causing the issue?\r\n\r\n(Just to provide some context, we typically get the error then I re-trigger the build and it's fine)\n", "before_files": [{"content": "# Copyright The PyTorch Lightning team.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\"\"\"General utilities\"\"\"\nimport importlib\nimport operator\nfrom importlib.util import find_spec\n\nfrom pkg_resources import DistributionNotFound\n\ntry:\n from packaging.version import Version\nexcept (ModuleNotFoundError, DistributionNotFound):\n Version = None\n\n\ndef _module_available(module_path: str) -> bool:\n \"\"\"\n Check if a path is available in your environment\n\n >>> _module_available('os')\n True\n >>> _module_available('bla.bla')\n False\n \"\"\"\n try:\n return find_spec(module_path) is not None\n except AttributeError:\n # Python 3.6\n return False\n except ModuleNotFoundError:\n # Python 3.7+\n return False\n\n\ndef _compare_version(package: str, op, version) -> bool:\n \"\"\"\n Compare package version with some requirements\n\n >>> _compare_version(\"torch\", operator.ge, \"0.1\")\n True\n \"\"\"\n try:\n pkg = importlib.import_module(package)\n except (ModuleNotFoundError, DistributionNotFound, ValueError):\n return False\n try:\n pkg_version = Version(pkg.__version__)\n except TypeError:\n # this is mock by sphinx, so it shall return True ro generate all summaries\n return True\n return op(pkg_version, Version(version))\n\n\n_TORCH_AVAILABLE = _module_available(\"torch\")\n_BOLTS_AVAILABLE = _module_available(\"pl_bolts\") and _compare_version(\"torch\", operator.lt, \"1.9.0\")\n_PANDAS_AVAILABLE = _module_available(\"pandas\")\n_SKLEARN_AVAILABLE = _module_available(\"sklearn\")\n_TABNET_AVAILABLE = _module_available(\"pytorch_tabnet\")\n_KORNIA_AVAILABLE = _module_available(\"kornia\")\n_COCO_AVAILABLE = _module_available(\"pycocotools\")\n_TIMM_AVAILABLE = _module_available(\"timm\")\n_TORCHVISION_AVAILABLE = _module_available(\"torchvision\")\n_PYTORCHVIDEO_AVAILABLE = _module_available(\"pytorchvideo\")\n_MATPLOTLIB_AVAILABLE = _module_available(\"matplotlib\")\n_TRANSFORMERS_AVAILABLE = _module_available(\"transformers\")\n_PYSTICHE_AVAILABLE = _module_available(\"pystiche\")\n_FIFTYONE_AVAILABLE = _module_available(\"fiftyone\")\n_FASTAPI_AVAILABLE = _module_available(\"fastapi\")\n_PYDANTIC_AVAILABLE = _module_available(\"pydantic\")\n_GRAPHVIZ_AVAILABLE = _module_available(\"graphviz\")\n_CYTOOLZ_AVAILABLE = _module_available(\"cytoolz\")\n_UVICORN_AVAILABLE = _module_available(\"uvicorn\")\n_PIL_AVAILABLE = _module_available(\"PIL\")\n\nif Version:\n _TORCHVISION_GREATER_EQUAL_0_9 = _compare_version(\"torchvision\", operator.ge, \"0.9.0\")\n _PYSTICHE_GREATER_EQUAL_0_7_2 = _compare_version(\"pystiche\", operator.ge, \"0.7.2\")\n\n_IMAGE_STLYE_TRANSFER = _PYSTICHE_AVAILABLE\n_TEXT_AVAILABLE = _TRANSFORMERS_AVAILABLE\n_TABULAR_AVAILABLE = _TABNET_AVAILABLE and _PANDAS_AVAILABLE\n_VIDEO_AVAILABLE = _PYTORCHVIDEO_AVAILABLE\n_IMAGE_AVAILABLE = _TORCHVISION_AVAILABLE and _TIMM_AVAILABLE and _PIL_AVAILABLE and _KORNIA_AVAILABLE and\\\n _MATPLOTLIB_AVAILABLE and _COCO_AVAILABLE and _FIFTYONE_AVAILABLE\n_SERVE_AVAILABLE = _FASTAPI_AVAILABLE and _PYDANTIC_AVAILABLE and _CYTOOLZ_AVAILABLE and _UVICORN_AVAILABLE\n", "path": "flash/core/utilities/imports.py"}, {"content": "# Configuration file for the Sphinx documentation builder.\n#\n# This file only contains a selection of the most common options. For a full\n# list see the documentation:\n# https://www.sphinx-doc.org/en/master/usage/configuration.html\n\n# -- Path setup --------------------------------------------------------------\n\n# If extensions (or modules to document with autodoc) are in another directory,\n# add these directories to sys.path here. If the directory is relative to the\n# documentation root, use os.path.abspath to make it absolute, like shown here.\n#\nimport os\nimport sys\nfrom importlib.util import module_from_spec, spec_from_file_location\n\nimport pt_lightning_sphinx_theme\n\n_PATH_HERE = os.path.abspath(os.path.dirname(__file__))\n_PATH_ROOT = os.path.join(_PATH_HERE, '..', '..')\nsys.path.insert(0, os.path.abspath(_PATH_ROOT))\n\ntry:\n from flash import __about__ as about\n\nexcept ModuleNotFoundError:\n\n def _load_py_module(fname, pkg=\"flash\"):\n spec = spec_from_file_location(os.path.join(pkg, fname), os.path.join(_PATH_ROOT, pkg, fname))\n py = module_from_spec(spec)\n spec.loader.exec_module(py)\n return py\n\n about = _load_py_module(\"__about__.py\")\n\nSPHINX_MOCK_REQUIREMENTS = int(os.environ.get('SPHINX_MOCK_REQUIREMENTS', True))\n\nhtml_favicon = '_static/images/icon.svg'\n\n# -- Project information -----------------------------------------------------\n\nproject = \"Flash\"\ncopyright = \"2020-2021, PyTorch Lightning\"\nauthor = \"PyTorch Lightning\"\n\n# -- General configuration ---------------------------------------------------\n\n# Add any Sphinx extension module names here, as strings. They can be\n# extensions coming with Sphinx (named 'sphinx.ext.*') or your custom\n# ones.\nextensions = [\n 'sphinx.ext.autodoc',\n 'sphinx.ext.doctest',\n 'sphinx.ext.intersphinx',\n # 'sphinx.ext.todo',\n # 'sphinx.ext.coverage',\n 'sphinx.ext.viewcode',\n 'sphinx.ext.autosummary',\n 'sphinx.ext.napoleon',\n 'sphinx.ext.imgmath',\n 'recommonmark',\n # 'sphinx.ext.autosectionlabel',\n # 'nbsphinx', # it seems some sphinx issue\n 'sphinx_autodoc_typehints',\n 'sphinx_copybutton',\n 'sphinx_paramlinks',\n 'sphinx_togglebutton',\n]\n\n# autodoc: Default to members and undoc-members\nautodoc_default_options = {\"members\": True}\n\n# autodoc: Don't inherit docstrings (e.g. for nn.Module.forward)\nautodoc_inherit_docstrings = False\n\n# Add any paths that contain templates here, relative to this directory.\ntemplates_path = [\"_templates\"]\n\n# List of patterns, relative to source directory, that match files and\n# directories to ignore when looking for source files.\n# This pattern also affects html_static_path and html_extra_path.\nexclude_patterns = []\n\n# The suffix(es) of source filenames.\n# You can specify multiple suffix as a list of string:\n#\nsource_suffix = [\".rst\", \".md\"]\n\nneeds_sphinx = \"4.0\"\n\n# -- Options for intersphinx extension ---------------------------------------\n\n# Example configuration for intersphinx: refer to the Python standard library.\nintersphinx_mapping = {\n \"python\": (\"https://docs.python.org/3\", None),\n \"torch\": (\"https://pytorch.org/docs/stable/\", None),\n \"numpy\": (\"https://numpy.org/doc/stable/\", None),\n \"PIL\": (\"https://pillow.readthedocs.io/en/stable/\", None),\n \"pytorchvideo\": (\"https://pytorchvideo.readthedocs.io/en/latest/\", None),\n \"pytorch_lightning\": (\"https://pytorch-lightning.readthedocs.io/en/stable/\", None),\n \"fiftyone\": (\"https://voxel51.com/docs/fiftyone/\", None),\n}\n\n# -- Options for HTML output -------------------------------------------------\n\n# The theme to use for HTML and HTML Help pages. See the documentation for\n# a list of builtin themes.\n#\nhtml_theme = \"pt_lightning_sphinx_theme\"\nhtml_theme_path = [pt_lightning_sphinx_theme.get_html_theme_path()]\n\n# Theme options are theme-specific and customize the look and feel of a theme\n# further. For a list of options available for each theme, see the\n# documentation.\n\nhtml_theme_options = {\n 'pytorch_project': 'https://pytorchlightning.ai',\n 'canonical_url': about.__docs_url__,\n \"collapse_navigation\": False,\n \"display_version\": True,\n \"logo_only\": False,\n}\n\n# Add any paths that contain custom static files (such as style sheets) here,\n# relative to this directory. They are copied after the builtin static files,\n# so a file named \"default.css\" will overwrite the builtin \"default.css\".\nhtml_static_path = [\"_static\"]\n\nhtml_css_files = []\n\n\ndef setup(app):\n # this is for hiding doctest decoration,\n # see: http://z4r.github.io/python/2011/12/02/hides-the-prompts-and-output/\n app.add_js_file('copybutton.js')\n\n\n# Ignoring Third-party packages\n# https://stackoverflow.com/questions/15889621/sphinx-how-to-exclude-imports-in-automodule\ndef _package_list_from_file(pfile):\n assert os.path.isfile(pfile)\n with open(pfile, 'r') as fp:\n lines = fp.readlines()\n list_pkgs = []\n for ln in lines:\n found = [ln.index(ch) for ch in list(',=<>#@') if ch in ln]\n pkg = ln[:min(found)] if found else ln\n if pkg.strip():\n list_pkgs.append(pkg.strip())\n return list_pkgs\n\n\n# define mapping from PyPI names to python imports\nPACKAGE_MAPPING = {\n 'pytorch-lightning': 'pytorch_lightning',\n 'scikit-learn': 'sklearn',\n 'Pillow': 'PIL',\n 'PyYAML': 'yaml',\n 'rouge-score': 'rouge_score',\n 'lightning-bolts': 'pl_bolts',\n 'pytorch-tabnet': 'pytorch_tabnet',\n 'pyDeprecate': 'deprecate',\n}\nMOCK_PACKAGES = []\nif SPHINX_MOCK_REQUIREMENTS:\n # mock also base packages when we are on RTD since we don't install them there\n MOCK_PACKAGES += _package_list_from_file(os.path.join(_PATH_ROOT, 'requirements.txt'))\n# replace PyPI packages by importing ones\nMOCK_PACKAGES = [PACKAGE_MAPPING.get(pkg, pkg) for pkg in MOCK_PACKAGES]\n\nautodoc_mock_imports = MOCK_PACKAGES\n\n# only run doctests marked with a \".. doctest::\" directive\ndoctest_test_doctest_blocks = ''\ndoctest_global_setup = \"\"\"\nimport torch\nimport pytorch_lightning as pl\nimport flash\n\"\"\"\n", "path": "docs/source/conf.py"}]}
| 3,862 | 403 |
gh_patches_debug_20378
|
rasdani/github-patches
|
git_diff
|
Qiskit__qiskit-3458
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Job Monitor fails in possible race condition
<!-- ⚠️ If you do not respect this template, your issue will be closed -->
<!-- ⚠️ Make sure to browse the opened and closed issues -->
### Information
- **Qiskit Terra version**: 0.11.0.dev0+cf9c3f8
- **Python version**: Python 3.6.8
- **Operating system**: Linux 4.15.0-66-generic #75-Ubuntu SMP Tue Oct 1 05:24:09 UTC 2019 x86_64 x86_64 x86_64 GNU/Linux
### What is the current behavior?
Job monitor fails unrepeatably in a fashion suggesting that if the job has finished right at the instant the job monitor loops it ends up comparing `None` with an `int`.
```
Job Status: job is queuedTraceback (most recent call last):
File "qyq.py", line 348, in <module>
job_monitor(job_exp)
File "/home/jax/work/QISKit/DEV/qiskit-terra/qiskit/tools/monitor/job_monitor.py", line 84, in job_monitor
quiet=quiet, output=output)
File "/home/jax/work/QISKit/DEV/qiskit-terra/qiskit/tools/monitor/job_monitor.py", line 49, in _text_checker
interval = max(job.queue_position(), 2)
TypeError: '>' not supported between instances of 'int' and 'NoneType'
```
### Steps to reproduce the problem
Not reproduceable on-demand.
This occured on `ibmq_london`
### What is the expected behavior?
Job monitor survive any value returned by backend.
### Suggested solutions
None at present.
</issue>
<code>
[start of qiskit/tools/jupyter/jupyter_magics.py]
1 # -*- coding: utf-8 -*-
2
3 # This code is part of Qiskit.
4 #
5 # (C) Copyright IBM 2017, 2018.
6 #
7 # This code is licensed under the Apache License, Version 2.0. You may
8 # obtain a copy of this license in the LICENSE.txt file in the root directory
9 # of this source tree or at http://www.apache.org/licenses/LICENSE-2.0.
10 #
11 # Any modifications or derivative works of this code must retain this
12 # copyright notice, and modified files need to carry a notice indicating
13 # that they have been altered from the originals.
14
15 """A module of magic functions"""
16
17 import time
18 import threading
19 from IPython.display import display # pylint: disable=import-error
20 from IPython.core import magic_arguments # pylint: disable=import-error
21 from IPython.core.magic import (cell_magic, line_magic,
22 Magics, magics_class) # pylint: disable=import-error
23
24 try:
25 import ipywidgets as widgets # pylint: disable=import-error
26 except ImportError:
27 raise ImportError('These functions need ipywidgets. '
28 'Run "pip install ipywidgets" before.')
29 import qiskit
30 from qiskit.tools.events.progressbar import TextProgressBar
31 from .progressbar import HTMLProgressBar
32
33
34 def _html_checker(job_var, interval, status, header,
35 _interval_set=False):
36 """Internal function that updates the status
37 of a HTML job monitor.
38
39 Args:
40 job_var (BaseJob): The job to keep track of.
41 interval (int): The status check interval
42 status (widget): HTML ipywidget for output ot screen
43 header (str): String representing HTML code for status.
44 _interval_set (bool): Was interval set by user?
45 """
46 job_status = job_var.status()
47 job_status_name = job_status.name
48 job_status_msg = job_status.value
49 status.value = header % (job_status_msg)
50 while job_status_name not in ['DONE', 'CANCELLED']:
51 time.sleep(interval)
52 job_status = job_var.status()
53 job_status_name = job_status.name
54 job_status_msg = job_status.value
55 if job_status_name == 'ERROR':
56 break
57 else:
58 if job_status_name == 'QUEUED':
59 job_status_msg += ' (%s)' % job_var.queue_position()
60 if not _interval_set:
61 interval = max(job_var.queue_position(), 2)
62 else:
63 if not _interval_set:
64 interval = 2
65 status.value = header % (job_status_msg)
66
67 status.value = header % (job_status_msg)
68
69
70 @magics_class
71 class StatusMagic(Magics):
72 """A class of status magic functions.
73 """
74 @cell_magic
75 @magic_arguments.magic_arguments()
76 @magic_arguments.argument(
77 '-i',
78 '--interval',
79 type=float,
80 default=None,
81 help='Interval for status check.'
82 )
83 def qiskit_job_status(self, line='', cell=None):
84 """A Jupyter magic function to check the status of a Qiskit job instance.
85 """
86 args = magic_arguments.parse_argstring(self.qiskit_job_status, line)
87
88 if args.interval is None:
89 args.interval = 2
90 _interval_set = False
91 else:
92 _interval_set = True
93
94 # Split cell lines to get LHS variables
95 cell_lines = cell.split('\n')
96 line_vars = []
97 for cline in cell_lines:
98 if '=' in cline and '==' not in cline:
99 line_vars.append(cline.replace(' ', '').split('=')[0])
100 elif '.append(' in cline:
101 line_vars.append(cline.replace(' ', '').split('(')[0])
102
103 # Execute the cell
104 self.shell.ex(cell)
105
106 # Look for all vars that are BaseJob instances
107 jobs = []
108 for var in line_vars:
109 iter_var = False
110 if '#' not in var:
111 # The line var is a list or array, but we cannot parse the index
112 # so just iterate over the whole array for jobs.
113 if '[' in var:
114 var = var.split('[')[0]
115 iter_var = True
116 elif '.append' in var:
117 var = var.split('.append')[0]
118 iter_var = True
119
120 if iter_var:
121 for item in self.shell.user_ns[var]:
122 if isinstance(item, qiskit.providers.basejob.BaseJob):
123 jobs.append(item)
124 else:
125 if isinstance(self.shell.user_ns[var],
126 qiskit.providers.basejob.BaseJob):
127 jobs.append(self.shell.user_ns[var])
128
129 # Must have one job class
130 if not any(jobs):
131 raise Exception(
132 "Cell must contain at least one variable of BaseJob type.")
133
134 # List index of job if checking status of multiple jobs.
135 multi_job = False
136 if len(jobs) > 1:
137 multi_job = True
138
139 job_checkers = []
140 # Loop over every BaseJob that was found.
141 for idx, job_var in enumerate(jobs):
142 style = "font-size:16px;"
143 if multi_job:
144 idx_str = '[%s]' % idx
145 else:
146 idx_str = ''
147 header = "<p style='{style}'>Job Status {id}: %s </p>".format(id=idx_str,
148 style=style)
149 status = widgets.HTML(
150 value=header % job_var.status().value)
151
152 thread = threading.Thread(target=_html_checker, args=(job_var, args.interval,
153 status, header,
154 _interval_set))
155 thread.start()
156 job_checkers.append(status)
157
158 # Group all HTML widgets into single vertical layout
159 box = widgets.VBox(job_checkers)
160 display(box)
161
162
163 @magics_class
164 class ProgressBarMagic(Magics):
165 """A class of progress bar magic functions.
166 """
167 @line_magic
168 @magic_arguments.magic_arguments()
169 @magic_arguments.argument(
170 '-t',
171 '--type',
172 type=str,
173 default='html',
174 help="Type of progress bar, 'html' or 'text'."
175 )
176 def qiskit_progress_bar(self, line='', cell=None): # pylint: disable=unused-argument
177 """A Jupyter magic function to generate progressbar.
178 """
179 args = magic_arguments.parse_argstring(self.qiskit_progress_bar, line)
180 if args.type == 'html':
181 pbar = HTMLProgressBar()
182 elif args.type == 'text':
183 pbar = TextProgressBar()
184 else:
185 raise qiskit.QiskitError('Invalid progress bar type.')
186
187 return pbar
188
[end of qiskit/tools/jupyter/jupyter_magics.py]
[start of qiskit/tools/monitor/job_monitor.py]
1 # -*- coding: utf-8 -*-
2
3 # This code is part of Qiskit.
4 #
5 # (C) Copyright IBM 2017, 2018.
6 #
7 # This code is licensed under the Apache License, Version 2.0. You may
8 # obtain a copy of this license in the LICENSE.txt file in the root directory
9 # of this source tree or at http://www.apache.org/licenses/LICENSE-2.0.
10 #
11 # Any modifications or derivative works of this code must retain this
12 # copyright notice, and modified files need to carry a notice indicating
13 # that they have been altered from the originals.
14
15
16 """A module for monitoring various qiskit functionality"""
17
18 import sys
19 import time
20
21
22 def _text_checker(job, interval, _interval_set=False, quiet=False, output=sys.stdout):
23 """A text-based job status checker
24
25 Args:
26 job (BaseJob): The job to check.
27 interval (int): The interval at which to check.
28 _interval_set (bool): Was interval time set by user?
29 quiet (bool): If True, do not print status messages.
30 output (file): The file like object to write status messages to.
31 By default this is sys.stdout.
32
33 """
34 status = job.status()
35 msg = status.value
36 prev_msg = msg
37 msg_len = len(msg)
38
39 if not quiet:
40 print('\r%s: %s' % ('Job Status', msg), end='', file=output)
41 while status.name not in ['DONE', 'CANCELLED', 'ERROR']:
42 time.sleep(interval)
43 status = job.status()
44 msg = status.value
45
46 if status.name == 'QUEUED':
47 msg += ' (%s)' % job.queue_position()
48 if not _interval_set:
49 interval = max(job.queue_position(), 2)
50 else:
51 if not _interval_set:
52 interval = 2
53
54 # Adjust length of message so there are no artifacts
55 if len(msg) < msg_len:
56 msg += ' ' * (msg_len - len(msg))
57 elif len(msg) > msg_len:
58 msg_len = len(msg)
59
60 if msg != prev_msg and not quiet:
61 print('\r%s: %s' % ('Job Status', msg), end='', file=output)
62 prev_msg = msg
63 if not quiet:
64 print('', file=output)
65
66
67 def job_monitor(job, interval=None, quiet=False, output=sys.stdout):
68 """Monitor the status of a IBMQJob instance.
69
70 Args:
71 job (BaseJob): Job to monitor.
72 interval (int): Time interval between status queries.
73 quiet (bool): If True, do not print status messages.
74 output (file): The file like object to write status messages to.
75 By default this is sys.stdout.
76 """
77 if interval is None:
78 _interval_set = False
79 interval = 5
80 else:
81 _interval_set = True
82
83 _text_checker(job, interval, _interval_set,
84 quiet=quiet, output=output)
85
[end of qiskit/tools/monitor/job_monitor.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/qiskit/tools/jupyter/jupyter_magics.py b/qiskit/tools/jupyter/jupyter_magics.py
--- a/qiskit/tools/jupyter/jupyter_magics.py
+++ b/qiskit/tools/jupyter/jupyter_magics.py
@@ -57,7 +57,9 @@
else:
if job_status_name == 'QUEUED':
job_status_msg += ' (%s)' % job_var.queue_position()
- if not _interval_set:
+ if job_var.queue_position() is None:
+ interval = 2
+ elif not _interval_set:
interval = max(job_var.queue_position(), 2)
else:
if not _interval_set:
diff --git a/qiskit/tools/monitor/job_monitor.py b/qiskit/tools/monitor/job_monitor.py
--- a/qiskit/tools/monitor/job_monitor.py
+++ b/qiskit/tools/monitor/job_monitor.py
@@ -45,7 +45,9 @@
if status.name == 'QUEUED':
msg += ' (%s)' % job.queue_position()
- if not _interval_set:
+ if job.queue_position() is None:
+ interval = 2
+ elif not _interval_set:
interval = max(job.queue_position(), 2)
else:
if not _interval_set:
|
{"golden_diff": "diff --git a/qiskit/tools/jupyter/jupyter_magics.py b/qiskit/tools/jupyter/jupyter_magics.py\n--- a/qiskit/tools/jupyter/jupyter_magics.py\n+++ b/qiskit/tools/jupyter/jupyter_magics.py\n@@ -57,7 +57,9 @@\n else:\n if job_status_name == 'QUEUED':\n job_status_msg += ' (%s)' % job_var.queue_position()\n- if not _interval_set:\n+ if job_var.queue_position() is None:\n+ interval = 2\n+ elif not _interval_set:\n interval = max(job_var.queue_position(), 2)\n else:\n if not _interval_set:\ndiff --git a/qiskit/tools/monitor/job_monitor.py b/qiskit/tools/monitor/job_monitor.py\n--- a/qiskit/tools/monitor/job_monitor.py\n+++ b/qiskit/tools/monitor/job_monitor.py\n@@ -45,7 +45,9 @@\n \n if status.name == 'QUEUED':\n msg += ' (%s)' % job.queue_position()\n- if not _interval_set:\n+ if job.queue_position() is None:\n+ interval = 2\n+ elif not _interval_set:\n interval = max(job.queue_position(), 2)\n else:\n if not _interval_set:\n", "issue": "Job Monitor fails in possible race condition\n<!-- \u26a0\ufe0f If you do not respect this template, your issue will be closed -->\r\n<!-- \u26a0\ufe0f Make sure to browse the opened and closed issues -->\r\n\r\n### Information\r\n\r\n- **Qiskit Terra version**: 0.11.0.dev0+cf9c3f8\r\n- **Python version**: Python 3.6.8\r\n- **Operating system**: Linux 4.15.0-66-generic #75-Ubuntu SMP Tue Oct 1 05:24:09 UTC 2019 x86_64 x86_64 x86_64 GNU/Linux \r\n\r\n### What is the current behavior?\r\nJob monitor fails unrepeatably in a fashion suggesting that if the job has finished right at the instant the job monitor loops it ends up comparing `None` with an `int`.\r\n\r\n```\r\nJob Status: job is queuedTraceback (most recent call last):\r\n File \"qyq.py\", line 348, in <module>\r\n job_monitor(job_exp)\r\n File \"/home/jax/work/QISKit/DEV/qiskit-terra/qiskit/tools/monitor/job_monitor.py\", line 84, in job_monitor\r\n quiet=quiet, output=output)\r\n File \"/home/jax/work/QISKit/DEV/qiskit-terra/qiskit/tools/monitor/job_monitor.py\", line 49, in _text_checker\r\n interval = max(job.queue_position(), 2)\r\nTypeError: '>' not supported between instances of 'int' and 'NoneType'\r\n```\r\n### Steps to reproduce the problem\r\nNot reproduceable on-demand.\r\nThis occured on `ibmq_london`\r\n\r\n### What is the expected behavior?\r\nJob monitor survive any value returned by backend.\r\n\r\n\r\n### Suggested solutions\r\nNone at present.\r\n\r\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\n# This code is part of Qiskit.\n#\n# (C) Copyright IBM 2017, 2018.\n#\n# This code is licensed under the Apache License, Version 2.0. You may\n# obtain a copy of this license in the LICENSE.txt file in the root directory\n# of this source tree or at http://www.apache.org/licenses/LICENSE-2.0.\n#\n# Any modifications or derivative works of this code must retain this\n# copyright notice, and modified files need to carry a notice indicating\n# that they have been altered from the originals.\n\n\"\"\"A module of magic functions\"\"\"\n\nimport time\nimport threading\nfrom IPython.display import display # pylint: disable=import-error\nfrom IPython.core import magic_arguments # pylint: disable=import-error\nfrom IPython.core.magic import (cell_magic, line_magic,\n Magics, magics_class) # pylint: disable=import-error\n\ntry:\n import ipywidgets as widgets # pylint: disable=import-error\nexcept ImportError:\n raise ImportError('These functions need ipywidgets. '\n 'Run \"pip install ipywidgets\" before.')\nimport qiskit\nfrom qiskit.tools.events.progressbar import TextProgressBar\nfrom .progressbar import HTMLProgressBar\n\n\ndef _html_checker(job_var, interval, status, header,\n _interval_set=False):\n \"\"\"Internal function that updates the status\n of a HTML job monitor.\n\n Args:\n job_var (BaseJob): The job to keep track of.\n interval (int): The status check interval\n status (widget): HTML ipywidget for output ot screen\n header (str): String representing HTML code for status.\n _interval_set (bool): Was interval set by user?\n \"\"\"\n job_status = job_var.status()\n job_status_name = job_status.name\n job_status_msg = job_status.value\n status.value = header % (job_status_msg)\n while job_status_name not in ['DONE', 'CANCELLED']:\n time.sleep(interval)\n job_status = job_var.status()\n job_status_name = job_status.name\n job_status_msg = job_status.value\n if job_status_name == 'ERROR':\n break\n else:\n if job_status_name == 'QUEUED':\n job_status_msg += ' (%s)' % job_var.queue_position()\n if not _interval_set:\n interval = max(job_var.queue_position(), 2)\n else:\n if not _interval_set:\n interval = 2\n status.value = header % (job_status_msg)\n\n status.value = header % (job_status_msg)\n\n\n@magics_class\nclass StatusMagic(Magics):\n \"\"\"A class of status magic functions.\n \"\"\"\n @cell_magic\n @magic_arguments.magic_arguments()\n @magic_arguments.argument(\n '-i',\n '--interval',\n type=float,\n default=None,\n help='Interval for status check.'\n )\n def qiskit_job_status(self, line='', cell=None):\n \"\"\"A Jupyter magic function to check the status of a Qiskit job instance.\n \"\"\"\n args = magic_arguments.parse_argstring(self.qiskit_job_status, line)\n\n if args.interval is None:\n args.interval = 2\n _interval_set = False\n else:\n _interval_set = True\n\n # Split cell lines to get LHS variables\n cell_lines = cell.split('\\n')\n line_vars = []\n for cline in cell_lines:\n if '=' in cline and '==' not in cline:\n line_vars.append(cline.replace(' ', '').split('=')[0])\n elif '.append(' in cline:\n line_vars.append(cline.replace(' ', '').split('(')[0])\n\n # Execute the cell\n self.shell.ex(cell)\n\n # Look for all vars that are BaseJob instances\n jobs = []\n for var in line_vars:\n iter_var = False\n if '#' not in var:\n # The line var is a list or array, but we cannot parse the index\n # so just iterate over the whole array for jobs.\n if '[' in var:\n var = var.split('[')[0]\n iter_var = True\n elif '.append' in var:\n var = var.split('.append')[0]\n iter_var = True\n\n if iter_var:\n for item in self.shell.user_ns[var]:\n if isinstance(item, qiskit.providers.basejob.BaseJob):\n jobs.append(item)\n else:\n if isinstance(self.shell.user_ns[var],\n qiskit.providers.basejob.BaseJob):\n jobs.append(self.shell.user_ns[var])\n\n # Must have one job class\n if not any(jobs):\n raise Exception(\n \"Cell must contain at least one variable of BaseJob type.\")\n\n # List index of job if checking status of multiple jobs.\n multi_job = False\n if len(jobs) > 1:\n multi_job = True\n\n job_checkers = []\n # Loop over every BaseJob that was found.\n for idx, job_var in enumerate(jobs):\n style = \"font-size:16px;\"\n if multi_job:\n idx_str = '[%s]' % idx\n else:\n idx_str = ''\n header = \"<p style='{style}'>Job Status {id}: %s </p>\".format(id=idx_str,\n style=style)\n status = widgets.HTML(\n value=header % job_var.status().value)\n\n thread = threading.Thread(target=_html_checker, args=(job_var, args.interval,\n status, header,\n _interval_set))\n thread.start()\n job_checkers.append(status)\n\n # Group all HTML widgets into single vertical layout\n box = widgets.VBox(job_checkers)\n display(box)\n\n\n@magics_class\nclass ProgressBarMagic(Magics):\n \"\"\"A class of progress bar magic functions.\n \"\"\"\n @line_magic\n @magic_arguments.magic_arguments()\n @magic_arguments.argument(\n '-t',\n '--type',\n type=str,\n default='html',\n help=\"Type of progress bar, 'html' or 'text'.\"\n )\n def qiskit_progress_bar(self, line='', cell=None): # pylint: disable=unused-argument\n \"\"\"A Jupyter magic function to generate progressbar.\n \"\"\"\n args = magic_arguments.parse_argstring(self.qiskit_progress_bar, line)\n if args.type == 'html':\n pbar = HTMLProgressBar()\n elif args.type == 'text':\n pbar = TextProgressBar()\n else:\n raise qiskit.QiskitError('Invalid progress bar type.')\n\n return pbar\n", "path": "qiskit/tools/jupyter/jupyter_magics.py"}, {"content": "# -*- coding: utf-8 -*-\n\n# This code is part of Qiskit.\n#\n# (C) Copyright IBM 2017, 2018.\n#\n# This code is licensed under the Apache License, Version 2.0. You may\n# obtain a copy of this license in the LICENSE.txt file in the root directory\n# of this source tree or at http://www.apache.org/licenses/LICENSE-2.0.\n#\n# Any modifications or derivative works of this code must retain this\n# copyright notice, and modified files need to carry a notice indicating\n# that they have been altered from the originals.\n\n\n\"\"\"A module for monitoring various qiskit functionality\"\"\"\n\nimport sys\nimport time\n\n\ndef _text_checker(job, interval, _interval_set=False, quiet=False, output=sys.stdout):\n \"\"\"A text-based job status checker\n\n Args:\n job (BaseJob): The job to check.\n interval (int): The interval at which to check.\n _interval_set (bool): Was interval time set by user?\n quiet (bool): If True, do not print status messages.\n output (file): The file like object to write status messages to.\n By default this is sys.stdout.\n\n \"\"\"\n status = job.status()\n msg = status.value\n prev_msg = msg\n msg_len = len(msg)\n\n if not quiet:\n print('\\r%s: %s' % ('Job Status', msg), end='', file=output)\n while status.name not in ['DONE', 'CANCELLED', 'ERROR']:\n time.sleep(interval)\n status = job.status()\n msg = status.value\n\n if status.name == 'QUEUED':\n msg += ' (%s)' % job.queue_position()\n if not _interval_set:\n interval = max(job.queue_position(), 2)\n else:\n if not _interval_set:\n interval = 2\n\n # Adjust length of message so there are no artifacts\n if len(msg) < msg_len:\n msg += ' ' * (msg_len - len(msg))\n elif len(msg) > msg_len:\n msg_len = len(msg)\n\n if msg != prev_msg and not quiet:\n print('\\r%s: %s' % ('Job Status', msg), end='', file=output)\n prev_msg = msg\n if not quiet:\n print('', file=output)\n\n\ndef job_monitor(job, interval=None, quiet=False, output=sys.stdout):\n \"\"\"Monitor the status of a IBMQJob instance.\n\n Args:\n job (BaseJob): Job to monitor.\n interval (int): Time interval between status queries.\n quiet (bool): If True, do not print status messages.\n output (file): The file like object to write status messages to.\n By default this is sys.stdout.\n \"\"\"\n if interval is None:\n _interval_set = False\n interval = 5\n else:\n _interval_set = True\n\n _text_checker(job, interval, _interval_set,\n quiet=quiet, output=output)\n", "path": "qiskit/tools/monitor/job_monitor.py"}]}
| 3,663 | 288 |
gh_patches_debug_8110
|
rasdani/github-patches
|
git_diff
|
OCA__bank-payment-48
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Crash in account_payment_purchase
When you create an invoice from an incoming products on v7 with account_payment_purchase:
File "/home/erp_super/erp/prod/src/addons/stock/stock.py", line 1153, in action_invoice_create
invoice_vals = self._prepare_invoice(cr, uid, picking, partner, inv_type, journal_id, context=context)
File "/home/erp_super/erp/prod/src/banking/account_payment_sale_stock/model/stock.py", line 34, in _prepare_invoice
cr, uid, picking, partner, inv_type, journal_id, context=context)
File "/home/erp_super/erp/prod/src/banking/account_payment_purchase/model/stock.py", line 38, in _prepare_invoice
picking.purchase_id.supplier_partner_bank.id or False,
File "/home/erp_super/erp/prod/src/server/openerp/osv/orm.py", line 504, in __getattr__
raise AttributeError(e)
AttributeError: "Field 'supplier_partner_bank' does not exist in object 'browse_record(purchase.order, 774)'"
It seems that, when we decided to change to datamodel of the account_payment_\* modules, the file account_payment_purchase/model/stock.py was not changed !!! I'll do a PR to fix this.
</issue>
<code>
[start of account_payment_purchase/model/stock.py]
1 # -*- encoding: utf-8 -*-
2 ##############################################################################
3 #
4 # Account Payment Purchase module for OpenERP
5 # Copyright (C) 2014 Akretion (http://www.akretion.com)
6 # @author Alexis de Lattre <[email protected]>
7 #
8 # This program is free software: you can redistribute it and/or modify
9 # it under the terms of the GNU Affero General Public License as
10 # published by the Free Software Foundation, either version 3 of the
11 # License, or (at your option) any later version.
12 #
13 # This program is distributed in the hope that it will be useful,
14 # but WITHOUT ANY WARRANTY; without even the implied warranty of
15 # MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
16 # GNU Affero General Public License for more details.
17 #
18 # You should have received a copy of the GNU Affero General Public License
19 # along with this program. If not, see <http://www.gnu.org/licenses/>.
20 #
21 ##############################################################################
22
23 from openerp.osv import orm
24
25
26 class stock_picking(orm.Model):
27 _inherit = "stock.picking"
28
29 def _prepare_invoice(
30 self, cr, uid, picking, partner, inv_type, journal_id,
31 context=None):
32 """Copy bank partner and payment type from PO to invoice"""
33 invoice_vals = super(stock_picking, self)._prepare_invoice(
34 cr, uid, picking, partner, inv_type, journal_id, context=context)
35 if picking.purchase_id:
36 invoice_vals.update({
37 'partner_bank_id':
38 picking.purchase_id.supplier_partner_bank.id or False,
39 'payment_mode_type':
40 picking.purchase_id.payment_mode_type.id or False,
41 })
42 return invoice_vals
43
[end of account_payment_purchase/model/stock.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/account_payment_purchase/model/stock.py b/account_payment_purchase/model/stock.py
--- a/account_payment_purchase/model/stock.py
+++ b/account_payment_purchase/model/stock.py
@@ -35,8 +35,8 @@
if picking.purchase_id:
invoice_vals.update({
'partner_bank_id':
- picking.purchase_id.supplier_partner_bank.id or False,
- 'payment_mode_type':
- picking.purchase_id.payment_mode_type.id or False,
+ picking.purchase_id.supplier_partner_bank_id.id or False,
+ 'payment_mode_id':
+ picking.purchase_id.payment_mode_id.id or False,
})
return invoice_vals
|
{"golden_diff": "diff --git a/account_payment_purchase/model/stock.py b/account_payment_purchase/model/stock.py\n--- a/account_payment_purchase/model/stock.py\n+++ b/account_payment_purchase/model/stock.py\n@@ -35,8 +35,8 @@\n if picking.purchase_id:\n invoice_vals.update({\n 'partner_bank_id':\n- picking.purchase_id.supplier_partner_bank.id or False,\n- 'payment_mode_type':\n- picking.purchase_id.payment_mode_type.id or False,\n+ picking.purchase_id.supplier_partner_bank_id.id or False,\n+ 'payment_mode_id':\n+ picking.purchase_id.payment_mode_id.id or False,\n })\n return invoice_vals\n", "issue": "Crash in account_payment_purchase\nWhen you create an invoice from an incoming products on v7 with account_payment_purchase:\n\n File \"/home/erp_super/erp/prod/src/addons/stock/stock.py\", line 1153, in action_invoice_create\n invoice_vals = self._prepare_invoice(cr, uid, picking, partner, inv_type, journal_id, context=context)\n File \"/home/erp_super/erp/prod/src/banking/account_payment_sale_stock/model/stock.py\", line 34, in _prepare_invoice\n cr, uid, picking, partner, inv_type, journal_id, context=context)\n File \"/home/erp_super/erp/prod/src/banking/account_payment_purchase/model/stock.py\", line 38, in _prepare_invoice\n picking.purchase_id.supplier_partner_bank.id or False,\n File \"/home/erp_super/erp/prod/src/server/openerp/osv/orm.py\", line 504, in __getattr__\n raise AttributeError(e)\nAttributeError: \"Field 'supplier_partner_bank' does not exist in object 'browse_record(purchase.order, 774)'\"\n\nIt seems that, when we decided to change to datamodel of the account_payment_\\* modules, the file account_payment_purchase/model/stock.py was not changed !!! I'll do a PR to fix this.\n\n", "before_files": [{"content": "# -*- encoding: utf-8 -*-\n##############################################################################\n#\n# Account Payment Purchase module for OpenERP\n# Copyright (C) 2014 Akretion (http://www.akretion.com)\n# @author Alexis de Lattre <[email protected]>\n#\n# This program is free software: you can redistribute it and/or modify\n# it under the terms of the GNU Affero General Public License as\n# published by the Free Software Foundation, either version 3 of the\n# License, or (at your option) any later version.\n#\n# This program is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU Affero General Public License for more details.\n#\n# You should have received a copy of the GNU Affero General Public License\n# along with this program. If not, see <http://www.gnu.org/licenses/>.\n#\n##############################################################################\n\nfrom openerp.osv import orm\n\n\nclass stock_picking(orm.Model):\n _inherit = \"stock.picking\"\n\n def _prepare_invoice(\n self, cr, uid, picking, partner, inv_type, journal_id,\n context=None):\n \"\"\"Copy bank partner and payment type from PO to invoice\"\"\"\n invoice_vals = super(stock_picking, self)._prepare_invoice(\n cr, uid, picking, partner, inv_type, journal_id, context=context)\n if picking.purchase_id:\n invoice_vals.update({\n 'partner_bank_id':\n picking.purchase_id.supplier_partner_bank.id or False,\n 'payment_mode_type':\n picking.purchase_id.payment_mode_type.id or False,\n })\n return invoice_vals\n", "path": "account_payment_purchase/model/stock.py"}]}
| 1,275 | 141 |
gh_patches_debug_28199
|
rasdani/github-patches
|
git_diff
|
quantumlib__Cirq-3205
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
ParamResolver is slow
Reconstructing a circuit op-wise and replacing all parametrized ops with new ops containing parameter updates is 10-50x faster than using `cirq.ParamResolver` with sympy symbols...
Example code to reproduce:
```
from timeit import default_timer as timer
import numpy as np
import sympy
import cirq
def update_params(circuit, params):
"""Competitor method to cirq.ParamResolver."""
new_op_tree = []
for op, param in zip(circuit.all_operations(), params):
new_op_tree.append(op.gate._with_exponent(param/np.pi)(*op.qubits))
return cirq.Circuit.from_ops(new_op_tree)
trials = 100
for depth in [10, 15, 20]:
sympy_circuit = cirq.Circuit.from_ops([cirq.Rx(sympy.Symbol(str(k)))(cirq.LineQubit(0)) for k in range(depth)])
random_params = np.random.randn(trials, depth)
# time twenty runs
start = timer()
for j in range(trials):
resolver = dict(zip([str(k) for k in range(depth)], random_params[j]))
wf1 = cirq.Simulator().simulate(sympy_circuit, param_resolver=resolver).final_state
end = timer() - start
print(f"{depth} parameters, {trials} trials using Sympy+ParamResolver: {end} seconds")
start = timer()
for j in range(trials):
float_circuit = update_params(sympy_circuit, random_params[j])
wf2 = cirq.Simulator().simulate(float_circuit).final_state
end = timer() - start
print(f"{depth} parameters, {trials} trials using reconstructed circuit: {end} seconds")
```
produced (cirq v0.5.0, Windows 10 + core i7 gen 7 processor)
```
>>> 10 parameters, 100 trials using Sympy+ParamResolver: 2.408036000095308 seconds
>>> 10 parameters, 100 trials using reconstructed circuit: 0.1671589999459684 seconds
>>> 15 parameters, 100 trials using Sympy+ParamResolver: 4.347879000008106 seconds
>>> 15 parameters, 100 trials using reconstructed circuit: 0.25207799999043345 seconds
>>> 20 parameters, 100 trials using Sympy+ParamResolver: 7.1194350000005215 seconds
>>> 20 parameters, 100 trials using reconstructed circuit: 0.31734399998094887 seconds
```
Some plots of how this scales with large numbers of parameters (generated from a different script using the same `update_params` method):
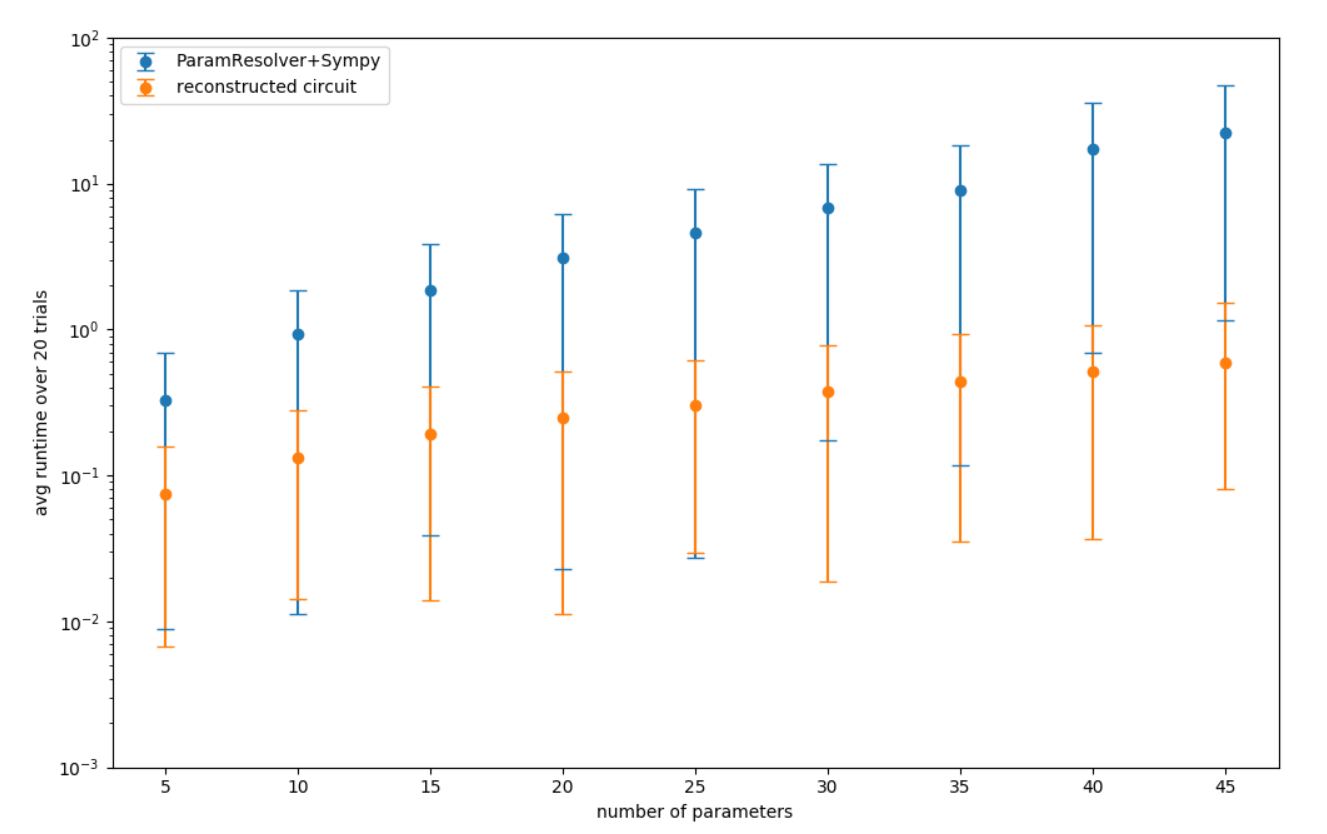
</issue>
<code>
[start of cirq/study/resolver.py]
1 # Copyright 2018 The Cirq Developers
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # https://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 """Resolves ParameterValues to assigned values."""
16
17 from typing import Any, Dict, Iterator, Optional, TYPE_CHECKING, Union, cast
18 import sympy
19 from cirq._compat import proper_repr
20 from cirq._doc import document
21
22 if TYPE_CHECKING:
23 import cirq
24
25
26 ParamDictType = Dict[Union[str, sympy.Symbol], Union[float, str, sympy.Basic]]
27 document(
28 ParamDictType, # type: ignore
29 """Dictionary from symbols to values.""")
30
31 ParamResolverOrSimilarType = Union['cirq.ParamResolver', ParamDictType, None]
32 document(
33 ParamResolverOrSimilarType, # type: ignore
34 """Something that can be used to turn parameters into values.""")
35
36
37 class ParamResolver:
38 """Resolves sympy.Symbols to actual values.
39
40 A Symbol is a wrapped parameter name (str). A ParamResolver is an object
41 that can be used to assign values for these keys.
42
43 ParamResolvers are hashable.
44
45 Attributes:
46 param_dict: A dictionary from the ParameterValue key (str) to its
47 assigned value.
48 """
49
50 def __new__(cls, param_dict: 'cirq.ParamResolverOrSimilarType' = None):
51 if isinstance(param_dict, ParamResolver):
52 return param_dict
53 return super().__new__(cls)
54
55 def __init__(self,
56 param_dict: 'cirq.ParamResolverOrSimilarType' = None) -> None:
57 if hasattr(self, 'param_dict'):
58 return # Already initialized. Got wrapped as part of the __new__.
59
60 self._param_hash: Optional[int] = None
61 self.param_dict = cast(ParamDictType,
62 {} if param_dict is None else param_dict)
63
64 def value_of(self,
65 value: Union[sympy.Basic, float, str]) -> 'cirq.TParamVal':
66 """Attempt to resolve a Symbol, string, or float to its assigned value.
67
68 Floats are returned without modification. Strings are resolved via
69 the parameter dictionary with exact match only. Otherwise, strings
70 are considered to be sympy.Symbols with the name as the input string.
71
72 sympy.Symbols are first checked for exact match in the parameter
73 dictionary. Otherwise, the symbol is resolved using sympy substitution.
74
75 Note that passing a formula to this resolver can be slow due to the
76 underlying sympy library. For circuits relying on quick performance,
77 it is recommended that all formulas are flattened before-hand using
78 cirq.flatten or other means so that formula resolution is avoided.
79 If unable to resolve a sympy.Symbol, returns it unchanged.
80 If unable to resolve a name, returns a sympy.Symbol with that name.
81
82 Args:
83 value: The sympy.Symbol or name or float to try to resolve into just
84 a float.
85
86 Returns:
87 The value of the parameter as resolved by this resolver.
88 """
89 # Input is a float, no resolution needed: return early
90 if isinstance(value, float):
91 return value
92
93 # Handles 2 cases:
94 # Input is a string and maps to a number in the dictionary
95 # Input is a symbol and maps to a number in the dictionary
96 # In both cases, return it directly.
97 if value in self.param_dict:
98 param_value = self.param_dict[value]
99 if isinstance(param_value, (float, int)):
100 return param_value
101
102 # Input is a string and is not in the dictionary.
103 # Treat it as a symbol instead.
104 if isinstance(value, str):
105 # If the string is in the param_dict as a value, return it.
106 # Otherwise, try using the symbol instead.
107 return self.value_of(sympy.Symbol(value))
108
109 # Input is a symbol (sympy.Symbol('a')) and its string maps to a number
110 # in the dictionary ({'a': 1.0}). Return it.
111 if (isinstance(value, sympy.Symbol) and value.name in self.param_dict):
112 param_value = self.param_dict[value.name]
113 if isinstance(param_value, (float, int)):
114 return param_value
115
116 # Input is either a sympy formula or the dictionary maps to a
117 # formula. Use sympy to resolve the value.
118 # Note that sympy.subs() is slow, so we want to avoid this and
119 # only use it for cases that require complicated resolution.
120 if isinstance(value, sympy.Basic):
121 v = value.subs(self.param_dict)
122 if v.free_symbols:
123 return v
124 elif sympy.im(v):
125 return complex(v)
126 else:
127 return float(v)
128
129 # No known way to resolve this variable, return unchanged.
130 return value
131
132 def __iter__(self) -> Iterator[Union[str, sympy.Symbol]]:
133 return iter(self.param_dict)
134
135 def __bool__(self) -> bool:
136 return bool(self.param_dict)
137
138 def __getitem__(self,
139 key: Union[sympy.Basic, float, str]) -> 'cirq.TParamVal':
140 return self.value_of(key)
141
142 def __hash__(self) -> int:
143 if self._param_hash is None:
144 self._param_hash = hash(frozenset(self.param_dict.items()))
145 return self._param_hash
146
147 def __eq__(self, other):
148 if not isinstance(other, ParamResolver):
149 return NotImplemented
150 return self.param_dict == other.param_dict
151
152 def __ne__(self, other):
153 return not self == other
154
155 def __repr__(self) -> str:
156 param_dict_repr = ('{' + ', '.join([
157 f'{proper_repr(k)}: {proper_repr(v)}'
158 for k, v in self.param_dict.items()
159 ]) + '}')
160 return f'cirq.ParamResolver({param_dict_repr})'
161
162 def _json_dict_(self) -> Dict[str, Any]:
163 return {
164 'cirq_type': self.__class__.__name__,
165 # JSON requires mappings to have keys of basic types.
166 'param_dict': list(self.param_dict.items())
167 }
168
169 @classmethod
170 def _from_json_dict_(cls, param_dict, **kwargs):
171 return cls(dict(param_dict))
172
[end of cirq/study/resolver.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/cirq/study/resolver.py b/cirq/study/resolver.py
--- a/cirq/study/resolver.py
+++ b/cirq/study/resolver.py
@@ -15,6 +15,7 @@
"""Resolves ParameterValues to assigned values."""
from typing import Any, Dict, Iterator, Optional, TYPE_CHECKING, Union, cast
+import numpy as np
import sympy
from cirq._compat import proper_repr
from cirq._doc import document
@@ -113,6 +114,27 @@
if isinstance(param_value, (float, int)):
return param_value
+ # The following resolves common sympy expressions
+ # If sympy did its job and wasn't slower than molasses,
+ # we wouldn't need the following block.
+ if isinstance(value, sympy.Add):
+ summation = self.value_of(value.args[0])
+ for addend in value.args[1:]:
+ summation += self.value_of(addend)
+ return summation
+ if isinstance(value, sympy.Mul):
+ product = self.value_of(value.args[0])
+ for factor in value.args[1:]:
+ product *= self.value_of(factor)
+ return product
+ if isinstance(value, sympy.Pow) and len(value.args) == 2:
+ return np.power(self.value_of(value.args[0]),
+ self.value_of(value.args[1]))
+ if value == sympy.pi:
+ return np.pi
+ if value == sympy.S.NegativeOne:
+ return -1
+
# Input is either a sympy formula or the dictionary maps to a
# formula. Use sympy to resolve the value.
# Note that sympy.subs() is slow, so we want to avoid this and
|
{"golden_diff": "diff --git a/cirq/study/resolver.py b/cirq/study/resolver.py\n--- a/cirq/study/resolver.py\n+++ b/cirq/study/resolver.py\n@@ -15,6 +15,7 @@\n \"\"\"Resolves ParameterValues to assigned values.\"\"\"\n \n from typing import Any, Dict, Iterator, Optional, TYPE_CHECKING, Union, cast\n+import numpy as np\n import sympy\n from cirq._compat import proper_repr\n from cirq._doc import document\n@@ -113,6 +114,27 @@\n if isinstance(param_value, (float, int)):\n return param_value\n \n+ # The following resolves common sympy expressions\n+ # If sympy did its job and wasn't slower than molasses,\n+ # we wouldn't need the following block.\n+ if isinstance(value, sympy.Add):\n+ summation = self.value_of(value.args[0])\n+ for addend in value.args[1:]:\n+ summation += self.value_of(addend)\n+ return summation\n+ if isinstance(value, sympy.Mul):\n+ product = self.value_of(value.args[0])\n+ for factor in value.args[1:]:\n+ product *= self.value_of(factor)\n+ return product\n+ if isinstance(value, sympy.Pow) and len(value.args) == 2:\n+ return np.power(self.value_of(value.args[0]),\n+ self.value_of(value.args[1]))\n+ if value == sympy.pi:\n+ return np.pi\n+ if value == sympy.S.NegativeOne:\n+ return -1\n+\n # Input is either a sympy formula or the dictionary maps to a\n # formula. Use sympy to resolve the value.\n # Note that sympy.subs() is slow, so we want to avoid this and\n", "issue": "ParamResolver is slow\nReconstructing a circuit op-wise and replacing all parametrized ops with new ops containing parameter updates is 10-50x faster than using `cirq.ParamResolver` with sympy symbols...\r\n\r\nExample code to reproduce:\r\n```\r\nfrom timeit import default_timer as timer\r\nimport numpy as np\r\nimport sympy\r\nimport cirq\r\n\r\n\r\ndef update_params(circuit, params):\r\n \"\"\"Competitor method to cirq.ParamResolver.\"\"\"\r\n new_op_tree = []\r\n for op, param in zip(circuit.all_operations(), params):\r\n new_op_tree.append(op.gate._with_exponent(param/np.pi)(*op.qubits))\r\n return cirq.Circuit.from_ops(new_op_tree)\r\n\r\n\r\ntrials = 100\r\nfor depth in [10, 15, 20]:\r\n sympy_circuit = cirq.Circuit.from_ops([cirq.Rx(sympy.Symbol(str(k)))(cirq.LineQubit(0)) for k in range(depth)])\r\n random_params = np.random.randn(trials, depth)\r\n # time twenty runs\r\n start = timer()\r\n for j in range(trials):\r\n resolver = dict(zip([str(k) for k in range(depth)], random_params[j]))\r\n wf1 = cirq.Simulator().simulate(sympy_circuit, param_resolver=resolver).final_state\r\n end = timer() - start\r\n print(f\"{depth} parameters, {trials} trials using Sympy+ParamResolver: {end} seconds\")\r\n\r\n start = timer()\r\n for j in range(trials):\r\n float_circuit = update_params(sympy_circuit, random_params[j])\r\n wf2 = cirq.Simulator().simulate(float_circuit).final_state\r\n end = timer() - start\r\n print(f\"{depth} parameters, {trials} trials using reconstructed circuit: {end} seconds\")\r\n```\r\nproduced (cirq v0.5.0, Windows 10 + core i7 gen 7 processor)\r\n```\r\n>>> 10 parameters, 100 trials using Sympy+ParamResolver: 2.408036000095308 seconds\r\n>>> 10 parameters, 100 trials using reconstructed circuit: 0.1671589999459684 seconds\r\n>>> 15 parameters, 100 trials using Sympy+ParamResolver: 4.347879000008106 seconds\r\n>>> 15 parameters, 100 trials using reconstructed circuit: 0.25207799999043345 seconds\r\n>>> 20 parameters, 100 trials using Sympy+ParamResolver: 7.1194350000005215 seconds\r\n>>> 20 parameters, 100 trials using reconstructed circuit: 0.31734399998094887 seconds\r\n```\r\nSome plots of how this scales with large numbers of parameters (generated from a different script using the same `update_params` method):\r\n\r\n\n", "before_files": [{"content": "# Copyright 2018 The Cirq Developers\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# https://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\"\"\"Resolves ParameterValues to assigned values.\"\"\"\n\nfrom typing import Any, Dict, Iterator, Optional, TYPE_CHECKING, Union, cast\nimport sympy\nfrom cirq._compat import proper_repr\nfrom cirq._doc import document\n\nif TYPE_CHECKING:\n import cirq\n\n\nParamDictType = Dict[Union[str, sympy.Symbol], Union[float, str, sympy.Basic]]\ndocument(\n ParamDictType, # type: ignore\n \"\"\"Dictionary from symbols to values.\"\"\")\n\nParamResolverOrSimilarType = Union['cirq.ParamResolver', ParamDictType, None]\ndocument(\n ParamResolverOrSimilarType, # type: ignore\n \"\"\"Something that can be used to turn parameters into values.\"\"\")\n\n\nclass ParamResolver:\n \"\"\"Resolves sympy.Symbols to actual values.\n\n A Symbol is a wrapped parameter name (str). A ParamResolver is an object\n that can be used to assign values for these keys.\n\n ParamResolvers are hashable.\n\n Attributes:\n param_dict: A dictionary from the ParameterValue key (str) to its\n assigned value.\n \"\"\"\n\n def __new__(cls, param_dict: 'cirq.ParamResolverOrSimilarType' = None):\n if isinstance(param_dict, ParamResolver):\n return param_dict\n return super().__new__(cls)\n\n def __init__(self,\n param_dict: 'cirq.ParamResolverOrSimilarType' = None) -> None:\n if hasattr(self, 'param_dict'):\n return # Already initialized. Got wrapped as part of the __new__.\n\n self._param_hash: Optional[int] = None\n self.param_dict = cast(ParamDictType,\n {} if param_dict is None else param_dict)\n\n def value_of(self,\n value: Union[sympy.Basic, float, str]) -> 'cirq.TParamVal':\n \"\"\"Attempt to resolve a Symbol, string, or float to its assigned value.\n\n Floats are returned without modification. Strings are resolved via\n the parameter dictionary with exact match only. Otherwise, strings\n are considered to be sympy.Symbols with the name as the input string.\n\n sympy.Symbols are first checked for exact match in the parameter\n dictionary. Otherwise, the symbol is resolved using sympy substitution.\n\n Note that passing a formula to this resolver can be slow due to the\n underlying sympy library. For circuits relying on quick performance,\n it is recommended that all formulas are flattened before-hand using\n cirq.flatten or other means so that formula resolution is avoided.\n If unable to resolve a sympy.Symbol, returns it unchanged.\n If unable to resolve a name, returns a sympy.Symbol with that name.\n\n Args:\n value: The sympy.Symbol or name or float to try to resolve into just\n a float.\n\n Returns:\n The value of the parameter as resolved by this resolver.\n \"\"\"\n # Input is a float, no resolution needed: return early\n if isinstance(value, float):\n return value\n\n # Handles 2 cases:\n # Input is a string and maps to a number in the dictionary\n # Input is a symbol and maps to a number in the dictionary\n # In both cases, return it directly.\n if value in self.param_dict:\n param_value = self.param_dict[value]\n if isinstance(param_value, (float, int)):\n return param_value\n\n # Input is a string and is not in the dictionary.\n # Treat it as a symbol instead.\n if isinstance(value, str):\n # If the string is in the param_dict as a value, return it.\n # Otherwise, try using the symbol instead.\n return self.value_of(sympy.Symbol(value))\n\n # Input is a symbol (sympy.Symbol('a')) and its string maps to a number\n # in the dictionary ({'a': 1.0}). Return it.\n if (isinstance(value, sympy.Symbol) and value.name in self.param_dict):\n param_value = self.param_dict[value.name]\n if isinstance(param_value, (float, int)):\n return param_value\n\n # Input is either a sympy formula or the dictionary maps to a\n # formula. Use sympy to resolve the value.\n # Note that sympy.subs() is slow, so we want to avoid this and\n # only use it for cases that require complicated resolution.\n if isinstance(value, sympy.Basic):\n v = value.subs(self.param_dict)\n if v.free_symbols:\n return v\n elif sympy.im(v):\n return complex(v)\n else:\n return float(v)\n\n # No known way to resolve this variable, return unchanged.\n return value\n\n def __iter__(self) -> Iterator[Union[str, sympy.Symbol]]:\n return iter(self.param_dict)\n\n def __bool__(self) -> bool:\n return bool(self.param_dict)\n\n def __getitem__(self,\n key: Union[sympy.Basic, float, str]) -> 'cirq.TParamVal':\n return self.value_of(key)\n\n def __hash__(self) -> int:\n if self._param_hash is None:\n self._param_hash = hash(frozenset(self.param_dict.items()))\n return self._param_hash\n\n def __eq__(self, other):\n if not isinstance(other, ParamResolver):\n return NotImplemented\n return self.param_dict == other.param_dict\n\n def __ne__(self, other):\n return not self == other\n\n def __repr__(self) -> str:\n param_dict_repr = ('{' + ', '.join([\n f'{proper_repr(k)}: {proper_repr(v)}'\n for k, v in self.param_dict.items()\n ]) + '}')\n return f'cirq.ParamResolver({param_dict_repr})'\n\n def _json_dict_(self) -> Dict[str, Any]:\n return {\n 'cirq_type': self.__class__.__name__,\n # JSON requires mappings to have keys of basic types.\n 'param_dict': list(self.param_dict.items())\n }\n\n @classmethod\n def _from_json_dict_(cls, param_dict, **kwargs):\n return cls(dict(param_dict))\n", "path": "cirq/study/resolver.py"}]}
| 3,172 | 401 |
gh_patches_debug_24830
|
rasdani/github-patches
|
git_diff
|
sanic-org__sanic-1501
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Module import fails when auto_reload is active
I have two piece of code (the structure has been simplified for clarity sake)
First in base.py
```
#! /usr/bin/env python
# -*- coding: utf-8 -*-
# module: init0
from abc import ABCMeta
from sanic import Sanic
class BaseService( metaclass = ABCMeta ):
def create_app( self ) -> Sanic:
app = Sanic( __name__ )
return app
# app = BaseService().create_app()
# app.run( host = '0.0.0.0',
# port = 5000,
# debug = True,
# )
print('[DONE]')
```
Second in run_test.py
```
#! /usr/bin/env python
# -*- coding: utf-8 -*-
# module: init0
from init0.base import BaseService
def main():
app = BaseService().create_app()
app.run( host = '0.0.0.0',
port = 5000,
debug = True,
)
return
if __name__ == '__main__':
main()
```
If I were to run `python -m init0.run_test` with `debug = False` then everything works perfectly, however if it's `debug = True`, then it'd throw me `ModuleNotFoundError: No module named 'init0'`
Is it some sort of loading error somewhere that I need to configure beforehand?
Thanks a lot in advance
</issue>
<code>
[start of sanic/reloader_helpers.py]
1 import os
2 import signal
3 import subprocess
4 import sys
5
6 from multiprocessing import Process
7 from time import sleep
8
9
10 def _iter_module_files():
11 """This iterates over all relevant Python files.
12
13 It goes through all
14 loaded files from modules, all files in folders of already loaded modules
15 as well as all files reachable through a package.
16 """
17 # The list call is necessary on Python 3 in case the module
18 # dictionary modifies during iteration.
19 for module in list(sys.modules.values()):
20 if module is None:
21 continue
22 filename = getattr(module, "__file__", None)
23 if filename:
24 old = None
25 while not os.path.isfile(filename):
26 old = filename
27 filename = os.path.dirname(filename)
28 if filename == old:
29 break
30 else:
31 if filename[-4:] in (".pyc", ".pyo"):
32 filename = filename[:-1]
33 yield filename
34
35
36 def _get_args_for_reloading():
37 """Returns the executable."""
38 rv = [sys.executable]
39 rv.extend(sys.argv)
40 return rv
41
42
43 def restart_with_reloader():
44 """Create a new process and a subprocess in it with the same arguments as
45 this one.
46 """
47 args = _get_args_for_reloading()
48 new_environ = os.environ.copy()
49 new_environ["SANIC_SERVER_RUNNING"] = "true"
50 cmd = " ".join(args)
51 worker_process = Process(
52 target=subprocess.call,
53 args=(cmd,),
54 kwargs=dict(shell=True, env=new_environ),
55 )
56 worker_process.start()
57 return worker_process
58
59
60 def kill_process_children_unix(pid):
61 """Find and kill child processes of a process (maximum two level).
62
63 :param pid: PID of parent process (process ID)
64 :return: Nothing
65 """
66 root_process_path = "/proc/{pid}/task/{pid}/children".format(pid=pid)
67 if not os.path.isfile(root_process_path):
68 return
69 with open(root_process_path) as children_list_file:
70 children_list_pid = children_list_file.read().split()
71
72 for child_pid in children_list_pid:
73 children_proc_path = "/proc/%s/task/%s/children" % (
74 child_pid,
75 child_pid,
76 )
77 if not os.path.isfile(children_proc_path):
78 continue
79 with open(children_proc_path) as children_list_file_2:
80 children_list_pid_2 = children_list_file_2.read().split()
81 for _pid in children_list_pid_2:
82 try:
83 os.kill(int(_pid), signal.SIGTERM)
84 except ProcessLookupError:
85 continue
86 try:
87 os.kill(int(child_pid), signal.SIGTERM)
88 except ProcessLookupError:
89 continue
90
91
92 def kill_process_children_osx(pid):
93 """Find and kill child processes of a process.
94
95 :param pid: PID of parent process (process ID)
96 :return: Nothing
97 """
98 subprocess.run(["pkill", "-P", str(pid)])
99
100
101 def kill_process_children(pid):
102 """Find and kill child processes of a process.
103
104 :param pid: PID of parent process (process ID)
105 :return: Nothing
106 """
107 if sys.platform == "darwin":
108 kill_process_children_osx(pid)
109 elif sys.platform == "linux":
110 kill_process_children_unix(pid)
111 else:
112 pass # should signal error here
113
114
115 def kill_program_completly(proc):
116 """Kill worker and it's child processes and exit.
117
118 :param proc: worker process (process ID)
119 :return: Nothing
120 """
121 kill_process_children(proc.pid)
122 proc.terminate()
123 os._exit(0)
124
125
126 def watchdog(sleep_interval):
127 """Watch project files, restart worker process if a change happened.
128
129 :param sleep_interval: interval in second.
130 :return: Nothing
131 """
132 mtimes = {}
133 worker_process = restart_with_reloader()
134 signal.signal(
135 signal.SIGTERM, lambda *args: kill_program_completly(worker_process)
136 )
137 signal.signal(
138 signal.SIGINT, lambda *args: kill_program_completly(worker_process)
139 )
140 while True:
141 for filename in _iter_module_files():
142 try:
143 mtime = os.stat(filename).st_mtime
144 except OSError:
145 continue
146
147 old_time = mtimes.get(filename)
148 if old_time is None:
149 mtimes[filename] = mtime
150 continue
151 elif mtime > old_time:
152 kill_process_children(worker_process.pid)
153 worker_process.terminate()
154 worker_process = restart_with_reloader()
155 mtimes[filename] = mtime
156 break
157
158 sleep(sleep_interval)
159
[end of sanic/reloader_helpers.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/sanic/reloader_helpers.py b/sanic/reloader_helpers.py
--- a/sanic/reloader_helpers.py
+++ b/sanic/reloader_helpers.py
@@ -36,7 +36,15 @@
def _get_args_for_reloading():
"""Returns the executable."""
rv = [sys.executable]
- rv.extend(sys.argv)
+ main_module = sys.modules["__main__"]
+ mod_spec = getattr(main_module, "__spec__", None)
+ if mod_spec:
+ # Parent exe was launched as a module rather than a script
+ rv.extend(["-m", mod_spec.name])
+ if len(sys.argv) > 1:
+ rv.extend(sys.argv[1:])
+ else:
+ rv.extend(sys.argv)
return rv
@@ -44,6 +52,7 @@
"""Create a new process and a subprocess in it with the same arguments as
this one.
"""
+ cwd = os.getcwd()
args = _get_args_for_reloading()
new_environ = os.environ.copy()
new_environ["SANIC_SERVER_RUNNING"] = "true"
@@ -51,7 +60,7 @@
worker_process = Process(
target=subprocess.call,
args=(cmd,),
- kwargs=dict(shell=True, env=new_environ),
+ kwargs={"cwd": cwd, "shell": True, "env": new_environ},
)
worker_process.start()
return worker_process
|
{"golden_diff": "diff --git a/sanic/reloader_helpers.py b/sanic/reloader_helpers.py\n--- a/sanic/reloader_helpers.py\n+++ b/sanic/reloader_helpers.py\n@@ -36,7 +36,15 @@\n def _get_args_for_reloading():\n \"\"\"Returns the executable.\"\"\"\n rv = [sys.executable]\n- rv.extend(sys.argv)\n+ main_module = sys.modules[\"__main__\"]\n+ mod_spec = getattr(main_module, \"__spec__\", None)\n+ if mod_spec:\n+ # Parent exe was launched as a module rather than a script\n+ rv.extend([\"-m\", mod_spec.name])\n+ if len(sys.argv) > 1:\n+ rv.extend(sys.argv[1:])\n+ else:\n+ rv.extend(sys.argv)\n return rv\n \n \n@@ -44,6 +52,7 @@\n \"\"\"Create a new process and a subprocess in it with the same arguments as\n this one.\n \"\"\"\n+ cwd = os.getcwd()\n args = _get_args_for_reloading()\n new_environ = os.environ.copy()\n new_environ[\"SANIC_SERVER_RUNNING\"] = \"true\"\n@@ -51,7 +60,7 @@\n worker_process = Process(\n target=subprocess.call,\n args=(cmd,),\n- kwargs=dict(shell=True, env=new_environ),\n+ kwargs={\"cwd\": cwd, \"shell\": True, \"env\": new_environ},\n )\n worker_process.start()\n return worker_process\n", "issue": "Module import fails when auto_reload is active\nI have two piece of code (the structure has been simplified for clarity sake)\r\nFirst in base.py\r\n```\r\n#! /usr/bin/env python\r\n# -*- coding: utf-8 -*-\r\n# module: init0\r\n\r\nfrom abc import ABCMeta\r\nfrom sanic import Sanic\r\n\r\nclass BaseService( metaclass = ABCMeta ):\r\n def create_app( self ) -> Sanic:\r\n app = Sanic( __name__ )\r\n return app\r\n\r\n# app = BaseService().create_app()\r\n\r\n# app.run( host = '0.0.0.0',\r\n# port = 5000,\r\n# debug = True,\r\n# )\r\n\r\nprint('[DONE]')\r\n\r\n```\r\nSecond in run_test.py\r\n```\r\n#! /usr/bin/env python\r\n# -*- coding: utf-8 -*-\r\n# module: init0\r\n\r\nfrom init0.base import BaseService\r\n\r\ndef main():\r\n app = BaseService().create_app()\r\n app.run( host = '0.0.0.0',\r\n port = 5000,\r\n debug = True,\r\n )\r\n return\r\n\r\nif __name__ == '__main__':\r\n main()\r\n\r\n```\r\n\r\nIf I were to run `python -m init0.run_test` with `debug = False` then everything works perfectly, however if it's `debug = True`, then it'd throw me `ModuleNotFoundError: No module named 'init0'`\r\n\r\nIs it some sort of loading error somewhere that I need to configure beforehand?\r\n\r\nThanks a lot in advance\n", "before_files": [{"content": "import os\nimport signal\nimport subprocess\nimport sys\n\nfrom multiprocessing import Process\nfrom time import sleep\n\n\ndef _iter_module_files():\n \"\"\"This iterates over all relevant Python files.\n\n It goes through all\n loaded files from modules, all files in folders of already loaded modules\n as well as all files reachable through a package.\n \"\"\"\n # The list call is necessary on Python 3 in case the module\n # dictionary modifies during iteration.\n for module in list(sys.modules.values()):\n if module is None:\n continue\n filename = getattr(module, \"__file__\", None)\n if filename:\n old = None\n while not os.path.isfile(filename):\n old = filename\n filename = os.path.dirname(filename)\n if filename == old:\n break\n else:\n if filename[-4:] in (\".pyc\", \".pyo\"):\n filename = filename[:-1]\n yield filename\n\n\ndef _get_args_for_reloading():\n \"\"\"Returns the executable.\"\"\"\n rv = [sys.executable]\n rv.extend(sys.argv)\n return rv\n\n\ndef restart_with_reloader():\n \"\"\"Create a new process and a subprocess in it with the same arguments as\n this one.\n \"\"\"\n args = _get_args_for_reloading()\n new_environ = os.environ.copy()\n new_environ[\"SANIC_SERVER_RUNNING\"] = \"true\"\n cmd = \" \".join(args)\n worker_process = Process(\n target=subprocess.call,\n args=(cmd,),\n kwargs=dict(shell=True, env=new_environ),\n )\n worker_process.start()\n return worker_process\n\n\ndef kill_process_children_unix(pid):\n \"\"\"Find and kill child processes of a process (maximum two level).\n\n :param pid: PID of parent process (process ID)\n :return: Nothing\n \"\"\"\n root_process_path = \"/proc/{pid}/task/{pid}/children\".format(pid=pid)\n if not os.path.isfile(root_process_path):\n return\n with open(root_process_path) as children_list_file:\n children_list_pid = children_list_file.read().split()\n\n for child_pid in children_list_pid:\n children_proc_path = \"/proc/%s/task/%s/children\" % (\n child_pid,\n child_pid,\n )\n if not os.path.isfile(children_proc_path):\n continue\n with open(children_proc_path) as children_list_file_2:\n children_list_pid_2 = children_list_file_2.read().split()\n for _pid in children_list_pid_2:\n try:\n os.kill(int(_pid), signal.SIGTERM)\n except ProcessLookupError:\n continue\n try:\n os.kill(int(child_pid), signal.SIGTERM)\n except ProcessLookupError:\n continue\n\n\ndef kill_process_children_osx(pid):\n \"\"\"Find and kill child processes of a process.\n\n :param pid: PID of parent process (process ID)\n :return: Nothing\n \"\"\"\n subprocess.run([\"pkill\", \"-P\", str(pid)])\n\n\ndef kill_process_children(pid):\n \"\"\"Find and kill child processes of a process.\n\n :param pid: PID of parent process (process ID)\n :return: Nothing\n \"\"\"\n if sys.platform == \"darwin\":\n kill_process_children_osx(pid)\n elif sys.platform == \"linux\":\n kill_process_children_unix(pid)\n else:\n pass # should signal error here\n\n\ndef kill_program_completly(proc):\n \"\"\"Kill worker and it's child processes and exit.\n\n :param proc: worker process (process ID)\n :return: Nothing\n \"\"\"\n kill_process_children(proc.pid)\n proc.terminate()\n os._exit(0)\n\n\ndef watchdog(sleep_interval):\n \"\"\"Watch project files, restart worker process if a change happened.\n\n :param sleep_interval: interval in second.\n :return: Nothing\n \"\"\"\n mtimes = {}\n worker_process = restart_with_reloader()\n signal.signal(\n signal.SIGTERM, lambda *args: kill_program_completly(worker_process)\n )\n signal.signal(\n signal.SIGINT, lambda *args: kill_program_completly(worker_process)\n )\n while True:\n for filename in _iter_module_files():\n try:\n mtime = os.stat(filename).st_mtime\n except OSError:\n continue\n\n old_time = mtimes.get(filename)\n if old_time is None:\n mtimes[filename] = mtime\n continue\n elif mtime > old_time:\n kill_process_children(worker_process.pid)\n worker_process.terminate()\n worker_process = restart_with_reloader()\n mtimes[filename] = mtime\n break\n\n sleep(sleep_interval)\n", "path": "sanic/reloader_helpers.py"}]}
| 2,229 | 321 |
gh_patches_debug_6147
|
rasdani/github-patches
|
git_diff
|
lutris__lutris-2419
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Importing of Steam games that are already in the library (uninstalled) does not make them appear installed
How to reproduce:
1. Add a game to your game library on Lutris.Net
2. Relaunch Lutris to let it fetch the new data and add the game to the library
3. Have that game installed locally through Steam
4. Import the game through "Import Games" menu
Expected behavior: the game now appears in the library as installed and is ready to be launched
Observed Behavior: nothing happens, the game remains uninstalled in the library until you manually run the installer it
A lot of users get confused by this because they think the Importing process failed as nothing happens after the importing process.
</issue>
<code>
[start of lutris/services/steam.py]
1 """Steam service"""
2 import os
3 import re
4
5 from lutris import pga
6 from lutris.config import make_game_config_id, LutrisConfig
7 from lutris.util.steam.appmanifest import AppManifest, get_appmanifests
8 from lutris.util.steam.config import get_steamapps_paths
9 from lutris.services.service_game import ServiceGame
10
11 NAME = "Steam"
12 ICON = "steam"
13 ONLINE = False
14
15
16 class SteamGame(ServiceGame):
17 """ServiceGame for Steam games"""
18 store = "steam"
19 installer_slug = "steam"
20 excluded_appids = [
21 "228980", # Steamworks Common Redistributables
22 ]
23
24 @classmethod
25 def new_from_steam_game(cls, appmanifest, game_id=None):
26 """Return a Steam game instance from an AppManifest"""
27 steam_game = SteamGame()
28 steam_game.appid = str(appmanifest.steamid)
29 steam_game.game_id = game_id
30 steam_game.name = appmanifest.name
31 steam_game.slug = appmanifest.slug
32 steam_game.runner = appmanifest.get_runner_name()
33 return steam_game
34
35 @classmethod
36 def new_from_lutris_id(cls, game_id):
37 steam_game = SteamGame()
38 steam_game.game_id = game_id
39 return steam_game
40
41 @property
42 def config_id(self):
43 return make_game_config_id(self.slug)
44
45 @classmethod
46 def is_importable(cls, appmanifest):
47 """Return whether a Steam game should be imported"""
48 if not appmanifest.is_installed():
49 return False
50 if appmanifest.steamid in cls.excluded_appids:
51 return False
52 if re.match(r"^Proton \d*", appmanifest.name):
53 return False
54 return True
55
56 def install(self, updated_info=None):
57 """Add an installed game to the library
58
59 Params:
60 updated_info (dict): Optional dictonary containing existing data not to overwrite
61 """
62 if updated_info:
63 name = updated_info["name"]
64 slug = updated_info["slug"]
65 else:
66 name = self.name
67 slug = self.slug
68 self.game_id = pga.add_or_update(
69 id=self.game_id,
70 name=name,
71 runner=self.runner,
72 slug=slug,
73 steamid=int(self.appid),
74 installed=1,
75 configpath=self.config_id,
76 installer_slug=self.installer_slug,
77 )
78 self.create_config()
79 return self.game_id
80
81 def create_config(self):
82 """Create the game configuration for a Steam game"""
83 game_config = LutrisConfig(runner_slug=self.runner, game_config_id=self.config_id)
84 game_config.raw_game_config.update({"appid": self.appid})
85 game_config.save()
86
87
88 class SteamSyncer:
89 platform = "linux"
90
91 def __init__(self):
92 self._lutris_games = None
93 self._lutris_steamids = None
94
95 @property
96 def runner(self):
97 return "steam" if self.platform == "linux" else "winesteam"
98
99 @property
100 def lutris_games(self):
101 if not self._lutris_games:
102 self._lutris_games = pga.get_games_where(
103 steamid__isnull=False,
104 steamid__not=""
105 )
106 return self._lutris_games
107
108 @property
109 def lutris_steamids(self):
110 if not self._lutris_steamids:
111 self._lutris_steamids = {str(game["steamid"]) for game in self.lutris_games}
112 return self._lutris_steamids
113
114 def load(self, force_reload=False):
115 """Return importable Steam games"""
116 games = []
117 steamapps_paths = get_steamapps_paths()
118 for steamapps_path in steamapps_paths[self.platform]:
119 for appmanifest_file in get_appmanifests(steamapps_path):
120 app_manifest = AppManifest(os.path.join(steamapps_path, appmanifest_file))
121 if SteamGame.is_importable(app_manifest):
122 games.append(SteamGame.new_from_steam_game(app_manifest))
123 return games
124
125 def get_pga_game(self, game):
126 """Return a PGA game if one is found"""
127 for pga_game in self.lutris_games:
128 if (
129 str(pga_game["steamid"]) == game.appid
130 and pga_game["runner"] == self.runner
131 and not pga_game["installed"]
132 ):
133 return pga_game
134
135 def sync(self, games, full=False):
136 """Syncs Steam games to Lutris"""
137 available_ids = set() # Set of Steam appids seen while browsing AppManifests
138 added_games = []
139 for game in games:
140 steamid = game.appid
141 available_ids.add(steamid)
142 pga_game = self.get_pga_game(game)
143
144 if pga_game:
145 if steamid in self.lutris_steamids and pga_game["installed"] != 1 and pga_game["installed"]:
146 added_games.append(game.install())
147
148 if steamid not in self.lutris_steamids:
149 added_games.append(game.install())
150 else:
151 if pga_game:
152 added_games.append(game.install(pga_game))
153
154 if not full:
155 return added_games
156
157 removed_games = []
158 unavailable_ids = self.lutris_steamids.difference(available_ids)
159 for steamid in unavailable_ids:
160 for pga_game in self.lutris_games:
161 if (
162 str(pga_game["steamid"]) == steamid
163 and pga_game["installed"]
164 and pga_game["runner"] == self.runner
165 ):
166 game = SteamGame.new_from_lutris_id(pga_game["id"])
167 game.uninstall()
168 removed_games.append(pga_game["id"])
169 return (added_games, removed_games)
170
171
172 SYNCER = SteamSyncer
173
[end of lutris/services/steam.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/lutris/services/steam.py b/lutris/services/steam.py
--- a/lutris/services/steam.py
+++ b/lutris/services/steam.py
@@ -127,7 +127,7 @@
for pga_game in self.lutris_games:
if (
str(pga_game["steamid"]) == game.appid
- and pga_game["runner"] == self.runner
+ and (pga_game["runner"] == self.runner or not pga_game["runner"])
and not pga_game["installed"]
):
return pga_game
|
{"golden_diff": "diff --git a/lutris/services/steam.py b/lutris/services/steam.py\n--- a/lutris/services/steam.py\n+++ b/lutris/services/steam.py\n@@ -127,7 +127,7 @@\n for pga_game in self.lutris_games:\n if (\n str(pga_game[\"steamid\"]) == game.appid\n- and pga_game[\"runner\"] == self.runner\n+ and (pga_game[\"runner\"] == self.runner or not pga_game[\"runner\"])\n and not pga_game[\"installed\"]\n ):\n return pga_game\n", "issue": "Importing of Steam games that are already in the library (uninstalled) does not make them appear installed\nHow to reproduce:\r\n1. Add a game to your game library on Lutris.Net\r\n2. Relaunch Lutris to let it fetch the new data and add the game to the library\r\n3. Have that game installed locally through Steam\r\n4. Import the game through \"Import Games\" menu\r\n\r\nExpected behavior: the game now appears in the library as installed and is ready to be launched\r\nObserved Behavior: nothing happens, the game remains uninstalled in the library until you manually run the installer it\r\n\r\nA lot of users get confused by this because they think the Importing process failed as nothing happens after the importing process.\n", "before_files": [{"content": "\"\"\"Steam service\"\"\"\nimport os\nimport re\n\nfrom lutris import pga\nfrom lutris.config import make_game_config_id, LutrisConfig\nfrom lutris.util.steam.appmanifest import AppManifest, get_appmanifests\nfrom lutris.util.steam.config import get_steamapps_paths\nfrom lutris.services.service_game import ServiceGame\n\nNAME = \"Steam\"\nICON = \"steam\"\nONLINE = False\n\n\nclass SteamGame(ServiceGame):\n \"\"\"ServiceGame for Steam games\"\"\"\n store = \"steam\"\n installer_slug = \"steam\"\n excluded_appids = [\n \"228980\", # Steamworks Common Redistributables\n ]\n\n @classmethod\n def new_from_steam_game(cls, appmanifest, game_id=None):\n \"\"\"Return a Steam game instance from an AppManifest\"\"\"\n steam_game = SteamGame()\n steam_game.appid = str(appmanifest.steamid)\n steam_game.game_id = game_id\n steam_game.name = appmanifest.name\n steam_game.slug = appmanifest.slug\n steam_game.runner = appmanifest.get_runner_name()\n return steam_game\n\n @classmethod\n def new_from_lutris_id(cls, game_id):\n steam_game = SteamGame()\n steam_game.game_id = game_id\n return steam_game\n\n @property\n def config_id(self):\n return make_game_config_id(self.slug)\n\n @classmethod\n def is_importable(cls, appmanifest):\n \"\"\"Return whether a Steam game should be imported\"\"\"\n if not appmanifest.is_installed():\n return False\n if appmanifest.steamid in cls.excluded_appids:\n return False\n if re.match(r\"^Proton \\d*\", appmanifest.name):\n return False\n return True\n\n def install(self, updated_info=None):\n \"\"\"Add an installed game to the library\n\n Params:\n updated_info (dict): Optional dictonary containing existing data not to overwrite\n \"\"\"\n if updated_info:\n name = updated_info[\"name\"]\n slug = updated_info[\"slug\"]\n else:\n name = self.name\n slug = self.slug\n self.game_id = pga.add_or_update(\n id=self.game_id,\n name=name,\n runner=self.runner,\n slug=slug,\n steamid=int(self.appid),\n installed=1,\n configpath=self.config_id,\n installer_slug=self.installer_slug,\n )\n self.create_config()\n return self.game_id\n\n def create_config(self):\n \"\"\"Create the game configuration for a Steam game\"\"\"\n game_config = LutrisConfig(runner_slug=self.runner, game_config_id=self.config_id)\n game_config.raw_game_config.update({\"appid\": self.appid})\n game_config.save()\n\n\nclass SteamSyncer:\n platform = \"linux\"\n\n def __init__(self):\n self._lutris_games = None\n self._lutris_steamids = None\n\n @property\n def runner(self):\n return \"steam\" if self.platform == \"linux\" else \"winesteam\"\n\n @property\n def lutris_games(self):\n if not self._lutris_games:\n self._lutris_games = pga.get_games_where(\n steamid__isnull=False,\n steamid__not=\"\"\n )\n return self._lutris_games\n\n @property\n def lutris_steamids(self):\n if not self._lutris_steamids:\n self._lutris_steamids = {str(game[\"steamid\"]) for game in self.lutris_games}\n return self._lutris_steamids\n\n def load(self, force_reload=False):\n \"\"\"Return importable Steam games\"\"\"\n games = []\n steamapps_paths = get_steamapps_paths()\n for steamapps_path in steamapps_paths[self.platform]:\n for appmanifest_file in get_appmanifests(steamapps_path):\n app_manifest = AppManifest(os.path.join(steamapps_path, appmanifest_file))\n if SteamGame.is_importable(app_manifest):\n games.append(SteamGame.new_from_steam_game(app_manifest))\n return games\n\n def get_pga_game(self, game):\n \"\"\"Return a PGA game if one is found\"\"\"\n for pga_game in self.lutris_games:\n if (\n str(pga_game[\"steamid\"]) == game.appid\n and pga_game[\"runner\"] == self.runner\n and not pga_game[\"installed\"]\n ):\n return pga_game\n\n def sync(self, games, full=False):\n \"\"\"Syncs Steam games to Lutris\"\"\"\n available_ids = set() # Set of Steam appids seen while browsing AppManifests\n added_games = []\n for game in games:\n steamid = game.appid\n available_ids.add(steamid)\n pga_game = self.get_pga_game(game)\n\n if pga_game:\n if steamid in self.lutris_steamids and pga_game[\"installed\"] != 1 and pga_game[\"installed\"]:\n added_games.append(game.install())\n\n if steamid not in self.lutris_steamids:\n added_games.append(game.install())\n else:\n if pga_game:\n added_games.append(game.install(pga_game))\n\n if not full:\n return added_games\n\n removed_games = []\n unavailable_ids = self.lutris_steamids.difference(available_ids)\n for steamid in unavailable_ids:\n for pga_game in self.lutris_games:\n if (\n str(pga_game[\"steamid\"]) == steamid\n and pga_game[\"installed\"]\n and pga_game[\"runner\"] == self.runner\n ):\n game = SteamGame.new_from_lutris_id(pga_game[\"id\"])\n game.uninstall()\n removed_games.append(pga_game[\"id\"])\n return (added_games, removed_games)\n\n\nSYNCER = SteamSyncer\n", "path": "lutris/services/steam.py"}]}
| 2,367 | 133 |
gh_patches_debug_19014
|
rasdani/github-patches
|
git_diff
|
mne-tools__mne-python-9070
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
use bibtex in plot_sensor_noise_level.py
convert references in `examples/visualization/plot_sensor_noise_level.py` to use footcite / footbibliography
</issue>
<code>
[start of examples/visualization/plot_sensor_noise_level.py]
1 # -*- coding: utf-8 -*-
2 """
3 ======================================
4 Show noise levels from empty room data
5 ======================================
6
7 This shows how to use :meth:`mne.io.Raw.plot_psd` to examine noise levels
8 of systems. See [1]_ for an example.
9
10 References
11 ----------
12 .. [1] Khan S, Cohen D (2013). Note: Magnetic noise from the inner wall of
13 a magnetically shielded room. Review of Scientific Instruments 84:56101.
14 https://doi.org/10.1063/1.4802845
15 """
16 # Author: Eric Larson <[email protected]>
17 #
18 # License: BSD (3-clause)
19
20 import os.path as op
21 import mne
22
23 data_path = mne.datasets.sample.data_path()
24
25 raw_erm = mne.io.read_raw_fif(op.join(data_path, 'MEG', 'sample',
26 'ernoise_raw.fif'), preload=True)
27
28 ###############################################################################
29 # We can plot the absolute noise levels:
30 raw_erm.plot_psd(tmax=10., average=True, spatial_colors=False,
31 dB=False, xscale='log')
32
[end of examples/visualization/plot_sensor_noise_level.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/examples/visualization/plot_sensor_noise_level.py b/examples/visualization/plot_sensor_noise_level.py
--- a/examples/visualization/plot_sensor_noise_level.py
+++ b/examples/visualization/plot_sensor_noise_level.py
@@ -5,13 +5,7 @@
======================================
This shows how to use :meth:`mne.io.Raw.plot_psd` to examine noise levels
-of systems. See [1]_ for an example.
-
-References
-----------
-.. [1] Khan S, Cohen D (2013). Note: Magnetic noise from the inner wall of
- a magnetically shielded room. Review of Scientific Instruments 84:56101.
- https://doi.org/10.1063/1.4802845
+of systems. See :footcite:`KhanCohen2013` for an example.
"""
# Author: Eric Larson <[email protected]>
#
@@ -29,3 +23,8 @@
# We can plot the absolute noise levels:
raw_erm.plot_psd(tmax=10., average=True, spatial_colors=False,
dB=False, xscale='log')
+###############################################################################
+# References
+# ----------
+#
+# .. footbibliography::
|
{"golden_diff": "diff --git a/examples/visualization/plot_sensor_noise_level.py b/examples/visualization/plot_sensor_noise_level.py\n--- a/examples/visualization/plot_sensor_noise_level.py\n+++ b/examples/visualization/plot_sensor_noise_level.py\n@@ -5,13 +5,7 @@\n ======================================\n \n This shows how to use :meth:`mne.io.Raw.plot_psd` to examine noise levels\n-of systems. See [1]_ for an example.\n-\n-References\n-----------\n-.. [1] Khan S, Cohen D (2013). Note: Magnetic noise from the inner wall of\n- a magnetically shielded room. Review of Scientific Instruments 84:56101.\n- https://doi.org/10.1063/1.4802845\n+of systems. See :footcite:`KhanCohen2013` for an example.\n \"\"\"\n # Author: Eric Larson <[email protected]>\n #\n@@ -29,3 +23,8 @@\n # We can plot the absolute noise levels:\n raw_erm.plot_psd(tmax=10., average=True, spatial_colors=False,\n dB=False, xscale='log')\n+###############################################################################\n+# References\n+# ----------\n+#\n+# .. footbibliography::\n", "issue": "use bibtex in plot_sensor_noise_level.py\nconvert references in `examples/visualization/plot_sensor_noise_level.py` to use footcite / footbibliography\r\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\"\"\"\n======================================\nShow noise levels from empty room data\n======================================\n\nThis shows how to use :meth:`mne.io.Raw.plot_psd` to examine noise levels\nof systems. See [1]_ for an example.\n\nReferences\n----------\n.. [1] Khan S, Cohen D (2013). Note: Magnetic noise from the inner wall of\n a magnetically shielded room. Review of Scientific Instruments 84:56101.\n https://doi.org/10.1063/1.4802845\n\"\"\"\n# Author: Eric Larson <[email protected]>\n#\n# License: BSD (3-clause)\n\nimport os.path as op\nimport mne\n\ndata_path = mne.datasets.sample.data_path()\n\nraw_erm = mne.io.read_raw_fif(op.join(data_path, 'MEG', 'sample',\n 'ernoise_raw.fif'), preload=True)\n\n###############################################################################\n# We can plot the absolute noise levels:\nraw_erm.plot_psd(tmax=10., average=True, spatial_colors=False,\n dB=False, xscale='log')\n", "path": "examples/visualization/plot_sensor_noise_level.py"}]}
| 886 | 277 |
gh_patches_debug_48854
|
rasdani/github-patches
|
git_diff
|
ultrabug__py3status-659
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
mpd_status' max_width bogus?
`max_width` doesn't seem to do what it is supposed to do.
When displaying a long title (like `Georg Danzer - Ballade von verstecken Tschurifetzen - Re-Mastered`), the title gets _longer_, the _smaller_ the value is.
</issue>
<code>
[start of py3status/modules/mpd_status.py]
1 # coding: utf-8
2 """
3 Display information from mpd.
4
5 Configuration parameters:
6 cache_timeout: how often we refresh this module in seconds (default 2)
7 format: template string (see below)
8 (default '%state% [[[%artist%] - %title%]|[%file%]]')
9 hide_when_paused: hide the status if state is paused (default False)
10 hide_when_stopped: hide the status if state is stopped (default True)
11 host: mpd host (default 'localhost')
12 max_width: maximum status length (default 120)
13 password: mpd password (default None)
14 port: mpd port (default '6600')
15 state_pause: label to display for "paused" state (default '[pause]')
16 state_play: label to display for "playing" state (default '[play]')
17 state_stop: label to display for "stopped" state (default '[stop]')
18
19 Color options:
20 color_pause: Paused, default color_degraded
21 color_play: Playing, default color_good
22 color_stop: Stopped, default color_bad
23
24 Requires:
25 python-mpd2: (NOT python2-mpd2)
26 ```
27 # pip install python-mpd2
28 ```
29
30 Refer to the mpc(1) manual page for the list of available placeholders to be
31 used in `format`.
32 You can also use the %state% placeholder, that will be replaced with the state
33 label (play, pause or stop).
34 Every placeholder can also be prefixed with `next_` to retrieve the data for
35 the song following the one currently playing.
36
37 You can also use {} instead of %% for placeholders (backward compatibility).
38
39 Examples of `format`
40 ```
41 # Show state and (artist -) title, if no title fallback to file:
42 %state% [[[%artist% - ]%title%]|[%file%]]
43
44 # Alternative legacy syntax:
45 {state} [[[{artist} - ]{title}]|[{file}]]
46
47 # Show state, [duration], title (or file) and next song title (or file):
48 %state% \[%time%\] [%title%|%file%] → [%next_title%|%next_file%]
49 ```
50
51 @author shadowprince, zopieux
52 @license Eclipse Public License
53 """
54
55 import ast
56 import datetime
57 import itertools
58 import socket
59 from mpd import MPDClient, CommandError
60
61
62 def parse_template(instr, value_getter, found=True):
63 """
64 MPC-like parsing of `instr` using `value_getter` callable to retrieve the
65 text representation of placeholders.
66 """
67 instr = iter(instr)
68 ret = []
69 for char in instr:
70 if char in '%{':
71 endchar = '%' if char == '%' else '}'
72 key = ''.join(itertools.takewhile(lambda e: e != endchar, instr))
73 value = value_getter(key)
74 if value:
75 found = True
76 ret.append(value)
77 else:
78 found = False
79 elif char == '#':
80 ret.append(next(instr, '#'))
81 elif char == '\\':
82 ln = next(instr, '\\')
83 if ln in 'abtnvfr':
84 ret.append(ast.literal_eval('"\\{}"'.format(ln)))
85 else:
86 ret.append(ln)
87 elif char == '[':
88 subret, found = parse_template(instr, value_getter, found)
89 subret = ''.join(subret)
90 ret.append(subret)
91 elif char == ']':
92 if found:
93 ret = ''.join(ret)
94 return ret, True
95 else:
96 return '', False
97 elif char == '|':
98 subret, subfound = parse_template(instr, value_getter, found)
99 if found:
100 pass
101 elif subfound:
102 ret.append(''.join(subret))
103 found = True
104 else:
105 return '', False
106 elif char == '&':
107 subret, subfound = parse_template(instr, value_getter, found)
108 if found and subfound:
109 subret = ''.join(subret)
110 ret.append(subret)
111 else:
112 return '', False
113 else:
114 ret.append(char)
115
116 ret = ''.join(ret)
117 return ret, found
118
119
120 def song_attr(song, attr):
121 def parse_mtime(date_str):
122 return datetime.datetime.strptime(date_str, '%Y-%m-%dT%H:%M:%SZ')
123
124 if attr == 'time':
125 try:
126 duration = int(song['time'])
127 if duration > 0:
128 minutes, seconds = divmod(duration, 60)
129 return '{:d}:{:02d}'.format(minutes, seconds)
130 raise ValueError
131 except (KeyError, ValueError):
132 return ''
133 elif attr == 'position':
134 try:
135 return '{}'.format(int(song['pos']) + 1)
136 except (KeyError, ValueError):
137 return ''
138 elif attr == 'mtime':
139 return parse_mtime(song['last-modified']).strftime('%c')
140 elif attr == 'mdate':
141 return parse_mtime(song['last-modified']).strftime('%x')
142
143 return song.get(attr, '')
144
145
146 class Py3status:
147 """
148 """
149 # available configuration parameters
150 cache_timeout = 2
151 format = '%state% [[[%artist%] - %title%]|[%file%]]'
152 hide_when_paused = False
153 hide_when_stopped = True
154 host = 'localhost'
155 max_width = 120
156 password = None
157 port = '6600'
158 state_pause = '[pause]'
159 state_play = '[play]'
160 state_stop = '[stop]'
161
162 def __init__(self):
163 self.text = ''
164
165 def _state_character(self, state):
166 if state == 'play':
167 return self.state_play
168 elif state == 'pause':
169 return self.state_pause
170 elif state == 'stop':
171 return self.state_stop
172 return '?'
173
174 def current_track(self):
175 try:
176 c = MPDClient()
177 c.connect(host=self.host, port=self.port)
178 if self.password:
179 c.password(self.password)
180
181 status = c.status()
182 song = int(status.get('song', 0))
183 next_song = int(status.get('nextsong', 0))
184
185 state = status.get('state')
186
187 if ((state == 'pause' and self.hide_when_paused) or
188 (state == 'stop' and self.hide_when_stopped)):
189 text = ''
190
191 else:
192 playlist_info = c.playlistinfo()
193 try:
194 song = playlist_info[song]
195 except IndexError:
196 song = {}
197 try:
198 next_song = playlist_info[next_song]
199 except IndexError:
200 next_song = {}
201
202 song['state'] = next_song['state'] \
203 = self._state_character(state)
204
205 def attr_getter(attr):
206 if attr.startswith('next_'):
207 return song_attr(next_song, attr[5:])
208 return song_attr(song, attr)
209
210 text, _ = parse_template(self.format, attr_getter)
211
212 except socket.error:
213 text = "Failed to connect to mpd!"
214 state = None
215 except CommandError:
216 text = "Failed to authenticate to mpd!"
217 state = None
218 c.disconnect()
219 else:
220 c.disconnect()
221
222 if len(text) > self.max_width:
223 text = text[:-self.max_width - 3] + '...'
224
225 if self.text != text:
226 transformed = True
227 self.text = text
228 else:
229 transformed = False
230
231 response = {
232 'cached_until': self.py3.time_in(self.cache_timeout),
233 'full_text': self.text,
234 'transformed': transformed
235 }
236
237 if state:
238 if state == 'play':
239 response['color'] = self.py3.COLOR_PLAY or self.py3.COLOR_GOOD
240 elif state == 'pause':
241 response['color'] = (self.py3.COLOR_PAUSE or
242 self.py3.COLOR_DEGRADED)
243 elif state == 'stop':
244 response['color'] = self.py3.COLOR_STOP or self.py3.COLOR_BAD
245
246 return response
247
248
249 if __name__ == "__main__":
250 """
251 Run module in test mode.
252 """
253 from py3status.module_test import module_test
254 module_test(Py3status)
255
[end of py3status/modules/mpd_status.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/py3status/modules/mpd_status.py b/py3status/modules/mpd_status.py
--- a/py3status/modules/mpd_status.py
+++ b/py3status/modules/mpd_status.py
@@ -220,7 +220,7 @@
c.disconnect()
if len(text) > self.max_width:
- text = text[:-self.max_width - 3] + '...'
+ text = u'{}...'.format(text[:self.max_width - 3])
if self.text != text:
transformed = True
|
{"golden_diff": "diff --git a/py3status/modules/mpd_status.py b/py3status/modules/mpd_status.py\n--- a/py3status/modules/mpd_status.py\n+++ b/py3status/modules/mpd_status.py\n@@ -220,7 +220,7 @@\n c.disconnect()\n \n if len(text) > self.max_width:\n- text = text[:-self.max_width - 3] + '...'\n+ text = u'{}...'.format(text[:self.max_width - 3])\n \n if self.text != text:\n transformed = True\n", "issue": "mpd_status' max_width bogus?\n`max_width` doesn't seem to do what it is supposed to do. \r\n\r\nWhen displaying a long title (like `Georg Danzer - Ballade von verstecken Tschurifetzen - Re-Mastered`), the title gets _longer_, the _smaller_ the value is. \n", "before_files": [{"content": "# coding: utf-8\n\"\"\"\nDisplay information from mpd.\n\nConfiguration parameters:\n cache_timeout: how often we refresh this module in seconds (default 2)\n format: template string (see below)\n (default '%state% [[[%artist%] - %title%]|[%file%]]')\n hide_when_paused: hide the status if state is paused (default False)\n hide_when_stopped: hide the status if state is stopped (default True)\n host: mpd host (default 'localhost')\n max_width: maximum status length (default 120)\n password: mpd password (default None)\n port: mpd port (default '6600')\n state_pause: label to display for \"paused\" state (default '[pause]')\n state_play: label to display for \"playing\" state (default '[play]')\n state_stop: label to display for \"stopped\" state (default '[stop]')\n\nColor options:\n color_pause: Paused, default color_degraded\n color_play: Playing, default color_good\n color_stop: Stopped, default color_bad\n\nRequires:\n python-mpd2: (NOT python2-mpd2)\n```\n# pip install python-mpd2\n```\n\nRefer to the mpc(1) manual page for the list of available placeholders to be\nused in `format`.\nYou can also use the %state% placeholder, that will be replaced with the state\nlabel (play, pause or stop).\nEvery placeholder can also be prefixed with `next_` to retrieve the data for\nthe song following the one currently playing.\n\nYou can also use {} instead of %% for placeholders (backward compatibility).\n\nExamples of `format`\n```\n# Show state and (artist -) title, if no title fallback to file:\n%state% [[[%artist% - ]%title%]|[%file%]]\n\n# Alternative legacy syntax:\n{state} [[[{artist} - ]{title}]|[{file}]]\n\n# Show state, [duration], title (or file) and next song title (or file):\n%state% \\[%time%\\] [%title%|%file%] \u2192 [%next_title%|%next_file%]\n```\n\n@author shadowprince, zopieux\n@license Eclipse Public License\n\"\"\"\n\nimport ast\nimport datetime\nimport itertools\nimport socket\nfrom mpd import MPDClient, CommandError\n\n\ndef parse_template(instr, value_getter, found=True):\n \"\"\"\n MPC-like parsing of `instr` using `value_getter` callable to retrieve the\n text representation of placeholders.\n \"\"\"\n instr = iter(instr)\n ret = []\n for char in instr:\n if char in '%{':\n endchar = '%' if char == '%' else '}'\n key = ''.join(itertools.takewhile(lambda e: e != endchar, instr))\n value = value_getter(key)\n if value:\n found = True\n ret.append(value)\n else:\n found = False\n elif char == '#':\n ret.append(next(instr, '#'))\n elif char == '\\\\':\n ln = next(instr, '\\\\')\n if ln in 'abtnvfr':\n ret.append(ast.literal_eval('\"\\\\{}\"'.format(ln)))\n else:\n ret.append(ln)\n elif char == '[':\n subret, found = parse_template(instr, value_getter, found)\n subret = ''.join(subret)\n ret.append(subret)\n elif char == ']':\n if found:\n ret = ''.join(ret)\n return ret, True\n else:\n return '', False\n elif char == '|':\n subret, subfound = parse_template(instr, value_getter, found)\n if found:\n pass\n elif subfound:\n ret.append(''.join(subret))\n found = True\n else:\n return '', False\n elif char == '&':\n subret, subfound = parse_template(instr, value_getter, found)\n if found and subfound:\n subret = ''.join(subret)\n ret.append(subret)\n else:\n return '', False\n else:\n ret.append(char)\n\n ret = ''.join(ret)\n return ret, found\n\n\ndef song_attr(song, attr):\n def parse_mtime(date_str):\n return datetime.datetime.strptime(date_str, '%Y-%m-%dT%H:%M:%SZ')\n\n if attr == 'time':\n try:\n duration = int(song['time'])\n if duration > 0:\n minutes, seconds = divmod(duration, 60)\n return '{:d}:{:02d}'.format(minutes, seconds)\n raise ValueError\n except (KeyError, ValueError):\n return ''\n elif attr == 'position':\n try:\n return '{}'.format(int(song['pos']) + 1)\n except (KeyError, ValueError):\n return ''\n elif attr == 'mtime':\n return parse_mtime(song['last-modified']).strftime('%c')\n elif attr == 'mdate':\n return parse_mtime(song['last-modified']).strftime('%x')\n\n return song.get(attr, '')\n\n\nclass Py3status:\n \"\"\"\n \"\"\"\n # available configuration parameters\n cache_timeout = 2\n format = '%state% [[[%artist%] - %title%]|[%file%]]'\n hide_when_paused = False\n hide_when_stopped = True\n host = 'localhost'\n max_width = 120\n password = None\n port = '6600'\n state_pause = '[pause]'\n state_play = '[play]'\n state_stop = '[stop]'\n\n def __init__(self):\n self.text = ''\n\n def _state_character(self, state):\n if state == 'play':\n return self.state_play\n elif state == 'pause':\n return self.state_pause\n elif state == 'stop':\n return self.state_stop\n return '?'\n\n def current_track(self):\n try:\n c = MPDClient()\n c.connect(host=self.host, port=self.port)\n if self.password:\n c.password(self.password)\n\n status = c.status()\n song = int(status.get('song', 0))\n next_song = int(status.get('nextsong', 0))\n\n state = status.get('state')\n\n if ((state == 'pause' and self.hide_when_paused) or\n (state == 'stop' and self.hide_when_stopped)):\n text = ''\n\n else:\n playlist_info = c.playlistinfo()\n try:\n song = playlist_info[song]\n except IndexError:\n song = {}\n try:\n next_song = playlist_info[next_song]\n except IndexError:\n next_song = {}\n\n song['state'] = next_song['state'] \\\n = self._state_character(state)\n\n def attr_getter(attr):\n if attr.startswith('next_'):\n return song_attr(next_song, attr[5:])\n return song_attr(song, attr)\n\n text, _ = parse_template(self.format, attr_getter)\n\n except socket.error:\n text = \"Failed to connect to mpd!\"\n state = None\n except CommandError:\n text = \"Failed to authenticate to mpd!\"\n state = None\n c.disconnect()\n else:\n c.disconnect()\n\n if len(text) > self.max_width:\n text = text[:-self.max_width - 3] + '...'\n\n if self.text != text:\n transformed = True\n self.text = text\n else:\n transformed = False\n\n response = {\n 'cached_until': self.py3.time_in(self.cache_timeout),\n 'full_text': self.text,\n 'transformed': transformed\n }\n\n if state:\n if state == 'play':\n response['color'] = self.py3.COLOR_PLAY or self.py3.COLOR_GOOD\n elif state == 'pause':\n response['color'] = (self.py3.COLOR_PAUSE or\n self.py3.COLOR_DEGRADED)\n elif state == 'stop':\n response['color'] = self.py3.COLOR_STOP or self.py3.COLOR_BAD\n\n return response\n\n\nif __name__ == \"__main__\":\n \"\"\"\n Run module in test mode.\n \"\"\"\n from py3status.module_test import module_test\n module_test(Py3status)\n", "path": "py3status/modules/mpd_status.py"}]}
| 3,052 | 121 |
gh_patches_debug_22727
|
rasdani/github-patches
|
git_diff
|
huggingface__accelerate-1904
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
SageMaker config TypeError
### System Info
```Shell
- `Accelerate` version: 0.22.0
- Platform: Linux-5.10.184-175.731.amzn2.x86_64-x86_64-with-glibc2.26
- Python version: 3.10.8
- Numpy version: 1.25.2
- PyTorch version (GPU?): 2.0.1+cu117 (False)
- PyTorch XPU available: False
- PyTorch NPU available: False
```
### Information
- [x] The official example scripts
- [ ] My own modified scripts
### Tasks
- [ ] One of the scripts in the examples/ folder of Accelerate or an officially supported `no_trainer` script in the `examples` folder of the `transformers` repo (such as `run_no_trainer_glue.py`)
- [ ] My own task or dataset (give details below)
### Reproduction
1. Install accelerate[sagemaker]
2. run `accelerate config`
3. Go through the configuration process
The result will be:
```
Traceback (most recent call last):
File "/home/ec2-user/anaconda3/envs/JupyterSystemEnv/bin/accelerate", line 8, in <module>
sys.exit(main())
File "/home/ec2-user/anaconda3/envs/JupyterSystemEnv/lib/python3.10/site-packages/accelerate/commands/accelerate_cli.py", line 45, in main
args.func(args)
File "/home/ec2-user/anaconda3/envs/JupyterSystemEnv/lib/python3.10/site-packages/accelerate/commands/config/config.py", line 67, in config_command
config = get_user_input()
File "/home/ec2-user/anaconda3/envs/JupyterSystemEnv/lib/python3.10/site-packages/accelerate/commands/config/config.py", line 38, in get_user_input
config = get_sagemaker_input()
File "/home/ec2-user/anaconda3/envs/JupyterSystemEnv/lib/python3.10/site-packages/accelerate/commands/config/sagemaker.py", line 243, in get_sagemaker_input
return SageMakerConfig(
TypeError: SageMakerConfig.__init__() missing 1 required positional argument: 'debug'
```
### Expected behavior
accelerate config works
</issue>
<code>
[start of src/accelerate/commands/config/sagemaker.py]
1 #!/usr/bin/env python
2
3 # Copyright 2021 The HuggingFace Team. All rights reserved.
4 #
5 # Licensed under the Apache License, Version 2.0 (the "License");
6 # you may not use this file except in compliance with the License.
7 # You may obtain a copy of the License at
8 #
9 # http://www.apache.org/licenses/LICENSE-2.0
10 #
11 # Unless required by applicable law or agreed to in writing, software
12 # distributed under the License is distributed on an "AS IS" BASIS,
13 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
14 # See the License for the specific language governing permissions and
15 # limitations under the License.
16 import json
17 import os
18
19 from ...utils.constants import SAGEMAKER_PARALLEL_EC2_INSTANCES, TORCH_DYNAMO_MODES
20 from ...utils.dataclasses import ComputeEnvironment, SageMakerDistributedType
21 from ...utils.imports import is_boto3_available
22 from .config_args import SageMakerConfig
23 from .config_utils import (
24 DYNAMO_BACKENDS,
25 _ask_field,
26 _ask_options,
27 _convert_dynamo_backend,
28 _convert_mixed_precision,
29 _convert_sagemaker_distributed_mode,
30 _convert_yes_no_to_bool,
31 )
32
33
34 if is_boto3_available():
35 import boto3 # noqa: F401
36
37
38 def _create_iam_role_for_sagemaker(role_name):
39 iam_client = boto3.client("iam")
40
41 sagemaker_trust_policy = {
42 "Version": "2012-10-17",
43 "Statement": [
44 {"Effect": "Allow", "Principal": {"Service": "sagemaker.amazonaws.com"}, "Action": "sts:AssumeRole"}
45 ],
46 }
47 try:
48 # create the role, associated with the chosen trust policy
49 iam_client.create_role(
50 RoleName=role_name, AssumeRolePolicyDocument=json.dumps(sagemaker_trust_policy, indent=2)
51 )
52 policy_document = {
53 "Version": "2012-10-17",
54 "Statement": [
55 {
56 "Effect": "Allow",
57 "Action": [
58 "sagemaker:*",
59 "ecr:GetDownloadUrlForLayer",
60 "ecr:BatchGetImage",
61 "ecr:BatchCheckLayerAvailability",
62 "ecr:GetAuthorizationToken",
63 "cloudwatch:PutMetricData",
64 "cloudwatch:GetMetricData",
65 "cloudwatch:GetMetricStatistics",
66 "cloudwatch:ListMetrics",
67 "logs:CreateLogGroup",
68 "logs:CreateLogStream",
69 "logs:DescribeLogStreams",
70 "logs:PutLogEvents",
71 "logs:GetLogEvents",
72 "s3:CreateBucket",
73 "s3:ListBucket",
74 "s3:GetBucketLocation",
75 "s3:GetObject",
76 "s3:PutObject",
77 ],
78 "Resource": "*",
79 }
80 ],
81 }
82 # attach policy to role
83 iam_client.put_role_policy(
84 RoleName=role_name,
85 PolicyName=f"{role_name}_policy_permission",
86 PolicyDocument=json.dumps(policy_document, indent=2),
87 )
88 except iam_client.exceptions.EntityAlreadyExistsException:
89 print(f"role {role_name} already exists. Using existing one")
90
91
92 def _get_iam_role_arn(role_name):
93 iam_client = boto3.client("iam")
94 return iam_client.get_role(RoleName=role_name)["Role"]["Arn"]
95
96
97 def get_sagemaker_input():
98 credentials_configuration = _ask_options(
99 "How do you want to authorize?",
100 ["AWS Profile", "Credentials (AWS_ACCESS_KEY_ID, AWS_SECRET_ACCESS_KEY) "],
101 int,
102 )
103 aws_profile = None
104 if credentials_configuration == 0:
105 aws_profile = _ask_field("Enter your AWS Profile name: [default] ", default="default")
106 os.environ["AWS_PROFILE"] = aws_profile
107 else:
108 print(
109 "Note you will need to provide AWS_ACCESS_KEY_ID and AWS_SECRET_ACCESS_KEY when you launch you training script with,"
110 "`accelerate launch --aws_access_key_id XXX --aws_secret_access_key YYY`"
111 )
112 aws_access_key_id = _ask_field("AWS Access Key ID: ")
113 os.environ["AWS_ACCESS_KEY_ID"] = aws_access_key_id
114
115 aws_secret_access_key = _ask_field("AWS Secret Access Key: ")
116 os.environ["AWS_SECRET_ACCESS_KEY"] = aws_secret_access_key
117
118 aws_region = _ask_field("Enter your AWS Region: [us-east-1]", default="us-east-1")
119 os.environ["AWS_DEFAULT_REGION"] = aws_region
120
121 role_management = _ask_options(
122 "Do you already have an IAM Role for executing Amazon SageMaker Training Jobs?",
123 ["Provide IAM Role name", "Create new IAM role using credentials"],
124 int,
125 )
126 if role_management == 0:
127 iam_role_name = _ask_field("Enter your IAM role name: ")
128 else:
129 iam_role_name = "accelerate_sagemaker_execution_role"
130 print(f'Accelerate will create an iam role "{iam_role_name}" using the provided credentials')
131 _create_iam_role_for_sagemaker(iam_role_name)
132
133 is_custom_docker_image = _ask_field(
134 "Do you want to use custom Docker image? [yes/NO]: ",
135 _convert_yes_no_to_bool,
136 default=False,
137 error_message="Please enter yes or no.",
138 )
139 docker_image = None
140 if is_custom_docker_image:
141 docker_image = _ask_field("Enter your Docker image: ", lambda x: str(x).lower())
142
143 is_sagemaker_inputs_enabled = _ask_field(
144 "Do you want to provide SageMaker input channels with data locations? [yes/NO]: ",
145 _convert_yes_no_to_bool,
146 default=False,
147 error_message="Please enter yes or no.",
148 )
149 sagemaker_inputs_file = None
150 if is_sagemaker_inputs_enabled:
151 sagemaker_inputs_file = _ask_field(
152 "Enter the path to the SageMaker inputs TSV file with columns (channel_name, data_location): ",
153 lambda x: str(x).lower(),
154 )
155
156 is_sagemaker_metrics_enabled = _ask_field(
157 "Do you want to enable SageMaker metrics? [yes/NO]: ",
158 _convert_yes_no_to_bool,
159 default=False,
160 error_message="Please enter yes or no.",
161 )
162 sagemaker_metrics_file = None
163 if is_sagemaker_metrics_enabled:
164 sagemaker_metrics_file = _ask_field(
165 "Enter the path to the SageMaker metrics TSV file with columns (metric_name, metric_regex): ",
166 lambda x: str(x).lower(),
167 )
168
169 distributed_type = _ask_options(
170 "What is the distributed mode?",
171 ["No distributed training", "Data parallelism"],
172 _convert_sagemaker_distributed_mode,
173 )
174 dynamo_config = {}
175 use_dynamo = _ask_field(
176 "Do you wish to optimize your script with torch dynamo?[yes/NO]:",
177 _convert_yes_no_to_bool,
178 default=False,
179 error_message="Please enter yes or no.",
180 )
181 if use_dynamo:
182 prefix = "dynamo_"
183 dynamo_config[prefix + "backend"] = _ask_options(
184 "Which dynamo backend would you like to use?",
185 [x.lower() for x in DYNAMO_BACKENDS],
186 _convert_dynamo_backend,
187 default=2,
188 )
189 use_custom_options = _ask_field(
190 "Do you want to customize the defaults sent to torch.compile? [yes/NO]: ",
191 _convert_yes_no_to_bool,
192 default=False,
193 error_message="Please enter yes or no.",
194 )
195
196 if use_custom_options:
197 dynamo_config[prefix + "mode"] = _ask_options(
198 "Which mode do you want to use?",
199 TORCH_DYNAMO_MODES,
200 lambda x: TORCH_DYNAMO_MODES[int(x)],
201 default="default",
202 )
203 dynamo_config[prefix + "use_fullgraph"] = _ask_field(
204 "Do you want the fullgraph mode or it is ok to break model into several subgraphs? [yes/NO]: ",
205 _convert_yes_no_to_bool,
206 default=False,
207 error_message="Please enter yes or no.",
208 )
209 dynamo_config[prefix + "use_dynamic"] = _ask_field(
210 "Do you want to enable dynamic shape tracing? [yes/NO]: ",
211 _convert_yes_no_to_bool,
212 default=False,
213 error_message="Please enter yes or no.",
214 )
215 ec2_instance_query = "Which EC2 instance type you want to use for your training?"
216 if distributed_type != SageMakerDistributedType.NO:
217 ec2_instance_type = _ask_options(
218 ec2_instance_query, SAGEMAKER_PARALLEL_EC2_INSTANCES, lambda x: SAGEMAKER_PARALLEL_EC2_INSTANCES[int(x)]
219 )
220 else:
221 ec2_instance_query += "? [ml.p3.2xlarge]:"
222 ec2_instance_type = _ask_field(ec2_instance_query, lambda x: str(x).lower(), default="ml.p3.2xlarge")
223
224 num_machines = 1
225 if distributed_type in (SageMakerDistributedType.DATA_PARALLEL, SageMakerDistributedType.MODEL_PARALLEL):
226 num_machines = _ask_field(
227 "How many machines do you want use? [1]: ",
228 int,
229 default=1,
230 )
231
232 mixed_precision = _ask_options(
233 "Do you wish to use FP16 or BF16 (mixed precision)?",
234 ["no", "fp16", "bf16", "fp8"],
235 _convert_mixed_precision,
236 )
237
238 if use_dynamo and mixed_precision == "no":
239 print(
240 "Torch dynamo used without mixed precision requires TF32 to be efficient. Accelerate will enable it by default when launching your scripts."
241 )
242
243 return SageMakerConfig(
244 image_uri=docker_image,
245 compute_environment=ComputeEnvironment.AMAZON_SAGEMAKER,
246 distributed_type=distributed_type,
247 use_cpu=False,
248 dynamo_config=dynamo_config,
249 ec2_instance_type=ec2_instance_type,
250 profile=aws_profile,
251 region=aws_region,
252 iam_role_name=iam_role_name,
253 mixed_precision=mixed_precision,
254 num_machines=num_machines,
255 sagemaker_inputs_file=sagemaker_inputs_file,
256 sagemaker_metrics_file=sagemaker_metrics_file,
257 )
258
[end of src/accelerate/commands/config/sagemaker.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/accelerate/commands/config/sagemaker.py b/src/accelerate/commands/config/sagemaker.py
--- a/src/accelerate/commands/config/sagemaker.py
+++ b/src/accelerate/commands/config/sagemaker.py
@@ -221,6 +221,15 @@
ec2_instance_query += "? [ml.p3.2xlarge]:"
ec2_instance_type = _ask_field(ec2_instance_query, lambda x: str(x).lower(), default="ml.p3.2xlarge")
+ debug = False
+ if distributed_type != SageMakerDistributedType.NO:
+ debug = _ask_field(
+ "Should distributed operations be checked while running for errors? This can avoid timeout issues but will be slower. [yes/NO]: ",
+ _convert_yes_no_to_bool,
+ default=False,
+ error_message="Please enter yes or no.",
+ )
+
num_machines = 1
if distributed_type in (SageMakerDistributedType.DATA_PARALLEL, SageMakerDistributedType.MODEL_PARALLEL):
num_machines = _ask_field(
@@ -254,4 +263,5 @@
num_machines=num_machines,
sagemaker_inputs_file=sagemaker_inputs_file,
sagemaker_metrics_file=sagemaker_metrics_file,
+ debug=debug,
)
|
{"golden_diff": "diff --git a/src/accelerate/commands/config/sagemaker.py b/src/accelerate/commands/config/sagemaker.py\n--- a/src/accelerate/commands/config/sagemaker.py\n+++ b/src/accelerate/commands/config/sagemaker.py\n@@ -221,6 +221,15 @@\n ec2_instance_query += \"? [ml.p3.2xlarge]:\"\n ec2_instance_type = _ask_field(ec2_instance_query, lambda x: str(x).lower(), default=\"ml.p3.2xlarge\")\n \n+ debug = False\n+ if distributed_type != SageMakerDistributedType.NO:\n+ debug = _ask_field(\n+ \"Should distributed operations be checked while running for errors? This can avoid timeout issues but will be slower. [yes/NO]: \",\n+ _convert_yes_no_to_bool,\n+ default=False,\n+ error_message=\"Please enter yes or no.\",\n+ )\n+\n num_machines = 1\n if distributed_type in (SageMakerDistributedType.DATA_PARALLEL, SageMakerDistributedType.MODEL_PARALLEL):\n num_machines = _ask_field(\n@@ -254,4 +263,5 @@\n num_machines=num_machines,\n sagemaker_inputs_file=sagemaker_inputs_file,\n sagemaker_metrics_file=sagemaker_metrics_file,\n+ debug=debug,\n )\n", "issue": "SageMaker config TypeError\n### System Info\n\n```Shell\n- `Accelerate` version: 0.22.0\r\n- Platform: Linux-5.10.184-175.731.amzn2.x86_64-x86_64-with-glibc2.26\r\n- Python version: 3.10.8\r\n- Numpy version: 1.25.2\r\n- PyTorch version (GPU?): 2.0.1+cu117 (False)\r\n- PyTorch XPU available: False\r\n- PyTorch NPU available: False\n```\n\n\n### Information\n\n- [x] The official example scripts\n- [ ] My own modified scripts\n\n### Tasks\n\n- [ ] One of the scripts in the examples/ folder of Accelerate or an officially supported `no_trainer` script in the `examples` folder of the `transformers` repo (such as `run_no_trainer_glue.py`)\n- [ ] My own task or dataset (give details below)\n\n### Reproduction\n\n1. Install accelerate[sagemaker]\r\n2. run `accelerate config`\r\n3. Go through the configuration process\r\n\r\nThe result will be:\r\n```\r\nTraceback (most recent call last): \r\n File \"/home/ec2-user/anaconda3/envs/JupyterSystemEnv/bin/accelerate\", line 8, in <module> \r\n sys.exit(main()) \r\n File \"/home/ec2-user/anaconda3/envs/JupyterSystemEnv/lib/python3.10/site-packages/accelerate/commands/accelerate_cli.py\", line 45, in main \r\n args.func(args)\r\n File \"/home/ec2-user/anaconda3/envs/JupyterSystemEnv/lib/python3.10/site-packages/accelerate/commands/config/config.py\", line 67, in config_command\r\n config = get_user_input()\r\n File \"/home/ec2-user/anaconda3/envs/JupyterSystemEnv/lib/python3.10/site-packages/accelerate/commands/config/config.py\", line 38, in get_user_input\r\n config = get_sagemaker_input()\r\n File \"/home/ec2-user/anaconda3/envs/JupyterSystemEnv/lib/python3.10/site-packages/accelerate/commands/config/sagemaker.py\", line 243, in get_sagemaker_input\r\n return SageMakerConfig(\r\nTypeError: SageMakerConfig.__init__() missing 1 required positional argument: 'debug'\r\n```\n\n### Expected behavior\n\naccelerate config works\n", "before_files": [{"content": "#!/usr/bin/env python\n\n# Copyright 2021 The HuggingFace Team. All rights reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\nimport json\nimport os\n\nfrom ...utils.constants import SAGEMAKER_PARALLEL_EC2_INSTANCES, TORCH_DYNAMO_MODES\nfrom ...utils.dataclasses import ComputeEnvironment, SageMakerDistributedType\nfrom ...utils.imports import is_boto3_available\nfrom .config_args import SageMakerConfig\nfrom .config_utils import (\n DYNAMO_BACKENDS,\n _ask_field,\n _ask_options,\n _convert_dynamo_backend,\n _convert_mixed_precision,\n _convert_sagemaker_distributed_mode,\n _convert_yes_no_to_bool,\n)\n\n\nif is_boto3_available():\n import boto3 # noqa: F401\n\n\ndef _create_iam_role_for_sagemaker(role_name):\n iam_client = boto3.client(\"iam\")\n\n sagemaker_trust_policy = {\n \"Version\": \"2012-10-17\",\n \"Statement\": [\n {\"Effect\": \"Allow\", \"Principal\": {\"Service\": \"sagemaker.amazonaws.com\"}, \"Action\": \"sts:AssumeRole\"}\n ],\n }\n try:\n # create the role, associated with the chosen trust policy\n iam_client.create_role(\n RoleName=role_name, AssumeRolePolicyDocument=json.dumps(sagemaker_trust_policy, indent=2)\n )\n policy_document = {\n \"Version\": \"2012-10-17\",\n \"Statement\": [\n {\n \"Effect\": \"Allow\",\n \"Action\": [\n \"sagemaker:*\",\n \"ecr:GetDownloadUrlForLayer\",\n \"ecr:BatchGetImage\",\n \"ecr:BatchCheckLayerAvailability\",\n \"ecr:GetAuthorizationToken\",\n \"cloudwatch:PutMetricData\",\n \"cloudwatch:GetMetricData\",\n \"cloudwatch:GetMetricStatistics\",\n \"cloudwatch:ListMetrics\",\n \"logs:CreateLogGroup\",\n \"logs:CreateLogStream\",\n \"logs:DescribeLogStreams\",\n \"logs:PutLogEvents\",\n \"logs:GetLogEvents\",\n \"s3:CreateBucket\",\n \"s3:ListBucket\",\n \"s3:GetBucketLocation\",\n \"s3:GetObject\",\n \"s3:PutObject\",\n ],\n \"Resource\": \"*\",\n }\n ],\n }\n # attach policy to role\n iam_client.put_role_policy(\n RoleName=role_name,\n PolicyName=f\"{role_name}_policy_permission\",\n PolicyDocument=json.dumps(policy_document, indent=2),\n )\n except iam_client.exceptions.EntityAlreadyExistsException:\n print(f\"role {role_name} already exists. Using existing one\")\n\n\ndef _get_iam_role_arn(role_name):\n iam_client = boto3.client(\"iam\")\n return iam_client.get_role(RoleName=role_name)[\"Role\"][\"Arn\"]\n\n\ndef get_sagemaker_input():\n credentials_configuration = _ask_options(\n \"How do you want to authorize?\",\n [\"AWS Profile\", \"Credentials (AWS_ACCESS_KEY_ID, AWS_SECRET_ACCESS_KEY) \"],\n int,\n )\n aws_profile = None\n if credentials_configuration == 0:\n aws_profile = _ask_field(\"Enter your AWS Profile name: [default] \", default=\"default\")\n os.environ[\"AWS_PROFILE\"] = aws_profile\n else:\n print(\n \"Note you will need to provide AWS_ACCESS_KEY_ID and AWS_SECRET_ACCESS_KEY when you launch you training script with,\"\n \"`accelerate launch --aws_access_key_id XXX --aws_secret_access_key YYY`\"\n )\n aws_access_key_id = _ask_field(\"AWS Access Key ID: \")\n os.environ[\"AWS_ACCESS_KEY_ID\"] = aws_access_key_id\n\n aws_secret_access_key = _ask_field(\"AWS Secret Access Key: \")\n os.environ[\"AWS_SECRET_ACCESS_KEY\"] = aws_secret_access_key\n\n aws_region = _ask_field(\"Enter your AWS Region: [us-east-1]\", default=\"us-east-1\")\n os.environ[\"AWS_DEFAULT_REGION\"] = aws_region\n\n role_management = _ask_options(\n \"Do you already have an IAM Role for executing Amazon SageMaker Training Jobs?\",\n [\"Provide IAM Role name\", \"Create new IAM role using credentials\"],\n int,\n )\n if role_management == 0:\n iam_role_name = _ask_field(\"Enter your IAM role name: \")\n else:\n iam_role_name = \"accelerate_sagemaker_execution_role\"\n print(f'Accelerate will create an iam role \"{iam_role_name}\" using the provided credentials')\n _create_iam_role_for_sagemaker(iam_role_name)\n\n is_custom_docker_image = _ask_field(\n \"Do you want to use custom Docker image? [yes/NO]: \",\n _convert_yes_no_to_bool,\n default=False,\n error_message=\"Please enter yes or no.\",\n )\n docker_image = None\n if is_custom_docker_image:\n docker_image = _ask_field(\"Enter your Docker image: \", lambda x: str(x).lower())\n\n is_sagemaker_inputs_enabled = _ask_field(\n \"Do you want to provide SageMaker input channels with data locations? [yes/NO]: \",\n _convert_yes_no_to_bool,\n default=False,\n error_message=\"Please enter yes or no.\",\n )\n sagemaker_inputs_file = None\n if is_sagemaker_inputs_enabled:\n sagemaker_inputs_file = _ask_field(\n \"Enter the path to the SageMaker inputs TSV file with columns (channel_name, data_location): \",\n lambda x: str(x).lower(),\n )\n\n is_sagemaker_metrics_enabled = _ask_field(\n \"Do you want to enable SageMaker metrics? [yes/NO]: \",\n _convert_yes_no_to_bool,\n default=False,\n error_message=\"Please enter yes or no.\",\n )\n sagemaker_metrics_file = None\n if is_sagemaker_metrics_enabled:\n sagemaker_metrics_file = _ask_field(\n \"Enter the path to the SageMaker metrics TSV file with columns (metric_name, metric_regex): \",\n lambda x: str(x).lower(),\n )\n\n distributed_type = _ask_options(\n \"What is the distributed mode?\",\n [\"No distributed training\", \"Data parallelism\"],\n _convert_sagemaker_distributed_mode,\n )\n dynamo_config = {}\n use_dynamo = _ask_field(\n \"Do you wish to optimize your script with torch dynamo?[yes/NO]:\",\n _convert_yes_no_to_bool,\n default=False,\n error_message=\"Please enter yes or no.\",\n )\n if use_dynamo:\n prefix = \"dynamo_\"\n dynamo_config[prefix + \"backend\"] = _ask_options(\n \"Which dynamo backend would you like to use?\",\n [x.lower() for x in DYNAMO_BACKENDS],\n _convert_dynamo_backend,\n default=2,\n )\n use_custom_options = _ask_field(\n \"Do you want to customize the defaults sent to torch.compile? [yes/NO]: \",\n _convert_yes_no_to_bool,\n default=False,\n error_message=\"Please enter yes or no.\",\n )\n\n if use_custom_options:\n dynamo_config[prefix + \"mode\"] = _ask_options(\n \"Which mode do you want to use?\",\n TORCH_DYNAMO_MODES,\n lambda x: TORCH_DYNAMO_MODES[int(x)],\n default=\"default\",\n )\n dynamo_config[prefix + \"use_fullgraph\"] = _ask_field(\n \"Do you want the fullgraph mode or it is ok to break model into several subgraphs? [yes/NO]: \",\n _convert_yes_no_to_bool,\n default=False,\n error_message=\"Please enter yes or no.\",\n )\n dynamo_config[prefix + \"use_dynamic\"] = _ask_field(\n \"Do you want to enable dynamic shape tracing? [yes/NO]: \",\n _convert_yes_no_to_bool,\n default=False,\n error_message=\"Please enter yes or no.\",\n )\n ec2_instance_query = \"Which EC2 instance type you want to use for your training?\"\n if distributed_type != SageMakerDistributedType.NO:\n ec2_instance_type = _ask_options(\n ec2_instance_query, SAGEMAKER_PARALLEL_EC2_INSTANCES, lambda x: SAGEMAKER_PARALLEL_EC2_INSTANCES[int(x)]\n )\n else:\n ec2_instance_query += \"? [ml.p3.2xlarge]:\"\n ec2_instance_type = _ask_field(ec2_instance_query, lambda x: str(x).lower(), default=\"ml.p3.2xlarge\")\n\n num_machines = 1\n if distributed_type in (SageMakerDistributedType.DATA_PARALLEL, SageMakerDistributedType.MODEL_PARALLEL):\n num_machines = _ask_field(\n \"How many machines do you want use? [1]: \",\n int,\n default=1,\n )\n\n mixed_precision = _ask_options(\n \"Do you wish to use FP16 or BF16 (mixed precision)?\",\n [\"no\", \"fp16\", \"bf16\", \"fp8\"],\n _convert_mixed_precision,\n )\n\n if use_dynamo and mixed_precision == \"no\":\n print(\n \"Torch dynamo used without mixed precision requires TF32 to be efficient. Accelerate will enable it by default when launching your scripts.\"\n )\n\n return SageMakerConfig(\n image_uri=docker_image,\n compute_environment=ComputeEnvironment.AMAZON_SAGEMAKER,\n distributed_type=distributed_type,\n use_cpu=False,\n dynamo_config=dynamo_config,\n ec2_instance_type=ec2_instance_type,\n profile=aws_profile,\n region=aws_region,\n iam_role_name=iam_role_name,\n mixed_precision=mixed_precision,\n num_machines=num_machines,\n sagemaker_inputs_file=sagemaker_inputs_file,\n sagemaker_metrics_file=sagemaker_metrics_file,\n )\n", "path": "src/accelerate/commands/config/sagemaker.py"}]}
| 4,045 | 302 |
gh_patches_debug_60781
|
rasdani/github-patches
|
git_diff
|
pypa__cibuildwheel-1065
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[Docs] Example may accidentally be encouraging users to write invalid `pyproject.toml` files
### Description
Hi guys, first of all thank you for the amazing project (always good to remember).
While I was working on adding support for PEP 621 to setuptools, I noticed a series of users having problems with invalid `pyproject.toml` files. The common pattern seem to be a almost empty `[project]` table with only a `requires-python` field set, which is invalid according to PEP 621.
It took me some time to find the reason for this behaviour but I think it comes from:
https://cibuildwheel.readthedocs.io/en/stable/options/#requires-python
I suspect that the example and notes about the preferred way of setting the config has been encouraging users that are unaware of PEP 621 to write technically invalid `pyproject.toml` files.
Please note that this issue is not necessarily related to setuptools itself.
The existence of the `[project]` table in the `pyproject.toml` allows (according to the standard) the installer/builder/consumer program to treat the package differently (specially regarding `dynamic`).
I think it would be nice to at least add a note about this so users became aware of the implications of adding a `[project]` table.
### Build log
_No response_
### CI config
_No response_
</issue>
<code>
[start of setup.py]
1 from setuptools import setup
2
3 extras = {
4 "docs": [
5 "mkdocs-include-markdown-plugin==2.8.0",
6 "mkdocs==1.0.4",
7 "pymdown-extensions",
8 "mkdocs-macros-plugin",
9 ],
10 "test": [
11 "jinja2",
12 "pytest>=6",
13 "pytest-timeout",
14 "pytest-xdist",
15 ],
16 "bin": [
17 "click",
18 "ghapi",
19 "pip-tools",
20 "pygithub",
21 "pyyaml",
22 "requests",
23 "rich>=9.6",
24 "packaging>=21.0",
25 ],
26 "mypy": [
27 "mypy>=0.901",
28 "types-jinja2",
29 "types-certifi",
30 "types-toml",
31 "types-jinja2",
32 "types-pyyaml",
33 "types-click",
34 "types-requests",
35 ],
36 }
37
38 extras["dev"] = [
39 *extras["mypy"],
40 *extras["test"],
41 *extras["bin"],
42 ]
43
44 extras["all"] = sum(extras.values(), [])
45
46 setup(extras_require=extras)
47
[end of setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -4,6 +4,7 @@
"docs": [
"mkdocs-include-markdown-plugin==2.8.0",
"mkdocs==1.0.4",
+ "jinja2==3.0.3",
"pymdown-extensions",
"mkdocs-macros-plugin",
],
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -4,6 +4,7 @@\n \"docs\": [\n \"mkdocs-include-markdown-plugin==2.8.0\",\n \"mkdocs==1.0.4\",\n+ \"jinja2==3.0.3\",\n \"pymdown-extensions\",\n \"mkdocs-macros-plugin\",\n ],\n", "issue": "[Docs] Example may accidentally be encouraging users to write invalid `pyproject.toml` files\n### Description\r\n\r\nHi guys, first of all thank you for the amazing project (always good to remember).\r\n\r\nWhile I was working on adding support for PEP 621 to setuptools, I noticed a series of users having problems with invalid `pyproject.toml` files. The common pattern seem to be a almost empty `[project]` table with only a `requires-python` field set, which is invalid according to PEP 621.\r\n\r\nIt took me some time to find the reason for this behaviour but I think it comes from:\r\nhttps://cibuildwheel.readthedocs.io/en/stable/options/#requires-python\r\n\r\nI suspect that the example and notes about the preferred way of setting the config has been encouraging users that are unaware of PEP 621 to write technically invalid `pyproject.toml` files.\r\n\r\nPlease note that this issue is not necessarily related to setuptools itself.\r\nThe existence of the `[project]` table in the `pyproject.toml` allows (according to the standard) the installer/builder/consumer program to treat the package differently (specially regarding `dynamic`).\r\n\r\nI think it would be nice to at least add a note about this so users became aware of the implications of adding a `[project]` table.\r\n\r\n### Build log\r\n\r\n_No response_\r\n\r\n### CI config\r\n\r\n_No response_\n", "before_files": [{"content": "from setuptools import setup\n\nextras = {\n \"docs\": [\n \"mkdocs-include-markdown-plugin==2.8.0\",\n \"mkdocs==1.0.4\",\n \"pymdown-extensions\",\n \"mkdocs-macros-plugin\",\n ],\n \"test\": [\n \"jinja2\",\n \"pytest>=6\",\n \"pytest-timeout\",\n \"pytest-xdist\",\n ],\n \"bin\": [\n \"click\",\n \"ghapi\",\n \"pip-tools\",\n \"pygithub\",\n \"pyyaml\",\n \"requests\",\n \"rich>=9.6\",\n \"packaging>=21.0\",\n ],\n \"mypy\": [\n \"mypy>=0.901\",\n \"types-jinja2\",\n \"types-certifi\",\n \"types-toml\",\n \"types-jinja2\",\n \"types-pyyaml\",\n \"types-click\",\n \"types-requests\",\n ],\n}\n\nextras[\"dev\"] = [\n *extras[\"mypy\"],\n *extras[\"test\"],\n *extras[\"bin\"],\n]\n\nextras[\"all\"] = sum(extras.values(), [])\n\nsetup(extras_require=extras)\n", "path": "setup.py"}]}
| 1,162 | 94 |
gh_patches_debug_14980
|
rasdani/github-patches
|
git_diff
|
conan-io__conan-center-index-3332
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[package] folly/2020.08.10.00: Compile errors on devtoolset-4 gcc5
<!--
Please don't forget to update the issue title.
Include all applicable information to help us reproduce your problem.
-->
### Package and Environment Details (include every applicable attribute)
* Package Name/Version: **folly/2020.08.10.00**
* Operating System+version: **Red Hat Enterprise 6**
* Compiler+version: **GCC 5.3.1 from devtoolset-4**
* Conan version: **conan 1.29.1**
* Python version: **Python 3.7.4**
### Conan profile (output of `conan profile show default` or `conan profile show <profile>` if custom profile is in use)
```
[settings]
os=Linux
os_build=Linux
arch=x86_64
arch_build=x86_64
compiler=gcc
compiler.version=5
compiler.libcxx=libstdc++
build_type=Debug
[options]
[build_requires]
[env]
```
### Steps to reproduce (Include if Applicable)
Build recipe using gcc 5.3.1 (devtoolset-4) on RHEL6. There are two compile errors:
```
/userhome/epederson/.conan/data/folly/2020.08.10.00/test/test/build/21e92cd0e529b036c562d4dfa4ad1adfee8a5c75/source_subfolder/folly/portability/Time.cpp:278:2: error: #error No clock_gettime(3) compatibility wrapper available for this platform.
#error No clock_gettime(3) compatibility wrapper available for this platform.
^
gmake[2]: *** [source_subfolder/CMakeFiles/folly_base.dir/folly/portability/Time.cpp.o] Error 1
```
```
/userhome/epederson/.conan/data/folly/2020.08.10.00/test/test/build/21e92cd0e529b036c562d4dfa4ad1adfee8a5c75/source_subfolder/folly/Benchmark.cpp:340:30: error: expected ‘)’ before ‘PRId64’
printf(" %-*" PRId64, int(name.length()), ptr->value);
^
```
I will submit a PR with a fix.
</issue>
<code>
[start of recipes/folly/all/conanfile.py]
1 import os
2 from conans import ConanFile, CMake, tools
3 from conans.tools import Version
4 from conans.errors import ConanInvalidConfiguration
5
6 required_conan_version = ">=1.28.0"
7
8 class FollyConan(ConanFile):
9 name = "folly"
10 description = "An open-source C++ components library developed and used at Facebook"
11 topics = ("conan", "folly", "facebook", "components", "core", "efficiency")
12 url = "https://github.com/conan-io/conan-center-index"
13 homepage = "https://github.com/facebook/folly"
14 license = "Apache-2.0"
15 settings = "os", "arch", "compiler", "build_type"
16 options = {"shared": [True, False], "fPIC": [True, False]}
17 default_options = {"shared": False, "fPIC": True}
18 exports_sources = ["CMakeLists.txt", "patches/*"]
19 generators = "cmake", "cmake_find_package"
20
21 _cmake = None
22
23 @property
24 def _source_subfolder(self):
25 return "source_subfolder"
26
27 @property
28 def _minimum_cpp_standard(self):
29 return 14
30
31 @property
32 def _minimum_compilers_version(self):
33 return {
34 "Visual Studio": "15",
35 "gcc": "5",
36 "clang": "6",
37 "apple-clang": "8",
38 }
39
40 def config_options(self):
41 if self.settings.os == "Windows":
42 del self.options.fPIC
43
44 def configure(self):
45 if self.options.shared:
46 del self.options.fPIC
47 if self.settings.get_safe("compiler.cppstd"):
48 tools.check_min_cppstd(self, self._minimum_cpp_standard)
49 min_version = self._minimum_compilers_version.get(
50 str(self.settings.compiler))
51 if not min_version:
52 self.output.warn("{} recipe lacks information about the {} compiler support.".format(
53 self.name, self.settings.compiler))
54 else:
55 if tools.Version(self.settings.compiler.version) < min_version:
56 raise ConanInvalidConfiguration("{} requires C++14 support. The current compiler {} {} does not support it.".format(
57 self.name, self.settings.compiler, self.settings.compiler.version))
58
59 if self.settings.os == "Windows" and self.settings.arch != "x86_64":
60 raise ConanInvalidConfiguration("Folly requires a 64bit target architecture")
61 elif self.settings.os == "Windows" and self.settings.compiler == "Visual Studio" and \
62 "MT" in self.settings.compiler.runtime:
63 raise ConanInvalidConfiguration("Folly could not be build with runtime MT")
64 elif self.settings.os == "Macos" and self.options.shared:
65 raise ConanInvalidConfiguration("Folly could not be built by apple-clang as shared library")
66 elif self.settings.os == "Windows" and self.options.shared:
67 raise ConanInvalidConfiguration("Folly could not be built on Windows as a shared library")
68 elif Version(self.version) >= "2020.08.10.00" and self.settings.compiler == "Visual Studio" and \
69 not self.options.shared:
70 raise ConanInvalidConfiguration("Folly could not be built on Windows as a static library")
71 elif Version(self.version) >= "2020.08.10.00" and self.settings.compiler == "clang" and \
72 self.options.shared:
73 raise ConanInvalidConfiguration("Folly could not be built by clang as a shared library")
74
75 self._strip_options_requirements()
76
77 def _strip_options_requirements(self):
78 self.options["boost"].header_only = False
79 for boost_comp in self._required_boost_components:
80 setattr(self.options["boost"], "without_{}".format(boost_comp), False)
81
82 @property
83 def _required_boost_components(self):
84 return ["context", "filesystem", "program_options", "regex", "system", "thread"]
85
86 def requirements(self):
87 self.requires("boost/1.74.0")
88 self.requires("bzip2/1.0.8")
89 self.requires("double-conversion/3.1.5")
90 self.requires("gflags/2.2.2")
91 self.requires("glog/0.4.0")
92 self.requires("libevent/2.1.12")
93 self.requires("lz4/1.9.2")
94 self.requires("openssl/1.1.1h")
95 self.requires("snappy/1.1.8")
96 self.requires("zlib/1.2.11")
97 self.requires("zstd/1.4.5")
98 if Version(self.version) >= "2019.01.01.00":
99 self.requires("libdwarf/20191104")
100 self.requires("libsodium/1.0.18")
101 self.requires("xz_utils/5.2.4")
102 if self.settings.os == "Linux":
103 self.requires("libiberty/9.1.0")
104 self.requires("libunwind/1.3.1")
105 if Version(self.version) >= "2020.08.10.00":
106 self.requires("fmt/7.0.3")
107
108 def _validate_dependency_graph(self):
109 miss_boost_required_comp = any(getattr(self.options["boost"], "without_{}".format(boost_comp), True) for boost_comp in self._required_boost_components)
110 if self.options["boost"].header_only or miss_boost_required_comp:
111 raise ConanInvalidConfiguration("Folly requires these boost components: {}".format(", ".join(self._required_boost_components)))
112
113 def source(self):
114 tools.get(**self.conan_data["sources"][self.version])
115 extracted_dir = self.name + "-" + self.version
116 os.rename(extracted_dir, self._source_subfolder)
117
118 def _configure_cmake(self):
119 if not self._cmake:
120 self._cmake = CMake(self)
121 self._cmake.definitions["CMAKE_POSITION_INDEPENDENT_CODE"] = self.options.get_safe("fPIC", True)
122 self._cmake.definitions["CXX_STD"] = self.settings.get_safe(
123 "compiler.cppstd") or "c++14"
124 if self.settings.compiler == "Visual Studio":
125 self._cmake.definitions["MSVC_ENABLE_ALL_WARNINGS"] = False
126 self._cmake.definitions["MSVC_USE_STATIC_RUNTIME"] = "MT" in self.settings.compiler.runtime
127 self._cmake.configure()
128 return self._cmake
129
130 def build(self):
131 self._validate_dependency_graph()
132 for patch in self.conan_data["patches"][self.version]:
133 tools.patch(**patch)
134 cmake = self._configure_cmake()
135 cmake.build()
136
137 def package(self):
138 self.copy(pattern="LICENSE", dst="licenses",
139 src=self._source_subfolder)
140 cmake = self._configure_cmake()
141 cmake.install()
142 tools.rmdir(os.path.join(self.package_folder, "lib", "cmake"))
143 tools.rmdir(os.path.join(self.package_folder, "lib", "pkgconfig"))
144
145 def package_info(self):
146 self.cpp_info.filenames["cmake_find_package"] = "folly"
147 self.cpp_info.filenames["cmake_find_package_multi"] = "folly"
148 self.cpp_info.names["cmake_find_package"] = "Folly"
149 self.cpp_info.names["cmake_find_package_multi"] = "Folly"
150 self.cpp_info.names["pkg_config"] = "libfolly"
151 self.cpp_info.components["libfolly"].names["cmake_find_package"] = "folly"
152 self.cpp_info.components["libfolly"].names["cmake_find_package_multi"] = "folly"
153 self.cpp_info.components["libfolly"].names["pkg_config"] = "libfolly"
154 self.cpp_info.components["libfolly"].libs = tools.collect_libs(self)
155 self.cpp_info.components["libfolly"].requires = [
156 "boost::boost",
157 "bzip2::bzip2",
158 "double-conversion::double-conversion",
159 "gflags::gflags",
160 "glog::glog",
161 "libevent::libevent",
162 "lz4::lz4",
163 "openssl::openssl",
164 "snappy::snappy",
165 "zlib::zlib",
166 "zstd::zstd"
167 ]
168 if Version(self.version) >= "2019.01.01.00":
169 self.cpp_info.components["libfolly"].requires.extend([
170 "libdwarf::libdwarf",
171 "libsodium::libsodium",
172 "xz_utils::xz_utils"
173 ])
174 if self.settings.os == "Linux":
175 self.cpp_info.components["libfolly"].requires.extend([
176 "libiberty::libiberty",
177 "libunwind::libunwind"
178 ])
179 if Version(self.version) >= "2020.08.10.00":
180 self.cpp_info.components["libfolly"].requires.append("fmt::fmt")
181 if self.settings.os == "Linux":
182 self.cpp_info.components["libfolly"].system_libs.extend(["pthread", "dl"])
183 elif self.settings.os == "Windows":
184 self.cpp_info.components["libfolly"].system_libs.extend(["ws2_32", "Iphlpapi", "Crypt32"])
185 if (self.settings.os == "Linux" and self.settings.compiler == "clang" and
186 self.settings.compiler.libcxx == "libstdc++") or \
187 (self.settings.os == "Macos" and self.settings.compiler == "apple-clang" and
188 Version(self.settings.compiler.version.value) == "9.0" and self.settings.compiler.libcxx == "libc++"):
189 self.cpp_info.components["libfolly"].system_libs.append("atomic")
190
[end of recipes/folly/all/conanfile.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/recipes/folly/all/conanfile.py b/recipes/folly/all/conanfile.py
--- a/recipes/folly/all/conanfile.py
+++ b/recipes/folly/all/conanfile.py
@@ -179,7 +179,7 @@
if Version(self.version) >= "2020.08.10.00":
self.cpp_info.components["libfolly"].requires.append("fmt::fmt")
if self.settings.os == "Linux":
- self.cpp_info.components["libfolly"].system_libs.extend(["pthread", "dl"])
+ self.cpp_info.components["libfolly"].system_libs.extend(["pthread", "dl", "rt"])
elif self.settings.os == "Windows":
self.cpp_info.components["libfolly"].system_libs.extend(["ws2_32", "Iphlpapi", "Crypt32"])
if (self.settings.os == "Linux" and self.settings.compiler == "clang" and
|
{"golden_diff": "diff --git a/recipes/folly/all/conanfile.py b/recipes/folly/all/conanfile.py\n--- a/recipes/folly/all/conanfile.py\n+++ b/recipes/folly/all/conanfile.py\n@@ -179,7 +179,7 @@\n if Version(self.version) >= \"2020.08.10.00\":\n self.cpp_info.components[\"libfolly\"].requires.append(\"fmt::fmt\")\n if self.settings.os == \"Linux\":\n- self.cpp_info.components[\"libfolly\"].system_libs.extend([\"pthread\", \"dl\"])\n+ self.cpp_info.components[\"libfolly\"].system_libs.extend([\"pthread\", \"dl\", \"rt\"])\n elif self.settings.os == \"Windows\":\n self.cpp_info.components[\"libfolly\"].system_libs.extend([\"ws2_32\", \"Iphlpapi\", \"Crypt32\"])\n if (self.settings.os == \"Linux\" and self.settings.compiler == \"clang\" and\n", "issue": "[package] folly/2020.08.10.00: Compile errors on devtoolset-4 gcc5\n<!-- \r\n Please don't forget to update the issue title.\r\n Include all applicable information to help us reproduce your problem.\r\n-->\r\n\r\n### Package and Environment Details (include every applicable attribute)\r\n * Package Name/Version: **folly/2020.08.10.00**\r\n * Operating System+version: **Red Hat Enterprise 6**\r\n * Compiler+version: **GCC 5.3.1 from devtoolset-4**\r\n * Conan version: **conan 1.29.1**\r\n * Python version: **Python 3.7.4**\r\n\r\n\r\n### Conan profile (output of `conan profile show default` or `conan profile show <profile>` if custom profile is in use)\r\n```\r\n[settings]\r\nos=Linux\r\nos_build=Linux\r\narch=x86_64\r\narch_build=x86_64\r\ncompiler=gcc\r\ncompiler.version=5\r\ncompiler.libcxx=libstdc++\r\nbuild_type=Debug\r\n[options]\r\n[build_requires]\r\n[env]\r\n```\r\n\r\n\r\n### Steps to reproduce (Include if Applicable)\r\n\r\nBuild recipe using gcc 5.3.1 (devtoolset-4) on RHEL6. There are two compile errors:\r\n\r\n```\r\n/userhome/epederson/.conan/data/folly/2020.08.10.00/test/test/build/21e92cd0e529b036c562d4dfa4ad1adfee8a5c75/source_subfolder/folly/portability/Time.cpp:278:2: error: #error No clock_gettime(3) compatibility wrapper available for this platform.\r\n #error No clock_gettime(3) compatibility wrapper available for this platform.\r\n ^\r\ngmake[2]: *** [source_subfolder/CMakeFiles/folly_base.dir/folly/portability/Time.cpp.o] Error 1\r\n```\r\n\r\n```\r\n/userhome/epederson/.conan/data/folly/2020.08.10.00/test/test/build/21e92cd0e529b036c562d4dfa4ad1adfee8a5c75/source_subfolder/folly/Benchmark.cpp:340:30: error: expected \u2018)\u2019 before \u2018PRId64\u2019\r\n printf(\" %-*\" PRId64, int(name.length()), ptr->value);\r\n ^\r\n```\r\n\r\nI will submit a PR with a fix.\n", "before_files": [{"content": "import os\nfrom conans import ConanFile, CMake, tools\nfrom conans.tools import Version\nfrom conans.errors import ConanInvalidConfiguration\n\nrequired_conan_version = \">=1.28.0\"\n\nclass FollyConan(ConanFile):\n name = \"folly\"\n description = \"An open-source C++ components library developed and used at Facebook\"\n topics = (\"conan\", \"folly\", \"facebook\", \"components\", \"core\", \"efficiency\")\n url = \"https://github.com/conan-io/conan-center-index\"\n homepage = \"https://github.com/facebook/folly\"\n license = \"Apache-2.0\"\n settings = \"os\", \"arch\", \"compiler\", \"build_type\"\n options = {\"shared\": [True, False], \"fPIC\": [True, False]}\n default_options = {\"shared\": False, \"fPIC\": True}\n exports_sources = [\"CMakeLists.txt\", \"patches/*\"]\n generators = \"cmake\", \"cmake_find_package\"\n\n _cmake = None\n\n @property\n def _source_subfolder(self):\n return \"source_subfolder\"\n\n @property\n def _minimum_cpp_standard(self):\n return 14\n\n @property\n def _minimum_compilers_version(self):\n return {\n \"Visual Studio\": \"15\",\n \"gcc\": \"5\",\n \"clang\": \"6\",\n \"apple-clang\": \"8\",\n }\n\n def config_options(self):\n if self.settings.os == \"Windows\":\n del self.options.fPIC\n\n def configure(self):\n if self.options.shared:\n del self.options.fPIC\n if self.settings.get_safe(\"compiler.cppstd\"):\n tools.check_min_cppstd(self, self._minimum_cpp_standard)\n min_version = self._minimum_compilers_version.get(\n str(self.settings.compiler))\n if not min_version:\n self.output.warn(\"{} recipe lacks information about the {} compiler support.\".format(\n self.name, self.settings.compiler))\n else:\n if tools.Version(self.settings.compiler.version) < min_version:\n raise ConanInvalidConfiguration(\"{} requires C++14 support. The current compiler {} {} does not support it.\".format(\n self.name, self.settings.compiler, self.settings.compiler.version))\n\n if self.settings.os == \"Windows\" and self.settings.arch != \"x86_64\":\n raise ConanInvalidConfiguration(\"Folly requires a 64bit target architecture\")\n elif self.settings.os == \"Windows\" and self.settings.compiler == \"Visual Studio\" and \\\n \"MT\" in self.settings.compiler.runtime:\n raise ConanInvalidConfiguration(\"Folly could not be build with runtime MT\")\n elif self.settings.os == \"Macos\" and self.options.shared:\n raise ConanInvalidConfiguration(\"Folly could not be built by apple-clang as shared library\")\n elif self.settings.os == \"Windows\" and self.options.shared:\n raise ConanInvalidConfiguration(\"Folly could not be built on Windows as a shared library\")\n elif Version(self.version) >= \"2020.08.10.00\" and self.settings.compiler == \"Visual Studio\" and \\\n not self.options.shared:\n raise ConanInvalidConfiguration(\"Folly could not be built on Windows as a static library\")\n elif Version(self.version) >= \"2020.08.10.00\" and self.settings.compiler == \"clang\" and \\\n self.options.shared:\n raise ConanInvalidConfiguration(\"Folly could not be built by clang as a shared library\")\n\n self._strip_options_requirements()\n\n def _strip_options_requirements(self):\n self.options[\"boost\"].header_only = False\n for boost_comp in self._required_boost_components:\n setattr(self.options[\"boost\"], \"without_{}\".format(boost_comp), False)\n\n @property\n def _required_boost_components(self):\n return [\"context\", \"filesystem\", \"program_options\", \"regex\", \"system\", \"thread\"]\n\n def requirements(self):\n self.requires(\"boost/1.74.0\")\n self.requires(\"bzip2/1.0.8\")\n self.requires(\"double-conversion/3.1.5\")\n self.requires(\"gflags/2.2.2\")\n self.requires(\"glog/0.4.0\")\n self.requires(\"libevent/2.1.12\")\n self.requires(\"lz4/1.9.2\")\n self.requires(\"openssl/1.1.1h\")\n self.requires(\"snappy/1.1.8\")\n self.requires(\"zlib/1.2.11\")\n self.requires(\"zstd/1.4.5\")\n if Version(self.version) >= \"2019.01.01.00\":\n self.requires(\"libdwarf/20191104\")\n self.requires(\"libsodium/1.0.18\")\n self.requires(\"xz_utils/5.2.4\")\n if self.settings.os == \"Linux\":\n self.requires(\"libiberty/9.1.0\")\n self.requires(\"libunwind/1.3.1\")\n if Version(self.version) >= \"2020.08.10.00\":\n self.requires(\"fmt/7.0.3\")\n\n def _validate_dependency_graph(self):\n miss_boost_required_comp = any(getattr(self.options[\"boost\"], \"without_{}\".format(boost_comp), True) for boost_comp in self._required_boost_components)\n if self.options[\"boost\"].header_only or miss_boost_required_comp:\n raise ConanInvalidConfiguration(\"Folly requires these boost components: {}\".format(\", \".join(self._required_boost_components)))\n\n def source(self):\n tools.get(**self.conan_data[\"sources\"][self.version])\n extracted_dir = self.name + \"-\" + self.version\n os.rename(extracted_dir, self._source_subfolder)\n\n def _configure_cmake(self):\n if not self._cmake:\n self._cmake = CMake(self)\n self._cmake.definitions[\"CMAKE_POSITION_INDEPENDENT_CODE\"] = self.options.get_safe(\"fPIC\", True)\n self._cmake.definitions[\"CXX_STD\"] = self.settings.get_safe(\n \"compiler.cppstd\") or \"c++14\"\n if self.settings.compiler == \"Visual Studio\":\n self._cmake.definitions[\"MSVC_ENABLE_ALL_WARNINGS\"] = False\n self._cmake.definitions[\"MSVC_USE_STATIC_RUNTIME\"] = \"MT\" in self.settings.compiler.runtime\n self._cmake.configure()\n return self._cmake\n\n def build(self):\n self._validate_dependency_graph()\n for patch in self.conan_data[\"patches\"][self.version]:\n tools.patch(**patch)\n cmake = self._configure_cmake()\n cmake.build()\n\n def package(self):\n self.copy(pattern=\"LICENSE\", dst=\"licenses\",\n src=self._source_subfolder)\n cmake = self._configure_cmake()\n cmake.install()\n tools.rmdir(os.path.join(self.package_folder, \"lib\", \"cmake\"))\n tools.rmdir(os.path.join(self.package_folder, \"lib\", \"pkgconfig\"))\n\n def package_info(self):\n self.cpp_info.filenames[\"cmake_find_package\"] = \"folly\"\n self.cpp_info.filenames[\"cmake_find_package_multi\"] = \"folly\"\n self.cpp_info.names[\"cmake_find_package\"] = \"Folly\"\n self.cpp_info.names[\"cmake_find_package_multi\"] = \"Folly\"\n self.cpp_info.names[\"pkg_config\"] = \"libfolly\"\n self.cpp_info.components[\"libfolly\"].names[\"cmake_find_package\"] = \"folly\"\n self.cpp_info.components[\"libfolly\"].names[\"cmake_find_package_multi\"] = \"folly\"\n self.cpp_info.components[\"libfolly\"].names[\"pkg_config\"] = \"libfolly\"\n self.cpp_info.components[\"libfolly\"].libs = tools.collect_libs(self)\n self.cpp_info.components[\"libfolly\"].requires = [\n \"boost::boost\",\n \"bzip2::bzip2\",\n \"double-conversion::double-conversion\",\n \"gflags::gflags\",\n \"glog::glog\",\n \"libevent::libevent\",\n \"lz4::lz4\",\n \"openssl::openssl\",\n \"snappy::snappy\",\n \"zlib::zlib\",\n \"zstd::zstd\"\n ]\n if Version(self.version) >= \"2019.01.01.00\":\n self.cpp_info.components[\"libfolly\"].requires.extend([\n \"libdwarf::libdwarf\",\n \"libsodium::libsodium\",\n \"xz_utils::xz_utils\"\n ])\n if self.settings.os == \"Linux\":\n self.cpp_info.components[\"libfolly\"].requires.extend([\n \"libiberty::libiberty\",\n \"libunwind::libunwind\"\n ])\n if Version(self.version) >= \"2020.08.10.00\":\n self.cpp_info.components[\"libfolly\"].requires.append(\"fmt::fmt\")\n if self.settings.os == \"Linux\":\n self.cpp_info.components[\"libfolly\"].system_libs.extend([\"pthread\", \"dl\"])\n elif self.settings.os == \"Windows\":\n self.cpp_info.components[\"libfolly\"].system_libs.extend([\"ws2_32\", \"Iphlpapi\", \"Crypt32\"])\n if (self.settings.os == \"Linux\" and self.settings.compiler == \"clang\" and\n self.settings.compiler.libcxx == \"libstdc++\") or \\\n (self.settings.os == \"Macos\" and self.settings.compiler == \"apple-clang\" and\n Version(self.settings.compiler.version.value) == \"9.0\" and self.settings.compiler.libcxx == \"libc++\"):\n self.cpp_info.components[\"libfolly\"].system_libs.append(\"atomic\")\n", "path": "recipes/folly/all/conanfile.py"}]}
| 3,699 | 216 |
gh_patches_debug_11712
|
rasdani/github-patches
|
git_diff
|
learningequality__kolibri-5001
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
ValueError: invalid literal for int() with base 10
Sentry Issue: [KOLIBRI-BACKEND-8](https://sentry.io/learningequality/kolibri-backend/issues/877480545/?referrer=github_integration)
```
ValueError: invalid literal for int() with base 10: '0.00293684005737'
File "django/core/handlers/exception.py", line 41, in inner
response = get_response(request)
File "django/utils/deprecation.py", line 142, in __call__
response = self.process_response(request, response)
File "kolibri/core/analytics/middleware.py", line 144, in process_response
if int(duration) > MetricsMiddleware.slowest_request_time:
```
</issue>
<code>
[start of kolibri/core/analytics/middleware.py]
1 from __future__ import absolute_import
2
3 import csv
4 import os
5 import time
6
7 from django.conf import settings
8 from django.core.cache import caches
9 from django.core.exceptions import MiddlewareNotUsed
10 from django.utils.deprecation import MiddlewareMixin
11
12 from kolibri.core.analytics import SUPPORTED_OS
13 from kolibri.utils import conf
14 from kolibri.utils.server import PROFILE_LOCK
15 from kolibri.utils.system import pid_exists
16
17 requests_profiling_file = os.path.join(conf.KOLIBRI_HOME,
18 'performance',
19 '{}_requests_performance.csv'.format(time.strftime('%Y%m%d_%H%M%S')))
20
21 cache = caches[settings.CACHE_MIDDLEWARE_ALIAS]
22 try:
23 import kolibri.core.analytics.pskolibri as psutil
24 kolibri_process = psutil.Process()
25 except NotImplementedError:
26 # This middleware can't work on this OS
27 kolibri_process = None
28
29
30 class Metrics(object):
31 def __init__(self):
32 """
33 Save the initial values when the request comes in
34 This class only will be used when MetricsMiddleware is not disabled, thus the OS is supported.
35 External instances of this class must check if the OS is supported before creating new objects.
36 """
37 self.memory = self.get_used_memory()
38 self.load = self.get_load_average()
39 self.time = time.time()
40
41 def get_used_memory(self):
42 return kolibri_process.memory_info().vms
43
44 def get_load_average(self):
45 return kolibri_process.cpu_percent()
46
47 def get_stats(self):
48 """
49 Calcutes time spent in processing the request
50 and difference in memory and load consumed
51 by kolibri while processing the request
52 :returns: tuple of strings containing time consumed (in seconds),
53 Kolibri used memory (in bytes) before and after executing the request,
54 Kolibri cpu load (in %) before and after executing the request.
55 """
56 memory = str(self.get_used_memory())
57 load = str(self.get_load_average())
58 time_delta = str(time.time() - self.time)
59 return (time_delta, str(self.memory), memory, str(self.load), load)
60
61
62 class MetricsMiddleware(MiddlewareMixin):
63 """
64 This Middleware will produce a requests_performance.log file, with one line per requests having this structure:
65 - Timestamp
66 - Request path
67 - Time spent processing the request
68 - Memory (in Kbytes) used by the kolibri process when the request came in
69 - Memory (in Kbytes) used by the kolibri process when the response was sent
70 - Percentage of use of cpu by the Kolibri process when the request came in
71 - Percentage of use of cpu by the Kolibri process when the response was sent
72 - One flag indicating if this request is the slowest since the analysis was started
73 """
74 slowest_request_time = 0
75 disabled = True
76 command_pid = 0
77
78 def __init__(self, get_response=None):
79 super(MetricsMiddleware, self).__init__(get_response=get_response)
80 if not conf.OPTIONS["Server"]["PROFILE"]:
81 raise MiddlewareNotUsed('Request profiling is not enabled')
82
83 def process_request(self, request):
84 """
85 Store the start time, memory and load when the request comes in.
86 """
87 if not self.disabled:
88 self.metrics = Metrics()
89
90 def shutdown(self):
91 """
92 Disable this middleware and clean all the static variables
93 """
94 MetricsMiddleware.disabled = True
95 MetricsMiddleware.command_pid = 0
96 delattr(self, 'metrics')
97 if os.path.exists(PROFILE_LOCK):
98 try:
99 os.remove(PROFILE_LOCK)
100 except OSError:
101 pass # lock file was deleted by other process
102
103 def check_start_conditions(self):
104 """
105 Do the needed checks to enable the Middleware if possible
106 """
107 if MetricsMiddleware.disabled and conf.OPTIONS["Server"]["PROFILE"]:
108 if os.path.exists(PROFILE_LOCK):
109 try:
110 with open(PROFILE_LOCK, 'r') as f:
111 MetricsMiddleware.command_pid = int(f.readline())
112 file_timestamp = f.readline()
113 if SUPPORTED_OS:
114 MetricsMiddleware.disabled = False
115 self.requests_profiling_file = os.path.join(conf.KOLIBRI_HOME,
116 'performance',
117 '{}_requests_performance.csv'.format(file_timestamp))
118 with open(self.requests_profiling_file, mode='a') as profile_file:
119 profile_writer = csv.writer(profile_file, delimiter=',', quotechar='"', quoting=csv.QUOTE_MINIMAL)
120 profile_writer.writerow(('Date', 'Path', 'Duration', 'Memory before (Kb)',
121 'Memory after (Kb)', 'Load before (%)', 'Load after(%)',
122 'Longest time up to now'))
123 except (IOError, TypeError, ValueError):
124 # Kolibri command PID file has been deleted or it's corrupted
125 try:
126 os.remove(PROFILE_LOCK)
127 except OSError:
128 pass # lock file was deleted by other process
129
130 def process_response(self, request, response):
131 """
132 Calculate and output the page generation details
133 Log output consist on:
134 Datetime, request path, request duration, memory before, memory after requests is finished,
135 cpu load before, cpu load after the request is finished, max
136 Being `max` True or False to indicate if this is the slowest request since logging began.
137 """
138 self.check_start_conditions()
139
140 if not MetricsMiddleware.disabled and hasattr(self, 'metrics'):
141 path = request.get_full_path()
142 duration, memory_before, memory, load_before, load = self.metrics.get_stats()
143 max_time = False
144 if int(duration) > MetricsMiddleware.slowest_request_time:
145 MetricsMiddleware.slowest_request_time = int(duration)
146 max_time = True
147 timestamp = time.strftime('%Y/%m/%d %H:%M:%S.%f')
148 collected_information = (timestamp, path, duration, memory_before, memory, load_before, load, str(max_time))
149 with open(self.requests_profiling_file, mode='a') as profile_file:
150 profile_writer = csv.writer(profile_file, delimiter=',', quotechar='"', quoting=csv.QUOTE_MINIMAL)
151 profile_writer.writerow(collected_information)
152 if not pid_exists(MetricsMiddleware.command_pid) or not os.path.exists(PROFILE_LOCK):
153 self.shutdown()
154 return response
155
[end of kolibri/core/analytics/middleware.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/kolibri/core/analytics/middleware.py b/kolibri/core/analytics/middleware.py
--- a/kolibri/core/analytics/middleware.py
+++ b/kolibri/core/analytics/middleware.py
@@ -141,7 +141,7 @@
path = request.get_full_path()
duration, memory_before, memory, load_before, load = self.metrics.get_stats()
max_time = False
- if int(duration) > MetricsMiddleware.slowest_request_time:
+ if float(duration) > MetricsMiddleware.slowest_request_time:
MetricsMiddleware.slowest_request_time = int(duration)
max_time = True
timestamp = time.strftime('%Y/%m/%d %H:%M:%S.%f')
|
{"golden_diff": "diff --git a/kolibri/core/analytics/middleware.py b/kolibri/core/analytics/middleware.py\n--- a/kolibri/core/analytics/middleware.py\n+++ b/kolibri/core/analytics/middleware.py\n@@ -141,7 +141,7 @@\n path = request.get_full_path()\n duration, memory_before, memory, load_before, load = self.metrics.get_stats()\n max_time = False\n- if int(duration) > MetricsMiddleware.slowest_request_time:\n+ if float(duration) > MetricsMiddleware.slowest_request_time:\n MetricsMiddleware.slowest_request_time = int(duration)\n max_time = True\n timestamp = time.strftime('%Y/%m/%d %H:%M:%S.%f')\n", "issue": "ValueError: invalid literal for int() with base 10\nSentry Issue: [KOLIBRI-BACKEND-8](https://sentry.io/learningequality/kolibri-backend/issues/877480545/?referrer=github_integration)\n\n```\nValueError: invalid literal for int() with base 10: '0.00293684005737'\n File \"django/core/handlers/exception.py\", line 41, in inner\n response = get_response(request)\n File \"django/utils/deprecation.py\", line 142, in __call__\n response = self.process_response(request, response)\n File \"kolibri/core/analytics/middleware.py\", line 144, in process_response\n if int(duration) > MetricsMiddleware.slowest_request_time:\n```\n", "before_files": [{"content": "from __future__ import absolute_import\n\nimport csv\nimport os\nimport time\n\nfrom django.conf import settings\nfrom django.core.cache import caches\nfrom django.core.exceptions import MiddlewareNotUsed\nfrom django.utils.deprecation import MiddlewareMixin\n\nfrom kolibri.core.analytics import SUPPORTED_OS\nfrom kolibri.utils import conf\nfrom kolibri.utils.server import PROFILE_LOCK\nfrom kolibri.utils.system import pid_exists\n\nrequests_profiling_file = os.path.join(conf.KOLIBRI_HOME,\n 'performance',\n '{}_requests_performance.csv'.format(time.strftime('%Y%m%d_%H%M%S')))\n\ncache = caches[settings.CACHE_MIDDLEWARE_ALIAS]\ntry:\n import kolibri.core.analytics.pskolibri as psutil\n kolibri_process = psutil.Process()\nexcept NotImplementedError:\n # This middleware can't work on this OS\n kolibri_process = None\n\n\nclass Metrics(object):\n def __init__(self):\n \"\"\"\n Save the initial values when the request comes in\n This class only will be used when MetricsMiddleware is not disabled, thus the OS is supported.\n External instances of this class must check if the OS is supported before creating new objects.\n \"\"\"\n self.memory = self.get_used_memory()\n self.load = self.get_load_average()\n self.time = time.time()\n\n def get_used_memory(self):\n return kolibri_process.memory_info().vms\n\n def get_load_average(self):\n return kolibri_process.cpu_percent()\n\n def get_stats(self):\n \"\"\"\n Calcutes time spent in processing the request\n and difference in memory and load consumed\n by kolibri while processing the request\n :returns: tuple of strings containing time consumed (in seconds),\n Kolibri used memory (in bytes) before and after executing the request,\n Kolibri cpu load (in %) before and after executing the request.\n \"\"\"\n memory = str(self.get_used_memory())\n load = str(self.get_load_average())\n time_delta = str(time.time() - self.time)\n return (time_delta, str(self.memory), memory, str(self.load), load)\n\n\nclass MetricsMiddleware(MiddlewareMixin):\n \"\"\"\n This Middleware will produce a requests_performance.log file, with one line per requests having this structure:\n - Timestamp\n - Request path\n - Time spent processing the request\n - Memory (in Kbytes) used by the kolibri process when the request came in\n - Memory (in Kbytes) used by the kolibri process when the response was sent\n - Percentage of use of cpu by the Kolibri process when the request came in\n - Percentage of use of cpu by the Kolibri process when the response was sent\n - One flag indicating if this request is the slowest since the analysis was started\n \"\"\"\n slowest_request_time = 0\n disabled = True\n command_pid = 0\n\n def __init__(self, get_response=None):\n super(MetricsMiddleware, self).__init__(get_response=get_response)\n if not conf.OPTIONS[\"Server\"][\"PROFILE\"]:\n raise MiddlewareNotUsed('Request profiling is not enabled')\n\n def process_request(self, request):\n \"\"\"\n Store the start time, memory and load when the request comes in.\n \"\"\"\n if not self.disabled:\n self.metrics = Metrics()\n\n def shutdown(self):\n \"\"\"\n Disable this middleware and clean all the static variables\n \"\"\"\n MetricsMiddleware.disabled = True\n MetricsMiddleware.command_pid = 0\n delattr(self, 'metrics')\n if os.path.exists(PROFILE_LOCK):\n try:\n os.remove(PROFILE_LOCK)\n except OSError:\n pass # lock file was deleted by other process\n\n def check_start_conditions(self):\n \"\"\"\n Do the needed checks to enable the Middleware if possible\n \"\"\"\n if MetricsMiddleware.disabled and conf.OPTIONS[\"Server\"][\"PROFILE\"]:\n if os.path.exists(PROFILE_LOCK):\n try:\n with open(PROFILE_LOCK, 'r') as f:\n MetricsMiddleware.command_pid = int(f.readline())\n file_timestamp = f.readline()\n if SUPPORTED_OS:\n MetricsMiddleware.disabled = False\n self.requests_profiling_file = os.path.join(conf.KOLIBRI_HOME,\n 'performance',\n '{}_requests_performance.csv'.format(file_timestamp))\n with open(self.requests_profiling_file, mode='a') as profile_file:\n profile_writer = csv.writer(profile_file, delimiter=',', quotechar='\"', quoting=csv.QUOTE_MINIMAL)\n profile_writer.writerow(('Date', 'Path', 'Duration', 'Memory before (Kb)',\n 'Memory after (Kb)', 'Load before (%)', 'Load after(%)',\n 'Longest time up to now'))\n except (IOError, TypeError, ValueError):\n # Kolibri command PID file has been deleted or it's corrupted\n try:\n os.remove(PROFILE_LOCK)\n except OSError:\n pass # lock file was deleted by other process\n\n def process_response(self, request, response):\n \"\"\"\n Calculate and output the page generation details\n Log output consist on:\n Datetime, request path, request duration, memory before, memory after requests is finished,\n cpu load before, cpu load after the request is finished, max\n Being `max` True or False to indicate if this is the slowest request since logging began.\n \"\"\"\n self.check_start_conditions()\n\n if not MetricsMiddleware.disabled and hasattr(self, 'metrics'):\n path = request.get_full_path()\n duration, memory_before, memory, load_before, load = self.metrics.get_stats()\n max_time = False\n if int(duration) > MetricsMiddleware.slowest_request_time:\n MetricsMiddleware.slowest_request_time = int(duration)\n max_time = True\n timestamp = time.strftime('%Y/%m/%d %H:%M:%S.%f')\n collected_information = (timestamp, path, duration, memory_before, memory, load_before, load, str(max_time))\n with open(self.requests_profiling_file, mode='a') as profile_file:\n profile_writer = csv.writer(profile_file, delimiter=',', quotechar='\"', quoting=csv.QUOTE_MINIMAL)\n profile_writer.writerow(collected_information)\n if not pid_exists(MetricsMiddleware.command_pid) or not os.path.exists(PROFILE_LOCK):\n self.shutdown()\n return response\n", "path": "kolibri/core/analytics/middleware.py"}]}
| 2,416 | 159 |
gh_patches_debug_10723
|
rasdani/github-patches
|
git_diff
|
Mailu__Mailu-3096
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Validation of redirect address in UI
There are several CMSs that require the forwarding address to be specified partially in uppercase. Validation does not allow this.


```
grep MAILU_VERSION docker-compose.yml mailu.env
docker-compose.yml: image: ${DOCKER_ORG:-ghcr.io/mailu}/${DOCKER_PREFIX:-}nginx:${MAILU_VERSION:-2.0}
docker-compose.yml: image: ${DOCKER_ORG:-ghcr.io/mailu}/${DOCKER_PREFIX:-}unbound:${MAILU_VERSION:-2.0}
docker-compose.yml: image: ${DOCKER_ORG:-ghcr.io/mailu}/${DOCKER_PREFIX:-}admin:${MAILU_VERSION:-2.0}
docker-compose.yml: image: ${DOCKER_ORG:-ghcr.io/mailu}/${DOCKER_PREFIX:-}dovecot:${MAILU_VERSION:-2.0}
docker-compose.yml: image: ${DOCKER_ORG:-ghcr.io/mailu}/${DOCKER_PREFIX:-}postfix:${MAILU_VERSION:-2.0}
docker-compose.yml: image: ${DOCKER_ORG:-ghcr.io/mailu}/${DOCKER_PREFIX:-}oletools:${MAILU_VERSION:-2.0}
docker-compose.yml: image: ${DOCKER_ORG:-ghcr.io/mailu}/${DOCKER_PREFIX:-}rspamd:${MAILU_VERSION:-2.0}
docker-compose.yml: image: ${DOCKER_ORG:-ghcr.io/mailu}/${DOCKER_PREFIX:-}radicale:${MAILU_VERSION:-2.0}
docker-compose.yml: image: ${DOCKER_ORG:-ghcr.io/mailu}/${DOCKER_PREFIX:-}fetchmail:${MAILU_VERSION:-2.0}
docker-compose.yml: image: ${DOCKER_ORG:-ghcr.io/mailu}/${DOCKER_PREFIX:-}webmail:${MAILU_VERSION:-2.0}
```
</issue>
<code>
[start of core/admin/mailu/ui/forms.py]
1 from wtforms import validators, fields, widgets
2 from wtforms_components import fields as fields_
3 from flask_babel import lazy_gettext as _
4
5 import flask_login
6 import flask_wtf
7 import re
8 import ipaddress
9
10 LOCALPART_REGEX = "^[a-zA-Z0-9!#$%&'*+/=?^_`{|}~-]+(?:\.[a-zA-Z0-9!#$%&'*+/=?^_`{|}~-]+)*$"
11
12 class DestinationField(fields.SelectMultipleField):
13 """ Allow for multiple emails selection from current user choices and
14 additional email addresses.
15 """
16
17 validator = re.compile(r'^.+@([^.@][^@]+)$', re.IGNORECASE)
18
19 def iter_choices(self):
20 managed = [
21 str(email)
22 for email in flask_login.current_user.get_managed_emails()
23 ]
24 for email in managed:
25 selected = self.data is not None and self.coerce(email) in self.data
26 yield (email, email, selected)
27 for email in self.data or ():
28 if email not in managed:
29 yield (email, email, True)
30
31 def pre_validate(self, form):
32 for item in self.data:
33 if not self.validator.match(item):
34 raise validators.ValidationError(_('Invalid email address.'))
35
36 class MultipleEmailAddressesVerify(object):
37 def __init__(self,message=_('Invalid email address.')):
38 self.message = message
39
40 def __call__(self, form, field):
41 pattern = re.compile(r'^([_a-z0-9\-\+]+)(\.[_a-z0-9\-\+]+)*@([a-z0-9\-]{1,}\.)*([a-z]{1,})(,([_a-z0-9\-\+]+)(\.[_a-z0-9\-\+]+)*@([a-z0-9\-]{1,}\.)*([a-z]{2,}))*$')
42 if not pattern.match(field.data.replace(" ", "")):
43 raise validators.ValidationError(self.message)
44
45 class MultipleFoldersVerify(object):
46 """ Ensure that we have CSV formated data """
47 def __init__(self,message=_('Invalid list of folders.')):
48 self.message = message
49
50 def __call__(self, form, field):
51 pattern = re.compile(r'^[^,]+(,[^,]+)*$')
52 if not pattern.match(field.data.replace(" ", "")):
53 raise validators.ValidationError(self.message)
54
55 class ConfirmationForm(flask_wtf.FlaskForm):
56 submit = fields.SubmitField(_('Confirm'))
57
58 class DomainForm(flask_wtf.FlaskForm):
59 name = fields.StringField(_('Domain name'), [validators.DataRequired()])
60 max_users = fields_.IntegerField(_('Maximum user count'), [validators.NumberRange(min=-1)], default=10)
61 max_aliases = fields_.IntegerField(_('Maximum alias count'), [validators.NumberRange(min=-1)], default=10)
62 max_quota_bytes = fields_.IntegerSliderField(_('Maximum user quota'), default=0)
63 signup_enabled = fields.BooleanField(_('Enable sign-up'), default=False)
64 comment = fields.StringField(_('Comment'))
65 submit = fields.SubmitField(_('Save'))
66
67
68 class DomainSignupForm(flask_wtf.FlaskForm):
69 name = fields.StringField(_('Domain name'), [validators.DataRequired()])
70 localpart = fields.StringField(_('Initial admin'), [validators.DataRequired()])
71 pw = fields.PasswordField(_('Admin password'), [validators.DataRequired()])
72 pw2 = fields.PasswordField(_('Confirm password'), [validators.EqualTo('pw')])
73 pwned = fields.HiddenField(label='', default=-1)
74 captcha = flask_wtf.RecaptchaField()
75 submit = fields.SubmitField(_('Create'))
76
77
78 class AlternativeForm(flask_wtf.FlaskForm):
79 name = fields.StringField(_('Alternative name'), [validators.DataRequired()])
80 submit = fields.SubmitField(_('Save'))
81
82
83 class RelayForm(flask_wtf.FlaskForm):
84 name = fields.StringField(_('Relayed domain name'), [validators.DataRequired()])
85 smtp = fields.StringField(_('Remote host'))
86 comment = fields.StringField(_('Comment'))
87 submit = fields.SubmitField(_('Save'))
88
89
90 class UserForm(flask_wtf.FlaskForm):
91 localpart = fields.StringField(_('E-mail'), [validators.DataRequired(), validators.Regexp(LOCALPART_REGEX)])
92 pw = fields.PasswordField(_('Password'))
93 pw2 = fields.PasswordField(_('Confirm password'), [validators.EqualTo('pw')])
94 pwned = fields.HiddenField(label='', default=-1)
95 quota_bytes = fields_.IntegerSliderField(_('Quota'), default=10**9)
96 enable_imap = fields.BooleanField(_('Allow IMAP access'), default=True)
97 enable_pop = fields.BooleanField(_('Allow POP3 access'), default=True)
98 allow_spoofing = fields.BooleanField(_('Allow the user to spoof the sender (send email as anyone)'), default=False)
99 displayed_name = fields.StringField(_('Displayed name'))
100 comment = fields.StringField(_('Comment'))
101 enabled = fields.BooleanField(_('Enabled'), default=True)
102 change_pw_next_login = fields.BooleanField(_('Force password change at next login'), default=True)
103 submit = fields.SubmitField(_('Save'))
104
105
106 class UserSignupForm(flask_wtf.FlaskForm):
107 localpart = fields.StringField(_('Email address'), [validators.DataRequired(), validators.Regexp(LOCALPART_REGEX)])
108 pw = fields.PasswordField(_('Password'), [validators.DataRequired()])
109 pw2 = fields.PasswordField(_('Confirm password'), [validators.EqualTo('pw')])
110 pwned = fields.HiddenField(label='', default=-1)
111 submit = fields.SubmitField(_('Sign up'))
112
113 class UserSignupFormCaptcha(UserSignupForm):
114 captcha = flask_wtf.RecaptchaField()
115
116 class UserSettingsForm(flask_wtf.FlaskForm):
117 displayed_name = fields.StringField(_('Displayed name'))
118 spam_enabled = fields.BooleanField(_('Enable spam filter'))
119 spam_mark_as_read = fields.BooleanField(_('Enable marking spam mails as read'))
120 spam_threshold = fields_.IntegerSliderField(_('Spam filter tolerance'))
121 forward_enabled = fields.BooleanField(_('Enable forwarding'))
122 forward_keep = fields.BooleanField(_('Keep a copy of the emails'))
123 forward_destination = fields.StringField(_('Destination'), [validators.Optional(), MultipleEmailAddressesVerify()])
124 submit = fields.SubmitField(_('Save settings'))
125
126
127 class UserPasswordForm(flask_wtf.FlaskForm):
128 pw = fields.PasswordField(_('Password'), [validators.DataRequired()])
129 pw2 = fields.PasswordField(_('Password check'), [validators.DataRequired()])
130 pwned = fields.HiddenField(label='', default=-1)
131 submit = fields.SubmitField(_('Update password'))
132
133 class UserPasswordChangeForm(flask_wtf.FlaskForm):
134 current_pw = fields.PasswordField(_('Current password'), [validators.DataRequired()])
135 pw = fields.PasswordField(_('Password'), [validators.DataRequired()])
136 pw2 = fields.PasswordField(_('Password check'), [validators.DataRequired()])
137 pwned = fields.HiddenField(label='', default=-1)
138 submit = fields.SubmitField(_('Update password'))
139
140 class UserReplyForm(flask_wtf.FlaskForm):
141 reply_enabled = fields.BooleanField(_('Enable automatic reply'))
142 reply_subject = fields.StringField(_('Reply subject'))
143 reply_body = fields.StringField(_('Reply body'),
144 widget=widgets.TextArea())
145 reply_startdate = fields.DateField(_('Start of vacation'))
146 reply_enddate = fields.DateField(_('End of vacation'))
147 submit = fields.SubmitField(_('Update'))
148
149
150 class TokenForm(flask_wtf.FlaskForm):
151 displayed_password = fields.StringField(
152 _('Your token (write it down, as it will never be displayed again)')
153 )
154 raw_password = fields.HiddenField([validators.DataRequired()])
155 comment = fields.StringField(_('Comment'))
156 ip = fields.StringField(
157 _('Authorized IP'), [validators.Optional()]
158 )
159 submit = fields.SubmitField(_('Save'))
160
161 def validate_ip(form, field):
162 if not field.data:
163 return True
164 try:
165 for candidate in field.data.replace(' ','').split(','):
166 ipaddress.ip_network(candidate, False)
167 except:
168 raise validators.ValidationError('Not a valid list of CIDRs')
169
170 class AliasForm(flask_wtf.FlaskForm):
171 localpart = fields.StringField(_('Alias'), [validators.DataRequired(), validators.Regexp(LOCALPART_REGEX)])
172 wildcard = fields.BooleanField(
173 _('Use SQL LIKE Syntax (e.g. for catch-all aliases)'))
174 destination = DestinationField(_('Destination'))
175 comment = fields.StringField(_('Comment'))
176 submit = fields.SubmitField(_('Save'))
177
178
179 class AdminForm(flask_wtf.FlaskForm):
180 admin = fields.SelectField(_('Admin email'), choices=[])
181 submit = fields.SubmitField(_('Submit'))
182
183
184 class ManagerForm(flask_wtf.FlaskForm):
185 manager = fields.SelectField(_('Manager email'))
186 submit = fields.SubmitField(_('Submit'))
187
188
189 class FetchForm(flask_wtf.FlaskForm):
190 protocol = fields.SelectField(_('Protocol'), choices=[
191 ('imap', 'IMAP'), ('pop3', 'POP3')
192 ])
193 host = fields.StringField(_('Hostname or IP'), [validators.DataRequired()])
194 port = fields.IntegerField(_('TCP port'), [validators.DataRequired(), validators.NumberRange(min=0, max=65535)], default=993)
195 tls = fields.BooleanField(_('Enable TLS'), default=True)
196 username = fields.StringField(_('Username'), [validators.DataRequired()])
197 password = fields.PasswordField(_('Password'))
198 keep = fields.BooleanField(_('Keep emails on the server'))
199 scan = fields.BooleanField(_('Rescan emails locally'))
200 folders = fields.StringField(_('Folders to fetch on the server'), [validators.Optional(), MultipleFoldersVerify()], default='INBOX,Junk')
201 submit = fields.SubmitField(_('Submit'))
202
203
204 class AnnouncementForm(flask_wtf.FlaskForm):
205 announcement_subject = fields.StringField(_('Announcement subject'),
206 [validators.DataRequired()])
207 announcement_body = fields.StringField(_('Announcement body'),
208 [validators.DataRequired()], widget=widgets.TextArea())
209 submit = fields.SubmitField(_('Send'))
210
[end of core/admin/mailu/ui/forms.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/core/admin/mailu/ui/forms.py b/core/admin/mailu/ui/forms.py
--- a/core/admin/mailu/ui/forms.py
+++ b/core/admin/mailu/ui/forms.py
@@ -38,7 +38,7 @@
self.message = message
def __call__(self, form, field):
- pattern = re.compile(r'^([_a-z0-9\-\+]+)(\.[_a-z0-9\-\+]+)*@([a-z0-9\-]{1,}\.)*([a-z]{1,})(,([_a-z0-9\-\+]+)(\.[_a-z0-9\-\+]+)*@([a-z0-9\-]{1,}\.)*([a-z]{2,}))*$')
+ pattern = re.compile(r'^([_a-z0-9\-\+]+)(\.[_a-z0-9\-\+]+)*@([a-z0-9\-]{1,}\.)*([a-z]{1,})(,([_a-z0-9\-\+]+)(\.[_a-z0-9\-\+]+)*@([a-z0-9\-]{1,}\.)*([a-z]{2,}))*$', re.IGNORECASE)
if not pattern.match(field.data.replace(" ", "")):
raise validators.ValidationError(self.message)
|
{"golden_diff": "diff --git a/core/admin/mailu/ui/forms.py b/core/admin/mailu/ui/forms.py\n--- a/core/admin/mailu/ui/forms.py\n+++ b/core/admin/mailu/ui/forms.py\n@@ -38,7 +38,7 @@\n self.message = message\n \n def __call__(self, form, field):\n- pattern = re.compile(r'^([_a-z0-9\\-\\+]+)(\\.[_a-z0-9\\-\\+]+)*@([a-z0-9\\-]{1,}\\.)*([a-z]{1,})(,([_a-z0-9\\-\\+]+)(\\.[_a-z0-9\\-\\+]+)*@([a-z0-9\\-]{1,}\\.)*([a-z]{2,}))*$')\n+ pattern = re.compile(r'^([_a-z0-9\\-\\+]+)(\\.[_a-z0-9\\-\\+]+)*@([a-z0-9\\-]{1,}\\.)*([a-z]{1,})(,([_a-z0-9\\-\\+]+)(\\.[_a-z0-9\\-\\+]+)*@([a-z0-9\\-]{1,}\\.)*([a-z]{2,}))*$', re.IGNORECASE)\n if not pattern.match(field.data.replace(\" \", \"\")):\n raise validators.ValidationError(self.message)\n", "issue": "Validation of redirect address in UI \nThere are several CMSs that require the forwarding address to be specified partially in uppercase. Validation does not allow this.\r\n\r\n\r\n\r\n\r\n\r\n```\r\ngrep MAILU_VERSION docker-compose.yml mailu.env\r\ndocker-compose.yml: image: ${DOCKER_ORG:-ghcr.io/mailu}/${DOCKER_PREFIX:-}nginx:${MAILU_VERSION:-2.0}\r\ndocker-compose.yml: image: ${DOCKER_ORG:-ghcr.io/mailu}/${DOCKER_PREFIX:-}unbound:${MAILU_VERSION:-2.0}\r\ndocker-compose.yml: image: ${DOCKER_ORG:-ghcr.io/mailu}/${DOCKER_PREFIX:-}admin:${MAILU_VERSION:-2.0}\r\ndocker-compose.yml: image: ${DOCKER_ORG:-ghcr.io/mailu}/${DOCKER_PREFIX:-}dovecot:${MAILU_VERSION:-2.0}\r\ndocker-compose.yml: image: ${DOCKER_ORG:-ghcr.io/mailu}/${DOCKER_PREFIX:-}postfix:${MAILU_VERSION:-2.0}\r\ndocker-compose.yml: image: ${DOCKER_ORG:-ghcr.io/mailu}/${DOCKER_PREFIX:-}oletools:${MAILU_VERSION:-2.0}\r\ndocker-compose.yml: image: ${DOCKER_ORG:-ghcr.io/mailu}/${DOCKER_PREFIX:-}rspamd:${MAILU_VERSION:-2.0}\r\ndocker-compose.yml: image: ${DOCKER_ORG:-ghcr.io/mailu}/${DOCKER_PREFIX:-}radicale:${MAILU_VERSION:-2.0}\r\ndocker-compose.yml: image: ${DOCKER_ORG:-ghcr.io/mailu}/${DOCKER_PREFIX:-}fetchmail:${MAILU_VERSION:-2.0}\r\ndocker-compose.yml: image: ${DOCKER_ORG:-ghcr.io/mailu}/${DOCKER_PREFIX:-}webmail:${MAILU_VERSION:-2.0}\r\n```\r\n\n", "before_files": [{"content": "from wtforms import validators, fields, widgets\nfrom wtforms_components import fields as fields_\nfrom flask_babel import lazy_gettext as _\n\nimport flask_login\nimport flask_wtf\nimport re\nimport ipaddress\n\nLOCALPART_REGEX = \"^[a-zA-Z0-9!#$%&'*+/=?^_`{|}~-]+(?:\\.[a-zA-Z0-9!#$%&'*+/=?^_`{|}~-]+)*$\"\n\nclass DestinationField(fields.SelectMultipleField):\n \"\"\" Allow for multiple emails selection from current user choices and\n additional email addresses.\n \"\"\"\n\n validator = re.compile(r'^.+@([^.@][^@]+)$', re.IGNORECASE)\n\n def iter_choices(self):\n managed = [\n str(email)\n for email in flask_login.current_user.get_managed_emails()\n ]\n for email in managed:\n selected = self.data is not None and self.coerce(email) in self.data\n yield (email, email, selected)\n for email in self.data or ():\n if email not in managed:\n yield (email, email, True)\n\n def pre_validate(self, form):\n for item in self.data:\n if not self.validator.match(item):\n raise validators.ValidationError(_('Invalid email address.'))\n\nclass MultipleEmailAddressesVerify(object):\n def __init__(self,message=_('Invalid email address.')):\n self.message = message\n\n def __call__(self, form, field):\n pattern = re.compile(r'^([_a-z0-9\\-\\+]+)(\\.[_a-z0-9\\-\\+]+)*@([a-z0-9\\-]{1,}\\.)*([a-z]{1,})(,([_a-z0-9\\-\\+]+)(\\.[_a-z0-9\\-\\+]+)*@([a-z0-9\\-]{1,}\\.)*([a-z]{2,}))*$')\n if not pattern.match(field.data.replace(\" \", \"\")):\n raise validators.ValidationError(self.message)\n\nclass MultipleFoldersVerify(object):\n \"\"\" Ensure that we have CSV formated data \"\"\"\n def __init__(self,message=_('Invalid list of folders.')):\n self.message = message\n\n def __call__(self, form, field):\n pattern = re.compile(r'^[^,]+(,[^,]+)*$')\n if not pattern.match(field.data.replace(\" \", \"\")):\n raise validators.ValidationError(self.message)\n\nclass ConfirmationForm(flask_wtf.FlaskForm):\n submit = fields.SubmitField(_('Confirm'))\n\nclass DomainForm(flask_wtf.FlaskForm):\n name = fields.StringField(_('Domain name'), [validators.DataRequired()])\n max_users = fields_.IntegerField(_('Maximum user count'), [validators.NumberRange(min=-1)], default=10)\n max_aliases = fields_.IntegerField(_('Maximum alias count'), [validators.NumberRange(min=-1)], default=10)\n max_quota_bytes = fields_.IntegerSliderField(_('Maximum user quota'), default=0)\n signup_enabled = fields.BooleanField(_('Enable sign-up'), default=False)\n comment = fields.StringField(_('Comment'))\n submit = fields.SubmitField(_('Save'))\n\n\nclass DomainSignupForm(flask_wtf.FlaskForm):\n name = fields.StringField(_('Domain name'), [validators.DataRequired()])\n localpart = fields.StringField(_('Initial admin'), [validators.DataRequired()])\n pw = fields.PasswordField(_('Admin password'), [validators.DataRequired()])\n pw2 = fields.PasswordField(_('Confirm password'), [validators.EqualTo('pw')])\n pwned = fields.HiddenField(label='', default=-1)\n captcha = flask_wtf.RecaptchaField()\n submit = fields.SubmitField(_('Create'))\n\n\nclass AlternativeForm(flask_wtf.FlaskForm):\n name = fields.StringField(_('Alternative name'), [validators.DataRequired()])\n submit = fields.SubmitField(_('Save'))\n\n\nclass RelayForm(flask_wtf.FlaskForm):\n name = fields.StringField(_('Relayed domain name'), [validators.DataRequired()])\n smtp = fields.StringField(_('Remote host'))\n comment = fields.StringField(_('Comment'))\n submit = fields.SubmitField(_('Save'))\n\n\nclass UserForm(flask_wtf.FlaskForm):\n localpart = fields.StringField(_('E-mail'), [validators.DataRequired(), validators.Regexp(LOCALPART_REGEX)])\n pw = fields.PasswordField(_('Password'))\n pw2 = fields.PasswordField(_('Confirm password'), [validators.EqualTo('pw')])\n pwned = fields.HiddenField(label='', default=-1)\n quota_bytes = fields_.IntegerSliderField(_('Quota'), default=10**9)\n enable_imap = fields.BooleanField(_('Allow IMAP access'), default=True)\n enable_pop = fields.BooleanField(_('Allow POP3 access'), default=True)\n allow_spoofing = fields.BooleanField(_('Allow the user to spoof the sender (send email as anyone)'), default=False)\n displayed_name = fields.StringField(_('Displayed name'))\n comment = fields.StringField(_('Comment'))\n enabled = fields.BooleanField(_('Enabled'), default=True)\n change_pw_next_login = fields.BooleanField(_('Force password change at next login'), default=True)\n submit = fields.SubmitField(_('Save'))\n\n\nclass UserSignupForm(flask_wtf.FlaskForm):\n localpart = fields.StringField(_('Email address'), [validators.DataRequired(), validators.Regexp(LOCALPART_REGEX)])\n pw = fields.PasswordField(_('Password'), [validators.DataRequired()])\n pw2 = fields.PasswordField(_('Confirm password'), [validators.EqualTo('pw')])\n pwned = fields.HiddenField(label='', default=-1)\n submit = fields.SubmitField(_('Sign up'))\n\nclass UserSignupFormCaptcha(UserSignupForm):\n captcha = flask_wtf.RecaptchaField()\n\nclass UserSettingsForm(flask_wtf.FlaskForm):\n displayed_name = fields.StringField(_('Displayed name'))\n spam_enabled = fields.BooleanField(_('Enable spam filter'))\n spam_mark_as_read = fields.BooleanField(_('Enable marking spam mails as read'))\n spam_threshold = fields_.IntegerSliderField(_('Spam filter tolerance'))\n forward_enabled = fields.BooleanField(_('Enable forwarding'))\n forward_keep = fields.BooleanField(_('Keep a copy of the emails'))\n forward_destination = fields.StringField(_('Destination'), [validators.Optional(), MultipleEmailAddressesVerify()])\n submit = fields.SubmitField(_('Save settings'))\n\n\nclass UserPasswordForm(flask_wtf.FlaskForm):\n pw = fields.PasswordField(_('Password'), [validators.DataRequired()])\n pw2 = fields.PasswordField(_('Password check'), [validators.DataRequired()])\n pwned = fields.HiddenField(label='', default=-1)\n submit = fields.SubmitField(_('Update password'))\n\nclass UserPasswordChangeForm(flask_wtf.FlaskForm):\n current_pw = fields.PasswordField(_('Current password'), [validators.DataRequired()])\n pw = fields.PasswordField(_('Password'), [validators.DataRequired()])\n pw2 = fields.PasswordField(_('Password check'), [validators.DataRequired()])\n pwned = fields.HiddenField(label='', default=-1)\n submit = fields.SubmitField(_('Update password'))\n\nclass UserReplyForm(flask_wtf.FlaskForm):\n reply_enabled = fields.BooleanField(_('Enable automatic reply'))\n reply_subject = fields.StringField(_('Reply subject'))\n reply_body = fields.StringField(_('Reply body'),\n widget=widgets.TextArea())\n reply_startdate = fields.DateField(_('Start of vacation'))\n reply_enddate = fields.DateField(_('End of vacation'))\n submit = fields.SubmitField(_('Update'))\n\n\nclass TokenForm(flask_wtf.FlaskForm):\n displayed_password = fields.StringField(\n _('Your token (write it down, as it will never be displayed again)')\n )\n raw_password = fields.HiddenField([validators.DataRequired()])\n comment = fields.StringField(_('Comment'))\n ip = fields.StringField(\n _('Authorized IP'), [validators.Optional()]\n )\n submit = fields.SubmitField(_('Save'))\n\n def validate_ip(form, field):\n if not field.data:\n return True\n try:\n for candidate in field.data.replace(' ','').split(','):\n ipaddress.ip_network(candidate, False)\n except:\n raise validators.ValidationError('Not a valid list of CIDRs')\n\nclass AliasForm(flask_wtf.FlaskForm):\n localpart = fields.StringField(_('Alias'), [validators.DataRequired(), validators.Regexp(LOCALPART_REGEX)])\n wildcard = fields.BooleanField(\n _('Use SQL LIKE Syntax (e.g. for catch-all aliases)'))\n destination = DestinationField(_('Destination'))\n comment = fields.StringField(_('Comment'))\n submit = fields.SubmitField(_('Save'))\n\n\nclass AdminForm(flask_wtf.FlaskForm):\n admin = fields.SelectField(_('Admin email'), choices=[])\n submit = fields.SubmitField(_('Submit'))\n\n\nclass ManagerForm(flask_wtf.FlaskForm):\n manager = fields.SelectField(_('Manager email'))\n submit = fields.SubmitField(_('Submit'))\n\n\nclass FetchForm(flask_wtf.FlaskForm):\n protocol = fields.SelectField(_('Protocol'), choices=[\n ('imap', 'IMAP'), ('pop3', 'POP3')\n ])\n host = fields.StringField(_('Hostname or IP'), [validators.DataRequired()])\n port = fields.IntegerField(_('TCP port'), [validators.DataRequired(), validators.NumberRange(min=0, max=65535)], default=993)\n tls = fields.BooleanField(_('Enable TLS'), default=True)\n username = fields.StringField(_('Username'), [validators.DataRequired()])\n password = fields.PasswordField(_('Password'))\n keep = fields.BooleanField(_('Keep emails on the server'))\n scan = fields.BooleanField(_('Rescan emails locally'))\n folders = fields.StringField(_('Folders to fetch on the server'), [validators.Optional(), MultipleFoldersVerify()], default='INBOX,Junk')\n submit = fields.SubmitField(_('Submit'))\n\n\nclass AnnouncementForm(flask_wtf.FlaskForm):\n announcement_subject = fields.StringField(_('Announcement subject'),\n [validators.DataRequired()])\n announcement_body = fields.StringField(_('Announcement body'),\n [validators.DataRequired()], widget=widgets.TextArea())\n submit = fields.SubmitField(_('Send'))\n", "path": "core/admin/mailu/ui/forms.py"}]}
| 3,663 | 299 |
gh_patches_debug_30748
|
rasdani/github-patches
|
git_diff
|
OpenNMT__OpenNMT-py-1301
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Ensemble decoding is broken
@flauted
Ensemble decoding is not tested I think and it is broken on master.
onmt/decoders/ensemble.py", line 133, in load_test_model
if field is not None and 'vocab' in field.__dict__:
AttributeError: 'list' object has no attribute '__dict__'
To replicate, just run the translate command with the same model twice in argument -model x x
Thanks.
</issue>
<code>
[start of onmt/decoders/ensemble.py]
1 """
2 Ensemble decoding.
3
4 Decodes using multiple models simultaneously,
5 combining their prediction distributions by averaging.
6 All models in the ensemble must share a target vocabulary.
7 """
8
9 import torch
10 import torch.nn as nn
11
12 from onmt.encoders.encoder import EncoderBase
13 from onmt.models import NMTModel
14 import onmt.model_builder
15
16
17 class EnsembleDecoderOutput(object):
18 """ Wrapper around multiple decoder final hidden states """
19 def __init__(self, model_dec_outs):
20 self.model_dec_outs = tuple(model_dec_outs)
21
22 def squeeze(self, dim=None):
23 """
24 Delegate squeeze to avoid modifying
25 :obj:`Translator.translate_batch()`
26 """
27 return EnsembleDecoderOutput([
28 x.squeeze(dim) for x in self.model_dec_outs])
29
30 def __getitem__(self, index):
31 return self.model_dec_outs[index]
32
33
34 class EnsembleEncoder(EncoderBase):
35 """ Dummy Encoder that delegates to individual real Encoders """
36 def __init__(self, model_encoders):
37 super(EnsembleEncoder, self).__init__()
38 self.model_encoders = nn.ModuleList(model_encoders)
39
40 def forward(self, src, lengths=None):
41 enc_hidden, memory_bank, _ = zip(*[
42 model_encoder(src, lengths)
43 for model_encoder in self.model_encoders])
44 return enc_hidden, memory_bank, lengths
45
46
47 class EnsembleDecoder(nn.Module):
48 """ Dummy Decoder that delegates to individual real Decoders """
49 def __init__(self, model_decoders):
50 super(EnsembleDecoder, self).__init__()
51 self.model_decoders = nn.ModuleList(model_decoders)
52
53 def forward(self, tgt, memory_bank, memory_lengths=None, step=None):
54 """ See :obj:`RNNDecoderBase.forward()` """
55 # Memory_lengths is a single tensor shared between all models.
56 # This assumption will not hold if Translator is modified
57 # to calculate memory_lengths as something other than the length
58 # of the input.
59 dec_outs, attns = zip(*[
60 model_decoder(
61 tgt, memory_bank[i], memory_lengths, step=step)
62 for i, model_decoder in enumerate(self.model_decoders)])
63 mean_attns = self.combine_attns(attns)
64 return EnsembleDecoderOutput(dec_outs), mean_attns
65
66 def combine_attns(self, attns):
67 result = {}
68 for key in attns[0].keys():
69 result[key] = torch.stack([attn[key] for attn in attns]).mean(0)
70 return result
71
72 def init_state(self, src, memory_bank, enc_hidden):
73 """ See :obj:`RNNDecoderBase.init_state()` """
74 for i, model_decoder in enumerate(self.model_decoders):
75 model_decoder.init_state(src, memory_bank[i], enc_hidden[i])
76
77 def map_state(self, fn):
78 for model_decoder in self.model_decoders:
79 model_decoder.map_state(fn)
80
81
82 class EnsembleGenerator(nn.Module):
83 """
84 Dummy Generator that delegates to individual real Generators,
85 and then averages the resulting target distributions.
86 """
87 def __init__(self, model_generators, raw_probs=False):
88 super(EnsembleGenerator, self).__init__()
89 self.model_generators = nn.ModuleList(model_generators)
90 self._raw_probs = raw_probs
91
92 def forward(self, hidden, attn=None, src_map=None):
93 """
94 Compute a distribution over the target dictionary
95 by averaging distributions from models in the ensemble.
96 All models in the ensemble must share a target vocabulary.
97 """
98 distributions = torch.stack(
99 [mg(h) if attn is None else mg(h, attn, src_map)
100 for h, mg in zip(hidden, self.model_generators)]
101 )
102 if self._raw_probs:
103 return torch.log(torch.exp(distributions).mean(0))
104 else:
105 return distributions.mean(0)
106
107
108 class EnsembleModel(NMTModel):
109 """ Dummy NMTModel wrapping individual real NMTModels """
110 def __init__(self, models, raw_probs=False):
111 encoder = EnsembleEncoder(model.encoder for model in models)
112 decoder = EnsembleDecoder(model.decoder for model in models)
113 super(EnsembleModel, self).__init__(encoder, decoder)
114 self.generator = EnsembleGenerator(
115 [model.generator for model in models], raw_probs)
116 self.models = nn.ModuleList(models)
117
118
119 def load_test_model(opt):
120 """ Read in multiple models for ensemble """
121 shared_fields = None
122 shared_model_opt = None
123 models = []
124 for model_path in opt.models:
125 fields, model, model_opt = \
126 onmt.model_builder.load_test_model(opt, model_path=model_path)
127 if shared_fields is None:
128 shared_fields = fields
129 else:
130 for key, field in fields.items():
131 if field is not None and 'vocab' in field.__dict__:
132 assert field.vocab.stoi == shared_fields[key].vocab.stoi, \
133 'Ensemble models must use the same preprocessed data'
134 models.append(model)
135 if shared_model_opt is None:
136 shared_model_opt = model_opt
137 ensemble_model = EnsembleModel(models, opt.avg_raw_probs)
138 return shared_fields, ensemble_model, shared_model_opt
139
[end of onmt/decoders/ensemble.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/onmt/decoders/ensemble.py b/onmt/decoders/ensemble.py
--- a/onmt/decoders/ensemble.py
+++ b/onmt/decoders/ensemble.py
@@ -58,7 +58,8 @@
# of the input.
dec_outs, attns = zip(*[
model_decoder(
- tgt, memory_bank[i], memory_lengths, step=step)
+ tgt, memory_bank[i],
+ memory_lengths=memory_lengths, step=step)
for i, model_decoder in enumerate(self.model_decoders)])
mean_attns = self.combine_attns(attns)
return EnsembleDecoderOutput(dec_outs), mean_attns
@@ -130,9 +131,25 @@
shared_fields = fields
else:
for key, field in fields.items():
- if field is not None and 'vocab' in field.__dict__:
- assert field.vocab.stoi == shared_fields[key].vocab.stoi, \
- 'Ensemble models must use the same preprocessed data'
+ assert len(field) == 1
+ n, f = field[0]
+ try:
+ f_iter = iter(f)
+ except TypeError:
+ f_iter = [(n, f)]
+ for sn, sf in f_iter:
+ if sf is not None and 'vocab' in sf.__dict__:
+ sh_field = shared_fields[key]
+ assert len(sh_field) == 1
+ sh_n, sh_f = sh_field[0]
+ try:
+ sh_f_iter = iter(sh_f)
+ except TypeError:
+ sh_f_iter = [(sh_n, sh_f)]
+ sh_f_dict = dict(sh_f_iter)
+ assert sf.vocab.stoi == sh_f_dict[sn].vocab.stoi, \
+ "Ensemble models must use the same " \
+ "preprocessed data"
models.append(model)
if shared_model_opt is None:
shared_model_opt = model_opt
|
{"golden_diff": "diff --git a/onmt/decoders/ensemble.py b/onmt/decoders/ensemble.py\n--- a/onmt/decoders/ensemble.py\n+++ b/onmt/decoders/ensemble.py\n@@ -58,7 +58,8 @@\n # of the input.\n dec_outs, attns = zip(*[\n model_decoder(\n- tgt, memory_bank[i], memory_lengths, step=step)\n+ tgt, memory_bank[i],\n+ memory_lengths=memory_lengths, step=step)\n for i, model_decoder in enumerate(self.model_decoders)])\n mean_attns = self.combine_attns(attns)\n return EnsembleDecoderOutput(dec_outs), mean_attns\n@@ -130,9 +131,25 @@\n shared_fields = fields\n else:\n for key, field in fields.items():\n- if field is not None and 'vocab' in field.__dict__:\n- assert field.vocab.stoi == shared_fields[key].vocab.stoi, \\\n- 'Ensemble models must use the same preprocessed data'\n+ assert len(field) == 1\n+ n, f = field[0]\n+ try:\n+ f_iter = iter(f)\n+ except TypeError:\n+ f_iter = [(n, f)]\n+ for sn, sf in f_iter:\n+ if sf is not None and 'vocab' in sf.__dict__:\n+ sh_field = shared_fields[key]\n+ assert len(sh_field) == 1\n+ sh_n, sh_f = sh_field[0]\n+ try:\n+ sh_f_iter = iter(sh_f)\n+ except TypeError:\n+ sh_f_iter = [(sh_n, sh_f)]\n+ sh_f_dict = dict(sh_f_iter)\n+ assert sf.vocab.stoi == sh_f_dict[sn].vocab.stoi, \\\n+ \"Ensemble models must use the same \" \\\n+ \"preprocessed data\"\n models.append(model)\n if shared_model_opt is None:\n shared_model_opt = model_opt\n", "issue": "Ensemble decoding is broken\n@flauted \r\nEnsemble decoding is not tested I think and it is broken on master.\r\nonmt/decoders/ensemble.py\", line 133, in load_test_model\r\n if field is not None and 'vocab' in field.__dict__:\r\nAttributeError: 'list' object has no attribute '__dict__'\r\n\r\nTo replicate, just run the translate command with the same model twice in argument -model x x\r\n\r\nThanks.\n", "before_files": [{"content": "\"\"\"\nEnsemble decoding.\n\nDecodes using multiple models simultaneously,\ncombining their prediction distributions by averaging.\nAll models in the ensemble must share a target vocabulary.\n\"\"\"\n\nimport torch\nimport torch.nn as nn\n\nfrom onmt.encoders.encoder import EncoderBase\nfrom onmt.models import NMTModel\nimport onmt.model_builder\n\n\nclass EnsembleDecoderOutput(object):\n \"\"\" Wrapper around multiple decoder final hidden states \"\"\"\n def __init__(self, model_dec_outs):\n self.model_dec_outs = tuple(model_dec_outs)\n\n def squeeze(self, dim=None):\n \"\"\"\n Delegate squeeze to avoid modifying\n :obj:`Translator.translate_batch()`\n \"\"\"\n return EnsembleDecoderOutput([\n x.squeeze(dim) for x in self.model_dec_outs])\n\n def __getitem__(self, index):\n return self.model_dec_outs[index]\n\n\nclass EnsembleEncoder(EncoderBase):\n \"\"\" Dummy Encoder that delegates to individual real Encoders \"\"\"\n def __init__(self, model_encoders):\n super(EnsembleEncoder, self).__init__()\n self.model_encoders = nn.ModuleList(model_encoders)\n\n def forward(self, src, lengths=None):\n enc_hidden, memory_bank, _ = zip(*[\n model_encoder(src, lengths)\n for model_encoder in self.model_encoders])\n return enc_hidden, memory_bank, lengths\n\n\nclass EnsembleDecoder(nn.Module):\n \"\"\" Dummy Decoder that delegates to individual real Decoders \"\"\"\n def __init__(self, model_decoders):\n super(EnsembleDecoder, self).__init__()\n self.model_decoders = nn.ModuleList(model_decoders)\n\n def forward(self, tgt, memory_bank, memory_lengths=None, step=None):\n \"\"\" See :obj:`RNNDecoderBase.forward()` \"\"\"\n # Memory_lengths is a single tensor shared between all models.\n # This assumption will not hold if Translator is modified\n # to calculate memory_lengths as something other than the length\n # of the input.\n dec_outs, attns = zip(*[\n model_decoder(\n tgt, memory_bank[i], memory_lengths, step=step)\n for i, model_decoder in enumerate(self.model_decoders)])\n mean_attns = self.combine_attns(attns)\n return EnsembleDecoderOutput(dec_outs), mean_attns\n\n def combine_attns(self, attns):\n result = {}\n for key in attns[0].keys():\n result[key] = torch.stack([attn[key] for attn in attns]).mean(0)\n return result\n\n def init_state(self, src, memory_bank, enc_hidden):\n \"\"\" See :obj:`RNNDecoderBase.init_state()` \"\"\"\n for i, model_decoder in enumerate(self.model_decoders):\n model_decoder.init_state(src, memory_bank[i], enc_hidden[i])\n\n def map_state(self, fn):\n for model_decoder in self.model_decoders:\n model_decoder.map_state(fn)\n\n\nclass EnsembleGenerator(nn.Module):\n \"\"\"\n Dummy Generator that delegates to individual real Generators,\n and then averages the resulting target distributions.\n \"\"\"\n def __init__(self, model_generators, raw_probs=False):\n super(EnsembleGenerator, self).__init__()\n self.model_generators = nn.ModuleList(model_generators)\n self._raw_probs = raw_probs\n\n def forward(self, hidden, attn=None, src_map=None):\n \"\"\"\n Compute a distribution over the target dictionary\n by averaging distributions from models in the ensemble.\n All models in the ensemble must share a target vocabulary.\n \"\"\"\n distributions = torch.stack(\n [mg(h) if attn is None else mg(h, attn, src_map)\n for h, mg in zip(hidden, self.model_generators)]\n )\n if self._raw_probs:\n return torch.log(torch.exp(distributions).mean(0))\n else:\n return distributions.mean(0)\n\n\nclass EnsembleModel(NMTModel):\n \"\"\" Dummy NMTModel wrapping individual real NMTModels \"\"\"\n def __init__(self, models, raw_probs=False):\n encoder = EnsembleEncoder(model.encoder for model in models)\n decoder = EnsembleDecoder(model.decoder for model in models)\n super(EnsembleModel, self).__init__(encoder, decoder)\n self.generator = EnsembleGenerator(\n [model.generator for model in models], raw_probs)\n self.models = nn.ModuleList(models)\n\n\ndef load_test_model(opt):\n \"\"\" Read in multiple models for ensemble \"\"\"\n shared_fields = None\n shared_model_opt = None\n models = []\n for model_path in opt.models:\n fields, model, model_opt = \\\n onmt.model_builder.load_test_model(opt, model_path=model_path)\n if shared_fields is None:\n shared_fields = fields\n else:\n for key, field in fields.items():\n if field is not None and 'vocab' in field.__dict__:\n assert field.vocab.stoi == shared_fields[key].vocab.stoi, \\\n 'Ensemble models must use the same preprocessed data'\n models.append(model)\n if shared_model_opt is None:\n shared_model_opt = model_opt\n ensemble_model = EnsembleModel(models, opt.avg_raw_probs)\n return shared_fields, ensemble_model, shared_model_opt\n", "path": "onmt/decoders/ensemble.py"}]}
| 2,053 | 444 |
gh_patches_debug_19725
|
rasdani/github-patches
|
git_diff
|
streamlink__streamlink-3247
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Can't find "tv3cat" plugin
## Plugin Issue
<!-- Replace [ ] with [x] in order to check the box -->
- [ X ] This is a plugin issue and I have read the contribution guidelines.
### Description
<!-- Explain the plugin issue as thoroughly as you can. -->
A image is worth a thousand words.

### Reproduction steps
<!-- How can we reproduce this? Please note the exact steps below using the list format supplied. If you need more steps please add them. -->
I've just using the "python3-streamlink" package provided by Fedora 32
Thanks!
</issue>
<code>
[start of src/streamlink/plugins/tv3cat.py]
1 import logging
2 import re
3
4 from streamlink.plugin import Plugin, PluginError
5 from streamlink.stream import HLSStream
6 from streamlink.plugin.api import validate
7
8 log = logging.getLogger(__name__)
9
10
11 class TV3Cat(Plugin):
12 _url_re = re.compile(r"http://(?:www.)?ccma.cat/tv3/directe/(.+?)/")
13 _stream_info_url = "http://dinamics.ccma.cat/pvideo/media.jsp" \
14 "?media=video&version=0s&idint={ident}&profile=pc&desplacament=0"
15 _media_schema = validate.Schema({
16 "geo": validate.text,
17 "url": validate.url(scheme=validate.any("http", "https"))
18 })
19 _channel_schema = validate.Schema({
20 "media": validate.any([_media_schema], _media_schema)},
21 validate.get("media"),
22 # If there is only one item, it's not a list ... silly
23 validate.transform(lambda x: x if isinstance(x, list) else [x])
24 )
25
26 @classmethod
27 def can_handle_url(cls, url):
28 return cls._url_re.match(url) is not None
29
30 def _get_streams(self):
31 match = self._url_re.match(self.url)
32 if match:
33 ident = match.group(1)
34 data_url = self._stream_info_url.format(ident=ident)
35 stream_infos = self.session.http.json(self.session.http.get(data_url), schema=self._channel_schema)
36
37 for stream in stream_infos:
38 try:
39 return HLSStream.parse_variant_playlist(self.session, stream['url'], name_fmt="{pixels}_{bitrate}")
40 except PluginError:
41 log.debug("Failed to get streams for: {0}".format(stream['geo']))
42 pass
43
44
45 __plugin__ = TV3Cat
46
[end of src/streamlink/plugins/tv3cat.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/streamlink/plugins/tv3cat.py b/src/streamlink/plugins/tv3cat.py
--- a/src/streamlink/plugins/tv3cat.py
+++ b/src/streamlink/plugins/tv3cat.py
@@ -9,7 +9,7 @@
class TV3Cat(Plugin):
- _url_re = re.compile(r"http://(?:www.)?ccma.cat/tv3/directe/(.+?)/")
+ _url_re = re.compile(r"https?://(?:www\.)?ccma\.cat/tv3/directe/(.+?)/")
_stream_info_url = "http://dinamics.ccma.cat/pvideo/media.jsp" \
"?media=video&version=0s&idint={ident}&profile=pc&desplacament=0"
_media_schema = validate.Schema({
@@ -39,7 +39,6 @@
return HLSStream.parse_variant_playlist(self.session, stream['url'], name_fmt="{pixels}_{bitrate}")
except PluginError:
log.debug("Failed to get streams for: {0}".format(stream['geo']))
- pass
__plugin__ = TV3Cat
|
{"golden_diff": "diff --git a/src/streamlink/plugins/tv3cat.py b/src/streamlink/plugins/tv3cat.py\n--- a/src/streamlink/plugins/tv3cat.py\n+++ b/src/streamlink/plugins/tv3cat.py\n@@ -9,7 +9,7 @@\n \n \n class TV3Cat(Plugin):\n- _url_re = re.compile(r\"http://(?:www.)?ccma.cat/tv3/directe/(.+?)/\")\n+ _url_re = re.compile(r\"https?://(?:www\\.)?ccma\\.cat/tv3/directe/(.+?)/\")\n _stream_info_url = \"http://dinamics.ccma.cat/pvideo/media.jsp\" \\\n \"?media=video&version=0s&idint={ident}&profile=pc&desplacament=0\"\n _media_schema = validate.Schema({\n@@ -39,7 +39,6 @@\n return HLSStream.parse_variant_playlist(self.session, stream['url'], name_fmt=\"{pixels}_{bitrate}\")\n except PluginError:\n log.debug(\"Failed to get streams for: {0}\".format(stream['geo']))\n- pass\n \n \n __plugin__ = TV3Cat\n", "issue": "Can't find \"tv3cat\" plugin\n## Plugin Issue\r\n\r\n<!-- Replace [ ] with [x] in order to check the box -->\r\n- [ X ] This is a plugin issue and I have read the contribution guidelines.\r\n\r\n\r\n### Description\r\n\r\n<!-- Explain the plugin issue as thoroughly as you can. -->\r\n\r\nA image is worth a thousand words.\r\n\r\n\r\n\r\n### Reproduction steps \r\n\r\n<!-- How can we reproduce this? Please note the exact steps below using the list format supplied. If you need more steps please add them. -->\r\n\r\nI've just using the \"python3-streamlink\" package provided by Fedora 32\r\n\r\nThanks!\r\n\n", "before_files": [{"content": "import logging\nimport re\n\nfrom streamlink.plugin import Plugin, PluginError\nfrom streamlink.stream import HLSStream\nfrom streamlink.plugin.api import validate\n\nlog = logging.getLogger(__name__)\n\n\nclass TV3Cat(Plugin):\n _url_re = re.compile(r\"http://(?:www.)?ccma.cat/tv3/directe/(.+?)/\")\n _stream_info_url = \"http://dinamics.ccma.cat/pvideo/media.jsp\" \\\n \"?media=video&version=0s&idint={ident}&profile=pc&desplacament=0\"\n _media_schema = validate.Schema({\n \"geo\": validate.text,\n \"url\": validate.url(scheme=validate.any(\"http\", \"https\"))\n })\n _channel_schema = validate.Schema({\n \"media\": validate.any([_media_schema], _media_schema)},\n validate.get(\"media\"),\n # If there is only one item, it's not a list ... silly\n validate.transform(lambda x: x if isinstance(x, list) else [x])\n )\n\n @classmethod\n def can_handle_url(cls, url):\n return cls._url_re.match(url) is not None\n\n def _get_streams(self):\n match = self._url_re.match(self.url)\n if match:\n ident = match.group(1)\n data_url = self._stream_info_url.format(ident=ident)\n stream_infos = self.session.http.json(self.session.http.get(data_url), schema=self._channel_schema)\n\n for stream in stream_infos:\n try:\n return HLSStream.parse_variant_playlist(self.session, stream['url'], name_fmt=\"{pixels}_{bitrate}\")\n except PluginError:\n log.debug(\"Failed to get streams for: {0}\".format(stream['geo']))\n pass\n\n\n__plugin__ = TV3Cat\n", "path": "src/streamlink/plugins/tv3cat.py"}]}
| 1,203 | 251 |
gh_patches_debug_67164
|
rasdani/github-patches
|
git_diff
|
keras-team__keras-2268
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Textual information for labels?
I seem unable to use text for labels, whilst using to_categorical
```
Using Theano backend.
Traceback (most recent call last):
File "playground.py", line 88, in <module>
train_model_and_test(number_of_epochs, number_of_classes, train_data, train_label, augmented_data_generator)
File "playground.py", line 62, in train_model_and_test
train_label = np_utils.to_categorical(train_label, number_of_classes)
File "/usr/local/lib/python2.7/dist-packages/keras/utils/np_utils.py", line 12, in to_categorical
y = np.asarray(y, dtype='int32')
File "/usr/lib/python2.7/dist-packages/numpy/core/numeric.py", line 460, in asarray
return array(a, dtype, copy=False, order=order)
ValueError: invalid literal for int() with base 10: 'yellow'
```
</issue>
<code>
[start of keras/utils/np_utils.py]
1 from __future__ import absolute_import
2 import numpy as np
3 import scipy as sp
4 from six.moves import range
5 from six.moves import zip
6
7
8 def to_categorical(y, nb_classes=None):
9 '''Convert class vector (integers from 0 to nb_classes)
10 to binary class matrix, for use with categorical_crossentropy.
11 '''
12 y = np.asarray(y, dtype='int32')
13 if not nb_classes:
14 nb_classes = np.max(y)+1
15 Y = np.zeros((len(y), nb_classes))
16 for i in range(len(y)):
17 Y[i, y[i]] = 1.
18 return Y
19
20
21 def normalize(a, axis=-1, order=2):
22 l2 = np.atleast_1d(np.linalg.norm(a, order, axis))
23 l2[l2 == 0] = 1
24 return a / np.expand_dims(l2, axis)
25
26
27 def binary_logloss(p, y):
28 epsilon = 1e-15
29 p = sp.maximum(epsilon, p)
30 p = sp.minimum(1-epsilon, p)
31 res = sum(y * sp.log(p) + sp.subtract(1, y) * sp.log(sp.subtract(1, p)))
32 res *= -1.0/len(y)
33 return res
34
35
36 def multiclass_logloss(P, Y):
37 npreds = [P[i][Y[i]-1] for i in range(len(Y))]
38 score = -(1. / len(Y)) * np.sum(np.log(npreds))
39 return score
40
41
42 def accuracy(p, y):
43 return np.mean([a == b for a, b in zip(p, y)])
44
45
46 def probas_to_classes(y_pred):
47 if len(y_pred.shape) > 1 and y_pred.shape[1] > 1:
48 return categorical_probas_to_classes(y_pred)
49 return np.array([1 if p > 0.5 else 0 for p in y_pred])
50
51
52 def categorical_probas_to_classes(p):
53 return np.argmax(p, axis=1)
54
[end of keras/utils/np_utils.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/keras/utils/np_utils.py b/keras/utils/np_utils.py
--- a/keras/utils/np_utils.py
+++ b/keras/utils/np_utils.py
@@ -9,7 +9,6 @@
'''Convert class vector (integers from 0 to nb_classes)
to binary class matrix, for use with categorical_crossentropy.
'''
- y = np.asarray(y, dtype='int32')
if not nb_classes:
nb_classes = np.max(y)+1
Y = np.zeros((len(y), nb_classes))
|
{"golden_diff": "diff --git a/keras/utils/np_utils.py b/keras/utils/np_utils.py\n--- a/keras/utils/np_utils.py\n+++ b/keras/utils/np_utils.py\n@@ -9,7 +9,6 @@\n '''Convert class vector (integers from 0 to nb_classes)\n to binary class matrix, for use with categorical_crossentropy.\n '''\n- y = np.asarray(y, dtype='int32')\n if not nb_classes:\n nb_classes = np.max(y)+1\n Y = np.zeros((len(y), nb_classes))\n", "issue": "Textual information for labels?\nI seem unable to use text for labels, whilst using to_categorical\n\n```\nUsing Theano backend.\nTraceback (most recent call last):\n File \"playground.py\", line 88, in <module>\n train_model_and_test(number_of_epochs, number_of_classes, train_data, train_label, augmented_data_generator)\n File \"playground.py\", line 62, in train_model_and_test\n train_label = np_utils.to_categorical(train_label, number_of_classes)\n File \"/usr/local/lib/python2.7/dist-packages/keras/utils/np_utils.py\", line 12, in to_categorical\n y = np.asarray(y, dtype='int32')\n File \"/usr/lib/python2.7/dist-packages/numpy/core/numeric.py\", line 460, in asarray\n return array(a, dtype, copy=False, order=order)\nValueError: invalid literal for int() with base 10: 'yellow'\n```\n\n", "before_files": [{"content": "from __future__ import absolute_import\nimport numpy as np\nimport scipy as sp\nfrom six.moves import range\nfrom six.moves import zip\n\n\ndef to_categorical(y, nb_classes=None):\n '''Convert class vector (integers from 0 to nb_classes)\n to binary class matrix, for use with categorical_crossentropy.\n '''\n y = np.asarray(y, dtype='int32')\n if not nb_classes:\n nb_classes = np.max(y)+1\n Y = np.zeros((len(y), nb_classes))\n for i in range(len(y)):\n Y[i, y[i]] = 1.\n return Y\n\n\ndef normalize(a, axis=-1, order=2):\n l2 = np.atleast_1d(np.linalg.norm(a, order, axis))\n l2[l2 == 0] = 1\n return a / np.expand_dims(l2, axis)\n\n\ndef binary_logloss(p, y):\n epsilon = 1e-15\n p = sp.maximum(epsilon, p)\n p = sp.minimum(1-epsilon, p)\n res = sum(y * sp.log(p) + sp.subtract(1, y) * sp.log(sp.subtract(1, p)))\n res *= -1.0/len(y)\n return res\n\n\ndef multiclass_logloss(P, Y):\n npreds = [P[i][Y[i]-1] for i in range(len(Y))]\n score = -(1. / len(Y)) * np.sum(np.log(npreds))\n return score\n\n\ndef accuracy(p, y):\n return np.mean([a == b for a, b in zip(p, y)])\n\n\ndef probas_to_classes(y_pred):\n if len(y_pred.shape) > 1 and y_pred.shape[1] > 1:\n return categorical_probas_to_classes(y_pred)\n return np.array([1 if p > 0.5 else 0 for p in y_pred])\n\n\ndef categorical_probas_to_classes(p):\n return np.argmax(p, axis=1)\n", "path": "keras/utils/np_utils.py"}]}
| 1,286 | 125 |
gh_patches_debug_32399
|
rasdani/github-patches
|
git_diff
|
buildbot__buildbot-5169
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
buildbot-2.6.0.gitarchive.tar.gz is not generated correctly
```
<rjarry> tardyp: the .gitarchive.tar.gz file of release 2.6.0 is corrupted
16:57:31 <rjarry> buildbot-v2.5.1.gitarchive.tar.gz
16:57:31 <rjarry> 4.69 MB
16:57:31 <rjarry> buildbot-v2.5.1.gitarchive.tar.gz.sig
16:57:31 <rjarry> 310 Bytes
16:57:47 <rjarry> last one does not
16:57:49 <rjarry> buildbot-2.6.0.gitarchive.tar.gz
16:57:49 <rjarry> 15 Bytes
16:57:49 <rjarry> buildbot-2.6.0.gitarchive.tar.gz.sig
16:57:49 <rjarry> 310 Bytes
```
We shall regenerate the archive and signature manually.
preferably @p12tic , which originaly signed the rest of the release
This archive is used by debian packaging as they require to build everything from source
</issue>
<code>
[start of common/download_release.py]
1 #!/usr/bin/env python3
2
3 import os
4
5 import requests
6 import yaml
7
8
9 def download(url, fn):
10 print(url, fn)
11 if os.path.exists(fn):
12 return
13 with open(fn, 'wb') as f:
14 r = s.get(url, stream=True)
15 for c in r.iter_content(1024):
16 f.write(c)
17
18
19 def main():
20 global s
21 with open(os.path.expanduser("~/.config/hub")) as f:
22 conf = yaml.safe_load(f)
23 token = conf['github.com'][0]['oauth_token']
24
25 s = requests.Session()
26 s.headers.update({'Authorization': 'token ' + token})
27 r = s.get("https://api.github.com/repos/buildbot/buildbot/releases/latest")
28 r.raise_for_status()
29 r = r.json()
30 tag = r['name']
31 upload_url = r['upload_url'].split('{')[0]
32 assets = s.get("https://api.github.com/repos/buildbot/buildbot/releases/{id}/assets".format(id=r['id']))
33 assets.raise_for_status()
34 assets = assets.json()
35 os.system("mkdir -p dist")
36 for url in (a['browser_download_url'] for a in assets):
37 if url.endswith(".whl") or url.endswith(".tar.gz"):
38 fn = os.path.join('dist', url.split('/')[-1])
39 download(url, fn)
40 # download tag archive
41 url = "https://github.com/buildbot/buildbot/archive/{tag}.tar.gz".format(tag=tag)
42 fn = os.path.join('dist', "buildbot-{tag}.gitarchive.tar.gz".format(tag=tag))
43 download(url, fn)
44 sigfn = fn + ".sig"
45 if os.path.exists(sigfn):
46 os.unlink(sigfn)
47 # sign the tag archive for debian
48 os.system("gpg --output {} -b {}".format(sigfn, fn))
49 sigfnbase = os.path.basename(sigfn)
50 r = s.post(upload_url,
51 headers={'Content-Type': "application/pgp-signature"},
52 params={"name": sigfnbase},
53 data=open(sigfn, 'rb'))
54 print(r.content)
55 fnbase = os.path.basename(fn)
56 r = s.post(upload_url,
57 headers={'Content-Type': "application/gzip"},
58 params={"name": fnbase},
59 data=open(fn, 'rb'))
60 print(r.content)
61 # remove files so that twine upload do not upload them
62 os.unlink(sigfn)
63 os.unlink(fn)
64
65
66 if __name__ == '__main__':
67 main()
68
[end of common/download_release.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/common/download_release.py b/common/download_release.py
--- a/common/download_release.py
+++ b/common/download_release.py
@@ -6,18 +6,19 @@
import yaml
-def download(url, fn):
- print(url, fn)
+def download(session, url, fn):
if os.path.exists(fn):
- return
+ print('Removing old file {}'.format(fn))
+ os.unlink(fn)
+ print('Downloading {} from {}'.format(fn, url))
with open(fn, 'wb') as f:
- r = s.get(url, stream=True)
+ r = session.get(url, stream=True)
+ r.raise_for_status()
for c in r.iter_content(1024):
f.write(c)
def main():
- global s
with open(os.path.expanduser("~/.config/hub")) as f:
conf = yaml.safe_load(f)
token = conf['github.com'][0]['oauth_token']
@@ -32,15 +33,15 @@
assets = s.get("https://api.github.com/repos/buildbot/buildbot/releases/{id}/assets".format(id=r['id']))
assets.raise_for_status()
assets = assets.json()
- os.system("mkdir -p dist")
+ os.makedirs('dist', exist_ok=True)
for url in (a['browser_download_url'] for a in assets):
if url.endswith(".whl") or url.endswith(".tar.gz"):
fn = os.path.join('dist', url.split('/')[-1])
- download(url, fn)
+ download(s, url, fn)
# download tag archive
url = "https://github.com/buildbot/buildbot/archive/{tag}.tar.gz".format(tag=tag)
fn = os.path.join('dist', "buildbot-{tag}.gitarchive.tar.gz".format(tag=tag))
- download(url, fn)
+ download(s, url, fn)
sigfn = fn + ".sig"
if os.path.exists(sigfn):
os.unlink(sigfn)
|
{"golden_diff": "diff --git a/common/download_release.py b/common/download_release.py\n--- a/common/download_release.py\n+++ b/common/download_release.py\n@@ -6,18 +6,19 @@\n import yaml\n \n \n-def download(url, fn):\n- print(url, fn)\n+def download(session, url, fn):\n if os.path.exists(fn):\n- return\n+ print('Removing old file {}'.format(fn))\n+ os.unlink(fn)\n+ print('Downloading {} from {}'.format(fn, url))\n with open(fn, 'wb') as f:\n- r = s.get(url, stream=True)\n+ r = session.get(url, stream=True)\n+ r.raise_for_status()\n for c in r.iter_content(1024):\n f.write(c)\n \n \n def main():\n- global s\n with open(os.path.expanduser(\"~/.config/hub\")) as f:\n conf = yaml.safe_load(f)\n token = conf['github.com'][0]['oauth_token']\n@@ -32,15 +33,15 @@\n assets = s.get(\"https://api.github.com/repos/buildbot/buildbot/releases/{id}/assets\".format(id=r['id']))\n assets.raise_for_status()\n assets = assets.json()\n- os.system(\"mkdir -p dist\")\n+ os.makedirs('dist', exist_ok=True)\n for url in (a['browser_download_url'] for a in assets):\n if url.endswith(\".whl\") or url.endswith(\".tar.gz\"):\n fn = os.path.join('dist', url.split('/')[-1])\n- download(url, fn)\n+ download(s, url, fn)\n # download tag archive\n url = \"https://github.com/buildbot/buildbot/archive/{tag}.tar.gz\".format(tag=tag)\n fn = os.path.join('dist', \"buildbot-{tag}.gitarchive.tar.gz\".format(tag=tag))\n- download(url, fn)\n+ download(s, url, fn)\n sigfn = fn + \".sig\"\n if os.path.exists(sigfn):\n os.unlink(sigfn)\n", "issue": "buildbot-2.6.0.gitarchive.tar.gz is not generated correctly\n```\r\n<rjarry> tardyp: the .gitarchive.tar.gz file of release 2.6.0 is corrupted\r\n16:57:31 <rjarry> buildbot-v2.5.1.gitarchive.tar.gz\r\n16:57:31 <rjarry> 4.69 MB\r\n16:57:31 <rjarry> buildbot-v2.5.1.gitarchive.tar.gz.sig\r\n16:57:31 <rjarry> 310 Bytes\r\n16:57:47 <rjarry> last one does not\r\n16:57:49 <rjarry> buildbot-2.6.0.gitarchive.tar.gz\r\n16:57:49 <rjarry> 15 Bytes\r\n16:57:49 <rjarry> buildbot-2.6.0.gitarchive.tar.gz.sig\r\n16:57:49 <rjarry> 310 Bytes\r\n```\r\nWe shall regenerate the archive and signature manually.\r\npreferably @p12tic , which originaly signed the rest of the release\r\n\r\nThis archive is used by debian packaging as they require to build everything from source\n", "before_files": [{"content": "#!/usr/bin/env python3\n\nimport os\n\nimport requests\nimport yaml\n\n\ndef download(url, fn):\n print(url, fn)\n if os.path.exists(fn):\n return\n with open(fn, 'wb') as f:\n r = s.get(url, stream=True)\n for c in r.iter_content(1024):\n f.write(c)\n\n\ndef main():\n global s\n with open(os.path.expanduser(\"~/.config/hub\")) as f:\n conf = yaml.safe_load(f)\n token = conf['github.com'][0]['oauth_token']\n\n s = requests.Session()\n s.headers.update({'Authorization': 'token ' + token})\n r = s.get(\"https://api.github.com/repos/buildbot/buildbot/releases/latest\")\n r.raise_for_status()\n r = r.json()\n tag = r['name']\n upload_url = r['upload_url'].split('{')[0]\n assets = s.get(\"https://api.github.com/repos/buildbot/buildbot/releases/{id}/assets\".format(id=r['id']))\n assets.raise_for_status()\n assets = assets.json()\n os.system(\"mkdir -p dist\")\n for url in (a['browser_download_url'] for a in assets):\n if url.endswith(\".whl\") or url.endswith(\".tar.gz\"):\n fn = os.path.join('dist', url.split('/')[-1])\n download(url, fn)\n # download tag archive\n url = \"https://github.com/buildbot/buildbot/archive/{tag}.tar.gz\".format(tag=tag)\n fn = os.path.join('dist', \"buildbot-{tag}.gitarchive.tar.gz\".format(tag=tag))\n download(url, fn)\n sigfn = fn + \".sig\"\n if os.path.exists(sigfn):\n os.unlink(sigfn)\n # sign the tag archive for debian\n os.system(\"gpg --output {} -b {}\".format(sigfn, fn))\n sigfnbase = os.path.basename(sigfn)\n r = s.post(upload_url,\n headers={'Content-Type': \"application/pgp-signature\"},\n params={\"name\": sigfnbase},\n data=open(sigfn, 'rb'))\n print(r.content)\n fnbase = os.path.basename(fn)\n r = s.post(upload_url,\n headers={'Content-Type': \"application/gzip\"},\n params={\"name\": fnbase},\n data=open(fn, 'rb'))\n print(r.content)\n # remove files so that twine upload do not upload them\n os.unlink(sigfn)\n os.unlink(fn)\n\n\nif __name__ == '__main__':\n main()\n", "path": "common/download_release.py"}]}
| 1,502 | 441 |
gh_patches_debug_10587
|
rasdani/github-patches
|
git_diff
|
nvaccess__nvda-13009
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
word problems 2013
### Steps to reproduce:
I have a friend's computer with problems.
This machine is with office 2013 and windows 10, I didn't install these 2 software.
I updated on this machine only nvda and the add-ons.
In several parts of the word, nvda doesn't say anything:
When we press alt inside word nvda doesn't announce the focus in the menu, and when we walk with tabe it doesn't read anything either.
This also occurred within outlook.
When we close the document without saving in the word question if we want to save the changes when walking with tabe again, nvda does not announce anything.
When opening the word on the first screen where you can choose the type of document to create nvda again is muted when walking with tabe or arrows.
I've already tested it with disabled add-ons and the problem continued.
I already ran the registry fix tool with and the error continues.
Nvda seems to work well in any other area of windows 10 and other programs.
### Actual behavior:
nvda mute on some word screens
### Expected behavior:
nvda read screens normally
### System configuration
#### NVDA installed/portable/running from source:
instaled
#### NVDA version:
alfa 24160
#### Windows version:
10 10.0.19043.
#### Name and version of other software in use when reproducing the issue:
office 2013
#### Other information about your system:
### Other questions
#### Does the issue still occur after restarting your computer?
yes
#### Have you tried any other versions of NVDA? If so, please report their behaviors.
no
#### If NVDA add-ons are disabled, is your problem still occurring?
yes
#### Does the issue still occur after you run the COM Registration Fixing Tool in NVDA's tools menu?
yes
log of the various screens where I noticed the error.
Sorry, there are so many errors that I couldn't selessionar only the point where it matters in the log, but I tried to turn on nvda at the time the error occurs to be relatively smaller.
[exit word.txt](https://github.com/nvaccess/nvda/files/7445713/exit.word.txt)
[select word.txt](https://github.com/nvaccess/nvda/files/7445714/select.word.txt)
[start word.txt](https://github.com/nvaccess/nvda/files/7445715/start.word.txt)
</issue>
<code>
[start of source/fileUtils.py]
1 # A part of NonVisual Desktop Access (NVDA)
2 # Copyright (C) 2017-2021 NV Access Limited, Bram Duvigneau, Łukasz Golonka
3 # This file is covered by the GNU General Public License.
4 # See the file COPYING for more details.
5
6 import os
7 import ctypes
8 import ctypes.wintypes
9 import array
10 from contextlib import contextmanager
11 from tempfile import NamedTemporaryFile
12 from logHandler import log
13 from six import text_type
14 import winKernel
15 import shlobj
16 from functools import wraps
17 import systemUtils
18
19
20 @contextmanager
21 def FaultTolerantFile(name):
22 '''Used to write out files in a more fault tolerant way. A temporary file is used, and replaces the
23 file `name' when the context manager scope ends and the the context manager __exit__ is called. This
24 means writing out the complete file can be performed with less concern of corrupting the original file
25 if the process is interrupted by windows shutting down.
26 `name` must be unicode.
27
28 Usage:
29 with FaultTolerantFile("myFile.txt") as f:
30 f.write("This is a test")
31
32 This creates a temporary file, and the writes actually happen on this temp file. At the end of the
33 `with` block, when `f` goes out of context the temporary file is closed and, this temporary file replaces "myFile.txt"
34 '''
35 if not isinstance(name, text_type):
36 raise TypeError("name must be an unicode string")
37 dirpath, filename = os.path.split(name)
38 with NamedTemporaryFile(dir=dirpath, prefix=filename, suffix='.tmp', delete=False) as f:
39 log.debug(f.name)
40 yield f
41 f.flush()
42 os.fsync(f)
43 f.close()
44 winKernel.moveFileEx(f.name, name, winKernel.MOVEFILE_REPLACE_EXISTING)
45
46
47 def _suspendWow64RedirectionForFileInfoRetrieval(func):
48 """
49 This decorator checks if the file provided as a `filePath`
50 is placed in a system32 directory, and if for the current system system32
51 redirects 32-bit processes such as NVDA to a different syswow64 directory
52 disables redirection for the duration of the function call.
53 This is necessary when fetching file version info since NVDA is a 32-bit application
54 and without redirection disabled we would either access a wrong file or not be able to access it at all.
55 """
56 @wraps(func)
57 def funcWrapper(filePath, *attributes):
58 nativeSys32 = shlobj.SHGetKnownFolderPath(shlobj.FolderId.SYSTEM)
59 if (
60 systemUtils.hasSyswow64Dir()
61 # `os.path.commonpath` is necessary to perform case-insensitive comparisons
62 and os.path.commonpath([nativeSys32]) == os.path.commonpath([nativeSys32, filePath])
63 ):
64 with winKernel.suspendWow64Redirection():
65 return func(filePath, *attributes)
66 else:
67 return func(filePath, *attributes)
68 return funcWrapper
69
70
71 @_suspendWow64RedirectionForFileInfoRetrieval
72 def getFileVersionInfo(name, *attributes):
73 """Gets the specified file version info attributes from the provided file."""
74 if not isinstance(name, text_type):
75 raise TypeError("name must be an unicode string")
76 if not os.path.exists(name):
77 raise RuntimeError("The file %s does not exist" % name)
78 fileVersionInfo = {}
79 # Get size needed for buffer (0 if no info)
80 size = ctypes.windll.version.GetFileVersionInfoSizeW(name, None)
81 if not size:
82 raise RuntimeError("No version information")
83 # Create buffer
84 res = ctypes.create_string_buffer(size)
85 # Load file informations into buffer res
86 ctypes.windll.version.GetFileVersionInfoW(name, None, size, res)
87 r = ctypes.c_uint()
88 l = ctypes.c_uint()
89 # Look for codepages
90 ctypes.windll.version.VerQueryValueW(res, u'\\VarFileInfo\\Translation',
91 ctypes.byref(r), ctypes.byref(l))
92 if not l.value:
93 raise RuntimeError("No codepage")
94 # Take the first codepage (what else ?)
95 codepage = array.array('H', ctypes.string_at(r.value, 4))
96 codepage = "%04x%04x" % tuple(codepage)
97 for attr in attributes:
98 if not ctypes.windll.version.VerQueryValueW(res,
99 u'\\StringFileInfo\\%s\\%s' % (codepage, attr),
100 ctypes.byref(r), ctypes.byref(l)
101 ):
102 log.warning("Invalid or unavailable version info attribute for %r: %s" % (name, attr))
103 fileVersionInfo[attr] = None
104 else:
105 fileVersionInfo[attr] = ctypes.wstring_at(r.value, l.value-1)
106 return fileVersionInfo
107
[end of source/fileUtils.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/source/fileUtils.py b/source/fileUtils.py
--- a/source/fileUtils.py
+++ b/source/fileUtils.py
@@ -58,8 +58,8 @@
nativeSys32 = shlobj.SHGetKnownFolderPath(shlobj.FolderId.SYSTEM)
if (
systemUtils.hasSyswow64Dir()
- # `os.path.commonpath` is necessary to perform case-insensitive comparisons
- and os.path.commonpath([nativeSys32]) == os.path.commonpath([nativeSys32, filePath])
+ # Path's returned from `appModule.appPath` and `shlobj.SHGetKnownFolderPath` often differ in case
+ and filePath.casefold().startswith(nativeSys32.casefold())
):
with winKernel.suspendWow64Redirection():
return func(filePath, *attributes)
|
{"golden_diff": "diff --git a/source/fileUtils.py b/source/fileUtils.py\n--- a/source/fileUtils.py\n+++ b/source/fileUtils.py\n@@ -58,8 +58,8 @@\n \t\tnativeSys32 = shlobj.SHGetKnownFolderPath(shlobj.FolderId.SYSTEM)\n \t\tif (\n \t\t\tsystemUtils.hasSyswow64Dir()\n-\t\t\t# `os.path.commonpath` is necessary to perform case-insensitive comparisons\n-\t\t\tand os.path.commonpath([nativeSys32]) == os.path.commonpath([nativeSys32, filePath])\n+\t\t\t# Path's returned from `appModule.appPath` and `shlobj.SHGetKnownFolderPath` often differ in case\n+\t\t\tand filePath.casefold().startswith(nativeSys32.casefold())\n \t\t):\n \t\t\twith winKernel.suspendWow64Redirection():\n \t\t\t\treturn func(filePath, *attributes)\n", "issue": "word problems 2013 \n\r\n### Steps to reproduce:\r\nI have a friend's computer with problems.\r\nThis machine is with office 2013 and windows 10, I didn't install these 2 software.\r\nI updated on this machine only nvda and the add-ons.\r\nIn several parts of the word, nvda doesn't say anything:\r\nWhen we press alt inside word nvda doesn't announce the focus in the menu, and when we walk with tabe it doesn't read anything either.\r\nThis also occurred within outlook.\r\nWhen we close the document without saving in the word question if we want to save the changes when walking with tabe again, nvda does not announce anything.\r\nWhen opening the word on the first screen where you can choose the type of document to create nvda again is muted when walking with tabe or arrows.\r\nI've already tested it with disabled add-ons and the problem continued.\r\nI already ran the registry fix tool with and the error continues.\r\nNvda seems to work well in any other area of windows 10 and other programs. \r\n### Actual behavior:\r\nnvda mute on some word screens \r\n### Expected behavior:\r\nnvda read screens normally \r\n### System configuration\r\n#### NVDA installed/portable/running from source:\r\ninstaled\r\n#### NVDA version:\r\nalfa 24160\r\n#### Windows version:\r\n10 10.0.19043.\r\n#### Name and version of other software in use when reproducing the issue:\r\noffice 2013\r\n#### Other information about your system:\r\n\r\n### Other questions\r\n#### Does the issue still occur after restarting your computer?\r\nyes\r\n#### Have you tried any other versions of NVDA? If so, please report their behaviors.\r\nno\r\n#### If NVDA add-ons are disabled, is your problem still occurring?\r\nyes\r\n#### Does the issue still occur after you run the COM Registration Fixing Tool in NVDA's tools menu?\r\nyes\r\nlog of the various screens where I noticed the error.\r\nSorry, there are so many errors that I couldn't selessionar only the point where it matters in the log, but I tried to turn on nvda at the time the error occurs to be relatively smaller. \r\n[exit word.txt](https://github.com/nvaccess/nvda/files/7445713/exit.word.txt)\r\n[select word.txt](https://github.com/nvaccess/nvda/files/7445714/select.word.txt)\r\n[start word.txt](https://github.com/nvaccess/nvda/files/7445715/start.word.txt)\r\n\n", "before_files": [{"content": "# A part of NonVisual Desktop Access (NVDA)\n# Copyright (C) 2017-2021 NV Access Limited, Bram Duvigneau, \u0141ukasz Golonka\n# This file is covered by the GNU General Public License.\n# See the file COPYING for more details.\n\nimport os\nimport ctypes\nimport ctypes.wintypes\nimport array\nfrom contextlib import contextmanager\nfrom tempfile import NamedTemporaryFile\nfrom logHandler import log\nfrom six import text_type\nimport winKernel\nimport shlobj\nfrom functools import wraps\nimport systemUtils\n\n\n@contextmanager\ndef FaultTolerantFile(name):\n\t'''Used to write out files in a more fault tolerant way. A temporary file is used, and replaces the \n\tfile `name' when the context manager scope ends and the the context manager __exit__ is called. This\n\tmeans writing out the complete file can be performed with less concern of corrupting the original file\n\tif the process is interrupted by windows shutting down.\n\t`name` must be unicode.\n\n\tUsage:\n\t\twith FaultTolerantFile(\"myFile.txt\") as f:\n\t\t\tf.write(\"This is a test\")\n\n\tThis creates a temporary file, and the writes actually happen on this temp file. At the end of the \n\t`with` block, when `f` goes out of context the temporary file is closed and, this temporary file replaces \"myFile.txt\"\n\t'''\n\tif not isinstance(name, text_type):\n\t\traise TypeError(\"name must be an unicode string\")\n\tdirpath, filename = os.path.split(name)\n\twith NamedTemporaryFile(dir=dirpath, prefix=filename, suffix='.tmp', delete=False) as f:\n\t\tlog.debug(f.name)\n\t\tyield f\n\t\tf.flush()\n\t\tos.fsync(f)\n\t\tf.close()\n\t\twinKernel.moveFileEx(f.name, name, winKernel.MOVEFILE_REPLACE_EXISTING)\n\n\ndef _suspendWow64RedirectionForFileInfoRetrieval(func):\n\t\"\"\"\n\tThis decorator checks if the file provided as a `filePath`\n\tis placed in a system32 directory, and if for the current system system32\n\tredirects 32-bit processes such as NVDA to a different syswow64 directory\n\tdisables redirection for the duration of the function call.\n\tThis is necessary when fetching file version info since NVDA is a 32-bit application\n\tand without redirection disabled we would either access a wrong file or not be able to access it at all.\n\t\"\"\"\n\t@wraps(func)\n\tdef funcWrapper(filePath, *attributes):\n\t\tnativeSys32 = shlobj.SHGetKnownFolderPath(shlobj.FolderId.SYSTEM)\n\t\tif (\n\t\t\tsystemUtils.hasSyswow64Dir()\n\t\t\t# `os.path.commonpath` is necessary to perform case-insensitive comparisons\n\t\t\tand os.path.commonpath([nativeSys32]) == os.path.commonpath([nativeSys32, filePath])\n\t\t):\n\t\t\twith winKernel.suspendWow64Redirection():\n\t\t\t\treturn func(filePath, *attributes)\n\t\telse:\n\t\t\treturn func(filePath, *attributes)\n\treturn funcWrapper\n\n\n@_suspendWow64RedirectionForFileInfoRetrieval\ndef getFileVersionInfo(name, *attributes):\n\t\"\"\"Gets the specified file version info attributes from the provided file.\"\"\"\n\tif not isinstance(name, text_type):\n\t\traise TypeError(\"name must be an unicode string\")\n\tif not os.path.exists(name):\n\t\traise RuntimeError(\"The file %s does not exist\" % name)\n\tfileVersionInfo = {}\n\t# Get size needed for buffer (0 if no info)\n\tsize = ctypes.windll.version.GetFileVersionInfoSizeW(name, None)\n\tif not size:\n\t\traise RuntimeError(\"No version information\")\n\t# Create buffer\n\tres = ctypes.create_string_buffer(size)\n\t# Load file informations into buffer res\n\tctypes.windll.version.GetFileVersionInfoW(name, None, size, res)\n\tr = ctypes.c_uint()\n\tl = ctypes.c_uint()\n\t# Look for codepages\n\tctypes.windll.version.VerQueryValueW(res, u'\\\\VarFileInfo\\\\Translation',\n\t\tctypes.byref(r), ctypes.byref(l))\n\tif not l.value:\n\t\traise RuntimeError(\"No codepage\")\n\t# Take the first codepage (what else ?)\n\tcodepage = array.array('H', ctypes.string_at(r.value, 4))\n\tcodepage = \"%04x%04x\" % tuple(codepage)\n\tfor attr in attributes:\n\t\tif not ctypes.windll.version.VerQueryValueW(res,\n\t\t\tu'\\\\StringFileInfo\\\\%s\\\\%s' % (codepage, attr),\n\t\t\tctypes.byref(r), ctypes.byref(l)\n\t\t):\n\t\t\tlog.warning(\"Invalid or unavailable version info attribute for %r: %s\" % (name, attr))\n\t\t\tfileVersionInfo[attr] = None\n\t\telse:\n\t\t\tfileVersionInfo[attr] = ctypes.wstring_at(r.value, l.value-1)\n\treturn fileVersionInfo\n", "path": "source/fileUtils.py"}]}
| 2,374 | 188 |
gh_patches_debug_23914
|
rasdani/github-patches
|
git_diff
|
netbox-community__netbox-4849
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Swagger references IP address family incorrectly as string in NestedIPAddress.
<!--
NOTE: IF YOUR ISSUE DOES NOT FOLLOW THIS TEMPLATE, IT WILL BE CLOSED.
This form is only for reproducible bugs. If you need assistance with
NetBox installation, or if you have a general question, DO NOT open an
issue. Instead, post to our mailing list:
https://groups.google.com/forum/#!forum/netbox-discuss
Please describe the environment in which you are running NetBox. Be sure
that you are running an unmodified instance of the latest stable release
before submitting a bug report, and that any plugins have been disabled.
-->
### Environment
* Python version: netbox-docker
* NetBox version: 2.8.6
<!--
Describe in detail the exact steps that someone else can take to reproduce
this bug using the current stable release of NetBox. Begin with the
creation of any necessary database objects and call out every operation
being performed explicitly. If reporting a bug in the REST API, be sure to
reconstruct the raw HTTP request(s) being made: Don't rely on a client
library such as pynetbox.
-->
### Steps to Reproduce
1. Generate go-netbox with latest swagger https://github.com/netbox-community/go-netbox
2. Attempt to pull device information with dcim.DcimDevicesListParams on a device / rack that contains a primary ip configured on an device.
3. "cannot unmarshal number into Go struct field NestedIPAddress.results.primary_ip.family of type string"
<!-- What did you expect to happen? -->
### Expected Behavior
Swagger to match returned data.
<!-- What happened instead? -->
### Observed Behavior
Api returns Family as an number instead of a string, mismatching with swagger.
```
json: cannot unmarshal number into Go struct field NestedIPAddress.results.primary_ip.family of type string
```
</issue>
<code>
[start of netbox/ipam/api/nested_serializers.py]
1 from rest_framework import serializers
2
3 from ipam import models
4 from utilities.api import WritableNestedSerializer
5
6 __all__ = [
7 'NestedAggregateSerializer',
8 'NestedIPAddressSerializer',
9 'NestedPrefixSerializer',
10 'NestedRIRSerializer',
11 'NestedRoleSerializer',
12 'NestedServiceSerializer',
13 'NestedVLANGroupSerializer',
14 'NestedVLANSerializer',
15 'NestedVRFSerializer',
16 ]
17
18
19 #
20 # VRFs
21 #
22
23 class NestedVRFSerializer(WritableNestedSerializer):
24 url = serializers.HyperlinkedIdentityField(view_name='ipam-api:vrf-detail')
25 prefix_count = serializers.IntegerField(read_only=True)
26
27 class Meta:
28 model = models.VRF
29 fields = ['id', 'url', 'name', 'rd', 'prefix_count']
30
31
32 #
33 # RIRs/aggregates
34 #
35
36 class NestedRIRSerializer(WritableNestedSerializer):
37 url = serializers.HyperlinkedIdentityField(view_name='ipam-api:rir-detail')
38 aggregate_count = serializers.IntegerField(read_only=True)
39
40 class Meta:
41 model = models.RIR
42 fields = ['id', 'url', 'name', 'slug', 'aggregate_count']
43
44
45 class NestedAggregateSerializer(WritableNestedSerializer):
46 url = serializers.HyperlinkedIdentityField(view_name='ipam-api:aggregate-detail')
47
48 class Meta:
49 model = models.Aggregate
50 fields = ['id', 'url', 'family', 'prefix']
51
52
53 #
54 # VLANs
55 #
56
57 class NestedRoleSerializer(WritableNestedSerializer):
58 url = serializers.HyperlinkedIdentityField(view_name='ipam-api:role-detail')
59 prefix_count = serializers.IntegerField(read_only=True)
60 vlan_count = serializers.IntegerField(read_only=True)
61
62 class Meta:
63 model = models.Role
64 fields = ['id', 'url', 'name', 'slug', 'prefix_count', 'vlan_count']
65
66
67 class NestedVLANGroupSerializer(WritableNestedSerializer):
68 url = serializers.HyperlinkedIdentityField(view_name='ipam-api:vlangroup-detail')
69 vlan_count = serializers.IntegerField(read_only=True)
70
71 class Meta:
72 model = models.VLANGroup
73 fields = ['id', 'url', 'name', 'slug', 'vlan_count']
74
75
76 class NestedVLANSerializer(WritableNestedSerializer):
77 url = serializers.HyperlinkedIdentityField(view_name='ipam-api:vlan-detail')
78
79 class Meta:
80 model = models.VLAN
81 fields = ['id', 'url', 'vid', 'name', 'display_name']
82
83
84 #
85 # Prefixes
86 #
87
88 class NestedPrefixSerializer(WritableNestedSerializer):
89 url = serializers.HyperlinkedIdentityField(view_name='ipam-api:prefix-detail')
90
91 class Meta:
92 model = models.Prefix
93 fields = ['id', 'url', 'family', 'prefix']
94
95
96 #
97 # IP addresses
98 #
99
100 class NestedIPAddressSerializer(WritableNestedSerializer):
101 url = serializers.HyperlinkedIdentityField(view_name='ipam-api:ipaddress-detail')
102
103 class Meta:
104 model = models.IPAddress
105 fields = ['id', 'url', 'family', 'address']
106
107
108 #
109 # Services
110 #
111
112 class NestedServiceSerializer(WritableNestedSerializer):
113 url = serializers.HyperlinkedIdentityField(view_name='ipam-api:service-detail')
114
115 class Meta:
116 model = models.Service
117 fields = ['id', 'url', 'name', 'protocol', 'port']
118
[end of netbox/ipam/api/nested_serializers.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/netbox/ipam/api/nested_serializers.py b/netbox/ipam/api/nested_serializers.py
--- a/netbox/ipam/api/nested_serializers.py
+++ b/netbox/ipam/api/nested_serializers.py
@@ -44,6 +44,7 @@
class NestedAggregateSerializer(WritableNestedSerializer):
url = serializers.HyperlinkedIdentityField(view_name='ipam-api:aggregate-detail')
+ family = serializers.IntegerField(read_only=True)
class Meta:
model = models.Aggregate
@@ -87,6 +88,7 @@
class NestedPrefixSerializer(WritableNestedSerializer):
url = serializers.HyperlinkedIdentityField(view_name='ipam-api:prefix-detail')
+ family = serializers.IntegerField(read_only=True)
class Meta:
model = models.Prefix
@@ -99,6 +101,7 @@
class NestedIPAddressSerializer(WritableNestedSerializer):
url = serializers.HyperlinkedIdentityField(view_name='ipam-api:ipaddress-detail')
+ family = serializers.IntegerField(read_only=True)
class Meta:
model = models.IPAddress
|
{"golden_diff": "diff --git a/netbox/ipam/api/nested_serializers.py b/netbox/ipam/api/nested_serializers.py\n--- a/netbox/ipam/api/nested_serializers.py\n+++ b/netbox/ipam/api/nested_serializers.py\n@@ -44,6 +44,7 @@\n \n class NestedAggregateSerializer(WritableNestedSerializer):\n url = serializers.HyperlinkedIdentityField(view_name='ipam-api:aggregate-detail')\n+ family = serializers.IntegerField(read_only=True)\n \n class Meta:\n model = models.Aggregate\n@@ -87,6 +88,7 @@\n \n class NestedPrefixSerializer(WritableNestedSerializer):\n url = serializers.HyperlinkedIdentityField(view_name='ipam-api:prefix-detail')\n+ family = serializers.IntegerField(read_only=True)\n \n class Meta:\n model = models.Prefix\n@@ -99,6 +101,7 @@\n \n class NestedIPAddressSerializer(WritableNestedSerializer):\n url = serializers.HyperlinkedIdentityField(view_name='ipam-api:ipaddress-detail')\n+ family = serializers.IntegerField(read_only=True)\n \n class Meta:\n model = models.IPAddress\n", "issue": "Swagger references IP address family incorrectly as string in NestedIPAddress.\n<!--\r\n NOTE: IF YOUR ISSUE DOES NOT FOLLOW THIS TEMPLATE, IT WILL BE CLOSED.\r\n\r\n This form is only for reproducible bugs. If you need assistance with\r\n NetBox installation, or if you have a general question, DO NOT open an\r\n issue. Instead, post to our mailing list:\r\n\r\n https://groups.google.com/forum/#!forum/netbox-discuss\r\n\r\n Please describe the environment in which you are running NetBox. Be sure\r\n that you are running an unmodified instance of the latest stable release\r\n before submitting a bug report, and that any plugins have been disabled.\r\n-->\r\n### Environment\r\n* Python version: netbox-docker\r\n* NetBox version: 2.8.6\r\n\r\n<!--\r\n Describe in detail the exact steps that someone else can take to reproduce\r\n this bug using the current stable release of NetBox. Begin with the\r\n creation of any necessary database objects and call out every operation\r\n being performed explicitly. If reporting a bug in the REST API, be sure to\r\n reconstruct the raw HTTP request(s) being made: Don't rely on a client\r\n library such as pynetbox.\r\n-->\r\n### Steps to Reproduce\r\n1. Generate go-netbox with latest swagger https://github.com/netbox-community/go-netbox\r\n2. Attempt to pull device information with dcim.DcimDevicesListParams on a device / rack that contains a primary ip configured on an device.\r\n3. \"cannot unmarshal number into Go struct field NestedIPAddress.results.primary_ip.family of type string\"\r\n\r\n<!-- What did you expect to happen? -->\r\n### Expected Behavior\r\nSwagger to match returned data.\r\n\r\n<!-- What happened instead? -->\r\n### Observed Behavior\r\nApi returns Family as an number instead of a string, mismatching with swagger.\r\n```\r\njson: cannot unmarshal number into Go struct field NestedIPAddress.results.primary_ip.family of type string\r\n```\n", "before_files": [{"content": "from rest_framework import serializers\n\nfrom ipam import models\nfrom utilities.api import WritableNestedSerializer\n\n__all__ = [\n 'NestedAggregateSerializer',\n 'NestedIPAddressSerializer',\n 'NestedPrefixSerializer',\n 'NestedRIRSerializer',\n 'NestedRoleSerializer',\n 'NestedServiceSerializer',\n 'NestedVLANGroupSerializer',\n 'NestedVLANSerializer',\n 'NestedVRFSerializer',\n]\n\n\n#\n# VRFs\n#\n\nclass NestedVRFSerializer(WritableNestedSerializer):\n url = serializers.HyperlinkedIdentityField(view_name='ipam-api:vrf-detail')\n prefix_count = serializers.IntegerField(read_only=True)\n\n class Meta:\n model = models.VRF\n fields = ['id', 'url', 'name', 'rd', 'prefix_count']\n\n\n#\n# RIRs/aggregates\n#\n\nclass NestedRIRSerializer(WritableNestedSerializer):\n url = serializers.HyperlinkedIdentityField(view_name='ipam-api:rir-detail')\n aggregate_count = serializers.IntegerField(read_only=True)\n\n class Meta:\n model = models.RIR\n fields = ['id', 'url', 'name', 'slug', 'aggregate_count']\n\n\nclass NestedAggregateSerializer(WritableNestedSerializer):\n url = serializers.HyperlinkedIdentityField(view_name='ipam-api:aggregate-detail')\n\n class Meta:\n model = models.Aggregate\n fields = ['id', 'url', 'family', 'prefix']\n\n\n#\n# VLANs\n#\n\nclass NestedRoleSerializer(WritableNestedSerializer):\n url = serializers.HyperlinkedIdentityField(view_name='ipam-api:role-detail')\n prefix_count = serializers.IntegerField(read_only=True)\n vlan_count = serializers.IntegerField(read_only=True)\n\n class Meta:\n model = models.Role\n fields = ['id', 'url', 'name', 'slug', 'prefix_count', 'vlan_count']\n\n\nclass NestedVLANGroupSerializer(WritableNestedSerializer):\n url = serializers.HyperlinkedIdentityField(view_name='ipam-api:vlangroup-detail')\n vlan_count = serializers.IntegerField(read_only=True)\n\n class Meta:\n model = models.VLANGroup\n fields = ['id', 'url', 'name', 'slug', 'vlan_count']\n\n\nclass NestedVLANSerializer(WritableNestedSerializer):\n url = serializers.HyperlinkedIdentityField(view_name='ipam-api:vlan-detail')\n\n class Meta:\n model = models.VLAN\n fields = ['id', 'url', 'vid', 'name', 'display_name']\n\n\n#\n# Prefixes\n#\n\nclass NestedPrefixSerializer(WritableNestedSerializer):\n url = serializers.HyperlinkedIdentityField(view_name='ipam-api:prefix-detail')\n\n class Meta:\n model = models.Prefix\n fields = ['id', 'url', 'family', 'prefix']\n\n\n#\n# IP addresses\n#\n\nclass NestedIPAddressSerializer(WritableNestedSerializer):\n url = serializers.HyperlinkedIdentityField(view_name='ipam-api:ipaddress-detail')\n\n class Meta:\n model = models.IPAddress\n fields = ['id', 'url', 'family', 'address']\n\n\n#\n# Services\n#\n\nclass NestedServiceSerializer(WritableNestedSerializer):\n url = serializers.HyperlinkedIdentityField(view_name='ipam-api:service-detail')\n\n class Meta:\n model = models.Service\n fields = ['id', 'url', 'name', 'protocol', 'port']\n", "path": "netbox/ipam/api/nested_serializers.py"}]}
| 1,922 | 243 |
gh_patches_debug_64137
|
rasdani/github-patches
|
git_diff
|
plotly__dash-2024
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Missing `f` prefix on f-strings
Some strings looks like they're meant to be f-strings but are missing the `f` prefix meaning variable interpolation won't happen.
https://github.com/plotly/dash/blob/f6b51a841e7deddebfbada374e7de4c297bb2ce8/dash/development/update_components.py#L48
I found this issue automatically. I'm a bot. Beep Boop 🦊. See other issues I found in your repo [here](https://codereview.doctor/plotly/dash)
</issue>
<code>
[start of dash/development/update_components.py]
1 import sys
2 import subprocess
3 import shlex
4 import os
5 import argparse
6 import shutil
7 import logging
8 import coloredlogs
9
10
11 class _CombinedFormatter(
12 argparse.ArgumentDefaultsHelpFormatter, argparse.RawDescriptionHelpFormatter
13 ):
14 pass
15
16
17 logger = logging.getLogger(__name__)
18 coloredlogs.install(
19 fmt="%(asctime)s,%(msecs)03d %(levelname)s - %(message)s", datefmt="%H:%M:%S"
20 )
21
22
23 def bootstrap_components(components_source, concurrency, install_type):
24
25 is_windows = sys.platform == "win32"
26
27 source_glob = (
28 components_source
29 if components_source != "all"
30 else "dash-core-components|dash-html-components|dash-table"
31 )
32
33 cmdstr = f"npx lerna exec --concurrency {concurrency} --scope *@({source_glob})* -- npm {install_type}"
34 cmd = shlex.split(cmdstr, posix=not is_windows)
35 print(cmdstr)
36
37 with subprocess.Popen(
38 cmd, stdout=subprocess.PIPE, stderr=subprocess.PIPE, shell=is_windows
39 ) as proc:
40 out, err = proc.communicate()
41 status = proc.poll()
42
43 if err:
44 print(("🛑 " if status else "") + err.decode(), file=sys.stderr)
45
46 if status or not out:
47 print(
48 "🚨 Failed installing npm dependencies for component packages: {source_glob} (status={status}) 🚨",
49 file=sys.stderr,
50 )
51 sys.exit(1)
52 else:
53 print(
54 f"🟢 Finished installing npm dependencies for component packages: {source_glob} 🟢",
55 file=sys.stderr,
56 )
57
58
59 def build_components(components_source, concurrency):
60
61 is_windows = sys.platform == "win32"
62
63 source_glob = (
64 components_source
65 if components_source != "all"
66 else "dash-core-components|dash-html-components|dash-table"
67 )
68
69 cmdstr = f"npx lerna exec --concurrency {concurrency} --scope *@({source_glob})* -- npm run build"
70 cmd = shlex.split(cmdstr, posix=not is_windows)
71 print(cmdstr)
72
73 with subprocess.Popen(
74 cmd, stdout=subprocess.PIPE, stderr=subprocess.PIPE, shell=is_windows
75 ) as proc:
76 out, err = proc.communicate()
77 status = proc.poll()
78
79 if err:
80 print(("🛑 " if status else "") + err.decode(), file=sys.stderr)
81
82 if status or not out:
83 print(
84 f"🚨 Finished updating component packages: {source_glob} (status={status}) 🚨",
85 file=sys.stderr,
86 )
87 sys.exit(1)
88
89 for package in source_glob.split("|"):
90 build_directory = os.path.join(
91 "components", package, package.replace("-", "_").rstrip("/\\")
92 )
93
94 dest_dir = (
95 "dcc"
96 if package == "dash-core-components"
97 else "html"
98 if package == "dash-html-components"
99 else "dash_table"
100 )
101
102 dest_path = os.path.join("dash", dest_dir)
103
104 if not os.path.exists(dest_path):
105 try:
106 os.makedirs(dest_path)
107 except OSError:
108 logger.exception("🚨 Having issues manipulating %s", dest_path)
109 sys.exit(1)
110
111 if not os.path.exists(build_directory):
112 print(
113 "🚨 Could not locate build artifacts."
114 + " Check that the npm build process completed"
115 + f" successfully for package: {package} 🚨"
116 )
117 sys.exit(1)
118 else:
119 print(f"🚚 Moving build artifacts from {build_directory} to Dash 🚚")
120 shutil.rmtree(dest_path)
121 shutil.copytree(build_directory, dest_path)
122 with open(os.path.join(dest_path, ".gitkeep"), "w"):
123 pass
124 print(f"🟢 Finished moving build artifacts from {build_directory} to Dash 🟢")
125
126
127 def cli():
128 parser = argparse.ArgumentParser(
129 prog="dash-update-components",
130 formatter_class=_CombinedFormatter,
131 description="Update the specified subcomponent libraries within Dash"
132 " by copying over build artifacts, dependencies, and dependency metadata.",
133 )
134 parser.add_argument(
135 "components_source",
136 help="A glob string that matches the Dash component libraries to be updated"
137 " (eg.'dash-table' // 'dash-core-components|dash-html-components' // 'all')."
138 " The default argument is 'all'.",
139 default="all",
140 )
141 parser.add_argument(
142 "--concurrency",
143 type=int,
144 default=3,
145 help="Maximum concurrent steps, up to 3 (ie all components in parallel)",
146 )
147 parser.add_argument(
148 "--ci",
149 help="For clean-install use '--ci True'",
150 default="False",
151 )
152
153 args = parser.parse_args()
154
155 bootstrap_components(
156 args.components_source, args.concurrency, "ci" if args.ci == "True" else "i"
157 )
158 build_components(args.components_source, args.concurrency)
159
160
161 if __name__ == "__main__":
162 cli()
163
[end of dash/development/update_components.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/dash/development/update_components.py b/dash/development/update_components.py
--- a/dash/development/update_components.py
+++ b/dash/development/update_components.py
@@ -45,7 +45,7 @@
if status or not out:
print(
- "🚨 Failed installing npm dependencies for component packages: {source_glob} (status={status}) 🚨",
+ f"🚨 Failed installing npm dependencies for component packages: {source_glob} (status={status}) 🚨",
file=sys.stderr,
)
sys.exit(1)
|
{"golden_diff": "diff --git a/dash/development/update_components.py b/dash/development/update_components.py\n--- a/dash/development/update_components.py\n+++ b/dash/development/update_components.py\n@@ -45,7 +45,7 @@\n \n if status or not out:\n print(\n- \"\ud83d\udea8 Failed installing npm dependencies for component packages: {source_glob} (status={status}) \ud83d\udea8\",\n+ f\"\ud83d\udea8 Failed installing npm dependencies for component packages: {source_glob} (status={status}) \ud83d\udea8\",\n file=sys.stderr,\n )\n sys.exit(1)\n", "issue": "Missing `f` prefix on f-strings\nSome strings looks like they're meant to be f-strings but are missing the `f` prefix meaning variable interpolation won't happen.\n\nhttps://github.com/plotly/dash/blob/f6b51a841e7deddebfbada374e7de4c297bb2ce8/dash/development/update_components.py#L48\n\nI found this issue automatically. I'm a bot. Beep Boop \ud83e\udd8a. See other issues I found in your repo [here](https://codereview.doctor/plotly/dash)\n", "before_files": [{"content": "import sys\nimport subprocess\nimport shlex\nimport os\nimport argparse\nimport shutil\nimport logging\nimport coloredlogs\n\n\nclass _CombinedFormatter(\n argparse.ArgumentDefaultsHelpFormatter, argparse.RawDescriptionHelpFormatter\n):\n pass\n\n\nlogger = logging.getLogger(__name__)\ncoloredlogs.install(\n fmt=\"%(asctime)s,%(msecs)03d %(levelname)s - %(message)s\", datefmt=\"%H:%M:%S\"\n)\n\n\ndef bootstrap_components(components_source, concurrency, install_type):\n\n is_windows = sys.platform == \"win32\"\n\n source_glob = (\n components_source\n if components_source != \"all\"\n else \"dash-core-components|dash-html-components|dash-table\"\n )\n\n cmdstr = f\"npx lerna exec --concurrency {concurrency} --scope *@({source_glob})* -- npm {install_type}\"\n cmd = shlex.split(cmdstr, posix=not is_windows)\n print(cmdstr)\n\n with subprocess.Popen(\n cmd, stdout=subprocess.PIPE, stderr=subprocess.PIPE, shell=is_windows\n ) as proc:\n out, err = proc.communicate()\n status = proc.poll()\n\n if err:\n print((\"\ud83d\uded1 \" if status else \"\") + err.decode(), file=sys.stderr)\n\n if status or not out:\n print(\n \"\ud83d\udea8 Failed installing npm dependencies for component packages: {source_glob} (status={status}) \ud83d\udea8\",\n file=sys.stderr,\n )\n sys.exit(1)\n else:\n print(\n f\"\ud83d\udfe2 Finished installing npm dependencies for component packages: {source_glob} \ud83d\udfe2\",\n file=sys.stderr,\n )\n\n\ndef build_components(components_source, concurrency):\n\n is_windows = sys.platform == \"win32\"\n\n source_glob = (\n components_source\n if components_source != \"all\"\n else \"dash-core-components|dash-html-components|dash-table\"\n )\n\n cmdstr = f\"npx lerna exec --concurrency {concurrency} --scope *@({source_glob})* -- npm run build\"\n cmd = shlex.split(cmdstr, posix=not is_windows)\n print(cmdstr)\n\n with subprocess.Popen(\n cmd, stdout=subprocess.PIPE, stderr=subprocess.PIPE, shell=is_windows\n ) as proc:\n out, err = proc.communicate()\n status = proc.poll()\n\n if err:\n print((\"\ud83d\uded1 \" if status else \"\") + err.decode(), file=sys.stderr)\n\n if status or not out:\n print(\n f\"\ud83d\udea8 Finished updating component packages: {source_glob} (status={status}) \ud83d\udea8\",\n file=sys.stderr,\n )\n sys.exit(1)\n\n for package in source_glob.split(\"|\"):\n build_directory = os.path.join(\n \"components\", package, package.replace(\"-\", \"_\").rstrip(\"/\\\\\")\n )\n\n dest_dir = (\n \"dcc\"\n if package == \"dash-core-components\"\n else \"html\"\n if package == \"dash-html-components\"\n else \"dash_table\"\n )\n\n dest_path = os.path.join(\"dash\", dest_dir)\n\n if not os.path.exists(dest_path):\n try:\n os.makedirs(dest_path)\n except OSError:\n logger.exception(\"\ud83d\udea8 Having issues manipulating %s\", dest_path)\n sys.exit(1)\n\n if not os.path.exists(build_directory):\n print(\n \"\ud83d\udea8 Could not locate build artifacts.\"\n + \" Check that the npm build process completed\"\n + f\" successfully for package: {package} \ud83d\udea8\"\n )\n sys.exit(1)\n else:\n print(f\"\ud83d\ude9a Moving build artifacts from {build_directory} to Dash \ud83d\ude9a\")\n shutil.rmtree(dest_path)\n shutil.copytree(build_directory, dest_path)\n with open(os.path.join(dest_path, \".gitkeep\"), \"w\"):\n pass\n print(f\"\ud83d\udfe2 Finished moving build artifacts from {build_directory} to Dash \ud83d\udfe2\")\n\n\ndef cli():\n parser = argparse.ArgumentParser(\n prog=\"dash-update-components\",\n formatter_class=_CombinedFormatter,\n description=\"Update the specified subcomponent libraries within Dash\"\n \" by copying over build artifacts, dependencies, and dependency metadata.\",\n )\n parser.add_argument(\n \"components_source\",\n help=\"A glob string that matches the Dash component libraries to be updated\"\n \" (eg.'dash-table' // 'dash-core-components|dash-html-components' // 'all').\"\n \" The default argument is 'all'.\",\n default=\"all\",\n )\n parser.add_argument(\n \"--concurrency\",\n type=int,\n default=3,\n help=\"Maximum concurrent steps, up to 3 (ie all components in parallel)\",\n )\n parser.add_argument(\n \"--ci\",\n help=\"For clean-install use '--ci True'\",\n default=\"False\",\n )\n\n args = parser.parse_args()\n\n bootstrap_components(\n args.components_source, args.concurrency, \"ci\" if args.ci == \"True\" else \"i\"\n )\n build_components(args.components_source, args.concurrency)\n\n\nif __name__ == \"__main__\":\n cli()\n", "path": "dash/development/update_components.py"}]}
| 2,133 | 127 |
gh_patches_debug_10101
|
rasdani/github-patches
|
git_diff
|
Mailu__Mailu-2651
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
plus mail in auto-forward destination
The email address in `admin -> User settings -> Auto-forward -> Destination` cannot contains a '+' character (error: Invalid email address). But the '+' in email address is valid and admin should accept it.
</issue>
<code>
[start of core/admin/mailu/ui/forms.py]
1 from wtforms import validators, fields, widgets
2 from wtforms_components import fields as fields_
3 from flask_babel import lazy_gettext as _
4
5 import flask_login
6 import flask_wtf
7 import re
8
9 LOCALPART_REGEX = "^[a-zA-Z0-9!#$%&'*+/=?^_`{|}~-]+(?:\.[a-zA-Z0-9!#$%&'*+/=?^_`{|}~-]+)*$"
10
11 class DestinationField(fields.SelectMultipleField):
12 """ Allow for multiple emails selection from current user choices and
13 additional email addresses.
14 """
15
16 validator = re.compile(r'^.+@([^.@][^@]+)$', re.IGNORECASE)
17
18 def iter_choices(self):
19 managed = [
20 str(email)
21 for email in flask_login.current_user.get_managed_emails()
22 ]
23 for email in managed:
24 selected = self.data is not None and self.coerce(email) in self.data
25 yield (email, email, selected)
26 for email in self.data or ():
27 if email not in managed:
28 yield (email, email, True)
29
30 def pre_validate(self, form):
31 for item in self.data:
32 if not self.validator.match(item):
33 raise validators.ValidationError(_('Invalid email address.'))
34
35 class MultipleEmailAddressesVerify(object):
36 def __init__(self,message=_('Invalid email address.')):
37 self.message = message
38
39 def __call__(self, form, field):
40 pattern = re.compile(r'^([_a-z0-9\-]+)(\.[_a-z0-9\-]+)*@([a-z0-9\-]{1,}\.)*([a-z]{1,})(,([_a-z0-9\-]+)(\.[_a-z0-9\-]+)*@([a-z0-9\-]{1,}\.)*([a-z]{2,}))*$')
41 if not pattern.match(field.data.replace(" ", "")):
42 raise validators.ValidationError(self.message)
43
44 class MultipleFoldersVerify(object):
45 """ Ensure that we have CSV formated data """
46 def __init__(self,message=_('Invalid list of folders.')):
47 self.message = message
48
49 def __call__(self, form, field):
50 pattern = re.compile(r'^[^,]+(,[^,]+)*$')
51 if not pattern.match(field.data.replace(" ", "")):
52 raise validators.ValidationError(self.message)
53
54 class ConfirmationForm(flask_wtf.FlaskForm):
55 submit = fields.SubmitField(_('Confirm'))
56
57 class DomainForm(flask_wtf.FlaskForm):
58 name = fields.StringField(_('Domain name'), [validators.DataRequired()])
59 max_users = fields_.IntegerField(_('Maximum user count'), [validators.NumberRange(min=-1)], default=10)
60 max_aliases = fields_.IntegerField(_('Maximum alias count'), [validators.NumberRange(min=-1)], default=10)
61 max_quota_bytes = fields_.IntegerSliderField(_('Maximum user quota'), default=0)
62 signup_enabled = fields.BooleanField(_('Enable sign-up'), default=False)
63 comment = fields.StringField(_('Comment'))
64 submit = fields.SubmitField(_('Save'))
65
66
67 class DomainSignupForm(flask_wtf.FlaskForm):
68 name = fields.StringField(_('Domain name'), [validators.DataRequired()])
69 localpart = fields.StringField(_('Initial admin'), [validators.DataRequired()])
70 pw = fields.PasswordField(_('Admin password'), [validators.DataRequired()])
71 pw2 = fields.PasswordField(_('Confirm password'), [validators.EqualTo('pw')])
72 pwned = fields.HiddenField(label='', default=-1)
73 captcha = flask_wtf.RecaptchaField()
74 submit = fields.SubmitField(_('Create'))
75
76
77 class AlternativeForm(flask_wtf.FlaskForm):
78 name = fields.StringField(_('Alternative name'), [validators.DataRequired()])
79 submit = fields.SubmitField(_('Save'))
80
81
82 class RelayForm(flask_wtf.FlaskForm):
83 name = fields.StringField(_('Relayed domain name'), [validators.DataRequired()])
84 smtp = fields.StringField(_('Remote host'))
85 comment = fields.StringField(_('Comment'))
86 submit = fields.SubmitField(_('Save'))
87
88
89 class UserForm(flask_wtf.FlaskForm):
90 localpart = fields.StringField(_('E-mail'), [validators.DataRequired(), validators.Regexp(LOCALPART_REGEX)])
91 pw = fields.PasswordField(_('Password'))
92 pw2 = fields.PasswordField(_('Confirm password'), [validators.EqualTo('pw')])
93 pwned = fields.HiddenField(label='', default=-1)
94 quota_bytes = fields_.IntegerSliderField(_('Quota'), default=10**9)
95 enable_imap = fields.BooleanField(_('Allow IMAP access'), default=True)
96 enable_pop = fields.BooleanField(_('Allow POP3 access'), default=True)
97 allow_spoofing = fields.BooleanField(_('Allow the user to spoof the sender (send email as anyone)'), default=False)
98 displayed_name = fields.StringField(_('Displayed name'))
99 comment = fields.StringField(_('Comment'))
100 enabled = fields.BooleanField(_('Enabled'), default=True)
101 submit = fields.SubmitField(_('Save'))
102
103
104 class UserSignupForm(flask_wtf.FlaskForm):
105 localpart = fields.StringField(_('Email address'), [validators.DataRequired(), validators.Regexp(LOCALPART_REGEX)])
106 pw = fields.PasswordField(_('Password'), [validators.DataRequired()])
107 pw2 = fields.PasswordField(_('Confirm password'), [validators.EqualTo('pw')])
108 pwned = fields.HiddenField(label='', default=-1)
109 submit = fields.SubmitField(_('Sign up'))
110
111 class UserSignupFormCaptcha(UserSignupForm):
112 captcha = flask_wtf.RecaptchaField()
113
114 class UserSettingsForm(flask_wtf.FlaskForm):
115 displayed_name = fields.StringField(_('Displayed name'))
116 spam_enabled = fields.BooleanField(_('Enable spam filter'))
117 spam_mark_as_read = fields.BooleanField(_('Enable marking spam mails as read'))
118 spam_threshold = fields_.IntegerSliderField(_('Spam filter tolerance'))
119 forward_enabled = fields.BooleanField(_('Enable forwarding'))
120 forward_keep = fields.BooleanField(_('Keep a copy of the emails'))
121 forward_destination = fields.StringField(_('Destination'), [validators.Optional(), MultipleEmailAddressesVerify()])
122 submit = fields.SubmitField(_('Save settings'))
123
124
125 class UserPasswordForm(flask_wtf.FlaskForm):
126 pw = fields.PasswordField(_('Password'), [validators.DataRequired()])
127 pw2 = fields.PasswordField(_('Password check'), [validators.DataRequired()])
128 pwned = fields.HiddenField(label='', default=-1)
129 submit = fields.SubmitField(_('Update password'))
130
131
132 class UserReplyForm(flask_wtf.FlaskForm):
133 reply_enabled = fields.BooleanField(_('Enable automatic reply'))
134 reply_subject = fields.StringField(_('Reply subject'))
135 reply_body = fields.StringField(_('Reply body'),
136 widget=widgets.TextArea())
137 reply_startdate = fields.DateField(_('Start of vacation'))
138 reply_enddate = fields.DateField(_('End of vacation'))
139 submit = fields.SubmitField(_('Update'))
140
141
142 class TokenForm(flask_wtf.FlaskForm):
143 displayed_password = fields.StringField(
144 _('Your token (write it down, as it will never be displayed again)')
145 )
146 raw_password = fields.HiddenField([validators.DataRequired()])
147 comment = fields.StringField(_('Comment'))
148 ip = fields.StringField(
149 _('Authorized IP'), [validators.Optional(), validators.IPAddress(ipv6=True)]
150 )
151 submit = fields.SubmitField(_('Save'))
152
153
154 class AliasForm(flask_wtf.FlaskForm):
155 localpart = fields.StringField(_('Alias'), [validators.DataRequired(), validators.Regexp(LOCALPART_REGEX)])
156 wildcard = fields.BooleanField(
157 _('Use SQL LIKE Syntax (e.g. for catch-all aliases)'))
158 destination = DestinationField(_('Destination'))
159 comment = fields.StringField(_('Comment'))
160 submit = fields.SubmitField(_('Save'))
161
162
163 class AdminForm(flask_wtf.FlaskForm):
164 admin = fields.SelectField(_('Admin email'), choices=[])
165 submit = fields.SubmitField(_('Submit'))
166
167
168 class ManagerForm(flask_wtf.FlaskForm):
169 manager = fields.SelectField(_('Manager email'))
170 submit = fields.SubmitField(_('Submit'))
171
172
173 class FetchForm(flask_wtf.FlaskForm):
174 protocol = fields.SelectField(_('Protocol'), choices=[
175 ('imap', 'IMAP'), ('pop3', 'POP3')
176 ])
177 host = fields.StringField(_('Hostname or IP'), [validators.DataRequired()])
178 port = fields.IntegerField(_('TCP port'), [validators.DataRequired(), validators.NumberRange(min=0, max=65535)], default=993)
179 tls = fields.BooleanField(_('Enable TLS'), default=True)
180 username = fields.StringField(_('Username'), [validators.DataRequired()])
181 password = fields.PasswordField(_('Password'))
182 keep = fields.BooleanField(_('Keep emails on the server'))
183 scan = fields.BooleanField(_('Rescan emails locally'))
184 folders = fields.StringField(_('Folders to fetch on the server'), [validators.Optional(), MultipleFoldersVerify()], default='INBOX,Junk')
185 submit = fields.SubmitField(_('Submit'))
186
187
188 class AnnouncementForm(flask_wtf.FlaskForm):
189 announcement_subject = fields.StringField(_('Announcement subject'),
190 [validators.DataRequired()])
191 announcement_body = fields.StringField(_('Announcement body'),
192 [validators.DataRequired()], widget=widgets.TextArea())
193 submit = fields.SubmitField(_('Send'))
194
[end of core/admin/mailu/ui/forms.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/core/admin/mailu/ui/forms.py b/core/admin/mailu/ui/forms.py
--- a/core/admin/mailu/ui/forms.py
+++ b/core/admin/mailu/ui/forms.py
@@ -37,7 +37,7 @@
self.message = message
def __call__(self, form, field):
- pattern = re.compile(r'^([_a-z0-9\-]+)(\.[_a-z0-9\-]+)*@([a-z0-9\-]{1,}\.)*([a-z]{1,})(,([_a-z0-9\-]+)(\.[_a-z0-9\-]+)*@([a-z0-9\-]{1,}\.)*([a-z]{2,}))*$')
+ pattern = re.compile(r'^([_a-z0-9\-\+]+)(\.[_a-z0-9\-\+]+)*@([a-z0-9\-]{1,}\.)*([a-z]{1,})(,([_a-z0-9\-\+]+)(\.[_a-z0-9\-\+]+)*@([a-z0-9\-]{1,}\.)*([a-z]{2,}))*$')
if not pattern.match(field.data.replace(" ", "")):
raise validators.ValidationError(self.message)
|
{"golden_diff": "diff --git a/core/admin/mailu/ui/forms.py b/core/admin/mailu/ui/forms.py\n--- a/core/admin/mailu/ui/forms.py\n+++ b/core/admin/mailu/ui/forms.py\n@@ -37,7 +37,7 @@\n self.message = message\n \n def __call__(self, form, field):\n- pattern = re.compile(r'^([_a-z0-9\\-]+)(\\.[_a-z0-9\\-]+)*@([a-z0-9\\-]{1,}\\.)*([a-z]{1,})(,([_a-z0-9\\-]+)(\\.[_a-z0-9\\-]+)*@([a-z0-9\\-]{1,}\\.)*([a-z]{2,}))*$')\n+ pattern = re.compile(r'^([_a-z0-9\\-\\+]+)(\\.[_a-z0-9\\-\\+]+)*@([a-z0-9\\-]{1,}\\.)*([a-z]{1,})(,([_a-z0-9\\-\\+]+)(\\.[_a-z0-9\\-\\+]+)*@([a-z0-9\\-]{1,}\\.)*([a-z]{2,}))*$')\n if not pattern.match(field.data.replace(\" \", \"\")):\n raise validators.ValidationError(self.message)\n", "issue": "plus mail in auto-forward destination\nThe email address in `admin -> User settings -> Auto-forward -> Destination` cannot contains a '+' character (error: Invalid email address). But the '+' in email address is valid and admin should accept it.\n", "before_files": [{"content": "from wtforms import validators, fields, widgets\nfrom wtforms_components import fields as fields_\nfrom flask_babel import lazy_gettext as _\n\nimport flask_login\nimport flask_wtf\nimport re\n\nLOCALPART_REGEX = \"^[a-zA-Z0-9!#$%&'*+/=?^_`{|}~-]+(?:\\.[a-zA-Z0-9!#$%&'*+/=?^_`{|}~-]+)*$\"\n\nclass DestinationField(fields.SelectMultipleField):\n \"\"\" Allow for multiple emails selection from current user choices and\n additional email addresses.\n \"\"\"\n\n validator = re.compile(r'^.+@([^.@][^@]+)$', re.IGNORECASE)\n\n def iter_choices(self):\n managed = [\n str(email)\n for email in flask_login.current_user.get_managed_emails()\n ]\n for email in managed:\n selected = self.data is not None and self.coerce(email) in self.data\n yield (email, email, selected)\n for email in self.data or ():\n if email not in managed:\n yield (email, email, True)\n\n def pre_validate(self, form):\n for item in self.data:\n if not self.validator.match(item):\n raise validators.ValidationError(_('Invalid email address.'))\n\nclass MultipleEmailAddressesVerify(object):\n def __init__(self,message=_('Invalid email address.')):\n self.message = message\n\n def __call__(self, form, field):\n pattern = re.compile(r'^([_a-z0-9\\-]+)(\\.[_a-z0-9\\-]+)*@([a-z0-9\\-]{1,}\\.)*([a-z]{1,})(,([_a-z0-9\\-]+)(\\.[_a-z0-9\\-]+)*@([a-z0-9\\-]{1,}\\.)*([a-z]{2,}))*$')\n if not pattern.match(field.data.replace(\" \", \"\")):\n raise validators.ValidationError(self.message)\n\nclass MultipleFoldersVerify(object):\n \"\"\" Ensure that we have CSV formated data \"\"\"\n def __init__(self,message=_('Invalid list of folders.')):\n self.message = message\n\n def __call__(self, form, field):\n pattern = re.compile(r'^[^,]+(,[^,]+)*$')\n if not pattern.match(field.data.replace(\" \", \"\")):\n raise validators.ValidationError(self.message)\n\nclass ConfirmationForm(flask_wtf.FlaskForm):\n submit = fields.SubmitField(_('Confirm'))\n\nclass DomainForm(flask_wtf.FlaskForm):\n name = fields.StringField(_('Domain name'), [validators.DataRequired()])\n max_users = fields_.IntegerField(_('Maximum user count'), [validators.NumberRange(min=-1)], default=10)\n max_aliases = fields_.IntegerField(_('Maximum alias count'), [validators.NumberRange(min=-1)], default=10)\n max_quota_bytes = fields_.IntegerSliderField(_('Maximum user quota'), default=0)\n signup_enabled = fields.BooleanField(_('Enable sign-up'), default=False)\n comment = fields.StringField(_('Comment'))\n submit = fields.SubmitField(_('Save'))\n\n\nclass DomainSignupForm(flask_wtf.FlaskForm):\n name = fields.StringField(_('Domain name'), [validators.DataRequired()])\n localpart = fields.StringField(_('Initial admin'), [validators.DataRequired()])\n pw = fields.PasswordField(_('Admin password'), [validators.DataRequired()])\n pw2 = fields.PasswordField(_('Confirm password'), [validators.EqualTo('pw')])\n pwned = fields.HiddenField(label='', default=-1)\n captcha = flask_wtf.RecaptchaField()\n submit = fields.SubmitField(_('Create'))\n\n\nclass AlternativeForm(flask_wtf.FlaskForm):\n name = fields.StringField(_('Alternative name'), [validators.DataRequired()])\n submit = fields.SubmitField(_('Save'))\n\n\nclass RelayForm(flask_wtf.FlaskForm):\n name = fields.StringField(_('Relayed domain name'), [validators.DataRequired()])\n smtp = fields.StringField(_('Remote host'))\n comment = fields.StringField(_('Comment'))\n submit = fields.SubmitField(_('Save'))\n\n\nclass UserForm(flask_wtf.FlaskForm):\n localpart = fields.StringField(_('E-mail'), [validators.DataRequired(), validators.Regexp(LOCALPART_REGEX)])\n pw = fields.PasswordField(_('Password'))\n pw2 = fields.PasswordField(_('Confirm password'), [validators.EqualTo('pw')])\n pwned = fields.HiddenField(label='', default=-1)\n quota_bytes = fields_.IntegerSliderField(_('Quota'), default=10**9)\n enable_imap = fields.BooleanField(_('Allow IMAP access'), default=True)\n enable_pop = fields.BooleanField(_('Allow POP3 access'), default=True)\n allow_spoofing = fields.BooleanField(_('Allow the user to spoof the sender (send email as anyone)'), default=False)\n displayed_name = fields.StringField(_('Displayed name'))\n comment = fields.StringField(_('Comment'))\n enabled = fields.BooleanField(_('Enabled'), default=True)\n submit = fields.SubmitField(_('Save'))\n\n\nclass UserSignupForm(flask_wtf.FlaskForm):\n localpart = fields.StringField(_('Email address'), [validators.DataRequired(), validators.Regexp(LOCALPART_REGEX)])\n pw = fields.PasswordField(_('Password'), [validators.DataRequired()])\n pw2 = fields.PasswordField(_('Confirm password'), [validators.EqualTo('pw')])\n pwned = fields.HiddenField(label='', default=-1)\n submit = fields.SubmitField(_('Sign up'))\n\nclass UserSignupFormCaptcha(UserSignupForm):\n captcha = flask_wtf.RecaptchaField()\n\nclass UserSettingsForm(flask_wtf.FlaskForm):\n displayed_name = fields.StringField(_('Displayed name'))\n spam_enabled = fields.BooleanField(_('Enable spam filter'))\n spam_mark_as_read = fields.BooleanField(_('Enable marking spam mails as read'))\n spam_threshold = fields_.IntegerSliderField(_('Spam filter tolerance'))\n forward_enabled = fields.BooleanField(_('Enable forwarding'))\n forward_keep = fields.BooleanField(_('Keep a copy of the emails'))\n forward_destination = fields.StringField(_('Destination'), [validators.Optional(), MultipleEmailAddressesVerify()])\n submit = fields.SubmitField(_('Save settings'))\n\n\nclass UserPasswordForm(flask_wtf.FlaskForm):\n pw = fields.PasswordField(_('Password'), [validators.DataRequired()])\n pw2 = fields.PasswordField(_('Password check'), [validators.DataRequired()])\n pwned = fields.HiddenField(label='', default=-1)\n submit = fields.SubmitField(_('Update password'))\n\n\nclass UserReplyForm(flask_wtf.FlaskForm):\n reply_enabled = fields.BooleanField(_('Enable automatic reply'))\n reply_subject = fields.StringField(_('Reply subject'))\n reply_body = fields.StringField(_('Reply body'),\n widget=widgets.TextArea())\n reply_startdate = fields.DateField(_('Start of vacation'))\n reply_enddate = fields.DateField(_('End of vacation'))\n submit = fields.SubmitField(_('Update'))\n\n\nclass TokenForm(flask_wtf.FlaskForm):\n displayed_password = fields.StringField(\n _('Your token (write it down, as it will never be displayed again)')\n )\n raw_password = fields.HiddenField([validators.DataRequired()])\n comment = fields.StringField(_('Comment'))\n ip = fields.StringField(\n _('Authorized IP'), [validators.Optional(), validators.IPAddress(ipv6=True)]\n )\n submit = fields.SubmitField(_('Save'))\n\n\nclass AliasForm(flask_wtf.FlaskForm):\n localpart = fields.StringField(_('Alias'), [validators.DataRequired(), validators.Regexp(LOCALPART_REGEX)])\n wildcard = fields.BooleanField(\n _('Use SQL LIKE Syntax (e.g. for catch-all aliases)'))\n destination = DestinationField(_('Destination'))\n comment = fields.StringField(_('Comment'))\n submit = fields.SubmitField(_('Save'))\n\n\nclass AdminForm(flask_wtf.FlaskForm):\n admin = fields.SelectField(_('Admin email'), choices=[])\n submit = fields.SubmitField(_('Submit'))\n\n\nclass ManagerForm(flask_wtf.FlaskForm):\n manager = fields.SelectField(_('Manager email'))\n submit = fields.SubmitField(_('Submit'))\n\n\nclass FetchForm(flask_wtf.FlaskForm):\n protocol = fields.SelectField(_('Protocol'), choices=[\n ('imap', 'IMAP'), ('pop3', 'POP3')\n ])\n host = fields.StringField(_('Hostname or IP'), [validators.DataRequired()])\n port = fields.IntegerField(_('TCP port'), [validators.DataRequired(), validators.NumberRange(min=0, max=65535)], default=993)\n tls = fields.BooleanField(_('Enable TLS'), default=True)\n username = fields.StringField(_('Username'), [validators.DataRequired()])\n password = fields.PasswordField(_('Password'))\n keep = fields.BooleanField(_('Keep emails on the server'))\n scan = fields.BooleanField(_('Rescan emails locally'))\n folders = fields.StringField(_('Folders to fetch on the server'), [validators.Optional(), MultipleFoldersVerify()], default='INBOX,Junk')\n submit = fields.SubmitField(_('Submit'))\n\n\nclass AnnouncementForm(flask_wtf.FlaskForm):\n announcement_subject = fields.StringField(_('Announcement subject'),\n [validators.DataRequired()])\n announcement_body = fields.StringField(_('Announcement body'),\n [validators.DataRequired()], widget=widgets.TextArea())\n submit = fields.SubmitField(_('Send'))\n", "path": "core/admin/mailu/ui/forms.py"}]}
| 3,005 | 288 |
gh_patches_debug_32320
|
rasdani/github-patches
|
git_diff
|
aimhubio__aim-2747
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Handling for aliases of PyTorch Lightning
## 🐛 Bug
Starting from PyTorch Lightning 1.8, this package has been renamed to `Lightning`. While both `lightning` and `pytorch_lightning` are in use as a package (`lightning` is a superset package for `pytorch_lightning` now).
This has caused a problem that `aim`'s code only support for PyTorch Lightning when `pytorch_lightning` is installed. When `lightning` is installed for some other users/developers, they will find that `aim` will wrongly suggest that they have not installed `pytorch_lightning` package.
Since parallel distribution for both `lightning` and `pytorch_lightning` would [stays for a long time](https://github.com/Lightning-AI/lightning/discussions/17095). It may be necessary to support both packages in `aim`'s code.
### To reproduce
Use `pip install lightning` instead of `pip install pytorch_lightning` to install `PyTorch Lightning`.
### Expected behavior
pytorch lightning addons should work for both those who installed `lightning` package and `pytorch-lightning` package.
### Environment
- Aim Version (e.g., 3.0.1): latest
- Python version: 3.10.1
- pip version
- OS (e.g., Linux): Linux
- PyTorch Lightning >= 1.8.0
### Additional context
None
</issue>
<code>
[start of aim/sdk/adapters/pytorch_lightning.py]
1 import os
2 from typing import Any, Dict, Optional, Union
3 from argparse import Namespace
4
5 import packaging.version
6
7 try:
8 import pytorch_lightning as pl
9
10 if packaging.version.parse(pl.__version__) < packaging.version.parse("1.7"):
11 from pytorch_lightning.loggers.base import (
12 LightningLoggerBase as Logger,
13 rank_zero_experiment,
14 )
15 else:
16 from pytorch_lightning.loggers.logger import (
17 Logger,
18 rank_zero_experiment,
19 )
20
21 from pytorch_lightning.utilities import rank_zero_only
22 except ImportError:
23 raise RuntimeError(
24 'This contrib module requires PyTorch Lightning to be installed. '
25 'Please install it with command: \n pip install pytorch-lightning'
26 )
27
28 from aim.sdk.run import Run
29 from aim.sdk.repo import Repo
30 from aim.sdk.utils import clean_repo_path, get_aim_repo_name
31 from aim.ext.resource.configs import DEFAULT_SYSTEM_TRACKING_INT
32
33
34 class AimLogger(Logger):
35 def __init__(self,
36 repo: Optional[str] = None,
37 experiment: Optional[str] = None,
38 train_metric_prefix: Optional[str] = 'train_',
39 val_metric_prefix: Optional[str] = 'val_',
40 test_metric_prefix: Optional[str] = 'test_',
41 system_tracking_interval: Optional[int]
42 = DEFAULT_SYSTEM_TRACKING_INT,
43 log_system_params: Optional[bool] = True,
44 capture_terminal_logs: Optional[bool] = True,
45 run_name: Optional[str] = None,
46 run_hash: Optional[str] = None,
47 ):
48 super().__init__()
49
50 self._experiment_name = experiment
51 self._run_name = run_name
52 self._repo_path = repo
53
54 self._train_metric_prefix = train_metric_prefix
55 self._val_metric_prefix = val_metric_prefix
56 self._test_metric_prefix = test_metric_prefix
57 self._system_tracking_interval = system_tracking_interval
58 self._log_system_params = log_system_params
59 self._capture_terminal_logs = capture_terminal_logs
60
61 self._run = None
62 self._run_hash = run_hash
63
64 @staticmethod
65 def _convert_params(params: Union[Dict[str, Any], Namespace]) -> Dict[str, Any]:
66 # in case converting from namespace
67 if isinstance(params, Namespace):
68 params = vars(params)
69
70 if params is None:
71 params = {}
72
73 return params
74
75 @property
76 @rank_zero_experiment
77 def experiment(self) -> Run:
78 if self._run is None:
79 if self._run_hash:
80 self._run = Run(
81 self._run_hash,
82 repo=self._repo_path,
83 system_tracking_interval=self._system_tracking_interval,
84 capture_terminal_logs=self._capture_terminal_logs
85 )
86 if self._run_name is not None:
87 self._run.name = self._run_name
88 else:
89 self._run = Run(
90 repo=self._repo_path,
91 experiment=self._experiment_name,
92 system_tracking_interval=self._system_tracking_interval,
93 log_system_params=self._log_system_params,
94 capture_terminal_logs=self._capture_terminal_logs,
95 )
96 self._run_hash = self._run.hash
97 return self._run
98
99 @rank_zero_only
100 def log_hyperparams(self, params: Union[Dict[str, Any], Namespace]):
101 params = self._convert_params(params)
102
103 # Handle OmegaConf object
104 try:
105 from omegaconf import OmegaConf
106 except ModuleNotFoundError:
107 pass
108 else:
109 # Convert to primitives
110 if OmegaConf.is_config(params):
111 params = OmegaConf.to_container(params, resolve=True)
112
113 for key, value in params.items():
114 self.experiment.set(('hparams', key), value, strict=False)
115
116 @rank_zero_only
117 def log_metrics(self, metrics: Dict[str, float],
118 step: Optional[int] = None):
119 assert rank_zero_only.rank == 0, \
120 'experiment tried to log from global_rank != 0'
121
122 metric_items: Dict[str: Any] = {k: v for k, v in metrics.items()}
123
124 if 'epoch' in metric_items:
125 epoch: int = metric_items.pop('epoch')
126 else:
127 epoch = None
128
129 for k, v in metric_items.items():
130 name = k
131 context = {}
132 if self._train_metric_prefix \
133 and name.startswith(self._train_metric_prefix):
134 name = name[len(self._train_metric_prefix):]
135 context['subset'] = 'train'
136 elif self._test_metric_prefix \
137 and name.startswith(self._test_metric_prefix):
138 name = name[len(self._test_metric_prefix):]
139 context['subset'] = 'test'
140 elif self._val_metric_prefix \
141 and name.startswith(self._val_metric_prefix):
142 name = name[len(self._val_metric_prefix):]
143 context['subset'] = 'val'
144 self.experiment.track(v, name=name, step=step, epoch=epoch, context=context)
145
146 @rank_zero_only
147 def finalize(self, status: str = '') -> None:
148 super().finalize(status)
149 if self._run:
150 self._run.close()
151 del self._run
152 self._run = None
153
154 def __del__(self):
155 self.finalize()
156
157 @property
158 def save_dir(self) -> str:
159 repo_path = clean_repo_path(self._repo_path) or Repo.default_repo_path()
160 return os.path.join(repo_path, get_aim_repo_name())
161
162 @property
163 def name(self) -> str:
164 return self._experiment_name
165
166 @property
167 def version(self) -> str:
168 return self.experiment.hash
169
[end of aim/sdk/adapters/pytorch_lightning.py]
[start of examples/pytorch_lightning_track.py]
1 from aim.pytorch_lightning import AimLogger
2
3 from argparse import ArgumentParser
4
5 import torch
6 import pytorch_lightning as pl
7 from torch.nn import functional as F
8 from torch.utils.data import DataLoader, random_split
9
10 try:
11 from torchvision.datasets.mnist import MNIST
12 from torchvision import transforms
13 except Exception as e:
14 from tests.base.datasets import MNIST
15
16
17 class LitClassifier(pl.LightningModule):
18 def __init__(self, hidden_dim=128, learning_rate=1e-3):
19 super().__init__()
20 self.save_hyperparameters()
21
22 self.l1 = torch.nn.Linear(28 * 28, self.hparams.hidden_dim)
23 self.l2 = torch.nn.Linear(self.hparams.hidden_dim, 10)
24
25 def forward(self, x):
26 x = x.view(x.size(0), -1)
27 x = torch.relu(self.l1(x))
28 x = torch.relu(self.l2(x))
29 return x
30
31 def training_step(self, batch, batch_idx):
32 x, y = batch
33 y_hat = self(x)
34 loss = F.cross_entropy(y_hat, y)
35 self.log('train_loss', loss)
36 return loss
37
38 def validation_step(self, batch, batch_idx):
39 x, y = batch
40 y_hat = self(x)
41 loss = F.cross_entropy(y_hat, y)
42 self.log('val_loss', loss)
43
44 def test_step(self, batch, batch_idx):
45 x, y = batch
46 y_hat = self(x)
47 loss = F.cross_entropy(y_hat, y)
48 self.log('test_loss', loss)
49 # Track metrics manually
50 self.logger.experiment.track(1, name='manually_tracked_metric')
51
52 def configure_optimizers(self):
53 return torch.optim.Adam(self.parameters(), lr=self.hparams.learning_rate)
54
55 @staticmethod
56 def add_model_specific_args(parent_parser):
57 parser = ArgumentParser(parents=[parent_parser], add_help=False)
58 parser.add_argument('--hidden_dim', type=int, default=128)
59 parser.add_argument('--learning_rate', type=float, default=0.0001)
60 return parser
61
62
63 def cli_main():
64 pl.seed_everything(1234)
65
66 # ------------
67 # args
68 # ------------
69 parser = ArgumentParser()
70 parser.add_argument('--batch_size', default=32, type=int)
71 parser = pl.Trainer.add_argparse_args(parser)
72 parser = LitClassifier.add_model_specific_args(parser)
73 args = parser.parse_args()
74
75 # ------------
76 # data
77 # ------------
78 dataset = MNIST('', train=True, download=True, transform=transforms.ToTensor())
79 mnist_test = MNIST('', train=False, download=True, transform=transforms.ToTensor())
80 mnist_train, mnist_val = random_split(dataset, [55000, 5000])
81
82 train_loader = DataLoader(mnist_train, batch_size=args.batch_size)
83 val_loader = DataLoader(mnist_val, batch_size=args.batch_size)
84 test_loader = DataLoader(mnist_test, batch_size=args.batch_size)
85
86 # ------------
87 # model
88 # ------------
89 model = LitClassifier(args.hidden_dim, args.learning_rate)
90
91 # ------------
92 # training
93 # ------------
94 aim_logger = AimLogger(
95 experiment='pt_lightning_exp',
96 train_metric_prefix='train_',
97 test_metric_prefix='test_',
98 val_metric_prefix='val_',
99 )
100 trainer = pl.Trainer(logger=aim_logger)
101 trainer.fit(model, train_loader, val_loader)
102
103 # ------------
104 # testing
105 # ------------
106 trainer.test(dataloaders=test_loader)
107
108
109 if __name__ == '__main__':
110 cli_main()
111
[end of examples/pytorch_lightning_track.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/aim/sdk/adapters/pytorch_lightning.py b/aim/sdk/adapters/pytorch_lightning.py
--- a/aim/sdk/adapters/pytorch_lightning.py
+++ b/aim/sdk/adapters/pytorch_lightning.py
@@ -1,10 +1,19 @@
import os
+import importlib.util
from typing import Any, Dict, Optional, Union
from argparse import Namespace
import packaging.version
-try:
+if importlib.util.find_spec("lightning"):
+ import lightning.pytorch as pl
+
+ from lightning.pytorch.loggers.logger import (
+ Logger, rank_zero_experiment
+ )
+
+ from lightning.pytorch.utilities import rank_zero_only
+elif importlib.util.find_spec("pytorch_lightning"):
import pytorch_lightning as pl
if packaging.version.parse(pl.__version__) < packaging.version.parse("1.7"):
@@ -19,10 +28,11 @@
)
from pytorch_lightning.utilities import rank_zero_only
-except ImportError:
+else:
raise RuntimeError(
'This contrib module requires PyTorch Lightning to be installed. '
'Please install it with command: \n pip install pytorch-lightning'
+ 'or \n pip install lightning'
)
from aim.sdk.run import Run
diff --git a/examples/pytorch_lightning_track.py b/examples/pytorch_lightning_track.py
--- a/examples/pytorch_lightning_track.py
+++ b/examples/pytorch_lightning_track.py
@@ -1,9 +1,19 @@
+import importlib.util
from aim.pytorch_lightning import AimLogger
from argparse import ArgumentParser
import torch
-import pytorch_lightning as pl
+if importlib.util.find_spec("lightning"):
+ import lightning.pytorch as pl
+elif importlib.util.find_spec("pytorch_lightning"): # noqa F401
+ import pytorch_lightning as pl
+else:
+ raise RuntimeError(
+ 'This contrib module requires PyTorch Lightning to be installed. '
+ 'Please install it with command: \n pip install pytorch-lightning \n'
+ 'or \n pip install lightning'
+ )
from torch.nn import functional as F
from torch.utils.data import DataLoader, random_split
|
{"golden_diff": "diff --git a/aim/sdk/adapters/pytorch_lightning.py b/aim/sdk/adapters/pytorch_lightning.py\n--- a/aim/sdk/adapters/pytorch_lightning.py\n+++ b/aim/sdk/adapters/pytorch_lightning.py\n@@ -1,10 +1,19 @@\n import os\n+import importlib.util\n from typing import Any, Dict, Optional, Union\n from argparse import Namespace\n \n import packaging.version\n \n-try:\n+if importlib.util.find_spec(\"lightning\"):\n+ import lightning.pytorch as pl\n+\n+ from lightning.pytorch.loggers.logger import (\n+ Logger, rank_zero_experiment\n+ )\n+\n+ from lightning.pytorch.utilities import rank_zero_only\n+elif importlib.util.find_spec(\"pytorch_lightning\"):\n import pytorch_lightning as pl\n \n if packaging.version.parse(pl.__version__) < packaging.version.parse(\"1.7\"):\n@@ -19,10 +28,11 @@\n )\n \n from pytorch_lightning.utilities import rank_zero_only\n-except ImportError:\n+else:\n raise RuntimeError(\n 'This contrib module requires PyTorch Lightning to be installed. '\n 'Please install it with command: \\n pip install pytorch-lightning'\n+ 'or \\n pip install lightning'\n )\n \n from aim.sdk.run import Run\ndiff --git a/examples/pytorch_lightning_track.py b/examples/pytorch_lightning_track.py\n--- a/examples/pytorch_lightning_track.py\n+++ b/examples/pytorch_lightning_track.py\n@@ -1,9 +1,19 @@\n+import importlib.util\n from aim.pytorch_lightning import AimLogger\n \n from argparse import ArgumentParser\n \n import torch\n-import pytorch_lightning as pl\n+if importlib.util.find_spec(\"lightning\"):\n+ import lightning.pytorch as pl\n+elif importlib.util.find_spec(\"pytorch_lightning\"): # noqa F401\n+ import pytorch_lightning as pl\n+else:\n+ raise RuntimeError(\n+ 'This contrib module requires PyTorch Lightning to be installed. '\n+ 'Please install it with command: \\n pip install pytorch-lightning \\n'\n+ 'or \\n pip install lightning'\n+ )\n from torch.nn import functional as F\n from torch.utils.data import DataLoader, random_split\n", "issue": "Handling for aliases of PyTorch Lightning\n## \ud83d\udc1b Bug\r\n\r\nStarting from PyTorch Lightning 1.8, this package has been renamed to `Lightning`. While both `lightning` and `pytorch_lightning` are in use as a package (`lightning` is a superset package for `pytorch_lightning` now).\r\n\r\nThis has caused a problem that `aim`'s code only support for PyTorch Lightning when `pytorch_lightning` is installed. When `lightning` is installed for some other users/developers, they will find that `aim` will wrongly suggest that they have not installed `pytorch_lightning` package.\r\n\r\nSince parallel distribution for both `lightning` and `pytorch_lightning` would [stays for a long time](https://github.com/Lightning-AI/lightning/discussions/17095). It may be necessary to support both packages in `aim`'s code.\r\n\r\n### To reproduce\r\n\r\nUse `pip install lightning` instead of `pip install pytorch_lightning` to install `PyTorch Lightning`.\r\n### Expected behavior\r\n\r\npytorch lightning addons should work for both those who installed `lightning` package and `pytorch-lightning` package.\r\n\r\n### Environment\r\n\r\n- Aim Version (e.g., 3.0.1): latest\r\n- Python version: 3.10.1\r\n- pip version\r\n- OS (e.g., Linux): Linux\r\n- PyTorch Lightning >= 1.8.0\r\n\r\n### Additional context\r\n\r\nNone\r\n\n", "before_files": [{"content": "import os\nfrom typing import Any, Dict, Optional, Union\nfrom argparse import Namespace\n\nimport packaging.version\n\ntry:\n import pytorch_lightning as pl\n\n if packaging.version.parse(pl.__version__) < packaging.version.parse(\"1.7\"):\n from pytorch_lightning.loggers.base import (\n LightningLoggerBase as Logger,\n rank_zero_experiment,\n )\n else:\n from pytorch_lightning.loggers.logger import (\n Logger,\n rank_zero_experiment,\n )\n\n from pytorch_lightning.utilities import rank_zero_only\nexcept ImportError:\n raise RuntimeError(\n 'This contrib module requires PyTorch Lightning to be installed. '\n 'Please install it with command: \\n pip install pytorch-lightning'\n )\n\nfrom aim.sdk.run import Run\nfrom aim.sdk.repo import Repo\nfrom aim.sdk.utils import clean_repo_path, get_aim_repo_name\nfrom aim.ext.resource.configs import DEFAULT_SYSTEM_TRACKING_INT\n\n\nclass AimLogger(Logger):\n def __init__(self,\n repo: Optional[str] = None,\n experiment: Optional[str] = None,\n train_metric_prefix: Optional[str] = 'train_',\n val_metric_prefix: Optional[str] = 'val_',\n test_metric_prefix: Optional[str] = 'test_',\n system_tracking_interval: Optional[int]\n = DEFAULT_SYSTEM_TRACKING_INT,\n log_system_params: Optional[bool] = True,\n capture_terminal_logs: Optional[bool] = True,\n run_name: Optional[str] = None,\n run_hash: Optional[str] = None,\n ):\n super().__init__()\n\n self._experiment_name = experiment\n self._run_name = run_name\n self._repo_path = repo\n\n self._train_metric_prefix = train_metric_prefix\n self._val_metric_prefix = val_metric_prefix\n self._test_metric_prefix = test_metric_prefix\n self._system_tracking_interval = system_tracking_interval\n self._log_system_params = log_system_params\n self._capture_terminal_logs = capture_terminal_logs\n\n self._run = None\n self._run_hash = run_hash\n\n @staticmethod\n def _convert_params(params: Union[Dict[str, Any], Namespace]) -> Dict[str, Any]:\n # in case converting from namespace\n if isinstance(params, Namespace):\n params = vars(params)\n\n if params is None:\n params = {}\n\n return params\n\n @property\n @rank_zero_experiment\n def experiment(self) -> Run:\n if self._run is None:\n if self._run_hash:\n self._run = Run(\n self._run_hash,\n repo=self._repo_path,\n system_tracking_interval=self._system_tracking_interval,\n capture_terminal_logs=self._capture_terminal_logs\n )\n if self._run_name is not None:\n self._run.name = self._run_name\n else:\n self._run = Run(\n repo=self._repo_path,\n experiment=self._experiment_name,\n system_tracking_interval=self._system_tracking_interval,\n log_system_params=self._log_system_params,\n capture_terminal_logs=self._capture_terminal_logs,\n )\n self._run_hash = self._run.hash\n return self._run\n\n @rank_zero_only\n def log_hyperparams(self, params: Union[Dict[str, Any], Namespace]):\n params = self._convert_params(params)\n\n # Handle OmegaConf object\n try:\n from omegaconf import OmegaConf\n except ModuleNotFoundError:\n pass\n else:\n # Convert to primitives\n if OmegaConf.is_config(params):\n params = OmegaConf.to_container(params, resolve=True)\n\n for key, value in params.items():\n self.experiment.set(('hparams', key), value, strict=False)\n\n @rank_zero_only\n def log_metrics(self, metrics: Dict[str, float],\n step: Optional[int] = None):\n assert rank_zero_only.rank == 0, \\\n 'experiment tried to log from global_rank != 0'\n\n metric_items: Dict[str: Any] = {k: v for k, v in metrics.items()}\n\n if 'epoch' in metric_items:\n epoch: int = metric_items.pop('epoch')\n else:\n epoch = None\n\n for k, v in metric_items.items():\n name = k\n context = {}\n if self._train_metric_prefix \\\n and name.startswith(self._train_metric_prefix):\n name = name[len(self._train_metric_prefix):]\n context['subset'] = 'train'\n elif self._test_metric_prefix \\\n and name.startswith(self._test_metric_prefix):\n name = name[len(self._test_metric_prefix):]\n context['subset'] = 'test'\n elif self._val_metric_prefix \\\n and name.startswith(self._val_metric_prefix):\n name = name[len(self._val_metric_prefix):]\n context['subset'] = 'val'\n self.experiment.track(v, name=name, step=step, epoch=epoch, context=context)\n\n @rank_zero_only\n def finalize(self, status: str = '') -> None:\n super().finalize(status)\n if self._run:\n self._run.close()\n del self._run\n self._run = None\n\n def __del__(self):\n self.finalize()\n\n @property\n def save_dir(self) -> str:\n repo_path = clean_repo_path(self._repo_path) or Repo.default_repo_path()\n return os.path.join(repo_path, get_aim_repo_name())\n\n @property\n def name(self) -> str:\n return self._experiment_name\n\n @property\n def version(self) -> str:\n return self.experiment.hash\n", "path": "aim/sdk/adapters/pytorch_lightning.py"}, {"content": "from aim.pytorch_lightning import AimLogger\n\nfrom argparse import ArgumentParser\n\nimport torch\nimport pytorch_lightning as pl\nfrom torch.nn import functional as F\nfrom torch.utils.data import DataLoader, random_split\n\ntry:\n from torchvision.datasets.mnist import MNIST\n from torchvision import transforms\nexcept Exception as e:\n from tests.base.datasets import MNIST\n\n\nclass LitClassifier(pl.LightningModule):\n def __init__(self, hidden_dim=128, learning_rate=1e-3):\n super().__init__()\n self.save_hyperparameters()\n\n self.l1 = torch.nn.Linear(28 * 28, self.hparams.hidden_dim)\n self.l2 = torch.nn.Linear(self.hparams.hidden_dim, 10)\n\n def forward(self, x):\n x = x.view(x.size(0), -1)\n x = torch.relu(self.l1(x))\n x = torch.relu(self.l2(x))\n return x\n\n def training_step(self, batch, batch_idx):\n x, y = batch\n y_hat = self(x)\n loss = F.cross_entropy(y_hat, y)\n self.log('train_loss', loss)\n return loss\n\n def validation_step(self, batch, batch_idx):\n x, y = batch\n y_hat = self(x)\n loss = F.cross_entropy(y_hat, y)\n self.log('val_loss', loss)\n\n def test_step(self, batch, batch_idx):\n x, y = batch\n y_hat = self(x)\n loss = F.cross_entropy(y_hat, y)\n self.log('test_loss', loss)\n # Track metrics manually\n self.logger.experiment.track(1, name='manually_tracked_metric')\n\n def configure_optimizers(self):\n return torch.optim.Adam(self.parameters(), lr=self.hparams.learning_rate)\n\n @staticmethod\n def add_model_specific_args(parent_parser):\n parser = ArgumentParser(parents=[parent_parser], add_help=False)\n parser.add_argument('--hidden_dim', type=int, default=128)\n parser.add_argument('--learning_rate', type=float, default=0.0001)\n return parser\n\n\ndef cli_main():\n pl.seed_everything(1234)\n\n # ------------\n # args\n # ------------\n parser = ArgumentParser()\n parser.add_argument('--batch_size', default=32, type=int)\n parser = pl.Trainer.add_argparse_args(parser)\n parser = LitClassifier.add_model_specific_args(parser)\n args = parser.parse_args()\n\n # ------------\n # data\n # ------------\n dataset = MNIST('', train=True, download=True, transform=transforms.ToTensor())\n mnist_test = MNIST('', train=False, download=True, transform=transforms.ToTensor())\n mnist_train, mnist_val = random_split(dataset, [55000, 5000])\n\n train_loader = DataLoader(mnist_train, batch_size=args.batch_size)\n val_loader = DataLoader(mnist_val, batch_size=args.batch_size)\n test_loader = DataLoader(mnist_test, batch_size=args.batch_size)\n\n # ------------\n # model\n # ------------\n model = LitClassifier(args.hidden_dim, args.learning_rate)\n\n # ------------\n # training\n # ------------\n aim_logger = AimLogger(\n experiment='pt_lightning_exp',\n train_metric_prefix='train_',\n test_metric_prefix='test_',\n val_metric_prefix='val_',\n )\n trainer = pl.Trainer(logger=aim_logger)\n trainer.fit(model, train_loader, val_loader)\n\n # ------------\n # testing\n # ------------\n trainer.test(dataloaders=test_loader)\n\n\nif __name__ == '__main__':\n cli_main()\n", "path": "examples/pytorch_lightning_track.py"}]}
| 3,533 | 493 |
gh_patches_debug_25464
|
rasdani/github-patches
|
git_diff
|
davanstrien__flyswot-550
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
remove unused dependenices
</issue>
<code>
[start of src/flyswot/models.py]
1 """Model Commands."""
2 import fnmatch
3 from dataclasses import dataclass
4 from pathlib import Path
5 from typing import List
6 from typing import Optional
7 from typing import Tuple
8 from typing import Union
9
10 import requests
11 import typer
12 import validators # type: ignore
13 from huggingface_hub import hf_hub_url
14 from huggingface_hub import snapshot_download
15 from huggingface_hub.hf_api import ModelInfo
16 from rich.markdown import Markdown
17 from rich.table import Table
18 from toolz import itertoolz
19 from toolz import recipes
20
21 from flyswot.config import APP_NAME
22 from flyswot.config import MODEL_REPO_ID
23 from flyswot.console import console
24
25 app = typer.Typer()
26
27
28 @dataclass
29 class LocalModel:
30 """A local model container"""
31
32 hf_cache: Path
33
34 def __post_init__(self):
35 """Returns model parts contained under hf_cache"""
36 self._get_model_parts(self.hf_cache)
37
38 def _get_model_parts(self, hf_cache: Path):
39 """Returns model path, vocab and metadata for a model"""
40 model_files = Path(hf_cache).iterdir()
41 for file in model_files:
42 if fnmatch.fnmatch(file.name, "vocab.txt"):
43 self.vocab = file
44 if fnmatch.fnmatch(file.name, "README.md"):
45 self.modelcard = file
46 if fnmatch.fnmatch(file.name, "*.onnx") or fnmatch.fnmatch(
47 file.name, "*.pkl"
48 ):
49 self.model = file
50
51
52 def _url_callback(url: str) -> Union[str, None]:
53 """Checks url is valid"""
54 if url == "latest":
55 return url
56 if validators.url(url):
57 return url
58 else:
59 raise typer.BadParameter(f"Please check {url} is a valid url")
60
61
62 def ensure_model_dir(model_dir_path: Union[Path, None] = None) -> Path:
63 """Checks for a local model dir and creates one if not found"""
64 if not model_dir_path:
65 app_dir = typer.get_app_dir(APP_NAME)
66 model_dir: Path = Path(app_dir) / "models"
67 else:
68 model_dir = Path(model_dir_path) / "models"
69 if not (model_dir.exists() and model_dir.is_dir()):
70 typer.echo(f"Creating directory for storing models in {model_dir}...")
71 try:
72 model_dir.mkdir(parents=True)
73 except PermissionError as e: # pragma: no cover
74 typer.echo(f"{model_dir} is not writeable: {e}")
75 raise typer.Exit(code=1) from None
76 typer.echo(f"Models stored in {model_dir}")
77 return model_dir
78
79
80 @app.command()
81 def show_model_dir() -> None:
82 """Print out the directory where models are stored"""
83 ensure_model_dir()
84
85
86 @app.command(name="download")
87 def get_model(
88 revision: Optional[str] = typer.Argument(None, callback=_url_callback),
89 model_dir: Path = typer.Argument(
90 None,
91 envvar="MODEL_DIR",
92 help="Optionally specify a directory to store model files in",
93 ),
94 local_only=False,
95 ) -> Path: # pragma: no cover
96 """Downloads models, defaults to the latest available model"""
97 repo_id = MODEL_REPO_ID
98 with console.status("Getting model", spinner="dots"):
99 model = snapshot_download(
100 repo_id, cache_dir=model_dir, revision=None, local_files_only=local_only
101 )
102 return Path(model)
103
104
105 def ensure_model(model_dir: Path) -> LocalModel: # pragma: no cover
106 """Checks for a local model and if not found downloads the latest available remote model"""
107 if model := get_model(model_dir=model_dir):
108 return LocalModel(model)
109 typer.echo("Not able to find a model")
110 raise typer.Exit()
111
112
113 def is_pipe(c: Tuple) -> bool:
114 """Checks if | in c"""
115 return "|" in c
116
117
118 def load_vocab(vocab: Path) -> List[List[str]]:
119 """loads vocab from `vocab` and returns as list contaning lists of vocab"""
120 with open(vocab, "r") as f:
121 raw_vocab = [line.strip("\n") for line in f.readlines()]
122 return list(
123 map(
124 list,
125 (itertoolz.remove(is_pipe, (recipes.partitionby(is_pipe, raw_vocab)))),
126 )
127 )
128
129
130 @app.command()
131 def vocab(model: str = typer.Argument("latest"), show: bool = typer.Option(True)):
132 """Prints out vocab for latest model"""
133 if model != "latest":
134 raise NotImplementedError
135 model_dir = ensure_model_dir()
136 if model_path := get_model(model_dir=model_dir):
137 local_model = LocalModel(model_path)
138 if local_model.vocab:
139 vocab = load_vocab(local_model.vocab)
140 if show:
141 console.print(Markdown("# Model Vocab"))
142 console.print(vocab)
143 return vocab
144
145
146 def show_model_card(localmodel: LocalModel):
147 """Shows model card for model"""
148 with open(localmodel.modelcard, "r") as f:
149 md = Markdown(f.read())
150 console.print(md)
151
152
153 def hub_model_link(model_id: str):
154 """Creates rich link for model card"""
155 url = f"https://huggingface.co/{model_id}"
156 return f"View [link={url}]model card[/link]!"
157
158
159 def create_markdown_model_card(model_id: str):
160 """Creates rich Markdown wrapper for hub readme"""
161 readme_url = hf_hub_url(model_id, filename="README.md")
162 r = requests.get(readme_url)
163 r.raise_for_status()
164 return Markdown(r.text)
165
166
167 def create_metrics_tables(model_info: ModelInfo) -> List[Table]:
168 """Creates a list of rich tables for metrics contained in `model_info`"""
169 model_indexes = list(model_info.cardData["model-index"])
170 metrics = []
171 for model in model_indexes:
172 for result in model["results"]:
173 for metric in result["metrics"]:
174 metrics.append(metric)
175 tables = []
176 for metric in metrics:
177 table = Table()
178 for name in metric.keys():
179 table.add_column(name.title())
180 metric_values = list(metric.values())
181 rounded_metric_values = [
182 round(item, ndigits=3) if isinstance(item, float) else item
183 for item in metric_values
184 ]
185 table.add_row(*list(map(str, rounded_metric_values)))
186 tables.append(table)
187 return tables
188
189
190 if __name__ == "__main__": # pragma: no cover
191 app()
192
[end of src/flyswot/models.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/flyswot/models.py b/src/flyswot/models.py
--- a/src/flyswot/models.py
+++ b/src/flyswot/models.py
@@ -9,7 +9,6 @@
import requests
import typer
-import validators # type: ignore
from huggingface_hub import hf_hub_url
from huggingface_hub import snapshot_download
from huggingface_hub.hf_api import ModelInfo
@@ -49,14 +48,14 @@
self.model = file
-def _url_callback(url: str) -> Union[str, None]:
- """Checks url is valid"""
- if url == "latest":
- return url
- if validators.url(url):
- return url
- else:
- raise typer.BadParameter(f"Please check {url} is a valid url")
+# def _url_callback(url: str) -> Union[str, None]:
+# """Checks url is valid"""
+# if url == "latest":
+# return url
+# if validators.url(url):
+# return url
+# else:
+# raise typer.BadParameter(f"Please check {url} is a valid url")
def ensure_model_dir(model_dir_path: Union[Path, None] = None) -> Path:
@@ -85,7 +84,7 @@
@app.command(name="download")
def get_model(
- revision: Optional[str] = typer.Argument(None, callback=_url_callback),
+ revision: Optional[str] = typer.Argument(None),
model_dir: Path = typer.Argument(
None,
envvar="MODEL_DIR",
|
{"golden_diff": "diff --git a/src/flyswot/models.py b/src/flyswot/models.py\n--- a/src/flyswot/models.py\n+++ b/src/flyswot/models.py\n@@ -9,7 +9,6 @@\n \n import requests\n import typer\n-import validators # type: ignore\n from huggingface_hub import hf_hub_url\n from huggingface_hub import snapshot_download\n from huggingface_hub.hf_api import ModelInfo\n@@ -49,14 +48,14 @@\n self.model = file\n \n \n-def _url_callback(url: str) -> Union[str, None]:\n- \"\"\"Checks url is valid\"\"\"\n- if url == \"latest\":\n- return url\n- if validators.url(url):\n- return url\n- else:\n- raise typer.BadParameter(f\"Please check {url} is a valid url\")\n+# def _url_callback(url: str) -> Union[str, None]:\n+# \"\"\"Checks url is valid\"\"\"\n+# if url == \"latest\":\n+# return url\n+# if validators.url(url):\n+# return url\n+# else:\n+# raise typer.BadParameter(f\"Please check {url} is a valid url\")\n \n \n def ensure_model_dir(model_dir_path: Union[Path, None] = None) -> Path:\n@@ -85,7 +84,7 @@\n \n @app.command(name=\"download\")\n def get_model(\n- revision: Optional[str] = typer.Argument(None, callback=_url_callback),\n+ revision: Optional[str] = typer.Argument(None),\n model_dir: Path = typer.Argument(\n None,\n envvar=\"MODEL_DIR\",\n", "issue": "remove unused dependenices\n\n", "before_files": [{"content": "\"\"\"Model Commands.\"\"\"\nimport fnmatch\nfrom dataclasses import dataclass\nfrom pathlib import Path\nfrom typing import List\nfrom typing import Optional\nfrom typing import Tuple\nfrom typing import Union\n\nimport requests\nimport typer\nimport validators # type: ignore\nfrom huggingface_hub import hf_hub_url\nfrom huggingface_hub import snapshot_download\nfrom huggingface_hub.hf_api import ModelInfo\nfrom rich.markdown import Markdown\nfrom rich.table import Table\nfrom toolz import itertoolz\nfrom toolz import recipes\n\nfrom flyswot.config import APP_NAME\nfrom flyswot.config import MODEL_REPO_ID\nfrom flyswot.console import console\n\napp = typer.Typer()\n\n\n@dataclass\nclass LocalModel:\n \"\"\"A local model container\"\"\"\n\n hf_cache: Path\n\n def __post_init__(self):\n \"\"\"Returns model parts contained under hf_cache\"\"\"\n self._get_model_parts(self.hf_cache)\n\n def _get_model_parts(self, hf_cache: Path):\n \"\"\"Returns model path, vocab and metadata for a model\"\"\"\n model_files = Path(hf_cache).iterdir()\n for file in model_files:\n if fnmatch.fnmatch(file.name, \"vocab.txt\"):\n self.vocab = file\n if fnmatch.fnmatch(file.name, \"README.md\"):\n self.modelcard = file\n if fnmatch.fnmatch(file.name, \"*.onnx\") or fnmatch.fnmatch(\n file.name, \"*.pkl\"\n ):\n self.model = file\n\n\ndef _url_callback(url: str) -> Union[str, None]:\n \"\"\"Checks url is valid\"\"\"\n if url == \"latest\":\n return url\n if validators.url(url):\n return url\n else:\n raise typer.BadParameter(f\"Please check {url} is a valid url\")\n\n\ndef ensure_model_dir(model_dir_path: Union[Path, None] = None) -> Path:\n \"\"\"Checks for a local model dir and creates one if not found\"\"\"\n if not model_dir_path:\n app_dir = typer.get_app_dir(APP_NAME)\n model_dir: Path = Path(app_dir) / \"models\"\n else:\n model_dir = Path(model_dir_path) / \"models\"\n if not (model_dir.exists() and model_dir.is_dir()):\n typer.echo(f\"Creating directory for storing models in {model_dir}...\")\n try:\n model_dir.mkdir(parents=True)\n except PermissionError as e: # pragma: no cover\n typer.echo(f\"{model_dir} is not writeable: {e}\")\n raise typer.Exit(code=1) from None\n typer.echo(f\"Models stored in {model_dir}\")\n return model_dir\n\n\[email protected]()\ndef show_model_dir() -> None:\n \"\"\"Print out the directory where models are stored\"\"\"\n ensure_model_dir()\n\n\[email protected](name=\"download\")\ndef get_model(\n revision: Optional[str] = typer.Argument(None, callback=_url_callback),\n model_dir: Path = typer.Argument(\n None,\n envvar=\"MODEL_DIR\",\n help=\"Optionally specify a directory to store model files in\",\n ),\n local_only=False,\n) -> Path: # pragma: no cover\n \"\"\"Downloads models, defaults to the latest available model\"\"\"\n repo_id = MODEL_REPO_ID\n with console.status(\"Getting model\", spinner=\"dots\"):\n model = snapshot_download(\n repo_id, cache_dir=model_dir, revision=None, local_files_only=local_only\n )\n return Path(model)\n\n\ndef ensure_model(model_dir: Path) -> LocalModel: # pragma: no cover\n \"\"\"Checks for a local model and if not found downloads the latest available remote model\"\"\"\n if model := get_model(model_dir=model_dir):\n return LocalModel(model)\n typer.echo(\"Not able to find a model\")\n raise typer.Exit()\n\n\ndef is_pipe(c: Tuple) -> bool:\n \"\"\"Checks if | in c\"\"\"\n return \"|\" in c\n\n\ndef load_vocab(vocab: Path) -> List[List[str]]:\n \"\"\"loads vocab from `vocab` and returns as list contaning lists of vocab\"\"\"\n with open(vocab, \"r\") as f:\n raw_vocab = [line.strip(\"\\n\") for line in f.readlines()]\n return list(\n map(\n list,\n (itertoolz.remove(is_pipe, (recipes.partitionby(is_pipe, raw_vocab)))),\n )\n )\n\n\[email protected]()\ndef vocab(model: str = typer.Argument(\"latest\"), show: bool = typer.Option(True)):\n \"\"\"Prints out vocab for latest model\"\"\"\n if model != \"latest\":\n raise NotImplementedError\n model_dir = ensure_model_dir()\n if model_path := get_model(model_dir=model_dir):\n local_model = LocalModel(model_path)\n if local_model.vocab:\n vocab = load_vocab(local_model.vocab)\n if show:\n console.print(Markdown(\"# Model Vocab\"))\n console.print(vocab)\n return vocab\n\n\ndef show_model_card(localmodel: LocalModel):\n \"\"\"Shows model card for model\"\"\"\n with open(localmodel.modelcard, \"r\") as f:\n md = Markdown(f.read())\n console.print(md)\n\n\ndef hub_model_link(model_id: str):\n \"\"\"Creates rich link for model card\"\"\"\n url = f\"https://huggingface.co/{model_id}\"\n return f\"View [link={url}]model card[/link]!\"\n\n\ndef create_markdown_model_card(model_id: str):\n \"\"\"Creates rich Markdown wrapper for hub readme\"\"\"\n readme_url = hf_hub_url(model_id, filename=\"README.md\")\n r = requests.get(readme_url)\n r.raise_for_status()\n return Markdown(r.text)\n\n\ndef create_metrics_tables(model_info: ModelInfo) -> List[Table]:\n \"\"\"Creates a list of rich tables for metrics contained in `model_info`\"\"\"\n model_indexes = list(model_info.cardData[\"model-index\"])\n metrics = []\n for model in model_indexes:\n for result in model[\"results\"]:\n for metric in result[\"metrics\"]:\n metrics.append(metric)\n tables = []\n for metric in metrics:\n table = Table()\n for name in metric.keys():\n table.add_column(name.title())\n metric_values = list(metric.values())\n rounded_metric_values = [\n round(item, ndigits=3) if isinstance(item, float) else item\n for item in metric_values\n ]\n table.add_row(*list(map(str, rounded_metric_values)))\n tables.append(table)\n return tables\n\n\nif __name__ == \"__main__\": # pragma: no cover\n app()\n", "path": "src/flyswot/models.py"}]}
| 2,428 | 355 |
gh_patches_debug_2596
|
rasdani/github-patches
|
git_diff
|
kornia__kornia-2610
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
bug in ycbcr_to_rgb function
### Describe the bug
https://github.com/kornia/kornia/blob/2c084f8dc108b3f0f3c8983ac3f25bf88638d01a/kornia/color/ycbcr.py#L70
#### now:
return torch.stack([r, g, b], -3)
#### need to be:
return torch.stack([r, g, b], -3).clamp(0,1)
#### because:

</issue>
<code>
[start of kornia/color/ycbcr.py]
1 import torch
2 from torch import Tensor, nn
3
4
5 def _rgb_to_y(r: Tensor, g: Tensor, b: Tensor) -> Tensor:
6 y: Tensor = 0.299 * r + 0.587 * g + 0.114 * b
7 return y
8
9
10 def rgb_to_ycbcr(image: Tensor) -> Tensor:
11 r"""Convert an RGB image to YCbCr.
12
13 .. image:: _static/img/rgb_to_ycbcr.png
14
15 Args:
16 image: RGB Image to be converted to YCbCr with shape :math:`(*, 3, H, W)`.
17
18 Returns:
19 YCbCr version of the image with shape :math:`(*, 3, H, W)`.
20
21 Examples:
22 >>> input = torch.rand(2, 3, 4, 5)
23 >>> output = rgb_to_ycbcr(input) # 2x3x4x5
24 """
25 if not isinstance(image, Tensor):
26 raise TypeError(f"Input type is not a Tensor. Got {type(image)}")
27
28 if len(image.shape) < 3 or image.shape[-3] != 3:
29 raise ValueError(f"Input size must have a shape of (*, 3, H, W). Got {image.shape}")
30
31 r: Tensor = image[..., 0, :, :]
32 g: Tensor = image[..., 1, :, :]
33 b: Tensor = image[..., 2, :, :]
34
35 delta: float = 0.5
36 y: Tensor = _rgb_to_y(r, g, b)
37 cb: Tensor = (b - y) * 0.564 + delta
38 cr: Tensor = (r - y) * 0.713 + delta
39 return torch.stack([y, cb, cr], -3)
40
41
42 def rgb_to_y(image: Tensor) -> Tensor:
43 r"""Convert an RGB image to Y.
44
45 Args:
46 image: RGB Image to be converted to Y with shape :math:`(*, 3, H, W)`.
47
48 Returns:
49 Y version of the image with shape :math:`(*, 1, H, W)`.
50
51 Examples:
52 >>> input = torch.rand(2, 3, 4, 5)
53 >>> output = rgb_to_y(input) # 2x1x4x5
54 """
55 if not isinstance(image, Tensor):
56 raise TypeError(f"Input type is not a Tensor. Got {type(image)}")
57
58 if len(image.shape) < 3 or image.shape[-3] != 3:
59 raise ValueError(f"Input size must have a shape of (*, 3, H, W). Got {image.shape}")
60
61 r: Tensor = image[..., 0:1, :, :]
62 g: Tensor = image[..., 1:2, :, :]
63 b: Tensor = image[..., 2:3, :, :]
64
65 y: Tensor = _rgb_to_y(r, g, b)
66 return y
67
68
69 def ycbcr_to_rgb(image: Tensor) -> Tensor:
70 r"""Convert an YCbCr image to RGB.
71
72 The image data is assumed to be in the range of (0, 1).
73
74 Args:
75 image: YCbCr Image to be converted to RGB with shape :math:`(*, 3, H, W)`.
76
77 Returns:
78 RGB version of the image with shape :math:`(*, 3, H, W)`.
79
80 Examples:
81 >>> input = torch.rand(2, 3, 4, 5)
82 >>> output = ycbcr_to_rgb(input) # 2x3x4x5
83 """
84 if not isinstance(image, Tensor):
85 raise TypeError(f"Input type is not a Tensor. Got {type(image)}")
86
87 if len(image.shape) < 3 or image.shape[-3] != 3:
88 raise ValueError(f"Input size must have a shape of (*, 3, H, W). Got {image.shape}")
89
90 y: Tensor = image[..., 0, :, :]
91 cb: Tensor = image[..., 1, :, :]
92 cr: Tensor = image[..., 2, :, :]
93
94 delta: float = 0.5
95 cb_shifted: Tensor = cb - delta
96 cr_shifted: Tensor = cr - delta
97
98 r: Tensor = y + 1.403 * cr_shifted
99 g: Tensor = y - 0.714 * cr_shifted - 0.344 * cb_shifted
100 b: Tensor = y + 1.773 * cb_shifted
101 return torch.stack([r, g, b], -3)
102
103
104 class RgbToYcbcr(nn.Module):
105 r"""Convert an image from RGB to YCbCr.
106
107 The image data is assumed to be in the range of (0, 1).
108
109 Returns:
110 YCbCr version of the image.
111
112 Shape:
113 - image: :math:`(*, 3, H, W)`
114 - output: :math:`(*, 3, H, W)`
115
116 Examples:
117 >>> input = torch.rand(2, 3, 4, 5)
118 >>> ycbcr = RgbToYcbcr()
119 >>> output = ycbcr(input) # 2x3x4x5
120 """
121
122 def forward(self, image: Tensor) -> Tensor:
123 return rgb_to_ycbcr(image)
124
125
126 class YcbcrToRgb(nn.Module):
127 r"""Convert an image from YCbCr to Rgb.
128
129 The image data is assumed to be in the range of (0, 1).
130
131 Returns:
132 RGB version of the image.
133
134 Shape:
135 - image: :math:`(*, 3, H, W)`
136 - output: :math:`(*, 3, H, W)`
137
138 Examples:
139 >>> input = torch.rand(2, 3, 4, 5)
140 >>> rgb = YcbcrToRgb()
141 >>> output = rgb(input) # 2x3x4x5
142 """
143
144 def forward(self, image: Tensor) -> Tensor:
145 return ycbcr_to_rgb(image)
146
[end of kornia/color/ycbcr.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/kornia/color/ycbcr.py b/kornia/color/ycbcr.py
--- a/kornia/color/ycbcr.py
+++ b/kornia/color/ycbcr.py
@@ -98,7 +98,7 @@
r: Tensor = y + 1.403 * cr_shifted
g: Tensor = y - 0.714 * cr_shifted - 0.344 * cb_shifted
b: Tensor = y + 1.773 * cb_shifted
- return torch.stack([r, g, b], -3)
+ return torch.stack([r, g, b], -3).clamp(0, 1)
class RgbToYcbcr(nn.Module):
|
{"golden_diff": "diff --git a/kornia/color/ycbcr.py b/kornia/color/ycbcr.py\n--- a/kornia/color/ycbcr.py\n+++ b/kornia/color/ycbcr.py\n@@ -98,7 +98,7 @@\n r: Tensor = y + 1.403 * cr_shifted\n g: Tensor = y - 0.714 * cr_shifted - 0.344 * cb_shifted\n b: Tensor = y + 1.773 * cb_shifted\n- return torch.stack([r, g, b], -3)\n+ return torch.stack([r, g, b], -3).clamp(0, 1)\n \n \n class RgbToYcbcr(nn.Module):\n", "issue": "bug in ycbcr_to_rgb function\n### Describe the bug\r\n\r\nhttps://github.com/kornia/kornia/blob/2c084f8dc108b3f0f3c8983ac3f25bf88638d01a/kornia/color/ycbcr.py#L70\r\n#### now:\r\n return torch.stack([r, g, b], -3)\r\n#### need to be:\r\n return torch.stack([r, g, b], -3).clamp(0,1)\r\n#### because:\r\n\r\n\n", "before_files": [{"content": "import torch\nfrom torch import Tensor, nn\n\n\ndef _rgb_to_y(r: Tensor, g: Tensor, b: Tensor) -> Tensor:\n y: Tensor = 0.299 * r + 0.587 * g + 0.114 * b\n return y\n\n\ndef rgb_to_ycbcr(image: Tensor) -> Tensor:\n r\"\"\"Convert an RGB image to YCbCr.\n\n .. image:: _static/img/rgb_to_ycbcr.png\n\n Args:\n image: RGB Image to be converted to YCbCr with shape :math:`(*, 3, H, W)`.\n\n Returns:\n YCbCr version of the image with shape :math:`(*, 3, H, W)`.\n\n Examples:\n >>> input = torch.rand(2, 3, 4, 5)\n >>> output = rgb_to_ycbcr(input) # 2x3x4x5\n \"\"\"\n if not isinstance(image, Tensor):\n raise TypeError(f\"Input type is not a Tensor. Got {type(image)}\")\n\n if len(image.shape) < 3 or image.shape[-3] != 3:\n raise ValueError(f\"Input size must have a shape of (*, 3, H, W). Got {image.shape}\")\n\n r: Tensor = image[..., 0, :, :]\n g: Tensor = image[..., 1, :, :]\n b: Tensor = image[..., 2, :, :]\n\n delta: float = 0.5\n y: Tensor = _rgb_to_y(r, g, b)\n cb: Tensor = (b - y) * 0.564 + delta\n cr: Tensor = (r - y) * 0.713 + delta\n return torch.stack([y, cb, cr], -3)\n\n\ndef rgb_to_y(image: Tensor) -> Tensor:\n r\"\"\"Convert an RGB image to Y.\n\n Args:\n image: RGB Image to be converted to Y with shape :math:`(*, 3, H, W)`.\n\n Returns:\n Y version of the image with shape :math:`(*, 1, H, W)`.\n\n Examples:\n >>> input = torch.rand(2, 3, 4, 5)\n >>> output = rgb_to_y(input) # 2x1x4x5\n \"\"\"\n if not isinstance(image, Tensor):\n raise TypeError(f\"Input type is not a Tensor. Got {type(image)}\")\n\n if len(image.shape) < 3 or image.shape[-3] != 3:\n raise ValueError(f\"Input size must have a shape of (*, 3, H, W). Got {image.shape}\")\n\n r: Tensor = image[..., 0:1, :, :]\n g: Tensor = image[..., 1:2, :, :]\n b: Tensor = image[..., 2:3, :, :]\n\n y: Tensor = _rgb_to_y(r, g, b)\n return y\n\n\ndef ycbcr_to_rgb(image: Tensor) -> Tensor:\n r\"\"\"Convert an YCbCr image to RGB.\n\n The image data is assumed to be in the range of (0, 1).\n\n Args:\n image: YCbCr Image to be converted to RGB with shape :math:`(*, 3, H, W)`.\n\n Returns:\n RGB version of the image with shape :math:`(*, 3, H, W)`.\n\n Examples:\n >>> input = torch.rand(2, 3, 4, 5)\n >>> output = ycbcr_to_rgb(input) # 2x3x4x5\n \"\"\"\n if not isinstance(image, Tensor):\n raise TypeError(f\"Input type is not a Tensor. Got {type(image)}\")\n\n if len(image.shape) < 3 or image.shape[-3] != 3:\n raise ValueError(f\"Input size must have a shape of (*, 3, H, W). Got {image.shape}\")\n\n y: Tensor = image[..., 0, :, :]\n cb: Tensor = image[..., 1, :, :]\n cr: Tensor = image[..., 2, :, :]\n\n delta: float = 0.5\n cb_shifted: Tensor = cb - delta\n cr_shifted: Tensor = cr - delta\n\n r: Tensor = y + 1.403 * cr_shifted\n g: Tensor = y - 0.714 * cr_shifted - 0.344 * cb_shifted\n b: Tensor = y + 1.773 * cb_shifted\n return torch.stack([r, g, b], -3)\n\n\nclass RgbToYcbcr(nn.Module):\n r\"\"\"Convert an image from RGB to YCbCr.\n\n The image data is assumed to be in the range of (0, 1).\n\n Returns:\n YCbCr version of the image.\n\n Shape:\n - image: :math:`(*, 3, H, W)`\n - output: :math:`(*, 3, H, W)`\n\n Examples:\n >>> input = torch.rand(2, 3, 4, 5)\n >>> ycbcr = RgbToYcbcr()\n >>> output = ycbcr(input) # 2x3x4x5\n \"\"\"\n\n def forward(self, image: Tensor) -> Tensor:\n return rgb_to_ycbcr(image)\n\n\nclass YcbcrToRgb(nn.Module):\n r\"\"\"Convert an image from YCbCr to Rgb.\n\n The image data is assumed to be in the range of (0, 1).\n\n Returns:\n RGB version of the image.\n\n Shape:\n - image: :math:`(*, 3, H, W)`\n - output: :math:`(*, 3, H, W)`\n\n Examples:\n >>> input = torch.rand(2, 3, 4, 5)\n >>> rgb = YcbcrToRgb()\n >>> output = rgb(input) # 2x3x4x5\n \"\"\"\n\n def forward(self, image: Tensor) -> Tensor:\n return ycbcr_to_rgb(image)\n", "path": "kornia/color/ycbcr.py"}]}
| 2,431 | 173 |
gh_patches_debug_21315
|
rasdani/github-patches
|
git_diff
|
freedomofpress__securedrop-2565
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Increase default session timeouts to 120 minutes
## Description
According to [this plot](https://metrics.torproject.org/torperf.html?start=2017-08-03&end=2017-11-01&source=all&server=onion&filesize=5mb), it currently takes about ~35 seconds to download a 5 MB file over Tor:
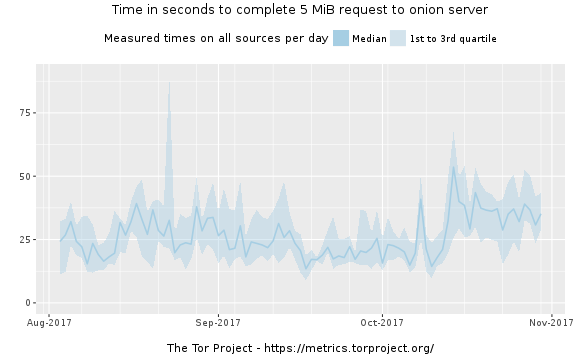
The maximum size of a SecureDrop submission is 500 MB, so the time it would take to download is 35 seconds * (500/5) = 3500 seconds, or just under an hour. As such, to be safe we should bump the session timeout to at least 120 minutes.
## User Stories
As a SecureDrop source/journalist, I don't want to wait a very long time to upload/download a file over Tor, only to be logged out by the SecureDrop session timeout.
</issue>
<code>
[start of securedrop/source_app/__init__.py]
1 from datetime import datetime, timedelta
2 from flask import (Flask, render_template, flash, Markup, request, g, session,
3 url_for, redirect)
4 from flask_babel import gettext
5 from flask_assets import Environment
6 from flask_wtf.csrf import CSRFProtect, CSRFError
7 from jinja2 import evalcontextfilter
8 from os import path
9 from sqlalchemy.orm.exc import NoResultFound
10
11 import crypto_util
12 import i18n
13 import store
14 import template_filters
15 import version
16
17 from db import Source, db_session
18 from request_that_secures_file_uploads import RequestThatSecuresFileUploads
19 from source_app import main, info, api
20 from source_app.decorators import ignore_static
21 from source_app.utils import logged_in
22
23
24 def create_app(config):
25 app = Flask(__name__,
26 template_folder=config.SOURCE_TEMPLATES_DIR,
27 static_folder=path.join(config.SECUREDROP_ROOT, 'static'))
28 app.request_class = RequestThatSecuresFileUploads
29 app.config.from_object(config.SourceInterfaceFlaskConfig)
30
31 # The default CSRF token expiration is 1 hour. Since large uploads can
32 # take longer than an hour over Tor, we increase the valid window to 24h.
33 app.config['WTF_CSRF_TIME_LIMIT'] = 60 * 60 * 24
34
35 CSRFProtect(app)
36
37 @app.errorhandler(CSRFError)
38 def handle_csrf_error(e):
39 msg = render_template('session_timeout.html')
40 session.clear()
41 flash(Markup(msg), "important")
42 return redirect(url_for('main.index'))
43
44 assets = Environment(app)
45 app.config['assets'] = assets
46
47 i18n.setup_app(app)
48
49 app.jinja_env.trim_blocks = True
50 app.jinja_env.lstrip_blocks = True
51 app.jinja_env.globals['version'] = version.__version__
52 if getattr(config, 'CUSTOM_HEADER_IMAGE', None):
53 app.jinja_env.globals['header_image'] = config.CUSTOM_HEADER_IMAGE
54 app.jinja_env.globals['use_custom_header_image'] = True
55 else:
56 app.jinja_env.globals['header_image'] = 'logo.png'
57 app.jinja_env.globals['use_custom_header_image'] = False
58
59 app.jinja_env.filters['rel_datetime_format'] = \
60 template_filters.rel_datetime_format
61 app.jinja_env.filters['nl2br'] = evalcontextfilter(template_filters.nl2br)
62 app.jinja_env.filters['filesizeformat'] = template_filters.filesizeformat
63
64 for module in [main, info, api]:
65 app.register_blueprint(module.make_blueprint(config))
66
67 @app.before_request
68 @ignore_static
69 def check_tor2web():
70 # ignore_static here so we only flash a single message warning
71 # about Tor2Web, corresponding to the initial page load.
72 if 'X-tor2web' in request.headers:
73 flash(Markup(gettext(
74 '<strong>WARNING:</strong> You appear to be using Tor2Web. '
75 'This <strong>does not</strong> provide anonymity. '
76 '<a href="{url}">Why is this dangerous?</a>')
77 .format(url=url_for('info.tor2web_warning'))),
78 "banner-warning")
79
80 @app.before_request
81 @ignore_static
82 def setup_g():
83 """Store commonly used values in Flask's special g object"""
84 g.locale = i18n.get_locale()
85 g.text_direction = i18n.get_text_direction(g.locale)
86 g.html_lang = i18n.locale_to_rfc_5646(g.locale)
87 g.locales = i18n.get_locale2name()
88
89 if 'expires' in session and datetime.utcnow() >= session['expires']:
90 msg = render_template('session_timeout.html')
91
92 # clear the session after we render the message so it's localized
93 session.clear()
94
95 flash(Markup(msg), "important")
96
97 session['expires'] = datetime.utcnow() + \
98 timedelta(minutes=getattr(config,
99 'SESSION_EXPIRATION_MINUTES',
100 30))
101
102 # ignore_static here because `crypto_util.hash_codename` is scrypt
103 # (very time consuming), and we don't need to waste time running if
104 # we're just serving a static resource that won't need to access
105 # these common values.
106 if logged_in():
107 g.codename = session['codename']
108 g.filesystem_id = crypto_util.hash_codename(g.codename)
109 try:
110 g.source = Source.query \
111 .filter(Source.filesystem_id == g.filesystem_id) \
112 .one()
113 except NoResultFound as e:
114 app.logger.error(
115 "Found no Sources when one was expected: %s" %
116 (e,))
117 del session['logged_in']
118 del session['codename']
119 return redirect(url_for('main.index'))
120 g.loc = store.path(g.filesystem_id)
121
122 @app.teardown_appcontext
123 def shutdown_session(exception=None):
124 """Automatically remove database sessions at the end of the request, or
125 when the application shuts down"""
126 db_session.remove()
127
128 @app.errorhandler(404)
129 def page_not_found(error):
130 return render_template('notfound.html'), 404
131
132 @app.errorhandler(500)
133 def internal_error(error):
134 return render_template('error.html'), 500
135
136 return app
137
[end of securedrop/source_app/__init__.py]
[start of securedrop/journalist_app/__init__.py]
1 # -*- coding: utf-8 -*-
2
3 from datetime import datetime, timedelta
4 from flask import Flask, session, redirect, url_for, flash, g, request
5 from flask_assets import Environment
6 from flask_babel import gettext
7 from flask_wtf.csrf import CSRFProtect, CSRFError
8 from os import path
9
10 import i18n
11 import template_filters
12 import version
13
14 from db import db_session, Journalist
15 from journalist_app import account, admin, main, col
16 from journalist_app.utils import get_source
17
18
19 def create_app(config):
20 app = Flask(__name__,
21 template_folder=config.JOURNALIST_TEMPLATES_DIR,
22 static_folder=path.join(config.SECUREDROP_ROOT, 'static'))
23
24 app.config.from_object(config.JournalistInterfaceFlaskConfig)
25
26 CSRFProtect(app)
27 Environment(app)
28
29 @app.errorhandler(CSRFError)
30 def handle_csrf_error(e):
31 # render the message first to ensure it's localized.
32 msg = gettext('You have been logged out due to inactivity')
33 session.clear()
34 flash(msg, 'error')
35 return redirect(url_for('main.login'))
36
37 i18n.setup_app(app)
38
39 app.jinja_env.trim_blocks = True
40 app.jinja_env.lstrip_blocks = True
41 app.jinja_env.globals['version'] = version.__version__
42 if hasattr(config, 'CUSTOM_HEADER_IMAGE'):
43 app.jinja_env.globals['header_image'] = config.CUSTOM_HEADER_IMAGE
44 app.jinja_env.globals['use_custom_header_image'] = True
45 else:
46 app.jinja_env.globals['header_image'] = 'logo.png'
47 app.jinja_env.globals['use_custom_header_image'] = False
48
49 app.jinja_env.filters['rel_datetime_format'] = \
50 template_filters.rel_datetime_format
51 app.jinja_env.filters['filesizeformat'] = template_filters.filesizeformat
52
53 @app.teardown_appcontext
54 def shutdown_session(exception=None):
55 """Automatically remove database sessions at the end of the request, or
56 when the application shuts down"""
57 db_session.remove()
58
59 @app.before_request
60 def setup_g():
61 """Store commonly used values in Flask's special g object"""
62 if 'expires' in session and datetime.utcnow() >= session['expires']:
63 session.clear()
64 flash(gettext('You have been logged out due to inactivity'),
65 'error')
66
67 session['expires'] = datetime.utcnow() + \
68 timedelta(minutes=getattr(config,
69 'SESSION_EXPIRATION_MINUTES',
70 30))
71
72 uid = session.get('uid', None)
73 if uid:
74 g.user = Journalist.query.get(uid)
75
76 g.locale = i18n.get_locale()
77 g.text_direction = i18n.get_text_direction(g.locale)
78 g.html_lang = i18n.locale_to_rfc_5646(g.locale)
79 g.locales = i18n.get_locale2name()
80
81 if request.method == 'POST':
82 filesystem_id = request.form.get('filesystem_id')
83 if filesystem_id:
84 g.filesystem_id = filesystem_id
85 g.source = get_source(filesystem_id)
86
87 app.register_blueprint(main.make_blueprint(config))
88 app.register_blueprint(account.make_blueprint(config),
89 url_prefix='/account')
90 app.register_blueprint(admin.make_blueprint(config), url_prefix='/admin')
91 app.register_blueprint(col.make_blueprint(config), url_prefix='/col')
92
93 return app
94
[end of securedrop/journalist_app/__init__.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/securedrop/journalist_app/__init__.py b/securedrop/journalist_app/__init__.py
--- a/securedrop/journalist_app/__init__.py
+++ b/securedrop/journalist_app/__init__.py
@@ -67,7 +67,7 @@
session['expires'] = datetime.utcnow() + \
timedelta(minutes=getattr(config,
'SESSION_EXPIRATION_MINUTES',
- 30))
+ 120))
uid = session.get('uid', None)
if uid:
diff --git a/securedrop/source_app/__init__.py b/securedrop/source_app/__init__.py
--- a/securedrop/source_app/__init__.py
+++ b/securedrop/source_app/__init__.py
@@ -97,7 +97,7 @@
session['expires'] = datetime.utcnow() + \
timedelta(minutes=getattr(config,
'SESSION_EXPIRATION_MINUTES',
- 30))
+ 120))
# ignore_static here because `crypto_util.hash_codename` is scrypt
# (very time consuming), and we don't need to waste time running if
|
{"golden_diff": "diff --git a/securedrop/journalist_app/__init__.py b/securedrop/journalist_app/__init__.py\n--- a/securedrop/journalist_app/__init__.py\n+++ b/securedrop/journalist_app/__init__.py\n@@ -67,7 +67,7 @@\n session['expires'] = datetime.utcnow() + \\\n timedelta(minutes=getattr(config,\n 'SESSION_EXPIRATION_MINUTES',\n- 30))\n+ 120))\n \n uid = session.get('uid', None)\n if uid:\ndiff --git a/securedrop/source_app/__init__.py b/securedrop/source_app/__init__.py\n--- a/securedrop/source_app/__init__.py\n+++ b/securedrop/source_app/__init__.py\n@@ -97,7 +97,7 @@\n session['expires'] = datetime.utcnow() + \\\n timedelta(minutes=getattr(config,\n 'SESSION_EXPIRATION_MINUTES',\n- 30))\n+ 120))\n \n # ignore_static here because `crypto_util.hash_codename` is scrypt\n # (very time consuming), and we don't need to waste time running if\n", "issue": "Increase default session timeouts to 120 minutes\n## Description\r\n\r\nAccording to [this plot](https://metrics.torproject.org/torperf.html?start=2017-08-03&end=2017-11-01&source=all&server=onion&filesize=5mb), it currently takes about ~35 seconds to download a 5 MB file over Tor: \r\n\r\n\r\n\r\nThe maximum size of a SecureDrop submission is 500 MB, so the time it would take to download is 35 seconds * (500/5) = 3500 seconds, or just under an hour. As such, to be safe we should bump the session timeout to at least 120 minutes. \r\n\r\n## User Stories\r\n\r\nAs a SecureDrop source/journalist, I don't want to wait a very long time to upload/download a file over Tor, only to be logged out by the SecureDrop session timeout. \n", "before_files": [{"content": "from datetime import datetime, timedelta\nfrom flask import (Flask, render_template, flash, Markup, request, g, session,\n url_for, redirect)\nfrom flask_babel import gettext\nfrom flask_assets import Environment\nfrom flask_wtf.csrf import CSRFProtect, CSRFError\nfrom jinja2 import evalcontextfilter\nfrom os import path\nfrom sqlalchemy.orm.exc import NoResultFound\n\nimport crypto_util\nimport i18n\nimport store\nimport template_filters\nimport version\n\nfrom db import Source, db_session\nfrom request_that_secures_file_uploads import RequestThatSecuresFileUploads\nfrom source_app import main, info, api\nfrom source_app.decorators import ignore_static\nfrom source_app.utils import logged_in\n\n\ndef create_app(config):\n app = Flask(__name__,\n template_folder=config.SOURCE_TEMPLATES_DIR,\n static_folder=path.join(config.SECUREDROP_ROOT, 'static'))\n app.request_class = RequestThatSecuresFileUploads\n app.config.from_object(config.SourceInterfaceFlaskConfig)\n\n # The default CSRF token expiration is 1 hour. Since large uploads can\n # take longer than an hour over Tor, we increase the valid window to 24h.\n app.config['WTF_CSRF_TIME_LIMIT'] = 60 * 60 * 24\n\n CSRFProtect(app)\n\n @app.errorhandler(CSRFError)\n def handle_csrf_error(e):\n msg = render_template('session_timeout.html')\n session.clear()\n flash(Markup(msg), \"important\")\n return redirect(url_for('main.index'))\n\n assets = Environment(app)\n app.config['assets'] = assets\n\n i18n.setup_app(app)\n\n app.jinja_env.trim_blocks = True\n app.jinja_env.lstrip_blocks = True\n app.jinja_env.globals['version'] = version.__version__\n if getattr(config, 'CUSTOM_HEADER_IMAGE', None):\n app.jinja_env.globals['header_image'] = config.CUSTOM_HEADER_IMAGE\n app.jinja_env.globals['use_custom_header_image'] = True\n else:\n app.jinja_env.globals['header_image'] = 'logo.png'\n app.jinja_env.globals['use_custom_header_image'] = False\n\n app.jinja_env.filters['rel_datetime_format'] = \\\n template_filters.rel_datetime_format\n app.jinja_env.filters['nl2br'] = evalcontextfilter(template_filters.nl2br)\n app.jinja_env.filters['filesizeformat'] = template_filters.filesizeformat\n\n for module in [main, info, api]:\n app.register_blueprint(module.make_blueprint(config))\n\n @app.before_request\n @ignore_static\n def check_tor2web():\n # ignore_static here so we only flash a single message warning\n # about Tor2Web, corresponding to the initial page load.\n if 'X-tor2web' in request.headers:\n flash(Markup(gettext(\n '<strong>WARNING:</strong> You appear to be using Tor2Web. '\n 'This <strong>does not</strong> provide anonymity. '\n '<a href=\"{url}\">Why is this dangerous?</a>')\n .format(url=url_for('info.tor2web_warning'))),\n \"banner-warning\")\n\n @app.before_request\n @ignore_static\n def setup_g():\n \"\"\"Store commonly used values in Flask's special g object\"\"\"\n g.locale = i18n.get_locale()\n g.text_direction = i18n.get_text_direction(g.locale)\n g.html_lang = i18n.locale_to_rfc_5646(g.locale)\n g.locales = i18n.get_locale2name()\n\n if 'expires' in session and datetime.utcnow() >= session['expires']:\n msg = render_template('session_timeout.html')\n\n # clear the session after we render the message so it's localized\n session.clear()\n\n flash(Markup(msg), \"important\")\n\n session['expires'] = datetime.utcnow() + \\\n timedelta(minutes=getattr(config,\n 'SESSION_EXPIRATION_MINUTES',\n 30))\n\n # ignore_static here because `crypto_util.hash_codename` is scrypt\n # (very time consuming), and we don't need to waste time running if\n # we're just serving a static resource that won't need to access\n # these common values.\n if logged_in():\n g.codename = session['codename']\n g.filesystem_id = crypto_util.hash_codename(g.codename)\n try:\n g.source = Source.query \\\n .filter(Source.filesystem_id == g.filesystem_id) \\\n .one()\n except NoResultFound as e:\n app.logger.error(\n \"Found no Sources when one was expected: %s\" %\n (e,))\n del session['logged_in']\n del session['codename']\n return redirect(url_for('main.index'))\n g.loc = store.path(g.filesystem_id)\n\n @app.teardown_appcontext\n def shutdown_session(exception=None):\n \"\"\"Automatically remove database sessions at the end of the request, or\n when the application shuts down\"\"\"\n db_session.remove()\n\n @app.errorhandler(404)\n def page_not_found(error):\n return render_template('notfound.html'), 404\n\n @app.errorhandler(500)\n def internal_error(error):\n return render_template('error.html'), 500\n\n return app\n", "path": "securedrop/source_app/__init__.py"}, {"content": "# -*- coding: utf-8 -*-\n\nfrom datetime import datetime, timedelta\nfrom flask import Flask, session, redirect, url_for, flash, g, request\nfrom flask_assets import Environment\nfrom flask_babel import gettext\nfrom flask_wtf.csrf import CSRFProtect, CSRFError\nfrom os import path\n\nimport i18n\nimport template_filters\nimport version\n\nfrom db import db_session, Journalist\nfrom journalist_app import account, admin, main, col\nfrom journalist_app.utils import get_source\n\n\ndef create_app(config):\n app = Flask(__name__,\n template_folder=config.JOURNALIST_TEMPLATES_DIR,\n static_folder=path.join(config.SECUREDROP_ROOT, 'static'))\n\n app.config.from_object(config.JournalistInterfaceFlaskConfig)\n\n CSRFProtect(app)\n Environment(app)\n\n @app.errorhandler(CSRFError)\n def handle_csrf_error(e):\n # render the message first to ensure it's localized.\n msg = gettext('You have been logged out due to inactivity')\n session.clear()\n flash(msg, 'error')\n return redirect(url_for('main.login'))\n\n i18n.setup_app(app)\n\n app.jinja_env.trim_blocks = True\n app.jinja_env.lstrip_blocks = True\n app.jinja_env.globals['version'] = version.__version__\n if hasattr(config, 'CUSTOM_HEADER_IMAGE'):\n app.jinja_env.globals['header_image'] = config.CUSTOM_HEADER_IMAGE\n app.jinja_env.globals['use_custom_header_image'] = True\n else:\n app.jinja_env.globals['header_image'] = 'logo.png'\n app.jinja_env.globals['use_custom_header_image'] = False\n\n app.jinja_env.filters['rel_datetime_format'] = \\\n template_filters.rel_datetime_format\n app.jinja_env.filters['filesizeformat'] = template_filters.filesizeformat\n\n @app.teardown_appcontext\n def shutdown_session(exception=None):\n \"\"\"Automatically remove database sessions at the end of the request, or\n when the application shuts down\"\"\"\n db_session.remove()\n\n @app.before_request\n def setup_g():\n \"\"\"Store commonly used values in Flask's special g object\"\"\"\n if 'expires' in session and datetime.utcnow() >= session['expires']:\n session.clear()\n flash(gettext('You have been logged out due to inactivity'),\n 'error')\n\n session['expires'] = datetime.utcnow() + \\\n timedelta(minutes=getattr(config,\n 'SESSION_EXPIRATION_MINUTES',\n 30))\n\n uid = session.get('uid', None)\n if uid:\n g.user = Journalist.query.get(uid)\n\n g.locale = i18n.get_locale()\n g.text_direction = i18n.get_text_direction(g.locale)\n g.html_lang = i18n.locale_to_rfc_5646(g.locale)\n g.locales = i18n.get_locale2name()\n\n if request.method == 'POST':\n filesystem_id = request.form.get('filesystem_id')\n if filesystem_id:\n g.filesystem_id = filesystem_id\n g.source = get_source(filesystem_id)\n\n app.register_blueprint(main.make_blueprint(config))\n app.register_blueprint(account.make_blueprint(config),\n url_prefix='/account')\n app.register_blueprint(admin.make_blueprint(config), url_prefix='/admin')\n app.register_blueprint(col.make_blueprint(config), url_prefix='/col')\n\n return app\n", "path": "securedrop/journalist_app/__init__.py"}]}
| 3,249 | 257 |
gh_patches_debug_27716
|
rasdani/github-patches
|
git_diff
|
pallets__click-774
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Bash auto-complete of options not working properly in command chains
Example:
$ cli cmd1 cmd2 --<TAB><TAB>
Auto-completes options of `cmd1`, not `cmd2`.
Observed in Python version 3.5.2 and click version 6.6.
</issue>
<code>
[start of click/_bashcomplete.py]
1 import collections
2 import copy
3 import os
4 import re
5
6 from .utils import echo
7 from .parser import split_arg_string
8 from .core import MultiCommand, Option, Argument
9 from .types import Choice
10
11 WORDBREAK = '='
12
13 COMPLETION_SCRIPT = '''
14 %(complete_func)s() {
15 COMPREPLY=( $( env COMP_WORDS="${COMP_WORDS[*]}" \\
16 COMP_CWORD=$COMP_CWORD \\
17 %(autocomplete_var)s=complete $1 ) )
18 return 0
19 }
20
21 complete -F %(complete_func)s -o default %(script_names)s
22 '''
23
24 _invalid_ident_char_re = re.compile(r'[^a-zA-Z0-9_]')
25
26
27 def get_completion_script(prog_name, complete_var):
28 cf_name = _invalid_ident_char_re.sub('', prog_name.replace('-', '_'))
29 return (COMPLETION_SCRIPT % {
30 'complete_func': '_%s_completion' % cf_name,
31 'script_names': prog_name,
32 'autocomplete_var': complete_var,
33 }).strip() + ';'
34
35
36 def resolve_ctx(cli, prog_name, args):
37 """
38 Parse into a hierarchy of contexts. Contexts are connected through the parent variable.
39 :param cli: command definition
40 :param prog_name: the program that is running
41 :param args: full list of args
42 :return: the final context/command parsed
43 """
44 ctx = cli.make_context(prog_name, args, resilient_parsing=True)
45 while ctx.protected_args + ctx.args and isinstance(ctx.command, MultiCommand):
46 a = ctx.protected_args + ctx.args
47 cmd = ctx.command.get_command(ctx, a[0])
48 if cmd is None:
49 return None
50 ctx = cmd.make_context(a[0], a[1:], parent=ctx, resilient_parsing=True)
51 return ctx
52
53
54 def start_of_option(param_str):
55 """
56 :param param_str: param_str to check
57 :return: whether or not this is the start of an option declaration (i.e. starts "-" or "--")
58 """
59 return param_str and param_str[:1] == '-'
60
61
62 def is_incomplete_option(all_args, cmd_param):
63 """
64 :param all_args: the full original list of args supplied
65 :param cmd_param: the current command paramter
66 :return: whether or not the last option declaration (i.e. starts "-" or "--") is incomplete and
67 corresponds to this cmd_param. In other words whether this cmd_param option can still accept
68 values
69 """
70 if cmd_param.is_flag:
71 return False
72 last_option = None
73 for index, arg_str in enumerate(reversed([arg for arg in all_args if arg != WORDBREAK])):
74 if index + 1 > cmd_param.nargs:
75 break
76 if start_of_option(arg_str):
77 last_option = arg_str
78
79 return True if last_option and last_option in cmd_param.opts else False
80
81
82 def is_incomplete_argument(current_params, cmd_param):
83 """
84 :param current_params: the current params and values for this argument as already entered
85 :param cmd_param: the current command parameter
86 :return: whether or not the last argument is incomplete and corresponds to this cmd_param. In
87 other words whether or not the this cmd_param argument can still accept values
88 """
89 current_param_values = current_params[cmd_param.name]
90 if current_param_values is None:
91 return True
92 if cmd_param.nargs == -1:
93 return True
94 if isinstance(current_param_values, collections.Iterable) \
95 and cmd_param.nargs > 1 and len(current_param_values) < cmd_param.nargs:
96 return True
97 return False
98
99 def get_user_autocompletions(ctx, args, incomplete, cmd_param):
100 """
101 :param ctx: context associated with the parsed command
102 :param args: full list of args
103 :param incomplete: the incomplete text to autocomplete
104 :param cmd_param: command definition
105 :return: all the possible user-specified completions for the param
106 """
107 if isinstance(cmd_param.type, Choice):
108 return cmd_param.type.choices
109 elif cmd_param.autocompletion is not None:
110 return cmd_param.autocompletion(ctx=ctx,
111 args=args,
112 incomplete=incomplete)
113 else:
114 return []
115
116 def get_choices(cli, prog_name, args, incomplete):
117 """
118 :param cli: command definition
119 :param prog_name: the program that is running
120 :param args: full list of args
121 :param incomplete: the incomplete text to autocomplete
122 :return: all the possible completions for the incomplete
123 """
124 all_args = copy.deepcopy(args)
125
126 ctx = resolve_ctx(cli, prog_name, args)
127 if ctx is None:
128 return
129
130 # In newer versions of bash long opts with '='s are partitioned, but it's easier to parse
131 # without the '='
132 if start_of_option(incomplete) and WORDBREAK in incomplete:
133 partition_incomplete = incomplete.partition(WORDBREAK)
134 all_args.append(partition_incomplete[0])
135 incomplete = partition_incomplete[2]
136 elif incomplete == WORDBREAK:
137 incomplete = ''
138
139 choices = []
140 found_param = False
141 if start_of_option(incomplete):
142 # completions for options
143 for param in ctx.command.params:
144 if isinstance(param, Option):
145 choices.extend([param_opt for param_opt in param.opts + param.secondary_opts
146 if param_opt not in all_args or param.multiple])
147 found_param = True
148 if not found_param:
149 # completion for option values by choices
150 for cmd_param in ctx.command.params:
151 if isinstance(cmd_param, Option) and is_incomplete_option(all_args, cmd_param):
152 choices.extend(get_user_autocompletions(ctx, all_args, incomplete, cmd_param))
153 found_param = True
154 break
155 if not found_param:
156 # completion for argument values by choices
157 for cmd_param in ctx.command.params:
158 if isinstance(cmd_param, Argument) and is_incomplete_argument(ctx.params, cmd_param):
159 choices.extend(get_user_autocompletions(ctx, all_args, incomplete, cmd_param))
160 found_param = True
161 break
162
163 if not found_param and isinstance(ctx.command, MultiCommand):
164 # completion for any subcommands
165 choices.extend(ctx.command.list_commands(ctx))
166
167 for item in choices:
168 if item.startswith(incomplete):
169 yield item
170
171
172 def do_complete(cli, prog_name):
173 cwords = split_arg_string(os.environ['COMP_WORDS'])
174 cword = int(os.environ['COMP_CWORD'])
175 args = cwords[1:cword]
176 try:
177 incomplete = cwords[cword]
178 except IndexError:
179 incomplete = ''
180
181 for item in get_choices(cli, prog_name, args, incomplete):
182 echo(item)
183
184 return True
185
186
187 def bashcomplete(cli, prog_name, complete_var, complete_instr):
188 if complete_instr == 'source':
189 echo(get_completion_script(prog_name, complete_var))
190 return True
191 elif complete_instr == 'complete':
192 return do_complete(cli, prog_name)
193 return False
194
[end of click/_bashcomplete.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/click/_bashcomplete.py b/click/_bashcomplete.py
--- a/click/_bashcomplete.py
+++ b/click/_bashcomplete.py
@@ -42,14 +42,18 @@
:return: the final context/command parsed
"""
ctx = cli.make_context(prog_name, args, resilient_parsing=True)
- while ctx.protected_args + ctx.args and isinstance(ctx.command, MultiCommand):
- a = ctx.protected_args + ctx.args
- cmd = ctx.command.get_command(ctx, a[0])
+ args_remaining = ctx.protected_args + ctx.args
+ while ctx is not None and args_remaining:
+ if isinstance(ctx.command, MultiCommand):
+ cmd = ctx.command.get_command(ctx, args_remaining[0])
if cmd is None:
return None
- ctx = cmd.make_context(a[0], a[1:], parent=ctx, resilient_parsing=True)
- return ctx
+ ctx = cmd.make_context(args_remaining[0], args_remaining[1:], parent=ctx, resilient_parsing=True)
+ args_remaining = ctx.protected_args + ctx.args
+ else:
+ ctx = ctx.parent
+ return ctx
def start_of_option(param_str):
"""
@@ -164,6 +168,11 @@
# completion for any subcommands
choices.extend(ctx.command.list_commands(ctx))
+ if not start_of_option(incomplete) and ctx.parent is not None and isinstance(ctx.parent.command, MultiCommand) and ctx.parent.command.chain:
+ # completion for chained commands
+ remaining_comands = set(ctx.parent.command.list_commands(ctx.parent))-set(ctx.parent.protected_args)
+ choices.extend(remaining_comands)
+
for item in choices:
if item.startswith(incomplete):
yield item
|
{"golden_diff": "diff --git a/click/_bashcomplete.py b/click/_bashcomplete.py\n--- a/click/_bashcomplete.py\n+++ b/click/_bashcomplete.py\n@@ -42,14 +42,18 @@\n :return: the final context/command parsed\n \"\"\"\n ctx = cli.make_context(prog_name, args, resilient_parsing=True)\n- while ctx.protected_args + ctx.args and isinstance(ctx.command, MultiCommand):\n- a = ctx.protected_args + ctx.args\n- cmd = ctx.command.get_command(ctx, a[0])\n+ args_remaining = ctx.protected_args + ctx.args\n+ while ctx is not None and args_remaining:\n+ if isinstance(ctx.command, MultiCommand):\n+ cmd = ctx.command.get_command(ctx, args_remaining[0])\n if cmd is None:\n return None\n- ctx = cmd.make_context(a[0], a[1:], parent=ctx, resilient_parsing=True)\n- return ctx\n+ ctx = cmd.make_context(args_remaining[0], args_remaining[1:], parent=ctx, resilient_parsing=True)\n+ args_remaining = ctx.protected_args + ctx.args\n+ else:\n+ ctx = ctx.parent\n \n+ return ctx\n \n def start_of_option(param_str):\n \"\"\"\n@@ -164,6 +168,11 @@\n # completion for any subcommands\n choices.extend(ctx.command.list_commands(ctx))\n \n+ if not start_of_option(incomplete) and ctx.parent is not None and isinstance(ctx.parent.command, MultiCommand) and ctx.parent.command.chain:\n+ # completion for chained commands\n+ remaining_comands = set(ctx.parent.command.list_commands(ctx.parent))-set(ctx.parent.protected_args)\n+ choices.extend(remaining_comands)\n+\n for item in choices:\n if item.startswith(incomplete):\n yield item\n", "issue": "Bash auto-complete of options not working properly in command chains\nExample:\r\n\r\n $ cli cmd1 cmd2 --<TAB><TAB>\r\n\r\nAuto-completes options of `cmd1`, not `cmd2`.\r\n\r\nObserved in Python version 3.5.2 and click version 6.6.\n", "before_files": [{"content": "import collections\nimport copy\nimport os\nimport re\n\nfrom .utils import echo\nfrom .parser import split_arg_string\nfrom .core import MultiCommand, Option, Argument\nfrom .types import Choice\n\nWORDBREAK = '='\n\nCOMPLETION_SCRIPT = '''\n%(complete_func)s() {\n COMPREPLY=( $( env COMP_WORDS=\"${COMP_WORDS[*]}\" \\\\\n COMP_CWORD=$COMP_CWORD \\\\\n %(autocomplete_var)s=complete $1 ) )\n return 0\n}\n\ncomplete -F %(complete_func)s -o default %(script_names)s\n'''\n\n_invalid_ident_char_re = re.compile(r'[^a-zA-Z0-9_]')\n\n\ndef get_completion_script(prog_name, complete_var):\n cf_name = _invalid_ident_char_re.sub('', prog_name.replace('-', '_'))\n return (COMPLETION_SCRIPT % {\n 'complete_func': '_%s_completion' % cf_name,\n 'script_names': prog_name,\n 'autocomplete_var': complete_var,\n }).strip() + ';'\n\n\ndef resolve_ctx(cli, prog_name, args):\n \"\"\"\n Parse into a hierarchy of contexts. Contexts are connected through the parent variable.\n :param cli: command definition\n :param prog_name: the program that is running\n :param args: full list of args\n :return: the final context/command parsed\n \"\"\"\n ctx = cli.make_context(prog_name, args, resilient_parsing=True)\n while ctx.protected_args + ctx.args and isinstance(ctx.command, MultiCommand):\n a = ctx.protected_args + ctx.args\n cmd = ctx.command.get_command(ctx, a[0])\n if cmd is None:\n return None\n ctx = cmd.make_context(a[0], a[1:], parent=ctx, resilient_parsing=True)\n return ctx\n\n\ndef start_of_option(param_str):\n \"\"\"\n :param param_str: param_str to check\n :return: whether or not this is the start of an option declaration (i.e. starts \"-\" or \"--\")\n \"\"\"\n return param_str and param_str[:1] == '-'\n\n\ndef is_incomplete_option(all_args, cmd_param):\n \"\"\"\n :param all_args: the full original list of args supplied\n :param cmd_param: the current command paramter\n :return: whether or not the last option declaration (i.e. starts \"-\" or \"--\") is incomplete and\n corresponds to this cmd_param. In other words whether this cmd_param option can still accept\n values\n \"\"\"\n if cmd_param.is_flag:\n return False\n last_option = None\n for index, arg_str in enumerate(reversed([arg for arg in all_args if arg != WORDBREAK])):\n if index + 1 > cmd_param.nargs:\n break\n if start_of_option(arg_str):\n last_option = arg_str\n\n return True if last_option and last_option in cmd_param.opts else False\n\n\ndef is_incomplete_argument(current_params, cmd_param):\n \"\"\"\n :param current_params: the current params and values for this argument as already entered\n :param cmd_param: the current command parameter\n :return: whether or not the last argument is incomplete and corresponds to this cmd_param. In\n other words whether or not the this cmd_param argument can still accept values\n \"\"\"\n current_param_values = current_params[cmd_param.name]\n if current_param_values is None:\n return True\n if cmd_param.nargs == -1:\n return True\n if isinstance(current_param_values, collections.Iterable) \\\n and cmd_param.nargs > 1 and len(current_param_values) < cmd_param.nargs:\n return True\n return False\n\ndef get_user_autocompletions(ctx, args, incomplete, cmd_param):\n \"\"\"\n :param ctx: context associated with the parsed command\n :param args: full list of args\n :param incomplete: the incomplete text to autocomplete\n :param cmd_param: command definition\n :return: all the possible user-specified completions for the param\n \"\"\"\n if isinstance(cmd_param.type, Choice):\n return cmd_param.type.choices\n elif cmd_param.autocompletion is not None:\n return cmd_param.autocompletion(ctx=ctx,\n args=args,\n incomplete=incomplete)\n else:\n return []\n\ndef get_choices(cli, prog_name, args, incomplete):\n \"\"\"\n :param cli: command definition\n :param prog_name: the program that is running\n :param args: full list of args\n :param incomplete: the incomplete text to autocomplete\n :return: all the possible completions for the incomplete\n \"\"\"\n all_args = copy.deepcopy(args)\n\n ctx = resolve_ctx(cli, prog_name, args)\n if ctx is None:\n return\n\n # In newer versions of bash long opts with '='s are partitioned, but it's easier to parse\n # without the '='\n if start_of_option(incomplete) and WORDBREAK in incomplete:\n partition_incomplete = incomplete.partition(WORDBREAK)\n all_args.append(partition_incomplete[0])\n incomplete = partition_incomplete[2]\n elif incomplete == WORDBREAK:\n incomplete = ''\n\n choices = []\n found_param = False\n if start_of_option(incomplete):\n # completions for options\n for param in ctx.command.params:\n if isinstance(param, Option):\n choices.extend([param_opt for param_opt in param.opts + param.secondary_opts\n if param_opt not in all_args or param.multiple])\n found_param = True\n if not found_param:\n # completion for option values by choices\n for cmd_param in ctx.command.params:\n if isinstance(cmd_param, Option) and is_incomplete_option(all_args, cmd_param):\n choices.extend(get_user_autocompletions(ctx, all_args, incomplete, cmd_param))\n found_param = True\n break\n if not found_param:\n # completion for argument values by choices\n for cmd_param in ctx.command.params:\n if isinstance(cmd_param, Argument) and is_incomplete_argument(ctx.params, cmd_param):\n choices.extend(get_user_autocompletions(ctx, all_args, incomplete, cmd_param))\n found_param = True\n break\n\n if not found_param and isinstance(ctx.command, MultiCommand):\n # completion for any subcommands\n choices.extend(ctx.command.list_commands(ctx))\n\n for item in choices:\n if item.startswith(incomplete):\n yield item\n\n\ndef do_complete(cli, prog_name):\n cwords = split_arg_string(os.environ['COMP_WORDS'])\n cword = int(os.environ['COMP_CWORD'])\n args = cwords[1:cword]\n try:\n incomplete = cwords[cword]\n except IndexError:\n incomplete = ''\n\n for item in get_choices(cli, prog_name, args, incomplete):\n echo(item)\n\n return True\n\n\ndef bashcomplete(cli, prog_name, complete_var, complete_instr):\n if complete_instr == 'source':\n echo(get_completion_script(prog_name, complete_var))\n return True\n elif complete_instr == 'complete':\n return do_complete(cli, prog_name)\n return False\n", "path": "click/_bashcomplete.py"}]}
| 2,599 | 395 |
gh_patches_debug_25784
|
rasdani/github-patches
|
git_diff
|
google__openhtf-185
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Start Test Prompt is timing out and raising PromptUnansweredError
Start Test Prompt appears to be using same timeout as user prompts. When using this in loop mode we shouldn't have a timeout
</issue>
<code>
[start of openhtf/exe/triggers.py]
1 # Copyright 2014 Google Inc. All Rights Reserved.
2
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6
7 # http://www.apache.org/licenses/LICENSE-2.0
8
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 """Module for handling the triggering of test start/stop.
16
17 In order for the TestExecutor (see exe/__init__.py) to know when to start a
18 test, it needs a way to know when a DUT has been connected. Also, the test
19 can't restart until the DUT is removed and re-appears. The serial for the
20 TestRun can be read from the DUT, or from the frontend.
21
22 This module provides some built-in triggers. Custom implementations of test
23 start and stop triggers must follow the following interface:
24
25 TestStart:
26 Args:
27 None
28 Returns:
29 DUT identifier, or None if it is not known at test start time.
30
31 TestStop:
32 Args:
33 dut_id: DUT identifier of the test that is stopping.
34 Returns:
35 Blocks until the test can re-start, then returns None.
36 """
37
38 import logging
39 import time
40
41 import gflags
42
43 from openhtf.io import user_input
44
45 gflags.DEFINE_string('dut_serial', 'UNKNOWN_DUT_ID',
46 'DUT serial to start the test with. '
47 'Only use if using the AutoStart trigger.')
48
49 FLAGS = gflags.FLAGS
50 _LOG = logging.getLogger(__name__)
51
52 def AutoStart(): # pylint: disable=invalid-name
53 """Start the test immediately with a dummy DUT ID."""
54 return FLAGS.dut_serial
55
56
57 def AutoStop(dummy_dut_id): # pylint: disable=invalid-name
58 """Stop the test immediately regardless of DUT ID given."""
59 pass
60
61
62 # pylint: disable=invalid-name
63 def PromptForTestStart(message='Provide a DUT ID in order to start the test.',
64 text_input=True):
65 """Make a test start trigger based on prompting the user for input."""
66 def trigger(): # pylint: disable=missing-docstring
67 prompt_manager = user_input.get_prompt_manager()
68 return prompt_manager.DisplayPrompt(message, text_input=text_input)
69 return trigger
70
71
72 def PromptForTestStop(message='Hit ENTER to complete the test.',
73 text_input=False):
74 """Make a test stop trigger based on prompting the user for a response."""
75 def trigger(dummy_dut_id): # pylint: disable=missing-docstring
76 prompt_manager = user_input.get_prompt_manager()
77 return prompt_manager.DisplayPrompt(message, text_input=text_input)
78 return trigger
79
[end of openhtf/exe/triggers.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/openhtf/exe/triggers.py b/openhtf/exe/triggers.py
--- a/openhtf/exe/triggers.py
+++ b/openhtf/exe/triggers.py
@@ -61,18 +61,20 @@
# pylint: disable=invalid-name
def PromptForTestStart(message='Provide a DUT ID in order to start the test.',
- text_input=True):
+ text_input=False, timeout_s=60*60*24):
"""Make a test start trigger based on prompting the user for input."""
def trigger(): # pylint: disable=missing-docstring
prompt_manager = user_input.get_prompt_manager()
- return prompt_manager.DisplayPrompt(message, text_input=text_input)
+ return prompt_manager.DisplayPrompt(
+ message, text_input=text_input, timeout_s=timeout_s)
return trigger
def PromptForTestStop(message='Hit ENTER to complete the test.',
- text_input=False):
+ text_input=False, timeout_s=60*60*24):
"""Make a test stop trigger based on prompting the user for a response."""
def trigger(dummy_dut_id): # pylint: disable=missing-docstring
prompt_manager = user_input.get_prompt_manager()
- return prompt_manager.DisplayPrompt(message, text_input=text_input)
+ return prompt_manager.DisplayPrompt(
+ message, text_input=text_input, timeout_s=timeout_s)
return trigger
|
{"golden_diff": "diff --git a/openhtf/exe/triggers.py b/openhtf/exe/triggers.py\n--- a/openhtf/exe/triggers.py\n+++ b/openhtf/exe/triggers.py\n@@ -61,18 +61,20 @@\n \n # pylint: disable=invalid-name\n def PromptForTestStart(message='Provide a DUT ID in order to start the test.',\n- text_input=True):\n+ text_input=False, timeout_s=60*60*24):\n \"\"\"Make a test start trigger based on prompting the user for input.\"\"\"\n def trigger(): # pylint: disable=missing-docstring\n prompt_manager = user_input.get_prompt_manager()\n- return prompt_manager.DisplayPrompt(message, text_input=text_input)\n+ return prompt_manager.DisplayPrompt(\n+ message, text_input=text_input, timeout_s=timeout_s)\n return trigger\n \n \n def PromptForTestStop(message='Hit ENTER to complete the test.',\n- text_input=False):\n+ text_input=False, timeout_s=60*60*24):\n \"\"\"Make a test stop trigger based on prompting the user for a response.\"\"\"\n def trigger(dummy_dut_id): # pylint: disable=missing-docstring\n prompt_manager = user_input.get_prompt_manager()\n- return prompt_manager.DisplayPrompt(message, text_input=text_input)\n+ return prompt_manager.DisplayPrompt(\n+ message, text_input=text_input, timeout_s=timeout_s)\n return trigger\n", "issue": "Start Test Prompt is timing out and raising PromptUnansweredError\nStart Test Prompt appears to be using same timeout as user prompts. When using this in loop mode we shouldn't have a timeout\n\n", "before_files": [{"content": "# Copyright 2014 Google Inc. All Rights Reserved.\n\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n\n# http://www.apache.org/licenses/LICENSE-2.0\n\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\"\"\"Module for handling the triggering of test start/stop.\n\nIn order for the TestExecutor (see exe/__init__.py) to know when to start a\ntest, it needs a way to know when a DUT has been connected. Also, the test\ncan't restart until the DUT is removed and re-appears. The serial for the\nTestRun can be read from the DUT, or from the frontend.\n\nThis module provides some built-in triggers. Custom implementations of test\nstart and stop triggers must follow the following interface:\n\nTestStart:\n Args:\n None\n Returns:\n DUT identifier, or None if it is not known at test start time.\n\nTestStop:\n Args:\n dut_id: DUT identifier of the test that is stopping.\n Returns:\n Blocks until the test can re-start, then returns None.\n\"\"\"\n\nimport logging\nimport time\n\nimport gflags\n\nfrom openhtf.io import user_input\n\ngflags.DEFINE_string('dut_serial', 'UNKNOWN_DUT_ID',\n 'DUT serial to start the test with. '\n 'Only use if using the AutoStart trigger.')\n\nFLAGS = gflags.FLAGS\n_LOG = logging.getLogger(__name__)\n\ndef AutoStart(): # pylint: disable=invalid-name\n \"\"\"Start the test immediately with a dummy DUT ID.\"\"\"\n return FLAGS.dut_serial\n\n\ndef AutoStop(dummy_dut_id): # pylint: disable=invalid-name\n \"\"\"Stop the test immediately regardless of DUT ID given.\"\"\"\n pass\n\n\n# pylint: disable=invalid-name\ndef PromptForTestStart(message='Provide a DUT ID in order to start the test.',\n text_input=True):\n \"\"\"Make a test start trigger based on prompting the user for input.\"\"\"\n def trigger(): # pylint: disable=missing-docstring\n prompt_manager = user_input.get_prompt_manager()\n return prompt_manager.DisplayPrompt(message, text_input=text_input)\n return trigger\n\n\ndef PromptForTestStop(message='Hit ENTER to complete the test.',\n text_input=False):\n \"\"\"Make a test stop trigger based on prompting the user for a response.\"\"\"\n def trigger(dummy_dut_id): # pylint: disable=missing-docstring\n prompt_manager = user_input.get_prompt_manager()\n return prompt_manager.DisplayPrompt(message, text_input=text_input)\n return trigger\n", "path": "openhtf/exe/triggers.py"}]}
| 1,367 | 314 |
gh_patches_debug_14909
|
rasdani/github-patches
|
git_diff
|
getsentry__sentry-python-2818
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Memory leak with unclosed span in opentelemetry integration
### How do you use Sentry?
Sentry Saas (sentry.io)
### Version
1.40.3
### Steps to Reproduce
`SentrySpanProcessor` stores all open span in `self.otel_span_map` dict. This leads to a memory leak if otel span is deleted without closing. E.g. due to a bug: https://github.com/open-telemetry/opentelemetry-python-contrib/issues/2149
### Expected Result
Sentry span should be deleted after otel span is deleted by GC.
### Actual Result
Sentry spans are stored in self.otel_span_map forever.
</issue>
<code>
[start of sentry_sdk/scrubber.py]
1 try:
2 from typing import cast
3 except ImportError:
4 cast = lambda _, obj: obj
5
6 from sentry_sdk.utils import (
7 capture_internal_exceptions,
8 AnnotatedValue,
9 iter_event_frames,
10 )
11 from sentry_sdk._types import TYPE_CHECKING
12
13 if TYPE_CHECKING:
14 from sentry_sdk._types import Event
15 from typing import List
16 from typing import Optional
17
18
19 DEFAULT_DENYLIST = [
20 # stolen from relay
21 "password",
22 "passwd",
23 "secret",
24 "api_key",
25 "apikey",
26 "auth",
27 "credentials",
28 "mysql_pwd",
29 "privatekey",
30 "private_key",
31 "token",
32 "ip_address",
33 "session",
34 # django
35 "csrftoken",
36 "sessionid",
37 # wsgi
38 "remote_addr",
39 "x_csrftoken",
40 "x_forwarded_for",
41 "set_cookie",
42 "cookie",
43 "authorization",
44 "x_api_key",
45 "x_forwarded_for",
46 "x_real_ip",
47 # other common names used in the wild
48 "aiohttp_session", # aiohttp
49 "connect.sid", # Express
50 "csrf_token", # Pyramid
51 "csrf", # (this is a cookie name used in accepted answers on stack overflow)
52 "_csrf", # Express
53 "_csrf_token", # Bottle
54 "PHPSESSID", # PHP
55 "_session", # Sanic
56 "symfony", # Symfony
57 "user_session", # Vue
58 "_xsrf", # Tornado
59 "XSRF-TOKEN", # Angular, Laravel
60 ]
61
62
63 class EventScrubber(object):
64 def __init__(self, denylist=None, recursive=False):
65 # type: (Optional[List[str]], bool) -> None
66 self.denylist = DEFAULT_DENYLIST if denylist is None else denylist
67 self.denylist = [x.lower() for x in self.denylist]
68 self.recursive = recursive
69
70 def scrub_list(self, lst):
71 # type: (object) -> None
72 """
73 If a list is passed to this method, the method recursively searches the list and any
74 nested lists for any dictionaries. The method calls scrub_dict on all dictionaries
75 it finds.
76 If the parameter passed to this method is not a list, the method does nothing.
77 """
78 if not isinstance(lst, list):
79 return
80
81 for v in lst:
82 self.scrub_dict(v) # no-op unless v is a dict
83 self.scrub_list(v) # no-op unless v is a list
84
85 def scrub_dict(self, d):
86 # type: (object) -> None
87 """
88 If a dictionary is passed to this method, the method scrubs the dictionary of any
89 sensitive data. The method calls itself recursively on any nested dictionaries (
90 including dictionaries nested in lists) if self.recursive is True.
91 This method does nothing if the parameter passed to it is not a dictionary.
92 """
93 if not isinstance(d, dict):
94 return
95
96 for k, v in d.items():
97 if isinstance(k, str) and k.lower() in self.denylist:
98 d[k] = AnnotatedValue.substituted_because_contains_sensitive_data()
99 elif self.recursive:
100 self.scrub_dict(v) # no-op unless v is a dict
101 self.scrub_list(v) # no-op unless v is a list
102
103 def scrub_request(self, event):
104 # type: (Event) -> None
105 with capture_internal_exceptions():
106 if "request" in event:
107 if "headers" in event["request"]:
108 self.scrub_dict(event["request"]["headers"])
109 if "cookies" in event["request"]:
110 self.scrub_dict(event["request"]["cookies"])
111 if "data" in event["request"]:
112 self.scrub_dict(event["request"]["data"])
113
114 def scrub_extra(self, event):
115 # type: (Event) -> None
116 with capture_internal_exceptions():
117 if "extra" in event:
118 self.scrub_dict(event["extra"])
119
120 def scrub_user(self, event):
121 # type: (Event) -> None
122 with capture_internal_exceptions():
123 if "user" in event:
124 self.scrub_dict(event["user"])
125
126 def scrub_breadcrumbs(self, event):
127 # type: (Event) -> None
128 with capture_internal_exceptions():
129 if "breadcrumbs" in event:
130 if "values" in event["breadcrumbs"]:
131 for value in event["breadcrumbs"]["values"]:
132 if "data" in value:
133 self.scrub_dict(value["data"])
134
135 def scrub_frames(self, event):
136 # type: (Event) -> None
137 with capture_internal_exceptions():
138 for frame in iter_event_frames(event):
139 if "vars" in frame:
140 self.scrub_dict(frame["vars"])
141
142 def scrub_spans(self, event):
143 # type: (Event) -> None
144 with capture_internal_exceptions():
145 if "spans" in event:
146 for span in event["spans"]:
147 if "data" in span:
148 self.scrub_dict(span["data"])
149
150 def scrub_event(self, event):
151 # type: (Event) -> None
152 self.scrub_request(event)
153 self.scrub_extra(event)
154 self.scrub_user(event)
155 self.scrub_breadcrumbs(event)
156 self.scrub_frames(event)
157 self.scrub_spans(event)
158
[end of sentry_sdk/scrubber.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/sentry_sdk/scrubber.py b/sentry_sdk/scrubber.py
--- a/sentry_sdk/scrubber.py
+++ b/sentry_sdk/scrubber.py
@@ -1,8 +1,3 @@
-try:
- from typing import cast
-except ImportError:
- cast = lambda _, obj: obj
-
from sentry_sdk.utils import (
capture_internal_exceptions,
AnnotatedValue,
@@ -94,6 +89,8 @@
return
for k, v in d.items():
+ # The cast is needed because mypy is not smart enough to figure out that k must be a
+ # string after the isinstance check.
if isinstance(k, str) and k.lower() in self.denylist:
d[k] = AnnotatedValue.substituted_because_contains_sensitive_data()
elif self.recursive:
|
{"golden_diff": "diff --git a/sentry_sdk/scrubber.py b/sentry_sdk/scrubber.py\n--- a/sentry_sdk/scrubber.py\n+++ b/sentry_sdk/scrubber.py\n@@ -1,8 +1,3 @@\n-try:\n- from typing import cast\n-except ImportError:\n- cast = lambda _, obj: obj\n-\n from sentry_sdk.utils import (\n capture_internal_exceptions,\n AnnotatedValue,\n@@ -94,6 +89,8 @@\n return\n \n for k, v in d.items():\n+ # The cast is needed because mypy is not smart enough to figure out that k must be a\n+ # string after the isinstance check.\n if isinstance(k, str) and k.lower() in self.denylist:\n d[k] = AnnotatedValue.substituted_because_contains_sensitive_data()\n elif self.recursive:\n", "issue": "Memory leak with unclosed span in opentelemetry integration\n### How do you use Sentry?\n\nSentry Saas (sentry.io)\n\n### Version\n\n1.40.3\n\n### Steps to Reproduce\n\n`SentrySpanProcessor` stores all open span in `self.otel_span_map` dict. This leads to a memory leak if otel span is deleted without closing. E.g. due to a bug: https://github.com/open-telemetry/opentelemetry-python-contrib/issues/2149\n\n### Expected Result\n\nSentry span should be deleted after otel span is deleted by GC.\n\n### Actual Result\n\nSentry spans are stored in self.otel_span_map forever.\n", "before_files": [{"content": "try:\n from typing import cast\nexcept ImportError:\n cast = lambda _, obj: obj\n\nfrom sentry_sdk.utils import (\n capture_internal_exceptions,\n AnnotatedValue,\n iter_event_frames,\n)\nfrom sentry_sdk._types import TYPE_CHECKING\n\nif TYPE_CHECKING:\n from sentry_sdk._types import Event\n from typing import List\n from typing import Optional\n\n\nDEFAULT_DENYLIST = [\n # stolen from relay\n \"password\",\n \"passwd\",\n \"secret\",\n \"api_key\",\n \"apikey\",\n \"auth\",\n \"credentials\",\n \"mysql_pwd\",\n \"privatekey\",\n \"private_key\",\n \"token\",\n \"ip_address\",\n \"session\",\n # django\n \"csrftoken\",\n \"sessionid\",\n # wsgi\n \"remote_addr\",\n \"x_csrftoken\",\n \"x_forwarded_for\",\n \"set_cookie\",\n \"cookie\",\n \"authorization\",\n \"x_api_key\",\n \"x_forwarded_for\",\n \"x_real_ip\",\n # other common names used in the wild\n \"aiohttp_session\", # aiohttp\n \"connect.sid\", # Express\n \"csrf_token\", # Pyramid\n \"csrf\", # (this is a cookie name used in accepted answers on stack overflow)\n \"_csrf\", # Express\n \"_csrf_token\", # Bottle\n \"PHPSESSID\", # PHP\n \"_session\", # Sanic\n \"symfony\", # Symfony\n \"user_session\", # Vue\n \"_xsrf\", # Tornado\n \"XSRF-TOKEN\", # Angular, Laravel\n]\n\n\nclass EventScrubber(object):\n def __init__(self, denylist=None, recursive=False):\n # type: (Optional[List[str]], bool) -> None\n self.denylist = DEFAULT_DENYLIST if denylist is None else denylist\n self.denylist = [x.lower() for x in self.denylist]\n self.recursive = recursive\n\n def scrub_list(self, lst):\n # type: (object) -> None\n \"\"\"\n If a list is passed to this method, the method recursively searches the list and any\n nested lists for any dictionaries. The method calls scrub_dict on all dictionaries\n it finds.\n If the parameter passed to this method is not a list, the method does nothing.\n \"\"\"\n if not isinstance(lst, list):\n return\n\n for v in lst:\n self.scrub_dict(v) # no-op unless v is a dict\n self.scrub_list(v) # no-op unless v is a list\n\n def scrub_dict(self, d):\n # type: (object) -> None\n \"\"\"\n If a dictionary is passed to this method, the method scrubs the dictionary of any\n sensitive data. The method calls itself recursively on any nested dictionaries (\n including dictionaries nested in lists) if self.recursive is True.\n This method does nothing if the parameter passed to it is not a dictionary.\n \"\"\"\n if not isinstance(d, dict):\n return\n\n for k, v in d.items():\n if isinstance(k, str) and k.lower() in self.denylist:\n d[k] = AnnotatedValue.substituted_because_contains_sensitive_data()\n elif self.recursive:\n self.scrub_dict(v) # no-op unless v is a dict\n self.scrub_list(v) # no-op unless v is a list\n\n def scrub_request(self, event):\n # type: (Event) -> None\n with capture_internal_exceptions():\n if \"request\" in event:\n if \"headers\" in event[\"request\"]:\n self.scrub_dict(event[\"request\"][\"headers\"])\n if \"cookies\" in event[\"request\"]:\n self.scrub_dict(event[\"request\"][\"cookies\"])\n if \"data\" in event[\"request\"]:\n self.scrub_dict(event[\"request\"][\"data\"])\n\n def scrub_extra(self, event):\n # type: (Event) -> None\n with capture_internal_exceptions():\n if \"extra\" in event:\n self.scrub_dict(event[\"extra\"])\n\n def scrub_user(self, event):\n # type: (Event) -> None\n with capture_internal_exceptions():\n if \"user\" in event:\n self.scrub_dict(event[\"user\"])\n\n def scrub_breadcrumbs(self, event):\n # type: (Event) -> None\n with capture_internal_exceptions():\n if \"breadcrumbs\" in event:\n if \"values\" in event[\"breadcrumbs\"]:\n for value in event[\"breadcrumbs\"][\"values\"]:\n if \"data\" in value:\n self.scrub_dict(value[\"data\"])\n\n def scrub_frames(self, event):\n # type: (Event) -> None\n with capture_internal_exceptions():\n for frame in iter_event_frames(event):\n if \"vars\" in frame:\n self.scrub_dict(frame[\"vars\"])\n\n def scrub_spans(self, event):\n # type: (Event) -> None\n with capture_internal_exceptions():\n if \"spans\" in event:\n for span in event[\"spans\"]:\n if \"data\" in span:\n self.scrub_dict(span[\"data\"])\n\n def scrub_event(self, event):\n # type: (Event) -> None\n self.scrub_request(event)\n self.scrub_extra(event)\n self.scrub_user(event)\n self.scrub_breadcrumbs(event)\n self.scrub_frames(event)\n self.scrub_spans(event)\n", "path": "sentry_sdk/scrubber.py"}]}
| 2,250 | 188 |
gh_patches_debug_12562
|
rasdani/github-patches
|
git_diff
|
comic__grand-challenge.org-3116
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Annotation CIV disapears after uploading image CIV
**Describe the bug**
When uploading a Generic Overlay CIV to an archive item that contains one or multiple annotations CIVs (tested with 2D bounding box and point annotations), those annotations disappear.
**To Reproduce**
Steps to reproduce the behavior:
1. Go to an archive item that contains some annotation CIVs
2. Upload an image CIV to the archive item.
3. Refresh to see the annotation CIVs disappeared from the archive item.
**Expected behavior**
The annotation CIVs should remain.
**Screenshots**
https://github.com/comic/grand-challenge.org/assets/2001094/7e54b5c1-4d17-40ae-8ebc-9acf743861cd
</issue>
<code>
[start of app/grandchallenge/archives/tasks.py]
1 from celery import chain, group, shared_task
2 from django.conf import settings
3 from django.db import transaction
4 from django.db.transaction import on_commit
5
6 from grandchallenge.archives.models import Archive, ArchiveItem
7 from grandchallenge.cases.models import Image, RawImageUploadSession
8 from grandchallenge.cases.tasks import build_images
9 from grandchallenge.components.models import (
10 ComponentInterface,
11 ComponentInterfaceValue,
12 )
13 from grandchallenge.components.tasks import (
14 add_image_to_component_interface_value,
15 )
16
17
18 @shared_task(**settings.CELERY_TASK_DECORATOR_KWARGS["acks-late-micro-short"])
19 def add_images_to_archive(*, upload_session_pk, archive_pk, interface_pk=None):
20 with transaction.atomic():
21 images = Image.objects.filter(origin_id=upload_session_pk)
22 archive = Archive.objects.get(pk=archive_pk)
23 if interface_pk is not None:
24 interface = ComponentInterface.objects.get(pk=interface_pk)
25 else:
26 interface = ComponentInterface.objects.get(
27 slug="generic-medical-image"
28 )
29
30 for image in images:
31 civ = ComponentInterfaceValue.objects.filter(
32 interface=interface, image=image
33 ).first()
34 if civ is None:
35 civ = ComponentInterfaceValue.objects.create(
36 interface=interface, image=image
37 )
38 if ArchiveItem.objects.filter(
39 archive=archive, values__in=[civ.pk]
40 ).exists():
41 continue
42 item = ArchiveItem.objects.create(archive=archive)
43 item.values.set([civ])
44
45
46 @shared_task(**settings.CELERY_TASK_DECORATOR_KWARGS["acks-late-micro-short"])
47 def add_images_to_archive_item(
48 *, upload_session_pk, archive_item_pk, interface_pk
49 ):
50 archive_item = ArchiveItem.objects.get(pk=archive_item_pk)
51 interface = ComponentInterface.objects.get(pk=interface_pk)
52 session = RawImageUploadSession.objects.get(pk=upload_session_pk)
53
54 if archive_item.values.filter(
55 interface=interface, image__in=session.image_set.all()
56 ).exists():
57 return
58
59 with transaction.atomic():
60 archive_item.values.remove(
61 *archive_item.values.filter(interface=interface)
62 )
63 new_civ = ComponentInterfaceValue.objects.create(interface=interface)
64 archive_item.values.add(new_civ)
65
66 on_commit(
67 add_image_to_component_interface_value.signature(
68 kwargs={
69 "component_interface_value_pk": new_civ.pk,
70 "upload_session_pk": upload_session_pk,
71 },
72 immutable=True,
73 ).apply_async
74 )
75
76
77 def update_archive_item_update_kwargs(
78 instance,
79 interface,
80 civ_pks_to_add,
81 upload_pks,
82 value=None,
83 image=None,
84 user_upload=None,
85 upload_session=None,
86 ):
87 """
88 Given an interface and a value/image/user_upload/upload_session, this task
89 determines whether to create a new CIV for the specified archive item instance
90 with those values, and whether to delete any existing CIVs from the archive item.
91 It appends the respective CIV pk(s) to the set of to be added and removed
92 civs and returns those. If an upload_session is specified,
93 it also appends the session pk together with the new civ pk to the list of
94 to be processed images.
95 """
96 with transaction.atomic():
97 if interface.is_image_kind:
98 if image:
99 civ, created = ComponentInterfaceValue.objects.get_or_create(
100 interface=interface, image=image
101 )
102 if created:
103 civ.full_clean()
104 civ.save()
105 elif upload_session:
106 civ = ComponentInterfaceValue.objects.create(
107 interface=interface
108 )
109 upload_pks[civ.pk] = upload_session.pk
110 civ.save()
111 civ_pks_to_add.add(civ.pk)
112 elif interface.requires_file:
113 civ = ComponentInterfaceValue.objects.create(interface=interface)
114 user_upload.copy_object(to_field=civ.file)
115 civ.full_clean()
116 civ.save()
117 user_upload.delete()
118 civ_pks_to_add.add(civ.pk)
119 else:
120 civ = interface.create_instance(value=value)
121 civ_pks_to_add.add(civ.pk)
122
123
124 @shared_task(**settings.CELERY_TASK_DECORATOR_KWARGS["acks-late-micro-short"])
125 def update_archive_item_values(*, archive_item_pk, civ_pks_to_add):
126 instance = ArchiveItem.objects.get(pk=archive_item_pk)
127 civ_pks_to_remove = []
128 civs = ComponentInterfaceValue.objects.filter(pk__in=civ_pks_to_add)
129 for civ in civs:
130 if instance.values.filter(interface=civ.interface.pk).exists():
131 for civ_pk in instance.values.filter(
132 interface=civ.interface.pk
133 ).values_list("pk", flat=True):
134 civ_pks_to_remove.append(civ_pk)
135 # for images, check if there are any CIVs with the provided image
136 if civ.interface.is_image_kind:
137 if instance.values.filter(image=civ.image).exists():
138 for civ_pk in instance.values.filter(
139 image=civ.image
140 ).values_list("pk", flat=True):
141 civ_pks_to_remove.append(civ_pk)
142
143 with transaction.atomic():
144 instance.values.remove(*civ_pks_to_remove)
145 instance.values.add(*civ_pks_to_add)
146
147
148 @shared_task(**settings.CELERY_TASK_DECORATOR_KWARGS["acks-late-micro-short"])
149 def start_archive_item_update_tasks(
150 archive_item_pk, civ_pks_to_add, upload_pks
151 ):
152 tasks = update_archive_item_values.signature(
153 kwargs={
154 "archive_item_pk": archive_item_pk,
155 "civ_pks_to_add": civ_pks_to_add,
156 },
157 immutable=True,
158 )
159
160 if len(upload_pks) > 0:
161 image_tasks = group(
162 # Chords and iterator groups are broken in Celery, send a list
163 # instead, see https://github.com/celery/celery/issues/7285
164 [
165 chain(
166 build_images.signature(
167 kwargs={"upload_session_pk": upload_pk}
168 ),
169 add_image_to_component_interface_value.signature(
170 kwargs={
171 "component_interface_value_pk": civ_pk,
172 "upload_session_pk": upload_pk,
173 },
174 immutable=True,
175 ),
176 )
177 for civ_pk, upload_pk in upload_pks.items()
178 ]
179 )
180 tasks = group(image_tasks, tasks)
181
182 with transaction.atomic():
183 on_commit(tasks.apply_async)
184
[end of app/grandchallenge/archives/tasks.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/app/grandchallenge/archives/tasks.py b/app/grandchallenge/archives/tasks.py
--- a/app/grandchallenge/archives/tasks.py
+++ b/app/grandchallenge/archives/tasks.py
@@ -133,7 +133,9 @@
).values_list("pk", flat=True):
civ_pks_to_remove.append(civ_pk)
# for images, check if there are any CIVs with the provided image
- if civ.interface.is_image_kind:
+ # this is necessary to enable updating the interface
+ # of a given image via the API
+ if civ.interface.is_image_kind and civ.image:
if instance.values.filter(image=civ.image).exists():
for civ_pk in instance.values.filter(
image=civ.image
|
{"golden_diff": "diff --git a/app/grandchallenge/archives/tasks.py b/app/grandchallenge/archives/tasks.py\n--- a/app/grandchallenge/archives/tasks.py\n+++ b/app/grandchallenge/archives/tasks.py\n@@ -133,7 +133,9 @@\n ).values_list(\"pk\", flat=True):\n civ_pks_to_remove.append(civ_pk)\n # for images, check if there are any CIVs with the provided image\n- if civ.interface.is_image_kind:\n+ # this is necessary to enable updating the interface\n+ # of a given image via the API\n+ if civ.interface.is_image_kind and civ.image:\n if instance.values.filter(image=civ.image).exists():\n for civ_pk in instance.values.filter(\n image=civ.image\n", "issue": "Annotation CIV disapears after uploading image CIV\n**Describe the bug**\r\nWhen uploading a Generic Overlay CIV to an archive item that contains one or multiple annotations CIVs (tested with 2D bounding box and point annotations), those annotations disappear.\r\n\r\n**To Reproduce**\r\nSteps to reproduce the behavior:\r\n1. Go to an archive item that contains some annotation CIVs\r\n2. Upload an image CIV to the archive item.\r\n3. Refresh to see the annotation CIVs disappeared from the archive item.\r\n\r\n\r\n**Expected behavior**\r\nThe annotation CIVs should remain.\r\n\r\n**Screenshots**\r\n\r\nhttps://github.com/comic/grand-challenge.org/assets/2001094/7e54b5c1-4d17-40ae-8ebc-9acf743861cd\r\n\r\n\n", "before_files": [{"content": "from celery import chain, group, shared_task\nfrom django.conf import settings\nfrom django.db import transaction\nfrom django.db.transaction import on_commit\n\nfrom grandchallenge.archives.models import Archive, ArchiveItem\nfrom grandchallenge.cases.models import Image, RawImageUploadSession\nfrom grandchallenge.cases.tasks import build_images\nfrom grandchallenge.components.models import (\n ComponentInterface,\n ComponentInterfaceValue,\n)\nfrom grandchallenge.components.tasks import (\n add_image_to_component_interface_value,\n)\n\n\n@shared_task(**settings.CELERY_TASK_DECORATOR_KWARGS[\"acks-late-micro-short\"])\ndef add_images_to_archive(*, upload_session_pk, archive_pk, interface_pk=None):\n with transaction.atomic():\n images = Image.objects.filter(origin_id=upload_session_pk)\n archive = Archive.objects.get(pk=archive_pk)\n if interface_pk is not None:\n interface = ComponentInterface.objects.get(pk=interface_pk)\n else:\n interface = ComponentInterface.objects.get(\n slug=\"generic-medical-image\"\n )\n\n for image in images:\n civ = ComponentInterfaceValue.objects.filter(\n interface=interface, image=image\n ).first()\n if civ is None:\n civ = ComponentInterfaceValue.objects.create(\n interface=interface, image=image\n )\n if ArchiveItem.objects.filter(\n archive=archive, values__in=[civ.pk]\n ).exists():\n continue\n item = ArchiveItem.objects.create(archive=archive)\n item.values.set([civ])\n\n\n@shared_task(**settings.CELERY_TASK_DECORATOR_KWARGS[\"acks-late-micro-short\"])\ndef add_images_to_archive_item(\n *, upload_session_pk, archive_item_pk, interface_pk\n):\n archive_item = ArchiveItem.objects.get(pk=archive_item_pk)\n interface = ComponentInterface.objects.get(pk=interface_pk)\n session = RawImageUploadSession.objects.get(pk=upload_session_pk)\n\n if archive_item.values.filter(\n interface=interface, image__in=session.image_set.all()\n ).exists():\n return\n\n with transaction.atomic():\n archive_item.values.remove(\n *archive_item.values.filter(interface=interface)\n )\n new_civ = ComponentInterfaceValue.objects.create(interface=interface)\n archive_item.values.add(new_civ)\n\n on_commit(\n add_image_to_component_interface_value.signature(\n kwargs={\n \"component_interface_value_pk\": new_civ.pk,\n \"upload_session_pk\": upload_session_pk,\n },\n immutable=True,\n ).apply_async\n )\n\n\ndef update_archive_item_update_kwargs(\n instance,\n interface,\n civ_pks_to_add,\n upload_pks,\n value=None,\n image=None,\n user_upload=None,\n upload_session=None,\n):\n \"\"\"\n Given an interface and a value/image/user_upload/upload_session, this task\n determines whether to create a new CIV for the specified archive item instance\n with those values, and whether to delete any existing CIVs from the archive item.\n It appends the respective CIV pk(s) to the set of to be added and removed\n civs and returns those. If an upload_session is specified,\n it also appends the session pk together with the new civ pk to the list of\n to be processed images.\n \"\"\"\n with transaction.atomic():\n if interface.is_image_kind:\n if image:\n civ, created = ComponentInterfaceValue.objects.get_or_create(\n interface=interface, image=image\n )\n if created:\n civ.full_clean()\n civ.save()\n elif upload_session:\n civ = ComponentInterfaceValue.objects.create(\n interface=interface\n )\n upload_pks[civ.pk] = upload_session.pk\n civ.save()\n civ_pks_to_add.add(civ.pk)\n elif interface.requires_file:\n civ = ComponentInterfaceValue.objects.create(interface=interface)\n user_upload.copy_object(to_field=civ.file)\n civ.full_clean()\n civ.save()\n user_upload.delete()\n civ_pks_to_add.add(civ.pk)\n else:\n civ = interface.create_instance(value=value)\n civ_pks_to_add.add(civ.pk)\n\n\n@shared_task(**settings.CELERY_TASK_DECORATOR_KWARGS[\"acks-late-micro-short\"])\ndef update_archive_item_values(*, archive_item_pk, civ_pks_to_add):\n instance = ArchiveItem.objects.get(pk=archive_item_pk)\n civ_pks_to_remove = []\n civs = ComponentInterfaceValue.objects.filter(pk__in=civ_pks_to_add)\n for civ in civs:\n if instance.values.filter(interface=civ.interface.pk).exists():\n for civ_pk in instance.values.filter(\n interface=civ.interface.pk\n ).values_list(\"pk\", flat=True):\n civ_pks_to_remove.append(civ_pk)\n # for images, check if there are any CIVs with the provided image\n if civ.interface.is_image_kind:\n if instance.values.filter(image=civ.image).exists():\n for civ_pk in instance.values.filter(\n image=civ.image\n ).values_list(\"pk\", flat=True):\n civ_pks_to_remove.append(civ_pk)\n\n with transaction.atomic():\n instance.values.remove(*civ_pks_to_remove)\n instance.values.add(*civ_pks_to_add)\n\n\n@shared_task(**settings.CELERY_TASK_DECORATOR_KWARGS[\"acks-late-micro-short\"])\ndef start_archive_item_update_tasks(\n archive_item_pk, civ_pks_to_add, upload_pks\n):\n tasks = update_archive_item_values.signature(\n kwargs={\n \"archive_item_pk\": archive_item_pk,\n \"civ_pks_to_add\": civ_pks_to_add,\n },\n immutable=True,\n )\n\n if len(upload_pks) > 0:\n image_tasks = group(\n # Chords and iterator groups are broken in Celery, send a list\n # instead, see https://github.com/celery/celery/issues/7285\n [\n chain(\n build_images.signature(\n kwargs={\"upload_session_pk\": upload_pk}\n ),\n add_image_to_component_interface_value.signature(\n kwargs={\n \"component_interface_value_pk\": civ_pk,\n \"upload_session_pk\": upload_pk,\n },\n immutable=True,\n ),\n )\n for civ_pk, upload_pk in upload_pks.items()\n ]\n )\n tasks = group(image_tasks, tasks)\n\n with transaction.atomic():\n on_commit(tasks.apply_async)\n", "path": "app/grandchallenge/archives/tasks.py"}]}
| 2,526 | 168 |
gh_patches_debug_40095
|
rasdani/github-patches
|
git_diff
|
saleor__saleor-5823
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
data_feeds - google_merchant doesn't fetch product's taxes
`saleor/data_feeds/google_merchant.py`
```
def item_tax(item, discounts):
"""Return item tax.
For some countries you need to set tax info
Read more:
https://support.google.com/merchants/answer/6324454
"""
price = item.get_price(discounts=discounts)
return "US::%s:y" % price.tax
```
Current approach requires taxes passed explicitly to product. In this case `price.tax` will be always zero.
After we merge logic that extracts taxes outside product, we should fix this.
</issue>
<code>
[start of saleor/data_feeds/google_merchant.py]
1 import csv
2 import gzip
3 from typing import Iterable
4
5 from django.conf import settings
6 from django.contrib.sites.models import Site
7 from django.contrib.syndication.views import add_domain
8 from django.core.files.storage import default_storage
9 from django.utils import timezone
10 from django.utils.encoding import smart_text
11
12 from ..core.taxes import zero_money
13 from ..discount import DiscountInfo
14 from ..discount.utils import fetch_discounts
15 from ..product.models import Attribute, AttributeValue, Category, ProductVariant
16 from ..warehouse.availability import is_variant_in_stock
17
18 CATEGORY_SEPARATOR = " > "
19
20 FILE_PATH = "google-feed.csv.gz"
21
22 ATTRIBUTES = [
23 "id",
24 "title",
25 "product_type",
26 "google_product_category",
27 "image_link",
28 "condition",
29 "availability",
30 "price",
31 "tax",
32 "sale_price",
33 "mpn",
34 "brand",
35 "item_group_id",
36 "gender",
37 "age_group",
38 "color",
39 "size",
40 "description",
41 ]
42
43
44 def get_feed_file_url():
45 return default_storage.url(FILE_PATH)
46
47
48 def get_feed_items():
49 items = ProductVariant.objects.all()
50 items = items.select_related("product")
51 items = items.prefetch_related(
52 "images",
53 "product__category",
54 "product__images",
55 "product__product_type__product_attributes",
56 "product__product_type__variant_attributes",
57 )
58 return items
59
60
61 def item_id(item: ProductVariant):
62 return item.sku
63
64
65 def item_mpn(item: ProductVariant):
66 return str(item.sku)
67
68
69 def item_guid(item: ProductVariant):
70 return item.sku
71
72
73 def item_title(item: ProductVariant):
74 return item.display_product()
75
76
77 def item_description(item: ProductVariant):
78 return item.product.plain_text_description[:100]
79
80
81 def item_condition(item: ProductVariant):
82 """Return a valid item condition.
83
84 Allowed values: new, refurbished, and used.
85 Read more:
86 https://support.google.com/merchants/answer/6324469
87 """
88 return "new"
89
90
91 def item_brand(item: ProductVariant, attributes_dict, attribute_values_dict):
92 """Return an item brand.
93
94 This field is required.
95 Read more:
96 https://support.google.com/merchants/answer/6324351?hl=en&ref_topic=6324338
97 """
98 brand = None
99 brand_attribute_pk = attributes_dict.get("brand")
100 publisher_attribute_pk = attributes_dict.get("publisher")
101
102 if brand_attribute_pk:
103 brand = item.attributes.get(str(brand_attribute_pk))
104 if brand is None:
105 brand = item.product.attributes.get(str(brand_attribute_pk))
106
107 if brand is None and publisher_attribute_pk is not None:
108 brand = item.attributes.get(str(publisher_attribute_pk))
109 if brand is None:
110 brand = item.product.attributes.get(str(publisher_attribute_pk))
111
112 if brand:
113 brand_name = attribute_values_dict.get(brand)
114 if brand_name is not None:
115 return brand_name
116 return brand
117
118
119 def item_tax(item: ProductVariant, discounts: Iterable[DiscountInfo]):
120 """Return item tax.
121
122 For some countries you need to set tax info
123 Read more:
124 https://support.google.com/merchants/answer/6324454
125 """
126 # FIXME https://github.com/mirumee/saleor/issues/4311
127 return "US::%s:y" % zero_money()
128
129
130 def item_group_id(item: ProductVariant):
131 return str(item.product.pk)
132
133
134 def item_image_link(item: ProductVariant, current_site):
135 product_image = item.get_first_image()
136 if product_image:
137 image = product_image.image
138 return add_domain(current_site.domain, image.url, False)
139 return None
140
141
142 def item_availability(item: ProductVariant):
143 if is_variant_in_stock(item, settings.DEFAULT_COUNTRY):
144 return "in stock"
145 return "out of stock"
146
147
148 def item_google_product_category(item: ProductVariant, category_paths):
149 """Return a canonical product category.
150
151 To have your categories accepted, please use names accepted by Google or
152 write custom function which maps your category names into to Google codes.
153 Read more:
154 https://support.google.com/merchants/answer/6324436
155 """
156 category = item.product.category
157 if not category:
158 raise Exception(f"Item {item} does not have category")
159 if category.pk in category_paths:
160 return category_paths[category.pk]
161 ancestors = [ancestor.name for ancestor in list(category.get_ancestors())]
162 category_path = CATEGORY_SEPARATOR.join(ancestors + [category.name])
163 category_paths[category.pk] = category_path
164 return category_path
165
166
167 def item_price(item: ProductVariant):
168 price = item.get_price(discounts=None)
169 return "%s %s" % (price.amount, price.currency)
170
171
172 def item_sale_price(item: ProductVariant, discounts: Iterable[DiscountInfo]):
173 sale_price = item.get_price(discounts=discounts)
174 return "%s %s" % (sale_price.amount, sale_price.currency)
175
176
177 def item_attributes(
178 item: ProductVariant,
179 categories,
180 category_paths,
181 current_site,
182 discounts: Iterable[DiscountInfo],
183 attributes_dict,
184 attribute_values_dict,
185 ):
186 product_data = {
187 "id": item_id(item),
188 "title": item_title(item),
189 "description": item_description(item),
190 "condition": item_condition(item),
191 "mpn": item_mpn(item),
192 "item_group_id": item_group_id(item),
193 "availability": item_availability(item),
194 "google_product_category": item_google_product_category(item, category_paths),
195 }
196
197 image_link = item_image_link(item, current_site)
198 if image_link:
199 product_data["image_link"] = image_link
200
201 price = item_price(item)
202 product_data["price"] = price
203 sale_price = item_sale_price(item, discounts)
204 if sale_price != price:
205 product_data["sale_price"] = sale_price
206
207 tax = item_tax(item, discounts)
208 if tax:
209 product_data["tax"] = tax
210
211 brand = item_brand(item, attributes_dict, attribute_values_dict)
212 if brand:
213 product_data["brand"] = brand
214
215 return product_data
216
217
218 def write_feed(file_obj):
219 """Write feed contents info provided file object."""
220 writer = csv.DictWriter(file_obj, ATTRIBUTES, dialect=csv.excel_tab)
221 writer.writeheader()
222 categories = Category.objects.all()
223 discounts = fetch_discounts(timezone.now())
224 attributes_dict = {a.slug: a.pk for a in Attribute.objects.all()}
225 attribute_values_dict = {
226 smart_text(a.pk): smart_text(a) for a in AttributeValue.objects.all()
227 }
228 category_paths = {}
229 current_site = Site.objects.get_current()
230 for item in get_feed_items():
231 item_data = item_attributes(
232 item,
233 categories,
234 category_paths,
235 current_site,
236 discounts,
237 attributes_dict,
238 attribute_values_dict,
239 )
240 writer.writerow(item_data)
241
242
243 def update_feed(file_path=FILE_PATH):
244 """Save updated feed into path provided as argument.
245
246 Default path is defined in module as FILE_PATH.
247 """
248 with default_storage.open(file_path, "wb") as output_file:
249 output = gzip.open(output_file, "wt")
250 write_feed(output)
251 output.close()
252
[end of saleor/data_feeds/google_merchant.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/saleor/data_feeds/google_merchant.py b/saleor/data_feeds/google_merchant.py
--- a/saleor/data_feeds/google_merchant.py
+++ b/saleor/data_feeds/google_merchant.py
@@ -8,10 +8,12 @@
from django.core.files.storage import default_storage
from django.utils import timezone
from django.utils.encoding import smart_text
+from django_countries.fields import Country
-from ..core.taxes import zero_money
+from ..core.taxes import charge_taxes_on_shipping
from ..discount import DiscountInfo
from ..discount.utils import fetch_discounts
+from ..plugins.manager import get_plugins_manager
from ..product.models import Attribute, AttributeValue, Category, ProductVariant
from ..warehouse.availability import is_variant_in_stock
@@ -116,15 +118,25 @@
return brand
-def item_tax(item: ProductVariant, discounts: Iterable[DiscountInfo]):
+def item_tax(
+ item: ProductVariant,
+ discounts: Iterable[DiscountInfo],
+ is_charge_taxes_on_shipping: bool,
+):
"""Return item tax.
For some countries you need to set tax info
Read more:
https://support.google.com/merchants/answer/6324454
"""
- # FIXME https://github.com/mirumee/saleor/issues/4311
- return "US::%s:y" % zero_money()
+ country = Country(settings.DEFAULT_COUNTRY)
+ tax_rate = get_plugins_manager().get_tax_rate_percentage_value(
+ item.product.product_type, country
+ )
+ if tax_rate:
+ tax_ship = "yes" if is_charge_taxes_on_shipping else "no"
+ return "%s::%s:%s" % (country.code, tax_rate, tax_ship)
+ return None
def item_group_id(item: ProductVariant):
@@ -182,6 +194,7 @@
discounts: Iterable[DiscountInfo],
attributes_dict,
attribute_values_dict,
+ is_charge_taxes_on_shipping: bool,
):
product_data = {
"id": item_id(item),
@@ -204,7 +217,7 @@
if sale_price != price:
product_data["sale_price"] = sale_price
- tax = item_tax(item, discounts)
+ tax = item_tax(item, discounts, is_charge_taxes_on_shipping)
if tax:
product_data["tax"] = tax
@@ -217,6 +230,7 @@
def write_feed(file_obj):
"""Write feed contents info provided file object."""
+ is_charge_taxes_on_shipping = charge_taxes_on_shipping()
writer = csv.DictWriter(file_obj, ATTRIBUTES, dialect=csv.excel_tab)
writer.writeheader()
categories = Category.objects.all()
@@ -236,6 +250,7 @@
discounts,
attributes_dict,
attribute_values_dict,
+ is_charge_taxes_on_shipping,
)
writer.writerow(item_data)
|
{"golden_diff": "diff --git a/saleor/data_feeds/google_merchant.py b/saleor/data_feeds/google_merchant.py\n--- a/saleor/data_feeds/google_merchant.py\n+++ b/saleor/data_feeds/google_merchant.py\n@@ -8,10 +8,12 @@\n from django.core.files.storage import default_storage\n from django.utils import timezone\n from django.utils.encoding import smart_text\n+from django_countries.fields import Country\n \n-from ..core.taxes import zero_money\n+from ..core.taxes import charge_taxes_on_shipping\n from ..discount import DiscountInfo\n from ..discount.utils import fetch_discounts\n+from ..plugins.manager import get_plugins_manager\n from ..product.models import Attribute, AttributeValue, Category, ProductVariant\n from ..warehouse.availability import is_variant_in_stock\n \n@@ -116,15 +118,25 @@\n return brand\n \n \n-def item_tax(item: ProductVariant, discounts: Iterable[DiscountInfo]):\n+def item_tax(\n+ item: ProductVariant,\n+ discounts: Iterable[DiscountInfo],\n+ is_charge_taxes_on_shipping: bool,\n+):\n \"\"\"Return item tax.\n \n For some countries you need to set tax info\n Read more:\n https://support.google.com/merchants/answer/6324454\n \"\"\"\n- # FIXME https://github.com/mirumee/saleor/issues/4311\n- return \"US::%s:y\" % zero_money()\n+ country = Country(settings.DEFAULT_COUNTRY)\n+ tax_rate = get_plugins_manager().get_tax_rate_percentage_value(\n+ item.product.product_type, country\n+ )\n+ if tax_rate:\n+ tax_ship = \"yes\" if is_charge_taxes_on_shipping else \"no\"\n+ return \"%s::%s:%s\" % (country.code, tax_rate, tax_ship)\n+ return None\n \n \n def item_group_id(item: ProductVariant):\n@@ -182,6 +194,7 @@\n discounts: Iterable[DiscountInfo],\n attributes_dict,\n attribute_values_dict,\n+ is_charge_taxes_on_shipping: bool,\n ):\n product_data = {\n \"id\": item_id(item),\n@@ -204,7 +217,7 @@\n if sale_price != price:\n product_data[\"sale_price\"] = sale_price\n \n- tax = item_tax(item, discounts)\n+ tax = item_tax(item, discounts, is_charge_taxes_on_shipping)\n if tax:\n product_data[\"tax\"] = tax\n \n@@ -217,6 +230,7 @@\n \n def write_feed(file_obj):\n \"\"\"Write feed contents info provided file object.\"\"\"\n+ is_charge_taxes_on_shipping = charge_taxes_on_shipping()\n writer = csv.DictWriter(file_obj, ATTRIBUTES, dialect=csv.excel_tab)\n writer.writeheader()\n categories = Category.objects.all()\n@@ -236,6 +250,7 @@\n discounts,\n attributes_dict,\n attribute_values_dict,\n+ is_charge_taxes_on_shipping,\n )\n writer.writerow(item_data)\n", "issue": "data_feeds - google_merchant doesn't fetch product's taxes\n`saleor/data_feeds/google_merchant.py`\r\n\r\n```\r\ndef item_tax(item, discounts):\r\n \"\"\"Return item tax.\r\n For some countries you need to set tax info\r\n Read more:\r\n https://support.google.com/merchants/answer/6324454\r\n \"\"\"\r\n price = item.get_price(discounts=discounts)\r\n return \"US::%s:y\" % price.tax\r\n```\r\nCurrent approach requires taxes passed explicitly to product. In this case `price.tax` will be always zero.\r\nAfter we merge logic that extracts taxes outside product, we should fix this.\n", "before_files": [{"content": "import csv\nimport gzip\nfrom typing import Iterable\n\nfrom django.conf import settings\nfrom django.contrib.sites.models import Site\nfrom django.contrib.syndication.views import add_domain\nfrom django.core.files.storage import default_storage\nfrom django.utils import timezone\nfrom django.utils.encoding import smart_text\n\nfrom ..core.taxes import zero_money\nfrom ..discount import DiscountInfo\nfrom ..discount.utils import fetch_discounts\nfrom ..product.models import Attribute, AttributeValue, Category, ProductVariant\nfrom ..warehouse.availability import is_variant_in_stock\n\nCATEGORY_SEPARATOR = \" > \"\n\nFILE_PATH = \"google-feed.csv.gz\"\n\nATTRIBUTES = [\n \"id\",\n \"title\",\n \"product_type\",\n \"google_product_category\",\n \"image_link\",\n \"condition\",\n \"availability\",\n \"price\",\n \"tax\",\n \"sale_price\",\n \"mpn\",\n \"brand\",\n \"item_group_id\",\n \"gender\",\n \"age_group\",\n \"color\",\n \"size\",\n \"description\",\n]\n\n\ndef get_feed_file_url():\n return default_storage.url(FILE_PATH)\n\n\ndef get_feed_items():\n items = ProductVariant.objects.all()\n items = items.select_related(\"product\")\n items = items.prefetch_related(\n \"images\",\n \"product__category\",\n \"product__images\",\n \"product__product_type__product_attributes\",\n \"product__product_type__variant_attributes\",\n )\n return items\n\n\ndef item_id(item: ProductVariant):\n return item.sku\n\n\ndef item_mpn(item: ProductVariant):\n return str(item.sku)\n\n\ndef item_guid(item: ProductVariant):\n return item.sku\n\n\ndef item_title(item: ProductVariant):\n return item.display_product()\n\n\ndef item_description(item: ProductVariant):\n return item.product.plain_text_description[:100]\n\n\ndef item_condition(item: ProductVariant):\n \"\"\"Return a valid item condition.\n\n Allowed values: new, refurbished, and used.\n Read more:\n https://support.google.com/merchants/answer/6324469\n \"\"\"\n return \"new\"\n\n\ndef item_brand(item: ProductVariant, attributes_dict, attribute_values_dict):\n \"\"\"Return an item brand.\n\n This field is required.\n Read more:\n https://support.google.com/merchants/answer/6324351?hl=en&ref_topic=6324338\n \"\"\"\n brand = None\n brand_attribute_pk = attributes_dict.get(\"brand\")\n publisher_attribute_pk = attributes_dict.get(\"publisher\")\n\n if brand_attribute_pk:\n brand = item.attributes.get(str(brand_attribute_pk))\n if brand is None:\n brand = item.product.attributes.get(str(brand_attribute_pk))\n\n if brand is None and publisher_attribute_pk is not None:\n brand = item.attributes.get(str(publisher_attribute_pk))\n if brand is None:\n brand = item.product.attributes.get(str(publisher_attribute_pk))\n\n if brand:\n brand_name = attribute_values_dict.get(brand)\n if brand_name is not None:\n return brand_name\n return brand\n\n\ndef item_tax(item: ProductVariant, discounts: Iterable[DiscountInfo]):\n \"\"\"Return item tax.\n\n For some countries you need to set tax info\n Read more:\n https://support.google.com/merchants/answer/6324454\n \"\"\"\n # FIXME https://github.com/mirumee/saleor/issues/4311\n return \"US::%s:y\" % zero_money()\n\n\ndef item_group_id(item: ProductVariant):\n return str(item.product.pk)\n\n\ndef item_image_link(item: ProductVariant, current_site):\n product_image = item.get_first_image()\n if product_image:\n image = product_image.image\n return add_domain(current_site.domain, image.url, False)\n return None\n\n\ndef item_availability(item: ProductVariant):\n if is_variant_in_stock(item, settings.DEFAULT_COUNTRY):\n return \"in stock\"\n return \"out of stock\"\n\n\ndef item_google_product_category(item: ProductVariant, category_paths):\n \"\"\"Return a canonical product category.\n\n To have your categories accepted, please use names accepted by Google or\n write custom function which maps your category names into to Google codes.\n Read more:\n https://support.google.com/merchants/answer/6324436\n \"\"\"\n category = item.product.category\n if not category:\n raise Exception(f\"Item {item} does not have category\")\n if category.pk in category_paths:\n return category_paths[category.pk]\n ancestors = [ancestor.name for ancestor in list(category.get_ancestors())]\n category_path = CATEGORY_SEPARATOR.join(ancestors + [category.name])\n category_paths[category.pk] = category_path\n return category_path\n\n\ndef item_price(item: ProductVariant):\n price = item.get_price(discounts=None)\n return \"%s %s\" % (price.amount, price.currency)\n\n\ndef item_sale_price(item: ProductVariant, discounts: Iterable[DiscountInfo]):\n sale_price = item.get_price(discounts=discounts)\n return \"%s %s\" % (sale_price.amount, sale_price.currency)\n\n\ndef item_attributes(\n item: ProductVariant,\n categories,\n category_paths,\n current_site,\n discounts: Iterable[DiscountInfo],\n attributes_dict,\n attribute_values_dict,\n):\n product_data = {\n \"id\": item_id(item),\n \"title\": item_title(item),\n \"description\": item_description(item),\n \"condition\": item_condition(item),\n \"mpn\": item_mpn(item),\n \"item_group_id\": item_group_id(item),\n \"availability\": item_availability(item),\n \"google_product_category\": item_google_product_category(item, category_paths),\n }\n\n image_link = item_image_link(item, current_site)\n if image_link:\n product_data[\"image_link\"] = image_link\n\n price = item_price(item)\n product_data[\"price\"] = price\n sale_price = item_sale_price(item, discounts)\n if sale_price != price:\n product_data[\"sale_price\"] = sale_price\n\n tax = item_tax(item, discounts)\n if tax:\n product_data[\"tax\"] = tax\n\n brand = item_brand(item, attributes_dict, attribute_values_dict)\n if brand:\n product_data[\"brand\"] = brand\n\n return product_data\n\n\ndef write_feed(file_obj):\n \"\"\"Write feed contents info provided file object.\"\"\"\n writer = csv.DictWriter(file_obj, ATTRIBUTES, dialect=csv.excel_tab)\n writer.writeheader()\n categories = Category.objects.all()\n discounts = fetch_discounts(timezone.now())\n attributes_dict = {a.slug: a.pk for a in Attribute.objects.all()}\n attribute_values_dict = {\n smart_text(a.pk): smart_text(a) for a in AttributeValue.objects.all()\n }\n category_paths = {}\n current_site = Site.objects.get_current()\n for item in get_feed_items():\n item_data = item_attributes(\n item,\n categories,\n category_paths,\n current_site,\n discounts,\n attributes_dict,\n attribute_values_dict,\n )\n writer.writerow(item_data)\n\n\ndef update_feed(file_path=FILE_PATH):\n \"\"\"Save updated feed into path provided as argument.\n\n Default path is defined in module as FILE_PATH.\n \"\"\"\n with default_storage.open(file_path, \"wb\") as output_file:\n output = gzip.open(output_file, \"wt\")\n write_feed(output)\n output.close()\n", "path": "saleor/data_feeds/google_merchant.py"}]}
| 2,951 | 665 |
gh_patches_debug_23857
|
rasdani/github-patches
|
git_diff
|
sktime__sktime-6079
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[BUG] `FeatureUnion` raises error with transformers with primitive output
**Describe the bug**
Feature Union raises error with transformers with primitive output, i.e., when the output is not a series or a panel sktime raises an exception.
**To Reproduce**
```python
from sktime.datasets import load_gunpoint
from sktime.transformations.panel.rocket import Rocket
X_train, y_train = load_gunpoint(split="train", return_X_y=True)
union = Rocket() + Rocket()
X_train_transformed = union.fit_transform(X_train)
```
raises:
```
No valid mtype could be identified for object of type <class 'pandas.core.frame.DataFrame'>. Errors returned are as follows, in format [mtype]: [error message]
df-list: obj must be list of pd.DataFrame, found <class 'pandas.core.frame.DataFrame'>
numpy3D: obj must be a numpy.ndarray, found <class 'pandas.core.frame.DataFrame'>
pd-multiindex: obj must have a MultiIndex, found <class 'pandas.core.indexes.range.RangeIndex'>
nested_univ: obj All columns must be object, found <class 'pandas.core.frame.DataFrame'>
```
**Expected behavior**
I think the expected behavior should be to simply concatenate the primitives on axis=1. With `set_config(**{"output_conversion": "off"})` the transformation seems to work fine.
**Additional context**
Maybe this has something to do with this to-do in the init:
```python
# todo: check for transform-input, transform-output
# for now, we assume it's always Series/Series or Series/Panel
# but no error is currently raised
```
**Versions**
System:
python: 3.9.16 | packaged by conda-forge | (main, Feb 1 2023, 21:42:20) [Clang 14.0.6 ]
machine: macOS-13.2.1-x86_64-i386-64bit
Python dependencies:
pip: 23.2.1
sktime: 0.27.0
sklearn: 1.3.0
skbase: 0.7.5
numpy: 1.24.0
scipy: 1.11.1
pandas: 2.0.3
matplotlib: 3.7.2
joblib: 1.3.1
numba: 0.57.1
statsmodels: None
pmdarima: None
statsforecast: None
tsfresh: None
tslearn: None
torch: None
tensorflow: None
tensorflow_probability: None
</issue>
<code>
[start of sktime/transformations/compose/_featureunion.py]
1 """Feature union."""
2 # copyright: sktime developers, BSD-3-Clause License (see LICENSE file)
3
4 __author__ = ["fkiraly", "mloning"]
5 __all__ = ["FeatureUnion"]
6
7 import pandas as pd
8
9 from sktime.base._meta import _HeterogenousMetaEstimator
10 from sktime.transformations.base import BaseTransformer
11 from sktime.transformations.compose._common import _coerce_to_sktime
12 from sktime.utils.multiindex import flatten_multiindex
13
14
15 class FeatureUnion(_HeterogenousMetaEstimator, BaseTransformer):
16 """Concatenates results of multiple transformer objects.
17
18 This estimator applies a list of transformer objects in parallel to the
19 input data, then concatenates the results. This is useful to combine
20 several feature extraction mechanisms into a single transformer.
21 Parameters of the transformations may be set using its name and the
22 parameter name separated by a '__'. A transformer may be replaced entirely by
23 setting the parameter with its name to another transformer,
24 or removed by setting to 'drop' or ``None``.
25
26 Parameters
27 ----------
28 transformer_list : list of (string, transformer) tuples
29 List of transformer objects to be applied to the data. The first
30 half of each tuple is the name of the transformer.
31 n_jobs : int or None, optional (default=None)
32 Number of jobs to run in parallel.
33 ``None`` means 1 unless in a :obj:`joblib.parallel_backend`
34 context.
35 ``-1`` means using all processors.
36 transformer_weights : dict, optional
37 Multiplicative weights for features per transformer.
38 Keys are transformer names, values the weights.
39 flatten_transform_index : bool, optional (default=True)
40 if True, columns of return DataFrame are flat, by "transformer__variablename"
41 if False, columns are MultiIndex (transformer, variablename)
42 has no effect if return mtype is one without column names
43 """
44
45 _tags = {
46 "authors": ["fkiraly", "mloning"],
47 "scitype:transform-input": "Series",
48 "scitype:transform-output": "Series",
49 "scitype:transform-labels": "None",
50 "scitype:instancewise": False, # depends on components
51 "univariate-only": False, # depends on components
52 "handles-missing-data": False, # depends on components
53 "X_inner_mtype": ["pd.DataFrame", "pd-multiindex", "pd_multiindex_hier"],
54 "y_inner_mtype": "None",
55 "X-y-must-have-same-index": False,
56 "enforce_index_type": None,
57 "fit_is_empty": False,
58 "transform-returns-same-time-index": False,
59 "skip-inverse-transform": False,
60 "capability:inverse_transform": False,
61 # unclear what inverse transform should be, since multiple inverse_transform
62 # would have to inverse transform to one
63 }
64
65 # for default get_params/set_params from _HeterogenousMetaEstimator
66 # _steps_attr points to the attribute of self
67 # which contains the heterogeneous set of estimators
68 # this must be an iterable of (name: str, estimator) pairs for the default
69 _steps_attr = "_transformer_list"
70 # if the estimator is fittable, _HeterogenousMetaEstimator also
71 # provides an override for get_fitted_params for params from the fitted estimators
72 # the fitted estimators should be in a different attribute, _steps_fitted_attr
73 _steps_fitted_attr = "transformer_list_"
74
75 def __init__(
76 self,
77 transformer_list,
78 n_jobs=None,
79 transformer_weights=None,
80 flatten_transform_index=True,
81 ):
82 self.transformer_list = transformer_list
83 self.transformer_list_ = self._check_estimators(
84 transformer_list, cls_type=BaseTransformer
85 )
86
87 self.n_jobs = n_jobs
88 self.transformer_weights = transformer_weights
89 self.flatten_transform_index = flatten_transform_index
90
91 super().__init__()
92
93 # todo: check for transform-input, transform-output
94 # for now, we assume it's always Series/Series or Series/Panel
95 # but no error is currently raised
96
97 # abbreviate for readability
98 ests = self.transformer_list_
99
100 # set property tags based on tags of components
101 self._anytag_notnone_set("y_inner_mtype", ests)
102 self._anytag_notnone_set("scitype:transform-labels", ests)
103
104 self._anytagis_then_set("scitype:instancewise", False, True, ests)
105 self._anytagis_then_set("X-y-must-have-same-index", True, False, ests)
106 self._anytagis_then_set("fit_is_empty", False, True, ests)
107 self._anytagis_then_set("transform-returns-same-time-index", False, True, ests)
108 self._anytagis_then_set("skip-inverse-transform", True, False, ests)
109 # self._anytagis_then_set("capability:inverse_transform", False, True, ests)
110 self._anytagis_then_set("handles-missing-data", False, True, ests)
111 self._anytagis_then_set("univariate-only", True, False, ests)
112
113 @property
114 def _transformer_list(self):
115 return self._get_estimator_tuples(self.transformer_list, clone_ests=False)
116
117 @_transformer_list.setter
118 def _transformer_list(self, value):
119 self.transformer_list = value
120 self.transformer_list_ = self._check_estimators(value, cls_type=BaseTransformer)
121
122 def __add__(self, other):
123 """Magic + method, return (right) concatenated FeatureUnion.
124
125 Implemented for ``other`` being a transformer, otherwise returns
126 ``NotImplemented``.
127
128 Parameters
129 ----------
130 other: ``sktime`` transformer, must inherit from BaseTransformer
131 otherwise, ``NotImplemented`` is returned
132
133 Returns
134 -------
135 TransformerPipeline object, concatenation of ``self`` (first) with ``other``
136 (last).
137 not nested, contains only non-FeatureUnion ``sktime`` transformers
138 """
139 other = _coerce_to_sktime(other)
140 return self._dunder_concat(
141 other=other,
142 base_class=BaseTransformer,
143 composite_class=FeatureUnion,
144 attr_name="transformer_list",
145 concat_order="left",
146 )
147
148 def __radd__(self, other):
149 """Magic + method, return (left) concatenated FeatureUnion.
150
151 Implemented for ``other`` being a transformer, otherwise returns
152 ``NotImplemented``.
153
154 Parameters
155 ----------
156 other: ``sktime`` transformer, must inherit from BaseTransformer
157 otherwise, ``NotImplemented`` is returned
158
159 Returns
160 -------
161 TransformerPipeline object, concatenation of ``self`` (last) with ``other``
162 (first).
163 not nested, contains only non-FeatureUnion ``sktime`` transformers
164 """
165 other = _coerce_to_sktime(other)
166 return self._dunder_concat(
167 other=other,
168 base_class=BaseTransformer,
169 composite_class=FeatureUnion,
170 attr_name="transformer_list",
171 concat_order="right",
172 )
173
174 def _fit(self, X, y=None):
175 """Fit transformer to X and y.
176
177 private _fit containing the core logic, called from fit
178
179 Parameters
180 ----------
181 X : pd.DataFrame, Series, Panel, or Hierarchical mtype format
182 Data to fit transform to
183 y : Series or Panel of mtype y_inner_mtype, default=None
184 Additional data, e.g., labels for transformation
185
186 Returns
187 -------
188 self: reference to self
189 """
190 self.transformer_list_ = self._check_estimators(
191 self.transformer_list, cls_type=BaseTransformer
192 )
193
194 for _, transformer in self.transformer_list_:
195 transformer.fit(X=X, y=y)
196
197 return self
198
199 def _transform(self, X, y=None):
200 """Transform X and return a transformed version.
201
202 private _transform containing core logic, called from transform
203
204 Parameters
205 ----------
206 X : pd.DataFrame, Series, Panel, or Hierarchical mtype format
207 Data to be transformed
208 y : Series or Panel of mtype y_inner_mtype, default=None
209 Additional data, e.g., labels for transformation
210
211 Returns
212 -------
213 transformed version of X
214 """
215 # retrieve fitted transformers, apply to the new data individually
216 transformers = self._get_estimator_list(self.transformer_list_)
217 if not self.get_tag("fit_is_empty", False):
218 Xt_list = [trafo.transform(X, y) for trafo in transformers]
219 else:
220 Xt_list = [trafo.fit_transform(X, y) for trafo in transformers]
221
222 transformer_names = self._get_estimator_names(self.transformer_list_)
223
224 Xt = pd.concat(
225 Xt_list, axis=1, keys=transformer_names, names=["transformer", "variable"]
226 )
227
228 if self.flatten_transform_index:
229 Xt.columns = flatten_multiindex(Xt.columns)
230
231 return Xt
232
233 @classmethod
234 def get_test_params(cls, parameter_set="default"):
235 """Test parameters for FeatureUnion."""
236 from sktime.transformations.series.boxcox import BoxCoxTransformer
237 from sktime.transformations.series.exponent import ExponentTransformer
238
239 # with name and estimator tuple, all transformers don't have fit
240 TRANSFORMERS = [
241 ("transformer1", ExponentTransformer(power=4)),
242 ("transformer2", ExponentTransformer(power=0.25)),
243 ]
244 params1 = {"transformer_list": TRANSFORMERS}
245
246 # only with estimators, some transformers have fit, some not
247 params2 = {
248 "transformer_list": [
249 ExponentTransformer(power=4),
250 ExponentTransformer(power=0.25),
251 BoxCoxTransformer(),
252 ]
253 }
254
255 return [params1, params2]
256
[end of sktime/transformations/compose/_featureunion.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/sktime/transformations/compose/_featureunion.py b/sktime/transformations/compose/_featureunion.py
--- a/sktime/transformations/compose/_featureunion.py
+++ b/sktime/transformations/compose/_featureunion.py
@@ -80,9 +80,10 @@
flatten_transform_index=True,
):
self.transformer_list = transformer_list
- self.transformer_list_ = self._check_estimators(
+ transformer_list_ = self._check_estimators(
transformer_list, cls_type=BaseTransformer
)
+ self.transformer_list_ = transformer_list_
self.n_jobs = n_jobs
self.transformer_weights = transformer_weights
@@ -90,9 +91,11 @@
super().__init__()
- # todo: check for transform-input, transform-output
- # for now, we assume it's always Series/Series or Series/Panel
- # but no error is currently raised
+ t_outs = [t.get_tag("scitype:transform-output") for _, t in transformer_list_]
+ t_ins = [t.get_tag("scitype:transform-input") for _, t in transformer_list_]
+ # todo: error or special case handling if these are not all the same
+ self.set_tags(**{"scitype:transform-output": t_outs[0]})
+ self.set_tags(**{"scitype:transform-input": t_ins[0]})
# abbreviate for readability
ests = self.transformer_list_
|
{"golden_diff": "diff --git a/sktime/transformations/compose/_featureunion.py b/sktime/transformations/compose/_featureunion.py\n--- a/sktime/transformations/compose/_featureunion.py\n+++ b/sktime/transformations/compose/_featureunion.py\n@@ -80,9 +80,10 @@\n flatten_transform_index=True,\n ):\n self.transformer_list = transformer_list\n- self.transformer_list_ = self._check_estimators(\n+ transformer_list_ = self._check_estimators(\n transformer_list, cls_type=BaseTransformer\n )\n+ self.transformer_list_ = transformer_list_\n \n self.n_jobs = n_jobs\n self.transformer_weights = transformer_weights\n@@ -90,9 +91,11 @@\n \n super().__init__()\n \n- # todo: check for transform-input, transform-output\n- # for now, we assume it's always Series/Series or Series/Panel\n- # but no error is currently raised\n+ t_outs = [t.get_tag(\"scitype:transform-output\") for _, t in transformer_list_]\n+ t_ins = [t.get_tag(\"scitype:transform-input\") for _, t in transformer_list_]\n+ # todo: error or special case handling if these are not all the same\n+ self.set_tags(**{\"scitype:transform-output\": t_outs[0]})\n+ self.set_tags(**{\"scitype:transform-input\": t_ins[0]})\n \n # abbreviate for readability\n ests = self.transformer_list_\n", "issue": "[BUG] `FeatureUnion` raises error with transformers with primitive output\n**Describe the bug**\r\nFeature Union raises error with transformers with primitive output, i.e., when the output is not a series or a panel sktime raises an exception.\r\n\r\n**To Reproduce**\r\n```python\r\nfrom sktime.datasets import load_gunpoint\r\nfrom sktime.transformations.panel.rocket import Rocket\r\nX_train, y_train = load_gunpoint(split=\"train\", return_X_y=True)\r\nunion = Rocket() + Rocket()\r\nX_train_transformed = union.fit_transform(X_train)\r\n```\r\n\r\nraises: \r\n```\r\nNo valid mtype could be identified for object of type <class 'pandas.core.frame.DataFrame'>. Errors returned are as follows, in format [mtype]: [error message] \r\ndf-list: obj must be list of pd.DataFrame, found <class 'pandas.core.frame.DataFrame'>\r\nnumpy3D: obj must be a numpy.ndarray, found <class 'pandas.core.frame.DataFrame'>\r\npd-multiindex: obj must have a MultiIndex, found <class 'pandas.core.indexes.range.RangeIndex'>\r\nnested_univ: obj All columns must be object, found <class 'pandas.core.frame.DataFrame'>\r\n```\r\n\r\n**Expected behavior**\r\nI think the expected behavior should be to simply concatenate the primitives on axis=1. With `set_config(**{\"output_conversion\": \"off\"})` the transformation seems to work fine.\r\n\r\n**Additional context**\r\nMaybe this has something to do with this to-do in the init:\r\n```python\r\n# todo: check for transform-input, transform-output\r\n# for now, we assume it's always Series/Series or Series/Panel\r\n# but no error is currently raised\r\n```\r\n\r\n**Versions**\r\nSystem:\r\n python: 3.9.16 | packaged by conda-forge | (main, Feb 1 2023, 21:42:20) [Clang 14.0.6 ]\r\n machine: macOS-13.2.1-x86_64-i386-64bit\r\n\r\nPython dependencies:\r\n pip: 23.2.1\r\n sktime: 0.27.0\r\n sklearn: 1.3.0\r\n skbase: 0.7.5\r\n numpy: 1.24.0\r\n scipy: 1.11.1\r\n pandas: 2.0.3\r\n matplotlib: 3.7.2\r\n joblib: 1.3.1\r\n numba: 0.57.1\r\n statsmodels: None\r\n pmdarima: None\r\nstatsforecast: None\r\n tsfresh: None\r\n tslearn: None\r\n torch: None\r\n tensorflow: None\r\ntensorflow_probability: None\r\n\n", "before_files": [{"content": "\"\"\"Feature union.\"\"\"\n# copyright: sktime developers, BSD-3-Clause License (see LICENSE file)\n\n__author__ = [\"fkiraly\", \"mloning\"]\n__all__ = [\"FeatureUnion\"]\n\nimport pandas as pd\n\nfrom sktime.base._meta import _HeterogenousMetaEstimator\nfrom sktime.transformations.base import BaseTransformer\nfrom sktime.transformations.compose._common import _coerce_to_sktime\nfrom sktime.utils.multiindex import flatten_multiindex\n\n\nclass FeatureUnion(_HeterogenousMetaEstimator, BaseTransformer):\n \"\"\"Concatenates results of multiple transformer objects.\n\n This estimator applies a list of transformer objects in parallel to the\n input data, then concatenates the results. This is useful to combine\n several feature extraction mechanisms into a single transformer.\n Parameters of the transformations may be set using its name and the\n parameter name separated by a '__'. A transformer may be replaced entirely by\n setting the parameter with its name to another transformer,\n or removed by setting to 'drop' or ``None``.\n\n Parameters\n ----------\n transformer_list : list of (string, transformer) tuples\n List of transformer objects to be applied to the data. The first\n half of each tuple is the name of the transformer.\n n_jobs : int or None, optional (default=None)\n Number of jobs to run in parallel.\n ``None`` means 1 unless in a :obj:`joblib.parallel_backend`\n context.\n ``-1`` means using all processors.\n transformer_weights : dict, optional\n Multiplicative weights for features per transformer.\n Keys are transformer names, values the weights.\n flatten_transform_index : bool, optional (default=True)\n if True, columns of return DataFrame are flat, by \"transformer__variablename\"\n if False, columns are MultiIndex (transformer, variablename)\n has no effect if return mtype is one without column names\n \"\"\"\n\n _tags = {\n \"authors\": [\"fkiraly\", \"mloning\"],\n \"scitype:transform-input\": \"Series\",\n \"scitype:transform-output\": \"Series\",\n \"scitype:transform-labels\": \"None\",\n \"scitype:instancewise\": False, # depends on components\n \"univariate-only\": False, # depends on components\n \"handles-missing-data\": False, # depends on components\n \"X_inner_mtype\": [\"pd.DataFrame\", \"pd-multiindex\", \"pd_multiindex_hier\"],\n \"y_inner_mtype\": \"None\",\n \"X-y-must-have-same-index\": False,\n \"enforce_index_type\": None,\n \"fit_is_empty\": False,\n \"transform-returns-same-time-index\": False,\n \"skip-inverse-transform\": False,\n \"capability:inverse_transform\": False,\n # unclear what inverse transform should be, since multiple inverse_transform\n # would have to inverse transform to one\n }\n\n # for default get_params/set_params from _HeterogenousMetaEstimator\n # _steps_attr points to the attribute of self\n # which contains the heterogeneous set of estimators\n # this must be an iterable of (name: str, estimator) pairs for the default\n _steps_attr = \"_transformer_list\"\n # if the estimator is fittable, _HeterogenousMetaEstimator also\n # provides an override for get_fitted_params for params from the fitted estimators\n # the fitted estimators should be in a different attribute, _steps_fitted_attr\n _steps_fitted_attr = \"transformer_list_\"\n\n def __init__(\n self,\n transformer_list,\n n_jobs=None,\n transformer_weights=None,\n flatten_transform_index=True,\n ):\n self.transformer_list = transformer_list\n self.transformer_list_ = self._check_estimators(\n transformer_list, cls_type=BaseTransformer\n )\n\n self.n_jobs = n_jobs\n self.transformer_weights = transformer_weights\n self.flatten_transform_index = flatten_transform_index\n\n super().__init__()\n\n # todo: check for transform-input, transform-output\n # for now, we assume it's always Series/Series or Series/Panel\n # but no error is currently raised\n\n # abbreviate for readability\n ests = self.transformer_list_\n\n # set property tags based on tags of components\n self._anytag_notnone_set(\"y_inner_mtype\", ests)\n self._anytag_notnone_set(\"scitype:transform-labels\", ests)\n\n self._anytagis_then_set(\"scitype:instancewise\", False, True, ests)\n self._anytagis_then_set(\"X-y-must-have-same-index\", True, False, ests)\n self._anytagis_then_set(\"fit_is_empty\", False, True, ests)\n self._anytagis_then_set(\"transform-returns-same-time-index\", False, True, ests)\n self._anytagis_then_set(\"skip-inverse-transform\", True, False, ests)\n # self._anytagis_then_set(\"capability:inverse_transform\", False, True, ests)\n self._anytagis_then_set(\"handles-missing-data\", False, True, ests)\n self._anytagis_then_set(\"univariate-only\", True, False, ests)\n\n @property\n def _transformer_list(self):\n return self._get_estimator_tuples(self.transformer_list, clone_ests=False)\n\n @_transformer_list.setter\n def _transformer_list(self, value):\n self.transformer_list = value\n self.transformer_list_ = self._check_estimators(value, cls_type=BaseTransformer)\n\n def __add__(self, other):\n \"\"\"Magic + method, return (right) concatenated FeatureUnion.\n\n Implemented for ``other`` being a transformer, otherwise returns\n ``NotImplemented``.\n\n Parameters\n ----------\n other: ``sktime`` transformer, must inherit from BaseTransformer\n otherwise, ``NotImplemented`` is returned\n\n Returns\n -------\n TransformerPipeline object, concatenation of ``self`` (first) with ``other``\n (last).\n not nested, contains only non-FeatureUnion ``sktime`` transformers\n \"\"\"\n other = _coerce_to_sktime(other)\n return self._dunder_concat(\n other=other,\n base_class=BaseTransformer,\n composite_class=FeatureUnion,\n attr_name=\"transformer_list\",\n concat_order=\"left\",\n )\n\n def __radd__(self, other):\n \"\"\"Magic + method, return (left) concatenated FeatureUnion.\n\n Implemented for ``other`` being a transformer, otherwise returns\n ``NotImplemented``.\n\n Parameters\n ----------\n other: ``sktime`` transformer, must inherit from BaseTransformer\n otherwise, ``NotImplemented`` is returned\n\n Returns\n -------\n TransformerPipeline object, concatenation of ``self`` (last) with ``other``\n (first).\n not nested, contains only non-FeatureUnion ``sktime`` transformers\n \"\"\"\n other = _coerce_to_sktime(other)\n return self._dunder_concat(\n other=other,\n base_class=BaseTransformer,\n composite_class=FeatureUnion,\n attr_name=\"transformer_list\",\n concat_order=\"right\",\n )\n\n def _fit(self, X, y=None):\n \"\"\"Fit transformer to X and y.\n\n private _fit containing the core logic, called from fit\n\n Parameters\n ----------\n X : pd.DataFrame, Series, Panel, or Hierarchical mtype format\n Data to fit transform to\n y : Series or Panel of mtype y_inner_mtype, default=None\n Additional data, e.g., labels for transformation\n\n Returns\n -------\n self: reference to self\n \"\"\"\n self.transformer_list_ = self._check_estimators(\n self.transformer_list, cls_type=BaseTransformer\n )\n\n for _, transformer in self.transformer_list_:\n transformer.fit(X=X, y=y)\n\n return self\n\n def _transform(self, X, y=None):\n \"\"\"Transform X and return a transformed version.\n\n private _transform containing core logic, called from transform\n\n Parameters\n ----------\n X : pd.DataFrame, Series, Panel, or Hierarchical mtype format\n Data to be transformed\n y : Series or Panel of mtype y_inner_mtype, default=None\n Additional data, e.g., labels for transformation\n\n Returns\n -------\n transformed version of X\n \"\"\"\n # retrieve fitted transformers, apply to the new data individually\n transformers = self._get_estimator_list(self.transformer_list_)\n if not self.get_tag(\"fit_is_empty\", False):\n Xt_list = [trafo.transform(X, y) for trafo in transformers]\n else:\n Xt_list = [trafo.fit_transform(X, y) for trafo in transformers]\n\n transformer_names = self._get_estimator_names(self.transformer_list_)\n\n Xt = pd.concat(\n Xt_list, axis=1, keys=transformer_names, names=[\"transformer\", \"variable\"]\n )\n\n if self.flatten_transform_index:\n Xt.columns = flatten_multiindex(Xt.columns)\n\n return Xt\n\n @classmethod\n def get_test_params(cls, parameter_set=\"default\"):\n \"\"\"Test parameters for FeatureUnion.\"\"\"\n from sktime.transformations.series.boxcox import BoxCoxTransformer\n from sktime.transformations.series.exponent import ExponentTransformer\n\n # with name and estimator tuple, all transformers don't have fit\n TRANSFORMERS = [\n (\"transformer1\", ExponentTransformer(power=4)),\n (\"transformer2\", ExponentTransformer(power=0.25)),\n ]\n params1 = {\"transformer_list\": TRANSFORMERS}\n\n # only with estimators, some transformers have fit, some not\n params2 = {\n \"transformer_list\": [\n ExponentTransformer(power=4),\n ExponentTransformer(power=0.25),\n BoxCoxTransformer(),\n ]\n }\n\n return [params1, params2]\n", "path": "sktime/transformations/compose/_featureunion.py"}]}
| 3,987 | 344 |
gh_patches_debug_22762
|
rasdani/github-patches
|
git_diff
|
quantumlib__Cirq-4777
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[cirq_web 3D circuit] X**0.5 and Y**0.5 look the same as X and Y
**Description of the issue**
The default look for `X**0.5` and `Y**0.5` look the same as `X` and `Y` in the 3D circuit.
**How to reproduce the issue**
```
import cirq_web
a, b, c, d = cirq.GridQubit.rect(2, 2)
cirq_web.Circuit3D(cirq.Circuit(cirq.X(a)**0.5, cirq.Y(b)**0.5, cirq.X(c), cirq.Y(d))).generate_html_file(
file_name="hello.html")
```

**Cirq version**
You can get the cirq version by printing `cirq.__version__`. From the command line:
0.13.1
</issue>
<code>
[start of cirq-web/cirq_web/circuits/symbols.py]
1 # Copyright 2021 The Cirq Developers
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # https://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 # This is more of a placeholder for now, we can add
16 # official color schemes in follow-ups.
17 import abc
18 import dataclasses
19 from typing import Iterable, List, Optional
20 import cirq
21
22
23 @dataclasses.dataclass
24 class SymbolInfo:
25 """Organizes information about a symbol."""
26
27 labels: List[str]
28 colors: List[str]
29
30 @staticmethod
31 def unknown_operation(num_qubits: int) -> 'SymbolInfo':
32 """Generates a SymbolInfo object for an unknown operation.
33
34 Args:
35 num_qubits: the number of qubits in the operation
36 """
37 symbol_info = SymbolInfo([], [])
38 for _ in range(num_qubits):
39 symbol_info.colors.append('gray')
40 symbol_info.labels.append('?')
41 return symbol_info
42
43
44 class SymbolResolver(metaclass=abc.ABCMeta):
45 """Abstract class providing the interface for users to specify information
46 about how a particular symbol should be displayed in the 3D circuit
47 """
48
49 def __call__(self, operation: cirq.Operation) -> Optional[SymbolInfo]:
50 return self.resolve(operation)
51
52 @abc.abstractmethod
53 def resolve(self, operation: cirq.Operation) -> Optional[SymbolInfo]:
54 """Converts cirq.Operation objects into SymbolInfo objects for serialization."""
55
56
57 class DefaultResolver(SymbolResolver):
58 """Default symbol resolver implementation. Takes information
59 from circuit_diagram_info, if unavailable, returns information representing
60 an unknown symbol.
61 """
62
63 _SYMBOL_COLORS = {
64 '@': 'black',
65 'H': 'yellow',
66 'I': 'orange',
67 'X': 'black',
68 'Y': 'pink',
69 'Z': 'cyan',
70 'S': '#90EE90',
71 'T': '#CBC3E3',
72 }
73
74 def resolve(self, operation: cirq.Operation) -> Optional[SymbolInfo]:
75 """Checks for the _circuit_diagram_info attribute of the operation,
76 and if it exists, build the symbol information from it. Otherwise,
77 builds symbol info for an unknown operation.
78
79 Args:
80 operation: the cirq.Operation object to resolve
81 """
82 try:
83 wire_symbols = cirq.circuit_diagram_info(operation).wire_symbols
84 except TypeError:
85 return SymbolInfo.unknown_operation(cirq.num_qubits(operation))
86
87 symbol_info = SymbolInfo(list(wire_symbols), [])
88 for symbol in wire_symbols:
89 symbol_info.colors.append(DefaultResolver._SYMBOL_COLORS.get(symbol, 'gray'))
90
91 return symbol_info
92
93
94 DEFAULT_SYMBOL_RESOLVERS: Iterable[SymbolResolver] = tuple([DefaultResolver()])
95
96
97 def resolve_operation(operation: cirq.Operation, resolvers: Iterable[SymbolResolver]) -> SymbolInfo:
98 """Builds a SymbolInfo object based off of a designated operation
99 and list of resolvers. The latest resolver takes precendent.
100
101 Args:
102 operation: the cirq.Operation object to resolve
103 resolvers: a list of SymbolResolvers which provides instructions
104 on how to build SymbolInfo objects.
105
106 Raises:
107 ValueError: if the operation cannot be resolved into a symbol.
108 """
109 symbol_info = None
110 for resolver in resolvers:
111 info = resolver(operation)
112 if info is not None:
113 symbol_info = info
114
115 if symbol_info is None:
116 raise ValueError(f'Cannot resolve operation: {operation}')
117 return symbol_info
118
119
120 class Operation3DSymbol:
121 def __init__(self, wire_symbols, location_info, color_info, moment):
122 """Gathers symbol information from an operation and builds an
123 object to represent it in 3D.
124
125 Args:
126 wire_symbols: a list of symbols taken from circuit_diagram_info()
127 that will be used to represent the operation in the 3D circuit.
128
129 location_info: A list of coordinates for each wire_symbol. The
130 index of the coordinate tuple in the location_info list must
131 correspond with the index of the symbol in the wire_symbols list.
132
133 color_info: a list representing the desired color of the symbol(s).
134 These will also correspond to index of the symbol in the
135 wire_symbols list.
136
137 moment: the moment where the symbol should be.
138 """
139 self.wire_symbols = wire_symbols
140 self.location_info = location_info
141 self.color_info = color_info
142 self.moment = moment
143
144 def to_typescript(self):
145 return {
146 'wire_symbols': list(self.wire_symbols),
147 'location_info': self.location_info,
148 'color_info': self.color_info,
149 'moment': self.moment,
150 }
151
[end of cirq-web/cirq_web/circuits/symbols.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/cirq-web/cirq_web/circuits/symbols.py b/cirq-web/cirq_web/circuits/symbols.py
--- a/cirq-web/cirq_web/circuits/symbols.py
+++ b/cirq-web/cirq_web/circuits/symbols.py
@@ -18,6 +18,7 @@
import dataclasses
from typing import Iterable, List, Optional
import cirq
+from cirq.protocols.circuit_diagram_info_protocol import CircuitDiagramInfoArgs
@dataclasses.dataclass
@@ -80,11 +81,15 @@
operation: the cirq.Operation object to resolve
"""
try:
- wire_symbols = cirq.circuit_diagram_info(operation).wire_symbols
+ info = cirq.circuit_diagram_info(operation)
except TypeError:
return SymbolInfo.unknown_operation(cirq.num_qubits(operation))
- symbol_info = SymbolInfo(list(wire_symbols), [])
+ wire_symbols = info.wire_symbols
+ symbol_exponent = info._wire_symbols_including_formatted_exponent(
+ CircuitDiagramInfoArgs.UNINFORMED_DEFAULT
+ )
+ symbol_info = SymbolInfo(list(symbol_exponent), [])
for symbol in wire_symbols:
symbol_info.colors.append(DefaultResolver._SYMBOL_COLORS.get(symbol, 'gray'))
|
{"golden_diff": "diff --git a/cirq-web/cirq_web/circuits/symbols.py b/cirq-web/cirq_web/circuits/symbols.py\n--- a/cirq-web/cirq_web/circuits/symbols.py\n+++ b/cirq-web/cirq_web/circuits/symbols.py\n@@ -18,6 +18,7 @@\n import dataclasses\n from typing import Iterable, List, Optional\n import cirq\n+from cirq.protocols.circuit_diagram_info_protocol import CircuitDiagramInfoArgs\n \n \n @dataclasses.dataclass\n@@ -80,11 +81,15 @@\n operation: the cirq.Operation object to resolve\n \"\"\"\n try:\n- wire_symbols = cirq.circuit_diagram_info(operation).wire_symbols\n+ info = cirq.circuit_diagram_info(operation)\n except TypeError:\n return SymbolInfo.unknown_operation(cirq.num_qubits(operation))\n \n- symbol_info = SymbolInfo(list(wire_symbols), [])\n+ wire_symbols = info.wire_symbols\n+ symbol_exponent = info._wire_symbols_including_formatted_exponent(\n+ CircuitDiagramInfoArgs.UNINFORMED_DEFAULT\n+ )\n+ symbol_info = SymbolInfo(list(symbol_exponent), [])\n for symbol in wire_symbols:\n symbol_info.colors.append(DefaultResolver._SYMBOL_COLORS.get(symbol, 'gray'))\n", "issue": "[cirq_web 3D circuit] X**0.5 and Y**0.5 look the same as X and Y\n**Description of the issue**\r\n\r\nThe default look for `X**0.5` and `Y**0.5` look the same as `X` and `Y` in the 3D circuit.\r\n\r\n**How to reproduce the issue**\r\n\r\n```\r\nimport cirq_web\r\na, b, c, d = cirq.GridQubit.rect(2, 2)\r\ncirq_web.Circuit3D(cirq.Circuit(cirq.X(a)**0.5, cirq.Y(b)**0.5, cirq.X(c), cirq.Y(d))).generate_html_file(\r\n file_name=\"hello.html\")\r\n```\r\n\r\n\r\n\r\n\r\n**Cirq version**\r\nYou can get the cirq version by printing `cirq.__version__`. From the command line:\r\n\r\n0.13.1\r\n\n", "before_files": [{"content": "# Copyright 2021 The Cirq Developers\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# https://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n# This is more of a placeholder for now, we can add\n# official color schemes in follow-ups.\nimport abc\nimport dataclasses\nfrom typing import Iterable, List, Optional\nimport cirq\n\n\[email protected]\nclass SymbolInfo:\n \"\"\"Organizes information about a symbol.\"\"\"\n\n labels: List[str]\n colors: List[str]\n\n @staticmethod\n def unknown_operation(num_qubits: int) -> 'SymbolInfo':\n \"\"\"Generates a SymbolInfo object for an unknown operation.\n\n Args:\n num_qubits: the number of qubits in the operation\n \"\"\"\n symbol_info = SymbolInfo([], [])\n for _ in range(num_qubits):\n symbol_info.colors.append('gray')\n symbol_info.labels.append('?')\n return symbol_info\n\n\nclass SymbolResolver(metaclass=abc.ABCMeta):\n \"\"\"Abstract class providing the interface for users to specify information\n about how a particular symbol should be displayed in the 3D circuit\n \"\"\"\n\n def __call__(self, operation: cirq.Operation) -> Optional[SymbolInfo]:\n return self.resolve(operation)\n\n @abc.abstractmethod\n def resolve(self, operation: cirq.Operation) -> Optional[SymbolInfo]:\n \"\"\"Converts cirq.Operation objects into SymbolInfo objects for serialization.\"\"\"\n\n\nclass DefaultResolver(SymbolResolver):\n \"\"\"Default symbol resolver implementation. Takes information\n from circuit_diagram_info, if unavailable, returns information representing\n an unknown symbol.\n \"\"\"\n\n _SYMBOL_COLORS = {\n '@': 'black',\n 'H': 'yellow',\n 'I': 'orange',\n 'X': 'black',\n 'Y': 'pink',\n 'Z': 'cyan',\n 'S': '#90EE90',\n 'T': '#CBC3E3',\n }\n\n def resolve(self, operation: cirq.Operation) -> Optional[SymbolInfo]:\n \"\"\"Checks for the _circuit_diagram_info attribute of the operation,\n and if it exists, build the symbol information from it. Otherwise,\n builds symbol info for an unknown operation.\n\n Args:\n operation: the cirq.Operation object to resolve\n \"\"\"\n try:\n wire_symbols = cirq.circuit_diagram_info(operation).wire_symbols\n except TypeError:\n return SymbolInfo.unknown_operation(cirq.num_qubits(operation))\n\n symbol_info = SymbolInfo(list(wire_symbols), [])\n for symbol in wire_symbols:\n symbol_info.colors.append(DefaultResolver._SYMBOL_COLORS.get(symbol, 'gray'))\n\n return symbol_info\n\n\nDEFAULT_SYMBOL_RESOLVERS: Iterable[SymbolResolver] = tuple([DefaultResolver()])\n\n\ndef resolve_operation(operation: cirq.Operation, resolvers: Iterable[SymbolResolver]) -> SymbolInfo:\n \"\"\"Builds a SymbolInfo object based off of a designated operation\n and list of resolvers. The latest resolver takes precendent.\n\n Args:\n operation: the cirq.Operation object to resolve\n resolvers: a list of SymbolResolvers which provides instructions\n on how to build SymbolInfo objects.\n\n Raises:\n ValueError: if the operation cannot be resolved into a symbol.\n \"\"\"\n symbol_info = None\n for resolver in resolvers:\n info = resolver(operation)\n if info is not None:\n symbol_info = info\n\n if symbol_info is None:\n raise ValueError(f'Cannot resolve operation: {operation}')\n return symbol_info\n\n\nclass Operation3DSymbol:\n def __init__(self, wire_symbols, location_info, color_info, moment):\n \"\"\"Gathers symbol information from an operation and builds an\n object to represent it in 3D.\n\n Args:\n wire_symbols: a list of symbols taken from circuit_diagram_info()\n that will be used to represent the operation in the 3D circuit.\n\n location_info: A list of coordinates for each wire_symbol. The\n index of the coordinate tuple in the location_info list must\n correspond with the index of the symbol in the wire_symbols list.\n\n color_info: a list representing the desired color of the symbol(s).\n These will also correspond to index of the symbol in the\n wire_symbols list.\n\n moment: the moment where the symbol should be.\n \"\"\"\n self.wire_symbols = wire_symbols\n self.location_info = location_info\n self.color_info = color_info\n self.moment = moment\n\n def to_typescript(self):\n return {\n 'wire_symbols': list(self.wire_symbols),\n 'location_info': self.location_info,\n 'color_info': self.color_info,\n 'moment': self.moment,\n }\n", "path": "cirq-web/cirq_web/circuits/symbols.py"}]}
| 2,263 | 283 |
gh_patches_debug_56851
|
rasdani/github-patches
|
git_diff
|
sublimelsp__LSP-1238
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Server is being shutdown on server sending empty stderr line
When server triggers stderr output that is an empty string (or becomes an empty string after `rstrip` then LSP closes the transports and thus the server.
Issue found when analyzing https://github.com/sublimelsp/LSP-angular/issues/1
</issue>
<code>
[start of plugin/core/transports.py]
1 from .logging import exception_log, debug
2 from .types import ClientConfig
3 from .typing import Dict, Any, Optional, IO, Protocol
4 from abc import ABCMeta, abstractmethod
5 from contextlib import closing
6 from queue import Queue
7 import json
8 import os
9 import shutil
10 import socket
11 import sublime
12 import subprocess
13 import threading
14 import time
15 import weakref
16
17
18 TCP_CONNECT_TIMEOUT = 5
19
20
21 class Transport(metaclass=ABCMeta):
22
23 @abstractmethod
24 def send(self, payload: Dict[str, Any]) -> None:
25 pass
26
27 @abstractmethod
28 def close(self) -> None:
29 pass
30
31
32 class TransportCallbacks(Protocol):
33
34 def on_transport_close(self, exit_code: int, exception: Optional[Exception]) -> None:
35 ...
36
37 def on_payload(self, payload: Dict[str, Any]) -> None:
38 ...
39
40 def on_stderr_message(self, message: str) -> None:
41 ...
42
43
44 class JsonRpcTransport(Transport):
45
46 def __init__(self, name: str, process: subprocess.Popen, socket: Optional[socket.socket], reader: IO[bytes],
47 writer: IO[bytes], stderr: Optional[IO[bytes]], callback_object: TransportCallbacks) -> None:
48 self._process = process
49 self._socket = socket
50 self._reader = reader
51 self._writer = writer
52 self._stderr = stderr
53 self._reader_thread = threading.Thread(target=self._read_loop, name='{}-reader'.format(name))
54 self._writer_thread = threading.Thread(target=self._write_loop, name='{}-writer'.format(name))
55 self._stderr_thread = threading.Thread(target=self._stderr_loop, name='{}-stderr'.format(name))
56 self._callback_object = weakref.ref(callback_object)
57 self._send_queue = Queue(0) # type: Queue[Optional[Dict[str, Any]]]
58 self._reader_thread.start()
59 self._writer_thread.start()
60 self._stderr_thread.start()
61 self._closed = False
62
63 def send(self, payload: Dict[str, Any]) -> None:
64 self._send_queue.put_nowait(payload)
65
66 def close(self) -> None:
67 if not self._closed:
68 self._send_queue.put_nowait(None)
69 if self._socket:
70 self._socket.close()
71 self._closed = True
72
73 def _join_thread(self, t: threading.Thread) -> None:
74 if t.ident == threading.current_thread().ident:
75 return
76 try:
77 t.join(2)
78 except TimeoutError as ex:
79 exception_log("failed to join {} thread".format(t.name), ex)
80
81 def __del__(self) -> None:
82 self.close()
83 self._join_thread(self._writer_thread)
84 self._join_thread(self._reader_thread)
85 self._join_thread(self._stderr_thread)
86
87 def _read_loop(self) -> None:
88 try:
89 while self._reader:
90 line = self._reader.readline()
91 if not line:
92 break
93 try:
94 num_bytes = _content_length(line)
95 except ValueError:
96 continue
97 if num_bytes is None:
98 continue
99 while line and line.strip():
100 line = self._reader.readline()
101 if not line:
102 continue
103 body = self._reader.read(num_bytes)
104 callback_object = self._callback_object()
105 if callback_object:
106 try:
107 callback_object.on_payload(_decode(body))
108 except Exception as ex:
109 exception_log("Error handling payload", ex)
110 else:
111 break
112 except (AttributeError, BrokenPipeError):
113 pass
114 except Exception as ex:
115 exception_log("Unexpected exception", ex)
116 self._send_queue.put_nowait(None)
117
118 def _end(self, exception: Optional[Exception]) -> None:
119 exit_code = 0
120 if not exception:
121 try:
122 # Allow the process to stop itself.
123 exit_code = self._process.wait(1)
124 except (AttributeError, ProcessLookupError, subprocess.TimeoutExpired):
125 pass
126 if self._process:
127 try:
128 # The process didn't stop itself. Terminate!
129 self._process.kill()
130 # still wait for the process to die, or zombie processes might be the result
131 # Ignore the exit code in this case, it's going to be something non-zero because we sent SIGKILL.
132 self._process.wait()
133 except (AttributeError, ProcessLookupError):
134 pass
135 except Exception as ex:
136 exception = ex # TODO: Old captured exception is overwritten
137 callback_object = self._callback_object()
138 if callback_object:
139 callback_object.on_transport_close(exit_code, exception)
140
141 def _write_loop(self) -> None:
142 exception = None # type: Optional[Exception]
143 try:
144 while self._writer:
145 d = self._send_queue.get()
146 if d is None:
147 break
148 body = _encode(d)
149 self._writer.writelines(("Content-Length: {}\r\n\r\n".format(len(body)).encode('ascii'), body))
150 self._writer.flush()
151 except (BrokenPipeError, AttributeError):
152 pass
153 except Exception as ex:
154 exception = ex
155 self._end(exception)
156
157 def _stderr_loop(self) -> None:
158 try:
159 while self._stderr:
160 message = self._stderr.readline().decode('utf-8', 'replace').rstrip()
161 if not message:
162 break
163 callback_object = self._callback_object()
164 if callback_object:
165 callback_object.on_stderr_message(message)
166 else:
167 break
168 except (BrokenPipeError, AttributeError):
169 pass
170 except Exception as ex:
171 exception_log('unexpected exception type in stderr loop', ex)
172 self._send_queue.put_nowait(None)
173
174
175 def create_transport(config: ClientConfig, cwd: Optional[str], window: sublime.Window,
176 callback_object: TransportCallbacks, variables: Dict[str, str]) -> JsonRpcTransport:
177 tcp_port = None # type: Optional[int]
178 if config.tcp_port is not None:
179 tcp_port = _find_free_port() if config.tcp_port == 0 else config.tcp_port
180 if tcp_port is not None:
181 variables["port"] = str(tcp_port)
182 args = sublime.expand_variables(config.binary_args, variables)
183 args = [os.path.expanduser(arg) for arg in args]
184 if tcp_port is not None:
185 # DEPRECATED -- replace {port} with $port or ${port} in your client config
186 args = [a.replace('{port}', str(tcp_port)) for a in args]
187 env = os.environ.copy()
188 for var, value in config.env.items():
189 env[var] = sublime.expand_variables(value, variables)
190 if tcp_port is not None:
191 stdout = subprocess.DEVNULL
192 stdin = subprocess.DEVNULL
193 else:
194 stdout = subprocess.PIPE
195 stdin = subprocess.PIPE
196 if sublime.platform() == "windows":
197 startupinfo = subprocess.STARTUPINFO() # type: ignore
198 startupinfo.dwFlags |= subprocess.SW_HIDE | subprocess.STARTF_USESHOWWINDOW # type: ignore
199 executable_arg = args[0]
200 fname, ext = os.path.splitext(executable_arg)
201 if len(ext) < 1:
202 path_to_executable = shutil.which(executable_arg)
203 # what extensions should we append so CreateProcess can find it?
204 # node has .cmd
205 # dart has .bat
206 # python has .exe wrappers - not needed
207 for extension in ['.cmd', '.bat']:
208 if path_to_executable and path_to_executable.lower().endswith(extension):
209 args[0] = executable_arg + extension
210 break
211 else:
212 startupinfo = None
213 debug("starting {} in {}".format(args, cwd if cwd else os.getcwd()))
214 process = subprocess.Popen(
215 args=args,
216 stdin=stdin,
217 stdout=stdout,
218 stderr=subprocess.PIPE,
219 startupinfo=startupinfo,
220 env=env,
221 cwd=cwd)
222 _subprocesses.add(process)
223 sock = None # type: Optional[socket.socket]
224 if tcp_port:
225 sock = _connect_tcp(tcp_port)
226 if sock is None:
227 raise RuntimeError("Failed to connect on port {}".format(config.tcp_port))
228 reader = sock.makefile('rwb') # type: IO[bytes]
229 writer = reader
230 else:
231 reader = process.stdout # type: ignore
232 writer = process.stdin # type: ignore
233 return JsonRpcTransport(config.name, process, sock, reader, writer, process.stderr, callback_object)
234
235
236 _subprocesses = weakref.WeakSet() # type: weakref.WeakSet[subprocess.Popen]
237
238
239 def kill_all_subprocesses() -> None:
240 global _subprocesses
241 subprocesses = list(_subprocesses)
242 for p in subprocesses:
243 try:
244 p.kill()
245 except Exception:
246 pass
247 for p in subprocesses:
248 try:
249 p.wait()
250 except Exception:
251 pass
252
253
254 def _connect_tcp(port: int) -> Optional[socket.socket]:
255 start_time = time.time()
256 while time.time() - start_time < TCP_CONNECT_TIMEOUT:
257 try:
258 return socket.create_connection(('localhost', port))
259 except ConnectionRefusedError:
260 pass
261 return None
262
263
264 def _find_free_port() -> int:
265 with closing(socket.socket(socket.AF_INET, socket.SOCK_STREAM)) as s:
266 s.bind(('', 0))
267 s.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
268 return s.getsockname()[1]
269
270
271 def _encode(d: Dict[str, Any]) -> bytes:
272 return json.dumps(d, sort_keys=False, check_circular=False, separators=(',', ':')).encode('utf-8')
273
274
275 def _decode(message: bytes) -> Dict[str, Any]:
276 return json.loads(message.decode('utf-8'))
277
278
279 def _content_length(line: bytes) -> Optional[int]:
280 if line.startswith(b'Content-Length: '):
281 _, value = line.split(b'Content-Length: ')
282 value = value.strip()
283 try:
284 return int(value)
285 except ValueError as ex:
286 raise ValueError("Invalid Content-Length header: {}".format(value.decode('ascii'))) from ex
287 return None
288
[end of plugin/core/transports.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/plugin/core/transports.py b/plugin/core/transports.py
--- a/plugin/core/transports.py
+++ b/plugin/core/transports.py
@@ -158,8 +158,6 @@
try:
while self._stderr:
message = self._stderr.readline().decode('utf-8', 'replace').rstrip()
- if not message:
- break
callback_object = self._callback_object()
if callback_object:
callback_object.on_stderr_message(message)
|
{"golden_diff": "diff --git a/plugin/core/transports.py b/plugin/core/transports.py\n--- a/plugin/core/transports.py\n+++ b/plugin/core/transports.py\n@@ -158,8 +158,6 @@\n try:\n while self._stderr:\n message = self._stderr.readline().decode('utf-8', 'replace').rstrip()\n- if not message:\n- break\n callback_object = self._callback_object()\n if callback_object:\n callback_object.on_stderr_message(message)\n", "issue": "Server is being shutdown on server sending empty stderr line\nWhen server triggers stderr output that is an empty string (or becomes an empty string after `rstrip` then LSP closes the transports and thus the server.\r\n\r\nIssue found when analyzing https://github.com/sublimelsp/LSP-angular/issues/1\n", "before_files": [{"content": "from .logging import exception_log, debug\nfrom .types import ClientConfig\nfrom .typing import Dict, Any, Optional, IO, Protocol\nfrom abc import ABCMeta, abstractmethod\nfrom contextlib import closing\nfrom queue import Queue\nimport json\nimport os\nimport shutil\nimport socket\nimport sublime\nimport subprocess\nimport threading\nimport time\nimport weakref\n\n\nTCP_CONNECT_TIMEOUT = 5\n\n\nclass Transport(metaclass=ABCMeta):\n\n @abstractmethod\n def send(self, payload: Dict[str, Any]) -> None:\n pass\n\n @abstractmethod\n def close(self) -> None:\n pass\n\n\nclass TransportCallbacks(Protocol):\n\n def on_transport_close(self, exit_code: int, exception: Optional[Exception]) -> None:\n ...\n\n def on_payload(self, payload: Dict[str, Any]) -> None:\n ...\n\n def on_stderr_message(self, message: str) -> None:\n ...\n\n\nclass JsonRpcTransport(Transport):\n\n def __init__(self, name: str, process: subprocess.Popen, socket: Optional[socket.socket], reader: IO[bytes],\n writer: IO[bytes], stderr: Optional[IO[bytes]], callback_object: TransportCallbacks) -> None:\n self._process = process\n self._socket = socket\n self._reader = reader\n self._writer = writer\n self._stderr = stderr\n self._reader_thread = threading.Thread(target=self._read_loop, name='{}-reader'.format(name))\n self._writer_thread = threading.Thread(target=self._write_loop, name='{}-writer'.format(name))\n self._stderr_thread = threading.Thread(target=self._stderr_loop, name='{}-stderr'.format(name))\n self._callback_object = weakref.ref(callback_object)\n self._send_queue = Queue(0) # type: Queue[Optional[Dict[str, Any]]]\n self._reader_thread.start()\n self._writer_thread.start()\n self._stderr_thread.start()\n self._closed = False\n\n def send(self, payload: Dict[str, Any]) -> None:\n self._send_queue.put_nowait(payload)\n\n def close(self) -> None:\n if not self._closed:\n self._send_queue.put_nowait(None)\n if self._socket:\n self._socket.close()\n self._closed = True\n\n def _join_thread(self, t: threading.Thread) -> None:\n if t.ident == threading.current_thread().ident:\n return\n try:\n t.join(2)\n except TimeoutError as ex:\n exception_log(\"failed to join {} thread\".format(t.name), ex)\n\n def __del__(self) -> None:\n self.close()\n self._join_thread(self._writer_thread)\n self._join_thread(self._reader_thread)\n self._join_thread(self._stderr_thread)\n\n def _read_loop(self) -> None:\n try:\n while self._reader:\n line = self._reader.readline()\n if not line:\n break\n try:\n num_bytes = _content_length(line)\n except ValueError:\n continue\n if num_bytes is None:\n continue\n while line and line.strip():\n line = self._reader.readline()\n if not line:\n continue\n body = self._reader.read(num_bytes)\n callback_object = self._callback_object()\n if callback_object:\n try:\n callback_object.on_payload(_decode(body))\n except Exception as ex:\n exception_log(\"Error handling payload\", ex)\n else:\n break\n except (AttributeError, BrokenPipeError):\n pass\n except Exception as ex:\n exception_log(\"Unexpected exception\", ex)\n self._send_queue.put_nowait(None)\n\n def _end(self, exception: Optional[Exception]) -> None:\n exit_code = 0\n if not exception:\n try:\n # Allow the process to stop itself.\n exit_code = self._process.wait(1)\n except (AttributeError, ProcessLookupError, subprocess.TimeoutExpired):\n pass\n if self._process:\n try:\n # The process didn't stop itself. Terminate!\n self._process.kill()\n # still wait for the process to die, or zombie processes might be the result\n # Ignore the exit code in this case, it's going to be something non-zero because we sent SIGKILL.\n self._process.wait()\n except (AttributeError, ProcessLookupError):\n pass\n except Exception as ex:\n exception = ex # TODO: Old captured exception is overwritten\n callback_object = self._callback_object()\n if callback_object:\n callback_object.on_transport_close(exit_code, exception)\n\n def _write_loop(self) -> None:\n exception = None # type: Optional[Exception]\n try:\n while self._writer:\n d = self._send_queue.get()\n if d is None:\n break\n body = _encode(d)\n self._writer.writelines((\"Content-Length: {}\\r\\n\\r\\n\".format(len(body)).encode('ascii'), body))\n self._writer.flush()\n except (BrokenPipeError, AttributeError):\n pass\n except Exception as ex:\n exception = ex\n self._end(exception)\n\n def _stderr_loop(self) -> None:\n try:\n while self._stderr:\n message = self._stderr.readline().decode('utf-8', 'replace').rstrip()\n if not message:\n break\n callback_object = self._callback_object()\n if callback_object:\n callback_object.on_stderr_message(message)\n else:\n break\n except (BrokenPipeError, AttributeError):\n pass\n except Exception as ex:\n exception_log('unexpected exception type in stderr loop', ex)\n self._send_queue.put_nowait(None)\n\n\ndef create_transport(config: ClientConfig, cwd: Optional[str], window: sublime.Window,\n callback_object: TransportCallbacks, variables: Dict[str, str]) -> JsonRpcTransport:\n tcp_port = None # type: Optional[int]\n if config.tcp_port is not None:\n tcp_port = _find_free_port() if config.tcp_port == 0 else config.tcp_port\n if tcp_port is not None:\n variables[\"port\"] = str(tcp_port)\n args = sublime.expand_variables(config.binary_args, variables)\n args = [os.path.expanduser(arg) for arg in args]\n if tcp_port is not None:\n # DEPRECATED -- replace {port} with $port or ${port} in your client config\n args = [a.replace('{port}', str(tcp_port)) for a in args]\n env = os.environ.copy()\n for var, value in config.env.items():\n env[var] = sublime.expand_variables(value, variables)\n if tcp_port is not None:\n stdout = subprocess.DEVNULL\n stdin = subprocess.DEVNULL\n else:\n stdout = subprocess.PIPE\n stdin = subprocess.PIPE\n if sublime.platform() == \"windows\":\n startupinfo = subprocess.STARTUPINFO() # type: ignore\n startupinfo.dwFlags |= subprocess.SW_HIDE | subprocess.STARTF_USESHOWWINDOW # type: ignore\n executable_arg = args[0]\n fname, ext = os.path.splitext(executable_arg)\n if len(ext) < 1:\n path_to_executable = shutil.which(executable_arg)\n # what extensions should we append so CreateProcess can find it?\n # node has .cmd\n # dart has .bat\n # python has .exe wrappers - not needed\n for extension in ['.cmd', '.bat']:\n if path_to_executable and path_to_executable.lower().endswith(extension):\n args[0] = executable_arg + extension\n break\n else:\n startupinfo = None\n debug(\"starting {} in {}\".format(args, cwd if cwd else os.getcwd()))\n process = subprocess.Popen(\n args=args,\n stdin=stdin,\n stdout=stdout,\n stderr=subprocess.PIPE,\n startupinfo=startupinfo,\n env=env,\n cwd=cwd)\n _subprocesses.add(process)\n sock = None # type: Optional[socket.socket]\n if tcp_port:\n sock = _connect_tcp(tcp_port)\n if sock is None:\n raise RuntimeError(\"Failed to connect on port {}\".format(config.tcp_port))\n reader = sock.makefile('rwb') # type: IO[bytes]\n writer = reader\n else:\n reader = process.stdout # type: ignore\n writer = process.stdin # type: ignore\n return JsonRpcTransport(config.name, process, sock, reader, writer, process.stderr, callback_object)\n\n\n_subprocesses = weakref.WeakSet() # type: weakref.WeakSet[subprocess.Popen]\n\n\ndef kill_all_subprocesses() -> None:\n global _subprocesses\n subprocesses = list(_subprocesses)\n for p in subprocesses:\n try:\n p.kill()\n except Exception:\n pass\n for p in subprocesses:\n try:\n p.wait()\n except Exception:\n pass\n\n\ndef _connect_tcp(port: int) -> Optional[socket.socket]:\n start_time = time.time()\n while time.time() - start_time < TCP_CONNECT_TIMEOUT:\n try:\n return socket.create_connection(('localhost', port))\n except ConnectionRefusedError:\n pass\n return None\n\n\ndef _find_free_port() -> int:\n with closing(socket.socket(socket.AF_INET, socket.SOCK_STREAM)) as s:\n s.bind(('', 0))\n s.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)\n return s.getsockname()[1]\n\n\ndef _encode(d: Dict[str, Any]) -> bytes:\n return json.dumps(d, sort_keys=False, check_circular=False, separators=(',', ':')).encode('utf-8')\n\n\ndef _decode(message: bytes) -> Dict[str, Any]:\n return json.loads(message.decode('utf-8'))\n\n\ndef _content_length(line: bytes) -> Optional[int]:\n if line.startswith(b'Content-Length: '):\n _, value = line.split(b'Content-Length: ')\n value = value.strip()\n try:\n return int(value)\n except ValueError as ex:\n raise ValueError(\"Invalid Content-Length header: {}\".format(value.decode('ascii'))) from ex\n return None\n", "path": "plugin/core/transports.py"}]}
| 3,558 | 106 |
gh_patches_debug_279
|
rasdani/github-patches
|
git_diff
|
sanic-org__sanic-1292
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
New release on Pypi ?
Hello,
I was looking for a tool to autoreload my code when I develop and I found this commit : https://github.com/channelcat/sanic/commit/52c2a8484e6aa5fa13aaade49e1f2597dd006e15
So it seems Sanic already integrates it since December 07, 2017. But the the latest version on Pypi dates from the day before (https://github.com/channelcat/sanic/commit/1ea3ab7fe8ab03a6ddf4d75a3de8cb719f4c584c) : https://pypi.org/project/Sanic/#history
Is-it possible to release a new version on Pypi please ? Other features (like the UUID support in routes) are also interesting :)
Thanks in advance !
</issue>
<code>
[start of sanic/__init__.py]
1 from sanic.app import Sanic
2 from sanic.blueprints import Blueprint
3
4 __version__ = '0.7.0'
5
6 __all__ = ['Sanic', 'Blueprint']
7
[end of sanic/__init__.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/sanic/__init__.py b/sanic/__init__.py
--- a/sanic/__init__.py
+++ b/sanic/__init__.py
@@ -1,6 +1,6 @@
from sanic.app import Sanic
from sanic.blueprints import Blueprint
-__version__ = '0.7.0'
+__version__ = '0.8.0'
__all__ = ['Sanic', 'Blueprint']
|
{"golden_diff": "diff --git a/sanic/__init__.py b/sanic/__init__.py\n--- a/sanic/__init__.py\n+++ b/sanic/__init__.py\n@@ -1,6 +1,6 @@\n from sanic.app import Sanic\n from sanic.blueprints import Blueprint\n \n-__version__ = '0.7.0'\n+__version__ = '0.8.0'\n \n __all__ = ['Sanic', 'Blueprint']\n", "issue": "New release on Pypi ?\nHello,\r\n\r\nI was looking for a tool to autoreload my code when I develop and I found this commit : https://github.com/channelcat/sanic/commit/52c2a8484e6aa5fa13aaade49e1f2597dd006e15\r\n\r\nSo it seems Sanic already integrates it since December 07, 2017. But the the latest version on Pypi dates from the day before (https://github.com/channelcat/sanic/commit/1ea3ab7fe8ab03a6ddf4d75a3de8cb719f4c584c) : https://pypi.org/project/Sanic/#history\r\n\r\nIs-it possible to release a new version on Pypi please ? Other features (like the UUID support in routes) are also interesting :)\r\n\r\nThanks in advance !\n", "before_files": [{"content": "from sanic.app import Sanic\nfrom sanic.blueprints import Blueprint\n\n__version__ = '0.7.0'\n\n__all__ = ['Sanic', 'Blueprint']\n", "path": "sanic/__init__.py"}]}
| 781 | 98 |
gh_patches_debug_10499
|
rasdani/github-patches
|
git_diff
|
paperless-ngx__paperless-ngx-2205
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[BUG] Filtering is inconsistent: tag exclusion does not apply with search term
### Description
Filtering documents is not working as expected in some cases.
When filtering for tags, it is possible to include/exclude or exactly match tags. That functionality is lost when using a search term at the same time. I assume that this is not intended behaviour.
### Steps to reproduce
1. Go to `Documents`
2. Enter a search term for filtering documents by that search term. This works fine.
3. Exclude a tag from the search results. The tag is not excluded, when a search term was entered.
### Webserver logs
```bash
Does not apply
```
### Browser logs
_No response_
### Paperless-ngx version
1.10.2
### Host OS
Ubuntu 22.04
### Installation method
Docker - official image
### Browser
Firefox
### Configuration changes
_No response_
### Other
_No response_
</issue>
<code>
[start of src/documents/index.py]
1 import logging
2 import math
3 import os
4 from contextlib import contextmanager
5
6 from dateutil.parser import isoparse
7 from django.conf import settings
8 from documents.models import Document
9 from whoosh import classify
10 from whoosh import highlight
11 from whoosh import query
12 from whoosh.fields import BOOLEAN
13 from whoosh.fields import DATETIME
14 from whoosh.fields import KEYWORD
15 from whoosh.fields import NUMERIC
16 from whoosh.fields import Schema
17 from whoosh.fields import TEXT
18 from whoosh.highlight import HtmlFormatter
19 from whoosh.index import create_in
20 from whoosh.index import exists_in
21 from whoosh.index import open_dir
22 from whoosh.qparser import MultifieldParser
23 from whoosh.qparser.dateparse import DateParserPlugin
24 from whoosh.searching import ResultsPage
25 from whoosh.searching import Searcher
26 from whoosh.writing import AsyncWriter
27
28 logger = logging.getLogger("paperless.index")
29
30
31 def get_schema():
32 return Schema(
33 id=NUMERIC(stored=True, unique=True),
34 title=TEXT(sortable=True),
35 content=TEXT(),
36 asn=NUMERIC(sortable=True),
37 correspondent=TEXT(sortable=True),
38 correspondent_id=NUMERIC(),
39 has_correspondent=BOOLEAN(),
40 tag=KEYWORD(commas=True, scorable=True, lowercase=True),
41 tag_id=KEYWORD(commas=True, scorable=True),
42 has_tag=BOOLEAN(),
43 type=TEXT(sortable=True),
44 type_id=NUMERIC(),
45 has_type=BOOLEAN(),
46 created=DATETIME(sortable=True),
47 modified=DATETIME(sortable=True),
48 added=DATETIME(sortable=True),
49 path=TEXT(sortable=True),
50 path_id=NUMERIC(),
51 has_path=BOOLEAN(),
52 )
53
54
55 def open_index(recreate=False):
56 try:
57 if exists_in(settings.INDEX_DIR) and not recreate:
58 return open_dir(settings.INDEX_DIR, schema=get_schema())
59 except Exception:
60 logger.exception("Error while opening the index, recreating.")
61
62 if not os.path.isdir(settings.INDEX_DIR):
63 os.makedirs(settings.INDEX_DIR, exist_ok=True)
64 return create_in(settings.INDEX_DIR, get_schema())
65
66
67 @contextmanager
68 def open_index_writer(optimize=False):
69 writer = AsyncWriter(open_index())
70
71 try:
72 yield writer
73 except Exception as e:
74 logger.exception(str(e))
75 writer.cancel()
76 finally:
77 writer.commit(optimize=optimize)
78
79
80 @contextmanager
81 def open_index_searcher():
82 searcher = open_index().searcher()
83
84 try:
85 yield searcher
86 finally:
87 searcher.close()
88
89
90 def update_document(writer, doc):
91 tags = ",".join([t.name for t in doc.tags.all()])
92 tags_ids = ",".join([str(t.id) for t in doc.tags.all()])
93 writer.update_document(
94 id=doc.pk,
95 title=doc.title,
96 content=doc.content,
97 correspondent=doc.correspondent.name if doc.correspondent else None,
98 correspondent_id=doc.correspondent.id if doc.correspondent else None,
99 has_correspondent=doc.correspondent is not None,
100 tag=tags if tags else None,
101 tag_id=tags_ids if tags_ids else None,
102 has_tag=len(tags) > 0,
103 type=doc.document_type.name if doc.document_type else None,
104 type_id=doc.document_type.id if doc.document_type else None,
105 has_type=doc.document_type is not None,
106 created=doc.created,
107 added=doc.added,
108 asn=doc.archive_serial_number,
109 modified=doc.modified,
110 path=doc.storage_path.name if doc.storage_path else None,
111 path_id=doc.storage_path.id if doc.storage_path else None,
112 has_path=doc.storage_path is not None,
113 )
114
115
116 def remove_document(writer, doc):
117 remove_document_by_id(writer, doc.pk)
118
119
120 def remove_document_by_id(writer, doc_id):
121 writer.delete_by_term("id", doc_id)
122
123
124 def add_or_update_document(document):
125 with open_index_writer() as writer:
126 update_document(writer, document)
127
128
129 def remove_document_from_index(document):
130 with open_index_writer() as writer:
131 remove_document(writer, document)
132
133
134 class DelayedQuery:
135 def _get_query(self):
136 raise NotImplementedError()
137
138 def _get_query_filter(self):
139 criterias = []
140 for k, v in self.query_params.items():
141 if k == "correspondent__id":
142 criterias.append(query.Term("correspondent_id", v))
143 elif k == "tags__id__all":
144 for tag_id in v.split(","):
145 criterias.append(query.Term("tag_id", tag_id))
146 elif k == "document_type__id":
147 criterias.append(query.Term("type_id", v))
148 elif k == "correspondent__isnull":
149 criterias.append(query.Term("has_correspondent", v == "false"))
150 elif k == "is_tagged":
151 criterias.append(query.Term("has_tag", v == "true"))
152 elif k == "document_type__isnull":
153 criterias.append(query.Term("has_type", v == "false"))
154 elif k == "created__date__lt":
155 criterias.append(
156 query.DateRange("created", start=None, end=isoparse(v)),
157 )
158 elif k == "created__date__gt":
159 criterias.append(
160 query.DateRange("created", start=isoparse(v), end=None),
161 )
162 elif k == "added__date__gt":
163 criterias.append(query.DateRange("added", start=isoparse(v), end=None))
164 elif k == "added__date__lt":
165 criterias.append(query.DateRange("added", start=None, end=isoparse(v)))
166 elif k == "storage_path__id":
167 criterias.append(query.Term("path_id", v))
168 elif k == "storage_path__isnull":
169 criterias.append(query.Term("has_path", v == "false"))
170
171 if len(criterias) > 0:
172 return query.And(criterias)
173 else:
174 return None
175
176 def _get_query_sortedby(self):
177 if "ordering" not in self.query_params:
178 return None, False
179
180 field: str = self.query_params["ordering"]
181
182 sort_fields_map = {
183 "created": "created",
184 "modified": "modified",
185 "added": "added",
186 "title": "title",
187 "correspondent__name": "correspondent",
188 "document_type__name": "type",
189 "archive_serial_number": "asn",
190 }
191
192 if field.startswith("-"):
193 field = field[1:]
194 reverse = True
195 else:
196 reverse = False
197
198 if field not in sort_fields_map:
199 return None, False
200 else:
201 return sort_fields_map[field], reverse
202
203 def __init__(self, searcher: Searcher, query_params, page_size):
204 self.searcher = searcher
205 self.query_params = query_params
206 self.page_size = page_size
207 self.saved_results = dict()
208 self.first_score = None
209
210 def __len__(self):
211 page = self[0:1]
212 return len(page)
213
214 def __getitem__(self, item):
215 if item.start in self.saved_results:
216 return self.saved_results[item.start]
217
218 q, mask = self._get_query()
219 sortedby, reverse = self._get_query_sortedby()
220
221 page: ResultsPage = self.searcher.search_page(
222 q,
223 mask=mask,
224 filter=self._get_query_filter(),
225 pagenum=math.floor(item.start / self.page_size) + 1,
226 pagelen=self.page_size,
227 sortedby=sortedby,
228 reverse=reverse,
229 )
230 page.results.fragmenter = highlight.ContextFragmenter(surround=50)
231 page.results.formatter = HtmlFormatter(tagname="span", between=" ... ")
232
233 if not self.first_score and len(page.results) > 0 and sortedby is None:
234 self.first_score = page.results[0].score
235
236 page.results.top_n = list(
237 map(
238 lambda hit: (
239 (hit[0] / self.first_score) if self.first_score else None,
240 hit[1],
241 ),
242 page.results.top_n,
243 ),
244 )
245
246 self.saved_results[item.start] = page
247
248 return page
249
250
251 class DelayedFullTextQuery(DelayedQuery):
252 def _get_query(self):
253 q_str = self.query_params["query"]
254 qp = MultifieldParser(
255 ["content", "title", "correspondent", "tag", "type"],
256 self.searcher.ixreader.schema,
257 )
258 qp.add_plugin(DateParserPlugin())
259 q = qp.parse(q_str)
260
261 corrected = self.searcher.correct_query(q, q_str)
262 if corrected.query != q:
263 corrected.query = corrected.string
264
265 return q, None
266
267
268 class DelayedMoreLikeThisQuery(DelayedQuery):
269 def _get_query(self):
270 more_like_doc_id = int(self.query_params["more_like_id"])
271 content = Document.objects.get(id=more_like_doc_id).content
272
273 docnum = self.searcher.document_number(id=more_like_doc_id)
274 kts = self.searcher.key_terms_from_text(
275 "content",
276 content,
277 numterms=20,
278 model=classify.Bo1Model,
279 normalize=False,
280 )
281 q = query.Or(
282 [query.Term("content", word, boost=weight) for word, weight in kts],
283 )
284 mask = {docnum}
285
286 return q, mask
287
288
289 def autocomplete(ix, term, limit=10):
290 with ix.reader() as reader:
291 terms = []
292 for (score, t) in reader.most_distinctive_terms(
293 "content",
294 number=limit,
295 prefix=term.lower(),
296 ):
297 terms.append(t)
298 return terms
299
[end of src/documents/index.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/documents/index.py b/src/documents/index.py
--- a/src/documents/index.py
+++ b/src/documents/index.py
@@ -143,6 +143,9 @@
elif k == "tags__id__all":
for tag_id in v.split(","):
criterias.append(query.Term("tag_id", tag_id))
+ elif k == "tags__id__none":
+ for tag_id in v.split(","):
+ criterias.append(query.Not(query.Term("tag_id", tag_id)))
elif k == "document_type__id":
criterias.append(query.Term("type_id", v))
elif k == "correspondent__isnull":
|
{"golden_diff": "diff --git a/src/documents/index.py b/src/documents/index.py\n--- a/src/documents/index.py\n+++ b/src/documents/index.py\n@@ -143,6 +143,9 @@\n elif k == \"tags__id__all\":\n for tag_id in v.split(\",\"):\n criterias.append(query.Term(\"tag_id\", tag_id))\n+ elif k == \"tags__id__none\":\n+ for tag_id in v.split(\",\"):\n+ criterias.append(query.Not(query.Term(\"tag_id\", tag_id)))\n elif k == \"document_type__id\":\n criterias.append(query.Term(\"type_id\", v))\n elif k == \"correspondent__isnull\":\n", "issue": "[BUG] Filtering is inconsistent: tag exclusion does not apply with search term\n### Description\n\nFiltering documents is not working as expected in some cases.\r\n\r\nWhen filtering for tags, it is possible to include/exclude or exactly match tags. That functionality is lost when using a search term at the same time. I assume that this is not intended behaviour.\n\n### Steps to reproduce\n\n1. Go to `Documents`\r\n2. Enter a search term for filtering documents by that search term. This works fine.\r\n3. Exclude a tag from the search results. The tag is not excluded, when a search term was entered.\n\n### Webserver logs\n\n```bash\nDoes not apply\n```\n\n\n### Browser logs\n\n_No response_\n\n### Paperless-ngx version\n\n1.10.2\n\n### Host OS\n\nUbuntu 22.04\n\n### Installation method\n\nDocker - official image\n\n### Browser\n\nFirefox\n\n### Configuration changes\n\n_No response_\n\n### Other\n\n_No response_\n", "before_files": [{"content": "import logging\nimport math\nimport os\nfrom contextlib import contextmanager\n\nfrom dateutil.parser import isoparse\nfrom django.conf import settings\nfrom documents.models import Document\nfrom whoosh import classify\nfrom whoosh import highlight\nfrom whoosh import query\nfrom whoosh.fields import BOOLEAN\nfrom whoosh.fields import DATETIME\nfrom whoosh.fields import KEYWORD\nfrom whoosh.fields import NUMERIC\nfrom whoosh.fields import Schema\nfrom whoosh.fields import TEXT\nfrom whoosh.highlight import HtmlFormatter\nfrom whoosh.index import create_in\nfrom whoosh.index import exists_in\nfrom whoosh.index import open_dir\nfrom whoosh.qparser import MultifieldParser\nfrom whoosh.qparser.dateparse import DateParserPlugin\nfrom whoosh.searching import ResultsPage\nfrom whoosh.searching import Searcher\nfrom whoosh.writing import AsyncWriter\n\nlogger = logging.getLogger(\"paperless.index\")\n\n\ndef get_schema():\n return Schema(\n id=NUMERIC(stored=True, unique=True),\n title=TEXT(sortable=True),\n content=TEXT(),\n asn=NUMERIC(sortable=True),\n correspondent=TEXT(sortable=True),\n correspondent_id=NUMERIC(),\n has_correspondent=BOOLEAN(),\n tag=KEYWORD(commas=True, scorable=True, lowercase=True),\n tag_id=KEYWORD(commas=True, scorable=True),\n has_tag=BOOLEAN(),\n type=TEXT(sortable=True),\n type_id=NUMERIC(),\n has_type=BOOLEAN(),\n created=DATETIME(sortable=True),\n modified=DATETIME(sortable=True),\n added=DATETIME(sortable=True),\n path=TEXT(sortable=True),\n path_id=NUMERIC(),\n has_path=BOOLEAN(),\n )\n\n\ndef open_index(recreate=False):\n try:\n if exists_in(settings.INDEX_DIR) and not recreate:\n return open_dir(settings.INDEX_DIR, schema=get_schema())\n except Exception:\n logger.exception(\"Error while opening the index, recreating.\")\n\n if not os.path.isdir(settings.INDEX_DIR):\n os.makedirs(settings.INDEX_DIR, exist_ok=True)\n return create_in(settings.INDEX_DIR, get_schema())\n\n\n@contextmanager\ndef open_index_writer(optimize=False):\n writer = AsyncWriter(open_index())\n\n try:\n yield writer\n except Exception as e:\n logger.exception(str(e))\n writer.cancel()\n finally:\n writer.commit(optimize=optimize)\n\n\n@contextmanager\ndef open_index_searcher():\n searcher = open_index().searcher()\n\n try:\n yield searcher\n finally:\n searcher.close()\n\n\ndef update_document(writer, doc):\n tags = \",\".join([t.name for t in doc.tags.all()])\n tags_ids = \",\".join([str(t.id) for t in doc.tags.all()])\n writer.update_document(\n id=doc.pk,\n title=doc.title,\n content=doc.content,\n correspondent=doc.correspondent.name if doc.correspondent else None,\n correspondent_id=doc.correspondent.id if doc.correspondent else None,\n has_correspondent=doc.correspondent is not None,\n tag=tags if tags else None,\n tag_id=tags_ids if tags_ids else None,\n has_tag=len(tags) > 0,\n type=doc.document_type.name if doc.document_type else None,\n type_id=doc.document_type.id if doc.document_type else None,\n has_type=doc.document_type is not None,\n created=doc.created,\n added=doc.added,\n asn=doc.archive_serial_number,\n modified=doc.modified,\n path=doc.storage_path.name if doc.storage_path else None,\n path_id=doc.storage_path.id if doc.storage_path else None,\n has_path=doc.storage_path is not None,\n )\n\n\ndef remove_document(writer, doc):\n remove_document_by_id(writer, doc.pk)\n\n\ndef remove_document_by_id(writer, doc_id):\n writer.delete_by_term(\"id\", doc_id)\n\n\ndef add_or_update_document(document):\n with open_index_writer() as writer:\n update_document(writer, document)\n\n\ndef remove_document_from_index(document):\n with open_index_writer() as writer:\n remove_document(writer, document)\n\n\nclass DelayedQuery:\n def _get_query(self):\n raise NotImplementedError()\n\n def _get_query_filter(self):\n criterias = []\n for k, v in self.query_params.items():\n if k == \"correspondent__id\":\n criterias.append(query.Term(\"correspondent_id\", v))\n elif k == \"tags__id__all\":\n for tag_id in v.split(\",\"):\n criterias.append(query.Term(\"tag_id\", tag_id))\n elif k == \"document_type__id\":\n criterias.append(query.Term(\"type_id\", v))\n elif k == \"correspondent__isnull\":\n criterias.append(query.Term(\"has_correspondent\", v == \"false\"))\n elif k == \"is_tagged\":\n criterias.append(query.Term(\"has_tag\", v == \"true\"))\n elif k == \"document_type__isnull\":\n criterias.append(query.Term(\"has_type\", v == \"false\"))\n elif k == \"created__date__lt\":\n criterias.append(\n query.DateRange(\"created\", start=None, end=isoparse(v)),\n )\n elif k == \"created__date__gt\":\n criterias.append(\n query.DateRange(\"created\", start=isoparse(v), end=None),\n )\n elif k == \"added__date__gt\":\n criterias.append(query.DateRange(\"added\", start=isoparse(v), end=None))\n elif k == \"added__date__lt\":\n criterias.append(query.DateRange(\"added\", start=None, end=isoparse(v)))\n elif k == \"storage_path__id\":\n criterias.append(query.Term(\"path_id\", v))\n elif k == \"storage_path__isnull\":\n criterias.append(query.Term(\"has_path\", v == \"false\"))\n\n if len(criterias) > 0:\n return query.And(criterias)\n else:\n return None\n\n def _get_query_sortedby(self):\n if \"ordering\" not in self.query_params:\n return None, False\n\n field: str = self.query_params[\"ordering\"]\n\n sort_fields_map = {\n \"created\": \"created\",\n \"modified\": \"modified\",\n \"added\": \"added\",\n \"title\": \"title\",\n \"correspondent__name\": \"correspondent\",\n \"document_type__name\": \"type\",\n \"archive_serial_number\": \"asn\",\n }\n\n if field.startswith(\"-\"):\n field = field[1:]\n reverse = True\n else:\n reverse = False\n\n if field not in sort_fields_map:\n return None, False\n else:\n return sort_fields_map[field], reverse\n\n def __init__(self, searcher: Searcher, query_params, page_size):\n self.searcher = searcher\n self.query_params = query_params\n self.page_size = page_size\n self.saved_results = dict()\n self.first_score = None\n\n def __len__(self):\n page = self[0:1]\n return len(page)\n\n def __getitem__(self, item):\n if item.start in self.saved_results:\n return self.saved_results[item.start]\n\n q, mask = self._get_query()\n sortedby, reverse = self._get_query_sortedby()\n\n page: ResultsPage = self.searcher.search_page(\n q,\n mask=mask,\n filter=self._get_query_filter(),\n pagenum=math.floor(item.start / self.page_size) + 1,\n pagelen=self.page_size,\n sortedby=sortedby,\n reverse=reverse,\n )\n page.results.fragmenter = highlight.ContextFragmenter(surround=50)\n page.results.formatter = HtmlFormatter(tagname=\"span\", between=\" ... \")\n\n if not self.first_score and len(page.results) > 0 and sortedby is None:\n self.first_score = page.results[0].score\n\n page.results.top_n = list(\n map(\n lambda hit: (\n (hit[0] / self.first_score) if self.first_score else None,\n hit[1],\n ),\n page.results.top_n,\n ),\n )\n\n self.saved_results[item.start] = page\n\n return page\n\n\nclass DelayedFullTextQuery(DelayedQuery):\n def _get_query(self):\n q_str = self.query_params[\"query\"]\n qp = MultifieldParser(\n [\"content\", \"title\", \"correspondent\", \"tag\", \"type\"],\n self.searcher.ixreader.schema,\n )\n qp.add_plugin(DateParserPlugin())\n q = qp.parse(q_str)\n\n corrected = self.searcher.correct_query(q, q_str)\n if corrected.query != q:\n corrected.query = corrected.string\n\n return q, None\n\n\nclass DelayedMoreLikeThisQuery(DelayedQuery):\n def _get_query(self):\n more_like_doc_id = int(self.query_params[\"more_like_id\"])\n content = Document.objects.get(id=more_like_doc_id).content\n\n docnum = self.searcher.document_number(id=more_like_doc_id)\n kts = self.searcher.key_terms_from_text(\n \"content\",\n content,\n numterms=20,\n model=classify.Bo1Model,\n normalize=False,\n )\n q = query.Or(\n [query.Term(\"content\", word, boost=weight) for word, weight in kts],\n )\n mask = {docnum}\n\n return q, mask\n\n\ndef autocomplete(ix, term, limit=10):\n with ix.reader() as reader:\n terms = []\n for (score, t) in reader.most_distinctive_terms(\n \"content\",\n number=limit,\n prefix=term.lower(),\n ):\n terms.append(t)\n return terms\n", "path": "src/documents/index.py"}]}
| 3,654 | 147 |
gh_patches_debug_1488
|
rasdani/github-patches
|
git_diff
|
google__openhtf-1112
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Unused `six` import in monitor code
In `openhtf/core/monitors.py`, it looks like there is an unused import of the `six` module:
https://github.com/google/openhtf/blob/c85fb069a1ce407e82bb47a8fb1b64220e974c5f/openhtf/core/monitors.py#L58
If the aforementioned import is in fact not needed, then it should be deleted.
</issue>
<code>
[start of openhtf/core/monitors.py]
1 # Copyright 2014 Google Inc. All Rights Reserved.
2
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6
7 # http://www.apache.org/licenses/LICENSE-2.0
8
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14 """Monitors provide a mechanism for periodically collecting a measurement.
15
16 Monitors are implemented similar to phase functions - they are decorated
17 with plugs.plug() to pass plugs in. The return value of a monitor
18 function, however, will be used to append a value to a measurement.
19
20 Monitors by default poll at a rate of 1 second between invocations of
21 the monitor function. The poll interval (given in milliseconds) determines the
22 approximate frequency at which values will be sampled. A sample is considered
23 to have been taken at the time when the monitor function *returns*, not when
24 it is called.
25
26 The approximate average duration of calls to the monitor function is taken into
27 account, so that samples are obtained on as close to interval_ms boundaries as
28 can be. A poll interval of 0 will cause the monitor function to be called in a
29 tight loop with no delays.
30
31 Example:
32
33 @plugs.plug(current_meter=current_meter.CurrentMeter)
34 def CurrentMonitor(test, current_meter):
35 return current_meter.GetReading()
36
37 @monitors.monitors('current_draw', CurrentMonitor, units=units.AMPERE)
38 def MyPhase(test):
39 # Do some stuff for a while...
40
41 # MyPhase will have a dimensioned measurement on it, with units of 'AMPERE' and
42 # a single dimension of 'MILLISECONDS', and will have values for roughly every
43 # second while MyPhase was executing.
44 """
45
46 import functools
47 import inspect
48 import time
49 from typing import Any, Callable, Dict, Optional, Text
50
51 import openhtf
52 from openhtf import plugs
53 from openhtf.core import measurements
54 from openhtf.core import phase_descriptor
55 from openhtf.core import test_state as core_test_state
56 from openhtf.util import threads
57 from openhtf.util import units as uom
58 import six
59
60
61 class _MonitorThread(threads.KillableThread):
62 """Background thread that runs a monitor."""
63
64 daemon = True
65
66 def __init__(self, measurement_name: Text,
67 monitor_desc: phase_descriptor.PhaseDescriptor,
68 extra_kwargs: Dict[Any, Any],
69 test_state: core_test_state.TestState, interval_ms: int):
70 super(_MonitorThread,
71 self).__init__(name='%s_MonitorThread' % measurement_name)
72 self.measurement_name = measurement_name
73 self.monitor_desc = monitor_desc
74 self.test_state = test_state
75 self.interval_ms = interval_ms
76 self.extra_kwargs = extra_kwargs
77
78 def get_value(self) -> Any:
79 argspec = inspect.getfullargspec(self.monitor_desc.func)
80 argspec_args = argspec.args
81 argspec_keywords = argspec.varkw
82 if argspec_keywords:
83 # Monitor phase takes **kwargs, so just pass everything in.
84 kwargs = self.extra_kwargs
85 else:
86 # Only pass in args that the monitor phase takes.
87 kwargs = {
88 arg: val for arg, val in self.extra_kwargs if arg in argspec_args
89 }
90 return self.monitor_desc.with_args(**kwargs)(self.test_state)
91
92 def _thread_proc(self):
93 measurement = getattr(self.test_state.test_api.measurements,
94 self.measurement_name)
95 start_time = time.time()
96
97 # Special case tight-loop monitoring.
98 if not self.interval_ms:
99 while True:
100 measurement[(time.time() - start_time) * 1000] = self.get_value()
101
102 # Helper to take sample, return sample number and sample duration.
103 def _take_sample():
104 pre_time, value, post_time = time.time(), self.get_value(), time.time()
105 measurement[(post_time - start_time) * 1000] = value
106 return (int((post_time - start_time) * 1000 / self.interval_ms),
107 (post_time - pre_time) * 1000)
108
109 # Track the last sample number, and an approximation of the mean time
110 # it takes to sample (so we can account for it in how long we sleep).
111 last_sample, mean_sample_ms = _take_sample()
112 while True:
113 # Find what sample number (float) we would be on if we sampled now.
114 current_time = time.time()
115 new_sample = ((((current_time - start_time) * 1000) + mean_sample_ms) /
116 self.interval_ms)
117 if new_sample < last_sample + 1:
118 time.sleep(start_time - current_time +
119 ((last_sample + 1) * self.interval_ms / 1000.0) -
120 (mean_sample_ms / 1000.0))
121 continue
122 elif new_sample > last_sample + 2:
123 self.test_state.state_logger.warning(
124 'Monitor for "%s" skipping %s sample(s).', self.measurement_name,
125 new_sample - last_sample - 1)
126 last_sample, cur_sample_ms = _take_sample()
127 # Approximate 10-element sliding window average.
128 mean_sample_ms = ((9 * mean_sample_ms) + cur_sample_ms) / 10.0
129
130
131 def monitors(
132 measurement_name: Text,
133 monitor_func: phase_descriptor.PhaseT,
134 units: Optional[uom.UnitDescriptor] = None,
135 poll_interval_ms: int = 1000
136 ) -> Callable[[phase_descriptor.PhaseT], phase_descriptor.PhaseDescriptor]:
137 """Returns a decorator that wraps a phase with a monitor."""
138 monitor_desc = openhtf.PhaseDescriptor.wrap_or_copy(monitor_func)
139
140 def wrapper(
141 phase_func: phase_descriptor.PhaseT) -> phase_descriptor.PhaseDescriptor:
142 phase_desc = openhtf.PhaseDescriptor.wrap_or_copy(phase_func)
143
144 # Re-key this dict so we don't have to worry about collisions with
145 # plug.plug() decorators on the phase function. Since we aren't
146 # updating kwargs here, we don't have to worry about collisions with
147 # kwarg names.
148 monitor_plugs = {('_' * idx) + measurement_name + '_monitor': plug.cls
149 for idx, plug in enumerate(monitor_desc.plugs, start=1)}
150
151 @openhtf.PhaseOptions(requires_state=True)
152 @plugs.plug(update_kwargs=False, **monitor_plugs)
153 @openhtf.measures(
154 measurements.Measurement(measurement_name).with_units(
155 units).with_dimensions(uom.MILLISECOND))
156 @functools.wraps(phase_desc.func)
157 def monitored_phase_func(test_state, *args, **kwargs):
158 # Start monitor thread, it will run monitor_desc periodically.
159 monitor_thread = _MonitorThread(measurement_name, monitor_desc,
160 phase_desc.extra_kwargs, test_state,
161 poll_interval_ms)
162 monitor_thread.start()
163 try:
164 return phase_desc(test_state, *args, **kwargs)
165 finally:
166 monitor_thread.kill()
167 monitor_thread.join()
168
169 return monitored_phase_func
170
171 return wrapper
172
[end of openhtf/core/monitors.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/openhtf/core/monitors.py b/openhtf/core/monitors.py
--- a/openhtf/core/monitors.py
+++ b/openhtf/core/monitors.py
@@ -55,7 +55,6 @@
from openhtf.core import test_state as core_test_state
from openhtf.util import threads
from openhtf.util import units as uom
-import six
class _MonitorThread(threads.KillableThread):
|
{"golden_diff": "diff --git a/openhtf/core/monitors.py b/openhtf/core/monitors.py\n--- a/openhtf/core/monitors.py\n+++ b/openhtf/core/monitors.py\n@@ -55,7 +55,6 @@\n from openhtf.core import test_state as core_test_state\n from openhtf.util import threads\n from openhtf.util import units as uom\n-import six\n \n \n class _MonitorThread(threads.KillableThread):\n", "issue": "Unused `six` import in monitor code\nIn `openhtf/core/monitors.py`, it looks like there is an unused import of the `six` module:\r\nhttps://github.com/google/openhtf/blob/c85fb069a1ce407e82bb47a8fb1b64220e974c5f/openhtf/core/monitors.py#L58\r\n\r\nIf the aforementioned import is in fact not needed, then it should be deleted.\n", "before_files": [{"content": "# Copyright 2014 Google Inc. All Rights Reserved.\n\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n\n# http://www.apache.org/licenses/LICENSE-2.0\n\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\"\"\"Monitors provide a mechanism for periodically collecting a measurement.\n\nMonitors are implemented similar to phase functions - they are decorated\nwith plugs.plug() to pass plugs in. The return value of a monitor\nfunction, however, will be used to append a value to a measurement.\n\nMonitors by default poll at a rate of 1 second between invocations of\nthe monitor function. The poll interval (given in milliseconds) determines the\napproximate frequency at which values will be sampled. A sample is considered\nto have been taken at the time when the monitor function *returns*, not when\nit is called.\n\nThe approximate average duration of calls to the monitor function is taken into\naccount, so that samples are obtained on as close to interval_ms boundaries as\ncan be. A poll interval of 0 will cause the monitor function to be called in a\ntight loop with no delays.\n\nExample:\n\[email protected](current_meter=current_meter.CurrentMeter)\ndef CurrentMonitor(test, current_meter):\n return current_meter.GetReading()\n\[email protected]('current_draw', CurrentMonitor, units=units.AMPERE)\ndef MyPhase(test):\n # Do some stuff for a while...\n\n# MyPhase will have a dimensioned measurement on it, with units of 'AMPERE' and\n# a single dimension of 'MILLISECONDS', and will have values for roughly every\n# second while MyPhase was executing.\n\"\"\"\n\nimport functools\nimport inspect\nimport time\nfrom typing import Any, Callable, Dict, Optional, Text\n\nimport openhtf\nfrom openhtf import plugs\nfrom openhtf.core import measurements\nfrom openhtf.core import phase_descriptor\nfrom openhtf.core import test_state as core_test_state\nfrom openhtf.util import threads\nfrom openhtf.util import units as uom\nimport six\n\n\nclass _MonitorThread(threads.KillableThread):\n \"\"\"Background thread that runs a monitor.\"\"\"\n\n daemon = True\n\n def __init__(self, measurement_name: Text,\n monitor_desc: phase_descriptor.PhaseDescriptor,\n extra_kwargs: Dict[Any, Any],\n test_state: core_test_state.TestState, interval_ms: int):\n super(_MonitorThread,\n self).__init__(name='%s_MonitorThread' % measurement_name)\n self.measurement_name = measurement_name\n self.monitor_desc = monitor_desc\n self.test_state = test_state\n self.interval_ms = interval_ms\n self.extra_kwargs = extra_kwargs\n\n def get_value(self) -> Any:\n argspec = inspect.getfullargspec(self.monitor_desc.func)\n argspec_args = argspec.args\n argspec_keywords = argspec.varkw\n if argspec_keywords:\n # Monitor phase takes **kwargs, so just pass everything in.\n kwargs = self.extra_kwargs\n else:\n # Only pass in args that the monitor phase takes.\n kwargs = {\n arg: val for arg, val in self.extra_kwargs if arg in argspec_args\n }\n return self.monitor_desc.with_args(**kwargs)(self.test_state)\n\n def _thread_proc(self):\n measurement = getattr(self.test_state.test_api.measurements,\n self.measurement_name)\n start_time = time.time()\n\n # Special case tight-loop monitoring.\n if not self.interval_ms:\n while True:\n measurement[(time.time() - start_time) * 1000] = self.get_value()\n\n # Helper to take sample, return sample number and sample duration.\n def _take_sample():\n pre_time, value, post_time = time.time(), self.get_value(), time.time()\n measurement[(post_time - start_time) * 1000] = value\n return (int((post_time - start_time) * 1000 / self.interval_ms),\n (post_time - pre_time) * 1000)\n\n # Track the last sample number, and an approximation of the mean time\n # it takes to sample (so we can account for it in how long we sleep).\n last_sample, mean_sample_ms = _take_sample()\n while True:\n # Find what sample number (float) we would be on if we sampled now.\n current_time = time.time()\n new_sample = ((((current_time - start_time) * 1000) + mean_sample_ms) /\n self.interval_ms)\n if new_sample < last_sample + 1:\n time.sleep(start_time - current_time +\n ((last_sample + 1) * self.interval_ms / 1000.0) -\n (mean_sample_ms / 1000.0))\n continue\n elif new_sample > last_sample + 2:\n self.test_state.state_logger.warning(\n 'Monitor for \"%s\" skipping %s sample(s).', self.measurement_name,\n new_sample - last_sample - 1)\n last_sample, cur_sample_ms = _take_sample()\n # Approximate 10-element sliding window average.\n mean_sample_ms = ((9 * mean_sample_ms) + cur_sample_ms) / 10.0\n\n\ndef monitors(\n measurement_name: Text,\n monitor_func: phase_descriptor.PhaseT,\n units: Optional[uom.UnitDescriptor] = None,\n poll_interval_ms: int = 1000\n) -> Callable[[phase_descriptor.PhaseT], phase_descriptor.PhaseDescriptor]:\n \"\"\"Returns a decorator that wraps a phase with a monitor.\"\"\"\n monitor_desc = openhtf.PhaseDescriptor.wrap_or_copy(monitor_func)\n\n def wrapper(\n phase_func: phase_descriptor.PhaseT) -> phase_descriptor.PhaseDescriptor:\n phase_desc = openhtf.PhaseDescriptor.wrap_or_copy(phase_func)\n\n # Re-key this dict so we don't have to worry about collisions with\n # plug.plug() decorators on the phase function. Since we aren't\n # updating kwargs here, we don't have to worry about collisions with\n # kwarg names.\n monitor_plugs = {('_' * idx) + measurement_name + '_monitor': plug.cls\n for idx, plug in enumerate(monitor_desc.plugs, start=1)}\n\n @openhtf.PhaseOptions(requires_state=True)\n @plugs.plug(update_kwargs=False, **monitor_plugs)\n @openhtf.measures(\n measurements.Measurement(measurement_name).with_units(\n units).with_dimensions(uom.MILLISECOND))\n @functools.wraps(phase_desc.func)\n def monitored_phase_func(test_state, *args, **kwargs):\n # Start monitor thread, it will run monitor_desc periodically.\n monitor_thread = _MonitorThread(measurement_name, monitor_desc,\n phase_desc.extra_kwargs, test_state,\n poll_interval_ms)\n monitor_thread.start()\n try:\n return phase_desc(test_state, *args, **kwargs)\n finally:\n monitor_thread.kill()\n monitor_thread.join()\n\n return monitored_phase_func\n\n return wrapper\n", "path": "openhtf/core/monitors.py"}]}
| 2,672 | 102 |
gh_patches_debug_4424
|
rasdani/github-patches
|
git_diff
|
mozilla__bugbug-2654
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Replace typing.Dict with dict
It is now possible to use `dict` directly instead of `typing.Dict` in type definitions.
</issue>
<code>
[start of setup.py]
1 # -*- coding: utf-8 -*-
2 # This Source Code Form is subject to the terms of the Mozilla Public
3 # License, v. 2.0. If a copy of the MPL was not distributed with this file,
4 # You can obtain one at http://mozilla.org/MPL/2.0/.
5
6 import os
7
8 from setuptools import find_packages, setup
9
10 here = os.path.dirname(__file__)
11
12
13 def read_requirements(file_):
14 with open(os.path.join(here, file_)) as f:
15 return sorted(list(set(line.split("#")[0].strip() for line in f)))
16
17
18 install_requires = read_requirements("requirements.txt")
19
20
21 with open(os.path.join(here, "VERSION")) as f:
22 version = f.read().strip()
23
24 # Read the extra requirements
25 extras = ["nlp", "nn"]
26
27 extras_require = {}
28
29 for extra in extras:
30 extras_require[extra] = read_requirements("extra-%s-requirements.txt" % extra)
31
32
33 setup(
34 name="bugbug",
35 version=version,
36 description="ML tools for Mozilla projects",
37 author="Marco Castelluccio",
38 author_email="[email protected]",
39 install_requires=install_requires,
40 extras_require=extras_require,
41 packages=find_packages(exclude=["contrib", "docs", "tests"]),
42 include_package_data=True,
43 license="MPL2",
44 entry_points={
45 "console_scripts": [
46 "bugbug-data-commits = scripts.commit_retriever:main",
47 "bugbug-data-bugzilla = scripts.bug_retriever:main",
48 "bugbug-data-test-scheduling-history = scripts.test_scheduling_history_retriever:main",
49 "bugbug-data-revisions = scripts.revision_retriever:main",
50 "bugbug-train = scripts.trainer:main",
51 "bugbug-train-similarity = scripts.similarity_trainer:main",
52 "bugbug-check = scripts.check:main",
53 "bugbug-microannotate-generate = scripts.microannotate_generator:main",
54 "bugbug-classify-commit = scripts.commit_classifier:main",
55 "bugbug-classify-bug = scripts.bug_classifier:main",
56 "bugbug-regressor-finder = scripts.regressor_finder:main",
57 "bugbug-retrieve-training-metrics = scripts.retrieve_training_metrics:main",
58 "bugbug-analyze-training-metrics = scripts.analyze_training_metrics:main",
59 "bugbug-check-all-metrics = scripts.check_all_metrics:main",
60 "bugbug-past-bugs-by-unit = scripts.past_bugs_by_unit:main",
61 "bugbug-testing-policy-stats = scripts.testing_policy_stats:main",
62 "bugbug-generate-landings-risk-report = scripts.generate_landings_risk_report:main",
63 "bugbug-shadow-scheduler-stats = scripts.shadow_scheduler_stats:main",
64 "bugbug-data-github = scripts.github_issue_retriever:main",
65 ]
66 },
67 classifiers=[
68 "Programming Language :: Python :: 3.7",
69 "Programming Language :: Python :: 3.8",
70 "Programming Language :: Python :: 3.9",
71 "Programming Language :: Python :: 3 :: Only",
72 "License :: OSI Approved :: Mozilla Public License 2.0 (MPL 2.0)",
73 ],
74 )
75
[end of setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -65,8 +65,6 @@
]
},
classifiers=[
- "Programming Language :: Python :: 3.7",
- "Programming Language :: Python :: 3.8",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3 :: Only",
"License :: OSI Approved :: Mozilla Public License 2.0 (MPL 2.0)",
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -65,8 +65,6 @@\n ]\n },\n classifiers=[\n- \"Programming Language :: Python :: 3.7\",\n- \"Programming Language :: Python :: 3.8\",\n \"Programming Language :: Python :: 3.9\",\n \"Programming Language :: Python :: 3 :: Only\",\n \"License :: OSI Approved :: Mozilla Public License 2.0 (MPL 2.0)\",\n", "issue": "Replace typing.Dict with dict\nIt is now possible to use `dict` directly instead of `typing.Dict` in type definitions.\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n# This Source Code Form is subject to the terms of the Mozilla Public\n# License, v. 2.0. If a copy of the MPL was not distributed with this file,\n# You can obtain one at http://mozilla.org/MPL/2.0/.\n\nimport os\n\nfrom setuptools import find_packages, setup\n\nhere = os.path.dirname(__file__)\n\n\ndef read_requirements(file_):\n with open(os.path.join(here, file_)) as f:\n return sorted(list(set(line.split(\"#\")[0].strip() for line in f)))\n\n\ninstall_requires = read_requirements(\"requirements.txt\")\n\n\nwith open(os.path.join(here, \"VERSION\")) as f:\n version = f.read().strip()\n\n# Read the extra requirements\nextras = [\"nlp\", \"nn\"]\n\nextras_require = {}\n\nfor extra in extras:\n extras_require[extra] = read_requirements(\"extra-%s-requirements.txt\" % extra)\n\n\nsetup(\n name=\"bugbug\",\n version=version,\n description=\"ML tools for Mozilla projects\",\n author=\"Marco Castelluccio\",\n author_email=\"[email protected]\",\n install_requires=install_requires,\n extras_require=extras_require,\n packages=find_packages(exclude=[\"contrib\", \"docs\", \"tests\"]),\n include_package_data=True,\n license=\"MPL2\",\n entry_points={\n \"console_scripts\": [\n \"bugbug-data-commits = scripts.commit_retriever:main\",\n \"bugbug-data-bugzilla = scripts.bug_retriever:main\",\n \"bugbug-data-test-scheduling-history = scripts.test_scheduling_history_retriever:main\",\n \"bugbug-data-revisions = scripts.revision_retriever:main\",\n \"bugbug-train = scripts.trainer:main\",\n \"bugbug-train-similarity = scripts.similarity_trainer:main\",\n \"bugbug-check = scripts.check:main\",\n \"bugbug-microannotate-generate = scripts.microannotate_generator:main\",\n \"bugbug-classify-commit = scripts.commit_classifier:main\",\n \"bugbug-classify-bug = scripts.bug_classifier:main\",\n \"bugbug-regressor-finder = scripts.regressor_finder:main\",\n \"bugbug-retrieve-training-metrics = scripts.retrieve_training_metrics:main\",\n \"bugbug-analyze-training-metrics = scripts.analyze_training_metrics:main\",\n \"bugbug-check-all-metrics = scripts.check_all_metrics:main\",\n \"bugbug-past-bugs-by-unit = scripts.past_bugs_by_unit:main\",\n \"bugbug-testing-policy-stats = scripts.testing_policy_stats:main\",\n \"bugbug-generate-landings-risk-report = scripts.generate_landings_risk_report:main\",\n \"bugbug-shadow-scheduler-stats = scripts.shadow_scheduler_stats:main\",\n \"bugbug-data-github = scripts.github_issue_retriever:main\",\n ]\n },\n classifiers=[\n \"Programming Language :: Python :: 3.7\",\n \"Programming Language :: Python :: 3.8\",\n \"Programming Language :: Python :: 3.9\",\n \"Programming Language :: Python :: 3 :: Only\",\n \"License :: OSI Approved :: Mozilla Public License 2.0 (MPL 2.0)\",\n ],\n)\n", "path": "setup.py"}]}
| 1,401 | 111 |
gh_patches_debug_18705
|
rasdani/github-patches
|
git_diff
|
weecology__retriever-147
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Mac App MySQL installations failing based on "Incorrect string value"
MCDB:
```
INSERT INTO MCDB.trapping (site_id, initial_year, final_year, n_sampling_months, trap_nights, months_of_sampling, pitfall_traps, small_traps, large_traps, snap_traps, notes) VALUES (1206, '1995', '1995', '1', '580', 'November', '1', '0', '0', '0', 'each pitfall trapline 100-500 m?; unclear how many or length');
(1366, "Incorrect string value: '\\xB2; unc...' for column 'notes' at row 1")
```
MarineSize (Barnes 2008):
```
INSERT INTO MarineSize.main (record_number, in_ref_id, individual_id, predator, predator_common_name, predator_taxon, predator_lifestage, type_of_feeding_interaction, predator_length, predator_length_unit, predator_dimension_measured, predator_standard_length, predator_fork_length, predator_total_length, predator_tl_fl_sl_conversion_reference, standardised_predator_length, predator_measurement_type, predator_length_mass_conversion_method, predator_length_mass_conversion_reference, predator_quality_of_length_mass_conversion, predator_mass, predator_mass_unit, predator_mass_check, predator_mass_check_diff, predator_ratio_mass_mass, si_predator_mass, diet_coverage, prey, prey_common_name, prey_taxon, prey_length, prey_length_unit, prey_conversion_to_length_method, prey_quality_of_conversion_to_length, prey_conversion_to_length_reference, si_prey_length, prey_dimension_measured, prey_width, prey_width_unit, prey_measurement_type, prey_mass, prey_mass_unit, prey_mass_check, prey_mass_check_diff, prey_ratio_mass_mass, si_prey_mass, prey_conversion_to_mass_method, prey_conversion_to_mass_reference, prey_quality_of_conversion_to_mass, geographic_location, latitude, lonitude, depth, mean_annual_temp, sd_annual_temp, mean_pp, sd_pp, reference, specific_habitat, notes_assumptions) VALUES (1, 'ATSH063', 1, 'Rhizoprionodon terraenovae', 'Atlantic sharpnose shark', 'ectotherm vertebrate', 'adult', 'predacious/piscivorous', 7.8000E+02, 'mm', 'fork length', 7.5433E+02, 7.8000E+02, 9.3990E+02, 'Fishbase (species)', 9.3990E+01, 'individual', 'M=0.0056SL^2.897', 'Bonfil et al. (1990)', 1, 1.5399E+03, 'g', 4.3453E+04, 4.1913E+04, 2.8218E+01, 1.5399E+03, 'all', 'teleosts/molluscs/crustaceans', 'teleosts/molluscs/crustaceans', 'mixed', 1.1259E+02, 'mm', null, 0, null, 1.1259E+01, 'length', null, null, 'individual', 1.4274E+01, 'g', 7.4699E+01, 6.0425E+01, 5.2333E+00, 1.4274E+01, 'M=0.01L^3', 'Generalised', 5, 'Apalachicola Bay, Florida', '29?40\'N', '85?10\'W', 30, 24.1, 4.2, 866, 214, 'Bethea et al (2004)', 'Coastal Bay', null);
(1366, "Incorrect string value: '\\xBA40'N' for column 'latitude' at row 1")
```
McGlinn2010:
```
INSERT INTO McGlinn2010.species (spnum, spcode, family, genus, species, variety, subspecies, spname, binomia_auth, trinomial_auth) VALUES (257, 'seneplat', 'Asteraceae', 'Packera', 'plattensis', '', '', 'Packera plattensis', '(Nutt.) W.A. Weber & A. L?ve', '');
(1366, "Incorrect string value: '\\xF6ve' for column 'binomia_auth' at row 1")
```
All of these datasets install fine using the source installation. When using the .app build from the CLI they also all report:
```
Couldn't create database (unsupported operand type(s) for +: 'NoneType' and 'str'). Trying to continue anyway.
```
but this appears to be reported by all of the datasets, including those that are successfully installed.
</issue>
<code>
[start of setup.py]
1 """Use the following command to install retriever: python setup.py install"""
2
3 from setuptools import setup
4 import platform
5
6 p = platform.platform().lower()
7 extra_includes = []
8 if "darwin" in p:
9 try: import py2app
10 except ImportError: pass
11 extra_includes = []
12 elif "win" in p:
13 try: import py2exe
14 except ImportError: pass
15 import sys
16 extra_includes = ['pyodbc', 'inspect']
17 sys.path.append("C:\\Windows\\winsxs\\x86_microsoft.vc90.crt_1fc8b3b9a1e18e3b_9.0.21022.8_none_bcb86ed6ac711f91")
18 from __init__ import VERSION
19
20
21 def clean_version(v):
22 if v == 'master':
23 return '1.0.0'
24 return v.replace('v', '').replace('.rc', '').replace('.beta', '')
25
26 packages = [
27 'retriever.lib',
28 'retriever.engines',
29 'retriever.app',
30 'retriever',
31 ]
32
33 try:
34 import pymysql
35 mysql_module = 'pymysql'
36 except ImportError:
37 try:
38 import MySQLdb
39 mysql_module = 'MySQLdb'
40 except ImportError:
41 mysql_module = 'pymysql'
42
43 includes = [
44 'xlrd',
45 'wx',
46 mysql_module,
47 'psycopg2',
48 'sqlite3',
49 ] + extra_includes
50
51 excludes = [
52 'pyreadline',
53 'doctest',
54 'optparse',
55 'getopt',
56 'pickle',
57 'calendar',
58 'pdb',
59 'inspect',
60 'email',
61 'pywin', 'pywin.debugger',
62 'pywin.debugger.dbgcon',
63 'pywin.dialogs', 'pywin.dialogs.list',
64 'Tkconstants', 'Tkinter', 'tcl',
65 ]
66
67
68 setup(name='retriever',
69 version=clean_version(VERSION),
70 description='EcoData Retriever',
71 author='Ben Morris',
72 author_email='[email protected]',
73 url='http://www.ecodataretriever.org',
74 packages=packages,
75 package_dir={
76 'retriever':''
77 },
78 entry_points={
79 'console_scripts': [
80 'retriever = retriever.__main__:main',
81 ],
82 },
83 install_requires=[
84 'xlrd',
85 ],
86
87 # py2exe flags
88 console = [{'script': "__main__.py",
89 'dest_base': "retriever",
90 'icon_resources':[(1,'icon.ico')]
91 }],
92 zipfile = None,
93
94 # py2app flags
95 app=['__main__.py'],
96 data_files=[('', ['CITATION'])],
97 setup_requires=['py2app'] if 'darwin' in p else [],
98
99 # options
100 options = {'py2exe': {'bundle_files': 1,
101 'compressed': 2,
102 'optimize': 2,
103 'packages': packages,
104 'includes': includes,
105 'excludes': excludes,
106 },
107 'py2app': {'packages': ['retriever'],
108 'includes': includes,
109 'site_packages': True,
110 'resources': [],
111 'optimize': 2,
112 'argv_emulation': True,
113 'no_chdir': True,
114 },
115 },
116 )
117
118
119 try:
120 from compile import compile
121 compile()
122 except:
123 pass
124
[end of setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -97,6 +97,7 @@
setup_requires=['py2app'] if 'darwin' in p else [],
# options
+ # optimize is set to 1 of py2app to avoid errors with pymysql
options = {'py2exe': {'bundle_files': 1,
'compressed': 2,
'optimize': 2,
@@ -108,7 +109,7 @@
'includes': includes,
'site_packages': True,
'resources': [],
- 'optimize': 2,
+ 'optimize': 1,
'argv_emulation': True,
'no_chdir': True,
},
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -97,6 +97,7 @@\n setup_requires=['py2app'] if 'darwin' in p else [],\n \n # options\n+ # optimize is set to 1 of py2app to avoid errors with pymysql\n options = {'py2exe': {'bundle_files': 1,\n 'compressed': 2,\n 'optimize': 2,\n@@ -108,7 +109,7 @@\n 'includes': includes,\n 'site_packages': True,\n 'resources': [],\n- 'optimize': 2,\n+ 'optimize': 1,\n 'argv_emulation': True,\n 'no_chdir': True,\n },\n", "issue": "Mac App MySQL installations failing based on \"Incorrect string value\"\nMCDB:\n\n```\nINSERT INTO MCDB.trapping (site_id, initial_year, final_year, n_sampling_months, trap_nights, months_of_sampling, pitfall_traps, small_traps, large_traps, snap_traps, notes) VALUES (1206, '1995', '1995', '1', '580', 'November', '1', '0', '0', '0', 'each pitfall trapline 100-500 m?; unclear how many or length');\n(1366, \"Incorrect string value: '\\\\xB2; unc...' for column 'notes' at row 1\")\n```\n\nMarineSize (Barnes 2008):\n\n```\nINSERT INTO MarineSize.main (record_number, in_ref_id, individual_id, predator, predator_common_name, predator_taxon, predator_lifestage, type_of_feeding_interaction, predator_length, predator_length_unit, predator_dimension_measured, predator_standard_length, predator_fork_length, predator_total_length, predator_tl_fl_sl_conversion_reference, standardised_predator_length, predator_measurement_type, predator_length_mass_conversion_method, predator_length_mass_conversion_reference, predator_quality_of_length_mass_conversion, predator_mass, predator_mass_unit, predator_mass_check, predator_mass_check_diff, predator_ratio_mass_mass, si_predator_mass, diet_coverage, prey, prey_common_name, prey_taxon, prey_length, prey_length_unit, prey_conversion_to_length_method, prey_quality_of_conversion_to_length, prey_conversion_to_length_reference, si_prey_length, prey_dimension_measured, prey_width, prey_width_unit, prey_measurement_type, prey_mass, prey_mass_unit, prey_mass_check, prey_mass_check_diff, prey_ratio_mass_mass, si_prey_mass, prey_conversion_to_mass_method, prey_conversion_to_mass_reference, prey_quality_of_conversion_to_mass, geographic_location, latitude, lonitude, depth, mean_annual_temp, sd_annual_temp, mean_pp, sd_pp, reference, specific_habitat, notes_assumptions) VALUES (1, 'ATSH063', 1, 'Rhizoprionodon terraenovae', 'Atlantic sharpnose shark', 'ectotherm vertebrate', 'adult', 'predacious/piscivorous', 7.8000E+02, 'mm', 'fork length', 7.5433E+02, 7.8000E+02, 9.3990E+02, 'Fishbase (species)', 9.3990E+01, 'individual', 'M=0.0056SL^2.897', 'Bonfil et al. (1990)', 1, 1.5399E+03, 'g', 4.3453E+04, 4.1913E+04, 2.8218E+01, 1.5399E+03, 'all', 'teleosts/molluscs/crustaceans', 'teleosts/molluscs/crustaceans', 'mixed', 1.1259E+02, 'mm', null, 0, null, 1.1259E+01, 'length', null, null, 'individual', 1.4274E+01, 'g', 7.4699E+01, 6.0425E+01, 5.2333E+00, 1.4274E+01, 'M=0.01L^3', 'Generalised', 5, 'Apalachicola Bay, Florida', '29?40\\'N', '85?10\\'W', 30, 24.1, 4.2, 866, 214, 'Bethea et al (2004)', 'Coastal Bay', null);\n(1366, \"Incorrect string value: '\\\\xBA40'N' for column 'latitude' at row 1\")\n```\n\nMcGlinn2010:\n\n```\nINSERT INTO McGlinn2010.species (spnum, spcode, family, genus, species, variety, subspecies, spname, binomia_auth, trinomial_auth) VALUES (257, 'seneplat', 'Asteraceae', 'Packera', 'plattensis', '', '', 'Packera plattensis', '(Nutt.) W.A. Weber & A. L?ve', '');\n(1366, \"Incorrect string value: '\\\\xF6ve' for column 'binomia_auth' at row 1\")\n```\n\nAll of these datasets install fine using the source installation. When using the .app build from the CLI they also all report:\n\n```\nCouldn't create database (unsupported operand type(s) for +: 'NoneType' and 'str'). Trying to continue anyway.\n```\n\nbut this appears to be reported by all of the datasets, including those that are successfully installed.\n\n", "before_files": [{"content": "\"\"\"Use the following command to install retriever: python setup.py install\"\"\"\n\nfrom setuptools import setup\nimport platform\n\np = platform.platform().lower()\nextra_includes = []\nif \"darwin\" in p:\n try: import py2app\n except ImportError: pass\n extra_includes = []\nelif \"win\" in p:\n try: import py2exe\n except ImportError: pass\n import sys\n extra_includes = ['pyodbc', 'inspect']\n sys.path.append(\"C:\\\\Windows\\\\winsxs\\\\x86_microsoft.vc90.crt_1fc8b3b9a1e18e3b_9.0.21022.8_none_bcb86ed6ac711f91\")\nfrom __init__ import VERSION\n\n\ndef clean_version(v):\n if v == 'master':\n return '1.0.0'\n return v.replace('v', '').replace('.rc', '').replace('.beta', '')\n\npackages = [\n 'retriever.lib',\n 'retriever.engines',\n 'retriever.app',\n 'retriever',\n ]\n\ntry:\n import pymysql\n mysql_module = 'pymysql'\nexcept ImportError:\n try:\n import MySQLdb\n mysql_module = 'MySQLdb'\n except ImportError:\n mysql_module = 'pymysql'\n\nincludes = [\n 'xlrd',\n 'wx',\n mysql_module,\n 'psycopg2',\n 'sqlite3',\n ] + extra_includes\n \nexcludes = [\n 'pyreadline',\n 'doctest',\n 'optparse',\n 'getopt',\n 'pickle',\n 'calendar',\n 'pdb',\n 'inspect',\n 'email',\n 'pywin', 'pywin.debugger',\n 'pywin.debugger.dbgcon',\n 'pywin.dialogs', 'pywin.dialogs.list',\n 'Tkconstants', 'Tkinter', 'tcl',\n ]\n\n\nsetup(name='retriever',\n version=clean_version(VERSION),\n description='EcoData Retriever',\n author='Ben Morris',\n author_email='[email protected]',\n url='http://www.ecodataretriever.org',\n packages=packages,\n package_dir={\n 'retriever':''\n },\n entry_points={\n 'console_scripts': [\n 'retriever = retriever.__main__:main',\n ],\n },\n install_requires=[\n 'xlrd',\n ],\n\n # py2exe flags\n console = [{'script': \"__main__.py\",\n 'dest_base': \"retriever\",\n 'icon_resources':[(1,'icon.ico')]\n }],\n zipfile = None,\n\n # py2app flags\n app=['__main__.py'],\n data_files=[('', ['CITATION'])],\n setup_requires=['py2app'] if 'darwin' in p else [],\n\n # options\n options = {'py2exe': {'bundle_files': 1,\n 'compressed': 2,\n 'optimize': 2,\n 'packages': packages,\n 'includes': includes,\n 'excludes': excludes,\n },\n 'py2app': {'packages': ['retriever'],\n 'includes': includes,\n 'site_packages': True,\n 'resources': [],\n 'optimize': 2,\n 'argv_emulation': True,\n 'no_chdir': True,\n },\n },\n )\n\n\ntry:\n from compile import compile\n compile()\nexcept:\n pass\n", "path": "setup.py"}]}
| 2,687 | 167 |
gh_patches_debug_24527
|
rasdani/github-patches
|
git_diff
|
cloud-custodian__cloud-custodian-7570
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
NoneType Issue
I dropped a yaml file into a new OU/SubOU and its not working, though it works in other OUs just fine. Nothing was changed in the file but I am still getting this error, not sure why.
```
Traceback (most recent call last):
File "/root/.pyenv/versions/3.9.12/bin/custodian", line 8, in <module>
sys.exit(main())
File "/root/.pyenv/versions/3.9.12/lib/python3.9/site-packages/c7n/cli.py", line 363, in main
command(config)
File "/root/.pyenv/versions/3.9.12/lib/python3.9/site-packages/c7n/commands.py", line 219, in validate
structure.validate(data)
File "/root/.pyenv/versions/3.9.12/lib/python3.9/site-packages/c7n/structure.py", line 48, in validate
self.validate_policy(p)
File "/root/.pyenv/versions/3.9.12/lib/python3.9/site-packages/c7n/structure.py", line 78, in validate_policy
for a in p.get('actions', ()):
TypeError: 'NoneType' object is not iterable
```
</issue>
<code>
[start of c7n/structure.py]
1 # Copyright The Cloud Custodian Authors.
2 # SPDX-License-Identifier: Apache-2.0
3
4 import json
5
6 from c7n.exceptions import PolicyValidationError
7
8
9 class StructureParser:
10 """Provide fast validation and inspection of a policy file.
11
12 Intent is to provide more humane validation for top level errors
13 instead of printing full schema as error message.
14 """
15 allowed_file_keys = {'vars', 'policies'}
16 required_policy_keys = {'name', 'resource'}
17 allowed_policy_keys = {'name', 'resource', 'title', 'description', 'mode',
18 'tags', 'max-resources', 'metadata', 'query',
19 'filters', 'actions', 'source', 'conditions',
20 # legacy keys subject to deprecation.
21 'region', 'start', 'end', 'tz', 'max-resources-percent',
22 'comments', 'comment'}
23
24 def validate(self, data):
25 if not isinstance(data, dict):
26 raise PolicyValidationError((
27 "Policy file top level data structure "
28 "should be a mapping/dict, instead found:%s") % (
29 type(data).__name__))
30 dkeys = set(data.keys())
31
32 extra = dkeys.difference(self.allowed_file_keys)
33 if extra:
34 raise PolicyValidationError((
35 'Policy files top level keys are %s, found extra: %s' % (
36 ', '.join(self.allowed_file_keys),
37 ', '.join(extra))))
38
39 if 'policies' not in data:
40 raise PolicyValidationError("`policies` list missing")
41
42 pdata = data.get('policies', [])
43 if not isinstance(pdata, list):
44 raise PolicyValidationError((
45 '`policies` key should be an array/list found: %s' % (
46 type(pdata).__name__)))
47 for p in pdata:
48 self.validate_policy(p)
49
50 def validate_policy(self, p):
51 if not isinstance(p, dict):
52 raise PolicyValidationError((
53 'policy must be a dictionary/mapping found:%s policy:\n %s' % (
54 type(p).__name__, json.dumps(p, indent=2))))
55 pkeys = set(p)
56 if self.required_policy_keys.difference(pkeys):
57 raise PolicyValidationError(
58 'policy missing required keys (name, resource) data:\n %s' % (
59 json.dumps(p, indent=2)))
60 if pkeys.difference(self.allowed_policy_keys):
61 raise PolicyValidationError(
62 'policy:%s has unknown keys: %s' % (
63 p['name'], ','.join(pkeys.difference(self.allowed_policy_keys))))
64 if not isinstance(p.get('filters', []), (list, type(None))):
65 raise PolicyValidationError((
66 'policy:%s must use a list for filters found:%s' % (
67 p['name'], type(p['filters']).__name__)))
68 element_types = (dict, str)
69 for f in p.get('filters', ()):
70 if not isinstance(f, element_types):
71 raise PolicyValidationError((
72 'policy:%s filter must be a mapping/dict found:%s' % (
73 p.get('name', 'unknown'), type(f).__name__)))
74 if not isinstance(p.get('actions', []), (list, type(None))):
75 raise PolicyValidationError((
76 'policy:%s must use a list for actions found:%s' % (
77 p.get('name', 'unknown'), type(p['actions']).__name__)))
78 for a in p.get('actions', ()):
79 if not isinstance(a, element_types):
80 raise PolicyValidationError((
81 'policy:%s action must be a mapping/dict found:%s' % (
82 p.get('name', 'unknown'), type(a).__name__)))
83
84 def get_resource_types(self, data):
85 resources = set()
86 for p in data.get('policies', []):
87 rtype = p['resource']
88 if '.' not in rtype:
89 rtype = 'aws.%s' % rtype
90 resources.add(rtype)
91 return resources
92
[end of c7n/structure.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/c7n/structure.py b/c7n/structure.py
--- a/c7n/structure.py
+++ b/c7n/structure.py
@@ -66,7 +66,7 @@
'policy:%s must use a list for filters found:%s' % (
p['name'], type(p['filters']).__name__)))
element_types = (dict, str)
- for f in p.get('filters', ()):
+ for f in p.get('filters', ()) or []:
if not isinstance(f, element_types):
raise PolicyValidationError((
'policy:%s filter must be a mapping/dict found:%s' % (
@@ -75,7 +75,7 @@
raise PolicyValidationError((
'policy:%s must use a list for actions found:%s' % (
p.get('name', 'unknown'), type(p['actions']).__name__)))
- for a in p.get('actions', ()):
+ for a in p.get('actions', ()) or []:
if not isinstance(a, element_types):
raise PolicyValidationError((
'policy:%s action must be a mapping/dict found:%s' % (
|
{"golden_diff": "diff --git a/c7n/structure.py b/c7n/structure.py\n--- a/c7n/structure.py\n+++ b/c7n/structure.py\n@@ -66,7 +66,7 @@\n 'policy:%s must use a list for filters found:%s' % (\n p['name'], type(p['filters']).__name__)))\n element_types = (dict, str)\n- for f in p.get('filters', ()):\n+ for f in p.get('filters', ()) or []:\n if not isinstance(f, element_types):\n raise PolicyValidationError((\n 'policy:%s filter must be a mapping/dict found:%s' % (\n@@ -75,7 +75,7 @@\n raise PolicyValidationError((\n 'policy:%s must use a list for actions found:%s' % (\n p.get('name', 'unknown'), type(p['actions']).__name__)))\n- for a in p.get('actions', ()):\n+ for a in p.get('actions', ()) or []:\n if not isinstance(a, element_types):\n raise PolicyValidationError((\n 'policy:%s action must be a mapping/dict found:%s' % (\n", "issue": "NoneType Issue\nI dropped a yaml file into a new OU/SubOU and its not working, though it works in other OUs just fine. Nothing was changed in the file but I am still getting this error, not sure why.\r\n\r\n```\r\nTraceback (most recent call last):\r\n File \"/root/.pyenv/versions/3.9.12/bin/custodian\", line 8, in <module>\r\n sys.exit(main())\r\n File \"/root/.pyenv/versions/3.9.12/lib/python3.9/site-packages/c7n/cli.py\", line 363, in main\r\n command(config)\r\n File \"/root/.pyenv/versions/3.9.12/lib/python3.9/site-packages/c7n/commands.py\", line 219, in validate\r\n structure.validate(data)\r\n File \"/root/.pyenv/versions/3.9.12/lib/python3.9/site-packages/c7n/structure.py\", line 48, in validate\r\n self.validate_policy(p)\r\n File \"/root/.pyenv/versions/3.9.12/lib/python3.9/site-packages/c7n/structure.py\", line 78, in validate_policy\r\n for a in p.get('actions', ()):\r\nTypeError: 'NoneType' object is not iterable\r\n```\n", "before_files": [{"content": "# Copyright The Cloud Custodian Authors.\n# SPDX-License-Identifier: Apache-2.0\n\nimport json\n\nfrom c7n.exceptions import PolicyValidationError\n\n\nclass StructureParser:\n \"\"\"Provide fast validation and inspection of a policy file.\n\n Intent is to provide more humane validation for top level errors\n instead of printing full schema as error message.\n \"\"\"\n allowed_file_keys = {'vars', 'policies'}\n required_policy_keys = {'name', 'resource'}\n allowed_policy_keys = {'name', 'resource', 'title', 'description', 'mode',\n 'tags', 'max-resources', 'metadata', 'query',\n 'filters', 'actions', 'source', 'conditions',\n # legacy keys subject to deprecation.\n 'region', 'start', 'end', 'tz', 'max-resources-percent',\n 'comments', 'comment'}\n\n def validate(self, data):\n if not isinstance(data, dict):\n raise PolicyValidationError((\n \"Policy file top level data structure \"\n \"should be a mapping/dict, instead found:%s\") % (\n type(data).__name__))\n dkeys = set(data.keys())\n\n extra = dkeys.difference(self.allowed_file_keys)\n if extra:\n raise PolicyValidationError((\n 'Policy files top level keys are %s, found extra: %s' % (\n ', '.join(self.allowed_file_keys),\n ', '.join(extra))))\n\n if 'policies' not in data:\n raise PolicyValidationError(\"`policies` list missing\")\n\n pdata = data.get('policies', [])\n if not isinstance(pdata, list):\n raise PolicyValidationError((\n '`policies` key should be an array/list found: %s' % (\n type(pdata).__name__)))\n for p in pdata:\n self.validate_policy(p)\n\n def validate_policy(self, p):\n if not isinstance(p, dict):\n raise PolicyValidationError((\n 'policy must be a dictionary/mapping found:%s policy:\\n %s' % (\n type(p).__name__, json.dumps(p, indent=2))))\n pkeys = set(p)\n if self.required_policy_keys.difference(pkeys):\n raise PolicyValidationError(\n 'policy missing required keys (name, resource) data:\\n %s' % (\n json.dumps(p, indent=2)))\n if pkeys.difference(self.allowed_policy_keys):\n raise PolicyValidationError(\n 'policy:%s has unknown keys: %s' % (\n p['name'], ','.join(pkeys.difference(self.allowed_policy_keys))))\n if not isinstance(p.get('filters', []), (list, type(None))):\n raise PolicyValidationError((\n 'policy:%s must use a list for filters found:%s' % (\n p['name'], type(p['filters']).__name__)))\n element_types = (dict, str)\n for f in p.get('filters', ()):\n if not isinstance(f, element_types):\n raise PolicyValidationError((\n 'policy:%s filter must be a mapping/dict found:%s' % (\n p.get('name', 'unknown'), type(f).__name__)))\n if not isinstance(p.get('actions', []), (list, type(None))):\n raise PolicyValidationError((\n 'policy:%s must use a list for actions found:%s' % (\n p.get('name', 'unknown'), type(p['actions']).__name__)))\n for a in p.get('actions', ()):\n if not isinstance(a, element_types):\n raise PolicyValidationError((\n 'policy:%s action must be a mapping/dict found:%s' % (\n p.get('name', 'unknown'), type(a).__name__)))\n\n def get_resource_types(self, data):\n resources = set()\n for p in data.get('policies', []):\n rtype = p['resource']\n if '.' not in rtype:\n rtype = 'aws.%s' % rtype\n resources.add(rtype)\n return resources\n", "path": "c7n/structure.py"}]}
| 1,834 | 254 |
gh_patches_debug_7875
|
rasdani/github-patches
|
git_diff
|
getsentry__sentry-python-875
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Incorrect parsing of complex urls in django
Sentry is parsing a complex URL as `/api/{version})/log` instead of `/api/{version}/log`.
<img width="207" alt="Screenshot 2020-10-17 at 10 40 47 AM" src="https://user-images.githubusercontent.com/4463796/96328987-70cb1c80-1066-11eb-94a4-ff8e15fb81ed.png">
</issue>
<code>
[start of sentry_sdk/integrations/django/transactions.py]
1 """
2 Copied from raven-python. Used for
3 `DjangoIntegration(transaction_fron="raven_legacy")`.
4 """
5
6 from __future__ import absolute_import
7
8 import re
9
10 from sentry_sdk._types import MYPY
11
12 if MYPY:
13 from django.urls.resolvers import URLResolver
14 from typing import Dict
15 from typing import List
16 from typing import Optional
17 from django.urls.resolvers import URLPattern
18 from typing import Tuple
19 from typing import Union
20 from re import Pattern
21
22 try:
23 from django.urls import get_resolver
24 except ImportError:
25 from django.core.urlresolvers import get_resolver
26
27
28 def get_regex(resolver_or_pattern):
29 # type: (Union[URLPattern, URLResolver]) -> Pattern[str]
30 """Utility method for django's deprecated resolver.regex"""
31 try:
32 regex = resolver_or_pattern.regex
33 except AttributeError:
34 regex = resolver_or_pattern.pattern.regex
35 return regex
36
37
38 class RavenResolver(object):
39 _optional_group_matcher = re.compile(r"\(\?\:([^\)]+)\)")
40 _named_group_matcher = re.compile(r"\(\?P<(\w+)>[^\)]+\)")
41 _non_named_group_matcher = re.compile(r"\([^\)]+\)")
42 # [foo|bar|baz]
43 _either_option_matcher = re.compile(r"\[([^\]]+)\|([^\]]+)\]")
44 _camel_re = re.compile(r"([A-Z]+)([a-z])")
45
46 _cache = {} # type: Dict[URLPattern, str]
47
48 def _simplify(self, pattern):
49 # type: (str) -> str
50 r"""
51 Clean up urlpattern regexes into something readable by humans:
52
53 From:
54 > "^(?P<sport_slug>\w+)/athletes/(?P<athlete_slug>\w+)/$"
55
56 To:
57 > "{sport_slug}/athletes/{athlete_slug}/"
58 """
59 # remove optional params
60 # TODO(dcramer): it'd be nice to change these into [%s] but it currently
61 # conflicts with the other rules because we're doing regexp matches
62 # rather than parsing tokens
63 result = self._optional_group_matcher.sub(lambda m: "%s" % m.group(1), pattern)
64
65 # handle named groups first
66 result = self._named_group_matcher.sub(lambda m: "{%s}" % m.group(1), result)
67
68 # handle non-named groups
69 result = self._non_named_group_matcher.sub("{var}", result)
70
71 # handle optional params
72 result = self._either_option_matcher.sub(lambda m: m.group(1), result)
73
74 # clean up any outstanding regex-y characters.
75 result = (
76 result.replace("^", "")
77 .replace("$", "")
78 .replace("?", "")
79 .replace("//", "/")
80 .replace("\\", "")
81 )
82
83 return result
84
85 def _resolve(self, resolver, path, parents=None):
86 # type: (URLResolver, str, Optional[List[URLResolver]]) -> Optional[str]
87
88 match = get_regex(resolver).search(path) # Django < 2.0
89
90 if not match:
91 return None
92
93 if parents is None:
94 parents = [resolver]
95 elif resolver not in parents:
96 parents = parents + [resolver]
97
98 new_path = path[match.end() :]
99 for pattern in resolver.url_patterns:
100 # this is an include()
101 if not pattern.callback:
102 match_ = self._resolve(pattern, new_path, parents)
103 if match_:
104 return match_
105 continue
106 elif not get_regex(pattern).search(new_path):
107 continue
108
109 try:
110 return self._cache[pattern]
111 except KeyError:
112 pass
113
114 prefix = "".join(self._simplify(get_regex(p).pattern) for p in parents)
115 result = prefix + self._simplify(get_regex(pattern).pattern)
116 if not result.startswith("/"):
117 result = "/" + result
118 self._cache[pattern] = result
119 return result
120
121 return None
122
123 def resolve(
124 self,
125 path, # type: str
126 urlconf=None, # type: Union[None, Tuple[URLPattern, URLPattern, URLResolver], Tuple[URLPattern]]
127 ):
128 # type: (...) -> str
129 resolver = get_resolver(urlconf)
130 match = self._resolve(resolver, path)
131 return match or path
132
133
134 LEGACY_RESOLVER = RavenResolver()
135
[end of sentry_sdk/integrations/django/transactions.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/sentry_sdk/integrations/django/transactions.py b/sentry_sdk/integrations/django/transactions.py
--- a/sentry_sdk/integrations/django/transactions.py
+++ b/sentry_sdk/integrations/django/transactions.py
@@ -37,7 +37,7 @@
class RavenResolver(object):
_optional_group_matcher = re.compile(r"\(\?\:([^\)]+)\)")
- _named_group_matcher = re.compile(r"\(\?P<(\w+)>[^\)]+\)")
+ _named_group_matcher = re.compile(r"\(\?P<(\w+)>[^\)]+\)+")
_non_named_group_matcher = re.compile(r"\([^\)]+\)")
# [foo|bar|baz]
_either_option_matcher = re.compile(r"\[([^\]]+)\|([^\]]+)\]")
|
{"golden_diff": "diff --git a/sentry_sdk/integrations/django/transactions.py b/sentry_sdk/integrations/django/transactions.py\n--- a/sentry_sdk/integrations/django/transactions.py\n+++ b/sentry_sdk/integrations/django/transactions.py\n@@ -37,7 +37,7 @@\n \n class RavenResolver(object):\n _optional_group_matcher = re.compile(r\"\\(\\?\\:([^\\)]+)\\)\")\n- _named_group_matcher = re.compile(r\"\\(\\?P<(\\w+)>[^\\)]+\\)\")\n+ _named_group_matcher = re.compile(r\"\\(\\?P<(\\w+)>[^\\)]+\\)+\")\n _non_named_group_matcher = re.compile(r\"\\([^\\)]+\\)\")\n # [foo|bar|baz]\n _either_option_matcher = re.compile(r\"\\[([^\\]]+)\\|([^\\]]+)\\]\")\n", "issue": "Incorrect parsing of complex urls in django\nSentry is parsing a complex URL as `/api/{version})/log` instead of `/api/{version}/log`.\r\n\r\n<img width=\"207\" alt=\"Screenshot 2020-10-17 at 10 40 47 AM\" src=\"https://user-images.githubusercontent.com/4463796/96328987-70cb1c80-1066-11eb-94a4-ff8e15fb81ed.png\">\r\n\n", "before_files": [{"content": "\"\"\"\nCopied from raven-python. Used for\n`DjangoIntegration(transaction_fron=\"raven_legacy\")`.\n\"\"\"\n\nfrom __future__ import absolute_import\n\nimport re\n\nfrom sentry_sdk._types import MYPY\n\nif MYPY:\n from django.urls.resolvers import URLResolver\n from typing import Dict\n from typing import List\n from typing import Optional\n from django.urls.resolvers import URLPattern\n from typing import Tuple\n from typing import Union\n from re import Pattern\n\ntry:\n from django.urls import get_resolver\nexcept ImportError:\n from django.core.urlresolvers import get_resolver\n\n\ndef get_regex(resolver_or_pattern):\n # type: (Union[URLPattern, URLResolver]) -> Pattern[str]\n \"\"\"Utility method for django's deprecated resolver.regex\"\"\"\n try:\n regex = resolver_or_pattern.regex\n except AttributeError:\n regex = resolver_or_pattern.pattern.regex\n return regex\n\n\nclass RavenResolver(object):\n _optional_group_matcher = re.compile(r\"\\(\\?\\:([^\\)]+)\\)\")\n _named_group_matcher = re.compile(r\"\\(\\?P<(\\w+)>[^\\)]+\\)\")\n _non_named_group_matcher = re.compile(r\"\\([^\\)]+\\)\")\n # [foo|bar|baz]\n _either_option_matcher = re.compile(r\"\\[([^\\]]+)\\|([^\\]]+)\\]\")\n _camel_re = re.compile(r\"([A-Z]+)([a-z])\")\n\n _cache = {} # type: Dict[URLPattern, str]\n\n def _simplify(self, pattern):\n # type: (str) -> str\n r\"\"\"\n Clean up urlpattern regexes into something readable by humans:\n\n From:\n > \"^(?P<sport_slug>\\w+)/athletes/(?P<athlete_slug>\\w+)/$\"\n\n To:\n > \"{sport_slug}/athletes/{athlete_slug}/\"\n \"\"\"\n # remove optional params\n # TODO(dcramer): it'd be nice to change these into [%s] but it currently\n # conflicts with the other rules because we're doing regexp matches\n # rather than parsing tokens\n result = self._optional_group_matcher.sub(lambda m: \"%s\" % m.group(1), pattern)\n\n # handle named groups first\n result = self._named_group_matcher.sub(lambda m: \"{%s}\" % m.group(1), result)\n\n # handle non-named groups\n result = self._non_named_group_matcher.sub(\"{var}\", result)\n\n # handle optional params\n result = self._either_option_matcher.sub(lambda m: m.group(1), result)\n\n # clean up any outstanding regex-y characters.\n result = (\n result.replace(\"^\", \"\")\n .replace(\"$\", \"\")\n .replace(\"?\", \"\")\n .replace(\"//\", \"/\")\n .replace(\"\\\\\", \"\")\n )\n\n return result\n\n def _resolve(self, resolver, path, parents=None):\n # type: (URLResolver, str, Optional[List[URLResolver]]) -> Optional[str]\n\n match = get_regex(resolver).search(path) # Django < 2.0\n\n if not match:\n return None\n\n if parents is None:\n parents = [resolver]\n elif resolver not in parents:\n parents = parents + [resolver]\n\n new_path = path[match.end() :]\n for pattern in resolver.url_patterns:\n # this is an include()\n if not pattern.callback:\n match_ = self._resolve(pattern, new_path, parents)\n if match_:\n return match_\n continue\n elif not get_regex(pattern).search(new_path):\n continue\n\n try:\n return self._cache[pattern]\n except KeyError:\n pass\n\n prefix = \"\".join(self._simplify(get_regex(p).pattern) for p in parents)\n result = prefix + self._simplify(get_regex(pattern).pattern)\n if not result.startswith(\"/\"):\n result = \"/\" + result\n self._cache[pattern] = result\n return result\n\n return None\n\n def resolve(\n self,\n path, # type: str\n urlconf=None, # type: Union[None, Tuple[URLPattern, URLPattern, URLResolver], Tuple[URLPattern]]\n ):\n # type: (...) -> str\n resolver = get_resolver(urlconf)\n match = self._resolve(resolver, path)\n return match or path\n\n\nLEGACY_RESOLVER = RavenResolver()\n", "path": "sentry_sdk/integrations/django/transactions.py"}]}
| 1,947 | 192 |
gh_patches_debug_26851
|
rasdani/github-patches
|
git_diff
|
streamlink__streamlink-1620
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
FILMON HLS Problem with Sat1
- [x] This is a bug report.
### Description
The Channel Sat1 on Filmon can not be played with Streamlink
### Expected / Actual behavior
Normally all streams from FilmOn can be played via the streamlink. The channel Sat1 is played via the HLS protocol
### Reproduction steps / Explicit stream URLs to test
http://www.filmon.com/tv/sat-1-schweiz
### Logs
```
127.0.0.1 - - [25/Mar/2018 21:23:39] "GET /http://www.filmon.com/tv/rts-deux HTTP/1.1" 200 -
127.0.0.1 - - [25/Mar/2018 21:23:39] URL: http://www.filmon.com/tv/rts-deux Quality: best
[streamlinksrv][info] Streams:
[u'low', u'high', 'worst', 'best']
127.0.0.1 - - [25/Mar/2018 21:23:45] "GET /http://www.filmon.com/tv/sat-1-schweiz HTTP/1.1" 200 -
127.0.0.1 - - [25/Mar/2018 21:23:45] URL: http://www.filmon.com/tv/sat-1-schweiz Quality: best
[streamlinksrv][error] Plugin error: Unable to open URL: http://www.filmon.com/api-v2/channel/sat-1-schweiz?protocol=hls (404 Client Error: Not Found for url: http://www.filmon.com/api-v2/channel/sat-1-schweiz?protocol=hls)
[streamlinksrv][info] Closing currently open stream...
[streamlinksrv][error] Got exception: End Of Data!
```
</issue>
<code>
[start of src/streamlink/plugins/filmon.py]
1 import re
2
3 import time
4
5 from streamlink import StreamError
6 from streamlink.plugin import Plugin
7 from streamlink.plugin.api import http, validate
8 from streamlink.stream import HLSStream
9
10
11 class FilmOnHLS(HLSStream):
12 __shortname__ = "hls-filmon"
13
14 def __init__(self, session_, channel=None, vod_id=None, quality="high", **args):
15 super(FilmOnHLS, self).__init__(session_, None, **args)
16 self.logger = self.session.logger.new_module("stream.hls-filmon")
17 self.channel = channel
18 self.vod_id = vod_id
19 if self.channel is None and self.vod_id is None:
20 raise ValueError("channel or vod_id must be set")
21 self.quality = quality
22 self.api = FilmOnAPI()
23 self._url = None
24 self.watch_timeout = 0
25
26 def _get_stream_data(self):
27 if self.channel:
28 self.logger.debug("Reloading FilmOn channel playlist: {0}", self.channel)
29 data = self.api.channel(self.channel)
30 for stream in data["streams"]:
31 yield stream
32 elif self.vod_id:
33 self.logger.debug("Reloading FilmOn VOD playlist: {0}", self.vod_id)
34 data = self.api.vod(self.vod_id)
35 for _, stream in data["streams"].items():
36 yield stream
37
38 @property
39 def url(self):
40 # If the watch timeout has passed then refresh the playlist from the API
41 if int(time.time()) >= self.watch_timeout:
42 for stream in self._get_stream_data():
43 if stream["quality"] == self.quality:
44 self.watch_timeout = int(time.time()) + stream["watch-timeout"]
45 self._url = stream["url"]
46 return self._url
47 raise StreamError("cannot refresh FilmOn HLS Stream playlist")
48 else:
49 return self._url
50
51 def to_url(self):
52 url = self.url
53 expires = self.watch_timeout - time.time()
54 if expires < 0:
55 raise TypeError("Stream has expired and cannot be converted to a URL")
56 return url
57
58
59 class FilmOnAPI(object):
60 channel_url = "http://www.filmon.com/api-v2/channel/{0}?protocol=hls"
61 vod_url = "http://www.filmon.com/vod/info/{0}"
62
63 stream_schema = {
64 "quality": validate.text,
65 "url": validate.url(),
66 "watch-timeout": int
67 }
68 api_schema = validate.Schema(
69 {
70 "data": {
71 "streams": validate.any(
72 {validate.text: stream_schema},
73 [stream_schema]
74 )
75 }
76 },
77 validate.get("data")
78 )
79
80 def channel(self, channel):
81 res = http.get(self.channel_url.format(channel))
82 return http.json(res, schema=self.api_schema)
83
84 def vod(self, vod_id):
85 res = http.get(self.vod_url.format(vod_id))
86 return http.json(res, schema=self.api_schema)
87
88
89 class Filmon(Plugin):
90 url_re = re.compile(r"""https?://(?:\w+\.)?filmon.(?:tv|com)/
91 (?:
92 (tv|channel)/(?P<channel>[^/]+)|
93 vod/view/(?P<vod_id>\d+)-|
94 group/
95 )
96 """, re.VERBOSE)
97
98 _channel_id_re = re.compile(r'channel_id\s*?=\s*"(\d+)"')
99 _channel_id_schema = validate.Schema(
100 validate.transform(_channel_id_re.search),
101 validate.any(None, validate.get(1))
102 )
103
104 quality_weights = {
105 "high": 720,
106 "low": 480
107 }
108
109 def __init__(self, url):
110 super(Filmon, self).__init__(url)
111 self.api = FilmOnAPI()
112
113 @classmethod
114 def can_handle_url(cls, url):
115 return cls.url_re.match(url) is not None
116
117 @classmethod
118 def stream_weight(cls, key):
119 weight = cls.quality_weights.get(key)
120 if weight:
121 return weight, "filmon"
122
123 return Plugin.stream_weight(key)
124
125 def _get_streams(self):
126 url_m = self.url_re.match(self.url)
127
128 channel = url_m and url_m.group("channel")
129 vod_id = url_m and url_m.group("vod_id")
130
131 if vod_id:
132 data = self.api.vod(vod_id)
133 for _, stream in data["streams"].items():
134 yield stream["quality"], FilmOnHLS(self.session, vod_id=vod_id, quality=stream["quality"])
135
136 else:
137 if not channel:
138 channel = http.get(self.url, schema=self._channel_id_schema)
139 data = self.api.channel(channel)
140 for stream in data["streams"]:
141 yield stream["quality"], FilmOnHLS(self.session, channel=channel, quality=stream["quality"])
142
143
144 __plugin__ = Filmon
145
[end of src/streamlink/plugins/filmon.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/streamlink/plugins/filmon.py b/src/streamlink/plugins/filmon.py
--- a/src/streamlink/plugins/filmon.py
+++ b/src/streamlink/plugins/filmon.py
@@ -89,16 +89,17 @@
class Filmon(Plugin):
url_re = re.compile(r"""https?://(?:\w+\.)?filmon.(?:tv|com)/
(?:
- (tv|channel)/(?P<channel>[^/]+)|
+ tv/|
+ channel/(?P<channel>\d+)|
vod/view/(?P<vod_id>\d+)-|
group/
)
""", re.VERBOSE)
- _channel_id_re = re.compile(r'channel_id\s*?=\s*"(\d+)"')
+ _channel_id_re = re.compile(r"""channel_id\s*=\s*(?P<quote>['"]?)(?P<value>\d+)(?P=quote)""")
_channel_id_schema = validate.Schema(
validate.transform(_channel_id_re.search),
- validate.any(None, validate.get(1))
+ validate.any(None, validate.get("value"))
)
quality_weights = {
@@ -136,6 +137,7 @@
else:
if not channel:
channel = http.get(self.url, schema=self._channel_id_schema)
+ self.logger.debug("Found channel ID: {0}", channel)
data = self.api.channel(channel)
for stream in data["streams"]:
yield stream["quality"], FilmOnHLS(self.session, channel=channel, quality=stream["quality"])
|
{"golden_diff": "diff --git a/src/streamlink/plugins/filmon.py b/src/streamlink/plugins/filmon.py\n--- a/src/streamlink/plugins/filmon.py\n+++ b/src/streamlink/plugins/filmon.py\n@@ -89,16 +89,17 @@\n class Filmon(Plugin):\n url_re = re.compile(r\"\"\"https?://(?:\\w+\\.)?filmon.(?:tv|com)/\n (?:\n- (tv|channel)/(?P<channel>[^/]+)|\n+ tv/|\n+ channel/(?P<channel>\\d+)|\n vod/view/(?P<vod_id>\\d+)-|\n group/\n )\n \"\"\", re.VERBOSE)\n \n- _channel_id_re = re.compile(r'channel_id\\s*?=\\s*\"(\\d+)\"')\n+ _channel_id_re = re.compile(r\"\"\"channel_id\\s*=\\s*(?P<quote>['\"]?)(?P<value>\\d+)(?P=quote)\"\"\")\n _channel_id_schema = validate.Schema(\n validate.transform(_channel_id_re.search),\n- validate.any(None, validate.get(1))\n+ validate.any(None, validate.get(\"value\"))\n )\n \n quality_weights = {\n@@ -136,6 +137,7 @@\n else:\n if not channel:\n channel = http.get(self.url, schema=self._channel_id_schema)\n+ self.logger.debug(\"Found channel ID: {0}\", channel)\n data = self.api.channel(channel)\n for stream in data[\"streams\"]:\n yield stream[\"quality\"], FilmOnHLS(self.session, channel=channel, quality=stream[\"quality\"])\n", "issue": "FILMON HLS Problem with Sat1 \n- [x] This is a bug report.\r\n\r\n### Description\r\n\r\nThe Channel Sat1 on Filmon can not be played with Streamlink\r\n\r\n### Expected / Actual behavior\r\n\r\nNormally all streams from FilmOn can be played via the streamlink. The channel Sat1 is played via the HLS protocol\r\n\r\n### Reproduction steps / Explicit stream URLs to test\r\n\r\nhttp://www.filmon.com/tv/sat-1-schweiz\r\n\r\n### Logs\r\n\r\n```\r\n127.0.0.1 - - [25/Mar/2018 21:23:39] \"GET /http://www.filmon.com/tv/rts-deux HTTP/1.1\" 200 -\r\n127.0.0.1 - - [25/Mar/2018 21:23:39] URL: http://www.filmon.com/tv/rts-deux Quality: best\r\n[streamlinksrv][info] Streams:\r\n[u'low', u'high', 'worst', 'best']\r\n127.0.0.1 - - [25/Mar/2018 21:23:45] \"GET /http://www.filmon.com/tv/sat-1-schweiz HTTP/1.1\" 200 -\r\n127.0.0.1 - - [25/Mar/2018 21:23:45] URL: http://www.filmon.com/tv/sat-1-schweiz Quality: best\r\n[streamlinksrv][error] Plugin error: Unable to open URL: http://www.filmon.com/api-v2/channel/sat-1-schweiz?protocol=hls (404 Client Error: Not Found for url: http://www.filmon.com/api-v2/channel/sat-1-schweiz?protocol=hls)\r\n[streamlinksrv][info] Closing currently open stream...\r\n[streamlinksrv][error] Got exception: End Of Data!\r\n```\r\n\r\n\n", "before_files": [{"content": "import re\n\nimport time\n\nfrom streamlink import StreamError\nfrom streamlink.plugin import Plugin\nfrom streamlink.plugin.api import http, validate\nfrom streamlink.stream import HLSStream\n\n\nclass FilmOnHLS(HLSStream):\n __shortname__ = \"hls-filmon\"\n\n def __init__(self, session_, channel=None, vod_id=None, quality=\"high\", **args):\n super(FilmOnHLS, self).__init__(session_, None, **args)\n self.logger = self.session.logger.new_module(\"stream.hls-filmon\")\n self.channel = channel\n self.vod_id = vod_id\n if self.channel is None and self.vod_id is None:\n raise ValueError(\"channel or vod_id must be set\")\n self.quality = quality\n self.api = FilmOnAPI()\n self._url = None\n self.watch_timeout = 0\n\n def _get_stream_data(self):\n if self.channel:\n self.logger.debug(\"Reloading FilmOn channel playlist: {0}\", self.channel)\n data = self.api.channel(self.channel)\n for stream in data[\"streams\"]:\n yield stream\n elif self.vod_id:\n self.logger.debug(\"Reloading FilmOn VOD playlist: {0}\", self.vod_id)\n data = self.api.vod(self.vod_id)\n for _, stream in data[\"streams\"].items():\n yield stream\n\n @property\n def url(self):\n # If the watch timeout has passed then refresh the playlist from the API\n if int(time.time()) >= self.watch_timeout:\n for stream in self._get_stream_data():\n if stream[\"quality\"] == self.quality:\n self.watch_timeout = int(time.time()) + stream[\"watch-timeout\"]\n self._url = stream[\"url\"]\n return self._url\n raise StreamError(\"cannot refresh FilmOn HLS Stream playlist\")\n else:\n return self._url\n\n def to_url(self):\n url = self.url\n expires = self.watch_timeout - time.time()\n if expires < 0:\n raise TypeError(\"Stream has expired and cannot be converted to a URL\")\n return url\n\n\nclass FilmOnAPI(object):\n channel_url = \"http://www.filmon.com/api-v2/channel/{0}?protocol=hls\"\n vod_url = \"http://www.filmon.com/vod/info/{0}\"\n\n stream_schema = {\n \"quality\": validate.text,\n \"url\": validate.url(),\n \"watch-timeout\": int\n }\n api_schema = validate.Schema(\n {\n \"data\": {\n \"streams\": validate.any(\n {validate.text: stream_schema},\n [stream_schema]\n )\n }\n },\n validate.get(\"data\")\n )\n\n def channel(self, channel):\n res = http.get(self.channel_url.format(channel))\n return http.json(res, schema=self.api_schema)\n\n def vod(self, vod_id):\n res = http.get(self.vod_url.format(vod_id))\n return http.json(res, schema=self.api_schema)\n\n\nclass Filmon(Plugin):\n url_re = re.compile(r\"\"\"https?://(?:\\w+\\.)?filmon.(?:tv|com)/\n (?:\n (tv|channel)/(?P<channel>[^/]+)|\n vod/view/(?P<vod_id>\\d+)-|\n group/\n )\n \"\"\", re.VERBOSE)\n\n _channel_id_re = re.compile(r'channel_id\\s*?=\\s*\"(\\d+)\"')\n _channel_id_schema = validate.Schema(\n validate.transform(_channel_id_re.search),\n validate.any(None, validate.get(1))\n )\n\n quality_weights = {\n \"high\": 720,\n \"low\": 480\n }\n\n def __init__(self, url):\n super(Filmon, self).__init__(url)\n self.api = FilmOnAPI()\n\n @classmethod\n def can_handle_url(cls, url):\n return cls.url_re.match(url) is not None\n\n @classmethod\n def stream_weight(cls, key):\n weight = cls.quality_weights.get(key)\n if weight:\n return weight, \"filmon\"\n\n return Plugin.stream_weight(key)\n\n def _get_streams(self):\n url_m = self.url_re.match(self.url)\n\n channel = url_m and url_m.group(\"channel\")\n vod_id = url_m and url_m.group(\"vod_id\")\n\n if vod_id:\n data = self.api.vod(vod_id)\n for _, stream in data[\"streams\"].items():\n yield stream[\"quality\"], FilmOnHLS(self.session, vod_id=vod_id, quality=stream[\"quality\"])\n\n else:\n if not channel:\n channel = http.get(self.url, schema=self._channel_id_schema)\n data = self.api.channel(channel)\n for stream in data[\"streams\"]:\n yield stream[\"quality\"], FilmOnHLS(self.session, channel=channel, quality=stream[\"quality\"])\n\n\n__plugin__ = Filmon\n", "path": "src/streamlink/plugins/filmon.py"}]}
| 2,406 | 356 |
gh_patches_debug_5874
|
rasdani/github-patches
|
git_diff
|
python-poetry__poetry-1862
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Document the --no-root option
<!--
Hi there! Thank you for wanting to make Poetry better.
Before you submit this; let's make sure of a few things.
Please make sure the following boxes are ticked if they are correct.
If not, please try and fulfill these first.
-->
<!-- Checked checkbox should look like this: [x] -->
- [x] I have searched the [issues](https://github.com/python-poetry/poetry/issues) of this repo and believe that this is not a duplicate.
- [x] I have searched the [documentation](https://python-poetry.org/docs/) and believe that my question is not covered.
## Feature Request
<!-- Now feel free to write your idea for improvement. Thanks again 🙌 ❤️ -->
The `--no-root` option described in https://github.com/python-poetry/poetry/issues/1525 works fine for installation. Unfortunately I found it only when looking for duplicate issues before raising this. `poetry help install` does not describe that option.
Please add it to the `help install` output.
Document the --no-root option
<!--
Hi there! Thank you for wanting to make Poetry better.
Before you submit this; let's make sure of a few things.
Please make sure the following boxes are ticked if they are correct.
If not, please try and fulfill these first.
-->
<!-- Checked checkbox should look like this: [x] -->
- [x] I have searched the [issues](https://github.com/python-poetry/poetry/issues) of this repo and believe that this is not a duplicate.
- [x] I have searched the [documentation](https://python-poetry.org/docs/) and believe that my question is not covered.
## Feature Request
<!-- Now feel free to write your idea for improvement. Thanks again 🙌 ❤️ -->
The `--no-root` option described in https://github.com/python-poetry/poetry/issues/1525 works fine for installation. Unfortunately I found it only when looking for duplicate issues before raising this. `poetry help install` does not describe that option.
Please add it to the `help install` output.
</issue>
<code>
[start of poetry/console/commands/install.py]
1 from cleo import option
2
3 from .env_command import EnvCommand
4
5
6 class InstallCommand(EnvCommand):
7
8 name = "install"
9 description = "Installs the project dependencies."
10
11 options = [
12 option("no-dev", None, "Do not install the development dependencies."),
13 option(
14 "no-root", None, "Do not install the root package (the current project)."
15 ),
16 option(
17 "dry-run",
18 None,
19 "Output the operations but do not execute anything "
20 "(implicitly enables --verbose).",
21 ),
22 option(
23 "extras",
24 "E",
25 "Extra sets of dependencies to install.",
26 flag=False,
27 multiple=True,
28 ),
29 ]
30
31 help = """The <info>install</info> command reads the <comment>poetry.lock</> file from
32 the current directory, processes it, and downloads and installs all the
33 libraries and dependencies outlined in that file. If the file does not
34 exist it will look for <comment>pyproject.toml</> and do the same.
35
36 <info>poetry install</info>
37 """
38
39 _loggers = ["poetry.repositories.pypi_repository"]
40
41 def handle(self):
42 from clikit.io import NullIO
43 from poetry.installation.installer import Installer
44 from poetry.masonry.builders import EditableBuilder
45 from poetry.masonry.utils.module import ModuleOrPackageNotFound
46
47 installer = Installer(
48 self.io, self.env, self.poetry.package, self.poetry.locker, self.poetry.pool
49 )
50
51 extras = []
52 for extra in self.option("extras"):
53 if " " in extra:
54 extras += [e.strip() for e in extra.split(" ")]
55 else:
56 extras.append(extra)
57
58 installer.extras(extras)
59 installer.dev_mode(not self.option("no-dev"))
60 installer.dry_run(self.option("dry-run"))
61 installer.verbose(self.option("verbose"))
62
63 return_code = installer.run()
64
65 if return_code != 0:
66 return return_code
67
68 if self.option("no-root"):
69 return 0
70
71 try:
72 builder = EditableBuilder(self.poetry, self._env, NullIO())
73 except ModuleOrPackageNotFound:
74 # This is likely due to the fact that the project is an application
75 # not following the structure expected by Poetry
76 # If this is a true error it will be picked up later by build anyway.
77 return 0
78
79 self.line(
80 " - Installing <c1>{}</c1> (<b>{}</b>)".format(
81 self.poetry.package.pretty_name, self.poetry.package.pretty_version
82 )
83 )
84
85 if self.option("dry-run"):
86 return 0
87
88 builder.build()
89
90 return 0
91
[end of poetry/console/commands/install.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/poetry/console/commands/install.py b/poetry/console/commands/install.py
--- a/poetry/console/commands/install.py
+++ b/poetry/console/commands/install.py
@@ -34,6 +34,12 @@
exist it will look for <comment>pyproject.toml</> and do the same.
<info>poetry install</info>
+
+By default, the above command will also install the current project. To install only the
+dependencies and not including the current project, run the command with the
+<info>--no-root</info> option like below:
+
+<info> poetry install --no-root</info>
"""
_loggers = ["poetry.repositories.pypi_repository"]
|
{"golden_diff": "diff --git a/poetry/console/commands/install.py b/poetry/console/commands/install.py\n--- a/poetry/console/commands/install.py\n+++ b/poetry/console/commands/install.py\n@@ -34,6 +34,12 @@\n exist it will look for <comment>pyproject.toml</> and do the same.\n \n <info>poetry install</info>\n+\n+By default, the above command will also install the current project. To install only the\n+dependencies and not including the current project, run the command with the\n+<info>--no-root</info> option like below:\n+\n+<info> poetry install --no-root</info>\n \"\"\"\n \n _loggers = [\"poetry.repositories.pypi_repository\"]\n", "issue": "Document the --no-root option\n<!--\r\n Hi there! Thank you for wanting to make Poetry better.\r\n\r\n Before you submit this; let's make sure of a few things.\r\n Please make sure the following boxes are ticked if they are correct.\r\n If not, please try and fulfill these first.\r\n-->\r\n\r\n<!-- Checked checkbox should look like this: [x] -->\r\n- [x] I have searched the [issues](https://github.com/python-poetry/poetry/issues) of this repo and believe that this is not a duplicate.\r\n- [x] I have searched the [documentation](https://python-poetry.org/docs/) and believe that my question is not covered.\r\n\r\n## Feature Request\r\n<!-- Now feel free to write your idea for improvement. Thanks again \ud83d\ude4c \u2764\ufe0f -->\r\nThe `--no-root` option described in https://github.com/python-poetry/poetry/issues/1525 works fine for installation. Unfortunately I found it only when looking for duplicate issues before raising this. `poetry help install` does not describe that option.\r\n\r\nPlease add it to the `help install` output.\nDocument the --no-root option\n<!--\r\n Hi there! Thank you for wanting to make Poetry better.\r\n\r\n Before you submit this; let's make sure of a few things.\r\n Please make sure the following boxes are ticked if they are correct.\r\n If not, please try and fulfill these first.\r\n-->\r\n\r\n<!-- Checked checkbox should look like this: [x] -->\r\n- [x] I have searched the [issues](https://github.com/python-poetry/poetry/issues) of this repo and believe that this is not a duplicate.\r\n- [x] I have searched the [documentation](https://python-poetry.org/docs/) and believe that my question is not covered.\r\n\r\n## Feature Request\r\n<!-- Now feel free to write your idea for improvement. Thanks again \ud83d\ude4c \u2764\ufe0f -->\r\nThe `--no-root` option described in https://github.com/python-poetry/poetry/issues/1525 works fine for installation. Unfortunately I found it only when looking for duplicate issues before raising this. `poetry help install` does not describe that option.\r\n\r\nPlease add it to the `help install` output.\n", "before_files": [{"content": "from cleo import option\n\nfrom .env_command import EnvCommand\n\n\nclass InstallCommand(EnvCommand):\n\n name = \"install\"\n description = \"Installs the project dependencies.\"\n\n options = [\n option(\"no-dev\", None, \"Do not install the development dependencies.\"),\n option(\n \"no-root\", None, \"Do not install the root package (the current project).\"\n ),\n option(\n \"dry-run\",\n None,\n \"Output the operations but do not execute anything \"\n \"(implicitly enables --verbose).\",\n ),\n option(\n \"extras\",\n \"E\",\n \"Extra sets of dependencies to install.\",\n flag=False,\n multiple=True,\n ),\n ]\n\n help = \"\"\"The <info>install</info> command reads the <comment>poetry.lock</> file from\nthe current directory, processes it, and downloads and installs all the\nlibraries and dependencies outlined in that file. If the file does not\nexist it will look for <comment>pyproject.toml</> and do the same.\n\n<info>poetry install</info>\n\"\"\"\n\n _loggers = [\"poetry.repositories.pypi_repository\"]\n\n def handle(self):\n from clikit.io import NullIO\n from poetry.installation.installer import Installer\n from poetry.masonry.builders import EditableBuilder\n from poetry.masonry.utils.module import ModuleOrPackageNotFound\n\n installer = Installer(\n self.io, self.env, self.poetry.package, self.poetry.locker, self.poetry.pool\n )\n\n extras = []\n for extra in self.option(\"extras\"):\n if \" \" in extra:\n extras += [e.strip() for e in extra.split(\" \")]\n else:\n extras.append(extra)\n\n installer.extras(extras)\n installer.dev_mode(not self.option(\"no-dev\"))\n installer.dry_run(self.option(\"dry-run\"))\n installer.verbose(self.option(\"verbose\"))\n\n return_code = installer.run()\n\n if return_code != 0:\n return return_code\n\n if self.option(\"no-root\"):\n return 0\n\n try:\n builder = EditableBuilder(self.poetry, self._env, NullIO())\n except ModuleOrPackageNotFound:\n # This is likely due to the fact that the project is an application\n # not following the structure expected by Poetry\n # If this is a true error it will be picked up later by build anyway.\n return 0\n\n self.line(\n \" - Installing <c1>{}</c1> (<b>{}</b>)\".format(\n self.poetry.package.pretty_name, self.poetry.package.pretty_version\n )\n )\n\n if self.option(\"dry-run\"):\n return 0\n\n builder.build()\n\n return 0\n", "path": "poetry/console/commands/install.py"}]}
| 1,767 | 162 |
gh_patches_debug_5564
|
rasdani/github-patches
|
git_diff
|
Parsl__parsl-930
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Log app args
For easier debugging, we should log the arguments apps are called with.
Requested by @mjwilde
</issue>
<code>
[start of parsl/app/bash.py]
1 import logging
2 from functools import update_wrapper
3 from inspect import signature, Parameter
4
5 from parsl.app.errors import wrap_error
6 from parsl.app.futures import DataFuture
7 from parsl.app.app import AppBase
8 from parsl.dataflow.dflow import DataFlowKernelLoader
9
10 logger = logging.getLogger(__name__)
11
12
13 def remote_side_bash_executor(func, *args, **kwargs):
14 """Execute the bash app type function and return the command line string.
15
16 This string is reformatted with the *args, and **kwargs
17 from call time.
18 """
19 import os
20 import time
21 import subprocess
22 import logging
23 import parsl.app.errors as pe
24
25 logging.basicConfig(filename='/tmp/bashexec.{0}.log'.format(time.time()), level=logging.DEBUG)
26
27 # start_t = time.time()
28
29 func_name = func.__name__
30
31 partial_cmdline = None
32
33 # Try to run the func to compose the commandline
34 try:
35 # Execute the func to get the commandline
36 partial_cmdline = func(*args, **kwargs)
37 # Reformat the commandline with current args and kwargs
38 executable = partial_cmdline.format(*args, **kwargs)
39
40 except AttributeError as e:
41 if partial_cmdline is not None:
42 raise pe.AppBadFormatting("App formatting failed for app '{}' with AttributeError: {}".format(func_name, e))
43 else:
44 raise pe.BashAppNoReturn("Bash app '{}' did not return a value, or returned none - with this exception: {}".format(func_name, e), None)
45
46 except IndexError as e:
47 raise pe.AppBadFormatting("App formatting failed for app '{}' with IndexError: {}".format(func_name, e))
48 except Exception as e:
49 logging.error("Caught exception during formatting of app '{}': {}".format(func_name, e))
50 raise e
51
52 logging.debug("Executable: %s", executable)
53
54 # Updating stdout, stderr if values passed at call time.
55
56 def open_std_fd(fdname):
57 # fdname is 'stdout' or 'stderr'
58 stdfspec = kwargs.get(fdname) # spec is str name or tuple (name, mode)
59 if stdfspec is None:
60 return None
61 elif isinstance(stdfspec, str):
62 fname = stdfspec
63 mode = 'a+'
64 elif isinstance(stdfspec, tuple):
65 if len(stdfspec) != 2:
66 raise pe.BadStdStreamFile("std descriptor %s has incorrect tuple length %s" % (fdname, len(stdfspec)), TypeError('Bad Tuple Length'))
67 fname, mode = stdfspec
68 else:
69 raise pe.BadStdStreamFile("std descriptor %s has unexpected type %s" % (fdname, str(type(stdfspec))), TypeError('Bad Tuple Type'))
70 try:
71 fd = open(fname, mode)
72 except Exception as e:
73 raise pe.BadStdStreamFile(fname, e)
74 return fd
75
76 std_out = open_std_fd('stdout')
77 std_err = open_std_fd('stderr')
78 timeout = kwargs.get('walltime')
79
80 returncode = None
81 try:
82 proc = subprocess.Popen(executable, stdout=std_out, stderr=std_err, shell=True, executable='/bin/bash')
83 proc.wait(timeout=timeout)
84 returncode = proc.returncode
85
86 except subprocess.TimeoutExpired:
87 # print("Timeout")
88 raise pe.AppTimeout("[{}] App exceeded walltime: {}".format(func_name, timeout))
89
90 except Exception as e:
91 # print("Caught exception: ", e)
92 raise pe.AppException("[{}] App caught exception: {}".format(func_name, proc.returncode), e)
93
94 if returncode != 0:
95 raise pe.AppFailure("[{}] App failed with exit code: {}".format(func_name, proc.returncode), proc.returncode)
96
97 # TODO : Add support for globs here
98
99 missing = []
100 for outputfile in kwargs.get('outputs', []):
101 fpath = outputfile
102 if type(outputfile) != str:
103 fpath = outputfile.filepath
104
105 if not os.path.exists(fpath):
106 missing.extend([outputfile])
107
108 if missing:
109 raise pe.MissingOutputs("[{}] Missing outputs".format(func_name), missing)
110
111 # exec_duration = time.time() - start_t
112 return returncode
113
114
115 class BashApp(AppBase):
116
117 def __init__(self, func, data_flow_kernel=None, walltime=60, cache=False, executors='all'):
118 super().__init__(func, data_flow_kernel=data_flow_kernel, walltime=60, executors=executors, cache=cache)
119 self.kwargs = {}
120
121 # We duplicate the extraction of parameter defaults
122 # to self.kwargs to ensure availability at point of
123 # command string format. Refer: #349
124 sig = signature(func)
125
126 for s in sig.parameters:
127 if sig.parameters[s].default != Parameter.empty:
128 self.kwargs[s] = sig.parameters[s].default
129
130 def __call__(self, *args, **kwargs):
131 """Handle the call to a Bash app.
132
133 Args:
134 - Arbitrary
135
136 Kwargs:
137 - Arbitrary
138
139 Returns:
140 If outputs=[...] was a kwarg then:
141 App_fut, [Data_Futures...]
142 else:
143 App_fut
144
145 """
146 # Update kwargs in the app definition with ones passed in at calltime
147 self.kwargs.update(kwargs)
148
149 if self.data_flow_kernel is None:
150 dfk = DataFlowKernelLoader.dfk()
151 else:
152 dfk = self.data_flow_kernel
153
154 app_fut = dfk.submit(wrap_error(update_wrapper(remote_side_bash_executor, self.func)),
155 self.func, *args,
156 executors=self.executors,
157 fn_hash=self.func_hash,
158 cache=self.cache,
159 **self.kwargs)
160
161 out_futs = [DataFuture(app_fut, o, tid=app_fut.tid)
162 for o in kwargs.get('outputs', [])]
163 app_fut._outputs = out_futs
164
165 return app_fut
166
[end of parsl/app/bash.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/parsl/app/bash.py b/parsl/app/bash.py
--- a/parsl/app/bash.py
+++ b/parsl/app/bash.py
@@ -77,6 +77,9 @@
std_err = open_std_fd('stderr')
timeout = kwargs.get('walltime')
+ if std_err is not None:
+ print('--> executable follows <--\n{}\n--> end executable <--'.format(executable), file=std_err)
+
returncode = None
try:
proc = subprocess.Popen(executable, stdout=std_out, stderr=std_err, shell=True, executable='/bin/bash')
|
{"golden_diff": "diff --git a/parsl/app/bash.py b/parsl/app/bash.py\n--- a/parsl/app/bash.py\n+++ b/parsl/app/bash.py\n@@ -77,6 +77,9 @@\n std_err = open_std_fd('stderr')\n timeout = kwargs.get('walltime')\n \n+ if std_err is not None:\n+ print('--> executable follows <--\\n{}\\n--> end executable <--'.format(executable), file=std_err)\n+\n returncode = None\n try:\n proc = subprocess.Popen(executable, stdout=std_out, stderr=std_err, shell=True, executable='/bin/bash')\n", "issue": "Log app args\nFor easier debugging, we should log the arguments apps are called with.\r\n\r\nRequested by @mjwilde \n", "before_files": [{"content": "import logging\nfrom functools import update_wrapper\nfrom inspect import signature, Parameter\n\nfrom parsl.app.errors import wrap_error\nfrom parsl.app.futures import DataFuture\nfrom parsl.app.app import AppBase\nfrom parsl.dataflow.dflow import DataFlowKernelLoader\n\nlogger = logging.getLogger(__name__)\n\n\ndef remote_side_bash_executor(func, *args, **kwargs):\n \"\"\"Execute the bash app type function and return the command line string.\n\n This string is reformatted with the *args, and **kwargs\n from call time.\n \"\"\"\n import os\n import time\n import subprocess\n import logging\n import parsl.app.errors as pe\n\n logging.basicConfig(filename='/tmp/bashexec.{0}.log'.format(time.time()), level=logging.DEBUG)\n\n # start_t = time.time()\n\n func_name = func.__name__\n\n partial_cmdline = None\n\n # Try to run the func to compose the commandline\n try:\n # Execute the func to get the commandline\n partial_cmdline = func(*args, **kwargs)\n # Reformat the commandline with current args and kwargs\n executable = partial_cmdline.format(*args, **kwargs)\n\n except AttributeError as e:\n if partial_cmdline is not None:\n raise pe.AppBadFormatting(\"App formatting failed for app '{}' with AttributeError: {}\".format(func_name, e))\n else:\n raise pe.BashAppNoReturn(\"Bash app '{}' did not return a value, or returned none - with this exception: {}\".format(func_name, e), None)\n\n except IndexError as e:\n raise pe.AppBadFormatting(\"App formatting failed for app '{}' with IndexError: {}\".format(func_name, e))\n except Exception as e:\n logging.error(\"Caught exception during formatting of app '{}': {}\".format(func_name, e))\n raise e\n\n logging.debug(\"Executable: %s\", executable)\n\n # Updating stdout, stderr if values passed at call time.\n\n def open_std_fd(fdname):\n # fdname is 'stdout' or 'stderr'\n stdfspec = kwargs.get(fdname) # spec is str name or tuple (name, mode)\n if stdfspec is None:\n return None\n elif isinstance(stdfspec, str):\n fname = stdfspec\n mode = 'a+'\n elif isinstance(stdfspec, tuple):\n if len(stdfspec) != 2:\n raise pe.BadStdStreamFile(\"std descriptor %s has incorrect tuple length %s\" % (fdname, len(stdfspec)), TypeError('Bad Tuple Length'))\n fname, mode = stdfspec\n else:\n raise pe.BadStdStreamFile(\"std descriptor %s has unexpected type %s\" % (fdname, str(type(stdfspec))), TypeError('Bad Tuple Type'))\n try:\n fd = open(fname, mode)\n except Exception as e:\n raise pe.BadStdStreamFile(fname, e)\n return fd\n\n std_out = open_std_fd('stdout')\n std_err = open_std_fd('stderr')\n timeout = kwargs.get('walltime')\n\n returncode = None\n try:\n proc = subprocess.Popen(executable, stdout=std_out, stderr=std_err, shell=True, executable='/bin/bash')\n proc.wait(timeout=timeout)\n returncode = proc.returncode\n\n except subprocess.TimeoutExpired:\n # print(\"Timeout\")\n raise pe.AppTimeout(\"[{}] App exceeded walltime: {}\".format(func_name, timeout))\n\n except Exception as e:\n # print(\"Caught exception: \", e)\n raise pe.AppException(\"[{}] App caught exception: {}\".format(func_name, proc.returncode), e)\n\n if returncode != 0:\n raise pe.AppFailure(\"[{}] App failed with exit code: {}\".format(func_name, proc.returncode), proc.returncode)\n\n # TODO : Add support for globs here\n\n missing = []\n for outputfile in kwargs.get('outputs', []):\n fpath = outputfile\n if type(outputfile) != str:\n fpath = outputfile.filepath\n\n if not os.path.exists(fpath):\n missing.extend([outputfile])\n\n if missing:\n raise pe.MissingOutputs(\"[{}] Missing outputs\".format(func_name), missing)\n\n # exec_duration = time.time() - start_t\n return returncode\n\n\nclass BashApp(AppBase):\n\n def __init__(self, func, data_flow_kernel=None, walltime=60, cache=False, executors='all'):\n super().__init__(func, data_flow_kernel=data_flow_kernel, walltime=60, executors=executors, cache=cache)\n self.kwargs = {}\n\n # We duplicate the extraction of parameter defaults\n # to self.kwargs to ensure availability at point of\n # command string format. Refer: #349\n sig = signature(func)\n\n for s in sig.parameters:\n if sig.parameters[s].default != Parameter.empty:\n self.kwargs[s] = sig.parameters[s].default\n\n def __call__(self, *args, **kwargs):\n \"\"\"Handle the call to a Bash app.\n\n Args:\n - Arbitrary\n\n Kwargs:\n - Arbitrary\n\n Returns:\n If outputs=[...] was a kwarg then:\n App_fut, [Data_Futures...]\n else:\n App_fut\n\n \"\"\"\n # Update kwargs in the app definition with ones passed in at calltime\n self.kwargs.update(kwargs)\n\n if self.data_flow_kernel is None:\n dfk = DataFlowKernelLoader.dfk()\n else:\n dfk = self.data_flow_kernel\n\n app_fut = dfk.submit(wrap_error(update_wrapper(remote_side_bash_executor, self.func)),\n self.func, *args,\n executors=self.executors,\n fn_hash=self.func_hash,\n cache=self.cache,\n **self.kwargs)\n\n out_futs = [DataFuture(app_fut, o, tid=app_fut.tid)\n for o in kwargs.get('outputs', [])]\n app_fut._outputs = out_futs\n\n return app_fut\n", "path": "parsl/app/bash.py"}]}
| 2,267 | 139 |
gh_patches_debug_24219
|
rasdani/github-patches
|
git_diff
|
bokeh__bokeh-9546
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Please replace MultiSelect widget with something more compact, effective and nicer looking
ORIGINALLY POSTED AS PANEL FEATURE REQUEST AT https://github.com/holoviz/panel/issues/874
#### My Pain
I know of experience that many of my dashboard have multiple multi-selections.
The MultiSelect widget of panel is not compact so it takes up a lot of space.
Furthermore I find the MultiSelect not very nicely looking. I would like my dashboards to look appealing and fresh.
Futhermore I think navigating and selecting in the MultiSelect widget is slow as soon as you have to start scrolling in the MultiSelect

#### Solution
Implement compact, efficient and nicer looking MultiSelect.
It should work as a dropdown with multiselect.
#### Additional Context
You can get inspiration from Dash, Streamlit and Tableau that all have a much more compact and modern looking widget.


FYI. Tableau has both a more compact Dropdown and something similar to the MultiSelect.
Here it's used an that's where I have my evaluation from. You can find it in the Gallery at awesome-panel.org.
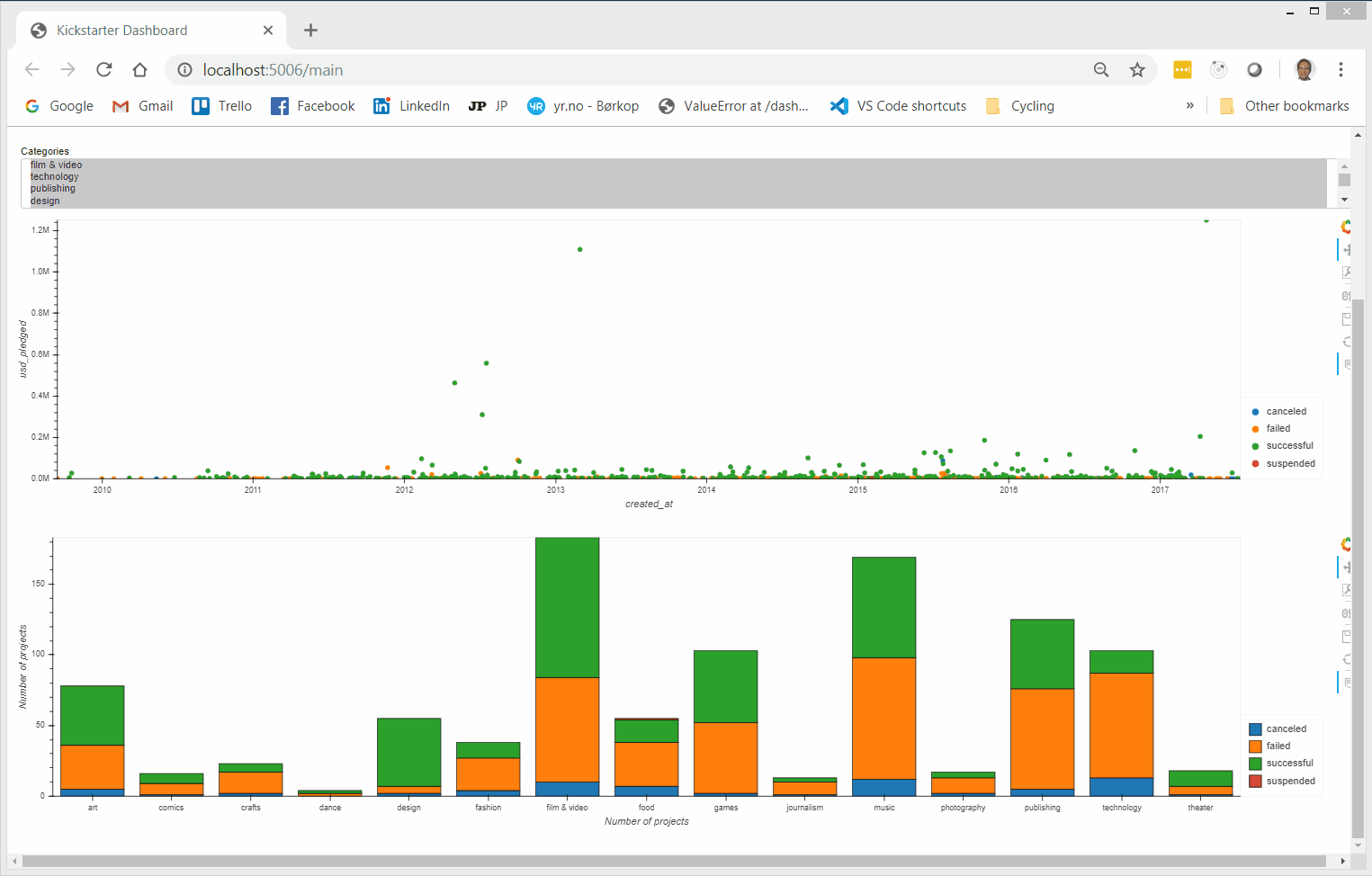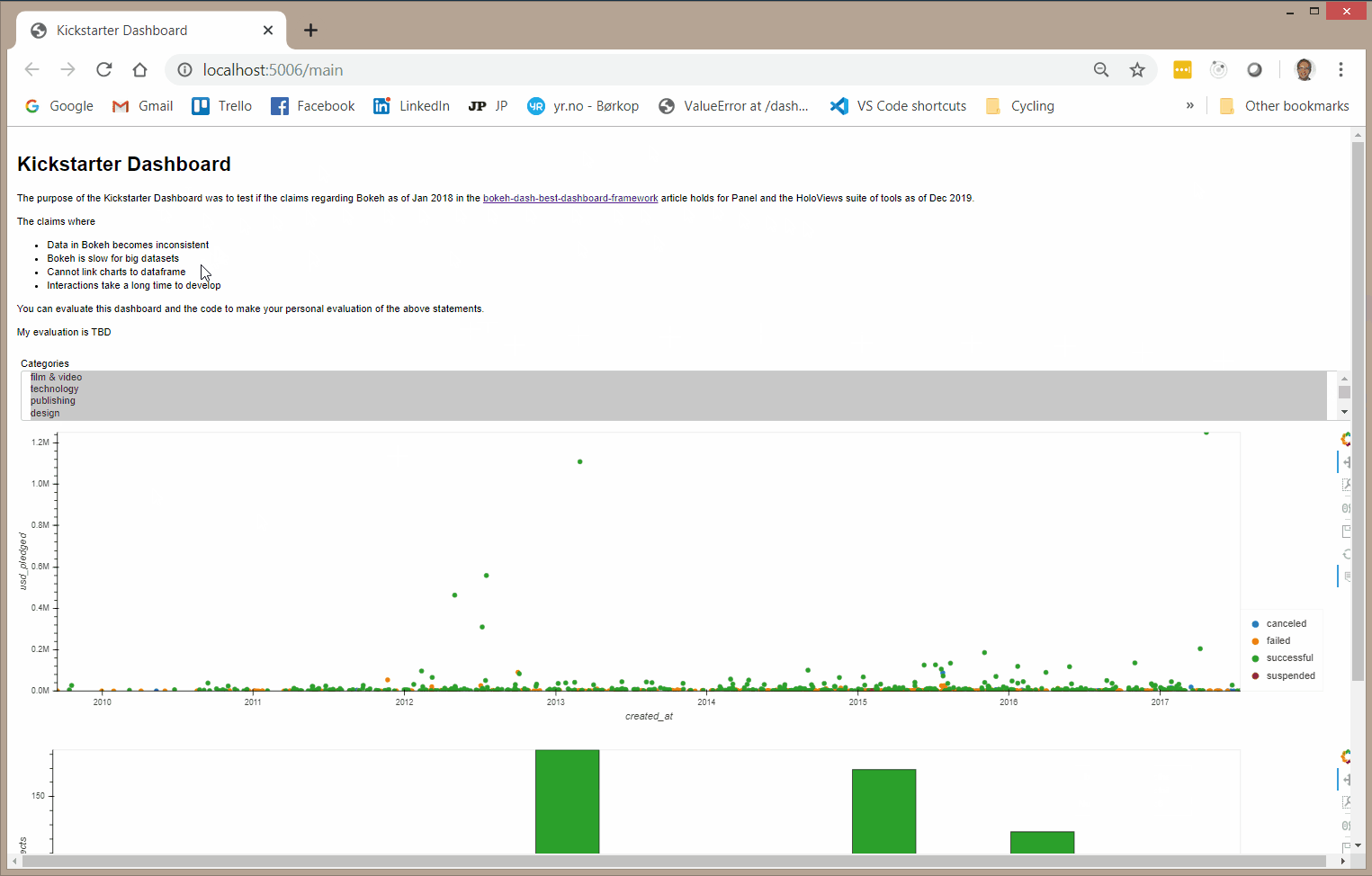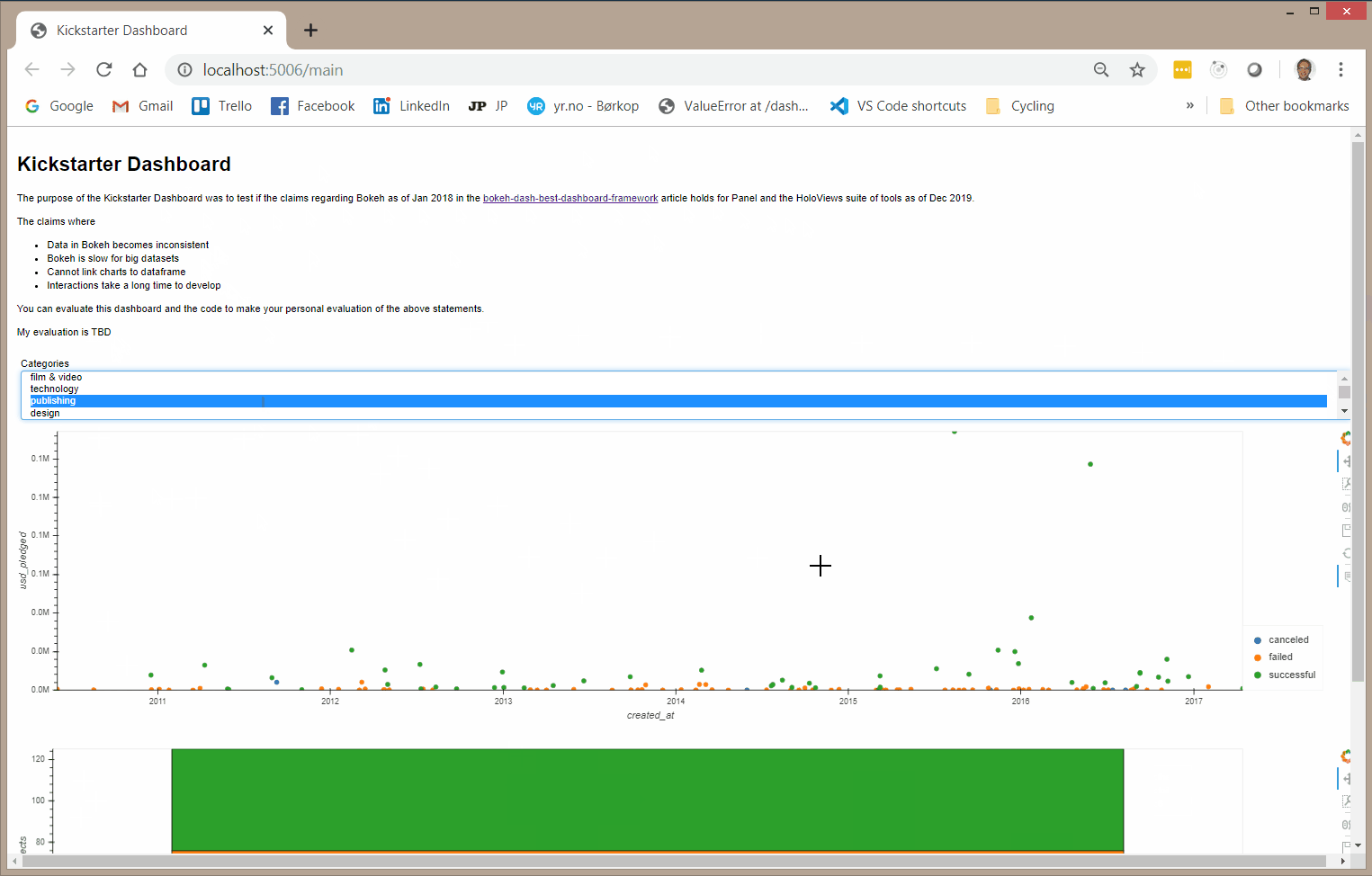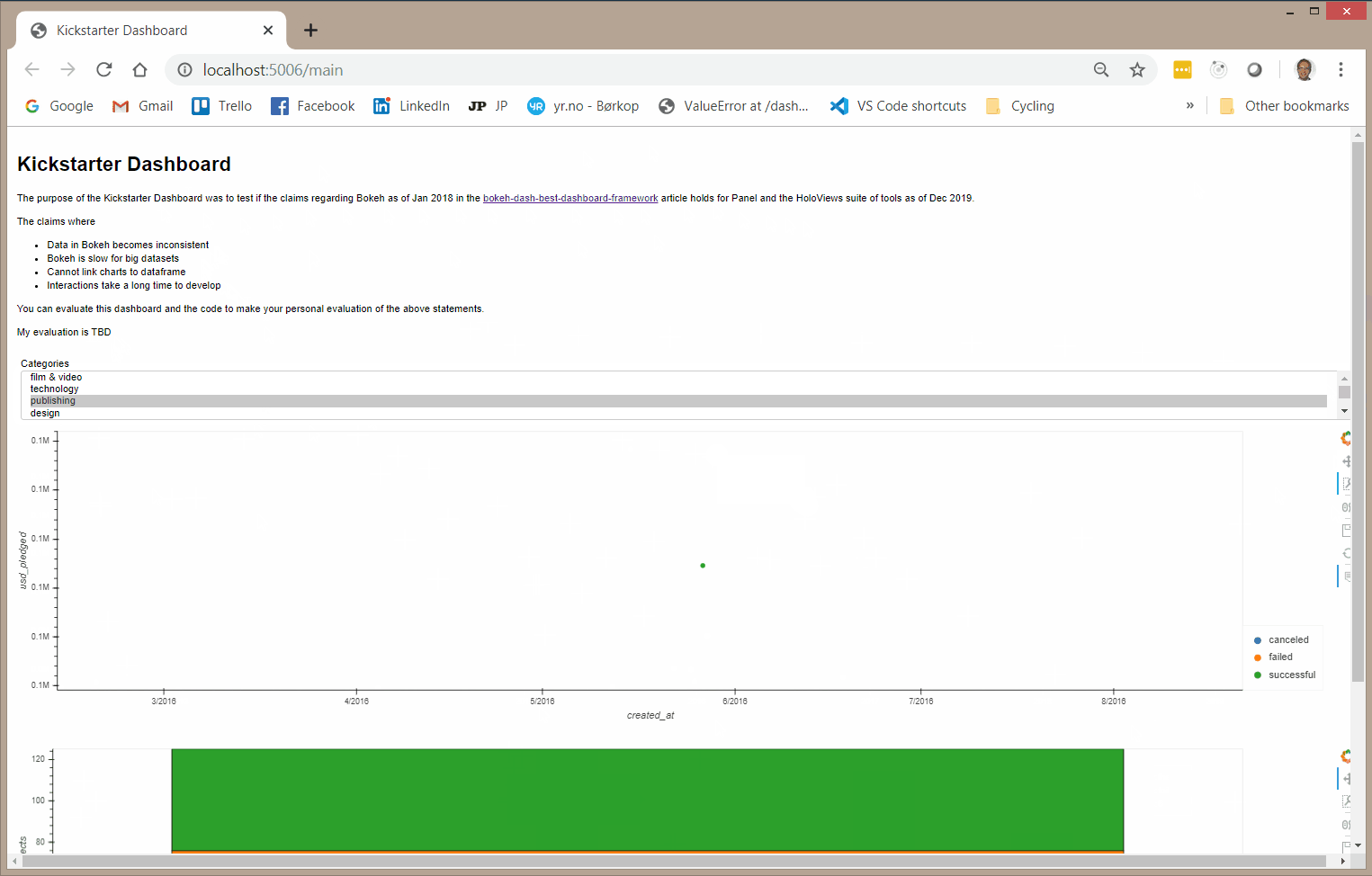
</issue>
<code>
[start of bokeh/models/widgets/inputs.py]
1 #-----------------------------------------------------------------------------
2 # Copyright (c) 2012 - 2020, Anaconda, Inc., and Bokeh Contributors.
3 # All rights reserved.
4 #
5 # The full license is in the file LICENSE.txt, distributed with this software.
6 #-----------------------------------------------------------------------------
7 ''' Various kinds of input widgets and form controls.
8
9 '''
10
11 #-----------------------------------------------------------------------------
12 # Boilerplate
13 #-----------------------------------------------------------------------------
14 import logging # isort:skip
15 log = logging.getLogger(__name__)
16
17 #-----------------------------------------------------------------------------
18 # Imports
19 #-----------------------------------------------------------------------------
20
21 # Bokeh imports
22 from ...core.enums import CalendarPosition
23 from ...core.has_props import abstract
24 from ...core.properties import (
25 Bool,
26 ColorHex,
27 Date,
28 Dict,
29 Either,
30 Enum,
31 Float,
32 Int,
33 List,
34 PositiveInt,
35 String,
36 Tuple,
37 )
38 from .widget import Widget
39
40 #-----------------------------------------------------------------------------
41 # Globals and constants
42 #-----------------------------------------------------------------------------
43
44 __all__ = (
45 'AutocompleteInput',
46 'ColorPicker',
47 'DatePicker',
48 'FileInput',
49 'InputWidget',
50 'MultiSelect',
51 'PasswordInput',
52 'Select',
53 'Spinner',
54 'TextInput',
55 'TextAreaInput'
56 )
57
58 #-----------------------------------------------------------------------------
59 # Dev API
60 #-----------------------------------------------------------------------------
61
62
63 @abstract
64 class InputWidget(Widget):
65 ''' Abstract base class for input widgets.
66
67 '''
68
69 title = String(default="", help="""
70 Widget's label.
71 """)
72
73 @classmethod
74 def coerce_value(cls, val):
75 prop_obj = cls.lookup('value')
76 if isinstance(prop_obj, Float):
77 return float(val)
78 elif isinstance(prop_obj, Int):
79 return int(val)
80 elif isinstance(prop_obj, String):
81 return str(val)
82 else:
83 return val
84
85 #-----------------------------------------------------------------------------
86 # General API
87 #-----------------------------------------------------------------------------
88
89 class FileInput(Widget):
90 ''' Present a file-chooser dialog to users and return the contents of a
91 selected file.
92
93 '''
94
95 value = String(default="", readonly=True, help="""
96 A base64-encoded string of the contents of the selected file.
97 """)
98
99 mime_type = String(default="", readonly=True, help="""
100 The mime type of the selected file.
101 """)
102
103 filename = String(default="", readonly=True, help="""
104 The filename of the selected file.
105
106 .. note::
107 The full file path is not included since browsers will not provide
108 access to that information for security reasons.
109 """)
110
111 accept = String(default="", help="""
112 Comma-separated list of standard HTML file input filters that restrict what
113 files the user can pick from. Values can be:
114
115 `<file extension>`:
116 Specific file extension(s) (e.g: .gif, .jpg, .png, .doc) are pickable
117
118 `audio/*`:
119 all sound files are pickable
120
121 `video/*`:
122 all video files are pickable
123
124 `image/*`:
125 all image files are pickable
126
127 `<media type>`:
128 A valid `IANA Media Type`_, with no parameters.
129
130 .. _IANA Media Type: https://www.iana.org/assignments/media-types/media-types.xhtml
131 """)
132
133
134 class TextInput(InputWidget):
135 ''' Single-line input widget.
136
137 '''
138
139 value = String(default="", help="""
140 Initial or entered text value.
141
142 Change events are triggered whenever <enter> is pressed.
143 """)
144
145 value_input = String(default="", help="""
146 Initial or current value.
147
148 Change events are triggered whenever any update happens, i.e. on every
149 keypress.
150 """)
151
152 placeholder = String(default="", help="""
153 Placeholder for empty input field.
154 """)
155
156
157 class TextAreaInput(TextInput):
158 ''' Multi-line input widget.
159
160 '''
161
162 cols = Int(default=20, help="""
163 Specifies the width of the text area (in average character width). Default: 20
164 """)
165
166 rows = Int(default=2, help="""
167 Specifies the height of the text area (in lines). Default: 2
168 """)
169
170 max_length = Int(default=500, help="""
171 Max count of characters in field
172 """)
173
174
175 class PasswordInput(TextInput):
176 ''' Single-line password input widget.
177
178 This widget hides the input value so that it is not visible in the browser.
179
180 .. warning::
181 Secure transmission of the password to Bokeh server application code
182 requires configuring the server for SSL (i.e. HTTPS) termination.
183
184 '''
185
186
187 class AutocompleteInput(TextInput):
188 ''' Single-line input widget with auto-completion.
189
190 '''
191
192 completions = List(String, help="""
193 A list of completion strings. This will be used to guide the
194 user upon typing the beginning of a desired value.
195 """)
196
197 min_characters = PositiveInt(default=2, help="""
198 The number of characters a user must type before completions are presented.
199 """)
200
201
202 class Select(InputWidget):
203 ''' Single-select widget.
204
205 '''
206 options = Either(List(Either(String, Tuple(Either(Int, String), String))),
207 Dict(String, List(Either(String, Tuple(Either(Int, String), String)))), help="""
208 Available selection options. Options may be provided either as a list of
209 possible string values, or as a list of tuples, each of the form
210 ``(value, label)``. In the latter case, the visible widget text for each
211 value will be corresponding given label. Option groupings can be provided
212 by supplying a dictionary object whose values are in the aforementioned
213 list format
214 """)
215
216 value = String(default="", help="""
217 Initial or selected value.
218 """)
219
220 class MultiSelect(InputWidget):
221 ''' Multi-select widget.
222
223 '''
224
225 options = List(Either(String, Tuple(String, String)), help="""
226 Available selection options. Options may be provided either as a list of
227 possible string values, or as a list of tuples, each of the form
228 ``(value, label)``. In the latter case, the visible widget text for each
229 value will be corresponding given label.
230 """)
231
232 value = List(String, help="""
233 Initial or selected values.
234 """)
235
236 size = Int(default=4, help="""
237 The number of visible options in the dropdown list. (This uses the
238 ``select`` HTML element's ``size`` attribute. Some browsers might not
239 show less than 3 options.)
240 """)
241
242
243 class DatePicker(InputWidget):
244 ''' Calendar-based date picker widget.
245
246 '''
247
248 value = Date(help="""
249 The initial or picked date.
250 """)
251
252 min_date = Date(default=None, help="""
253 Optional earliest allowable date.
254 """)
255
256 max_date = Date(default=None, help="""
257 Optional latest allowable date.
258 """)
259
260 disabled_dates = List(Either(Date, Tuple(Date, Date)), default=[], help="""
261 A list of dates of ``(start, end)`` date ranges to make unavailable for
262 selection. All other dates will be avalable.
263
264 .. note::
265 Only one of ``disabled_dates`` and ``enabled_dates`` should be specified.
266 """)
267
268 enabled_dates = List(Either(Date, Tuple(Date, Date)), default=[], help="""
269 A list of dates of ``(start, end)`` date ranges to make available for
270 selection. All other dates will be unavailable.
271
272 .. note::
273 Only one of ``disabled_dates`` and ``enabled_dates`` should be specified.
274 """)
275
276 position = Enum(CalendarPosition, default="auto", help="""
277 Where the calendar is rendered relative to the input when ``inline`` is False.
278 """)
279
280 inline = Bool(default=False, help="""
281 Whether the calendar sholud be displayed inline.
282 """)
283
284 class ColorPicker(InputWidget):
285 ''' Color picker widget
286
287 .. warning::
288 This widget as a limited support on *Internet Explorer* (it will be displayed
289 as a simple text input).
290
291 '''
292
293 color = ColorHex(default='#000000', help="""
294 The initial color of the picked color (named or hexadecimal)
295 """)
296
297 class Spinner(InputWidget):
298 ''' Spinner widget for numerical inputs
299
300 '''
301
302 value = Float(default=0, help="""
303 The initial value of the spinner
304 """)
305
306 step = Float(default=1, help="""
307 The step added or subtracted to the current value
308 """)
309
310 low = Float(help="""
311 Optional lowest allowable value.
312 """)
313
314 high = Float(help="""
315 Optional highest allowable value.
316 """)
317
318 #-----------------------------------------------------------------------------
319 # Private API
320 #-----------------------------------------------------------------------------
321
322 #-----------------------------------------------------------------------------
323 # Code
324 #-----------------------------------------------------------------------------
325
[end of bokeh/models/widgets/inputs.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/bokeh/models/widgets/inputs.py b/bokeh/models/widgets/inputs.py
--- a/bokeh/models/widgets/inputs.py
+++ b/bokeh/models/widgets/inputs.py
@@ -47,6 +47,7 @@
'DatePicker',
'FileInput',
'InputWidget',
+ 'MultiChoice',
'MultiSelect',
'PasswordInput',
'Select',
@@ -240,6 +241,42 @@
""")
+class MultiChoice(InputWidget):
+ ''' MultiChoice widget.
+
+ '''
+
+ options = List(Either(String, Tuple(String, String)), help="""
+ Available selection options. Options may be provided either as a list of
+ possible string values, or as a list of tuples, each of the form
+ ``(value, label)``. In the latter case, the visible widget text for each
+ value will be corresponding given label.
+ """)
+
+ value = List(String, help="""
+ Initial or selected values.
+ """)
+
+ delete_button = Bool(default=True, help="""
+ Whether to add a button to remove a selected option.
+ """)
+
+ max_items = Int(default=None, help="""
+ The maximum number of items that can be selected.
+ """)
+
+ option_limit = Int(default=None, help="""
+ The number of choices that will be rendered in the dropdown.
+ """)
+
+ placeholder = String(default=None, help="""
+ A string that is displayed if not item is added.
+ """)
+
+ solid = Bool(default=True, help="""
+ Specify whether the choices should be solidly filled.""")
+
+
class DatePicker(InputWidget):
''' Calendar-based date picker widget.
|
{"golden_diff": "diff --git a/bokeh/models/widgets/inputs.py b/bokeh/models/widgets/inputs.py\n--- a/bokeh/models/widgets/inputs.py\n+++ b/bokeh/models/widgets/inputs.py\n@@ -47,6 +47,7 @@\n 'DatePicker',\n 'FileInput',\n 'InputWidget',\n+ 'MultiChoice',\n 'MultiSelect',\n 'PasswordInput',\n 'Select',\n@@ -240,6 +241,42 @@\n \"\"\")\n \n \n+class MultiChoice(InputWidget):\n+ ''' MultiChoice widget.\n+\n+ '''\n+\n+ options = List(Either(String, Tuple(String, String)), help=\"\"\"\n+ Available selection options. Options may be provided either as a list of\n+ possible string values, or as a list of tuples, each of the form\n+ ``(value, label)``. In the latter case, the visible widget text for each\n+ value will be corresponding given label.\n+ \"\"\")\n+\n+ value = List(String, help=\"\"\"\n+ Initial or selected values.\n+ \"\"\")\n+\n+ delete_button = Bool(default=True, help=\"\"\"\n+ Whether to add a button to remove a selected option.\n+ \"\"\")\n+\n+ max_items = Int(default=None, help=\"\"\"\n+ The maximum number of items that can be selected.\n+ \"\"\")\n+\n+ option_limit = Int(default=None, help=\"\"\"\n+ The number of choices that will be rendered in the dropdown.\n+ \"\"\")\n+\n+ placeholder = String(default=None, help=\"\"\"\n+ A string that is displayed if not item is added.\n+ \"\"\")\n+\n+ solid = Bool(default=True, help=\"\"\"\n+ Specify whether the choices should be solidly filled.\"\"\")\n+\n+\n class DatePicker(InputWidget):\n ''' Calendar-based date picker widget.\n", "issue": "Please replace MultiSelect widget with something more compact, effective and nicer looking\nORIGINALLY POSTED AS PANEL FEATURE REQUEST AT https://github.com/holoviz/panel/issues/874\r\n\r\n#### My Pain\r\n\r\nI know of experience that many of my dashboard have multiple multi-selections. \r\n\r\nThe MultiSelect widget of panel is not compact so it takes up a lot of space.\r\n\r\nFurthermore I find the MultiSelect not very nicely looking. I would like my dashboards to look appealing and fresh.\r\n\r\nFuthermore I think navigating and selecting in the MultiSelect widget is slow as soon as you have to start scrolling in the MultiSelect\r\n\r\n\r\n\r\n#### Solution\r\n\r\nImplement compact, efficient and nicer looking MultiSelect. \r\n\r\nIt should work as a dropdown with multiselect.\r\n\r\n#### Additional Context\r\n\r\nYou can get inspiration from Dash, Streamlit and Tableau that all have a much more compact and modern looking widget.\r\n\r\n\r\n\r\n\r\n\r\nFYI. Tableau has both a more compact Dropdown and something similar to the MultiSelect.\r\n\r\nHere it's used an that's where I have my evaluation from. You can find it in the Gallery at awesome-panel.org.\r\n\r\n\n", "before_files": [{"content": "#-----------------------------------------------------------------------------\n# Copyright (c) 2012 - 2020, Anaconda, Inc., and Bokeh Contributors.\n# All rights reserved.\n#\n# The full license is in the file LICENSE.txt, distributed with this software.\n#-----------------------------------------------------------------------------\n''' Various kinds of input widgets and form controls.\n\n'''\n\n#-----------------------------------------------------------------------------\n# Boilerplate\n#-----------------------------------------------------------------------------\nimport logging # isort:skip\nlog = logging.getLogger(__name__)\n\n#-----------------------------------------------------------------------------\n# Imports\n#-----------------------------------------------------------------------------\n\n# Bokeh imports\nfrom ...core.enums import CalendarPosition\nfrom ...core.has_props import abstract\nfrom ...core.properties import (\n Bool,\n ColorHex,\n Date,\n Dict,\n Either,\n Enum,\n Float,\n Int,\n List,\n PositiveInt,\n String,\n Tuple,\n)\nfrom .widget import Widget\n\n#-----------------------------------------------------------------------------\n# Globals and constants\n#-----------------------------------------------------------------------------\n\n__all__ = (\n 'AutocompleteInput',\n 'ColorPicker',\n 'DatePicker',\n 'FileInput',\n 'InputWidget',\n 'MultiSelect',\n 'PasswordInput',\n 'Select',\n 'Spinner',\n 'TextInput',\n 'TextAreaInput'\n)\n\n#-----------------------------------------------------------------------------\n# Dev API\n#-----------------------------------------------------------------------------\n\n\n@abstract\nclass InputWidget(Widget):\n ''' Abstract base class for input widgets.\n\n '''\n\n title = String(default=\"\", help=\"\"\"\n Widget's label.\n \"\"\")\n\n @classmethod\n def coerce_value(cls, val):\n prop_obj = cls.lookup('value')\n if isinstance(prop_obj, Float):\n return float(val)\n elif isinstance(prop_obj, Int):\n return int(val)\n elif isinstance(prop_obj, String):\n return str(val)\n else:\n return val\n\n#-----------------------------------------------------------------------------\n# General API\n#-----------------------------------------------------------------------------\n\nclass FileInput(Widget):\n ''' Present a file-chooser dialog to users and return the contents of a\n selected file.\n\n '''\n\n value = String(default=\"\", readonly=True, help=\"\"\"\n A base64-encoded string of the contents of the selected file.\n \"\"\")\n\n mime_type = String(default=\"\", readonly=True, help=\"\"\"\n The mime type of the selected file.\n \"\"\")\n\n filename = String(default=\"\", readonly=True, help=\"\"\"\n The filename of the selected file.\n\n .. note::\n The full file path is not included since browsers will not provide\n access to that information for security reasons.\n \"\"\")\n\n accept = String(default=\"\", help=\"\"\"\n Comma-separated list of standard HTML file input filters that restrict what\n files the user can pick from. Values can be:\n\n `<file extension>`:\n Specific file extension(s) (e.g: .gif, .jpg, .png, .doc) are pickable\n\n `audio/*`:\n all sound files are pickable\n\n `video/*`:\n all video files are pickable\n\n `image/*`:\n all image files are pickable\n\n `<media type>`:\n A valid `IANA Media Type`_, with no parameters.\n\n .. _IANA Media Type: https://www.iana.org/assignments/media-types/media-types.xhtml\n \"\"\")\n\n\nclass TextInput(InputWidget):\n ''' Single-line input widget.\n\n '''\n\n value = String(default=\"\", help=\"\"\"\n Initial or entered text value.\n\n Change events are triggered whenever <enter> is pressed.\n \"\"\")\n\n value_input = String(default=\"\", help=\"\"\"\n Initial or current value.\n\n Change events are triggered whenever any update happens, i.e. on every\n keypress.\n \"\"\")\n\n placeholder = String(default=\"\", help=\"\"\"\n Placeholder for empty input field.\n \"\"\")\n\n\nclass TextAreaInput(TextInput):\n ''' Multi-line input widget.\n\n '''\n\n cols = Int(default=20, help=\"\"\"\n Specifies the width of the text area (in average character width). Default: 20\n \"\"\")\n\n rows = Int(default=2, help=\"\"\"\n Specifies the height of the text area (in lines). Default: 2\n \"\"\")\n\n max_length = Int(default=500, help=\"\"\"\n Max count of characters in field\n \"\"\")\n\n\nclass PasswordInput(TextInput):\n ''' Single-line password input widget.\n\n This widget hides the input value so that it is not visible in the browser.\n\n .. warning::\n Secure transmission of the password to Bokeh server application code\n requires configuring the server for SSL (i.e. HTTPS) termination.\n\n '''\n\n\nclass AutocompleteInput(TextInput):\n ''' Single-line input widget with auto-completion.\n\n '''\n\n completions = List(String, help=\"\"\"\n A list of completion strings. This will be used to guide the\n user upon typing the beginning of a desired value.\n \"\"\")\n\n min_characters = PositiveInt(default=2, help=\"\"\"\n The number of characters a user must type before completions are presented.\n \"\"\")\n\n\nclass Select(InputWidget):\n ''' Single-select widget.\n\n '''\n options = Either(List(Either(String, Tuple(Either(Int, String), String))),\n Dict(String, List(Either(String, Tuple(Either(Int, String), String)))), help=\"\"\"\n Available selection options. Options may be provided either as a list of\n possible string values, or as a list of tuples, each of the form\n ``(value, label)``. In the latter case, the visible widget text for each\n value will be corresponding given label. Option groupings can be provided\n by supplying a dictionary object whose values are in the aforementioned\n list format\n \"\"\")\n\n value = String(default=\"\", help=\"\"\"\n Initial or selected value.\n \"\"\")\n\nclass MultiSelect(InputWidget):\n ''' Multi-select widget.\n\n '''\n\n options = List(Either(String, Tuple(String, String)), help=\"\"\"\n Available selection options. Options may be provided either as a list of\n possible string values, or as a list of tuples, each of the form\n ``(value, label)``. In the latter case, the visible widget text for each\n value will be corresponding given label.\n \"\"\")\n\n value = List(String, help=\"\"\"\n Initial or selected values.\n \"\"\")\n\n size = Int(default=4, help=\"\"\"\n The number of visible options in the dropdown list. (This uses the\n ``select`` HTML element's ``size`` attribute. Some browsers might not\n show less than 3 options.)\n \"\"\")\n\n\nclass DatePicker(InputWidget):\n ''' Calendar-based date picker widget.\n\n '''\n\n value = Date(help=\"\"\"\n The initial or picked date.\n \"\"\")\n\n min_date = Date(default=None, help=\"\"\"\n Optional earliest allowable date.\n \"\"\")\n\n max_date = Date(default=None, help=\"\"\"\n Optional latest allowable date.\n \"\"\")\n\n disabled_dates = List(Either(Date, Tuple(Date, Date)), default=[], help=\"\"\"\n A list of dates of ``(start, end)`` date ranges to make unavailable for\n selection. All other dates will be avalable.\n\n .. note::\n Only one of ``disabled_dates`` and ``enabled_dates`` should be specified.\n \"\"\")\n\n enabled_dates = List(Either(Date, Tuple(Date, Date)), default=[], help=\"\"\"\n A list of dates of ``(start, end)`` date ranges to make available for\n selection. All other dates will be unavailable.\n\n .. note::\n Only one of ``disabled_dates`` and ``enabled_dates`` should be specified.\n \"\"\")\n\n position = Enum(CalendarPosition, default=\"auto\", help=\"\"\"\n Where the calendar is rendered relative to the input when ``inline`` is False.\n \"\"\")\n\n inline = Bool(default=False, help=\"\"\"\n Whether the calendar sholud be displayed inline.\n \"\"\")\n\nclass ColorPicker(InputWidget):\n ''' Color picker widget\n\n .. warning::\n This widget as a limited support on *Internet Explorer* (it will be displayed\n as a simple text input).\n\n '''\n\n color = ColorHex(default='#000000', help=\"\"\"\n The initial color of the picked color (named or hexadecimal)\n \"\"\")\n\nclass Spinner(InputWidget):\n ''' Spinner widget for numerical inputs\n\n '''\n\n value = Float(default=0, help=\"\"\"\n The initial value of the spinner\n \"\"\")\n\n step = Float(default=1, help=\"\"\"\n The step added or subtracted to the current value\n \"\"\")\n\n low = Float(help=\"\"\"\n Optional lowest allowable value.\n \"\"\")\n\n high = Float(help=\"\"\"\n Optional highest allowable value.\n \"\"\")\n\n#-----------------------------------------------------------------------------\n# Private API\n#-----------------------------------------------------------------------------\n\n#-----------------------------------------------------------------------------\n# Code\n#-----------------------------------------------------------------------------\n", "path": "bokeh/models/widgets/inputs.py"}]}
| 3,771 | 394 |
gh_patches_debug_1187
|
rasdani/github-patches
|
git_diff
|
freedomofpress__securedrop-6051
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Alembic operations fail with multiple head revisions
## Description
All Alembic operations fail with Alembic error:
ERROR [alembic.util.messaging] Multiple head revisions are present for given argument 'head'; please specify a specific target revision, '<branchname>@head' to narrow to a specific head, or 'heads' for all heads
Cf. consistent recent failures of CI jobs `app-tests` and `staging-test-with-rebase` since #5974.
## Steps to Reproduce
`make test` on `develop`; open or push to a PR; etc.
## Expected Behavior
Alembic operations succeed and Alembic-based tests pass.
## Actual Behavior
All Alembic operations and tests fail with Alembic error:
ERROR [alembic.util.messaging] Multiple head revisions are present for given argument 'head'; please specify a specific target revision, '<branchname>@head' to narrow to a specific head, or 'heads' for all heads
## Comments
This is essentially an Alembic-level merge-conflict. PR forthcoming with the one-line fix.
</issue>
<code>
[start of securedrop/alembic/versions/1ddb81fb88c2_unique_index_for_instanceconfig_valid_.py]
1 """unique_index_for_instanceconfig_valid_until
2
3 Revision ID: 1ddb81fb88c2
4 Revises: 92fba0be98e9
5 Create Date: 2021-06-04 17:28:25.725563
6
7 """
8 from alembic import op
9 import sqlalchemy as sa
10
11
12 # revision identifiers, used by Alembic.
13 revision = '1ddb81fb88c2'
14 down_revision = '92fba0be98e9'
15 branch_labels = None
16 depends_on = None
17
18
19 def upgrade():
20 # ### commands auto generated by Alembic - please adjust! ###
21 with op.batch_alter_table('instance_config', schema=None) as batch_op:
22 batch_op.create_index('ix_one_active_instance_config', [sa.text('valid_until IS NULL')], unique=True, sqlite_where=sa.text('valid_until IS NULL'))
23
24 # ### end Alembic commands ###
25
26
27 def downgrade():
28 # ### commands auto generated by Alembic - please adjust! ###
29 with op.batch_alter_table('instance_config', schema=None) as batch_op:
30 batch_op.drop_index('ix_one_active_instance_config')
31
32 # ### end Alembic commands ###
33
[end of securedrop/alembic/versions/1ddb81fb88c2_unique_index_for_instanceconfig_valid_.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/securedrop/alembic/versions/1ddb81fb88c2_unique_index_for_instanceconfig_valid_.py b/securedrop/alembic/versions/1ddb81fb88c2_unique_index_for_instanceconfig_valid_.py
--- a/securedrop/alembic/versions/1ddb81fb88c2_unique_index_for_instanceconfig_valid_.py
+++ b/securedrop/alembic/versions/1ddb81fb88c2_unique_index_for_instanceconfig_valid_.py
@@ -11,7 +11,7 @@
# revision identifiers, used by Alembic.
revision = '1ddb81fb88c2'
-down_revision = '92fba0be98e9'
+down_revision = 'b060f38c0c31'
branch_labels = None
depends_on = None
|
{"golden_diff": "diff --git a/securedrop/alembic/versions/1ddb81fb88c2_unique_index_for_instanceconfig_valid_.py b/securedrop/alembic/versions/1ddb81fb88c2_unique_index_for_instanceconfig_valid_.py\n--- a/securedrop/alembic/versions/1ddb81fb88c2_unique_index_for_instanceconfig_valid_.py\n+++ b/securedrop/alembic/versions/1ddb81fb88c2_unique_index_for_instanceconfig_valid_.py\n@@ -11,7 +11,7 @@\n \n # revision identifiers, used by Alembic.\n revision = '1ddb81fb88c2'\n-down_revision = '92fba0be98e9'\n+down_revision = 'b060f38c0c31'\n branch_labels = None\n depends_on = None\n", "issue": "Alembic operations fail with multiple head revisions\n## Description\r\n\r\nAll Alembic operations fail with Alembic error:\r\n\r\n ERROR [alembic.util.messaging] Multiple head revisions are present for given argument 'head'; please specify a specific target revision, '<branchname>@head' to narrow to a specific head, or 'heads' for all heads\r\n\r\nCf. consistent recent failures of CI jobs `app-tests` and `staging-test-with-rebase` since #5974.\r\n\r\n## Steps to Reproduce\r\n\r\n`make test` on `develop`; open or push to a PR; etc.\r\n\r\n## Expected Behavior\r\n\r\nAlembic operations succeed and Alembic-based tests pass.\r\n\r\n## Actual Behavior\r\n\r\nAll Alembic operations and tests fail with Alembic error:\r\n\r\n ERROR [alembic.util.messaging] Multiple head revisions are present for given argument 'head'; please specify a specific target revision, '<branchname>@head' to narrow to a specific head, or 'heads' for all heads\r\n\r\n## Comments\r\n\r\nThis is essentially an Alembic-level merge-conflict. PR forthcoming with the one-line fix.\n", "before_files": [{"content": "\"\"\"unique_index_for_instanceconfig_valid_until\n\nRevision ID: 1ddb81fb88c2\nRevises: 92fba0be98e9\nCreate Date: 2021-06-04 17:28:25.725563\n\n\"\"\"\nfrom alembic import op\nimport sqlalchemy as sa\n\n\n# revision identifiers, used by Alembic.\nrevision = '1ddb81fb88c2'\ndown_revision = '92fba0be98e9'\nbranch_labels = None\ndepends_on = None\n\n\ndef upgrade():\n # ### commands auto generated by Alembic - please adjust! ###\n with op.batch_alter_table('instance_config', schema=None) as batch_op:\n batch_op.create_index('ix_one_active_instance_config', [sa.text('valid_until IS NULL')], unique=True, sqlite_where=sa.text('valid_until IS NULL'))\n\n # ### end Alembic commands ###\n\n\ndef downgrade():\n # ### commands auto generated by Alembic - please adjust! ###\n with op.batch_alter_table('instance_config', schema=None) as batch_op:\n batch_op.drop_index('ix_one_active_instance_config')\n\n # ### end Alembic commands ###\n", "path": "securedrop/alembic/versions/1ddb81fb88c2_unique_index_for_instanceconfig_valid_.py"}]}
| 1,145 | 199 |
gh_patches_debug_25395
|
rasdani/github-patches
|
git_diff
|
aws-cloudformation__cfn-lint-1444
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Unexpected E1029 error
*cfn-lint version: (0.29.1)*
*Description of issue.*
After this version was released, I started getting an error when linting a template. This error specific to `BuildSpec` attributes for a `AWS::CodeBuild::Project` project.
E1029 Found an embedded parameter outside of an "Fn::Sub" at
Resources/MyCodeBuild/Properties/Source/BuildSpec
cloudformation.json:151:11
I mocked up a JSON template that showcases the problem and [attached](https://github.com/aws-cloudformation/cfn-python-lint/files/4383494/cloudformation.txt) it.
</issue>
<code>
[start of src/cfnlint/rules/functions/SubNeeded.py]
1 """
2 Copyright 2019 Amazon.com, Inc. or its affiliates. All Rights Reserved.
3 SPDX-License-Identifier: MIT-0
4 """
5 import re
6 import six
7 from cfnlint.rules import CloudFormationLintRule
8 from cfnlint.rules import RuleMatch
9
10
11 class SubNeeded(CloudFormationLintRule):
12 """Check if a substitution string exists without a substitution function"""
13 id = 'E1029'
14 shortdesc = 'Sub is required if a variable is used in a string'
15 description = 'If a substitution variable exists in a string but isn\'t wrapped with the Fn::Sub function the deployment will fail.'
16 source_url = 'https://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/intrinsic-function-reference-sub.html'
17 tags = ['functions', 'sub']
18
19 # Free-form text properties to exclude from this rule
20 # content is part of AWS::CloudFormation::Init
21 excludes = ['UserData', 'ZipFile', 'Condition', 'AWS::CloudFormation::Init',
22 'CloudWatchAlarmDefinition', 'TopicRulePayload']
23 api_excludes = ['Uri', 'Body']
24
25 # IAM Policy has special variables that don't require !Sub, Check for these
26 # https://docs.aws.amazon.com/IAM/latest/UserGuide/reference_policies_variables.html
27 # https://docs.aws.amazon.com/iot/latest/developerguide/basic-policy-variables.html
28 # https://docs.aws.amazon.com/iot/latest/developerguide/thing-policy-variables.html
29 # https://docs.aws.amazon.com/transfer/latest/userguide/users.html#users-policies-scope-down
30 # https://docs.aws.amazon.com/IAM/latest/UserGuide/reference_policies_iam-condition-keys.html
31 resource_excludes = ['${aws:CurrentTime}', '${aws:EpochTime}',
32 '${aws:TokenIssueTime}', '${aws:principaltype}',
33 '${aws:SecureTransport}', '${aws:SourceIp}',
34 '${aws:UserAgent}', '${aws:userid}',
35 '${aws:username}', '${ec2:SourceInstanceARN}',
36 '${iot:Connection.Thing.ThingName}',
37 '${iot:Connection.Thing.ThingTypeName}',
38 '${iot:Connection.Thing.IsAttached}',
39 '${iot:ClientId}', '${transfer:HomeBucket}',
40 '${transfer:HomeDirectory}', '${transfer:HomeFolder}',
41 '${transfer:UserName}', '${redshift:DbUser}',
42 '${cognito-identity.amazonaws.com:aud}',
43 '${cognito-identity.amazonaws.com:sub}',
44 '${cognito-identity.amazonaws.com:amr}']
45
46 # https://docs.aws.amazon.com/redshift/latest/mgmt/redshift-iam-access-control-identity-based.html
47 condition_excludes = [
48 '${redshift:DbUser}',
49 ]
50
51 def __init__(self):
52 """Init"""
53 super(SubNeeded, self).__init__()
54 self.config_definition = {
55 'custom_excludes': {
56 'default': '',
57 'type': 'string'
58 }
59 }
60 self.configure()
61 self.subParameterRegex = re.compile(r'(\$\{[A-Za-z0-9_:\.]+\})')
62
63 def _match_values(self, cfnelem, path):
64 """Recursively search for values matching the searchRegex"""
65 values = []
66 if isinstance(cfnelem, dict):
67 for key in cfnelem:
68 pathprop = path[:]
69 pathprop.append(key)
70 values.extend(self._match_values(cfnelem[key], pathprop))
71 elif isinstance(cfnelem, list):
72 for index, item in enumerate(cfnelem):
73 pathprop = path[:]
74 pathprop.append(index)
75 values.extend(self._match_values(item, pathprop))
76 else:
77 # Leaf node
78 if isinstance(cfnelem, six.string_types): # and re.match(searchRegex, cfnelem):
79 for variable in re.findall(self.subParameterRegex, cfnelem):
80 values.append(path + [variable])
81
82 return values
83
84 def match_values(self, cfn):
85 """
86 Search for values in all parts of the templates that match the searchRegex
87 """
88 results = []
89 results.extend(self._match_values(cfn.template, []))
90 # Globals are removed during a transform. They need to be checked manually
91 results.extend(self._match_values(cfn.template.get('Globals', {}), []))
92 return results
93
94 def _api_exceptions(self, value):
95 """ Key value exceptions """
96 parameter_search = re.compile(r'^\$\{stageVariables\..*\}$')
97 return re.match(parameter_search, value)
98
99 def _variable_custom_excluded(self, value):
100 """ User-defined exceptions for variables, anywhere in the file """
101 custom_excludes = self.config['custom_excludes']
102 if custom_excludes:
103 custom_search = re.compile(custom_excludes)
104 return re.match(custom_search, value)
105 return False
106
107 def match(self, cfn):
108 """Basic Rule Matching"""
109
110 matches = []
111
112 # Get a list of paths to every leaf node string containing at least one ${parameter}
113 parameter_string_paths = self.match_values(cfn)
114 # We want to search all of the paths to check if each one contains an 'Fn::Sub'
115 for parameter_string_path in parameter_string_paths:
116 if parameter_string_path[0] in ['Parameters']:
117 continue
118 # Exclude the special IAM variables
119 variable = parameter_string_path[-1]
120
121 if 'Resource' in parameter_string_path:
122 if variable in self.resource_excludes:
123 continue
124 if 'NotResource' in parameter_string_path:
125 if variable in self.resource_excludes:
126 continue
127 if 'Condition' in parameter_string_path:
128 if variable in self.condition_excludes:
129 continue
130
131 # Exclude variables that match custom exclude filters, if configured
132 # (for third-party tools that pre-process templates before uploading them to AWS)
133 if self._variable_custom_excluded(variable):
134 continue
135
136 # Exclude literals (https://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/intrinsic-function-reference-sub.html)
137 if variable.startswith('${!'):
138 continue
139
140 found_sub = False
141 # Does the path contain an 'Fn::Sub'?
142 for step in parameter_string_path:
143 if step in self.api_excludes:
144 if self._api_exceptions(parameter_string_path[-1]):
145 found_sub = True
146 elif step == 'Fn::Sub' or step in self.excludes:
147 found_sub = True
148
149 # If we didn't find an 'Fn::Sub' it means a string containing a ${parameter} may not be evaluated correctly
150 if not found_sub:
151 # Remove the last item (the variable) to prevent multiple errors on 1 line errors
152 path = parameter_string_path[:-1]
153 message = 'Found an embedded parameter outside of an "Fn::Sub" at {}'.format(
154 '/'.join(map(str, path)))
155 matches.append(RuleMatch(path, message))
156
157 return matches
158
[end of src/cfnlint/rules/functions/SubNeeded.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/cfnlint/rules/functions/SubNeeded.py b/src/cfnlint/rules/functions/SubNeeded.py
--- a/src/cfnlint/rules/functions/SubNeeded.py
+++ b/src/cfnlint/rules/functions/SubNeeded.py
@@ -19,7 +19,7 @@
# Free-form text properties to exclude from this rule
# content is part of AWS::CloudFormation::Init
excludes = ['UserData', 'ZipFile', 'Condition', 'AWS::CloudFormation::Init',
- 'CloudWatchAlarmDefinition', 'TopicRulePayload']
+ 'CloudWatchAlarmDefinition', 'TopicRulePayload', 'BuildSpec']
api_excludes = ['Uri', 'Body']
# IAM Policy has special variables that don't require !Sub, Check for these
@@ -150,8 +150,8 @@
if not found_sub:
# Remove the last item (the variable) to prevent multiple errors on 1 line errors
path = parameter_string_path[:-1]
- message = 'Found an embedded parameter outside of an "Fn::Sub" at {}'.format(
- '/'.join(map(str, path)))
+ message = 'Found an embedded parameter "{}" outside of an "Fn::Sub" at {}'.format(
+ variable, '/'.join(map(str, path)))
matches.append(RuleMatch(path, message))
return matches
|
{"golden_diff": "diff --git a/src/cfnlint/rules/functions/SubNeeded.py b/src/cfnlint/rules/functions/SubNeeded.py\n--- a/src/cfnlint/rules/functions/SubNeeded.py\n+++ b/src/cfnlint/rules/functions/SubNeeded.py\n@@ -19,7 +19,7 @@\n # Free-form text properties to exclude from this rule\n # content is part of AWS::CloudFormation::Init\n excludes = ['UserData', 'ZipFile', 'Condition', 'AWS::CloudFormation::Init',\n- 'CloudWatchAlarmDefinition', 'TopicRulePayload']\n+ 'CloudWatchAlarmDefinition', 'TopicRulePayload', 'BuildSpec']\n api_excludes = ['Uri', 'Body']\n \n # IAM Policy has special variables that don't require !Sub, Check for these\n@@ -150,8 +150,8 @@\n if not found_sub:\n # Remove the last item (the variable) to prevent multiple errors on 1 line errors\n path = parameter_string_path[:-1]\n- message = 'Found an embedded parameter outside of an \"Fn::Sub\" at {}'.format(\n- '/'.join(map(str, path)))\n+ message = 'Found an embedded parameter \"{}\" outside of an \"Fn::Sub\" at {}'.format(\n+ variable, '/'.join(map(str, path)))\n matches.append(RuleMatch(path, message))\n \n return matches\n", "issue": "Unexpected E1029 error\n*cfn-lint version: (0.29.1)*\r\n\r\n*Description of issue.*\r\n\r\nAfter this version was released, I started getting an error when linting a template. This error specific to `BuildSpec` attributes for a `AWS::CodeBuild::Project` project.\r\n\r\n E1029 Found an embedded parameter outside of an \"Fn::Sub\" at \r\n Resources/MyCodeBuild/Properties/Source/BuildSpec\r\n cloudformation.json:151:11\r\n\r\nI mocked up a JSON template that showcases the problem and [attached](https://github.com/aws-cloudformation/cfn-python-lint/files/4383494/cloudformation.txt) it.\r\n\n", "before_files": [{"content": "\"\"\"\nCopyright 2019 Amazon.com, Inc. or its affiliates. All Rights Reserved.\nSPDX-License-Identifier: MIT-0\n\"\"\"\nimport re\nimport six\nfrom cfnlint.rules import CloudFormationLintRule\nfrom cfnlint.rules import RuleMatch\n\n\nclass SubNeeded(CloudFormationLintRule):\n \"\"\"Check if a substitution string exists without a substitution function\"\"\"\n id = 'E1029'\n shortdesc = 'Sub is required if a variable is used in a string'\n description = 'If a substitution variable exists in a string but isn\\'t wrapped with the Fn::Sub function the deployment will fail.'\n source_url = 'https://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/intrinsic-function-reference-sub.html'\n tags = ['functions', 'sub']\n\n # Free-form text properties to exclude from this rule\n # content is part of AWS::CloudFormation::Init\n excludes = ['UserData', 'ZipFile', 'Condition', 'AWS::CloudFormation::Init',\n 'CloudWatchAlarmDefinition', 'TopicRulePayload']\n api_excludes = ['Uri', 'Body']\n\n # IAM Policy has special variables that don't require !Sub, Check for these\n # https://docs.aws.amazon.com/IAM/latest/UserGuide/reference_policies_variables.html\n # https://docs.aws.amazon.com/iot/latest/developerguide/basic-policy-variables.html\n # https://docs.aws.amazon.com/iot/latest/developerguide/thing-policy-variables.html\n # https://docs.aws.amazon.com/transfer/latest/userguide/users.html#users-policies-scope-down\n # https://docs.aws.amazon.com/IAM/latest/UserGuide/reference_policies_iam-condition-keys.html\n resource_excludes = ['${aws:CurrentTime}', '${aws:EpochTime}',\n '${aws:TokenIssueTime}', '${aws:principaltype}',\n '${aws:SecureTransport}', '${aws:SourceIp}',\n '${aws:UserAgent}', '${aws:userid}',\n '${aws:username}', '${ec2:SourceInstanceARN}',\n '${iot:Connection.Thing.ThingName}',\n '${iot:Connection.Thing.ThingTypeName}',\n '${iot:Connection.Thing.IsAttached}',\n '${iot:ClientId}', '${transfer:HomeBucket}',\n '${transfer:HomeDirectory}', '${transfer:HomeFolder}',\n '${transfer:UserName}', '${redshift:DbUser}',\n '${cognito-identity.amazonaws.com:aud}',\n '${cognito-identity.amazonaws.com:sub}',\n '${cognito-identity.amazonaws.com:amr}']\n\n # https://docs.aws.amazon.com/redshift/latest/mgmt/redshift-iam-access-control-identity-based.html\n condition_excludes = [\n '${redshift:DbUser}',\n ]\n\n def __init__(self):\n \"\"\"Init\"\"\"\n super(SubNeeded, self).__init__()\n self.config_definition = {\n 'custom_excludes': {\n 'default': '',\n 'type': 'string'\n }\n }\n self.configure()\n self.subParameterRegex = re.compile(r'(\\$\\{[A-Za-z0-9_:\\.]+\\})')\n\n def _match_values(self, cfnelem, path):\n \"\"\"Recursively search for values matching the searchRegex\"\"\"\n values = []\n if isinstance(cfnelem, dict):\n for key in cfnelem:\n pathprop = path[:]\n pathprop.append(key)\n values.extend(self._match_values(cfnelem[key], pathprop))\n elif isinstance(cfnelem, list):\n for index, item in enumerate(cfnelem):\n pathprop = path[:]\n pathprop.append(index)\n values.extend(self._match_values(item, pathprop))\n else:\n # Leaf node\n if isinstance(cfnelem, six.string_types): # and re.match(searchRegex, cfnelem):\n for variable in re.findall(self.subParameterRegex, cfnelem):\n values.append(path + [variable])\n\n return values\n\n def match_values(self, cfn):\n \"\"\"\n Search for values in all parts of the templates that match the searchRegex\n \"\"\"\n results = []\n results.extend(self._match_values(cfn.template, []))\n # Globals are removed during a transform. They need to be checked manually\n results.extend(self._match_values(cfn.template.get('Globals', {}), []))\n return results\n\n def _api_exceptions(self, value):\n \"\"\" Key value exceptions \"\"\"\n parameter_search = re.compile(r'^\\$\\{stageVariables\\..*\\}$')\n return re.match(parameter_search, value)\n\n def _variable_custom_excluded(self, value):\n \"\"\" User-defined exceptions for variables, anywhere in the file \"\"\"\n custom_excludes = self.config['custom_excludes']\n if custom_excludes:\n custom_search = re.compile(custom_excludes)\n return re.match(custom_search, value)\n return False\n\n def match(self, cfn):\n \"\"\"Basic Rule Matching\"\"\"\n\n matches = []\n\n # Get a list of paths to every leaf node string containing at least one ${parameter}\n parameter_string_paths = self.match_values(cfn)\n # We want to search all of the paths to check if each one contains an 'Fn::Sub'\n for parameter_string_path in parameter_string_paths:\n if parameter_string_path[0] in ['Parameters']:\n continue\n # Exclude the special IAM variables\n variable = parameter_string_path[-1]\n\n if 'Resource' in parameter_string_path:\n if variable in self.resource_excludes:\n continue\n if 'NotResource' in parameter_string_path:\n if variable in self.resource_excludes:\n continue\n if 'Condition' in parameter_string_path:\n if variable in self.condition_excludes:\n continue\n\n # Exclude variables that match custom exclude filters, if configured\n # (for third-party tools that pre-process templates before uploading them to AWS)\n if self._variable_custom_excluded(variable):\n continue\n\n # Exclude literals (https://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/intrinsic-function-reference-sub.html)\n if variable.startswith('${!'):\n continue\n\n found_sub = False\n # Does the path contain an 'Fn::Sub'?\n for step in parameter_string_path:\n if step in self.api_excludes:\n if self._api_exceptions(parameter_string_path[-1]):\n found_sub = True\n elif step == 'Fn::Sub' or step in self.excludes:\n found_sub = True\n\n # If we didn't find an 'Fn::Sub' it means a string containing a ${parameter} may not be evaluated correctly\n if not found_sub:\n # Remove the last item (the variable) to prevent multiple errors on 1 line errors\n path = parameter_string_path[:-1]\n message = 'Found an embedded parameter outside of an \"Fn::Sub\" at {}'.format(\n '/'.join(map(str, path)))\n matches.append(RuleMatch(path, message))\n\n return matches\n", "path": "src/cfnlint/rules/functions/SubNeeded.py"}]}
| 2,547 | 296 |
gh_patches_debug_23068
|
rasdani/github-patches
|
git_diff
|
getredash__redash-605
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Row count limitation when creating chart visualization
Graphing query with series data works fine when there are 1150 rows returned (total) but not when I go back further in time and get 1543 rows. The chart shows just one of the two data points used as series. The error in the console shows: "Highcharts error #12: www.highcharts.com/errors/12", and the link refers to the turboThreshold. I did not see any references to this when searching through the code.
Row count limitation when creating chart visualization
Graphing query with series data works fine when there are 1150 rows returned (total) but not when I go back further in time and get 1543 rows. The chart shows just one of the two data points used as series. The error in the console shows: "Highcharts error #12: www.highcharts.com/errors/12", and the link refers to the turboThreshold. I did not see any references to this when searching through the code.
</issue>
<code>
[start of redash/handlers/static.py]
1 import hashlib
2 import json
3
4 from flask import render_template, send_from_directory, current_app
5 from flask_login import current_user, login_required
6
7 from redash import settings
8 from redash.wsgi import app
9
10
11 @app.route('/admin/<anything>/<whatever>')
12 @app.route('/admin/<anything>')
13 @app.route('/dashboard/<anything>')
14 @app.route('/alerts')
15 @app.route('/alerts/<pk>')
16 @app.route('/queries')
17 @app.route('/data_sources')
18 @app.route('/data_sources/<pk>')
19 @app.route('/users')
20 @app.route('/users/<pk>')
21 @app.route('/queries/<query_id>')
22 @app.route('/queries/<query_id>/<anything>')
23 @app.route('/personal')
24 @app.route('/')
25 @login_required
26 def index(**kwargs):
27 email_md5 = hashlib.md5(current_user.email.lower()).hexdigest()
28 gravatar_url = "https://www.gravatar.com/avatar/%s?s=40" % email_md5
29
30 user = {
31 'gravatar_url': gravatar_url,
32 'id': current_user.id,
33 'name': current_user.name,
34 'email': current_user.email,
35 'groups': current_user.groups,
36 'permissions': current_user.permissions
37 }
38
39 features = {
40 'clientSideMetrics': settings.CLIENT_SIDE_METRICS,
41 'allowScriptsInUserInput': settings.ALLOW_SCRIPTS_IN_USER_INPUT
42 }
43
44 return render_template("index.html", user=json.dumps(user), name=settings.NAME,
45 features=json.dumps(features),
46 analytics=settings.ANALYTICS)
47
48
49 @app.route('/<path:filename>')
50 def send_static(filename):
51 if current_app.debug:
52 cache_timeout = 0
53 else:
54 cache_timeout = None
55
56 return send_from_directory(settings.STATIC_ASSETS_PATH, filename, cache_timeout=cache_timeout)
57
[end of redash/handlers/static.py]
[start of redash/settings.py]
1 import json
2 import os
3 import urlparse
4 from funcy import distinct
5
6
7 def parse_db_url(url):
8 url_parts = urlparse.urlparse(url)
9 connection = {'threadlocals': True}
10
11 if url_parts.hostname and not url_parts.path:
12 connection['name'] = url_parts.hostname
13 else:
14 connection['name'] = url_parts.path[1:]
15 connection['host'] = url_parts.hostname
16 connection['port'] = url_parts.port
17 connection['user'] = url_parts.username
18 connection['password'] = url_parts.password
19
20 return connection
21
22
23 def fix_assets_path(path):
24 fullpath = os.path.join(os.path.dirname(__file__), path)
25 return fullpath
26
27
28 def array_from_string(str):
29 array = str.split(',')
30 if "" in array:
31 array.remove("")
32
33 return array
34
35
36 def set_from_string(str):
37 return set(array_from_string(str))
38
39
40 def parse_boolean(str):
41 return json.loads(str.lower())
42
43
44 def all_settings():
45 from types import ModuleType
46
47 settings = {}
48 for name, item in globals().iteritems():
49 if not callable(item) and not name.startswith("__") and not isinstance(item, ModuleType):
50 settings[name] = item
51
52 return settings
53
54
55 NAME = os.environ.get('REDASH_NAME', 're:dash')
56
57 REDIS_URL = os.environ.get('REDASH_REDIS_URL', "redis://localhost:6379/0")
58
59 STATSD_HOST = os.environ.get('REDASH_STATSD_HOST', "127.0.0.1")
60 STATSD_PORT = int(os.environ.get('REDASH_STATSD_PORT', "8125"))
61 STATSD_PREFIX = os.environ.get('REDASH_STATSD_PREFIX', "redash")
62
63 # Connection settings for re:dash's own database (where we store the queries, results, etc)
64 DATABASE_CONFIG = parse_db_url(os.environ.get("REDASH_DATABASE_URL", "postgresql://postgres"))
65
66 # Celery related settings
67 CELERY_BROKER = os.environ.get("REDASH_CELERY_BROKER", REDIS_URL)
68 CELERY_BACKEND = os.environ.get("REDASH_CELERY_BACKEND", CELERY_BROKER)
69
70 # The following enables periodic job (every 5 minutes) of removing unused query results.
71 QUERY_RESULTS_CLEANUP_ENABLED = parse_boolean(os.environ.get("REDASH_QUERY_RESULTS_CLEANUP_ENABLED", "true"))
72
73 AUTH_TYPE = os.environ.get("REDASH_AUTH_TYPE", "api_key")
74 PASSWORD_LOGIN_ENABLED = parse_boolean(os.environ.get("REDASH_PASSWORD_LOGIN_ENABLED", "true"))
75
76 # Google Apps domain to allow access from; any user with email in this Google Apps will be allowed
77 # access
78 GOOGLE_APPS_DOMAIN = set_from_string(os.environ.get("REDASH_GOOGLE_APPS_DOMAIN", ""))
79
80 GOOGLE_CLIENT_ID = os.environ.get("REDASH_GOOGLE_CLIENT_ID", "")
81 GOOGLE_CLIENT_SECRET = os.environ.get("REDASH_GOOGLE_CLIENT_SECRET", "")
82 GOOGLE_OAUTH_ENABLED = GOOGLE_CLIENT_ID and GOOGLE_CLIENT_SECRET
83
84 SAML_METADATA_URL = os.environ.get("REDASH_SAML_METADATA_URL", "")
85 SAML_LOGIN_ENABLED = SAML_METADATA_URL != ""
86 SAML_CALLBACK_SERVER_NAME = os.environ.get("REDASH_SAML_CALLBACK_SERVER_NAME", "")
87
88 STATIC_ASSETS_PATH = fix_assets_path(os.environ.get("REDASH_STATIC_ASSETS_PATH", "../rd_ui/app/"))
89 JOB_EXPIRY_TIME = int(os.environ.get("REDASH_JOB_EXPIRY_TIME", 3600 * 6))
90 COOKIE_SECRET = os.environ.get("REDASH_COOKIE_SECRET", "c292a0a3aa32397cdb050e233733900f")
91 LOG_LEVEL = os.environ.get("REDASH_LOG_LEVEL", "INFO")
92 ANALYTICS = os.environ.get("REDASH_ANALYTICS", "")
93
94 # Mail settings:
95 MAIL_SERVER = os.environ.get('REDASH_MAIL_SERVER', 'localhost')
96 MAIL_PORT = int(os.environ.get('REDASH_MAIL_PORT', 25))
97 MAIL_USE_TLS = parse_boolean(os.environ.get('REDASH_MAIL_USE_TLS', 'false'))
98 MAIL_USE_SSL = parse_boolean(os.environ.get('REDASH_MAIL_USE_SSL', 'false'))
99 MAIL_USERNAME = os.environ.get('REDASH_MAIL_USERNAME', None)
100 MAIL_PASSWORD = os.environ.get('REDASH_MAIL_PASSWORD', None)
101 MAIL_DEFAULT_SENDER = os.environ.get('REDASH_MAIL_DEFAULT_SENDER', None)
102 MAIL_MAX_EMAILS = os.environ.get('REDASH_MAIL_MAX_EMAILS', None)
103 MAIL_ASCII_ATTACHMENTS = parse_boolean(os.environ.get('REDASH_MAIL_ASCII_ATTACHMENTS', 'false'))
104
105 HOST = os.environ.get('REDASH_HOST', '')
106
107 # CORS settings for the Query Result API (and possbily future external APIs).
108 # In most cases all you need to do is set REDASH_CORS_ACCESS_CONTROL_ALLOW_ORIGIN
109 # to the calling domain (or domains in a comma separated list).
110 ACCESS_CONTROL_ALLOW_ORIGIN = set_from_string(os.environ.get("REDASH_CORS_ACCESS_CONTROL_ALLOW_ORIGIN", ""))
111 ACCESS_CONTROL_ALLOW_CREDENTIALS = parse_boolean(os.environ.get("REDASH_CORS_ACCESS_CONTROL_ALLOW_CREDENTIALS", "false"))
112 ACCESS_CONTROL_REQUEST_METHOD = os.environ.get("REDASH_CORS_ACCESS_CONTROL_REQUEST_METHOD", "GET, POST, PUT")
113 ACCESS_CONTROL_ALLOW_HEADERS = os.environ.get("REDASH_CORS_ACCESS_CONTROL_ALLOW_HEADERS", "Content-Type")
114
115 # Query Runners
116 default_query_runners = [
117 'redash.query_runner.big_query',
118 'redash.query_runner.google_spreadsheets',
119 'redash.query_runner.graphite',
120 'redash.query_runner.mongodb',
121 'redash.query_runner.mysql',
122 'redash.query_runner.pg',
123 'redash.query_runner.url',
124 'redash.query_runner.influx_db',
125 'redash.query_runner.elasticsearch',
126 'redash.query_runner.presto',
127 'redash.query_runner.hive_ds',
128 'redash.query_runner.impala_ds',
129 'redash.query_runner.vertica',
130 'redash.query_runner.treasuredata'
131 ]
132
133 enabled_query_runners = array_from_string(os.environ.get("REDASH_ENABLED_QUERY_RUNNERS", ",".join(default_query_runners)))
134 additional_query_runners = array_from_string(os.environ.get("REDASH_ADDITIONAL_QUERY_RUNNERS", ""))
135
136 QUERY_RUNNERS = distinct(enabled_query_runners + additional_query_runners)
137
138 # Support for Sentry (http://getsentry.com/). Just set your Sentry DSN to enable it:
139 SENTRY_DSN = os.environ.get("REDASH_SENTRY_DSN", "")
140
141 # Client side toggles:
142 ALLOW_SCRIPTS_IN_USER_INPUT = parse_boolean(os.environ.get("REDASH_ALLOW_SCRIPTS_IN_USER_INPUT", "false"))
143 CLIENT_SIDE_METRICS = parse_boolean(os.environ.get("REDASH_CLIENT_SIDE_METRICS", "false"))
144
145 # Features:
146 FEATURE_ALLOW_ALL_TO_EDIT_QUERIES = parse_boolean(os.environ.get("REDASH_FEATURE_ALLOW_ALL_TO_EDIT", "true"))
147 FEATURE_TABLES_PERMISSIONS = parse_boolean(os.environ.get("REDASH_FEATURE_TABLES_PERMISSIONS", "false"))
148
149 # BigQuery
150 BIGQUERY_HTTP_TIMEOUT = int(os.environ.get("REDASH_BIGQUERY_HTTP_TIMEOUT", "600"))
151
[end of redash/settings.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/redash/handlers/static.py b/redash/handlers/static.py
--- a/redash/handlers/static.py
+++ b/redash/handlers/static.py
@@ -38,7 +38,8 @@
features = {
'clientSideMetrics': settings.CLIENT_SIDE_METRICS,
- 'allowScriptsInUserInput': settings.ALLOW_SCRIPTS_IN_USER_INPUT
+ 'allowScriptsInUserInput': settings.ALLOW_SCRIPTS_IN_USER_INPUT,
+ 'highChartsTurboThreshold': settings.HIGHCHARTS_TURBO_THRESHOLD
}
return render_template("index.html", user=json.dumps(user), name=settings.NAME,
diff --git a/redash/settings.py b/redash/settings.py
--- a/redash/settings.py
+++ b/redash/settings.py
@@ -142,6 +142,8 @@
# Client side toggles:
ALLOW_SCRIPTS_IN_USER_INPUT = parse_boolean(os.environ.get("REDASH_ALLOW_SCRIPTS_IN_USER_INPUT", "false"))
CLIENT_SIDE_METRICS = parse_boolean(os.environ.get("REDASH_CLIENT_SIDE_METRICS", "false"))
+# http://api.highcharts.com/highcharts#plotOptions.series.turboThreshold
+HIGHCHARTS_TURBO_THRESHOLD = int(os.environ.get("REDASH_HIGHCHARTS_TURBO_THRESHOLD", "1000"))
# Features:
FEATURE_ALLOW_ALL_TO_EDIT_QUERIES = parse_boolean(os.environ.get("REDASH_FEATURE_ALLOW_ALL_TO_EDIT", "true"))
|
{"golden_diff": "diff --git a/redash/handlers/static.py b/redash/handlers/static.py\n--- a/redash/handlers/static.py\n+++ b/redash/handlers/static.py\n@@ -38,7 +38,8 @@\n \n features = {\n 'clientSideMetrics': settings.CLIENT_SIDE_METRICS,\n- 'allowScriptsInUserInput': settings.ALLOW_SCRIPTS_IN_USER_INPUT\n+ 'allowScriptsInUserInput': settings.ALLOW_SCRIPTS_IN_USER_INPUT,\n+ 'highChartsTurboThreshold': settings.HIGHCHARTS_TURBO_THRESHOLD\n }\n \n return render_template(\"index.html\", user=json.dumps(user), name=settings.NAME,\ndiff --git a/redash/settings.py b/redash/settings.py\n--- a/redash/settings.py\n+++ b/redash/settings.py\n@@ -142,6 +142,8 @@\n # Client side toggles:\n ALLOW_SCRIPTS_IN_USER_INPUT = parse_boolean(os.environ.get(\"REDASH_ALLOW_SCRIPTS_IN_USER_INPUT\", \"false\"))\n CLIENT_SIDE_METRICS = parse_boolean(os.environ.get(\"REDASH_CLIENT_SIDE_METRICS\", \"false\"))\n+# http://api.highcharts.com/highcharts#plotOptions.series.turboThreshold\n+HIGHCHARTS_TURBO_THRESHOLD = int(os.environ.get(\"REDASH_HIGHCHARTS_TURBO_THRESHOLD\", \"1000\"))\n \n # Features:\n FEATURE_ALLOW_ALL_TO_EDIT_QUERIES = parse_boolean(os.environ.get(\"REDASH_FEATURE_ALLOW_ALL_TO_EDIT\", \"true\"))\n", "issue": "Row count limitation when creating chart visualization\nGraphing query with series data works fine when there are 1150 rows returned (total) but not when I go back further in time and get 1543 rows. The chart shows just one of the two data points used as series. The error in the console shows: \"Highcharts error #12: www.highcharts.com/errors/12\", and the link refers to the turboThreshold. I did not see any references to this when searching through the code. \n\nRow count limitation when creating chart visualization\nGraphing query with series data works fine when there are 1150 rows returned (total) but not when I go back further in time and get 1543 rows. The chart shows just one of the two data points used as series. The error in the console shows: \"Highcharts error #12: www.highcharts.com/errors/12\", and the link refers to the turboThreshold. I did not see any references to this when searching through the code. \n\n", "before_files": [{"content": "import hashlib\nimport json\n\nfrom flask import render_template, send_from_directory, current_app\nfrom flask_login import current_user, login_required\n\nfrom redash import settings\nfrom redash.wsgi import app\n\n\[email protected]('/admin/<anything>/<whatever>')\[email protected]('/admin/<anything>')\[email protected]('/dashboard/<anything>')\[email protected]('/alerts')\[email protected]('/alerts/<pk>')\[email protected]('/queries')\[email protected]('/data_sources')\[email protected]('/data_sources/<pk>')\[email protected]('/users')\[email protected]('/users/<pk>')\[email protected]('/queries/<query_id>')\[email protected]('/queries/<query_id>/<anything>')\[email protected]('/personal')\[email protected]('/')\n@login_required\ndef index(**kwargs):\n email_md5 = hashlib.md5(current_user.email.lower()).hexdigest()\n gravatar_url = \"https://www.gravatar.com/avatar/%s?s=40\" % email_md5\n\n user = {\n 'gravatar_url': gravatar_url,\n 'id': current_user.id,\n 'name': current_user.name,\n 'email': current_user.email,\n 'groups': current_user.groups,\n 'permissions': current_user.permissions\n }\n\n features = {\n 'clientSideMetrics': settings.CLIENT_SIDE_METRICS,\n 'allowScriptsInUserInput': settings.ALLOW_SCRIPTS_IN_USER_INPUT\n }\n\n return render_template(\"index.html\", user=json.dumps(user), name=settings.NAME,\n features=json.dumps(features),\n analytics=settings.ANALYTICS)\n\n\[email protected]('/<path:filename>')\ndef send_static(filename):\n if current_app.debug:\n cache_timeout = 0\n else:\n cache_timeout = None\n\n return send_from_directory(settings.STATIC_ASSETS_PATH, filename, cache_timeout=cache_timeout)\n", "path": "redash/handlers/static.py"}, {"content": "import json\nimport os\nimport urlparse\nfrom funcy import distinct\n\n\ndef parse_db_url(url):\n url_parts = urlparse.urlparse(url)\n connection = {'threadlocals': True}\n\n if url_parts.hostname and not url_parts.path:\n connection['name'] = url_parts.hostname\n else:\n connection['name'] = url_parts.path[1:]\n connection['host'] = url_parts.hostname\n connection['port'] = url_parts.port\n connection['user'] = url_parts.username\n connection['password'] = url_parts.password\n\n return connection\n\n\ndef fix_assets_path(path):\n fullpath = os.path.join(os.path.dirname(__file__), path)\n return fullpath\n\n\ndef array_from_string(str):\n array = str.split(',')\n if \"\" in array:\n array.remove(\"\")\n\n return array\n\n\ndef set_from_string(str):\n return set(array_from_string(str))\n\n\ndef parse_boolean(str):\n return json.loads(str.lower())\n\n\ndef all_settings():\n from types import ModuleType\n\n settings = {}\n for name, item in globals().iteritems():\n if not callable(item) and not name.startswith(\"__\") and not isinstance(item, ModuleType):\n settings[name] = item\n\n return settings\n\n\nNAME = os.environ.get('REDASH_NAME', 're:dash')\n\nREDIS_URL = os.environ.get('REDASH_REDIS_URL', \"redis://localhost:6379/0\")\n\nSTATSD_HOST = os.environ.get('REDASH_STATSD_HOST', \"127.0.0.1\")\nSTATSD_PORT = int(os.environ.get('REDASH_STATSD_PORT', \"8125\"))\nSTATSD_PREFIX = os.environ.get('REDASH_STATSD_PREFIX', \"redash\")\n\n# Connection settings for re:dash's own database (where we store the queries, results, etc)\nDATABASE_CONFIG = parse_db_url(os.environ.get(\"REDASH_DATABASE_URL\", \"postgresql://postgres\"))\n\n# Celery related settings\nCELERY_BROKER = os.environ.get(\"REDASH_CELERY_BROKER\", REDIS_URL)\nCELERY_BACKEND = os.environ.get(\"REDASH_CELERY_BACKEND\", CELERY_BROKER)\n\n# The following enables periodic job (every 5 minutes) of removing unused query results.\nQUERY_RESULTS_CLEANUP_ENABLED = parse_boolean(os.environ.get(\"REDASH_QUERY_RESULTS_CLEANUP_ENABLED\", \"true\"))\n\nAUTH_TYPE = os.environ.get(\"REDASH_AUTH_TYPE\", \"api_key\")\nPASSWORD_LOGIN_ENABLED = parse_boolean(os.environ.get(\"REDASH_PASSWORD_LOGIN_ENABLED\", \"true\"))\n\n# Google Apps domain to allow access from; any user with email in this Google Apps will be allowed\n# access\nGOOGLE_APPS_DOMAIN = set_from_string(os.environ.get(\"REDASH_GOOGLE_APPS_DOMAIN\", \"\"))\n\nGOOGLE_CLIENT_ID = os.environ.get(\"REDASH_GOOGLE_CLIENT_ID\", \"\")\nGOOGLE_CLIENT_SECRET = os.environ.get(\"REDASH_GOOGLE_CLIENT_SECRET\", \"\")\nGOOGLE_OAUTH_ENABLED = GOOGLE_CLIENT_ID and GOOGLE_CLIENT_SECRET\n\nSAML_METADATA_URL = os.environ.get(\"REDASH_SAML_METADATA_URL\", \"\")\nSAML_LOGIN_ENABLED = SAML_METADATA_URL != \"\"\nSAML_CALLBACK_SERVER_NAME = os.environ.get(\"REDASH_SAML_CALLBACK_SERVER_NAME\", \"\")\n\nSTATIC_ASSETS_PATH = fix_assets_path(os.environ.get(\"REDASH_STATIC_ASSETS_PATH\", \"../rd_ui/app/\"))\nJOB_EXPIRY_TIME = int(os.environ.get(\"REDASH_JOB_EXPIRY_TIME\", 3600 * 6))\nCOOKIE_SECRET = os.environ.get(\"REDASH_COOKIE_SECRET\", \"c292a0a3aa32397cdb050e233733900f\")\nLOG_LEVEL = os.environ.get(\"REDASH_LOG_LEVEL\", \"INFO\")\nANALYTICS = os.environ.get(\"REDASH_ANALYTICS\", \"\")\n\n# Mail settings:\nMAIL_SERVER = os.environ.get('REDASH_MAIL_SERVER', 'localhost')\nMAIL_PORT = int(os.environ.get('REDASH_MAIL_PORT', 25))\nMAIL_USE_TLS = parse_boolean(os.environ.get('REDASH_MAIL_USE_TLS', 'false'))\nMAIL_USE_SSL = parse_boolean(os.environ.get('REDASH_MAIL_USE_SSL', 'false'))\nMAIL_USERNAME = os.environ.get('REDASH_MAIL_USERNAME', None)\nMAIL_PASSWORD = os.environ.get('REDASH_MAIL_PASSWORD', None)\nMAIL_DEFAULT_SENDER = os.environ.get('REDASH_MAIL_DEFAULT_SENDER', None)\nMAIL_MAX_EMAILS = os.environ.get('REDASH_MAIL_MAX_EMAILS', None)\nMAIL_ASCII_ATTACHMENTS = parse_boolean(os.environ.get('REDASH_MAIL_ASCII_ATTACHMENTS', 'false'))\n\nHOST = os.environ.get('REDASH_HOST', '')\n\n# CORS settings for the Query Result API (and possbily future external APIs).\n# In most cases all you need to do is set REDASH_CORS_ACCESS_CONTROL_ALLOW_ORIGIN\n# to the calling domain (or domains in a comma separated list).\nACCESS_CONTROL_ALLOW_ORIGIN = set_from_string(os.environ.get(\"REDASH_CORS_ACCESS_CONTROL_ALLOW_ORIGIN\", \"\"))\nACCESS_CONTROL_ALLOW_CREDENTIALS = parse_boolean(os.environ.get(\"REDASH_CORS_ACCESS_CONTROL_ALLOW_CREDENTIALS\", \"false\"))\nACCESS_CONTROL_REQUEST_METHOD = os.environ.get(\"REDASH_CORS_ACCESS_CONTROL_REQUEST_METHOD\", \"GET, POST, PUT\")\nACCESS_CONTROL_ALLOW_HEADERS = os.environ.get(\"REDASH_CORS_ACCESS_CONTROL_ALLOW_HEADERS\", \"Content-Type\")\n\n# Query Runners\ndefault_query_runners = [\n 'redash.query_runner.big_query',\n 'redash.query_runner.google_spreadsheets',\n 'redash.query_runner.graphite',\n 'redash.query_runner.mongodb',\n 'redash.query_runner.mysql',\n 'redash.query_runner.pg',\n 'redash.query_runner.url',\n 'redash.query_runner.influx_db',\n 'redash.query_runner.elasticsearch',\n 'redash.query_runner.presto',\n 'redash.query_runner.hive_ds',\n 'redash.query_runner.impala_ds',\n 'redash.query_runner.vertica',\n 'redash.query_runner.treasuredata'\n]\n\nenabled_query_runners = array_from_string(os.environ.get(\"REDASH_ENABLED_QUERY_RUNNERS\", \",\".join(default_query_runners)))\nadditional_query_runners = array_from_string(os.environ.get(\"REDASH_ADDITIONAL_QUERY_RUNNERS\", \"\"))\n\nQUERY_RUNNERS = distinct(enabled_query_runners + additional_query_runners)\n\n# Support for Sentry (http://getsentry.com/). Just set your Sentry DSN to enable it:\nSENTRY_DSN = os.environ.get(\"REDASH_SENTRY_DSN\", \"\")\n\n# Client side toggles:\nALLOW_SCRIPTS_IN_USER_INPUT = parse_boolean(os.environ.get(\"REDASH_ALLOW_SCRIPTS_IN_USER_INPUT\", \"false\"))\nCLIENT_SIDE_METRICS = parse_boolean(os.environ.get(\"REDASH_CLIENT_SIDE_METRICS\", \"false\"))\n\n# Features:\nFEATURE_ALLOW_ALL_TO_EDIT_QUERIES = parse_boolean(os.environ.get(\"REDASH_FEATURE_ALLOW_ALL_TO_EDIT\", \"true\"))\nFEATURE_TABLES_PERMISSIONS = parse_boolean(os.environ.get(\"REDASH_FEATURE_TABLES_PERMISSIONS\", \"false\"))\n\n# BigQuery\nBIGQUERY_HTTP_TIMEOUT = int(os.environ.get(\"REDASH_BIGQUERY_HTTP_TIMEOUT\", \"600\"))\n", "path": "redash/settings.py"}]}
| 3,132 | 319 |
gh_patches_debug_33549
|
rasdani/github-patches
|
git_diff
|
nextcloud__appstore-56
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Test if zip bombs are possible
We should know if zip bombs are possible currently
</issue>
<code>
[start of nextcloudappstore/core/api/v1/release/parser.py]
1 import re
2 import tarfile # type: ignore
3 import lxml.etree # type: ignore
4 from typing import Dict, Any, Tuple
5
6 from nextcloudappstore.core.api.v1.release import ReleaseConfig
7 from nextcloudappstore.core.versioning import pad_max_version, pad_min_version
8 from rest_framework.exceptions import APIException # type: ignore
9
10
11 class MaxSizeAppMetadataXmlException(APIException):
12 pass
13
14
15 class InvalidAppMetadataXmlException(APIException):
16 pass
17
18
19 class UnsupportedAppArchiveException(APIException):
20 pass
21
22
23 class InvalidAppPackageStructureException(APIException):
24 pass
25
26
27 class XMLSyntaxError(APIException):
28 pass
29
30
31 class GunZipAppMetadataExtractor:
32 def __init__(self, config: ReleaseConfig) -> None:
33 """
34 :argument config the config
35 """
36 self.config = config
37 self.app_folder_regex = re.compile(r'^[a-z]+[a-z_]*$')
38
39 def extract_app_metadata(self, archive_path: str) -> Tuple[str, str]:
40 """
41 Extracts the info.xml from an tar.gz archive
42 :argument archive_path the path to the tar.gz archive
43 :raises InvalidAppPackageStructureException if the first level folder
44 does not equal the app_id or no info.xml file could be found in the
45 appinfo folder
46 :return the info.xml as string
47 """
48 if not tarfile.is_tarfile(archive_path):
49 msg = '%s is not a valid tar.gz archive ' % archive_path
50 raise UnsupportedAppArchiveException(msg)
51
52 with tarfile.open(archive_path, 'r:gz') as tar:
53 result = self._parse_archive(tar)
54 return result
55
56 def _parse_archive(self, tar: Any) -> Tuple[str, str]:
57 folder = list(
58 filter(lambda name: re.match(self.app_folder_regex, name),
59 tar.getnames()
60 )
61 )
62 if len(folder) > 1:
63 msg = 'More than one possible app folder found'
64 raise InvalidAppPackageStructureException(msg)
65 elif len(folder) == 0:
66 msg = 'No possible app folder found. App folder must contain ' \
67 'only lowercase ASCII characters or underscores'
68 raise InvalidAppPackageStructureException(msg)
69
70 app_id = folder[0]
71 info_path = '%s/appinfo/info.xml' % app_id
72 try:
73 app_member = tar.getmember(app_id)
74 appinfo_member = tar.getmember('%s/appinfo' % app_id)
75 info_member = tar.getmember(info_path)
76 possible_links = [app_member, appinfo_member, info_member]
77
78 for possible_link in possible_links:
79 if possible_link.issym() or possible_link.islnk():
80 msg = 'Symlinks and hard links can not be used for %s' %\
81 possible_link
82 raise InvalidAppPackageStructureException(msg)
83
84 if info_member.size > self.config.max_info_size:
85 msg = '%s was bigger than allowed %i bytes' % (
86 info_path, self.config.max_info_size)
87 raise MaxSizeAppMetadataXmlException(msg)
88 info_file = tar.extractfile(info_member)
89 return info_file.read().decode('utf-8'), app_id
90 except KeyError:
91 msg = 'Could not find %s file inside the archive' % info_path
92 raise InvalidAppPackageStructureException(msg)
93
94
95 def element_to_dict(element: Any) -> Dict:
96 type = element.get('type')
97 key = element.tag.replace('-', '_')
98 if type == 'int':
99 return {key: int(element.text)}
100 elif type == 'list':
101 return {key: list(map(element_to_dict, element.iterchildren()))}
102 elif type == 'min-version':
103 return {key: pad_min_version(element.text)}
104 elif type == 'max-version':
105 return {key: pad_max_version(element.text)}
106 elif len(list(element)) > 0:
107 contents = {}
108 for child in element.iterchildren():
109 contents.update(element_to_dict(child))
110 return {key: contents}
111 else:
112 return {key: element.text}
113
114
115 def parse_app_metadata(xml: str, schema: str, pre_xslt: str,
116 xslt: str) -> Dict:
117 """
118 Parses, validates and maps the xml onto a dict
119 :argument xml the info.xml string to parse
120 :argument schema the schema xml as string
121 :argument pre_xslt xslt which is run before validation to ensure that
122 everything is in the correct order and that unknown elements are excluded
123 :argument xslt the xslt to transform it to a matching structure
124 :raises InvalidAppMetadataXmlException if the schema does not validate
125 :return the parsed xml as dict
126 """
127 parser = lxml.etree.XMLParser(resolve_entities=False, no_network=True,
128 remove_comments=True, load_dtd=False,
129 remove_blank_text=True, dtd_validation=False
130 )
131 try:
132 doc = lxml.etree.fromstring(bytes(xml, encoding='utf-8'), parser)
133 except lxml.etree.XMLSyntaxError as e:
134 msg = 'info.xml contains malformed xml: %s' % e
135 raise XMLSyntaxError(msg)
136 for _ in doc.iter(lxml.etree.Entity):
137 raise InvalidAppMetadataXmlException('Must not contain entities')
138 pre_transform = lxml.etree.XSLT(lxml.etree.XML(pre_xslt))
139 pre_transformed_doc = pre_transform(doc)
140 schema_doc = lxml.etree.fromstring(bytes(schema, encoding='utf-8'), parser)
141 schema = lxml.etree.XMLSchema(schema_doc)
142 try:
143 schema.assertValid(pre_transformed_doc) # type: ignore
144 except lxml.etree.DocumentInvalid as e:
145 msg = 'info.xml did not validate: %s' % e
146 raise InvalidAppMetadataXmlException(msg)
147 transform = lxml.etree.XSLT(lxml.etree.XML(xslt))
148 transformed_doc = transform(pre_transformed_doc)
149 mapped = element_to_dict(transformed_doc.getroot())
150 return mapped
151
[end of nextcloudappstore/core/api/v1/release/parser.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/nextcloudappstore/core/api/v1/release/parser.py b/nextcloudappstore/core/api/v1/release/parser.py
--- a/nextcloudappstore/core/api/v1/release/parser.py
+++ b/nextcloudappstore/core/api/v1/release/parser.py
@@ -77,20 +77,44 @@
for possible_link in possible_links:
if possible_link.issym() or possible_link.islnk():
- msg = 'Symlinks and hard links can not be used for %s' %\
+ msg = 'Symlinks and hard links can not be used for %s' % \
possible_link
raise InvalidAppPackageStructureException(msg)
-
- if info_member.size > self.config.max_info_size:
- msg = '%s was bigger than allowed %i bytes' % (
- info_path, self.config.max_info_size)
- raise MaxSizeAppMetadataXmlException(msg)
info_file = tar.extractfile(info_member)
- return info_file.read().decode('utf-8'), app_id
+ contents = self._stream_read_file(info_file,
+ self.config.max_info_size)
+ return contents, app_id
except KeyError:
msg = 'Could not find %s file inside the archive' % info_path
raise InvalidAppPackageStructureException(msg)
+ def _stream_read_file(self, info_file: Any, max_info_size: int) -> str:
+ """
+ Instead of reading everything in one go which is vulnerable to
+ zip bombs, stream and accumulate the bytes
+ :argument info_file: buffered io reader
+ :argument max_info_size: maximum file size in bytes
+ :raises MaxSizeAppMetadataXmlException if the maximum size was reached
+ :return: the parsed info.xml
+ """
+ # FIXME: If someone finds a less ugly version, please feel free to
+ # improve it
+ size = 0
+ result = b''
+ while True:
+ size += 1024
+ if size > max_info_size:
+ msg = 'info.xml was bigger than allowed %i bytes' % \
+ max_info_size
+ raise MaxSizeAppMetadataXmlException(msg)
+
+ chunk = info_file.read(1024)
+ if not chunk:
+ break
+ result += chunk
+
+ return result.decode('utf-8')
+
def element_to_dict(element: Any) -> Dict:
type = element.get('type')
|
{"golden_diff": "diff --git a/nextcloudappstore/core/api/v1/release/parser.py b/nextcloudappstore/core/api/v1/release/parser.py\n--- a/nextcloudappstore/core/api/v1/release/parser.py\n+++ b/nextcloudappstore/core/api/v1/release/parser.py\n@@ -77,20 +77,44 @@\n \n for possible_link in possible_links:\n if possible_link.issym() or possible_link.islnk():\n- msg = 'Symlinks and hard links can not be used for %s' %\\\n+ msg = 'Symlinks and hard links can not be used for %s' % \\\n possible_link\n raise InvalidAppPackageStructureException(msg)\n-\n- if info_member.size > self.config.max_info_size:\n- msg = '%s was bigger than allowed %i bytes' % (\n- info_path, self.config.max_info_size)\n- raise MaxSizeAppMetadataXmlException(msg)\n info_file = tar.extractfile(info_member)\n- return info_file.read().decode('utf-8'), app_id\n+ contents = self._stream_read_file(info_file,\n+ self.config.max_info_size)\n+ return contents, app_id\n except KeyError:\n msg = 'Could not find %s file inside the archive' % info_path\n raise InvalidAppPackageStructureException(msg)\n \n+ def _stream_read_file(self, info_file: Any, max_info_size: int) -> str:\n+ \"\"\"\n+ Instead of reading everything in one go which is vulnerable to\n+ zip bombs, stream and accumulate the bytes\n+ :argument info_file: buffered io reader\n+ :argument max_info_size: maximum file size in bytes\n+ :raises MaxSizeAppMetadataXmlException if the maximum size was reached\n+ :return: the parsed info.xml\n+ \"\"\"\n+ # FIXME: If someone finds a less ugly version, please feel free to\n+ # improve it\n+ size = 0\n+ result = b''\n+ while True:\n+ size += 1024\n+ if size > max_info_size:\n+ msg = 'info.xml was bigger than allowed %i bytes' % \\\n+ max_info_size\n+ raise MaxSizeAppMetadataXmlException(msg)\n+\n+ chunk = info_file.read(1024)\n+ if not chunk:\n+ break\n+ result += chunk\n+\n+ return result.decode('utf-8')\n+\n \n def element_to_dict(element: Any) -> Dict:\n type = element.get('type')\n", "issue": "Test if zip bombs are possible\nWe should know if zip bombs are possible currently\n\n", "before_files": [{"content": "import re\nimport tarfile # type: ignore\nimport lxml.etree # type: ignore\nfrom typing import Dict, Any, Tuple\n\nfrom nextcloudappstore.core.api.v1.release import ReleaseConfig\nfrom nextcloudappstore.core.versioning import pad_max_version, pad_min_version\nfrom rest_framework.exceptions import APIException # type: ignore\n\n\nclass MaxSizeAppMetadataXmlException(APIException):\n pass\n\n\nclass InvalidAppMetadataXmlException(APIException):\n pass\n\n\nclass UnsupportedAppArchiveException(APIException):\n pass\n\n\nclass InvalidAppPackageStructureException(APIException):\n pass\n\n\nclass XMLSyntaxError(APIException):\n pass\n\n\nclass GunZipAppMetadataExtractor:\n def __init__(self, config: ReleaseConfig) -> None:\n \"\"\"\n :argument config the config\n \"\"\"\n self.config = config\n self.app_folder_regex = re.compile(r'^[a-z]+[a-z_]*$')\n\n def extract_app_metadata(self, archive_path: str) -> Tuple[str, str]:\n \"\"\"\n Extracts the info.xml from an tar.gz archive\n :argument archive_path the path to the tar.gz archive\n :raises InvalidAppPackageStructureException if the first level folder\n does not equal the app_id or no info.xml file could be found in the\n appinfo folder\n :return the info.xml as string\n \"\"\"\n if not tarfile.is_tarfile(archive_path):\n msg = '%s is not a valid tar.gz archive ' % archive_path\n raise UnsupportedAppArchiveException(msg)\n\n with tarfile.open(archive_path, 'r:gz') as tar:\n result = self._parse_archive(tar)\n return result\n\n def _parse_archive(self, tar: Any) -> Tuple[str, str]:\n folder = list(\n filter(lambda name: re.match(self.app_folder_regex, name),\n tar.getnames()\n )\n )\n if len(folder) > 1:\n msg = 'More than one possible app folder found'\n raise InvalidAppPackageStructureException(msg)\n elif len(folder) == 0:\n msg = 'No possible app folder found. App folder must contain ' \\\n 'only lowercase ASCII characters or underscores'\n raise InvalidAppPackageStructureException(msg)\n\n app_id = folder[0]\n info_path = '%s/appinfo/info.xml' % app_id\n try:\n app_member = tar.getmember(app_id)\n appinfo_member = tar.getmember('%s/appinfo' % app_id)\n info_member = tar.getmember(info_path)\n possible_links = [app_member, appinfo_member, info_member]\n\n for possible_link in possible_links:\n if possible_link.issym() or possible_link.islnk():\n msg = 'Symlinks and hard links can not be used for %s' %\\\n possible_link\n raise InvalidAppPackageStructureException(msg)\n\n if info_member.size > self.config.max_info_size:\n msg = '%s was bigger than allowed %i bytes' % (\n info_path, self.config.max_info_size)\n raise MaxSizeAppMetadataXmlException(msg)\n info_file = tar.extractfile(info_member)\n return info_file.read().decode('utf-8'), app_id\n except KeyError:\n msg = 'Could not find %s file inside the archive' % info_path\n raise InvalidAppPackageStructureException(msg)\n\n\ndef element_to_dict(element: Any) -> Dict:\n type = element.get('type')\n key = element.tag.replace('-', '_')\n if type == 'int':\n return {key: int(element.text)}\n elif type == 'list':\n return {key: list(map(element_to_dict, element.iterchildren()))}\n elif type == 'min-version':\n return {key: pad_min_version(element.text)}\n elif type == 'max-version':\n return {key: pad_max_version(element.text)}\n elif len(list(element)) > 0:\n contents = {}\n for child in element.iterchildren():\n contents.update(element_to_dict(child))\n return {key: contents}\n else:\n return {key: element.text}\n\n\ndef parse_app_metadata(xml: str, schema: str, pre_xslt: str,\n xslt: str) -> Dict:\n \"\"\"\n Parses, validates and maps the xml onto a dict\n :argument xml the info.xml string to parse\n :argument schema the schema xml as string\n :argument pre_xslt xslt which is run before validation to ensure that\n everything is in the correct order and that unknown elements are excluded\n :argument xslt the xslt to transform it to a matching structure\n :raises InvalidAppMetadataXmlException if the schema does not validate\n :return the parsed xml as dict\n \"\"\"\n parser = lxml.etree.XMLParser(resolve_entities=False, no_network=True,\n remove_comments=True, load_dtd=False,\n remove_blank_text=True, dtd_validation=False\n )\n try:\n doc = lxml.etree.fromstring(bytes(xml, encoding='utf-8'), parser)\n except lxml.etree.XMLSyntaxError as e:\n msg = 'info.xml contains malformed xml: %s' % e\n raise XMLSyntaxError(msg)\n for _ in doc.iter(lxml.etree.Entity):\n raise InvalidAppMetadataXmlException('Must not contain entities')\n pre_transform = lxml.etree.XSLT(lxml.etree.XML(pre_xslt))\n pre_transformed_doc = pre_transform(doc)\n schema_doc = lxml.etree.fromstring(bytes(schema, encoding='utf-8'), parser)\n schema = lxml.etree.XMLSchema(schema_doc)\n try:\n schema.assertValid(pre_transformed_doc) # type: ignore\n except lxml.etree.DocumentInvalid as e:\n msg = 'info.xml did not validate: %s' % e\n raise InvalidAppMetadataXmlException(msg)\n transform = lxml.etree.XSLT(lxml.etree.XML(xslt))\n transformed_doc = transform(pre_transformed_doc)\n mapped = element_to_dict(transformed_doc.getroot())\n return mapped\n", "path": "nextcloudappstore/core/api/v1/release/parser.py"}]}
| 2,205 | 555 |
gh_patches_debug_27856
|
rasdani/github-patches
|
git_diff
|
pulp__pulpcore-2391
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Reduce memory usage of the pipeline
Author: @bmbouter (bmbouter)
Redmine Issue: 9635, https://pulp.plan.io/issues/9635
---
## Motivation
It would be nice if users could specify a desired maximum amount of RAM to be used during sync. For example, a user can say I only want 1500 MB of RAM to be used max.
## What is already in place
The stages pipeline restricts memory usage by only allowing 1000 declarative content objects between each stage (so for 8-9 stages that's 8000-9000 declarative content objects. This happens [here](https://github.com/pulp/pulpcore/blob/main/pulpcore/plugin/stages/api.py#L217).
Interestingly the docstring says this defaults to 100, but it seems to actually be 1000!
Also the stages perform batching, so they will only taking in a limited number of items (the batch size). That happens [with minsize](https://github.com/pulp/pulpcore/blob/main/pulpcore/plugin/stages/api.py#L84).
## Why this isn't enough
These are count-based mechnisms and don't correspond to actual MB or GB of memory used. Some content units vary a lot in how much memory each DeclarativeContent objects take up.
Another lesser problem is that it doesn't help plugin writers restrict their usage of memory in FirstStage.
## Idea
Add a new param called `max_mb` to base Remote, which defaults to None. If specified, the user will be specifying the desired maximum MB used by process syncing.
Have the queues between the stages, and the bather implementation, both check the total memory the current process is using and asyncio.sleep() polling until it goes down. This should keep the maximum amount used by all objects roughly to that number.
## Details
Introduce a new `MBSizeQueue` which is a wrapper around `asyncio.Queue` used today. It will have the same `put()` call, only wait if the amount of memory in use is greater than the remote is configured for.
Then introduce the same memory checking feature in the batcher. I'm not completely sure this second part is needed though.
We have to be very careful not to deadlock with this feature. For example, we have to account for the base case where even a single item is larger than the memory desired. Repos in pulp_rpm have had a single unit use more than 1.2G if I remember right, so if someone was syncing with 800 MB and we weren't careful to allow that unit to still flow through the pipeline we'd deadlock.....
</issue>
<code>
[start of pulpcore/plugin/stages/api.py]
1 import asyncio
2 import logging
3
4 from gettext import gettext as _
5
6 from django.conf import settings
7
8 from .profiler import ProfilingQueue
9
10
11 log = logging.getLogger(__name__)
12
13
14 class Stage:
15 """
16 The base class for all Stages API stages.
17
18 To make a stage, inherit from this class and implement :meth:`run` on the subclass.
19 """
20
21 def __init__(self):
22 self._in_q = None
23 self._out_q = None
24
25 def _connect(self, in_q, out_q):
26 """
27 Connect to queues within a pipeline.
28
29 Args:
30 in_q (asyncio.Queue): The stage input queue.
31 out_q (asyncio.Queue): The stage output queue.
32 """
33 self._in_q = in_q
34 self._out_q = out_q
35
36 async def __call__(self):
37 """
38 This coroutine makes the stage callable.
39
40 It calls :meth:`run` and signals the next stage that its work is finished.
41 """
42 log.debug(_("%(name)s - begin."), {"name": self})
43 await self.run()
44 await self._out_q.put(None)
45 log.debug(_("%(name)s - put end-marker."), {"name": self})
46
47 async def run(self):
48 """
49 The coroutine that is run as part of this stage.
50
51 Returns:
52 The coroutine that runs this stage.
53
54 """
55 raise NotImplementedError(_("A plugin writer must implement this method"))
56
57 async def items(self):
58 """
59 Asynchronous iterator yielding items of :class:`DeclarativeContent` from `self._in_q`.
60
61 The iterator will get instances of :class:`DeclarativeContent` one by one as they get
62 available.
63
64 Yields:
65 An instance of :class:`DeclarativeContent`
66
67 Examples:
68 Used in stages to get d_content instances one by one from `self._in_q`::
69
70 class MyStage(Stage):
71 async def run(self):
72 async for d_content in self.items():
73 # process declarative content
74 await self.put(d_content)
75
76 """
77 while True:
78 content = await self._in_q.get()
79 if content is None:
80 break
81 log.debug("%(name)s - next: %(content)s.", {"name": self, "content": content})
82 yield content
83
84 async def batches(self, minsize=500):
85 """
86 Asynchronous iterator yielding batches of :class:`DeclarativeContent` from `self._in_q`.
87
88 The iterator will try to get as many instances of
89 :class:`DeclarativeContent` as possible without blocking, but
90 at least `minsize` instances.
91
92 Args:
93 minsize (int): The minimum batch size to yield (unless it is the final batch)
94
95 Yields:
96 A list of :class:`DeclarativeContent` instances
97
98 Examples:
99 Used in stages to get large chunks of d_content instances from `self._in_q`::
100
101 class MyStage(Stage):
102 async def run(self):
103 async for batch in self.batches():
104 for d_content in batch:
105 # process declarative content
106 await self.put(d_content)
107
108 """
109 batch = []
110 shutdown = False
111 no_block = False
112 thaw_queue_event = asyncio.Event()
113
114 def add_to_batch(content):
115 nonlocal batch
116 nonlocal shutdown
117 nonlocal no_block
118 nonlocal thaw_queue_event
119
120 if content is None:
121 shutdown = True
122 log.debug(_("%(name)s - shutdown."), {"name": self})
123 else:
124 if not content.does_batch:
125 no_block = True
126 content._thaw_queue_event = thaw_queue_event
127 batch.append(content)
128
129 get_listener = asyncio.ensure_future(self._in_q.get())
130 thaw_event_listener = asyncio.ensure_future(thaw_queue_event.wait())
131 while not shutdown:
132 done, pending = await asyncio.wait(
133 [thaw_event_listener, get_listener], return_when=asyncio.FIRST_COMPLETED
134 )
135 if thaw_event_listener in done:
136 thaw_event_listener = asyncio.ensure_future(thaw_queue_event.wait())
137 no_block = True
138 if get_listener in done:
139 content = await get_listener
140 add_to_batch(content)
141 get_listener = asyncio.ensure_future(self._in_q.get())
142 while not shutdown:
143 try:
144 content = self._in_q.get_nowait()
145 except asyncio.QueueEmpty:
146 break
147 else:
148 add_to_batch(content)
149
150 if batch and (len(batch) >= minsize or shutdown or no_block):
151 log.debug(
152 _("%(name)s - next batch[%(length)d]."), {"name": self, "length": len(batch)}
153 )
154 for content in batch:
155 content._thaw_queue_event = None
156 thaw_queue_event.clear()
157 yield batch
158 batch = []
159 no_block = False
160 thaw_event_listener.cancel()
161 get_listener.cancel()
162
163 async def put(self, item):
164 """
165 Coroutine to pass items to the next stage.
166
167 Args:
168 item: A handled instance of :class:`pulpcore.plugin.stages.DeclarativeContent`
169
170 Raises:
171 ValueError: When `item` is None.
172 """
173 if item is None:
174 raise ValueError(_("(None) not permitted."))
175 await self._out_q.put(item)
176 log.debug("{name} - put: {content}".format(name=self, content=item))
177
178 def __str__(self):
179 return "[{id}] {name}".format(id=id(self), name=self.__class__.__name__)
180
181
182 async def create_pipeline(stages, maxsize=1000):
183 """
184 A coroutine that builds a Stages API linear pipeline from the list `stages` and runs it.
185
186 Each stage is an instance of a class derived from :class:`pulpcore.plugin.stages.Stage` that
187 implements the :meth:`run` coroutine. This coroutine reads asyncromously either from the
188 `items()` iterator or the `batches()` iterator and outputs the items with `put()`. Here is an
189 example of the simplest stage that only passes data::
190
191 class MyStage(Stage):
192 async def run(self):
193 async for d_content in self.items(): # Fetch items from the previous stage
194 await self.put(d_content) # Hand them over to the next stage
195
196 Args:
197 stages (list of coroutines): A list of Stages API compatible coroutines.
198 maxsize (int): The maximum amount of items a queue between two stages should hold. Optional
199 and defaults to 100.
200
201 Returns:
202 A single coroutine that can be used to run, wait, or cancel the entire pipeline with.
203 Raises:
204 ValueError: When a stage instance is specified more than once.
205 """
206 futures = []
207 history = set()
208 in_q = None
209 for i, stage in enumerate(stages):
210 if stage in history:
211 raise ValueError(_("Each stage instance must be unique."))
212 history.add(stage)
213 if i < len(stages) - 1:
214 if settings.PROFILE_STAGES_API:
215 out_q = ProfilingQueue.make_and_record_queue(stages[i + 1], i + 1, maxsize)
216 else:
217 out_q = asyncio.Queue(maxsize=maxsize)
218 else:
219 out_q = None
220 stage._connect(in_q, out_q)
221 futures.append(asyncio.ensure_future(stage()))
222 in_q = out_q
223
224 try:
225 await asyncio.gather(*futures)
226 except Exception:
227 # One of the stages raised an exception, cancel all stages...
228 pending = []
229 for task in futures:
230 if not task.done():
231 task.cancel()
232 pending.append(task)
233 # ...and run until all Exceptions show up
234 if pending:
235 await asyncio.wait(pending, timeout=60)
236 raise
237
238
239 class EndStage(Stage):
240 """
241 A Stages API stage that drains incoming items and does nothing with the items. This is
242 required at the end of all pipelines.
243
244 Without this stage, the `maxsize` of the last stage's `_out_q` could fill up and block the
245 entire pipeline.
246 """
247
248 async def __call__(self):
249 """
250 This method drains items from the last queue and drops them.
251
252 Importantly it does not try to put items into the nonexistent next queue.
253 """
254 # We overwrite __call__ here to avoid trying to put None in `self._out_q`.
255 async for _ in self.items(): # noqa
256 pass
257
[end of pulpcore/plugin/stages/api.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/pulpcore/plugin/stages/api.py b/pulpcore/plugin/stages/api.py
--- a/pulpcore/plugin/stages/api.py
+++ b/pulpcore/plugin/stages/api.py
@@ -179,12 +179,12 @@
return "[{id}] {name}".format(id=id(self), name=self.__class__.__name__)
-async def create_pipeline(stages, maxsize=1000):
+async def create_pipeline(stages, maxsize=1):
"""
A coroutine that builds a Stages API linear pipeline from the list `stages` and runs it.
Each stage is an instance of a class derived from :class:`pulpcore.plugin.stages.Stage` that
- implements the :meth:`run` coroutine. This coroutine reads asyncromously either from the
+ implements the :meth:`run` coroutine. This coroutine reads asynchronously either from the
`items()` iterator or the `batches()` iterator and outputs the items with `put()`. Here is an
example of the simplest stage that only passes data::
@@ -196,7 +196,7 @@
Args:
stages (list of coroutines): A list of Stages API compatible coroutines.
maxsize (int): The maximum amount of items a queue between two stages should hold. Optional
- and defaults to 100.
+ and defaults to 1.
Returns:
A single coroutine that can be used to run, wait, or cancel the entire pipeline with.
|
{"golden_diff": "diff --git a/pulpcore/plugin/stages/api.py b/pulpcore/plugin/stages/api.py\n--- a/pulpcore/plugin/stages/api.py\n+++ b/pulpcore/plugin/stages/api.py\n@@ -179,12 +179,12 @@\n return \"[{id}] {name}\".format(id=id(self), name=self.__class__.__name__)\n \n \n-async def create_pipeline(stages, maxsize=1000):\n+async def create_pipeline(stages, maxsize=1):\n \"\"\"\n A coroutine that builds a Stages API linear pipeline from the list `stages` and runs it.\n \n Each stage is an instance of a class derived from :class:`pulpcore.plugin.stages.Stage` that\n- implements the :meth:`run` coroutine. This coroutine reads asyncromously either from the\n+ implements the :meth:`run` coroutine. This coroutine reads asynchronously either from the\n `items()` iterator or the `batches()` iterator and outputs the items with `put()`. Here is an\n example of the simplest stage that only passes data::\n \n@@ -196,7 +196,7 @@\n Args:\n stages (list of coroutines): A list of Stages API compatible coroutines.\n maxsize (int): The maximum amount of items a queue between two stages should hold. Optional\n- and defaults to 100.\n+ and defaults to 1.\n \n Returns:\n A single coroutine that can be used to run, wait, or cancel the entire pipeline with.\n", "issue": "Reduce memory usage of the pipeline\nAuthor: @bmbouter (bmbouter)\n\n\nRedmine Issue: 9635, https://pulp.plan.io/issues/9635\n\n---\n\n## Motivation\r\n\r\nIt would be nice if users could specify a desired maximum amount of RAM to be used during sync. For example, a user can say I only want 1500 MB of RAM to be used max.\r\n\r\n## What is already in place\r\n\r\nThe stages pipeline restricts memory usage by only allowing 1000 declarative content objects between each stage (so for 8-9 stages that's 8000-9000 declarative content objects. This happens [here](https://github.com/pulp/pulpcore/blob/main/pulpcore/plugin/stages/api.py#L217).\r\n\r\nInterestingly the docstring says this defaults to 100, but it seems to actually be 1000!\r\n\r\nAlso the stages perform batching, so they will only taking in a limited number of items (the batch size). That happens [with minsize](https://github.com/pulp/pulpcore/blob/main/pulpcore/plugin/stages/api.py#L84).\r\n\r\n## Why this isn't enough\r\n\r\nThese are count-based mechnisms and don't correspond to actual MB or GB of memory used. Some content units vary a lot in how much memory each DeclarativeContent objects take up.\r\n\r\nAnother lesser problem is that it doesn't help plugin writers restrict their usage of memory in FirstStage.\r\n\r\n## Idea\r\n\r\nAdd a new param called `max_mb` to base Remote, which defaults to None. If specified, the user will be specifying the desired maximum MB used by process syncing.\r\n\r\nHave the queues between the stages, and the bather implementation, both check the total memory the current process is using and asyncio.sleep() polling until it goes down. This should keep the maximum amount used by all objects roughly to that number.\r\n\r\n## Details\r\n\r\nIntroduce a new `MBSizeQueue` which is a wrapper around `asyncio.Queue` used today. It will have the same `put()` call, only wait if the amount of memory in use is greater than the remote is configured for.\r\n\r\nThen introduce the same memory checking feature in the batcher. I'm not completely sure this second part is needed though.\r\n\r\nWe have to be very careful not to deadlock with this feature. For example, we have to account for the base case where even a single item is larger than the memory desired. Repos in pulp_rpm have had a single unit use more than 1.2G if I remember right, so if someone was syncing with 800 MB and we weren't careful to allow that unit to still flow through the pipeline we'd deadlock.....\n\n\n\n", "before_files": [{"content": "import asyncio\nimport logging\n\nfrom gettext import gettext as _\n\nfrom django.conf import settings\n\nfrom .profiler import ProfilingQueue\n\n\nlog = logging.getLogger(__name__)\n\n\nclass Stage:\n \"\"\"\n The base class for all Stages API stages.\n\n To make a stage, inherit from this class and implement :meth:`run` on the subclass.\n \"\"\"\n\n def __init__(self):\n self._in_q = None\n self._out_q = None\n\n def _connect(self, in_q, out_q):\n \"\"\"\n Connect to queues within a pipeline.\n\n Args:\n in_q (asyncio.Queue): The stage input queue.\n out_q (asyncio.Queue): The stage output queue.\n \"\"\"\n self._in_q = in_q\n self._out_q = out_q\n\n async def __call__(self):\n \"\"\"\n This coroutine makes the stage callable.\n\n It calls :meth:`run` and signals the next stage that its work is finished.\n \"\"\"\n log.debug(_(\"%(name)s - begin.\"), {\"name\": self})\n await self.run()\n await self._out_q.put(None)\n log.debug(_(\"%(name)s - put end-marker.\"), {\"name\": self})\n\n async def run(self):\n \"\"\"\n The coroutine that is run as part of this stage.\n\n Returns:\n The coroutine that runs this stage.\n\n \"\"\"\n raise NotImplementedError(_(\"A plugin writer must implement this method\"))\n\n async def items(self):\n \"\"\"\n Asynchronous iterator yielding items of :class:`DeclarativeContent` from `self._in_q`.\n\n The iterator will get instances of :class:`DeclarativeContent` one by one as they get\n available.\n\n Yields:\n An instance of :class:`DeclarativeContent`\n\n Examples:\n Used in stages to get d_content instances one by one from `self._in_q`::\n\n class MyStage(Stage):\n async def run(self):\n async for d_content in self.items():\n # process declarative content\n await self.put(d_content)\n\n \"\"\"\n while True:\n content = await self._in_q.get()\n if content is None:\n break\n log.debug(\"%(name)s - next: %(content)s.\", {\"name\": self, \"content\": content})\n yield content\n\n async def batches(self, minsize=500):\n \"\"\"\n Asynchronous iterator yielding batches of :class:`DeclarativeContent` from `self._in_q`.\n\n The iterator will try to get as many instances of\n :class:`DeclarativeContent` as possible without blocking, but\n at least `minsize` instances.\n\n Args:\n minsize (int): The minimum batch size to yield (unless it is the final batch)\n\n Yields:\n A list of :class:`DeclarativeContent` instances\n\n Examples:\n Used in stages to get large chunks of d_content instances from `self._in_q`::\n\n class MyStage(Stage):\n async def run(self):\n async for batch in self.batches():\n for d_content in batch:\n # process declarative content\n await self.put(d_content)\n\n \"\"\"\n batch = []\n shutdown = False\n no_block = False\n thaw_queue_event = asyncio.Event()\n\n def add_to_batch(content):\n nonlocal batch\n nonlocal shutdown\n nonlocal no_block\n nonlocal thaw_queue_event\n\n if content is None:\n shutdown = True\n log.debug(_(\"%(name)s - shutdown.\"), {\"name\": self})\n else:\n if not content.does_batch:\n no_block = True\n content._thaw_queue_event = thaw_queue_event\n batch.append(content)\n\n get_listener = asyncio.ensure_future(self._in_q.get())\n thaw_event_listener = asyncio.ensure_future(thaw_queue_event.wait())\n while not shutdown:\n done, pending = await asyncio.wait(\n [thaw_event_listener, get_listener], return_when=asyncio.FIRST_COMPLETED\n )\n if thaw_event_listener in done:\n thaw_event_listener = asyncio.ensure_future(thaw_queue_event.wait())\n no_block = True\n if get_listener in done:\n content = await get_listener\n add_to_batch(content)\n get_listener = asyncio.ensure_future(self._in_q.get())\n while not shutdown:\n try:\n content = self._in_q.get_nowait()\n except asyncio.QueueEmpty:\n break\n else:\n add_to_batch(content)\n\n if batch and (len(batch) >= minsize or shutdown or no_block):\n log.debug(\n _(\"%(name)s - next batch[%(length)d].\"), {\"name\": self, \"length\": len(batch)}\n )\n for content in batch:\n content._thaw_queue_event = None\n thaw_queue_event.clear()\n yield batch\n batch = []\n no_block = False\n thaw_event_listener.cancel()\n get_listener.cancel()\n\n async def put(self, item):\n \"\"\"\n Coroutine to pass items to the next stage.\n\n Args:\n item: A handled instance of :class:`pulpcore.plugin.stages.DeclarativeContent`\n\n Raises:\n ValueError: When `item` is None.\n \"\"\"\n if item is None:\n raise ValueError(_(\"(None) not permitted.\"))\n await self._out_q.put(item)\n log.debug(\"{name} - put: {content}\".format(name=self, content=item))\n\n def __str__(self):\n return \"[{id}] {name}\".format(id=id(self), name=self.__class__.__name__)\n\n\nasync def create_pipeline(stages, maxsize=1000):\n \"\"\"\n A coroutine that builds a Stages API linear pipeline from the list `stages` and runs it.\n\n Each stage is an instance of a class derived from :class:`pulpcore.plugin.stages.Stage` that\n implements the :meth:`run` coroutine. This coroutine reads asyncromously either from the\n `items()` iterator or the `batches()` iterator and outputs the items with `put()`. Here is an\n example of the simplest stage that only passes data::\n\n class MyStage(Stage):\n async def run(self):\n async for d_content in self.items(): # Fetch items from the previous stage\n await self.put(d_content) # Hand them over to the next stage\n\n Args:\n stages (list of coroutines): A list of Stages API compatible coroutines.\n maxsize (int): The maximum amount of items a queue between two stages should hold. Optional\n and defaults to 100.\n\n Returns:\n A single coroutine that can be used to run, wait, or cancel the entire pipeline with.\n Raises:\n ValueError: When a stage instance is specified more than once.\n \"\"\"\n futures = []\n history = set()\n in_q = None\n for i, stage in enumerate(stages):\n if stage in history:\n raise ValueError(_(\"Each stage instance must be unique.\"))\n history.add(stage)\n if i < len(stages) - 1:\n if settings.PROFILE_STAGES_API:\n out_q = ProfilingQueue.make_and_record_queue(stages[i + 1], i + 1, maxsize)\n else:\n out_q = asyncio.Queue(maxsize=maxsize)\n else:\n out_q = None\n stage._connect(in_q, out_q)\n futures.append(asyncio.ensure_future(stage()))\n in_q = out_q\n\n try:\n await asyncio.gather(*futures)\n except Exception:\n # One of the stages raised an exception, cancel all stages...\n pending = []\n for task in futures:\n if not task.done():\n task.cancel()\n pending.append(task)\n # ...and run until all Exceptions show up\n if pending:\n await asyncio.wait(pending, timeout=60)\n raise\n\n\nclass EndStage(Stage):\n \"\"\"\n A Stages API stage that drains incoming items and does nothing with the items. This is\n required at the end of all pipelines.\n\n Without this stage, the `maxsize` of the last stage's `_out_q` could fill up and block the\n entire pipeline.\n \"\"\"\n\n async def __call__(self):\n \"\"\"\n This method drains items from the last queue and drops them.\n\n Importantly it does not try to put items into the nonexistent next queue.\n \"\"\"\n # We overwrite __call__ here to avoid trying to put None in `self._out_q`.\n async for _ in self.items(): # noqa\n pass\n", "path": "pulpcore/plugin/stages/api.py"}]}
| 3,625 | 335 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.